安全性与合规性
了解和管理 OpenShift Container Platform 的安全性
摘要
第 1 章 OpenShift Container Platform 安全和合规性
1.1. 安全概述
了解如何正确保护 OpenShift Container Platform 集群的各个方面非常重要。
容器安全性
了解 OpenShift Container Platform 安全性的良好起点是回顾了解容器安全性中的概念。本节和接下来的章节介绍了 OpenShift Container Platform 中提供的容器安全措施,包括主机层、容器和编配层以及构建和应用程序层的解决方案。这些部分还包括有关以下主题的信息:
- 为什么容器安全性很重要,以及它与现有安全标准相比较的情况。
- 哪些容器安全措施是由主机(RHCOS 和 RHEL)层提供的,哪些是由 OpenShift Container Platform 提供的。
- 如何评估您的容器内容和漏洞来源。
- 如何设计您的构建和部署过程,以主动检查容器的内容。
- 如何通过身份验证和授权控制对容器的访问。
- 如何在 OpenShift Container Platform 中保护网络和附加存储。
- 用于 API 管理和 SSO 的容器化解决方案。
Auditing
OpenShift Container Platform auditing(审计)提供一组安全相关的按时间排序的记录,记录各个用户、管理员或其他系统组件影响系统的一系列活动。管理员可以配置审计日志策略,并查看审计日志。
证书
证书供各种组件用于验证对集群的访问。管理员可以替换默认入口证书、添加 API 服务器证书或添加服务证书。
您还可以查看集群使用的证书类型的更多详情:
加密数据
您可以为集群启用 etcd 加密以提供额外的数据安全层。例如,如果 etcd 备份暴露给不应该获得这个数据的人员,它会帮助保护敏感数据。
漏洞扫描
管理员可以使用 Red Hat Quay Container Security Operator 运行 漏洞扫描 并查看有关检测到的漏洞的信息。
1.2. 合规性概述
对于许多 OpenShift Container Platform 客户,在将任何系统投入生产前需要达到一定级别的法规就绪状态或合规性。这种法规就绪性可通过国家标准、行业标准或组织的企业管理框架来实施。
合规性检查
管理员可以使用 Compliance Operator 运行合规性扫描,并为发现的问题推荐补救。oc-compliance 插件 是一个 OpenShift CLI (oc) 插件,提供一组实用程序来轻松地与 Compliance Operator 交互。
文件完整性检查
管理员可以使用 File Integrity Operator 在集群节点上持续运行文件完整性检查,并提供已修改的文件日志。
第 2 章 容器安全性
2.1. 了解容器安全性
保护容器化应用程序需要依赖于多个级别的安全性:
容器安全性从可信基础容器镜像开始,一直到经过您的 CI/CD 管道的容器构建过程。
重要默认情况下,镜像流不会自动更新。这个默认行为可能会造成安全问题,因为镜像流引用的镜像的安全更新不会自动进行。有关如何覆盖此默认行为的详情,请参阅配置定期导入 imagestreamtag。
- 部署容器时,其安全性取决于它运行在安全的操作系统和网络上,并在容器本身和与之交互的用户和主机之间建立明确界限。
- 持续安全性取决于能够扫描容器镜像以获取漏洞,并具有高效的方法来更正和替换有漏洞的镜像。
除了 OpenShift Container Platform 等平台提供的开箱即用的功能外,您的机构可能会有自己的安全需求。在将 OpenShift Container Platform 放入数据中心之前,可能需要进行一定程度的合规性验证。
同样,您可能需要将自己的代理、专用硬件驱动程序或加密功能添加到 OpenShift Container Platform 中,才能满足您机构的安全标准。
本指南全面介绍了 OpenShift Container Platform 中提供的容器安全措施,包括主机层、容器和编配层以及构建和应用程序层的解决方案。然后,它会指引您参考特定的 OpenShift Container Platform 文档以帮助您实现这些安全措施。
本指南包含以下信息:
- 为什么容器安全性很重要,以及它与现有安全标准相比较的情况。
- 哪些容器安全措施是由主机(RHCOS 和 RHEL)层提供的,哪些是由 OpenShift Container Platform 提供的。
- 如何评估您的容器内容和漏洞来源。
- 如何设计您的构建和部署过程,以主动检查容器的内容。
- 如何通过身份验证和授权控制对容器的访问。
- 如何在 OpenShift Container Platform 中保护网络和附加存储。
- 用于 API 管理和 SSO 的容器化解决方案。
本指南的目的是了解将 OpenShift Container Platform 用于容器化工作负载的极大安全优势,以及整个红帽生态系统在提供和保持容器安全方面发挥的作用。它还将帮助您了解如何与 OpenShift Container Platform 互动以实现您机构的安全目标。
2.1.1. 什么是容器?
容器将一个应用程序及其所有依赖项打包成单一镜像,可在不发生改变的情况下从开发环境提升到测试环境,再提升到生产环境。容器可能是大型应用程序的一部分,与其他容器紧密合作。
容器提供不同环境间的一致性和多个部署目标:物理服务器、虚拟机 (VM) 和私有或公有云。
使用容器的一些好处包括:
| 基础架构 | 应用程序 |
|---|---|
| 在共享的 Linux 操作系统内核上将应用程序进程沙盒化 | 将我的应用程序及其所有依赖项打包 |
| 与虚拟机相比更简单、更轻便且密度更高 | 部署到任意环境只需几秒并启用 CI/CD |
| 可在不同环境间移植 | 轻松访问和共享容器化组件 |
请参阅红帽客户门户中的了解 Linux 容器以查找更多有关 Linux 容器的信息。如需了解有关 RHEL 容器工具的信息,请参阅 RHEL 产品文档中的构建、运行和管理容器。
2.1.2. OpenShift Container Platform 是什么?
OpenShift Container Platform 等平台的任务是自动化部署、运行和管理容器化应用程序。作为核心功能,OpenShift Container Platform 依赖于 Kubernetes 项目来提供在可扩展数据中心跨许多节点编配容器的引擎。
Kubernetes 是一个项目,可使用不同的操作系统和附加组件来运行,它们不提供项目的支持性保证。因此,不同 Kubernetes 平台的安全性可能会有所不同。
OpenShift Container Platform 旨在锁定 Kubernetes 安全性,并将平台与各种扩展组件集成。为实现这一目标,OpenShift Container Platform 利用了广泛的红帽开源技术生态系统,包括操作系统、身份验证、存储、网络、开发工具、基础容器镜像和其他许多组件。
OpenShift Container Platform 可以利用红帽的经验,发现平台本身以及在平台上运行的容器化应用程序中存在的漏洞并快速部署修复程序。红帽的经验还涉及到在新组件可用后高效地将它们与 OpenShift Container Platform 集成,以及根据各个客户的需求对技术进行调整。
2.2. 了解主机和虚拟机安全性
容器和虚拟机都提供了将主机上运行的应用程序与操作系统分开的方法。了解 OpenShift Container Platform 使用的 RHCOS 操作系统将帮助您理解主机系统如何保护容器和主机不受彼此影响。
2.2.1. 保护 Red Hat Enterprise Linux CoreOS (RHCOS) 上的容器
容器简化了将许多应用程序部署在同一主机上运行的操作,每个容器启动都使用相同的内核和容器运行时。应用程序可以归很多用户所有,并且由于是保持独立的,他们可以毫无问题地同时运行这些应用程序的不同版本甚至不兼容的版本。
在 Linux 中,容器只是一种特殊的进程,因此在很多方面,保护容器与保护任何其他运行的进程类似。运行容器的环境始于操作系统,它可以保护主机内核不受容器和主机上运行的其他进程的影响,同时还可以保护容器不受彼此的影响。
由于 OpenShift Container Platform 4.8 在 RHCOS 主机上运行,同时可选择使用 Red Hat Enterprise Linux (RHEL) 作为 worker 节点,因此以下概念将默认应用于任何已部署的 OpenShift Container Platform 集群。这些 RHEL 安全功能是确保在 OpenShift Container Platform 中运行容器的核心所在:
- Linux 命名空间支持创建特定全局系统资源的抽象集,使其显示为一个实例,独立于命名空间中的进程。因此,几个容器可以同时使用相同的计算资源,而不会产生冲突。默认情况下独立于主机的容器命名空间包括挂载表、进程表、网络接口、用户、控制组、UTS 和 IPC 命名空间。需要直接访问主机命名空间的容器需要具有升级权限才能请求该访问权限。如需了解有关命名空间类型的详细信息,请参阅 RHEL 7 容器文档中的红帽系统中的容器概述。
- SELinux 提供了额外一层安全性,可以使容器相互隔离并与主机隔离。SELinux 允许管理员为每个用户、应用程序、进程和文件实行强制访问控制 (MAC)。
不支持在 RHCOS 节点上禁用 SELinux。
- CGroups(控制组)限制、说明和隔离一组进程的资源用量(CPU、内存、磁盘 I/O、网络等等)。CGroups 用于确保同一主机上的容器不会相互影响。
- 安全计算模式 (seccomp) 配置集可以与容器关联来限制可用的系统调用。有关 seccomp 的详情,请参阅 OpenShift 安全性指南的第 94 页。
- 使用 RHCOS 部署容器可最大程度缩小主机环境并根据容器进行调整,从而减少攻击面。CRI-O 容器引擎只会实现 Kubernetes 和 OpenShift Container Platform 运行和管理容器所需的功能,而不像其他容器引擎一样实现面向桌面的独立功能,因此进一步减少了这一攻击面。
RHCOS 是 Red Hat Enterprise Linux (RHEL) 的一个版本,它经过特别配置,可用作 OpenShift Container Platform 集群上的 control plane (master) 和 worker 节点。因此,RHCOS 被调优为高效地运行容器工作负载,以及 Kubernetes 和 OpenShift Container Platform 服务。
为了进一步保护 OpenShift Container Platform 集群中的 RHCOS 系统,大多数容器(除了管理或监控主机系统本身的容器外)都应以非 root 用户身份运行。要保护您自己的 OpenShift Container Platform 集群,推荐的最佳实践是降低权限级别或创建包含最少权限的容器。
2.2.2. 虚拟化和容器比较
传统虚拟化提供了另一种在相同物理主机上将应用程序环境保持独立的方法。但是,虚拟机的工作方式与容器不同。虚拟化依赖于虚拟机监控程序启动虚拟客户机 (VM),每个虚拟机都有自己的操作系统 (OS),具体表现为运行的内核、正在运行的应用程序及其依赖项。
使用 VM,虚拟机监控程序会将虚拟客户机相互隔离并与主机内核隔离。这样可减少可访问虚拟机监控程序的个人和进程,进而缩小物理服务器上的攻击面。尽管如此,仍然必须对安全性进行监控:一个虚拟客户机可能利用虚拟机监控程序的错误来获取对另一个虚拟机或主机内核的访问权限。当需要修补操作系统时,必须对所有使用该操作系统的虚拟客户机进行修补。
容器可在虚拟客户机中运行,这种方式在有些用例中可能是可取的。例如,您可能在容器中部署传统应用程序,以便将某个应用程序转移到云端。
但是,在单一主机上进行容器分离提供了一种更加轻便、灵活且易于部署的解决方案。这种部署模型特别适合云原生应用程序。容器通常比 VM 小得多,消耗的内存和 CPU 也更少。
请参阅 RHEL 7 容器文档中的 Linux 容器与 KVM 虚拟化的比较,以了解容器和虚拟机之间的差别。
2.2.3. 保护 OpenShift Container Platform
在部署 OpenShift Container Platform 时,您可以选择安装程序置备的基础架构(有多个可用的平台)或您自己的用户置备的基础架构。用户置备的基础架构可能有益于一些低级别的安全相关配置,如启用 FIPS 合规性或在第一次引导时添加内核模块。同样,用户置备的基础架构适合用于断开连接的 OpenShift Container Platform 部署。
请记住,在为 OpenShift Container Platform 进行安全增强和其他配置更改方面,应包括以下目标:
- 尽可能保持底层节点的通用性。您需要能够快速、轻松地以指定的方式丢弃和启动类似的节点。
- 尽可能通过 OpenShift Container Platform 管理对节点的修改,而不是对节点进行直接的一次性更改。
为实现这些目标,应该在安装过程中使用 Machine Config Operator 应用到各组节点的 MachineConfig,通过 Ignition 或更高版本进行大多数节点更改。您可以通过这种方式进行的与安全性相关的配置更改示例包括:
- 添加内核参数
- 添加内核模块
- 启用 FIPS 加密支持
- 配置磁盘加密
- 配置 chrony 时间服务
除了 Machine Config Operator 外,还有一些其他的 Operator 可用来配置由 Cluster Version Operator (CVO) 管理的 OpenShift Container Platform 基础架构。CVO 可以为 OpenShift Container Platform 集群更新的很多方面实现自动化。
2.3. 强化 RHCOS
RHCOS 在创建后经过调整以部署到 OpenShift Container Platform 中,只需对 RHCOS 节点进行很少更改甚至无需更改。每个采用 OpenShift Container Platform 的机构都对系统加强有自己的要求。作为一个 RHEL 系统,RHCOS 中添加了针对 OpenShift 的修改和功能(如 Ignition、ostree 和一个只读 /usr,用来提供有限的不可变性),像任何 RHEL 系统一样,可以对它进行强化。不同之处在于您管理强化的方式。
OpenShift Container Platform 及其 Kubernetes 引擎的一个主要功能就是根据需要迅速缩放应用程序和基础架构。除非不可避免,否则您不需要通过登录到主机并添加软件或更改设置来直接更改 RHCOS。您需要让 OpenShift Container Platform 安装程序和 control plane 管理对 RHCOS 的更改,以便可以在不手动干预的情况下启动新节点。
因此,如果您准备在 OpenShift Container Platform 中强化 RHCOS 节点来满足安全需求,您应该同时考虑要强化的功能以及如何着手进行这种强化。
2.3.1. 在 RHCOS 中选择要强化的功能
RHEL 8 安全强化指南介绍了如何处理任何 RHEL 系统的安全问题。
使用本指南来学习如何处理加密、评估漏洞以及评估不同服务受到的威胁。同样,您可以了解如何扫描合规标准、检查文件完整性、执行审核以及对存储设备进行加密。
了解了您要强化的功能后,您可以决定如何在 RHCOS 中强化它们。
2.3.2. 选择如何强化 RHCOS
不建议在 OpenShift Container Platform 中直接修改 RHCOS 系统。取而代之,您应该考虑在节点池中修改系统,如 worker 节点和 control plane 节点(也称为主节点)。在非裸机安装中,当需要一个新节点时,您可以请求一个您所需的类型的新节点,并且它将从 RHCOS 镜像创建,再加上之前创建的修改。
在安装前、在安装过程中以及集群启动和运行后,您有机会修改 RHCOS。
2.3.2.1. 安装前强化
对于裸机安装,您可以在开始 OpenShift Container Platform 安装前为 RHCOS 添加强化功能。例如,您可以在引导 RHCOS 安装程序时添加内核选项来开启或关闭安全功能,如各种 SELinux 布尔值或低级别设置,如对称多线程。
虽然裸机 RHCOS 安装难度更大,但有机会在开始 OpenShift Container Platform 安装前完成操作系统更改。如果您需要确保尽早设置某些功能,比如磁盘加密或者特殊联网设置,这一点就很重要。
不支持在 RHCOS 节点上禁用 SELinux。
2.3.2.2. 安装过程中强化
您可以中断 OpenShift Container Platform 安装过程并更改 Ignition 配置。通过 Ignition 配置,您可以将自己的文件和 systemd 服务添加到 RHCOS 节点中。您还可以对用于安装的 install-config.yaml 文件进行一些基本的安全相关更改。以这种方式添加的内容将在每个节点第一次引导时可用。
2.3.2.3. 集群运行后强化
在 OpenShift Container Platform 集群启动并运行后,有几种方法可用来将强化功能应用到 RHCOS:
-
守护进程集:如果您需要在每个节点上运行某个服务,您可以使用 Kubernetes 的
DaemonSet对象添加该服务。 -
机器配置:
MachineConfig对象包含 Ignition 配置的子集,其格式相同。通过将机器配置应用到所有 worker 或 control plane 节点,您可以确保添加到集群中的同类型的下一个节点会应用相同的更改。
这里提到的所有功能在 OpenShift Container Platform 产品文档中都有介绍。
2.4. 容器镜像签名
红帽为 Red Hat Container Registries 中的镜像提供签名。在使用 Machine Config Operator(MCO)拉取到 OpenShift Container Platform 4 集群时,会自动验证这些签名。
Quay.io 提供了组成 OpenShift Container Platform 的大多数镜像,只有发行镜像会被签名。发行镜像指的是批准的 OpenShift Container Platform 镜像,它可以对供应链攻击提供一定程度的保护。但是,OpenShift Container Platform 的一些扩展(如日志记录、监控和服务网格)会作为 Operator Lifecycle Manager(OLM)的 Operator 提供。这些镜像来自 红帽生态系统目录容器镜像 registry。
要验证这些镜像在红帽 registry 和您的基础架构间的完整性,启用签名验证。
2.4.1. 为 Red Hat Container registry 启用签名验证
为 Red Hat Container Registries 启用容器签名验证需要编写签名验证策略文件,指定从这些 registry 中验证镜像的密钥。对于 RHEL8 节点,默认已在 /etc/containers/registries.d 中定义 registry。
流程
创建 Butane 配置文件
51-worker-rh-registry-trust.bu,其中包含 worker 节点的必要配置。注意如需有关 Butane 的信息,请参阅"使用 Butane 创建机器配置"。
variant: openshift version: 4.8.0 metadata: name: 51-worker-rh-registry-trust labels: machineconfiguration.openshift.io/role: worker storage: files: - path: /etc/containers/policy.json mode: 0644 overwrite: true contents: inline: | { "default": [ { "type": "insecureAcceptAnything" } ], "transports": { "docker": { "registry.access.redhat.com": [ { "type": "signedBy", "keyType": "GPGKeys", "keyPath": "/etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release" } ], "registry.redhat.io": [ { "type": "signedBy", "keyType": "GPGKeys", "keyPath": "/etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release" } ] }, "docker-daemon": { "": [ { "type": "insecureAcceptAnything" } ] } } }使用 Butane 生成机器配置 YAML 文件
51-worker-rh-registry-trust.yaml,其中包含要写入 worker 节点上的磁盘的文件:$ butane 51-worker-rh-registry-trust.bu -o 51-worker-rh-registry-trust.yaml应用创建的机器配置:
$ oc apply -f 51-worker-rh-registry-trust.yaml检查 worker 机器配置池已使用新机器配置推出:
检查是否创建了新机器配置:
$ oc get mc输出示例
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 25m 00-worker a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 25m 01-master-container-runtime a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 25m 01-master-kubelet a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 25m 01-worker-container-runtime a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 25m 01-worker-kubelet a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 25m 51-master-rh-registry-trust 3.2.0 13s 51-worker-rh-registry-trust 3.2.0 53s1 99-master-generated-crio-seccomp-use-default 3.2.0 25m 99-master-generated-registries a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 25m 99-master-ssh 3.2.0 28m 99-worker-generated-crio-seccomp-use-default 3.2.0 25m 99-worker-generated-registries a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 25m 99-worker-ssh 3.2.0 28m rendered-master-af1e7ff78da0a9c851bab4be2777773b a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 8s rendered-master-cd51fd0c47e91812bfef2765c52ec7e6 a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 24m rendered-worker-2b52f75684fbc711bd1652dd86fd0b82 a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 24m rendered-worker-be3b3bce4f4aa52a62902304bac9da3c a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 48s2 检查 worker 机器配置池是否使用新机器配置更新:
$ oc get mcp输出示例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-af1e7ff78da0a9c851bab4be2777773b True False False 3 3 3 0 30m worker rendered-worker-be3b3bce4f4aa52a62902304bac9da3c False True False 3 0 0 0 30m1 - 1
- 当
UPDATING字段为True时,机器配置池会使用新机器配置进行更新。当字段变为False时,代表 worker 机器配置池已应用到新机器配置。
如果您的集群使用任何 RHEL7 worker 节点,当 worker 机器配置池被更新时,在
/etc/containers/registries.d目录中在这些节点上创建 YAML 文件,用于指定给定 registry 服务器的分离签名的位置。以下示例只适用于托管在registry.access.redhat.com和registry.redhat.io中的镜像。为每个 RHEL7 worker 节点启动一个 debug 会话:
$ oc debug node/<node_name>将您的根目录改为
/host:sh-4.2# chroot /host创建一个包含以下内容的
/etc/containers/registries.d/registry.redhat.io.yaml文件:docker: registry.redhat.io: sigstore: https://registry.redhat.io/containers/sigstore创建一个包含以下内容的
/etc/containers/registries.d/registry.access.redhat.com.yaml文件:docker: registry.access.redhat.com: sigstore: https://access.redhat.com/webassets/docker/content/sigstore- 退出 debug 会话。
2.4.2. 验证签名验证配置
将机器配置应用到集群后,Machine Config Controller 会检测到新的 MachineConfig 对象,并生成新的 rendered-worker-<hash> 版本。
先决条件
- 您可以使用机器配置文件启用签名验证。
流程
在命令行中运行以下命令显示所需 worker 的信息:
$ oc describe machineconfigpool/worker初始 worker 监控的输出示例
Name: worker Namespace: Labels: machineconfiguration.openshift.io/mco-built-in= Annotations: <none> API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfigPool Metadata: Creation Timestamp: 2019-12-19T02:02:12Z Generation: 3 Resource Version: 16229 Self Link: /apis/machineconfiguration.openshift.io/v1/machineconfigpools/worker UID: 92697796-2203-11ea-b48c-fa163e3940e5 Spec: Configuration: Name: rendered-worker-f6819366eb455a401c42f8d96ab25c02 Source: API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 00-worker API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 01-worker-container-runtime API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 01-worker-kubelet API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 51-worker-rh-registry-trust API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 99-worker-92697796-2203-11ea-b48c-fa163e3940e5-registries API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 99-worker-ssh Machine Config Selector: Match Labels: machineconfiguration.openshift.io/role: worker Node Selector: Match Labels: node-role.kubernetes.io/worker: Paused: false Status: Conditions: Last Transition Time: 2019-12-19T02:03:27Z Message: Reason: Status: False Type: RenderDegraded Last Transition Time: 2019-12-19T02:03:43Z Message: Reason: Status: False Type: NodeDegraded Last Transition Time: 2019-12-19T02:03:43Z Message: Reason: Status: False Type: Degraded Last Transition Time: 2019-12-19T02:28:23Z Message: Reason: Status: False Type: Updated Last Transition Time: 2019-12-19T02:28:23Z Message: All nodes are updating to rendered-worker-f6819366eb455a401c42f8d96ab25c02 Reason: Status: True Type: Updating Configuration: Name: rendered-worker-d9b3f4ffcfd65c30dcf591a0e8cf9b2e Source: API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 00-worker API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 01-worker-container-runtime API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 01-worker-kubelet API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 99-worker-92697796-2203-11ea-b48c-fa163e3940e5-registries API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 99-worker-ssh Degraded Machine Count: 0 Machine Count: 1 Observed Generation: 3 Ready Machine Count: 0 Unavailable Machine Count: 1 Updated Machine Count: 0 Events: <none>再次运行
oc describe命令:$ oc describe machineconfigpool/workerworker 更新后的输出示例
... Last Transition Time: 2019-12-19T04:53:09Z Message: All nodes are updated with rendered-worker-f6819366eb455a401c42f8d96ab25c02 Reason: Status: True Type: Updated Last Transition Time: 2019-12-19T04:53:09Z Message: Reason: Status: False Type: Updating Configuration: Name: rendered-worker-f6819366eb455a401c42f8d96ab25c02 Source: API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 00-worker API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 01-worker-container-runtime API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 01-worker-kubelet API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 51-worker-rh-registry-trust API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 99-worker-92697796-2203-11ea-b48c-fa163e3940e5-registries API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 99-worker-ssh Degraded Machine Count: 0 Machine Count: 3 Observed Generation: 4 Ready Machine Count: 3 Unavailable Machine Count: 0 Updated Machine Count: 3 ...注意Observed Generation参数显示基于控制器生成的配置的生成数量的增加数。此控制器即使没有处理规格并生成修订,也会更新这个值。Configuration Source值指向51-worker-rh-registry-trust配置。使用以下命令确认
policy.json文件已存在:$ oc debug node/<node> -- chroot /host cat /etc/containers/policy.json输出示例
Starting pod/<node>-debug ... To use host binaries, run `chroot /host` { "default": [ { "type": "insecureAcceptAnything" } ], "transports": { "docker": { "registry.access.redhat.com": [ { "type": "signedBy", "keyType": "GPGKeys", "keyPath": "/etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release" } ], "registry.redhat.io": [ { "type": "signedBy", "keyType": "GPGKeys", "keyPath": "/etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release" } ] }, "docker-daemon": { "": [ { "type": "insecureAcceptAnything" } ] } } }使用以下命令确认
registry.redhat.io.yaml文件已存在:$ oc debug node/<node> -- chroot /host cat /etc/containers/registries.d/registry.redhat.io.yaml输出示例
Starting pod/<node>-debug ... To use host binaries, run `chroot /host` docker: registry.redhat.io: sigstore: https://registry.redhat.io/containers/sigstore使用以下命令确认
registry.access.redhat.com.yaml文件已存在:$ oc debug node/<node> -- chroot /host cat /etc/containers/registries.d/registry.access.redhat.com.yaml输出示例
Starting pod/<node>-debug ... To use host binaries, run `chroot /host` docker: registry.access.redhat.com: sigstore: https://access.redhat.com/webassets/docker/content/sigstore
2.5. 了解合规性
对于许多 OpenShift Container Platform 客户,在将任何系统投入生产前需要达到一定级别的法规就绪状态或合规性。这种法规就绪状态可通过国家标准、行业标准或机构的企业监管框架来施加。
2.5.1. 了解合规性及风险管理
FIPS 合规性是高安全性环境中所需的最重要的组件之一,可确保节点上只允许使用支持的加密技术。
只有在 x86_64 架构中的 OpenShift Container Platform 部署支持 FIPS 验证的/Modules in Process 加密库。
要了解红帽对 OpenShift Container Platform 合规框架的观点,请参阅 OpenShift 安全性指南手册中的“风险管理和法规就绪状态”一章。
2.6. 保护容器内容
要确保容器内所含内容的安全性,需要以可信的基础镜像(如红帽通用基础镜像)开始,并添加可信软件。为了检查容器镜像的持续安全性,红帽及第三方都有可用于扫描镜像的工具。
2.6.1. 确保容器内安全
应用程序和基础架构由随时可用的组件组成,许多组件都是开源软件包,如 Linux 操作系统、JBoss Web Server、PostgreSQL 和 Node.js。
这些软件包也有容器化版本可用。然而,您需要知道软件包最初来自哪里,使用什么版本,是谁构建的,以及软件包内是否有恶意代码。
需要回答的一些问题包括:
- 容器内的内容是否会破坏您的基础架构?
- 应用程序层是否存在已知的漏洞?
- 运行时和操作系统层是不是最新的?
通过从红帽通用基础镜像 (UBI) 构建容器,您可以保证您的容器镜像基础由 Red Hat Enterprise Linux 中包含的同一 RPM 打包软件组成。使用或重新分发 UBI 镜像不需要订阅。
为确保容器本身持续安全,安全扫描功能(直接从 RHEL 使用或添加到 OpenShift Container Platform)可在您使用的镜像有漏洞时发出警告。RHEL 中提供了 OpenSCAP 镜像扫描,并且可添加 Red Hat Quay Container Security Operator 来检查 OpenShift Container Platform 中使用的容器镜像。
2.6.2. 使用 UBI 创建可重新分发的镜像
要创建容器化应用程序,您通常以可信基础镜像开始,该镜像提供的组件通常由操作系统提供。这些组件包括库、实用程序以及应用程序在操作系统文件系统中应该看到的其他功能。
创建红帽通用基础镜像 (UBI) 是为了鼓励任何人在构建其自己的容器时都先使用一个完全由 Red Hat Enterprise Linux rpm 软件包及其他内容组成的容器镜像。这些 UBI 镜像会定期更新,以应用最新的安全补丁,并可自由地与构建用来包含您自己的软件的容器镜像一起使用和重新分发。
搜索红帽生态系统目录,以便查找和检查不同 UBI 镜像的健康状态。作为创建安全容器镜像的人员,您可能对两种通用 UBI 镜像类型感兴趣:
-
UBI:RHEL 7 和 8 有标准的 UBI 镜像(
ubi7/ubi和ubi8/ubi),以及基于这些系统的最小镜像(ubi7/ubi-minimal和ubi8/ubi-mimimal)。所有这些镜像已预先配置,以指向您可以使用标准yum和dnf命令添加到构建的容器镜像中的免费 RHEL 软件存储库。红帽鼓励人们在其他发行版(如 Fedora 和 Ubuntu)上使用这些镜像。 -
Red Hat Software Collections:在红帽生态系统目录中搜索
rhscl/以查找为用作特定应用程序类型的基础镜像而创建的镜像。例如,有 Apache httpd (rhscl/httpd-*)、Python (rhscl/python-*), Ruby (rhscl/ruby-*)、Node.js (rhscl/nodejs-*) 和 Perl (rhscl/perl-*) rhscl 镜像。
请记住,虽然 UBI 镜像可自由使用且可重新发布,但红帽对这些镜像的支持只能通过 Red Hat 产品订阅获得。
请参阅 Red Hat Enterprise Linux 文档中 的使用红帽通用基础镜像来获得有关如何使用标准、最小和 init UBI 镜像作为构建基础的信息。
2.6.3. RHEL 中的安全扫描
对于 Red Hat Enterprise Linux (RHEL) 系统,可从 openscap-utils 软件包中获得 OpenSCAP 扫描功能。在 RHEL 中,您可以使用 openscap-podman 命令扫描针镜像中的漏洞。请参阅 Red Hat Enterprise Linux 文档中的扫描容器和容器镜像中的漏洞。
OpenShift Container Platform 可让您在 CI/CD 过程中利用 RHEL 扫描程序。例如,您可以集成静态代码分析工具来测试源代码中的安全漏洞,并集成软件组成分析工具来标识开源库,以提供关于这些库的元数据,如已知漏洞。
2.6.3.1. 扫描 OpenShift 镜像
对于在 OpenShift Container Platform 中运行并且从 Red Hat Quay registry 中拉取的容器镜像,您可以使用 Operator 来列出这些镜像的漏洞。Red Hat Quay Container Security Operator 可以添加到 OpenShift Container Platform 中,为添加到所选命名空间的镜像提供漏洞报告。
Red Hat Quay 的容器镜像扫描由 Clair 安全扫描程序执行。在 Red Hat Quay 中,Clair 可以搜索和报告从 RHEL、CentOS、Oracle、Alpine、Debian 和 Ubuntu 操作系统软件构建的镜像中的漏洞。
2.6.4. 集成外部扫描
OpenShift Container Platform 使用对象注解来扩展功能。外部工具(如漏洞扫描程序)可以使用元数据为镜像对象添加注解,以汇总结果和控制 Pod 执行。本节描述了该注解的公认格式,以便在控制台中可靠使用它来为用户显示有用的数据。
2.6.4.1. 镜像元数据
镜像质量数据有多种不同的类型,包括软件包漏洞和开源软件 (OSS) 许可证合规性。另外,该元数据的供应商可能不止一个。为此,保留了以下注解格式:
quality.images.openshift.io/<qualityType>.<providerId>: {}| 组件 | 描述 | 可接受值 |
|---|---|---|
|
| 元数据类型 |
|
|
| 供应商 ID 字符串 |
|
2.6.4.1.1. 注解键示例
quality.images.openshift.io/vulnerability.blackduck: {}
quality.images.openshift.io/vulnerability.jfrog: {}
quality.images.openshift.io/license.blackduck: {}
quality.images.openshift.io/vulnerability.openscap: {}镜像质量注解的值是必须遵循以下格式的结构化数据:
| 字段 | 必需? | 描述 | 类型 |
|---|---|---|---|
|
| 是 | 供应商显示名称 | 字符串 |
|
| 是 | 扫描时间戳 | 字符串 |
|
| 否 | 简短描述 | 字符串 |
|
| 是 | 信息来源的 URL 或更多详细信息。必需,以便用户可以验证数据。 | 字符串 |
|
| 否 | 扫描程序版本 | 字符串 |
|
| 否 | 合规性通过或未通过 | 布尔值 |
|
| 否 | 找到的问题摘要 | 列表(请参阅下表) |
summary 字段必须遵循以下格式:
| 字段 | 描述 | 类型 |
|---|---|---|
|
| 显示组件标签(例如:"critical"、"important"、"moderate"、"low" 或 "health") | 字符串 |
|
| 此组件的数据(例如:发现的漏洞计数或分数) | 字符串 |
|
|
组件索引,允许对图形表示进行排序和分配。该值范围为 | 整数 |
|
| 信息来源的 URL 或更多详细信息。可选。 | 字符串 |
2.6.4.1.2. 注解值示例
本示例显示了一个镜像的 OpenSCAP 注解,带有漏洞概述数据以及一个合规性布尔值:
OpenSCAP 注解
{
"name": "OpenSCAP",
"description": "OpenSCAP vulnerability score",
"timestamp": "2016-09-08T05:04:46Z",
"reference": "https://www.open-scap.org/930492",
"compliant": true,
"scannerVersion": "1.2",
"summary": [
{ "label": "critical", "data": "4", "severityIndex": 3, "reference": null },
{ "label": "important", "data": "12", "severityIndex": 2, "reference": null },
{ "label": "moderate", "data": "8", "severityIndex": 1, "reference": null },
{ "label": "low", "data": "26", "severityIndex": 0, "reference": null }
]
}本例演示了红帽生态系统目录注解中镜像的容器镜像部分,包含健康索引数据以及获取更多详细信息的外部 URL:
红帽生态系统目录注解
{
"name": "Red Hat Ecosystem Catalog",
"description": "Container health index",
"timestamp": "2016-09-08T05:04:46Z",
"reference": "https://access.redhat.com/errata/RHBA-2016:1566",
"compliant": null,
"scannerVersion": "1.2",
"summary": [
{ "label": "Health index", "data": "B", "severityIndex": 1, "reference": null }
]
}2.6.4.2. 为镜像对象添加注解
虽然 OpenShift Container Platform 最终用户操作针对的是镜像流对象,但会使用安全元数据为镜像对象添加注解。镜像对象是集群范围的,指向可能由多个镜像流和标签引用的单一镜像。
2.6.4.2.1. 注解 CLI 命令示例
将 <image> 替换为镜像摘要,如 sha256:401e359e0f45bfdcf004e258b72e253fd07fba8cc5c6f2ed4f4608fb119ecc2:
$ oc annotate image <image> \
quality.images.openshift.io/vulnerability.redhatcatalog='{ \
"name": "Red Hat Ecosystem Catalog", \
"description": "Container health index", \
"timestamp": "2020-06-01T05:04:46Z", \
"compliant": null, \
"scannerVersion": "1.2", \
"reference": "https://access.redhat.com/errata/RHBA-2020:2347", \
"summary": "[ \
{ "label": "Health index", "data": "B", "severityIndex": 1, "reference": null } ]" }'2.6.4.3. 控制 Pod 执行
使用 images.openshift.io/deny-execution 镜像策略,以编程方式控制镜像是否可以运行。
2.6.4.3.1. 注解示例
annotations:
images.openshift.io/deny-execution: true2.6.4.4. 集成参考
在大多数情况下,漏洞扫描程序等外部工具会开发一个脚本或插件来监视镜像更新,执行扫描,并使用结果为相关的镜像对象添加注解。通常,这个自动化过程会调用 OpenShift Container Platform 4.8 REST API 来编写注解。有关 REST API 的常规信息,请参阅 OpenShift Container Platform REST API。
2.6.4.4.1. REST API 调用示例
以下使用 curl 的示例调用会覆盖注解值。请务必替换 <token>、<openshift_server>、<image_id> 和 <image_annotation> 的值。
修补 API 调用
$ curl -X PATCH \
-H "Authorization: Bearer <token>" \
-H "Content-Type: application/merge-patch+json" \
https://<openshift_server>:6443/apis/image.openshift.io/v1/images/<image_id> \
--data '{ <image_annotation> }'
以下是 PATCH 有效负载数据的示例:
修补调用数据
{
"metadata": {
"annotations": {
"quality.images.openshift.io/vulnerability.redhatcatalog":
"{ 'name': 'Red Hat Ecosystem Catalog', 'description': 'Container health index', 'timestamp': '2020-06-01T05:04:46Z', 'compliant': null, 'reference': 'https://access.redhat.com/errata/RHBA-2020:2347', 'summary': [{'label': 'Health index', 'data': '4', 'severityIndex': 1, 'reference': null}] }"
}
}
}2.7. 安全地使用容器 registry
容器 registry 存储容器镜像以便:
- 使镜像可供其他用户访问
- 将镜像组织到可包含多个镜像版本的存储库中
- 选择性地根据不同的身份验证方法限制对镜像的访问,或者将其设为可公开使用
有一些公共容器 registry(如 Quay.io 和 Docker Hub)可供很多个人和机构共享其镜像。红帽 Registry 提供支持的红帽和合作伙伴镜像,而红帽生态系统目录为这些镜像提供了详细的描述和健康状态检查。要管理自己的 registry,您可以购买一个容器 registry,如 Red Hat Quay。
从安全角度来说,有些 registry 提供了特殊的功能来检查并改进容器的健康状态。例如,Red Hat Quay 通过 Clair 安全扫描程序提供容器漏洞扫描功能,提供构建触发器以在 GitHub 和其他位置的源代码发生更改时自动重建镜像,并支持使用基于角色的访问控制 (RBAC) 来保护对镜像的访问。
2.7.1. 知道容器来自哪里?
您可以使用一些工具来扫描和跟踪您下载和部署的容器镜像的内容。但是,容器镜像有很多公共来源。在使用公共容器 registry 时,您可以使用可信源添加一层保护。
2.7.2. 不可变和已认证的容器
在管理不可变容器时,消耗安全更新尤其重要。不可变容器是在运行时永远不会更改的容器。当您部署不可变容器时,您不会介入正在运行的容器来替换一个或多个二进制文件。从操作角度来说,您可以重建并重新部署更新的容器镜像以替换某个容器,而不是更改该容器。
红帽的已认证镜像:
- 在平台组件或层中没有已知漏洞
- 在 RHEL 平台间兼容,从裸机到云端
- 受红帽支持
已知漏洞列表不断扩展,因此您必须一直跟踪部署的容器镜像的内容以及新下载的镜像。您可以使用红帽安全公告 (RHSA) 来提醒您红帽的已认证容器镜像中出现的任何新问题,并指引您找到更新的镜像。另外,您还可以访问红帽生态系统目录查找每个红帽镜像的各种安全相关问题。
2.7.3. 从红帽 Registry 和生态系统目录获取容器
红帽在红帽生态系统目录的容器镜像部分列出了适用于红帽产品和合作伙伴产品的已认证容器镜像。在该目录中,您可以查看每个镜像的详情,包括 CVE、软件包列表和健康状态分数。
红帽镜像实际存储在所谓的 红帽 Registry 中,其具体代表为公共容器 registry (registry.access.redhat.com) 和经过身份验证的 registry (registry.redhat.io)。这两者基本包括同一组容器镜像,其中 registry.redhat.io 包括了一些需要使用红帽订阅凭证进行身份验证的额外镜像。
红帽会监控容器内容以了解漏洞,并定期进行更新。当红帽发布安全更新(如 glibc、DROWN 或 Dirty Cow 的修复程序)时,任何受影响的容器镜像也会被重建并推送到 Red Hat Registry。
红帽使用 health index 来反映通过红帽生态系统目录提供的每个容器的安全风险。由于容器消耗红帽提供的软件和勘误表流程,旧的、过时的容器不安全,而全新容器则更安全。
为了说明容器的年龄,红帽生态系统目录使用一个等级系统。新鲜度等级是一个镜像可用的最旧、最严重的安全公告衡量标准。“A”比“F”状态更新。如需了解这个等级系统的更多详情,请参阅 Red Hat Ecosystem Catalog 内部使用的容器健康状态索引等级。
2.7.4. OpenShift Container Registry
OpenShift Container Platform 包括 OpenShift Container Registry,它是作为平台集成组件运行的私有 registry,可用于管理容器镜像。OpenShift Container Registry 提供基于角色的访问控制,供您管理谁可以拉取和推送哪些容器镜像。
OpenShift Container Platform 还支持与其他您可能已经使用的私有 registry 集成,如 Red Hat Quay。
2.7.5. 使用 Red Hat Quay 存储容器
Red Hat Quay 是红帽的一个企业级容器 registry 产品。Red Hat Quay 的开发是通过上游 Project Quay 完成的。Red Hat Quay 可用于在内部部署,或通过 Red Hat Quay 在 Quay.io 的托管版本部署。
与安全性相关的 Red Hat Quay 功能包括:
- 时间机器:允许带有旧标签的镜像在一段设定时间后或基于用户选择的过期时间过期。
- 存储库镜像:让您出于安全原因为其他 registry 创建镜像,如在公司防火墙后面的 Red Hat Quay 上托管公共存储库,或出于性能原因让 registry 更接近使用的位置。
- 操作日志存储:将 Red Hat Quay 日志输出保存到 Elasticsearch 存储,以便稍后进行搜索和分析。
- Clair 安全扫描:根据每个容器镜像的来源,针对各种 Linux 漏洞数据库扫描镜像。
- 内部身份验证:使用默认本地数据库处理面向 Red Hat Quay 的 RBAC 身份验证,或者从 LDAP、Keystone (OpenStack)、JWT 自定义身份验证或 External Application Token 身份验证中选择。
- 外部授权 (OAuth):允许通过 GitHub、GitHub Enterprise 或 Google 身份验证对 Red Hat Quay 进行授权。
- 访问设置:生成令牌,允许从 docker、rkt、匿名访问、用户创建的帐户、加密客户端密码或前缀用户名自动完成访问 Red Hat Quay。
Red Hat Quay 不断与 OpenShift Container Platform 持续集成,包含几个特别值得关注的 OpenShift Container Platform Operator。Quay Bridge Operator 可让您将 OpenShift Container Platform 内部 registry 替换为 Red Hat Quay。Red Hat Quay Container Security Operator 可让您检查从 Red Hat Quay registry 中拉取的 OpenShift Container Platform 中运行的镜像的漏洞。
2.8. 保护构建过程
在容器环境中,软件构建过程是生命周期中应用程序代码与所需的运行时库集成的阶段。管理此构建过程是保护软件堆栈的关键。
2.8.1. 一次构建,随处部署
使用 OpenShift Container Platform 作为容器构建的标准平台可保证构建环境的安全。遵循“一次构建,随处部署”的原则可确保构建过程的产品就是在生产环境中部署的产品。
保持容器的不可变性也是很重要的。您不应该修补运行中的容器,而应该重建并重新部署这些容器。
随着您的软件逐步进入构建、测试和生产阶段,组成软件供给链的工具必须是可信的。下图演示了可整合到容器化软件的可信软件供应链中的流程和工具:

OpenShift Container Platform 可以与可信代码存储库(如 GitHub)和开发平台(如 Che)集成,用于创建和管理安全代码。单元测试可以依赖 Cucumber 和 JUnit。您可以通过 Anchore 或 Twistlock 检查容器中的漏洞和合规问题,并使用镜像扫描工具,如 AtomicScan 或 Clair。Sysdig 等工具可以提供对容器化应用程序的持续监控。
2.8.2. 管理构建
您可以使用 Source-to-Image (S2I) 将源代码和基础镜像组合起来。构建器镜像利用 S2I 使您的开发和运维团队能够就可重复生成的构建环境展开合作。对于可作为通用基础镜像 (UBI) 镜像的 Red Hat S2I 镜像,您现在可以使用从真实 RHEL RPM 软件包构建的基础镜像自由重新分发您的软件。红帽取消了订阅限制以允许这一操作。
当开发人员使用构建镜像通过 Git 提交某个应用程序的代码时,OpenShift Container Platform 可以执行以下功能:
- 通过使用代码存储库上的 Webhook 或其他自动持续集成 (CI) 过程进行触发,以从可用的工件、S2I 构建器镜像和新提交的代码中自动编译新镜像。
- 自动部署新构建的镜像以进行测试。
- 将测试镜像提升到生产环境中,以使用 CI 过程自动进行部署。
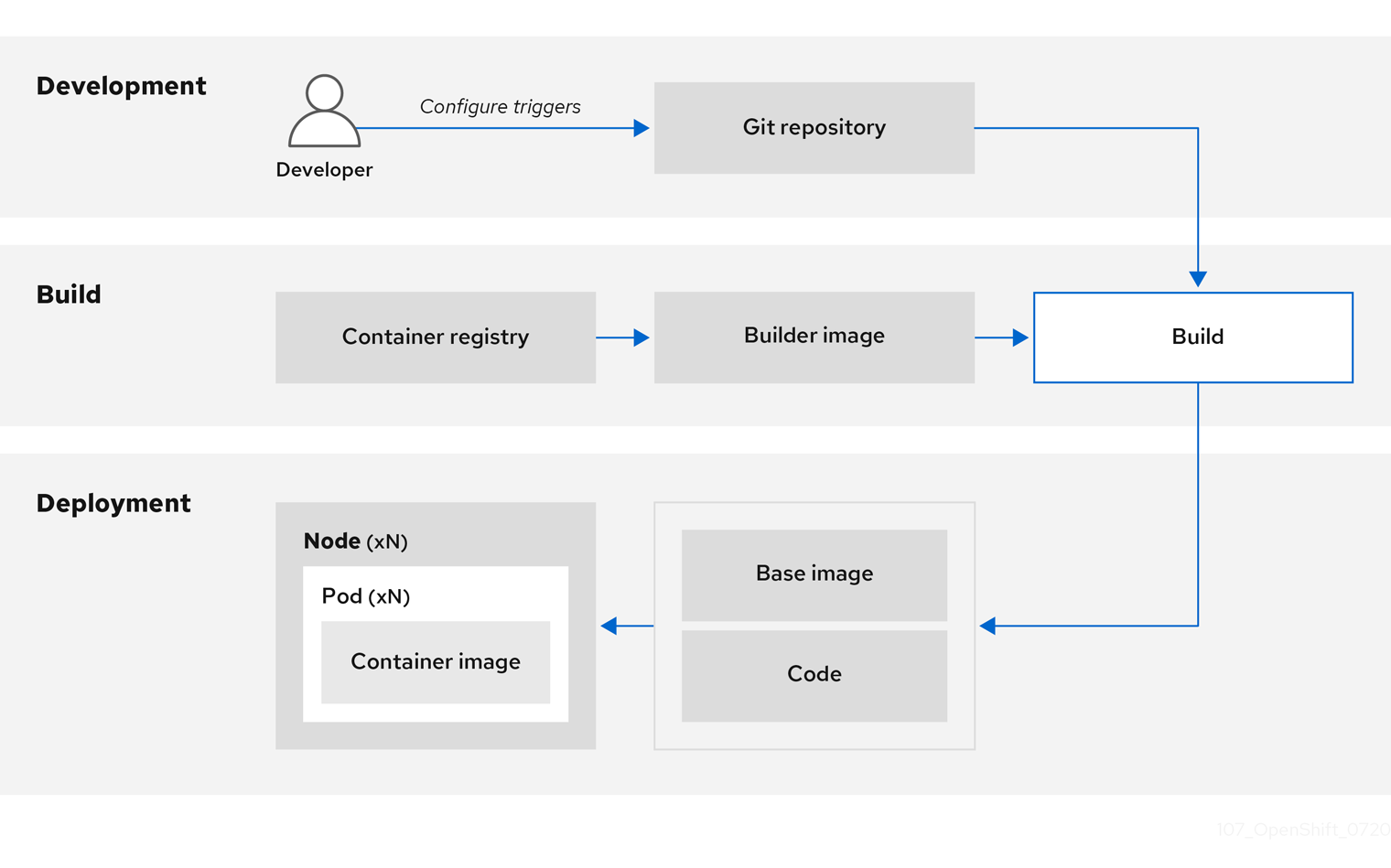
您可以使用集成的 OpenShift Container Registry 来管理对最终镜像的访问。S2I 和原生构建镜像会自动推送到 OpenShift Container Registry。
除了包含的用于 CI 的 Jenkins 外,您还可以使用 RESTful API 将您自己的构建和 CI 环境与 OpenShift Container Platform 集成,并使用与 API 兼容的镜像 registry。
2.8.3. 在构建期间保护输入
在某些情况下,构建操作需要凭证才能访问依赖的资源,但这些凭证最好不要在通过构建生成的最终应用程序镜像中可用。您可以定义输入 secret 以实现这一目的。
例如,在构建 Node.js 应用程序时,您可以为 Node.js 模块设置私有镜像。要从该私有镜像下载模块,您必须为包含 URL、用户名和密码的构建提供自定义的 .npmrc 文件。为安全起见,不应在应用程序镜像中公开您的凭证。
通过使用此示例场景,您可以在新 BuildConfig 对象中添加输入 secret:
如果 secret 不存在,则进行创建:
$ oc create secret generic secret-npmrc --from-file=.npmrc=~/.npmrc这会创建一个名为
secret-npmrc的新 secret,其包含~/.npmrc文件的 base64 编码内容。将该 secret 添加到现有
BuildConfig对象的source部分中:source: git: uri: https://github.com/sclorg/nodejs-ex.git secrets: - destinationDir: . secret: name: secret-npmrc要在新
BuildConfig对象中包含该 secret,请运行以下命令:$ oc new-build \ openshift/nodejs-010-centos7~https://github.com/sclorg/nodejs-ex.git \ --build-secret secret-npmrc
2.8.4. 设计构建过程
您可以对容器镜像管理和构建过程进行设计以使用容器层,以便您可以分开控制。
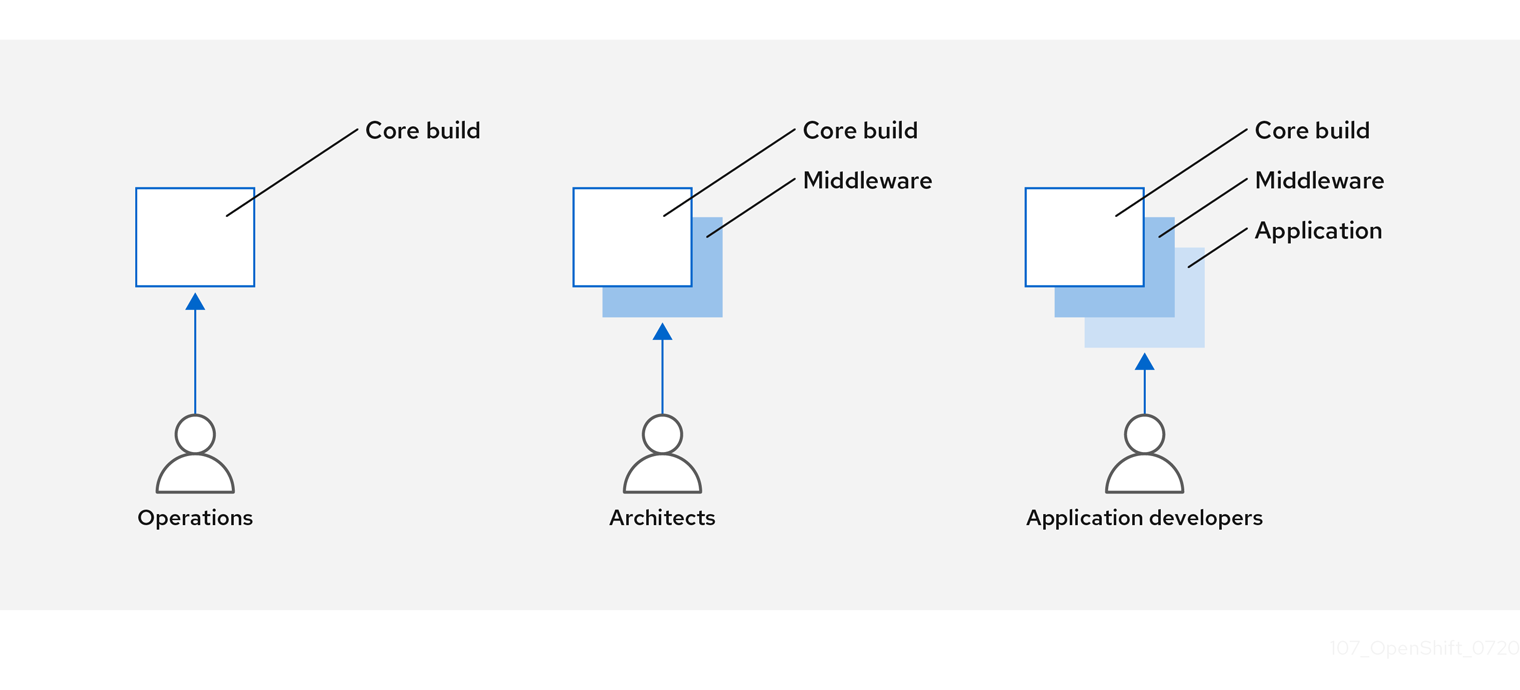
例如,一个运维团队负责管理基础镜像,而架构师则负责管理中间件、运行时、数据库和其他解决方案。然后开发人员可以专注于应用程序层并专注于编写代码。
由于每天都会识别出新的漏洞,因此您需要一直主动检查容器内容。要做到这一点,您应该将自动安全测试集成到构建或 CI 过程中。例如:
- SAST / DAST – 静态和动态安全测试工具。
- 根据已知漏洞进行实时检查的扫描程序。这类工具会为您的容器中的开源软件包编目,就任何已知漏洞通知您,并在之前扫描的软件包中发现新漏洞时为您提供最新信息。
您的 CI 过程应该包含相应的策略,为构建标记出通过安全扫描发现的问题,以便您的团队能够采取适当行动来解决这些问题。您应该为自定义构建容器签名,以确保在构建和部署之间不会修改任何内容。
利用 GitOps 方法,您不仅可以使用相同的 CI/CD 机制来管理应用程序配置,还可以管理 OpenShift Container Platform 基础架构。
2.8.5. 构建 Knative 无服务器应用程序
通过使用 Kubernetes 和 Kourier,您可以在 OpenShift Container Platform 中使用 OpenShift Serverless 来构建、部署和管理无服务器应用程序。
和其他构建一样,您可以使用 S2I 镜像来构建容器,然后使用 Knative 服务提供它们。通过 OpenShift Container Platform Web 控制台的 Topology 视图 查看 Knative 应用程序构建。
2.9. 部署容器
您可以使用各种技术来确保所部署的容器包含最新的生产级内容,并确保这些容器没有被修改。这些技术包括设置构建触发器以纳入最新的代码,以及使用签名来确保容器来自可信源且未修改。
2.9.1. 使用触发器控制容器部署
如果在构建过程中发生某种情况,或者部署了镜像后发现一个漏洞,您可以使用基于策略的自动化部署工具进行修复。您可以使用触发器来重建和替换镜像,确保不可变的容器进程,而不是修补正在运行的容器,这种做法是不推荐的。
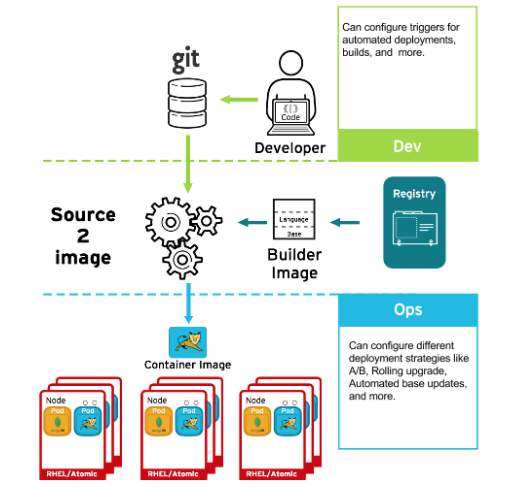
例如,您使用三个容器镜像层构建了一个应用程序:核心、中间件和应用程序。由于在核心镜像中发现了一个问题,该镜像被重建。构建完成后,该镜像被推送到 OpenShift Container Registry。OpenShift Container Platform 检测到镜像已更改,并根据定义的触发器自动重建并部署应用程序镜像。这一更改包含了固定的库,并确保产品代码与最新镜像是一致的。
您可以使用 oc set triggers 命令来设置部署触发器。例如,要为名为 deployment-example 的部署设置触发器:
$ oc set triggers deploy/deployment-example \
--from-image=example:latest \
--containers=web2.9.2. 控制可以部署的镜像源
务必要确保实际部署了所需的镜像,还要确保包括容器内容的镜像来自可信源,且尚未更改。加密签名提供了这一保证。OpenShift Container Platform 可让集群管理员应用广泛或狭窄的安全策略,以反应部署环境和安全要求。该策略由两个参数定义:
- 一个或多个带有可选项目命名空间的 registry
- 信任类型,如接受、拒绝或要求公钥
您可以使用这些策略参数来允许、拒绝整个 registry、部分 registry 或单独的镜像,或者要求具有信任关系。使用可信公钥,您可以确保以加密的方式验证源。该策略规则应用于节点。策略可以在所有节点中统一应用,或针对不同的节点工作负载(例如:构建、区域或环境)加以应用。
镜像签名策略文件示例
{
"default": [{"type": "reject"}],
"transports": {
"docker": {
"access.redhat.com": [
{
"type": "signedBy",
"keyType": "GPGKeys",
"keyPath": "/etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release"
}
]
},
"atomic": {
"172.30.1.1:5000/openshift": [
{
"type": "signedBy",
"keyType": "GPGKeys",
"keyPath": "/etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release"
}
],
"172.30.1.1:5000/production": [
{
"type": "signedBy",
"keyType": "GPGKeys",
"keyPath": "/etc/pki/example.com/pubkey"
}
],
"172.30.1.1:5000": [{"type": "reject"}]
}
}
}
该策略可以在节点上保存为 /etc/containers/policy.json。最好使用新的 MachineConfig 对象将此文件保存到节点。这个示例强制执行以下规则:
-
要求 Red Hat Registry (
registry.access.redhat.com) 中的镜像由红帽公钥签名。 -
要求
openshift命名空间中的 OpenShift Container Registry 中的镜像由 Red Hat 公钥签名。 -
要求
production命名空间中的 OpenShift Container Registry 中的镜像由example.com的公钥签名。 -
拒绝未由全局
默认定义指定的所有其他 registry。
2.9.3. 使用签名传输
签名传输是一种存储和检索二进制签名 blob 的方法。签名传输有两种类型。
-
Atomic:由 OpenShift Container Platform API 管理。 -
Docker:作为本地文件或通过 Web 服务器提供。
OpenShift Container Platform API 负责管理使用 atomic 传输类型的签名。您必须将使用此签名类型的镜像存储在 OpenShift Container Registry 中。由于 docker/distribution extensions API 会自动发现镜像签名端点,因此不需要额外的配置。
使用 docker 传输类型的签名由本地文件或者 Web 服务器提供。这些签名更为灵活,您可以提供来自任何容器镜像 registry 的镜像,并使用独立的服务器来提供二进制签名。
但是,docker 传输类型需要进行额外的配置。您必须为节点配置签名服务器的 URI,方法是将随机命名的 YAML 文件放在主机系统上的目录中,默认为 /etc/containers/registries.d。YAML 配置文件包含 registry URI 和签名服务器 URI,或 sigstore:
Registries.d 文件示例
docker:
access.redhat.com:
sigstore: https://access.redhat.com/webassets/docker/content/sigstore
在这个示例中,Red Hat Registry access.redhat.com 是为 docker 传输类型提供签名的签名服务器。其 URI 在 sigstore 参数中定义。您可以将此文件命名为 /etc/containers/registries.d/redhat.com.yaml,并使用 Machine Config Operator 自动将文件放在集群中的每个节点上。由于策略和 registry.d 文件由容器运行时动态加载,因此不需要重启服务。
2.9.4. 创建 secret 和配置映射
Secret 对象类型提供了一种机制来保存敏感信息,如密码、OpenShift Container Platform 客户端配置文件、dockercfg 文件和私有源存储库凭证。Secret 将敏感内容与 Pod 分离。您可以使用卷插件将 secret 信息挂载到容器中,系统也可以使用 secret 代表 Pod 执行操作。
例如,要在部署配置中添加 secret,以便它可以访问私有镜像存储库,请执行以下操作:
流程
- 登陆到 OpenShift Container Platform Web 控制台。
- 创建新项目。
-
导航到 Resources → Secrets 并创建新 secret。将
Secret Type设为Image Secret,并将Authentication Type设为Image Registry Credentials,以输入用于访问私有镜像存储库的凭证。 -
在创建部署配置时(例如,从 Add to Project → Deploy Image 页面),将
Pull Secret设置为您的新 secret。
配置映射与 secret 类似,但设计为能支持与不含敏感信息的字符串配合使用。ConfigMap 对象包含配置数据的键值对,这些数据可在 Pod 中消耗或用于存储控制器等系统组件的配置数据。
2.9.5. 自动化持续部署
您可以将自己的持续部署 (CD) 工具与 OpenShift Container Platform 集成。
利用 CI/CD 和 OpenShift Container Platform,您可以自动执行重建应用程序的过程,以纳入最新的修复、测试,并确保它在环境中随处部署。
2.10. 保护容器平台
OpenShift Container Platform 和 Kubernetes API 是大规模自动化容器管理的关键。API 用于:
- 验证并配置 Pod、服务和复制控制器的数据。
- 在收到传入请求时执行项目验证,并对其他主要系统组件调用触发器。
OpenShift Container Platform 中基于 Kubernetes 的安全相关功能包括:
- 多租户,将基于角色的访问控制和网络策略组合起来,以在多个级别上隔离容器。
- 准入插件,在 API 和向 API 发出请求的各方之间形成界限。
OpenShift Container Platform 使用 Operator 来自动化和简化 Kubernetes 级别安全功能的管理。
2.10.1. 使用多租户隔离容器
多租户允许 OpenShift Container Platform 集群上由多个用户拥有并在多个主机和命名空间中运行的应用程序保持相互隔离并与外部攻击隔离。要获取多租户,您可以将基于角色的访问控制 (RBAC) 应用到 Kubernetes 命名空间。
在 Kubernetes 中,命名空间是应用程序可以独立于其他应用程序运行的区域。OpenShift Container Platform 使用和扩展命名空间的方式是添加额外的注解,包括在 SELinux 中的 MCS 标签,并将这些扩展命名空间标识为项目。在项目范围内,用户可以维护自己的集群资源,包括服务帐户、策略、限制和各种其他对象。
可将 RBAC 对象分配给项目,以便授权所选用户访问这些项目。该授权采用规则、角色和绑定的形式:
- 规则会定义用户可在项目中创建或访问的内容。
- 角色是您可以绑定到所选用户或组的规则集合。
- 绑定会定义用户或组与角色之间的关联。
本地 RBAC 角色和绑定将用户或组附加到特定项目。集群 RBAC 可将集群范围的角色和绑定附加到集群中的所有项目。有默认的集群角色可以分配,用来提供 admin、basic-user、cluster-admin 和 cluster-status 访问。
2.10.2. 使用准入插件保护 control plane
RBAC 可控制用户和组与可用项目之间的访问规则,而准入插件可定义对 OpenShift Container Platform 主 API 的访问。准入插件形成一个由以下部分组成的规则链:
- 默认准入插件:这些插件实现了一组默认策略和资源限制以应用于 OpenShift Container Platform control plane 的组件。
- 变异准入插件:这些插件会动态地扩展准入链。它们调用 Webhook 服务器,不仅可对请求进行身份验证,还可修改所选资源。
- 验证准入插件: 这些插件验证所选资源的请求,不仅可验证请求,还可确保资源不会再次更改。
API 请求经过一个链中的准入插件,沿途的任何失败都会导致请求遭到拒绝。每个准入插件都与特定资源关联,且只响应这些资源的请求。
2.10.2.1. 安全性上下文约束(SCC)
您可以使用安全性上下文约束 (SCC) 定义 Pod 运行必须满足的一组条件,以便其能被系统接受。
可由 SCC 管理的一些方面包括:
- 运行特权容器
- 容器可请求添加的功能
- 将主机目录用作卷。
- 容器的 SELinux 上下文。
- 容器用户 ID。
如果具有所需的权限,您可以根据需要将默认 SCC 策略调整为更宽松。
2.10.2.2. 为服务帐户授予角色
就像为用户分配基于角色的访问一样,您可以为服务帐户分配角色。为每个项目创建的默认服务帐户有三个。服务帐户:
- 范围限制为特定项目
- 名称来自其项目
- 会被自动分配一个 API 令牌和凭证来访问 OpenShift Container Registry
与平台组件关联的服务帐户自动使其密钥轮转。
2.10.3. 认证和授权
2.10.3.1. 使用 OAuth 控制访问
您可以通过身份验证和授权使用 API 访问控制来保护容器平台。OpenShift Container Platform master 包含内置的 OAuth 服务器。用户可以获取 OAuth 访问令牌来对自身进行 API 身份验证。
作为管理员,您可以使用用户身份供应商(如 LDAP、GitHub 或 Google)配置 OAuth 以进行身份验证。用户身份供应商默认用于新的 OpenShift Container Platform 部署,但您可以在初始安装时或安装后进行此配置。
2.10.3.2. API 访问控制和管理
应用程序可以拥有多个独立的 API 服务,这些服务具有不同的端点需要管理。OpenShift Container Platform 包含 3scale API 网关的容器化版本,以便您管理 API 并控制访问。
3scale 为您提供用于 API 身份验证和安全性的各种标准选项,它们可单独或组合起来用于发布凭证和控制访问:标准 API 密钥、应用程序 ID 和密钥对以及 OAuth 2.0。
您可以限制对特定端点、方法和服务的访问,并为用户组应用访问策略。您可以通过应用程序计划来为各组开发人员设置 API 使用率限制并控制流量。
有关使用容器化 3scale API 网关 APIcast v2 的教程,请参阅 3scale 文档中的在 Red Hat OpenShift 上运行 APIcast。
2.10.3.3. 红帽单点登录
通过红帽单点登录服务器,您可以提供基于标准的 Web 单点登录功能,包括 SAML 2.0、OpenID Connect 和 OAuth 2.0,从而保护应用程序。该服务器可充当基于 SAML 或 OpenID Connect 的用户身份供应商 (IdP),使用基于标准的令牌在您的企业用户目录或用于身份信息的第三方用户身份供应商与您的应用程序之间进行调和。您可以将红帽单点登录与基于 LDAP 的目录服务集成,包括 Microsoft Active Directory 和 Red Hat Enterprise Linux Identity Management。
2.10.3.4. 安全自助服务 Web 控制台
OpenShift Container Platform 提供了一个自助服务 Web 控制台,以确保团队在没有授权的情况下无法访问其他环境。OpenShift Container Platform 通过提供以下功能来确保安全多租户 master:
- 使用传输层安全 (TLS) 访问 master
- 使用 X.509 证书或 OAuth 访问令牌访问 API 服务器
- 通过项目配额限制异常令牌可以造成的破坏
- Etcd 服务不直接向集群公开
2.10.4. 为平台管理证书
OpenShift Container Platform 的框架中有多个组件,它们使用基于 REST 的 HTTPS 通信,通过 TLS 证书利用加密功能。OpenShift Container Platform 的安装程序会在安装过程中配置这些证书。生成此流量的一些主要组件如下:
- master(API 服务器和控制器)
- etcd
- 节点
- registry
- 路由器
2.10.4.1. 配置自定义证书
您可以在初始安装过程中或在重新部署证书时为 API 服务器和 Web 控制台的公共主机名配置自定义服务证书。您还可以使用自定义 CA。
2.11. 保护网络
可以在多个级别管理网络安全性。在 Pod 级别上,网络命名空间可以通过限制网络访问来防止容器查看其他 Pod 或主机系统。网络策略可让您控制允许或拒绝连接。您可以管理容器化应用程序的入口和出口流量。
2.11.1. 使用网络命名空间
OpenShift Container Platform 使用软件定义网络 (SDN) 来提供一个统一的集群网络,它允许集群中的不同容器相互间进行通信。
默认情况下,网络策略模式使项目中的所有 Pod 都可被其他 Pod 和网络端点访问。要在一个项目中隔离一个或多个 Pod,您可以在该项目中创建 NetworkPolicy 对象来指示允许的入站连接。使用多租户模式,您可以为 Pod 和服务提供项目级别的隔离。
2.11.2. 使用网络策略隔离 Pod
使用网络策略,您可以在同一项目中将 Pod 相互隔离。网络策略可以拒绝对 Pod 的所有网络访问,只允许入口控制器的连接,拒绝其他项目中的 Pod 的连接,或为网络的行为方式设置类似的规则。
2.11.3. 使用多个 Pod 网络
默认情况下,每个运行中的容器只有一个网络接口。Multus CNI 插件可让您创建多个 CNI 网络,然后将任何这些网络附加到您的 Pod。这样,您可以执行一些操作,例如将私有数据单独放在更为受限的网络上,并在每个节点上使用多个网络接口。
2.11.4. 隔离应用程序
OpenShift Container Platform 允许您为单个集群上的网络流量分段以创建多租户集群,使用户、团队、应用程序和环境与非全局资源隔离。
2.11.5. 保护入口流量
如何配置从 OpenShift Container Platform 集群外对 Kubernetes 服务的访问会产生很多安全影响。除了公开 HTTP 和 HTTPS 路由外,入口路由还允许您设置 NodePort 或 LoadBalancer 入口类型。NodePort 从每个集群 worker 中公开应用程序的服务 API 对象。借助 LoadBalancer,您可以将外部负载均衡器分配给 OpenShift Container Platform 集群中关联的服务 API 对象。
2.11.6. 保护出口流量
OpenShift Container Platform 提供了使用路由器或防火墙方法控制出口流量的功能。例如,您可以使用 IP 白名单来控制对数据库的访问。集群管理员可以为 OpenShift Container Platform SDN 网络供应商中的项目分配一个或多个出口 IP 地址。同样,集群管理员可以使用出口防火墙防止出口流量传到 OpenShift Container Platform 集群之外。
通过分配固定出口 IP 地址,您可以将特定项目的所有出站流量分配到该 IP 地址。使用出口防火墙时,您可以防止 Pod 连接到外部网络,防止 Pod 连接到内部网络,或限制 Pod 对特定内部子网的访问。
2.12. 保护附加存储
OpenShift Container Platform 支持多种存储类型,包括内部存储和云供应商。特别是,OpenShift Container Platform 可以使用支持 Container Storage Interface 的存储类型。
2.12.1. 持久性卷插件
容器对于无状态和有状态的应用程序都很有用。保护附加存储是保护有状态服务的一个关键元素。通过使用 Container Storage Interface (CSI),OpenShift Container Platform 可以包含支持 CSI 接口的任何存储后端中的存储。
OpenShift Container Platform 为多种存储提供插件,包括:
- Red Hat OpenShift Container Storage *
- AWS Elastic Block Stores (EBS) *
- AWS Elastic File System (EFS) *
- Azure Disk *
- Azure File *
- OpenStack Cinder *
- GCE Persistent Disks *
- VMware vSphere *
- 网络文件系统 (NFS)
- FlexVolume
- Fibre Channel
- iSCSI
具有动态置备的存储类型的插件标记为星号 (*)。对于相互通信的所有 OpenShift Container Platform 组件,传输中的数据都通过 HTTPS 来加密。
您可以以任何方式在主机上挂载持久性卷(PV)。不同的存储类型具有不同的功能,每个 PV 的访问模式可以被设置为特定卷支持的特定模式。
例如:NFS 可以支持多个读/写客户端,但一个特定的 NFS PV 可能会以只读方式导出。每个 PV 都有自己的一组访问模式来描述特定 PV 的功能,如 ReadWriteOnce、ReadOnlyMany 和 ReadWriteMany。
2.12.3. 块存储
对于 AWS Elastic Block Store (EBS)、GCE Persistent Disk 和 iSCSI 等块存储供应商,OpenShift Container Platform 使用 SELinux 功能为非特权 Pod 保护挂载卷的根目录,从而使所挂载的卷由与其关联的容器所有并只对该容器可见。
2.13. 监控集群事件和日志
监控和审核 OpenShift Container Platform 集群的功能是防止集群及其用户遭到不当使用的重要措施。
有两个主要的集群级别信息来源可用来实现这一目的:事件和日志记录。
2.13.1. 监视集群事件
建议集群管理员熟悉 Event 资源类型,并查看系统事件列表以确定值得关注的事件。事件与命名空间关联,可以是与它们相关的资源的命名空间,对于集群事件,也可以是 default 命名空间。default 命名空间包含与监控或审核集群相关的事件,如节点事件和与基础架构组件相关的资源事件。
Master API 和 oc 命令不通过提供参数来将事件列表的范围限定为与节点相关的事件。一个简单的方法是使用 grep:
$ oc get event -n default | grep Node输出示例
1h 20h 3 origin-node-1.example.local Node Normal NodeHasDiskPressure ...
更灵活的方法是以其他工具可以处理的形式输出事件。例如,以下示例针对 JSON 输出使用 jq 工具以仅提取 NodeHasDiskPressure 事件:
$ oc get events -n default -o json \
| jq '.items[] | select(.involvedObject.kind == "Node" and .reason == "NodeHasDiskPressure")'输出示例
{
"apiVersion": "v1",
"count": 3,
"involvedObject": {
"kind": "Node",
"name": "origin-node-1.example.local",
"uid": "origin-node-1.example.local"
},
"kind": "Event",
"reason": "NodeHasDiskPressure",
...
}与资源创建、修改或删除相关的事件也很适合用来检测到集群误用情况。例如,以下查询可以用来查找过度拉取镜像:
$ oc get events --all-namespaces -o json \
| jq '[.items[] | select(.involvedObject.kind == "Pod" and .reason == "Pulling")] | length'输出示例
4删除命名空间时,也会被删除其事件。也可以让事件过期并将其删除以防止占用 etcd 存储。事件不作为持久记录存储,且需要持续进行频繁的轮询来捕获统计数据。
2.13.2. 日志记录
使用 oc log 命令,您可以实时查看容器日志、构建配置和部署。不同的用户可对日志具有不同的访问权限:
- 有权访问项目的用户默认可以查看该项目的日志。
- 具有 admin 角色的用户可以访问所有容器日志。
要保存日志以供进一步审核和分析,您可以启用 cluster-logging 附加功能来收集、管理和查看系统、容器和审计日志。您可以通过 OpenShift Elasticsearch Operator 和 Red Hat OpenShift Logging Operator 部署、管理和升级 OpenShift Logging。
2.13.3. 审计日志
使用审计日志,您可以跟踪与用户、管理员或其他 OpenShift Container Platform 组件的行为方式相关的一系列活动。API 审计日志记录在每个服务器上完成。
第 3 章 配置证书
3.1. 替换默认入口证书
3.1.1. 了解默认入口证书
默认情况下,OpenShift Container Platform 使用 Ingress Operator 创建内部 CA 并发布对 .apps 子域下应用程序有效的通配符证书。web 控制台和 CLI 也使用此证书。
内部基础架构 CA 证书是自签名的。虽然这种流程被某些安全或 PKI 团队认为是不当做法,但这里的风险非常小。隐式信任这些证书的客户端仅是集群中的其他组件。将默认通配符证书替换为由 CA bundle 中已包括的公共 CA 发布的证书,该证书由容器用户空间提供,允许外部客户端安全地连接到 .apps 子域下运行的应用程序。
3.1.2. 替换默认入口证书
您可以替换 .apps 子域下所有应用程序的默认入口证书。替换了证书后,包括 web 控制台和 CLI 在内的所有应用程序都会具有指定证书提供的加密。
先决条件
-
您必须有用于完全限定
.apps子域及其对应私钥的通配符证书。每个文件都应该采用单独的 PEM 格式。 - 私钥必须取消加密。如果您的密钥是加密的,请在将其导入到 OpenShift Container Platform 前对其进行解密。
-
证书必须包含显示
*.apps.<clustername>.<domain>的subjectAltName扩展。 - 证书文件可以包含链中的一个或者多个证书。通配符证书必须是文件中的第一个证书。然后可以跟随所有中间证书,文件以 root CA 证书结尾。
- 将 root CA 证书复制到额外的 PEM 格式文件中。
流程
创建仅包含用于为通配符证书签名的 root CA 证书的配置映射:
$ oc create configmap custom-ca \ --from-file=ca-bundle.crt=</path/to/example-ca.crt> \1 -n openshift-config- 1
</path/to/cert.crt>是 root CA 证书文件在本地文件系统中的路径。
使用新创建的配置映射更新集群范围的代理配置:
$ oc patch proxy/cluster \ --type=merge \ --patch='{"spec":{"trustedCA":{"name":"custom-ca"}}}'创建包含通配符证书链和密钥的 secret :
$ oc create secret tls <secret> \1 --cert=</path/to/cert.crt> \2 --key=</path/to/cert.key> \3 -n openshift-ingress使用新创建的 secret 更新 Ingress Controller 配置:
$ oc patch ingresscontroller.operator default \ --type=merge -p \ '{"spec":{"defaultCertificate": {"name": "<secret>"}}}' \1 -n openshift-ingress-operator- 1
- 将
<secret>替换为上一步中用于 secret 的名称。
其他资源
3.2. 添加 API 服务器证书
默认 API 服务器证书由内部 OpenShift Container Platform 集群 CA 发布。默认情况下,位于集群外的客户端无法验证 API 服务器的证书。此证书可以替换为由客户端信任的 CA 发布的证书。
3.2.1. 向 API 服务器添加指定名称的证书
默认 API 服务器证书由内部 OpenShift Container Platform 集群 CA 发布。您可以添加一个或多个 API 服务器将根据客户端请求的完全限定域名(FQDN)返回的证书,例如使用反向代理或负载均衡器时。
先决条件
- 您必须有 FQDN 及其对应私钥的证书。每个文件都应该采用单独的 PEM 格式。
- 私钥必须取消加密。如果您的密钥是加密的,请在将其导入到 OpenShift Container Platform 前对其进行解密。
-
证书必须包含显示 FQDN 的
subjectAltName扩展。 - 证书文件可以包含链中的一个或者多个证书。API 服务器 FQDN 的证书必须是文件中的第一个证书。然后可以跟随所有中间证书,文件以 root CA 证书结尾。
不要为内部负载均衡器(主机名 api-int.<cluster_name>.<base_domain>)提供指定了名称的证书。这样可让集群处于降级状态。
流程
以
kubeadmin用户身份登录新的 API。$ oc login -u kubeadmin -p <password> https://FQDN:6443获取
kubeconfig文件。$ oc config view --flatten > kubeconfig-newapi创建一个包含
openshift-config命名空间中证书链和密钥的 secret。$ oc create secret tls <secret> \1 --cert=</path/to/cert.crt> \2 --key=</path/to/cert.key> \3 -n openshift-config更新 API 服务器以引用所创建的 secret。
$ oc patch apiserver cluster \ --type=merge -p \ '{"spec":{"servingCerts": {"namedCertificates": [{"names": ["<FQDN>"],1 "servingCertificate": {"name": "<secret>"}}]}}}'2 检查
apiserver/cluster对象并确认该 secret 现已被引用。$ oc get apiserver cluster -o yaml输出示例
... spec: servingCerts: namedCertificates: - names: - <FQDN> servingCertificate: name: <secret> ...检查
kube-apiserveroperator,并验证 Kubernetes API 服务器的新修订版本是否已推出。可能需要一分钟时间,Operator 才会检测配置更改并触发新部署。当新修订版本被推出时,PROGRESSING会报告True。$ oc get clusteroperators kube-apiserver在
PROGRESSING列为False前不要继续进入下一步,如下所示:输出示例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE kube-apiserver 4.8.0 True False False 145m如果
PROGRESSING显示为True,请等待几分钟后再试一次。
3.3. 使用服务提供的证书 secret 保护服务流量
3.3.1. 了解服务用证书
服务用证书旨在为需要加密的复杂中间件应用程序提供支持。这些证书是作为 TLS web 服务器证书发布的。
service-ca 控制器使用 x509.SHA256WithRSA 签名算法来生成服务证书。
生成的证书和密钥采用 PEM 格式,分别存储在所创建 secret 的 tls.crt 和 tls.key 中。证书和密钥在接近到期时自动替换。
用于发布服务证书的服务 CA 证书在 26 个月内有效,并在有效期少于 13 个月时进行自动轮转。轮转后,以前的服务 CA 配置仍会被信任直到其过期为止。这将为所有受影响的服务建立一个宽限期,以在过期前刷新其密钥内容。如果没有在这个宽限期内对集群进行升级(升级会重启服务并刷新其密钥),您可能需要手动重启服务以避免在上一个服务 CA 过期后出现故障。
您可以使用以下命令来手动重启集群中的所有 pod。此命令会导致服务中断,因为它将删除每个命名空间中运行的所有 pod。这些 Pod 会在删除后自动重启。
$ for I in $(oc get ns -o jsonpath='{range .items[*]} {.metadata.name}{"\n"} {end}'); \
do oc delete pods --all -n $I; \
sleep 1; \
done3.3.2. 添加服务证书
要保证与服务的通信的安全,请在与服务相同的命名空间中将签名的服务证书和密钥对生成 secret。
生成的证书仅对内部服务 DNS 名称 <service.name>.<service.namespace>.svc 有效,并且只适用于内部通信。如果您的服务是一个无头服务(未设置 clusterIP 值),则生成的证书还包含通配符主题,格式为 *.<service.name>.<service.namespace>.svc。
因为生成的证书包含无头服务的通配符主题,因此如果您的客户端必须区分不同的 pod,则不得使用服务 CA。在这种情况下:
- 使用其他 CA 生成各个 TLS 证书。
- 对于定向到单个 pod 且不得被其他 pod 模拟的连接,不接受服务 CA 作为可信 CA。这些连接必须配置为信任用于生成单个 TLS 证书的 CA。
先决条件:
- 必须定义了服务。
流程
使用
service.beta.openshift.io/serving-cert-secret-name注解该服务:$ oc annotate service <service_name> \1 service.beta.openshift.io/serving-cert-secret-name=<secret_name>2 例如,使用以下命令来注解服务
test1:$ oc annotate service test1 service.beta.openshift.io/serving-cert-secret-name=test1检查服务以确认是否存在注解:
$ oc describe service <service_name>输出示例
... Annotations: service.beta.openshift.io/serving-cert-secret-name: <service_name> service.beta.openshift.io/serving-cert-signed-by: openshift-service-serving-signer@1556850837 ...-
在集群为服务生成 secret 后,
Podspec 可以挂载它,pod 将在可用后运行。
3.3.3. 将服务 CA 捆绑包添加到配置映射中
Pod 可通过挂载使用 service.beta.openshift.io/inject-cabundle=true 注解的 ConfigMap 对象来访问服务 CA 证书。注解后,集群会自动将服务 CA 证书注入配置映射上的 service-ca.crt 键。访问此 CA 证书可允许 TLS 客户端使用服务用证书验证服务连接。
将这个注解添加到配置映射后,会删除其中的所有现有数据。建议您使用单独的配置映射来包含 service-ca.crt,而不是使用存储您的 Pod 配置的同一配置映射。
流程
使用
service.beta.openshift.io/inject-cabundle=true注解配置映射:$ oc annotate configmap <config_map_name> \1 service.beta.openshift.io/inject-cabundle=true- 1
- 将
<config_map_name>替换为配置映射的名称。
注意在卷挂载中明确引用
service-ca.crt键可防止 pod 启动,直到配置映射使用 CA 捆绑包注入为止。可通过为卷的 serving 证书将optional字段设置为true来覆盖此行为。例如,使用以下命令来注解配置映射
test1:$ oc annotate configmap test1 service.beta.openshift.io/inject-cabundle=true查看配置映射,以确保注入了服务 CA 捆绑包:
$ oc get configmap <config_map_name> -o yamlCA 捆绑包在 YAML 输出中作为
service-ca.crt键的值显示:apiVersion: v1 data: service-ca.crt: | -----BEGIN CERTIFICATE----- ...
3.3.4. 将服务 CA 捆绑包添加到 API 服务
您可以使用 service.beta.openshift.io/inject-cabundle=true 注解 APIService 对象,使其 spec.caBundle 字段由服务 CA 捆绑包填充。这可让 Kubernetes API 服务器验证用于保护目标端点的安全的服务 CA 证书。
流程
使用
service.beta.openshift.io/inject-cabundle=true注解 API 服务:$ oc annotate apiservice <api_service_name> \1 service.beta.openshift.io/inject-cabundle=true- 1
- 将
<api_service_name>替换为要注解的 API 服务的名称。
例如,使用以下命令来注解 API 服务
test1:$ oc annotate apiservice test1 service.beta.openshift.io/inject-cabundle=true查看 API 服务,以确保注入了服务 CA 捆绑包:
$ oc get apiservice <api_service_name> -o yamlCA 捆绑包在 YAML 输出中的
spec.caBundle字段中显示:apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: annotations: service.beta.openshift.io/inject-cabundle: "true" ... spec: caBundle: <CA_BUNDLE> ...
3.3.5. 将服务 CA 捆绑包添加到自定义资源定义中
您可以使用 service.beta.openshift.io/inject-cabundle=true 注解 CustomResourceDefinition(CRD)对象,使其 spec.conversion.webhook.clientConfig.caBundle 字段 由服务 CA 捆绑包填充。这可让 Kubernetes API 服务器验证用于保护目标端点的安全的服务 CA 证书。
只有在 CRD 被配置为使用 webhook 进行转换,才会将服务 CA 捆绑包注入 CRD。只有在 CRD 的 webhook 需要使用服务 CA 证书时,注入服务 CA 捆绑包才有意义。
流程
使用
service.beta.openshift.io/inject-cabundle=true注解 CRD:$ oc annotate crd <crd_name> \1 service.beta.openshift.io/inject-cabundle=true- 1
- 将
<crd_name>替换为要注解的 CRD 的名称。
例如,使用以下命令来注解 CRD
test1:$ oc annotate crd test1 service.beta.openshift.io/inject-cabundle=true查看 CRD,以确保注入了服务 CA 捆绑包:
$ oc get crd <crd_name> -o yamlCA 捆绑包在 YAML 输出中的
spec.conversion.webhook.clientConfig.caBundle字段中显示:apiVersion: apiextensions.k8s.io/v1 kind: CustomResourceDefinition metadata: annotations: service.beta.openshift.io/inject-cabundle: "true" ... spec: conversion: strategy: Webhook webhook: clientConfig: caBundle: <CA_BUNDLE> ...
3.3.6. 将服务 CA 捆绑包添加到变异的 webhook 配置中
您可以使用 service.beta.openshift.io/inject-cabundle=true 注解 MutatingWebhookConfiguration 对象,使每个 webhook 的 clientConfig.caBundle 字段由服务 CA 捆绑包填充。这可让 Kubernetes API 服务器验证用于保护目标端点的安全的服务 CA 证书。
不要为 admission webhook 配置设置此注解,不同的 webhook 需要指定不同的 CA 捆绑包。如果您这样做了,则会为所有 webhook 注入这个服务 CA 捆绑包。
流程
使用
service.beta.openshift.io/inject-cabundle=true注解变异 Webhook 配置:$ oc annotate mutatingwebhookconfigurations <mutating_webhook_name> \1 service.beta.openshift.io/inject-cabundle=true- 1
- 将
<mutating_webhook_name>替换为要注解的变异 Webhook 配置的名称。
例如,使用以下命令来注解变异 Webhook 配置
test1:$ oc annotate mutatingwebhookconfigurations test1 service.beta.openshift.io/inject-cabundle=true查看变异 Webhook 配置,以确保注入了服务 CA 捆绑包:
$ oc get mutatingwebhookconfigurations <mutating_webhook_name> -o yamlCA 捆包在 YAML 输出中所有 webhook 的
clientConfig.caBundle字段中显示:apiVersion: admissionregistration.k8s.io/v1 kind: MutatingWebhookConfiguration metadata: annotations: service.beta.openshift.io/inject-cabundle: "true" ... webhooks: - myWebhook: - v1beta1 clientConfig: caBundle: <CA_BUNDLE> ...
3.3.7. 将服务 CA 捆绑包添加到验证 webhook 配置中
您可以使用 service.beta.openshift.io/inject-cabundle=true 注解 ValidatingWebhookConfiguration 对象,使每个 webhook 的 clientConfig.caBundle 字段 由服务 CA 捆绑包填充。这可让 Kubernetes API 服务器验证用于保护目标端点的安全的服务 CA 证书。
不要为 admission webhook 配置设置此注解,不同的 webhook 需要指定不同的 CA 捆绑包。如果您这样做了,则会为所有 webhook 注入这个服务 CA 捆绑包。
流程
使用
service.beta.openshift.io/inject-cabundle=true注解验证 Webhook 配置:$ oc annotate validatingwebhookconfigurations <validating_webhook_name> \1 service.beta.openshift.io/inject-cabundle=true- 1
- 将
<validating_webhook_name>替换为要注解的验证 webhook 配置的名称。
例如,使用以下命令来注解验证 webhook 配置
test1:$ oc annotate validatingwebhookconfigurations test1 service.beta.openshift.io/inject-cabundle=true查看验证 Webhook 配置,以确保注入了服务 CA 捆绑包:
$ oc get validatingwebhookconfigurations <validating_webhook_name> -o yamlCA 捆包在 YAML 输出中所有 webhook 的
clientConfig.caBundle字段中显示:apiVersion: admissionregistration.k8s.io/v1 kind: ValidatingWebhookConfiguration metadata: annotations: service.beta.openshift.io/inject-cabundle: "true" ... webhooks: - myWebhook: - v1beta1 clientConfig: caBundle: <CA_BUNDLE> ...
3.3.8. 手动轮转生成的服务证书
您可以通过删除关联的 secret 来轮换服务证书。删除 secret 会导致自动创建新 secret,进而生成新的证书。
先决条件
- 必须为服务生成了包含证书和密钥对的 secret。
流程
检查该服务以确定包含证书的 secret。这可以在
service-cert-secret-name注解中找到,如下所示。$ oc describe service <service_name>输出示例
... service.beta.openshift.io/serving-cert-secret-name: <secret> ...删除为服务生成的 secret。此过程将自动重新创建 secret。
$ oc delete secret <secret>1 - 1
- 将
<secret>替换为前一步中的 secret 名称。
通过获取新 secret 并检查
AGE来确认已经重新创建了证书。$ oc get secret <service_name>输出示例
NAME TYPE DATA AGE <service.name> kubernetes.io/tls 2 1s
3.3.9. 手动轮转服务 CA 证书
服务 CA 在 26 个月内有效,并在有效期少于 13 个月时进行刷新。
如果需要,您可以按照以下步骤手动刷新服务 CA。
手动轮换的服务 CA 不会保留对上一个服务 CA 的信任。在集群中的 pod 重启完成前,您的服务可能会临时中断。pod 重启可以确保 Pod 使用由新服务 CA 发布的证书服务。
先决条件
- 必须以集群管理员身份登录。
流程
使用以下命令,查看当前服务 CA 证书的到期日期。
$ oc get secrets/signing-key -n openshift-service-ca \ -o template='{{index .data "tls.crt"}}' \ | base64 --decode \ | openssl x509 -noout -enddate手动轮转服务 CA。此过程会生成一个新的服务 CA,用来为新服务证书签名。
$ oc delete secret/signing-key -n openshift-service-ca要将新证书应用到所有服务,请重启集群中的所有 pod。此命令确保所有服务都使用更新的证书。
$ for I in $(oc get ns -o jsonpath='{range .items[*]} {.metadata.name}{"\n"} {end}'); \ do oc delete pods --all -n $I; \ sleep 1; \ done警告此命令会导致服务中断,因为它将遍历并删除每个命名空间中运行的 Pod。这些 Pod 会在删除后自动重启。
3.4. 更新 CA 捆绑包
3.4.1. 了解 CA 捆绑包证书
通过代理证书,用户可以指定,在平台组件创建出口连接时使用的一个或多个自定义证书颁发机构 (CA) 。
Proxy 对象的 trustedCA 字段是对包含用户提供的可信证书颁发机构 (CA) 捆绑包的配置映射的引用。这个捆绑包与 Red Hat Enterprise Linux CoreOS (RHCOS) 信任捆绑包合并,并注入到生成出口 HTTPS 调用的平台组件的信任存储中。例如,image-registry-operator 调用外部镜像 registry 来下载镜像。如果没有指定 trustedCA,则只有 RHCOS 信任的捆绑包用于代理 HTTPS 连接。如果您想要使用自己的证书基础架构,请向 RHCOS 信任捆绑包提供自定义 CA 证书。
trustedCA 字段应当仅由代理验证器使用。验证程序负责从所需的键 ca-bundle.crt 中读取证书捆绑包,并将其复制到 openshift-config-managed 命名空间中名为 trusted-ca-bundle 的配置映射中。被 trustedCA 引用的配置映射的命名空间是 openshift-config:
apiVersion: v1
kind: ConfigMap
metadata:
name: user-ca-bundle
namespace: openshift-config
data:
ca-bundle.crt: |
-----BEGIN CERTIFICATE-----
Custom CA certificate bundle.
-----END CERTIFICATE-----3.4.2. 替换 CA Bundle 证书
流程
创建包含用于为通配符证书签名的 root CA 证书的配置映射:
$ oc create configmap custom-ca \ --from-file=ca-bundle.crt=</path/to/example-ca.crt> \1 -n openshift-config- 1
</path/to/example-ca.crt>是 CA 证书捆绑包在本地文件系统中的路径。
使用新创建的配置映射更新集群范围的代理配置:
$ oc patch proxy/cluster \ --type=merge \ --patch='{"spec":{"trustedCA":{"name":"custom-ca"}}}'
其他资源
第 4 章 证书类型和描述
4.1. API 服务器的用户提供的证书
4.1.1. 用途
集群以外的客户端通过 api.<cluster_name>.<base_domain> 可访问 API 服务器。您可能希望客户端使用不同主机名访问 API 服务器,无需向客户端发布集群管理的证书颁发机构 (CA) 证书。管理员必须在提供内容时设置 API 服务器使用的自定义默认证书。
4.1.2. 位置
用户提供的证书必须在 openshift-config 命名空间中的 kubernetes.io/tls 类型 Secret 中提供。更新 API 服务器集群配置( apiserver/cluster 资源),以启用用户提供的证书。
4.1.3. 管理
用户提供的证书由用户管理。
4.1.4. 过期
API 服务器客户端证书过期时间少于五分钟。
用户提供的证书由用户管理。
4.1.5. 自定义
根据需要,更新包含用户管理的证书的 secret。
其他资源
4.2. 代理证书
4.2.1. 用途
通过代理证书,用户可以指定,在平台组件创建出口连接时使用的一个或多个自定义证书颁发机构 (CA) 证书。
Proxy 对象的 trustedCA 字段是对包含用户提供的可信证书颁发机构 (CA) 捆绑包的配置映射的引用。这个捆绑包与 Red Hat Enterprise Linux CoreOS (RHCOS) 信任捆绑包合并,并注入到生成出口 HTTPS 调用的平台组件的信任存储中。例如,image-registry-operator 调用外部镜像 registry 来下载镜像。如果没有指定 trustedCA,则只有 RHCOS 信任的捆绑包用于代理 HTTPS 连接。如果您想要使用自己的证书基础架构,请向 RHCOS 信任捆绑包提供自定义 CA 证书。
trustedCA 字段应当仅由代理验证器使用。验证程序负责从所需的键 ca-bundle.crt 中读取证书捆绑包,并将其复制到 openshift-config-managed 命名空间中名为 trusted-ca-bundle 的配置映射中。被 trustedCA 引用的配置映射的命名空间是 openshift-config:
apiVersion: v1
kind: ConfigMap
metadata:
name: user-ca-bundle
namespace: openshift-config
data:
ca-bundle.crt: |
-----BEGIN CERTIFICATE-----
Custom CA certificate bundle.
-----END CERTIFICATE-----其他资源
4.2.2. 在安装过程中管理代理证书
安装程序配置的 additionalTrustBundle 值用于在安装过程中指定任何代理信任的 CA 证书。例如:
$ cat install-config.yaml输出示例
...
proxy:
httpProxy: http://<https://username:password@proxy.example.com:123/>
httpsProxy: https://<https://username:password@proxy.example.com:123/>
noProxy: <123.example.com,10.88.0.0/16>
additionalTrustBundle: |
-----BEGIN CERTIFICATE-----
<MY_HTTPS_PROXY_TRUSTED_CA_CERT>
-----END CERTIFICATE-----
...4.2.3. 位置
用户提供的信任捆绑包以配置映射表示。配置映射挂载到进行 HTTPS 调用的平台组件的文件系统中。通常,Operator 会将配置映射挂载到 /etc/pki/ca-trust/extracted/pem/tls-ca-bundle.pem,但代理并不要求这样做。代理可以修改或检查 HTTPS 连接。在这两种情况下,代理都必须为连接生成新证书并为新证书签名。
完整的代理支持意味着连接到指定的代理服务器并信任它所生成的所有签名。因此,需要让用户指定一个信任的根用户,以便任何连接到该可信根的证书链都被信任。
如果使用 RHCOS 信任捆绑包,请将 CA 证书放在 /etc/pki/ca-trust/source/anchors 中。
详情请参阅 Red Hat Enterprise Linxu 文档的使用共享系统证书。
4.2.4. 过期
用户为用户提供的信任捆绑包设定了过期期限。
默认到期条件由 CA 证书本身定义。在 OpenShift Container Platform 或 RHCOS 使用前,由 CA 管理员为证书配置这个证书。
红帽不会监控 CA 何时到期。但是,由于 CA 的长生命周期,这通常不是个问题。但是,您可能需要周期性更新信任捆绑包。
4.2.5. 服务
默认情况下,所有使用出口 HTTPS 调用的平台组件将使用 RHCOS 信任捆绑包。如果定义了 trustedCA,它将会被使用。
任何在 RHCOS 节点上运行的服务都可以使用该节点的信任捆绑包。
4.2.6. 管理
这些证书由系统而不是用户管理。
4.2.7. 自定义
更新用户提供的信任捆绑包包括:
-
在
trustedCA引用的配置映射中更新 PEM 编码的证书,或 -
在命名空间
openshift-config中创建配置映射,其中包含新的信任捆绑包并更新trustedCA来引用新配置映射的名称。
将 CA 证书写入 RHCOS 信任捆绑包的机制与将其它文件写入 RHCOS(使用机器配置)完全相同。当 Machine Config Operator (MCO) 应用包含新 CA 证书的新机器配置时,节点将重启。在下次引导过程中,服务 coreos-update-ca-trust.service 在 RHCOS 节点上运行,该节点上使用新的 CA 证书自动更新信任捆绑包。例如:
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: 50-examplecorp-ca-cert
spec:
config:
ignition:
version: 3.1.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUVORENDQXh5Z0F3SUJBZ0lKQU51bkkwRDY2MmNuTUEwR0NTcUdTSWIzRFFFQkN3VUFNSUdsTVFzd0NRWUQKV1FRR0V3SlZVekVYTUJVR0ExVUVDQXdPVG05eWRHZ2dRMkZ5YjJ4cGJtRXhFREFPQmdOVkJBY01CMUpoYkdWcApBMmd4RmpBVUJnTlZCQW9NRFZKbFpDQklZWFFzSUVsdVl5NHhFekFSQmdOVkJBc01DbEpsWkNCSVlYUWdTVlF4Ckh6QVpCZ05WQkFNTUVsSmxaQ0JJWVhRZ1NWUWdVbTl2ZENCRFFURWhNQjhHQ1NxR1NJYjNEUUVKQVJZU2FXNW0KWGpDQnBURUxNQWtHQTFVRUJoTUNWVk14RnpBVkJnTlZCQWdNRGs1dmNuUm9JRU5oY205c2FXNWhNUkF3RGdZRApXUVFIREFkU1lXeGxhV2RvTVJZd0ZBWURWUVFLREExU1pXUWdTR0YwTENCSmJtTXVNUk13RVFZRFZRUUxEQXBTCkFXUWdTR0YwSUVsVU1Sc3dHUVlEVlFRRERCSlNaV1FnU0dGMElFbFVJRkp2YjNRZ1EwRXhJVEFmQmdrcWhraUcKMHcwQkNRRVdFbWx1Wm05elpXTkFjbVZrYUdGMExtTnZiVENDQVNJd0RRWUpLb1pJaHZjTkFRRUJCUUFEZ2dFUApCRENDQVFvQ2dnRUJBTFF0OU9KUWg2R0M1TFQxZzgwcU5oMHU1MEJRNHNaL3laOGFFVHh0KzVsblBWWDZNSEt6CmQvaTdsRHFUZlRjZkxMMm55VUJkMmZRRGsxQjBmeHJza2hHSUlaM2lmUDFQczRsdFRrdjhoUlNvYjNWdE5xU28KSHhrS2Z2RDJQS2pUUHhEUFdZeXJ1eTlpckxaaW9NZmZpM2kvZ0N1dDBaV3RBeU8zTVZINXFXRi9lbkt3Z1BFUwpZOXBvK1RkQ3ZSQi9SVU9iQmFNNzYxRWNyTFNNMUdxSE51ZVNmcW5obzNBakxRNmRCblBXbG82MzhabTFWZWJLCkNFTHloa0xXTVNGa0t3RG1uZTBqUTAyWTRnMDc1dkNLdkNzQ0F3RUFBYU5qTUdFd0hRWURWUjBPQkJZRUZIN1IKNXlDK1VlaElJUGV1TDhacXczUHpiZ2NaTUI4R0ExVWRJd1FZTUJhQUZIN1I0eUMrVWVoSUlQZXVMOFpxdzNQegpjZ2NaTUE4R0ExVWRFd0VCL3dRRk1BTUJBZjh3RGdZRFZSMFBBUUgvQkFRREFnR0dNQTBHQ1NxR1NJYjNEUUVCCkR3VUFBNElCQVFCRE52RDJWbTlzQTVBOUFsT0pSOCtlbjVYejloWGN4SkI1cGh4Y1pROGpGb0cwNFZzaHZkMGUKTUVuVXJNY2ZGZ0laNG5qTUtUUUNNNFpGVVBBaWV5THg0ZjUySHVEb3BwM2U1SnlJTWZXK0tGY05JcEt3Q3NhawpwU29LdElVT3NVSks3cUJWWnhjckl5ZVFWMnFjWU9lWmh0UzV3QnFJd09BaEZ3bENFVDdaZTU4UUhtUzQ4c2xqCjVlVGtSaml2QWxFeHJGektjbGpDNGF4S1Fsbk92VkF6eitHbTMyVTB4UEJGNEJ5ZVBWeENKVUh3MVRzeVRtZWwKU3hORXA3eUhvWGN3bitmWG5hK3Q1SldoMWd4VVp0eTMKLS0tLS1FTkQgQ0VSVElGSUNBVEUtLS0tLQo=
mode: 0644
overwrite: true
path: /etc/pki/ca-trust/source/anchors/examplecorp-ca.crt机器的信任存储还必须支持更新节点的信任存储。
4.2.8. 续订
没有 Operator 可以自动更新 RHCOS 节点上的证书。
红帽不会监控 CA 何时到期。但是,由于 CA 的长生命周期,这通常不是个问题。但是,您可能需要周期性更新信任捆绑包。
4.3. 服务 CA 证书
4.3.1. 用途
service-ca 是部署 OpenShift Container Platform 集群时创建自签名 CA 的一个 Operator。
4.3.2. 过期
不支持自定义过期条件。自签名 CA 存储在一个限定名为 service-ca/signing-key 的 secret 中。它在 tls.crt (certificate(s))、tls.key (private key) 和 ca-bundle.crt (CA bundle) 项中。
其他服务可通过使用 service.beta.openshift.io/serving-cert-secret-name: <secret name> 注解一个服务资源来请求一个 service serving 证书。作为响应,Operator 会为指定的 secret 生成一个新证书, tls.crt,以及一个私钥,tls.key。该证书的有效期为两年。
其他服务可通过使用 service.beta.openshift.io/inject-cabundle:true 注解来请求将服务 CA 的 CA 捆绑包注入 API 服务或配置映射资源,以支持通过服务 CA 生成的证书。作为响应,Operator 会将其当前 CA 捆绑包写入 API 服务的 CABundle 字段,或将 service-ca.crt 写入配置映射。
自 OpenShift Container Platform 4.3.5 起,支持自动轮转,并将其向后移植到一些 4.2.z 和 4.3.z 版本中。对于任何支持自动轮转的版本,服务 CA 证书在 26 个月内有效,并在有效期少于 13 个月时进行刷新。如果需要,您可以手动刷新服务 CA。
服务 CA 26 个月的过期时间比支持的 OpenShift Container Platform 集群的预期升级间隔更长,因此使用服务 CA 证书的非 control plane 系统将会在 CA 轮转后刷新。这会发生在轮转前使用的 CA 过期前。
手动轮换的服务 CA 不会保留对上一个服务 CA 的信任。在集群中的 pod 重启完成前,您的服务可能会临时中断。pod 重启可以确保 Pod 使用由新服务 CA 发布的证书服务。
4.3.3. 管理
这些证书由系统而不是用户管理。
4.3.4. 服务
使用服务 CA 证书的服务包括:
- cluster-autoscaler-operator
- cluster-monitoring-operator
- cluster-authentication-operator
- cluster-image-registry-operator
- cluster-ingress-operator
- cluster-kube-apiserver-operator
- cluster-kube-controller-manager-operator
- cluster-kube-scheduler-operator
- cluster-networking-operator
- cluster-openshift-apiserver-operator
- cluster-openshift-controller-manager-operator
- cluster-samples-operator
- machine-config-operator
- console-operator
- insights-operator
- machine-api-operator
- operator-lifecycle-manager
这不是一个完整的列表。
其他资源
4.4. 节点证书
4.4.1. 用途
节点证书由集群签名; 证书来自由 bootstrap 过程生成的证书颁发机构 (CA)。安装集群后,节点证书会被自动轮转。
4.4.2. 管理
这些证书由系统而不是用户管理。
其他资源
4.5. Bootstrap 证书
4.5.1. 用途
OpenShift Container Platform 4 及之后的版本中的 kubelet 使用位于 /etc/kubernetes/kubeconfig 中的 bootstrap 证书来启动 bootstrap。然后是 bootstrap 初始化过程 和 kubelet 授权来创建一个 CSR。
在此过程中,kubelet 在通过 bootstrap 频道进行通信时会生成一个 CSR。控制器管理器为 CSR 签名,以生成 kubelet 管理的证书。
4.5.2. 管理
这些证书由系统而不是用户管理。
4.5.3. 过期
此 bootstrap CA 有效时间为 10 年。
kubelet 管理的证书的有效期为一年,并在一年经过了大约 80% 时进行自动轮转。
4.5.4. 自定义
您无法自定义 bootstrap 证书。
4.6. etcd 证书
4.6.1. 用途
etcd 证书由 etcd-signer 签名; 证书来自由 bootstrap 过程生成的证书颁发机构 (CA)。
4.6.2. 过期
CA 证书有效期为 10 年。对等证书、客户端证书和服务器证书的有效期为三年。
4.6.3. 管理
这些证书由系统而不是用户管理。
4.6.4. 服务
etcd 证书用于 etcd 对等成员间通信的加密,以及加密客户端流量。以下证书由 etcd 和其他与 etcd 通信的进程生成和使用:
- 对等证书(Peer cerfificate): 用于 etcd 成员之间的通信。
-
客户端证书(Client certificate): 用于加密服务器和客户端间的通信。目前,API 服务器只使用客户端证书,除代理外,其他服务都不应该直接连接到 etcd。客户端 secret(
etcd-client、etcd-metric-client、etcd-metric-signer和etcd-signer)添加到openshift-config、openshift-monitoring和openshift-kube-apiserver命名空间中。 - 服务器证书(Server certificate): etcd 服务器用来验证客户端请求。
- 指标证书(Metric certificate):所有使用指标的系统都使用 metric-client 证书连接到代理。
其他资源
4.7. olm 证书
4.7.1. 管理
OpenShift Lifecycle Manager (OLM) 组件(olm-operator、catalog-operator、packageserver 和 marketplace-operator) 的所有证书均由系统管理。
安装在它们的 ClusterServiceVersion(CSV)对象中安装包含 webhook 或 API 服务的 Operator 时,OLM 会为这些资源创建和轮转证书。openshift-operator-lifecycle-manager 命名空间中的资源的证书由 OLM 管理。
OLM 不会更新它在代理环境中管理的 Operator 证书。这些证书必须由用户使用订阅配置进行管理。
4.8. 聚合的 API 客户端证书
4.8.1. 目的
聚合的 API 客户端证书用于在连接到 Aggregated API 服务器时验证 KubeAPIServer。
4.8.2. 管理
这些证书由系统而不是用户管理。
4.8.3. 过期
此 CA 在 30 天内有效。
受管客户端证书在 30 天内有效。
CA 和客户端证书通过使用控制器自动轮转。
4.8.4. 自定义
您无法自定义聚合的 API 服务器证书。
4.9. Machine Config Operator 证书
4.9.1. 目的
Machine Config Operator 证书用于保护 Red Hat Enterprise Linux CoreOS (RHCOS) 节点和 Machine Config Server 之间的连接。
4.9.2. 管理
这些证书由系统而不是用户管理。
4.9.3. 过期
此 CA 有效时间为 10 年。
发布的服务证书有效期为 10 年。
4.9.4. 自定义
您无法自定义 Machine Config Operator 证书。
4.10. 用户提供的默认入口证书
4.10.1. 用途
应用程序通常通过 <route_name>.apps.<cluster_name>.<base_domain> 来公开。<cluster_name> 和 <base_domain> 来自安装配置文件。<route_name> 是路由的主机字段(如果指定)或路由名称。例如,hello-openshift-default.apps.username.devcluster.openshift.com。hello-openshift 是路由的名称,路由位于 default 命名空间。您可能希望客户端访问应用程序而无需向客户端发布集群管理的 CA 证书。在提供应用程序内容时,管理员必须设置自定义默认证书。
Ingress Operator 为 Ingress Controller 生成默认证书,以充当占位符,直到您配置了自定义默认证书为止。不要在生产环境集群中使用 Operator 生成的默认证书。
4.10.2. 位置
用户提供的证书必须在 openshift-ingress 命名空间中的 tls 类型 Secret 资源中提供。更新 openshift-ingress-operator 命名空间中的 IngressController CR,以启用用户提供的证书的使用。有关此过程的更多信息,请参阅设置自定义默认证书。
4.10.3. 管理
用户提供的证书由用户管理。
4.10.4. 过期
用户提供的证书由用户管理。
4.10.5. 服务
在集群中部署的应用程序使用用户提供的证书作为默认入口。
4.10.6. 自定义
根据需要,更新包含用户管理的证书的 secret。
其他资源
4.11. 入口证书(Ingress certificate)
4.11.1. 用途
Ingress Operator 使用以下证书:
- 保证 Prometheus 指标的访问安全。
- 保证对路由的访问安全。
4.11.2. 位置
为了保证对 Ingress Operator 和 Ingress Controller 指标的访问安全,Ingress Operator 使用 service serving 证书。Operator 为自己的指标从 service-ca 控制器请求证书,service-ca 控制器将证书放置在 openshift-ingress-operator 命名空间中的名为 metrics-tls 的 secret 中。另外,Ingress Operator 会为每个 Ingress Controller 请求一个证书,service-ca 控制器会将证书放在名为 router-metrics-certs-<name> 的 secret 中,其中 <name> 是 Ingress Controller 的名称(在 openshift-ingress 命名空间中)。
每个 Ingress Controller 都有一个默认证书,用于没有指定其自身证书的安全路由。除非指定了自定义证书,Operator 默认使用自签名证书。Operator 使用自己的自签名签名证书为其生成的任何默认证书签名。Operator 生成此签名证书,并将其置于 openshift-ingress-operator 命名空间中的名为 router-ca 的 secret 中。当 Operator 生成默认证书时,它会将默认证书放在 openshift-ingress 命名空间的名为 router-certs-<name>(其中 <name> 是 Ingress Controller 的名称)的 secret 中。
Ingress Operator 为 Ingress Controller 生成默认证书,以充当占位符,直到您配置了自定义默认证书为止。不要在生产环境集群中使用 Operator 生成的默认证书。
4.11.3. 工作流
图 4.1. 自定义证书工作流
图 4.2. 默认证书工作流
![]() 空的
空的 defaultCertificate 项会使 Ingress Operator 使用它自己签名的 CA 来为指定的域生成 serving 证书。
![]() Ingress Operator 生成的默认 CA 证书和密钥。用来为 Operator 生成的默认 serving 证书签名。
Ingress Operator 生成的默认 CA 证书和密钥。用来为 Operator 生成的默认 serving 证书签名。
![]() 在默认工作流中,通配符默认服务证书,由 Ingress Operator 创建,并使用生成的默认 CA 证书签名。在自定义工作流中,这是用户提供的证书。
在默认工作流中,通配符默认服务证书,由 Ingress Operator 创建,并使用生成的默认 CA 证书签名。在自定义工作流中,这是用户提供的证书。
![]() 路由器部署。使用
路由器部署。使用 secrets/router-certs-default 中的证书作为其默认前端服务器证书。
![]() 在默认工作流中,通配符默认服务证书(公共和私有组件)的内容在此复制,以启用 OAuth 集成。在自定义工作流中,这是用户提供的证书。
在默认工作流中,通配符默认服务证书(公共和私有组件)的内容在此复制,以启用 OAuth 集成。在自定义工作流中,这是用户提供的证书。
![]() 默认服务证书的公共(certificate)部分。替换
默认服务证书的公共(certificate)部分。替换 configmaps/router-ca 资源。
![]() 用户使用对
用户使用对 ingresscontroller serving 证书签名的 CA 证书更新集群代理配置。这可让 auth、console 和 registry 等组件信任 serving 证书。
![]() 包含合并的 Red Hat Enterprise Linux CoreOS (RHCOS) 和用户提供的 CA 捆绑包(如果未提供用户捆绑包)的集群范围可信 CA 捆绑包。
包含合并的 Red Hat Enterprise Linux CoreOS (RHCOS) 和用户提供的 CA 捆绑包(如果未提供用户捆绑包)的集群范围可信 CA 捆绑包。
![]() 自定义 CA 证书捆绑包,用于指示其他组件(如
自定义 CA 证书捆绑包,用于指示其他组件(如 auth 和 console)信任配置了自定义证书的 ingresscontroller。
![]()
trustedCA 字段用来引用用户提供的 CA 捆绑包。
![]() Cluster Network Operator 将可信 CA 捆绑包注入
Cluster Network Operator 将可信 CA 捆绑包注入 proxy-ca 配置映射。
![]() OpenShift Container Platform 4.8 及更新版本使用
OpenShift Container Platform 4.8 及更新版本使用 default-ingress-cert。
4.11.4. 过期
Ingress Operator 证书的过期条件如下:
-
service-ca控制器创建的指标证书的过期日期为创建日期后的两年。 - Operator 的签名证书的过期日期是创建日期后的两年。
- Operator 生成的默认证书的过期日期是在创建日期后两年的时间。
您不能自定义 Ingress Operator 或 service-ca 控制器创建的证书的过期条款。
安装 OpenShift Container Platform 时,不能为 Ingress Operator 或 service-ca 控制器创建的证书指定过期条款。
4.11.5. 服务
Prometheus 使用的用来确保指标安全的证书。
Ingress Operator 使用它的签名证书来为 Ingress Controller 签名默认证书,您不要为其设置自定义默认证书。
使用安全路由的集群组件可使用默认 Ingress Controller 默认证书。
通过安全路由进入集群的入口使用 Ingress Controller 的默认证书,该证书将访问该路由,除非该路由指定了自己的证书。
4.11.6. 管理
入口证书由用户管理。如需更多信息,请参阅替换默认入口证书。
4.11.7. 续订
service-ca 控制器自动轮转其发放的证书。但是,可以使用 oc delete secret <secret> 来手动轮转 service serving 证书。
Ingress Operator 不轮转其自身的签名证书或它生成的默认证书。Operator 生成的默认证书的目的是作为您配置的自定义默认证书的占位者。
4.12. 监控和 OpenShift Logging Operator 组件证书
4.12.1. 过期
监控组件使用服务 CA 证书保护其流量。这些证书有效 2 年,并可在服务 CA 轮转时自动替换。轮转每每 13 个月进行一次。
如果证书在 openshift-monitoring 或 openshift-logging 命名空间中,它会被自动管理并轮转。
4.12.2. 管理
这些证书由系统而不是用户管理。
4.13. Control plane 证书
4.13.1. 位置
Control plane 证书包括在这些命名空间中:
- openshift-config-managed
- openshift-kube-apiserver
- openshift-kube-apiserver-operator
- openshift-kube-controller-manager
- openshift-kube-controller-manager-operator
- openshift-kube-scheduler
4.13.2. 管理
Control plane 证书由系统管理并自动轮转。
当 control plane 证书出现罕见的过期情形时,请参阅恢复过期的 control plane 证书
第 5 章 Compliance Operator
5.1. Compliance Operator 发行注记
通过 Compliance Operator,OpenShift Container Platform 管理员可以描述集群所需的合规状态,并概述缺陷及修复方法。
本发行注记介绍了 OpenShift Container Platform 中 Compliance Operator 的开发。
有关 Compliance Operator 的概述,请参阅了解 Compliance Operator。
要访问最新版本,请参阅更新 Compliance Operator。
5.1.1. OpenShift Compliance Operator 0.1.59
以下公告可用于 OpenShift Compliance Operator 0.1.59:
5.1.1.1. 新功能及功能增强
-
Compliance Operator 现在支持
ppc64le架构上的支付卡行业数据安全标准 (PCI-DSS)ocp4-pci-dss和ocp4-pci-dss-node配置集。
5.1.1.2. 程序错误修复
-
在以前的版本中,Compliance Operator 不支持在不同架构上(如
ppc64le)的 Payment Card industry Data Security Standard (PCI DSS)ocp4-pci-dss和ocp4-pci-dss-node配置集。现在,Compliance Operator 在ppc64le架构上支持ocp4-pci-dss和ocp4-pci-dss-node配置集。(OCPBUGS-3252) -
在以前的版本中,在最近更新到 0.1.57 后,
rerunner服务帐户 (SA) 不再被集群服务版本 (CSV) 所有,这会导致在 Operator 升级过程中删除 SA。现在,CSV 拥有 0.1.59 中的rerunnerSA,从任何以前的版本升级都不会造成缺少的 SA。(OCPBUGS-3452) -
在 0.1.57 中,Operator 启动了侦听端口
8080的控制器指标端点。这会导致TargetDown警报,因为集群监控的预期端口为8383。使用 0.1.59 时,Operator 会如预期启动侦听端口8383的端点。(OCPBUGS-3097)
5.1.2. OpenShift Compliance Operator 0.1.57
以下公告可用于 OpenShift Compliance Operator 0.1.57:
5.1.2.1. 新功能及功能增强
-
KubeletConfig检查从Node改为Platform类型。KubeletConfig检查KubeletConfig的默认配置。配置文件从所有节点聚合到每个节点池的一个位置。请参阅针对默认配置值评估KubeletConfig规则。 -
ScanSetting自定义资源现在允许用户通过scanLimits属性覆盖扫描程序 Pod 的默认 CPU 和内存限值。如需更多信息,请参阅增加 Compliance Operator 资源限制。 -
现在,可以通过
ScanSetting设置PriorityClass对象。这样可确保 Compliance Operator 被优先处理,并尽可能减少集群不合规的可能性。如需更多信息,请参阅为ScanSetting扫描设置PriorityClass。
5.1.2.2. 程序错误修复
-
在以前的版本中,Compliance Operator 硬编码通知到默认的
openshift-compliance命名空间。如果 Operator 安装在非默认命名空间中,通知将无法正常工作。现在,通知可以在非默认openshift-compliance命名空间中工作。(BZ#2060726) - 在以前的版本中,Compliance Operator 无法评估 kubelet 对象使用的默认配置,从而导致结果准确和假的正状态。这个新功能会评估 kubelet 配置,现在可以准确报告。(BZ#2075041)
-
在以前的版本中,在应用自动补救后,Compliance Operator 会报告
ocp4-kubelet-configure-event-creation规则为FAIL状态,因为eventRecordQPS被设置为默认值。现在,ocp4-kubelet-configure-event-creation规则补救会设置默认值,规则会正确应用。(BZ#2082416) -
ocp4-configure-network-policies规则需要人工干预才能有效地执行。新的描述性指令和规则更新增加使用 Calico CNI 的集群的ocp4-configure-network-policies规则的适用性。(BZ#2091794) -
在以前的版本中,在扫描设置中使用
debug=true选项时,Compliance Operator 不会清理用于扫描基础架构的 pod。这会导致 pod 在删除ScanSettingBinding后保留在集群中。现在,当一个ScanSettingBinding被删除时,pod 总是被删除。(BZ#2092913) -
在以前的版本中,Compliance Operator 使用了一个
operator-sdk命令的旧版本,该命令可导致有关已弃用功能的警报。现在,包括了operator-sdk命令的更新版本,且没有更多用于已弃用的功能的警报。(BZ#2098581) - 在以前的版本中,如果 Compliance Operator 无法决定 kubelet 和机器配置之间的关系,则无法应用补救。现在,Compliance Operator 改进了机器配置的处理,并可确定 kubelet 配置是否为机器配置的子集。(BZ#2102511)
-
在以前的版本中,
ocp4-cis-node-master-kubelet-enable-cert-rotation的规则没有正确描述成功标准。因此,RotateKubeletClientCertificate的要求不明确。现在,无论 kubelet 配置文件中存在的配置如何,ocp4-cis-node-master-kubelet-enable-cert-rotation的规则会准确进行。(BZ#2105153) - 在以前的版本中,检查闲置流超时的规则不会考虑默认值,从而导致规则报告不准确。现在,更强大的检查确保了根据默认配置值的准确性增加。(BZ#2105878)
-
在以前的版本中,当在没有 Ignition 规格的情况下解析机器配置时,Compliance Operator 无法获取 API 资源,这会导致
api-check-pods进程崩溃循环。现在,Compliance Operator 处理没有 Ignition 规格的机器配置池。(BZ#2117268) -
在以前的版本中,因为
modprobe配置的值不匹配,评估modprobe配置的规则也会失败。现在,相同的值用于modprobe配置检查和补救,以确保结果保持一致。(BZ#2117747)
5.1.2.3. 启用
-
指定 Install into all namespaces in the cluster 或将
WATCH_NAMESPACES环境变量设置为""时不会在影响所有命名空间。在 Compliance Operator 安装时没有指定的命名空间中安装的任何 API 资源都不再可以正常工作。API 资源可能需要在所选命名空间中创建,或默认在openshift-compliance命名空间中创建。此更改改进了 Compliance Operator 的内存用量。
5.1.3. OpenShift Compliance Operator 0.1.53
以下公告可用于 OpenShift Compliance Operator 0.1.53:
5.1.3.1. 程序错误修复
-
在以前的版本中,
ocp4-kubelet-enable-streaming-connections规则包含不正确的变量比较,从而导致假的扫描结果。现在,在设置streamingConnectionIdleTimeout时,Compliance Operator 提供了准确的扫描结果。(BZ#2069891) -
在以前的版本中,在 IBM Z 构架中,
/etc/openvswitch/conf.db的组所有权不正确,从而导致ocp4-cis-node-worker-file-groupowner-ovs-conf-db检查失败。现在,这个检查在 IBM Z 架构系统中被标记为NOT-APPLICABLE。(BZ#2072597) -
在以前的版本中,
ocp4-cis-scc-limit-container-allowed-capabilities规则因为部署中安全性上下文约束(SCC)规则不完整,以FAIL状态报告。现在,结果为MANUAL,它与需要人工干预的其他检查一致。(BZ#2077916) 在以前的版本中,以下规则无法考虑 API 服务器和 TLS 证书和密钥的额外配置路径,即使正确设置了证书和密钥也会导致报告失败:
-
ocp4-cis-api-server-kubelet-client-cert -
ocp4-cis-api-server-kubelet-client-key -
ocp4-cis-kubelet-configure-tls-cert -
ocp4-cis-kubelet-configure-tls-key
现在,规则报告会准确观察 kubelet 配置文件中指定的旧文件路径。(BZ#2079813)
-
-
在以前的版本中,在评估超时时,
content_rule_oauth_or_oauthclient_inactivity_timeout规则不会考虑部署设置的可配置超时。这会导致规则失败,即使超时有效。现在,Compliance Operator 使用var_oauth_inactivity_timeout变量来设置有效的超时长度。(BZ#2081952) - 在以前的版本中,Compliance Operator 使用在命名空间上没有适当标记命名空间的管理权限进行特权使用,从而导致有关 Pod 安全级别违反情况的警告信息。现在,Compliance Operator 有适当的命名空间标签,并对访问结果进行适当的调整,而不违反权限。(BZ#2088202)
-
在以前的版本中,为
rhcos4-high-master-sysctl-kernel-yama-ptrace-scope和rhcos4-sysctl-kernel-core-pattern应用自动补救会导致后续这些规则失败,即使它们被修复。现在,在应用了补救后,规则会正确报告PASS。(BZ#2094382) -
在以前的版本中,因为内存不足例外,Compliance Operator 会以
CrashLoopBackoff状态失败。现在,Compliance Operator 被改进,在内存和可以正常工作的情况下可以正确处理大型机器配置数据集。(BZ#2094854)
5.1.3.2. 已知问题
当在
ScanSettingBinding对象中设置"debug":true时,当删除该绑定时,由ScanSettingBinding对象生成的 pod 不会被删除。作为临时解决方案,运行以下命令来删除剩余的 pod:$ oc delete pods -l compliance.openshift.io/scan-name=ocp4-cis
5.1.4. OpenShift Compliance Operator 0.1.52
以下公告可用于 OpenShift Compliance Operator 0.1.52:
5.1.4.1. 新功能及功能增强
- FedRAMP high SCAP 配置集现在可用于 OpenShift Container Platform 环境。如需更多信息,请参阅支持的合规性配置集。
5.1.4.2. 程序错误修复
-
在以前的版本中,因为存在
DAC_OVERRIDE功能的安全环境中存在挂载权限问题,OpenScap容器会崩溃。现在,可执行的挂载权限适用于所有用户。(BZ#2082151) -
在以前的版本中,合规性规则
ocp4-configure-network-policies可以被配置为MANUAL。现在,合规性规则ocp4-configure-network-policies设置为AUTOMATIC。(BZ#2072431) - 在以前的版本中,Cluster Autoscaler 将无法缩减,因为 Compliance Operator 扫描 pod 在扫描后永远不会被删除。现在,pod 默认从每个节点中删除,除非明确为调试目的保存。(BZ#2075029)
-
在以前的版本中,将 Compliance Operator 应用到
KubeletConfig会导致节点进入NotReady状态,因为无法立即暂停 Machine Config Pools。现在,机器配置池会被正确取消暂停,节点可以正常工作。(BZ#2071854) -
在以前的版本中,Machine Config Operator 在最新版本中使用
base64而不是url-encoded代码,从而导致 Compliance Operator 修复失败。现在,Compliance Operator 会检查编码来处理base64和url-encodedMachine Config 代码,补救会正确应用。(BZ#2082431)
5.1.4.3. 已知问题
当在
ScanSettingBinding对象中设置"debug":true时,当删除该绑定时,由ScanSettingBinding对象生成的 pod 不会被删除。作为临时解决方案,运行以下命令来删除剩余的 pod:$ oc delete pods -l compliance.openshift.io/scan-name=ocp4-cis
5.1.5. OpenShift Compliance Operator 0.1.49
以下公告可用于 OpenShift Compliance Operator 0.1.49:
5.1.5.1. 程序错误修复
-
在以前的版本中,
openshift-compliance内容不包括对网络类型的特定平台检查。因此,特定于 OVN 和 SDN 的检查会显示failed,而不是基于网络配置的not-applicable。现在,新规则包含检查联网规则的平台检查,从而更加精确地评估特定于网络的检查。(BZ#1994609) -
在以前的版本中,
ocp4-moderate-routes-protected-by-tls规则会错误地检查导致规则失败的 TLS 设置,即使连接安全 SSL TLS 协议也是如此。现在,检查会正确地评估与网络指导和配置集建议一致的 TLS 设置。(BZ#2002695) -
在以前的版本中,在请求命名空间时
ocp-cis-configure-network-policies-namespace使用分页。这会导致规则失败,因为部署会截断超过 500 个命名空间的列表。现在,会请求整个命名空间列表,检查配置的网络策略的规则将可用于部署超过 500 个命名空间的部署。(BZ#2038909) -
在以前的版本中,使用
sshd jinja宏进行补救被硬编码为特定的 sshd 配置。因此,配置与规则检查的内容不一致,检查会失败。现在,sshd 配置已被参数化,规则会成功应用。(BZ#2049141) -
在以前的版本中,
ocp4-cluster-version-operator-verify-integrity始终检查 Cluter Version Operator(CVO)历史记录中的第一个条目。因此,当验证后续版本的 {product-name} 时,升级会失败。现在,ocp4-cluster-version-operator-verify-integrity的合规性检查结果可以检测到验证的版本,且与 CVO 历史记录准确。(BZ#2053602) -
在以前的版本中,
ocp4-api-server-no-adm-ctrl-plugins-disabled规则没有检查空准入插件列表。因此,即使启用了所有准入插件,该规则也会始终失败。现在,对ocp4-api-server-no-adm-ctrl-plugins-disabled规则的更强大的检查会准确传递所有准入控制器插件。(BZ#2058631) - 在以前的版本中,扫描不包含针对 Linux worker 节点运行的平台检查。因此,对不是基于 Linux 的 worker 节点运行扫描会导致永不结束扫描循环。现在,扫描将根据平台类型和标签进行适当调度,并会完全成功。(BZ#2056911)
5.1.6. OpenShift Compliance Operator 0.1.48
以下公告可用于 OpenShift Compliance Operator 0.1.48:
5.1.6.1. 程序错误修复
-
在以前的版本中,与扩展开放漏洞和评估语言(OVAL)定义关联的规则带有为
None的checkType。这是因为 Compliance Operator 在解析规则时没有处理扩展的 OVAL 定义。在这个版本中,通过扩展 OVAL 定义的内容会被解析,这些规则现在具有Node或Platform的checkType。(BZ#2040282) -
在以前的版本中,为
KubeletConfig手动创建的MachineConfig对象会阻止为补救生成KubeletConfig对象,从而使补救处于Pending状态。在这个版本中,补救会创建一个KubeletConfig对象,无论是否有为KubeletConfig手动创建的MachineConfig对象。因此,KubeletConfig补救现在可以正常工作。(BZ#2040401)
5.1.7. OpenShift Compliance Operator 0.1.47
以下公告可用于 OpenShift Compliance Operator 0.1.47:
5.1.7.1. 新功能及功能增强
Compliance Operator 现在支持支付卡行业数据安全标准(PCI DSS)的以下合规性基准:
- ocp4-pci-dss
- ocp4-pci-dss-node
- FedRAMP 模式影响级别的额外规则和补救被添加到 OCP4-moderate、OCP4-moderate-node 和 rhcos4-moderate 配置集中。
- KubeletConfig 的补救现在包括在节点级别的配置集中。
5.1.7.2. 程序错误修复
在以前的版本中,如果集群运行 OpenShift Container Platform 4.6 或更早版本,则与 USBGuard 相关的规则的补救将失败。这是因为 Compliance Operator 创建的补救基于旧版本的 USBGuard,但不支持丢弃目录。现在,为运行 OpenShift Container Platform 4.6 的集群不会创建与 USBGuard 相关的规则无效的补救。如果您的集群使用 OpenShift Container Platform 4.6,则必须为 USBGuard 相关的规则手动创建补救。
另外,只会针对满足最低版本要求的规则创建补救。(BZ#1965511)
-
在以前的版本中,当渲染补救时,合规 Operator 会使用一个太严格的正则表达式来检查补救是否良好。因此,一些补救(如呈现
sshd_config)不会传递正则表达式检查,因此不会被创建。一些正则表达式已被认定为不必要并被删除。现在,补救可以正确地进行。(BZ#2033009)
5.1.8. OpenShift Compliance Operator 0.1.44
以下公告可用于 OpenShift Compliance Operator 0.1.44:
5.1.8.1. 新功能及功能增强
-
在这个发行版本中,
strictNodeScan选项被添加到ComplianceScan、ComplianceSuite和ScanSettingCR 中。这个选项默认为与之前行为匹配的true,当扫描无法调度到某个节点上时出现错误。将选项设置为false可让 Compliance Operator 针对调度扫描更加宽松。具有临时节点的环境可将strictNodeScan值设为 false,这可以允许进行合规性扫描,即使集群中的某些节点无法调度。 -
现在,您可以通过配置
ScanSetting对象的nodeSelector和tolerations属性来自定义用于调度结果服务器工作负载的节点。这些属性用于放置ResultServerpod,用于挂载 PV 存储卷并存储原始资产报告格式(ARF)结果。在以前的版本中,nodeSelector和tolerations参数默认选择其中一个 control plane 节点,并容限node-role.kubernetes.io/master 污点。在不允许 control plane 节点挂载 PV 的环境中工作。此功能为您提供了选择节点并容许这些环境中的不同污点的方法。 -
Compliance Operator 现在可以修复
KubeletConfig对象。 - 现在,添加了一个包含错误消息的注释,以帮助内容开发人员区分集群中不存在的对象与无法获取的对象。
-
规则对象现在包含两个新属性,
checkType和description。通过这些属性,您可以确定与节点检查或平台检查相关的规则,并允许您检查规则的作用。 -
此功能增强删除了需要扩展现有配置集的要求,以创建定制的配置集。这意味着
TailoredProfileCRD 中的extends字段不再是必需的。现在,您可以选择用于创建定制配置集的规则对象列表。请注意,您必须通过设置compliance.openshift.io/product-type:注解或为TailoredProfileCR 设置-node后缀来选择您的配置集是否应用到节点或平台。 -
在本发行版本中,Compliance Operator 现在可以在其污点的所有节点上调度扫描。在以前的版本中,扫描 pod 只容许
node-role.kubernetes.io/master 污点,这意味着它们可以在没有污点的节点上运行,或者仅在具有node-role.kubernetes.io/master污点的节点上运行。在将自定义污点用于其节点的部署中,这会导致扫描不会被调度到这些节点上。现在,扫描 pod 可以容限所有节点污点。 在本发行版本中,Compliance Operator 支持以下 North American Electric Reliability Corporation (NERC 安全配置集:
- ocp4-nerc-cip
- ocp4-nerc-cip-node
- rhcos4-nerc-cip
- 在本发行版本中,Compliance Operator 支持 Red Hat OpenShift - Node level、ocp4-moderate-node、security 配置集中的 NIST 800-53 Moderate-Impact Baseline。
5.1.8.2. 模板和变量使用
- 在本发行版本中,补救模板现在允许多值变量。
-
在这个版本中,Compliance Operator 可以根据合规性配置集中设置的变量更改补救。这可用于包括特定于部署的补救值,如超时、NTP 服务器主机名或类似值。另外,
ComplianceCheckResult对象现在使用标签compliance.openshift.io/check-has-value列出检查使用的变量。
5.1.8.3. 程序错误修复
- 在以前的版本中,在执行扫描时,pod 的扫描程序容器中会发生意外终止。在本发行版本中,Compliance Operator 使用最新的 OpenSCAP 版本 1.3.5 来避免崩溃。
-
在以前的版本中,使用
autoReplyRemediations应用补救会触发对集群节点的更新。如果某些补救不包括所有所需的输入变量,则会出现破坏性。现在,如果缺少一个或多个所需的输入变量,则会为其分配一个NeedsReview状态。如果一个或多个补救处于NeedsReview状态,机器配置池会保持暂停,且在设置所有需要的变量前不会应用补救。这有助于最小化对节点的中断。 - 用于 Prometheus 指标的 RBAC 角色和角色绑定改为 'ClusterRole' 和 'ClusterRoleBinding',以确保监控在没有自定义的情况下正常工作。
-
在以前的版本中,如果在解析配置集时出现错误,规则或变量对象会从配置集中删除并删除。现在,如果解析过程中出现错误,
profileparser会使用临时注解为对象添加注解,该注解会阻止对象在解析完成后被删除。(BZ#1988259) -
在以前的版本中,当自定义配置集中没有标题或描述时会出现一个错误。由于 XCCDF 标准需要定制配置集的标题和描述,现在需要在
TailoredProfileCR 中设置标题和描述。 -
在以前的版本中,当使用定制配置集时,允许使用特定的选择设置
TailoredProfile变量值。这个限制现已被删除,TailoredProfile变量可以设置为任何值。
5.1.9. Compliance Operator 0.1.39 发行注记
以下公告可用于 OpenShift Compliance Operator 0.1.39:
5.1.9.1. 新功能及功能增强
- 在以前的版本中,Compliance Operator 无法解析 Payment Card Industry Data Security Standard(PCI DSS)参考。现在,Operator 可以解析 PCI DSS 配置集附带的合规性内容。
- 在以前的版本中,Compliance Operator 无法在 moderate 配置集中为 AU-5 控制执行规则。现在,权限被添加到 Operator 中,以便它可以读取 Prometheusrules.monitoring.coreos.com 对象,并运行在 moderate 配置集中涵盖 AU-5 控制的规则。
5.2. 支持的合规性配置集
有多个配置集可用于安装 Compliance Operator(CO)。
Compliance Operator 可能会报告有关受管平台(如 OpenShift Dedicated、Red Hat OpenShift Service on AWS)和 Azure Red Hat OpenShift 的不正确的结果。如需更多信息,请参阅红帽知识库解决方案 #6983418。
5.2.1. 合规性配置集
Compliance Operator 提供以下合规配置集:
| profile | 配置集标题 | Compliance Operator 版本 | 行业标准基准 | 支持的构架 |
|---|---|---|---|---|
| ocp4-cis | CIS Red Hat OpenShift Container Platform 4 Benchmark | 0.1.39+ |
CIS Benchmarks ™ footnote:cisbenchmark[To locate the CIS RedHat OpenShift Container Platform v4 Benchmarks,进入 CIS Benchmarks 并在搜索框中输入 |
|
| ocp4-cis-node | CIS Red Hat OpenShift Container Platform 4 Benchmark | 0.1.39+ | CIS Benchmarks ™ footnote:cisbenchmark[] |
|
| ocp4-e8 | Australian Cyber Security Centre (ACSC) Essential Eight | 0.1.39+ |
| |
| ocp4-moderate | NIST 800-53 Moderate-Impact Baseline for Red Hat OpenShift - Platform 级别 | 0.1.39+ |
| |
| rhcos4-e8 | Australian Cyber Security Centre (ACSC) Essential Eight | 0.1.39+ |
| |
| rhcos4-moderate | NIST 800-53 Moderate-Impact Baseline for Red Hat Enterprise Linux CoreOS | 0.1.39+ |
| |
| ocp4-moderate-node | NIST 800-53 Moderate-Impact Baseline for Red Hat OpenShift - 节点级别 | 0.1.44+ |
| |
| ocp4-nerc-cip | Red Hat OpenShift Container Platform 的 North American Electric Reliability Corporation (NERC) Critical Infrastructure Protection (CIP) cybersecurity 标准 - 平台级别 | 0.1.44+ |
| |
| ocp4-nerc-cip-node | Red Hat OpenShift Container Platform 的 North American Electric Reliability Corporation (NERC) Critical Infrastructure Protection (CIP) cybersecurity 标准配置集 - 节点级别 | 0.1.44+ |
| |
| rhcos4-nerc-cip | Red Hat Enterprise Linux CoreOS 的 North American Electric Reliability Corporation (NERC) Critical Infrastructure Protection (CIP) cybersecurity 标准配置集 | 0.1.44+ |
| |
| ocp4-pci-dss | PCI-DSS v3.2.1 Control Baseline for Red Hat OpenShift Container Platform 4 | 0.1.47+ |
| |
| ocp4-pci-dss-node | PCI-DSS v3.2.1 Control Baseline for Red Hat OpenShift Container Platform 4 | 0.1.47+ |
| |
| ocp4-high | NIST 800-53 HighImpact Baseline for Red Hat OpenShift - Platform 级别 | 0.1.52+ |
| |
| ocp4-high-node | NIST 800-53 HighImpact Baseline for Red Hat OpenShift - 节点级别 | 0.1.52+ |
| |
| rhcos4-high | NIST 800-53 high-Impact Baseline for Red Hat Enterprise Linux CoreOS | 0.1.52+ |
|
5.3. 安装 Compliance Operator
在使用 Compliance Operator 之前,您必须保证在集群中部署它。
5.3.1. 通过 Web 控制台安装 Compliance Operator
先决条件
-
您必须具有
admin权限。
流程
- 在 OpenShift Container Platform Web 控制台中导航至 Operators → OperatorHub。
- 搜索 Compliance Operator,然后点 Install。
-
保留 安装模式 和 命名空间 的默认选择,以确保将 Operator 安装到
openshift-compliance命名空间中。 - 点 Install。
验证
确认安装成功:
- 导航到 Operators → Installed Operators 页面。
-
检查 Compliance Operator 是否已安装在
openshift-compliance命名空间中,其状态为Succeeded。
如果 Operator 没有成功安装:
-
导航到 Operators → Installed Operators 页面,并检查
Status列中是否有任何错误或故障。 -
导航到 Workloads → Pods 页面,检查
openshift-compliance项目中报告问题的 pod 的日志。
如果 restricted 安全性上下文约束(SCC)已被修改为包含 system:authenticated 组或添加了 requiredDropCapabilities,则 Compliance Operator 可能会因为权限问题而无法正常工作。
您可以为 Compliance Operator scanner Pod 服务帐户创建自定义 SCC。如需更多信息,请参阅为 Compliance Operator 创建自定义 SCC。
5.3.2. 使用 CLI 安装 Compliance Operator
先决条件
-
您必须具有
admin权限。
流程
定义一个
Namespace对象:namespace-object.yaml示例apiVersion: v1 kind: Namespace metadata: labels: openshift.io/cluster-monitoring: "true" name: openshift-compliance创建
Namespace对象:$ oc create -f namespace-object.yaml定义一个
OperatorGroup对象:operator-group-object.yaml示例apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: compliance-operator namespace: openshift-compliance spec: targetNamespaces: - openshift-compliance创建
OperatorGroup对象:$ oc create -f operator-group-object.yaml定义一个
Subscription对象:subscription-object.yaml示例apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: compliance-operator-sub namespace: openshift-compliance spec: channel: "release-0.1" installPlanApproval: Automatic name: compliance-operator source: redhat-operators sourceNamespace: openshift-marketplace创建
Subscription对象:$ oc create -f subscription-object.yaml
如果要设置全局调度程序功能并启用 defaultNodeSelector,您必须手动创建命名空间并更新 openshift-compliance 命名空间的注解,或安装 Compliance Operator 的命名空间,使用 openshift.io/node-selector: ""。这会删除默认节点选择器并防止部署失败。
验证
通过检查 CSV 文件来验证安装是否成功:
$ oc get csv -n openshift-compliance验证 Compliance Operator 是否正在运行:
$ oc get deploy -n openshift-compliance
如果 restricted 安全性上下文约束(SCC)已被修改为包含 system:authenticated 组或添加了 requiredDropCapabilities,则 Compliance Operator 可能会因为权限问题而无法正常工作。
您可以为 Compliance Operator scanner Pod 服务帐户创建自定义 SCC。如需更多信息,请参阅为 Compliance Operator 创建自定义 SCC。
5.4. 更新 Compliance Operator
作为集群管理员,您可以在 OpenShift Container Platform 集群上更新 Compliance Operator。
5.4.1. 准备 Operator 更新
已安装的 Operator 的订阅指定一个更新频道,用于跟踪和接收 Operator 的更新。您可以更改更新频道,以开始跟踪并从更新频道接收更新。
订阅中更新频道的名称可能会因 Operator 而异,但应遵守给定 Operator 中的常规约定。例如,频道名称可能会遵循 Operator 提供的应用程序的次发行版本更新流(1.2、1.3)或发行的频率(stable、fast)。
您不能将已安装的 Operator 更改为比当前频道旧的频道。
红帽客户门户网站 Labs 包括以下应用程序,可帮助管理员准备更新其 Operator:
您可以使用应用程序搜索基于 Operator Lifecycle Manager 的 Operator,并在不同版本的 OpenShift Container Platform 中验证每个更新频道的可用 Operator 版本。不包含基于 Cluster Version Operator 的 Operator。
5.4.2. 更改 Operator 的更新频道
您可以使用 OpenShift Container Platform Web 控制台更改 Operator 的更新频道。
如果订阅中的批准策略被设置为 Automatic,则更新过程会在所选频道中提供新的 Operator 版本时立即启动。如果批准策略设为 Manual,则必须手动批准待处理的更新。
先决条件
- 之前使用 Operator Lifecycle Manager(OLM)安装的 Operator。
流程
- 在 web 控制台的 Administrator 视角中,导航到 Operators → Installed Operators。
- 点击您要更改更新频道的 Operator 名称。
- 点 Subscription 标签页。
- 点 Channel 中的更新频道的名称。
- 点要更改的更新频道,然后点 Save。
对于带有 自动批准策略 的订阅,更新会自动开始。返回到 Operators → Installed Operators 页面,以监控更新的进度。完成后,状态会变为 Succeeded 和 Up to date。
对于采用手动批准策略的订阅,您可以从 Subscription 选项卡中手动批准更新。
5.4.3. 手动批准待处理的 Operator 更新
如果已安装的 Operator 的订阅被设置为 Manual,则当其当前更新频道中发布新更新时,在开始安装前必须手动批准更新。
先决条件
- 之前使用 Operator Lifecycle Manager(OLM)安装的 Operator。
流程
- 在 OpenShift Container Platform Web 控制台的 Administrator 视角中,进入 Operators → Installed Operators。
- 处于待定更新的 Operator 会显示 Upgrade available 状态。点您要更新的 Operator 的名称。
- 点 Subscription 标签页。任何需要批准的更新都会在 Upgrade Status 旁边显示。例如:它可能会显示 1 requires approval。
- 点 1 requires approval,然后点 Preview Install Plan。
- 检查列出可用于更新的资源。在满意后,点 Approve。
- 返回到 Operators → Installed Operators 页面,以监控更新的进度。完成后,状态会变为 Succeeded 和 Up to date。
5.5. Compliance Operator 扫描
建议使用 ScanSetting 和 ScanSettingBinding API 来通过 Compliance Operator 运行合规性扫描。如需有关这些 API 对象的更多信息,请运行:
$ oc explain scansettings或者
$ oc explain scansettingbindings5.5.1. 运行合规性扫描
您可以使用互联网安全中心(CIS)配置集运行扫描。为方便起见,Compliance Operator 创建一个在启动时具有合理的默认值的 ScanSetting 对象。这个 ScanSetting 对象名为 default。
对于 all-in-one control plane 和 worker 节点,合规性扫描在 worker 和 control plane 节点上运行两次。合规性扫描可能会导致扫描结果不一致。您可以通过在 ScanSetting 对象中只定义单个角色来避免结果不一致。
流程
运行以下命令检查
ScanSetting对象:$ oc describe scansettings default -n openshift-compliance输出示例
Name: default Namespace: openshift-compliance Labels: <none> Annotations: <none> API Version: compliance.openshift.io/v1alpha1 Kind: ScanSetting Metadata: Creation Timestamp: 2022-10-10T14:07:29Z Generation: 1 Managed Fields: API Version: compliance.openshift.io/v1alpha1 Fields Type: FieldsV1 fieldsV1: f:rawResultStorage: .: f:nodeSelector: .: f:node-role.kubernetes.io/master: f:pvAccessModes: f:rotation: f:size: f:tolerations: f:roles: f:scanTolerations: f:schedule: f:showNotApplicable: f:strictNodeScan: Manager: compliance-operator Operation: Update Time: 2022-10-10T14:07:29Z Resource Version: 56111 UID: c21d1d14-3472-47d7-a450-b924287aec90 Raw Result Storage: Node Selector: node-role.kubernetes.io/master: Pv Access Modes: ReadWriteOnce1 Rotation: 32 Size: 1Gi3 Tolerations: Effect: NoSchedule Key: node-role.kubernetes.io/master Operator: Exists Effect: NoExecute Key: node.kubernetes.io/not-ready Operator: Exists Toleration Seconds: 300 Effect: NoExecute Key: node.kubernetes.io/unreachable Operator: Exists Toleration Seconds: 300 Effect: NoSchedule Key: node.kubernetes.io/memory-pressure Operator: Exists Roles: master4 worker5 Scan Tolerations:6 Operator: Exists Schedule: 0 1 * * *7 Show Not Applicable: false Strict Node Scan: true Events: <none>- 1
- Compliance Operator 创建一个包含扫描结果的持久性卷(PV)。默认情况下,PV 将使用访问模式
ReadWriteOnce,因为 Compliance Operator 无法假定集群中配置的存储类。另外,多数集群中可以使用ReadWriteOnce访问模式。如果需要获取扫描结果,可以使用一个 helper pod 来完成此操作,该 pod 也绑定卷。使用ReadWriteOnce访问模式的卷只能由一个 pod 挂载,因此请记住删除帮助程序 pod。否则,Compliance Operator 将无法重复使用卷进行后续扫描。 - 2
- Compliance Operator 在卷中保留三个后续扫描的结果,旧的扫描会被轮转。
- 3
- Compliance Operator 将为扫描结果分配一个 GB 存储。
- 4 5
- 如果扫描设置使用扫描集群节点的任何配置集,请扫描这些节点角色。
- 6
- 默认扫描设置对象还会扫描所有节点。
- 7
- 默认扫描设置对象每天 01:00 运行扫描。
作为默认扫描设置的替代,您可以使用
default-auto-apply,它有以下设置:Name: default-auto-apply Namespace: openshift-compliance Labels: <none> Annotations: <none> API Version: compliance.openshift.io/v1alpha1 Auto Apply Remediations: true Auto Update Remediations: true Kind: ScanSetting Metadata: Creation Timestamp: 2022-10-18T20:21:00Z Generation: 1 Managed Fields: API Version: compliance.openshift.io/v1alpha1 Fields Type: FieldsV1 fieldsV1: f:autoApplyRemediations:1 f:autoUpdateRemediations:2 f:rawResultStorage: .: f:nodeSelector: .: f:node-role.kubernetes.io/master: f:pvAccessModes: f:rotation: f:size: f:tolerations: f:roles: f:scanTolerations: f:schedule: f:showNotApplicable: f:strictNodeScan: Manager: compliance-operator Operation: Update Time: 2022-10-18T20:21:00Z Resource Version: 38840 UID: 8cb0967d-05e0-4d7a-ac1c-08a7f7e89e84 Raw Result Storage: Node Selector: node-role.kubernetes.io/master: Pv Access Modes: ReadWriteOnce Rotation: 3 Size: 1Gi Tolerations: Effect: NoSchedule Key: node-role.kubernetes.io/master Operator: Exists Effect: NoExecute Key: node.kubernetes.io/not-ready Operator: Exists Toleration Seconds: 300 Effect: NoExecute Key: node.kubernetes.io/unreachable Operator: Exists Toleration Seconds: 300 Effect: NoSchedule Key: node.kubernetes.io/memory-pressure Operator: Exists Roles: master worker Scan Tolerations: Operator: Exists Schedule: 0 1 * * * Show Not Applicable: false Strict Node Scan: true Events: <none>创建一个
ScanSettingBinding对,,它绑定到默认的ScanSetting对象,并使用cis和cis-node配置集扫描集群。例如:apiVersion: compliance.openshift.io/v1alpha1 kind: ScanSettingBinding metadata: name: cis-compliance namespace: openshift-compliance profiles: - name: ocp4-cis-node kind: Profile apiGroup: compliance.openshift.io/v1alpha1 - name: ocp4-cis kind: Profile apiGroup: compliance.openshift.io/v1alpha1 settingsRef: name: default kind: ScanSetting apiGroup: compliance.openshift.io/v1alpha1运行以下命令来创建
ScanSettingBinding对象:$ oc create -f <file-name>.yaml -n openshift-compliance此时,
ScanSettingBinding对象已协调,并以Binding和Bound设置为基础。Compliance Operator 会创建一个ComplianceSuite对象和关联的ComplianceScan对象。运行以下命令跟踪合规性扫描进度:
$ oc get compliancescan -w -n openshift-compliance扫描过程通过扫描阶段进行,最终完成后到达
DONE阶段。在大多数情况下,扫描的结果是NON-COMPLIANT。您可以检查扫描结果,并开始应用补救使集群兼容。如需更多信息,请参阅管理 Compliance Operator 补救。
5.5.2. 将结果服务器 pod 调度到 worker 节点上
结果服务器 pod 挂载存储原始资产报告格式(ARF)扫描结果的持久性卷(PV)。nodeSelector 和 tolerations 属性允许您配置结果服务器 pod 的位置。
这适用于那些不允许 control plane 节点挂载持久性卷的环境。
流程
为 Compliance Operator 创建
ScanSetting自定义资源(CR):定义
ScanSettingCR,并保存 YAML 文件,如rs-workers.yaml:apiVersion: compliance.openshift.io/v1alpha1 kind: ScanSetting metadata: name: rs-on-workers namespace: openshift-compliance rawResultStorage: nodeSelector: node-role.kubernetes.io/worker: ""1 pvAccessModes: - ReadWriteOnce rotation: 3 size: 1Gi tolerations: - operator: Exists2 roles: - worker - master scanTolerations: - operator: Exists schedule: 0 1 * * *要创建
ScanSettingCR,请运行以下命令:$ oc create -f rs-workers.yaml
验证
要验证
ScanSetting对象是否已创建,请运行以下命令:$ oc get scansettings rs-on-workers -n openshift-compliance -o yaml输出示例
apiVersion: compliance.openshift.io/v1alpha1 kind: ScanSetting metadata: creationTimestamp: "2021-11-19T19:36:36Z" generation: 1 name: rs-on-workers namespace: openshift-compliance resourceVersion: "48305" uid: 43fdfc5f-15a7-445a-8bbc-0e4a160cd46e rawResultStorage: nodeSelector: node-role.kubernetes.io/worker: "" pvAccessModes: - ReadWriteOnce rotation: 3 size: 1Gi tolerations: - operator: Exists roles: - worker - master scanTolerations: - operator: Exists schedule: 0 1 * * * strictNodeScan: true
5.5.3. ScanSetting 自定义资源
ScanSetting 自定义资源现在允许您通过扫描限值属性覆盖扫描程序 Pod 的默认 CPU 和内存限值。Compliance Operator 的默认值为 500Mi 内存,100m CPU 用于扫描程序容器;对于 api-resource-collector 容器为 200Mi 内存,100m CPU。要设置 Operator 的内存限值,如果通过 OLM 或 Operator 部署本身安装,请修改 Subscription 对象。
要增加 Compliance Operator 的默认 CPU 和内存限值,请参阅增加 Compliance Operator 资源限值。
如果默认限值不足且 Operator 或扫描程序 Pod 被 Out Of Memory (OOM) 进程停止,则需要提高 Compliance Operator 或 scanner Pod 的内存限值。
5.5.4. 应用资源请求和限值
当 kubelet 作为 Pod 的一部分启动容器时,kubelet 会将该容器的请求和限值传递给容器运行时。在 Linux 中,容器运行时配置应用并强制实施您定义的限制的内核 cgroup。
CPU 限制定义容器可以使用的 CPU 时间。在每个调度间隔中,Linux 内核会检查是否超过这个限制。如果是这样,内核会在允许 cgroup 恢复执行前等待。
如果几个不同的容器(cgroups)希望在扩展系统上运行,则具有较大的 CPU 请求的工作负载会比具有小请求的工作负载分配更多的 CPU 时间。内存请求在 Pod 调度期间使用。在使用 cgroup v2 的节点上,容器运行时可能会使用内存请求作为提示来设置 memory.min 和 memory.low 值。
如果容器尝试分配超过这个限制的内存,Linux 内核的 out-of-memory 子系统会被激活,并通过停止容器中的一个进程来进行干预。Pod 或容器的内存限值也可以应用到由内存支持的卷的页面,如 emptyDir。
kubelet 将 tmpfs emptyDir 视为容器使用的内存进行跟踪,而不是视为本地临时存储。如果容器超过其内存请求,且在其中运行的节点变得缺少内存,则 Pod 的容器可能会被驱除。
容器无法在超过 CPU 限制的情况下长时间运行。容器运行时不会停止 Pod 或容器超量使 CPU。要确定容器是否因为资源限值而无法调度或正在被终止,请参阅 Compliance Operator 故障排除。
5.5.5. 使用资源请求调度 Pod
创建 Pod 时,调度程序会选择要在其上运行的 Pod 的节点。每个节点都有一个最大容量,用于每种资源类型的 CPU 和它可为 Pod 提供的内存。调度程序确保调度容器的资源请求总和小于每种资源类型的节点容量。
虽然节点上的内存或 CPU 资源使用量非常低,但如果容量检查无法防止节点出现资源短缺的情况,则调度程序仍可能会拒绝在节点上放置 Pod。
对于每个容器,您可以指定以下资源限值和请求:
spec.containers[].resources.limits.cpu
spec.containers[].resources.limits.memory
spec.containers[].resources.limits.hugepages-<size>
spec.containers[].resources.requests.cpu
spec.containers[].resources.requests.memory
spec.containers[].resources.requests.hugepages-<size>虽然您只能为单个容器指定请求和限值,但考虑 Pod 的整体资源请求和限值也很有用。对于特定资源,Pod 资源请求和限值是 Pod 中每个容器这个类型的资源请求/限制总和。
Pod 资源请求和限值示例
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"5.6. 了解 Compliance Operator
通过 Compliance Operator,OpenShift Container Platform 管理员可以描述集群所需的合规状态,并概述缺陷及修复方法。Compliance Operator 评估 OpenShift Container Platform 的 Kubernetes API 资源以及运行集群的节点的合规性。Compliance Operator 使用 NIST 认证工具 OpenSCAP 扫描并执行内容所提供的安全性策略。
Compliance Operator 仅适用于 Red Hat Enterprise Linux CoreOS(RHCOS)部署。
5.6.1. Compliance Operator 配置集
有多个配置集可用于安装 Compliance Operator。您可以使用 oc get 命令来查看可用的配置集、配置集详情和特定规则。
查看可用的配置集:
$ oc get -n openshift-compliance profiles.compliance输出示例
NAME AGE ocp4-cis 94m ocp4-cis-node 94m ocp4-e8 94m ocp4-high 94m ocp4-high-node 94m ocp4-moderate 94m ocp4-moderate-node 94m ocp4-nerc-cip 94m ocp4-nerc-cip-node 94m ocp4-pci-dss 94m ocp4-pci-dss-node 94m rhcos4-e8 94m rhcos4-high 94m rhcos4-moderate 94m rhcos4-nerc-cip 94m这些配置集代表不同的合规性基准。每个配置集将其应用到的产品名称添加为配置集名称的前缀。
ocp4-e8将 Essential 8 基准应用到 OpenShift Container Platform 产品,而rhcos4-e8将 Essential 8 基准应用到 Red Hat Enterprise Linux CoreOS (RHCOS) 产品。运行以下命令,以查看
rhcos4-e8配置集的详情:$ oc get -n openshift-compliance -oyaml profiles.compliance rhcos4-e8输出示例
apiVersion: compliance.openshift.io/v1alpha1 description: 'This profile contains configuration checks for Red Hat Enterprise Linux CoreOS that align to the Australian Cyber Security Centre (ACSC) Essential Eight. A copy of the Essential Eight in Linux Environments guide can be found at the ACSC website: https://www.cyber.gov.au/acsc/view-all-content/publications/hardening-linux-workstations-and-servers' id: xccdf_org.ssgproject.content_profile_e8 kind: Profile metadata: annotations: compliance.openshift.io/image-digest: pb-rhcos4hrdkm compliance.openshift.io/product: redhat_enterprise_linux_coreos_4 compliance.openshift.io/product-type: Node creationTimestamp: "2022-10-19T12:06:49Z" generation: 1 labels: compliance.openshift.io/profile-bundle: rhcos4 name: rhcos4-e8 namespace: openshift-compliance ownerReferences: - apiVersion: compliance.openshift.io/v1alpha1 blockOwnerDeletion: true controller: true kind: ProfileBundle name: rhcos4 uid: 22350850-af4a-4f5c-9a42-5e7b68b82d7d resourceVersion: "43699" uid: 86353f70-28f7-40b4-bf0e-6289ec33675b rules: - rhcos4-accounts-no-uid-except-zero - rhcos4-audit-rules-dac-modification-chmod - rhcos4-audit-rules-dac-modification-chown - rhcos4-audit-rules-execution-chcon - rhcos4-audit-rules-execution-restorecon - rhcos4-audit-rules-execution-semanage - rhcos4-audit-rules-execution-setfiles - rhcos4-audit-rules-execution-setsebool - rhcos4-audit-rules-execution-seunshare - rhcos4-audit-rules-kernel-module-loading-delete - rhcos4-audit-rules-kernel-module-loading-finit - rhcos4-audit-rules-kernel-module-loading-init - rhcos4-audit-rules-login-events - rhcos4-audit-rules-login-events-faillock - rhcos4-audit-rules-login-events-lastlog - rhcos4-audit-rules-login-events-tallylog - rhcos4-audit-rules-networkconfig-modification - rhcos4-audit-rules-sysadmin-actions - rhcos4-audit-rules-time-adjtimex - rhcos4-audit-rules-time-clock-settime - rhcos4-audit-rules-time-settimeofday - rhcos4-audit-rules-time-stime - rhcos4-audit-rules-time-watch-localtime - rhcos4-audit-rules-usergroup-modification - rhcos4-auditd-data-retention-flush - rhcos4-auditd-freq - rhcos4-auditd-local-events - rhcos4-auditd-log-format - rhcos4-auditd-name-format - rhcos4-auditd-write-logs - rhcos4-configure-crypto-policy - rhcos4-configure-ssh-crypto-policy - rhcos4-no-empty-passwords - rhcos4-selinux-policytype - rhcos4-selinux-state - rhcos4-service-auditd-enabled - rhcos4-sshd-disable-empty-passwords - rhcos4-sshd-disable-gssapi-auth - rhcos4-sshd-disable-rhosts - rhcos4-sshd-disable-root-login - rhcos4-sshd-disable-user-known-hosts - rhcos4-sshd-do-not-permit-user-env - rhcos4-sshd-enable-strictmodes - rhcos4-sshd-print-last-log - rhcos4-sshd-set-loglevel-info - rhcos4-sysctl-kernel-dmesg-restrict - rhcos4-sysctl-kernel-kptr-restrict - rhcos4-sysctl-kernel-randomize-va-space - rhcos4-sysctl-kernel-unprivileged-bpf-disabled - rhcos4-sysctl-kernel-yama-ptrace-scope - rhcos4-sysctl-net-core-bpf-jit-harden title: Australian Cyber Security Centre (ACSC) Essential Eight运行以下命令,以查看
rhcos4-audit-rules-login-events规则的详情:$ oc get -n openshift-compliance -oyaml rules rhcos4-audit-rules-login-events输出示例
apiVersion: compliance.openshift.io/v1alpha1 checkType: Node description: |- The audit system already collects login information for all users and root. If the auditd daemon is configured to use the augenrules program to read audit rules during daemon startup (the default), add the following lines to a file with suffix.rules in the directory /etc/audit/rules.d in order to watch for attempted manual edits of files involved in storing logon events: -w /var/log/tallylog -p wa -k logins -w /var/run/faillock -p wa -k logins -w /var/log/lastlog -p wa -k logins If the auditd daemon is configured to use the auditctl utility to read audit rules during daemon startup, add the following lines to /etc/audit/audit.rules file in order to watch for unattempted manual edits of files involved in storing logon events: -w /var/log/tallylog -p wa -k logins -w /var/run/faillock -p wa -k logins -w /var/log/lastlog -p wa -k logins id: xccdf_org.ssgproject.content_rule_audit_rules_login_events kind: Rule metadata: annotations: compliance.openshift.io/image-digest: pb-rhcos4hrdkm compliance.openshift.io/rule: audit-rules-login-events control.compliance.openshift.io/NIST-800-53: AU-2(d);AU-12(c);AC-6(9);CM-6(a) control.compliance.openshift.io/PCI-DSS: Req-10.2.3 policies.open-cluster-management.io/controls: AU-2(d),AU-12(c),AC-6(9),CM-6(a),Req-10.2.3 policies.open-cluster-management.io/standards: NIST-800-53,PCI-DSS creationTimestamp: "2022-10-19T12:07:08Z" generation: 1 labels: compliance.openshift.io/profile-bundle: rhcos4 name: rhcos4-audit-rules-login-events namespace: openshift-compliance ownerReferences: - apiVersion: compliance.openshift.io/v1alpha1 blockOwnerDeletion: true controller: true kind: ProfileBundle name: rhcos4 uid: 22350850-af4a-4f5c-9a42-5e7b68b82d7d resourceVersion: "44819" uid: 75872f1f-3c93-40ca-a69d-44e5438824a4 rationale: Manual editing of these files may indicate nefarious activity, such as an attacker attempting to remove evidence of an intrusion. severity: medium title: Record Attempts to Alter Logon and Logout Events warning: Manual editing of these files may indicate nefarious activity, such as an attacker attempting to remove evidence of an intrusion.
5.7. 管理 Compliance Operator
本节介绍安全性内容的生命周期,包括如何使用合规性内容的更新版本以及如何创建自定义 ProfileBundle 对象。
5.7.1. ProfileBundle CR 示例
ProfileBundle 对象需要两个信息:包含 contentImage 的容器镜像的 URL 以及包含合规性内容的文件。contentFile 参数相对于文件系统的根目录。您可以定义内置的 rhcos4 ProfileBundle 对象,如下例所示:
apiVersion: compliance.openshift.io/v1alpha1
kind: ProfileBundle
metadata:
creationTimestamp: "2022-10-19T12:06:30Z"
finalizers:
- profilebundle.finalizers.compliance.openshift.io
generation: 1
name: rhcos4
namespace: openshift-compliance
resourceVersion: "46741"
uid: 22350850-af4a-4f5c-9a42-5e7b68b82d7d
spec:
contentFile: ssg-rhcos4-ds.xml
contentImage: registry.redhat.io/compliance/openshift-compliance-content-rhel8@sha256:900e...
status:
conditions:
- lastTransitionTime: "2022-10-19T12:07:51Z"
message: Profile bundle successfully parsed
reason: Valid
status: "True"
type: Ready
dataStreamStatus: VALID5.7.2. 更新安全性内容
安全内容作为 ProfileBundle 对象引用的容器镜像包括。要准确跟踪从捆绑包(如 Rules 或 Profiles)解析的 ProfileBundles 和 CustomResources 的更新,请使用摘要而不是标签来识别包含合规性内容的容器镜像:
$ oc -n openshift-compliance get profilebundles rhcos4 -oyaml输出示例
apiVersion: compliance.openshift.io/v1alpha1
kind: ProfileBundle
metadata:
creationTimestamp: "2022-10-19T12:06:30Z"
finalizers:
- profilebundle.finalizers.compliance.openshift.io
generation: 1
name: rhcos4
namespace: openshift-compliance
resourceVersion: "46741"
uid: 22350850-af4a-4f5c-9a42-5e7b68b82d7d
spec:
contentFile: ssg-rhcos4-ds.xml
contentImage: registry.redhat.io/compliance/openshift-compliance-content-rhel8@sha256:900e...
status:
conditions:
- lastTransitionTime: "2022-10-19T12:07:51Z"
message: Profile bundle successfully parsed
reason: Valid
status: "True"
type: Ready
dataStreamStatus: VALID- 1
- 安全性容器镜像。
每个 ProfileBundle 都由一个部署来支持。当 Compliance Operator 检测到容器镜像摘要已更改时,会更新部署来反映内容的变化并再次解析内容。使用摘要而不是标签可确保您使用稳定且可预测的配置集集合。
5.8. 定制 Compliance Operator
虽然 Compliance Operator 附带随时可用的配置集,但必须对其进行修改才能满足机构的需求和要求。修改配置集的过程称为定制。
Compliance Operator 提供了 TailoredProfile 对象来帮助定制配置集。
5.8.1. 创建新的定制配置集
您可以使用 TailoredProfile 对象从头开始编写定制的配置集。设置适当的 title 和 description,并将 extends 字段留空。向 Compliance Operator 指明此自定义配置集生成的扫描类型:
- 节点扫描:扫描操作系统。
- 平台扫描 :扫描 OpenShift 配置。
流程
在 TailoredProfile 对象中设置以下注解:
+ .Example new-profile.yaml
apiVersion: compliance.openshift.io/v1alpha1
kind: TailoredProfile
metadata:
name: new-profile
annotations:
compliance.openshift.io/product-type: Node
spec:
extends:
description: My custom profile
title: Custom profile 5.8.2. 使用定制配置集扩展现有 ProfileBundle
尽管 TailoredProfile CR 支持最常见的定制操作,但 XCCDF 标准在定制 OpenSCAP 配置集方面具有更大的灵活性。此外,如果您的机构之前一直使用 OpenScap,则您可能有一个现有的 XCCDF 定制文件可重复使用。
ComplianceSuite 对象包含可指向自定义定制文件的可选 TailoringConfigMap 属性。TailoringConfigMap 属性的值是一个配置映射的名称,它必须包含名为 tailoring.xml 的键,这个键的值是定制内容。
流程
浏览 Red Hat Enterprise Linux CoreOS (RHCOS)
ProfileBundle的可用规则:$ oc get rules.compliance -n openshift-compliance -l compliance.openshift.io/profile-bundle=rhcos4浏览同一
ProfileBundle中的可用变量:$ oc get variables.compliance -n openshift-compliance -l compliance.openshift.io/profile-bundle=rhcos4创建名为
nist-moderate-modified的定制配置集:选择您要添加到
nist-moderate-modified定制配置集中的规则。这个示例通过禁用两个规则并更改一个值来扩展rhcos4-moderate配置集。使用rationale值描述进行这些更改的原因:new-profile-node.yaml示例apiVersion: compliance.openshift.io/v1alpha1 kind: TailoredProfile metadata: name: nist-moderate-modified spec: extends: rhcos4-moderate description: NIST moderate profile title: My modified NIST moderate profile disableRules: - name: rhcos4-file-permissions-var-log-messages rationale: The file contains logs of error messages in the system - name: rhcos4-account-disable-post-pw-expiration rationale: No need to check this as it comes from the IdP setValues: - name: rhcos4-var-selinux-state rationale: Organizational requirements value: permissiveExpand 表 5.2. spec 变量的属性 属性 描述 extends构建此
TailoredProfile的Profile对象的名称。titleTailoredProfile的人类可读标题.disableRules名称和理由对列表。每个名称引用要禁用的规则对象的名称。合理值是人类可读的文本,描述禁用规则的原因。
manualRules名称和理由对列表。添加手动规则时,检查结果状态始终是
manual,且不会生成补救。此属性是自动的,在默认情况下,设置手动规则时没有值。enableRules名称和理由对列表。每个名称引用要启用的规则对象的名称。合理值是人类可读的文本,描述启用规则的原因。
description描述
TailoredProfile的人类可读文本.setValues名称、理由和值分组列表。每个名称都引用值集的名称。理由是人类可读的文本描述该集合。值是实际设置。
添加
tailoredProfile.spec.manualRules属性:示例
tailoredProfile.spec.manualRules.yamlapiVersion: compliance.openshift.io/v1alpha1 kind: TailoredProfile metadata: name: ocp4-manual-scc-check spec: extends: ocp4-cis description: This profile extends ocp4-cis by forcing the SCC check to always return MANUAL title: OCP4 CIS profile with manual SCC check manualRules: - name: ocp4-scc-limit-container-allowed-capabilities rationale: We use third party software that installs its own SCC with extra privileges创建
TailoredProfile对象:$ oc create -n openshift-compliance -f new-profile-node.yaml1 - 1
TailoredProfile对象在默认的openshift-compliance命名空间中创建。
输出示例
tailoredprofile.compliance.openshift.io/nist-moderate-modified created
定义
ScanSettingBinding对象,将新的nist-moderate-modified定制配置集绑定到默认的ScanSetting对象。new-scansettingbinding.yaml示例apiVersion: compliance.openshift.io/v1alpha1 kind: ScanSettingBinding metadata: name: nist-moderate-modified profiles: - apiGroup: compliance.openshift.io/v1alpha1 kind: Profile name: ocp4-moderate - apiGroup: compliance.openshift.io/v1alpha1 kind: TailoredProfile name: nist-moderate-modified settingsRef: apiGroup: compliance.openshift.io/v1alpha1 kind: ScanSetting name: default创建
ScanSettingBinding对象:$ oc create -n openshift-compliance -f new-scansettingbinding.yaml输出示例
scansettingbinding.compliance.openshift.io/nist-moderate-modified created
5.9. 检索 Compliance Operator 原始结果
为 OpenShift Container Platform 集群提供合规性时,您可能需要提供扫描结果以供审核。
5.9.1. 从持久性卷中获取 Compliance Operator 原始结果
流程
Compliance Operator 生成原始结果并将其存储在持久性卷中。这些结果采用资产报告格式 (ARF)。
探索
ComplianceSuite对象:$ oc get compliancesuites nist-moderate-modified \ -o json -n openshift-compliance | jq '.status.scanStatuses[].resultsStorage'输出示例
{ "name": "ocp4-moderate", "namespace": "openshift-compliance" } { "name": "nist-moderate-modified-master", "namespace": "openshift-compliance" } { "name": "nist-moderate-modified-worker", "namespace": "openshift-compliance" }这显示了可以访问原始结果的持久性卷声明。
使用其中一个结果的名称和命名空间来验证原始数据位置:
$ oc get pvc -n openshift-compliance rhcos4-moderate-worker输出示例
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE rhcos4-moderate-worker Bound pvc-548f6cfe-164b-42fe-ba13-a07cfbc77f3a 1Gi RWO gp2 92m通过生成挂载卷并复制结果的 Pod 来获取原始结果:
$ oc create -n openshift-compliance -f pod.yamlpod.yaml 示例
apiVersion: "v1" kind: Pod metadata: name: pv-extract spec: containers: - name: pv-extract-pod image: registry.access.redhat.com/ubi8/ubi command: ["sleep", "3000"] volumeMounts: - mountPath: "/workers-scan-results" name: workers-scan-vol volumes: - name: workers-scan-vol persistentVolumeClaim: claimName: rhcos4-moderate-workerPod 运行后,下载结果:
$ oc cp pv-extract:/workers-scan-results -n openshift-compliance .重要生成挂载持久性卷的 Pod 会将声明保留为
Bound。如果使用中的卷存储类的权限设置为ReadWriteOnce,则该卷每次只能被一个 Pod 挂载。您必须在完成后删除 Pod,否则 Operator 将无法调度 Pod 并继续在此位置存储结果。提取完成后,可以删除 Pod:
$ oc delete pod pv-extract -n openshift-compliance
5.10. 管理 Compliance Operator 结果和补救
每个 ComplianceCheckResult 都代表一次合规性规则检查的结果。如果该规则可自动修复,则创建一个具有相同名称的 ComplianceRemediation 对象,由 ComplianceCheckResult 拥有。除非请求,否则不会自动应用补救,这使 OpenShift Container Platform 管理员有机会审阅补救的用途,且仅在验证后应用补救。
5.10.1. 过滤合规性检查结果
默认情况下,ComplianceCheckResult 对象使用几个有用的标签标记,允许您查询检查,并决定生成结果后的后续步骤。
列出属于特定套件的检查:
$ oc get -n openshift-compliance compliancecheckresults \
-l compliance.openshift.io/suite=workers-compliancesuite列出属于特定扫描的检查:
$ oc get -n openshift-compliance compliancecheckresults \
-l compliance.openshift.io/scan=workers-scan
不是所有的 ComplianceCheckResult 对象都会创建 ComplianceRemediation 对象。只有可自动修复的 ComplianceCheckResult 对象。如果 ComplianceCheckResult 对象带有 compliance.openshift.io/automated-remediation 标签,则该对象具有相关的补救。补救的名称与检查的名称相同。
列出可自动修复的所有失败检查:
$ oc get -n openshift-compliance compliancecheckresults \
-l 'compliance.openshift.io/check-status=FAIL,compliance.openshift.io/automated-remediation'列出所有失败的检查(按严重性排序):
$ oc get compliancecheckresults -n openshift-compliance \
-l 'compliance.openshift.io/check-status=FAIL,compliance.openshift.io/check-severity=high'输出示例
NAME STATUS SEVERITY
nist-moderate-modified-master-configure-crypto-policy FAIL high
nist-moderate-modified-master-coreos-pti-kernel-argument FAIL high
nist-moderate-modified-master-disable-ctrlaltdel-burstaction FAIL high
nist-moderate-modified-master-disable-ctrlaltdel-reboot FAIL high
nist-moderate-modified-master-enable-fips-mode FAIL high
nist-moderate-modified-master-no-empty-passwords FAIL high
nist-moderate-modified-master-selinux-state FAIL high
nist-moderate-modified-worker-configure-crypto-policy FAIL high
nist-moderate-modified-worker-coreos-pti-kernel-argument FAIL high
nist-moderate-modified-worker-disable-ctrlaltdel-burstaction FAIL high
nist-moderate-modified-worker-disable-ctrlaltdel-reboot FAIL high
nist-moderate-modified-worker-enable-fips-mode FAIL high
nist-moderate-modified-worker-no-empty-passwords FAIL high
nist-moderate-modified-worker-selinux-state FAIL high
ocp4-moderate-configure-network-policies-namespaces FAIL high
ocp4-moderate-fips-mode-enabled-on-all-nodes FAIL high列出必须手动修复的所有失败检查:
$ oc get -n openshift-compliance compliancecheckresults \
-l 'compliance.openshift.io/check-status=FAIL,!compliance.openshift.io/automated-remediation'
手动补救步骤通常存储在 ComplianceCheckResult 对象的 description 属性中。
| ComplianceCheckResult 状态 | 描述 |
|---|---|
| PASS | 合规检查运行完成并通过。 |
| FAIL | 合规检查运行完并失败。 |
| INFO | 合规检查运行完毕,并发现一些不严重的、不被视为错误的问题。 |
| 手动 | 合规检查没有方法自动评估成功或失败,必须手动检查。 |
| INCONSISTENT | 合规检查报告来自不同来源的结果,通常是集群节点。 |
| ERROR | 合规性检查运行,但无法正确完成。 |
| NOT-APPLICABLE | 合规检查未运行,因为它不适用或未选中。 |
5.10.2. 审阅补救
审阅拥有补救的 ComplianceRemediation 对象和 ComplianceCheckResult 对象。ComplianceCheckResult 对象包含有关检查作用和试图避免的强化的人类可读描述,以及其他 metadata,如重要性和相关的安全控制。ComplianceRemediation 对象代表可以解决 ComplianceCheckResult 中描述的问题的一种方式。第一次扫描后,检查状态为 MissingDependencies 的补救。
下面是名为 sysctl-net-ipv4-conf-all-accept-redirects 的检查和补救示例。此示例经过修订,仅显示 spec 和 status,省略了 metadata:
spec:
apply: false
current:
object:
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- path: /etc/sysctl.d/75-sysctl_net_ipv4_conf_all_accept_redirects.conf
mode: 0644
contents:
source: data:,net.ipv4.conf.all.accept_redirects%3D0
outdated: {}
status:
applicationState: NotApplied
补救有效负载存储在 spec.current 属性中。有效负载可以是任何 Kubernetes 对象,但因为此补救是通过节点扫描生成的,上例中的补救有效负载是 MachineConfig 对象。对于平台扫描,补救有效负载通常是其他类型的对象(如 ConfigMap 或 Secret),但是否应用这种补救通常取决于管理员,否则 Compliance Operator 需要一组非常广泛的权限才能操作任何通用 Kubernetes 对象。本文稍后会提供补救平台检查的示例。
要查看应用补救时的具体操作,MachineConfig 对象内容将使用 Ignition 对象进行配置。有关格式的更多信息,请参阅 Ignition 规格。在示例中,spec.config.storage.files[0].path 属性指定由该补救创建的文件 (/etc/sysctl.d/75-sysctl_net_ipv4_conf_all_accept_redirects.conf),spec.config.storage.files[0].contents.source 属性指定该文件的内容。
文件的内容是 URL 编码的。
使用以下 Python 脚本查看内容:
$ echo "net.ipv4.conf.all.accept_redirects%3D0" | python3 -c "import sys, urllib.parse; print(urllib.parse.unquote(''.join(sys.stdin.readlines())))"输出示例
net.ipv4.conf.all.accept_redirects=05.10.3. 使用自定义机器配置池时应用补救
当您创建自定义 MachineConfigPool 时,在 MachineConfigPool 中添加一个标签,以便 KubeletConfig 中的 machineConfigPoolSelector 可以与 MachineConfigPool 的标签匹配。
不要在 KubeletConfig 文件中设置 protectKernelDefaults: false,因为 Compliance Operator 完成应用补救后,MachineConfigPool 对象可能无法意外暂停。
流程
列出节点。
$ oc get nodes -n openshift-compliance输出示例
NAME STATUS ROLES AGE VERSION ip-10-0-128-92.us-east-2.compute.internal Ready master 5h21m v1.23.3+d99c04f ip-10-0-158-32.us-east-2.compute.internal Ready worker 5h17m v1.23.3+d99c04f ip-10-0-166-81.us-east-2.compute.internal Ready worker 5h17m v1.23.3+d99c04f ip-10-0-171-170.us-east-2.compute.internal Ready master 5h21m v1.23.3+d99c04f ip-10-0-197-35.us-east-2.compute.internal Ready master 5h22m v1.23.3+d99c04f为节点添加标签。
$ oc -n openshift-compliance \ label node ip-10-0-166-81.us-east-2.compute.internal \ node-role.kubernetes.io/<machine_config_pool_name>=输出示例
node/ip-10-0-166-81.us-east-2.compute.internal labeled创建自定义
MachineConfigPoolCR。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: <machine_config_pool_name> labels: pools.operator.machineconfiguration.openshift.io/<machine_config_pool_name>: ''1 spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,<machine_config_pool_name>]} nodeSelector: matchLabels: node-role.kubernetes.io/<machine_config_pool_name>: ""- 1
labels字段定义要为机器配置池(MCP)添加的标签名称。
验证 MCP 是否已成功创建。
$ oc get mcp -w
5.10.4. 根据默认配置值评估 KubeletConfig 规则
OpenShift Container Platform 基础架构可能会在运行时包含不完整的配置文件,节点会假定缺少配置选项的默认配置值。某些配置选项可以作为命令行参数传递。因此,Compliance Operator 无法验证节点上的配置文件是否已完成,因为它可能会在规则检查中缺失选项。
要防止出现假的负结果(默认配置值通过检查,但实际应该失败),Compliance Operator 使用 Node/Proxy API 获取节点池中每个节点的配置,然后节点池中的所有配置选项都存储在代表该节点池中所有节点配置的文件中。这提高了扫描结果的准确性。
使用带有默认 master 和 worker 节点池配置的此功能不需要额外的配置更改。
5.10.5. 扫描自定义节点池
Compliance Operator 不会维护每个节点池配置的副本。Compliance Operator 将单一节点池中的所有节点的一致性配置选项聚合到配置文件的一个副本中。然后,Compliance Operator 使用特定节点池的配置文件来评估针对该池中的节点的规则。
如果您的集群使用默认 worker 和 master 节点池以外的自定义节点池,则必须提供额外变量以确保 Compliance Operator 聚合了该节点池的配置文件。
流程
要针对包含
master、worker和自定义示例节点池的example集群中的所有池检查配置,将TailoredProfile对象中的ocp-var-role-master和opc-var-role-worker字段的值设置为example:apiVersion: compliance.openshift.io/v1alpha1 kind: TailoredProfile metadata: name: cis-example-tp spec: extends: ocp4-cis title: My modified NIST profile to scan example nodes setValues: - name: ocp4-var-role-master value: example rationale: test for example nodes - name: ocp4-var-role-worker value: example rationale: test for example nodes description: cis-example-scan将
example角色添加到要存储在ScanSettingBindingCR 中的ScanSetting对象中:apiVersion: compliance.openshift.io/v1alpha1 kind: ScanSetting metadata: name: default namespace: openshift-compliance rawResultStorage: rotation: 3 size: 1Gi roles: - worker - master - example scanTolerations: - effect: NoSchedule key: node-role.kubernetes.io/master operator: Exists schedule: '0 1 * * *'创建使用
ScanSettingBindingCR 的扫描:apiVersion: compliance.openshift.io/v1alpha1 kind: ScanSettingBinding metadata: name: cis namespace: openshift-compliance profiles: - apiGroup: compliance.openshift.io/v1alpha1 kind: Profile name: ocp4-cis - apiGroup: compliance.openshift.io/v1alpha1 kind: Profile name: ocp4-cis-node - apiGroup: compliance.openshift.io/v1alpha1 kind: TailoredProfile name: cis-example-tp settingsRef: apiGroup: compliance.openshift.io/v1alpha1 kind: ScanSetting name: default
Compliance Operator 通过 Node/Proxy API 对象检查运行时 KubeletConfig,然后使用 ocp-var-role-master 和 ocp-var-role-worker 等变量来确定它对其执行检查的节点。在 ComplianceCheckResult 中,Kubelet 规则显示为 ocp4-cis-kubelet-*。只有在所有选择的节点都通过此检查时,才会通过扫描。
验证
平台 KubeletConfig 规则通过
Node/Proxy对象检查。您可以运行以下命令来查找这些规则:$ oc get rules -o json | jq '.items[] | select(.checkType == "Platform") | select(.metadata.name | contains("ocp4-kubelet-")) | .metadata.name'
5.10.6. 修复 KubeletConfig 子池
KubeletConfig 补救标签可以应用到 MachineConfigPool 子池。
流程
在子池
MachineConfigPoolCR 中添加标签:$ oc label mcp <sub-pool-name> pools.operator.machineconfiguration.openshift.io/<sub-pool-name>=
5.10.7. 应用补救
布尔值属性 spec.apply 控制 Compliance Operator 是否应该应用补救。您可以通过将属性设置为 true 来应用补救:
$ oc -n openshift-compliance \
patch complianceremediations/<scan-name>-sysctl-net-ipv4-conf-all-accept-redirects \
--patch '{"spec":{"apply":true}}' --type=merge
在 Compliance Operator 处理应用的补救后,status.ApplicationState 属性会更改为 Applied 或在出错时更改为 Error。应用机器配置补救时,该补救与其他应用的补救一起渲染为名为 75-$scan-name-$suite-name 的 MachineConfig 对象。MachineConfig 对象随后由 Machine Config Operator 渲染,最终由在每个节点上运行的机器控制守护进程实例应用到机器配置池中的所有节点。
请注意,当 MachineConfigOperator 将新的 MachineConfig 对象应用到池中的节点时,属于池的所有节点都会重启。应用多个补救时,这可能会不方便,每个补救都会重新渲染组合 75-$scan-name-$suite-name MachineConfig 对象。要防止立即应用补救,您可以通过将 MachineConfigPool 对象的 .spec.paused 属性设置为 true 来暂停机器配置池。
Compliance Operator 可以自动应用补救。在 ScanSetting 顶层对象中设置 autoApplyRemediations: true。
只有经过仔细考虑才能自动应用补救。
5.10.8. 手动补救平台检查
检查平台扫描通常必须由管理员手动修复,原因有两个:
- 并不总是能够自动决定必须设置的值。其中一项检查要求提供允许的 registry 列表,但扫描程序并不知道组织要允许哪些 registry。
-
不同的检查会修改不同的 API 对象,需要自动补救以拥有
root或超级用户访问权限来修改集群中的对象,但不建议这样做。
流程
以下示例使用
ocp4-ocp-allowed-registries-for-import规则,这在默认 OpenShift Container Platform 安装中会失败。检查规则oc get rule. compliance/ocp4-ocp-allowed-registries-for-import -oyaml,该规则通过设置allowedRegistriesForImport属性来限制允许用户从中导入镜像的 registry,该规则的 warning 属性还会显示已检查的 API 对象,因此可以修改它并修复问题:$ oc edit image.config.openshift.io/cluster输出示例
apiVersion: config.openshift.io/v1 kind: Image metadata: annotations: release.openshift.io/create-only: "true" creationTimestamp: "2020-09-10T10:12:54Z" generation: 2 name: cluster resourceVersion: "363096" selfLink: /apis/config.openshift.io/v1/images/cluster uid: 2dcb614e-2f8a-4a23-ba9a-8e33cd0ff77e spec: allowedRegistriesForImport: - domainName: registry.redhat.io status: externalRegistryHostnames: - default-route-openshift-image-registry.apps.user-cluster-09-10-12-07.devcluster.openshift.com internalRegistryHostname: image-registry.openshift-image-registry.svc:5000重新运行扫描:
$ oc -n openshift-compliance \ annotate compliancescans/rhcos4-e8-worker compliance.openshift.io/rescan=
5.10.9. 更新补救
使用新版本的合规性内容时,可能会提供与之前版本不同的新补救版本。Compliance Operator 将保留应用的旧版本补救。OpenShift Container Platform 管理员还收到要审核和应用的新版本通知。之前应用的 ComplianceRemediation 对象已更新,它的状态已更改为 Outdated。过时的对象已标识,因此可轻松搜索。
以前应用的补救内容将存储在 ComplianceRemediation 对象的 spec.outdated 属性中,新的更新内容将存储在 spec.current 属性中。将内容更新至新版本后,管理员需要审查补救。只要 spec.outdated 属性存在,它将用来渲染生成的 MachineConfig 对象。删除 spec.outdated 属性后,Compliance Operator 会重新渲染生成的 MachineConfig 对象,导致 Operator 将配置推送到节点。
流程
搜索任何过时的补救:
$ oc -n openshift-compliance get complianceremediations \ -l complianceoperator.openshift.io/outdated-remediation=输出示例
NAME STATE workers-scan-no-empty-passwords Outdated当前应用的补救存储在
Outdated属性中,未应用的新补救存储在Current属性中。如果您对新版本满意,可删除Outdated字段。如果要保留更新的内容,可删除Current和Outdated属性。应用更新的补救版本:
$ oc -n openshift-compliance patch complianceremediations workers-scan-no-empty-passwords \ --type json -p '[{"op":"remove", "path":/spec/outdated}]'补救状态将从
Outdated切换为Applied:$ oc get -n openshift-compliance complianceremediations workers-scan-no-empty-passwords输出示例
NAME STATE workers-scan-no-empty-passwords Applied- 节点将应用更新的补救版本并重新引导。
5.10.10. 取消应用补救
可能需要取消应用之前应用的补救。
流程
将
apply标志设置为false:$ oc -n openshift-compliance \ patch complianceremediations/rhcos4-moderate-worker-sysctl-net-ipv4-conf-all-accept-redirects \ --patch '{"spec":{"apply":false}}' --type=merge补救状态将更改为
NotApplied,组合MachineConfig对象会被重新渲染,不包含补救。重要所有包含补救的受影响节点都将被重新引导。
5.10.11. 删除 KubeletConfig 补救
KubeletConfig 补救包括在节点级别的配置集中。要删除 KubeletConfig 补救,您必须手动将其从 KubeletConfig 对象中删除。本例演示了如何删除 one-rule-tp-node-master-kubelet-eviction-thresholds-set-hard-imagefs-available 补救的合规性检查。
流程
找到
one-rule-tp-node-master-kubelet-eviction-thresholds-set-hard-imagefs-available补救的scan-name和合规检查:$ oc -n openshift-compliance get remediation \ one-rule-tp-node-master-kubelet-eviction-thresholds-set-hard-imagefs-available -o yaml输出示例
apiVersion: compliance.openshift.io/v1alpha1 kind: ComplianceRemediation metadata: annotations: compliance.openshift.io/xccdf-value-used: var-kubelet-evictionhard-imagefs-available creationTimestamp: "2022-01-05T19:52:27Z" generation: 1 labels: compliance.openshift.io/scan-name: one-rule-tp-node-master1 compliance.openshift.io/suite: one-rule-ssb-node name: one-rule-tp-node-master-kubelet-eviction-thresholds-set-hard-imagefs-available namespace: openshift-compliance ownerReferences: - apiVersion: compliance.openshift.io/v1alpha1 blockOwnerDeletion: true controller: true kind: ComplianceCheckResult name: one-rule-tp-node-master-kubelet-eviction-thresholds-set-hard-imagefs-available uid: fe8e1577-9060-4c59-95b2-3e2c51709adc resourceVersion: "84820" uid: 5339d21a-24d7-40cb-84d2-7a2ebb015355 spec: apply: true current: object: apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig spec: kubeletConfig: evictionHard: imagefs.available: 10%2 outdated: {} type: Configuration status: applicationState: Applied注意如果补救调用
evictionHardkubelet 配置,您必须指定所有evictionHard参数:memory.available、nodefs.available、nodefs.inodesFree、imagefs.available和imagefs.inodesFree。如果没有指定所有参数,则只应用指定的参数,补救无法正常工作。删除补救:
为补救对象将
apply设置为 false:$ oc -n openshift-compliance patch \ complianceremediations/one-rule-tp-node-master-kubelet-eviction-thresholds-set-hard-imagefs-available \ -p '{"spec":{"apply":false}}' --type=merge使用
scan-name,找到补救应用到的KubeletConfig对象:$ oc -n openshift-compliance get kubeletconfig \ --selector compliance.openshift.io/scan-name=one-rule-tp-node-master输出示例
NAME AGE compliance-operator-kubelet-master 2m34s从
KubeletConfig对象手动删除补救imagefs.available: 10%:$ oc edit -n openshift-compliance KubeletConfig compliance-operator-kubelet-master重要所有包含补救的受影响节点都将被重新引导。
您还必须在定制的配置集中排除任何调度的扫描规则,这些配置集自动应用补救,否则会在下一次调度的扫描过程中重新应用补救。
5.10.12. Inconsistent ComplianceScan
ScanSetting 对象列出了合规性扫描从 ScanSetting 或 ScanSettingBinding 对象扫描的节点角色。每个节点角色通常映射到机器配置池。
机器配置池中的所有机器都应该相同,池中节点的所有扫描结果都应该相同。
如果某些结果与其他结果不同,Compliance Operator 将标记一些节点将报告为 INCONSISTENT 的 ComplianceCheckResult 对象。所有 ComplianceCheckResult 对象也都标有 compliance.openshift.io/inconsistent-check。
因为池中的机器数量可能非常大,所以 Compliance Operator 会尝试找到最常用的状态,并列出与常见状态不同的节点。最常见的状态存储在 compliance.openshift.io/most-common-status 注解中,注解 compliance.openshift.io/inconsistent-source 包含与最常见状态不同的 hostname:status 检查状态对。如果没有找到常见状态,则所有 hostname:status 对都列在 compliance.openshift.io/inconsistent-source annotation 中。
如果可能,仍会创建补救,以便集群可以整合到兼容状态。但是,并非总是能够创建补救,必须手动纠正节点之间的差异。必须使用 compliance.openshift.io/rescan= 选项为扫描添加注解来重新运行合规性扫描,以得到一致的结果:
$ oc -n openshift-compliance \
annotate compliancescans/rhcos4-e8-worker compliance.openshift.io/rescan=5.11. 执行高级 Compliance Operator 任务
Compliance Operator 包含适用于高级用户的选项,用于调试或与现有工具集成。
5.11.1. 直接使用 ComplianceSuite 和 ComplianceScan 对象
虽然建议用户利用 ScanSetting 和 ScanSettingBinding 对象来定义套件和扫描,但也有直接定义 ComplianceSuite 对象的有效用例:
-
仅指定单个规则进行扫描。这可与
debug: true属性一起用于调试,提高 OpenSCAP 扫描程序的详细程度,否则调试模式会变得非常冗长。将测试限制为一条规则有助于减少调试信息的数量。 - 提供自定义 nodeSelector。要使补救适用,nodeSelector 必须与一个池匹配。
- 使用定制文件将 Scan 指向定制配置映射。
- 不需要从捆绑包解析配置集的消耗成本时用于测试或开发。
以下示例显示仅使用一条规则扫描 worker 机器的 ComplianceSuite:
apiVersion: compliance.openshift.io/v1alpha1
kind: ComplianceSuite
metadata:
name: workers-compliancesuite
spec:
scans:
- name: workers-scan
profile: xccdf_org.ssgproject.content_profile_moderate
content: ssg-rhcos4-ds.xml
contentImage: quay.io/complianceascode/ocp4:latest
debug: true
rule: xccdf_org.ssgproject.content_rule_no_direct_root_logins
nodeSelector:
node-role.kubernetes.io/worker: ""
上面提到的 ComplianceSuite 对象和 ComplianceScan 对象以 OpenSCAP 期望的格式指定多个属性。
要找到配置集、内容或规则值,您可以先从 ScanSetting 和 ScanSettingBinding 创建类似的 Suite 或检查从 ProfileBundle 对象中解析的对象,如规则或配置集。这些对象包含可以从 ComplianceSuite 中引用它们的 xccdf_org 标识符。
5.11.2. 为 ScanSetting 扫描设置 PriorityClass
在大规模环境中,默认的 PriorityClass 对象可能太低,以保证 Pod 在其上执行扫描。对于必须保持合规或保证自动扫描的集群,建议设置 PriorityClass 变量,以确保 Compliance Operator 始终在资源约束的情况下赋予优先级。
流程
设置
PriorityClass变量:apiVersion: compliance.openshift.io/v1alpha1 strictNodeScan: true metadata: name: default namespace: openshift-compliance priorityClass: compliance-high-priority1 kind: ScanSetting showNotApplicable: false rawResultStorage: nodeSelector: node-role.kubernetes.io/master: '' pvAccessModes: - ReadWriteOnce rotation: 3 size: 1Gi tolerations: - effect: NoSchedule key: node-role.kubernetes.io/master operator: Exists - effect: NoExecute key: node.kubernetes.io/not-ready operator: Exists tolerationSeconds: 300 - effect: NoExecute key: node.kubernetes.io/unreachable operator: Exists tolerationSeconds: 300 - effect: NoSchedule key: node.kubernetes.io/memory-pressure operator: Exists schedule: 0 1 * * * roles: - master - worker scanTolerations: - operator: Exists- 1
- 如果无法找到
ScanSetting中引用的PriorityClass,Operator 会将PriorityClass留空,发出警告,并在没有PriorityClass的情况下继续调度扫描。
5.11.3. 使用原始定制配置集
尽管 TailoredProfile CR 支持最常见的定制操作,但 XCCDF 标准在定制 OpenSCAP 配置集方面具有更大的灵活性。此外,如果您的机构之前一直使用 OpenScap,则您可能有一个现有的 XCCDF 定制文件可重复使用。
ComplianceSuite 对象包含可指向自定义定制文件的可选 TailoringConfigMap 属性。TailoringConfigMap 属性的值是一个配置映射的名称,它必须包含名为 tailoring.xml 的键,这个键的值是定制内容。
流程
从一个文件创建
ConfigMap对象:$ oc -n openshift-compliance \ create configmap nist-moderate-modified \ --from-file=tailoring.xml=/path/to/the/tailoringFile.xml在属于 Suite 的 Scan 中引用定制文件:
apiVersion: compliance.openshift.io/v1alpha1 kind: ComplianceSuite metadata: name: workers-compliancesuite spec: debug: true scans: - name: workers-scan profile: xccdf_org.ssgproject.content_profile_moderate content: ssg-rhcos4-ds.xml contentImage: quay.io/complianceascode/ocp4:latest debug: true tailoringConfigMap: name: nist-moderate-modified nodeSelector: node-role.kubernetes.io/worker: ""
5.11.4. 执行重新扫描
通常,您希望按指定时间表重新运行扫描,如每周一或每天。在修复节点上的问题后,重新运行一次扫描也很有用。要执行单次扫描,可使用 compliance.openshift.io/rescan= 选项注解扫描:
$ oc -n openshift-compliance \
annotate compliancescans/rhcos4-e8-worker compliance.openshift.io/rescan=
一个重新扫描会为 rhcos-moderate 配置集生成四个额外的 mc :
$ oc get mc输出示例
75-worker-scan-chronyd-or-ntpd-specify-remote-server
75-worker-scan-configure-usbguard-auditbackend
75-worker-scan-service-usbguard-enabled
75-worker-scan-usbguard-allow-hid-and-hub
应用扫描设置 default-auto-apply 标签时,补救会自动应用并过时的补救更新。如果存在由于依赖项或已经过时的补救没有被应用的补救,重新扫描会应用补救,并可能会触发重启。只有使用 MachineConfig 对象触发器重启的补救。如果没有要应用的更新或依赖项,则不会重启。
5.11.5. 为结果设置自定义存储大小
虽然 ComplianceCheckResult 等自定义资源表示一次检查跨所有扫描节点的聚合结果,但审阅扫描程序生成的原始结果会很有用。原始结果以 ARF 格式生成,可能较大(每个节点几十兆字节),将其存储在由 etcd 键-值存储支持的 Kubernetes 资源中是不切实际的。相反,每次扫描都会创建一个默认为 1GB 大小的 PV。根据您的环境,您可能想要相应地增大 PV 大小。这可以使用在 ScanSetting 和 ComplianceScan 资源中公开的 rawResultStorage.size 属性完成。
相关的参数是 rawResultStorage.rotation,它控制在旧的扫描被轮转前 PV 中保留的扫描次数。默认值为 3,将轮转策略设置为 0 可禁用轮转。根据默认轮转策略和每个原始 ARF 扫描报告 100MB 的估计大小,您可以计算出环境的正确 PV 大小。
5.11.5.1. 使用自定义结果存储值
由于 OpenShift Container Platform 可以在各种公有云或裸机中部署,因此 Compliance Operator 无法决定可用的存储配置。默认情况下,Compliance Operator 会尝试使用集群的默认存储类创建 PV 来存储结果,但可以使用 rawResultStorage.StorageClassName 属性配置自定义存储类。
如果您的集群没有指定默认存储类,则必须设置此属性。
将 ScanSetting 自定义资源配置为使用标准存储类,并创建大小为 10GB 的持久性卷,并保留最后 10 个结果:
ScanSetting CR 示例
apiVersion: compliance.openshift.io/v1alpha1
kind: ScanSetting
metadata:
name: default
namespace: openshift-compliance
rawResultStorage:
storageClassName: standard
rotation: 10
size: 10Gi
roles:
- worker
- master
scanTolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
operator: Exists
schedule: '0 1 * * *'5.11.6. 应用套件扫描生成的补救
虽然您可以使用 ComplianceSuite 对象中的 autoApplyRemediations 布尔值参数但您可以使用 compliance.openshift.io/apply-remediations 为对象添加注解。这允许 Operator 应用所有创建的补救。
流程
-
运行以下命令应用
compliance.openshift.io/apply-remediations注解:
$ oc -n openshift-compliance \
annotate compliancesuites/workers-compliancesuite compliance.openshift.io/apply-remediations=5.11.7. 自动更新补救
在某些情况下带有较新内容的扫描可能会将补救标记为 OUTDATED。作为管理员您可以应用 compliance.openshift.io/remove-outdated 注解来应用新的补救并删除过时的补救。
流程
-
应用
compliance.openshift.io/remove-outdated注解:
$ oc -n openshift-compliance \
annotate compliancesuites/workers-compliancesuite compliance.openshift.io/remove-outdated=
或者在 ScanSetting 或 ComplianceSuite 对象中设置 autoUpdateRemediations 标志以自动更新补救。
5.11.8. 为 Compliance Operator 创建自定义 SCC
在一些环境中,您必须创建一个自定义安全性上下文约束(SCC)文件,以确保 Compliance Operator api-resource-collector 使用正确的权限。
先决条件
-
您必须具有
admin权限。
流程
在名为
restricted-adjusted-compliance.yaml的 YAML 文件中定义 SCC:SecurityContextConstraints对象定义allowHostDirVolumePlugin: false allowHostIPC: false allowHostNetwork: false allowHostPID: false allowHostPorts: false allowPrivilegeEscalation: true allowPrivilegedContainer: false allowedCapabilities: null apiVersion: security.openshift.io/v1 defaultAddCapabilities: null fsGroup: type: MustRunAs kind: SecurityContextConstraints metadata: name: restricted-adjusted-compliance priority: 301 readOnlyRootFilesystem: false requiredDropCapabilities: - KILL - SETUID - SETGID - MKNOD runAsUser: type: MustRunAsRange seLinuxContext: type: MustRunAs supplementalGroups: type: RunAsAny users: - system:serviceaccount:openshift-compliance:api-resource-collector2 volumes: - configMap - downwardAPI - emptyDir - persistentVolumeClaim - projected - secret创建 SCC:
$ oc create -n openshift-compliance -f restricted-adjusted-compliance.yaml输出示例
securitycontextconstraints.security.openshift.io/restricted-adjusted-compliance created
验证
验证是否已创建 SCC:
$ oc get -n openshift-compliance scc restricted-adjusted-compliance输出示例
NAME PRIV CAPS SELINUX RUNASUSER FSGROUP SUPGROUP PRIORITY READONLYROOTFS VOLUMES restricted-adjusted-compliance false <no value> MustRunAs MustRunAsRange MustRunAs RunAsAny 30 false ["configMap","downwardAPI","emptyDir","persistentVolumeClaim","projected","secret"]
5.12. 对 Compliance Operator 进行故障排除
本节介绍如何对 Compliance Operator 进行故障排除。该信息可用于诊断问题或在错误报告中提供信息。一些常规提示:
出现重大事件时,Compliance Operator 会发出 Kubernetes 事件。您可以使用以下命令查看集群中的所有事件:
$ oc get events -n openshift-compliance或者使用以下命令查看 Scan 等对象的事件:
$ oc describe -n openshift-compliance compliancescan/cis-complianceCompliance Operator 由多个控制器组成,大约每个 API 对象一个。仅过滤对应于有问题的 API 对象的控制器很有用。如果无法应用
ComplianceRemediation,请查看remediationctrl控制器中的信息。可以通过使用jq进行解析来过滤单个控制器中的信息:$ oc -n openshift-compliance logs compliance-operator-775d7bddbd-gj58f \ | jq -c 'select(.logger == "profilebundlectrl")'在 UTC 中,自 UNIX 时间戳以来的时间戳以秒为单位记录。要将其转换为人类可读的日期,请使用
date -d @timestamp --utc,例如:$ date -d @1596184628.955853 --utc-
很多自定义资源允许设置
debug选项,最重要的是ComplianceSuite和ScanSetting。启用此选项会增加 OpenSCAP 扫描程序 Pod 以及其他一些帮助程序 Pod 的详细程度。 -
如果单个规则意外传递或失败,则仅使用该规则运行单次扫描或 suite 从相应的
ComplianceCheckResult对象中查找规则 ID 并将其用作ScanCR 中的rule属性值会很有帮助。然后再启用debug选项,扫描程序 Pod 中的scanner容器日志会显示原始 OpenSCAP 日志。
5.12.1. 扫描剖析
以下各节概述了 Compliance Operator 扫描的组件和阶段。
5.12.1.1. 合规性源
合规性内容存储在从 ProfileBundle 对象生成的 Profile 对象中。Compliance Operator 为集群创建一个 ProfileBundle 对象,并为集群节点创建另一个对象。
$ oc get -n openshift-compliance profilebundle.compliance$ oc get -n openshift-compliance profile.compliance
ProfileBundle 对象由带有 Bundle 名称标签的部署处理。要使用 Bundle 排除问题,可以查找部署并查看部署中的 Pod 日志:
$ oc logs -n openshift-compliance -lprofile-bundle=ocp4 -c profileparser$ oc get -n openshift-compliance deployments,pods -lprofile-bundle=ocp4$ oc logs -n openshift-compliance pods/<pod-name>$ oc describe -n openshift-compliance pod/<pod-name> -c profileparser5.12.1.2. ScanSetting 和 ScanSettingBinding 对象生命周期和调试
通过有效的合规性内容源,可以使用高级 ScanSetting 和 ScanSettingBinding 对象来生成 ComplianceSuite 和 ComplianceScan 对象:
apiVersion: compliance.openshift.io/v1alpha1
kind: ScanSetting
metadata:
name: my-companys-constraints
debug: true
# For each role, a separate scan will be created pointing
# to a node-role specified in roles
roles:
- worker
---
apiVersion: compliance.openshift.io/v1alpha1
kind: ScanSettingBinding
metadata:
name: my-companys-compliance-requirements
profiles:
# Node checks
- name: rhcos4-e8
kind: Profile
apiGroup: compliance.openshift.io/v1alpha1
# Cluster checks
- name: ocp4-e8
kind: Profile
apiGroup: compliance.openshift.io/v1alpha1
settingsRef:
name: my-companys-constraints
kind: ScanSetting
apiGroup: compliance.openshift.io/v1alpha1
ScanSetting 和 ScanSettingBinding 对象均由标记为 logger=scansettingbindingctrl 的同一控制器处理。这些对象没有状态。任何问题都以事件的形式传递:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuiteCreated 9m52s scansettingbindingctrl ComplianceSuite openshift-compliance/my-companys-compliance-requirements created
现在创建一个 ComplianceSuite 对象。流继续协调新创建的 ComplianceSuite。
5.12.1.3. ComplianceSuite 自定义资源生命周期和调试
ComplianceSuite CR 是一个围绕 ComplianceScan CR 的 wrapper。ComplianceSuite CR 由标记为 logger=suitectrl 的控制器处理。该控制器处理从 Suite 创建 Scan 的过程,将单个扫描状态协调并整合为一个 Suite 状态。如果将 Suite 设置为定期执行,suitectrl 也会处理创建 CronJob CR 的事件,该 CR 在初始运行完成后会在 Suite 中重新运行 Scan:
$ oc get cronjobs输出示例
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
<cron_name> 0 1 * * * False 0 <none> 151m
对于最重要的问题,会发出事件。使用 oc describe compliancesuites/<name> 查看它们。Suite 对象还有一个 Status 子资源,当属于这个 Suite 的任何 Scan 对象更新其 Status 子资源时,这个子资源会更新。创建所有预期扫描后,控制会被传递给扫描控制器。
5.12.1.4. ComplianceScan 自定义资源生命周期和调试
ComplianceScan CR 由 scanctrl 控制器处理。这也是进行实际扫描以及创建扫描结果的地方。每次扫描都经过几个阶段:
5.12.1.4.1. 待处理阶段
在此阶段验证扫描是否正确。如果存储大小等参数无效,则扫描会转换为 DONE,并包含 ERROR 结果,否则进入启动阶段。
5.12.1.4.2. 启动阶段
在此阶段,一些配置映射包含扫描程序 Pod 的环境或直接包含扫描程序 Pod 要评估的脚本。列出配置映射:
$ oc -n openshift-compliance get cm \
-l compliance.openshift.io/scan-name=rhcos4-e8-worker,complianceoperator.openshift.io/scan-script=扫描程序 pod 将使用这些配置映射。如果您需要修改扫描程序行为,更改扫描程序调试级别或打印原始结果,修改配置映射是一种好方法。随后,每次扫描都会创建一个持久性卷声明,以存储原始 ARF 结果:
$ oc get pvc -n openshift-compliance -lcompliance.openshift.io/scan-name=rhcos4-e8-worker
PVC 由每次扫描进行的 ResultServer 部署挂载。ResultServer 是一个简单的 HTTP 服务器,单个扫描程序 Pod 会将完整 ARF 结果上传到其中。每个服务器都可以在不同节点中运行。完整 ARF 结果可能非常大,您不能假定可以创建同时从多个节点挂载的卷。扫描完成后,ResultServer 部署会缩减。包含原始结果的 PVC 可从另一个自定义 Pod 挂载,并可获取或检查结果。扫描程序 Pod 和 ResultServer 之间的流量受 mutual TLS 协议保护。
最后,扫描程序 Pod 在此阶段启动;一个扫描程序 Pod 用于一个 Platform 扫描实例,每个匹配节点的一个扫描程序 Pod 用于一个 node 扫描实例。每节点 Pod 使用节点名称标识。每个 Pod 始终使用 ComplianceScan 名称标识:
$ oc get pods -lcompliance.openshift.io/scan-name=rhcos4-e8-worker,workload=scanner --show-labels输出示例
NAME READY STATUS RESTARTS AGE LABELS
rhcos4-e8-worker-ip-10-0-169-90.eu-north-1.compute.internal-pod 0/2 Completed 0 39m compliance.openshift.io/scan-name=rhcos4-e8-worker,targetNode=ip-10-0-169-90.eu-north-1.compute.internal,workload=scanner+ 扫描然后进入 Running 阶段。
5.12.1.4.3. 运行阶段
运行阶段会等待扫描程序 Pod 完成。运行阶段使用以下术语和进程:
-
init 容器:有一个名为
content-container的 init 容器。它运行 contentImage 容器,并执行单个命令,该命令将 contentFile 复制到与这个 Pod 中其他容器共享的/content目录中。 -
scanner:此容器运行扫描。对于节点扫描,该容器将节点文件系统作为
/host挂载,并挂载 init 容器交付的内容。该容器还挂载启动阶段创建的entrypointConfigMap并执行它。入口点ConfigMap中的默认脚本执行 OpenSCAP,并将结果文件存储在 Pod 容器之间共享的/results目录中。可查看此 Pod 中的日志以确定 OpenSCAP 扫描程序检查了哪些内容。可使用debug标记查看更详细的输出。 logcollector:logcollector 容器会等待扫描程序容器完成。然后,它会将完整的 ARF 结果上传到
ResultServer,并以ConfigMap的形式单独上传 XCCDF 结果以及扫描结果和 OpenSCAP 结果代码。这些结果配置映射使用扫描名称 (compliance.openshift.io/scan-name=rhcos4-e8-worker) 进行标记:$ oc describe cm/rhcos4-e8-worker-ip-10-0-169-90.eu-north-1.compute.internal-pod输出示例
Name: rhcos4-e8-worker-ip-10-0-169-90.eu-north-1.compute.internal-pod Namespace: openshift-compliance Labels: compliance.openshift.io/scan-name-scan=rhcos4-e8-worker complianceoperator.openshift.io/scan-result= Annotations: compliance-remediations/processed: compliance.openshift.io/scan-error-msg: compliance.openshift.io/scan-result: NON-COMPLIANT OpenSCAP-scan-result/node: ip-10-0-169-90.eu-north-1.compute.internal Data ==== exit-code: ---- 2 results: ---- <?xml version="1.0" encoding="UTF-8"?> ...
用于 Platform 扫描的扫描程序 Pod 类似,以下情况除外:
-
名为
api-resource-collector的一个额外 init 容器读取由 content-container init 容器提供的 OpenSCAP 内容,确定内容需要检查的 API 资源,并将这些 API 资源存储到scanner容器将从中读取它们的共享目录中。 -
scanner容器不需要挂载主机文件系统。
扫描程序 Pod 完成后,扫描将进入聚合阶段。
5.12.1.4.4. 聚合阶段
在聚合阶段,扫描控制器会生成另一个名为聚合器 Pod 的 Pod。它的目的是获取生成的 ConfigMap 对象,读取结果,并为每个检查结果创建对应的 Kubernete 对象。如果可自动补救检查失败,将创建一个 ComplianceRemediation 对象。为了提供人类可读的检查和补救元数据,聚合器 Pod 也会使用 init 容器挂载 OpenSCAP 内容。
当一个配置映射由聚合器 Pod 处理时,会使用 compliance-remediations/processed 标签进行标识。这个阶段会生成 ComplianceCheckResult 对象:
$ oc get compliancecheckresults -lcompliance.openshift.io/scan-name=rhcos4-e8-worker输出示例
NAME STATUS SEVERITY
rhcos4-e8-worker-accounts-no-uid-except-zero PASS high
rhcos4-e8-worker-audit-rules-dac-modification-chmod FAIL medium
和 ComplianceRemediation 对象:
$ oc get complianceremediations -lcompliance.openshift.io/scan-name=rhcos4-e8-worker输出示例
NAME STATE
rhcos4-e8-worker-audit-rules-dac-modification-chmod NotApplied
rhcos4-e8-worker-audit-rules-dac-modification-chown NotApplied
rhcos4-e8-worker-audit-rules-execution-chcon NotApplied
rhcos4-e8-worker-audit-rules-execution-restorecon NotApplied
rhcos4-e8-worker-audit-rules-execution-semanage NotApplied
rhcos4-e8-worker-audit-rules-execution-setfiles NotApplied创建这些 CR 后,聚合器 Pod 将退出,扫描进入完成阶段。
5.12.1.4.5. 完成阶段
在最后的扫描阶段,会根据需要清理扫描资源,如果扫描是一次性的,ResultServer 部署会被缩减,如果扫描是连续性的,会被删除;下一个扫描实例将重新创建部署。
也可以在完成阶段通过注解来触发扫描重新运行:
$ oc -n openshift-compliance \
annotate compliancescans/rhcos4-e8-worker compliance.openshift.io/rescan=
扫描到达完成阶段后,除非将补救设置为使用 autoApplyRemediations: true 自动应用,否则不会自动执行任何其他操作。OpenShift Container Platform 管理员现在将审阅补救并根据需要应用它们。如果将补救设置为自动应用,ComplianceSuite 控制器会在完成阶段接管,暂停扫描映射到的机器配置池,并一次性应用所有补救。如果应用了补救,ComplianceRemediation 控制器将接管。
5.12.1.5. ComplianceRemediation 控制器生命周期和调试
示例扫描报告了一些结果。通过将 apply 属性切换为 true 可启用其中一个补救:
$ oc patch complianceremediations/rhcos4-e8-worker-audit-rules-dac-modification-chmod --patch '{"spec":{"apply":true}}' --type=merge
ComplianceRemediation 控制器 (logger=remediationctrl) 协调修改后的对象。协调的结果是会更改已协调补救对象的状态,也会更改包含所有已应用补救的已渲染的每套件 MachineConfig 对象。
MachineConfig 对象始终以 75- 开头,并以扫描和套件命名:
$ oc get mc | grep 75-输出示例
75-rhcos4-e8-worker-my-companys-compliance-requirements 3.2.0 2m46s
当前包含 mc 的补救列在机器配置的注解中:
$ oc describe mc/75-rhcos4-e8-worker-my-companys-compliance-requirements输出示例
Name: 75-rhcos4-e8-worker-my-companys-compliance-requirements
Labels: machineconfiguration.openshift.io/role=worker
Annotations: remediation/rhcos4-e8-worker-audit-rules-dac-modification-chmod:
ComplianceRemediation 控制器的算法如下:
- 所有当前应用的补救都读取到初始补救集合中。
- 如果要应用协调后的补救,会将其添加到该集合中。
-
MachineConfig对象从集合中渲染,并使用集合中的补救名称进行注解。如果集合为空(未应用最后一个补救),将删除渲染的MachineConfig对象。 - 只有渲染的机器配置与集群中已应用的 MC 不同时,才会更新(或创建,或删除)应用的 MC。
-
创建或修改
MachineConfig对象会触发与machineconfiguration.openshift.io/role标签匹配的节点重新引导 - 请参阅 MachineConfig Operator 文档以了解更多详细信息。
根据需要更新渲染的机器配置并更新协调的补救对象状态后,补救循环即告终止。在本例中,应用补救会触发重新引导。重新引导后,注解扫描以重新运行它:
$ oc -n openshift-compliance \
annotate compliancescans/rhcos4-e8-worker compliance.openshift.io/rescan=扫描将运行并完成。检查补救是否通过:
$ oc -n openshift-compliance \
get compliancecheckresults/rhcos4-e8-worker-audit-rules-dac-modification-chmod输出示例
NAME STATUS SEVERITY
rhcos4-e8-worker-audit-rules-dac-modification-chmod PASS medium5.12.1.6. 有用的标签
Compliance Operator 生成的每个 pod 都专门使用其所属的扫描及其工作来标识。扫描标识符使用 compliance.openshift.io/scan-name 标签进行标识。工作负载标识符使用 workload 标签进行标识。
Compliance Operator 调度以下工作负载:
- scanner:执行合规性扫描。
- resultserver:存储合规性扫描的原始结果。
- aggregator:汇总结果,检测不一致和输出结果对象(检查结果和补救)。
- suitererunner:将标记一个要重新运行的套件(设定时间表时)。
- profileparser:解析数据流并创建适当的配置集、规则和变量。
需要对某个工作负载进行调试和记录日志时,请运行:
$ oc logs -l workload=<workload_name> -c <container_name>5.12.2. 增加 Compliance Operator 资源限值
在某些情况下,Compliance Operator 可能需要的内存超过默认限制允许的数量。缓解此问题的最佳方法是设置自定义资源限制。
要增加扫描程序 Pod 的默认内存和 CPU 限值,请参阅 'ScanSetting' 自定义资源。
流程
要将 Operator 的内存限值增加到 500 Mi,请创建名为
co-memlimit-patch.yaml的以下补丁文件:spec: config: resources: limits: memory: 500Mi应用补丁文件:
$ oc patch sub compliance-operator -nopenshift-compliance --patch-file co-memlimit-patch.yaml --type=merge
5.12.3. 配置 Operator 资源限制
resources 字段为 Operator Lifecycle Manager (OLM) 创建的 Pod 中所有容器定义资源约束。
此流程中应用的资源约束会覆盖现有的资源限制。
流程
通过编辑
Subscription对象,注入 0.25 cpu 和 64 Mi 内存的请求,以及每个容器 0.5 cpu 和 128 Mi 内存:kind: Subscription metadata: name: custom-operator spec: package: etcd channel: alpha config: resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m"
5.12.4. 获取支持
如果您在执行本文档所述的某个流程或 OpenShift Container Platform 时遇到问题,请访问 红帽客户门户网站。通过红帽客户门户网站:
- 搜索或者浏览红帽知识库,了解与红帽产品相关的文章和解决方案。
- 提交问题单给红帽支持。
- 访问其他产品文档。
要识别集群中的问题,您可以在 OpenShift Cluster Manager 中使用 Insights。Insights 提供了问题的详细信息,并在有可用的情况下,提供了如何解决问题的信息。
如果您对本文档有任何改进建议,或发现了任何错误,请为相关文档组件提交 JIRA 问题。请提供具体详情,如章节名称和 OpenShift Container Platform 版本。
5.13. 卸载 Compliance Operator
您可以使用 OpenShift Container Platform Web 控制台从集群中删除 OpenShift Compliance Operator。
要删除 Compliance Operator,首先需要删除 Compliance Operator 自定义资源定义(CRD)。删除 CRD 后,您可以通过删除 openshift-compliance 项目来删除 Operator 及其命名空间。
先决条件
-
使用具有
cluster-admin权限的账户访问 OpenShift Container Platform 集群。 - 必须安装 OpenShift Compliance Operator。
流程
使用 OpenShift Container Platform Web 控制台删除 Compliance Operator:
- 进入到 Operators → Installed Operators 页面。
- 删除所有 ScanSettingBinding、ComplainceSuite、ComplianceScan 和 ProfileBundle 对象。
- 切换到 Administration → Operators → Installed Operators 页面。
-
点 Compliance Operator 条目
 中的 Options 菜单并选择 Uninstall Operator。
中的 Options 菜单并选择 Uninstall Operator。
- 切换到 Home → Projects 页面。
- 搜索 'compliance'。
点 openshift-compliance 项目
旁边的 Options 菜单,然后选择 Delete Project。
-
通过在对话框中输入
openshift-compliance并点 Delete 来确认删除。
-
通过在对话框中输入
5.14. 使用 oc-compliance 插件
虽然 Compliance Operator 为集群自动执行许多检查和补救,但将集群设置为合规的完整过程通常需要管理员与 Compliance Operator API 和其他组件交互。oc-compliance 插件使进程变得更加容易。
5.14.1. 安装 oc-compliance 插件
流程
提取
oc-compliance镜像以获取oc-compliance二进制文件:$ podman run --rm -v ~/.local/bin:/mnt/out:Z registry.redhat.io/compliance/oc-compliance-rhel8:stable /bin/cp /usr/bin/oc-compliance /mnt/out/输出示例
W0611 20:35:46.486903 11354 manifest.go:440] Chose linux/amd64 manifest from the manifest list.现在,您可以运行
oc-compliance。
5.14.2. 获取原始结果
当合规性扫描完成后,生成的 ComplianceCheckResult 自定义资源(CR)中会列出单个检查的结果。但是,管理员或审核员可能需要扫描的完整详情。OpenSCAP 工具创建带有详细结果的高级记录格式(ARF)格式的文件。这个 ARF 文件太大,无法存储在配置映射或其他标准 Kubernetes 资源中,因此会创建一个持久性卷(PV)来包含它。
流程
使用 Compliance Operator 从 PV 获取结果是一个包括四步的过程。但是,在
oc-compliance插件中,您可以使用单个命令:$ oc compliance fetch-raw <object-type> <object-name> -o <output-path>-
<object-type>可以是scansettingbinding、compliancescan或compliancesuite,具体取决于扫描通过哪个对象启动。 <object-name>是用于收集 ARF 文件的绑定、套件或扫描对象的名称,<output-path>是放置结果的本地目录。例如:
$ oc compliance fetch-raw scansettingbindings my-binding -o /tmp/输出示例
Fetching results for my-binding scans: ocp4-cis, ocp4-cis-node-worker, ocp4-cis-node-master Fetching raw compliance results for scan 'ocp4-cis'....... The raw compliance results are available in the following directory: /tmp/ocp4-cis Fetching raw compliance results for scan 'ocp4-cis-node-worker'........... The raw compliance results are available in the following directory: /tmp/ocp4-cis-node-worker Fetching raw compliance results for scan 'ocp4-cis-node-master'...... The raw compliance results are available in the following directory: /tmp/ocp4-cis-node-master
查看目录中的文件列表:
$ ls /tmp/ocp4-cis-node-master/输出示例
ocp4-cis-node-master-ip-10-0-128-89.ec2.internal-pod.xml.bzip2 ocp4-cis-node-master-ip-10-0-150-5.ec2.internal-pod.xml.bzip2 ocp4-cis-node-master-ip-10-0-163-32.ec2.internal-pod.xml.bzip2提取结果:
$ bunzip2 -c resultsdir/worker-scan/worker-scan-stage-459-tqkg7-compute-0-pod.xml.bzip2 > resultsdir/worker-scan/worker-scan-ip-10-0-170-231.us-east-2.compute.internal-pod.xml查看结果:
$ ls resultsdir/worker-scan/输出示例
worker-scan-ip-10-0-170-231.us-east-2.compute.internal-pod.xml
worker-scan-stage-459-tqkg7-compute-0-pod.xml.bzip2
worker-scan-stage-459-tqkg7-compute-1-pod.xml.bzip25.14.3. 重新运行扫描
虽然可以作为调度的作业运行扫描,但通常必须根据需要重新运行扫描,特别是在应用修复或进行其他更改集群时。
流程
使用 Compliance Operator 重新运行扫描需要使用扫描对象上的注解。但是,通过
oc-compliance插件,您可以使用单个命令重新运行扫描。输入以下命令为名为my-binding的ScanSettingBinding对象重新运行扫描:$ oc compliance rerun-now scansettingbindings my-binding输出示例
Rerunning scans from 'my-binding': ocp4-cis Re-running scan 'openshift-compliance/ocp4-cis'
5.14.4. 使用 ScanSettingBinding 自定义资源
当使用由 Compliance Operator 提供的 ScanSetting 和 ScanSettingBinding 自定义资源(CR)时,可以在使用一组常用的扫描选项时,对多个配置集运行扫描,如 schedule、machine roles、tolerations 等。虽然这比使用多个 ComplianceSuite 或 ComplianceScan 对象更容易,但可能会让新用户混淆。
oc compliance bind 子命令可帮助您创建 ScanSettingBinding CR。
流程
运行:
$ oc compliance bind [--dry-run] -N <binding name> [-S <scansetting name>] <objtype/objname> [..<objtype/objname>]-
如果省略
-S标志,则使用 Compliance Operator 提供的default扫描设置。 -
对象类型是 Kubernetes 对象类型,可以是
profile或tailorprofile。可以提供多个对象。 -
对象名称是 Kubernetes 资源的名称,如
.metadata.name。 添加
--dry-run选项,以显示所创建对象的 YAML 文件。例如,给定以下配置集和扫描设置:
$ oc get profile.compliance -n openshift-compliance输出示例
NAME AGE ocp4-cis 9m54s ocp4-cis-node 9m54s ocp4-e8 9m54s ocp4-moderate 9m54s ocp4-ncp 9m54s rhcos4-e8 9m54s rhcos4-moderate 9m54s rhcos4-ncp 9m54s rhcos4-ospp 9m54s rhcos4-stig 9m54s$ oc get scansettings -n openshift-compliance输出示例
NAME AGE default 10m default-auto-apply 10m
-
如果省略
要将
default设置应用到ocp4-cis和ocp4-cis-node配置集,请运行:$ oc compliance bind -N my-binding profile/ocp4-cis profile/ocp4-cis-node输出示例
Creating ScanSettingBinding my-binding创建
ScanSettingBindingCR 后,绑定配置集开始使用相关设置扫描两个配置集。总体而言,这是开始使用 Compliance Operator 扫描的最快方法。
5.14.5. 打印控制
合规标准通常分为层次结构,如下所示:
- 基准是特定标准的一组控制的顶级定义。例如,FedRAMP Moderate 或 Center for Internet Security(CIS)v.1.6.0。
- 控制描述了遵守基准必须满足的一系列要求。例如,FedRAMP AC-01(访问控制政策和程序)。
- 规则是单一检查,特定于要纳入合规性的系统,以及一个或多个这些规则映射到控制。
- Compliance Operator 处理将规则分组到配置集中的单个基准测试。可能很难确定哪些控制配置集中的规则集是否满足要求。
流程
oc compliancecontrol子命令提供有关给定配置集满足的标准和控制标准的报告:$ oc compliance controls profile ocp4-cis-node输出示例
+-----------+----------+ | FRAMEWORK | CONTROLS | +-----------+----------+ | CIS-OCP | 1.1.1 | + +----------+ | | 1.1.10 | + +----------+ | | 1.1.11 | + +----------+ ...
5.14.6. 获取合规补救详情
Compliance Operator 提供了补救对象,用于自动执行与集群兼容所需的更改。fetch-fixes 子命令可帮助您准确了解使用了哪些配置修复。使用 fetch-fixes 子命令,将修复对象从配置集、规则或 ComplianceRemediation 对象提取到要检查的目录中。
流程
查看配置集的补救:
$ oc compliance fetch-fixes profile ocp4-cis -o /tmp输出示例
No fixes to persist for rule 'ocp4-api-server-api-priority-flowschema-catch-all'1 No fixes to persist for rule 'ocp4-api-server-api-priority-gate-enabled' No fixes to persist for rule 'ocp4-api-server-audit-log-maxbackup' Persisted rule fix to /tmp/ocp4-api-server-audit-log-maxsize.yaml No fixes to persist for rule 'ocp4-api-server-audit-log-path' No fixes to persist for rule 'ocp4-api-server-auth-mode-no-aa' No fixes to persist for rule 'ocp4-api-server-auth-mode-node' No fixes to persist for rule 'ocp4-api-server-auth-mode-rbac' No fixes to persist for rule 'ocp4-api-server-basic-auth' No fixes to persist for rule 'ocp4-api-server-bind-address' No fixes to persist for rule 'ocp4-api-server-client-ca' Persisted rule fix to /tmp/ocp4-api-server-encryption-provider-cipher.yaml Persisted rule fix to /tmp/ocp4-api-server-encryption-provider-config.yaml- 1
- 当配置集中没有对应的修复规则时会出现
No fixes to persist警告,因为规则无法自动修复,或者没有提供相应的补救。
您可以查看 YAML 文件示例。
head命令将显示前 10 行:$ head /tmp/ocp4-api-server-audit-log-maxsize.yaml输出示例
apiVersion: config.openshift.io/v1 kind: APIServer metadata: name: cluster spec: maximumFileSizeMegabytes: 100查看扫描后创建的
ComplianceRemediation对象的补救:$ oc get complianceremediations -n openshift-compliance输出示例
NAME STATE ocp4-cis-api-server-encryption-provider-cipher NotApplied ocp4-cis-api-server-encryption-provider-config NotApplied$ oc compliance fetch-fixes complianceremediations ocp4-cis-api-server-encryption-provider-cipher -o /tmp输出示例
Persisted compliance remediation fix to /tmp/ocp4-cis-api-server-encryption-provider-cipher.yaml您可以查看 YAML 文件示例。
head命令将显示前 10 行:$ head /tmp/ocp4-cis-api-server-encryption-provider-cipher.yaml输出示例
apiVersion: config.openshift.io/v1 kind: APIServer metadata: name: cluster spec: encryption: type: aescbc
在直接应用补救前请小心。有些补救可能不适用于批量,如中等配置集中的 usbguard 规则。在这些情况下,允许 Compliance Operator 应用规则,因为它解决了依赖项并确保集群处于良好状态。
5.14.7. 查看 ComplianceCheckResult 对象详情
扫描运行结束时,会针对各个扫描规则创建 ComplianceCheckResult 对象。view-result 子命令提供了 ComplianceCheckResult 对象详细信息人类可读的输出。
流程
运行:
$ oc compliance view-result ocp4-cis-scheduler-no-bind-address
5.15. 了解自定义资源定义
OpenShift Container Platform 中的 Compliance Operator 为您提供了几个自定义资源定义(CRD)来完成合规性扫描。要运行合规性扫描,它会利用预定义的安全策略,该策略从 ComplianceAsCode 社区项目衍生而来。Compliance Operator 把这些安全策略转换为 CRD,您可以使用它来运行合规性扫描,并为发现的问题获取补救。
5.15.1. CRD 工作流
CRD 为您提供了以下工作流来完成合规性扫描:
- 定义合规性扫描要求
- 配置合规性扫描设置
- 使用合规性扫描设置处理合规性要求
- 监控合规性扫描
- 检查合规性扫描结果
5.15.2. 定义合规性扫描要求
默认情况下,Compliance Operator CRD 包含 ProfileBundle 和 Profile 对象,您可以在其中定义和设置合规性扫描要求的规则。您还可以使用 TailoredProfile 对象自定义默认配置集。
5.15.2.1. ProfileBundle 对象
安装 Compliance Operator 时,它包含 ready-to-run ProfileBundle 对象。Compliance Operator 解析 ProfileBundle 对象,并为捆绑包中的每个配置集创建一个 Profile 对象。它还会解析 Rule 和 Variable 对象,这些对象会被 Profile 对象使用。
ProfileBundle 对象示例
apiVersion: compliance.openshift.io/v1alpha1
kind: ProfileBundle
name: <profile bundle name>
namespace: openshift-compliance
status:
dataStreamStatus: VALID - 1
- 指明 Compliance Operator 是否能够解析内容文件。
当 contentFile 失败时,会出现一个 errorMessage 属性,它提供所发生错误的详细信息。
故障排除
当您从无效的镜像回滚到已知内容镜像时,ProfileBundle 对象停止响应并显示 PENDING 状态。作为临时解决方案,您可以移到与上一个镜像不同的镜像。另外,您可以删除并重新创建 ProfileBundle 对象以返回到工作状态。
5.15.2.2. 配置集对象
Profile 对象定义可以为某个合规性标准评估的规则和变量。它包含 OpenSCAP 配置集的解析详情,如其 XCCDF 标识符和配置集会检查 Node 或 Platform 类型。您可以直接使用 Profile 对象,也可以使用 TailorProfile 对象进一步自定义它。
您无法手动创建或修改 Profile 对象,因为它是从单个 ProfileBundle 对象衍生而来。通常,单个 ProfileBundle 对象可以包含多个 Profile 对象。
Profile 对象示例
apiVersion: compliance.openshift.io/v1alpha1
description: <description of the profile>
id: xccdf_org.ssgproject.content_profile_moderate
kind: Profile
metadata:
annotations:
compliance.openshift.io/product: <product name>
compliance.openshift.io/product-type: Node
creationTimestamp: "YYYY-MM-DDTMM:HH:SSZ"
generation: 1
labels:
compliance.openshift.io/profile-bundle: <profile bundle name>
name: rhcos4-moderate
namespace: openshift-compliance
ownerReferences:
- apiVersion: compliance.openshift.io/v1alpha1
blockOwnerDeletion: true
controller: true
kind: ProfileBundle
name: <profile bundle name>
uid: <uid string>
resourceVersion: "<version number>"
selfLink: /apis/compliance.openshift.io/v1alpha1/namespaces/openshift-compliance/profiles/rhcos4-moderate
uid: <uid string>
rules:
- rhcos4-account-disable-post-pw-expiration
- rhcos4-accounts-no-uid-except-zero
- rhcos4-audit-rules-dac-modification-chmod
- rhcos4-audit-rules-dac-modification-chown
title: <title of the profile>5.15.2.3. 规则对象
Rule 对象形成了配置文件,也会作为对象公开。使用 Rule 对象定义合规检查要求,并指定它是如何修复的。
Rule 对象示例
apiVersion: compliance.openshift.io/v1alpha1
checkType: Platform
description: <description of the rule>
id: xccdf_org.ssgproject.content_rule_configure_network_policies_namespaces
instructions: <manual instructions for the scan>
kind: Rule
metadata:
annotations:
compliance.openshift.io/rule: configure-network-policies-namespaces
control.compliance.openshift.io/CIS-OCP: 5.3.2
control.compliance.openshift.io/NERC-CIP: CIP-003-3 R4;CIP-003-3 R4.2;CIP-003-3
R5;CIP-003-3 R6;CIP-004-3 R2.2.4;CIP-004-3 R3;CIP-007-3 R2;CIP-007-3 R2.1;CIP-007-3
R2.2;CIP-007-3 R2.3;CIP-007-3 R5.1;CIP-007-3 R6.1
control.compliance.openshift.io/NIST-800-53: AC-4;AC-4(21);CA-3(5);CM-6;CM-6(1);CM-7;CM-7(1);SC-7;SC-7(3);SC-7(5);SC-7(8);SC-7(12);SC-7(13);SC-7(18)
labels:
compliance.openshift.io/profile-bundle: ocp4
name: ocp4-configure-network-policies-namespaces
namespace: openshift-compliance
rationale: <description of why this rule is checked>
severity: high
title: <summary of the rule>
Rule 对象获取适当的标签,以便轻松识别关联的 ProfileBundle 对象。ProfileBundle 也在此对象的 OwnerReferences 中指定。
5.15.2.4. TailoredProfile 对象
使用 TailoredProfile 对象根据您的机构要求修改默认的 Profile 对象。您可以启用或禁用规则,设置变量值,并为自定义提供合理化。验证后,TailoredProfile 对象会创建一个 ConfigMap,它可以被 ComplianceScan 对象引用。
您可以通过在 ScanSettingBinding 对象中引用 TailoredProfile 对象来使用 TailoredProfile 对象。有关 ScanSettingBinding 的更多信息,请参阅 ScanSettingBinding 对象。
TailoredProfile 对象示例
apiVersion: compliance.openshift.io/v1alpha1
kind: TailoredProfile
metadata:
name: rhcos4-with-usb
spec:
extends: rhcos4-moderate
title: <title of the tailored profile>
disableRules:
- name: <name of a rule object to be disabled>
rationale: <description of why this rule is checked>
status:
id: xccdf_compliance.openshift.io_profile_rhcos4-with-usb
outputRef:
name: rhcos4-with-usb-tp
namespace: openshift-compliance
state: READY
使用 TailoredProfile 对象时,可以使用 TailoredProfile 构造来创建新的 Profile 对象。要创建新 配置集,请设置以下配置参数:
- 合适的标题
-
extends值必须为空 TailoredProfile对象上的扫描类型注解:compliance.openshift.io/product-type: Platform/Node注意如果您没有设置
product-type注解,Compliance Operator 会默认使用Platform扫描类型。在TailoredProfile对象的名称中添加-node后缀会导致node扫描类型。
5.15.3. 配置合规性扫描设置
在定义了合规性扫描的要求后,您可以通过指定扫描类型、扫描和扫描位置来配置它。要做到这一点,Compliance Operator 为您提供了 ScanSetting 对象。
5.15.3.1. ScanSetting 对象
使用 ScanSetting 对象定义并重用操作策略来运行扫描。默认情况下,Compliance Operator 会创建以下 ScanSetting 对象:
- default - 它在 master 和 worker 节点(使用 1Gi PV)上每天的 1 AM 运行一次扫描,并保留最后三条结果。补救都不会自动更新。
-
default-auto-apply - 它在 control plane 和 worker 节点(使用 1Gi PV)上每天 1AM 运行一次扫描,并保留最后三个结果。
autoApplyRemediations和autoUpdateRemediations设置为 true。
ScanSetting 对象示例
Name: default-auto-apply
Namespace: openshift-compliance
Labels: <none>
Annotations: <none>
API Version: compliance.openshift.io/v1alpha1
Auto Apply Remediations: true
Auto Update Remediations: true
Kind: ScanSetting
Metadata:
Creation Timestamp: 2022-10-18T20:21:00Z
Generation: 1
Managed Fields:
API Version: compliance.openshift.io/v1alpha1
Fields Type: FieldsV1
fieldsV1:
f:autoApplyRemediations:
f:autoUpdateRemediations:
f:rawResultStorage:
.:
f:nodeSelector:
.:
f:node-role.kubernetes.io/master:
f:pvAccessModes:
f:rotation:
f:size:
f:tolerations:
f:roles:
f:scanTolerations:
f:schedule:
f:showNotApplicable:
f:strictNodeScan:
Manager: compliance-operator
Operation: Update
Time: 2022-10-18T20:21:00Z
Resource Version: 38840
UID: 8cb0967d-05e0-4d7a-ac1c-08a7f7e89e84
Raw Result Storage:
Node Selector:
node-role.kubernetes.io/master:
Pv Access Modes:
ReadWriteOnce
Rotation: 3
Size: 1Gi
Tolerations:
Effect: NoSchedule
Key: node-role.kubernetes.io/master
Operator: Exists
Effect: NoExecute
Key: node.kubernetes.io/not-ready
Operator: Exists
Toleration Seconds: 300
Effect: NoExecute
Key: node.kubernetes.io/unreachable
Operator: Exists
Toleration Seconds: 300
Effect: NoSchedule
Key: node.kubernetes.io/memory-pressure
Operator: Exists
Roles:
master
worker
Scan Tolerations:
Operator: Exists
Schedule: "0 1 * * *"
Show Not Applicable: false
Strict Node Scan: true
Events: <none>5.15.4. 使用合规性扫描设置处理合规性扫描要求
当您定义了合规性扫描要求并将设置配置为运行扫描时,Compliance Operator 会使用 ScanSettingBinding 对象处理它。
5.15.4.1. ScanSettingBinding 对象
使用 ScanSettingBinding 对象指定您的合规要求,并引用 Profile 或 TailoredProfile 对象。然后,它会链接到一个 ScanSetting 对象,它为扫描提供操作限制。然后,Compliance Operator 根据 ScanSetting 和 ScanSettingBinding 对象生成 ComplianceSuite 对象。
ScanSettingBinding 对象示例
apiVersion: compliance.openshift.io/v1alpha1
kind: ScanSettingBinding
metadata:
name: <name of the scan>
profiles:
# Node checks
- name: rhcos4-with-usb
kind: TailoredProfile
apiGroup: compliance.openshift.io/v1alpha1
# Cluster checks
- name: ocp4-moderate
kind: Profile
apiGroup: compliance.openshift.io/v1alpha1
settingsRef:
name: my-companys-constraints
kind: ScanSetting
apiGroup: compliance.openshift.io/v1alpha1
创建 ScanSetting 和 ScanSettingBinding 对象会导致合规性套件。要获取合规套件列表,请运行以下命令:
$ oc get compliancesuites
如果删除了 ScanSettingBinding,则也会删除合规性套件。
5.15.5. 跟踪合规性扫描
创建合规套件后,您可以使用 ComplianceSuite 对象监控部署的扫描的状态。
5.15.5.1. ComplianceSuite 对象
ComplianceSuite 对象可帮助您跟踪扫描的状态。它包含创建扫描的原始设置以及总体结果。
对于 Node 类型扫描,您应该将扫描映射到 MachineConfigPool,因为它包含任何问题的补救。如果指定了标签,请确保它直接应用到池。
ComplianceSuite 对象示例
apiVersion: compliance.openshift.io/v1alpha1
kind: ComplianceSuite
metadata:
name: <name of the scan>
spec:
autoApplyRemediations: false
schedule: "0 1 * * *"
scans:
- name: workers-scan
scanType: Node
profile: xccdf_org.ssgproject.content_profile_moderate
content: ssg-rhcos4-ds.xml
contentImage: quay.io/complianceascode/ocp4:latest
rule: "xccdf_org.ssgproject.content_rule_no_netrc_files"
nodeSelector:
node-role.kubernetes.io/worker: ""
status:
Phase: DONE
Result: NON-COMPLIANT
scanStatuses:
- name: workers-scan
phase: DONE
result: NON-COMPLIANT
后台中的套件会根据 scan 参数创建 ComplianceScan 对象。您可以以编程方式获取 ComplianceSuites 事件。要获取套件的事件,请运行以下命令:
$ oc get events --field-selector involvedObject.kind=ComplianceSuite,involvedObject.name=<name of the suite>
在手动定义 ComplianceSuite 时可能会创建错误,因为它包含 XCCDF 属性。
5.15.5.2. 高级 ComplianceScan 对象
Compliance Operator 包括用于调试或与现有工具集成的高级用户的选项。虽然建议您不要直接创建一个 ComplianceScan 对象,但您可以使用 ComplianceSuite 对象来管理它。
高级 ComplianceScan 对象示例
apiVersion: compliance.openshift.io/v1alpha1
kind: ComplianceScan
metadata:
name: <name of the scan>
spec:
scanType: Node
profile: xccdf_org.ssgproject.content_profile_moderate
content: ssg-ocp4-ds.xml
contentImage: quay.io/complianceascode/ocp4:latest
rule: "xccdf_org.ssgproject.content_rule_no_netrc_files"
nodeSelector:
node-role.kubernetes.io/worker: ""
status:
phase: DONE
result: NON-COMPLIANT - 1
- 指定
Node或Platform。节点配置集扫描集群节点和平台配置集扫描 Kubernetes 平台。 - 2
- 指定您要运行的配置集的 XCCDF 标识符。
- 3
- 指定封装配置集文件的容器镜像。
- 4
- 它是可选的。指定要运行单个规则的扫描。该规则必须使用 XCCDF ID 标识,并且必须属于指定的配置集。注意
如果您跳过
rule参数,则针对指定配置集的所有可用规则运行扫描。 - 5
- 如果您在 OpenShift Container Platform 上,并希望生成补救,则 nodeSelector 标签必须与
MachineConfigPool标签匹配。注意如果没有指定
nodeSelector参数或与MachineConfig标签匹配,则扫描仍将运行,但不会创建补救。 - 6
- 指示扫描的当前阶段。
- 7
- 表示扫描的结果。
如果您删除了 ComplianceSuite 对象,则所有关联的扫描都会被删除。
扫描完成后,它将生成结果作为 ComplianceCheckResult 对象的自定义资源。但是,原始结果以 ARF 格式提供。这些结果存储在持久性卷(PV)中,它具有与扫描名称关联的持久性卷声明(PVC)。您可以以编程方式获取 ComplianceScans 事件。要为套件生成事件,请运行以下命令:
oc get events --field-selector involvedObject.kind=ComplianceScan,involvedObject.name=<name of the suite>5.15.6. 查看合规性结果
当合规性套件达到 DONE 阶段时,您可以查看扫描结果和可能的补救方法。
5.15.6.1. ComplianceCheckResult 对象
当使用特定配置集运行扫描时,会验证配置集中的多个规则。对于每个规则,都会创建一个 ComplianceCheckResult 对象,它为特定规则提供集群状态。
ComplianceCheckResult 对象示例
apiVersion: compliance.openshift.io/v1alpha1
kind: ComplianceCheckResult
metadata:
labels:
compliance.openshift.io/check-severity: medium
compliance.openshift.io/check-status: FAIL
compliance.openshift.io/suite: example-compliancesuite
compliance.openshift.io/scan-name: workers-scan
name: workers-scan-no-direct-root-logins
namespace: openshift-compliance
ownerReferences:
- apiVersion: compliance.openshift.io/v1alpha1
blockOwnerDeletion: true
controller: true
kind: ComplianceScan
name: workers-scan
description: <description of scan check>
instructions: <manual instructions for the scan>
id: xccdf_org.ssgproject.content_rule_no_direct_root_logins
severity: medium
status: FAIL 要获得套件中的所有检查结果,请运行以下命令:
oc get compliancecheckresults \
-l compliance.openshift.io/suite=workers-compliancesuite5.15.6.2. ComplianceRemediation 对象
对于特定的检查,您可以有一个 datastream 指定的修复。但是,如果 Kubernetes 修复可用,则 Compliance Operator 会创建一个 ComplianceRemediation 对象。
ComplianceRemediation 对象示例
apiVersion: compliance.openshift.io/v1alpha1
kind: ComplianceRemediation
metadata:
labels:
compliance.openshift.io/suite: example-compliancesuite
compliance.openshift.io/scan-name: workers-scan
machineconfiguration.openshift.io/role: worker
name: workers-scan-disable-users-coredumps
namespace: openshift-compliance
ownerReferences:
- apiVersion: compliance.openshift.io/v1alpha1
blockOwnerDeletion: true
controller: true
kind: ComplianceCheckResult
name: workers-scan-disable-users-coredumps
uid: <UID>
spec:
apply: false
object:
current:
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
spec:
config:
ignition:
version: 2.2.0
storage:
files:
- contents:
source: data:,%2A%20%20%20%20%20hard%20%20%20core%20%20%20%200
filesystem: root
mode: 420
path: /etc/security/limits.d/75-disable_users_coredumps.conf
outdated: {} 要从套件中获得所有补救,请运行以下命令:
oc get complianceremediations \
-l compliance.openshift.io/suite=workers-compliancesuite要列出可自动修复的所有失败检查,请运行以下命令:
oc get compliancecheckresults \
-l 'compliance.openshift.io/check-status in (FAIL),compliance.openshift.io/automated-remediation'要列出可手动修复的所有失败检查,请运行以下命令:
oc get compliancecheckresults \
-l 'compliance.openshift.io/check-status in (FAIL),!compliance.openshift.io/automated-remediation'第 6 章 File Integrity Operator
6.1. File Integrity Operator 发行注记
OpenShift Container Platform 的 File Integrity Operator 在 RHCOS 节点上持续运行文件完整性检查。
本发行注记介绍了 OpenShift Container Platform 中 File Integrity Operator 的开发。
有关 File Integrity Operator 的概述,请参阅了解 File Integrity Operator。
要访问最新版本,请参阅更新 File Integrity Operator。
6.1.1. OpenShift File Integrity Operator 1.0.0
以下公告可用于 OpenShift File Integrity Operator 1.0.0:
File Integrity Operator 现在是稳定的,发行频道已升级到 v1。将来的版本将遵循 Semantic Versioning。要访问最新版本,请参阅更新 File Integrity Operator。
6.1.2. OpenShift File Integrity Operator 0.1.32
以下公告可用于 OpenShift File Integrity Operator 0.1.32:
6.1.2.1. 程序错误修复
- 在以前的版本中,File Integrity Operator 发布的警报没有设置命名空间,因此很难了解警报来自于哪个命名空间。现在,Operator 会设置适当的命名空间,提供有关该警报的更多信息。(BZ#2112394)
- 在以前的版本中,File Integrity Operator 不会更新 Operator 启动时的指标服务,从而导致指标目标无法访问。在这个版本中,File Integrity Operator 可确保在 Operator 启动时更新 metrics 服务。(BZ#2115821)
6.1.3. OpenShift File Integrity Operator 0.1.30
以下公告可用于 OpenShift File Integrity Operator 0.1.30:
6.1.3.1. 程序错误修复
- 在以前的版本中,File Integrity Operator 发布的警报没有设置命名空间,因此很难了解警报的来源位置。现在,Operator 会设置适当的命名空间,从而增加对警报的了解。(BZ#2101393)
6.1.4. OpenShift File Integrity Operator 0.1.24
以下公告可用于 OpenShift File Integrity Operator 0.1.24:
6.1.4.1. 新功能及功能增强
-
现在,您可以使用
config.maxBackups属性配置FileIntegrity自定义资源(CR)中的最大备份数量。此属性指定从re-init进程保留的 AIDE 数据库和日志备份数量,以保留在节点上。超出配置数目之外的旧备份会自动修剪。默认值为五个备份。
6.1.4.2. 程序错误修复
-
在以前的版本中,将 Operator 从 0.1.21 之前的版本升级到 0.1.22 可能会导致
re-init功能失败。这是因为 Operator 无法更新configMap资源标签。现在,升级到最新版本会修复资源标签。(BZ#2049206) -
在以前的版本中,当强制默认
configMap脚本内容强制时,会比较错误的数据密钥。这会导致在 Operator 升级后,aide-reinit脚本无法正确更新,并导致re-init进程失败。现在,daemonSet运行完毕,AIDE 数据库re-init过程可以成功执行。(BZ#2072058)
6.1.5. OpenShift File Integrity Operator 0.1.22
以下公告可用于 OpenShift File Integrity Operator 0.1.22:
6.1.5.1. 程序错误修复
-
在以前的版本中,安装有 File Integrity Operator 的系统可能会因为
/etc/kubernetes/aide.reinit文件而中断 OpenShift Container Platform 更新。如果/etc/kubernetes/aide.reinit文件存在,则会出现这种情况,但稍后在ostree验证前被删除。在这个版本中,/etc/kubernetes/aide.reinit被移到/run目录中,以便它不会与 OpenShift Container Platform 更新冲突。(BZ#2033311)
6.1.6. OpenShift File Integrity Operator 0.1.21
以下公告可用于 OpenShift File Integrity Operator 0.1.21:
6.1.6.1. 新功能及功能增强
-
web 控制台的 Monitoring 仪表板中会显示与
FileIntegrity扫描结果和处理指标相关的指标。结果使用file_integrity_operator_前缀标记。 -
如果节点在超过 1 秒的情况下存在完整性失败,则 operator 命名空间警报中提供的默认
PrometheusRule带有一个警告。 以下动态 Machine Config Operator 和 Cluster Version Operator 相关文件路径不包括在默认的 AIDE 策略中,以帮助在节点更新过程中阻止假的正状态:
- /etc/machine-config-daemon/currentconfig
- /etc/pki/ca-trust/extracted/java/cacerts
- /etc/cvo/updatepayloads
- /root/.kube
- AIDE 守护进程进程具有 v0.1.16 的稳定性改进,并且对 AIDE 数据库初始化时可能发生的错误更具弹性。
6.1.6.2. 程序错误修复
- 在以前的版本中,当 Operator 自动升级时,过时的守护进程集不会被删除。在这个版本中,过期的守护进程集会在自动升级过程中被删除。
6.2. 安装 File Integrity Operator
6.2.1. 使用 Web 控制台安装 File Integrity Operator
先决条件
-
您必须具有
admin权限。
流程
- 在 OpenShift Container Platform Web 控制台中导航至 Operators → OperatorHub。
- 搜索 File Integrity Operator,然后点 Install。
-
保留 安装模式 和 命名空间 的默认选择,以确保将 Operator 安装到
openshift-file-integrity命名空间中。 - 点 Install。
验证
确认安装成功:
- 导航到 Operators → Installed Operators 页面。
-
检查是否在
openshift-file-integrity命名空间中安装 Operator,其状态为Succeeded。
如果 Operator 没有成功安装:
-
导航到 Operators → Installed Operators 页面,并检查
Status列中是否有任何错误或故障。 -
导航到 Workloads → Pods 页面,检查
openshift-file-integrity项目中报告问题的 pod 的日志。
6.2.2. 使用 CLI 安装 File Integrity Operator
先决条件
-
您必须具有
admin权限。
流程
运行以下命令,创建一个
Namespace对象 YAML 文件:$ oc create -f <file-name>.yaml输出示例
apiVersion: v1 kind: Namespace metadata: labels: openshift.io/cluster-monitoring: "true" name: openshift-file-integrity创建
OperatorGroup对象 YAML 文件:$ oc create -f <file-name>.yaml输出示例
apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: file-integrity-operator namespace: openshift-file-integrity spec: targetNamespaces: - openshift-file-integrity创建
Subscription对象 YAML 文件:$ oc create -f <file-name>.yaml输出示例
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: file-integrity-operator namespace: openshift-file-integrity spec: channel: "v1" installPlanApproval: Automatic name: file-integrity-operator source: redhat-operators sourceNamespace: openshift-marketplace
验证
通过检查 CSV 文件来验证安装是否成功:
$ oc get csv -n openshift-file-integrity验证 File Integrity Operator 是否正在运行:
$ oc get deploy -n openshift-file-integrity
6.3. 更新 File Integrity Operator
作为集群管理员,您可以更新 OpenShift Container Platform 集群上的 File Integrity Operator。
6.3.1. 准备 Operator 更新
已安装的 Operator 的订阅指定一个更新频道,用于跟踪和接收 Operator 的更新。您可以更改更新频道,以开始跟踪并从更新频道接收更新。
订阅中更新频道的名称可能会因 Operator 而异,但应遵守给定 Operator 中的常规约定。例如,频道名称可能会遵循 Operator 提供的应用程序的次发行版本更新流(1.2、1.3)或发行的频率(stable、fast)。
您不能将已安装的 Operator 更改为比当前频道旧的频道。
红帽客户门户网站 Labs 包括以下应用程序,可帮助管理员准备更新其 Operator:
您可以使用应用程序搜索基于 Operator Lifecycle Manager 的 Operator,并在不同版本的 OpenShift Container Platform 中验证每个更新频道的可用 Operator 版本。不包含基于 Cluster Version Operator 的 Operator。
6.3.2. 更改 Operator 的更新频道
您可以使用 OpenShift Container Platform Web 控制台更改 Operator 的更新频道。
如果订阅中的批准策略被设置为 Automatic,则更新过程会在所选频道中提供新的 Operator 版本时立即启动。如果批准策略设为 Manual,则必须手动批准待处理的更新。
先决条件
- 之前使用 Operator Lifecycle Manager(OLM)安装的 Operator。
流程
- 在 web 控制台的 Administrator 视角中,导航到 Operators → Installed Operators。
- 点击您要更改更新频道的 Operator 名称。
- 点 Subscription 标签页。
- 点 Channel 中的更新频道的名称。
- 点要更改的更新频道,然后点 Save。
对于带有 自动批准策略 的订阅,更新会自动开始。返回到 Operators → Installed Operators 页面,以监控更新的进度。完成后,状态会变为 Succeeded 和 Up to date。
对于采用手动批准策略的订阅,您可以从 Subscription 选项卡中手动批准更新。
6.3.3. 手动批准待处理的 Operator 更新
如果已安装的 Operator 的订阅被设置为 Manual,则当其当前更新频道中发布新更新时,在开始安装前必须手动批准更新。
先决条件
- 之前使用 Operator Lifecycle Manager(OLM)安装的 Operator。
流程
- 在 OpenShift Container Platform Web 控制台的 Administrator 视角中,进入 Operators → Installed Operators。
- 处于待定更新的 Operator 会显示 Upgrade available 状态。点您要更新的 Operator 的名称。
- 点 Subscription 标签页。任何需要批准的更新都会在 Upgrade Status 旁边显示。例如:它可能会显示 1 requires approval。
- 点 1 requires approval,然后点 Preview Install Plan。
- 检查列出可用于更新的资源。在满意后,点 Approve。
- 返回到 Operators → Installed Operators 页面,以监控更新的进度。完成后,状态会变为 Succeeded 和 Up to date。
6.4. 了解 File Integrity Operator
File Integrity Operator 是一个 OpenShift Container Platform Operator,其在集群节点上持续运行文件完整性检查。它部署一个守护进程集,在每个节点上初始化并运行特权高级入侵检测环境 (AIDE) 容器,从而提供一个状态对象和在守护进程集初始运行时修改的文件日志。
目前,仅支持 Red Hat Enterprise Linux CoreOS (RHCOS) 节点。
6.4.1. 创建 FileIntegrity 自定义资源
FileIntegrity 自定义资源 (CR) 的实例代表一组对一个或多个节点进行的持续文件完整性扫描。
每个 FileIntegrity CR 都由一个在符合 FileIntegrity CR 规格的节点上运行 AIDE 的守护进程集支持。
流程
创建名为
worker-fileintegrity.yaml的FileIntegrityCR 示例,以便在 worker 节点上启用扫描:示例 FileIntegrity CR
apiVersion: fileintegrity.openshift.io/v1alpha1 kind: FileIntegrity metadata: name: worker-fileintegrity namespace: openshift-file-integrity spec: nodeSelector: node-role.kubernetes.io/worker: "" config: {}将 YAML 文件应用到
openshift-file-integrity命名空间:$ oc apply -f worker-fileintegrity.yaml -n openshift-file-integrity
验证
运行以下命令确认
FileIntegrity对象已创建成功:$ oc get fileintegrities -n openshift-file-integrity输出示例
NAME AGE worker-fileintegrity 14s
6.4.2. 检查 FileIntegrity 自定义资源状态
FileIntegrity 自定义资源 (CR) 通过 .status.phase 子资源报告其状态。
流程
要查询
FileIntegrityCR 状态,请运行:$ oc get fileintegrities/worker-fileintegrity -o jsonpath="{ .status.phase }"输出示例
Active
6.4.3. FileIntegrity 自定义资源阶段
-
待处理- 创建自定义资源 (CR) 后的阶段。 -
Active- 后备守护进程集启动并运行的阶段。 -
初始化- AIDE 数据库重新初始化的阶段。
6.4.4. 了解 FileIntegrityNodeStatuses 对象
FileIntegrity CR 的扫描结果会在名为 FileIntegrityNodeStatuses 的另一个对象中报告。
$ oc get fileintegritynodestatuses输出示例
NAME AGE
worker-fileintegrity-ip-10-0-130-192.ec2.internal 101s
worker-fileintegrity-ip-10-0-147-133.ec2.internal 109s
worker-fileintegrity-ip-10-0-165-160.ec2.internal 102s
可能需要经过一段时间 FileIntegrityNodeStatus 对象才会可用。
每个节点都有一个结果对象。每个 FileIntegrityNodeStatus 对象的 nodeName 属性都对应于被扫描的节点。文件完整性扫描的状态在 results 数组中表示,其中包含扫描条件。
$ oc get fileintegritynodestatuses.fileintegrity.openshift.io -ojsonpath='{.items[*].results}' | jq
fileintegritynodestatus 对象报告 AIDE 运行的最新状态,并在 status 字段中公开状态为 Failed、Succeeded 或 Errored。
$ oc get fileintegritynodestatuses -w输出示例
NAME NODE STATUS
example-fileintegrity-ip-10-0-134-186.us-east-2.compute.internal ip-10-0-134-186.us-east-2.compute.internal Succeeded
example-fileintegrity-ip-10-0-150-230.us-east-2.compute.internal ip-10-0-150-230.us-east-2.compute.internal Succeeded
example-fileintegrity-ip-10-0-169-137.us-east-2.compute.internal ip-10-0-169-137.us-east-2.compute.internal Succeeded
example-fileintegrity-ip-10-0-180-200.us-east-2.compute.internal ip-10-0-180-200.us-east-2.compute.internal Succeeded
example-fileintegrity-ip-10-0-194-66.us-east-2.compute.internal ip-10-0-194-66.us-east-2.compute.internal Failed
example-fileintegrity-ip-10-0-222-188.us-east-2.compute.internal ip-10-0-222-188.us-east-2.compute.internal Succeeded
example-fileintegrity-ip-10-0-134-186.us-east-2.compute.internal ip-10-0-134-186.us-east-2.compute.internal Succeeded
example-fileintegrity-ip-10-0-222-188.us-east-2.compute.internal ip-10-0-222-188.us-east-2.compute.internal Succeeded
example-fileintegrity-ip-10-0-194-66.us-east-2.compute.internal ip-10-0-194-66.us-east-2.compute.internal Failed
example-fileintegrity-ip-10-0-150-230.us-east-2.compute.internal ip-10-0-150-230.us-east-2.compute.internal Succeeded
example-fileintegrity-ip-10-0-180-200.us-east-2.compute.internal ip-10-0-180-200.us-east-2.compute.internal Succeeded6.4.5. FileIntegrityNodeStatus CR 状态类型
这些条件会在对应的 FileIntegrityNodeStatus CR 状态的结果数组中报告:
-
Succeeded- 通过完整性检查;AIDE 检查中所涵盖的文件和目录自数据库上次初始化以来没有被修改。 -
Failed- 完整性检查失败;AIDE 检查中所涵盖的一些文件和目录自数据库上次初始化以来已被修改。 -
Errored- AIDE 扫描程序遇到内部错误。
6.4.5.1. FileIntegrityNodeStatus CR 成功示例
成功状态条件的输出示例
[
{
"condition": "Succeeded",
"lastProbeTime": "2020-09-15T12:45:57Z"
}
]
[
{
"condition": "Succeeded",
"lastProbeTime": "2020-09-15T12:46:03Z"
}
]
[
{
"condition": "Succeeded",
"lastProbeTime": "2020-09-15T12:45:48Z"
}
]在这种情况下,所有三个扫描都成功,目前没有其他条件。
6.4.5.2. FileIntegrityNodeStatus CR 失败状态示例
要模拟失败条件,请修改 AIDE 跟踪的其中一个文件。例如,在其中一个 worker 节点上修改 /etc/resolv.conf:
$ oc debug node/ip-10-0-130-192.ec2.internal输出示例
Creating debug namespace/openshift-debug-node-ldfbj ...
Starting pod/ip-10-0-130-192ec2internal-debug ...
To use host binaries, run `chroot /host`
Pod IP: 10.0.130.192
If you don't see a command prompt, try pressing enter.
sh-4.2# echo "# integrity test" >> /host/etc/resolv.conf
sh-4.2# exit
Removing debug pod ...
Removing debug namespace/openshift-debug-node-ldfbj ...
一段时间后,相应的 FileIntegrityNodeStatus 对象的结果数组中会报告 Failed 条件。之前的 Succeeded 条件被保留,便于您查明检查失败的时间。
$ oc get fileintegritynodestatuses.fileintegrity.openshift.io/worker-fileintegrity-ip-10-0-130-192.ec2.internal -ojsonpath='{.results}' | jq -r或者,如果您没有提到对象名称,则运行:
$ oc get fileintegritynodestatuses.fileintegrity.openshift.io -ojsonpath='{.items[*].results}' | jq输出示例
[
{
"condition": "Succeeded",
"lastProbeTime": "2020-09-15T12:54:14Z"
},
{
"condition": "Failed",
"filesChanged": 1,
"lastProbeTime": "2020-09-15T12:57:20Z",
"resultConfigMapName": "aide-ds-worker-fileintegrity-ip-10-0-130-192.ec2.internal-failed",
"resultConfigMapNamespace": "openshift-file-integrity"
}
]
Failed 条件指向一个配置映射,该映射详细介绍了具体的失败及失败原因:
$ oc describe cm aide-ds-worker-fileintegrity-ip-10-0-130-192.ec2.internal-failed输出示例
Name: aide-ds-worker-fileintegrity-ip-10-0-130-192.ec2.internal-failed
Namespace: openshift-file-integrity
Labels: file-integrity.openshift.io/node=ip-10-0-130-192.ec2.internal
file-integrity.openshift.io/owner=worker-fileintegrity
file-integrity.openshift.io/result-log=
Annotations: file-integrity.openshift.io/files-added: 0
file-integrity.openshift.io/files-changed: 1
file-integrity.openshift.io/files-removed: 0
Data
integritylog:
------
AIDE 0.15.1 found differences between database and filesystem!!
Start timestamp: 2020-09-15 12:58:15
Summary:
Total number of files: 31553
Added files: 0
Removed files: 0
Changed files: 1
---------------------------------------------------
Changed files:
---------------------------------------------------
changed: /hostroot/etc/resolv.conf
---------------------------------------------------
Detailed information about changes:
---------------------------------------------------
File: /hostroot/etc/resolv.conf
SHA512 : sTQYpB/AL7FeoGtu/1g7opv6C+KT1CBJ , qAeM+a8yTgHPnIHMaRlS+so61EN8VOpg
Events: <none>
由于配置映射数据大小限制,超过 1MB 的 AIDE 日志会作为 base64 编码的 gzip 存档添加到失败配置映射中。在这种情况下,您要将以上命令的输出输出管道到 base64 --decode | gunzip。压缩的日志由配置映射中存在 file-integrity.openshift.io/compressed 注解键来表示。
6.4.6. 了解事件
FileIntegrity 和 FileIntegrityNodeStatus 对象的状态由 事件 记录。事件的创建时间反映了最新变化,如从 Initializing 变为 Active,它不一定是最新的扫描结果。但是,最新的事件始终反映最新的状态。
$ oc get events --field-selector reason=FileIntegrityStatus输出示例
LAST SEEN TYPE REASON OBJECT MESSAGE
97s Normal FileIntegrityStatus fileintegrity/example-fileintegrity Pending
67s Normal FileIntegrityStatus fileintegrity/example-fileintegrity Initializing
37s Normal FileIntegrityStatus fileintegrity/example-fileintegrity Active
当节点扫描失败时,会使用 add/changed/removed 和配置映射信息创建事件。
$ oc get events --field-selector reason=NodeIntegrityStatus输出示例
LAST SEEN TYPE REASON OBJECT MESSAGE
114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-134-173.ec2.internal
114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-168-238.ec2.internal
114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-169-175.ec2.internal
114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-152-92.ec2.internal
114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-158-144.ec2.internal
114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-131-30.ec2.internal
87m Warning NodeIntegrityStatus fileintegrity/example-fileintegrity node ip-10-0-152-92.ec2.internal has changed! a:1,c:1,r:0 \ log:openshift-file-integrity/aide-ds-example-fileintegrity-ip-10-0-152-92.ec2.internal-failed更改添加、更改或删除的文件数量会导致新的事件,即使节点的状态尚未转换。
$ oc get events --field-selector reason=NodeIntegrityStatus输出示例
LAST SEEN TYPE REASON OBJECT MESSAGE
114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-134-173.ec2.internal
114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-168-238.ec2.internal
114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-169-175.ec2.internal
114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-152-92.ec2.internal
114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-158-144.ec2.internal
114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-131-30.ec2.internal
87m Warning NodeIntegrityStatus fileintegrity/example-fileintegrity node ip-10-0-152-92.ec2.internal has changed! a:1,c:1,r:0 \ log:openshift-file-integrity/aide-ds-example-fileintegrity-ip-10-0-152-92.ec2.internal-failed
40m Warning NodeIntegrityStatus fileintegrity/example-fileintegrity node ip-10-0-152-92.ec2.internal has changed! a:3,c:1,r:0 \ log:openshift-file-integrity/aide-ds-example-fileintegrity-ip-10-0-152-92.ec2.internal-failed6.5. 配置自定义 File Integrity Operator
6.5.1. 查看 FileIntegrity 对象属性
和任何 Kubernetes 自定义资源 (CR) 一样,您可以运行 oc explain fileintegrity,然后使用以下方法查看各个属性:
$ oc explain fileintegrity.spec$ oc explain fileintegrity.spec.config6.5.2. 重要属性
| 属性 | 描述 |
|---|---|
|
|
键值对映射必须与节点标签匹配,才能在该节点上调度 AIDE Pod。典型的用途是仅设置一个键值对,其中 |
|
|
布尔值属性。如果设为 |
|
| 在带有自定义污点的节点上指定调度容限。如果没有指定,则会应用默认的容限,允许容限在 control plane 节点上运行(也称为 master 节点)。 |
|
|
AIDE 完整性检查之间暂停的秒数。在节点中频繁进行 AIDE 检查需要大量资源,因此可以指定较长的时间间隔。默认为 |
|
|
从 |
|
| 包含自定义 AIDE 配置的 configMap 的名称。如果省略,则会创建一个默认配置。 |
|
| 包含自定义 AIDE 配置的 configMap 的命名空间。如果未设置,FIO 会生成适合 RHCOS 系统的默认配置。 |
|
|
在由 |
6.5.3. 检查默认配置
默认 File Integrity Operator 配置存储在与 FileIntegrity CR 名称相同的配置映射中。
流程
要检查默认配置,请运行:
$ oc describe cm/worker-fileintegrity
6.5.4. 了解默认的 File Integrity Operator 配置
下面是配置映射的 aide.conf 键的摘录:
@@define DBDIR /hostroot/etc/kubernetes
@@define LOGDIR /hostroot/etc/kubernetes
database=file:@@{DBDIR}/aide.db.gz
database_out=file:@@{DBDIR}/aide.db.gz
gzip_dbout=yes
verbose=5
report_url=file:@@{LOGDIR}/aide.log
report_url=stdout
PERMS = p+u+g+acl+selinux+xattrs
CONTENT_EX = sha512+ftype+p+u+g+n+acl+selinux+xattrs
/hostroot/boot/ CONTENT_EX
/hostroot/root/\..* PERMS
/hostroot/root/ CONTENT_EX
FileIntegrity 实例的默认配置涵盖以下目录下的文件:
-
/root -
/boot -
/usr -
/etc
不涵盖以下目录:
-
/var -
/opt -
/etc/下一些特定于 OpenShift Container Platform 的排除项
6.5.5. 提供自定义 AIDE 配置
任何配置 AIDE 内部行为的条目,如 DBDIR、LOGDIR、database 和 database_out 都会被 Operator 覆盖。对于要监视是否发生了完整性更改的所有路径,Operator 会在其前面为 /hostroot/ 添加前缀。这样,要重复使用可能通常不适用于容器化环境并从根目录启动的现有 AIDE 配置,就会更方便。
/hostroot 是运行 AIDE 的 Pod 挂载主机文件系统的目录。更改配置会触发重新初始化数据库。
6.5.6. 定义自定义 File Integrity Operator 配置
本例重点根据为 worker-fileintegrity CR 提供的默认配置,为 control plane 节点(也称为 master 节点)上运行的扫描程序定义自定义配置。如果您计划部署作为守护进程集运行的自定义软件,并将其数据存储在 control plane 节点上的 /opt/mydaemon 下,则此工作流可能很有用。
流程
- 复制默认配置。
- 使用必须监视或排除的文件编辑默认配置。
- 将已编辑的内容存储至新配置映射中。
-
通过
spec.config中的属性将FileIntegrity对象指向新的配置映射。 提取默认配置:
$ oc extract cm/worker-fileintegrity --keys=aide.conf这将创建一个名为
aide.conf的文件,您可对其进行编辑。为了说明 Operator 如何对路径进行后期处理,本例添加一个不含前缀的排除目录:$ vim aide.conf输出示例
/hostroot/etc/kubernetes/static-pod-resources !/hostroot/etc/kubernetes/aide.* !/hostroot/etc/kubernetes/manifests !/hostroot/etc/docker/certs.d !/hostroot/etc/selinux/targeted !/hostroot/etc/openvswitch/conf.db排除特定于 control plane 节点的路径:
!/opt/mydaemon/将其他内容存储在
/etc中:/hostroot/etc/ CONTENT_EX根据该文件创建配置映射:
$ oc create cm master-aide-conf --from-file=aide.conf定义引用该配置映射的
FileIntegrityCR 清单:apiVersion: fileintegrity.openshift.io/v1alpha1 kind: FileIntegrity metadata: name: master-fileintegrity namespace: openshift-file-integrity spec: nodeSelector: node-role.kubernetes.io/master: "" config: name: master-aide-conf namespace: openshift-file-integrityOperator 处理所提供的配置映射文件,并使用与
FileIntegrity对象相同的名称将结果存储在配置映射中:$ oc describe cm/master-fileintegrity | grep /opt/mydaemon输出示例
!/hostroot/opt/mydaemon
6.5.7. 更改自定义文件完整性配置
要更改文件完整性配置,切勿更改生成的配置映射。相反,可通过 spec.name、namespace 和 key 属性更改链接到 FileIntegrity 对象的配置映射。
6.6. 执行高级自定义 File Integrity Operator 任务
6.6.1. 重新初始化数据库
如果 File Integrity Operator 检测到计划进行的更改,则可能需要重新初始化数据库。
流程
使用
file-integrity.openshift.io/re-init注解FileIntegrity自定义资源(CR):$ oc annotate fileintegrities/worker-fileintegrity file-integrity.openshift.io/re-init=旧的数据库和日志文件已备份,新的数据库被初始化。旧的数据库和日志保留在
/etc/kubernetes下的节点上,参见使用oc debug生成的 Pod 中的以下输出:输出示例
ls -lR /host/etc/kubernetes/aide.* -rw-------. 1 root root 1839782 Sep 17 15:08 /host/etc/kubernetes/aide.db.gz -rw-------. 1 root root 1839783 Sep 17 14:30 /host/etc/kubernetes/aide.db.gz.backup-20200917T15_07_38 -rw-------. 1 root root 73728 Sep 17 15:07 /host/etc/kubernetes/aide.db.gz.backup-20200917T15_07_55 -rw-r--r--. 1 root root 0 Sep 17 15:08 /host/etc/kubernetes/aide.log -rw-------. 1 root root 613 Sep 17 15:07 /host/etc/kubernetes/aide.log.backup-20200917T15_07_38 -rw-r--r--. 1 root root 0 Sep 17 15:07 /host/etc/kubernetes/aide.log.backup-20200917T15_07_55为了提供一些永久记录,生成的配置映射不归
FileIntegrity所有,因此需要手动清理。因此,任何之前的完整性失败仍在FileIntegrityNodeStatus对象中可见。
6.6.2. 机器配置集成
在 OpenShift Container Platform 4 中,集群节点配置通过 MachineConfig 对象提供。您可以假定因 MachineConfig 对象导致的对文件进行的更改是预期行为,不应该导致文件完整性扫描失败。为禁止由于 MachineConfig 对象更新导致对文件进行更改,File Integrity Operator 会监视节点对象;在更新节点期间,会暂停 AIDE 扫描。更新完成后,数据库会重新初始化并恢复扫描。
此暂停和恢复逻辑只适用于通过 MachineConfig API 进行的更新,因为它们反映在节点对象注解中。
6.6.3. 探索守护进程集
每个 FileIntegrity 对象代表多个节点上的扫描。扫描本身由守护进程集管理的 Pod 执行。
要查找代表 FileIntegrity 对象的守护进程集,请运行:
$ oc -n openshift-file-integrity get ds/aide-worker-fileintegrity要列出该守护进程集中的 Pod,请运行:
$ oc -n openshift-file-integrity get pods -lapp=aide-worker-fileintegrity
要查看单个 AIDE Pod 的日志,调用其中一个 Pod 上的 oc logs。
$ oc -n openshift-file-integrity logs pod/aide-worker-fileintegrity-mr8x6输出示例
Starting the AIDE runner daemon
initializing AIDE db
initialization finished
running aide check
...
由 AIDE 守护进程创建的配置映射不会保留,在 File Integrity Operator 处理后会被删除。但是,如果失败和出错,这些配置映射的内容会被复制到 FileIntegrityNodeStatus 对象指向的配置映射中。
6.7. 对 File Integrity Operator 进行故障排除
6.7.1. 常规故障排除
- 问题
- 您通常希望在 File Integrity Operator 中排除问题。
- 解决方案
-
在
FileIntegrity对象中启用 debug 标记。debug标记会增加在DaemonSetpod 中运行并运行 AIDE 检查的守护进程详细程度。
6.7.2. 检查 AIDE 配置
- 问题
- 您需要检查 AIDE 配置。
- 解决方案
-
AIDE 配置存储在与
FileIntegrity对象同名的配置映射中。所有 AIDE 配置的配置映射都标有file-integrity.openshift.io/aide-conf。
6.7.3. 确定 FileIntegrity 对象的阶段
- 问题
-
您需要确定
FileIntegrity对象是否存在并查看其当前状态。 - 解决方案
要查看
FileIntegrity对象的当前状态,请运行:$ oc get fileintegrities/worker-fileintegrity -o jsonpath="{ .status }"一旦创建
FileIntegrity对象和后备守护进程集,状态就应切换为Active。如果没有,请检查 Operator Pod 日志。
6.7.4. 确定守护进程集的 Pod 是否在预期节点上运行
- 问题
- 您需要确认守护进程集是否存在,其 Pod 是否在您期望的节点上运行。
- 解决方案
运行:
$ oc -n openshift-file-integrity get pods -lapp=aide-worker-fileintegrity注意添加
-owide包括运行 pod 的节点的 IP 地址。要检查守护进程 pod 的日志,请运行
oc logs。检查 AIDE 命令的返回值,以查看检查通过还是失败。
第 7 章 查看审计日志
OpenShift Container Platform auditing(审计)提供一组安全相关的按时间排序的记录,记录各个用户、管理员或其他系统组件影响系统的一系列活动。
7.1. 关于 API 审计日志
审计在 API 服务器级别运作,记录所有传入到服务器的请求。每个审计日志包含以下信息:
| 字段 | 描述 |
|---|---|
|
| 生成事件的审计级别。 |
|
| 为每个请求生成的唯一审计 ID。 |
|
| 生成此事件实例时请求处理的阶段。 |
|
| 客户端向服务器发送的请求 URI。 |
|
| 与请求相关联的 Kubernetes 操作动词。对于非资源请求,这是小写 HTTP 方法。 |
|
| 经过身份验证的用户信息。 |
|
| 可选。如果请求模拟了另一个用户,则为被模拟的用户信息。 |
|
| 可选。源 IP,请求发起的源和任何中间代理。 |
|
| 可选。客户端报告的用户代理字符串。请注意,用户代理由客户端提供,且必须不可信任。 |
|
|
可选。这个请求的目标对象引用。这不适用于 |
|
|
可选。响应的状态,即使 |
|
|
可选。请求中的 API 对象,采用 JSON 格式。在进行 version conversion、defaulting、admission 或 merging 之前,在请求中的 |
|
|
可选。响应中返回的 API 对象,使用 JSON 格式。在转换为外部类型后, |
|
| 请求到达 API 服务器的时间。 |
|
| 请求到达当前审计阶段的时间。 |
|
|
可选。一个无结构的键值映射,它存储在一个审计事件中,可以通过在请求服务链中调用的插件来设置它,包括认证、授权和准入插件。请注意,这些注解用于审计事件,且与所提交对象的 |
Kubernetes API 服务器的输出示例:
{"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Metadata","auditID":"ad209ce1-fec7-4130-8192-c4cc63f1d8cd","stage":"ResponseComplete","requestURI":"/api/v1/namespaces/openshift-kube-controller-manager/configmaps/cert-recovery-controller-lock?timeout=35s","verb":"update","user":{"username":"system:serviceaccount:openshift-kube-controller-manager:localhost-recovery-client","uid":"dd4997e3-d565-4e37-80f8-7fc122ccd785","groups":["system:serviceaccounts","system:serviceaccounts:openshift-kube-controller-manager","system:authenticated"]},"sourceIPs":["::1"],"userAgent":"cluster-kube-controller-manager-operator/v0.0.0 (linux/amd64) kubernetes/$Format","objectRef":{"resource":"configmaps","namespace":"openshift-kube-controller-manager","name":"cert-recovery-controller-lock","uid":"5c57190b-6993-425d-8101-8337e48c7548","apiVersion":"v1","resourceVersion":"574307"},"responseStatus":{"metadata":{},"code":200},"requestReceivedTimestamp":"2020-04-02T08:27:20.200962Z","stageTimestamp":"2020-04-02T08:27:20.206710Z","annotations":{"authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":"RBAC: allowed by ClusterRoleBinding \"system:openshift:operator:kube-controller-manager-recovery\" of ClusterRole \"cluster-admin\" to ServiceAccount \"localhost-recovery-client/openshift-kube-controller-manager\""}}7.2. 查看审计日志
您可以查看每个 control plane 节点(也称为主节点)的 OpenShift API 服务器、Kubernetes API 服务器和 OpenShift OAuth API 服务器的日志。
流程
查看审计日志:
查看 OpenShift API 服务器日志:
列出每个 control plane 节点可用的 OpenShift API 服务器日志:
$ oc adm node-logs --role=master --path=openshift-apiserver/输出示例
ci-ln-m0wpfjb-f76d1-vnb5x-master-0 audit-2021-03-09T00-12-19.834.log ci-ln-m0wpfjb-f76d1-vnb5x-master-0 audit.log ci-ln-m0wpfjb-f76d1-vnb5x-master-1 audit-2021-03-09T00-11-49.835.log ci-ln-m0wpfjb-f76d1-vnb5x-master-1 audit.log ci-ln-m0wpfjb-f76d1-vnb5x-master-2 audit-2021-03-09T00-13-00.128.log ci-ln-m0wpfjb-f76d1-vnb5x-master-2 audit.log通过提供节点名称和日志名称来查看特定的 OpenShift API 服务器日志:
$ oc adm node-logs <node_name> --path=openshift-apiserver/<log_name>例如:
$ oc adm node-logs ci-ln-m0wpfjb-f76d1-vnb5x-master-0 --path=openshift-apiserver/audit-2021-03-09T00-12-19.834.log输出示例
{"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Metadata","auditID":"381acf6d-5f30-4c7d-8175-c9c317ae5893","stage":"ResponseComplete","requestURI":"/metrics","verb":"get","user":{"username":"system:serviceaccount:openshift-monitoring:prometheus-k8s","uid":"825b60a0-3976-4861-a342-3b2b561e8f82","groups":["system:serviceaccounts","system:serviceaccounts:openshift-monitoring","system:authenticated"]},"sourceIPs":["10.129.2.6"],"userAgent":"Prometheus/2.23.0","responseStatus":{"metadata":{},"code":200},"requestReceivedTimestamp":"2021-03-08T18:02:04.086545Z","stageTimestamp":"2021-03-08T18:02:04.107102Z","annotations":{"authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":"RBAC: allowed by ClusterRoleBinding \"prometheus-k8s\" of ClusterRole \"prometheus-k8s\" to ServiceAccount \"prometheus-k8s/openshift-monitoring\""}}
查看 Kubernetes API 服务器日志:
列出每个 control plane 节点可用的 Kubernetes API 服务器日志:
$ oc adm node-logs --role=master --path=kube-apiserver/输出示例
ci-ln-m0wpfjb-f76d1-vnb5x-master-0 audit-2021-03-09T14-07-27.129.log ci-ln-m0wpfjb-f76d1-vnb5x-master-0 audit.log ci-ln-m0wpfjb-f76d1-vnb5x-master-1 audit-2021-03-09T19-24-22.620.log ci-ln-m0wpfjb-f76d1-vnb5x-master-1 audit.log ci-ln-m0wpfjb-f76d1-vnb5x-master-2 audit-2021-03-09T18-37-07.511.log ci-ln-m0wpfjb-f76d1-vnb5x-master-2 audit.log通过提供节点名称和日志名称来查看特定的 Kubernetes API 服务器日志:
$ oc adm node-logs <node_name> --path=kube-apiserver/<log_name>例如:
$ oc adm node-logs ci-ln-m0wpfjb-f76d1-vnb5x-master-0 --path=kube-apiserver/audit-2021-03-09T14-07-27.129.log输出示例
{"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Metadata","auditID":"cfce8a0b-b5f5-4365-8c9f-79c1227d10f9","stage":"ResponseComplete","requestURI":"/api/v1/namespaces/openshift-kube-scheduler/serviceaccounts/openshift-kube-scheduler-sa","verb":"get","user":{"username":"system:serviceaccount:openshift-kube-scheduler-operator:openshift-kube-scheduler-operator","uid":"2574b041-f3c8-44e6-a057-baef7aa81516","groups":["system:serviceaccounts","system:serviceaccounts:openshift-kube-scheduler-operator","system:authenticated"]},"sourceIPs":["10.128.0.8"],"userAgent":"cluster-kube-scheduler-operator/v0.0.0 (linux/amd64) kubernetes/$Format","objectRef":{"resource":"serviceaccounts","namespace":"openshift-kube-scheduler","name":"openshift-kube-scheduler-sa","apiVersion":"v1"},"responseStatus":{"metadata":{},"code":200},"requestReceivedTimestamp":"2021-03-08T18:06:42.512619Z","stageTimestamp":"2021-03-08T18:06:42.516145Z","annotations":{"authentication.k8s.io/legacy-token":"system:serviceaccount:openshift-kube-scheduler-operator:openshift-kube-scheduler-operator","authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":"RBAC: allowed by ClusterRoleBinding \"system:openshift:operator:cluster-kube-scheduler-operator\" of ClusterRole \"cluster-admin\" to ServiceAccount \"openshift-kube-scheduler-operator/openshift-kube-scheduler-operator\""}}
查看 OpenShift OAuth API 服务器日志:
列出每个 control plane 节点可用的 OpenShift OAuth API 服务器日志:
$ oc adm node-logs --role=master --path=oauth-apiserver/输出示例
ci-ln-m0wpfjb-f76d1-vnb5x-master-0 audit-2021-03-09T13-06-26.128.log ci-ln-m0wpfjb-f76d1-vnb5x-master-0 audit.log ci-ln-m0wpfjb-f76d1-vnb5x-master-1 audit-2021-03-09T18-23-21.619.log ci-ln-m0wpfjb-f76d1-vnb5x-master-1 audit.log ci-ln-m0wpfjb-f76d1-vnb5x-master-2 audit-2021-03-09T17-36-06.510.log ci-ln-m0wpfjb-f76d1-vnb5x-master-2 audit.log通过提供节点名称和日志名称来查看特定的 OpenShift OAuth API 服务器日志:
$ oc adm node-logs <node_name> --path=oauth-apiserver/<log_name>例如:
$ oc adm node-logs ci-ln-m0wpfjb-f76d1-vnb5x-master-0 --path=oauth-apiserver/audit-2021-03-09T13-06-26.128.log输出示例
{"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Metadata","auditID":"dd4c44e2-3ea1-4830-9ab7-c91a5f1388d6","stage":"ResponseComplete","requestURI":"/apis/user.openshift.io/v1/users/~","verb":"get","user":{"username":"system:serviceaccount:openshift-monitoring:prometheus-k8s","groups":["system:serviceaccounts","system:serviceaccounts:openshift-monitoring","system:authenticated"]},"sourceIPs":["10.0.32.4","10.128.0.1"],"userAgent":"dockerregistry/v0.0.0 (linux/amd64) kubernetes/$Format","objectRef":{"resource":"users","name":"~","apiGroup":"user.openshift.io","apiVersion":"v1"},"responseStatus":{"metadata":{},"code":200},"requestReceivedTimestamp":"2021-03-08T17:47:43.653187Z","stageTimestamp":"2021-03-08T17:47:43.660187Z","annotations":{"authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":"RBAC: allowed by ClusterRoleBinding \"basic-users\" of ClusterRole \"basic-user\" to Group \"system:authenticated\""}}
7.3. 过滤审计日志
您可以使用 jq 或另一个 JSON 解析工具来过滤 API 服务器审计日志。
日志记录到 API 服务器审计日志的信息量是由设置的审计日志策略控制的。
以下流程提供了使用 jq 在 control plane 节点 node-1.example.com 上过滤审计日志的示例。有关使用 jq 的详情,请参考 jq 手册。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。 -
您已安装了
jq。
流程
根据用户过滤 OpenShift API 服务器审计日志:
$ oc adm node-logs node-1.example.com \ --path=openshift-apiserver/audit.log \ | jq 'select(.user.username == "myusername")'根据用户代理过滤 OpenShift API 服务器审计日志:
$ oc adm node-logs node-1.example.com \ --path=openshift-apiserver/audit.log \ | jq 'select(.userAgent == "cluster-version-operator/v0.0.0 (linux/amd64) kubernetes/$Format")'通过特定 API 版本过滤 Kubernetes API 服务器审计日志,仅输出用户代理:
$ oc adm node-logs node-1.example.com \ --path=kube-apiserver/audit.log \ | jq 'select(.requestURI | startswith("/apis/apiextensions.k8s.io/v1beta1")) | .userAgent'通过排除动词来过滤 OpenShift OAuth API 服务器审计日志:
$ oc adm node-logs node-1.example.com \ --path=oauth-apiserver/audit.log \ | jq 'select(.verb != "get")'
7.4. 收集审计日志
您可以使用 must-gather 工具来收集审计日志以调试集群,您可以检查或发送到红帽支持。
流程
使用
-- /usr/bin/gather_audit_logs标志运行oc adm must-gather命令:$ oc adm must-gather -- /usr/bin/gather_audit_logs从工作目录中刚刚创建的
must-gather目录创建一个压缩文件。例如,在使用 Linux 操作系统的计算机上运行以下命令:$ tar cvaf must-gather.tar.gz must-gather.local.4722904036990062481 - 1
- 将
must-gather-local.472290403699006248替换为实际目录名称。
- 在红帽客户门户中为您的问题单附上压缩文件。
第 8 章 配置审计日志策略
您可以通过选择要使用的审计日志策略配置集来控制记录到 API 服务器审计日志的信息量。
8.1. 关于审计日志策略配置集
审计日志配置集定义了如何记录 OpenShift API 服务器、Kubernetes API 服务器和 OAuth API 服务器的请求。
OpenShift Container Platform 提供以下预定义的审计策略配置集:
| 配置集 | 描述 |
|---|---|
|
| 仅记录读取和写入请求的日志元数据 ;除了 OAuth 访问令牌请求外,不记录请求正文。这是默认策略。 |
|
|
除了记录所有请求的元数据外,同时记录对 API 服务器的写入请求( |
|
|
除了记录所有请求的元数据外,对 API 服务器的每个读写请求( |
-
敏感资源,如
Secret、Route和OAuthClient对象,永远不会记录在元数据级别上。
默认情况下,OpenShift Container Platform 使用 Default 审计日志配置集。您可以使用另一个审计策略配置集来记录请求的具体数据,但注意这会消耗更多资源(CPU、内存和 I/O)。
8.2. 配置审计日志策略
您可以配置审计日志策略,使其在记录 API 服务器的请求时使用。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。
流程
编辑
APIServer资源:$ oc edit apiserver cluster更新
spec.audit.profile字段:apiVersion: config.openshift.io/v1 kind: APIServer metadata: ... spec: audit: profile: WriteRequestBodies1 - 1
- 设置为
Default、WriteRequestBodies或AllRequestBodies。默认配置集为Default。
- 保存文件以使改变生效。
验证是否已推出 Kubernetes API 服务器 pod 的新修订版本。这需要几分钟时间。
$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'查看 Kubernetes API 服务器的
NodeInstallerProgressing状态条件,以验证所有节点是否处于最新的修订版本。在更新成功后,输出会显示AllNodesAtLatestRevision:AllNodesAtLatestRevision 3 nodes are at revision 121 - 1
- 在本例中,最新的修订版本号为
12。
如果输出显示的信息类似如下,这意味着更新仍在进行中。等待几分钟后重试。
-
3 nodes are at revision 11; 0 nodes have achieved new revision 12 -
2 nodes are at revision 11; 1 nodes are at revision 12
第 9 章 配置 TLS 安全配置集
TLS 安全配置文件为服务器提供了一种方式,以规范在连接到服务器时可以使用什么加密方式。这样可确保 OpenShift Container Platform 组件使用加密库,它们不允许已知的不安全协议、密码或算法。
集群管理员可选择要用于以下每个组件的 TLS 安全配置集:
- Ingress Controller
control plane
这包括 Kubernetes API 服务器、Kubernetes 控制器管理器、Kubernetes 调度程序、OpenShift API 服务器、OpenShift OAuth API 服务器和 OpenShift OAuth 服务器。
- kubelet,当作为 Kubernetes API 服务器的 HTTP 服务器时
9.1. 了解 TLS 安全配置集
您可以使用 TLS(Transport Layer Security)安全配置集来定义各种 OpenShift Container Platform 组件需要哪些 TLS 密码。OpenShift Container Platform TLS 安全配置集基于 Mozilla 推荐的配置。
您可以为每个组件指定以下 TLS 安全配置集之一:
| profile | 描述 |
|---|---|
|
| 此配置集用于旧的客户端或库。该配置集基于旧的向后兼容性建议配置。
注意 对于 Ingress Controller,最小 TLS 版本从 1.0 转换为 1.1。 |
|
| 这个配置集是大多数客户端的建议配置。它是 Ingress Controller、kubelet 和 control plane 的默认 TLS 安全配置集。该配置集基于 Intermediate 兼容性推荐的配置。
|
|
| 此配置集主要用于不需要向后兼容的现代客户端。这个配置集基于 Modern 兼容性推荐的配置。
注意
在 OpenShift Container Platform 4.6、4.7 和 4.8 中, 重要
|
|
| 此配置集允许您定义要使用的 TLS 版本和密码。 警告
使用 注意
OpenShift Container Platform router 会启用由红帽提供的 OpenSSL 默认 TLS |
当使用预定义的配置集类型时,有效的配置集配置可能会在发行版本之间有所改变。例如,使用在版本 X.Y.Z 中部署的 Intermediate 配置集指定了一个规格,升级到版本 X.Y.Z+1 可能会导致应用新的配置集配置,从而导致推出部署。
9.2. 查看 TLS 安全配置集详情
您可以查看以下组件的预定义 TLS 安全配置集的最小 TLS 版本和密码:Ingress Controller、control plane 和 kubelet。
最低 TLS 版本和配置集密码列表的有效配置可能因组件而异。
流程
查看特定 TLS 安全配置集的详情:
$ oc explain <component>.spec.tlsSecurityProfile.<profile>1 - 1
- 对于
<component>,指定ingresscontroller、apiserver或kubeletconfig。对于<profile>,指定old、intermediate或custom。
例如,检查 control plane 的
intermediate配置集中包含的密码:$ oc explain apiserver.spec.tlsSecurityProfile.intermediate输出示例
KIND: APIServer VERSION: config.openshift.io/v1 DESCRIPTION: intermediate is a TLS security profile based on: https://wiki.mozilla.org/Security/Server_Side_TLS#Intermediate_compatibility_.28recommended.29 and looks like this (yaml): ciphers: - TLS_AES_128_GCM_SHA256 - TLS_AES_256_GCM_SHA384 - TLS_CHACHA20_POLY1305_SHA256 - ECDHE-ECDSA-AES128-GCM-SHA256 - ECDHE-RSA-AES128-GCM-SHA256 - ECDHE-ECDSA-AES256-GCM-SHA384 - ECDHE-RSA-AES256-GCM-SHA384 - ECDHE-ECDSA-CHACHA20-POLY1305 - ECDHE-RSA-CHACHA20-POLY1305 - DHE-RSA-AES128-GCM-SHA256 - DHE-RSA-AES256-GCM-SHA384 minTLSVersion: TLSv1.2查看组件的
tlsSecurityProfile字段的所有详情:$ oc explain <component>.spec.tlsSecurityProfile1 - 1
- 对于
<component>,指定ingresscontroller、apiserver或kubeletconfig。
例如,检查 Ingress Controller 的
tlsSecurityProfile字段的所有详情:$ oc explain ingresscontroller.spec.tlsSecurityProfile输出示例
KIND: IngressController VERSION: operator.openshift.io/v1 RESOURCE: tlsSecurityProfile <Object> DESCRIPTION: ... FIELDS: custom <> custom is a user-defined TLS security profile. Be extremely careful using a custom profile as invalid configurations can be catastrophic. An example custom profile looks like this: ciphers: - ECDHE-ECDSA-CHACHA20-POLY1305 - ECDHE-RSA-CHACHA20-POLY1305 - ECDHE-RSA-AES128-GCM-SHA256 - ECDHE-ECDSA-AES128-GCM-SHA256 minTLSVersion: TLSv1.1 intermediate <> intermediate is a TLS security profile based on: https://wiki.mozilla.org/Security/Server_Side_TLS#Intermediate_compatibility_.28recommended.29 and looks like this (yaml): ...1 modern <> modern is a TLS security profile based on: https://wiki.mozilla.org/Security/Server_Side_TLS#Modern_compatibility and looks like this (yaml): ...2 NOTE: Currently unsupported. old <> old is a TLS security profile based on: https://wiki.mozilla.org/Security/Server_Side_TLS#Old_backward_compatibility and looks like this (yaml): ...3 type <string> ...
9.3. 为 Ingress Controller 配置 TLS 安全配置集
要为 Ingress Controller 配置 TLS 安全配置集,请编辑 IngressController 自定义资源(CR)来指定预定义或自定义 TLS 安全配置集。如果没有配置 TLS 安全配置集,则默认值基于为 API 服务器设置的 TLS 安全配置集。
配置 Old TLS 安全配置集的 IngressController CR 示例
apiVersion: operator.openshift.io/v1
kind: IngressController
...
spec:
tlsSecurityProfile:
old: {}
type: Old
...TLS 安全配置集定义 Ingress Controller 的 TLS 连接的最低 TLS 版本和 TLS 密码。
您可以在 Status.Tls Profile 和 Spec.Tls Security Profile 下看到 IngressController 自定义资源(CR)中配置的 TLS 安全配置集的密码和最小 TLS 版本。对于 Custom TLS 安全配置集,这两个参数下列出了特定的密码和最低 TLS 版本。
HAProxy Ingress Controller 镜像不支持 TLS 1.3,因为 Modern 配置集需要 TLS 1.3,因此不支持它。Ingress Operator 会将 Modern 配置集转换为 Intermediate。
Ingress Operator 还会将 Old 或 Custom 配置集的 TLS 1.0 转换为 1.1,将Custom 配置集的 TLS 1.3 转换为 1.2。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。
流程
编辑
openshift-ingress-operator项目中的IngressControllerCR,以配置 TLS 安全配置集:$ oc edit IngressController default -n openshift-ingress-operator添加
spec.tlsSecurityProfile字段:Custom配置集的IngressControllerCR 示例apiVersion: operator.openshift.io/v1 kind: IngressController ... spec: tlsSecurityProfile: type: Custom1 custom:2 ciphers:3 - ECDHE-ECDSA-CHACHA20-POLY1305 - ECDHE-RSA-CHACHA20-POLY1305 - ECDHE-RSA-AES128-GCM-SHA256 - ECDHE-ECDSA-AES128-GCM-SHA256 minTLSVersion: VersionTLS11 ...- 保存文件以使改变生效。
验证
验证
IngressControllerCR 中是否设置了配置集:$ oc describe IngressController default -n openshift-ingress-operator输出示例
Name: default Namespace: openshift-ingress-operator Labels: <none> Annotations: <none> API Version: operator.openshift.io/v1 Kind: IngressController ... Spec: ... Tls Security Profile: Custom: Ciphers: ECDHE-ECDSA-CHACHA20-POLY1305 ECDHE-RSA-CHACHA20-POLY1305 ECDHE-RSA-AES128-GCM-SHA256 ECDHE-ECDSA-AES128-GCM-SHA256 Min TLS Version: VersionTLS11 Type: Custom ...
9.4. 为 control plane 配置 TLS 安全配置集
要为 control plane 配置 TLS 安全配置集,请编辑 APIServer 自定义资源(CR)来指定预定义或自定义 TLS 安全配置集。在 APIServer CR 中设置 TLS 安全配置集将设置传播到以下 control plane 组件:
- Kubernetes API 服务器
- Kubernetes 控制器管理器
- Kubernetes 调度程序
- OpenShift API 服务器
- OpenShift OAuth API 服务器
- OpenShift OAuth 服务器
如果没有配置 TLS 安全配置集,则默认 TLS 安全配置集为 Intermediate。
Ingress Controller 的默认 TLS 安全配置集基于为 API 服务器设置的 TLS 安全配置集。
配置 Old TLS 安全配置集的 APIServer CR 示例
apiVersion: config.openshift.io/v1
kind: APIServer
...
spec:
tlsSecurityProfile:
old: {}
type: Old
...TLS 安全配置集定义与 control plane 组件通信的最低 TLS 版本和所需的 TLS 密码。
您可以在 Spec.Tls Security Profile 下的 APIServer 自定义资源(CR)中看到配置的 TLS 安全配置集。对于 Custom TLS 安全配置集,会列出特定的密码和最小 TLS 版本。
control plane 不支持 TLS 1.3 作为最小 TLS 版本;不支持 Modern 配置集,因为它需要 TLS 1.3。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。
流程
编辑默认
APIServerCR 以配置 TLS 安全配置集:$ oc edit APIServer cluster添加
spec.tlsSecurityProfile字段:Custom配置集的APIServerCR 示例apiVersion: config.openshift.io/v1 kind: APIServer metadata: name: cluster spec: tlsSecurityProfile: type: Custom1 custom:2 ciphers:3 - ECDHE-ECDSA-CHACHA20-POLY1305 - ECDHE-RSA-CHACHA20-POLY1305 - ECDHE-RSA-AES128-GCM-SHA256 - ECDHE-ECDSA-AES128-GCM-SHA256 minTLSVersion: VersionTLS11- 保存文件以使改变生效。
验证
验证
APIServerCR 中是否设置了 TLS 安全配置集:$ oc describe apiserver cluster输出示例
Name: cluster Namespace: ... API Version: config.openshift.io/v1 Kind: APIServer ... Spec: Audit: Profile: Default Tls Security Profile: Custom: Ciphers: ECDHE-ECDSA-CHACHA20-POLY1305 ECDHE-RSA-CHACHA20-POLY1305 ECDHE-RSA-AES128-GCM-SHA256 ECDHE-ECDSA-AES128-GCM-SHA256 Min TLS Version: VersionTLS11 Type: Custom ...
9.5. 为 kubelet 配置 TLS 安全配置集
要在作为 HTTP 服务器时为 kubelet 配置 TLS 安全配置集,请创建一个 KubeletConfig 自定义资源(CR)来为特定节点指定预定义或自定义 TLS 安全配置集。如果没有配置 TLS 安全配置集,则默认 TLS 安全配置集为 Intermediate。
kubelet 使用其 HTTP/GRPC 服务器与 Kubernetes API 服务器通信,后者向 pod 发送命令,收集日志,并通过 kubelet 对 pod 运行 exec 命令。
在 worker 节点上配置 Old TLS 安全配置集的 KubeletConfig CR 示例
apiVersion: config.openshift.io/v1
kind: KubeletConfig
...
spec:
tlsSecurityProfile:
old: {}
type: Old
machineConfigPoolSelector:
matchLabels:
pools.operator.machineconfiguration.openshift.io/worker: ""
您可以在配置的节点上的 kubelet.conf 文件中看到配置 TLS 安全配置集的密码和最小 TLS 版本。
先决条件
-
您可以使用具有
cluster-admin角色的用户访问集群。
流程
创建
KubeletConfigCR 来配置 TLS 安全配置集:Custom配置集的KubeletConfigCR 示例apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-kubelet-tls-security-profile spec: tlsSecurityProfile: type: Custom1 custom:2 ciphers:3 - ECDHE-ECDSA-CHACHA20-POLY1305 - ECDHE-RSA-CHACHA20-POLY1305 - ECDHE-RSA-AES128-GCM-SHA256 - ECDHE-ECDSA-AES128-GCM-SHA256 minTLSVersion: VersionTLS11 machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: ""4 创建
KubeletConfig对象:$ oc create -f <filename>根据集群中的 worker 节点数量,等待配置的节点被逐个重启。
验证
要验证是否设置了配置集,请在节点处于 Ready 状态后执行以下步骤:
为配置的节点启动 debug 会话:
$ oc debug node/<node_name>将
/host设置为 debug shell 中的根目录:sh-4.4# chroot /host查看
kubelet.conf文件:sh-4.4# cat /etc/kubernetes/kubelet.conf输出示例
kind: KubeletConfiguration apiVersion: kubelet.config.k8s.io/v1beta1 ... "tlsCipherSuites": [ "TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256", "TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256", "TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384", "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384", "TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256", "TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256" ], "tlsMinVersion": "VersionTLS12",
第 10 章 配置 seccomp 配置集
OpenShift Container Platform 容器或 pod 运行一个应用程序,它执行一个或多个定义明确的任务。应用程序通常只需要底层操作系统内核 API 的一小部分。seccomp、安全计算模式是一种 Linux 内核功能,可用于将容器中运行的进程限制为仅调用可用系统调用的一个子集。可以通过创建应用到容器或 pod 的配置集来配置这些系统调用。seccomp 配置集作为 JSON 文件存储在磁盘上。
OpenShift 工作负载默认运行 unconfined,不应用任何 seccomp 配置集。
seccomp 配置集不能应用到特权容器。
10.1. 为所有 pod 启用默认 seccomp 配置集
OpenShift Container Platform 附带了一个默认的 seccomp 配置集,它被引用为 runtime/default。您可以通过创建自定义安全性上下文约束 (SCC),为 pod 或容器工作负载启用默认的 seccomp 配置集。
需要创建自定义 SCC。不要编辑默认 SCC。编辑默认 SCC 可能会导致升级某些平台 Pod 或 OpenShift Container Platform 时出现问题。如需更多信息,请参阅标题为"默认安全性上下文约束"部分。
按照以下步骤为所有 pod 启用默认 seccomp 配置集:
将可用的
restrictedSCC 导出至 yaml 文件中:$ oc get scc restricted -o yaml > restricted-seccomp.yaml编辑创建的
restrictedSCC yaml 文件:$ vi restricted-seccomp.yaml如本例所示更新:
kind: SecurityContextConstraints metadata: name: restricted1 <..snip..> seccompProfiles:2 - runtime/default3 创建自定义 SCC:
$ oc create -f restricted-seccomp.yaml预期输出
securitycontextconstraints.security.openshift.io/restricted-seccomp created将自定义 SCC 添加到 ServiceAccount:
$ oc adm policy add-scc-to-user restricted-seccomp -z default注意默认服务帐户是应用的 ServiceAccount,除非用户配置不同的对象。OpenShift Container Platform 根据 SCC 中的信息配置 pod 的 seccomp 配置集。
预期输出
clusterrole.rbac.authorization.k8s.io/system:openshift:scc:restricted-seccomp added: "default"
在 OpenShift Container Platform 4.8 中,添加 pod 注解 seccomp.security.alpha.kubernetes.io/pod: runtime/default 和 container.seccomp.security.alpha.kubernetes.io/<container_name>: runtime/default 已被弃用。
10.2. 配置自定义 seccomp 配置集
您可以配置自定义 seccomp 配置集,允许您根据应用要求更新过滤器。这使得集群管理员能够更好地控制在 OpenShift Container Platform 中运行的工作负载的安全性。
10.2.1. 设置自定义 seccomp 配置集
前提条件
- 有集群管理员权限。
- 您已创建了自定义安全上下文约束 (SCC)。如需更多信息,请参阅"附加资源"。
- 您已创建了自定义 seccomp 配置集。
流程
-
使用 Machine Config 将自定义 seccomp 配置集上传到
/var/lib/kubelet/seccomp/<custom-name>.json。有关详细信息,请参阅"附加资源"。 通过引用创建的自定义 seccomp 配置集来更新自定义 SCC:
seccompProfiles: - localhost/<custom-name>.json1 - 1
- 提供自定义 seccomp 配置集的名称。
10.2.2. 将自定义 seccomp 配置集应用到工作负载
前提条件
- 集群管理员已设置了自定义 seccomp 配置集。如需了解更多详细信息,请参阅 "设置自定义 seccomp 配置集"。
流程
通过设置
securityContext.seccompProfile.type字段,将 seccomp 配置集应用到工作负载,如下所示:示例
spec: securityContext: seccompProfile: type: Localhost localhostProfile: <custom-name>.json1 - 1
- 提供自定义 seccomp 配置集的名称。
另外,您可以使用 pod 注解
seccomp.security.alpha.kubernetes.io/pod: localhost/<custom-name>.json。但是,此方法在 OpenShift Container Platform 4.8 中已弃用。
在部署过程中,准入控制器会验证以下内容:
- 用户角色允许的当前 SCC 的注解。
- Pod 允许包含 seccomp 配置集的 SCC。
如果 pod 允许 SCC,kubelet 会使用指定的 seccomp 配置集运行 pod。
确保 seccomp 配置集已部署到所有 worker 节点。
自定义 SCC 必须具有自动分配给 pod 的适当优先级,或满足 Pod 所需的其他条件,如允许 CAP_NET_ADMIN。
第 11 章 允许从其他主机对 API 服务器进行基于 JavaScript 的访问
11.1. 允许从其他主机对 API 服务器进行基于 JavaScript 的访问
默认的 OpenShift Container Platform 配置只允许 Web 控制台向 API 服务器发送请求。
如果需要使用不同的主机名从 JavaScript 应用程序访问 API 服务器或 OAuth 服务器,您可以配置额外的主机名来允许。
先决条件
-
使用具有
cluster-admin角色的用户访问集群。
流程
编辑
APIServer资源:$ oc edit apiserver.config.openshift.io cluster在
spec部分下添加additionalCORSAllowedOrigins字段,并指定一个或多个额外主机名:apiVersion: config.openshift.io/v1 kind: APIServer metadata: annotations: release.openshift.io/create-only: "true" creationTimestamp: "2019-07-11T17:35:37Z" generation: 1 name: cluster resourceVersion: "907" selfLink: /apis/config.openshift.io/v1/apiservers/cluster uid: 4b45a8dd-a402-11e9-91ec-0219944e0696 spec: additionalCORSAllowedOrigins: - (?i)//my\.subdomain\.domain\.com(:|\z)1 - 1
- 主机名用 Golang 正则表达式指定,与来自对 API 服务器和 OAuth 服务器的 HTTP 请求的 CORS 标头匹配。
注意此示例采用以下语法:
-
(?i)使它不区分大小写。 -
//固定到域的开头,并且匹配http:或https:后面的双斜杠。 -
\.对域名中的点进行转义。 -
(:|\z)匹配域名末尾(\z)或端口分隔符(:)。
- 保存文件以使改变生效。
第 12 章 加密 etcd 数据
12.1. 关于 etcd 加密
默认情况下,OpenShift Container Platform 不加密 etcd 数据。在集群中启用对 etcd 进行加密的功能可为数据的安全性提供额外的保护层。例如,如果 etcd 备份暴露给不应该获得这个数据的人员,它会帮助保护敏感数据。
启用 etcd 加密时,以下 OpenShift API 服务器和 Kubernetes API 服务器资源将被加密:
- Secrets
- 配置映射
- Routes
- OAuth 访问令牌
- OAuth 授权令牌
当您启用 etcd 加密时,会创建加密密钥。这些密钥会每周进行轮转。您必须具有这些密钥才能从 etcd 备份中恢复。
etcd 加密只加密值,而不加密键。资源类型、命名空间和对象名称是未加密的。
如果在备份过程中启用了 etcd 加密,static_kuberesources_<datetimestamp>.tar.gz 文件包含 etcd 快照的加密密钥。为安全起见,请将此文件与 etcd 快照分开存储。但是,需要这个文件才能从相应的 etcd 快照恢复以前的 etcd 状态。
12.2. 启用 etcd 加密
您可以启用 etcd 加密来加密集群中的敏感资源。
在初始加密过程完成前,不要备份 etcd 资源。如果加密过程还没有完成,则备份可能只被部分加密。
启用 etcd 加密后,可能会出现一些更改:
- etcd 加密可能会影响几个资源的内存消耗。
- 您可能会注意到对备份性能具有临时影响,因为领导必须提供备份服务。
- 磁盘 I/O 可能会影响接收备份状态的节点。
先决条件
-
使用具有
cluster-admin角色的用户访问集群。
流程
修改
APIServer对象:$ oc edit apiserver把
encryption项类型设置为aescbc:spec: encryption: type: aescbc1 - 1
aescbc类型表示 AES-CBC 使用 PKCS#7 padding 和 32 字节密钥来执行加密。
保存文件以使改变生效。
加密过程开始。根据集群的大小,这个过程可能需要 20 分钟或更长的时间才能完成。
验证 etcd 加密是否成功。
查看 OpenShift API 服务器的
Encrypted状态条件,以验证其资源是否已成功加密:$ oc get openshiftapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'在成功加密后输出显示
EncryptionCompleted:EncryptionCompleted All resources encrypted: routes.route.openshift.io如果输出显示
EncryptionInProgress,加密仍在进行中。等待几分钟后重试。查看 Kubernetes API 服务器的
Encrypted状态条件,以验证其资源是否已成功加密:$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'在成功加密后输出显示
EncryptionCompleted:EncryptionCompleted All resources encrypted: secrets, configmaps如果输出显示
EncryptionInProgress,加密仍在进行中。等待几分钟后重试。查看 OpenShift OAuth API 服务器的
Encrypted状态条件,以验证其资源是否已成功加密:$ oc get authentication.operator.openshift.io -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'在成功加密后输出显示
EncryptionCompleted:EncryptionCompleted All resources encrypted: oauthaccesstokens.oauth.openshift.io, oauthauthorizetokens.oauth.openshift.io如果输出显示
EncryptionInProgress,加密仍在进行中。等待几分钟后重试。
12.3. 禁用 etcd 加密
您可以在集群中禁用 etcd 数据的加密。
先决条件
-
使用具有
cluster-admin角色的用户访问集群。
流程
修改
APIServer对象:$ oc edit apiserver将
encryption字段类型设置为identity:spec: encryption: type: identity1 - 1
identity类型是默认值,意味着没有执行任何加密。
保存文件以使改变生效。
解密过程开始。根据集群的大小,这个过程可能需要 20 分钟或更长的时间才能完成。
验证 etcd 解密是否成功。
查看 OpenShift API 服务器的
Encrypted状态条件,以验证其资源是否已成功解密:$ oc get openshiftapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'在成功解密后输出显示
DecryptionCompleted:DecryptionCompleted Encryption mode set to identity and everything is decrypted如果输出显示
DecryptionInProgress,解密仍在进行中。等待几分钟后重试。查看 Kubernetes API 服务器的
Encrypted状态条件,以验证其资源是否已成功解密:$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'在成功解密后输出显示
DecryptionCompleted:DecryptionCompleted Encryption mode set to identity and everything is decrypted如果输出显示
DecryptionInProgress,解密仍在进行中。等待几分钟后重试。查看 OpenShift OAuth API 服务器的
Encrypted状态条件,以验证其资源是否已成功解密:$ oc get authentication.operator.openshift.io -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'在成功解密后输出显示
DecryptionCompleted:DecryptionCompleted Encryption mode set to identity and everything is decrypted如果输出显示
DecryptionInProgress,解密仍在进行中。等待几分钟后重试。
第 13 章 对 pod 进行安全漏洞扫描
使用 Red Hat Quay Container Security Operator,您可以访问 OpenShift Container Platform Web 控制台中用于集群中活跃 pod 的容器镜像,访问 OpenShift Container Platform Web 控制台中的漏洞扫描结果。Red Hat Quay Container Security Operator:
- 监视与所有或指定命名空间中的 pod 关联的容器
- 查询容器来自漏洞信息的容器 registry,提供镜像的 registry 正在运行镜像扫描(如 Quay.io 或带有 Clair 扫描的 Red Hat Quay registry)
-
通过 Kubernetes API 中的
ImageManifestVuln对象公开漏洞
根据这里的说明,Red Hat Quay Container Security Operator 安装在 openshift-operators 命名空间中,因此 OpenShift Container Platform 集群中的所有命名空间都可以使用它。
13.1. 运行 Red Hat Quay Container Security Operator
您可以通过从 Operator Hub 选择并安装该 Operator,从 OpenShift Container Platform Web 控制台启动 Red Hat Quay Container Security Operator,如下所述。
先决条件
- 具有 OpenShift Container Platform 集群的管理员特权
- 来自集群中运行的 Red Hat Quay 或 Quay.io registry 的容器
流程
- 导航到 Operators → OperatorHub 并选择 Security。
- 选择 Container Security Operator,然后选择 Install 进入 Create Operator Subscription 页面。
- 检查设置。所有命名空间和自动批准策略都被默认选择。
- 选择 Install。在 Installed Operators 屏幕中几分钟后会出现 Container Security Operator。
可选: 您可以将自定义证书添加到 Red Hat Quay Container Security Operator。在本例中,在当前目录中创建一个名为
quay.crt的证书。然后,运行以下命令将证书添加到 Red Hat Quay Container Security Operator 中:$ oc create secret generic container-security-operator-extra-certs --from-file=quay.crt -n openshift-operators- 如果添加了自定义证书,请重启 Operator Pod 以使新证书生效。
打开 OpenShift Dashboard(
Home→Overview)。至 Quay Image Security 的链接会出现在 status 部分,其中列出了目前发现的漏洞数量。选择该链接以查看 Quay 镜像安全分类,如下图所示:
对于任何检测到的安全漏洞,您可以在此时进行两个操作之一:
选择到这个漏洞的链接。您会进入容器来自的容器 registry,在那里查看有关该漏洞的信息。下图显示了从 Quay.io registry 中检测到的漏洞示例:

选择 namespaces 链接以进入 ImageManifestVuln 界面,您可以在其中查看所选镜像的名称以及该镜像正在运行的所有命名空间。下图表示,一个存在特定漏洞的镜像正在
quay-enterprise命名空间中运行:
此时,您知道哪些镜像存在这个安全漏洞,需要做什么来修复这些漏洞,以及镜像在中运行的每个命名空间。您可以:
- 警告运行镜像的用户需要修正这个漏洞
- 通过删除启动镜像所在 Pod 的部署或其他对象来停止镜像运行
请注意,如果您删除 pod,可能需要几分钟时间才能在仪表板上重置漏洞。
13.2. 通过 CLI 查询镜像安全漏洞
使用 oc 命令,可以显示 Red Hat Quay Container Security Operator 检测到的漏洞信息。
先决条件
- 在 OpenShift Container Platform 实例上运行 Red Hat Quay Container Security Operator
流程
要查询检测到的容器镜像漏洞,请输入:
$ oc get vuln --all-namespaces输出示例
NAMESPACE NAME AGE default sha256.ca90... 6m56s skynet sha256.ca90... 9m37s要显示特定漏洞的详情,在
oc describe命令中提供漏洞名称及其命名空间。本例演示了一个活跃的容器,其镜像包含存在漏洞的 RPM 软件包:$ oc describe vuln --namespace mynamespace sha256.ac50e3752...输出示例
Name: sha256.ac50e3752... Namespace: quay-enterprise ... Spec: Features: Name: nss-util Namespace Name: centos:7 Version: 3.44.0-3.el7 Versionformat: rpm Vulnerabilities: Description: Network Security Services (NSS) is a set of libraries...
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.