Überblick über die Cluster-Suite
Red Hat Cluster Suite für Red Hat Enterprise Linux 5
Ausgabe 3
Zusammenfassung
Einführung
- Red Hat Enterprise Linux Installationshandbuch — Liefert Informationen bezüglich der Installation von Red Hat Enterprise Linux 5.
- Red Hat Enterprise Linux Deployment-Handbuch — Liefert Informationen bezüglich des Einsatzes, der Konfiguration und der Administration von Red Hat Enterprise Linux 5.
- Konfiguration und Verwaltung eines Red Hat Clusters — Liefert Informationen zur Installation, Konfiguration und Verwaltung von Red Hat Cluster-Komponenten.
- Logical Volume Manager Administration — Provides a description of the Logical Volume Manager (LVM), including information on running LVM in a clustered environment.
- Global File System: Konfiguration und Administration — Liefert Informationen zur Installation, Konfiguration und Pflege von Red Hat GFS (Red Hat Global File System).
- Global File System 2: Konfiguration und Administration — Liefert Informationen zur Installation, Konfiguration und Pflege von Red Hat GFS (Red Hat Global File System 2).
- Verwendung des Device-Mapper Multipath — Liefert Informationen bezüglich des Device-Mapper Multipath Features von Red Hat Enterprise Linux 5.
- Verwendung von GNBD mit Global File System — Liefert einen Überblick über die Verwendung des Global Network Block Device (GNBD) mit Red Hat GFS.
- Linux-Virtual-Server Administration — Liefert Informationen zur Konfiguration von Hochleistungssystemen und -diensten mit dem Linux Virtual Server (LVS).
- Red Hat Cluster Suite Release Notes — Liefert Informationen zum aktuellen Release der Red Hat Cluster Suite.
1. Feedback
Cluster_Suite_Overview(EN)-5 (2009-08-18T15:49)
Cluster_Suite_Overview(EN)-5 (2009-08-18T15:49)
Kapitel 1. Überblick über die Red Hat Cluster Suite
1.1. Cluster-Grundlagen
- Speicher-Cluster
- Hochverfügbarkeits-Cluster
- Lastverteilungs-Cluster
- Hochleistungs-Cluster
Anmerkung
1.2. Red Hat Cluster Suite Introduction
- Cluster-Infrastruktur — Bietet grundlegende Funktionen für Knoten für die Zusammenarbeit als ein Cluster: Verwalten der Konfigurationsdatei, der Zugehörigkeit, der Sperrung und der Datenabgrenzung (Fencing).
- Hochverfügbarkeitsdienst-Management — Bietet die Übertragung von Diensten von einem Knoten auf einen anderen, falls ein Knoten nicht mehr funktionsfähig ist.
- Cluster Administrations-Tools — Konfigurations- und Management-Tools zum Einrichten, Konfigurieren und Verwalten eines Red Hat-Clusters. Die Tools sind zur Verwendung mit den Cluster-Infrastruktur-Komponenten, den Hochverfügbarkeits-Komponenten und den Dienst-Management-Komponenten und Speicher gedacht.
- Linux Virtual Server (LVS) — Routing-Software, die IP-Lastverteilung bietet. LVS läuft als ein Paar redundanter Server, die Client-Anfragen gleichmäßig auf reale Server hinter den LVS-Servern verteilen.
- Red Hat GFS (Global File System) — Bietet ein Cluster-Dateisystem zur Verwendung mit der Red Hat Cluster Suite. GFS ermöglicht mehreren Knoten, Speicher auf einem Blocklevel gemeinsam zu nutzen, als ob der Speicher lokal mit jedem Cluster-Knoten verbunden wäre.
- Cluster Logical Volume Manager (CLVM) — Bietet das Verwalten von Datenträgern eines Cluster-Speichers.
Anmerkung
When you create or modify a CLVM volume for a clustered environment, you must ensure that you are running theclvmddaemon. For further information, refer to Abschnitt 1.6, »Cluster Logical-Volume-Manager«. - Global Network Block Device (GNBD) — Eine Hilfskomponente von GFS, die Blocklevel-Speicher für das Ethernet exportiert. Dies ist eine ökonomische Art und Weise, Blocklevel-Speicher für Red Hat GFS verfügbar zu machen.

Abbildung 1.1. Red Hat Cluster Suite Introduction
Anmerkung
1.3. Cluster Infrastructure
- Cluster-Management
- Lock-Management
- Fencing
- Cluster-Konfigurations-Management
1.3.1. Cluster-Management
Anmerkung

Abbildung 1.2. CMAN/DLM Overview
1.3.2. Lock-Management
1.3.3. Fencing
fenced.
fenced von dem Ausfall unterrichtet ist, grenzt er den ausgefallenen Knoten ab. Die anderen Cluster-Infrastruktur-Komponenten bestimmen, welche Schritte einzuleiten sind — d.h. sie führen sämtliche Wiederherstellungsmaßnahmen durch, die durchgeführt werden müssen. So suspendieren beispielsweise DLM und GFS beim Erhalt der Information über einen Knoten-Ausfall sämtliche Aktivitäten, bis sie feststellen, dass der fenced den Fencing-Prozess für den ausgefallenen Knoten abgeschlossen hat. Nach der Bestätigung, dass der ausgefallene Knoten abgegrenzt ist, führen DLM und GFS Wiederherstellungsmaßnahmen durch. DLM gibt die Locks für den ausgefallenen Knoten frei und GFS stellt das Journal des ausgefallenen Knotens wieder her.
- Power-Fencing — Eine Fencing-Methode, die einen Power-Kontroller verwendet, um einen nicht mehr funktionierenden Knoten auszuschalten.
- Fibre-Channel-Switch-Fencing — Eine Fencing-Methode, die den Fibre-Channel-Port deaktiviert, der den Speicher mit einem nicht funktionsfähigen Knoten verbindet.
- GNBD fencing — A fencing method that disables an inoperable node's access to a GNBD server.
- Sonstiges Fencing — Mehrere sonstige Fencing-Methoden, die I/O oder den Strom eines nicht funktionsfähigen Knotens deaktiviert, inklusive IBM-Bladecenters, PAP, DRAC/MC, ILO, IPMI, IBM RSA II und weitere.

Abbildung 1.3. Power Fencing Example

Abbildung 1.4. Fibre Channel Switch Fencing Example

Abbildung 1.5. Fencing a Node with Dual Power Supplies

Abbildung 1.6. Fencing a Node with Dual Fibre Channel Connections
1.3.4. Cluster Configuration System

Abbildung 1.7. CCS Overview

Abbildung 1.8. Accessing Configuration Information
/etc/cluster/cluster.conf) ist eine XML-Datei, die die folgenden Cluster-Charakteristiken beschreibt:
- Cluster-Name — Zeigt den Cluster-Namen, das Revisionslevel der Cluster-Konfigurationsdatei und grundlegende Fence-Timing-Eigenschaften an, die verwendet werden, wenn ein Knoten einem Cluster beitritt oder aus einem Cluster abgegrenzt wird.
- Cluster — Zeigt jeden Knoten des Clusters an, unter Angabe des Knoten-Namens, der Knoten-ID, der Zahl der Quorum-Stimmen und der Fencing-Methode für diesen Knoten.
- Fence-Gerät — Zeigt die Fence-Geräte im Cluster an. Die Parameter variieren je nach Typ des Fence-Geräts. Für einen Power-Kontroller beispielsweise, der als Fence-Gerät benutzt wird, definiert die Cluster-Konfiguration den Namen des Power-Kontroller, dessen IP-Adresse, das Login und das Passwort.
- Verwaltete Ressourcen — Zeigt die Ressourcen an, die zum Erstellen von Cluster-Diensten benötigt werden. Verwaltete Ressourcen umfassen die Definition von Ausfallsicherungs-Domains, Ressourcen (zum Beispiel einer IP-Adresse) und Dienste. Zusammen definieren die verwalteten Ressourcen Cluster-Dienste und Ausfallsicherungsverhalten der Cluster-Dienste.
1.4. Hochverfügbarkeitsdienst-Management
rgmanager, implementiert Ausfallsicherung für Standardapplikationen. In einem Red Hat-Cluster wird eine Applikation mit anderen Cluster-Ressourcen konfiguriert, um ein einen Hochverfügbarkeits-Cluster-Dienst zu bilden. Ein Hochverfügbarkeits-Cluster-Dienst kann zur Ausfallsicherung von einem Cluster-Knoten auf einen anderen wechseln, ohne signifikante Unterbrechung für Cluster-Clients. Cluster-Dienst-Ausfallsicherung kann dann in Kraft treten, wenn ein Knoten ausfällt, oder wenn ein Cluster-Systemadministrator den Dienst von einem Cluster-Knoten auf einen anderen verschiebt (beispielsweise für einen geplanten Ausfall eines Cluster-Knotens).
Anmerkung

Abbildung 1.9. Ausfallsicherungs-Domains
- IP Adressen-Ressource — IP-Adresse 10.10.10.201.
- An application resource named "httpd-content" — a web server application init script
/etc/init.d/httpd(specifyinghttpd). - A file system resource — Red Hat GFS named "gfs-content-webserver".

Abbildung 1.10. Web Server Cluster Service Example
1.5. Red Hat GFS
- Vereinfachung Ihrer Daten-Infrastruktur
- Installation und Fehlerbehebung von Applikationen für das gesamte Cluster.
- Der Bedarf redundanter Kopien von Applikationsdaten (Duplikation) wird eliminiert.
- Paralleler Lese-/Schreib-Zugriff auf Daten durch viele Clients wird ermöglicht.
- Backup und Notfallsicherung wird vereinfacht (nur ein Dateisystem muss gesichert oder wiederhergestellt werden).
- Die Verwendung von Speicherressourcen wird maximiert, was die Administrationskosten gleichzeitig minimiert.
- Speicher kann als Ganzes verwaltet werden, anstatt pro Partition.
- Verringerung der gesamten Speicheranforderungen durch das Eliminieren von Datenreplikationen.
- Nahtlose Skalierung des Clusters durch Hinzufügen von Servern oder Speicher im laufenden Betrieb.
- Kein Partitionierungsspeicher mehr durch komplizierte Techniken.
- Hinzufügen von Servern zum Cluster im laufenden Betrieb durch das Einhängen in das allgemeine Dateisystem.
Anmerkung
1.5.1. Höhere Leistung und Skalierbarkeit

Abbildung 1.11. GFS with a SAN
1.5.2. Leistung, Skalierbarkeit, Angemessener Preis

Abbildung 1.12. GFS and GNBD with a SAN
1.5.3. Wirtschaftlichkeit und Leistung

Abbildung 1.13. GFS und GNBD mit direkt angehängtem Speicher
1.6. Cluster Logical-Volume-Manager
clvmd. clvmd is a daemon that provides clustering extensions to the standard LVM2 tool set and allows LVM2 commands to manage shared storage. clvmd runs in each cluster node and distributes LVM metadata updates in a cluster, thereby presenting each cluster node with the same view of the logical volumes (refer to Abbildung 1.14, »CLVM Overview«). Logical volumes created with CLVM on shared storage are visible to all nodes that have access to the shared storage. CLVM allows a user to configure logical volumes on shared storage by locking access to physical storage while a logical volume is being configured. CLVM uses the lock-management service provided by the cluster infrastructure (refer to Abschnitt 1.3, »Cluster Infrastructure«).
Anmerkung
clvmd) oder die High Availability Logical Volume Management Agenten (HA-LVM) ausgeführt werden. Falls Sie aus betrieblichen Gründen oder aufgrund unzureichender Berechtigungen weder den clvmd-Daemon, noch HA-LVM besitzen, dürfen Sie kein Single-Instance-LVM auf den gemeinsam genutzten Platten einsetzen, da dies zu korrumpierten Daten führen kann. Falls Sie Bedenken haben, setzen Sie sich bitte mit einem Red Hat Service-Vertreter in Verbindung.
Anmerkung
/etc/lvm/lvm.conf für clusterweites Locking (Dateisperren) erforderlich.

Abbildung 1.14. CLVM Overview

Abbildung 1.15. LVM Graphical User Interface

Abbildung 1.16. Conga LVM Graphical User Interface

Abbildung 1.17. Creating Logical Volumes
1.7. Global Network Blockgerät

Abbildung 1.18. GNBD Überblick
1.8. Linux Virtual Server
- Gleichmäßige Verteilung der Auslastung unter den realen Servern.
- Überprüfung der Integrität der Dienste auf jedem realen Server.
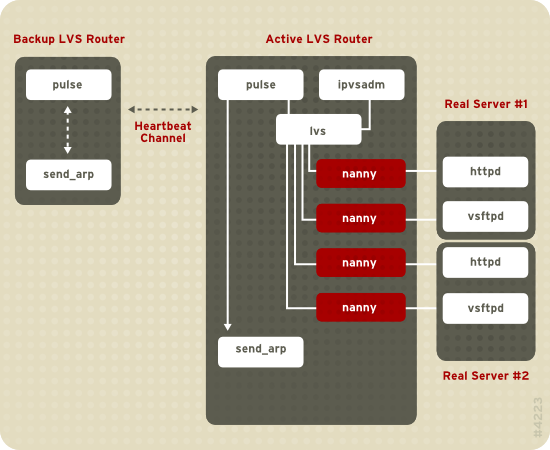
Abbildung 1.19. Components of a Running LVS Cluster
pulse-Daemon läuft sowohl auf den aktiven als auch den passiven LVS-Routern. Auf dem Backup-LVS-Router sendet pulse einen heartbeat an die öffentliche Schnittstelle des aktiven Router, um sicherzustellen, dass der aktive LVS-Router ordnungsgemäß funktioniert. Auf dem aktiven LVS-Router startet pulse den lvs-Daemon und reagiert auf heartbeat-Anfragen des Backup-LVS-Routers.
lvs-Daemon das ipvsadm-Dienstprogramm auf, um die IPVS (IP Virtual Server) Routing-Tabelle im Kernel zu konfigurieren und zu pflegen, und startet einen nanny-Prozess für jeden konfigurierten virtuellen Server auf jedem realen Server. Jeder nanny-Prozess überprüft den Status eines konfigurierten Dienstes auf einem realen Server und unterrichtet den lvs-Daemon darüber, ob der Dienst auf diesem realen Server nicht korrekt funktioniert. Falls eine Fehlfunktion entdeckt wird, weist der lvs-Daemon ipvsadm an, diesen realen Server aus der IPVS-Routing-Tabelle zu entfernen.
send_arp aufruft, alle virtuellen IP-Adressen den NIC Hardware-Adressen (MAC Adressen) des Backup-LVS-Router neu zuzuweisen. Weiterhin sendet er einen Befehl an den aktiven LVS-Router, sowohl durch die öffentliche, als auch die private Netzwerkschnittstelle, den lvs-Daemon auf dem aktiven LVS-Router zu beenden, und startet den lvs-Daemon auf dem Backup-LVS-Router, um Anfragen für die konfigurierten virtuellen Server zu akzeptieren.
- Synchronisation der Daten unter den realen Servern.
- Hinzufügen einer dritten Ebene zur Topologie für den Zugriff auf gemeinsam genutzte Daten.
rsync verwenden, um aktualisierte Daten im Rahmen eines bestimmten Intervalls auf allen Knoten zu replizieren. Allerdings funktionieren Skripte in Umgebungen, in denen Benutzer häufig Dateien hochladen oder Datenbank-Transaktionen durchführen, nicht optimal. Aus diesem Grund ist eine three-tiered topology besser geeignet zur Synchronisation von Daten für reale Server, auf die eine große Menge Daten hochgeladen wird oder mit Datenbank-Transaktionen oder ähnlichem Datenverkehr.
1.8.1. Two-Tier LVS Topology
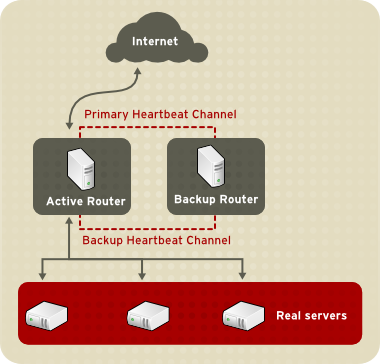
Abbildung 1.20. Two-Tier LVS Topology
eth0:1 erhalten. Alternativ kann jeder virtuelle Server mit einem separaten Gerät pro Dienst verknüpft werden. Beispielsweise kann HTTP-Datenverkehr auf eth0:1 und FTP-Datenverkehr auf eth0:2 verwaltet werden.
- Round-Robin-Scheduling — Verteilt jede Anfrage nacheinander in einen Pool von realen Servern. Bei der Verwendung dieses Algorithmus werden alle realen Server als gleichwertig behandelt, ohne Rücksicht auf deren Kapazität oder Auslastung.
- Gewichtetes Round-Robin-Scheduling — Verteilt jede Anfrage nacheinander in einem Pool von realen Servern, teilt jedoch Servern mit einer höheren Kapazität mehr Jobs zu. Die Kapazität wird durch einen durch einen Benutzer zugewiesenen Gewichtungsfaktor angezeigt, der dann durch eine dynamische Auslastungsinformation entweder nach oben oder unten korrigiert wird. Dies ist die bevorzugte Wahl falls signifikante Unterschiede der Kapazität von realen Servern in einem Server-Pool vorliegen. Wenn die Last durch Anfragen jedoch dramatisch variiert, kann ein stark gewichteter Server ggf. mehr Anfragen beantworten, als ihm zugeteilt sind.
- Least-Connection — Verteilt mehr Anfragen an reale Server mit weniger aktiven Verbindungen. Dies ist ein dynamischer Scheduling-Algorithmus-Typ und stellt eine bessere Wahl dar, falls eine hohes Maß an Abweichung in der Anfragelast vorliegt. Es ist am besten für einen Pool von realen Server geeignet, in dem jeder Server-Knoten in etwa dieselbe Kapazität besitzt. Falls die realen Server unterschiedliche Kapazitäten besitzen, ist das gewichtete Least-Connection-Scheduling die bessere Wahl.
- Gewichtete Least-Connections (Standard) — Verteilt mehrere Anfragen an Server mit weniger aktiven Verbindungen in Relation zu ihrer Kapazität. Die Kapazität wird durch eine benutzerdefinierte Gewichtung angezeigt, welche dann wiederum je nach dynamischer Lastinformation nach oben oder unten korrigiert wird. Der Zusatz der Gewichtung macht diesen Algorithmus zu einer idealen Alternative, wenn der Pool der realen Server aus Hardware mit unterschiedlichen Kapazitäten besteht.
- Locality-Based Least-Connection Scheduling — Verteilt mehrere Anfragen an Server mit weniger aktiven Verbindungen in Relation zu ihren Ziel-IPs. Dieser Algorithmus ist für den Einsatz in einem Proxy-Cache-Server-Cluster gedacht. Er routet die Pakete für eine IP-Adresse solange an den Server für diese Adresse, bis dieser Server seine Kapazitätsgrenze überschreitet und einen Server mit dessen halber Last vorliegen hat. In diesem Fall weist er die IP-Adresse einem realen Server mit der geringsten Auslastung zu.
- Locality-Based Least-Connection Scheduling mit Replication Scheduling — Verteilt mehr Anfragen an Server mit weniger aktiven Verbindungen in Relation zu ihren Ziel-IPs. Dieser Algorithmus ist auch für den Einsatz in einem Proxy-Cache-Server-Cluster gedacht. Es unterscheidet sich vom Locality-Based Least-Connection Scheduling durch das Zuordnen der Ziel-IP-Adresse zu einer Teilmenge von realer Server-Knoten. Anfragen werden anschließend zum Server in dieser Teilmenge mit der niedrigsten Anzahl an Verbindungen geroutet. Falls alle Knoten für die Ziel-IP über der Kapazität liegen, repliziert er einen neuen Server für diese Ziel-IP-Adresse, indem er den realen Server mit den wenigsten Verbindungen aus dem gesamten Pool der realen Server zur Teilmenge der realen Server für diese Ziel-IP hinzufügt. Der Knoten mit der höchsten Last wird dann aus der Teilmenge der realen Server entfernt, um eine Überreplikation zu verhindern.
- Source-Hash-Scheduling — Verteilt Anfragen an den Pool realer Server, in dem er die Quell-IP in einer statischen Hash-Tabelle sucht. Dieser Algorithmus ist für LVS-Router mit mehreren Firewalls gedacht.
1.8.2. Three-Tier LVS Topology
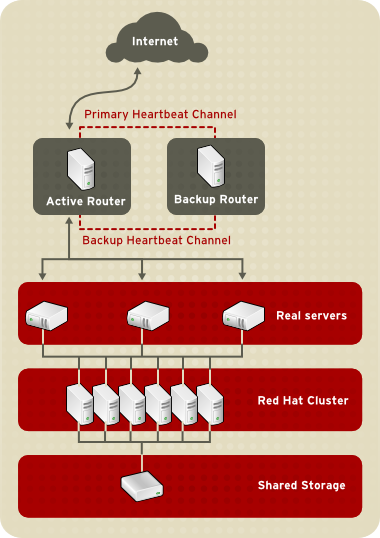
Abbildung 1.21. Three-Tier LVS Topology
1.8.3. Routing-Methoden
1.8.3.1. NAT-Routing
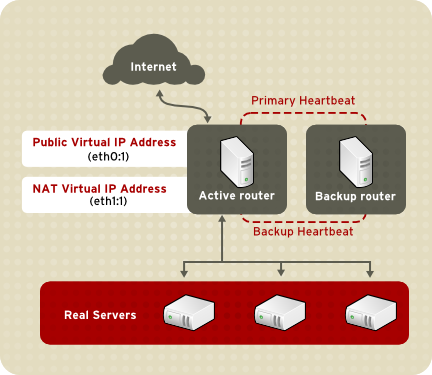
Abbildung 1.22. LVS Implemented with NAT Routing
1.8.3.2. Direktes Routing
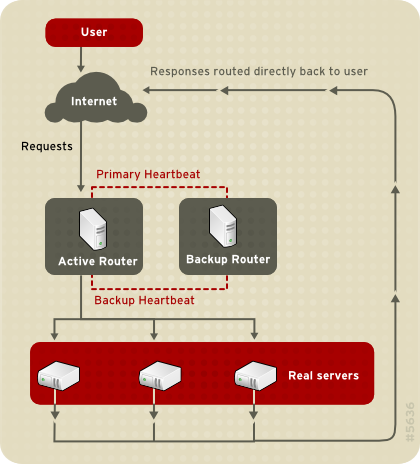
Abbildung 1.23. LVS Implemented with Direct Routing
arptables zur Paketfilterung durchgeführt werden.
1.8.4. Persistenz und Firewall-Markierungen
1.8.4.1. Persistence
1.8.4.2. Firewall-Markierungen
1.9. Cluster Administrations-Tools
1.9.1. Conga
- Eine Web-Oberfläche zur Verwaltung von Cluster und Speicher
- Automatisierter Einsatz von Cluster-Daten und Hilfspakete
- Einfache Integration in existierende Cluster
- Kein Bedarf einer erneuten Authentifizierung
- Integration des Cluster-Status und Protokolldateien
- Differenzierte Kontrolle über Benutzerberechtigungen
- — Liefert Tools für das Hinzufügen und Löschen von Computern und Benutzern, sowie das Konfigurieren von Benutzerberechtigungen. Nur ein Systemadministrator darf auf diesen Reiter zugreifen.
- — Bietet Tools für das Erstellen und Konfigurieren von Clustern. Jede Instanz von luci listet Cluster auf, die mit luci erstellt wurden. Ein Systemadministrator kann alle auf diesem Reiter aufgelisteten Cluster administrieren. Andere Benutzer können nur Cluster administrieren, für die sie (von einem Administrator zugewiesene) Berechtigungen zur Verwaltung besitzen.
- — Bietet Tools für die Administration von Speicher von remote aus. Mit den Tools auf diesem Reiter können Sie Speicher auf Computern verwalten, unabhängig davon, ob sie zu einem Cluster gehören, oder nicht.

Abbildung 1.24. luci -Reiter

Abbildung 1.25. luci -Reiter

Abbildung 1.26. luci -Reiter
1.9.2. Cluster Administrations-GUI
system-config-cluster cluster administration graphical user interface (GUI) available with Red Hat Cluster Suite. The GUI is for use with the cluster infrastructure and the high-availability service management components (refer to Abschnitt 1.3, »Cluster Infrastructure« and Abschnitt 1.4, »Hochverfügbarkeitsdienst-Management«). The GUI consists of two major functions: the Cluster Configuration Tool and the Cluster Status Tool. The Cluster Configuration Tool provides the capability to create, edit, and propagate the cluster configuration file (/etc/cluster/cluster.conf). The Cluster Status Tool provides the capability to manage high-availability services. The following sections summarize those functions.
1.9.2.1. Cluster Configuration Tool

Abbildung 1.27. Cluster Configuration Tool
/etc/cluster/cluster.conf) mit einer hierarchischen grafischen Anzeige im linken Panel. Ein dreieckiges Symbol links neben dem Namen einer Komponente zeigt an, dass der Komponente eine oder mehrere untergeordnete Komponenten zugewiesen sind. Ein Klick auf das dreieckige Symbol klappt dem Teilbereich eines Verzeichnisbaums unterhalb einer Komponente auf und zu. Die im GUI angezeigten Komponenten können wie folgt zusammengefasst werden:
- Cluster Nodes — Zeigt Cluster-Knoten an. Knoten werden durch ihren Namen als untergeordnete Elemente unter Cluster Nodes dargestellt. Mit Hilfe von Konfigurationsschaltflächen am unteren Ende des rechten Frames (unterhalb von Properties können Sie Knoten hinzufügen, löschen und deren Eigenschaften bearbeiten und Fencing-Methoden für jeden Knoten konfigurieren.
- Fence Devices — Zeigt Fence-Geräte an. Fence-Geräte werden durch untergeordnete Elemente unter Fence Devices dargestellt. Mit Hilfe von Konfigurationsschaltflächen am unteren Ende des rechten Frames (unterhalb von Eigenschaften können Sie Fence-Geräte hinzufügen, löschen und deren Eigenschaften bearbeiten. Fence-Geräte müssen definiert werden, bevor Sie Fencing (mit der Schaltfläche ) für jeden Knoten konfigurieren können.
- Managed Resources — Zeigt Ausfallsicherungs-Domains, Ressourcen und Dienstes an.
- Failover Domains — Zur Konfiguration von einem oder mehreren Subsets von Cluster-Knoten, die dazu verwendet werden, einen Hochverfügbarkeitsservice im Falle eines Ausfalls eines Knotens auszuführen. Ausfallsicherungs-Domains werden als untergeordnete Elemente unter Failover Domains dargestellt. Mit Hilfe von Konfigurationsschaltflächen am unteren Ende des rechten Frames (unterhalb von Properties können Sie Ausfallsicherungs-Domains hinzufügen (wenn Failover Domains ausgewählt ist) oder die Eigenschaften von Ausfallsicherungs-Domains bearbeiten (wenn eine Failover Domain ausgewählt ist).
- Resources — Zur Konfiguration von gemeinsam genutzten Ressourcen, die von Hochverfügbarkeitsdienste verwendet werden sollen. Gemeinsam genutzte Ressourcen bestehen aus Dateisystemen, IP-Adressen, NFS-Einhängepunkten und -Exporte und von Benutzern erstellte Skripte, die jedem beliebigen Hochverfügbarkeitsdienst in dem Cluster zur Verfügung stehen. Ressourcen werden als untergeordnete Elemente unter Resources dargestellt. Mit Hilfe von Konfigurationsschaltflächen am unteren Ende des rechten Frames (unterhalb von Properties können Sie Ressourcen erstellen (wenn Resources ausgewählt ist) oder die Eigenschaften von Ressourcen bearbeiten (wenn eine Ressource ausgewählt ist).
Anmerkung
Das Cluster Configuration Tool bietet auch die Fähigkeit zur Konfiguration privater Ressourcen. Eine private Ressource ist eine Ressource, die zur Verwendung von lediglich einem Dienst konfiguriert wird. Sie können eine private Ressource im Rahmen einer Dienst-Komponente im GUI konfigurieren. - Services — Zur Erstellung und Konfiguration von Hochverfügbarkeitsdiensten. Ein Dienst wird konfiguriert, indem Ressourcen zugewiesen werden (gemeinsam genutzte oder private), eine Ausfallsicherungs-Domain zugewiesen wird und eine Richtlinie zur Wiederherstellung des Dienstes definiert wird. Dienste werden als untergeordnete Elemente unter Services dargestellt. Mit Hilfe der Konfigurationsschaltflächen im unteren Bereich des rechten Frames (unterhalb von Properties) können Sie Dienste erstellen (wenn Services ausgewählt ist), oder die Diensteigenschaften bearbeiten (wenn ein Dienst ausgewählt ist).
1.9.2.2. Cluster Status Tool

Abbildung 1.28. Cluster Status Tool
/etc/cluster/cluster.conf) bestimmt. Sie können das Cluster Status Tool verwenden, um einen Hochverfügbarkeitsdienst zu aktivieren, zu deaktivieren, neuzustarten oder zu verschieben.
1.9.3. Administrationstools für die Kommandozeile
system-config-cluster Cluster Administration GUI, command line tools are available for administering the cluster infrastructure and the high-availability service management components. The command line tools are used by the Cluster Administration GUI and init scripts supplied by Red Hat. Tabelle 1.1, »Kommandozeilentools« summarizes the command line tools.
| Kommandozeilentool | Wird verwendet mit | Zweck |
|---|---|---|
ccs_tool — Cluster Configuration System Tool | Cluster Infrastructure | ccs_tool ist ein Programm zur Durchführung von Online-Aktualisierungen an der Cluster-Konfigurationsdatei. Es bietet die Fähigkeit, Cluster-Infrastruktur-Komponenten zu erstellen und zu modifizieren (zum Beispiel, Erstellen eines Clusters, Hinzufügen und Entfernen eines Knotens). Für weitere Informationen zu diesem Tool, werfen Sie einen Blick auf die Handbuchseite von ccs_tool(8). |
cman_tool — Cluster Management Tool | Cluster Infrastructure | cman_tool ist ein Programm, dass den CMAN-Cluster-Manager verwaltet. Es bietet die Fähigkeit, einem Cluster beizutreten, es zu verlassen, einen Knoten zu entfernen oder die erwarteten Quorum-Stimmen eines Knotens in einem Cluster verändern. Für weitere Informationen, werfen Sie einen Blick auf die cman_tool(8) Handbuchseite. |
fence_tool — Fence-Tool | Cluster Infrastructure | fence_tool ist ein Programm, das dazu verwendet wird, der Standard-Fence-Domain beizutreten oder sie zu verlassen. Speziell startet es den Fence-Daemon (fenced), um der Domain beizutreten und beendet den fenced, um die Domain zu verlassen. Für weitere Informationen, werfen Sie einen Blick auf die fence_tool(8) Handbuchseite. |
clustat — Cluster Status Dienstprogramm | Hochverfügbarkeitsdienst-Management-Komponenten | Der Befehl clustat zeigt den Status des Clusters an. Es zeigt Informationen über Zugehörigkeiten, Quorum-Anzeige und den Zustand aller konfigurierten Benutzerdienste. Für weitere Informationen, werfen Sie einen Blick auf die clustat(8) Handbuchseite. |
clusvcadm — Cluster User Service Administration Dienstprogramm | Hochverfügbarkeitsdienst-Management-Komponenten | Der Befehl clusvcadm ermöglicht Ihnen, Hochverfügbarkeitsdienste in einem Cluster zu aktivieren, zu deaktivieren, zu verschieben und neuzustarten. Für weitere Informationen, werfen Sie einen Blick auf die clusvcadm(8) Handbuchseite. |
1.10. Linux Virtual Server Administrations-GUI
/etc/sysconfig/ha/lvs.cf.
piranha-gui auf dem aktiven LVS-Router laufen. Sie können auf das Piranha Configuration Tool lokal oder von remote aus mit einem Web-Browser zugreifen. Unter der URL http://localhost:3636 erreichen sie das Tool lokal. Von remote aus erreichen Sie das Tool durch die Eingabe von entweder des Hostnamens oder der realen IP-Adresse, gefolgt von :3636. Wenn Sie von remote aus auf das Piranha Configuration Tool zugreifen, benötigen Sie eine ssh-Verbindung als Root-Benutzer mit dem aktiven LVS-Router.
Abbildung 1.29. The Welcome Panel
1.10.1. CONTROL/MONITORING
pulse-Daemons, der LVS-Routing-Tabelle und der von LVS erzeugten nanny-Prozesse dar.
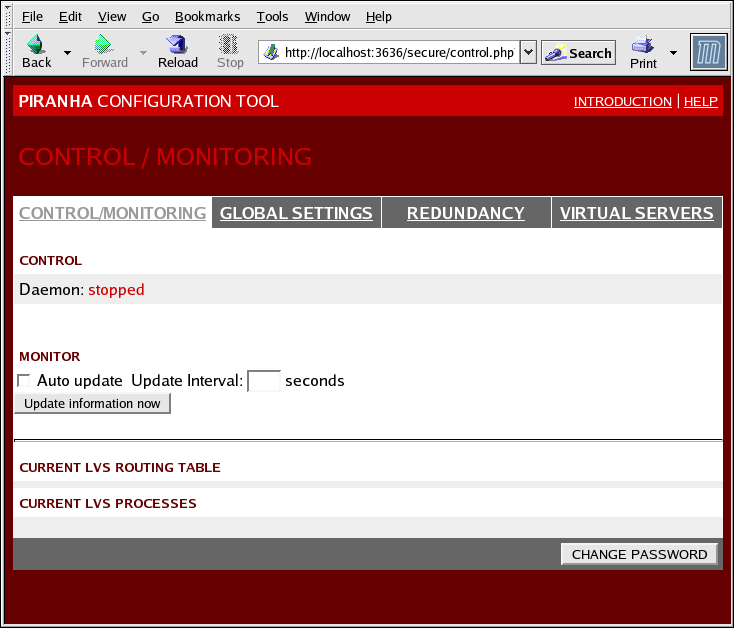
Abbildung 1.30. The CONTROL/MONITORING Panel
- Auto update
- Aktiviert das automatische Aktualisieren der Statusanzeige zu einem vom Benutzer konfigurierten Intervall, das im Textfeld Update frequency in seconds (der Standardwert ist 10 Sekunden).Es wird nicht empfohlen, die automatische Aktualisierung auf einen Zeitintervall von weniger als 10 Sekunden zu setzen. Andernfalls kann es problematisch werden, das Zeitintervall für die Auto update neu zu konfigurieren, da die Seite zu schnell neu lädt. Falls Sie dieses Problem haben, klicken Sie einfach auf ein anderes Panel und dann zurück auf CONTROL/MONITORING.
- Bietet eine manuelle Aktualisierung der Statusinformationen.
- Ein Klick auf diese Schaltfläche führt Sie zu einer Hilfeseite mit Informationen, wie Sie das administrative Passwort für das Piranha Configuration Tool ändern können.
1.10.2. GLOBAL SETTINGS
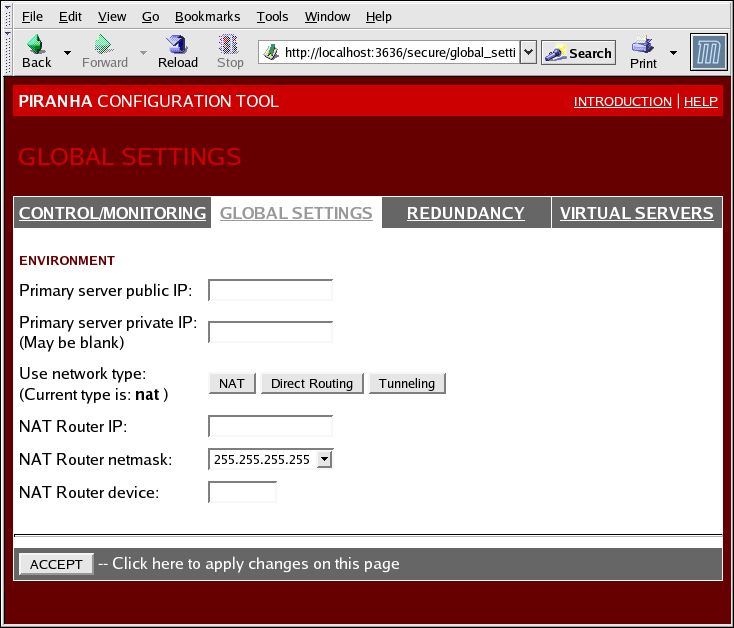
Abbildung 1.31. The GLOBAL SETTINGS Panel
- Primary server public IP
- Die öffentlich routbare reale IP-Adresse für den primären LVS-Knoten.
- Primary server private IP
- Die reale IP-Adresse für eine alternative Netzwerkschnittstelle auf dem primären LVS-Knoten. Diese Adresse wird ausschließlich als alternativer Heartbeat-Channel für den Backup-Router verwendet.
- Use network type
- Wählt NAT-Routing aus.
- NAT Router IP
- Die private floating IP in diesem Textfeld. Diese floating IP sollte als das Gateway für die realen Server verwendet werden.
- NAT Router netmask
- If the NAT router's floating IP needs a particular netmask, select it from drop-down list.
- NAT Router device
- Definiert den Gerätenamen der Netzwerkschnittstelle für die floating IP-Adresse, wie z.B.
eth1:1.
1.10.3. REDUNDANCY
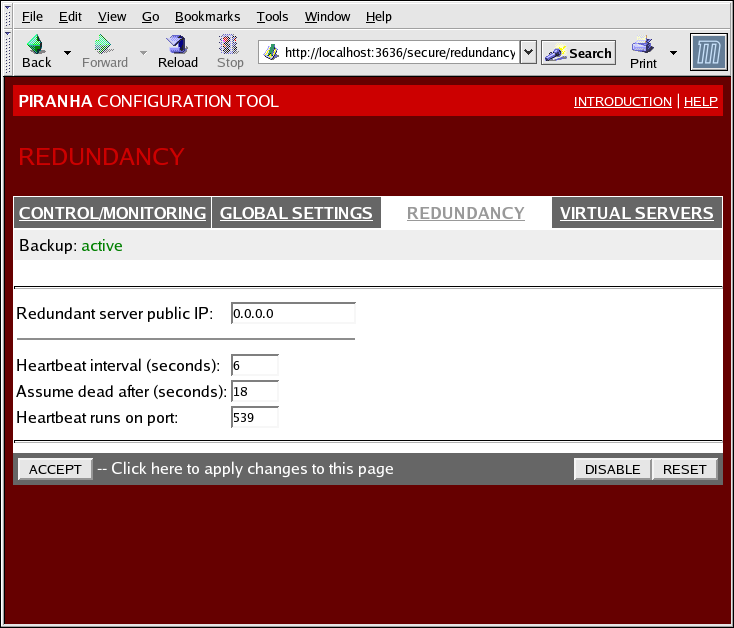
Abbildung 1.32. The REDUNDANCY Panel
- Redundant server public IP
- Die öffentliche reale IP-Adresse für den Backup-LVS-Router.
- Redundant server private IP
- The backup router's private real IP address.
- Heartbeat Interval (seconds)
- Stellt die Anzahl an Sekunden zwischen Heartbeats ein — Das Zeitintervall, im Rahmen dessen der Backup-Knoten den funktionalen Status des primären LVS-Knoten überprüft.
- Assume dead after (seconds)
- Falls der primäre LVS-Knoten nicht nach dieser Anzahl an Sekunden antwortet, leitet der Backup-LVS-Knoten die Ausfallsicherung ein.
- Heartbeat runs on port
- Stellt den Port ein, auf dem Heartbeat mit dem primären LVS-Knoten kommuniziert. Der Standardwert ist auf 539 eingestellt, falls dieses Feld leer gelassen wird.
1.10.4. VIRTUAL SERVERS

Abbildung 1.33. The VIRTUAL SERVERS Panel
1.10.4.1. Der Unterabschnitt VIRTUAL SERVER
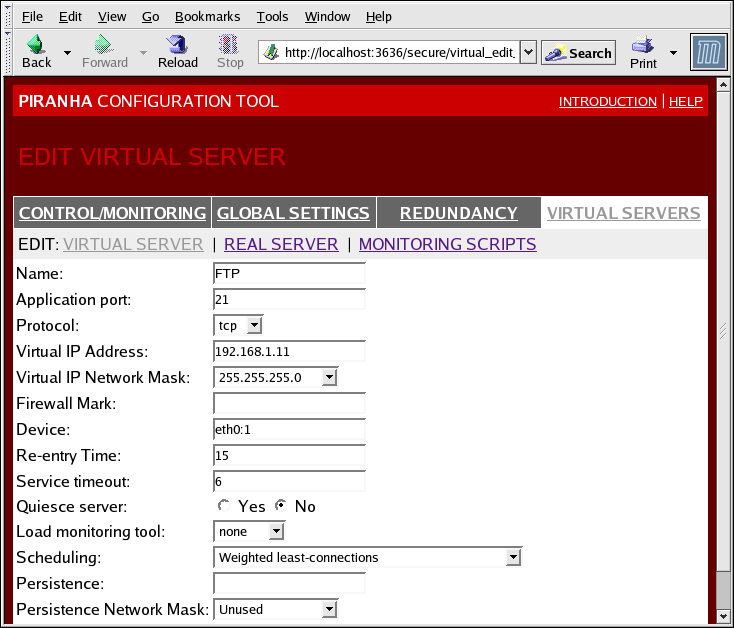
Abbildung 1.34. The VIRTUAL SERVERS Subsection
- Name
- Ein aussagekräftiger Name zur Identifizierung des virtuellen Server. Dieser Name ist nicht der Hostname für die Maschine und sollte daher veranschaulichend und einfach identifizierbar sein. Sie können sogar das Protokoll angeben, das vom virtuellen Server verwendet werden soll, wie zum Beispiel HTTP.
- Application port
- Die Portnummer, auf der die Dienst-Applikation horcht.
- Bietet eine Wahl zwischen UDP oder TCP, in einem Drop-Down-Menü.
- Virtual IP Address
- The virtual server's floating IP address.
- Die Netzmaske für diesen virtuellen Server, im Drop-Down-Menü.
- Firewall Mark
- Zur Eingabe eines ganzzahligen Wert für die Firewall-Markierung bei der Bündelung von Protokollen mit mehreren Ports oder zur Erstellung eines virtuellen Servers mit mehreren Ports für separate, aber benachbarte Protokolle.
- Device
- Der Name des Netzwerkgeräts, mit dem sich die im Feld Virtual IP Address definierte floating IP-Adresse verbinden soll.Sie sollten ein Alias für die öffentliche floating IP-Adresse zur Ethernet-Schnittstelle, die mit dem öffentlichen Netzwerk verbunden ist, erstellen.
- Re-entry Time
- Ein ganzzahliger Wert, der die Anzahl der Sekunden definiert, bevor der aktive LVS-Router versucht, einen realen Server zu verwenden, nachdem der reale Server ausgefallen ist.
- Service Timeout
- Ein ganzzahliger Wert, der die Anzahl der Sekunden definiert, bevor ein realer Server als funktionsuntüchtig und nicht verfügbar eingestuft wird.
- Quiesce server
- Wenn das Auswahlsymbol Quiesce server aktiviert ist, wird - jedes Mal, wenn ein neuer realer Server-Knoten online geht - die Tabelle mit den wenigsten Verbindungen auf Null zurückgesetzt, so dass der aktive LVS-Router Anfragen so routet, als ob alle realen Server frisch zum Cluster hinzugefügt wurden. Diese Optionen verhindert, dass sich ein neuer Server beim Eintreten in ein Cluster durch eine hohe Anzahl an Verbindungen verzettelt.
- Load monitoring tool
- Der LVS-Router kann die Auslastung auf verschiedenen realen Servern entweder mit Hilfe von
rupoderruptimeüberwachen. Falls Sierupaus dem Drop-Down-Menü auswählen muss auf jedem realen Server derrstatd-Dienst laufen. Falls Sieruptimeauswählen, muss auf jedem realen Server derrwhod-Dienst laufen. - Scheduling
- Der bevorzugte Scheduling-Algorithmus aus dem Drop-Down-Menü. Der Standardwert lautet
Weighted Least-Connection. - Persistence
- Wird verwendet, wenn Sie persistente Verbindungen mit dem virtuellen Server während Client-Transaktionen benötigen. Gibt die Zahl der Sekunden für Inaktivität an, bevor eine Verbindung in diesem Textfeld die Zeit überschreitet.
- Um die Persistenz für ein bestimmtes Subnetz einzuschränken, wählen Sie die entsprechende Netzwerkmaske aus dem Drop-Down-Menü.
1.10.4.2. REAL SERVER Unterabschnitt
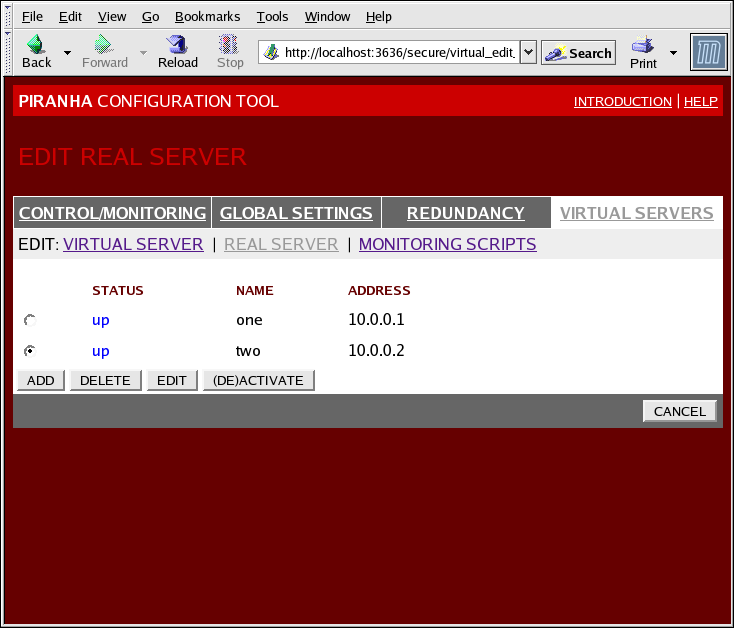
Abbildung 1.35. The REAL SERVER Subsection
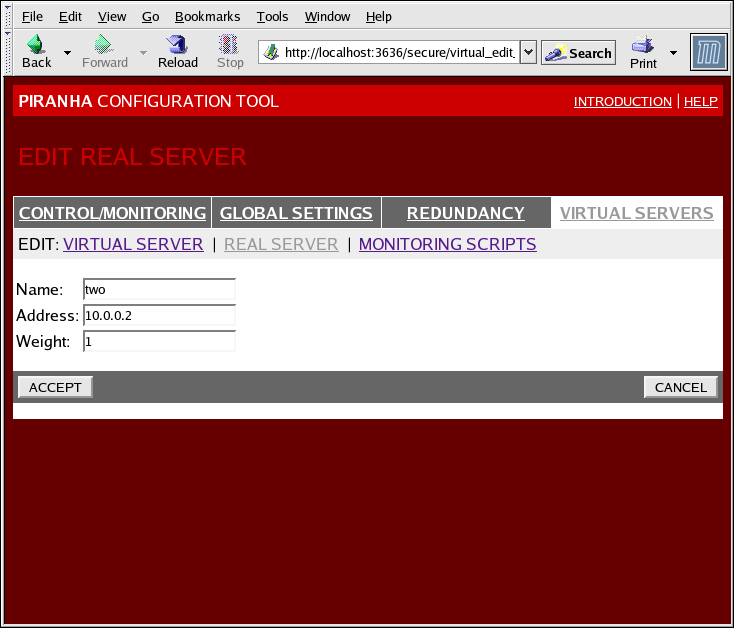
Abbildung 1.36. The REAL SERVER Configuration Panel
- Name
- Ein veranschaulichender Name für den realen Server.
Anmerkung
Dieser Name ist nicht der Hostname für die Maschine und sollte daher veranschaulichend und einfach identifizierbar sein. - Address
- The real server's IP address. Since the listening port is already specified for the associated virtual server, do not add a port number.
- Weight
- An integer value indicating this host's capacity relative to that of other hosts in the pool. The value can be arbitrary, but treat it as a ratio in relation to other real servers.
1.10.4.3. EDIT MONITORING SCRIPTS Subsection
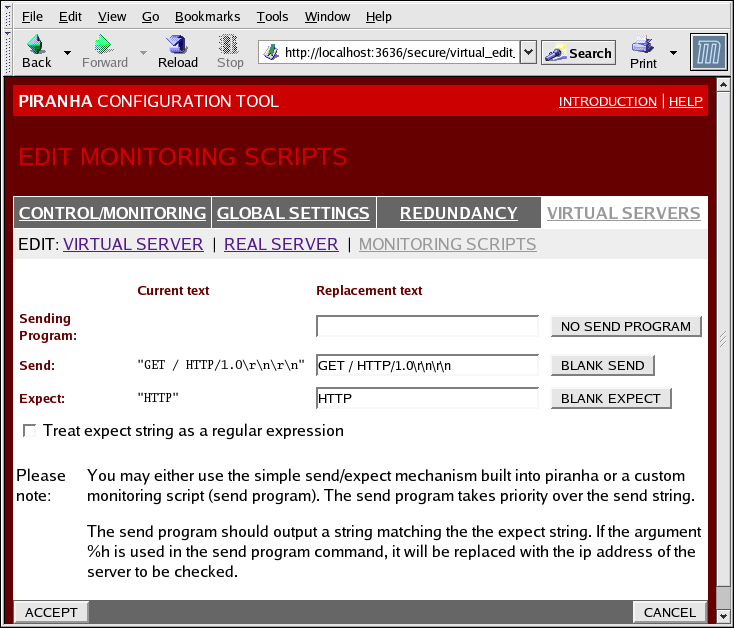
Abbildung 1.37. The EDIT MONITORING SCRIPTS Subsection
- Sending Program
- Zur etwas fortgeschrittenen Dienstverifizierung können Sie dieses Feld zur Angabe des Pfades zu einem Skript zur Überprüfung eines Dienstes verwenden. Diese Funktion ist besonders für Dienste hilfreich, die dynamisch verändernde Daten erfordern, wie beispielsweise HTTPS oder SSL.Um diese Funktion zu verwenden, müssen Sie ein Skript schreiben, das eine Antwort in Textform zurückgibt, dieses ausführbar machen und den Pfad im Feld Sending Program eingeben.
Anmerkung
Falls im Feld Sending Program ein externes Programm eingegeben wird, dann wird das Feld Send ignoriert. - Send
- Ein String für den
nanny-Daemon für das Versenden an jeden realen Server in diesem Feld. Standardmäßig wird das Feld 'Senden' für HTTP vervollständigt. Sie können diesen Wert gemäß Ihrer Anforderungen anpassen. Falls Sie dieses Feld leer lassen, versucht dernanny-Daemon, den Port zu öffnen und geht davon aus, dass der Dienst läuft, wenn er erfolgreich ist.Nur eine Send-Sequenz ist in diesem Feld gestattet und es kann nur druckbare, ASCII-Zeichen, sowie die folgenden Code-Umschaltzeichen enthalten:- \n für Zeilenumbruch.
- \r für Wagenrücklauf.
- \t für Tabulator.
- \ für den Escape des nächsten Zeichens, das darauf folgt.
- Expect
- Die Antwort in Textform, die der Server zurückgeben sollte, wenn er korrekt funktioniert. Falls Sie Ihre eigenes Programm zum Versenden geschrieben haben, geben Sie die von Ihnen vorgegebene zu versendende Antwort ein, falls es erfolgreich war.
Kapitel 2. Zusammenfassung der Komponenten der Red Hat Cluster Suite
2.1. Cluster-Komponenten
| Funktion | Komponenten | Beschreibung |
|---|---|---|
| Conga | luci | Remote-Management-System - Management-Station. |
ricci | Remote-Management-System - Verwaltete Station. | |
| Cluster Configuration Tool | system-config-cluster | Der Befehl, der zur Verwaltung einer Cluster-Konfiguration in einer grafischen Umgebung verwendet wird. |
| Cluster Logical Volume Manager (CLVM) | clvmd | Der Daemon, der Aktualisierungen von LVM-Metadaten in einem Cluster verteilt. Er muss auf allen Knoten im Cluster laufen und gibt einen Fehler zurück, falls der Daemon auf einem Knoten im Cluster nicht läuft. |
lvm | LVM2-Tools. Liefert die Kommandozeilen-Tools für LVM2. | |
system-config-lvm | Liefert die grafische Benutzeroberfläche für LVM2. | |
lvm.conf | Die Konfigurationsdatei für LVM. Der vollständige Pfad lautet /etc/lvm/lvm.conf.. | |
| Cluster Configuration System (CCS) | ccs_tool | ccs_tool ist Bestandteil des Cluster Configuration Systems (CCS). Es wird für Online-Aktualisierungen von CCS-Konfigurationsdateien verwendet. Zusätzlich kann es dazu verwendet werden, Cluster-Konfigurationsdateien von mit GFS 6.0 (oder älter) erstellten CCS-Archiven auf das in diesem Release der Red Hat Cluster Suite verwendete XML-Format-Konfigurationsformat zu verbessern. |
ccs_test | Ein Befehl zur Diagnose und zum Testen, der für das Abrufen von Informationen von Konfigurationsdateien via ccsd verwendet wird. | |
ccsd | Der CCS-Daemon, der auf allen Cluster-Knoten läuft und Konfigurationsdateidaten für die Cluster-Software bereitstellt. | |
cluster.conf | Dies ist die Cluster-Konfigurationsdatei. Der vollständige Pfad lautet /etc/cluster/cluster.conf. | |
| Cluster Manager (CMAN) | cman.ko | Das Kernelmodul für CMAN. |
cman_tool | Dies ist das administrative Front-End für CMAN. Es startet und stoppt CMAN und kann einige interne Parameter wie "votes" verändern. | |
dlm_controld | Der Daemon, der vom cman Init-Skript gestartet wird, um dlm im Kernel zu verwalten. Wird nicht vom Benutzer verwendet. | |
gfs_controld | Der Daemon, der vom cman Init-Skript gestartet wird, um gfs im Kernel zu verwalten. Wird nicht vom Benutzer verwendet. | |
group_tool | Wird dazu verwendet, um eine Liste von den Gruppen zu bekommen, die in Verbindung stehen mit "fencing", DLM, GFS und um Debug-Informationen abzurufen. Umfasst Funktionen, die in RHEL 4 durch cman_tool services zur Verfügung gestellt wurde. | |
groupd | Der Daemon, der vom cman Init-Skript gestartet wird, um zwischen openais/cman und dlm_controld/gfs_controld/fenced zu koordinieren. Wird vom Benutzer nicht verwendet. | |
libcman.so.<version number> | Die Bibliothek für Programme, die mit cman.ko interagieren müssen. | |
| Resource Group Manager (rgmanager) | clusvcadm | Der Befehl, der verwendet wird, um Benutzerdienste in einem Cluster manuell zu aktivieren, zu deaktivieren, zu verlagern und neu zu starten. |
clustat | Der Befehl, um den Status des Clusters anzuzeigen, inklusive der Knoten-Mitgliedschaften und der laufenden Dienste. | |
clurgmgrd | Der Daemon, der zur Verwertung der Benutzerdienstanfragen verwendet wird, inklusive Starten, Deaktivieren, Verlagerung und Neustart des Dienstes. | |
clurmtabd | Der Daemon, der zur Handhabung von geclusterten NFS-Mount-Tabellen verwendet wird. | |
| Fence | fence_apc | Fence-Agent für das APC-Netzteil. |
fence_bladecenter | Fence-Agent für IBM-Bladecenters mit Telnet-Schnittstelle. | |
fence_bullpap | Fence-Agent für die Bull Novascale Platform Administration Processor (PAP) Schnittstelle. | |
fence_drac | Fencing-Agent für die Dell Remote Access Card. | |
fence_ipmilan | Fence-Agent für Maschinen, die via LAN von IPMI (Intelligent Platform Management Interface) kontrolliert werden. | |
fence_wti | Fence-Agent für das WTI-Netzteil. | |
fence_brocade | Fence-Agent für den Brocade Fibre Channel Switch. | |
fence_mcdata | Fence-Agent für den McData Fibre Channel Switch. | |
fence_vixel | Fence-Agent für den Vixel Fibre Channel switch. | |
fence_sanbox2 | Fence-Agent für den SANBox2 Fibre Channel Switch. | |
fence_ilo | Fence-Agent für HP-ILO-Schnittstellen (formerly fence_rib). | |
fence_rsa | I/O Fencing-Agent für IBM RSA II. | |
fence_gnbd | Fence-Agent, der mit GNBD-Speicher verwendet wird. | |
fence_scsi | I/O Fencing-Agent für SCSI-persistente Reservierungen. | |
fence_egenera | Fence-Agent, der mit dem Egenera BladeFrame System verwendet wird. | |
fence_manual | Fence-Agent zur manuellen Interaktion. HINWEIS Diese Komponente wird für Produktionsumgebungen nicht unterstützt. | |
fence_ack_manual | Benutzerschnittstelle für den fence_manual-Agent. | |
fence_node | Ein Programm, dass IO-Fencing auf einem einzelnen Knoten durchführt. | |
fence_xvm | I/O-Fencing-Agent für virtuelle Xen-Maschinen. | |
fence_xvmd | I/O-Fencing-Agent-Host für virtuelle Xen-Maschinen. | |
fence_tool | Ein Programm zum Beitreten und Verlassen der Fence-Domain. | |
fenced | Der I/O Fencing-Daemon. | |
| DLM | libdlm.so.<version number> | Eine Bibliothek zur Unterstützung des Distributed Lock Manager (DLM). |
| GFS | gfs.ko | Kernelmodul, das das GFS-Dateisystem implementiert und auf GFS-Cluster-Knoten geladen wird. |
gfs_fsck | Ein Befehl, der ein nicht eingehängtes GFS-Dateisystem repariert. | |
gfs_grow | Ein Befehl, der ein eingehängtes GFS-Dateisystem vergrößert. | |
gfs_jadd | Ein Befehl, der Journals zu einem eingehängten GFS-Dateisystem hinzufügt. | |
gfs_mkfs | Ein Befehl, der ein GFS-Dateisystem auf einem Speichergerät erstellt. | |
gfs_quota | Ein Befehl, der Quotas auf einem eingehängten GFS-Dateisystem verwaltet. | |
gfs_tool | Ein Befehl, der ein GFS-Dateisystem konfiguriert oder tunt. Dieser Befehl kann weiterhin eine Vielfalt an Informationen über das Dateisystem sammeln. | |
mount.gfs | Mount-Hilfsprogramm, das von mount(8) aufgerufen wird. Wird vom Benutzer nicht verwendet. | |
| GNBD | gnbd.ko | Kernelmodul, das den GNBD-Gerätetreiber auf Clients implementiert. |
gnbd_export | Ein Befehl zum Erstellen, Exportieren und Verwalten von GNBDs auf einem GNBD-Server. | |
gnbd_import | Ein Befehl zum Importieren und Verwalten von GNBDs auf einem GNBD-Client. | |
gnbd_serv | Ein Server-Daemon, der einem Knoten gestattet, lokalen Speicher via Netzwerk zu exportieren. | |
| LVS | pulse | This is the controlling process which starts all other daemons related to LVS routers. At boot time, the daemon is started by the /etc/rc.d/init.d/pulse script. It then reads the configuration file /etc/sysconfig/ha/lvs.cf. On the active LVS router, pulse starts the LVS daemon. On the backup router, pulse determines the health of the active router by executing a simple heartbeat at a user-configurable interval. If the active LVS router fails to respond after a user-configurable interval, it initiates failover. During failover, pulse on the backup LVS router instructs the pulse daemon on the active LVS router to shut down all LVS services, starts the send_arp program to reassign the floating IP addresses to the backup LVS router's MAC address, and starts the lvs daemon. |
lvsd | Der lvs-Daemon läuft auf dem aktiven LVS-Router, sobald er von pulse aufgerufen wird. Er liest die Konfigurationsdatei /etc/sysconfig/ha/lvs.cf, ruft das Dienstprogramm ipvsadm auf, um die IPVS-Routing-Tabelle zu erstellen und zu pflegen und weist jedem konfigurierten LVS-Dienst einen nanny-Prozess zu. Falls nanny meldet, dass ein realer Server nicht mehr erreichbar ist, weist lvs das Dienstprogramm ipvsadm an, den realen Server aus der IPVS-Routing-Tabelle zu entfernen. | |
ipvsadm | Dieser Dienst aktualisiert die IPVS-Routing-Tabelle im Kernel. Der lvs-Daemon richtet LVS ein und verwaltet es, indem er ipvsadm aufruft, um Einträge in der IPVS-Routing-Tabelle hinzuzufügen, zu ändern oder zu löschen. | |
nanny | Der nanny Überwachungs-Daemon läuft auf dem aktiven LVS-Router. Mit Hilfe dieses Daemons bestimmt der aktive LVS-Router die Verfassung eines jeden realen Servers und überwacht optional dessen Arbeitsbelastung überwachen. Ein separater Prozess läuft für jeden Dienst, der auf jedem realen Server definiert ist. | |
lvs.cf | Dies ist die LVS-Konfigurationsdatei. Der vollständige Pfad für die Datei lautet /etc/sysconfig/ha/lvs.cf. Alle Daemons erhalten ihre Konfigurationsinformationen direkt oder indirekt von dieser Datei. | |
| Piranha Configuration Tool | Dies ist das webbasierte Tool zur Überwachung, Konfiguration und Administration von LVS. Es ist das Standard-Tool zur Pflege der LVS-Konfigurationsdatei /etc/sysconfig/ha/lvs.cf. | |
send_arp | Dieses Programm sendet während der Ausfallsicherung ARP-Broadcasts beim Übertragen von IP-Adressänderungen von einem Knoten auf einen anderen. | |
| Quorum-Platte | qdisk | Ein plattenbasierter Quorum-Daemon für CMAN- / Linux-Cluster. |
mkqdisk | Cluster-Quorum-Platten-Dienstprogramm. | |
qdiskd | Cluster-Quorum-Platten-Daemon. |
2.2. Handbuchseiten
- Cluster-Infrastruktur
- ccs_tool (8) - Das Tool, das für die Online-Aktualisierung von CCS-Konfigurationsdateien verwendet wird
- ccs_test (8) - Das Diagnose-Tool für ein laufendes Cluster Configuration System
- ccsd (8) - Der Daemon, der für den Zugriff auf CCS-Cluster-Konfigurationsdateien verwendet wird
- ccs (7) - Cluster Configuration System
- cman_tool (8) - Cluster Management Tool
- cluster.conf [cluster] (5) - Die Konfigurationsdatei für Cluster-Produkte
- qdisk (5) - Ein plattenbasierter Quorum-Daemon für CMAN- / Linux-Cluster
- mkqdisk (8) - Cluster-Quorum-Platten-Dienstprogramm
- qdiskd (8) - Cluster-Quorum-Platten-Daemon
- fence_ack_manual (8) - Ein Programm, das von einem Operator als ein Teil des manuellen I/O-Fencing ausgeführt wird
- fence_apc (8) - I/O-Fencing-Agent für APC MasterSwitch
- fence_bladecenter (8) - I/O-Fencing-Agent für IBM-Bladecenter
- fence_brocade (8) - I/O-Fencing-Agent für Brocade FC Switches
- fence_bullpap (8) - I/O-Fencing-Agent für die Bull FAME-Architektur, kontrolliert von einer PAP-Managment-Konsole
- fence_drac (8) - Fencing-Agent für die Dell Remote Access Card
- fence_egenera (8) - I/O-Fencing-Agent für das Egenera BladeFrame
- fence_gnbd (8) - I/O-Fencing-Agent für GNBD-basierte GFS-Cluster
- fence_ilo (8) - I/O-Fencing-Agent für die HP Integrated Lights Out Card
- fence_ipmilan (8) - I/O-Fencing-Agent für Maschinen, die von IPMI via LAN kontrolliert werden
- fence_manual (8) - Ein Programm, das von 'fenced' als Teil des manuellen I/O-Fencing ausgeführt wird.
- fence_mcdata (8) - I/O-Fencing-Agent für McData FC Switches
- fence_node (8) - Ein Programm, das I/O-Fencing auf einem einzelnen Knoten durchführt
- fence_rib (8) - I/O-Fencing-Agent für die Compaq Remote Insight Lights Out Card
- fence_rsa (8) - I/O-Fencing-Agent für IBM RSA II
- fence_sanbox2 (8) - I/O-Fencing-Agent für QLogic SANBox2 FC Switches
- fence_scsi (8) - I/O-Fencing-Agent für SCSI-persistente Reservierungen
- fence_tool (8) - Ein Programm zum Beitreten und Verlassen der Fence-Domain
- fence_vixel (8) - I/O-Fencing-Agent für Vixel FC Switches
- fence_wti (8) - I/O-Fencing-Agent für WTI Network Power Switch
- fence_xvm (8) - I/O-Fencing-Agent für virtuelle Xen-Maschinen
- fence_xvmd (8) - I/O-Fencing-Agent-Host für virtuelle Xen-Maschinen
- fenced (8) - Der I/O-Fencing-Daemon
- Hochverfügbarkeits-Service-Management
- clusvcadm (8) - Cluster User Service Administrations-Dienstprogramm
- clustat (8) - Cluster Status-Dienstprogramm
- Clurgmgrd [clurgmgrd] (8) - Resource Group (Cluster Service) Manager Daemon
- clurmtabd (8) - Cluster NFS Remote Mount Table Daemon
- GFS
- gfs_fsck (8) - Offline GFS-Dateisystem-Checker
- gfs_grow (8) - Vergrößern eines GFS-Dateisystems
- gfs_jadd (8) - Hinzufügen von Journals zu einem GFS-Dateisystem
- gfs_mount (8) - GFS-Einhängeoptionen
- gfs_quota (8) - GFS Platten-Quotas bearbeiten
- gfs_tool (8) - Schnittstelle für GFS ioctl-Aufrufe
- Cluster Logical-Volume-Manager
- clvmd (8) - Cluster-LVM-Daemon
- lvm (8) - LVM2-Tools
- lvm.conf [lvm] (5) - Konfigurationsdatei für LVM2
- lvmchange (8) - Attribute des Logical Volume Manager verändern
- pvcreate (8) - Eine Platte oder Partition für die Verwendung durch LVM initialisieren
- lvs (8) - Informationen über logische Datenträger ausgeben
- Global Network Blockgerät
- gnbd_export (8) - Die Schnittstelle, um GNBDs zu exportieren
- gnbd_import (8) - GNBD-Blockgeräte auf einem Client bearbeiten
- gnbd_serv (8) - GNBD Server-Daemon
- LVS
- pulse (8) - Heartbeating-Daemon zur Überwachung der Verfassung von Cluster-Knoten
- lvs.cf [lvs] (5) - Konfigurationsdatei für LVS
- lvscan (8) - Auf logische Datenträger überprüfen (alle Platten)
- lvsd (8) - Daemon zur Kontrolle der Red Hat Clustering-Dienste
- ipvsadm (8) - Linux Virtual Server Administration
- ipvsadm-restore (8) - Wiederherstellung der IPVS-Tabelle von stdin
- ipvsadm-save (8) - Speichern der IPVS-Tabelle nach stdout
- nanny (8) - Tool zur Überwachung des Status der Dienste in einem Cluster
- send_arp (8) - Tool zur Benachrichtigung des Netzwerks über eine neue IP-Adress- / MAC-Adress-Zuweisung
2.3. Kompatible Hardware
Anhang A. Revisionsverlauf
| Versionsgeschichte | |||
|---|---|---|---|
| Version 3-8.400 | 2013-10-31 | ||
| |||
| Version 3-8 | 2012-07-18 | ||
| |||
| Version 1.0-0 | Tue Jan 20 2008 | ||
| |||
Stichwortverzeichnis
C
- cluster
- displaying status, Cluster Status Tool
- cluster administration
- displaying cluster and service status, Cluster Status Tool
- cluster component compatible hardware, Kompatible Hardware
- cluster component man pages, Handbuchseiten
- cluster components table, Cluster-Komponenten
- Cluster Configuration Tool
- accessing, Cluster Configuration Tool
- cluster service
- displaying status, Cluster Status Tool
- command line tools table, Administrationstools für die Kommandozeile
- compatible hardware
- cluster components, Kompatible Hardware
- Conga
- overview, Conga
- Conga overview, Conga
F
- feedback, Feedback
I
- introduction, Einführung
- other Red Hat Enterprise Linux documents, Einführung
L
- LVS
- direct routing
- requirements, hardware, Direktes Routing
- requirements, network, Direktes Routing
- requirements, software, Direktes Routing
- routing methods
- NAT, Routing-Methoden
- three tiered
- high-availability cluster, Three-Tier LVS Topology
M
- man pages
- cluster components, Handbuchseiten
N
- NAT
- routing methods, LVS, Routing-Methoden
- network address translation (Siehe NAT)
O
- overview
- economy, Red Hat GFS
- performance, Red Hat GFS
- scalability, Red Hat GFS
P
- Piranha Configuration Tool
- CONTROL/MONITORING, CONTROL/MONITORING
- EDIT MONITORING SCRIPTS Subsection, EDIT MONITORING SCRIPTS Subsection
- GLOBAL SETTINGS, GLOBAL SETTINGS
- login panel, Linux Virtual Server Administrations-GUI
- necessary software, Linux Virtual Server Administrations-GUI
- REAL SERVER subsection, REAL SERVER Unterabschnitt
- REDUNDANCY, REDUNDANCY
- VIRTUAL SERVER subsection, VIRTUAL SERVERS
- Firewall Mark , Der Unterabschnitt VIRTUAL SERVER
- Persistence , Der Unterabschnitt VIRTUAL SERVER
- Scheduling , Der Unterabschnitt VIRTUAL SERVER
- Virtual IP Address , Der Unterabschnitt VIRTUAL SERVER
- VIRTUAL SERVERS, VIRTUAL SERVERS
R
- Red Hat Cluster Suite
- components, Cluster-Komponenten
T
- table
- cluster components, Cluster-Komponenten
- command line tools, Administrationstools für die Kommandozeile