Deployment Guide
Deployment, configuration and administration of Red Hat Enterprise Linux 5
Edition 11
Abstract
Introduction
- Setting up a network interface card (NIC)
- Configuring a Virtual Private Network (VPN)
- Configuring Samba shares
- Managing your software with RPM
- Determining information about your system
- Upgrading your kernel
- File systems
- Package management
- Network-related configuration
- System configuration
- System monitoring
- Kernel and Driver Configuration
- Security and Authentication
- Red Hat Training and Certification
1. Document Conventions
command- Linux commands (and other operating system commands, when used) are represented this way. This style should indicate to you that you can type the word or phrase on the command line and press Enter to invoke a command. Sometimes a command contains words that would be displayed in a different style on their own (such as file names). In these cases, they are considered to be part of the command, so the entire phrase is displayed as a command. For example:Use the
cat testfilecommand to view the contents of a file, namedtestfile, in the current working directory. file name- File names, directory names, paths, and RPM package names are represented this way. This style indicates that a particular file or directory exists with that name on your system. Examples:The
.bashrcfile in your home directory contains bash shell definitions and aliases for your own use.The/etc/fstabfile contains information about different system devices and file systems.Install thewebalizerRPM if you want to use a Web server log file analysis program. - application
- This style indicates that the program is an end-user application (as opposed to system software). For example:Use Mozilla to browse the Web.
- key
- A key on the keyboard is shown in this style. For example:To use Tab completion to list particular files in a directory, type
ls, then a character, and finally the Tab key. Your terminal displays the list of files in the working directory that begin with that character. - key+combination
- A combination of keystrokes is represented in this way. For example:The Ctrl+Alt+Backspace key combination exits your graphical session and returns you to the graphical login screen or the console.
- text found on a GUI interface
- A title, word, or phrase found on a GUI interface screen or window is shown in this style. Text shown in this style indicates a particular GUI screen or an element on a GUI screen (such as text associated with a checkbox or field). Example:Select the Require Password checkbox if you would like your screensaver to require a password before stopping.
- A word in this style indicates that the word is the top level of a pulldown menu. If you click on the word on the GUI screen, the rest of the menu should appear. For example:Under on a GNOME terminal, the option allows you to open multiple shell prompts in the same window.Instructions to type in a sequence of commands from a GUI menu look like the following example:Go to (the main menu on the panel) > > to start the Emacs text editor.
- This style indicates that the text can be found on a clickable button on a GUI screen. For example:Click on the button to return to the webpage you last viewed.
computer output- Text in this style indicates text displayed to a shell prompt such as error messages and responses to commands. For example:The
lscommand displays the contents of a directory. For example:Desktop about.html logs paulwesterberg.png Mail backupfiles mail reports
Desktop about.html logs paulwesterberg.png Mail backupfiles mail reportsCopy to Clipboard Copied! Toggle word wrap Toggle overflow The output returned in response to the command (in this case, the contents of the directory) is shown in this style. prompt- A prompt, which is a computer's way of signifying that it is ready for you to input something, is shown in this style. Examples:
$#[stephen@maturin stephen]$leopard login: user input- Text that the user types, either on the command line or into a text box on a GUI screen, is displayed in this style. In the following example,
textis displayed in this style:To boot your system into the text based installation program, you must type in thetextcommand at theboot:prompt. - <replaceable>
- Text used in examples that is meant to be replaced with data provided by the user is displayed in this style. In the following example, <version-number> is displayed in this style:The directory for the kernel source is
/usr/src/kernels/<version-number>/, where <version-number> is the version and type of kernel installed on this system.
Note
Note
/usr/share/doc/ contains additional documentation for packages installed on your system.
Important
Warning
Warning
2. Send in Your Feedback
http://bugzilla.redhat.com/bugzilla/) against the component Deployment_Guide.
Part I. File Systems
parted utility to manage partitions and access control lists (ACLs) to customize file permissions.
Chapter 1. File System Structure
1.1. Why Share a Common Structure?
- Shareable vs. unshareable files
- Variable vs. static files
1.2. Overview of File System Hierarchy Standard (FHS)
/usr/ partition as read-only. This second point is important because the directory contains common executables and should not be changed by users. Also, since the /usr/ directory is mounted as read-only, it can be mounted from the CD-ROM or from another machine via a read-only NFS mount.
1.2.1. FHS Organization
1.2.1.1. The /boot/ Directory
/boot/ directory contains static files required to boot the system, such as the Linux kernel. These files are essential for the system to boot properly.
Warning
/boot/ directory. Doing so renders the system unbootable.
1.2.1.2. The /dev/ Directory
/dev/ directory contains device nodes that either represent devices that are attached to the system or virtual devices that are provided by the kernel. These device nodes are essential for the system to function properly. The udev daemon takes care of creating and removing all these device nodes in /dev/.
/dev directory and subdirectories are either character (providing only a serial stream of input/output) or block (accessible randomly). Character devices include mouse, keyboard, modem while block devices include hard disk, floppy drive etc. If you have GNOME or KDE installed in your system, devices such as external drives or cds are automatically detected when connected (e.g via usb) or inserted (e.g via CD or DVD drive) and a popup window displaying the contents is automatically displayed. Files in the /dev directory are essential for the system to function properly.
| File | Description |
|---|---|
| /dev/hda | The master device on primary IDE channel. |
| /dev/hdb | The slave device on primary IDE channel. |
| /dev/tty0 | The first virtual console. |
| /dev/tty1 | The second virtual console. |
| /dev/sda | The first device on primary SCSI or SATA channel. |
| /dev/lp0 | The first parallel port. |
1.2.1.3. The /etc/ Directory
/etc/ directory is reserved for configuration files that are local to the machine. No binaries are to be placed in /etc/. Any binaries that were once located in /etc/ should be placed into /sbin/ or /bin/.
/etc are the X11/ and skel/:
/etc |- X11/ |- skel/
/etc
|- X11/
|- skel//etc/X11/ directory is for X Window System configuration files, such as xorg.conf. The /etc/skel/ directory is for "skeleton" user files, which are used to populate a home directory when a user is first created. Applications also store their configuration files in this directory and may reference them when they are executed.
1.2.1.4. The /lib/ Directory
/lib/ directory should contain only those libraries needed to execute the binaries in /bin/ and /sbin/. These shared library images are particularly important for booting the system and executing commands within the root file system.
1.2.1.5. The /media/ Directory
/media/ directory contains subdirectories used as mount points for removable media such as usb storage media, DVDs, CD-ROMs, and Zip disks.
1.2.1.6. The /mnt/ Directory
/mnt/ directory is reserved for temporarily mounted file systems, such as NFS file system mounts. For all removable media, please use the /media/ directory. Automatically detected removable media will be mounted in the /media directory.
Note
/mnt directory must not be used by installation programs.
1.2.1.7. The /opt/ Directory
/opt/ directory provides storage for most application software packages.
/opt/ directory creates a directory bearing the same name as the package. This directory, in turn, holds files that otherwise would be scattered throughout the file system, giving the system administrator an easy way to determine the role of each file within a particular package.
sample is the name of a particular software package located within the /opt/ directory, then all of its files are placed in directories inside the /opt/sample/ directory, such as /opt/sample/bin/ for binaries and /opt/sample/man/ for manual pages.
/opt/ directory, giving that large package a way to organize itself. In this way, our sample package may have different tools that each go in their own sub-directories, such as /opt/sample/tool1/ and /opt/sample/tool2/, each of which can have their own bin/, man/, and other similar directories.
1.2.1.8. The /proc/ Directory
/proc/ directory contains special files that either extract information from or send information to the kernel. Examples include system memory, cpu information, hardware configuration etc.
/proc/ and the many ways this directory can be used to communicate with the kernel, an entire chapter has been devoted to the subject. For more information, refer to Chapter 5, The proc File System.
1.2.1.9. The /sbin/ Directory
/sbin/ directory stores executables used by the root user. The executables in /sbin/ are used at boot time, for system administration and to perform system recovery operations. Of this directory, the FHS says:
/sbincontains binaries essential for booting, restoring, recovering, and/or repairing the system in addition to the binaries in/bin. Programs executed after/usr/is known to be mounted (when there are no problems) are generally placed into/usr/sbin. Locally-installed system administration programs should be placed into/usr/local/sbin.
/sbin/:
1.2.1.10. The /srv/ Directory
/srv/ directory contains site-specific data served by your system running Red Hat Enterprise Linux. This directory gives users the location of data files for a particular service, such as FTP, WWW, or CVS. Data that only pertains to a specific user should go in the /home/ directory.
1.2.1.11. The /sys/ Directory
/sys/ directory utilizes the new sysfs virtual file system specific to the 2.6 kernel. With the increased support for hot plug hardware devices in the 2.6 kernel, the /sys/ directory contains information similarly held in /proc/, but displays a hierarchical view of specific device information in regards to hot plug devices.
1.2.1.12. The /usr/ Directory
/usr/ directory is for files that can be shared across multiple machines. The /usr/ directory is often on its own partition and is mounted read-only. At a minimum, the following directories should be subdirectories of /usr/:
/usr/ directory, the bin/ subdirectory contains executables, etc/ contains system-wide configuration files, games is for games, include/ contains C header files, kerberos/ contains binaries and other Kerberos-related files, and lib/ contains object files and libraries that are not designed to be directly utilized by users or shell scripts. The libexec/ directory contains small helper programs called by other programs, sbin/ is for system administration binaries (those that do not belong in the /sbin/ directory), share/ contains files that are not architecture-specific, src/ is for source code.
1.2.1.13. The /usr/local/ Directory
The/usr/localhierarchy is for use by the system administrator when installing software locally. It needs to be safe from being overwritten when the system software is updated. It may be used for programs and data that are shareable among a group of hosts, but not found in/usr.
/usr/local/ directory is similar in structure to the /usr/ directory. It has the following subdirectories, which are similar in purpose to those in the /usr/ directory:
/usr/local/ directory is slightly different from that specified by the FHS. The FHS says that /usr/local/ should be where software that is to remain safe from system software upgrades is stored. Since software upgrades can be performed safely with RPM Package Manager (RPM), it is not necessary to protect files by putting them in /usr/local/. Instead, the /usr/local/ directory is used for software that is local to the machine.
/usr/ directory is mounted as a read-only NFS share from a remote host, it is still possible to install a package or program under the /usr/local/ directory.
1.2.1.14. The /var/ Directory
/usr/ as read-only, any programs that write log files or need spool/ or lock/ directories should write them to the /var/ directory. The FHS states /var/ is for:
...variable data files. This includes spool directories and files, administrative and logging data, and transient and temporary files.
/var/ directory:
messages and lastlog, go in the /var/log/ directory. The /var/lib/rpm/ directory contains RPM system databases. Lock files go in the /var/lock/ directory, usually in directories for the program using the file. The /var/spool/ directory has subdirectories for programs in which data files are stored.
1.3. Special File Locations Under Red Hat Enterprise Linux
/var/lib/rpm/ directory. For more information on RPM, refer to the chapter Chapter 12, Package Management with RPM.
/var/cache/yum/ directory contains files used by the Package Updater, including RPM header information for the system. This location may also be used to temporarily store RPMs downloaded while updating the system. For more information about Red Hat Network, refer to Chapter 15, Registering a System and Managing Subscriptions.
/etc/sysconfig/ directory. This directory stores a variety of configuration information. Many scripts that run at boot time use the files in this directory. Refer to Chapter 32, The sysconfig Directory for more information about what is within this directory and the role these files play in the boot process.
Chapter 2. Using the mount Command
mount or umount command respectively. This chapter describes the basic usage of these commands, and covers some advanced topics such as moving a mount point or creating shared subtrees.
2.1. Listing Currently Mounted File Systems
mount command with no additional arguments:
mount
mountdevice on directory type type (options)
sysfs, tmpfs, and others. To display only the devices with a certain file system type, supply the -t option on the command line:
mount -t type
mount -t typemount command to list the mounted file systems, see Example 2.1, “Listing Currently Mounted ext3 File Systems”.
Example 2.1. Listing Currently Mounted ext3 File Systems
/ and /boot partitions are formatted to use ext3. To display only the mount points that use this file system, type the following at a shell prompt:
mount -t ext3 /dev/mapper/VolGroup00-LogVol00 on / type ext3 (rw) /dev/vda1 on /boot type ext3 (rw)
~]$ mount -t ext3
/dev/mapper/VolGroup00-LogVol00 on / type ext3 (rw)
/dev/vda1 on /boot type ext3 (rw)2.2. Mounting a File System
mount command in the following form:
mount [option…] device directory
mount [option…] device directorymount command is run, it reads the content of the /etc/fstab configuration file to see if the given file system is listed. This file contains a list of device names and the directory in which the selected file systems should be mounted, as well as the file system type and mount options. Because of this, when you are mounting a file system that is specified in this file, you can use one of the following variants of the command:
mount [option…] directory mount [option…] device
mount [option…] directory
mount [option…] deviceroot, you must have permissions to mount the file system (see Section 2.2.2, “Specifying the Mount Options”).
2.2.1. Specifying the File System Type
mount detects the file system automatically. However, there are certain file systems, such as NFS (Network File System) or CIFS (Common Internet File System), that are not recognized, and need to be specified manually. To specify the file system type, use the mount command in the following form:
mount -t type device directory
mount -t type device directorymount command. For a complete list of all available file system types, consult the relevant manual page as referred to in Section 2.4.1, “Installed Documentation”.
| Type | Description |
|---|---|
ext2 | The ext2 file system. |
ext3 | The ext3 file system. |
ext4 | The ext4 file system. |
iso9660 | The ISO 9660 file system. It is commonly used by optical media, typically CDs. |
jfs | The JFS file system created by IBM. |
nfs | The NFS file system. It is commonly used to access files over the network. |
nfs4 | The NFSv4 file system. It is commonly used to access files over the network. |
ntfs | The NTFS file system. It is commonly used on machines that are running the Windows operating system. |
udf | The UDF file system. It is commonly used by optical media, typically DVDs. |
vfat | The FAT file system. It is commonly used on machines that are running the Windows operating system, and on certain digital media such as USB flash drives or floppy disks. |
Example 2.2. Mounting a USB Flash Drive
/dev/sdc1 device and that the /media/flashdisk/ directory exists, you can mount it to this directory by typing the following at a shell prompt as root:
mount -t vfat /dev/sdc1 /media/flashdisk
~]# mount -t vfat /dev/sdc1 /media/flashdisk2.2.2. Specifying the Mount Options
mount -o options
mount -o optionsmount will incorrectly interpret the values following spaces as additional parameters.
| Option | Description |
|---|---|
async | Allows the asynchronous input/output operations on the file system. |
auto | Allows the file system to be mounted automatically using the mount -a command. |
defaults | Provides an alias for async,auto,dev,exec,nouser,rw,suid. |
exec | Allows the execution of binary files on the particular file system. |
loop | Mounts an image as a loop device. |
noauto | Disallows the automatic mount of the file system using the mount -a command. |
noexec | Disallows the execution of binary files on the particular file system. |
nouser | Disallows an ordinary user (that is, other than root) to mount and unmount the file system. |
remount | Remounts the file system in case it is already mounted. |
ro | Mounts the file system for reading only. |
rw | Mounts the file system for both reading and writing. |
user | Allows an ordinary user (that is, other than root) to mount and unmount the file system. |
Example 2.3. Mounting an ISO Image
/media/cdrom/ directory exists, you can mount the image to this directory by running the following command as root:
mount -o ro,loop Fedora-14-x86_64-Live-Desktop.iso /media/cdrom
~]# mount -o ro,loop Fedora-14-x86_64-Live-Desktop.iso /media/cdrom2.2.3. Sharing Mounts
mount command implements the --bind option that provides a means for duplicating certain mounts. Its usage is as follows:
mount --bind old_directory new_directory
mount --bind old_directory new_directorymount --rbind old_directory new_directory
mount --rbind old_directory new_directory- Shared Mount
- A shared mount allows you to create an exact replica of a given mount point. When a shared mount is created, any mount within the original mount point is reflected in it, and vice versa. To create a shared mount, type the following at a shell prompt:
mount --make-shared mount_point
mount --make-shared mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow Alternatively, you can change the mount type for the selected mount point and all mount points under it:mount --make-rshared mount_point
mount --make-rshared mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow See Example 2.4, “Creating a Shared Mount Point” for an example usage. - Slave Mount
- A slave mount allows you to create a limited duplicate of a given mount point. When a slave mount is created, any mount within the original mount point is reflected in it, but no mount within a slave mount is reflected in its original. To create a slave mount, type the following at a shell prompt:
mount --make-slave mount_point
mount --make-slave mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow Alternatively, you can change the mount type for the selected mount point and all mount points under it:mount --make-rslave mount_point
mount --make-rslave mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow See Example 2.5, “Creating a Slave Mount Point” for an example usage.Example 2.5. Creating a Slave Mount Point
Imagine you want the content of the/mediadirectory to appear in/mntas well, but you do not want any mounts in the/mntdirectory to be reflected in/media. To do so, asroot, first mark the/mediadirectory as “shared”:mount --bind /media /media mount --make-shared /media
~]# mount --bind /media /media ~]# mount --make-shared /mediaCopy to Clipboard Copied! Toggle word wrap Toggle overflow Then create its duplicate in/mnt, but mark it as “slave”:mount --bind /media /mnt mount --make-slave /mnt
~]# mount --bind /media /mnt ~]# mount --make-slave /mntCopy to Clipboard Copied! Toggle word wrap Toggle overflow You can now verify that a mount within/mediaalso appears in/mnt. For example, if you have non-empty media in your CD-ROM drive and the/media/cdrom/directory exists, run the following commands:mount /dev/cdrom /media/cdrom ls /media/cdrom EFI GPL isolinux LiveOS ls /mnt/cdrom EFI GPL isolinux LiveOS
~]# mount /dev/cdrom /media/cdrom ~]# ls /media/cdrom EFI GPL isolinux LiveOS ~]# ls /mnt/cdrom EFI GPL isolinux LiveOSCopy to Clipboard Copied! Toggle word wrap Toggle overflow You can also verify that file systems mounted in the/mntdirectory are not reflected in/media. For instance, if you have a non-empty USB flash drive that uses the/dev/sdc1device plugged in and the/mnt/flashdisk/directory is present, type: :mount /dev/sdc1 /mnt/flashdisk ls /media/flashdisk ls /mnt/flashdisk en-US publican.cfg
~]# mount /dev/sdc1 /mnt/flashdisk ~]# ls /media/flashdisk ~]# ls /mnt/flashdisk en-US publican.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Private Mount
- A private mount allows you to create an ordinary mount. When a private mount is created, no subsequent mounts within the original mount point are reflected in it, and no mount within a private mount is reflected in its original. To create a private mount, type the following at a shell prompt:
mount --make-private mount_point
mount --make-private mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow Alternatively, you can change the mount type for the selected mount point and all mount points under it:mount --make-rprivate mount_point
mount --make-rprivate mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow See Example 2.6, “Creating a Private Mount Point” for an example usage.Example 2.6. Creating a Private Mount Point
Taking into account the scenario in Example 2.4, “Creating a Shared Mount Point”, assume that you have previously created a shared mount point by using the following commands asroot:mount --bind /media /media mount --make-shared /media mount --bind /media /mnt
~]# mount --bind /media /media ~]# mount --make-shared /media ~]# mount --bind /media /mntCopy to Clipboard Copied! Toggle word wrap Toggle overflow To mark the/mntdirectory as “private”, type:mount --make-private /mnt
~]# mount --make-private /mntCopy to Clipboard Copied! Toggle word wrap Toggle overflow You can now verify that none of the mounts within/mediaappears in/mnt. For example, if you have non-empty media in your CD-ROM drive and the/media/cdrom/directory exists, run the following commands:mount /dev/cdrom /media/cdrom ls /media/cdrom EFI GPL isolinux LiveOS ls /mnt/cdrom ~]#
~]# mount /dev/cdrom /media/cdrom ~]# ls /media/cdrom EFI GPL isolinux LiveOS ~]# ls /mnt/cdrom ~]#Copy to Clipboard Copied! Toggle word wrap Toggle overflow You can also verify that file systems mounted in the/mntdirectory are not reflected in/media. For instance, if you have a non-empty USB flash drive that uses the/dev/sdc1device plugged in and the/mnt/flashdisk/directory is present, type:mount /dev/sdc1 /mnt/flashdisk ls /media/flashdisk ls /mnt/flashdisk en-US publican.cfg
~]# mount /dev/sdc1 /mnt/flashdisk ~]# ls /media/flashdisk ~]# ls /mnt/flashdisk en-US publican.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Unbindable Mount
- An unbindable mount allows you to prevent a given mount point from being duplicated whatsoever. To create an unbindable mount, type the following at a shell prompt:
mount --make-unbindable mount_point
mount --make-unbindable mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow Alternatively, you can change the mount type for the selected mount point and all mount points under it:mount --make-runbindable mount_point
mount --make-runbindable mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow See Example 2.7, “Creating an Unbindable Mount Point” for an example usage.Example 2.7. Creating an Unbindable Mount Point
To prevent the/mediadirectory from being shared, asroot, type the following at a shell prompt:mount --bind /media /media mount --make-unbindable /media
~]# mount --bind /media /media ~]# mount --make-unbindable /mediaCopy to Clipboard Copied! Toggle word wrap Toggle overflow This way, any subsequent attempt to make a duplicate of this mount will fail with an error:mount --bind /media /mnt mount: wrong fs type, bad option, bad superblock on /media/, missing code page or other error In some cases useful info is found in syslog - try dmesg | tail or so~]# mount --bind /media /mnt mount: wrong fs type, bad option, bad superblock on /media/, missing code page or other error In some cases useful info is found in syslog - try dmesg | tail or soCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.4. Moving a Mount Point
mount --move old_directory new_directory
mount --move old_directory new_directoryExample 2.8. Moving an Existing NFS Mount Point
/mnt/userdirs/, as root, you can move this mount point to /home by using the following command:
mount --move /mnt/userdirs /home
~]# mount --move /mnt/userdirs /homels /mnt/userdirs ls /home jill joe
~]# ls /mnt/userdirs
~]# ls /home
jill joe2.3. Unmounting a File System
umount command:
umount directory umount device
umount directory
umount deviceroot, you must have permissions to unmount the file system (see Section 2.2.2, “Specifying the Mount Options”). See Example 2.9, “Unmounting a CD” for an example usage.
Important
umount command will fail with an error. To determine which processes are accessing the file system, use the fuser command in the following form:
fuser -m directory
fuser -m directory/media/cdrom/ directory, type:
fuser -m /media/cdrom /media/cdrom: 1793 2013 2022 2435 10532c 10672c
~]$ fuser -m /media/cdrom
/media/cdrom: 1793 2013 2022 2435 10532c 10672cExample 2.9. Unmounting a CD
/media/cdrom/ directory, type the following at a shell prompt:
umount /media/cdrom
~]$ umount /media/cdrom2.4. Additional Resources
2.4.1. Installed Documentation
man 8 mount— The manual page for themountcommand that provides a full documentation on its usage.man 8 umount— The manual page for theumountcommand that provides a full documentation on its usage.man 5 fstab— The manual page providing a thorough description of the/etc/fstabfile format.
2.4.2. Useful Websites
- Shared subtrees — An LWN article covering the concept of shared subtrees.
- sharedsubtree.txt — Extensive documentation that is shipped with the shared subtrees patches.
Chapter 3. The ext3 File System
3.1. Features of ext3
- Availability
- After an unexpected power failure or system crash (also called an unclean system shutdown), each mounted ext2 file system on the machine must be checked for consistency by the
e2fsckprogram. This is a time-consuming process that can delay system boot time significantly, especially with large volumes containing a large number of files. During this time, any data on the volumes is unreachable.The journaling provided by the ext3 file system means that this sort of file system check is no longer necessary after an unclean system shutdown. The only time a consistency check occurs using ext3 is in certain rare hardware failure cases, such as hard drive failures. The time to recover an ext3 file system after an unclean system shutdown does not depend on the size of the file system or the number of files; rather, it depends on the size of the journal used to maintain consistency. The default journal size takes about a second to recover, depending on the speed of the hardware. - Data Integrity
- The ext3 file system prevents loss of data integrity in the event that an unclean system shutdown occurs. The ext3 file system allows you to choose the type and level of protection that your data receives. By default, the ext3 volumes are configured to keep a high level of data consistency with regard to the state of the file system.
- Speed
- Despite writing some data more than once, ext3 has a higher throughput in most cases than ext2 because ext3's journaling optimizes hard drive head motion. You can choose from three journaling modes to optimize speed, but doing so means trade-offs in regards to data integrity if the system was to fail.
- Easy Transition
- It is easy to migrate from ext2 to ext3 and gain the benefits of a robust journaling file system without reformatting. Refer to Section 3.3, “Converting to an ext3 File System” for more on how to perform this task.
3.2. Creating an ext3 File System
- Format the partition with the ext3 file system using
mkfs. - Label the partition using
e2label.
3.3. Converting to an ext3 File System
tune2fs allows you to convert an ext2 filesystem to ext3.
Note
e2fsck utility to check your filesystem before and after using tune2fs. A default installation of Red Hat Enterprise Linux uses ext3 for all file systems.
ext2 filesystem to ext3, log in as root and type the following command in a terminal:
tune2fs -j <block_device>
tune2fs -j <block_device>- A mapped device — A logical volume in a volume group, for example,
/dev/mapper/VolGroup00-LogVol02. - A static device — A traditional storage volume, for example,
/dev/hdbX, where hdb is a storage device name and X is the partition number.
df command to display mounted file systems.
/dev/mapper/VolGroup00-LogVol02
/dev/mapper/VolGroup00-LogVol02mkinitrd program. For information on using the mkinitrd command, type man mkinitrd. Also, make sure your GRUB configuration loads the initrd.
3.4. Reverting to an ext2 File System
umount /dev/mapper/VolGroup00-LogVol02
umount /dev/mapper/VolGroup00-LogVol02tune2fs -O ^has_journal /dev/mapper/VolGroup00-LogVol02
tune2fs -O ^has_journal /dev/mapper/VolGroup00-LogVol02e2fsck -y /dev/mapper/VolGroup00-LogVol02
e2fsck -y /dev/mapper/VolGroup00-LogVol02mount -t ext2 /dev/mapper/VolGroup00-LogVol02 /mount/point
mount -t ext2 /dev/mapper/VolGroup00-LogVol02 /mount/point.journal file at the root level of the partition by changing to the directory where it is mounted and typing:
rm -f .journal
rm -f .journal/etc/fstab file.
Chapter 4. The ext4 File System
4.1. Features of ext4
- Main Features
- The ext4 file system uses extents (as opposed to the traditional block mapping scheme used by ext2 and ext3), which improves performance when using large files and reduces metadata overhead for large files. In addition, ext4 also labels unallocated block groups and inode table sections accordingly, which allows them to be skipped during a file system check. This makes for quicker file system checks, which becomes more beneficial as the file system grows in size.
- Allocation Features
- The ext4 file system features the following allocation schemes:
- Persistent pre-allocation
- Delayed allocation
- Multi-block allocation
- Stripe-aware allocation
Because of delayed allocation and other performance optimizations, ext4's behavior of writing files to disk is different from ext3. In ext4, a program's writes to the file system are not guaranteed to be on-disk unless the program issues anfsync()call afterwards.By default, ext3 automatically forces newly created files to disk almost immediately even withoutfsync(). This behavior hid bugs in programs that did not usefsync()to ensure that written data was on-disk. The ext4 file system, on the other hand, often waits several seconds to write out changes to disk, allowing it to combine and reorder writes for better disk performance than ext3.Warning
Unlike ext3, the ext4 file system does not force data to disk on transaction commit. As such, it takes longer for buffered writes to be flushed to disk. As with any file system, use data integrity calls such asfsync()to ensure that data is written to permanent storage. - Other ext4 Features
- The ext4 file system also supports the following:
- Extended attributes (
xattr), which allows the system to associate several additional name/value pairs per file. - Quota journaling, which avoids the need for lengthy quota consistency checks after a crash.
Note
The only supported journaling mode in ext4 isdata=ordered(default). - Subsecond timestamps, which allow to specify inode timestamp fields in nanosecond resolution.
4.2. Managing an ext4 File System
yum install e4fsprogs
~]# yum install e4fsprogsmke4fs— A utility used to create an ext4 file system.mkfs.ext4— Another command used to create an ext4 file system.e4fsck— A utility used to repair inconsistencies of an ext4 file system.tune4fs— A utility used to modify ext4 file system attributes.resize4fs— A utility used to resize an ext4 file system.e4label— A utility used to display or modify the label of the ext4 file system.dumpe4fs— A utility used to display the super block and blocks group information for the ext4 file system.debuge4fs— An interactive file system debugger, used to examine ext4 file systems, manually repair corrupted file systems and create test cases fore4fsck.
4.3. Creating an ext4 File System
mke4fs and mkfs.ext4 commands for available options. Also, you may want to examine and modify the configuration file of mke4fs, /etc/mke4fs.conf, if you plan to create ext4 file systems more often.
- Format the partition with the ext4 file system using the
mkfs.ext4ormke4fscommand:mkfs.ext4 block_device
~]# mkfs.ext4 block_deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow mke4fs -t ext4 block_device
~]# mke4fs -t ext4 block_deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow where block_device is a partition which will contain the ext4 filesystem you wish to create. - Label the partition using the
e4labelcommand.e4label <block_device> new-label
~]# e4label <block_device> new-labelCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Create a mount point and mount the new file system to that mount point:
mkdir /mount/point mount block_device /mount/point
~]# mkdir /mount/point ~]# mount block_device /mount/pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow
- A mapped device — A logical volume in a volume group, for example,
/dev/mapper/VolGroup00-LogVol02. - A static device — A traditional storage volume, for example,
/dev/hdbX, where hdb is a storage device name and X is the partition number.
mkfs.ext4 chooses an optimal geometry. This may also be true on some hardware RAIDs which export geometry information to the operating system.
-E option of mkfs.ext4 (that is, extended file system options) with the following sub-options:
- stride=value
- Specifies the RAID chunk size.
- stripe-width=value
- Specifies the number of data disks in a RAID device, or the number of stripe units in the stripe.
value must be specified in file system block units. For example, to create a file system with a 64k stride (that is, 16 x 4096) on a 4k-block file system, use the following command:
mkfs.ext4 -E stride=16,stripe-width=64 block_device
~]# mkfs.ext4 -E stride=16,stripe-width=64 block_deviceman mkfs.ext4.
4.4. Mounting an ext4 File System
mount block_device /mount/point
~]# mount block_device /mount/pointacl, noacl, data, quota, noquota, user_xattr, nouser_xattr, and many others that were already used with the ext2 and ext3 file systems, are backward compatible and have the same usage and functionality. Also, with the ext4 file system, several new ext4-specific mount options have been added, for example:
- barrier / nobarrier
- By default, ext4 uses write barriers to ensure file system integrity even when power is lost to a device with write caches enabled. For devices without write caches, or with battery-backed write caches, you disable barriers using the
nobarrieroption:mount -o nobarrier block_device /mount/point
~]# mount -o nobarrier block_device /mount/pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow - stripe=value
- This option allows you to specify the number of file system blocks allocated for a single file operation. For RAID5 this number should be equal the RAID chunk size multiplied by the number of disks.
- journal_ioprio=value
- This option allows you to set priority of I/O operations submitted during a commit operation. The option can have a value from 7 to 0 (0 is the highest priority), and is set to 3 by default, which is slightly higher priority than the default I/O priority.
tune4fs utility. For example, the following command sets the file system on the /dev/mapper/VolGroup00-LogVol02 device to be mounted by default with debugging disabled and user-specified extended attributes and Posix access control lists enabled:
tune4fs -o ^debug,user_xattr,acl /dev/mapper/VolGroup00-LogVol02
~]# tune4fs -o ^debug,user_xattr,acl /dev/mapper/VolGroup00-LogVol02tune4fs(8) manual page.
mount -t ext4 block_device /mount/point
~]# mount -t ext4 block_device /mount/pointdelayed allocation and multi-block allocation, and exclude features such as extent mapping.
Warning
mount(8) manual page.
Note
/etc/fstab file accordingly. For example:
/dev/mapper/VolGroup00-LogVol02 /test ext4 defaults 0 0
/dev/mapper/VolGroup00-LogVol02 /test ext4 defaults 0 04.5. Resizing an ext4 File System
resize4fs command:
resize4fs block_devicenew_size
~]# resize4fs block_devicenew_sizeresize2fs utility reads the size in units of file system block size, unless a suffix indicating a specific unit is used. The following suffixes indicate specific units:
s— 512 byte sectorsK— kilobytesM— megabytesG— gigabytes
size parameter is optional (and often redundant) when expanding. The resize4fs automatically expands to fill all available space of the container, usually a logical volume or partition. For more information about resizing an ext4 file system, refer to the resize4fs(8) manual page.
Chapter 5. The proc File System
/proc/ directory — also called the proc file system — contains a hierarchy of special files which represent the current state of the kernel — allowing applications and users to peer into the kernel's view of the system.
/proc/ directory, one can find a wealth of information detailing the system hardware and any processes currently running. In addition, some of the files within the /proc/ directory tree can be manipulated by users and applications to communicate configuration changes to the kernel.
5.1. A Virtual File System
/proc/ directory contains another type of file called a virtual file. It is for this reason that /proc/ is often referred to as a virtual file system.
/proc/interrupts, /proc/meminfo, /proc/mounts, and /proc/partitions provide an up-to-the-moment glimpse of the system's hardware. Others, like the /proc/filesystems file and the /proc/sys/ directory provide system configuration information and interfaces.
/proc/ide/ contains information for all physical IDE devices. Likewise, process directories contain information about each running process on the system.
5.1.1. Viewing Virtual Files
cat, more, or less commands on files within the /proc/ directory, users can immediately access enormous amounts of information about the system. For example, to display the type of CPU a computer has, type cat /proc/cpuinfo to receive output similar to the following:
/proc/ file system, some of the information is easily understandable while some is not human-readable. This is in part why utilities exist to pull data from virtual files and display it in a useful way. Examples of these utilities include lspci, apm, free, and top.
Note
/proc/ directory are readable only by the root user.
5.1.2. Changing Virtual Files
/proc/ directory are read-only. However, some can be used to adjust settings in the kernel. This is especially true for files in the /proc/sys/ subdirectory.
echo command and a greater than symbol (>) to redirect the new value to the file. For example, to change the hostname on the fly, type:
echo www.example.com > /proc/sys/kernel/hostname
echo www.example.com > /proc/sys/kernel/hostname cat /proc/sys/net/ipv4/ip_forward returns either a 0 or a 1. A 0 indicates that the kernel is not forwarding network packets. Using the echo command to change the value of the ip_forward file to 1 immediately turns packet forwarding on.
Note
/proc/sys/ subdirectory is /sbin/sysctl. For more information on this command, refer to Section 5.4, “Using the sysctl Command”
/proc/sys/ subdirectory, refer to Section 5.3.9, “ /proc/sys/ ”.
5.1.3. Restricting Access to Process Directories
/proc/ so that they can be viewed only by the root user. You can restrict the access to these directories with the use of the hidepid option.
mount command with the -o remount option. As root, type:
mount -o remount,hidepid=value /proc
mount -o remount,hidepid=value /prochidepid is one of:
0(default) — every user can read all world-readable files stored in a process directory.1— users can access only their own process directories. This protects the sensitive files likecmdline,sched, orstatusfrom access by non-root users. This setting does not affect the actual file permissions.2— process files are invisible to non-root users. The existence of a process can be learned by other means, but its effective UID and GID is hidden. Hiding these IDs complicates an intruder's task of gathering information about running processes.
Example 5.1. Restricting access to process directories
root user, type:
mount -o remount,hidepid=1 /proc
~]# mount -o remount,hidepid=1 /prochidepid=1, a non-root user cannot access the contents of process directories. An attempt to do so fails with the following message:
ls /proc/1/ ls: /proc/1/: Operation not permitted
~]$ ls /proc/1/
ls: /proc/1/: Operation not permitted
hidepid=2 enabled, process directories are made invisible to non-root users:
ls /proc/1/ ls: /proc/1/: No such file or directory
~]$ ls /proc/1/
ls: /proc/1/: No such file or directory
hidepid is set to 1 or 2. To do this, use the gid option. As root, type:
mount -o remount,hidepid=value,gid=gid /proc
mount -o remount,hidepid=value,gid=gid /prochidepid was set to 0. However, users which are not supposed to monitor the tasks in the whole system should not be added to the group. For more information on managing users and groups see Chapter 37, Users and Groups.
5.2. Top-level Files within the proc File System
/proc/ directory.
Note
5.2.1. /proc/apm
apm command. If a system with no battery is connected to an AC power source, this virtual file would look similar to the following:
1.16 1.2 0x07 0x01 0xff 0x80 -1% -1 ?
1.16 1.2 0x07 0x01 0xff 0x80 -1% -1 ?apm -v command on such a system results in output similar to the following:
APM BIOS 1.2 (kernel driver 1.16ac) AC on-line, no system battery
APM BIOS 1.2 (kernel driver 1.16ac) AC on-line, no system batteryapm is able do little more than put the machine in standby mode. The apm command is much more useful on laptops. For example, the following output is from the command cat /proc/apm on a laptop while plugged into a power outlet:
1.16 1.2 0x03 0x01 0x03 0x09 100% -1 ?
1.16 1.2 0x03 0x01 0x03 0x09 100% -1 ?apm file changes to something like the following:
1.16 1.2 0x03 0x00 0x00 0x01 99% 1792 min
1.16 1.2 0x03 0x00 0x00 0x01 99% 1792 minapm -v command now yields more useful data, such as the following:
APM BIOS 1.2 (kernel driver 1.16) AC off-line, battery status high: 99% (1 day, 5:52)
APM BIOS 1.2 (kernel driver 1.16) AC off-line, battery status high: 99% (1 day, 5:52)5.2.2. /proc/buddyinfo
DMA row references the first 16 MB on a system, the HighMem row references all memory greater than 4 GB on a system, and the Normal row references all memory in between.
/proc/buddyinfo:
Node 0, zone DMA 90 6 2 1 1 ... Node 0, zone Normal 1650 310 5 0 0 ... Node 0, zone HighMem 2 0 0 1 1 ...
Node 0, zone DMA 90 6 2 1 1 ...
Node 0, zone Normal 1650 310 5 0 0 ...
Node 0, zone HighMem 2 0 0 1 1 ...5.2.3. /proc/cmdline
/proc/cmdline file looks like the following:
ro root=/dev/VolGroup00/LogVol00 rhgb quiet 3
ro root=/dev/VolGroup00/LogVol00 rhgb quiet 3- ro
- The root device is mounted read-only at boot time. The presence of
roon the kernel boot line overrides any instances ofrw. - root=/dev/VolGroup00/LogVol00
- This tells us on which disk device or, in this case, on which logical volume, the root filesystem image is located. With our sample
/proc/cmdlineoutput, the root filesystem image is located on the first logical volume (LogVol00) of the first LVM volume group (VolGroup00). On a system not using Logical Volume Management, the root file system might be located on/dev/sda1or/dev/sda2, meaning on either the first or second partition of the first SCSI or SATA disk drive, depending on whether we have a separate (preceding) boot or swap partition on that drive.For more information on LVM used in Red Hat Enterprise Linux, refer to http://www.tldp.org/HOWTO/LVM-HOWTO/index.html. - rhgb
- A short lowercase acronym that stands for Red Hat Graphical Boot, providing "rhgb" on the kernel command line signals that graphical booting is supported, assuming that
/etc/inittabshows that the default runlevel is set to 5 with a line like this:id:5:initdefault:
id:5:initdefault:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - quiet
- Indicates that all verbose kernel messages except those which are extremely serious should be suppressed at boot time.
5.2.4. /proc/cpuinfo
/proc/cpuinfo:
processor— Provides each processor with an identifying number. On systems that have one processor, only a0is present.cpu family— Authoritatively identifies the type of processor in the system. For an Intel-based system, place the number in front of "86" to determine the value. This is particularly helpful for those attempting to identify the architecture of an older system such as a 586, 486, or 386. Because some RPM packages are compiled for each of these particular architectures, this value also helps users determine which packages to install.model name— Displays the common name of the processor, including its project name.cpu MHz— Shows the precise speed in megahertz for the processor to the thousandths decimal place.cache size— Displays the amount of level 2 memory cache available to the processor.siblings— Displays the number of sibling CPUs on the same physical CPU for architectures which use hyper-threading.flags— Defines a number of different qualities about the processor, such as the presence of a floating point unit (FPU) and the ability to process MMX instructions.
5.2.5. /proc/crypto
/proc/crypto file looks like the following:
5.2.6. /proc/devices
/proc/devices includes the major number and name of the device, and is broken into two major sections: Character devices and Block devices.
- Character devices do not require buffering. Block devices have a buffer available, allowing them to order requests before addressing them. This is important for devices designed to store information — such as hard drives — because the ability to order the information before writing it to the device allows it to be placed in a more efficient order.
- Character devices send data with no preconfigured size. Block devices can send and receive information in blocks of a size configured per device.
/usr/share/doc/kernel-doc-<version>/Documentation/devices.txt
/usr/share/doc/kernel-doc-<version>/Documentation/devices.txt5.2.7. /proc/dma
/proc/dma files looks like the following:
4: cascade
4: cascade5.2.8. /proc/execdomains
0-0 Linux [kernel]
0-0 Linux [kernel]PER_LINUX execution domain, different personalities can be implemented as dynamically loadable modules.
5.2.9. /proc/fb
/proc/fb for systems which contain frame buffer devices looks similar to the following:
0 VESA VGA
0 VESA VGA5.2.10. /proc/filesystems
/proc/filesystems file looks similar to the following:
nodev are not mounted on a device. The second column lists the names of the file systems supported.
mount command cycles through the file systems listed here when one is not specified as an argument.
5.2.11. /proc/interrupts
/proc/interrupts looks similar to the following:
XT-PIC— This is the old AT computer interrupts.IO-APIC-edge— The voltage signal on this interrupt transitions from low to high, creating an edge, where the interrupt occurs and is only signaled once. This kind of interrupt, as well as theIO-APIC-levelinterrupt, are only seen on systems with processors from the 586 family and higher.IO-APIC-level— Generates interrupts when its voltage signal is high until the signal is low again.
5.2.12. /proc/iomem
5.2.13. /proc/ioports
/proc/ioports provides a list of currently registered port regions used for input or output communication with a device. This file can be quite long. The following is a partial listing:
5.2.14. /proc/kcore
/proc/ files, kcore displays a size. This value is given in bytes and is equal to the size of the physical memory (RAM) used plus 4 KB.
gdb, and is not human readable.
Warning
/proc/kcore virtual file. The contents of the file scramble text output on the terminal. If this file is accidentally viewed, press Ctrl+C to stop the process and then type reset to bring back the command line prompt.
5.2.15. /proc/kmsg
/sbin/klogd or /bin/dmesg.
5.2.16. /proc/loadavg
uptime and other commands. A sample /proc/loadavg file looks similar to the following:
0.20 0.18 0.12 1/80 11206
0.20 0.18 0.12 1/80 112065.2.17. /proc/locks
/proc/locks file for a lightly loaded system looks similar to the following:
FLOCK signifying the older-style UNIX file locks from a flock system call and POSIX representing the newer POSIX locks from the lockf system call.
ADVISORY or MANDATORY. ADVISORY means that the lock does not prevent other people from accessing the data; it only prevents other attempts to lock it. MANDATORY means that no other access to the data is permitted while the lock is held. The fourth column reveals whether the lock is allowing the holder READ or WRITE access to the file. The fifth column shows the ID of the process holding the lock. The sixth column shows the ID of the file being locked, in the format of MAJOR-DEVICE:MINOR-DEVICE:INODE-NUMBER . The seventh and eighth column shows the start and end of the file's locked region.
5.2.18. /proc/mdstat
/proc/mdstat looks similar to the following:
Personalities : read_ahead not set unused devices: <none>
Personalities : read_ahead not set unused devices: <none>md device is present. In that case, view /proc/mdstat to find the current status of mdX RAID devices.
/proc/mdstat file below shows a system with its md0 configured as a RAID 1 device, while it is currently re-syncing the disks:
Personalities : [linear] [raid1] read_ahead 1024 sectors md0: active raid1 sda2[1] sdb2[0] 9940 blocks [2/2] [UU] resync=1% finish=12.3min algorithm 2 [3/3] [UUU] unused devices: <none>
Personalities : [linear] [raid1] read_ahead 1024 sectors
md0: active raid1 sda2[1] sdb2[0] 9940 blocks [2/2] [UU] resync=1% finish=12.3min algorithm 2 [3/3] [UUU]
unused devices: <none>5.2.19. /proc/meminfo
/proc/ directory, as it reports a large amount of valuable information about the systems RAM usage.
/proc/meminfo virtual file is from a system with 256 MB of RAM and 512 MB of swap space:
free, top, and ps commands. In fact, the output of the free command is similar in appearance to the contents and structure of /proc/meminfo. But by looking directly at /proc/meminfo, more details are revealed:
MemTotal— Total amount of physical RAM, in kilobytes.MemFree— The amount of physical RAM, in kilobytes, left unused by the system.Buffers— The amount of physical RAM, in kilobytes, used for file buffers.Cached— The amount of physical RAM, in kilobytes, used as cache memory.SwapCached— The amount of swap, in kilobytes, used as cache memory.Active— The total amount of buffer or page cache memory, in kilobytes, that is in active use. This is memory that has been recently used and is usually not reclaimed for other purposes.Inactive— The total amount of buffer or page cache memory, in kilobytes, that are free and available. This is memory that has not been recently used and can be reclaimed for other purposes.HighTotalandHighFree— The total and free amount of memory, in kilobytes, that is not directly mapped into kernel space. TheHighTotalvalue can vary based on the type of kernel used.LowTotalandLowFree— The total and free amount of memory, in kilobytes, that is directly mapped into kernel space. TheLowTotalvalue can vary based on the type of kernel used.SwapTotal— The total amount of swap available, in kilobytes.SwapFree— The total amount of swap free, in kilobytes.Dirty— The total amount of memory, in kilobytes, waiting to be written back to the disk.Writeback— The total amount of memory, in kilobytes, actively being written back to the disk.Mapped— The total amount of memory, in kilobytes, which have been used to map devices, files, or libraries using themmapcommand.Slab— The total amount of memory, in kilobytes, used by the kernel to cache data structures for its own use.Committed_AS— The total amount of memory, in kilobytes, estimated to complete the workload. This value represents the worst case scenario value, and also includes swap memory.PageTables— The total amount of memory, in kilobytes, dedicated to the lowest page table level.VMallocTotal— The total amount of memory, in kilobytes, of total allocated virtual address space.VMallocUsed— The total amount of memory, in kilobytes, of used virtual address space.VMallocChunk— The largest contiguous block of memory, in kilobytes, of available virtual address space.HugePages_Total— The total number of hugepages for the system. The number is derived by dividingHugepagesizeby the megabytes set aside for hugepages specified in/proc/sys/vm/hugetlb_pool. This statistic only appears on the x86, Itanium, and AMD64 architectures.HugePages_Free— The total number of hugepages available for the system. This statistic only appears on the x86, Itanium, and AMD64 architectures.Hugepagesize— The size for each hugepages unit in kilobytes. By default, the value is 4096 KB on uniprocessor kernels for 32 bit architectures. For SMP, hugemem kernels, and AMD64, the default is 2048 KB. For Itanium architectures, the default is 262144 KB. This statistic only appears on the x86, Itanium, and AMD64 architectures.
5.2.20. /proc/misc
63 device-mapper 175 agpgart 135 rtc 134 apm_bios
63 device-mapper 175 agpgart 135 rtc 134 apm_bios5.2.21. /proc/modules
/proc/modules file output:
Note
/sbin/lsmod command.
Live, Loading, or Unloading are the only possible values.
oprofile.
5.2.22. /proc/mounts
/etc/mtab, except that /proc/mount is more up-to-date.
ro) or read-write (rw). The fifth and sixth columns are dummy values designed to match the format used in /etc/mtab.
5.2.23. /proc/mtrr
/proc/mtrr file may look similar to the following:
reg00: base=0x00000000 ( 0MB), size= 256MB: write-back, count=1 reg01: base=0xe8000000 (3712MB), size= 32MB: write-combining, count=1
reg00: base=0x00000000 ( 0MB), size= 256MB: write-back, count=1
reg01: base=0xe8000000 (3712MB), size= 32MB: write-combining, count=1/proc/mtrr file can increase performance more than 150%.
/usr/share/doc/kernel-doc-<version>/Documentation/mtrr.txt
/usr/share/doc/kernel-doc-<version>/Documentation/mtrr.txt5.2.24. /proc/partitions
major— The major number of the device with this partition. The major number in the/proc/partitions, (3), corresponds with the block deviceide0, in/proc/devices.minor— The minor number of the device with this partition. This serves to separate the partitions into different physical devices and relates to the number at the end of the name of the partition.#blocks— Lists the number of physical disk blocks contained in a particular partition.name— The name of the partition.
5.2.25. /proc/pci
/proc/pci can be rather long. A sampling of this file from a basic system looks similar to the following:
Note
lspci -vb
lspci -vb5.2.26. /proc/slabinfo
/proc/slabinfo file manually, the /usr/bin/slabtop program displays kernel slab cache information in real time. This program allows for custom configurations, including column sorting and screen refreshing.
/usr/bin/slabtop usually looks like the following example:
/proc/slabinfo that are included into /usr/bin/slabtop include:
OBJS— The total number of objects (memory blocks), including those in use (allocated), and some spares not in use.ACTIVE— The number of objects (memory blocks) that are in use (allocated).USE— Percentage of total objects that are active. ((ACTIVE/OBJS)(100))OBJ SIZE— The size of the objects.SLABS— The total number of slabs.OBJ/SLAB— The number of objects that fit into a slab.CACHE SIZE— The cache size of the slab.NAME— The name of the slab.
/usr/bin/slabtop program, refer to the slabtop man page.
5.2.27. /proc/stat
/proc/stat, which can be quite long, usually begins like the following example:
cpu— Measures the number of jiffies (1/100 of a second for x86 systems) that the system has been in user mode, user mode with low priority (nice), system mode, idle task, I/O wait, IRQ (hardirq), and softirq respectively. The IRQ (hardirq) is the direct response to a hardware event. The IRQ takes minimal work for queuing the "heavy" work up for the softirq to execute. The softirq runs at a lower priority than the IRQ and therefore may be interrupted more frequently. The total for all CPUs is given at the top, while each individual CPU is listed below with its own statistics. The following example is a 4-way Intel Pentium Xeon configuration with multi-threading enabled, therefore showing four physical processors and four virtual processors totaling eight processors.page— The number of memory pages the system has written in and out to disk.swap— The number of swap pages the system has brought in and out.intr— The number of interrupts the system has experienced.btime— The boot time, measured in the number of seconds since January 1, 1970, otherwise known as the epoch.
5.2.28. /proc/swaps
/proc/swaps may look similar to the following:
Filename Type Size Used Priority /dev/mapper/VolGroup00-LogVol01 partition 524280 0 -1
Filename Type Size Used Priority
/dev/mapper/VolGroup00-LogVol01 partition 524280 0 -1/proc/ directory, /proc/swaps provides a snapshot of every swap file name, the type of swap space, the total size, and the amount of space in use (in kilobytes). The priority column is useful when multiple swap files are in use. The lower the priority, the more likely the swap file is to be used.
5.2.29. /proc/sysrq-trigger
echo command to write to this file, a remote root user can execute most System Request Key commands remotely as if at the local terminal. To echo values to this file, the /proc/sys/kernel/sysrq must be set to a value other than 0. For more information about the System Request Key, refer to Section 5.3.9.3, “ /proc/sys/kernel/ ”.
5.2.30. /proc/uptime
/proc/uptime is quite minimal:
350735.47 234388.90
350735.47 234388.905.2.31. /proc/version
gcc in use, as well as the version of Red Hat Enterprise Linux installed on the system:
Linux version 2.6.8-1.523 (user@foo.redhat.com) (gcc version 3.4.1 20040714 \ (Red Hat Enterprise Linux 3.4.1-7)) #1 Mon Aug 16 13:27:03 EDT 2004
Linux version 2.6.8-1.523 (user@foo.redhat.com) (gcc version 3.4.1 20040714 \ (Red Hat Enterprise Linux 3.4.1-7)) #1 Mon Aug 16 13:27:03 EDT 20045.3. Directories within /proc/
/proc/ directory.
5.3.1. Process Directories
/proc/ directory contains a number of directories with numerical names. A listing of them may be similar to the following:
/proc/ process directory vanishes.
cmdline— Contains the command issued when starting the process.cwd— A symbolic link to the current working directory for the process.environ— A list of the environment variables for the process. The environment variable is given in all upper-case characters, and the value is in lower-case characters.exe— A symbolic link to the executable of this process.fd— A directory containing all of the file descriptors for a particular process. These are given in numbered links:Copy to Clipboard Copied! Toggle word wrap Toggle overflow maps— A list of memory maps to the various executables and library files associated with this process. This file can be rather long, depending upon the complexity of the process, but sample output from thesshdprocess begins like the following:Copy to Clipboard Copied! Toggle word wrap Toggle overflow mem— The memory held by the process. This file cannot be read by the user.root— A link to the root directory of the process.stat— The status of the process.statm— The status of the memory in use by the process. Below is a sample/proc/statmfile:263 210 210 5 0 205 0
263 210 210 5 0 205 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow The seven columns relate to different memory statistics for the process. From left to right, they report the following aspects of the memory used:- Total program size, in kilobytes.
- Size of memory portions, in kilobytes.
- Number of pages that are shared.
- Number of pages that are code.
- Number of pages of data/stack.
- Number of library pages.
- Number of dirty pages.
status— The status of the process in a more readable form thanstatorstatm. Sample output forsshdlooks similar to the following:Copy to Clipboard Copied! Toggle word wrap Toggle overflow The information in this output includes the process name and ID, the state (such asS (sleeping)orR (running)), user/group ID running the process, and detailed data regarding memory usage.
5.3.1.1. /proc/self/
/proc/self/ directory is a link to the currently running process. This allows a process to look at itself without having to know its process ID.
/proc/self/ directory produces the same contents as listing the process directory for that process.
5.3.2. /proc/bus/
/proc/bus/ by the same name, such as /proc/bus/pci/.
/proc/bus/ vary depending on the devices connected to the system. However, each bus type has at least one directory. Within these bus directories are normally at least one subdirectory with a numerical name, such as 001, which contain binary files.
/proc/bus/usb/ subdirectory contains files that track the various devices on any USB buses, as well as the drivers required for them. The following is a sample listing of a /proc/bus/usb/ directory:
total 0 dr-xr-xr-x 1 root root 0 May 3 16:25 001 -r--r--r-- 1 root root 0 May 3 16:25 devices -r--r--r-- 1 root root 0 May 3 16:25 drivers
total 0 dr-xr-xr-x 1 root root 0 May 3 16:25 001
-r--r--r-- 1 root root 0 May 3 16:25 devices
-r--r--r-- 1 root root 0 May 3 16:25 drivers/proc/bus/usb/001/ directory contains all devices on the first USB bus and the devices file identifies the USB root hub on the motherboard.
/proc/bus/usb/devices file:
5.3.3. /proc/driver/
rtc which provides output from the driver for the system's Real Time Clock (RTC), the device that keeps the time while the system is switched off. Sample output from /proc/driver/rtc looks like the following:
/usr/share/doc/kernel-doc-<version>/Documentation/rtc.txt.
5.3.4. /proc/fs
cat /proc/fs/nfsd/exports displays the file systems being shared and the permissions granted for those file systems. For more on file system sharing with NFS, refer to Chapter 21, Network File System (NFS).
5.3.5. /proc/ide/
/proc/ide/ide0 and /proc/ide/ide1. In addition, a drivers file is available, providing the version number of the various drivers used on the IDE channels:
ide-floppy version 0.99. newide ide-cdrom version 4.61 ide-disk version 1.18
ide-floppy version 0.99.
newide ide-cdrom version 4.61
ide-disk version 1.18/proc/ide/piix file which reveals whether DMA or UDMA is enabled for the devices on the IDE channels:
ide0, provides additional information. The channel file provides the channel number, while the model identifies the bus type for the channel (such as pci).
5.3.5.1. Device Directories
/dev/ directory. For instance, the first IDE drive on ide0 would be hda.
Note
/proc/ide/ directory.
cache— The device cache.capacity— The capacity of the device, in 512 byte blocks.driver— The driver and version used to control the device.geometry— The physical and logical geometry of the device.media— The type of device, such as adisk.model— The model name or number of the device.settings— A collection of current device parameters. This file usually contains quite a bit of useful, technical information. A samplesettingsfile for a standard IDE hard disk looks similar to the following:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.3.6. /proc/irq/
/proc/irq/prof_cpu_mask file is a bitmask that contains the default values for the smp_affinity file in the IRQ directory. The values in smp_affinity specify which CPUs handle that particular IRQ.
/proc/irq/ directory, refer to the following installed documentation:
/usr/share/doc/kernel-doc-<version>/Documentation/filesystems/proc.txt
/usr/share/doc/kernel-doc-<version>/Documentation/filesystems/proc.txt5.3.7. /proc/net/
/proc/net/ directory:
arp— Lists the kernel's ARP table. This file is particularly useful for connecting a hardware address to an IP address on a system.atm/directory — The files within this directory contain Asynchronous Transfer Mode (ATM) settings and statistics. This directory is primarily used with ATM networking and ADSL cards.dev— Lists the various network devices configured on the system, complete with transmit and receive statistics. This file displays the number of bytes each interface has sent and received, the number of packets inbound and outbound, the number of errors seen, the number of packets dropped, and more.dev_mcast— Lists Layer2 multicast groups on which each device is listening.igmp— Lists the IP multicast addresses which this system joined.ip_conntrack— Lists tracked network connections for machines that are forwarding IP connections.ip_tables_names— Lists the types ofiptablesin use. This file is only present ifiptablesis active on the system and contains one or more of the following values:filter,mangle, ornat.ip_mr_cache— Lists the multicast routing cache.ip_mr_vif— Lists multicast virtual interfaces.netstat— Contains a broad yet detailed collection of networking statistics, including TCP timeouts, SYN cookies sent and received, and much more.psched— Lists global packet scheduler parameters.raw— Lists raw device statistics.route— Lists the kernel's routing table.rt_cache— Contains the current routing cache.snmp— List of Simple Network Management Protocol (SNMP) data for various networking protocols in use.sockstat— Provides socket statistics.tcp— Contains detailed TCP socket information.tr_rif— Lists the token ring RIF routing table.udp— Contains detailed UDP socket information.unix— Lists UNIX domain sockets currently in use.wireless— Lists wireless interface data.
5.3.8. /proc/scsi/
/proc/ide/ directory, but it is for connected SCSI devices.
/proc/scsi/scsi, which contains a list of every recognized SCSI device. From this listing, the type of device, as well as the model name, vendor, SCSI channel and ID data is available.
/proc/scsi/, which contains files specific to each SCSI controller using that driver. From the previous example, aic7xxx/ and megaraid/ directories are present, since two drivers are in use. The files in each of the directories typically contain an I/O address range, IRQ information, and statistics for the SCSI controller using that driver. Each controller can report a different type and amount of information. The Adaptec AIC-7880 Ultra SCSI host adapter's file in this example system produces the following output:
5.3.9. /proc/sys/
/proc/sys/ directory is different from others in /proc/ because it not only provides information about the system but also allows the system administrator to immediately enable and disable kernel features.
Warning
/proc/sys/ directory. Changing the wrong setting may render the kernel unstable, requiring a system reboot.
/proc/sys/.
-l option at the shell prompt. If the file is writable, it may be used to configure the kernel. For example, a partial listing of /proc/sys/fs looks like the following:
-r--r--r-- 1 root root 0 May 10 16:14 dentry-state -rw-r--r-- 1 root root 0 May 10 16:14 dir-notify-enable -r--r--r-- 1 root root 0 May 10 16:14 dquot-nr -rw-r--r-- 1 root root 0 May 10 16:14 file-max -r--r--r-- 1 root root 0 May 10 16:14 file-nr
-r--r--r-- 1 root root 0 May 10 16:14 dentry-state
-rw-r--r-- 1 root root 0 May 10 16:14 dir-notify-enable
-r--r--r-- 1 root root 0 May 10 16:14 dquot-nr
-rw-r--r-- 1 root root 0 May 10 16:14 file-max
-r--r--r-- 1 root root 0 May 10 16:14 file-nrdir-notify-enable and file-max can be written to and, therefore, can be used to configure the kernel. The other files only provide feedback on current settings.
/proc/sys/ file is done by echoing the new value into the file. For example, to enable the System Request Key on a running kernel, type the command:
echo 1 > /proc/sys/kernel/sysrq
echo 1 > /proc/sys/kernel/sysrqsysrq from 0 (off) to 1 (on).
/proc/sys/ configuration files contain more than one value. To correctly send new values to them, place a space character between each value passed with the echo command, such as is done in this example:
echo 4 2 45 > /proc/sys/kernel/acct
echo 4 2 45 > /proc/sys/kernel/acctNote
echo command disappear when the system is restarted. To make configuration changes take effect after the system is rebooted, refer to Section 5.4, “Using the sysctl Command”.
/proc/sys/ directory contains several subdirectories controlling different aspects of a running kernel.
5.3.9.1. /proc/sys/dev/
cdrom/ and raid/. Customized kernels can have other directories, such as parport/, which provides the ability to share one parallel port between multiple device drivers.
cdrom/ directory contains a file called info, which reveals a number of important CD-ROM parameters:
/proc/sys/dev/cdrom, such as autoclose and checkmedia, can be used to control the system's CD-ROM. Use the echo command to enable or disable these features.
/proc/sys/dev/raid/ directory becomes available with at least two files in it: speed_limit_min and speed_limit_max. These settings determine the acceleration of RAID devices for I/O intensive tasks, such as resyncing the disks.
5.3.9.2. /proc/sys/fs/
binfmt_misc/ directory is used to provide kernel support for miscellaneous binary formats.
/proc/sys/fs/ include:
dentry-state— Provides the status of the directory cache. The file looks similar to the following:57411 52939 45 0 0 0
57411 52939 45 0 0 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow The first number reveals the total number of directory cache entries, while the second number displays the number of unused entries. The third number tells the number of seconds between when a directory has been freed and when it can be reclaimed, and the fourth measures the pages currently requested by the system. The last two numbers are not used and display only zeros.dquot-nr— Lists the maximum number of cached disk quota entries.file-max— Lists the maximum number of file handles that the kernel allocates. Raising the value in this file can resolve errors caused by a lack of available file handles.file-nr— Lists the number of allocated file handles, used file handles, and the maximum number of file handles.overflowgidandoverflowuid— Defines the fixed group ID and user ID, respectively, for use with file systems that only support 16-bit group and user IDs.super-max— Controls the maximum number of superblocks available.super-nr— Displays the current number of superblocks in use.
5.3.9.3. /proc/sys/kernel/
acct— Controls the suspension of process accounting based on the percentage of free space available on the file system containing the log. By default, the file looks like the following:4 2 30
4 2 30Copy to Clipboard Copied! Toggle word wrap Toggle overflow The first value dictates the percentage of free space required for logging to resume, while the second value sets the threshold percentage of free space when logging is suspended. The third value sets the interval, in seconds, that the kernel polls the file system to see if logging should be suspended or resumed.cap-bound— Controls the capability bounding settings, which provides a list of capabilities for any process on the system. If a capability is not listed here, then no process, no matter how privileged, can do it. The idea is to make the system more secure by ensuring that certain things cannot happen, at least beyond a certain point in the boot process.For a valid list of values for this virtual file, refer to the following installed documentation:/lib/modules/<kernel-version>/build/include/linux/capability.h.ctrl-alt-del— Controls whether Ctrl+Alt+Delete gracefully restarts the computer usinginit(0) or forces an immediate reboot without syncing the dirty buffers to disk (1).domainname— Configures the system domain name, such asexample.com.exec-shield— Configures the Exec Shield feature of the kernel. Exec Shield provides protection against certain types of buffer overflow attacks.There are two possible values for this virtual file:0— Disables Exec Shield.1— Enables Exec Shield. This is the default value.
Important
If a system is running security-sensitive applications that were started while Exec Shield was disabled, these applications must be restarted when Exec Shield is enabled in order for Exec Shield to take effect.exec-shield-randomize— Enables location randomization of various items in memory. This helps deter potential attackers from locating programs and daemons in memory. Each time a program or daemon starts, it is put into a different memory location each time, never in a static or absolute memory address.There are two possible values for this virtual file:0— Disables randomization of Exec Shield. This may be useful for application debugging purposes.1— Enables randomization of Exec Shield. This is the default value. Note: Theexec-shieldfile must also be set to1forexec-shield-randomizeto be effective.
hostname— Configures the system hostname, such aswww.example.com.hotplug— Configures the utility to be used when a configuration change is detected by the system. This is primarily used with USB and Cardbus PCI. The default value of/sbin/hotplugshould not be changed unless testing a new program to fulfill this role.modprobe— Sets the location of the program used to load kernel modules. The default value is/sbin/modprobewhich meanskmodcalls it to load the module when a kernel thread callskmod.msgmax— Sets the maximum size of any message sent from one process to another and is set to8192bytes by default. Be careful when raising this value, as queued messages between processes are stored in non-swappable kernel memory. Any increase inmsgmaxwould increase RAM requirements for the system.msgmnb— Sets the maximum number of bytes in a single message queue. The default is16384.msgmni— Sets the maximum number of message queue identifiers. The default is16.osrelease— Lists the Linux kernel release number. This file can only be altered by changing the kernel source and recompiling.ostype— Displays the type of operating system. By default, this file is set toLinux, and this value can only be changed by changing the kernel source and recompiling.overflowgidandoverflowuid— Defines the fixed group ID and user ID, respectively, for use with system calls on architectures that only support 16-bit group and user IDs.panic— Defines the number of seconds the kernel postpones rebooting when the system experiences a kernel panic. By default, the value is set to0, which disables automatic rebooting after a panic.printk— This file controls a variety of settings related to printing or logging error messages. Each error message reported by the kernel has a loglevel associated with it that defines the importance of the message. The loglevel values break down in this order:0— Kernel emergency. The system is unusable.1— Kernel alert. Action must be taken immediately.2— Condition of the kernel is considered critical.3— General kernel error condition.4— General kernel warning condition.5— Kernel notice of a normal but significant condition.6— Kernel informational message.7— Kernel debug-level messages.
Four values are found in theprintkfile:6 4 1 7
6 4 1 7Copy to Clipboard Copied! Toggle word wrap Toggle overflow Each of these values defines a different rule for dealing with error messages. The first value, called the console loglevel, defines the lowest priority of messages printed to the console. (Note that, the lower the priority, the higher the loglevel number.) The second value sets the default loglevel for messages without an explicit loglevel attached to them. The third value sets the lowest possible loglevel configuration for the console loglevel. The last value sets the default value for the console loglevel.random/directory — Lists a number of values related to generating random numbers for the kernel.rtsig-max— Configures the maximum number of POSIX real-time signals that the system may have queued at any one time. The default value is1024.rtsig-nr— Lists the current number of POSIX real-time signals queued by the kernel.sem— Configures semaphore settings within the kernel. A semaphore is a System V IPC object that is used to control utilization of a particular process.shmall— Sets the total amount of shared memory pages that can be used at one time, system-wide. By default, this value is2097152.shmmax— Sets the largest shared memory segment size allowed by the kernel. By default, this value is33554432. However, the kernel supports much larger values than this.shmmni— Sets the maximum number of shared memory segments for the whole system. By default, this value is4096.sysrq— Activates the System Request Key, if this value is set to anything other than zero (0), the default.The System Request Key allows immediate input to the kernel through simple key combinations. For example, the System Request Key can be used to immediately shut down or restart a system, sync all mounted file systems, or dump important information to the console. To initiate a System Request Key, type Alt+SysRq+ <system request code> . Replace <system request code> with one of the following system request codes:r— Disables raw mode for the keyboard and sets it to XLATE (a limited keyboard mode which does not recognize modifiers such as Alt, Ctrl, or Shift for all keys).k— Kills all processes active in a virtual console. Also called Secure Access Key (SAK), it is often used to verify that the login prompt is spawned frominitand not a Trojan copy designed to capture usernames and passwords.b— Reboots the kernel without first unmounting file systems or syncing disks attached to the system.c— Crashes the system without first unmounting file systems or syncing disks attached to the system.o— Shuts off the system.s— Attempts to sync disks attached to the system.u— Attempts to unmount and remount all file systems as read-only.p— Outputs all flags and registers to the console.t— Outputs a list of processes to the console.m— Outputs memory statistics to the console.0through9— Sets the log level for the console.e— Kills all processes exceptinitusing SIGTERM.i— Kills all processes exceptinitusing SIGKILL.l— Kills all processes using SIGKILL (includinginit). The system is unusable after issuing this System Request Key code.h— Displays help text.
This feature is most beneficial when using a development kernel or when experiencing system freezes.Warning
The System Request Key feature is considered a security risk because an unattended console provides an attacker with access to the system. For this reason, it is turned off by default.Refer to/usr/share/doc/kernel-doc-<version>/Documentation/sysrq.txtfor more information about the System Request Key.sysrq-key— Defines the key code for the System Request Key (84is the default).sysrq-sticky— Defines whether the System Request Key is a chorded key combination. The accepted values are as follows:0— Alt+SysRq and the system request code must be pressed simultaneously. This is the default value.1— Alt+SysRq must be pressed simultaneously, but the system request code can be pressed anytime before the number of seconds specified in/proc/sys/kernel/sysrq-timerelapses.
sysrq-timer— Specifies the number of seconds allowed to pass before the system request code must be pressed. The default value is10.tainted— Indicates whether a non-GPL module is loaded.0— No non-GPL modules are loaded.1— At least one module without a GPL license (including modules with no license) is loaded.2— At least one module was force-loaded with the commandinsmod -f.
threads-max— Sets the maximum number of threads to be used by the kernel, with a default value of2048.version— Displays the date and time the kernel was last compiled. The first field in this file, such as#3, relates to the number of times a kernel was built from the source base.
5.3.9.4. /proc/sys/net/
ethernet/, ipv4/, ipx/, and ipv6/. By altering the files within these directories, system administrators are able to adjust the network configuration on a running system.
/proc/sys/net/ directories are discussed.
/proc/sys/net/core/ directory contains a variety of settings that control the interaction between the kernel and networking layers. The most important of these files are:
message_burst— Sets the amount of time in tenths of a second required to write a new warning message. This setting is used to mitigate Denial of Service (DoS) attacks. The default setting is50.message_cost— Sets a cost on every warning message. The higher the value of this file (default of5), the more likely the warning message is ignored. This setting is used to mitigate DoS attacks.The idea of a DoS attack is to bombard the targeted system with requests that generate errors and fill up disk partitions with log files or require all of the system's resources to handle the error logging. The settings inmessage_burstandmessage_costare designed to be modified based on the system's acceptable risk versus the need for comprehensive logging.netdev_max_backlog— Sets the maximum number of packets allowed to queue when a particular interface receives packets faster than the kernel can process them. The default value for this file is300.optmem_max— Configures the maximum ancillary buffer size allowed per socket.rmem_default— Sets the receive socket buffer default size in bytes.rmem_max— Sets the receive socket buffer maximum size in bytes.wmem_default— Sets the send socket buffer default size in bytes.wmem_max— Sets the send socket buffer maximum size in bytes.
/proc/sys/net/ipv4/ directory contains additional networking settings. Many of these settings, used in conjunction with one another, are useful in preventing attacks on the system or when using the system to act as a router.
Warning
/proc/sys/net/ipv4/ directory:
icmp_destunreach_rate,icmp_echoreply_rate,icmp_paramprob_rate, andicmp_timeexeed_rate— Set the maximum ICMP send packet rate, in 1/100 of a second, to hosts under certain conditions. A setting of0removes any delay and is not a good idea.icmp_echo_ignore_allandicmp_echo_ignore_broadcasts— Allows the kernel to ignore ICMP ECHO packets from every host or only those originating from broadcast and multicast addresses, respectively. A value of0allows the kernel to respond, while a value of1ignores the packets.ip_default_ttl— Sets the default Time To Live (TTL), which limits the number of hops a packet may make before reaching its destination. Increasing this value can diminish system performance.ip_forward— Permits interfaces on the system to forward packets to one other. By default, this file is set to0. Setting this file to1enables network packet forwarding.ip_local_port_range— Specifies the range of ports to be used by TCP or UDP when a local port is needed. The first number is the lowest port to be used and the second number specifies the highest port. Any systems that expect to require more ports than the default 1024 to 4999 should use a range from 32768 to 61000.tcp_syn_retries— Provides a limit on the number of times the system re-transmits a SYN packet when attempting to make a connection.tcp_retries1— Sets the number of permitted re-transmissions attempting to answer an incoming connection. Default of3.tcp_retries2— Sets the number of permitted re-transmissions of TCP packets. Default of15.
/usr/share/doc/kernel-doc-<version>/Documentation/networking/ ip-sysctl.txt
/usr/share/doc/kernel-doc-<version>/Documentation/networking/ ip-sysctl.txt/proc/sys/net/ipv4/ directory.
/proc/sys/net/ipv4/ directory and each covers a different aspect of the network stack. The /proc/sys/net/ipv4/conf/ directory allows each system interface to be configured in different ways, including the use of default settings for unconfigured devices (in the /proc/sys/net/ipv4/conf/default/ subdirectory) and settings that override all special configurations (in the /proc/sys/net/ipv4/conf/all/ subdirectory).
/proc/sys/net/ipv4/neigh/ directory contains settings for communicating with a host directly connected to the system (called a network neighbor) and also contains different settings for systems more than one hop away.
/proc/sys/net/ipv4/route/. Unlike conf/ and neigh/, the /proc/sys/net/ipv4/route/ directory contains specifications that apply to routing with any interfaces on the system. Many of these settings, such as max_size, max_delay, and min_delay, relate to controlling the size of the routing cache. To clear the routing cache, write any value to the flush file.
/usr/share/doc/kernel-doc-<version>/Documentation/filesystems/proc.txt
/usr/share/doc/kernel-doc-<version>/Documentation/filesystems/proc.txt5.3.9.5. /proc/sys/vm/
/proc/sys/vm/ directory:
block_dump— Configures block I/O debugging when enabled. All read/write and block dirtying operations done to files are logged accordingly. This can be useful if diagnosing disk spin up and spin downs for laptop battery conservation. All output whenblock_dumpis enabled can be retrieved viadmesg. The default value is0.Note
Ifblock_dumpis enabled at the same time as kernel debugging, it is prudent to stop theklogddaemon, as it generates erroneous disk activity caused byblock_dump.dirty_background_ratio— Starts background writeback of dirty data at this percentage of total memory, via a pdflush daemon. The default value is10.dirty_expire_centisecs— Defines when dirty in-memory data is old enough to be eligible for writeout. Data which has been dirty in-memory for longer than this interval is written out next time a pdflush daemon wakes up. The default value is3000, expressed in hundredths of a second.dirty_ratio— Starts active writeback of dirty data at this percentage of total memory for the generator of dirty data, via pdflush. The default value is40.dirty_writeback_centisecs— Defines the interval between pdflush daemon wakeups, which periodically writes dirty in-memory data out to disk. The default value is500, expressed in hundredths of a second.laptop_mode— Minimizes the number of times that a hard disk needs to spin up by keeping the disk spun down for as long as possible, therefore conserving battery power on laptops. This increases efficiency by combining all future I/O processes together, reducing the frequency of spin ups. The default value is0, but is automatically enabled in case a battery on a laptop is used.This value is controlled automatically by the acpid daemon once a user is notified battery power is enabled. No user modifications or interactions are necessary if the laptop supports the ACPI (Advanced Configuration and Power Interface) specification.For more information, refer to the following installed documentation:/usr/share/doc/kernel-doc-<version>/Documentation/laptop-mode.txtlower_zone_protection— Determines how aggressive the kernel is in defending lower memory allocation zones. This is effective when utilized with machines configured withhighmemmemory space enabled. The default value is0, no protection at all. All other integer values are in megabytes, andlowmemmemory is therefore protected from being allocated by users.For more information, refer to the following installed documentation:/usr/share/doc/kernel-doc-<version>/Documentation/filesystems/proc.txtmax_map_count— Configures the maximum number of memory map areas a process may have. In most cases, the default value of65536is appropriate.min_free_kbytes— Forces the Linux VM (virtual memory manager) to keep a minimum number of kilobytes free. The VM uses this number to compute apages_minvalue for eachlowmemzone in the system. The default value is in respect to the total memory on the machine.nr_hugepages— Indicates the current number of configuredhugetlbpages in the kernel.For more information, refer to the following installed documentation:/usr/share/doc/kernel-doc-<version>/Documentation/vm/hugetlbpage.txtnr_pdflush_threads— Indicates the number of pdflush daemons that are currently running. This file is read-only, and should not be changed by the user. Under heavy I/O loads, the default value of two is increased by the kernel.overcommit_memory— Configures the conditions under which a large memory request is accepted or denied. The following three modes are available:0— The kernel performs heuristic memory over commit handling by estimating the amount of memory available and failing requests that are blatantly invalid. Unfortunately, since memory is allocated using a heuristic rather than a precise algorithm, this setting can sometimes allow available memory on the system to be overloaded. This is the default setting.1— The kernel performs no memory over commit handling. Under this setting, the potential for memory overload is increased, but so is performance for memory intensive tasks (such as those executed by some scientific software).2— The kernel fails requests for memory that add up to all of swap plus the percent of physical RAM specified in/proc/sys/vm/overcommit_ratio. This setting is best for those who desire less risk of memory overcommitment.Note
This setting is only recommended for systems with swap areas larger than physical memory.
overcommit_ratio— Specifies the percentage of physical RAM considered when/proc/sys/vm/overcommit_memoryis set to2. The default value is50.page-cluster— Sets the number of pages read in a single attempt. The default value of3, which actually relates to 16 pages, is appropriate for most systems.swappiness— Determines how much a machine should swap. The higher the value, the more swapping occurs. The default value, as a percentage, is set to60.
/usr/share/doc/kernel-doc-<version>/Documentation/, which contains additional information.
5.3.10. /proc/sysvipc/
msg), semaphores (sem), and shared memory (shm).
5.3.11. /proc/tty/
drivers file is a list of the current tty devices in use, as in the following example:
/proc/tty/driver/serial file lists the usage statistics and status of each of the serial tty lines.
ldiscs file, and more detailed information is available within the ldisc/ directory.
5.3.12. /proc//
/proc/sys/vm/panic_on_oom. When set to 1 the kernel will panic on OOM. A setting of 0 instructs the kernel to call a function named oom_killer on an OOM. Usually, oom_killer can kill rogue processes and the system will survive.
/proc/sys/vm/panic_on_oom.
~]# cat /proc/sys/vm/panic_on_oom 1 ~]# echo 0 > /proc/sys/vm/panic_on_oom ~]# cat /proc/sys/vm/panic_on_oom 0
~]# cat /proc/sys/vm/panic_on_oom
1
~]# echo 0 > /proc/sys/vm/panic_on_oom
~]# cat /proc/sys/vm/panic_on_oom
0oom_killer score. In /proc/<PID>/ there are two tools labelled oom_adj and oom_score. Valid scores for oom_adj are in the range -16 to +15. To see the current oom_killer score, view the oom_score for the process. oom_killer will kill processes with the highest scores first.
oom_killer will kill it.
~]# cat /proc/12465/oom_score 79872 ~]# echo -5 > /proc/12465/oom_adj ~]# cat /proc/12465/oom_score 78
~]# cat /proc/12465/oom_score
79872
~]# echo -5 > /proc/12465/oom_adj
~]# cat /proc/12465/oom_score
78oom_killer for that process. In the example below, oom_score returns a value of 0, indicating that this process would not be killed.
~]# cat /proc/12465/oom_score 78 ~]# echo -17 > /proc/12465/oom_adj ~]# cat /proc/12465/oom_score 0
~]# cat /proc/12465/oom_score
78
~]# echo -17 > /proc/12465/oom_adj
~]# cat /proc/12465/oom_score
0badness() is used to determine the actual score for each process. This is done by adding up 'points' for each examined process. The process scoring is done in the following way:
- The basis of each process's score is its memory size.
- The memory size of any of the process's children (not including a kernel thread) is also added to the score
- The process's score is increased for 'niced' processes and decreased for long running processes.
- Processes with the
CAP_SYS_ADMINandCAP_SYS_RAWIOcapabilities have their scores reduced. - The final score is then bitshifted by the value saved in the
oom_adjfile.
oom_score value will most probably be a non-privileged, recently started process that, along with its children, uses a large amount of memory, has been 'niced', and handles no raw I/O.
5.4. Using the sysctl Command
/sbin/sysctl command is used to view, set, and automate kernel settings in the /proc/sys/ directory.
/proc/sys/ directory, type the /sbin/sysctl -a command as root. This creates a large, comprehensive list, a small portion of which looks something like the following:
net.ipv4.route.min_delay = 2 kernel.sysrq = 0 kernel.sem = 250 32000 32 128
net.ipv4.route.min_delay = 2 kernel.sysrq = 0 kernel.sem = 250 32000 32 128/proc/sys/net/ipv4/route/min_delay file is listed as net.ipv4.route.min_delay, with the directory slashes replaced by dots and the proc.sys portion assumed.
sysctl command can be used in place of echo to assign values to writable files in the /proc/sys/ directory. For example, instead of using the command
echo 1 > /proc/sys/kernel/sysrq
echo 1 > /proc/sys/kernel/sysrqsysctl command as follows:
sysctl -w kernel.sysrq="1" kernel.sysrq = 1
~]# sysctl -w kernel.sysrq="1"
kernel.sysrq = 1/proc/sys/ is helpful during testing, this method does not work as well on a production system as special settings within /proc/sys/ are lost when the machine is rebooted. To preserve custom settings, add them to the /etc/sysctl.conf file.
init program runs the /etc/rc.d/rc.sysinit script. This script contains a command to execute sysctl using /etc/sysctl.conf to determine the values passed to the kernel. Any values added to /etc/sysctl.conf therefore take effect each time the system boots.
5.5. Additional Resources
proc file system.
5.5.1. Installed Documentation
proc file system is installed on the system by default.
/usr/share/doc/kernel-doc-<version>/Documentation/filesystems/proc.txt— Contains assorted, but limited, information about all aspects of the/proc/directory./usr/share/doc/kernel-doc-<version>/Documentation/sysrq.txt— An overview of System Request Key options./usr/share/doc/kernel-doc-<version>/Documentation/sysctl/— A directory containing a variety ofsysctltips, including modifying values that concern the kernel (kernel.txt), accessing file systems (fs.txt), and virtual memory use (vm.txt)./usr/share/doc/kernel-doc-<version>/Documentation/networking/ip-sysctl.txt— A detailed overview of IP networking options.
5.5.2. Useful Websites
- http://www.linuxhq.com/ — This website maintains a complete database of source, patches, and documentation for various versions of the Linux kernel.
Chapter 6. Redundant Array of Independent Disks (RAID)
6.1. What is RAID?
6.1.1. Who Should Use RAID?
- Enhances speed
- Increases storage capacity using a single virtual disk
- Minimizes disk failure
6.1.2. Hardware RAID versus Software RAID
- Hardware RAID
- The hardware-based array manages the RAID subsystem independently from the host. It presents a single disk per RAID array to the host.A hardware RAID device connects to the SCSI controller and presents the RAID arrays as a single SCSI drive. An external RAID system moves all RAID handling “intelligence” into a controller located in the external disk subsystem. The whole subsystem is connected to the host via a normal SCSI controller and appears to the host as a single disk.RAID controller cards function like a SCSI controller to the operating system, and handle all the actual drive communications. The user plugs the drives into the RAID controller (just like a normal SCSI controller) and then adds them to the RAID controllers configuration, and the operating system won't know the difference.
- Software RAID
- Software RAID implements the various RAID levels in the kernel disk (block device) code. It offers the cheapest possible solution, as expensive disk controller cards or hot-swap chassis[1] are not required. Software RAID also works with cheaper IDE disks as well as SCSI disks. With today's faster CPUs, software RAID outperforms hardware RAID.The Linux kernel contains an MD driver that allows the RAID solution to be completely hardware independent. The performance of a software-based array depends on the server CPU performance and load.To learn more about software RAID, here are the key features:
- Threaded rebuild process
- Kernel-based configuration
- Portability of arrays between Linux machines without reconstruction
- Backgrounded array reconstruction using idle system resources
- Hot-swappable drive support
- Automatic CPU detection to take advantage of certain CPU optimizations
6.1.3. RAID Levels and Linear Support
- Level 0
- RAID level 0, often called “striping”, is a performance-oriented striped data mapping technique. This means the data being written to the array is broken down into strips and written across the member disks of the array, allowing high I/O performance at low inherent cost but provides no redundancy. The storage capacity of a level 0 array is equal to the total capacity of the member disks in a hardware RAID or the total capacity of member partitions in a software RAID.
- Level 1
- RAID level 1, or “mirroring”, has been used longer than any other form of RAID. Level 1 provides redundancy by writing identical data to each member disk of the array, leaving a “mirrored” copy on each disk. Mirroring remains popular due to its simplicity and high level of data availability. Level 1 operates with two or more disks that may use parallel access for high data-transfer rates when reading but more commonly operate independently to provide high I/O transaction rates. Level 1 provides very good data reliability and improves performance for read-intensive applications but at a relatively high cost. The storage capacity of the level 1 array is equal to the capacity of one of the mirrored hard disks in a hardware RAID or one of the mirrored partitions in a software RAID.
Note
RAID level 1 comes at a high cost because you write the same information to all of the disks in the array, which wastes drive space. For example, if you have RAID level 1 set up so that your root (/) partition exists on two 40G drives, you have 80G total but are only able to access 40G of that 80G. The other 40G acts like a mirror of the first 40G. - Level 4
- RAID level 4 uses parity[2] concentrated on a single disk drive to protect data. It is better suited to transaction I/O rather than large file transfers. Because the dedicated parity disk represents an inherent bottleneck, level 4 is seldom used without accompanying technologies such as write-back caching. Although RAID level 4 is an option in some RAID partitioning schemes, it is not an option allowed in Red Hat Enterprise Linux RAID installations. The storage capacity of hardware RAID level 4 is equal to the capacity of member disks, minus the capacity of one member disk. The storage capacity of software RAID level 4 is equal to the capacity of the member partitions, minus the size of one of the partitions if they are of equal size.
Note
RAID level 4 takes up the same amount of space as RAID level 5, but level 5 has more advantages. For this reason, level 4 is not supported. - Level 5
- RAID level 5 is the most common type of RAID. By distributing parity across some or all of an array's member disk drives, RAID level 5 eliminates the write bottleneck inherent in level 4. The only performance bottleneck is the parity calculation process. With modern CPUs and software RAID, that usually is not a very big problem. As with level 4, the result is asymmetrical performance, with reads substantially outperforming writes. Level 5 is often used with write-back caching to reduce the asymmetry. The storage capacity of hardware RAID level 5 is equal to the capacity of member disks, minus the capacity of one member disk. The storage capacity of software RAID level 5 is equal to the capacity of the member partitions, minus the size of one of the partitions if they are of equal size.
- Linear RAID
- Linear RAID is a simple grouping of drives to create a larger virtual drive. In linear RAID, the chunks are allocated sequentially from one member drive, going to the next drive only when the first is completely filled. This grouping provides no performance benefit, as it is unlikely that any I/O operations will be split between member drives. Linear RAID also offers no redundancy and, in fact, decreases reliability — if any one member drive fails, the entire array cannot be used. The capacity is the total of all member disks.
6.2. Configuring Software RAID
- Creating software RAID partitions on physical hard drives.
- Creating RAID devices from the software RAID partitions.
- (Optional) Configuring LVM from the RAID devices.
- Creating file systems from the RAID devices.
/dev/hda and /dev/hdb) to illustrate the creation of simple RAID 1 and RAID 0 configurations, and detail how to create a simple RAID configuration by implementing multiple RAID devices.
6.2.1. Creating the RAID Partitions
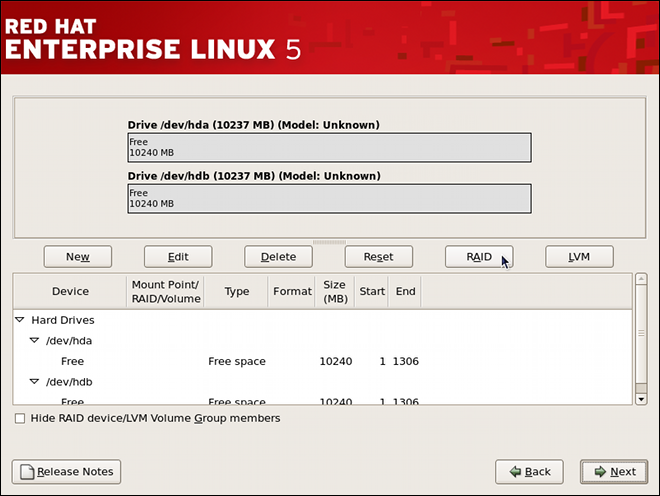
Figure 6.1. Two Blank Drives, Ready For Configuration
- In Disk Druid, click the button to enter the software RAID creation screen.
- Choose to create a RAID partition as shown in Figure 6.2, “RAID Partition Options”. Note that no other RAID options (such as entering a mount point) are available until RAID partitions, as well as RAID devices, are created. Click to confirm the choice.
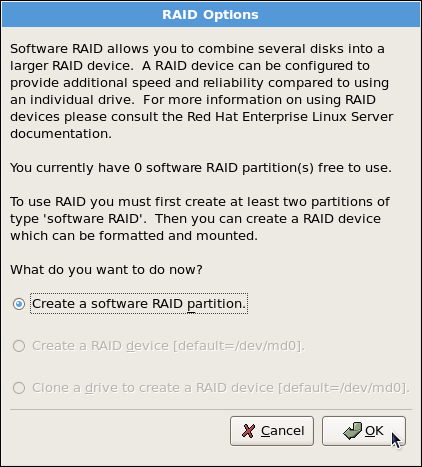
Figure 6.2. RAID Partition Options
- A software RAID partition must be constrained to one drive. For , select the drive to use for RAID. If you have multiple drives, by default all drives are selected and you must deselect the drives you do not want.

Figure 6.3. Adding a RAID Partition
- Edit the Size (MB) field, and enter the size that you want the partition to be (in MB).
- Select Fixed Size to specify partition size. Select Fill all space up to (MB) and enter a value (in MB) to specify partition size range. Select Fill to maximum allowable size to allow maximum available space of the hard disk. Note that if you make more than one space growable, they share the available free space on the disk.
- Select Force to be a primary partition if you want the partition to be a primary partition. A primary partition is one of the first four partitions on the hard drive. If unselected, the partition is created as a logical partition. If other operating systems are already on the system, unselecting this option should be considered. For more information on primary versus logical/extended partitions, refer to the appendix section of the Red Hat Enterprise Linux Installation Guide.
/boot partition as a software RAID device, leaving the root partition (/), /home, and swap as regular file systems. Figure 6.4, “RAID 1 Partitions Ready, Pre-Device and Mount Point Creation” shows successfully allocated space for the RAID 1 configuration (for /boot), which is now ready for RAID device and mount point creation:
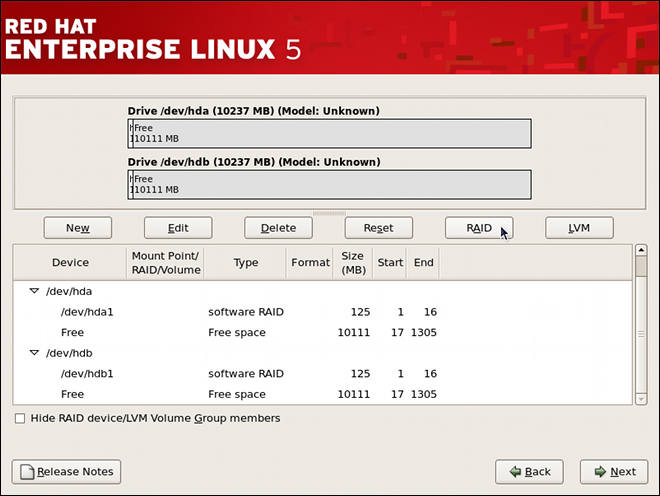
Figure 6.4. RAID 1 Partitions Ready, Pre-Device and Mount Point Creation
6.2.2. Creating the RAID Devices and Mount Points
- On the main partitioning screen, click the button. The RAID Options dialog appears as shown in Figure 6.5, “RAID Options”.

Figure 6.5. RAID Options
- Select the Create a RAID device option, and click . As shown in Figure 6.6, “Making a RAID Device and Assigning a Mount Point”, the Make RAID Device dialog appears, allowing you to make a RAID device and assign a mount point.

Figure 6.6. Making a RAID Device and Assigning a Mount Point
- Select a mount point from the Mount Point pulldown list.
- Choose the file system type for the partition from the File System Type pulldown list. At this point you can either configure a dynamic LVM file system or a traditional static ext2/ext3 file system. For more information on LVM and its configuration during the installation process, refer to Chapter 11, LVM (Logical Volume Manager). If LVM is not required, continue on with the following instructions.
- From the RAID Device pulldown list, select a device name such as md0.
- From the RAID Level, choose the required RAID level.
Note
If you are making a RAID partition of/boot, you must choose RAID level 1, and it must use one of the first two drives (IDE first, SCSI second). If you are not creating a separate RAID partition of/boot, and you are making a RAID partition for the root file system (that is,/), it must be RAID level 1 and must use one of the first two drives (IDE first, SCSI second). - The RAID partitions created appear in the RAID Members list. Select which of these partitions should be used to create the RAID device.
- If configuring RAID 1 or RAID 5, specify the number of spare partitions in the Number of spares field. If a software RAID partition fails, the spare is automatically used as a replacement. For each spare you want to specify, you must create an additional software RAID partition (in addition to the partitions for the RAID device). Select the partitions for the RAID device and the partition(s) for the spare(s).
- Click to confirm the setup. The RAID device appears in the Drive Summary list.
- Repeat this chapter's entire process for configuring additional partitions, devices, and mount points, such as the root partition (
/), home partition (/home), orswap.
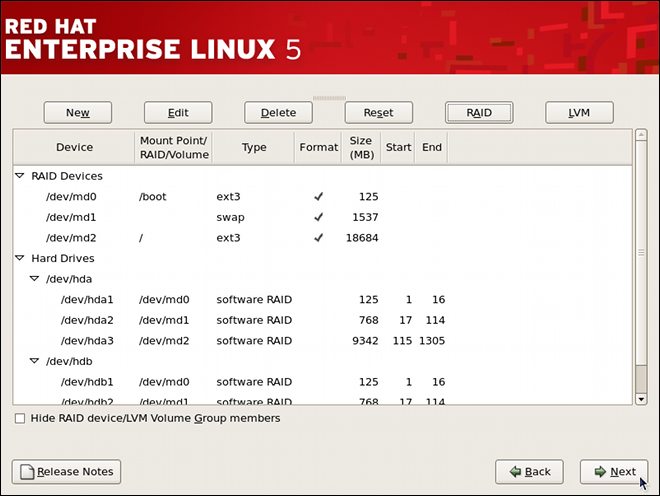
Figure 6.7. Sample RAID Configuration
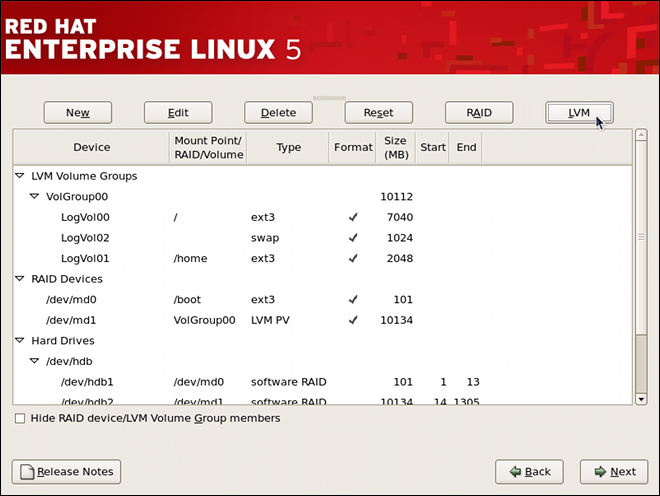
Figure 6.8. Sample RAID With LVM Configuration
6.3. Managing Software RAID
- Reviewing existing software RAID configuration.
- Creating a new RAID device.
- Replacing a faulty device in an array.
- Adding a new device to an existing array.
- Deactivating and removing an existing RAID device.
- Saving the configuration.
6.3.1. Reviewing RAID Configuration
/proc/mdstat special file. To list these devices, display the content of this file by typing the following at a shell prompt:
cat /proc/mdstat
cat /proc/mdstatroot:
mdadm --query device…
mdadm --query device…mdadm --detail raid_device…
mdadm --detail raid_device…mdadm --examine component_device…
mdadm --examine component_device…mdadm --detail command displays information about a RAID device, mdadm --examine only relays information about a RAID device as it relates to a given component device. This distinction is particularly important when working with a RAID device that itself is a component of another RAID device.
mdadm --query command, as well as both mdadm --detail and mdadm --examine commands allow you to specify multiple devices at once.
Example 6.1. Reviewing RAID configuration
/dev/md0 is a RAID device by typing the following at a shell prompt:
mdadm --query /dev/md0 /dev/md0: 125.38MiB raid1 2 devices, 0 spares. Use mdadm --detail for more detail. /dev/md0: No md super block found, not an md component.
~]# mdadm --query /dev/md0
/dev/md0: 125.38MiB raid1 2 devices, 0 spares. Use mdadm --detail for more detail.
/dev/md0: No md super block found, not an md component.6.3.2. Creating a New RAID Device
root:
mdadm --create raid_device --level=level --raid-devices=number component_device…
mdadm --create raid_device --level=level --raid-devices=number component_device…mdadm(8) manual page.
Example 6.2. Creating a new RAID device
ls /dev/sd* /dev/sda /dev/sda1 /dev/sdb /dev/sdb1
~]# ls /dev/sd*
/dev/sda /dev/sda1 /dev/sdb /dev/sdb1/dev/md3 as a new RAID level 1 array from /dev/sda1 and /dev/sdb1, run the following command:
mdadm --create /dev/md3 --level=1 --raid-devices=2 /dev/sda1 /dev/sdb1 mdadm: array /dev/md3 started.
~]# mdadm --create /dev/md3 --level=1 --raid-devices=2 /dev/sda1 /dev/sdb1
mdadm: array /dev/md3 started.6.3.3. Replacing a Faulty Device
root:
mdadm raid_device --fail component_device
mdadm raid_device --fail component_devicemdadm raid_device --remove component_device
mdadm raid_device --remove component_devicemdadm raid_device --add component_device
mdadm raid_device --add component_deviceExample 6.3. Replacing a faulty device
/dev/md3, with the following layout (that is, the RAID device created in Example 6.2, “Creating a new RAID device”):
mdadm --detail /dev/md3 | tail -n 3
Number Major Minor RaidDevice State
0 8 1 0 active sync /dev/sda1
1 8 17 1 active sync /dev/sdb1
~]# mdadm --detail /dev/md3 | tail -n 3
Number Major Minor RaidDevice State
0 8 1 0 active sync /dev/sda1
1 8 17 1 active sync /dev/sdb1/dev/sdb1 device as faulty:
mdadm /dev/md3 --fail /dev/sdb1 mdadm: set /dev/sdb1 faulty in /dev/md3
~]# mdadm /dev/md3 --fail /dev/sdb1
mdadm: set /dev/sdb1 faulty in /dev/md3mdadm /dev/md3 --remove /dev/sdb1 mdadm: hot removed /dev/sdb1
~]# mdadm /dev/md3 --remove /dev/sdb1
mdadm: hot removed /dev/sdb1mdadm /dev/md3 --add /dev/sdb1 mdadm: added /dev/sdb1
~]# mdadm /dev/md3 --add /dev/sdb1
mdadm: added /dev/sdb16.3.4. Extending a RAID Device
root:
mdadm raid_device --add component_device
mdadm raid_device --add component_devicemdadm --grow raid_device --raid-devices=number
mdadm --grow raid_device --raid-devices=numberExample 6.4. Extending a RAID device
/dev/md3, with the following layout (that is, the RAID device created in Example 6.2, “Creating a new RAID device”):
mdadm --detail /dev/md3 | tail -n 3
Number Major Minor RaidDevice State
0 8 1 0 active sync /dev/sda1
1 8 17 1 active sync /dev/sdb1
~]# mdadm --detail /dev/md3 | tail -n 3
Number Major Minor RaidDevice State
0 8 1 0 active sync /dev/sda1
1 8 17 1 active sync /dev/sdb1/dev/sdc, has been added and has exactly one partition. To add it to the /dev/md3 array, type the following at a shell prompt:
mdadm /dev/md3 --add /dev/sdc1 mdadm: added /dev/sdc1
~]# mdadm /dev/md3 --add /dev/sdc1
mdadm: added /dev/sdc1/dev/sdc1 as a spare device. To change the size of the array to actually use it, type:
mdadm --grow /dev/md3 --raid-devices=3
~]# mdadm --grow /dev/md3 --raid-devices=36.3.5. Removing a RAID Device
root:
mdadm --stop raid_device
mdadm --stop raid_devicemdadm --remove raid_device
mdadm --remove raid_devicemdadm --zero-superblock component_device…
mdadm --zero-superblock component_device…Example 6.5. Removing a RAID device
/dev/md3, with the following layout (that is, the RAID device created in Example 6.4, “Extending a RAID device”):
mdadm --detail /dev/md3 | tail -n 4
Number Major Minor RaidDevice State
0 8 1 0 active sync /dev/sda1
1 8 17 1 active sync /dev/sdb1
2 8 33 2 active sync /dev/sdc1
~]# mdadm --detail /dev/md3 | tail -n 4
Number Major Minor RaidDevice State
0 8 1 0 active sync /dev/sda1
1 8 17 1 active sync /dev/sdb1
2 8 33 2 active sync /dev/sdc1mdadm --stop /dev/md3 mdadm: stopped /dev/md3
~]# mdadm --stop /dev/md3
mdadm: stopped /dev/md3/dev/md3 device by running the following command:
mdadm --remove /dev/md3
~]# mdadm --remove /dev/md3mdadm --zero-superblock /dev/sda1 /dev/sdb1 /dev/sdc1
~]# mdadm --zero-superblock /dev/sda1 /dev/sdb1 /dev/sdc16.3.6. Preserving the Configuration
mdadm command only apply to the current session, and will not survive a system restart. At boot time, the mdmonitor service reads the content of the /etc/mdadm.conf configuration file to see which RAID devices to start. If the software RAID was configured during the graphical installation process, this file contains directives listed in Table 6.1, “Common mdadm.conf directives” by default.
| Option | Description |
|---|---|
ARRAY |
Allows you to identify a particular array.
|
DEVICE |
Allows you to specify a list of devices to scan for a RAID component (for example, “/dev/hda1”). You can also use the keyword
partitions to use all partitions listed in /proc/partitions, or containers to specify an array container.
|
MAILADDR | Allows you to specify an email address to use in case of an alert. |
ARRAY lines are presently in use regardless of the configuration, run the following command as root:
mdadm --detail --scan
mdadm --detail --scan/etc/mdadm.conf file. You can also display the ARRAY line for a particular device:
mdadm --detail --brief raid_device
mdadm --detail --brief raid_devicemdadm --detail --brief raid_device >> /etc/mdadm.conf
mdadm --detail --brief raid_device >> /etc/mdadm.confExample 6.6. Preserving the configuration
/etc/mdadm.conf contains the software RAID configuration created during the system installation:
/dev/md3 device as shown in Example 6.2, “Creating a new RAID device”, you can make it persistent by running the following command:
mdadm --detail --brief /dev/md3 >> /etc/mdadm.conf
~]# mdadm --detail --brief /dev/md3 >> /etc/mdadm.conf6.4. Additional Resources
6.4.1. Installed Documentation
mdadmman page — A manual page for themdadmutility.mdadm.confman page — A manual page that provides a comprehensive list of available/etc/mdadm.confconfiguration options.
Chapter 7. Swap Space
7.1. What is Swap Space?
| Amount of RAM in the System | Recommended Amount of Swap Space |
|---|---|
| 4GB of RAM or less | a minimum of 2GB of swap space |
| 4GB to 16GB of RAM | a minimum of 4GB of swap space |
| 16GB to 64GB of RAM | a minimum of 8GB of swap space |
| 64GB to 256GB of RAM | a minimum of 16GB of swap space |
| 256GB to 512GB of RAM | a minimum of 32GB of swap space |
Important
free and cat /proc/swaps commands to verify how much and where swap is in use.
7.2. Adding Swap Space
7.2.1. Extending Swap on an LVM2 Logical Volume
/dev/VolGroup00/LogVol01 is the volume you want to extend):
- Disable swapping for the associated logical volume:
swapoff -v /dev/VolGroup00/LogVol01
swapoff -v /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Resize the LVM2 logical volume by 256 MB:
lvm lvresize /dev/VolGroup00/LogVol01 -L +256M
lvm lvresize /dev/VolGroup00/LogVol01 -L +256MCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Format the new swap space:
mkswap /dev/VolGroup00/LogVol01
mkswap /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Enable the extended logical volume:
swapon -va
swapon -vaCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Test that the logical volume has been extended properly:
cat /proc/swaps free
cat /proc/swaps freeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
7.2.2. Creating an LVM2 Logical Volume for Swap
/dev/VolGroup00/LogVol02 is the swap volume you want to add):
- Create the LVM2 logical volume of size 256 MB:
lvm lvcreate VolGroup00 -n LogVol02 -L 256M
lvm lvcreate VolGroup00 -n LogVol02 -L 256MCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Format the new swap space:
mkswap /dev/VolGroup00/LogVol02
mkswap /dev/VolGroup00/LogVol02Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Add the following entry to the
/etc/fstabfile:/dev/VolGroup00/LogVol02 swap swap defaults 0 0
/dev/VolGroup00/LogVol02 swap swap defaults 0 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Enable the extended logical volume:
swapon -va
swapon -vaCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Test that the logical volume has been extended properly:
cat /proc/swaps free
cat /proc/swaps freeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
7.2.3. Creating a Swap File
- Determine the size of the new swap file in megabytes and multiply by 1024 to determine the number of blocks. For example, the block size of a 64 MB swap file is 65536.
- At a shell prompt as root, type the following command with
countbeing equal to the desired block size:dd if=/dev/zero of=/swapfile bs=1024 count=65536
dd if=/dev/zero of=/swapfile bs=1024 count=65536Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Change the persmissions of the newly created file:
chmod 0600 /swapfile
chmod 0600 /swapfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Setup the swap file with the command:
mkswap /swapfile
mkswap /swapfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow - To enable the swap file immediately but not automatically at boot time:
swapon /swapfile
swapon /swapfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow - To enable it at boot time, edit
/etc/fstabto include the following entry:/swapfile swap swap defaults 0 0
/swapfile swap swap defaults 0 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow The next time the system boots, it enables the new swap file. - After adding the new swap file and enabling it, verify it is enabled by viewing the output of the command
cat /proc/swapsorfree.
7.3. Removing Swap Space
7.3.1. Reducing Swap on an LVM2 Logical Volume
/dev/VolGroup00/LogVol01 is the volume you want to reduce):
- Disable swapping for the associated logical volume:
swapoff -v /dev/VolGroup00/LogVol01
swapoff -v /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Reduce the LVM2 logical volume by 512 MB:
lvm lvreduce /dev/VolGroup00/LogVol01 -L -512M
lvm lvreduce /dev/VolGroup00/LogVol01 -L -512MCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Format the new swap space:
mkswap /dev/VolGroup00/LogVol01
mkswap /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Enable the extended logical volume:
swapon -va
swapon -vaCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Test that the logical volume has been reduced properly:
cat /proc/swaps free
cat /proc/swaps freeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
7.3.2. Removing an LVM2 Logical Volume for Swap
/dev/VolGroup00/LogVol02 is the swap volume you want to remove):
- Disable swapping for the associated logical volume:
swapoff -v /dev/VolGroup00/LogVol02
swapoff -v /dev/VolGroup00/LogVol02Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Remove the LVM2 logical volume of size 512 MB:
lvm lvremove /dev/VolGroup00/LogVol02
lvm lvremove /dev/VolGroup00/LogVol02Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Remove the following entry from the
/etc/fstabfile:/dev/VolGroup00/LogVol02 swap swap defaults 0 0
/dev/VolGroup00/LogVol02 swap swap defaults 0 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Test that the logical volume has been removed:
cat /proc/swaps free
cat /proc/swaps freeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
7.3.3. Removing a Swap File
- At a shell prompt as root, execute the following command to disable the swap file (where
/swapfileis the swap file):swapoff -v /swapfile
swapoff -v /swapfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Remove its entry from the
/etc/fstabfile. - Remove the actual file:
rm /swapfile
rm /swapfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
7.4. Moving Swap Space
Chapter 8. Managing Disk Storage
8.1. Standard Partitions using parted
parted allows users to:
- View the existing partition table
- Change the size of existing partitions
- Add partitions from free space or additional hard drives
parted package is included when installing Red Hat Enterprise Linux. To start parted, log in as root and type the command parted /dev/sda at a shell prompt (where /dev/sda is the device name for the drive you want to configure).
umount command and turn off all the swap space on the hard drive with the swapoff command.
parted commands” contains a list of commonly used parted commands. The sections that follow explain some of these commands and arguments in more detail.
| Command | Description |
|---|---|
check minor-num | Perform a simple check of the file system |
cp from to | Copy file system from one partition to another; from and to are the minor numbers of the partitions |
help | Display list of available commands |
mklabel label | Create a disk label for the partition table |
mkfs minor-num file-system-type | Create a file system of type file-system-type |
mkpart part-type fs-type start-mb end-mb | Make a partition without creating a new file system |
mkpartfs part-type fs-type start-mb end-mb | Make a partition and create the specified file system |
move minor-num start-mb end-mb | Move the partition |
name minor-num name | Name the partition for Mac and PC98 disklabels only |
print | Display the partition table |
quit | Quit parted |
rescue start-mb end-mb | Rescue a lost partition from start-mb to end-mb |
resize minor-num start-mb end-mb | Resize the partition from start-mb to end-mb |
rm minor-num | Remove the partition |
select device | Select a different device to configure |
set minor-num flag state | Set the flag on a partition; state is either on or off |
toggle [NUMBER [FLAG] | Toggle the state of FLAG on partition NUMBER |
unit UNIT | Set the default unit to UNIT |
8.1.1. Viewing the Partition Table
parted, use the command print to view the partition table. A table similar to the following appears:
number. For example, the partition with minor number 1 corresponds to /dev/sda1. The Start and End values are in megabytes. Valid Type are metadata, free, primary, extended, or logical. The Filesystem is the file system type, which can be any of the following:
- ext2
- ext3
- fat16
- fat32
- hfs
- jfs
- linux-swap
- ntfs
- reiserfs
- hp-ufs
- sun-ufs
- xfs
Filesystem of a device shows no value, this means that its file system type is unknown.
8.1.2. Creating a Partition
Warning
parted, where /dev/sda is the device on which to create the partition:
parted /dev/sda
parted /dev/sdaprint8.1.2.1. Making the Partition
mkpart primary ext3 1024 2048
mkpart primary ext3 1024 2048Note
mkpartfs command instead, the file system is created after the partition is created. However, parted does not support creating an ext3 file system. Thus, if you wish to create an ext3 file system, use mkpart and create the file system with the mkfs command as described later.
print command to confirm that it is in the partition table with the correct partition type, file system type, and size. Also remember the minor number of the new partition so that you can label it. You should also view the output of
cat /proc/partitions
cat /proc/partitions8.1.2.2. Formatting the Partition
mkfs -t ext3 /dev/sda6
mkfs -t ext3 /dev/sda6Warning
8.1.2.3. Labeling the Partition
/dev/sda6 and you want to label it /work:
e2label /dev/sda6 /work
e2label /dev/sda6 /work8.1.2.4. Creating the Mount Point
mkdir /work
mkdir /work8.1.2.5. Add to /etc/fstab
/etc/fstab file to include the new partition. The new line should look similar to the following:
LABEL=/work /work ext3 defaults 1 2
LABEL=/work /work ext3 defaults 1 2LABEL= followed by the label you gave the partition. The second column should contain the mount point for the new partition, and the next column should be the file system type (for example, ext3 or swap). If you need more information about the format, read the man page with the command man fstab.
defaults, the partition is mounted at boot time. To mount the partition without rebooting, as root, type the command:
mount /work
mount /work8.1.3. Removing a Partition
Warning
parted, where /dev/sda is the device on which to remove the partition:
parted /dev/sda
parted /dev/sdaprintrm. For example, to remove the partition with minor number 3:
rm 3
rm 3print command to confirm that it is removed from the partition table. You should also view the output of
cat /proc/partitions
cat /proc/partitions/etc/fstab file. Find the line that declares the removed partition, and remove it from the file.
8.1.4. Resizing a Partition
Warning
parted, where /dev/sda is the device on which to resize the partition:
parted /dev/sda
parted /dev/sdaprintresize command followed by the minor number for the partition, the starting place in megabytes, and the end place in megabytes. For example:
resize 3 1024 2048
resize 3 1024 2048Warning
print command to confirm that the partition has been resized correctly, is the correct partition type, and is the correct file system type.
df to make sure the partition was mounted and is recognized with the new size.
8.2. LVM Partition Management
lvm help at a command prompt.
| Command | Description |
|---|---|
dumpconfig | Dump the active configuration |
formats | List the available metadata formats |
help | Display the help commands |
lvchange | Change the attributes of logical volume(s) |
lvcreate | Create a logical volume |
lvdisplay | Display information about a logical volume |
lvextend | Add space to a logical volume |
lvmchange | Due to use of the device mapper, this command has been deprecated |
lvmdiskscan | List devices that may be used as physical volumes |
lvmsadc | Collect activity data |
lvmsar | Create activity report |
lvreduce | Reduce the size of a logical volume |
lvremove | Remove logical volume(s) from the system |
lvrename | Rename a logical volume |
lvresize | Resize a logical volume |
lvs | Display information about logical volumes |
lvscan | List all logical volumes in all volume groups |
pvchange | Change attributes of physical volume(s) |
pvcreate | Initialize physical volume(s) for use by LVM |
pvdata | Display the on-disk metadata for physical volume(s) |
pvdisplay | Display various attributes of physical volume(s) |
pvmove | Move extents from one physical volume to another |
pvremove | Remove LVM label(s) from physical volume(s) |
pvresize | Resize a physical volume in use by a volume group |
pvs | Display information about physical volumes |
pvscan | List all physical volumes |
segtypes | List available segment types |
vgcfgbackup | Backup volume group configuration |
vgcfgrestore | Restore volume group configuration |
vgchange | Change volume group attributes |
vgck | Check the consistency of a volume group |
vgconvert | Change volume group metadata format |
vgcreate | Create a volume group |
vgdisplay | Display volume group information |
vgexport | Unregister a volume group from the system |
vgextend | Add physical volumes to a volume group |
vgimport | Register exported volume group with system |
vgmerge | Merge volume groups |
vgmknodes | Create the special files for volume group devices in /dev/ |
vgreduce | Remove a physical volume from a volume group |
vgremove | Remove a volume group |
vgrename | Rename a volume group |
vgs | Display information about volume groups |
vgscan | Search for all volume groups |
vgsplit | Move physical volumes into a new volume group |
version | Display software and driver version information |
Chapter 9. Implementing Disk Quotas
quota RPM must be installed to implement disk quotas. Note
9.1. Configuring Disk Quotas
- Enable quotas per file system by modifying the
/etc/fstabfile. - Remount the file system(s).
- Create the quota database files and generate the disk usage table.
- Assign quota policies.
9.1.1. Enabling Quotas
/etc/fstab file. Add the usrquota and/or grpquota options to the file systems that require quotas:
/home file system has both user and group quotas enabled.
Note
/home partition was created during the installation of Red Hat Enterprise Linux. The root (/) partition can be used for setting quota policies in the /etc/fstab file.
9.1.2. Remounting the File Systems
usrquota and/or grpquota options, remount each file system whose fstab entry has been modified. If the file system is not in use by any process, use one of the following methods:
- Issue the
umountcommand followed by themountcommand to remount the file system.(See themanpage for bothumountandmountfor the specific syntax for mounting and unmounting various filesystem types.) - Issue the
mount -o remount <file-system>command (where<file-system>is the name of the file system) to remount the file system. For example, to remount the/homefile system, the command to issue ismount -o remount /home.
9.1.3. Creating the Quota Database Files
quotacheck command.
quotacheck command examines quota-enabled file systems and builds a table of the current disk usage per file system. The table is then used to update the operating system's copy of disk usage. In addition, the file system's disk quota files are updated.
aquota.user and aquota.group) on the file system, use the -c option of the quotacheck command. For example, if user and group quotas are enabled for the /home file system, create the files in the /home directory:
quotacheck -cug /home
quotacheck -cug /home-c option specifies that the quota files should be created for each file system with quotas enabled, the -u option specifies to check for user quotas, and the -g option specifies to check for group quotas.
-u or -g options are specified, only the user quota file is created. If only -g is specified, only the group quota file is created.
quotacheck -avug
quotacheck -avuga— Check all quota-enabled, locally-mounted file systemsv— Display verbose status information as the quota check proceedsu— Check user disk quota informationg— Check group disk quota information
quotacheck has finished running, the quota files corresponding to the enabled quotas (user and/or group) are populated with data for each quota-enabled locally-mounted file system such as /home.
9.1.4. Assigning Quotas per User
edquota command.
edquota username
edquota username/etc/fstab for the /home partition (/dev/VolGroup00/LogVol02 in the example below) and the command edquota testuser is executed, the following is shown in the editor configured as the default for the system:
Disk quotas for user testuser (uid 501): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440436 0 0 37418 0 0
Disk quotas for user testuser (uid 501):
Filesystem blocks soft hard inodes soft hard
/dev/VolGroup00/LogVol02 440436 0 0 37418 0 0Note
EDITOR environment variable is used by edquota. To change the editor, set the EDITOR environment variable in your ~/.bash_profile file to the full path of the editor of your choice.
inodes column shows how many inodes the user is currently using. The last two columns are used to set the soft and hard inode limits for the user on the file system.
Disk quotas for user testuser (uid 501): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440436 500000 550000 37418 0 0
Disk quotas for user testuser (uid 501):
Filesystem blocks soft hard inodes soft hard
/dev/VolGroup00/LogVol02 440436 500000 550000 37418 0 0quota testuser
quota testuser9.1.5. Assigning Quotas per Group
devel group (the group must exist prior to setting the group quota), use the command:
edquota -g devel
edquota -g develDisk quotas for group devel (gid 505): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440400 0 0 37418 0 0
Disk quotas for group devel (gid 505):
Filesystem blocks soft hard inodes soft hard
/dev/VolGroup00/LogVol02 440400 0 0 37418 0 0quota -g devel
quota -g devel9.1.6. Setting the Grace Period for Soft Limits
edquota -t
edquota -tedquota commands operate on a particular user's or group's quota, the -t option operates on every filesystem with quotas enabled.
9.2. Managing Disk Quotas
9.2.1. Enabling and Disabling
quotaoff -vaug
quotaoff -vaug-u or -g options are specified, only the user quotas are disabled. If only -g is specified, only group quotas are disabled. The -v switch causes verbose status information to display as the command executes.
quotaon command with the same options.
quotaon -vaug
quotaon -vaug/home, use the following command:
quotaon -vug /home
quotaon -vug /home-u or -g options are specified, only the user quotas are enabled. If only -g is specified, only group quotas are enabled.
9.2.2. Reporting on Disk Quotas
repquota utility. For example, the command repquota /home produces this output:
-a) quota-enabled file systems, use the command:
repquota -a
repquota -a-- displayed after each user is a quick way to determine whether the block or inode limits have been exceeded. If either soft limit is exceeded, a + appears in place of the corresponding -; the first - represents the block limit, and the second represents the inode limit.
grace columns are normally blank. If a soft limit has been exceeded, the column contains a time specification equal to the amount of time remaining on the grace period. If the grace period has expired, none appears in its place.
9.2.3. Keeping Quotas Accurate
quotacheck include:
- Ensuring quotacheck runs on next reboot
Note
This method works best for (busy) multiuser systems which are periodically rebooted.As root, place a shell script into the/etc/cron.daily/or/etc/cron.weekly/directory—or schedule one using thecrontab -ecommand—that contains thetouch /forcequotacheckcommand. This creates an emptyforcequotacheckfile in the root directory, which the system init script looks for at boot time. If it is found, the init script runsquotacheck. Afterward, the init script removes the/forcequotacheckfile; thus, scheduling this file to be created periodically withcronensures thatquotacheckis run during the next reboot.Refer to Chapter 39, Automated Tasks for more information about configuringcron.- Running quotacheck in single user mode
- An alternative way to safely run
quotacheckis to (re-)boot the system into single-user mode to prevent the possibility of data corruption in quota files and run:quotaoff -vaug /<file_system> quotacheck -vaug /<file_system> quotaon -vaug /<file_system>
~]# quotaoff -vaug /<file_system> ~]# quotacheck -vaug /<file_system> ~]# quotaon -vaug /<file_system>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Running quotacheck on a running system
- If necessary, it is possible to run
quotacheckon a machine during a time when no users are logged in, and thus have no open files on the file system being checked. Run the commandquotacheck -vaug <file_system>; this command will fail ifquotacheckcannot remount the given <file_system> as read-only. Note that, following the check, the file system will be remounted read-write.Important
Runningquotacheckon a live file system mounted read-write is not recommended due to the possibility of quota file corruption.
cron.
9.3. Additional Resources
9.3.1. Installed Documentation
- The
quotacheck,edquota,repquota,quota,quotaon, andquotaoffman pages
Chapter 10. Access Control Lists
acl package is required to implement ACLs. It contains the utilities used to add, modify, remove, and retrieve ACL information.
cp and mv commands copy or move any ACLs associated with files and directories.
10.1. Mounting File Systems
mount -t ext3 -o acl <device-name> <partition>
mount -t ext3 -o acl <device-name> <partition>mount -t ext3 -o acl /dev/VolGroup00/LogVol02 /work
mount -t ext3 -o acl /dev/VolGroup00/LogVol02 /work/etc/fstab file, the entry for the partition can include the acl option:
LABEL=/work /work ext3 acl 1 2
LABEL=/work /work ext3 acl 1 2--with-acl-support option. No special flags are required when accessing or mounting a Samba share.
10.1.1. NFS
no_acl option in the /etc/exports file. To disable ACLs on an NFS share when mounting it on a client, mount it with the no_acl option via the command line or the /etc/fstab file.
10.2. Setting Access ACLs
- Per user
- Per group
- Via the effective rights mask
- For users not in the user group for the file
setfacl utility sets ACLs for files and directories. Use the -m option to add or modify the ACL of a file or directory:
setfacl -m <rules> <files>
setfacl -m <rules> <files>u:<uid>:<perms>- Sets the access ACL for a user. The user name or UID may be specified. The user may be any valid user on the system.
g:<gid>:<perms>- Sets the access ACL for a group. The group name or GID may be specified. The group may be any valid group on the system.
m:<perms>- Sets the effective rights mask. The mask is the union of all permissions of the owning group and all of the user and group entries.
o:<perms>- Sets the access ACL for users other than the ones in the group for the file.
r, w, and x for read, write, and execute.
setfacl command is used, the additional rules are added to the existing ACL or the existing rule is modified.
setfacl -m u:andrius:rw /project/somefile
setfacl -m u:andrius:rw /project/somefile-x option and do not specify any permissions:
setfacl -x <rules> <files>
setfacl -x <rules> <files>setfacl -x u:500 /project/somefile
setfacl -x u:500 /project/somefile10.3. Setting Default ACLs
d: before the rule and specify a directory instead of a file name.
/share/ directory to read and execute for users not in the user group (an access ACL for an individual file can override it):
setfacl -m d:o:rx /share
setfacl -m d:o:rx /share10.4. Retrieving ACLs
getfacl command. In the example below, the getfacl is used to determine the existing ACLs for a file.
getfacl home/john/picture.png
getfacl home/john/picture.png10.5. Archiving File Systems With ACLs
Warning
tar and dump commands do not backup ACLs.
star utility is similar to the tar utility in that it can be used to generate archives of files; however, some of its options are different. Refer to Table 10.1, “Command Line Options for star” for a listing of more commonly used options. For all available options, refer to the star man page. The star package is required to use this utility.
| Option | Description |
|---|---|
-c | Creates an archive file. |
-n | Do not extract the files; use in conjunction with -x to show what extracting the files does. |
-r | Replaces files in the archive. The files are written to the end of the archive file, replacing any files with the same path and file name. |
-t | Displays the contents of the archive file. |
-u | Updates the archive file. The files are written to the end of the archive if they do not exist in the archive or if the files are newer than the files of the same name in the archive. This option only work if the archive is a file or an unblocked tape that may backspace. |
-x | Extracts the files from the archive. If used with -U and a file in the archive is older than the corresponding file on the file system, the file is not extracted. |
-help | Displays the most important options. |
-xhelp | Displays the least important options. |
-/ | Do not strip leading slashes from file names when extracting the files from an archive. By default, they are striped when files are extracted. |
-acl | When creating or extracting, archive or restore any ACLs associated with the files and directories. |
10.6. Compatibility with Older Systems
ext_attr attribute. This attribute can be seen using the following command:
tune2fs -l <filesystem-device>
tune2fs -l <filesystem-device>ext_attr attribute can be mounted with older kernels, but those kernels do not enforce any ACLs which have been set.
e2fsck utility included in version 1.22 and higher of the e2fsprogs package (including the versions in Red Hat Enterprise Linux 2.1 and 4) can check a file system with the ext_attr attribute. Older versions refuse to check it.
10.7. Additional Resources
10.7.1. Installed Documentation
aclman page — Description of ACLsgetfaclman page — Discusses how to get file access control listssetfaclman page — Explains how to set file access control listsstarman page — Explains more about thestarutility and its many options
10.7.2. Useful Websites
- http://acl.bestbits.at/ — Website for ACLs
Chapter 11. LVM (Logical Volume Manager)
11.1. What is LVM?
/boot partition. The /boot partition cannot be on a logical volume group because the boot loader cannot read it. If the root (/) partition is on a logical volume, create a separate /boot partition which is not a part of a volume group.
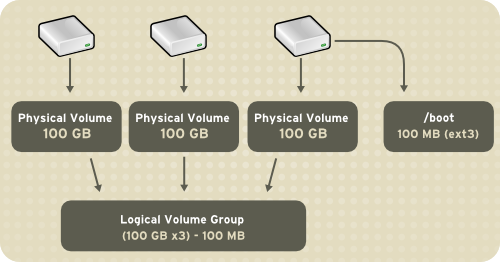
Figure 11.1. Logical Volumes
/home and / and file system types, such as ext2 or ext3. When "partitions" reach their full capacity, free space from the volume group can be added to the logical volume to increase the size of the partition. When a new hard drive is added to the system, it can be added to the volume group, and partitions that are logical volumes can be increased in size.
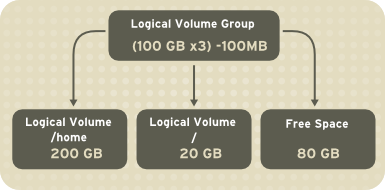
Figure 11.2. Logical Volumes
11.1.1. What is LVM2?
11.2. LVM Configuration
system-config-lvm utility to create your own LVM configuration post-installation. The next two sections focus on using Disk Druid during installation to complete this task. The third section introduces the LVM utility (system-config-lvm) which allows you to manage your LVM volumes in X windows or graphically.
- Creating physical volumes from the hard drives.
- Creating volume groups from the physical volumes.
- Creating logical volumes from the volume groups and assign the logical volumes mount points.
/dev/sda and /dev/sdb) are used in the following examples. They detail how to create a simple configuration using a single LVM volume group with associated logical volumes during installation.
11.3. Automatic Partitioning
- The
/bootpartition resides on its own non-LVM partition. In the following example, it is the first partition on the first drive (/dev/sda1). Bootable partitions cannot reside on LVM logical volumes. - A single LVM volume group (
VolGroup00) is created, which spans all selected drives and all remaining space available. In the following example, the remainder of the first drive (/dev/sda2), and the entire second drive (/dev/sdb1) are allocated to the volume group. - Two LVM logical volumes (
LogVol00andLogVol01) are created from the newly created spanned volume group. In the following example, the recommended swap space is automatically calculated and assigned toLogVol01, and the remainder is allocated to the root file system,LogVol00.
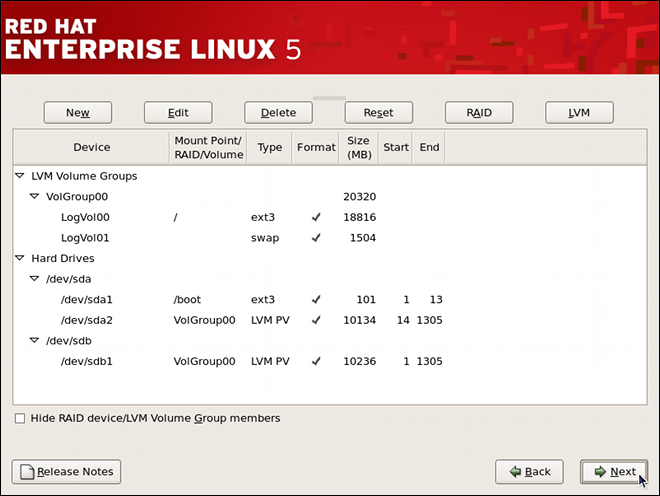
Figure 11.3. Automatic LVM Configuration With Two SCSI Drives
Note
/home or /var, so that each file system has its own independent quota configuration limits.
Note
11.4. Manual LVM Partitioning
11.4.1. Creating the /boot Partition
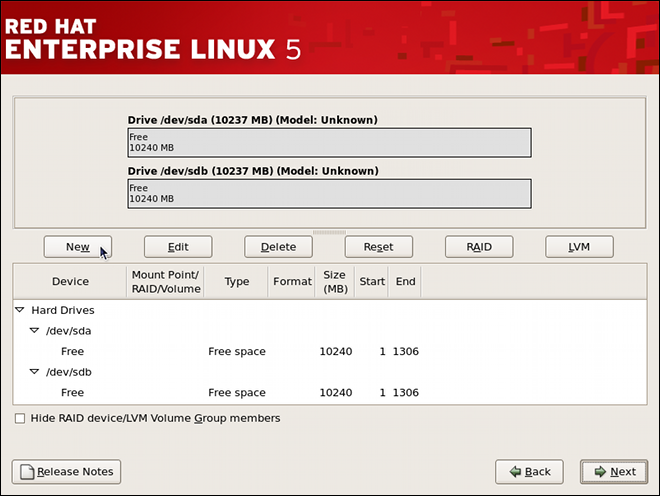
Figure 11.4. Two Blank Drives, Ready for Configuration
Warning
/boot partition cannot reside on an LVM volume because the GRUB boot loader cannot read it.
- Select .
- Select /boot from the Mount Point pulldown menu.
- Select ext3 from the File System Type pulldown menu.
- Select only the sda checkbox from the Allowable Drives area.
- Leave 100 (the default) in the Size (MB) menu.
- Leave the Fixed size (the default) radio button selected in the Additional Size Options area.
- Select Force to be a primary partition to make the partition be a primary partition. A primary partition is one of the first four partitions on the hard drive. If unselected, the partition is created as a logical partition. If other operating systems are already on the system, unselecting this option should be considered. For more information on primary versus logical/extended partitions, refer to the appendix section of the Red Hat Enterprise Linux Installation Guide.
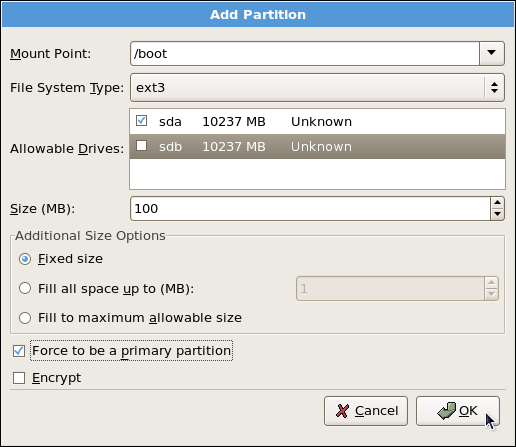
Figure 11.5. Creation of the Boot Partition
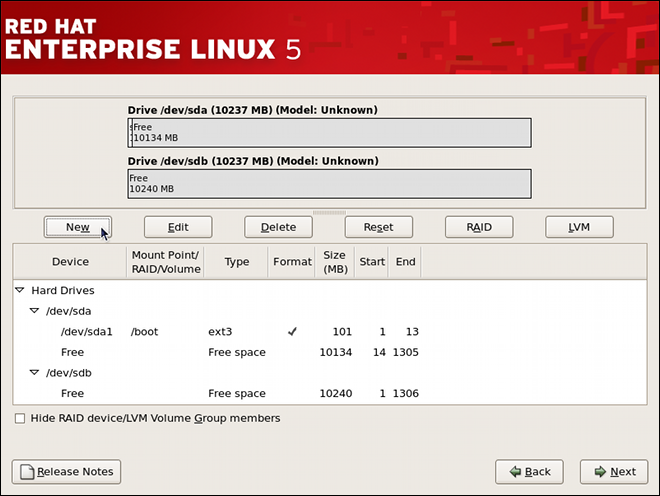
Figure 11.6. The /boot Partition Displayed
11.4.2. Creating the LVM Physical Volumes
- Select .
- Select physical volume (LVM) from the File System Type pulldown menu as shown in Figure 11.7, “Creating a Physical Volume”.
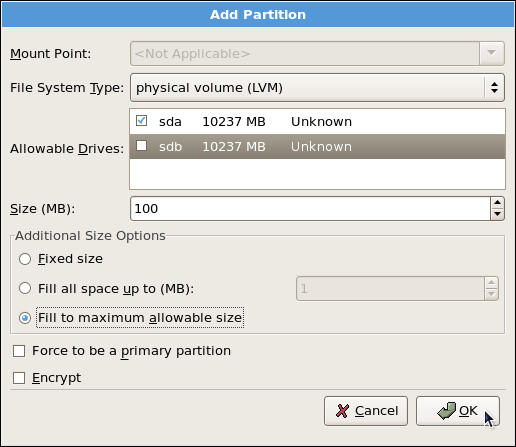
Figure 11.7. Creating a Physical Volume
- You cannot enter a mount point yet (you can once you have created all your physical volumes and then all volume groups).
- A physical volume must be constrained to one drive. For , select the drive on which the physical volume are created. If you have multiple drives, all drives are selected, and you must deselect all but one drive.
- Enter the size that you want the physical volume to be.
- Select Fixed size to make the physical volume the specified size, select Fill all space up to (MB) and enter a size in MBs to give range for the physical volume size, or select Fill to maximum allowable size to make it grow to fill all available space on the hard disk. If you make more than one growable, they share the available free space on the disk.
- Select Force to be a primary partition if you want the partition to be a primary partition.
- Click to return to the main screen.
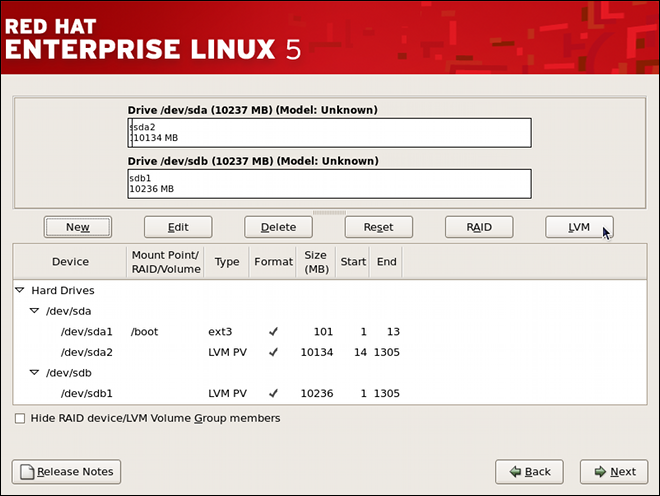
Figure 11.8. Two Physical Volumes Created
11.4.3. Creating the LVM Volume Groups
- Click the button to collect the physical volumes into volume groups. A volume group is basically a collection of physical volumes. You can have multiple logical volumes, but a physical volume can only be in one volume group.
Note
There is overhead disk space reserved in the volume group. The volume group size is slightly less than the total of physical volume sizes.
Figure 11.9. Creating an LVM Volume Group
- Change the Volume Group Name if desired.
- Select which physical volumes to use for the volume group.
11.4.4. Creating the LVM Logical Volumes
/, /home, and swap space. Remember that /boot cannot be a logical volume. To add a logical volume, click the button in the Logical Volumes section. A dialog window as shown in Figure 11.10, “Creating a Logical Volume” appears.
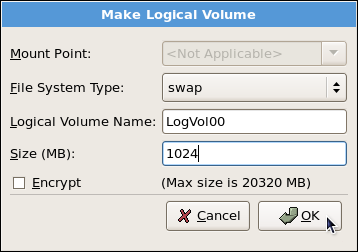
Figure 11.10. Creating a Logical Volume
Note
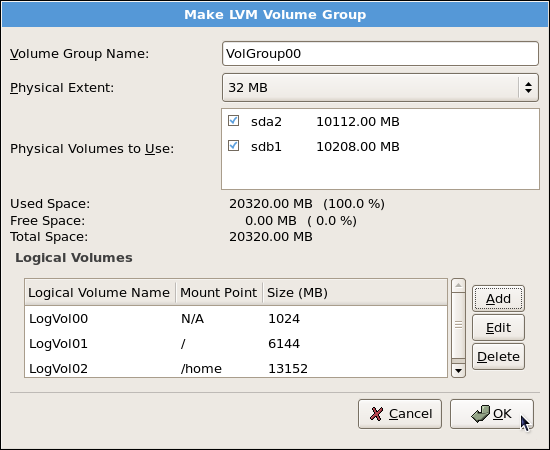
Figure 11.11. Pending Logical Volumes
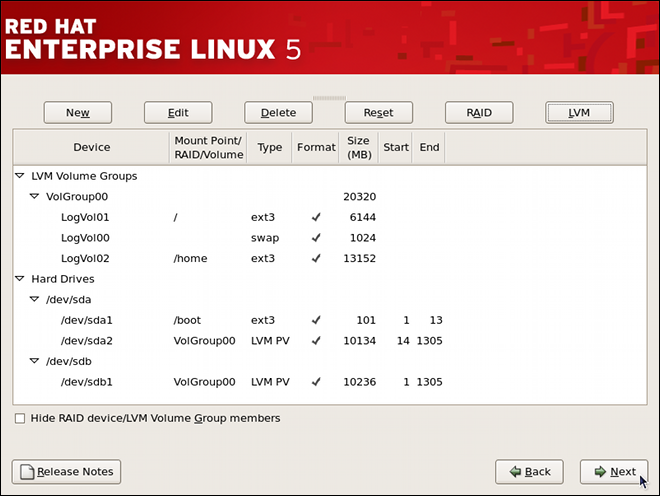
Figure 11.12. Final Manual Configuration
11.5. Using the LVM utility system-config-lvm
system-config-lvm from a terminal.
/boot - (Ext3) file system. Displayed under 'Uninitialized Entities'. (DO NOT initialize this partition). LogVol00 - (LVM) contains the (/) directory (312 extents). LogVol02 - (LVM) contains the (/home) directory (128 extents). LogVol03 - (LVM) swap (28 extents).
/boot - (Ext3) file system. Displayed under 'Uninitialized Entities'. (DO NOT initialize this partition).
LogVol00 - (LVM) contains the (/) directory (312 extents).
LogVol02 - (LVM) contains the (/home) directory (128 extents).
LogVol03 - (LVM) swap (28 extents)./dev/hda2 while /boot was created in /dev/hda1. The system also consists of 'Uninitialized Entities' which are illustrated in Figure 11.17, “Uninitialized Entities”. The figure below illustrates the main window in the LVM utility. The logical and the physical views of the above configuration are illustrated below. The three logical volumes exist on the same physical volume (hda2).
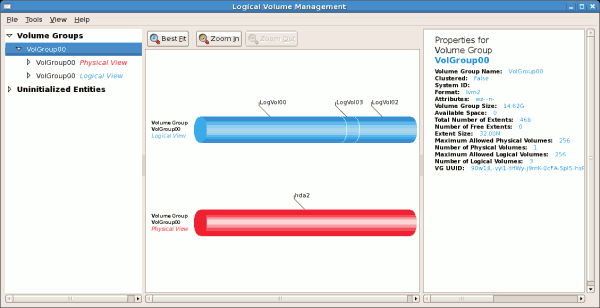
Figure 11.13. Main LVM Window
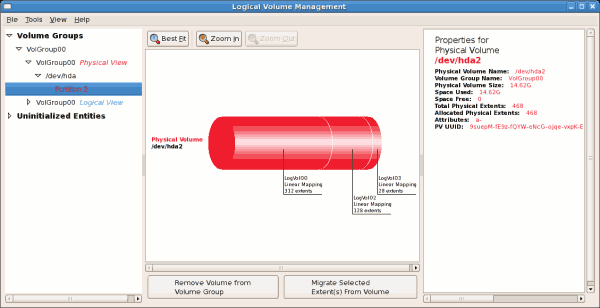
Figure 11.14. Physical View Window
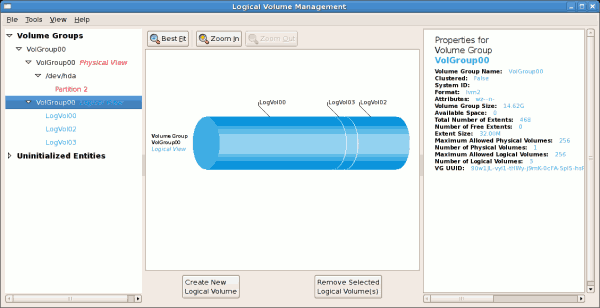
Figure 11.15. Logical View Window
/ (root) directory, this task will not be successful as the volume cannot be unmounted.
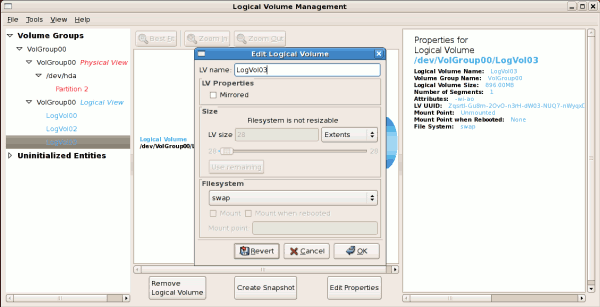
Figure 11.16. Edit Logical Volume
11.5.1. Utilizing uninitialized entities
/boot. Uninitialized entities are illustrated below.
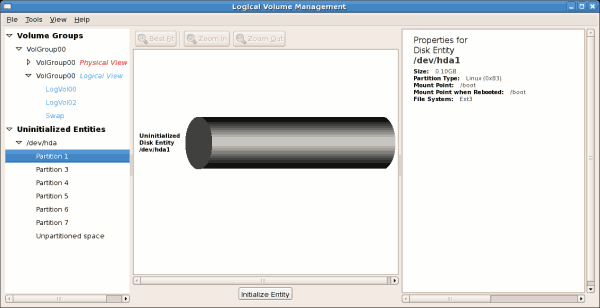
Figure 11.17. Uninitialized Entities
11.5.2. Adding Unallocated Volumes to a volume group
- create a new volume group,
- add the unallocated volume to an existing volume group,
- remove the volume from LVM.
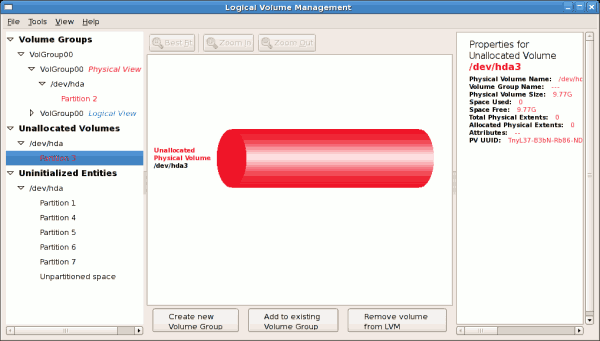
Figure 11.18. Unallocated Volumes
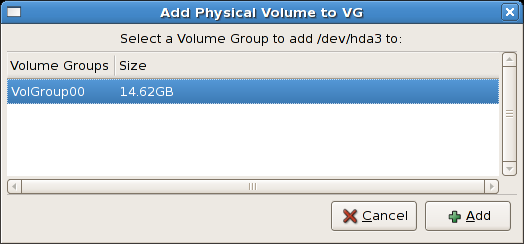
Figure 11.19. Add physical volume to volume group
- create a new logical volume (click on the button,
- select one of the existing logical volumes and increase the extents (see Section 11.5.6, “Extending a volume group”),
- select an existing logical volume and remove it from the volume group by clicking on the button. Please note that you cannot select unused space to perform this operation.
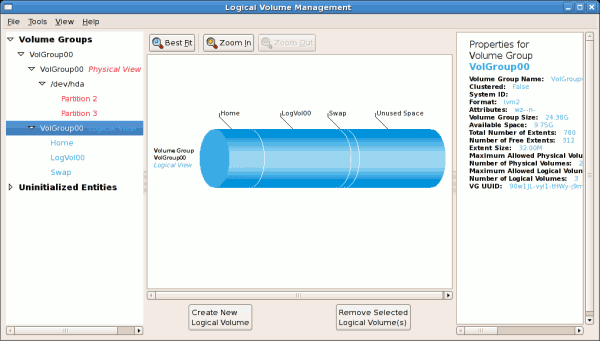
Figure 11.20. Logical view of volume group
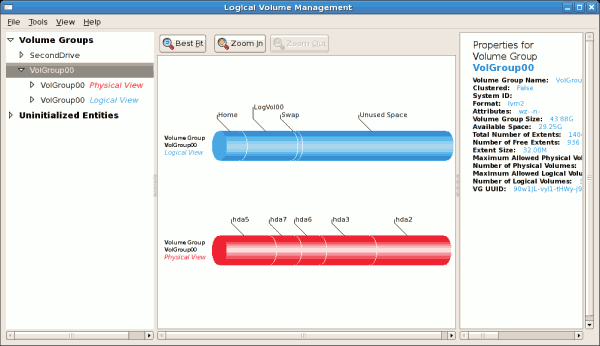
Figure 11.21. Logical view of volume group
11.5.3. Migrating extents
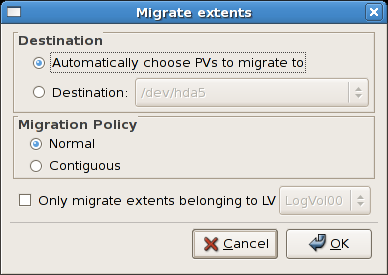
Figure 11.22. Migrate Extents
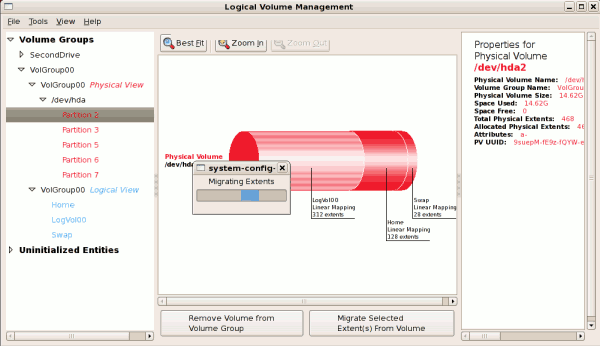
Figure 11.23. Migrating extents in progress
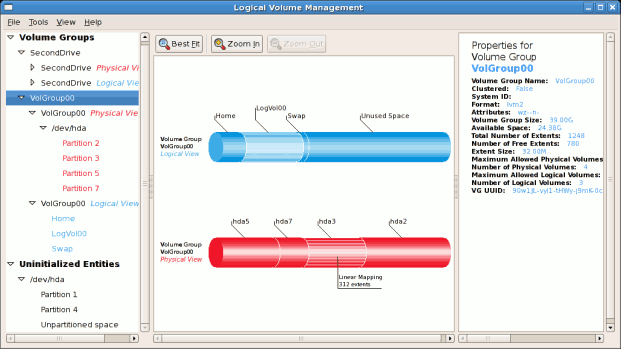
Figure 11.24. Logical and physical view of volume group
11.5.4. Adding a new hard disk using LVM
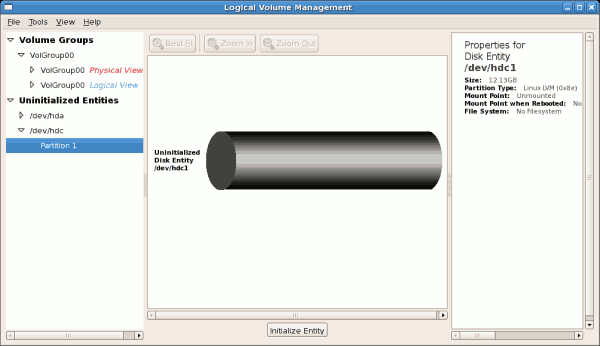
Figure 11.25. Uninitialized hard disk
11.5.5. Adding a new volume group
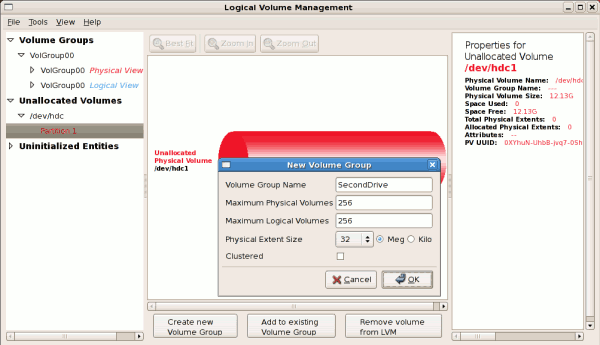
Figure 11.26. Create new volume group
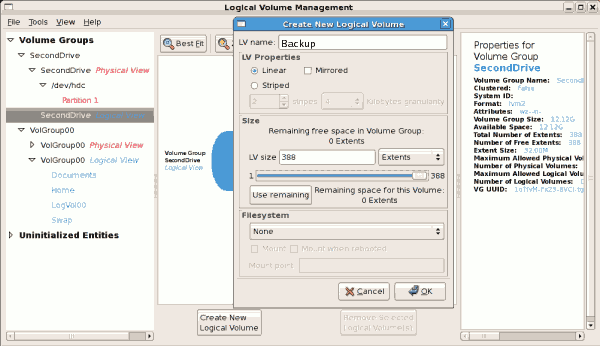
Figure 11.27. Create new logical volume
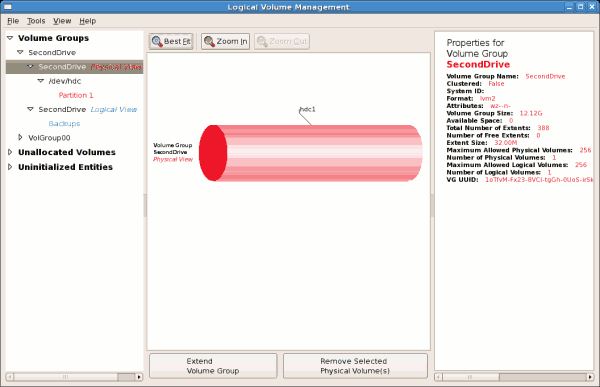
Figure 11.28. Physical view of new volume group
11.5.6. Extending a volume group
/dev/hda6 was selected as illustrated below.
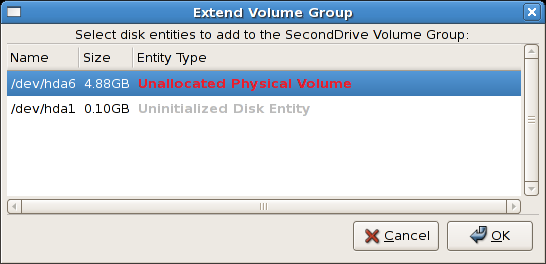
Figure 11.29. Select disk entities
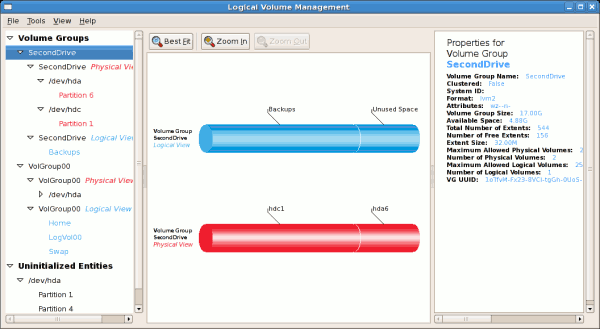
Figure 11.30. Logical and physical view of an extended volume group
11.5.7. Editing a Logical Volume
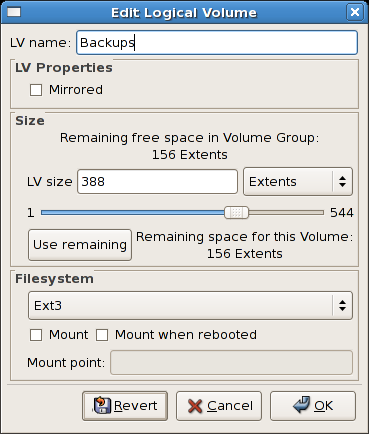
Figure 11.31. Edit logical volume
/mnt/backups. This is illustrated in the figure below.
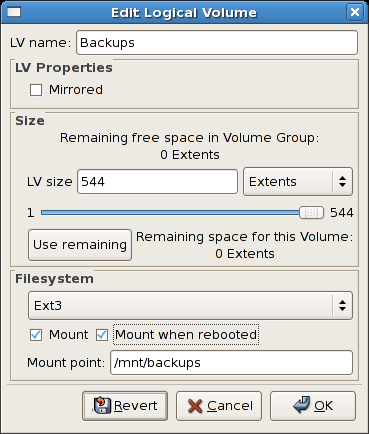
Figure 11.32. Edit logical volume - specifying mount options
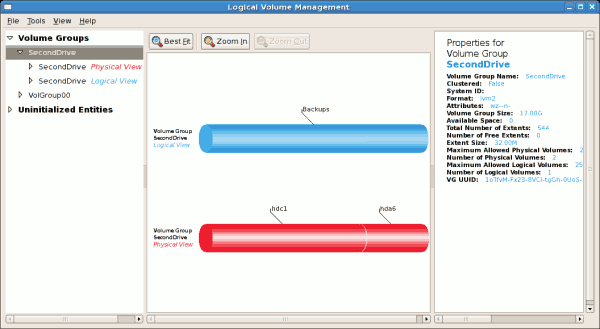
Figure 11.33. Edit logical volume
11.6. Additional Resources
11.6.1. Installed Documentation
rpm -qd lvm2— This command shows all the documentation available from thelvmpackage, including man pages.lvm help— This command shows all LVM commands available.
11.6.2. Useful Websites
- http://sources.redhat.com/lvm2 — LVM2 webpage, which contains an overview, link to the mailing lists, and more.
- http://tldp.org/HOWTO/LVM-HOWTO/ — LVM HOWTO from the Linux Documentation Project.
Part II. Package Management
Chapter 12. Package Management with RPM
rpm package. For the end user, RPM makes system updates easy. Installing, uninstalling, and upgrading RPM packages can be accomplished with short commands. RPM maintains a database of installed packages and their files, so you can invoke powerful queries and verifications on your system. If you prefer a graphical interface, you can use the Package Management Tool to perform many RPM commands. Refer to Chapter 13, Package Management Tool for details.
Important
.tar.gz files.
Note
12.1. RPM Design Goals
- Upgradability
- With RPM, you can upgrade individual components of your system without completely reinstalling. When you get a new release of an operating system based on RPM (such as Red Hat Enterprise Linux), you do not need to reinstall on your machine (as you do with operating systems based on other packaging systems). RPM allows intelligent, fully-automated, in-place upgrades of your system. Configuration files in packages are preserved across upgrades, so you do not lose your customizations. There are no special upgrade files needed to upgrade a package because the same RPM file is used to install and upgrade the package on your system.
- Powerful Querying
- RPM is designed to provide powerful querying options. You can do searches through your entire database for packages or just for certain files. You can also easily find out what package a file belongs to and from where the package came. The files an RPM package contains are in a compressed archive, with a custom binary header containing useful information about the package and its contents, allowing you to query individual packages quickly and easily.
- System Verification
- Another powerful RPM feature is the ability to verify packages. If you are worried that you deleted an important file for some package, you can verify the package. You are then notified of any anomalies, if any — at which point, you can reinstall the package if necessary. Any configuration files that you modified are preserved during reinstallation.
- Pristine Sources
- A crucial design goal was to allow the use of pristine software sources, as distributed by the original authors of the software. With RPM, you have the pristine sources along with any patches that were used, plus complete build instructions. This is an important advantage for several reasons. For instance, if a new version of a program is released, you do not necessarily have to start from scratch to get it to compile. You can look at the patch to see what you might need to do. All the compiled-in defaults, and all of the changes that were made to get the software to build properly, are easily visible using this technique.The goal of keeping sources pristine may seem important only for developers, but it results in higher quality software for end users, too.
12.2. Using RPM
rpm --help or man rpm. You can also refer to Section 12.5, “Additional Resources” for more information on RPM.
12.2.1. Finding RPM Packages
- The Red Hat Enterprise Linux CD-ROMs
- The Red Hat Errata Page available at http://www.redhat.com/apps/support/errata/
- Red Hat Network — Refer to Chapter 15, Registering a System and Managing Subscriptions for more details on Red Hat Network.
12.2.2. Installing
foo-1.0-1.i386.rpm. The file name includes the package name (foo), version (1.0), release (1), and architecture (i386). To install a package, log in as root and type the following command at a shell prompt:
rpm -ivh foo-1.0-1.i386.rpm
rpm -ivh foo-1.0-1.i386.rpmrpm -Uvh foo-1.0-1.i386.rpm
rpm -Uvh foo-1.0-1.i386.rpmPreparing... ########################################### [100%] 1:foo ########################################### [100%]
Preparing... ########################################### [100%]
1:foo ########################################### [100%]error: V3 DSA signature: BAD, key ID 0352860f
error: V3 DSA signature: BAD, key ID 0352860ferror: Header V3 DSA signature: BAD, key ID 0352860f
error: Header V3 DSA signature: BAD, key ID 0352860fNOKEY such as:
warning: V3 DSA signature: NOKEY, key ID 0352860f
warning: V3 DSA signature: NOKEY, key ID 0352860fWarning
rpm -ivh instead. Refer to Chapter 44, Manually Upgrading the Kernel for details.
12.2.2.1. Package Already Installed
Preparing... ########################################### [100%] package foo-1.0-1 is already installed
Preparing... ########################################### [100%]
package foo-1.0-1 is already installed--replacepkgs option, which tells RPM to ignore the error:
rpm -ivh --replacepkgs foo-1.0-1.i386.rpm
rpm -ivh --replacepkgs foo-1.0-1.i386.rpm12.2.2.2. Conflicting Files
Preparing... ########################################### [100%] file /usr/bin/foo from install of foo-1.0-1 conflicts with file from package bar-2.0.20
Preparing... ########################################### [100%]
file /usr/bin/foo from install of foo-1.0-1 conflicts with file from package bar-2.0.20--replacefiles option:
rpm -ivh --replacefiles foo-1.0-1.i386.rpm
rpm -ivh --replacefiles foo-1.0-1.i386.rpm12.2.2.3. Unresolved Dependency
error: Failed dependencies:
bar.so.2 is needed by foo-1.0-1
Suggested resolutions:
bar-2.0.20-3.i386.rpm
error: Failed dependencies:
bar.so.2 is needed by foo-1.0-1
Suggested resolutions:
bar-2.0.20-3.i386.rpmrpm -ivh foo-1.0-1.i386.rpm bar-2.0.20-3.i386.rpm
rpm -ivh foo-1.0-1.i386.rpm bar-2.0.20-3.i386.rpmPreparing... ########################################### [100%] 1:foo ########################################### [ 50%] 2:bar ########################################### [100%]
Preparing... ########################################### [100%]
1:foo ########################################### [ 50%]
2:bar ########################################### [100%]-q --whatprovides option combination to determine which package contains the required file.
rpm -q --whatprovides bar.so.2
rpm -q --whatprovides bar.so.2--nodeps option.
12.2.3. Uninstalling
rpm -e foo
rpm -e fooNote
foo, not the name of the original package file foo-1.0-1.i386.rpm. To uninstall a package, replace foo with the actual package name of the original package.
error: Failed dependencies: foo is needed by (installed) bar-2.0.20-3.i386.rpm
error: Failed dependencies:
foo is needed by (installed) bar-2.0.20-3.i386.rpm--nodeps option.
12.2.4. Upgrading
rpm -Uvh foo-2.0-1.i386.rpm
rpm -Uvh foo-2.0-1.i386.rpmfoo package. Note that -U will also install a package even when there are no previous versions of the package installed.
Note
-U option for installing kernel packages, because RPM replaces the previous kernel package. This does not affect a running system, but if the new kernel is unable to boot during your next restart, there would be no other kernel to boot instead.
-i option adds the kernel to your GRUB boot menu (/etc/grub.conf). Similarly, removing an old, unneeded kernel removes the kernel from GRUB.
saving /etc/foo.conf as /etc/foo.conf.rpmsave
saving /etc/foo.conf as /etc/foo.conf.rpmsavepackage foo-2.0-1 (which is newer than foo-1.0-1) is already installed
package foo-2.0-1 (which is newer than foo-1.0-1) is already installed--oldpackage option:
rpm -Uvh --oldpackage foo-1.0-1.i386.rpm
rpm -Uvh --oldpackage foo-1.0-1.i386.rpm12.2.5. Freshening
rpm -Fvh foo-1.2-1.i386.rpm
rpm -Fvh foo-1.2-1.i386.rpmrpm -Fvh *.rpm
rpm -Fvh *.rpm12.2.6. Querying
/var/lib/rpm/, and is used to query what packages are installed, what versions each package is, and any changes to any files in the package since installation, among others.
-q option. The rpm -q package name command displays the package name, version, and release number of the installed package package name . For example, using rpm -q foo to query installed package foo might generate the following output:
foo-2.0-1
foo-2.0-1-q to further refine or qualify your query:
-a— queries all currently installed packages.-f— queries the RPM database for which package owns<filename>f<filename>. When specifying a file, specify the absolute path of the file (for example,rpm -qf)./bin/ls-p— queries the uninstalled package<packagefile><packagefile>.
-idisplays package information including name, description, release, size, build date, install date, vendor, and other miscellaneous information.-ldisplays the list of files that the package contains.-sdisplays the state of all the files in the package.-ddisplays a list of files marked as documentation (man pages, info pages, READMEs, etc.).-cdisplays a list of files marked as configuration files. These are the files you edit after installation to adapt and customize the package to your system (for example,sendmail.cf,passwd,inittab, etc.).
-v to the command to display the lists in a familiar ls -l format.
12.2.7. Verifying
rpm -V verifies a package. You can use any of the Verify Options listed for querying to specify the packages you wish to verify. A simple use of verifying is rpm -V foo, which verifies that all the files in the foo package are as they were when they were originally installed. For example:
- To verify a package containing a particular file:
rpm -Vf /usr/bin/foo
rpm -Vf /usr/bin/fooCopy to Clipboard Copied! Toggle word wrap Toggle overflow In this example,/usr/bin/foois the absolute path to the file used to query a package. - To verify ALL installed packages throughout the system:
rpm -Va
rpm -VaCopy to Clipboard Copied! Toggle word wrap Toggle overflow - To verify an installed package against an RPM package file:
rpm -Vp foo-1.0-1.i386.rpm
rpm -Vp foo-1.0-1.i386.rpmCopy to Clipboard Copied! Toggle word wrap Toggle overflow This command can be useful if you suspect that your RPM databases are corrupt.
c denotes a configuration file) and then the file name. Each of the eight characters denotes the result of a comparison of one attribute of the file to the value of that attribute recorded in the RPM database. A single period (.) means the test passed. The following characters denote specific discrepancies:
5— MD5 checksumS— file sizeL— symbolic linkT— file modification timeD— deviceU— userG— groupM— mode (includes permissions and file type)?— unreadable file
12.3. Checking a Package's Signature
rpm -K --nosignature <rpm-file>
rpm -K --nosignature <rpm-file><rpm-file>: md5 OK is displayed. This brief message means that the file was not corrupted by the download. To see a more verbose message, replace -K with -Kvv in the command.
12.3.1. Importing Keys
rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-releaserpm -qa gpg-pubkey*
rpm -qa gpg-pubkey*gpg-pubkey-37017186-45761324
gpg-pubkey-37017186-45761324rpm -qi followed by the output from the previous command:
rpm -qi gpg-pubkey-37017186-45761324
rpm -qi gpg-pubkey-37017186-4576132412.3.2. Verifying Signature of Packages
rpm -K <rpm-file>
rpm -K <rpm-file>md5 gpg OK. This means that the signature of the package has been verified, and that it is not corrupt.
12.4. Practical and Common Examples of RPM Usage
- Perhaps you have deleted some files by accident, but you are not sure what you deleted. To verify your entire system and see what might be missing, you could try the following command:
rpm -Va
rpm -VaCopy to Clipboard Copied! Toggle word wrap Toggle overflow If some files are missing or appear to have been corrupted, you should probably either re-install the package or uninstall and then re-install the package. - At some point, you might see a file that you do not recognize. To find out which package owns it, enter:
rpm -qf /usr/bin/ggv
rpm -qf /usr/bin/ggvCopy to Clipboard Copied! Toggle word wrap Toggle overflow The output would look like the following:ggv-2.6.0-2
ggv-2.6.0-2Copy to Clipboard Copied! Toggle word wrap Toggle overflow - We can combine the above two examples in the following scenario. Say you are having problems with
/usr/bin/paste. You would like to verify the package that owns that program, but you do not know which package ownspaste. Enter the following command,rpm -Vf /usr/bin/paste
rpm -Vf /usr/bin/pasteCopy to Clipboard Copied! Toggle word wrap Toggle overflow and the appropriate package is verified. - Do you want to find out more information about a particular program? You can try the following command to locate the documentation which came with the package that owns that program:
rpm -qdf /usr/bin/free
rpm -qdf /usr/bin/freeCopy to Clipboard Copied! Toggle word wrap Toggle overflow The output would be similar to the following:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - You may find a new RPM, but you do not know what it does. To find information about it, use the following command:
rpm -qip crontabs-1.10-7.noarch.rpm
rpm -qip crontabs-1.10-7.noarch.rpmCopy to Clipboard Copied! Toggle word wrap Toggle overflow The output would be similar to the following:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Perhaps you now want to see what files the
crontabsRPM installs. You would enter the following:rpm -qlp crontabs-1.10-5.noarch.rpm
rpm -qlp crontabs-1.10-5.noarch.rpmCopy to Clipboard Copied! Toggle word wrap Toggle overflow The output is similar to the following:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12.5. Additional Resources
12.5.1. Installed Documentation
rpm --help— This command displays a quick reference of RPM parameters.man rpm— The RPM man page gives more detail about RPM parameters than therpm --helpcommand.
12.5.2. Useful Websites
- http://www.rpm.org/ — The RPM website.
- https://lists.rpm.org/mailman/listinfo/rpm-list — Visit this link to subscribe to the RPM mailing list, which is archived there.
Chapter 13. Package Management Tool
rpm command does.
Note
rpm -e --nodeps or rpm -U --nodeps can.
system-config-packages or pirut at shell prompt.
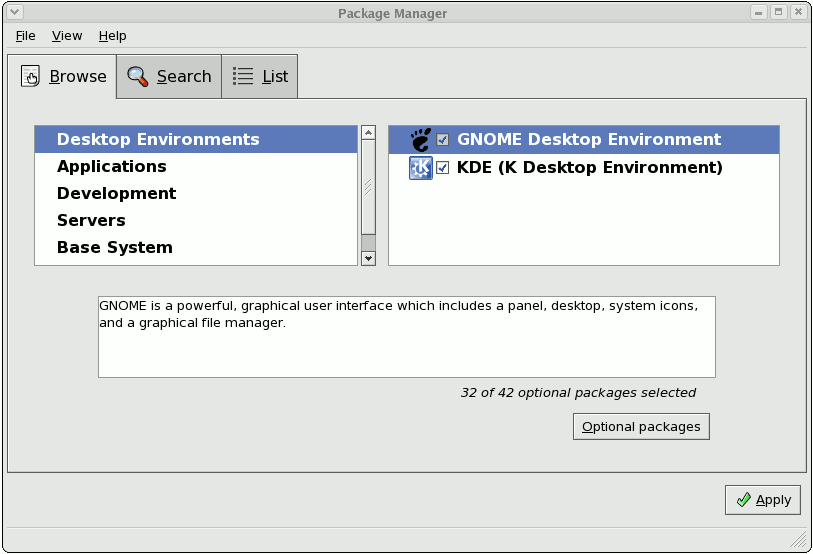
Figure 13.1. Package Management Tool
13.1. Listing and Analyzing Packages
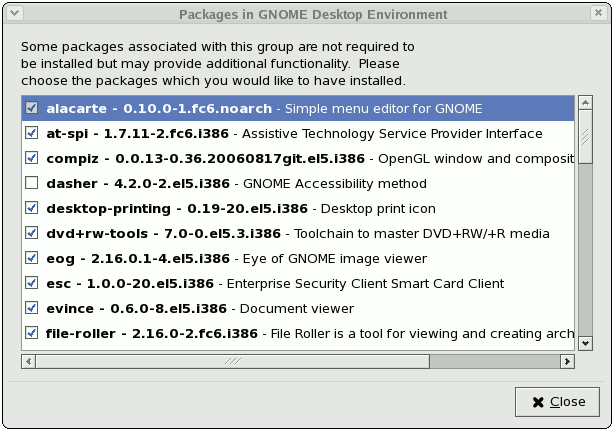
Figure 13.2. Optional Packages
13.2. Installing and Removing Packages
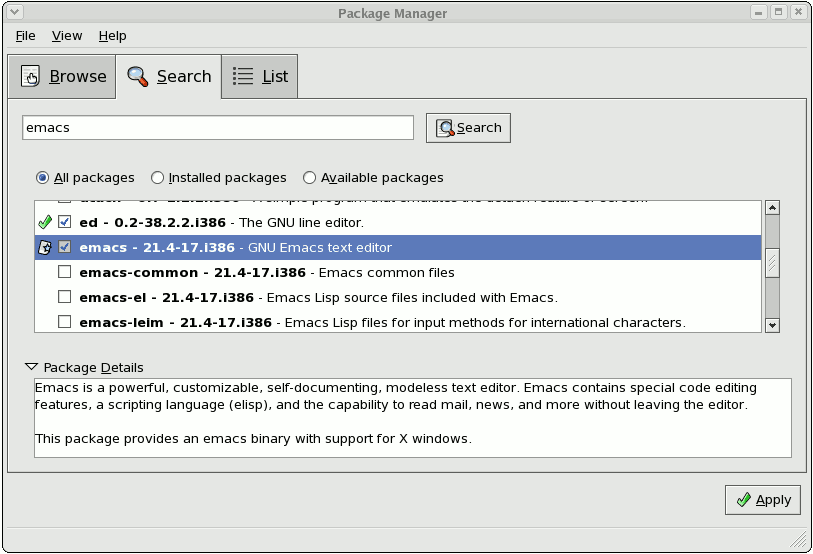
Figure 13.3. Package installation
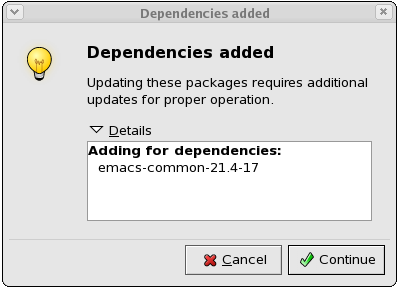
Figure 13.4. Package dependencies: installation
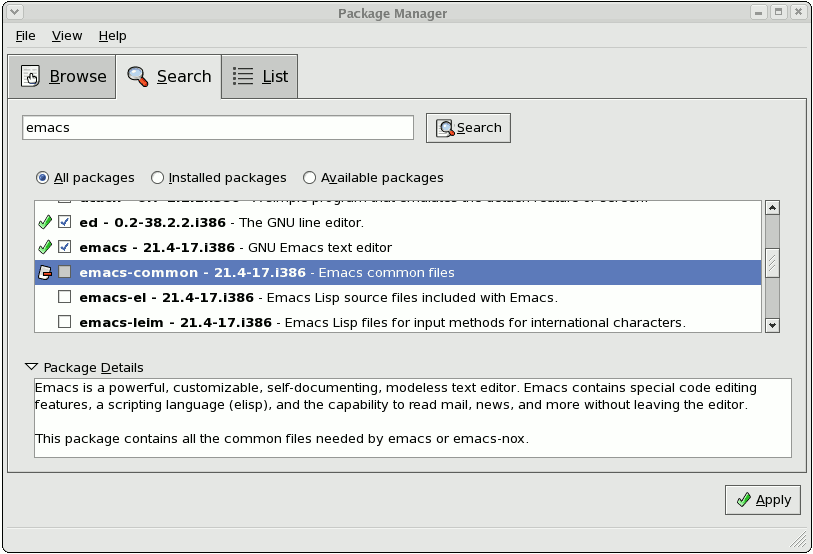
Figure 13.5. Package removal
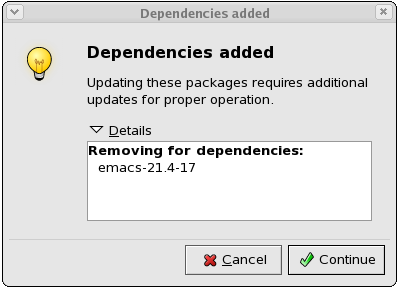
Figure 13.6. Package dependencies: removal
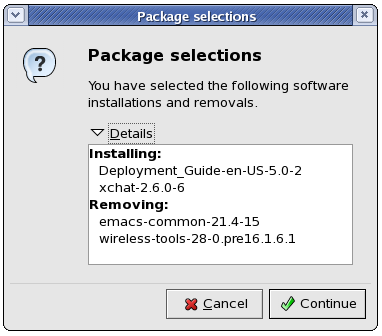
Figure 13.7. Installing and removing packages simultaneously
Chapter 14. YUM (Yellowdog Updater Modified)
yum searches numerous repositories for packages and their dependencies so they may be installed together in an effort to alleviate dependency issues. Red Hat Enterprise Linux 5.10 uses yum to fetch packages and install RPMs.
up2date is now deprecated in favor of yum (Yellowdog Updater Modified). The entire stack of tools which installs and updates software in Red Hat Enterprise Linux 5.10 is now based on yum. This includes everything, from the initial installation via Anaconda to host software management tools like pirut.
yum also allows system administrators to configure a local (i.e. available over a local network) repository to supplement packages provided by Red Hat. This is useful for user groups that use applications and packages that are not officially supported by Red Hat.
yum repository also saves bandwidth for the entire network. Further, clients that use local yum repositories do not need to be registered individually to install or update the latest packages from Red Hat Network.
14.1. Setting Up a Yum Repository
- Install the
createrepopackage:yum install createrepo
~]# yum install createrepoCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Copy all the packages you want to provide in the repository into one directory (
/mnt/local_repofor example). - Run
createrepoon that directory (for example,createrepo /mnt/local_repo). This will create the necessary metadata for your Yum repository.
14.2. yum Commands
yum commands are typically run as yum <command> <package name/s> . By default, yum will automatically attempt to check all configured repositories to resolve all package dependencies during an installation/upgrade.
yum commands. For a complete list of available yum commands, refer to man yum.
-
yum install <package name/s> - Used to install the latest version of a package or group of packages. If no package matches the specified package name(s), they are assumed to be a shell glob, and any matches are then installed.
-
yum update <package name/s> - Used to update the specified packages to the latest available version. If no package name/s are specified, then
yumwill attempt to update all installed packages.If the--obsoletesoption is used (i.e.yum --obsoletes <package name/s>,yumwill process obsolete packages. As such, packages that are obsoleted across updates will be removed and replaced accordingly. -
yum check-update - This command allows you to determine whether any updates are available for your installed packages.
yumreturns a list of all package updates from all repositories if any are available. -
yum remove <package name/s> - Used to remove specified packages, along with any other packages dependent on the packages being removed.
-
yum provides <file name> - Used to determine which packages provide a specific file or feature.
-
yum search <keyword> - This command is used to find any packages containing the specified keyword in the description, summary, packager and package name fields of RPMs in all repositories.
-
yum localinstall <absolute path to package name/s> - Used when using
yumto install a package located locally in the machine.
14.3. yum Options
yum options are typically stated before specific yum commands; i.e. yum <options> <command> <package name/s> . Most of these options can be set as default using the configuration file.
yum options. For a complete list of available yum options, refer to man yum.
-
-y - Answer "yes" to every question in the transaction.
-
-t - Sets
yumto be "tolerant" of errors with regard to packages specified in the transaction. For example, if you runyum update package1 package2andpackage2is already installed,yumwill continue to installpackage1. -
--exclude=<package name> - Excludes a specific package by name or glob in a specific transaction.
14.4. Configuring yum
yum is configured through /etc/yum.conf. The following is an example of a typical /etc/yum.conf file:
/etc/yum.conf file is made up of two types of sections: a [main] section, and a repository section. There can only be one [main] section, but you can specify multiple repositories in a single /etc/yum.conf.
14.4.1. [main] Options
[main] section is mandatory, and there must only be one. For a complete list of options you can use in the [main] section, refer to man yum.conf.
[main] section.
-
cachedir - This option specifies the directory where
yumshould store its cache and database files. By default, the cache directory ofyumis/var/cache/yum. -
keepcache=<1 or 0> - Setting
keepcache=1instructsyumto keep the cache of headers and packages after a successful installation.keepcache=1is the default. -
reposdir=<absolute path to directory of .repo files> - This option allows you to specify a directory where
.repofiles are located..repofiles contain repository information (similar to the[repository]section of/etc/yum.conf).yumcollects all repository information from.repofiles and the[repository]section of the/etc/yum.conffile to create a master list of repositories to use for each transaction. Refer to Section 14.4.2, “[repository]Options” for more information about options you can use for both the[repository]section and.repofiles.Ifreposdiris not set,yumuses the default directory/etc/yum.repos.d. -
gpgcheck=<1 or 0> - This disables/enables GPG signature checking on packages on all repositories, including local package installation. The default is
gpgcheck=0, which disables GPG checking.If this option is set in the[main]section of the/etc/yum.conffile, it sets the GPG checking rule for all repositories. However, you can also set this on individual repositories instead; i.e., you can enable GPG checking on one repository while disabling it on another. -
assumeyes=<1 or 0> - This determines whether or not
yumshould prompt for confirmation of critical actions. The default ifassumeyes=0, which meansyumwill prompt you for confirmation.Ifassumeyes=1is set,yumbehaves in the same way that the command line option-ydoes. -
tolerant=<1 or 0> - When enabled (
tolerant=1),yumwill be tolerant of errors on the command line with regard to packages. This is similar to theyumcommand line option-t.The default value for this istolerant=0(not tolerant). -
exclude=<package name/s> - This option allows you to exclude packages by keyword during installation/updates. If you are specifying multiple packages, this is a space-delimited list. Shell globs using wildcards (for example, * and ?) are allowed.
-
retries=<number of retries> - This sets the number of times
yumshould attempt to retrieve a file before returning an error. Setting this to 0 makesyumretry forever. The default value is 6.
14.4.2. [repository] Options
[repository] section of the /etc/yum.conf file contains information about a repository yum can use to find packages during package installation, updating and dependency resolution. A repository entry takes the following form:
[repository ID] name=repository name baseurl=url, file or ftp://path to repository
[repository ID]
name=repository name
baseurl=url, file or ftp://path to repository.repo files (for example, rhel5.repo). The format of repository information placed in .repo files is identical with the [repository] of /etc/yum.conf.
.repo files are typically placed in /etc/yum.repos.d, unless you specify a different repository path in the [main] section of /etc/yum.conf with reposdir=. .repo files and the /etc/yum.conf file can contain multiple repository entries.
- [repository ID]
- The repository ID is a unique, one-word string that serves as a repository identifier.
-
name=repository name - This is a human-readable string describing the repository.
-
baseurl=http, file or ftp://path - This is a URL to the directory where the
repodatadirectory of a repository is located. If the repository is local to the machine, usebaseurl=file://path to local repository. If the repository is located online using HTTP, usebaseurl=http://link. If the repository is online and uses FTP, usebaseurl=ftp://link.If a specific online repository requires basic HTTP authentication, you can specify your username and password in thebaseurlline by prepending it as username:password@link. For example, if a repository on http://www.example.com/repo/ requires a username of "user" and a password os "password", then thebaseurllink can be specified asbaseurl=http://user:password@www.example.com/repo/.
man yum.conf.
-
gpgcheck=<1 or 0> - This disables/enables GPG signature checking a specific repository. The default is
gpgcheck=0, which disables GPG checking. -
gpgkey=URL - This option allows you to point to a URL of the ASCII-armoured GPG key file for a repository. This option is normally used if
yumneeds a public key to verify a package and the required key was not imported into the RPM database.If this option is set,yumwill automatically import the key from the specified URL. You will be prompted before the key is installed unless you setassumeyes=1(in the[main]section of/etc/yum.conf) or-y(in ayumtransaction). -
exclude=<package name/s> - This option is similar to the
excludeoption in the[main]section of/etc/yum.conf. However, it only applies to the repository in which it is specified. -
includepkgs=<package name/s> - This option is the opposite of
exclude. When this option is set on a repository,yumwill only be able to see the specified packages in that repository. By default, all packages in a repository are visible toyum.
14.5. Upgrading the System Off-line with ISO and Yum
yum update command with the Red Hat Enterprise Linux installation ISO image is an easy and quick way to upgrade systems to the latest minor version. The following steps illustrate the upgrading process:
- Create a target directory to mount your ISO image. This directory is not automatically created when mounting, so create it before proceeding to the next step, as
root, type:mkdir mount_dir
mkdir mount_dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow Replace mount_dir with a path to the mount directory. Typicaly, users create it as a subdirectory in the/media/directory. - Mount the Red Hat Enterprise Linux 5 installation ISO image to the previously created target directory. As
root, type:mount -o loop iso_name mount_dir
mount -o loop iso_name mount_dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow Replace iso_name with a path to your ISO image and mount_dir with a path to the target directory. Here, the-oloopoption is required to mount the file as a block device. - Check the numeric value found on the first line of the
.discinfofile from the mount directory:head -n1 mount_dir/.discinfo
head -n1 mount_dir/.discinfoCopy to Clipboard Copied! Toggle word wrap Toggle overflow The output of this command is an identification number of the ISO image, you need to know it to perform the following step. - Create a new file in the
/etc/yum.repos.d/directory, named for instance new.repo, and add a content in the following form. Note that configuration files in this directory must have the .repo extension to function properly.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Replace media_id with the numeric value found inmount_dir/.discinfo. Set the repository name instead of repository_name, replace repository_url with a path to a repository directory in the mount point and gpg_key with a path to the GPG key.For example, the repository settings for Red Hat Enterprise Linux 5 Server ISO can look as follows:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Update all yum repositories including
/etc/yum.repos.d/new.repocreated in previous steps. Asroot, type:yum update
yum updateCopy to Clipboard Copied! Toggle word wrap Toggle overflow This upgrades your system to the version provided by the mounted ISO image. - After successful upgrade, you can unmount the ISO image, with the
rootprivileges:umount mount_dir
umount mount_dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow where mount_dir is a path to your mount directory. Also, you can remove the mount directory created in the first step. Asroot, type:rmdir mount_dir
rmdir mount_dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow - If you will not use the previously created configuration file for another installation or update, you can remove it. As
root, type:rm /etc/yum.repos.d/new.repo
rm /etc/yum.repos.d/new.repoCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Example 14.1. Upgrading from Red Hat Enterprise Linux 5.8 to 5.9
RHEL5.9-Server-20121129.0-x86_64-DVD1.iso. You have crated a target directory /media/rhel5/. As root, change into the directory with your ISO image and type:
mount -o loop RHEL5.9-Server-20121129.0-x86_64-DVD1.iso /media/rhel5/
~]# mount -o loop RHEL5.9-Server-20121129.0-x86_64-DVD1.iso /media/rhel5/head -n1 /media/rhel5/.discinfo 1354216429.587870
~]# head -n1 /media/rhel5/.discinfo
1354216429.587870
/etc/yum.repos.d/rhel5.repo file and insert the following text into it:
RHEL5.9-Server-20121129.0-x86_64-DVD1.iso. As root, execute:
yum update
~]# yum updateumount /media/rhel5/
~]# umount /media/rhel5/rmdir /media/rhel5/
~]# rmdir /media/rhel5/rm /etc/yum.repos.d/rhel5.repo
~]# rm /etc/yum.repos.d/rhel5.repo14.6. Useful yum Variables
yum commands and yum configuration files (i.e. /etc/yum.conf and .repo files).
-
$releasever - This is replaced with the package's version, as listed in
distroverpkg. This defaults to the version of theredhat-releasepackage. -
$arch - This is replaced with your system's architecture, as listed by
os.uname()in Python. -
$basearch - This is replaced with your base architecture. For example, if
$arch=i686 then$basearch=i386. -
$YUM0-9 - This is replaced with the value of the shell environment variable of the same name. If the shell environment variable does not exist, then the configuration file variable will not be replaced.
Chapter 15. Registering a System and Managing Subscriptions
yum to unite content delivery with subscription management. The Subscription Manager handles only the subscription-system associations. yum or other package management tools handle the actual content delivery. Chapter 14, YUM (Yellowdog Updater Modified) describes how to use yum.
15.1. Using Red Hat Subscription Manager Tools
Note
root because of the nature of the changes to the system. However, Red Hat Subscription Manager connects to the subscription service as a user account for the subscription service.
15.1.1. Launching the Red Hat Subscription Manager GUI

Figure 15.1. Red Hat Subscription Manager Menu Option
subscription-manager-gui
[root@server1 ~]# subscription-manager-gui15.1.2. Running the subscription-manager Command-Line Tool
subscription-manager tool. This tool has the following format:
subscription-manager command [options]
[root@server1 ~]# subscription-manager command [options]subscription-manager help and manpage have more information.
| Command | Description |
|---|---|
| register | Registers or identifies a new system to the subscription service. |
| unregister | Unregisters a machine, which strips its subscriptions and removes the machine from the subscription service. |
| subscribe | Attaches a specific subscription to the machine. |
| redeem | Auto-attaches a machine to a pre-specified subscription that was purchased from a vendor, based on its hardware and BIOS information. |
| unsubscribe | Removes a specific subscription or all subscriptions from the machine. |
| list | Lists all of the subscriptions that are compatible with a machine, either subscriptions that are actually attached to the machine or unused subscriptions that are available to the machine. |
15.2. Registering and Unregistering a System
15.2.1. Registering from the GUI
- Launch Subscription Manager. For example:
subscription-manager-gui
[root@server ~]# subscription-manager-guiCopy to Clipboard Copied! Toggle word wrap Toggle overflow - If the system is not already registered, then there will be a button at the top of the window in the top right corner of the My Installed Products tab.
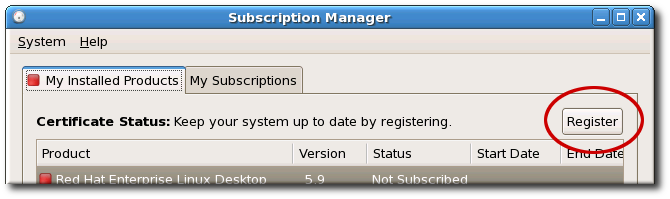
- To identify which subscription server to use for registration, enter the hostname of the service. The default service is Customer Portal Subscription Management, with the hostname subscription.rhn.redhat.com. To use a different subscription service, such as Subscription Asset Manager, enter the hostname of the local server.
 There are seveal different subscription services which use and recognize certificate-based subscriptions, and a system can be registered with any of them in firstboot:
There are seveal different subscription services which use and recognize certificate-based subscriptions, and a system can be registered with any of them in firstboot:- Customer Portal Subscription Management, hosted services from Red Hat (the default)
- Subscription Asset Manager, an on-premise subscription server which proxies content delivery back to the Customer Portal's services
- CloudForms System Engine, an on-premise service which handles both subscription services and content delivery
- Enter the user credentials for the given subscription service to log in.
 The user credentials to use depend on the subscription service. When registering with the Customer Portal, use the Red Hat Network credentials for the administrator or company account.However, for Subscription Asset Manager or CloudForms System engine, the user account to use is created within the on-premise service and probably is not the same as the Customer Portal user account.
The user credentials to use depend on the subscription service. When registering with the Customer Portal, use the Red Hat Network credentials for the administrator or company account.However, for Subscription Asset Manager or CloudForms System engine, the user account to use is created within the on-premise service and probably is not the same as the Customer Portal user account. - Optionally, select the Manually assign subscriptions after registration checkbox.By default, the registration process automatically attaches the best-matched subscription to the system. This can be turned off so that the subscriptions can be selected manually, as in Section 15.3, “Attaching and Removing Subscriptions”.
- When registration begins, Subscription Manager scans for organizations and environments (sub-domains within the organization) to which to register the system.
 IT environments that use Customer Portal Subscription Management have only a single organization, so no further configuration is necessary. IT infrastructures that use a local subscription service like Subscription Asset Manager might have multiple organizations configured, and those organizations may have multiple environments configured within them.If multiple organizations are detected, Subscription Manager prompts to select the one to join.
IT environments that use Customer Portal Subscription Management have only a single organization, so no further configuration is necessary. IT infrastructures that use a local subscription service like Subscription Asset Manager might have multiple organizations configured, and those organizations may have multiple environments configured within them.If multiple organizations are detected, Subscription Manager prompts to select the one to join.
- With the default setting, subscriptions are automatically selected and attached to the system. Review and confirm the subscriptions to attach to the system.
- If prompted, select the service level to use for the discovered subscriptions.
- Subscription Manager lists the selected subscription. This subscription selection must be confirmed by clicking the button for the wizard to complete.

15.2.2. Registering from the Command Line
register command with the user account information required to authenticate to Customer Portal Subscription Management. When the system is successfully authenticated, it echoes back the newly-assigned system inventory ID and the user account name which registered it.
register options are listed in Table 15.2, “register Options”.
Example 15.1. Registering a System to the Customer Portal
subscription-manager register --username admin-example --password secret The system has been registered with id: 7d133d55-876f-4f47-83eb-0ee931cb0a97
[root@server1 ~]# subscription-manager register --username admin-example --password secret
The system has been registered with id: 7d133d55-876f-4f47-83eb-0ee931cb0a97Example 15.2. Automatically Subscribing While Registering
register command has an option, --autosubscribe, which allows the system to be registered to the subscription service and immediately attaches the subscription which best matches the system's architecture, in a single step.
subscription-manager register --username admin-example --password secret --autosubscribe
[root@server1 ~]# subscription-manager register --username admin-example --password secret --autosubscribeExample 15.3. Registering a System with Subscription Asset Manager
--org option in addition to the username and password. The given user must also have the access permissions to add systems to that organization.
- The username and password for the user account withint the subscription service itself
--serverurlto give the hostname of the subscription service--baseurlto give the hostname of the content delivery service (for CloudForms System Engine only)--orgto give the name of the organization under which to register the system--environmentto give the name of an environment (group) within the organization to which to add the system; this is optional, since a default environment is set for any organizationA system can only be added to an environment during registration.
subscription-manager register --username=admin-example --password=secret --org="IT Department" --environment="dev" --serverurl=sam-server.example.com The system has been registered with id: 7d133d55-876f-4f47-83eb-0ee931cb0a97
[root@server1 ~]# subscription-manager register --username=admin-example --password=secret --org="IT Department" --environment="dev" --serverurl=sam-server.example.com
The system has been registered with id: 7d133d55-876f-4f47-83eb-0ee931cb0a97Note
register command returns a Remote Server error.
| Options | Description | Required |
|---|---|---|
| --username=name | Gives the content server user account name. | Required |
| --password=password | Gives the password for the user account. | Required |
| --serverurl=hostname | Gives the hostname of the subscription service to use. The default is for Customer Portal Subcription Management, subscription.rhn.redhat.com. If this option is not used, the system is registered with Customer Portal Subscription Management. | Required for Subscription Asset Manager or CloudForms System Engine |
| --baseurl=URL | Gives the hostname of the content delivery server to use to receive updates. Both Customer Portal Subscription Management and Subscription Asset Manager use Red Hat's hosted content delivery services, with the URL https://cdn.redhat.com. Since CloudForms System Engine hosts its own content, the URL must be used for systems registered with System Engine. | Required for CloudForms System Engine |
| --org=name | Gives the organization to which to join the system. | Required, except for hosted environments |
| --environment=name | Registers the system to an environment within an organization. | Optional |
| --name=machine_name | Sets the name of the system to register. This defaults to be the same as the hostname. | Optional |
| --autosubscribe | Automatically ataches the best-matched compatible subscription. This is good for automated setup operations, since the system can be configured in a single step. | Optional |
| --activationkey=key | Attaches existing subscriptions as part of the registration process. The subscriptions are pre-assigned by a vendor or by a systems administrator using Subscription Asset Manager. | Optional |
| --servicelevel=None|Standard|Premium | Sets the service level to use for subscriptions on that machine. This is only used with the --autosubscribe option. | Optional |
| --release=NUMBER | Sets the operating system minor release to use for subscriptions for the system. Products and updates are limited to that specific minor release version. This is used only used with the --autosubscribe option. | Optional |
| --force | Registers the system even if it is already registered. Normally, any register operations will fail if the machine is already registered. | Optional |
15.2.3. Unregistering
unregister command. This removes the system's entry from the subscription service, removes any subscriptions, and, locally, deletes its identity and subscription certificates.
unregister command.
Example 15.4. Unregistering a System
subscription-manager unregister
[root@server1 ~]# subscription-manager unregister- Open the Subscription Manager UI.
subscription-manager-gui
[root@server ~]# subscription-manager-guiCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Open the System menu, and select the item.
- Confirm that the system should be unregistered.
15.3. Attaching and Removing Subscriptions
15.3.1. Attaching and Removing Subscriptions through the GUI
15.3.1.1. Attaching a Subscription
- Launch Subscription Manager. For example:
subscription-manager-gui
[root@server ~]# subscription-manager-guiCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Open the All Available Subscriptions tab.
- Optionally, set the date range and click the button to set the filters to use to search for available subscriptions.
 Subscriptions can be filtered by their active date and by their name. The checkboxes provide more fine-grained filtering:
Subscriptions can be filtered by their active date and by their name. The checkboxes provide more fine-grained filtering:- match my system shows only subscriptions which match the system architecture.
- match my installed products shows subscriptions which work with currently installed products on the system.
- have no overlap with existing subscriptions excludes subscriptions with duplicate products. If a subscription is already attached to the system for a specific product or if multiple subscriptions supply the same product, then the subscription service filters those subscriptions and shows only the best fit.
- contain the text searches for strings, such as the product name, within the subscription or pool.
 After setting the date and filters, click the button to apply them.
After setting the date and filters, click the button to apply them. - Select one of the available subscriptions.

- Click the button.
15.3.1.2. Removing Subscriptions
- Launch Subscription Manager. For example:
subscription-manager-gui
[root@server ~]# subscription-manager-guiCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Open the My Subscriptions tab.All of the active subscriptions to which the system is currently attached are listed. (The products available through the subscription may or may not be installed.)
- Select the subscription to remove.
- Click the button in the bottom right of the window.
15.3.2. Attaching and Removing Subscriptions through the Command Line
15.3.2.1. Attaching Subscriptions
--pool option.
subscription-manager subscribe --pool=XYZ01234567
[root@server1 ~]# subscription-manager subscribe --pool=XYZ01234567subscribe command are listed in Table 15.3, “subscribe Options”.
list command:
--auto option (which is analogous to the --autosubscribe option with the register command).
subscription-manager subscribe --auto
[root@server1 ~]# subscription-manager subscribe --auto| Options | Description | Required |
|---|---|---|
| --pool=pool-id | Gives the ID for the subscription to attach to the system. | Required, unless --auto is used |
| --auto | Automatically attaches the system to the best-match subscription or subscriptions. | Optional |
| --quantity=number | Attaches multiple counts of a subscription to the system. This is used to cover subscriptions that define a count limit, like using two 2-socket server subscriptions to cover a 4-socket machine. | Optional |
| --servicelevel=None|Standard|Premium | Sets the service level to use for subscriptions on that machine. This is only used with the --auto option. | Optional |
15.3.2.2. Removing Subscriptions from the Command Line
unsubscribe command with the --all option removes every product subscription and subscription pool that is currently attached to the system.
subscription-manager unsubscribe --all
[root@server1 ~]# subscription-manager unsubscribe --allunsubscribe command by referencing the ID number of that X.509 certificate.
- Get the serial number for the product certificate, if you are removing a single product subscription. The serial number can be obtained from the subscription#
.pemfile (for example,392729555585697907.pem) or by using thelistcommand. For example:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Run the subscription-manager tool with the
--serialoption to specify the certificate.subscription-manager unsubscribe --serial=11287514358600162
[root@server1 ~]# subscription-manager unsubscribe --serial=11287514358600162Copy to Clipboard Copied! Toggle word wrap Toggle overflow
15.4. Redeeming Vendor Subscriptions
15.4.1. Redeeming Subscriptions through the GUI
Note
- Launch Subscription Manager. For example:
subscription-manager-gui
[root@server ~]# subscription-manager-guiCopy to Clipboard Copied! Toggle word wrap Toggle overflow - If necessary, register the system, as described in Section 15.2.1, “Registering from the GUI”.
- Open the menu in the top left of the window, and click the item.
- In the dialog window, enter the email address to send the notification to when the redemption is complete. Because the redemption process can take several minutes to contact the vendor and receive information about the pre-configured subscriptions, the notification message is sent through email rather than through the Subscription Manager dialog window.
- Click the button.
15.4.2. Redeeming Subscriptions through the Command Line
Note
redeem command, with an email address to send the redemption email to when the process is complete.
subscription-manager redeem --email=jsmith@example.com
# subscription-manager redeem --email=jsmith@example.com15.5. Attaching Subscriptions from a Subscription Asset Manager Activation Key
subscription-manager register --username=jsmith --password=secret --org="IT Dept" --activationkey=abcd1234
# subscription-manager register --username=jsmith --password=secret --org="IT Dept" --activationkey=abcd123415.6. Setting Preferences for Systems
- Service levels for subscriptions
- The operating system minor version (X.Y) to use
15.6.1. Setting Preferences in the UI
- Open the Subscription Manager.
- Open the System menu.
- Select the System Preferences menu item.
- Select the desired service level agreement preference from the drop-down menu. Only service levels available to the Red Hat account, based on all of its active subscriptions, are listed.
- Select the operating system release preference in the Release version drop-down menu. The only versions listed are Red Hat Enterprise Linux versions for which the account has an active subscription.
- The preferences are saved and applied to future subscription operations when they are set. To close the dialog, click .
15.6.2. Setting Service Levels Through the Command Line
service-level --set command.
Example 15.5. Setting a Service Level Preference
--list option with the service-level command.
subscription-manager service-level --set=self-support Service level set to: self-support
[root@server ~]# subscription-manager service-level --set=self-support
Service level set to: self-support--show option:
[root#server ~]# subscription-manager service-level --show Current service level: self-support
[root#server ~]# subscription-manager service-level --show
Current service level: self-supportregister and subscribe commands have the --servicelevel option to set a preference for that action.
Example 15.6. Autoattaching Subscriptions with a Premium Service Level
[root#server ~]# subscription-manager subscribe --auto --servicelevel Premium Service level set to: Premium Installed Product Current Status: ProductName: Red Hat Enterprise Linux 5 Server Status: Subscribed
[root#server ~]# subscription-manager subscribe --auto --servicelevel Premium
Service level set to: Premium
Installed Product Current Status:
ProductName: Red Hat Enterprise Linux 5 Server
Status: SubscribedNote
--servicelevel option requires the --autosubscribe option (for register) or --auto option (for subscribe). It cannot be used when attaching a specified pool or when importing a subscription.
15.6.3. Setting a Preferred Operating System Release Version in the Command Line
yum update and move from version to version.
Example 15.7. Setting an Operating System Release During Registration
--release option with the register. This applies the release preference to any subscriptions selected and auto-attached to the system at registration time.
--autosubscribe option, because it is one of the criteria used to select subscriptions to auto-attach.
[root#server ~]# subscription-manager register --autosubscribe --release=5.9 --username=admin@example.com...
[root#server ~]# subscription-manager register --autosubscribe --release=5.9 --username=admin@example.com...Note
subscribe command.
Example 15.8. Setting an Operating System Release Preference
release command can display the available operating system releases, based on the available, purchased (not only attached) subscriptions for the organization.
--set then sets the preference to one of the available release versions:
[root#server ~]# subscription-manager release --set=5.9 Release version set to: 5.9
[root#server ~]# subscription-manager release --set=5.9
Release version set to: 5.915.6.4. Removing a Preference
--unset with the appropriate command. For example, to unset a release version preference:
[root#server ~]# subscription-manager release --unset Release version set to:
[root#server ~]# subscription-manager release --unset
Release version set to:- Open the Subscription Manager.
- Open the System menu.
- Select the System Preferences menu item.
- Set the service level or release version value to the blank line in the corresponding drop-down menu.
- Click .
15.7. Managing Subscription Expiration and Notifications
Figure 15.2. Valid Until...
Figure 15.3. Color-Coded Status Views
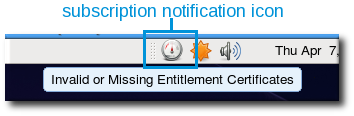
Figure 15.4. Subscription Notification Icon
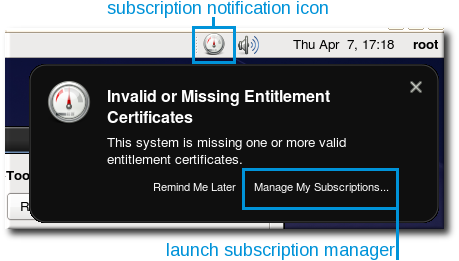
Figure 15.5. Subscription Warning Message
Figure 15.6. Autosubscribe Button
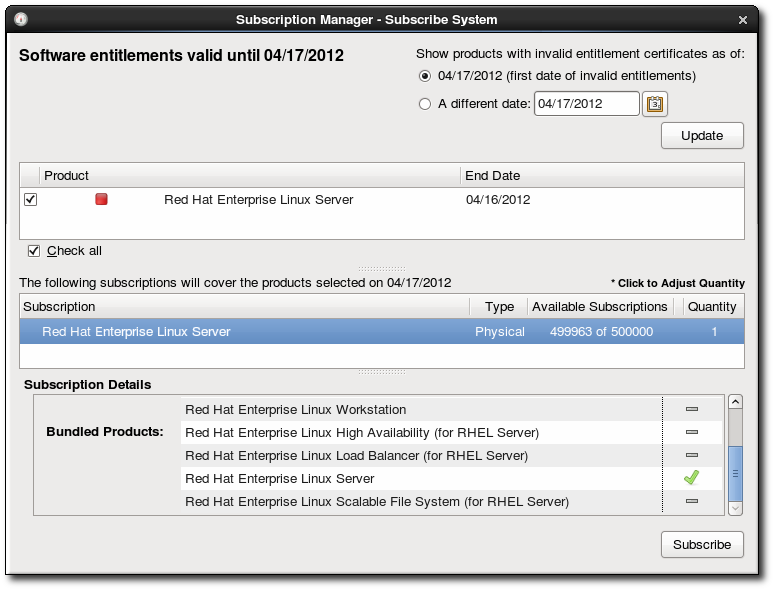
Figure 15.7. Subscribe System
Part III. Network-Related Configuration
Chapter 16. Network Interfaces
/etc/sysconfig/network-scripts/ directory. The scripts used to activate and deactivate these network interfaces are also located here. Although the number and type of interface files can differ from system to system, there are three categories of files that exist in this directory:
- Interface configuration files
- Interface control scripts
- Network function files
16.1. Network Configuration Files
-
/etc/hosts - The main purpose of this file is to resolve host names that cannot be resolved any other way. It can also be used to resolve host names on small networks with no
DNSserver. Regardless of the type of network the computer is on, this file should contain a line specifying theIPaddress of the loopback device (127.0.0.1) aslocalhost.localdomain. For more information, refer to thehosts(5)man page. -
/etc/resolv.conf - This file specifies the
IPaddresses ofDNSservers and the search domain. Unless configured to do otherwise, the network initialization scripts populate this file. For more information about this file, refer to theresolv.conf(5)man page. -
/etc/sysconfig/network - This file specifies routing and host information for all network interfaces. It is used to contain directives which are to have global effect and not to be interface specific. For more information about this file and the directives it accepts, refer to Section 32.1.22, “
/etc/sysconfig/network”. -
/etc/sysconfig/network-scripts/ifcfg-<interface-name> - For each network interface, there is a corresponding interface configuration script. Each of these files provide information specific to a particular network interface. Refer to Section 16.2, “Interface Configuration Files” for more information on this type of file and the directives it accepts.
Warning
/etc/sysconfig/networking/ directory is used by the Network Administration Tool (system-config-network) and its contents should not be edited manually. Using only one method for network configuration is strongly encouraged, due to the risk of configuration deletion.
16.2. Interface Configuration Files
ifcfg-<name> , where <name> refers to the name of the device that the configuration file controls.
16.2.1. Ethernet Interfaces
/etc/sysconfig/network-scripts/ifcfg-eth0, which controls the first Ethernet network interface card or NIC in the system. In a system with multiple NICs, there are multiple ifcfg-eth<X> files (where <X> is a unique number corresponding to a specific interface). Because each device has its own configuration file, an administrator can control how each interface functions individually.
ifcfg-eth0 file for a system using a fixed IP address:
ifcfg-eth0 file for an interface using DHCP looks different because IP information is provided by the DHCP server:
DEVICE=eth0 BOOTPROTO=dhcp ONBOOT=yes
DEVICE=eth0
BOOTPROTO=dhcp
ONBOOT=yessystem-config-network) is an easy way to make changes to the various network interface configuration files (refer to Chapter 17, Network Configuration for detailed instructions on using this tool).
-
BONDING_OPTS=<parameters> - sets the configuration parameters for the bonding device, and is used in
/etc/sysconfig/network-scripts/ifcfg-bond<N>(see Section 16.2.3, “Channel Bonding Interfaces”). These parameters are identical to those used for bonding devices in/sys/class/net/<bonding device>/bonding, and the module parameters for the bonding driver as described inbondingModule Directives.This configuration method is used so that multiple bonding devices can have different configurations. If you useBONDING_OPTSinifcfg-<name>, do not use/etc/modprobe.confto specify options for the bonding device. -
BOOTPROTO=<protocol> - where
<protocol>is one of the following:none— No boot-time protocol should be used.bootp— The BOOTP protocol should be used.dhcp— TheDHCPprotocol should be used.
-
BROADCAST=<address> - where
<address>is the broadcast address. This directive is deprecated, as the value is calculated automatically withipcalc. -
DEVICE=<name> - where
<name>is the name of the physical device (except for dynamically-allocated PPP devices where it is the logical name). -
DHCP_HOSTNAME=<name> - where
<name>is a short host name to be sent to theDHCPserver. Use this option only if theDHCPserver requires the client to specify a host name before receiving anIPaddress. -
DNS{1,2}=<address> - where
<address>is a name server address to be placed in/etc/resolv.confif thePEERDNSdirective is set toyes. -
ETHTOOL_OPTS=<options> - where
<options>are any device-specific options supported byethtool. For example, if you wanted to force 100Mb, full duplex:ETHTOOL_OPTS="autoneg off speed 100 duplex full"
ETHTOOL_OPTS="autoneg off speed 100 duplex full"Copy to Clipboard Copied! Toggle word wrap Toggle overflow Instead of a custom initscript, useETHTOOL_OPTSto set the interface speed and duplex settings. Custom initscripts run outside of the network init script lead to unpredictable results during a post-boot network service restart.Note
Changing speed or duplex settings almost always requires disabling autonegotiation with theautoneg offoption. This needs to be stated first, as the option entries are order-dependent. -
GATEWAY=<address> - where <address> is the
IPaddress of the network router or gateway device (if any). -
HOTPLUG=<answer> - where <answer> is one of the following:
yes— This device should be activated when it is hot-plugged (this is the default option).no— This device should not be activated when it is hot-plugged.
TheHOTPLUG=nooption can be used to prevent a channel bonding interface from being activated when a bonding kernel module is loaded.Refer to Section 16.2.3, “Channel Bonding Interfaces” for more about channel bonding interfaces. -
HWADDR=<MAC-address> - where <MAC-address> is the hardware address of the Ethernet device in the form AA:BB:CC:DD:EE:FF. This directive must be used in machines containing more than one NIC to ensure that the interfaces are assigned the correct device names regardless of the configured load order for each NIC's module. This directive should not be used in conjunction with
MACADDR. -
IPADDR=<address> - where
<address>is theIPaddress. -
LINKDELAY=<time> - where <time> is the number of seconds to wait for link negotiation before configuring the device.
-
MACADDR=<MAC-address> - where <MAC-address> is the hardware address of the Ethernet device in the form AA:BB:CC:DD:EE:FF. This directive is used to assign a MAC address to an interface, overriding the one assigned to the physical NIC. This directive should not be used in conjunction with
HWADDR. -
MASTER=<bond-interface> - where
<bond-interface>is the channel bonding interface to which the Ethernet interface is linked.This directive is used in conjunction with theSLAVEdirective.Refer to Section 16.2.3, “Channel Bonding Interfaces” for more information about channel bonding interfaces. -
NETMASK=<mask> - where
<mask>is the netmask value. -
NETWORK=<address> - where
<address>is the network address. This directive is deprecated, as the value is calculated automatically withipcalc. -
ONBOOT=<answer> - where
<answer>is one of the following:yes— This device should be activated at boot-time.no— This device should not be activated at boot-time.
-
PEERDNS=<answer> - where
<answer>is one of the following:yes— Modify/etc/resolv.confif the DNS directive is set. If usingDHCP, thenyesis the default.no— Do not modify/etc/resolv.conf.
-
SLAVE=<answer> - where
<answer>is one of the following:yes— This device is controlled by the channel bonding interface specified in theMASTERdirective.no— This device is not controlled by the channel bonding interface specified in theMASTERdirective.
This directive is used in conjunction with theMASTERdirective.Refer to Section 16.2.3, “Channel Bonding Interfaces” for more about channel bonding interfaces. -
SRCADDR=<address> - where
<address>is the specified sourceIPaddress for outgoing packets. -
USERCTL=<answer> - where
<answer>is one of the following:yes— Non-root users are allowed to control this device.no— Non-root users are not allowed to control this device.
16.2.2. IPsec Interfaces
ifcfg file for a network-to-network IPsec connection for LAN A. The unique name to identify the connection in this example is ipsec1, so the resulting file is named /etc/sysconfig/network-scripts/ifcfg-ipsec1.
IP address of the destination IPsec router.
-
DST=<address> - where <address> is the
IPaddress of the IPsec destination host or router. This is used for both host-to-host and network-to-network IPsec configurations. -
DSTNET=<network> - where <network> is the network address of the IPsec destination network. This is only used for network-to-network IPsec configurations.
-
SRC=<address> - where <address> is the
IPaddress of the IPsec source host or router. This setting is optional and is only used for host-to-host IPsec configurations. -
SRCNET=<network> - where <network> is the network address of the IPsec source network. This is only used for network-to-network IPsec configurations.
-
TYPE=<interface-type> - where <interface-type> is
IPSEC. Both applications are part of theipsec-toolspackage.
/usr/share/doc/initscripts-<version-number>/sysconfig.txt (replace <version-number> with the version of the initscripts package installed) for configuration parameters.
racoon IKEv1 key management daemon negotiates and configures a set of parameters for IPSec. It can use preshared keys, RSA signatures, or GSS-API. If racoon is used to automatically manage key encryption, the following options are required:
-
IKE_METHOD=<encryption-method> - where <encryption-method> is either
PSK,X509, orGSSAPI. IfPSKis specified, theIKE_PSKparameter must also be set. IfX509is specified, theIKE_CERTFILEparameter must also be set. -
IKE_PSK=<shared-key> - where <shared-key> is the shared, secret value for the PSK (preshared keys) method.
-
IKE_CERTFILE=<cert-file> - where <cert-file> is a valid
X.509certificate file for the host. -
IKE_PEER_CERTFILE=<cert-file> - where <cert-file> is a valid
X.509certificate file for the remote host. -
IKE_DNSSEC=<answer> - where <answer> is
yes. Theracoondaemon retrieves the remote host'sX.509certificate via DNS. If aIKE_PEER_CERTFILEis specified, do not include this parameter.
setkey man page. For more information about racoon, refer to the racoon and racoon.conf man pages.
16.2.3. Channel Bonding Interfaces
bonding kernel module and a special network interface called a channel bonding interface. Channel bonding enables two or more network interfaces to act as one, simultaneously increasing the bandwidth and providing redundancy.
/etc/sysconfig/network-scripts/ directory called ifcfg-bond<N> , replacing <N> with the number for the interface, such as 0.
DEVICE= directive must be bond<N> , replacing <N> with the number for the interface.
ifcfg-bond0:
MASTER= and SLAVE= directives to their configuration files. The configuration files for each of the channel-bonded interfaces can be nearly identical.
eth0 and eth1 may look like the following example:
/etc/modprobe.conf:
alias bond<N> bonding
alias bond<N> bonding0.
Important
BONDING_OPTS="bonding parameters" directive in the ifcfg-bondN interface file. Do not specify options for the bonding device in the /etc/modprobe.conf file.
debug and max_bonds parameters are not interface specific and therefore, if required, should be specified in /etc/modprobe.conf as follows:
options bonding debug=1 max_bonds=1
options bonding debug=1 max_bonds=1max_bonds parameter should not be set when using ifcfg-bondN files with the BONDING_OPTS directive as this directive will cause the network scripts to create the bond interfaces as required.
/etc/modprobe.conf will not take effect until the module is next loaded. A running module must first be unloaded. For further instructions and advice on configuring the bonding module, as well as to view the list of bonding parameters, refer to Section 45.5.1, “The Channel Bonding Module”.
16.2.4. Alias and Clone Files
ifcfg-<if-name>:<alias-value> naming scheme.
ifcfg-eth0:0 file could be configured to specify DEVICE=eth0:0 and a static IP address of 10.0.0.2, serving as an alias of an Ethernet interface already configured to receive its IP information via DHCP in ifcfg-eth0. Under this configuration, eth0 is bound to a dynamic IP address, but the same physical network card can receive requests via the fixed, 10.0.0.2 IP address.
Warning
DHCP.
ifcfg-<if-name>-<clone-name> . While an alias file allows multiple addresses for an existing interface, a clone file is used to specify additional options for an interface. For example, a standard DHCP Ethernet interface called eth0, may look similar to this:
DEVICE=eth0 ONBOOT=yes BOOTPROTO=dhcp
DEVICE=eth0
ONBOOT=yes
BOOTPROTO=dhcpUSERCTL directive is no if it is not specified, users cannot bring this interface up and down. To give users the ability to control the interface, create a clone by copying ifcfg-eth0 to ifcfg-eth0-user and add the following line to ifcfg-eth0-user:
USERCTL=yes
USERCTL=yeseth0 interface using the /sbin/ifup eth0-user command because the configuration options from ifcfg-eth0 and ifcfg-eth0-user are combined. While this is a very basic example, this method can be used with a variety of options and interfaces.
16.2.5. Dialup Interfaces
ifcfg-ppp<X>- where <X> is a unique number corresponding to a specific interface.
wvdial, the Network Administration Tool or Kppp is used to create a dialup account. It is also possible to create and edit this file manually.
ifcfg-ppp0 file:
ifcfg-sl0.
-
DEFROUTE=<answer> - where
<answer>is one of the following:yes— Set this interface as the default route.no— Do not set this interface as the default route.
-
DEMAND=<answer> - where
<answer>is one of the following:yes— This interface allowspppdto initiate a connection when someone attempts to use it.no— A connection must be manually established for this interface.
-
IDLETIMEOUT=<value> - where
<value>is the number of seconds of idle activity before the interface disconnects itself. -
INITSTRING=<string> - where
<string>is the initialization string passed to the modem device. This option is primarily used in conjunction with SLIP interfaces. -
LINESPEED=<value> - where
<value>is the baud rate of the device. Possible standard values include57600,38400,19200, and9600. -
MODEMPORT=<device> - where
<device>is the name of the serial device that is used to establish the connection for the interface. -
MTU=<value> - where
<value>is the Maximum Transfer Unit (MTU) setting for the interface. The MTU refers to the largest number of bytes of data a frame can carry, not counting its header information. In some dialup situations, setting this to a value of576results in fewer packets dropped and a slight improvement to the throughput for a connection. -
NAME=<name> - where
<name>is the reference to the title given to a collection of dialup connection configurations. -
PAPNAME=<name> - where
<name>is the username given during the Password Authentication Protocol (PAP) exchange that occurs to allow connections to a remote system. -
PERSIST=<answer> - where
<answer>is one of the following:yes— This interface should be kept active at all times, even if deactivated after a modem hang up.no— This interface should not be kept active at all times.
-
REMIP=<address> - where
<address>is theIPaddress of the remote system. This is usually left unspecified. -
WVDIALSECT=<name> - where
<name>associates this interface with a dialer configuration in/etc/wvdial.conf. This file contains the phone number to be dialed and other important information for the interface.
16.2.6. Other Interfaces
-
ifcfg-lo - A local loopback interface is often used in testing, as well as being used in a variety of applications that require an
IPaddress pointing back to the same system. Any data sent to the loopback device is immediately returned to the host's network layer.Warning
The loopback interface script,/etc/sysconfig/network-scripts/ifcfg-lo, should never be edited manually. Doing so can prevent the system from operating correctly. -
ifcfg-irlan0 - An infrared interface allows information between devices, such as a laptop and a printer, to flow over an infrared link. This works in a similar way to an Ethernet device except that it commonly occurs over a peer-to-peer connection.
-
ifcfg-plip0 - A Parallel Line Interface Protocol (PLIP) connection works much the same way as an Ethernet device, except that it utilizes a parallel port.
-
ifcfg-tr0 - Token Ring topologies are not as common on Local Area Networks (LANs) as they once were, having been eclipsed by Ethernet.
16.3. Interface Control Scripts
/etc/sysconfig/network-scripts/ directory: /sbin/ifdown and /sbin/ifup.
ifup and ifdown interface scripts are symbolic links to scripts in the /sbin/ directory. When either of these scripts are called, they require the value of the interface to be specified, such as:
ifup eth0
ifup eth0Warning
ifup and ifdown interface scripts are the only scripts that the user should use to bring up and take down network interfaces.
/etc/rc.d/init.d/functions and /etc/sysconfig/network-scripts/network-functions. Refer to Section 16.6, “Network Function Files” for more information.
/etc/sysconfig/network-scripts/ directory:
-
ifup-aliases - Configures
IPaliases from interface configuration files when more than oneIPaddress is associated with an interface. -
ifup-ipppandifdown-ippp - Brings ISDN interfaces up and down.
-
ifup-ipsecandifdown-ipsec - Brings IPsec interfaces up and down.
-
ifup-ipv6andifdown-ipv6 - Brings
IPv6interfaces up and down. -
ifup-ipx - Brings up an IPX interface.
-
ifup-plip - Brings up a PLIP interface.
-
ifup-plusb - Brings up a USB interface for network connections.
-
ifup-postandifdown-post - Contains commands to be executed after an interface is brought up or down.
-
ifup-pppandifdown-ppp - Brings a PPP interface up or down.
-
ifup-routes - Adds static routes for a device as its interface is brought up.
-
ifdown-sitandifup-sit - Contains function calls related to bringing up and down an
IPv6tunnel within anIPv4connection. -
ifup-slandifdown-sl - Brings a SLIP interface up or down.
-
ifup-wireless - Brings up a wireless interface.
Warning
/etc/sysconfig/network-scripts/ directory can cause interface connections to act irregularly or fail. Only advanced users should modify scripts related to a network interface.
/sbin/service command on the network service (/etc/rc.d/init.d/network), as illustrated the following command:
service network <action>
service network <action>start, stop, or restart.
service network status
service network status16.4. Static Routes and the Default Gateway
Configuring Static Routes Using the Command Line
ip route add command and removed using the ip route del command. The more frequently used ip route commands take the following form: ip route [ add | del | change | append | replace ] destination-address
ip route [ add | del | change | append | replace ] destination-addressip-route(8) man page for more details on the options and formats.
ip route command without options to display the IP routing table. For example:
ip route default via 192.168.122.1 dev eth0 proto static metric 1024 192.168.122.0/24 dev ens9 proto kernel scope link src 192.168.122.107 192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.126
~]$ ip route
default via 192.168.122.1 dev eth0 proto static metric 1024
192.168.122.0/24 dev ens9 proto kernel scope link src 192.168.122.107
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.126IP address, issue a command as root:
ip route add 192.0.2.1 via 10.0.0.1 [dev ifname]
~]# ip route add 192.0.2.1 via 10.0.0.1 [dev ifname]IP address of the host in dotted decimal notation, 10.0.0.1 is the next hop address and ifname is the exit interface leading to the next hop.
IP address representing a range of IP addresses, issue the following command as root:
ip route add 192.0.2.0/24 via 10.0.0.1 [dev ifname]
~]# ip route add 192.0.2.0/24 via 10.0.0.1 [dev ifname]IP address of the destination network in dotted decimal notation and /24 is the network prefix. The network prefix is the number of enabled bits in the subnet mask. This format of network address slash network prefix length is sometimes referred to as classless inter-domain routing (CIDR) notation.
/etc/sysconfig/network-scripts/route-interface file. For example, static routes for the eth0 interface would be stored in the /etc/sysconfig/network-scripts/route-eth0 file. The route-interface file has two formats: ip command arguments and network/netmask directives. These are described below.
ip-route(8) man page for more information on the ip route command.
Configuring The Default Gateway
/etc/sysconfig/network file first and then the network interface ifcfg files for interfaces that are “up”. The ifcfg files are parsed in numerically ascending order, and the last GATEWAY directive to be read is used to compose a default route in the routing table.
/etc/sysconfig/network file. This file specifies gateway and host information for all network interfaces. For more information about this file and the directives it accepts, refer to Section 32.1.22, “/etc/sysconfig/network”.
16.5. Configuring Static Routes in ifcfg files
/etc/sysconfig/network-scripts/ directory. The file name should be of the format route-ifname. There are two types of commands to use in the configuration files; ip commands as explained in Section 16.5.1, “Static Routes Using the IP Command Arguments Format” and the Network/Netmask format as explained in Section 16.5.2, “Network/Netmask Directives Format”.
16.5.1. Static Routes Using the IP Command Arguments Format
/etc/sysconfig/network-scripts/route-eth0, define a route to a default gateway on the first line. This is only required if the gateway is not set via DHCP and is not set globally in the /etc/sysconfig/network file:
default via 192.168.1.1 dev interface
default via 192.168.1.1 dev interfaceIP address of the default gateway. The interface is the interface that is connected to, or can reach, the default gateway. The dev option can be omitted, it is optional. Note that this setting takes precedence over a setting in the /etc/sysconfig/network file.
10.10.10.0/24 via 192.168.1.1 [dev interface]
10.10.10.0/24 via 192.168.1.1 [dev interface]IP address leading to the remote network. It is preferably the next hop address but the address of the exit interface will work. The “next hop” means the remote end of a link, for example a gateway or router. The dev option can be used to specify the exit interface interface but it is not required. Add as many static routes as required.
route-interface file using the ip command arguments format. The default gateway is 192.168.0.1, interface eth0 and a leased line or WAN connection is available at 192.168.0.10. The two static routes are for reaching the 10.10.10.0/24 network and the 172.16.1.10/32 host:
default via 192.168.0.1 dev eth0 10.10.10.0/24 via 192.168.0.10 dev eth0 172.16.1.10/32 via 192.168.0.10 dev eth0
default via 192.168.0.1 dev eth0
10.10.10.0/24 via 192.168.0.10 dev eth0
172.16.1.10/32 via 192.168.0.10 dev eth0192.168.0.0/24 network will be directed out the interface attached to that network. Packets going to the 10.10.10.0/24 network and 172.16.1.10/32 host will be directed to 192.168.0.10. Packets to unknown, remote, networks will use the default gateway therefore static routes should only be configured for remote networks or hosts if the default route is not suitable. Remote in this context means any networks or hosts that are not directly attached to the system.
Important
DHCP, the IP command arguments format can cause one of two errors during start-up, or when bringing up an interface from the down state using the ifup command: "RTNETLINK answers: File exists" or 'Error: either "to" is a duplicate, or "X.X.X.X" is a garbage.', where X.X.X.X is the gateway, or a different IP address. These errors can also occur if you have another route to another network using the default gateway. Both of these errors are safe to ignore.
16.5.2. Network/Netmask Directives Format
route-interface files. The following is a template for the network/netmask format, with instructions following afterwards:
ADDRESS0=10.10.10.0 NETMASK0=255.255.255.0 GATEWAY0=192.168.1.1
ADDRESS0=10.10.10.0
NETMASK0=255.255.255.0
GATEWAY0=192.168.1.1ADDRESS0=10.10.10.0is the network address of the remote network or host to be reached.NETMASK0=255.255.255.0is the netmask for the network address defined withADDRESS0=10.10.10.0.GATEWAY0=192.168.1.1is the default gateway, or anIPaddress that can be used to reachADDRESS0=10.10.10.0
route-interface file using the network/netmask directives format. The default gateway is 192.168.0.1 but a leased line or WAN connection is available at 192.168.0.10. The two static routes are for reaching the 10.10.10.0/24 and 172.16.1.0/24 networks:
ADDRESS0, ADDRESS1, ADDRESS2, and so on.
16.6. Network Function Files
/etc/sysconfig/network-scripts/network-functions file contains the most commonly used IPv4 functions, which are useful to many interface control scripts. These functions include contacting running programs that have requested information about changes in the status of an interface, setting host names, finding a gateway device, verifying whether or not a particular device is down, and adding a default route.
IPv6 interfaces are different from IPv4 interfaces, a /etc/sysconfig/network-scripts/network-functions-ipv6 file exists specifically to hold this information. The functions in this file configure and delete static IPv6 routes, create and remove tunnels, add and remove IPv6 addresses to an interface, and test for the existence of an IPv6 address on an interface.
16.7. Additional Resources
16.7.1. Installed Documentation
-
/usr/share/doc/initscripts-<version>/sysconfig.txt - A guide to available options for network configuration files, including
IPv6options not covered in this chapter. -
/usr/share/doc/iproute-<version>/ip-cref.ps - This file contains a wealth of information about the
ipcommand, which can be used to manipulate routing tables, among other things. Use the ggv or kghostview application to view this file.
Chapter 17. Network Configuration
- Ethernet
- ISDN
- modem
- xDSL
- token ring
- CIPE
- wireless devices
/etc/hosts file used to store additional hostnames and IP address combinations.
system-config-network at a shell prompt (for example, in an XTerm or a GNOME terminal). If you type the command, the graphical version is displayed if X is running; otherwise, the text-based version is displayed.
system-config-network-cmd --help as root to view all of the options.
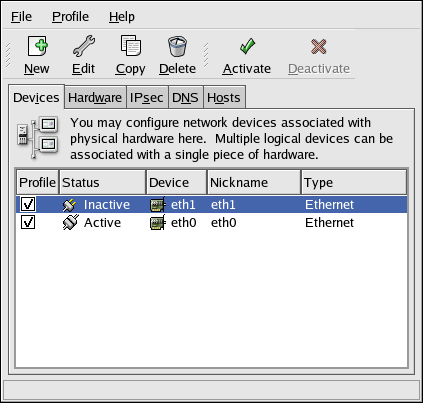
Figure 17.1. Network Administration Tool
Note
17.1. Overview
- Add a network device associated with the physical hardware device.
- Add the physical hardware device to the hardware list, if it does not already exist.
- Configure the hostname and DNS settings.
- Configure any hosts that cannot be looked up through DNS.
17.2. Establishing an Ethernet Connection
- Click the Devices tab.
- Click the button on the toolbar.
- Select Ethernet connection from the Device Type list, and click .
- If you have already added the network interface card to the hardware list, select it from the Ethernet card list. Otherwise, select Other Ethernet Card to add the hardware device.
Note
The installation program detects supported Ethernet devices and prompts you to configure them. If you configured any Ethernet devices during the installation, they are displayed in the hardware list on the Hardware tab. - If you selected Other Ethernet Card, the Select Ethernet Adapter window appears. Select the manufacturer and model of the Ethernet card. Select the device name. If this is the system's first Ethernet card, select eth0 as the device name; if this is the second Ethernet card, select eth1 (and so on). The Network Administration Tool also allows you to configure the resources for the NIC. Click to continue.
- In the Configure Network Settings window shown in Figure 17.2, “Ethernet Settings”, choose between DHCP and a static IP address. If the device receives a different IP address each time the network is started, do not specify a hostname.
- Do not specify a value for the Set MTU to or Set MRU to fields. MTU stands for Maximum Transmission Unit and MRU for Maximum Receive Unit; the network configuration tool will choose appropriate values for both of these parameters. Click to continue.
- Click on the Create Ethernet Device page.
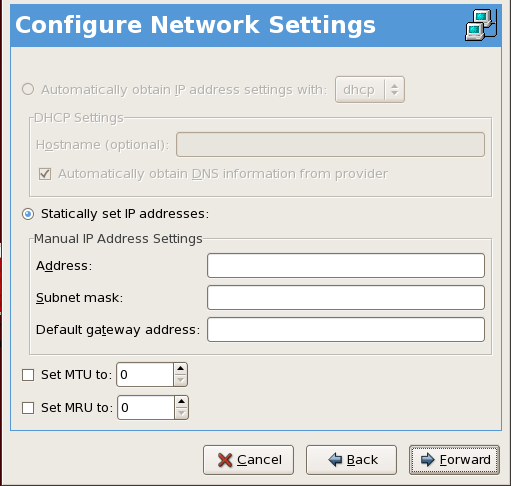
Figure 17.2. Ethernet Settings
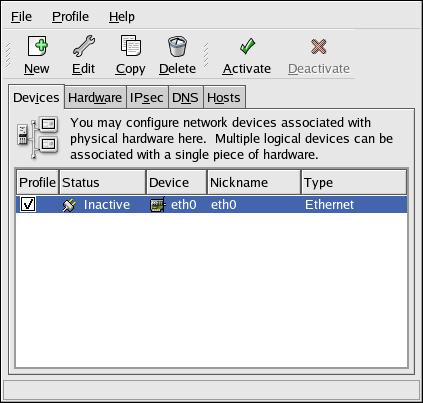
Figure 17.3. Ethernet Device
17.3. Establishing an ISDN Connection
- Click the Devices tab.
- Click the button on the toolbar.
- Select ISDN connection from the Device Type list, and click .
- Select the ISDN adapter from the pulldown menu. Then configure the resources and D channel protocol for the adapter. Click to continue.
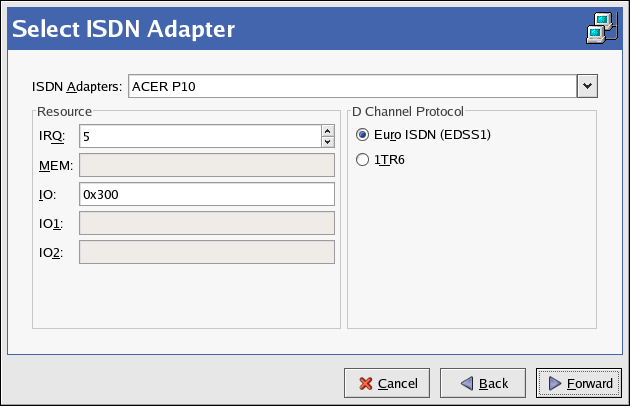
Figure 17.4. ISDN Settings
- If your Internet Service Provider (ISP) is in the pre-configured list, select it. Otherwise, enter the required information about your ISP account. If you do not know the values, contact your ISP. Click .
- In the IP Settings window, select the Encapsulation Mode and whether to obtain an IP address automatically or to set a static IP instead. Click when finished.
- On the Create Dialup Connection page, click .
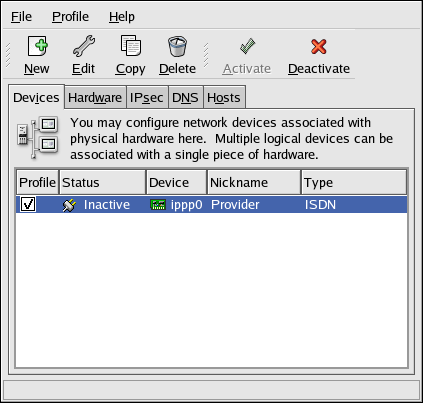
Figure 17.5. ISDN Device
17.4. Establishing a Modem Connection
- Click the Devices tab.
- Click the button on the toolbar.
- Select Modem connection from the Device Type list, and click .
- If there is a modem already configured in the hardware list (on the Hardware tab), the Network Administration Tool assumes you want to use it to establish a modem connection. If there are no modems already configured, it tries to detect any modems in the system. This probe might take a while. If a modem is not found, a message is displayed to warn you that the settings shown are not values found from the probe.
- After probing, the window in Figure 17.6, “Modem Settings” appears.

Figure 17.6. Modem Settings
- Configure the modem device, baud rate, flow control, and modem volume. If you do not know these values, accept the defaults if the modem was probed successfully. If you do not have touch tone dialing, uncheck the corresponding checkbox. Click .
- If your ISP is in the pre-configured list, select it. Otherwise, enter the required information about your ISP account. If you do not know these values, contact your ISP. Click .
- On the IP Settings page, select whether to obtain an IP address automatically or whether to set one statically. Click when finished.
- On the Create Dialup Connection page, click .
Modem as shown in Figure 17.7, “Modem Device”.
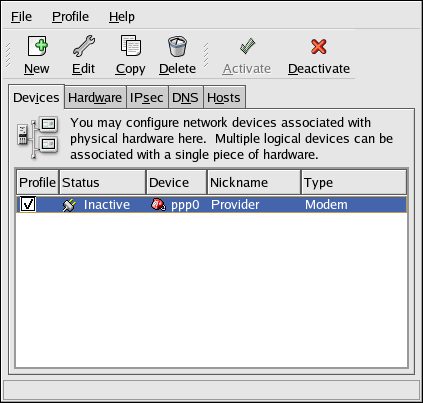
Figure 17.7. Modem Device
17.5. Establishing an xDSL Connection
- Click the Devices tab.
- Click the button.
- Select xDSL connection from the Device Type list, and click as shown in Figure 17.8, “Select Device Type”.
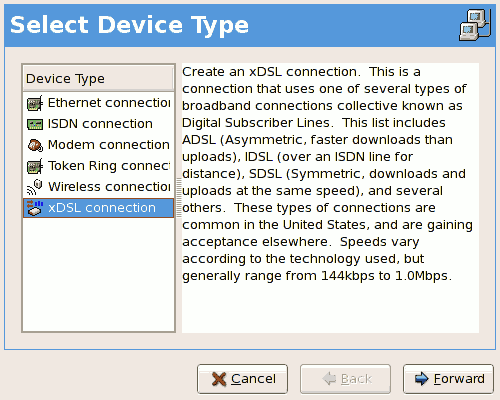
Figure 17.8. Select Device Type
- If your Ethernet card is in the hardware list, select the Ethernet Device from the pulldown menu from the page shown in Figure 17.9, “xDSL Settings”. Otherwise, the Select Ethernet Adapter window appears.
Note
The installation program detects supported Ethernet devices and prompts you to configure them. If you configured any Ethernet devices during the installation, they are displayed in the hardware list on the Hardware tab.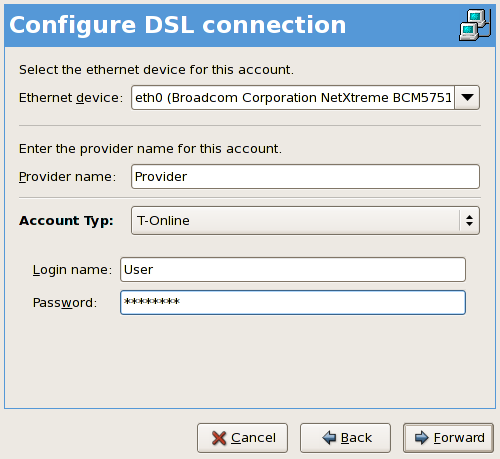
Figure 17.9. xDSL Settings
- Enter the Provider Name, Login Name, and Password. If you are not setting up a T-Online account, select Normal from the Account Type pulldown menu.If you are setting up a T-Online account, select T-Online from the Account Type pulldown menu and enter any values in the Login name and Password field. You can further configure your T-Online account settings once the DSL connection has been fully configured (refer to Setting Up a T-Online Account).
- Click the to go to the menu. Check your settings and click to finish.
- After configuring the DSL connection, it appears in the device list as shown in Figure 17.10, “xDSL Device”.

Figure 17.10. xDSL Device
- After adding the xDSL connection, you can edit its configuration by selecting the device from the device list and clicking .
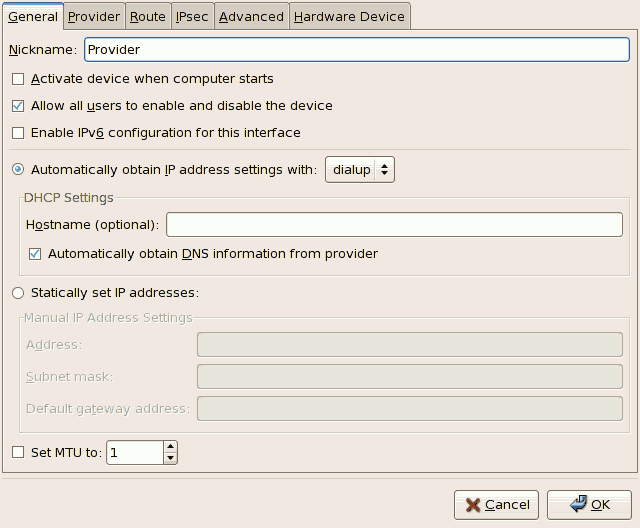
Figure 17.11. xDSL Configuration
For example, when the device is added, it is configured not to start at boot time by default. Edit its configuration to modify this setting. Click when finished. - Once you are satisfied with your xDSL connection settings, select > to save the changes.
If you are setting up a T-Online Account, follow these additional steps:
- Select the device from the device list and click .
- Select the Provider tab from the menu as shown in Figure 17.12, “xDSL Configuration - Provider Tab”.
Figure 17.12. xDSL Configuration - Provider Tab
- Click the button. This will open the window for your T-Online account as shown in Figure 17.13, “Account Setup”.

Figure 17.13. Account Setup
- Enter your Adapter identifier, Associated T-Online number, Concurrent user number/suffix, and Personal password.. Click when finished to close the window.
- On the window, click . Be sure to select > from the Network Administration Tool to save the changes.
17.6. Establishing a Token Ring Connection
Note
- Click the Devices tab.
- Click the button on the toolbar.
- Select Token Ring connection from the Device Type list and click .
- If you have already added the token ring card to the hardware list, select it from the Tokenring card list. Otherwise, select Other Tokenring Card to add the hardware device.
- If you selected Other Tokenring Card, the Select Token Ring Adapter window as shown in Figure 17.14, “Token Ring Settings” appears. Select the manufacturer and model of the adapter. Select the device name. If this is the system's first token ring card, select tr0; if this is the second token ring card, select tr1 (and so on). The Network Administration Tool also allows the user to configure the resources for the adapter. Click to continue.

Figure 17.14. Token Ring Settings
- On the Configure Network Settings page, choose between DHCP and static IP address. You may specify a hostname for the device. If the device receives a dynamic IP address each time the network is started, do not specify a hostname. Click to continue.
- Click on the Create Tokenring Device page.
Figure 17.15. Token Ring Device
17.7. Establishing a Wireless Connection
- Click the Devices tab.
- Click the button on the toolbar.
- Select Wireless connection from the Device Type list and click .
- If you have already added the wireless network interface card to the hardware list, select it from the Wireless card list. Otherwise, select Other Wireless Card to add the hardware device.
Note
The installation program usually detects supported wireless Ethernet devices and prompts you to configure them. If you configured them during the installation, they are displayed in the hardware list on the Hardware tab. - If you selected Other Wireless Card, the Select Ethernet Adapter window appears. Select the manufacturer and model of the Ethernet card and the device. If this is the first Ethernet card for the system, select eth0; if this is the second Ethernet card for the system, select eth1 (and so on). The Network Administration Tool also allows the user to configure the resources for the wireless network interface card. Click to continue.
- On the Configure Wireless Connection page as shown in Figure 17.16, “Wireless Settings”, configure the settings for the wireless device.
Note
For the dropdown, note that wireless access points using WEP encryption have a choice between using open system and shared key authentication. Shared key authentication requires an exchange between the client and the access point during the association process that proves that the client has the correct WEP key. Open system authentication allows all wireless clients to connect. Counterintuitively, shared key authentication is less secure than open system, and thus is less widely deployed. It is therefore recommended to select Open System (open) as the authentication method when you do not know which method the access point requires. If connecting to the access point using open system fails, then try switching to shared key authentication.
Figure 17.16. Wireless Settings
- On the Configure Network Settings page, choose between DHCP and static IP address. You may specify a hostname for the device. If the device receives a dynamic IP address each time the network is started, do not specify a hostname. Click to continue.
- Click on the Create Wireless Device page.
Figure 17.17. Wireless Device
17.8. Managing DNS Settings
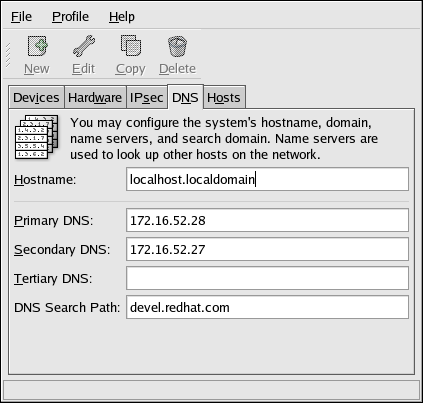
Figure 17.18. DNS Configuration
Note
Warning
system-config-network is started on the local host, you may not be able to start another X11 application. As such, you may have to re-login to a new desktop session.
17.9. Managing Hosts
/etc/hosts file. This file contains IP addresses and their corresponding hostnames.
/etc/hosts file before using the name servers (if you are using the default Red Hat Enterprise Linux configuration). If the IP address is listed in the /etc/hosts file, the name servers are not used. If your network contains computers whose IP addresses are not listed in DNS, it is recommended that you add them to the /etc/hosts file.
/etc/hosts file, go to the Hosts tab, click the button on the toolbar, provide the requested information, and click OK. Select > or press Ctrl+S to save the changes to the /etc/hosts file. The network or network services do not need to be restarted since the current version of the file is referred to each time an address is resolved.
Warning
localhost entry. Even if the system does not have a network connection or have a network connection running constantly, some programs need to connect to the system via the localhost loopback interface.
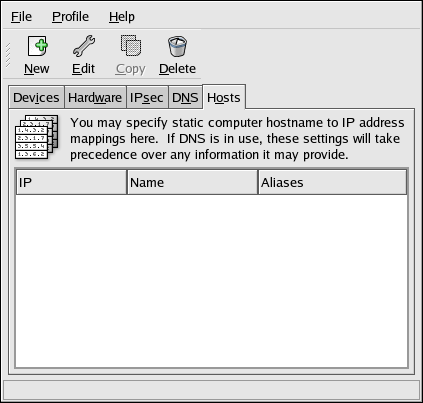
Figure 17.19. Hosts Configuration
Note
/etc/host.conf file. The line order hosts, bind specifies that /etc/hosts takes precedence over the name servers. Changing the line to order bind, hosts configures the system to resolve hostnames and IP addresses using the name servers first. If the IP address cannot be resolved through the name servers, the system then looks for the IP address in the /etc/hosts file.
17.10. Working with Profiles
eth0_office, so that it can be recognized more easily. Once you have finished editing your new profile, make sure to save it by clicking from the menu. If you forget to save after creating a profile, that profile will be lost.
eth0_office in a profile called Office and want to activate the logical device if the profile is selected, uncheck the eth0 device and check the eth0_office device.
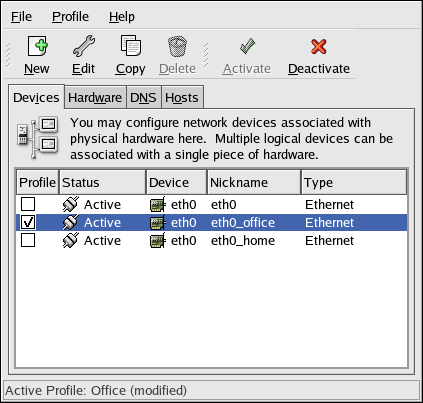
Figure 17.20. Office Profile
eth0.
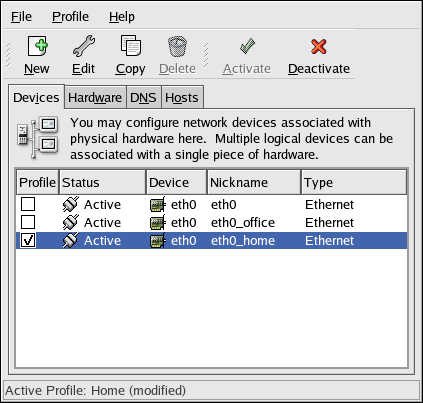
Figure 17.21. Home Profile
eth0 to activate in the Office profile only and to activate a PPP (modem) device in the Home profile only. Another example is to have the Common profile activate eth0 and an Away profile activate a PPP device for use while traveling.
netprofile=<profilename> option. For example, if the system uses GRUB as the boot loader and /boot/grub/grub.conf contains:
title Red Hat Enterprise Linux (2.6.9-5.EL)
root (hd0,0)
kernel /vmlinuz-2.6.9-5.EL ro root=/dev/VolGroup00/LogVol00 rhgb quiet
initrd /initrd-2.6.9-5.EL.img
title Red Hat Enterprise Linux (2.6.9-5.EL)
root (hd0,0)
kernel /vmlinuz-2.6.9-5.EL ro root=/dev/VolGroup00/LogVol00 rhgb quiet
initrd /initrd-2.6.9-5.EL.imgtitle Red Hat Enterprise Linux (2.6.9-5.EL)
root (hd0,0)
kernel /vmlinuz-2.6.9-5.EL ro root=/dev/VolGroup00/LogVol00 \
netprofile=<profilename> \ rhgb quiet
initrd /initrd-2.6.9-5.EL.img
title Red Hat Enterprise Linux (2.6.9-5.EL)
root (hd0,0)
kernel /vmlinuz-2.6.9-5.EL ro root=/dev/VolGroup00/LogVol00 \
netprofile=<profilename> \ rhgb quiet
initrd /initrd-2.6.9-5.EL.imgsystem-control-network) to select a profile and activate it. The activate profile section only appears in the Network Device Control interface if more than the default Common interface exists.
system-config-network-cmd --profile <profilename> --activate
system-config-network-cmd --profile <profilename> --activate17.11. Device Aliases
eth0 —to use a static IP address (DHCP does not work with aliases), go to the Devices tab and click . Select the Ethernet card to configure with an alias, set the static IP address for the alias, and click to create it. Since a device already exists for the Ethernet card, the one just created is the alias, such as eth0:1.
Warning
eth0 device. Notice the eth0:1 device — the first alias for eth0. The second alias for eth0 would have the device name eth0:2, and so on. To modify the settings for the device alias, such as whether to activate it at boot time and the alias number, select it from the list and click the button.
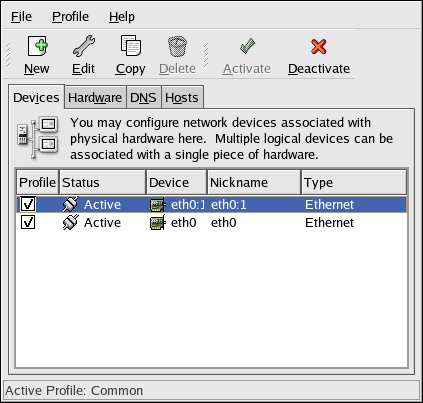
Figure 17.22. Network Device Alias Example
/sbin/ifconfig. The output should show the device and the device alias with different IP addresses:
17.12. Saving and Restoring the Network Configuration
/tmp/network-config, execute the following command as root:
system-config-network-cmd -e > /tmp/network-config
system-config-network-cmd -e > /tmp/network-configsystem-config-network-cmd -i -c -f /tmp/network-config
system-config-network-cmd -i -c -f /tmp/network-config-i option means to import the data, the -c option means to clear the existing configuration prior to importing, and the -f option specifies that the file to import is as follows.
Chapter 18. Controlling Access to Services
httpd if you are running a Web server). However, if you do not need to provide a service, you should turn it off to minimize your exposure to possible bug exploits.
xinetd and the services in the /etc/rc.d/init.d hierarchy (also known as SysV services) can be configured to start or stop using three different applications:
- Services Configuration Tool
- This is a graphical application that displays a description of each service, displays whether each service is started at boot time (for runlevels 3, 4, and 5), and allows services to be started, stopped, and restarted.
- ntsysv
- This is a text-based application that allows you to configure which services are started at boot time for each runlevel. Non-
xinetdservices can not be started, stopped, or restarted using this program. chkconfig- This is a command line utility that allows you to turn services on and off for the different runlevels. Non-
xinetdservices can not be started, stopped, or restarted using this utility.
/etc/rc.d by hand or editing the xinetd configuration files in /etc/xinetd.d.
iptables to configure an IP firewall. If you are a new Linux user, note that iptables may not be the best solution for you. Setting up iptables can be complicated, and is best tackled by experienced Linux system administrators.
iptables is flexibility. For example, if you need a customized solution which provides certain hosts access to certain services, iptables can provide it for you. Refer to Section 48.8.1, “Netfilter and IPTables” and Section 48.8.3, “Using IPTables” for more information about iptables.
system-config-securitylevel), which allows you to select the security level for your system, similar to the Firewall Configuration screen in the installation program.
Important
18.1. Runlevels
/etc/rc.d/rc<x>.d, where <x> is the number of the runlevel.
- 0 — Halt
- 1 — Single-user mode
- 2 — Not used (user-definable)
- 3 — Full multi-user mode
- 4 — Not used (user-definable)
- 5 — Full multi-user mode (with an X-based login screen)
- 6 — Reboot
/etc/inittab file, which contains a line near the top of the file similar to the following:
id:5:initdefault:
id:5:initdefault:18.2. TCP Wrappers
xinetd (as well as any program with built-in support for libwrap) can use TCP wrappers to manage access. xinetd can use the /etc/hosts.allow and /etc/hosts.deny files to configure access to system services. As the names imply, hosts.allow contains a list of rules that allow clients to access the network services controlled by xinetd, and hosts.deny contains rules to deny access. The hosts.allow file takes precedence over the hosts.deny file. Permissions to grant or deny access can be based on individual IP address (or hostnames) or on a pattern of clients. Refer to hosts_access in section 5 of the man pages (man 5 hosts_access) for details.
18.2.1. xinetd
xinetd, which is a secure replacement for inetd. The xinetd daemon conserves system resources, provides access control and logging, and can be used to start special-purpose servers. xinetd can also be used to grant or deny access to particular hosts, provide service access at specific times, limit the rate of incoming connections, limit the load created by connections, and more.
xinetd runs constantly and listens on all ports for the services it manages. When a connection request arrives for one of its managed services, xinetd starts up the appropriate server for that service.
xinetd is /etc/xinetd.conf, but the file only contains a few defaults and an instruction to include the /etc/xinetd.d directory. To enable or disable an xinetd service, edit its configuration file in the /etc/xinetd.d directory. If the disable attribute is set to yes, the service is disabled. If the disable attribute is set to no, the service is enabled. You can edit any of the xinetd configuration files or change its enabled status using the Services Configuration Tool, ntsysv, or chkconfig. For a list of network services controlled by xinetd, review the contents of the /etc/xinetd.d directory with the command ls /etc/xinetd.d.
18.3. Services Configuration Tool
/etc/rc.d/init.d directory are started at boot time (for runlevels 3, 4, and 5) and which xinetd services are enabled. It also allows you to start, stop, and restart SysV services as well as reload xinetd.
system-config-services at a shell prompt (for example, in an XTerm or a GNOME terminal).
Figure 18.1. Services Configuration Tool
/etc/rc.d/init.d directory as well as the services controlled by xinetd. Click on the name of the service from the list on the left-hand side of the application to display a brief description of that service as well as the status of the service. If the service is not an xinetd service, the status window shows whether the service is currently running. If the service is controlled by xinetd, the status window displays the phrase xinetd service.
xinetd service, the action buttons are disabled because they cannot be started or stopped individually.
xinetd service by checking or unchecking the checkbox next to the service name, you must select > from the pulldown menu (or the button above the tabs) to reload xinetd and immediately enable/disable the xinetd service that you changed. xinetd is also configured to remember the setting. You can enable/disable multiple xinetd services at a time and save the changes when you are finished.
rsync to enable it in runlevel 3 and then save the changes. The rsync service is immediately enabled. The next time xinetd is started, rsync is still enabled.
Note
xinetd services, xinetd is reloaded, and the changes take place immediately. When you save changes to other services, the runlevel is reconfigured, but the changes do not take effect immediately.
xinetd service to start at boot time for the currently selected runlevel, check the box beside the name of the service in the list. After configuring the runlevel, apply the changes by selecting > from the pulldown menu. The runlevel configuration is changed, but the runlevel is not restarted; thus, the changes do not take place immediately.
httpd service from checked to unchecked and then select , the runlevel 3 configuration changes so that httpd is not started at boot time. However, runlevel 3 is not reinitialized, so httpd is still running. Select one of following options at this point:
- Stop the
httpdservice — Stop the service by selecting it from the list and clicking the button. A message appears stating that the service was stopped successfully. - Reinitialize the runlevel — Reinitialize the runlevel by going to a shell prompt and typing the command
telinit x(where x is the runlevel number; in this example, 3.). This option is recommended if you change the Start at Boot value of multiple services and want to activate the changes immediately. - Do nothing else — You do not have to stop the
httpdservice. You can wait until the system is rebooted for the service to stop. The next time the system is booted, the runlevel is initialized without thehttpdservice running.
18.4. ntsysv
xinetd-managed service on or off. You can also use ntsysv to configure runlevels. By default, only the current runlevel is configured. To configure a different runlevel, specify one or more runlevels with the --level option. For example, the command ntsysv --level 345 configures runlevels 3, 4, and 5.
Figure 18.2. The ntsysv utility
Warning
xinetd are immediately affected by ntsysv. For all other services, changes do not take effect immediately. You must stop or start the individual service with the command service <daemon> stop (where <daemon> is the name of the service you want to stop; for example, httpd). Replace stop with start or restart to start or restart the service.
18.5. chkconfig
chkconfig command can also be used to activate and deactivate services. The chkconfig --list command displays a list of system services and whether they are started (on) or stopped (off) in runlevels 0-6. At the end of the list is a section for the services managed by xinetd.
chkconfig --list command is used to query a service managed by xinetd, it displays whether the xinetd service is enabled (on) or disabled (off). For example, the command chkconfig --list rsync returns the following output:
rsync on
rsync onrsync is enabled as an xinetd service. If xinetd is running, rsync is enabled.
chkconfig --list to query a service in /etc/rc.d, that service's settings for each runlevel are displayed. For example, the command chkconfig --list httpd returns the following output:
httpd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
httpd 0:off 1:off 2:on 3:on 4:on 5:on 6:offchkconfig can also be used to configure a service to be started (or not) in a specific runlevel. For example, to turn nscd off in runlevels 3, 4, and 5, use the following command:
chkconfig --level 345 nscd off
chkconfig --level 345 nscd offWarning
xinetd are immediately affected by chkconfig. For example, if xinetd is running while rsync is disabled, and the command chkconfig rsync on is executed, then rsync is immediately enabled without having to restart xinetd manually. Changes for other services do not take effect immediately after using chkconfig. You must stop or start the individual service with the command service <daemon> stop (where <daemon> is the name of the service you want to stop; for example, httpd). Replace stop with start or restart to start or restart the service.
18.6. Additional Resources
18.6.1. Installed Documentation
- The man pages for
ntsysv,chkconfig,xinetd, andxinetd.conf. man 5 hosts_access— The man page for the format of host access control files (in section 5 of the man pages).
18.6.2. Useful Websites
- http://www.xinetd.org — The
xinetdwebpage. It contains sample configuration files and a more detailed list of features.
Chapter 19. Berkeley Internet Name Domain (BIND)
Note
named in Red Hat Enterprise Linux. You can manage it via the Services Configuration Tool (system-config-service).
19.1. Introduction to DNS
19.1.1. Nameserver Zones
bob.sales.example.com
bob.sales.example.com.). In this example, com defines the top level domain for this FQDN. The name example is a sub-domain under com, while sales is a sub-domain under example. The name furthest to the left, bob, identifies a specific machine hostname.
19.1.2. Nameserver Types
- master
- Stores original and authoritative zone records for a namespace, and answers queries about the namespace from other nameservers.
- slave
- Answers queries from other nameservers concerning namespaces for which it is considered an authority. However, slave nameservers get their namespace information from master nameservers.
- caching-only
- Offers name-to-IP resolution services, but is not authoritative for any zones. Answers for all resolutions are cached in memory for a fixed period of time, which is specified by the retrieved zone record.
- forwarding
- Forwards requests to a specific list of nameservers for name resolution. If none of the specified nameservers can perform the resolution, the resolution fails.
19.1.3. BIND as a Nameserver
/usr/sbin/named daemon. BIND also includes an administration utility called /usr/sbin/rndc. More information about rndc can be found in Section 19.4, “Using rndc ”.
-
/etc/named.conf - The configuration file for the
nameddaemon -
/var/named/directory - The
namedworking directory which stores zone, statistic, and cache files
Note
bind-chroot package, the BIND service will run in the /var/named/chroot environment. All configuration files will be moved there. As such, named.conf will be located in /var/named/chroot/etc/named.conf, and so on.
Note
caching-nameserver package, the default configuration file is /etc/named.caching-nameserver.conf. To override this default configuration, you can create your own custom configuration file in /etc/named.conf. BIND will use the /etc/named.conf custom file instead of the default configuration file after you restart.
19.2. /etc/named.conf
named.conf file is a collection of statements using nested options surrounded by opening and closing ellipse characters, { }. Administrators must be careful when editing named.conf to avoid syntax errors as many seemingly minor errors prevent the named service from starting.
named.conf file is organized similar to the following example:
19.2.1. Common Statement Types
/etc/named.conf:
19.2.1.1. acl Statement
acl statement (or access control statement) defines groups of hosts which can then be permitted or denied access to the nameserver.
acl statement takes the following form:
acl <acl-name> {
<match-element>;
[<match-element>; ...]
};
acl <acl-name> {
<match-element>;
[<match-element>; ...]
};10.0.1.0/24) is used to identify the IP addresses within the acl statement.
any— Matches every IP addresslocalhost— Matches any IP address in use by the local systemlocalnets— Matches any IP address on any network to which the local system is connectednone— Matches no IP addresses
options statement), acl statements can be very useful in preventing the misuse of a BIND nameserver.
options statement to define how they are treated by the nameserver:
black-hats and red-hats. Hosts in the black-hats list are denied access to the nameserver, while hosts in the red-hats list are given normal access.
19.2.1.2. include Statement
include statement allows files to be included in a named.conf file. In this way, sensitive configuration data (such as keys) can be placed in a separate file with restrictive permissions.
include statement takes the following form:
include "<file-name>"
include "<file-name>"19.2.1.3. options Statement
options statement defines global server configuration options and sets defaults for other statements. It can be used to specify the location of the named working directory, the types of queries allowed, and much more.
options statement takes the following form:
options {
<option>;
[<option>; ...]
};
options {
<option>;
[<option>; ...]
};-
allow-query - Specifies which hosts are allowed to query this nameserver. By default, all hosts are allowed to query. An access control list, or collection of IP addresses or networks, may be used here to allow only particular hosts to query the nameserver.
-
allow-recursion - Similar to
allow-query, this option applies to recursive queries. By default, all hosts are allowed to perform recursive queries on the nameserver. -
blackhole - Specifies which hosts are not allowed to query the server.
-
directory - Specifies the
namedworking directory if different from the default value,/var/named/. -
forwarders - Specifies a list of valid IP addresses for nameservers where requests should be forwarded for resolution.
-
forward - Specifies the forwarding behavior of a
forwardersdirective.The following options are accepted:first— Specifies that the nameservers listed in theforwardersdirective be queried beforenamedattempts to resolve the name itself.only— Specifies thatnameddoes not attempt name resolution itself in the event that queries to nameservers specified in theforwardersdirective fail.
-
listen-on - Specifies the network interface on which
namedlistens for queries. By default, all interfaces are used.Using this directive on a DNS server which also acts a gateway, BIND can be configured to only answer queries that originate from one of the networks.The following is an example of alisten-ondirective:options { listen-on { 10.0.1.1; }; };options { listen-on { 10.0.1.1; }; };Copy to Clipboard Copied! Toggle word wrap Toggle overflow In this example, only requests that arrive from the network interface serving the private network (10.0.1.1) are accepted. -
notify - Controls whether
namednotifies the slave servers when a zone is updated. It accepts the following options:yes— Notifies slave servers.no— Does not notify slave servers.explicit— Only notifies slave servers specified in analso-notifylist within a zone statement.
-
pid-file - Specifies the location of the process ID file created by
named. -
root-delegation-only - Turns on the enforcement of delegation properties in top-level domains (TLDs) and root zones with an optional exclude list. Delegation is the process of dividing a single zone into multiple subzones. In order to create a delegated zone, items known as NS records are used. NameServer records (delegation records) announce the authoritative nameservers for a particular zone.The following
root-delegation-onlyexample specifies an exclude list of TLDs from whom undelegated responses are expected and trusted:options { root-delegation-only exclude { "ad"; "ar"; "biz"; "cr"; "cu"; "de"; "dm"; "id"; "lu"; "lv"; "md"; "ms"; "museum"; "name"; "no"; "pa"; "pf"; "se"; "sr"; "to"; "tw"; "us"; "uy"; }; };options { root-delegation-only exclude { "ad"; "ar"; "biz"; "cr"; "cu"; "de"; "dm"; "id"; "lu"; "lv"; "md"; "ms"; "museum"; "name"; "no"; "pa"; "pf"; "se"; "sr"; "to"; "tw"; "us"; "uy"; }; };Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
statistics-file - Specifies an alternate location for statistics files. By default,
namedstatistics are saved to the/var/named/named.statsfile.
bind.conf man page for more details.
19.2.1.4. zone Statement
zone statement defines the characteristics of a zone, such as the location of its configuration file and zone-specific options. This statement can be used to override the global options statements.
zone statement takes the following form:
zone <zone-name> <zone-class> {
<zone-options>;
[<zone-options>; ...]
};
zone <zone-name> <zone-class> {
<zone-options>;
[<zone-options>; ...]
};$ORIGIN directive used within the corresponding zone file located in the /var/named/ directory. The named daemon appends the name of the zone to any non-fully qualified domain name listed in the zone file.
Note
caching-nameserver package, the default configuration file will be in /etc/named.rfc1912.zones.
zone statement defines the namespace for example.com, use example.com as the <zone-name> so it is placed at the end of hostnames within the example.com zone file.
zone statement options include the following:
-
allow-query - Specifies the clients that are allowed to request information about this zone. The default is to allow all query requests.
-
allow-transfer - Specifies the slave servers that are allowed to request a transfer of the zone's information. The default is to allow all transfer requests.
-
allow-update - Specifies the hosts that are allowed to dynamically update information in their zone. The default is to deny all dynamic update requests.Be careful when allowing hosts to update information about their zone. Do not enable this option unless the host specified is completely trusted. In general, it is better to have an administrator manually update the records for a zone and reload the
namedservice. -
file - Specifies the name of the file in the
namedworking directory that contains the zone's configuration data. -
masters - Specifies the IP addresses from which to request authoritative zone information and is used only if the zone is defined as
typeslave. -
notify - Specifies whether or not
namednotifies the slave servers when a zone is updated. This directive accepts the following options:yes— Notifies slave servers.no— Does not notify slave servers.explicit— Only notifies slave servers specified in analso-notifylist within a zone statement.
-
type - Defines the type of zone.Below is a list of valid options:
delegation-only— Enforces the delegation status of infrastructure zones such as COM, NET, or ORG. Any answer that is received without an explicit or implicit delegation is treated asNXDOMAIN. This option is only applicable in TLDs or root zone files used in recursive or caching implementations.forward— Forwards all requests for information about this zone to other nameservers.hint— A special type of zone used to point to the root nameservers which resolve queries when a zone is not otherwise known. No configuration beyond the default is necessary with ahintzone.master— Designates the nameserver as authoritative for this zone. A zone should be set as themasterif the zone's configuration files reside on the system.slave— Designates the nameserver as a slave server for this zone. Also specifies the IP address of the master nameserver for the zone.
-
zone-statistics - Configures
namedto keep statistics concerning this zone, writing them to either the default location (/var/named/named.stats) or the file listed in thestatistics-fileoption in theserverstatement. Refer to Section 19.2.2, “Other Statement Types” for more information about theserverstatement.
19.2.1.5. Sample zone Statements
/etc/named.conf file of a master or slave nameserver involves adding, modifying, or deleting zone statements. While these zone statements can contain many options, most nameservers require only a small subset to function efficiently. The following zone statements are very basic examples illustrating a master-slave nameserver relationship.
zone statement for the primary nameserver hosting example.com (192.168.0.1):
zone "example.com" IN {
type master;
file "example.com.zone";
allow-update { none; };
};
zone "example.com" IN {
type master;
file "example.com.zone";
allow-update { none; };
};example.com, the type is set to master, and the named service is instructed to read the /var/named/example.com.zone file. It also tells named not to allow any other hosts to update.
zone statement for example.com is slightly different from the previous example. For a slave server, the type is set to slave and in place of the allow-update line is a directive telling named the IP address of the master server.
zone statement for example.com zone:
zone "example.com" {
type slave;
file "example.com.zone";
masters { 192.168.0.1; };
};
zone "example.com" {
type slave;
file "example.com.zone";
masters { 192.168.0.1; };
};zone statement configures named on the slave server to query the master server at the 192.168.0.1 IP address for information about the example.com zone. The information that the slave server receives from the master server is saved to the /var/named/example.com.zone file.
19.2.2. Other Statement Types
named.conf:
-
controls - Configures various security requirements necessary to use the
rndccommand to administer thenamedservice.Refer to Section 19.4.1, “Configuring/etc/named.conf” to learn more about how thecontrolsstatement is structured and what options are available. -
key "<key-name>" - Defines a particular key by name. Keys are used to authenticate various actions, such as secure updates or the use of the
rndccommand. Two options are used withkey:algorithm <algorithm-name>— The type of algorithm used, such asdsaorhmac-md5.secret "<key-value>"— The encrypted key.
Refer to Section 19.4.2, “Configuring/etc/rndc.conf” for instructions on how to write akeystatement. -
logging - Allows for the use of multiple types of logs, called channels. By using the
channeloption within theloggingstatement, a customized type of log can be constructed — with its own file name (file), size limit (size), versioning (version), and level of importance (severity). Once a customized channel is defined, acategoryoption is used to categorize the channel and begin logging whennamedis restarted.By default,namedlogs standard messages to thesyslogdaemon, which places them in/var/log/messages. This occurs because several standard channels are built into BIND with various severity levels, such asdefault_syslog(which handles informational logging messages) anddefault_debug(which specifically handles debugging messages). A default category, calleddefault, uses the built-in channels to do normal logging without any special configuration.Customizing the logging process can be a very detailed process and is beyond the scope of this chapter. For information on creating custom BIND logs, refer to the BIND 9 Administrator Reference Manual referenced in Section 19.7.1, “Installed Documentation”. -
server - Specifies options that affect how
namedshould respond to remote nameservers, especially with regard to notifications and zone transfers.Thetransfer-formatoption controls whether one resource record is sent with each message (one-answer) or multiple resource records are sent with each message (many-answers). Whilemany-answersis more efficient, only newer BIND nameservers understand it. -
trusted-keys - Contains assorted public keys used for secure DNS (DNSSEC). Refer to Section 19.5.3, “Security” for more information concerning BIND security.
-
view "<view-name>" - Creates special views depending upon which network the host querying the nameserver is on. This allows some hosts to receive one answer regarding a zone while other hosts receive totally different information. Alternatively, certain zones may only be made available to particular trusted hosts while non-trusted hosts can only make queries for other zones.Multiple views may be used, but their names must be unique. The
match-clientsoption specifies the IP addresses that apply to a particular view. Anyoptionsstatement may also be used within a view, overriding the global options already configured fornamed. Mostviewstatements contain multiplezonestatements that apply to thematch-clientslist. The order in whichviewstatements are listed is important, as the firstviewstatement that matches a particular client's IP address is used.Refer to Section 19.5.2, “Multiple Views” for more information about theviewstatement.
19.2.3. Comment Tags
named.conf:
//— When placed at the beginning of a line, that line is ignored bynamed.#— When placed at the beginning of a line, that line is ignored bynamed./*and*/— When text is enclosed in these tags, the block of text is ignored bynamed.
19.3. Zone Files
named working directory (/var/named/) by default. Each zone file is named according to the file option data in the zone statement, usually in a way that relates to the domain in question and identifies the file as containing zone data, such as example.com.zone.
Note
bind-chroot package, the BIND service will run in the /var/named/chroot environment. All configuration files will be moved there. As such, you can find the zone files in /var/named/chroot/var/named.
;) in zone files.
19.3.1. Zone File Directives
$) followed by the name of the directive. They usually appear at the top of the zone file.
-
$INCLUDE - Configures
namedto include another zone file in this zone file at the place where the directive appears. This allows additional zone settings to be stored apart from the main zone file. -
$ORIGIN - Appends the domain name to unqualified records, such as those with the hostname and nothing more.For example, a zone file may contain the following line:
$ORIGIN example.com.
$ORIGIN example.com.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Any names used in resource records that do not end in a trailing period (.) are appended withexample.com.Note
The use of the$ORIGINdirective is unnecessary if the zone is specified in/etc/named.confbecause the zone name is used as the value for the$ORIGINdirective by default. -
$TTL - Sets the default Time to Live (TTL) value for the zone. This is the length of time, in seconds, that a zone resource record is valid. Each resource record can contain its own TTL value, which overrides this directive.Increasing this value allows remote nameservers to cache the zone information for a longer period of time, reducing the number of queries for the zone and lengthening the amount of time required to proliferate resource record changes.
19.3.2. Zone File Resource Records
-
A - This refers to the Address record, which specifies an IP address to assign to a name, as in this example:
<host> IN A <IP-address>
<host> IN A <IP-address>Copy to Clipboard Copied! Toggle word wrap Toggle overflow If the <host> value is omitted, then anArecord points to a default IP address for the top of the namespace. This system is the target for all non-FQDN requests.Consider the followingArecord examples for theexample.comzone file:server1 IN A 10.0.1.3 IN A 10.0.1.5
server1 IN A 10.0.1.3 IN A 10.0.1.5Copy to Clipboard Copied! Toggle word wrap Toggle overflow Requests forexample.comare pointed to 10.0.1.3 or 10.0.1.5. -
CNAME - This refers to the Canonical Name record, which maps one name to another. This type of record can also be referred to as an alias record.The next example tells
namedthat any requests sent to the <alias-name> should point to the host, <real-name>.CNAMErecords are most commonly used to point to services that use a common naming scheme, such aswwwfor Web servers.<alias-name> IN CNAME <real-name>
<alias-name> IN CNAME <real-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow In the following example, anArecord binds a hostname to an IP address, while aCNAMErecord points the commonly usedwwwhostname to it.server1 IN A 10.0.1.5 www IN CNAME server1
server1 IN A 10.0.1.5 www IN CNAME server1Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
MX - This refers to the Mail eXchange record, which tells where mail sent to a particular namespace controlled by this zone should go.
IN MX <preference-value> <email-server-name>
IN MX <preference-value> <email-server-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Here, the <preference-value> allows numerical ranking of the email servers for a namespace, giving preference to some email systems over others. TheMXresource record with the lowest <preference-value> is preferred over the others. However, multiple email servers can possess the same value to distribute email traffic evenly among them.The <email-server-name> may be a hostname or FQDN.IN MX 10 mail.example.com. IN MX 20 mail2.example.com.
IN MX 10 mail.example.com. IN MX 20 mail2.example.com.Copy to Clipboard Copied! Toggle word wrap Toggle overflow In this example, the firstmail.example.comemail server is preferred to themail2.example.comemail server when receiving email destined for theexample.comdomain. -
NS - This refers to the NameServer record, which announces the authoritative nameservers for a particular zone.The following illustrates the layout of an
NSrecord:IN NS <nameserver-name>
IN NS <nameserver-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Here, <nameserver-name> should be an FQDN.Next, two nameservers are listed as authoritative for the domain. It is not important whether these nameservers are slaves or if one is a master; they are both still considered authoritative.IN NS dns1.example.com. IN NS dns2.example.com.
IN NS dns1.example.com. IN NS dns2.example.com.Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
PTR - This refers to the PoinTeR record, which is designed to point to another part of the namespace.
PTRrecords are primarily used for reverse name resolution, as they point IP addresses back to a particular name. Refer to Section 19.3.4, “Reverse Name Resolution Zone Files” for more examples ofPTRrecords in use. -
SOA - This refers to the Start Of Authority resource record, which proclaims important authoritative information about a namespace to the nameserver.Located after the directives, an
SOAresource record is the first resource record in a zone file.The following shows the basic structure of anSOAresource record:Copy to Clipboard Copied! Toggle word wrap Toggle overflow The@symbol places the$ORIGINdirective (or the zone's name, if the$ORIGINdirective is not set) as the namespace being defined by thisSOAresource record. The hostname of the primary nameserver that is authoritative for this domain is the <primary-name-server> directive, and the email of the person to contact about this namespace is the <hostmaster-email> directive.The <serial-number> directive is a numerical value incremented every time the zone file is altered to indicate it is time fornamedto reload the zone. The <time-to-refresh> directive is the numerical value slave servers use to determine how long to wait before asking the master nameserver if any changes have been made to the zone. The <serial-number> directive is a numerical value used by the slave servers to determine if it is using outdated zone data and should therefore refresh it.The <time-to-retry> directive is a numerical value used by slave servers to determine the length of time to wait before issuing a refresh request in the event that the master nameserver is not answering. If the master has not replied to a refresh request before the amount of time specified in the <time-to-expire> directive elapses, the slave servers stop responding as an authority for requests concerning that namespace.In BIND 4 and 8, the <minimum-TTL> directive is the amount of time other nameservers cache the zone's information. However, in BIND 9, the <minimum-TTL> directive defines how long negative answers are cached for. Caching of negative answers can be set to a maximum of 3 hours (3H).When configuring BIND, all times are specified in seconds. However, it is possible to use abbreviations when specifying units of time other than seconds, such as minutes (M), hours (H), days (D), and weeks (W). The table in Table 19.1, “Seconds compared to other time units” shows an amount of time in seconds and the equivalent time in another format.Expand Table 19.1. Seconds compared to other time units Seconds Other Time Units 601M180030M36001H108003H216006H4320012H864001D2592003D6048001W31536000365DThe following example illustrates the form anSOAresource record might take when it is populated with real values.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
19.3.3. Example Zone File
SOA values are used. The authoritative nameservers are set as dns1.example.com and dns2.example.com, which have A records that tie them to 10.0.1.1 and 10.0.1.2, respectively.
MX records point to mail and mail2 via A records. Since the mail and mail2 names do not end in a trailing period (.), the $ORIGIN domain is placed after them, expanding them to mail.example.com and mail2.example.com. Through the related A resource records, their IP addresses can be determined.
www.example.com (WWW), are pointed at the appropriate servers using a CNAME record.
zone statement in the named.conf similar to the following:
19.3.4. Reverse Name Resolution Zone Files
PTR resource records are used to link the IP addresses to a fully qualified domain name.
PTR record:
<last-IP-digit> IN PTR <FQDN-of-system>
<last-IP-digit> IN PTR <FQDN-of-system> 10.0.1.1 through 10.0.1.6 are pointed to corresponding FQDNs. It can be located in /var/named/example.com.rr.zone.
zone statement in the named.conf file similar to the following:
zone statement, except for the zone name. Note that a reverse name resolution zone requires the first three blocks of the IP address reversed followed by .in-addr.arpa. This allows the single block of IP numbers used in the reverse name resolution zone file to be associated with the zone.
19.4. Using rndc
rndc which allows command line administration of the named daemon from the localhost or a remote host.
named daemon, BIND uses a shared secret key authentication method to grant privileges to hosts. This means an identical key must be present in both /etc/named.conf and the rndc configuration file, /etc/rndc.conf.
Note
bind-chroot package, the BIND service will run in the /var/named/chroot environment. All configuration files will be moved there. As such, the rndc.conf file is located in /var/named/chroot/etc/rndc.conf.
rndc utility does not run in a chroot environment, /etc/rndc.conf is a symlink to /var/named/chroot/etc/rndc.conf.
19.4.1. Configuring /etc/named.conf
rndc to connect to a named service, there must be a controls statement in the BIND server's /etc/named.conf file.
controls statement, shown in the following example, allows rndc to connect from the localhost.
controls {
inet 127.0.0.1
allow { localhost; } keys { <key-name>; };
};
controls {
inet 127.0.0.1
allow { localhost; } keys { <key-name>; };
};
named to listen on the default TCP port 953 of the loopback address and allow rndc commands coming from the localhost, if the proper key is given. The <key-name> specifies a name in the key statement within the /etc/named.conf file. The next example illustrates a sample key statement.
key "<key-name>" {
algorithm hmac-md5;
secret "<key-value>";
};
key "<key-name>" {
algorithm hmac-md5;
secret "<key-value>";
};
dnssec-keygen -a hmac-md5 -b <bit-length> -n HOST <key-file-name>
dnssec-keygen -a hmac-md5 -b <bit-length> -n HOST <key-file-name> <key-file-name> file generated by this command.
Warning
/etc/named.conf is world-readable, it is advisable to place the key statement in a separate file, readable only by root, and then use an include statement to reference it. For example:
include "/etc/rndc.key";
include "/etc/rndc.key";19.4.1.1. Firewall Blocking Communication
named daemon to other nameservers, the recommended best practice is to change the firewall settings whenever possible.
Warning
query-source (and query-source-v6) directive, or one randomly chosen at startup. When a static query source port is used, TXID offers insufficient protection against spoofed replies and allows an attacker to efficiently perform cache-poisoning attacks. To address this issue, BIND was updated to allow the use of a randomly-selected source port for each DNS query, making it more difficult for an attacker to spoof replies, when the query packets cannot be detected. A security update [3] was released for all the affected Red Hat Enterprise Linux versions. Additionally, the default configuration provided by the caching-nameserver package was updated to no longer specify a fixed query source port.
53 as a query source port, and only allow DNS queries from that port on the firewall.
19.4.2. Configuring /etc/rndc.conf
key is the most important statement in /etc/rndc.conf.
key "<key-name>" {
algorithm hmac-md5;
secret "<key-value>";
};
key "<key-name>" {
algorithm hmac-md5;
secret "<key-value>";
};
/etc/named.conf.
/etc/named.conf, add the following lines to /etc/rndc.conf.
options {
default-server localhost;
default-key "<key-name>";
};
options {
default-server localhost;
default-key "<key-name>";
};
rndc configuration file can also specify different keys for different servers, as in the following example:
server localhost {
key "<key-name>";
};
server localhost {
key "<key-name>";
};
Important
/etc/rndc.conf file.
/etc/rndc.conf file, refer to the rndc.conf man page.
19.4.3. Command Line Options
rndc command takes the following form:
rndc <options> <command> <command-options>
rndc <options> <command> <command-options> rndc on a properly configured localhost, the following commands are available:
halt— Stops thenamedservice immediately.querylog— Logs all queries made to this nameserver.refresh— Refreshes the nameserver's database.reload— Reloads the zone files but keeps all other previously cached responses. This command also allows changes to zone files without losing all stored name resolutions.If changes made only affect a specific zone, reload only that specific zone by adding the name of the zone after thereloadcommand.stats— Dumps the currentnamedstatistics to the/var/named/named.statsfile.stop— Stops the server gracefully, saving any dynamic update and Incremental Zone Transfers (IXFR) data before exiting.
/etc/rndc.conf file. The following options are available:
-c <configuration-file>— Specifies the alternate location of a configuration file.-p <port-number>— Specifies a port number to use for therndcconnection other than the default port 953.-s <server>— Specifies a server other than thedefault-serverlisted in/etc/rndc.conf.-y <key-name>— Specifies a key other than thedefault-keyoption in/etc/rndc.conf.
rndc man page.
19.5. Advanced Features of BIND
named to provide name resolution services or to act as an authority for a particular domain or sub-domain. However, BIND version 9 has a number of advanced features that allow for a more secure and efficient DNS service.
Warning
19.5.1. DNS Protocol Enhancements
19.5.2. Multiple Views
view statement in named.conf, BIND can present different information depending on which network a request originates from.
view statement uses the match-clients option to match IP addresses or entire networks and give them special options and zone data.
19.5.3. Security
- DNSSEC
- Short for DNS SECurity, this feature allows for zones to be cryptographically signed with a zone key.In this way, the information about a specific zone can be verified as coming from a nameserver that has signed it with a particular private key, as long as the recipient has that nameserver's public key.BIND version 9 also supports the SIG(0) public/private key method of message authentication.
- TSIG
- Short for Transaction SIGnatures, this feature allows a transfer from master to slave only after verifying that a shared secret key exists on both nameservers.This feature strengthens the standard IP address-based method of transfer authorization. An attacker would not only need to have access to the IP address to transfer the zone, but they would also need to know the secret key.BIND version 9 also supports TKEY, which is another shared secret key method of authorizing zone transfers.
19.5.4. IP version 6
A6 zone records.
lwresd lightweight resolver daemon on all network clients. This daemon is a very efficient, caching-only nameserver which understands the new A6 and DNAME records used under IPv6. Refer to the lwresd man page for more information.
19.6. Common Mistakes to Avoid
- Take care to increment the serial number when editing a zone file.If the serial number is not incremented, the master nameserver has the correct, new information, but the slave nameservers are never notified of the change and do not attempt to refresh their data of that zone.
- Be careful to use ellipses and semi-colons correctly in the
/etc/named.conffile.An omitted semi-colon or unclosed ellipse section can causenamedto refuse to start. - Remember to place periods (
.) in zone files after all FQDNs and omit them on hostnames.A period at the end of a domain name denotes a fully qualified domain name. If the period is omitted, thennamedappends the name of the zone or the$ORIGINvalue to complete it. - If a firewall is blocking connections from the
nameddaemon to other nameservers, the recommended best practice is to change the firewall settings whenever possible. For important security information regarding fixed UDP source ports, refer to Section 19.4.1.1, “Firewall Blocking Communication”
19.7. Additional Resources
19.7.1. Installed Documentation
bind installed on the system:
-
/usr/share/doc/bind-<version-number>/ - This directory lists the most recent features.
-
/usr/share/doc/bind-<version-number>/arm/ - This directory contains the BIND 9 Administrator Reference Manual in HTML and SGML formats, which details BIND resource requirements, how to configure different types of nameservers, how to perform load balancing, and other advanced topics. For most new users of BIND, this is the best place to start.
-
/usr/share/doc/bind-<version-number>/draft/ - This directory contains assorted technical documents that review issues related to DNS service and propose some methods to address them.
-
/usr/share/doc/bind-<version-number>/misc/ - This directory contains documents designed to address specific advanced issues. Users of BIND version 8 should consult the
migrationdocument for specific changes they must make when moving to BIND 9. Theoptionsfile lists all of the options implemented in BIND 9 that are used in/etc/named.conf. -
/usr/share/doc/bind-<version-number>/rfc/ - This directory provides every RFC document related to BIND.
- Administrative Applications
man rndc— Explains the different options available when using therndccommand to control a BIND nameserver.
- Server Applications
man named— Explores assorted arguments that can be used to control the BIND nameserver daemon.man lwresd— Describes the purpose of and options available for the lightweight resolver daemon.
- Configuration Files
man named.conf— A comprehensive list of options available within thenamedconfiguration file.man rndc.conf— A comprehensive list of options available within therndcconfiguration file.
19.7.2. Useful Websites
- http://www.isc.org/index.pl?/sw/bind/ — The home page of the BIND project containing information about current releases as well as a PDF version of the BIND 9 Administrator Reference Manual.
- http://www.redhat.com/mirrors/LDP/HOWTO/DNS-HOWTO.html — Covers the use of BIND as a resolving, caching nameserver and the configuration of various zone files necessary to serve as the primary nameserver for a domain.
Chapter 20. OpenSSH
telnet or rsh. A related program called scp replaces older programs designed to copy files between hosts, such as rcp. Because these older applications do not encrypt passwords transmitted between the client and the server, avoid them whenever possible. Using secure methods to log into remote systems decreases the risks for both the client system and the remote host.
20.1. Features of SSH
- After an initial connection, the client can verify that it is connecting to the same server it had connected to previously.
- The client transmits its authentication information to the server using strong, 128-bit encryption.
- All data sent and received during a session is transferred using 128-bit encryption, making intercepted transmissions extremely difficult to decrypt and read.
- The client can forward X11[4] applications from the server. This technique, called X11 forwarding, provides a secure means to use graphical applications over a network.
openssh) as well as the OpenSSH server (openssh-server) and client (openssh-clients) packages. Note, the OpenSSH packages require the OpenSSL package (openssl) which installs several important cryptographic libraries, enabling OpenSSH to provide encrypted communications.
20.1.1. Why Use SSH?
- Interception of communication between two systems — In this scenario, the attacker can be somewhere on the network between the communicating parties, copying any information passed between them. The attacker may intercept and keep the information, or alter the information and send it on to the intended recipient.This attack can be mounted through the use of a packet sniffer — a common network utility.
- Impersonation of a particular host — Using this strategy, an attacker's system is configured to pose as the intended recipient of a transmission. If this strategy works, the user's system remains unaware that it is communicating with the wrong host.
20.2. SSH Protocol Versions
Important
20.3. Event Sequence of an SSH Connection
- A cryptographic handshake is made so that the client can verify that it is communicating with the correct server.
- The transport layer of the connection between the client and remote host is encrypted using a symmetric cipher.
- The client authenticates itself to the server.
- The remote client interacts with the remote host over the encrypted connection.
20.3.1. Transport Layer
- Keys are exchanged
- The public key encryption algorithm is determined
- The symmetric encryption algorithm is determined
- The message authentication algorithm is determined
- The hash algorithm is determined
Warning
20.3.2. Authentication
20.3.3. Channels
20.4. Configuring an OpenSSH Server
openssh-server package is required and is dependent on the openssh package.
/etc/ssh/sshd_config. The default configuration file should be sufficient for most purposes. If you want to configure the daemon in ways not provided by the default sshd_config, read the sshd man page for a list of the keywords that can be defined in the configuration file.
/sbin/service sshd start. To stop the OpenSSH server, use the command /sbin/service sshd stop. If you want the daemon to start automatically at boot time, refer to Chapter 18, Controlling Access to Services for information on how to manage services.
/etc/ssh/ssh_host*key* files and restore them after the reinstall. This process retains the system's identity, and when clients try to connect to the system after the reinstall, they will not receive the warning message.
20.4.1. Requiring SSH for Remote Connections
telnetrshrloginvsftpd
chkconfig, the ncurses-based program /usr/sbin/ntsysv, or the Services Configuration Tool (system-config-services) graphical application. All of these tools require root level access.
chkconfig, /usr/sbin/ntsysv, and the Services Configuration Tool, refer to Chapter 18, Controlling Access to Services.
20.5. OpenSSH Configuration Files
ssh, scp, and sftp) and one for the server daemon (sshd).
/etc/ssh/ directory:
moduli— Contains Diffie-Hellman groups used for the Diffie-Hellman key exchange which is critical for constructing a secure transport layer. When keys are exchanged at the beginning of an SSH session, a shared, secret value is created which cannot be determined by either party alone. This value is then used to provide host authentication.ssh_config— The system-wide default SSH client configuration file. It is overridden if one is also present in the user's home directory (~/.ssh/config).sshd_config— The configuration file for thesshddaemon.ssh_host_dsa_key— The DSA private key used by thesshddaemon.ssh_host_dsa_key.pub— The DSA public key used by thesshddaemon.ssh_host_key— The RSA private key used by thesshddaemon for version 1 of the SSH protocol.ssh_host_key.pub— The RSA public key used by thesshddaemon for version 1 of the SSH protocol.ssh_host_rsa_key— The RSA private key used by thesshddaemon for version 2 of the SSH protocol.ssh_host_rsa_key.pub— The RSA public key used by thesshdfor version 2 of the SSH protocol.
~/.ssh/ directory:
authorized_keys— This file holds a list of authorized public keys for servers. When the client connects to a server, the server authenticates the client by checking its signed public key stored within this file.id_dsa— Contains the DSA private key of the user.id_dsa.pub— The DSA public key of the user.id_rsa— The RSA private key used bysshfor version 2 of the SSH protocol.id_rsa.pub— The RSA public key used bysshfor version 2 of the SSH protocolidentity— The RSA private key used bysshfor version 1 of the SSH protocol.identity.pub— The RSA public key used bysshfor version 1 of the SSH protocol.known_hosts— This file contains DSA host keys of SSH servers accessed by the user. This file is very important for ensuring that the SSH client is connecting the correct SSH server.Important
If an SSH server's host key has changed, the client notifies the user that the connection cannot proceed until the server's host key is deleted from theknown_hostsfile using a text editor. Before doing this, however, contact the system administrator of the SSH server to verify the server is not compromised.
ssh_config and sshd_config man pages for information concerning the various directives available in the SSH configuration files.
20.6. Configuring an OpenSSH Client
openssh-clients and openssh packages installed on the client machine.
20.6.1. Using the ssh Command
ssh command is a secure replacement for the rlogin, rsh, and telnet commands. It allows you to log in to a remote machine as well as execute commands on a remote machine.
ssh is similar to using telnet. To log in to a remote machine named penguin.example.net, type the following command at a shell prompt:
ssh penguin.example.net
ssh penguin.example.netssh to a remote machine, you will see a message similar to the following:
The authenticity of host 'penguin.example.net' can't be established. DSA key fingerprint is 94:68:3a:3a:bc:f3:9a:9b:01:5d:b3:07:38:e2:11:0c. Are you sure you want to continue connecting (yes/no)?
The authenticity of host 'penguin.example.net' can't be established.
DSA key fingerprint is 94:68:3a:3a:bc:f3:9a:9b:01:5d:b3:07:38:e2:11:0c.
Are you sure you want to continue connecting (yes/no)?yes to continue. This will add the server to your list of known hosts (~/.ssh/known_hosts) as seen in the following message:
Warning: Permanently added 'penguin.example.net' (RSA) to the list of known hosts.
Warning: Permanently added 'penguin.example.net' (RSA) to the list of known hosts.ssh username@penguin.example.net
ssh username@penguin.example.netssh -l username penguin.example.net.
ssh command can be used to execute a command on the remote machine without logging in to a shell prompt. The syntax is ssh hostname command. For example, if you want to execute the command ls /usr/share/doc on the remote machine penguin.example.net, type the following command at a shell prompt:
ssh penguin.example.net ls /usr/share/doc
ssh penguin.example.net ls /usr/share/doc/usr/share/doc will be displayed, and you will return to your local shell prompt.
20.6.2. Using the scp Command
scp command can be used to transfer files between machines over a secure, encrypted connection. It is similar to rcp.
scp <localfile> username@tohostname:<remotefile>
scp <localfile> username@tohostname:<remotefile>/var/log/maillog. The <remotefile> specifies the destination, which can be a new filename such as /tmp/hostname-maillog. For the remote system, if you do not have a preceding /, the path will be relative to the home directory of username, typically /home/username/.
shadowman to the home directory of your account on penguin.example.net, type the following at a shell prompt (replace username with your username):
scp shadowman username@penguin.example.net:shadowman
scp shadowman username@penguin.example.net:shadowmanshadowman to /home/username/shadowman on penguin.example.net. Alternately, you can leave off the final shadowman in the scp command.
scp username@tohostname:<remotefile> <newlocalfile>
scp username@tohostname:<remotefile> <newlocalfile>downloads/ to an existing directory called uploads/ on the remote machine penguin.example.net, type the following at a shell prompt:
scp downloads/* username@penguin.example.net:uploads/
scp downloads/* username@penguin.example.net:uploads/20.6.3. Using the sftp Command
sftp utility can be used to open a secure, interactive FTP session. It is similar to ftp except that it uses a secure, encrypted connection. The general syntax is sftp username@hostname.com. Once authenticated, you can use a set of commands similar to those used by FTP. Refer to the sftp man page for a list of these commands. To read the man page, execute the command man sftp at a shell prompt. The sftp utility is only available in OpenSSH version 2.5.0p1 and higher.
20.7. More Than a Secure Shell
20.7.1. X11 Forwarding
-Y option and running an X program on a local machine.
ssh -Y <user>@example.com
ssh -Y <user>@example.comsystem-config-printer &
system-config-printer &20.7.2. Port Forwarding
ssh -L local-port:remote-hostname:remote-port username@hostname
ssh -L local-port:remote-hostname:remote-port username@hostnameNote
mail.example.com using POP3 through an encrypted connection, use the following command:
ssh -L 1100:mail.example.com:110 mail.example.com
ssh -L 1100:mail.example.com:110 mail.example.commail.example.com server.
mail.example.com is not running an SSH server, but another machine on the same network is, SSH can still be used to secure part of the connection. However, a slightly different command is necessary:
ssh -L 1100:mail.example.com:110 other.example.com
ssh -L 1100:mail.example.com:110 other.example.comother.example.com. Then, other.example.com connects to port 110 on mail.example.com to check for new mail. Note, when using this technique only the connection between the client system and other.example.com SSH server is secure.
Note
No parameter for the AllowTcpForwarding line in /etc/ssh/sshd_config and restarting the sshd service.
20.7.3. Generating Key Pairs
ssh, scp, or sftp to connect to a remote machine, you can generate an authorization key pair.
~/.ssh/authorized_keys2, ~/.ssh/known_hosts2, and /etc/ssh_known_hosts2 are obsolete. SSH Protocol 1 and 2 share the ~/.ssh/authorized_keys, ~/.ssh/known_hosts, and /etc/ssh/ssh_known_hosts files.
Note
.ssh directory in your home directory. After reinstalling, copy this directory back to your home directory. This process can be done for all users on your system, including root.
20.7.3.1. Generating an RSA Key Pair for Version 2
- To generate an RSA key pair to work with version 2 of the protocol, type the following command at a shell prompt:
ssh-keygen -t rsa
ssh-keygen -t rsaCopy to Clipboard Copied! Toggle word wrap Toggle overflow Accept the default file location of~/.ssh/id_rsa. Enter a passphrase different from your account password and confirm it by entering it again.The public key is written to~/.ssh/id_rsa.pub. The private key is written to~/.ssh/id_rsa. Never distribute your private key to anyone. - Change the permissions of the
.sshdirectory using the following command:chmod 755 ~/.ssh
chmod 755 ~/.sshCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Copy the contents of
~/.ssh/id_rsa.pubinto the file~/.ssh/authorized_keyson the machine to which you want to connect. If the file~/.ssh/authorized_keysexist, append the contents of the file~/.ssh/id_rsa.pubto the file~/.ssh/authorized_keyson the other machine. - Change the permissions of the
authorized_keysfile using the following command:chmod 644 ~/.ssh/authorized_keys
chmod 644 ~/.ssh/authorized_keysCopy to Clipboard Copied! Toggle word wrap Toggle overflow - If you are running GNOME or are running in a graphical desktop with GTK2+ libraries installed, skip to Section 20.7.3.4, “Configuring
ssh-agentwith a GUI”. If you are not running the X Window System, skip to Section 20.7.3.5, “Configuringssh-agent”.
20.7.3.2. Generating a DSA Key Pair for Version 2
- To generate a DSA key pair to work with version 2 of the protocol, type the following command at a shell prompt:
ssh-keygen -t dsa
ssh-keygen -t dsaCopy to Clipboard Copied! Toggle word wrap Toggle overflow Accept the default file location of~/.ssh/id_dsa. Enter a passphrase different from your account password and confirm it by entering it again.Note
A passphrase is a string of words and characters used to authenticate a user. Passphrases differ from passwords in that you can use spaces or tabs in the passphrase. Passphrases are generally longer than passwords because they are usually phrases instead of a single word.The public key is written to~/.ssh/id_dsa.pub. The private key is written to~/.ssh/id_dsa. It is important never to give anyone the private key. - Change the permissions of the
.sshdirectory with the following command:chmod 755 ~/.ssh
chmod 755 ~/.sshCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Copy the contents of
~/.ssh/id_dsa.pubinto the file~/.ssh/authorized_keyson the machine to which you want to connect. If the file~/.ssh/authorized_keysexist, append the contents of the file~/.ssh/id_dsa.pubto the file~/.ssh/authorized_keyson the other machine. - Change the permissions of the
authorized_keysfile using the following command:chmod 644 ~/.ssh/authorized_keys
chmod 644 ~/.ssh/authorized_keysCopy to Clipboard Copied! Toggle word wrap Toggle overflow - If you are running GNOME or a graphical desktop environment with the GTK2+ libraries installed, skip to Section 20.7.3.4, “Configuring
ssh-agentwith a GUI”. If you are not running the X Window System, skip to Section 20.7.3.5, “Configuringssh-agent”.
20.7.3.3. Generating an RSA Key Pair for Version 1.3 and 1.5
- To generate an RSA (for version 1.3 and 1.5 protocol) key pair, type the following command at a shell prompt:
ssh-keygen -t rsa1
ssh-keygen -t rsa1Copy to Clipboard Copied! Toggle word wrap Toggle overflow Accept the default file location (~/.ssh/identity). Enter a passphrase different from your account password. Confirm the passphrase by entering it again.The public key is written to~/.ssh/identity.pub. The private key is written to~/.ssh/identity. Do not give anyone the private key. - Change the permissions of your
.sshdirectory and your key with the commandschmod 755 ~/.sshandchmod 644 ~/.ssh/identity.pub. - Copy the contents of
~/.ssh/identity.pubinto the file~/.ssh/authorized_keyson the machine to which you wish to connect. If the file~/.ssh/authorized_keysdoes not exist, you can copy the file~/.ssh/identity.pubto the file~/.ssh/authorized_keyson the remote machine. - If you are running GNOME, skip to Section 20.7.3.4, “Configuring
ssh-agentwith a GUI”. If you are not running GNOME, skip to Section 20.7.3.5, “Configuringssh-agent”.
20.7.3.4. Configuring ssh-agent with a GUI
ssh-agent utility can be used to save your passphrase so that you do not have to enter it each time you initiate an ssh or scp connection. If you are using GNOME, the gnome-ssh-askpass package contains the application used to prompt you for your passphrase when you log in to GNOME and save it until you log out of GNOME. You will not have to enter your password or passphrase for any ssh or scp connection made during that GNOME session. If you are not using GNOME, refer to Section 20.7.3.5, “Configuring ssh-agent”.
- You will need to have the package
gnome-ssh-askpassinstalled; you can use the commandrpm -q openssh-askpassto determine if it is installed or not. If it is not installed, install it from your Red Hat Enterprise Linux CD-ROM set, from a Red Hat FTP mirror site, or using Red Hat Network. - Select (on the Panel) > > > Sessions, and click on the Startup Programs tab. Click and enter
/usr/bin/ssh-addin the Startup Command text area. Set it a priority to a number higher than any existing commands to ensure that it is executed last. A good priority number forssh-addis 70 or higher. The higher the priority number, the lower the priority. If you have other programs listed, this one should have the lowest priority. Click to exit the program. - Log out and then log back into GNOME; in other words, restart X. After GNOME is started, a dialog box will appear prompting you for your passphrase(s). Enter the passphrase requested. If you have both DSA and RSA key pairs configured, you will be prompted for both. From this point on, you should not be prompted for a password by
ssh,scp, orsftp.
20.7.3.5. Configuring ssh-agent
ssh-agent can be used to store your passphrase so that you do not have to enter it each time you make a ssh or scp connection. If you are not running the X Window System, follow these steps from a shell prompt. If you are running GNOME but you do not want to configure it to prompt you for your passphrase when you log in (refer to Section 20.7.3.4, “Configuring ssh-agent with a GUI”), this procedure will work in a terminal window, such as an XTerm. If you are running X but not GNOME, this procedure will work in a terminal window. However, your passphrase will only be remembered for that terminal window; it is not a global setting.
- At a shell prompt, type the following command:
exec /usr/bin/ssh-agent $SHELL
exec /usr/bin/ssh-agent $SHELLCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Then type the command:
ssh-add
ssh-addCopy to Clipboard Copied! Toggle word wrap Toggle overflow and enter your passphrase(s). If you have more than one key pair configured, you will be prompted for each one. - When you log out, your passphrase(s) will be forgotten. You must execute these two commands each time you log in to a virtual console or open a terminal window.
20.8. Additional Resources
20.8.1. Installed Documentation
- The
ssh,scp,sftp,sshd, andssh-keygenman pages — These man pages include information on how to use these commands as well as all the parameters that can be used with them.
20.8.2. Useful Websites
- http://www.openssh.com/ — The OpenSSH FAQ page, bug reports, mailing lists, project goals, and a more technical explanation of the security features.
- http://www.openssl.org/ — The OpenSSL FAQ page, mailing lists, and a description of the project goal.
- http://www.freesshd.com/ — SSH client software for other platforms.
Chapter 21. Network File System (NFS)
21.1. How It Works
portmap, rpc.lockd, and rpc.statd daemons. NFSv4 listens on the well-known TCP port 2049, which eliminates the need for portmap interaction. The mounting and locking protocols have been incorporated into the V4 protocol which eliminates the need for interaction with rpc.lockd and rpc.statd. The rpc.mountd daemon is still required on the server, but is not involved in any over-the-wire operations.
Note
-p command line option that can set the port, making firewall configuration easier.
/etc/exports, to determine whether the client is allowed to access any of the exported file systems. Once access is granted, all file and directory operations are available to the user.
Important
rpc.nfsd process now allow binding to any specified port during system start up. However, this can be error prone if the port is unavailable or conflicts with another daemon.
21.1.1. Required Services
portmap service. To share or mount NFS file systems, the following services work together, depending on which version of NFS is implemented:
nfs— (/sbin/service nfs start) starts the NFS server and the appropriate RPC processes to service requests for shared NFS file systems.nfslock— (/sbin/service nfslock start) is a mandatory service that starts the appropriate RPC processes to allow NFS clients to lock files on the server.portmap— accepts port reservations from local RPC services. These ports are then made available (or advertised) so the corresponding remote RPC services access them.portmapresponds to requests for RPC services and sets up connections to the requested RPC service.
rpc.mountd— This process receives mount requests from NFS clients and verifies the requested file system is currently exported. This process is started automatically by thenfsservice and does not require user configuration.rpc.nfsd— Allows explicit NFS versions and protocols the server advertises to be defined. It works with the Linux kernel to meet the dynamic demands of NFS clients, such as providing server threads each time an NFS client connects. This process corresponds to thenfsservice.rpc.lockd— allows NFS clients to lock files on the server. Ifrpc.lockdis not started, file locking will fail.rpc.lockdimplements the Network Lock Manager (NLM) protocol. This process corresponds to thenfslockservice. This is not used with NFSv4.rpc.statd— This process implements the Network Status Monitor (NSM) RPC protocol which notifies NFS clients when an NFS server is restarted without being gracefully brought down. This process is started automatically by thenfslockservice and does not require user configuration. This is not used with NFSv4.rpc.rquotad— This process provides user quota information for remote users. This process is started automatically by thenfsservice and does not require user configuration.rpc.idmapd— This process provides NFSv4 client and server upcalls which map between on-the-wire NFSv4 names (which are strings in the form of user@domain) and local UIDs and GIDs. Foridmapdto function with NFSv4, the/etc/idmapd.confmust be configured. This service is required for use with NFSv4.
21.2. NFS Client Configuration
mount command. The format of the command is as follows:
mount -t <nfs-type> -o <options> <host>:</remote/export> </local/directory>
mount -t <nfs-type> -o <options> <host>:</remote/export> </local/directory>nfs for NFSv2 or NFSv3 servers, or nfs4 for NFSv4 servers. Replace <options> with a comma separated list of options for the NFS file system (refer to Section 21.4, “Common NFS Mount Options” for details). Replace <host> with the remote host, </remote/export> with the remote directory being mounted, and </local/directory> with the local directory where the remote file system is to be mounted.
mount man page for more details.
mount command, the file system must be remounted manually after the system is rebooted. Red Hat Enterprise Linux offers two methods for mounting remote file systems automatically at boot time: the /etc/fstab file or the autofs service.
21.2.1. Mounting NFS File Systems using /etc/fstab
/etc/fstab file. The /etc/fstab file is referenced by the netfs service at boot time, so lines referencing NFS shares have the same effect as manually typing the mount command during the boot process. Each line in this file must state the hostname of the NFS server, the directory on the server being exported, and the directory on the local machine where the NFS share is to be mounted. You must be root to modify the /etc/fstab file.
/etc/fstab is as follows:
<server>:</remote/export> </local/directory> <nfs-type> <options> 0 0
<server>:</remote/export> </local/directory> <nfs-type> <options> 0 0<server> with the hostname, IP address, or fully qualified domain name of the server exporting the file system. Replace </remote/export> with the path to the exported directory, and </local/directory> with the local file system on which the exported directory is mounted. Replace <nfs-type> with either nfs for NFSv2 or NFSv3 servers, or nfs4 for NFSv4 servers. Finally, replace <options> with a comma separated list of options for the NFS file system (see Section 21.4, “Common NFS Mount Options” for details). Note that the mount point must exist before /etc/fstab is read, otherwise the mount fails.
/etc/fstab line to mount an NFS export:
server:/usr/local/pub /pub nfs defaults 0 0
server:/usr/local/pub /pub nfs defaults 0 0/etc/fstab on the client system, type the command mount /pub at a shell prompt, and the mount point /pub is mounted from the server. The mount point /pub must exist on the client machine before this command can be executed.
/etc/fstab configuration file and its contents, refer to the fstab manual page.
21.3. autofs
/etc/fstab is that, regardless of how infrequently a user accesses the NFS mounted file system, the system must dedicate resources to keep the mounted file system in place. This is not a problem with one or two mounts, but when the system is maintaining mounts to many systems at one time, overall system performance can be affected. An alternative to /etc/fstab is to use the kernel-based automount utility. An automounter consists of two components. One is a kernel module that implements a file system, while the other is a user-space daemon that performs all of the other functions. The automount utility can mount and unmount NFS file systems automatically (on demand mounting) therefore saving system resources. The automount utility can be used to mount other file systems including AFS, SMBFS, CIFS and local file systems.
autofs uses /etc/auto.master (master map) as its default primary configuration file. This can be changed to use another supported network source and name using the autofs configuration (in /etc/sysconfig/autofs) in conjunction with the Name Service Switch mechanism. An instance of the version 4 daemon was run for each mount point configured in the master map and so it could be run manually from the command line for any given mount point. This is not possible with version 5 because it uses a single daemon to manage all configured mount points, so all automounts must be configured in the master map. This is in line with the usual requirements of other industry standard automounters. Mount point, hostname, exported directory, and options can all be specified in a set of files (or other supported network sources) rather than configuring them manually for each host. Please ensure that you have the autofs package installed if you wish to use this service.
21.3.1. What's new in autofs version 5?
- Direct map support
- Autofs direct maps provide a mechanism to automatically mount file systems at arbitrary points in the file system hierarchy. A direct map is denoted by a mount point of "/-" in the master map. Entries in a direct map contain an absolute path name as a key (instead of the relative path names used in indirect maps).
- Lazy mount and unmount support
- Multimount map entries describe a hierarchy of mount points under a single key. A good example of this is the "-hosts" map, commonly used for automounting all exports from a host under "
/net/<host>" as a multi-mount map entry. When using the "-hosts" map, an 'ls' of "/net/<host>" will mount autofs trigger mounts for each export from<host>and mount and expire them as they are accessed. This can greatly reduce the number of active mounts needed when accessing a server with a large number of exports. - Enhanced LDAP support
- The Lightweight Directory Access Protocol, or LDAP, support in autofs version 5 has been enhanced in several ways with respect to autofs version 4. The autofs configuration file (
/etc/sysconfig/autofs) provides a mechanism to specify the autofs schema that a site implements, thus precluding the need to determine this via trial and error in the application itself. In addition, authenticated binds to the LDAP server are now supported, using most mechanisms supported by the common LDAP server implementations. A new configuration file has been added for this support:/etc/autofs_ldap_auth.conf. The default configuration file is self-documenting, and uses an XML format. - Proper use of the Name Service Switch (
nsswitch) configuration. - The Name Service Switch configuration file exists to provide a means of determining from where specific configuration data comes. The reason for this configuration is to allow administrators the flexibility of using the back-end database of choice, while maintaining a uniform software interface to access the data. While the version 4 automounter is becoming increasingly better at handling the name service switch configuration, it is still not complete. Autofs version 5, on the other hand, is a complete implementation. See the manual page for nsswitch.conf for more information on the supported syntax of this file. Please note that not all nss databases are valid map sources and the parser will reject ones that are invalid. Valid sources are files, yp, nis, nisplus, ldap and hesiod.
- Multiple master map entries per autofs mount point
- One thing that is frequently used but not yet mentioned is the handling of multiple master map entries for the direct mount point "/-". The map keys for each entry are merged and behave as one map.An example is seen in the connectathon test maps for the direct mounts below:
/- /tmp/auto_dcthon /- /tmp/auto_test3_direct /- /tmp/auto_test4_direct
/- /tmp/auto_dcthon /- /tmp/auto_test3_direct /- /tmp/auto_test4_directCopy to Clipboard Copied! Toggle word wrap Toggle overflow
21.3.2. autofs Configuration
/etc/auto.master, also referred to as the master map which may be changed as described in the introduction section above. The master map lists autofs-controlled mount points on the system, and their corresponding configuration files or network sources known as automount maps. The format of the master map is as follows:
<mount-point> <map-name> <options>
<mount-point> <map-name> <options>mount-pointis the autofs mount point such as/home.map-nameis the name of a map source which contains a list of mount points, and the file system location from which those mount points should be mounted. The syntax for a map entry is described below.optionsif supplied, will apply to all entries in the given map provided they don't themselves have options specified. This behavior is different from autofs version 4 where the options where cumulative. This has been changed to meet our primary goal of mixed environment compatibility.
/etc/auto.master file:
~]$ cat /etc/auto.master /home /etc/auto.misc
~]$ cat /etc/auto.master
/home /etc/auto.misc<mount-point> [<options>] <location>
<mount-point> [<options>] <location><mount-point>is the autofs mount point. This can be a single directory name for an indirect mount or the full path of the mount point for direct mounts. Each direct and indirect map entry key (<mount-point>above) may be followed by a space separated list of offset directories (sub directory names each beginning with a "/") making them what is known as a mutli-mount entry.- <options> if supplied, are the mount options for the map entries that do not specify their own options.
- <location> is the file system location such as a local file system path (preceded with the Sun map format escape character ":" for map names beginning with "/"), an NFS file system or other valid file system location.
~]$ cat /etc/auto.misc payroll -fstype=nfs personnel:/dev/hda3 sales -fstype=ext3 :/dev/hda4
~]$ cat /etc/auto.misc
payroll -fstype=nfs personnel:/dev/hda3
sales -fstype=ext3 :/dev/hda4sales and payroll from the server called personnel). The second column indicates the options for the autofs mount while the third column indicates the source of the mount. Following the above configuration, the autofs mount points will be /home/payroll and /home/sales. The -fstype= option is often omitted and is generally not needed for correct operation.
service autofs start
service autofs startservice autofs restart
service autofs restart/home/payroll/2006/July.sxc, the automount daemon automatically mounts the directory. If a timeout is specified, the directory will automatically be unmounted if the directory is not accessed for the timeout period.
/sbin/service/autofs status
/sbin/service/autofs status21.3.3. autofs Common Tasks
21.3.3.1. Overriding or augmenting site configuration files
/etc/nsswitch.conf file has the following directive:
automount: files nis
automount: files nisauto.master map file contains the following:
/home auto.home
/home auto.homeauto.home map contains the following:
beth fileserver.example.com:/export/home/beth joe fileserver.example.com:/export/home/joe * fileserver.example.com:/export/home/&
beth fileserver.example.com:/export/home/beth
joe fileserver.example.com:/export/home/joe
* fileserver.example.com:/export/home/&/etc/auto.home does not exist.
/etc/auto.master map:
/home /etc/auto.home2 +auto.master
/home /etc/auto.home2
+auto.master/etc/auto.home2 map contains the entry:
* labserver.example.com:/export/home/&
* labserver.example.com:/export/home/&/home will contain the contents of /etc/auto.home2 instead of the NIS auto.home map.
auto.home map with a few entries, create a /etc/auto.home file map, and in it put your new entries and at the end, include the NIS auto.home map. Then the /etc/auto.home file map might look similar to:
mydir someserver:/export/mydir +auto.home
mydir someserver:/export/mydir
+auto.homeauto.home map listed above, an ls of /home would now give:
ls /home beth joe mydir
~]$ ls /home
beth joe mydirautofs knows not to include the contents of a file map of the same name as the one it is reading and so moves on to the next map source in the nsswitch configuration.
21.3.3.2. Using LDAP to Store Automounter Maps
openldap package should be installed automatically as a dependency of the automounter. To configure LDAP access, modify /etc/openldap/ldap.conf. Ensure that BASE and URI are set appropriately for your site. Please also ensure that the schema is set in the configuration.
rfc2307bis. To use this schema it is necessary to set it in the autofs configuration (/etc/sysconfig/autofs) by removing the comment characters from the schema definition. For example:
DEFAULT_MAP_OBJECT_CLASS="automountMap" DEFAULT_ENTRY_OBJECT_CLASS="automount" DEFAULT_MAP_ATTRIBUTE="automountMapName" DEFAULT_ENTRY_ATTRIBUTE="automountKey" DEFAULT_VALUE_ATTRIBUTE="automountInformation"
DEFAULT_MAP_OBJECT_CLASS="automountMap"
DEFAULT_ENTRY_OBJECT_CLASS="automount"
DEFAULT_MAP_ATTRIBUTE="automountMapName"
DEFAULT_ENTRY_ATTRIBUTE="automountKey"
DEFAULT_VALUE_ATTRIBUTE="automountInformation"automountKey replaces the cn attribute in the rfc2307bis schema. An LDIF of a sample configuration is described below:
21.3.3.3. Adapting Autofs v4 Maps To Autofs v5
Autofs version 4 introduced the notion of a multi-map entry in the master map. A multi-map entry is of the form:
<mount-point> <maptype1> <mapname1> <options1> -- <maptype2> <mapname2> <options2> -- ...
<mount-point> <maptype1> <mapname1> <options1> -- <maptype2> <mapname2> <options2> -- .../home file /etc/auto.home -- nis auto.home
/home file /etc/auto.home -- nis auto.home/etc/nsswitch.conf must list:
automount: files nis
automount: files nis/etc/auto.master should contain:
/home auto.home
/home auto.home/etc/auto.home should contain:
<entries for the home directory> +auto.home
<entries for the home directory>
+auto.home/etc/auto.home and the nis auto.home map are combined.
In autofs version 4, it is possible to merge the contents of master maps from each source, such as files, nis, hesiod, and LDAP. The version 4 automounter looks for a master map for each of the sources listed in /etc/nsswitch.conf. The map is read if it exists and its contents are merged into one large auto.master map.
nsswitch.conf is consulted. If it is desirable to merge the contents of multiple master maps, included maps can be used. Consider the following example:
/etc/nsswitch.conf: automount: files nis
/etc/nsswitch.conf:
automount: files nis/etc/auto.master: /home /etc/auto.home +auto.master
/etc/auto.master:
/home /etc/auto.home
+auto.masterauto.master and the NIS-based auto.master. However, because included map entries are only allowed in file maps, there is no way to include both an NIS auto.master and an LDAP auto.master.
auto.master.ldap we could also add "+auto.master.ldap" to the file based master map and provided that "ldap" is listed as a source in our nsswitch configuration it would also be included.
21.4. Common NFS Mount Options
mount commands, /etc/fstab settings, and autofs.
hardorsoft— Specifies whether the program using a file via an NFS connection should stop and wait (hard) for the server to come back online, if the host serving the exported file system is unavailable, or if it should report an error (soft).Ifhardis specified, the user cannot terminate the process waiting for the NFS communication to resume unless theintroption is also specified.Ifsoftis specified, the user can set an additionaltimeo=<value>option, where<value>specifies the number of seconds to pass before the error is reported.
Note
intr— Allows NFS requests to be interrupted if the server goes down or cannot be reached.nfsvers=2ornfsvers=3— Specifies which version of the NFS protocol to use. This is useful for hosts that run multiple NFS servers. If no version is specified, NFS uses the highest supported version by the kernel andmountcommand. This option is not supported with NFSv4 and should not be used.noacl— Turns off all ACL processing. This may be needed when interfacing with older versions of Red Hat Enterprise Linux, Red Hat Linux, or Solaris, since the most recent ACL technology is not compatible with older systems.nolock— Disables file locking. This setting is occasionally required when connecting to older NFS servers.noexec— Prevents execution of binaries on mounted file systems. This is useful if the system is mounting a non-Linux file system via NFS containing incompatible binaries.nosuid— Disables set-user-identifier or set-group-identifier bits. This prevents remote users from gaining higher privileges by running a setuid program.port=num— Specifies the numeric value of the NFS server port. Ifnumis0(the default), thenmountqueries the remote host's portmapper for the port number to use. If the remote host's NFS daemon is not registered with its portmapper, the standard NFS port number of TCP 2049 is used instead.rsize=numandwsize=num— These settings speed up NFS communication for reads (rsize) and writes (wsize) by setting a larger data block size, in bytes, to be transferred at one time. Be careful when changing these values; some older Linux kernels and network cards do not work well with larger block sizes. For NFSv2 or NFSv3, the default values for both parameters is set to 8192. For NFSv4, the default values for both parameters is set to 32768.sec=mode— Specifies the type of security to utilize when authenticating an NFS connection.sec=sysis the default setting, which uses local UNIX UIDs and GIDs by means of AUTH_SYS to authenticate NFS operations.sec=krb5uses Kerberos V5 instead of local UNIX UIDs and GIDs to authenticate users.sec=krb5iuses Kerberos V5 for user authentication and performs integrity checking of NFS operations using secure checksums to prevent data tampering.sec=krb5puses Kerberos V5 for user authentication, integrity checking, and encrypts NFS traffic to prevent traffic sniffing. This is the most secure setting, but it also has the most performance overhead involved.tcp— Specifies for the NFS mount to use the TCP protocol.udp— Specifies for the NFS mount to use the UDP protocol.
mount and nfs man pages.
21.5. Starting and Stopping NFS
portmap service must be running. To verify that portmap is active, type the following command as root:
service portmap status
service portmap statusportmap service is running, then the nfs service can be started. To start an NFS server, as root type:
service nfs start
service nfs startNote
nfslock also has to be started for both the NFS client and server to function properly. To start NFS locking as root type: /sbin/service nfslock start. If NFS is set to start at boot, please ensure that nfslock also starts by running chkconfig --list nfslock. If nfslock is not set to on, this implies that you will need to manually run the /sbin/service nfslock start each time the computer starts. To set nfslock to automatically start on boot, type the following command in a terminal chkconfig nfslock on.
service nfs stop
service nfs stoprestart option is a shorthand way of stopping and then starting NFS. This is the most efficient way to make configuration changes take effect after editing the configuration file for NFS.
service nfs restart
service nfs restartcondrestart (conditional restart) option only starts nfs if it is currently running. This option is useful for scripts, because it does not start the daemon if it is not running.
service nfs condrestart
service nfs condrestartservice nfs reload
service nfs reloadnfs service does not start automatically at boot time. To configure the NFS to start up at boot time, use an initscript utility, such as /sbin/chkconfig, /usr/sbin/ntsysv, or the Services Configuration Tool program. Refer to Chapter 18, Controlling Access to Services for more information regarding these tools.
21.6. NFS Server Configuration
system-config-nfs), manually editing its configuration file (/etc/exports), or using the /usr/sbin/exportfs command.
system-config-nfs in a terminal. The NFS Server Configuration tool window is illustrated below.

Figure 21.1. NFS Server Configuration Tool

Figure 21.2. NFS Server Settings
21.6.1. Exporting or Sharing NFS File Systems
- Directory — Specify the directory to share, such as
/tmp. - Host(s) — Specify the host(s) with which to share the directory. Refer to Section 21.6.4, “Hostname Formats” for an explanation of possible formats.
- Basic permissions — Specify whether the directory should have read-only or read/write permissions.
Figure 21.3. Add Share

Figure 21.4. NFS General Options
- Allow connections from port 1024 and higher — Services started on port numbers less than 1024 must be started as root. Select this option to allow the NFS service to be started by a user other than root. This option corresponds to
insecure. - Allow insecure file locking — Do not require a lock request. This option corresponds to
insecure_locks. - Disable subtree checking — If a subdirectory of a file system is exported, but the entire file system is not exported, the server checks to see if the requested file is in the subdirectory exported. This check is called subtree checking. Select this option to disable subtree checking. If the entire file system is exported, selecting to disable subtree checking can increase the transfer rate. This option corresponds to
no_subtree_check. - Sync write operations on request — Enabled by default, this option does not allow the server to reply to requests before the changes made by the request are written to the disk. This option corresponds to
sync. If this is not selected, theasyncoption is used.- Force sync of write operations immediately — Do not delay writing to disk. This option corresponds to
no_wdelay.
- Hide filesystems beneath turns the
nohideoption on or off. When thenohideoption is off, nested directories are revealed. The clients can therefore navigate through a filesystem from the parent without noticing any changes. - Export only if mounted sets the
mountpointoption which allows a directory to be exported only if it has been mounted. - Optional Mount Point specifies the path to an optional mount point. Click on the to navigate to the preferred mount point or type the path if known.
- Set explicit Filesystem ID: sets the
fsid=Xoption. This is mainly used in a clustered setup. Using a consistent filesystem ID in all clusters avoids having stale NFS filehandles.
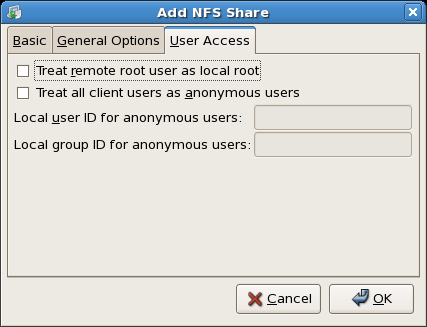
Figure 21.5. NFS User Access
- Treat remote root user as local root — By default, the user and group IDs of the root user are both 0. Root squashing maps the user ID 0 and the group ID 0 to the user and group IDs of anonymous so that root on the client does not have root privileges on the NFS server. If this option is selected, root is not mapped to anonymous, and root on a client has root privileges to exported directories. Selecting this option can greatly decrease the security of the system. Do not select it unless it is absolutely necessary. This option corresponds to
no_root_squash. - Treat all client users as anonymous users — If this option is selected, all user and group IDs are mapped to the anonymous user. This option corresponds to
all_squash.- Specify local user ID for anonymous users — If Treat all client users as anonymous users is selected, this option lets you specify a user ID for the anonymous user. This option corresponds to
anonuid. - Specify local group ID for anonymous users — If Treat all client users as anonymous users is selected, this option lets you specify a group ID for the anonymous user. This option corresponds to
anongid.
/etc/exports.bak. The new configuration is written to /etc/exports.
/etc/exports configuration file. Thus, the file can be modified manually after using the tool, and the tool can be used after modifying the file manually (provided the file was modified with correct syntax).
/etc/exports and using the /usr/sbin/exportfs command to export NFS file systems.
21.6.2. Command Line Configuration
/etc/exports file controls what directories the NFS server exports. Its format is as follows:
directory hostname(options)
directory hostname(options)sync or async (sync is recommended). If sync is specified, the server does not reply to requests before the changes made by the request are written to the disk.
/misc/export speedy.example.com(sync)
/misc/export speedy.example.com(sync)speedy.example.com to mount /misc/export with the default read-only permissions, but,
/misc/export speedy.example.com(rw,sync)
/misc/export speedy.example.com(rw,sync)speedy.example.com to mount /misc/export with read/write privileges.
Warning
/etc/exports file. If there are no spaces between the hostname and the options in parentheses, the options apply only to the hostname. If there is a space between the hostname and the options, the options apply to the rest of the world. For example, examine the following lines:
/misc/export speedy.example.com(rw,sync) /misc/export speedy.example.com (rw,sync)
/misc/export speedy.example.com(rw,sync) /misc/export speedy.example.com (rw,sync)speedy.example.com read-write access and denies all other users. The second line grants users from speedy.example.com read-only access (the default) and allows the rest of the world read-write access.
/etc/exports, you must inform the NFS daemon of the change, or reload the configuration file with the following command:
service nfs reload
service nfs reload21.6.3. Running NFS Behind a Firewall
/etc/sysconfig/nfs configuration file to control which ports the required RPC services run on. Refer to and read Section 32.1.23, “/etc/sysconfig/nfs” for instructions on how to configure a firewall to allow NFS.
21.6.4. Hostname Formats
- Single machine — A fully qualified domain name (that can be resolved by the server), hostname (that can be resolved by the server), or an IP address.
- Series of machines specified with wildcards — Use the * or ? character to specify a string match. Wildcards are not to be used with IP addresses; however, they may accidentally work if reverse DNS lookups fail. When specifying wildcards in fully qualified domain names, dots (.) are not included in the wildcard. For example,
*.example.comincludes one.example.com but does not include one.two.example.com. - IP networks — Use a.b.c.d/z, where a.b.c.d is the network and z is the number of bits in the netmask (for example 192.168.0.0/24). Another acceptable format is a.b.c.d/netmask, where a.b.c.d is the network and netmask is the netmask (for example, 192.168.100.8/255.255.255.0).
- Netgroups — In the format @group-name, where group-name is the NIS netgroup name.
21.7. The /etc/exports Configuration File
/etc/exports file controls which file systems are exported to remote hosts and specifies options. Blank lines are ignored, comments can be made by starting a line with the hash mark (#), and long lines can be wrapped with a backslash (\). Each exported file system should be on its own individual line, and any lists of authorized hosts placed after an exported file system must be separated by space characters. Options for each of the hosts must be placed in parentheses directly after the host identifier, without any spaces separating the host and the first parenthesis. Valid host types are gss/krb5, gss/krb5i, and gss/krb5p.
<export> <host1>(<options>) <hostN>(<options>)...
<export> <host1>(<options>) <hostN>(<options>)...- single host — Where one particular host is specified with a fully qualified domain name, hostname, or IP address.
- wildcards — Where a
*or?character is used to take into account a grouping of fully qualified domain names that match a particular string of letters. Wildcards should not be used with IP addresses; however, it is possible for them to work accidentally if reverse DNS lookups fail.Be careful when using wildcards with fully qualified domain names, as they tend to be more exact than expected. For example, the use of*.example.comas a wildcard allows sales.example.com to access an exported file system, but not bob.sales.example.com. To match both possibilities both*.example.comand*.*.example.commust be specified. - IP networks — Allows the matching of hosts based on their IP addresses within a larger network. For example,
192.168.0.0/28allows the first 16 IP addresses, from 192.168.0.0 to 192.168.0.15, to access the exported file system, but not 192.168.0.16 and higher. - netgroups — Permits an NIS netgroup name, written as
@<group-name>, to be used. This effectively puts the NIS server in charge of access control for this exported file system, where users can be added and removed from an NIS group without affecting/etc/exports.
/etc/exports file only specifies the exported directory and the hosts permitted to access it, as in the following example:
/exported/directory bob.example.com
/exported/directory bob.example.combob.example.com can mount /exported/directory/. Because no options are specified in this example, the following default NFS options take effect:
ro— Mounts of the exported file system are read-only. Remote hosts are not able to make changes to the data shared on the file system. To allow hosts to make changes to the file system, the read/write (rw) option must be specified.wdelay— Causes the NFS server to delay writing to the disk if it suspects another write request is imminent. This can improve performance by reducing the number of times the disk must be accessed by separate write commands, reducing write overhead. Theno_wdelayoption turns off this feature, but is only available when using thesyncoption.root_squash— Prevents root users connected remotely from having root privileges and assigns them the user ID for the usernfsnobody. This effectively "squashes" the power of the remote root user to the lowest local user, preventing unauthorized alteration of files on the remote server. Alternatively, theno_root_squashoption turns off root squashing. To squash every remote user, including root, use theall_squashoption. To specify the user and group IDs to use with remote users from a particular host, use theanonuidandanongidoptions, respectively. In this case, a special user account can be created for remote NFS users to share and specify(anonuid=<uid-value>,anongid=<gid-value>), where<uid-value>is the user ID number and<gid-value>is the group ID number.
Important
no_acl option when exporting the file system.
rw option is not specified, then the exported file system is shared as read-only. The following is a sample line from /etc/exports which overrides two default options:
/another/exported/directory 192.168.0.3(rw,sync)
/another/exported/directory 192.168.0.3(rw,sync)192.168.0.3 can mount /another/exported/directory/ read/write and all transfers to disk are committed to the disk before the write request by the client is completed.
exports man page for details on these lesser used options.
Warning
/etc/exports file is very precise, particularly in regards to use of the space character. Remember to always separate exported file systems from hosts and hosts from one another with a space character. However, there should be no other space characters in the file except on comment lines.
/home bob.example.com(rw) /home bob.example.com (rw)
/home bob.example.com(rw)
/home bob.example.com (rw)bob.example.com read/write access to the /home directory. The second line allows users from bob.example.com to mount the directory as read-only (the default), while the rest of the world can mount it read/write.
21.7.1. The exportfs Command
/etc/exports file. When the nfs service starts, the /usr/sbin/exportfs command launches and reads this file, passes control to rpc.mountd (if NFSv2 or NFSv3) for the actual mounting process, then to rpc.nfsd where the file systems are then available to remote users.
/usr/sbin/exportfs command allows the root user to selectively export or unexport directories without restarting the NFS service. When given the proper options, the /usr/sbin/exportfs command writes the exported file systems to /var/lib/nfs/xtab. Since rpc.mountd refers to the xtab file when deciding access privileges to a file system, changes to the list of exported file systems take effect immediately.
/usr/sbin/exportfs:
-r— Causes all directories listed in/etc/exportsto be exported by constructing a new export list in/etc/lib/nfs/xtab. This option effectively refreshes the export list with any changes that have been made to/etc/exports.-a— Causes all directories to be exported or unexported, depending on what other options are passed to/usr/sbin/exportfs. If no other options are specified,/usr/sbin/exportfsexports all file systems specified in/etc/exports.-o file-systems— Specifies directories to be exported that are not listed in/etc/exports. Replace file-systems with additional file systems to be exported. These file systems must be formatted in the same way they are specified in/etc/exports. Refer to Section 21.7, “The/etc/exportsConfiguration File” for more information on/etc/exportssyntax. This option is often used to test an exported file system before adding it permanently to the list of file systems to be exported.-i— Ignores/etc/exports; only options given from the command line are used to define exported file systems.-u— Unexports all shared directories. The command/usr/sbin/exportfs -uasuspends NFS file sharing while keeping all NFS daemons up. To re-enable NFS sharing, typeexportfs -r.-v— Verbose operation, where the file systems being exported or unexported are displayed in greater detail when theexportfscommand is executed.
/usr/sbin/exportfs command, it displays a list of currently exported file systems.
/usr/sbin/exportfs command, refer to the exportfs man page.
21.7.1.1. Using exportfs with NFSv4
exportfs command is used in maintaining the NFS table of exported file systems. When typed in a terminal with no arguments, the exportfs command shows all the exported directories.
MOUNT protocol, which was used with the NFSv2 and NFSv3 protocols, the mounting of file systems has changed.
fsid=0 option.
--bind option which creates unbreakable links.
/home /home/sam /home/john /home/joe
/home
/home/sam
/home/john
/home/joe/home *(rw,fsid=0,sync)
/home *(rw,fsid=0,sync)mount server:/home /mnt/home ls /mnt/home/joe
mount server:/home /mnt/home
ls /mnt/home/joemount -t nfs4 server:/ /mnt/home ls /mnt/home/joe
mount -t nfs4 server:/ /mnt/home
ls /mnt/home/joeserver:/home" and "server:/". To make the exports configurations compatible for all version, one needs to export (read only) the root filesystem with an fsid=0. The fsid=0 signals the NFS server that this export is the root.
/ *(ro,fsid=0) /home *(rw,sync,nohide)
/ *(ro,fsid=0)
/home *(rw,sync,nohide)mount server:/home /mnt/home" and "mount -t nfs server:/home /mnt/home" will work as expected.
21.8. Securing NFS
21.8.1. Host Access
21.8.1.1. Using NFSv2 or NFSv3
portmap service via TCP wrappers. Access to ports used by portmap, rpc.mountd, and rpc.nfsd can also be limited by creating firewall rules with iptables.
portmap, refer to Section 48.9, “IPTables”.
21.8.1.2. Using NFSv4
Note
Important
rpc.svcgssd and rpc.gssd inter operate, refer to http://www.citi.umich.edu/projects/nfsv4/gssd/.
21.8.2. File Permissions
su - command to become a user who could access particular files via the NFS share.
nfsnobody account. Never turn off root squashing.
all_squash option, which makes every user accessing the exported file system take the user ID of the nfsnobody user.
21.9. NFS and portmap
Note
portmap service for backward compatibility.
portmapper maps RPC services to the ports they are listening on. RPC processes notify portmap when they start, registering the ports they are listening on and the RPC program numbers they expect to serve. The client system then contacts portmap on the server with a particular RPC program number. The portmap service redirects the client to the proper port number so it can communicate with the requested service.
portmap to make all connections with incoming client requests, portmap must be available before any of these services start.
portmap service uses TCP wrappers for access control, and access control rules for portmap affect all RPC-based services. Alternatively, it is possible to specify access control rules for each of the NFS RPC daemons. The man pages for rpc.mountd and rpc.statd contain information regarding the precise syntax for these rules.
21.9.1. Troubleshooting NFS and portmap
portmap provides coordination between RPC services and the port numbers used to communicate with them, it is useful to view the status of current RPC services using portmap when troubleshooting. The rpcinfo command shows each RPC-based service with port numbers, an RPC program number, a version number, and an IP protocol type (TCP or UDP).
portmap, issue the following command as root:
rpcinfo -p
rpcinfo -pportmap is unable to map RPC requests from clients for that service to the correct port. In many cases, if NFS is not present in rpcinfo output, restarting NFS causes the service to correctly register with portmap and begin working. For instructions on starting NFS, refer to Section 21.5, “Starting and Stopping NFS”.
rpcinfo command. Refer to the rpcinfo man page for more information.
21.10. Using NFS over TCP
- Improved connection durability, thus less
NFS stale file handlesmessages. - Performance gain on heavily loaded networks because TCP acknowledges every packet, unlike UDP which only acknowledges completion.
- TCP has better congestion control than UDP. On a very congested network, UDP packets are the first packets that are dropped. This means that if NFS is writing data (in 8K chunks) all of that 8K must be retransmitted over UDP. Because of TCP's reliability, only parts of that 8K data are transmitted at a time.
- Error detection. When a TCP connection breaks (due to the server being unavailable) the client stops sending data and restarts the connection process once the server becomes available. With UDP, since it's connection-less, the client continues to pound the network with data until the server reestablishes a connection.
21.11. Additional Resources
21.11.1. Installed Documentation
/usr/share/doc/nfs-utils-<version-number>/— Replace <version-number> with the version number of the NFS package installed. This directory contains a wealth of information about the NFS implementation for Linux, including a look at various NFS configurations and their impact on file transfer performance.man mount— Contains a comprehensive look at mount options for both NFS server and client configurations.man fstab— Gives details for the format of the/etc/fstabfile used to mount file systems at boot-time.man nfs— Provides details on NFS-specific file system export and mount options.man exports— Shows common options used in the/etc/exportsfile when exporting NFS file systems.
21.11.2. Useful Websites
- http://nfs.sourceforge.net/ — The home of the Linux NFS project and a great place for project status updates.
- http://www.citi.umich.edu/projects/nfsv4/linux/ — An NFSv4 for Linux 2.6 kernel resource.
- http://www.nfsv4.org — The home of NFS version 4 and all related standards.
- http://www.vanemery.com/Linux/NFSv4/NFSv4-no-rpcsec.html — Describes the details of NFSv4 with Fedora Core 2, which includes the 2.6 kernel.
- http://www.sane.nl/events/sane2000/papers/pawlowski.pdf — An excellent whitepaper on the features and enhancements of the NFS Version 4 protocol.
- http://wiki.autofs.net — The Autofs wiki, discussions, documentation and enhancements.
Chapter 22. Samba
22.1. Introduction to Samba
- The ability to join an Active Directory domain by means of LDAP and Kerberos
- Built in Unicode support for internationalization
- Support for Microsoft Windows XP Professional client connections to Samba servers without needing local registry hacking
- Two new documents developed by the Samba.org team, which include a 400+ page reference manual, and a 300+ page implementation and integration manual. For more information about these published titles, refer to Section 22.12.2, “Related Books”.
22.1.1. Samba Features
- Serve directory trees and printers to Linux, UNIX, and Windows clients
- Assist in network browsing (with or without NetBIOS)
- Authenticate Windows domain logins
- Provide Windows Internet Name Service (WINS) name server resolution
- Act as a Windows NT®-style Primary Domain Controller (PDC)
- Act as a Backup Domain Controller (BDC) for a Samba-based PDC
- Act as an Active Directory domain member server
- Join a Windows NT/2000/2003 PDC
- Act as a BDC for a Windows PDC (and vice versa)
- Act as an Active Directory domain controller
22.2. Samba Daemons and Related Services
22.2.1. Samba Daemons
smbd, nmbd, and winbindd). Two services (smb and windbind) control how the daemons are started, stopped, and other service-related features. Each daemon is listed in detail, as well as which specific service has control over it.
smbd
The smbd server daemon provides file sharing and printing services to Windows clients. In addition, it is responsible for user authentication, resource locking, and data sharing through the SMB protocol. The default ports on which the server listens for SMB traffic are TCP ports 139 and 445.
smbd daemon is controlled by the smb service.
nmbd
The nmbd server daemon understands and replies to NetBIOS name service requests such as those produced by SMB/CIFS in Windows-based systems. These systems include Windows 95/98/ME, Windows NT, Windows 2000, Windows XP, and LanManager clients. It also participates in the browsing protocols that make up the Windows Network Neighborhood view. The default port that the server listens to for NMB traffic is UDP port 137.
nmbd daemon is controlled by the smb service.
winbindd
The winbind service resolves user and group information on a server running Windows NT 2000 or Windows Server 2003. This makes Windows user / group information understandable by UNIX platforms. This is achieved by using Microsoft RPC calls, Pluggable Authentication Modules (PAM), and the Name Service Switch (NSS). This allows Windows NT domain users to appear and operate as UNIX users on a UNIX machine. Though bundled with the Samba distribution, the winbind service is controlled separately from the smb service.
winbindd daemon is controlled by the winbind service and does not require the smb service to be started in order to operate. Winbindd is also used when Samba is an Active Directory member, and may also be used on a Samba domain controller (to implement nested groups and/or interdomain trust). Because winbind is a client-side service used to connect to Windows NT-based servers, further discussion of winbind is beyond the scope of this manual.
Note
22.3. Connecting to a Samba Share
smb: in the File > Open Location bar of Nautilus to view the workgroups.
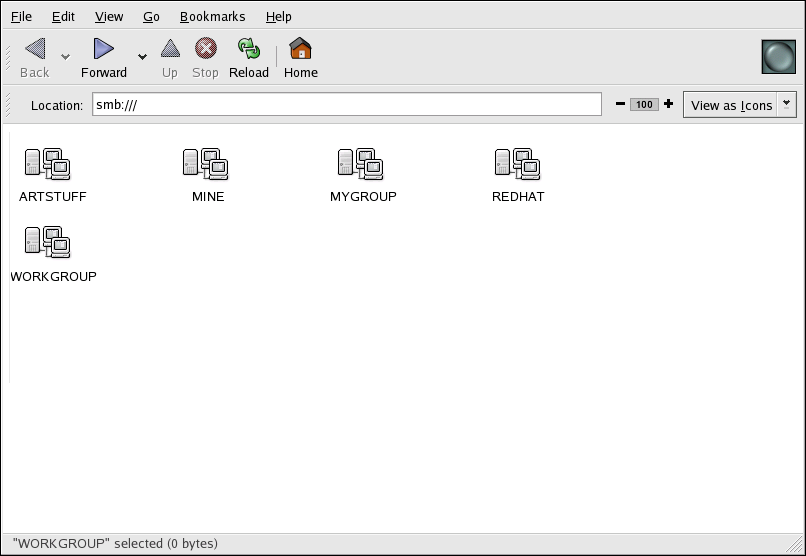
Figure 22.1. SMB Workgroups in Nautilus
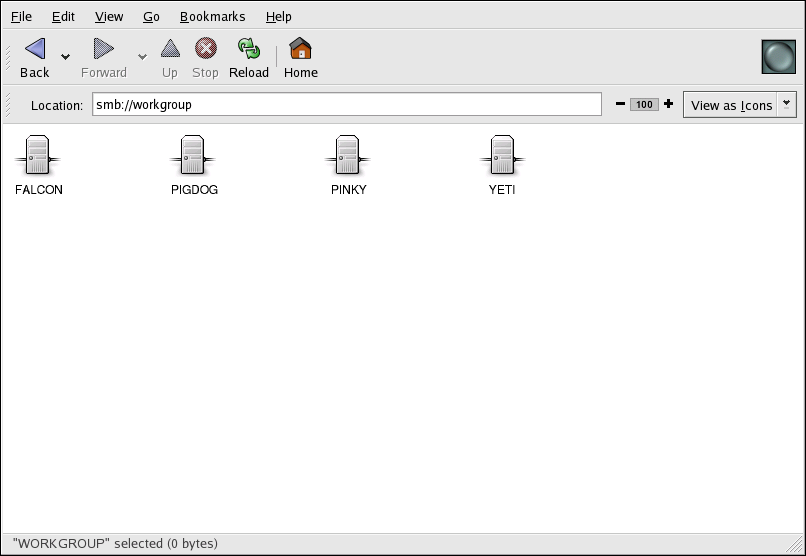
Figure 22.2. SMB Machines in Nautilus
smb://<servername>/<sharename>
smb://<servername>/<sharename>22.3.2. Mounting the Share
mount -t cifs -o <username>,<password> //<servername>/<sharename> /mnt/point/
mount -t cifs -o <username>,<password> //<servername>/<sharename> /mnt/point/man mount.cifs.
22.4. Configuring a Samba Server
/etc/samba/smb.conf) allows users to view their home directories as a Samba share. It also shares all printers configured for the system as Samba shared printers. In other words, you can attach a printer to the system and print to it from the Windows machines on your network.
22.4.1. Graphical Configuration
/etc/samba/ directory. Any changes to these files not made using the application are preserved.
system-config-samba RPM package installed. To start the Samba Server Configuration Tool from the desktop, go to the (on the Panel) > > > or type the command system-config-samba at a shell prompt (for example, in an XTerm or a GNOME terminal).
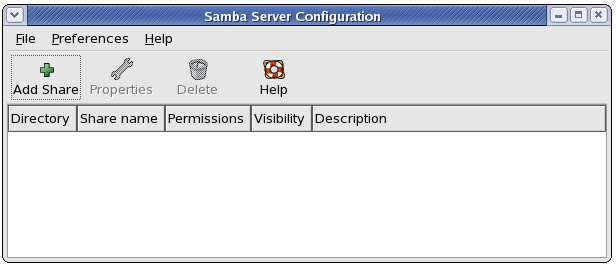
Figure 22.3. Samba Server Configuration Tool
Note
22.4.1.1. Configuring Server Settings
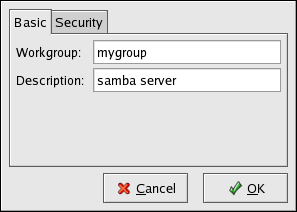
Figure 22.4. Configuring Basic Server Settings
workgroup and server string options in smb.conf.
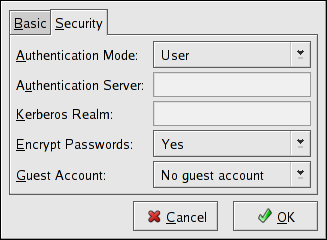
Figure 22.5. Configuring Security Server Settings
- Authentication Mode — This corresponds to the
securityoption. Select one of the following types of authentication.- ADS — The Samba server acts as a domain member in an Active Directory Domain (ADS) realm. For this option, Kerberos must be installed and configured on the server, and Samba must become a member of the ADS realm using the
netutility, which is part of thesamba-clientpackage. Refer to thenetman page for details. This option does not configure Samba to be an ADS Controller. Specify the realm of the Kerberos server in the Kerberos Realm field.Note
The Kerberos Realm field must be supplied in all uppercase letters, such asEXAMPLE.COM.Using a Samba server as a domain member in an ADS realm assumes proper configuration of Kerberos, including the/etc/krb5.conffile. - Domain — The Samba server relies on a Windows NT Primary or Backup Domain Controller to verify the user. The server passes the username and password to the Controller and waits for it to return. Specify the NetBIOS name of the Primary or Backup Domain Controller in the Authentication Server field.The Encrypted Passwords option must be set to Yes if this is selected.
- Server — The Samba server tries to verify the username and password combination by passing them to another Samba server. If it can not, the server tries to verify using the user authentication mode. Specify the NetBIOS name of the other Samba server in the Authentication Server field.
- Share — Samba users do not have to enter a username and password combination on a per Samba server basis. They are not prompted for a username and password until they try to connect to a specific shared directory from a Samba server.
- User — (Default) Samba users must provide a valid username and password on a per Samba server basis. Select this option if you want the Windows Username option to work. Refer to Section 22.4.1.2, “Managing Samba Users” for details.
- Encrypt Passwords — This option must be enabled if the clients are connecting from a system with Windows 98, Windows NT 4.0 with Service Pack 3, or other more recent versions of Microsoft Windows. The passwords are transferred between the server and the client in an encrypted format instead of as a plain-text word that can be intercepted. This corresponds to the
encrypted passwordsoption. Refer to Section 22.4.3, “Encrypted Passwords” for more information about encrypted Samba passwords. - Guest Account — When users or guest users log into a Samba server, they must be mapped to a valid user on the server. Select one of the existing usernames on the system to be the guest Samba account. When guests log in to the Samba server, they have the same privileges as this user. This corresponds to the
guest accountoption.
22.4.1.2. Managing Samba Users
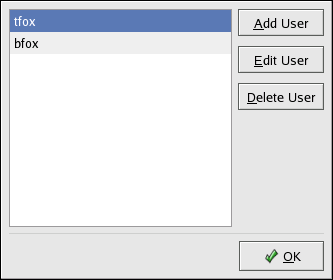
Figure 22.6. Managing Samba Users
22.4.1.3. Adding a Share
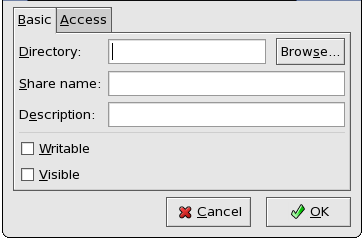
Figure 22.7. Adding a Share
- Directory — The directory to share via Samba. The directory must exist before it can be entered here.
- Share name — The actual name of the share that is seen from remote machines. By default, it is the same value as Directory, but can be configured.
- Descriptions — A brief description of the share.
- Writable — Enables users to read and write to the shared directory
- Visible — Grants read-only rights to users for the shared directory.
22.4.2. Command Line Configuration
/etc/samba/smb.conf as its configuration file. If you change this configuration file, the changes do not take effect until you restart the Samba daemon with the command service smb restart.
smb.conf file:
workgroup = WORKGROUPNAME server string = BRIEF COMMENT ABOUT SERVER
workgroup = WORKGROUPNAME
server string = BRIEF COMMENT ABOUT SERVERsmb.conf file (after modifying it to reflect your needs and your system):
tfox and carole to read and write to the directory /home/share, on the Samba server, from a Samba client.
22.4.3. Encrypted Passwords
smbpasswd -a <username> .
22.5. Starting and Stopping Samba
service smb start
service smb startImportant
net join command before starting the smb service.
service smb stop
service smb stoprestart option is a quick way of stopping and then starting Samba. This is the most reliable way to make configuration changes take effect after editing the configuration file for Samba. Note that the restart option starts the daemon even if it was not running originally.
service smb restart
service smb restartcondrestart (conditional restart) option only starts smb on the condition that it is currently running. This option is useful for scripts, because it does not start the daemon if it is not running.
Note
smb.conf file is changed, Samba automatically reloads it after a few minutes. Issuing a manual restart or reload is just as effective.
service smb condrestart
service smb condrestartsmb.conf file can be useful in case of a failed automatic reload by the smb service. To ensure that the Samba server configuration file is reloaded without restarting the service, type the following command as root:
service smb reload
service smb reloadsmb service does not start automatically at boot time. To configure Samba to start at boot time, use an initscript utility, such as /sbin/chkconfig, /usr/sbin/ntsysv, or the Services Configuration Tool program. Refer to Chapter 18, Controlling Access to Services for more information regarding these tools.
22.6. Samba Server Types and the smb.conf File
/etc/samba/smb.conf configuration file. Although the default smb.conf file is well documented, it does not address complex topics such as LDAP, Active Directory, and the numerous domain controller implementations.
smb.conf file for a successful configuration.
22.6.1. Stand-alone Server
22.6.1.1. Anonymous Read-Only
smb.conf file shows a sample configuration needed to implement anonymous read-only file sharing. The security = share parameter makes a share anonymous. Note, security levels for a single Samba server cannot be mixed. The security directive is a global Samba parameter located in the [global] configuration section of the smb.conf file.
22.6.1.2. Anonymous Read/Write
smb.conf file shows a sample configuration needed to implement anonymous read/write file sharing. To enable anonymous read/write file sharing, set the read only directive to no. The force user and force group directives are also added to enforce the ownership of any newly placed files specified in the share.
Note
force user) and group (force group) in the smb.conf file.
22.6.1.3. Anonymous Print Server
smb.conf file shows a sample configuration needed to implement an anonymous print server. Setting browseable to no as shown does not list the printer in Windows Network Neighborhood. Although hidden from browsing, configuring the printer explicitly is possible. By connecting to DOCS_SRV using NetBIOS, the client can have access to the printer if the client is also part of the DOCS workgroup. It is also assumed that the client has the correct local printer driver installed, as the use client driver directive is set to Yes. In this case, the Samba server has no responsibility for sharing printer drivers to the client.
22.6.1.4. Secure Read/Write File and Print Server
smb.conf file shows a sample configuration needed to implement a secure read/write print server. Setting the security directive to user forces Samba to authenticate client connections. Notice the [homes] share does not have a force user or force group directive as the [public] share does. The [homes] share uses the authenticated user details for any files created as opposed to the force user and force group in [public].
22.6.2. Domain Member Server
22.6.2.1. Active Directory Domain Member Server
smb.conf file shows a sample configuration needed to implement an Active Directory domain member server. In this example, Samba authenticates users for services being run locally but is also a client of the Active Directory. Ensure that your kerberos realm parameter is shown in all caps (for example realm = EXAMPLE.COM). Since Windows 2000/2003 requires Kerberos for Active Directory authentication, the realm directive is required. If Active Directory and Kerberos are running on different servers, the password server directive may be required to help the distinction.
- Configuration of the
smb.conffile on the member server - Configuration of Kerberos, including the
/etc/krb5.conffile, on the member server - Creation of the machine account on the Active Directory domain server
- Association of the member server to the Active Directory domain
kinit administrator@EXAMPLE.COM
kinit administrator@EXAMPLE.COMkinit command is a Kerberos initialization script that references the Active Directory administrator account and Kerberos realm. Since Active Directory requires Kerberos tickets, kinit obtains and caches a Kerberos ticket-granting ticket for client/server authentication. For more information on Kerberos, the /etc/krb5.conf file, and the kinit command, refer to Section 48.6, “Kerberos”.
net ads join -S windows1.example.com -U administrator%password
net ads join -S windows1.example.com -U administrator%passwordwindows1 was automatically found in the corresponding Kerberos realm (the kinit command succeeded), the net command connects to the Active Directory server using its required administrator account and password. This creates the appropriate machine account on the Active Directory and grants permissions to the Samba domain member server to join the domain.
Note
security = ads and not security = user is used, a local password backend such as smbpasswd is not needed. Older clients that do not support security = ads are authenticated as if security = domain had been set. This change does not affect functionality and allows local users not previously in the domain.
22.6.2.2. Windows NT4-based Domain Member Server
smb.conf file shows a sample configuration needed to implement a Windows NT4-based domain member server. Becoming a member server of an NT4-based domain is similar to connecting to an Active Directory. The main difference is NT4-based domains do not use Kerberos in their authentication method, making the smb.conf file simpler. In this instance, the Samba member server functions as a pass through to the NT4-based domain server.
smb.conf file to convert the server to a Samba-based PDC. If Windows NT-based servers are upgraded to Windows 2000/2003, the smb.conf file is easily modifiable to incorporate the infrastructure change to Active Directory if needed.
Important
smb.conf file, join the domain before starting Samba by typing the following command as root:
net rpc join -U administrator%password
net rpc join -U administrator%password-S option, which specifies the domain server hostname, does not need to be stated in the net rpc join command. Samba uses the hostname specified by the workgroup directive in the smb.conf file instead of it being stated explicitly.
22.6.3. Domain Controller
Important
22.6.3.1. Primary Domain Controller (PDC) using tdbsam
tdbsam password database backend. Planned to replace the aging smbpasswd backend, tdbsam has numerous improvements that are explained in more detail in Section 22.8, “Samba Account Information Databases”. The passdb backend directive controls which backend is to be used for the PDC.
tdbsam follow these steps:
- Use a configuration of the
smb.conffile as shown in the example above. - Add the root user to the Samba password database.
smbpasswd -a root Provide the password here.
smbpasswd -a root Provide the password here.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Start the
smbservice. - Make sure all profile, user, and netlogon directories are created.
- Add groups that users can be members of.
groupadd -f users groupadd -f nobody groupadd -f ntadmins
groupadd -f users groupadd -f nobody groupadd -f ntadminsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Associate the UNIX groups with their respective Windows groups.
net groupmap add ntgroup="Domain Users" unixgroup=users net groupmap add ntgroup="Domain Guests" unixgroup=nobody net groupmap add ntgroup="Domain Admins" unixgroup=ntadmins
net groupmap add ntgroup="Domain Users" unixgroup=users net groupmap add ntgroup="Domain Guests" unixgroup=nobody net groupmap add ntgroup="Domain Admins" unixgroup=ntadminsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Grant access rights to a user or a group. For example, to grant the right to add client machines to the domain on a Samba domain controller, to the members to the Domain Admins group, execute the following command:
net rpc rights grant 'DOCS\Domain Admins' SetMachineAccountPrivilege -S PDC -U root
net rpc rights grant 'DOCS\Domain Admins' SetMachineAccountPrivilege -S PDC -U rootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Note
tdbsam authentication backend. LDAP is recommended in these cases.
22.6.3.2. Primary Domain Controller (PDC) with Active Directory
22.7. Samba Security Modes
22.7.1. User-Level Security
security = user directive is not listed in the smb.conf file, it is used by Samba. If the server accepts the client's username/password, the client can then mount multiple shares without specifying a password for each instance. Samba can also accept session-based username/password requests. The client maintains multiple authentication contexts by using a unique UID for each logon.
smb.conf, the security = user directive that sets user-level security is:
[GLOBAL] ... security = user ...
[GLOBAL]
...
security = user
...22.7.1.1. Domain Security Mode (User-Level Security)
smb.conf:
[GLOBAL] ... security = domain workgroup = MARKETING ...
[GLOBAL]
...
security = domain
workgroup = MARKETING
...22.7.1.2. Active Directory Security Mode (User-Level Security)
smb.conf, the following directives make Samba an Active Directory member server:
22.7.1.3. Server Security Mode (User-Level Security)
Note
smb.conf, the following directives enable Samba to operate in server security mode:
22.8. Samba Account Information Databases
- Plain Text
- Plain text backends are nothing more than the
/etc/passwdtype backends. With a plain text backend, all usernames and passwords are sent unencrypted between the client and the Samba server. This method is very unsecure and is not recommended for use by any means. It is possible that different Windows clients connecting to the Samba server with plain text passwords cannot support such an authentication method. -
smbpasswd - A popular backend used in previous Samba packages, the
smbpasswdbackend utilizes a plain ASCII text layout that includes the MS Windows LanMan and NT account, and encrypted password information. Thesmbpasswdbackend lacks the storage of the Windows NT/2000/2003 SAM extended controls. Thesmbpasswdbackend is not recommended because it does not scale well or hold any Windows information, such as RIDs for NT-based groups. Thetdbsambackend solves these issues for use in a smaller database (250 users), but is still not an enterprise-class solution. -
ldapsam_compat - The
ldapsam_compatbackend allows continued OpenLDAP support for use with upgraded versions of Samba. This option normally used when migrating to Samba 3.0. -
tdbsam - The
tdbsambackend provides an ideal database backend for local servers, servers that do not need built-in database replication, and servers that do not require the scalability or complexity of LDAP. Thetdbsambackend includes all of thesmbpasswddatabase information as well as the previously-excluded SAM information. The inclusion of the extended SAM data allows Samba to implement the same account and system access controls as seen with Windows NT/2000/2003-based systems.Thetdbsambackend is recommended for 250 users at most. Larger organizations should require Active Directory or LDAP integration due to scalability and possible network infrastructure concerns. -
ldapsam - The
ldapsambackend provides an optimal distributed account installation method for Samba. LDAP is optimal because of its ability to replicate its database to any number of servers using the OpenLDAPslurpddaemon. LDAP databases are light-weight and scalable, and as such are preferred by large enterprises.If you are upgrading from a previous version of Samba to 3.0, note that the/usr/share/doc/samba-<version>/LDAP/samba.schemahas changed. This file contains the attribute syntax definitions and objectclass definitions that theldapsambackend will need in order to function properly.As such, if you are using theldapsambackend for your Samba server, you will need to configureslapdto include this schema file. Refer to Section 28.5, “The/etc/openldap/schema/Directory” for directions on how to do this.Note
You will need to have theopenldap-serverpackage installed if you want to use theldapsambackend. -
mysqlsam - The
mysqlsambackend uses a MySQL-based database backend. This is useful for sites that already implement MySQL. At present,mysqlsamis now packed in a module separate from Samba, and as such is not officially supported by Samba.
22.9. Samba Network Browsing
/etc/hosts) or DNS, must be used.
22.9.1. Domain Browsing
smb.conf for a local master browser (or no browsing at all) in a domain controller environment is the same as workgroup configuration.
22.9.2. WINS (Windows Internetworking Name Server)
smb.conf file in which the Samba server is serving as a WINS server:
[global] wins support = Yes
[global]
wins support = YesNote
22.10. Samba with CUPS Printing Support
22.10.1. Simple smb.conf Settings
smb.conf configuration for CUPS support:
print$ share contains printer drivers for clients to access if not available locally. The print$ share is optional and may not be required depending on the organization.
browseable to Yes enables the printer to be viewed in the Windows Network Neighborhood, provided the Samba server is set up correctly in the domain/workgroup.
22.11. Samba Distribution Programs
findsmb program is a Perl script which reports information about SMB-aware systems on a specific subnet. If no subnet is specified the local subnet is used. Items displayed include IP address, NetBIOS name, workgroup or domain name, operating system, and version.
findsmb as any valid user on a system:
net utility is similar to the net utility used for Windows and MS-DOS. The first argument is used to specify the protocol to use when executing a command. The <protocol> option can be ads, rap, or rpc for specifying the type of server connection. Active Directory uses ads, Win9x/NT3 uses rap, and Windows NT4/2000/2003 uses rpc. If the protocol is omitted, net automatically tries to determine it.
wakko:
wakko:
nmblookup program resolves NetBIOS names into IP addresses. The program broadcasts its query on the local subnet until the target machine replies.
nmblookup trek querying trek on 10.1.59.255 10.1.56.45 trek<00>
~]# nmblookup trek
querying trek on 10.1.59.255
10.1.56.45 trek<00>pdbedit program manages accounts located in the SAM database. All backends are supported including smbpasswd, LDAP, NIS+, and the tdb database library.
rpcclient program issues administrative commands using Microsoft RPCs, which provide access to the Windows administration graphical user interfaces (GUIs) for systems management. This is most often used by advanced users that understand the full complexity of Microsoft RPCs.
smbcacls program modifies Windows ACLs on files and directories shared by the Samba server.
smbclient program is a versatile UNIX client which provides functionality similar to ftp.
smbcontrol <options> <destination> <messagetype> <parameters>
smbcontrol program sends control messages to running smbd or nmbd daemons. Executing smbcontrol -i runs commands interactively until a blank line or a 'q' is entered.
smbpasswd program manages encrypted passwords. This program can be run by a superuser to change any user's password as well as by an ordinary user to change their own Samba password.
smbspool program is a CUPS-compatible printing interface to Samba. Although designed for use with CUPS printers, smbspool can work with non-CUPS printers as well.
smbstatus program displays the status of current connections to a Samba server.
smbtar program performs backup and restores of Windows-based share files and directories to a local tape archive. Though similar to the tar command, the two are not compatible.
testparm program checks the syntax of the smb.conf file. If your smb.conf file is in the default location (/etc/samba/smb.conf) you do not need to specify the location. Specifying the hostname and IP address to the testparm program verifies that the hosts.allow and host.deny files are configured correctly. The testparm program also displays a summary of your smb.conf file and the server's role (stand-alone, domain, etc.) after testing. This is convenient when debugging as it excludes comments and concisely presents information for experienced administrators to read.
wbinfo program displays information from the winbindd daemon. The winbindd daemon must be running for wbinfo to work.
22.12. Additional Resources
22.12.1. Installed Documentation
/usr/share/doc/samba-<version-number>/— All additional files included with the Samba distribution. This includes all helper scripts, sample configuration files, and documentation.This directory also contains online versions of The Official Samba-3 HOWTO-Collection and Samba-3 by Example, both of which are cited below.
22.12.2. Related Books
- The Official Samba-3 HOWTO-Collection by John H. Terpstra and Jelmer R. Vernooij; Prentice Hall — The official Samba-3 documentation as issued by the Samba development team. This is more of a reference guide than a step-by-step guide.
- Samba-3 by Example by John H. Terpstra; Prentice Hall — This is another official release issued by the Samba development team which discusses detailed examples of OpenLDAP, DNS, DHCP, and printing configuration files. This has step-by-step related information that helps in real-world implementations.
- Using Samba, 2nd Edition by Jay T's, Robert Eckstein, and David Collier-Brown; O'Reilly — A good resource for novice to advanced users, which includes comprehensive reference material.
22.12.3. Useful Websites
- http://www.samba.org/ — Homepage for the Samba distribution and all official documentation created by the Samba development team. Many resources are available in HTML and PDF formats, while others are only available for purchase. Although many of these links are not Red Hat Enterprise Linux specific, some concepts may apply.
- http://samba.org/samba/archives.html — Active email lists for the Samba community. Enabling digest mode is recommended due to high levels of list activity.
- Samba newsgroups — Samba threaded newsgroups, such as gmane.org, that use the NNTP protocol are also available. This an alternative to receiving mailing list emails.
Chapter 23. Dynamic Host Configuration Protocol (DHCP)
23.1. Why Use DHCP?
23.2. Configuring a DHCP Server
dhcp package contains an ISC DHCP server. First, install the package as the superuser:
yum install dhcp
~]# yum install dhcpdhcp package creates a file, /etc/dhcpd.conf, which is merely an empty configuration file:
~]# cat /etc/dhcpd.conf # # DHCP Server Configuration file. see /usr/share/doc/dhcp*/dhcpd.conf.sample
~]# cat /etc/dhcpd.conf
#
# DHCP Server Configuration file.
# see /usr/share/doc/dhcp*/dhcpd.conf.sample/usr/share/doc/dhcp-<version>/dhcpd.conf.sample. You should use this file to help you configure /etc/dhcpd.conf, which is explained in detail below.
/var/lib/dhcpd/dhcpd.leases to store the client lease database. Refer to Section 23.2.2, “Lease Database” for more information.
23.2.1. Configuration File
ddns-update-style ad-hoc;
ddns-update-style ad-hoc;ddns-update-style interim;
ddns-update-style interim;dhcpd.conf man page for details about the different modes.
- Parameters — State how to perform a task, whether to perform a task, or what network configuration options to send to the client.
- Declarations — Describe the topology of the network, describe the clients, provide addresses for the clients, or apply a group of parameters to a group of declarations.
Important
service dhcpd restart.
Note
omshell command provides an interactive way to connect to, query, and change the configuration of a DHCP server. By using omshell, all changes can be made while the server is running. For more information on omshell, refer to the omshell man page.
routers, subnet-mask, domain-name, domain-name-servers, and time-offset options are used for any host statements declared below it.
subnet can be declared, a subnet declaration must be included for every subnet in the network. If it is not, the DHCP server fails to start.
range declared. Clients are assigned an IP address within the range.
Example 23.1. Subnet Declaration
shared-network declaration as shown in Example 23.2, “Shared-network Declaration”. Parameters within the shared-network, but outside the enclosed subnet declarations, are considered to be global parameters. The name of the shared-network must be a descriptive title for the network, such as using the title 'test-lab' to describe all the subnets in a test lab environment.
group declaration is used to apply global parameters to a group of declarations. For example, shared networks, subnets, and hosts can be grouped.
Example 23.3. Group Declaration
range 192.168.1.10 and 192.168.1.100 to client systems.
Example 23.4. Range Parameter
hardware ethernet parameter within a host declaration. As demonstrated in Example 23.5, “Static IP Address using DHCP”, the host apex declaration specifies that the network interface card with the MAC address 00:A0:78:8E:9E:AA always receives the IP address 192.168.1.4.
host-name can also be used to assign a host name to the client.
Example 23.5. Static IP Address using DHCP
host apex {
option host-name "apex.example.com";
hardware ethernet 00:A0:78:8E:9E:AA;
fixed-address 192.168.1.4;
}
host apex {
option host-name "apex.example.com";
hardware ethernet 00:A0:78:8E:9E:AA;
fixed-address 192.168.1.4;
}Note
cp /usr/share/doc/dhcp-<version-number>/dhcpd.conf.sample /etc/dhcpd.conf
cp /usr/share/doc/dhcp-<version-number>/dhcpd.conf.sample /etc/dhcpd.confdhcp-options man page.
23.2.2. Lease Database
/var/lib/dhcpd/dhcpd.leases stores the DHCP client lease database. Do not change this file. DHCP lease information for each recently assigned IP address is automatically stored in the lease database. The information includes the length of the lease, to whom the IP address has been assigned, the start and end dates for the lease, and the MAC address of the network interface card that was used to retrieve the lease.
dhcpd.leases file is renamed dhcpd.leases~ and the temporary lease database is written to dhcpd.leases.
dhcpd.leases file does not exist, but it is required to start the service. Do not create a new lease file. If you do, all old leases are lost which causes many problems. The correct solution is to rename the dhcpd.leases~ backup file to dhcpd.leases and then start the daemon.
23.2.3. Starting and Stopping the Server
Important
dhcpd.leases file exists. Use the command touch /var/lib/dhcpd/dhcpd.leases to create the file if it does not exist.
named service automatically checks for a dhcpd.leases file.
/sbin/service dhcpd start. To stop the DHCP server, use the command /sbin/service dhcpd stop.
/etc/sysconfig/dhcpd, add the name of the interface to the list of DHCPDARGS:
# Command line options here DHCPDARGS=eth0
# Command line options here
DHCPDARGS=eth0/etc/sysconfig/dhcpd include:
-p <portnum>— Specifies the UDP port number on whichdhcpdshould listen. The default is port 67. The DHCP server transmits responses to the DHCP clients at a port number one greater than the UDP port specified. For example, if the default port 67 is used, the server listens on port 67 for requests and responses to the client on port 68. If a port is specified here and the DHCP relay agent is used, the same port on which the DHCP relay agent should listen must be specified. Refer to Section 23.2.4, “DHCP Relay Agent” for details.-f— Runs the daemon as a foreground process. This is mostly used for debugging.-d— Logs the DHCP server daemon to the standard error descriptor. This is mostly used for debugging. If this is not specified, the log is written to/var/log/messages.-cf <filename>— Specifies the location of the configuration file. The default location is/etc/dhcpd.conf.-lf <filename>— Specifies the location of the lease database file. If a lease database file already exists, it is very important that the same file be used every time the DHCP server is started. It is strongly recommended that this option only be used for debugging purposes on non-production machines. The default location is/var/lib/dhcpd/dhcpd.leases.-q— Do not print the entire copyright message when starting the daemon.
23.2.4. DHCP Relay Agent
dhcrelay) allows for the relay of DHCP and BOOTP requests from a subnet with no DHCP server on it to one or more DHCP servers on other subnets.
/etc/sysconfig/dhcrelay with the INTERFACES directive.
service dhcrelay start.
23.3. Configuring a DHCP Client
/etc/sysconfig/network file to enable networking and the configuration file for each network device in the /etc/sysconfig/network-scripts directory. In this directory, each device should have a configuration file named ifcfg-eth0, where eth0 is the network device name.
/etc/sysconfig/network file should contain the following line:
NETWORKING=yes
NETWORKING=yesNETWORKING variable must be set to yes if you want networking to start at boot time.
/etc/sysconfig/network-scripts/ifcfg-eth0 file should contain the following lines:
DEVICE=eth0 BOOTPROTO=dhcp ONBOOT=yes
DEVICE=eth0
BOOTPROTO=dhcp
ONBOOT=yesDHCP_HOSTNAME— Only use this option if the DHCP server requires the client to specify a hostname before receiving an IP address. (The DHCP server daemon in Red Hat Enterprise Linux does not support this feature.)PEERDNS=<answer>, where<answer>is one of the following:yes— Modify/etc/resolv.confwith information from the server. If using DHCP, thenyesis the default.no— Do not modify/etc/resolv.conf.
SRCADDR=<address>, where<address>is the specified source IP address for outgoing packets.USERCTL=<answer>, where<answer>is one of the following:yes— Non-root users are allowed to control this device.no— Non-root users are not allowed to control this device.
Note
dhclient and dhclient.conf man pages.
23.4. Configuring a Multihomed DHCP Server
/etc/sysconfig/dhcpd and /etc/dhcpd.conf files.
/etc/sysconfig/dhcpd file to specify which network interfaces the DHCP daemon listens on. The following /etc/sysconfig/dhcpd example specifies that the DHCP daemon listens on the eth0 and eth1 interfaces:
DHCPDARGS="eth0 eth1";
DHCPDARGS="eth0 eth1";eth0, eth1, and eth2 -- and it is only desired that the DHCP daemon listens on eth0, then only specify eth0 in /etc/sysconfig/dhcpd:
DHCPDARGS="eth0";
DHCPDARGS="eth0";/etc/dhcpd.conf file, for a server that has two network interfaces, eth0 in a 10.0.0.0/24 network, and eth1 in a 172.16.0.0/24 network. Multiple subnet declarations allow different settings to be defined for multiple networks:
-
subnet 10.0.0.0 netmask 255.255.255.0 - A
subnetdeclaration is required for every network your DHCP server is serving. Multiple subnets require multiplesubnetdeclarations. If the DHCP server does not have a network interface in a range of asubnetdeclaration, the DHCP server does not serve that network.If there is only onesubnetdeclaration, and no network interfaces are in the range of that subnet, the DHCP daemon fails to start, and an error such as the following is logged to/var/log/messages:Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
option subnet-mask 255.255.255.0; - The
option subnet-maskoption defines a subnet mask, and overrides thenetmaskvalue in thesubnetdeclaration. In simple cases, the subnet and netmask values are the same. -
option routers 10.0.0.1; - The
option routersoption defines the default gateway for the subnet. This is required for systems to reach internal networks on a different subnet, as well as external networks. -
range 10.0.0.5 10.0.0.15; - The
rangeoption specifies the pool of available IP addresses. Systems are assigned an address from the range of specified IP addresses.
dhcpd.conf(5) man page.
Warning
/etc/dhcpd.conf, the DHCP daemon fails to start.
23.4.1. Host Configuration
/etc/sysconfig/dhcpd and /etc/dhcpd.conf files.
The following /etc/dhcpd.conf example creates two subnets, and configures an IP address for the same system, depending on which network it connects to:
-
host example0 - The
hostdeclaration defines specific parameters for a single system, such as an IP address. To configure specific parameters for multiple hosts, use multiplehostdeclarations.Most DHCP clients ignore the name inhostdeclarations, and as such, this name can anything, as long as it is unique to otherhostdeclarations. To configure the same system for multiple networks, use a different name for eachhostdeclaration, otherwise the DHCP daemon fails to start. Systems are identified by thehardware ethernetoption, not the name in thehostdeclaration. -
hardware ethernet 00:1A:6B:6A:2E:0B; - The
hardware ethernetoption identifies the system. To find this address, run theifconfigcommand on the desired system, and look for theHWaddraddress. -
fixed-address 10.0.0.20; - The
fixed-addressoption assigns a valid IP address to the system specified by thehardware ethernetoption. This address must be outside the IP address pool specified with therangeoption.
option statements do not end with a semicolon, the DHCP daemon fails to start, and an error such as the following is logged to /var/log/messages:
The following host declarations configure a single system, that has multiple network interfaces, so that each interface receives the same IP address. This configuration will not work if both network interfaces are connected to the same network at the same time:
interface0 is the first network interface, and interface1 is the second interface. The different hardware ethernet options identify each interface.
host declarations, remembering to:
- assign a valid
fixed-addressfor the network the host is connecting to. - make the name in the
hostdeclaration unique.
host declaration is not unique, the DHCP daemon fails to start, and an error such as the following is logged to /var/log/messages:
dhcpd: /etc/dhcpd.conf line 31: host interface0: already exists dhcpd: } dhcpd: ^ dhcpd: Configuration file errors encountered -- exiting
dhcpd: /etc/dhcpd.conf line 31: host interface0: already exists
dhcpd: }
dhcpd: ^
dhcpd: Configuration file errors encountered -- exitinghost interface0 declarations defined in /etc/dhcpd.conf.
23.5. Additional Resources
23.5.1. Installed Documentation
dhcpdman page — Describes how the DHCP daemon works.dhcpd.confman page — Explains how to configure the DHCP configuration file; includes some examples.dhcpd.leasesman page — Explains how to configure the DHCP leases file; includes some examples.dhcp-optionsman page — Explains the syntax for declaring DHCP options indhcpd.conf; includes some examples.dhcrelayman page — Explains the DHCP Relay Agent and its configuration options./usr/share/doc/dhcp-<version>/— Contains sample files, README files, and release notes for current versions of the DHCP service.
Chapter 24. Migrating from MySQL 5.0 to MySQL 5.5
Note
24.1. Upgrading from MySQL 5.0 to MySQL 5.5
my.cnf configuration files to prevent specific resources from conflicting.
- Using the mysqldump and mysql utilities — the dump and restore upgrade generates an entirely new dump of all databases from one database. Next, the MySQL command line interface is run with the dump file as an input (alternatively, use the mysqlimport utility or the
LOAD DATA INFILESQL command) within the other database. Appropriate daemons have to be running during both dumping and restoring. Use the--all-databasesoption when executing the mysqldump command to include all databases in the resulting dump. The--routines,--triggers, and--events(valid only for MySQL 5.1 and above) options can be used if needed.Example 24.1, “Dump and Restore Upgrade” shows the specific commands used to upgrade using the dump and restore method. - In-place upgrade — consists of copying data files from one database directory to another database directory while both MySQL daemons are stopped. Appropriate permissions and SELinux context must be set for the copied files. The in-place upgrade is usually faster and easier for large databases, but there are some risks and known problems. For more information, refer to the release notes for MySQL 5.1 and MySQL 5.5, linked to at the beginning of this chapter.Example 24.2, “In-place Upgrade” shows the specific commands used to perform an in-place upgrade.
mysql_upgrade command. Running the mysql_upgrade is necessary to check and repair internal tables. Note that all scripts that interact with a MySQL server from a Software Collection, especially the mysql_upgrade script, should be run inside an scl enable environment.
Note
mysql_upgrade command, you may encounter the following errors:
You can't use locks with log tables.
You can't use locks with log tables.
my.cnf configuration file to reflect the new environment.
Example 24.1. Dump and Restore Upgrade
Example 24.2. In-place Upgrade
Chapter 25. Apache HTTP Server
/etc/httpd/conf/httpd.conf) to aid those who require a custom configuration or need to convert a configuration file from the older Apache HTTP Server 1.3 format.
Warning
25.1. Apache HTTP Server 2.2
25.1.1. Features of Apache HTTP Server 2.2
- Improved caching modules (mod_cache, mod_disk_cache, mod_mem_cache).
- A new structure for authentication and authorization support, replacing the authentication modules provided in previous versions.
- Support for proxy load balancing (mod_proxy_balancer)
- support for handling large files (namely, greater than 2GB) on 32-bit platforms
- The mod_cern_meta and mod_asis modules are no longer loaded by default.
- The mod_ext_filter module is now loaded by default.
25.2. Migrating Apache HTTP Server Configuration Files
25.2.1. Migrating Apache HTTP Server 2.0 Configuration Files
- Configuration files and startup scripts from version 2.0 need minor adjustments particularly in module names which may have changed. Third party modules which worked in version 2.0 can also work in version 2.2 but need to be recompiled before you load them. Key modules that need to be noted are authentication and authorization modules. For each of the modules which has been renamed the
LoadModuleline will need to be updated. - The
mod_userdirmodule will only act on requests if you provide aUserDirdirective indicating a directory name. If you wish to maintain the procedures used in version 2.0, add the directiveUserDir public_htmlin your configuration file. - To enable SSL, edit the
httpd.conffile adding the necessarymod_ssldirectives. Useapachectl startasapachectl startsslis unavailable in version 2.2. You can view an example of SSL configuration for httpd inconf/extra/httpd-ssl.conf. - To test your configuration it is advisable to use
service httpd configtestwhich will detect configuration errors.
Important
SSL and using only TLSv1.1 or TLSv1.2. Backwards compatibility can be achieved using TLSv1.0. Many products Red Hat supports have the ability to use SSLv2 or SSLv3 protocols, or enable them by default. However, the use of SSLv2 or SSLv3 is now strongly recommended against.
25.2.2. Migrating Apache HTTP Server 1.3 Configuration Files to 2.0
/etc/httpd/conf/httpd.conf.rpmnew and the original version 1.3 httpd.conf is left untouched. It is entirely up to you whether to use the new configuration file and migrate the old settings to it, or use the existing file as a base and modify it to suit; however, some parts of the file have changed more than others and a mixed approach is generally the best. The stock configuration files for both version 1.3 and 2.0 are divided into three sections.
/etc/httpd/conf/httpd.conf file is a modified version of the newly installed default and a saved a copy of the original configuration file is available, it may be easiest to invoke the diff command, as in the following example (logged in as root):
diff -u httpd.conf.orig httpd.conf | less
diff -u httpd.conf.orig httpd.conf | lessrpm2cpio and cpio commands, as in the following example:
rpm2cpio apache-<version-number>.i386.rpm | cpio -i --make
rpm2cpio apache-<version-number>.i386.rpm | cpio -i --makeapache package.
apachectl configtest
apachectl configtest25.2.2.1. Global Environment Configuration
25.2.2.1.1. Interface and Port Binding
BindAddress and Port directives no longer exist; their functionality is now provided by a more flexible Listen directive.
Port 80 was set in the 1.3 version configuration file, change it to Listen 80 in the 2.0 configuration file. If Port was set to some value other than 80, then append the port number to the contents of the ServerName directive.
Port 123 ServerName www.example.com
Port 123
ServerName www.example.comListen 123 ServerName www.example.com:123
Listen 123
ServerName www.example.com:12325.2.2.1.2. Server-Pool Size Regulation
prefork, worker, and perchild. Currently only the prefork and worker MPMs are available, although the perchild MPM may be available at a later date.
prefork MPM. The prefork MPM accepts the same directives as Apache HTTP Server 1.3, so the following directives may be migrated directly:
StartServersMinSpareServersMaxSpareServersMaxClientsMaxRequestsPerChild
worker MPM implements a multi-process, multi-threaded server providing greater scalability. When using this MPM, requests are handled by threads, conserving system resources and allowing large numbers of requests to be served efficiently. Although some of the directives accepted by the worker MPM are the same as those accepted by the prefork MPM, the values for those directives should not be transferred directly from an Apache HTTP Server 1.3 installation. It is best to instead use the default values as a guide, then experiment to determine what values work best.
Important
worker MPM, create the file /etc/sysconfig/httpd and add the following directive:
HTTPD=/usr/sbin/httpd.worker
HTTPD=/usr/sbin/httpd.worker25.2.2.1.3. Dynamic Shared Object (DSO) Support
- The
AddModuleandClearModuleListdirectives no longer exist. These directives where used to ensure that modules could be enabled in the correct order. The Apache HTTP Server 2.0 API allows modules to specify their ordering, eliminating the need for these two directives. - The order of the
LoadModulelines are no longer relevant in most cases. - Many modules have been added, removed, renamed, split up, or incorporated into others.
LoadModulelines for modules packaged in their own RPMs (mod_ssl,php,mod_perl, and the like) are no longer necessary as they can be found in their relevant files within the/etc/httpd/conf.d/directory.- The various
HAVE_XXXdefinitions are no longer defined.
Important
httpd.conf contains the following directive:
Include conf.d/*.conf
Include conf.d/*.confmod_perl, php, and mod_ssl).
25.2.2.1.4. Other Global Environment Changes
ServerType— The Apache HTTP Server can only be run asServerType standalonemaking this directive irrelevant.AccessConfigandResourceConfig— These directives have been removed as they mirror the functionality of theIncludedirective. If theAccessConfigandResourceConfigdirectives are set, replace them withIncludedirectives.To ensure that the files are read in the order implied by the older directives, theIncludedirectives should be placed at the end of thehttpd.conf, with the one corresponding toResourceConfigpreceding the one corresponding toAccessConfig. If using the default values, include them explicitly asconf/srm.confandconf/access.conffiles.
25.2.2.2. Main Server Configuration
<VirtualHost> container. Values here also provide defaults for any <VirtualHost> containers defined.
25.2.2.2.1. UserDir Mapping
UserDir directive is used to enable URLs such as http://example.com/~bob/ to map to a subdirectory within the home directory of the user bob, such as /home/bob/public_html/. A side-effect of this feature allows a potential attacker to determine whether a given username is present on the system. For this reason, the default configuration for Apache HTTP Server 2.0 disables this directive.
UserDir mapping, change the directive in httpd.conf from:
UserDir disable
UserDir disableUserDir public_html
UserDir public_html25.2.2.2.2. Logging
AgentLogRefererLogRefererIgnore
CustomLog and LogFormat directives.
25.2.2.2.3. Directory Indexing
FancyIndexing directive has now been removed. The same functionality is available through the FancyIndexing option within the IndexOptions directive.
VersionSort option to the IndexOptions directive causes files containing version numbers to be sorted in a more natural way. For example, httpd-2.0.6.tar appears before httpd-2.0.36.tar in a directory index page.
ReadmeName and HeaderName directives have changed from README and HEADER to README.html and HEADER.html.
25.2.2.2.4. Content Negotiation
CacheNegotiatedDocs directive now takes the argument on or off. Existing instances of CacheNegotiatedDocs should be replaced with CacheNegotiatedDocs on.
25.2.2.2.5. Error Documents
ErrorDocument directive, the message should be enclosed in a pair of double quotation marks ", rather than just preceded by a double quotation mark as required in Apache HTTP Server 1.3.
ErrorDocument 404 "The document was not found
ErrorDocument 404 "The document was not foundErrorDocument setting to Apache HTTP Server 2.0, use the following structure:
ErrorDocument 404 "The document was not found"
ErrorDocument 404 "The document was not found"ErrorDocument directive example.
25.2.2.3. Virtual Host Configuration
<VirtualHost> containers should be migrated in the same way as the main server section as described in Section 25.2.2.2, “Main Server Configuration”.
Important
/etc/httpd/conf.d/ssl.conf.
25.2.2.4. Modules and Apache HTTP Server 2.0
mod_include. This opens up a tremendous number of possibilities with regards to how modules can be combined to achieve a specific goal.
mod_perl). Under Apache HTTP Server 2.0, the request is initially handled by the core module — which serves static files — and is then filtered by mod_perl.
PATH_INFO directive is used for a document which is handled by a module that is now implemented as a filter, as each contains trailing path information after the true file name. The core module, which initially handles the request, does not by default understand PATH_INFO and returns 404 Not Found errors for requests that contain such information. As an alternative, use the AcceptPathInfo directive to coerce the core module into accepting requests with PATH_INFO.
AcceptPathInfo on
AcceptPathInfo on25.2.2.4.1. The suexec Module
mod_suexec module uses the SuexecUserGroup directive, rather than the User and Group directives, which is used for configuring virtual hosts. The User and Group directives can still be used in general, but are deprecated for configuring virtual hosts.
<VirtualHost vhost.example.com:80> User someone Group somegroup </VirtualHost>
<VirtualHost vhost.example.com:80>
User someone
Group somegroup
</VirtualHost><VirtualHost vhost.example.com:80> SuexecUserGroup someone somegroup </VirtualHost>
<VirtualHost vhost.example.com:80>
SuexecUserGroup someone somegroup
</VirtualHost>25.2.2.4.2. The mod_ssl Module
mod_ssl has been moved from the httpd.conf file into the /etc/httpd/conf.d/ssl.conf file. For this file to be loaded, and for mod_ssl to work, the statement Include conf.d/*.conf must be in the httpd.conf file as described in Section 25.2.2.1.3, “Dynamic Shared Object (DSO) Support”.
ServerName directives in SSL virtual hosts must explicitly specify the port number.
<VirtualHost _default_:443> # General setup for the virtual host ServerName ssl.example.name ... </VirtualHost>
<VirtualHost _default_:443>
# General setup for the virtual host
ServerName ssl.example.name
...
</VirtualHost><VirtualHost _default_:443> # General setup for the virtual host ServerName ssl.host.name:443 ... </VirtualHost>
<VirtualHost _default_:443>
# General setup for the virtual host
ServerName ssl.host.name:443
...
</VirtualHost>SSLLog and SSLLogLevel directives have been removed. The mod_ssl module now obeys the ErrorLog and LogLevel directives. Refer to ErrorLog and LogLevel for more information about these directives.
Important
SSL and using only TLSv1.1 or TLSv1.2. Backwards compatibility can be achieved using TLSv1.0. Many products Red Hat supports have the ability to use SSLv2 or SSLv3 protocols, or enable them by default. However, the use of SSLv2 or SSLv3 is now strongly recommended against.
25.2.2.4.3. The mod_proxy Module
<Proxy> block rather than a <Directory proxy:>.
mod_proxy has been split out into the following three modules:
mod_cachemod_disk_cachemod_mem_cache
mod_proxy module, but it is advisable to verify each directive before migrating any cache settings.
25.2.2.4.4. The mod_include Module
mod_include module is now implemented as a filter and is therefore enabled differently. Refer to Section 25.2.2.4, “Modules and Apache HTTP Server 2.0” for more about filters.
AddType text/html .shtml AddHandler server-parsed .shtml
AddType text/html .shtml
AddHandler server-parsed .shtmlAddType text/html .shtml AddOutputFilter INCLUDES .shtml
AddType text/html .shtml
AddOutputFilter INCLUDES .shtmlOptions +Includes directive is still required for the <Directory> container or in a .htaccess file.
25.2.2.4.5. The mod_auth_dbm and mod_auth_db Modules
mod_auth_db and mod_auth_dbm, which used Berkeley Databases and DBM databases respectively. These modules have been combined into a single module named mod_auth_dbm in Apache HTTP Server 2.0, which can access several different database formats. To migrate from mod_auth_db, configuration files should be adjusted by replacing AuthDBUserFile and AuthDBGroupFile with the mod_auth_dbm equivalents, AuthDBMUserFile and AuthDBMGroupFile. Also, the directive AuthDBMType DB must be added to indicate the type of database file in use.
mod_auth_db configuration for Apache HTTP Server 1.3:
AuthDBMUserFile directive can also be used in .htaccess files.
dbmmanage Perl script, used to manipulate username and password databases, has been replaced by htdbm in Apache HTTP Server 2.0. The htdbm program offers equivalent functionality and, like mod_auth_dbm, can operate a variety of database formats; the -T option can be used on the command line to specify the format to use.
dbmmanage to htdbm” shows how to migrate from a DBM-format database to htdbm format using dbmmanage.
| Action | dbmmanage command (1.3) | Equivalent htdbm command (2.0) |
|---|---|---|
| Add user to database (using given password) | dbmmanage authdb add username password | htdbm -b -TDB authdb username password |
| Add user to database (prompts for password) | dbmmanage authdb adduser username | htdbm -TDB authdb username |
| Remove user from database | dbmmanage authdb delete username | htdbm -x -TDB authdb username |
| List users in database | dbmmanage authdb view | htdbm -l -TDB authdb |
| Verify a password | dbmmanage authdb check username | htdbm -v -TDB authdb username |
-m and -s options work with both dbmmanage and htdbm, enabling the use of the MD5 or SHA1 algorithms for hashing passwords, respectively.
htdbm, the -c option must be used.
25.2.2.4.6. The mod_perl Module
mod_perl has been moved from httpd.conf into the file /etc/httpd/conf.d/perl.conf. For this file to be loaded, and hence for mod_perl to work, the statement Include conf.d/*.conf must be included in httpd.conf as described in Section 25.2.2.1.3, “Dynamic Shared Object (DSO) Support”.
Apache:: in httpd.conf must be replaced with ModPerl::. Additionally, the manner in which handlers are registered has been changed.
mod_perl configuration:
<Directory /var/www/perl> SetHandler perl-script PerlHandler Apache::Registry Options +ExecCGI </Directory>
<Directory /var/www/perl>
SetHandler perl-script
PerlHandler Apache::Registry
Options +ExecCGI
</Directory>mod_perl for Apache HTTP Server 2.0:
<Directory /var/www/perl> SetHandler perl-script PerlResponseHandler ModPerl::Registry Options +ExecCGI </Directory>
<Directory /var/www/perl>
SetHandler perl-script
PerlResponseHandler ModPerl::Registry
Options +ExecCGI
</Directory>mod_perl 1.x should work without modification with mod_perl 2.x. XS modules require recompilation and may require minor Makefile modifications.
25.2.2.4.7. The mod_python Module
mod_python has moved from httpd.conf to the /etc/httpd/conf.d/python.conf file. For this file to be loaded, and hence for mod_python to work, the statement Include conf.d/*.conf must be in httpd.conf as described in Section 25.2.2.1.3, “Dynamic Shared Object (DSO) Support”.
25.2.2.4.8. PHP
httpd.conf into the file /etc/httpd/conf.d/php.conf. For this file to be loaded, the statement Include conf.d/*.conf must be in httpd.conf as described in Section 25.2.2.1.3, “Dynamic Shared Object (DSO) Support”.
Note
register_globals to On in the file /etc/php.ini.
25.2.2.4.9. The mod_authz_ldap Module
mod_authz_ldap module for the Apache HTTP Server. This module uses the short form of the distinguished name for a subject and the issuer of the client SSL certificate to determine the distinguished name of the user within an LDAP directory. It is also capable of authorizing users based on attributes of that user's LDAP directory entry, determining access to assets based on the user and group privileges of the asset, and denying access for users with expired passwords. The mod_ssl module is required when using the mod_authz_ldap module.
Important
mod_authz_ldap module does not authenticate a user to an LDAP directory using an encrypted password hash. This functionality is provided by the experimental mod_auth_ldap module. Refer to the mod_auth_ldap module documentation online at http://httpd.apache.org/docs-2.0/mod/mod_auth_ldap.html for details on the status of this module.
/etc/httpd/conf.d/authz_ldap.conf file configures the mod_authz_ldap module.
/usr/share/doc/mod_authz_ldap-<version>/index.html (replacing <version> with the version number of the package) or http://authzldap.othello.ch/ for more information on configuring the mod_authz_ldap third party module.
25.3. Starting and Stopping httpd
httpd package, review the Apache HTTP Server's documentation available online at http://httpd.apache.org/docs/2.2/.
httpd RPM installs the /etc/init.d/httpd script, which can be accessed using the /sbin/service command.
httpd using the apachectl control script sets the environmental variables in /etc/sysconfig/httpd and starts httpd. You can also set the environment variables using the init script.
apachectl control script as root type:
apachectl start
apachectl starthttpd using /sbin/service httpd start. This starts httpd but does not set the environment variables. If you are using the default Listen directive in httpd.conf, which is port 80, you will need to have root privileges to start the apache server.
apachectl stop
apachectl stophttpd using /sbin/service httpd stop. The restart option is a shorthand way of stopping and then starting the Apache HTTP Server.
apachectl restart
apachectl restartservice httpd restart
service httpd restartErrorLog if it encounters an error while starting.
httpd service does not start automatically at boot time. If you would wish to have Apache startup at boot time, you will need to add a call to apachectl in your startup files within the rc.N directory. A typical file used is rc.local. As this starts Apache as root, it is recommended to properly configure your security and authentication before adding this call.
httpd service to start up at boot time, using an initscript utility, such as /sbin/chkconfig, /usr/sbin/ntsysv, or the Services Configuration Tool program.
apachectl status
apachectl statusmod_status however needs to be enabled in your httpd.conf configuration file for this to work. For more details on mod_status can be found on http://httpd.apache.org/docs/2.2/mod/mod_status.html.
Note
25.4. Apache HTTP Server Configuration
/etc/httpd/conf/httpd.conf configuration file for the Apache HTTP Server. It does not use the old srm.conf or access.conf configuration files; leave them empty. Through the graphical interface, you can configure directives such as virtual hosts, logging attributes, and maximum number of connections. To start the HTTD Configuration Tool, click on System > Administration > Server Settings > HTTP.
Warning
/etc/httpd/conf/httpd.conf configuration file by hand if you wish to use this tool. The HTTP Configuration Tool generates this file after you save your changes and exit the program. If you want to add additional modules or configuration options that are not available in HTTP Configuration Tool, you cannot use this tool.
- Configure the basic settings under the Main tab.
- Click on the Virtual Hosts tab and configure the default settings.
- Under the Virtual Hosts tab, configure the Default Virtual Host.
- To serve more than one URL or virtual host, add any additional virtual hosts.
- Configure the server settings under the Server tab.
- Configure the connections settings under the Performance Tuning tab.
- Copy all necessary files to the
DocumentRootandcgi-bindirectories. - Exit the application and select to save your settings.
25.4.1. Basic Settings
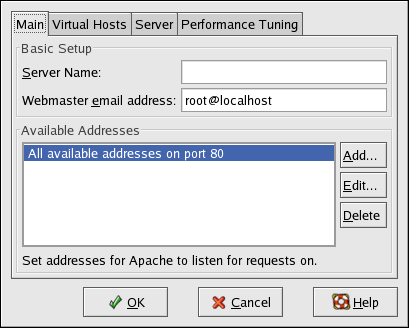
Figure 25.1. Basic Settings
ServerName directive in httpd.conf. The ServerName directive sets the hostname of the Web server. It is used when creating redirection URLs. If you do not define a server name, the Web server attempts to resolve it from the IP address of the system. The server name does not have to be the domain name resolved from the IP address of the server. For example, you might set the server name to www.example.com while the server's real DNS name is foo.example.com.
ServerAdmin directive in httpd.conf. If you configure the server's error pages to contain an email address, this email address is used so that users can report a problem to the server's administrator. The default value is root@localhost.
Listen directive in httpd.conf. By default, Red Hat configures the Apache HTTP Server to listen to port 80 for non-secure Web communications.
Note
httpd can be started as a regular user.
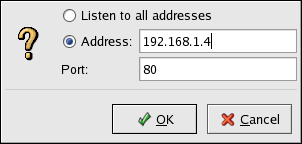
Figure 25.2. Available Addresses
25.4.2. Default Settings
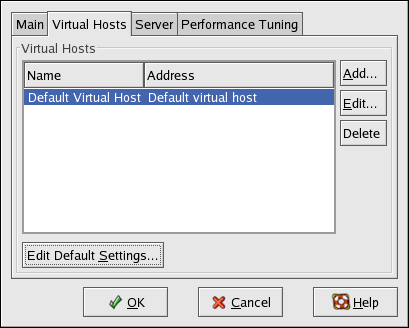
Figure 25.3. Virtual Hosts Tab
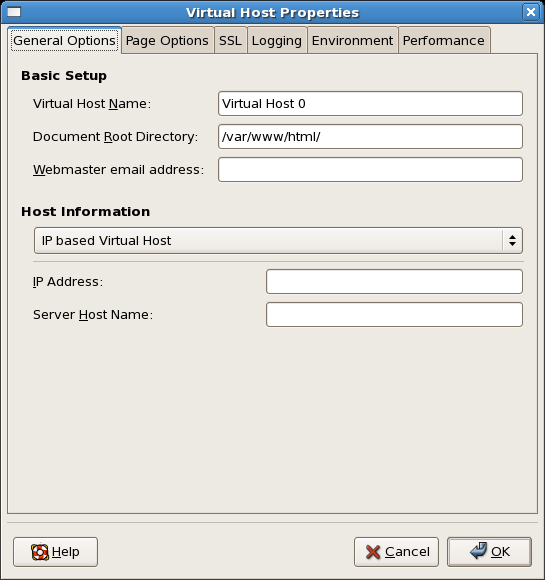
Figure 25.4. General Options
25.4.2.1. Site Configuration
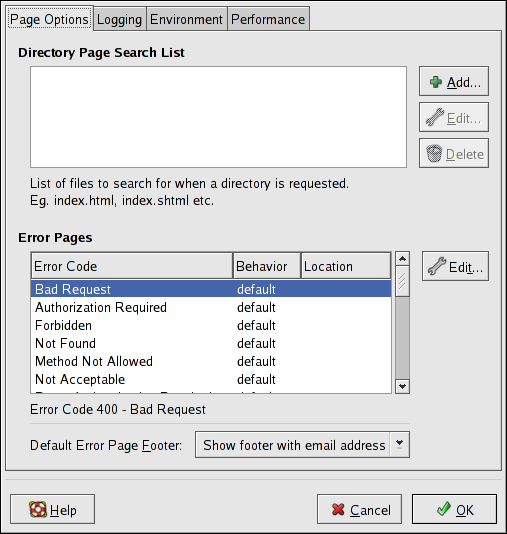
Figure 25.5. Site Configuration
DirectoryIndex directive. The DirectoryIndex is the default page served by the server when a user requests an index of a directory by specifying a forward slash (/) at the end of the directory name.
http://www.example.com/this_directory/, they are going to get either the DirectoryIndex page, if it exists, or a server-generated directory list. The server tries to find one of the files listed in the DirectoryIndex directive and returns the first one it finds. If it does not find any of these files and if Options Indexes is set for that directory, the server generates and returns a list, in HTML format, of the subdirectories and files in the directory.
ErrorDocument directive. If a problem or error occurs when a client tries to connect to the Apache HTTP Server, the default action is to display the short error message shown in the Error Code column. To override this default configuration, select the error code and click the Edit button. Choose to display the default short error message. Choose to redirect the client to an external URL and enter a complete URL, including the http://, in the Location field. Choose to redirect the client to an internal URL and enter a file location under the document root for the Web server. The location must begin the a slash (/) and be relative to the Document Root.
404.html, copy 404.html to DocumentRoot/../error/404.html. In this case, DocumentRoot is the Document Root directory that you have defined (the default is /var/www/html/). If the Document Root is left as the default location, the file should be copied to /var/www/error/404.html. Then, choose as the Behavior for 404 - Not Found error code and enter /error/404.html as the .
- Show footer with email address — Display the default footer at the bottom of all error pages along with the email address of the website maintainer specified by the
ServerAdmindirective. - Show footer — Display just the default footer at the bottom of error pages.
- No footer — Do not display a footer at the bottom of error pages.
25.4.2.2. SSL Support
mod_ssl enables encryption of the HTTP protocol over SSL. SSL (Secure Sockets Layer) protocol is used for communication and encryption over TCP/IP networks. The SSL tab enables you to configure SSL for your server. To configure SSL you need to provide the path to your:
- Certificate file - equivalent to using the
SSLCertificateFiledirective which points the path to the PEM (Privacy Enhanced Mail)-encoded server certificate file. - Key file - equivalent to using the
SSLCertificateKeyFiledirective which points the path to the PEM-encoded server private key file. - Certificate chain file - equivalent to using the
SSLCertificateChainFiledirective which points the path to the certificate file containing all the server's chain of certificates. - Certificate authority file - is an encrypted file used to confirm the authenticity or identity of parties communicating with the server.
SSLOptions with the following options:
- FakeBasicAuth - enables standard authentication methods used by Apache. This means that the Client X509 certificate's Subject Distinguished Name (DN) is translated into a basic HTTP username.
- ExportCertData - creates CGI environment variables in
SSL_SERVER_CERT,SSL_CLIENT_CERTandSSL_CLIENT_CERT_CHAIN_nwhere n is a number 0,1,2,3,4... These files are used for more certificate checks by CGI scripts. - CompatEnvVars - enables backward compatibility for Apache SSL by adding CGI environment variables.
- StrictRequire - enables strict access which forces denial of access whenever the
SSLRequireSSLandSSLRequiredirectives indicate access is forbidden. - OptRenegotiate - enables avoidance of unnecessary handshakes by
mod_sslwhich also performs safe parameter checks. It is recommended to enable OptRenegotiate on a per directory basis.
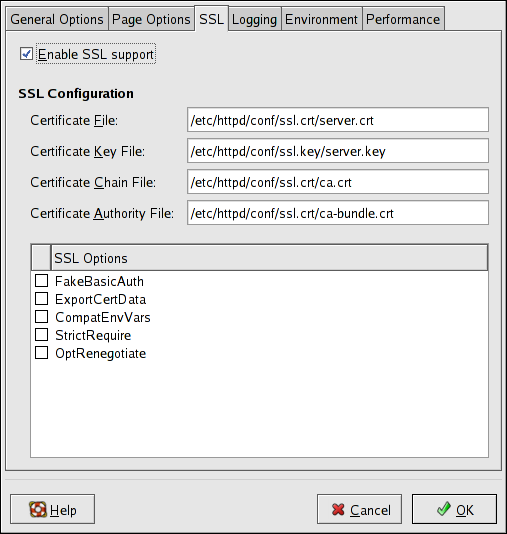
Figure 25.6. SSL
Important
SSL and using only TLSv1.1 or TLSv1.2. Backwards compatibility can be achieved using TLSv1.0. Many products Red Hat supports have the ability to use SSLv2 or SSLv3 protocols, or enable them by default. However, the use of SSLv2 or SSLv3 is now strongly recommended against.
25.4.2.3. Logging
/var/log/httpd/access_log file and the error log to the /var/log/httpd/error_log file.
TransferLog directive.
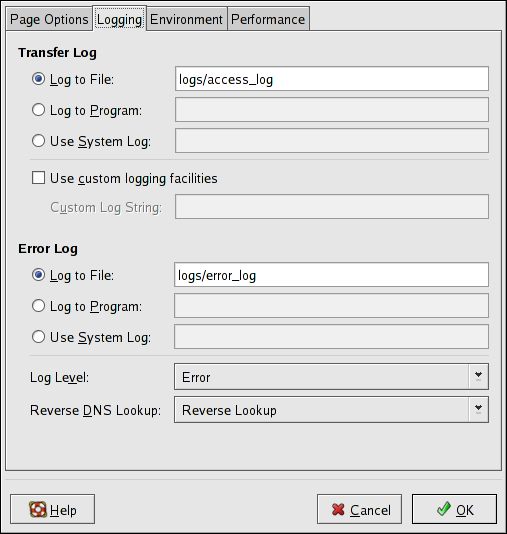
Figure 25.7. Logging
LogFormat directive. Refer to http://httpd.apache.org/docs/2.2/mod/mod_log_config.html#logformat for details on the format of this directive.
ErrorLog directive.
LogLevel directive.
HostnameLookups directive. Choosing No Reverse Lookup sets the value to off. Choosing Reverse Lookup sets the value to on. Choosing Double Reverse Lookup sets the value to double.
25.4.2.4. Environment Variables
mod_env module to configure the environment variables which are passed to CGI scripts and SSI pages. Use the Environment Variables page to configure the directives for this module.
MAXNUM to 50, click the button inside the Set for CGI Script section, as shown in Figure 25.8, “Environment Variables”, and type MAXNUM in the Environment Variable text field and 50 in the Value to set text field. Click to add it to the list. The Set for CGI Scripts section configures the SetEnv directive.
env at a shell prompt. Click the button inside the Pass to CGI Scripts section and enter the name of the environment variable in the resulting dialog box. Click to add it to the list. The Pass to CGI Scripts section configures the PassEnv directive.
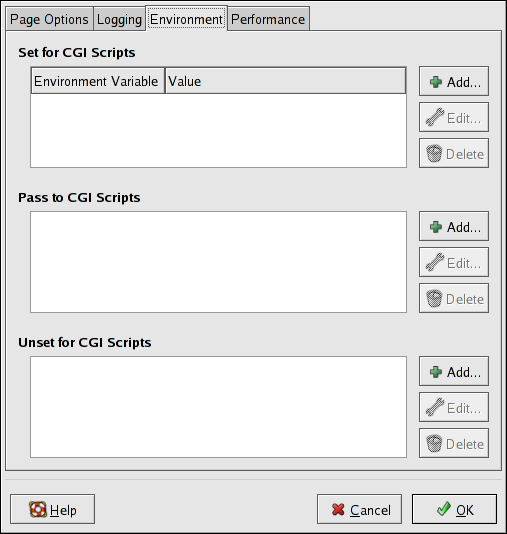
Figure 25.8. Environment Variables
UnsetEnv directive.
25.4.2.5. Directories
<Directory> directive.
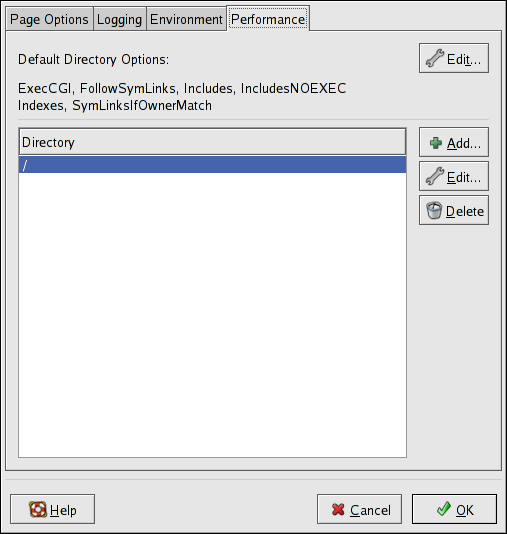
Figure 25.9. Directories
Options directive within the <Directory> directive. You can configure the following options:
- ExecCGI — Allow execution of CGI scripts. CGI scripts are not executed if this option is not chosen.
- FollowSymLinks — Allow symbolic links to be followed.
- Includes — Allow server-side includes.
- IncludesNOEXEC — Allow server-side includes, but disable the
#execand#includecommands in CGI scripts. - Indexes — Display a formatted list of the directory's contents, if no
DirectoryIndex(such asindex.html) exists in the requested directory. - Multiview — Support content-negotiated multiviews; this option is disabled by default.
- SymLinksIfOwnerMatch — Only follow symbolic links if the target file or directory has the same owner as the link.
Order directive with the left-hand side options. The Order directive controls the order in which allow and deny directives are evaluated. In the Allow hosts from and Deny hosts from text field, you can specify one of the following:
- Allow all hosts — Type
allto allow access to all hosts. - Partial domain name — Allow all hosts whose names match or end with the specified string.
- Full IP address — Allow access to a specific IP address.
- A subnet — Such as
192.168.1.0/255.255.255.0 - A network CIDR specification — such as
10.3.0.0/16
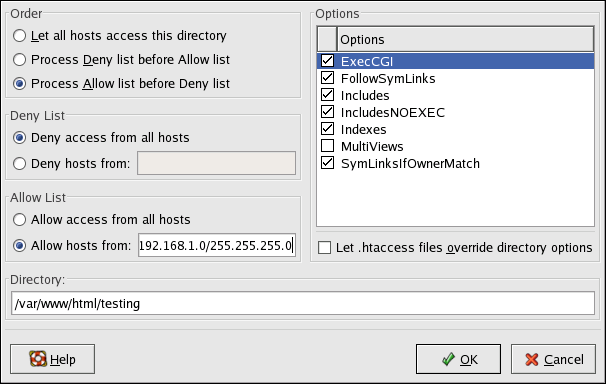
Figure 25.10. Directory Settings
.htaccess file take precedence.
25.5. Configuration Directives in httpd.conf
/etc/httpd/conf/httpd.conf. The httpd.conf file is well-commented and mostly self-explanatory. The default configuration works for most situations; however, it is a good idea to become familiar some of the more important configuration options.
Warning
25.5.1. General Configuration Tips
/etc/httpd/conf/httpd.conf and then either reload, restart, or stop and start the httpd process as outlined in Section 25.3, “Starting and Stopping httpd”.
httpd.conf, make a copy the original file. Creating a backup makes it easier to recover from mistakes made while editing the configuration file.
httpd.conf to verify there are no typos.
/var/log/httpd/error_log. The error log may not be easy to interpret, depending on your level of expertise. However, the last entries in the error log should provide useful information.
httpd.conf. These descriptions are not exhaustive. For more information, refer to the Apache documentation online at http://httpd.apache.org/docs/2.2/.
mod_ssl directives, refer to the documentation online at http://httpd.apache.org/docs/2.2/mod/mod_ssl.html.
AccessFileName names the file which the server should use for access control information in each directory. The default is .htaccess.
AccessFileName directive, a set of Files tags apply access control to any file beginning with a .ht. These directives deny Web access to any .htaccess files (or other files which begin with .ht) for security reasons.
Action specifies a MIME content type and CGI script pair, so that when a file of that media type is requested, a particular CGI script is executed.
When using FancyIndexing as an IndexOptions parameter, the AddDescription directive can be used to display user-specified descriptions for certain files or file types in a server generated directory listing. The AddDescription directive supports listing specific files, wildcard expressions, or file extensions.
AddEncoding names file name extensions which should specify a particular encoding type. AddEncoding can also be used to instruct some browsers to uncompress certain files as they are downloaded.
AddHandler maps file extensions to specific handlers. For example, the cgi-script handler can be matched with the extension .cgi to automatically treat a file ending with .cgi as a CGI script. The following is a sample AddHandler directive for the .cgi extension.
AddHandler cgi-script .cgi
AddHandler cgi-script .cgicgi-bin to function in any directory on the server which has the ExecCGI option within the directories container. Refer to Directory for more information about setting the ExecCGI option for a directory.
AddHandler directive is used to process server-parsed HTML and image-map files.
AddIcon specifies which icon to show in server generated directory listings for files with certain extensions. For example, the Web server is set to show the icon binary.gif for files with .bin or .exe extensions.
This directive names icons which are displayed by files with MIME encoding in server generated directory listings. For example, by default, the Web server shows the compressed.gif icon next to MIME encoded x-compress and x-gzip files in server generated directory listings.
This directive names icons which are displayed next to files with MIME types in server generated directory listings. For example, the server shows the icon text.gif next to files with a mime-type of text, in server generated directory listings.
AddLanguage associates file name extensions with specific languages. This directive is useful for Apache HTTP Servers which serve content in multiple languages based on the client Web browser's language settings.
Use the AddType directive to define or override a default MIME type and file extension pairs. The following example directive tells the Apache HTTP Server to recognize the .tgz file extension:
AddType application/x-tar .tgz
AddType application/x-tar .tgz
The Alias setting allows directories outside the DocumentRoot directory to be accessible. Any URL ending in the alias automatically resolves to the alias' path. By default, one alias for an icons/ directory is already set up. An icons/ directory can be accessed by the Web server, but the directory is not in the DocumentRoot.
Allow specifies which client can access a given directory. The client can be all, a domain name, an IP address, a partial IP address, a network/netmask pair, and so on. The DocumentRoot directory is configured to Allow requests from all, meaning everyone has access.
The AllowOverride directive sets whether any Options can be overridden by the declarations in an .htaccess file. By default, both the root directory and the DocumentRoot are set to allow no .htaccess overrides.
The BrowserMatch directive allows the server to define environment variables and take appropriate actions based on the User-Agent HTTP header field — which identifies the client's Web browser type. By default, the Web server uses BrowserMatch to deny connections to specific browsers with known problems and also to disable keepalives and HTTP header flushes for browsers that are known to have problems with those actions.
A number of commented cache directives are supplied by the default Apache HTTP Server configuration file. In most cases, uncommenting these lines by removing the hash mark (#) from the beginning of the line is sufficient. The following, however, is a list of some of the more important cache-related directives.
CacheEnable— Specifies whether the cache is a disk, memory, or file descriptor cache. By defaultCacheEnableconfigures a disk cache for URLs at or below/.CacheRoot— Specifies the name of the directory containing cached files. The defaultCacheRootis the/var/httpd/proxy/directory.CacheSize— Specifies how much space the cache can use in kilobytes. The defaultCacheSizeis5KB.
CacheMaxExpire— Specifies how long HTML documents are retained (without a reload from the originating Web server) in the cache. The default is24hours (86400seconds).CacheLastModifiedFactor— Specifies the creation of an expiry (expiration) date for a document which did not come from its originating server with its own expiry set. The defaultCacheLastModifiedFactoris set to0.1, meaning that the expiry date for such documents equals one-tenth of the amount of time since the document was last modified.CacheDefaultExpire— Specifies the expiry time in hours for a document that was received using a protocol that does not support expiry times. The default is set to1hour (3600seconds).NoProxy— Specifies a space-separated list of subnets, IP addresses, domains, or hosts whose content is not cached. This setting is most useful for Intranet sites.
By default, the Web server asks proxy servers not to cache any documents which were negotiated on the basis of content (that is, they may change over time or because of the input from the requester). If CacheNegotiatedDocs is set to on, this function is disabled and proxy servers are allowed to cache such documents.
CustomLog identifies the log file and the log file format. By default, the access log is recorded to the /var/log/httpd/access_log file while errors are recorded in the /var/log/httpd/error_log file.
CustomLog format is the combined log file format, as illustrated here:
remotehost rfc931 user date "request" status bytes referrer user-agent
remotehost rfc931 user date "request" status bytes referrer user-agent
DefaultIcon specifies the icon displayed in server generated directory listings for files which have no other icon specified. The unknown.gif image file is the default.
DefaultType sets a default content type for the Web server to use for documents whose MIME types cannot be determined. The default is text/plain.
Deny works similar to Allow, except it specifies who is denied access. The DocumentRoot is not configured to Deny requests from anyone by default.
<Directory /path/to/directory> and </Directory> tags create a container used to enclose a group of configuration directives which apply only to a specific directory and its subdirectories. Any directive which is applicable to a directory may be used within Directory tags.
/), using the Options (refer to Options) and AllowOverride (refer to AllowOverride) directives. Under this configuration, any directory on the system which needs more permissive settings has to be explicitly given those settings.
Directory container is configured for the DocumentRoot which assigns less rigid parameters to the directory tree so that the Apache HTTP Server can access the files residing there.
Directory container can be also be used to configure additional cgi-bin directories for server-side applications outside of the directory specified in the ScriptAlias directive (refer to ScriptAlias for more information).
Directory container must set the ExecCGI option for that directory.
/home/my_cgi_directory, add the following Directory container to the httpd.conf file:
<Directory /home/my_cgi_directory> Options +ExecCGI </Directory>
<Directory /home/my_cgi_directory>
Options +ExecCGI
</Directory>AddHandler directive must be uncommented to identify files with the .cgi extension as CGI scripts. Refer to AddHandler for instructions on setting AddHandler.
The DirectoryIndex is the default page served by the server when a user requests an index of a directory by specifying a forward slash (/) at the end of the directory name.
DirectoryIndex page, if it exists, or a server-generated directory list. The default for DirectoryIndex is index.html and the index.html.var type map. The server tries to find either of these files and returns the first one it finds. If it does not find one of these files and Options Indexes is set for that directory, the server generates and returns a listing, in HTML format, of the subdirectories and files within the directory, unless the directory listing feature is turned off.
DocumentRoot is the directory which contains most of the HTML files which are served in response to requests. The default DocumentRoot, for both the non-secure and secure Web servers, is the /var/www/html directory. For example, the server might receive a request for the following document:
http://example.com/foo.html
http://example.com/foo.html/var/www/html/foo.html
/var/www/html/foo.htmlDocumentRoot so that it is not shared by the secure and the non-secure Web servers, refer to Section 25.7, “Virtual Hosts”.
The ErrorDocument directive associates an HTTP response code with a message or a URL to be sent back to the client. By default, the Web server outputs a simple and usually cryptic error message when an error occurs. The ErrorDocument directive forces the Web server to instead output a customized message or page.
Important
".
ErrorLog specifies the file where server errors are logged. By default, this directive is set to /var/log/httpd/error_log.
The ExtendedStatus directive controls whether Apache generates basic (off) or detailed server status information (on), when the server-status handler is called. The server-status handler is called using Location tags. More information on calling server-status is included in Location.
Group is set to apache.
HeaderName names the file which, if it exists in the directory, is prepended to the start of server generated directory listings. Like ReadmeName, the server tries to include it as an HTML document if possible or in plain text if not.
HostnameLookups can be set to on, off, or double. If HostnameLookups is set to on, the server automatically resolves the IP address for each connection. Resolving the IP address means that the server makes one or more connections to a DNS server, adding processing overhead. If HostnameLookups is set to double, the server performs a double-reverse DNS look up adding even more processing overhead.
HostnameLookups is set to off by default.
The IfDefine tags surround configuration directives that are applied if the "test" stated in the IfDefine tag is true. The directives are ignored if the test is false.
IfDefine tags is a parameter name (for example, HAVE_PERL). If the parameter is defined, meaning that it is provided as an argument to the server's start-up command, then the test is true. In this case, when the Web server is started, the test is true and the directives contained in the IfDefine tags are applied.
<IfModule> and </IfModule> tags create a conditional container which are only activated if the specified module is loaded. Directives within the IfModule container are processed under one of two conditions. The directives are processed if the module contained within the starting <IfModule> tag is loaded. Or, if an exclamation point ! appears before the module name, the directives are processed only if the module specified in the <IfModule> tag is not loaded.
ServerRoot.
Important
mod_ssl, mod_perl, and php, the following directive must be included in Section 1: Global Environment of httpd.conf:
Include conf.d/*.conf
Include conf.d/*.conf
IndexIgnore lists file extensions, partial file names, wildcard expressions, or full file names. The Web server does not include any files which match any of those parameters in server generated directory listings.
IndexOptions controls the appearance of server generated directing listings, by adding icons, file descriptions, and so on. If Options Indexes is set (refer to Options), the Web server generates a directory listing when the Web server receives an HTTP request for a directory without an index.
DirectoryIndex directive (usually, index.html). If an index.html file is not found, Apache HTTP Server creates an HTML directory listing of the requested directory. The appearance of this directory listing is controlled, in part, by the IndexOptions directive.
FancyIndexing. This means that a user can re-sort a directory listing by clicking on column headers. Another click on the same header switches from ascending to descending order. FancyIndexing also shows different icons for different files, based upon file extensions.
AddDescription option, when used in conjunction with FancyIndexing, presents a short description for the file in server generated directory listings.
IndexOptions has a number of other parameters which can be set to control the appearance of server generated directories. The IconHeight and IconWidth parameters require the server to include HTML HEIGHT and WIDTH tags for the icons in server generated webpages. The IconsAreLinks parameter combines the graphical icon with the HTML link anchor, which contains the URL link target.
KeepAlive sets whether the server allows more than one request per connection and can be used to prevent any one client from consuming too much of the server's resources.
Keepalive is set to off. If Keepalive is set to on and the server becomes very busy, the server can quickly spawn the maximum number of child processes. In this situation, the server slows down significantly. If Keepalive is enabled, it is a good idea to set the KeepAliveTimeout low (refer to KeepAliveTimeout for more information about the KeepAliveTimeout directive) and monitor the /var/log/httpd/error_log log file on the server. This log reports when the server is running out of child processes.
KeepAliveTimeout sets the number of seconds the server waits after a request has been served before it closes the connection. Once the server receives a request, the Timeout directive applies instead. The KeepAliveTimeout directive is set to 15 seconds by default.
LanguagePriority sets precedence for different languages in case the client Web browser has no language preference set.
The Listen command identifies the ports on which the Web server accepts incoming requests. By default, the Apache HTTP Server is set to listen to port 80 for non-secure Web communications and (in the /etc/httpd/conf.d/ssl.conf file which defines any secure servers) to port 443 for secure Web communications.
httpd can be started as a regular user.
Listen directive can also be used to specify particular IP addresses over which the server accepts connections.
LoadModule is used to load Dynamic Shared Object (DSO) modules. More information on the Apache HTTP Server's DSO support, including instructions for using the LoadModule directive, can be found in Section 25.6, “Adding Modules”. Note, the load order of the modules is no longer important with Apache HTTP Server 2.0. Refer to Section 25.2.2.1.3, “Dynamic Shared Object (DSO) Support” for more information about Apache HTTP Server 2.0 DSO support.
The <Location> and </Location> tags create a container in which access control based on URL can be specified.
The LogFormat directive configures the format of the various Web server log files. The actual LogFormat used depends on the settings given in the CustomLog directive (refer to CustomLog).
CustomLog directive is set to combined:
%h(remote host's IP address or hostname)- Lists the remote IP address of the requesting client. If
HostnameLookupsis set toon, the client hostname is recorded unless it is not available from DNS. %l(rfc931)- Not used. A hyphen - appears in the log file for this field.
%u(authenticated user)- Lists the username of the user recorded if authentication was required. Usually, this is not used, so a hyphen - appears in the log file for this field.
%t(date)- Lists the date and time of the request.
%r(request string)- Lists the request string exactly as it came from the browser or client.
%s(status)- Lists the HTTP status code which was returned to the client host.
%b(bytes)- Lists the size of the document.
%\"%{Referer}i\"(referrer)- Lists the URL of the webpage which referred the client host to Web server.
%\"%{User-Agent}i\"(user-agent)- Lists the type of Web browser making the request.
LogLevel sets how verbose the error messages in the error logs are. LogLevel can be set (from least verbose to most verbose) to emerg, alert, crit, error, warn, notice, info, or debug. The default LogLevel is warn.
This directive sets the maximum number of requests allowed per persistent connection. The Apache Project recommends a high setting, which improves the server's performance. MaxKeepAliveRequests is set to 100 by default, which should be appropriate for most situations.
The NameVirtualHost directive associates an IP address and port number, if necessary, for any name-based virtual hosts. Name-based virtual hosting allows one Apache HTTP Server to serve different domains without using multiple IP addresses.
Note
NameVirtualHost configuration directive and add the correct IP address. Then add additional VirtualHost containers for each virtual host as is necessary for your configuration.
The Options directive controls which server features are available in a particular directory. For example, under the restrictive parameters specified for the root directory, Options is only set to the FollowSymLinks directive. No features are enabled, except that the server is allowed to follow symbolic links in the root directory.
DocumentRoot directory, Options is set to include Indexes and FollowSymLinks. Indexes permits the server to generate a directory listing for a directory if no DirectoryIndex (for example, index.html) is specified. FollowSymLinks allows the server to follow symbolic links in that directory.
Note
Options statements from the main server configuration section need to be replicated to each VirtualHost container individually. Refer to VirtualHost for more information.
The Order directive controls the order in which allow and deny directives are evaluated. The server is configured to evaluate the Allow directives before the Deny directives for the DocumentRoot directory.
PidFile names the file where the server records its process ID (PID). By default the PID is listed in /var/run/httpd.pid.
<Proxy *> and </Proxy> tags create a container which encloses a group of configuration directives meant to apply only to the proxy server. Many directives which are allowed within a <Directory> container may also be used within <Proxy> container.
To configure the Apache HTTP Server to function as a proxy server, remove the hash mark (#) from the beginning of the <IfModule mod_proxy.c> line, the ProxyRequests, and each line in the <Proxy> stanza. Set the ProxyRequests directive to On, and set which domains are allowed access to the server in the Allow from directive of the <Proxy> stanza.
ReadmeName names the file which, if it exists in the directory, is appended to the end of server generated directory listings. The Web server first tries to include the file as an HTML document and then tries to include it as plain text. By default, ReadmeName is set to README.html.
When a webpage is moved, Redirect can be used to map the file location to a new URL. The format is as follows:
Redirect /<old-path>/<file-name> http://<current-domain>/<current-path>/<file-name>
Redirect /<old-path>/<file-name> http://<current-domain>/<current-path>/<file-name>mod_rewrite module included with the Apache HTTP Server. For more information about configuring the mod_rewrite module, refer to the Apache Software Foundation documentation online at http://httpd.apache.org/docs/2.2/mod/mod_rewrite.html.
The ScriptAlias directive defines where CGI scripts are located. Generally, it is not good practice to leave CGI scripts within the DocumentRoot, where they can potentially be viewed as text documents. For this reason, a special directory outside of the DocumentRoot directory containing server-side executables and scripts is designated by the ScriptAlias directive. This directory is known as a cgi-bin and is set to /var/www/cgi-bin/ by default.
cgi-bin/ directory. For instructions on doing so, refer to AddHandler and Directory.
Sets the ServerAdmin directive to the email address of the Web server administrator. This email address shows up in error messages on server-generated Web pages, so users can report a problem by sending email to the server administrator.
ServerAdmin is set to root@localhost.
ServerAdmin is to set it to webmaster@example.com. Once set, alias webmaster to the person responsible for the Web server in /etc/aliases and run /usr/bin/newaliases.
ServerName specifies a hostname and port number (matching the Listen directive) for the server. The ServerName does not need to match the machine's actual hostname. For example, the Web server may be www.example.com, but the server's hostname is actually foo.example.com. The value specified in ServerName must be a valid Domain Name Service (DNS) name that can be resolved by the system — do not make something up.
ServerName directive:
ServerName www.example.com:80
ServerName www.example.com:80ServerName, be sure the IP address and server name pair are included in the /etc/hosts file.
The ServerRoot directive specifies the top-level directory containing website content. By default, ServerRoot is set to "/etc/httpd" for both secure and non-secure servers.
The ServerSignature directive adds a line containing the Apache HTTP Server server version and the ServerName to any server-generated documents, such as error messages sent back to clients. ServerSignature is set to on by default.
ServerSignature can be set to EMail which adds a mailto:ServerAdmin HTML tag to the signature line of auto-generated responses. ServerSignature can also be set to Off to stop Apache from sending out its version number and module information. Please also check the ServerTokens settings.
The ServerTokens directive determines if the Server response header field sent back to clients should include details of the Operating System type and information about compiled-in modules. By default, ServerTokens is set to Full which sends information about the Operating System type and compiled-in modules. Setting the ServerTokens to Prod sends the product name only and is recommended as many hackers check information in the Server header when scanning for vulnerabilities. You can also set the ServerTokens to Min (minimal) or to OS (operating system).
The SuexecUserGroup directive, which originates from the mod_suexec module, allows the specification of user and group execution privileges for CGI programs. Non-CGI requests are still processed with the user and group specified in the User and Group directives.
Note
SuexecUserGroup directive replaced the Apache HTTP Server 1.3 configuration of using the User and Group directives inside the configuration of VirtualHosts sections.
Timeout defines, in seconds, the amount of time that the server waits for receipts and transmissions during communications. Timeout is set to 300 seconds by default, which is appropriate for most situations.
TypesConfig names the file which sets the default list of MIME type mappings (file name extensions to content types). The default TypesConfig file is /etc/mime.types. Instead of editing /etc/mime.types, the recommended way to add MIME type mappings is to use the AddType directive.
AddType, refer to AddType.
When set to on, this directive configures the Apache HTTP Server to reference itself using the value specified in the ServerName and Port directives. When UseCanonicalName is set to off, the server instead uses the value used by the requesting client when referring to itself.
UseCanonicalName is set to off by default.
The User directive sets the username of the server process and determines what files the server is allowed to access. Any files inaccessible to this user are also inaccessible to clients connecting to the Apache HTTP Server.
User is set to apache.
Note
UserDir is the subdirectory within each user's home directory where they should place personal HTML files which are served by the Web server. This directive is set to disable by default.
public_html in the default configuration. For example, the server might receive the following request:
http://example.com/~username/foo.html
http://example.com/~username/foo.html/home/username/public_html/foo.html
/home/username/public_html/foo.html/home/username/ is the user's home directory (note that the default path to users' home directories may vary).
public_html directories (0755 also works). Files that are served in a users' public_html directories must be set to at least 0644.
<VirtualHost> and </VirtualHost> tags create a container outlining the characteristics of a virtual host. The VirtualHost container accepts most configuration directives.
VirtualHost container is provided in httpd.conf, which illustrates the minimum set of configuration directives necessary for each virtual host. Refer to Section 25.7, “Virtual Hosts” for more information about virtual hosts.
Note
/etc/httpd/conf.d/ssl.conf.
25.5.2. Configuration Directives for SSL
/etc/httpd/conf.d/ssl.conf file can be configured to enable secure Web communications using TLS. See Resolution for POODLE SSLv3.0 vulnerability (CVE-2014-3566) in httpd for important information on disabling SSL while enabling TLS.
Important
SSL and using only TLSv1.1 or TLSv1.2. Backwards compatibility can be achieved using TLSv1.0. Many products Red Hat supports have the ability to use SSLv2 or SSLv3 protocols, or enable them by default. However, the use of SSLv2 or SSLv3 is now strongly recommended against.
SetEnvIf sets environment variables based on the headers of incoming connections. It is not solely an SSL directive, though it is present in the supplied /etc/httpd/conf.d/ssl.conf file. It's purpose in this context is to disable HTTP keepalive and to allow SSL to close the connection without a closing notification from the client browser. This setting is necessary for certain browsers that do not reliably shut down the SSL connection.
- http://localhost/manual/mod/mod_ssl.html
Note
25.5.3. MPM Specific Server-Pool Directives
IfModule container is necessary to define the server-pool for the MPM in use.
prefork and worker MPMs.
MaxClients sets a limit on the total number of server processes, or simultaneously connected clients, that can run at one time. The main purpose of this directive is to keep a runaway Apache HTTP Server from crashing the operating system. For busy servers this value should be set to a high value. The server's default is set to 150 regardless of the MPM in use. However, it is not recommended that the value for MaxClients exceeds 256 when using the prefork MPM.
MaxRequestsPerChild sets the total number of requests each child server process serves before the child dies. The main reason for setting MaxRequestsPerChild is to avoid long-lived process induced memory leaks. The default MaxRequestsPerChild for the prefork MPM is 4000 and for the worker MPM is 0.
These values are only used with the prefork MPM. They adjust how the Apache HTTP Server dynamically adapts to the perceived load by maintaining an appropriate number of spare server processes based on the number of incoming requests. The server checks the number of servers waiting for a request and kills some if there are more than MaxSpareServers or creates some if the number of servers is less than MinSpareServers.
MinSpareServers value is 5; the default MaxSpareServers value is 20. These default settings should be appropriate for most situations. Be careful not to increase the MinSpareServers to a large number as doing so creates a heavy processing load on the server even when traffic is light.
These values are only used with the worker MPM. They adjust how the Apache HTTP Server dynamically adapts to the perceived load by maintaining an appropriate number of spare server threads based on the number of incoming requests. The server checks the number of server threads waiting for a request and kills some if there are more than MaxSpareThreads or creates some if the number of servers is less than MinSpareThreads.
MinSpareThreads value is 25; the default MaxSpareThreads value is 75. These default settings should be appropriate for most situations. The value for MaxSpareThreads must be greater than or equal to the sum of MinSpareThreads and ThreadsPerChild, else the Apache HTTP Server automatically corrects it.
The StartServers directive sets how many server processes are created upon startup. Since the Web server dynamically kills and creates server processes based on traffic load, it is not necessary to change this parameter. The Web server is set to start 8 server processes at startup for the prefork MPM and 2 for the worker MPM.
25.6. Adding Modules
http-manual package is installed, documentation about DSOs can be found online at http://localhost/manual/mod/.
LoadModule directive within /etc/httpd/conf/httpd.conf. If the module is provided by a separate package, the line must appear within the modules configuration file in the /etc/httpd/conf.d/ directory. Refer to LoadModule for more information.
http.conf, Apache HTTP Server must be reloaded or restarted, as referred to in Section 25.3, “Starting and Stopping httpd”.
httpd-devel package which contains the include files, the header files, as well as the APache eXtenSion (/usr/sbin/apxs) application, which uses the include files and the header files to compile DSOs.
/usr/sbin/apxs to compile the module sources outside the Apache source tree. For more information about using the /usr/sbin/apxs command, refer to the Apache documentation online at http://httpd.apache.org/docs/2.2/dso.html as well as the apxs man page.
/usr/lib/httpd/modules/ directory. For RHEL platforms using default-64-bit userspace (x86_64, ia64, ?) this path will be /usr/lib64/httpd/modules/. Then add a LoadModule line to the httpd.conf, using the following structure:
LoadModule <module-name> <path/to/module.so>
LoadModule <module-name> <path/to/module.so>25.7. Virtual Hosts
25.7.1. Setting Up Virtual Hosts
httpd.conf as an example.
NameVirtualHost line by removing the hash mark (#) and replace the asterisk (*) with the IP address assigned to the machine.
<VirtualHost> container.
<VirtualHost> line, change the asterisk (*) to the server's IP address. Change the ServerName to a valid DNS name assigned to the machine, and configure the other directives as necessary.
<VirtualHost> container is highly customizable and accepts almost every directive available within the main server configuration.
Note
Listen directive in the global settings section of /etc/httpd/conf/httpd.conf file.
httpd” for further instructions.
25.8. Apache HTTP Secure Server Configuration
mod_ssl security module enabled to use the OpenSSL library and toolkit. The combination of these three components are referred to in this section as the secure Web server or just as the secure server.
mod_ssl module is a security module for the Apache HTTP Server. The mod_ssl module uses the tools provided by the OpenSSL Project to add a very important feature to the Apache HTTP Server — the ability to encrypt communications. In contrast, regular HTTP communications between a browser and a Web server are sent in plain text, which could be intercepted and read by someone along the route between the browser and the server.
mod_ssl configuration file is located at /etc/httpd/conf.d/ssl.conf. For this file to be loaded, and hence for mod_ssl to work, you must have the statement Include conf.d/*.conf in the /etc/httpd/conf/httpd.conf file. This statement is included by default in the default Apache HTTP Server configuration file.
25.8.1. An Overview of Security-Related Packages
httpd- The
httpdpackage contains thehttpddaemon and related utilities, configuration files, icons, Apache HTTP Server modules, man pages, and other files used by the Apache HTTP Server. mod_ssl- The
mod_sslpackage includes themod_sslmodule, which provides strong cryptography for the Apache HTTP Server via the Secure Sockets Layer (SSL) and Transport Layer Security (TLS) protocols. openssl- The
opensslpackage contains the OpenSSL toolkit. The OpenSSL toolkit implements the SSL and TLS protocols, and also includes a general purpose cryptography library.
25.8.2. An Overview of Certificates and Security
https:// prefix is used at the beginning of the Uniform Resource Locator (URL) in the navigation bar.
25.8.3. Using Pre-Existing Keys and Certificates
- If you are changing your IP address or domain name — Certificates are issued for a particular IP address and domain name pair. You must get a new certificate if you are changing your IP address or domain name.
- If you have a certificate from VeriSign and you are changing your server software — VeriSign is a widely used CA. If you already have a VeriSign certificate for another purpose, you may have been considering using your existing VeriSign certificate with your new secure server. However, you are not be allowed to because VeriSign issues certificates for one specific server software and IP address/domain name combination.If you change either of those parameters (for example, if you previously used a different secure server product), the VeriSign certificate you obtained to use with the previous configuration will not work with the new configuration. You must obtain a new certificate.
/etc/pki/tls/private/server.key
/etc/pki/tls/private/server.key/etc/pki/tls/certs/server.crt
/etc/pki/tls/certs/server.crthttpsd.key) and certificate (httpsd.crt) are located in /etc/httpd/conf/. Move and rename your key and certificate so that the secure server can use them. Use the following two commands to move and rename your key and certificate files:
mv /etc/httpd/conf/httpsd.key /etc/pki/tls/private/server.key mv /etc/httpd/conf/httpsd.crt /etc/pki/tls/certs/server.crt
mv /etc/httpd/conf/httpsd.key /etc/pki/tls/private/server.key
mv /etc/httpd/conf/httpsd.crt /etc/pki/tls/certs/server.crtservice httpd start
service httpd start25.8.4. Types of Certificates
- Browsers (usually) automatically recognize the certificate and allow a secure connection to be made, without prompting the user.
- When a CA issues a signed certificate, they are guaranteeing the identity of the organization that is providing the webpages to the browser.
- Create an encryption private and public key pair.
- Create a certificate request based on the public key. The certificate request contains information about your server and the company hosting it.
- Send the certificate request, along with documents proving your identity, to a CA. Red Hat does not make recommendations on which certificate authority to choose. Your decision may be based on your past experiences, on the experiences of your friends or colleagues, or purely on monetary factors.Once you have decided upon a CA, you need to follow the instructions they provide on how to obtain a certificate from them.
- When the CA is satisfied that you are indeed who you claim to be, they provide you with a digital certificate.
- Install this certificate on your secure server and begin handling secure transactions.
25.8.5. Generating a Key
cd command to change to the /etc/pki/tls/ directory. Remove the fake key and certificate that were generated during the installation with the following commands:
rm private/server.key rm certs/server.crt
rm private/server.key
rm certs/server.crtcrypto-utils package contains the genkey utility which you can use to generate keys as the name implies. To create your own private key, please ensure the crypto-utils package is installed. You can view more options by typing man genkey in your terminal. Assuming you wish to generate keys for www.example.com using the genkey utility, type in the following command in your terminal:
genkey www.example.com
genkey www.example.commake based process is no longer shipped with RHEL 5. This will start the genkey graphical user interface. The figure below illustrates the first screen. To navigate, use the keyboard arrow and tab keys. This windows indicates where your key will be stored and prompts you to proceed or cancel the operation. To proceed to the next step, select Next and press the Return (Enter) key.
Figure 25.11. Keypair generation
Figure 25.12. Choose key size
Figure 25.13. Generating random bits
Figure 25.14. Generate CSR
Figure 25.15. Choose Certificate Authority (CA)
Figure 25.16. Enter details for your certificate
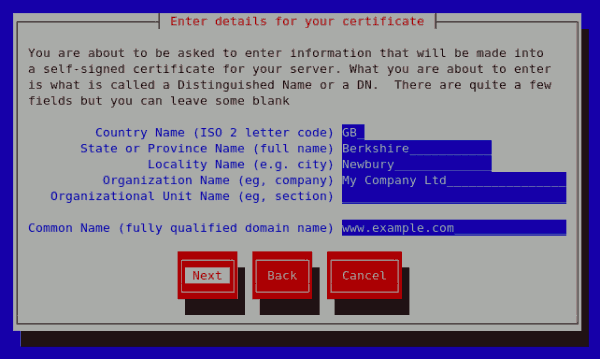
Figure 25.17. Generating a self signed certificate for your server
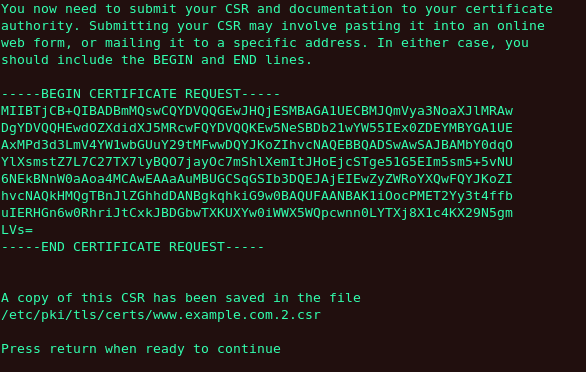
Figure 25.18. Begin certificate request

Figure 25.19. Protecting your private key
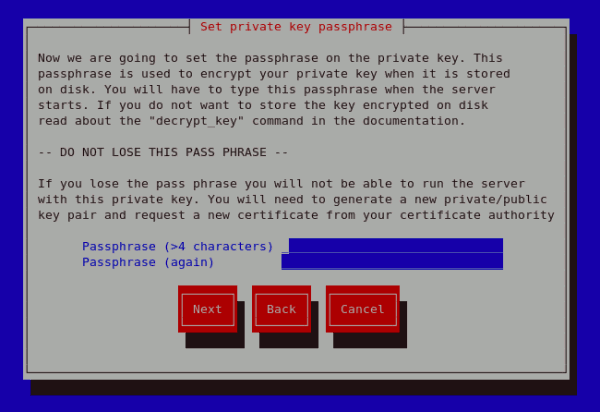
Figure 25.20. Set passphrase
genkey www.example.com on a server that already has an existing key pair for the particular hostname, an error message will be displayed as illustrated below. You need to delete your existing key file as indicated to generate a new key pair.
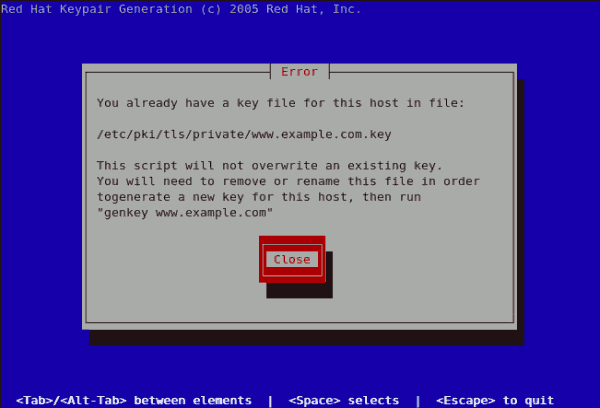
Figure 25.21. genkey error
25.8.6. How to configure the server to use the new key
- Obtain the signed certificate from the CA after submitting the CSR.
- Copy the certificate to the path, for example
/etc/pki/tls/certs/www.example.com.crt - Edit
/etc/httpd/conf.d/ssl.conf. Change the SSLCertificateFile and SSLCertificateKey lines to be.Note that the “www.example.com” part should match the argument passed on theSSLCertificateFile /etc/pki/tls/certs/www.example.com.crt SSLCertificateKeyFile /etc/pki/tls/private/www.example.com.key
SSLCertificateFile /etc/pki/tls/certs/www.example.com.crt SSLCertificateKeyFile /etc/pki/tls/private/www.example.com.keyCopy to Clipboard Copied! Toggle word wrap Toggle overflow genkeycommand.
25.9. Additional Resources
25.9.1. Useful Websites
- http://httpd.apache.org/ — The official website for the Apache HTTP Server with documentation on all the directives and default modules.
- http://www.modssl.org/ — The official website for
mod_ssl. - http://www.apacheweek.com/ — A comprehensive online weekly newsletter about all things Apache.
Chapter 26. FTP
vsftpd.
26.1. The File Transfer Protocol
sftp from the OpenSSH suite of tools. For information about configuring OpenSSH, refer to Chapter 20, OpenSSH.
26.1.1. Multiple Ports, Multiple Modes
- active mode
- Active mode is the original method used by the FTP protocol for transferring data to the client application. When an active mode data transfer is initiated by the FTP client, the server opens a connection from port 20 on the server to the IP address and a random, unprivileged port (greater than 1024) specified by the client. This arrangement means that the client machine must be allowed to accept connections over any port above 1024. With the growth of insecure networks, such as the Internet, the use of firewalls to protect client machines is now prevalent. Because these client-side firewalls often deny incoming connections from active mode FTP servers, passive mode was devised.
- passive mode
- Passive mode, like active mode, is initiated by the FTP client application. When requesting data from the server, the FTP client indicates it wants to access the data in passive mode and the server provides the IP address and a random, unprivileged port (greater than 1024) on the server. The client then connects to that port on the server to download the requested information.While passive mode resolves issues for client-side firewall interference with data connections, it can complicate administration of the server-side firewall. You can reduce the number of open ports on a server by limiting the range of unprivileged ports on the FTP server. This also simplifies the process of configuring firewall rules for the server. Refer to Section 26.2.5.8, “Network Options” for more about limiting passive ports.
26.2. FTP Servers
- Red Hat Content Accelerator — A kernel-based Web server that delivers high performance Web server and FTP services. Since speed as its primary design goal, it has limited functionality and runs only as an anonymous FTP server. For more information about configuring and administering Red Hat Content Accelerator, consult the documentation available online at http://www.redhat.com/docs/manuals/tux/.
vsftpd— A fast, secure FTP daemon which is the preferred FTP server for Red Hat Enterprise Linux. The remainder of this chapter focuses onvsftpd.
26.2.1. vsftpd
vsftpd) is designed from the ground up to be fast, stable, and, most importantly, secure. vsftpd is the only stand-alone FTP server distributed with Red Hat Enterprise Linux, due to its ability to handle large numbers of connections efficiently and securely.
vsftpd has three primary aspects:
- Strong separation of privileged and non-privileged processes — Separate processes handle different tasks, and each of these processes run with the minimal privileges required for the task.
- Tasks requiring elevated privileges are handled by processes with the minimal privilege necessary — By leveraging compatibilities found in the
libcaplibrary, tasks that usually require full root privileges can be executed more safely from a less privileged process. - Most processes run in a
chrootjail — Whenever possible, processes are change-rooted to the directory being shared; this directory is then considered achrootjail. For example, if the directory/var/ftp/is the primary shared directory,vsftpdreassigns/var/ftp/to the new root directory, known as/. This disallows any potential malicious hacker activities for any directories not contained below the new root directory.
vsftpd deals with requests:
- The parent process runs with the least privileges required — The parent process dynamically calculates the level of privileges it requires to minimize the level of risk. Child processes handle direct interaction with the FTP clients and run with as close to no privileges as possible.
- All operations requiring elevated privileges are handled by a small parent process — Much like the Apache HTTP Server,
vsftpdlaunches unprivileged child processes to handle incoming connections. This allows the privileged, parent process to be as small as possible and handle relatively few tasks. - All requests from unprivileged child processes are distrusted by the parent process — Communication with child processes are received over a socket, and the validity of any information from child processes is checked before being acted on.
- Most interaction with FTP clients is handled by unprivileged child processes in a
chrootjail — Because these child processes are unprivileged and only have access to the directory being shared, any crashed processes only allows the attacker access to the shared files.
26.2.2. Files Installed with vsftpd
vsftpd RPM installs the daemon (/usr/sbin/vsftpd), its configuration and related files, as well as FTP directories onto the system. The following lists the files and directories related to vsftpd configuration:
/etc/rc.d/init.d/vsftpd— The initialization script (initscript) used by the/sbin/servicecommand to start, stop, or reloadvsftpd. Refer to Section 26.2.3, “Starting and Stoppingvsftpd” for more information about using this script./etc/pam.d/vsftpd— The Pluggable Authentication Modules (PAM) configuration file forvsftpd. This file specifies the requirements a user must meet to login to the FTP server. For more information, refer to Section 48.4, “Pluggable Authentication Modules (PAM)”./etc/vsftpd/vsftpd.conf— The configuration file forvsftpd. Refer to Section 26.2.5, “vsftpdConfiguration Options” for a list of important options contained within this file./etc/vsftpd/ftpusers— A list of users not allowed to log intovsftpd. By default, this list includes theroot,bin, anddaemonusers, among others./etc/vsftpd/user_list— This file can be configured to either deny or allow access to the users listed, depending on whether theuserlist_denydirective is set toYES(default) orNOin/etc/vsftpd/vsftpd.conf. If/etc/vsftpd/user_listis used to grant access to users, the usernames listed must not appear in/etc/vsftpd/ftpusers./var/ftp/— The directory containing files served byvsftpd. It also contains the/var/ftp/pub/directory for anonymous users. Both directories are world-readable, but writable only by the root user.
26.2.3. Starting and Stopping vsftpd
vsftpd RPM installs the /etc/rc.d/init.d/vsftpd script, which can be accessed using the /sbin/service command.
service vsftpd start
service vsftpd startservice vsftpd stop
service vsftpd stoprestart option is a shorthand way of stopping and then starting vsftpd. This is the most efficient way to make configuration changes take effect after editing the configuration file for vsftpd.
service vsftpd restart
service vsftpd restartcondrestart (conditional restart) option only starts vsftpd if it is currently running. This option is useful for scripts, because it does not start the daemon if it is not running.
service vsftpd condrestart
service vsftpd condrestartvsftpd service does not start automatically at boot time. To configure the vsftpd service to start at boot time, use an initscript utility, such as /sbin/chkconfig, /usr/sbin/ntsysv, or the Services Configuration Tool program. Refer to Chapter 18, Controlling Access to Services for more information regarding these tools.
26.2.3.1. Starting Multiple Copies of vsftpd
vsftpd is by running multiple copies of the daemon, each with its own configuration file.
vsftpd to answer requests on different IP addresses, multiple copies of the daemon must be running. The first copy must be run using the vsftpd initscripts, as outlined in Section 26.2.3, “Starting and Stopping vsftpd”. This copy uses the standard configuration file, /etc/vsftpd/vsftpd.conf.
/etc/vsftpd/ directory, such as /etc/vsftpd/vsftpd-site-2.conf. Each configuration file must be readable and writable only by root. Within each configuration file for each FTP server listening on an IPv4 network, the following directive must be unique:
listen_address=N.N.N.N
listen_address=N.N.N.Nlisten_address6 directive instead.
vsftpd daemon must be launched from a root shell prompt using the following command:
vsftpd /etc/vsftpd/<configuration-file> [amp ]
vsftpd /etc/vsftpd/<configuration-file> [amp ]/etc/vsftpd/vsftpd-site-2.conf.
anon_rootlocal_rootvsftpd_log_filexferlog_file
vsftpd's configuration file, refer to Section 26.2.5, “vsftpd Configuration Options”.
/etc/rc.local file.
26.2.4. Encrypting vsftpd Connections Using TLS
FTP, which transmits user names, passwords, and data without encryption by default, the vsftpd daemon can be configured to utilize the TLS protocol to authenticate connections and encrypt all transfers. Note that an FTP client that supports TLS is needed to communicate with vsftpd with TLS enabled.
Note
SSL (Secure Sockets Layer) is the name of an older implementation of the security protocol. The new versions are called TLS (Transport Layer Security). Only the newer versions (TLS) should be used as SSL suffers from serious security vulnerabilities. The documentation included with the vsftpd server, as well as the configuration directives used in the vsftpd.conf file, use the SSL name when referring to security-related matters, but TLS is supported and used by default when the ssl_enable directive is set to YES.
ssl_enable configuration directive in the vsftpd.conf file to YES to turn on TLS support. The default settings of other TLS-related directives that become automatically active when the ssl_enable option is enabled provide for a reasonably well-configured TLS set up. This includes, among other things, the requirement to only use the TLS v1 protocol for all connections (the use of the insecure SSL protocol versions is disabled by default) or forcing all non-anonymous logins to use TLS for sending passwords and data transfers.
Example 26.1. Configuring vsftpd to Use TLS
SSL versions of the security protocol in the vsftpd.conf file:
ssl_enable=YES ssl_tlsv1=YES ssl_sslv2=NO ssl_sslv3=NO
ssl_enable=YES
ssl_tlsv1=YES
ssl_sslv2=NO
ssl_sslv3=NOvsftpd service after you modify its configuration:
service vsftpd restart
~]# service vsftpd restartTLS-related configuration directives for fine-tuning the use of TLS by vsftpd. Also, see Section 26.2.5, “vsftpd Configuration Options” for a description of other commonly used vsftpd.conf configuration directives.
26.2.5. vsftpd Configuration Options
vsftpd may not offer the level of customization other widely available FTP servers have, it offers enough options to fill most administrator's needs. The fact that it is not overly feature-laden limits configuration and programmatic errors.
vsftpd is handled by its configuration file, /etc/vsftpd/vsftpd.conf. Each directive is on its own line within the file and follows the following format:
<directive>=<value>
<directive>=<value>Important
#) and are ignored by the daemon.
vsftpd.conf.
Important
vsftpd, refer to Section 48.2, “Server Security”.
/etc/vsftpd/vsftpd.conf. All directives not explicitly found within vsftpd's configuration file are set to their default value.
26.2.5.1. Daemon Options
vsftpd daemon.
listen— When enabled,vsftpdruns in stand-alone mode. Red Hat Enterprise Linux sets this value toYES. This directive cannot be used in conjunction with thelisten_ipv6directive.The default value isNO.listen_ipv6— When enabled,vsftpdruns in stand-alone mode, but listens only to IPv6 sockets. This directive cannot be used in conjunction with thelistendirective.The default value isNO.session_support— When enabled,vsftpdattempts to maintain login sessions for each user through Pluggable Authentication Modules (PAM). Refer to Section 48.4, “Pluggable Authentication Modules (PAM)” for more information. If session logging is not necessary, disabling this option allowsvsftpdto run with less processes and lower privileges.The default value isYES.
26.2.5.2. Log In Options and Access Controls
anonymous_enable— When enabled, anonymous users are allowed to log in. The usernamesanonymousandftpare accepted.The default value isYES.Refer to Section 26.2.5.3, “Anonymous User Options” for a list of directives affecting anonymous users.banned_email_file— If thedeny_email_enabledirective is set toYES, this directive specifies the file containing a list of anonymous email passwords which are not permitted access to the server.The default value is/etc/vsftpd.banned_emails.banner_file— Specifies the file containing text displayed when a connection is established to the server. This option overrides any text specified in theftpd_bannerdirective.There is no default value for this directive.cmds_allowed— Specifies a comma-delimited list of FTP commands allowed by the server. All other commands are rejected.There is no default value for this directive.deny_email_enable— When enabled, any anonymous user utilizing email passwords specified in the/etc/vsftpd.banned_emailsare denied access to the server. The name of the file referenced by this directive can be specified using thebanned_email_filedirective.The default value isNO.ftpd_banner— When enabled, the string specified within this directive is displayed when a connection is established to the server. This option can be overridden by thebanner_filedirective.By defaultvsftpddisplays its standard banner.local_enable— When enabled, local users are allowed to log into the system.The default value isYES.Refer to Section 26.2.5.4, “Local User Options” for a list of directives affecting local users.pam_service_name— Specifies the PAM service name forvsftpd.The default value isftp. On Red Hat Enterprise Linux 5.10, this option is set tovsftpdin the configuration file.tcp_wrappers— When enabled, TCP wrappers are used to grant access to the server. If the FTP server is configured on multiple IP addresses, theVSFTPD_LOAD_CONFoption can be used to load different configuration files based on the IP address being requested by the client.The default value isNO. On Red Hat Enterprise Linux 5.10, this option is set toYESin the configuration file.Refer to Section 48.5, “TCP Wrappers and xinetd” for more information about TCP wrappers.userlist_deny— When used in conjunction with theuserlist_enabledirective and set toNO, all local users are denied access unless the username is listed in the file specified by theuserlist_filedirective. Because access is denied before the client is asked for a password, setting this directive toNOprevents local users from submitting unencrypted passwords over the network.The default value isYES.userlist_enable— When enabled, the users listed in the file specified by theuserlist_filedirective are denied access. Because access is denied before the client is asked for a password, users are prevented from submitting unencrypted passwords over the network.The default value isNO. On Red Hat Enterprise Linux 5.10, this option is set toYESin the configuration file.userlist_file— Specifies the file referenced byvsftpdwhen theuserlist_enabledirective is enabled.The default value is/etc/vsftpd.user_listand is created during installation.
26.2.5.3. Anonymous User Options
anonymous_enable directive must be set to YES.
anon_mkdir_write_enable— When enabled in conjunction with thewrite_enabledirective, anonymous users are allowed to create new directories within a parent directory which has write permissions.The default value isNO.anon_root— Specifies the directoryvsftpdchanges to after an anonymous user logs in.There is no default value for this directive.anon_upload_enable— When enabled in conjunction with thewrite_enabledirective, anonymous users are allowed to upload files within a parent directory which has write permissions.The default value isNO.anon_world_readable_only— When enabled, anonymous users are only allowed to download world-readable files.The default value isYES.ftp_username— Specifies the local user account (listed in/etc/passwd) used for the anonymous FTP user. The home directory specified in/etc/passwdfor the user is the root directory of the anonymous FTP user.The default value isftp.no_anon_password— When enabled, the anonymous user is not asked for a password.The default value isNO.secure_email_list_enable— When enabled, only a specified list of email passwords for anonymous logins are accepted. This is a convenient way to offer limited security to public content without the need for virtual users.Anonymous logins are prevented unless the password provided is listed in/etc/vsftpd.email_passwords. The file format is one password per line, with no trailing white spaces.The default value isNO.
26.2.5.4. Local User Options
local_enable directive must be set to YES.
chmod_enable— When enabled, the FTP commandSITE CHMODis allowed for local users. This command allows the users to change the permissions on files.The default value isYES.chroot_list_enable— When enabled, the local users listed in the file specified in thechroot_list_filedirective are placed in achrootjail upon log in.If enabled in conjunction with thechroot_local_userdirective, the local users listed in the file specified in thechroot_list_filedirective are not placed in achrootjail upon log in.The default value isNO.chroot_list_file— Specifies the file containing a list of local users referenced when thechroot_list_enabledirective is set toYES.The default value is/etc/vsftpd.chroot_list.chroot_local_user— When enabled, local users are change-rooted to their home directories after logging in.The default value isNO.Warning
Enablingchroot_local_useropens up a number of security issues, especially for users with upload privileges. For this reason, it is not recommended.guest_enable— When enabled, all non-anonymous users are logged in as the userguest, which is the local user specified in theguest_usernamedirective.The default value isNO.guest_username— Specifies the username theguestuser is mapped to.The default value isftp.local_root— Specifies the directoryvsftpdchanges to after a local user logs in.There is no default value for this directive.local_umask— Specifies the umask value for file creation. Note that the default value is in octal form (a numerical system with a base of eight), which includes a "0" prefix. Otherwise the value is treated as a base-10 integer.The default value is022.passwd_chroot_enable— When enabled in conjunction with thechroot_local_userdirective,vsftpdchange-roots local users based on the occurrence of the/./in the home directory field within/etc/passwd.The default value isNO.user_config_dir— Specifies the path to a directory containing configuration files bearing the name of local system users that contain specific setting for that user. Any directive in the user's configuration file overrides those found in/etc/vsftpd/vsftpd.conf.There is no default value for this directive.
26.2.5.5. Directory Options
dirlist_enable— When enabled, users are allowed to view directory lists.The default value isYES.dirmessage_enable— When enabled, a message is displayed whenever a user enters a directory with a message file. This message resides within the current directory. The name of this file is specified in themessage_filedirective and is.messageby default.The default value isNO. On Red Hat Enterprise Linux 5.10, this option is set toYESin the configuration file.force_dot_files— When enabled, files beginning with a dot (.) are listed in directory listings, with the exception of the.and..files.The default value isNO.hide_ids— When enabled, all directory listings showftpas the user and group for each file.The default value isNO.message_file— Specifies the name of the message file when using thedirmessage_enabledirective.The default value is.message.text_userdb_names— When enabled, text usernames and group names are used in place of UID and GID entries. Enabling this option may slow performance of the server.The default value isNO.use_localtime— When enabled, directory listings reveal the local time for the computer instead of GMT.The default value isNO.
26.2.5.6. File Transfer Options
download_enable— When enabled, file downloads are permitted.The default value isYES.chown_uploads— When enabled, all files uploaded by anonymous users are owned by the user specified in thechown_usernamedirective.The default value isNO.chown_username— Specifies the ownership of anonymously uploaded files if thechown_uploadsdirective is enabled.The default value isroot.write_enable— When enabled, FTP commands which can change the file system are allowed, such asDELE,RNFR, andSTOR.The default value isYES.
26.2.5.7. Logging Options
vsftpd's logging behavior.
dual_log_enable— When enabled in conjunction withxferlog_enable,vsftpdwrites two files simultaneously: awu-ftpd-compatible log to the file specified in thexferlog_filedirective (/var/log/xferlogby default) and a standardvsftpdlog file specified in thevsftpd_log_filedirective (/var/log/vsftpd.logby default).The default value isNO.log_ftp_protocol— When enabled in conjunction withxferlog_enableand withxferlog_std_formatset toNO, all FTP commands and responses are logged. This directive is useful for debugging.The default value isNO.syslog_enable— When enabled in conjunction withxferlog_enable, all logging normally written to the standardvsftpdlog file specified in thevsftpd_log_filedirective (/var/log/vsftpd.logby default) is sent to the system logger instead under the FTPD facility.The default value isNO.vsftpd_log_file— Specifies thevsftpdlog file. For this file to be used,xferlog_enablemust be enabled andxferlog_std_formatmust either be set toNOor, ifxferlog_std_formatis set toYES,dual_log_enablemust be enabled. It is important to note that ifsyslog_enableis set toYES, the system log is used instead of the file specified in this directive.The default value is/var/log/vsftpd.log.xferlog_enable— When enabled,vsftpdlogs connections (vsftpdformat only) and file transfer information to the log file specified in thevsftpd_log_filedirective (/var/log/vsftpd.logby default). Ifxferlog_std_formatis set toYES, file transfer information is logged but connections are not, and the log file specified inxferlog_file(/var/log/xferlogby default) is used instead. It is important to note that both log files and log formats are used ifdual_log_enableis set toYES.The default value isNO. On Red Hat Enterprise Linux 5.10, this option is set toYESin the configuration file.xferlog_file— Specifies thewu-ftpd-compatible log file. For this file to be used,xferlog_enablemust be enabled andxferlog_std_formatmust be set toYES. It is also used ifdual_log_enableis set toYES.The default value is/var/log/xferlog.xferlog_std_format— When enabled in conjunction withxferlog_enable, only awu-ftpd-compatible file transfer log is written to the file specified in thexferlog_filedirective (/var/log/xferlogby default). It is important to note that this file only logs file transfers and does not log connections to the server.The default value isNO. On Red Hat Enterprise Linux 5.10, this option is set toYESin the configuration file.
Important
wu-ftpd FTP server, the xferlog_std_format directive is set to YES under Red Hat Enterprise Linux. However, this setting means that connections to the server are not logged.
vsftpd format and maintain a wu-ftpd-compatible file transfer log, set dual_log_enable to YES.
wu-ftpd-compatible file transfer log is not important, either set xferlog_std_format to NO, comment the line with a hash mark (#), or delete the line entirely.
26.2.5.8. Network Options
vsftpd interacts with the network.
accept_timeout— Specifies the amount of time for a client using passive mode to establish a connection.The default value is60.anon_max_rate— Specifies the maximum data transfer rate for anonymous users in bytes per second.The default value is0, which does not limit the transfer rate.connect_from_port_20When enabled,vsftpdruns with enough privileges to open port 20 on the server during active mode data transfers. Disabling this option allowsvsftpdto run with less privileges, but may be incompatible with some FTP clients.The default value isNO. On Red Hat Enterprise Linux 5.10, this option is set toYESin the configuration file.connect_timeout— Specifies the maximum amount of time a client using active mode has to respond to a data connection, in seconds.The default value is60.data_connection_timeout— Specifies maximum amount of time data transfers are allowed to stall, in seconds. Once triggered, the connection to the remote client is closed.The default value is300.ftp_data_port— Specifies the port used for active data connections whenconnect_from_port_20is set toYES.The default value is20.idle_session_timeout— Specifies the maximum amount of time between commands from a remote client. Once triggered, the connection to the remote client is closed.The default value is300.listen_address— Specifies the IP address on whichvsftpdlistens for network connections.There is no default value for this directive.Note
If running multiple copies ofvsftpdserving different IP addresses, the configuration file for each copy of thevsftpddaemon must have a different value for this directive. Refer to Section 26.2.3.1, “Starting Multiple Copies ofvsftpd” for more information about multihomed FTP servers.listen_address6— Specifies the IPv6 address on whichvsftpdlistens for network connections whenlisten_ipv6is set toYES.There is no default value for this directive.Note
If running multiple copies ofvsftpdserving different IP addresses, the configuration file for each copy of thevsftpddaemon must have a different value for this directive. Refer to Section 26.2.3.1, “Starting Multiple Copies ofvsftpd” for more information about multihomed FTP servers.listen_port— Specifies the port on whichvsftpdlistens for network connections.The default value is21.local_max_rate— Specifies the maximum rate data is transferred for local users logged into the server in bytes per second.The default value is0, which does not limit the transfer rate.max_clients— Specifies the maximum number of simultaneous clients allowed to connect to the server when it is running in standalone mode. Any additional client connections would result in an error message.The default value is0, which does not limit connections.max_per_ip— Specifies the maximum of clients allowed to connected from the same source IP address.The default value is0, which does not limit connections.pasv_address— Specifies the IP address for the public facing IP address of the server for servers behind Network Address Translation (NAT) firewalls. This enablesvsftpdto hand out the correct return address for passive mode connections.There is no default value for this directive.pasv_enable— When enabled, passive mode connects are allowed.The default value isYES.pasv_max_port— Specifies the highest possible port sent to the FTP clients for passive mode connections. This setting is used to limit the port range so that firewall rules are easier to create.The default value is0, which does not limit the highest passive port range. The value must not exceed65535.pasv_min_port— Specifies the lowest possible port sent to the FTP clients for passive mode connections. This setting is used to limit the port range so that firewall rules are easier to create.The default value is0, which does not limit the lowest passive port range. The value must not be lower1024.pasv_promiscuous— When enabled, data connections are not checked to make sure they are originating from the same IP address. This setting is only useful for certain types of tunneling.The default value isNO.Warning
Do not enable this option unless absolutely necessary as it disables an important security feature which verifies that passive mode connections originate from the same IP address as the control connection that initiates the data transfer.port_enable— When enabled, active mode connects are allowed.The default value isYES.
26.2.6. Additional Resources
vsftpd, refer to the following resources.
26.2.6.1. Installed Documentation
- The
/usr/share/doc/vsftpd-<version-number>/directory — Replace <version-number> with the installed version of thevsftpdpackage. This directory contains aREADMEwith basic information about the software. TheTUNINGfile contains basic performance tuning tips and theSECURITY/directory contains information about the security model employed byvsftpd. vsftpdrelated man pages — There are a number of man pages for the daemon and configuration files. The following lists some of the more important man pages.- Server Applications
man vsftpd— Describes available command line options forvsftpd.
- Configuration Files
man vsftpd.conf— Contains a detailed list of options available within the configuration file forvsftpd.man 5 hosts_access— Describes the format and options available within the TCP wrappers configuration files:hosts.allowandhosts.deny.
26.2.6.2. Useful Websites
- http://vsftpd.beasts.org/ — The
vsftpdproject page is a great place to locate the latest documentation and to contact the author of the software. - http://slacksite.com/other/ftp.html — This website provides a concise explanation of the differences between active and passive mode FTP.
- http://www.ietf.org/rfc/rfc0959.txt — The original Request for Comments (RFC) of the FTP protocol from the IETF.
Chapter 27. Email
27.1. Email Protocols
27.1.1. Mail Transport Protocols
27.1.1.1. SMTP
/usr/sbin/sendmail) is the default SMTP program under Red Hat Enterprise Linux. However, a simpler mail server application called Postfix (/usr/sbin/postfix) is also available.
27.1.2. Mail Access Protocols
27.1.2.1. POP
/usr/lib/cyrus-imapd/pop3d and is provided by the cyrus-imapd package. When using a POP server, email messages are downloaded by email client applications. By default, most POP email clients are automatically configured to delete the message on the email server after it has been successfully transferred, however this setting usually can be changed.
- APOP — POP3 with MDS authentication. An encoded hash of the user's password is sent from the email client to the server rather then sending an unencrypted password.
- KPOP — POP3 with Kerberos authentication. Refer to Section 48.6, “Kerberos” for more information.
- RPOP — POP3 with RPOP authentication. This uses a per-user ID, similar to a password, to authenticate POP requests. However, this ID is not encrypted, so RPOP is no more secure than standard POP.
ipop3s service or by using the /usr/sbin/stunnel program. Refer to Section 27.6.1, “Securing Communication” for more information.
27.1.2.2. IMAP
/usr/lib/cyrus-imapd/imapd and is provided by the cyrus-imapd package. When using an IMAP mail server, email messages remain on the server where users can read or delete them. IMAP also allows client applications to create, rename, or delete mail directories on the server to organize and store email.
imaps service, or by using the /usr/sbin/stunnel program. Refer to Section 27.6.1, “Securing Communication” for more information.
27.1.2.3. Dovecot
imap-login and pop3-login daemons which implement the IMAP and POP3 protocols are included in the dovecot package. The use of IMAP and POP is configured through dovecot. By default dovecot listens on both IMAP and POP3 ports and also their secure variants. To start using dovecot:
- Start the daemon:
service dovecot start
service dovecot startCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Make the daemon start automatically after the next reboot:
chkconfig dovecot on
chkconfig dovecot onCopy to Clipboard Copied! Toggle word wrap Toggle overflow Note thatdovecotonly reports that it started the IMAP server, but also starts the POP3 server.
- Edit the
dovecotconfiguration file/etc/pki/dovecot/dovecot-openssl.cnfas you prefer. However in a typical installation, this file does not require modification. - Rename, move or delete the files
/etc/pki/dovecot/certs/dovecot.pemand/etc/pki/dovecot/private/dovecot.pem. - Execute the
/usr/share/doc/dovecot-1.0/examples/mkcert.shscript which creates the dovecot self signed certificates. The certificates are copied in the/etc/pki/dovecot/certsand/etc/pki/dovecot/privatedirectories. To implement the changes, restartdovecot(/sbin/service dovecot restart).
dovecot can be found online at http://www.dovecot.org.
Note
SSLv2 and SSLv3 are disallowed by Dovecot. This is due to the POODLE SSL vulnerability (CVE-2014-3566). See Resolution for POODLE SSL 3.0 vulnerability (CVE-2014-3566) in Postfix and Dovecot for details.
27.2. Email Program Classifications
27.2.1. Mail Transport Agent
27.2.2. Mail Delivery Agent
mail or Procmail.
27.2.3. Mail User Agent
mutt.
27.3. Mail Transport Agents
27.3.1. Sendmail
27.3.1.1. Purpose and Limitations
27.3.1.2. The Default Sendmail Installation
/usr/sbin/sendmail.
/etc/mail/sendmail.cf. Avoid editing the sendmail.cf file directly. To make configuration changes to Sendmail, edit the /etc/mail/sendmail.mc file, back up the original /etc/mail/sendmail.cf, and use the following alternatives to generate a new configuration file:
- Use the included makefile in
/etc/mail(make all -C /etc/mail) to create a new/etc/mail/sendmail.cfconfiguration file. All other generated files in/etc/mail(db files) will be regenerated if needed. The old makemap commands are still usable. The make command will automatically be used byservice sendmail start | restart | reloadif themakepackage is installed. - Alternatively you may use the included
m4macro processor to create a new/etc/mail/sendmail.cf.
/etc/mail/ directory including:
access— Specifies which systems can use Sendmail for outbound email.domaintable— Specifies domain name mapping.local-host-names— Specifies aliases for the host.mailertable— Specifies instructions that override routing for particular domains.virtusertable— Specifies a domain-specific form of aliasing, allowing multiple virtual domains to be hosted on one machine.
/etc/mail/, such as access, domaintable, mailertable and virtusertable, must actually store their information in database files before Sendmail can use any configuration changes. To include any changes made to these configurations in their database files, run the following command:
makemap hash /etc/mail/<name> < /etc/mail/<name>
example.com domain delivered to bob@other-example.com, add the following line to the virtusertable file:
@example.com bob@other-example.com
@example.com bob@other-example.comvirtusertable.db file must be updated using the following command as root:
makemap hash /etc/mail/virtusertable < /etc/mail/virtusertable
makemap hash /etc/mail/virtusertable < /etc/mail/virtusertablevirtusertable.db file containing the new configuration.
27.3.1.3. Common Sendmail Configuration Changes
/etc/mail/sendmail.cf file.
Warning
sendmail.cf file, it is a good idea to create a backup copy.
/etc/mail/sendmail.mc file as the root user. When finished, use the m4 macro processor to generate a new sendmail.cf by executing the following command:
m4 /etc/mail/sendmail.mc > /etc/mail/sendmail.cf
m4 /etc/mail/sendmail.mc > /etc/mail/sendmail.cfm4 macro processor is installed with Sendmail but is part of the m4 package.
/etc/mail/sendmail.cf file, restart Sendmail for the changes to take effect. The easiest way to do this is to type the following command:
service sendmail restart
service sendmail restartImportant
sendmail.cf file does not allow Sendmail to accept network connections from any host other than the local computer. To configure Sendmail as a server for other clients, edit the /etc/mail/sendmail.mc file, and either change the address specified in the Addr= option of the DAEMON_OPTIONS directive from 127.0.0.1 to the IP address of an active network device or comment out the DAEMON_OPTIONS directive all together by placing dnl at the beginning of the line. When finished, regenerate /etc/mail/sendmail.cf by executing the following command:
m4 /etc/mail/sendmail.mc > /etc/mail/sendmail.cf
m4 /etc/mail/sendmail.mc > /etc/mail/sendmail.cf/etc/mail/sendmail.mc file must be reconfigured and a new /etc/mail/sendmail.cf must be generated.
/usr/share/sendmail-cf/README file before editing any files in the directories under the /usr/share/sendmail-cf directory, as they can affect the future configuration of /etc/mail/sendmail.cf files.
27.3.1.4. Masquerading
mail.example.com that handles all of their email and assigns a consistent return address to all outgoing mail.
user@example.com instead of user@host.example.com.
/etc/mail/sendmail.mc:
sendmail.cf using m4, this configuration makes all mail from inside the network appear as if it were sent from bigcorp.com.
27.3.1.5. Stopping Spam
x.edu) to accept messages from one party (y.com) and sent them to a different party (z.net). Now, however, Sendmail must be configured to permit any domain to relay mail through the server. To configure relay domains, edit the /etc/mail/relay-domains file and restart Sendmail.
/etc/mail/access file can be used to prevent connections from unwanted hosts. The following example illustrates how this file can be used to both block and specifically allow access to the Sendmail server:
badspammer.com ERROR:550 "Go away and do not spam us anymore" tux.badspammer.com OK 10.0 RELAY
badspammer.com ERROR:550 "Go away and do not spam us anymore"
tux.badspammer.com OK
10.0 RELAYbadspammer.com is blocked with a 550 RFC-821 compliant error code, with a message sent back to the spammer. Email sent from the tux.badspammer.com sub-domain, is accepted. The last line shows that any email sent from the 10.0.*.* network can be relayed through the mail server.
/etc/mail/access.db is a database, use makemap to activate any changes. Do this using the following command as root:
makemap hash /etc/mail/access < /etc/mail/access
makemap hash /etc/mail/access < /etc/mail/access/usr/share/sendmail-cf/README for more information and examples.
27.3.1.6. Using Sendmail with LDAP
aliases and virtusertables, on different mail servers that work together to support a medium- to enterprise-level organization. In short, LDAP abstracts the mail routing level from Sendmail and its separate configuration files to a powerful LDAP cluster that can be leveraged by many different applications.
/etc/mail/sendmail.mc to include the following:
LDAPROUTE_DOMAIN('yourdomain.com')dnl
FEATURE('ldap_routing')dnl
LDAPROUTE_DOMAIN('yourdomain.com')dnl
FEATURE('ldap_routing')dnlNote
/usr/share/sendmail-cf/README for detailed LDAP routing configuration instructions and examples.
/etc/mail/sendmail.cf file by running m4 and restarting Sendmail. Refer to Section 27.3.1.3, “Common Sendmail Configuration Changes” for instructions.
27.3.2. Postfix
Important
27.3.2.1. The Default Postfix Installation
/usr/sbin/postfix. This daemon launches all related processes needed to handle mail delivery.
/etc/postfix/ directory. The following is a list of the more commonly used files:
access— Used for access control, this file specifies which hosts are allowed to connect to Postfix.aliases— A configurable list required by the mail protocol.main.cf— The global Postfix configuration file. The majority of configuration options are specified in this file.master.cf— Specifies how Postfix interacts with various processes to accomplish mail delivery.transport— Maps email addresses to relay hosts.
Important
/etc/postfix/main.cf file does not allow Postfix to accept network connections from a host other than the local computer. For instructions on configuring Postfix as a server for other clients, refer to Section 27.3.2.2, “Basic Postfix Configuration”.
/etc/postfix/ directory, it may be necessary to restart the postfix service for the changes to take effect. The easiest way to do this is to type the following command:
service postfix restart
service postfix restart27.3.2.2. Basic Postfix Configuration
- Edit the
/etc/postfix/main.cffile with a text editor, such asvi. - Uncomment the
mydomainline by removing the hash mark (#), and replace domain.tld with the domain the mail server is servicing, such asexample.com. - Uncomment the
myorigin = $mydomainline. - Uncomment the
myhostnameline, and replace host.domain.tld with the hostname for the machine. - Uncomment the
mydestination = $myhostname, localhost.$mydomainline. - Uncomment the
mynetworksline, and replace 168.100.189.0/28 with a valid network setting for hosts that can connect to the server. - Uncomment the
inet_interfaces = allline. - Comment the
inet_interfaces = localhostline. - Restart the
postfixservice.
/etc/postfix/main.cf file. Also, with Red Hat Enterprise Linux version 5.9, Postfix provides MySQL maps support which allows Postfix to use a MySQL database and configure various lookup tables for various operations over MySQL databases. For example, the virtual table for handling global mail redirection, the access table for controlling access to an SMTP server and the aliases table for managing system-wide mail redirection. Configuration details and examples, as well as other additional resources including information about LDAP and SpamAssassin integration are available online at http://www.postfix.org/.
27.3.3. Fetchmail
.fetchmailrc file in the user's home directory.
.fetchmailrc file, Fetchmail checks for email on a remote server and downloads it. It then delivers it to port 25 on the local machine, using the local MTA to place the email in the correct user's spool file. If Procmail is available, it is launched to filter the email and place it in a mailbox so that it can be read by an MUA.
27.3.3.1. Fetchmail Configuration Options
.fetchmailrc file is much easier. Place any desired configuration options in the .fetchmailrc file for those options to be used each time the fetchmail command is issued. It is possible to override these at the time Fetchmail is run by specifying that option on the command line.
.fetchmailrc file contains three classes of configuration options:
- global options — Gives Fetchmail instructions that control the operation of the program or provide settings for every connection that checks for email.
- server options — Specifies necessary information about the server being polled, such as the hostname, as well as preferences for specific email servers, such as the port to check or number of seconds to wait before timing out. These options affect every user using that server.
- user options — Contains information, such as username and password, necessary to authenticate and check for email using a specified email server.
.fetchmailrc file, followed by one or more server options, each of which designate a different email server that Fetchmail should check. User options follow server options for each user account checking that email server. Like server options, multiple user options may be specified for use with a particular server as well as to check multiple email accounts on the same server.
.fetchmailrc file by the use of a special option verb, poll or skip, that precedes any of the server information. The poll action tells Fetchmail to use this server option when it is run, which checks for email using the specified user options. Any server options after a skip action, however, are not checked unless this server's hostname is specified when Fetchmail is invoked. The skip option is useful when testing configurations in .fetchmailrc because it only checks skipped servers when specifically invoked, and does not affect any currently working configurations.
.fetchmailrc file looks similar to the following example:
postmaster option) and all email errors are sent to the postmaster instead of the sender (bouncemail option). The set action tells Fetchmail that this line contains a global option. Then, two email servers are specified, one set to check using POP3, the other for trying various protocols to find one that works. Two users are checked using the second server option, but all email found for any user is sent to user1's mail spool. This allows multiple mailboxes to be checked on multiple servers, while appearing in a single MUA inbox. Each user's specific information begins with the user action.
Note
.fetchmailrc file. Omitting the with password '<password>' section causes Fetchmail to ask for a password when it is launched.
fetchmail man page explains each option in detail, but the most common ones are listed here.
27.3.3.2. Global Options
set action.
daemon <seconds>— Specifies daemon-mode, where Fetchmail stays in the background. Replace <seconds> with the number of seconds Fetchmail is to wait before polling the server.postmaster— Specifies a local user to send mail to in case of delivery problems.syslog— Specifies the log file for errors and status messages. By default, this is/var/log/maillog.
27.3.3.3. Server Options
.fetchmailrc after a poll or skip action.
auth <auth-type>— Replace <auth-type> with the type of authentication to be used. By default,passwordauthentication is used, but some protocols support other types of authentication, includingkerberos_v5,kerberos_v4, andssh. If theanyauthentication type is used, Fetchmail first tries methods that do not require a password, then methods that mask the password, and finally attempts to send the password unencrypted to authenticate to the server.interval <number>— Polls the specified server every<number>of times that it checks for email on all configured servers. This option is generally used for email servers where the user rarely receives messages.port <port-number>— Replace <port-number> with the port number. This value overrides the default port number for the specified protocol.proto <protocol>— Replace <protocol> with the protocol, such aspop3orimap, to use when checking for messages on the server.timeout <seconds>— Replace <seconds> with the number of seconds of server inactivity after which Fetchmail gives up on a connection attempt. If this value is not set, a default of300seconds is assumed.
27.3.3.4. User Options
user option (defined below).
fetchall— Orders Fetchmail to download all messages in the queue, including messages that have already been viewed. By default, Fetchmail only pulls down new messages.fetchlimit <number>— Replace <number> with the number of messages to be retrieved before stopping.flush— Deletes all previously viewed messages in the queue before retrieving new messages.limit <max-number-bytes>— Replace <max-number-bytes> with the maximum size in bytes that messages are allowed to be when retrieved by Fetchmail. This option is useful with slow network links, when a large message takes too long to download.password '<password>'— Replace <password> with the user's password.preconnect "<command>"— Replace <command> with a command to be executed before retrieving messages for the user.postconnect "<command>"— Replace <command> with a command to be executed after retrieving messages for the user.ssl— Activates SSL encryption.sslproto— Defines allowed SSL or TLS protocols. Possible values areSSL2,SSL3,SSL23, andTLS1; however, due to the POODLE: SSLv3 vulnerability (CVE-2014-3566), be sure to set this option toTLS1.user "<username>"— Replace <username> with the username used by Fetchmail to retrieve messages. This option must precede all other user options.
27.3.3.5. Fetchmail Command Options
fetchmail command mirror the .fetchmailrc configuration options. In this way, Fetchmail may be used with or without a configuration file. These options are not used on the command line by most users because it is easier to leave them in the .fetchmailrc file.
fetchmail command with other options for a particular purpose. It is possible to issue command options to temporarily override a .fetchmailrc setting that is causing an error, as any options specified at the command line override configuration file options.
27.3.3.6. Informational or Debugging Options
fetchmail command can supply important information.
--configdump— Displays every possible option based on information from.fetchmailrcand Fetchmail defaults. No email is retrieved for any users when using this option.-s— Executes Fetchmail in silent mode, preventing any messages, other than errors, from appearing after thefetchmailcommand.-v— Executes Fetchmail in verbose mode, displaying every communication between Fetchmail and remote email servers.-V— Displays detailed version information, lists its global options, and shows settings to be used with each user, including the email protocol and authentication method. No email is retrieved for any users when using this option.
27.3.3.7. Special Options
.fetchmailrc file.
-a— Fetchmail downloads all messages from the remote email server, whether new or previously viewed. By default, Fetchmail only downloads new messages.-k— Fetchmail leaves the messages on the remote email server after downloading them. This option overrides the default behavior of deleting messages after downloading them.-l <max-number-bytes>— Fetchmail does not download any messages over a particular size and leaves them on the remote email server.--quit— Quits the Fetchmail daemon process.
.fetchmailrc options can be found in the fetchmail man page.
27.4. Mail Transport Agent (MTA) Configuration
/bin/mail command to send email containing log messages to the root user of the local system.
sendmail is the default MTA. The Mail Transport Agent Switcher allows for the selection of either sendmail, postfix, or exim as the default MTA for the system.
system-switch-mail RPM package must be installed to use the text-based version of the Mail Transport Agent Switcher program. If you want to use the graphical version, the system-switch-mail-gnome package must also be installed. Note
system-switch-mail at a shell prompt (for example, in an XTerm or GNOME terminal).
system-switch-mail-nox.
Figure 27.1. Mail Transport Agent Switcher
27.5. Mail Delivery Agents
mail. Both of the applications are considered LDAs and both move email from the MTA's spool file into the user's mailbox. However, Procmail provides a robust filtering system.
mail command, consult its man page.
/etc/procmailrc or of a .procmailrc file (also called an rc file) in the user's home directory invokes Procmail whenever an MTA receives a new message.
rc file. If a message matches a recipe, then the email is placed in a specified file, is deleted, or is otherwise processed.
/etc/procmailrc and rc files in the /etc/procmailrcs directory for default, system-wide, Procmail environmental variables and recipes. Procmail then searches for a .procmailrc file in the user's home directory. Many users also create additional rc files for Procmail that are referred to within the .procmailrc file in their home directory.
rc files exist in the /etc/ directory and no .procmailrc files exist in any user's home directory. Therefore, to use Procmail, each user must construct a .procmailrc file with specific environment variables and rules.
27.5.1. Procmail Configuration
.procmailrc in the following format:
<env-variable>="<value>"
<env-variable>="<value>"<env-variable> is the name of the variable and <value> defines the variable.
DEFAULT— Sets the default mailbox where messages that do not match any recipes are placed.The defaultDEFAULTvalue is the same as$ORGMAIL.INCLUDERC— Specifies additionalrcfiles containing more recipes for messages to be checked against. This breaks up the Procmail recipe lists into individual files that fulfill different roles, such as blocking spam and managing email lists, that can then be turned off or on by using comment characters in the user's.procmailrcfile.For example, lines in a user's.procmailrcfile may look like this:MAILDIR=$HOME/Msgs INCLUDERC=$MAILDIR/lists.rc INCLUDERC=$MAILDIR/spam.rc
MAILDIR=$HOME/Msgs INCLUDERC=$MAILDIR/lists.rc INCLUDERC=$MAILDIR/spam.rcCopy to Clipboard Copied! Toggle word wrap Toggle overflow If the user wants to turn off Procmail filtering of their email lists but leave spam control in place, they would comment out the firstINCLUDERCline with a hash mark character (#).LOCKSLEEP— Sets the amount of time, in seconds, between attempts by Procmail to use a particular lockfile. The default is eight seconds.LOCKTIMEOUT— Sets the amount of time, in seconds, that must pass after a lockfile was last modified before Procmail assumes that the lockfile is old and can be deleted. The default is 1024 seconds.LOGFILE— The file to which any Procmail information or error messages are written.MAILDIR— Sets the current working directory for Procmail. If set, all other Procmail paths are relative to this directory.ORGMAIL— Specifies the original mailbox, or another place to put the messages if they cannot be placed in the default or recipe-required location.By default, a value of/var/spool/mail/$LOGNAMEis used.SUSPEND— Sets the amount of time, in seconds, that Procmail pauses if a necessary resource, such as swap space, is not available.SWITCHRC— Allows a user to specify an external file containing additional Procmail recipes, much like theINCLUDERCoption, except that recipe checking is actually stopped on the referring configuration file and only the recipes on theSWITCHRC-specified file are used.VERBOSE— Causes Procmail to log more information. This option is useful for debugging.
LOGNAME, which is the login name; HOME, which is the location of the home directory; and SHELL, which is the default shell.
procmailrc man page.
27.5.2. Procmail Recipes
<flags> section specifies that a lockfile is created for this message. If a lockfile is created, the name can be specified by replacing <lockfile-name> .
* character can further control the condition.
<action-to-perform> specifies the action taken when the message matches one of the conditions. There can only be one action per recipe. In many cases, the name of a mailbox is used here to direct matching messages into that file, effectively sorting the email. Special action characters may also be used before the action is specified. Refer to Section 27.5.2.4, “Special Conditions and Actions” for more information.
27.5.2.1. Delivering vs. Non-Delivering Recipes
{ }, that are performed on messages which match the recipe's conditions. Nesting blocks can be nested inside one another, providing greater control for identifying and performing actions on messages.
27.5.2.2. Flags
A— Specifies that this recipe is only used if the previous recipe without anAoraflag also matched this message.a— Specifies that this recipe is only used if the previous recipe with anAoraflag also matched this message and was successfully completed.B— Parses the body of the message and looks for matching conditions.b— Uses the body in any resulting action, such as writing the message to a file or forwarding it. This is the default behavior.c— Generates a carbon copy of the email. This is useful with delivering recipes, since the required action can be performed on the message and a copy of the message can continue being processed in thercfiles.D— Makes theegrepcomparison case-sensitive. By default, the comparison process is not case-sensitive.E— While similar to theAflag, the conditions in the recipe are only compared to the message if the immediately preceding the recipe without anEflag did not match. This is comparable to an else action.e— The recipe is compared to the message only if the action specified in the immediately preceding recipe fails.f— Uses the pipe as a filter.H— Parses the header of the message and looks for matching conditions. This occurs by default.h— Uses the header in a resulting action. This is the default behavior.w— Tells Procmail to wait for the specified filter or program to finish, and reports whether or not it was successful before considering the message filtered.W— Is identical towexcept that "Program failure" messages are suppressed.
procmailrc man page.
27.5.2.3. Specifying a Local Lockfile
:) after any flags on a recipe's first line. This creates a local lockfile based on the destination file name plus whatever has been set in the LOCKEXT global environment variable.
27.5.2.4. Special Conditions and Actions
* character at the beginning of a recipe's condition line:
!— In the condition line, this character inverts the condition, causing a match to occur only if the condition does not match the message.<— Checks if the message is under a specified number of bytes.>— Checks if the message is over a specified number of bytes.
!— In the action line, this character tells Procmail to forward the message to the specified email addresses.$— Refers to a variable set earlier in thercfile. This is often used to set a common mailbox that is referred to by various recipes.|— Starts a specified program to process the message.{and}— Constructs a nesting block, used to contain additional recipes to apply to matching messages.
27.5.2.5. Recipe Examples
grep man page.
:0: new-mail.spool
:0:
new-mail.spoolLOCKEXT environment variable. No condition is specified, so every message matches this recipe and is placed in the single spool file called new-mail.spool, located within the directory specified by the MAILDIR environment variable. An MUA can then view messages in this file.
rc files to direct messages to a default location.
:0 * ^From: spammer@domain.com /dev/null
:0
* ^From: spammer@domain.com
/dev/nullspammer@domain.com are sent to the /dev/null device, deleting them.
Warning
/dev/null for permanent deletion. If a recipe inadvertently catches unintended messages, and those messages disappear, it becomes difficult to troubleshoot the rule.
/dev/null.
:0: * ^(From|CC|To).*tux-lug tuxlug
:0:
* ^(From|CC|To).*tux-lug
tuxlugtux-lug@domain.com mailing list are placed in the tuxlug mailbox automatically for the MUA. Note that the condition in this example matches the message if it has the mailing list's email address on the From, CC, or To lines.
27.5.2.6. Spam Filters
~/.procmailrc file:
INCLUDERC=/etc/mail/spamassassin/spamassassin-default.rc
INCLUDERC=/etc/mail/spamassassin/spamassassin-default.rc/etc/mail/spamassassin/spamassassin-default.rc contains a simple Procmail rule that activates SpamAssassin for all incoming email. If an email is determined to be spam, it is tagged in the header as such and the title is prepended with the following pattern:
*****SPAM*****
*****SPAM*****:0 Hw * ^X-Spam-Status: Yes spam
:0 Hw
* ^X-Spam-Status: Yes
spamspam.
spamd) and client application (spamc). Configuring SpamAssassin this way, however, requires root access to the host.
spamd daemon, type the following command as root:
service spamassassin start
service spamassassin startsystem-config-services), to turn on the spamassassin service. Refer to Chapter 18, Controlling Access to Services for more information about initscript utilities.
~/.procmailrc file. For a system-wide configuration, place it in /etc/procmailrc:
INCLUDERC=/etc/mail/spamassassin/spamassassin-spamc.rc
INCLUDERC=/etc/mail/spamassassin/spamassassin-spamc.rc27.6. Mail User Agents
mutt.
27.6.1. Securing Communication
mutt offer SSL-encrypted email sessions.
27.6.1.1. Secure Email Clients
27.6.1.2. Securing Email Client Communications
Warning
/etc/pki/tls/certs/ directory and type the following commands as root:
rm -f cyrus-imapd.pem make cyrus-imapd.pem
rm -f cyrus-imapd.pem make cyrus-imapd.pem/etc/pki/tls/certs/ directory, and type the following commands as root:
rm -f ipop3d.pem make ipop3d.pem
rm -f ipop3d.pem make ipop3d.pemImportant
imapd.pem and ipop3d.pem files before issuing each make command.
/etc/imapd.conf file:
tls_cipher_list: TLSv1+HIGH:!aNull:@STRENGTH
tls_cipher_list: TLSv1+HIGH:!aNull:@STRENGTH/sbin/service cyrus-imapd start command to start the Cyrus IMAP and POP daemons.
stunnel command can be used as an SSL encryption wrapper around the standard, non-secure IMAP and POP protocols. In that case, however, you must disable IMAPS and POP3 in the Cyrus configuration file, /etc/cyrus.conf. To do so, comment out the lines containing imaps and pop3s, and restart the cyrus-imapd service.
stunnel program uses external OpenSSL libraries included with Red Hat Enterprise Linux to provide strong cryptography and protect the connections. It is best to apply to a CA to obtain an SSL certificate, but it is also possible to create a self-signed certificate.
/etc/pki/tls/certs/ directory, and type the following command:
make stunnel.pem
make stunnel.pem/etc/stunnel/ directory, in which you can store the configuration file. Although stunnel does not require any special format of the file name or its extension, use /etc/stunnel/stunnel.conf. The following content configures stunnel as a TLS wrapper for secure IMAP and POP:
stunnel /etc/stunnel/stunnel.conf
stunnel /etc/stunnel/stunnel.confstunnel, read the stunnel man page or refer to the documents in the /usr/share/doc/stunnel-<version-number> / directory, where <version-number> is the version number for stunnel.
27.7. Additional Resources
27.7.1. Installed Documentation
- Information on configuring Sendmail is included with the
sendmailandsendmail-cfpackages./usr/share/sendmail-cf/README— Contains information onm4, file locations for Sendmail, supported mailers, how to access enhanced features, and more.
In addition, thesendmailandaliasesman pages contain helpful information covering various Sendmail options and the proper configuration of the Sendmail/etc/mail/aliasesfile. /usr/share/doc/postfix-<version-number>— Contains a large amount of information about ways to configure Postfix. Replace <version-number> with the version number of Postfix./usr/share/doc/fetchmail-<version-number>— Contains a full list of Fetchmail features in theFEATURESfile and an introductoryFAQdocument. Replace <version-number> with the version number of Fetchmail./usr/share/doc/procmail-<version-number>— Contains aREADMEfile that provides an overview of Procmail, aFEATURESfile that explores every program feature, and anFAQfile with answers to many common configuration questions. Replace <version-number> with the version number of Procmail.When learning how Procmail works and creating new recipes, the following Procmail man pages are invaluable:procmail— Provides an overview of how Procmail works and the steps involved with filtering email.procmailrc— Explains thercfile format used to construct recipes.procmailex— Gives a number of useful, real-world examples of Procmail recipes.procmailsc— Explains the weighted scoring technique used by Procmail to match a particular recipe to a message./usr/share/doc/spamassassin-<version-number>/— Contains a large amount of information pertaining to SpamAssassin. Replace <version-number> with the version number of thespamassassinpackage.
27.7.2. Useful Websites
- http://www.sendmail.org/ — Offers a thorough technical breakdown of Sendmail features, documentation and configuration examples.
- http://www.sendmail.com/ — Contains news, interviews and articles concerning Sendmail, including an expanded view of the many options available.
- http://www.postfix.org/ — The Postfix project home page contains a wealth of information about Postfix. The mailing list is a particularly good place to look for information.
- http://fetchmail.berlios.de/ — The home page for Fetchmail, featuring an online manual, and a thorough FAQ.
- http://www.procmail.org/ — The home page for Procmail with links to assorted mailing lists dedicated to Procmail as well as various FAQ documents.
- http://partmaps.org/era/procmail/mini-faq.html — An excellent Procmail FAQ, offers troubleshooting tips, details about file locking, and the use of wildcard characters.
- http://www.uwasa.fi/~ts/info/proctips.html — Contains dozens of tips that make using Procmail much easier. Includes instructions on how to test
.procmailrcfiles and use Procmail scoring to decide if a particular action should be taken. - http://www.spamassassin.org/ — The official site of the SpamAssassin project.
Chapter 28. Lightweight Directory Access Protocol (LDAP)
28.1. Why Use LDAP?
Important
SSLv3 protocol for security. OpenLDAP is one of the system components that do not provide configuration parameters that allow SSLv3 to be effectively disabled. To mitigate the risk, it is recommended that you use the stunnel command to provide a secure tunnel, and disable stunnel from using SSLv3.
28.1.1. OpenLDAP Features
- LDAPv3 Support — OpenLDAP supports Simple Authentication and Security Layer (SASL), and Transport Layer Security (TLS) among other improvements. Many of the changes in the protocol since LDAPv2 are designed to make LDAP more secure.
- IPv6 Support — OpenLDAP supports the next generation Internet Protocol version 6.
- LDAP Over IPC — OpenLDAP can communicate within a system using interprocess communication (IPC). This enhances security by eliminating the need to communicate over a network.
- Updated C API — Improves the way programmers can connect to and use LDAP directory servers.
- LDIFv1 Support — Provides full compliance with the LDAP Data Interchange Format (LDIF) version 1.
- Enhanced Stand-Alone LDAP Server — Includes an updated access control system, thread pooling, better tools, and much more.
28.2. LDAP Terminology
- entry — A single unit within an LDAP directory. Each entry is identified by its unique Distinguished Name (DN).
- attributes — Information directly associated with an entry. For example, an organization could be represented as an LDAP entry. Attributes associated with the organization might include a fax number, an address, and so on. People can also be represented as entries in an LDAP directory, with common attributes such as the person's telephone number and email address.Some attributes are required, while other attributes are optional. An objectclass definition sets which attributes are required for each entry. Objectclass definitions are found in various schema files, located in the
/etc/openldap/schema/directory. For more information, refer to Section 28.5, “The/etc/openldap/schema/Directory”.The assertion of an attribute and its corresponding value is also referred to as a Relative Distinguished Name (RDN). An RDN is only unique per entry, whereas a DN is globally unique. - LDIF — The LDAP Data Interchange Format (LDIF) is an ASCII text representation of LDAP entries. Files used for importing data to LDAP servers must be in LDIF format. An LDIF entry looks similar to the following example:
[<id>] dn: <distinguished name> <attrtype>: <attrvalue> <attrtype>: <attrvalue> <attrtype>: <attrvalue>
[<id>] dn: <distinguished name> <attrtype>: <attrvalue> <attrtype>: <attrvalue> <attrtype>: <attrvalue>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Each entry can contain as many<attrtype>: <attrvalue>pairs as needed. A blank line indicates the end of an entry.Warning
All<attrtype>and<attrvalue>pairs must be defined in a corresponding schema file to use this information.Any value enclosed within a<and a>is a variable and can be set whenever a new LDAP entry is created. This rule does not apply, however, to<id>. The<id>is a number determined by the application used to edit the entry.
28.3. OpenLDAP Daemons and Utilities
openldap— Contains the libraries necessary to run the OpenLDAP server and client applications.openldap-clients— Contains command line tools for viewing and modifying directories on an LDAP server.openldap-servers— Contains the servers and other utilities necessary to configure and run an LDAP server.
openldap-servers package: the Standalone LDAP Daemon (/usr/sbin/slapd) and the Standalone LDAP Update Replication Daemon (/usr/sbin/slurpd).
slapd daemon is the standalone LDAP server while the slurpd daemon is used to synchronize changes from one LDAP server to other LDAP servers on the network. The slurpd daemon is only used when dealing with multiple LDAP servers.
openldap-servers package installs the following utilities into the /usr/sbin/ directory:
slapadd— Adds entries from an LDIF file to an LDAP directory. For example, the command/usr/sbin/slapadd -l ldif-inputreads in the LDIF file,ldif-input, containing the new entries.Important
Only the root user may use/usr/sbin/slapadd. However, the directory server runs as theldapuser. Therefore the directory server is unable to modify any files created byslapadd. To correct this issue, after usingslapadd, type the following command:chown -R ldap /var/lib/ldap
chown -R ldap /var/lib/ldapCopy to Clipboard Copied! Toggle word wrap Toggle overflow slapcat— Pulls entries from an LDAP directory in the default format, Sleepycat Software's Berkeley DB system, and saves them in an LDIF file. For example, the command/usr/sbin/slapcat -l ldif-outputoutputs an LDIF file calledldif-outputcontaining the entries from the LDAP directory.slapindex— Re-indexes theslapddirectory based on the current content. This tool should be run whenever indexing options within/etc/openldap/slapd.confare changed.slappasswd— Generates an encrypted user password value for use withldapmodifyor therootpwvalue in theslapdconfiguration file,/etc/openldap/slapd.conf. Execute the/usr/sbin/slappasswdcommand to create the password.
Warning
slapd by issuing the /sbin/service ldap stop command before using slapadd, slapcat or slapindex. Otherwise, the integrity of the LDAP directory is at risk.
openldap-clients package installs tools into /usr/bin/ which are used to add, modify, and delete entries in an LDAP directory. These tools include the following:
ldapadd— Adds entries to an LDAP directory by accepting input via a file or standard input;ldapaddis actually a hard link toldapmodify -a.ldapdelete— Deletes entries from an LDAP directory by accepting user input at a shell prompt or via a file.ldapmodify— Modifies entries in an LDAP directory, accepting input via a file or standard input.ldappasswd— Sets the password for an LDAP user.ldapsearch— Searches for entries in an LDAP directory using a shell prompt.ldapcompare— Opens a connection to an LDAP server, binds, and performs a comparison using specified parameters.ldapwhoami— Opens a connection to an LDAP server, binds, and performs awhoamioperation.ldapmodrdn— Opens a connection to an LDAP server, binds, and modifies the RDNs of entries.
ldapsearch, each of these utilities is more easily used by referencing a file containing the changes to be made rather than typing a command for each entry to be changed within an LDAP directory. The format of such a file is outlined in the man page for each utility.
28.3.1. NSS, PAM, and LDAP
nss_ldap, which enhances LDAP's ability to integrate into both Linux and other UNIX environments.
nss_ldap package provides the following modules (where <version> refers to the version of libnss_ldap in use):
/lib/libnss_ldap-<version>.so/lib/security/pam_ldap.so
nss_ldap package provides the following modules for Itanium or AMD64 architectures:
/lib64/libnss_ldap-<version>.so/lib64/security/pam_ldap.so
libnss_ldap-<version>.so module allows applications to look up users, groups, hosts, and other information using an LDAP directory via the Nameservice Switch (NSS) interface of glibc. NSS allows applications to authenticate using LDAP in conjunction with the NIS name service and flat authentication files.
pam_ldap module allows PAM-aware applications to authenticate users using information stored in an LDAP directory. PAM-aware applications include console login, POP and IMAP mail servers, and Samba. By deploying an LDAP server on a network, all of these applications can authenticate using the same user ID and password combination, greatly simplifying administration.
28.3.2. PHP4, LDAP, and the Apache HTTP Server
php-ldap package adds LDAP support to the PHP4 HTML-embedded scripting language via the /usr/lib/php4/ldap.so module. This module allows PHP4 scripts to access information stored in an LDAP directory.
mod_authz_ldap module for the Apache HTTP Server. This module uses the short form of the distinguished name for a subject and the issuer of the client SSL certificate to determine the distinguished name of the user within an LDAP directory. It is also capable of authorizing users based on attributes of that user's LDAP directory entry, determining access to assets based on the user and group privileges of the asset, and denying access for users with expired passwords. The mod_ssl module is required when using the mod_authz_ldap module.
Important
mod_authz_ldap module does not authenticate a user to an LDAP directory using an encrypted password hash. This functionality is provided by the experimental mod_auth_ldap module, which is not included with Red Hat Enterprise Linux. Refer to the Apache Software Foundation website online at http://www.apache.org/ for details on the status of this module.
28.3.3. LDAP Client Applications
28.4. OpenLDAP Configuration Files
/etc/openldap/ directory. The following is a brief list highlighting the most important directories and files:
/etc/openldap/ldap.conf— This is the configuration file for all client applications which use the OpenLDAP libraries such asldapsearch,ldapadd, Sendmail, Evolution, and Gnome Meeting./etc/openldap/slapd.conf— This is the configuration file for theslapddaemon. Refer to Section 28.6.1, “Editing/etc/openldap/slapd.conf” for more information./etc/openldap/schema/directory — This subdirectory contains the schema used by theslapddaemon. Refer to Section 28.5, “The/etc/openldap/schema/Directory” for more information.
Note
nss_ldap package is installed, it creates a file named /etc/ldap.conf. This file is used by the PAM and NSS modules supplied by the nss_ldap package. Refer to Section 28.7, “Configuring a System to Authenticate Using OpenLDAP” for more information.
28.5. The /etc/openldap/schema/ Directory
/etc/openldap/schema/ directory holds LDAP definitions, previously located in the slapd.at.conf and slapd.oc.conf files. The /etc/openldap/schema/redhat/ directory holds customized schemas distributed by Red Hat for Red Hat Enterprise Linux.
/etc/openldap/slapd.conf using include lines, as shown in this example:
Warning
local.schema file in the /etc/openldap/schema/ directory. Reference this new schema within slapd.conf by adding the following line below the default include schema lines:
include /etc/openldap/schema/local.schema
include /etc/openldap/schema/local.schemalocal.schema file. Many organizations use existing attribute types from the schema files installed by default and add new object classes to the local.schema file.
28.6. OpenLDAP Setup Overview
- http://www.openldap.org/doc/admin/quickstart.html — The Quick-Start Guide on the OpenLDAP website.
- http://www.tldp.org/HOWTO/LDAP-HOWTO/index.html — The LDAP Linux HOWTO from the Linux Documentation Project.
- Install the
openldap,openldap-servers, andopenldap-clientsRPMs. - Edit the
/etc/openldap/slapd.conffile to specify the LDAP domain and server. Refer to Section 28.6.1, “Editing/etc/openldap/slapd.conf” for more information. - Start
slapdwith the command:service ldap start
service ldap startCopy to Clipboard Copied! Toggle word wrap Toggle overflow After configuring LDAP, usechkconfig,/usr/sbin/ntsysv, or the Services Configuration Tool to configure LDAP to start at boot time. For more information about configuring services, refer to Chapter 18, Controlling Access to Services. - Add entries to an LDAP directory with
ldapadd. - Use
ldapsearchto determine ifslapdis accessing the information correctly. - At this point, the LDAP directory should be functioning properly and can be configured with LDAP-enabled applications.
28.6.1. Editing /etc/openldap/slapd.conf
slapd LDAP server, modify its configuration file, /etc/openldap/slapd.conf, to specify the correct domain and server.
suffix line names the domain for which the LDAP server provides information and should be changed from:
suffix "dc=your-domain,dc=com"
suffix "dc=your-domain,dc=com"suffix "dc=example,dc=com"
suffix "dc=example,dc=com"rootdn entry is the Distinguished Name (DN) for a user who is unrestricted by access controls or administrative limit parameters set for operations on the LDAP directory. The rootdn user can be thought of as the root user for the LDAP directory. In the configuration file, change the rootdn line from its default value as in the following example:
rootdn "cn=root,dc=example,dc=com"
rootdn "cn=root,dc=example,dc=com"rootpw line — replacing the default value with an encrypted password string. To create an encrypted password string, type the following command:
slappasswd
slappasswd/etc/openldap/slapd.conf on one of the rootpw lines and remove the hash mark (#).
rootpw {SSHA}vv2y+i6V6esazrIv70xSSnNAJE18bb2u
rootpw {SSHA}vv2y+i6V6esazrIv70xSSnNAJE18bb2uWarning
rootpw directive specified in /etc/openldap/slapd.conf, are sent over the network unencrypted, unless TLS encryption is enabled.
/etc/openldap/slapd.conf and refer to the man page for slapd.conf.
rootpw directive should be commented out after populating the LDAP directory by preceding it with a hash mark (#).
/usr/sbin/slapadd command line tool locally to populate the LDAP directory, use of the rootpw directive is not necessary.
Important
/usr/sbin/slapadd. However, the directory server runs as the ldap user. Therefore, the directory server is unable to modify any files created by slapadd. To correct this issue, after using slapadd, type the following command:
chown -R ldap /var/lib/ldap
chown -R ldap /var/lib/ldap28.7. Configuring a System to Authenticate Using OpenLDAP
First, make sure that the appropriate packages are installed on both the LDAP server and the LDAP client machines. The LDAP server needs the openldap-servers package.
openldap, openldap-clients, and nss_ldap packages need to be installed on all LDAP client machines.
- On the server, edit the
/etc/openldap/slapd.conffile on the LDAP server to make sure it matches the specifics of the organization. Refer to Section 28.6.1, “Editing/etc/openldap/slapd.conf” for instructions about editingslapd.conf. - On the client machines, both
/etc/ldap.confand/etc/openldap/ldap.confneed to contain the proper server and search base information for the organization.To do this, run the graphical Authentication Configuration Tool (system-config-authentication) and select Enable LDAP Support under the User Information tab.It is also possible to edit these files by hand. - On the client machines, the
/etc/nsswitch.confmust be edited to use LDAP.To do this, run the Authentication Configuration Tool (system-config-authentication) and select Enable LDAP Support under the User Information tab.If editing/etc/nsswitch.confby hand, addldapto the appropriate lines.For example:passwd: files ldap shadow: files ldap group: files ldap
passwd: files ldap shadow: files ldap group: files ldapCopy to Clipboard Copied! Toggle word wrap Toggle overflow
28.7.1. PAM and LDAP
system-config-authentication) and select Enable LDAP Support under the Authentication tab. For more about configuring PAM, refer to Section 48.4, “Pluggable Authentication Modules (PAM)” and the PAM man pages.
28.7.2. Migrating Old Authentication Information to LDAP Format
/usr/share/openldap/migration/ directory contains a set of shell and Perl scripts for migrating authentication information into an LDAP format.
Note
migrate_common.ph file so that it reflects the correct domain. The default DNS domain should be changed from its default value to something like:
$DEFAULT_MAIL_DOMAIN = "example";
$DEFAULT_MAIL_DOMAIN = "example";$DEFAULT_BASE = "dc=example,dc=com";
$DEFAULT_BASE = "dc=example,dc=com";README and the migration-tools.txt files in the /usr/share/openldap/migration/ directory provide more details on how to migrate the information.
| Existing name service | Is LDAP running? | Script to Use |
|---|---|---|
/etc flat files | yes | migrate_all_online.sh |
/etc flat files | no | migrate_all_offline.sh |
| NetInfo | yes | migrate_all_netinfo_online.sh |
| NetInfo | no | migrate_all_netinfo_offline.sh |
| NIS (YP) | yes | migrate_all_nis_online.sh |
| NIS (YP) | no | migrate_all_nis_offline.sh |
28.8. Migrating Directories from Earlier Releases
- Before upgrading the operating system, run the command
/usr/sbin/slapcat -l ldif-output. This outputs an LDIF file calledldif-outputcontaining the entries from the LDAP directory. - Upgrade the operating system, being careful not to reformat the partition containing the LDIF file.
- Re-import the LDAP directory to the upgraded Berkeley DB format by executing the command
/usr/sbin/slapadd -l ldif-output.
28.9. Additional Resources
28.9.1. Installed Documentation
/usr/share/docs/openldap-<versionnumber>/directory — Contains a generalREADMEdocument and miscellaneous information.- LDAP related man pages — There are a number of man pages for the various applications and configuration files involved with LDAP. The following is a list of some of the more important man pages.
- Client Applications
man ldapadd— Describes how to add entries to an LDAP directory.man ldapdelete— Describes how to delete entries within an LDAP directory.man ldapmodify— Describes how to modify entries within an LDAP directory.man ldapsearch— Describes how to search for entries within an LDAP directory.man ldappasswd— Describes how to set or change the password of an LDAP user.man ldapcompare— Describes how to use theldapcomparetool.man ldapwhoami— Describes how to use theldapwhoamitool.man ldapmodrdn— Describes how to modify the RDNs of entries.
- Server Applications
man slapd— Describes command line options for the LDAP server.man slurpd— Describes command line options for the LDAP replication server.
- Administrative Applications
man slapadd— Describes command line options used to add entries to aslapddatabase.man slapcat— Describes command line options used to generate an LDIF file from aslapddatabase.man slapindex— Describes command line options used to regenerate an index based upon the contents of aslapddatabase.man slappasswd— Describes command line options used to generate user passwords for LDAP directories.
- Configuration Files
man ldap.conf— Describes the format and options available within the configuration file for LDAP clients.man slapd.conf— Describes the format and options available within the configuration file referenced by both the LDAP server applications (slapdandslurpd) and the LDAP administrative tools (slapadd,slapcat, andslapindex).
28.9.2. Useful Websites
- http://www.openldap.org/ — Home of the OpenLDAP Project. This website contains a wealth of information about configuring OpenLDAP as well as a future roadmap and version changes.
- http://www.kingsmountain.com/ldapRoadmap.shtml — Jeff Hodges' LDAP Road Map contains links to several useful FAQs and emerging news concerning the LDAP protocol.
- http://www.ldapman.org/articles/ — Articles that offer a good introduction to LDAP, including methods to design a directory tree and customizing directory structures.
Chapter 29. Authentication Configuration
Note
system-config-authentication at a shell prompt (for example, in an XTerm or a GNOME terminal).
Important
29.1. User Information
Figure 29.1. User Information
The Enable NIS Support option configures the system to connect to an NIS server (as an NIS client) for user and password authentication. Click the button to specify the NIS domain and NIS server. If the NIS server is not specified, the daemon attempts to find it via broadcast.
ypbind package must be installed for this option to work. If NIS support is enabled, the portmap and ypbind services are started and are also enabled to start at boot time.
The Enable LDAP Support option instructs the system to retrieve user information via LDAP. Click the button to specify the following:
- LDAP Search Base DN — Specifies that user information should be retrieved using the listed Distinguished Name (DN).
- LDAP Server — Specifies the IP address of the LDAP server.
- Use TLS to encrypt connections — When enabled, Transport Layer Security will be used to encrypt passwords sent to the LDAP server. The option allows you to specify a URL from which to download a valid CA (Certificate Authority) Certificate. A valid CA Certificate must be in PEM (Privacy Enhanced Mail) format.For more information about CA Certificates, refer to Section 25.8.2, “An Overview of Certificates and Security”.
openldap-clients package must be installed for this option to work.
The Enable Hesiod Support option configures the system to retrieve information (including user information) from a remote Hesiod database. Click the button to specify the following:
- Hesiod LHS — Specifies the domain prefix used for Hesiod queries.
- Hesiod RHS — Specifies the default Hesiod domain.
hesiod package must be installed for this option to work.
man hesiod. You can also refer to the hesiod.conf man page (man hesiod.conf) for more information on LHS and RHS.
The Enable Winbind Support option configures the system to connect to a Windows Active Directory or a Windows domain controller. User information from the specified directory or domain controller can then be accessed, and server authentication options can be configured. Click the button to specify the following:
- Winbind Domain — Specifies the Windows Active Directory or domain controller to connect to.
- Security Model — Allows you to select a security model, which configures how clients should respond to Samba. The drop-down list allows you select any of the following:
- user — This is the default mode. With this level of security, a client must first log in with a valid username and password. Encrypted passwords can also be used in this security mode.
- server — In this mode, Samba will attempt to validate the username/password by authenticating it through another SMB server (for example, a Windows NT Server). If the attempt fails, the user mode will take effect instead.
- domain — In this mode, Samba will attempt to validate the username/password by authenticating it through a Windows NT Primary or Backup Domain Controller, similar to how a Windows NT Server would.
- ads — This mode instructs Samba to act as a domain member in an Active Directory Server (ADS) realm. To operate in this mode, the
krb5-serverpackage must be installed, and Kerberos must be configured properly.
- Winbind ADS Realm — When the ads Security Model is selected, this allows you to specify the ADS Realm the Samba server should act as a domain member of.
- Winbind Domain Controllers — Use this option to specify which domain controller
winbindshould use. For more information about domain controllers, please refer to Section 22.6.3, “Domain Controller”. - Template Shell — When filling out the user information for a Windows NT user, the
winbindddaemon uses the value chosen here to to specify the login shell for that user.
winbind service, refer to winbindd under Section 22.2, “Samba Daemons and Related Services”.
29.2. Authentication
Figure 29.2. Authentication
The Enable Kerberos Support option enables Kerberos authentication. Click the button to open the dialogue and configure the following:
- Realm — Configures the realm for the Kerberos server. The realm is the network that uses Kerberos, composed of one or more KDCs and a potentially large number of clients.
- KDC — Defines the Key Distribution Center (KDC), which is the server that issues Kerberos tickets.
- Admin Servers — Specifies the administration server(s) running
kadmind.
krb5-libs and krb5-workstation packages must be installed for this option to work. For more information about Kerberos, refer to Section 48.6, “Kerberos”.
The Enable LDAP Support option instructs standard PAM-enabled applications to use LDAP for authentication. The button allows you to configure LDAP support with options identical to those present in Configure LDAP... under the tab. For more information about these options, refer to Section 29.1, “User Information”.
openldap-clients package must be installed for this option to work.
The Enable Smart Card Support option enables Smart Card authentication. This allows users to log in using a certificate and key associated stored on a smart card. Click the button for more options.
pam_pkcs11 and coolkey packages must be installed for this option to work. For more information about smart cards, refer to Section 48.3.1.3, “Supported Smart Cards” under Section 48.3, “Single Sign-on (SSO)”.
The Enable SMB Support option configures PAM to use a Server Message Block (SMB) server to authenticate users. SMB refers to a client-server protocol used for cross-system communication; it is also the protocol used by Samba to appear as a Windows server to Windows clients. Click the button to specify the following:
- Workgroup — Specifies the SMB workgroup to use.
- Domain Controllers — Specifies the SMB domain controllers to use.
The Enable Winbind Support option configures the system to connect to a Windows Active Directory or a Windows domain controller. User information from the specified directory or domain controller can then be accessed, and server authentication options can be configured.
29.3. Options
Figure 29.3. Options
Select this option to enable the name service cache daemon (nscd) and configure it to start at boot time.
nscd package must be installed for this option to work. For more information about nscd, refer to its man page using the command man nscd.
Select this option to store passwords in shadow password format in the /etc/shadow file instead of /etc/passwd. Shadow passwords are enabled by default during installation and are highly recommended to increase the security of the system.
shadow-utils package must be installed for this option to work. For more information about shadow passwords, refer to Section 37.6, “Shadow Passwords”.
Select this option to enable MD5 passwords, which allows passwords to be up to 256 characters instead of eight characters or less. It is selected by default during installation and is highly recommended for increased security.
29.4. Command Line Version
Note
authconfig man page or by typing authconfig --help at a shell prompt.
| Option | Description |
|---|---|
--enableshadow | Enable shadow passwords |
--disableshadow | Disable shadow passwords |
--enablemd5 | Enable MD5 passwords |
--disablemd5 | Disable MD5 passwords |
--enablenis | Enable NIS |
--disablenis | Disable NIS |
--nisdomain=<domain> | Specify NIS domain |
--nisserver=<server> | Specify NIS server |
--enableldap | Enable LDAP for user information |
--disableldap | Disable LDAP for user information |
--enableldaptls | Enable use of TLS with LDAP |
--disableldaptls | Disable use of TLS with LDAP |
--enableldapauth | Enable LDAP for authentication |
--disableldapauth | Disable LDAP for authentication |
--ldapserver=<server> | Specify LDAP server |
--ldapbasedn=<dn> | Specify LDAP base DN |
--enablekrb5 | Enable Kerberos |
--disablekrb5 | Disable Kerberos |
--krb5kdc=<kdc> | Specify Kerberos KDC |
--krb5adminserver=<server> | Specify Kerberos administration server |
--krb5realm=<realm> | Specify Kerberos realm |
--enablekrb5kdcdns | Enable use of DNS to find Kerberos KDCs |
--disablekrb5kdcdns | Disable use of DNS to find Kerberos KDCs |
--enablekrb5realmdns | Enable use of DNS to find Kerberos realms |
--disablekrb5realmdns | Disable use of DNS to find Kerberos realms |
--enablesmbauth | Enable SMB |
--disablesmbauth | Disable SMB |
--smbworkgroup=<workgroup> | Specify SMB workgroup |
--smbservers=<server> | Specify SMB servers |
--enablewinbind | Enable winbind for user information by default |
--disablewinbind | Disable winbind for user information by default |
--enablewinbindauth | Enable winbindauth for authentication by default |
--disablewinbindauth | Disable winbindauth for authentication by default |
--smbsecurity=<user|server|domain|ads> | Security mode to use for Samba and winbind |
--smbrealm=<STRING> | Default realm for Samba and winbind when security=ads |
--smbidmapuid=<lowest-highest> | UID range winbind assigns to domain or ADS users |
--smbidmapgid=<lowest-highest> | GID range winbind assigns to domain or ADS users |
--winbindseparator=<\> | Character used to separate the domain and user part of winbind usernames if winbindusedefaultdomain is not enabled |
--winbindtemplatehomedir=</home/%D/%U> | Directory that winbind users have as their home |
--winbindtemplateprimarygroup=<nobody> | Group that winbind users have as their primary group |
--winbindtemplateshell=</bin/false> | Shell that winbind users have as their default login shell |
--enablewinbindusedefaultdomain | Configures winbind to assume that users with no domain in their usernames are domain users |
--disablewinbindusedefaultdomain | Configures winbind to assume that users with no domain in their usernames are not domain users |
--winbindjoin=<Administrator> | Joins the winbind domain or ADS realm now as this administrator |
--enablewins | Enable WINS for hostname resolution |
--disablewins | Disable WINS for hostname resolution |
--enablehesiod | Enable Hesiod |
--disablehesiod | Disable Hesiod |
--hesiodlhs=<lhs> | Specify Hesiod LHS |
--hesiodrhs=<rhs> | Specify Hesiod RHS |
--enablecache | Enable nscd |
--disablecache | Disable nscd |
--nostart | Do not start or stop the portmap, ypbind, or nscd services even if they are configured |
--kickstart | Do not display the user interface |
--probe | Probe and display network defaults |
Chapter 30. Using and Caching Credentials with SSSD
- Reducing the load on identification/authentication servers. Rather than having every client service attempt to contact the identification server directly, all of the local clients can contact SSSD which can connect to the identification server or check its cache.
- Permitting offline authentication. SSSD can optionally keep a cache of user identities and credentials that it retrieves from remote services. This allows users to authenticate to resources successfully, even if the remote identification server is offline or the local machine is offline.
- Using a single user account. Remote users frequently have two (or even more) user accounts, such as one for their local system and one for the organizational system. This is necessary to connect to a virtual private network (VPN). Because SSSD supports caching and offline authentication, remote users can connect to network resources simply by authenticating to their local machine and then SSSD maintains their network credentials.
30.1. About the sssd.conf File
.conf file. The default file is /etc/sssd/sssd.conf, although alternative files can be passed to SSSD by using the -c option with the sssd command:
sssd -c /etc/sssd/customfile.conf
# sssd -c /etc/sssd/customfile.conf[domain/LDAP]. The configuration file uses simple key = value lines to set the configuration. Comment lines are set by either a hash sign (#) or a semicolon (;)
[section] # Comment line key1 = val1 key10 = val1,val2
[section]
# Comment line
key1 = val1
key10 = val1,val2
30.2. Starting and Stopping SSSD
Note
service command or the /etc/init.d/sssd script can start SSSD. For example:
service sssd start
# service sssd startchkconfig command:
chkconfig sssd on
[root@server ~]# chkconfig sssd on30.3. Configuring SSSD to Work with System Services
sssd.conf file. on sections. The [sssd] section also lists the services that are active and should be started when sssd starts within the services directive.
- A Name Service Switch (NSS) provider service that answers name service requests from the
sssd_nssmodule. This is configured in the[nss]section of the SSSD configuration. - A PAM provider service that manages a PAM conversation through the
sssd_pammodule. This is configured in the[pam]section of the configuration. monitor, a special service that monitors and starts or restarts all other SSSD services. Its options are specified in the[sssd]section of the/etc/sssd/sssd.confconfiguration file.
Note
lookup family order option in the sssd.conf configuration file.
30.3.1. Configuring NSS Services
sssd_nss, which instructs the system to use SSSD to retrieve user information. The NSS configuration must include a reference to the SSSD module, and then the SSSD configuration sets how SSSD interacts with NSS.
30.3.1.1. About NSS Service Maps and SSSD
- Passwords (
passwd) - User groups (
shadow) - Groups (
groups) - Netgroups (
netgroups)
30.3.1.2. Configuring NSS Services to Use SSSD
nss_sss module has to be included for the desired service type.
nsswitch.conf file to use SSSD as a provider.
authconfig --enablesssd --update
[root@server ~]# authconfig --enablesssd --updatepasswd: files sss shadow: files sss group: files sss netgroup: files sss
passwd: files sss
shadow: files sss
group: files sss
netgroup: files sss30.3.1.3. Configuring SSSD to Work with NSS
[nss] services section.
- Open the
sssd.conffile.vim /etc/sssd/sssd.conf
[root@server ~]# vim /etc/sssd/sssd.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Make sure that NSS is listed as one of the services that works with SSSD.
[sssd] config_file_version = 2 reconnection_retries = 3 sbus_timeout = 30 services = nss, pam
[sssd] config_file_version = 2 reconnection_retries = 3 sbus_timeout = 30 services = nss, pamCopy to Clipboard Copied! Toggle word wrap Toggle overflow - In the
[nss]section, change any of the NSS parameters. These are listed in Table 30.1, “SSSD [nss] Configuration Parameters”.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Restart SSSD.
service sssd restart
[root@server ~]# service sssd restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow
| Parameter | Value Format | [root@server ~] Description |
|---|---|---|
| enum_cache_timeout | integer | Specifies how long, in seconds, sssd_nss should cache requests for information about all users (enumerations). |
| entry_cache_nowait_percentage | integer | Specifies how long sssd_nss should return cached entries before refreshing the cache. Setting this to zero (0) disables the entry cache refresh.
This configures the entry cache to update entries in the background automatically if they are requested if the time before the next update is a certain percentage of the next interval. For example, if the interval is 300 seconds and the cache percentage is 75, then the entry cache will begin refreshing when a request comes in at 225 seconds — 75% of the interval.
The allowed values for this option are 0 to 99, which sets the percentage based on the
entry_cache_timeout value. The default value is 50%.
|
| entry_negative_timeout | integer | Specifies how long, in seconds, sssd_nss should cache negative cache hits. A negative cache hit is a query for an invalid database entries, including non-existent entries. |
| filter_users, filter_groups | string | Tells SSSD to exclude certain users from being fetched from the NSS database. This is particularly useful for system accounts such as root. |
| filter_users_in_groups | Boolean | Sets whether users listed in the filter_users list appear in group memberships when performing group lookups. If set to false, group lookups return all users that are members of that group. If not specified, this value defaults to true, which filters the group member lists. |
30.3.2. Configuring the PAM Service
Warning
sssd_pam, which instructs the system to use SSSD to retrieve user information. The PAM configuration must include a reference to the SSSD module, and then the SSSD configuration sets how SSSD interacts with PAM.
- The Authentication Configuration tool automatically writes to the
/etc/pam.d/system-auth-acfile, which is symlinked to/etc/pam.d/system-auth. Any changes made to/etc/pam.d/system-authare overwritten the next time thatauthconfigis run.So, remove the/etc/pam.d/system-authsymlink.rm /etc/pam.d/system-auth rm: remove symbolic link `/etc/pam.d/system-auth'? y
[root@server ~]# rm /etc/pam.d/system-auth rm: remove symbolic link `/etc/pam.d/system-auth'? yCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Create a new
/etc/pam.d/system-auth-localfile. One easy way to do this is simply to copy the/etc/pam.d/system-auth-acfile.cp /etc/pam.d/system-auth-ac /etc/pam.d/system-auth-local
[root@server ~]# cp /etc/pam.d/system-auth-ac /etc/pam.d/system-auth-localCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Create a new symlink between the
/etc/pam.d/system-auth-localfile and/etc/pam.d/system-auth.ln -s /etc/pam.d/system-auth-local /etc/pam.d/system-auth
[root@server ~]# ln -s /etc/pam.d/system-auth-local /etc/pam.d/system-authCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Edit the
/etc/pam.d/system-auth-localfile, and add all of the SSSD modules to the PAM configuration:Copy to Clipboard Copied! Toggle word wrap Toggle overflow These modules can be set toincludestatements, as necessary. - Open the
sssd.conffile.vim /etc/sssd/sssd.conf
# vim /etc/sssd/sssd.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Make sure that PAM is listed as one of the services that works with SSSD.
[sssd] config_file_version = 2 reconnection_retries = 3 sbus_timeout = 30 services = nss, pam
[sssd] config_file_version = 2 reconnection_retries = 3 sbus_timeout = 30 services = nss, pamCopy to Clipboard Copied! Toggle word wrap Toggle overflow - In the
[pam]section, change any of the PAM parameters. These are listed in Table 30.2, “SSSD [pam] Configuration Parameters”.[pam] reconnection_retries = 3 offline_credentials_expiration = 2 offline_failed_login_attempts = 3 offline_failed_login_delay = 5
[pam] reconnection_retries = 3 offline_credentials_expiration = 2 offline_failed_login_attempts = 3 offline_failed_login_delay = 5Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Restart SSSD.
service sssd restart
[root@server ~]# service sssd restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow
| Parameter | Value Format | Description |
|---|---|---|
| offline_credentials_expiration | integer | Sets how long, in days, to allow cached logins if the authentication provider is offline. This value is measured from the last successful online login. If not specified, this defaults to zero (0), which is unlimited. |
| offline_failed_login_attempts | integer | Sets how many failed login attempts are allowed if the authentication provider is offline. If not specified, this defaults to zero (0), which is unlimited. |
| offline_failed_login_delay | integer | Sets how long to prevent login attempts if a user hits the failed login attempt limit. If set to zero (0), the user cannot authenticate while the provider is offline once he hits the failed attempt limit. Only a successful online authentication can re-enable offline authentication. If not specified, this defaults to five (5). |
30.4. Creating Domains
jsmith in the ldap.example.com domain and jsmith in the ldap.otherexample.com domain. SSSD allows requests using fully-qualified domain names, so requesting information for jsmith@ldap.example.com returns the proper user account. Specifying only the username returns the user for whichever domain comes first in the lookup order.
Note
filter_users option, which excludes the specified users from being returned in a search.
| Identification Provider | Authentication Provider |
|---|---|
| LDAP | LDAP |
| LDAP | Kerberos |
| proxy | LDAP |
| proxy | Kerberos |
| proxy | proxy |
30.4.1. General Rules and Options for Configuring a Domain
| Parameter | Value Format | Description |
|---|---|---|
| id_provider | string | Specifies the data provider identity backend to use for this domain. The supported identity backends are:
|
| auth_provider | string | Sets the authentication provider used for the domain. The default value for this option is the value of id_provider. The supported authentication providers are ldap, ipa, krb5 (Kerberos), proxy, and none. |
| min_id,max_id | integer | Optional. Specifies the UID and GID range for the domain. If a domain contains entries that are outside that range, they are ignored. The default value for min_id is 1; the default value for max_id is 0, which is unlimited.
Important
The default min_id value is the same for all types of identity provider. If LDAP directories are using UID numbers that start at one, it could cause conflicts with users in the local /etc/passwd file. To avoid these conflicts, set min_id to 1000 or higher as possible.
|
| enumerate | Boolean | Optional. Specifies whether to list the users and groups of a domain. Enumeration means that the entire set of available users and groups on the remote source is cached on the local machine. When enumeration is disabled, users and groups are only cached as they are requested.
Warning
When enumeration is enabled, reinitializing a client results in a complete refresh of the entire set of available users and groups from the remote source. Similarly, when SSSD is connected to a new server, the entire set of available users and groups from the remote source is pulled and cached on the local machine. In a domain with a large number of clients connected to a remote source, this refresh process can harm the network performance because of frequent queries from the clients. If the set of available users and groups is large enough, it degrades client performance as well.
false, which disables enumeration. |
| cache_credentials | Boolean | Optional. Specifies whether to store user credentials in the local SSSD domain database cache. The default value for this parameter is false. Set this value to true for domains other than the LOCAL domain to enable offline authentication. |
| entry_cache_timeout | integer | Optional. Specifies how long, in seconds, SSSD should cache positive cache hits. A positive cache hit is a successful query. |
| use_fully_qualified_names | Boolean | Optional. Specifies whether requests to this domain require fully-qualified domain names. If set to true, all requests to this domain must use fully-qualified domain names. It also means that the output from the request displays the fully-qualified name. Restricting requests to fully-qualified user names allows SSSD to differentiate between domains with users with conflicting usernames.
If
use_fully_qualified_names is set to false, it is possible to use the fully-qualified name in the requests, but only the simplified version is displayed in the output.
SSSD can only parse names based on the domain name, not the realm name. The same name can be used for both domains and realms, however.
|
30.4.2. Configuring an LDAP Domain
- Red Hat Directory Server
- OpenLDAP
- Microsoft Active Directory 2008, with Subsystem for UNIX-based Applications
Note
30.4.2.1. Parameters for Configuring an LDAP Domain
Note
sssd-ldap(5).
| Parameter | Description |
|---|---|
| ldap_uri | Gives a comma-separated list of the URIs of the LDAP servers to which SSSD will connect. The list is given in order of preference, so the first server in the list is tried first. Listing additional servers provides failover protection. This can be detected from the DNS SRV records if it is not given. |
| ldap_search_base | Gives the base DN to use for performing LDAP user operations. |
| ldap_tls_reqcert | Specifies how to check for SSL server certificates in a TLS session. There are four options:
|
| ldap_tls_cacert | Gives the full path and file name to the file that contains the CA certificates for all of the CAs that SSSD recognizes. SSSD will accept any certificate issued by these CAs.
This uses the OpenLDAP system defaults if it is not given explicitly.
|
| ldap_referrals | Sets whether SSSD will use LDAP referrals, meaning forwarding queries from one LDAP database to another. SSSD supports database-level and subtree referrals. For referrals within the same LDAP server, SSSD will adjust the DN of the entry being queried. For referrals that go to different LDAP servers, SSSD does an exact match on the DN. Setting this value to true enables referrals. This is the default. |
| ldap_schema | Sets what version of schema to use when searching for user entries. This can be either rfc2307 or rfc2307bis. The default is rfc2307.
In RFC 2307, group objects use a multi-valued attribute,
memberuid, which lists the names of the users that belong to that group. In RFC 2307bis, group objects use the member attribute, which contains the full distinguished name (DN) of a user or group entry. RFC 2307bis allows nested groups usning the member attribute. Because these different schema use different definitions for group membership, using the wrong LDAP schema with SSSD can affect both viewing and managing network resources, even if the appropriate permissions are in place.
For example, with RFC 2307bis, all groups are returned when using nested groups or primary/secondary groups.
id uid=500(myserver) gid=500(myserver) groups=500(myserver),510(myothergroup)
If SSSD is using RFC 2307 schema, only the primary group is returned.
This setting only affects how SSSD determines the group members. It does not change the actual user data.
|
| ldap_search_timeout | Sets the time, in seconds, that LDAP searches are allowed to run before they are canceled and cached results are returned. This defaults to five when the enumerate value is false and defaults to 30 when enumerate is true.
When an LDAP search times out, SSSD automatically switches to offline mode.
|
| ldap_network_timeout | Sets the time, in seconds, SSSD attempts to poll an LDAP server after a connection attempt fails. The default is six seconds. |
| ldap_opt_timeout | Sets the time, in seconds, to wait before aborting synchronous LDAP operations if no response is received from the server. This option also controls the timeout when communicating with the KDC in case of a SASL bind. The default is five seconds. |
30.4.2.2. LDAP Domain Example
Note
sssd.conf file. For example:
domains = LOCAL,LDAP1,AD,PROXYNIS
domains = LOCAL,LDAP1,AD,PROXYNISExample 30.1. A Basic LDAP Domain Configuration
- An LDAP server
- The search base
- A way to establish a secure connection
ldap_uri option:
ldap_id_use_start_tls option to use Start TLS and then ldap_tls_cacert to identify the CA certificate which issued the SSL server certificates.
30.4.2.3. Active Directory Domain Example
Note
- Using
authconfig, set the Linux client to use Active Directory as its LDAP identity provider. For example:authconfig --enableldap --enableldapauth --ldapserver=ldap://ad.example.com:389 --enablekrb5 --krb5realm AD-REALM.EXAMPLE.COM --krb5kdc ad-kdc.example.com:88 --krb5adminserver ad-kdc.example.com:749 --update
authconfig --enableldap --enableldapauth --ldapserver=ldap://ad.example.com:389 --enablekrb5 --krb5realm AD-REALM.EXAMPLE.COM --krb5kdc ad-kdc.example.com:88 --krb5adminserver ad-kdc.example.com:749 --updateCopy to Clipboard Copied! Toggle word wrap Toggle overflow Theauthconfigcommand is described in Section 29.4, “Command Line Version”. - Create the Active Directory Domain Services role.
- Add the Identity Management for UNIX service to the Active Directory Domain Services role. Use the Unix NIS domain as the domain name in the configuration.
- On the Active Directory server, create a new Computer object with the name of the Linux client.
- In the Administrative Tools menu, select the Active Directory Users and Computers application.
- Expand the Active Directory root object, such as
ad.example.com. - Right-click Computers, and select the and the item.
- Enter the name for the Linux client, such as
rhel-server, and click . - Expand the Computers object.
- Right-click the
rhel-serverobject, and select . - In the UNIX Attributes, enter the name of the Linux NIS domain and the IP address of the Linux server.Click .
- From the command prompt on the Active Directory server, create a machine account, password, and UPN for the Linux host principal.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Copy the keytab from the Active Directory server to the Linux client, and save it as
/etc/krb5.keytab. - On the Linux system, reset the permissions and owner for the keytab file.
chown root:root /etc/krb5.keytab chmod 0600 /etc/krb5.keytab
[root@rhel-server ~]# chown root:root /etc/krb5.keytab [root@rhel-server ~]# chmod 0600 /etc/krb5.keytabCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Restore the SELinux file permissions for the keytab.
restorecon /etc/krb5.keytab
[root@rhel-server ~]# restorecon /etc/krb5.keytabCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Verify that the host can connect to the Active Directory domain.
kinit -k -t /etc/krb5.keytab host/rhel-server.example.com@AD-REALM.EXAMPLE.COM
[root@rhel-server ~]# kinit -k -t /etc/krb5.keytab host/rhel-server.example.com@AD-REALM.EXAMPLE.COMCopy to Clipboard Copied! Toggle word wrap Toggle overflow - On the Active Directory server, create a a group for the Linux users.
- Create a new group named unixusers.
- Open the unixusers group and open the Unix Attributes tab.
- Configure the Unix settings:
- The NIS domain
- The UID
- The login shell, to
/bin/bash - The home directory, to
/home/aduser - The primary group name, to
unixusers
- Then, configure the SSSD domain on the Linux machine.
Example 30.2. An Active Directory 2008 Domain
Copy to Clipboard Copied! Toggle word wrap Toggle overflow These options are described in the man page for LDAP domain configuration,sssd-ldap(5). - Restart SSSD.
service sssd restart
[root@rhel-server ~]# service sssd restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow
30.4.2.4. Using IP Addresses in Certificate Subject Names
ldap_uri option instead of the server name may cause the TLS/SSL connection to fail. TLS/SSL certificates contain the server name, not the IP address. However, the subject alternative name field in the certificate can be used to include the IP address of the server, which allows a successful secure connection using an IP address.
- Convert an existing certificate into a certificate request. The signing key (
-signkey) is the key of the issuer of whatever CA originally issued the certificate. If this is done by an external CA, it requires a separate PEM file; if the certificate is self-signed, then this is the certificate itself. For example:openssl x509 -x509toreq -in old_cert.pem -out req.pem -signkey key.pem
openssl x509 -x509toreq -in old_cert.pem -out req.pem -signkey key.pemCopy to Clipboard Copied! Toggle word wrap Toggle overflow With a self-signed certificate:openssl x509 -x509toreq -in old_cert.pem -out req.pem -signkey old_cert.pem
openssl x509 -x509toreq -in old_cert.pem -out req.pem -signkey old_cert.pemCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Edit the
/etc/pki/tls/openssl.cnfconfiguration file to include the server's IP address under the[ v3_ca ]section:subjectAltName = IP:10.0.0.10
subjectAltName = IP:10.0.0.10Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Use the generated certificate request to generate a new self-signed certificate with the specified IP address:
openssl x509 -req -in req.pem -out new_cert.pem -extfile ./openssl.cnf -extensions v3_ca -signkey old_cert.pem
openssl x509 -req -in req.pem -out new_cert.pem -extfile ./openssl.cnf -extensions v3_ca -signkey old_cert.pemCopy to Clipboard Copied! Toggle word wrap Toggle overflow The-extensionsoption sets which extensions to use with the certificate. For this, it should be v3_ca to load the appropriate section. - Copy the private key block from the
old_cert.pemfile into thenew_cert.pemfile to keep all relevant information in one file.
30.4.3. Configuring Kerberos Authentication with a Domain
Note
krb5_kpasswd option to specify where the password changing service is running or if it is running on a non-default port. If the krb5_kpasswd option is not defined, SSSD tries to use the Kerberos KDC to change the password.
sssd-krb5(5) man page has more information about Kerberos configuration options.
Example 30.3. Basic Kerberos Authentication
| Parameter | Description |
|---|---|
| chpass_provider | Specifies which service to use for password change operations. This is assumed to be the same as the authentication provider. To use Kerberos, set this to krb5. |
| krb5_server | Gives a comma-separated list of IP addresses or hostnames of Kerberos servers to which SSSD will connect. The list is given in order of preference, so the first server in the list is tried first. Listing additional servers provides failover protection.
When using service discovery for KDC or kpasswd servers, SSSD first searches for DNS entries that specify UDP as the connection protocol, and then falls back to TCP.
|
| krb5_realm | Identifies the Kerberos realm served by the KDC. |
| krb5_lifetime | Requests a Kerberos ticket with the specified lifetime in seconds (s), minutes (m), hours (h) or days (d). |
| krb5_renewable_lifetime | Requests a renewable Kerberos ticket with a total lifetime that is specified in seconds (s), minutes (m), hours (h) or days (d). |
| krb5_renew_interval | Sets the time, in seconds, for SSSD to check if tickets should be renewed. Tickets are renewed automatically once they exceed half their lifetime. If this option is missing or set to zero, then automatic ticket renewal is disabled. |
| krb5_store_password_if_offline | Sets whether to store user passwords if the Kerberos authentication provider is offline, and then to use that cache to request tickets when the provider is back online. The default is false, which does not store passwords. |
| krb5_kpasswd | Lists alternate Kerberos kadmin servers to use if the change password service is not running on the KDC. |
| krb5_ccname_template | Gives the directory to use to store the user's credential cache. This can be templatized, and the following tokens are supported:
krb5_ccname_template = FILE:%d/krb5cc_%U_XXXXXX |
| krb5_ccachedir | Specifies the directory to store credential caches. This can be templatized, using the same tokens as krb5_ccname_template, except for %d and %P. If %u, %U, %p, or %h are used, then SSSD creates a private directory for each user; otherwise, it creates a public directory. |
| krb5_auth_timeout | Gives the time, in seconds, before an online authentication or change password request is aborted. If possible, the authentication request is continued offline. The default is 15 seconds. |
30.4.4. Configuring a Proxy Domain
| Parameter | Description |
|---|---|
| proxy_pam_target | Specifies the target to which PAM must proxy as an authentication provider. The PAM target is a file containing PAM stack information in the default PAM directory, /etc/pam.d/.
This is used to proxy an authentication provider.
Important
Ensure that the proxy PAM stack does not recursively include pam_sss.so.
|
| proxy_lib_name | Specifies which existing NSS library to proxy identity requests through.
This is used to proxy an identity provider.
|
Example 30.4. Proxy Identity and Kerberos Authentication
proxy_lib_name parameter. This library can be anything as long as it is compatible with the given authentication service. For a Kerberos authentication provider, it must be a Kerberos-compatible library, like NIS.
Example 30.5. LDAP Identity and Proxy Authentication
proxy_pam_target parameter. This library must be a PAM module that is compatible with the given identity provider. For example, this uses a PAM fingerprint module with LDAP:
sssdpamproxy, so create a /etc/pam.d/sssdpamproxy file and load the PAM/LDAP modules:
auth required pam_frprint.so account required pam_frprint.so password required pam_frprint.so session required pam_frprint.so
auth required pam_frprint.so
account required pam_frprint.so
password required pam_frprint.so
session required pam_frprint.soExample 30.6. Proxy Identity and Authentication
proxy_pam_target for the authentication PAM module and proxy_lib_name for the service, like NIS or LDAP.
- Create an
/etc/pam.d/sssdproxyldapfile which requires thepam_ldap.somodule:auth required pam_ldap.so account required pam_ldap.so password required pam_ldap.so session required pam_ldap.so
auth required pam_ldap.so account required pam_ldap.so password required pam_ldap.so session required pam_ldap.soCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Make sure the
nss-pam-ldappackage is installed.yum install nss-pam-ldap
[root@server ~]# yum install nss-pam-ldapCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Edit the
/etc/nslcd.conffile, the configuration file for the LDAP name service daemon, to contain the information for the LDAP directory:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
30.5. Configuring Access Control for SSSD Domains
30.5.1. Using the Simple Access Provider
simple_allow_users and simple_allow_groups, which grant access explicitly to specific users (either the given users or group members) and deny access to everyone else. It is also possible to create deny lists (which deny access only to explicit people and implicitly allow everyone else access).
- If both the allow and deny lists are empty, access is granted.
- If any list is provided, allow rules are evaluated first, and then deny rules. Practically, this means that deny rules supersede allow rules.
- If an allowed list is provided, then all users are denied access unless they are in the list.
- If only deny lists are provided, then all users are allowed access unless they are in the list.
[domain/example.com] access_provider = simple simple_allow_users = jsmith,bjensen simple_allow_groups = itgroup
[domain/example.com]
access_provider = simple
simple_allow_users = jsmith,bjensen
simple_allow_groups = itgroupNote
simple as an access provider.
sssd-simple man page, but these are rarely used.
30.5.2. Using the LDAP Access Filter
ldap_access_filter) specifies which users are granted access to the specified host. The user filter must be used or all users are denied access.
[domain/example.com] access_provider = ldap ldap_access_filter = memberOf=cn=allowedusers,ou=Groups,dc=example,dc=com
[domain/example.com]
access_provider = ldap
ldap_access_filter = memberOf=cn=allowedusers,ou=Groups,dc=example,dc=comNote
authorizedService attribute.
30.6. Configuring Domain Failover
30.6.1. Configuring Failover
/etc/sssd/sssd.conf file. The servers are listed in order of preference. This list can contain any number of servers.
ldap_uri = ldap://ldap0.example.com, ldap://ldap1.example.com, ldap://ldap2.example.com
ldap_uri = ldap://ldap0.example.com, ldap://ldap1.example.com, ldap://ldap2.example.comldap://ldap0.example.com, is the primary server. If this server fails, SSSD first attempts to connect to ldap1.example.com and then ldap2.example.com.
Important
30.6.2. Using SRV Records with Failover
_service._protocol._domain TTL priority weight port hostname
_service._protocol._domain TTL priority weight port hostname30.7. Deleting Domain Cache Files
/var/lib/sss/db/ directory.
exampleldap, the cache file is named cache_exampleldap.ldb.
- Deleting the cache file deletes all user data, both identification and cached credentials. Consequently, do not delete a cache file unless the system is online and can authenticate with a username against the domain's servers. Without a credentials cache, offline authentication will fail.
- If the configuration is changed to reference a different identity provider, SSSD will recognize users from both providers until the cached entries from the original provider time out.It is possible to avoid this by purging the cache, but the better option is to use a different domain name for the new provider. When SSSD is restarted, it creates a new cache file with the new name and the old file is ignored.
30.8. Using NSCD with SSSD
resolv.conf file. This file is typically only read once, and so any changes made to this file are not automatically applied. This can cause NFS locking to fail on the machine where the NSCD service is running, unless that service is manually restarted.
/etc/nscd.conf file and rely on the SSSD cache for the passwd, group, and netgroup entries.
/etc/nscd.conf file:
enable-cache hosts yes enable-cache passwd no enable-cache group no enable-cache netgroup no
enable-cache hosts yes
enable-cache passwd no
enable-cache group no
enable-cache netgroup no
30.9. Troubleshooting SSSD
30.9.1. Checking SSSD Log Files
/var/log/sssd/ directory. SSSD produces a log file for each domain, as well as an sssd_pam.log and an sssd_nss.log file.
/var/log/secure file logs authentication failures and the reason for the failure.
debug_level parameter for each section in the sssd.conf file for which to product extra logs. For example:
[sssd] config_file_version = 2 services = nss, pam domains = LDAP debug_level = 9
[sssd]
config_file_version = 2
services = nss, pam
domains = LDAP
debug_level = 9| Level | Description |
|---|---|
| 0 | Fatal failures. Anything that would prevent SSSD from starting up or causes it to cease running. |
| 1 | Critical failures. An error that doesn't kill the SSSD, but one that indicates that at least one major feature is not going to work properly. |
| 2 | Serious failures. An error announcing that a particular request or operation has failed. |
| 3 | Minor failures. These are the errors that would percolate down to cause the operation failure of 2. |
| 4 | Configuration settings. |
| 5 | Function data. |
| 6 | Trace messages for operation functions. |
| 7 | Trace messages for internal control functions. |
| 8 | Contents of function-internal variables that may be interesting. |
| 9 | Extremely low-level tracing information. |
30.9.2. Problems with SSSD Configuration
SSSD requires that the configuration file be properly set up, with all the required entries, before the daemon will start.
- SSSD requires at least one properly configured domain before the service will start. Without a domain, attempting to start SSSD returns an error that no domains are configured:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Edit the/etc/sssd/sssd.conffile and create at least one domain. - SSSD also requires at least one available service provider before it will start. If the problem is with the service provider configuration, the error message indicates that there are no services configured:
[sssd] [get_monitor_config] (0): No services configured!
[sssd] [get_monitor_config] (0): No services configured!Copy to Clipboard Copied! Toggle word wrap Toggle overflow Edit the/etc/sssd/sssd.conffile and configure at least one service provider.Important
SSSD requires that service providers be configured as a comma-separated list in a singleservicesentry in the/etc/sssd/sssd.conffile. If services are listed in multiple entries, only the last entry is recognized by SSSD.
This may be due to an incorrect ldap_schema setting in the [domain/DOMAINNAME] section of sssd.conf.
memberuid attribute, which contains the name of the users that are members. In an RFC2307bis server, group members are stored as the multi-valued member or uniqueMember attribute which contains the DN of the user or group that is a member of this group. RFC2307bis allows nested groups to be maintained as well.
- Set
ldap_schematorfc2307bis. - Delete
/var/lib/sss/db/cache_DOMAINNAME.ldb. - Restarting SSSD.
sssd.conf:
ldap_group_name = uniqueMember
ldap_group_name = uniqueMember
To perform authentication, SSSD requires that the communication channel be encrypted. This means that if sssd.conf is configured to connect over a standard protocol (ldap://), it attempts to encrypt the communication channel with Start TLS. If sssd.conf is configured to connect over a secure protocol (ldaps://), then SSSD uses SSL.
syslog message is written, indicating that TLS encryption could not be started. The certificate configuration can be tested by checking if the LDAP server is accessible apart from SSSD. For example, this tests an anonymous bind over a TLS connection to test.example.com:
ldapsearch -x -ZZ -h test.example.com -b dc=example,dc=com
$ ldapsearch -x -ZZ -h test.example.com -b dc=example,dc=comldap_start_tls: Connect error (-11) additional info: TLS error -8179:Unknown code ___f 13
ldap_start_tls: Connect error (-11) additional info: TLS error -8179:Unknown code ___f 13- Obtain a copy of the public CA certificate for the certificate authority used to sign the LDAP server certificate and save it to the local system.
- Add a line to the
sssd.conffile that points to the CA certificate on the filesystem.ldap_tls_cacert = /path/to/cacert
ldap_tls_cacert = /path/to/cacertCopy to Clipboard Copied! Toggle word wrap Toggle overflow - If the LDAP server uses a self-signed certificate, remove the
ldap_tls_reqcertline from thesssd.conffile.This parameter directs SSSD to trust any certificate issued by the CA certificate, which is a security risk with a self-signed CA certificate.
When running SELinux in enforcing mode, the client's SELinux policy has to be modified to connect to the LDAP server over the non-standard port. For example:
semanage port -a -t ldap_port_t -p tcp 1389
# semanage port -a -t ldap_port_t -p tcp 1389This usually means that SSSD cannot connect to the NSS service.
- Ensure that NSS is running:
service sssd status
# service sssd statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow - If NSS is running, make sure that the provider is properly configured in the
[nss]section of the/etc/sssd/sssd.conffile. Especially check thefilter_usersandfilter_groupsattributes. - Make sure that NSS is included in the list of services that SSSD uses.
- Check the configuration in the
/etc/nsswitch.conffile.
If searches are returning the incorrect user information, check that there are not conflicting usernames in separate domains. When there are multiple domains, set the use_fully_qualified_domains attribute to true in the /etc/sssd/sssd.conf file. This differentiates between different users in different domains with the same name.
When attempting to change a local SSSD user's password, it may prompt for the password twice:
use_authtok option is correctly configured in your /etc/pam.d/system-auth file.
Part IV. System Configuration
Chapter 31. Console Access
- They can run certain programs that they would otherwise be unable to run.
- They can access certain files (normally special device files used to access diskettes, CD-ROMs, and so on) that they would otherwise be unable to access.
halt, poweroff, and reboot.
31.1. Disabling Shutdown Via Ctrl+Alt+Del
/etc/inittab specifies that your system is set to shutdown and reboot in response to a Ctrl+Alt+Del key combination used at the console. To completely disable this ability, comment out the following line in /etc/inittab by putting a hash mark (#) in front of it:
ca::ctrlaltdel:/sbin/shutdown -t3 -r now
ca::ctrlaltdel:/sbin/shutdown -t3 -r now- Add the
-aoption to the/etc/inittabline shown above, so that it reads:ca::ctrlaltdel:/sbin/shutdown -a -t3 -r now
ca::ctrlaltdel:/sbin/shutdown -a -t3 -r nowCopy to Clipboard Copied! Toggle word wrap Toggle overflow The-aflag tellsshutdownto look for the/etc/shutdown.allowfile. - Create a file named
shutdown.allowin/etc. Theshutdown.allowfile should list the usernames of any users who are allowed to shutdown the system using Ctrl+Alt+Del . The format of theshutdown.allowfile is a list of usernames, one per line, like the following:stephen jack sophie
stephen jack sophieCopy to Clipboard Copied! Toggle word wrap Toggle overflow
shutdown.allow file, the users stephen, jack, and sophie are allowed to shutdown the system from the console using Ctrl+Alt+Del . When that key combination is used, the shutdown -a command in /etc/inittab checks to see if any of the users in /etc/shutdown.allow (or root) are logged in on a virtual console. If one of them is, the shutdown of the system continues; if not, an error message is written to the system console instead.
shutdown.allow, refer to the shutdown man page.
31.2. Disabling Console Program Access
rm -f /etc/security/console.apps/*
rm -f /etc/security/console.apps/*poweroff, halt, and reboot, which are accessible from the console by default.
rm -f /etc/security/console.apps/poweroff rm -f /etc/security/console.apps/halt rm -f /etc/security/console.apps/reboot
rm -f /etc/security/console.apps/poweroff
rm -f /etc/security/console.apps/halt
rm -f /etc/security/console.apps/reboot31.3. Defining the Console
pam_console.so module uses the /etc/security/console.perms file to determine the permissions for users at the system console. The syntax of the file is very flexible; you can edit the file so that these instructions no longer apply. However, the default file has a line that looks like this:
<console>=tty[0-9][0-9]* vc/[0-9][0-9]* :[0-9]\.[0-9] :[0-9]
<console>=tty[0-9][0-9]* vc/[0-9][0-9]* :[0-9]\.[0-9] :[0-9]:0 or mymachine.example.com:1.0, or a device like /dev/ttyS0 or /dev/pts/2. The default is to define that local virtual consoles and local X servers are considered local, but if you want to consider the serial terminal next to you on port /dev/ttyS1 to also be local, you can change that line to read:
<console>=tty[0-9][0-9]* vc/[0-9][0-9]* :[0-9]\.[0-9] :[0-9] /dev/ttyS1
<console>=tty[0-9][0-9]* vc/[0-9][0-9]* :[0-9]\.[0-9] :[0-9] /dev/ttyS131.4. Making Files Accessible From the Console
/etc/security/console.perms.d/50-default.perms. To edit file and device permissions, it is advisable to create a new default file in /etc/security/console.perms.d/ containing your preferred settings for a specified set of files or devices. The name of the new default file must begin with a number higher than 50 (for example, 51-default.perms) in order to override 50-default.perms.
51-default.perms in /etc/security/console.perms.d/:
touch /etc/security/console.perms.d/51-default.perms
touch /etc/security/console.perms.d/51-default.permsperms file, 50-default.perms. The first section defines device classes, with lines similar to the following:
<cdrom> refers to the CD-ROM drive. To add a new device, do not define it in the default 50-default.perms file; instead, define it in 51-default.perms. For example, to define a scanner, add the following line to 51-default.perms:
<scanner>=/dev/scanner /dev/usb/scanner*
<scanner>=/dev/scanner /dev/usb/scanner*/dev/scanner is really your scanner and not some other device, such as your hard drive.
/etc/security/console.perms.d/50-default.perms defines this, with lines similar to the following:
<console> 0660 <floppy> 0660 root.floppy <console> 0600 <sound> 0640 root <console> 0600 <cdrom> 0600 root.disk
<console> 0660 <floppy> 0660 root.floppy
<console> 0600 <sound> 0640 root
<console> 0600 <cdrom> 0600 root.disk51-default.perms:
<console> 0600 <scanner> 0600 root
<console> 0600 <scanner> 0600 root/dev/scanner device with the permissions of 0600 (readable and writable by you only). When you log out, the device is owned by root, and still has the permissions 0600 (now readable and writable by root only).
Warning
50-default.perms file. To edit permissions for a device already defined in 50-default.perms, add the desired permission definition for that device in 51-default.perms. This will override whatever permissions are defined in 50-default.perms.
31.5. Enabling Console Access for Other Applications
/sbin/ or /usr/sbin/, so the application that you wish to run must be there. After verifying that, perform the following steps:
- Create a link from the name of your application, such as our sample
fooprogram, to the/usr/bin/consolehelperapplication:cd /usr/bin ln -s consolehelper foo
cd /usr/bin ln -s consolehelper fooCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Create the file
/etc/security/console.apps/foo:touch /etc/security/console.apps/foo
touch /etc/security/console.apps/fooCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Create a PAM configuration file for the
fooservice in/etc/pam.d/. An easy way to do this is to copy the PAM configuration file of thehaltservice, and then modify the copy if you want to change the behavior:cp /etc/pam.d/halt /etc/pam.d/foo
cp /etc/pam.d/halt /etc/pam.d/fooCopy to Clipboard Copied! Toggle word wrap Toggle overflow
/usr/bin/foo is executed, consolehelper is called, which authenticates the user with the help of /usr/sbin/userhelper. To authenticate the user, consolehelper asks for the user's password if /etc/pam.d/foo is a copy of /etc/pam.d/halt (otherwise, it does precisely what is specified in /etc/pam.d/foo) and then runs /usr/sbin/foo with root permissions.
pam_timestamp and run from the same session is automatically authenticated for the user — the user does not have to enter the root password again.
pam package. To enable this feature, add the following lines to your PAM configuration file in etc/pam.d/:
auth include config-util account include config-util session include config-util
auth include config-util
account include config-util
session include config-util/etc/pam.d/system-config-* configuration files. Note that these lines must be added below any other auth sufficient session optional lines in your PAM configuration file.
pam_timestamp is successfully authenticated from the Applications (the main menu on the panel), the
31.6. The floppy Group
floppy group. Add the user(s) to the floppy group using the tool of your choice. For example, the gpasswd command can be used to add user fred to the floppy group:
gpasswd -a fred floppy
gpasswd -a fred floppyfred is able to access the system's diskette drive from the console.
Chapter 32. The sysconfig Directory
/etc/sysconfig/ directory contains a variety of system configuration files for Red Hat Enterprise Linux.
/etc/sysconfig/ directory, their function, and their contents. The information in this chapter is not intended to be complete, as many of these files have a variety of options that are only used in very specific or rare circumstances.
32.1. Files in the /etc/sysconfig/ Directory
/etc/sysconfig/ directory. Files not listed here, as well as extra file options, are found in the /usr/share/doc/initscripts-<version-number>/sysconfig.txt file (replace <version-number> with the version of the initscripts package). Alternatively, looking through the initscripts in the /etc/rc.d/ directory can prove helpful.
Note
/etc/sysconfig/ directory, then the corresponding program may not be installed.
32.1.1. /etc/sysconfig/amd
/etc/sysconfig/amd file contains various parameters used by amd; these parameters allow for the automatic mounting and unmounting of file systems.
32.1.2. /etc/sysconfig/apmd
/etc/sysconfig/apmd file is used by apmd to configure what power settings to start/stop/change on suspend or resume. This file configures how apmd functions at boot time, depending on whether the hardware supports Advanced Power Management (APM) or whether the user has configured the system to use it. The apm daemon is a monitoring program that works with power management code within the Linux kernel. It is capable of alerting users to low battery power on laptops and other power-related settings.
32.1.3. /etc/sysconfig/arpwatch
/etc/sysconfig/arpwatch file is used to pass arguments to the arpwatch daemon at boot time. The arpwatch daemon maintains a table of Ethernet MAC addresses and their IP address pairings. By default, this file sets the owner of the arpwatch process to the user pcap and sends any messages to the root mail queue. For more information regarding available parameters for this file, refer to the arpwatch man page.
32.1.4. /etc/sysconfig/authconfig
/etc/sysconfig/authconfig file sets the authorization to be used on the host. It contains one or more of the following lines:
USEMD5=<value>, where<value>is one of the following:yes— MD5 is used for authentication.no— MD5 is not used for authentication.
USEKERBEROS=<value>, where<value>is one of the following:yes— Kerberos is used for authentication.no— Kerberos is not used for authentication.
USELDAPAUTH=<value>, where<value>is one of the following:yes— LDAP is used for authentication.no— LDAP is not used for authentication.
32.1.5. /etc/sysconfig/autofs
/etc/sysconfig/autofs file defines custom options for the automatic mounting of devices. This file controls the operation of the automount daemons, which automatically mount file systems when you use them and unmount them after a period of inactivity. File systems can include network file systems, CD-ROMs, diskettes, and other media.
/etc/sysconfig/autofs file may contain the following:
LOCALOPTIONS="<value>", where <value> is a string for defining machine-specific automount rules. The default value is an empty string ("").DAEMONOPTIONS="<value>", where <value> is the timeout length in seconds before unmounting the device. The default value is 60 seconds ("--timeout=60").UNDERSCORETODOT=<value>, where <value> is a binary value that controls whether to convert underscores in file names into dots. For example,auto_hometoauto.homeandauto_mnttoauto.mnt. The default value is 1 (true).DISABLE_DIRECT=<value>, where <value> is a binary value that controls whether to disable direct mount support, as the Linux implementation does not conform to the Sun Microsystems' automounter behavior. The default value is 1 (true), and allows for compatibility with the Sun automounter options specification syntax.
32.1.6. /etc/sysconfig/clock
/etc/sysconfig/clock file controls the interpretation of values read from the system hardware clock.
UTC=<value>, where<value>is one of the following boolean values:trueoryes— The hardware clock is set to Universal Time.falseorno— The hardware clock is set to local time.
ARC=<value>, where<value>is the following:falseorno— This value indicates that the normal UNIX epoch is in use. Other values are used by systems not supported by Red Hat Enterprise Linux.
SRM=<value>, where<value>is the following:falseorno— This value indicates that the normal UNIX epoch is in use. Other values are used by systems not supported by Red Hat Enterprise Linux.
ZONE=— The time zone file under<filename>/usr/share/zoneinfothat/etc/localtimeis a copy of. The file contains information such as:ZONE="America/New York"
ZONE="America/New York"Copy to Clipboard Copied! Toggle word wrap Toggle overflow Note that theZONEparameter is read by the Time and Date Properties Tool (system-config-date), and manually editing it does not change the system timezone.
CLOCKMODE=<value>, where<value>is one of the following:GMT— The clock is set to Universal Time (Greenwich Mean Time).ARC— The ARC console's 42-year time offset is in effect (for Alpha-based systems only).
32.1.7. /etc/sysconfig/desktop
/etc/sysconfig/desktop file specifies the desktop for new users and the display manager to run when entering runlevel 5.
DESKTOP="<value>", where"<value>"is one of the following:GNOME— Selects the GNOME desktop environment.KDE— Selects the KDE desktop environment.
DISPLAYMANAGER="<value>", where"<value>"is one of the following:GNOME— Selects the GNOME Display Manager.KDE— Selects the KDE Display Manager.XDM— Selects the X Display Manager.
32.1.8. /etc/sysconfig/dhcpd
/etc/sysconfig/dhcpd file is used to pass arguments to the dhcpd daemon at boot time. The dhcpd daemon implements the Dynamic Host Configuration Protocol (DHCP) and the Internet Bootstrap Protocol (BOOTP). DHCP and BOOTP assign hostnames to machines on the network. For more information about what parameters are available in this file, refer to the dhcpd man page.
32.1.9. /etc/sysconfig/exim
/etc/sysconfig/exim file allows messages to be sent to one or more clients, routing the messages over whatever networks are necessary. The file sets the default values for exim to run. Its default values are set to run as a background daemon and to check its queue each hour in case something has backed up.
DAEMON=<value>, where<value>is one of the following:yes—eximshould be configured to listen to port 25 for incoming mail.yesimplies the use of the Exim's-bdoptions.no—eximshould not be configured to listen to port 25 for incoming mail.
QUEUE=1hwhich is given toeximas-q$QUEUE. The-qoption is not given toeximif/etc/sysconfig/eximexists andQUEUEis empty or undefined.
32.1.10. /etc/sysconfig/firstboot
/sbin/init program calls the etc/rc.d/init.d/firstboot script, which in turn launches the Setup Agent. This application allows the user to install the latest updates as well as additional applications and documentation.
/etc/sysconfig/firstboot file tells the Setup Agent application not to run on subsequent reboots. To run it the next time the system boots, remove /etc/sysconfig/firstboot and execute chkconfig --level 5 firstboot on.
32.1.11. /etc/sysconfig/gpm
/etc/sysconfig/gpm file is used to pass arguments to the gpm daemon at boot time. The gpm daemon is the mouse server which allows mouse acceleration and middle-click pasting. For more information about what parameters are available for this file, refer to the gpm man page. By default, the DEVICE directive is set to /dev/input/mice.
32.1.12. /etc/sysconfig/hwconf
/etc/sysconfig/hwconf file lists all the hardware that kudzu detected on the system, as well as the drivers used, vendor ID, and device ID information. The kudzu program detects and configures new and/or changed hardware on a system. The /etc/sysconfig/hwconf file is not meant to be manually edited. If edited, devices could suddenly show up as being added or removed.
32.1.13. /etc/sysconfig/i18n
/etc/sysconfig/i18n file sets the default language, any supported languages, and the default system font. For example:
LANG="en_US.UTF-8" SUPPORTED="en_US.UTF-8:en_US:en" SYSFONT="latarcyrheb-sun16"
LANG="en_US.UTF-8"
SUPPORTED="en_US.UTF-8:en_US:en"
SYSFONT="latarcyrheb-sun16"32.1.14. /etc/sysconfig/init
/etc/sysconfig/init file controls how the system appears and functions during the boot process.
BOOTUP=<value>, where<value>is one of the following:color— The standard color boot display, where the success or failure of devices and services starting up is shown in different colors.verbose— An old style display which provides more information than purely a message of success or failure.- Anything else means a new display, but without ANSI-formatting.
RES_COL=<value>, where<value>is the number of the column of the screen to start status labels. The default is set to 60.MOVE_TO_COL=<value>, where<value>moves the cursor to the value in theRES_COLline via theecho -encommand.SETCOLOR_SUCCESS=<value>, where<value>sets the success color via theecho -encommand. The default color is set to green.SETCOLOR_FAILURE=<value>, where<value>sets the failure color via theecho -encommand. The default color is set to red.SETCOLOR_WARNING=<value>, where<value>sets the warning color via theecho -encommand. The default color is set to yellow.SETCOLOR_NORMAL=<value>, where<value>resets the color to "normal" via theecho -en.LOGLEVEL=<value>, where<value>sets the initial console logging level for the kernel. The default is 3; 8 means everything (including debugging), while 1 means only kernel panics. Thesyslogddaemon overrides this setting once started.PROMPT=<value>, where<value>is one of the following boolean values:yes— Enables the key check for interactive mode.no— Disables the key check for interactive mode.
32.1.15. /etc/sysconfig/ip6tables-config
/etc/sysconfig/ip6tables-config file stores information used by the kernel to set up IPv6 packet filtering at boot time or whenever the ip6tables service is started.
ip6tables rules. Rules also can be created manually using the /sbin/ip6tables command. Once created, add the rules to the /etc/sysconfig/ip6tables file by typing the following command:
service ip6tables save
service ip6tables saveip6tables, refer to Section 48.9, “IPTables”.
32.1.16. /etc/sysconfig/iptables-config
/etc/sysconfig/iptables-config file stores information used by the kernel to set up packet filtering services at boot time or whenever the service is started.
iptables rules. The easiest way to add rules is to use the Security Level Configuration Tool (system-config-securitylevel) application to create a firewall. These applications automatically edit this file at the end of the process.
/sbin/iptables command. Once created, add the rule(s) to the /etc/sysconfig/iptables file by typing the following command:
service iptables save
service iptables saveiptables, refer to Section 48.9, “IPTables”.
32.1.17. /etc/sysconfig/irda
/etc/sysconfig/irda file controls how infrared devices on the system are configured at startup.
IRDA=<value>, where<value>is one of the following boolean values:yes—irattachruns and periodically checks to see if anything is trying to connect to the infrared port, such as another notebook computer trying to make a network connection. For infrared devices to work on the system, this line must be set toyes.no—irattachdoes not run, preventing infrared device communication.
DEVICE=<value>, where<value>is the device (usually a serial port) that handles infrared connections. A sample serial device entry could be/dev/ttyS2.DONGLE=<value>, where<value>specifies the type of dongle being used for infrared communication. This setting exists for people who use serial dongles rather than real infrared ports. A dongle is a device that is attached to a traditional serial port to communicate via infrared. This line is commented out by default because notebooks with real infrared ports are far more common than computers with add-on dongles. A sample dongle entry could beactisys+.DISCOVERY=<value>, where<value>is one of the following boolean values:yes— Startsirattachin discovery mode, meaning it actively checks for other infrared devices. This must be turned on for the machine to actively look for an infrared connection (meaning the peer that does not initiate the connection).no— Does not startirattachin discovery mode.
32.1.18. /etc/sysconfig/kernel
/etc/sysconfig/kernel configuration file controls the kernel selection at boot. It has two options with the following default values:
UPDATEDEFAULT=yes- This option makes a newly installed kernel as the default in the boot entry selection.
DEFAULTKERNEL=kernel- This option specifies what package type will be used as the default.
32.1.18.1. Keeping an old kernel version as the default
- Comment out the UPDATEDEFAULT option in /etc/sysconfig/kernel as follows:
UPDATEDEFAULT=yes
# UPDATEDEFAULT=yesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
32.1.18.2. Setting a kernel debugger as the default kernel
- Edit the /etc/sysconfig/kernel configuration file as follows:
DEFAULTKERNEL=kernel-debug
DEFAULTKERNEL=kernel-debugCopy to Clipboard Copied! Toggle word wrap Toggle overflow
32.1.19. /etc/sysconfig/keyboard
/etc/sysconfig/keyboard file controls the behavior of the keyboard. The following values may be used:
KEYBOARDTYPE="sun|pc"wheresunmeans a Sun keyboard is attached on/dev/kbd, orpcmeans a PS/2 keyboard connected to a PS/2 port.KEYTABLE="<file>", where<file>is the name of a keytable file.For example:KEYTABLE="us". The files that can be used as keytables start in/lib/kbd/keymaps/i386and branch into different keyboard layouts from there, all labeled<file>.kmap.gz. The first file found beneath/lib/kbd/keymaps/i386that matches theKEYTABLEsetting is used.
32.1.20. /etc/sysconfig/kudzu
/etc/sysconfig/kuzdu file triggers a safe probe of the system hardware by kudzu at boot time. A safe probe is one that disables serial port probing.
SAFE=<value>, where<value>is one of the following:yes—kuzdudoes a safe probe.no—kuzdudoes a normal probe.
32.1.21. /etc/sysconfig/named
/etc/sysconfig/named file is used to pass arguments to the named daemon at boot time. The named daemon is a Domain Name System (DNS) server which implements the Berkeley Internet Name Domain (BIND) version 9 distribution. This server maintains a table of which hostnames are associated with IP addresses on the network.
ROOTDIR="</some/where>", where</some/where>refers to the full directory path of a configured chroot environment under whichnamedruns. This chroot environment must first be configured. Typeinfo chrootfor more information.OPTIONS="<value>", where<value>is any option listed in the man page fornamedexcept-t. In place of-t, use theROOTDIRline above.
named man page. For detailed information on how to configure a BIND DNS server, refer to Chapter 19, Berkeley Internet Name Domain (BIND). By default, the file contains no parameters.
32.1.22. /etc/sysconfig/network
/etc/sysconfig/network file is used to specify information about the desired network configuration. The following values may be used:
NETWORKING=<value>, where<value>is one of the following boolean values:yes— Networking should be configured.no— Networking should not be configured.
HOSTNAME=<value>, where<value>should be the Fully Qualified Domain Name (FQDN), such ashostname.expample.com, but can be whatever hostname is necessary.GATEWAY=<value>, where<value>is the IP address of the network's gateway.GATEWAYDEV=<value>, where<value>is the gateway device, such aseth0. Configure this option if you have multiple interfaces on the same subnet, and require one of those interfaces to be the preferred route to the default gateway.NISDOMAIN=<value>, where<value>is the NIS domain name.NOZEROCONF=<value>, where setting<value>totruedisables the zeroconf route.By default, the zeroconf route (169.254.0.0) is enabled when the system boots. For more information about zeroconf, refer to http://www.zeroconf.org/.
Warning
32.1.23. /etc/sysconfig/nfs
/etc/sysconfig/nfs file to control which ports the required RPC services run on.
/etc/sysconfig/nfs may not exist by default on all systems. If it does not exist, create it and add the following variables (alternatively, if the file exists, un-comment and change the default entries as required):
MOUNTD_PORT=x- control which TCP and UDP port mountd (rpc.mountd) uses. Replace x with an unused port number.
STATD_PORT=x- control which TCP and UDP port status (rpc.statd) uses. Replace x with an unused port number.
LOCKD_TCPPORT=x- control which TCP port nlockmgr (rpc.lockd) uses. Replace x with an unused port number.
LOCKD_UDPPORT=x- control which UDP port nlockmgr (rpc.lockd) uses. Replace x with an unused port number.
/var/log/messages. Normally, NFS will fail to start if you specify a port number that is already in use. After editing /etc/sysconfig/nfs restart the NFS service by running the service nfs restart command. Run the rpcinfo -p command to confirm the changes.
- Allow TCP and UDP port 2049 for NFS.
- Allow TCP and UDP port 111 (portmap/sunrpc).
- Allow the TCP and UDP port specified with
MOUNTD_PORT="x" - Allow the TCP and UDP port specified with
STATD_PORT="x" - Allow the TCP port specified with
LOCKD_TCPPORT="x" - Allow the UDP port specified with
LOCKD_UDPPORT="x"
32.1.24. /etc/sysconfig/ntpd
/etc/sysconfig/ntpd file is used to pass arguments to the ntpd daemon at boot time. The ntpd daemon sets and maintains the system clock to synchronize with an Internet standard time server. It implements version 4 of the Network Time Protocol (NTP). For more information about what parameters are available for this file, use a Web browser to view the following file: /usr/share/doc/ntp-<version>/ntpd.htm (where <version> is the version number of ntpd). By default, this file sets the owner of the ntpd process to the user ntp.
32.1.25. /etc/sysconfig/radvd
/etc/sysconfig/radvd file is used to pass arguments to the radvd daemon at boot time. The radvd daemon listens for router requests and sends router advertisements for the IP version 6 protocol. This service allows hosts on a network to dynamically change their default routers based on these router advertisements. For more information about available parameters for this file, refer to the radvd man page. By default, this file sets the owner of the radvd process to the user radvd.
32.1.26. /etc/sysconfig/samba
/etc/sysconfig/samba file is used to pass arguments to the smbd and the nmbd daemons at boot time. The smbd daemon offers file sharing connectivity for Windows clients on the network. The nmbd daemon offers NetBIOS over IP naming services. For more information about what parameters are available for this file, refer to the smbd man page. By default, this file sets smbd and nmbd to run in daemon mode.
32.1.27. /etc/sysconfig/selinux
/etc/sysconfig/selinux file contains the basic configuration options for SELinux. This file is a symbolic link to /etc/selinux/config.
32.1.28. /etc/sysconfig/sendmail
/etc/sysconfig/sendmail file allows messages to be sent to one or more clients, routing the messages over whatever networks are necessary. The file sets the default values for the Sendmail application to run. Its default values are set to run as a background daemon and to check its queue each hour in case something has backed up.
DAEMON=<value>, where<value>is one of the following:yes— Sendmail should be configured to listen to port 25 for incoming mail.yesimplies the use of Sendmail's-bdoptions.no— Sendmail should not be configured to listen to port 25 for incoming mail.
QUEUE=1hwhich is given to Sendmail as-q$QUEUE. The-qoption is not given to Sendmail if/etc/sysconfig/sendmailexists andQUEUEis empty or undefined.
32.1.29. /etc/sysconfig/spamassassin
/etc/sysconfig/spamassassin file is used to pass arguments to the spamd daemon (a daemonized version of Spamassassin) at boot time. Spamassassin is an email spam filter application. For a list of available options, refer to the spamd man page. By default, it configures spamd to run in daemon mode, create user preferences, and auto-create whitelists (allowed bulk senders).
32.1.30. /etc/sysconfig/squid
/etc/sysconfig/squid file is used to pass arguments to the squid daemon at boot time. The squid daemon is a proxy caching server for Web client applications. For more information on configuring a squid proxy server, use a Web browser to open the /usr/share/doc/squid-<version>/ directory (replace <version> with the squid version number installed on the system). By default, this file sets squid to start in daemon mode and sets the amount of time before it shuts itself down.
32.1.31. /etc/sysconfig/system-config-securitylevel
/etc/sysconfig/system-config-securitylevel file contains all options chosen by the user the last time the Security Level Configuration Tool (system-config-securitylevel) was run. Users should not modify this file by hand. For more information about the Security Level Configuration Tool, refer to Section 48.8.2, “Basic Firewall Configuration”.
32.1.32. /etc/sysconfig/system-config-selinux
/etc/sysconfig/system-config-selinux file contains all options chosen by the user the last time the SELinux Administration Tool (system-config-selinux) was run. Users should not modify this file by hand. For more information about the SELinux Administration Tool and SELinux in general, refer to Section 49.2, “Introduction to SELinux”.
32.1.33. /etc/sysconfig/system-config-users
/etc/sysconfig/system-config-users file is the configuration file for the graphical application, User Manager. This file is used to filter out system users such as root, daemon, or lp. This file is edited by the > pull-down menu in the User Manager application and should never be edited by hand. For more information on using this application, refer to Section 37.1, “User and Group Configuration”.
32.1.34. /etc/sysconfig/system-logviewer
/etc/sysconfig/system-logviewer file is the configuration file for the graphical, interactive log viewing application, Log Viewer. This file is edited by the > pull-down menu in the Log Viewer application and should not be edited by hand. For more information on using this application, refer to Chapter 40, Log Files.
32.1.35. /etc/sysconfig/tux
/etc/sysconfig/tux file is the configuration file for the Red Hat Content Accelerator (formerly known as TUX), the kernel-based Web server. For more information on configuring the Red Hat Content Accelerator, use a Web browser to open the /usr/share/doc/tux-<version>/tux/index.html file (replace <version> with the version number of TUX installed on the system). The parameters available for this file are listed in /usr/share/doc/tux-<version>/tux/parameters.html.
32.1.36. /etc/sysconfig/vncservers
/etc/sysconfig/vncservers file configures the way the Virtual Network Computing (VNC) server starts up.
VNCSERVERS=<value>, where<value>is set to something like"1:fred", to indicate that a VNC server should be started for user fred on display :1. User fred must have set a VNC password using thevncpasswdcommand before attempting to connect to the remote VNC server.
32.1.37. /etc/sysconfig/xinetd
/etc/sysconfig/xinetd file is used to pass arguments to the xinetd daemon at boot time. The xinetd daemon starts programs that provide Internet services when a request to the port for that service is received. For more information about available parameters for this file, refer to the xinetd man page. For more information on the xinetd service, refer to Section 48.5.3, “xinetd”.
32.2. Directories in the /etc/sysconfig/ Directory
/etc/sysconfig/.
apm-scripts/- This directory contains the APM suspend/resume script. Do not edit the files directly. If customization is necessary, create a file called
/etc/sysconfig/apm-scripts/apmcontinuewhich is called at the end of the script. It is also possible to control the script by editing/etc/sysconfig/apmd. cbq/networking/- This directory is used by the Network Administration Tool (
system-config-network), and its contents should not be edited manually. For more information about configuring network interfaces using the Network Administration Tool, refer to Chapter 17, Network Configuration. network-scripts/- Network configuration files for each configured network interface, such as
ifcfg-eth0for theeth0Ethernet interface. - Scripts used to bring network interfaces up and down, such as
ifupandifdown. - Scripts used to bring ISDN interfaces up and down, such as
ifup-isdnandifdown-isdn. - Various shared network function scripts which should not be edited directly.
For more information on thenetwork-scriptsdirectory, refer to Chapter 16, Network Interfaces.rhn/- Deprecated. This directory contains the configuration files and GPG keys used by the RHN Classic content service. No files in this directory should be edited by hand.This directory is available for legacy systems which are still managed by RHN Classic. Systems which are registered against the Certificate-Based Red Hat Network do not use this directory.
32.3. Additional Resources
/etc/sysconfig/ directory. The following source contains more comprehensive information.
32.3.1. Installed Documentation
/usr/share/doc/initscripts-<version-number>/sysconfig.txt— This file contains a more authoritative listing of the files found in the/etc/sysconfig/directory and the configuration options available for them. The <version-number> in the path to this file corresponds to the version of theinitscriptspackage installed.
Chapter 33. Date and Time Configuration
- From the desktop, go to Applications (the main menu on the panel) > >
- From the desktop, right-click on the time in the toolbar and select .
- Type the command
system-config-date,system-config-time, ordateconfigat a shell prompt (for example, in an XTerm or a GNOME terminal).
33.1. Time and Date Properties
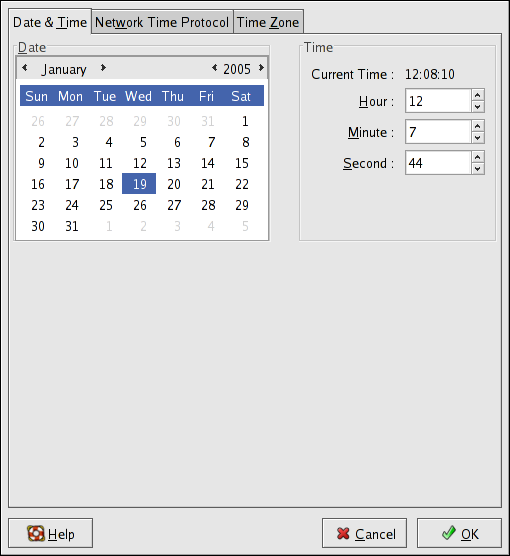
Figure 33.1. Time and Date Properties
33.2. Network Time Protocol (NTP) Properties
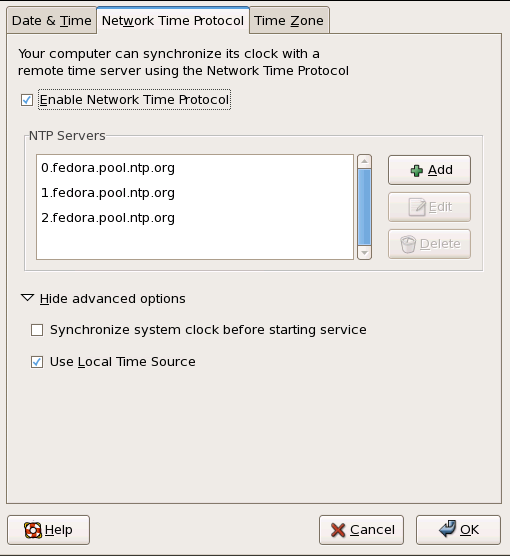
Figure 33.2. NTP Properties
33.3. Time Zone Configuration
Chapter 34. Keyboard Configuration
system-config-keyboard at a shell prompt.
Figure 34.1. Keyboard Configuration Tool
Chapter 35. The X Window System
Xorg binary) listens for connections from X client applications via a network or local loopback interface. The server communicates with the hardware, such as the video card, monitor, keyboard, and mouse. X client applications exist in the user-space, creating a graphical user interface (GUI) for the user and passing user requests to the X server.
35.1. The X11R7.1 Release
Important
/usr/ instead of /usr/X11R6. The /etc/X11/ directory contains configuration files for X client and server applications. This includes configuration files for the X server itself, the xfs font server, the X display managers, and many other base components.
/etc/fonts/fonts.conf. For more on configuring and adding fonts, refer to Section 35.4, “Fonts”.
system-config-display), particularly for devices that are not detected manually.
/etc/X11/xorg.conf. For information about the structure of this file, refer to Section 35.3, “X Server Configuration Files”.
35.2. Desktop Environments and Window Managers
35.2.1. Desktop Environments
- GNOME — The default desktop environment for Red Hat Enterprise Linux based on the GTK+ 2 graphical toolkit.
- KDE — An alternative desktop environment based on the Qt 3 graphical toolkit.
35.2.2. Window Managers
kwin- The KWin window manager is the default window manager for KDE. It is an efficient window manager which supports custom themes.
metacity- The Metacity window manager is the default window manager for GNOME. It is a simple and efficient window manager which also supports custom themes. To run this window manager, you need to install the
metacitypackage. mwm- The Motif Window Manager (
mwm) is a basic, stand-alone window manager. Since it is designed to be a stand-alone window manager, it should not be used in conjunction with GNOME or KDE. To run this window manager, you need to install theopenmotifpackage. twm- The minimalist Tab Window Manager (
twm, which provides the most basic tool set of any of the window managers, can be used either as a stand-alone or with a desktop environment. It is installed as part of the X11R7.1 release.
xinit -e <path-to-window-manager> at the prompt.
<path-to-window-manager> is the location of the window manager binary file. The binary file can be located by typing which window-manager-name, where window-manager-name is the name of the window manager you want to run.
which twm /usr/bin/twm xinit -e /usr/bin/twm
~]# which twm
/usr/bin/twm
~]# xinit -e /usr/bin/twmtwm window manager, the second command starts twm.
startx at the prompt.
35.3. X Server Configuration Files
/usr/bin/Xorg). Associated configuration files are stored in the /etc/X11/ directory (as is a symbolic link — X — which points to /usr/bin/Xorg). The configuration file for the X server is /etc/X11/xorg.conf.
/usr/lib/xorg/modules/ contains X server modules that can be loaded dynamically at runtime. By default, only some modules in /usr/lib/xorg/modules/ are automatically loaded by the X server.
/etc/X11/xorg.conf. For more information about loading modules, refer to Section 35.3.1.5, “Module”.
35.3.1. xorg.conf
/etc/X11/xorg.conf file, it is useful to understand the various sections and optional parameters available, especially when troubleshooting.
35.3.1.1. The Structure
/etc/X11/xorg.conf file is comprised of many different sections which address specific aspects of the system hardware.
Section "<section-name>" line (where <section-name> is the title for the section) and ends with an EndSection line. Each section contains lines that include option names and one or more option values. These are sometimes enclosed in double quotes (").
#) are not read by the X server and are used for human-readable comments.
/etc/X11/xorg.conf file accept a boolean switch which turns the feature on or off. Acceptable boolean values are:
1,on,true, oryes— Turns the option on.0,off,false, orno— Turns the option off.
/etc/X11/xorg.conf file. More detailed information about the X server configuration file can be found in the xorg.conf man page.
35.3.1.2. ServerFlags
ServerFlags section contains miscellaneous global X server settings. Any settings in this section may be overridden by options placed in the ServerLayout section (refer to Section 35.3.1.3, “ServerLayout” for details).
ServerFlags section is on its own line and begins with the term Option followed by an option enclosed in double quotation marks (").
ServerFlags section:
Section "ServerFlags" Option "DontZap" "true" EndSection
Section "ServerFlags"
Option "DontZap" "true"
EndSection"DontZap" "<boolean>"— When the value of <boolean> is set to true, this setting prevents the use of the Ctrl+Alt+Backspace key combination to immediately terminate the X server."DontZoom" "<boolean>"— When the value of <boolean> is set to true, this setting prevents cycling through configured video resolutions using the Ctrl+Alt+Keypad-Plus and Ctrl+Alt+Keypad-Minus key combinations.
35.3.1.3. ServerLayout
ServerLayout section binds together the input and output devices controlled by the X server. At a minimum, this section must specify one output device and one input device. By default, a monitor (output device) and keyboard (input device) are specified.
ServerLayout section:
ServerLayout section:
Identifier— Specifies a unique name for thisServerLayoutsection.Screen— Specifies the name of aScreensection to be used with the X server. More than oneScreenoption may be present.The following is an example of a typicalScreenentry:Screen 0 "Screen0" 0 0
Screen 0 "Screen0" 0 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow The first number in this exampleScreenentry (0) indicates that the first monitor connector or head on the video card uses the configuration specified in theScreensection with the identifier"Screen0".An example of aScreensection with the identifier"Screen0"can be found in Section 35.3.1.9, “Screen”.If the video card has more than one head, anotherScreenentry with a different number and a differentScreensection identifier is necessary .The numbers to the right of"Screen0"give the absolute X and Y coordinates for the upper-left corner of the screen (0 0by default).InputDevice— Specifies the name of anInputDevicesection to be used with the X server.It is advisable that there be at least twoInputDeviceentries: one for the default mouse and one for the default keyboard. The optionsCorePointerandCoreKeyboardindicate that these are the primary mouse and keyboard.Option "<option-name>"— An optional entry which specifies extra parameters for the section. Any options listed here override those listed in theServerFlagssection.Replace <option-name> with a valid option listed for this section in thexorg.confman page.
ServerLayout section in the /etc/X11/xorg.conf file. By default, the server only reads the first one it encounters, however.
ServerLayout section, it can be specified as a command line argument when starting an X session.
35.3.1.4. Files
Files section sets paths for services vital to the X server, such as the font path. This is an optional section, these paths are normally detected automatically. This section may be used to override any automatically detected defaults.
Files section:
Section "Files" RgbPath "/usr/share/X11/rgb.txt" FontPath "unix/:7100" EndSection
Section "Files"
RgbPath "/usr/share/X11/rgb.txt"
FontPath "unix/:7100"
EndSectionFiles section:
RgbPath— Specifies the location of the RGB color database. This database defines all valid color names in X and ties them to specific RGB values.FontPath— Specifies where the X server must connect to obtain fonts from thexfsfont server.By default, theFontPathisunix/:7100. This tells the X server to obtain font information using UNIX-domain sockets for inter-process communication (IPC) on port 7100.Refer to Section 35.4, “Fonts” for more information concerning X and fonts.ModulePath— An optional parameter which specifies alternate directories which store X server modules.
35.3.1.5. Module
/usr/lib/xorg/modules/ directory:
extmoddbeglxfreetypetype1recorddri
ModulePath parameter in the Files section. Refer to Section 35.3.1.4, “Files” for more information on this section.
Module section to /etc/X11/xorg.conf instructs the X server to load the modules listed in this section instead of the default modules.
Module section:
Section "Module" Load "fbdevhw" EndSection
Section "Module"
Load "fbdevhw"
EndSectionfbdevhw instead of the default modules.
Module section to /etc/X11/xorg.conf, you will need to specify any default modules you want to load as well as any extra modules.
35.3.1.6. InputDevice
InputDevice section configures one input device for the X server. Systems typically have at least one InputDevice section for the keyboard. It is perfectly normal to have no entry for a mouse, as most mouse settings are automatically detected.
InputDevice section for a keyboard:
InputDevice section:
Identifier— Specifies a unique name for thisInputDevicesection. This is a required entry.Driver— Specifies the name of the device driver X must load for the device.Option— Specifies necessary options pertaining to the device.A mouse may also be specified to override any autodetected defaults for the device. The following options are typically included when adding a mouse in thexorg.conf:Protocol— Specifies the protocol used by the mouse, such asIMPS/2.Device— Specifies the location of the physical device.Emulate3Buttons— Specifies whether to allow a two-button mouse to act like a three-button mouse when both mouse buttons are pressed simultaneously.
Consult thexorg.confman page for a list of valid options for this section.
35.3.1.7. Monitor
Monitor section configures one type of monitor used by the system. This is an optional entry as well, as most monitors are now automatically detected.
Monitor section for a monitor:
Warning
Monitor section of /etc/X11/xorg.conf. Inappropriate values can damage or destroy a monitor. Consult the monitor's documentation for a listing of safe operating parameters.
Monitor section:
Identifier— Specifies a unique name for thisMonitorsection. This is a required entry.VendorName— An optional parameter which specifies the vendor of the monitor.ModelName— An optional parameter which specifies the monitor's model name.DisplaySize— An optional parameter which specifies, in millimeters, the physical size of the monitor's picture area.HorizSync— Specifies the range of horizontal sync frequencies compatible with the monitor in kHz. These values help the X server determine the validity of built-in or specifiedModelineentries for the monitor.VertRefresh— Specifies the range of vertical refresh frequencies supported by the monitor, in kHz. These values help the X server determine the validity of built in or specifiedModelineentries for the monitor.Modeline— An optional parameter which specifies additional video modes for the monitor at particular resolutions, with certain horizontal sync and vertical refresh resolutions. Refer to thexorg.confman page for a more detailed explanation ofModelineentries.Option "<option-name>"— An optional entry which specifies extra parameters for the section. Replace <option-name> with a valid option listed for this section in thexorg.confman page.
35.3.1.8. Device
Device section configures one video card on the system. While one Device section is the minimum, additional instances may occur for each video card installed on the machine.
Device section for a video card:
Device section:
Identifier— Specifies a unique name for thisDevicesection. This is a required entry.Driver— Specifies which driver the X server must load to utilize the video card. A list of drivers can be found in/usr/share/hwdata/videodrivers, which is installed with thehwdatapackage.VendorName— An optional parameter which specifies the vendor of the video card.BoardName— An optional parameter which specifies the name of the video card.VideoRam— An optional parameter which specifies the amount of RAM available on the video card in kilobytes. This setting is only necessary for video cards the X server cannot probe to detect the amount of video RAM.BusID— An entry which specifies the bus location of the video card. On systems with only one video card aBusIDentry is optional and may not even be present in the default/etc/X11/xorg.conffile. On systems with more than one video card, however, aBusIDentry must be present.Screen— An optional entry which specifies which monitor connector or head on the video card theDevicesection configures. This option is only useful for video cards with multiple heads.If multiple monitors are connected to different heads on the same video card, separateDevicesections must exist and each of these sections must have a differentScreenvalue.Values for theScreenentry must be an integer. The first head on the video card has a value of0. The value for each additional head increments this value by one.Option "<option-name>"— An optional entry which specifies extra parameters for the section. Replace <option-name> with a valid option listed for this section in thexorg.confman page.One of the more common options is"dpms"(for Display Power Management Signaling, a VESA standard), which activates the Service Star energy compliance setting for the monitor.
35.3.1.9. Screen
Screen section binds one video card (or video card head) to one monitor by referencing the Device section and the Monitor section for each. While one Screen section is the minimum, additional instances may occur for each video card and monitor combination present on the machine.
Screen section:
Screen section:
Identifier— Specifies a unique name for thisScreensection. This is a required entry.Device— Specifies the unique name of aDevicesection. This is a required entry.Monitor— Specifies the unique name of aMonitorsection. This is only required if a specificMonitorsection is defined in thexorg.conffile. Normally, monitors are automatically detected.DefaultDepth— Specifies the default color depth in bits. In the previous example,16(which provides thousands of colors) is the default. Only oneDefaultDepthis permitted, although this can be overridden with the Xorg command line option-depth <n>,where<n>is any additional depth specified.SubSection "Display"— Specifies the screen modes available at a particular color depth. TheScreensection can have multipleDisplaysubsections, which are entirely optional since screen modes are automatically detected.This subsection is normally used to override autodetected modes.Option "<option-name>"— An optional entry which specifies extra parameters for the section. Replace <option-name> with a valid option listed for this section in thexorg.confman page.
35.3.1.10. DRI
DRI section specifies parameters for the Direct Rendering Infrastructure (DRI). DRI is an interface which allows 3D software applications to take advantage of 3D hardware acceleration capabilities built into most modern video hardware. In addition, DRI can improve 2D performance via hardware acceleration, if supported by the video card driver.
xorg.conf file will override those defaults.
DRI section:
Section "DRI" Group 0 Mode 0666 EndSection
Section "DRI"
Group 0
Mode 0666
EndSection35.4. Fonts
xfs.
35.4.1. Fontconfig
Important
/etc/fonts/fonts.conf configuration file, which should not be edited by hand.
Note
~/.gtkrc.mine:
style "user-font" {
fontset = "<font-specification>"
}
widget_class "*" style "user-font"
style "user-font" {
fontset = "<font-specification>"
}
widget_class "*" style "user-font"-adobe-helvetica-medium-r-normal--*-120-*-*-*-*-*-*. A full list of core fonts can be obtained by running xlsfonts or created interactively using the xfontsel command.
35.4.1.1. Adding Fonts to Fontconfig
- To add fonts system-wide, copy the new fonts into the
/usr/share/fonts/directory. It is a good idea to create a new subdirectory, such aslocal/or similar, to help distinguish between user-installed and default fonts.To add fonts for an individual user, copy the new fonts into the.fonts/directory in the user's home directory. - Use the
fc-cachecommand to update the font information cache, as in the following example:fc-cache <path-to-font-directory>
fc-cache <path-to-font-directory>Copy to Clipboard Copied! Toggle word wrap Toggle overflow In this command, replace <path-to-font-directory> with the directory containing the new fonts (either/usr/share/fonts/local/or/home/<user>/.fonts/).
Note
fonts:/// into the Nautilus address bar, and dragging the new font files there.
Important
.gz extension, it is compressed and cannot be used until uncompressed. To do this, use the gunzip command or double-click the file and drag the font to a directory in Nautilus.
35.4.2. Core X Font System
xfs) to provide fonts to X client applications.
FontPath directive within the Files section of the /etc/X11/xorg.conf configuration file. Refer to Section 35.3.1.4, “Files” for more information about the FontPath entry.
xfs server on a specified port to acquire font information. For this reason, the xfs service must be running for X to start. For more about configuring services for a particular runlevel, refer to Chapter 18, Controlling Access to Services.
35.4.2.1. xfs Configuration
/etc/rc.d/init.d/xfs script starts the xfs server. Several options can be configured within its configuration file, /etc/X11/fs/config.
alternate-servers— Specifies a list of alternate font servers to be used if this font server is not available. A comma must separate each font server in a list.catalogue— Specifies an ordered list of font paths to use. A comma must separate each font path in a list.Use the string:unscaledimmediately after the font path to make the unscaled fonts in that path load first. Then specify the entire path again, so that other scaled fonts are also loaded.client-limit— Specifies the maximum number of clients the font server services. The default is10.clone-self— Allows the font server to clone a new version of itself when theclient-limitis hit. By default, this option ison.default-point-size— Specifies the default point size for any font that does not specify this value. The value for this option is set in decipoints. The default of120corresponds to a 12 point font.default-resolutions— Specifies a list of resolutions supported by the X server. Each resolution in the list must be separated by a comma.deferglyphs— Specifies whether to defer loading glyphs (the graphic used to visually represent a font). To disable this feature usenone, to enable this feature for all fonts useall, or to turn this feature on only for 16-bit fonts use16.error-file— Specifies the path and file name of a location wherexfserrors are logged.no-listen— Preventsxfsfrom listening to particular protocols. By default, this option is set totcpto preventxfsfrom listening on TCP ports for security reasons.Note
Ifxfsis used to serve fonts over the network, remove this line.port— Specifies the TCP port thatxfslistens on ifno-listendoes not exist or is commented out.use-syslog— Specifies whether to use the system error log.
35.4.2.2. Adding Fonts to xfs
xfs), follow these steps:
- If it does not already exist, create a directory called
/usr/share/fonts/local/using the following command as root:mkdir /usr/share/fonts/local/
mkdir /usr/share/fonts/local/Copy to Clipboard Copied! Toggle word wrap Toggle overflow If creating the/usr/share/fonts/local/directory is necessary, it must be added to thexfspath using the following command as root:chkfontpath --add /usr/share/fonts/local/
chkfontpath --add /usr/share/fonts/local/Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Copy the new font file into the
/usr/share/fonts/local/directory - Update the font information by issuing the following command as root:
ttmkfdir -d /usr/share/fonts/local/ -o /usr/share/fonts/local/fonts.scale
ttmkfdir -d /usr/share/fonts/local/ -o /usr/share/fonts/local/fonts.scaleCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Reload the
xfsfont server configuration file by issuing the following command as root:service xfs reload
service xfs reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.5. Runlevels and X
35.5.1. Runlevel 3
startx. The startx command is a front-end to the xinit command, which launches the X server (Xorg) and connects X client applications to it. Because the user is already logged into the system at runlevel 3, startx does not launch a display manager or authenticate users. Refer to Section 35.5.2, “Runlevel 5” for more information about display managers.
startx command is executed, it searches for the .xinitrc file in the user's home directory to define the desktop environment and possibly other X client applications to run. If no .xinitrc file is present, it uses the system default /etc/X11/xinit/xinitrc file instead.
xinitrc script then searches for user-defined files and default system files, including .Xresources, .Xmodmap, and .Xkbmap in the user's home directory, and Xresources, Xmodmap, and Xkbmap in the /etc/X11/ directory. The Xmodmap and Xkbmap files, if they exist, are used by the xmodmap utility to configure the keyboard. The Xresources file is read to assign specific preference values to applications.
xinitrc script executes all scripts located in the /etc/X11/xinit/xinitrc.d/ directory. One important script in this directory is xinput.sh, which configures settings such as the default language.
xinitrc script attempts to execute .Xclients in the user's home directory and turns to /etc/X11/xinit/Xclients if it cannot be found. The purpose of the Xclients file is to start the desktop environment or, possibly, just a basic window manager. The .Xclients script in the user's home directory starts the user-specified desktop environment in the .Xclients-default file. If .Xclients does not exist in the user's home directory, the standard /etc/X11/xinit/Xclients script attempts to start another desktop environment, trying GNOME first and then KDE followed by twm.
35.5.2. Runlevel 5
GNOME— The default display manager for Red Hat Enterprise Linux,GNOMEallows the user to configure language settings, shutdown, restart or log in to the system.KDE— KDE's display manager which allows the user to shutdown, restart or log in to the system.xdm— A very basic display manager which only lets the user log in to the system.
prefdm script determines the preferred display manager by referencing the /etc/sysconfig/desktop file. A list of options for this file is available in this file:
/usr/share/doc/initscripts-<version-number>/sysconfig.txt
/usr/share/doc/initscripts-<version-number>/sysconfig.txtinitscripts package.
/etc/X11/xdm/Xsetup_0 file to set up the login screen. Once the user logs into the system, the /etc/X11/xdm/GiveConsole script runs to assign ownership of the console to the user. Then, the /etc/X11/xdm/Xsession script runs to accomplish many of the tasks normally performed by the xinitrc script when starting X from runlevel 3, including setting system and user resources, as well as running the scripts in the /etc/X11/xinit/xinitrc.d/ directory.
GNOME or KDE display managers by selecting it from the menu item (accessed by selecting System (on the panel) > > > ). If the desktop environment is not specified in the display manager, the /etc/X11/xdm/Xsession script checks the .xsession and .Xclients files in the user's home directory to decide which desktop environment to load. As a last resort, the /etc/X11/xinit/Xclients file is used to select a desktop environment or window manager to use in the same way as runlevel 3.
:0) and logs out, the /etc/X11/xdm/TakeConsole script runs and reassigns ownership of the console to the root user. The original display manager, which continues running after the user logged in, takes control by spawning a new display manager. This restarts the X server, displays a new login window, and starts the entire process over again.
/usr/share/doc/gdm-<version-number>/README (where <version-number> is the version number for the gdm package installed) and the xdm man page.
35.6. Additional Resources
35.6.1. Installed Documentation
/usr/share/X11/doc/— contains detailed documentation on the X Window System architecture, as well as how to get additional information about the Xorg project as a new user.man xorg.conf— Contains information about thexorg.confconfiguration files, including the meaning and syntax for the different sections within the files.man Xorg— Describes theXorgdisplay server.
35.6.2. Useful Websites
- http://www.X.org/ — Home page of the X.Org Foundation, which produces the X11R7.1 release of the X Window System. The X11R7.1 release is bundled with Red Hat Enterprise Linux to control the necessary hardware and provide a GUI environment.
- http://dri.sourceforge.net/ — Home page of the DRI (Direct Rendering Infrastructure) project. The DRI is the core hardware 3D acceleration component of X.
- http://www.gnome.org/ — Home of the GNOME project.
- http://www.kde.org/ — Home of the KDE desktop environment.
Chapter 36. X Window System Configuration
system-config-display at a shell prompt (for example, in an XTerm or GNOME terminal). If the X Window System is not running, a small version of X is started to run the program.
36.1. Display Settings
Figure 36.1. Display Settings
36.2. Display Hardware Settings
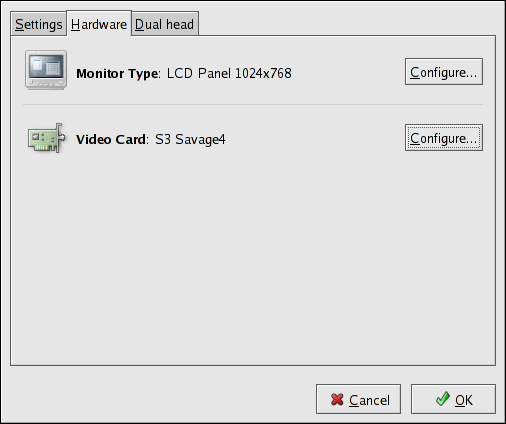
Figure 36.2. Display Hardware Settings
36.3. Dual Head Display Settings
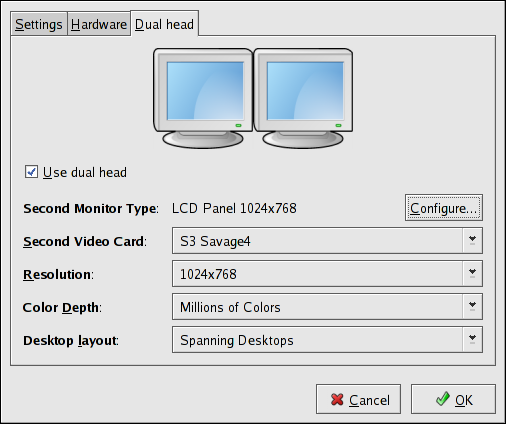
Figure 36.3. Dual Head Display Settings
Chapter 37. Users and Groups
37.1. User and Group Configuration
system-config-users RPM package installed. To start the User Manager from the desktop, go to System (on the panel) > > . You can also type the command system-config-users at a shell prompt (for example, in an XTerm or a GNOME terminal).
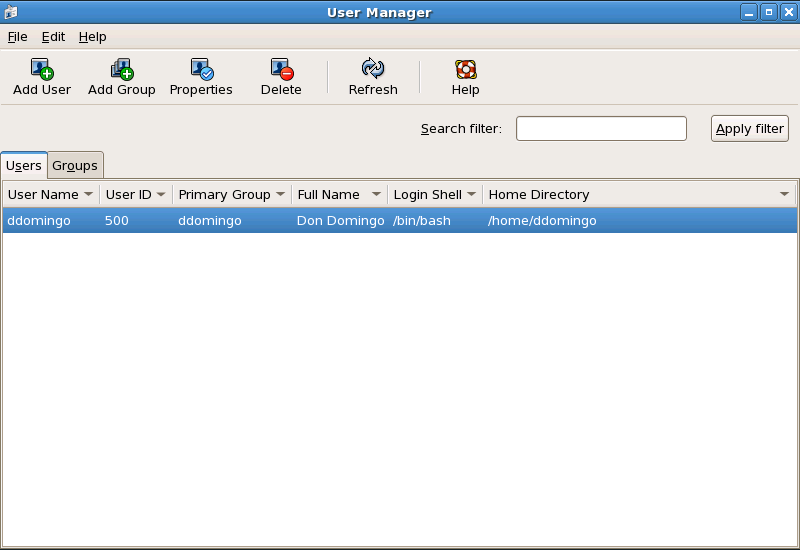
Figure 37.1. User Manager
37.1.1. Adding a New User
Note
/bin/bash. The default home directory is /home/<username>/. You can change the home directory that is created for the user, or you can choose not to create the home directory by unselecting Create home directory.
/etc/skel/ directory into the new home directory.
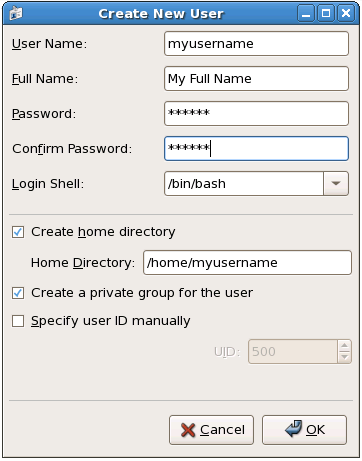
Figure 37.2. New User
37.1.2. Modifying User Properties
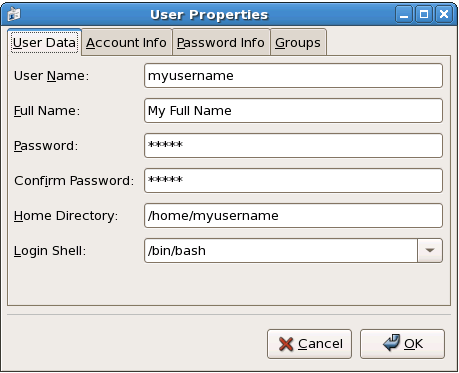
Figure 37.3. User Properties
- User Data — Shows the basic user information configured when you added the user. Use this tab to change the user's full name, password, home directory, or login shell.
- Password Info — Displays the date that the user's password last changed. To force the user to change passwords after a certain number of days, select Enable password expiration and enter a desired value in the Days before change required: field. The number of days before the user's password expires, the number of days before the user is warned to change passwords, and days before the account becomes inactive can also be changed.
37.1.3. Adding a New Group
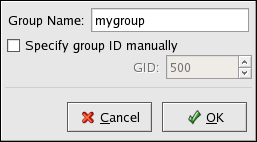
Figure 37.4. New Group
37.1.4. Modifying Group Properties
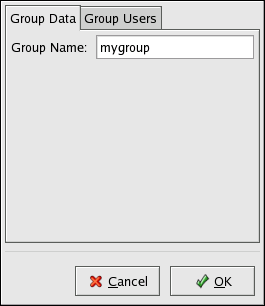
Figure 37.5. Group Properties
37.2. User and Group Management Tools
system-config-users). For more information on User Manager, refer to Section 37.1, “User and Group Configuration”.
useradd,usermod, anduserdel— Industry-standard methods of adding, deleting and modifying user accountsgroupadd,groupmod, andgroupdel— Industry-standard methods of adding, deleting, and modifying user groupsgpasswd— Industry-standard method of administering the/etc/groupfilepwck,grpck— Tools used for the verification of the password, group, and associated shadow filespwconv,pwunconv— Tools used for the conversion of passwords to shadow passwords and back to standard passwords
37.2.1. Command Line Configuration
37.2.2. Adding a User
- Issue the
useraddcommand to create a locked user account:useradd <username>
useradd <username>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Unlock the account by issuing the
passwdcommand to assign a password and set password aging guidelines:passwd <username>
passwd <username>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
useradd are detailed in Table 37.1, “useradd Command Line Options”.
| Option | Description |
|---|---|
-c '<comment>' | <comment> can be replaced with any string. This option is generally used to specify the full name of a user. |
-d <home-dir> | Home directory to be used instead of default /home/<username>/ |
-e <date> | Date for the account to be disabled in the format YYYY-MM-DD |
-f <days> | Number of days after the password expires until the account is disabled. If 0 is specified, the account is disabled immediately after the password expires. If -1 is specified, the account is not be disabled after the password expires. |
-g <group-name> | Group name or group number for the user's default group. The group must exist prior to being specified here. |
-G <group-list> | List of additional (other than default) group names or group numbers, separated by commas, of which the user is a member. The groups must exist prior to being specified here. |
-m | Create the home directory if it does not exist. |
-M | Do not create the home directory. |
-n | Do not create a user private group for the user. |
-r | Create a system account with a UID less than 500 and without a home directory |
-p <password> | The password encrypted with crypt |
-s | User's login shell, which defaults to /bin/bash |
-u <uid> | User ID for the user, which must be unique and greater than 499 |
37.2.3. Adding a Group
groupadd:
groupadd <group-name>
groupadd <group-name>groupadd are detailed in Table 37.2, “groupadd Command Line Options”.
| Option | Description |
|---|---|
-g <gid> | Group ID for the group, which must be unique and greater than 499 |
-r | Create a system group with a GID less than 500 |
-f | When used with -g <gid> and <gid> already exists, groupadd will choose another unique <gid> for the group. |
37.2.4. Password Aging
chage command with an option from Table 37.3, “chage Command Line Options”, followed by the username.
Important
chage command. For more information, see Section 37.6, “Shadow Passwords”.
| Option | Description |
|---|---|
-m <days> | Specifies the minimum number of days between which the user must change passwords. If the value is 0, the password does not expire. |
-M <days> | Specifies the maximum number of days for which the password is valid. When the number of days specified by this option plus the number of days specified with the -d option is less than the current day, the user must change passwords before using the account. |
-d <days> | Specifies the number of days since January 1, 1970 the password was changed |
-I <days> | Specifies the number of inactive days after the password expiration before locking the account. If the value is 0, the account is not locked after the password expires. |
-E <date> | Specifies the date on which the account is locked, in the format YYYY-MM-DD. Instead of the date, the number of days since January 1, 1970 can also be used. |
-W <days> | Specifies the number of days before the password expiration date to warn the user. |
-l | Lists current account aging settings. |
Note
chage command is followed directly by a username (with no options), it displays the current password aging values and allows them to be changed interactively.
- Set up an initial password — There are two common approaches to this step. The administrator can assign a default password or assign a null password.To assign a default password, use the following steps:
- Start the command line Python interpreter with the
pythoncommand. It displays the following:Python 2.4.3 (#1, Jul 21 2006, 08:46:09) [GCC 4.1.1 20060718 (Red Hat 4.1.1-9)] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>>
Python 2.4.3 (#1, Jul 21 2006, 08:46:09) [GCC 4.1.1 20060718 (Red Hat 4.1.1-9)] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - At the prompt, type the following commands. Replace <password> with the password to encrypt and <salt> with a random combination of at least 2 of the following: any alphanumeric character, the slash (/) character or a dot (.):
import crypt print crypt.crypt("<password>","<salt>")import crypt print crypt.crypt("<password>","<salt>")Copy to Clipboard Copied! Toggle word wrap Toggle overflow The output is the encrypted password, similar to'12CsGd8FRcMSM'. - Press Ctrl-D to exit the Python interpreter.
- At the shell, enter the following command (replacing <encrypted-password> with the encrypted output of the Python interpreter):
usermod -p "<encrypted-password>" <username>
usermod -p "<encrypted-password>" <username>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Alternatively, you can assign a null password instead of an initial password. To do this, use the following command:usermod -p "" username
usermod -p "" usernameCopy to Clipboard Copied! Toggle word wrap Toggle overflow Warning
Using a null password, while convenient, is a highly unsecure practice, as any third party can log in first an access the system using the unsecure username. Always make sure that the user is ready to log in before unlocking an account with a null password. - Force immediate password expiration — Type the following command:
chage -d 0 username
chage -d 0 usernameCopy to Clipboard Copied! Toggle word wrap Toggle overflow This command sets the value for the date the password was last changed to the epoch (January 1, 1970). This value forces immediate password expiration no matter what password aging policy, if any, is in place.
37.2.5. Explaining the Process
useradd juan is issued on a system that has shadow passwords enabled:
- A new line for
juanis created in/etc/passwd. The line has the following characteristics:- It begins with the username
juan. - There is an
xfor the password field indicating that the system is using shadow passwords. - A UID greater than 499 is created. (Under Red Hat Enterprise Linux, UIDs and GIDs below 500 are reserved for system use.)
- A GID greater than 499 is created.
- The optional GECOS information is left blank.
- The home directory for
juanis set to/home/juan/. - The default shell is set to
/bin/bash.
- A new line for
juanis created in/etc/shadow. The line has the following characteristics:- It begins with the username
juan. - Two exclamation points (
!!) appear in the password field of the/etc/shadowfile, which locks the account.Note
If an encrypted password is passed using the-pflag, it is placed in the/etc/shadowfile on the new line for the user. - The password is set to never expire.
- A new line for a group named
juanis created in/etc/group. A group with the same name as a user is called a user private group. For more information on user private groups, refer to Section 37.1.1, “Adding a New User”.The line created in/etc/grouphas the following characteristics:- It begins with the group name
juan. - An
xappears in the password field indicating that the system is using shadow group passwords. - The GID matches the one listed for user
juanin/etc/passwd.
- A new line for a group named
juanis created in/etc/gshadow. The line has the following characteristics:- It begins with the group name
juan. - An exclamation point (
!) appears in the password field of the/etc/gshadowfile, which locks the group. - All other fields are blank.
- A directory for user
juanis created in the/home/directory. This directory is owned by userjuanand groupjuan. However, it has read, write, and execute privileges only for the userjuan. All other permissions are denied. - The files within the
/etc/skel/directory (which contain default user settings) are copied into the new/home/juan/directory.
juan exists on the system. To activate it, the administrator must next assign a password to the account using the passwd command and, optionally, set password aging guidelines.
37.3. Standard Users
/etc/passwd file by an Everything installation. The groupid (GID) in this table is the primary group for the user. See Section 37.4, “Standard Groups” for a listing of standard groups.
| User | UID | GID | Home Directory | Shell |
|---|---|---|---|---|
| root | 0 | 0 | /root | /bin/bash |
| bin | 1 | 1 | /bin | /sbin/nologin |
| daemon | 2 | 2 | /sbin | /sbin/nologin |
| adm | 3 | 4 | /var/adm | /sbin/nologin |
| lp | 4 | 7 | /var/spool/lpd | /sbin/nologin |
| sync | 5 | 0 | /sbin | /bin/sync |
| shutdown | 6 | 0 | /sbin | /sbin/shutdown |
| halt | 7 | 0 | /sbin | /sbin/halt |
| 8 | 12 | /var/spool/mail | /sbin/nologin | |
| news | 9 | 13 | /etc/news | |
| uucp | 10 | 14 | /var/spool/uucp | /sbin/nologin |
| operator | 11 | 0 | /root | /sbin/nologin |
| games | 12 | 100 | /usr/games | /sbin/nologin |
| gopher | 13 | 30 | /var/gopher | /sbin/nologin |
| ftp | 14 | 50 | /var/ftp | /sbin/nologin |
| nobody | 99 | 99 | / | /sbin/nologin |
| rpm | 37 | 37 | /var/lib/rpm | /sbin/nologin |
| vcsa | 69 | 69 | /dev | /sbin/nologin |
| dbus | 81 | 81 | / | /sbin/nologin |
| ntp | 38 | 38 | /etc/ntp | /sbin/nologin |
| canna | 39 | 39 | /var/lib/canna | /sbin/nologin |
| nscd | 28 | 28 | / | /sbin/nologin |
| rpc | 32 | 32 | / | /sbin/nologin |
| postfix | 89 | 89 | /var/spool/postfix | /sbin/nologin |
| mailman | 41 | 41 | /var/mailman | /sbin/nologin |
| named | 25 | 25 | /var/named | /bin/false |
| amanda | 33 | 6 | var/lib/amanda/ | /bin/bash |
| postgres | 26 | 26 | /var/lib/pgsql | /bin/bash |
| exim | 93 | 93 | /var/spool/exim | /sbin/nologin |
| sshd | 74 | 74 | /var/empty/sshd | /sbin/nologin |
| rpcuser | 29 | 29 | /var/lib/nfs | /sbin/nologin |
| nsfnobody | 65534 | 65534 | /var/lib/nfs | /sbin/nologin |
| pvm | 24 | 24 | /usr/share/pvm3 | /bin/bash |
| apache | 48 | 48 | /var/www | /sbin/nologin |
| xfs | 43 | 43 | /etc/X11/fs | /sbin/nologin |
| gdm | 42 | 42 | /var/gdm | /sbin/nologin |
| htt | 100 | 101 | /usr/lib/im | /sbin/nologin |
| mysql | 27 | 27 | /var/lib/mysql | /bin/bash |
| webalizer | 67 | 67 | /var/www/usage | /sbin/nologin |
| mailnull | 47 | 47 | /var/spool/mqueue | /sbin/nologin |
| smmsp | 51 | 51 | /var/spool/mqueue | /sbin/nologin |
| squid | 23 | 23 | /var/spool/squid | /sbin/nologin |
| ldap | 55 | 55 | /var/lib/ldap | /bin/false |
| netdump | 34 | 34 | /var/crash | /bin/bash |
| pcap | 77 | 77 | /var/arpwatch | /sbin/nologin |
| radiusd | 95 | 95 | / | /bin/false |
| radvd | 75 | 75 | / | /sbin/nologin |
| quagga | 92 | 92 | /var/run/quagga | /sbin/login |
| wnn | 49 | 49 | /var/lib/wnn | /sbin/nologin |
| dovecot | 97 | 97 | /usr/libexec/dovecot | /sbin/nologin |
37.4. Standard Groups
/etc/group file.
| Group | GID | Members |
|---|---|---|
| root | 0 | root |
| bin | 1 | root, bin, daemon |
| daemon | 2 | root, bin, daemon |
| sys | 3 | root, bin, adm |
| adm | 4 | root, adm, daemon |
| tty | 5 | |
| disk | 6 | root |
| lp | 7 | daemon, lp |
| mem | 8 | |
| kmem | 9 | |
| wheel | 10 | root |
| 12 | mail, postfix, exim | |
| news | 13 | news |
| uucp | 14 | uucp |
| man | 15 | |
| games | 20 | |
| gopher | 30 | |
| dip | 40 | |
| ftp | 50 | |
| lock | 54 | |
| nobody | 99 | |
| users | 100 | |
| rpm | 37 | |
| utmp | 22 | |
| floppy | 19 | |
| vcsa | 69 | |
| dbus | 81 | |
| ntp | 38 | |
| canna | 39 | |
| nscd | 28 | |
| rpc | 32 | |
| postdrop | 90 | |
| postfix | 89 | |
| mailman | 41 | |
| exim | 93 | |
| named | 25 | |
| postgres | 26 | |
| sshd | 74 | |
| rpcuser | 29 | |
| nfsnobody | 65534 | |
| pvm | 24 | |
| apache | 48 | |
| xfs | 43 | |
| gdm | 42 | |
| htt | 101 | |
| mysql | 27 | |
| webalizer | 67 | |
| mailnull | 47 | |
| smmsp | 51 | |
| squid | 23 | |
| ldap | 55 | |
| netdump | 34 | |
| pcap | 77 | |
| quaggavt | 102 | |
| quagga | 92 | |
| radvd | 75 | |
| slocate | 21 | |
| wnn | 49 | |
| dovecot | 97 | |
| radiusd | 95 |
37.5. User Private Groups
/etc/bashrc file. Traditionally on UNIX systems, the umask is set to 022, which allows only the user who created the file or directory to make modifications. Under this scheme, all other users, including members of the creator's group, are not allowed to make any modifications. However, under the UPG scheme, this "group protection" is not necessary since every user has their own private group.
37.5.1. Group Directories
/usr/share/emacs/site-lisp/ directory. Some people are trusted to modify the directory, but certainly not everyone is trusted. First create an emacs group, as in the following command:
groupadd emacs
groupadd emacsemacs group, type:
chown -R root.emacs /usr/share/emacs/site-lisp
chown -R root.emacs /usr/share/emacs/site-lispgpasswd command:
gpasswd -a <username> emacs
gpasswd -a <username> emacschmod 775 /usr/share/emacs/site-lisp
chmod 775 /usr/share/emacs/site-lispemacs). Use the following command:
chmod 2775 /usr/share/emacs/site-lisp
chmod 2775 /usr/share/emacs/site-lispemacs group can create and edit files in the /usr/share/emacs/site-lisp/ directory without the administrator having to change file permissions every time users write new files.
37.6. Shadow Passwords
shadow-utils package). Doing so enhances the security of system authentication files. For this reason, the installation program enables shadow passwords by default.
- Improves system security by moving encrypted password hashes from the world-readable
/etc/passwdfile to/etc/shadow, which is readable only by the root user. - Stores information about password aging.
- Allows the use the
/etc/login.defsfile to enforce security policies.
shadow-utils package work properly whether or not shadow passwords are enabled. However, since password aging information is stored exclusively in the /etc/shadow file, any commands which create or modify password aging information do not work.
chagegpasswd/usr/sbin/usermod-eor-foptions/usr/sbin/useradd-eor-foptions
37.7. Additional Resources
37.7.1. Installed Documentation
- Related man pages — There are a number of man pages for the various applications and configuration files involved with managing users and groups. Some of the more important man pages have been listed here:
- User and Group Administrative Applications
man chage— A command to modify password aging policies and account expiration.man gpasswd— A command to administer the/etc/groupfile.man groupadd— A command to add groups.man grpck— A command to verify the/etc/groupfile.man groupdel— A command to remove groups.man groupmod— A command to modify group membership.man pwck— A command to verify the/etc/passwdand/etc/shadowfiles.man pwconv— A tool to convert standard passwords to shadow passwords.man pwunconv— A tool to convert shadow passwords to standard passwords.man useradd— A command to add users.man userdel— A command to remove users.man usermod— A command to modify users.
- Configuration Files
man 5 group— The file containing group information for the system.man 5 passwd— The file containing user information for the system.man 5 shadow— The file containing passwords and account expiration information for the system.
Chapter 38. Printer Configuration
Important
cupsd.conf man page documents configuration of a CUPS server. It includes directives for enabling SSL support. However, CUPS does not allow control of the protocol versions used. Due to the vulnerability described in Resolution for POODLE SSLv3.0 vulnerability (CVE-2014-3566) for components that do not allow SSLv3 to be disabled via configuration settings, Red Hat recommends that you do not rely on this for security. It is recommend that you use stunnel to provide a secure tunnel and disable SSLv3.
SSH as described in Section 20.7.1, “X11 Forwarding”.
system-config-printer at a shell prompt.
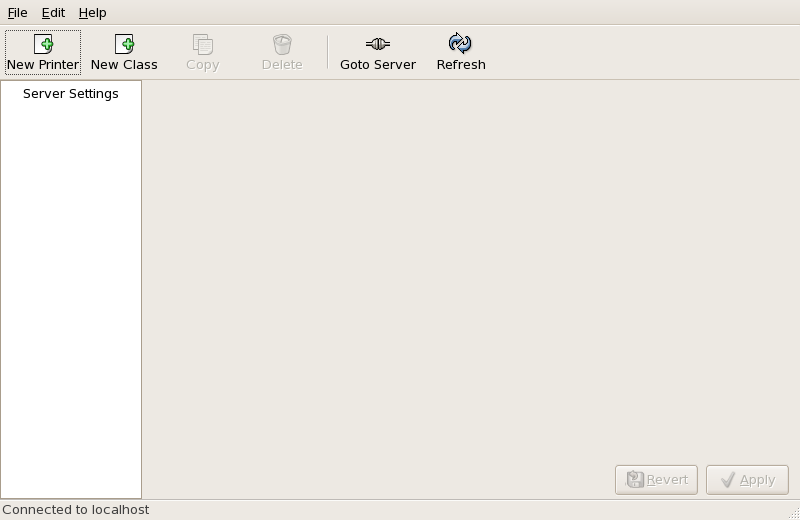
Figure 38.1. Printer Configuration Tool
- — a printer connected directly to the network through HP JetDirect or Appsocket interface instead of a computer.
- — a printer that can be accessed over a TCP/IP network via the Internet Printing Protocol (for example, a printer attached to another Red Hat Enterprise Linux system running CUPS on the network).
- — a printer attached to a different UNIX system that can be accessed over a TCP/IP network (for example, a printer attached to another Red Hat Enterprise Linux system running LPD on the network).
- — a printer attached to a different system which is sharing a printer over an SMB network (for example, a printer attached to a Microsoft Windows™ machine).
- — a printer connected directly to the network through HP JetDirect instead of a computer.
Important
38.1. Adding a Local Printer
Figure 38.2. Adding a Printer
Figure 38.3. Adding a Local Printer
38.2. Adding an IPP Printer
Figure 38.4. Adding an IPP Printer
38.3. Adding a Samba (SMB) Printer
Figure 38.5. Adding a SMB Printer
dellbox, while the printer share is r2.
guest for Windows servers, or nobody for Samba servers.
Warning
38.4. Adding a JetDirect Printer
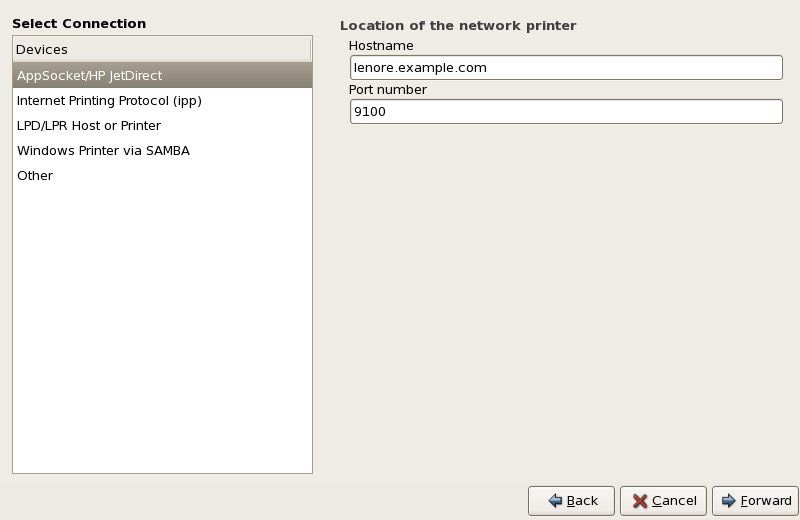
Figure 38.6. Adding a JetDirect Printer
- Hostname — The hostname or IP address of the JetDirect printer.
- Port Number — The port on the JetDirect printer that is listening for print jobs. The default port is 9100.
38.5. Selecting the Printer Model and Finishing
- Select a Printer from database - If you select this option, choose the make of your printer from the list of Makes. If your printer make is not listed, choose Generic.
- Provide PPD file - A PostScript Printer Description (PPD) file may also be provided with your printer. This file is normally provided by the manufacturer. If you are provided with a PPD file, you can choose this option and use the browser bar below the option description to select the PPD file.
Figure 38.7. Selecting a Printer Model
38.5.1. Confirming Printer Configuration
38.6. Printing a Test Page
38.7. Modifying Existing Printers
38.7.1. The Settings Tab
Figure 38.8. Settings Tab
38.7.2. The Policies Tab
Figure 38.9. Policies Tab
38.7.3. The Access Control Tab
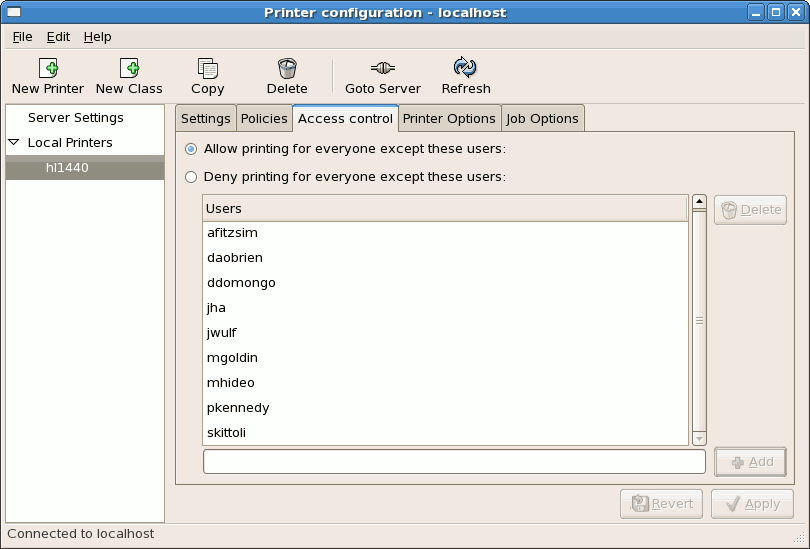
Figure 38.10. Access Control Tab
38.7.4. The Printer and Job OptionsTab
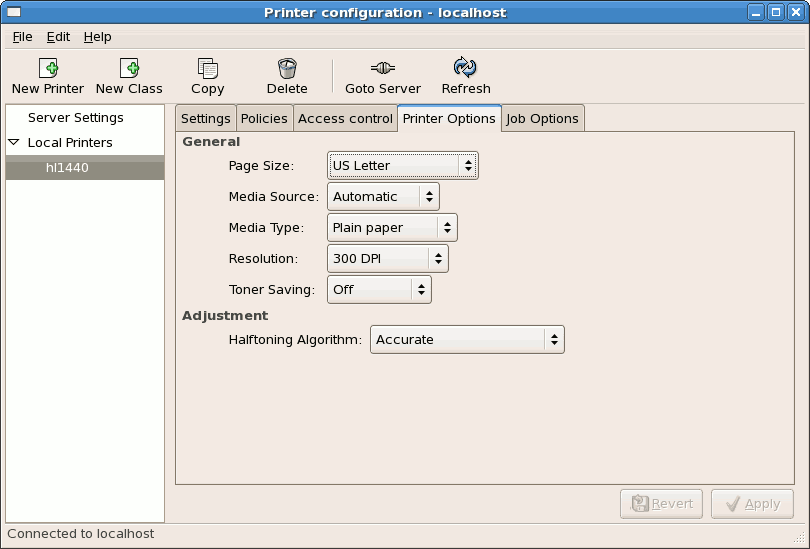
Figure 38.11. Printer Options Tab
- Page Size — Allows the paper size to be selected. The options include US Letter, US Legal, A3, and A4
- Media Source — set to Automatic by default. Change this option to use paper from a different tray.
- Media Type — Allows you to change paper type. Options include: Plain, thick, bond, and transparency.
- Resolution — Configure the quality and detail of the printout. Default is 300 dots per inch (dpi).
- Toner Saving — Choose whether the printer uses less toner to conserve resources.
38.8. Managing Print Jobs
Figure 38.12. GNOME Print Status
lpq. The last few lines look similar to the following:
Example 38.1. Example of lpq output
Rank Owner/ID Class Job Files Size Time active user@localhost+902 A 902 sample.txt 2050 01:20:46
Rank Owner/ID Class Job Files Size Time
active user@localhost+902 A 902 sample.txt 2050 01:20:46lpq and then use the command lprm job number. For example, lprm 902 would cancel the print job in Example 38.1, “Example of lpq output”. You must have proper permissions to cancel a print job. You can not cancel print jobs that were started by other users unless you are logged in as root on the machine to which the printer is attached.
lpr sample.txt prints the text file sample.txt. The print filter determines what type of file it is and converts it into a format the printer can understand.
38.9. Additional Resources
38.9.1. Installed Documentation
map lpr— The manual page for thelprcommand that allows you to print files from the command line.man lprm— The manual page for the command line utility to remove print jobs from the print queue.man mpage— The manual page for the command line utility to print multiple pages on one sheet of paper.man cupsd— The manual page for the CUPS printer daemon.man cupsd.conf— The manual page for the CUPS printer daemon configuration file.man classes.conf— The manual page for the class configuration file for CUPS.
38.9.2. Useful Websites
- http://www.linuxprinting.org — GNU/Linux Printing contains a large amount of information about printing in Linux.
- http://www.cups.org/ — Documentation, FAQs, and newsgroups about CUPS.
Chapter 39. Automated Tasks
locate command is updated daily. A system administrator can use automated tasks to perform periodic backups, monitor the system, run custom scripts, and more.
cron, at, and batch.
39.1. Cron
vixie-cron RPM package must be installed and the crond service must be running. To determine if the package is installed, use the rpm -q vixie-cron command. To determine if the service is running, use the command /sbin/service crond status.
39.1.1. Configuring Cron Jobs
/etc/crontab, contains the following lines:
SHELL variable tells the system which shell environment to use (in this example the bash shell), while the PATH variable defines the path used to execute commands. The output of the cron jobs are emailed to the username defined with the MAILTO variable. If the MAILTO variable is defined as an empty string (MAILTO=""), email is not sent. The HOME variable can be used to set the home directory to use when executing commands or scripts.
/etc/crontab file represents a job and has the following format:
minute hour day month dayofweek command
minute hour day month dayofweek commandminute— any integer from 0 to 59hour— any integer from 0 to 23day— any integer from 1 to 31 (must be a valid day if a month is specified)month— any integer from 1 to 12 (or the short name of the month such as jan or feb)dayofweek— any integer from 0 to 7, where 0 or 7 represents Sunday (or the short name of the week such as sun or mon)command— the command to execute (the command can either be a command such asls /proc >> /tmp/procor the command to execute a custom script)
1-4 means the integers 1, 2, 3, and 4.
3, 4, 6, 8 indicates those four specific integers.
/<integer>. For example, 0-59/2 can be used to define every other minute in the minute field. Step values can also be used with an asterisk. For instance, the value */3 can be used in the month field to run the job every third month.
/etc/crontab file, the run-parts script executes the scripts in the /etc/cron.hourly/, /etc/cron.daily/, /etc/cron.weekly/, and /etc/cron.monthly/ directories on an hourly, daily, weekly, or monthly basis respectively. The files in these directories should be shell scripts.
/etc/cron.d/ directory. All files in this directory use the same syntax as /etc/crontab. Refer to Example 39.1, “Sample of /etc/crontab” for examples.
Example 39.1. Sample of /etc/crontab
record the memory usage of the system every monday at 3:30AM in the file /tmp/meminfo 30 3 * * mon cat /proc/meminfo >> /tmp/meminfo run custom script the first day of every month at 4:10AM 10 4 1 * * /root/scripts/backup.sh
# record the memory usage of the system every monday
# at 3:30AM in the file /tmp/meminfo
30 3 * * mon cat /proc/meminfo >> /tmp/meminfo
# run custom script the first day of every month at 4:10AM
10 4 1 * * /root/scripts/backup.shcrontab utility. All user-defined crontabs are stored in the /var/spool/cron/ directory and are executed using the usernames of the users that created them. To create a crontab as a user, login as that user and type the command crontab -e to edit the user's crontab using the editor specified by the VISUAL or EDITOR environment variable. The file uses the same format as /etc/crontab. When the changes to the crontab are saved, the crontab is stored according to username and written to the file /var/spool/cron/username.
/etc/crontab file, the /etc/cron.d/ directory, and the /var/spool/cron/ directory every minute for any changes. If any changes are found, they are loaded into memory. Thus, the daemon does not need to be restarted if a crontab file is changed.
/etc/sysconfig/run-parts file by specifying the following parameters:
RANDOMIZE— When set to1, it enables randomize functionality. When set to0, cron job randomization is disabled.RANDOM— Specifies the initial random seed. It has to be set to an integer value greater than or equal to1.RANDOMTIME— When set to an integer value greater than or equal to1, it provides an additional level of randomization.
Example 39.2. Sample of /etc/sysconfig/run-parts - Job Randomization Setting
RANDOMIZE=1 RANDOM=4 RANDOMTIME=8
RANDOMIZE=1
RANDOM=4
RANDOMTIME=8
39.1.2. Controlling Access to Cron
/etc/cron.allow and /etc/cron.deny files are used to restrict access to cron. The format of both access control files is one username on each line. Whitespace is not permitted in either file. The cron daemon (crond) does not have to be restarted if the access control files are modified. The access control files are read each time a user tries to add or delete a cron job.
cron.allow exists, only users listed in it are allowed to use cron, and the cron.deny file is ignored.
cron.allow does not exist, users listed in cron.deny are not allowed to use cron.
39.1.3. Starting and Stopping the Service
/sbin/service crond start. To stop the service, use the command /sbin/service crond stop. It is recommended that you start the service at boot time. Refer to Chapter 18, Controlling Access to Services for details on starting the cron service automatically at boot time.
39.2. At and Batch
at command is used to schedule a one-time job at a specific time and the batch command is used to schedule a one-time job to be executed when the systems load average drops below 0.8.
at or batch, the at RPM package must be installed, and the atd service must be running. To determine if the package is installed, use the rpm -q at command. To determine if the service is running, use the command /sbin/service atd status.
39.2.1. Configuring At Jobs
at time, where time is the time to execute the command.
- HH:MM format — For example, 04:00 specifies 4:00 a.m. If the time is already past, it is executed at the specified time the next day.
- midnight — Specifies 12:00 a.m.
- noon — Specifies 12:00 p.m.
- teatime — Specifies 4:00 p.m.
- month-name day year format — For example, January 15 2002 specifies the 15th day of January in the year 2002. The year is optional.
- MMDDYY, MM/DD/YY, or MM.DD.YY formats — For example, 011502 for the 15th day of January in the year 2002.
- now + time — time is in minutes, hours, days, or weeks. For example, now + 5 days specifies that the command should be executed at the same time five days from now.
/usr/share/doc/at-<version>/timespec text file.
at command with the time argument, the at> prompt is displayed. Type the command to execute, press Enter, and type Ctrl+D . Multiple commands can be specified by typing each command followed by the Enter key. After typing all the commands, press Enter to go to a blank line and type Ctrl+D . Alternatively, a shell script can be entered at the prompt, pressing Enter after each line in the script, and typing Ctrl+D on a blank line to exit. If a script is entered, the shell used is the shell set in the user's SHELL environment, the user's login shell, or /bin/sh (whichever is found first).
atq to view pending jobs. Refer to Section 39.2.3, “Viewing Pending Jobs” for more information.
at command can be restricted. For more information, refer to Section 39.2.5, “Controlling Access to At and Batch” for details.
39.2.2. Configuring Batch Jobs
batch command.
batch command, the at> prompt is displayed. Type the command to execute, press Enter, and type Ctrl+D . Multiple commands can be specified by typing each command followed by the Enter key. After typing all the commands, press Enter to go to a blank line and type Ctrl+D . Alternatively, a shell script can be entered at the prompt, pressing Enter after each line in the script, and typing Ctrl+D on a blank line to exit. If a script is entered, the shell used is the shell set in the user's SHELL environment, the user's login shell, or /bin/sh (whichever is found first). As soon as the load average is below 0.8, the set of commands or script is executed.
atq to view pending jobs. Refer to Section 39.2.3, “Viewing Pending Jobs” for more information.
batch command can be restricted. For more information, refer to Section 39.2.5, “Controlling Access to At and Batch” for details.
39.2.3. Viewing Pending Jobs
at and batch jobs, use the atq command. The atq command displays a list of pending jobs, with each job on a line. Each line follows the job number, date, hour, job class, and username format. Users can only view their own jobs. If the root user executes the atq command, all jobs for all users are displayed.
39.2.4. Additional Command Line Options
at and batch include:
| Option | Description |
|---|---|
-f | Read the commands or shell script from a file instead of specifying them at the prompt. |
-m | Send email to the user when the job has been completed. |
-v | Display the time that the job is executed. |
39.2.5. Controlling Access to At and Batch
/etc/at.allow and /etc/at.deny files can be used to restrict access to the at and batch commands. The format of both access control files is one username on each line. Whitespace is not permitted in either file. The at daemon (atd) does not have to be restarted if the access control files are modified. The access control files are read each time a user tries to execute the at or batch commands.
at and batch commands, regardless of the access control files.
at.allow exists, only users listed in it are allowed to use at or batch, and the at.deny file is ignored.
at.allow does not exist, users listed in at.deny are not allowed to use at or batch.
39.2.6. Starting and Stopping the Service
at service, use the command /sbin/service atd start. To stop the service, use the command /sbin/service atd stop. It is recommended that you start the service at boot time. Refer to Chapter 18, Controlling Access to Services for details on starting the cron service automatically at boot time.
39.3. Additional Resources
39.3.1. Installed Documentation
cronman page — overview of cron.crontabman pages in sections 1 and 5 — The man page in section 1 contains an overview of thecrontabfile. The man page in section 5 contains the format for the file and some example entries./usr/share/doc/at-<version>/timespeccontains more detailed information about the times that can be specified for cron jobs.atman page — description ofatandbatchand their command line options.
Chapter 40. Log Files
syslogd. A list of log messages maintained by syslogd can be found in the /etc/syslog.conf configuration file.
40.1. Locating Log Files
/var/log/ directory. Some applications such as httpd and samba have a directory within /var/log/ for their log files.
logrotate package contains a cron task that automatically rotates log files according to the /etc/logrotate.conf configuration file and the configuration files in the /etc/logrotate.d/ directory. By default, it is configured to rotate every week and keep four weeks worth of previous log files.
40.2. Viewing Log Files
Vi or Emacs. Some log files are readable by all users on the system; however, root privileges are required to read most log files.
gnome-system-log at a shell prompt.
Figure 40.1. System Log Viewer
Figure 40.2. System Log Viewer - View Menu
Figure 40.3. System Log Viewer - Filter
40.3. Adding a Log File
Figure 40.4. Adding a Log File
40.4. Monitoring Log Files
Figure 40.5. Log File Alert
Figure 40.6. Log file contents
Figure 40.7. Log file contents after five seconds
Part V. System Monitoring
Chapter 41. SystemTap
41.1. Introduction
41.2. Implementation
Figure 41.1. Flow of Data in SystemTap
41.3. Using SystemTap
stap.
41.3.1. Tracing
41.3.1.1. Where to Probe
stapprobes man page for details. All these events are named using a unified syntax that looks like dot-separated parameterized identifiers:
| Event | Description |
|---|---|
begin | The startup of the systemtap session. |
end | The end of the systemtap session. |
kernel.function("sys_open") | The entry to the function named sys_open in the kernel. |
syscall.close.return | The return from the close system call.. |
module("ext3").statement(0xdeadbeef) | The addressed instruction in the ext3 filesystem driver. |
timer.ms(200) | A timer that fires every 200 milliseconds. |
net/socket.c in the kernel. The kernel.function probe point lets you express that easily, since systemtap examines the kernel's debugging information to relate object code to source code. It works like a debugger: if you can name or place it, you can probe it. Use kernel.function("*@net/socket.c") for the function entries, and kernel.function("*@net/socket.c").return for the exits. Note the use of wildcards in the function name part, and the subsequent @FILENAME part. You can also put wildcards into the file name, and even add a colon (:) and a line number, if you want to restrict the search that precisely. Since systemtap will put a separate probe in every place that matches a probe point, a few wildcards can expand to hundreds or thousands of probes, so be careful what you ask for.
probe keyword introduces a probe point, or a comma-separated list of them. The following { and } braces enclose the handler for all listed probe points.
stap -v FILE. Terminate it any time with ^C. (The -v option tells systemtap to print more verbose messages during its processing. Try the -h option to see more options.)
41.3.1.2. What to Print
Chapter 42. Gathering System Information
42.1. System Processes
ps ax command displays a list of current system processes, including processes owned by other users. To display the owner alongside each process, use the ps aux command. This list is a static list; in other words, it is a snapshot of what was running when you invoked the command. If you want a constantly updated list of running processes, use top as described below.
ps output can be long. To prevent it from scrolling off the screen, you can pipe it through less:
ps aux | less
ps aux | lessps command in combination with the grep command to see if a process is running. For example, to determine if Emacs is running, use the following command:
ps ax | grep emacs
ps ax | grep emacstop command displays currently running processes and important information about them including their memory and CPU usage. The list is both real-time and interactive. An example of output from the top command is provided as follows:
top, press the q key.
top commands” contains useful interactive commands that you can use with top. For more information, refer to the top(1) manual page.
| Command | Description |
|---|---|
| Space | Immediately refresh the display |
| h | Display a help screen |
| k | Kill a process. You are prompted for the process ID and the signal to send to it. |
| n | Change the number of processes displayed. You are prompted to enter the number. |
| u | Sort by user. |
| M | Sort by memory usage. |
| P | Sort by CPU usage. |
top, you can use the GNOME System Monitor. To start it from the desktop, select > > or type gnome-system-monitor at a shell prompt (such as an XTerm). Select the Process Listing tab.
- Stop a process.
- Continue or start a process.
- End a processes.
- Kill a process.
- Change the priority of a selected process.
- Edit the System Monitor preferences. These include changing the interval seconds to refresh the list and selecting process fields to display in the System Monitor window.
- View only active processes.
- View all processes.
- View my processes.
- View process dependencies.
- Hide a process.
- View hidden processes.
- View memory maps.
- View the files opened by the selected process.
Figure 42.1. GNOME System Monitor
42.2. Memory Usage
free command displays the total amount of physical memory and swap space for the system as well as the amount of memory that is used, free, shared, in kernel buffers, and cached.
total used free shared buffers cached Mem: 645712 549720 95992 0 176248 224452 -/+ buffers/cache: 149020 496692 Swap: 1310712 0 1310712
total used free shared buffers cached
Mem: 645712 549720 95992 0 176248 224452
-/+ buffers/cache: 149020 496692
Swap: 1310712 0 1310712free -m shows the same information in megabytes, which are easier to read.
total used free shared buffers cached Mem: 630 536 93 0 172 219 -/+ buffers/cache: 145 485 Swap: 1279 0 1279
total used free shared buffers cached
Mem: 630 536 93 0 172 219
-/+ buffers/cache: 145 485
Swap: 1279 0 1279free, you can use the GNOME System Monitor. To start it from the desktop, go to > > or type gnome-system-monitor at a shell prompt (such as an XTerm). Click on the Resources tab.
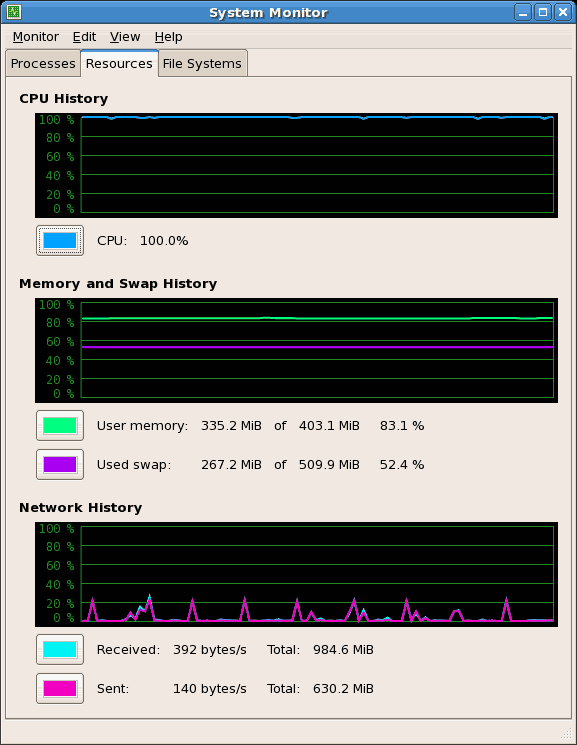
Figure 42.2. GNOME System Monitor - Resources tab
42.3. File Systems
df command reports the system's disk space usage. If you type the command df at a shell prompt, the output looks similar to the following:
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
11675568 6272120 4810348 57% / /dev/sda1
100691 9281 86211 10% /boot
none 322856 0 322856 0% /dev/shm
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
11675568 6272120 4810348 57% / /dev/sda1
100691 9281 86211 10% /boot
none 322856 0 322856 0% /dev/shmdf -h. The -h argument stands for human-readable format. The output looks similar to the following:
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
12G 6.0G 4.6G 57% / /dev/sda1
99M 9.1M 85M 10% /boot
none 316M 0 316M 0% /dev/shm
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
12G 6.0G 4.6G 57% / /dev/sda1
99M 9.1M 85M 10% /boot
none 316M 0 316M 0% /dev/shm/dev/shm. This entry represents the system's virtual memory file system.
du command displays the estimated amount of space being used by files in a directory. If you type du at a shell prompt, the disk usage for each of the subdirectories is displayed in a list. The grand total for the current directory and subdirectories are also shown as the last line in the list. If you do not want to see the totals for all the subdirectories, use the command du -hs to see only the grand total for the directory in human-readable format. Use the du --help command to see more options.
gnome-system-monitor at a shell prompt (such as an XTerm). Select the File Systems tab to view the system's partitions. The figure below illustrates the File Systems tab.
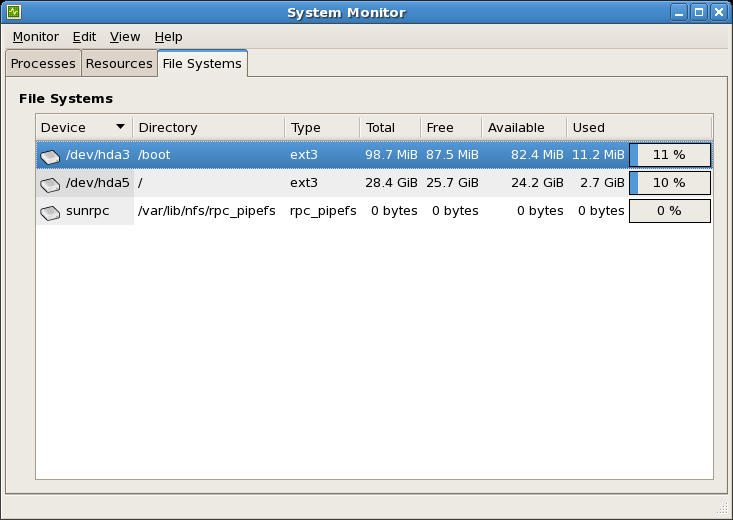
Figure 42.3. GNOME System Monitor - File Systems
42.4. Hardware
hwbrowser at a shell prompt. As shown in Figure 42.4, “Hardware Browser”, it displays your CD-ROM devices, diskette drives, hard drives and their partitions, network devices, pointing devices, system devices, and video cards. Click on the category name in the left menu, and the information is displayed.
Figure 42.4. Hardware Browser
hal-device-manager. Depending on your installation preferences, the graphical menu above may start this application or the Hardware Browser when clicked. The figure below illustrates the Device Manager window.
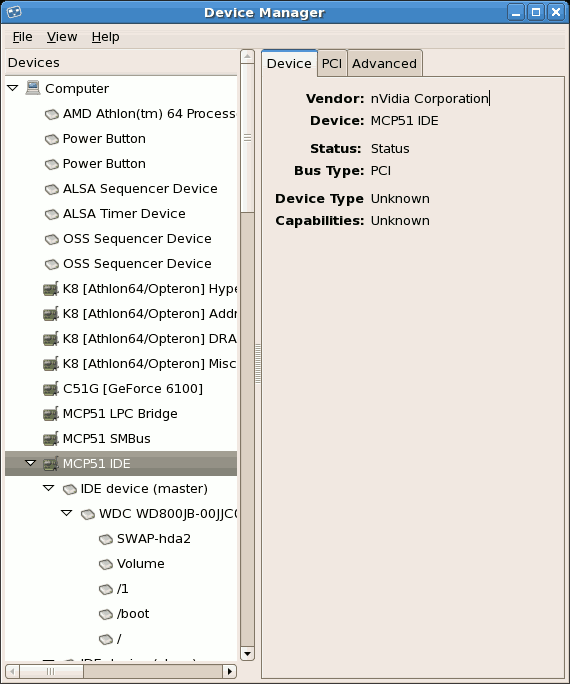
Figure 42.5. Device Manager
lspci command to list all PCI devices. Use the command lspci -v for more verbose information or lspci -vv for very verbose output.
lspci can be used to determine the manufacturer, model, and memory size of a system's video card:
lspci is also useful to determine the network card in your system if you do not know the manufacturer or model number.
42.5. Additional Resources
42.5.1. Installed Documentation
ps --help— Displays a list of options that can be used withps.topmanual page — Typeman topto learn more abouttopand its many options.freemanual page — typeman freeto learn more aboutfreeand its many options.dfmanual page — Typeman dfto learn more about thedfcommand and its many options.dumanual page — Typeman duto learn more about theducommand and its many options.lspcimanual page — Typeman lspcito learn more about thelspcicommand and its many options.
Chapter 43. OProfile
oprofile RPM package must be installed to use this tool.
- Use of shared libraries — Samples for code in shared libraries are not attributed to the particular application unless the
--separate=libraryoption is used. - Performance monitoring samples are inexact — When a performance monitoring register triggers a sample, the interrupt handling is not precise like a divide by zero exception. Due to the out-of-order execution of instructions by the processor, the sample may be recorded on a nearby instruction.
opreportdoes not associate samples for inline functions' properly —opreportuses a simple address range mechanism to determine which function an address is in. Inline function samples are not attributed to the inline function but rather to the function the inline function was inserted into.- OProfile accumulates data from multiple runs — OProfile is a system-wide profiler and expects processes to start up and shut down multiple times. Thus, samples from multiple runs accumulate. Use the command
opcontrol --resetto clear out the samples from previous runs. - Non-CPU-limited performance problems — OProfile is oriented to finding problems with CPU-limited processes. OProfile does not identify processes that are asleep because they are waiting on locks or for some other event to occur (for example an I/O device to finish an operation).
43.1. Overview of Tools
oprofile package.
| Command | Description |
|---|---|
ophelp |
Displays available events for the system's processor along with a brief description of each.
|
opimport |
Converts sample database files from a foreign binary format to the native format for the system. Only use this option when analyzing a sample database from a different architecture.
|
opannotate | Creates annotated source for an executable if the application was compiled with debugging symbols. Refer to Section 43.5.4, “Using opannotate” for details. |
opcontrol |
Configures what data is collected. Refer to Section 43.2, “Configuring OProfile” for details.
|
opreport |
Retrieves profile data. Refer to Section 43.5.1, “Using
opreport” for details.
|
oprofiled |
Runs as a daemon to periodically write sample data to disk.
|
43.2. Configuring OProfile
opcontrol utility to configure OProfile. As the opcontrol commands are executed, the setup options are saved to the /root/.oprofile/daemonrc file.
43.2.1. Specifying the Kernel
opcontrol --setup --vmlinux=/usr/lib/debug/lib/modules/`uname -r`/vmlinux
opcontrol --setup --vmlinux=/usr/lib/debug/lib/modules/`uname -r`/vmlinuxNote
debuginfo package must be installed (which contains the uncompressed kernel) in order to monitor the kernel.
opcontrol --setup --no-vmlinux
opcontrol --setup --no-vmlinuxoprofile kernel module, if it is not already loaded, and creates the /dev/oprofile/ directory, if it does not already exist. Refer to Section 43.6, “Understanding /dev/oprofile/” for details about this directory.
Note
oprofile module can be loaded from it.
43.2.2. Setting Events to Monitor
| Processor | cpu_type | Number of Counters |
|---|---|---|
| Pentium Pro | i386/ppro | 2 |
| Pentium II | i386/pii | 2 |
| Pentium III | i386/piii | 2 |
| Pentium 4 (non-hyper-threaded) | i386/p4 | 8 |
| Pentium 4 (hyper-threaded) | i386/p4-ht | 4 |
| Athlon | i386/athlon | 4 |
| AMD64 | x86-64/hammer | 4 |
| Itanium | ia64/itanium | 4 |
| Itanium 2 | ia64/itanium2 | 4 |
| TIMER_INT | timer | 1 |
| IBM eServer iSeries and pSeries | timer | 1 |
| ppc64/power4 | 8 | |
| ppc64/power5 | 6 | |
| ppc64/970 | 8 | |
| IBM eServer S/390 and S/390x | timer | 1 |
| IBM eServer zSeries | timer | 1 |
timer is used as the processor type if the processor does not have supported performance monitoring hardware.
timer is used, events cannot be set for any processor because the hardware does not have support for hardware performance counters. Instead, the timer interrupt is used for profiling.
timer is not used as the processor type, the events monitored can be changed, and counter 0 for the processor is set to a time-based event by default. If more than one counter exists on the processor, the counters other than counter 0 are not set to an event by default. The default events monitored are shown in Table 43.3, “Default Events”.
| Processor | Default Event for Counter | Description |
|---|---|---|
| Pentium Pro, Pentium II, Pentium III, Athlon, AMD64 | CPU_CLK_UNHALTED | The processor's clock is not halted |
| Pentium 4 (HT and non-HT) | GLOBAL_POWER_EVENTS | The time during which the processor is not stopped |
| Itanium 2 | CPU_CYCLES | CPU Cycles |
| TIMER_INT | (none) | Sample for each timer interrupt |
| ppc64/power4 | CYCLES | Processor Cycles |
| ppc64/power5 | CYCLES | Processor Cycles |
| ppc64/970 | CYCLES | Processor Cycles |
ls -d /dev/oprofile/[0-9]*
ls -d /dev/oprofile/[0-9]*ophelp
ophelpopcontrol:
opcontrol --event=<event-name>:<sample-rate>
opcontrol --event=<event-name>:<sample-rate>ophelp, and replace <sample-rate> with the number of events between samples.
43.2.2.1. Sampling Rate
cpu_type is not timer, each event can have a sampling rate set for it. The sampling rate is the number of events between each sample snapshot.
opcontrol --event=<event-name>:<sample-rate>
opcontrol --event=<event-name>:<sample-rate>Warning
43.2.2.2. Unit Masks
ophelp command. The values for each unit mask are listed in hexadecimal format. To specify more than one unit mask, the hexadecimal values must be combined using a bitwise or operation.
opcontrol --event=<event-name>:<sample-rate>:<unit-mask>
opcontrol --event=<event-name>:<sample-rate>:<unit-mask>43.2.3. Separating Kernel and User-space Profiles
opcontrol --event=<event-name>:<sample-rate>:<unit-mask>:0
opcontrol --event=<event-name>:<sample-rate>:<unit-mask>:0opcontrol --event=<event-name>:<sample-rate>:<unit-mask>:1
opcontrol --event=<event-name>:<sample-rate>:<unit-mask>:1opcontrol --event=<event-name>:<sample-rate>:<unit-mask>:<kernel>:0
opcontrol --event=<event-name>:<sample-rate>:<unit-mask>:<kernel>:0opcontrol --event=<event-name>:<sample-rate>:<unit-mask>:<kernel>:1
opcontrol --event=<event-name>:<sample-rate>:<unit-mask>:<kernel>:1opcontrol --separate=<choice>
opcontrol --separate=<choice>none— do not separate the profiles (default)library— generate per-application profiles for librarieskernel— generate per-application profiles for the kernel and kernel modulesall— generate per-application profiles for libraries and per-application profiles for the kernel and kernel modules
--separate=library is used, the sample file name includes the name of the executable as well as the name of the library.
Note
oprofile is restarted.
43.3. Starting and Stopping OProfile
opcontrol --start
opcontrol --startUsing log file /var/lib/oprofile/oprofiled.log Daemon started. Profiler running.
Using log file /var/lib/oprofile/oprofiled.log Daemon started. Profiler running./root/.oprofile/daemonrc are used.
oprofiled, is started; it periodically writes the sample data to the /var/lib/oprofile/samples/ directory. The log file for the daemon is located at /var/lib/oprofile/oprofiled.log.
opcontrol --shutdown
opcontrol --shutdown43.4. Saving Data
opcontrol --save=<name>
opcontrol --save=<name>/var/lib/oprofile/samples/name/ is created and the current sample files are copied to it.
43.5. Analyzing the Data
oprofiled, collects the samples and writes them to the /var/lib/oprofile/samples/ directory. Before reading the data, make sure all data has been written to this directory by executing the following command as root:
opcontrol --dump
opcontrol --dump/bin/bash becomes:
\{root\}/bin/bash/\{dep\}/\{root\}/bin/bash/CPU_CLK_UNHALTED.100000
\{root\}/bin/bash/\{dep\}/\{root\}/bin/bash/CPU_CLK_UNHALTED.100000opreportopannotate
Warning
oparchive can be used to address this problem.
43.5.1. Using opreport
opreport tool provides an overview of all the executables being profiled.
opreport man page for a list of available command line options, such as the -r option used to sort the output from the executable with the smallest number of samples to the one with the largest number of samples.
43.5.2. Using opreport on a Single Executable
opreport:
opreport <mode> <executable>
opreport <mode> <executable>-l- List sample data by symbols. For example, the following is part of the output from running the command
opreport -l /lib/tls/libc-<version>.so:Copy to Clipboard Copied! Toggle word wrap Toggle overflow The first column is the number of samples for the symbol, the second column is the percentage of samples for this symbol relative to the overall samples for the executable, and the third column is the symbol name.To sort the output from the largest number of samples to the smallest (reverse order), use-rin conjunction with the-loption. -i <symbol-name>- List sample data specific to a symbol name. For example, the following output is from the command
opreport -l -i __gconv_transform_utf8_internal /lib/tls/libc-<version>.so:samples % symbol name 12 100.000 __gconv_transform_utf8_internal
samples % symbol name 12 100.000 __gconv_transform_utf8_internalCopy to Clipboard Copied! Toggle word wrap Toggle overflow The first line is a summary for the symbol/executable combination.The first column is the number of samples for the memory symbol. The second column is the percentage of samples for the memory address relative to the total number of samples for the symbol. The third column is the symbol name. -d- List sample data by symbols with more detail than
-l. For example, the following output is from the commandopreport -l -d __gconv_transform_utf8_internal /lib/tls/libc-<version>.so:Copy to Clipboard Copied! Toggle word wrap Toggle overflow The data is the same as the-loption except that for each symbol, each virtual memory address used is shown. For each virtual memory address, the number of samples and percentage of samples relative to the number of samples for the symbol is displayed. -x<symbol-name>- Exclude the comma-separated list of symbols from the output.
session:<name>- Specify the full path to the session or a directory relative to the
/var/lib/oprofile/samples/directory.
43.5.3. Getting more detailed output on the modules
ln -s /lib/modules/`uname -r`/kernel/fs/ext3/ext3.ko /ext3
~]# ln -s /lib/modules/`uname -r`/kernel/fs/ext3/ext3.ko /ext343.5.4. Using opannotate
opannotate tool tries to match the samples for particular instructions to the corresponding lines in the source code. The resulting files generated should have the samples for the lines at the left. It also puts in a comment at the beginning of each function listing the total samples for the function.
-g option. By default, Red Hat Enterprise Linux packages are not compiled with this option.
opannotate is as follows:
opannotate --search-dirs <src-dir> --source <executable>
opannotate --search-dirs <src-dir> --source <executable>opannotate man page for a list of additional command line options.
43.6. Understanding /dev/oprofile/
/dev/oprofile/ directory contains the file system for OProfile. Use the cat command to display the values of the virtual files in this file system. For example, the following command displays the type of processor OProfile detected:
cat /dev/oprofile/cpu_type
cat /dev/oprofile/cpu_type/dev/oprofile/ for each counter. For example, if there are 2 counters, the directories /dev/oprofile/0/ and dev/oprofile/1/ exist.
count— The interval between samples.enabled— If 0, the counter is off and no samples are collected for it; if 1, the counter is on and samples are being collected for it.event— The event to monitor.kernel— If 0, samples are not collected for this counter event when the processor is in kernel-space; if 1, samples are collected even if the processor is in kernel-space.unit_mask— Defines which unit masks are enabled for the counter.user— If 0, samples are not collected for the counter event when the processor is in user-space; if 1, samples are collected even if the processor is in user-space.
cat command. For example:
cat /dev/oprofile/0/count
cat /dev/oprofile/0/count43.7. Example Usage
- Determine which applications and services are used the most on a system —
opreportcan be used to determine how much processor time an application or service uses. If the system is used for multiple services but is under performing, the services consuming the most processor time can be moved to dedicated systems. - Determine processor usage — The
CPU_CLK_UNHALTEDevent can be monitored to determine the processor load over a given period of time. This data can then be used to determine if additional processors or a faster processor might improve system performance.
43.8. Graphical Interface
oprof_start command as root at a shell prompt. To use the graphical interface, you will need to have the oprofile-gui package installed.
/root/.oprofile/daemonrc, and the application exits. Exiting the application does not stop OProfile from sampling.
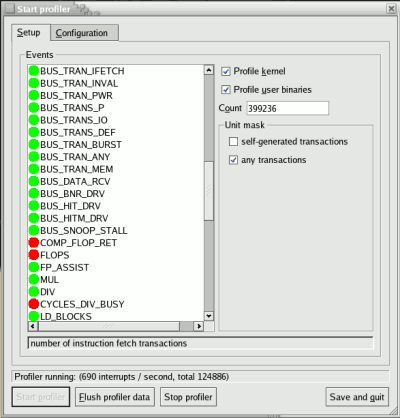
Figure 43.1. OProfile Setup
vmlinux file for the kernel to monitor in the Kernel image file text field. To configure OProfile not to monitor the kernel, select No kernel image.
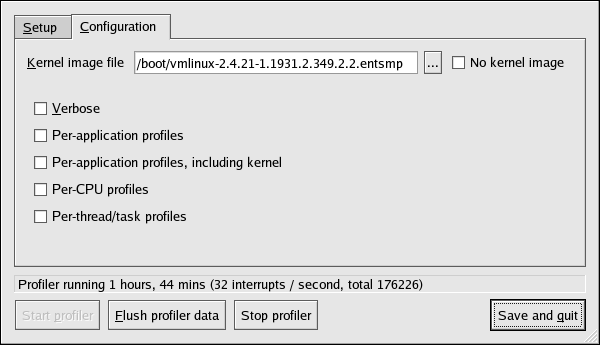
Figure 43.2. OProfile Configuration
oprofiled daemon log includes more information.
opcontrol --separate=kernel command. If Per-application shared libs samples files is selected, OProfile generates per-application profiles for libraries. This is equivalent to the opcontrol --separate=library command.
opcontrol --dump command.
43.9. Additional Resources
43.9.1. Installed Docs
/usr/share/doc/oprofile-<version>/oprofile.html— OProfile Manualoprofileman page — Discussesopcontrol,opreport,opannotate, andophelp
43.9.2. Useful Websites
- http://oprofile.sourceforge.net/ — Contains the latest documentation, mailing lists, IRC channels, and more.
Part VI. Kernel and Driver Configuration
Chapter 44. Manually Upgrading the Kernel
yum command. The Package Management Tool automatically queries the Red Hat Enterprise Linux servers and determines which packages need to be updated on your machine, including the kernel. This chapter is only useful for those individuals that require manual updating of kernel packages, without using the yum command.
Warning
Note
yum is highly recommended by Red Hat for installing upgraded kernels.
yum, refer to Chapter 15, Registering a System and Managing Subscriptions.
44.1. Overview of Kernel Packages
kernel— Contains the kernel for multi-processor systems. For x86 system, only the first 4GB of RAM is used. As such, x86 systems with over 4GB of RAM should use thekernel-PAE.kernel-devel— Contains the kernel headers and makefiles sufficient to build modules against thekernelpackage.kernel-PAE(only for i686 systems) — This package offers the following key configuration option (in addition to the options already enabled for thekernelpackage):- PAE (Physical Address Extension) support for systems with more than 4GB of RAM, and reliably up to 16GB.
Important
Physical Address Extension allows x86 processors to address up to 64GB of physical RAM, but due to differences between the Red Hat Enterprise Linux 4 and 5 kernels, only Red Hat Enterprise Linux 4 (with thekernel-hugemempackage) is able to reliably address all 64GB of memory. Additionally, the Red Hat Enterprise Linux 5 PAE variant does not allow 4GB of addressable memory per-process like the Red Hat Enterprise Linux 4kernel-hugememvariant does. However, the x86_64 kernel does not suffer from any of these limitations, and is the suggested Red Hat Enterprise Linux 5 architecture to use with large-memory systems.
kernel-PAE-devel— Contains the kernel headers and makefiles required to build modules against thekernel-PAEpackage.kernel-doc— Contains documentation files from the kernel source. Various portions of the Linux kernel and the device drivers shipped with it are documented in these files. Installation of this package provides a reference to the options that can be passed to Linux kernel modules at load time.By default, these files are placed in the/usr/share/doc/kernel-doc-<version>/directory.kernel-headers— Includes the C header files that specify the interface between the Linux kernel and userspace libraries and programs. The header files define structures and constants that are needed for building most standard programs.kernel-xen— Includes a version of the Linux kernel which is needed to run Virtualization.kernel-xen-devel— Contains the kernel headers and makefiles required to build modules against thekernel-xenpackage
Note
kernel-source package has been removed and replaced with an RPM that can only be retrieved from Red Hat Network. This *.src.rpm package must then be rebuilt locally using the rpmbuild command. For more information on obtaining and installing the kernel source package, refer to the latest updated Release Notes (including all updates) at http://www.redhat.com/docs/manuals/enterprise/
44.2. Preparing to Upgrade
/sbin/mkbootdisk `uname -r` at a shell prompt.
Note
mkbootdisk man page for more options. You can create bootable media via CD-Rs, CD-RWs, and USB flash drives, provided that your system BIOS also supports it.
rpm -qa | grep kernel at a shell prompt:
kernel package. Refer to Section 44.1, “Overview of Kernel Packages” for descriptions of the different packages.
PAE, xen, and so forth. The <arch> is one of the following:
x86_64for the AMD64 and Intel EM64T architecturesia64for the Intel® Itanium™ architectureppc64for the IBM® eServer™ pSeries™ architectures390for the IBM® S/390® architectures390xfor the IBM® eServer™ System z® architecturei686for Intel® Pentium® II, Intel® Pentium® III, Intel® Pentium® 4, AMD Athlon®, and AMD Duron® systems
44.3. Downloading the Upgraded Kernel
- Security Errata — Refer to http://www.redhat.com/security/updates/ for information on security errata, including kernel upgrades that fix security issues.
- Via Red Hat Network — Download and install the kernel RPM packages. Red Hat Network can download the latest kernel, upgrade the kernel on the system, create an initial RAM disk image if needed, and configure the boot loader to boot the new kernel. For more information, refer to http://www.redhat.com/docs/manuals/RHNetwork/.
44.4. Performing the Upgrade
Important
-i argument with the rpm command to keep the old kernel. Do not use the -U option, since it overwrites the currently installed kernel, which creates boot loader problems. For example:
rpm -ivh kernel-<kernel version>.<arch>.rpm
44.5. Verifying the Initial RAM Disk Image
/etc/fstab, an initial RAM disk is needed. The initial RAM disk allows a modular kernel to have access to modules that it might need to boot from before the kernel has access to the device where the modules normally reside.
mkinitrd command. However, this step is performed automatically if the kernel and its associated packages are installed or upgraded from the RPM packages distributed by Red Hat; in such cases, you do not need to create the initial RAM disk manually. To verify that an initial RAM disk already exists, use the command ls -l /boot to make sure the initrd-<version>.img file was created (the version should match the version of the kernel just installed).
vmlinux file are combined into one file, which is created with the addRamDisk command. This step is performed automatically if the kernel and its associated packages are installed or upgraded from the RPM packages distributed by Red Hat, Inc.; thus, it does not need to be executed manually. To verify that it was created, use the command ls -l /boot to make sure the /boot/vmlinitrd-<kernel-version> file already exists (the <kernel-version> should match the version of the kernel just installed).
44.6. Verifying the Boot Loader
kernel RPM package configures the boot loader to boot the newly installed kernel (except for IBM eServer iSeries systems). However, it does not configure the boot loader to boot the new kernel by default.
44.6.1. x86 Systems
44.6.1.1. GRUB
/boot/grub/grub.conf contains a title section with the same version as the kernel package just installed
/boot/ partition was created, the paths to the kernel and initrd image are relative to /boot/.
default variable to the title section number for the title section that contains the new kernel. The count starts with 0. For example, if the new kernel is the first title section, set default to 0.
44.6.2. Itanium Systems
/boot/efi/EFI/redhat/elilo.conf as the configuration file. Confirm that this file contains an image section with the same version as the kernel package just installed:
default variable to the value of the label for the image section that contains the new kernel.
44.6.3. IBM S/390 and IBM System z Systems
/etc/zipl.conf as the configuration file. Confirm that the file contains a section with the same version as the kernel package just installed:
default variable to the name of the section that contains the new kernel. The first line of each section contains the name in brackets.
/sbin/zipl as root to enable the changes.
44.6.4. IBM eServer iSeries Systems
/boot/vmlinitrd-<kernel-version> file is installed when you upgrade the kernel. However, you must use the dd command to configure the system to boot the new kernel:
- As root, issue the command
cat /proc/iSeries/mf/sideto determine the default side (either A, B, or C). - As root, issue the following command, where <kernel-version> is the version of the new kernel and <side> is the side from the previous command:
dd if=/boot/vmlinitrd-<kernel-version> of=/proc/iSeries/mf/<side>/vmlinux bs=8k
44.6.5. IBM eServer pSeries Systems
/etc/aboot.conf as the configuration file. Confirm that the file contains an image section with the same version as the kernel package just installed:
default and set it to the label of the image stanza that contains the new kernel.
Chapter 45. General Parameters and Modules
Important
kernel-smp-unsupported-<kernel-version> and kernel-hugemem-unsupported-<kernel-version> . Replace <kernel-version> with the version of the kernel installed on the system. These packages are not installed by the Red Hat Enterprise Linux installation program, and the modules provided are not supported by Red Hat, Inc.
45.1. Kernel Module Utilities
module-init-tools package is installed. Use these commands to determine if a module has been loaded successfully or when trying different modules for a piece of new hardware.
/sbin/lsmod displays a list of currently loaded modules. For example:
/sbin/lsmod output is less verbose and easier to read than the output from viewing /proc/modules.
/sbin/modprobe command followed by the kernel module name. By default, modprobe attempts to load the module from the /lib/modules/<kernel-version>/kernel/drivers/ subdirectories. There is a subdirectory for each type of module, such as the net/ subdirectory for network interface drivers. Some kernel modules have module dependencies, meaning that other modules must be loaded first for it to load. The /sbin/modprobe command checks for these dependencies and loads the module dependencies before loading the specified module.
modprobe e100
modprobe e100e100 module.
/sbin/modprobe executes them, use the -v option. For example:
modprobe -v e100
modprobe -v e100insmod /lib/modules/2.6.9-5.EL/kernel/drivers/net/e100.ko Using /lib/modules/2.6.9-5.EL/kernel/drivers/net/e100.ko Symbol version prefix 'smp_'
insmod /lib/modules/2.6.9-5.EL/kernel/drivers/net/e100.ko
Using /lib/modules/2.6.9-5.EL/kernel/drivers/net/e100.ko
Symbol version prefix 'smp_'/sbin/insmod command also exists to load kernel modules; however, it does not resolve dependencies. Thus, it is recommended that the /sbin/modprobe command be used.
/sbin/rmmod command followed by the module name. The rmmod utility only unloads modules that are not in use and that are not a dependency of other modules in use.
rmmod e100
rmmod e100e100 kernel module.
modinfo. Use the command /sbin/modinfo to display information about a kernel module. The general syntax is:
modinfo [options] <module>
modinfo [options] <module>-d, which displays a brief description of the module, and -p, which lists the parameters the module supports. For a complete list of options, refer to the modinfo man page (man modinfo).
45.2. Persistent Module Loading
/etc/modprobe.conf file. However, it is sometimes necessary to explicitly force the loading of a module at boot time.
/etc/rc.modules file at boot time, which contains various commands to load modules. The rc.modules should be used, and not rc.local because rc.modules is executed earlier in the boot process.
foo module at boot time (as root):
echo modprobe foo >> /etc/rc.modules chmod +x /etc/rc.modules
echo modprobe foo >> /etc/rc.modules
chmod +x /etc/rc.modulesNote
45.3. Specifying Module Parameters
e100 driver with the e100_speed_duplex=4 option.
Warning
Note
modinfo command is also useful for listing various information about a kernel module, such as version, dependencies, parameter options, and aliases.
45.4. Storage parameters
| Hardware | Module | Parameters |
|---|---|---|
| 3ware Storage Controller and 9000 series | 3w-xxxx.ko, 3w-9xxx.ko | |
| Adaptec Advanced Raid Products, Dell PERC2, 2/Si, 3/Si, 3/Di, HP NetRAID-4M, IBM ServeRAID, and ICP SCSI driver | aacraid.ko | nondasd — Control scanning of hba for nondasd devices. 0=off, 1=on
dacmode — Control whether dma addressing is using 64 bit DAC. 0=off, 1=on
commit — Control whether a COMMIT_CONFIG is issued to the adapter for foreign arrays. This is typically needed in systems that do not have a BIOS. 0=off, 1=on
startup_timeout — The duration of time in seconds to wait for adapter to have it's kernel up and running. This is typically adjusted for large systems that do not have a BIOS
aif_timeout — The duration of time in seconds to wait for applications to pick up AIFs before deregistering them. This is typically adjusted for heavily burdened systems.
numacb — Request a limit to the number of adapter control blocks (FIB) allocated. Valid values are 512 and down. Default is to use suggestion from Firmware.
acbsize — Request a specific adapter control block (FIB) size. Valid values are 512, 2048, 4096 and 8192. Default is to use suggestion from Firmware.
|
| Adaptec 28xx, R9xx, 39xx AHA-284x, AHA-29xx, AHA-394x, AHA-398x, AHA-274x, AHA-274xT, AHA-2842, AHA-2910B, AHA-2920C, AHA-2930/U/U2, AHA-2940/W/U/UW/AU/, U2W/U2/U2B/, U2BOEM, AHA-2944D/WD/UD/UWD, AHA-2950U2/W/B, AHA-3940/U/W/UW/, AUW/U2W/U2B, AHA-3950U2D, AHA-3985/U/W/UW, AIC-777x, AIC-785x, AIC-786x, AIC-787x, AIC-788x , AIC-789x, AIC-3860 | aic7xxx.ko | verbose — Enable verbose/diagnostic logging
allow_memio — Allow device registers to be memory mapped
debug — Bitmask of debug values to enable
no_probe — Toggle EISA/VLB controller probing
probe_eisa_vl — Toggle EISA/VLB controller probing
no_reset — Supress initial bus resets
extended — Enable extended geometry on all controllers
periodic_otag — Send an ordered tagged transaction periodically to prevent tag starvation. This may be required by some older disk drives or RAID arrays.
tag_info:<tag_str> — Set per-target tag depth
global_tag_depth:<int> — Global tag depth for every target on every bus
seltime:<int> — Selection Timeout (0/256ms,1/128ms,2/64ms,3/32ms)
|
| IBM ServeRAID | ips.ko | |
| LSI Logic MegaRAID Mailbox Driver | megaraid_mbox.ko | unconf_disks — Set to expose unconfigured disks to kernel (default=0)
busy_wait — Max wait for mailbox in microseconds if busy (default=10)
max_sectors — Maximum number of sectors per IO command (default=128)
cmd_per_lun — Maximum number of commands per logical unit (default=64)
fast_load — Faster loading of the driver, skips physical devices! (default=0)
debug_level — Debug level for driver (default=0)
|
| Emulex LightPulse Fibre Channel SCSI driver | lpfc.ko | lpfc_poll — FCP ring polling mode control: 0 - none, 1 - poll with interrupts enabled 3 - poll and disable FCP ring interrupts
lpfc_log_verbose — Verbose logging bit-mask
lpfc_lun_queue_depth — Max number of FCP commands we can queue to a specific LUN
lpfc_hba_queue_depth — Max number of FCP commands we can queue to a lpfc HBA
lpfc_scan_down — Start scanning for devices from highest ALPA to lowest
lpfc_nodev_tmo — Seconds driver will hold I/O waiting for a device to come back
lpfc_topology — Select Fibre Channel topology
lpfc_link_speed — Select link speed
lpfc_fcp_class — Select Fibre Channel class of service for FCP sequences
lpfc_use_adisc — Use ADISC on rediscovery to authenticate FCP devices
lpfc_ack0 — Enable ACK0 support
lpfc_cr_delay — A count of milliseconds after which an interrupt response is generated
lpfc_cr_count — A count of I/O completions after which an interrupt response is generated
lpfc_multi_ring_support — Determines number of primary SLI rings to spread IOCB entries across
lpfc_fdmi_on — Enable FDMI support
lpfc_discovery_threads — Maximum number of ELS commands during discovery
lpfc_max_luns — Maximum allowed LUN
lpfc_poll_tmo — Milliseconds driver will wait between polling FCP ring
|
| HP Smart Array | cciss.ko | |
| LSI Logic MPT Fusion | mptbase.ko mptctl.ko mptfc.ko mptlan.ko mptsas.ko mptscsih.ko mptspi.ko | mpt_msi_enable — MSI Support Enable
mptfc_dev_loss_tmo — Initial time the driver programs the transport to wait for an rport to return following a device loss event.
mpt_pt_clear — Clear persistency table
mpt_saf_te — Force enabling SEP Processor
|
| QLogic Fibre Channel Driver | qla2xxx.ko | ql2xlogintimeout — Login timeout value in seconds.
qlport_down_retry — Maximum number of command retries to a port that returns a PORT-DOWN status
ql2xplogiabsentdevice — Option to enable PLOGI to devices that are not present after a Fabric scan.
ql2xloginretrycount — Specify an alternate value for the NVRAM login retry count.
ql2xallocfwdump — Option to enable allocation of memory for a firmware dump during HBA initialization. Default is 1 - allocate memory.
extended_error_logging — Option to enable extended error logging.
ql2xfdmienable — Enables FDMI registrations.
|
| NCR, Symbios and LSI 8xx and 1010 | sym53c8xx | cmd_per_lun — The maximum number of tags to use by default
tag_ctrl — More detailed control over tags per LUN
burst — Maximum burst. 0 to disable, 255 to read from registers
led — Set to 1 to enable LED support
diff — 0 for no differential mode, 1 for BIOS, 2 for always, 3 for not GPIO3
irqm — 0 for open drain, 1 to leave alone, 2 for totem pole
buschk — 0 to not check, 1 for detach on error, 2 for warn on error
hostid — The SCSI ID to use for the host adapters
verb — 0 for minimal verbosity, 1 for normal, 2 for excessive
debug — Set bits to enable debugging
settle — Settle delay in seconds. Default 3
nvram — Option currently not used
excl — List ioport addresses here to prevent controllers from being attached
safe — Set other settings to a "safe mode"
|
45.5. Ethernet Parameters
Important
ethtool or mii-tool. Only after these tools fail to work should module parameters be adjusted. Module parameters can be viewed using the modinfo command.
Note
ethtool, mii-tool, and modinfo.
| Hardware | Module | Parameters |
|---|---|---|
| 3Com EtherLink PCI III/XL Vortex (3c590, 3c592, 3c595, 3c597) Boomerang (3c900, 3c905, 3c595) | 3c59x.ko | debug — 3c59x debug level (0-6)
options — 3c59x: Bits 0-3: media type, bit 4: bus mastering, bit 9: full duplex
global_options — 3c59x: same as options, but applies to all NICs if options is unset
full_duplex — 3c59x full duplex setting(s) (1)
global_full_duplex — 3c59x: same as full_duplex, but applies to all NICs if full_duplex is unset
hw_checksums — 3c59x Hardware checksum checking by adapter(s) (0-1)
flow_ctrl — 3c59x 802.3x flow control usage (PAUSE only) (0-1)
enable_wol — 3c59x: Turn on Wake-on-LAN for adapter(s) (0-1)
global_enable_wol — 3c59x: same as enable_wol, but applies to all NICs if enable_wol is unset
rx_copybreak — 3c59x copy breakpoint for copy-only-tiny-frames
max_interrupt_work — 3c59x maximum events handled per interrupt
compaq_ioaddr — 3c59x PCI I/O base address (Compaq BIOS problem workaround)
compaq_irq — 3c59x PCI IRQ number (Compaq BIOS problem workaround)
compaq_device_id — 3c59x PCI device ID (Compaq BIOS problem workaround)
watchdog — 3c59x transmit timeout in milliseconds
global_use_mmio — 3c59x: same as use_mmio, but applies to all NICs if options is unset
use_mmio — 3c59x: use memory-mapped PCI I/O resource (0-1)
|
| RTL8139, SMC EZ Card Fast Ethernet, RealTek cards using RTL8129, or RTL8139 Fast Ethernet chipsets | 8139too.ko | |
| Broadcom 4400 10/100 PCI ethernet driver | b44.ko | b44_debug — B44 bitmapped debugging message enable value
|
| Broadcom NetXtreme II BCM5706/5708 Driver | bnx2.ko | disable_msi — Disable Message Signaled Interrupt (MSI)
|
| Intel Ether Express/100 driver | e100.ko | debug — Debug level (0=none,...,16=all)
eeprom_bad_csum_allow — Allow bad eeprom checksums
|
| Intel EtherExpress/1000 Gigabit | e1000.ko | TxDescriptors — Number of transmit descriptors
RxDescriptors — Number of receive descriptors
Speed — Speed setting
Duplex — Duplex setting
AutoNeg — Advertised auto-negotiation setting
FlowControl — Flow Control setting
XsumRX — Disable or enable Receive Checksum offload
TxIntDelay — Transmit Interrupt Delay
TxAbsIntDelay — Transmit Absolute Interrupt Delay
RxIntDelay — Receive Interrupt Delay
RxAbsIntDelay — Receive Absolute Interrupt Delay
InterruptThrottleRate — Interrupt Throttling Rate
SmartPowerDownEnable — Enable PHY smart power down
KumeranLockLoss — Enable Kumeran lock loss workaround
|
| Myricom 10G driver (10GbE) | myri10ge.ko | myri10ge_fw_name — Firmware image name
myri10ge_ecrc_enable — Enable Extended CRC on PCI-E
myri10ge_max_intr_slots — Interrupt queue slots
myri10ge_small_bytes — Threshold of small packets
myri10ge_msi — Enable Message Signalled Interrupts
myri10ge_intr_coal_delay — Interrupt coalescing delay
myri10ge_flow_control — Pause parameter
myri10ge_deassert_wait — Wait when deasserting legacy interrupts
myri10ge_force_firmware — Force firmware to assume aligned completions
myri10ge_skb_cross_4k — Can a small skb cross a 4KB boundary?
myri10ge_initial_mtu — Initial MTU
myri10ge_napi_weight — Set NAPI weight
myri10ge_watchdog_timeout — Set watchdog timeout
myri10ge_max_irq_loops — Set stuck legacy IRQ detection threshold
|
| NatSemi DP83815 Fast Ethernet | natsemi.ko | mtu — DP8381x MTU (all boards)
debug — DP8381x default debug level
rx_copybreak — DP8381x copy breakpoint for copy-only-tiny-frames
options — DP8381x: Bits 0-3: media type, bit 17: full duplex
full_duplex — DP8381x full duplex setting(s) (1)
|
| AMD PCnet32 and AMD PCnetPCI | pcnet32.ko | |
| PCnet32 and PCnetPCI | pcnet32.ko | debug — pcnet32 debug level
max_interrupt_work — pcnet32 maximum events handled per interrupt
rx_copybreak — pcnet32 copy breakpoint for copy-only-tiny-frames
tx_start_pt — pcnet32 transmit start point (0-3)
pcnet32vlb — pcnet32 Vesa local bus (VLB) support (0/1)
options — pcnet32 initial option setting(s) (0-15)
full_duplex — pcnet32 full duplex setting(s) (1)
homepna — pcnet32 mode for 79C978 cards (1 for HomePNA, 0 for Ethernet, default Ethernet
|
| RealTek RTL-8169 Gigabit Ethernet driver | r8169.ko | media — force phy operation. Deprecated by ethtool (8).
rx_copybreak — Copy breakpoint for copy-only-tiny-frames
use_dac — Enable PCI DAC. Unsafe on 32 bit PCI slot.
debug — Debug verbosity level (0=none, ..., 16=all)
|
| Neterion Xframe 10GbE Server Adapter | s2io.ko | |
| SIS 900/701G PCI Fast Ethernet | sis900.ko | multicast_filter_limit — SiS 900/7016 maximum number of filtered multicast addresses
max_interrupt_work — SiS 900/7016 maximum events handled per interrupt
sis900_debug — SiS 900/7016 bitmapped debugging message level
|
| Adaptec Starfire Ethernet driver | starfire.ko | max_interrupt_work — Maximum events handled per interrupt
mtu — MTU (all boards)
debug — Debug level (0-6)
rx_copybreak — Copy breakpoint for copy-only-tiny-frames
intr_latency — Maximum interrupt latency, in microseconds
small_frames — Maximum size of receive frames that bypass interrupt latency (0,64,128,256,512)
options — Deprecated: Bits 0-3: media type, bit 17: full duplex
full_duplex — Deprecated: Forced full-duplex setting (0/1)
enable_hw_cksum — Enable/disable hardware cksum support (0/1)
|
| Broadcom Tigon3 | tg3.ko | tg3_debug — Tigon3 bitmapped debugging message enable value
|
| ThunderLAN PCI | tlan.ko | aui — ThunderLAN use AUI port(s) (0-1)
duplex — ThunderLAN duplex setting(s) (0-default, 1-half, 2-full)
speed — ThunderLAN port speen setting(s) (0,10,100)
debug — ThunderLAN debug mask
bbuf — ThunderLAN use big buffer (0-1)
|
| Digital 21x4x Tulip PCI Ethernet cards SMC EtherPower 10 PCI(8432T/8432BT) SMC EtherPower 10/100 PCI(9332DST) DEC EtherWorks 100/10 PCI(DE500-XA) DEC EtherWorks 10 PCI(DE450) DEC QSILVER's, Znyx 312 etherarray Allied Telesis LA100PCI-T Danpex EN-9400, Cogent EM110 | tulip.ko | io io_port |
| VIA Rhine PCI Fast Ethernet cards with either the VIA VT86c100A Rhine-II PCI or 3043 Rhine-I D-Link DFE-930-TX PCI 10/100 | via-rhine.ko | max_interrupt_work — VIA Rhine maximum events handled per interrupt
debug — VIA Rhine debug level (0-7)
rx_copybreak — VIA Rhine copy breakpoint for copy-only-tiny-frames
avoid_D3 — Avoid power state D3 (work-around for broken BIOSes)
|
45.5.1. The Channel Bonding Module
bonding kernel module and a special network interface, called a channel bonding interface. Channel bonding enables two or more network interfaces to act as one, simultaneously increasing the bandwidth and providing redundancy.
- Add the following line to
/etc/modprobe.conf:alias bond<N> bonding
alias bond<N> bondingCopy to Clipboard Copied! Toggle word wrap Toggle overflow Replace <N> with the interface number, such as0. For each configured channel bonding interface, there must be a corresponding entry in/etc/modprobe.conf. - Configure a channel bonding interface as outlined in Section 16.2.3, “Channel Bonding Interfaces”.
- To enhance performance, adjust available module options to ascertain what combination works best. Pay particular attention to the
miimonorarp_intervaland thearp_ip_targetparameters. Refer to Section 45.5.1.1, “bonding Module Directives” for a list of available options and how to quickly determine the best ones for your bonded interface.
45.5.1.1. bonding Module Directives
BONDING_OPTS="<bonding parameters>" directive in your bonding interface configuration file (ifcfg-bond0 for example). Parameters to bonded interfaces can be configured without unloading (and reloading) the bonding module by manipulating files in the sysfs file system.
sysfs is a virtual file system that represents kernel objects as directories, files and symbolic links. sysfs can be used to query for information about kernel objects, and can also manipulate those objects through the use of normal file system commands. The sysfs virtual file system has a line in /etc/fstab, and is mounted under /sys. All bonded interfaces can be configured dynamically by interacting with and manipulating files under the /sys/class/net/ directory.
ifcfg-bond0 and inserted SLAVE=yes and MASTER=bond0 directives in the bonded interfaces following the instructions in Section 16.2.3, “Channel Bonding Interfaces”, you can proceed to testing and determining the best parameters for your bonded interface.
ifconfig bond<N> up as root:
ifconfig bond0 up
ifconfig bond0 upifcfg-bond0 bonding interface file, you will be able to see bond0 listed in the output of running ifconfig (without any options):
~]# cat /sys/class/net/bonding_masters bond0
~]# cat /sys/class/net/bonding_masters
bond0/sys/class/net/bond<N>/bonding/ directory. First, the bond you are configuring must be taken down:
ifconfig bond0 down
ifconfig bond0 downecho 1000 > /sys/class/net/bond0/bonding/miimon
echo 1000 > /sys/class/net/bond0/bonding/miimonbalance-alb mode, you could run either:
echo 6 > /sys/class/net/bond0/bonding/mode
echo 6 > /sys/class/net/bond0/bonding/modeecho balance-alb > /sys/class/net/bond0/bonding/mode
echo balance-alb > /sys/class/net/bond0/bonding/modeifconfig bond<N> up . If you decide to change the options, take the interface down, modify its parameters using sysfs, bring it back up, and re-test.
BONDING_OPTS= directive of the /etc/sysconfig/network-scripts/ifcfg-bond<N> file for the bonded interface you are configuring. Whenever that bond is brought up (for example, by the system during the boot sequence if the ONBOOT=yes directive is set), the bonding options specified in the BONDING_OPTS will take effect for that bond. For more information on configuring bonded interfaces (and BONDING_OPTS), refer to Section 16.2.3, “Channel Bonding Interfaces”.
bonding module. For more in-depth information on configuring channel bonding and the exhaustive list of bonding module parameters, install the kernel-doc package and then locating and opening the included bonding.txt file:
yum -y install kernel-doc nano -w $(rpm -ql kernel-doc | grep bonding.txt)
yum -y install kernel-doc
nano -w $(rpm -ql kernel-doc | grep bonding.txt)Bonding Interface Parameters
-
arp_interval=<time_in_milliseconds> - Specifies (in milliseconds) how often ARP monitoring occurs.
Important
It is essential that botharp_intervalandarp_ip_targetparameters are specified, or, alternatively, themiimonparameter is specified. Failure to do so can cause degradation of network performance in the event that a link fails.If using this setting while inmode=0ormode=1(the two load-balancing modes), the network switch must be configured to distribute packets evenly across the NICs. For more information on how to accomplish this, refer to/usr/share/doc/kernel-doc-<kernel_version>/Documentation/networking/bonding.txtThe value is set to0by default, which disables it. -
arp_ip_target=<ip_address> [,<ip_address_2>,...<ip_address_16> ] - Specifies the target IP address of ARP requests when the
arp_intervalparameter is enabled. Up to 16 IP addresses can be specified in a comma separated list. -
arp_validate=<value> - Validate source/distribution of ARP probes; default is
none. Other valid values areactive,backup, andall. -
debug=<number> - Enables debug messages. Possible values are:
0— Debug messages are disabled. This is the default.1— Debug messages are enabled.
-
downdelay=<time_in_milliseconds> - Specifies (in milliseconds) how long to wait after link failure before disabling the link. The value must be a multiple of the value specified in the
miimonparameter. The value is set to0by default, which disables it. - lacp_rate=<value>
- Specifies the rate at which link partners should transmit LACPDU packets in 802.3ad mode. Possible values are:
slowor0— Default setting. This specifies that partners should transmit LACPDUs every 30 seconds.fastor1— Specifies that partners should transmit LACPDUs every 1 second.
-
miimon=<time_in_milliseconds> - Specifies (in milliseconds) how often MII link monitoring occurs. This is useful if high availability is required because MII is used to verify that the NIC is active. To verify that the driver for a particular NIC supports the MII tool, type the following command as root:
ethtool <interface_name> | grep "Link detected:"
ethtool <interface_name> | grep "Link detected:"Copy to Clipboard Copied! Toggle word wrap Toggle overflow In this command, replace <interface_name> with the name of the device interface, such aseth0, not the bond interface. If MII is supported, the command returns:Link detected: yes
Link detected: yesCopy to Clipboard Copied! Toggle word wrap Toggle overflow If using a bonded interface for high availability, the module for each NIC must support MII. Setting the value to0(the default), turns this feature off. When configuring this setting, a good starting point for this parameter is100.Important
It is essential that botharp_intervalandarp_ip_targetparameters are specified, or, alternatively, themiimonparameter is specified. Failure to do so can cause degradation of network performance in the event that a link fails. -
mode=<value> - ...where <value> is one of:
balance-rror0— Sets a round-robin policy for fault tolerance and load balancing. Transmissions are received and sent out sequentially on each bonded slave interface beginning with the first one available.active-backupor1— Sets an active-backup policy for fault tolerance. Transmissions are received and sent out via the first available bonded slave interface. Another bonded slave interface is only used if the active bonded slave interface fails.balance-xoror2— Sets an XOR (exclusive-or) policy for fault tolerance and load balancing. Using this method, the interface matches up the incoming request's MAC address with the MAC address for one of the slave NICs. Once this link is established, transmissions are sent out sequentially beginning with the first available interface.broadcastor3— Sets a broadcast policy for fault tolerance. All transmissions are sent on all slave interfaces.802.3ador4— Sets an IEEE 802.3ad dynamic link aggregation policy. Creates aggregation groups that share the same speed and duplex settings. Transmits and receives on all slaves in the active aggregator. Requires a switch that is 802.3ad compliant.balance-tlbor5— Sets a Transmit Load Balancing (TLB) policy for fault tolerance and load balancing. The outgoing traffic is distributed according to the current load on each slave interface. Incoming traffic is received by the current slave. If the receiving slave fails, another slave takes over the MAC address of the failed slave.balance-albor6— Sets an Active Load Balancing (ALB) policy for fault tolerance and load balancing. Includes transmit and receive load balancing for IPV4 traffic. Receive load balancing is achieved through ARP negotiation.
-
num_unsol_na=<number> - Specifies the number of unsolicited IPv6 Neighbor Advertisements to be issued after a failover event. One unsolicited NA is issued immediately after the failover.The valid range is
0 - 255; the default value is1. This option affects only the active-backup mode. -
primary=<interface_name> - Specifies the interface name, such as
eth0, of the primary device. Theprimarydevice is the first of the bonding interfaces to be used and is not abandoned unless it fails. This setting is particularly useful when one NIC in the bonding interface is faster and, therefore, able to handle a bigger load.This setting is only valid when the bonding interface is inactive-backupmode. Refer to/usr/share/doc/kernel-doc-<kernel-version>/Documentation/networking/bonding.txtfor more information. -
primary_reselect=<value> - Specifies the reselection policy for the primary slave. This affects how the primary slave is chosen to become the active slave when failure of the active slave or recovery of the primary slave occurs. This option is designed to prevent flip-flopping between the primary slave and other slaves. Possible values are:
alwaysor0(default) — The primary slave becomes the active slave whenever it comes back up.betteror1— The primary slave becomes the active slave when it comes back up, if the speed and duplex of the primary slave is better than the speed and duplex of the current active slave.failureor2— The primary slave becomes the active slave only if the current active slave fails and the primary slave is up.
Theprimary_reselectsetting is ignored in two cases:- If no slaves are active, the first slave to recover is made the active slave.
- When initially enslaved, the primary slave is always made the active slave.
Changing theprimary_reselectpolicy viasysfswill cause an immediate selection of the best active slave according to the new policy. This may or may not result in a change of the active slave, depending upon the circumstances -
updelay=<time_in_milliseconds> - Specifies (in milliseconds) how long to wait before enabling a link. The value must be a multiple of the value specified in the
miimonparameter. The value is set to0by default, which disables it. -
use_carrier=<number> - Specifies whether or not
miimonshould use MII/ETHTOOL ioctls ornetif_carrier_ok()to determine the link state. Thenetif_carrier_ok()function relies on the device driver to maintains its state withnetif_carrier_on/off; most device drivers support this function.The MII/ETHROOL ioctls tools utilize a deprecated calling sequence within the kernel. However, this is still configurable in case your device driver does not supportnetif_carrier_on/off.Valid values are:1— Default setting. Enables the use ofnetif_carrier_ok().0— Enables the use of MII/ETHTOOL ioctls.
Note
If the bonding interface insists that the link is up when it should not be, it is possible that your network device driver does not supportnetif_carrier_on/off. -
xmit_hash_policy=<value> - Selects the transmit hash policy used for slave selection in
balance-xorand802.3admodes. Possible values are:0orlayer2— Default setting. This option uses the XOR of hardware MAC addresses to generate the hash. The formula used is:(<source_MAC_address> XOR <destination_MAC>) MODULO <slave_count>
(<source_MAC_address> XOR <destination_MAC>) MODULO <slave_count>Copy to Clipboard Copied! Toggle word wrap Toggle overflow This algorithm will place all traffic to a particular network peer on the same slave, and is 802.3ad compliant.1orlayer3+4— Uses upper layer protocol information (when available) to generate the hash. This allows for traffic to a particular network peer to span multiple slaves, although a single connection will not span multiple slaves.The formula for unfragmented TCP and UDP packets used is:((<source_port> XOR <dest_port>) XOR ((<source_IP> XOR <dest_IP>) AND 0xffff) MODULO <slave_count>((<source_port> XOR <dest_port>) XOR ((<source_IP> XOR <dest_IP>) AND 0xffff) MODULO <slave_count>Copy to Clipboard Copied! Toggle word wrap Toggle overflow For fragmented TCP or UDP packets and all other IP protocol traffic, the source and destination port information is omitted. For non-IP traffic, the formula is the same as thelayer2transmit hash policy.This policy intends to mimic the behavior of certain switches; particularly, Cisco switches with PFC2 as well as some Foundry and IBM products.The algorithm used by this policy is not 802.3ad compliant.2orlayer2+3— Uses a combination of layer2 and layer3 protocol information to generate the hash.Uses XOR of hardware MAC addresses and IP addresses to generate the hash. The formula is:(((<source_IP> XOR <dest_IP>) AND 0xffff) XOR ( <source_MAC> XOR <destination_MAC> )) MODULO <slave_count>(((<source_IP> XOR <dest_IP>) AND 0xffff) XOR ( <source_MAC> XOR <destination_MAC> )) MODULO <slave_count>Copy to Clipboard Copied! Toggle word wrap Toggle overflow This algorithm will place all traffic to a particular network peer on the same slave. For non-IP traffic, the formula is the same as for the layer2 transmit hash policy.This policy is intended to provide a more balanced distribution of traffic than layer2 alone, especially in environments where a layer3 gateway device is required to reach most destinations.This algorithm is 802.3ad compliant.
45.6. Additional Resources
45.6.1. Installed Documentation
lsmodman page — description and explanation of its output.insmodman page — description and list of command line options.modprobeman page — description and list of command line options.rmmodman page — description and list of command line options.modinfoman page — description and list of command line options./usr/share/doc/kernel-doc-<version>/Documentation/kbuild/modules.txt— how to compile and use kernel modules. Note you must have thekernel-docpackage installed to read this file.
45.6.2. Useful Websites
- http://tldp.org/HOWTO/Module-HOWTO/ — Linux Loadable Kernel Module HOWTO from the Linux Documentation Project.
Chapter 46. The kdump Crash Recovery Service
kdump is an advanced crash dumping mechanism. When enabled, the system is booted from the context of another kernel. This second kernel reserves a small amount of memory and its only purpose is to capture the core dump image in case the system crashes. The ability to analyze the core dump significantly helps to determine the exact cause of the system failure, and as a consequence, it is strongly recommended to have this feature enabled.
kdump service in Red Hat Enterprise Linux, and provides a brief overview of how to analyze the resulting core dump using the crash debugging utility.
46.1. Installing the kdump Service
kdump service on your system, make sure you have the kexec-tools package installed. To do so, type the following at a shell prompt as root:
yum install kexec-tools
~]# yum install kexec-tools46.2. Configuring the kdump Service
kdump service: you can enable and configure it at the first boot, use the Kernel Dump Configuration utility for the graphical user interface, or do so manually on the command line.
Important
Intel IOMMU driver can occasionally prevent the kdump service from capturing the core dump image. To use kdump on Intel architectures reliably, it is advised that the IOMMU support is disabled.
Warning
kdump service does not work reliably on certain combinations of HP Smart Array devices and system boards from the same vendor. Consequent to this, users are strongly advised to test the configuration before using it in production environment, and if necessary, configure kdump to store the kernel crash dump to a remote machine over a network. For more information on how to test the kdump configuration, refer to Section 46.2.4, “Testing the Configuration”.
46.2.1. Configuring kdump at First Boot
firstboot application is launched to guide the user through the initial configuration of the freshly installed system. To configure kdump, navigate to the Kdump page and follow the instructions below.
Important
kdump crash recovery is enabled, the minimum memory requirements increase by the amount of memory reserved for it. This value is determined by the user and on x86, AMD64, and Intel 64 architectures, it defaults to 128 MB plus 64 MB for each TB of physical memory (that is, a total of 192 MB for a system with 1 TB of physical memory).
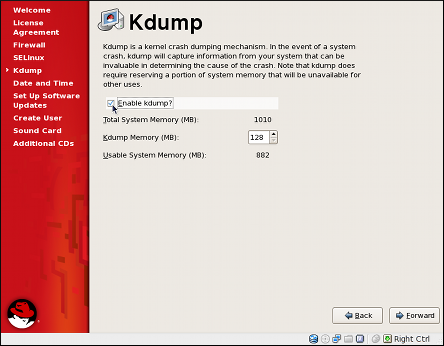
Figure 46.1. The kdump configuration screen
46.2.1.1. Enabling the Service
kdump daemon at boot time, select the Enable kdump? checkbox. This will enable the service for runlevels 2, 3, 4, and 5, and start it for the current session. Similarly, clearing the checkbox will disable it for all runlevels and stop the service immediately.
46.2.1.2. Configuring the Memory Usage
kdump kernel, click the up and down arrow buttons next to the Kdump Memory field to increase or decrease the value. Notice that the Usable System Memory field changes accordingly showing you the remaining memory that will be available to the system.
46.2.2. Using the Kernel Dump Configuration Utility
system-config-kdump at a shell prompt. Unless you are already authenticated, you will be prompted to enter the root password.
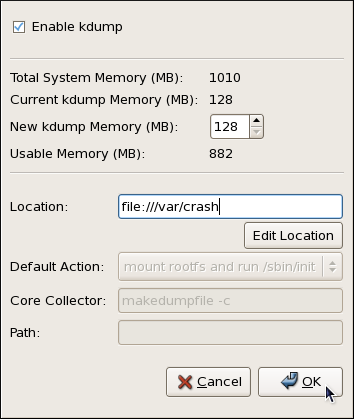
Figure 46.2. The Kernel Dump Configuration utility
kdump as well as to enable or disable starting the service at boot time. When you are done, click to save the changes. The system reboot will be requested.
Important
kdump crash recovery is enabled, the minimum memory requirements increase by the amount of memory reserved for it. This value is determined by the user and on x86, AMD64, and Intel 64 architectures, it defaults to 128 MB plus 64 MB for each TB of physical memory (that is, a total of 192 MB for a system with 1 TB of physical memory).
46.2.2.1. Enabling the Service
kdump daemon at boot time, select the Enable kdump checkbox. This will enable the service for runlevels 2, 3, 4, and 5, and start it for the current session. Similarly, clearing the checkbox will disable it for all runlevels and stop the service immediately.
46.2.2.2. Configuring the Memory Usage
kdump kernel, click the up and down arrow buttons next to the New kdump Memory field to increase or decrease the value. Notice that the Usable Memory field changes accordingly showing you the remaining memory that will be available to the system.
46.2.2.3. Configuring the Target Type
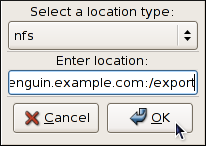
Figure 46.3. The Edit Location dialog
/dev/sdb1). When you are done, click to confirm your choice.
penguin.example.com:/export). Clicking the button will confirm your changes. Finally, edit the value of the Path field to customize the destination directory (for instance, cores).
john@penguin.example.com). Clicking the button will confirm your changes. Finally, edit the value of the Path field to customize the destination directory (for instance, /export/cores).
46.2.2.4. Configuring the Core Collector
vmcore dump file, kdump allows you to specify an external application (that is, a core collector) to compress the data, and optionally leave out all irrelevant information. Currently, the only fully supported core collector is makedumpfile.
-c parameter is listed after the makedumpfile command in the Core Collector field (for example, makedumpfile -c).
-d value parameter after the makedumpfile command in the Core Collector field. The value is a sum of values of pages you want to omit as described in Table 46.1, “Supported filtering levels”. For example, to remove both zero and free pages, use makedumpfile -d 17.
makedumpfile for a complete list of available options.
46.2.2.5. Changing the Default Action
kdump fails to create a core dump, select the appropriate option from the Default Action pulldown list. Available options are (the default action), (to reboot the system), (to present a user with an interactive shell prompt), and (to halt the system).
46.2.3. Configuring kdump on the Command Line
46.2.3.1. Configuring the Memory Usage
kdump kernel on x86, AMD64, and Intel 64 architectures, open the /boot/grub/grub.conf file as root and add the crashkernel=<size>M@16M parameter to the list of kernel options as shown in Example 46.1, “Sample /boot/grub/grub.conf file”.
Important
kdump crash recovery service will not be operational. For information on minimum memory requirements, refer to the Red Hat Enterprise Linux comparison chart. When kdump is enabled, the minimum memory requirements increase by the amount of memory reserved for it. This value is determined by the user and on x86, AMD64, and Intel 64 architectures, it defaults to 128 MB plus 64 MB for each TB of physical memory (that is, a total of 192 MB for a system with 1 TB of physical memory).
Example 46.1. Sample /boot/grub/grub.conf file
46.2.3.2. Configuring the Target Type
vmcore file in the /var/crash/ directory of the local file system. To change this, open the /etc/kdump.conf configuration file as root and edit the options as described below.
#path /var/crash line, and replace the value with a desired directory path. Optionally, if you wish to write the file to a different partition, follow the same procedure with the #ext3 /dev/sda3 line as well, and change both the file system type and the device (a device name, a file system label, and UUID are all supported) accordingly. For example:
ext3 /dev/sda4 path /usr/local/cores
ext3 /dev/sda4
path /usr/local/cores#raw /dev/sda5 line, and replace the value with a desired device name. For example:
raw /dev/sdb1
raw /dev/sdb1#net my.server.com:/export/tmp line, and replace the value with a valid hostname and directory path. For example:
net penguin.example.com:/export/cores
net penguin.example.com:/export/cores#net user@my.server.com line, and replace the value with a valid username and hostname. For example:
net john@penguin.example.com
net john@penguin.example.com46.2.3.3. Configuring the Core Collector
vmcore dump file, kdump allows you to specify an external application (that is, a core collector) to compress the data, and optionally leave out all irrelevant information. Currently, the only fully supported core collector is makedumpfile.
/etc/kdump.conf configuration file as root, remove the hash sign (“#”) from the beginning of the #core_collector makedumpfile -c --message-level 1 line, and edit the command line options as described below.
-c parameter. For example:
core_collector makedumpfile -c
core_collector makedumpfile -c-d value parameter, where value is a sum of values of pages you want to omit as described in Table 46.1, “Supported filtering levels”. For example, to remove both zero and free pages, use the following:
core_collector makedumpfile -d 17 -c
core_collector makedumpfile -d 17 -cmakedumpfile for a complete list of available options.
| Option | Description |
|---|---|
1 | Zero pages |
2 | Cache pages |
4 | Cache private |
8 | User pages |
16 | Free pages |
46.2.3.4. Changing the Default Action
kdump fails to create a core dump, the root file system is mounted and /sbin/init is run. To change this behavior, open the /etc/kdump.conf configuration file as root, remove the hash sign (“#”) from the beginning of the #default shell line, and replace the value with a desired action as described in Table 46.2, “Supported actions”. For example:
default halt
default halt| Option | Action |
|---|---|
reboot | Reboot the system, losing the core in the process. |
halt | After failing to capture a core, halt the system. |
shell | Run the msh session from within the initramfs, allowing a user to record the core manually. |
46.2.3.5. Enabling the Service
kdump daemon at boot time, type the following at a shell prompt as root:
chkconfig kdump on
~]# chkconfig kdump on2, 3, 4, and 5. Similarly, typing chkconfig kdump off will disable it for all runlevels. To start the service in the current session, use the following command as root:
service kdump start No kdump initial ramdisk found. [WARNING] Rebuilding /boot/initrd-2.6.18-194.8.1.el5kdump.img Starting kdump: [ OK ]
~]# service kdump start
No kdump initial ramdisk found. [WARNING]
Rebuilding /boot/initrd-2.6.18-194.8.1.el5kdump.img
Starting kdump: [ OK ]46.2.4. Testing the Configuration
Warning
kdump enabled, and as root, make sure that the service is running:
service kdump status Kdump is operational
~]# service kdump status
Kdump is operationalroot:
echo 1 > /proc/sys/kernel/sysrq echo c > /proc/sysrq-trigger
~]# echo 1 > /proc/sys/kernel/sysrq
~]# echo c > /proc/sysrq-triggerYYYY-MM-DD-HH:MM/vmcore file will be copied to the location you have selected in the configuration (that is, to /var/crash/ by default).
46.3. Analyzing the Core Dump
Note
vmcore dump file, you must have the crash and kernel-debuginfo packages installed. To do so, type the following at a shell prompt as root:
yum install --enablerepo=rhel-debuginfo crash kernel-debuginfo
~]# yum install --enablerepo=rhel-debuginfo crash kernel-debuginfocrash utility. This utility allows you to interactively analyze a running Linux system as well as a core dump created by netdump, diskdump, xendump, or kdump. When started, it presents you with an interactive prompt very similar to the GNU Debugger (GDB).
crash /var/crash/timestamp/vmcore /usr/lib/debug/lib/modules/kernel/vmlinux
crash /var/crash/timestamp/vmcore /usr/lib/debug/lib/modules/kernel/vmlinuxkdump. To find out which kernel you are currently running, use the uname -r command.
Example 46.2. Running the crash utility
crash, type exit.
46.3.1. Displaying the Message Buffer
log command at the interactive prompt.
Example 46.3. Displaying the kernel message buffer
help log for more information on the command usage.
46.3.2. Displaying a Backtrace
bt command at the interactive prompt. You can use bt pid to display the backtrace of the selected process.
Example 46.4. Displaying the kernel stack trace
help bt for more information on the command usage.
46.3.3. Displaying a Process Status
ps command at the interactive prompt. You can use ps pid to display the status of the selected process.
Example 46.5. Displaying status of processes in the system
help ps for more information on the command usage.
46.3.4. Displaying Virtual Memory Information
vm command at the interactive prompt. You can use vm pid to display information on the selected process.
Example 46.6. Displaying virtual memory information of the current context
help vm for more information on the command usage.
46.3.5. Displaying Open Files
files command at the interactive prompt. You can use files pid to display files opened by the selected process.
Example 46.7. Displaying information about open files of the current context
help files for more information on the command usage.
46.4. Additional Resources
46.4.1. Installed Documentation
man kdump.conf- The manual page for the
/etc/kdump.confconfiguration file containing the full documentation of available options. man kexec- The manual page for
kexeccontaining the full documentation on its usage. man crash- The manual page for the
crashutility containing the full documentation on its usage. /usr/share/doc/kexec-tools-version/kexec-kdump-howto.txt- An overview of the
kdumpandkexecinstallation and usage.
46.4.2. Useful Websites
- https://access.redhat.com/kb/docs/DOC-6039
- The Red Hat Knowledgebase article about the
kexecandkdumpconfiguration. - http://people.redhat.com/anderson/
- The
crashutility homepage.
Part VII. Security And Authentication
Chapter 47. Security Overview
47.1. Introduction to Security
47.1.1. What is Computer Security?
47.1.1.1. How did Computer Security Come about?
47.1.1.2. Security Today
- On any given day, there are approximately 225 major incidences of security breach reported to the CERT Coordination Center at Carnegie Mellon University.[10]
- In 2003, the number of CERT reported incidences jumped to 137,529 from 82,094 in 2002 and from 52,658 in 2001.[11]
- The worldwide economic impact of the three most dangerous Internet Viruses of the last three years was estimated at US$13.2 Billion.[12]
47.1.1.3. Standardizing Security
- Confidentiality — Sensitive information must be available only to a set of pre-defined individuals. Unauthorized transmission and usage of information should be restricted. For example, confidentiality of information ensures that a customer's personal or financial information is not obtained by an unauthorized individual for malicious purposes such as identity theft or credit fraud.
- Integrity — Information should not be altered in ways that render it incomplete or incorrect. Unauthorized users should be restricted from the ability to modify or destroy sensitive information.
- Availability — Information should be accessible to authorized users any time that it is needed. Availability is a warranty that information can be obtained with an agreed-upon frequency and timeliness. This is often measured in terms of percentages and agreed to formally in Service Level Agreements (SLAs) used by network service providers and their enterprise clients.
47.1.2. Security Controls
- Physical
- Technical
- Administrative
47.1.2.1. Physical Controls
- Closed-circuit surveillance cameras
- Motion or thermal alarm systems
- Security guards
- Picture IDs
- Locked and dead-bolted steel doors
- Biometrics (includes fingerprint, voice, face, iris, handwriting, and other automated methods used to recognize individuals)
47.1.2.2. Technical Controls
- Encryption
- Smart cards
- Network authentication
- Access control lists (ACLs)
- File integrity auditing software
47.1.2.3. Administrative Controls
- Training and awareness
- Disaster preparedness and recovery plans
- Personnel recruitment and separation strategies
- Personnel registration and accounting
47.1.3. Conclusion
47.2. Vulnerability Assessment
- The expertise of the staff responsible for configuring, monitoring, and maintaining the technologies.
- The ability to patch and update services and kernels quickly and efficiently.
- The ability of those responsible to keep constant vigilance over the network.
47.2.1. Thinking Like the Enemy
47.2.2. Defining Assessment and Testing
Warning
- Creates proactive focus on information security
- Finds potential exploits before crackers find them
- Results in systems being kept up to date and patched
- Promotes growth and aids in developing staff expertise
- Abates Financial loss and negative publicity
47.2.2.1. Establishing a Methodology
- http://www.isecom.org/projects/osstmm.htm The Open Source Security Testing Methodology Manual (OSSTMM)
- http://www.owasp.org/ The Open Web Application Security Project
47.2.3. Evaluating the Tools
47.2.3.1. Scanning Hosts with Nmap
47.2.3.1.1. Using Nmap
nmap command followed by the hostname or IP address of the machine to scan.
nmap foo.example.com
nmap foo.example.com47.2.3.2. Nessus
Note
47.2.3.3. Nikto
Note
47.2.3.4. VLAD the Scanner
Note
47.2.3.5. Anticipating Your Future Needs
47.3. Attackers and Vulnerabilities
47.3.1. A Quick History of Hackers
47.3.1.1. Shades of Gray
47.3.2. Threats to Network Security
47.3.2.1. Insecure Architectures
47.3.2.1.1. Broadcast Networks
47.3.2.1.2. Centralized Servers
47.3.3. Threats to Server Security
47.3.3.1. Unused Services and Open Ports
47.3.3.2. Unpatched Services
47.3.3.3. Inattentive Administration
47.3.3.4. Inherently Insecure Services
47.3.4. Threats to Workstation and Home PC Security
47.3.4.1. Bad Passwords
47.3.4.2. Vulnerable Client Applications
47.4. Common Exploits and Attacks
| Exploit | Description | Notes | |||
|---|---|---|---|---|---|
| Null or Default Passwords | Leaving administrative passwords blank or using a default password set by the product vendor. This is most common in hardware such as routers and firewalls, though some services that run on Linux can contain default administrator passwords (though Red Hat Enterprise Linux 5 does not ship with them). |
| |||
| Default Shared Keys | Secure services sometimes package default security keys for development or evaluation testing purposes. If these keys are left unchanged and are placed in a production environment on the Internet, all users with the same default keys have access to that shared-key resource, and any sensitive information that it contains. |
| |||
| IP Spoofing | A remote machine acts as a node on your local network, finds vulnerabilities with your servers, and installs a backdoor program or Trojan horse to gain control over your network resources. |
| |||
| Eavesdropping | Collecting data that passes between two active nodes on a network by eavesdropping on the connection between the two nodes. |
| |||
| Service Vulnerabilities | An attacker finds a flaw or loophole in a service run over the Internet; through this vulnerability, the attacker compromises the entire system and any data that it may hold, and could possibly compromise other systems on the network. |
| |||
| Application Vulnerabilities | Attackers find faults in desktop and workstation applications (such as e-mail clients) and execute arbitrary code, implant Trojan horses for future compromise, or crash systems. Further exploitation can occur if the compromised workstation has administrative privileges on the rest of the network. |
| |||
| Denial of Service (DoS) Attacks | Attacker or group of attackers coordinate against an organization's network or server resources by sending unauthorized packets to the target host (either server, router, or workstation). This forces the resource to become unavailable to legitimate users. |
|
47.5. Security Updates
47.5.1. Updating Packages
- Listed and available for download on Red Hat Network
- Listed and unlinked on the Red Hat Errata website
Note
47.5.1.1. Using Automatic Updates with RHN Classic
Warning
Important
47.5.1.2. Using the Red Hat Errata Website
/tmp/updates, and save all the downloaded packages to it.
47.5.1.3. Verifying Signed Packages
/mnt/cdrom, use the following command to import it into the keyring (a database of trusted keys on the system):
rpm --import /mnt/cdrom/RPM-GPG-KEY-redhat-release
rpm --import /mnt/cdrom/RPM-GPG-KEY-redhat-releaserpm -qa gpg-pubkey*
rpm -qa gpg-pubkey*gpg-pubkey-37017186-45761324
gpg-pubkey-37017186-45761324rpm -qi command followed by the output from the previous command, as in this example:
rpm -qi gpg-pubkey-37017186-45761324
rpm -qi gpg-pubkey-37017186-45761324rpm -K /tmp/updates/*.rpm
rpm -K /tmp/updates/*.rpmgpg OK. If it doesn't, make sure you are using the correct Red Hat public key, as well as verifying the source of the content. Packages that do not pass GPG verifications should not be installed, as they may have been altered by a third party.
47.5.1.4. Installing Signed Packages
rpm -Uvh /tmp/updates/*.rpm
rpm -Uvh /tmp/updates/*.rpmrpm -ivh /tmp/updates/<kernel-package>
rpm -ivh /tmp/updates/<kernel-package>rpm -e <old-kernel-package>
rpm -e <old-kernel-package>Note
Important
47.5.1.5. Applying the Changes
Note
- Applications
- User-space applications are any programs that can be initiated by a system user. Typically, such applications are used only when a user, script, or automated task utility launches them and they do not persist for long periods of time.Once such a user-space application is updated, halt any instances of the application on the system and launch the program again to use the updated version.
- Kernel
- The kernel is the core software component for the Red Hat Enterprise Linux operating system. It manages access to memory, the processor, and peripherals as well as schedules all tasks.Because of its central role, the kernel cannot be restarted without also stopping the computer. Therefore, an updated version of the kernel cannot be used until the system is rebooted.
- Shared Libraries
- Shared libraries are units of code, such as
glibc, which are used by a number of applications and services. Applications utilizing a shared library typically load the shared code when the application is initialized, so any applications using the updated library must be halted and relaunched.To determine which running applications link against a particular library, use thelsofcommand as in the following example:lsof /usr/lib/libwrap.so*
lsof /usr/lib/libwrap.so*Copy to Clipboard Copied! Toggle word wrap Toggle overflow This command returns a list of all the running programs which use TCP wrappers for host access control. Therefore, any program listed must be halted and relaunched if thetcp_wrapperspackage is updated. - SysV Services
- SysV services are persistent server programs launched during the boot process. Examples of SysV services include
sshd,vsftpd, andxinetd.Because these programs usually persist in memory as long as the machine is booted, each updated SysV service must be halted and relaunched after the package is upgraded. This can be done using the Services Configuration Tool or by logging into a root shell prompt and issuing the/sbin/servicecommand as in the following example:service <service-name> restart
service <service-name> restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow In the previous example, replace <service-name> with the name of the service, such assshd.Refer to Chapter 17, Network Configuration for more information on the Services Configuration Tool. xinetdServices- Services controlled by the
xinetdsuper service only run when a there is an active connection. Examples of services controlled byxinetdinclude Telnet, IMAP, and POP3.Because new instances of these services are launched byxinetdeach time a new request is received, connections that occur after an upgrade are handled by the updated software. However, if there are active connections at the time thexinetdcontrolled service is upgraded, they are serviced by the older version of the software.To kill off older instances of a particularxinetdcontrolled service, upgrade the package for the service then halt all processes currently running. To determine if the process is running, use thepscommand and then use thekillorkillallcommand to halt current instances of the service.For example, if security errataimappackages are released, upgrade the packages, then type the following command as root into a shell prompt:ps -aux | grep imap
ps -aux | grep imapCopy to Clipboard Copied! Toggle word wrap Toggle overflow This command returns all active IMAP sessions. Individual sessions can then be terminated by issuing the following command:kill <PID>
kill <PID>Copy to Clipboard Copied! Toggle word wrap Toggle overflow If this fails to terminate the session, use the following command instead:kill -9 <PID>
kill -9 <PID>Copy to Clipboard Copied! Toggle word wrap Toggle overflow In the previous examples, replace <PID> with the process identification number (found in the second column of thepscommand) for an IMAP session.To kill all active IMAP sessions, issue the following command:killall imapd
killall imapdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Chapter 48. Securing Your Network
48.1. Workstation Security
48.1.1. Evaluating Workstation Security
- BIOS and Boot Loader Security — Can an unauthorized user physically access the machine and boot into single user or rescue mode without a password?
- Password Security — How secure are the user account passwords on the machine?
- Administrative Controls — Who has an account on the system and how much administrative control do they have?
- Available Network Services — What services are listening for requests from the network and should they be running at all?
- Personal Firewalls — What type of firewall, if any, is necessary?
- Security Enhanced Communication Tools — Which tools should be used to communicate between workstations and which should be avoided?
48.1.2. BIOS and Boot Loader Security
48.1.2.1. BIOS Passwords
- Preventing Changes to BIOS Settings — If an intruder has access to the BIOS, they can set it to boot from a diskette or CD-ROM. This makes it possible for them to enter rescue mode or single user mode, which in turn allows them to start arbitrary processes on the system or copy sensitive data.
- Preventing System Booting — Some BIOSes allow password protection of the boot process. When activated, an attacker is forced to enter a password before the BIOS launches the boot loader.
48.1.2.1.1. Securing Non-x86 Platforms
48.1.2.2. Boot Loader Passwords
- Preventing Access to Single User Mode — If attackers can boot the system into single user mode, they are logged in automatically as root without being prompted for the root password.
- Preventing Access to the GRUB Console — If the machine uses GRUB as its boot loader, an attacker can use the GRUB editor interface to change its configuration or to gather information using the
catcommand. - Preventing Access to Insecure Operating Systems — If it is a dual-boot system, an attacker can select an operating system at boot time (for example, DOS), which ignores access controls and file permissions.
48.1.2.2.1. Password Protecting GRUB
grub-md5-crypt
grub-md5-crypt/boot/grub/grub.conf. Open the file and below the timeout line in the main section of the document, add the following line:
password --md5 <password-hash>
password --md5 <password-hash>/sbin/grub-md5-crypt[15].
/boot/grub/grub.conf file must be edited.
title line of the operating system that you want to secure, and add a line with the lock directive immediately beneath it.
title DOS lock
title DOS lockWarning
password line must be present in the main section of the /boot/grub/grub.conf file for this method to work properly. Otherwise, an attacker can access the GRUB editor interface and remove the lock line.
lock line to the stanza, followed by a password line.
title DOS lock password --md5 <password-hash>
title DOS lock password --md5 <password-hash>48.1.3. Password Security
/etc/passwd file, which makes the system vulnerable to offline password cracking attacks. If an intruder can gain access to the machine as a regular user, they can copy the /etc/passwd file to their own machine and run any number of password cracking programs against it. If there is an insecure password in the file, it is only a matter of time before the password cracker discovers it.
/etc/shadow, which is readable only by the root user.
48.1.3.1. Creating Strong Passwords
- Do Not Use Only Words or Numbers — Never use only numbers or words in a password.Some insecure examples include the following:
- 8675309
- juan
- hackme
- Do Not Use Recognizable Words — Words such as proper names, dictionary words, or even terms from television shows or novels should be avoided, even if they are bookended with numbers.Some insecure examples include the following:
- john1
- DS-9
- mentat123
- Do Not Use Words in Foreign Languages — Password cracking programs often check against word lists that encompass dictionaries of many languages. Relying on foreign languages for secure passwords is not secure.Some insecure examples include the following:
- cheguevara
- bienvenido1
- 1dumbKopf
- Do Not Use Hacker Terminology — If you think you are elite because you use hacker terminology — also called l337 (LEET) speak — in your password, think again. Many word lists include LEET speak.Some insecure examples include the following:
- H4X0R
- 1337
- Do Not Use Personal Information — Avoid using any personal information in your passwords. If the attacker knows your identity, the task of deducing your password becomes easier. The following is a list of the types of information to avoid when creating a password:Some insecure examples include the following:
- Your name
- The names of pets
- The names of family members
- Any birth dates
- Your phone number or zip code
- Do Not Invert Recognizable Words — Good password checkers always reverse common words, so inverting a bad password does not make it any more secure.Some insecure examples include the following:
- R0X4H
- nauj
- 9-DS
- Do Not Write Down Your Password — Never store a password on paper. It is much safer to memorize it.
- Do Not Use the Same Password For All Machines — It is important to make separate passwords for each machine. This way if one system is compromised, all of your machines are not immediately at risk.
- Make the Password at Least Eight Characters Long — The longer the password, the better. If using MD5 passwords, it should be 15 characters or longer. With DES passwords, use the maximum length (eight characters).
- Mix Upper and Lower Case Letters — Red Hat Enterprise Linux is case sensitive, so mix cases to enhance the strength of the password.
- Mix Letters and Numbers — Adding numbers to passwords, especially when added to the middle (not just at the beginning or the end), can enhance password strength.
- Include Non-Alphanumeric Characters — Special characters such as &, $, and > can greatly improve the strength of a password (this is not possible if using DES passwords).
- Pick a Password You Can Remember — The best password in the world does little good if you cannot remember it; use acronyms or other mnemonic devices to aid in memorizing passwords.
48.1.3.1.1. Secure Password Creation Methodology
- Think of an easily-remembered phrase, such as:"over the river and through the woods, to grandmother's house we go."
- Next, turn it into an acronym (including the punctuation).
otrattw,tghwg. - Add complexity by substituting numbers and symbols for letters in the acronym. For example, substitute
7fortand the at symbol (@) fora:o7r@77w,7ghwg. - Add more complexity by capitalizing at least one letter, such as
H.o7r@77w,7gHwg. - Finally, do not use the example password above for any systems, ever.
48.1.3.2. Creating User Passwords Within an Organization
48.1.3.2.1. Forcing Strong Passwords
passwd, which is Pluggable Authentication Manager (PAM) aware and therefore checks to see if the password is too short or otherwise easy to crack. This check is performed using the pam_cracklib.so PAM module. Since PAM is customizable, it is possible to add more password integrity checkers, such as pam_passwdqc (available from http://www.openwall.com/passwdqc/) or to write a new module. For a list of available PAM modules, refer to http://www.kernel.org/pub/linux/libs/pam/modules.html. For more information about PAM, refer to Section 48.4, “Pluggable Authentication Modules (PAM)”.
Note
- John The Ripper — A fast and flexible password cracking program. It allows the use of multiple word lists and is capable of brute-force password cracking. It is available online at http://www.openwall.com/john/.
- Crack — Perhaps the most well known password cracking software, Crack is also very fast, though not as easy to use as John The Ripper. It can be found online at http://www.openwall.com/john/.
- Slurpie — Slurpie is similar to John The Ripper and Crack, but it is designed to run on multiple computers simultaneously, creating a distributed password cracking attack. It can be found along with a number of other distributed attack security evaluation tools online at http://www.ussrback.com/distributed.htm.
Warning
48.1.3.2.2. Password Aging
chage command or the graphical User Manager (system-config-users) application.
-M option of the chage command specifies the maximum number of days the password is valid. For example, to set a user's password to expire in 90 days, use the following command:
chage -M 90 <username>
chage -M 90 <username>99999 after the -M option (this equates to a little over 273 years).
chage command in interactive mode to modify multiple password aging and account details. Use the following command to enter interactive mode:
chage <username>
chage <username>- Click the menu on the Panel, point to and then click to display the User Manager. Alternatively, type the command
system-config-usersat a shell prompt. - Click the Users tab, and select the required user in the list of users.
- Click on the toolbar to display the User Properties dialog box (or choose on the menu).
- Click the Password Info tab, and select the check box for Enable password expiration.
- Enter the required value in the Days before change required field, and click .
Figure 48.1. Specifying password aging options
48.1.4. Administrative Controls
sudo or su. A setuid program is one that operates with the user ID (UID) of the program's owner rather than the user operating the program. Such programs are denoted by an s in the owner section of a long format listing, as in the following example:
-rwsr-xr-x 1 root root 47324 May 1 08:09 /bin/su
-rwsr-xr-x 1 root root 47324 May 1 08:09 /bin/suNote
s may be upper case or lower case. If it appears as upper case, it means that the underlying permission bit has not been set.
pam_console.so, some activities normally reserved only for the root user, such as rebooting and mounting removable media are allowed for the first user that logs in at the physical console (refer to Section 48.4, “Pluggable Authentication Modules (PAM)” for more information about the pam_console.so module.) However, other important system administration tasks, such as altering network settings, configuring a new mouse, or mounting network devices, are not possible without administrative privileges. As a result, system administrators must decide how much access the users on their network should receive.
48.1.4.1. Allowing Root Access
- Machine Misconfiguration — Users with root access can misconfigure their machines and require assistance to resolve issues. Even worse, they might open up security holes without knowing it.
- Running Insecure Services — Users with root access might run insecure servers on their machine, such as FTP or Telnet, potentially putting usernames and passwords at risk. These services transmit this information over the network in plain text.
- Running Email Attachments As Root — Although rare, email viruses that affect Linux do exist. The only time they are a threat, however, is when they are run by the root user.
48.1.4.2. Disallowing Root Access
- Changing the root shell
- To prevent users from logging in directly as root, the system administrator can set the root account's shell to
/sbin/nologinin the/etc/passwdfile.Expand Table 48.1. Disabling the Root Shell Effects Does Not Affect Prevents access to the root shell and logs any such attempts. The following programs are prevented from accessing the root account:logingdmkdmxdmsusshscpsftp
Programs that do not require a shell, such as FTP clients, mail clients, and many setuid programs. The following programs are not prevented from accessing the root account:sudo- FTP clients
- Email clients
- Disabling root access via any console device (tty)
- To further limit access to the root account, administrators can disable root logins at the console by editing the
/etc/securettyfile. This file lists all devices the root user is allowed to log into. If the file does not exist at all, the root user can log in through any communication device on the system, whether via the console or a raw network interface. This is dangerous, because a user can log in to their machine as root via Telnet, which transmits the password in plain text over the network.By default, Red Hat Enterprise Linux's/etc/securettyfile only allows the root user to log in at the console physically attached to the machine. To prevent the root user from logging in, remove the contents of this file by typing the following command at a shell prompt as root:echo > /etc/securetty
echo > /etc/securettyCopy to Clipboard Copied! Toggle word wrap Toggle overflow To enablesecurettysupport in the KDM, GDM, and XDM login managers, add the following line:auth [user_unknown=ignore success=ok ignore=ignore default=bad] pam_securetty.so
auth [user_unknown=ignore success=ok ignore=ignore default=bad] pam_securetty.soCopy to Clipboard Copied! Toggle word wrap Toggle overflow to the files listed below:/etc/pam.d/gdm/etc/pam.d/gdm-autologin/etc/pam.d/gdm-fingerprint/etc/pam.d/gdm-password/etc/pam.d/gdm-smartcard/etc/pam.d/kdm/etc/pam.d/kdm-np/etc/pam.d/xdm
Warning
A blank/etc/securettyfile does not prevent the root user from logging in remotely using the OpenSSH suite of tools because the console is not opened until after authentication.Expand Table 48.2. Disabling Root Logins Effects Does Not Affect Prevents access to the root account via the console or the network. The following programs are prevented from accessing the root account:logingdmkdmxdm- Other network services that open a tty
Programs that do not log in as root, but perform administrative tasks through setuid or other mechanisms. The following programs are not prevented from accessing the root account:susudosshscpsftp
- Disabling root SSH logins
- To prevent root logins via the SSH protocol, edit the SSH daemon's configuration file,
/etc/ssh/sshd_config, and change the line that reads:#PermitRootLogin yes
#PermitRootLogin yesCopy to Clipboard Copied! Toggle word wrap Toggle overflow to read as follows:PermitRootLogin no
PermitRootLogin noCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand Table 48.3. Disabling Root SSH Logins Effects Does Not Affect Prevents root access via the OpenSSH suite of tools. The following programs are prevented from accessing the root account:sshscpsftp
Programs that are not part of the OpenSSH suite of tools. - Using PAM to limit root access to services
- PAM, through the
/lib/security/pam_listfile.somodule, allows great flexibility in denying specific accounts. The administrator can use this module to reference a list of users who are not allowed to log in. To limit root access to a system service, edit the file for the target service in the/etc/pam.d/directory and make sure thepam_listfile.somodule is required for authentication.The following is an example of how the module is used for thevsftpdFTP server in the/etc/pam.d/vsftpdPAM configuration file (the\character at the end of the first line is not necessary if the directive is on a single line):auth required /lib/security/pam_listfile.so item=user \ sense=deny file=/etc/vsftpd.ftpusers onerr=succeed
auth required /lib/security/pam_listfile.so item=user \ sense=deny file=/etc/vsftpd.ftpusers onerr=succeedCopy to Clipboard Copied! Toggle word wrap Toggle overflow This instructs PAM to consult the/etc/vsftpd.ftpusersfile and deny access to the service for any listed user. The administrator can change the name of this file, and can keep separate lists for each service or use one central list to deny access to multiple services.If the administrator wants to deny access to multiple services, a similar line can be added to the PAM configuration files, such as/etc/pam.d/popand/etc/pam.d/imapfor mail clients, or/etc/pam.d/sshfor SSH clients.For more information about PAM, refer to Section 48.4, “Pluggable Authentication Modules (PAM)”.Expand Table 48.4. Disabling Root Using PAM Effects Does Not Affect Prevents root access to network services that are PAM aware. The following services are prevented from accessing the root account:logingdmkdmxdmsshscpsftp- FTP clients
- Email clients
- Any PAM aware services
Programs and services that are not PAM aware.
48.1.4.3. Limiting Root Access
su or sudo.
48.1.4.3.1. The su Command
su command, they are prompted for the root password and, after authentication, is given a root shell prompt.
su command, the user is the root user and has absolute administrative access to the system[16]. In addition, once a user has become root, it is possible for them to use the su command to change to any other user on the system without being prompted for a password.
usermod -G wheel <username>
usermod -G wheel <username>wheel group.
- Click the menu on the Panel, point to and then click to display the User Manager. Alternatively, type the command
system-config-usersat a shell prompt. - Click the Users tab, and select the required user in the list of users.
- Click on the toolbar to display the User Properties dialog box (or choose on the menu).
- Click the Groups tab, select the check box for the wheel group, and then click . Refer to Figure 48.2, “Adding users to the "wheel" group.”.
- Open the PAM configuration file for
su(/etc/pam.d/su) in a text editor and remove the comment # from the following line:auth required pam_wheel.so use_uid
auth required pam_wheel.so use_uidCopy to Clipboard Copied! Toggle word wrap Toggle overflow This change means that only members of the administrative groupwheelcan switch to another user using the su command.
Figure 48.2. Adding users to the "wheel" group.
Note
wheel group by default.
48.1.4.3.2. The sudo Command
sudo command offers another approach to giving users administrative access. When trusted users precede an administrative command with sudo, they are prompted for their own password. Then, when they have been authenticated and assuming that the command is permitted, the administrative command is executed as if they were the root user.
sudo command is as follows:
sudo <command>
sudo <command>mount.
Important
sudo command should take extra care to log out before walking away from their machines since sudoers can use the command again without being asked for a password within a five minute period. This setting can be altered via the configuration file, /etc/sudoers.
sudo command allows for a high degree of flexibility. For instance, only users listed in the /etc/sudoers configuration file are allowed to use the sudo command and the command is executed in the user's shell, not a root shell. This means the root shell can be completely disabled, as shown in Section 48.1.4.2, “Disallowing Root Access”.
sudo command also provides a comprehensive audit trail. Each successful authentication is logged to the file /var/log/messages and the command issued along with the issuer's user name is logged to the file /var/log/secure.
sudo command is that an administrator can allow different users access to specific commands based on their needs.
sudo configuration file, /etc/sudoers, should use the visudo command.
visudo and add a line similar to the following in the user privilege specification section:
juan ALL=(ALL) ALL
juan ALL=(ALL) ALLjuan, can use sudo from any host and execute any command.
sudo:
%users localhost=/sbin/shutdown -h now
%users localhost=/sbin/shutdown -h now/sbin/shutdown -h now as long as it is issued from the console.
sudoers has a detailed listing of options for this file.
48.1.5. Available Network Services
48.1.5.1. Risks To Services
- Denial of Service Attacks (DoS) — By flooding a service with requests, a denial of service attack can render a system unusable as it tries to log and answer each request.
- Script Vulnerability Attacks — If a server is using scripts to execute server-side actions, as Web servers commonly do, a cracker can attack improperly written scripts. These script vulnerability attacks can lead to a buffer overflow condition or allow the attacker to alter files on the system.
- Buffer Overflow Attacks — Services that connect to ports numbered 0 through 1023 must run as an administrative user. If the application has an exploitable buffer overflow, an attacker could gain access to the system as the user running the daemon. Because exploitable buffer overflows exist, crackers use automated tools to identify systems with vulnerabilities, and once they have gained access, they use automated rootkits to maintain their access to the system.
Note
Note
48.1.5.2. Identifying and Configuring Services
cupsd— The default print server for Red Hat Enterprise Linux.lpd— An alternative print server.xinetd— A super server that controls connections to a range of subordinate servers, such asgssftpandtelnet.sendmail— The Sendmail Mail Transport Agent (MTA) is enabled by default, but only listens for connections from the localhost.sshd— The OpenSSH server, which is a secure replacement for Telnet.
cupsd running. The same is true for portmap. If you do not mount NFSv3 volumes or use NIS (the ypbind service), then portmap should be disabled.
system-config-services), ntsysv, and chkconfig. For information on using these tools, refer to Chapter 18, Controlling Access to Services.
Figure 48.3. Services Configuration Tool
48.1.5.3. Insecure Services
- Transmit Usernames and Passwords Over a Network Unencrypted — Many older protocols, such as Telnet and FTP, do not encrypt the authentication session and should be avoided whenever possible.
- Transmit Sensitive Data Over a Network Unencrypted — Many protocols transmit data over the network unencrypted. These protocols include Telnet, FTP, HTTP, and SMTP. Many network file systems, such as NFS and SMB, also transmit information over the network unencrypted. It is the user's responsibility when using these protocols to limit what type of data is transmitted.Remote memory dump services, like
netdump, transmit the contents of memory over the network unencrypted. Memory dumps can contain passwords or, even worse, database entries and other sensitive information.Other services likefingerandrwhodreveal information about users of the system.
rlogin, rsh, telnet, and vsftpd.
rlogin, rsh, and telnet) should be avoided in favor of SSH. Refer to Section 48.1.7, “Security Enhanced Communication Tools” for more information about sshd.
fingerauthd(this was calledidentdin previous Red Hat Enterprise Linux releases.)netdumpnetdump-servernfsrwhodsendmailsmb(Samba)yppasswddypservypxfrd
48.1.6. Personal Firewalls
Important
system-config-securitylevel). This tool creates broad iptables rules for a general-purpose firewall using a control panel interface.
iptables is probably a better option. Refer to Section 48.8, “Firewalls” for more information. Refer to Section 48.9, “IPTables” for a comprehensive guide to the iptables command.
48.1.7. Security Enhanced Communication Tools
- OpenSSH — A free implementation of the SSH protocol for encrypting network communication.
- Gnu Privacy Guard (GPG) — A free implementation of the PGP (Pretty Good Privacy) encryption application for encrypting data.
telnet and rsh. OpenSSH includes a network service called sshd and three command line client applications:
ssh— A secure remote console access client.scp— A secure remote copy command.sftp— A secure pseudo-ftp client that allows interactive file transfer sessions.
Important
sshd service is inherently secure, the service must be kept up-to-date to prevent security threats. Refer to Section 47.5, “Security Updates” for more information.
48.2. Server Security
- Keep all services current, to protect against the latest threats.
- Use secure protocols whenever possible.
- Serve only one type of network service per machine whenever possible.
- Monitor all servers carefully for suspicious activity.
48.2.1. Securing Services With TCP Wrappers and xinetd
xinetd, a super server that provides additional access, logging, binding, redirection, and resource utilization control.
Note
xinetd to create redundancy within service access controls. Refer to Section 48.8, “Firewalls” for more information about implementing firewalls with iptables commands.
xinetd.
48.2.1.1. Enhancing Security With TCP Wrappers
hosts_options man page for information about the TCP Wrapper functionality and control language.
48.2.1.1.1. TCP Wrappers and Connection Banners
banner option.
vsftpd. To begin, create a banner file. It can be anywhere on the system, but it must have same name as the daemon. For this example, the file is called /etc/banners/vsftpd and contains the following line:
220-Hello, %c 220-All activity on ftp.example.com is logged. 220-Inappropriate use will result in your access privileges being removed.
220-Hello, %c
220-All activity on ftp.example.com is logged.
220-Inappropriate use will result in your access privileges being removed.%c token supplies a variety of client information, such as the username and hostname, or the username and IP address to make the connection even more intimidating.
/etc/hosts.allow file:
vsftpd : ALL : banners /etc/banners/
vsftpd : ALL : banners /etc/banners/48.2.1.1.2. TCP Wrappers and Attack Warnings
spawn directive.
/etc/hosts.deny file to deny any connection attempts from that network, and to log the attempts to a special file:
ALL : 206.182.68.0 : spawn /bin/ 'date' %c %d >> /var/log/intruder_alert
ALL : 206.182.68.0 : spawn /bin/ 'date' %c %d >> /var/log/intruder_alert%d token supplies the name of the service that the attacker was trying to access.
spawn directive in the /etc/hosts.allow file.
Note
spawn directive executes any shell command, create a special script to notify the administrator or execute a chain of commands in the event that a particular client attempts to connect to the server.
48.2.1.1.3. TCP Wrappers and Enhanced Logging
severity option.
emerg flag in the log files instead of the default flag, info, and deny the connection.
/etc/hosts.deny:
in.telnetd : ALL : severity emerg
in.telnetd : ALL : severity emergauthpriv logging facility, but elevates the priority from the default value of info to emerg, which posts log messages directly to the console.
48.2.1.2. Enhancing Security With xinetd
xinetd to set a trap service and using it to control resource levels available to any given xinetd service. Setting resource limits for services can help thwart Denial of Service (DoS) attacks. Refer to the man pages for xinetd and xinetd.conf for a list of available options.
48.2.1.2.1. Setting a Trap
xinetd is its ability to add hosts to a global no_access list. Hosts on this list are denied subsequent connections to services managed by xinetd for a specified period or until xinetd is restarted. You can do this using the SENSOR attribute. This is an easy way to block hosts attempting to scan the ports on the server.
SENSOR is to choose a service you do not plan on using. For this example, Telnet is used.
/etc/xinetd.d/telnet and change the flags line to read:
flags = SENSOR
flags = SENSORdeny_time = 30
deny_time = 30deny_time attribute are FOREVER, which keeps the ban in effect until xinetd is restarted, and NEVER, which allows the connection and logs it.
disable = no
disable = noSENSOR is a good way to detect and stop connections from undesirable hosts, it has two drawbacks:
- It does not work against stealth scans.
- An attacker who knows that a
SENSORis running can mount a Denial of Service attack against particular hosts by forging their IP addresses and connecting to the forbidden port.
48.2.1.2.2. Controlling Server Resources
xinetd is its ability to set resource limits for services under its control.
cps = <number_of_connections> <wait_period>— Limits the rate of incoming connections. This directive takes two arguments:<number_of_connections>— The number of connections per second to handle. If the rate of incoming connections is higher than this, the service is temporarily disabled. The default value is fifty (50).<wait_period>— The number of seconds to wait before re-enabling the service after it has been disabled. The default interval is ten (10) seconds.
instances = <number_of_connections>— Specifies the total number of connections allowed to a service. This directive accepts either an integer value orUNLIMITED.per_source = <number_of_connections>— Specifies the number of connections allowed to a service by each host. This directive accepts either an integer value orUNLIMITED.rlimit_as = <number[K|M]>— Specifies the amount of memory address space the service can occupy in kilobytes or megabytes. This directive accepts either an integer value orUNLIMITED.rlimit_cpu = <number_of_seconds>— Specifies the amount of time in seconds that a service may occupy the CPU. This directive accepts either an integer value orUNLIMITED.
xinetd service from overwhelming the system, resulting in a denial of service.
48.2.2. Securing Portmap
portmap service is a dynamic port assignment daemon for RPC services such as NIS and NFS. It has weak authentication mechanisms and has the ability to assign a wide range of ports for the services it controls. For these reasons, it is difficult to secure.
Note
portmap only affects NFSv2 and NFSv3 implementations, since NFSv4 no longer requires it. If you plan to implement an NFSv2 or NFSv3 server, then portmap is required, and the following section applies.
48.2.2.1. Protect portmap With TCP Wrappers
portmap service since it has no built-in form of authentication.
48.2.2.2. Protect portmap With iptables
portmap service, it is a good idea to add iptables rules to the server and restrict access to specific networks.
portmap service) from the 192.168.0.0/24 network. The second allows TCP connections to the same port from the localhost. This is necessary for the sgi_fam service used by Nautilus. All other packets are dropped.
iptables -A INPUT -p tcp -s! 192.168.0.0/24 --dport 111 -j DROP iptables -A INPUT -p tcp -s 127.0.0.1 --dport 111 -j ACCEPT
iptables -A INPUT -p tcp -s! 192.168.0.0/24 --dport 111 -j DROP
iptables -A INPUT -p tcp -s 127.0.0.1 --dport 111 -j ACCEPTiptables -A INPUT -p udp -s! 192.168.0.0/24 --dport 111 -j DROP
iptables -A INPUT -p udp -s! 192.168.0.0/24 --dport 111 -j DROPNote
48.2.3. Securing NIS
ypserv,--> which is used in conjunction with portmap and other related services to distribute maps of usernames, passwords, and other sensitive information to any computer claiming to be within its domain.
/usr/sbin/rpc.yppasswdd— Also called theyppasswddservice, this daemon allows users to change their NIS passwords./usr/sbin/rpc.ypxfrd— Also called theypxfrdservice, this daemon is responsible for NIS map transfers over the network./usr/sbin/yppush— This application propagates changed NIS databases to multiple NIS servers./usr/sbin/ypserv— This is the NIS server daemon.
portmap service as outlined in Section 48.2.2, “Securing Portmap”, then address the following issues, such as network planning.
48.2.3.1. Carefully Plan the Network
48.2.3.2. Use a Password-like NIS Domain Name and Hostname
/etc/passwd map:
ypcat -d <NIS_domain> -h <DNS_hostname> passwd
ypcat -d <NIS_domain> -h <DNS_hostname> passwd/etc/shadow file by typing the following command:
ypcat -d <NIS_domain> -h <DNS_hostname> shadow
ypcat -d <NIS_domain> -h <DNS_hostname> shadowNote
/etc/shadow file is not stored within an NIS map.
o7hfawtgmhwg.domain.com. Similarly, create a different randomized NIS domain name. This makes it much more difficult for an attacker to access the NIS server.
48.2.3.3. Edit the /var/yp/securenets File
/var/yp/securenets file is blank or does not exist (as is the case after a default installation), NIS listens to all networks. One of the first things to do is to put netmask/network pairs in the file so that ypserv only responds to requests from the appropriate network.
/var/yp/securenets file:
255.255.255.0 192.168.0.0
255.255.255.0 192.168.0.0Warning
/var/yp/securenets file.
48.2.3.4. Assign Static Ports and Use iptables Rules
rpc.yppasswdd — the daemon that allows users to change their login passwords. Assigning ports to the other two NIS server daemons, rpc.ypxfrd and ypserv, allows for the creation of firewall rules to further protect the NIS server daemons from intruders.
/etc/sysconfig/network:
YPSERV_ARGS="-p 834" YPXFRD_ARGS="-p 835"
YPSERV_ARGS="-p 834" YPXFRD_ARGS="-p 835"iptables -A INPUT -p tcp -s! 192.168.0.0/24 --dport 834 -j DROP iptables -A INPUT -p tcp -s! 192.168.0.0/24 --dport 835 -j DROP iptables -A INPUT -p udp -s! 192.168.0.0/24 --dport 834 -j DROP iptables -A INPUT -p udp -s! 192.168.0.0/24 --dport 835 -j DROP
iptables -A INPUT -p tcp -s! 192.168.0.0/24 --dport 834 -j DROP
iptables -A INPUT -p tcp -s! 192.168.0.0/24 --dport 835 -j DROP
iptables -A INPUT -p udp -s! 192.168.0.0/24 --dport 834 -j DROP
iptables -A INPUT -p udp -s! 192.168.0.0/24 --dport 835 -j DROPNote
48.2.3.5. Use Kerberos Authentication
/etc/shadow map is sent over the network. If an intruder gains access to an NIS domain and sniffs network traffic, they can collect usernames and password hashes. With enough time, a password cracking program can guess weak passwords, and an attacker can gain access to a valid account on the network.
48.2.4. Securing NFS
Important
portmap service as outlined in Section 48.2.2, “Securing Portmap”. NFS traffic now utilizes TCP in all versions, rather than UDP, and requires it when using NFSv4. NFSv4 now includes Kerberos user and group authentication, as part of the RPCSEC_GSS kernel module. Information on portmap is still included, since Red Hat Enterprise Linux supports NFSv2 and NFSv3, both of which utilize portmap.
48.2.4.1. Carefully Plan the Network
48.2.4.2. Beware of Syntax Errors
/etc/exports file. Be careful not to add extraneous spaces when editing this file.
/etc/exports file shares the directory /tmp/nfs/ to the host bob.example.com with read/write permissions.
/tmp/nfs/ bob.example.com(rw)
/tmp/nfs/ bob.example.com(rw)/etc/exports file, on the other hand, shares the same directory to the host bob.example.com with read-only permissions and shares it to the world with read/write permissions due to a single space character after the hostname.
/tmp/nfs/ bob.example.com (rw)
/tmp/nfs/ bob.example.com (rw)showmount command to verify what is being shared:
showmount -e <hostname>
showmount -e <hostname>48.2.4.3. Do Not Use the no_root_squash Option
nfsnobody user, an unprivileged user account. This changes the owner of all root-created files to nfsnobody, which prevents uploading of programs with the setuid bit set.
no_root_squash is used, remote root users are able to change any file on the shared file system and leave applications infected by Trojans for other users to inadvertently execute.
48.2.5. Securing the Apache HTTP Server
48.2.5.1. FollowSymLinks
/.
48.2.5.2. The Indexes Directive
48.2.5.3. The UserDir Directive
UserDir directive is disabled by default because it can confirm the presence of a user account on the system. To enable user directory browsing on the server, use the following directives:
UserDir enabled UserDir disabled root
UserDir enabled
UserDir disabled root/root/. To add users to the list of disabled accounts, add a space-delimited list of users on the UserDir disabled line.
48.2.5.4. Do Not Remove the IncludesNoExec Directive
48.2.5.5. Restrict Permissions for Executable Directories
chown root <directory_name> chmod 755 <directory_name>
chown root <directory_name>
chmod 755 <directory_name>Important
48.2.6. Securing FTP
gssftpd— A Kerberos-awarexinetd-based FTP daemon that does not transmit authentication information over the network.- Red Hat Content Accelerator (
tux) — A kernel-space Web server with FTP capabilities. vsftpd— A standalone, security oriented implementation of the FTP service.
vsftpd FTP service.
48.2.6.1. FTP Greeting Banner
vsftpd, add the following directive to the /etc/vsftpd/vsftpd.conf file:
ftpd_banner=<insert_greeting_here>
ftpd_banner=<insert_greeting_here>/etc/banners/. The banner file for FTP connections in this example is /etc/banners/ftp.msg. Below is an example of what such a file may look like:
######### # Hello, all activity on ftp.example.com is logged. #########
######### # Hello, all activity on ftp.example.com is logged. #########Note
220 as specified in Section 48.2.1.1.1, “TCP Wrappers and Connection Banners”.
vsftpd, add the following directive to the /etc/vsftpd/vsftpd.conf file:
banner_file=/etc/banners/ftp.msg
banner_file=/etc/banners/ftp.msgImportant
/etc/vsftpd/vsftpd.conf, or else every attempt to connect to vsftpd will result in the connection being closed immediately and a 500 OOPS: cannot open banner <path_to_banner_file> error message.
banner_file directive in /etc/vsftpd/vfsftpd.conf takes precedence over any ftpd_banner directives in the configuration file: if banner_file is specified, then ftpd_banner is ignored.
48.2.6.2. Anonymous Access
/var/ftp/ directory activates the anonymous account.
vsftpd package. This package establishes a directory tree for anonymous users and configures the permissions on directories to read-only for anonymous users.
Warning
48.2.6.2.1. Anonymous Upload
/var/ftp/pub/.
mkdir /var/ftp/pub/upload
mkdir /var/ftp/pub/uploadchmod 730 /var/ftp/pub/upload
chmod 730 /var/ftp/pub/uploaddrwx-wx--- 2 root ftp 4096 Feb 13 20:05 upload
drwx-wx--- 2 root ftp 4096 Feb 13 20:05 uploadWarning
vsftpd, add the following line to the /etc/vsftpd/vsftpd.conf file:
anon_upload_enable=YES
anon_upload_enable=YES48.2.6.3. User Accounts
vsftpd, add the following directive to /etc/vsftpd/vsftpd.conf:
local_enable=NO
local_enable=NO48.2.6.3.1. Restricting User Accounts
sudo privileges, the easiest way is to use a PAM list file as described in Section 48.1.4.2, “Disallowing Root Access”. The PAM configuration file for vsftpd is /etc/pam.d/vsftpd.
vsftpd, add the username to /etc/vsftpd.ftpusers
48.2.6.4. Use TCP Wrappers To Control Access
48.2.7. Securing Sendmail
/etc/mail/sendmail.cf by editing the /etc/mail/sendmail.mc and using the m4 command.
48.2.7.1. Limiting a Denial of Service Attack
/etc/mail/sendmail.mc, the effectiveness of such attacks is limited.
confCONNECTION_RATE_THROTTLE— The number of connections the server can receive per second. By default, Sendmail does not limit the number of connections. If a limit is set and reached, further connections are delayed.confMAX_DAEMON_CHILDREN— The maximum number of child processes that can be spawned by the server. By default, Sendmail does not assign a limit to the number of child processes. If a limit is set and reached, further connections are delayed.confMIN_FREE_BLOCKS— The minimum number of free blocks which must be available for the server to accept mail. The default is 100 blocks.confMAX_HEADERS_LENGTH— The maximum acceptable size (in bytes) for a message header.confMAX_MESSAGE_SIZE— The maximum acceptable size (in bytes) for a single message.
48.2.7.2. NFS and Sendmail
/var/spool/mail/, on an NFS shared volume.
Note
SECRPC_GSS kernel module does not utilize UID-based authentication. However, it is considered good practice not to put the mail spool directory on NFS shared volumes.
48.2.7.3. Mail-only Users
/etc/passwd file should be set to /sbin/nologin (with the possible exception of the root user).
48.2.8. Verifying Which Ports Are Listening
netstat -an or lsof -i. This method is less reliable since these programs do not connect to the machine from the network, but rather check to see what is running on the system. For this reason, these applications are frequent targets for replacement by attackers. Crackers attempt to cover their tracks if they open unauthorized network ports by replacing netstat and lsof with their own, modified versions.
nmap.
nmap -sT -O localhost
nmap -sT -O localhostportmap due to the presence of the sunrpc service. However, there is also a mystery service on port 834. To check if the port is associated with the official list of known services, type:
cat /etc/services | grep 834
cat /etc/services | grep 834netstat or lsof. To check for port 834 using netstat, use the following command:
netstat -anp | grep 834
netstat -anp | grep 834tcp 0 0 0.0.0.0:834 0.0.0.0:* LISTEN 653/ypbind
tcp 0 0 0.0.0.0:834 0.0.0.0:* LISTEN 653/ypbindnetstat is reassuring because a cracker opening a port surreptitiously on a hacked system is not likely to allow it to be revealed through this command. Also, the [p] option reveals the process ID (PID) of the service that opened the port. In this case, the open port belongs to ypbind (NIS), which is an RPC service handled in conjunction with the portmap service.
lsof command reveals similar information to netstat since it is also capable of linking open ports to services:
lsof -i | grep 834
lsof -i | grep 834ypbind 653 0 7u IPv4 1319 TCP *:834 (LISTEN) ypbind 655 0 7u IPv4 1319 TCP *:834 (LISTEN) ypbind 656 0 7u IPv4 1319 TCP *:834 (LISTEN) ypbind 657 0 7u IPv4 1319 TCP *:834 (LISTEN)
ypbind 653 0 7u IPv4 1319 TCP *:834 (LISTEN)
ypbind 655 0 7u IPv4 1319 TCP *:834 (LISTEN)
ypbind 656 0 7u IPv4 1319 TCP *:834 (LISTEN)
ypbind 657 0 7u IPv4 1319 TCP *:834 (LISTEN)lsof, netstat, nmap, and services for more information.
48.3. Single Sign-on (SSO)
48.3.1. Introduction
48.3.1.1. Supported Applications
- Login
- Screensaver
- Firefox and Thunderbird
48.3.1.2. Supported Authentication Mechanisms
- Kerberos name/password login
- Smart card/PIN login
48.3.1.3. Supported Smart Cards
48.3.1.4. Advantages of Red Hat Enterprise Linux Single Sign-on
- Provides a single, shared instance of the NSS crypto libraries on each operating system.
- Ships the Certificate System's Enterprise Security Client (ESC) with the base operating system. The ESC application monitors smart card insertion events. If it detects that the user has inserted a smart card that was designed to be used with the Red Hat Enterprise Linux Certificate System server product, it displays a user interface instructing the user how to enroll that smart card.
- Unifies Kerberos and NSS so that users who log in to the operating system using a smart card also obtain a Kerberos credential (which allows them to log in to file servers, etc.)
48.3.2. Getting Started with your new Smart Card
Note
- Log in with your Kerberos name and password
- Make sure you have the
nss-toolspackage loaded. - Download and install your corporate-specific root certificates. Use the following command to install the root CA certificate:
certutil -A -d /etc/pki/nssdb -n "root ca cert" -t "CT,C,C" \ -i ./ca_cert_in_base64_format.crt
certutil -A -d /etc/pki/nssdb -n "root ca cert" -t "CT,C,C" \ -i ./ca_cert_in_base64_format.crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Verify that you have the following RPMs installed on your system: esc, pam_pkcs11, coolkey, ifd-egate, ccid, gdm, authconfig, and authconfig-gtk.
- Enable Smart Card Login Support
- On the Gnome Title Bar, select System->Administration->Authentication.
- Type your machine's root password if necessary.
- In the Authentication Configuration dialog, click the Authentication tab.
- Select the Enable Smart Card Support check box.
- Click the button to display the Smartcard Settings dialog, and specify the required settings:
- Require smart card for login — Clear this check box. After you have successfully logged in with the smart card you can select this option to prevent users from logging in without a smart card.
- Card Removal Action — This controls what happens when you remove the smart card after you have logged in. The available options are:
- Lock — Removing the smart card locks the X screen.
- Ignore — Removing the smart card has no effect.
- If you need to enable the Online Certificate Status Protocol (OCSP), open the
/etc/pam_pkcs11/pam_pkcs11.conffile, and locate the following line:enable_ocsp = false;Change this value to true, as follows:enable_ocsp = true; - Enroll your smart card
- If you are using a CAC card, you also need to perform the following steps:
- Change to the root account and create a file called
/etc/pam_pkcs11/cn_map. - Add the following entry to the
cn_mapfile:MY.CAC_CN.123454 -> myloginidwhere MY.CAC_CN.123454 is the Common Name on your CAC and myloginid is your UNIX login ID.
- Logout
48.3.2.1. Troubleshooting
pklogin_finder debug
pklogin_finder debugpklogin_finder tool in debug mode while an enrolled smart card is plugged in, it attempts to output information about the validity of certificates, and if it is successful in attempting to map a login ID from the certificates that are on the card.
48.3.3. How Smart Card Enrollment Works
- The user inserts their smart card into the smart card reader on their workstation. This event is recognized by the Enterprise Security Client (ESC).
- The enrollment page is displayed on the user's desktop. The user completes the required details and the user's system then connects to the Token Processing System (TPS) and the CA.
- The TPS enrolls the smart card using a certificate signed by the CA.
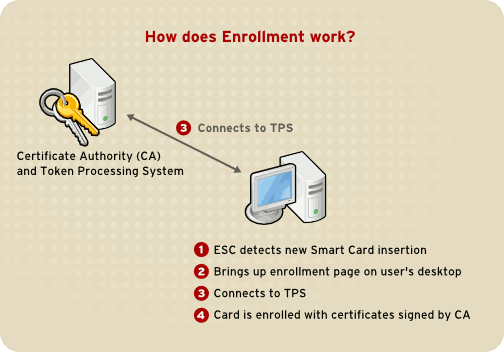
Figure 48.4. How Smart Card Enrollment Works
48.3.4. How Smart Card Login Works
- When the user inserts their smart card into the smart card reader, this event is recognized by the PAM facility, which prompts for the user's PIN.
- The system then looks up the user's current certificates and verifies their validity. The certificate is then mapped to the user's UID.
- This is validated against the KDC and login granted.
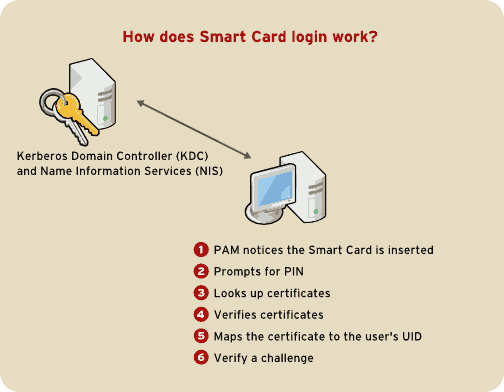
Figure 48.5. How Smart Card Login Works
Note
48.3.5. Configuring Firefox to use Kerberos for SSO
- In the address bar of Firefox, type
about:configto display the list of current configuration options. - In the Filter field, type
negotiateto restrict the list of options. - Double-click the network.negotiate-auth.trusted-uris entry to display the Enter string value dialog box.
- Enter the name of the domain against which you want to authenticate, for example, .example.com.
- Repeat the above procedure for the network.negotiate-auth.delegation-uris entry, using the same domain.
Note
You can leave this value blank, as it allows Kerberos ticket passing, which is not required.If you do not see these two configuration options listed, your version of Firefox may be too old to support Negotiate authentication, and you should consider upgrading.
Figure 48.6. Configuring Firefox for SSO with Kerberos
kinit to retrieve Kerberos tickets. To display the list of available tickets, type klist. The following shows an example output from these commands:
48.3.5.1. Troubleshooting
- Close all instances of Firefox.
- Open a command shell, and enter the following commands:
export NSPR_LOG_MODULES=negotiateauth:5 export NSPR_LOG_FILE=/tmp/moz.log
export NSPR_LOG_MODULES=negotiateauth:5 export NSPR_LOG_FILE=/tmp/moz.logCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Restart Firefox from that shell, and visit the website you were unable to authenticate to earlier. Information will be logged to
/tmp/moz.log, and may give a clue to the problem. For example:-1208550944[90039d0]: entering nsNegotiateAuth::GetNextToken() -1208550944[90039d0]: gss_init_sec_context() failed: Miscellaneous failure No credentials cache found
-1208550944[90039d0]: entering nsNegotiateAuth::GetNextToken() -1208550944[90039d0]: gss_init_sec_context() failed: Miscellaneous failure No credentials cache foundCopy to Clipboard Copied! Toggle word wrap Toggle overflow This indicates that you do not have Kerberos tickets, and need to runkinit.
kinit successfully from your machine but you are unable to authenticate, you might see something like this in the log file:
-1208994096[8d683d8]: entering nsAuthGSSAPI::GetNextToken() -1208994096[8d683d8]: gss_init_sec_context() failed: Miscellaneous failure Server not found in Kerberos database
-1208994096[8d683d8]: entering nsAuthGSSAPI::GetNextToken()
-1208994096[8d683d8]: gss_init_sec_context() failed: Miscellaneous failure
Server not found in Kerberos database/etc/krb5.conf file. For example:
.example.com = EXAMPLE.COM example.com = EXAMPLE.COM
.example.com = EXAMPLE.COM
example.com = EXAMPLE.COM48.4. Pluggable Authentication Modules (PAM)
48.4.1. Advantages of PAM
- a common authentication scheme that can be used with a wide variety of applications.
- significant flexibility and control over authentication for both system administrators and application developers.
- a single, fully-documented library which allows developers to write programs without having to create their own authentication schemes.
48.4.2. PAM Configuration Files
/etc/pam.d/ directory contains the PAM configuration files for each PAM-aware application. In earlier versions of PAM, the /etc/pam.conf file was used, but this file is now deprecated and is only used if the /etc/pam.d/ directory does not exist.
48.4.2.1. PAM Service Files
/etc/pam.d/ directory. Each file in this directory has the same name as the service to which it controls access.
/etc/pam.d/ directory. For example, the login program defines its service name as login and installs the /etc/pam.d/login PAM configuration file.
48.4.3. PAM Configuration File Format
<module interface> <control flag> <module name> <module arguments>
<module interface> <control flag> <module name> <module arguments>48.4.3.1. Module Interface
auth— This module interface authenticates use. For example, it requests and verifies the validity of a password. Modules with this interface can also set credentials, such as group memberships or Kerberos tickets.account— This module interface verifies that access is allowed. For example, it may check if a user account has expired or if a user is allowed to log in at a particular time of day.password— This module interface is used for changing user passwords.session— This module interface configures and manages user sessions. Modules with this interface can also perform additional tasks that are needed to allow access, like mounting a user's home directory and making the user's mailbox available.
Note
pam_unix.so provides all four module interfaces.
auth required pam_unix.so
auth required pam_unix.sopam_unix.so module's auth interface.
48.4.3.1.1. Stacking Module Interfaces
reboot command normally uses several stacked modules, as seen in its PAM configuration file:
- The first line is a comment and is not processed.
auth sufficient pam_rootok.so— This line uses thepam_rootok.somodule to check whether the current user is root, by verifying that their UID is 0. If this test succeeds, no other modules are consulted and the command is executed. If this test fails, the next module is consulted.auth required pam_console.so— This line uses thepam_console.somodule to attempt to authenticate the user. If this user is already logged in at the console,pam_console.sochecks whether there is a file in the/etc/security/console.apps/directory with the same name as the service name (reboot). If such a file exists, authentication succeeds and control is passed to the next module.#auth include system-auth— This line is commented and is not processed.account required pam_permit.so— This line uses thepam_permit.somodule to allow the root user or anyone logged in at the console to reboot the system.
48.4.3.2. Control Flag
required— The module result must be successful for authentication to continue. If the test fails at this point, the user is not notified until the results of all module tests that reference that interface are complete.requisite— The module result must be successful for authentication to continue. However, if a test fails at this point, the user is notified immediately with a message reflecting the first failedrequiredorrequisitemodule test.sufficient— The module result is ignored if it fails. However, if the result of a module flaggedsufficientis successful and no previous modules flaggedrequiredhave failed, then no other results are required and the user is authenticated to the service.optional— The module result is ignored. A module flagged asoptionalonly becomes necessary for successful authentication when no other modules reference the interface.
Important
required modules are called is not critical. Only the sufficient and requisite control flags cause order to become important.
pam.d man page, and the PAM documentation, located in the /usr/share/doc/pam-<version-number>/ directory, where <version-number> is the version number for PAM on your system, describe this newer syntax in detail.
48.4.3.3. Module Name
/lib64/security/ directory, the directory name is omitted because the application is linked to the appropriate version of libpam, which can locate the correct version of the module.
48.4.3.4. Module Arguments
pam_userdb.so module uses information stored in a Berkeley DB file to authenticate the user. Berkeley DB is an open source database system embedded in many applications. The module takes a db argument so that Berkeley DB knows which database to use for the requested service.
pam_userdb.so line in a PAM configuration. The <path-to-file> is the full path to the Berkeley DB database file:
auth required pam_userdb.so db=<path-to-file>
auth required pam_userdb.so db=<path-to-file>/var/log/secure file.
48.4.4. Sample PAM Configuration Files
- The first line is a comment, indicated by the hash mark (
#) at the beginning of the line. - Lines two through four stack three modules for login authentication.
auth required pam_securetty.so— This module ensures that if the user is trying to log in as root, the tty on which the user is logging in is listed in the/etc/securettyfile, if that file exists.If the tty is not listed in the file, any attempt to log in as root fails with aLogin incorrectmessage.auth required pam_unix.so nullok— This module prompts the user for a password and then checks the password using the information stored in/etc/passwdand, if it exists,/etc/shadow.In the authentication phase, thepam_unix.somodule automatically detects whether the user's password is in thepasswdfile or theshadowfile. Refer to Section 37.6, “Shadow Passwords” for more information. auth required pam_nologin.so— This is the final authentication step. It checks whether the/etc/nologinfile exists. If it exists and the user is not root, authentication fails.Note
In this example, all threeauthmodules are checked, even if the firstauthmodule fails. This prevents the user from knowing at what stage their authentication failed. Such knowledge in the hands of an attacker could allow them to more easily deduce how to crack the system.account required pam_unix.so— This module performs any necessary account verification. For example, if shadow passwords have been enabled, the account interface of thepam_unix.somodule checks to see if the account has expired or if the user has not changed the password within the allowed grace period.password required pam_cracklib.so retry=3— If a password has expired, the password component of thepam_cracklib.somodule prompts for a new password. It then tests the newly created password to see whether it can easily be determined by a dictionary-based password cracking program.- The argument
retry=3specifies that if the test fails the first time, the user has two more chances to create a strong password.
password required pam_unix.so shadow nullok use_authtok— This line specifies that if the program changes the user's password, it should use thepasswordinterface of thepam_unix.somodule to do so.- The argument
shadowinstructs the module to create shadow passwords when updating a user's password. - The argument
nullokinstructs the module to allow the user to change their password from a blank password, otherwise a null password is treated as an account lock. - The final argument on this line,
use_authtok, provides a good example of the importance of order when stacking PAM modules. This argument instructs the module not to prompt the user for a new password. Instead, it accepts any password that was recorded by a previous password module. In this way, all new passwords must pass thepam_cracklib.sotest for secure passwords before being accepted.
session required pam_unix.so— The final line instructs the session interface of thepam_unix.somodule to manage the session. This module logs the user name and the service type to/var/log/secureat the beginning and end of each session. This module can be supplemented by stacking it with other session modules for additional functionality.
48.4.5. Creating PAM Modules
/usr/share/doc/pam-<version-number>/ directory, where <version-number> is the version number for PAM on your system.
48.4.6. PAM and Administrative Credential Caching
pam_timestamp.so module. It is important to understand how this mechanism works, because a user who walks away from a terminal while pam_timestamp.so is in effect leaves the machine open to manipulation by anyone with physical access to the console.
pam_timestamp.so module creates a timestamp file. By default, this is created in the /var/run/sudo/ directory. If the timestamp file already exists, graphical administrative programs do not prompt for a password. Instead, the pam_timestamp.so module freshens the timestamp file, reserving an extra five minutes of unchallenged administrative access for the user.
/var/run/sudo/<user> file. For the desktop, the relevant file is unknown:root. If it is present and its timestamp is less than five minutes old, the credentials are valid.

Figure 48.7. The Authentication Icon
48.4.6.1. Removing the Timestamp File
Figure 48.8. Dismiss Authentication Dialog
- If logged in to the system remotely using
ssh, use the/sbin/pam_timestamp_check -k rootcommand to destroy the timestamp file. - You need to run the
/sbin/pam_timestamp_check -k rootcommand from the same terminal window from which you launched the privileged application. - You must be logged in as the user who originally invoked the
pam_timestamp.somodule in order to use the/sbin/pam_timestamp_check -kcommand. Do not log in as root to use this command. - If you want to kill the credentials on the desktop (without using the action on the icon), use the following command:
pam_timestamp_check -k root </dev/null >/dev/null 2>/dev/null
pam_timestamp_check -k root </dev/null >/dev/null 2>/dev/nullCopy to Clipboard Copied! Toggle word wrap Toggle overflow Failure to use this command will only remove the credentials (if any) from the pty where you run the command.
pam_timestamp_check man page for more information about destroying the timestamp file using pam_timestamp_check.
48.4.6.2. Common pam_timestamp Directives
pam_timestamp.so module accepts several directives. The following are the two most commonly used options:
timestamp_timeout— Specifies the period (in seconds) for which the timestamp file is valid. The default value is 300 (five minutes).timestampdir— Specifies the directory in which the timestamp file is stored. The default value is/var/run/sudo/.
pam_timestamp.so module.
48.4.7. PAM and Device Ownership
pam_console.so.
48.4.7.1. Device Ownership
pam_console.so module is called by login or the graphical login programs, gdm, kdm, and xdm. If this user is the first user to log in at the physical console — referred to as the console user — the module grants the user ownership of a variety of devices normally owned by root. The console user owns these devices until the last local session for that user ends. After this user has logged out, ownership of the devices reverts back to the root user.
pam_console.so by editing the following files:
/etc/security/console.perms/etc/security/console.perms.d/50-default.perms
50-default.perms file, you should create a new file (for example, xx-name.perms) and enter the required modifications. The name of the new default file must begin with a number higher than 50 (for example, 51-default.perms). This will override the defaults in the 50-default.perms file.
Warning
<console> and <xconsole> directives in the /etc/security/console.perms to the following values:
<console>=tty[0-9][0-9]* vc/[0-9][0-9]* :0\.[0-9] :0 <xconsole>=:0\.[0-9] :0
<console>=tty[0-9][0-9]* vc/[0-9][0-9]* :0\.[0-9] :0
<xconsole>=:0\.[0-9] :0<xconsole> directive entirely and change the <console> directive to the following value:
<console>=tty[0-9][0-9]* vc/[0-9][0-9]*
<console>=tty[0-9][0-9]* vc/[0-9][0-9]*48.4.7.2. Application Access
/etc/security/console.apps/ directory.
/sbin and /usr/sbin.
/sbin/halt/sbin/reboot/sbin/poweroff
pam_console.so module as a requirement for use.
48.4.8. Additional Resources
48.4.8.1. Installed Documentation
- PAM-related man pages — Several man pages exist for the various applications and configuration files involved with PAM. The following is a list of some of the more important man pages.
- Configuration Files
pam— Good introductory information on PAM, including the structure and purpose of the PAM configuration files.Note that this man page discusses both/etc/pam.confand individual configuration files in the/etc/pam.d/directory. By default, Red Hat Enterprise Linux uses the individual configuration files in the/etc/pam.d/directory, ignoring/etc/pam.confeven if it exists.pam_console— Describes the purpose of thepam_console.somodule. It also describes the appropriate syntax for an entry within a PAM configuration file.console.apps— Describes the format and options available in the/etc/security/console.appsconfiguration file, which defines which applications are accessible by the console user assigned by PAM.console.perms— Describes the format and options available in the/etc/security/console.permsconfiguration file, which specifies the console user permissions assigned by PAM.pam_timestamp— Describes thepam_timestamp.somodule.
/usr/share/doc/pam-<version-number>— Contains a System Administrators' Guide, a Module Writers' Manual, and the Application Developers' Manual, as well as a copy of the PAM standard, DCE-RFC 86.0, where <version-number> is the version number of PAM./usr/share/doc/pam-<version-number>/txts/README.pam_timestamp— Contains information about thepam_timestamp.soPAM module, where <version-number> is the version number of PAM.
48.4.8.2. Useful Websites
- http://www.kernel.org/pub/linux/libs/pam/ — The primary distribution website for the Linux-PAM project, containing information on various PAM modules, a FAQ, and additional PAM documentation.
Note
The documentation in the above website is for the last released upstream version of PAM and might not be 100% accurate for the PAM version included in Red Hat Enterprise Linux.
48.5. TCP Wrappers and xinetd
iptables-based firewall filters out unwelcome network packets within the kernel's network stack. For network services that utilize it, TCP Wrappers add an additional layer of protection by defining which hosts are or are not allowed to connect to "wrapped" network services. One such wrapped network service is the xinetd super server. This service is called a super server because it controls connections to a subset of network services and further refines access control.
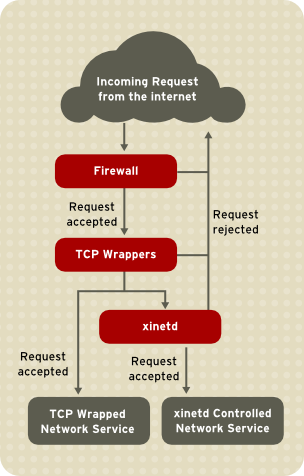
Figure 48.9. Access Control to Network Services
xinetd in controlling access to network services and reviews how these tools can be used to enhance both logging and utilization management. Refer to Section 48.9, “IPTables” for information about using firewalls with iptables.
48.5.1. TCP Wrappers
tcp_wrappers) is installed by default and provides host-based access control to network services. The most important component within the package is the /usr/lib/libwrap.a library. In general terms, a TCP-wrapped service is one that has been compiled against the libwrap.a library.
/etc/hosts.allow and /etc/hosts.deny) to determine whether or not the client is allowed to connect. In most cases, it then uses the syslog daemon (syslogd) to write the name of the requesting client and the requested service to /var/log/secure or /var/log/messages.
libwrap.a library. Some such applications include /usr/sbin/sshd, /usr/sbin/sendmail, and /usr/sbin/xinetd.
Note
libwrap.a, type the following command as the root user:
ldd <binary-name> | grep libwrap
ldd <binary-name> | grep libwraplibwrap.a.
/usr/sbin/sshd is linked to libwrap.a:
ldd /usr/sbin/sshd | grep libwrap
libwrap.so.0 => /usr/lib/libwrap.so.0 (0x00655000)
~]#
~]# ldd /usr/sbin/sshd | grep libwrap
libwrap.so.0 => /usr/lib/libwrap.so.0 (0x00655000)
~]#48.5.1.1. Advantages of TCP Wrappers
- Transparency to both the client and the wrapped network service — Both the connecting client and the wrapped network service are unaware that TCP Wrappers are in use. Legitimate users are logged and connected to the requested service while connections from banned clients fail.
- Centralized management of multiple protocols — TCP Wrappers operate separately from the network services they protect, allowing many server applications to share a common set of access control configuration files, making for simpler management.
48.5.2. TCP Wrappers Configuration Files
/etc/hosts.allow/etc/hosts.deny
- It references
/etc/hosts.allow. — The TCP-wrapped service sequentially parses the/etc/hosts.allowfile and applies the first rule specified for that service. If it finds a matching rule, it allows the connection. If not, it moves on to the next step. - It references
/etc/hosts.deny. — The TCP-wrapped service sequentially parses the/etc/hosts.denyfile. If it finds a matching rule, it denies the connection. If not, it grants access to the service.
- Because access rules in
hosts.alloware applied first, they take precedence over rules specified inhosts.deny. Therefore, if access to a service is allowed inhosts.allow, a rule denying access to that same service inhosts.denyis ignored. - The rules in each file are read from the top down and the first matching rule for a given service is the only one applied. The order of the rules is extremely important.
- If no rules for the service are found in either file, or if neither file exists, access to the service is granted.
- TCP-wrapped services do not cache the rules from the hosts access files, so any changes to
hosts.alloworhosts.denytake effect immediately, without restarting network services.
Warning
/var/log/messages or /var/log/secure. This is also the case for a rule that spans multiple lines without using the backslash character. The following example illustrates the relevant portion of a log message for a rule failure due to either of these circumstances:
warning: /etc/hosts.allow, line 20: missing newline or line too long
warning: /etc/hosts.allow, line 20: missing newline or line too long48.5.2.1. Formatting Access Rules
/etc/hosts.allow and /etc/hosts.deny is identical. Each rule must be on its own line. Blank lines or lines that start with a hash (#) are ignored.
<daemon list>: <client list> [: <option>: <option>: ...]
<daemon list>: <client list> [: <option>: <option>: ...]- <daemon list> — A comma-separated list of process names (not service names) or the
ALLwildcard. The daemon list also accepts operators (refer to Section 48.5.2.1.4, “Operators”) to allow greater flexibility. - <client list> — A comma-separated list of hostnames, host IP addresses, special patterns, or wildcards which identify the hosts affected by the rule. The client list also accepts operators listed in Section 48.5.2.1.4, “Operators” to allow greater flexibility.
- <option> — An optional action or colon-separated list of actions performed when the rule is triggered. Option fields support expansions, launch shell commands, allow or deny access, and alter logging behavior.
Note
vsftpd : .example.com
vsftpd : .example.comvsftpd) from any host in the example.com domain. If this rule appears in hosts.allow, the connection is accepted. If this rule appears in hosts.deny, the connection is rejected.
sshd : .example.com \ : spawn /bin/echo `/bin/date` access denied>>/var/log/sshd.log \ : deny
sshd : .example.com \ : spawn /bin/echo `/bin/date` access denied>>/var/log/sshd.log \ : denysshd) is attempted from a host in the example.com domain, execute the echo command to append the attempt to a special log file, and deny the connection. Because the optional deny directive is used, this line denies access even if it appears in the hosts.allow file. Refer to Section 48.5.2.2, “Option Fields” for a more detailed look at available options.
48.5.2.1.1. Wildcards
ALL— Matches everything. It can be used for both the daemon list and the client list.LOCAL— Matches any host that does not contain a period (.), such as localhost.KNOWN— Matches any host where the hostname and host address are known or where the user is known.UNKNOWN— Matches any host where the hostname or host address are unknown or where the user is unknown.PARANOID— Matches any host where the hostname does not match the host address.
Warning
KNOWN, UNKNOWN, and PARANOID wildcards should be used with care, because they rely on functioning DNS server for correct operation. Any disruption to name resolution may prevent legitimate users from gaining access to a service.
48.5.2.1.2. Patterns
- Hostname beginning with a period (.) — Placing a period at the beginning of a hostname matches all hosts sharing the listed components of the name. The following example applies to any host within the
example.comdomain:ALL : .example.com
ALL : .example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow - IP address ending with a period (.) — Placing a period at the end of an IP address matches all hosts sharing the initial numeric groups of an IP address. The following example applies to any host within the
192.168.x.xnetwork:ALL : 192.168.
ALL : 192.168.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - IP address/netmask pair — Netmask expressions can also be used as a pattern to control access to a particular group of IP addresses. The following example applies to any host with an address range of
192.168.0.0through192.168.1.255:ALL : 192.168.0.0/255.255.254.0
ALL : 192.168.0.0/255.255.254.0Copy to Clipboard Copied! Toggle word wrap Toggle overflow Important
When working in the IPv4 address space, the address/prefix length (prefixlen) pair declarations (CIDR notation) are not supported. Only IPv6 rules can use this format. - [IPv6 address]/prefixlen pair — [net]/prefixlen pairs can also be used as a pattern to control access to a particular group of IPv6 addresses. The following example would apply to any host with an address range of
3ffe:505:2:1::through3ffe:505:2:1:ffff:ffff:ffff:ffff:ALL : [3ffe:505:2:1::]/64
ALL : [3ffe:505:2:1::]/64Copy to Clipboard Copied! Toggle word wrap Toggle overflow - The asterisk (*) — Asterisks can be used to match entire groups of hostnames or IP addresses, as long as they are not mixed in a client list containing other types of patterns. The following example would apply to any host within the
example.comdomain:ALL : *.example.com
ALL : *.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow - The slash (/) — If a client list begins with a slash, it is treated as a file name. This is useful if rules specifying large numbers of hosts are necessary. The following example refers TCP Wrappers to the
/etc/telnet.hostsfile for all Telnet connections:in.telnetd : /etc/telnet.hosts
in.telnetd : /etc/telnet.hostsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
hosts_access man 5 page for more information.
Warning
48.5.2.1.3. Portmap and TCP Wrappers
Portmap's implementation of TCP Wrappers does not support host look-ups, which means portmap can not use hostnames to identify hosts. Consequently, access control rules for portmap in hosts.allow or hosts.deny must use IP addresses, or the keyword ALL, for specifying hosts.
portmap access control rules may not take effect immediately. You may need to restart the portmap service.
portmap to operate, so be aware of these limitations.
48.5.2.1.4. Operators
EXCEPT. It can be used in both the daemon list and the client list of a rule.
EXCEPT operator allows specific exceptions to broader matches within the same rule.
hosts.allow file, all example.com hosts are allowed to connect to all services except cracker.example.com:
ALL: .example.com EXCEPT cracker.example.com
ALL: .example.com EXCEPT cracker.example.comhosts.allow file, clients from the 192.168.0.x network can use all services except for FTP:
ALL EXCEPT vsftpd: 192.168.0.
ALL EXCEPT vsftpd: 192.168.0.Note
EXCEPT operators. This allows other administrators to quickly scan the appropriate files to see what hosts are allowed or denied access to services, without having to sort through EXCEPT operators.
48.5.2.2. Option Fields
48.5.2.2.1. Logging
severity directive.
example.com domain are logged to the default authpriv syslog facility (because no facility value is specified) with a priority of emerg:
sshd : .example.com : severity emerg
sshd : .example.com : severity emergseverity option. The following example logs any SSH connection attempts by hosts from the example.com domain to the local0 facility with a priority of alert:
sshd : .example.com : severity local0.alert
sshd : .example.com : severity local0.alertNote
syslogd) is configured to log to the local0 facility. Refer to the syslog.conf man page for information about configuring custom log facilities.
48.5.2.2.2. Access Control
allow or deny directive as the final option.
client-1.example.com, but deny connections from client-2.example.com:
sshd : client-1.example.com : allow sshd : client-2.example.com : deny
sshd : client-1.example.com : allow
sshd : client-2.example.com : denyhosts.allow or hosts.deny. Some administrators consider this an easier way of organizing access rules.
48.5.2.2.3. Shell Commands
spawn— Launches a shell command as a child process. This directive can perform tasks like using/usr/sbin/safe_fingerto get more information about the requesting client or create special log files using theechocommand.In the following example, clients attempting to access Telnet services from theexample.comdomain are quietly logged to a special file:in.telnetd : .example.com \ : spawn /bin/echo `/bin/date` from %h>>/var/log/telnet.log \ : allow
in.telnetd : .example.com \ : spawn /bin/echo `/bin/date` from %h>>/var/log/telnet.log \ : allowCopy to Clipboard Copied! Toggle word wrap Toggle overflow twist— Replaces the requested service with the specified command. This directive is often used to set up traps for intruders (also called "honey pots"). It can also be used to send messages to connecting clients. Thetwistdirective must occur at the end of the rule line.In the following example, clients attempting to access FTP services from theexample.comdomain are sent a message using theechocommand:vsftpd : .example.com \ : twist /bin/echo "421 This domain has been black-listed. Access denied!"
vsftpd : .example.com \ : twist /bin/echo "421 This domain has been black-listed. Access denied!"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
hosts_options man page.
48.5.2.2.4. Expansions
spawn and twist directives, provide information about the client, server, and processes involved.
%a— Returns the client's IP address.%A— Returns the server's IP address.%c— Returns a variety of client information, such as the username and hostname, or the username and IP address.%d— Returns the daemon process name.%h— Returns the client's hostname (or IP address, if the hostname is unavailable).%H— Returns the server's hostname (or IP address, if the hostname is unavailable).%n— Returns the client's hostname. If unavailable,unknownis printed. If the client's hostname and host address do not match,paranoidis printed.%N— Returns the server's hostname. If unavailable,unknownis printed. If the server's hostname and host address do not match,paranoidis printed.%p— Returns the daemon's process ID.%s—Returns various types of server information, such as the daemon process and the host or IP address of the server.%u— Returns the client's username. If unavailable,unknownis printed.
spawn command to identify the client host in a customized log file.
sshd) are attempted from a host in the example.com domain, execute the echo command to log the attempt, including the client hostname (by using the %h expansion), to a special file:
sshd : .example.com \ : spawn /bin/echo `/bin/date` access denied to %h>>/var/log/sshd.log \ : deny
sshd : .example.com \
: spawn /bin/echo `/bin/date` access denied to %h>>/var/log/sshd.log \
: denyexample.com domain are informed that they have been banned from the server:
vsftpd : .example.com \ : twist /bin/echo "421 %h has been banned from this server!"
vsftpd : .example.com \
: twist /bin/echo "421 %h has been banned from this server!"hosts_access (man 5 hosts_access) and the man page for hosts_options.
48.5.3. xinetd
xinetd daemon is a TCP-wrapped super service which controls access to a subset of popular network services, including FTP, IMAP, and Telnet. It also provides service-specific configuration options for access control, enhanced logging, binding, redirection, and resource utilization control.
xinetd, the super service receives the request and checks for any TCP Wrappers access control rules.
xinetd verifies that the connection is allowed under its own access rules for that service. It also checks that the service can have more resources allotted to it and that it is not in breach of any defined rules.
xinetd then starts an instance of the requested service and passes control of the connection to it. After the connection has been established, xinetd takes no further part in the communication between the client and the server.
48.5.4. xinetd Configuration Files
xinetd are as follows:
/etc/xinetd.conf— The globalxinetdconfiguration file./etc/xinetd.d/— The directory containing all service-specific files.
48.5.4.1. The /etc/xinetd.conf File
/etc/xinetd.conf file contains general configuration settings which affect every service under xinetd's control. It is read when the xinetd service is first started, so for configuration changes to take effect, you need to restart the xinetd service. The following is a sample /etc/xinetd.conf file:
xinetd:
instances— Specifies the maximum number of simultaneous requests thatxinetdcan process.log_type— Configuresxinetdto use theauthprivlog facility, which writes log entries to the/var/log/securefile. Adding a directive such asFILE /var/log/xinetdlogwould create a custom log file calledxinetdlogin the/var/log/directory.log_on_success— Configuresxinetdto log successful connection attempts. By default, the remote host's IP address and the process ID of the server processing the request are recorded.log_on_failure— Configuresxinetdto log failed connection attempts or if the connection was denied.cps— Configuresxinetdto allow no more than 25 connections per second to any given service. If this limit is exceeded, the service is retired for 30 seconds.includedir/etc/xinetd.d/— Includes options declared in the service-specific configuration files located in the/etc/xinetd.d/directory. Refer to Section 48.5.4.2, “The /etc/xinetd.d/ Directory” for more information.
Note
log_on_success and log_on_failure settings in /etc/xinetd.conf are further modified in the service-specific configuration files. More information may therefore appear in a given service's log file than the /etc/xinetd.conf file may indicate. Refer to Section 48.5.4.3.1, “Logging Options” for further information.
48.5.4.2. The /etc/xinetd.d/ Directory
/etc/xinetd.d/ directory contains the configuration files for each service managed by xinetd and the names of the files correlate to the service. As with xinetd.conf, this directory is read only when the xinetd service is started. For any changes to take effect, the administrator must restart the xinetd service.
/etc/xinetd.d/ directory use the same conventions as /etc/xinetd.conf. The primary reason the configuration for each service is stored in a separate file is to make customization easier and less likely to affect other services.
/etc/xinetd.d/krb5-telnet file:
telnet service:
service— Specifies the service name, usually one of those listed in the/etc/servicesfile.flags— Sets any of a number of attributes for the connection.REUSEinstructsxinetdto reuse the socket for a Telnet connection.Note
TheREUSEflag is deprecated. All services now implicitly use theREUSEflag.socket_type— Sets the network socket type tostream.wait— Specifies whether the service is single-threaded (yes) or multi-threaded (no).user— Specifies which user ID the process runs under.server— Specifies which binary executable to launch.log_on_failure— Specifies logging parameters forlog_on_failurein addition to those already defined inxinetd.conf.disable— Specifies whether the service is disabled (yes) or enabled (no).
xinetd.conf man page for more information about these options and their usage.
48.5.4.3. Altering xinetd Configuration Files
xinetd. This section highlights some of the more commonly used options.
48.5.4.3.1. Logging Options
/etc/xinetd.conf and the service-specific configuration files within the /etc/xinetd.d/ directory.
ATTEMPT— Logs the fact that a failed attempt was made (log_on_failure).DURATION— Logs the length of time the service is used by a remote system (log_on_success).EXIT— Logs the exit status or termination signal of the service (log_on_success).HOST— Logs the remote host's IP address (log_on_failureandlog_on_success).PID— Logs the process ID of the server receiving the request (log_on_success).USERID— Logs the remote user using the method defined in RFC 1413 for all multi-threaded stream services (log_on_failureandlog_on_success).
xinetd.conf man page.
48.5.4.3.2. Access Control Options
xinetd services can choose to use the TCP Wrappers hosts access rules, provide access control via the xinetd configuration files, or a mixture of both. Refer to Section 48.5.2, “TCP Wrappers Configuration Files” for more information about TCP Wrappers hosts access control files.
xinetd to control access to services.
Note
xinetd administrator restarts the xinetd service.
xinetd only affects services controlled by xinetd.
xinetd hosts access control differs from the method used by TCP Wrappers. While TCP Wrappers places all of the access configuration within two files, /etc/hosts.allow and /etc/hosts.deny, xinetd's access control is found in each service's configuration file in the /etc/xinetd.d/ directory.
xinetd:
only_from— Allows only the specified hosts to use the service.no_access— Blocks listed hosts from using the service.access_times— Specifies the time range when a particular service may be used. The time range must be stated in 24-hour format notation, HH:MM-HH:MM.
only_from and no_access options can use a list of IP addresses or host names, or can specify an entire network. Like TCP Wrappers, combining xinetd access control with the enhanced logging configuration can increase security by blocking requests from banned hosts while verbosely recording each connection attempt.
/etc/xinetd.d/telnet file can be used to block Telnet access from a particular network group and restrict the overall time range that even allowed users can log in:
10.0.1.0/24 network, such as 10.0.1.2, tries to access the Telnet service, it receives the following message:
Connection closed by foreign host.
Connection closed by foreign host./var/log/messages as follows:
Sep 7 14:58:33 localhost xinetd[5285]: FAIL: telnet address from=172.16.45.107 Sep 7 14:58:33 localhost xinetd[5283]: START: telnet pid=5285 from=172.16.45.107 Sep 7 14:58:33 localhost xinetd[5283]: EXIT: telnet status=0 pid=5285 duration=0(sec)
Sep 7 14:58:33 localhost xinetd[5285]: FAIL: telnet address from=172.16.45.107
Sep 7 14:58:33 localhost xinetd[5283]: START: telnet pid=5285 from=172.16.45.107
Sep 7 14:58:33 localhost xinetd[5283]: EXIT: telnet status=0 pid=5285 duration=0(sec)xinetd access controls, it is important to understand the relationship between the two access control mechanisms.
xinetd when a client requests a connection:
- The
xinetddaemon accesses the TCP Wrappers hosts access rules using alibwrap.alibrary call. If a deny rule matches the client, the connection is dropped. If an allow rule matches the client, the connection is passed toxinetd. - The
xinetddaemon checks its own access control rules both for thexinetdservice and the requested service. If a deny rule matches the client, the connection is dropped. Otherwise,xinetdstarts an instance of the requested service and passes control of the connection to that service.
Important
xinetd access controls. Misconfiguration can cause undesirable effects.
48.5.4.3.3. Binding and Redirection Options
xinetd support binding the service to an IP address and redirecting incoming requests for that service to another IP address, hostname, or port.
bind option in the service-specific configuration files and links the service to one IP address on the system. When this is configured, the bind option only allows requests to the correct IP address to access the service. You can use this method to bind different services to different network interfaces based on requirements.
redirect option accepts an IP address or hostname followed by a port number. It configures the service to redirect any requests for this service to the specified host and port number. This feature can be used to point to another port number on the same system, redirect the request to a different IP address on the same machine, shift the request to a totally different system and port number, or any combination of these options. A user connecting to a certain service on a system may therefore be rerouted to another system without disruption.
xinetd daemon is able to accomplish this redirection by spawning a process that stays alive for the duration of the connection between the requesting client machine and the host actually providing the service, transferring data between the two systems.
bind and redirect options are most clearly evident when they are used together. By binding a service to a particular IP address on a system and then redirecting requests for this service to a second machine that only the first machine can see, an internal system can be used to provide services for a totally different network. Alternatively, these options can be used to limit the exposure of a particular service on a multi-homed machine to a known IP address, as well as redirect any requests for that service to another machine especially configured for that purpose.
bind and redirect options in this file ensure that the Telnet service on the machine is bound to the external IP address (123.123.123.123), the one facing the Internet. In addition, any requests for Telnet service sent to 123.123.123.123 are redirected via a second network adapter to an internal IP address (10.0.1.13) that only the firewall and internal systems can access. The firewall then sends the communication between the two systems, and the connecting system thinks it is connected to 123.123.123.123 when it is actually connected to a different machine.
xinetd are configured with the bind and redirect options, the gateway machine can act as a proxy between outside systems and a particular internal machine configured to provide the service. In addition, the various xinetd access control and logging options are also available for additional protection.
48.5.4.3.4. Resource Management Options
xinetd daemon can add a basic level of protection from Denial of Service (DoS) attacks. The following is a list of directives which can aid in limiting the effectiveness of such attacks:
per_source— Defines the maximum number of instances for a service per source IP address. It accepts only integers as an argument and can be used in bothxinetd.confand in the service-specific configuration files in thexinetd.d/directory.cps— Defines the maximum number of connections per second. This directive takes two integer arguments separated by white space. The first argument is the maximum number of connections allowed to the service per second. The second argument is the number of seconds thatxinetdmust wait before re-enabling the service. It accepts only integers as arguments and can be used in either thexinetd.conffile or the service-specific configuration files in thexinetd.d/directory.max_load— Defines the CPU usage or load average threshold for a service. It accepts a floating point number argument.The load average is a rough measure of how many processes are active at a given time. See theuptime,who, andprocinfocommands for more information about load average.
xinetd. Refer to the xinetd.conf man page for more information.
48.5.5. Additional Resources
xinetd is available from system documentation and on the Internet.
48.5.5.1. Installed Documentation
xinetd, and access control.
/usr/share/doc/tcp_wrappers-<version>/— This directory contains aREADMEfile that discusses how TCP Wrappers work and the various hostname and host address spoofing risks that exist./usr/share/doc/xinetd-<version>/— This directory contains aREADMEfile that discusses aspects of access control and asample.conffile with various ideas for modifying service-specific configuration files in the/etc/xinetd.d/directory.- TCP Wrappers and
xinetd-related man pages — A number of man pages exist for the various applications and configuration files involved with TCP Wrappers andxinetd. The following are some of the more important man pages:- Server Applications
man xinetd— The man page forxinetd.
- Configuration Files
man 5 hosts_access— The man page for the TCP Wrappers hosts access control files.man hosts_options— The man page for the TCP Wrappers options fields.man xinetd.conf— The man page listingxinetdconfiguration options.
48.5.5.2. Useful Websites
- http://www.xinetd.org/ — The home of
xinetd, containing sample configuration files, a full listing of features, and an informative FAQ. - http://www.macsecurity.org/resources/xinetd/tutorial.shtml — A thorough tutorial that discusses many different ways to optimize default
xinetdconfiguration files to meet specific security goals.
48.6. Kerberos
48.6.1. What is Kerberos?
48.6.1.1. Advantages of Kerberos
48.6.1.2. Disadvantages of Kerberos
- Migrating user passwords from a standard UNIX password database, such as
/etc/passwdor/etc/shadow, to a Kerberos password database can be tedious, as there is no automated mechanism to perform this task. Refer to Question 2.23 in the online Kerberos FAQ: - Kerberos has only partial compatibility with the Pluggable Authentication Modules (PAM) system used by most Red Hat Enterprise Linux servers. Refer to Section 48.6.4, “Kerberos and PAM” for more information about this issue.
- Kerberos assumes that each user is trusted but is using an untrusted host on an untrusted network. Its primary goal is to prevent unencrypted passwords from being transmitted across that network. However, if anyone other than the proper user has access to the one host that issues tickets used for authentication — called the key distribution center (KDC) — the entire Kerberos authentication system is at risk.
- For an application to use Kerberos, its source must be modified to make the appropriate calls into the Kerberos libraries. Applications modified in this way are considered to be Kerberos-aware, or kerberized. For some applications, this can be quite problematic due to the size of the application or its design. For other incompatible applications, changes must be made to the way in which the server and client communicate. Again, this may require extensive programming. Closed-source applications that do not have Kerberos support by default are often the most problematic.
- Kerberos is an all-or-nothing solution. If Kerberos is used on the network, any unencrypted passwords transferred to a non-Kerberos aware service is at risk. Thus, the network gains no benefit from the use of Kerberos. To secure a network with Kerberos, one must either use Kerberos-aware versions of all client/server applications that transmit passwords unencrypted, or not use any such client/server applications at all.
48.6.2. Kerberos Terminology
- authentication server (AS)
- A server that issues tickets for a desired service which are in turn given to users for access to the service. The AS responds to requests from clients who do not have or do not send credentials with a request. It is usually used to gain access to the ticket-granting server (TGS) service by issuing a ticket-granting ticket (TGT). The AS usually runs on the same host as the key distribution center (KDC).
- ciphertext
- Encrypted data.
- client
- An entity on the network (a user, a host, or an application) that can receive a ticket from Kerberos.
- credentials
- A temporary set of electronic credentials that verify the identity of a client for a particular service. Also called a ticket.
- credential cache or ticket file
- A file which contains the keys for encrypting communications between a user and various network services. Kerberos 5 supports a framework for using other cache types, such as shared memory, but files are more thoroughly supported.
- crypt hash
- A one-way hash used to authenticate users. These are more secure than using unencrypted data, but they are still relatively easy to decrypt for an experienced cracker.
- GSS-API
- The Generic Security Service Application Program Interface (defined in RFC-2743 published by The Internet Engineering Task Force) is a set of functions which provide security services. This API is used by clients and services to authenticate to each other without either program having specific knowledge of the underlying mechanism. If a network service (such as cyrus-IMAP) uses GSS-API, it can authenticate using Kerberos.
- hash
- Also known as a hash value. A value generated by passing a string through a hash function. These values are typically used to ensure that transmitted data has not been tampered with.
- hash function
- A way of generating a digital "fingerprint" from input data. These functions rearrange, transpose or otherwise alter data to produce a hash value.
- key
- Data used when encrypting or decrypting other data. Encrypted data cannot be decrypted without the proper key or extremely good fortune on the part of the cracker.
- key distribution center (KDC)
- A service that issues Kerberos tickets, and which usually run on the same host as the ticket-granting server (TGS).
- keytab (or key table)
- A file that includes an unencrypted list of principals and their keys. Servers retrieve the keys they need from keytab files instead of using
kinit. The default keytab file is/etc/krb5.keytab. The KDC administration server,/usr/kerberos/sbin/kadmind, is the only service that uses any other file (it uses/var/kerberos/krb5kdc/kadm5.keytab). - kinit
- The
kinitcommand allows a principal who has already logged in to obtain and cache the initial ticket-granting ticket (TGT). Refer to thekinitman page for more information. - principal (or principal name)
- The principal is the unique name of a user or service allowed to authenticate using Kerberos. A principal follows the form
root[/instance]@REALM. For a typical user, the root is the same as their login ID. Theinstanceis optional. If the principal has an instance, it is separated from the root with a forward slash ("/"). An empty string ("") is considered a valid instance (which differs from the defaultNULLinstance), but using it can be confusing. All principals in a realm have their own key, which for users is derived from a password or is randomly set for services. - realm
- A network that uses Kerberos, composed of one or more servers called KDCs and a potentially large number of clients.
- service
- A program accessed over the network.
- ticket
- A temporary set of electronic credentials that verify the identity of a client for a particular service. Also called credentials.
- ticket-granting server (TGS)
- A server that issues tickets for a desired service which are in turn given to users for access to the service. The TGS usually runs on the same host as the KDC.
- ticket-granting ticket (TGT)
- A special ticket that allows the client to obtain additional tickets without applying for them from the KDC.
- unencrypted password
- A plain text, human-readable password.
48.6.3. How Kerberos Works
kinit program after the user logs in.
kinit program on the client then decrypts the TGT using the user's key, which it computes from the user's password. The user's key is used only on the client machine and is not transmitted over the network.
Warning
Note
- Approximate clock synchronization between the machines on the network.A clock synchronization program should be set up for the network, such as
ntpd. Refer to/usr/share/doc/ntp-<version-number>/index.htmlfor details on setting up Network Time Protocol servers (where <version-number> is the version number of thentppackage installed on your system). - Domain Name Service (DNS).You should ensure that the DNS entries and hosts on the network are all properly configured. Refer to the Kerberos V5 System Administrator's Guide in
/usr/share/doc/krb5-server-<version-number>for more information (where <version-number> is the version number of thekrb5-serverpackage installed on your system).
48.6.4. Kerberos and PAM
pam_krb5 module (provided in the pam_krb5 package) is installed. The pam_krb5 package contains sample configuration files that allow services such as login and gdm to authenticate users as well as obtain initial credentials using their passwords. If access to network servers is always performed using Kerberos-aware services or services that use GSS-API, such as IMAP, the network can be considered reasonably safe.
Note
48.6.5. Configuring a Kerberos 5 Server
- Ensure that time synchronization and DNS are functioning correctly on all client and server machines before configuring Kerberos. Pay particular attention to time synchronization between the Kerberos server and its clients. If the time difference between the server and client is greater than five minutes (this is configurable in Kerberos 5), Kerberos clients can not authenticate to the server. This time synchronization is necessary to prevent an attacker from using an old Kerberos ticket to masquerade as a valid user.It is advisable to set up a Network Time Protocol (NTP) compatible client/server network even if Kerberos is not being used. Red Hat Enterprise Linux includes the
ntppackage for this purpose. Refer to/usr/share/doc/ntp-<version-number>/index.html(where <version-number> is the version number of thentppackage installed on your system) for details about how to set up Network Time Protocol servers, and http://www.ntp.org for more information about NTP. - Install the
krb5-libs,krb5-server, andkrb5-workstationpackages on the dedicated machine which runs the KDC. This machine needs to be very secure — if possible, it should not run any services other than the KDC. - Edit the
/etc/krb5.confand/var/kerberos/krb5kdc/kdc.confconfiguration files to reflect the realm name and domain-to-realm mappings. A simple realm can be constructed by replacing instances of EXAMPLE.COM and example.com with the correct domain name — being certain to keep uppercase and lowercase names in the correct format — and by changing the KDC from kerberos.example.com to the name of the Kerberos server. By convention, all realm names are uppercase and all DNS hostnames and domain names are lowercase. For full details about the formats of these configuration files, refer to their respective man pages. - Create the database using the
kdb5_utilutility from a shell prompt:/usr/kerberos/sbin/kdb5_util create -s
/usr/kerberos/sbin/kdb5_util create -sCopy to Clipboard Copied! Toggle word wrap Toggle overflow Thecreatecommand creates the database that stores keys for the Kerberos realm. The-sswitch forces creation of a stash file in which the master server key is stored. If no stash file is present from which to read the key, the Kerberos server (krb5kdc) prompts the user for the master server password (which can be used to regenerate the key) every time it starts. - Edit the
/var/kerberos/krb5kdc/kadm5.aclfile. This file is used bykadmindto determine which principals have administrative access to the Kerberos database and their level of access. Most organizations can get by with a single line:*/admin@EXAMPLE.COM *
*/admin@EXAMPLE.COM *Copy to Clipboard Copied! Toggle word wrap Toggle overflow Most users are represented in the database by a single principal (with a NULL, or empty, instance, such as joe@EXAMPLE.COM). In this configuration, users with a second principal with an instance of admin (for example, joe/admin@EXAMPLE.COM) are able to wield full power over the realm's Kerberos database.Afterkadmindhas been started on the server, any user can access its services by runningkadminon any of the clients or servers in the realm. However, only users listed in thekadm5.aclfile can modify the database in any way, except for changing their own passwords.Note
Thekadminutility communicates with thekadmindserver over the network, and uses Kerberos to handle authentication. Consequently, the first principal must already exist before connecting to the server over the network to administer it. Create the first principal with thekadmin.localcommand, which is specifically designed to be used on the same host as the KDC and does not use Kerberos for authentication.Type the followingkadmin.localcommand at the KDC terminal to create the first principal:/usr/kerberos/sbin/kadmin.local -q "addprinc username/admin"
/usr/kerberos/sbin/kadmin.local -q "addprinc username/admin"Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Start Kerberos using the following commands:
service krb5kdc start service kadmin start service krb524 start
service krb5kdc start service kadmin start service krb524 startCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Add principals for the users using the
addprinccommand withinkadmin.kadminandkadmin.localare command line interfaces to the KDC. As such, many commands — such asaddprinc— are available after launching thekadminprogram. Refer to thekadminman page for more information. - Verify that the KDC is issuing tickets. First, run
kinitto obtain a ticket and store it in a credential cache file. Next, useklistto view the list of credentials in the cache and usekdestroyto destroy the cache and the credentials it contains.Note
By default,kinitattempts to authenticate using the same system login username (not the Kerberos server). If that username does not correspond to a principal in the Kerberos database,kinitissues an error message. If that happens, supplykinitwith the name of the correct principal as an argument on the command line (kinit <principal>).
48.6.6. Configuring a Kerberos 5 Client
krb5.conf configuration file. While ssh and slogin are the preferred method of remotely logging in to client systems, Kerberized versions of rsh and rlogin are still available, though deploying them requires that a few more configuration changes be made.
- Be sure that time synchronization is in place between the Kerberos client and the KDC. Refer to Section 48.6.5, “Configuring a Kerberos 5 Server” for more information. In addition, verify that DNS is working properly on the Kerberos client before configuring the Kerberos client programs.
- Install the
krb5-libsandkrb5-workstationpackages on all of the client machines. Supply a valid/etc/krb5.conffile for each client (usually this can be the samekrb5.conffile used by the KDC). - Before a workstation in the realm can use Kerberos to authenticate users who connect using
sshor Kerberizedrshorrlogin, it must have its own host principal in the Kerberos database. Thesshd,kshd, andklogindserver programs all need access to the keys for the host service's principal. Additionally, in order to use the kerberizedrshandrloginservices, that workstation must have thexinetdpackage installed.Usingkadmin, add a host principal for the workstation on the KDC. The instance in this case is the hostname of the workstation. Use the-randkeyoption for thekadmin'saddprinccommand to create the principal and assign it a random key:addprinc -randkey host/blah.example.com
addprinc -randkey host/blah.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow Now that the principal has been created, keys can be extracted for the workstation by runningkadminon the workstation itself, and using thektaddcommand withinkadmin:ktadd -k /etc/krb5.keytab host/blah.example.com
ktadd -k /etc/krb5.keytab host/blah.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow - To use other kerberized network services, they must first be started. Below is a list of some common kerberized services and instructions about enabling them:
ssh— OpenSSH uses GSS-API to authenticate users to servers if the client's and server's configuration both haveGSSAPIAuthenticationenabled. If the client also hasGSSAPIDelegateCredentialsenabled, the user's credentials are made available on the remote system.rshandrlogin— To use the kerberized versions ofrshandrlogin, enableklogin,eklogin, andkshell.- Telnet — To use kerberized Telnet,
krb5-telnetmust be enabled. - FTP — To provide FTP access, create and extract a key for the principal with a root of
ftp. Be certain to set the instance to the fully qualified hostname of the FTP server, then enablegssftp. - IMAP — To use a kerberized IMAP server, the
cyrus-imappackage uses Kerberos 5 if it also has thecyrus-sasl-gssapipackage installed. Thecyrus-sasl-gssapipackage contains the Cyrus SASL plugins which support GSS-API authentication. Cyrus IMAP should function properly with Kerberos as long as thecyrususer is able to find the proper key in/etc/krb5.keytab, and the root for the principal is set toimap(created withkadmin).An alternative tocyrus-imapcan be found in thedovecotpackage, which is also included in Red Hat Enterprise Linux. This package contains an IMAP server but does not, to date, support GSS-API and Kerberos. - CVS — To use a kerberized CVS server,
gserveruses a principal with a root ofcvsand is otherwise identical to the CVSpserver.
Refer to Chapter 18, Controlling Access to Services for details about how to enable services.
48.6.7. Domain-to-Realm Mapping
foo.example.org → EXAMPLE.ORG
foo.example.com → EXAMPLE.COM
foo.hq.example.com → HQ.EXAMPLE.COM
krb5.conf. For example:
[domain_realm] .example.com = EXAMPLE.COM example.com = EXAMPLE.COM
[domain_realm]
.example.com = EXAMPLE.COM
example.com = EXAMPLE.COM48.6.8. Setting Up Secondary KDCs
kadmind (it is also your realm's admin server), and one or more KDCs (slave KDCs) keep read-only copies of the database and run kpropd.
krb5.conf and kdc.conf files are copied to the slave KDC.
kadmin.local from a root shell on the master KDC and use its add_principal command to create a new entry for the master KDC's host service, and then use its ktadd command to simultaneously set a random key for the service and store the random key in the master's default keytab file. This key will be used by the kprop command to authenticate to the slave servers. You will only need to do this once, regardless of how many slave servers you install.
kadmin from a root shell on the slave KDC and use its add_principal command to create a new entry for the slave KDC's host service, and then use kadmin's ktadd command to simultaneously set a random key for the service and store the random key in the slave's default keytab file. This key is used by the kpropd service when authenticating clients.
kprop service with a new realm database. To restrict access, the kprop service on the slave KDC will only accept updates from clients whose principal names are listed in /var/kerberos/krb5kdc/kpropd.acl. Add the master KDC's host service's name to that file.
echo host/masterkdc.example.com@EXAMPLE.COM > /var/kerberos/krb5kdc/kpropd.acl
~]# echo host/masterkdc.example.com@EXAMPLE.COM > /var/kerberos/krb5kdc/kpropd.acl/var/kerberos/krb5kdc/.k5.REALM, either copy it to the slave KDC using any available secure method, or create a dummy database and identical stash file on the slave KDC by running kdb5_util create -s (the dummy database will be overwritten by the first successful database propagation) and supplying the same password.
kprop service. Then, double-check that the kadmin service is disabled.
kprop command will read (/var/kerberos/krb5kdc/slave_datatrans), and then use the kprop command to transmit its contents to the slave KDC.
/usr/kerberos/sbin/kdb5_util dump /var/kerberos/krb5kdc/slave_datatrans kprop slavekdc.example.com
~]# /usr/kerberos/sbin/kdb5_util dump /var/kerberos/krb5kdc/slave_datatrans
~]# kprop slavekdc.example.comkinit, verify that a client system whose krb5.conf lists only the slave KDC in its list of KDCs for your realm is now correctly able to obtain initial credentials from the slave KDC.
kprop command to transmit the database to each slave KDC in turn, and configure the cron service to run the script periodically.
48.6.9. Setting Up Cross Realm Authentication
A.EXAMPLE.COM to access a service in the B.EXAMPLE.COM realm, both realms must share a key for a principal named krbtgt/B.EXAMPLE.COM@A.EXAMPLE.COM, and both keys must have the same key version number associated with them.
get_principal command to verify that both entries have matching key version numbers (kvno values) and encryption types.
Warning
add_principal command's -randkey option to assign a random key instead of a password, dump the new entry from the database of the first realm, and import it into the second. This will not work unless the master keys for the realm databases are identical, as the keys contained in a database dump are themselves encrypted using the master key.
A.EXAMPLE.COM realm are now able to authenticate to services in the B.EXAMPLE.COM realm. Put another way, the B.EXAMPLE.COM realm now trusts the A.EXAMPLE.COM realm, or phrased even more simply, B.EXAMPLE.COM now trusts A.EXAMPLE.COM.
B.EXAMPLE.COM realm may trust clients from the A.EXAMPLE.COM to authenticate to services in the B.EXAMPLE.COM realm, but the fact that it does has no effect on whether or not clients in the B.EXAMPLE.COM realm are trusted to authenticate to services in the A.EXAMPLE.COM realm. To establish trust in the other direction, both realms would need to share keys for the krbtgt/A.EXAMPLE.COM@B.EXAMPLE.COM service (take note of the reversed in order of the two realms compared to the example above).
A.EXAMPLE.COM can authenticate to services in B.EXAMPLE.COM, and clients from B.EXAMPLE.COM can authenticate to services in C.EXAMPLE.COM, then clients in A.EXAMPLE.COM can also authenticate to services in C.EXAMPLE.COM, even if C.EXAMPLE.COM doesn't directly trust A.EXAMPLE.COM. This means that, on a network with multiple realms which all need to trust each other, making good choices about which trust relationships to set up can greatly reduce the amount of effort required.
service/server.example.com@EXAMPLE.COM
service/server.example.com@EXAMPLE.COMEXAMPLE.COM is the name of the realm.
domain_realm section of /etc/krb5.conf to map either a hostname (server.example.com) or a DNS domain name (.example.com) to the name of a realm (EXAMPLE.COM).
A.EXAMPLE.COM, B.EXAMPLE.COM, and EXAMPLE.COM. When a client in the A.EXAMPLE.COM realm attempts to authenticate to a service in B.EXAMPLE.COM, it will, by default, first attempt to get credentials for the EXAMPLE.COM realm, and then to use those credentials to obtain credentials for use in the B.EXAMPLE.COM realm.
A.EXAMPLE.COM, authenticating to a service in B.EXAMPLE.COM:
A.EXAMPLE.COM → EXAMPLE.COM → B.EXAMPLE.COM
A.EXAMPLE.COMandEXAMPLE.COMshare a key forkrbtgt/EXAMPLE.COM@A.EXAMPLE.COMEXAMPLE.COMandB.EXAMPLE.COMshare a key forkrbtgt/B.EXAMPLE.COM@EXAMPLE.COM
SITE1.SALES.EXAMPLE.COM, authenticating to a service in EVERYWHERE.EXAMPLE.COM:
SITE1.SALES.EXAMPLE.COM → SALES.EXAMPLE.COM → EXAMPLE.COM → EVERYWHERE.EXAMPLE.COM
SITE1.SALES.EXAMPLE.COMandSALES.EXAMPLE.COMshare a key forkrbtgt/SALES.EXAMPLE.COM@SITE1.SALES.EXAMPLE.COMSALES.EXAMPLE.COMandEXAMPLE.COMshare a key forkrbtgt/EXAMPLE.COM@SALES.EXAMPLE.COMEXAMPLE.COMandEVERYWHERE.EXAMPLE.COMshare a key forkrbtgt/EVERYWHERE.EXAMPLE.COM@EXAMPLE.COM
DEVEL.EXAMPLE.COM and PROD.EXAMPLE.ORG):
DEVEL.EXAMPLE.COM → EXAMPLE.COM → COM → ORG → EXAMPLE.ORG → PROD.EXAMPLE.ORG
DEVEL.EXAMPLE.COMandEXAMPLE.COMshare a key forkrbtgt/EXAMPLE.COM@DEVEL.EXAMPLE.COMEXAMPLE.COMandCOMshare a key forkrbtgt/COM@EXAMPLE.COMCOMandORGshare a key forkrbtgt/ORG@COMORGandEXAMPLE.ORGshare a key forkrbtgt/EXAMPLE.ORG@ORGEXAMPLE.ORGandPROD.EXAMPLE.ORGshare a key forkrbtgt/PROD.EXAMPLE.ORG@EXAMPLE.ORG
capaths section of /etc/krb5.conf, so that clients which have credentials for one realm will be able to look up which realm is next in the chain which will eventually lead to the being able to authenticate to servers.
capaths section is relatively straightforward: each entry in the section is named after a realm in which a client might exist. Inside of that subsection, the set of intermediate realms from which the client must obtain credentials is listed as values of the key which corresponds to the realm in which a service might reside. If there are no intermediate realms, the value "." is used.
A.EXAMPLE.COM realm can obtain cross-realm credentials for B.EXAMPLE.COM directly from the A.EXAMPLE.COM KDC.
C.EXAMPLE.COM realm, they will first need to obtain necessary credentials from the B.EXAMPLE.COM realm (this requires that krbtgt/B.EXAMPLE.COM@A.EXAMPLE.COM exist), and then use those credentials to obtain credentials for use in the C.EXAMPLE.COM realm (using krbtgt/C.EXAMPLE.COM@B.EXAMPLE.COM).
D.EXAMPLE.COM realm, they will first need to obtain necessary credentials from the B.EXAMPLE.COM realm, and then credentials from the C.EXAMPLE.COM realm, before finally obtaining credentials for use with the D.EXAMPLE.COM realm.
Note
A.EXAMPLE.COM realm can obtain cross-realm credentials from B.EXAMPLE.COM realm directly. Without the "." indicating this, the client would instead attempt to use a hierarchical path, in this case:
A.EXAMPLE.COM → EXAMPLE.COM → B.EXAMPLE.COM
48.6.10. Additional Resources
48.6.10.1. Installed Documentation
- The Kerberos V5 Installation Guide and the Kerberos V5 System Administrator's Guide in PostScript and HTML formats. These can be found in the
/usr/share/doc/krb5-server-<version-number>/directory (where <version-number> is the version number of thekrb5-serverpackage installed on your system). - The Kerberos V5 UNIX User's Guide in PostScript and HTML formats. These can be found in the
/usr/share/doc/krb5-workstation-<version-number>/directory (where <version-number> is the version number of thekrb5-workstationpackage installed on your system). - Kerberos man pages — There are a number of man pages for the various applications and configuration files involved with a Kerberos implementation. The following is a list of some of the more important man pages.
- Client Applications
man kerberos— An introduction to the Kerberos system which describes how credentials work and provides recommendations for obtaining and destroying Kerberos tickets. The bottom of the man page references a number of related man pages.man kinit— Describes how to use this command to obtain and cache a ticket-granting ticket.man kdestroy— Describes how to use this command to destroy Kerberos credentials.man klist— Describes how to use this command to list cached Kerberos credentials.
- Administrative Applications
man kadmin— Describes how to use this command to administer the Kerberos V5 database.man kdb5_util— Describes how to use this command to create and perform low-level administrative functions on the Kerberos V5 database.
- Server Applications
man krb5kdc— Describes available command line options for the Kerberos V5 KDC.man kadmind— Describes available command line options for the Kerberos V5 administration server.
- Configuration Files
man krb5.conf— Describes the format and options available within the configuration file for the Kerberos V5 library.man kdc.conf— Describes the format and options available within the configuration file for the Kerberos V5 AS and KDC.
48.6.10.2. Useful Websites
- http://web.mit.edu/kerberos/www/ — Kerberos: The Network Authentication Protocol webpage from MIT.
- http://www.nrl.navy.mil/CCS/people/kenh/kerberos-faq.html — The Kerberos Frequently Asked Questions (FAQ).
- ftp://athena-dist.mit.edu/pub/kerberos/doc/usenix.PS — The PostScript version of Kerberos: An Authentication Service for Open Network Systems by Jennifer G. Steiner, Clifford Neuman, and Jeffrey I. Schiller. This document is the original paper describing Kerberos.
- http://web.mit.edu/kerberos/www/dialogue.html — Designing an Authentication System: a Dialogue in Four Scenes originally by Bill Bryant in 1988, modified by Theodore Ts'o in 1997. This document is a conversation between two developers who are thinking through the creation of a Kerberos-style authentication system. The conversational style of the discussion make this a good starting place for people who are completely unfamiliar with Kerberos.
- http://www.ornl.gov/~jar/HowToKerb.html — How to Kerberize your site is a good reference for kerberizing a network.
- http://www.networkcomputing.com/netdesign/kerb1.html — Kerberos Network Design Manual is a thorough overview of the Kerberos system.
48.7. Virtual Private Networks (VPNs)
48.7.1. How Does a VPN Work?
48.7.2. VPNs and Red Hat Enterprise Linux
48.7.3. IPsec
48.7.4. Creating an IPsec Connection
racoon keying daemon handles the IKE key distribution and exchange. Refer to the racoon man page for more information about this daemon.
48.7.5. IPsec Installation
ipsec-tools RPM package be installed on all IPsec hosts (if using a host-to-host configuration) or routers (if using a network-to-network configuration). The RPM package contains essential libraries, daemons, and configuration files for setting up the IPsec connection, including:
/sbin/setkey— manipulates the key management and security attributes of IPsec in the kernel. This executable is controlled by theracoonkey management daemon. Refer to thesetkey(8) man page for more information./usr/sbin/racoon— the IKE key management daemon, used to manage and control security associations and key sharing between IPsec-connected systems./etc/racoon/racoon.conf— theracoondaemon configuration file used to configure various aspects of the IPsec connection, including authentication methods and encryption algorithms used in the connection. Refer to theracoon.conf(5) man page for a complete listing of available directives.
- To connect two network-connected hosts via IPsec, refer to Section 48.7.6, “IPsec Host-to-Host Configuration”.
- To connect one LAN/WAN to another via IPsec, refer to Section 48.7.7, “IPsec Network-to-Network Configuration”.
48.7.6. IPsec Host-to-Host Configuration
48.7.6.1. Host-to-Host Connection
Note
- In a command shell, type
system-config-networkto start the Network Administration Tool. - On the IPsec tab, click to start the IPsec configuration wizard.
- Click to start configuring a host-to-host IPsec connection.
- Enter a unique name for the connection, for example,
ipsec0. If required, select the check box to automatically activate the connection when the computer starts. Click to continue. - Select Host to Host encryption as the connection type, and then click .
- Select the type of encryption to use: manual or automatic.If you select manual encryption, an encryption key must be provided later in the process. If you select automatic encryption, the
racoondaemon manages the encryption key. Theipsec-toolspackage must be installed if you want to use automatic encryption.Click to continue. - Enter the IP address of the remote host.To determine the IP address of the remote host, use the following command on the remote host:
ifconfig <device>
ifconfig <device>Copy to Clipboard Copied! Toggle word wrap Toggle overflow where <device> is the Ethernet device that you want to use for the VPN connection.If only one Ethernet card exists in the system, the device name is typically eth0. The following example shows the relevant information from this command (note that this is an example output only):eth0 Link encap:Ethernet HWaddr 00:0C:6E:E8:98:1D inet addr:172.16.44.192 Bcast:172.16.45.255 Mask:255.255.254.0eth0 Link encap:Ethernet HWaddr 00:0C:6E:E8:98:1D inet addr:172.16.44.192 Bcast:172.16.45.255 Mask:255.255.254.0Copy to Clipboard Copied! Toggle word wrap Toggle overflow The IP address is the number following theinet addr:label.Note
For host-to-host connections, both hosts should have a public, routable address. Alternatively, both hosts can have a private, non-routable address (for example, from the 10.x.x.x or 192.168.x.x ranges) as long as they are on the sam LAN.If the hosts are on different LANs, or one has a public address while the other has a private address, refer to Section 48.7.7, “IPsec Network-to-Network Configuration”.Click to continue. - If manual encryption was selected in step 6, specify the encryption key to use, or click to create one.
- Specify an authentication key or click to generate one. It can be any combination of numbers and letters.
- Click to continue.
- Verify the information on the IPsec — Summary page, and then click .
- Click > to save the configuration.You may need to restart the network for the changes to take effect. To restart the network, use the following command:
service network restart
service network restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Select the IPsec connection from the list and click the button.
- Repeat the entire procedure for the other host. It is essential that the same keys from step 8 be used on the other hosts. Otherwise, IPsec will not work.
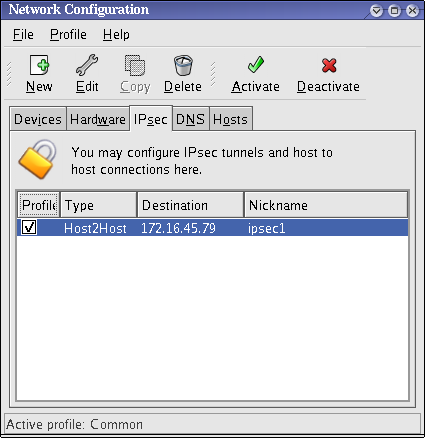
Figure 48.10. IPsec Connection
/etc/sysconfig/network-scripts/ifcfg-<nickname>/etc/sysconfig/network-scripts/keys-<nickname>/etc/racoon/<remote-ip>.conf/etc/racoon/psk.txt
/etc/racoon/racoon.conf is also created.
/etc/racoon/racoon.conf is modified to include <remote-ip>.conf.
48.7.6.2. Manual IPsec Host-to-Host Configuration
- The IP address of each host
- A unique name, for example,
ipsec1. This is used to identify the IPsec connection and to distinguish it from other devices or connections. - A fixed encryption key or one automatically generated by
racoon. - A pre-shared authentication key that is used during the initial stage of the connection and to exchange encryption keys during the session.
Key_Value01, and the users agree to let racoon automatically generate and share an authentication key between each host. Both host users decide to name their connections ipsec1.
Note
/etc/sysconfig/network-scripts/ifcfg-ipsec1.
DST=X.X.X.X TYPE=IPSEC ONBOOT=no IKE_METHOD=PSK
DST=X.X.X.X
TYPE=IPSEC
ONBOOT=no
IKE_METHOD=PSKONBOOT=no) and it uses the pre-shared key method of authentication (IKE_METHOD=PSK).
/etc/sysconfig/network-scripts/keys-ipsec1) that both workstations need to authenticate each other. The contents of this file should be identical on both workstations, and only the root user should be able to read or write this file.
IKE_PSK=Key_Value01
IKE_PSK=Key_Value01Important
keys-ipsec1 file so that only the root user can read or edit the file, use the following command after creating the file:
chmod 600 /etc/sysconfig/network-scripts/keys-ipsec1
chmod 600 /etc/sysconfig/network-scripts/keys-ipsec1keys-ipsec1 file on both workstations. Both authentication keys must be identical for proper connectivity.
X.X.X.X.conf, where X.X.X.X is the IP address of the remote IPsec host. Note that this file is automatically generated when the IPsec tunnel is activated and should not be edited directly.
- remote X.X.X.X
- Specifies that the subsequent stanzas of this configuration file apply only to the remote node identified by the X.X.X.X IP address.
- exchange_mode aggressive
- The default configuration for IPsec on Red Hat Enterprise Linux uses an aggressive authentication mode, which lowers the connection overhead while allowing configuration of several IPsec connections with multiple hosts.
- my_identifier address
- Specifies the identification method to use when authenticating nodes. Red Hat Enterprise Linux uses IP addresses to identify nodes.
- encryption_algorithm 3des
- Specifies the encryption cipher used during authentication. By default, Triple Data Encryption Standard (3DES) is used.
- hash_algorithm sha1;
- Specifies the hash algorithm used during phase 1 negotiation between nodes. By default, Secure Hash Algorithm version 1 is used.
- authentication_method pre_shared_key
- Specifies the authentication method used during node negotiation. By default, Red Hat Enterprise Linux uses pre-shared keys for authentication.
- dh_group 2
- Specifies the Diffie-Hellman group number for establishing dynamically-generated session keys. By default, modp1024 (group 2) is used.
48.7.6.2.1. The Racoon Configuration File
/etc/racoon/racoon.conf files should be identical on all IPsec nodes except for the include "/etc/racoon/X.X.X.X.conf" statement. This statement (and the file it references) is generated when the IPsec tunnel is activated. For Workstation A, the X.X.X.X in the include statement is Workstation B's IP address. The opposite is true of Workstation B. The following shows a typical racoon.conf file when the IPsec connection is activated.
racoon.conf file includes defined paths for IPsec configuration, pre-shared key files, and certificates. The fields in sainfo anonymous describe the phase 2 SA between the IPsec nodes — the nature of the IPsec connection (including the supported encryption algorithms used) and the method of exchanging keys. The following list defines the fields of phase 2:
- sainfo anonymous
- Denotes that SA can anonymously initialize with any peer provided that the IPsec credentials match.
- pfs_group 2
- Defines the Diffie-Hellman key exchange protocol, which determines the method by which the IPsec nodes establish a mutual temporary session key for the second phase of IPsec connectivity. By default, the Red Hat Enterprise Linux implementation of IPsec uses group 2 (or
modp1024) of the Diffie-Hellman cryptographic key exchange groups. Group 2 uses a 1024-bit modular exponentiation that prevents attackers from decrypting previous IPsec transmissions even if a private key is compromised. - lifetime time 1 hour
- This parameter specifies the lifetime of an SA and can be quantified either by time or by bytes of data. The default Red Hat Enterprise Linux implementation of IPsec specifies a one hour lifetime.
- encryption_algorithm 3des, blowfish 448, rijndael
- Specifies the supported encryption ciphers for phase 2. Red Hat Enterprise Linux supports 3DES, 448-bit Blowfish, and Rijndael (the cipher used in the Advanced Encryption Standard, or AES).
- authentication_algorithm hmac_sha1, hmac_md5
- Lists the supported hash algorithms for authentication. Supported modes are sha1 and md5 hashed message authentication codes (HMAC).
- compression_algorithm deflate
- Defines the Deflate compression algorithm for IP Payload Compression (IPCOMP) support, which allows for potentially faster transmission of IP datagrams over slow connections.
ifup <nickname>
ifup <nickname>tcpdump utility to view the network packets being transferred between the hosts and verify that they are encrypted via IPsec. The packet should include an AH header and should be shown as ESP packets. ESP means it is encrypted. For example:
tcpdump -n -i eth0 host <targetSystem> IP 172.16.45.107 > 172.16.44.192: AH(spi=0x0954ccb6,seq=0xbb): ESP(spi=0x0c9f2164,seq=0xbb)
~]# tcpdump -n -i eth0 host <targetSystem>
IP 172.16.45.107 > 172.16.44.192: AH(spi=0x0954ccb6,seq=0xbb): ESP(spi=0x0c9f2164,seq=0xbb)48.7.7. IPsec Network-to-Network Configuration
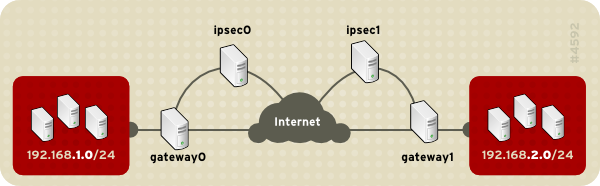
Figure 48.11. A network-to-network IPsec tunneled connection
- The externally-accessible IP addresses of the dedicated IPsec routers
- The network address ranges of the LAN/WAN served by the IPsec routers (such as 192.168.1.0/24 or 10.0.1.0/24)
- The IP addresses of the gateway devices that route the data from the network nodes to the Internet
- A unique name, for example,
ipsec1. This is used to identify the IPsec connection and to distinguish it from other devices or connections. - A fixed encryption key or one automatically generated by
racoon - A pre-shared authentication key that is used during the initial stage of the connection and to exchange encryption keys during the session.
48.7.7.1. Network-to-Network (VPN) Connection
Figure 48.12. Network-to-Network IPsec
- In a command shell, type
system-config-networkto start the Network Administration Tool. - On the IPsec tab, click to start the IPsec configuration wizard.
- Click to start configuring a network-to-network IPsec connection.
- Enter a unique nickname for the connection, for example,
ipsec0. If required, select the check box to automatically activate the connection when the computer starts. Click to continue. - Select Network to Network encryption (VPN) as the connection type, and then click .
- Select the type of encryption to use: manual or automatic.If you select manual encryption, an encryption key must be provided later in the process. If you select automatic encryption, the
racoondaemon manages the encryption key. Theipsec-toolspackage must be installed if you want to use automatic encryption.Click to continue. - On the Local Network page, enter the following information:
- Local Network Address — The IP address of the device on the IPsec router connected to the private network.
- Local Subnet Mask — The subnet mask of the local network IP address.
- Local Network Gateway — The gateway for the private subnet.
Click to continue.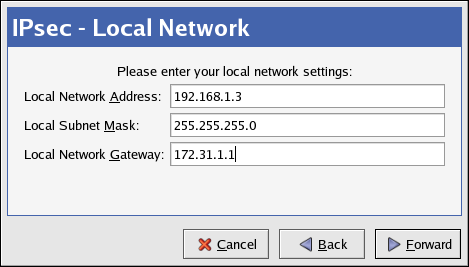
Figure 48.13. Local Network Information
- On the Remote Network page, enter the following information:
- Remote IP Address — The publicly addressable IP address of the IPsec router for the other private network. In our example, for ipsec0, enter the publicly addressable IP address of ipsec1, and vice versa.
- Remote Network Address — The network address of the private subnet behind the other IPsec router. In our example, enter
192.168.1.0if configuring ipsec1, and enter192.168.2.0if configuring ipsec0. - Remote Subnet Mask — The subnet mask of the remote IP address.
- Remote Network Gateway — The IP address of the gateway for the remote network address.
- If manual encryption was selected in step 6, specify the encryption key to use or click to create one.Specify an authentication key or click to generate one. This key can be any combination of numbers and letters.
Click to continue.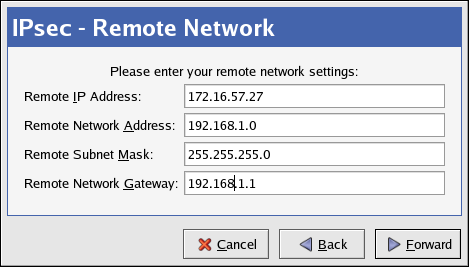
Figure 48.14. Remote Network Information
- Verify the information on the IPsec — Summary page, and then click .
- Select > to save the configuration.
- Select the IPsec connection from the list, and then click to activate the connection.
- Enable IP forwarding:
- Edit
/etc/sysctl.confand setnet.ipv4.ip_forwardto1. - Use the following command to enable the change:
sysctl -p /etc/sysctl.conf
sysctl -p /etc/sysctl.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow
48.7.7.2. Manual IPsec Network-to-Network Configuration
r3dh4tl1nux, and the administrators of A and B agree to let racoon automatically generate and share an authentication key between each IPsec router. The administrator of LAN A decides to name the IPsec connection ipsec0, while the administrator of LAN B names the IPsec connection ipsec1.
ifcfg file for a network-to-network IPsec connection for LAN A. The unique name to identify the connection in this example is ipsec0, so the resulting file is called /etc/sysconfig/network-scripts/ifcfg-ipsec0.
- TYPE=IPSEC
- Specifies the type of connection.
- ONBOOT=yes
- Specifies that the connection should initiate on boot-up.
- IKE_METHOD=PSK
- Specifies that the connection uses the pre-shared key method of authentication.
- SRCGW=192.168.1.254
- The IP address of the source gateway. For LAN A, this is the LAN A gateway, and for LAN B, the LAN B gateway.
- DSTGW=192.168.2.254
- The IP address of the destination gateway. For LAN A, this is the LAN B gateway, and for LAN B, the LAN A gateway.
- SRCNET=192.168.1.0/24
- Specifies the source network for the IPsec connection, which in this example is the network range for LAN A.
- DSTNET=192.168.2.0/24
- Specifies the destination network for the IPsec connection, which in this example is the network range for LAN B.
- DST=X.X.X.X
- The externally-accessible IP address of LAN B.
/etc/sysconfig/network-scripts/keys-ipsecX (where X is 0 for LAN A and 1 for LAN B) that both networks use to authenticate each other. The contents of this file should be identical and only the root user should be able to read or write this file.
IKE_PSK=r3dh4tl1nux
IKE_PSK=r3dh4tl1nuxImportant
keys-ipsecX file so that only the root user can read or edit the file, use the following command after creating the file:
chmod 600 /etc/sysconfig/network-scripts/keys-ipsec1
chmod 600 /etc/sysconfig/network-scripts/keys-ipsec1keys-ipsecX file on both IPsec routers. Both keys must be identical for proper connectivity.
/etc/racoon/racoon.conf configuration file for the IPsec connection. Note that the include line at the bottom of the file is automatically generated and only appears if the IPsec tunnel is running.
X.X.X.X.conf (where X.X.X.X is the IP address of the remote IPsec router). Note that this file is automatically generated when the IPsec tunnel is activated and should not be edited directly.
- Edit
/etc/sysctl.confand setnet.ipv4.ip_forwardto1. - Use the following command to enable the change:
sysctl -p /etc/sysctl.conf
sysctl -p /etc/sysctl.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow
ifup ipsec0
ifup ipsec0ifup on the IPsec connection. To show a list of routes for the network, use the following command:
ip route list
ip route listtcpdump utility on the externally-routable device (eth0 in this example) to view the network packets being transferred between the hosts (or networks), and verify that they are encrypted via IPsec. For example, to check the IPsec connectivity of LAN A, use the following command:
tcpdump -n -i eth0 host lana.example.com
tcpdump -n -i eth0 host lana.example.com12:24:26.155529 lanb.example.com > lana.example.com: AH(spi=0x021c9834,seq=0x358): \ lanb.example.com > lana.example.com: ESP(spi=0x00c887ad,seq=0x358) (DF) \ (ipip-proto-4)
12:24:26.155529 lanb.example.com > lana.example.com: AH(spi=0x021c9834,seq=0x358): \
lanb.example.com > lana.example.com: ESP(spi=0x00c887ad,seq=0x358) (DF) \
(ipip-proto-4)48.7.8. Starting and Stopping an IPsec Connection
ifup <nickname>
ifup <nickname>ipsec0.
ifdown <nickname>
ifdown <nickname>48.8. Firewalls
| Method | Description | Advantages | Disadvantages | ||||||
|---|---|---|---|---|---|---|---|---|---|
| NAT | Network Address Translation (NAT) places private IP subnetworks behind one or a small pool of public IP addresses, masquerading all requests to one source rather than several. The Linux kernel has built-in NAT functionality through the Netfilter kernel subsystem. |
|
| ||||||
| Packet Filter | A packet filtering firewall reads each data packet that passes through a LAN. It can read and process packets by header information and filters the packet based on sets of programmable rules implemented by the firewall administrator. The Linux kernel has built-in packet filtering functionality through the Netfilter kernel subsystem. |
|
| ||||||
| Proxy | Proxy firewalls filter all requests of a certain protocol or type from LAN clients to a proxy machine, which then makes those requests to the Internet on behalf of the local client. A proxy machine acts as a buffer between malicious remote users and the internal network client machines. |
|
|
48.8.1. Netfilter and IPTables
iptables tool.
48.8.1.1. IPTables Overview
iptables administration tool, a command line tool similar in syntax to its predecessor, ipchains.
ipchains requires intricate rule sets for: filtering source paths; filtering destination paths; and filtering both source and destination connection ports.
iptables uses the Netfilter subsystem to enhance network connection, inspection, and processing. iptables features advanced logging, pre- and post-routing actions, network address translation, and port forwarding, all in one command line interface.
iptables. For more detailed information, refer to Section 48.9, “IPTables”.
48.8.2. Basic Firewall Configuration
48.8.2.1. Security Level Configuration Tool
system-config-securitylevel
system-config-securitylevel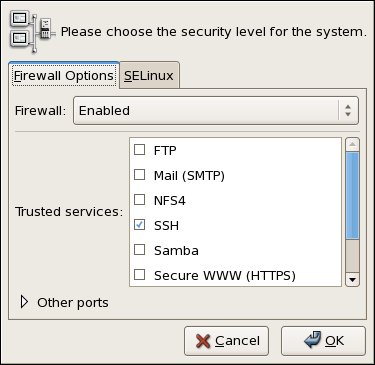
Figure 48.15. Security Level Configuration Tool
Note
iptables rules.
48.8.2.2. Enabling and Disabling the Firewall
- Disabled — Disabling the firewall provides complete access to your system and does no security checking. This should only be selected if you are running on a trusted network (not the Internet) or need to configure a custom firewall using the iptables command line tool.
Warning
Firewall configurations and any customized firewall rules are stored in the/etc/sysconfig/iptablesfile. If you choose Disabled and click , these configurations and firewall rules will be lost. - Enabled — This option configures the system to reject incoming connections that are not in response to outbound requests, such as DNS replies or DHCP requests. If access to services running on this machine is needed, you can choose to allow specific services through the firewall.If you are connecting your system to the Internet, but do not plan to run a server, this is the safest choice.
48.8.2.3. Trusted Services
- WWW (HTTP)
- The HTTP protocol is used by Apache (and by other Web servers) to serve web pages. If you plan on making your Web server publicly available, select this check box. This option is not required for viewing pages locally or for developing web pages. This service requires that the
httpdpackage be installed.Enabling WWW (HTTP) will not open a port for HTTPS, the SSL version of HTTP. If this service is required, select the Secure WWW (HTTPS) check box. - FTP
- The FTP protocol is used to transfer files between machines on a network. If you plan on making your FTP server publicly available, select this check box. This service requires that the
vsftpdpackage be installed. - SSH
- Secure Shell (SSH) is a suite of tools for logging into and executing commands on a remote machine. To allow remote access to the machine via ssh, select this check box. This service requires that the
openssh-serverpackage be installed. - Telnet
- Telnet is a protocol for logging into remote machines. Telnet communications are unencrypted and provide no security from network snooping. Allowing incoming Telnet access is not recommended. To allow remote access to the machine via telnet, select this check box. This service requires that the
telnet-serverpackage be installed. - Mail (SMTP)
- SMTP is a protocol that allows remote hosts to connect directly to your machine to deliver mail. You do not need to enable this service if you collect your mail from your ISP's server using POP3 or IMAP, or if you use a tool such as
fetchmail. To allow delivery of mail to your machine, select this check box. Note that an improperly configured SMTP server can allow remote machines to use your server to send spam. - NFS4
- The Network File System (NFS) is a file sharing protocol commonly used on *NIX systems. Version 4 of this protocol is more secure than its predecessors. If you want to share files or directories on your system with other network users, select this check box.
- Samba
- Samba is an implementation of Microsoft's proprietary SMB networking protocol. If you need to share files, directories, or locally-connected printers with Microsoft Windows machines, select this check box.
48.8.2.4. Other Ports
iptables. For example, to allow IRC and Internet printing protocol (IPP) to pass through the firewall, add the following to the Other ports section:
194:tcp,631:tcp
48.8.2.5. Saving the Settings
iptables commands and written to the /etc/sysconfig/iptables file. The iptables service is also started so that the firewall is activated immediately after saving the selected options. If Disable firewall was selected, the /etc/sysconfig/iptables file is removed and the iptables service is stopped immediately.
/etc/sysconfig/system-config-securitylevel file so that the settings can be restored the next time the application is started. Do not edit this file by hand.
iptables service is not configured to start automatically at boot time. Refer to Section 48.8.2.6, “Activating the IPTables Service” for more information.
48.8.2.6. Activating the IPTables Service
iptables service is running. To manually start the service, use the following command:
service iptables restart
service iptables restartiptables starts when the system is booted, use the following command:
chkconfig --level 345 iptables on
chkconfig --level 345 iptables onipchains service is not included in Red Hat Enterprise Linux. However, if ipchains is installed (for example, an upgrade was performed and the system had ipchains previously installed), the ipchains and iptables services should not be activated simultaneously. To make sure the ipchains service is disabled and configured not to start at boot time, use the following two commands:
service ipchains stop chkconfig --level 345 ipchains off
service ipchains stop
chkconfig --level 345 ipchains off48.8.3. Using IPTables
iptables is to start the iptables service. Use the following command to start the iptables service:
service iptables start
service iptables startNote
ip6tables service can be turned off if you intend to use the iptables service only. If you deactivate the ip6tables service, remember to deactivate the IPv6 network also. Never leave a network device active without the matching firewall.
iptables to start by default when the system is booted, use the following command:
chkconfig --level 345 iptables on
chkconfig --level 345 iptables oniptables to start whenever the system is booted into runlevel 3, 4, or 5.
48.8.3.1. IPTables Command Syntax
iptables command illustrates the basic command syntax:
iptables -A <chain> -j <target>
iptables -A <chain> -j <target>-A option specifies that the rule be appended to <chain>. Each chain is comprised of one or more rules, and is therefore also known as a ruleset.
-j <target> option specifies the target of the rule; i.e., what to do if the packet matches the rule. Examples of built-in targets are ACCEPT, DROP, and REJECT.
iptables man page for more information on the available chains, options, and targets.
48.8.3.2. Basic Firewall Policies
iptables chain is comprised of a default policy, and zero or more rules which work in concert with the default policy to define the overall ruleset for the firewall.
iptables -P INPUT DROP iptables -P OUTPUT DROP
iptables -P INPUT DROP
iptables -P OUTPUT DROPiptables -P FORWARD DROP
iptables -P FORWARD DROP48.8.3.3. Saving and Restoring IPTables Rules
iptables are transitory; if the system is rebooted or if the iptables service is restarted, the rules are automatically flushed and reset. To save the rules so that they are loaded when the iptables service is started, use the following command:
service iptables save
service iptables save/etc/sysconfig/iptables and are applied whenever the service is started or the machine is rebooted.
48.8.4. Common IPTables Filtering
iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPTiptables -A INPUT -p tcp -m tcp --dport 443 -j ACCEPT
iptables -A INPUT -p tcp -m tcp --dport 443 -j ACCEPTImportant
iptables ruleset, order is important.
-I option. For example:
iptables -I INPUT 1 -i lo -p all -j ACCEPT
iptables -I INPUT 1 -i lo -p all -j ACCEPTiptables to accept connections from remote SSH clients. For example, the following rules allow remote SSH access:
iptables -A INPUT -p tcp --dport 22 -j ACCEPT iptables -A OUTPUT -p tcp --sport 22 -j ACCEPT
iptables -A INPUT -p tcp --dport 22 -j ACCEPT
iptables -A OUTPUT -p tcp --sport 22 -j ACCEPTiptables filtering rules.
48.8.5. FORWARD and NAT Rules
iptables provides routing and forwarding policies that can be implemented to prevent abnormal usage of network resources.
FORWARD chain allows an administrator to control where packets can be routed within a LAN. For example, to allow forwarding for the entire LAN (assuming the firewall/gateway is assigned an internal IP address on eth1), use the following rules:
iptables -A FORWARD -i eth1 -j ACCEPT iptables -A FORWARD -o eth1 -j ACCEPT
iptables -A FORWARD -i eth1 -j ACCEPT
iptables -A FORWARD -o eth1 -j ACCEPTeth1 device.
Note
sysctl -w net.ipv4.ip_forward=1
sysctl -w net.ipv4.ip_forward=1/etc/sysctl.conf file as follows:
net.ipv4.ip_forward = 0
net.ipv4.ip_forward = 0net.ipv4.ip_forward = 1
net.ipv4.ip_forward = 1sysctl.conf file:
sysctl -p /etc/sysctl.conf
sysctl -p /etc/sysctl.conf48.8.5.1. Postrouting and IP Masquerading
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE-t nat) and specifies the built-in POSTROUTING chain for NAT (-A POSTROUTING) on the firewall's external networking device (-o eth0).
-j MASQUERADE target is specified to mask the private IP address of a node with the external IP address of the firewall/gateway.
48.8.5.2. Prerouting
-j DNAT target of the PREROUTING chain in NAT to specify a destination IP address and port where incoming packets requesting a connection to your internal service can be forwarded.
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j DNAT --to 172.31.0.23:80
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j DNAT --to 172.31.0.23:80Note
iptables -A FORWARD -i eth0 -p tcp --dport 80 -d 172.31.0.23 -j ACCEPT
iptables -A FORWARD -i eth0 -p tcp --dport 80 -d 172.31.0.23 -j ACCEPT48.8.5.3. DMZs and IPTables
iptables rules to route traffic to certain machines, such as a dedicated HTTP or FTP server, in a demilitarized zone (DMZ). A DMZ is a special local subnetwork dedicated to providing services on a public carrier, such as the Internet.
PREROUTING table to forward the packets to the appropriate destination:
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j DNAT --to-destination 10.0.4.2:80
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j DNAT --to-destination 10.0.4.2:8048.8.6. Malicious Software and Spoofed IP Addresses
iptables -A OUTPUT -o eth0 -p tcp --dport 31337 --sport 31337 -j DROP iptables -A FORWARD -o eth0 -p tcp --dport 31337 --sport 31337 -j DROP
iptables -A OUTPUT -o eth0 -p tcp --dport 31337 --sport 31337 -j DROP
iptables -A FORWARD -o eth0 -p tcp --dport 31337 --sport 31337 -j DROPiptables -A FORWARD -s 192.168.1.0/24 -i eth0 -j DROP
iptables -A FORWARD -s 192.168.1.0/24 -i eth0 -j DROPNote
DROP and REJECT targets when dealing with appended rules.
REJECT target denies access and returns a connection refused error to users who attempt to connect to the service. The DROP target, as the name implies, drops the packet without any warning.
REJECT target is recommended.
48.8.7. IPTables and Connection Tracking
iptables uses a method called connection tracking to store information about incoming connections. You can allow or deny access based on the following connection states:
NEW— A packet requesting a new connection, such as an HTTP request.ESTABLISHED— A packet that is part of an existing connection.RELATED— A packet that is requesting a new connection but is part of an existing connection. For example, FTP uses port 21 to establish a connection, but data is transferred on a different port (typically port 20).INVALID— A packet that is not part of any connections in the connection tracking table.
iptables connection tracking with any network protocol, even if the protocol itself is stateless (such as UDP). The following example shows a rule that uses connection tracking to forward only the packets that are associated with an established connection:
iptables -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT48.8.8. IPv6
ip6tables command. In Red Hat Enterprise Linux 5, both IPv4 and IPv6 services are enabled by default.
ip6tables command syntax is identical to iptables in every aspect except that it supports 128-bit addresses. For example, use the following command to enable SSH connections on an IPv6-aware network server:
ip6tables -A INPUT -i eth0 -p tcp -s 3ffe:ffff:100::1/128 --dport 22 -j ACCEPT
ip6tables -A INPUT -i eth0 -p tcp -s 3ffe:ffff:100::1/128 --dport 22 -j ACCEPT48.8.9. Additional Resources
48.8.9.1. Installed Documentation
- Refer to Section 48.9, “IPTables” for more detailed information on the
iptablescommand, including definitions for many command options. - The
iptablesman page contains a brief summary of the various options.
48.8.9.2. Useful Websites
- http://www.netfilter.org/ — The official homepage of the Netfilter and
iptablesproject. - http://www.tldp.org/ — The Linux Documentation Project contains several useful guides relating to firewall creation and administration.
- http://www.iana.org/assignments/port-numbers — The official list of registered and common service ports as assigned by the Internet Assigned Numbers Authority.
48.8.9.3. Related Documentation
- Red Hat Linux Firewalls, by Bill McCarty; Red Hat Press — a comprehensive reference to building network and server firewalls using open source packet filtering technology such as Netfilter and
iptables. It includes topics that cover analyzing firewall logs, developing firewall rules, and customizing your firewall using various graphical tools. - Linux Firewalls, by Robert Ziegler; New Riders Press — contains a wealth of information on building firewalls using both 2.2 kernel
ipchainsas well as Netfilter andiptables. Additional security topics such as remote access issues and intrusion detection systems are also covered.
48.9. IPTables
ipchains for packet filtering and used lists of rules applied to packets at each step of the filtering process. The 2.4 kernel introduced iptables (also called netfilter), which is similar to ipchains but greatly expands the scope and control available for filtering network packets.
ipchains and iptables, explains various options available with iptables commands, and explains how filtering rules can be preserved between system reboots.
iptables rules and setting up a firewall based on these rules.
Warning
iptables, but iptables cannot be used if ipchains is already running. If ipchains is present at boot time, the kernel issues an error and fails to start iptables.
ipchains is not affected by these errors.
48.9.1. Packet Filtering
filter— The default table for handling network packets.nat— Used to alter packets that create a new connection and used for Network Address Translation (NAT).mangle— Used for specific types of packet alteration.
netfilter.
filter table are as follows:
- INPUT — Applies to network packets that are targeted for the host.
- OUTPUT — Applies to locally-generated network packets.
- FORWARD — Applies to network packets routed through the host.
nat table are as follows:
- PREROUTING — Alters network packets when they arrive.
- OUTPUT — Alters locally-generated network packets before they are sent out.
- POSTROUTING — Alters network packets before they are sent out.
mangle table are as follows:
- INPUT — Alters network packets targeted for the host.
- OUTPUT — Alters locally-generated network packets before they are sent out.
- FORWARD — Alters network packets routed through the host.
- PREROUTING — Alters incoming network packets before they are routed.
- POSTROUTING — Alters network packets before they are sent out.
Note
/etc/sysconfig/iptables or /etc/sysconfig/ip6tables files.
iptables service starts before any DNS-related services when a Linux system is booted. This means that firewall rules can only reference numeric IP addresses (for example, 192.168.0.1). Domain names (for example, host.example.com) in such rules produce errors.
ACCEPT target for a matching packet, the packet skips the rest of the rule checks and is allowed to continue to its destination. If a rule specifies a DROP target, that packet is refused access to the system and nothing is sent back to the host that sent the packet. If a rule specifies a QUEUE target, the packet is passed to user-space. If a rule specifies the optional REJECT target, the packet is dropped, but an error packet is sent to the packet's originator.
ACCEPT, DROP, REJECT, or QUEUE. If none of the rules in the chain apply to the packet, then the packet is dealt with in accordance with the default policy.
iptables command configures these tables, as well as sets up new tables if necessary.
48.9.2. Differences Between IPTables and IPChains
ipchains and iptables use chains of rules that operate within the Linux kernel to filter packets based on matches with specified rules or rule sets. However, iptables offers a more extensible way of filtering packets, giving the administrator greater control without building undue complexity into the system.
ipchains and iptables:
- Using
iptables, each filtered packet is processed using rules from only one chain rather than multiple chains. - For example, a FORWARD packet coming into a system using
ipchainswould have to go through the INPUT, FORWARD, and OUTPUT chains to continue to its destination. However,iptablesonly sends packets to the INPUT chain if they are destined for the local system, and only sends them to the OUTPUT chain if the local system generated the packets. It is therefore important to place the rule designed to catch a particular packet within the chain that actually handles the packet. - The DENY target has been changed to DROP.
- In
ipchains, packets that matched a rule in a chain could be directed to the DENY target. This target must be changed to DROP iniptables. - Order matters when placing options in a rule.
- In
ipchains, the order of the rule options does not matter.Theiptablescommand has a stricter syntax. Theiptablescommand requires that the protocol (ICMP, TCP, or UDP) be specified before the source or destination ports. - Network interfaces must be associated with the correct chains in firewall rules.
- For example, incoming interfaces (
-ioption) can only be used in INPUT or FORWARD chains. Similarly, outgoing interfaces (-ooption) can only be used in FORWARD or OUTPUT chains.In other words, INPUT chains and incoming interfaces work together; OUTPUT chains and outgoing interfaces work together. FORWARD chains work with both incoming and outgoing interfaces.OUTPUT chains are no longer used by incoming interfaces, and INPUT chains are not seen by packets moving through outgoing interfaces.
48.9.3. Command Options for IPTables
iptables command. The following aspects of the packet are most often used as criteria:
- Packet Type — Specifies the type of packets the command filters.
- Packet Source/Destination — Specifies which packets the command filters based on the source or destination of the packet.
- Target — Specifies what action is taken on packets matching the above criteria.
iptables rules must be grouped logically, based on the purpose and conditions of the overall rule, for the rule to be valid. The remainder of this section explains commonly-used options for the iptables command.
48.9.3.1. Structure of IPTables Command Options
iptables commands have the following structure:
iptables [-t <table-name>] <command> <chain-name> \ <parameter-1> <option-1> \ <parameter-n> <option-n>
iptables [-t <table-name>] <command> <chain-name> \
<parameter-1> <option-1> \
<parameter-n> <option-n>filter table is used.
iptables command can change significantly, based on its purpose.
iptables -D <chain-name> <line-number>
iptables commands, it is important to remember that some parameters and options require further parameters and options to construct a valid rule. This can produce a cascading effect, with the further parameters requiring yet more parameters. Until every parameter and option that requires another set of options is satisfied, the rule is not valid.
iptables -h to view a comprehensive list of iptables command structures.
48.9.3.2. Command Options
iptables to perform a specific action. Only one command option is allowed per iptables command. With the exception of the help command, all commands are written in upper-case characters.
iptables commands are as follows:
-A— Appends the rule to the end of the specified chain. Unlike the-Ioption described below, it does not take an integer argument. It always appends the rule to the end of the specified chain.-C— Checks a particular rule before adding it to the user-specified chain. This command can help you construct complexiptablesrules by prompting you for additional parameters and options.-D <integer> | <rule>— Deletes a rule in a particular chain by number (such as5for the fifth rule in a chain), or by rule specification. The rule specification must exactly match an existing rule.-E— Renames a user-defined chain. A user-defined chain is any chain other than the default, pre-existing chains. (Refer to the-Noption, below, for information on creating user-defined chains.) This is a cosmetic change and does not affect the structure of the table.Note
If you attempt to rename one of the default chains, the system reports aMatch not founderror. You cannot rename the default chains.-F— Flushes the selected chain, which effectively deletes every rule in the chain. If no chain is specified, this command flushes every rule from every chain.-h— Provides a list of command structures, as well as a quick summary of command parameters and options.-I [<integer>]— Inserts the rule in the specified chain at a point specified by a user-defined integer argument. If no argument is specified, the rule is inserted at the top of the chain.Warning
As noted above, the order of rules in a chain determines which rules apply to which packets. This is important to remember when adding rules using either the-Aor-Ioption.This is especially important when adding rules using the-Iwith an integer argument. If you specify an existing number when adding a rule to a chain,iptablesadds the new rule before (or above) the existing rule.-L— Lists all of the rules in the chain specified after the command. To list all rules in all chains in the defaultfiltertable, do not specify a chain or table. Otherwise, the following syntax should be used to list the rules in a specific chain in a particular table:iptables -L <chain-name> -t <table-name>
iptables -L <chain-name> -t <table-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Additional options for the-Lcommand option, which provide rule numbers and allow more verbose rule descriptions, are described in Section 48.9.3.6, “Listing Options”.-N— Creates a new chain with a user-specified name. The chain name must be unique, otherwise an error message is displayed.-P— Sets the default policy for the specified chain, so that when packets traverse an entire chain without matching a rule, they are sent to the specified target, such as ACCEPT or DROP.-R— Replaces a rule in the specified chain. The rule's number must be specified after the chain's name. The first rule in a chain corresponds to rule number one.-X— Deletes a user-specified chain. You cannot delete a built-in chain.-Z— Sets the byte and packet counters in all chains for a table to zero.
48.9.3.3. IPTables Parameter Options
iptables commands, including those used to add, append, delete, insert, or replace rules within a particular chain, require various parameters to construct a packet filtering rule.
-c— Resets the counters for a particular rule. This parameter accepts thePKTSandBYTESoptions to specify which counter to reset.-d— Sets the destination hostname, IP address, or network of a packet that matches the rule. When matching a network, the following IP address/netmask formats are supported:N.N.N.N/M.M.M.M— Where N.N.N.N is the IP address range and M.M.M.M is the netmask.N.N.N.N/M— Where N.N.N.N is the IP address range and M is the bitmask.
-f— Applies this rule only to fragmented packets.You can use the exclamation point character (!) option after this parameter to specify that only unfragmented packets are matched.Note
Distinguishing between fragmented and unfragmented packets is desirable, despite fragmented packets being a standard part of the IP protocol.Originally designed to allow IP packets to travel over networks with differing frame sizes, these days fragmentation is more commonly used to generate DoS attacks using mal-formed packets. It's also worth noting that IPv6 disallows fragmentation entirely.-i— Sets the incoming network interface, such aseth0orppp0. Withiptables, this optional parameter may only be used with the INPUT and FORWARD chains when used with thefiltertable and the PREROUTING chain with thenatandmangletables.This parameter also supports the following special options:- Exclamation point character (
!) — Reverses the directive, meaning any specified interfaces are excluded from this rule. - Plus character (
+) — A wildcard character used to match all interfaces that match the specified string. For example, the parameter-i eth+would apply this rule to any Ethernet interfaces but exclude any other interfaces, such asppp0.
If the-iparameter is used but no interface is specified, then every interface is affected by the rule.-j— Jumps to the specified target when a packet matches a particular rule.The standard targets areACCEPT,DROP,QUEUE, andRETURN.Extended options are also available through modules loaded by default with the Red Hat Enterprise LinuxiptablesRPM package. Valid targets in these modules includeLOG,MARK, andREJECT, among others. Refer to theiptablesman page for more information about these and other targets.This option can also be used to direct a packet matching a particular rule to a user-defined chain outside of the current chain so that other rules can be applied to the packet.If no target is specified, the packet moves past the rule with no action taken. The counter for this rule, however, increases by one.-o— Sets the outgoing network interface for a rule. This option is only valid for the OUTPUT and FORWARD chains in thefiltertable, and the POSTROUTING chain in thenatandmangletables. This parameter accepts the same options as the incoming network interface parameter (-i).-p <protocol>— Sets the IP protocol affected by the rule. This can be eithericmp,tcp,udp, orall, or it can be a numeric value, representing one of these or a different protocol. You can also use any protocols listed in the/etc/protocolsfile.The "all" protocol means the rule applies to every supported protocol. If no protocol is listed with this rule, it defaults to "all".-s— Sets the source for a particular packet using the same syntax as the destination (-d) parameter.
48.9.3.4. IPTables Match Options
iptables command. For example, -p <protocol-name> enables options for the specified protocol. Note that you can also use the protocol ID, instead of the protocol name. Refer to the following examples, each of which have the same effect:
iptables -A INPUT -p icmp --icmp-type any -j ACCEPT iptables -A INPUT -p 5813 --icmp-type any -j ACCEPT
iptables -A INPUT -p icmp --icmp-type any -j ACCEPT
iptables -A INPUT -p 5813 --icmp-type any -j ACCEPT/etc/services file. For readability, it is recommended that you use the service names rather than the port numbers.
Important
/etc/services file to prevent unauthorized editing. If this file is editable, crackers can use it to enable ports on your machine you have otherwise closed. To secure this file, type the following commands as root:
chown root.root /etc/services chmod 0644 /etc/services chattr +i /etc/services
chown root.root /etc/services
chmod 0644 /etc/services
chattr +i /etc/services48.9.3.4.1. TCP Protocol
-p tcp):
--dport— Sets the destination port for the packet.To configure this option, use a network service name (such as www or smtp); a port number; or a range of port numbers.To specify a range of port numbers, separate the two numbers with a colon (:). For example:-p tcp --dport 3000:3200. The largest acceptable valid range is0:65535.Use an exclamation point character (!) after the--dportoption to match all packets that do not use that network service or port.To browse the names and aliases of network services and the port numbers they use, view the/etc/servicesfile.The--destination-portmatch option is synonymous with--dport.--sport— Sets the source port of the packet using the same options as--dport. The--source-portmatch option is synonymous with--sport.--syn— Applies to all TCP packets designed to initiate communication, commonly called SYN packets. Any packets that carry a data payload are not touched.Use an exclamation point character (!) after the--synoption to match all non-SYN packets.--tcp-flags <tested flag list> <set flag list>— Allows TCP packets that have specific bits (flags) set, to match a rule.The--tcp-flagsmatch option accepts two parameters. The first parameter is the mask; a comma-separated list of flags to be examined in the packet. The second parameter is a comma-separated list of flags that must be set for the rule to match.The possible flags are:ACKFINPSHRSTSYNURGALLNONE
For example, aniptablesrule that contains the following specification only matches TCP packets that have the SYN flag set and the ACK and FIN flags not set:--tcp-flags ACK,FIN,SYN SYNUse the exclamation point character (!) after the--tcp-flagsto reverse the effect of the match option.--tcp-option— Attempts to match with TCP-specific options that can be set within a particular packet. This match option can also be reversed with the exclamation point character (!).
48.9.3.4.2. UDP Protocol
-p udp):
--dport— Specifies the destination port of the UDP packet, using the service name, port number, or range of port numbers. The--destination-portmatch option is synonymous with--dport.--sport— Specifies the source port of the UDP packet, using the service name, port number, or range of port numbers. The--source-portmatch option is synonymous with--sport.
--dport and --sport options, to specify a range of port numbers, separate the two numbers with a colon (:). For example: -p tcp --dport 3000:3200. The largest acceptable valid range is 0:65535.
48.9.3.4.3. ICMP Protocol
-p icmp):
--icmp-type— Sets the name or number of the ICMP type to match with the rule. A list of valid ICMP names can be retrieved by typing theiptables -p icmp -hcommand.
48.9.3.4.4. Additional Match Option Modules
iptables command.
-m <module-name>, where <module-name> is the name of the module.
limitmodule — Places limits on how many packets are matched to a particular rule.When used in conjunction with theLOGtarget, thelimitmodule can prevent a flood of matching packets from filling up the system log with repetitive messages or using up system resources.Refer to Section 48.9.3.5, “Target Options” for more information about theLOGtarget.Thelimitmodule enables the following options:--limit— Sets the maximum number of matches for a particular time period, specified as a<value>/<period>pair. For example, using--limit 5/hourallows five rule matches per hour.Periods can be specified in seconds, minutes, hours, or days.If a number and time modifier are not used, the default value of3/houris assumed.--limit-burst— Sets a limit on the number of packets able to match a rule at one time.This option is specified as an integer and should be used in conjunction with the--limitoption.If no value is specified, the default value of five (5) is assumed.
statemodule — Enables state matching.Thestatemodule enables the following options:--state— match a packet with the following connection states:ESTABLISHED— The matching packet is associated with other packets in an established connection. You need to accept this state if you want to maintain a connection between a client and a server.INVALID— The matching packet cannot be tied to a known connection.NEW— The matching packet is either creating a new connection or is part of a two-way connection not previously seen. You need to accept this state if you want to allow new connections to a service.RELATED— The matching packet is starting a new connection related in some way to an existing connection. An example of this is FTP, which uses one connection for control traffic (port 21), and a separate connection for data transfer (port 20).
These connection states can be used in combination with one another by separating them with commas, such as-m state --state INVALID,NEW.
macmodule — Enables hardware MAC address matching.Themacmodule enables the following option:--mac-source— Matches a MAC address of the network interface card that sent the packet. To exclude a MAC address from a rule, place an exclamation point character (!) after the--mac-sourcematch option.
iptables man page for more match options available through modules.
48.9.3.5. Target Options
<user-defined-chain>— A user-defined chain within the table. User-defined chain names must be unique. This target passes the packet to the specified chain.ACCEPT— Allows the packet through to its destination or to another chain.DROP— Drops the packet without responding to the requester. The system that sent the packet is not notified of the failure.QUEUE— The packet is queued for handling by a user-space application.RETURN— Stops checking the packet against rules in the current chain. If the packet with aRETURNtarget matches a rule in a chain called from another chain, the packet is returned to the first chain to resume rule checking where it left off. If theRETURNrule is used on a built-in chain and the packet cannot move up to its previous chain, the default target for the current chain is used.
LOG— Logs all packets that match this rule. Because the packets are logged by the kernel, the/etc/syslog.conffile determines where these log entries are written. By default, they are placed in the/var/log/messagesfile.Additional options can be used after theLOGtarget to specify the way in which logging occurs:--log-level— Sets the priority level of a logging event. Refer to thesyslog.confman page for a list of priority levels.--log-ip-options— Logs any options set in the header of an IP packet.--log-prefix— Places a string of up to 29 characters before the log line when it is written. This is useful for writing syslog filters for use in conjunction with packet logging.Note
Due to an issue with this option, you should add a trailing space to the log-prefix value.--log-tcp-options— Logs any options set in the header of a TCP packet.--log-tcp-sequence— Writes the TCP sequence number for the packet in the log.
REJECT— Sends an error packet back to the remote system and drops the packet.TheREJECTtarget accepts--reject-with <type>(where <type> is the rejection type) allowing more detailed information to be returned with the error packet. The messageport-unreachableis the default error type given if no other option is used. Refer to theiptablesman page for a full list of<type>options.
nat table, or with packet alteration using the mangle table, can be found in the iptables man page.
48.9.3.6. Listing Options
iptables -L [<chain-name>], provides a very basic overview of the default filter table's current chains. Additional options provide more information:
-v— Displays verbose output, such as the number of packets and bytes each chain has processed, the number of packets and bytes each rule has matched, and which interfaces apply to a particular rule.-x— Expands numbers into their exact values. On a busy system, the number of packets and bytes processed by a particular chain or rule may be abbreviated toKilobytes,Megabytes(Megabytes) orGigabytes. This option forces the full number to be displayed.-n— Displays IP addresses and port numbers in numeric format, rather than the default hostname and network service format.--line-numbers— Lists rules in each chain next to their numeric order in the chain. This option is useful when attempting to delete the specific rule in a chain or to locate where to insert a rule within a chain.-t <table-name>— Specifies a table name. If omitted, defaults to the filter table.
-x option.
48.9.4. Saving IPTables Rules
iptables command are stored in memory. If the system is restarted before saving the iptables rule set, all rules are lost. For netfilter rules to persist through a system reboot, they need to be saved. To save netfilter rules, type the following command as root:
service iptables save
service iptables saveiptables init script, which runs the /sbin/iptables-save program and writes the current iptables configuration to /etc/sysconfig/iptables. The existing /etc/sysconfig/iptables file is saved as /etc/sysconfig/iptables.save.
iptables init script reapplies the rules saved in /etc/sysconfig/iptables by using the /sbin/iptables-restore command.
iptables rule before committing it to the /etc/sysconfig/iptables file, it is possible to copy iptables rules into this file from another system's version of this file. This provides a quick way to distribute sets of iptables rules to multiple machines.
iptables-save > <filename>
iptables-save > <filename>Important
/etc/sysconfig/iptables file to other machines, type /sbin/service iptables restart for the new rules to take effect.
Note
iptables command (/sbin/iptables), which is used to manipulate the tables and chains that constitute the iptables functionality, and the iptables service (/sbin/iptables service), which is used to enable and disable the iptables service itself.
48.9.5. IPTables Control Scripts
iptables in Red Hat Enterprise Linux:
- Security Level Configuration Tool (
system-config-securitylevel) — A graphical interface for creating, activating, and saving basic firewall rules. Refer to Section 48.8.2, “Basic Firewall Configuration” for more information. /sbin/service iptables <option>— Used to manipulate various functions ofiptablesusing its initscript. The following options are available:start— If a firewall is configured (that is,/etc/sysconfig/iptablesexists), all runningiptablesare stopped completely and then started using the/sbin/iptables-restorecommand. This option only works if theipchainskernel module is not loaded. To check if this module is loaded, type the following command as root:lsmod | grep ipchains
lsmod | grep ipchainsCopy to Clipboard Copied! Toggle word wrap Toggle overflow If this command returns no output, it means the module is not loaded. If necessary, use the/sbin/rmmodcommand to remove the module.stop— If a firewall is running, the firewall rules in memory are flushed, and all iptables modules and helpers are unloaded.If theIPTABLES_SAVE_ON_STOPdirective in the/etc/sysconfig/iptables-configconfiguration file is changed from its default value toyes, current rules are saved to/etc/sysconfig/iptablesand any existing rules are moved to the file/etc/sysconfig/iptables.save.Refer to Section 48.9.5.1, “IPTables Control Scripts Configuration File” for more information about theiptables-configfile.restart— If a firewall is running, the firewall rules in memory are flushed, and the firewall is started again if it is configured in/etc/sysconfig/iptables. This option only works if theipchainskernel module is not loaded.If theIPTABLES_SAVE_ON_RESTARTdirective in the/etc/sysconfig/iptables-configconfiguration file is changed from its default value toyes, current rules are saved to/etc/sysconfig/iptablesand any existing rules are moved to the file/etc/sysconfig/iptables.save.Refer to Section 48.9.5.1, “IPTables Control Scripts Configuration File” for more information about theiptables-configfile.status— Displays the status of the firewall and lists all active rules.The default configuration for this option displays IP addresses in each rule. To display domain and hostname information, edit the/etc/sysconfig/iptables-configfile and change the value ofIPTABLES_STATUS_NUMERICtono. Refer to Section 48.9.5.1, “IPTables Control Scripts Configuration File” for more information about theiptables-configfile.panic— Flushes all firewall rules. The policy of all configured tables is set toDROP.This option could be useful if a server is known to be compromised. Rather than physically disconnecting from the network or shutting down the system, you can use this option to stop all further network traffic but leave the machine in a state ready for analysis or other forensics.save— Saves firewall rules to/etc/sysconfig/iptablesusingiptables-save. Refer to Section 48.9.4, “Saving IPTables Rules” for more information.
Note
ip6tables for iptables in the /sbin/service commands listed in this section. For more information about IPv6 and netfilter, refer to Section 48.9.6, “IPTables and IPv6”.
48.9.5.1. IPTables Control Scripts Configuration File
iptables initscripts is controlled by the /etc/sysconfig/iptables-config configuration file. The following is a list of directives contained in this file:
IPTABLES_MODULES— Specifies a space-separated list of additionaliptablesmodules to load when a firewall is activated. These can include connection tracking and NAT helpers.IPTABLES_MODULES_UNLOAD— Unloads modules on restart and stop. This directive accepts the following values:yes— The default value. This option must be set to achieve a correct state for a firewall restart or stop.no— This option should only be set if there are problems unloading the netfilter modules.
IPTABLES_SAVE_ON_STOP— Saves current firewall rules to/etc/sysconfig/iptableswhen the firewall is stopped. This directive accepts the following values:yes— Saves existing rules to/etc/sysconfig/iptableswhen the firewall is stopped, moving the previous version to the/etc/sysconfig/iptables.savefile.no— The default value. Does not save existing rules when the firewall is stopped.
IPTABLES_SAVE_ON_RESTART— Saves current firewall rules when the firewall is restarted. This directive accepts the following values:yes— Saves existing rules to/etc/sysconfig/iptableswhen the firewall is restarted, moving the previous version to the/etc/sysconfig/iptables.savefile.no— The default value. Does not save existing rules when the firewall is restarted.
IPTABLES_SAVE_COUNTER— Saves and restores all packet and byte counters in all chains and rules. This directive accepts the following values:yes— Saves the counter values.no— The default value. Does not save the counter values.
IPTABLES_STATUS_NUMERIC— Outputs IP addresses in numeric form instead of domain or hostnames. This directive accepts the following values:yes— The default value. Returns only IP addresses within a status output.no— Returns domain or hostnames within a status output.
48.9.6. IPTables and IPv6
iptables-ipv6 package is installed, netfilter in Red Hat Enterprise Linux can filter the next-generation IPv6 Internet protocol. The command used to manipulate the IPv6 netfilter is ip6tables.
iptables, except the nat table is not yet supported. This means that it is not yet possible to perform IPv6 network address translation tasks, such as masquerading and port forwarding.
ip6tables are saved in the /etc/sysconfig/ip6tables file. Previous rules saved by the ip6tables initscripts are saved in the /etc/sysconfig/ip6tables.save file.
ip6tables init script are stored in /etc/sysconfig/ip6tables-config, and the names for each directive vary slightly from their iptables counterparts.
iptables-config directive IPTABLES_MODULES:the equivalent in the ip6tables-config file is IP6TABLES_MODULES.
48.9.7. Additional Resources
iptables.
- Section 48.8, “Firewalls” — Contains a chapter about the role of firewalls within an overall security strategy as well as strategies for constructing firewall rules.
48.9.7.1. Installed Documentation
man iptables— Contains a description ofiptablesas well as a comprehensive list of targets, options, and match extensions.
48.9.7.2. Useful Websites
- http://www.netfilter.org/ — The home of the netfilter/iptables project. Contains assorted information about
iptables, including a FAQ addressing specific problems and various helpful guides by Rusty Russell, the Linux IP firewall maintainer. The HOWTO documents on the site cover subjects such as basic networking concepts, kernel packet filtering, and NAT configurations. - http://www.linuxnewbie.org/nhf/Security/IPtables_Basics.html — An introduction to the way packets move through the Linux kernel, plus an introduction to constructing basic
iptablescommands.
Chapter 49. Security and SELinux
49.1. Access Control Mechanisms (ACMs)
49.1.1. Discretionary Access Control (DAC)
49.1.2. Access Control Lists (ACLs)
49.1.3. Mandatory Access Control (MAC)
49.1.4. Role-based Access Control (RBAC)
49.1.5. Multi-Level Security (MLS)
49.1.6. Multi-Category Security (MCS)
49.2. Introduction to SELinux
49.2.1. SELinux Overview
When a subject, (for example, an application), attempts to access an object (for example, a file), the policy enforcement server in the kernel checks an access vector cache (AVC), where subject and object permissions are cached. If a decision cannot be made based on data in the AVC, the request continues to the security server, which looks up the security context of the application and the file in a matrix. Permission is then granted or denied, with an avc: denied message detailed in /var/log/messages if permission is denied. The security context of subjects and objects is applied from the installed policy, which also provides the information to populate the security server's matrix.
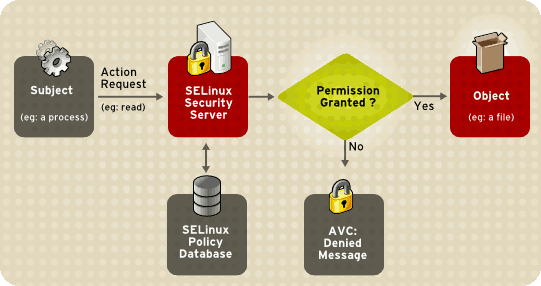
Figure 49.1. SELinux Decision Process
Instead of running in enforcing mode, SELinux can run in permissive mode, where the AVC is checked and denials are logged, but SELinux does not enforce the policy. This can be useful for troubleshooting and for developing or fine-tuning SELinux policy.
49.2.2. Files Related to SELinux
49.2.2.1. The SELinux Pseudo-File System
/selinux/ pseudo-file system contains commands that are most commonly used by the kernel subsystem. This type of file system is similar to the /proc/ pseudo-file system.
/selinux/ directory:
cat command on the enforce file reveals either a 1 for enforcing mode or 0 for permissive mode.
49.2.2.2. SELinux Configuration Files
/etc/ directory.
49.2.2.2.1. The /etc/sysconfig/selinux Configuration File
system-config-selinux), or manually editing the configuration file (/etc/sysconfig/selinux).
/etc/sysconfig/selinux file is the primary configuration file for enabling or disabling SELinux, as well as for setting which policy to enforce on the system and how to enforce it.
Note
/etc/sysconfig/selinux contains a symbolic link to the actual configuration file, /etc/selinux/config.
SELINUX=enforcing|permissive|disabled— Defines the top-level state of SELinux on a system.enforcing— The SELinux security policy is enforced.permissive— The SELinux system prints warnings but does not enforce policy.This is useful for debugging and troubleshooting purposes. In permissive mode, more denials are logged because subjects can continue with actions that would otherwise be denied in enforcing mode. For example, traversing a directory tree in permissive mode producesavc: deniedmessages for every directory level read. In enforcing mode, SELinux would have stopped the initial traversal and kept further denial messages from occurring.disabled— SELinux is fully disabled. SELinux hooks are disengaged from the kernel and the pseudo-file system is unregistered.Note
Actions made while SELinux is disabled may result in the file system no longer having the correct security context. That is, the security context defined by the policy. The best way to relabel the file system is to create the flag file/.autorelabeland reboot the machine. This causes the relabel to occur very early in the boot process, before any processes are running on the system. Using this procedure means that processes can not accidentally create files in the wrong context or start up in the wrong context.It is possible to use thefixfiles relabelcommand prior to enabling SELinux to relabel the file system. This method is not recommended, however, because after it is complete, it is still possible to have processes potentially running on the system in the wrong context. These processes could create files that would also be in the wrong context.
Note
Additional white space at the end of a configuration line or as extra lines at the end of the file may cause unexpected behavior. To be safe, remove unnecessary white space.SELINUXTYPE=— Specifies which policy SELinux should enforce.targeted|stricttargeted— Only targeted network daemons are protected.Important
The following daemons are protected in the default targeted policy:dhcpd, httpd (apache.te), named, nscd, ntpd, portmap, snmpd, squid, andsyslogd. The rest of the system runs in the unconfined_t domain. This domain allows subjects and objects with that security context to operate using standard Linux security.The policy files for these daemons are located in/etc/selinux/targeted/src/policy/domains/program. These files are subject to change as newer versions of Red Hat Enterprise Linux are released.Policy enforcement for these daemons can be turned on or off, using Boolean values controlled by the SELinux Administration Tool (system-config-selinux).Setting a Boolean value for a targeted daemon to1disables SELinux protection for the daemon. For example, you can setdhcpd_disable_transto1to preventinit, which executes apps labeleddhcpd_exec_t, from transitioning to thedhcpd_tdomain.Use thegetsebool -acommand to list all SELinux booleans. The following is an example of using thesetseboolcommand to set an SELinux boolean. The-Poption makes the change permanent. Without this option, the boolean would be reset to1at reboot.setsebool -P dhcpd_disable_trans=0
setsebool -P dhcpd_disable_trans=0Copy to Clipboard Copied! Toggle word wrap Toggle overflow strict— Full SELinux protection, for all daemons. Security contexts are defined for all subjects and objects, and every action is processed by the policy enforcement server.
SETLOCALDEFS=— Controls how local definitions (users and booleans) are set. Set this value to 1 to have these definitions controlled by0|1load_policyfrom files in/etc/selinux/<policyname>. or set it to 0 to have them controlled bysemanage.Warning
You should not change this value from the default (0) unless you are fully aware of the impact of such a change.
49.2.2.2.2. The /etc/selinux/ Directory
/etc/selinux/ directory is the primary location for all policy files as well as the main configuration file.
/etc/selinux/ directory:
-rw-r--r-- 1 root root 448 Sep 22 17:34 config drwxr-xr-x 5 root root 4096 Sep 22 17:27 strict drwxr-xr-x 5 root root 4096 Sep 22 17:28 targeted
-rw-r--r-- 1 root root 448 Sep 22 17:34 config
drwxr-xr-x 5 root root 4096 Sep 22 17:27 strict
drwxr-xr-x 5 root root 4096 Sep 22 17:28 targetedstrict/ and targeted/, are the specific directories where the policy files of the same name (that is, strict and targeted) are contained.
49.2.2.3. SELinux Utilities
/usr/sbin/setenforce— Modifies in real-time the mode in which SELinux runs.For example:setenforce 1— SELinux runs in enforcing mode.setenforce 0— SELinux runs in permissive mode.To actually disable SELinux, you need to either specify the appropriatesetenforceparameter in/etc/sysconfig/selinuxor pass the parameterselinux=0to the kernel, either in/etc/grub.confor at boot time./usr/sbin/sestatus -v— Displays the detailed status of a system running SELinux. The following example shows an excerpt ofsestatus -voutput:Copy to Clipboard Copied! Toggle word wrap Toggle overflow /usr/bin/newrole— Runs a new shell in a new context, or role. Policy must allow the transition to the new role.Note
This command is only available if you have thepolicycoreutils-newrolepackage installed, which is required for the strict and MLS policies./sbin/restorecon— Sets the security context of one or more files by marking the extended attributes with the appropriate file or security context./sbin/fixfiles— Checks or corrects the security context database on the file system.
setools or policycoreutils package contents for more information on all available binary utilities. To view the contents of a package, use the following command:
rpm -ql <package-name>
49.2.3. Additional Resources
49.2.3.1. Installed Documentation
/usr/share/doc/setools-<version-number>/All documentation for utilities contained in thesetoolspackage. This includes all helper scripts, sample configuration files, and documentation.
49.2.3.2. Useful Websites
- http://www.nsa.gov/research/selinux/index.shtml Homepage for the NSA SELinux development team. Many resources are available in HTML and PDF formats. Although many of these links are not SELinux specific, some concepts may apply.
- http://docs.fedoraproject.org/ Homepage for the Fedora documentation project, which contains Fedora Core specific materials that may be more timely, since the release cycle is much shorter.
- http://selinux.sourceforge.net Homepage for the SELinux community.
49.3. Brief Background and History of SELinux
49.4. Multi-Category Security (MCS)
49.4.1. Introduction
49.4.1.1. What is Multi-Category Security?
49.4.2. Applications for Multi-Category Security
49.4.3. SELinux Security Contexts
"security." namespace is used for security modules, and the security.selinux name is used to persistently store SELinux security labels on files. The contents of this attribute will vary depending on the file or directory you inspect and the policy the machine is enforcing.
Note
getxattr(2) always returns the kernel's canonicalized version of the label.
ls -Z command to view the category label of a file:
ls -Z gravityControl.txt -rw-r--r-- user user user_u:object_r:tmp_t:Moonbase_Plans gravityControl.txt
~]# ls -Z gravityControl.txt
-rw-r--r-- user user user_u:object_r:tmp_t:Moonbase_Plans gravityControl.txtgefattr(1) command to view the internal category value (c10):
getfattr -n security.selinux gravityControl.txt # file: gravityControl.txt security.selinux="user_u:object_r:tmp_t:s0:c10\000"
~]# getfattr -n security.selinux gravityControl.txt
# file: gravityControl.txt
security.selinux="user_u:object_r:tmp_t:s0:c10\000"49.5. Getting Started with Multi-Category Security (MCS)
49.5.1. Introduction
49.5.2. Comparing SELinux and Standard Linux User Identities
- system_u — System processes
- root — System administrator
- user_u — All login users
semanage user -l command to list SELinux users:
One of the properties of targeted policy is that login users all run in the same security context. From a TE point of view, in targeted policy, they are security-equivalent. To effectively use MCS, however, we need to be able to assign different sets of categories to different Linux users, even though they are all the same SELinux user (user_u). This is solved by introducing the concept of an SELinux login. This is used during the login process to assign MCS categories to Linux users when their shell is launched.
semanage login -a command to assign Linux users to SELinux user identities:
semanage login -a james semanage login -a daniel semanage login -a olga
~]# semanage login -a james
~]# semanage login -a daniel
~]# semanage login -a olga49.5.3. Configuring Categories
setrans.conf file. The system administrator edits this file to manage and maintain the required categories.
chcat -L command to list the current categories:
chcat -L s0 s0-s0:c0.c1023 SystemLow-SystemHigh s0:c0.c1023 SystemHigh
~]# chcat -L
s0
s0-s0:c0.c1023 SystemLow-SystemHigh
s0:c0.c1023 SystemHigh/etc/selinux/<selinuxtype>/setrans.conf file. For the example introduced above, add the Marketing, Finance, Payroll, and Personnel categories as follows (this example uses the targeted policy, and irrelevant sections of the file have been omitted):
vi /etc/selinux/targeted/setrans.conf s0:c0=Marketing s0:c1=Finance s0:c2=Payroll s0:c3=Personnel
~]# vi /etc/selinux/targeted/setrans.conf
s0:c0=Marketing
s0:c1=Finance
s0:c2=Payroll
s0:c3=Personnelchcat -L command to check the newly-added categories:
Note
setrans.conf file, you need to restart the MCS translation service before those changes take effect. Use the following command to restart the service:
service mcstrans restart
~]# service mcstrans restart49.5.4. Assigning Categories to Users
chcat command to assign MCS categories to SELinux logins:
chcat -l -- +Marketing james chcat -l -- +Finance,+Payroll daniel chcat -l -- +Personnel olga
~]# chcat -l -- +Marketing james
~]# chcat -l -- +Finance,+Payroll daniel
~]# chcat -l -- +Personnel olgachcat command with additional command-line arguments to list the categories that are assigned to users:
chcat -L -l daniel james olga daniel: Finance,Payroll james: Marketing olga: Personnel
~]# chcat -L -l daniel james olga
daniel: Finance,Payroll
james: Marketing
olga: Personnelchcat command to verify the addition of the new user:
chcat -L -l daniel james olga karl daniel: Finance,Payroll james: Marketing olga: Personnel karl: Marketing,Finance,Payroll,Personnel
~]# chcat -L -l daniel james olga karl
daniel: Finance,Payroll
james: Marketing
olga: Personnel
karl: Marketing,Finance,Payroll,PersonnelNote
49.5.5. Assigning Categories to Files
echo "Financial Records 2006" > financeRecords.txt
[daniel@dhcp-133 ~]$ echo "Financial Records 2006" > financeRecords.txtls -Z command to check the initial security context of the file:
ls -Z financeRecords.txt -rw-r--r-- daniel daniel user_u:object_r:user_home_t financeRecords.txt
[daniel@dhcp-133 ~]$ ls -Z financeRecords.txt
-rw-r--r-- daniel daniel user_u:object_r:user_home_t financeRecords.txtuser_home_t) and has no categories assigned to it. We can add the required category using the chcat command. Now when you check the security context of the file, you can see the category has been applied.
chcat -- +Finance financeRecords.txt ls -Z financeRecords.txt -rw-r--r-- daniel daniel root:object_r:user_home_t:Finance financeRecords.txt
[daniel@dhcp-133 ~]$ chcat -- +Finance financeRecords.txt
[daniel@dhcp-133 ~]$ ls -Z financeRecords.txt
-rw-r--r-- daniel daniel root:object_r:user_home_t:Finance financeRecords.txtchcat -- +Payroll financeRecords.txt ls -Z financeRecords.txt -rw-r--r-- daniel daniel root:object_r:user_home_t:Finance,Payroll financeRecords.txt
[daniel@dhcp-133 ~]$ chcat -- +Payroll financeRecords.txt
[daniel@dhcp-133 ~]$ ls -Z financeRecords.txt
-rw-r--r-- daniel daniel root:object_r:user_home_t:Finance,Payroll financeRecords.txt[olga@dhcp-133 ~]$ cat financeRecords.txt cat: financeRecords.txt: Permission Denied
[olga@dhcp-133 ~]$ cat financeRecords.txt
cat: financeRecords.txt: Permission DeniedNote
semanage and chcat for more information on the available options for these commands.
49.6. Multi-Level Security (MLS)
49.6.1. Why Multi-Level?
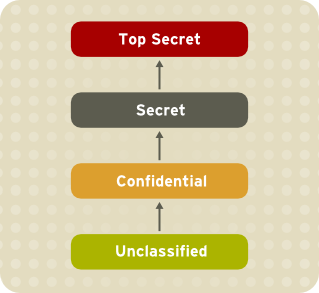
Figure 49.2. Information Security Levels
49.6.1.1. The Bell-La Padula Model (BLP)
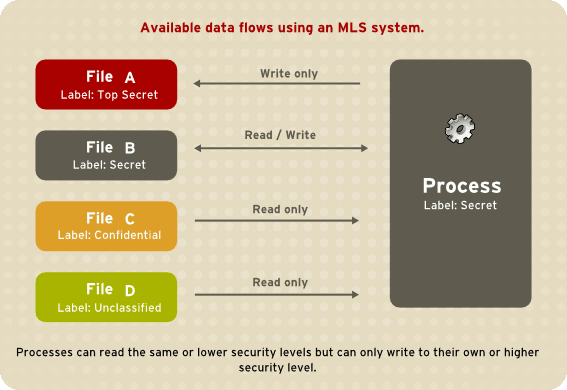
Figure 49.3. Available data flows using an MLS system
49.6.1.2. MLS and System Privileges
49.6.2. Security Levels, Objects and Subjects
Sensitivity: — A hierarchical attribute such as "Secret" or "Top Secret".Categories: — A set of non-hierarchical attributes such as "US Only" or "UFO".
Note
- Security Levels on objects are called Classifications.
- Security Levels on subjects are called Clearances.
49.6.3. MLS Policy
49.6.4. Enabling MLS in SELinux
Note
- Install the selinux-policy-mls package:
yum install selinux-policy-mls
~]# yum install selinux-policy-mlsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Before the MLS policy is enabled, each file on the file system must be relabeled with an MLS label. When the file system is relabeled, confined domains may be denied access, which may prevent your system from booting correctly. To prevent this from happening, configure
SELINUX=permissivein the/etc/selinux/configfile. Also, enable the MLS policy by configuringSELINUXTYPE=mls. Your configuration file should look like this:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Make sure SELinux is running in the permissive mode:
setenforce 0 getenforce Permissive
~]# setenforce 0 ~]# getenforce PermissiveCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Create the
.autorelabelfile in root's home directory to ensure that files are relabeled upon next reboot:touch /.autorelabel
~]# touch /.autorelabelCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Reboot your system. During the next boot, all file systems will be relabeled according to the MLS policy. The label process labels all files with an appropriate SELinux context:
*** Warning -- SELinux mls policy relabel is required. *** Relabeling could take a very long time, depending on file *** system size and speed of hard drives. ***********
*** Warning -- SELinux mls policy relabel is required. *** Relabeling could take a very long time, depending on file *** system size and speed of hard drives. ***********Copy to Clipboard Copied! Toggle word wrap Toggle overflow Each * (asterisk) character on the bottom line represents 1000 files that have been labeled. In the above example, eleven * characters represent 11000 files which have been labeled. The time it takes to label all files depends upon the number of files on the system, and the speed of the hard disk drives. On modern systems, this process can take as little as 10 minutes. Once the labeling process finishes, the system will automatically reboot. - Once the file system is relabeled, execute the following commands to assure that the
/rootdirectory and all other home directories are properly labeled:genhomedircon restorecon -R -v /root /home <other_home_directories>
~]# genhomedircon ~]# restorecon -R -v /root /home <other_home_directories>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - In permissive mode, SELinux policy is not enforced, but denials are still logged for actions that would have been denied if running in enforcing mode. Before changing to enforcing mode, as the Linux root user, run the
grep "SELinux is preventing" /var/log/messagescommand to confirm that SELinux did not deny actions during the last boot. If SELinux did not deny actions during the last boot, this command does not return any output. - If there were no denial messages in
/var/log/messages, or you have resolved all existing denials, configureSELINUX=enforcingin the/etc/selinux/configfile:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Reboot your system and make sure SELinux is running in permissive mode:
getenforce Enforcing
~]$ getenforce EnforcingCopy to Clipboard Copied! Toggle word wrap Toggle overflow and the MLS policy is enabled:sestatus |grep mls Policy from config file: mls
~]# sestatus |grep mls Policy from config file: mlsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
49.6.5. LSPP Certification
49.7. SELinux Policy Overview
49.7.1. What is the SELinux Policy?
49.7.1.1. SELinux Types
user_home_t.
unconfined_t domain have an executable file with a type such as sbin_t. From an SELinux perspective, this means they are all equivalent in terms of what they can and cannot do on the system.
/usr/bin/postgres has the type postgresql_exec_t. All of the targeted daemons have their own *_exec_t type for their executable applications. In fact, the entire set of PostgreSQL executables such as createlang, pg_dump, and pg_restore have the same type, postgresql_exec_t, and they transition to the same domain, postgresql_t, upon execution.
49.7.1.1.1. Using Policy Rules to Define Type Access
$AUDIT_LOG file. In Red Hat Enterprise Linux, this is set to /var/log/messages. The policy is compiled into binary format for loading into the kernel security server, and each time the security server makes a decision, it is cached in the AVC to optimize performance.
init, as explained in Section 49.7.3, “The Role of Policy in the Boot Process”. Ultimately, every system operation is determined by the policy and the type-labeling of the files.
Important
49.7.1.2. SELinux and Mandatory Access Control
m4 macros to capture common sets of low-level rules. A number of m4 macros are defined in the existing policy, which facilitate the writing of new policy. These rules are preprocessed into many additional rules as part of building the policy.conf file, which is compiled into the binary policy.
newrole, or by requiring a new process execution in the new domain. This movement between domains is referred to as a transition
.
49.7.2. Where is the Policy?
selinux-policy-<policyname> package and supplies the binary policy file.
selinux-policy-devel package is installed.
Note
49.7.2.1. Binary Tree Files
/etc/selinux/targeted/— this is the root directory for the targeted policy, and contains the binary tree./etc/selinux/targeted/policy/— this is the location of the binary policy filepolicy.<xx>. In this guide, the variableSELINUX_POLICYis used for this directory./etc/selinux/targeted/contexts/— this is the location of the security context information and configuration files, which are used during runtime by various applications./etc/selinux/targeted/contexts/files/— contains the default contexts for the entire file system. This is referenced byrestoreconwhen performing relabeling operations./etc/selinux/targeted/contexts/users/— in the targeted policy, only therootfile is in this directory. These files are used for determining context when a user logs in. For example, for the root user, the context is user_u:system_r:unconfined_t./etc/selinux/targeted/modules/active/booleans*— this is where the runtime Booleans are configured.Note
These files should never be manually changed. You should use thegetsebool,setseboolandsemanagetools to manipulate runtime Booleans.
49.7.2.2. Source Tree Files
selinux-policy-devel package includes all of the interface files used to build policy. It is recommended that people who build policy use these files to build the policy modules.
/usr/share/selinux/devel/include and has make files installed in /usr/share/selinux/devel/Makefile.
libselinux provides a number of functions that return the paths to the different configuration files and directories. This negates the need for applications to hard-code the paths, especially since the active policy location is dependent on the SELINUXTYPE setting in /etc/selinux/config.
/etc/selinux/strict.
man 3 selinux_binary_policy_path
man 3 selinux_binary_policy_pathNote
libselinux-devel RPM installed.
libselinux and related functions is outside the scope of this document.
49.7.3. The Role of Policy in the Boot Process
init performs some essential operations early in the boot process to maintain synchronization between labeling and policy enforcement.
- After the kernel has been loaded during the boot process, the initial process is assigned the predefined initial SELinux ID (initial SID) kernel. Initial SIDs are used for bootstrapping before the policy is loaded.
/sbin/initmounts/proc/, and then searches for theselinuxfsfile system type. If it is present, that means SELinux is enabled in the kernel.- If
initdoes not find SELinux in the kernel, or if it is disabled via theselinux=0boot parameter, or if/etc/selinux/configspecifies thatSELINUX=disabled, the boot process proceeds with a non-SELinux system.At the same time,initsets the enforcing status if it is different from the setting in/etc/selinux/config. This happens when a parameter is passed during the boot process, such asenforcing=0orenforcing=1. The kernel does not enforce any policy until the initial policy is loaded. - If SELinux is present,
/selinux/is mounted. initchecks/selinux/policyversfor the supported policy version. The version number in/selinux/policyversis the latest policy version your kernel supports.initinspects/etc/selinux/configto determine which policy is active, such as the targeted policy, and loads the associated file at$SELINUX_POLICY/policy.<version>.If the binary policy is not the version supported by the kernel,initattempts to load the policy file if it is a previous version. This provides backward compatibility with older policy versions.If the local settings in/etc/selinux/targeted/booleansare different from those compiled in the policy,initmodifies the policy in memory based on the local settings prior to loading the policy into the kernel.- By this stage of the process, the policy is fully loaded into the kernel. The initial SIDs are then mapped to security contexts in the policy. In the case of the targeted policy, the new domain is user_u:system_r:unconfined_t. The kernel can now begin to retrieve security contexts dynamically from the in-kernel security server.
initthen re-executes itself so that it can transition to a different domain, if the policy defines it. For the targeted policy, there is no transition defined andinitremains in theunconfined_tdomain.- At this point,
initcontinues with its normal boot process.
init re-executes itself is to accommodate stricter SELinux policy controls. The objective of re-execution is to transition to a new domain with its own granular rules. The only way that a process can enter a domain is during execution, which means that such processes are the only entry points
into the domains.
init, such as init_t, a method is required to change from the initial SID, such as kernel, to the correct runtime domain for init. Because this transition may need to occur, init is coded to re-execute itself after loading the policy.
init transition occurs if the domain_auto_trans(kernel_t, init_exec_t, <target_domain_t>) rule is present in the policy. This rule states that an automatic transition occurs on anything executing in the kernel_t domain that executes a file of type init_exec_t. When this execution occurs, the new process is assigned the domain <target_domain_t>, using an actual target domain such as init_t.
49.7.4. Object Classes and Permissions
- File-related classes include
filesystemfor file systems,filefor files, anddirfor directories. Each class has its own associated set of permissions.Thefilesystemclass can mount, unmount, get attributes, set quotas, relabel, and so forth. Thefileclass has common file permissions such as read, write, get and set attributes, lock, relabel, link, rename, append, etc. - Network related classes include
tcp_socketfor TCP sockets,netiffor network interfaces, andnodefor network nodes.Thenetifclass, for example, can send and receive on TCP, UDP and raw sockets (tcp_recv,tcp_send,udp_send,udp_recv,rawip_recv, andrawip_send.)
49.8. Targeted Policy Overview
49.8.1. What is the Targeted Policy?
unconfined_t domain except for the specific targeted daemons. Objects that are in the unconfined_t domain have no restrictions and fall back to using standard Linux security, that is, DAC. The daemons that are part of the targeted policy run in their own domains and are restricted in every operation they perform on the system. This way daemons that are exploited or compromised in any way are contained and can only cause limited damage.
http and ntp daemons are both protected in the default targeted policy, and run in the httpd_t and ntpd_t domains, respectively. The ssh daemon, however, is not protected in this policy, and consequently runs in the unconfined_t domain.
user_u:system_r:httpd_t 25129 ? 00:00:00 httpd user_u:system_r:ntpd_t 25176 ? 00:00:00 ntpd system_u:system_r:unconfined_t 25245 ? 00:00:00 sshd
user_u:system_r:httpd_t 25129 ? 00:00:00 httpd
user_u:system_r:ntpd_t 25176 ? 00:00:00 ntpd
system_u:system_r:unconfined_t 25245 ? 00:00:00 sshdThe opposite of the targeted policy is the strict policy . In the strict policy, every subject and object exists in a specific security domain, and all interactions and transitions are individually considered within the policy rules.
dhcpd; httpd; mysqld; named; nscd; ntpd; portmap; postgres; snmpd; squid; syslogd; and winbind.
Note
49.8.2. Files and Directories of the Targeted Policy
49.8.3. Understanding the Users and Roles in the Targeted Policy
unconfined_t type exists in every role, which significantly reduces the usefulness of roles in the targeted policy. More extensive use of roles requires a change to the strict policy paradigm, where every process runs in an individually considered domain.
system_r and object_r. The initial role is system_r, and everything else inherits that role. The remaining roles are defined for compatibility purposes between the targeted policy and the strict policy.[20]
object_r, is an implied role and is not found in policy source. Because roles are created and populated by types using one or more declarations in the policy, there is no single file that declares all roles. (Remember that the policy itself is generated from a number of separate files.)
system_r- This role is for all system processes except user processes:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow user_r- This is the default user role for regular Linux users. In a strict policy, individual users might be used, allowing for the users to have special roles to perform privileged operations. In the targeted policy, all users run in the
unconfined_tdomain. object_r- In SELinux, roles are not utilized for objects when RBAC is being used. Roles are strictly for subjects. This is because roles are task-oriented and they group together entities which perform actions (for example, processes). All such entities are collectively referred to as subjects. For this reason, all objects have the role
object_r, and the role is only used as a placeholder in the label. sysadm_r- This is the system administrator role in a strict policy. If you log in directly as the root user, the default role may actually be
staff_r. If this is true, use thenewrole -r sysadm_rcommand to change to the SELinux system administrator role to perform system administration tasks. In the targeted policy, the following retainsysadm_rfor compatibility:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
user_u identity was chosen because libselinux falls back to user_u as the default SELinux user identity. This occurs when there is no matching SELinux user for the Linux user who is logging in. Using user_u as the single user in the targeted policy makes it easier to change to the strict policy. The remaining users exist for compatibility with the strict policy.[21]
root. You may notice root as the user identity in a process's context. This occurs when the SELinux user root starts daemons from the command line, or restarts a daemon originally started by init.
system_r already had existing authorization for the daemon domains, simplifying the process. This was done because no mechanism currently exists to alias roles.
Chapter 50. Working With SELinux
50.1. End User Control of SELinux
unconfined_t along with the rest of the system except the targeted daemons.
avc: denied message.
50.1.1. Moving and Copying Files
mv and cp may have unexpected results.
Unless you specify otherwise, cp follows the default behavior of creating a new file based on the domain of the creating process and the type of the target directory. Unless there is a specific rule to set the label, the file inherits the type from the target directory.
-Z user:role:type option to specify the required label for the new file.
-p (or --preserve=mode,ownership,timestamps) option preserves the specified attributes and, if possible, additional attributes such as links.
touch bar foo ls -Z bar foo -rw-rw-r-- auser auser user_u:object_r:user_home_t bar -rw-rw-r-- auser auser user_u:object_r:user_home_t foo
touch bar foo
ls -Z bar foo
-rw-rw-r-- auser auser user_u:object_r:user_home_t bar
-rw-rw-r-- auser auser user_u:object_r:user_home_t foo
cp command without any additional command-line arguments, a copy of the file is created in the new location using the default type of the creating process and the target directory. In this case, because there is no specific rule that applies to cp and /tmp, the new file has the type of the parent directory:
cp bar /tmp ls -Z /tmp/bar -rw-rw-r-- auser auser user_u:object_r:tmp_t /tmp/bar
cp bar /tmp
ls -Z /tmp/bar
-rw-rw-r-- auser auser user_u:object_r:tmp_t /tmp/bar
tmp_t is the default type for temporary files.
-Z option to specify the label for the new file:
cp -Z user_u:object_r:user_home_t foo /tmp ls -Z /tmp/foo -rw-rw-r-- auser auser user_u:object_r:user_home_t /tmp/foo
cp -Z user_u:object_r:user_home_t foo /tmp
ls -Z /tmp/foo
-rw-rw-r-- auser auser user_u:object_r:user_home_t /tmp/foo
Moving files with mv retains the original type associated with the file. Care should be taken using this command as it can cause problems. For example, if you move files with the type user_home_t into ~/public_html, then the httpd daemon is not able to serve those files until you relabel them. Refer to Section 50.1.3, “Relabeling a File or Directory” for more information about file labeling.
| Command | Behavior |
|---|---|
mv | The file retains its original label. This may cause problems, confusion, or minor insecurity. For example, the tmpwatch program running in the sbin_t domain might not be allowed to delete an aged file in the /tmp directory because of the file's type. |
cp | Makes a copy of the file using the default behavior based on the domain of the creating process (cp) and the type of the target directory. |
cp -p | Makes a copy of the file, preserving the specified attributes and security contexts, if possible. The default attributes are mode, ownership, and timestamps. Additional attributes are links and all. |
cp -Z <user:role:type> | Makes a copy of the file with the specified labels. The -Z option is synonymous with --context. |
50.1.2. Checking the Security Context of a Process, User, or File Object
In Red Hat Enterprise Linux, the -Z option is equivalent to --context, and can be used with the ps, id, ls, and cp commands. The behavior of the cp command with respect to SELinux is explained in Table 50.1, “Behavior of mv and cp Commands”.
ps command. Most of the processes are running in the unconfined_t domain, with a few exceptions.
You can use the -Z option with the id command to determine a user's security context. Note that with this command you cannot combine -Z with other options.
id -Z user_u:system_r:unconfined_t
[root@localhost ~]# id -Z
user_u:system_r:unconfined_t
-Z option with the id command to inspect the security context of a different user. That is, you can only display the security context of the currently logged-in user:
You can use the -Z option with the ls command to group common long-format information. You can display mode, user, group, security context, and filename information.
50.1.3. Relabeling a File or Directory
~/public_html directories, or when writing scripts that work in directories outside of /home.
- Deliberately changing the type of a file
- Restoring files to the default state according to policy
Note
Note
/usr/sbin/mysqld has the wrong security label, and you address this by using a relabeling operation such as restorecon, you must restart mysqld after the relabeling operation. Setting the executable file to have the correct type (mysqld_exec_t) ensures that it transitions to the proper domain when started.
chcon command to change a file to the correct type. You need to know the correct type that you want to apply to use this command. The directories and files in the following example are labeled with the default type defined for file system objects created in /home:
public_html directory, they retain the original type:
httpd has permissions to read, presuming the Apache HTTP Server is configured for UserDir and the Boolean value httpd_enable_homedirs is enabled.
Note
chcon system_u:object_r:shlib_t foo.so. Otherwise, you will receive an error about applying a partial context to an unlabeled file.
restorecon command to restore files to the default values according to the policy. There are two other methods for performing this operation that work on the entire file system: fixfiles or a policy relabeling operation. Each of these methods requires superuser privileges. Cautions against both of these methods appear in Section 50.2.2, “Relabeling a File System”.
archives/ directory already has the default type because it was created in the user's home directory:
ls -Zd archives/ drwxrwxr-x auser auser user_u:object_r:user_home_t archives/
ls -Zd archives/
drwxrwxr-x auser auser user_u:object_r:user_home_t archives/
restorecon command to relabel the files uses the default file contexts set by the policy, so these files are labeled with the default label for their current directory.
50.1.4. Creating Archives That Retain Security Contexts
tar or star utilities to create archives that retain SELinux security contexts. The following example uses star to demonstrate how to create such an archive. You need to use the appropriate -xattr and -H=exustar options to ensure that the extra attributes are captured and that the header for the *.star file is of a type that fully supports xattrs. Refer to the man page for more information about these and other options.
star -xattr -H=exustar -c -f all_web.star public_html/ web_files/ star: 11 blocks + 0 bytes (total of 112640 bytes = 110.00k).
star -xattr -H=exustar -c -f all_web.star public_html/ web_files/
star: 11 blocks + 0 bytes (total of 112640 bytes = 110.00k).
ls command with the -Z option to validate the security context:
ls -Z all_web.star -rw-rw-r-- auser auser user_u:object_r:user_home_t \ all_web.star
ls -Z all_web.star
-rw-rw-r-- auser auser user_u:object_r:user_home_t \ all_web.star
/tmp. If there is no specific policy to make a derivative temporary type, the default behavior is to acquire the tmp_t type.
cp all_web.star /tmp/ cd /tmp/ ls -Z all_web.star -rw-rw-r-- auser auser user_u:object_r:tmp_t all_web.star
cp all_web.star /tmp/ cd /tmp/
ls -Z all_web.star
-rw-rw-r-- auser auser user_u:object_r:tmp_t all_web.star
star and it restores the extended attributes:
Warning
star, the archive expands on that same path. For example, an archive made with this command restores the files to /var/log/httpd/:
star -xattr -H=exustar -c -f httpd_logs.star /var/log/httpd/
star -xattr -H=exustar -c -f httpd_logs.star /var/log/httpd/
star issues a warning if the files in the path are newer than the ones in the archive.
50.2. Administrator Control of SELinux
50.2.1. Viewing the Status of SELinux
sestatus command provides a configurable view into the status of SELinux. The simplest form of this command shows the following information:
-v option includes information about the security contexts of a series of files that are specified in /etc/sestatus.conf:
-b displays the current state of booleans. You can use this in combination with grep or other tools to determine the status of particular booleans:
50.2.2. Relabeling a File System
The recommended method for relabeling a file system is to reboot the machine. This allows the init process to perform the relabeling, ensuring that applications have the correct labels when they are started and that they are started in the right order. If you relabel a file system without rebooting, some processes may continue running with an incorrect context. Manually ensuring that all the daemons are restarted and running in the correct context can be difficult.
touch /.autorelabel reboot
touch /.autorelabel
rebootinit.rc checks for the existence of /.autorelabel. If this file exists, SELinux performs a complete file system relabel (using the /sbin/fixfiles -f -F relabel command), and then deletes /.autorelabel.
It is possible to relabel a file system using the fixfiles command, or to relabel based on the RPM database:
fixfiles command:
fixfiles relabel
fixfiles relabelfixfiles -R <packagename> restore
fixfiles -R <packagename> restorefixfiles to restore contexts from packages is safer and quicker.
Warning
fixfiles on the entire file system without rebooting may make the system unstable.
fixfiles relabel prompts for approval to empty /tmp/ because it is not possible to reliably relabel /tmp/. Since fixfiles is run as root, temporary files that applications are relying upon are erased. This could make the system unstable or behave unexpectedly.
50.2.3. Managing NFS Home Directories
nfs_t type, which is not a type that httpd_t is allowed to execute.
nfs_t, try mounting the home directories with a different context:
mount -t nfs -o context=user_u:object_r:user_home_dir_t \ fileserver.example.com:/shared/homes/ /home
mount -t nfs -o context=user_u:object_r:user_home_dir_t \
fileserver.example.com:/shared/homes/ /homeWarning
httpd can execute scripts. If you do this for user home directories, it gives the Apache HTTP Server increased access to those directories. Remember that a mountpoint label applies to the entire mounted file system.
50.2.4. Granting Access to a Directory or a Tree
root_t, tmp_t, and usr_t that grant read access for a directory. These types are suitable for directories that do not contain any confidential information, and that you want to be widely readable. They could also be used for a parent directory of more secured directories with different contexts.
avc: denied message, there are some common problems that arise with directory traversal. For example, many programs run a command equivalent to ls -l / that is not necessary to their operation but generates a denial message in the logs. For this you need to create a dontaudit rule in your local.te file.
path=/ component. This path is not related to the label for the root file system, /. It is actually relative to the root of the file system on the device node. For example, if your /var/ directory is located on an LVM (Logical Volume Management [22]) device, /dev/dm-0, the device node is identified in the message as dev=dm-0. When you see path=/ in this example, that is the top level of the LVM device dm-0, not necessarily the same as the root file system designation /.
50.2.5. Backing Up and Restoring the System
50.2.6. Enabling or Disabling Enforcement
setenforce command to change between permissive and enforcing modes at runtime. Use setenforce 0 to enter permissive mode; use setenforce 1 to enter enforcing mode.
sestatus command displays the current mode and the mode from the configuration file referenced during boot:
sestatus | grep -i mode Current mode: permissive Mode from config file: permissive
~]# sestatus | grep -i mode
Current mode: permissive
Mode from config file: permissivesetenforce 1 sestatus | grep -i mode Current mode: enforcing Mode from config file: permissive
~]# setenforce 1
~]# sestatus | grep -i mode
Current mode: enforcing
Mode from config file: permissivenamed daemon and SELinux, you can turn off enforcing for just that daemon.
getsebool command to get the current status of the boolean:
getsebool named_disable_trans named_disable_trans --> off
~]# getsebool named_disable_trans
named_disable_trans --> offsetsebool named_disable_trans 1 getsebool named_disable_trans named_disable_trans --> on
~]# setsebool named_disable_trans 1
~]# getsebool named_disable_trans
named_disable_trans --> onNote
-P option to make the change persistent across reboots.
getsebool -a | grep disable.*on httpd_disable_trans=1 mysqld_disable_trans=1 ntpd_disable_trans=1
~]# getsebool -a | grep disable.*on
httpd_disable_trans=1
mysqld_disable_trans=1
ntpd_disable_trans=1setsebool command:
setsebool -P httpd_disable_trans=1 mysqld_disable_trans=1 ntpd_disable_trans=1
setsebool -P httpd_disable_trans=1 mysqld_disable_trans=1 ntpd_disable_trans=1togglesebool <boolean_name> to change the value of a specific boolean:
getsebool httpd_disable_trans httpd_disable_trans --> off togglesebool httpd_disable_trans httpd_disable_trans: active
~]# getsebool httpd_disable_trans
httpd_disable_trans --> off
~]# togglesebool httpd_disable_trans
httpd_disable_trans: activeUse the following procedure to change a runtime boolean using the GUI.
Note
- On the menu, point to and then click to display the Security Level Configuration dialog box.
- Click the SELinux tab, and then click Modify SELinux Policy.
- In the selection list, click the arrow next to the Name Service entry, and select the Disable SELinux protection for named daemon check box.
- Click to apply the change. Note that it may take a short time for the policy to be reloaded.
Figure 50.1. Using the Security Level Configuration dialog box to change a runtime boolean.
setenforce(1), getenforce(1), and selinuxenabled(1) commands.
50.2.7. Enable or Disable SELinux
Important
/etc/sysconfig/selinux file. This file is a symlink to /etc/selinux/config. The configuration file is self-explanatory. Changing the value of SELINUX or SELINUXTYPE changes the state of SELinux and the name of the policy to be used the next time the system boots.
Use the following procedure to change the mode of SELinux using the GUI.
Note
- On the menu, point to and then click to display the Security Level Configuration dialog box.
- Click the SELinux tab.
- In the SELinux Setting select either
Disabled,EnforcingorPermissive, and then click . - If you changed from
EnabledtoDisabledor vice versa, you need to restart the machine for the change to take effect.
/etc/sysconfig/selinux.
50.2.8. Changing the Policy
/etc/sysconfig/selinux:
SELINUXTYPE=<policyname>
SELINUXTYPE=<policyname>/etc/selinux/. This assumes that you have the custom policy installed. After changing the SELINUXTYPE parameter, run the following commands:
touch /.autorelabel reboot
touch /.autorelabel
rebootNote
- Ensure that the complete directory structure for the required policy exists under
/etc/selinux. - On the menu, point to and then click to display the Security Level Configuration dialog box.
- Click the SELinux tab.
- In the Policy Type list, select the policy that you want to load, and then click . This list is only visible if more than one policy is installed.
- Restart the machine for the change to take effect.
Figure 50.2. Using the Security Level Configuration dialog box to load a custom policy.
50.2.9. Specifying the Security Context of Entire File Systems
mount -o context= command to set a single context for an entire file system. This might be a file system that is already mounted and that supports xattrs, or a network file system that obtains a genfs label such as cifs_t or nfs_t.
httpd_sys_content_t:
mount -t nfs -o context=system_u:object_r:httpd_sys_content_t \ server1.example.com:/shared/scripts /var/www/cgi
mount -t nfs -o context=system_u:object_r:httpd_sys_content_t \
server1.example.com:/shared/scripts /var/www/cgiNote
httpd and SELinux problems, reduce the complexity of your situation. For example, if you have the file system mounted at /mnt and then symbolically linked to /var/www/html/foo, you have two security contexts to be concerned with. Because one security context is of the object class file and the other of type lnk_file, they are treated differently by the policy and unexpected behavior may occur.
50.2.10. Changing the Security Category of a File or User
50.2.11. Running a Command in a Specific Security Context
runcon command to run a command in a specific context. This is useful for scripting or for testing policy, but care should be taken to ensure that it is implemented correctly.
~/bin/contexttest is a user-defined script.)
runcon -t httpd_t ~/bin/contexttest -ARG1 -ARG2
runcon -t httpd_t ~/bin/contexttest -ARG1 -ARG2runcon user_u:system_r:httpd_t ~/bin/contexttest
runcon user_u:system_r:httpd_t ~/bin/contexttest50.2.12. Useful Commands for Scripts
getenforce- This command returns the enforcing status of SELinux.
setenforce [ Enforcing | Permissive | 1 | 0 ]- This command controls the enforcing mode of SELinux. The option
1orEnforcingtells SELinux to enter enforcing mode. The option0orPermissivetells SELinux to enter passive mode. Access violations are still logged, but not prevented. selinuxenabled- This command exits with a status of
0if SELinux is enabled, and1if SELinux is disabled.selinuxenabled echo $? 0
~]# selinuxenabled ~]# echo $? 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow getsebool [-a] [boolean_name]- This command shows the status of all booleans (
-a) or a specific boolean (<boolean_name>). setsebool [-P] <boolean_name> value | bool1=val1 bool2=val2 ...- This command sets one or more boolean values. The
-Poption makes the changes persistent across reboots. togglesebool boolean ...- This command toggles the setting of one or more booleans. This effects boolean settings in memory only; changes are not persistent across reboots.
50.2.13. Changing to a Different Role
newrole command to run a new shell with the specified type and/or role. Changing roles is typically only meaningful in the strict policy; the targeted policy is generally restricted to a single role. Changing types may be useful for testing, validation, and development purposes.
newrole -r <role_r> -t <type_t> [-- [ARGS]...]
newrole -r <role_r> -t <type_t> [-- [ARGS]...]ARGS are passed directly to the shell specified in the user's entry in the /etc/passwd file.
Note
newrole command is part of the policycoreutils-newrole package, which is required if you install the strict or MLS policy. It is not installed by default in Red Hat Enterprise Linux.
50.2.14. When to Reboot
50.3. Analyst Control of SELinux
50.3.1. Enabling Kernel Auditing
audit=1 parameter to your kernel boot line, either in the /etc/grub.conf file or on the GRUB menu at boot time.
httpd is denied access to ~/public_html because the directory is not labeled as Web content. Notice that the time and serial number stamps in the audit(...) field are identical in each case. This makes it easier to track a specific event in the audit logs:
Jan 15 08:03:56 hostname kernel: audit(1105805036.075:2392892): \
avc: denied { getattr } for pid=2239 exe=/usr/sbin/httpd \
path=/home/auser/public_html dev=hdb2 ino=921135 \
scontext=user_u:system_r:httpd_t \
tcontext=system_u:object_r:user_home_t tclass=dir
Jan 15 08:03:56 hostname kernel: audit(1105805036.075:2392892): \
avc: denied { getattr } for pid=2239 exe=/usr/sbin/httpd \
path=/home/auser/public_html dev=hdb2 ino=921135 \
scontext=user_u:system_r:httpd_t \
tcontext=system_u:object_r:user_home_t tclass=dirJan 15 08:03:56 hostname kernel: audit(1105805036.075:2392892): \ syscall=195 exit=4294967283 a0=9ef88e0 a1=bfecc0d4 a2=a97ff4 \ a3=bfecc0d4 items=1 pid=2239 loginuid=-1 uid=48 gid=48 euid=48 \ suid=48 fsuid=48 egid=48 sgid=48 fsgid=48
Jan 15 08:03:56 hostname kernel: audit(1105805036.075:2392892): \
syscall=195 exit=4294967283 a0=9ef88e0 a1=bfecc0d4 a2=a97ff4 \
a3=bfecc0d4 items=1 pid=2239 loginuid=-1 uid=48 gid=48 euid=48 \
suid=48 fsuid=48 egid=48 sgid=48 fsgid=48Jan 15 08:03:56 hostname kernel: audit(1105805036.075:2392892): \ item=0 name=/home/auser/public_html inode=921135 dev=00:00
Jan 15 08:03:56 hostname kernel: audit(1105805036.075:2392892): \
item=0 name=/home/auser/public_html inode=921135 dev=00:00Note
/var/log/messages, such as /var/log/audit/audit.log.
50.3.2. Dumping and Viewing Logs
/var/log/messages. You can use any of the standard search utilities (for example, grep), to search for lines containing avc or audit.
Chapter 51. Customizing SELinux Policy
51.1. Introduction
selinux-policy-targeted-sources packages and then to create a local.te file in the /etc/selinux/targeted/src/policy/domains/misc directory. You could use the audit2allow utility to translate the AVC messages into allow rules, and then rebuild and reload the policy.
selinux-policy-XYZ.src.rpm. A further package, selinux-policy-devel, has also been added, which provides further customization functionality.
51.1.1. Modular Policy
semodule.
semodule is the tool used to manage SELinux policy modules, including installing, upgrading, listing and removing modules. You can also use semodule to force a rebuild of policy from the module store and/or to force a reload of policy without performing any other transaction. semodule acts on module packages created by semodule_package. Conventionally, these files have a .pp suffix (policy package), although this is not mandated in any way.
51.1.1.1. Listing Policy Modules
semodule -l command:
Note
/usr/share/selinux/targeted/ directory contains a number of policy package (*.pp) files. These files are included in the selinux-policy rpm and are used to build the policy file.
51.2. Building a Local Policy Module
ypbind init script, which executes the setsebool command, which in turn tries to use the terminal. This is generating the following denial:
type=AVC msg=audit(1164222416.269:22): avc: denied { use } for pid=1940 comm="setsebool" name="0" dev=devpts ino=2 \
scontext=system_u:system_r:semanage_t:s0 tcontext=system_u:system_r:init_t:s0 tclass=fd
type=AVC msg=audit(1164222416.269:22): avc: denied { use } for pid=1940 comm="setsebool" name="0" dev=devpts ino=2 \
scontext=system_u:system_r:semanage_t:s0 tcontext=system_u:system_r:init_t:s0 tclass=fd51.2.1. Using audit2allow to Build a Local Policy Module
audit2allow utility now has the ability to build policy modules. Use the following command to build a policy module based on specific contents of the audit.log file:
ausearch -m AVC --comm setsebool | audit2allow -M mysemanage
audit2allow utility has built a type enforcement file (mysemanage.te). It then executed the checkmodule command to compile a module file (mysemanage.mod). Lastly, it uses the semodule_package command to create a policy package (mysemanage.pp). The semodule_package command combines different policy files (usually just the module and potentially a file context file) into a policy package.
51.2.2. Analyzing the Type Enforcement (TE) File
cat command to inspect the contents of the TE file:
module command, which identifies the module name and version. The module name must be unique. If you create an semanage module using the name of a pre-existing module, the system would try to replace the existing module package with the newly-created version. The last part of the module line is the version. semodule can update module packages and checks the update version against the currently installed version.
require block. This informs the policy loader which types, classes and roles are required in the system policy before this module can be installed. If any of these fields are undefined, the semodule command will fail.
dontaudit, because semodule does not need to access the file descriptor.
51.2.3. Loading the Policy Package
semodule command to load the policy package:
semodule -i mysemanage.pp
~]# semodule -i mysemanage.ppmysemanage.pp) to other machines and install it using semodule.
audit2allow command outputs the commands it executed to create the policy package so that you can edit the TE file. This means you can add new rules as required or change the allow rule to dontaudit. You could then recompile and repackage the policy package to be installed again.
Chapter 52. References
Books
- SELinux by Example
- Mayer, MacMillan, and CaplanPrentice Hall, 2007
Tutorials and Help
- Understanding and Customizing the Apache HTTP SELinux Policy
- Tutorials and talks from Russell Coker
- Generic Writing SELinux policy HOWTO
- Red Hat Knowledgebase
General Information
- NSA SELinux main website
- NSA SELinux FAQ
- Fedora SELinux FAQ
- SELinux NSA's Open Source Security Enhanced Linux
Technology
- An Overview of Object Classes and Permissions
- Integrating Flexible Support for Security Policies into the Linux Operating System (a history of Flask implementation in Linux)
- Implementing SELinux as a Linux Security Module
- A Security Policy Configuration for the Security-Enhanced Linux
Community
- SELinux community page
- IRC
- irc.freenode.net, #rhel-selinux
History
- Quick history of Flask
- Full background on Fluke
Part VIII. Red Hat Training And Certification
Chapter 53. Red Hat Training and Certification
53.1. Three Ways to Train
- Open Enrollment
- Open enrollment courses are offered continually in 50+ locations across North America and 125+ locations worldwide. Red Hat courses are performance—based—students have access to at least one dedicated system, and in some courses, as many as five. Instructors are all experienced Red Hat Certified Engineers (RHCEs) who are intimately familiar with course curriculum.Course schedules are available at http://www.redhat.com/explore/training
- Onsite Training
- Onsite training is delivered by Red Hat at your facility for teams of 12 to 16 people per class. Red Hat's technical staff will assist your technical staff prior to arrival to ensure the training venue is prepared to run Red Hat Enterprise Linux, Red Hat or JBoss courses, and/or Red Hat certification exams. Onsites are a great way to train large groups at once. Open enrollment can be leveraged later for incremental training.For more information, visit http://www.redhat.com/explore/onsite
- eLearning
- Fully updated for Red Hat Enterprise Linux 4! No time for class? Red Hat's e—Learning titles are delivered online and cover RHCT and RHCE track skills. Our growing catalog also includes courses on the latest programming languages, scripting and ecommerce.For course listings visit http://www.redhat.com/explore/elearning
53.2. Microsoft Certified Professional Resource Center
Chapter 54. Certification Tracks
- Red Hat Certified Technician® (RHCT®)
- Now entering its third year, Red Hat Certified Technician is the fastest-growing credential in all of Linux, with currently over 15,000 certification holders. RHCT is the best first step in establishing Linux credentials and is an ideal initial certification for those transitioning from non-UNIX®/ Linux environments.Red Hat certifications are indisputably regarded as the best in Linux, and perhaps, according to some, in all of IT. Taught entirely by experienced Red Hat experts, our certification programs measure competency on actual live systems and are in great demand by employers and IT professionals alike.Choosing the right certification depends on your background and goals. Whether you have advanced, minimal, or no UNIX or Linux experience whatsoever, Red Hat Training has a training and certification path that is right for you.
- Red Hat Certified Engineer® (RHCE®)
- Red Hat Certified Engineer began in 1999 and has been earned by more than 20,000 Linux experts. Called the "crown jewel of Linux certifications," independent surveys have ranked the RHCE program #1 in all of IT.
- Red Hat Certified Security Specialist (RHCSS)
- An RHCSS has RHCE security knowledge plus specialized skills in Red Hat Enterprise Linux, Red Hat Directory Server and SELinux to meet the security requirements of today's enterprise environments. RHCSS is Red Hat's newest certification, and the only one of its kind in Linux.
- Red Hat Certified Architect (RHCA)
- RHCEs who seek advanced training can enroll in Enterprise Architect courses and prove their competency with the newly announced Red Hat Certified Architect (RHCA) certification. RHCA is the capstone certification to Red Hat Certified Technician (RHCT) and Red Hat Certified Engineer (RHCE), the most acclaimed certifications in the Linux space.
54.1. Free Pre-assessment tests
Chapter 55. RH033: Red Hat Linux Essentials
55.1. Course Description
55.1.1. Prerequisites
55.1.2. Goal
55.1.3. Audience
55.1.4. Course Objectives
- Understand the Linux file system
- Perform common file maintenance
- Use and customize the GNOME interface
- Issue essential Linux commands from the command line
- Perform common tasks using the GNOME GUI
- Open, edit, and save text documents using the vi editor
- File access permissions
- Customize X Window System
- Regular expression pattern matching and I/O redirection
- Install, upgrade, delete and query packages on your system
- Network utilities for the user
- Power user utilities
55.1.5. Follow-on Courses
Chapter 56. RH035: Red Hat Linux Essentials for Windows Professionals
56.1. Course Description
56.1.1. Prerequisites
56.1.2. Goal
56.1.3. Audience
56.1.4. Course Objectives
- Learn to install software, configure the network, configure authentication, and install and configure various services using graphical tools
- Understand the Linux file system
- Issue essential Linux commands from the command line
- Understand file access permissions
- Customize X Window System
- Use regular expression pattern matching and I/O redirection
56.1.5. Follow-on Courses
Chapter 57. RH133: Red Hat Linux System Administration and Red Hat Certified Technician (RHCT) Certification
57.1. Course Description
57.1.1. Prerequisites
57.1.2. Goal
57.1.3. Audience
57.1.4. Course Objectives
- Install Red Hat Linux interactively and with Kickstart
- Control common system hardware; administer Linux printing subsystem
- Create and maintain the Linux filesystem
- Perform user and group administration
- Integrate a workstation with an existing network
- Configure a workstation as a client to NIS, DNS, and DHCP services
- Automate tasks with at, cron, and anacron
- Back up filesystems to tape and tar archive
- Manipulate software packages with RPM
- Configure the X Window System and the GNOME d.e.
- Perform performance, memory, and process mgmt.
- Configure basic host security
57.1.5. Follow-on Courses
Chapter 58. RH202 RHCT EXAM - The fastest growing credential in all of Linux.
- RHCT exam is included with RH133. It can also be purchased on its own for $349
- RHCT exams occur on the fifth day of all RH133 classes
58.1. Course Description
58.1.1. Prerequisites
Chapter 59. RH253 Red Hat Linux Networking and Security Administration
59.1. Course Description
59.1.1. Prerequisites
59.1.2. Goal
59.1.3. Audience
59.1.4. Course Objectives
- Networking services on Red Hat Linux server-side setup, configuration, and basic administration of common networking services: DNS, NIS, Apache, SMB, DHCP, Sendmail, FTP. Other common services: tftp, pppd, proxy.
- Introduction to security
- Developing a security policy
- Local security
- Files and filesystem security
- Password security
- Kernel security
- Basic elements of a firewall
- Red Hat Linux-based security tools
- Responding to a break-in attempt
- Security sources and methods
- Overview of OSS security tools
59.1.5. Follow-on Courses
Chapter 60. RH300: RHCE Rapid track course (and RHCE exam)
60.1. Course Description
60.1.1. Prerequisites
60.1.2. Goal
60.1.3. Audience
60.1.4. Course Objectives
- Hardware and Installation (x86 architecture)
- Configuration and administration
- Alternate installation methods
- Kernel services and configuration
- Standard networking services
- X Window system
- User and host security
- Routers, Firewalls, Clusters and Troubleshooting
60.1.5. Follow-on Courses
Chapter 61. RH302 RHCE EXAM
- RHCE exams are included with RH300. It can also be purchased on its own.
- RHCE exams occur on the fifth day of all RH300 classes
61.1. Course Description
61.1.1. Prerequisites
61.1.2. Content
- Section I: Troubleshooting and System Maintenance (2.5 hrs)
- Section II: Installation and Configuration (3 hrs.)
Chapter 62. RHS333: RED HAT enterprise security: network services
62.1. Course Description
62.1.1. Prerequisites
62.1.2. Goal
62.1.3. Audience
62.1.4. Course Objectives
- Mastering basic service security
- Understanding cryptography
- Logging system activity
- Securing BIND and DNS
- Network user authentication security
- Improving NFS security
- The secure shell: OpenSSH
- Securing email with Sendmail and Postfix
- Managing FTP access
- Apache security
- Basics of intrusion response
62.1.5. Follow-on Courses
Chapter 63. RH401: Red Hat Enterprise Deployment and systems management
63.1. Course Description
63.1.1. Prerequisites
63.1.2. Goal
63.1.3. Audience
63.1.4. Course Objectives
- Configuration management using CVS
- Construction of custom RPM packages
- Software management with Red Hat Network Proxy Server
- Assembling a host provisioning and management system
- Performance tuning and analysis
- High-availability network load-balancing clusters
- High-availability application failover clusters
63.1.5. Follow-on Courses
Chapter 64. RH423: Red Hat Enterprise Directory services and authentication
64.1. Course Description
64.1.1. Prerequisites
64.1.2. Goal
64.1.3. Audience
64.1.4. Course Objectives
- Basic LDAP concepts
- How to configure and manage an OpenLDAP server
- Using LDAP as a "white pages" directory service
- Using LDAP for user authentication and management
- Integrating multiple LDAP servers
64.1.5. Follow-on Courses
Chapter 65. SELinux Courses
65.1. RHS427: Introduction to SELinux and Red Hat Targeted Policy
65.1.1. Audience
65.1.2. Course Summary
65.2. RHS429: Red Hat Enterprise SELinux Policy Administration
Chapter 66. RH436: Red Hat Enterprise storage management
- five servers
- storage array
66.1. Course Description
66.1.1. Prerequisites
66.1.2. Goal
66.1.3. Audience
66.1.4. Course Objectives
- Review Red Hat Enterprise Linux storage management technologies
- Data storage design: Data sharing
- Cluster Suite overview
- Global File System (GFS) overview
- GFS management
- Modify the online GFS environment: Managing data capacity
- Monitor GFS
- Implement GFS modifications
- Migrating Cluster Suite NFS from DAS to GFS
- Re-visit Cluster Suite using GFS
66.1.5. Follow-on Courses
Chapter 67. RH442: Red Hat Enterprise system monitoring and performance tuning
67.1. Course Description
67.1.1. Prerequisites
67.1.2. Goal
- A discussion of system architecture with an emphasis on understanding the implications of system architecture on system performance
- Methods for testing the effects of performance adjustments (benchmarking)
- Open source benchmarking utilities
- Methods for analyzing system performance and networking performance
- Tuning configurations for specific application loads
67.1.3. Audience
67.1.4. Course Objectives
- Overview of system components and architecture as they relate to system performance
- Translating manufacturers' hardware specifications into useful information
- Using standard monitoring tools effectively to gather and analyze trend information
- Gathering performance-related data with SNMP
- Using open source benchmarking utilities
- Network performance tuning
- Application performance tuning considerations
- Tuning for specific configurations
67.1.5. Follow-on Courses
Chapter 68. Red Hat Enterprise Linux Developer Courses
68.1. RHD143: Red Hat Linux Programming Essentials
68.2. RHD221 Red Hat Linux Device Drivers
68.3. RHD236 Red Hat Linux Kernel Internals
68.4. RHD256 Red Hat Linux Application Development and Porting
Chapter 69. JBoss Courses
69.1. RHD161 JBoss and EJB3 for Java
69.1.1. Prerequisites
- The object-oriented concepts of inheritance, polymorphism and encapsulation
- Java syntax, specifically for data types, variables, operators, statements and control flow
- Writing Java classes as well as using Java interfaces and abstract classes
69.2. RHD163 JBoss for Web Developers
69.2.1. Prerequisites
- JNDI
- The Servlet 2.3/2.4 API
- The JSP 2.0 API
- J2EE application development and deployment on the JBoss Application Server
- Deployment of a Web Application on embedded (stand alone) Tomcat or on integrated Tomcat (JBossWeb)
- A working knowledge of JDBC and EJB2.1 or EJB3.0
69.3. RHD167: JBOSS - HIBERNATE ESSENTIALS
69.3.1. Prerequisites
- An understanding of the relational persistence model
- Competency with the Java language
- Knowledge of OOAD concepts
- Familiarity with the UML
- Experience with a dialect of SQL
- Using the JDK and creating the necessary environment for compilation and execution of a Java executable from the command line
- An understanding of JDB
69.3.2. Course Summary
69.4. RHD267: JBOSS - ADVANCED HIBERNATE
69.4.1. Prerequisites
- Basic Hibernate knowledge.
- Competency with the Java language
- Knowledge of OOAD concepts
- Familiarity with the UML
- Experience with a dialect of SQL
- Using the JDK and creating the necessary environment for compilation and execution of a Java executable from the command line.
- Experience with, or comprehensive knowledge of JNDI and JDBC.
- Entity EJB2.1 or EJB3.0 knowledge, while not a prerequisite, is helpful.
- Prior reading of the book Hibernate in Action, by Christian Bauer and Gavin King (published by Manning) is recommended.
69.5. RHD261:JBOSS for advanced J2EE developers
69.5.1. Prerequisites
- JNDI
- JDBC
- Servlets and JSPs
- Enterprise Java Beans
- JMS
- The J2EE Security Model
- J2EE application development and deployment on the JBoss Application
- Experience with ANT and XDoclet or similar technologies.
69.6. RH336: JBOSS for Administrators
69.6.1. Prerequisites
- Creating directories, files and modifying access rights to the file store
- Installing a JDK
- Configuring environment variables, such as JAVA_HOME, for an Operating system
- Launching Java applications and executing an OS-dependent script that launches a Java application.
- Creating and expanding a Java archive file (the jar utility)
69.6.2. Course Summary
69.7. RHD439: JBoss Clustering
69.7.1. Prerequisites
- JTA, Transactions, Java concurrency
- EJB 2.1, JMS, reliable messaging technologies
- Previous experience with Apache httpd and some exposure to mod_jk and/or mod_proxy
- Familiar with JBoss AS microkernel and JMX
- Familiarity with TCP/IP, UDP, Multicasting
69.8. RHD449: JBoss jBPM
69.8.1. Description
69.8.2. Prerequisites
- The student must have previous experience developing an Hibernate application. The student must know how to configure a simple Session Factory for Hibernate, utilize a Hibernate Session and transactional demarcation and how to perform basic queries on Hibernate objects.
- Competency with Java application development.
- Previous exposure to the concepts of workflow and business process modeling (BPM) is not required
- Experience with JBoss Eclipse or the Eclipse IDE with the JBoss plugin is recommended but not required
- Basic notions of JUnit test framework is recommended.
69.9. RHD451 JBoss Rules
69.9.1. Prerequisites
- Basic Java competency
- Some understanding of what constitutes an inferencing rule engine versus a scripting engine
- Viewing of the Jboss Rules webinars and demos is recommended but not required
- Java EE specific experience is not required for the course, but students who need to know how to integrate with Java EE will need the appropriate experience
Appendix A. Revision History
| Revision History | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Revision 11-1 | Tue 30 Jun 2015 | ||||||||||||
| |||||||||||||
| Revision 11-0 | Fri 12 Sep 2014 | ||||||||||||
| |||||||||||||
| Revision 10-0 | Tue 01 Oct 2013 | ||||||||||||
| |||||||||||||
| Revision 9-6 | Tue Jan 08 2013 | ||||||||||||
| |||||||||||||
| Revision 8-0 | Tue Feb 21 2012 | ||||||||||||
| |||||||||||||
| Revision 7-0 | Thu Jul 21 2011 | ||||||||||||
| |||||||||||||
| Revision 6-0 | Thu Jan 13 2011 | ||||||||||||
| |||||||||||||
| Revision 5-0 | Thu July 30 2010 | ||||||||||||
| |||||||||||||
| Revision 4-2 | Wed Sep 30 2009 | , , | |||||||||||
| |||||||||||||
| Revision 4-1 | Mon Sep 14 2009 | ||||||||||||
| |||||||||||||
| Revision 4-0 | Wed Sep 02 2009 | ||||||||||||
| |||||||||||||
| Revision 3-0 | Wed Jan 28 2009 | ||||||||||||
| |||||||||||||
Appendix B. Colophon
- East Asian Languages
- Simplified Chinese
- Tony Tongjie Fu
- Simon Xi Huang
- Leah Wei Liu
- Sarah Saiying Wang
- Traditional Chinese
- Chester Cheng
- Terry Chuang
- Ben Hung-Pin Wu
- Japanese
- Kiyoto Hashida
- Junko Ito
- Noriko Mizumoto
- Takuro Nagamoto
- Korean
- Eun-ju Kim
- Michelle Kim
- Latin Languages
- French
- Jean-Paul Aubry
- Fabien Decroux
- Myriam Malga
- Audrey Simons
- Corina Roe
- German
- Jasna Dimanoski
- Verena Furhuer
- Bernd Groh
- Daniela Kugelmann
- Timo Trinks
- Italian
- Francesco Valente
- Brazilian Portuguese
- Glaucia de Freitas
- Leticia de Lima
- David Barzilay
- Spanish
- Angela Garcia
- Gladys Guerrero
- Yelitza Louze
- Manuel Ospina
- Russian
- Yuliya Poyarkova
- Indic Languages
- Bengali
- Runa Bhattacharjee
- Gujarati
- Ankitkumar Rameshchandra Patel
- Sweta Kothari
- Hindi
- Rajesh Ranjan
- Malayalam
- Ani Peter
- Marathi
- Sandeep Shedmake
- Punjabi
- Amanpreet Singh Alam
- Jaswinder Singh
- Tamil
- I Felix
- N Jayaradha