CLI Guide
Simplify Migration of Java Applications
Abstract
Chapter 1. Introduction
1.1. About the CLI Guide
This guide is for engineers, consultants, and others who want to use Red Hat Application Migration Toolkit (RHAMT) to migrate Java applications or other components. It describes how to install and run the CLI, review the generated reports, and take advantage of additional features.
1.1.1. Use of RHAMT_HOME in This Guide
This guide uses the RHAMT_HOME replaceable variable to denote the path to your RHAMT installation. The installation directory is the rhamt-cli-4.0.1.Final directory where you extracted the RHAMT ZIP distribution.
When you encounter RHAMT_HOME in this guide, be sure to replace it with the actual path to your RHAMT installation.
1.2. About Red Hat Application Migration Toolkit
What is Red Hat Application Migration Toolkit?
Red Hat Application Migration Toolkit (RHAMT) is an extensible and customizable rule-based tool that helps simplify migration of Java applications.
RHAMT examines application artifacts, including project source directories and application archives, then produces an HTML report that highlights areas needing changes. RHAMT can be used to migrate Java applications from previous versions of Red Hat JBoss Enterprise Application Platform or from other containers, such as Oracle® WebLogic Server or IBM® WebSphere® Application Server.
How Does Red Hat Application Migration Toolkit Simplify Migration?
Red Hat Application Migration Toolkit looks for common resources and highlights technologies and known trouble spots when migrating applications. The goal is to provide a high-level view into the technologies used by the application and provide a detailed report organizations can use to estimate, document, and migrate enterprise applications to Java EE and Red Hat JBoss Enterprise Application Platform.
How Do I Learn More?
See the Getting Started Guide to learn more about the features, supported configurations, system requirements, and available tools in the Red Hat Application Migration Toolkit.
1.3. About the CLI
The CLI is a command-line tool in the Red Hat Application Migration Toolkit that allows users to assess and prioritize migration and modernization efforts for applications. It provides numerous reports that highlight the analysis results. The CLI is for advanced users with highly customized needs looking for fine-grained control of RHAMT analysis options or to integrate with external automation tools.
Chapter 2. Getting Started
2.1. Prerequisites
Before installing the CLI, verify that you meet the following prerequisites.
- Java Platform, JRE version 8+
- A minimum of 4 GB RAM; 8 GB recommended
If you are running macOS, it is recommended to set the maximum number of user processes, maxproc, to at least 2048, and the maximum number of open files, maxfiles, to 100000.
2.2. Install the CLI
- Download the CLI from the RHAMT Download page.
- Extract the ZIP file to a directory of your choice.
The extracted directory is known as RHAMT_HOME in this guide.
2.3. Run the CLI
Use the following steps to run RHAMT against your application.
-
Open a terminal and navigate to the
RHAMT_HOME/bin/directory. Execute the
rhamt-cliscript, orrhamt-cli.batfor Windows, and specify the appropriate arguments.$ ./rhamt-cli --input /path/to/jee-example-app-1.0.0.ear --output /path/to/output --source weblogic --target eap:6 --packages com.acme org.apache
-
--input: The application to be evaluated. See the--inputargument description. -
--output: The output directory for the generated reports. See the--outputargument description. -
--source: The source technology for the application migration. See the--sourceargument description. -
--target: The target technology for the application migration. See the--targetargument description. -
--packages: The packages to be evaluated. This argument is highly recommended to improve performance. See the--packagesargument description.
See RHAMT Command-line Arguments for a detailed description of all available command-line arguments.
-
- Access the report.
See RHAMT Command Examples below for examples of commands that use source code directories and archives located in the RHAMT GitHub repository.
RHAMT Command Examples
Running RHAMT on an Application Archive
The following command analyzes the com.acme and org.apache packages of the jee-example-app-1.0.0.ear example EAR archive for migrating from JBoss EAP 5 to JBoss EAP 7.
$ RHAMT_HOME/bin/rhamt-cli --input /path/to/jee-example-app-1.0.0.ear --output /path/to/report-output/ --source eap:5 --target eap:7 --packages com.acme org.apacheRunning RHAMT on Source Code
The following command analyzes the org.jboss.seam packages of the seam-booking-5.2 example source code for migrating to JBoss EAP 6.
$ RHAMT_HOME/bin/rhamt-cli --sourceMode --input /path/to/seam-booking-5.2/ --output /path/to/report-output/ --target eap:6 --packages org.jboss.seamRunning Cloud-readiness Rules
The following command analyzes the com.acme and org.apache packages of the jee-example-app-1.0.0.ear example EAR archive for migrating to JBoss EAP 7. It also evaluates for cloud readiness.
$ RHAMT_HOME/bin/rhamt-cli --input /path/to/jee-example-app-1.0.0.ear --output /path/to/report-output/ --target eap:7 --target cloud-readiness --packages com.acme org.apacheOverride RHAMT Properties
To override the default Fernflower decompiler, pass the -Dwindup.decompiler argument on the command line. For example, to use the Procyon decompiler, use the following syntax:
$ RHAMT_HOME/bin/rhamt-cli -Dwindup.decompiler=procyon --input INPUT_ARCHIVE_OR_DIRECTORY --output OUTPUT_REPORT_DIRECTORY --target TARGET_TECHNOLOGY --packages PACKAGE_1 PACKAGE_2
RHAMT CLI Bash Completion
The RHAMT CLI provides an option to enable bash completion for Linux systems, allowing the RHAMT command-line arguments to be auto completed by pressing Tab when entering the commands. For instance, when bash completion is enabled, entering the following displays a list of available arguments.
$ RHAMT_HOME/bin/rhamt-cli [TAB]Enable Bash Completion
To enable bash completion for the current shell, execute the following command. After the prompt returns, follow the steps in Run the CLI.
$ source RHAMT_HOME/bash-completion/rhamt-cliEnable Persistent Bash Completion
The following commands allow bash completion to persist across restarts; however, if bash completion is desired for the current shell then the steps in Enable Bash Completion must be followed.
To enable bash completion for a specific user across system restarts, include the following line in that user’s
~/.bashrcfile.source RHAMT_HOME/bash-completion/rhamt-cliTo enable bash completion for all users across system restarts, copy the Red Hat Application Migration Toolkit CLI bash completion file to the
/etc/bash_completion.d/directory. By default, this directory is only writable by the root user.# cp RHAMT_HOME/bash-completion/rhamt-cli /etc/bash_completion.d/
RHAMT Help
To see the complete list of available arguments for the rhamt-cli command, open a terminal, navigate to the RHAMT_HOME directory, and execute the following command:
$ RHAMT_HOME/bin/rhamt-cli --help2.4. Access the Report
When you execute Red Hat Application Migration Toolkit, the report is generated in the OUTPUT_REPORT_DIRECTORY that you specify using the --output argument in the command line. Upon completion of execution, you will see the following message in the terminal with the location of the report.
Report created: OUTPUT_REPORT_DIRECTORY/index.html Access it at this URL: file:///OUTPUT_REPORT_DIRECTORY/index.html
The output directory contains the following files and subdirectories:
OUTPUT_REPORT_DIRECTORY/ ├── index.html // Landing page for the report ├── EXPORT_FILE.csv // Optional export of data in CSV format ├── archives/ // Archives extracted from the application ├── mavenized/ // Optional Maven project structure ├── reports/ // Generated HTML reports ├── stats/ // Performance statistics
Use a browser to open the index.html file located in the report output directory. See Review the Reports for information on navigating the RHAMT reports.
Chapter 3. Review the Reports
The report examples shown in the following sections are a result of analyzing the com.acme and org.apache packages in the jee-example-app-1.0.0.ear example application, which is located in the RHAMT GitHub source repository. The report was generated using the following command.
$ RHAMT_HOME/bin/rhamt-cli --input /home/username/rhamt-cli-source/test-files/jee-example-app-1.0.0.ear/ --output /home/username/rhamt-cli-reports/jee-example-app-1.0.0.ear-report --target eap:6 --packages com.acme org.apache
Use a browser to open the index.html file located in the report output directory. This opens a landing page that lists the applications that were processed. Each row contains a high-level overview of the story points, number of incidents, and technologies encountered in that application.
Figure 3.1. Application List
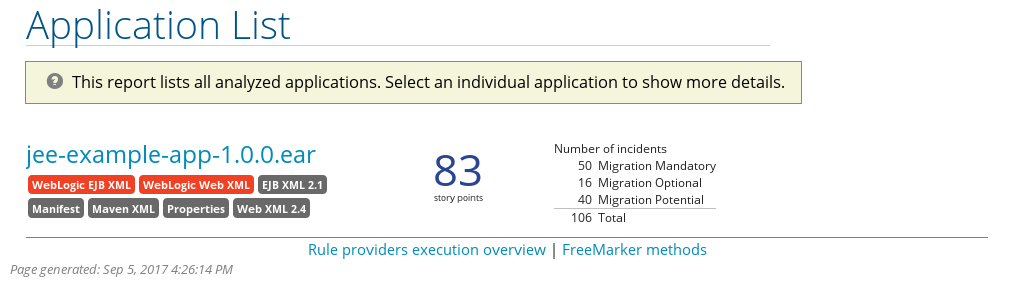
The incidents and estimated story points change as new rules are added to RHAMT. The values here may not match what you see when you test this application.
The following table lists all of the reports and pages that can be accessed from this main RHAMT landing page. Click on the name of the application, jee-example-app-1.0.0.ear, to view the application report.
| Page | How to Access |
|---|---|
| Click on the name of the application. | |
| Click on the Archives shared by multiple applications link. Note that this link is only available when there are shared archives across multiple applications. | |
| Click on the Rule providers execution overview link at the bottom of the page. | |
| Click on the FreeMarker methods link at the bottom of the page. | |
| Click on the Send Feedback link in the top navigation bar to open a form that allows you to submit feedback to the RHAMT team. |
Note that if an application shares archives with other analyzed applications, you will see a breakdown of how many story points are from shared archives and how many are unique to this application.
Figure 3.2. Shared Archives
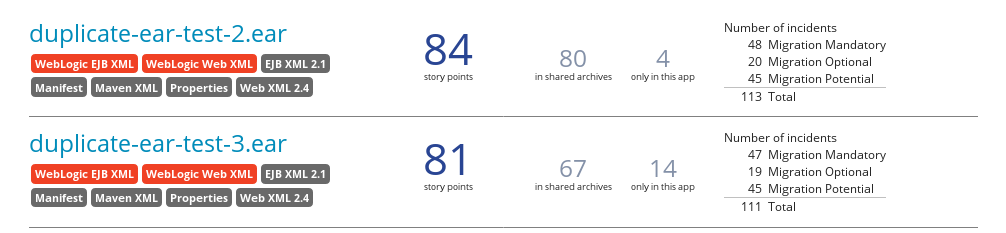
Information about the archives that are shared among applications can be found in the Archives Shared by Multiple Applications reports.
3.1. Application Report
3.1.1. Dashboard
Access this report from the report landing page by clicking on the application name in the Application List.
The dashboard gives an overview of the entire application migration effort. It summarizes:
- The incidents and story points by category
- The incidents and story points by level of effort of the suggested changes
- The incidents by package
Figure 3.3. Dashboard
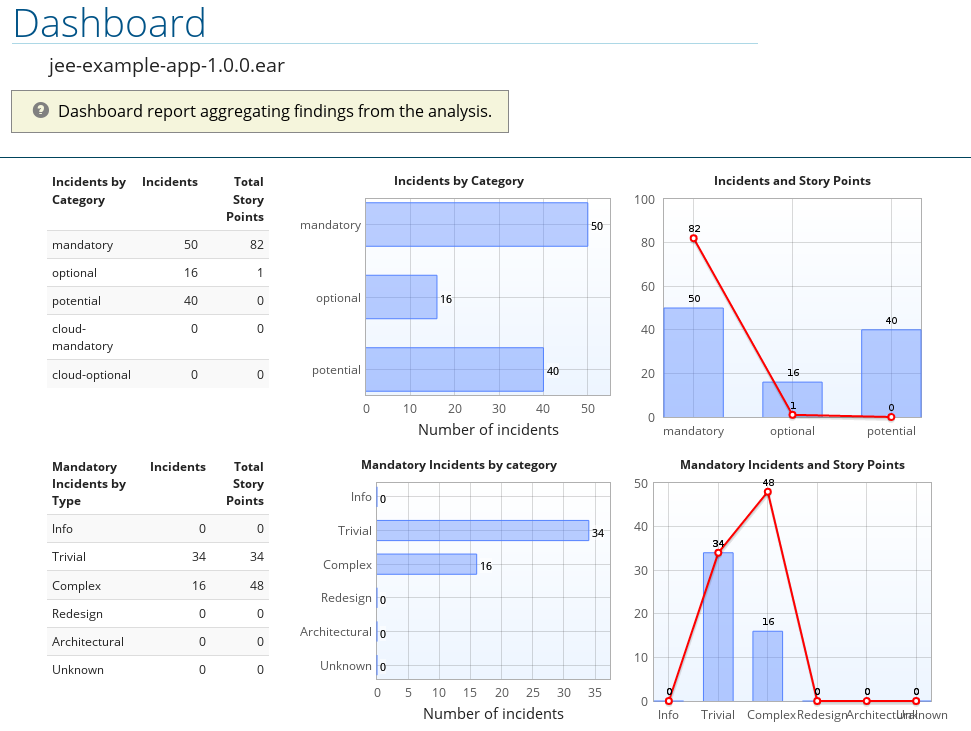
The top navigation bar lists the various reports that contain additional details about the migration of this application. Note that only those reports that are applicable to the current application will be available.
| Report | Description |
|---|---|
| Issues | Provides a concise summary of all issues that require attention. |
| Application Details | Provides a detailed overview of all resources found within the application that may need attention during the migration. |
| Unparsable |
Shows all files that RHAMT could not parse in the expected format. For instance, a file with a |
| Dependencies | Displays all Java-packaged dependencies found within the application. |
| Remote Services | Displays all remote services references that were found within the application. |
| EJBs | Contains a list of EJBs found within the application. |
| JBPM | Contains all of the JBPM-related resources that were discovered during analysis. |
| JPA | Contains details on all JPA-related resources that were found in the application. |
| Hibernate | Contains details on all Hibernate-related resources that were found in the application. |
| Server Resources | Displays all server resources (for example, JNDI resources) in the input application. |
| Spring Beans | Contains a list of Spring beans found during the analysis. |
| Hard-coded IP Addresses | Provides a list of all hard-coded IP addresses that were found in the application. |
| Ignored Files |
Lists the files found in the application that, based on certain rules and RHAMT configuration, were not processed. See the |
| About | Describes the current version of RHAMT and provides helpful links for further assistance. |
3.1.2. Application Details Report
Access this report from the dashboard by clicking the Application Details link.
The report lists the story points, the Java incidents by package, and a count of the occurrences of the technologies found in the application. Next is a display of application messages generated during the migration process. Finally, there is a breakdown of this information for each archive analyzed during the process.
Figure 3.4. Application Details Report
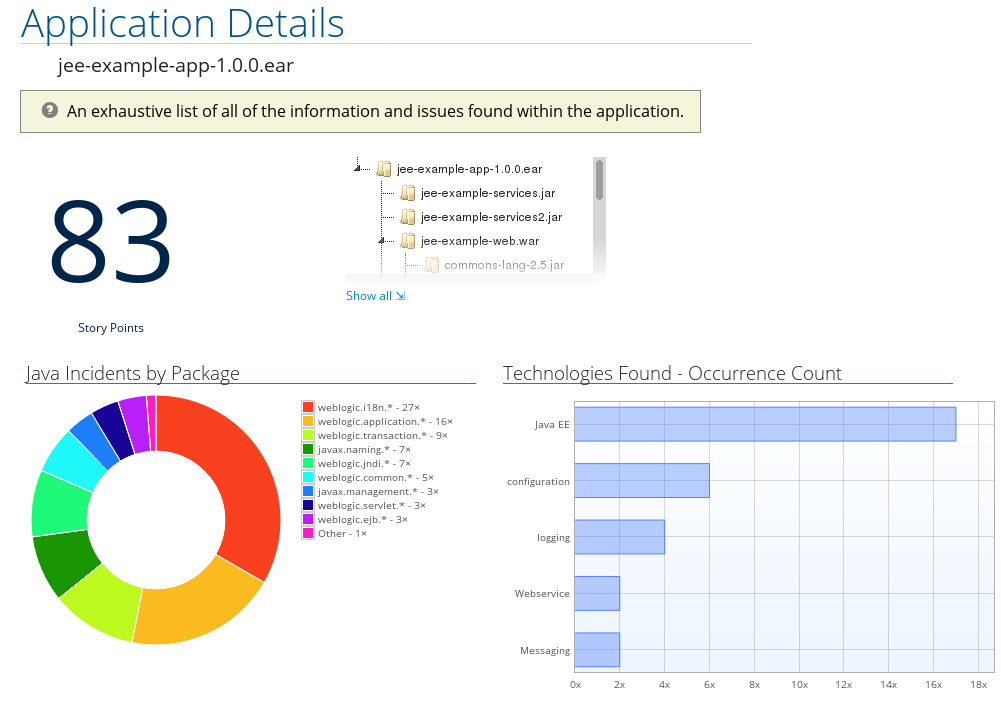
Expand the jee-example-app-1.0.0.ear/jee-example-services.jar to review the story points, Java incidents by package, and a count of the occurrences of the technologies found in this archive. This summary begins with a total of the story points assigned to its migration, followed by a table detailing the changes required for each file in the archive. The report contains the following columns.
| Column Name | Description |
|---|---|
| Name | The name of the file being analyzed. |
| Technology | The type of file being analyzed, for example, Decompiled Java File or Properties. |
| Issues | Warnings about areas of code that need review or changes. |
| Story Points | Level of effort required to migrate the file. See Rule Story Points for more details. |
Note that if an archive is duplicated several times in an application, it will be listed just once in the report and will be tagged with [Included Multiple Times].
Figure 3.5. Duplicate Archive in an Application

The story points for archives that are duplicated within an application will be counted only once in the total story point count for that application.
3.1.3. Source Report
The analysis of the jee-example-services.jar lists the files in the JAR and the warnings and story points assigned to each one. Notice the com.acme.anvil.listener.AnvilWebLifecycleListener file, at the time of this test, has 22 warnings and is assigned 16 story points. Click on the file link to see the detail.
- The Information section provides a summary of the story points.
- This is followed by the file source code. Warnings appear in the file at the point where migration is required.
In this example, warnings appear at various import statements, declarations, and method calls. Each warning describes the issue and the action that should be taken.
Figure 3.6. Source Report
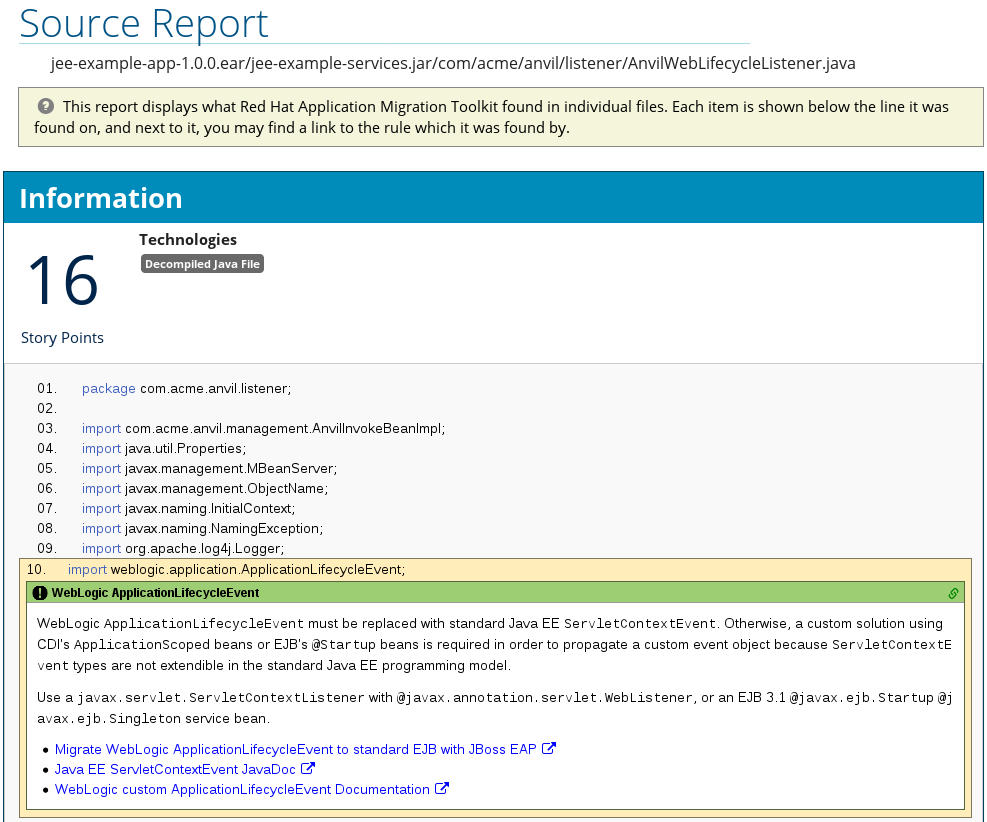
3.2. Archives Shared by Multiple Applications
Access these reports from the report landing page by clicking the Archives shared by multiple applications link. Note that this link is only available if there are applicable shared archives.
Figure 3.7. Archives Shared by Multiple Applications

This allows you to view the detailed reports for all archives that are shared across multiple applications.
3.3. Rule Provider Execution Overview
Access this report from the report landing page by clicking the Rule providers execution overview link.
This report provides the list of rules that executed when running the RHAMT migration command against the application.
Figure 3.8. Rule Provider Execution Overview
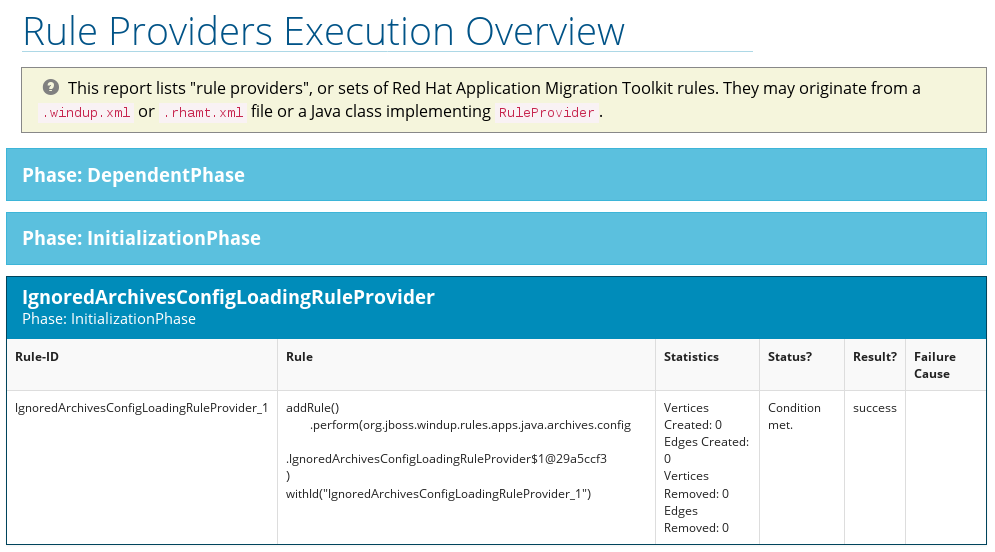
3.4. Used FreeMarker Functions and Directives
Access this report from the report landing page by clicking the Red Hat Application Migration Toolkit FreeMarker methods link.
This report lists all the registered functions and directives that were used to build the report. It is useful for debugging purposes or if you plan to build your own custom report.
Figure 3.9. FreeMarker Functions and Directives

3.5. Send Feedback Form
Access this feedback form from the report landing page by clicking the Send feedback link.
This form allows you to rate the product, talk about what you like, and make suggestions for improvements.
Figure 3.10. Send Feedback Form
Chapter 4. Export the Report in CSV Format
RHAMT provides the ability to export the report data, including the classifications and hints, to a flat file on your local file system. The export function currently supports the CSV file format, which presents the report data as fields separated by commas (,).
The CSV file can be imported and manipulated by spreadsheet software such as Microsoft Excel, OpenOffice Calc, or LibreOffice Calc. Spreadsheet software provides the ability to sort, analyze, evaluate, and manage the result data from an RHAMT report.
4.1. Export the Report
To export the report into a CSV file, run RHAMT with --exportCSV argument. The CSV file will be created in the directory specified by the --output argument.
4.2. Import the CSV File into a Spreadsheet Program
- Launch the spreadsheet software, for example, Microsoft Excel.
- Choose File → Open.
- Browse to the CSV exported file and select it.
- The data is now ready to analyze in the spreadsheet software.
For more information or to resolve any issues, check the help for your spreadsheet software.
4.3. Overview of the CSV Data Structure
The CSV formatted output file contains the following data fields:
- Rule Id
- The ID of the rule that generated the given item.
- Problem type
- hint or classification
- Title
- The title of the classification or hint. This field summarizes the issue for the given item.
- Description
- The detailed description of the issue for the given item.
- Links
- URLs that provide additional information about the issue. A link consists of two attributes: the link and a description of the link.
- Application
- The name of the application for which this item was generated.
- File Name
- The name of the file for the given item.
- File Path
- The file path for the given item.
- Line
- The line number of the file for the given item.
- Story points
- The number of story points, which represent the level of effort, assigned to the given item.
Chapter 5. Mavenize Your Application
RHAMT provides the ability to generate an Apache Maven project structure based on the application provided. This will create a directory structure with the necessary Maven Project Object Model (POM) files that specify the appropriate dependencies.
Note that this feature is not intended to create a final solution for your project. It is meant to give you a starting point and identify the necessary dependencies and APIs for your application. Your project may require further customization.
5.1. Generate the Maven Project Structure
You can generate a Maven project structure for the provided application by passing in the --mavenize flag when executing RHAMT.
The following example runs RHAMT using the jee-example-app-1.0.0.ear test application.
$ RHAMT_HOME/bin/rhamt-cli --input /path/to/jee-example-app-1.0.0.ear --output /path/to/output --target eap:6 --packages com.acme org.apache --mavenize
This generates the Maven project structure in the /path/to/output/mavenized directory.
You can only use the --mavenize option when providing a compiled application for the --input argument. This feature is not available when running RHAMT against source code.
You can also use the --mavenizeGroupId option to specify the <groupId> to be used for the POM files. If unspecified, RHAMT will attempt to identify an appropriate <groupId> for the application, or will default to com.mycompany.mavenized.
5.2. Review the Maven Project Structure
The /path/to/output/mavenized/APPLICATION_NAME/ directory will contain the following items:
-
A root POM file. This is the
pom.xmlfile at the top-level directory. -
A BOM file. This is the POM file in the directory ending with
-bom. - One or more application POM files. Each module has its POM file in a directory named after the archive.
The example jee-example-app-1.0.0.ear application is an EAR archive that contains a WAR and several JARs. There is a separate directory created for each of these artifacts. Below is the Maven project structure created for this application.
/path/to/output/mavenized/jee-example-app/
jee-example-app-bom/pom.xml
jee-example-app-ear/pom.xml
jee-example-services2-jar/pom.xml
jee-example-services-jar/pom.xml
jee-example-web-war/pom.xml
pom.xmlReview each of the generated files and customize as appropriate for your project. To learn more about Maven POM files, see the Introduction to the POM section of the Apache Maven documentation.
Root POM File
The root POM file for the jee-example-app-1.0.0.ear application can be found at /path/to/output/mavenized/jee-example-app/pom.xml. This file identifies the directories for all of the project modules.
The following modules are listed in the root POM for the example jee-example-app-1.0.0.ear application.
<modules> <module>jee-example-app-bom</module> <module>jee-example-services2-jar</module> <module>jee-example-services-jar</module> <module>jee-example-web-war</module> <module>jee-example-app-ear</module> </modules>
Be sure to reorder the list of modules if necessary so that they are listed in an appropriate build order for your project.
The root POM is also configured to use the Red Hat JBoss Enterprise Application Platform Maven repository to download project dependencies.
BOM File
The Bill of Materials (BOM) file is generated in the directory ending in -bom. For the example jee-example-app-1.0.0.ear application, the BOM file can be found at /path/to/output/mavenized/jee-example-app/jee-example-app-bom/pom.xml. The purpose of this BOM is to have the versions of third-party dependencies used by the project defined in one place. For more information on using a BOM, see the Introduction to the Dependency Mechanism section of the Apache Maven documentation.
The following dependencies are listed in the BOM for the example jee-example-app-1.0.0.ear application
<dependencyManagement>
<dependencies>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.6</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.5</version>
</dependency>
</dependencies>
</dependencyManagement>Application POM Files
Each application module that can be mavenized has a separate directory containing its POM file. The directory name contains the name of the archive and ends in a -jar, -war, or -ear suffix, depending on the archive type.
Each application POM file lists that module’s dependencies, including:
- Third-party libraries
- Java EE APIs
- Application submodules
For example, the POM file for the jee-example-app-1.0.0.ear EAR, /path/to/output/mavenized/jee-example-app/jee-example-app-ear/pom.xml, lists the following dependencies.
<dependencies>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.6</version>
</dependency>
<dependency>
<groupId>org.jboss.seam</groupId>
<artifactId>jee-example-web-war</artifactId>
<version>1.0</version>
<type>war</type>
</dependency>
<dependency>
<groupId>org.jboss.seam</groupId>
<artifactId>jee-example-services-jar</artifactId>
<version>1.0</version>
</dependency>
<dependency>
<groupId>org.jboss.seam</groupId>
<artifactId>jee-example-services2-jar</artifactId>
<version>1.0</version>
</dependency>
</dependencies>Chapter 6. Optimize RHAMT Performance
RHAMT performance depends on a number of factors, including hardware configuration, the number and types of files in the application, the size and number of applications to be evaluated, and whether the application contains source or compiled code. For example, a file that is larger than 10 MB may need a lot of time to process.
In general, RHAMT spends about 40% of the time decompiling classes, 40% of the time executing rules, and the remainder of the time processing other tasks and generating reports. This section describes what you can do to improve the performance of RHAMT.
6.1. Tips to Optimize Performance
6.1.1. Application and Command-line Suggestions
Try these suggestions first before upgrading hardware.
- If possible, execute RHAMT against the source code instead of the archives. This eliminates the need to decompile additional JARs and archives.
-
Specify a comma-separated list of the packages to be evaluated by RHAMT using the
--packagesargument on theRHAMT_HOME/bin/rhamt-clicommand line. If you omit this argument, RHAMT will decompile everything, which has a big impact on performance. -
Specify the
--excludePackagesand--excludeTagsarguments where possible to exclude them from processing. -
Add additional proprietary packages that should not be processed to the
ignore/proprietary.package-ignore.txtfile in the RHAMT distribution directory. RHAMT can still find the references to the packages in the application source code, but avoids the need to decompile and analyze the proprietary classes. - Increase your ulimit when analyzing large applications. See this Red Hat Knowledgebase article for instructions on how to do this for Red Hat Enterprise Linux.
- If you have access to a server that has better resources than your laptop or desktop machine, you may want to consider running RHAMT on that server.
6.1.2. Hardware Upgrade Suggestions
If the application and command-line suggestions above do not improve performance, you may need to upgrade your hardware.
- If you have access to a server that has better resources than your laptop/desktop, then you may want to consider running RHAMT on that server.
- Very large applications that require decompilation have large memory requirements. 8 GB RAM is recommended. This allows 3 - 4 GB RAM for use by the JVM.
- An upgrade from a single or dual-core to a quad-core CPU processor provides better performance.
- Disk space and fragmentation can impact performance. A fast disk, especially a solid-state drive (SSD), with greater than 4 GB of defragmented disk space should improve performance.
Appendix A. Reference Material
A.1. RHAMT Command-line Arguments
The following is a detailed description of the available RHAMT command line arguments.
To run the RHAMT command without prompting, for example when executing from a script, use --batchMode to take the default values for unspecified parameters and --overwrite to force delete the output directory. Also be sure to specify the required --input and --target arguments.
See the description for each argument for more details.
| Argument | Description |
|---|---|
| --additionalClassPath | A space-delimited list of additional JAR files or directories to add to the class path so that they are available for decompilation or other analysis. |
| --addonDir | Add the specified directory as a custom add-on repository. |
| --batchMode | Flag to specify that RHAMT should be run in a non-interactive mode without prompting for confirmation. This mode takes the default values for any parameters not passed in to the command line. |
| --debug | Flag to run RHAMT in debug mode. |
| --discoverPackages | Flag to list all available packages in the input binary application. |
| --enableClassNotFoundAnalysis | Flag to enable analysis of Java files that are not available on the class path. This should not be used if some classes will be unavailable at analysis time. |
| --enableCompatibleFilesReport | Flag to enable generation of the Compatible Files report. Due to processing all files without found issues, this report may take a long time for large applications. |
| --enableTattletale | Flag to enable generate a Tattletale report for each application. |
| --excludePackages | A space-delimited list of packages to exclude from evaluation. For example, entering "com.mycompany.commonutilities" would exclude all classes whose package name begins with "com.mycompany.commonutilities". |
| --excludeTags |
A space-delimited list of tags to exclude. When specified, rules with these tags will not be processed. To see the full list of tags, use the |
| --explodedApp | Flag to indicate that the provided input directory contains source files for a single application. See the Input File Argument Tables for details. |
| --exportCSV |
Flag to export the report data to a CSV file on your local file system. RHAMT creates the file in the directory specified by the |
| --help | Display the RHAMT help message. |
| --immutableAddonDir | Add the specified directory as a custom read-only add-on repository. |
| --includeTags |
A space-delimited list of tags to use. When specified, only rules with these tags will be processed. To see the full list of tags, use the |
| --input | A space-delimited list of the path to the file or directory containing one or more applications to be analyzed. This argument is required. See Specify the Input for more information. |
| --install |
Specify add-ons to install. The syntax is |
| --keepWorkDirs | Flag to instruct RHAMT to not delete temporary working files, such as the graph database and unzipped archives. This is useful for debugging purposes. |
| --list | Flag to list installed add-ons. |
| --listSourceTechnologies | Flag to list all available source technologies. |
| --listTags | Flag to list all available tags. |
| --listTargetTechnologies | Flag to list all available target technologies. |
| --mavenize |
Flag to create a Maven project directory structure based on the structure and content of the application. This creates |
| --mavenizeGroupId |
When used with the |
| --online | Flag to allow network access for features that require it. Currently only validating XML schemas against external resources relies on Internet access. Note that this comes with a performance penalty. |
| --output | Specify the path to the directory to output the report information generated by RHAMT. See Specify the Output Directory for more information. |
| --overwrite |
Flag to force delete the existing output directory specified by Warning Be careful not to specify a report output directory that contains important information! |
| --packages | A space-delimited list of the packages to be evaluated by RHAMT. It is highly recommended to use this argument. See Select Packages for more information. |
| --remove |
Remove the specified add-ons. The syntax is |
| --skipReports |
Flag to indicate that HTML reports should not be generated. A common use of this argument is when exporting report data to a CSV file using |
| --source |
A space-delimited list of one or more source technologies, servers, platforms, or frameworks to migrate from. This argument, in conjunction with the |
| --sourceMode | Flag to indicate that the application to be evaluated contains source files rather than compiled binaries. See the Input File Argument Tables for details. |
| --target |
A space-delimited list of one or more target technologies, servers, platforms, or frameworks to migrate to. This argument, in conjunction with the |
| --userIgnorePath |
Specify a location, in addition to |
| --userRulesDirectory |
Specify a location, in addition to |
| --version | Display the RHAMT version. |
A.1.1. Specify the Input
A space-delimited list of the path to the file or directory containing one or more applications to be analyzed. This argument is required.
Usage
--input INPUT_ARCHIVE_OR_DIRECTORY [...]
Depending on whether the input file type provided to the --input argument is a file or directory, it will be evaluated as follows depending on the additional arguments provided.
- Directory
--explodedApp --sourceMode Neither Argument The directory is evaluated as a single application.
The directory is evaluated as a single application.
Each subdirectory is evaluated as an application.
- File
--explodedApp --sourceMode Neither Argument Argument is ignored; the file is evaluated as a single application.
The file is evaluated as a compressed project.
The file is evaluated as a single application.
A.1.2. Specify the Output Directory
Specify the path to the directory to output the report information generated by RHAMT.
Usage
--output OUTPUT_REPORT_DIRECTORY
-
If omitted, the report will be generated in an
INPUT_ARCHIVE_OR_DIRECTORY.reportdirectory. If the output directory exists, you will be prompted with the following (with a default of N).
Overwrite all contents of "/home/username/OUTPUT_REPORT_DIRECTORY" (anything already in the directory will be deleted)? [y,N]
However, if you specify the --overwrite argument, RHAMT will proceed to delete and recreate the directory. See the description of this argument for more information.
A.1.3. Set the Source Technology
A space-delimited list of one or more source technologies, servers, platforms, or frameworks to migrate from. This argument, in conjunction with the --target argument, helps to determine which rulesets are used. Use the --listSourceTechnologies argument to list all available sources.
Usage
--source SOURCE_1 SOURCE_2
The --source argument now provides version support, which follows the Maven version range syntax. This instructs RHAMT to only run the rulesets matching the specified versions. For example, --source eap:5.
When migrating to JBoss EAP, be sure to specify the version, for example, eap:6. Specifying only eap will run rulesets for all versions of JBoss EAP, including those not relevant to your migration path.
See Supported Migration Paths in the RHAMT Getting Started Guide for which JBoss EAP version is appropriate for your source platform.
A.1.4. Set the Target Technology
A space-delimited list of one or more target technologies, servers, platforms, or frameworks to migrate to. This argument, in conjunction with the --source argument, helps to determine which rulesets are used. If you do not specify this option, you are prompted to select a target. Use the --listTargetTechnologies argument to list all available targets.
Usage
--target TARGET_1 TARGET_2
The --target argument now provides version support, which follows the Maven version range syntax. This instructs RHAMT to only run the rulesets matching the specified versions. For example, --target eap:7.
When migrating to JBoss EAP, be sure to specify the version in the target, for example, eap:6. Specifying only eap will run rulesets for all versions of JBoss EAP, including those not relevant to your migration path.
See Supported Migration Paths in the RHAMT Getting Started Guide for which JBoss EAP version is appropriate for your source platform.
A.1.5. Select Packages
A space-delimited list of the packages to be evaluated by RHAMT. It is highly recommended to use this argument.
Usage
--packages PACKAGE_1 PACKAGE_2 PACKAGE_N
-
In most cases, you are interested only in evaluating custom application class packages and not standard Java EE or third party packages. The
PACKAGE_Nargument is a package prefix; all subpackages will be scanned. For example, to scan the packagescom.mycustomappandcom.myotherapp, use--packages com.mycustomapp com.myotherappargument on the command line. -
While you can provide package names for standard Java EE third party software like
org.apache, it is usually best not to include them as they should not impact the migration effort.
If you omit the --packages argument, every package in the application is scanned, which can impact performance. It is best to provide this argument with one or more packages. For additional tips on how to improve performance, see Optimize RHAMT Performance.
A.2. Rule Story Points
A.2.1. What are Story Points?
Story points are an abstract metric commonly used in Agile software development to estimate the level of effort needed to implement a feature or change.
Red Hat Application Migration Toolkit uses story points to express the level of effort needed to migrate particular application constructs, and the application as a whole. It does not necessarily translate to man-hours, but the value should be consistent across tasks.
A.2.2. How Story Points are Estimated in Rules
Estimating the level of effort for the story points for a rule can be tricky. The following are the general guidelines RHAMT uses when estimating the level of effort required for a rule.
| Level of Effort | Story Points | Description |
|---|---|---|
| Information | 0 | An informational warning with very low or no priority for migration. |
| Trivial | 1 | The migration is a trivial change or a simple library swap with no or minimal API changes. |
| Complex | 3 | The changes required for the migration task are complex, but have a documented solution. |
| Redesign | 5 | The migration task requires a redesign or a complete library change, with significant API changes. |
| Rearchitecture | 7 | The migration requires a complete rearchitecture of the component or subsystem. |
| Unknown | 13 | The migration solution is not known and may need a complete rewrite. |
A.2.3. Task Severity
In addition to the level of effort, you can categorize migration tasks to indicate the severity of the task. The following categories are used to indicate whether a task must be completed or can be postponed.
- Mandatory
- The task must be completed for a successful migration. If the changes are not made, the resulting application will not build or run successfully. Examples include replacement of proprietary APIs that are not supported in the target platform.
- Optional
- If the migration task is not completed, the application should work, but the results may not be the optimal. If the change is not made at the time of migration, it is recommended to put it on the schedule soon after migration is completed. An example of this would be the upgrade of EJB 2.x code to EJB 3.
For more information on categorizing tasks, see Using Custom Rule Categories in the Rules Development Guide.
A.3. Additional Resources
A.3.1. Get Involved
To help make Red Hat Application Migration Toolkit cover most application constructs and server configurations, including yours, you can help with any of the following items.
- Send an email to jboss-migration-feedback@redhat.com and let us know what RHAMT migration rules should cover.
- Provide example applications to test migration rules.
Identify application components and problem areas that may be difficult to migrate.
- Write a short description of these problem migration areas.
- Write a brief overview describing how to solve the problem migration areas.
- Try Red Hat Application Migration Toolkit on your application. Be sure to report any issues you encounter.
Contribute to the Red Hat Application Migration Toolkit rules repository.
- Write a Red Hat Application Migration Toolkit rule to identify or automate a migration process.
- Create a test for the new rule.
- Details are provided in the Rules Development Guide.
Contribute to the project source code.
- Create a core rule.
- Improve RHAMT performance or efficiency.
- See the Core Development Guide for information about how to configure your environment and set up the project.
Any level of involvement is greatly appreciated!
A.3.2. Important Links
- RHAMT forums: https://developer.jboss.org/en/windup
RHAMT JIRA issue trackers
- Core RHAMT: https://issues.jboss.org/browse/WINDUP
- RHAMT Rules: https://issues.jboss.org/browse/WINDUPRULE
- RHAMT mailing list: jboss-migration-feedback@redhat.com
- RHAMT on Twitter: @JBossWindup
-
RHAMT IRC channel: Server FreeNode (
irc.freenode.net), channel#windup(transcripts).
A.3.3. Known RHAMT Issues
You can review known issues for RHAMT here: Open RHAMT issues.
A.3.4. Report Issues with RHAMT
Red Hat Application Migration Toolkit uses JIRA as its issue tracking system. If you encounter an issue executing RHAMT, please file a JIRA Issue.
If you do not have one already, you must sign up for a JIRA account in order to create a JIRA issue.
A.3.4.1. Create a JIRA Issue
Open a browser and navigate to the JIRA Create Issue page.
If you have not yet logged in, click the Log In link at the top right side of the page and enter your credentials.
Choose the following options and click the Next button.
Project
For core RHAMT issues, choose Red Hat Application Migration Toolkit (WINDUP).
For issues with RHAMT rules, choose: Red Hat Application Migration Toolkit rules (WINDUPRULE).
- Issue Type: Bug
On the next screen complete the following fields.
- Summary: Enter a brief description of the problem or issue.
- Environment: Provide the details of your operating system, version of Java, and any other pertinent information.
- Description: Provide a detailed description of the issue. Be sure to include logs and exceptions traces.
- Attachment: If the application or archive causing the issue does not contain sensitive information and you are comfortable sharing it with the RHAMT development team, attach it to the issue using the browse button.
- Click the Create button to create the JIRA issue.
Revised on 2018-04-04 12:20:53 EDT