在裸机上部署安装程序置备的集群
在裸机上部署安装程序置备的 OpenShift Container Platform 集群
摘要
第 1 章 概述
裸机节点上的安装程序置备安装会部署并配置运行 OpenShift Container Platform 集群的基础架构。本指南提供了一种成功实现安装程序置备的裸机安装的方法。下图演示了部署阶段 1 中的安装环境:

对于安装,上图中的关键元素是:
- Provisioner:运行安装程序的物理计算机,并托管部署新 OpenShift Container Platform 集群的控制平面的 bootstrap 虚拟机。
- Bootstrap 虚拟机 :部署 OpenShift Container Platform 集群过程中使用的虚拟机。
-
网络桥接 :bootstrap 虚拟机连接到裸机网络,如果存在,通过网桥
eno1和eno2连接到 provisioning 网络。 -
API VIP :API 虚拟 IP 地址 (VIP) 用于在 control plane 节点上提供 API 服务器的故障切换。API VIP 首先位于 bootstrap 虚拟机上。在启动服务前,脚本会生成
keepalived.conf配置文件。在 bootstrap 过程完成后,VIP 被移到一个 control plane 节点,bootstrap 虚拟机会停止。
在部署阶段 2 中,置备程序会自动销毁 bootstrap 虚拟机,并将虚拟 IP 地址 (VIP) 移到适当的节点。
keepalived.conf 文件会将 control plane 机器设置为其虚拟路由器冗余协议 (VRRP 优先级比 bootstrap 虚拟机的设置低,这样可确保在 API VIP 从 bootstrap 虚拟机移到控制平面机器前,控制平面上的 API 可以完全正常工作。当 API VIP 移动到其中一个 control plane 节点后,从外部客户端发送到 API VIP 路由的流量发送到该 control plane 节点上运行的 haproxy 负载均衡器。此 haproxy 实例在 control plane 节点之间负载均衡 API VIP 流量。
Ingress VIP 移到 worker 节点。keepalived 实例还管理 Ingress VIP。
下图演示了部署的阶段 2:

此时,置备程序使用的节点可以被移除或重新使用。在这里,所有额外的置备任务都由 control plane 执行。
对于安装程序置备的基础架构安装,CoreDNS 在节点级别公开端口 53,使其可以从其他可路由网络访问。
provisioning 网络是可选的,但 PXE 启动需要它。如果在没有 provisioning 网络的情况下部署,则必须使用虚拟介质管理控制器 (BMC) 寻址选项,如 redfish-virtualmedia 或 idrac-virtualmedia。
第 2 章 先决条件
OpenShift Container Platform 安装程序置备的安装需要:
- 安装了 Red Hat Enterprise Linux(RHEL) 9.x 的一个置备程序节点。在安装后可以删除置备程序。
- 三个 control plane 节点
- 对每个节点的 Baseboard 管理控制器 (BMC) 访问
至少一个网络:
- 一个必需的可路由网络
- 一个可选的 provisioning 网络
- 一个可选的管理网络
在开始 OpenShift Container Platform 安装程序置备的安装前,请确保硬件环境满足以下要求。
2.1. 节点要求
安装程序置备的安装涉及多个硬件节点要求:
-
CPU 架构: 所有节点都必须使用
x86_64或aarch64CPU 架构。 - 类似的节点: 红帽建议每个角色都有相同的配置。也就是说,红帽建议节点具有相同的品牌和型号,它们具有相同的 CPU、内存和存储配置。
-
Baseboard Management Controller:
provisioner节点必须能够访问每个 OpenShift Container Platform 集群节点的基板管理控制器(BMC)。您可以使用 IPMI、Redfish 或专有协议。 -
最新一代: 节点必须是最新一代。安装程序置备的安装依赖于 BMC 协议,这些协议必须在节点间兼容。另外,RHEL 9.x 附带了 RAID 控制器的最新驱动程序。确保节点足以支持
provisioner节点的 RHEL 9.x,支持 control plane 和 worker 节点的 RHCOS 9.x。 - registry 节点:( 可选)如果设置了一个断开连接的镜像 registry,建议 registry 驻留在自己的节点上。
-
provisioner 节点: 安装程序置备的安装需要一个
provisioner节点。 - control plane: 安装程序置备的安装需要三个 control plane 节点才能实现高可用性。您可以部署仅具有三个 control plane 节点的 OpenShift Container Platform 集群,使 control plane 节点可以作为 worker 节点调度。较小的集群在开发、生产和测试过程中为管理员和开发人员提供更多资源。
Worker 节点: 虽然不是必须的的,但典型的生产环境集群一般会有两个或者多个 worker 节点。
重要不要只部署一个 worker 节点的集群,因为集群将使用降级状态的路由器和入口流量进行部署。
网络接口: 每个节点必须至少有一个网络接口用于可路由的
baremetal网络。在使用provisioning网络进行部署时,每个节点都必须有一个网络接口用于provisioning网络。使用provisioning网络是默认配置。注意在同一子网上只能有一个网卡 (NIC) 可以通过网关路由流量。默认情况下,地址解析协议 (ARP) 使用编号最低的 NIC。对同一子网中的每个节点都使用一个单独的 NIC,以确保网络负载均衡按预期工作。当为同一子网中的一个节点使用多个 NIC 时,需要使用一个绑定或组接口。然后,以一个别名 IP 地址的形式将其他 IP 地址添加到该接口。如果您需要在网络接口级别进行容错或负载均衡,请在绑定或团队接口上使用别名 IP 地址。或者,您可以在同一子网中禁用二级 NIC,或者确保它没有 IP 地址。
统一可扩展固件接口(UEFI): 安装程序置备的安装需要在
置备网络中使用 IPv6 时在所有 OpenShift Container Platform 节点上进行 UEFI 引导。另外,UEFI Device PXE 设置必须设置为在provisioning网络 NIC 中使用 IPv6 协议,但忽略provisioning网络会删除这个要求。重要从 ISO 镜像启动安装时,删除所有旧的 UEFI 引导条目。如果引导条目包含不是固件提供通用条目的条目,则安装可能会失败。
安全引导: 许多生产环境中需要启用安全引导的节点来验证节点仅使用可信软件引导,如 UEFI 固件驱动程序、EFI 应用程序和操作系统。您可以使用安全引导手动或管理进行部署。
- 手动: 要使用安全引导机制手动部署 OpenShift Container Platform 集群,您必须在每个 control plane 节点上和每个 worker 节点上启用 UEFI 引导模式和安全引导。红帽支持仅在安装程序置备的安装使用 Redfish 虚拟介质时手动启用 UEFI 和安全引导。如需了解更多详细信息,请参阅"配置节点"一节中的"手动配置安全引导节点"。
Managed: 要使用受管安全引导机制部署 OpenShift Container Platform 集群,您必须在
install-config.yaml文件中将bootMode值设置为UEFISecureBoot。红帽仅在第 10 代 HPE 硬件和 13 代运行固件版本2.75.75.75或更高版本的 Dell 硬件中支持带受管安全引导的安装程序置备安装。使用受管安全引导进行部署不需要 Redfish 虚拟介质。详情请参阅"为 OpenShift 安装设置环境"一节中的"配置受管安全引导"。注意红帽不支持为安全引导管理自生成的密钥或其他密钥。
2.2. 集群安装的最低资源要求
每台集群机器都必须满足以下最低要求:
| 机器 | 操作系统 | CPU [1] | RAM | Storage | 每秒输入/输出 (IOPS) [2] |
|---|---|---|---|---|---|
| bootstrap | RHEL | 4 | 16 GB | 100 GB | 300 |
| Control plane(控制平面) | RHCOS | 4 | 16 GB | 100 GB | 300 |
| Compute | RHCOS | 2 | 8 GB | 100 GB | 300 |
- 当未启用并发多线程 (SMT) 或超线程时,一个 CPU 相当于一个物理内核。启用后,使用以下公式来计算对应的比例:(每个内核数的线程)× sockets = CPU。
- OpenShift Container Platform 和 Kubernetes 对磁盘性能敏感,建议使用更快的存储,特别是 control plane 节点上的 etcd。请注意,在许多云平台上,存储大小和 IOPS 可一起扩展,因此您可能需要过度分配存储卷来获取足够的性能。
从 OpenShift Container Platform 版本 4.13 开始,RHCOS 基于 RHEL 版本 9.2,它更新了微架构要求。以下列表包含每个架构需要的最小指令集架构 (ISA):
- x86-64 体系结构需要 x86-64-v2 ISA
- ARM64 架构需要 ARMv8.0-A ISA
- IBM Power 架构需要 Power 9 ISA
- s390x 架构需要 z14 ISA
如需更多信息,请参阅 RHEL 架构。
如果平台的实例类型满足集群机器的最低要求,则 OpenShift Container Platform 支持使用它。
2.3. 为 OpenShift Virtualization 规划裸机集群
如果使用 OpenShift Virtualization,必须在安装裸机集群前了解一些要求。
如果要使用实时迁移功能,在集群安装时需要有多个 worker 节点。这是因为实时迁移需要集群级别的高可用性 (HA) 标记设置为 true。当安装集群时,会设置 HA 标志,之后无法更改。如果在安装集群时定义少于两个 worker 节点,则集群生命周期中的 HA 标记被设置为 false。
注意您可以在单节点集群中安装 OpenShift Virtualization,但单节点 OpenShift 不支持高可用性。
- 实时迁移需要共享存储。OpenShift Virtualization 的存储必须支持并使用 ReadWriteMany (RWX) 访问模式。
- 如果您计划使用单根 I/O 虚拟化 (SR-IOV),请确保 OpenShift Container Platform 支持网络接口控制器 (NIC)。
2.4. 使用虚拟介质安装的固件要求
安装程序置备的 OpenShift Container Platform 集群的安装程序会验证与 Redfish 虚拟介质的硬件和固件兼容性。如果节点固件不兼容,安装程序不会在节点上开始安装。下表列出了经过测试并验证以使用 Redfish 虚拟介质部署的安装程序置备的 OpenShift Container Platform 集群的最低固件版本。
红帽不测试固件、硬件或其他第三方组件的组合。有关第三方支持的更多信息,请参阅红帽第三方支持政策。有关更新固件的详情,请查看硬件文档了解节点或联系硬件厂商。
| model | 管理 | 固件版本 |
|---|---|---|
| 第 10 代 | iLO5 | 2.63 或更高版本 |
| model | 管理 | 固件版本 |
|---|---|---|
| 第 15 代 | iDRAC 9 | v6.10.30.00 |
| 第 14 代 | iDRAC 9 | v6.10.30.00 |
| 第 13 代 | iDRAC 8 | v2.75.75.75 或更高版本 |
2.5. 网络要求
OpenShift Container Platform 安装程序置备的安装涉及多网络要求。首先,安装程序置备的安装涉及一个可选的不可路由 置备 网络,用于在每个裸机节点上置备操作系统。其次,安装程序置备的安装涉及一个可路由的 baremetal 网络。
2.5.1. 确保打开所需的端口
某些端口必须在集群节点之间打开,才能成功完成安装程序置备的安装。在某些情况下,比如在边缘 worker 节点中使用单独的子网,您必须确保这些子网中的节点可以与以下所需端口上其他子网中的节点通信。
| port | 描述 |
|---|---|
|
|
在使用 provisioning 网络时,集群节点使用端口 |
|
|
在使用 provisioning 网络时,集群节点使用它们的置备网络接口与端口 |
|
|
如果没有使用镜像缓存选项或使用虚拟介质,则 provisioner 节点必须在 |
|
|
集群节点必须使用 |
|
|
Ironic Inspector API 在 control plane 节点上运行,并侦听端口 |
|
|
端口 |
|
|
当使用虚拟介质而不是 TLS 部署时,provisioner 节点和 control plane 节点必须在 |
|
|
当使用虚拟介质并使用 TLS 部署时,provisioner 节点和 control plane 节点必须在 |
|
|
Ironic API 服务器最初在 bootstrap 虚拟机上运行,稍后在 control plane 节点上运行,并侦听端口 |
|
|
端口 |
|
|
在不使用 TLS 的情况下使用镜像缓存时,必须在 provisioner 节点上打开端口 |
|
|
当将镜像缓存选项与 TLS 搭配使用时,必须在 provisioner 节点上打开端口 |
|
|
默认情况下,Ironic Python 代理(IPA)侦听来自 Ironic 编排器服务的 API 调用的 TCP 端口 |
2.5.2. 增加网络 MTU
在部署 OpenShift Container Platform 前,将网络最大传输单元 (MTU) 增加到 1500 或更多。如果 MTU 小于 1500,用于引导节点的 Ironic 镜像可能无法与 Ironic 检查 pod 通信,检查将失败。如果发生了这种情况,安装会停止,因为节点无法用于安装。
2.5.3. 配置 NIC
OpenShift Container Platform 使用两个网络部署:
provisioning:置备网络是一个可选的不可路由的网络,用于在作为 OpenShift Container Platform 集群一部分的每个节点上置备底层操作系统。每个集群节点上provisioning网络的网络接口必须将 BIOS 或 UEFI 配置为 PXE 引导。provisioningNetworkInterface配置设置指定 control plane 节点上的provisioning网络 NIC 名称,它在 control plane 节点上必须相同。bootMACAddress配置设置提供了一种方法,用于在每个节点上为provisioning网络指定特定的 NIC。调配网络是可选的,但 PXE 引导需要该网络。如果您在没有provisioning网络的情况下部署,则必须使用虚拟介质 BMC 寻址选项,如redfish-virtualmedia或idrac-virtualmedia。-
baremetal:baremetal网络是一个可路由的网络。您可以使用任何 NIC 与baremetal 网络进行接口,只要 NIC 没有配置为使用provisioning网络。
在使用 VLAN 时,每个 NIC 必须位于与相应网络对应的独立 VLAN 中。
2.5.4. DNS 要求
客户端通过 baremetal 网络访问 OpenShift Container Platform 集群节点。网络管理员必须配置子域或子区,其中规范名称扩展是集群名称。
<cluster_name>.<base_domain>例如:
test-cluster.example.comOpenShift Container Platform 包含使用集群成员资格信息来生成 A/AAAA 记录的功能。这会将节点名称解析为其 IP 地址。使用 API 注册节点后,集群可以在不使用 CoreDNS-mDNS 的情况下分散节点信息。这可消除与多播 DNS 关联的网络流量。
CoreDNS 需要 TCP 和 UDP 连接到上游 DNS 服务器才能正常工作。确保上游 DNS 服务器可以从 OpenShift Container Platform 集群节点接收 TCP 和 UDP 连接。
在 OpenShift Container Platform 部署中,以下组件需要 DNS 名称解析:
- The Kubernetes API
- OpenShift Container Platform 应用程序通配符入口 API
A/AAAA 记录用于名称解析,而 PTR 记录用于反向名称解析。Red Hat Enterprise Linux CoreOS(RHCOS)使用反向记录或 DHCP 为所有节点设置主机名。
安装程序置备的安装包括使用集群成员资格信息生成 A/AAAA 记录的功能。这会将节点名称解析为其 IP 地址。在每个记录中,<cluster_name> 是集群名称,<base_domain> 是您在 install-config.yaml 文件中指定的基域。完整的 DNS 记录采用以下形式: <component>.<cluster_name>.<base_domain>.。
| 组件 | 记录 | 描述 |
|---|---|---|
| Kubernetes API |
| A/AAAA 记录和 PTR 记录可识别 API 负载均衡器。这些记录必须由集群外的客户端和集群中的所有节点解析。 |
| Routes |
| 通配符 A/AAAA 记录指的是应用程序入口负载均衡器。应用程序入口负载均衡器以运行 Ingress Controller pod 的节点为目标。默认情况下,Ingress Controller pod 在 worker 节点上运行。这些记录必须由集群外的客户端和集群中的所有节点解析。
例如,console |
您可以使用 dig 命令验证 DNS 解析。
2.5.5. 动态主机配置协议(DHCP)要求
默认情况下,安装程序置备的安装会在 provisioning 网络启用了 DHCP 的情况下部署 ironic-dnsmasq。当 provisioningNetwork 配置设置为 managed 时(默认值),不能有其他 DHCP 服务器在 provisioning 网络中运行。如果您在 provisioning 网络上运行 DHCP 服务器,则必须在 install-config.yaml 文件中将 provisioningNetwork 配置设置设置为 非受管。
网络管理员必须为 OpenShift Container Platform 集群中的各个节点为外部 DHCP 服务器上的 baremetal 网络 保留 IP 地址。
2.5.6. 使用 DHCP 服务器为节点保留 IP 地址
对于 baremetal 网络,网络管理员必须保留几个 IP 地址,包括:
两个唯一的虚拟 IP 地址。
- API 端点的一个虚拟 IP 地址。
- 一个用于通配符入口端点的虚拟 IP 地址。
- 一个用于 provisioner 节点的 IP 地址。
- 每个 control plane 节点有一个 IP 地址。
- 每个 worker 节点有一个 IP 地址(如果适用)。
有些管理员更喜欢使用静态 IP 地址,以便在没有 DHCP 服务器时每个节点的 IP 地址保持恒定状态。要使用 NMState 配置静态 IP 地址,请参阅"设置 OpenShift 安装环境"部分中的" (可选)配置节点网络接口"。
当使用 VLAN 在负载均衡服务和 control plane 节点之间路由流量时,外部负载平衡服务和 control plane 节点必须在同一个 L2 网络上运行,并使用 VLAN 来路由负载平衡服务和 control plane 节点之间的流量。
存储接口需要 DHCP 保留或静态 IP。
下表提供了完全限定域名的实例化。API 和 Nameserver 地址以规范名称扩展开头。control plane 和 worker 节点的主机名是示例,您可以使用您喜欢的任何主机命名规则。
| 用法 | 主机名 | IP |
|---|---|---|
| API |
|
|
| Ingress LB(apps) |
|
|
| provisioner 节点 |
|
|
| control-plane-0 |
|
|
| Control-plane-1 |
|
|
| Control-plane-2 |
|
|
| Worker-0 |
|
|
| Worker-1 |
|
|
| Worker-n |
|
|
如果您不创建 DHCP 保留,安装程序需要反向 DNS 解析来为 Kubernetes API 节点、provisioner 节点、control plane 节点和 worker 节点设置主机名。
2.5.7. provisioner 节点要求
您必须在安装配置中为 provisioner 节点指定 MAC 地址。bootMacAddress 规范通常与 PXE 网络引导关联。但是,Ironic 置备服务还需要 bootMacAddress 规格,以便在检查集群期间或集群中重新部署节点时识别节点。
provisioner 节点需要第 2 层连接才能进行网络引导、DHCP 和 DNS 解析,以及本地网络通信。provisioner 节点需要第 3 层连接才能进行虚拟介质引导。
2.5.8. 网络时间协议(NTP)
集群中的每个 OpenShift Container Platform 节点都必须有权访问 NTP 服务器。OpenShift Container Platform 节点使用 NTP 来同步其时钟。例如,集群节点使用需要验证的 SSL/TLS 证书,如果节点之间的日期和时间未同步,则可能会失败。
在每个群集节点的 BIOS 设置中定义一致的时钟日期和时间格式,或者安装可能会失败。
您可以重新配置 control plane 节点,作为断开连接的集群中的 NTP 服务器,并重新配置 worker 节点以从 control plane 节点检索时间。
2.5.9. 带外管理 IP 地址的端口访问
带外管理 IP 地址位于与节点分开的网络中。为确保带外管理可以在安装过程中与 provisioner 节点通信,带外管理 IP 地址必须被授予对 provisioner 节点和 OpenShift Container Platform control plane 节点上端口 6180 的访问权限。虚拟介质安装需要 TLS 端口 6183,例如使用 Redfish。
2.6. 配置节点
在使用 provisioning 网络时配置节点
集群中的每个节点都需要以下配置才能正确安装。
在节点间不匹配将导致安装失败。
虽然集群节点可以包含多于 2 个 NIC,但安装过程只关注于前两个 NIC:在下表中,NIC1 是一个不可路由的网络(置备),它仅用于安装 OpenShift Container Platform 集群。
| NIC | 网络 | VLAN |
|---|---|---|
| NIC1 |
|
|
| NIC2 |
|
|
provisioner 节点上的 Red Hat Enterprise Linux(RHEL) 9.x 安装过程可能会有所不同。要使用本地 Satellite 服务器或 PXE 服务器安装 Red Hat Enterprise Linux(RHEL) 9.x,PXE 启用 NIC2。
| PXE | 引导顺序 |
|---|---|
|
NIC1 PXE-enabled | 1 |
|
NIC2 | 2 |
确保在所有其他 NIC 上禁用 PXE。
配置 control plane 和 worker 节点,如下所示:
| PXE | 引导顺序 |
|---|---|
| NIC1 PXE-enabled(调配网络) | 1 |
在没有 provisioning 网络的情况下配置节点
安装过程需要一个 NIC:
| NIC | 网络 | VLAN |
|---|---|---|
| NICx |
|
|
NICx 是一个可路由的网络(baremetal),用于安装 OpenShift Container Platform 集群,并可路由到互联网。
调配 网络是可选的,但 PXE 引导需要该网络。如果您在没有 provisioning 网络的情况下部署,则必须使用虚拟介质 BMC 寻址选项,如 redfish-virtualmedia 或 idrac-virtualmedia。
为安全引导手动配置节点
安全引导可防止节点引导,除非它只验证节点只使用可信软件,如 UEFI 固件驱动程序、EFI 应用程序和操作系统。
红帽仅在使用 Redfish 虚拟介质部署时支持手动配置安全引导机制。
要手动启用安全引导,请参阅节点的硬件指南并执行以下内容:
流程
- 引导节点并进入 BIOS 菜单。
-
将节点的引导模式设置为
UEFI Enabled。 - 启用安全引导.
红帽不支持使用自生成的密钥进行安全引导。
2.7. 带外管理
节点通常有一个额外的 NIC,供 Baseboard Management Controller(BMC)使用。这些 BMC 必须可以从 provisioner 节点访问。
每个节点必须通过带外管理进行访问。在使用带外管理网络时,provisioner 节点需要访问带外管理网络才能成功安装 OpenShift Container Platform。
带外管理设置超出了本文档的范围。使用单独的管理网络进行带外管理可能会提高性能并提高安全性。但是,使用 provisioning 网络或 baremetal 网络是有效的选项。
bootstrap 虚拟机具有最多两个网络接口。如果您为带外管理配置一个单独的管理网络,并且您使用 provisioning 网络,bootstrap 虚拟机需要通过其中一个网络接口路由到管理网络。在这种情况下,bootstrap 虚拟机可以访问三个网络:
- 裸机网络
- provisioning 网络
- 通过其中一个网络接口的管理网络
2.8. 安装所需的数据
在安装 OpenShift Container Platform 集群前,从所有集群节点收集以下信息:
带外管理 IP
示例
- Dell(iDRAC)IP
- HP(iLO)IP
- Fujitsu(iRMC)IP
在使用 provisioning 网络时
-
NIC(
置备)MAC 地址 -
NIC(
裸机)MAC 地址
在省略 provisioning 网络时
-
NIC(
裸机)MAC 地址
2.9. 节点验证清单
在使用 provisioning 网络时
-
❏ 为
provisioning网络配置了 NIC1 VLAN。 -
❏
置备网络的 NIC1 在 provisioner、control plane 和 worker 节点上启用了 PXE。 -
❏ 为
baremetal 网络配置了 NIC2 VLAN。 - ❏ PXE 在所有其他 NIC 上都被禁用。
- ❏ DNS 被配置为使用 API 和 Ingress 端点。
- ❏ 已配置 control plane 和 worker 节点。
- ❏ 所有节点都可通过带外管理访问。
- ❏ (可选)已创建一个单独的管理网络。
- ❏ 安装所需的数据。
在省略 provisioning 网络时
-
❏ 为
baremetal网络配置了 NIC1 VLAN。 - ❏ DNS 被配置为使用 API 和 Ingress 端点。
- ❏ 已配置 control plane 和 worker 节点。
- ❏ 所有节点都可通过带外管理访问。
- ❏ (可选)已创建一个单独的管理网络。
- ❏ 安装所需的数据。
第 3 章 为 OpenShift 安装设置环境
3.1. 在置备程序节点上安装 RHEL
完成先决条件后,下一步是在置备程序节点上安装 RHEL 9.x。安装 OpenShift Container Platform 集群时,安装程序使用 provisioner 节点作为编配器。在本文档中,在 provisioner 节点上安装 RHEL 超出了范围。但是,选项包括但不限于使用 RHEL Satellite 服务器、PXE 或安装介质。
3.2. 为 OpenShift Container Platform 安装准备 provisioner 节点
执行以下步骤准备环境。
流程
-
通过
ssh登录到 provisioner 节点。 创建非 root 用户(
kni)并为该用户提供sudo权限:# useradd kni# passwd kni# echo "kni ALL=(root) NOPASSWD:ALL" | tee -a /etc/sudoers.d/kni# chmod 0440 /etc/sudoers.d/kni为新用户创建
ssh密钥:# su - kni -c "ssh-keygen -t ed25519 -f /home/kni/.ssh/id_rsa -N ''"以新用户身份登录到 provisioner 节点:
# su - kni使用 Red Hat Subscription Manager 注册 provisioner 节点:
$ sudo subscription-manager register --username=<user> --password=<pass> --auto-attach$ sudo subscription-manager repos --enable=rhel-9-for-<architecture>-appstream-rpms --enable=rhel-9-for-<architecture>-baseos-rpms注意有关 Red Hat Subscription Manager 的详情,请参考 使用和配置 Red Hat Subscription Manager。
安装以下软件包:
$ sudo dnf install -y libvirt qemu-kvm mkisofs python3-devel jq ipmitool修改用户,将
libvirt组添加到新创建的用户:$ sudo usermod --append --groups libvirt <user>重启
firewalld并启用http服务:$ sudo systemctl start firewalld$ sudo firewall-cmd --zone=public --add-service=http --permanent$ sudo firewall-cmd --reload启动并启用
libvirtd服务:$ sudo systemctl enable libvirtd --now创建
默认存储池并启动它:$ sudo virsh pool-define-as --name default --type dir --target /var/lib/libvirt/images$ sudo virsh pool-start default$ sudo virsh pool-autostart default创建
pull-secret.txt文件:$ vim pull-secret.txt在 Web 浏览器中,进入 Install OpenShift on Bare Metal with installer-provisioned infrastructure。点 Copy pull secret。将内容粘贴到
pull-secret.txt文件中,并将内容保存到kni用户的主目录中。
3.3. 检查 NTP 服务器同步
OpenShift Container Platform 安装程序在集群节点上安装 chrony 网络时间协议(NTP)服务。要完成安装,每个节点都必须有权访问 NTP 时间服务器。您可以使用 chrony 服务验证 NTP 服务器同步。
对于断开连接的集群,您必须在 control plane 节点上配置 NTP 服务器。如需更多信息,请参阅附加资源部分。
先决条件
-
在目标节点上安装了
chrony软件包。
流程
-
使用
ssh命令登录节点。 运行以下命令,查看节点可用的 NTP 服务器:
$ chronyc sources输出示例
MS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^+ time.cloudflare.com 3 10 377 187 -209us[ -209us] +/- 32ms ^+ t1.time.ir2.yahoo.com 2 10 377 185 -4382us[-4382us] +/- 23ms ^+ time.cloudflare.com 3 10 377 198 -996us[-1220us] +/- 33ms ^* brenbox.westnet.ie 1 10 377 193 -9538us[-9761us] +/- 24ms使用
ping命令确保节点可以访问 NTP 服务器,例如:$ ping time.cloudflare.com输出示例
PING time.cloudflare.com (162.159.200.123) 56(84) bytes of data. 64 bytes from time.cloudflare.com (162.159.200.123): icmp_seq=1 ttl=54 time=32.3 ms 64 bytes from time.cloudflare.com (162.159.200.123): icmp_seq=2 ttl=54 time=30.9 ms 64 bytes from time.cloudflare.com (162.159.200.123): icmp_seq=3 ttl=54 time=36.7 ms ...
3.4. 配置网络
在安装前,您必须在 provisioner 节点上配置网络。安装程序置备的集群使用裸机网桥和网络部署,以及可选的 provisioning 网桥和网络。
您还可以从 Web 控制台配置网络。
流程
运行以下命令导出裸机网络 NIC 名称:
$ export PUB_CONN=<baremetal_nic_name>配置裸机网络:
注意执行这些步骤后 SSH 连接可能会断开。
对于使用 DHCP 的网络,运行以下命令:
$ sudo nohup bash -c " nmcli con down \"$PUB_CONN\" nmcli con delete \"$PUB_CONN\" # RHEL 8.1 appends the word \"System\" in front of the connection, delete in case it exists nmcli con down \"System $PUB_CONN\" nmcli con delete \"System $PUB_CONN\" nmcli connection add ifname baremetal type bridge <con_name> baremetal bridge.stp no1 nmcli con add type bridge-slave ifname \"$PUB_CONN\" master baremetal pkill dhclient;dhclient baremetal "- 1
- 将
<con_name>替换为连接名称。
对于使用静态 IP 地址并且没有 DHCP 的网络,请运行以下命令:
$ sudo nohup bash -c " nmcli con down \"$PUB_CONN\" nmcli con delete \"$PUB_CONN\" # RHEL 8.1 appends the word \"System\" in front of the connection, delete in case it exists nmcli con down \"System $PUB_CONN\" nmcli con delete \"System $PUB_CONN\" nmcli connection add ifname baremetal type bridge con-name baremetal bridge.stp no ipv4.method manual ipv4.addr "x.x.x.x/yy" ipv4.gateway "a.a.a.a" ipv4.dns "b.b.b.b"1 nmcli con add type bridge-slave ifname \"$PUB_CONN\" master baremetal nmcli con up baremetal "- 1
- 将
<con_name>替换为连接名称。将x.x.x.x/yy替换为网络的 IP 地址和 CIDR。将a.a.a.a替换为网络网关。将b.b.b.b替换为 DNS 服务器的 IP 地址。
可选:如果您使用 provisioning 网络部署,请运行以下命令导出 provisioning 网络 NIC 名称:
$ export PROV_CONN=<prov_nic_name>可选:如果您使用 provisioning 网络部署,请运行以下命令配置 provisioning 网络:
$ sudo nohup bash -c " nmcli con down \"$PROV_CONN\" nmcli con delete \"$PROV_CONN\" nmcli connection add ifname provisioning type bridge con-name provisioning nmcli con add type bridge-slave ifname \"$PROV_CONN\" master provisioning nmcli connection modify provisioning ipv6.addresses fd00:1101::1/64 ipv6.method manual nmcli con down provisioning nmcli con up provisioning "注意执行这些步骤后 SSH 连接可能会断开。
IPv6 地址可以是任何无法通过裸机网络路由的地址。
在使用 IPv6 地址时,请确保启用了 UEFI,并将 UEFI PXE 设置设置为 IPv6 协议。
可选:如果您使用 provisioning 网络部署,请运行以下命令在 provisioning 网络连接上配置 IPv4 地址:
$ nmcli connection modify provisioning ipv4.addresses 172.22.0.254/24 ipv4.method manual运行以下命令,重新 SSH 到
provisioner节点(如果需要):# ssh kni@provisioner.<cluster-name>.<domain>运行以下命令验证连接网桥是否已正确创建:
$ sudo nmcli con show输出示例
NAME UUID TYPE DEVICE baremetal 4d5133a5-8351-4bb9-bfd4-3af264801530 bridge baremetal provisioning 43942805-017f-4d7d-a2c2-7cb3324482ed bridge provisioning virbr0 d9bca40f-eee1-410b-8879-a2d4bb0465e7 bridge virbr0 bridge-slave-eno1 76a8ed50-c7e5-4999-b4f6-6d9014dd0812 ethernet eno1 bridge-slave-eno2 f31c3353-54b7-48de-893a-02d2b34c4736 ethernet eno2
3.5. 在子网间建立通信
在典型的 OpenShift Container Platform 集群设置中,所有节点(包括 control plane 和 worker 节点)都驻留在同一网络中。但是,对于边缘计算场景,找到接近边缘的 worker 节点会很有用。这通常涉及为与 control plane 和本地 worker 节点使用的子网不同的远程 worker 节点使用不同的网络片段或子网。此类设置可以降低边缘的延迟并允许增强的可扩展性。但是,在安装 OpenShift Container Platform 前,必须正确配置网络,以确保包含远程 worker 节点的边缘子网可以访问包含 control plane 节点的子网,并从 control plane 节点接收流量。
所有 control plane 节点必须在同一子网中运行。当使用多个子网时,您还可以使用清单将 Ingress VIP 配置为在 control plane 节点上运行。详情请参阅"配置要在 control plane 上运行的网络组件"。
使用多个子网部署集群需要使用虚拟介质。
此流程详细介绍了允许第二个子网中的远程 worker 节点与第一个子网中的 control plane 节点有效通信所需的网络配置,并允许第一个子网中的 control plane 节点与第二个子网中的远程 worker 节点有效通信。
在此过程中,集群跨越两个子网:
-
第一个子网 (
10.0.0.0) 包含 control plane 和本地 worker 节点。 -
第二个子网 (
192.168.0.0) 包含边缘工作程序节点。
流程
配置第一个子网与第二个子网通信:
运行以下命令,以
root用户身份登录 control plane 节点:$ sudo su -运行以下命令,获取网络接口的名称:
# nmcli dev status运行以下命令,通过网关向第二个子网(
192.168.0.0)添加路由:# nmcli connection modify <interface_name> +ipv4.routes "192.168.0.0/24 via <gateway>"将
<interface_name>替换为接口名称。使用实际网关的 IP 地址替换<gateway>。示例
# nmcli connection modify eth0 +ipv4.routes "192.168.0.0/24 via 192.168.0.1"运行以下命令来应用更改:
# nmcli connection up <interface_name>将
<interface_name>替换为接口名称。验证路由表以确保路由已被成功添加:
# ip route对第一个子网中的每个 control plane 节点重复前面的步骤。
注意调整命令以匹配您的实际接口名称和网关。
将第二个子网配置为与第一个子网通信:
运行以下命令,以
root用户身份登录远程 worker 节点:$ sudo su -运行以下命令,获取网络接口的名称:
# nmcli dev status运行以下命令,通过网关向第一个子网(
10.0.0.0)添加路由:# nmcli connection modify <interface_name> +ipv4.routes "10.0.0.0/24 via <gateway>"将
<interface_name>替换为接口名称。使用实际网关的 IP 地址替换<gateway>。示例
# nmcli connection modify eth0 +ipv4.routes "10.0.0.0/24 via 10.0.0.1"运行以下命令来应用更改:
# nmcli connection up <interface_name>将
<interface_name>替换为接口名称。运行以下命令,验证路由表以确保路由已被成功添加:
# ip route对第二个子网中的每个 worker 节点重复前面的步骤。
注意调整命令以匹配您的实际接口名称和网关。
配置网络后,测试连接以确保远程 worker 节点可以访问 control plane 节点,control plane 节点可以访问远程 worker 节点。
从第一个子网中的 control plane 节点,运行以下命令来在第二个子网中 ping 远程 worker 节点:
$ ping <remote_worker_node_ip_address>如果 ping 成功,这意味着第一个子网中的 control plane 节点可以访问第二个子网中的远程 worker 节点。如果您没有收到响应,请检查网络配置并重复该节点的步骤。
从第二个子网中的远程 worker 节点,运行以下命令来在第一个子网中 ping control plane 节点:
$ ping <control_plane_node_ip_address>如果 ping 成功,则意味着第二个子网中的远程 worker 节点可以访问第一个子网中的 control plane。如果您没有收到响应,请检查网络配置并重复该节点的步骤。
3.6. 检索 OpenShift Container Platform 安装程序
使用安装程序的 stable-4.x 版本和您选择的架构来部署 OpenShift Container Platform 的一般稳定版本:
$ export VERSION=stable-4.14$ export RELEASE_ARCH=<architecture>$ export RELEASE_IMAGE=$(curl -s https://mirror.openshift.com/pub/openshift-v4/$RELEASE_ARCH/clients/ocp/$VERSION/release.txt | grep 'Pull From: quay.io' | awk -F ' ' '{print $3}')3.7. 提取 OpenShift Container Platform 安装程序
在获取安装程序后,下一步是提取它。
流程
设置环境变量:
$ export cmd=openshift-baremetal-install$ export pullsecret_file=~/pull-secret.txt$ export extract_dir=$(pwd)获取
oc二进制文件:$ curl -s https://mirror.openshift.com/pub/openshift-v4/clients/ocp/$VERSION/openshift-client-linux.tar.gz | tar zxvf - oc解压安装程序:
$ sudo cp oc /usr/local/bin$ oc adm release extract --registry-config "${pullsecret_file}" --command=$cmd --to "${extract_dir}" ${RELEASE_IMAGE}$ sudo cp openshift-baremetal-install /usr/local/bin
3.8. 可选:创建 RHCOS 镜像缓存
要使用镜像缓存,您必须下载 bootstrap 虚拟机使用的 Red Hat Enterprise Linux CoreOS(RHCOS)镜像,以置备集群节点。镜像缓存是可选的,但在有限带宽的网络中运行安装程序时特别有用。
安装程序不再需要 clusterOSImage RHCOS 镜像,因为正确的镜像位于发行版本有效负载中。
如果您在带有有限带宽的网络中运行安装程序,且 RHCOS 镜像下载时间超过 15 到 20 分钟,安装程序会超时。在这种情况下,将映像缓存到 Web 服务器上将有所帮助。
如果为 HTTPD 服务器启用 TLS,您必须确认 root 证书由客户端信任的颁发机构签名,并验证 OpenShift Container Platform hub 和 spoke 集群和 HTTPD 服务器之间的可信证书链。使用配置了不受信任的证书的服务器可防止将镜像下载到创建镜像中。不支持使用不受信任的 HTTPS 服务器。
安装包含镜像的容器。
流程
安装
podman:$ sudo dnf install -y podman打开防火墙端口
8080以用于 RHCOS 镜像缓存:$ sudo firewall-cmd --add-port=8080/tcp --zone=public --permanent$ sudo firewall-cmd --reload创建用于存储
bootstraposimage的目录:$ mkdir /home/kni/rhcos_image_cache为新创建的目录设置适当的 SELinux 上下文:
$ sudo semanage fcontext -a -t httpd_sys_content_t "/home/kni/rhcos_image_cache(/.*)?"$ sudo restorecon -Rv /home/kni/rhcos_image_cache/获取安装程序要在 bootstrap 虚拟机上部署的 RHCOS 镜像的 URI:
$ export RHCOS_QEMU_URI=$(/usr/local/bin/openshift-baremetal-install coreos print-stream-json | jq -r --arg ARCH "$(arch)" '.architectures[$ARCH].artifacts.qemu.formats["qcow2.gz"].disk.location')获取安装程序要在 bootstrap 虚拟机上部署的镜像名称:
$ export RHCOS_QEMU_NAME=${RHCOS_QEMU_URI##*/}获取要在 bootstrap 虚拟机上部署的 RHCOS 镜像的 SHA 哈希:
$ export RHCOS_QEMU_UNCOMPRESSED_SHA256=$(/usr/local/bin/openshift-baremetal-install coreos print-stream-json | jq -r --arg ARCH "$(arch)" '.architectures[$ARCH].artifacts.qemu.formats["qcow2.gz"].disk["uncompressed-sha256"]')下载镜像并将其放在
/home/kni/rhcos_image_cache目录中:$ curl -L ${RHCOS_QEMU_URI} -o /home/kni/rhcos_image_cache/${RHCOS_QEMU_NAME}为新文件确认 SELinux 类型为
httpd_sys_content_t:$ ls -Z /home/kni/rhcos_image_cache创建 pod:
$ podman run -d --name rhcos_image_cache \1 -v /home/kni/rhcos_image_cache:/var/www/html \ -p 8080:8080/tcp \ registry.access.redhat.com/ubi9/httpd-24- 1
- 创建名为
rhcos_image_cache的缓存 webserver。此 pod 在install-config.yaml文件中为部署提供bootstrapOSImage镜像。
生成
bootstrapOSImage配置:$ export BAREMETAL_IP=$(ip addr show dev baremetal | awk '/inet /{print $2}' | cut -d"/" -f1)$ export BOOTSTRAP_OS_IMAGE="http://${BAREMETAL_IP}:8080/${RHCOS_QEMU_NAME}?sha256=${RHCOS_QEMU_UNCOMPRESSED_SHA256}"$ echo " bootstrapOSImage=${BOOTSTRAP_OS_IMAGE}"在 platform.
baremetal下将所需的配置添加到install-config.yaml文件中:platform: baremetal: bootstrapOSImage: <bootstrap_os_image>1 - 1
- 将
<bootstrap_os_image>替换为$BOOTSTRAP_OS_IMAGE的值。
如需了解更多详细信息,请参阅"配置 install-config.yaml 文件"部分。
3.9. 通过 DHCP 设置集群节点主机名
在 Red Hat Enterprise Linux CoreOS (RHCOS)机器上,NetworkManager 会设置主机名。默认情况下,DHCP 为 NetworkManager 提供主机名,这是推荐的方法。在以下情况下,NetworkManager 通过反向 DNS 查找获取主机名:
- 如果 DHCP 不提供主机名
- 如果您使用内核参数设置主机名
- 如果您使用其它方法设置主机名
反向 DNS 查找发生在网络在节点上初始化后,并可增加 NetworkManager 设置主机名所需的时间。其他系统服务可以在 NetworkManager 设置主机名之前启动,这可能会导致这些服务使用默认的主机名,如 localhost。
您可以使用 DHCP 为每个集群节点提供主机名,以避免在分配主机名时避免此延迟。另外,通过 DHCP 设置主机名可以绕过实施 DNS split-horizon 的环境中的手动 DNS 记录名称配置错误。
3.10. 配置 install-config.yaml 文件
3.10.1. 配置 install-config.yaml 文件
install-config.yaml 文件需要一些额外的详情。大多数信息都教授安装程序,生成的集群有足够的集群来完全管理它。
安装程序不再需要 clusterOSImage RHCOS 镜像,因为正确的镜像位于发行版本有效负载中。
配置
install-config.yaml。更改适当的变量以匹配环境,包括pullSecret和sshKey:apiVersion: v1 baseDomain: <domain> metadata: name: <cluster_name> networking: machineNetwork: - cidr: <public_cidr> networkType: OVNKubernetes compute: - name: worker replicas: 21 controlPlane: name: master replicas: 3 platform: baremetal: {} platform: baremetal: apiVIPs: - <api_ip> ingressVIPs: - <wildcard_ip> provisioningNetworkCIDR: <CIDR> bootstrapExternalStaticIP: <bootstrap_static_ip_address>2 bootstrapExternalStaticGateway: <bootstrap_static_gateway>3 bootstrapExternalStaticDNS: <bootstrap_static_dns>4 hosts: - name: openshift-master-0 role: master bmc: address: ipmi://<out_of_band_ip>5 username: <user> password: <password> bootMACAddress: <NIC1_mac_address> rootDeviceHints: deviceName: "<installation_disk_drive_path>"6 - name: <openshift_master_1> role: master bmc: address: ipmi://<out_of_band_ip> username: <user> password: <password> bootMACAddress: <NIC1_mac_address> rootDeviceHints: deviceName: "<installation_disk_drive_path>" - name: <openshift_master_2> role: master bmc: address: ipmi://<out_of_band_ip> username: <user> password: <password> bootMACAddress: <NIC1_mac_address> rootDeviceHints: deviceName: "<installation_disk_drive_path>" - name: <openshift_worker_0> role: worker bmc: address: ipmi://<out_of_band_ip> username: <user> password: <password> bootMACAddress: <NIC1_mac_address> - name: <openshift_worker_1> role: worker bmc: address: ipmi://<out_of_band_ip> username: <user> password: <password> bootMACAddress: <NIC1_mac_address> rootDeviceHints: deviceName: "<installation_disk_drive_path>" pullSecret: '<pull_secret>' sshKey: '<ssh_pub_key>'- 1
- 根据作为 OpenShift Container Platform 集群一部分的 worker 节点数量,扩展 worker 机器。
replicas值可以是0,以及大于或等于2的整数。将副本数设置为0以部署一个三节点集群,该集群仅包含三个 control plane 机器。三节点集群是一个较小的、效率更高的集群,可用于测试、开发和生产。您不能只使用一个 worker 安装集群。 - 2
- 当使用静态 IP 地址部署集群时,您必须设置
bootstrapExternalStaticIP配置设置,以便在裸机网络上没有 DHCP 服务器时可以指定 bootstrap 虚拟机的静态 IP 地址。 - 3
- 当使用静态 IP 地址部署集群时,您必须设置
bootstrapExternalStaticGateway配置设置,以便当裸机网络上没有 DHCP 服务器时可以为 bootstrap 虚拟机指定网关 IP 地址。 - 4
- 当使用静态 IP 地址部署集群时,您必须设置
bootstrapExternalStaticDNS配置设置,以便在裸机网络上没有 DHCP 服务器时指定 bootstrap 虚拟机的 DNS 地址。 - 5
- 如需了解更多选项,请参阅 BMC 寻址部分。
- 6
- 要设置安装磁盘驱动器的路径,请输入磁盘的内核名称。例如:
/dev/sda。重要由于磁盘发现顺序无法保证,因此磁盘的内核名称可以在具有多个磁盘的机器的引导选项之间更改。例如:
/dev/sda变为/dev/sdb,反之亦然。要避免这个问题,您必须使用持久性磁盘属性,如 disk World Wide Name (WWN) 或/dev/disk/by-path/。建议您使用/dev/disk/by-path/<device_path>链接到存储位置。要使用磁盘 WWN,请将deviceName参数替换为wwnWithExtension参数。根据您使用的参数,输入以下值之一:-
磁盘名称。例如:
/dev/sda或/dev/disk/by-path/。 -
磁盘 WWN。例如,
"0x64cd98f04fde100024684cf3034da5c2"。确保您在引号中输入磁盘 WWN 值,使其用作字符串值,而不是十六进制值。
无法满足
rootDeviceHints参数的这些要求可能会导致以下错误:ironic-inspector inspection failed: No disks satisfied root device hints -
磁盘名称。例如:
注意在 OpenShift Container Platform 4.12 之前,集群安装程序只接受
apiVIP和ingressVIP配置设置的 IPv4 地址或 IPv6 地址。在 OpenShift Container Platform 4.12 及更新的版本中,这些配置设置已弃用。反之,使用apiVIPs和ingressVIPs配置设置中的列表格式来指定 IPv4 地址、IPv6 地址或两个 IP 地址格式。创建用于存储集群配置的目录:
$ mkdir ~/clusterconfigs将
install-config.yaml文件复制到新目录中:$ cp install-config.yaml ~/clusterconfigs在安装 OpenShift Container Platform 集群前,请确保关闭所有裸机节点:
$ ipmitool -I lanplus -U <user> -P <password> -H <management-server-ip> power off如果以前的部署尝试中保留了旧的 bootstrap 资源,请删除旧的 bootstrap 资源:
for i in $(sudo virsh list | tail -n +3 | grep bootstrap | awk {'print $2'}); do sudo virsh destroy $i; sudo virsh undefine $i; sudo virsh vol-delete $i --pool $i; sudo virsh vol-delete $i.ign --pool $i; sudo virsh pool-destroy $i; sudo virsh pool-undefine $i; done
3.10.2. 其他 install-config 参数
下表列出了 install-config.yaml 文件所需的 参数、hosts 参数和 bmc 参数。
| 参数 | default | 描述 |
|---|---|---|
|
|
集群的域名。例如: | |
|
|
|
节点的引导模式。选项为 |
|
|
bootstrap 节点的静态网络 DNS。当裸机网络上没有动态主机配置协议 (DHCP) 服务器时,您必须使用静态 IP 地址部署集群时设置这个值。如果没有设置这个值,安装程序将使用 | |
|
| bootstrap 虚拟机的静态 IP 地址。当 bare-metal 网络中没有 DHCP 服务器时部署使用静态 IP 地址的集群时,必须设置这个值。 | |
|
| bootstrap 虚拟机网关的静态 IP 地址。当 bare-metal 网络中没有 DHCP 服务器时部署使用静态 IP 地址的集群时,必须设置这个值。 | |
|
|
| |
|
|
| |
|
提供给 OpenShift Container Platform 集群的名称。例如: | |
|
外部网络的公共 CIDR(Classless Inter-Domain Routing)。例如: | |
| OpenShift Container Platform 集群需要为 worker(或计算节点)节点提供一个名称,即使没有节点也是如此。 | |
| replicas 设置 OpenShift Container Platform 集群中 worker(或计算)节点的数量。 | |
| OpenShift Container Platform 集群需要一个 control plane(master)节点的名称。 | |
| replicas 设置作为 OpenShift Container Platform 集群一部分的 control plane(master)节点数量。 | |
|
|
连接到 provisioning 网络的节点上的网络接口名称。对于 OpenShift Container Platform 4.9 及更新的版本,使用 | |
|
| 用于没有平台配置的机器池的默认配置。 | |
|
| (可选)用于 Kubernetes API 通信的虚拟 IP 地址。
此设置必须在 注意
在 OpenShift Container Platform 4.12 之前,集群安装程序只接受 | |
|
|
|
|
|
| (可选)入口流量的虚拟 IP 地址。
此设置必须在 注意
在 OpenShift Container Platform 4.12 之前,集群安装程序只接受 |
| 参数 | default | 描述 |
|---|---|---|
|
|
| 定义 provisioning 网络上节点的 IP 范围。 |
|
|
| 用于置备的网络的 CIDR。在 provisioning 网络中不使用默认地址范围时需要这个选项。 |
|
|
|
运行置备服务的集群中的 IP 地址。默认为 provisioning 子网的第三个 IP 地址。例如: |
|
|
|
在安装程序部署 control plane(master)节点时运行置备服务的 bootstrap 虚拟机上的 IP 地址。默认为 provisioning 子网的第二个 IP 地址。例如: |
|
|
| 附加到裸机网络的虚拟机监控程序的裸机网桥名称。 |
|
|
|
附加到 provisioning 网络的 |
|
|
定义集群的主机架构。有效值为 | |
|
| 用于没有平台配置的机器池的默认配置。 | |
|
|
用于覆盖 bootstrap 节点的默认操作系统镜像的 URL。URL 必须包含镜像的 SHA-256 哈希。例如: | |
|
|
| |
|
| 将此参数设置为环境中使用的适当 HTTP 代理。 | |
|
| 将此参数设置为环境中使用的适当 HTTPS 代理。 | |
|
| 将此参数设置为适合环境中代理使用的排除项。 |
主机
hosts 参数是用于构建集群的独立裸机资产列表。
| 名称 | default | 描述 |
|---|---|---|
|
|
与详细信息 | |
|
|
裸机节点的角色。 | |
|
| 基板管理控制器的连接详情。如需了解更多详细信息,请参阅 BMC 寻址部分。 | |
|
|
主机用于 provisioning 网络的 NIC 的 MAC 地址。Ironic 使用 注意 如果您禁用了 provisioning 网络,则必须从主机提供有效的 MAC 地址。 | |
|
| 设置此可选参数来配置主机的网络接口。如需了解更多详细信息,请参阅"(可选)配置主机网络接口"。 |
3.10.3. BMC 地址
大多数供应商支持使用智能平台管理接口(IPMI)寻址的基板管理控制器(BMC)。IPMI 不加密通信。它适用于通过安全或专用管理网络在数据中心内使用。检查您的供应商,了解它们是否支持 Redfish 网络引导。RedFish 为融合、混合型 IT 和软件定义型数据中心(SDDC)提供简单而安全的管理。RedFish 是人类可读的,能够使用通用的互联网和 Web 服务标准将信息直接公开给现代工具链。如果您的硬件不支持 Redfish 网络引导,请使用 IPMI。
IPMI
使用 IPMI 的主机使用 ipmi://<out-of-band-ip>:<port> 地址格式,如果未指定则默认为端口 623。以下示例演示了 install-config.yaml 文件中的 IPMI 配置。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: ipmi://<out-of-band-ip>
username: <user>
password: <password>
当 PXE 引导使用 IPMI 进行 BMC 寻址时,需要 provisioning 网络。没有 provisioning 网络,就无法 PXE 引导主机。如果您在没有 provisioning 网络的情况下部署,则必须使用虚拟介质 BMC 寻址选项,如 redfish-virtualmedia 或 idrac-virtualmedia。详情请查看 "Redfish 虚拟介质 for HPE iLO" 部分的"适用于 HPE iLO 的 BMC 寻址"部分或"适用于戴尔 iDRAC 的"红帽虚拟媒体"部分中的"红帽虚拟介质"。
RedFish 网络引导
要启用 Redfish,请使用 redfish:// 或 redfish+http:// 禁用 TLS。安装程序需要主机名或 IP 地址,以及系统 ID 的路径。以下示例演示了 install-config.yaml 文件中的 Redfish 配置。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish://<out-of-band-ip>/redfish/v1/Systems/1
username: <user>
password: <password>
虽然建议为带外管理地址提供颁发机构证书,但在使用自签名证书时,您必须在 bmc 配置中包含 disableCertificateVerification: True。以下示例演示了在 install-config.yaml 文件中使用 disableCertificateVerification: True 配置参数的 Redfish 配置。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish://<out-of-band-ip>/redfish/v1/Systems/1
username: <user>
password: <password>
disableCertificateVerification: TrueRedfish API
在使用裸机安装程序置备的基础架构时,在您的 BCM 中调用几个 redfish API 端点。
您需要在安装前确保 BMC 支持所有 redfish API。
- redfish API 列表
开机
curl -u $USER:$PASS -X POST -H'Content-Type: application/json' -H'Accept: application/json' -d '{"ResetType": "On"}' https://$SERVER/redfish/v1/Systems/$SystemID/Actions/ComputerSystem.Reset关闭
curl -u $USER:$PASS -X POST -H'Content-Type: application/json' -H'Accept: application/json' -d '{"ResetType": "ForceOff"}' https://$SERVER/redfish/v1/Systems/$SystemID/Actions/ComputerSystem.Reset使用
pxe临时引导curl -u $USER:$PASS -X PATCH -H "Content-Type: application/json" https://$Server/redfish/v1/Systems/$SystemID/ -d '{"Boot": {"BootSourceOverrideTarget": "pxe", "BootSourceOverrideEnabled": "Once"}}使用
Legacy或UEFI设置 BIOS 引导模式curl -u $USER:$PASS -X PATCH -H "Content-Type: application/json" https://$Server/redfish/v1/Systems/$SystemID/ -d '{"Boot": {"BootSourceOverrideMode":"UEFI"}}
- redfish-virtualmedia API 列表
使用
cd或dvd设置临时引导设备curl -u $USER:$PASS -X PATCH -H "Content-Type: application/json" https://$Server/redfish/v1/Systems/$SystemID/ -d '{"Boot": {"BootSourceOverrideTarget": "cd", "BootSourceOverrideEnabled": "Once"}}'挂载虚拟介质
curl -u $USER:$PASS -X PATCH -H "Content-Type: application/json" -H "If-Match: *" https://$Server/redfish/v1/Managers/$ManagerID/VirtualMedia/$VmediaId -d '{"Image": "https://example.com/test.iso", "TransferProtocolType": "HTTPS", "UserName": "", "Password":""}'
redfish API 的 PowerOn 和 PowerOff 命令与 redfish-virtualmedia API 相同。
HTTPS 和 HTTP 是 TransferProtocolTypes 唯一支持的参数类型。
3.10.4. 适用于 Dell iDRAC 的 BMC 寻址
每个 bmc 条目 的地址 字段是连接到 OpenShift Container Platform 集群节点的 URL,包括 URL 方案中的控制器类型及其网络中的位置。
platform:
baremetal:
hosts:
- name: <hostname>
role: <master | worker>
bmc:
address: <address>
username: <user>
password: <password>- 1
地址配置设置指定协议。
对于 Dell 硬件,红帽支持集成 Dell Remote Access Controller(iDRAC)虚拟介质、Redfish 网络引导和 IPMI。
Dell iDRAC 的 BMC 地址格式
| 协议 | 地址格式 |
|---|---|
| iDRAC 虚拟介质 |
|
| RedFish 网络引导 |
|
| IPMI |
|
使用 idrac-virtualmedia 作为 Redfish 虚拟介质的协议。RedFish-virtualmedia 无法在 Dell 硬件上运行。Dell 的 idrac-virtualmedia 使用带 Dell OEM 扩展的 Redfish 标准。
详情请查看以下部分。
Dell iDRAC 的 RedFish 虚拟介质
对于 Dell 服务器上的 Redfish 虚拟介质,在 address 设置中使用 idrac-virtualmedia://。使用 redfish-virtualmedia:// 无法正常工作。
使用 idrac-virtualmedia:// 作为 Redfish 虚拟介质的协议。使用 redfish-virtualmedia:// 无法在 Dell 硬件中工作,因为 idrac-virtualmedia:// 协议与 Ironic 中的 idrac 硬件类型和 Redfish 协议对应。Dell 的 idrac-virtualmedia:// 协议使用带有 Dell OEM 扩展的 Redfish 标准。Ironic 还支持带有 WSMAN 协议的 idrac 类型。因此,您必须指定 idrac-virtualmedia://,以避免在 Dell 硬件上选择使用 Redfish 和虚拟介质时出现意外行为。
以下示例演示了在 install-config.yaml 文件中使用 iDRAC 虚拟介质。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: idrac-virtualmedia://<out-of-band-ip>/redfish/v1/Systems/System.Embedded.1
username: <user>
password: <password>
虽然建议为带外管理地址提供颁发机构证书,但在使用自签名证书时,您必须在 bmc 配置中包含 disableCertificateVerification: True。
通过 iDRAC 控制台,确保 OpenShift Container Platform 集群节点启用了 AutoAttach。菜单路径为: Configuration → Virtual Media → Attach Mode → AutoAttach。
以下示例演示了在 install-config.yaml 文件中使用 disableCertificateVerification: True 配置参数的 Redfish 配置。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: idrac-virtualmedia://<out-of-band-ip>/redfish/v1/Systems/System.Embedded.1
username: <user>
password: <password>
disableCertificateVerification: TrueiDRAC 的 RedFish 网络引导
要启用 Redfish,请使用 redfish:// 或 redfish+http:// 禁用传输层安全(TLS)。安装程序需要主机名或 IP 地址,以及系统 ID 的路径。以下示例演示了 install-config.yaml 文件中的 Redfish 配置。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish://<out-of-band-ip>/redfish/v1/Systems/System.Embedded.1
username: <user>
password: <password>
虽然建议为带外管理地址提供颁发机构证书,但在使用自签名证书时,您必须在 bmc 配置中包含 disableCertificateVerification: True。以下示例演示了在 install-config.yaml 文件中使用 disableCertificateVerification: True 配置参数的 Redfish 配置。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish://<out-of-band-ip>/redfish/v1/Systems/System.Embedded.1
username: <user>
password: <password>
disableCertificateVerification: True
Dell iDRAC 9 中存在一个已知问题,带有固件版本 04.40.00.00,所有版本都包括 5xx 系列,用于裸机部署中的安装程序置备安装。虚拟控制台插件默认为 eHTML5,它是 HTML5 的增强版本,这会导致 InsertVirtualMedia 工作流出现问题。将插件设置为使用 HTML5 以避免出现这个问题。菜单路径为 Configuration → Virtual console → Plug-in Type → HTML5。
通过 iDRAC 控制台,确保 OpenShift Container Platform 集群节点启用了 AutoAttach。菜单路径为: Configuration → Virtual Media → Attach Mode → AutoAttach。
3.10.5. HPE iLO 的 BMC 寻址
每个 bmc 条目 的地址 字段是连接到 OpenShift Container Platform 集群节点的 URL,包括 URL 方案中的控制器类型及其网络中的位置。
platform:
baremetal:
hosts:
- name: <hostname>
role: <master | worker>
bmc:
address: <address>
username: <user>
password: <password>- 1
地址配置设置指定协议。
对于 HPE 集成 Lights Out(iLO),红帽支持红帽虚拟媒体、Redfish 网络引导和 IPMI。
| 协议 | 地址格式 |
|---|---|
| RedFish 虚拟介质 |
|
| RedFish 网络引导 |
|
| IPMI |
|
详情请查看以下部分。
HPE iLO 的 RedFish 虚拟介质
要为 HPE 服务器启用 Redfish 虚拟介质,请在 address 设置中使用 redfish-virtualmedia://。以下示例演示了在 install-config.yaml 文件中使用 Redfish 虚拟介质。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish-virtualmedia://<out-of-band-ip>/redfish/v1/Systems/1
username: <user>
password: <password>
虽然建议为带外管理地址提供颁发机构证书,但在使用自签名证书时,您必须在 bmc 配置中包含 disableCertificateVerification: True。以下示例演示了在 install-config.yaml 文件中使用 disableCertificateVerification: True 配置参数的 Redfish 配置。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish-virtualmedia://<out-of-band-ip>/redfish/v1/Systems/1
username: <user>
password: <password>
disableCertificateVerification: True运行 iLO4 的 9 代系统上不支持 RedFish 虚拟介质,因为 Ironic 不支持使用虚拟介质的 iLO4。
HPE iLO 的 RedFish 网络引导
要启用 Redfish,请使用 redfish:// 或 redfish+http:// 禁用 TLS。安装程序需要主机名或 IP 地址,以及系统 ID 的路径。以下示例演示了 install-config.yaml 文件中的 Redfish 配置。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish://<out-of-band-ip>/redfish/v1/Systems/1
username: <user>
password: <password>
虽然建议为带外管理地址提供颁发机构证书,但在使用自签名证书时,您必须在 bmc 配置中包含 disableCertificateVerification: True。以下示例演示了在 install-config.yaml 文件中使用 disableCertificateVerification: True 配置参数的 Redfish 配置。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish://<out-of-band-ip>/redfish/v1/Systems/1
username: <user>
password: <password>
disableCertificateVerification: True3.10.6. Fujitsu iRMC 的 BMC 寻址
每个 bmc 条目 的地址 字段是连接到 OpenShift Container Platform 集群节点的 URL,包括 URL 方案中的控制器类型及其网络中的位置。
platform:
baremetal:
hosts:
- name: <hostname>
role: <master | worker>
bmc:
address: <address>
username: <user>
password: <password>- 1
地址配置设置指定协议。
对于富士通硬件,红帽支持集成远程管理控制器(iRMC)和 IPMI。
| 协议 | 地址格式 |
|---|---|
| iRMC |
|
| IPMI |
|
iRMC
Fujitsu 节点可以使用 irmc://<out-of-band-ip>,默认为端口 443。以下示例演示了 install-config.yaml 文件中的 iRMC 配置。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: irmc://<out-of-band-ip>
username: <user>
password: <password>目前,Fujitsu 支持 iRMC S5 固件版本 3.05 及更高版本用于裸机上的安装程序置备安装。
3.10.7. Root 设备提示
rootDeviceHints 参数可让安装程序将 Red Hat Enterprise Linux CoreOS(RHCOS)镜像置备到特定的设备。安装程序会按照发现设备的顺序检查设备,并将发现的值与 hint 值进行比较。安装程序使用第一个与 hint 值匹配的发现设备。配置可以组合多个 hint,但设备必须与所有提示匹配,以便安装程序进行选择。
| 子字段 | 描述 |
|---|---|
|
|
包含 Linux 设备名称的字符串(如 |
|
|
包含类似 |
|
| 包含特定厂商的设备标识符的字符串。hint 可以是实际值的子字符串。 |
|
| 包含该设备厂商或制造商名称的字符串。hint 可以是实际值的子字符串。 |
|
| 包含设备序列号的字符串。hint 必须与实际值完全匹配。 |
|
| 以 GB 为单位代表设备的最小大小的整数。 |
|
| 包含唯一存储标识符的字符串。hint 必须与实际值完全匹配。 |
|
| 包含唯一存储标识符的字符串,并附加厂商扩展。hint 必须与实际值完全匹配。 |
|
| 包含唯一厂商存储标识符的字符串。hint 必须与实际值完全匹配。 |
|
| 指明该设备为旋转磁盘(true)还是非旋转磁盘(false)的布尔值。 |
用法示例
- name: master-0
role: master
bmc:
address: ipmi://10.10.0.3:6203
username: admin
password: redhat
bootMACAddress: de:ad:be:ef:00:40
rootDeviceHints:
deviceName: "/dev/sda"3.10.8. 可选:设置代理设置
要使用代理部署 OpenShift Container Platform 集群,请对 install-config.yaml 文件进行以下更改。
apiVersion: v1
baseDomain: <domain>
proxy:
httpProxy: http://USERNAME:PASSWORD@proxy.example.com:PORT
httpsProxy: https://USERNAME:PASSWORD@proxy.example.com:PORT
noProxy: <WILDCARD_OF_DOMAIN>,<PROVISIONING_NETWORK/CIDR>,<BMC_ADDRESS_RANGE/CIDR>
以下是带有值的 noProxy 示例。
noProxy: .example.com,172.22.0.0/24,10.10.0.0/24启用代理后,在对应的键/值对中设置代理的适当值。
主要考虑:
-
如果代理没有 HTTPS 代理,请将
httpsProxy 的值从 https:// 改为http://。 -
如果使用 provisioning 网络,将其包含在
noProxy设置中,否则安装程序将失败。 -
将所有代理设置设置为 provisioner 节点中的环境变量。例如:
HTTP_PROXY、HTTPS_PROXY和NO_PROXY。
使用 IPv6 置备时,您无法在 noProxy 设置中定义 CIDR 地址块。您必须单独定义每个地址。
3.10.9. 可选:在没有 provisioning 网络的情况下进行部署
要在没有 provisioning 网络的情况下部署 OpenShift Container Platform 集群,请对 install-config.yaml 文件进行以下更改。
platform:
baremetal:
apiVIPs:
- <api_VIP>
ingressVIPs:
- <ingress_VIP>
provisioningNetwork: "Disabled" - 1
- 如果需要,添加
provisioningNetwork配置设置并将其设置为Disabled。
PXE 引导需要 provisioning 网络。如果您在没有 provisioning 网络的情况下部署,则必须使用虚拟介质 BMC 寻址选项,如 redfish-virtualmedia 或 idrac-virtualmedia。详情请查看 "Redfish 虚拟介质 for HPE iLO" 部分的"适用于 HPE iLO 的 BMC 寻址"部分或"适用于戴尔 iDRAC 的"红帽虚拟媒体"部分中的"红帽虚拟介质"。
3.10.10. 可选:使用双栈网络部署
对于 OpenShift Container Platform 集群中的双栈网络,您可以为集群节点配置 IPv4 和 IPv6 地址端点。要为集群节点配置 IPv4 和 IPv6 地址端点,请编辑 install-config.yaml 文件中的 machineNetwork、clusterNetwork 和 serviceNetwork 配置设置。每个设置必须分别有两个 CIDR 条目。对于将 IPv4 系列用作主地址系列的集群,请首先指定 IPv4 设置。对于将 IPv6 系列用作主地址系列的集群,请首先指定 IPv6 设置。
machineNetwork:
- cidr: {{ extcidrnet }}
- cidr: {{ extcidrnet6 }}
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
- cidr: fd02::/48
hostPrefix: 64
serviceNetwork:
- 172.30.0.0/16
- fd03::/112
在裸机平台上,如果您在 install-config.yaml 文件的 networkConfig 部分中指定了 NMState 配置,请将 interfaces.wait-ip: ipv4+ipv6 添加到 NMState YAML 文件中,以解决阻止集群在双栈网络上部署的问题。
包含 wait-ip 参数的 NMState YAML 配置文件示例
networkConfig:
nmstate:
interfaces:
- name: <interface_name>
# ...
wait-ip: ipv4+ipv6
# ...
要为使用 IPv4 和 IPv6 地址的应用程序提供接口,请为 Ingress VIP 和 API VIP 服务配置 IPv4 和 IPv6 虚拟 IP (VIP) 地址端点。要配置 IPv4 和 IPv6 地址端点,请编辑 install-config.yaml 文件中的 apiVIPs 和 ingressVIPs 配置设置。apiVIPs 和 ingressVIPs 配置设置使用列表格式。列表的顺序决定了每个服务的主 VIP 地址和次 VIP 地址。
platform:
baremetal:
apiVIPs:
- <api_ipv4>
- <api_ipv6>
ingressVIPs:
- <wildcard_ipv4>
- <wildcard_ipv6>对于具有双栈网络配置的集群,您必须将 IPv4 和 IPv6 地址分配到同一接口。
3.10.11. 可选:配置主机网络接口
在安装前,您可以在 install-config.yaml 文件中设置 networkConfig 配置设置,以使用 NMState 配置主机网络接口。
此功能的最常见用例是在 bare-metal 网络中指定一个静态 IP 地址,但您也可以配置其他网络,如存储网络。此功能支持 VLAN、VXLAN、网桥、绑定、路由、MTU 和 DNS 解析器设置等其他 NMState 功能。
先决条件
-
使用静态 IP 地址为每个节点配置带有有效主机名的
PTRDNS 记录。 -
安装 NMState CLI (
nmstate)。
流程
可选:在
install-config.yaml文件中包括nmstatectl gc前测试 NMState 语法,因为安装程序不会检查 NMState YAML 语法。注意YAML 语法中的错误可能会导致无法应用网络配置。另外,在部署后或在扩展集群时应用 Kubernetes NMState 更改时,维护所验证的 YAML 语法会很有用。
创建 NMState YAML 文件:
interfaces: - name: <nic1_name>1 type: ethernet state: up ipv4: address: - ip: <ip_address>2 prefix-length: 24 enabled: true dns-resolver: config: server: - <dns_ip_address>3 routes: config: - destination: 0.0.0.0/0 next-hop-address: <next_hop_ip_address>4 next-hop-interface: <next_hop_nic1_name>5 运行以下命令来测试配置文件:
$ nmstatectl gc <nmstate_yaml_file>将
<nmstate_yaml_file>替换为配置文件名称。
通过在
install-config.yaml文件中的主机中添加 NMState 配置,使用networkConfig配置设置:hosts: - name: openshift-master-0 role: master bmc: address: redfish+http://<out_of_band_ip>/redfish/v1/Systems/ username: <user> password: <password> disableCertificateVerification: null bootMACAddress: <NIC1_mac_address> bootMode: UEFI rootDeviceHints: deviceName: "/dev/sda" networkConfig:1 interfaces: - name: <nic1_name>2 type: ethernet state: up ipv4: address: - ip: <ip_address>3 prefix-length: 24 enabled: true dns-resolver: config: server: - <dns_ip_address>4 routes: config: - destination: 0.0.0.0/0 next-hop-address: <next_hop_ip_address>5 next-hop-interface: <next_hop_nic1_name>6 重要部署集群后,您无法修改
install-config.yaml文件的networkConfig配置设置,以更改主机网络接口。在部署后,使用 Kubernetes NMState Operator 更改主机网络接口。
3.10.12. 为子网配置主机网络接口
对于边缘计算场景,定位接近边缘的计算节点会很有用。要在子网中定位远程节点,您可以对远程节点使用不同的网络片段或子网,而不是用于 control plane 子网和本地计算节点。您可以通过为边缘计算场景设置子网来减少边缘延迟并允许增强可扩展性。
当使用默认负载均衡器时,OpenShiftManagedDefault 并将远程节点添加到 OpenShift Container Platform 集群中,所有 control plane 节点必须在同一子网中运行。当使用多个子网时,您还可以使用清单将 Ingress VIP 配置为在 control plane 节点上运行。详情请参阅"配置要在 control plane 上运行的网络组件"。
如果您为远程节点创建了不同的网络段或子网,如 "Establishing communication" 部分所述,如果 worker 使用静态 IP 地址、绑定或其他高级网络,您必须在 machineNetwork 配置设置中指定子网。当为每个远程节点在 networkConfig 参数中设置节点 IP 地址时,还必须在使用静态 IP 地址时为包含 control plane 节点的子网指定网关和 DNS 服务器。这样可确保远程节点可以访问包含 control plane 的子网,并可从 control plane 接收网络流量。
使用多个子网部署集群需要使用虚拟介质,如 redfish-virtualmedia 或 idrac-virtualmedia,因为远程节点无法访问本地置备网络。
流程
在使用静态 IP 地址时,将子网添加到
install-config.yaml文件中的machineNetwork中:networking: machineNetwork: - cidr: 10.0.0.0/24 - cidr: 192.168.0.0/24 networkType: OVNKubernetes在使用静态 IP 地址或高级网络(如绑定)时,使用 NMState 语法将网关和 DNS 配置添加到每个边缘计算节点的
networkConfig参数中:networkConfig: interfaces: - name: <interface_name>1 type: ethernet state: up ipv4: enabled: true dhcp: false address: - ip: <node_ip>2 prefix-length: 24 gateway: <gateway_ip>3 dns-resolver: config: server: - <dns_ip>4
3.10.13. 可选:在双栈网络中为 SLAAC 配置地址生成模式
对于使用 Stateless Address AutoConfiguration (SLAAC)的双栈集群,您必须为 ipv6.addr-gen-mode 网络设置指定一个全局值。您可以使用 NMState 设置这个值来配置 ramdisk 和集群配置文件。如果您没有在这些位置配置一致的 ipv6.addr-gen-mode,则集群中的 CSR 资源和 BareMetalHost 资源之间可能会发生 IPv6 地址不匹配。
先决条件
-
安装 NMState CLI (
nmstate)。
流程
可选:在
install-config.yaml文件中包括nmstatectl gc命令前使用 nmstatectl gc 命令测试 NMState YAML 语法,因为安装程序不会检查 NMState YAML 语法。将 NMState 配置添加到 install-config.yaml 文件中的
hosts.networkConfig部分:hosts: - name: openshift-master-0 role: master bmc: address: redfish+http://<out_of_band_ip>/redfish/v1/Systems/ username: <user> password: <password> disableCertificateVerification: null bootMACAddress: <NIC1_mac_address> bootMode: UEFI rootDeviceHints: deviceName: "/dev/sda" networkConfig: interfaces: - name: eth0 ipv6: addr-gen-mode: <address_mode>1 ...- 1
- 将
<address_mode>替换为集群中 IPv6 地址所需的地址生成模式类型。有效值为eui64、stable-privacy或random。
3.10.14. 可选:为双端口 NIC 配置主机网络接口
在安装前,您可以在 install-config.yaml 文件中设置 networkConfig 配置设置,以使用 NMState 配置主机网络接口来支持双端口 NIC。
支持与为 SR-IOV 设备启用 NIC 分区关联的第 1 天操作只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
OpenShift Virtualization 只支持以下绑定模式:
-
mode=1 active-backup
-
mode=2 balance-xor
-
mode=4 802.3ad
先决条件
-
使用静态 IP 地址为每个节点配置带有有效主机名的
PTRDNS 记录。 -
安装 NMState CLI (
nmstate)。
YAML 语法中的错误可能会导致无法应用网络配置。另外,在部署后或在扩展集群时应用 Kubernetes NMState 更改时,维护所验证的 YAML 语法会很有用。
流程
将 NMState 配置添加到
install-config.yaml文件中的networkConfig主机中:hosts: - name: worker-0 role: worker bmc: address: redfish+http://<out_of_band_ip>/redfish/v1/Systems/ username: <user> password: <password> disableCertificateVerification: false bootMACAddress: <NIC1_mac_address> bootMode: UEFI networkConfig:1 interfaces:2 - name: eno13 type: ethernet4 state: up mac-address: 0c:42:a1:55:f3:06 ipv4: enabled: true dhcp: false5 ethernet: sr-iov: total-vfs: 26 ipv6: enabled: false dhcp: false - name: sriov:eno1:0 type: ethernet state: up7 ipv4: enabled: false8 ipv6: enabled: false - name: sriov:eno1:1 type: ethernet state: down - name: eno2 type: ethernet state: up mac-address: 0c:42:a1:55:f3:07 ipv4: enabled: true ethernet: sr-iov: total-vfs: 2 ipv6: enabled: false - name: sriov:eno2:0 type: ethernet state: up ipv4: enabled: false ipv6: enabled: false - name: sriov:eno2:1 type: ethernet state: down - name: bond0 type: bond state: up min-tx-rate: 1009 max-tx-rate: 20010 link-aggregation: mode: active-backup11 options: primary: sriov:eno1:012 port: - sriov:eno1:0 - sriov:eno2:0 ipv4: address: - ip: 10.19.16.5713 prefix-length: 23 dhcp: false enabled: true ipv6: enabled: false dns-resolver: config: server: - 10.11.5.160 - 10.2.70.215 routes: config: - destination: 0.0.0.0/0 next-hop-address: 10.19.17.254 next-hop-interface: bond014 table-id: 254- 1
networkConfig字段包含主机的网络配置的信息,子字段包括interfaces、dns-resolver和routes。- 2
interfaces字段是为主机定义的网络接口数组。- 3
- 接口的名称。
- 4
- 接口的类型。这个示例创建了一个以太网接口。
- 5
- 如果物理功能 (PF) 没有被严格要求,则将其设置为 'false 以禁用 DHCP。
- 6
- 设置为要实例化的 SR-IOV 虚拟功能 (VF) 的数量。
- 7
- 把它设置为
up。 - 8
- 把它设置为
false,以禁用附加到绑定的 VF 的 IPv4 寻址。 - 9
- 为 VF 设置最小传输率(以 Mbps 为单位)。这个示例值设置 100 Mbps 的速度。
- 这个值必须小于或等于最大传输率。
-
Intel NIC 不支持
min-tx-rate参数。如需更多信息,请参阅 BZ#1772847。
- 10
- 为 VF 设置最大传输率(以 Mbps 为单位)。此示例值设置 200 Mbps 的速度。
- 11
- 设置所需的绑定模式。
- 12
- 设置绑定接口的首选端口。该绑定使用主设备作为绑定接口的第一个设备。这个绑定不会取消主设备接口,除非失败。当绑定接口中的一个 NIC 速度更快时,此设置特别有用,因此可以处理较大的负载。只有在绑定接口处于 active-backup 模式(模式 1)和 balance-tlb (模式 5)时,此设置才有效。
- 13
- 为绑定接口设置静态 IP 地址。这是节点 IP 地址。
- 14
- 将
bond0设置为默认路由的网关。重要部署集群后,您无法更改
install-config.yaml文件的networkConfig配置设置,以更改主机网络接口。在部署后,使用 Kubernetes NMState Operator 更改主机网络接口。
3.10.15. 配置多个集群节点
您可以使用相同的设置同时配置 OpenShift Container Platform 集群节点。配置多个集群节点可避免在 install-config.yaml 文件中添加每个节点的冗余信息。这个文件包含特定的参数,可将相同的配置应用到集群中的多个节点。
Compute 节点与控制器节点独立配置。但是,两个节点类型的配置都使用 install-config.yaml 文件中突出显示的参数启用多节点配置。将 networkConfig 参数设置为 BOND,如下例所示:
hosts:
- name: ostest-master-0
[...]
networkConfig: &BOND
interfaces:
- name: bond0
type: bond
state: up
ipv4:
dhcp: true
enabled: true
link-aggregation:
mode: active-backup
port:
- enp2s0
- enp3s0
- name: ostest-master-1
[...]
networkConfig: *BOND
- name: ostest-master-2
[...]
networkConfig: *BOND配置多个集群节点仅适用于安装程序置备的基础架构上的初始部署。
3.10.16. 可选:配置管理的安全引导
在使用 Redfish BMC 寻址(如 redfish, redfish-virtualmedia, 或 idrac-virtualmedia)部署安装程序置备的集群时,您可以启用受管安全引导。要启用受管安全引导,请在每个节点中添加 bootMode 配置设置:
示例
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish://<out_of_band_ip>
username: <username>
password: <password>
bootMACAddress: <NIC1_mac_address>
rootDeviceHints:
deviceName: "/dev/sda"
bootMode: UEFISecureBoot 请参阅"先决条件"中的"配置节点",以确保节点能够支持受管安全引导。如果节点不支持受管安全引导,请参阅"配置节点"部分中的"手动配置安全引导节点"。手动配置安全引导机制需要 Redfish 虚拟介质。
红帽不支持使用 IPMI 进行安全引导,因为 IPMI 不提供安全引导管理功能。
3.11. 清单配置文件
3.11.1. 创建 OpenShift Container Platform 清单
创建 OpenShift Container Platform 清单。
$ ./openshift-baremetal-install --dir ~/clusterconfigs create manifestsINFO Consuming Install Config from target directory WARNING Making control-plane schedulable by setting MastersSchedulable to true for Scheduler cluster settings WARNING Discarding the OpenShift Manifest that was provided in the target directory because its dependencies are dirty and it needs to be regenerated
3.11.2. 可选:为断开连接的集群配置 NTP
OpenShift Container Platform 在集群节点上安装 chrony 网络时间协议(NTP)服务。

OpenShift Container Platform 节点必须在日期和时间上达成一致才能正确运行。当 worker 节点从 control plane 节点上的 NTP 服务器检索日期和时间时,它会启用未连接到可路由网络的集群的安装和操作,因此无法访问更高的 stratum NTP 服务器。
流程
使用以下命令在安装主机上安装 Butane:
$ sudo dnf -y install butane为 control plane 节点创建一个 Butane 配置
99-master-chrony-conf-override.bu,包括chrony.conf文件的内容。注意如需有关 Butane 的信息,请参阅"使用 Butane 创建机器配置"。
但ane 配置示例
variant: openshift version: 4.14.0 metadata: name: 99-master-chrony-conf-override labels: machineconfiguration.openshift.io/role: master storage: files: - path: /etc/chrony.conf mode: 0644 overwrite: true contents: inline: | # Use public servers from the pool.ntp.org project. # Please consider joining the pool (https://www.pool.ntp.org/join.html). # The Machine Config Operator manages this file server openshift-master-0.<cluster-name>.<domain> iburst1 server openshift-master-1.<cluster-name>.<domain> iburst server openshift-master-2.<cluster-name>.<domain> iburst stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 keyfile /etc/chrony.keys commandkey 1 generatecommandkey noclientlog logchange 0.5 logdir /var/log/chrony # Configure the control plane nodes to serve as local NTP servers # for all worker nodes, even if they are not in sync with an # upstream NTP server. # Allow NTP client access from the local network. allow all # Serve time even if not synchronized to a time source. local stratum 3 orphan- 1
- 您必须将
<cluster-name>替换为集群名称,并将<domain>替换为完全限定域名。
使用 Butane 生成
MachineConfig对象文件99-master-chrony-conf-override.yaml,其中包含要发送到 control plane 节点的配置:$ butane 99-master-chrony-conf-override.bu -o 99-master-chrony-conf-override.yaml为引用 control plane 节点上的 NTP 服务器的 worker 节点创建 Butane 配置
99-worker-chrony-conf-override.bu,包括chrony.conf文件的内容。但ane 配置示例
variant: openshift version: 4.14.0 metadata: name: 99-worker-chrony-conf-override labels: machineconfiguration.openshift.io/role: worker storage: files: - path: /etc/chrony.conf mode: 0644 overwrite: true contents: inline: | # The Machine Config Operator manages this file. server openshift-master-0.<cluster-name>.<domain> iburst1 server openshift-master-1.<cluster-name>.<domain> iburst server openshift-master-2.<cluster-name>.<domain> iburst stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 keyfile /etc/chrony.keys commandkey 1 generatecommandkey noclientlog logchange 0.5 logdir /var/log/chrony- 1
- 您必须将
<cluster-name>替换为集群名称,并将<domain>替换为完全限定域名。
使用 Butane 生成
MachineConfig对象文件99-worker-chrony-conf-override.yaml,其中包含要交付至 worker 节点的配置:$ butane 99-worker-chrony-conf-override.bu -o 99-worker-chrony-conf-override.yaml
3.11.3. 配置要在 control plane 上运行的网络组件
您可以配置网络组件,使其仅在 control plane 节点上运行。默认情况下,OpenShift Container Platform 允许机器配置池中的任何节点托管 ingressVIP 虚拟 IP 地址。但是,有些环境在与 control plane 节点独立的子网中部署 worker 节点,这需要将 ingressVIP 虚拟 IP 地址配置为在 control plane 节点上运行。
在单独的子网中部署远程 worker 时,您必须将 ingressVIP 虚拟 IP 地址专门用于 control plane 节点。

流程
进入存储
install-config.yaml文件的目录:$ cd ~/clusterconfigs切换到
manifests子目录:$ cd manifests创建名为
cluster-network-avoid-workers-99-config.yaml的文件:$ touch cluster-network-avoid-workers-99-config.yaml在编辑器中打开
cluster-network-avoid-workers-99-config.yaml文件,并输入描述 Operator 配置的自定义资源(CR):apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: name: 50-worker-fix-ipi-rwn labels: machineconfiguration.openshift.io/role: worker spec: config: ignition: version: 3.2.0 storage: files: - path: /etc/kubernetes/manifests/keepalived.yaml mode: 0644 contents: source: data:,此清单将
ingressVIP虚拟 IP 地址放在 control plane 节点上。另外,此清单仅在 control plane 节点上部署以下进程:-
openshift-ingress-operator -
keepalived
-
-
保存
cluster-network-avoid-workers-99-config.yaml文件。 创建
manifests/cluster-ingress-default-ingresscontroller.yaml文件:apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: nodePlacement: nodeSelector: matchLabels: node-role.kubernetes.io/master: ""-
考虑备份
manifests目录。在创建集群时,安装程序会删除manifests/目录。 通过将
mastersSchedulable字段设置为true来修改cluster-scheduler-02-config.yml清单,使 control plane 节点可以调度。默认情况下,control plane 节点不可调度。例如:$ sed -i "s;mastersSchedulable: false;mastersSchedulable: true;g" clusterconfigs/manifests/cluster-scheduler-02-config.yml注意如果在完成此步骤后 control plane 节点不可调度,则部署集群将失败。
3.11.4. 可选:在 worker 节点上部署路由器
在安装过程中,安装程序会在 worker 节点上部署路由器 Pod。默认情况下,安装程序会安装两个路由器 Pod。如果部署的集群需要额外的路由器来处理用于 OpenShift Container Platform 集群中服务的外部流量负载,您可以创建一个 yaml 文件来设置适当数量的路由器副本。
不支持只使用一个 worker 节点部署集群。虽然在使用一个 worker 时修改路由器副本数量会解决降级状态的问题,但集群丢失了入口 API 的高可用性,它不适用于生产环境。
默认情况下,安装程序会部署两个路由器。如果集群没有 worker 节点,安装程序默认会在 control plane 节点上部署两个路由器。
流程
创建
router-replicas.yaml文件:apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: <num-of-router-pods> endpointPublishingStrategy: type: HostNetwork nodePlacement: nodeSelector: matchLabels: node-role.kubernetes.io/worker: ""注意将
<num-of-router-pods>替换为适当的值。如果只使用一个 worker 节点,请将replicas:设置为1。如果使用 3 个以上 worker 节点,您可以根据情况增加replicas:的默认值2。将
router-replicas.yaml文件复制到clusterconfigs/openshift目录中:$ cp ~/router-replicas.yaml clusterconfigs/openshift/99_router-replicas.yaml
3.11.5. 可选:配置 BIOS
以下流程在安装过程中配置 BIOS。
流程
- 创建清单。
修改与节点对应的
BareMetalHost资源文件:$ vim clusterconfigs/openshift/99_openshift-cluster-api_hosts-*.yaml将 BIOS 配置添加到
BareMetalHost资源的spec部分:spec: firmware: simultaneousMultithreadingEnabled: true sriovEnabled: true virtualizationEnabled: true注意红帽支持三种 BIOS 配置:仅支持 BMC 类型
irmc的服务器。目前不支持其他类型的服务器。- 创建集群。
3.11.6. 可选:配置 RAID
以下流程在安装过程中配置独立磁盘的冗余阵列 (RAID)。
- OpenShift Container Platform 仅支持使用 iRMC 协议进行基板管理控制器 (BMC) 的硬件 RAID。OpenShift Container Platform 4.14 不支持软件 RAID。
- 如果要为节点配置硬件 RAID,请验证节点是否具有 RAID 控制器。
流程
- 创建清单。
修改与节点对应的
BareMetalHost资源:$ vim clusterconfigs/openshift/99_openshift-cluster-api_hosts-*.yaml注意以下示例使用硬件 RAID 配置,因为 OpenShift Container Platform 4.14 不支持软件 RAID。
如果您在
spec部分添加了特定的 RAID 配置,这会导致节点在preparing阶段删除原始 RAID 配置,并在 RAID 上执行指定的配置。例如:spec: raid: hardwareRAIDVolumes: - level: "0"1 name: "sda" numberOfPhysicalDisks: 1 rotational: true sizeGibibytes: 0- 1
level是必填字段,另一个是可选字段。
如果您在
spec部分添加了空的 RAID 配置,空配置会导致节点在preparing阶段删除原始 RAID 配置,但不执行新配置。例如:spec: raid: hardwareRAIDVolumes: []-
如果您没有在
spec部分添加raid字段,则原始 RAID 配置不会被删除,且不会执行新的配置。
- 创建集群。
3.11.7. 可选:在节点上配置存储
您可以通过创建由 Machine Config Operator (MCO) 管理的 MachineConfig 对象来更改 OpenShift Container Platform 节点上的操作系统。
MachineConfig 规格包括一个 ignition 配置,用于在第一次引导时配置机器。此配置对象可用于修改 OpenShift Container Platform 机器上运行的文件、systemd 服务和其他操作系统功能。
流程
使用 ignition 配置在节点上配置存储。以下 MachineSet 清单示例演示了如何将分区添加到主节点上的设备中。在本例中,在安装前应用清单,其名为 restore 的分区,大小为 16 GiB。
创建
custom-partitions.yaml文件,并包含一个包含分区布局的MachineConfig对象:apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: primary name: 10_primary_storage_config spec: config: ignition: version: 3.2.0 storage: disks: - device: </dev/xxyN> partitions: - label: recovery startMiB: 32768 sizeMiB: 16384 filesystems: - device: /dev/disk/by-partlabel/recovery label: recovery format: xfs将
custom-partitions.yaml文件复制到clusterconfigs/openshift目录中:$ cp ~/<MachineConfig_manifest> ~/clusterconfigs/openshift
3.12. 创建断开连接的 registry
在某些情况下,您可能想要使用安装 registry 的本地副本安装 OpenShift Container Platform 集群。这可能是为了提高网络效率,因为集群节点位于无法访问互联网的网络中。
一个本地的或被镜像的 registry 副本需要以下内容:
- registry 节点的证书。这可以是自签名证书。
- 系统中的容器将服务的 Web 服务器。
- 包含证书和本地存储库信息的更新的 pull secret。
在 registry 节点上创建断开连接的 registry 是可选的。如果需要在 registry 节点上创建断开连接的 registry,您必须完成以下所有子章节。
先决条件
3.12.1. 准备 registry 节点以托管已镜像的 registry
在裸机上托管镜像的 registry 之前,必须完成以下步骤。
流程
打开 registry 节点上的防火墙端口:
$ sudo firewall-cmd --add-port=5000/tcp --zone=libvirt --permanent$ sudo firewall-cmd --add-port=5000/tcp --zone=public --permanent$ sudo firewall-cmd --reload为 registry 节点安装所需的软件包:
$ sudo yum -y install python3 podman httpd httpd-tools jq创建保存存储库信息的目录结构:
$ sudo mkdir -p /opt/registry/{auth,certs,data}
完成以下步骤,为断开连接的 registry 镜像 OpenShift Container Platform 镜像存储库。
先决条件
- 您的镜像主机可访问互联网。
- 您已将镜像 registry 配置为在受限网络中使用,并可访问您配置的证书和凭证。
- 您已从 Red Hat OpenShift Cluster Manager 下载了 pull secret,并已修改为包含镜像存储库的身份验证。
流程
- 查看 OpenShift Container Platform 下载页面,以确定您要安装的 OpenShift Container Platform 版本,并决定 Repository Tags 页中的相应标签(tag)。
设置所需的环境变量:
导出发行版本信息:
$ OCP_RELEASE=<release_version>对于
<release_version>,请指定与 OpenShift Container Platform 版本对应的标签,用于您的架构,如4.5.4。导出本地 registry 名称和主机端口:
$ LOCAL_REGISTRY='<local_registry_host_name>:<local_registry_host_port>'对于
<local_registry_host_name>,请指定镜像存储库的 registry 域名;对于<local_registry_host_port>,请指定用于提供内容的端口。导出本地存储库名称:
$ LOCAL_REPOSITORY='<local_repository_name>'对于
<local_repository_name>,请指定要在 registry 中创建的仓库名称,如ocp4/openshift4。导出要进行镜像的存储库名称:
$ PRODUCT_REPO='openshift-release-dev'对于生产环境版本,必须指定
openshift-release-dev。导出 registry pull secret 的路径:
$ LOCAL_SECRET_JSON='<path_to_pull_secret>'对于
<path_to_pull_secret>,请指定您创建的镜像 registry 的 pull secret 的绝对路径和文件名。导出发行版本镜像:
$ RELEASE_NAME="ocp-release"对于生产环境版本,您必须指定
ocp-release。为您的集群导出构架类型:
$ ARCHITECTURE=<cluster_architecture>1 - 1
- 指定集群的构架,如
x86_64,aarch64,s390x, 获ppc64le。
导出托管镜像的目录的路径:
$ REMOVABLE_MEDIA_PATH=<path>1 - 1
- 指定完整路径,包括开始的前斜杠(/)字符。
将版本镜像(mirror)到镜像 registry:
如果您的镜像主机无法访问互联网,请执行以下操作:
- 将可移动介质连接到连接到互联网的系统。
查看要镜像的镜像和配置清单:
$ oc adm release mirror -a ${LOCAL_SECRET_JSON} \ --from=quay.io/${PRODUCT_REPO}/${RELEASE_NAME}:${OCP_RELEASE}-${ARCHITECTURE} \ --to=${LOCAL_REGISTRY}/${LOCAL_REPOSITORY} \ --to-release-image=${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE} --dry-run-
记录上一命令输出中的
imageContentSources部分。您的镜像信息与您的镜像存储库相对应,您必须在安装过程中将imageContentSources部分添加到install-config.yaml文件中。 将镜像镜像到可移动介质的目录中:
$ oc adm release mirror -a ${LOCAL_SECRET_JSON} --to-dir=${REMOVABLE_MEDIA_PATH}/mirror quay.io/${PRODUCT_REPO}/${RELEASE_NAME}:${OCP_RELEASE}-${ARCHITECTURE}将介质上传到受限网络环境中,并将镜像上传到本地容器 registry。
$ oc image mirror -a ${LOCAL_SECRET_JSON} --from-dir=${REMOVABLE_MEDIA_PATH}/mirror "file://openshift/release:${OCP_RELEASE}*" ${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}1 - 1
- 对于
REMOVABLE_MEDIA_PATH,您必须使用与镜像镜像时指定的同一路径。
如果本地容器 registry 连接到镜像主机,请执行以下操作:
使用以下命令直接将发行版镜像推送到本地 registry:
$ oc adm release mirror -a ${LOCAL_SECRET_JSON} \ --from=quay.io/${PRODUCT_REPO}/${RELEASE_NAME}:${OCP_RELEASE}-${ARCHITECTURE} \ --to=${LOCAL_REGISTRY}/${LOCAL_REPOSITORY} \ --to-release-image=${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE}该命令将发行信息提取为摘要,其输出包括安装集群时所需的
imageContentSources数据。记录上一命令输出中的
imageContentSources部分。您的镜像信息与您的镜像存储库相对应,您必须在安装过程中将imageContentSources部分添加到install-config.yaml文件中。注意镜像名称在镜像过程中被修补到 Quay.io, podman 镜像将在 bootstrap 虚拟机的 registry 中显示 Quay.io。
要创建基于您镜像内容的安装程序,请提取内容并将其固定到发行版中:
如果您的镜像主机无法访问互联网,请运行以下命令:
$ oc adm release extract -a ${LOCAL_SECRET_JSON} --command=openshift-baremetal-install "${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}"如果本地容器 registry 连接到镜像主机,请运行以下命令:
$ oc adm release extract -a ${LOCAL_SECRET_JSON} --command=openshift-baremetal-install "${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE}"重要要确保将正确的镜像用于您选择的 OpenShift Container Platform 版本,您必须从镜像内容中提取安装程序。
您必须在有活跃互联网连接的机器上执行这个步骤。
如果您位于断开连接的环境中,请使用
--image标志作为 must-gather 的一部分,指向有效负载镜像。
对于使用安装程序置备的基础架构的集群,运行以下命令:
$ openshift-baremetal-install
3.12.3. 修改 install-config.yaml 文件以使用断开连接的 registry
在 provisioner 节点上,install -config.yaml 文件应该使用从 pull-secret- update.txt 文件中新创建的 pull-secret。install-config.yaml 文件还必须包含断开连接的 registry 节点的证书和 registry 信息。
流程
将断开连接的 registry 节点的证书添加到
install-config.yaml文件中:$ echo "additionalTrustBundle: |" >> install-config.yaml证书应跟在
"additionalTrustBundle: |"行后面,并正确缩进(通常为两个空格)。$ sed -e 's/^/ /' /opt/registry/certs/domain.crt >> install-config.yaml将 registry 的镜像信息添加到
install-config.yaml文件中:$ echo "imageContentSources:" >> install-config.yaml$ echo "- mirrors:" >> install-config.yaml$ echo " - registry.example.com:5000/ocp4/openshift4" >> install-config.yaml将
registry.example.com替换为 registry 的完全限定域名。$ echo " source: quay.io/openshift-release-dev/ocp-release" >> install-config.yaml$ echo "- mirrors:" >> install-config.yaml$ echo " - registry.example.com:5000/ocp4/openshift4" >> install-config.yaml将
registry.example.com替换为 registry 的完全限定域名。$ echo " source: quay.io/openshift-release-dev/ocp-v4.0-art-dev" >> install-config.yaml
3.13. 安装的验证清单
- ❏ 已检索到 OpenShift Container Platform 安装程序。
- ❏ 已提取 OpenShift Container Platform 安装程序。
-
❏ 已配置了
install-config.yaml的必要参数。 -
❏ 已配置了
install-config.yaml的hosts参数。 -
❏ 已配置了
install-config.yaml的bmc参数。 -
❏ 在
bmcaddress字段中配置的值已被应用。 - ❏ 创建 OpenShift Container Platform 清单。
- ❏ (可选)在 worker 节点上部署路由器。
- ❏ (可选)创建断开连接的 registry。
- ❏ (可选)如果使用,验证断开连接的 registry 设置。
第 4 章 安装集群
4.1. 清理以前的安装
如果以前部署失败,请在尝试再次部署 OpenShift Container Platform 前从失败的尝试中删除工件。
流程
使用以下命令安装 OpenShift Container Platform 集群前关闭所有裸机节点:
$ ipmitool -I lanplus -U <user> -P <password> -H <management_server_ip> power off使用以下脚本,删除所有旧的 bootstrap 资源:
for i in $(sudo virsh list | tail -n +3 | grep bootstrap | awk {'print $2'}); do sudo virsh destroy $i; sudo virsh undefine $i; sudo virsh vol-delete $i --pool $i; sudo virsh vol-delete $i.ign --pool $i; sudo virsh pool-destroy $i; sudo virsh pool-undefine $i; done使用以下命令删除早期安装生成的工件:
$ cd ; /bin/rm -rf auth/ bootstrap.ign master.ign worker.ign metadata.json \ .openshift_install.log .openshift_install_state.json使用以下命令重新创建 OpenShift Container Platform 清单:
$ ./openshift-baremetal-install --dir ~/clusterconfigs create manifests
4.2. 通过 OpenShift Container Platform 安装程序部署集群
运行 OpenShift Container Platform 安装程序:
$ ./openshift-baremetal-install --dir ~/clusterconfigs --log-level debug create cluster4.3. 监控安装进度
在部署过程中,您可以通过向安装目录文件夹中的 .openshift_install.log 日志文件发出 tail 命令来检查安装的整体状态:
$ tail -f /path/to/install-dir/.openshift_install.log4.4. 验证静态 IP 地址配置
如果集群节点的 DHCP 保留指定了无限租期,安装程序成功置备该节点后,分配程序脚本会检查节点的网络配置。如果脚本确定网络配置包含无限 DHCP 租期,它将 DHCP 租期的 IP 地址用作静态 IP 地址来创建新连接。
分配程序脚本可能会在成功置备的节点上运行,同时持续置备集群中的其他节点。
验证网络配置是否正常工作。
流程
- 检查节点上的网络接口配置。
- 关闭 DHCP 服务器并重启 OpenShift Container Platform 节点,并确保网络配置可以正常工作。
第 5 章 安装故障排除
5.1. 安装程序工作流故障排除
在对安装环境进行故障排除前,务必要了解裸机上安装程序置备安装的整体流。下图显示了一个故障排除流程,并按步骤划分环境。

当 install-config.yaml 文件出错或者无法访问 Red Hat Enterprise Linux CoreOS(RHCOS)镜像时,工作流 1(共 4 步) 的工作流演示了故障排除工作流。故障排除建议可在 故障排除 install-config.yaml 中找到。

工作流 2(共 4 步)描述了对 bootstrap 虚拟机问题、 无法引导集群节点的 bootstrap 虚拟机 以及 检查日志 的故障排除工作流。当在没有 provisioning 网络的情况下安装 OpenShift Container Platform 集群时,此工作流将不应用。

工作流 3(共 4 步)描述了 不能 PXE 引导的集群节点 的故障排除工作流。如果使用 Redfish 虚拟介质进行安装,则每个节点都必须满足安装程序部署该节点的最低固件要求。如需了解更多详细信息,请参阅先决条件部分中的使用虚拟介质安装的固件要求。
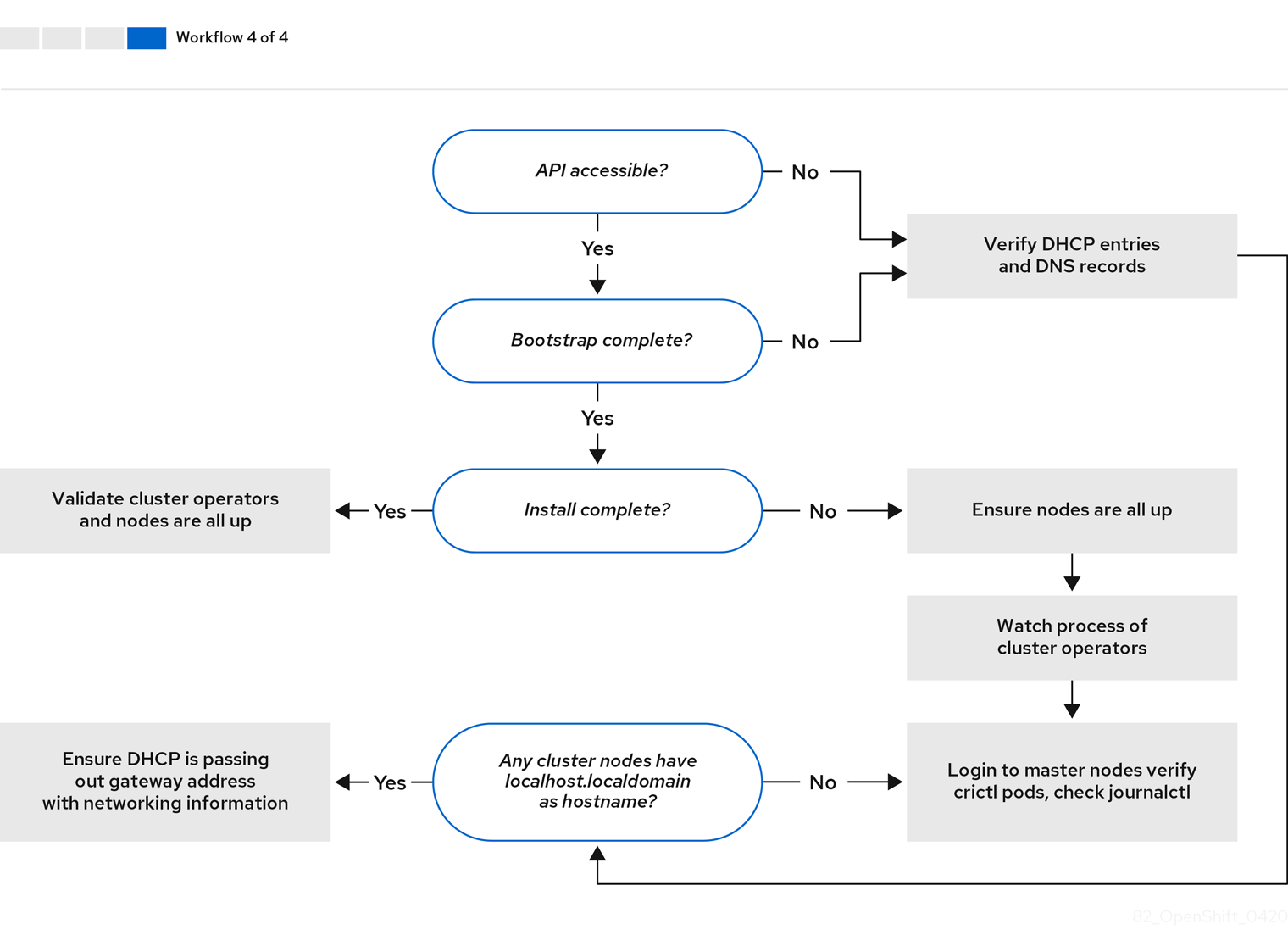
5.2. install-config.yaml故障排除
install-config.yaml 配置文件代表属于 OpenShift Container Platform 集群的所有节点。该文件包含由 apiVersion、baseDomain、imageContentSources 和虚拟 IP 地址组成的必要选项。如果在 OpenShift Container Platform 集群部署早期发生错误,install-config.yaml 配置文件中可能会出现错误。
流程
- 使用 YAML-tips 中的指南。
- 使用 syntax-check 验证 YAML 语法是否正确。
验证 Red Hat Enterprise Linux CoreOS(RHCOS)QEMU 镜像是否已正确定义,并可通过
install-config.yaml提供的 URL 访问。例如:$ curl -s -o /dev/null -I -w "%{http_code}\n" http://webserver.example.com:8080/rhcos-44.81.202004250133-0-qemu.<architecture>.qcow2.gz?sha256=7d884b46ee54fe87bbc3893bf2aa99af3b2d31f2e19ab5529c60636fbd0f1ce7如果输出为
200,则会从存储 bootstrap 虚拟机镜像的 webserver 获得有效的响应。
5.3. Bootstrap 虚拟机问题
OpenShift Container Platform 安装程序生成 bootstrap 节点虚拟机,该虚拟机处理置备 OpenShift Container Platform 集群节点。
流程
触发安装程序后大约 10 到 15 分钟,使用
virsh命令检查 bootstrap 虚拟机是否正常工作:$ sudo virsh listId Name State -------------------------------------------- 12 openshift-xf6fq-bootstrap running注意bootstrap 虚拟机的名称始终是集群名称,后跟一组随机字符,并以"bootstrap"结尾。
如果 bootstrap 虚拟机在 10-15 分钟后没有运行,请对它进行故障排除。可能的问题包括:
验证
libvirtd是否在系统中运行:$ systemctl status libvirtd● libvirtd.service - Virtualization daemon Loaded: loaded (/usr/lib/systemd/system/libvirtd.service; enabled; vendor preset: enabled) Active: active (running) since Tue 2020-03-03 21:21:07 UTC; 3 weeks 5 days ago Docs: man:libvirtd(8) https://libvirt.org Main PID: 9850 (libvirtd) Tasks: 20 (limit: 32768) Memory: 74.8M CGroup: /system.slice/libvirtd.service ├─ 9850 /usr/sbin/libvirtd如果 bootstrap 虚拟机可以正常工作,请登录它。
使用
virsh console命令查找 bootstrap 虚拟机的 IP 地址:$ sudo virsh console example.comConnected to domain example.com Escape character is ^] Red Hat Enterprise Linux CoreOS 43.81.202001142154.0 (Ootpa) 4.3 SSH host key: SHA256:BRWJktXZgQQRY5zjuAV0IKZ4WM7i4TiUyMVanqu9Pqg (ED25519) SSH host key: SHA256:7+iKGA7VtG5szmk2jB5gl/5EZ+SNcJ3a2g23o0lnIio (ECDSA) SSH host key: SHA256:DH5VWhvhvagOTaLsYiVNse9ca+ZSW/30OOMed8rIGOc (RSA) ens3: fd35:919d:4042:2:c7ed:9a9f:a9ec:7 ens4: 172.22.0.2 fe80::1d05:e52e:be5d:263f localhost login:重要当在没有
provisioning网络的情况下部署 OpenShift Container Platform 集群时,您必须使用公共 IP 地址,而不是专用 IP 地址,如172.22.0.2。获取 IP 地址后,使用
ssh命令登录到 bootstrap 虚拟机:注意在上一步的控制台输出中,您可以使用 ens3 提供的 IPv6 IP 地址或
ens4 提供的 IPv4 IP 地址。$ ssh core@172.22.0.2
如果您无法成功登录 bootstrap 虚拟机,您可能会遇到以下情况之一:
-
您无法访问
172.22.0.0/24网络。验证 provisioner 和provisioning网桥之间的网络连接。如果您使用provisioning网络,则可能会出现此问题。' -
您无法通过公共网络访问 bootstrap 虚拟机。当尝试 SSH via
baremetal 网络时,验证provisioner主机上的连接情况,特别是baremetal网桥的连接。 -
您遇到了
Permission denied(publickey,password,keyboard-interactive)的问题。当尝试访问 bootstrap 虚拟机时,可能会出现Permission denied错误。验证尝试登录到虚拟机的用户的 SSH 密钥是否在install-config.yaml文件中设置。
5.3.1. Bootstrap 虚拟机无法引导集群节点
在部署过程中,bootstrap 虚拟机可能无法引导集群节点,这会阻止虚拟机使用 RHCOS 镜像置备节点。这可能是因为以下原因:
-
install-config.yaml文件存在问题。 - 使用 baremetal 网络时出现带外网络访问的问题。
要验证这个问题,有三个与 ironic 相关的容器:
-
ironic -
ironic-inspector
流程
登录到 bootstrap 虚拟机:
$ ssh core@172.22.0.2要检查容器日志,请执行以下操作:
[core@localhost ~]$ sudo podman logs -f <container_name>将
<container_name>替换为ironic或ironic-inspector之一。如果您遇到 control plane 节点没有从 PXE 引导的问题,请检查ironicpod。ironicpod 包含有关尝试引导集群节点的信息,因为它尝试通过 IPMI 登录节点。
潜在原因
集群节点在部署启动时可能处于 ON 状态。
解决方案
在通过 IPMI 开始安装前关闭 OpenShift Container Platform 集群节点:
$ ipmitool -I lanplus -U root -P <password> -H <out_of_band_ip> power off5.3.2. 检查日志
在下载或访问 RHCOS 镜像时,首先验证 install-config.yaml 配置文件中的 URL 是否正确。
内部 webserver 托管 RHCOS 镜像的示例
bootstrapOSImage: http://<ip:port>/rhcos-43.81.202001142154.0-qemu.<architecture>.qcow2.gz?sha256=9d999f55ff1d44f7ed7c106508e5deecd04dc3c06095d34d36bf1cd127837e0c
clusterOSImage: http://<ip:port>/rhcos-43.81.202001142154.0-openstack.<architecture>.qcow2.gz?sha256=a1bda656fa0892f7b936fdc6b6a6086bddaed5dafacedcd7a1e811abb78fe3b0
coreos-downloader 容器从 webserver 或外部 quay.io registry 下载资源(由 install-config.yaml 配置文件指定)。验证 coreos-downloader 容器是否正在运行,并根据需要检查其日志。
流程
登录到 bootstrap 虚拟机:
$ ssh core@172.22.0.2运行以下命令,检查 bootstrap 虚拟机中的
coreos-downloader容器的状态:[core@localhost ~]$ sudo podman logs -f coreos-downloader如果 bootstrap 虚拟机无法访问镜像的 URL,请使用
curl命令验证虚拟机是否可以访问镜像。要检查
bootkube日志,以指示部署阶段是否启动了所有容器,请执行以下操作:[core@localhost ~]$ journalctl -xe[core@localhost ~]$ journalctl -b -f -u bootkube.service验证包括
dnsmasq、mariadb、httpd和ironic等所有 pod 都在运行:[core@localhost ~]$ sudo podman ps如果 pod 存在问题,请检查有问题的容器日志。要检查
ironic服务的日志,请运行以下命令:[core@localhost ~]$ sudo podman logs ironic
5.4. 集群节点不能 PXE 引导
当 OpenShift Container Platform 集群节点无法 PXE 引导时,请在不能 PXE 引导的集群节点上执行以下检查。在没有 provisioning 网络安装 OpenShift Container Platform 集群时,此流程不适用。
流程
-
检查与
provisioning网络的网络连接。 -
确保
provisioning网络的 NIC 上启用了 PXE,并为所有其他 NIC 禁用 PXE。 验证
install-config.yaml配置文件是否包含rootDeviceHints参数,以及连接到provisioning网络的 NIC 的引导 MAC 地址。例如:control plane 节点设置
bootMACAddress: 24:6E:96:1B:96:90 # MAC of bootable provisioning NICWorker 节点设置
bootMACAddress: 24:6E:96:1B:96:90 # MAC of bootable provisioning NIC
5.5. 无法使用 BMC 发现新的裸机主机
在某些情况下,安装程序将无法发现新的裸机主机并发出错误,因为它无法挂载远程虚拟介质共享。
例如:
ProvisioningError 51s metal3-baremetal-controller Image provisioning failed: Deploy step deploy.deploy failed with BadRequestError: HTTP POST
https://<bmc_address>/redfish/v1/Managers/iDRAC.Embedded.1/VirtualMedia/CD/Actions/VirtualMedia.InsertMedia
returned code 400.
Base.1.8.GeneralError: A general error has occurred. See ExtendedInfo for more information
Extended information: [
{
"Message": "Unable to mount remote share https://<ironic_address>/redfish/boot-<uuid>.iso.",
"MessageArgs": [
"https://<ironic_address>/redfish/boot-<uuid>.iso"
],
"MessageArgs@odata.count": 1,
"MessageId": "IDRAC.2.5.RAC0720",
"RelatedProperties": [
"#/Image"
],
"RelatedProperties@odata.count": 1,
"Resolution": "Retry the operation.",
"Severity": "Informational"
}
].在这种情况下,如果您使用带有未知证书颁发机构的虚拟介质,您可以配置基板管理控制器 (BMC) 远程文件共享设置,以信任未知证书颁发机构以避免这个错误。
这个解析已在带有 Dell iDRAC 9 的 OpenShift Container Platform 4.11 上测试,固件版本 5.10.50。
5.6. API 无法访问
当集群正在运行且客户端无法访问 API 时,域名解析问题可能会妨碍对 API 的访问。
流程
主机名解析: 检查集群节点,确保它们具有完全限定域名,而不只是
localhost.localdomain。例如:$ hostname如果没有设置主机名,请设置正确的主机名。例如:
$ hostnamectl set-hostname <hostname>错误的名称解析: 使用
dig和nslookup,确保每个节点在 DNS 服务器中具有正确的名称解析。例如:$ dig api.<cluster_name>.example.com; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.el8 <<>> api.<cluster_name>.example.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 37551 ;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 1, ADDITIONAL: 2 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ; COOKIE: 866929d2f8e8563582af23f05ec44203d313e50948d43f60 (good) ;; QUESTION SECTION: ;api.<cluster_name>.example.com. IN A ;; ANSWER SECTION: api.<cluster_name>.example.com. 10800 IN A 10.19.13.86 ;; AUTHORITY SECTION: <cluster_name>.example.com. 10800 IN NS <cluster_name>.example.com. ;; ADDITIONAL SECTION: <cluster_name>.example.com. 10800 IN A 10.19.14.247 ;; Query time: 0 msec ;; SERVER: 10.19.14.247#53(10.19.14.247) ;; WHEN: Tue May 19 20:30:59 UTC 2020 ;; MSG SIZE rcvd: 140示例中的输出显示
api.<cluster_name>.example.comVIP 的适当 IP 地址为10.19.13.86。此 IP 地址应当位于baremetal网络中。
5.7. 无法加入集群的 worker 节点故障排除
安装程序置备的集群使用 DNS 服务器部署,其中包含 api-int.<cluster_name>.<base_domain> URL 的 DNS 条目。如果集群中的节点使用外部或上游 DNS 服务器解析 api-int.<cluster_name>.<base_domain> URL,且没有这样的条目,则 worker 节点可能无法加入集群。确保集群中的所有节点都可以解析域名。
流程
添加 DNS A/AAAA 或 CNAME 记录,以内部标识 API 负载均衡器。例如,在使用 dnsmasq 时,修改
dnsmasq.conf配置文件:$ sudo nano /etc/dnsmasq.confaddress=/api-int.<cluster_name>.<base_domain>/<IP_address> address=/api-int.mycluster.example.com/192.168.1.10 address=/api-int.mycluster.example.com/2001:0db8:85a3:0000:0000:8a2e:0370:7334添加 DNS PTR 记录以内部标识 API 负载均衡器。例如,在使用 dnsmasq 时,修改
dnsmasq.conf配置文件:$ sudo nano /etc/dnsmasq.confptr-record=<IP_address>.in-addr.arpa,api-int.<cluster_name>.<base_domain> ptr-record=10.1.168.192.in-addr.arpa,api-int.mycluster.example.com重启 DNS 服务器。例如,在使用 dnsmasq 时执行以下命令:
$ sudo systemctl restart dnsmasq
这些记录必须可以从集群中的所有节点解析。
5.8. 清理以前的安装
如果以前部署失败,请在尝试再次部署 OpenShift Container Platform 前从失败的尝试中删除工件。
流程
使用以下命令安装 OpenShift Container Platform 集群前关闭所有裸机节点:
$ ipmitool -I lanplus -U <user> -P <password> -H <management_server_ip> power off使用以下脚本,删除所有旧的 bootstrap 资源:
for i in $(sudo virsh list | tail -n +3 | grep bootstrap | awk {'print $2'}); do sudo virsh destroy $i; sudo virsh undefine $i; sudo virsh vol-delete $i --pool $i; sudo virsh vol-delete $i.ign --pool $i; sudo virsh pool-destroy $i; sudo virsh pool-undefine $i; done使用以下命令删除早期安装生成的工件:
$ cd ; /bin/rm -rf auth/ bootstrap.ign master.ign worker.ign metadata.json \ .openshift_install.log .openshift_install_state.json使用以下命令重新创建 OpenShift Container Platform 清单:
$ ./openshift-baremetal-install --dir ~/clusterconfigs create manifests
5.9. 创建 registry 的问题
在创建断开连接的 registry 时,在尝试镜像 registry 时,可能会遇到 "User Not Authorized" 错误。如果您没有将新身份验证附加到现有的 pull-secret.txt 文件中,可能会发生这个错误。
流程
检查以确保身份验证成功:
$ /usr/local/bin/oc adm release mirror \ -a pull-secret-update.json --from=$UPSTREAM_REPO \ --to-release-image=$LOCAL_REG/$LOCAL_REPO:${VERSION} \ --to=$LOCAL_REG/$LOCAL_REPO注意用于镜像安装镜像的变量输出示例:
UPSTREAM_REPO=${RELEASE_IMAGE} LOCAL_REG=<registry_FQDN>:<registry_port> LOCAL_REPO='ocp4/openshift4'在为 OpenShift 安装设置环境 部分的 获取 OpenShift 安装程序 步骤中,设置了
RELEASE_IMAGE和VERSION的值。镜像 registry 后,确认您可以在断开连接的环境中访问它:
$ curl -k -u <user>:<password> https://registry.example.com:<registry_port>/v2/_catalog {"repositories":["<Repo_Name>"]}
5.10. 其它问题
5.10.1. 解决 运行时网络未就绪 错误
部署集群后,您可能会收到以下错误:
`runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: Missing CNI default network`
Cluster Network Operator 负责部署网络组件以响应安装程序创建的特殊对象。它会在安装过程的早期阶段运行(在 control plane(master)节点启动后,bootstrap control plane 被停止前运行。它可能表明存在更细微的安装程序问题,如启动 control plane(master)节点时延迟时间过长,或者 apiserver 通讯的问题。
流程
检查
openshift-network-operator命名空间中的 pod:$ oc get all -n openshift-network-operatorNAME READY STATUS RESTARTS AGE pod/network-operator-69dfd7b577-bg89v 0/1 ContainerCreating 0 149m在
provisioner节点上,确定存在网络配置:$ kubectl get network.config.openshift.io cluster -oyamlapiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: serviceNetwork: - 172.30.0.0/16 clusterNetwork: - cidr: 10.128.0.0/14 hostPrefix: 23 networkType: OVNKubernetes如果不存在,安装程序不会创建它。要确定安装程序没有创建它的原因,请执行以下操作:
$ openshift-install create manifests检查
network-operator是否正在运行:$ kubectl -n openshift-network-operator get pods检索日志:
$ kubectl -n openshift-network-operator logs -l "name=network-operator"在具有三个或更多 control plane(master)节点的高可用性集群中,Operator 将执行领导选举机制,所有其他 Operator 会休眠。如需了解更多详细信息,请参阅 故障排除。
部署集群后,您可能会收到以下出错信息:
No disk found with matching rootDeviceHints
要解决 No disk found with matching rootDeviceHints 错误,一个临时解决方法是将 rootDeviceHints 更改为 minSizeGigabytes: 300。
更改 rootDeviceHints 设置后,使用以下命令引导 CoreOS,然后使用以下命令验证磁盘信息:
$ udevadm info /dev/sda
如果您使用 DL360 Gen 10 服务器,请注意它们有一个 SD-card 插槽,它可能会被分配 /dev/sda 设备名称。如果服务器中没有 SD 卡,可能会导致冲突。确定在服务器的 BIOS 设置中禁用 SD 卡插槽。
如果 minSizeGigabytes 临时解决方案没有满足要求,您可能需要将 rootDeviceHints 恢复为 /dev/sda。此更改允许 ironic 镜像成功引导。
修复此问题的另一种方法是使用磁盘的串行 ID。但是,请注意,发现串行 ID 可能具有挑战性,并且可能会导致配置文件无法读取。如果选择此路径,请确保使用之前记录的命令收集串行 ID,并将其合并到您的配置中。
5.10.3. 集群节点没有通过 DHCP 获得正确的 IPv6 地址
如果集群节点没有通过 DHCP 获得正确的 IPv6 地址,请检查以下内容:
- 确保保留的 IPv6 地址不在 DHCP 范围内。
在 DHCP 服务器上的 IP 地址保留中,确保保留指定了正确的 DHCP 唯一标识符(DUID)。例如:
# This is a dnsmasq dhcp reservation, 'id:00:03:00:01' is the client id and '18:db:f2:8c:d5:9f' is the MAC Address for the NIC id:00:03:00:01:18:db:f2:8c:d5:9f,openshift-master-1,[2620:52:0:1302::6]- 确保路由声明正常工作。
- 确保 DHCP 服务器正在侦听提供 IP 地址范围所需的接口。
5.10.4. 集群节点没有通过 DHCP 获得正确的主机名
在 IPv6 部署过程中,集群节点必须通过 DHCP 获得其主机名。有时 NetworkManager 不会立即分配主机名。control plane(master)节点可能会报告错误,例如:
Failed Units: 2
NetworkManager-wait-online.service
nodeip-configuration.service
这个错误表示集群节点可能在没有从 DHCP 服务器接收主机名的情况下引导,这会导致 kubelet 使用 localhost.localdomain 主机名引导。要解决错误,请强制节点更新主机名。
流程
检索
主机名:[core@master-X ~]$ hostname如果主机名是
localhost,请执行以下步骤。注意其中
X是 control plane 节点号。强制集群节点续订 DHCP 租期:
[core@master-X ~]$ sudo nmcli con up "<bare_metal_nic>"将
<bare_metal_nic>替换为与baremetal网络对应的有线连接。再次检查
主机名:[core@master-X ~]$ hostname如果主机名仍然是
localhost.localdomain,重启NetworkManager:[core@master-X ~]$ sudo systemctl restart NetworkManager-
如果主机名仍然是
localhost.localdomain,请等待几分钟并再次检查。如果主机名仍为localhost.localdomain,请重复前面的步骤。 重启
nodeip-configuration服务:[core@master-X ~]$ sudo systemctl restart nodeip-configuration.service此服务将使用正确的主机名引用来重新配置
kubelet服务。因为 kubelet 在上一步中更改,所以重新载入单元文件定义:
[core@master-X ~]$ sudo systemctl daemon-reload重启
kubelet服务:[core@master-X ~]$ sudo systemctl restart kubelet.service确保
kubelet使用正确的主机名引导:[core@master-X ~]$ sudo journalctl -fu kubelet.service
如果集群节点在集群启动并运行后没有通过 DHCP 获得正确的主机名,比如在重启过程中,集群会有一个待处理的 csr。不要 批准 csr,否则可能会出现其他问题。
处理 csr
在集群上获取 CSR:
$ oc get csr验证待处理的
csr是否包含Subject Name: localhost.localdomain:$ oc get csr <pending_csr> -o jsonpath='{.spec.request}' | base64 --decode | openssl req -noout -text删除包含
Subject Name: localhost.localdomain的任何csr:$ oc delete csr <wrong_csr>
5.10.5. 路由无法访问端点
在安装过程中,可能会出现虚拟路由器冗余协议(VRRP)冲突。如果之前使用特定集群名称部署的 OpenShift Container Platform 节点仍在运行,但不是使用相同集群名称部署的当前 OpenShift Container Platform 集群的一部分,则可能会出现冲突。例如,一个集群使用集群名称 openshift 部署,它 部署了三个 control plane(master)节点和三个 worker 节点。之后,一个单独的安装使用相同的集群名称 openshift,但这个重新部署只安装了三个 control plane(master)节点,使以前部署的三个 worker 节点处于 ON 状态。这可能导致 Virtual Router Identifier(VRID)冲突和 VRRP 冲突。
获取路由:
$ oc get route oauth-openshift检查服务端点:
$ oc get svc oauth-openshiftNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE oauth-openshift ClusterIP 172.30.19.162 <none> 443/TCP 59m尝试从 control plane(master)节点访问该服务:
[core@master0 ~]$ curl -k https://172.30.19.162{ "kind": "Status", "apiVersion": "v1", "metadata": { }, "status": "Failure", "message": "forbidden: User \"system:anonymous\" cannot get path \"/\"", "reason": "Forbidden", "details": { }, "code": 403识别
provisioner节点的 authentication-operator错误:$ oc logs deployment/authentication-operator -n openshift-authentication-operatorEvent(v1.ObjectReference{Kind:"Deployment", Namespace:"openshift-authentication-operator", Name:"authentication-operator", UID:"225c5bd5-b368-439b-9155-5fd3c0459d98", APIVersion:"apps/v1", ResourceVersion:"", FieldPath:""}): type: 'Normal' reason: 'OperatorStatusChanged' Status for clusteroperator/authentication changed: Degraded message changed from "IngressStateEndpointsDegraded: All 2 endpoints for oauth-server are reporting"
解决方案
- 确保每个部署的集群名称都是唯一的,确保没有冲突。
- 关闭所有不是使用相同集群名称的集群部署的一部分的节点。否则,OpenShift Container Platform 集群的身份验证 pod 可能无法成功启动。
5.10.6. 在 Firstboot 过程中 Ignition 失败
在 Firstboot 过程中,Ignition 配置可能会失败。
流程
连接到 Ignition 配置失败的节点:
Failed Units: 1 machine-config-daemon-firstboot.service重启
machine-config-daemon-firstboot服务:[core@worker-X ~]$ sudo systemctl restart machine-config-daemon-firstboot.service
5.10.7. NTP 不同步
OpenShift Container Platform 集群的部署需要集群节点间的 NTP 同步时钟。如果没有同步时钟,如果时间差大于 2 秒,则部署可能会因为时钟偏移而失败。
流程
检查集群节点的
AGE的不同。例如:$ oc get nodesNAME STATUS ROLES AGE VERSION master-0.cloud.example.com Ready master 145m v1.27.3 master-1.cloud.example.com Ready master 135m v1.27.3 master-2.cloud.example.com Ready master 145m v1.27.3 worker-2.cloud.example.com Ready worker 100m v1.27.3检查时钟偏移导致的时间延迟。例如:
$ oc get bmh -n openshift-machine-apimaster-1 error registering master-1 ipmi://<out_of_band_ip>$ sudo timedatectlLocal time: Tue 2020-03-10 18:20:02 UTC Universal time: Tue 2020-03-10 18:20:02 UTC RTC time: Tue 2020-03-10 18:36:53 Time zone: UTC (UTC, +0000) System clock synchronized: no NTP service: active RTC in local TZ: no
处理现有集群中的时钟偏移
创建一个 Butane 配置文件,其中包含要发送到节点的
chrony.conf文件的内容。在以下示例中,创建99-master-chrony.bu将文件添加到 control plane 节点。您可以修改 worker 节点的 文件,或者对 worker 角色重复此步骤。注意有关 Butane 的信息,请参阅"使用 Butane 创建机器配置"。
variant: openshift version: 4.14.0 metadata: name: 99-master-chrony labels: machineconfiguration.openshift.io/role: master storage: files: - path: /etc/chrony.conf mode: 0644 overwrite: true contents: inline: | server <NTP_server> iburst1 stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 keyfile /etc/chrony.keys commandkey 1 generatecommandkey noclientlog logchange 0.5 logdir /var/log/chrony- 1
- 将
<NTP_server>替换为 NTP 服务器的 IP 地址。
使用 Butane 生成
MachineConfig对象文件99-master-chrony.yaml,其中包含要交付至节点的配置:$ butane 99-master-chrony.bu -o 99-master-chrony.yaml应用
MachineConfig对象文件:$ oc apply -f 99-master-chrony.yaml确保
系统时钟同步值为 yes :$ sudo timedatectlLocal time: Tue 2020-03-10 19:10:02 UTC Universal time: Tue 2020-03-10 19:10:02 UTC RTC time: Tue 2020-03-10 19:36:53 Time zone: UTC (UTC, +0000) System clock synchronized: yes NTP service: active RTC in local TZ: no要在部署前设置时钟同步,请生成清单文件并将此文件添加到
openshift目录中。例如:$ cp chrony-masters.yaml ~/clusterconfigs/openshift/99_masters-chrony-configuration.yaml然后,继续创建集群。
5.11. 检查安装
安装后,请确保安装程序成功部署了节点和容器集。
流程
当正确安装 OpenShift Container Platform 集群节点时,在
STATUS列中会显示以下Ready 状态:$ oc get nodesNAME STATUS ROLES AGE VERSION master-0.example.com Ready master,worker 4h v1.27.3 master-1.example.com Ready master,worker 4h v1.27.3 master-2.example.com Ready master,worker 4h v1.27.3确认安装程序成功部署了所有容器集。以下命令将移除仍在运行或已完成的 pod 作为输出的一部分。
$ oc get pods --all-namespaces | grep -iv running | grep -iv complete
第 6 章 安装程序置备的安装后配置
成功部署安装程序置备的集群后,请考虑以下安装后流程。
6.1. 可选:为断开连接的集群配置 NTP
OpenShift Container Platform 在集群节点上安装 chrony 网络时间协议(NTP)服务。使用以下步骤在 control plane 节点上配置 NTP 服务器,并将 worker 节点配置为成功部署后,将 worker 节点配置为 control plane 节点的 NTP 客户端。
OpenShift Container Platform 节点必须在日期和时间上达成一致才能正确运行。当 worker 节点从 control plane 节点上的 NTP 服务器检索日期和时间时,它会启用未连接到可路由网络的集群的安装和操作,因此无法访问更高的 stratum NTP 服务器。
流程
使用以下命令在安装主机上安装 Butane:
$ sudo dnf -y install butane为 control plane 节点创建一个 Butane 配置
99-master-chrony-conf-override.bu,包括chrony.conf文件的内容。注意如需有关 Butane 的信息,请参阅"使用 Butane 创建机器配置"。
但ane 配置示例
variant: openshift version: 4.14.0 metadata: name: 99-master-chrony-conf-override labels: machineconfiguration.openshift.io/role: master storage: files: - path: /etc/chrony.conf mode: 0644 overwrite: true contents: inline: | # Use public servers from the pool.ntp.org project. # Please consider joining the pool (https://www.pool.ntp.org/join.html). # The Machine Config Operator manages this file server openshift-master-0.<cluster-name>.<domain> iburst1 server openshift-master-1.<cluster-name>.<domain> iburst server openshift-master-2.<cluster-name>.<domain> iburst stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 keyfile /etc/chrony.keys commandkey 1 generatecommandkey noclientlog logchange 0.5 logdir /var/log/chrony # Configure the control plane nodes to serve as local NTP servers # for all worker nodes, even if they are not in sync with an # upstream NTP server. # Allow NTP client access from the local network. allow all # Serve time even if not synchronized to a time source. local stratum 3 orphan- 1
- 您必须将
<cluster-name>替换为集群名称,并将<domain>替换为完全限定域名。
使用 Butane 生成
MachineConfig对象文件99-master-chrony-conf-override.yaml,其中包含要发送到 control plane 节点的配置:$ butane 99-master-chrony-conf-override.bu -o 99-master-chrony-conf-override.yaml为引用 control plane 节点上的 NTP 服务器的 worker 节点创建 Butane 配置
99-worker-chrony-conf-override.bu,包括chrony.conf文件的内容。但ane 配置示例
variant: openshift version: 4.14.0 metadata: name: 99-worker-chrony-conf-override labels: machineconfiguration.openshift.io/role: worker storage: files: - path: /etc/chrony.conf mode: 0644 overwrite: true contents: inline: | # The Machine Config Operator manages this file. server openshift-master-0.<cluster-name>.<domain> iburst1 server openshift-master-1.<cluster-name>.<domain> iburst server openshift-master-2.<cluster-name>.<domain> iburst stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 keyfile /etc/chrony.keys commandkey 1 generatecommandkey noclientlog logchange 0.5 logdir /var/log/chrony- 1
- 您必须将
<cluster-name>替换为集群名称,并将<domain>替换为完全限定域名。
使用 Butane 生成
MachineConfig对象文件99-worker-chrony-conf-override.yaml,其中包含要交付至 worker 节点的配置:$ butane 99-worker-chrony-conf-override.bu -o 99-worker-chrony-conf-override.yaml将
99-master-chrony-conf-override.yaml策略应用到 control plane 节点。$ oc apply -f 99-master-chrony-conf-override.yaml输出示例
machineconfig.machineconfiguration.openshift.io/99-master-chrony-conf-override created将
99-worker-chrony-conf-override.yaml策略应用到 worker 节点。$ oc apply -f 99-worker-chrony-conf-override.yaml输出示例
machineconfig.machineconfiguration.openshift.io/99-worker-chrony-conf-override created检查应用的 NTP 设置的状态。
$ oc describe machineconfigpool
6.2. 安装后启用置备网络
通过为裸机集群提供支持的安装程序和安装程序置备安装,可以在没有 provisioning 网络的情况下部署集群。当每个节点的基板管理控制器可以通过 baremetal 网络 路由时,此功能适用于概念验证集群或仅使用 Redfish 虚拟介质单独部署的情况。
您可在安装后使用 Cluster Baremetal Operator(CBO)启用 置备 网络。
先决条件
- 必须存在专用物理网络,连接到所有 worker 和 control plane 节点。
- 您必须隔离原生、未标记的物理网络。
-
当
provisioningNetwork配置设置为Managed时,网络无法有一个 DHCP 服务器。 -
您可以省略 OpenShift Container Platform 4.10 中的
provisioningInterface设置,以使用bootMACAddress配置设置。
流程
-
设置
provisioningInterface设置时,首先确定集群节点的调配接口名称。例如:eth0oreno1。 -
在集群节点的
调配网络接口上启用预引导执行环境(PXE)。 检索
provisioning网络的当前状态,并将其保存到 provisioning 自定义资源(CR)文件中:$ oc get provisioning -o yaml > enable-provisioning-nw.yaml修改 provisioning CR 文件:
$ vim ~/enable-provisioning-nw.yaml向下滚动到
provisioningNetwork配置设置,并将它从Disabled改为Managed。然后,在provisioningNetwork设置后添加provisioningIP、provisioningNetworkCIDR、provisioningDHCPRange、provisioningInterface和watchAllNameSpaces配置设置。为每项设置提供适当的值。apiVersion: v1 items: - apiVersion: metal3.io/v1alpha1 kind: Provisioning metadata: name: provisioning-configuration spec: provisioningNetwork:1 provisioningIP:2 provisioningNetworkCIDR:3 provisioningDHCPRange:4 provisioningInterface:5 watchAllNameSpaces:6 - 1
provisioningNetwork是Managed、Unmanaged 或Disabled之一。当设置为Managed时,Metal3 管理调配网络,CBO 使用配置的 DHCP 服务器部署 Metal3 pod。当设置为Unmanaged时,系统管理员手动配置 DHCP 服务器。- 2
provisioningIP是 DHCP 服务器和 ironic 用于调配网络的静态 IP 地址。这个静态 IP 地址必须在provisioning子网内,且不在 DHCP 范围内。如果配置这个设置,它必须具有有效的 IP 地址,即使provisioning网络是Disabled。静态 IP 地址绑定到 metal3 pod。如果 metal3 pod 失败并移动到其他服务器,静态 IP 地址也会移到新服务器。- 3
- 无类别域间路由(CIDR)地址。如果配置这个设置,它必须具有有效的 CIDR 地址,即使
provisioning网络是Disabled。例如:192.168.0.1/24。 - 4
- DHCP 范围。此设置仅适用于
受管置备网络。如果provisioning网络为Disabled,则省略此配置设置。例如:192.168.0.64, 192.168.0.253。 - 5
- 集群节点上
置备接口的 NIC 名称。provisioningInterface设置仅适用于受管和非受管置备网络。如果provisioning网络为Disabled,忽略provisioningInterface配置设置。省略provisioningInterface配置设置,以使用bootMACAddress配置设置。 - 6
- 如果您希望 metal3 监视默认
openshift-machine-api命名空间以外的命名空间,请将此设置设置为true。默认值为false。
- 保存对 provisioning CR 文件的更改。
将 provisioning CR 文件应用到集群:
$ oc apply -f enable-provisioning-nw.yaml
6.3. 外部负载均衡器的服务
您可以将 OpenShift Container Platform 集群配置为使用外部负载均衡器来代替默认负载均衡器。
配置外部负载均衡器取决于您的供应商的负载均衡器。
本节中的信息和示例仅用于指导目的。有关供应商负载均衡器的更多信息,请参阅供应商文档。
红帽支持外部负载均衡器的以下服务:
- Ingress Controller
- OpenShift API
- OpenShift MachineConfig API
您可以选择是否为外部负载均衡器配置一个或多个所有服务。仅配置 Ingress Controller 服务是一个通用的配置选项。要更好地了解每个服务,请查看以下图表:
图 6.1. 显示 OpenShift Container Platform 环境中运行的 Ingress Controller 的网络工作流示例

图 6.2. 显示 OpenShift Container Platform 环境中运行的 OpenShift API 的网络工作流示例

图 6.3. 显示 OpenShift Container Platform 环境中运行的 OpenShift MachineConfig API 的网络工作流示例

外部负载均衡器支持以下配置选项:
- 使用节点选择器将 Ingress Controller 映射到一组特定的节点。您必须为这个集合中的每个节点分配一个静态 IP 地址,或者将每个节点配置为从动态主机配置协议(DHCP)接收相同的 IP 地址。基础架构节点通常接收这种类型的配置。
以子网上的所有 IP 地址为目标。此配置可减少维护开销,因为您可以在这些网络中创建和销毁节点,而无需重新配置负载均衡器目标。如果您使用较小的网络上的机器集来部署入口 pod,如
/27或/28,您可以简化负载均衡器目标。提示您可以通过检查机器配置池的资源来列出网络中存在的所有 IP 地址。
在为 OpenShift Container Platform 集群配置外部负载均衡器前,请考虑以下信息:
- 对于前端 IP 地址,您可以对前端 IP 地址、Ingress Controller 的负载均衡器和 API 负载均衡器使用相同的 IP 地址。查看厂商的文档以获取此功能的相关信息。
对于后端 IP 地址,请确保 OpenShift Container Platform control plane 节点的 IP 地址在外部负载均衡器的生命周期内不会改变。您可以通过完成以下操作之一来实现此目的:
- 为每个 control plane 节点分配一个静态 IP 地址。
- 将每个节点配置为在每次节点请求 DHCP 租期时从 DHCP 接收相同的 IP 地址。根据供应商,DHCP 租期可能采用 IP 保留或静态 DHCP 分配的形式。
- 在 Ingress Controller 后端服务的外部负载均衡器中手动定义运行 Ingress Controller 的每个节点。例如,如果 Ingress Controller 移到未定义节点,则可能会出现连接中断。
6.3.1. 配置外部负载均衡器
您可以将 OpenShift Container Platform 集群配置为使用外部负载均衡器来代替默认负载均衡器。
在配置外部负载均衡器前,请确定您阅读了外部负载均衡器的"服务"部分。
阅读适用于您要为外部负载均衡器配置的服务的以下先决条件。
MetalLB,在集群中运行,充当外部负载均衡器。
OpenShift API 的先决条件
- 您定义了前端 IP 地址。
TCP 端口 6443 和 22623 在负载均衡器的前端 IP 地址上公开。检查以下项:
- 端口 6443 提供对 OpenShift API 服务的访问。
- 端口 22623 可以为节点提供 ignition 启动配置。
- 前端 IP 地址和端口 6443 可以被您的系统的所有用户访问,其位置为 OpenShift Container Platform 集群外部。
- 前端 IP 地址和端口 22623 只能被 OpenShift Container Platform 节点访问。
- 负载均衡器后端可以在端口 6443 和 22623 上与 OpenShift Container Platform control plane 节点通信。
Ingress Controller 的先决条件
- 您定义了前端 IP 地址。
- TCP 端口 443 和 80 在负载均衡器的前端 IP 地址上公开。
- 前端 IP 地址、端口 80 和端口 443 可以被您的系统所有用户访问,以及 OpenShift Container Platform 集群外部的位置。
- 前端 IP 地址、端口 80 和端口 443 可被 OpenShift Container Platform 集群中运行的所有节点访问。
- 负载均衡器后端可以在端口 80、443 和 1936 上与运行 Ingress Controller 的 OpenShift Container Platform 节点通信。
健康检查 URL 规格的先决条件
您可以通过设置健康检查 URL 来配置大多数负载均衡器,以确定服务是否可用或不可用。OpenShift Container Platform 为 OpenShift API、Machine Configuration API 和 Ingress Controller 后端服务提供这些健康检查。
以下示例演示了以前列出的后端服务的健康检查规格:
Kubernetes API 健康检查规格示例
Path: HTTPS:6443/readyz
Healthy threshold: 2
Unhealthy threshold: 2
Timeout: 10
Interval: 10Machine Config API 健康检查规格示例
Path: HTTPS:22623/healthz
Healthy threshold: 2
Unhealthy threshold: 2
Timeout: 10
Interval: 10Ingress Controller 健康检查规格示例
Path: HTTP:1936/healthz/ready
Healthy threshold: 2
Unhealthy threshold: 2
Timeout: 5
Interval: 10流程
配置 HAProxy Ingress Controller,以便您可以在端口 6443、443 和 80 上从负载均衡器访问集群:
HAProxy 配置示例
#... listen my-cluster-api-6443 bind 192.168.1.100:6443 mode tcp balance roundrobin option httpchk http-check connect http-check send meth GET uri /readyz http-check expect status 200 server my-cluster-master-2 192.168.1.101:6443 check inter 10s rise 2 fall 2 server my-cluster-master-0 192.168.1.102:6443 check inter 10s rise 2 fall 2 server my-cluster-master-1 192.168.1.103:6443 check inter 10s rise 2 fall 2 listen my-cluster-machine-config-api-22623 bind 192.168.1.100:22623 mode tcp balance roundrobin option httpchk http-check connect http-check send meth GET uri /healthz http-check expect status 200 server my-cluster-master-2 192.168.1.101:22623 check inter 10s rise 2 fall 2 server my-cluster-master-0 192.168.1.102:22623 check inter 10s rise 2 fall 2 server my-cluster-master-1 192.168.1.103:22623 check inter 10s rise 2 fall 2 listen my-cluster-apps-443 bind 192.168.1.100:443 mode tcp balance roundrobin option httpchk http-check connect http-check send meth GET uri /healthz/ready http-check expect status 200 server my-cluster-worker-0 192.168.1.111:443 check port 1936 inter 10s rise 2 fall 2 server my-cluster-worker-1 192.168.1.112:443 check port 1936 inter 10s rise 2 fall 2 server my-cluster-worker-2 192.168.1.113:443 check port 1936 inter 10s rise 2 fall 2 listen my-cluster-apps-80 bind 192.168.1.100:80 mode tcp balance roundrobin option httpchk http-check connect http-check send meth GET uri /healthz/ready http-check expect status 200 server my-cluster-worker-0 192.168.1.111:80 check port 1936 inter 10s rise 2 fall 2 server my-cluster-worker-1 192.168.1.112:80 check port 1936 inter 10s rise 2 fall 2 server my-cluster-worker-2 192.168.1.113:80 check port 1936 inter 10s rise 2 fall 2 # ...使用
curlCLI 命令验证外部负载均衡器及其资源是否正常运行:运行以下命令并查看响应,验证集群机器配置 API 是否可以被 Kubernetes API 服务器资源访问:
$ curl https://<loadbalancer_ip_address>:6443/version --insecure如果配置正确,您会收到 JSON 对象的响应:
{ "major": "1", "minor": "11+", "gitVersion": "v1.11.0+ad103ed", "gitCommit": "ad103ed", "gitTreeState": "clean", "buildDate": "2019-01-09T06:44:10Z", "goVersion": "go1.10.3", "compiler": "gc", "platform": "linux/amd64" }运行以下命令并观察输出,验证集群机器配置 API 是否可以被 Machine 配置服务器资源访问:
$ curl -v https://<loadbalancer_ip_address>:22623/healthz --insecure如果配置正确,命令的输出会显示以下响应:
HTTP/1.1 200 OK Content-Length: 0运行以下命令并观察输出,验证控制器是否可以被端口 80 上的 Ingress Controller 资源访问:
$ curl -I -L -H "Host: console-openshift-console.apps.<cluster_name>.<base_domain>" http://<load_balancer_front_end_IP_address>如果配置正确,命令的输出会显示以下响应:
HTTP/1.1 302 Found content-length: 0 location: https://console-openshift-console.apps.ocp4.private.opequon.net/ cache-control: no-cache运行以下命令并观察输出,验证控制器是否可以被端口 443 上的 Ingress Controller 资源访问:
$ curl -I -L --insecure --resolve console-openshift-console.apps.<cluster_name>.<base_domain>:443:<Load Balancer Front End IP Address> https://console-openshift-console.apps.<cluster_name>.<base_domain>如果配置正确,命令的输出会显示以下响应:
HTTP/1.1 200 OK referrer-policy: strict-origin-when-cross-origin set-cookie: csrf-token=UlYWOyQ62LWjw2h003xtYSKlh1a0Py2hhctw0WmV2YEdhJjFyQwWcGBsja261dGLgaYO0nxzVErhiXt6QepA7g==; Path=/; Secure; SameSite=Lax x-content-type-options: nosniff x-dns-prefetch-control: off x-frame-options: DENY x-xss-protection: 1; mode=block date: Wed, 04 Oct 2023 16:29:38 GMT content-type: text/html; charset=utf-8 set-cookie: 1e2670d92730b515ce3a1bb65da45062=1bf5e9573c9a2760c964ed1659cc1673; path=/; HttpOnly; Secure; SameSite=None cache-control: private
为您的集群配置 DNS 记录,以外部负载均衡器的前端 IP 地址为目标。您必须在负载均衡器上将记录更新为集群 API 和应用程序的 DNS 服务器。
修改 DNS 记录示例
<load_balancer_ip_address> A api.<cluster_name>.<base_domain> A record pointing to Load Balancer Front End<load_balancer_ip_address> A apps.<cluster_name>.<base_domain> A record pointing to Load Balancer Front End重要DNS 传播可能需要一些时间才能获得每个 DNS 记录。在验证每个记录前,请确保每个 DNS 记录传播。
使用
curlCLI 命令验证外部负载均衡器和 DNS 记录配置是否正常运行:运行以下命令并查看输出,验证您可以访问集群 API:
$ curl https://api.<cluster_name>.<base_domain>:6443/version --insecure如果配置正确,您会收到 JSON 对象的响应:
{ "major": "1", "minor": "11+", "gitVersion": "v1.11.0+ad103ed", "gitCommit": "ad103ed", "gitTreeState": "clean", "buildDate": "2019-01-09T06:44:10Z", "goVersion": "go1.10.3", "compiler": "gc", "platform": "linux/amd64" }运行以下命令并查看输出,验证您可以访问集群机器配置:
$ curl -v https://api.<cluster_name>.<base_domain>:22623/healthz --insecure如果配置正确,命令的输出会显示以下响应:
HTTP/1.1 200 OK Content-Length: 0运行以下命令并查看输出,验证您可以在端口上访问每个集群应用程序:
$ curl http://console-openshift-console.apps.<cluster_name>.<base_domain> -I -L --insecure如果配置正确,命令的输出会显示以下响应:
HTTP/1.1 302 Found content-length: 0 location: https://console-openshift-console.apps.<cluster-name>.<base domain>/ cache-control: no-cacheHTTP/1.1 200 OK referrer-policy: strict-origin-when-cross-origin set-cookie: csrf-token=39HoZgztDnzjJkq/JuLJMeoKNXlfiVv2YgZc09c3TBOBU4NI6kDXaJH1LdicNhN1UsQWzon4Dor9GWGfopaTEQ==; Path=/; Secure x-content-type-options: nosniff x-dns-prefetch-control: off x-frame-options: DENY x-xss-protection: 1; mode=block date: Tue, 17 Nov 2020 08:42:10 GMT content-type: text/html; charset=utf-8 set-cookie: 1e2670d92730b515ce3a1bb65da45062=9b714eb87e93cf34853e87a92d6894be; path=/; HttpOnly; Secure; SameSite=None cache-control: private运行以下命令并查看输出,验证您可以在端口 443 上访问每个集群应用程序:
$ curl https://console-openshift-console.apps.<cluster_name>.<base_domain> -I -L --insecure如果配置正确,命令的输出会显示以下响应:
HTTP/1.1 200 OK referrer-policy: strict-origin-when-cross-origin set-cookie: csrf-token=UlYWOyQ62LWjw2h003xtYSKlh1a0Py2hhctw0WmV2YEdhJjFyQwWcGBsja261dGLgaYO0nxzVErhiXt6QepA7g==; Path=/; Secure; SameSite=Lax x-content-type-options: nosniff x-dns-prefetch-control: off x-frame-options: DENY x-xss-protection: 1; mode=block date: Wed, 04 Oct 2023 16:29:38 GMT content-type: text/html; charset=utf-8 set-cookie: 1e2670d92730b515ce3a1bb65da45062=1bf5e9573c9a2760c964ed1659cc1673; path=/; HttpOnly; Secure; SameSite=None cache-control: private
第 7 章 扩展集群
部署安装程序置备的 OpenShift Container Platform 集群后,您可以使用以下步骤扩展 worker 节点的数量。确保每个 worker 节点都满足先决条件。
使用 RedFish Virtual Media 扩展集群需要满足最低固件要求。有关使用 RedFish Virtual Media 扩展集群的详情,请参阅先决条件部分中的使用虚拟介质安装的固件要求。
7.1. 准备裸机节点
要扩展集群,必须为节点提供相关 IP 地址。这可以通过静态配置,或使用 DHCP (动态主机配置协议)服务器来完成。在使用 DHCP 服务器扩展集群时,每个节点都必须有 DHCP 保留。
有些管理员更喜欢使用静态 IP 地址,以便在没有 DHCP 服务器时每个节点的 IP 地址保持恒定状态。要使用 NMState 配置静态 IP 地址,请参阅 install-config.yaml 文件中的 "可选:配置主机网络接口,以了解更多详细信息。
准备裸机节点需要从 provisioner 节点执行以下步骤。
流程
获取
oc二进制文件:$ curl -s https://mirror.openshift.com/pub/openshift-v4/clients/ocp/$VERSION/openshift-client-linux-$VERSION.tar.gz | tar zxvf - oc$ sudo cp oc /usr/local/bin- 使用基板管理控制器 (BMC) 关闭裸机节点,并确保它已关闭。
检索裸机节点基板管理控制器的用户名和密码。然后,从用户名和密码创建
base64字符串:$ echo -ne "root" | base64$ echo -ne "password" | base64为裸机节点创建配置文件。根据您是否使用静态配置还是 DHCP 服务器,请使用以下示例
bmh.yaml文件,替换 YAML 中的值以匹配您的环境:$ vim bmh.yaml静态配置
bmh.yaml:--- apiVersion: v11 kind: Secret metadata: name: openshift-worker-<num>-network-config-secret2 namespace: openshift-machine-api type: Opaque stringData: nmstate: |3 interfaces:4 - name: <nic1_name>5 type: ethernet state: up ipv4: address: - ip: <ip_address>6 prefix-length: 24 enabled: true dns-resolver: config: server: - <dns_ip_address>7 routes: config: - destination: 0.0.0.0/0 next-hop-address: <next_hop_ip_address>8 next-hop-interface: <next_hop_nic1_name>9 --- apiVersion: v1 kind: Secret metadata: name: openshift-worker-<num>-bmc-secret10 namespace: openshift-machine-api type: Opaque data: username: <base64_of_uid>11 password: <base64_of_pwd>12 --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: openshift-worker-<num>13 namespace: openshift-machine-api spec: online: True bootMACAddress: <nic1_mac_address>14 bmc: address: <protocol>://<bmc_url>15 credentialsName: openshift-worker-<num>-bmc-secret16 disableCertificateVerification: True17 username: <bmc_username>18 password: <bmc_password>19 rootDeviceHints: deviceName: <root_device_hint>20 preprovisioningNetworkDataName: openshift-worker-<num>-network-config-secret21 - 1
- 要为新创建的节点配置网络接口,请指定包含网络配置的 secret 的名称。按照
nmstate语法为节点定义网络配置。有关配置 NMState 语法的详情,请参阅"可选:在 install-config.yaml 文件中配置主机网络接口"。 - 2 10 13 16
- 在
name、credentialsName字段和preprovisioningNetworkDataName字段中,使用裸机节点的 worker 数量替换<num>。 - 3
- 添加 NMState YAML 语法来配置主机接口。
- 4
- 可选:如果您使用
nmstate配置网络接口,并且您要禁用接口,请将state:设置为enabled: false,如下所示:--- interfaces: - name: <nic_name> type: ethernet state: up ipv4: enabled: false ipv6: enabled: false - 5 6 7 8 9
- 使用适当的值替换
<nic1_name>,<ip_address>,<dns_ip_address>,<next_hop_ip_address>和<next_hop_nic1_name>。 - 11 12
- 将
<base64_of_uid>和<base64_of_pwd>替换为用户名和密码的 base64 字符串。 - 14
- 将
<nic1_mac_address>替换为裸机节点第一个 NIC 的 MAC 地址。如需了解更多 BMC 配置选项,请参阅"BMC 寻址"部分。 - 15
- 将
<protocol>替换为 BMC 协议,如 IPMI、RedFish 或其他协议。将<bmc_url>替换为裸机节点基板管理控制器的 URL。 - 17
- 要跳过证书验证,将
disableCertificateVerification设为 true。 - 18 19
- 将
<bmc_username>和<bmc_password>替换为 BMC 用户名和密码的字符串。 - 20
- 可选:如果您指定了 root 设备提示,将
<root_device_hint>替换为设备路径。 - 21
- 可选: 如果您为新创建的节点配置了网络接口,请在 BareMetalHost CR 的
preprovisioningNetworkDataName中提供网络配置 secret 名称。
DHCP 配置
bmh.yaml:--- apiVersion: v1 kind: Secret metadata: name: openshift-worker-<num>-bmc-secret1 namespace: openshift-machine-api type: Opaque data: username: <base64_of_uid>2 password: <base64_of_pwd>3 --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: openshift-worker-<num>4 namespace: openshift-machine-api spec: online: True bootMACAddress: <nic1_mac_address>5 bmc: address: <protocol>://<bmc_url>6 credentialsName: openshift-worker-<num>-bmc-secret7 disableCertificateVerification: True8 username: <bmc_username>9 password: <bmc_password>10 rootDeviceHints: deviceName: <root_device_hint>11 preprovisioningNetworkDataName: openshift-worker-<num>-network-config-secret12 - 1 4 7
- 在
name、credentialsName字段和preprovisioningNetworkDataName字段中,使用裸机节点的 worker 数量替换<num>。 - 2 3
- 将
<base64_of_uid>和<base64_of_pwd>替换为用户名和密码的 base64 字符串。 - 5
- 将
<nic1_mac_address>替换为裸机节点第一个 NIC 的 MAC 地址。如需了解更多 BMC 配置选项,请参阅"BMC 寻址"部分。 - 6
- 将
<protocol>替换为 BMC 协议,如 IPMI、RedFish 或其他协议。将<bmc_url>替换为裸机节点基板管理控制器的 URL。 - 8
- 要跳过证书验证,将
disableCertificateVerification设为 true。 - 9 10
- 将
<bmc_username>和<bmc_password>替换为 BMC 用户名和密码的字符串。 - 11
- 可选:如果您指定了 root 设备提示,将
<root_device_hint>替换为设备路径。 - 12
- 可选: 如果您为新创建的节点配置了网络接口,请在 BareMetalHost CR 的
preprovisioningNetworkDataName中提供网络配置 secret 名称。
注意如果现有裸机节点的 MAC 地址与您试图置备的裸机主机的 MAC 地址匹配,则 Ironic 安装将失败。如果主机注册、检查、清理或其他 Ironic 步骤失败,Bare Metal Operator 会持续重试安装。如需更多信息,请参阅"诊断主机重复的 MAC 地址"。
创建裸机节点:
$ oc -n openshift-machine-api create -f bmh.yaml输出示例
secret/openshift-worker-<num>-network-config-secret created secret/openshift-worker-<num>-bmc-secret created baremetalhost.metal3.io/openshift-worker-<num> created其中
<num> 是worker 号。启动并检查裸机节点:
$ oc -n openshift-machine-api get bmh openshift-worker-<num>其中
<num>是 worker 节点号。输出示例
NAME STATE CONSUMER ONLINE ERROR openshift-worker-<num> available true注意要允许 worker 节点加入集群,请将
machineset对象扩展到BareMetalHost对象的数量。您可以手动或自动缩放节点。要自动扩展节点,请为machineset使用metal3.io/autoscale-to-hosts注解。
7.2. 替换裸机 control plane 节点
使用以下步骤替换安装程序置备的 OpenShift Container Platform control plane 节点。
如果您从现有 control plane 主机重复使用 BareMetalHost 对象定义,请不要将 externallyProvisioned 字段保留为 true。
如果 OpenShift Container Platform 安装程序置备,现有 control plane BareMetalHost 对象可能会将 externallyProvisioned 标记设为 true。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。 已进行 etcd 备份。
重要执行此流程前进行 etcd 备份,以便在遇到任何问题时可以恢复集群。有关获取 etcd 备份的更多信息,请参阅附加资源部分。
流程
确保 Bare Metal Operator 可用:
$ oc get clusteroperator baremetal输出示例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE baremetal 4.14.0 True False False 3d15h删除旧的
BareMetalHost和Machine对象:$ oc delete bmh -n openshift-machine-api <host_name> $ oc delete machine -n openshift-machine-api <machine_name>将
<host_name>替换为主机名,<machine_name>替换为机器的名称。机器名称会出现在CONSUMER字段下。删除
BareMetalHost和Machine对象后,机器控制器会自动删除Node对象。创建新的
BareMetalHost对象和 secret,以存储 BMC 凭证:$ cat <<EOF | oc apply -f - apiVersion: v1 kind: Secret metadata: name: control-plane-<num>-bmc-secret1 namespace: openshift-machine-api data: username: <base64_of_uid>2 password: <base64_of_pwd>3 type: Opaque --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: control-plane-<num>4 namespace: openshift-machine-api spec: automatedCleaningMode: disabled bmc: address: <protocol>://<bmc_ip>5 credentialsName: control-plane-<num>-bmc-secret6 bootMACAddress: <NIC1_mac_address>7 bootMode: UEFI externallyProvisioned: false online: true EOF- 1 4 6
- 在
name字段和credentialsName字段中,使用裸机节点的 control plane 数量替换<num>。 - 2
- 将
<base64_of_uid>替换为用户名的base64格式的字符串。 - 3
- 将
<base64_of_pwd>替换为密码的base64格式的字符串。 - 5
- 将
<protocol>替换为 BMC 协议,如redfish、redfish-virtualmedia、idrac-virtualmedia或其他。将<bmc_ip>替换为裸机节点基板管理控制器的 IP 地址。如需了解更多 BMC 配置选项,请参阅附加资源部分中的 "BMC 寻址"。 - 7
- 将
<NIC1_mac_address>替换为裸机节点第一个 NIC 的 MAC 地址。
检查完成后,
BareMetalHost对象会被创建并可用置备。查看可用的
BareMetalHost对象:$ oc get bmh -n openshift-machine-api输出示例
NAME STATE CONSUMER ONLINE ERROR AGE control-plane-1.example.com available control-plane-1 true 1h10m control-plane-2.example.com externally provisioned control-plane-2 true 4h53m control-plane-3.example.com externally provisioned control-plane-3 true 4h53m compute-1.example.com provisioned compute-1-ktmmx true 4h53m compute-1.example.com provisioned compute-2-l2zmb true 4h53mcontrol plane 节点没有
MachineSet对象,因此您必须创建Machine对象。您可以从另一个 control planeMachine对象复制providerSpec。创建
Machine对象:$ cat <<EOF | oc apply -f - apiVersion: machine.openshift.io/v1beta1 kind: Machine metadata: annotations: metal3.io/BareMetalHost: openshift-machine-api/control-plane-<num>1 labels: machine.openshift.io/cluster-api-cluster: control-plane-<num>2 machine.openshift.io/cluster-api-machine-role: master machine.openshift.io/cluster-api-machine-type: master name: control-plane-<num>3 namespace: openshift-machine-api spec: metadata: {} providerSpec: value: apiVersion: baremetal.cluster.k8s.io/v1alpha1 customDeploy: method: install_coreos hostSelector: {} image: checksum: "" url: "" kind: BareMetalMachineProviderSpec metadata: creationTimestamp: null userData: name: master-user-data-managed EOF要查看
BareMetalHost对象,请运行以下命令:$ oc get bmh -A输出示例
NAME STATE CONSUMER ONLINE ERROR AGE control-plane-1.example.com provisioned control-plane-1 true 2h53m control-plane-2.example.com externally provisioned control-plane-2 true 5h53m control-plane-3.example.com externally provisioned control-plane-3 true 5h53m compute-1.example.com provisioned compute-1-ktmmx true 5h53m compute-2.example.com provisioned compute-2-l2zmb true 5h53m在 RHCOS 安装后,验证
BareMetalHost是否已添加到集群中:$ oc get nodes输出示例
NAME STATUS ROLES AGE VERSION control-plane-1.example.com available master 4m2s v1.27.6 control-plane-2.example.com available master 141m v1.27.6 control-plane-3.example.com available master 141m v1.27.6 compute-1.example.com available worker 87m v1.27.6 compute-2.example.com available worker 87m v1.27.6注意替换新的 control plane 节点后,在新节点上运行的 etcd pod 处于
crashloopback状态。如需更多信息,请参阅附加资源部分中的 "替换不健康的 etcd 成员"。
7.3. 准备在 baremetal 网络中使用 Virtual Media 进行部署
如果启用了 provisioning 网络,且您要使用 baremetal 网络中的 Virtual Media 扩展集群,请使用以下步骤。
先决条件
-
有一个带有 a
baremetal 网络和provisioning网络的现有集群。
流程
编辑
置备自定义资源(CR),以在baremetal网络中使用 Virtual Media 启用部署:oc edit provisioningapiVersion: metal3.io/v1alpha1 kind: Provisioning metadata: creationTimestamp: "2021-08-05T18:51:50Z" finalizers: - provisioning.metal3.io generation: 8 name: provisioning-configuration resourceVersion: "551591" uid: f76e956f-24c6-4361-aa5b-feaf72c5b526 spec: provisioningDHCPRange: 172.22.0.10,172.22.0.254 provisioningIP: 172.22.0.3 provisioningInterface: enp1s0 provisioningNetwork: Managed provisioningNetworkCIDR: 172.22.0.0/24 virtualMediaViaExternalNetwork: true1 status: generations: - group: apps hash: "" lastGeneration: 7 name: metal3 namespace: openshift-machine-api resource: deployments - group: apps hash: "" lastGeneration: 1 name: metal3-image-cache namespace: openshift-machine-api resource: daemonsets observedGeneration: 8 readyReplicas: 0- 1
- 将
virtualMediaViaExternalNetwork: true添加到provisioningCR。
如果镜像 URL 存在,请编辑
machineset以使用 API VIP 地址。此步骤只适用于在 4.9 或更早版本安装的集群。oc edit machinesetapiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: creationTimestamp: "2021-08-05T18:51:52Z" generation: 11 labels: machine.openshift.io/cluster-api-cluster: ostest-hwmdt machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker name: ostest-hwmdt-worker-0 namespace: openshift-machine-api resourceVersion: "551513" uid: fad1c6e0-b9da-4d4a-8d73-286f78788931 spec: replicas: 2 selector: matchLabels: machine.openshift.io/cluster-api-cluster: ostest-hwmdt machine.openshift.io/cluster-api-machineset: ostest-hwmdt-worker-0 template: metadata: labels: machine.openshift.io/cluster-api-cluster: ostest-hwmdt machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker machine.openshift.io/cluster-api-machineset: ostest-hwmdt-worker-0 spec: metadata: {} providerSpec: value: apiVersion: baremetal.cluster.k8s.io/v1alpha1 hostSelector: {} image: checksum: http:/172.22.0.3:6181/images/rhcos-<version>.<architecture>.qcow2.<md5sum>1 url: http://172.22.0.3:6181/images/rhcos-<version>.<architecture>.qcow22 kind: BareMetalMachineProviderSpec metadata: creationTimestamp: null userData: name: worker-user-data status: availableReplicas: 2 fullyLabeledReplicas: 2 observedGeneration: 11 readyReplicas: 2 replicas: 2
7.4. 在集群中置备新主机时诊断重复的 MAC 地址
如果集群中现有裸机节点的 MAC 地址与您试图添加到集群的裸机主机的 MAC 地址匹配,Bare Metal Operator 将主机与现有节点关联。如果主机注册、检查、清理或其他 Ironic 步骤失败,Bare Metal Operator 会持续重试安装。失败的裸机主机会显示注册错误。
您可以通过检查在 openshift-machine-api 命名空间中运行的裸机主机来诊断重复的 MAC 地址。
先决条件
- 在裸机上安装 OpenShift Container Platform 集群。
-
安装 OpenShift Container Platform CLI
oc。 -
以具有
cluster-admin权限的用户身份登录。
流程
要确定置备失败的裸机主机是否具有与现有节点相同的 MAC 地址,请执行以下操作:
获取在
openshift-machine-api命名空间中运行的裸机主机:$ oc get bmh -n openshift-machine-api输出示例
NAME STATUS PROVISIONING STATUS CONSUMER openshift-master-0 OK externally provisioned openshift-zpwpq-master-0 openshift-master-1 OK externally provisioned openshift-zpwpq-master-1 openshift-master-2 OK externally provisioned openshift-zpwpq-master-2 openshift-worker-0 OK provisioned openshift-zpwpq-worker-0-lv84n openshift-worker-1 OK provisioned openshift-zpwpq-worker-0-zd8lm openshift-worker-2 error registering要查看失败主机状态的更多详细信息,请运行以下命令将
<bare_metal_host_name>替换为主机名称:$ oc get -n openshift-machine-api bmh <bare_metal_host_name> -o yaml输出示例
... status: errorCount: 12 errorMessage: MAC address b4:96:91:1d:7c:20 conflicts with existing node openshift-worker-1 errorType: registration error ...
7.5. 置备裸机节点
置备裸机节点需要从 provisioner 节点执行以下步骤。
流程
在置备裸机节点前,请确保
STATE为available。$ oc -n openshift-machine-api get bmh openshift-worker-<num>其中
<num>是 worker 节点号。NAME STATE ONLINE ERROR AGE openshift-worker available true 34h获取 worker 节点数量。
$ oc get nodesNAME STATUS ROLES AGE VERSION openshift-master-1.openshift.example.com Ready master 30h v1.27.3 openshift-master-2.openshift.example.com Ready master 30h v1.27.3 openshift-master-3.openshift.example.com Ready master 30h v1.27.3 openshift-worker-0.openshift.example.com Ready worker 30h v1.27.3 openshift-worker-1.openshift.example.com Ready worker 30h v1.27.3获取计算机器集。
$ oc get machinesets -n openshift-machine-apiNAME DESIRED CURRENT READY AVAILABLE AGE ... openshift-worker-0.example.com 1 1 1 1 55m openshift-worker-1.example.com 1 1 1 1 55m将 worker 节点数量增加一个。
$ oc scale --replicas=<num> machineset <machineset> -n openshift-machine-api将
<num>替换为新的 worker 节点数。将<machineset>替换为上一步中计算机器设置的名称。检查裸机节点的状态。
$ oc -n openshift-machine-api get bmh openshift-worker-<num>其中
<num>是 worker 节点号。STATE 从ready变为provisioning。NAME STATE CONSUMER ONLINE ERROR openshift-worker-<num> provisioning openshift-worker-<num>-65tjz trueprovisioning状态会保持,直到 OpenShift Container Platform 集群置备节点。这可能需要 30 分钟或更长时间。在调配节点后,其状态将更改为provisioned。NAME STATE CONSUMER ONLINE ERROR openshift-worker-<num> provisioned openshift-worker-<num>-65tjz true在置备完成后,确保裸机节点就绪。
$ oc get nodesNAME STATUS ROLES AGE VERSION openshift-master-1.openshift.example.com Ready master 30h v1.27.3 openshift-master-2.openshift.example.com Ready master 30h v1.27.3 openshift-master-3.openshift.example.com Ready master 30h v1.27.3 openshift-worker-0.openshift.example.com Ready worker 30h v1.27.3 openshift-worker-1.openshift.example.com Ready worker 30h v1.27.3 openshift-worker-<num>.openshift.example.com Ready worker 3m27s v1.27.3您还可以检查 kubelet。
$ ssh openshift-worker-<num>[kni@openshift-worker-<num>]$ journalctl -fu kubelet
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.