네트워킹
AWS 네트워킹에서 Red Hat OpenShift Service 구성
초록
1장. 네트워킹 정보
Red Hat OpenShift Networking은 클러스터가 하나 이상의 하이브리드 클러스터의 네트워크 트래픽을 관리하는 데 필요한 고급 네트워킹 관련 기능을 사용하여 Kubernetes 네트워킹을 개선하는 기능, 플러그인 및 고급 네트워킹 기능으로 구성된 에코시스템입니다. 이 네트워킹 기능의 에코시스템은 수신, 송신, 로드 밸런싱, 고성능 처리량, 보안 및 클러스터 내부 트래픽 관리를 통합합니다. Red Hat OpenShift Networking 에코시스템은 또한 역할 기반 관찰 툴을 제공하여 자연의 복잡성을 줄일 수 있습니다.
다음은 클러스터에서 사용할 수 있는 가장 일반적으로 사용되는 Red Hat OpenShift Networking 기능 중 일부입니다.
- 네트워크 플러그인 관리를 위한 Cluster Network Operator
다음 CNI(Container Network Interface) 플러그인에서 제공하는 기본 클러스터 네트워크입니다.
- 기본 CNI 플러그인인 OVN-Kubernetes 네트워크 플러그인 .
- OpenShift SDN 네트워크 플러그인 - OpenShift 4.16에서 더 이상 사용되지 않고 OpenShift 4.17에서 제거되었습니다.
OpenShift SDN 네트워크 플러그인으로 구성된 ROSA(classic architecture) 클러스터를 버전 4.17로 업그레이드하기 전에 OVN-Kubernetes 네트워크 플러그인으로 마이그레이션해야 합니다. 자세한 내용은 추가 리소스 섹션의 OpenShift SDN 네트워크 플러그인에서 OVN-Kubernetes 네트워크 플러그인으로 마이그레이션 을 참조하십시오.
추가 리소스
2장. Networking Operator
2.1. AWS Load Balancer Operator
AWS Load Balancer Operator는 Red Hat에서 지원하는 Operator로, 사용자가 선택적으로 AWS(ROSA) 클러스터의 SRE 관리 Red Hat OpenShift Service에 설치할 수 있습니다. AWS Load Balancer Operator는 ROSA 클러스터에서 실행되는 애플리케이션에 대해 AWS Elastic Load Balancing v2(ELBv2) 서비스를 프로비저닝하는 AWS Load Balancer 컨트롤러의 라이프사이클을 관리합니다.
AWS Load Balancer Operator에서 생성한 로드 밸런서는 OpenShift 경로에 사용할 수 없으며 OpenShift 경로 의 전체 계층 7 기능이 필요하지 않은 개별 서비스 또는 인그레스 리소스에만 사용해야 합니다.
AWS Load Balancer 컨트롤러는 AWS(ROSA) 클러스터에서 Red Hat OpenShift Service의 AWS Elastic Load Balancer를 관리합니다. 컨트롤러는 LoadBalancer 유형의 Kubernetes 서비스 리소스를 구현할 때 Kubernetes Ingress 리소스 및 AWS NLB(Network Load Balancer)를 생성할 때 AWS Application Load Balancer( ALB )를 프로비저닝합니다.
기본 AWS in-tree 로드 밸런서 공급자와 비교하여 이 컨트롤러는 ALB 및 NLB 모두에 대한 고급 주석으로 개발됩니다. 일부 고급 사용 사례는 다음과 같습니다.
- ALB에서 네이티브 Kubernetes Ingress 오브젝트 사용
- ALB를 AWS Web Application Firewall(WAF) 서비스와 통합
- 사용자 정의 NLB 소스 IP 범위 지정
- 사용자 정의 NLB 내부 IP 주소 지정
AWS Load Balancer Operator 는 ROSA 클러스터에서 aws-load-balancer-controller 인스턴스를 설치, 관리 및 구성하는 데 사용됩니다.
2.1.1. AWS Load Balancer Operator를 설치하도록 환경 설정
AWS Load Balancer Operator에는 여러 가용 영역(AZ)이 있는 클러스터와 클러스터와 동일한 가상 프라이빗 클라우드(VPC)의 3개의 퍼블릭 서브넷이 분할되어야 합니다.
이러한 요구 사항으로 인해 많은 PrivateLink 클러스터에 AWS Load Balancer Operator가 적합하지 않을 수 있습니다. AWS NLB에는 이러한 제한이 없습니다.
AWS Load Balancer Operator를 설치하기 전에 다음을 구성해야 합니다.
- 여러 가용성 영역이 있는 ROSA(클래식 아키텍처) 클러스터
- BYO VPC 클러스터
- AWS CLI
- OC CLI
2.1.1.1. AWS Load Balancer Operator 환경 설정
선택 사항: 임시 환경 변수를 설정하여 설치 명령을 간소화할 수 있습니다.
환경 변수를 사용하지 않으려면 코드 조각에 묻는 값을 수동으로 입력합니다.
프로세스
admin 사용자로 클러스터에 로그인한 후 다음 명령을 실행합니다.
$ export CLUSTER_NAME=$(oc get infrastructure cluster -o=jsonpath="{.status.infrastructureName}") $ export REGION=$(oc get infrastructure cluster -o=jsonpath="{.status.platformStatus.aws.region}") $ export OIDC_ENDPOINT=$(oc get authentication.config.openshift.io cluster -o jsonpath='{.spec.serviceAccountIssuer}' | sed 's|^https://||') $ export AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) $ export SCRATCH="/tmp/${CLUSTER_NAME}/alb-operator" $ mkdir -p ${SCRATCH}다음 명령을 실행하여 변수가 설정되었는지 확인할 수 있습니다.
$ echo "Cluster name: ${CLUSTER_NAME}, Region: ${REGION}, OIDC Endpoint: ${OIDC_ENDPOINT}, AWS Account ID: ${AWS_ACCOUNT_ID}"출력 예
Cluster name: <cluster_id>, Region: us-east-2, OIDC Endpoint: oidc.op1.openshiftapps.com/<oidc_id>, AWS Account ID: <aws_id>
2.1.1.2. AWS VPC 및 서브넷
AWS Load Balancer Operator를 설치하려면 먼저 AWS VPC 리소스에 태그를 지정해야 합니다.
프로세스
ROSA 배포의 적절한 값으로 환경 변수를 설정합니다.
$ export VPC_ID=<vpc-id> $ export PUBLIC_SUBNET_IDS="<public-subnet-a-id> <public-subnet-b-id> <public-subnet-c-id>" $ export PRIVATE_SUBNET_IDS="<private-subnet-a-id> <private-subnet-b-id> <private-subnet-c-id>"클러스터 이름을 사용하여 클러스터의 VPC에 태그를 추가합니다.
$ aws ec2 create-tags --resources ${VPC_ID} --tags Key=kubernetes.io/cluster/${CLUSTER_NAME},Value=owned --region ${REGION}퍼블릭 서브넷에 태그를 추가합니다.
$ aws ec2 create-tags \ --resources ${PUBLIC_SUBNET_IDS} \ --tags Key=kubernetes.io/role/elb,Value='' \ --region ${REGION}프라이빗 서브넷에 태그를 추가합니다.
$ aws ec2 create-tags \ --resources ${PRIVATE_SUBNET_IDS} \ --tags Key=kubernetes.io/role/internal-elb,Value='' \ --region ${REGION}
- 여러 가용성 영역이 있는 ROSA 클래식 클러스터를 설정하려면 기본 옵션을 사용하여 STS를 사용하여 ROSA 클러스터 생성을참조하십시오.
2.1.2. AWS Load Balancer Operator 설치
클러스터로 환경을 설정한 후 CLI를 사용하여 AWS Load Balancer Operator를 설치할 수 있습니다.
프로세스
AWS Load Balancer Operator에 대한 클러스터 내에 새 프로젝트를 생성합니다.
$ oc new-project aws-load-balancer-operatorAWS Load Balancer Controller에 대한 AWS IAM 정책을 생성합니다.
참고업스트림 AWS Load Balancer 컨트롤러 정책에서 AWS IAM 정책을 찾을 수 있습니다. 이 정책에는 Operator가 작동하는 데 필요한 모든 권한이 포함됩니다.
$ POLICY_ARN=$(aws iam list-policies --query \ "Policies[?PolicyName=='aws-load-balancer-operator-policy'].{ARN:Arn}" \ --output text) $ if [[ -z "${POLICY_ARN}" ]]; then wget -O "${SCRATCH}/load-balancer-operator-policy.json" \ https://raw.githubusercontent.com/rh-mobb/documentation/main/content/rosa/aws-load-balancer-operator/load-balancer-operator-policy.json POLICY_ARN=$(aws --region "$REGION" --query Policy.Arn \ --output text iam create-policy \ --policy-name aws-load-balancer-operator-policy \ --policy-document "file://${SCRATCH}/load-balancer-operator-policy.json") fi $ echo $POLICY_ARNAWS Load Balancer Operator에 대한 AWS IAM 신뢰 정책을 생성합니다.
$ cat <<EOF > "${SCRATCH}/trust-policy.json" { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Condition": { "StringEquals" : { "${OIDC_ENDPOINT}:sub": ["system:serviceaccount:aws-load-balancer-operator:aws-load-balancer-operator-controller-manager", "system:serviceaccount:aws-load-balancer-operator:aws-load-balancer-controller-cluster"] } }, "Principal": { "Federated": "arn:aws:iam::$AWS_ACCOUNT_ID:oidc-provider/${OIDC_ENDPOINT}" }, "Action": "sts:AssumeRoleWithWebIdentity" } ] } EOFAWS Load Balancer Operator에 대한 AWS IAM 역할을 생성합니다.
$ ROLE_ARN=$(aws iam create-role --role-name "${ROSA_CLUSTER_NAME}-alb-operator" \ --assume-role-policy-document "file://${SCRATCH}/trust-policy.json" \ --query Role.Arn --output text) $ echo $ROLE_ARN $ aws iam attach-role-policy --role-name "${ROSA_CLUSTER_NAME}-alb-operator" \ --policy-arn $POLICY_ARNAWS Load Balancer Operator가 새로 생성된 AWS IAM 역할을 가정할 시크릿을 생성합니다.
$ cat << EOF | oc apply -f - apiVersion: v1 kind: Secret metadata: name: aws-load-balancer-operator namespace: aws-load-balancer-operator stringData: credentials: | [default] role_arn = $ROLE_ARN web_identity_token_file = /var/run/secrets/openshift/serviceaccount/token EOFAWS Load Balancer Operator를 설치합니다.
$ cat << EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: aws-load-balancer-operator namespace: aws-load-balancer-operator spec: upgradeStrategy: Default --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: aws-load-balancer-operator namespace: aws-load-balancer-operator spec: channel: stable-v1.0 installPlanApproval: Automatic name: aws-load-balancer-operator source: redhat-operators sourceNamespace: openshift-marketplace startingCSV: aws-load-balancer-operator.v1.0.0 EOFOperator를 사용하여 AWS Load Balancer 컨트롤러 인스턴스를 배포합니다.
참고여기에서 오류가 발생하면 1분 정도 기다린 후 다시 시도하면 Operator가 아직 설치를 완료하지 않은 것입니다.
$ cat << EOF | oc apply -f - apiVersion: networking.olm.openshift.io/v1 kind: AWSLoadBalancerController metadata: name: cluster spec: credentials: name: aws-load-balancer-operator EOFOperator 및 컨트롤러 Pod가 둘 다 실행 중인지 확인합니다.
$ oc -n aws-load-balancer-operator get pods잠시 대기하지 않고 다시 시도하면 다음이 표시됩니다.
NAME READY STATUS RESTARTS AGE aws-load-balancer-controller-cluster-6ddf658785-pdp5d 1/1 Running 0 99s aws-load-balancer-operator-controller-manager-577d9ffcb9-w6zqn 2/2 Running 0 2m4s
2.1.2.1. 배포 검증
새 프로젝트를 생성합니다.
$ oc new-project hello-worldhello world 애플리케이션을 배포합니다.
$ oc new-app -n hello-world --image=docker.io/openshift/hello-openshiftAWS ALB에 연결하도록 NodePort 서비스를 구성합니다.
$ cat << EOF | oc apply -f - apiVersion: v1 kind: Service metadata: name: hello-openshift-nodeport namespace: hello-world spec: ports: - port: 80 targetPort: 8080 protocol: TCP type: NodePort selector: deployment: hello-openshift EOFAWS Load Balancer Operator를 사용하여 AWS ALB를 배포합니다.
$ cat << EOF | oc apply -f - apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: hello-openshift-alb namespace: hello-world annotations: alb.ingress.kubernetes.io/scheme: internet-facing spec: ingressClassName: alb rules: - http: paths: - path: / pathType: Exact backend: service: name: hello-openshift-nodeport port: number: 80 EOFAWS ALB Ingress 끝점을 curl하여 hello world 애플리케이션에 액세스할 수 있는지 확인합니다.
참고AWS ALB 프로비저닝에는 몇 분이 걸립니다.
curl: (6) 호스트를 해결할 수 없는오류가 발생하면 기다렸다가 다시 시도하십시오.$ INGRESS=$(oc -n hello-world get ingress hello-openshift-alb \ -o jsonpath='{.status.loadBalancer.ingress[0].hostname}') $ curl "http://${INGRESS}"출력 예
Hello OpenShift!hello world 애플리케이션에 사용할 AWS NLB를 배포합니다.
$ cat << EOF | oc apply -f - apiVersion: v1 kind: Service metadata: name: hello-openshift-nlb namespace: hello-world annotations: service.beta.kubernetes.io/aws-load-balancer-type: external service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: instance service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing spec: ports: - port: 80 targetPort: 8080 protocol: TCP type: LoadBalancer selector: deployment: hello-openshift EOFAWS NLB 끝점을 테스트합니다.
참고NLB 프로비저닝에는 몇 분이 걸립니다.
curl: (6) 호스트를 해결할 수 없는오류가 발생하면 기다렸다가 다시 시도하십시오.$ NLB=$(oc -n hello-world get service hello-openshift-nlb \ -o jsonpath='{.status.loadBalancer.ingress[0].hostname}') $ curl "http://${NLB}"출력 예
Hello OpenShift!
2.1.3. AWS Load Balancer Operator 설치 예 삭제
hello world 애플리케이션 네임스페이스(및 네임스페이스의 모든 리소스)를 삭제합니다.
$ oc delete project hello-worldAWS Load Balancer Operator 및 AWS IAM 역할을 삭제합니다.
$ oc delete subscription aws-load-balancer-operator -n aws-load-balancer-operator $ aws iam detach-role-policy \ --role-name "${ROSA_CLUSTER_NAME}-alb-operator" \ --policy-arn $POLICY_ARN $ aws iam delete-role \ --role-name "${ROSA_CLUSTER_NAME}-alb-operator"AWS IAM 정책을 삭제합니다.
$ aws iam delete-policy --policy-arn $POLICY_ARN
2.2. AWS의 Red Hat OpenShift Service의 DNS Operator
AWS의 Red Hat OpenShift Service에서 DNS Operator는 CoreDNS 인스턴스를 배포 및 관리하여 클러스터 내부 Pod에 이름 확인 서비스를 제공하고 DNS 기반 Kubernetes 서비스 검색을 활성화하며 내부 cluster.local 이름을 확인합니다.
2.2.1. DNS 전달 사용
DNS 전달을 사용하여 다음과 같은 방법으로 /etc/resolv.conf 파일의 기본 전달 구성을 덮어쓸 수 있습니다.
모든 영역에 대해 이름 서버(
spec.servers)를 지정합니다. 전달된 영역이 AWS의 Red Hat OpenShift Service에서 관리하는 인그레스 도메인인 경우 도메인에 대한 업스트림 이름 서버를 인증해야 합니다.중요하나 이상의 영역을 지정해야 합니다. 그렇지 않으면 클러스터가 기능을 손실할 수 있습니다.
-
업스트림 DNS 서버 목록 제공(
spec.upstreamResolvers). - 기본 전달 정책을 변경합니다.
기본 도메인의 DNS 전달 구성에는 /etc/resolv.conf 파일과 업스트림 DNS 서버에 지정된 기본 서버가 모두 있을 수 있습니다.
프로세스
이름이
default인 DNS Operator 오브젝트를 수정합니다.$ oc edit dns.operator/default이전 명령을 실행한 후 Operator는
spec.servers를 기반으로 추가 서버 구성 블록을 사용하여dns-default라는 구성 맵을 생성하고 업데이트합니다.중요zones매개 변수의 값을 지정할 때 인트라넷과 같은 특정 영역으로만 전달해야 합니다. 하나 이상의 영역을 지정해야 합니다. 그렇지 않으면 클러스터가 기능을 손실할 수 있습니다.서버에 쿼리와 일치하는 영역이 없는 경우 이름 확인은 업스트림 DNS 서버로 대체됩니다.
DNS 전달 구성
apiVersion: operator.openshift.io/v1 kind: DNS metadata: name: default spec: cache: negativeTTL: 0s positiveTTL: 0s logLevel: Normal nodePlacement: {} operatorLogLevel: Normal servers: - name: example-server1 zones: - example.com2 forwardPlugin: policy: Random3 upstreams:4 - 1.1.1.1 - 2.2.2.2:5353 upstreamResolvers:5 policy: Random6 protocolStrategy: ""7 transportConfig: {}8 upstreams: - type: SystemResolvConf9 - type: Network address: 1.2.3.410 port: 5311 status: clusterDomain: cluster.local clusterIP: x.y.z.10 conditions: ...- 1
rfc6335서비스 이름 구문을 준수해야 합니다.- 2
rfc1123서비스 이름 구문의 하위 도메인 정의를 준수해야 합니다. 클러스터 도메인인cluster.local은zones필드에 대해 유효하지 않은 하위 도메인입니다.- 3
forwardPlugin에 나열된 업스트림 리졸버를 선택하는 정책을 정의합니다. 기본값은Random입니다.RoundRobin및Sequential값을 사용할 수도 있습니다.- 4
forwardPlugin당 최대 15개의업스트림이 허용됩니다.- 5
upstreamResolvers를 사용하여 기본 전달 정책을 재정의하고 기본 도메인의 지정된 DNS 확인자(업스트림 확인자)로 DNS 확인을 전달할 수 있습니다. 업스트림 확인자를 제공하지 않으면 DNS 이름 쿼리는/etc/resolv.conf에 선언된 서버로 이동합니다.- 6
- 쿼리용으로 업스트림에 나열된
업스트림서버의 순서를 결정합니다. 이러한 값 중 하나를 지정할 수 있습니다.Random,RoundRobin또는Sequential. 기본값은Sequential입니다. - 7
- 생략하면 플랫폼은 원래 클라이언트 요청의 프로토콜인 기본값을 선택합니다. 클라이언트 요청이 UDP를 사용하는 경우에도 플랫폼에서 모든 업스트림 DNS 요청에
TCP를 사용하도록 지정하려면 TCP로 설정합니다. - 8
- DNS 요청을 업스트림 확인기로 전달할 때 사용할 전송 유형, 서버 이름 및 선택적 사용자 정의 CA 또는 CA 번들을 구성하는 데 사용됩니다.
- 9
- 두 가지 유형의
업스트림을 지정할 수 있습니다 :SystemResolvConf또는Network.SystemResolvConf는/etc/resolv.conf를 사용하도록 업스트림을 구성하고Network는Networkresolver를 정의합니다. 하나 또는 둘 다를 지정할 수 있습니다. - 10
- 지정된 유형이
Network인 경우 IP 주소를 제공해야 합니다.address필드는 유효한 IPv4 또는 IPv6 주소여야 합니다. - 11
- 지정된 유형이
네트워크인 경우 선택적으로 포트를 제공할 수 있습니다.port필드에는1에서65535사이의 값이 있어야 합니다. 업스트림에 대한 포트를 지정하지 않으면 기본 포트는 853입니다.
2.3. AWS의 Red Hat OpenShift Service의 Ingress Operator
Ingress Operator는 IngressController API를 구현하며 AWS 클러스터 서비스에서 Red Hat OpenShift Service에 대한 외부 액세스를 활성화하는 구성 요소입니다.
2.3.1. AWS Ingress Operator의 Red Hat OpenShift Service
AWS 클러스터에서 Red Hat OpenShift Service를 생성하면 클러스터에서 실행되는 Pod 및 서비스에 각각 자체 IP 주소가 할당됩니다. IP 주소는 내부에서 실행되지만 외부 클라이언트가 액세스할 수 없는 다른 pod 및 서비스에 액세스할 수 있습니다.
Ingress Operator를 사용하면 라우팅을 처리하기 위해 하나 이상의 HAProxy 기반 Ingress 컨트롤러를 배포하고 관리하여 외부 클라이언트가 서비스에 액세스할 수 있습니다. Red Hat 사이트 안정성 엔지니어(SRE)는 AWS 클러스터에서 Red Hat OpenShift Service용 Ingress Operator를 관리합니다. Ingress Operator의 설정을 변경할 수는 없지만 기본 Ingress 컨트롤러 구성, 상태 및 로그와 Ingress Operator 상태를 볼 수 있습니다.
2.3.2. Ingress 구성 자산
설치 프로그램은 config.openshift.io API 그룹인 cluster-ingress-02-config.yml에 Ingress 리소스가 포함된 자산을 생성합니다.
Ingress 리소스의 YAML 정의
apiVersion: config.openshift.io/v1
kind: Ingress
metadata:
name: cluster
spec:
domain: apps.openshiftdemos.com
설치 프로그램은 이 자산을 manifests / 디렉터리의 cluster-ingress-02-config.yml 파일에 저장합니다. 이 Ingress 리소스는 Ingress와 관련된 전체 클러스터 구성을 정의합니다. 이 Ingress 구성은 다음과 같이 사용됩니다.
- Ingress Operator는 클러스터 Ingress 구성에 설정된 도메인을 기본 Ingress 컨트롤러의 도메인으로 사용합니다.
-
OpenShift API Server Operator는 클러스터 Ingress 구성의 도메인을 사용합니다. 이 도메인은 명시적 호스트를 지정하지 않는
Route리소스에 대한 기본 호스트를 생성할 수도 있습니다.
2.3.3. Ingress 컨트롤러 구성 매개변수
IngressController CR(사용자 정의 리소스)에는 조직의 특정 요구 사항을 충족하도록 구성할 수 있는 선택적 구성 매개변수가 포함되어 있습니다.
| 매개변수 | 설명 |
|---|---|
|
|
비어 있는 경우 기본값은 |
|
|
|
|
|
클라우드 환경의 경우
다음
설정되지 않은 경우, 기본값은
|
|
|
보안에는 키와 데이터, 즉 *
설정하지 않으면 와일드카드 인증서가 자동으로 생성되어 사용됩니다. 인증서는 Ingress 컨트롤러 생성된 인증서 또는 사용자 지정 인증서는 AWS 기본 제공 OAuth 서버의 Red Hat OpenShift Service와 자동으로 통합됩니다. |
|
|
|
|
|
|
|
|
설정하지 않으면 기본값이 사용됩니다. 참고
|
|
|
설정되지 않으면, 기본값은
Ingress 컨트롤러의 최소 TLS 버전은 참고
구성된 보안 프로파일의 암호 및 최소 TLS 버전은 중요
Ingress Operator는 |
|
|
|
|
|
|
|
|
|
|
|
기본적으로 정책은
이러한 조정은 HTTP/1을 사용하는 경우에만 일반 텍스트, 에지 종료 및 재암호화 경로에 적용됩니다.
요청 헤더의 경우 이러한 조정은
|
|
|
|
|
|
|
|
|
캡처하려는 모든 쿠키의 경우 다음 매개변수가
예를 들면 다음과 같습니다. |
|
|
|
|
|
|
|
|
|
|
|
이러한 연결은 로드 밸런서 상태 프로브 또는 웹 브라우저 추측 연결(preconnect)에서 제공되며 무시해도 됩니다. 그러나 이러한 요청은 네트워크 오류로 인해 발생할 수 있으므로 이 필드를 |
2.3.3.1. Ingress 컨트롤러 TLS 보안 프로필
TLS 보안 프로필은 서버가 서버에 연결할 때 연결 클라이언트가 사용할 수 있는 암호를 규제하는 방법을 제공합니다.
2.3.3.1.1. TLS 보안 프로필 이해
TLS(Transport Layer Security) 보안 프로필을 사용하여 AWS 구성 요소의 다양한 Red Hat OpenShift Service에 필요한 TLS 암호를 정의할 수 있습니다. AWS TLS 보안 프로필의 Red Hat OpenShift Service는 Mozilla 권장 구성 을 기반으로 합니다.
각 구성 요소에 대해 다음 TLS 보안 프로필 중 하나를 지정할 수 있습니다.
| Profile | 설명 |
|---|---|
|
| 이 프로필은 레거시 클라이언트 또는 라이브러리와 함께 사용하기 위한 것입니다. 프로필은 이전 버전과의 호환성 권장 구성을 기반으로 합니다.
참고 Ingress 컨트롤러의 경우 최소 TLS 버전이 1.0에서 1.1로 변환됩니다. |
|
| 이 프로필은 Ingress 컨트롤러, kubelet 및 컨트롤 플레인의 기본 TLS 보안 프로필입니다. 프로필은 중간 호환성 권장 구성을 기반으로 합니다.
참고 이 프로필은 대부분의 클라이언트에서 권장되는 구성입니다. |
|
| 이 프로필은 이전 버전과의 호환성이 필요하지 않은 최신 클라이언트와 사용하기 위한 것입니다. 이 프로필은 최신 호환성 권장 구성을 기반으로 합니다.
|
|
| 이 프로필을 사용하면 사용할 TLS 버전과 암호를 정의할 수 있습니다. 주의
|
미리 정의된 프로파일 유형 중 하나를 사용하는 경우 유효한 프로파일 구성은 릴리스마다 변경될 수 있습니다. 예를 들어 릴리스 X.Y.Z에 배포된 중간 프로필을 사용하는 사양이 있는 경우 릴리스 X.Y.Z+1로 업그레이드하면 새 프로필 구성이 적용되어 롤아웃이 발생할 수 있습니다.
2.3.3.1.2. Ingress 컨트롤러의 TLS 보안 프로필 구성
Ingress 컨트롤러에 대한 TLS 보안 프로필을 구성하려면 IngressController CR(사용자 정의 리소스)을 편집하여 사전 정의된 또는 사용자 지정 TLS 보안 프로필을 지정합니다. TLS 보안 프로필이 구성되지 않은 경우 기본값은 API 서버에 설정된 TLS 보안 프로필을 기반으로 합니다.
Old TLS 보안 프로파일을 구성하는 샘플 IngressController CR
apiVersion: operator.openshift.io/v1
kind: IngressController
...
spec:
tlsSecurityProfile:
old: {}
type: Old
...TLS 보안 프로필은 Ingress 컨트롤러의 TLS 연결에 대한 최소 TLS 버전과 TLS 암호를 정의합니다.
Status.Tls Profile 아래의 IngressController CR(사용자 정의 리소스) 및 Spec.Tls Security Profile 아래 구성된 TLS 보안 프로필에서 구성된 TLS 보안 프로필의 암호 및 최소 TLS 버전을 확인할 수 있습니다. Custom TLS 보안 프로필의 경우 특정 암호 및 최소 TLS 버전이 두 매개변수 아래에 나열됩니다.
HAProxy Ingress 컨트롤러 이미지는 TLS 1.3 및 Modern 프로필을 지원합니다.
Ingress Operator는 Old 또는 Custom 프로파일의 TLS 1.0을 1.1로 변환합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
절차
openshift-ingress-operator프로젝트에서IngressControllerCR을 편집하여 TLS 보안 프로필을 구성합니다.$ oc edit IngressController default -n openshift-ingress-operatorspec.tlsSecurityProfile필드를 추가합니다.Custom프로필에 대한IngressControllerCR 샘플apiVersion: operator.openshift.io/v1 kind: IngressController ... spec: tlsSecurityProfile: type: Custom1 custom:2 ciphers:3 - ECDHE-ECDSA-CHACHA20-POLY1305 - ECDHE-RSA-CHACHA20-POLY1305 - ECDHE-RSA-AES128-GCM-SHA256 - ECDHE-ECDSA-AES128-GCM-SHA256 minTLSVersion: VersionTLS11 ...- 파일을 저장하여 변경 사항을 적용합니다.
검증
IngressControllerCR에 프로파일이 설정되어 있는지 확인합니다.$ oc describe IngressController default -n openshift-ingress-operator출력 예
Name: default Namespace: openshift-ingress-operator Labels: <none> Annotations: <none> API Version: operator.openshift.io/v1 Kind: IngressController ... Spec: ... Tls Security Profile: Custom: Ciphers: ECDHE-ECDSA-CHACHA20-POLY1305 ECDHE-RSA-CHACHA20-POLY1305 ECDHE-RSA-AES128-GCM-SHA256 ECDHE-ECDSA-AES128-GCM-SHA256 Min TLS Version: VersionTLS11 Type: Custom ...
2.3.3.1.3. 상호 TLS 인증 구성
spec.clientTLS 값을 설정하여 mTLS(mTLS) 인증을 사용하도록 Ingress 컨트롤러를 구성할 수 있습니다. clientTLS 값은 클라이언트 인증서를 확인하도록 Ingress 컨트롤러를 구성합니다. 이 구성에는 구성 맵에 대한 참조인 clientCA 값 설정이 포함됩니다. 구성 맵에는 클라이언트의 인증서를 확인하는 데 사용되는 PEM 인코딩 CA 인증서 번들이 포함되어 있습니다. 필요한 경우 인증서 제목 필터 목록을 구성할 수도 있습니다.
clientCA 값이 X509v3 인증서 취소 목록(CRL) 배포 지점을 지정하는 경우 Ingress Operator는 각 인증서에 지정된 HTTP URI X509v3 CRL Distribution Point 를 기반으로 CRL 구성 맵을 다운로드하고 관리합니다. Ingress 컨트롤러는 mTLS/TLS 협상 중에 이 구성 맵을 사용합니다. 유효한 인증서를 제공하지 않는 요청은 거부됩니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - PEM 인코딩 CA 인증서 번들이 있습니다.
CA 번들이 CRL 배포 지점을 참조하는 경우 클라이언트 CA 번들에 엔드센티 또는 리프 인증서도 포함해야 합니다. RFC 5280에 설명된 대로 이 인증서에는
CRL 배포 지점아래에 HTTP URI가 포함되어 있어야 합니다. 예를 들면 다음과 같습니다.Issuer: C=US, O=Example Inc, CN=Example Global G2 TLS RSA SHA256 2020 CA1 Subject: SOME SIGNED CERT X509v3 CRL Distribution Points: Full Name: URI:http://crl.example.com/example.crl
절차
openshift-config네임스페이스에서 CA 번들에서 구성 맵을 생성합니다.$ oc create configmap \ router-ca-certs-default \ --from-file=ca-bundle.pem=client-ca.crt \1 -n openshift-config- 1
- 구성 맵 데이터 키는
ca-bundle.pem이어야 하며 데이터 값은 PEM 형식의 CA 인증서여야 합니다.
openshift-ingress-operator프로젝트에서IngressController리소스를 편집합니다.$ oc edit IngressController default -n openshift-ingress-operatorspec.clientTLS필드 및 하위 필드를 추가하여 상호 TLS를 구성합니다.패턴 필터링을 지정하는
clientTLS프로필에 대한IngressControllerCR 샘플apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: clientTLS: clientCertificatePolicy: Required clientCA: name: router-ca-certs-default allowedSubjectPatterns: - "^/CN=example.com/ST=NC/C=US/O=Security/OU=OpenShift$"-
선택 사항, 다음 명령을 입력하여
allowedSubjectPatterns에 대한 Distinguished Name (DN)을 가져옵니다.
$ openssl x509 -in custom-cert.pem -noout -subject
subject= /CN=example.com/ST=NC/C=US/O=Security/OU=OpenShift2.3.4. 기본 Ingress 컨트롤러 보기
Ingress Operator는 AWS에서 Red Hat OpenShift Service의 핵심 기능이며 즉시 활성화됩니다.
AWS 설치 시 모든 새로운 Red Hat OpenShift Service에는 이름이 default인 ingresscontroller 가 있습니다. 추가 Ingress 컨트롤러를 추가할 수 있습니다. 기본 ingresscontroller가 삭제되면 Ingress Operator가 1분 이내에 자동으로 다시 생성합니다.
프로세스
기본 Ingress 컨트롤러를 확인합니다.
$ oc describe --namespace=openshift-ingress-operator ingresscontroller/default
2.3.5. Ingress Operator 상태 보기
Ingress Operator의 상태를 확인 및 조사할 수 있습니다.
프로세스
Ingress Operator 상태를 확인합니다.
$ oc describe clusteroperators/ingress
2.3.6. Ingress 컨트롤러 로그 보기
Ingress 컨트롤러의 로그를 확인할 수 있습니다.
프로세스
Ingress 컨트롤러 로그를 확인합니다.
$ oc logs --namespace=openshift-ingress-operator deployments/ingress-operator -c <container_name>
2.3.7. Ingress 컨트롤러 상태 보기
특정 Ingress 컨트롤러의 상태를 확인할 수 있습니다.
프로세스
Ingress 컨트롤러의 상태를 확인합니다.
$ oc describe --namespace=openshift-ingress-operator ingresscontroller/<name>
2.3.8. 사용자 정의 Ingress 컨트롤러 생성
클러스터 관리자는 새 사용자 정의 Ingress 컨트롤러를 생성할 수 있습니다. 기본 Ingress 컨트롤러는 AWS의 Red Hat OpenShift Service 중에 변경될 수 있으므로 사용자 정의 Ingress 컨트롤러를 생성하면 클러스터 업데이트 전체에서 지속되는 구성을 수동으로 유지 관리할 때 유용할 수 있습니다.
이 예에서는 사용자 정의 Ingress 컨트롤러에 대한 최소 사양을 제공합니다. 사용자 정의 Ingress 컨트롤러를 추가로 사용자 지정하려면 " Ingress 컨트롤러 구성"을 참조하십시오.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
절차
사용자 지정
IngressController오브젝트를 정의하는 YAML 파일을 생성합니다.custom-ingress-controller.yaml파일 예apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: <custom_name>1 namespace: openshift-ingress-operator spec: defaultCertificate: name: <custom-ingress-custom-certs>2 replicas: 13 domain: <custom_domain>4 다음 명령을 실행하여 오브젝트를 생성합니다.
$ oc create -f custom-ingress-controller.yaml
2.3.9. Ingress 컨트롤러 구성
2.3.9.1. 사용자 정의 기본 인증서 설정
관리자는 Secret 리소스를 생성하고 IngressController CR(사용자 정의 리소스)을 편집하여 사용자 정의 인증서를 사용하도록 Ingress 컨트롤러를 구성할 수 있습니다.
사전 요구 사항
- PEM 인코딩 파일에 인증서/키 쌍이 있어야 합니다. 이때 인증서는 신뢰할 수 있는 인증 기관 또는 사용자 정의 PKI에서 구성한 신뢰할 수 있는 개인 인증 기관의 서명을 받은 인증서입니다.
인증서가 다음 요구 사항을 충족합니다.
- 인증서가 Ingress 도메인에 유효해야 합니다.
-
인증서는
subjectAltName확장자를 사용하여*.apps.ocp4.example.com과같은 와일드카드 도메인을 지정합니다.
IngressControllerCR이 있어야 합니다. 기본 설정을 사용할 수 있어야 합니다.$ oc --namespace openshift-ingress-operator get ingresscontrollers출력 예
NAME AGE default 10m
임시 인증서가 있는 경우 사용자 정의 기본 인증서가 포함 된 보안의 tls.crt 파일에 인증서가 포함되어 있어야 합니다. 인증서를 지정하는 경우에는 순서가 중요합니다. 서버 인증서 다음에 임시 인증서를 나열해야 합니다.
절차
아래에서는 사용자 정의 인증서 및 키 쌍이 현재 작업 디렉터리의 tls.crt 및 tls.key 파일에 있다고 가정합니다. 그리고 tls.crt 및 tls.key의 실제 경로 이름으로 변경합니다. Secret 리소스를 생성하고 IngressController CR에서 참조하는 경우 custom-certs-default를 다른 이름으로 변경할 수도 있습니다.
이 작업을 수행하면 롤링 배포 전략에 따라 Ingress 컨트롤러가 재배포됩니다.
tls.crt및tls.key파일을 사용하여openshift-ingress네임스페이스에 사용자 정의 인증서를 포함하는 Secret 리소스를 만듭니다.$ oc --namespace openshift-ingress create secret tls custom-certs-default --cert=tls.crt --key=tls.key새 인증서 보안 키를 참조하도록 IngressController CR을 업데이트합니다.
$ oc patch --type=merge --namespace openshift-ingress-operator ingresscontrollers/default \ --patch '{"spec":{"defaultCertificate":{"name":"custom-certs-default"}}}'업데이트가 적용되었는지 확인합니다.
$ echo Q |\ openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null |\ openssl x509 -noout -subject -issuer -enddate다음과 같습니다.
<domain>- 클러스터의 기본 도메인 이름을 지정합니다.
출력 예
subject=C = US, ST = NC, L = Raleigh, O = RH, OU = OCP4, CN = *.apps.example.com issuer=C = US, ST = NC, L = Raleigh, O = RH, OU = OCP4, CN = example.com notAfter=May 10 08:32:45 2022 GM작은 정보다음 YAML을 적용하여 사용자 지정 기본 인증서를 설정할 수 있습니다.
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: defaultCertificate: name: custom-certs-default인증서 보안 이름은 CR을 업데이트하는 데 사용된 값과 일치해야 합니다.
IngressController CR이 수정되면 Ingress Operator는 사용자 정의 인증서를 사용하도록 Ingress 컨트롤러의 배포를 업데이트합니다.
2.3.9.2. 사용자 정의 기본 인증서 제거
관리자는 사용할 Ingress 컨트롤러를 구성한 사용자 정의 인증서를 제거할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다. - 이전에는 Ingress 컨트롤러에 대한 사용자 정의 기본 인증서를 구성했습니다.
절차
사용자 정의 인증서를 제거하고 AWS에서 Red Hat OpenShift Service와 함께 제공되는 인증서를 복원하려면 다음 명령을 입력합니다.
$ oc patch -n openshift-ingress-operator ingresscontrollers/default \ --type json -p $'- op: remove\n path: /spec/defaultCertificate'클러스터가 새 인증서 구성을 조정하는 동안 지연이 발생할 수 있습니다.
검증
원래 클러스터 인증서가 복원되었는지 확인하려면 다음 명령을 입력합니다.
$ echo Q | \ openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null | \ openssl x509 -noout -subject -issuer -enddate다음과 같습니다.
<domain>- 클러스터의 기본 도메인 이름을 지정합니다.
출력 예
subject=CN = *.apps.<domain> issuer=CN = ingress-operator@1620633373 notAfter=May 10 10:44:36 2023 GMT
2.3.9.3. Ingress 컨트롤러 자동 스케일링
처리량 증가 요구와 같은 라우팅 성능 또는 가용성 요구 사항을 동적으로 충족하도록 Ingress 컨트롤러를 자동으로 확장할 수 있습니다.
다음 절차에서는 기본 Ingress 컨트롤러를 확장하는 예제를 제공합니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있어야 합니다. -
cluster-admin역할의 사용자로 AWS 클러스터의 Red Hat OpenShift Service에 액세스할 수 있습니다. Custom Metrics Autoscaler Operator 및 관련 KEDA 컨트롤러가 설치되어 있습니다.
-
웹 콘솔에서 OperatorHub를 사용하여 Operator를 설치할 수 있습니다. Operator를 설치한 후
KedaController의 인스턴스를 생성할 수 있습니다.
-
웹 콘솔에서 OperatorHub를 사용하여 Operator를 설치할 수 있습니다. Operator를 설치한 후
절차
다음 명령을 실행하여 Thanos로 인증할 서비스 계정을 생성합니다.
$ oc create -n openshift-ingress-operator serviceaccount thanos && oc describe -n openshift-ingress-operator serviceaccount thanos출력 예
Name: thanos Namespace: openshift-ingress-operator Labels: <none> Annotations: <none> Image pull secrets: thanos-dockercfg-kfvf2 Mountable secrets: thanos-dockercfg-kfvf2 Tokens: <none> Events: <none>다음 명령을 사용하여 서비스 계정 시크릿 토큰을 수동으로 생성합니다.
$ oc apply -f - <<EOF apiVersion: v1 kind: Secret metadata: name: thanos-token namespace: openshift-ingress-operator annotations: kubernetes.io/service-account.name: thanos type: kubernetes.io/service-account-token EOF서비스 계정의 토큰을 사용하여
openshift-ingress-operator네임스페이스에TriggerAuthentication오브젝트를 정의합니다.TriggerAuthentication오브젝트를 생성하고secret변수 값을TOKEN매개변수에 전달합니다.$ oc apply -f - <<EOF apiVersion: keda.sh/v1alpha1 kind: TriggerAuthentication metadata: name: keda-trigger-auth-prometheus namespace: openshift-ingress-operator spec: secretTargetRef: - parameter: bearerToken name: thanos-token key: token - parameter: ca name: thanos-token key: ca.crt EOF
Thanos에서 메트릭을 읽는 역할을 생성하고 적용합니다.
Pod 및 노드에서 지표를 읽는 새 역할
thanos-metrics-reader.yaml을 생성합니다.thanos-metrics-reader.yaml
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: thanos-metrics-reader namespace: openshift-ingress-operator rules: - apiGroups: - "" resources: - pods - nodes verbs: - get - apiGroups: - metrics.k8s.io resources: - pods - nodes verbs: - get - list - watch - apiGroups: - "" resources: - namespaces verbs: - get다음 명령을 실행하여 새 역할을 적용합니다.
$ oc apply -f thanos-metrics-reader.yaml
다음 명령을 입력하여 서비스 계정에 새 역할을 추가합니다.
$ oc adm policy -n openshift-ingress-operator add-role-to-user thanos-metrics-reader -z thanos --role-namespace=openshift-ingress-operator$ oc adm policy -n openshift-ingress-operator add-cluster-role-to-user cluster-monitoring-view -z thanos참고add-cluster-role-to-user인수는 네임스페이스 간 쿼리를 사용하는 경우에만 필요합니다. 다음 단계에서는 이 인수가 필요한kube-metrics네임스페이스의 쿼리를 사용합니다.기본 Ingress 컨트롤러 배포를 대상으로 하는 새 scaled
ObjectYAML 파일ingress-autoscaler.yaml을 만듭니다.scaled
Object정의의 예apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: ingress-scaler namespace: openshift-ingress-operator spec: scaleTargetRef:1 apiVersion: operator.openshift.io/v1 kind: IngressController name: default envSourceContainerName: ingress-operator minReplicaCount: 1 maxReplicaCount: 202 cooldownPeriod: 1 pollingInterval: 1 triggers: - type: prometheus metricType: AverageValue metadata: serverAddress: https://thanos-querier.openshift-monitoring.svc.cluster.local:90913 namespace: openshift-ingress-operator4 metricName: 'kube-node-role' threshold: '1' query: 'sum(kube_node_role{role="worker",service="kube-state-metrics"})'5 authModes: "bearer" authenticationRef: name: keda-trigger-auth-prometheus중요네임스페이스 간 쿼리를 사용하는 경우
serverAddress필드에서 포트 9091이 아닌 포트 9091을 대상으로 지정해야 합니다. 또한 이 포트에서 메트릭을 읽을 수 있는 높은 권한이 있어야 합니다.다음 명령을 실행하여 사용자 정의 리소스 정의를 적용합니다.
$ oc apply -f ingress-autoscaler.yaml
검증
다음 명령을 실행하여 기본 Ingress 컨트롤러가
kube-state-metrics쿼리에서 반환된 값과 일치하도록 확장되었는지 확인합니다.grep명령을 사용하여 Ingress 컨트롤러 YAML 파일에서 복제본을 검색합니다.$ oc get -n openshift-ingress-operator ingresscontroller/default -o yaml | grep replicas:출력 예
replicas: 3openshift-ingress프로젝트에서 Pod를 가져옵니다.$ oc get pods -n openshift-ingress출력 예
NAME READY STATUS RESTARTS AGE router-default-7b5df44ff-l9pmm 2/2 Running 0 17h router-default-7b5df44ff-s5sl5 2/2 Running 0 3d22h router-default-7b5df44ff-wwsth 2/2 Running 0 66s
2.3.9.4. Ingress 컨트롤러 확장
처리량 증가 요구 등 라우팅 성능 또는 가용성 요구 사항을 충족하도록 Ingress 컨트롤러를 수동으로 확장할 수 있습니다. IngressController 리소스를 확장하려면 oc 명령을 사용합니다. 다음 절차는 기본 IngressController를 확장하는 예제입니다.
원하는 수의 복제본을 만드는 데에는 시간이 걸리기 때문에 확장은 즉시 적용되지 않습니다.
절차
기본
IngressController의 현재 사용 가능한 복제본 개수를 살펴봅니다.$ oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'출력 예
2oc patch명령을 사용하여 기본IngressController의 복제본 수를 원하는 대로 조정합니다. 다음 예제는 기본IngressController를 3개의 복제본으로 조정합니다.$ oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"replicas": 3}}' --type=merge출력 예
ingresscontroller.operator.openshift.io/default patched기본
IngressController가 지정한 복제본 수에 맞게 조정되었는지 확인합니다.$ oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'출력 예
3작은 정보또는 다음 YAML을 적용하여 Ingress 컨트롤러를 세 개의 복제본으로 확장할 수 있습니다.
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 31 - 1
- 다른 양의 복제본이 필요한 경우
replicas값을 변경합니다.
2.3.9.5. 수신 액세스 로깅 구성
Ingress 컨트롤러가 로그에 액세스하도록 구성할 수 있습니다. 수신 트래픽이 많지 않은 클러스터의 경우 사이드카에 로그를 기록할 수 있습니다. 트래픽이 많은 클러스터가 있는 경우 로깅 스택의 용량을 초과하지 않거나 AWS의 Red Hat OpenShift Service 외부에서 로깅 인프라와 통합하기 위해 사용자 정의 syslog 끝점으로 로그를 전달할 수 있습니다. 액세스 로그의 형식을 지정할 수도 있습니다.
컨테이너 로깅은 기존 Syslog 로깅 인프라가 없는 경우 트래픽이 적은 클러스터에서 액세스 로그를 활성화하거나 Ingress 컨트롤러의 문제를 진단하는 동안 단기적으로 사용하는 데 유용합니다.
액세스 로그가 OpenShift 로깅 스택 용량을 초과할 수 있는 트래픽이 많은 클러스터 또는 로깅 솔루션이 기존 Syslog 로깅 인프라와 통합되어야 하는 환경에는 Syslog가 필요합니다. Syslog 사용 사례는 중첩될 수 있습니다.
사전 요구 사항
-
cluster-admin권한이 있는 사용자로 로그인합니다.
절차
사이드카에 Ingress 액세스 로깅을 구성합니다.
수신 액세스 로깅을 구성하려면
spec.logging.access.destination을 사용하여 대상을 지정해야 합니다. 사이드카 컨테이너에 로깅을 지정하려면Containerspec.logging.access.destination.type을 지정해야 합니다. 다음 예제는Container대상에 로그를 기록하는 Ingress 컨트롤러 정의입니다.apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: Container사이드카에 로그를 기록하도록 Ingress 컨트롤러를 구성하면 Operator는 Ingress 컨트롤러 Pod에
logs라는 컨테이너를 만듭니다.$ oc -n openshift-ingress logs deployment.apps/router-default -c logs출력 예
2020-05-11T19:11:50.135710+00:00 router-default-57dfc6cd95-bpmk6 router-default-57dfc6cd95-bpmk6 haproxy[108]: 174.19.21.82:39654 [11/May/2020:19:11:50.133] public be_http:hello-openshift:hello-openshift/pod:hello-openshift:hello-openshift:10.128.2.12:8080 0/0/1/0/1 200 142 - - --NI 1/1/0/0/0 0/0 "GET / HTTP/1.1"
Syslog 끝점에 대한 Ingress 액세스 로깅을 구성합니다.
수신 액세스 로깅을 구성하려면
spec.logging.access.destination을 사용하여 대상을 지정해야 합니다. Syslog 끝점 대상에 로깅을 지정하려면spec.logging.access.destination.type에 대한Syslog를 지정해야 합니다. 대상 유형이Syslog인 경우spec.logging.access.destination.syslog.address를 사용하여 대상 끝점도 지정해야 하며spec.logging.access.destination.syslog.facility를 사용하여 기능을 지정할 수 있습니다. 다음 예제는Syslog대상에 로그를 기록하는 Ingress 컨트롤러 정의입니다.apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: Syslog syslog: address: 1.2.3.4 port: 10514참고syslog대상 포트는 UDP여야 합니다.syslog대상 주소는 IP 주소여야 합니다. DNS 호스트 이름을 지원하지 않습니다.
특정 로그 형식으로 Ingress 액세스 로깅을 구성합니다.
spec.logging.access.httpLogFormat을 지정하여 로그 형식을 사용자 정의할 수 있습니다. 다음 예제는 IP 주소 1.2.3.4 및 포트 10514를 사용하여syslog끝점에 로그하는 Ingress 컨트롤러 정의입니다.apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: Syslog syslog: address: 1.2.3.4 port: 10514 httpLogFormat: '%ci:%cp [%t] %ft %b/%s %B %bq %HM %HU %HV'
Ingress 액세스 로깅을 비활성화합니다.
Ingress 액세스 로깅을 비활성화하려면
spec.logging또는spec.logging.access를 비워 둡니다.apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: null
사이드카를 사용할 때 Ingress 컨트롤러에서 HAProxy 로그 길이를 수정할 수 있도록 허용합니다.
spec.logging.access.destination.destination.를 사용합니다.type: Syslog를 사용하는 경우 spec.logging.access.destination.maxLengthapiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: Syslog syslog: address: 1.2.3.4 maxLength: 4096 port: 10514spec.logging.access.destination.destination.를 사용합니다.type: Container를 사용하는 경우 spec.logging.access.destination.maxLengthapiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: Container container: maxLength: 8192
2.3.9.6. Ingress 컨트롤러 스레드 수 설정
클러스터 관리자는 클러스터에서 처리할 수 있는 들어오는 연결의 양을 늘리기 위해 스레드 수를 설정할 수 있습니다. 기존 Ingress 컨트롤러에 패치하여 스레드의 양을 늘릴 수 있습니다.
사전 요구 사항
- 다음은 Ingress 컨트롤러를 이미 생성했다고 가정합니다.
절차
스레드 수를 늘리도록 Ingress 컨트롤러를 업데이트합니다.
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"threadCount": 8}}}'참고많은 리소스를 실행할 수 있는 노드가 있는 경우 원하는 노드의 용량과 일치하는 라벨을 사용하여
spec.nodePlacement.nodeSelector를 구성하고spec.tuningOptions.threadCount를 적절하게 높은 값으로 구성할 수 있습니다.
2.3.9.7. 내부 로드 밸런서를 사용하도록 Ingress 컨트롤러 구성
클라우드 플랫폼에서 Ingress 컨트롤러를 생성할 때 Ingress 컨트롤러는 기본적으로 퍼블릭 클라우드 로드 밸런서에 의해 게시됩니다. 관리자는 내부 클라우드 로드 밸런서를 사용하는 Ingress 컨트롤러를 생성할 수 있습니다.
IngressController 의 범위를 변경하려면 CR(사용자 정의 리소스)을 생성한 후 .spec.endpointPublishingStrategy.loadBalancer.scope 매개변수를 변경할 수 있습니다.
그림 2.1. LoadBalancer 다이어그램
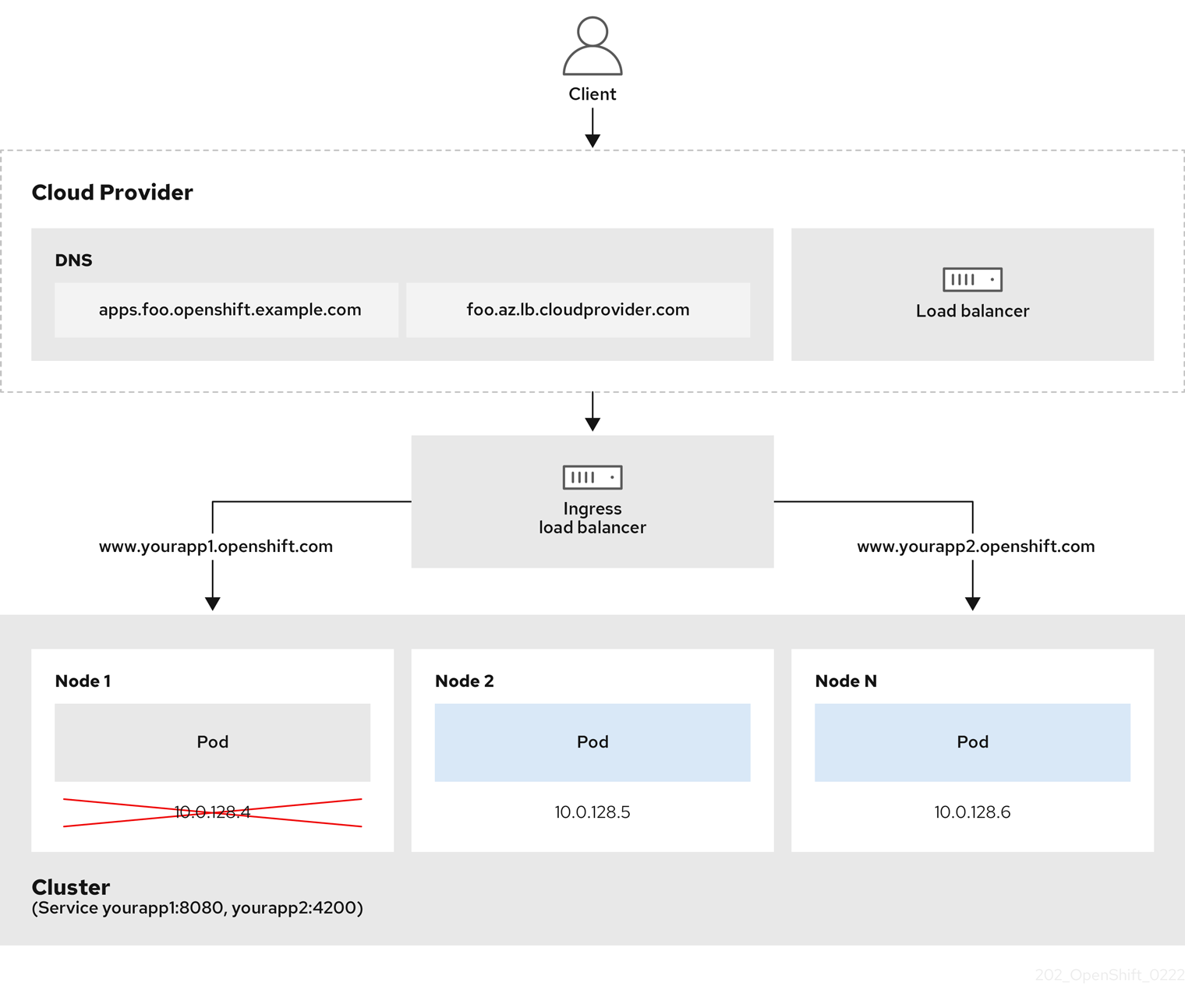
이전 그래픽은 AWS Ingress LoadBalancerService 끝점 게시 전략의 Red Hat OpenShift Service와 관련된 다음 개념을 보여줍니다.
- 클라우드 공급자 로드 밸런서를 사용하거나 내부적으로 OpenShift Ingress 컨트롤러 로드 밸런서를 사용하여 외부에서 부하를 분산할 수 있습니다.
- 그래픽에 표시된 클러스터에 표시된 대로 로드 밸런서의 단일 IP 주소와 8080 및 4200과 같은 더 친숙한 포트를 사용할 수 있습니다.
- 외부 로드 밸런서의 트래픽은 Pod에서 전달되고 다운 노드의 인스턴스에 표시된 대로 로드 밸런서에 의해 관리됩니다. 구현 세부 사항은 Kubernetes 서비스 설명서를 참조하십시오.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
프로세스
다음 예제와 같이
<name>-ingress-controller.yam파일에IngressControllerCR(사용자 정의 리소스)을 생성합니다.apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: <name>1 spec: domain: <domain>2 endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: Internal3 다음 명령을 실행하여 이전 단계에서 정의된 Ingress 컨트롤러를 생성합니다.
$ oc create -f <name>-ingress-controller.yaml1 - 1
<name>을IngressController오브젝트의 이름으로 변경합니다.
선택 사항: Ingress 컨트롤러가 생성되었는지 확인하려면 다음 명령을 실행합니다.
$ oc --all-namespaces=true get ingresscontrollers
2.3.9.8. Ingress 컨트롤러 상태 점검 간격 설정
클러스터 관리자는 상태 점검 간격을 설정하여 라우터가 연속 상태 점검 사이에 대기하는 시간을 정의할 수 있습니다. 이 값은 모든 경로에 대해 전역적으로 적용됩니다. 기본값은 5초입니다.
사전 요구 사항
- 다음은 Ingress 컨트롤러를 이미 생성했다고 가정합니다.
프로세스
백엔드 상태 점검 간 간격을 변경하도록 Ingress 컨트롤러를 업데이트합니다.
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"healthCheckInterval": "8s"}}}'참고단일 경로의
healthCheckInterval을 재정의하려면 경로 주석router.openshift.io/haproxy.health.check.interval을 사용합니다.
2.3.9.9. 클러스터의 기본 Ingress 컨트롤러를 내부로 구성
클러스터를 삭제하고 다시 생성하여 클러스터의 default Ingress 컨트롤러를 내부용으로 구성할 수 있습니다.
IngressController 의 범위를 변경하려면 CR(사용자 정의 리소스)을 생성한 후 .spec.endpointPublishingStrategy.loadBalancer.scope 매개변수를 변경할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
프로세스
클러스터의
기본Ingress 컨트롤러를 삭제하고 다시 생성하여 내부용으로 구성합니다.$ oc replace --force --wait --filename - <<EOF apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: default spec: endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: Internal EOF
2.3.9.10. 경로 허용 정책 구성
관리자 및 애플리케이션 개발자는 도메인 이름이 동일한 여러 네임스페이스에서 애플리케이션을 실행할 수 있습니다. 이는 여러 팀이 동일한 호스트 이름에 노출되는 마이크로 서비스를 개발하는 조직을 위한 것입니다.
네임스페이스 간 클레임은 네임스페이스 간 신뢰가 있는 클러스터에 대해서만 허용해야 합니다. 그렇지 않으면 악의적인 사용자가 호스트 이름을 인수할 수 있습니다. 따라서 기본 승인 정책에서는 네임스페이스 간에 호스트 이름 클레임을 허용하지 않습니다.
사전 요구 사항
- 클러스터 관리자 권한이 있어야 합니다.
프로세스
다음 명령을 사용하여
ingresscontroller리소스 변수의.spec.routeAdmission필드를 편집합니다.$ oc -n openshift-ingress-operator patch ingresscontroller/default --patch '{"spec":{"routeAdmission":{"namespaceOwnership":"InterNamespaceAllowed"}}}' --type=merge샘플 Ingress 컨트롤러 구성
spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed ...작은 정보다음 YAML을 적용하여 경로 승인 정책을 구성할 수 있습니다.
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed
2.3.9.11. 와일드카드 경로 사용
HAProxy Ingress 컨트롤러는 와일드카드 경로를 지원합니다. Ingress Operator는 wildcardPolicy를 사용하여 Ingress 컨트롤러의 ROUTER_ALLOW_WILDCARD_ROUTES 환경 변수를 구성합니다.
Ingress 컨트롤러의 기본 동작은 와일드카드 정책이 None인 경로를 허용하고, 이는 기존 IngressController 리소스의 이전 버전과 호환됩니다.
프로세스
와일드카드 정책을 구성합니다.
다음 명령을 사용하여
IngressController리소스를 편집합니다.$ oc edit IngressControllerspec에서wildcardPolicy필드를WildcardsDisallowed또는WildcardsAllowed로 설정합니다.spec: routeAdmission: wildcardPolicy: WildcardsDisallowed # or WildcardsAllowed
2.3.9.12. HTTP 헤더 구성
Red Hat OpenShift Service on AWS는 HTTP 헤더로 작업할 수 있는 다양한 방법을 제공합니다. 헤더를 설정하거나 삭제할 때 Ingress 컨트롤러의 특정 필드를 사용하거나 개별 경로를 사용하여 요청 및 응답 헤더를 수정할 수 있습니다. 경로 주석을 사용하여 특정 헤더를 설정할 수도 있습니다. 헤더를 구성하는 다양한 방법은 함께 작업할 때 문제가 발생할 수 있습니다.
IngressController 또는 Route CR 내에서 헤더만 설정하거나 삭제할 수 있으므로 추가할 수 없습니다. HTTP 헤더가 값으로 설정된 경우 해당 값은 완료되어야 하며 나중에 추가할 필요가 없습니다. X-Forwarded-For 헤더와 같은 헤더를 추가하는 것이 적합한 경우 spec.httpHeaders.actions 대신 spec.httpHeaders.forwardedHeaderPolicy 필드를 사용합니다.
2.3.9.12.1. 우선순위 순서
Ingress 컨트롤러와 경로에서 동일한 HTTP 헤더를 수정하는 경우 HAProxy는 요청 또는 응답 헤더인지 여부에 따라 특정 방식으로 작업에 우선순위를 부여합니다.
- HTTP 응답 헤더의 경우 경로에 지정된 작업 후에 Ingress 컨트롤러에 지정된 작업이 실행됩니다. 즉, Ingress 컨트롤러에 지정된 작업이 우선합니다.
- HTTP 요청 헤더의 경우 경로에 지정된 작업은 Ingress 컨트롤러에 지정된 작업 후에 실행됩니다. 즉, 경로에 지정된 작업이 우선합니다.
예를 들어 클러스터 관리자는 다음 구성을 사용하여 Ingress 컨트롤러에서 값이 DENY 인 X-Frame-Options 응답 헤더를 설정합니다.
IngressController 사양 예
apiVersion: operator.openshift.io/v1
kind: IngressController
# ...
spec:
httpHeaders:
actions:
response:
- name: X-Frame-Options
action:
type: Set
set:
value: DENY
경로 소유자는 클러스터 관리자가 Ingress 컨트롤러에 설정한 것과 동일한 응답 헤더를 설정하지만 다음 구성을 사용하여 SAMEORIGIN 값이 사용됩니다.
Route 사양의 예
apiVersion: route.openshift.io/v1
kind: Route
# ...
spec:
httpHeaders:
actions:
response:
- name: X-Frame-Options
action:
type: Set
set:
value: SAMEORIGIN
IngressController 사양과 Route 사양 모두에서 X-Frame-Options 응답 헤더를 구성하는 경우 특정 경로에서 프레임을 허용하는 경우에도 Ingress 컨트롤러의 글로벌 수준에서 이 헤더에 설정된 값이 우선합니다. 요청 헤더의 경우 Route spec 값은 IngressController 사양 값을 재정의합니다.
이 우선순위는 haproxy.config 파일에서 다음 논리를 사용하므로 Ingress 컨트롤러가 프런트 엔드로 간주되고 개별 경로가 백엔드로 간주되기 때문입니다. 프런트 엔드 구성에 적용된 헤더 값 DENY 는 백엔드에 설정된 SAMEORIGIN 값으로 동일한 헤더를 재정의합니다.
frontend public
http-response set-header X-Frame-Options 'DENY'
frontend fe_sni
http-response set-header X-Frame-Options 'DENY'
frontend fe_no_sni
http-response set-header X-Frame-Options 'DENY'
backend be_secure:openshift-monitoring:alertmanager-main
http-response set-header X-Frame-Options 'SAMEORIGIN'또한 Ingress 컨트롤러 또는 경로 주석을 사용하여 설정된 경로 덮어쓰기 값에 정의된 모든 작업입니다.
2.3.9.12.2. 특수 케이스 헤더
다음 헤더는 완전히 설정되거나 삭제되지 않거나 특정 상황에서 허용되지 않습니다.
| 헤더 이름 | IngressController 사양을 사용하여 구성 가능 | Route 사양을 사용하여 구성 가능 | 허용하지 않는 이유 | 다른 방법을 사용하여 구성 가능 |
|---|---|---|---|---|
|
| 없음 | 없음 |
| 없음 |
|
| 없음 | 제공됨 |
| 없음 |
|
| 없음 | 없음 |
|
제공됨: |
|
| 없음 | 없음 | HAProxy가 클라이언트 연결을 특정 백엔드 서버에 매핑하는 세션 추적에 사용되는 쿠키입니다. 이러한 헤더를 설정하도록 허용하면 HAProxy의 세션 선호도를 방해하고 HAProxy의 쿠키 소유권을 제한할 수 있습니다. | 예:
|
2.3.9.13. Ingress 컨트롤러에서 HTTP 요청 및 응답 헤더 설정 또는 삭제
규정 준수 목적 또는 기타 이유로 특정 HTTP 요청 및 응답 헤더를 설정하거나 삭제할 수 있습니다. Ingress 컨트롤러에서 제공하는 모든 경로 또는 특정 경로에 대해 이러한 헤더를 설정하거나 삭제할 수 있습니다.
예를 들어 상호 TLS를 사용하기 위해 클러스터에서 실행 중인 애플리케이션을 마이그레이션할 수 있습니다. 이 경우 애플리케이션에서 X-Forwarded-Client-Cert 요청 헤더를 확인해야 하지만 AWS 기본 Ingress 컨트롤러의 Red Hat OpenShift Service는 X-SSL-Client-Der 요청 헤더를 제공합니다.
다음 절차에서는 X-Forwarded-Client-Cert 요청 헤더를 설정하도록 Ingress 컨트롤러를 수정하고 X-SSL-Client-Der 요청 헤더를 삭제합니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
cluster-admin역할의 사용자로 AWS 클러스터의 Red Hat OpenShift Service에 액세스할 수 있습니다.
절차
Ingress 컨트롤러 리소스를 편집합니다.
$ oc -n openshift-ingress-operator edit ingresscontroller/defaultX-SSL-Client-Der HTTP 요청 헤더를 X-Forwarded-Client-Cert HTTP 요청 헤더로 바꿉니다.
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpHeaders: actions:1 request:2 - name: X-Forwarded-Client-Cert3 action: type: Set4 set: value: "%{+Q}[ssl_c_der,base64]"5 - name: X-SSL-Client-Der action: type: Delete- 1
- HTTP 헤더에서 수행할 작업 목록입니다.
- 2
- 변경할 헤더 유형입니다. 이 경우 요청 헤더가 있습니다.
- 3
- 변경할 헤더의 이름입니다. 설정하거나 삭제할 수 있는 사용 가능한 헤더 목록은 HTTP 헤더 구성 을 참조하십시오.
- 4
- 헤더에서 수행되는 작업 유형입니다. 이 필드에는
Set또는Delete값이 있을 수 있습니다. - 5
- HTTP 헤더를 설정할 때
값을제공해야 합니다. 값은 해당 헤더에 사용 가능한 지시문 목록(예:DENY)의 문자열이거나 HAProxy의 동적 값 구문을 사용하여 해석되는 동적 값이 될 수 있습니다. 이 경우 동적 값이 추가됩니다.
참고HTTP 응답에 대한 동적 헤더 값을 설정하기 위해 허용되는 샘플 페이퍼는
res.hdr및ssl_c_der입니다. HTTP 요청에 대한 동적 헤더 값을 설정하는 경우 허용되는 샘플 페더는req.hdr및ssl_c_der입니다. request 및 response 동적 값은 모두lower및base64컨버터를 사용할 수 있습니다.- 파일을 저장하여 변경 사항을 적용합니다.
2.3.9.14. X-Forwarded 헤더 사용
HAProxy Ingress 컨트롤러를 구성하여 Forwarded 및 X-Forwarded-For를 포함한 HTTP 헤더 처리 방법에 대한 정책을 지정합니다. Ingress Operator는 HTTPHeaders 필드를 사용하여 Ingress 컨트롤러의 ROUTER_SET_FORWARDED_HEADERS 환경 변수를 구성합니다.
프로세스
Ingress 컨트롤러에 대한
HTTPHeaders필드를 구성합니다.다음 명령을 사용하여
IngressController리소스를 편집합니다.$ oc edit IngressControllerspec에서HTTPHeaders정책 필드를Append,Replace,IfNone또는Never로 설정합니다.apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpHeaders: forwardedHeaderPolicy: Append
사용 사례 예
클러스터 관리자는 다음을 수행할 수 있습니다.
Ingress 컨트롤러로 전달하기 전에
X-Forwarded-For헤더를 각 요청에 삽입하는 외부 프록시를 구성합니다.헤더를 수정하지 않은 상태로 전달하도록 Ingress 컨트롤러를 구성하려면
never정책을 지정합니다. 그러면 Ingress 컨트롤러에서 헤더를 설정하지 않으며 애플리케이션은 외부 프록시에서 제공하는 헤더만 수신합니다.외부 프록시에서 외부 클러스터 요청에 설정한
X-Forwarded-For헤더를 수정하지 않은 상태로 전달하도록 Ingress 컨트롤러를 구성합니다.외부 프록시를 통과하지 않는 내부 클러스터 요청에
X-Forwarded-For헤더를 설정하도록 Ingress 컨트롤러를 구성하려면if-none정책을 지정합니다. HTTP 요청에 이미 외부 프록시를 통해 설정된 헤더가 있는 경우 Ingress 컨트롤러에서 해당 헤더를 보존합니다. 요청이 프록시를 통해 제공되지 않아 헤더가 없는 경우에는 Ingress 컨트롤러에서 헤더를 추가합니다.
애플리케이션 개발자는 다음을 수행할 수 있습니다.
X-Forwarded-For헤더를 삽입하는 애플리케이션별 외부 프록시를 구성합니다.다른 경로에 대한 정책에 영향을 주지 않으면서 애플리케이션 경로에 대한 헤더를 수정하지 않은 상태로 전달하도록 Ingress 컨트롤러를 구성하려면 애플리케이션 경로에 주석
haproxy.router.openshift.io/set-forwarded-headers: if-none또는haproxy.router.openshift.io/set-forwarded-headers: never를 추가하십시오.참고Ingress 컨트롤러에 전역적으로 설정된 값과 관계없이 경로별로
haproxy.router.openshift.io/set-forwarded-headers주석을 설정할 수 있습니다.
2.3.9.15. Ingress 컨트롤러에서 HTTP/2 활성화 또는 비활성화
HAProxy에서 투명한 엔드 투 엔드 HTTP/2 연결을 활성화하거나 비활성화할 수 있습니다. 애플리케이션 소유자는 단일 연결, 헤더 압축, 바이너리 스트림 등을 포함하여 HTTP/2 프로토콜 기능을 사용할 수 있습니다.
개별 Ingress 컨트롤러 또는 전체 클러스터에 대해 HTTP/2 연결을 활성화하거나 비활성화할 수 있습니다.
개별 Ingress 컨트롤러 및 전체 클러스터에 대해 HTTP/2 연결을 활성화하거나 비활성화하는 경우 Ingress 컨트롤러의 HTTP/2 구성이 클러스터의 HTTP/2 구성보다 우선합니다.
클라이언트에서 HAProxy 인스턴스로의 연결에 HTTP/2 사용을 활성화하려면 경로에서 사용자 정의 인증서를 지정해야 합니다. 기본 인증서를 사용하는 경로에서는 HTTP/2를 사용할 수 없습니다. 이것은 동일한 인증서를 사용하는 다른 경로의 연결을 클라이언트가 재사용하는 등 동시 연결로 인한 문제를 방지하기 위한 제한입니다.
각 경로 유형에 대한 HTTP/2 연결에 대해 다음 사용 사례를 고려하십시오.
- 재암호화 경로의 경우 애플리케이션이 ALPN(Application-Level Protocol Negotiation)을 사용하여 HTTP/2를 협상하는 경우 HAProxy에서 애플리케이션 Pod로의 연결은 HTTP/2를 사용할 수 있습니다. Ingress 컨트롤러에 HTTP/2가 활성화된 경우가 아니면 재암호화 경로와 함께 HTTP/2를 사용할 수 없습니다.
- 패스스루 경로의 경우 애플리케이션에서 ALPN 사용을 지원하여 HTTP/2를 클라이언트와 협상하는 경우 HTTP/2를 사용할 수 있습니다. Ingress Controller에 HTTP/2가 활성화되거나 비활성화된 경우 통과 경로와 함께 HTTP/2를 사용할 수 있습니다.
-
에지 종료 보안 경로의 경우 서비스에서
appProtocol: kubernetes.io/h2c만 지정하는 경우 HTTP/2를 사용합니다. Ingress Controller에 HTTP/2가 활성화되거나 비활성화된 경우 에지 종료 보안 경로와 함께 HTTP/2를 사용할 수 있습니다. -
비보안 경로의 경우 서비스에서
appProtocol: kubernetes.io/h2c만 지정하는 경우 HTTP/2를 사용합니다. Ingress Controller에 HTTP/2가 활성화되거나 비활성화된 경우 비보안 경로와 HTTP/2를 사용할 수 있습니다.
패스스루(passthrough)가 아닌 경로의 경우 Ingress 컨트롤러는 클라이언트와의 연결과 관계없이 애플리케이션에 대한 연결을 협상합니다. 즉, 클라이언트가 Ingress 컨트롤러에 연결하고 HTTP/1.1을 협상할 수 있습니다. 그러면 Ingress 컨트롤러가 애플리케이션에 연결하고 HTTP/2를 협상하고, HTTP/2 연결을 사용하여 클라이언트 HTTP/1.1 연결에서 요청을 전달할 수 있습니다.
이러한 이벤트 시퀀스로 인해 클라이언트가 HTTP/1.1에서 WebSocket 프로토콜로 연결을 업그레이드하려고 하면 문제가 발생합니다. WebSocket 연결을 수락하려는 애플리케이션이 있고 애플리케이션에서 HTTP/2 프로토콜 협상을 허용하려고 하면 클라이언트는 WebSocket 프로토콜로 업그레이드하지 못합니다.
2.3.9.15.1. HTTP/2 활성화
특정 Ingress 컨트롤러에서 HTTP/2를 활성화하거나 전체 클러스터에 HTTP/2를 활성화할 수 있습니다.
프로세스
특정 Ingress 컨트롤러에서 HTTP/2를 활성화하려면
oc annotate명령을 입력합니다.$ oc -n openshift-ingress-operator annotate ingresscontrollers/<ingresscontroller_name> ingress.operator.openshift.io/default-enable-http2=true1 - 1
- &
lt;ingresscontroller_name>을 HTTP/2를 활성화하려면 Ingress 컨트롤러의 이름으로 바꿉니다.
전체 클러스터에 HTTP/2를 사용하려면
oc annotate명령을 입력합니다.$ oc annotate ingresses.config/cluster ingress.operator.openshift.io/default-enable-http2=true
또는 다음 YAML 코드를 적용하여 HTTP/2를 활성화할 수 있습니다.
apiVersion: config.openshift.io/v1
kind: Ingress
metadata:
name: cluster
annotations:
ingress.operator.openshift.io/default-enable-http2: "true"2.3.9.15.2. HTTP/2 비활성화
특정 Ingress 컨트롤러에서 HTTP/2를 비활성화하거나 전체 클러스터에 대해 HTTP/2를 비활성화할 수 있습니다.
프로세스
특정 Ingress 컨트롤러에서 HTTP/2를 비활성화하려면
oc annotate명령을 입력합니다.$ oc -n openshift-ingress-operator annotate ingresscontrollers/<ingresscontroller_name> ingress.operator.openshift.io/default-enable-http2=false1 - 1
- &
lt;ingresscontroller_name>을 HTTP/2를 비활성화하려면 Ingress 컨트롤러의 이름으로 바꿉니다.
전체 클러스터에 대해 HTTP/2를 비활성화하려면
oc annotate명령을 입력합니다.$ oc annotate ingresses.config/cluster ingress.operator.openshift.io/default-enable-http2=false
또는 다음 YAML 코드를 적용하여 HTTP/2를 비활성화할 수 있습니다.
apiVersion: config.openshift.io/v1
kind: Ingress
metadata:
name: cluster
annotations:
ingress.operator.openshift.io/default-enable-http2: "false"2.3.9.16. Ingress 컨트롤러에 대한 PROXY 프로토콜 구성
클러스터 관리자는 Ingress 컨트롤러에서 HostNetwork,NodePortService 또는 Private 엔드포인트 게시 전략 유형을 사용하는 경우 PROXY 프로토콜 을 구성할 수 있습니다. PROXY 프로토콜을 사용하면 로드 밸런서에서 Ingress 컨트롤러가 수신하는 연결에 대한 원래 클라이언트 주소를 유지할 수 있습니다. 원래 클라이언트 주소는 HTTP 헤더를 로깅, 필터링 및 삽입하는 데 유용합니다. 기본 구성에서 Ingress 컨트롤러가 수신하는 연결에는 로드 밸런서와 연결된 소스 주소만 포함됩니다.
Keepalived Ingress 가상 IP(VIP)를 사용하는 클라우드 플랫폼에 설치 관리자 프로비저닝 클러스터가 있는 기본 Ingress 컨트롤러는 PROXY 프로토콜을 지원하지 않습니다.
PROXY 프로토콜을 사용하면 로드 밸런서에서 Ingress 컨트롤러가 수신하는 연결에 대한 원래 클라이언트 주소를 유지할 수 있습니다. 원래 클라이언트 주소는 HTTP 헤더를 로깅, 필터링 및 삽입하는 데 유용합니다. 기본 구성에서 Ingress 컨트롤러에서 수신하는 연결에는 로드 밸런서와 연결된 소스 IP 주소만 포함됩니다.
패스스루 경로 구성의 경우 AWS 클러스터의 Red Hat OpenShift Service의 서버는 원래 클라이언트 소스 IP 주소를 관찰할 수 없습니다. 원래 클라이언트 소스 IP 주소를 알아야 하는 경우 클라이언트 소스 IP 주소를 볼 수 있도록 Ingress 컨트롤러에 대한 Ingress 액세스 로깅을 구성합니다.
재암호화 및 엣지 경로의 경우 AWS 라우터의 Red Hat OpenShift Service는 애플리케이션 워크로드가 클라이언트 소스 IP 주소를 확인하도록 Forwarded 및 X-Forwarded-For 헤더를 설정합니다.
Ingress 액세스 로깅에 대한 자세한 내용은 " Ingress 액세스 로깅 구성"을 참조하십시오.
LoadBalancerService 끝점 게시 전략 유형을 사용하는 경우 Ingress 컨트롤러에 대한 PROXY 프로토콜 구성은 지원되지 않습니다. 이는 AWS의 Red Hat OpenShift Service가 클라우드 플랫폼에서 실행되고 Ingress 컨트롤러가 서비스 로드 밸런서를 사용해야 함을 지정하는 경우 Ingress Operator는 로드 밸런서 서비스를 구성하고 소스 주소를 유지하기 위한 플랫폼 요구 사항에 따라 PROXY 프로토콜을 활성화하기 때문입니다.
PROXY 프로토콜 또는 TCP를 사용하도록 AWS에서 Red Hat OpenShift Service와 외부 로드 밸런서를 모두 구성해야 합니다.
이 기능은 클라우드 배포에서 지원되지 않습니다. 이는 AWS의 Red Hat OpenShift Service가 클라우드 플랫폼에서 실행되고 Ingress 컨트롤러가 서비스 로드 밸런서를 사용해야 함을 지정하는 경우 Ingress Operator는 로드 밸런서 서비스를 구성하고 소스 주소를 유지하기 위한 플랫폼 요구 사항에 따라 PROXY 프로토콜을 활성화하기 때문입니다.
PROXY 프로토콜을 사용하거나 TCP(Transmission Control Protocol)를 사용하려면 AWS의 Red Hat OpenShift Service와 외부 로드 밸런서를 모두 구성해야 합니다.
사전 요구 사항
- Ingress 컨트롤러가 생성되어 있습니다.
프로세스
CLI에 다음 명령을 입력하여 Ingress 컨트롤러 리소스를 편집합니다.
$ oc -n openshift-ingress-operator edit ingresscontroller/defaultPROXY 구성을 설정합니다.
Ingress 컨트롤러에서
HostNetwork끝점 게시 전략 유형을 사용하는 경우spec.endpointPublishingStrategy.hostNetwork.protocol하위 필드를PROXY:로 설정합니다.PROXY에 대한hostNetwork구성 샘플# ... spec: endpointPublishingStrategy: hostNetwork: protocol: PROXY type: HostNetwork # ...Ingress 컨트롤러에서
NodePortService끝점 게시 전략 유형을 사용하는 경우spec.endpointPublishingStrategy.nodePort.protocol하위 필드를PROXY로 설정합니다.PROXY에 대한nodePort구성 샘플# ... spec: endpointPublishingStrategy: nodePort: protocol: PROXY type: NodePortService # ...Ingress 컨트롤러에서
Private끝점 게시 전략 유형을 사용하는 경우spec.endpointPublishingStrategy.private.protocol하위 필드를PROXY로 설정합니다.PROXY에 대한개인구성 샘플# ... spec: endpointPublishingStrategy: private: protocol: PROXY type: Private # ...
2.3.9.17. appsDomain 옵션을 사용하여 대체 클러스터 도메인 지정
클러스터 관리자는 appsDomain 필드를 구성하여 사용자가 생성한 경로에 대한 기본 클러스터 도메인의 대안을 지정할 수 있습니다. appsDomain 필드는 domain 필드에 지정된 기본값 대신 사용할 AWS의 Red Hat OpenShift Service의 선택적 도메인 입니다. 대체 도메인을 지정하면 새 경로의 기본 호스트를 결정하기 위해 기본 클러스터 도메인을 덮어씁니다.
예를 들어, 회사의 DNS 도메인을 클러스터에서 실행되는 애플리케이션의 경로 및 인그레스의 기본 도메인으로 사용할 수 있습니다.
사전 요구 사항
- AWS 클러스터에 Red Hat OpenShift Service를 배포했습니다.
-
oc명령줄 인터페이스를 설치했습니다.
프로세스
사용자 생성 경로에 대한 대체 기본 도메인을 지정하여
appsDomain필드를 구성합니다.ingress
클러스터리소스를 편집합니다.$ oc edit ingresses.config/cluster -o yamlYAML 파일을 편집합니다.
test.example.com에 대한appsDomain구성 샘플apiVersion: config.openshift.io/v1 kind: Ingress metadata: name: cluster spec: domain: apps.example.com1 appsDomain: <test.example.com>2
경로를 노출하고 경로 도메인 변경을 확인하여 기존 경로에
appsDomain필드에 지정된 도메인 이름이 포함되어 있는지 확인합니다.참고경로를 노출하기 전에
openshift-apiserver가 롤링 업데이트를 완료할 때까지 기다립니다.경로를 노출합니다.
$ oc expose service hello-openshift route.route.openshift.io/hello-openshift exposed출력 예
$ oc get routes NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD hello-openshift hello_openshift-<my_project>.test.example.com hello-openshift 8080-tcp None
2.3.9.18. HTTP 헤더 대소문자 변환
HAProxy 소문자 HTTP 헤더 이름(예: Host: xyz.com 을 host: xyz.com )으로 변경합니다. 기존 애플리케이션이 HTTP 헤더 이름의 대문자에 민감한 경우 Ingress Controller spec.httpHeaders.headerNameCaseAdjustments API 필드를 사용하여 기존 애플리케이션을 수정할 때 까지 지원합니다.
AWS의 Red Hat OpenShift Service에는 HAProxy 2.8이 포함되어 있습니다. 이 웹 기반 로드 밸런서 버전으로 업데이트하려면 spec.httpHeaders.headerNameCaseAdjustments 섹션을 클러스터의 구성 파일에 추가해야 합니다.
클러스터 관리자는 oc patch 명령을 입력하거나 Ingress 컨트롤러 YAML 파일에서 HeaderNameCaseAdjustments 필드를 설정하여 HTTP 헤더 케이스를 변환할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
프로세스
oc patch명령을 사용하여 HTTP 헤더를 대문자로 설정합니다.다음 명령을 실행하여 HTTP 헤더를
host에서Host로 변경합니다.$ oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"httpHeaders":{"headerNameCaseAdjustments":["Host"]}}}'주석을 애플리케이션에 적용할 수 있도록
Route리소스 YAML 파일을 생성합니다.my-application이라는 경로 예apiVersion: route.openshift.io/v1 kind: Route metadata: annotations: haproxy.router.openshift.io/h1-adjust-case: true1 name: <application_name> namespace: <application_name> # ...- 1
- Ingress 컨트롤러가 지정된 대로
호스트요청 헤더를 조정할 수 있도록haproxy.router.openshift.io/h1-adjust-case를 설정합니다.
Ingress 컨트롤러 YAML 구성 파일에서
HeaderNameCaseAdjustments필드를 구성하여 조정을 지정합니다.다음 예제 Ingress 컨트롤러 YAML 파일은 적절한 주석이 달린 경로에 대해 HTTP/1 요청에 대해
호스트헤더를Host로 조정합니다.Ingress 컨트롤러 YAML 예시
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpHeaders: headerNameCaseAdjustments: - Host다음 예제 경로에서는
haproxy.router.openshift.io/h1-adjust-case주석을 사용하여 HTTP 응답 헤더 이름 대소문자 조정을 활성화합니다.경로 YAML의 예
apiVersion: route.openshift.io/v1 kind: Route metadata: annotations: haproxy.router.openshift.io/h1-adjust-case: true1 name: my-application namespace: my-application spec: to: kind: Service name: my-application- 1
haproxy.router.openshift.io/h1-adjust-case를 true로 설정합니다.
2.3.9.19. 라우터 압축 사용
특정 MIME 유형에 대해 전역적으로 라우터 압축을 지정하도록 HAProxy Ingress 컨트롤러를 구성합니다. mimeTypes 변수를 사용하여 압축이 적용되는 MIME 유형의 형식을 정의할 수 있습니다. 유형은 application, image, message, multipart, text, video 또는 "X-"가 붙은 사용자 지정 유형입니다. MIME 유형 및 하위 유형에 대한 전체 표기법을 보려면 RFC1341 을 참조하십시오.
압축에 할당된 메모리는 최대 연결에 영향을 미칠 수 있습니다. 또한 큰 버퍼를 압축하면 많은 regex 또는 긴 regex 목록과 같은 대기 시간이 발생할 수 있습니다.
모든 MIME 유형이 압축의 이점은 아니지만 HAProxy는 여전히 리소스를 사용하여 다음을 지시한 경우 압축합니다. 일반적으로 html, css, js와 같은 텍스트 형식은 압축할 수 있지만 이미 압축한 형식(예: 이미지, 오디오, 비디오 등)은 압축에 소요되는 시간과 리소스를 거의 교환하지 못합니다.
프로세스
Ingress 컨트롤러의
httpCompression필드를 구성합니다.다음 명령을 사용하여
IngressController리소스를 편집합니다.$ oc edit -n openshift-ingress-operator ingresscontrollers/defaultspec에서httpCompression정책 필드를mimeTypes로 설정하고 압축이 적용되어야 하는 MIME 유형 목록을 지정합니다.apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpCompression: mimeTypes: - "text/html" - "text/css; charset=utf-8" - "application/json" ...
2.3.9.20. 라우터 지표 노출
기본 통계 포트인 1936에서 Prometheus 형식으로 기본적으로 HAProxy 라우터 지표를 노출할 수 있습니다. Prometheus와 같은 외부 메트릭 컬렉션 및 집계 시스템은 HAProxy 라우터 지표에 액세스할 수 있습니다. 브라우저에서 HAProxy 라우터 메트릭을 HTML 및 쉼표로 구분된 값(CSV) 형식으로 볼 수 있습니다.
사전 요구 사항
- 기본 통계 포트인 1936에 액세스하도록 방화벽을 구성했습니다.
프로세스
다음 명령을 실행하여 라우터 Pod 이름을 가져옵니다.
$ oc get pods -n openshift-ingress출력 예
NAME READY STATUS RESTARTS AGE router-default-76bfffb66c-46qwp 1/1 Running 0 11h라우터 Pod가
/var/lib/haproxy/conf/metrics-auth/statsUsername및/var/lib/haproxy/conf/metrics-auth/statsPassword파일에 저장하는 라우터의 사용자 이름과 암호를 가져옵니다.다음 명령을 실행하여 사용자 이름을 가져옵니다.
$ oc rsh <router_pod_name> cat metrics-auth/statsUsername다음 명령을 실행하여 암호를 가져옵니다.
$ oc rsh <router_pod_name> cat metrics-auth/statsPassword
다음 명령을 실행하여 라우터 IP 및 메트릭 인증서를 가져옵니다.
$ oc describe pod <router_pod>다음 명령을 실행하여 Prometheus 형식으로 원시 통계를 가져옵니다.
$ curl -u <user>:<password> http://<router_IP>:<stats_port>/metrics다음 명령을 실행하여 메트릭에 안전하게 액세스합니다.
$ curl -u user:password https://<router_IP>:<stats_port>/metrics -k다음 명령을 실행하여 기본 stats 포트 1936에 액세스합니다.
$ curl -u <user>:<password> http://<router_IP>:<stats_port>/metrics예 2.1. 출력 예
... # HELP haproxy_backend_connections_total Total number of connections. # TYPE haproxy_backend_connections_total gauge haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route"} 0 haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route-alt"} 0 haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route01"} 0 ... # HELP haproxy_exporter_server_threshold Number of servers tracked and the current threshold value. # TYPE haproxy_exporter_server_threshold gauge haproxy_exporter_server_threshold{type="current"} 11 haproxy_exporter_server_threshold{type="limit"} 500 ... # HELP haproxy_frontend_bytes_in_total Current total of incoming bytes. # TYPE haproxy_frontend_bytes_in_total gauge haproxy_frontend_bytes_in_total{frontend="fe_no_sni"} 0 haproxy_frontend_bytes_in_total{frontend="fe_sni"} 0 haproxy_frontend_bytes_in_total{frontend="public"} 119070 ... # HELP haproxy_server_bytes_in_total Current total of incoming bytes. # TYPE haproxy_server_bytes_in_total gauge haproxy_server_bytes_in_total{namespace="",pod="",route="",server="fe_no_sni",service=""} 0 haproxy_server_bytes_in_total{namespace="",pod="",route="",server="fe_sni",service=""} 0 haproxy_server_bytes_in_total{namespace="default",pod="docker-registry-5-nk5fz",route="docker-registry",server="10.130.0.89:5000",service="docker-registry"} 0 haproxy_server_bytes_in_total{namespace="default",pod="hello-rc-vkjqx",route="hello-route",server="10.130.0.90:8080",service="hello-svc-1"} 0 ...브라우저에 다음 URL을 입력하여 통계 창을 시작합니다.
http://<user>:<password>@<router_IP>:<stats_port>선택 사항: 브라우저에 다음 URL을 입력하여 CSV 형식으로 통계를 가져옵니다.
http://<user>:<password>@<router_ip>:1936/metrics;csv
2.3.9.21. HAProxy 오류 코드 응답 페이지 사용자 정의
클러스터 관리자는 503, 404 또는 두 오류 페이지에 대한 사용자 지정 오류 코드 응답 페이지를 지정할 수 있습니다. HAProxy 라우터는 애플리케이션 pod가 실행 중이 아닌 경우 503 오류 페이지 또는 요청된 URL이 없는 경우 404 오류 페이지를 제공합니다. 예를 들어 503 오류 코드 응답 페이지를 사용자 지정하면 애플리케이션 pod가 실행되지 않을 때 페이지가 제공되며 HAProxy 라우터에서 잘못된 경로 또는 존재하지 않는 경로에 대해 기본 404 오류 코드 HTTP 응답 페이지가 제공됩니다.
사용자 정의 오류 코드 응답 페이지가 구성 맵에 지정되고 Ingress 컨트롤러에 패치됩니다. 구성 맵 키의 사용 가능한 파일 이름은 error-page-503.http 및 error-page-404.http 입니다.
사용자 지정 HTTP 오류 코드 응답 페이지는 HAProxy HTTP 오류 페이지 구성 지침을 따라야 합니다. 다음은 AWS HAProxy 라우터 http 503 오류 코드 응답 페이지의 기본 Red Hat OpenShift Service의 예입니다. 기본 콘텐츠를 고유한 사용자 지정 페이지를 생성하기 위한 템플릿으로 사용할 수 있습니다.
기본적으로 HAProxy 라우터는 애플리케이션이 실행 중이 아니거나 경로가 올바르지 않거나 존재하지 않는 경우 503 오류 페이지만 제공합니다. 이 기본 동작은 AWS 4.8 및 이전 버전의 Red Hat OpenShift Service의 동작과 동일합니다. HTTP 오류 코드 응답 사용자 정의에 대한 구성 맵이 제공되지 않고 사용자 정의 HTTP 오류 코드 응답 페이지를 사용하는 경우 라우터는 기본 404 또는 503 오류 코드 응답 페이지를 제공합니다.
AWS의 Red Hat OpenShift Service를 기본 503 오류 코드 페이지를 사용자 지정 템플릿으로 사용하는 경우 파일의 헤더에는 CRLF 줄 끝을 사용할 수 있는 편집기가 필요합니다.
절차
openshift-config네임스페이스에my-custom-error-code-pages라는 구성 맵을 생성합니다.$ oc -n openshift-config create configmap my-custom-error-code-pages \ --from-file=error-page-503.http \ --from-file=error-page-404.http중요사용자 정의 오류 코드 응답 페이지에 올바른 형식을 지정하지 않으면 라우터 Pod 중단이 발생합니다. 이 중단을 해결하려면 구성 맵을 삭제하거나 수정하고 영향을 받는 라우터 Pod를 삭제하여 올바른 정보로 다시 생성해야 합니다.
이름별로
my-custom-error-code-pages구성 맵을 참조하도록 Ingress 컨트롤러를 패치합니다.$ oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"httpErrorCodePages":{"name":"my-custom-error-code-pages"}}}' --type=mergeIngress Operator는
my-custom-error-code-pages구성 맵을openshift-config네임스페이스에서openshift-ingress네임스페이스로 복사합니다. Operator는openshift-ingress네임스페이스에서<your_ingresscontroller_name>-errorpages패턴에 따라 구성 맵의 이름을 지정합니다.복사본을 표시합니다.
$ oc get cm default-errorpages -n openshift-ingress출력 예
NAME DATA AGE default-errorpages 2 25s1 - 1
defaultIngress 컨트롤러 CR(사용자 정의 리소스)이 패치되었기 때문에 구성 맵 이름은default-errorpages입니다.
사용자 정의 오류 응답 페이지가 포함된 구성 맵이 라우터 볼륨에 마운트되는지 확인합니다. 여기서 구성 맵 키는 사용자 정의 HTTP 오류 코드 응답이 있는 파일 이름입니다.
503 사용자 지정 HTTP 사용자 정의 오류 코드 응답의 경우:
$ oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-503.http404 사용자 지정 HTTP 사용자 정의 오류 코드 응답의 경우:
$ oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-404.http
검증
사용자 정의 오류 코드 HTTP 응답을 확인합니다.
테스트 프로젝트 및 애플리케이션을 생성합니다.
$ oc new-project test-ingress$ oc new-app django-psql-example503 사용자 정의 http 오류 코드 응답의 경우:
- 애플리케이션의 모든 pod를 중지합니다.
다음 curl 명령을 실행하거나 브라우저에서 경로 호스트 이름을 방문합니다.
$ curl -vk <route_hostname>
404 사용자 정의 http 오류 코드 응답의 경우:
- 존재하지 않는 경로 또는 잘못된 경로를 방문합니다.
다음 curl 명령을 실행하거나 브라우저에서 경로 호스트 이름을 방문합니다.
$ curl -vk <route_hostname>
errorfile속성이haproxy.config파일에 제대로 있는지 확인합니다.$ oc -n openshift-ingress rsh <router> cat /var/lib/haproxy/conf/haproxy.config | grep errorfile
2.3.9.22. Ingress 컨트롤러 최대 연결 설정
클러스터 관리자는 OpenShift 라우터 배포에 대한 최대 동시 연결 수를 설정할 수 있습니다. 기존 Ingress 컨트롤러를 패치하여 최대 연결 수를 늘릴 수 있습니다.
사전 요구 사항
- 다음은 Ingress 컨트롤러를 이미 생성했다고 가정합니다.
프로세스
HAProxy의 최대 연결 수를 변경하도록 Ingress 컨트롤러를 업데이트합니다.
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"maxConnections": 7500}}}'주의spec.tuningOptions.maxConnections값을 현재 운영 체제 제한보다 크게 설정하면 HAProxy 프로세스가 시작되지 않습니다. 이 매개변수에 대한 자세한 내용은 "Ingress Controller 구성 매개변수" 섹션의 표를 참조하십시오.
2.3.10. Red Hat OpenShift Service on AWS Ingress Operator 구성
다음 표에서는 Ingress Operator의 구성 요소와 Red Hat 사이트 안정성 엔지니어(SRE)가 AWS 클러스터의 Red Hat OpenShift Service에서 이 구성 요소를 유지보수하는 경우 자세히 설명합니다.
| Ingress 구성 요소 | 관리 대상 | 기본 설정 |
|---|---|---|
| Ingress 컨트롤러 스케일링 | SRE | 제공됨 |
| Ingress Operator 스레드 수 | SRE | 제공됨 |
| Ingress 컨트롤러 액세스 로깅 | SRE | 제공됨 |
| Ingress 컨트롤러 분할 | SRE | 제공됨 |
| Ingress 컨트롤러 경로 허용 정책 | SRE | 제공됨 |
| Ingress 컨트롤러 와일드카드 경로 | SRE | 제공됨 |
| Ingress 컨트롤러 X-Forwarded 헤더 | SRE | 제공됨 |
| Ingress 컨트롤러 경로 압축 | SRE | 제공됨 |
2.4. AWS의 Red Hat OpenShift Service의 Ingress Node Firewall Operator
Ingress Node Firewall Operator는 AWS의 Red Hat OpenShift Service에서 노드 수준 인그레스 트래픽을 관리하기 위한 상태 비저장 eBPF 기반 방화벽을 제공합니다.
2.4.1. Ingress 노드 방화벽 Operator
Ingress Node Firewall Operator는 방화벽 구성에서 지정 및 관리하는 노드에 데몬 세트를 배포하여 노드 수준에서 Ingress 방화벽 규칙을 제공합니다. 데몬 세트를 배포하려면 IngressNodeFirewallConfig CR(사용자 정의 리소스)을 생성합니다. Operator는 IngressNodeFirewallConfig CR을 적용하여 nodeSelector 와 일치하는 모든 노드에서 실행되는 수신 노드 방화벽 데몬 세트를 생성합니다.
IngressNodeFirewall CR의 규칙을 구성하고 nodeSelector 를 사용하여 클러스터에 적용하고 값을 "true"로 설정합니다.
Ingress Node Firewall Operator는 상태 비저장 방화벽 규칙만 지원합니다.
기본 XDP 드라이버를 지원하지 않는 NIC(네트워크 인터페이스 컨트롤러)는 더 낮은 성능에서 실행됩니다.
AWS 4.14 이상에서 Red Hat OpenShift Service의 경우 RHEL 9.0 이상에서 Ingress Node Firewall Operator를 실행해야 합니다.
2.4.2. Ingress Node Firewall Operator 설치
클러스터 관리자는 AWS CLI 또는 웹 콘솔에서 Red Hat OpenShift Service를 사용하여 Ingress Node Firewall Operator를 설치할 수 있습니다.
2.4.2.1. CLI를 사용하여 Ingress Node Firewall Operator 설치
클러스터 관리자는 CLI를 사용하여 Operator를 설치할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. - 관리자 권한이 있는 계정이 있습니다.
절차
openshift-ingress-node-firewall네임스페이스를 생성하려면 다음 명령을 입력합니다.$ cat << EOF| oc create -f - apiVersion: v1 kind: Namespace metadata: labels: pod-security.kubernetes.io/enforce: privileged pod-security.kubernetes.io/enforce-version: v1.24 name: openshift-ingress-node-firewall EOFOperatorGroupCR을 생성하려면 다음 명령을 입력합니다.$ cat << EOF| oc create -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: ingress-node-firewall-operators namespace: openshift-ingress-node-firewall EOFIngress Node Firewall Operator에 등록합니다.
Ingress Node Firewall Operator에 대한
서브스크립션CR을 생성하려면 다음 명령을 입력합니다.$ cat << EOF| oc create -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: ingress-node-firewall-sub namespace: openshift-ingress-node-firewall spec: name: ingress-node-firewall channel: stable source: redhat-operators sourceNamespace: openshift-marketplace EOF
Operator가 설치되었는지 확인하려면 다음 명령을 입력합니다.
$ oc get ip -n openshift-ingress-node-firewall출력 예
NAME CSV APPROVAL APPROVED install-5cvnz ingress-node-firewall.4.0-202211122336 Automatic trueOperator 버전을 확인하려면 다음 명령을 입력합니다.
$ oc get csv -n openshift-ingress-node-firewall출력 예
NAME DISPLAY VERSION REPLACES PHASE ingress-node-firewall.4.0-202211122336 Ingress Node Firewall Operator 4.0-202211122336 ingress-node-firewall.4.0-202211102047 Succeeded
2.4.2.2. 웹 콘솔을 사용하여 Ingress Node Firewall Operator 설치
클러스터 관리자는 웹 콘솔을 사용하여 Operator를 설치할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. - 관리자 권한이 있는 계정이 있습니다.
절차
Ingress Node Firewall Operator를 설치합니다.
- AWS 웹 콘솔의 Red Hat OpenShift Service에서 Operator → OperatorHub 를 클릭합니다.
- 사용 가능한 Operator 목록에서 Ingress Node Firewall Operator 를 선택한 다음 설치를 클릭합니다.
- Operator 설치 페이지의 설치된 네임스페이스 에서 Operator 권장 네임스페이스를 선택합니다.
- 설치를 클릭합니다.
Ingress Node Firewall Operator가 성공적으로 설치되었는지 확인합니다.
- Operator → 설치된 Operator 페이지로 이동합니다.
Ingress Node Firewall Operator 가 openshift-ingress-node-firewall 프로젝트에 InstallSucceeded 상태로 나열되어 있는지 확인합니다.
참고설치 중에 Operator는 실패 상태를 표시할 수 있습니다. 나중에 InstallSucceeded 메시지와 함께 설치에 성공하면 이 실패 메시지를 무시할 수 있습니다.
Operator에 InstallSucceeded 상태가 없는 경우 다음 단계를 사용하여 문제를 해결합니다.
- Operator 서브스크립션 및 설치 계획 탭의 상태 아래에서 실패 또는 오류가 있는지 검사합니다.
-
워크로드 → Pod 페이지로 이동하여
openshift-ingress-node-firewall프로젝트에서 Pod 로그를 확인합니다. YAML 파일의 네임스페이스를 확인합니다. 주석이 없는 경우 다음 명령을 사용하여 주석
workload.openshift.io/allowed=management를 Operator 네임스페이스에 추가할 수 있습니다.$ oc annotate ns/openshift-ingress-node-firewall workload.openshift.io/allowed=management참고단일 노드 OpenShift 클러스터의 경우
openshift-ingress-node-firewall네임스페이스에workload.openshift.io/allowed=management주석이 필요합니다.
2.4.3. Ingress Node Firewall Operator 배포
사전 요구 사항
- Ingress Node Firewall Operator가 설치되어 있습니다.
절차
Ingress Node Firewall Operator를 배포하려면 Operator의 데몬 세트를 배포할 IngressNodeFirewallConfig 사용자 정의 리소스를 생성합니다. 방화벽 규칙을 적용하여 하나 이상의 IngressNodeFirewall CRD를 노드에 배포할 수 있습니다.
-
ingressnodefirewallconfig라는openshift-ingress-node-firewall네임스페이스에IngressNodeFirewallConfig를 생성합니다. 다음 명령을 실행하여 Ingress Node Firewall Operator 규칙을 배포합니다.
$ oc apply -f rule.yaml
2.4.3.1. Ingress 노드 방화벽 구성 오브젝트
Ingress 노드 방화벽 구성 오브젝트의 필드는 다음 표에 설명되어 있습니다.
| 필드 | 유형 | 설명 |
|---|---|---|
|
|
|
CR 오브젝트의 이름입니다. 방화벽 규칙 오브젝트의 이름은 |
|
|
|
Ingress Firewall Operator CR 오브젝트의 네임스페이스입니다. |
|
|
| 지정된 노드 라벨을 통해 노드를 대상으로 지정하는 데 사용되는 노드 선택 제약 조건입니다. 예를 들면 다음과 같습니다. 참고
|
|
|
| Node Ingress Firewall Operator에서 eBPF Manager Operator를 사용하거나 eBPF 프로그램을 관리하지 않는지를 지정합니다. 이 기능은 기술 프리뷰 기능입니다. Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오. |
Operator는 CR을 사용하고 nodeSelector 와 일치하는 모든 노드에 Ingress 노드 방화벽 데몬 세트를 생성합니다.
Ingress Node Firewall Operator 구성 예
다음 예제에서는 전체 Ingress 노드 방화벽 구성이 지정됩니다.
Ingress 노드 방화벽 구성 오브젝트의 예
apiVersion: ingressnodefirewall.openshift.io/v1alpha1
kind: IngressNodeFirewallConfig
metadata:
name: ingressnodefirewallconfig
namespace: openshift-ingress-node-firewall
spec:
nodeSelector:
node-role.kubernetes.io/worker: ""
Operator는 CR을 사용하고 nodeSelector 와 일치하는 모든 노드에 Ingress 노드 방화벽 데몬 세트를 생성합니다.
2.4.3.2. Ingress 노드 방화벽 규칙 오브젝트
Ingress 노드 방화벽 규칙 오브젝트의 필드는 다음 표에 설명되어 있습니다.
| 필드 | 유형 | 설명 |
|---|---|---|
|
|
| CR 오브젝트의 이름입니다. |
|
|
|
이 오브젝트의 필드는 방화벽 규칙을 적용할 인터페이스를 지정합니다. 예: |
|
|
|
|
|
|
|
|
Ingress 오브젝트 구성
ingress 오브젝트의 값은 다음 표에 정의되어 있습니다.
| 필드 | 유형 | 설명 |
|---|---|---|
|
|
| CIDR 블록을 설정할 수 있습니다. 다른 주소 제품군에서 여러 CIDR을 구성할 수 있습니다. 참고
다른 CIDR을 사용하면 동일한 주문 규칙을 사용할 수 있습니다. CIDR이 겹치는 동일한 노드 및 인터페이스에 |
|
|
|
Ingress 방화벽
규칙을 적용하거나 참고 Ingress 방화벽 규칙은 잘못된 구성을 차단하는 확인 Webhook를 사용하여 확인합니다. 확인 Webhook를 사용하면 API 서버와 같은 중요한 클러스터 서비스를 차단할 수 없습니다. |
Ingress 노드 방화벽 규칙 오브젝트 예
다음 예제에서는 전체 Ingress 노드 방화벽 구성이 지정됩니다.
Ingress 노드 방화벽 구성의 예
apiVersion: ingressnodefirewall.openshift.io/v1alpha1
kind: IngressNodeFirewall
metadata:
name: ingressnodefirewall
spec:
interfaces:
- eth0
nodeSelector:
matchLabels:
<ingress_firewall_label_name>: <label_value>
ingress:
- sourceCIDRs:
- 172.16.0.0/12
rules:
- order: 10
protocolConfig:
protocol: ICMP
icmp:
icmpType: 8 #ICMP Echo request
action: Deny
- order: 20
protocolConfig:
protocol: TCP
tcp:
ports: "8000-9000"
action: Deny
- sourceCIDRs:
- fc00:f853:ccd:e793::0/64
rules:
- order: 10
protocolConfig:
protocol: ICMPv6
icmpv6:
icmpType: 128 #ICMPV6 Echo request
action: Deny- 1
- <label_name> 및 <label_value>는 노드에 있어야 하며
ingressfirewallconfigCR을 실행할 노드에 적용되는nodeselector레이블 및 값과 일치해야 합니다. <label_value>는true또는false일 수 있습니다.nodeSelector레이블을 사용하면 별도의 노드 그룹을 대상으로 하여ingressfirewallconfigCR을 사용하는 데 다른 규칙을 적용할 수 있습니다.
제로 신뢰 Ingress 노드 방화벽 규칙 오브젝트 예
제로 트러스트 Ingress 노드 방화벽 규칙은 다중 인터페이스 클러스터에 추가 보안을 제공할 수 있습니다. 예를 들어 제로 신뢰 Ingress 노드 방화벽 규칙을 사용하여 SSH를 제외한 특정 인터페이스에서 모든 트래픽을 삭제할 수 있습니다.
다음 예에서는 제로 신뢰 Ingress 노드 방화벽 규칙 세트의 전체 구성이 지정됩니다.
사용자는 적절한 기능을 보장하기 위해 애플리케이션이 허용 목록에 사용하는 모든 포트를 추가해야 합니다.
제로 트러스트 Ingress 노드 방화벽 규칙의 예
apiVersion: ingressnodefirewall.openshift.io/v1alpha1
kind: IngressNodeFirewall
metadata:
name: ingressnodefirewall-zero-trust
spec:
interfaces:
- eth1
nodeSelector:
matchLabels:
<ingress_firewall_label_name>: <label_value>
ingress:
- sourceCIDRs:
- 0.0.0.0/0
rules:
- order: 10
protocolConfig:
protocol: TCP
tcp:
ports: 22
action: Allow
- order: 20
action: Deny eBPF Manager Operator 통합은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
2.4.4. Ingress Node Firewall Operator 통합
Ingress 노드 방화벽은 eBPF 프로그램을 사용하여 일부 주요 방화벽 기능을 구현합니다. 기본적으로 이러한 eBPF 프로그램은 Ingress 노드 방화벽과 관련된 메커니즘을 사용하여 커널에 로드됩니다. 대신 eBPF Manager Operator를 사용하여 이러한 프로그램을 로드 및 관리하도록 Ingress Node Firewall Operator를 구성할 수 있습니다.
이 통합을 활성화하면 다음과 같은 제한 사항이 적용됩니다.
- Ingress Node Firewall Operator는 XDP를 사용할 수 없는 경우 TCX를 사용하고 TCX는 bpfman과 호환되지 않습니다.
-
Ingress Node Firewall Operator 데몬 세트 Pod는 방화벽 규칙이 적용될 때까지
ContainerCreating상태로 유지됩니다. - Ingress Node Firewall Operator 데몬 세트 Pod는 privileged로 실행됩니다.
2.4.5. eBPF Manager Operator를 사용하도록 Ingress Node Firewall Operator 구성
Ingress 노드 방화벽은 eBPF 프로그램을 사용하여 일부 주요 방화벽 기능을 구현합니다. 기본적으로 이러한 eBPF 프로그램은 Ingress 노드 방화벽과 관련된 메커니즘을 사용하여 커널에 로드됩니다.
클러스터 관리자는 eBPF Manager Operator를 사용하여 이러한 프로그램을 로드 및 관리하도록 Ingress Node Firewall Operator를 구성하여 추가 보안 및 관찰 기능을 추가할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. - 관리자 권한이 있는 계정이 있습니다.
- Ingress Node Firewall Operator가 설치되어 있어야 합니다.
- eBPF Manager Operator가 설치되어 있습니다.
절차
ingress-node-firewall-system네임스페이스에 다음 라벨을 적용합니다.$ oc label namespace openshift-ingress-node-firewall \ pod-security.kubernetes.io/enforce=privileged \ pod-security.kubernetes.io/warn=privileged --overwriteingressnodefirewallconfig라는IngressNodeFirewallConfig오브젝트를 편집하고ebpfProgramManagerMode필드를 설정합니다.Ingress Node Firewall Operator 구성 오브젝트
apiVersion: ingressnodefirewall.openshift.io/v1alpha1 kind: IngressNodeFirewallConfig metadata: name: ingressnodefirewallconfig namespace: openshift-ingress-node-firewall spec: nodeSelector: node-role.kubernetes.io/worker: "" ebpfProgramManagerMode: <ebpf_mode>다음과 같습니다.
<ebpf_mode> : Ingress Node Firewall Operator에서 eBPF Manager Operator를 사용하여 eBPF 프로그램을 관리할지 여부를 지정합니다.true또는false여야 합니다. 설정되지 않은 경우 eBPF Manager가 사용되지 않습니다.
2.4.6. Ingress Node Firewall Operator 규칙 보기
절차
다음 명령을 실행하여 현재 모든 규칙을 확인합니다.
$ oc get ingressnodefirewall반환된 <
resource>이름 중 하나를 선택하고 다음 명령을 실행하여 규칙 또는 구성을 확인합니다.$ oc get <resource> <name> -o yaml
2.4.7. Ingress Node Firewall Operator 문제 해결
다음 명령을 실행하여 설치된 Ingress Node Firewall CRD(사용자 정의 리소스 정의)를 나열합니다.
$ oc get crds | grep ingressnodefirewall출력 예
NAME READY UP-TO-DATE AVAILABLE AGE ingressnodefirewallconfigs.ingressnodefirewall.openshift.io 2022-08-25T10:03:01Z ingressnodefirewallnodestates.ingressnodefirewall.openshift.io 2022-08-25T10:03:00Z ingressnodefirewalls.ingressnodefirewall.openshift.io 2022-08-25T10:03:00Z다음 명령을 실행하여 Ingress Node Firewall Operator의 상태를 확인합니다.
$ oc get pods -n openshift-ingress-node-firewall출력 예
NAME READY STATUS RESTARTS AGE ingress-node-firewall-controller-manager 2/2 Running 0 5d21h ingress-node-firewall-daemon-pqx56 3/3 Running 0 5d21h다음 필드는 Operator 상태에 대한 정보를 제공합니다.
READY,STATUS,AGE,RESTARTS. Ingress Node Firewall Operator가 할당된 노드에 데몬 세트를 배포할 때STATUS필드는Running입니다.다음 명령을 실행하여 모든 수신 방화벽 노드 Pod의 로그를 수집합니다.
$ oc adm must-gather – gather_ingress_node_firewall로그는 /s
os_commands/ebpff .에 있는 eBPF보고서에서 사용할 수 있습니다. 이러한 보고서에는 수신 방화벽 XDP가 패킷 처리를 처리하고 통계를 업데이트하고 이벤트를 발송할 때 사용되거나 업데이트된 조회 테이블이 포함됩니다.bpftool출력이 포함된 sos 노드의
3장. ROSA 클러스터에 대한 네트워크 확인
네트워크 확인 검사는 AWS(ROSA)의 Red Hat OpenShift Service를 기존 VPC(Virtual Private Cloud)에 배포하거나 클러스터에 새로 추가된 서브넷을 사용하여 추가 머신 풀을 생성할 때 자동으로 실행됩니다. 이 검사에서는 네트워크 구성을 검증하고 오류를 강조 표시하므로 배포 전에 구성 문제를 해결할 수 있습니다.
네트워크 확인 검사를 수동으로 실행하여 기존 클러스터의 구성을 검증할 수도 있습니다.
3.1. ROSA 클러스터에 대한 네트워크 확인 이해
AWS(ROSA) 클러스터에 Red Hat OpenShift Service를 기존 VPC(Virtual Private Cloud)에 배포하거나 클러스터에 새로 추가된 서브넷을 사용하여 추가 머신 풀을 생성하면 네트워크 확인이 자동으로 실행됩니다. 이를 통해 배포 전에 구성 문제를 식별하고 해결할 수 있습니다.
Red Hat OpenShift Cluster Manager를 사용하여 클러스터 설치를 준비하면 VPC(Virtual Private Cloud) 서브넷 설정 페이지의 서브넷 ID 필드에 서브넷 ID를 입력한 후 자동 검사가 실행됩니다. ROSA CLI(rosa)를 대화형 모드로 사용하여 클러스터를 생성하는 경우 필요한 VPC 네트워크 정보를 제공한 후 검사가 실행됩니다. 대화형 모드 없이 CLI를 사용하는 경우 클러스터 생성 직전에 검사가 시작됩니다.
서브넷이 새로 추가된 서브넷으로 머신 풀을 추가하면 자동 네트워크 확인에서 서브넷을 확인하여 머신 풀을 프로비저닝하기 전에 네트워크 연결을 사용할 수 있는지 확인합니다.
자동 네트워크 확인이 완료되면 서비스 로그에 레코드가 전송됩니다. 레코드는 네트워크 구성 오류를 포함하여 확인 확인 결과를 제공합니다. 배포 전에 확인된 문제를 해결할 수 있으며 배포의 성공 가능성이 더 높습니다.
기존 클러스터에 대해 네트워크 확인을 수동으로 실행할 수도 있습니다. 이를 통해 구성을 변경한 후 클러스터의 네트워크 구성을 확인할 수 있습니다. 네트워크 확인 검사를 수동으로 실행하는 단계는 네트워크 확인 수동 실행을 참조하십시오.
3.2. 네트워크 검증 검사 범위
네트워크 확인에는 다음 요구사항 각각에 대한 검사가 포함됩니다.
- 상위 VPC(Virtual Private Cloud)가 있습니다.
- 지정된 모든 서브넷이 VPC에 속합니다.
-
VPC에
enableDnsSupport가 활성화되어 있습니다. -
VPC에
enableDnsHostnames가 활성화되어 있습니다. - egress는 AWS 방화벽 사전 요구 사항 섹션에 지정된 필수 도메인 및 포트 조합에서 사용할 수 있습니다.
3.3. 자동 네트워크 확인 우회
알려진 네트워크 구성 문제가 있는 AWS(ROSA) 클러스터에 Red Hat OpenShift Service를 기존 VPC(Virtual Private Cloud)에 배포하려면 자동 네트워크 확인을 바이패스할 수 있습니다.
클러스터를 생성할 때 네트워크 확인을 바이패스하면 클러스터의 지원 상태가 제한됩니다. 설치 후 문제를 해결한 다음 네트워크 확인을 수동으로 실행할 수 있습니다. 제한된 지원 상태는 검증에 성공한 후 제거됩니다.
OpenShift Cluster Manager를 사용하여 자동 네트워크 확인 우회
Red Hat OpenShift Cluster Manager를 사용하여 기존 VPC에 클러스터를 설치하는 경우 VPC(Virtual Private Cloud) 서브넷 설정 페이지에서 Bypass network verification 을 선택하여 자동 확인을 바이패스할 수 있습니다.
3.4. 수동으로 네트워크 확인 실행
AWS(ROSA) 클러스터에 Red Hat OpenShift Service를 설치한 후 Red Hat OpenShift Cluster Manager 또는 ROSA CLI(rosa)를 사용하여 네트워크 확인 검사를 수동으로 실행할 수 있습니다.
OpenShift Cluster Manager를 사용하여 네트워크 확인 수동으로 실행
Red Hat OpenShift Cluster Manager를 사용하여 AWS(ROSA) 클러스터에서 기존 Red Hat OpenShift Service에 대한 네트워크 확인 검사를 수동으로 실행할 수 있습니다.
사전 요구 사항
- 기존 ROSA 클러스터가 있습니다.
- 클러스터 소유자이거나 클러스터 편집기 역할이 있습니다.
절차
- OpenShift Cluster Manager 로 이동하여 클러스터를 선택합니다.
- 작업 드롭다운 메뉴에서 네트워크 확인을 선택합니다.
CLI를 사용하여 수동으로 네트워크 확인 실행
ROSA CLI(rosa)를 사용하여 AWS(ROSA) 클러스터에서 기존 Red Hat OpenShift Service에 대한 네트워크 확인 검사를 수동으로 실행할 수 있습니다.
네트워크 확인을 실행하면 VPC 서브넷 ID 세트 또는 클러스터 이름을 지정할 수 있습니다.
사전 요구 사항
-
설치 호스트에 최신 ROSA CLI(
rosa)를 설치하고 구성했습니다. - 기존 ROSA 클러스터가 있습니다.
- 클러스터 소유자이거나 클러스터 편집기 역할이 있습니다.
절차
다음 방법 중 하나를 사용하여 네트워크 구성을 확인합니다.
클러스터 이름을 지정하여 네트워크 구성을 확인합니다. 서브넷 ID가 자동으로 탐지됩니다.
$ rosa verify network --cluster <cluster_name>1 - 1
- &
lt;cluster_name>을 클러스터 이름으로 바꿉니다.
출력 예
I: Verifying the following subnet IDs are configured correctly: [subnet-03146b9b52b6024cb subnet-03146b9b52b2034cc] I: subnet-03146b9b52b6024cb: pending I: subnet-03146b9b52b2034cc: passed I: Run the following command to wait for verification to all subnets to complete: rosa verify network --watch --status-only --region us-east-1 --subnet-ids subnet-03146b9b52b6024cb,subnet-03146b9b52b2034cc모든 서브넷에 대한 확인이 완료되었는지 확인합니다.
$ rosa verify network --watch \1 --status-only \2 --region <region_name> \3 --subnet-ids subnet-03146b9b52b6024cb,subnet-03146b9b52b2034cc4 - 1
watch플래그는 test의 모든 서브넷이 실패 또는 전달된 상태에 있는 후 명령이 완료되도록 합니다.- 2
status-only플래그는 네트워크 확인을 트리거하지 않지만 현재 상태를 반환합니다(예:subnet-123(확인은 여전히 진행 중). 기본적으로 이 옵션이 없으면 이 명령을 호출하면 지정된 서브넷의 확인이 항상 트리거됩니다.- 3
- AWS_REGION 환경 변수를 재정의하는 특정 AWS 리전을 사용합니다.
- 4
- 쉼표로 구분된 서브넷 ID 목록을 입력하여 확인합니다. 서브넷이 없는 경우
'subnet-<subnet_number> 서브넷에 대한 Network 확인 메시지가 표시되고 서브넷을 확인하지 않습니다.
출력 예
I: Checking the status of the following subnet IDs: [subnet-03146b9b52b6024cb subnet-03146b9b52b2034cc] I: subnet-03146b9b52b6024cb: passed I: subnet-03146b9b52b2034cc: passed작은 정보전체 확인 테스트 목록을 출력하려면
rosa verify network명령을 실행할 때--debug인수를 포함할 수 있습니다.
VPC 서브넷 ID를 지정하여 네트워크 구성을 확인합니다. <
region_name>을 AWS 리전으로 바꾸고 <AWS_account_ID>를 AWS 계정 ID로 바꿉니다.$ rosa verify network --subnet-ids 03146b9b52b6024cb,subnet-03146b9b52b2034cc --region <region_name> --role-arn arn:aws:iam::<AWS_account_ID>:role/my-Installer-Role출력 예
I: Verifying the following subnet IDs are configured correctly: [subnet-03146b9b52b6024cb subnet-03146b9b52b2034cc] I: subnet-03146b9b52b6024cb: pending I: subnet-03146b9b52b2034cc: passed I: Run the following command to wait for verification to all subnets to complete: rosa verify network --watch --status-only --region us-east-1 --subnet-ids subnet-03146b9b52b6024cb,subnet-03146b9b52b2034cc모든 서브넷에 대한 확인이 완료되었는지 확인합니다.
$ rosa verify network --watch --status-only --region us-east-1 --subnet-ids subnet-03146b9b52b6024cb,subnet-03146b9b52b2034cc출력 예
I: Checking the status of the following subnet IDs: [subnet-03146b9b52b6024cb subnet-03146b9b52b2034cc] I: subnet-03146b9b52b6024cb: passed I: subnet-03146b9b52b2034cc: passed
4장. 클러스터 전체 프록시 구성
기존 VPC(Virtual Private Cloud)를 사용하는 경우 Red Hat OpenShift Service on AWS(ROSA) 클러스터 설치 중 또는 클러스터가 설치된 후 클러스터 전체 프록시를 구성할 수 있습니다. 프록시를 활성화하면 코어 클러스터 구성 요소가 인터넷에 대한 직접 액세스가 거부되지만 프록시는 사용자 워크로드에 영향을 미치지 않습니다.
클라우드 공급자 API에 대한 호출을 포함하여 시스템 송신 트래픽만 프록시됩니다.
클러스터 전체 프록시를 사용하는 경우 클러스터에 대한 프록시의 가용성을 유지 관리해야 합니다. 프록시를 사용할 수 없게 되면 클러스터의 상태 및 지원 가능성에 영향을 미칠 수 있습니다.
4.1. 클러스터 전체 프록시 구성을 위한 사전 요구 사항
클러스터 전체 프록시를 구성하려면 다음 요구 사항을 충족해야 합니다. 이러한 요구 사항은 설치 중 또는 설치 후 프록시를 구성할 때 유효합니다.
일반 요구 사항
- 클러스터 소유자입니다.
- 계정에는 충분한 권한이 있습니다.
- 클러스터의 기존 VPC(Virtual Private Cloud)가 있습니다.
- 프록시는 클러스터의 VPC 및 VPC의 프라이빗 서브넷에 액세스할 수 있습니다. 이 프록시는 클러스터의 VPC 및 VPC의 프라이빗 서브넷에서도 액세스할 수 있습니다.
VPC 끝점에 다음 끝점을 추가했습니다.
-
ec2.<aws_region>.amazonaws.com -
elasticloadbalancing.<aws_region>.amazonaws.com s3.<aws_region>.amazonaws.com이러한 끝점은 노드에서 AWS EC2 API로 요청을 완료하는 데 필요합니다. 프록시는 노드 수준이 아닌 컨테이너 수준에서 작동하기 때문에 이러한 요청을 AWS 사설 네트워크를 통해 AWS EC2 API로 라우팅해야 합니다. 프록시 서버의 허용 목록에 EC2 API의 공용 IP 주소를 추가하는 것만으로는 충분하지 않습니다.
중요클러스터 전체 프록시를 사용하는 경우
게이트웨이유형으로s3.<aws_region>.amazonaws.com끝점을 구성해야 합니다.
-
네트워크 요구 사항
프록시에서 송신 트래픽을 다시 암호화하는 경우 도메인 및 포트 조합에 대한 제외를 생성해야 합니다. 다음 표에서는 이러한 예외에 대한 지침을 제공합니다.
프록시는 다음 OpenShift URL을 다시 암호화하도록 제외해야 합니다.
Expand address 프로토콜/포트 함수 observatorium-mst.api.openshift.comhttps/443
필수 항목입니다. Managed OpenShift별 Telemetry에 사용됩니다.
sso.redhat.comhttps/443
https://cloud.redhat.com/openshift 사이트에서는 sso.redhat.com의 인증을 사용하여 클러스터 풀 시크릿을 다운로드하고 Red Hat SaaS 솔루션을 사용하여 서브스크립션, 클러스터 인벤토리 및 관련 보고를 원활하게 모니터링할 수 있습니다.
4.2. 추가 신뢰 번들에 대한 책임
추가 신뢰 번들을 제공하는 경우 다음 요구 사항을 담당합니다.
- 추가 신뢰 번들의 콘텐츠가 유효한지 확인
- 추가 신뢰 번들에 포함된 중간 인증서를 포함하여 인증서가 만료되지 않았는지 확인
- 만료 추적 및 추가 신뢰 번들에 포함된 인증서에 필요한 갱신 수행
- 업데이트된 추가 신뢰 번들로 클러스터 구성 업데이트
4.3. 설치 중 프록시 구성
ROSA(Red Hat OpenShift Service) 클러스터를 기존 VPC(Virtual Private Cloud)에 설치할 때 HTTP 또는 HTTPS 프록시를 구성할 수 있습니다. Red Hat OpenShift Cluster Manager 또는 ROSA CLI(로사)를 사용하여 설치 중에 프록시를 구성할 수있습니다.
4.3.1. OpenShift Cluster Manager를 사용하여 설치 중에 프록시 구성
AWS(ROSA) 클러스터의 Red Hat OpenShift Service를 기존 VPC(Virtual Private Cloud)에 설치하는 경우 Red Hat OpenShift Cluster Manager를 사용하여 설치 중에 클러스터 전체 HTTP 또는 HTTPS 프록시를 활성화할 수 있습니다.
설치하기 전에 클러스터를 설치하는 VPC에서 프록시에 액세스할 수 있는지 확인해야 합니다. VPC의 프라이빗 서브넷에서도 프록시에 액세스할 수 있어야 합니다.
OpenShift Cluster Manager를 사용하여 설치 중에 클러스터 전체 프록시를 구성하는 방법에 대한 자세한 단계는 OpenShift Cluster Manager 를 사용하여 사용자 지정으로 클러스터 생성을 참조하십시오.
4.3.2. CLI를 사용하여 설치 중에 프록시 구성
AWS(ROSA) 클러스터의 Red Hat OpenShift Service를 기존 VPC(Virtual Private Cloud)에 설치하는 경우 ROSA CLI(rosa)를 사용하여 설치 중에 클러스터 전체 HTTP 또는 HTTPS 프록시를 활성화할 수 있습니다.
다음 절차에서는 설치 중에 클러스터 전체 프록시를 구성하는 데 사용되는 ROSA CLI(rosa) 인수에 대한 세부 정보를 제공합니다. ROSA CLI를 사용하는 일반적인 설치 단계는 CLI를 사용하여 사용자 지정으로 클러스터 생성을 참조하십시오.
사전 요구 사항
- 클러스터가 설치되고 있는 VPC에서 프록시에 액세스할 수 있는지 확인했습니다. VPC의 프라이빗 서브넷에서도 프록시에 액세스할 수 있어야 합니다.
절차
클러스터를 생성할 때 프록시 구성을 지정합니다.
$ rosa create cluster \ <other_arguments_here> \ --additional-trust-bundle-file <path_to_ca_bundle_file> \1 2 3 --http-proxy http://<username>:<password>@<ip>:<port> \4 5 --https-proxy https://<username>:<password>@<ip>:<port> \6 7 --no-proxy example.com8 - 1 4 6
additional-trust-bundle-file,http-proxy,https-proxy인수는 모두 선택 사항입니다.- 2
additional-trust-bundle-file인수는 모두 서로 연결된 PEM 인코딩 X.509 인증서 번들을 가리키는 파일 경로입니다. 프록시의 ID 인증서를 RHCOS(Red Hat Enterprise Linux CoreOS) 신뢰 번들의 기관에서 서명하지 않는 한 TLS-inspecting 프록시를 사용하는 사용자에게는 additional-trust-bundle-file 인수가 필요합니다. 이는 프록시가 투명하든 http-proxy 및 https-proxy 인수를 사용하여 명시적 구성이 필요한지 여부와 관계없이 적용됩니다.- 3 5 7
http-proxy및https-proxy인수는 유효한 URL을 가리켜야 합니다.- 8
- 프록시를 제외할 대상 도메인 이름, IP 주소 또는 네트워크 CIDR의 쉼표로 구분된 목록입니다.
하위 도메인과 일치하려면 도메인 앞에
.을 입력합니다. 예를 들어,.y.com은x.y.com과 일치하지만y.com은 일치하지 않습니다.*를 사용하여 모든 대상에 대해 프록시를 바이패스합니다.networking.machineNetwork[].cidr필드에 의해 정의된 네트워크에 포함되어 있지 않은 작업자를 설치 구성에서 확장하려면 연결 문제를 방지하기 위해 이 목록에 해당 작업자를 추가해야 합니다.httpProxy와httpsProxy필드가 모두 설정되지 않은 경우 이 필드는 무시됩니다.
4.4. 설치 후 프록시 구성
AWS(ROSA) 클러스터의 Red Hat OpenShift Service를 기존 VPC(Virtual Private Cloud)에 설치한 후 HTTP 또는 HTTPS 프록시를 구성할 수 있습니다. Red Hat OpenShift Cluster Manager 또는 ROSA CLI(rosa)를 사용하여 설치 후 프록시를 구성할 수 있습니다.
4.4.1. OpenShift Cluster Manager를 사용하여 설치 후 프록시 구성
Red Hat OpenShift Cluster Manager를 사용하여 VPC(Virtual Private Cloud)의 기존 Red Hat OpenShift Service에 클러스터 전체 프록시 구성을 추가할 수 있습니다.
OpenShift Cluster Manager를 사용하여 기존 클러스터 전체 프록시 구성을 업데이트할 수도 있습니다. 예를 들어 프록시의 인증 기관이 만료되면 프록시의 네트워크 주소를 업데이트하거나 추가 신뢰 번들을 교체해야 할 수 있습니다.
클러스터는 컨트롤 플레인 및 컴퓨팅 노드에 프록시 설정을 적용합니다. 구성을 적용하는 동안 각 클러스터 노드는 일시적으로 스케줄링할 수 없는 상태로 배치되어 워크로드를 드레인합니다. 각 노드는 프로세스의 일부로 재시작됩니다.
사전 요구 사항
- AWS 클러스터에 Red Hat OpenShift Service가 있습니다.
- 클러스터는 VPC에 배포되어 있습니다.
절차
- OpenShift Cluster Manager 로 이동하여 클러스터를 선택합니다.
- 네트워킹 페이지의 VPC(Virtual Private Cloud) 섹션에서 Edit cluster-wide proxy 를 클릭합니다.
클러스터 전체 프록시 편집 페이지에서 프록시 구성 세부 정보를 입력합니다.
다음 필드 중 하나 이상에 값을 입력합니다.
- 유효한 HTTP 프록시 URL 을 지정합니다.
- 유효한 HTTPS 프록시 URL 을 지정합니다.
-
추가 신뢰 번들 필드에서 PEM 인코딩 X.509 인증서 번들을 제공합니다. 기존 신뢰 번들 파일을 교체하는 경우 파일 교체를 선택하여 필드를 확인합니다. 번들은 클러스터 노드의 신뢰할 수 있는 인증서 저장소에 추가됩니다. 프록시의 ID 인증서가 RHCOS(Red Hat Enterprise Linux CoreOS) 신뢰 번들의 기관에서 서명되지 않는 한 TLS 지정 프록시를 사용하는 경우 추가 신뢰 번들 파일이 필요합니다. 이 요구 사항은 프록시가 투명했는지 또는
http-proxy인수 및https-proxy인수를 사용하여 명시적 구성이 필요한지 여부와 관계없이 적용됩니다.
- Confirm 을 클릭합니다.
검증
- 네트워킹 페이지의 VPC(Virtual Private Cloud) 섹션에서 클러스터의 프록시 구성이 예상대로 구성되어 있는지 확인합니다.
4.4.2. CLI를 사용하여 설치 후 프록시 구성
ROSA(Red Hat OpenShift Service on AWS) CLI(rosa)를 사용하여 가상 프라이빗 클라우드(Virtual Private Cloud)의 기존 ROSA 클러스터에 클러스터 전체 프록시 구성을 추가할 수 있습니다.
rosa 를 사용하여 기존 클러스터 전체 프록시 구성을 업데이트할 수도 있습니다. 예를 들어 프록시의 인증 기관이 만료되면 프록시의 네트워크 주소를 업데이트하거나 추가 신뢰 번들을 교체해야 할 수 있습니다.
클러스터는 컨트롤 플레인 및 컴퓨팅 노드에 프록시 설정을 적용합니다. 구성을 적용하는 동안 각 클러스터 노드는 일시적으로 스케줄링할 수 없는 상태로 배치되어 워크로드를 드레인합니다. 각 노드는 프로세스의 일부로 재시작됩니다.
사전 요구 사항
-
설치 호스트에 최신 ROSA(
rosa) 및 OpenShift(oc) CLI를 설치하고 구성했습니다. - VPC에 배포된 ROSA 클러스터가 있습니다.
절차
클러스터 구성을 편집하여 클러스터 전체 프록시 세부 정보를 추가하거나 업데이트합니다.
$ rosa edit cluster \ --cluster $CLUSTER_NAME \ --additional-trust-bundle-file <path_to_ca_bundle_file> \1 2 3 --http-proxy http://<username>:<password>@<ip>:<port> \4 5 --https-proxy https://<username>:<password>@<ip>:<port> \6 7 --no-proxy example.com8 - 1 4 6
additional-trust-bundle-file,http-proxy,https-proxy인수는 모두 선택 사항입니다.- 2
additional-trust-bundle-file인수는 모두 서로 연결된 PEM 인코딩 X.509 인증서 번들을 가리키는 파일 경로입니다. additional-trust-bundle-file 인수는 모두 함께 연결된 PEM 인코딩 X.509 인증서 번들을 가리키는 파일 경로입니다. 프록시의 ID 인증서를 RHCOS(Red Hat Enterprise Linux CoreOS) 신뢰 번들의 기관에서 서명하지 않는 한 TLS-inspecting 프록시를 사용하는 사용자에게는 additional-trust-bundle-file 인수가 필요합니다. 이는 프록시가 투명하든http-proxy및https-proxy인수를 사용하여 명시적 구성이 필요한지 여부와 관계없이 적용됩니다.참고클러스터에서 프록시 또는 추가 신뢰 번들 구성을 직접 변경하지 않아야 합니다. 이러한 변경 사항은 ROSA CLI(
rosa) 또는 Red Hat OpenShift Cluster Manager를 사용하여 적용해야 합니다. 클러스터에 직접 변경한 모든 변경 사항은 자동으로 취소됩니다.- 3 5 7
http-proxy및https-proxy인수는 유효한 URL을 가리켜야 합니다.- 8
- 프록시를 제외할 대상 도메인 이름, IP 주소 또는 네트워크 CIDR의 쉼표로 구분된 목록입니다.
하위 도메인과 일치하려면 도메인 앞에
.을 입력합니다. 예를 들어,.y.com은x.y.com과 일치하지만y.com은 일치하지 않습니다.*를 사용하여 모든 대상에 대해 프록시를 바이패스합니다.networking.machineNetwork[].cidr필드에 의해 정의된 네트워크에 포함되어 있지 않은 작업자를 설치 구성에서 확장하려면 연결 문제를 방지하기 위해 이 목록에 해당 작업자를 추가해야 합니다.httpProxy와httpsProxy필드가 모두 설정되지 않은 경우 이 필드는 무시됩니다.
검증
머신 구성 풀의 상태를 나열하고 업데이트가 업데이트되었는지 확인합니다.
$ oc get machineconfigpools출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-d9a03f612a432095dcde6dcf44597d90 True False False 3 3 3 0 31h worker rendered-worker-f6827a4efe21e155c25c21b43c46f65e True False False 6 6 6 0 31h클러스터의 프록시 구성을 표시하고 세부 정보가 예상대로 표시되는지 확인합니다.
$ oc get proxy cluster -o yaml출력 예
apiVersion: config.openshift.io/v1 kind: Proxy spec: httpProxy: http://proxy.host.domain:<port> httpsProxy: https://proxy.host.domain:<port> <...more...> status: httpProxy: http://proxy.host.domain:<port> httpsProxy: https://proxy.host.domain:<port> <...more...>
4.5. 클러스터 전체 프록시 제거
ROSA CLI를 사용하여 클러스터 전체 프록시를 제거할 수 있습니다. 클러스터를 제거한 후 클러스터에 추가된 신뢰 번들도 제거해야 합니다.
4.5.1. CLI를 사용하여 클러스터 전체 프록시 제거
클러스터에서 프록시 주소를 제거하려면 AWS(ROSA) CLI( ROSA ) CLI를 사용하여 프록시 주소를 제거해야 합니다.
사전 요구 사항
- 클러스터 관리자 권한이 있어야합니다.
-
ROSA CLI(
rosa)를 설치했습니다.
절차
프록시를 수정하려면
rosa edit명령을 사용합니다. 클러스터에서 프록시를 지우려면 빈 문자열을--http-proxy및--https-proxy인수에 전달해야 합니다.$ rosa edit cluster -c <cluster_name> --http-proxy "" --https-proxy ""참고프록시 인수 중 하나만 사용할 수 있지만 빈 필드는 무시되므로
--http-proxy및--https-proxy인수 모두에 빈 문자열을 전달해도 문제가 발생하지 않습니다.출력 예
I: Updated cluster <cluster_name>
검증
rosa describe명령을 사용하여 클러스터에서 프록시가 제거되었는지 확인할 수 있습니다.$ rosa describe cluster -c <cluster_name>제거하기 전에 프록시 IP가 프록시 섹션에 표시됩니다.
Name: <cluster_name> ID: <cluster_internal_id> External ID: <cluster_external_id> OpenShift Version: 4.0 Channel Group: stable DNS: <dns> AWS Account: <aws_account_id> API URL: <api_url> Console URL: <console_url> Region: us-east-1 Multi-AZ: false Nodes: - Control plane: 3 - Infra: 2 - Compute: 2 Network: - Type: OVNKubernetes - Service CIDR: <service_cidr> - Machine CIDR: <machine_cidr> - Pod CIDR: <pod_cidr> - Host Prefix: <host_prefix> Proxy: - HTTPProxy: <proxy_url> Additional trust bundle: REDACTED프록시를 제거하면 프록시 섹션이 제거됩니다.
Name: <cluster_name> ID: <cluster_internal_id> External ID: <cluster_external_id> OpenShift Version: 4.0 Channel Group: stable DNS: <dns> AWS Account: <aws_account_id> API URL: <api_url> Console URL: <console_url> Region: us-east-1 Multi-AZ: false Nodes: - Control plane: 3 - Infra: 2 - Compute: 2 Network: - Type: OVNKubernetes - Service CIDR: <service_cidr> - Machine CIDR: <machine_cidr> - Pod CIDR: <pod_cidr> - Host Prefix: <host_prefix> Additional trust bundle: REDACTED
4.5.2. AWS 클러스터의 Red Hat OpenShift Service에서 인증 기관 제거
ROSA(Red Hat OpenShift Service on AWS) CLI, rosa 를 사용하여 클러스터에서 CA(인증 기관)를 제거할 수 있습니다.
사전 요구 사항
- 클러스터 관리자 권한이 있어야합니다.
-
ROSA CLI(
rosa)를 설치했습니다. - 클러스터에 인증 기관이 추가되었습니다.
절차
rosa edit명령을 사용하여 CA 신뢰 번들을 수정합니다. 클러스터에서 신뢰 번들을 지우려면 빈 문자열을--additional-trust-bundle-file인수로 전달해야 합니다.$ rosa edit cluster -c <cluster_name> --additional-trust-bundle-file ""출력 예
I: Updated cluster <cluster_name>
검증
rosa describe명령을 사용하여 신뢰 번들이 클러스터에서 제거되었는지 확인할 수 있습니다.$ rosa describe cluster -c <cluster_name>제거하기 전에 보안 목적으로 해당 값을 수정하고 추가 신뢰 번들 섹션이 표시됩니다.
Name: <cluster_name> ID: <cluster_internal_id> External ID: <cluster_external_id> OpenShift Version: 4.0 Channel Group: stable DNS: <dns> AWS Account: <aws_account_id> API URL: <api_url> Console URL: <console_url> Region: us-east-1 Multi-AZ: false Nodes: - Control plane: 3 - Infra: 2 - Compute: 2 Network: - Type: OVNKubernetes - Service CIDR: <service_cidr> - Machine CIDR: <machine_cidr> - Pod CIDR: <pod_cidr> - Host Prefix: <host_prefix> Proxy: - HTTPProxy: <proxy_url> Additional trust bundle: REDACTED프록시를 제거하면 추가 신뢰 번들 섹션이 제거됩니다.
Name: <cluster_name> ID: <cluster_internal_id> External ID: <cluster_external_id> OpenShift Version: 4.0 Channel Group: stable DNS: <dns> AWS Account: <aws_account_id> API URL: <api_url> Console URL: <console_url> Region: us-east-1 Multi-AZ: false Nodes: - Control plane: 3 - Infra: 2 - Compute: 2 Network: - Type: OVNKubernetes - Service CIDR: <service_cidr> - Machine CIDR: <machine_cidr> - Pod CIDR: <pod_cidr> - Host Prefix: <host_prefix> Proxy: - HTTPProxy: <proxy_url>
5장. CIDR 범위 정의
클러스터에서 OVN-Kubernetes를 사용하는 경우 CIDR(Classless Inter-Domain Routing) 서브넷에 대해 겹치지 않는 범위를 지정해야 합니다.
AWS 4.17 이상 버전의 Red Hat OpenShift Service의 경우 클러스터는 IPv4에 169.254.0.0/17 을 사용하고 IPv6의 경우 fd69::/112 를 기본 masquerade 서브넷으로 사용합니다. 이러한 범위도 사용자가 피해야 합니다. 업그레이드된 클러스터의 경우 기본 masquerade 서브넷이 변경되지 않습니다.
다음 서브넷 유형 및 OVN-Kubernetes를 사용하는 클러스터에는 필수입니다.
- join: 조인 스위치를 사용하여 게이트웨이 라우터를 분산 라우터에 연결합니다. 조인 스위치는 분산 라우터의 IP 주소 수를 줄입니다. OVN-Kubernetes 플러그인을 사용하는 클러스터의 경우 전용 서브넷의 IP 주소가 조인 스위치에 연결된 논리 포트에 할당됩니다.
- masquerade: 로드 밸런서가 라우팅 결정을 내린 후 노드에서 hairpin 트래픽이 동일한 노드로 전송되는 동일한 소스 및 대상 IP 주소에 대한 충돌을 방지합니다.
- 전송 스위치는 클러스터의 모든 노드에 걸쳐 있는 분산 스위치 유형입니다. 전송 스위치는 다른 영역 간에 트래픽을 라우팅합니다. OVN-Kubernetes 플러그인을 사용하는 클러스터의 경우 전용 서브넷의 IP 주소가 전송 스위치에 연결된 논리 포트에 할당됩니다.
설치 후 작업으로 클러스터의 조인, 마스커레이드 및 전송 CIDR 범위를 변경할 수 있습니다.
서브넷 CIDR 범위를 지정할 때 서브넷 CIDR 범위가 정의된 Machine CIDR 내에 있는지 확인합니다. 서브넷 CIDR 범위가 클러스터가 호스팅되는 플랫폼에 따라 모든 의도한 워크로드에 대해 충분한 IP 주소를 허용하는지 확인해야 합니다.
AWS 4.14 이상 버전의 Red Hat OpenShift Service의 기본 네트워크 공급자인 OVN-Kubernetes는 내부적으로 다음 IP 주소 서브넷 범위를 사용합니다.
-
V4JoinSubnet:100.64.0.0/16 -
V6JoinSubnet:fd98::/64 -
V4TransitSwitchSubnet:100.88.0.0/16 -
V6TransitSwitchSubnet:fd97::/64 -
defaultV4MasqueradeSubnet:169.254.0.0/17 -
defaultV6MasqueradeSubnet:fd69::/112
이전 목록에는 조인, 전송, 마스커레이드 IPv4 및 IPv6 주소 서브넷이 포함됩니다. 클러스터에서 OVN-Kubernetes를 사용하는 경우 클러스터 또는 인프라의 다른 CIDR 정의에 이러한 IP 주소 서브넷 범위를 포함하지 마십시오.
5.1. Machine CIDR
CIDR(Machine classless inter-domain routing) 필드에서 시스템 또는 클러스터 노드의 IP 주소 범위를 지정해야 합니다.
머신 CIDR 범위는 클러스터를 생성한 후에는 변경할 수 없습니다.
이 범위는 VPC(가상 프라이빗 클라우드) 서브넷에 대한 모든 CIDR 주소 범위를 포함해야 합니다. 서브넷이 연속되어야 합니다. 단일 가용성 영역 배포에 대해 서브넷 접두사 /25 를 사용하는 최소 128 주소 범위가 지원됩니다. 여러 가용 영역을 사용하는 배포에는 서브넷 접두사 /24 를 사용하는 최소 주소 범위 256 주소가 지원됩니다.
기본값은 10.0.0.0/16 입니다. 이 범위는 연결된 네트워크와 충돌해서는 안 됩니다.
ROSA를 HCP와 함께 사용하면 고정 IP 주소 172.20.0.1 이 내부 Kubernetes API 주소용으로 예약되어 있습니다. 시스템, Pod 및 서비스 CIDR 범위가 이 IP 주소와 충돌해서는 안 됩니다.
5.2. Service CIDR
Service CIDR 필드에서 서비스의 IP 주소 범위를 지정해야 합니다. 클러스터 간에 주소 블록이 동일하지만 필수는 아닙니다. 이는 IP 주소 충돌을 생성하지 않습니다. 범위는 워크로드를 수용할 수 있을 만큼 충분히 커야 합니다. address 블록은 클러스터 내에서 액세스한 외부 서비스와 겹치지 않아야 합니다. 기본값은 172.30.0.0/16입니다.
5.3. Pod CIDR
Pod CIDR 필드에서 Pod의 IP 주소 범위를 지정해야 합니다.
클러스터 간에 주소 블록이 동일하지만 필수는 아닙니다. 이는 IP 주소 충돌을 생성하지 않습니다. 범위는 워크로드를 수용할 수 있을 만큼 충분히 커야 합니다. address 블록은 클러스터 내에서 액세스한 외부 서비스와 겹치지 않아야 합니다. 기본값은 10.128.0.0/14 입니다.
5.4. 호스트 접두사
Host Prefix 필드에서 개별 머신에 예약된 Pod에 할당된 서브넷 접두사 길이를 지정해야 합니다. 호스트 접두사는 각 머신의 Pod IP 주소 풀을 결정합니다.
예를 들어 호스트 접두사를 /23 으로 설정하면 Pod CIDR 주소 범위의 /23 서브넷이 각 시스템에 할당됩니다. 기본값은 /23 입니다. 이로 인해 512개의 클러스터 노드와 노드당 512개의 포드가 허용됩니다(두 가지 모두 최대 지원 범위를 초과함).
5.5. 호스팅된 컨트롤 플레인의 CIDR 범위
AWS의 Red Hat OpenShift Service에 호스팅되는 컨트롤 플레인을 배포하려면 다음과 같은 필수 CIDR(Classless Inter-Domain Routing) 서브넷 범위를 사용합니다.
-
v4InternalSubnet: 100.65.0.0/16 (OVN-Kubernetes) -
clusterNetwork: 10.132.0.0/14 (pod 네트워크) -
serviceNetwork: 172.31.0.0/16
AWS CIDR 범위 정의의 Red Hat OpenShift Service에 대한 자세한 내용은 "CIDR 범위 정의"를 참조하십시오.
6장. 네트워크 보안
6.1. 네트워크 정책 API 이해
Kubernetes는 사용자가 네트워크 보안을 적용하는 데 사용할 수 있는 두 가지 기능을 제공합니다. 사용자가 네트워크 정책을 적용할 수 있는 한 가지 기능은 애플리케이션 개발자 및 네임스페이스 테넌트가 네임스페이스 범위 정책을 생성하여 네임스페이스를 보호하기 위해 주로 설계된 NetworkPolicy API입니다.
두 번째 기능은 AdminNetworkPolicy (ANP) API와 Baseline (BANP) API의 두 API로 구성된 AdminNetworkPolicy입니다. ANP 및 BANP는 클러스터 범위 정책을 생성하여 클러스터 및 네트워크 관리자가 전체 클러스터를 보호하도록 설계되었습니다. 클러스터 관리자는 ANPs를 사용하여 AdminNetworkPolicy NetworkPolicy 오브젝트보다 우선하는 복구 불가능한 정책을 적용할 수 있습니다. 관리자는 BANP를 사용하여 필요한 경우 NetworkPolicy 오브젝트를 사용하는 사용자가 덮어쓸 수 있는 선택적 클러스터 범위 네트워크 정책 규칙을 설정하고 적용할 수 있습니다. ANP, BANP 및 네트워크 정책을 함께 사용하면 관리자가 클러스터를 보호하는 데 사용할 수 있는 완전한 다중 테넌트 격리를 수행할 수 있습니다.
AWS의 Red Hat OpenShift Service의 OVN-Kubernetes CNI는 ACL(Access Control List) 계층을 사용하여 이러한 네트워크 정책을 구현하여 이를 평가하고 적용합니다. ACL은 계층 1에서 계층 3까지 내림차순으로 평가됩니다.
계층 1은 관리NetworkPolicy (ANP) 오브젝트를 평가합니다. 계층 2는 NetworkPolicy 오브젝트를 평가합니다. 계층 3은 BaselineAdminNetworkPolicy (BANP) 오브젝트를 평가합니다.

ANP가 먼저 평가됩니다. 일치 항목이 ANP 허용 또는 거부 규칙인 경우 클러스터의 기존 NetworkPolicy 및 BANP( BaselineAdminNetworkPolicy ) 오브젝트는 평가에서 건너뜁니다. 일치 항목이 ANP 통과 규칙인 경우 평가는 ACL의 계층 1에서 NetworkPolicy 정책이 평가되는 계층 2로 이동합니다. NetworkPolicy 가 트래픽과 일치하지 않으면 평가는 계층 2 ACL에서 BANP가 평가되는 계층 3 ACL로 이동합니다.
6.1.1. AdminNetworkPolicy와 NetworkPolicy 사용자 정의 리소스의 주요 차이점
다음 표에서는 클러스터 범위 AdminNetworkPolicy API와 네임스페이스 범위 NetworkPolicy API 간의 주요 차이점을 설명합니다.
| 정책 요소 | AdminNetworkPolicy | NetworkPolicy |
|---|---|---|
| 적용 가능한 사용자 | 클러스터 관리자 또는 이에 상응하는 | 네임스페이스 소유자 |
| 범위 | Cluster | namespaced |
| 트래픽 드롭 |
명시적 |
정책 생성 시 암시적 |
| 트래픽 위임 |
규칙으로 | 해당 없음 |
| 트래픽 허용 |
명시적 | 모든 규칙에 대한 기본 작업은 허용하는 것입니다. |
| 정책 내에서 규칙 우선순위 | ANP 내에 표시되는 순서에 따라 달라집니다. 규칙의 위치가 높을수록 우선순위가 높습니다. | 규칙이 추가됩니다. |
| 정책 우선순위 |
ANPs 중 | 정책 간에는 정책 순서가 없습니다. |
| 기능 우선 순위 | 계층 1 ACL 및 BANP를 통해 먼저 평가되는 것은 계층 3 ACL을 통해 마지막으로 평가됩니다. | ANP 및 BANP 전에 시행되며 ACL의 계층 2에서 평가됩니다. |
| Pod 선택 일치 | 네임스페이스에 다른 규칙을 적용할 수 있습니다. | 단일 네임스페이스의 Pod에 다른 규칙을 적용할 수 있습니다. |
| 클러스터 송신 트래픽 |
|
허용되는 CIDR 구문과 함께 |
| 클러스터 인그레스 트래픽 | 지원되지 않음 | 지원되지 않음 |
| FQDN(정규화된 도메인 이름) 피어 지원 | 지원되지 않음 | 지원되지 않음 |
| 네임스페이스 선택기 |
|
|
6.2. 관리자 네트워크 정책
6.2.1. OVN-Kubernetes AdminNetworkPolicy
6.2.1.1. AdminNetworkPolicy
관리NetworkPolicy (ANP)는 클러스터 범위의 CRD(사용자 정의 리소스 정의)입니다. AWS 관리자의 Red Hat OpenShift Service는 네임스페이스를 생성하기 전에 네트워크 정책을 생성하여 ANP를 사용하여 네트워크를 보호할 수 있습니다. 또한 NetworkPolicy 오브젝트에서 덮어쓸 수 없는 클러스터 범위 수준에서 네트워크 정책을 생성할 수 있습니다.
AdminNetworkPolicy 와 NetworkPolicy 오브젝트의 주요 차이점은 전자는 관리자용이고 후자는 테넌트 소유자용이고 네임스페이스 범위가 지정되는 동안 클러스터 범위라는 것입니다.
관리자는 ANP를 사용하여 다음을 지정할 수 있습니다.
-
평가 순서를 결정하는
우선순위값입니다. 우선 순위가 가장 높은 값이 낮을 수 있습니다. - 정책이 적용되는 네임스페이스 또는 네임스페이스 세트로 구성된 Pod 세트입니다.
-
제목을 향하는 모든 인그레스 트래픽에 적용할 수신 규칙 목록입니다. -
제목의 모든 송신 트래픽에 적용할 송신 규칙
목록입니다.
AdminNetworkPolicy 예
예 6.1. ANP에 대한 YAML 파일의 예
apiVersion: policy.networking.k8s.io/v1alpha1
kind: AdminNetworkPolicy
metadata:
name: sample-anp-deny-pass-rules
spec:
priority: 50
subject:
namespaces:
matchLabels:
kubernetes.io/metadata.name: example.name
ingress:
- name: "deny-all-ingress-tenant-1"
action: "Deny"
from:
- pods:
namespaceSelector:
matchLabels:
custom-anp: tenant-1
podSelector:
matchLabels:
custom-anp: tenant-1
egress:
- name: "pass-all-egress-to-tenant-1"
action: "Pass"
to:
- pods:
namespaceSelector:
matchLabels:
custom-anp: tenant-1
podSelector:
matchLabels:
custom-anp: tenant-1- 1
- ANP의 이름을 지정합니다.
- 2
spec.priority필드는 클러스터의 값0-99범위에서 최대 100개의 ANP를 지원합니다. 값이 낮을수록 범위가 가장 낮은 값에서 가장 높은 값으로 읽혀지므로 우선 순위가 높습니다. ANP가 동일한 우선 순위로 생성될 때 정책이 우선 순위가 적용되는 보장이 없기 때문에 우선 순위가 결정되도록 ANP를 다른 우선순위로 설정합니다.- 3
- ANP 리소스를 적용할 네임스페이스를 지정합니다.
- 4
- ANP에는 ingress 및 egress 규칙이 모두 있습니다.
spec.ingress필드의 ANP 규칙은Pass,Deny및Allowfor theaction필드를 허용합니다. - 5
ingress.name의 이름을 지정합니다.- 6
namespaceSelector.matchLabels에서 선택한 네임스페이스 내에서 Ingress 피어로 Pod를 선택하려면podSelector.matchLabels를 지정합니다.- 7
- ANP에는 수신 및 송신 규칙이 모두 있습니다.
spec.egress필드에 대한 ANP 규칙은Pass,Deny및Allowfor theaction필드를 허용합니다.
6.2.1.1.1. 규칙에 대한 AdminNetworkPolicy 작업
관리자는 AdminNetworkPolicy 규칙에 대한 작업 필드로 Allow,Deny 또는 Pass 를 설정할 수 있습니다. OVN-Kubernetes는 계층화된 ACL을 사용하여 네트워크 트래픽 규칙을 평가하므로 관리자가 이를 수정하거나, 규칙을 삭제하거나, 우선 순위 규칙을 설정하여만 변경할 수 있는 매우 강력한 정책 규칙을 설정할 수 있습니다.
AdminNetworkPolicy 허용 예
우선 순위 9에 정의된 다음 ANP는 모니터링 네임스페이스에서 클러스터의 테넌트(다른 모든 네임스페이스)로 모든 수신 트래픽을 허용합니다.
예 6.2. 강력한 허용 ANP를 위한 YAML 파일의 예
apiVersion: policy.networking.k8s.io/v1alpha1
kind: AdminNetworkPolicy
metadata:
name: allow-monitoring
spec:
priority: 9
subject:
namespaces: {} # Use the empty selector with caution because it also selects OpenShift namespaces as well.
ingress:
- name: "allow-ingress-from-monitoring"
action: "Allow"
from:
- namespaces:
matchLabels:
kubernetes.io/metadata.name: monitoring
# ...
이는 관련된 모든 당사자가 해결할 수 없기 때문에 강력한 Allow ANP의 예입니다. 테넌트는 NetworkPolicy 오브젝트를 사용하여 자체적으로 모니터링되는 것을 차단할 수 없으며 모니터링 테넌트도 모니터링할 수 있거나 모니터링할 수 없습니다.
AdminNetworkPolicy 거부 예
우선순위 5에 정의된 다음 ANP는 모니터링 네임스페이스의 모든 수신 트래픽이 제한된 테넌트( 보안: restricted)로 차단되도록 합니다.
예 6.3. 강력한 Deny ANP를 위한 YAML 파일의 예
apiVersion: policy.networking.k8s.io/v1alpha1
kind: AdminNetworkPolicy
metadata:
name: block-monitoring
spec:
priority: 5
subject:
namespaces:
matchLabels:
security: restricted
ingress:
- name: "deny-ingress-from-monitoring"
action: "Deny"
from:
- namespaces:
matchLabels:
kubernetes.io/metadata.name: monitoring
# ...
이는 강력한 Deny ANP로, 관련된 모든 당사자가 해결할 수 없는 강력한 Deny ANP입니다. 제한된 테넌트 소유자는 모니터링 트래픽을 허용하도록 권한을 부여할 수 없으며 인프라의 모니터링 서비스는 이러한 민감한 네임스페이스에서 아무것도 스크랩할 수 없습니다.
강력한 Allow 예제와 결합할 때 block-monitoring ANP는 우선순위가 높은 우선 순위 값을 가지므로 제한된 테넌트가 모니터링되지 않습니다.
AdminNetworkPolicy Pass 예
우선순위 7에 정의된 다음 ANP는 모니터링 네임스페이스에서 내부 인프라 테넌트(네트러블 security가 있는 네임스페이스)로 들어오는 모든 수신 트래픽을 ACL의 계층 2로 전달되고 네임스페이스의 NetworkPolicy 오브젝트에 의해 평가됩니다.
예 6.4. 강력한 Pass ANP를 위한 YAML 파일의 예
apiVersion: policy.networking.k8s.io/v1alpha1
kind: AdminNetworkPolicy
metadata:
name: pass-monitoring
spec:
priority: 7
subject:
namespaces:
matchLabels:
security: internal
ingress:
- name: "pass-ingress-from-monitoring"
action: "Pass"
from:
- namespaces:
matchLabels:
kubernetes.io/metadata.name: monitoring
# ...
이 예는 테넌트 소유자가 정의한 NetworkPolicy 오브젝트에 결정을 위임하기 때문에 강력한 Pass 작업 ANP입니다. 이 pass-monitoring ANP를 사용하면 모든 테넌트 소유자가 내부 보안 수준에서 그룹화하여 네임스페이스 범위 NetworkPolicy 오브젝트를 사용하여 인프라의 모니터링 서비스에서 메트릭을 스크랩해야 하는지 여부를 선택할 수 있습니다.
6.2.2. OVN-Kubernetes BaselineAdminNetworkPolicy
6.2.2.1. BaselineAdminNetworkPolicy
BMC( BaselineAdminNetworkPolicy )는 클러스터 범위의 CRD(사용자 정의 리소스 정의)입니다. AWS 관리자의 Red Hat OpenShift Service는 BANP를 사용하여 NetworkPolicy 오브젝트를 사용하는 사용자가 덮어쓸 수 있는 선택적 기본 네트워크 정책 규칙을 설정하고 시행할 수 있습니다. BANP에 대한 규칙 작업은 허용 또는 거부 됩니다.
BaselineAdminNetworkPolicy 리소스는 전달된 트래픽 정책이 클러스터의 NetworkPolicy 오브젝트와 일치하지 않는 경우 가드레일 정책으로 사용할 수 있는 클러스터 싱글톤 오브젝트 입니다. BANP는 클러스터 내 트래픽이 기본적으로 차단되는 가드레일을 제공하는 기본 보안 모델로 사용할 수 있으며 사용자는 알려진 트래픽을 허용하기 위해 NetworkPolicy 오브젝트를 사용해야 합니다. BANP 리소스를 생성할 때 이름으로 default 를 사용해야 합니다.
관리자는 BANP를 사용하여 다음을 지정할 수 있습니다.
-
네임스페이스 또는 네임스페이스 세트로 구성된
제목입니다. -
제목을 향하는 모든 인그레스 트래픽에 적용할 수신 규칙 목록입니다. -
제목의 모든 송신 트래픽에 적용할 송신 규칙
목록입니다.
BaselineAdminNetworkPolicy 예
예 6.5. BANP의 YAML 파일 예
apiVersion: policy.networking.k8s.io/v1alpha1
kind: BaselineAdminNetworkPolicy
metadata:
name: default
spec:
subject:
namespaces:
matchLabels:
kubernetes.io/metadata.name: example.name
ingress:
- name: "deny-all-ingress-from-tenant-1"
action: "Deny"
from:
- pods:
namespaceSelector:
matchLabels:
custom-banp: tenant-1
podSelector:
matchLabels:
custom-banp: tenant-1
egress:
- name: "allow-all-egress-to-tenant-1"
action: "Allow"
to:
- pods:
namespaceSelector:
matchLabels:
custom-banp: tenant-1
podSelector:
matchLabels:
custom-banp: tenant-1- 1
- BANP는 싱글톤 오브젝트이므로 정책 이름을
기본값으로 설정해야 합니다. - 2
- ANP를 적용할 네임스페이스를 지정합니다.
- 3
- BANP에는 ingress 및 egress 규칙이 모두 있습니다.
spec.ingress및spec.egress필드에 대한 BANP 규칙은Deny및Allowfor theaction필드를 허용합니다. - 4
ingress.name의 이름을 지정- 5
- BANP 리소스를 적용하려면 에서 Pod를 선택하도록 네임스페이스를 지정합니다.
- 6
- BANP 리소스를 적용할 Pod의
podSelector.matchLabels이름을 지정합니다.
BaselineAdminNetworkPolicy Deny 예
다음 BANP 싱글톤은 관리자가 내부 보안 수준에서 테넌트로 들어오는 모든 수신 모니터링 트래픽에 대한 기본 거부 정책을 설정하도록 합니다. "AdminNetworkPolicy Pass example"과 결합하면 이 거부 정책은 ANP pass-monitoring 정책에서 전달하는 모든 인그레스 트래픽에 대한 보호 정책 역할을 합니다.
예 6.6. guardrail Deny 규칙의 YAML 파일의 예
apiVersion: policy.networking.k8s.io/v1alpha1
kind: BaselineAdminNetworkPolicy
metadata:
name: default
spec:
subject:
namespaces:
matchLabels:
security: internal
ingress:
- name: "deny-ingress-from-monitoring"
action: "Deny"
from:
- namespaces:
matchLabels:
kubernetes.io/metadata.name: monitoring
# ...
Baseline 리소스와 함께 AdminNetworkPolicy 작업 필드의 Pass 값과 함께 AdminNetworkPolicy 리소스를 사용하여 다중 테넌트 정책을 생성할 수 있습니다. 이 다중 테넌트 정책을 사용하면 한 테넌트에서 두 번째 테넌트에서 데이터를 동시에 수집하지 않고 애플리케이션에서 모니터링 데이터를 수집할 수 있습니다.
관리자는 "AdminNetworkPolicy Pass 작업 예"와 "BaselineAdminNetwork Policy Deny example"을 모두 적용하면 테넌트는 BANP 전에 평가할 NetworkPolicy 리소스를 생성하도록 선택할 수 있는 기능을 남겨 둡니다.
예를 들어 Tenant 1은 다음 NetworkPolicy 리소스를 설정하여 수신 트래픽을 모니터링할 수 있습니다.
예 6.7. NetworkPolicy예
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-monitoring
namespace: tenant 1
spec:
podSelector:
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: monitoring
# ...
이 시나리오에서 Tenant 1의 정책은 "AdminNetworkPolicy Pass 작업 예제" 및 "BaselineAdminNetwork Policy Deny example" 이전에 평가되며 보안 수준 internal 이 있는 테넌트로 들어오는 모든 수신 모니터링 트래픽을 거부합니다. Tenant 1의 NetworkPolicy 오브젝트를 사용하면 애플리케이션에서 데이터를 수집할 수 있습니다. 테넌트 2 그러나 NetworkPolicy 오브젝트가 없는 사용자는 데이터를 수집할 수 없습니다. 관리자는 기본적으로 내부 테넌트를 모니터링하지 않았으며 대신 테넌트가 NetworkPolicy 오브젝트를 사용하여 BANP의 기본 동작을 재정의할 수 있는 BANP를 생성했습니다.
6.3. 네트워크 정책
6.3.1. 네트워크 정책 정의
개발자는 클러스터의 Pod로 트래픽을 제한하는 네트워크 정책을 정의할 수 있습니다.
6.3.1.1. 네트워크 정책 정의
기본적으로 네트워크 정책 모드에서는 다른 Pod 및 네트워크 끝점에서 프로젝트의 모든 Pod에 액세스할 수 있습니다. 프로젝트에서 하나 이상의 Pod를 분리하기 위해 해당 프로젝트에서 NetworkPolicy 오브젝트를 생성하여 수신되는 연결을 표시할 수 있습니다. 프로젝트 관리자는 자신의 프로젝트 내에서 NetworkPolicy 오브젝트를 만들고 삭제할 수 있습니다.
하나 이상의 NetworkPolicy 오브젝트에서 선택기와 Pod가 일치하면 Pod는 해당 NetworkPolicy 오브젝트 중 하나 이상에서 허용되는 연결만 허용합니다. NetworkPolicy 오브젝트가 선택하지 않은 Pod에 완전히 액세스할 수 있습니다.
네트워크 정책은 TCP(Transmission Control Protocol), UDP(User Datagram Protocol), IMP(Internet Control Message Protocol) 및 SCTP(Stream Control Transmission Protocol) 프로토콜에만 적용됩니다. 다른 프로토콜은 영향을 받지 않습니다.
- 네트워크 정책은 호스트 네트워크 네임스페이스에 적용되지 않습니다. 호스트 네트워킹이 활성화된 Pod는 네트워크 정책 규칙의 영향을 받지 않습니다. 그러나 호스트 네트워크 pod에 연결하는 Pod는 네트워크 정책 규칙의 영향을 받을 수 있습니다.
-
podSelector필드를{}로 설정하지 않고namespaceSelector필드를 사용하면hostNetworkPod가 포함되지 않습니다. 네트워크 정책을 생성할 때hostNetworkPod를 대상으로 하려면namespaceSelector필드와 함께{}로 설정된podSelector를 사용해야 합니다. - 네트워크 정책은 localhost 또는 상주 노드의 트래픽을 차단할 수 없습니다.
다음 예제 NetworkPolicy 오브젝트는 다양한 시나리오 지원을 보여줍니다.
모든 트래픽 거부:
기본적으로 프로젝트를 거부하려면 모든 Pod와 일치하지만 트래픽을 허용하지 않는
NetworkPolicy오브젝트를 추가합니다.kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default spec: podSelector: {} ingress: []AWS Ingress 컨트롤러의 Red Hat OpenShift Service의 연결만 허용합니다.
프로젝트에서 AWS Ingress 컨트롤러의 Red Hat OpenShift Service의 연결만 허용하도록 하려면 다음
NetworkPolicy오브젝트를 추가합니다.apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-ingress spec: ingress: - from: - namespaceSelector: matchLabels: policy-group.network.openshift.io/ingress: "" podSelector: {} policyTypes: - Ingress프로젝트 내 Pod 연결만 허용:
중요동일한 네임스페이스에 있는
hostNetworkPod의 수신 연결을 허용하려면allow-from-hostnetwork정책을allow-same-namespace정책과 함께 적용해야 합니다.Pod가 동일한 프로젝트 내 다른 Pod의 연결은 수락하지만 다른 프로젝트에 속하는 Pod의 기타 모든 연결을 거부하도록 하려면 다음
NetworkPolicy오브젝트를 추가합니다.kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-same-namespace spec: podSelector: {} ingress: - from: - podSelector: {}Pod 레이블을 기반으로 하는 HTTP 및 HTTPS 트래픽만 허용:
특정 레이블(다음 예에서
role=frontend)을 사용하여 Pod에 대한 HTTP 및 HTTPS 액세스만 활성화하려면 다음과 유사한NetworkPolicy오브젝트를 추가합니다.kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-http-and-https spec: podSelector: matchLabels: role: frontend ingress: - ports: - protocol: TCP port: 80 - protocol: TCP port: 443네임스페이스와 Pod 선택기를 모두 사용하여 연결 수락:
네임스페이스와 Pod 선택기를 결합하여 네트워크 트래픽을 일치시키려면 다음과 유사한
NetworkPolicy오브젝트를 사용하면 됩니다.kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-pod-and-namespace-both spec: podSelector: matchLabels: name: test-pods ingress: - from: - namespaceSelector: matchLabels: project: project_name podSelector: matchLabels: name: test-pods
NetworkPolicy 오브젝트는 추가 기능이므로 여러 NetworkPolicy 오브젝트를 결합하여 복잡한 네트워크 요구 사항을 충족할 수 있습니다.
예를 들어, 이전 샘플에서 정의된 NetworkPolicy 오브젝트의 경우 동일한 프로젝트 내에서 allow-same-namespace 정책과 allow-http-and-https 정책을 모두 정의할 수 있습니다. 따라서 레이블이 role=frontend로 지정된 Pod는 각 정책에서 허용하는 모든 연결을 허용할 수 있습니다. 즉 동일한 네임스페이스에 있는 Pod의 모든 포트 연결과 모든 네임스페이스에 있는 Pod에서 포트 80 및 443에 대한 연결이 허용됩니다.
6.3.1.1.1. allow-from-router 네트워크 정책 사용
다음 NetworkPolicy 를 사용하여 라우터 구성에 관계없이 외부 트래픽을 허용합니다.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-from-router
spec:
ingress:
- from:
- namespaceSelector:
matchLabels:
policy-group.network.openshift.io/ingress: ""
podSelector: {}
policyTypes:
- Ingress- 1
policy-group.network.openshift.io/ingress:"레이블은 OVN-Kubernetes를 지원합니다.
6.3.1.1.2. allow-from-hostnetwork 네트워크 정책 사용
다음 allow-from-hostnetwork NetworkPolicy 오브젝트를 추가하여 호스트 네트워크 Pod에서 트래픽을 전달합니다.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-from-hostnetwork
spec:
ingress:
- from:
- namespaceSelector:
matchLabels:
policy-group.network.openshift.io/host-network: ""
podSelector: {}
policyTypes:
- Ingress6.3.1.2. OVN-Kubernetes 네트워크 플러그인을 사용하여 네트워크 정책 최적화
네트워크 정책을 설계할 때 다음 지침을 참조하십시오.
-
동일한
spec.podSelector사양이 있는 네트워크 정책의 경우 수신 또는 송신 규칙의 서브 세트가 있는 여러 네트워크 정책보다 여러수신또는송신규칙이 있는 하나의 네트워크 정책을 사용하는 것이 더 효율적입니다. podSelector또는namespaceSelector사양을 기반으로 하는 모든수신또는송신규칙은수신 또는 송신 규칙에서 선택한 네트워크 정책 + Pod 수에 비례하여 OVS 흐름 수를생성합니다. 따라서 모든 Pod에 대해 개별 규칙을 생성하는 대신 하나의 규칙에서 필요한 만큼의 Pod를 선택할 수 있는podSelector또는namespaceSelector사양을 사용하는 것이 좋습니다.예를 들어 다음 정책에는 두 개의 규칙이 있습니다.
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: test-network-policy spec: podSelector: {} ingress: - from: - podSelector: matchLabels: role: frontend - from: - podSelector: matchLabels: role: backend다음 정책은 다음과 같은 두 가지 규칙을 나타냅니다.
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: test-network-policy spec: podSelector: {} ingress: - from: - podSelector: matchExpressions: - {key: role, operator: In, values: [frontend, backend]}spec.podSelector사양에 동일한 지침이 적용됩니다. 다른 네트워크 정책에 대해 동일한수신또는송신규칙이 있는 경우 공통spec.podSelector사양을 사용하여 하나의 네트워크 정책을 생성하는 것이 더 효과적일 수 있습니다. 예를 들어 다음 두 정책에는 다른 규칙이 있습니다.apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: policy1 spec: podSelector: matchLabels: role: db ingress: - from: - podSelector: matchLabels: role: frontend --- apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: policy2 spec: podSelector: matchLabels: role: client ingress: - from: - podSelector: matchLabels: role: frontend다음 네트워크 정책은 다음과 같은 두 가지 규칙을 나타냅니다.
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: policy3 spec: podSelector: matchExpressions: - {key: role, operator: In, values: [db, client]} ingress: - from: - podSelector: matchLabels: role: frontend이 최적화는 여러 개의 선택기만 하나의 선택기로 표시되는 경우에만 적용할 수 있습니다. 선택기가 다른 레이블을 기반으로 하는 경우 이 최적화를 적용하지 못할 수 있습니다. 이러한 경우 네트워크 정책 최적화에 새로운 레이블을 적용하는 것이 좋습니다.
6.3.1.2.1. OVN-Kubernetes의 NetworkPolicy CR 및 외부 IP
OVN-Kubernetes에서 NetworkPolicy CR(사용자 정의 리소스)은 엄격한 격리 규칙을 적용합니다. 외부 IP를 사용하여 서비스가 노출되면 트래픽을 허용하도록 명시적으로 구성되지 않는 한 네트워크 정책에서 다른 네임스페이스의 액세스를 차단할 수 있습니다.
네임스페이스에서 외부 IP에 대한 액세스를 허용하려면 필요한 네임스페이스에서 수신을 명시적으로 허용하고 지정된 서비스 포트에 대한 트래픽을 허용하는 NetworkPolicy CR을 생성합니다. 필요한 포트에 대한 트래픽을 허용하지 않고 액세스는 계속 제한될 수 있습니다.
출력 예
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
annotations:
name: <policy_name>
namespace: openshift-ingress
spec:
ingress:
- ports:
- port: 80
protocol: TCP
- ports:
- port: 443
protocol: TCP
- from:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: <my_namespace>
podSelector: {}
policyTypes:
- Ingress다음과 같습니다.
<policy_name>- 정책의 이름을 지정합니다.
<my_namespace>- 정책이 배포된 네임스페이스의 이름을 지정합니다.
자세한 내용은 "네트워크 정책 정보"를 참조하십시오.
6.3.1.3. 다음 단계
6.3.2. 네트워크 정책 생성
admin 역할이 있는 사용자는 네임스페이스에 대한 네트워크 정책을 생성할 수 있습니다.
6.3.2.1. NetworkPolicy 오브젝트 예
다음은 예제 NetworkPolicy 오브젝트에 대한 주석입니다.
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-27107
spec:
podSelector:
matchLabels:
app: mongodb
ingress:
- from:
- podSelector:
matchLabels:
app: app
ports:
- protocol: TCP
port: 270176.3.2.2. CLI를 사용하여 네트워크 정책 생성
클러스터의 네임스페이스에서 허용된 수신 또는 송신 네트워크 트래픽을 설명하는 세분화된 규칙을 정의하기 위해 네트워크 정책을 생성할 수 있습니다.
cluster-admin 역할로 사용자로 로그인하는 경우 클러스터의 모든 네임스페이스에서 네트워크 정책을 생성할 수 있습니다.
사전 요구 사항
-
클러스터는
mode:로 설정된 OVN-Kubernetes 네트워크 플러그인과 같은 NetworkPolicy 오브젝트를 지원하는 네트워크 플러그인을 사용합니다.NetworkPolicy -
OpenShift CLI(
oc)를 설치합니다. -
admin권한이 있는 사용자로 클러스터에 로그인합니다. - 네트워크 정책이 적용되는 네임스페이스에서 작업하고 있습니다.
절차
다음과 같이 정책 규칙을 생성합니다.
<policy_name>.yaml파일을 생성합니다.$ touch <policy_name>.yaml다음과 같습니다.
<policy_name>- 네트워크 정책 파일 이름을 지정합니다.
방금 만든 파일에서 다음 예와 같이 네트워크 정책을 정의합니다.
모든 네임스페이스의 모든 Pod에서 수신 거부
이는 다른 네트워크 정책 구성에서 허용하는 크로스 포드 트래픽 이외의 모든 크로스 포드 네트워킹을 차단하는 기본 정책입니다.
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default spec: podSelector: {} policyTypes: - Ingress ingress: []동일한 네임 스페이스에 있는 모든 Pod의 수신 허용
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-same-namespace spec: podSelector: ingress: - from: - podSelector: {}특정 네임스페이스에서 하나의 Pod로 들어오는 트래픽 허용
이 정책을 사용하면
namespace-y에서 실행되는 Pod의pod-a레이블이 지정된 Pod로의 트래픽을 수행할 수 있습니다.kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-traffic-pod spec: podSelector: matchLabels: pod: pod-a policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: namespace-y
다음 명령을 실행하여 네트워크 정책 오브젝트를 생성합니다.
$ oc apply -f <policy_name>.yaml -n <namespace>다음과 같습니다.
<policy_name>- 네트워크 정책 파일 이름을 지정합니다.
<namespace>- 선택 사항: 오브젝트가 현재 네임스페이스와 다른 네임스페이스에 정의된 경우 이를 사용하여 네임스페이스를 지정합니다.
출력 예
networkpolicy.networking.k8s.io/deny-by-default created
cluster-admin 권한을 사용하여 웹 콘솔에 로그인하는 경우 YAML 또는 웹 콘솔의 양식에서 클러스터의 모든 네임스페이스에서 네트워크 정책을 생성할 수 있습니다.
6.3.2.3. 기본 거부 모든 네트워크 정책 생성
이 정책은 다른 배포된 네트워크 정책 및 호스트 네트워크 Pod 간 트래픽에서 허용하는 네트워크 트래픽 이외의 모든 포드 간 네트워킹을 차단합니다. 이 절차에서는 my 정책을 적용합니다.
-project 네임스페이스에 기본 거부 정책을 적용하여 강력한 거부
트래픽 통신을 허용하는 NetworkPolicy CR(사용자 정의 리소스)을 구성하지 않으면 다음 정책으로 클러스터 전체에서 통신 문제가 발생할 수 있습니다.
사전 요구 사항
-
클러스터는
mode:로 설정된 OVN-Kubernetes 네트워크 플러그인과 같은 NetworkPolicy 오브젝트를 지원하는 네트워크 플러그인을 사용합니다.NetworkPolicy -
OpenShift CLI(
oc)를 설치합니다. -
admin권한이 있는 사용자로 클러스터에 로그인합니다. - 네트워크 정책이 적용되는 네임스페이스에서 작업하고 있습니다.
절차
모든 네임스페이스의 모든 Pod에서 수신을
거부하는 거부-별-기본정책을 정의하는 다음 YAML을 생성합니다. YAML을deny-by-default.yaml파일에 저장합니다.kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default namespace: my-project1 spec: podSelector: {}2 ingress: []3 다음 명령을 입력하여 정책을 적용합니다.
$ oc apply -f deny-by-default.yaml출력 예
networkpolicy.networking.k8s.io/deny-by-default created
6.3.2.4. 외부 클라이언트의 트래픽을 허용하는 네트워크 정책 생성
deny-by-default 정책을 사용하여 외부 클라이언트에서 라벨이 app=web 인 Pod로의 트래픽을 허용하는 정책을 구성할 수 있습니다.
cluster-admin 역할로 사용자로 로그인하는 경우 클러스터의 모든 네임스페이스에서 네트워크 정책을 생성할 수 있습니다.
다음 절차에 따라 공용 인터넷의 외부 서비스를 직접 또는 로드 밸런서를 사용하여 Pod에 액세스할 수 있는 정책을 구성합니다. 트래픽은 app=web 레이블이 있는 Pod에만 허용됩니다.
사전 요구 사항
-
클러스터는
mode:로 설정된 OVN-Kubernetes 네트워크 플러그인과 같은 NetworkPolicy 오브젝트를 지원하는 네트워크 플러그인을 사용합니다.NetworkPolicy -
OpenShift CLI(
oc)를 설치합니다. -
admin권한이 있는 사용자로 클러스터에 로그인합니다. - 네트워크 정책이 적용되는 네임스페이스에서 작업하고 있습니다.
프로세스
공용 인터넷의 트래픽을 직접 또는 로드 밸런서를 사용하여 Pod에 액세스할 수 있는 정책을 생성합니다.
web-allow-external.yaml파일에 YAML을 저장합니다.kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: web-allow-external namespace: default spec: policyTypes: - Ingress podSelector: matchLabels: app: web ingress: - {}다음 명령을 입력하여 정책을 적용합니다.
$ oc apply -f web-allow-external.yaml출력 예
networkpolicy.networking.k8s.io/web-allow-external created이 정책은 다음 다이어그램에 설명된 외부 트래픽을 포함하여 모든 리소스의 트래픽을 허용합니다.
6.3.2.5. 모든 네임스페이스에서 애플리케이션으로의 트래픽을 허용하는 네트워크 정책 생성
cluster-admin 역할로 사용자로 로그인하는 경우 클러스터의 모든 네임스페이스에서 네트워크 정책을 생성할 수 있습니다.
다음 절차에 따라 모든 네임스페이스의 모든 Pod에서 특정 애플리케이션으로의 트래픽을 허용하는 정책을 구성합니다.
사전 요구 사항
-
클러스터는
mode:로 설정된 OVN-Kubernetes 네트워크 플러그인과 같은 NetworkPolicy 오브젝트를 지원하는 네트워크 플러그인을 사용합니다.NetworkPolicy -
OpenShift CLI(
oc)를 설치합니다. -
admin권한이 있는 사용자로 클러스터에 로그인합니다. - 네트워크 정책이 적용되는 네임스페이스에서 작업하고 있습니다.
프로세스
모든 네임스페이스의 모든 Pod에서 특정 애플리케이션으로의 트래픽을 허용하는 정책을 생성합니다. YAML을
web-allow-all-namespaces.yaml파일에 저장합니다.kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: web-allow-all-namespaces namespace: default spec: podSelector: matchLabels: app: web1 policyTypes: - Ingress ingress: - from: - namespaceSelector: {}2 참고기본적으로
namespaceSelector를 지정하지 않으면 정책이 네트워크 정책이 배포된 네임스페이스에서만 트래픽을 허용하는 네임스페이스를 선택하지 않습니다.다음 명령을 입력하여 정책을 적용합니다.
$ oc apply -f web-allow-all-namespaces.yaml출력 예
networkpolicy.networking.k8s.io/web-allow-all-namespaces created
검증
다음 명령을 입력하여
default네임스페이스에서 웹 서비스를 시작합니다.$ oc run web --namespace=default --image=nginx --labels="app=web" --expose --port=80다음 명령을 실행하여
보조네임스페이스에alpine이미지를 배포하고 쉘을 시작합니다.$ oc run test-$RANDOM --namespace=secondary --rm -i -t --image=alpine -- sh쉘에서 다음 명령을 실행하고 요청이 허용되는지 확인합니다.
# wget -qO- --timeout=2 http://web.default예상 출력
<!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> html { color-scheme: light dark; } body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>
6.3.2.6. 네임스페이스에서 애플리케이션으로의 트래픽을 허용하는 네트워크 정책 생성
cluster-admin 역할로 사용자로 로그인하는 경우 클러스터의 모든 네임스페이스에서 네트워크 정책을 생성할 수 있습니다.
다음 절차에 따라 특정 네임스페이스에서 app=web 레이블이 있는 Pod로의 트래픽을 허용하는 정책을 구성합니다. 다음 작업을 수행할 수 있습니다.
- 프로덕션 워크로드가 배포된 네임스페이스로만 프로덕션 데이터베이스로 트래픽을 제한합니다.
- 특정 네임스페이스에 배포된 모니터링 툴을 활성화하여 현재 네임스페이스에서 메트릭을 스크랩할 수 있습니다.
사전 요구 사항
-
클러스터는
mode:로 설정된 OVN-Kubernetes 네트워크 플러그인과 같은 NetworkPolicy 오브젝트를 지원하는 네트워크 플러그인을 사용합니다.NetworkPolicy -
OpenShift CLI(
oc)를 설치합니다. -
admin권한이 있는 사용자로 클러스터에 로그인합니다. - 네트워크 정책이 적용되는 네임스페이스에서 작업하고 있습니다.
절차
purpose=production레이블이 있는 특정 네임스페이스의 모든 Pod의 트래픽을 허용하는 정책을 생성합니다. YAML을web-allow-prod.yaml파일에 저장합니다.kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: web-allow-prod namespace: default spec: podSelector: matchLabels: app: web1 policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: purpose: production2 다음 명령을 입력하여 정책을 적용합니다.
$ oc apply -f web-allow-prod.yaml출력 예
networkpolicy.networking.k8s.io/web-allow-prod created
검증
다음 명령을 입력하여
default네임스페이스에서 웹 서비스를 시작합니다.$ oc run web --namespace=default --image=nginx --labels="app=web" --expose --port=80다음 명령을 실행하여
prod네임스페이스를 생성합니다.$ oc create namespace prod다음 명령을 실행하여
prod네임스페이스에 레이블을 지정합니다.$ oc label namespace/prod purpose=production다음 명령을 실행하여
dev네임스페이스를 생성합니다.$ oc create namespace dev다음 명령을 실행하여
dev네임스페이스에 레이블을 지정합니다.$ oc label namespace/dev purpose=testing다음 명령을 실행하여
dev네임스페이스에alpine이미지를 배포하고 쉘을 시작합니다.$ oc run test-$RANDOM --namespace=dev --rm -i -t --image=alpine -- sh쉘에서 다음 명령을 실행하고 요청이 차단되었는지 확인합니다.
# wget -qO- --timeout=2 http://web.default예상 출력
wget: download timed out다음 명령을 실행하여
prod네임스페이스에alpine이미지를 배포하고 쉘을 시작합니다.$ oc run test-$RANDOM --namespace=prod --rm -i -t --image=alpine -- sh쉘에서 다음 명령을 실행하고 요청이 허용되는지 확인합니다.
# wget -qO- --timeout=2 http://web.default예상 출력
<!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> html { color-scheme: light dark; } body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>
6.3.2.7. OpenShift Cluster Manager를 사용하여 네트워크 정책 생성
클러스터의 네임스페이스에서 허용된 수신 또는 송신 네트워크 트래픽을 설명하는 세분화된 규칙을 정의하기 위해 네트워크 정책을 생성할 수 있습니다.
사전 요구 사항
- OpenShift Cluster Manager 에 로그인했습니다.
- AWS 클러스터에서 Red Hat OpenShift Service를 생성하셨습니다.
- 클러스터의 ID 공급자를 구성했습니다.
- 구성된 ID 공급자에 사용자 계정을 추가했습니다.
- AWS 클러스터의 Red Hat OpenShift Service 내에 프로젝트를 생성하셨습니다.
절차
- OpenShift Cluster Manager 에서 액세스할 클러스터를 클릭합니다.
- Open console 을 클릭하여 OpenShift 웹 콘솔로 이동합니다.
- ID 공급자를 클릭하고 클러스터에 로그인할 수 있는 인증 정보를 제공합니다.
- 관리자 관점에서 Networking 에서 NetworkPolicies 를 클릭합니다.
- NetworkPolicy 생성을 클릭합니다.
- 정책 이름 필드에 정책의 이름을 입력합니다.
- 선택 사항: 이 정책이 하나 이상의 특정 Pod에만 적용되는 경우 특정 Pod에 대한 라벨 및 선택기를 제공할 수 있습니다. 특정 Pod를 선택하지 않으면 이 정책은 클러스터의 모든 Pod에 적용됩니다.
- 선택 사항: 모든 수신 트래픽 거부를 사용하거나 모든 송신 트래픽 확인란을 거부하여 모든 수신 및 송신 트래픽 을 차단할 수 있습니다.
- 또한 수신 및 송신 규칙의 조합을 추가하여 승인하려는 포트, 네임스페이스 또는 IP 블록을 지정할 수 있습니다.
정책에 수신 규칙을 추가합니다.
수신 규칙 추가 를 선택하여 새 규칙을 구성합니다. 이 작업은 인바운드 트래픽을 제한하려는 방법을 지정할 수 있는 Add allowed source 드롭다운 메뉴를 사용하여 새 Ingress 규칙 행을 생성합니다. 드롭다운 메뉴에는 인그레스 트래픽을 제한하는 세 가지 옵션이 있습니다.
- 동일한 네임스페이스의 Pod는 동일한 네임스페이스 내의 Pod로 트래픽을 제한합니다. 네임스페이스에서 Pod를 지정할 수 있지만 이 옵션을 비워 두면 네임스페이스의 Pod의 모든 트래픽이 허용됩니다.
- 클러스터 내부에서 포드가 정책과 동일한 클러스터 내의 Pod로 트래픽을 제한할 수 있습니다. 인바운드 트래픽을 허용하려는 네임스페이스 및 Pod를 지정할 수 있습니다. 이 옵션을 비워 두면 이 클러스터 내의 모든 네임스페이스 및 Pod의 인바운드 트래픽이 허용됩니다.
- IP 블록별 피어 는 지정된 CIDR(Classless Inter-Domain Routing) IP 블록의 트래픽을 제한합니다. 예외 옵션으로 특정 IP를 차단할 수 있습니다. CIDR 필드를 비워 두면 모든 외부 소스의 인바운드 트래픽이 모두 허용됩니다.
- 모든 인바운드 트래픽을 포트로 제한할 수 있습니다. 포트를 추가하지 않으면 모든 포트에 트래픽에 액세스할 수 있습니다.
네트워크 정책에 송신 규칙을 추가합니다.
송신 규칙 추가 를 선택하여 새 규칙을 구성합니다. 이 작업은 아웃바운드 트래픽을 제한하려는 방법을 지정할 수 있는 Add allowed destination"* 드롭다운 메뉴를 사용하여 새 Egress 규칙 행을 생성합니다. 드롭다운 메뉴에서는 송신 트래픽을 제한하는 세 가지 옵션을 제공합니다.
- 동일한 네임스페이스의 Pod는 동일한 네임스페이스 내의 pod로 아웃바운드 트래픽을 제한합니다. 네임스페이스에서 Pod를 지정할 수 있지만 이 옵션을 비워 두면 네임스페이스의 Pod의 모든 트래픽이 허용됩니다.
- 클러스터 내부에서 포드가 정책과 동일한 클러스터 내의 Pod로 트래픽을 제한할 수 있습니다. 아웃바운드 트래픽을 허용하려는 네임스페이스 및 Pod를 지정할 수 있습니다. 이 옵션을 비워 두면 이 클러스터 내의 모든 네임스페이스 및 Pod의 아웃바운드 트래픽이 허용됩니다.
- IP 블록별 피어를 허용 하면 지정된 CIDR IP 블록의 트래픽을 제한합니다. 예외 옵션으로 특정 IP를 차단할 수 있습니다. CIDR 필드를 비워 두면 모든 외부 소스의 아웃바운드 트래픽이 모두 허용됩니다.
- 모든 아웃바운드 트래픽을 포트로 제한할 수 있습니다. 포트를 추가하지 않으면 모든 포트에 트래픽에 액세스할 수 있습니다.
6.3.3. 네트워크 정책 보기
admin 역할이 있는 사용자는 네임스페이스에 대한 네트워크 정책을 볼 수 있습니다.
6.3.3.1. NetworkPolicy 오브젝트 예
다음은 예제 NetworkPolicy 오브젝트에 대한 주석입니다.
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-27107
spec:
podSelector:
matchLabels:
app: mongodb
ingress:
- from:
- podSelector:
matchLabels:
app: app
ports:
- protocol: TCP
port: 270176.3.3.2. CLI를 사용하여 네트워크 정책 보기
네임스페이스에서 네트워크 정책을 검사할 수 있습니다.
cluster-admin 역할을 가진 사용자로 로그인하면 클러스터의 모든 네트워크 정책을 볼 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
admin권한이 있는 사용자로 클러스터에 로그인합니다. - 네트워크 정책이 존재하는 네임스페이스에서 작업하고 있습니다.
프로세스
네임스페이스의 네트워크 정책을 나열합니다.
네임스페이스에 정의된 네트워크 정책 개체를 보려면 다음 명령을 입력합니다.
$ oc get networkpolicy선택 사항: 특정 네트워크 정책을 검사하려면 다음 명령을 입력합니다.
$ oc describe networkpolicy <policy_name> -n <namespace>다음과 같습니다.
<policy_name>- 검사할 네트워크 정책의 이름을 지정합니다.
<namespace>- 선택 사항: 오브젝트가 현재 네임스페이스와 다른 네임스페이스에 정의된 경우 이를 사용하여 네임스페이스를 지정합니다.
예를 들면 다음과 같습니다.
$ oc describe networkpolicy allow-same-namespaceoc describe명령의 출력Name: allow-same-namespace Namespace: ns1 Created on: 2021-05-24 22:28:56 -0400 EDT Labels: <none> Annotations: <none> Spec: PodSelector: <none> (Allowing the specific traffic to all pods in this namespace) Allowing ingress traffic: To Port: <any> (traffic allowed to all ports) From: PodSelector: <none> Not affecting egress traffic Policy Types: Ingress
cluster-admin 권한을 사용하여 웹 콘솔에 로그인하는 경우 YAML에서 직접 또는 웹 콘솔의 양식에서 클러스터의 모든 네임스페이스에서 네트워크 정책을 볼 수 있습니다.
6.3.3.3. OpenShift Cluster Manager를 사용하여 네트워크 정책 보기
Red Hat OpenShift Cluster Manager에서 네트워크 정책의 구성 세부 정보를 볼 수 있습니다.
사전 요구 사항
- OpenShift Cluster Manager 에 로그인했습니다.
- AWS 클러스터에서 Red Hat OpenShift Service를 생성하셨습니다.
- 클러스터의 ID 공급자를 구성했습니다.
- 구성된 ID 공급자에 사용자 계정을 추가했습니다.
- 네트워크 정책을 생성했습니다.
프로세스
- OpenShift Cluster Manager 웹 콘솔의 Administrator 관점에서 Networking 에서 NetworkPolicies 를 클릭합니다.
- 확인할 네트워크 정책을 선택합니다.
- 네트워크 정책 세부 정보 페이지에서 연결된 모든 수신 및 송신 규칙을 볼 수 있습니다.
네트워크 정책 세부 정보에서 YAML 을 선택하여 YAML 형식으로 정책 구성을 확인합니다.
참고이러한 정책의 세부 사항만 볼 수 있습니다. 이러한 정책을 편집할 수 없습니다.
6.3.4. 네트워크 정책 편집
관리자 역할이 있는 사용자는 네임스페이스에 대한 기존 네트워크 정책을 편집할 수 있습니다.
6.3.4.1. 네트워크 정책 편집
네임스페이스에서 네트워크 정책을 편집할 수 있습니다.
cluster-admin 역할을 가진 사용자로 로그인하면 클러스터의 모든 네임스페이스에서 네트워크 정책을 편집할 수 있습니다.
사전 요구 사항
-
클러스터는
mode:로 설정된 OVN-Kubernetes 네트워크 플러그인과 같은 NetworkPolicy 오브젝트를 지원하는 네트워크 플러그인을 사용합니다.NetworkPolicy -
OpenShift CLI(
oc)를 설치합니다. -
admin권한이 있는 사용자로 클러스터에 로그인합니다. - 네트워크 정책이 존재하는 네임스페이스에서 작업하고 있습니다.
프로세스
선택 사항: 네임스페이스의 네트워크 정책 개체를 나열하려면 다음 명령을 입력합니다.
$ oc get networkpolicy다음과 같습니다.
<namespace>- 선택 사항: 오브젝트가 현재 네임스페이스와 다른 네임스페이스에 정의된 경우 이를 사용하여 네임스페이스를 지정합니다.
네트워크 정책 오브젝트를 편집합니다.
네트워크 정책 정의를 파일에 저장한 경우 파일을 편집하고 필요한 사항을 변경한 후 다음 명령을 입력합니다.
$ oc apply -n <namespace> -f <policy_file>.yaml다음과 같습니다.
<namespace>- 선택 사항: 오브젝트가 현재 네임스페이스와 다른 네임스페이스에 정의된 경우 이를 사용하여 네임스페이스를 지정합니다.
<policy_file>- 네트워크 정책이 포함된 파일의 이름을 지정합니다.
네트워크 정책 개체를 직접 업데이트해야 하는 경우 다음 명령을 입력합니다.
$ oc edit networkpolicy <policy_name> -n <namespace>다음과 같습니다.
<policy_name>- 네트워크 정책의 이름을 지정합니다.
<namespace>- 선택 사항: 오브젝트가 현재 네임스페이스와 다른 네임스페이스에 정의된 경우 이를 사용하여 네임스페이스를 지정합니다.
네트워크 정책 개체가 업데이트되었는지 확인합니다.
$ oc describe networkpolicy <policy_name> -n <namespace>다음과 같습니다.
<policy_name>- 네트워크 정책의 이름을 지정합니다.
<namespace>- 선택 사항: 오브젝트가 현재 네임스페이스와 다른 네임스페이스에 정의된 경우 이를 사용하여 네임스페이스를 지정합니다.
cluster-admin 권한을 사용하여 웹 콘솔에 로그인하는 경우 Actions 메뉴를 통해 클러스터의 모든 네임스페이스에서 직접 또는 웹 콘솔의 정책에서 네트워크 정책을 편집할 수 있습니다.
6.3.4.2. NetworkPolicy 오브젝트 예
다음은 예제 NetworkPolicy 오브젝트에 대한 주석입니다.
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-27107
spec:
podSelector:
matchLabels:
app: mongodb
ingress:
- from:
- podSelector:
matchLabels:
app: app
ports:
- protocol: TCP
port: 270176.3.5. 네트워크 정책 삭제
admin 역할이 있는 사용자는 네임스페이스에서 네트워크 정책을 삭제할 수 있습니다.
6.3.5.1. CLI를 사용하여 네트워크 정책 삭제
네임스페이스에서 네트워크 정책을 삭제할 수 있습니다.
cluster-admin 역할을 가진 사용자로 로그인하면 클러스터의 모든 네트워크 정책을 삭제할 수 있습니다.
사전 요구 사항
-
클러스터는
mode:로 설정된 OVN-Kubernetes 네트워크 플러그인과 같은 NetworkPolicy 오브젝트를 지원하는 네트워크 플러그인을 사용합니다.NetworkPolicy -
OpenShift CLI(
oc)를 설치합니다. -
admin권한이 있는 사용자로 클러스터에 로그인합니다. - 네트워크 정책이 존재하는 네임스페이스에서 작업하고 있습니다.
프로세스
네트워크 정책 개체를 삭제하려면 다음 명령을 입력합니다.
$ oc delete networkpolicy <policy_name> -n <namespace>다음과 같습니다.
<policy_name>- 네트워크 정책의 이름을 지정합니다.
<namespace>- 선택 사항: 오브젝트가 현재 네임스페이스와 다른 네임스페이스에 정의된 경우 이를 사용하여 네임스페이스를 지정합니다.
출력 예
networkpolicy.networking.k8s.io/default-deny deleted
cluster-admin 권한을 사용하여 웹 콘솔에 로그인하는 경우 작업 메뉴를 통해 클러스터의 네임스페이스에서 직접 또는 웹 콘솔의 정책에서 네트워크 정책을 삭제할 수 있습니다.
6.3.5.2. OpenShift Cluster Manager를 사용하여 네트워크 정책 삭제
네임스페이스에서 네트워크 정책을 삭제할 수 있습니다.
사전 요구 사항
- OpenShift Cluster Manager 에 로그인했습니다.
- AWS 클러스터에서 Red Hat OpenShift Service를 생성하셨습니다.
- 클러스터의 ID 공급자를 구성했습니다.
- 구성된 ID 공급자에 사용자 계정을 추가했습니다.
프로세스
- OpenShift Cluster Manager 웹 콘솔의 Administrator 관점에서 Networking 에서 NetworkPolicies 를 클릭합니다.
다음 방법 중 하나를 사용하여 네트워크 정책을 삭제합니다.
네트워크 정책 표에서 정책을 삭제합니다.
- Network Policies (네트워크 정책) 표에서 삭제할 네트워크 정책 행의 스택 메뉴를 선택한 다음 Delete NetworkPolicy 를 클릭합니다.
개별 네트워크 정책 세부 정보에서 작업 드롭다운 메뉴를 사용하여 정책을 삭제합니다.
- 네트워크 정책의 작업 드롭다운 메뉴를 클릭합니다.
- 메뉴에서 NetworkPolicy 삭제 를 선택합니다.
6.3.6. 프로젝트의 기본 네트워크 정책 정의
클러스터 관리자는 새 프로젝트를 만들 때 네트워크 정책을 자동으로 포함하도록 새 프로젝트 템플릿을 수정할 수 있습니다. 새 프로젝트에 대한 사용자 정의 템플릿이 아직 없는 경우에는 우선 생성해야 합니다.
6.3.6.1. 새 프로젝트의 템플릿 수정
클러스터 관리자는 사용자 정의 요구 사항을 사용하여 새 프로젝트를 생성하도록 기본 프로젝트 템플릿을 수정할 수 있습니다.
사용자 정의 프로젝트 템플릿을 만들려면:
사전 요구 사항
-
dedicated-admin권한이 있는 계정을 사용하여 AWS 클러스터의 Red Hat OpenShift Service에 액세스할 수 있습니다.
절차
-
cluster-admin권한이 있는 사용자로 로그인합니다. 기본 프로젝트 템플릿을 생성합니다.
$ oc adm create-bootstrap-project-template -o yaml > template.yaml-
텍스트 편집기를 사용하여 오브젝트를 추가하거나 기존 오브젝트를 수정하여 생성된
template.yaml파일을 수정합니다. 프로젝트 템플릿은
openshift-config네임스페이스에서 생성해야 합니다. 수정된 템플릿을 불러옵니다.$ oc create -f template.yaml -n openshift-config웹 콘솔 또는 CLI를 사용하여 프로젝트 구성 리소스를 편집합니다.
웹 콘솔에 액세스:
- 관리 → 클러스터 설정으로 이동합니다.
- 구성 을 클릭하여 모든 구성 리소스를 확인합니다.
- 프로젝트 항목을 찾아 YAML 편집을 클릭합니다.
CLI 사용:
다음과 같이
project.config.openshift.io/cluster리소스를 편집합니다.$ oc edit project.config.openshift.io/cluster
projectRequestTemplate및name매개변수를 포함하도록spec섹션을 업데이트하고 업로드된 프로젝트 템플릿의 이름을 설정합니다. 기본 이름은project-request입니다.사용자 정의 프로젝트 템플릿이 포함된 프로젝트 구성 리소스
apiVersion: config.openshift.io/v1 kind: Project metadata: # ... spec: projectRequestTemplate: name: <template_name> # ...- 변경 사항을 저장한 후 새 프로젝트를 생성하여 변경 사항이 성공적으로 적용되었는지 확인합니다.
6.3.6.2. 새 프로젝트 템플릿에 네트워크 정책 추가
클러스터 관리자는 네트워크 정책을 새 프로젝트의 기본 템플릿에 추가할 수 있습니다. AWS의 Red Hat OpenShift Service는 프로젝트의 템플릿에 지정된 모든 NetworkPolicy 오브젝트를 자동으로 생성합니다.
사전 요구 사항
-
클러스터는 OVN-Kubernetes와 같은
NetworkPolicy오브젝트를 지원하는 기본 CNI 네트워크 플러그인을 사용합니다. -
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 클러스터에 로그인해야 합니다. - 새 프로젝트에 대한 사용자 정의 기본 프로젝트 템플릿을 생성해야 합니다.
절차
다음 명령을 실행하여 새 프로젝트의 기본 템플릿을 편집합니다.
$ oc edit template <project_template> -n openshift-config<project_template>을 클러스터에 대해 구성한 기본 템플릿의 이름으로 변경합니다. 기본 템플릿 이름은project-request입니다.템플릿에서 각
NetworkPolicy오브젝트를objects매개변수의 요소로 추가합니다.objects매개변수는 하나 이상의 오브젝트 컬렉션을 허용합니다.다음 예제에서
objects매개변수 컬렉션에는 여러NetworkPolicy오브젝트가 포함됩니다.objects: - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-same-namespace spec: podSelector: {} ingress: - from: - podSelector: {} - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-ingress spec: ingress: - from: - namespaceSelector: matchLabels: policy-group.network.openshift.io/ingress: podSelector: {} policyTypes: - Ingress - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-kube-apiserver-operator spec: ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: openshift-kube-apiserver-operator podSelector: matchLabels: app: kube-apiserver-operator policyTypes: - Ingress ...선택 사항: 다음 명령을 실행하여 새 프로젝트를 생성하고 네트워크 정책 오브젝트가 생성되었는지 확인합니다.
새 프로젝트를 생성합니다.
$ oc new-project <project>1 - 1
<project>를 생성중인 프로젝트의 이름으로 변경합니다.
새 프로젝트 템플릿의 네트워크 정책 오브젝트가 새 프로젝트에 있는지 확인합니다.
$ oc get networkpolicy NAME POD-SELECTOR AGE allow-from-openshift-ingress <none> 7s allow-from-same-namespace <none> 7s
6.3.7. 네트워크 정책으로 다중 테넌트 격리 구성
클러스터 관리자는 다중 테넌트 네트워크 격리를 제공하도록 네트워크 정책을 구성할 수 있습니다.
이 섹션에 설명된 대로 네트워크 정책을 구성하면 AWS의 이전 Red Hat OpenShift Service에서 OpenShift SDN의 다중 테넌트 모드와 유사한 네트워크 격리가 제공됩니다.
6.3.7.1. 네트워크 정책을 사용하여 다중 테넌트 격리 구성
다른 프로젝트 네임스페이스의 Pod 및 서비스에서 격리하도록 프로젝트를 구성할 수 있습니다.
사전 요구 사항
-
클러스터는
mode:로 설정된 OVN-Kubernetes 네트워크 플러그인과 같은 NetworkPolicy 오브젝트를 지원하는 네트워크 플러그인을 사용합니다.NetworkPolicy -
OpenShift CLI(
oc)를 설치합니다. -
admin권한이 있는 사용자로 클러스터에 로그인합니다.
프로세스
다음
NetworkPolicy오브젝트를 생성합니다.이름이
allow-from-openshift-ingress인 정책입니다.$ cat << EOF| oc create -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-ingress spec: ingress: - from: - namespaceSelector: matchLabels: policy-group.network.openshift.io/ingress: "" podSelector: {} policyTypes: - Ingress EOF참고policy-group.network.openshift.io/ingress: ""는 OVN-Kubernetes의 기본 네임스페이스 선택기 레이블입니다.이름이
allow-from-openshift-monitoring인 정책:$ cat << EOF| oc create -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-monitoring spec: ingress: - from: - namespaceSelector: matchLabels: network.openshift.io/policy-group: monitoring podSelector: {} policyTypes: - Ingress EOF이름이
allow-same-namespace인 정책:$ cat << EOF| oc create -f - kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-same-namespace spec: podSelector: ingress: - from: - podSelector: {} EOF이름이
allow-from-kube-apiserver-operator인 정책:$ cat << EOF| oc create -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-kube-apiserver-operator spec: ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: openshift-kube-apiserver-operator podSelector: matchLabels: app: kube-apiserver-operator policyTypes: - Ingress EOF자세한 내용은 웹 후크 의 상태를 검증하는 New
kube-apiserver-operatorwebhook 컨트롤러를 참조하십시오.
선택 사항: 현재 프로젝트에 네트워크 정책이 있는지 확인하려면 다음 명령을 입력합니다.
$ oc describe networkpolicy출력 예
Name: allow-from-openshift-ingress Namespace: example1 Created on: 2020-06-09 00:28:17 -0400 EDT Labels: <none> Annotations: <none> Spec: PodSelector: <none> (Allowing the specific traffic to all pods in this namespace) Allowing ingress traffic: To Port: <any> (traffic allowed to all ports) From: NamespaceSelector: policy-group.network.openshift.io/ingress: Not affecting egress traffic Policy Types: Ingress Name: allow-from-openshift-monitoring Namespace: example1 Created on: 2020-06-09 00:29:57 -0400 EDT Labels: <none> Annotations: <none> Spec: PodSelector: <none> (Allowing the specific traffic to all pods in this namespace) Allowing ingress traffic: To Port: <any> (traffic allowed to all ports) From: NamespaceSelector: network.openshift.io/policy-group: monitoring Not affecting egress traffic Policy Types: Ingress
6.4. 네트워크 보안을 위한 감사 로깅
OVN-Kubernetes 네트워크 플러그인은 OVN(Open Virtual Network) 액세스 제어 목록(ACL)을 사용하여 AdminNetworkPolicy,BaselineAdminNetworkPolicy,NetworkPolicy, EgressFirewall 오브젝트를 관리합니다. 감사 로깅은 NetworkPolicy ,EgressFirewall 및 BaselineAdmin 사용자 정의 리소스(CR)에 대한 ACL 이벤트를 NetworkPolicy 허용 및 거부합니다. 로깅은 관리NetworkPolicy (ANP) CR에 대한 ACL 이벤트도 노출하고,거부할 수 있습니다.
감사 로깅은 OVN-Kubernetes 네트워크 플러그인 에서만 사용할 수 있습니다.
6.4.1. 감사 구성
감사 로깅 구성은 OVN-Kubernetes 클러스터 네트워크 공급자 구성의 일부로 지정됩니다. 다음 YAML은 감사 로깅의 기본값을 보여줍니다.
감사 로깅 구성
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
defaultNetwork:
ovnKubernetesConfig:
policyAuditConfig:
destination: "null"
maxFileSize: 50
rateLimit: 20
syslogFacility: local0다음 표에서는 감사 로깅을 위한 구성 필드를 설명합니다.
| 필드 | 유형 | 설명 |
|---|---|---|
|
| integer |
노드당 1초마다 생성할 최대 메시지 수입니다. 기본값은 초당 |
|
| integer |
감사 로그의 최대 크기(바이트)입니다. 기본값은 |
|
| integer | 유지되는 최대 로그 파일 수입니다. |
|
| string | 다음 추가 감사 로그 대상 중 하나입니다.
|
|
| string |
RFC5424에 정의된 |
6.4.2. 감사 로깅
syslog 서버 또는 UNIX 도메인 소켓과 같은 감사 로그의 대상을 구성할 수 있습니다. 추가 구성에 관계없이 감사 로그는 항상 클러스터의 각 OVN-Kubernetes Pod의 /var/log/ovn/acl-audit-log.log에 저장됩니다.
k8s.ovn.org/acl-logging 섹션을 사용하여 각 네임스페이스 구성에 주석을 달아 각 네임스페이스에 대해 감사 로깅을 활성화할 수 있습니다. k8s.ovn.org/acl-logging 섹션에서 네임스페이스에 대한 감사 로깅을 활성화하려면 allow,deny 또는 두 값을 지정해야 합니다.
네트워크 정책은 Pass 작업 세트를 규칙으로 설정하는 것을 지원하지 않습니다.
ACL-logging 구현에서는 네트워크에 대한 ACL(액세스 제어 목록) 이벤트를 기록합니다. 이러한 로그를 보고 잠재적인 보안 문제를 분석할 수 있습니다.
네임스페이스 주석의 예
kind: Namespace
apiVersion: v1
metadata:
name: example1
annotations:
k8s.ovn.org/acl-logging: |-
{
"deny": "info",
"allow": "info"
}
기본 ACL 로깅 구성 값을 보려면 cluster-network-03-config.yml 파일의 policyAuditConfig 오브젝트를 참조하십시오. 필요한 경우 이 파일에서 로그 파일 매개변수에 대한 ACL 로깅 구성 값을 변경할 수 있습니다.
로깅 메시지 형식은 RFC5424에 정의된 대로 syslog와 호환됩니다. syslog 기능은 구성 가능하며 기본값은 local0입니다. 다음 예제에서는 로그 메시지에 출력된 주요 매개변수 및 해당 값을 보여줍니다.
매개변수 및 해당 값을 출력하는 로깅 메시지의 예
<timestamp>|<message_serial>|acl_log(ovn_pinctrl0)|<severity>|name="<acl_name>", verdict="<verdict>", severity="<severity>", direction="<direction>": <flow>다음과 같습니다.
-
<timestamp>는 로그 메시지 생성 시간 및 날짜를 지정합니다. -
<message_serial>은 로그 메시지의 일련 번호를 나열합니다. -
acl_log(ovn_pinctrl0)는 OVN-Kubernetes 플러그인에 로그 메시지의 위치를 출력하는 리터럴 문자열입니다. -
<severity>는 로그 메시지의 심각도 수준을 설정합니다.allow및deny작업을 지원하는 감사 로깅을 활성화하면 두 가지 심각도 수준이 로그 메시지 출력에 표시됩니다. -
<name>은 네트워크 정책에서 생성된 OVN 네트워크 브리징 데이터베이스(nbdb)에 ACL-logging 구현의 이름을 지정합니다. -
<verdict>는허용또는드롭일 수 있습니다. -
<direction>은to-lport또는from-lport중 하나로, Pod에서 나가는 트래픽에 정책이 적용되었음을 나타냅니다. -
<flow>는OpenFlow프로토콜과 동일한 형식으로 패킷 정보를 표시합니다. 이 매개변수는 OVS(Open vSwitch) 필드로 구성됩니다.
다음 예제에서는 flow 매개변수가 시스템 메모리에서 패킷 정보를 추출하는 데 사용하는 OVS 필드를 보여줍니다.
패킷 정보를 추출하기 위해 flow 매개변수에서 사용하는 OVS 필드의 예
<proto>,vlan_tci=0x0000,dl_src=<src_mac>,dl_dst=<source_mac>,nw_src=<source_ip>,nw_dst=<target_ip>,nw_tos=<tos_dscp>,nw_ecn=<tos_ecn>,nw_ttl=<ip_ttl>,nw_frag=<fragment>,tp_src=<tcp_src_port>,tp_dst=<tcp_dst_port>,tcp_flags=<tcp_flags>다음과 같습니다.
-
&
lt;proto>는 프로토콜을 표시합니다. 유효한 값은tcp및udp입니다. -
VLAN ID가 내부 Pod 네트워크 트래픽에 설정되지 않았기 때문에
vlan_tci=0x0000은 VLAN 헤더를0으로 지정합니다. -
<src_mac>는 MAC(Media Access Control) 주소의 소스를 지정합니다. -
<source_mac>는 MAC 주소의 대상을 지정합니다. -
<SOURCE_IP>는 소스 IP 주소 나열 -
<target_ip>는 대상 IP 주소를 나열합니다. -
<
tos_dscp>는 다른 트래픽보다 특정 네트워크 트래픽을 분류하고 우선 순위를 지정할 수 있는 다양한 서비스 코드 포인트(DSCP) 값을 나타냅니다. -
<tos_ecn>은 네트워크에서 혼잡한 트래픽을 나타내는 ECN(Explicit Congestion Notification) 값을 나타냅니다. -
<ip_ttl>은 패킷에 대한 TTP(Time To Live) 정보를 표시합니다. -
<fragment>는 일치시킬 IP 조각 또는 IP의 유형을 지정합니다. -
<tcp_src_port>는 TCP 및 UDP 프로토콜의 포트 소스를 보여줍니다. -
<tcp_dst_port>는 TCP 및 UDP 프로토콜의 대상 포트를 나열합니다. -
<tcp_flags>는SYN,ACK,PSH등과 같은 다양한 플래그를 지원합니다. 여러 값을 설정해야 하는 경우 각 값은 세로 막대(|)로 구분됩니다. UDP 프로토콜은 이 매개변수를 지원하지 않습니다.
이전 필드 설명에 대한 자세한 내용은 ovs-fields 의 OVS 매뉴얼 페이지로 이동하십시오.
네트워크 정책에 대한 ACL 거부 로그 항목의 예
2023-11-02T16:28:54.139Z|00004|acl_log(ovn_pinctrl0)|INFO|name="NP:verify-audit-logging:Ingress", verdict=drop, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:81:02:01,dl_dst=0a:58:0a:81:02:23,nw_src=10.131.0.39,nw_dst=10.129.2.35,nw_tos=0,nw_ecn=0,nw_ttl=62,nw_frag=no,tp_src=58496,tp_dst=8080,tcp_flags=syn
2023-11-02T16:28:55.187Z|00005|acl_log(ovn_pinctrl0)|INFO|name="NP:verify-audit-logging:Ingress", verdict=drop, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:81:02:01,dl_dst=0a:58:0a:81:02:23,nw_src=10.131.0.39,nw_dst=10.129.2.35,nw_tos=0,nw_ecn=0,nw_ttl=62,nw_frag=no,tp_src=58496,tp_dst=8080,tcp_flags=syn
2023-11-02T16:28:57.235Z|00006|acl_log(ovn_pinctrl0)|INFO|name="NP:verify-audit-logging:Ingress", verdict=drop, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:81:02:01,dl_dst=0a:58:0a:81:02:23,nw_src=10.131.0.39,nw_dst=10.129.2.35,nw_tos=0,nw_ecn=0,nw_ttl=62,nw_frag=no,tp_src=58496,tp_dst=8080,tcp_flags=syn다음 표에서는 네임스페이스 주석 값에 대해 설명합니다.
| 필드 | 설명 |
|---|---|
|
|
|
|
|
허용 작업과 함께 ACL 규칙과 일치하는 모든 트래픽에 대한 네임스페이스 액세스를 |
|
|
|
6.4.3. AdminNetworkPolicy 감사 로깅
다음 예와 같이 k8s.ovn.org/acl-logging 키로 ANP 정책에 주석을 달아 AdminNetworkPolicy CR별로 감사 로깅이 활성화됩니다.
예 6.8. AdminNetworkPolicy CR 주석의 예
apiVersion: policy.networking.k8s.io/v1alpha1
kind: AdminNetworkPolicy
metadata:
annotations:
k8s.ovn.org/acl-logging: '{ "deny": "alert", "allow": "alert", "pass" : "warning" }'
name: anp-tenant-log
spec:
priority: 5
subject:
namespaces:
matchLabels:
tenant: backend-storage # Selects all pods owned by storage tenant.
ingress:
- name: "allow-all-ingress-product-development-and-customer" # Product development and customer tenant ingress to backend storage.
action: "Allow"
from:
- pods:
namespaceSelector:
matchExpressions:
- key: tenant
operator: In
values:
- product-development
- customer
podSelector: {}
- name: "pass-all-ingress-product-security"
action: "Pass"
from:
- namespaces:
matchLabels:
tenant: product-security
- name: "deny-all-ingress" # Ingress to backend from all other pods in the cluster.
action: "Deny"
from:
- namespaces: {}
egress:
- name: "allow-all-egress-product-development"
action: "Allow"
to:
- pods:
namespaceSelector:
matchLabels:
tenant: product-development
podSelector: {}
- name: "pass-egress-product-security"
action: "Pass"
to:
- namespaces:
matchLabels:
tenant: product-security
- name: "deny-all-egress" # Egress from backend denied to all other pods.
action: "Deny"
to:
- namespaces: {}
특정 OVN ACL에 도달할 때마다 로그가 생성되고 로깅 주석에 설정된 작업 기준을 충족합니다. 예를 들어 테넌트: product-devel이라는 라벨이 있는 네임스페이스 중 하나라도 라는 레이블이 있는 네임스페이스에 액세스하는 경우 로그가 생성됩니다.
backend- storage
ACL 로깅은 60자로 제한됩니다. ANP 이름 필드가 길면 나머지 로그가 잘립니다.
다음은 다음 예제 로그 항목에 대한 방향 인덱스입니다.
| 방향 | Rule |
|---|---|
| Ingress |
|
| Egress |
|
예 6.9. Ingress:0 및 Egress:0을 사용하여 anp-tenant-log 라는 AdminNetworkPolicy 작업의 허용 로그 항목의 예
2024-06-10T16:27:45.194Z|00052|acl_log(ovn_pinctrl0)|INFO|name="ANP:anp-tenant-log:Ingress:0", verdict=allow, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:1a,dl_dst=0a:58:0a:80:02:19,nw_src=10.128.2.26,nw_dst=10.128.2.25,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=57814,tp_dst=8080,tcp_flags=syn
2024-06-10T16:28:23.130Z|00059|acl_log(ovn_pinctrl0)|INFO|name="ANP:anp-tenant-log:Ingress:0", verdict=allow, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:18,dl_dst=0a:58:0a:80:02:19,nw_src=10.128.2.24,nw_dst=10.128.2.25,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=38620,tp_dst=8080,tcp_flags=ack
2024-06-10T16:28:38.293Z|00069|acl_log(ovn_pinctrl0)|INFO|name="ANP:anp-tenant-log:Egress:0", verdict=allow, severity=alert, direction=from-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:19,dl_dst=0a:58:0a:80:02:1a,nw_src=10.128.2.25,nw_dst=10.128.2.26,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=47566,tp_dst=8080,tcp_flags=fin|ack=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=55704,tp_dst=8080,tcp_flags=ack예 6.10. Ingress:1 및 Egress:1을 사용하여 anp-tenant-log 라는 AdminNetworkPolicy 동작에 대한 ACL 로그 항목의 예
2024-06-10T16:33:12.019Z|00075|acl_log(ovn_pinctrl0)|INFO|name="ANP:anp-tenant-log:Ingress:1", verdict=pass, severity=warning, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:1b,dl_dst=0a:58:0a:80:02:19,nw_src=10.128.2.27,nw_dst=10.128.2.25,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=37394,tp_dst=8080,tcp_flags=ack
2024-06-10T16:35:04.209Z|00081|acl_log(ovn_pinctrl0)|INFO|name="ANP:anp-tenant-log:Egress:1", verdict=pass, severity=warning, direction=from-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:19,dl_dst=0a:58:0a:80:02:1b,nw_src=10.128.2.25,nw_dst=10.128.2.27,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=34018,tp_dst=8080,tcp_flags=ack예 6.11. Egress:2 및 Ingress2를 사용하여 anp-tenant-log 라는 AdminNetworkPolicy 작업의 거부 작업의 예
2024-06-10T16:43:05.287Z|00087|acl_log(ovn_pinctrl0)|INFO|name="ANP:anp-tenant-log:Egress:2", verdict=drop, severity=alert, direction=from-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:19,dl_dst=0a:58:0a:80:02:18,nw_src=10.128.2.25,nw_dst=10.128.2.24,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=51598,tp_dst=8080,tcp_flags=syn
2024-06-10T16:44:43.591Z|00090|acl_log(ovn_pinctrl0)|INFO|name="ANP:anp-tenant-log:Ingress:2", verdict=drop, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:1c,dl_dst=0a:58:0a:80:02:19,nw_src=10.128.2.28,nw_dst=10.128.2.25,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=33774,tp_dst=8080,tcp_flags=syn다음 표에서는 ANP 주석을 설명합니다.
| 주석 | 현재의 |
|---|---|
|
|
네임스페이스에 대한 감사 로깅을 활성화하려면
|
6.4.4. BaselineAdminNetworkPolicy 감사 로깅
다음 예와 같이 k8s.ovn.org/acl-logging 키로 BANP 정책에 주석을 달아 BaselineAdminNetworkPolicy CR에서 감사 로깅이 활성화됩니다.
예 6.12. BaselineAdminNetworkPolicy CR 주석의 예
apiVersion: policy.networking.k8s.io/v1alpha1
kind: BaselineAdminNetworkPolicy
metadata:
annotations:
k8s.ovn.org/acl-logging: '{ "deny": "alert", "allow": "alert"}'
name: default
spec:
subject:
namespaces:
matchLabels:
tenant: workloads # Selects all workload pods in the cluster.
ingress:
- name: "default-allow-dns" # This rule allows ingress from dns tenant to all workloads.
action: "Allow"
from:
- namespaces:
matchLabels:
tenant: dns
- name: "default-deny-dns" # This rule denies all ingress from all pods to workloads.
action: "Deny"
from:
- namespaces: {} # Use the empty selector with caution because it also selects OpenShift namespaces as well.
egress:
- name: "default-deny-dns" # This rule denies all egress from workloads. It will be applied when no ANP or network policy matches.
action: "Deny"
to:
- namespaces: {} # Use the empty selector with caution because it also selects OpenShift namespaces as well.
이 예제에서는 tenant: dns 레이블이 있는 네임스페이스 중 하나에 tenant: workloads 라는 레이블이 있는 네임스페이스에 액세스하는 경우 로그가 생성됩니다.
다음은 다음 예제 로그 항목에 대한 방향 인덱스입니다.
| 방향 | Rule |
|---|---|
| Ingress |
|
| Egress |
|
예 6.13. ACL의 예는 Ingress:0을 사용하여 기본 BANP의 허용 작업에 대한 로그 항목을 허용합니다.
2024-06-10T18:11:58.263Z|00022|acl_log(ovn_pinctrl0)|INFO|name="BANP:default:Ingress:0", verdict=allow, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:82:02:57,dl_dst=0a:58:0a:82:02:56,nw_src=10.130.2.87,nw_dst=10.130.2.86,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=60510,tp_dst=8080,tcp_flags=syn
2024-06-10T18:11:58.264Z|00023|acl_log(ovn_pinctrl0)|INFO|name="BANP:default:Ingress:0", verdict=allow, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:82:02:57,dl_dst=0a:58:0a:82:02:56,nw_src=10.130.2.87,nw_dst=10.130.2.86,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=60510,tp_dst=8080,tcp_flags=psh|ack
2024-06-10T18:11:58.264Z|00024|acl_log(ovn_pinctrl0)|INFO|name="BANP:default:Ingress:0", verdict=allow, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:82:02:57,dl_dst=0a:58:0a:82:02:56,nw_src=10.130.2.87,nw_dst=10.130.2.86,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=60510,tp_dst=8080,tcp_flags=ack
2024-06-10T18:11:58.264Z|00025|acl_log(ovn_pinctrl0)|INFO|name="BANP:default:Ingress:0", verdict=allow, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:82:02:57,dl_dst=0a:58:0a:82:02:56,nw_src=10.130.2.87,nw_dst=10.130.2.86,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=60510,tp_dst=8080,tcp_flags=ack
2024-06-10T18:11:58.264Z|00026|acl_log(ovn_pinctrl0)|INFO|name="BANP:default:Ingress:0", verdict=allow, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:82:02:57,dl_dst=0a:58:0a:82:02:56,nw_src=10.130.2.87,nw_dst=10.130.2.86,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=60510,tp_dst=8080,tcp_flags=fin|ack
2024-06-10T18:11:58.264Z|00027|acl_log(ovn_pinctrl0)|INFO|name="BANP:default:Ingress:0", verdict=allow, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:82:02:57,dl_dst=0a:58:0a:82:02:56,nw_src=10.130.2.87,nw_dst=10.130.2.86,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=60510,tp_dst=8080,tcp_flags=ack예 6.14. ACL의 예는 Egress:0 및 Ingress:1이 있는 기본 BANP의 허용 작업에 대한 로그 항목을 허용합니다.
2024-06-10T18:09:57.774Z|00016|acl_log(ovn_pinctrl0)|INFO|name="BANP:default:Egress:0", verdict=drop, severity=alert, direction=from-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:82:02:56,dl_dst=0a:58:0a:82:02:57,nw_src=10.130.2.86,nw_dst=10.130.2.87,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=45614,tp_dst=8080,tcp_flags=syn
2024-06-10T18:09:58.809Z|00017|acl_log(ovn_pinctrl0)|INFO|name="BANP:default:Egress:0", verdict=drop, severity=alert, direction=from-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:82:02:56,dl_dst=0a:58:0a:82:02:57,nw_src=10.130.2.86,nw_dst=10.130.2.87,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=45614,tp_dst=8080,tcp_flags=syn
2024-06-10T18:10:00.857Z|00018|acl_log(ovn_pinctrl0)|INFO|name="BANP:default:Egress:0", verdict=drop, severity=alert, direction=from-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:82:02:56,dl_dst=0a:58:0a:82:02:57,nw_src=10.130.2.86,nw_dst=10.130.2.87,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=45614,tp_dst=8080,tcp_flags=syn
2024-06-10T18:10:25.414Z|00019|acl_log(ovn_pinctrl0)|INFO|name="BANP:default:Ingress:1", verdict=drop, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:82:02:58,dl_dst=0a:58:0a:82:02:56,nw_src=10.130.2.88,nw_dst=10.130.2.86,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=40630,tp_dst=8080,tcp_flags=syn
2024-06-10T18:10:26.457Z|00020|acl_log(ovn_pinctrl0)|INFO|name="BANP:default:Ingress:1", verdict=drop, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:82:02:58,dl_dst=0a:58:0a:82:02:56,nw_src=10.130.2.88,nw_dst=10.130.2.86,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=40630,tp_dst=8080,tcp_flags=syn
2024-06-10T18:10:28.505Z|00021|acl_log(ovn_pinctrl0)|INFO|name="BANP:default:Ingress:1", verdict=drop, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:82:02:58,dl_dst=0a:58:0a:82:02:56,nw_src=10.130.2.88,nw_dst=10.130.2.86,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,tp_src=40630,tp_dst=8080,tcp_flags=syn다음 표에서는 BANP 주석을 설명합니다.
| 주석 | 현재의 |
|---|---|
|
|
네임스페이스에 대한 감사 로깅을 활성화하려면
|
6.4.5. 클러스터에 대한 송신 방화벽 및 네트워크 정책 감사 구성
클러스터 관리자는 클러스터의 감사 로깅을 사용자 지정할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 클러스터에 로그인합니다.
프로세스
감사 로깅 구성을 사용자 지정하려면 다음 명령을 입력합니다.
$ oc edit network.operator.openshift.io/cluster작은 정보또는 다음 YAML을 사용자 지정하고 적용하여 감사 로깅을 구성할 수 있습니다.
apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: defaultNetwork: ovnKubernetesConfig: policyAuditConfig: destination: "null" maxFileSize: 50 rateLimit: 20 syslogFacility: local0
검증
네트워크 정책을 사용하여 네임스페이스를 생성하려면 다음 단계를 완료합니다.
검증을 위해 네임스페이스를 생성합니다.
$ cat <<EOF| oc create -f - kind: Namespace apiVersion: v1 metadata: name: verify-audit-logging annotations: k8s.ovn.org/acl-logging: '{ "deny": "alert", "allow": "alert" }' EOF출력 예
namespace/verify-audit-logging created네임스페이스의 네트워크 정책을 생성합니다.
$ cat <<EOF| oc create -n verify-audit-logging -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: deny-all spec: podSelector: matchLabels: policyTypes: - Ingress - Egress --- apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-same-namespace namespace: verify-audit-logging spec: podSelector: {} policyTypes: - Ingress - Egress ingress: - from: - podSelector: {} egress: - to: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: verify-audit-logging EOF출력 예
networkpolicy.networking.k8s.io/deny-all created networkpolicy.networking.k8s.io/allow-from-same-namespace created
default네임스페이스에서 소스 트래픽에 사용할 Pod를 생성합니다.$ cat <<EOF| oc create -n default -f - apiVersion: v1 kind: Pod metadata: name: client spec: containers: - name: client image: registry.access.redhat.com/rhel7/rhel-tools command: ["/bin/sh", "-c"] args: ["sleep inf"] EOFverify-audit-logging네임스페이스에 두 개의 Pod를 생성합니다.$ for name in client server; do cat <<EOF| oc create -n verify-audit-logging -f - apiVersion: v1 kind: Pod metadata: name: ${name} spec: containers: - name: ${name} image: registry.access.redhat.com/rhel7/rhel-tools command: ["/bin/sh", "-c"] args: ["sleep inf"] EOF done출력 예
pod/client created pod/server created트래픽을 생성하고 네트워크 정책 감사 로그 항목을 생성하려면 다음 단계를 완료합니다.
verify-audit-logging네임스페이스에서server라는 Pod의 IP 주소를 가져옵니다.$ POD_IP=$(oc get pods server -n verify-audit-logging -o jsonpath='{.status.podIP}')default네임스페이스에 있는client라는 Pod에서 이전 명령의 IP 주소를 ping하고 모든 패킷이 삭제되었는지 확인합니다.$ oc exec -it client -n default -- /bin/ping -c 2 $POD_IP출력 예
PING 10.128.2.55 (10.128.2.55) 56(84) bytes of data. --- 10.128.2.55 ping statistics --- 2 packets transmitted, 0 received, 100% packet loss, time 2041msverify-audit-logging네임스페이스의client라는 Pod에서POD_IP쉘 환경 변수에 저장된 IP 주소를 ping하고 모든 패킷이 허용되는지 확인합니다.$ oc exec -it client -n verify-audit-logging -- /bin/ping -c 2 $POD_IP출력 예
PING 10.128.0.86 (10.128.0.86) 56(84) bytes of data. 64 bytes from 10.128.0.86: icmp_seq=1 ttl=64 time=2.21 ms 64 bytes from 10.128.0.86: icmp_seq=2 ttl=64 time=0.440 ms --- 10.128.0.86 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1001ms rtt min/avg/max/mdev = 0.440/1.329/2.219/0.890 ms
네트워크 정책 감사 로그의 최신 항목을 표시합니다.
$ for pod in $(oc get pods -n openshift-ovn-kubernetes -l app=ovnkube-node --no-headers=true | awk '{ print $1 }') ; do oc exec -it $pod -n openshift-ovn-kubernetes -- tail -4 /var/log/ovn/acl-audit-log.log done출력 예
2023-11-02T16:28:54.139Z|00004|acl_log(ovn_pinctrl0)|INFO|name="NP:verify-audit-logging:Ingress", verdict=drop, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:81:02:01,dl_dst=0a:58:0a:81:02:23,nw_src=10.131.0.39,nw_dst=10.129.2.35,nw_tos=0,nw_ecn=0,nw_ttl=62,nw_frag=no,tp_src=58496,tp_dst=8080,tcp_flags=syn 2023-11-02T16:28:55.187Z|00005|acl_log(ovn_pinctrl0)|INFO|name="NP:verify-audit-logging:Ingress", verdict=drop, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:81:02:01,dl_dst=0a:58:0a:81:02:23,nw_src=10.131.0.39,nw_dst=10.129.2.35,nw_tos=0,nw_ecn=0,nw_ttl=62,nw_frag=no,tp_src=58496,tp_dst=8080,tcp_flags=syn 2023-11-02T16:28:57.235Z|00006|acl_log(ovn_pinctrl0)|INFO|name="NP:verify-audit-logging:Ingress", verdict=drop, severity=alert, direction=to-lport: tcp,vlan_tci=0x0000,dl_src=0a:58:0a:81:02:01,dl_dst=0a:58:0a:81:02:23,nw_src=10.131.0.39,nw_dst=10.129.2.35,nw_tos=0,nw_ecn=0,nw_ttl=62,nw_frag=no,tp_src=58496,tp_dst=8080,tcp_flags=syn 2023-11-02T16:49:57.909Z|00028|acl_log(ovn_pinctrl0)|INFO|name="NP:verify-audit-logging:allow-from-same-namespace:Egress:0", verdict=allow, severity=alert, direction=from-lport: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:81:02:22,dl_dst=0a:58:0a:81:02:23,nw_src=10.129.2.34,nw_dst=10.129.2.35,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,icmp_type=8,icmp_code=0 2023-11-02T16:49:57.909Z|00029|acl_log(ovn_pinctrl0)|INFO|name="NP:verify-audit-logging:allow-from-same-namespace:Ingress:0", verdict=allow, severity=alert, direction=to-lport: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:81:02:22,dl_dst=0a:58:0a:81:02:23,nw_src=10.129.2.34,nw_dst=10.129.2.35,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,icmp_type=8,icmp_code=0 2023-11-02T16:49:58.932Z|00030|acl_log(ovn_pinctrl0)|INFO|name="NP:verify-audit-logging:allow-from-same-namespace:Egress:0", verdict=allow, severity=alert, direction=from-lport: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:81:02:22,dl_dst=0a:58:0a:81:02:23,nw_src=10.129.2.34,nw_dst=10.129.2.35,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,icmp_type=8,icmp_code=0 2023-11-02T16:49:58.932Z|00031|acl_log(ovn_pinctrl0)|INFO|name="NP:verify-audit-logging:allow-from-same-namespace:Ingress:0", verdict=allow, severity=alert, direction=to-lport: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:81:02:22,dl_dst=0a:58:0a:81:02:23,nw_src=10.129.2.34,nw_dst=10.129.2.35,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,icmp_type=8,icmp_code=0
6.4.6. 네임스페이스에 대한 송신 방화벽 및 네트워크 정책 감사 로깅 활성화
클러스터 관리자는 네임스페이스에 대한 감사 로깅을 활성화할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 클러스터에 로그인합니다.
절차
네임스페이스에 대한 감사 로깅을 활성화하려면 다음 명령을 입력합니다.
$ oc annotate namespace <namespace> \ k8s.ovn.org/acl-logging='{ "deny": "alert", "allow": "notice" }'다음과 같습니다.
<namespace>- 네임스페이스의 이름을 지정합니다.
작은 정보다음 YAML을 적용하여 감사 로깅을 활성화할 수 있습니다.
kind: Namespace apiVersion: v1 metadata: name: <namespace> annotations: k8s.ovn.org/acl-logging: |- { "deny": "alert", "allow": "notice" }출력 예
namespace/verify-audit-logging annotated
검증
감사 로그의 최신 항목을 표시합니다.
$ for pod in $(oc get pods -n openshift-ovn-kubernetes -l app=ovnkube-node --no-headers=true | awk '{ print $1 }') ; do oc exec -it $pod -n openshift-ovn-kubernetes -- tail -4 /var/log/ovn/acl-audit-log.log done출력 예
2023-11-02T16:49:57.909Z|00028|acl_log(ovn_pinctrl0)|INFO|name="NP:verify-audit-logging:allow-from-same-namespace:Egress:0", verdict=allow, severity=alert, direction=from-lport: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:81:02:22,dl_dst=0a:58:0a:81:02:23,nw_src=10.129.2.34,nw_dst=10.129.2.35,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,icmp_type=8,icmp_code=0 2023-11-02T16:49:57.909Z|00029|acl_log(ovn_pinctrl0)|INFO|name="NP:verify-audit-logging:allow-from-same-namespace:Ingress:0", verdict=allow, severity=alert, direction=to-lport: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:81:02:22,dl_dst=0a:58:0a:81:02:23,nw_src=10.129.2.34,nw_dst=10.129.2.35,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,icmp_type=8,icmp_code=0 2023-11-02T16:49:58.932Z|00030|acl_log(ovn_pinctrl0)|INFO|name="NP:verify-audit-logging:allow-from-same-namespace:Egress:0", verdict=allow, severity=alert, direction=from-lport: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:81:02:22,dl_dst=0a:58:0a:81:02:23,nw_src=10.129.2.34,nw_dst=10.129.2.35,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,icmp_type=8,icmp_code=0 2023-11-02T16:49:58.932Z|00031|acl_log(ovn_pinctrl0)|INFO|name="NP:verify-audit-logging:allow-from-same-namespace:Ingress:0", verdict=allow, severity=alert, direction=to-lport: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:81:02:22,dl_dst=0a:58:0a:81:02:23,nw_src=10.129.2.34,nw_dst=10.129.2.35,nw_tos=0,nw_ecn=0,nw_ttl=64,nw_frag=no,icmp_type=8,icmp_code=0
6.4.7. 네임스페이스에 대한 송신 방화벽 및 네트워크 정책 감사 로깅 비활성화
클러스터 관리자는 네임스페이스에 대한 감사 로깅을 비활성화할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 클러스터에 로그인합니다.
프로세스
네임스페이스에 대한 감사 로깅을 비활성화하려면 다음 명령을 입력합니다.
$ oc annotate --overwrite namespace <namespace> k8s.ovn.org/acl-logging-다음과 같습니다.
<namespace>- 네임스페이스의 이름을 지정합니다.
작은 정보다음 YAML을 적용하여 감사 로깅을 비활성화할 수 있습니다.
kind: Namespace apiVersion: v1 metadata: name: <namespace> annotations: k8s.ovn.org/acl-logging: null출력 예
namespace/verify-audit-logging annotated
7장. OVN-Kubernetes 네트워크 플러그인
7.1. OVN-Kubernetes 네트워크 플러그인 정보
AWS 클러스터의 Red Hat OpenShift Service는 Pod 및 서비스 네트워크에 가상화된 네트워크를 사용합니다.
Red Hat OpenShift Networking의 일부인 OVN-Kubernetes 네트워크 플러그인은 AWS에서 Red Hat OpenShift Service의 기본 네트워크 공급자입니다. OVN-Kubernetes는 OVN(Open Virtual Network)을 기반으로 하며 오버레이 기반 네트워킹 구현을 제공합니다. OVN-Kubernetes 플러그인을 사용하는 클러스터는 각 노드에서 OVS(Open vSwitch)도 실행합니다. OVN은 각 노드에서 선언된 네트워크 구성을 구현하도록 OVS를 구성합니다.
OVN-Kubernetes는 AWS 및 단일 노드 OpenShift 배포에서 Red Hat OpenShift Service의 기본 네트워킹 솔루션입니다.
OVS 프로젝트에서 발생한 OVN-Kubernetes는 공개 흐름 규칙과 같은 많은 동일한 구성을 사용하여 패킷을 네트워크를 통과하는 방법을 결정합니다. 자세한 내용은 Open Virtual Network 웹 사이트를 참조하십시오.
OVN-Kubernetes는 가상 네트워크 구성을 OpenFlow 규칙으로 변환하는 OVS의 일련의 데몬입니다. OpenFlow 는 네트워크 스위치 및 라우터와 통신하기 위한 프로토콜로, 네트워크 관리자가 네트워크 트래픽 흐름을 구성, 관리 및 모니터링할 수 있도록 네트워크 장치에서 네트워크 트래픽 흐름을 원격으로 제어하는 수단을 제공합니다.
OVN-Kubernetes는 OpenFlow 에서 사용할 수 없는 고급 기능을 더 많이 제공합니다. OVN은 분산 가상 라우팅, 분산 논리 스위치, 액세스 제어, DHCP(Dynamic Host Configuration Protocol) 및 DNS를 지원합니다. OVN은 흐름을 여는 논리 흐름 내에서 분산 가상 라우팅을 구현합니다. 예를 들어 네트워크의 DHCP 요청을 네트워크의 DHCP 서버로 보내는 Pod가 있는 경우 요청의 논리 흐름 규칙은 OVN-Kubernetes가 게이트웨이, DNS 서버, IP 주소 및 기타 정보로 응답할 수 있도록 패킷을 처리하는 데 도움이 됩니다.
OVN-Kubernetes는 각 노드에서 데몬을 실행합니다. 데이터베이스와 모든 노드에서 실행되는 OVN 컨트롤러에 대한 데몬 세트가 있습니다. OVN 컨트롤러는 노드에서 Open vSwitch 데몬을 프로그래밍하여 송신 IP, 방화벽, 라우터, 하이브리드 네트워킹, IPSEC 암호화, IPv6, 네트워크 정책, 네트워크 정책 로그, 하드웨어 오프로드 및 멀티 캐스트와 같은 네트워크 공급자 기능을 지원합니다.
7.1.1. OVN-Kubernetes 용도
OVN-Kubernetes 네트워크 플러그인은 OVN(Open Virtual Network)을 사용하여 네트워크 트래픽 흐름을 관리하는 오픈 소스 완전한 기능을 갖춘 Kubernetes CNI 플러그인입니다. OVN은 커뮤니티에서 개발한 벤더와 무관한 네트워크 가상화 솔루션입니다. OVN-Kubernetes 네트워크 플러그인은 다음 기술을 사용합니다.
- OVN을 사용하여 네트워크 트래픽 흐름을 관리합니다.
- 수신 및 송신 규칙을 포함한 Kubernetes 네트워크 정책 지원 및 로그.
- VXLAN(Virtual Extensible LAN)이 아닌 일반 네트워크 가상화 캡슐화(Geneve) 프로토콜을 사용하여 노드 간에 오버레이 네트워크를 생성합니다.
OVN-Kubernetes 네트워크 플러그인은 다음 기능을 지원합니다.
- Linux 및 Microsoft Windows 워크로드를 모두 실행할 수 있는 하이브리드 클러스터입니다. 이 환경을 하이브리드 네트워킹 이라고 합니다.
- 호스트 CPU(중앙 처리 장치)에서 호환 가능한 네트워크 카드 및 DPDK(데이터 처리 장치)로 네트워크 데이터 처리 오프로드. 이를 하드웨어 오프로드 라고 합니다.
- 베어 메탈, VMware vSphere, IBM Power®, IBM Z® 및 RHOSP(Red Hat OpenStack Platform) 플랫폼에서 IPv4-primary 듀얼 스택 네트워킹.
- RHOSP 및 베어 메탈 플랫폼의 IPv6 단일 스택 네트워킹.
- 베어 메탈, VMware vSphere 또는 RHOSP 플랫폼에서 실행되는 클러스터의 IPv6-primary 듀얼 스택 네트워킹.
- 송신 방화벽 장치 및 송신 IP 주소입니다.
- 리디렉션 모드에서 작동하는 송신 라우터 장치입니다.
- 클러스터 내 통신의 IPsec 암호화
7.1.2. OVN-Kubernetes IPv6 및 듀얼 스택 제한 사항
OVN-Kubernetes 네트워크 플러그인에는 다음과 같은 제한 사항이 있습니다.
듀얼 스택 네트워킹을 위해 구성된 클러스터의 경우 IPv4 및 IPv6 트래픽 모두 기본 게이트웨이와 동일한 네트워크 인터페이스를 사용해야 합니다. 이 요구 사항이 충족되지 않으면
ovnkube-node데몬 세트의 호스트의 Pod가CrashLoopBackOff상태가 됩니다.oc get pod -n openshift-ovn-kubernetes -l app=ovnkube-node -o yaml과 같은 명령으로 Pod를 표시하는 경우status필드에 다음 출력에 표시된 대로 기본 게이트웨이에 대한 메시지가 두 개 이상 포함됩니다.I1006 16:09:50.985852 60651 helper_linux.go:73] Found default gateway interface br-ex 192.168.127.1 I1006 16:09:50.985923 60651 helper_linux.go:73] Found default gateway interface ens4 fe80::5054:ff:febe:bcd4 F1006 16:09:50.985939 60651 ovnkube.go:130] multiple gateway interfaces detected: br-ex ens4유일한 해결 방법은 두 IP 제품군이 기본 게이트웨이에 동일한 네트워크 인터페이스를 사용하도록 호스트 네트워킹을 재구성하는 것입니다.
듀얼 스택 네트워킹을 위해 구성된 클러스터의 경우 IPv4 및 IPv6 라우팅 테이블 모두 기본 게이트웨이를 포함해야 합니다. 이 요구 사항이 충족되지 않으면
ovnkube-node데몬 세트의 호스트의 Pod가CrashLoopBackOff상태가 됩니다.oc get pod -n openshift-ovn-kubernetes -l app=ovnkube-node -o yaml과 같은 명령으로 Pod를 표시하는 경우status필드에 다음 출력에 표시된 대로 기본 게이트웨이에 대한 메시지가 두 개 이상 포함됩니다.I0512 19:07:17.589083 108432 helper_linux.go:74] Found default gateway interface br-ex 192.168.123.1 F0512 19:07:17.589141 108432 ovnkube.go:133] failed to get default gateway interface유일한 해결 방법은 두 IP 제품군에 기본 게이트웨이가 포함되도록 호스트 네트워킹을 재구성하는 것입니다.
7.1.3. 세션 선호도
세션 선호도는 Kubernetes Service 오브젝트에 적용되는 기능입니다. <service_VIP>:<Port>에 연결할 때마다 트래픽이 항상 동일한 백엔드에 분산되도록 하려면 세션 선호도를 사용할 수 있습니다. 클라이언트의 IP 주소를 기반으로 세션 선호도를 설정하는 방법을 포함한 자세한 내용은 세션 선호도를 참조하십시오.
세션 선호도에 대한 고정 시간 제한
AWS에서 Red Hat OpenShift Service의 OVN-Kubernetes 네트워크 플러그인은 마지막 패킷을 기반으로 클라이언트에서 세션의 고정 시간 초과를 계산합니다. 예를 들어 curl 명령을 10번 실행하면 고정 세션 타이머가 첫 번째 패킷이 아닌 10번째 패킷에서 시작됩니다. 결과적으로 클라이언트가 지속적으로 서비스에 문의하는 경우 세션이 시간 초과되지 않습니다. 서비스가 timeoutSeconds 매개변수에 설정된 시간 양에 대한 패킷을 수신하지 않으면 시간 초과가 시작됩니다.
7.2. 송신 IP 주소 구성
클러스터 관리자는 OVN-Kubernetes CNI(Container Network Interface) 네트워크 플러그인을 구성하여 하나 이상의 송신 IP 주소를 네임스페이스 또는 네임스페이스의 특정 Pod에 할당할 수 있습니다.
7.2.1. 송신 IP 주소 아키텍처 설계 및 구현
AWS의 Red Hat OpenShift Service on AWS 송신 IP 주소 기능을 사용하면 하나 이상의 네임스페이스에 있는 하나 이상의 Pod의 트래픽이 클러스터 네트워크 외부의 서비스에 대한 소스 IP 주소가 일관되게 유지되도록 할 수 있습니다.
예를 들어 클러스터 외부 서버에서 호스팅되는 데이터베이스를 주기적으로 쿼리하는 Pod가 있을 수 있습니다. 서버에 대한 액세스 요구 사항을 적용하기 위해 패킷 필터링 장치는 특정 IP 주소의 트래픽만 허용하도록 구성됩니다. 특정 Pod에서만 서버에 안정적으로 액세스할 수 있도록 허용하려면 서버에 요청하는 Pod에 대해 특정 송신 IP 주소를 구성하면 됩니다.
네임스페이스에 할당된 송신 IP 주소는 특정 대상으로 트래픽을 보내는 데 사용되는 송신 라우터와 다릅니다.
HCP 클러스터가 있는 ROSA에서 애플리케이션 pod 및 Ingress 라우터 Pod는 동일한 노드에서 실행됩니다. 이 시나리오에서 애플리케이션 프로젝트에 대한 송신 IP 주소를 구성하는 경우 애플리케이션 프로젝트의 경로에 요청을 보낼 때 IP 주소가 사용되지 않습니다.
EgressIP 기능이 있는 컨트롤 플레인 노드에 대한 송신 IP 주소 할당은 지원되지 않습니다.
다음 예제에서는 여러 퍼블릭 클라우드 공급자의 노드의 주석을 보여줍니다. 가독성을 위해 주석을 들여쓰기합니다.
AWS의 cloud.network.openshift.io/egress-ipconfig 주석의 예
cloud.network.openshift.io/egress-ipconfig: [
{
"interface":"eni-078d267045138e436",
"ifaddr":{"ipv4":"10.0.128.0/18"},
"capacity":{"ipv4":14,"ipv6":15}
}
]다음 섹션에서는 용량 계산에 사용할 지원되는 퍼블릭 클라우드 환경의 IP 주소 용량에 대해 설명합니다.
7.2.1.1. AWS(Amazon Web Services) IP 주소 용량 제한
AWS에서 IP 주소 할당에 대한 제약 조건은 구성된 인스턴스 유형에 따라 다릅니다. 자세한 내용은 인스턴스 유형당 네트워크 인터페이스당 IP 주소를참조하십시오.
7.2.1.2. Pod에 송신 IP 할당
하나 이상의 송신 IP를 네임스페이스 또는 네임스페이스의 특정 Pod에 할당하려면 다음 조건을 충족해야 합니다.
-
클러스터에서 하나 이상의 노드에
k8s.ovn.org/egress-assignable: ""레이블이 있어야 합니다. -
네임스페이스의 Pod에서 클러스터를 떠나는 트래픽의 소스 IP 주소로 사용할 하나 이상의 송신 IP 주소를 정의하는
EgressIP오브젝트가 있습니다.
송신 IP 할당을 위해 클러스터의 노드에 레이블을 지정하기 전에 EgressIP 오브젝트를 생성하는 경우 AWS의 Red Hat OpenShift Service는 k8s.ovn.org/egress-assignable: "" 레이블이 있는 첫 번째 노드에 모든 송신 IP 주소를 할당할 수 있습니다.
송신 IP 주소가 클러스터의 여러 노드에 널리 분산되도록 하려면 EgressIP 오브젝트를 만들기 전에 송신 IP 주소를 호스팅할 노드에 항상 레이블을 적용하십시오.
7.2.1.3. 노드에 송신 IP 할당
EgressIP 오브젝트를 생성할 때 k8s.ovn.org/egress-assignable: "" 레이블이 지정된 노드에 다음 조건이 적용됩니다.
- 송신 IP 주소는 한 번에 두 개 이상의 노드에 할당되지 않습니다.
- 송신 IP 주소는 송신 IP 주소를 호스팅할 수 있는 사용 가용한 노드 간에 균형을 이룹니다.
EgressIP오브젝트의spec.EgressIPs배열에서 둘 이상의 IP 주소를 지정하는 경우 다음 조건이 적용됩니다.- 지정된 IP 주소 중 두 개 이상을 호스팅할 노드는 없습니다.
- 지정된 네임스페이스에 대해 지정된 IP 주소 간에 트래픽이 거의 동일하게 분산됩니다.
- 노드를 사용할 수 없게 되면 할당된 모든 송신 IP 주소가 이전에 설명한 조건에 따라 자동으로 재할당됩니다.
Pod가 여러 EgressIP 오브젝트의 선택기와 일치하는 경우 EgressIP 오브젝트에 지정된 송신 IP 주소 중 어느 것이 Pod의 송신 IP 주소로 할당되는지 보장할 수 없습니다.
또한 EgressIP 오브젝트가 여러 송신 IP 주소를 지정하는 경우 송신 IP 주소 중 사용할 수 있는 보장이 없습니다. 예를 들어 Pod가 두 개의 송신 IP 주소 10.10.20.1 및 10.10.20.2 가 있는 EgressIP 오브젝트의 선택기와 일치하는 경우 각 TCP 연결 또는 UDP 대화에 사용할 수 있습니다.
7.2.1.4. 송신 IP 주소 구성에 대한 아키텍처 다이어그램
다음 다이어그램에서는 송신 IP 주소 구성을 보여줍니다. 다이어그램은 클러스터의 세 개 노드에서 실행 중인 두 개의 다른 네임스페이스에 있는 포드 4개를 설명합니다. 노드는 호스트 네트워크의 192.168.126.0/18 CIDR 블록에서 할당된 IP 주소입니다.
노드 1과 노드 3은 모두 k8s.ovn.org/egress-assignable: ""로 레이블이 지정되어 있으므로 송신 IP 주소 할당에 사용할 수 있습니다.
다이어그램에 있는 점선은 노드 1 및 노드 3에서 클러스터를 나가기 위해 포드 네트워크를 통해 이동하는 pod1, pod2, pod3의 트래픽 흐름을 나타냅니다. 외부 서비스에서 예제의 EgressIP 오브젝트에서 선택한 Pod 중 하나에서 트래픽을 수신하는 경우 소스 IP 주소는 192.168.126.10 또는 192.168.126.102입니다. 트래픽은 이 두 노드 간에 대략적으로 균등하게 분산됩니다.
다이어그램의 다음 리소스는 자세히 설명되어 있습니다.
Namespace오브젝트네임스페이스는 다음 매니페스트에 정의됩니다.
네임스페이스 오브젝트
apiVersion: v1 kind: Namespace metadata: name: namespace1 labels: env: prod --- apiVersion: v1 kind: Namespace metadata: name: namespace2 labels: env: prodEgressIP오브젝트다음
EgressIP오브젝트는env라벨이prod로 설정된 모든 포드를 선택하는 구성을 설명합니다. 선택한 포드의 송신 IP 주소는192.168.126.10및192.168.126.102입니다.EgressIP오브젝트apiVersion: k8s.ovn.org/v1 kind: EgressIP metadata: name: egressips-prod spec: egressIPs: - 192.168.126.10 - 192.168.126.102 namespaceSelector: matchLabels: env: prod status: items: - node: node1 egressIP: 192.168.126.10 - node: node3 egressIP: 192.168.126.102이전 예제의 구성에 대해 AWS의 Red Hat OpenShift Service는 두 송신 IP 주소를 사용 가능한 노드에 할당합니다.
status필드는 송신 IP 주소가 할당되었는지 여부와 위치를 반영합니다.
7.2.2. EgressIP 오브젝트
다음 YAML에서는 EgressIP 오브젝트의 API를 설명합니다. 오브젝트의 범위는 클러스터 전체이며 네임스페이스에 생성되지 않습니다.
apiVersion: k8s.ovn.org/v1
kind: EgressIP
metadata:
name: <name>
spec:
egressIPs:
- <ip_address>
namespaceSelector:
...
podSelector:
...다음 YAML은 네임스페이스 선택기에 대한 스탠자를 설명합니다.
네임스페이스 선택기 스탠자
namespaceSelector:
matchLabels:
<label_name>: <label_value>- 1
- 네임스페이스에 대해 일치하는 하나 이상의 규칙입니다. 둘 이상의 일치 규칙이 제공되면 일치하는 모든 네임스페이스가 선택됩니다.
다음 YAML은 Pod 선택기에 대한 선택적 스탠자를 설명합니다.
Pod 선택기 스탠자
podSelector:
matchLabels:
<label_name>: <label_value>- 1
- 선택사항: 지정된
namespaceSelector규칙과 일치하는 네임스페이스의 Pod에 대해 일치하는 하나 이상의 규칙입니다. 지정된 경우 일치하는 Pod만 선택됩니다. 네임스페이스의 다른 Pod는 선택되지 않습니다.
다음 예에서 EgressIP 오브젝트는 192.168.126.11 및 192.168.126.102 송신 IP 주소를 app 라벨을 web으로 설정하고 env 라벨을 prod로 설정한 네임스페이스에 있는 포드와 연결합니다.
EgressIP 오브젝트의 예
apiVersion: k8s.ovn.org/v1
kind: EgressIP
metadata:
name: egress-group1
spec:
egressIPs:
- 192.168.126.11
- 192.168.126.102
podSelector:
matchLabels:
app: web
namespaceSelector:
matchLabels:
env: prod
다음 예에서 EgressIP 오브젝트는 192.168.127.30 및 192.168.127.40 송신 IP 주소를 environment 레이블이 development로 설정되지 않은 모든 Pod와 연결합니다.
EgressIP 오브젝트의 예
apiVersion: k8s.ovn.org/v1
kind: EgressIP
metadata:
name: egress-group2
spec:
egressIPs:
- 192.168.127.30
- 192.168.127.40
namespaceSelector:
matchExpressions:
- key: environment
operator: NotIn
values:
- development7.2.3. 송신 IP 주소 호스팅을 위해 노드에 레이블 지정
AWS의 Red Hat OpenShift Service가 노드에 하나 이상의 송신 IP 주소를 할당할 수 있도록 k8s.ovn.org/egress-assignable="" 레이블을 클러스터의 노드에 적용할 수 있습니다.
사전 요구 사항
-
ROSA CLI(
rosa)를 설치합니다. - 클러스터 관리자로 클러스터에 로그인합니다.
프로세스
하나 이상의 송신 IP 주소를 호스팅할 수 있도록 노드에 레이블을 지정하려면 다음 명령을 입력합니다.
$ rosa edit machinepool <machinepool_name> --cluster=<cluster_name> --labels "k8s.ovn.org/egress-assignable="중요이 명령은 machinepool의 모든 흥미로운 노드 레이블을 대체합니다. 기존 노드 레이블이 유지되도록
--labels필드에 원하는 라벨을 포함해야 합니다.
7.2.4. 다음 단계
7.3. OpenShift SDN 네트워크 플러그인에서 OVN-Kubernetes 네트워크 플러그인으로 마이그레이션
Red Hat OpenShift Service on AWS (ROSA) (classic architecture) 클러스터 관리자는 OpenShift SDN 네트워크 플러그인에서 OVN-Kubernetes 네트워크 플러그인으로 마이그레이션을 시작하고 ROSA CLI를 사용하여 마이그레이션 상태를 확인할 수 있습니다.
마이그레이션 시작 전에 고려해야 할 몇 가지 사항은 다음과 같습니다.
- 클러스터 버전은 4.16.24 이상이어야 합니다.
- 마이그레이션 프로세스를 중단할 수 없습니다.
- SDN 네트워크 플러그인으로 다시 마이그레이션하는 것은 불가능합니다.
- 마이그레이션 중에 클러스터 노드가 재부팅됩니다.
- 노드 중단에 탄력적인 워크로드에는 영향을 미치지 않습니다.
- 마이그레이션 시간은 클러스터 크기 및 워크로드 구성에 따라 몇 분과 시간마다 다를 수 있습니다.
7.3.1. ROSA CLI를 사용하여 마이그레이션 시작
버전 4.16.24 이상인 클러스터에서만 마이그레이션을 시작할 수 있습니다.
마이그레이션을 시작하려면 다음 명령을 실행합니다.
$ rosa edit cluster -c <cluster_id>
--network-type OVNKubernetes
--ovn-internal-subnets <configuration>
--network-type 플래그의 값을 정의하지 않으면 명령에 선택적 플래그 --ovn-internal-subnets 를 포함할 수 없습니다.
검증
마이그레이션 상태를 확인하려면 다음 명령을 실행합니다.
$ rosa describe cluster -c <cluster_id>1 - 1
- 마이그레이션 상태를 확인하려면 <
;cluster_id>를 클러스터 ID로 바꿉니다.
8장. OpenShift SDN 네트워크 플러그인
8.1. 프로젝트에 멀티 캐스트 사용
8.1.1. 멀티 캐스트 정보
IP 멀티 캐스트를 사용하면 데이터가 여러 IP 주소로 동시에 브로드캐스트됩니다.
- 현재 멀티 캐스트는 고 대역폭 솔루션이 아닌 저 대역폭 조정 또는 서비스 검색에 가장 적합합니다.
-
기본적으로 네트워크 정책은 네임스페이스의 모든 연결에 영향을 미칩니다. 그러나 멀티캐스트는 네트워크 정책의 영향을 받지 않습니다. 네트워크 정책과 동일한 네임스페이스에서 멀티 캐스트를 활성화하면
모든 네트워크 정책이 거부된 경우에도 항상 허용됩니다. 클러스터 관리자는 활성화하기 전에 네트워크 정책에서 멀티 캐스트에 미치는 영향을 고려해야 합니다.
AWS Pod의 Red Hat OpenShift Service 간 멀티 캐스트 트래픽은 기본적으로 비활성화되어 있습니다. OVN-Kubernetes 네트워크 플러그인을 사용하는 경우 프로젝트별로 멀티 캐스트를 활성화할 수 있습니다.
8.1.2. Pod 간 멀티 캐스트 활성화
프로젝트의 Pod 간 멀티 캐스트를 활성화할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin또는dedicated-admin역할이 있는 사용자로 클러스터에 로그인해야 합니다.
프로세스
다음 명령을 실행하여 프로젝트에 대한 멀티 캐스트를 활성화합니다. 멀티 캐스트를 활성화하려는 프로젝트의 네임스페이스로
<namespace>를 바꿉니다.$ oc annotate namespace <namespace> \ k8s.ovn.org/multicast-enabled=true작은 정보다음 YAML을 적용하여 주석을 추가할 수도 있습니다.
apiVersion: v1 kind: Namespace metadata: name: <namespace> annotations: k8s.ovn.org/multicast-enabled: "true"
검증
프로젝트에 멀티 캐스트가 활성화되어 있는지 확인하려면 다음 절차를 완료합니다.
멀티 캐스트를 활성화한 프로젝트로 현재 프로젝트를 변경합니다.
<project>를 프로젝트 이름으로 바꿉니다.$ oc project <project>멀티 캐스트 수신자 역할을 할 pod를 만듭니다.
$ cat <<EOF| oc create -f - apiVersion: v1 kind: Pod metadata: name: mlistener labels: app: multicast-verify spec: containers: - name: mlistener image: registry.access.redhat.com/ubi9 command: ["/bin/sh", "-c"] args: ["dnf -y install socat hostname && sleep inf"] ports: - containerPort: 30102 name: mlistener protocol: UDP EOF멀티 캐스트 발신자 역할을 할 pod를 만듭니다.
$ cat <<EOF| oc create -f - apiVersion: v1 kind: Pod metadata: name: msender labels: app: multicast-verify spec: containers: - name: msender image: registry.access.redhat.com/ubi9 command: ["/bin/sh", "-c"] args: ["dnf -y install socat && sleep inf"] EOF새 터미널 창 또는 탭에서 멀티 캐스트 리스너를 시작합니다.
Pod의 IP 주소를 가져옵니다.
$ POD_IP=$(oc get pods mlistener -o jsonpath='{.status.podIP}')다음 명령을 입력하여 멀티 캐스트 리스너를 시작합니다.
$ oc exec mlistener -i -t -- \ socat UDP4-RECVFROM:30102,ip-add-membership=224.1.0.1:$POD_IP,fork EXEC:hostname
멀티 캐스트 송신기를 시작합니다.
Pod 네트워크 IP 주소 범위를 가져옵니다.
$ CIDR=$(oc get Network.config.openshift.io cluster \ -o jsonpath='{.status.clusterNetwork[0].cidr}')멀티 캐스트 메시지를 보내려면 다음 명령을 입력합니다.
$ oc exec msender -i -t -- \ /bin/bash -c "echo | socat STDIO UDP4-DATAGRAM:224.1.0.1:30102,range=$CIDR,ip-multicast-ttl=64"멀티 캐스트가 작동하는 경우 이전 명령은 다음 출력을 반환합니다.
mlistener
9장. 경로 구성
9.1. 경로 구성
9.1.1. HTTP 기반 경로 생성
공용 URL에서 애플리케이션을 호스팅할 경로를 생성합니다. 경로는 애플리케이션의 네트워크 보안 구성에 따라 보안 또는 비보안일 수 있습니다. HTTP 기반 경로는 기본 HTTP 라우팅 프로토콜을 사용하고 보안되지 않은 애플리케이션 포트에서 서비스를 노출하는 비보안 라우팅입니다.
다음 절차에서는 hello-openshift 애플리케이션을 예로 사용하여 웹 애플리케이션에 대한 간단한 HTTP 기반 경로를 생성하는 방법을 설명합니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. - 관리자로 로그인되어 있습니다.
- 포트 및 포트의 트래픽을 수신하는 TCP 엔드포인트를 노출하는 웹 애플리케이션이 있습니다.
절차
다음 명령을 실행하여
hello-openshift라는 프로젝트를 생성합니다.$ oc new-project hello-openshift다음 명령을 실행하여 프로젝트에 Pod를 생성합니다.
$ oc create -f https://raw.githubusercontent.com/openshift/origin/master/examples/hello-openshift/hello-pod.json다음 명령을 실행하여
hello-openshift라는 서비스를 생성합니다.$ oc expose pod/hello-openshift다음 명령을 실행하여
hello-openshift애플리케이션에 대한 비보안 경로를 생성합니다.$ oc expose svc hello-openshift
검증
생성한
경로리소스가 있는지 확인하려면 다음 명령을 실행합니다.$ oc get routes -o yaml <name of resource>1 - 1
- 이 예제에서 경로 이름은
hello-openshift입니다.
생성된 비보안 경로에 대한 YAML 정의 샘플
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: hello-openshift
spec:
host: www.example.com
port:
targetPort: 8080
to:
kind: Service
name: hello-openshift9.1.2. 경로 시간 초과 구성
SLA(Service Level Availability) 목적에 필요한 낮은 시간 초과 또는 백엔드가 느린 경우 높은 시간 초과가 필요한 서비스가 있는 경우 기존 경로에 대한 기본 시간 초과를 구성할 수 있습니다.
사전 요구 사항
- 실행 중인 클러스터에 배포된 Ingress 컨트롤러가 필요합니다.
프로세스
oc annotate명령을 사용하여 경로에 시간 초과를 추가합니다.$ oc annotate route <route_name> \ --overwrite haproxy.router.openshift.io/timeout=<timeout><time_unit>1 - 1
- 지원되는 시간 단위는 마이크로초(us), 밀리초(ms), 초(s), 분(m), 시간(h) 또는 일(d)입니다.
다음 예제는 이름이
myroute인 경로에서 2초의 시간 초과를 설정합니다.$ oc annotate route myroute --overwrite haproxy.router.openshift.io/timeout=2s
9.1.3. HSTS(HTTP Strict Transport Security)
HSTS(HTTP Strict Transport Security) 정책은 라우트 호스트에서 HTTPS 트래픽만 허용됨을 브라우저 클라이언트에 알리는 보안 강화 정책입니다. 또한 HSTS는 HTTP 리디렉션을 사용하지 않고 HTTPS 전송 신호를 통해 웹 트래픽을 최적화합니다. HSTS는 웹사이트와의 상호 작용을 가속화하는 데 유용합니다.
HSTS 정책이 적용되면 HSTS는 사이트의 HTTP 및 HTTPS 응답에 Strict Transport Security 헤더를 추가합니다. 경로에서 insecureEdgeTerminationPolicy 값을 사용하여 HTTP를 HTTPS로 리디렉션할 수 있습니다. HSTS를 적용하면 클라이언트는 요청을 전송하기 전에 HTTP URL의 모든 요청을 HTTPS로 변경하여 리디렉션이 필요하지 않습니다.
클러스터 관리자는 다음을 수행하도록 HSTS를 구성할 수 있습니다.
- 경로당 HSTS 활성화
- 라우팅당 HSTS 비활성화
- 도메인당 HSTS 시행, 도메인 집합 또는 도메인과 함께 네임스페이스 라벨 사용
HSTS는 보안 경로(엣지 종료 또는 재암호화)에서만 작동합니다. HTTP 또는 패스스루(passthrough) 경로에서는 구성이 유효하지 않습니다.
9.1.3.1. 라우팅당 HSTS(HTTP Strict Transport Security) 활성화
HSTS(HTTP Strict Transport Security)는 HAProxy 템플릿에 구현되고 haproxy.router.openshift.io/hsts_header 주석이 있는 에지 및 재암호화 경로에 적용됩니다.
사전 요구 사항
- 프로젝트에 대한 관리자 권한이 있는 사용자로 클러스터에 로그인합니다.
-
OpenShift CLI(
oc)를 설치합니다.
절차
경로에서 HSTS를 활성화하려면
haproxy.router.openshift.io/hsts_header값을 에지 종료 또는 재암호화 경로에 추가합니다.oc annotatetool을 사용하여 다음 명령을 실행하여 이 작업을 수행할 수 있습니다. 명령을 올바르게 실행하려면haproxy.router.openshift.io/hsts_header경로 주석의 username(;)이 큰따옴표("")로 묶여 있는지 확인합니다.최대 기간을
31536000ms로 설정하는주석명령 예 (약 8.5 시간)$ oc annotate route <route_name> -n <namespace> --overwrite=true "haproxy.router.openshift.io/hsts_header=max-age=31536000;\ includeSubDomains;preload"주석으로 구성된 경로 예
apiVersion: route.openshift.io/v1 kind: Route metadata: annotations: haproxy.router.openshift.io/hsts_header: max-age=31536000;includeSubDomains;preload1 2 3 # ... spec: host: def.abc.com tls: termination: "reencrypt" ... wildcardPolicy: "Subdomain" # ...- 1
- 필수 항목입니다.
Max-age는 HSTS 정책이 적용되는 시간(초)을 측정합니다.0으로 설정하면 정책이 무효화됩니다. - 2
- 선택 사항: 포함되는 경우
includeSubDomains는 호스트의 모든 하위 도메인에 호스트와 동일한 HSTS 정책이 있어야 함을 알려줍니다. - 3
- 선택 사항:
max-age가 0보다 크면haproxy.router.openshift.io/hsts_header에preload를 추가하여 외부 서비스에서 이 사이트를 HSTS 사전 로드 목록에 포함할 수 있습니다. 예를 들어 Google과 같은 사이트는preload가 설정된 사이트 목록을 구성할 수 있습니다. 그런 다음 브라우저는 이 목록을 사용하여 사이트와 상호 작용하기 전에 HTTPS를 통해 통신할 수 있는 사이트를 결정할 수 있습니다.preload를 설정하지 않으면 브라우저가 HTTPS를 통해 사이트와 상호 작용하여 헤더를 가져와야 합니다.
9.1.3.2. 라우팅당 HSTS(HTTP Strict Transport Security) 비활성화
경로당 HSTS(HTTP Strict Transport Security)를 비활성화하려면 경로 주석에서 max-age 값을 0으로 설정할 수 있습니다.
사전 요구 사항
- 프로젝트에 대한 관리자 권한이 있는 사용자로 클러스터에 로그인합니다.
-
OpenShift CLI(
oc)를 설치합니다.
절차
HSTS를 비활성화하려면 다음 명령을 입력하여 경로 주석의
max-age값을0으로 설정합니다.$ oc annotate route <route_name> -n <namespace> --overwrite=true "haproxy.router.openshift.io/hsts_header"="max-age=0"작은 정보다음 YAML을 적용하여 구성 맵을 만들 수 있습니다.
경로당 HSTS 비활성화 예
metadata: annotations: haproxy.router.openshift.io/hsts_header: max-age=0네임스페이스의 모든 경로에 대해 HSTS를 비활성화하려면 다음 명령을 입력합니다.
$ oc annotate route --all -n <namespace> --overwrite=true "haproxy.router.openshift.io/hsts_header"="max-age=0"
검증
모든 경로에 대한 주석을 쿼리하려면 다음 명령을 입력합니다.
$ oc get route --all-namespaces -o go-template='{{range .items}}{{if .metadata.annotations}}{{$a := index .metadata.annotations "haproxy.router.openshift.io/hsts_header"}}{{$n := .metadata.name}}{{with $a}}Name: {{$n}} HSTS: {{$a}}{{"\n"}}{{else}}{{""}}{{end}}{{end}}{{end}}'출력 예
Name: routename HSTS: max-age=0
9.1.4. 쿠키를 사용하여 경로 상태 유지
AWS의 Red Hat OpenShift Service는 고정 세션을 제공하므로 모든 트래픽이 동일한 엔드포인트에 도달하도록 하여 상태 저장 애플리케이션 트래픽을 사용할 수 있습니다. 그러나 재시작, 스케일링 또는 구성 변경 등으로 인해 끝점 pod가 종료되면 이러한 상태 저장 특성이 사라질 수 있습니다.
AWS의 Red Hat OpenShift Service는 쿠키를 사용하여 세션 지속성을 구성할 수 있습니다. 수신 컨트롤러는 사용자 요청을 처리할 끝점을 선택하고 세션에 대한 쿠키를 생성합니다. 쿠키는 요청에 대한 응답으로 다시 전달되고 사용자는 세션의 다음 요청과 함께 쿠키를 다시 보냅니다. 쿠키는 세션을 처리하는 끝점을 Ingress 컨트롤러에 알려 클라이언트 요청이 쿠키를 사용하여 동일한 pod로 라우팅되도록 합니다.
HTTP 트래픽을 볼 수 없기 때문에 패스스루 경로에서 쿠키를 설정할 수 없습니다. 대신 백엔드를 결정하는 소스 IP 주소를 기반으로 숫자가 계산됩니다.
백엔드가 변경되면 트래픽을 잘못된 서버로 전달하여 덜 고정시킬 수 있습니다. 소스 IP를 숨기는 로드 밸런서를 사용하는 경우 모든 연결에 대해 동일한 번호가 설정되고 트래픽이 동일한 Pod로 전송됩니다.
9.1.4.1. 쿠키를 사용하여 경로에 주석 달기
쿠키 이름을 설정하여 경로에 자동 생성되는 기본 쿠키 이름을 덮어쓸 수 있습니다. 그러면 경로 트래픽을 수신하는 애플리케이션에서 쿠키 이름을 확인할 수 있게 됩니다. 쿠키를 삭제하면 다음 요청이 끝점을 다시 선택하도록 강제할 수 있습니다. 결과적으로 서버가 과부하된 경우 해당 서버에서 클라이언트의 요청을 제거하고 재배포하려고 합니다.
프로세스
지정된 쿠키 이름으로 경로에 주석을 답니다.
$ oc annotate route <route_name> router.openshift.io/cookie_name="<cookie_name>"다음과 같습니다.
<route_name>- 경로 이름을 지정합니다.
<cookie_name>- 쿠키 이름을 지정합니다.
예를 들어 쿠키 이름
my_cookie로my_route경로에 주석을 달 수 있습니다.$ oc annotate route my_route router.openshift.io/cookie_name="my_cookie"경로 호스트 이름을 변수에 캡처합니다.
$ ROUTE_NAME=$(oc get route <route_name> -o jsonpath='{.spec.host}')다음과 같습니다.
<route_name>- 경로 이름을 지정합니다.
쿠키를 저장한 다음 경로에 액세스합니다.
$ curl $ROUTE_NAME -k -c /tmp/cookie_jar경로에 연결할 때 이전 명령으로 저장된 쿠키를 사용합니다.
$ curl $ROUTE_NAME -k -b /tmp/cookie_jar
9.1.5. 경로 기반 라우터
경로 기반 라우터는 URL과 비교할 수 있는 경로 구성 요소를 지정하며 이를 위해 라우트의 트래픽이 HTTP 기반이어야 합니다. 따라서 동일한 호스트 이름을 사용하여 여러 경로를 제공할 수 있으며 각각 다른 경로가 있습니다. 라우터는 가장 구체적인 경로를 기반으로 하는 라우터와 일치해야 합니다.
다음 표에서는 경로 및 액세스 가능성을 보여줍니다.
| 경로 | 비교 대상 | 액세스 가능 |
|---|---|---|
| www.example.com/test | www.example.com/test | 제공됨 |
| www.example.com | 없음 | |
| www.example.com/test 및 www.example.com | www.example.com/test | 제공됨 |
| www.example.com | 제공됨 | |
| www.example.com | www.example.com/text | 예 (경로가 아닌 호스트에 의해 결정됨) |
| www.example.com | 제공됨 |
경로가 있는 보안되지 않은 라우터
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: route-unsecured
spec:
host: www.example.com
path: "/test"
to:
kind: Service
name: service-name- 1
- 경로는 경로 기반 라우터에 대해 추가된 유일한 속성입니다.
라우터가 해당 경우 TLS를 종료하지 않고 요청 콘텐츠를 읽을 수 없기 때문에 패스스루 TLS를 사용할 때 경로 기반 라우팅을 사용할 수 없습니다.
9.1.6. HTTP 헤더 구성
Red Hat OpenShift Service on AWS는 HTTP 헤더로 작업할 수 있는 다양한 방법을 제공합니다. 헤더를 설정하거나 삭제할 때 Ingress 컨트롤러의 특정 필드를 사용하거나 개별 경로를 사용하여 요청 및 응답 헤더를 수정할 수 있습니다. 경로 주석을 사용하여 특정 헤더를 설정할 수도 있습니다. 헤더를 구성하는 다양한 방법은 함께 작업할 때 문제가 발생할 수 있습니다.
IngressController 또는 Route CR 내에서 헤더만 설정하거나 삭제할 수 있으므로 추가할 수 없습니다. HTTP 헤더가 값으로 설정된 경우 해당 값은 완료되어야 하며 나중에 추가할 필요가 없습니다. X-Forwarded-For 헤더와 같은 헤더를 추가하는 것이 적합한 경우 spec.httpHeaders.actions 대신 spec.httpHeaders.forwardedHeaderPolicy 필드를 사용합니다.
9.1.6.1. 우선순위 순서
Ingress 컨트롤러와 경로에서 동일한 HTTP 헤더를 수정하는 경우 HAProxy는 요청 또는 응답 헤더인지 여부에 따라 특정 방식으로 작업에 우선순위를 부여합니다.
- HTTP 응답 헤더의 경우 경로에 지정된 작업 후에 Ingress 컨트롤러에 지정된 작업이 실행됩니다. 즉, Ingress 컨트롤러에 지정된 작업이 우선합니다.
- HTTP 요청 헤더의 경우 경로에 지정된 작업은 Ingress 컨트롤러에 지정된 작업 후에 실행됩니다. 즉, 경로에 지정된 작업이 우선합니다.
예를 들어 클러스터 관리자는 다음 구성을 사용하여 Ingress 컨트롤러에서 값이 DENY 인 X-Frame-Options 응답 헤더를 설정합니다.
IngressController 사양 예
apiVersion: operator.openshift.io/v1
kind: IngressController
# ...
spec:
httpHeaders:
actions:
response:
- name: X-Frame-Options
action:
type: Set
set:
value: DENY
경로 소유자는 클러스터 관리자가 Ingress 컨트롤러에 설정한 것과 동일한 응답 헤더를 설정하지만 다음 구성을 사용하여 SAMEORIGIN 값이 사용됩니다.
Route 사양의 예
apiVersion: route.openshift.io/v1
kind: Route
# ...
spec:
httpHeaders:
actions:
response:
- name: X-Frame-Options
action:
type: Set
set:
value: SAMEORIGIN
IngressController 사양과 Route 사양 모두에서 X-Frame-Options 응답 헤더를 구성하는 경우 특정 경로에서 프레임을 허용하는 경우에도 Ingress 컨트롤러의 글로벌 수준에서 이 헤더에 설정된 값이 우선합니다. 요청 헤더의 경우 Route spec 값은 IngressController 사양 값을 재정의합니다.
이 우선순위는 haproxy.config 파일에서 다음 논리를 사용하므로 Ingress 컨트롤러가 프런트 엔드로 간주되고 개별 경로가 백엔드로 간주되기 때문입니다. 프런트 엔드 구성에 적용된 헤더 값 DENY 는 백엔드에 설정된 SAMEORIGIN 값으로 동일한 헤더를 재정의합니다.
frontend public
http-response set-header X-Frame-Options 'DENY'
frontend fe_sni
http-response set-header X-Frame-Options 'DENY'
frontend fe_no_sni
http-response set-header X-Frame-Options 'DENY'
backend be_secure:openshift-monitoring:alertmanager-main
http-response set-header X-Frame-Options 'SAMEORIGIN'또한 Ingress 컨트롤러 또는 경로 주석을 사용하여 설정된 경로 덮어쓰기 값에 정의된 모든 작업입니다.
9.1.6.2. 특수 케이스 헤더
다음 헤더는 완전히 설정되거나 삭제되지 않거나 특정 상황에서 허용되지 않습니다.
| 헤더 이름 | IngressController 사양을 사용하여 구성 가능 | Route 사양을 사용하여 구성 가능 | 허용하지 않는 이유 | 다른 방법을 사용하여 구성 가능 |
|---|---|---|---|---|
|
| 없음 | 없음 |
| 없음 |
|
| 없음 | 제공됨 |
| 없음 |
|
| 없음 | 없음 |
|
제공됨: |
|
| 없음 | 없음 | HAProxy가 클라이언트 연결을 특정 백엔드 서버에 매핑하는 세션 추적에 사용되는 쿠키입니다. 이러한 헤더를 설정하도록 허용하면 HAProxy의 세션 선호도를 방해하고 HAProxy의 쿠키 소유권을 제한할 수 있습니다. | 예:
|
9.1.7. 경로에서 HTTP 요청 및 응답 헤더 설정 또는 삭제
규정 준수 목적 또는 기타 이유로 특정 HTTP 요청 및 응답 헤더를 설정하거나 삭제할 수 있습니다. Ingress 컨트롤러에서 제공하는 모든 경로 또는 특정 경로에 대해 이러한 헤더를 설정하거나 삭제할 수 있습니다.
예를 들어 경로를 제공하는 Ingress 컨트롤러에서 지정하는 기본 글로벌 위치가 있더라도 해당 콘텐츠가 여러 언어로 작성된 경우 웹 애플리케이션에서 특정 경로에 대한 콘텐츠를 제공할 수 있도록 할 수 있습니다.
다음 절차에서는 애플리케이션 https://app.example.com 과 연결된 URL이 위치 https://app.example.com/lang/en-us 로 전달되도록 Content-Location HTTP 요청 헤더를 설정하는 경로를 생성합니다. 애플리케이션 트래픽을 이 위치로 전달한다는 것은 특정 경로를 사용하는 사람이 미국 영어로 작성된 웹 콘텐츠에 액세스하는 것을 의미합니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. - 프로젝트 관리자로 AWS 클러스터의 Red Hat OpenShift Service에 로그인되어 있습니다.
- 포트에서 트래픽을 수신하는 포트와 HTTP 또는 TLS 끝점을 노출하는 웹 애플리케이션이 있습니다.
프로세스
경로 정의를 생성하고
app-example-route.yaml이라는 파일에 저장합니다.HTTP 헤더 지시문을 사용하여 생성된 경로의 YAML 정의
apiVersion: route.openshift.io/v1 kind: Route # ... spec: host: app.example.com tls: termination: edge to: kind: Service name: app-example httpHeaders: actions:1 response:2 - name: Content-Location3 action: type: Set4 set: value: /lang/en-us5 - 1
- HTTP 헤더에서 수행할 작업 목록입니다.
- 2
- 변경할 헤더 유형입니다. 이 경우 응답 헤더입니다.
- 3
- 변경할 헤더의 이름입니다. 설정하거나 삭제할 수 있는 사용 가능한 헤더 목록은 HTTP 헤더 구성 을 참조하십시오.
- 4
- 헤더에서 수행되는 작업 유형입니다. 이 필드에는
Set또는Delete값이 있을 수 있습니다. - 5
- HTTP 헤더를 설정할 때
값을제공해야 합니다. 값은 해당 헤더에 사용 가능한 지시문 목록(예:DENY)의 문자열이거나 HAProxy의 동적 값 구문을 사용하여 해석되는 동적 값이 될 수 있습니다. 이 경우 값은 콘텐츠의 상대 위치로 설정됩니다.
새로 생성된 경로 정의를 사용하여 기존 웹 애플리케이션에 대한 경로를 생성합니다.
$ oc -n app-example create -f app-example-route.yaml
HTTP 요청 헤더의 경우 경로 정의에 지정된 작업이 Ingress 컨트롤러의 HTTP 요청 헤더에 실행된 후 실행됩니다. 즉, 경로의 해당 요청 헤더에 설정된 모든 값이 Ingress 컨트롤러에 설정된 값보다 우선합니다. HTTP 헤더 처리 순서에 대한 자세한 내용은 HTTP 헤더 구성 을 참조하십시오.
9.1.8. 경로별 주석
Ingress 컨트롤러는 노출하는 모든 경로에 기본 옵션을 설정할 수 있습니다. 개별 경로는 주석에 특정 구성을 제공하는 방식으로 이러한 기본값 중 일부를 덮어쓸 수 있습니다. Red Hat은 operator 관리 경로에 경로 주석 추가를 지원하지 않습니다.
여러 소스 IP 또는 서브넷이 있는 허용 목록을 만들려면 공백으로 구분된 목록을 사용합니다. 다른 구분 기호 유형으로 인해 경고 또는 오류 메시지 없이 목록이 무시됩니다.
| 변수 | 설명 | 기본값으로 사용되는 환경 변수 |
|---|---|---|
|
|
로드 밸런싱 알고리즘을 설정합니다. 사용 가능한 옵션은 |
경유 경로의 경우 |
|
|
쿠키를 사용하여 관련 연결을 추적하지 않도록 설정합니다. | |
|
| 이 경로에 사용할 선택적 쿠키를 지정합니다. 이름은 대문자와 소문자, 숫자, ‘_’, ‘-’의 조합으로 구성해야 합니다. 기본값은 경로의 해시된 내부 키 이름입니다. | |
|
|
라우터에서 백업 pod로 허용되는 최대 연결 수를 설정합니다. | |
|
|
| |
|
|
동일한 소스 IP 주소를 통해 만든 동시 TCP 연결 수를 제한합니다. 숫자 값을 허용합니다. | |
|
|
동일한 소스 IP 주소가 있는 클라이언트에서 HTTP 요청을 수행할 수 있는 속도를 제한합니다. 숫자 값을 허용합니다. | |
|
|
동일한 소스 IP 주소가 있는 클라이언트에서 TCP 연결을 수행할 수 있는 속도를 제한합니다. 숫자 값을 허용합니다. | |
|
| 경로에 대한 서버 쪽 타임아웃을 설정합니다. (TimeUnits) |
|
|
| 이 시간 초과는 일반 텍스트, 에지, 재암호화 또는 패스스루 경로와 같은 터널 연결에 적용됩니다. 일반 텍스트, 에지 또는 재암호화 경로 유형을 사용하면 이 주석이 기존 시간 초과 값을 사용하여 시간 제한 터널로 적용됩니다. passthrough 경로 유형의 경우 주석은 기존의 시간 초과 값보다 우선합니다. |
|
|
|
IngressController 또는 ingress 구성을 설정할 수 있습니다. 이 주석은 라우터를 재배포하고 전체 소프트 중지를 수행하는 데 허용되는 최대 시간을 정의하는 haproxy |
|
|
| 백엔드 상태 점검 간격을 설정합니다. (TimeUnits) |
|
|
| 경로에 대한 허용 목록을 설정합니다. 허용 목록은 승인된 소스 주소에 대한 IP 주소 및 CIDR 범위로 이루어진 공백으로 구분된 목록입니다. 허용 목록에 없는 IP 주소의 요청은 삭제됩니다.
| |
|
| 엣지 종단 경로 또는 재암호화 경로에 Strict-Transport-Security 헤더를 설정합니다. | |
|
| 백엔드의 요청 재작성 경로를 설정합니다. | |
|
| 쿠키를 제한하는 값을 설정합니다. 값은 다음과 같습니다.
이 값은 재암호화 및 엣지 경로에만 적용됩니다. 자세한 내용은 SameSite 쿠키 설명서를 참조하십시오. | |
|
|
라우터당
|
|
-
기본적으로 라우터는 5s마다 다시 로드되어 처음부터 포드 간에 분산 연결을 재설정합니다. 결과적으로
roundrobin상태는 다시 로드해도 유지되지 않습니다. 이 알고리즘은 Pod에 거의 동일한 컴퓨팅 용량 및 스토리지 용량이 있는 경우 가장 잘 작동합니다. 예를 들어 CI/CD 파이프라인을 사용하므로 애플리케이션 또는 서비스에서 끝점을 지속적으로 변경한 경우 분산이 일관되지 않을 수 있습니다. 이 경우 다른 알고리즘을 사용하십시오. 허용 목록의 IP 주소 및 CIDR 범위가 61를 초과하면
haproxy.config파일에서 참조되는 별도의 파일에 작성됩니다. 이 파일은/var/lib/haproxy/router/allowlists폴더에 저장됩니다.참고주소가 허용 목록에 작성되도록 하려면 전체 CIDR 범위가 Ingress 컨트롤러 구성 파일에 나열되어 있는지 확인합니다. etcd 오브젝트 크기 제한은 경로 주석의 크기를 제한합니다. 이로 인해 허용 목록에 포함할 수 있는 최대 IP 주소 및 CIDR 범위에 대한 임계값이 생성됩니다.
환경 변수는 편집할 수 없습니다.
라우터 시간 제한 변수
TimeUnits는 다음과 같이 표시됩니다. us *(마이크로초), ms (밀리초, 기본값), s (초), m (분), h *(시간), d (일).
정규 표현식은 [1-9][0-9]*(us\|ms\|s\|m\|h\|d)입니다.
| Variable | Default | 설명 |
|---|---|---|
|
|
| 백엔드에서 후속 활성 검사 사이의 시간입니다. |
|
|
| 경로에 연결된 클라이언트의 TCP FIN 시간 제한 기간을 제어합니다. FIN이 연결을 닫도록 전송한 경우 지정된 시간 내에 응답하지 않으면 HAProxy가 연결을 종료합니다. 낮은 값으로 설정하면 문제가 없으며 라우터에서 더 적은 리소스를 사용합니다. |
|
|
| 클라이언트가 데이터를 승인하거나 보내야 하는 시간입니다. |
|
|
| 최대 연결 시간입니다. |
|
|
| 라우터에서 경로를 지원하는 pod로의 TCP FIN 시간 초과를 제어합니다. |
|
|
| 서버에서 데이터를 승인하거나 보내야 하는 시간입니다. |
|
|
| TCP 또는 WebSocket 연결이 열린 상태로 유지되는 동안의 시간입니다. 이 시간 제한 기간은 HAProxy를 다시 로드할 때마다 재설정됩니다. |
|
|
|
새 HTTP 요청이 표시될 때까지 대기할 최대 시간을 설정합니다. 이 값을 너무 낮게 설정하면 작은
일부 유효한 시간 제한 값은 예상되는 특정 시간 초과가 아니라 특정 변수의 합계일 수 있습니다. 예를 들어 |
|
|
| HTTP 요청 전송에 걸리는 시간입니다. |
|
|
| 라우터의 최소 빈도가 새 변경 사항을 다시 로드하고 승인하도록 허용합니다. |
|
|
| HAProxy 메트릭 수집에 대한 시간 제한입니다. |
경로 설정 사용자 정의 타임아웃
apiVersion: route.openshift.io/v1
kind: Route
metadata:
annotations:
haproxy.router.openshift.io/timeout: 5500ms
...- 1
- HAProxy 지원 단위(
us,ms,s,m,h,d)를 사용하여 새 타임아웃을 지정합니다. 단위가 제공되지 않는 경우ms가 기본값입니다.
패스스루(passthrough) 경로에 대한 서버 쪽 타임아웃 값을 너무 낮게 설정하면 해당 경로에서 WebSocket 연결이 자주 시간 초과될 수 있습니다.
하나의 특정 IP 주소만 허용하는 경로
metadata:
annotations:
haproxy.router.openshift.io/ip_allowlist: 192.168.1.10여러 IP 주소를 허용하는 경로
metadata:
annotations:
haproxy.router.openshift.io/ip_allowlist: 192.168.1.10 192.168.1.11 192.168.1.12IP 주소 CIDR 네트워크를 허용하는 경로
metadata:
annotations:
haproxy.router.openshift.io/ip_allowlist: 192.168.1.0/24IP 주소 및 IP 주소 CIDR 네트워크를 둘 다 허용하는 경로
metadata:
annotations:
haproxy.router.openshift.io/ip_allowlist: 180.5.61.153 192.168.1.0/24 10.0.0.0/8재작성 대상을 지정하는 경로
apiVersion: route.openshift.io/v1
kind: Route
metadata:
annotations:
haproxy.router.openshift.io/rewrite-target: /
...- 1
/를 백엔드의 요청 재작성 경로로 설정합니다.
경로에 haproxy.router.openshift.io/rewrite-target 주석을 설정하면 Ingress Controller에서 요청을 백엔드 애플리케이션으로 전달하기 전에 이 경로를 사용하여 HTTP 요청의 경로를 재작성해야 합니다. spec.path에 지정된 경로와 일치하는 요청 경로 부분은 주석에 지정된 재작성 대상으로 교체됩니다.
다음 표에 spec.path, 요청 경로, 재작성 대상의 다양한 조합에 따른 경로 재작성 동작의 예가 있습니다.
| Route.spec.path | 요청 경로 | 재작성 대상 | 전달된 요청 경로 |
|---|---|---|---|
| /foo | /foo | / | / |
| /foo | /foo/ | / | / |
| /foo | /foo/bar | / | /bar |
| /foo | /foo/bar/ | / | /bar/ |
| /foo | /foo | /bar | /bar |
| /foo | /foo/ | /bar | /bar/ |
| /foo | /foo/bar | /baz | /baz/bar |
| /foo | /foo/bar/ | /baz | /baz/bar/ |
| /foo/ | /foo | / | N/A(요청 경로가 라우팅 경로와 일치하지 않음) |
| /foo/ | /foo/ | / | / |
| /foo/ | /foo/bar | / | /bar |
haproxy.router.openshift.io/rewrite-target 의 특정 특수 문자는 올바르게 이스케이프해야 하므로 특수 처리가 필요합니다. 이러한 문자를 처리하는 방법을 알아보려면 다음 표를 참조하십시오.
| 문자의 경우 | 문자 사용 | 참고 |
|---|---|---|
| # | \# | #을 사용하지 마십시오. 재작성 표현식이 종료되기 때문입니다. |
| % | % 또는 %% | %%와 같은 홀수 시퀀스를 사용하지 마십시오. |
| ‘ | \’ | 무시될 수 있기 때문에 방지 |
다른 모든 유효한 URL 문자는 이스케이프 없이 사용할 수 있습니다.
9.1.9. Ingress 오브젝트를 통해 기본 인증서를 사용하여 경로 생성
TLS 구성을 지정하지 않고 Ingress 오브젝트를 생성하면 AWS의 Red Hat OpenShift Service가 비보안 경로를 생성합니다. 기본 수신 인증서를 사용하여 에지 종료 보안 경로를 생성하는 Ingress 오브젝트를 생성하려면 다음과 같이 빈 TLS 구성을 지정할 수 있습니다.
사전 요구 사항
- 노출하려는 서비스가 있습니다.
-
OpenShift CLI(
oc)에 액세스할 수 있습니다.
프로세스
Ingress 오브젝트에 대한 YAML 파일을 생성합니다. 이 예제에서는 파일을
example-ingress.yaml이라고 합니다.Ingress 오브젝트의 YAML 정의
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: frontend ... spec: rules: ... tls: - {}1 - 1
- 이 정확한 구문을 사용하여 사용자 정의 인증서를 지정하지 않고 TLS를 지정합니다.
다음 명령을 실행하여 Ingress 오브젝트를 생성합니다.
$ oc create -f example-ingress.yaml
검증
다음 명령을 실행하여 AWS의 Red Hat OpenShift Service가 Ingress 오브젝트에 대한 예상 경로를 생성했는지 확인합니다.
$ oc get routes -o yaml출력 예
apiVersion: v1 items: - apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend-j9sdd1 ... spec: ... tls:2 insecureEdgeTerminationPolicy: Redirect termination: edge3 ...
9.1.10. Ingress 주석의 대상 CA 인증서를 사용하여 경로 생성
route.openshift.io/destination-ca-certificate-secret 주석을 Ingress 오브젝트에서 사용하여 사용자 정의 대상 CA 인증서로 경로를 정의할 수 있습니다.
사전 요구 사항
- PEM 인코딩 파일에 인증서/키 쌍이 있고, 인증서가 경로 호스트에 유효할 수 있습니다.
- 인증서 체인을 완성하는 PEM 인코딩 파일에 별도의 CA 인증서가 있을 수 있습니다.
- PEM 인코딩 파일에 별도의 대상 CA 인증서가 있어야 합니다.
- 노출하려는 서비스가 있어야 합니다.
프로세스
다음 명령을 입력하여 대상 CA 인증서에 대한 보안을 생성합니다.
$ oc create secret generic dest-ca-cert --from-file=tls.crt=<file_path>예를 들면 다음과 같습니다.
$ oc -n test-ns create secret generic dest-ca-cert --from-file=tls.crt=tls.crt출력 예
secret/dest-ca-cert createdIngress 주석에
route.openshift.io/destination-ca-certificate-secret을 추가합니다.apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: frontend annotations: route.openshift.io/termination: "reencrypt" route.openshift.io/destination-ca-certificate-secret: secret-ca-cert1 ...- 1
- 주석은 kubernetes 보안을 참조합니다.
이 주석에서 참조하는 보안은 생성된 경로에 삽입됩니다.
출력 예
apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend annotations: route.openshift.io/termination: reencrypt route.openshift.io/destination-ca-certificate-secret: secret-ca-cert spec: ... tls: insecureEdgeTerminationPolicy: Redirect termination: reencrypt destinationCACertificate: | -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- ...
9.2. 보안 경로
보안 경로는 여러 유형의 TLS 종료를 사용하여 클라이언트에 인증서를 제공하는 기능을 제공합니다. 다음 섹션에서는 사용자 정의 인증서를 사용하여 재암호화 에지 및 패스스루 경로를 생성하는 방법을 설명합니다.
9.2.1. 사용자 정의 인증서를 사용하여 재암호화 경로 생성
oc create route 명령을 사용하면 재암호화 TLS 종료와 사용자 정의 인증서로 보안 경로를 구성할 수 있습니다.
사전 요구 사항
- PEM 인코딩 파일에 인증서/키 쌍이 있고 해당 인증서가 경로 호스트에 유효해야 합니다.
- 인증서 체인을 완성하는 PEM 인코딩 파일에 별도의 CA 인증서가 있을 수 있습니다.
- PEM 인코딩 파일에 별도의 대상 CA 인증서가 있어야 합니다.
- 노출하려는 서비스가 있어야 합니다.
암호로 보호되는 키 파일은 지원되지 않습니다. 키 파일에서 암호를 제거하려면 다음 명령을 사용하십시오.
$ openssl rsa -in password_protected_tls.key -out tls.key프로세스
이 절차에서는 사용자 정의 인증서를 사용하여 Route 리소스를 생성하고 TLS 종료를 재암호화합니다. 다음 예에서는 인증서/키 쌍이 현재 작업 디렉터리의 tls.crt 및 tls.key 파일에 있다고 가정합니다. Ingress 컨트롤러에서 서비스의 인증서를 신뢰하도록 하려면 대상 CA 인증서도 지정해야 합니다. 인증서 체인을 완료하는 데 필요한 경우 CA 인증서를 지정할 수도 있습니다. tls.crt, tls.key, cacert.crt, ca.crt(옵션)에 실제 경로 이름을 사용하십시오. frontend에는 노출하려는 서비스 리소스 이름을 사용합니다. www.example.com을 적절한 호스트 이름으로 바꿉니다.
재암호화 TLS 종료 및 사용자 정의 인증서를 사용하여 보안
Route리소스를 생성합니다.$ oc create route reencrypt --service=frontend --cert=tls.crt --key=tls.key --dest-ca-cert=destca.crt --ca-cert=ca.crt --hostname=www.example.com생성된
Route리소스는 다음과 유사합니다.보안 경로의 YAML 정의
apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend spec: host: www.example.com to: kind: Service name: frontend tls: termination: reencrypt key: |- -----BEGIN PRIVATE KEY----- [...] -----END PRIVATE KEY----- certificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- caCertificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- destinationCACertificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE-----자세한 옵션은
oc create route reencrypt --help를 참조하십시오.
9.2.2. 사용자 정의 인증서를 사용하여 엣지 경로 생성
oc create route 명령을 사용하면 엣지 TLS 종료와 사용자 정의 인증서로 보안 경로를 구성할 수 있습니다. 엣지 경로를 사용하면 Ingress 컨트롤러에서 트래픽을 대상 Pod로 전달하기 전에 TLS 암호화를 종료합니다. 이 경로는 Ingress 컨트롤러가 경로에 사용하는 TLS 인증서 및 키를 지정합니다.
사전 요구 사항
- PEM 인코딩 파일에 인증서/키 쌍이 있고 해당 인증서가 경로 호스트에 유효해야 합니다.
- 인증서 체인을 완성하는 PEM 인코딩 파일에 별도의 CA 인증서가 있을 수 있습니다.
- 노출하려는 서비스가 있어야 합니다.
암호로 보호되는 키 파일은 지원되지 않습니다. 키 파일에서 암호를 제거하려면 다음 명령을 사용하십시오.
$ openssl rsa -in password_protected_tls.key -out tls.key프로세스
이 절차에서는 사용자 정의 인증서 및 엣지 TLS 종료를 사용하여 Route 리소스를 생성합니다. 다음 예에서는 인증서/키 쌍이 현재 작업 디렉터리의 tls.crt 및 tls.key 파일에 있다고 가정합니다. 인증서 체인을 완료하는 데 필요한 경우 CA 인증서를 지정할 수도 있습니다. tls.crt, tls.key, ca.crt(옵션)에 실제 경로 이름을 사용하십시오. frontend에는 노출하려는 서비스 이름을 사용합니다. www.example.com을 적절한 호스트 이름으로 바꿉니다.
엣지 TLS 종료 및 사용자 정의 인증서를 사용하여 보안
Route리소스를 생성합니다.$ oc create route edge --service=frontend --cert=tls.crt --key=tls.key --ca-cert=ca.crt --hostname=www.example.com생성된
Route리소스는 다음과 유사합니다.보안 경로의 YAML 정의
apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend spec: host: www.example.com to: kind: Service name: frontend tls: termination: edge key: |- -----BEGIN PRIVATE KEY----- [...] -----END PRIVATE KEY----- certificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- caCertificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE-----추가 옵션은
oc create route edge --help를 참조하십시오.
9.2.3. 패스스루 라우팅 생성
oc create route 명령을 사용하면 패스스루 종료와 사용자 정의 인증서로 보안 경로를 구성할 수 있습니다. 패스스루 종료를 사용하면 암호화된 트래픽이 라우터에서 TLS 종료를 제공하지 않고 바로 대상으로 전송됩니다. 따라서 라우터에 키 또는 인증서가 필요하지 않습니다.
사전 요구 사항
- 노출하려는 서비스가 있어야 합니다.
프로세스
Route리소스를 생성합니다.$ oc create route passthrough route-passthrough-secured --service=frontend --port=8080생성된
Route리소스는 다음과 유사합니다.패스스루 종료를 사용하는 보안 경로
apiVersion: route.openshift.io/v1 kind: Route metadata: name: route-passthrough-secured1 spec: host: www.example.com port: targetPort: 8080 tls: termination: passthrough2 insecureEdgeTerminationPolicy: None3 to: kind: Service name: frontend대상 Pod는 끝점의 트래픽에 대한 인증서를 제공해야 합니다. 현재 이 방법은 양방향 인증이라고도 하는 클라이언트 인증서도 지원할 수 있는 유일한 방법입니다.
9.2.4. 외부 관리 인증서를 사용하여 경로 생성
TLS 시크릿에서 외부 인증서로 경로를 보호하는 것은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
경로 API의 .spec.tls.externalCertificate 필드를 사용하여 타사 인증서 관리 솔루션을 사용하여 AWS 경로에서 Red Hat OpenShift Service를 구성할 수 있습니다. 시크릿을 통해 외부 관리형 TLS 인증서를 참조할 수 있으므로 수동 인증서 관리가 필요하지 않습니다. 외부 관리형 인증서를 사용하면 인증서 업데이트를 원활하게 롤아웃하는 오류를 줄일 수 있으므로 OpenShift 라우터에서 업데이트된 인증서를 즉시 제공할 수 있습니다.
이 기능은 에지 경로와 재암호화 경로에 모두 적용됩니다.
사전 요구 사항
-
RouteExternalCertificate기능 게이트를 활성화해야 합니다. -
routes/custom-host에 대한생성및업데이트권한이 있어야 합니다. -
tls.key및tls.crt키가 모두 포함된kubernetes.io/tls유형의 PEM 인코딩 형식의 유효한 인증서/키 쌍이 포함된 시크릿이 있어야 합니다. - 참조된 보안을 보안하려는 경로와 동일한 네임스페이스에 배치해야 합니다.
프로세스
다음 명령을 실행하여 라우터 서비스 계정을 읽을 수 있도록 시크릿과 동일한 네임스페이스에
역할을생성합니다.$ oc create role secret-reader --verb=get,list,watch --resource=secrets --resource-name=<secret-name> \1 --namespace=<current-namespace>2 보안과 동일한 네임스페이스에
rolebinding을 생성하고 다음 명령을 실행하여 라우터 서비스 계정을 새로 생성된 역할에 바인딩합니다.$ oc create rolebinding secret-reader-binding --role=secret-reader --serviceaccount=openshift-ingress:router --namespace=<current-namespace>1 - 1
- 시크릿과 경로가 모두 있는 네임스페이스를 지정합니다.
경로를정의하는 YAML 파일을 생성하고 다음 예제를 사용하여 인증서가 포함된 보안을 지정합니다.보안 경로에 대한 YAML 정의
apiVersion: route.openshift.io/v1 kind: Route metadata: name: myedge namespace: test spec: host: myedge-test.apps.example.com tls: externalCertificate: name: <secret-name>1 termination: edge [...] [...]- 1
- 시크릿의 실제 이름을 지정합니다.
다음 명령을 실행하여
경로리소스를 생성합니다.$ oc apply -f <route.yaml>1 - 1
- 생성된 YAML 파일 이름을 지정합니다.
보안이 존재하고 인증서/키 쌍이 있는 경우 라우터는 모든 사전 요구 사항을 충족하는 경우 생성된 인증서를 제공합니다.
.spec.tls.externalCertificate 를 제공하지 않으면 라우터에서 기본 생성된 인증서를 사용합니다.
.spec.tls.externalCertificate 필드를 사용하는 경우 .spec.tls.certificate 필드 또는 .spec.tls.key 필드를 지정할 수 없습니다.
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.