Developer Guide
For use with Red Hat JBoss Data Grid 7.0
Abstract
Part I. Programmable APIs
- Cache
- Batching
- Grouping
- Persistence (formerly CacheStore)
- ConfigurationBuilder
- Externalizable
- Notification (also known as the Listener API because it deals with Notifications and Listeners)
Chapter 1. The Cache API
ConcurrentMap interface. How entries are stored depends on the cache mode in use. For example, an entry may be replicated to a remote node or an entry may be looked up in a cache store.
Note
1.1. Using the ConfigurationBuilder API to Configure the Cache API
ConfigurationBuilder helper object.
Procedure 1.1. Programmatic Cache Configuration
Configuration c = new ConfigurationBuilder().clustering().cacheMode(CacheMode.REPL_SYNC).build();
String newCacheName = "repl";
manager.defineConfiguration(newCacheName, c);
Cache<String, String> cache = manager.getCache(newCacheName);- In the first line of the configuration, a new cache configuration object (named
c) is created using theConfigurationBuilder. Configurationcis assigned the default values for all cache configuration options except the cache mode, which is overridden and set to synchronous replication (REPL_SYNC). - In the second line of the configuration, a new variable (of type
String) is created and assigned the valuerepl. - In the third line of the configuration, the cache manager is used to define a named cache configuration for itself. This named cache configuration is called
repland its configuration is based on the configuration provided for cache configurationcin the first line. - In the fourth line of the configuration, the cache manager is used to obtain a reference to the unique instance of the
replthat is held by the cache manager. This cache instance is now ready to be used to perform operations to store and retrieve data.
Note
org.infinispan.jmx.JmxDomainConflictException: Domain already registered org.infinispan.
GlobalConfiguration glob = new GlobalConfigurationBuilder()
.clusteredDefault()
.globalJmxStatistics()
.allowDuplicateDomains(true)
.enable()
.build();1.2. Per-Invocation Flags
1.2.1. Per-Invocation Flag Functions
putForExternalRead() method in Red Hat JBoss Data Grid's Cache API uses flags internally. This method can load a JBoss Data Grid cache with data loaded from an external resource. To improve the efficiency of this call, JBoss Data Grid calls a normal put operation passing the following flags:
- The
ZERO_LOCK_ACQUISITION_TIMEOUTflag: JBoss Data Grid uses an almost zero lock acquisition time when loading data from an external source into a cache. - The
FAIL_SILENTLYflag: If the locks cannot be acquired, JBoss Data Grid fails silently without throwing any lock acquisition exceptions. - The
FORCE_ASYNCHRONOUSflag: If clustered, the cache replicates asynchronously, irrespective of the cache mode set. As a result, a response from other nodes is not required.
putForExternalRead calls of this type are used because the client can retrieve the required data from a persistent store if the data cannot be found in memory. If the client encounters a cache miss, it retries the operation.
1.2.2. Configure Per-Invocation Flags
withFlags() method call.
Example 1.1. Configuring Per-Invocation Flags
Cache cache = ...
cache.getAdvancedCache()
.withFlags(Flag.SKIP_CACHE_STORE, Flag.CACHE_MODE_LOCAL)
.put("local", "only");Note
withFlags() method for each invocation. If the cache operation must be replicated onto another node, the flags are also carried over to the remote nodes.
1.2.3. Per-Invocation Flags Example
put(), must not return the previous value, the IGNORE_RETURN_VALUES flag is used. This flag prevents a remote lookup (to get the previous value) in a distributed environment, which in turn prevents the retrieval of the undesired, potential, previous value. Additionally, if the cache is configured with a cache loader, this flag prevents the previous value from being loaded from its cache store.
Example 1.2. Using the IGNORE_RETURN_VALUES Flag
Cache cache = ...
cache.getAdvancedCache()
.withFlags(Flag.IGNORE_RETURN_VALUES)
.put("local", "only")1.3. The AdvancedCache Interface
AdvancedCache interface, geared towards extending JBoss Data Grid, in addition to its simple Cache Interface. The AdvancedCache Interface can:
- Inject custom interceptors
- Access certain internal components
- Apply flags to alter the behavior of certain cache methods
AdvancedCache:
AdvancedCache advancedCache = cache.getAdvancedCache();1.3.1. Flag Usage with the AdvancedCache Interface
AdvancedCache.withFlags() to apply any number of flags to a cache invocation.
Example 1.3. Applying Flags to a Cache Invocation
advancedCache.withFlags(Flag.CACHE_MODE_LOCAL, Flag.SKIP_LOCKING)
.withFlags(Flag.FORCE_SYNCHRONOUS)
.put("hello", "world");1.3.2. Custom Interceptors and the AdvancedCache Interface
AdvancedCache Interface provides a mechanism that allows advanced developers to attach custom interceptors. Custom interceptors can alter the behavior of the Cache API methods and the AdvacedCache Interface can be used to attach such interceptors programmatically at run time.
1.3.3. Limitations of Map Methods
size(), values(), keySet() and entrySet(), can be used with certain limitations with Red Hat JBoss Data Grid as they are unreliable. These methods do not acquire locks (global or local) and concurrent modification, additions and removals are excluded from consideration in these calls.
In JBoss Data Grid 7.0 the map methods size(), values(), keySet(), and entrySet() include entries in the cache loader by default. The cache loader in use will determine the performance of these commands; for instance, when using a database these methods will run a complete scan of the table where data is stored, which may result in slower processing. To not load entries from the cache loader, and avoid any potential performance hit, use Cache.getAdvancedCache().withFlags(Flag.SKIP_CACHE_LOAD) before executing the desired method.
In JBoss Data Grid 7.0 the Cache.size() method provides a count of all elements in both this cache and cache loader across the entire cluster. When using a loader or remote entries, only a subset of entries is held in memory at any given time to prevent possible memory issues, and the loading of all entries may be slow.
size() method is affected by the flags org.infinispan.context.Flag#CACHE_MODE_LOCAL, to force it to return the number of entries present on the local node, and org.infinispan.context.Flag#SKIP_CACHE_LOAD, to ignore any passivated entries. Either of these flags may be used to increase performance of this method, at the cost of not returning a count of all elements across the entire cluster.
In JBoss Data Grid 7.0 the Hot Rod protocol contain a dedicated SIZE operation, and the clients use this operation to calculate the size of all entries.
1.3.4. Custom Interceptors
Warning
1.3.4.1. Custom Interceptor Design
- A custom interceptor must extend the
CommandInterceptor. - A custom interceptor must declare a public, empty constructor to allow for instantiation.
- A custom interceptor must have JavaBean style setters defined for any property that is defined through the
propertyelement.
1.3.4.2. Adding Custom Interceptors Programmatically
AdvancedCache.
Example 1.4. Obtain a Reference to the AdvancedCache
CacheManager cm = getCacheManager();
Cache aCache = cm.getCache("aName");
AdvancedCache advCache = aCache.getAdvancedCache();addInterceptor() method to add the interceptor.
Example 1.5. Add the Interceptor
advCache.addInterceptor(new MyInterceptor(), 0);1.4. GET and PUT Usage in Distribution Mode
GET command before a write command. This occurs because certain methods (for example, Cache.put()) return the previous value associated with the specified key according to the java.util.Map contract. When this is performed on an instance that does not own the key and the entry is not found in the L1 cache, the only reliable way to elicit this return value is to perform a remote GET before the PUT.
GET operation that occurs before the PUT operation is always synchronous, whether the cache is synchronous or asynchronous, because Red Hat JBoss Data Grid must wait for the return value.
1.4.1. Distributed GET and PUT Operation Resource Usage
GET operation before executing the desired PUT operation.
GET operation does not wait for all responses, which would result in wasted resources. The GET process accepts the first valid response received, which allows its performance to be unrelated to cluster size.
Flag.SKIP_REMOTE_LOOKUP flag for a per-invocation setting if return values are not required for your implementation.
java.util.Map interface contract. The contract breaks because unreliable and inaccurate return values are provided to certain methods. As a result, ensure that these return values are not used for any important purpose on your configuration.
Chapter 2. The Asynchronous API
Async appended to each method name. Asynchronous methods return a Future that contains the result of the operation.
Cache<String, String>, Cache.put(String key, String value) returns a String, while Cache.putAsync(String key, String value) returns a Future<String>.
2.1. Asynchronous API Benefits
- The guarantee of synchronous communication, with the added ability to handle failures and exceptions.
- Not being required to block a thread's operations until the call completes.
Example 2.1. Using the Asynchronous API
Set<Future<?>> futures = new HashSet<Future<?>>();
futures.add(cache.putAsync("key1", "value1"));
futures.add(cache.putAsync("key2", "value2"));
futures.add(cache.putAsync("key3", "value3"));futures.add(cache.putAsync(key1, value1));futures.add(cache.putAsync(key2, value2));futures.add(cache.putAsync(key3, value3));
2.2. About Asynchronous Processes
- Network calls
- Marshalling
- Writing to a cache store (optional)
- Locking
2.3. Return Values and the Asynchronous API
Future or the CompletableFuture in order to query the previous value.
Future.get()Chapter 3. The Batching API
Note
3.1. About Java Transaction API
- First, it retrieves the transactions currently associated with the thread.
- If not already done, it registers an
XAResourcewith the transaction manager to receive notifications when a transaction is committed or rolled back.
3.2. Batching and the Java Transaction API (JTA)
- Locks acquired during an invocation are retained until the transaction commits or rolls back.
- All changes are replicated in a batch on all nodes in the cluster as part of the transaction commit process. Ensuring that multiple changes occur within the single transaction, the replication traffic remains lower and improves performance.
- When using synchronous replication or invalidation, a replication or invalidation failure causes the transaction to roll back.
- When a cache is transactional and a cache loader is present, the cache loader is not enlisted in the cache's transaction. This results in potential inconsistencies at the cache loader level when the transaction applies the in-memory state but (partially) fails to apply the changes to the store.
- All configurations related to a transaction apply for batching as well.
Note
3.3. Using the Batching API
3.3.1. Configure the Batching API
Configuration c = new ConfigurationBuilder().transaction().transactionMode(TransactionMode.TRANSACTIONAL).invocationBatching().enable().build();Note
3.3.2. Use the Batching API
startBatch() and endBatch() on the cache as follows to use batching:
Cache cache = cacheManager.getCache();Example 3.1. Without Using Batch
cache.put("key", "value"); cache.put(key, value); line executes, the values are replaced immediately.
Example 3.2. Using Batch
cache.startBatch();
cache.put("k1", "value");
cache.put("k2", "value");
cache.put("k3", "value");
cache.endBatch(true);
cache.startBatch();
cache.put("k1", "value");
cache.put("k2", "value");
cache.put("k3", "value");
cache.endBatch(false); cache.endBatch(true); executes, all modifications made since the batch started are replicated.
cache.endBatch(false); executes, changes made in the batch are discarded.
3.3.3. Batching API Usage Example
Example 3.3. Batching API Usage Example
Chapter 4. The Grouping API
4.1. Grouping API Operations
- Every node can determine which node owns a particular key without expensive metadata updates across nodes.
- Redundancy is improved because ownership information does not need to be replicated if a node fails.
- Intrinsic to the entry, which means it was generated by the key class.
- Extrinsic to the entry, which means it was generated by an external function.
4.2. Grouping API Use Case
Example 4.1. Grouping API Example
DistributedExecutor only checks node AB and quickly and easily retrieves the required employee records.
4.3. Configure the Grouping API
- Enable groups using either the declarative or programmatic method.
- Specify either an intrinsic or extrinsic group. For more information about these group types, see Section 4.1, “Grouping API Operations”
- Register all specified groupers.
4.3.1. Enable Groups
Configuration c = new ConfigurationBuilder().clustering().hash().groups().enabled().build();4.3.2. Specify an Intrinsic Group
- the key class definition can be altered, that is if it is not part of an unmodifiable library.
- if the key class is not concerned with the determination of a key/value pair group.
@Group annotation in the relevant method to specify an intrinsic group. The group must always be a String, as illustrated in the example:
Example 4.2. Specifying an Intrinsic Group Example
class User {
<!-- Additional configuration information here -->
String office;
<!-- Additional configuration information here -->
public int hashCode() {
// Defines the hash for the key, normally used to determine location
<!-- Additional configuration information here -->
}
// Override the location by specifying a group, all keys in the same
// group end up with the same owner
@Group
String getOffice() {
return office;
}
}4.3.3. Specify an Extrinsic Group
- the key class definition cannot be altered, that is if it is part of an unmodifiable library.
- if the key class is concerned with the determination of a key/value pair group.
Grouper interface. This interface uses the computeGroup method to return the group.
Grouper interface acts as an interceptor by passing the computed value to computeGroup. If the @Group annotation is used, the group using it is passed to the first Grouper. As a result, using an intrinsic group provides even greater control.
Example 4.3. Specifying an Extrinsic Group Example
Grouper that uses the key class to extract the group from a key using a pattern. Any group information specified on the key class is ignored in such a situation.
public class KXGrouper implements Grouper<String> {
// A pattern that can extract from a "kX" (e.g. k1, k2) style key
// The pattern requires a String key, of length 2, where the first character is
// "k" and the second character is a digit. We take that digit, and perform
// modular arithmetic on it to assign it to group "1" or group "2".
private static Pattern kPattern = Pattern.compile("(^k)(\\d)$");
public String computeGroup(String key, String group) {
Matcher matcher = kPattern.matcher(key);
if (matcher.matches()) {
String g = Integer.parseInt(matcher.group(2)) % 2 + "";
return g;
} else
return null;
}
public Class<String> getKeyType() {
return String.class;
}
}4.3.4. Register Groupers
Example 4.4. Programmatically Register a Grouper
Configuration c = new ConfigurationBuilder().clustering().hash().groups().addGrouper(new KXGrouper()).enabled().build();Chapter 5. The Persistence SPI
- Memory is volatile and a cache store can increase the life span of the information in the cache, which results in improved durability.
- Using persistent external stores as a caching layer between an application and a custom storage engine provides improved Write-Through functionality.
- Using a combination of eviction and passivation, only the frequently required information is stored in-memory and other data is stored in the external storage.
5.1. Persistence SPI Benefits
- Alignment with JSR-107 (http://jcp.org/en/jsr/detail?id=107). JBoss Data Grid's
CacheWriterandCacheLoaderinterfaces are similar to the JSR-107 writer and reader. As a result, alignment with JSR-107 provides improved portability for stores across JCache-compliant vendors. - Simplified transaction integration. JBoss Data Grid handles locking automatically and so implementations do not have to coordinate concurrent access to the store. Depending on the locking mode, concurrent writes on the same key may not occur. However, implementors expect operations on the store to originate from multiple threads and add the implementation code accordingly.
- Reduced serialization, resulting in reduced CPU usage. The new SPI exposes stored entries in a serialized format. If an entry is fetched from persistent storage to be sent remotely, it does not need to be deserialized (when reading from the store) and then serialized again (when writing to the wire). Instead, the entry is written to the wire in the serialized format as fetched from the storage.
5.2. Programmatically Configure the Persistence SPI
Example 5.1. Configure the Single File Store via the Persistence SPI
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence()
.passivation(false)
.addSingleFileStore()
.preload(true)
.shared(false)
.fetchPersistentState(true)
.ignoreModifications(false)
.purgeOnStartup(false)
.location(System.getProperty("java.io.tmpdir"))
.async()
.enabled(true)
.threadPoolSize(5)
.singleton()
.enabled(true)
.pushStateWhenCoordinator(true)
.pushStateTimeout(20000);Note
5.3. Persistence Examples
Note
5.3.1. Configure the Cache Store Programmatically
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence()
.passivation(false)
.addSingleFileStore()
.shared(false)
.preload(true)
.fetchPersistentState(true)
.purgeOnStartup(false)
.location(System.getProperty("java.io.tmpdir"))
.async()
.enabled(true)
.flushLockTimeout(15000)
.threadPoolSize(5)
.singleton()
.enabled(true)
.pushStateWhenCoordinator(true)
.pushStateTimeout(20000);Note
location are specific to the single-file cache store and are not used for other types of cache stores.
Procedure 5.1. Configure the Cache store Programatically
- Use the
ConfigurationBuilderto create a new configuration object. - The
passivationelements affects the way Red Hat JBoss Data Grid interacts with stores. Passivation removes an object from an in-memory cache and writes it to a secondary data store, such as a system or database. If no secondary data store exists, then the object will only be removed from the in-memory cache. Passivation isfalseby default. - The
addSingleFileStore()elements adds the SingleFileStore as the cache store for this configuration. It is possible to create other stores, such as a JDBC Cache Store, which can be added using theaddStoremethod. - The
sharedparameter indicates that the cache store is shared by different cache instances. For example, where all instances in a cluster use the same JDBC settings to talk to the same remote, shared database.sharedisfalseby default. When set totrue, it prevents duplicate data being written to the cache store by different cache instances. - The
preloadelement is set tofalseby default. When set totruethe data stored in the cache store is preloaded into the memory when the cache starts. This allows data in the cache store to be available immediately after startup and avoids cache operations delays as a result of loading data lazily. Preloaded data is only stored locally on the node, and there is no replication or distribution of the preloaded data. JBoss Data Grid will only preload up to the maximum configured number of entries in eviction. - The
fetchPersistentStateelement determines whether or not to fetch the persistent state of a cache and apply it to the local cache store when joining the cluster. If the cache store is shared the fetch persistent state is ignored, as caches access the same cache store. A configuration exception will be thrown when starting the cache service if more than one cache store has this property set totrue. ThefetchPersistentStateproperty isfalseby default. - The
purgeOnStartupelement controls whether cache store is purged when it starts up and isfalseby default. - The
locationelement configuration element sets a location on disk where the store can write. - These attributes configure aspects specific to each cache store. For example, the
locationattribute points to where the SingleFileStore will keep files containing data. Other stores may require more complex configuration. - The
singletonelement enables modifications to be stored by only one node in the cluster. This node is called the coordinator. The coordinator pushes the caches in-memory states to disk. This function is activated by setting theenabledattribute totruein all nodes. Thesharedparameter cannot be defined withsingletonenabled at the same time. Theenabledattribute isfalseby default. - The
pushStateWhenCoordinatorelement is set totrueby default. Iftrue, this property will cause a node that has become the coordinator to transfer in-memory state to the underlying cache store. This parameter is useful where the coordinator has crashed and a new coordinator is elected.
5.3.2. LevelDB Cache Store Programmatic Configuration
Configuration cacheConfig = new ConfigurationBuilder().persistence()
.addStore(LevelDBStoreConfigurationBuilder.class)
.location("/tmp/leveldb/data")
.expiredLocation("/tmp/leveldb/expired").build();Procedure 5.2. LevelDB Cache Store programmatic configuration
- Use the
ConfigurationBuilderto create a new configuration object. - Add the store using
LevelDBCacheStoreConfigurationBuilderclass to build its configuration. - Set the LevelDB Cache Store location path. The specified path stores the primary cache store data. The directory is automatically created if it does not exist.
- Specify the location for expired data using the
expiredLocationparameter for the LevelDB Store. The specified path stores expired data before it is purged. The directory is automatically created if it does not exist.
Note
5.3.3. JdbcBinaryStore Programmatic Configuration
JdbcBinaryStore:
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence()
.addStore(JdbcBinaryStoreConfigurationBuilder.class)
.fetchPersistentState(false)
.ignoreModifications(false)
.purgeOnStartup(false)
.table()
.dropOnExit(true)
.createOnStart(true)
.tableNamePrefix("ISPN_BUCKET_TABLE")
.idColumnName("ID_COLUMN").idColumnType("VARCHAR(255)")
.dataColumnName("DATA_COLUMN").dataColumnType("BINARY")
.timestampColumnName("TIMESTAMP_COLUMN").timestampColumnType("BIGINT")
.connectionPool()
.connectionUrl("jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1")
.username("sa")
.driverClass("org.h2.Driver");Procedure 5.3. JdbcBinaryStore Programmatic Configuration (Library Mode)
- Use the
ConfigurationBuilderto create a new configuration object. - Add the
JdbcBinaryStoreconfiguration builder to build a specific configuration related to this store. - The
fetchPersistentStateelement determines whether or not to fetch the persistent state of a cache and apply it to the local cache store when joining the cluster. If the cache store is shared the fetch persistent state is ignored, as caches access the same cache store. A configuration exception will be thrown when starting the cache service if more than one cache loader has this property set totrue. ThefetchPersistentStateproperty isfalseby default. - The
ignoreModificationselement determines whether write methods are pushed to the specific cache loader by allowing write operations to the local file cache loader, but not the shared cache loader. In some cases, transient application data should only reside in a file-based cache loader on the same server as the in-memory cache. For example, this would apply with a further JDBC based cache loader used by all servers in the network.ignoreModificationsisfalseby default. - The
purgeOnStartupelement specifies whether the cache is purged when initially started. - Configure the table as follows:
dropOnExitdetermines if the table will be dropped when the cache store is stopped. This is set tofalseby default.createOnStartcreates the table when starting the cache store if no table currently exists. This method istrueby default.tableNamePrefixsets the prefix for the name of the table in which the data will be stored.- The
idColumnNameproperty defines the column where the cache key or bucket ID is stored. - The
dataColumnNameproperty specifies the column where the cache entry or bucket is stored. - The
timestampColumnNameelement specifies the column where the time stamp of the cache entry or bucket is stored.
- The
connectionPoolelement specifies a connection pool for the JDBC driver using the following parameters:- The
connectionUrlparameter specifies the JDBC driver-specific connection URL. - The
usernameparameter contains the user name used to connect via theconnectionUrl. - The
driverClassparameter specifies the class name of the driver used to connect to the database.
Note
5.3.4. JdbcStringBasedStore Programmatic Configuration
JdbcStringBasedStore:
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence().addStore(JdbcStringBasedStoreConfigurationBuilder.class)
.fetchPersistentState(false)
.ignoreModifications(false)
.purgeOnStartup(false)
.table()
.dropOnExit(true)
.createOnStart(true)
.tableNamePrefix("ISPN_STRING_TABLE")
.idColumnName("ID_COLUMN").idColumnType("VARCHAR(255)")
.dataColumnName("DATA_COLUMN").dataColumnType("BINARY")
.timestampColumnName("TIMESTAMP_COLUMN").timestampColumnType("BIGINT")
.dataSource()
.jndiUrl("java:jboss/datasources/JdbcDS");Procedure 5.4. Configure the JdbcStringBasedStore Programmatically
- Use the
ConfigurationBuilderto create a new configuration object. - Add the
JdbcStringBasedStoreconfiguration builder to build a specific configuration related to this store. - The
fetchPersistentStateparameter determines whether or not to fetch the persistent state of a cache and apply it to the local cache store when joining the cluster. If the cache store is shared the fetch persistent state is ignored, as caches access the same cache store. A configuration exception will be thrown when starting the cache service if more than one cache loader has this property set totrue. ThefetchPersistentStateproperty isfalseby default. - The
ignoreModificationsparameter determines whether write methods are pushed to the specific cache loader by allowing write operations to the local file cache loader, but not the shared cache loader. In some cases, transient application data should only reside in a file-based cache loader on the same server as the in-memory cache. For example, this would apply with a further JDBC based cache loader used by all servers in the network.ignoreModificationsisfalseby default. - The
purgeOnStartupparameter specifies whether the cache is purged when initially started. - Configure the Table
dropOnExitdetermines if the table will be dropped when the cache store is stopped. This is set tofalseby default.createOnStartcreates the table when starting the cache store if no table currently exists. This method istrueby default.tableNamePrefixsets the prefix for the name of the table in which the data will be stored.- The
idColumnNameproperty defines the column where the cache key or bucket ID is stored. - The
dataColumnNameproperty specifies the column where the cache entry or bucket is stored. - The
timestampColumnNameelement specifies the column where the time stamp of the cache entry or bucket is stored.
- The
dataSourceelement specifies a data source using the following parameters:- The
jndiUrlspecifies the JNDI URL to the existing JDBC.
Note
Note
JdbcStringBasedStore indicates that your data column type is set to VARCHAR, CLOB or something similar instead of the correct type, BLOB or VARBINARY. Despite its name, JdbcStringBasedStore only requires that the keys are strings while the values can be any data type, so that they can be stored in a binary column.
5.3.5. JdbcMixedStore Programmatic Configuration
JdbcMixedStore:
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence().addStore(JdbcMixedStoreConfigurationBuilder.class)
.fetchPersistentState(false)
.ignoreModifications(false)
.purgeOnStartup(false)
.stringTable()
.dropOnExit(true)
.createOnStart(true)
.tableNamePrefix("ISPN_MIXED_STR_TABLE")
.idColumnName("ID_COLUMN").idColumnType("VARCHAR(255)")
.dataColumnName("DATA_COLUMN").dataColumnType("BINARY")
.timestampColumnName("TIMESTAMP_COLUMN").timestampColumnType("BIGINT")
.binaryTable()
.dropOnExit(true)
.createOnStart(true)
.tableNamePrefix("ISPN_MIXED_BINARY_TABLE")
.idColumnName("ID_COLUMN").idColumnType("VARCHAR(255)")
.dataColumnName("DATA_COLUMN").dataColumnType("BINARY")
.timestampColumnName("TIMESTAMP_COLUMN").timestampColumnType("BIGINT")
.connectionPool()
.connectionUrl("jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1")
.username("sa")
.driverClass("org.h2.Driver");Procedure 5.5. Configure JdbcMixedStore Programmatically
- Use the
ConfigurationBuilderto create a new configuration object. - Add the
JdbcMixedStoreconfiguration builder to build a specific configuration related to this store. - The
fetchPersistentStateparameter determines whether or not to fetch the persistent state of a cache and apply it to the local cache store when joining the cluster. If the cache store is shared the fetch persistent state is ignored, as caches access the same cache store. A configuration exception will be thrown when starting the cache service if more than one cache loader has this property set totrue. ThefetchPersistentStateproperty isfalseby default. - The
ignoreModificationsparameter determines whether write methods are pushed to the specific cache loader by allowing write operations to the local file cache loader, but not the shared cache loader. In some cases, transient application data should only reside in a file-based cache loader on the same server as the in-memory cache. For example, this would apply with a further JDBC based cache loader used by all servers in the network.ignoreModificationsisfalseby default. - The
purgeOnStartupparameter specifies whether the cache is purged when initially started. - Configure the table as follows:
dropOnExitdetermines if the table will be dropped when the cache store is stopped. This is set tofalseby default.createOnStartcreates the table when starting the cache store if no table currently exists. This method istrueby default.tableNamePrefixsets the prefix for the name of the table in which the data will be stored.- The
idColumnNameproperty defines the column where the cache key or bucket ID is stored. - The
dataColumnNameproperty specifies the column where the cache entry or bucket is stored. - The
timestampColumnNameelement specifies the column where the time stamp of the cache entry or bucket is stored.
- The
connectionPoolelement specifies a connection pool for the JDBC driver using the following parameters:- The
connectionUrlparameter specifies the JDBC driver-specific connection URL. - The
usernameparameter contains the username used to connect via theconnectionUrl. - The
driverClassparameter specifies the class name of the driver used to connect to the database.
Note
5.3.6. JPA Cache Store Sample Programmatic Configuration
Configuration cacheConfig = new ConfigurationBuilder().persistence()
.addStore(JpaStoreConfigurationBuilder.class)
.persistenceUnitName("org.infinispan.loaders.jpa.configurationTest")
.entityClass(User.class)
.build();- The
persistenceUnitNameparameter specifies the name of the JPA cache store in the configuration file (persistence.xml) that contains the JPA entity class. - The
entityClassparameter specifies the JPA entity class that is stored in this cache. Only one class can be specified for each configuration.
5.3.7. Cassandra Cache Store Sample Programmatic Configuration
Configuration cacheConfig = new ConfigurationBuilder()
.persistence()
.addStore(CassandraStoreConfigurationBuilder.class)
.addServer()
.host("127.0.0.1")
.port("9042")
.addServer()
.host("127.0.0.1")
.port("9041")
.autoCreateKeyspace(true)
.keyspace("TestKeyspace")
.entryTable("TestEntryTable")
.consistencyLevel("LOCAL_ONE")
.serialConsistencyLevel("SERIAL")
.connectionPool()
.heartbeatIntervalSeconds(30)
.idleTimeoutSeconds(120)
.poolTimeoutMillis(5)
.build();Chapter 6. The ConfigurationBuilder API
- Chain coding of configuration options in order to make the coding process more efficient
- Improve the readability of the configuration
6.1. Using the ConfigurationBuilder API
6.1.1. Programmatically Create a CacheManager and Replicated Cache
Procedure 6.1. Configure the CacheManager Programmatically
EmbeddedCacheManager manager = new DefaultCacheManager("my-config-file.xml");
Cache defaultCache = manager.getCache();
Configuration c = new ConfigurationBuilder().clustering().cacheMode(CacheMode.REPL_SYNC)
.build();
String newCacheName = "repl";
manager.defineConfiguration(newCacheName, c);
Cache<String, String> cache = manager.getCache(newCacheName);- Create a CacheManager as a starting point in an XML file. If required, this CacheManager can be programmed in runtime to the specification that meets the requirements of the use case.
- Create a new synchronously replicated cache programmatically.
- Create a new configuration object instance using the ConfigurationBuilder helper object:In the first line of the configuration, a new cache configuration object (named
c) is created using theConfigurationBuilder. Configurationcis assigned the default values for all cache configuration options except the cache mode, which is overridden and set to synchronous replication (REPL_SYNC). - Define or register the configuration with a manager:In the third line of the configuration, the cache manager is used to define a named cache configuration for itself. This named cache configuration is called
repland its configuration is based on the configuration provided for cache configurationcin the first line. - In the fourth line of the configuration, the cache manager is used to obtain a reference to the unique instance of the
replthat is held by the cache manager. This cache instance is now ready to be used to perform operations to store and retrieve data.
Note
6.1.2. Create a Customized Cache Using the Default Named Cache
infinispan-config-file.xml specifies the configuration for a replicated cache as a default and a distributed cache with a customized lifespan value is required. The required distributed cache must retain all aspects of the default cache specified in the infinispan-config-file.xml file except the mentioned aspects.
Procedure 6.2. Customize the Default Cache
String newCacheName = "newCache";
EmbeddedCacheManager manager = new DefaultCacheManager("infinispan-config-file.xml");
Configuration dcc = manager.getDefaultCacheConfiguration();
Configuration c = new ConfigurationBuilder().read(dcc).clustering()
.cacheMode(CacheMode.DIST_SYNC).l1().lifespan(60000L).enable()
.build();
manager.defineConfiguration(newCacheName, c);
Cache<String, String> cache = manager.getCache(newCacheName);- Read an instance of a default
Configurationobject to get the default configuration. - Use the
ConfigurationBuilderto construct and modify the cache mode and L1 cache lifespan on a new configuration object. - Register/define your cache configuration with a cache manager.
- Obtain a reference to
newCache, containing the specified configuration.
6.1.3. Create a Customized Cache Using a Non-Default Named Cache
replicatedCache as the base instead of the default cache.
Procedure 6.3. Creating a Customized Cache Using a Non-Default Named Cache
String newCacheName = "newCache";
EmbeddedCacheManager manager = new DefaultCacheManager("infinispan-config-file.xml");
Configuration rc = manager.getCacheConfiguration("replicatedCache");
Configuration c = new ConfigurationBuilder().read(rc).clustering()
.cacheMode(CacheMode.DIST_SYNC).l1().lifespan(60000L).enable()
.build();
manager.defineConfiguration(newCacheName, c);
Cache<String, String> cache = manager.getCache(newCacheName);- Read the
replicatedCacheto get the default configuration. - Use the
ConfigurationBuilderto construct and modify the desired configuration on a new configuration object. - Register/define your cache configuration with a cache manager.
- Obtain a reference to
newCache, containing the specified configuration.
6.1.4. Using the Configuration Builder to Create Caches Programmatically
6.1.5. Global Configuration Examples
6.1.5.1. Globally Configure the Transport Layer
Example 6.1. Configuring the Transport Layer
GlobalConfiguration globalConfig = new GlobalConfigurationBuilder()
.transport().defaultTransport()
.build();6.1.5.2. Globally Configure the Cache Manager Name
Example 6.2. Configuring the Cache Manager Name
GlobalConfiguration globalConfig = new GlobalConfigurationBuilder()
.globalJmxStatistics()
.cacheManagerName("SalesCacheManager")
.mBeanServerLookup(new JBossMBeanServerLookup())
.enable()
.build();6.1.5.3. Globally Configure JGroups
Example 6.3. JGroups Programmatic Configuration
GlobalConfiguration gc = new GlobalConfigurationBuilder()
.transport()
.defaultTransport()
.addProperty("configurationFile","jgroups.xml")
.build();jgroups.xml in the classpath; if no instances are found in the classpath it will then search for an absolute path name.
6.1.6. Cache Level Configuration Examples
6.1.6.1. Cache Level Configuration for the Cluster Mode
Example 6.4. Configure Cluster Mode at Cache Level
Configuration config = new ConfigurationBuilder()
.clustering()
.cacheMode(CacheMode.DIST_SYNC)
.sync()
.l1().lifespan(25000L).enable()
.hash().numOwners(3)
.build();6.1.6.2. Cache Level Eviction and Expiration Configuration
Example 6.5. Configuring Expiration and Eviction at the Cache Level
Configuration config = new ConfigurationBuilder()
.eviction()
.maxEntries(20000).strategy(EvictionStrategy.LIRS).expiration()
.wakeUpInterval(5000L)
.maxIdle(120000L)
.build();6.1.6.3. Cache Level Configuration for JTA Transactions
Example 6.6. Configuring JTA Transactions at Cache Level
Configuration config = new ConfigurationBuilder()
.locking()
.concurrencyLevel(10000).isolationLevel(IsolationLevel.REPEATABLE_READ)
.lockAcquisitionTimeout(12000L).useLockStriping(false).writeSkewCheck(true)
.transaction()
.transactionManagerLookup(new GenericTransactionManagerLookup())
.recovery().enable()
.jmxStatistics().enable()
.build();6.1.6.4. Cache Level Configuration Using Chained Persistent Stores
Example 6.7. Configuring Chained Persistent Stores at Cache Level
Configuration conf = new ConfigurationBuilder()
.persistence()
.passivation(false)
.addSingleFileStore()
.location("/tmp/firstDir")
.persistence()
.passivation(false)
.addSingleFileStore()
.location("/tmp/secondDir")
.build();6.1.6.5. Cache Level Configuration for Advanced Externalizers
Example 6.8. Configuring Advanced Externalizers at Cache Level
GlobalConfiguration globalConfig = new GlobalConfigurationBuilder()
.serialization()
.addAdvancedExternalizer(new PersonExternalizer())
.addAdvancedExternalizer(999, new AddressExternalizer())
.build();6.1.6.6. Cache Level Configuration for Partition Handling (Library Mode)
ConfigurationBuilder dcc = new ConfigurationBuilder();
dcc.clustering().partitionHandling().enabled(true);Note
Chapter 7. The Externalizable API
Externalizer is a class that can:
- Marshall a given object type to a byte array.
- Unmarshall the contents of a byte array into an instance of the object type.
7.1. Customize Externalizers
- Use an Externalizable Interface. For details, see Chapter 7, The Externalizable API.
- Use an advanced externalizer.
7.2. Annotating Objects for Marshalling Using @SerializeWith
@SerializeWith indicating the Externalizer class to use.
Example 7.1. Using the @SerializeWith Annotation
import org.infinispan.commons.marshall.Externalizer;
import org.infinispan.commons.marshall.SerializeWith;
@SerializeWith(Person.PersonExternalizer.class)
public class Person {
final String name;
final int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public static class PersonExternalizer implements Externalizer<Person> {
@Override
public void writeObject(ObjectOutput output, Person person)
throws IOException {
output.writeObject(person.name);
output.writeInt(person.age);
}
@Override
public Person readObject(ObjectInput input)
throws IOException, ClassNotFoundException {
return new Person((String) input.readObject(), input.readInt());
}
}
}@SerializeWith annotation. JBoss Marshalling will therefore marshall the object using the Externalizer class passed.
- The payload sizes generated using this method are not the most efficient. This is due to some constraints in the model, such as support for different versions of the same class, or the need to marshall the Externalizer class.
- This model requires the marshalled class to be annotated with
@SerializeWith, however an Externalizer may need to be provided for a class for which source code is not available, or for any other constraints, it cannot be modified. - Annotations used in this model may be limiting for framework developers or service providers that attempt to abstract lower level details, such as the marshalling layer, away from the user.
Note
7.3. Using an Advanced Externalizer
- Define and implement the
readObject()andwriteObject()methods. - Link externalizers with marshaller classes.
- Register the advanced externalizer.
7.3.1. Implement the Methods
readObject() and writeObject() methods. The following is a sample definition:
Example 7.2. Define and Implement the Methods
import org.infinispan.commons.marshall.AdvancedExternalizer;
public class Person {
final String name;
final int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public static class PersonExternalizer implements AdvancedExternalizer<Person> {
@Override
public void writeObject(ObjectOutput output, Person person)
throws IOException {
output.writeObject(person.name);
output.writeInt(person.age);
}
@Override
public Person readObject(ObjectInput input)
throws IOException, ClassNotFoundException {
return new Person((String) input.readObject(), input.readInt());
}
@Override
public Set<Class<? extends Person>> getTypeClasses() {
return Util.<Class<? extends Person>>asSet(Person.class);
}
@Override
public Integer getId() {
return 2345;
}
}
}Note
7.3.2. Link Externalizers with Marshaller Classes
getTypeClasses() to discover the classes that this externalizer can marshall and to link the readObject() and writeObject() classes.
import org.infinispan.util.Util;
<!-- Additional configuration information here -->
@Override
public Set<Class<? extends ReplicableCommand>> getTypeClasses() {
return Util.asSet(LockControlCommand.class, GetKeyValueCommand.class,
ClusteredGetCommand.class, MultipleRpcCommand.class,
SingleRpcCommand.class, CommitCommand.class,
PrepareCommand.class, RollbackCommand.class,
ClearCommand.class, EvictCommand.class,
InvalidateCommand.class, InvalidateL1Command.class,
PutKeyValueCommand.class, PutMapCommand.class,
RemoveCommand.class, ReplaceCommand.class);
}ReplicableCommandExternalizer indicates that it can externalize several command types. This sample marshalls all commands that extend the ReplicableCommand interface but the framework only supports class equality comparison so it is not possible to indicate that the classes marshalled are all children of a particular class or interface.
@Override
public Set<Class<? extends List>> getTypeClasses() {
return Util.<Class<? extends List>>asSet(
Util.<List>loadClass("java.util.Collections$SingletonList", null));
}7.3.3. Register the Advanced Externalizer (Programmatically)
Example 7.3. Registering the Advanced Externalizer Programmatically
GlobalConfigurationBuilder builder = ...
builder.serialization()
.addAdvancedExternalizer(new Person.PersonExternalizer());7.3.4. Register Multiple Externalizers
GlobalConfiguration.addExternalizer() accepts varargs. Before registering the new externalizers, ensure that their IDs are already defined using the @Marshalls annotation.
Example 7.4. Registering Multiple Externalizers
builder.serialization()
.addAdvancedExternalizer(new Person.PersonExternalizer(),
new Address.AddressExternalizer());7.4. Custom Externalizer ID Values
| ID Range | Reserved For |
|---|---|
| 1000-1099 | The Infinispan Tree Module |
| 1100-1199 | Red Hat JBoss Data Grid Server modules |
| 1200-1299 | Hibernate Infinispan Second Level Cache |
| 1300-1399 | JBoss Data Grid Lucene Directory |
| 1400-1499 | Hibernate OGM |
| 1500-1599 | Hibernate Search |
| 1600-1699 | Infinispan Query Module |
| 1700-1799 | Infinispan Remote Query Module |
| 1800-1849 | JBoss Data Grid Scripting Module |
| 1850-1899 | JBoss Data Grid Server Event Logger Module |
| 1900-1999 | JBoss Data Grid Remote Store |
7.4.1. Customize the Externalizer ID (Programmatically)
Example 7.5. Assign an ID to the Externalizer
GlobalConfiguration globalConfiguration = new GlobalConfigurationBuilder()
.serialization()
.addAdvancedExternalizer($ID, new Person.PersonExternalizer())
.build();Chapter 8. The Notification/Listener API
8.1. Listener Example
Example 8.1. Configuring a Listener
@Listener
public class PrintWhenAdded {
@CacheEntryCreated
public void print(CacheEntryCreatedEvent event) {
System.out.println("New entry " + event.getKey() + " created in the cache");
}
}8.2. Listener Notifications
@Listener. A Listenable is an interface that denotes that the implementation can have listeners attached to it. Each listener is registered using methods defined in the Listenable.
8.2.1. About Cache-level Notifications
8.2.2. Cache Manager-level Notifications
- The starting and stopping of caches
- Nodes joining or leaving a cluster;
CacheStarted and CacheStopped are highly similar, and the following example demonstrates printing out the name of the cache that has started or stopped:
@CacheStarted
public void cacheStarted(CacheStartedEvent event){
// Print the name of the Cache that started
log.info("Cache Started: " + event.getCacheName());
}
@CacheStopped
public void cacheStopped(CacheStoppedEvent event){
// Print the name of the Cache that stopped
log.info("Cache Stopped: " + event.getCacheName());
}ViewChangedEvent or MergeEvent note that the list of old and new members is from the node that generated the event. For instance, consider the following scenario:
- A JDG Cluster currently consists of nodes A, B, and C.
- Node D joins the cluster.
- Nodes A, B, and C will receive a
ViewChangedEventwith [A,B,C] as the list of old members, and [A,B,C,D] as the list of new members. - Node D will receive a
ViewChangedEventwith [D] as the list of old members, and [A,B,C,D] as the list of new members.
getOldMembers() in conjunction with getNewMembers(), we may determine the set of nodes that have joined or left the cluster, as seen below:
@ViewChanged
public void viewChanged(ViewChangedEvent event){
HashSet<Address> oldMembers = new HashSet(event.getOldMembers());
HashSet<Address> newMembers = new HashSet(event.getNewMembers());
HashSet<Address> oldCopy = (HashSet<Address>)oldMembers.clone();
// Remove all new nodes from the old view.
// The resulting set indicates nodes that have left the cluster.
oldCopy.removeAll(newMembers);
if(oldCopy.size() > 0){
for (Address oldAdd : oldCopy){
log.info("Node left:" + oldAdd.toString());
}
}
// Remove all old nodes from the new view.
// The resulting set indicates nodes that have joined the cluster.
newMembers.removeAll(oldMembers);
if(newMembers.size() > 0){
for(Address newAdd : newMembers){
log.info("Node joined: " + newAdd.toString());
}
}
}MergeEvent to determine the new set of members in the cluster.
8.2.3. About Synchronous and Asynchronous Notifications
@Listener (sync = false)
public class MyAsyncListener { .... }<asyncListenerExecutor/> element in the configuration file to tune the thread pool that is used to dispatch asynchronous notifications.
Important
CacheEntryExpiredEvent ensure that this listener does not block execution, as the expiration reaper is also synchronous in a non-clustered environment.
8.3. Modifying Cache Entries
8.3.1. Cache Entry Modified Listener Configuration
getValue() method's behavior is specific to whether the callback is triggered before or after the actual operation has been performed. For example, if event.isPre() is true, then event.getValue() would return the old value, prior to modification. If event.isPre() is false, then event.getValue() would return new value. If the event is creating and inserting a new entry, the old value would be null. For more information about isPre(), see the Red Hat JBoss Data Grid API Documentation's listing for the org.infinispan.notifications.cachelistener.event package.
8.3.2. Cache Entry Modified Listener Example
Example 8.2. Modified Listener
@Listener
public class PrintWhenModified {
@CacheEntryModified
public void print(CacheEntryModifiedEvent event) {
System.out.println("Cache entry modified. Details = " + event);
}
}8.4. Clustered Listeners
8.4.1. Configuring Clustered Listeners
Procedure 8.1. Clustered Listener Configuration
@Listener(clustered = true)
protected static class ClusterListener {
List<CacheEntryEvent> events = Collections.synchronizedList(new ArrayList<CacheEntryEvent>());
@CacheEntryCreated
@CacheEntryModified
@CacheEntryExpired
@CacheEntryRemoved
public void onCacheEvent(CacheEntryEvent event) {
log.debugf("Adding new cluster event %s", event);
events.add(event);
}
}
public void addClusterListener(Cache<?, ?> cache) {
ClusterListener clusterListener = new ClusterListener();
cache.addListener(clusterListener);
}
- Clustered listeners are enabled by annotating the
@Listenerclass withclustered=true. - The following methods are annotated to allow client applications to be notified when entries are added, modified, expired, or removed.
@CacheEntryCreated@CacheEntryModified@CacheEntryExpired@CacheEntryRemoved
- The listener is registered with a cache, with the option of passing on a filter or converter.
- A cluster listener can only listen to entries that are created, modified, expired, or removed. No other events are listened to by a clustered listener.
- Only post events are sent to a clustered listener, pre events are ignored.
8.4.2. The Cache Listener API
@CacheListener API via the addListener method.
Example 8.3. The Cache Listener API
cache.addListener(Object listener, Filter filter, Converter converter);
public @interface Listener {
boolean clustered() default false;
boolean includeCurrentState() default false;
boolean sync() default true;
}
interface CacheEventFilter<K,V> {
public boolean accept(K key, V oldValue, Metadata oldMetadata, V newValue, Metadata newMetadata, EventType eventType);
}
interface CacheEventConverter<K,V,C> {
public C convert(K key, V oldValue, Metadata oldMetadata, V newValue, Metadata newMetadata, EventType eventType);
}- The Cache API
- The local or clustered listener can be registered with the
cache.addListenermethod, and is active until one of the following events occur.- The listener is explicitly unregistered by invoking
cache.removeListener. - The node on which the listener was registered crashes.
- Listener Annotation
- The listener annotation is enhanced with three attributes:
clustered():This attribute defines whether the annotated listener is clustered or not. Note that clustered listeners can only be notified for@CacheEntryRemoved,@CacheEntryCreated,@CacheEntryExpired, and@CacheEntryModifiedevents. This attribute is false by default.includeCurrentState(): This attribute applies to clustered listeners only, and is false by default. When set totrue, the entire existing state within the cluster is evaluated. When being registered, a listener will immediately be sent aCacheCreatedEventfor every entry in the cache.- Refer to Section 8.2.3, “About Synchronous and Asynchronous Notifications” for information regarding
sync().
oldValueandoldMetadata- The
oldValueandoldMetadatavalues are extra methods on the accept method ofCacheEventFilterandCacheEventConverterclasses. They values are provided to any listener, including local listeners. For more information about these values, see the JBoss Data Grid API Documentation. EventType- The
EventTypeincludes the type of event, whether it was a retry, and if it was a pre or post event.
includeCurrentState.
8.4.3. Clustered Listener Example
Example 8.4. Use Case: Filtering and Converting the New York orders
class CityStateFilter implements CacheEventFilter<String, Order> {
private final String state;
private final String city;
public boolean accept(String orderId, Order oldOrder,
Metadata oldMetadata, Order newOrder,
Metadata newMetadata, EventType eventType) {
switch (eventType.getType()) {
// Only send update if the order is going to our city
case Type.CACHE_ENTRY_CREATED:
return city.equals(newOrder.getCity()) &&
state.equals(newOrder.getState());
// Only send update if our order has changed from our city to elsewhere or if is now going to our city
case Type.CACHE_ENTRY_MODIFIED:
if (city.equals(oldOrder.getCity()) &&
state.equals(oldOrder.getState())) {
// If old city matches then we have to compare if new order is no longer going to our city
return !city.equals(newOrder.getCity()) ||
!state.equals(newOrder.getState());
} else {
// If the old city doesn't match ours then only send update if new update does match ours
return city.equals(newOrder.getCity()) &&
state.equals(newOrder.getState());
}
// On remove we have to send update if our order was originally going to city
case Type.CACHE_ENTRY_REMOVED:
return city.equals(oldOrder.getCity()) &&
state.equals(oldOrder.getState());
}
return false;
}
}
class OrderDateConverter implements CacheEventConverter<String, Order, Date> {
private final String state;
private final String city;
public Date convert(String orderId, Order oldValue,
Metadata oldMetadata, Order newValue,
Metadata newMetadata, EventType eventType) {
// If remove we do not care about date - this tells listener to remove its data
if (eventType.isRemove()) {
return null;
} else if (eventType.isModified()) {
if (state.equals(newValue.getState()) &&
city.equals(newValue.getCity())) {
// If it is a modification meaning the destination has changed to ours then we allow it
return newValue.getDate();
} else {
// If destination is no longer our city it means it was changed from us so send null
return null;
}
} else {
// This was a create so we always send date
return newValue.getDate();
}
}
}8.4.4. Optimized Cache Filter Converter
CacheEventFilterConverter, in order to perform the filtering and converting of results into one step.
CacheEventFilterConverter is an optimization that allows the event filter and conversion to be performed in one step. This can be used when an event filter and converter are most efficiently used as the same object, composing the filtering and conversion in the same method. This can only be used in situations where your conversion will not return a null value, as a returned value of null indicates that the value did not pass the filter. To convert a null value, use the CacheEventFilter and the CacheEventConverter interfaces independently.
CacheEventFilterConverter:
Example 8.5. CacheEventFilterConverter
class OrderDateFilterConverter extends AbstractCacheEventFilterConverter<String, Order, Date> {
private final String state;
private final String city;
public Date filterAndConvert(String orderId, Order oldValue,
Metadata oldMetadata, Order newValue,
Metadata newMetadata, EventType eventType) {
// Remove if the date is not required - this tells listener to remove its data
if (eventType.isRemove()) {
return null;
} else if (eventType.isModified()) {
if (state.equals(newValue.getState()) &&
city.equals(newValue.getCity())) {
// If it is a modification meaning the destination has changed to ours then we allow it
return newValue.getDate();
} else {
// If destination is no longer our city it means it was changed from us so send null
return null;
}
} else {
// This was a create so we always send date
return newValue.getDate();
}
}
}FilterConverter as both arguments to the filter and converter:
OrderDateFilterConverter filterConverter = new OrderDateFilterConverter("NY", "New York");
cache.addListener(listener, filterConveter, filterConverter);8.5. Remote Event Listeners (Hot Rod)
CacheEntryCreated, CacheEntryModified, CacheEntryExpired and CacheEntryRemoved. Clients can choose whether or not to listen to these events to avoid flooding connected clients. This assumes that clients maintain persistent connections to the servers.
Example 8.6. Event Print Listener
import org.infinispan.client.hotrod.annotation.*;
import org.infinispan.client.hotrod.event.*;
@ClientListener
public class EventLogListener {
@ClientCacheEntryCreated
public void handleCreatedEvent(ClientCacheEntryCreatedEvent e) {
System.out.println(e);
}
@ClientCacheEntryModified
public void handleModifiedEvent(ClientCacheEntryModifiedEvent e) {
System.out.println(e);
}
@ClientCacheEntryExpired
public void handleExpiredEvent(ClientCacheEntryExpiredEvent e) {
System.out.println(e);
}
@ClientCacheEntryRemoved
public void handleRemovedEvent(ClientCacheEntryRemovedEvent e) {
System.out.println(e);
}
}
ClientCacheEntryCreatedEventandClientCacheEntryModifiedEventinstances provide information on the key and version of the entry. This version can be used to invoke conditional operations on the server, such areplaceWithVersionorremoveWithVersion.ClientCacheEntryExpiredEventevents are sent when either aget()is called on an expired entry, or when the expiration reaper detects that an entry has expired. Once the entry has expired the cache will nullify the entry, and adjust its size appropriately; however, the event will only be generated in the two scenarios listed.ClientCacheEntryRemovedEventevents are only sent when the remove operation succeeds. If a remove operation is invoked and no entry is found or there are no entries to remove, no event is generated. If users require remove events regardless of whether or not they are successful, a customized event logic can be created.- All client cache entry created, modified, and removed events provide a
boolean isCommandRetried()method that will returntrueif the write command that caused it has to be retried due to a topology change. This indicates that the event has been duplicated or that another event was dropped and replaced, such as where a Modified event replaced a Created event.
Important
Important
8.5.1. Adding and Removing Event Listeners
The following example registers the Event Print Listener with the server. See Example 8.6, “Event Print Listener”.
Example 8.7. Adding an Event Listener
RemoteCache<Integer, String> cache = rcm.getCache();
cache.addClientListener(new EventLogListener());
A client event listener can be removed as follows
Example 8.8. Removing an Event Listener
EventLogListener listener = ...
cache.removeClientListener(listener);
8.5.2. Remote Event Client Listener Example
Procedure 8.2. Configuring Remote Event Listeners
Download the Red Hat JBoss Data Grid Server distribution from the Red Hat Customer Portal
The latest Red Hat JBoss Data Grid distribution includes the Hot Rod server with which the client will communicate.Start the server
Start the JBoss Data Grid server by using the following command from the root of the server.$ ./bin/standalone.shWrite an application to interact with the Hot Rod server
Maven users
Create an application with the following dependency, changing the version to8.3.0-Final-redhat-1or better.<properties> <infinispan.version>8.3.0-Final-redhat-1</infinispan.version> </properties> [...] <dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-remote</artifactId> <version>${infinispan.version}</version> </dependency>- Non-Maven users, adjust according to your chosen build tool or download the distribution containing all JBoss Data Grid jars.
Write the client application
The following demonstrates a simple remote event listener that logs all events received.import org.infinispan.client.hotrod.annotation.*; import org.infinispan.client.hotrod.event.*; @ClientListener public class EventLogListener { @ClientCacheEntryCreated @ClientCacheEntryModified @ClientCacheEntryRemoved public void handleRemoteEvent(ClientEvent event) { System.out.println(event); } }Use the remote event listener to execute operations against the remote cache
The following example demonstrates a simple main java class, which adds the remote event listener and executes some operations against the remote cache.import org.infinispan.client.hotrod.*; RemoteCacheManager rcm = new RemoteCacheManager(); RemoteCache<Integer, String> cache = rcm.getCache(); EventLogListener listener = new EventLogListener(); try { cache.addClientListener(listener); cache.put(1, "one"); cache.put(1, "new-one"); cache.remove(1); } finally { cache.removeClientListener(listener); }
Once executed, the console output should appear similar to the following:
ClientCacheEntryCreatedEvent(key=1,dataVersion=1)
ClientCacheEntryModifiedEvent(key=1,dataVersion=2)
ClientCacheEntryRemovedEvent(key=1)
8.5.3. Filtering Remote Events
Example 8.9. KeyValueFilter
package sample;
import java.io.Serializable;
import org.infinispan.notifications.cachelistener.filter.*;
import org.infinispan.metadata.*;
@NamedFactory(name = "basic-filter-factory")
public class BasicKeyValueFilterFactory implements CacheEventFilterFactory {
@Override public CacheEventFilter<Integer, String> getFilter(final Object[] params) {
return new BasicKeyValueFilter();
}
static class BasicKeyValueFilter implements CacheEventFilter<Integer, String>, Serializable {
@Override public boolean accept(Integer key, String oldValue, Metadata oldMetadata, String newValue, Metadata newMetadata, EventType eventType) {
return !"2".equals(key);
}
}
}8.5.3.1. Custom Filters for Remote Events
Procedure 8.3. Using a Custom Filter
- Create a
JARfile with the filter implementation within it. Each factory must have a name assigned to it via theorg.infinispan.filter.NamedFactoryannotation. The example uses aKeyValueFilterFactory. - Create a
META-INF/services/org.infinispan.notifications.cachelistener.filter. CacheEventFilterFactoryfile within theJARfile, and within it write the fully qualified class name of the filter class implementation. - Deploy the
JARfile in the JBoss Data Grid Server by performing any of the following options:Procedure 8.4. Option 1: Deploy the JAR through the deployment scanner.
- Copy the
JARto the$JDG_HOME/standalone/deployments/directory. The deployment scanner actively monitors this directory and will deploy the newly placed file.
Procedure 8.5. Option 2: Deploy the JAR through the CLI
- Connect to the desired instance with the CLI:
[$JDG_HOME] $ bin/cli.sh --connect=$IP:$PORT - Once connected execute the
deploycommand:deploy /path/to/artifact.jar
Procedure 8.6. Option 3: Deploy the JAR as a custom module
- Connect to the JDG server by running the below command:
[$JDG_HOME] $ bin/cli.sh --connect=$IP:$PORT - The jar containing the Custom Filter must be defined as a module for the Server; to add this substitute the desired name of the module and the .jar name in the below command, adding additional dependencies as necessary for the Custom Filter:
module add --name=$MODULE-NAME --resources=$JAR-NAME.jar --dependencies=org.infinispan - In a different window add the newly added module as a dependency to the
org.infinispanmodule by editing$JDG_HOME/modules/system/layers/base/org/infinispan/main/module.xml. In this file add the following entry:<dependencies> [...] <module name="$MODULE-NAME"> </dependencies> - Restart the JDG server.
@ClientListener annotation to indicate the filter factory to use with the listener.
Example 8.10. Add Filter Factory to the Listener
@org.infinispan.client.hotrod.annotation.ClientListener(filterFactoryName = "basic-filter-factory")
public class BasicFilteredEventLogListener extends EventLogListener {}
Example 8.11. Register the Listener with the Server
import org.infinispan.client.hotrod.*;
RemoteCacheManager rcm = new RemoteCacheManager();
RemoteCache<Integer, String> cache = rcm.getCache();
BasicFilteredEventLogListener listener = new BasicFilteredEventLogListener();
try {
cache.addClientListener(listener);
cache.putIfAbsent(1, "one");
cache.replace(1, "new-one");
cache.putIfAbsent(2, "two");
cache.replace(2, "new-two");
cache.putIfAbsent(3, "three");
cache.replace(3, "new-three");
cache.remove(1);
cache.remove(2);
cache.remove(3);
} finally {
cache.removeClientListener(listener);
}
The following demonstrates the resulting system output from the provided example.
ClientCacheEntryCreatedEvent(key=1,dataVersion=1)
ClientCacheEntryModifiedEvent(key=1,dataVersion=2)
ClientCacheEntryCreatedEvent(key=3,dataVersion=5)
ClientCacheEntryModifiedEvent(key=3,dataVersion=6)
ClientCacheEntryRemovedEvent(key=1)
ClientCacheEntryRemovedEvent(key=3)
Important
8.5.3.2. Enhanced Filter Factories
Example 8.12. Configuring an Enhanced Filter Factory
package sample;
import java.io.Serializable;
import org.infinispan.notifications.cachelistener.filter.*;
import org.infinispan.metadata.*;
@NamedFactory(name = "basic-filter-factory")
public class BasicKeyValueFilterFactory implements CacheEventFilterFactory {
@Override public CacheEventFilter<Integer, String> getFilter(final Object[] params) {
return new BasicKeyValueFilter(params);
}
static class BasicKeyValueFilter implements CacheEventFilter<Integer, String>, Serializable {
private final Object[] params;
public BasicKeyValueFilter(Object[] params) { this.params = params; }
@Override public boolean accept(Integer key, String oldValue, Metadata oldMetadata, String newValue, Metadata newMetadata, EventType eventType) {
return !params[0].equals(key);
}
}
}Example 8.13. Running an Enhanced Filter Factory
import org.infinispan.client.hotrod.*;
RemoteCacheManager rcm = new RemoteCacheManager();
RemoteCache<Integer, String> cache = rcm.getCache();
BasicFilteredEventLogListener listener = new BasicFilteredEventLogListener();
try {
cache.addClientListener(listener, new Object[]{3}, null); // <- Filter parameter passed
cache.putIfAbsent(1, "one");
cache.replace(1, "new-one");
cache.putIfAbsent(2, "two");
cache.replace(2, "new-two");
cache.putIfAbsent(3, "three");
cache.replace(3, "new-three");
cache.remove(1);
cache.remove(2);
cache.remove(3);
} finally {
cache.removeClientListener(listener);
}The provided example results in the following output:
ClientCacheEntryCreatedEvent(key=1,dataVersion=1)
ClientCacheEntryModifiedEvent(key=1,dataVersion=2)
ClientCacheEntryCreatedEvent(key=2,dataVersion=3)
ClientCacheEntryModifiedEvent(key=2,dataVersion=4)
ClientCacheEntryRemovedEvent(key=1)
ClientCacheEntryRemovedEvent(key=2)8.5.4. Customizing Remote Events
CacheEventConverter instances, which are created by implementing a CacheEventConverterFactory class. Each factory must have a name associated to it via the @NamedFactory annotation.
Procedure 8.7. Using a Converter
- Create a
JARfile with the converter implementation within it. Each factory must have a name assigned to it via theorg.infinispan.filter.NamedFactoryannotation. - Create a
META-INF/services/org.infinispan.notifications.cachelistener.filter.CacheEventConverterFactoryfile within theJARfile and within it, write the fully qualified class name of the converter class implementation. - Deploy the
JARfile in the JBoss Data Grid Server by performing any of the following options:Procedure 8.8. Option 1: Deploy the JAR through the deployment scanner.
- Copy the
JARto the$JDG_HOME/standalone/deployments/directory. The deployment scanner actively monitors this directory and will deploy the newly placed file.
Procedure 8.9. Option 2: Deploy the JAR through the CLI
- Connect to the desired instance with the CLI:
[$JDG_HOME] $ bin/cli.sh --connect=$IP:$PORT - Once connected execute the
deploycommand:deploy /path/to/artifact.jar
Procedure 8.10. Option 3: Deploy the JAR as a custom module
- Connect to the JDG server by running the below command:
[$JDG_HOME] $ bin/cli.sh --connect=$IP:$PORT - The jar containing the Custom Converter must be defined as a module for the Server; to add this substitute the desired name of the module and the .jar name in the below command, adding additional dependencies as necessary for the Custom Converter:
module add --name=$MODULE-NAME --resources=$JAR-NAME.jar --dependencies=org.infinispan - In a different window add the newly added module as a dependency to the
org.infinispanmodule by editing$JDG_HOME/modules/system/layers/base/org/infinispan/main/module.xml. In this file add the following entry:<dependencies> [...] <module name="$MODULE-NAME"> </dependencies> - Restart the JDG server.
8.5.4.1. Adding a Converter
getConverter method to get a org.infinispan.filter.Converter class instance to customize events server side.
Example 8.14. Sending Custom Events
import org.infinispan.notifications.cachelistener.filter.*;
@NamedFactory(name = "value-added-converter-factory")
class ValueAddedConverterFactory implements CacheEventConverterFactory {
// The following types correspond to the Key, Value, and the returned Event, respectively.
public CacheEventConverter<Integer, String, ValueAddedEvent> getConverter(final Object[] params) {
return new ValueAddedConverter();
}
static class ValueAddedConverter implements CacheEventConverter<Integer, String, ValueAddedEvent> {
public ValueAddedEvent convert(Integer key, String oldValue,
Metadata oldMetadata, String newValue,
Metadata newMetadata, EventType eventType) {
return new ValueAddedEvent(key, newValue);
}
}
}
// Must be Serializable or Externalizable.
class ValueAddedEvent implements Serializable {
final Integer key;
final String value;
ValueAddedEvent(Integer key, String value) {
this.key = key;
this.value = value;
}
}8.5.4.2. Lightweight Events
JAR file including a service definition inside the META-INF/services/org.infinispan.notifications.cachelistener.filter.CacheEventConverterFactory file as follows:
sample.ValueAddedConverterFactor@ClientListener annotation.
@ClientListener(converterFactoryName = "value-added-converter-factory")
public class CustomEventLogListener { ... }
8.5.4.3. Dynamic Converter Instances
Example 8.15. Dynamic Converter
import org.infinispan.notifications.cachelistener.filter.CacheEventConverterFactory;
import org.infinispan.notifications.cachelistener.filter.CacheEventConverter;
class DynamicCacheEventConverterFactory implements CacheEventConverterFactory {
// The following types correspond to the Key, Value, and the returned Event, respectively.
public CacheEventConverter<Integer, String, CustomEvent> getConverter(final Object[] params) {
return new DynamicCacheEventConverter(params);
}
}
// Serializable, Externalizable or marshallable with Infinispan Externalizers needed when running in a cluster
class DynamicCacheEventConverter implements CacheEventConverter<Integer, String, CustomEvent>, Serializable {
final Object[] params;
DynamicCacheEventConverter(Object[] params) {
this.params = params;
}
public CustomEvent convert(Integer key, String oldValue, Metadata metadata, String newValue, Metadata prevMetadata, EventType eventType) {
// If the key matches a key given via parameter, only send the key information
if (params[0].equals(key))
return new ValueAddedEvent(key, null);
return new ValueAddedEvent(key, newValue);
}
}
RemoteCache<Integer, String> cache = rcm.getCache();
cache.addClientListener(new EventLogListener(), null, new Object[]{1});
8.5.4.4. Adding a Remote Client Listener for Custom Events
ClientCacheEntryCustomEvent<T>, where T is the type of custom event we are sending from the server. For example:
Example 8.16. Custom Event Listener Implementation
import org.infinispan.client.hotrod.annotation.*;
import org.infinispan.client.hotrod.event.*;
@ClientListener(converterFactoryName = "value-added-converter-factory")
public class CustomEventLogListener {
@ClientCacheEntryCreated
@ClientCacheEntryModified
@ClientCacheEntryRemoved
public void handleRemoteEvent(ClientCacheEntryCustomEvent<ValueAddedEvent> event)
{
System.out.println(event);
}
}
Example 8.17. Execute Operations against the Remote Cache
import org.infinispan.client.hotrod.*;
RemoteCacheManager rcm = new RemoteCacheManager();
RemoteCache<Integer, String> cache = rcm.getCache();
CustomEventLogListener listener = new CustomEventLogListener();
try {
cache.addClientListener(listener);
cache.put(1, "one");
cache.put(1, "new-one");
cache.remove(1);
} finally {
cache.removeClientListener(listener);
}
Once executed, the console output should appear similar to the following:
ClientCacheEntryCustomEvent(eventData=ValueAddedEvent{key=1, value='one'}, eventType=CLIENT_CACHE_ENTRY_CREATED)
ClientCacheEntryCustomEvent(eventData=ValueAddedEvent{key=1, value='new-one'}, eventType=CLIENT_CACHE_ENTRY_MODIFIED)
ClientCacheEntryCustomEvent(eventData=ValueAddedEvent{key=1, value='null'}, eventType=CLIENT_CACHE_ENTRY_REMOVED
Important
8.5.5. Event Marshalling
Procedure 8.11. Deploying a Marshaller
- Create a
JARfile with the converter implementation within it. Each factory must have a name assigned to it via theorg.infinispan.filter.NamedFactoryannotation. - Create a
META-INF/services/org.infinispan.commons.marshall.Marshallerfile within theJARfile and within it, write the fully qualified class name of the marshaller class implementation - Deploy the
JARfile in the JBoss Data Grid Server by performing any of the following options:Procedure 8.12. Option 1: Deploy the JAR through the deployment scanner.
- Copy the
JARto the$JDG_HOME/standalone/deployments/directory. The deployment scanner actively monitors this directory and will deploy the newly placed file.
Procedure 8.13. Option 2: Deploy the JAR through the CLI
- Connect to the desired instance with the CLI:
[$JDG_HOME] $ bin/cli.sh --connect=$IP:$PORT - Once connected execute the
deploycommand:deploy /path/to/artifact.jar
Procedure 8.14. Option 3: Deploy the JAR as a custom module
- Connect to the JDG server by running the below command:
[$JDG_HOME] $ bin/cli.sh --connect=$IP:$PORT - The jar containing the Custom Marshaller must be defined as a module for the Server; to add this substitute the desired name of the module and the .jar name in the below command, adding additional dependencies as necessary for the Custom Marshaller:
module add --name=$MODULE-NAME --resources=$JAR-NAME.jar --dependencies=org.infinispan - In a different window add the newly added module as a dependency to the
org.infinispanmodule by editing$JDG_HOME/modules/system/layers/base/org/infinispan/main/module.xml. In this file add the following entry:<dependencies> [...] <module name="$MODULE-NAME"> </dependencies> - Restart the JDG server.
Note
8.5.6. Remote Event Clustering and Failover
The @ClientListener annotation has an optional includeCurrentState parameter, which when enabled, has the server send CacheEntryCreatedEvent event instances for all existing cache entries to the client. As this behavior is driven by the client it detects when the node where the listener is registered goes offline and automatically registers the listener on another node in the cluster. By enabling includeCurrentState clients may recompute their state or computation in the event the Hot Rod client transparently fails over registered listeners. The performance of the includeCurrentState parameter is impacted by the cache size, and therefore it is disabled by default.
Rather than relying on receiving state, users can define a method with the @ClientCacheFailover annotation, which receives ClientCacheFailoverEvent parameter inside the client listener implementation. If the node where a Hot Rod client has registered a client listener fails, the Hot Rod client detects it transparently, and fails over all listeners registered in the node that failed to another node.
includeCurrentState parameter can be set to true. With this enabled a client is able to clear its data, receive all of the CacheEntryCreatedEvent instances, and cache these events with all keys. Alternatively, Hot Rod clients can be made aware of failover events by adding a callback handler. This callback method is an efficient solution to handling cluster topology changes affecting client listeners, and allows the client listener to determine how to behave on a failover. Near Caching takes this approach and clears the near cache upon receiving a ClientCacheFailoverEvent.
Example 8.18. @ClientCacheFailover
import org.infinispan.client.hotrod.annotation.*;
import org.infinispan.client.hotrod.event.*;
@ClientListener
public class EventLogListener {
// ...
@ClientCacheFailover
public void handleFailover(ClientCacheFailoverEvent e) {
// Deal with client failover, e.g. clear a near cache.
}
}Note
ClientCacheFailoverEvent is only thrown when the node that has the client listener installed fails.
Chapter 9. JSR-107 (JCache) API
9.1. Dependencies
In order to use the JCache implementation the following dependencies need to be added to the Maven pom.xml depending on how it is used:
- embedded:
<dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-embedded</artifactId> <version>${infinispan.version}</version> </dependency> <dependency> <groupId>javax.cache</groupId> <artifactId>cache-api</artifactId> <version>1.0.0.redhat-1</version> </dependency> - remote:
<dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-remote</artifactId> <version>${infinispan.version}</version> </dependency> <dependency> <groupId>javax.cache</groupId> <artifactId>cache-api</artifactId> <version>1.0.0.redhat-1</version> </dependency>
When not using Maven the necessary jar files must be on the classpath at runtime. Having these available at runtime may either be accomplished by embedding the jar files directly, by specifying them at runtime, or by adding them into the container used to deploy the application.
Procedure 9.1. Embedded Mode
- Download the
Red Hat JBoss Data Grid 7.0.0 Libraryfrom the Red Hat Customer Portal. - Extract the downloaded archive to a local directory.
- Locate the following files:
jboss-datagrid-7.0.0-library/infinispan-embedded-8.3.0.Final-redhat-1.jarjboss-datagrid-7.0.0-library/lib/cache-api-1.0.0.redhat-1.jar
- Ensure both of the above jar files are on the classpath at runtime.
Procedure 9.2. Remote Mode
- Download the
Red Hat JBoss Data Grid 7.0.0 Hot Rod Java Clientfrom the Red Hat Customer Portal. - Extract the downloaded archive to a local directory.
- Locate the following files:
jboss-datagrid-7.0.0-remote-java-client/infinispan-remote-8.3.0.Final-redhat-1.jarjboss-datagrid-7.0.0-remote-java-client/lib/cache-api-1.0.0.redhat-1.jar
- Ensure both of the above jar files are on the classpath at runtime.
9.2. Create a local cache
import javax.cache.*;
import javax.cache.configuration.*;
// Retrieve the system wide cache manager
CacheManager cacheManager = Caching.getCachingProvider().getCacheManager();
// Define a named cache with default JCache configuration
Cache<String, String> cache = cacheManager.createCache("namedCache",
new MutableConfiguration<String, String>());Warning
storeByValue, so that object state mutations outside of operations to the cache, won’t have an impact in the objects stored in the cache. JBoss Data Grid has so far implemented this using serialization/marshalling to make copies to store in the cache, and that way adhere to the spec. Hence, if using default JCache configuration with Infinispan, data stored must be marshallable.
Cache<String, String> cache = cacheManager.createCache("namedCache",
new MutableConfiguration<String, String>().setStoreByValue(false));Library Mode
CacheManager may be configured by specifying the location of a configuration file via the URL parameter of CachingProvider.getCacheManager. This allows the opportunity to define clustered caches in a configuration file, and then obtain a reference to the preconfigured cache by passing the cache's name to the CacheManager.getCache method; otherwise local caches can only be used, created from the CacheManager.createCache .
Client-Server Mode
CacheManager is performed by passing standard HotRod client properties via properties parameter of CachingProvider.getCacheManager. The remote servers referenced must be running and able to receive the request.
CacheManager.createCache must be used so that the cache may be registered internally. Subsequent queries may be performed via CacheManager.getCache.
9.3. Store and retrieve data
import javax.cache.*;
import javax.cache.configuration.*;
CacheManager cacheManager = Caching.getCachingProvider().getCacheManager();
Cache<String, String> cache = cacheManager.createCache("namedCache",
new MutableConfiguration<String, String>());
cache.put("hello", "world"); // Notice that javax.cache.Cache.put(K) returns void!
String value = cache.get("hello"); // Returns "world"put and getAndPut. The former returns void whereas the latter returns the previous value associated with the key. The equivalent of java.util.Map.put(K) in JCache is javax.cache.Cache.getAndPut(K).
Note
9.4. Comparing java.util.concurrent.ConcurrentMap and javax.cache.Cache APIs
| Operation |
|
|
|---|---|---|
| store and no return | N/A |
|
| store and return previous value |
|
|
| store if not present |
|
|
| retrieve |
|
|
| delete if present |
|
|
| delete and return previous value |
|
|
| delete conditional |
|
|
| replace if present |
|
|
| replace and return previous value |
|
|
| replace conditional |
|
|
| Operation |
|
|
|---|---|---|
| calculate size of cache |
| N/A |
| return all keys in the cache |
| N/A |
| return all values in the cache |
| N/A |
| return all entries in the cache |
| N/A |
| iterate over the cache | use iterator() method on keySet, values, or entrySet |
|
9.5. Clustering JCache instances
<namedCache name="namedCache">
<clustering mode="replication"/>
</namedCache>import javax.cache.*;
import java.net.URI;
// For multiple cache managers to be constructed with the standard JCache API
// and live in the same JVM, either their names, or their classloaders, must
// be different.
// This example shows how to force their classloaders to be different.
// An alternative method would have been to duplicate the XML file and give
// it a different name, but this results in unnecessary file duplication.
ClassLoader tccl = Thread.currentThread().getContextClassLoader();
CacheManager cacheManager1 = Caching.getCachingProvider().getCacheManager(
URI.create("infinispan-jcache-cluster.xml"), new TestClassLoader(tccl));
CacheManager cacheManager2 = Caching.getCachingProvider().getCacheManager(
URI.create("infinispan-jcache-cluster.xml"), new TestClassLoader(tccl));
Cache<String, String> cache1 = cacheManager1.getCache("namedCache");
Cache<String, String> cache2 = cacheManager2.getCache("namedCache");
cache1.put("hello", "world");
String value = cache2.get("hello"); // Returns "world" if clustering is working
// --
public static class TestClassLoader extends ClassLoader {
public TestClassLoader(ClassLoader parent) {
super(parent);
}
}9.6. Multiple Caching Providers
javax.cache.Caching using the overloaded getCachingProvider() method; by default this method will attempt to load any META-INF/services/javax.cache.spi.CachingProvider files found in the classpath. If one is found it will determine the caching provider in use.
getCachingProvider(ClassLoader classLoader)getCachingProvider(String fullyQualifiedClassName)
javax.cache.spi.CachingProviders that are detected or have been loaded by the Caching class are maintained in an internal registry, and subsequent requests for the same caching provider will be returned from this registry instead of being reloaded or reinstantiating the caching provider implementation. To view the current caching providers either of the following methods may be used:
getCachingProviders()- provides a list of caching providers in the default class loader.getCachingProviders(ClassLoader classLoader)- provides a list of caching providers in the specified class loader.
Chapter 10. The REST API
Important
authentication and encryption parameters from the connector.
10.1. Ruby Client Code
Example 10.1. Using the REST API with Ruby
require 'net/http'
http = Net::HTTP.new('localhost', 8080)
#An example of how to create a new entry
http.post('/rest/MyData/MyKey', 'DATA_HERE', {"Content-Type" => "text/plain"})
#An example of using a GET operation to retrieve the key
puts http.get('/rest/MyData/MyKey').body
#An Example of using a PUT operation to overwrite the key
http.put('/rest/MyData/MyKey', 'MORE DATA', {"Content-Type" => "text/plain"})
#An example of Removing the remote copy of the key
http.delete('/rest/MyData/MyKey')
#An example of creating binary data
http.put('/rest/MyImages/Image.png', File.read('/Users/michaelneale/logo.png'), {"Content-Type" => "image/png"})10.2. Using JSON with Ruby Example
To use JavaScript Object Notation (JSON) with ruby to interact with Red Hat JBoss Data Grid's REST Interface, install the JSON Ruby library (see your platform's package manager or the Ruby documentation) and declare the requirement using the following code:
require 'json'
The following code is an example of how to use JavaScript Object Notation (JSON) in conjunction with Ruby to send specific data, in this case the name and age of an individual, using the PUT function.
data = {:name => "michael", :age => 42 }
http.put('/rest/Users/data/0', data.to_json, {"Content-Type" => "application/json"})10.3. Python Client Code
Example 10.2. Using the REST API with Python
import httplib
#How to insert data
conn = httplib.HTTPConnection("localhost:8080")
data = "SOME DATA HERE \!" #could be string, or a file...
conn.request("POST", "/rest/default/0", data, {"Content-Type": "text/plain"})
response = conn.getresponse()
print response.status
#How to retrieve data
import httplib
conn = httplib.HTTPConnection("localhost:8080")
conn.request("GET", "/rest/default/0")
response = conn.getresponse()
print response.status
print response.read()10.4. Java Client Code
Example 10.3. Defining Imports
import java.io.BufferedReader;import java.io.IOException;
import java.io.InputStreamReader;import java.io.OutputStreamWriter;
import java.net.HttpURLConnection;import java.net.URL;Example 10.4. Adding a String Value to a Cache
// Using the imports in the previous example
public class RestExample {
/**
* Method that puts a String value in cache.
* @param urlServerAddress
* @param value
* @throws IOException
*/
public void putMethod(String urlServerAddress, String value) throws IOException {
System.out.println("----------------------------------------");
System.out.println("Executing PUT");
System.out.println("----------------------------------------");
URL address = new URL(urlServerAddress);
System.out.println("executing request " + urlServerAddress);
HttpURLConnection connection = (HttpURLConnection) address.openConnection();
System.out.println("Executing put method of value: " + value);
connection.setRequestMethod("PUT");
connection.setRequestProperty("Content-Type", "text/plain");
connection.setDoOutput(true);
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(connection.getOutputStream());
outputStreamWriter.write(value);
connection.connect();
outputStreamWriter.flush();
System.out.println("----------------------------------------");
System.out.println(connection.getResponseCode() + " " + connection.getResponseMessage());
System.out.println("----------------------------------------");
connection.disconnect();
}Example 10.5. Get a String Value from a Cache
// Continuation of RestExample defined in previous example
/**
* Method that gets an value by a key in url as param value.
* @param urlServerAddress
* @return String value
* @throws IOException
*/
public String getMethod(String urlServerAddress) throws IOException {
String line = new String();
StringBuilder stringBuilder = new StringBuilder();
System.out.println("----------------------------------------");
System.out.println("Executing GET");
System.out.println("----------------------------------------");
URL address = new URL(urlServerAddress);
System.out.println("executing request " + urlServerAddress);
HttpURLConnection connection = (HttpURLConnection) address.openConnection();
connection.setRequestMethod("GET");
connection.setRequestProperty("Content-Type", "text/plain");
connection.setDoOutput(true);
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(connection.getInputStream()));
connection.connect();
while ((line = bufferedReader.readLine()) != null) {
stringBuilder.append(line + '\n');
}
System.out.println("Executing get method of value: " + stringBuilder.toString());
System.out.println("----------------------------------------");
System.out.println(connection.getResponseCode() + " " + connection.getResponseMessage());
System.out.println("----------------------------------------");
connection.disconnect();
return stringBuilder.toString();
}Example 10.6. Using a Java Main Method
// Continuation of RestExample defined in previous example
/**
* Main method example.
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
//Note that the cache name is "cacheX"
RestExample restExample = new RestExample();
restExample.putMethod("http://localhost:8080/rest/cacheX/1", "Infinispan REST Test");
restExample.getMethod("http://localhost:8080/rest/cacheX/1");
}
}10.5. Using the REST Interface
- Adding data
- Retrieving data
- Removing data
10.5.1. Adding Data Using REST
- HTTP
PUTmethod - HTTP
POSTmethod
PUT and POST methods are used, the body of the request contains this data, which includes any information added by the user.
PUT and POST methods require a Content-Type header.
10.5.1.1. About PUT /{cacheName}/{cacheKey}
PUT request from the provided URL form places the payload, from the request body in the targeted cache using the provided key. The targeted cache must exist on the server for this task to successfully complete.
hr is the cache name and payRoll%2F3 is the key. The value %2F indicates that a / was used in the key.
http://someserver/rest/hr/payRoll%2F3Time-To-Live and Last-Modified values are updated, if an update is required.
Note
%2F to represent a / in the key (as in the provided example) can be successfully run if the server is started using the following argument:
-Dorg.apache.tomcat.util.buf.UDecoder.ALLOW_ENCODED_SLASH=true10.5.1.2. About POST /{cacheName}/{cacheKey}
POST method from the provided URL form places the payload (from the request body) in the targeted cache using the provided key. However, in a POST method, if a value in a cache/key exists, a HTTP CONFLICT status is returned and the content is not updated.
10.5.2. Retrieving Data Using REST
- HTTP
GETmethod. - HTTP
HEADmethod.
10.5.2.1. About GET /{cacheName}/{cacheKey}
GET method returns the data located in the supplied cacheName, matched to the relevant key, as the body of the response. The Content-Type header provides the type of the data. A browser can directly access the cache.
10.5.2.2. About HEAD /{cacheName}/{cacheKey}
HEAD method operates in a manner similar to the GET method, however returns no content (header fields are returned).
10.5.3. Removing Data Using REST
DELETE method to retrieve data from the cache. The DELETE method can:
- Remove a cache entry/value. (
DELETE /{cacheName}/{cacheKey}) - Remove all entries from a cache. (
DELETE /{cacheName})
10.5.3.1. About DELETE /{cacheName}/{cacheKey}
DELETE /{cacheName}/{cacheKey}), the DELETE method removes the key/value from the cache for the provided key.
10.5.3.2. About DELETE /{cacheName}
DELETE /{cacheName}), the DELETE method removes all entries in the named cache. After a successful DELETE operation, the HTTP status code 200 is returned.
10.5.3.3. Background Delete Operations
performAsync header to true to ensure an immediate return while the removal operation continues in the background.
10.5.4. REST Interface Operation Headers
| Headers | Mandatory/Optional | Values | Default Value | Details |
|---|---|---|---|---|
| Content-Type | Mandatory | - | - | If the Content-Type is set to application/x-java-serialized-object, it is stored as a Java object. |
| performAsync | Optional | True/False | - | If set to true, an immediate return occurs, followed by a replication of data to the cluster on its own. This feature is useful when dealing with bulk data inserts and large clusters. |
| timeToLiveSeconds | Optional | Numeric (positive and negative numbers) | -1 (This value prevents expiration as a direct result of timeToLiveSeconds. Expiration values set elsewhere override this default value.) | Reflects the number of seconds before the entry in question is automatically deleted. Setting a negative value for timeToLiveSeconds provides the same result as the default value. |
| maxIdleTimeSeconds | Optional | Numeric (positive and negative numbers) | -1 (This value prevents expiration as a direct result of maxIdleTimeSeconds. Expiration values set elsewhere override this default value.) | Contains the number of seconds after the last usage when the entry will be automatically deleted. Passing a negative value provides the same result as the default value. |
timeToLiveSeconds and maxIdleTimeSeconds headers:
- If both the
timeToLiveSecondsandmaxIdleTimeSecondsheaders are assigned the value0, the cache uses the defaulttimeToLiveSecondsandmaxIdleTimeSecondsvalues configured either using XML or programatically. - If only the
maxIdleTimeSecondsheader value is set to0, thetimeToLiveSecondsvalue should be passed as the parameter (or the default-1, if the parameter is not present). Additionally, themaxIdleTimeSecondsparameter value defaults to the values configured either using XML or programatically. - If only the
timeToLiveSecondsheader value is set to0, expiration occurs immediately and themaxIdleTimeSecondsvalue is set to the value passed as a parameter (or the default-1if no parameter was supplied).
ETags (Entity Tags) are returned for each REST Interface entry, along with a Last-Modified header that indicates the state of the data at the supplied URL. ETags are used in HTTP operations to request data exclusively in cases where the data has changed to save bandwidth. The following headers support ETags (Entity Tags) based optimistic locking:
| Header | Algorithm | Example | Details |
|---|---|---|---|
| If-Match | If-Match = "If-Match" ":" ( "*" | 1#entity-tag ) | - | Used in conjunction with a list of associated entity tags to verify that a specified entity (that was previously obtained from a resource) remains current. |
| If-None-Match | - | Used in conjunction with a list of associated entity tags to verify that none of the specified entities (that was previously obtained from a resource) are current. This feature facilitates efficient updates of cached information when required and with minimal transaction overhead. | |
| If-Modified-Since | If-Modified-Since = "If-Modified-Since" ":" HTTP-date | If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT | Compares the requested variant's last modification time and date with a supplied time and date value. If the requested variant has not been modified since the specified time and date, a 304 (not modified) response is returned without a message-body instead of an entity. |
| If-Unmodified-Since | If-Unmodified-Since = "If-Unmodified-Since" ":" HTTP-date | If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT | Compares the requested variant's last modification time and date with a supplied time and date value. If the requested resources has not been modified since the supplied date and time, the specified operation is performed. If the requested resource has been modified since the supplied date and time, the operation is not performed and a 412 (Precondition Failed) response is returned. |
Chapter 11. The Hot Rod Interface
11.1. Hot Rod Headers
11.1.1. Hot Rod Header Data Types
| Data Type | Size | Details |
|---|---|---|
| vInt | Between 1-5 bytes. | Unsigned variable length integer values. |
| vLong | Between 1-9 bytes. | Unsigned variable length long values. |
| string | - | Strings are always represented using UTF-8 encoding. |
11.1.2. Request Header
| Field Name | Data Type/Size | Details |
|---|---|---|
| Magic | 1 byte | Indicates whether the header is a request header or response header. |
| Message ID | vLong | Contains the message ID. Responses use this unique ID when responding to a request. This allows Hot Rod clients to implement the protocol in an asynchronous manner. |
| Version | 1 byte | Contains the Hot Rod server version. |
| Opcode | 1 byte | Contains the relevant operation code. In a request header, opcode can only contain the request operation codes. |
| Cache Name Length | vInt | Stores the length of the cache name. If Cache Name Length is set to 0 and no value is supplied for Cache Name, the operation interacts with the default cache. |
| Cache Name | string | Stores the name of the target cache for the specified operation. This name must match the name of a predefined cache in the cache configuration file. |
| Flags | vInt | Contains a numeric value of variable length that represents flags passed to the system. Each bit represents a flag, except the most significant bit, which is used to determine whether more bytes must be read. Using a bit to represent each flag facilitates the representation of flag combinations in a condensed manner. |
| Client Intelligence | 1 byte | Contains a value that indicates the client capabilities to the server. |
| Topology ID | vInt | Contains the last known view ID in the client. Basic clients supply the value 0 for this field. Clients that support topology or hash information supply the value 0 until the server responds with the current view ID, which is subsequently used until a new view ID is returned by the server to replace the current view ID. |
11.1.3. Response Header
| Field Name | Data Type | Details |
|---|---|---|
| Magic | 1 byte | Indicates whether the header is a request or response header. |
| Message ID | vLong | Contains the message ID. This unique ID is used to pair the response with the original request. This allows Hot Rod clients to implement the protocol in an asynchronous manner. |
| Opcode | 1 byte | Contains the relevant operation code. In a response header, opcode can only contain the response operation codes. |
| Status | 1 byte | Contains a code that represents the status of the response. |
| Topology Change Marker | 1 byte | Contains a marker byte that indicates whether the response is included in the topology change information. |
11.1.4. Topology Change Headers
topology ID and the topology ID sent by the client and, if the two differ, it returns a new topology ID.
11.1.4.1. Topology Change Marker Values
Topology Change Marker field in a response header:
| Value | Details |
|---|---|
| 0 | No topology change information is added. |
| 1 | Topology change information is added. |
11.1.4.2. Topology Change Headers for Topology-Aware Clients
| Response Header Fields | Data Type/Size | Details |
|---|---|---|
| Response Header with Topology Change Marker | variable | Refer to Section 11.1.3, “Response Header”. |
| Topology ID | vInt | Topology ID. |
| Num Servers in Topology | vInt | Contains the number of Hot Rod servers running in the cluster. This value can be a subset of the entire cluster if only some nodes are running Hot Rod servers. |
| mX: Host/IP Length | vInt | Contains the length of the hostname or IP address of an individual cluster member. Variable length allows this element to include hostnames, IPv4 and IPv6 addresses. |
| mX: Host/IP Address | string | Contains the hostname or IP address of an individual cluster member. The Hot Rod client uses this information to access the individual cluster member. |
| mX: Port | Unsigned Short. 2 bytes | Contains the port used by Hot Rod clients to communicate with the cluster member. |
mX, are repeated for each server in the topology. The first server in the topology's information fields will be prefixed with m1 and the numerical value is incremented by one for each additional server till the value of X equals the number of servers specified in the num servers in topology field.
11.1.4.3. Topology Change Headers for Hash Distribution-Aware Clients
| Field | Data Type/Size | Details |
|---|---|---|
| Response Header with Topology Change Marker | variable | Refer to Section 11.1.3, “Response Header”. |
| Topology ID | vInt | Topology ID. |
| Number Key Owners | Unsigned short. 2 bytes. | Contains the number of globally configured copies for each distributed key. Contains the value 0 if distribution is not configured on the cache. |
| Hash Function Version | 1 byte | Contains a pointer to the hash function in use. Contains the value 0 if distribution is not configured on the cache. |
| Hash Space Size | vInt | Contains the modulus used by JBoss Data Grid for all module arithmetic related to hash code generation. Clients use this information to apply the correct hash calculations to the keys. Contains the value 0 if distribution is not configured on the cache. |
| Number servers in topology | vInt | Contains the number of Hot Rod servers running in the cluster. This value can be a subset of the entire cluster if only some nodes are running Hot Rod servers. This value also represents the number of host to port pairings included in the header. |
| Number Virtual Nodes Owners | vInt | Contains the number of configured virtual nodes. Contains the value 0 if no virtual nodes are configured or if distribution is not configured on the cache. |
| mX: Host/IP Length | vInt | Contains the length of the hostname or IP address of an individual cluster member. Variable length allows this element to include hostnames, IPv4 and IPv6 addresses. |
| mX: Host/IP Address | string | Contains the hostname or IP address of an individual cluster member. The Hot Rod client uses this information to access the individual cluster member. |
| mX: Port | Unsigned short. 2 bytes. | Contains the port used by Hot Rod clients to communicate with the cluster member. |
| Hash Function Version | 1 byte | 0x03 |
| Number of Segments in Topology | vInt | Total number of segments in the topology. |
| Number of Owners in Segment | 1 byte | This can be either 0, 1, or 2 owners. |
| First Wwner's Index | vInt | Given the list of all nodes, the position of this owner in this list. This is only present if number of owners for this segment is 1 or 2. |
| Second Owner's Index | vInt | Given the list of all nodes, the position of this owner in this list. This is only present if number of owners for this segment is 2. |
Note
mX, are repeated for each server in the topology. The first server in the topology's information fields will be prefixed with m1 and the numerical value is incremented by one for each additional server till the value of X equals the number of servers specified in the num servers in topology field.
11.2. Hot Rod Operations
- Authenticate
- AuthMechList
- BulkGet
- BulkKeysGet
- Clear
- ContainsKey
- Exec
- Get
- GetAll
- GetWithMetadata
- GetWithVersion
- IterationEnd
- IterationNext
- IterationStart
- Ping
- Put
- PutAll
- PutIfAbsent
- Query
- Remove
- RemoveIfUnmodified
- Replace
- ReplaceIfUnmodified
- Stats
- Size
Important
Put, PutIfAbsent, Replace, and ReplaceWithVersion operations, if lifespan is set to a value greater than 30 days, the value is treated as UNIX time and represents the number of seconds since the date 1/1/1970.
11.2.1. Hot Rod Authenticate Operation
Authenticate operation request format includes the following:
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request header. |
| Mech | String | String containing the name of the mech chosen by the client for authentication. Empty on the successive invocations. |
| Response length | vInt | Length of the SASL client response. |
| Response data | byte array | The SASL client response. |
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Response header. |
| Completed | byte | 0 if further processing is needed, or 1 if authentication is complete. |
| Challenge length | vInt | Length of the SASL server challenge. |
| Challenge data | byte array | The SASL server challenge. |
11.2.2. Hot Rod AuthMechList Operation
Authenticate request with the preferred mech.
AuthMechList operation request format includes the following:
| Field | Data Type | Details |
|---|---|---|
| Header | Variable | Request header |
| Field | Data Type | Details |
|---|---|---|
| Header | Variable | Response header |
| Mech count | vInt | The number of mechs. |
| Mech | String | String containing the name of the SASL mech in its IANA-registered form (e.g. GSSAPI, CRAM-MD5, etc) |
Mech value recurs for each supported mech.
11.2.3. Hot Rod BulkGet Operation
BulkGet operation uses the following request format:
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request Header. |
| Entry Count | vInt | Contains the maximum number of Red Hat JBoss Data Grid entries to be returned by the server. The entry is the key and value pair. |
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Response Header |
| More | vInt | Represents if more entries must be read from the stream. While More is set to 1, additional entries follow until the value of More is set to 0, which indicates the end of the stream. |
| Key Length | vInt | Contains the length of the key. |
| Key | byte array | Contains the key value. |
| Value Length | vInt | Contains the length of the value. |
| Value | byte array | Contains the value. |
More, Key Size, Key, Value Size and Value entry is appended to the response.
11.2.4. Hot Rod BulkKeysGet Operation
BulkKeysGet operation uses the following request format:
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request header. |
| Scope | vInt |
|
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Response header. |
| Response Status | 1 byte | 0x00 = success, data follows. |
| More | 1 byte | One byte representing whether more keys need to be read from the stream. When set to 1 an entry follows, when set to 0, it is the end of stream and no more entries are left to read. |
| Key Length | vInt | Length of key |
| Key | byte array | Retrieved key. |
| More | 1 byte | One byte representing whether more entries need to be read from the stream. So, when it’s set to 1, it means that an entry follows, whereas when it’s set to 0, it’s the end of stream and no more entries are left to read. |
Key Length and Key recur for each key.
11.2.5. Hot Rod Clear Operation
clear operation format includes only a header.
| Response Status | Details |
|---|---|
| 0x00 | Red Hat JBoss Data Grid was successfully cleared. |
11.2.6. Hot Rod ContainsKey Operation
ContainsKey operation uses the following request format:
| Field | Data Type | Details |
|---|---|---|
| Header | - | - |
| Key Length | vInt | Contains the length of the key. The vInt data type is used because of its size (up to 5 bytes), which is larger than the size of Integer.MAX_VALUE. However, Java disallows single array sizes to exceed the size of Integer.MAX_VALUE. As a result, this vInt is also limited to the maximum size of Integer.MAX_VALUE. |
| Key | Byte array | Contains a key, the corresponding value of which is requested. |
| Response Status | Details |
|---|---|
| 0x00 | Successful operation. |
| 0x02 | The key does not exist. |
11.2.7. Hot Rod Exec Operation
Exec operation request format includes the following:
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request header. |
| Script | String | Name of the script to execute. |
| Parameter Count | vInt | The number of parameters. |
| Parameter Name (per parameter) | String | The name of the parameter. |
| Parameter Length (per parameter) | vInt | The length of the parameter. |
| Parameter Value (per parameter) | byte array | The value of the parameter. |
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Response header. |
| Response status | 1 byte | 0x00 if the execution completed successfully. 0x85 if the server resulted in an error. |
| Value Length | vInt | If success, length of return value. |
| Value | byte array | If success, the result of the execution. |
11.2.8. Hot Rod Get Operation
Get operation uses the following request format:
| Field | Data Type | Details |
|---|---|---|
| Header | Variable | Request Header |
| Key Length | vInt | Contains the length of the key. The vInt data type is used because of its size (up to 5 bytes), which is larger than the size of Integer.MAX_VALUE. However, Java disallows single array sizes to exceed the size of Integer.MAX_VALUE. As a result, this vInt is also limited to the maximum size of Integer.MAX_VALUE. |
| Key | Byte array | Contains a key, the corresponding value of which is requested. |
| Response Status | Details |
|---|---|
| 0x00 | Successful operation. |
| 0x02 | The key does not exist. |
get operation's response when the key is found is as follows:
| Field | Data Type | Details |
|---|---|---|
| Header | Variable | Response Header |
| Value Length | vInt | Contains the length of the value. |
| Value | Byte array | Contains the requested value. |
11.2.9. Hot Rod GetAll Operation
GetAll operation uses the following request format:
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request header |
| Key Count | vInt | How many keys to find entities for. |
| Key Length | vInt | Length of key. |
| Key | byte array | Retrieved key. |
Key Length and Key values recur for each key.
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Response header |
| Entry count | vInt | How many entries are being returned. |
| Key Length | vInt | Length of key. |
| Key | byte array | Retrieved key. |
| Value Length | vInt | Length of value. |
| Value | byte array | Retrieved value. |
Key Length, Key, Value Length, and Value entries recur per key and value.
11.2.10. Hot Rod GetWithMetadata Operation
GetWithMetadata operation uses the following request format:
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request header. |
| Key Length | vInt | Length of key. Note that the size of a vInt can be up to five bytes, which theoretically can produce bigger numbers than Integer.MAX_VALUE. However, Java cannot create a single array that is bigger than Integer.MAX_VALUE, hence the protocol limits vInt array lengths to Integer.MAX_VALUE. |
| Key | byte array | Byte array containing the key whose value is being requested. |
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Response header. |
| Response status | 1 byte | 0x00 = success, if key retrieved.
0x02 = if key does not exist.
|
| Flag | 1 byte | A flag indicating whether the response contains expiration information. The value of the flag is obtained as a bitwise OR operation between INFINITE_LIFESPAN (0x01) and INFINITE_MAXIDLE (0x02). |
| Created | Long | (optional) a Long representing the timestamp when the entry was created on the server. This value is returned only if the flag's INFINITE_LIFESPAN bit is not set. |
| Lifespan | vInt | (optional) a vInt representing the lifespan of the entry in seconds. This value is returned only if the flag's INFINITE_LIFESPAN bit is not set. |
| LastUsed | Long | (optional) a Long representing the timestamp when the entry was last accessed on the server. This value is returned only if the flag's INFINITE_MAXIDLE bit is not set. |
| MaxIdle | vInt | (optional) a vInt representing the maxIdle of the entry in seconds. This value is returned only if the flag's INFINITE_MAXIDLE bit is not set. |
| Entry Version | 8 bytes | Unique value of an existing entry modification. The protocol does not mandate that entry_version values are sequential, however they need to be unique per update at the key level. |
| Value Length | vInt | If success, length of value. |
| Value | byte array | If success, the requested value. |
11.2.11. Hot Rod GetWithVersion Operation
GetWithVersion operation uses the following request format:
| Field | Data Type | Details |
|---|---|---|
| Header | Variable | Request Header |
| Key Length | vInt | Contains the length of the key. The vInt data type is used because of its size (up to 5 bytes), which is larger than the size of Integer.MAX_VALUE. However, Java disallows single array sizes to exceed the size of Integer.MAX_VALUE. As a result, this vInt is also limited to the maximum size of Integer.MAX_VALUE. |
| Key | Byte array | Contains a key, the corresponding value of which is requested. |
| Response Status | Details |
|---|---|
| 0x00 | Successful operation. |
| 0x02 | The key does not exist. |
GetWithVersion operation's response when the key is found is as follows:
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Response header |
| Entry Version | 8 bytes | Unique value of an existing entry’s modification. The protocol does not mandate that entry_version values are sequential. They just need to be unique per update at the key level. |
| Value Length | vInt | Contains the length of the value. |
| Value | Byte array | Contains the requested value. |
11.2.12. Hot Rod IterationEnd Operation
IterationEnd operation request format includes the following:
| Field | Data Type | Details |
|---|---|---|
| iterationId | String | The unique id of the iteration. |
| Response Status | Details |
|---|---|
| 0x00 | Successful operation. |
| 0x05 | Error for non existent iterationId. |
11.2.13. Hot Rod IterationNext Operation
IterationNext operation request format includes the following:
| Field | Data Type | Details |
|---|---|---|
| IterationId | String | The unique id of the iteration. |
| Field | Data Type | Details |
|---|---|---|
| Finished segments size | vInt | Size of the bitset representing segments that were finished iterating. |
| Finished segments | byte array | Bitset encoding of the segments that were finished iterating. |
| Entry count | vInt | How many entries are being returned. |
| Number of value projections | vInt | Number of projections for the values. |
| Metadata | 1 byte | If set, entry has metadata associated. |
| Expiration | 1 byte | A flag indicating whether the response contains expiration information. The value of the flag is obtained as a bitwise OR operation between INFINITE_LIFESPAN (0x01) and INFINITE_MAXIDLE (0x02). Only present if the metadata flag above is set. |
| Created | Long | (optional) a Long representing the timestamp when the entry was created on the server. This value is returned only if the flag’s INFINITE_LIFESPAN bit is not set. |
| Lifespan | vInt | (optional) a vInt representing the lifespan of the entry in seconds. This value is returned only if the flag’s INFINITE_LIFESPAN bit is not set. |
| LastUsed | Long | (optional) a Long representing the timestamp when the entry was last accessed on the server. This value is returned only if the flag’s INFINITE_MAXIDLE bit is not set. |
| MaxIdle | vInt | (optional) a vInt representing the maxIdle of the entry in seconds. This value is returned only if the flag’s INFINITE_MAXIDLE bit is not set. |
| Entry Version | 8 bytes | Unique value of an existing entry’s modification. Only present if Metadata flag is set. |
| Key Length | vInt | Length of key. |
| Key | byte array | Retrieved key. |
| Value Length | vInt | Length of value. |
| Value | byte array | Retrieved value. |
Metadata, Expiration, Created, Lifespan, LastUsed, MaxIdle, Entry Version, Key Length, Key, Value Length, and Value fields recur.
11.2.14. Hot Rod IterationStart Operation
IterationStart operation request format includes the following:
| Field | Data Type | Details |
|---|---|---|
| Segments size | signed vInt | Size of the bitset encoding of the segments ids to iterate on. The size is the maximum segment id rounded to nearest multiple of 8. A value -1 indicates no segment filtering is to be done |
| Segments | byte array | (Optional) Contains the segments ids bitset encoded, where each bit with value 1 represents a segment in the set. Byte order is little-endian. Example: segments [1,3,12,13] would result in the following encoding:
java.util.BitSet implementation. Segments will be sent if the previous field is not negative |
| FilterConverter size | signed vInt | The size of the String representing a KeyValueFilterConverter factory name deployed on the server, or -1 if no filter will be used. |
| FilterConverter | UTF-8 byte array | (Optional) KeyValueFilterConverter factory name deployed on the server. Present if previous field is not negative. |
| Parameters size | byte | The number of parameters of the filter. Only present when FilterConverter is provided. |
| Parameters | byte[][] | An array of parameters. Each parameter is a byte array. Only present if Parameters size is greater than 0. |
| BatchSize | vInt | Number of entries to transfers from the server at one go. |
| Metadata | 1 byte | 1 if metadata is to be returned for each entry, 0 otherwise. |
| Field | Data Type | Details |
|---|---|---|
| IterationId | String | The unique id of the iteration. |
11.2.15. Hot Rod Ping Operation
ping is an application level request to check for server availability.
| Response Status | Details |
|---|---|
| 0x00 | Successful ping without any errors. |
11.2.16. Hot Rod Put Operation
put operation request format includes the following:
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request header. |
| Key Length | - | Contains the length of the key. |
| Key | Byte array | Contains the key value. |
| TimeUnits | Byte | Time units of lifespan (first 4 bits) and maxIdle (last 4 bits). Special units DEFAULT and INFINITE can be used for default server expiration and no expiration respectively. Possible values:
|
| Lifespan | vInt | Duration which the entry is allowed to life. Only sent when time unit is not DEFAULT or INFINITE |
| Max Idle | vInt | Duration that each entry can be idle before it’s evicted from the cache. Only sent when time unit is not DEFAULT or INFINITE. |
| Value Length | vInt | Contains the length of the value. |
| Value | Byte array | The requested value. |
| Response Status | Details |
|---|---|
| 0x00 | The value was successfully stored. |
| 0x03 | The value was successfully stored, and the previous value follows. |
ForceReturnPreviousValue is passed, the previous value and key are returned. If the previous key and value do not exist, the value length would contain the value 0.
11.2.17. Hot Rod PutAll Operation
PutAll operation request format includes the following:
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request header. |
| TimeUnits | Byte | Time units of lifespan (first 4 bits) and maxIdle (last 4 bits). Special units DEFAULT and INFINITE can be used for default server expiration and no expiration respectively. Possible values:
|
| Lifespan | vInt | Duration which the entry is allowed to life. Only sent when time unit is not DEFAULT or INFINITE |
| Max Idle | vInt | Duration that each entry can be idle before it’s evicted from the cache. Only sent when time unit is not DEFAULT or INFINITE. |
| Entry count | vInt | How many entries are being inserted. |
| Key Length | vInt | Length of key. |
| Key | byte array | Retrieved key. |
| Value Length | vInt | Length of value. |
| Value | byte array | Retrieved value. |
Key Length, Key, Value Length, and Value fields repeat for each entry that will be placed.
| Response Status | Details |
|---|---|
| 0x00 | Successful operation, indicating all keys were successfully put. |
11.2.18. Hot Rod PutIfAbsent Operation
putIfAbsent operation request format includes the following:
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request header. |
| Key Length | vInt | Contains the length of the key. |
| Key | Byte array | Contains the key value. |
| TimeUnits | Byte | Time units of lifespan (first 4 bits) and maxIdle (last 4 bits). Special units DEFAULT and INFINITE can be used for default server expiration and no expiration respectively. Possible values:
|
| Lifespan | vInt | Duration which the entry is allowed to life. Only sent when time unit is not DEFAULT or INFINITE |
| Max Idle | vInt | Duration that each entry can be idle before it’s evicted from the cache. Only sent when time unit is not DEFAULT or INFINITE. |
| Value Length | vInt | Contains the length of the value. |
| Value | Byte array | Contains the requested value. |
| Response Status | Details |
|---|---|
| 0x00 | The value was successfully stored. |
| 0x01 | The key was present, therefore the value was not stored. The current value of the key is returned. |
| 0x04 | The operation failed because the key was present and its value follows in the response. |
ForceReturnPreviousValue is passed, the previous value and key are returned. If the previous key and value do not exist, the value length would contain the value 0.
11.2.19. Hot Rod Query Operation
Query operation request format includes the following:
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request header. |
| Query Length | vInt | The length of the Protobuf encoded query object. |
| Query | Byte array | Byte array containing the Protobuf encoded query object, having a length specified by previous field. |
| Response Status | Data | Details |
|---|---|---|
| Header | variable | Response header. |
| Response payload Length | vInt | The length of the Protobuf encoded response object. |
| Response payload | Byte array | Byte array containing the Protobuf encoded response object, having a length specified by previous field. |
11.2.20. Hot Rod Remove Operation
Hot Rod Remove operation uses the following request format:
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request header. |
| Key Length | vInt | Contains the length of the key. The vInt data type is used because of its size (up to 5 bytes), which is larger than the size of Integer.MAX_VALUE. However, Java disallows single array sizes to exceed the size of Integer.MAX_VALUE. As a result, this vInt is also limited to the maximum size of Integer.MAX_VALUE. |
| Key | Byte array | Contains a key, the corresponding value of which is requested. |
| Response Status | Details |
|---|---|
| 0x00 | Successful operation. |
| 0x02 | The key does not exist. |
| 0x03 | The key was removed, and the previous or removed value follows in the response. |
ForceReturnPreviousValue is passed, the response header contains either:
- The value and length of the previous key.
- The value length
0and the response status0x02to indicate that the key does not exist.
ForceReturnPreviousValue is passed. If the key does not exist or the previous value was null, the value length is 0.
11.2.21. Hot Rod RemoveIfUnmodified Operation
RemoveIfUnmodified operation request format includes the following:
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request header. |
| Key Length | vInt | Contains the length of the key. |
| Key | Byte array | Contains the key value. |
| Entry Version | 8 bytes | The version number for the entry. |
| Response Status | Details |
|---|---|
| 0x00 | The entry was replaced or removed. |
| 0x01 | The entry replace or remove was unsuccessful because the key was modified. |
| 0x02 | The key does not exist. |
| 0x03 | The key was removed, and the previous or replaced value follows in the response. |
| 0x04 | The entry remove was unsuccessful because the key was modified, and the modified value follows in the response. |
ForceReturnPreviousValue is passed, the previous value and key are returned. If the previous key and value do not exist, the value length would contain the value 0.
11.2.22. Hot Rod Replace Operation
replace operation request format includes the following:
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request header. |
| Key Length | vInt | Contains the length of the key. |
| Key | Byte array | Contains the key value. |
| TimeUnits | Byte | Time units of lifespan (first 4 bits) and maxIdle (last 4 bits). Special units DEFAULT and INFINITE can be used for default server expiration and no expiration respectively. Possible values:
|
| Lifespan | vInt | Duration which the entry is allowed to life. Only sent when time unit is not DEFAULT or INFINITE |
| Max Idle | vInt | Duration that each entry can be idle before it’s evicted from the cache. Only sent when time unit is not DEFAULT or INFINITE. |
| Value Length | vInt | Contains the length of the value. |
| Value | Byte array | Contains the requested value. |
| Response Status | Details |
|---|---|
| 0x00 | The value was successfully stored. |
| 0x01 | The value was not stored because the key does not exist. |
| 0x03 | The value was successfully replaced, and the previous or replaced value follows in the response. |
ForceReturnPreviousValue is passed, the previous value and key are returned. If the previous key and value do not exist, the value length would contain the value 0.
11.2.23. Hot Rod ReplaceIfUnmodified Operation
ReplaceIfUnmodified operation request format includes the following:
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request header. |
| Key Length | vInt | Length of key. Note that the size of a vint can be up to 5 bytes which in theory can produce bigger numbers than Integer.MAX_VALUE. However, Java cannot create a single array that’s bigger than Integer.MAX_VALUE, hence the protocol is limiting vint array lengths to Integer.MAX_VALUE. |
| Key | byte array | Byte array containing the key whose value is being requested. |
| TimeUnits | Byte | Time units of lifespan (first 4 bits) and maxIdle (last 4 bits). Special units DEFAULT and INFINITE can be used for default server expiration and no expiration respectively. Possible values:
|
| Lifespan | vInt | Duration which the entry is allowed to life. Only sent when time unit is not DEFAULT or INFINITE |
| Max Idle | vInt | Duration that each entry can be idle before it’s evicted from the cache. Only sent when time unit is not DEFAULT or INFINITE. |
| Entry Version | 8 bytes | Use the value returned by GetWithVersion operation. |
| Value Length | vInt | Length of value. |
| Value | byte array | Value to be stored. |
| Response Status | Details |
|---|---|
| 0x00 | The value was successfully stored. |
| 0x01 | Replace did not happen because key had been modified. |
| 0x02 | Replace did not happen because key does not exist. |
| 0x03 | The key was replaced, and the previous or replaced value follows in the response. |
| 0x04 | The entry replace was unsuccessful because the key was modified, and the modified value follows in the response. |
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Response header. |
| Previous value length | vInt | If force return previous value flag was sent in the request, the length of the previous value will be returned. If the key does not exist, value length would be 0. If no flag was sent, no value length would be present. |
| Previous value | byte array | If force return previous value flag was sent in the request and the key was replaced, previous value. |
11.2.24. Hot Rod ReplaceWithVersion Operation
ReplaceWithVersion operation request format includes the following:
Note
ReplaceWithVersion operation uses the ReplaceIfUnmodified operation. As a result, these two operations are exactly the same in JBoss Data Grid.
| Field | Data Type | Details |
|---|---|---|
| Header | - | - |
| Key Length | vInt | Contains the length of the key. |
| Key | Byte array | Contains the key value. |
| Lifespan | vInt | Contains the number of seconds before the entry expires. If the number of seconds exceeds thirty days, the value is treated as UNIX time (i.e. the number of seconds since the date 1/1/1970) as the entry lifespan. When set to the value 0, the entry will never expire. |
| Max Idle | vInt | Contains the number of seconds an entry is allowed to remain idle before it is evicted from the cache. If this entry is set to 0, the entry is allowed to remain idle indefinitely without being evicted due to the max idle value. |
| Entry Version | 8 bytes | The version number for the entry. |
| Value Length | vInt | Contains the length of the value. |
| Value | Byte array | Contains the requested value. |
| Response Status | Details |
|---|---|
| 0x00 | Returned status if the entry was replaced or removed. |
| 0x01 | Returns status if the entry replace or remove was unsuccessful because the key was modified. |
| 0x02 | Returns status if the key does not exist. |
ForceReturnPreviousValue is passed, the previous value and key are returned. If the previous key and value do not exist, the value length would contain the value 0.
11.2.25. Hot Rod Stats Operation
| Name | Details |
|---|---|
| timeSinceStart | Contains the number of seconds since Hot Rod started. |
| currentNumberOfEntries | Contains the number of entries that currently exist in the Hot Rod server. |
| totalNumberOfEntries | Contains the total number of entries stored in the Hot Rod server. |
| stores | Contains the number of put operations attempted. |
| retrievals | Contains the number of get operations attempted. |
| hits | Contains the number of get hits. |
| misses | Contains the number of get misses. |
| removeHits | Contains the number of remove hits. |
| removeMisses | Contains the number of removal misses. |
| globalCurrentNumberOfEntries | Number of entries currently across the Hot Rod cluster. |
| globalStores | Total number of put operations across the Hot Rod cluster. |
| globalRetrievals | Total number of get operations across the Hot Rod cluster. |
| globalHits | Total number of get hits across the Hot Rod cluster. |
| globalMisses | Total number of get misses across the Hot Rod cluster. |
| globalRemoveHits | Total number of removal hits across the Hot Rod cluster. |
| globalRemoveMisses | Total number of removal misses across the Hot Rod cluster. |
Note
global are not available if Hot Rod is running in local mode.
| Name | Data Type | Details |
|---|---|---|
| Header | variable | Response Header. |
| Number of Stats | vInt | Contains the number of individual statistics returned. |
| Name Length | vInt | Contains the length of the named statistic. |
| Name | string | Contains the name of the statistic. |
| Value Length | vInt | Contains the length of the value. |
| Value | string | Contains the statistic value. |
Name Length, Name, Value Length and Value recur for each statistic requested.
11.2.26. Hot Rod Size Operation
Size operation request format includes the following:
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request header |
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Response header. |
| Size | vInt | Size of the remote cache, which is calculated globally in the clustered set ups, and if present, takes cache store contents into account as well. |
11.3. Hot Rod Operation Values
opcode values for a request header and their corresponding response header values:
| Operation | Request Operation Code | Response Operation Code |
|---|---|---|
| put | 0x01 | 0x02 |
| get | 0x03 | 0x04 |
| putIfAbsent | 0x05 | 0x06 |
| replace | 0x07 | 0x08 |
| replaceIfUnmodified | 0x09 | 0x0A |
| remove | 0x0B | 0x0C |
| removeIfUnmodified | 0x0D | 0x0E |
| containsKey | 0x0F | 0x10 |
| clear | 0x13 | 0x14 |
| stats | 0x15 | 0x16 |
| ping | 0x17 | 0x18 |
| bulkGet | 0x19 | 0x1A |
| getWithMetadata | 0x1B | 0x1C |
| bulkKeysGet | 0x1D | 0x1E |
| query | 0x1F | 0x20 |
| authMechList | 0x21 | 0x22 |
| auth | 0x23 | 0x24 |
| addClientListener | 0x25 | 0x26 |
| removeClientListener | 0x27 | 0x28 |
| size | 0x29 | 0x2A |
| exec | 0x2B | 0x2C |
| putAll | 0x2D | 0x2E |
| getAll | 0x2F | 0x30 |
| iterationStart | 0x31 | 0x32 |
| iterationNext | 0x33 | 0x34 |
| iterationEnd | 0x35 | 0x36 |
opcode value is 0x50, it indicates an error response.
11.3.1. Magic Values
Magic field in request and response headers:
| Value | Details |
|---|---|
| 0xA0 | Cache request marker. |
| 0xA1 | Cache response marker. |
11.3.2. Status Values
Status field in a response header:
| Value | Details |
|---|---|
| 0x00 | No error. |
| 0x01 | Not put/removed/replaced. |
| 0x02 | Key does not exist. |
| 0x06 | Success status and compatibility mode is enabled. |
| 0x07 | Success status and return previous value, with compatibility mode is enabled. |
| 0x08 | Not executed and return previous value, with compatibility mode is enabled. |
| 0x81 | Invalid Magic value or Message ID. |
| 0x82 | Unknown command. |
| 0x83 | Unknown version. |
| 0x84 | Request parsing error. |
| 0x85 | Server error. |
| 0x86 | Command timed out. |
11.3.3. Client Intelligence Values
Client Intelligence in a request header:
| Value | Details |
|---|---|
| 0x01 | Indicates a basic client that does not require any cluster or hash information. |
| 0x02 | Indicates a client that is aware of topology and requires cluster information. |
| 0x03 | Indicates a client that is aware of hash and distribution and requires both the cluster and hash information. |
11.3.4. Flag Values
flag values in the request header:
| Value | Details |
|---|---|
| 0x0001 | ForceReturnPreviousValue |
11.3.5. Hot Rod Error Handling
| Field | Data Type | Details |
|---|---|---|
| Error Opcode | - | Contains the error operation code. |
| Error Status Number | - | Contains a status number that corresponds to the error opcode. |
| Error Message Length | vInt | Contains the length of the error message. |
| Error Message | string | Contains the actual error message. If an 0x84 error code returns, which indicates that there was an error in parsing the request, this field contains the latest version supported by the Hot Rod server. |
11.4. Hot Rod Remote Events
11.4.1. Hot Rod Add Client Listener for Remote Events
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request Header. |
| Listener ID | byte array | Listener identifier. |
| Include state | byte | When this byte is set to 1, cached state is sent back to remote clients when either adding a cache listener for the first time, or when the node where a remote listener is registered changes in a clustered environment. When enabled, state is sent back as cache entry created events to the clients. If set to 0, no state is sent back to the client when adding a listener, nor it gets state when the node where the listener is registered changes. |
| Key/value filter factory name | String | Optional name of the key/value filter factory to be used with this listener. The factory is used to create key/value filter instances which allow events to be filtered directly in the Hot Rod server, avoiding sending events that the client is not interested in. If no factory is to be used, the length of the string is 0. |
| Key/value filter factory parameter count | byte | The key/value filter factory, when creating a filter instance, can take an arbitrary number of parameters, enabling the factory to be used to create different filter instances dynamically. This count field indicates how many parameters will be passed to the factory. If no factory name was provided, this field is not present in the request. |
| Key/value filter factory parameter (per parameter) | byte array | Key/value filter factory parameter. |
| Converter factory name | String | Optional name of the converter factory to be used with this listener. The factory is used to transform the contents of the events sent to clients. By default, when no converter is in use, events are well defined, according to the type of event generated. However, there might be situations where users want to add extra information to the event, or they want to reduce the size of the events. In these cases, a converter can be used to transform the event contents. The given converter factory name produces converter instances to do this job. If no factory is to be used, the length of the string is 0. |
| Converter factory parameter count | byte | The converter factory, when creating a converter instance, can take an arbitrary number of parameters, enabling the factory to be used to create different converter instances dynamically. This count field indicates how many parameters will be passed to the factory. If no factory name was provided, this field is not present in the request. |
| Converter factory parameter (per parameter) | byte array | Converter factory parameter. |
| Use raw data | byte | If filter/converter parameters should be raw binary, then 1, otherwise 0. |
| Field | Data Type | Details |
|---|---|---|
| Header | Variable | Response Header. |
11.4.2. Hot Rod Remote Client Listener for Remote Events
| Field | Data Type | Details |
|---|---|---|
| Header | variable | Request Header. |
| Listener ID | byte array | Listener Identifier |
| Field | Data Type | Details |
|---|---|---|
| Header | Variable | Response Header. |
11.4.3. Hot Rod Event Header
| Field Name | Size | Value |
|---|---|---|
| Magic | 1 byte | 0xA1 = response |
| Message ID | vLong | ID of event |
| Opcode | 1 byte | A code responding to the Event type:
|
| Status | 1 byte | Status of the response, with the following possible values:
|
| Topology Change Marker | 1 byte | Since events are not associated with a particular incoming topology ID to be able to decide whether a new topology is required to be sent or not, new topologies will never be sent with events. Hence, this marker will always have 0 value for events. |
11.4.4. Hot Rod Cache Entry Created Event
CacheEntryCreated event includes the following:
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Event header with 0x60 operation code. |
| Listener ID | byte array | Listener for which this event is directed |
| Custom Marker | byte | Custom event marker. For created events, this is 0. |
| Command Retried | byte | Marker for events that are result of retried commands. If command is retried, it returns 1, otherwise 0. |
| Key | byte array | Created key. |
| Version | long | Version of the created entry. This version information can be used to make conditional operations on this cache entry. |
11.4.5. Hot Rod Cache Entry Modified Event
CacheEntryModified event includes the following:
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Event header with 0x61 operation code. |
| Listener ID | byte array | Listener for which this event is directed |
| Custom Marker | byte | Custom event marker. For created events, this is 0. |
| Command Retried | byte | Marker for events that are result of retried commands. If command is retried, it returns 1, otherwise 0. |
| Key | byte array | Modified key. |
| Version | long | Version of the modified entry. This version information can be used to make conditional operations on this cache entry. |
11.4.6. Hot Rod Cache Entry Removed Event
CacheEntryRemoved event includes the following:
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Event header with 0x62 operation code. |
| Listener ID | byte array | Listener for which this event is directed |
| Custom Marker | byte | Custom event marker. For created events, this is 0. |
| Command Retried | byte | Marker for events that are result of retried commands. If command is retried, it returns 1, otherwise 0. |
| Key | byte array | Removed key. |
11.4.7. Hot Rod Custom Event
Custom event includes the following:
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Event header with event specific operation code |
| Listener ID | byte array | Listener for which this event is directed |
| Custom Marker | byte | Custom event marker. For custom events whose event data needs to be unmarshalled before returning to user the value is 1. For custom events that need to return the event data as-is to the user, the value is 2. |
| Event Data | byte array | Custom event data. If the custom marker is 1, the bytes represent the marshalled version of the instance returned by the converter. If custom marker is 2, it represents the byte array, as returned by the converter. |
11.5. Put Request Example
put request using Hot Rod:
| Byte | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 8 | 0xA0 | 0x09 | 0x41 | 0x01 | 0x07 | 0x4D ('M') | 0x79 ('y') | 0x43 ('C') |
| 16 | 0x61 ('a') | 0x63 ('c') | 0x68 ('h') | 0x65 ('e') | 0x00 | 0x03 | 0x00 | 0x00 |
| 24 | 0x00 | 0x05 | 0x48 ('H') | 0x65 ('e') | 0x6C ('l') | 0x6C ('l') | 0x6F ('o') | 0x00 |
| 32 | 0x00 | 0x05 | 0x57 ('W') | 0x6F ('o') | 0x72 ('r') | 0x6C ('l') | 0x64 ('d') | - |
| Field Name | Byte | Value |
|---|---|---|
| Magic | 0 | 0xA0 |
| Version | 2 | 0x41 |
| Cache Name Length | 4 | 0x07 |
| Flag | 12 | 0x00 |
| Topology ID | 14 | 0x00 |
| Transaction ID | 16 | 0x00 |
| Key | 18-22 | 'Hello' |
| Max Idle | 24 | 0x00 |
| Value | 26-30 | 'World' |
| Message ID | 1 | 0x09 |
| Opcode | 3 | 0x01 |
| Cache Name | 5-11 | 'MyCache' |
| Client Intelligence | 13 | 0x03 |
| Transaction Type | 15 | 0x00 |
| Key Field Length | 17 | 0x05 |
| Lifespan | 23 | 0x00 |
| Value Field Length | 25 | 0x05 |
put request:
| Byte | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 8 | 0xA1 | 0x09 | 0x01 | 0x00 | 0x00 | - | - | - |
| Field Name | Byte | Value |
|---|---|---|
| Magic | 0 | 0xA1 |
| Opcode | 2 | 0x01 |
| Topology Change Marker | 4 | 0x00 |
| Message ID | 1 | 0x09 |
| Status | 3 | 0x00 |
11.6. Hot Rod Java Client
11.6.1. Hot Rod Java Client Download
Procedure 11.1. Download Hot Rod Java Client
- Log into the Customer Portal at https://access.redhat.com.
- Click the button near the top of the page.
- In the Product Downloads page, click .
- Select the appropriate JBoss Data Grid version from the Version: drop down menu.
- Locate the Red Hat JBoss Data Grid ${VERSION} Hot Rod Java Client entry and click the corresponding link.
11.6.2. Hot Rod Java Client Configuration
Example 11.1. Client Instance Creation
org.infinispan.client.hotrod.configuration.ConfigurationBuilder cb
= new org.infinispan.client.hotrod.configuration.ConfigurationBuilder();
cb.tcpNoDelay(true)
.connectionPool()
.numTestsPerEvictionRun(3)
.testOnBorrow(false)
.testOnReturn(false)
.testWhileIdle(true)
.addServer()
.host("localhost")
.port(11222);
RemoteCacheManager rmc = new RemoteCacheManager(cb.build());
To configure the Hot Rod Java client, edit the hotrod-client.properties file on the classpath.
hotrod-client.properties file.
Example 11.2. Configuration
infinispan.client.hotrod.transport_factory = org.infinispan.client.hotrod.impl.transport.tcp.TcpTransportFactory
infinispan.client.hotrod.server_list = 127.0.0.1:11222
infinispan.client.hotrod.marshaller = org.infinispan.commons.marshall.jboss.GenericJBossMarshaller
infinispan.client.hotrod.async_executor_factory = org.infinispan.client.hotrod.impl.async.DefaultAsyncExecutorFactory
infinispan.client.hotrod.default_executor_factory.pool_size = 1
infinispan.client.hotrod.default_executor_factory.queue_size = 10000
infinispan.client.hotrod.hash_function_impl.1 = org.infinispan.client.hotrod.impl.consistenthash.ConsistentHashV1
infinispan.client.hotrod.tcp_no_delay = true
infinispan.client.hotrod.ping_on_startup = true
infinispan.client.hotrod.request_balancing_strategy = org.infinispan.client.hotrod.impl.transport.tcp.RoundRobinBalancingStrategy
infinispan.client.hotrod.key_size_estimate = 64
infinispan.client.hotrod.value_size_estimate = 512
infinispan.client.hotrod.force_return_values = false
infinispan.client.hotrod.tcp_keep_alive = true
## below is connection pooling config
maxActive=-1
maxTotal = -1
maxIdle = -1
whenExhaustedAction = 1
timeBetweenEvictionRunsMillis=120000
minEvictableIdleTimeMillis=300000
testWhileIdle = true
minIdle = 1Note
TCP KEEPALIVE configuration is enabled/disabled on the Hot Rod Java client either through a config property as seen in the example (infinispan.client.hotrod.tcp_keep_alive = true/false or programmatically through the org.infinispan.client.hotrod.ConfigurationBuilder.tcpKeepAlive() method.
new RemoteCacheManager(boolean start)new RemoteCacheManager()
11.6.3. Hot Rod Java Client Basic API
localhost:11222.
Example 11.3. Basic API
//API entry point, by default it connects to localhost:11222
BasicCacheContainer cacheContainer = new RemoteCacheManager();
//obtain a handle to the remote default cache
BasicCache<String, String> cache = cacheContainer.getCache();
//now add something to the cache and ensure it is there
cache.put("car", "ferrari");
assert cache.get("car").equals("ferrari");
//remove the data
cache.remove("car");
assert !cache.containsKey("car") : "Value must have been removed!";RemoteCacheManager corresponds to DefaultCacheManager, and both implement BasicCacheContainer.
DefaultCacheManager and RemoteCacheManager, which is simplified by the common BasicCacheContainer interface.
keySet() method. If the remote cache is a distributed cache, the server will start a Map/Reduce job to retrieve all keys from clustered nodes and return all keys to the client.
Set keys = remoteCache.keySet();11.6.4. Hot Rod Java Client Versioned API
getVersioned, clients can retrieve the value associated with the key as well as the current version.
RemoteCacheManager provides instances of the RemoteCache interface that accesses the named or default cache on the remote cluster. This extends the Cache interface to which it adds new methods, including the versioned API.
Example 11.4. Using Versioned Methods
// To use the versioned API, remote classes are specifically needed
RemoteCacheManager remoteCacheManager = new RemoteCacheManager();
RemoteCache<String, String> remoteCache = remoteCacheManager.getCache();
remoteCache.put("car", "ferrari");
VersionedValue valueBinary = remoteCache.getVersioned("car");
// removal only takes place only if the version has not been changed
// in between. (a new version is associated with 'car' key on each change)
assert remoteCache.removeWithVersion("car", valueBinary.getVersion());
assert !remoteCache.containsKey("car");Example 11.5. Using Replace
remoteCache.put("car", "ferrari");
VersionedValue valueBinary = remoteCache.getVersioned("car");
assert remoteCache.replaceWithVersion("car", "lamborghini", valueBinary.getVersion());11.7. Hot Rod C++ Client
- Red Hat Enterprise Linux 6, 64-bit
- Red Hat Enterprise Linux 7, 64-bit
11.7.1. Hot Rod C++ Client Formats
- Static library
- Shared/Dynamic library
The static library is statically linked to an application. This increases the size of the final executable. The application is self-contained and it does not need to ship a separate library.
Shared/Dynamic libraries are dynamically linked to an application at runtime. The library is stored in a separate file and can be upgraded separately from the application, without recompiling the application.
Note
11.7.2. Hot Rod C++ Client Prerequisites
| Operating System | Hot Rod C++ Client Prerequisites |
|---|---|
| RHEL 6, 64-bit | C++ 03 compiler with support for shared_ptr TR1 (GCC 4.0+) |
| RHEL 7, 64-bit | C++ 11 compiler (GCC 4.8.1) |
| Windows 7 x64 | C++ 11 compiler (Visual Studio 2015, Microsoft Visual C++ 2013 Redistributable Package for the x64 platform) |
11.7.3. Hot Rod C++ Client Download
jboss-datagrid-<version>-hotrod-cpp-client-<platform>.zip under Red Hat JBoss Data Grid binaries on the Red Hat Customer Portal at https://access.redhat.com. Download the appropriate Hot Rod C++ client which applies to your operating system.
11.7.4. Utilizing the Protobuf Compiler with the Hot Rod C++ Client
11.7.4.1. Using the Protobuf Compiler in RHEL 7
- Extract the
jboss-datagrid-<version>-hotrod-cpp-client-RHEL7-x86_64.ziplocally to the filesystem:unzip jboss-datagrid-<version>-hotrod-cpp-client-RHEL7-x86_64.zip - Add the included protobuf libraries to the library path:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/jboss-datagrid-<version>-remote-cpp-client-RHEL7-x86_64/lib64 - Compile the desired protobuf files into C++ header and source files:
/path/to/jboss-datagrid-<version>-remote-cpp-client-RHEL7-x86_64/bin/protoc --cpp_out dllexport_decl=HR_PROTO_EXPORT:/path/to/output/ $FILENote
HR_PROTO_EXOPRTis a macro defined within the Hot Rod client code, and will be expanded when the files are subsequently compiled. - The resulting header and source files will be generated in the designated output directory, allowing them to be referenced and compiled as normal with the specific application code.
11.7.4.2. Using the Protobuf Compiler in Windows
- Extract the
jboss-datagrid-<version>-hotrod-cpp-client-WIN-x86_64.ziplocally to the filesystem. - Open a command prompt and navigate to the newly extracted directory.
- Compile the desired protobuf files into C++ header and source files:
bin\protoc --cpp_out dllexport_decl=HR_PROTO_EXPORT:path\to\output\ $FILENote
HR_PROTO_EXOPRTis a macro defined within the Hot Rod client code, and will be expanded when the files are subsequently compiled. - The resulting header and source files will be generated in the designated output directory, allowing them to be referenced and compiled as normal with the specific application code.
11.7.5. Hot Rod C++ Client Configuration
- The initial set of servers to connect to.
- Connection pooling attributes.
- Connection/Socket timeouts and TCP nodelay.
- Hot Rod protocol version.
The following example shows how to use the ConfigurationBuilder to configure a RemoteCacheManager and how to obtain the default remote cache:
Example 11.6. SimpleMain.cpp
#include "infinispan/hotrod/ConfigurationBuilder.h"
#include "infinispan/hotrod/RemoteCacheManager.h"
#include "infinispan/hotrod/RemoteCache.h"
#include <stdlib.h>
using namespace infinispan::hotrod;
int main(int argc, char** argv) {
ConfigurationBuilder b;
b.addServer().host("127.0.0.1").port(11222);
RemoteCacheManager cm(builder.build());
RemoteCache<std::string, std::string> cache = cm.getCache<std::string, std::string>();
return 0;
}11.7.6. Hot Rod C++ Client Asynchronous API
Important
Async is appended to the end of each method. Asynchronous methods return a std::future containing the result of the operation. If a method were to return a std::string, instead it will return a std::future < std::string* >
getAsyncputAsyncputAllAsyncreplaceWithVersionAsync
Example 11.7. Hot Rod C++ Asynchronous API Example
#include "infinispan/hotrod/ConfigurationBuilder.h"
#include "infinispan/hotrod/RemoteCacheManager.h"
#include "infinispan/hotrod/RemoteCache.h"
#include "infinispan/hotrod/Version.h"
#include "infinispan/hotrod/JBasicMarshaller.h"
#include <iostream>
#include <thread>
#include <future>
using namespace infinispan::hotrod;
int main(int argc, char** argv) {
ConfigurationBuilder builder;
builder.addServer().host(argc > 1 ? argv[1] : "127.0.0.1").port(argc > 2 ? atoi(argv[2]) : 11222).protocolVersion(Configuration::PROTOCOL_VERSION_24);
RemoteCacheManager cacheManager(builder.build(), false);
auto *km = new BasicMarshaller<std::string>();
auto *vm = new BasicMarshaller<std::string>();
auto cache = cacheManager.getCache<std::string, std::string>(km, &Marshaller<std::string>::destroy, vm, &Marshaller<std::string>::destroy );
cacheManager.start();
std::string ak1("asyncK1");
std::string av1("asyncV1");
std::string ak2("asyncK2");
std::string av2("asyncV2");
cache.clear();
// Put ak1,av1 in async thread
std::future<std::string*> future_put= cache.putAsync(ak1,av1);
// Get the value in this thread
std::string* arv1= cache.get(ak1);
// Now wait for put completion
future_put.wait();
// All is synch now
std::string* arv11= cache.get(ak1);
if (!arv11 || arv11->compare(av1))
{
std::cout << "fail: expected " << av1 << "got " << (arv11 ? *arv11 : "null") << std::endl;
return 1;
}
// Read ak1 again, but in async way and test that the result is the same
std::future<std::string*> future_ga= cache.getAsync(ak1);
std::string* arv2= future_ga.get();
if (!arv2 || arv2->compare(av1))
{
std::cerr << "fail: expected " << av1 << " got " << (arv2 ? *arv2 : "null") << std::endl;
return 1;
}
// Now user pass a simple lambda func that set a flag to true when the put completes
bool flag=false;
std::future<std::string*> future_put1= cache.putAsync(ak2,av2,0,0,[&] (std::string *v){flag=true; return v;});
// The put is not completed here so flag must be false
if (flag)
{
std::cerr << "fail: expected false got true" << std::endl;
return 1;
}
// Now wait for put completion
future_put1.wait();
// The user lambda must be executed so flag must be true
if (!flag)
{
std::cerr << "fail: expected true got false" << std::endl;
return 1;
}
// Same test for get
flag=false;
// Now user pass a simple lambda func that set a flag to true when the put completes
std::future<std::string*> future_get1= cache.getAsync(ak2,[&] (std::string *v){flag=true; return v;});
// The get is not completed here so flag must be false
if (flag)
{
std::cerr << "fail: expected false got true" << std::endl;
return 1;
}
// Now wait for get completion
future_get1.wait();
if (!flag)
{
std::cerr << "fail: expected true got false" << std::endl;
return 1;
}
std::string* arv3= future_get1.get();
if (!arv3 || arv3->compare(av2))
{
std::cerr << "fail: expected " << av2 << " got " << (arv3 ? *arv3 : "null") << std::endl;
return 1;
}
cacheManager.stop();
}11.7.7. Hot Rod C++ Client API
Example 11.8. SimpleMain.cpp
RemoteCache<std::string, std::string> rc = cm.getCache<std::string, std::string>();
std::string k1("key13");
std::string v1("boron");
// put
rc.put(k1, v1);
std::auto_ptr<std::string> rv(rc.get(k1));
rc.putIfAbsent(k1, v1);
std::auto_ptr<std::string> rv2(rc.get(k1));
std::map<HR_SHARED_PTR<std::string>,HR_SHARED_PTR<std::string> > map = rc.getBulk(0);
std::cout << "getBulk size" << map.size() << std::endl;
..
.
cm.stop();11.8. Hot Rod C# Client
11.8.1. Hot Rod C# Client Download and Installation
jboss-datagrid-<version>-hotrod-dotnet-client.msi packed for download with Red Hat JBoss Data Grid . To install the Hot Rod C# client, execute the following instructions.
Procedure 11.2. Installing the Hot Rod C# Client
- As an administrator, navigate to the location where the Hot Rod C# .msi file is downloaded. Run the .msi file to launch the windows installer and then click .
Figure 11.1. Hot Rod C# Client Setup Welcome
- Review the end-user license agreement. Select the I accept the terms in the License Agreement check box and then click .
Figure 11.2. Hot Rod C# Client End-User License Agreement
- To change the default directory, click or click to install in the default directory.
Figure 11.3. Hot Rod C# Client Destination Folder
- Click to complete the Hot Rod C# client installation.
Figure 11.4. Hot Rod C# Client Setup Completion
11.8.2. Hot Rod C# Client Configuration
The following example shows how to use the ConfigurationBuilder to configure a RemoteCacheManager.
Example 11.9. C# configuration
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Infinispan.HotRod;
using Infinispan.HotRod.Config;
namespace simpleapp
{
class Program
{
static void Main(string[] args)
{
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.AddServer()
.Host(args.Length > 1 ? args[0] : "127.0.0.1")
.Port(args.Length > 2 ? int.Parse(args[1]) : 11222);
Configuration config = builder.Build();
RemoteCacheManager cacheManager = new RemoteCacheManager(config);
[...]
}
}
}11.8.3. Hot Rod C# Client API
RemoteCacheManager is a starting point to obtain a reference to a RemoteCache.
Example 11.10.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Infinispan.HotRod;
using Infinispan.HotRod.Config;
namespace simpleapp
{
class Program
{
static void Main(string[] args)
{
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.AddServer()
.Host(args.Length > 1 ? args[0] : "127.0.0.1")
.Port(args.Length > 2 ? int.Parse(args[1]) : 11222);
Configuration config = builder.Build();
RemoteCacheManager cacheManager = new RemoteCacheManager(config);
cacheManager.Start();
// Retrieve a reference to the default cache.
IRemoteCache<String, String> cache = cacheManager.GetCache<String, String>();
// Add entries.
cache.Put("key1", "value1");
cache.PutIfAbsent("key1", "anotherValue1");
cache.PutIfAbsent("key2", "value2");
cache.PutIfAbsent("key3", "value3");
// Retrive entries.
Console.WriteLine("key1 -> " + cache.Get("key1"));
// Bulk retrieve key/value pairs.
int limit = 10;
IDictionary<String, String> result = cache.GetBulk(limit);
foreach (KeyValuePair<String, String> kv in result)
{
Console.WriteLine(kv.Key + " -> " + kv.Value);
}
// Remove entries.
cache.Remove("key2");
Console.WriteLine("key2 -> " + cache.Get("key2"));
cacheManager.Stop();
}
}
}11.8.4. String Marshaller for Interoperability
CompatibilityMarshaller to the Marshaller() method of the ConfigurationBuilder object similar to this:
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.Marshaller(new CompatibilityMarshaller());
RemoteCacheManager cacheManager = new RemoteCacheManager(builder.build(), true);
IRemoteCache<String, String> cache = cacheManager.GetCache<String, String>();
[....]
cache.Put("key", "value");
[...]
cache.Get("key");
[...]Note
HotRodClientException being thrown.
11.9. Hot Rod Node.js Client
Promise instances, allowing the client to easily chain multiple invocations together and centralizing error handling.
11.9.1. Installing the Hot Rod Node.js Client
Procedure 11.3. Installing the Hot Rod Node.js Client
- Download the
jboss-datagrid-<version>-nodejs-client.zipfrom the Red Hat Customer Portal. - Extract the downloaded archive.
- Use
npmto install the provided tarball, as seen in the following command:npm install /path/to/jboss-datagrid-7.0.0-nodejs-client/infinispan-0.2.0.Final-redhat-1.tgz
11.9.2. Hot Rod Node.js Requirements
- Node.js version 0.10 or higher.
- JBoss Data Grid server instance 7.0.0 or higher.
11.9.3. Hot Rod Node.js Basic Functionality
localhost:11222:
var infinispan = require('infinispan');
// Obtain a connection to the JBoss Data Grid server
// As no cache is specified all operations will occur on the 'default' cache
var connected = infinispan.client({port: 11222, host: '127.0.0.1'});
connected.then(function (client) {
// Attempt to put a value in the cache.
var clientPut = client.put('key', 'value');
// Retrieve the value just placed
var clientGet = clientPut.then(
function() { return client.get('key'); });
// Print out the value that was retrieved
var showGet = clientGet.then(
function(value) { console.log('get(key)=' + value); });
// Disconnect from the server
return showGet.finally(
function() { return client.disconnect(); });
}).catch(function(error) {
// Log any errors received
console.log("Got error: " + error.message);
});
To connect to a specific cache the cacheName attribute may be defined when specifying the location of the JBoss Data Grid server instance, as seen in the following example:
var infinispan = require('infinispan');
// Obtain a connection to the JBoss Data Grid server
// and connect to namedCache
var connected = infinispan.client(
{port: 11222, host: '127.0.0.1'}, {cacheName: 'namedCache'});
connected.then(function (client) {
// Log the result of the connection
console.log('Connected to `namedCache`');
// Disconnect from the server
return client.disconnect();
}).catch(function(error) {
// Log any errors received
console.log("Got error: " + error.message);
});
In addition to placing single entries the putAll and getAll methods may be used to place or retrieve a set of data. The following example walks through these operations:
var infinispan = require('infinispan');
// Obtain a connection to the JBoss Data Grid server
// As no cache is specified all operations will occur on the 'default' cache
var connected = infinispan.client({port: 11222, host: '127.0.0.1'});
connected.then(function (client) {
var data = [
{key: 'multi1', value: 'v1'},
{key: 'multi2', value: 'v2'},
{key: 'multi3', value: 'v3'}];
// Place all of the key/value pairs in the cache
var clientPutAll = client.putAll(data);
// Obtain the values for two of the keys
var clientGetAll = clientPutAll.then(
function() { return client.getAll(['multi2', 'multi3']); });
// Print out the values obtained.
var showGetAll = clientGetAll.then(
function(entries) {
console.log('getAll(multi2, multi3)=%s', JSON.stringify(entries));
}
);
// Obtain an iterator for the cache
var clientIterator = showGetAll.then(
function() { return client.iterator(1); });
// Iterate over the entries in the cache, printing the values
var showIterated = clientIterator.then(
function(it) {
function loop(promise, fn) {
// Simple recursive loop over iterator's next() call
return promise.then(fn).then(function (entry) {
return !entry.done ? loop(it.next(), fn) : entry.value;
});
}
return loop(it.next(), function (entry) {
console.log('iterator.next()=' + JSON.stringify(entry));
return entry;
});
}
);
// Clear the cache of all values
var clientClear = showIterated.then(
function() { return client.clear(); });
// Disconnect from the server
return clientClear.finally(
function() { return client.disconnect(); });
}).catch(function(error) {
// Log any errors received
console.log("Got error: " + error.message);
});11.9.4. Hot Rod Node.js Conditional Operations
getWithMetadata will retrieve the value and any associated metadata with the key.
var infinispan = require('infinispan');
// Obtain a connection to the JBoss Data Grid server
// As no cache is specified all operations will occur on the 'default' cache
var connected = infinispan.client({port: 11222, host: '127.0.0.1'});
connected.then(function (client) {
// Attempt to put a value in the cache if it does not exist
var clientPut = client.putIfAbsent('cond', 'v0');
// Print out the result of the put operation
var showPut = clientPut.then(
function(success) { console.log(':putIfAbsent(cond)=' + success); });
// Replace the value in the cache
var clientReplace = showPut.then(
function() { return client.replace('cond', 'v1'); } );
// Print out the result of the replace
var showReplace = clientReplace.then(
function(success) { console.log('replace(cond)=' + success); });
// Obtain the value and metadata
var clientGetMetaForReplace = showReplace.then(
function() { return client.getWithMetadata('cond'); });
// Replace the value only if the version matches
var clientReplaceWithVersion = clientGetMetaForReplace.then(
function(entry) {
console.log('getWithMetadata(cond)=' + JSON.stringify(entry));
return client.replaceWithVersion('cond', 'v2', entry.version);
}
);
// Print out the result of the previous replace
var showReplaceWithVersion = clientReplaceWithVersion.then(
function(success) { console.log('replaceWithVersion(cond)=' + success); });
// Obtain the value and metadata
var clientGetMetaForRemove = showReplaceWithVersion.then(
function() { return client.getWithMetadata('cond'); });
// Remove the value only if the version matches
var clientRemoveWithVersion = clientGetMetaForRemove.then(
function(entry) {
console.log('getWithMetadata(cond)=' + JSON.stringify(entry));
return client.removeWithVersion('cond', entry.version);
}
);
// Print out the result of the previous remove
var showRemoveWithVersion = clientRemoveWithVersion.then(
function(success) { console.log('removeWithVersion(cond)=' + success)});
// Disconnect from the server
return showRemoveWithVersion.finally(
function() { return client.disconnect(); });
}).catch(function(error) {
// Log any errors received
console.log("Got error: " + error.message);
});11.9.5. Hot Rod Node.js Data Sets
var infinispan = require('infinispan');
// Accepts multiple addresses and fails over if connection not possible
var connected = infinispan.client(
[{port: 99999, host: '127.0.0.1'}, {port: 11222, host: '127.0.0.1'}]);
connected.then(function (client) {
// Obtain a list of all members in the cluster
var members = client.getTopologyInfo().getMembers();
// Print out the list of members
console.log('Connected to: ' + JSON.stringify(members));
// Disconnect from the server
return client.disconnect();
}).catch(function(error) {
// Log any errors received
console.log("Got error: " + error.message);
});11.9.6. Hot Rod Node.js Remote Events
addListener method. This method takes the event type (create, modify, remove, or expiry) and the function callback as parameter. For more information on Remote Event Listeners refer to Section 8.5, “Remote Event Listeners (Hot Rod)”. An example of this is shown below:
var infinispan = require('infinispan');
var Promise = require('promise');
var connected = infinispan.client({port: 11222, host: '127.0.0.1'});
connected.then(function (client) {
var clientAddListenerCreate = client.addListener(
'create', function(key) { console.log('[Event] Created key: ' + key); });
var clientAddListeners = clientAddListenerCreate.then(
function(listenerId) {
// Multiple callbacks can be associated with a single client-side listener.
// This is achieved by registering listeners with the same listener id
// as shown in the example below.
var clientAddListenerModify = client.addListener(
'modify', function(key) { console.log('[Event] Modified key: ' + key); },
{listenerId: listenerId});
var clientAddListenerRemove = client.addListener(
'remove', function(key) { console.log('[Event] Removed key: ' + key); },
{listenerId: listenerId});
return Promise.all([clientAddListenerModify, clientAddListenerRemove]);
});
var clientCreate = clientAddListeners.then(
function() { return client.putIfAbsent('eventful', 'v0'); });
var clientModify = clientCreate.then(
function() { return client.replace('eventful', 'v1'); });
var clientRemove = clientModify.then(
function() { return client.remove('eventful'); });
var clientRemoveListener =
Promise.all([clientAddListenerCreate, clientRemove]).then(
function(values) {
var listenerId = values[0];
return client.removeListener(listenerId);
});
return clientRemoveListener.finally(
function() { return client.disconnect(); });
}).catch(function(error) {
console.log("Got error: " + error.message);
});11.9.7. Hot Rod Node.js Working with Clusters
- The client only needs to know about a single server's address to receive information about the entire server cluster, regardless of the cluster size.
- For distributed caches, key-based operations are routed in the cluster using the same consistent hash algorithms used by the server. This means that the client can locate where any particular key resides without the need for extra network hops.
- For distributed caches, multi-key or key-less operations routed in round-robin fashion.
- For replicated and invalidated caches, all operations are routed in round-robin fashion, regardless of whether they are key-based or multi-key/key-less.
var infinispan = require('infinispan');
var connected = infinispan.client({port: 11322, host: '127.0.0.1'});
connected.then(function (client) {
var members = client.getTopologyInfo().getMembers();
// Should show all expected cluster members
console.log('Connected to: ' + JSON.stringify(members));
// Add your own operations here...
return client.disconnect();
}).catch(function(error) {
// Log any errors received
console.log("Got error: " + error.message);
});11.10. Interoperability Between Hot Rod C++ and Hot Rod Java Client
Person object structured and serialized using Protobuf, and the Hot Rod Java client can read the same Person object structured as Protobuf.
Example 11.11. Using Interoperability Between Languages
package sample;
message Person {
required int32 age = 1;
required string name = 2;
}11.11. Compatibility Between Server and Hot Rod Client Versions
Note
The following will be the impact on the client side:
- client will not have advantage of the latest protocol improvements.
- client might run into known issues which are fixed for the server-side version.
- client can only use the functionalities available in its current version and the previous versions.
In this case, when a Hot Rod client connects to a JBoss Data Grid server, the connection will be rejected with an exception error. The client can be downgraded to a known protocol version by either setting the client side property infinispan.client.hotrod.protocol_version, or by using the ConfigurationBuilder's protocolVersion(String version) method. When downgraded the client version using either of these methods a String containing the desired version should be passed in. In this case the client is able to connect to the server, but will be restricted to the functionality of that version. Any command which is not supported by this protocol version will not work and throw an exception; in addition, the topology information might be inefficient in this case.
Example 11.12. Downgrading Client Hot Rod Protocol Version
protocolVersion(String version) method:
Configuration config = new ConfigurationBuilder()
[...]
.protocolVersion("2.2")
.build();Note
| JBoss Data Grid Server Version | Hot Rod Protocol Version |
|---|---|
| JBoss Data Grid 7.0.0 | Hot Rod 2.5 and later |
Part II. Creating and Using Infinispan Queries in Red Hat JBoss Data Grid
Chapter 12. Getting Started with Infinispan Query
12.1. Introduction
- Keyword, Range, Fuzzy, Wildcard, and Phrase queries
- Combining queries
- Sorting, filtering, and pagination of query results
The Querying API is enabled by default in Remote Client-Server Mode. Instructions for enabling Querying in Library Mode are found in the Red Hat JBoss Data Grid Administration and Configuration Guide.
12.2. Installing Querying for Red Hat JBoss Data Grid
Warning
infinispan-embedded-query.jar file. Do not include other versions of Hibernate Search and Lucene in the same deployment as infinispan-embedded-query. This action will cause classpath conflicts and result in unexpected behavior.
12.3. About Querying in Red Hat JBoss Data Grid
12.3.1. Hibernate Search and the Query Module
- Retrieve all red cars (an exact metadata match).
- Search for all books about a specific topic (full text search and relevance scoring).
Warning
12.3.2. Apache Lucene and the Query Module
- Apache Lucene is a document indexing tool and search engine. JBoss Data Grid uses Apache Lucene 3.6.
- JBoss Data Grid's Query Module is a toolkit based on Hibernate Search that reduces Java objects into a format similar to a document, which is able to be indexed and queried by Apache Lucene.
12.4. Indexing
12.4.1. Indexing with Transactional and Non-transactional Caches
- If the cache is transactional, index updates are applied using a listener after the commit process (after-commit listener). Index update failure does not cause the write to fail.
- If the cache is not transactional, index updates are applied using a listener that works after the event completes (post-event listener). Index update failure does not cause the write to fail.
12.4.2. Configure Indexing Programmatically
Author, which is stored in the grid and made searchable via two properties, without annotating the class.
Example 12.1. Configure Indexing Programmatically
import java.util.Properties;
import org.hibernate.search.cfg.SearchMapping;
import org.infinispan.Cache;
import org.infinispan.configuration.cache.Configuration;
import org.infinispan.configuration.cache.ConfigurationBuilder;
import org.infinispan.manager.DefaultCacheManager;
import org.infinispan.query.CacheQuery;
import org.infinispan.query.Search;
import org.infinispan.query.SearchManager;
import org.infinispan.query.dsl.Query;
import org.infinispan.query.dsl.QueryBuilder;
[...]
SearchMapping mapping = new SearchMapping();
mapping.entity(Author.class).indexed().providedId()
.property("name", ElementType.METHOD).field()
.property("surname", ElementType.METHOD).field();
Properties properties = new Properties();
properties.put(org.hibernate.search.Environment.MODEL_MAPPING, mapping);
properties.put("[other.options]", "[...]");
Configuration infinispanConfiguration = new ConfigurationBuilder()
.indexing()
.enable()
.withProperties(properties)
.build();
DefaultCacheManager cacheManager = new DefaultCacheManager(infinispanConfiguration);
Cache<Long, Author> cache = cacheManager.getCache();
SearchManager sm = Search.getSearchManager(cache);
Author author = new Author(1, "FirstName", "Surname");
cache.put(author.getId(), author);
QueryBuilder qb = sm.buildQueryBuilderForClass(Author.class).get();
Query q = qb.keyword().onField("name").matching("FirstName").createQuery();
CacheQuery cq = sm.getQuery(q, Author.class);
Assert.assertEquals(cq.getResultSize(), 1);12.4.3. Rebuilding the Index
- The definition of what is indexed in the types has changed.
- A parameter affecting how the index is defined, such as the
Analyserchanges. - The index is destroyed or corrupted, possibly due to a system administration error.
MassIndexer and start it as follows:
SearchManager searchManager = Search.getSearchManager(cache);
searchManager.getMassIndexer().start();12.5. Searching
org.infinispan.query.CacheQuery to get the required functionality from the Lucene-based API. The following code prepares a query against the indexed fields. Executing the code returns a list of Books.
Example 12.2. Using Infinispan Query to Create and Execute a Search
QueryBuilder qb = Search.getSearchManager(cache).buildQueryBuilderForClass(Book.class).get();
org.apache.lucene.search.Query query = qb
.keyword()
.onFields("title", "author")
.matching("Java rocks!")
.createQuery();
// wrap Lucene query in a org.infinispan.query.CacheQuery
CacheQuery cacheQuery = Search.getSearchManager(cache).getQuery(query);
List list = cacheQuery.list();Chapter 13. Annotating Objects and Querying
@Indexed
@Field.
Example 13.1. Annotating Objects with @Field
@Indexed
public class Person implements Serializable {
@Field(store = Store.YES)
private String name;
@Field(store = Store.YES)
private String description;
@Field(store = Store.YES)
private int age;
}Important
module.xml file. The custom annotations are not picked by the queries without the org.infinispan.query dependency and results in an error.
13.1. Registering a Transformer via Annotations
org.infinispan.query.Transformer.
org.infinispan.query.Transformer:
Example 13.2. Annotating the Key Type
@Transformable(transformer = CustomTransformer.class)
public class CustomKey {
}
public class CustomTransformer implements Transformer {
@Override
public Object fromString(String s) {
return new CustomKey(...);
}
@Override
public String toString(Object customType) {
CustomKey ck = (CustomKey) customType;
return ck.toString();
}
}Example 13.3. Biunique Correspondence
A.equals(transformer.fromString(transformer.toString(A));13.2. Querying Example
Person object has been annotated using the following:
Example 13.4. Annotating the Person Object
@Indexed
public class Person implements Serializable {
@Field(store = Store.YES)
private String name;
@Field
private String description;
@Field(store = Store.YES)
private int age;
}Person objects have been stored in JBoss DataGrid, they can be searched using querying. The following code creates a SearchManager and QueryBuilder instance:
Example 13.5. Creating the SearchManager and QueryBuilder
SearchManager manager = Search.getSearchManager(cache);
QueryBuilder builder = manager.buildQueryBuilderForClass(Person.class) .get();
Query luceneQuery = builder.keyword()
.onField("name")
.matching("FirstName")
.createQuery();SearchManager and QueryBuilder are used to construct a Lucene query. The Lucene query is then passed to the SearchManager to obtain a CacheQuery instance:
Example 13.6. Running the Query
CacheQuery query = manager.getQuery(luceneQuery);
List<Object> results = query.list();
for (Object result : results) {
System.out.println("Found " + result);
}CacheQuery instance contains the results of the query, and can be used to produce a list or it can be used for repeat queries.
Chapter 14. Mapping Domain Objects to the Index Structure
14.1. Basic Mapping
@Indexed objects is the key used to store the value. How the key is indexed can still be customized by using a combination of @Transformable, @ProvidedId, custom types and custom FieldBridge implementations.
@DocumentId identifier does not apply to JBoss Data Grid values.
- @Indexed
- @Field
- @NumericField
14.1.1. @Indexed
@Indexed annotation declares a cached entry indexable. All entries not annotated with @Indexed are ignored.
Example 14.1. Making a class indexable with @Indexed
@Indexed
public class Essay {
}index attribute of the @Indexed annotation to change the default name of the index.
14.1.2. @Field
@Field annotation declares a property as indexed and allows the configuration of several aspects of the indexing process by setting one or more of the following attributes:
name- The name under which the property will be stored in the Lucene Document. By default, this attribute is the same as the property name, following the JavaBeans convention.
store- Specifies if the property is stored in the Lucene index. When a property is stored it can be retrieved in its original value from the Lucene Document. This is regardless of whether or not the element is indexed. Valid options are:
Store.YES: Consumes more index space but allows projection. See Section 15.1.3.4, “Projection”Store.COMPRESS: Stores the property as compressed. This attribute consumes more CPU.Store.NO: No storage. This is the default setting for the store attribute.
index- Describes if property is indexed or not. The following values are applicable:
Index.NO: No indexing is applied; cannot be found by querying. This setting is used for properties that are not required to be searchable, but are able to be projected.Index.YES: The element is indexed and is searchable. This is the default setting for the index attribute.
analyze- Determines if the property is analyzed. The analyze attribute allows a property to be searched by its contents. For example, it may be worthwhile to analyze a text field, whereas a date field does not need to be analyzed. Enable or disable the Analyze attribute using the following:The analyze attribute is enabled by default. The
Analyze.YESAnalyze.NO
Analyze.YESsetting requires the property to be indexed via theIndex.YESattribute.
norms- Determines whether or not to store index time boosting information. Valid settings are:The default for this attribute is
Norms.YESNorms.NO
Norms.YES. Disabling norms conserves memory, however no index time boosting information will be available. termVector- Describes collections of term-frequency pairs. This attribute enables the storing of the term vectors within the documents during indexing. The default value is
TermVector.NO. Available settings for this attribute are:TermVector.YES: Stores the term vectors of each document. This produces two synchronized arrays, one contains document terms and the other contains the term's frequency.TermVector.NO: Does not store term vectors.TermVector.WITH_OFFSETS: Stores the term vector and token offset information. This is the same asTermVector.YESplus it contains the starting and ending offset position information for the terms.TermVector.WITH_POSITIONS: Stores the term vector and token position information. This is the same asTermVector.YESplus it contains the ordinal positions of each occurrence of a term in a document.TermVector.WITH_POSITION_OFFSETS: Stores the term vector, token position and offset information. This is a combination of theYES,WITH_OFFSETS, andWITH_POSITIONS.
indexNullAs- By default, null values are ignored and not indexed. However, using
indexNullAspermits specification of a string to be inserted as token for the null value. When using theindexNullAsparameter, use the same token in the search query to search for null value. Use this feature only withAnalyze.NO. Valid settings for this attribute are:Field.DO_NOT_INDEX_NULL: This is the default value for this attribute. This setting indicates that null values will not be indexed.Field.DEFAULT_NULL_TOKEN: Indicates that a default null token is used. This default null token can be specified in the configuration using the default_null_token property. If this property is not set andField.DEFAULT_NULL_TOKENis specified, the string "_null_" will be used as default.
Warning
FieldBridge or TwoWayFieldBridge it is up to the developer to handle the indexing of null values (see JavaDocs of LuceneOptions.indexNullAs()).
14.1.3. @NumericField
@NumericField annotation can be specified in the same scope as @Field.
@NumericField annotation can be specified for Integer, Long, Float, and Double properties. At index time the value will be indexed using a Trie structure. When a property is indexed as numeric field, it enables efficient range query and sorting, orders of magnitude faster than doing the same query on standard @Field properties. The @NumericField annotation accept the following optional parameters:
forField: Specifies the name of the related@Fieldthat will be indexed as numeric. It is mandatory when a property contains more than a@Fielddeclaration.precisionStep: Changes the way that the Trie structure is stored in the index. SmallerprecisionStepslead to more disk space usage, and faster range and sort queries. Larger values lead to less space used, and range query performance closer to the range query in normal@Fields. The default value forprecisionStepis 4.
@NumericField supports only Double, Long, Integer, and Float. It is not possible to take any advantage from a similar functionality in Lucene for the other numeric types, therefore remaining types must use the string encoding via the default or custom TwoWayFieldBridge.
NumericFieldBridge can also be used. Custom configurations require approximation during type transformation. The following is an example defines a custom NumericFieldBridge.
Example 14.2. Defining a custom NumericFieldBridge
public class BigDecimalNumericFieldBridge extends NumericFieldBridge {
private static final BigDecimal storeFactor = BigDecimal.valueOf(100);
@Override
public void set(String name,
Object value,
Document document,
LuceneOptions luceneOptions) {
if (value != null) {
BigDecimal decimalValue = (BigDecimal) value;
Long indexedValue = Long.valueOf(
decimalValue
.multiply(storeFactor)
.longValue());
luceneOptions.addNumericFieldToDocument(name, indexedValue, document);
}
}
@Override
public Object get(String name, Document document) {
String fromLucene = document.get(name);
BigDecimal storedBigDecimal = new BigDecimal(fromLucene);
return storedBigDecimal.divide(storeFactor);
}
}14.2. Mapping Properties Multiple Times
@Fields can be used to perform this search. For example:
Example 14.3. Using @Fields to map a property multiple times
@Indexed(index = "Book")
public class Book {
@Fields( {
@Field,
@Field(name = "summary_forSort", analyze = Analyze.NO, store = Store.YES)
})
public String getSummary() {
return summary;
}
}summary is indexed twice - once as summary in a tokenized way, and once as summary_forSort in an untokenized way. @Field supports 2 attributes useful when @Fields is used:
- analyzer: defines a @Analyzer annotation per field rather than per property
- bridge: defines a @FieldBridge annotation per field rather than per property
14.3. Embedded and Associated Objects
14.3.1. Indexing Associated Objects
address.city:Atlanta. The place fields are indexed in the Place index. The Place index documents also contain the following fields:
address.streetaddress.city
Example 14.4. Indexing associations
@Indexed
public class Place {
@Field
private String name;
@IndexedEmbedded
@ManyToOne(cascade = {CascadeType.PERSIST, CascadeType.REMOVE})
private Address address;
}
public class Address {
@Field
private String street;
@Field
private String city;
@ContainedIn
@OneToMany(mappedBy = "address")
private Set<Place> places;
}14.3.2. @IndexedEmbedded
@IndexedEmbedded technique, data is denormalized in the Lucene index. As a result, the Lucene-based Query API must be updated with any changes in the Place and Address objects to keep the index up to date. Ensure the Place Lucene document is updated when its Address changes by marking the other side of the bidirectional relationship with @ContainedIn. @ContainedIn can be used for both associations pointing to entities and on embedded objects.
@IndexedEmbedded annotation can be nested. Attributes can be annotated with @IndexedEmbedded. The attributes of the associated class are then added to the main entity index. In the following example, the index will contain the following fields:
- name
- address.street
- address.city
- address.ownedBy_name
Example 14.5. Nested usage of @IndexedEmbedded and @ContainedIn
@Indexed
public class Place {
@Field
private String name;
@IndexedEmbedded
@ManyToOne(cascade = {CascadeType.PERSIST, CascadeType.REMOVE})
private Address address;
}
public class Address {
@Field
private String street;
@Field
private String city;
@IndexedEmbedded(depth = 1, prefix = "ownedBy_")
private Owner ownedBy;
@ContainedIn
@OneToMany(mappedBy = "address")
private Set<Place> places;
}
public class Owner {
@Field
private String name;
}propertyName, following the traditional object navigation convention. This can be overridden using the prefix attribute as it is shown on the ownedBy property.
Note
depth property is used when the object graph contains a cyclic dependency of classes. For example, if Owner points to Place. the Query Module stops including attributes after reaching the expected depth, or object graph boundaries. A self-referential class is an example of cyclic dependency. In the provided example, because depth is set to 1, any @IndexedEmbedded attribute in Owner is ignored.
@IndexedEmbedded for object associations allows queries to be expressed using Lucene's query syntax. For example:
- Return places where name contains JBoss and where address city is Atlanta. In Lucene query this is:
+name:jboss +address.city:atlanta - Return places where name contains JBoss and where owner's name contain Joe. In Lucene query this is:
+name:jboss +address.ownedBy_name:joe
@Indexed. When @IndexedEmbedded points to an entity, the association must be directional and the other side must be annotated using @ContainedIn. If not, the Lucene-based Query API cannot update the root index when the associated entity is updated. In the provided example, a Place index document is updated when the associated Address instance updates.
14.3.3. The targetElement Property
targetElement parameter. This method can be used when the object type annotated by @IndexedEmbedded is not the object type targeted by the data grid and the Lucene-based Query API. This occurs when interfaces are used instead of their implementation.
Example 14.6. Using the targetElement property of @IndexedEmbedded
@Indexed
public class Address {
@Field
private String street;
@IndexedEmbedded(depth = 1, prefix = "ownedBy_", targetElement = Owner.class)
private Person ownedBy;
...
}
public class Owner implements Person { ... }14.4. Boosting
14.4.1. Static Index Time Boosting
@Boost annotation is used to define a static boost value for an indexed class or property. This annotation can be used within @Field, or can be specified directly on the method or class level.
- the probability of Essay reaching the top of the search list will be multiplied by 1.7.
@Field.boostand@Booston a property are cumulative, therefore the summary field will be 3.0 (2 x 1.5), and more important than the ISBN field.- The text field is 1.2 times more important than the ISBN field.
Example 14.7. Different ways of using @Boost
@Indexed
@Boost(1.7f)
public class Essay {
@Field(name = "Abstract", store=Store.YES, boost = @Boost(2f))
@Boost(1.5f)
public String getSummary() { return summary; }
@Field(boost = @Boost(1.2f))
public String getText() { return text; }
@Field
public String getISBN() { return isbn; }
}14.4.2. Dynamic Index Time Boosting
@Boost annotation defines a static boost factor that is independent of the state of the indexed entity at runtime. However, in some cases the boost factor may depend on the actual state of the entity. In this case, use the @DynamicBoost annotation together with an accompanying custom BoostStrategy.
@Boost and @DynamicBoost annotations can both be used in relation to an entity, and all defined boost factors are cumulative. The @DynamicBoost can be placed at either class or field level.
VIPBoostStrategy as implementation of the BoostStrategy interface used at indexing time. Depending on the annotation placement, either the whole entity is passed to the defineBoost method or only the annotated field/property value. The passed object must be cast to the correct type.
Example 14.8. Dynamic boost example
public enum PersonType {
NORMAL,
VIP
}
@Indexed
@DynamicBoost(impl = VIPBoostStrategy.class)
public class Person {
private PersonType type;
}
public class VIPBoostStrategy implements BoostStrategy {
public float defineBoost(Object value) {
Person person = (Person) value;
if (person.getType().equals(PersonType.VIP)) {
return 2.0f;
}
else {
return 1.0f;
}
}
}Note
BoostStrategy implementation must define a public no argument constructor.
14.5. Analysis
Analyzers to control this process.
14.5.1. Default Analyzer and Analyzer by Class
default.analyzer property. The default value for this property is org.apache.lucene.analysis.standard.StandardAnalyzer.
@Field, which is useful when multiple fields are indexed from a single property.
EntityAnalyzer is used to index all tokenized properties, such as name except, summary and body, which are indexed with PropertyAnalyzer and FieldAnalyzer respectively.
Example 14.9. Different ways of using @Analyzer
@Indexed
@Analyzer(impl = EntityAnalyzer.class)
public class MyEntity {
@Field
private String name;
@Field
@Analyzer(impl = PropertyAnalyzer.class)
private String summary;
@Field(analyzer = @Analyzer(impl = FieldAnalyzer.class))
private String body;
}Note
QueryParser. Use the same analyzer for indexing and querying on any field.
14.5.2. Named Analyzers
@Analyzer declarations and includes the following:
- a name: the unique string used to refer to the definition.
- a list of
CharFilters: eachCharFilteris responsible to pre-process input characters before the tokenization.CharFilterscan add, change, or remove characters. One common usage is for character normalization. - a
Tokenizer: responsible for tokenizing the input stream into individual words. - a list of filters: each filter is responsible to remove, modify, or sometimes add words into the stream provided by the
Tokenizer.
Analyzer separates these components into multiple tasks, allowing individual components to be reused and components to be built with flexibility using the following procedure:
Procedure 14.1. The Analyzer Process
- The
CharFiltersprocess the character input. Tokenizerconverts the character input into tokens.- The tokens are the processed by the
TokenFilters.
14.5.3. Analyzer Definitions
@Analyzer annotation.
Example 14.10. Referencing an analyzer by name
@Indexed
@AnalyzerDef(name = "customanalyzer")
public class Team {
@Field
private String name;
@Field
private String location;
@Field
@Analyzer(definition = "customanalyzer")
private String description;
}@AnalyzerDef are also available by their name in the SearchFactory, which is useful when building queries.
Analyzer analyzer = Search.getSearchManager(cache).getSearchFactory().getAnalyzer("customanalyzer")14.5.4. @AnalyzerDef for Solr
org.hibernate:hibernate-search-analyzers. Add the following dependency:
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-search-analyzers</artifactId>
<version>${version.hibernate.search}</version>
<dependency>CharFilter is defined by its factory. In this example, a mapping char filter is used, which will replace characters in the input based on the rules specified in the mapping file. Finally, a list of filters is defined by their factories. In this example, the StopFilter filter is built reading the dedicated words property file. The filter will ignore case.
Procedure 14.2. @AnalyzerDef and the Solr framework
Configure the CharFilter
Define aCharFilterby factory. In this example, a mappingCharFilteris used, which will replace characters in the input based on the rules specified in the mapping file.@AnalyzerDef(name = "customanalyzer", charFilters = { @CharFilterDef(factory = MappingCharFilterFactory.class, params = { @Parameter(name = "mapping", value = "org/hibernate/search/test/analyzer/solr/mapping-chars.properties") }) },Define the Tokenizer
ATokenizeris then defined using theStandardTokenizerFactory.class.@AnalyzerDef(name = "customanalyzer", charFilters = { @CharFilterDef(factory = MappingCharFilterFactory.class, params = { @Parameter(name = "mapping", value = "org/hibernate/search/test/analyzer/solr/mapping-chars.properties") }) }, tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class)List of Filters
Define a list of filters by their factories. In this example, theStopFilterfilter is built reading the dedicated words property file. The filter will ignore case.@AnalyzerDef(name = "customanalyzer", charFilters = { @CharFilterDef(factory = MappingCharFilterFactory.class, params = { @Parameter(name = "mapping", value = "org/hibernate/search/test/analyzer/solr/mapping-chars.properties") }) }, tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class), filters = { @TokenFilterDef(factory = ISOLatin1AccentFilterFactory.class), @TokenFilterDef(factory = LowerCaseFilterFactory.class), @TokenFilterDef(factory = StopFilterFactory.class, params = { @Parameter(name = "words", value= "org/hibernate/search/test/analyzer/solr/stoplist.properties" ), @Parameter(name = "ignoreCase", value = "true") }) }) public class Team { }
Note
CharFilters are applied in the order they are defined in the @AnalyzerDef annotation.
14.5.5. Loading Analyzer Resources
Tokenizers, TokenFilters, and CharFilters can load resources such as configuration or metadata files using the StopFilterFactory.class or the synonym filter. The virtual machine default can be explicitly specified by adding a resource_charset parameter.
Example 14.11. Use a specific charset to load the property file
@AnalyzerDef(name = "customanalyzer",
charFilters = {
@CharFilterDef(factory = MappingCharFilterFactory.class, params = {
@Parameter(name = "mapping",
value =
"org/hibernate/search/test/analyzer/solr/mapping-chars.properties")
})
},
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class),
filters = {
@TokenFilterDef(factory = ISOLatin1AccentFilterFactory.class),
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = StopFilterFactory.class, params = {
@Parameter(name="words",
value= "org/hibernate/search/test/analyzer/solr/stoplist.properties"),
@Parameter(name = "resource_charset", value = "UTF-16BE"),
@Parameter(name = "ignoreCase", value = "true")
})
})
public class Team {
}14.5.6. Dynamic Analyzer Selection
@AnalyzerDiscriminator annotation to enable the dynamic analyzer selection.
BlogEntry class, the analyzer can depend on the language property of the entry. Depending on this property, the correct language-specific stemmer can then be chosen to index the text.
Discriminator interface must return the name of an existing Analyzer definition, or null if the default analyzer is not overridden.
de' or 'en', which is specified in the @AnalyzerDefs.
Procedure 14.3. Configure the @AnalyzerDiscriminator
Predefine Dynamic Analyzers
The@AnalyzerDiscriminatorrequires that all analyzers that are to be used dynamically are predefined via@AnalyzerDef. The@AnalyzerDiscriminatorannotation can then be placed either on the class, or on a specific property of the entity, in order to dynamically select an analyzer. An implementation of theDiscriminatorinterface can be specified using the@AnalyzerDiscriminatorimplparameter.@Indexed @AnalyzerDefs({ @AnalyzerDef(name = "en", tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class), filters = { @TokenFilterDef(factory = LowerCaseFilterFactory.class), @TokenFilterDef(factory = EnglishPorterFilterFactory.class) }), @AnalyzerDef(name = "de", tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class), filters = { @TokenFilterDef(factory = LowerCaseFilterFactory.class), @TokenFilterDef(factory = GermanStemFilterFactory.class) }) }) public class BlogEntry { @Field @AnalyzerDiscriminator(impl = LanguageDiscriminator.class) private String language; @Field private String text; private Set<BlogEntry> references; // standard getter/setter }Implement the Discriminator Interface
Implement thegetAnalyzerDefinitionName()method, which is called for each field added to the Lucene document. The entity being indexed is also passed to the interface method.Thevalueparameter is set if the@AnalyzerDiscriminatoris placed on the property level instead of the class level. In this example, the value represents the current value of this property.public class LanguageDiscriminator implements Discriminator { public String getAnalyzerDefinitionName(Object value, Object entity, String field) { if (value == null || !(entity instanceof Article)) { return null; } return (String) value; } }
14.5.7. Retrieving an Analyzer
- Standard analyzer: used in the
titlefield. - Stemming analyzer: used in the
title_stemmedfield.
Example 14.12. Using the scoped analyzer when building a full-text query
SearchManager manager = Search.getSearchManager(cache);
org.apache.lucene.queryParser.QueryParser parser = new QueryParser(
org.apache.lucene.util.Version.LUCENE_36,
"title",
manager.getSearchFactory().getAnalyzer(Song.class)
);
org.apache.lucene.search.Query luceneQuery =
parser.parse("title:sky Or title_stemmed:diamond");
// wrap Lucene query in a org.infinispan.query.CacheQuery
CacheQuery cacheQuery = manager.getQuery(luceneQuery, Song.class);
List result = cacheQuery.list();
//return the list of matching objectsNote
@AnalyzerDef can also be retrieved by their definition name using searchFactory.getAnalyzer(String).
14.5.8. Available Analyzers
CharFilters, tokenizers, and filters. A complete list of CharFilter, tokenizer, and filter factories is available at http://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters. The following tables provide some example CharFilters, tokenizers, and filters.
| Factory | Description | Parameters | Additional dependencies |
|---|---|---|---|
MappingCharFilterFactory | Replaces one or more characters with one or more characters, based on mappings specified in the resource file | mapping: points to a resource file containing the mappings using the format:
| none |
HTMLStripCharFilterFactory | Remove HTML standard tags, keeping the text | none | none |
| Factory | Description | Parameters | Additional dependencies |
|---|---|---|---|
StandardTokenizerFactory | Use the Lucene StandardTokenizer | none | none |
HTMLStripCharFilterFactory | Remove HTML tags, keep the text and pass it to a StandardTokenizer. | none | solr-core |
PatternTokenizerFactory | Breaks text at the specified regular expression pattern. | pattern: the regular expression to use for tokenizing
group: says which pattern group to extract into tokens
| solr-core |
| Factory | Description | Parameters | Additional dependencies |
|---|---|---|---|
StandardFilterFactory | Remove dots from acronyms and 's from words | none | solr-core |
LowerCaseFilterFactory | Lowercases all words | none | solr-core |
StopFilterFactory | Remove words (tokens) matching a list of stop words | words: points to a resource file containing the stop words
ignoreCase: true if
case should be ignored when comparing stop words, false otherwise
| solr-core |
SnowballPorterFilterFactory | Reduces a word to it's root in a given language. (example: protect, protects, protection share the same root). Using such a filter allows searches matching related words. | language: Danish, Dutch, English, Finnish, French, German, Italian, Norwegian, Portuguese, Russian, Spanish, Swedish and a few more | solr-core |
ISOLatin1AccentFilterFactory | Remove accents for languages like French | none | solr-core |
PhoneticFilterFactory | Inserts phonetically similar tokens into the token stream | encoder: One of DoubleMetaphone, Metaphone, Soundex or RefinedSoundex
inject:
true will add tokens to the stream, false will replace the existing token
maxCodeLength: sets the maximum length of the code to be generated. Supported only for Metaphone and DoubleMetaphone encodings
| solr-core and commons-codec |
CollationKeyFilterFactory | Converts each token into its java.text.CollationKey, and then encodes the CollationKey with IndexableBinaryStringTools, to allow it to be stored as an index term. | custom, language, country, variant, strength, decompositionsee Lucene's CollationKeyFilter javadocs for more info | solr-core and commons-io |
org.apache.solr.analysis.TokenizerFactory and org.apache.solr.analysis.TokenFilterFactory are checked in your IDE to see available implementations.
14.6. Bridges
@Field are converted to strings to be indexed. Built-in bridges automatically translates properties for the Lucene-based Query API. The bridges can be customized to gain control over the translation process.
14.6.1. Built-in Bridges
- null
- Per default
nullelements are not indexed. Lucene does not support null elements. However, in some situation it can be useful to insert a custom token representing thenullvalue. See Section 14.1.2, “@Field” for more information. - java.lang.String
- Strings are indexed, as are:
short,Shortinteger,Integerlong,Longfloat,Floatdouble,DoubleBigIntegerBigDecimal
Numbers are converted into their string representation. Note that numbers cannot be compared by Lucene, or used in ranged queries out of the box, and must be paddedNote
Using a Range query has disadvantages. An alternative approach is to use a Filter query which will filter the result query to the appropriate range.The Query Module supports using a customStringBridge. See Section 14.6.2, “Custom Bridges”. - java.util.Date
- Dates are stored as yyyyMMddHHmmssSSS in GMT time (200611072203012 for Nov 7th of 2006 4:03PM and 12ms EST). When using a
TermRangeQuery, dates are expressed in GMT.@DateBridgedefines the appropriate resolution to store in the index, for example:@DateBridge(resolution=Resolution.DAY). The date pattern will then be truncated accordingly.@Indexed public class Meeting { @Field(analyze=Analyze.NO) @DateBridge(resolution=Resolution.MINUTE) private Date date;The defaultDatebridge uses Lucene'sDateToolsto convert from and toString. All dates are expressed in GMT time. Implement a custom date bridge in order to store dates in a fixed time zone. - java.net.URI, java.net.URL
- URI and URL are converted to their string representation
- java.lang.Class
- Class are converted to their fully qualified class name. The thread context classloader is used when the class is rehydrated
14.6.2. Custom Bridges
14.6.2.1. FieldBridge
FieldBridge. The FieldBridge interface provides a property value, which can then be mapped in the Lucene Document. For example, a property can be stored in two different document fields.
Example 14.13. Implementing the FieldBridge Interface
public class DateSplitBridge implements FieldBridge {
private final static TimeZone GMT = TimeZone.getTimeZone("GMT");
public void set(String name,
Object value,
Document document,
LuceneOptions luceneOptions) {
Date date = (Date) value;
Calendar cal = GregorianCalendar.getInstance(GMT);
cal.setTime(date);
int year = cal.get(Calendar.YEAR);
int month = cal.get(Calendar.MONTH) + 1;
int day = cal.get(Calendar.DAY_OF_MONTH);
// set year
luceneOptions.addFieldToDocument(
name + ".year",
String.valueOf(year),
document);
// set month and pad it if needed
luceneOptions.addFieldToDocument(
name + ".month",
month < 10 ? "0" : "" + String.valueOf(month),
document);
// set day and pad it if needed
luceneOptions.addFieldToDocument(
name + ".day",
day < 10 ? "0" : "" + String.valueOf(day),
document);
}
}
//property
@FieldBridge(impl = DateSplitBridge.class)
private Date date;Lucene Document. Instead the addition is delegated to the LuceneOptions helper. The helper will apply the options selected on @Field, such as Store or TermVector, or apply the chosen @Boost value.
LuceneOptions is delegated to add fields to the Document, however the Document can also be edited directly, ignoring the LuceneOptions.
Note
LuceneOptions shields the application from changes in Lucene API and simplifies the code.
14.6.2.2. StringBridge
org.infinispan.query.bridge.StringBridge interface to provide the Lucene-based Query API with an implementation of the expected Object to String bridge, or StringBridge. All implementations are used concurrently, and therefore must be thread-safe.
Example 14.14. Custom StringBridge implementation
/**
* Padding Integer bridge.
* All numbers will be padded with 0 to match 5 digits
*
* @author Emmanuel Bernard
*/
public class PaddedIntegerBridge implements StringBridge {
private int PADDING = 5;
public String objectToString(Object object) {
String rawInteger = ((Integer) object).toString();
if (rawInteger.length() > PADDING)
throw new IllegalArgumentException("Try to pad on a number too big");
StringBuilder paddedInteger = new StringBuilder();
for (int padIndex = rawInteger.length() ; padIndex < PADDING ; padIndex++) {
paddedInteger.append('0');
}
return paddedInteger.append(rawInteger).toString();
}
}@FieldBridge annotation allows any property or field in the provided example to use the bridge:
@FieldBridge(impl = PaddedIntegerBridge.class)
private Integer length;14.6.2.3. Two-Way Bridge
TwoWayStringBridge is an extended version of a StringBridge, which can be used when the bridge implementation is used on an ID property. The Lucene-based Query API reads the string representation of the identifier and uses it to generate an object. The @FieldBridge annotation is used in the same way.
Example 14.15. Implementing a TwoWayStringBridge for ID Properties
public class PaddedIntegerBridge implements TwoWayStringBridge, ParameterizedBridge {
public static String PADDING_PROPERTY = "padding";
private int padding = 5; //default
public void setParameterValues(Map parameters) {
Object padding = parameters.get(PADDING_PROPERTY);
if (padding != null) this.padding = (Integer) padding;
}
public String objectToString(Object object) {
String rawInteger = ((Integer) object).toString();
if (rawInteger.length() > padding)
throw new IllegalArgumentException("Try to pad on a number too big");
StringBuilder paddedInteger = new StringBuilder();
for (int padIndex = rawInteger.length(); padIndex < padding; padIndex++) {
paddedInteger.append('0');
}
return paddedInteger.append(rawInteger).toString();
}
public Object stringToObject(String stringValue) {
return new Integer(stringValue);
}
}
@FieldBridge(impl = PaddedIntegerBridge.class,
params = @Parameter(name = "padding", value = "10"))
private Integer id;Important
14.6.2.4. Parameterized Bridge
ParameterizedBridge interface passes parameters to the bridge implementation, making it more flexible. The ParameterizedBridge interface can be implemented by StringBridge, TwoWayStringBridge, FieldBridge implementations. All implementations must be thread-safe.
ParameterizedBridge interface, with parameters passed through the @FieldBridge annotation.
Example 14.16. Configure the ParameterizedBridge Interface
public class PaddedIntegerBridge implements StringBridge, ParameterizedBridge {
public static String PADDING_PROPERTY = "padding";
private int padding = 5; //default
public void setParameterValues(Map <String,String> parameters) {
String padding = parameters.get(PADDING_PROPERTY);
if (padding != null) this.padding = Integer.parseInt(padding);
}
public String objectToString(Object object) {
String rawInteger = ((Integer) object).toString();
if (rawInteger.length() > padding)
throw new IllegalArgumentException("Try to pad on a number too big");
StringBuilder paddedInteger = new StringBuilder();
for (int padIndex = rawInteger.length() ; padIndex < padding ; padIndex++) {
paddedInteger.append('0');
}
return paddedInteger.append(rawInteger).toString();
}
}
//property
@FieldBridge(impl = PaddedIntegerBridge.class,
params = @Parameter(name = "padding", value = "10")
)
private Integer length;14.6.2.5. Type Aware Bridge
AppliedOnTypeAwareBridge will get the type the bridge is applied on injected. For example:
- the return type of the property for field/getter-level bridges.
- the class type for class-level bridges.
14.6.2.6. ClassBridge
@ClassBridge annotation. @ClassBridge can be defined at class level, and supports the termVector attribute.
FieldBridge implementation receives the entity instance as the value parameter, rather than a particular property. The particular CatFieldsClassBridge is applied to the department instance.The FieldBridge then concatenates both branch and network, and indexes the concatenation.
Example 14.17. Implementing a ClassBridge
@Indexed
@ClassBridge(name = "branchnetwork",
store = Store.YES,
impl = CatFieldsClassBridge.class,
params = @Parameter(name = "sepChar", value = ""))
public class Department {
private int id;
private String network;
private String branchHead;
private String branch;
private Integer maxEmployees;
}
public class CatFieldsClassBridge implements FieldBridge, ParameterizedBridge {
private String sepChar;
public void setParameterValues(Map parameters) {
this.sepChar = (String) parameters.get("sepChar");
}
public void set(String name,
Object value,
Document document,
LuceneOptions luceneOptions) {
Department dep = (Department) value;
String fieldValue1 = dep.getBranch();
if (fieldValue1 == null) {
fieldValue1 = "";
}
String fieldValue2 = dep.getNetwork();
if (fieldValue2 == null) {
fieldValue2 = "";
}
String fieldValue = fieldValue1 + sepChar + fieldValue2;
Field field = new Field(name, fieldValue, luceneOptions.getStore(),
luceneOptions.getIndex(), luceneOptions.getTermVector());
field.setBoost(luceneOptions.getBoost());
document.add(field);
}
}Chapter 15. Querying
Procedure 15.1. Prepare and Execute a Query
- Get
SearchManagerof an indexing enabled cache as follows:SearchManager manager = Search.getSearchManager(cache); - Create a
QueryBuilderto build queries forMyth.classas follows:final org.hibernate.search.query.dsl.QueryBuilder queryBuilder = manager.buildQueryBuilderForClass(Myth.class).get(); - Create an Apache Lucene query that queries the
Myth.classclass' atributes as follows:org.apache.lucene.search.Query query = queryBuilder.keyword() .onField("history").boostedTo(3) .matching("storm") .createQuery(); // wrap Lucene query in a org.infinispan.query.CacheQuery CacheQuery cacheQuery = manager.getQuery(query); // Get query result List<Object> result = cacheQuery.list();
15.1. Building Queries
15.1.1. Building a Lucene Query Using the Lucene-based Query API
15.1.2. Building a Lucene Query
QueryBuilder for this task.
- Method names are in English. As a result, API operations can be read and understood as a series of English phrases and instructions.
- It uses IDE autocompletion which helps possible completions for the current input prefix and allows the user to choose the right option.
- It often uses the chaining method pattern.
- It is easy to use and read the API operations.
QueryBuilder knows what analyzer to use and what field bridge to apply. Several QueryBuilders (one for each type involved in the root of your query) can be created. The QueryBuilder is derived from the SearchFactory.
Search.getSearchManager(cache).buildQueryBuilderForClass(Myth.class).get();SearchFactory searchFactory = Search.getSearchManager(cache).getSearchFactory();
QueryBuilder mythQB = searchFactory.buildQueryBuilder()
.forEntity(Myth.class)
.overridesForField("history","stem_analyzer_definition")
.get();15.1.2.1. Keyword Queries
Example 15.1. Keyword Search
Query luceneQuery = mythQB.keyword().onField("history").matching("storm").createQuery();| Parameter | Description |
|---|---|
| keyword() | Use this parameter to find a specific word |
| onField() | Use this parameter to specify in which lucene field to search the word |
| matching() | use this parameter to specify the match for search string |
| createQuery() | creates the Lucene query object |
- The value "storm" is passed through the
historyFieldBridge. This is useful when numbers or dates are involved. - The field bridge value is then passed to the analyzer used to index the field
history. This ensures that the query uses the same term transformation than the indexing (lower case, ngram, stemming and so on). If the analyzing process generates several terms for a given word, a boolean query is used with theSHOULDlogic (roughly anORlogic).
@Indexed
public class Myth {
@Field(analyze = Analyze.NO)
@DateBridge(resolution = Resolution.YEAR)
public Date getCreationDate() { return creationDate; }
public Date setCreationDate(Date creationDate) { this.creationDate = creationDate; }
private Date creationDate;
}
Date birthdate = ...;
Query luceneQuery = mythQb.keyword()
.onField("creationDate")
.matching(birthdate)
.createQuery();Note
Date object had to be converted to its string representation (in this case the year)
FieldBridge has an objectToString method (and all built-in FieldBridge implementations do).
Example 15.2. Searching Using Ngram Analyzers
@AnalyzerDef(name = "ngram",
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class),
filters = {
@TokenFilterDef(factory = StandardFilterFactory.class),
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = StopFilterFactory.class),
@TokenFilterDef(factory = NGramFilterFactory.class,
params = {
@Parameter(name = "minGramSize", value = "3"),
@Parameter(name = "maxGramSize", value = "3")})
})
public class Myth {
@Field(analyzer = @Analyzer(definition = "ngram"))
public String getName() { return name; }
public String setName(String name) { this.name = name; }
private String name;
}
Date birthdate = ...;
Query luceneQuery = mythQb.keyword()
.onField("name")
.matching("Sisiphus")
.createQuery();y). All that is transparently done for the user.
Note
ignoreAnalyzer() or ignoreFieldBridge() functions can be called.
Example 15.3. Searching for Multiple Words
//search document with storm or lightning in their history
Query luceneQuery =
mythQB.keyword().onField("history").matching("storm lightning").createQuery();onFields method.
Example 15.4. Searching Multiple Fields
Query luceneQuery = mythQB
.keyword()
.onFields("history","description","name")
.matching("storm")
.createQuery();andField() method.
Example 15.5. Using the andField Method
Query luceneQuery = mythQB.keyword()
.onField("history")
.andField("name")
.boostedTo(5)
.andField("description")
.matching("storm")
.createQuery();15.1.2.2. Fuzzy Queries
keyword query and add the fuzzy flag.
Example 15.6. Fuzzy Query
Query luceneQuery = mythQB.keyword()
.fuzzy()
.withThreshold(.8f)
.withPrefixLength(1)
.onField("history")
.matching("starm")
.createQuery();threshold is the limit above which two terms are considering matching. It is a decimal between 0 and 1 and the default value is 0.5. The prefixLength is the length of the prefix ignored by the "fuzzyness". While the default value is 0, a non zero value is recommended for indexes containing a huge amount of distinct terms.
15.1.2.3. Wildcard Queries
? represents a single character and * represents any character sequence. Note that for performance purposes, it is recommended that the query does not start with either ? or *.
Example 15.7. Wildcard Query
Query luceneQuery = mythQB.keyword()
.wildcard()
.onField("history")
.matching("sto*")
.createQuery();Note
* or ? being mangled is too high.
15.1.2.4. Phrase Queries
phrase() to do so.
Example 15.8. Phrase Query
Query luceneQuery = mythQB.phrase()
.onField("history")
.sentence("Thou shalt not kill")
.createQuery();Example 15.9. Adding Slop Factor
Query luceneQuery = mythQB.phrase()
.withSlop(3)
.onField("history")
.sentence("Thou kill")
.createQuery();15.1.2.5. Range Queries
Example 15.10. Range Query
//look for 0 <= starred < 3
Query luceneQuery = mythQB.range()
.onField("starred")
.from(0).to(3).excludeLimit()
.createQuery();
//look for myths strictly BC
Date beforeChrist = ...;
Query luceneQuery = mythQB.range()
.onField("creationDate")
.below(beforeChrist).excludeLimit()
.createQuery();15.1.2.6. Combining Queries
SHOULD: the query should contain the matching elements of the subquery.MUST: the query must contain the matching elements of the subquery.MUST NOT: the query must not contain the matching elements of the subquery.
Example 15.11. Combining Subqueries
//look for popular modern myths that are not urban
Date twentiethCentury = ...;
Query luceneQuery = mythQB.bool()
.must(mythQB.keyword().onField("description").matching("urban").createQuery())
.not()
.must(mythQB.range().onField("starred").above(4).createQuery())
.must(mythQB.range()
.onField("creationDate")
.above(twentiethCentury)
.createQuery())
.createQuery();
//look for popular myths that are preferably urban
Query luceneQuery = mythQB
.bool()
.should(mythQB.keyword()
.onField("description")
.matching("urban")
.createQuery())
.must(mythQB.range().onField("starred").above(4).createQuery())
.createQuery();
//look for all myths except religious ones
Query luceneQuery = mythQB.all()
.except(mythQb.keyword()
.onField("description_stem")
.matching("religion")
.createQuery())
.createQuery();15.1.2.7. Query Options
boostedTo(on query type and on field) boosts the query or field to a provided factor.withConstantScore(on query) returns all results that match the query and have a constant score equal to the boost.filteredBy(Filter)(on query) filters query results using theFilterinstance.ignoreAnalyzer(on field) ignores the analyzer when processing this field.ignoreFieldBridge(on field) ignores the field bridge when processing this field.
Example 15.12. Querying Options
Query luceneQuery = mythQB
.bool()
.should(mythQB.keyword().onField("description").matching("urban").createQuery())
.should(mythQB
.keyword()
.onField("name")
.boostedTo(3)
.ignoreAnalyzer()
.matching("urban").createQuery())
.must(mythQB
.range()
.boostedTo(5)
.withConstantScore()
.onField("starred")
.above(4).createQuery())
.createQuery();
15.1.3. Build a Query with Infinispan Query
15.1.3.1. Generality
Example 15.13. Wrapping a Lucene Query in an Infinispan CacheQuery
CacheQuery cacheQuery = Search.getSearchManager(cache).getQuery(luceneQuery);Example 15.14. Filtering the Search Result by Entity Type
CacheQuery cacheQuery =
Search.getSearchManager(cache).getQuery(luceneQuery, Customer.class);
// or
CacheQuery cacheQuery =
Search.getSearchManager(cache).getQuery(luceneQuery, Item.class, Actor.class);Customer instances. The second part of the same example returns matching Actor and Item instances. The type restriction is polymorphic. As a result, if the two subclasses Salesman and Customer of the base class Person return, specify Person.class to filter based on result types.
15.1.3.2. Pagination
Example 15.15. Defining pagination for a search query
CacheQuery cacheQuery = Search.getSearchManager(cache)
.getQuery(luceneQuery, Customer.class);
cacheQuery.firstResult(15); //start from the 15th element
cacheQuery.maxResults(10); //return 10 elementsNote
cacheQuery.getResultSize().
15.1.3.3. Sorting
Example 15.16. Specifying a Lucene Sort
org.infinispan.query.CacheQuery cacheQuery = Search.getSearchManager(cache).getQuery(luceneQuery, Book.class);
org.apache.lucene.search.Sort sort = new Sort(
new SortField("title", SortField.STRING));
cacheQuery.sort(sort);
List results = cacheQuery.list();Note
15.1.3.4. Projection
Example 15.17. Using Projection Instead of Returning the Full Domain Object
SearchManager searchManager = Search.getSearchManager(cache);
CacheQuery cacheQuery = searchManager.getQuery(luceneQuery, Book.class);
cacheQuery.projection("id", "summary", "body", "mainAuthor.name");
List results = cacheQuery.list();
Object[] firstResult = (Object[]) results.get(0);
Integer id = (Integer) firstResult[0];
String summary = (String) firstResult[1];
String body = (String) firstResult[2];
String authorName = (String) firstResult[3];Object[]. Projections prevent a time consuming database round-trip. However, they have following constraints:
- The properties projected must be stored in the index (
@Field(store=Store.YES)), which increases the index size. - The properties projected must use a
FieldBridgeimplementingorg.infinispan.query.bridge.TwoWayFieldBridgeororg.infinispan.query.bridge.TwoWayStringBridge, the latter being the simpler version.Note
All Lucene-based Query API built-in types are two-way. - Only the simple properties of the indexed entity or its embedded associations can be projected. Therefore a whole embedded entity cannot be projected.
- Projection does not work on collections or maps which are indexed via
@IndexedEmbedded
Example 15.18. Using Projection to Retrieve Metadata
SearchManager searchManager = Search.getSearchManager(cache);
CacheQuery cacheQuery = searchManager.getQuery(luceneQuery, Book.class);
cacheQuery.projection("mainAuthor.name");
List results = cacheQuery.list();
Object[] firstResult = (Object[]) results.get(0);
float score = (Float) firstResult[0];
Book book = (Book) firstResult[1];
String authorName = (String) firstResult[2];FullTextQuery.THISreturns the initialized and managed entity as a non-projected query does.FullTextQuery.DOCUMENTreturns the Lucene Document related to the projected object.FullTextQuery.OBJECT_CLASSreturns the indexed entity's class.FullTextQuery.SCOREreturns the document score in the query. Use scores to compare one result against another for a given query. However, scores are not relevant to compare the results of two different queries.FullTextQuery.IDis the ID property value of the projected object.FullTextQuery.DOCUMENT_IDis the Lucene document ID. The Lucene document ID changes between two IndexReader openings.FullTextQuery.EXPLANATIONreturns the Lucene Explanation object for the matching object/document in the query. This is not suitable for retrieving large amounts of data. RunningFullTextQuery.EXPLANATIONis as expensive as running a Lucene query for each matching element. As a result, projection is recommended.
15.1.3.5. Limiting the Time of a Query
- Raise an exception when arriving at the limit.
- Limit to the number of results retrieved when the time limit is raised.
15.1.3.6. Raise an Exception on Time Limit
Example 15.19. Defining a Timeout in Query Execution
SearchManagerImplementor searchManager = (SearchManagerImplementor) Search.getSearchManager(cache);
searchManager.setTimeoutExceptionFactory(new MyTimeoutExceptionFactory());
CacheQuery cacheQuery = searchManager.getQuery(luceneQuery, Book.class);
//define the timeout in seconds
cacheQuery.timeout(2, TimeUnit.SECONDS)
try {
query.list();
}
catch (MyTimeoutException e) {
//do something, too slow
}
private static class MyTimeoutExceptionFactory implements TimeoutExceptionFactory {
@Override
public RuntimeException createTimeoutException(String message, Query query) {
return new MyTimeoutException();
}
}
public static class MyTimeoutException extends RuntimeException {
}getResultSize(), iterate() and scroll() honor the timeout until the end of the method call. As a result, Iterable or the ScrollableResults ignore the timeout. Additionally, explain() does not honor this timeout period. This method is used for debugging and to check the reasons for slow performance of a query.
Important
15.2. Retrieving the Results
list().
15.2.1. Performance Considerations
list() can be used to receive a reasonable number of results (for example when using pagination) and to work on them all. list() works best if the batch-size entity is correctly set up. If list() is used, the Query Module processes all Lucene Hits elements within the pagination.
15.2.2. Result Size
Example 15.20. Determining the Result Size of a Query
CacheQuery cacheQuery = Search.getSearchManager(cache).getQuery(luceneQuery,
Book.class);
//return the number of matching books without loading a single one
assert 3245 == query.getResultSize();
CacheQuery cacheQueryLimited =
Search.getSearchManager(cache).getQuery(luceneQuery, Book.class);
query.maxResults(10);
List results = query.list();
assert 10 == results.size()
//return the total number of matching books regardless of pagination
assert 3245 == query.getResultSize();15.2.3. Understanding Results
Explanation object for a given result (in a given query). This is an advanced class. Access the Explanation object as follows:
cacheQuery.explain(int) method
This method requires a document ID as a parameter and returns the Explanation object.
Note
15.3. Filters
- security
- temporal data (example, view only last month's data)
- population filter (example, search limited to a given category)
- and many more
15.3.1. Defining and Implementing a Filter
Example 15.21. Enabling Fulltext Filters for a Query
cacheQuery = Search.getSearchManager(cache).getQuery(query, Driver.class);
cacheQuery.enableFullTextFilter("bestDriver");
cacheQuery.enableFullTextFilter("security").setParameter("login", "andre");
cacheQuery.list(); //returns only best drivers where andre has credentials@FullTextFilterDef annotation. This annotation applies to @Indexed entities irrespective of the filter's query. Filter definitions are global therefore each filter must have a unique name. If two @FullTextFilterDef annotations with the same name are defined, a SearchException is thrown. Each named filter must specify its filter implementation.
Example 15.22. Defining and Implementing a Filter
@FullTextFilterDefs({
@FullTextFilterDef(name = "bestDriver", impl = BestDriversFilter.class),
@FullTextFilterDef(name = "security", impl = SecurityFilterFactory.class)
})
public class Driver { ... }public class BestDriversFilter extends org.apache.lucene.search.Filter {
public DocIdSet getDocIdSet(IndexReader reader) throws IOException {
OpenBitSet bitSet = new OpenBitSet(reader.maxDoc());
TermDocs termDocs = reader.termDocs(new Term("score", "5"));
while (termDocs.next()) {
bitSet.set(termDocs.doc());
}
return bitSet;
}
}BestDriversFilter is a Lucene filter that reduces the result set to drivers where the score is 5. In the example, the filter implements the org.apache.lucene.search.Filter directly and contains a no-arg constructor.
15.3.2. The @Factory Filter
Example 15.23. Creating a filter using the factory pattern
@FullTextFilterDef(name = "bestDriver", impl = BestDriversFilterFactory.class)
public class Driver { ... }
public class BestDriversFilterFactory {
@Factory
public Filter getFilter() {
//some additional steps to cache the filter results per IndexReader
Filter bestDriversFilter = new BestDriversFilter();
return new CachingWrapperFilter(bestDriversFilter);
}
}@Factory annotated method to build the filter instance. The factory must have a no argument constructor.
Example 15.24. Passing parameters to a defined filter
cacheQuery = Search.getSearchManager(cache).getQuery(query, Driver.class);
cacheQuery.enableFullTextFilter("security").setParameter("level", 5);Example 15.25. Using parameters in the actual filter implementation
public class SecurityFilterFactory {
private Integer level;
/**
* injected parameter
*/
public void setLevel(Integer level) {
this.level = level;
}
@Key
public FilterKey getKey() {
StandardFilterKey key = new StandardFilterKey();
key.addParameter(level);
return key;
}
@Factory
public Filter getFilter() {
Query query = new TermQuery(new Term("level", level.toString()));
return new CachingWrapperFilter(new QueryWrapperFilter(query));
}
}@Key returns a FilterKey object. The returned object has a special contract: the key object must implement equals() / hashCode() so that two keys are equal if and only if the given Filter types are the same and the set of parameters are the same. In other words, two filter keys are equal if and only if the filters from which the keys are generated can be interchanged. The key object is used as a key in the cache mechanism.
15.3.3. Key Objects
@Key methods are needed only if:
- the filter caching system is enabled (enabled by default)
- the filter has parameters
StandardFilterKey delegates the equals() / hashCode() implementation to each of the parameters equals and hashcode methods.
SoftReferences when needed. Once the limit of the hard reference cache is reached additional filters are cached as SoftReferences. To adjust the size of the hard reference cache, use default.filter.cache_strategy.size (defaults to 128). For advanced use of filter caching, you can implement your own FilterCachingStrategy. The classname is defined by default.filter.cache_strategy.
IndexReader around a CachingWrapperFilter. The wrapper will cache the DocIdSet returned from the getDocIdSet(IndexReader reader) method to avoid expensive recomputation. It is important to mention that the computed DocIdSet is only cachable for the same IndexReader instance, because the reader effectively represents the state of the index at the moment it was opened. The document list cannot change within an opened IndexReader. A different/newIndexReader instance, however, works potentially on a different set of Documents (either from a different index or simply because the index has changed), hence the cached DocIdSet has to be recomputed.
15.3.4. Full Text Filter
cache flag of @FullTextFilterDef, set to FilterCacheModeType.INSTANCE_AND_DOCIDSETRESULTS which automatically caches the filter instance and wraps the filter around a Hibernate specific implementation of CachingWrapperFilter. Unlike Lucene's version of this class, SoftReferences are used with a hard reference count (see discussion about filter cache). The hard reference count is adjusted using default.filter.cache_docidresults.size (defaults to 5). Wrapping is controlled using the @FullTextFilterDef.cache parameter. There are three different values for this parameter:
| Value | Definition |
|---|---|
| FilterCacheModeType.NONE | No filter instance and no result is cached by the Query Module. For every filter call, a new filter instance is created. This setting addresses rapidly changing data sets or heavily memory constrained environments. |
| FilterCacheModeType.INSTANCE_ONLY | The filter instance is cached and reused across concurrent Filter.getDocIdSet() calls. DocIdSet results are not cached. This setting is useful when a filter uses its own specific caching mechanism or the filter results change dynamically due to application specific events making DocIdSet caching in both cases unnecessary. |
| FilterCacheModeType.INSTANCE_AND_DOCIDSETRESULTS | Both the filter instance and the DocIdSet results are cached. This is the default value. |
- The system does not update the targeted entity index often (in other words, the IndexReader is reused a lot).
- The Filter's DocIdSet is expensive to compute (compared to the time spent to execute the query).
15.3.5. Using Filters in a Sharded Environment
- Create a sharding strategy to select a subset of
IndexManagers depending on filter configurations. - Activate the filter when running the query.
Example 15.26. Querying a Specific Shard
public class CustomerShardingStrategy implements IndexShardingStrategy {
// stored IndexManagers in a array indexed by customerID
private IndexManager[] indexManagers;
public void initialize(Properties properties, IndexManager[] indexManagers) {
this.indexManagers = indexManagers;
}
public IndexManager[] getIndexManagersForAllShards() {
return indexManagers;
}
public IndexManager getIndexManagerForAddition(
Class<?> entity, Serializable id, String idInString, Document document) {
Integer customerID = Integer.parseInt(document.getFieldable("customerID")
.stringValue());
return indexManagers[customerID];
}
public IndexManager[] getIndexManagersForDeletion(
Class<?> entity, Serializable id, String idInString) {
return getIndexManagersForAllShards();
}
/**
* Optimization; don't search ALL shards and union the results; in this case, we
* can be certain that all the data for a particular customer Filter is in a single
* shard; return that shard by customerID.
*/
public IndexManager[] getIndexManagersForQuery(
FullTextFilterImplementor[] filters) {
FullTextFilter filter = getCustomerFilter(filters, "customer");
if (filter == null) {
return getIndexManagersForAllShards();
}
else {
return new IndexManager[] { indexManagers[Integer.parseInt(
filter.getParameter("customerID").toString())] };
}
}
private FullTextFilter getCustomerFilter(FullTextFilterImplementor[] filters,
String name) {
for (FullTextFilterImplementor filter: filters) {
if (filter.getName().equals(name)) return filter;
}
return null;
}
}customer filter is present in the example, the query only uses the shard dedicated to the customer. The query returns all shards if the customer filter is not found. The sharding strategy reacts to each filter depending on the provided parameters.
ShardSensitiveOnlyFilter class to declare the filter.
Example 15.27. Using the ShardSensitiveOnlyFilter Class
@Indexed
@FullTextFilterDef(name = "customer", impl = ShardSensitiveOnlyFilter.class)
public class Customer {
...
}
CacheQuery cacheQuery = Search.getSearchManager(cache).getQuery(query,
Customer.class);
cacheQuery.enableFullTextFilter("customer").setParameter("CustomerID", 5);
@SuppressWarnings("unchecked")
List results = cacheQuery.list();ShardSensitiveOnlyFilter filter is used, Lucene filters do not need to be implemented. Use filters and sharding strategies reacting to these filters for faster query execution in a sharded environment.
15.4. Continuous Queries
- Return all persons with an age between 18 and 25 (assuming the
Personentity has an age property and is updated by the user application). - Return all transactions higher than $2000.
- Return all times where the lap speed of F1 racers were less than 1:45.00s (assuming the cache contains
Lapentries and that laps are entered live during the race).
15.4.1. Continuous Query Evaluation
- An entry starts matching the specified query, represented by a
Joinevent. - An entry stops matching the specified query, represented by a
Leaveevent.
Join events as described above. In addition, it will receive subsequent notifications when other entries begin matching the query, as Join events, or stop matching the query, as Leave events, as a consequence of any cache operations that would normally generate creation, modification, removal, or expiration events.
Join or Leave event the following logic is used:
- If the query on both the old and new values evaluate false, then the event is suppressed.
- If the query on both the old and new values evaluate true, then the event is suppressed.
- If the query on the old value evaluates false and the query on the new value evaluates true, then a
Joinevent is sent. - If the query on the old value evaluates true and the query on the new value evaluates false, then a
Leaveevent is sent. - If the query on the old value evaluates true and the entry is removed, then a
Leaveevent is sent.
Note
15.4.2. Using Continuous Queries
To create a Continuous Query the Query object will be created similar to other querying methods; however, ensure that the Query is registered with a org.infinispan.query.api.continuous.ContinuousQuery and a org.infinispan.query.api.continuous.ContinuousQueryListener is in use.
ContinuousQuery object associated to a cache can be obtained by calling the static method org.infinispan.client.hotrod.Search.getContinuousQuery(RemoteCache<K, V> cache) if running in Client-Server mode or org.infinispan.query.Search.getContinuousQuery(Cache<K, V> cache) when running in Library mode.
ContinuousQueryListener has been defined it may be added by using the addContinuousQueryListener method of ContinuousQuery:
continuousQuery.addContinuousQueryListener(query, listener)Example 15.28. Defining and Adding a Continuous Query
import org.infinispan.query.api.continuous.ContinuousQuery;
import org.infinispan.query.api.continuous.ContinuousQueryListener;
import org.infinispan.query.Search;
import org.infinispan.query.dsl.QueryFactory;
import org.infinispan.query.dsl.Query;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
[...]
// To begin we create a ContinuousQuery instance on the cache
ContinuousQuery<Integer, Person> continuousQuery = Search.getContinuousQuery(cache);
// Define our query. In this case we will be looking for any
// Person instances under 21 years of age.
QueryFactory queryFactory = Search.getQueryFactory(cache);
Query query = queryFactory.from(Person.class)
.having("age").lt(21)
.toBuilder().build();
final Map<Integer, Person> matches = new ConcurrentHashMap<Integer, Person>();
// Define the ContinuousQueryListener
ContinuousQueryListener<Integer, Person> listener = new ContinuousQueryListener<Integer, Person>() {
@Override
public void resultJoining(Integer key, Person value) {
matches.put(key, value);
}
@Override
public void resultLeaving(Integer key) {
matches.remove(key);
}
};
// Add the listener and generated query
continuousQuery.addContinuousQueryListener(query, listener);
[...]
// Remove the listener to stop receiving notifications
continuousQuery.removeContinuousQueryListener(listener);Person instances are added to the cache that contain an Age less than 21 they will be placed into matches, and when these entries are removed from the cache they will be also be removed from matches.
To stop the query from further execution remove the listener:
continuousQuery.removeContinuousQueryListener(listener);15.4.3. Performance Considerations with Continuous Queries
ContinuousQueryListener is designed to quickly process all received events.
Chapter 16. The Infinispan Query DSL
16.1. Creating Queries with Infinispan Query DSL
QueryFactory instance, which is obtained using Search.getQueryFactory(). Each QueryFactory instance is bound to the one cache instance, and is a stateless and thread-safe object that can be used for creating multiple parallel queries.
- A query is created by invocating the
from(Class entityType)method, which returns aQueryBuilderobject that is responsible for creating queries for the specified entity class from the given cache. - The
QueryBuilderaccumulates search criteria and configuration specified through invoking its DSL methods, and is used to build aQueryobject by invoking theQueryBuilder.build()method, which completes the construction. TheQueryBuilderobject cannot be used for constructing multiple queries at the same time except for nested queries, however it can be reused afterwards. - Invoke the
list()method of theQueryobject to execute the query and fetch the results. Once executed, theQueryobject is not reusable. If new results must be fetched, a new instance must be obtained by callingQueryBuilder.build().
Important
16.2. Enabling Infinispan Query DSL-based Queries
- All libraries required for Infinispan Query on the classpath. Refer to the Administration and Configuration Guide for details.
- Indexing enabled and configured for caches (optional). Refer to the Administration and Configuration Guide for details.
- Annotated POJO cache values (optional). If indexing is not enabled, POJO annotations are also not required and are ignored if set. If indexing is not enabled, all fields that follow JavaBeans conventions are searchable instead of only the fields with Hibernate Search annotations.
16.3. Running Infinispan Query DSL-based Queries
QueryFactory from the Search in order to run a DSL-based query.
In Library mode, obtain a QueryFactory as follows:
QueryFactory qf = org.infinispan.query.Search.getQueryFactory(cache)Example 16.1. Constructing a DSL-based Query
import org.infinispan.query.Search;
import org.infinispan.query.dsl.QueryFactory;
import org.infinispan.query.dsl.Query;
QueryFactory qf = Search.getQueryFactory(cache);
Query q = qf.from(User.class)
.having("name").eq("John")
.toBuilder().build();
List list = q.list();
assertEquals(1, list.size());
assertEquals("John", list.get(0).getName());
assertEquals("Doe", list.get(0).getSurname());Search object resides in package org.infinispan.client.hotrod. See the example in Section 17.2, “Performing Remote Queries via the Hot Rod Java Client” for details.
Example 16.2. Combining Multiple Conditions
Query q = qf.from(User.class)
.having("name").eq("John")
.and().having("surname").eq("Doe")
.and().not(qf.having("address.street").like("%Tanzania%")
.or().having("address.postCode").in("TZ13", "TZ22"))
.toBuilder().build();Book entity.
Example 16.3. Querying the Book Entity
import org.infinispan.query.Search;
import org.infinispan.query.dsl.*;
// get the DSL query factory, to be used for constructing the Query object:
QueryFactory qf = Search.getQueryFactory(cache);
// create a query for all the books that have a title which contains the word "engine":
Query query = qf.from(Book.class)
.having("title").like("%engine%")
.toBuilder().build();
// get the results
List<Book> list = query.list();16.4. Projection Queries
Query.list() will not return the whole domain entity (List<Object>), but instead will return a List<Object[]>, with each entry in the array corresponding to a projected attribute.
select(...) method when building the query, as seen in the following example:
Example 16.4. Retrieving title and publication year
// Match all books that have the word "engine" in their title or description
// and return only their title and publication year.
Query query = queryFactory.from(Book.class)
.select(Expression.property("title"), Expression.property("publicationYear"))
.having("title").like("%engine%")
.or().having("description").like("%engine%")
.toBuilder()
.build();
// results.get(0)[0] contains the first matching entry's title
// results.get(0)[1] contains the first matching entry's publication year
List<Object[]> results = query.list();16.5. Grouping and Aggregation Operations
groupBy(field) multiple times. The order of grouping fields is not relevant.
Example 16.5. Grouping Books by author and counting them
Query query = queryFactory.from(Book.class)
.select(Expression.property("author"), Expression.count("title"))
.having("title").like("%engine%")
.groupBy("author")
.toBuilder()
.build();
// results.get(0)[0] will contain the first matching entry's author
// results.get(0)[1] will contain the first matching entry's title
List<Object[]> results = query.list();The following aggregation operations may be performed on a given field:
avg()- Computes the average of a set ofNumbers, represented as aDouble. If there are no non-null values the result is null instead.count()- Returns the number of non-null rows as aLong. If there are no non-null values the result is 0 instead.max()- Returns the greatest value found in the specified field, with a return type equal to the field in which it was applied. If there are no non-null values the result is null instead.Note
Values in the given field must be of typeComparable, otherwise anIllegalStateExceptionwill be thrown.min()- Returns the smallest value found in the specified field, with a return type equal to the field in which it was applied. If there are no non-null values the result is null instead.Note
Values in the given field must be of typeComparable, otherwise anIllegalStateExceptionwill be thrown.sum()- Computes and returns the sum of a set ofNumbers, with a return type dependent on the indicated field's type. If there are no non-null values the result is null instead.The following table indicates the return type based on the specified field.Expand Table 16.1. Sum Return Type Field Type Return Type Integral (other than BigInteger)LongFloating Point DoubleBigIntegerBigIntegerBigDecimalBigDecimal
The following cases items describe special use cases with projection queries:
- A projection query in which all selected fields are aggregated and none is used for grouping is legal. In this case the aggregations will be computed globally instead of being computed per each group.
- A grouping field can be used in an aggregation. This is a degenerated case in which the aggregation will be computed over a single data point, the value belonging to current group.
- A query that selects only grouping fields but no aggregation fields is legal.
Aggregation queries can include filtering conditions, like usual queries, which may be optionally performed before and after the grouping operation.
groupBy method will be applied directly to the cache entries before the grouping operation is performed. These filter conditions may refer to any properties of the queried entity type, and are meant to restrict the data set that is going to be later used for grouping.
groupBy method will be applied to the projection that results from the grouping operation. These filter conditions can either reference any of the fields specified by groupBy or aggregated fields. Referencing aggregated fields that are not specified in the select clause is allowed; however, referencing non-aggregated and non-grouping fields is forbidden. Filtering in this phase will reduce the amount of groups based on their properties.
16.6. Using Named Parameters
Expression.param(...) operator on the right hand side of any comparison operator from the having(...):
Example 16.6. Defining Named Parameters
import org.infinispan.query.Search;
import org.infinispan.query.dsl.*;
[...]
QueryFactory queryFactory = Search.getQueryFactory(cache);
// Defining a query to search for various authors
Query query = queryFactory.from(Book.class)
.select("title")
.having("author").eq(Expression.param("authorName"))
.toBuilder()
.build()
[...]
By default all declared parameters are null, and all defined parameters must be updated to non-null values before the query must be executed. Once the parameters have been declared they may then be updated by invoking either setParameter(parameterName, value) or setParameters(parameterMap) on the query with the new values; in addition, the query does not need to be rebuilt. It may be executed again after the new parameters have been defined.
Example 16.7. Updating Parameters Individually
[...]
query.setParameter("authorName","Smith");
// Rerun the query and update the results
resultList = query.list();
[...]
Example 16.8. Updating Parameters as a Map
[...]
parameterMap.put("authorName","Smith");
query.setParameters(parameterMap);
// Rerun the query and update the results
resultList = query.list();
[...]Chapter 17. Remote Querying
JBoss Data Grid uses its own query language based on an internal DSL. The Infinispan Query DSL provides a simplified way of writing queries, and is agnostic of the underlying query mechanisms. Querying via the Hot Rod client allows remote, language-neutral querying, and is implementable in all languages currently available for the Hot Rod client.
Google's Protocol Buffers is used as an encoding format for both storing and querying data. The Infinispan Query DSL can be used remotely via the Hot Rod client that is configured to use the Protobuf marshaller. Protocol Buffers are used to adopt a common format for storing cache entries and marshalling them.
17.1. Querying Comparison
| Feature | Library Mode/Lucene Query | Library Mode/DSL Query | Remote Client-Server Mode/DSL Query |
|---|---|---|---|
| Indexing |
Mandatory
|
Optional but highly recommended
|
Optional but highly recommended
|
|
Index contents
|
Selected fields
|
Selected fields
|
Selected fields
|
| Data Storage Format |
Java objects
|
Java objects
|
Protocol buffers
|
| Keyword Queries |
Yes
|
No
|
No
|
| Range Queries |
Yes
|
Yes
|
Yes
|
| Fuzzy Queries |
Yes
|
No
|
No
|
| Wildcard |
Yes
|
Limited to like queries (Matches a wildcard pattern that follows JPA rules).
|
Limited to like queries (Matches a wildcard pattern that follows JPA rules).
|
| Phrase Queries |
Yes
|
No
|
No
|
| Combining Queries |
AND, OR, NOT, SHOULD
|
AND, OR, NOT
|
AND, OR, NOT
|
| Sorting Results |
Yes
|
Yes
|
Yes
|
| Filtering Results |
Yes, both within the query and as appended operator
|
Within the query
|
Within the query
|
| Pagination of Results |
Yes
|
Yes
|
Yes
|
| Continuous Queries | No | Yes | Yes |
| Query Aggregation Operations | No | Yes | Yes |
17.2. Performing Remote Queries via the Hot Rod Java Client
RemoteCacheManager has been configured with the Protobuf marshaller.
RemoteCacheManager must be configured to use the Protobuf Marshaller.
Procedure 17.1. Enabling Remote Querying via Hot Rod
Add the
infinispan-remote.jarTheinfinispan-remote.jaris an uberjar, and therefore no other dependencies are required for this feature.Enable indexing on the cache configuration.
Indexing is not mandatory for Remote Queries, but it is highly recommended because it makes searches on caches that contain large amounts of data significantly faster. Indexing can be configured at any time. Enabling and configuring indexing is the same as for Library mode.Add the following configuration within thecache-containerelement loated inside the Infinispan subsystem element.<!-- A basic example of an indexed local cache that uses the RAM Lucene directory provider --> <local-cache name="an-indexed-cache" start="EAGER"> <!-- Enable indexing using the RAM Lucene directory provider --> <indexing index="ALL"> <property name="default.directory_provider">ram</property> </indexing> </local-cache>Register the Protobuf schema definition files
Register the Protobuf schema definition files by adding them in the___protobuf_metadatasystem cache. The cache key is a string that denotes the file name and the value is.protofile, as a string. Alternatively, protobuf schemas can also be registered by invoking theregisterProtofilemethods of the server'sProtobufMetadataManagerMBean. There is one instance of this MBean per cache container and is backed by the___protobuf_metadata, so that the two approaches are equivalent.For an example of providing the protobuf schema via___protobuf_metadatasystem cache, see Example 17.8, “Registering a Protocol Buffers schema file”.The following example demonstrates how to invoke theregisterProtofilemethods of theProtobufMetadataManagerMBean.Example 17.1. Registering Protobuf schema definition files via JMX
import javax.management.MBeanServerConnection; import javax.management.ObjectName; import javax.management.remote.JMXConnector; import javax.management.remote.JMXServiceURL; ... String serverHost = ... // The address of your JDG server int serverJmxPort = ... // The JMX port of your server String cacheContainerName = ... // The name of your cache container String schemaFileName = ... // The name of the schema file String schemaFileContents = ... // The Protobuf schema file contents JMXConnector jmxConnector = JMXConnectorFactory.connect(new JMXServiceURL( "service:jmx:remoting-jmx://" + serverHost + ":" + serverJmxPort)); MBeanServerConnection jmxConnection = jmxConnector.getMBeanServerConnection(); ObjectName protobufMetadataManagerObjName = new ObjectName("jboss.infinispan:type=RemoteQuery,name=" + ObjectName.quote(cacheContainerName) + ",component=ProtobufMetadataManager"); jmxConnection.invoke(protobufMetadataManagerObjName, "registerProtofile", new Object[]{schemaFileName, schemaFileContents}, new String[]{String.class.getName(), String.class.getName()}); jmxConnector.close();
All data placed in the cache is immediately searchable, whether or not indexing is in use. Entries do not need to be annotated, unlike embedded queries. The entity classes are only meaningful to the Java client and do not exist on the server.
QueryFactory can be obtained using the following:
Example 17.2. Obtaining the QueryFactory
import org.infinispan.client.hotrod.Search;
import org.infinispan.query.dsl.QueryFactory;
import org.infinispan.query.dsl.Query;
import org.infinispan.query.dsl.SortOrder;
...
remoteCache.put(2, new User("John", 33));
remoteCache.put(3, new User("Alfred", 40));
remoteCache.put(4, new User("Jack", 56));
remoteCache.put(4, new User("Jerry", 20));
QueryFactory qf = Search.getQueryFactory(remoteCache);
Query query = qf.from(User.class)
.orderBy("age", SortOrder.ASC)
.having("name").like("J%")
.and().having("age").gte(33)
.toBuilder().build();
List<User> list = query.list();
assertEquals(2, list.size());
assertEquals("John", list.get(0).getName());
assertEquals(33, list.get(0).getAge());
assertEquals("Jack", list.get(1).getName());
assertEquals(56, list.get(1).getAge());
17.3. Performing Remote Queries via the Hot Rod C++ Client
RemoteCacheManager has been configured with the Protobuf marshaller.
Important
Procedure 17.2. Enable Remote Querying on the Hot Rod C++ Client
- Obtain a connection to the remote JBoss Data Grid server:
#include "addressbook.pb.h" #include "bank.pb.h" #include <infinispan/hotrod/BasicTypesProtoStreamMarshaller.h> #include <infinispan/hotrod/ProtoStreamMarshaller.h> #include "infinispan/hotrod/ConfigurationBuilder.h" #include "infinispan/hotrod/RemoteCacheManager.h" #include "infinispan/hotrod/RemoteCache.h" #include "infinispan/hotrod/Version.h" #include "infinispan/hotrod/query.pb.h" #include "infinispan/hotrod/QueryUtils.h" #include <vector> #include <tuple> #define PROTOBUF_METADATA_CACHE_NAME "___protobuf_metadata" #define ERRORS_KEY_SUFFIX ".errors" using namespace infinispan::hotrod; using namespace org::infinispan::query::remote::client; std::string read(std::string file) { std::ifstream t(file); std::stringstream buffer; buffer << t.rdbuf(); return buffer.str(); } int main(int argc, char** argv) { std::cout << "Tests for Query" << std::endl; ConfigurationBuilder builder; builder.addServer().host(argc > 1 ? argv[1] : "127.0.0.1").port(argc > 2 ? atoi(argv[2]) : 11222).protocolVersion(Configuration::PROTOCOL_VERSION_24); RemoteCacheManager cacheManager(builder.build(), false); cacheManager.start(); - Create the Protobuf metadata cache with the Protobuf Marshaller:
// This example continues the previous codeblock // Create the Protobuf Metadata cache peer with a Protobuf marshaller auto *km = new BasicTypesProtoStreamMarshaller<std::string>(); auto *vm = new BasicTypesProtoStreamMarshaller<std::string>(); auto metadataCache = cacheManager.getCache<std::string, std::string>( km, &Marshaller<std::string>::destroy, vm, &Marshaller<std::string>::destroy,PROTOBUF_METADATA_CACHE_NAME, false); - Install the data model in the Protobuf metadata cache:
// This example continues the previous codeblock // Install the data model into the Protobuf metadata cache metadataCache.put("sample_bank_account/bank.proto", read("proto/bank.proto")); if (metadataCache.containsKey(ERRORS_KEY_SUFFIX)) { std::cerr << "fail: error in registering .proto model" << std::endl; return -1; } - This step adds data to the cache for the purposes of this demonstration, and may be ignored when simply querying a remote cache:
// This example continues the previous codeblock // Fill the cache with the application data: two users Tom and Jerry testCache.clear(); sample_bank_account::User_Address a; sample_bank_account::User user1; user1.set_id(3); user1.set_name("Tom"); user1.set_surname("Cat"); user1.set_gender(sample_bank_account::User_Gender_MALE); sample_bank_account::User_Address * addr= user1.add_addresses(); addr->set_street("Via Roma"); addr->set_number(3); addr->set_postcode("202020"); testCache.put(3, user1); user1.set_id(4); user1.set_name("Jerry"); user1.set_surname("Mouse"); addr->set_street("Via Milano"); user1.set_gender(sample_bank_account::User_Gender_MALE); testCache.put(4, user1); - Query the remote cache:
// This example continues the previous codeblock // Simple query to get User objects { QueryRequest qr; std::cout << "Query: from sample_bank_account.User" << std::endl; qr.set_jpqlstring("from sample_bank_account.User"); QueryResponse resp = testCache.query(qr); std::vector<sample_bank_account::User> res; unwrapResults(resp, res); for (auto i = 0; i < res.size(); i++) { std::cout << "User(id=" << res[i].id() << ",name=" << res[i].name() << ",surname=" << res[i].surname() << ")" << std::endl; } } cacheManager.stop(); return 0; }
The following examples are included to demonstrate more complicated queries, and may be used on the same dataset found in the above procedure.
Example 17.3. Using a query with a conditional
// Simple query to get User objects with where condition
{
QueryRequest qr;
std::cout << "from sample_bank_account.User u where u.addresses.street=\"Via Milano\"" << std::endl;
qr.set_jpqlstring("from sample_bank_account.User u where u.addresses.street=\"Via Milano\"");
QueryResponse resp = testCache.query(qr);
std::vector<sample_bank_account::User> res;
unwrapResults(resp, res);
for (auto i = 0; i < res.size(); i++) {
std::cout << "User(id=" << res[i].id() << ",name=" << res[i].name()
<< ",surname=" << res[i].surname() << ")" << std::endl;
}
}Example 17.4. Using a query with a projection
// Simple query to get projection (name, surname)
{
QueryRequest qr;
std::cout << "Query: select u.name, u.surname from sample_bank_account.User u" << std::endl;
qr.set_jpqlstring(
"select u.name, u.surname from sample_bank_account.User u");
QueryResponse resp = testCache.query(qr);
//Typed resultset
std::vector<std::tuple<std::string, std::string> > prjRes;
unwrapProjection(resp, prjRes);
for (auto i = 0; i < prjRes.size(); i++) {
std::cout << "Name: " << std::get<0> (prjRes[i])
<< " Surname: " << std::get<1> (prjRes[i]) << std::endl;
}
}17.4. Performing Remote Queries via the Hot Rod C# Client
RemoteCacheManager has been configured with the Protobuf marshaller.
Important
Procedure 17.3. Enable Remote Querying on the Hot Rod C# Client
- Obtain a connection to the remote JBoss Data Grid server, passing the Protobuf marshaller into the configuration:
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using Infinispan.HotRod; using Infinispan.HotRod.Config; using Google.Protobuf; using Org.Infinispan.Protostream; using Org.Infinispan.Query.Remote.Client; using QueryExampleBankAccount; using System.IO; namespace Query { /// <summary> /// This sample code shows how to perform Infinispan queries using the C# client /// </summary> class Query { static void Main(string[] args) { // Cache manager setup RemoteCacheManager remoteManager; const string ERRORS_KEY_SUFFIX = ".errors"; const string PROTOBUF_METADATA_CACHE_NAME = "___protobuf_metadata"; ConfigurationBuilder conf = new ConfigurationBuilder(); conf.AddServer().Host("127.0.0.1").Port(11222).ConnectionTimeout(90000).SocketTimeout(6000); conf.Marshaller(new BasicTypesProtoStreamMarshaller()); remoteManager = new RemoteCacheManager(conf.Build(), true); IRemoteCache<String, String> metadataCache = remoteManager.GetCache<String, String>(PROTOBUF_METADATA_CACHE_NAME); IRemoteCache<int, User> testCache = remoteManager.GetCache<int, User>("namedCache"); - Install any protobuf entities model:
// This example continues the previous codeblock // Installing the entities model into the Infinispan __protobuf_metadata cache metadataCache.Put("sample_bank_account/bank.proto", File.ReadAllText("resources/proto2/bank.proto")); if (metadataCache.ContainsKey(ERRORS_KEY_SUFFIX)) { Console.WriteLine("fail: error in registering .proto model"); Environment.Exit(-1); } - This step adds data to the cache for the purposes of this demonstration, and may be ignored when simply querying a remote cache:
// This example continues the previous codeblock // The application cache must contain entities only testCache.Clear(); // Fill the application cache User user1 = new User(); user1.Id = 4; user1.Name = "Jerry"; user1.Surname = "Mouse"; User ret = testCache.Put(4, user1); - Query the remote cache:
// This example continues the previous codeblock // Run a query QueryRequest qr = new QueryRequest(); qr.JpqlString = "from sample_bank_account.User"; QueryResponse result = testCache.Query(qr); List<User> listOfUsers = new List<User>(); unwrapResults(result, listOfUsers); } - To process the results convert the protobuf matter into C# objects. The following method demonstrates this conversion:
// Convert Protobuf matter into C# objects private static bool unwrapResults<T>(QueryResponse resp, List<T> res) where T : IMessage<T> { if (resp.ProjectionSize > 0) { // Query has select return false; } for (int i = 0; i < resp.NumResults; i++) { WrappedMessage wm = resp.Results.ElementAt(i); if (wm.WrappedBytes != null) { WrappedMessage wmr = WrappedMessage.Parser.ParseFrom(wm.WrappedBytes); if (wmr.WrappedMessageBytes != null) { System.Reflection.PropertyInfo pi = typeof(T).GetProperty("Parser"); MessageParser<T> p = (MessageParser<T>)pi.GetValue(null); T u = p.ParseFrom(wmr.WrappedMessageBytes); res.Add(u); } } } return true; } } }
17.5. Protobuf Encoding
17.5.1. Storing Protobuf Encoded Entities
.proto files
Example 17.5. .library.proto
package book_sample;
message Book {
required string title = 1;
required string description = 2;
required int32 publicationYear = 3; // no native Date type available in Protobuf
repeated Author authors = 4;
}
message Author {
required string name = 1;
required string surname = 2;
}- An entity named
Bookis placed in a package namedbook_sample.package book_sample; message Book { - The entity declares several fields of primitive types and a repeatable field named
authors.required string title = 1; required string description = 2; required int32 publicationYear = 3; // no native Date type available in Protobuf repeated Author authors = 4; } - The
Authormessage instances are embedded in theBookmessage instance.message Author { required string name = 1; required string surname = 2; }
17.5.2. About Protobuf Messages
- Nesting of messages is possible, however the resulting structure is strictly a tree, and never a graph.
- There is no type inheritance.
- Collections are not supported, however arrays can be easily emulated using repeated fields.
17.5.3. Using Protobuf with Hot Rod
- Configure the client to use a dedicated marshaller, in this case, the
ProtoStreamMarshaller. This marshaller uses theProtoStreamlibrary to assist in encoding objects.Important
If theinfinispan-remotejar is not in use, then the infinispan-remote-query-client Maven dependency must be added to use theProtoStreamMarshaller. - Instruct
ProtoStreamlibrary on how to marshall message types by registering per entity marshallers.
Example 17.6. Use the ProtoStreamMarshaller to Encode and Marshall Messages
import org.infinispan.client.hotrod.configuration.ConfigurationBuilder;
import org.infinispan.client.hotrod.marshall.ProtoStreamMarshaller;
import org.infinispan.protostream.FileDescriptorSource;
import org.infinispan.protostream.SerializationContext;
...
ConfigurationBuilder clientBuilder = new ConfigurationBuilder();
clientBuilder.addServer()
.host("127.0.0.1").port(11234)
.marshaller(new ProtoStreamMarshaller());
RemoteCacheManager remoteCacheManager = new RemoteCacheManager(clientBuilder.build());
SerializationContext serCtx =
ProtoStreamMarshaller.getSerializationContext(remoteCacheManager);
serCtx.registerProtoFiles(FileDescriptorSource.fromResources("/library.proto"));
serCtx.registerMarshaller(new BookMarshaller());
serCtx.registerMarshaller(new AuthorMarshaller());
// Book and Author classes omitted for brevity- The
SerializationContextis provided by theProtoStreamlibrary. - The
SerializationContext.registerProtofilemethod receives the name of a.protoclasspath resource file that contains the message type definitions. - The
SerializationContextassociated with theRemoteCacheManageris obtained, thenProtoStreamis instructed to marshall the protobuf types.
Note
RemoteCacheManager has no SerializationContext associated with it unless it was configured to use ProtoStreamMarshaller.
17.5.4. Registering Per Entity Marshallers
ProtoStreamMarshaller for remote querying purposes, registration of per entity marshallers for domain model types must be provided by the user for each type or marshalling will fail. When writing marshallers, it is essential that they are stateless and threadsafe, as a single instance of them is being used.
Example 17.7. BookMarshaller.java
import org.infinispan.protostream.MessageMarshaller;
...
public class BookMarshaller implements MessageMarshaller<Book> {
@Override
public String getTypeName() {
return "book_sample.Book";
}
@Override
public Class<? extends Book> getJavaClass() {
return Book.class;
}
@Override
public void writeTo(ProtoStreamWriter writer, Book book) throws IOException {
writer.writeString("title", book.getTitle());
writer.writeString("description", book.getDescription());
writer.writeCollection("authors", book.getAuthors(), Author.class);
}
@Override
public Book readFrom(ProtoStreamReader reader) throws IOException {
String title = reader.readString("title");
String description = reader.readString("description");
int publicationYear = reader.readInt("publicationYear");
Set<Author> authors = reader.readCollection("authors",
new HashSet<Author>(), Author.class);
return new Book(title, description, publicationYear, authors);
}
}Book and Author.
17.5.5. Indexing Protobuf Encoded Entities
.proto extension. The schema is supplied to the server either by placing it in the ___protobuf_metadata cache by a put, putAll, putIfAbsent, or replace operation, or alternatively by invoking ProtobufMetadataManager MBean via JMX. Both keys and values of ___protobuf_metadata cache are Strings, the key being the file name, while the value is the schema file contents.
Example 17.8. Registering a Protocol Buffers schema file
import org.infinispan.client.hotrod.RemoteCache;
import org.infinispan.client.hotrod.RemoteCacheManager;
import org.infinispan.query.remote.client.ProtobufMetadataManagerConstants;
RemoteCacheManager remoteCacheManager = ... // obtain a RemoteCacheManager
// obtain the '__protobuf_metadata' cache
RemoteCache<String, String> metadataCache =
remoteCacheManager.getCache(
ProtobufMetadataManagerConstants.PROTOBUF_METADATA_CACHE_NAME);
String schemaFileContents = ... // this is the contents of the schema file
metadataCache.put("my_protobuf_schema.proto", schemaFileContents);ProtobufMetadataManager is a cluster-wide replicated repository of Protobuf schema definitions or.proto files. For each running cache manager, a separate ProtobufMetadataManager MBean instance exists, and is backed by the ___protobuf_metadata cache. The ProtobufMetadataManager ObjectName uses the following pattern:
<jmx domain>:type=RemoteQuery,
name=<cache manager<methodname>putAllname>,
component=ProtobufMetadataManagervoid registerProtofile(String name, String contents)Note
17.5.6. Custom Fields Indexing with Protobuf
@Indexed and @IndexedField annotations directly to the Protobuf schema in the documentation comments of message type definitions and field definitions.
Example 17.9. Specifying Which Fields are Indexed
/*
This type is indexed, but not all its fields are.
@Indexed
*/
message Note {
/*
This field is indexed but not stored.
It can be used for querying but not for projections.
@IndexedField(index=true, store=false)
*/
optional string text = 1;
/*
A field that is both indexed and stored.
@IndexedField
*/
optional string author = 2;
/* @IndexedField(index=false, store=true) */
optional bool isRead = 3;
/* This field is not annotated, so it is neither indexed nor stored. */
optional int32 priority;
}@Indexed annotation only applies to message types, has a boolean value (the default is true). As a result, using @Indexed is equivalent to @Indexed(true). This annotation is used to selectively specify the fields of the message type which must be indexed. Using @Indexed(false), however, indicates that no fields are to be indexed and so the eventual @IndexedField annotation at the field level is ignored.
@IndexedField annotation only applies to fields, has two attributes (index and store), both of which default to true (using @IndexedField is equivalent to @IndexedField(index=true, store=true)). The index attribute indicates whether the field is indexed, and is therefore used for indexed queries. The store attributes indicates whether the field value must be stored in the index, so that the value is available for projections.
Note
@IndexedField annotation is only effective if the message type that contains it is annotated with @Indexed.
17.5.7. Defining Protocol Buffers Schemas With Java Annotations
MessageMarshaller implementation and a .proto schema file, you can add minimal annotations to a Java class and its fields.
ProtoStream library. The ProtoStream library internally generates the marshallar and does not require a manually implemented one. The Java annotations require minimal information such as the Protobuf tag number. The rest is inferred based on common sense defaults ( Protobuf type, Java collection type, and collection element type) and is possible to override.
SerializationContext and is also available to the users to be used as a reference to implement domain model classes and marshallers for other languages.
Example 17.10. User.Java
package sample;
import org.infinispan.protostream.annotations.ProtoEnum;
import org.infinispan.protostream.annotations.ProtoEnumValue;
import org.infinispan.protostream.annotations.ProtoField;
import org.infinispan.protostream.annotations.ProtoMessage;
@ProtoMessage(name = "ApplicationUser")
public class User {
@ProtoEnum(name = "Gender")
public enum Gender {
@ProtoEnumValue(number = 1, name = "M")
MALE,
@ProtoEnumValue(number = 2, name = "F")
FEMALE
}
@ProtoField(number = 1, required = true)
public String name;
@ProtoField(number = 2)
public Gender gender;
}Example 17.11. Note.Java
package sample;
import org.infinispan.protostream.annotations.ProtoDoc;
import org.infinispan.protostream.annotations.ProtoField;
@ProtoDoc("@Indexed")
public class Note {
private String text;
private User author;
@ProtoDoc("@IndexedField(index = true, store = false)")
@ProtoField(number = 1)
public String getText() {
return text;
}
public void setText(String text) {
this.text = text;
}
@ProtoDoc("@IndexedField")
@ProtoField(number = 2)
public User getAuthor() {
return author;
}
public void setAuthor(User author) {
this.author = author;
}
}Example 17.12. ProtoSchemaBuilderDemo.Java
import org.infinispan.protostream.SerializationContext;
import org.infinispan.protostream.annotations.ProtoSchemaBuilder;
import org.infinispan.client.hotrod.RemoteCacheManager;
import org.infinispan.client.hotrod.marshall.ProtoStreamMarshaller;
...
RemoteCacheManager remoteCacheManager = ... // we have a RemoteCacheManager
SerializationContext serCtx =
ProtoStreamMarshaller.getSerializationContext(remoteCacheManager);
// generate and register a Protobuf schema and marshallers based
// on Note class and the referenced classes (User class)
ProtoSchemaBuilder protoSchemaBuilder = new ProtoSchemaBuilder();
String generatedSchema = protoSchemaBuilder
.fileName("sample_schema.proto")
.packageName("sample_package")
.addClass(Note.class)
.build(serCtx);
// the types can be marshalled now
assertTrue(serCtx.canMarshall(User.class));
assertTrue(serCtx.canMarshall(Note.class));
assertTrue(serCtx.canMarshall(User.Gender.class));
// display the schema file
System.out.println(generatedSchema);.proto file that is generated by the ProtoSchemaBuilderDemo.java example.
Example 17.13. Sample_Schema.Proto
package sample_package;
/* @Indexed */
message Note {
/* @IndexedField(index = true, store = false) */
optional string text = 1;
/* @IndexedField */
optional ApplicationUser author = 2;
}
message ApplicationUser {
enum Gender {
M = 1;
F = 2;
}
required string name = 1;
optional Gender gender = 2;
}| Annotation | Applies To | Purpose | Requirement | Parameters |
|---|---|---|---|---|
@ProtoDoc | Class/Field/Enum/Enum member | Specifies the documentation comment that will be attached to the generated Protobuf schema element (message type, field definition, enum type, enum value definition) | Optional | A single String parameter, the documentation text |
@ProtoMessage | Class | Specifies the name of the generated message type. If missing, the class name if used instead | Optional | name (String), the name of the generated message type; if missing the Java class name is used by default |
@ProtoField | Field, Getter or Setter |
Specifies the Protobuf field number and its Protobuf type. Also indicates if the field is repeated, optional or required and its (optional) default value. If the Java field type is an interface or an abstract class, its actual type must be indicated. If the field is repeatable and the declared collection type is abstract then the actual collection implementation type must be specified. If this annotation is missing, the field is ignored for marshalling (it is transient). A class must have at least one
@ProtoField annotated field to be considered Protobuf marshallable.
| Required | number (int, mandatory), the Protobuf number type (org.infinispan.protostream.descriptors.Type, optional), the Protobuf type, it can usually be inferred required (boolean, optional)name (String, optional), the Protobuf namejavaType (Class, optional), the actual type, only needed if declared type is abstract collectionImplementation (Class, optional), the actual collection type, only needed if declared type is abstract defaultValue (String, optional), the string must have the proper format according to the Java field type |
@ProtoEnum | Enum | Specifies the name of the generated enum type. If missing, the Java enum name if used instead | Optional | name (String), the name of the generated enum type; if missing the Java enum name is used by default |
@ProtoEnumValue | Enum member | Specifies the numeric value of the corresponding Protobuf enum value | Required | number (int, mandatory), the Protobuf number name (String), the Protobuf name; if missing the name of the Java member is used |
Note
@ProtoDoc annotation can be used to provide documentation comments in the generated schema and also allows to inject the @Indexed and @IndexedField annotations where needed (see Section 17.5.6, “Custom Fields Indexing with Protobuf”).
Chapter 18. Monitoring
generate_statistics property in the configuration.
18.1. About Java Management Extensions (JMX)
MBeans.
18.1.1. Using JMX with Red Hat JBoss Data Grid
18.1.2. Enable JMX for Cache Instances
Add the following code to programmatically enable JMX at the cache level:
Configuration configuration = new
ConfigurationBuilder().jmxStatistics().enable().build();18.1.3. Enable JMX for CacheManagers
CacheManager level, JMX statistics can be enabled either declaratively or programmatically, as follows.
Add the following code to programmatically enable JMX at the CacheManager level:
GlobalConfiguration globalConfiguration = new
GlobalConfigurationBuilder()..globalJmxStatistics().enable().build();18.1.4. Multiple JMX Domains
CacheManager instances exist on a single virtual machine, or if the names of cache instances in different CacheManagers clash.
CacheManager in manner that allows it to be easily identified and used by monitoring tools such as JMX and JBoss Operations Network.
Add the following code to set the CacheManager name programmatically:
GlobalConfiguration globalConfiguration = new
GlobalConfigurationBuilder().globalJmxStatistics().enable().
cacheManagerName("Hibernate2LC").build();18.1.5. Registering MBeans in Non-Default MBean Servers
getMBeanServer() method returns the desired (non default) MBeanServer.
Add the following code:
GlobalConfiguration globalConfiguration = new
GlobalConfigurationBuilder().globalJmxStatistics().enable().
mBeanServerLookup("com.acme.MyMBeanServerLookup").build();18.2. StatisticsInfoMBean
StatisticsInfoMBean MBean accesses the Statistics object as described in the previous section.
Chapter 19. Red Hat JBoss Data Grid as Lucene Directory
Note
19.1. Configuration
default index is specified then all indexes will use the directory provider unless specified:
hibernate.search.[default|<indexname>].directory_provider = infinispan
CacheManager to use Infinispan. It can look up and reuse an existing CacheManager, via JNDI, or start and manage a new one. When looking up an existing CacheManager this will be provided from the Infinispan subsystem where it was originally registered; for instance, if this was registered via JBoss EAP, then JBoss EAP's Infinispan subsystem will provide the CacheManager.
Note
CacheManager, it must be done using Red Hat JBoss Data Grid configuration files only.
hibernate.search.infinispan.cachemanager_jndiname = [jndiname]
CacheManager from a configuration file (optional parameter):
hibernate.search.infinispan.configuration_resourcename = [infinispan configuration filename]
19.2. Red Hat JBoss Data Grid Modules
MANIFEST.MF file in the project archive:
Dependencies: org.hibernate.search.orm services19.3. Lucene Directory Configuration for Replicated Indexing
hibernate.search.default.directory_provider=infinispantickets and actors are index names:
hibernate.search.tickets.directory_provider=infinispan
hibernate.search.actors.directory_provider=filesystemDirectoryProvider uses the following options to configure the cache names:
locking_cachename- Cache name where Lucene's locks are stored. Defaults toLuceneIndexesLocking.data_cachename- Cache name where Lucene's data is stored, including the largest data chunks and largest objects. Defaults toLuceneIndexesData.metadata_cachename- Cache name where Lucene's metadata is stored. Defaults toLuceneIndexesMetadata.
CustomLockingCache use the following:
hibernate.search.default.directory_provider.locking_cachname="CustomLockingCache"chunk_size to the highest value that may be handled efficiently by the network.
Important
LuceneIndexesMetadata and LuceneIndexesLocking caches should always use replication mode in all the cases.
19.4. JMS Master and Slave Back End Configuration
IndexWriter is active on different nodes, it acquires the lock on the same index. So instead of sending updates directly to the index, send it to a JMS queue and make a single node apply all changes on behalf of all other nodes.
Warning
Part III. Securing Data in Red Hat JBoss Data Grid
JBoss Data Grid features role-based access control for operations on designated secured caches. Roles can be assigned to users who access your application, with roles mapped to permissions for cache and cache-manager operations. Only authenticated users are able to perform the operations that are authorized for their role.
Node-level security requires new nodes or merging partitions to authenticate before joining a cluster. Only authenticated nodes that are authorized to join the cluster are permitted to do so. This provides data protection by preventing authorized servers from storing your data.
JBoss Data Grid increases data security by supporting encrypted communications between the nodes in a cluster by using a user-specified cryptography algorithm, as supported by Java Cryptography Architecture (JCA).
Chapter 20. Red Hat JBoss Data Grid Security: Authorization and Authentication
20.1. Red Hat JBoss Data Grid Security: Authorization and Authentication
SecureCache. SecureCache is a simple wrapper around a cache, which checks whether the "current user" has the permissions required to perform an operation. The "current user" is a Subject associated with the AccessControlContext.
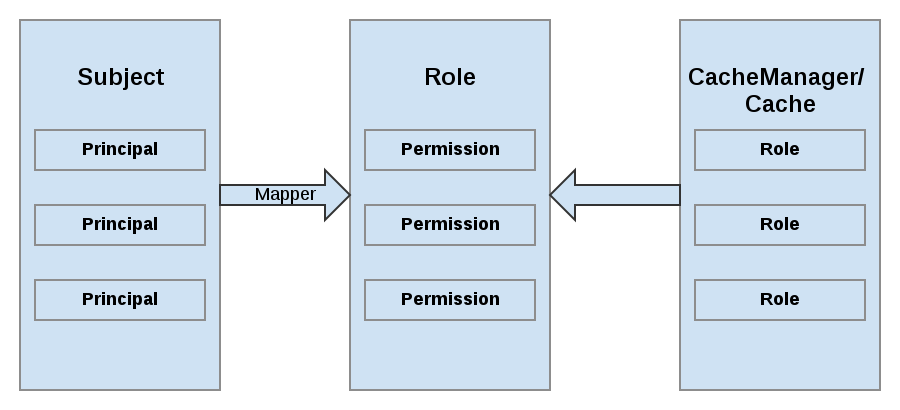
Figure 20.1. Roles and Permissions Mapping
20.2. Permissions
| Permission | Function | Description |
|---|---|---|
| CONFIGURATION | defineConfiguration | Whether a new cache configuration can be defined. |
| LISTEN | addListener | Whether listeners can be registered against a cache manager. |
| LIFECYCLE | stop, start | Whether the cache manager can be stopped or started respectively. |
| ALL | A convenience permission which includes all of the above. |
| Permission | Function | Description |
|---|---|---|
| READ | get, contains | Whether entries can be retrieved from the cache. |
| WRITE | put, putIfAbsent, replace, remove, evict | Whether data can be written/replaced/removed/evicted from the cache. |
| EXEC | distexec, mapreduce | Whether code execution can be run against the cache. |
| LISTEN | addListener | Whether listeners can be registered against a cache. |
| BULK_READ | keySet, values, entrySet,query | Whether bulk retrieve operations can be executed. |
| BULK_WRITE | clear, putAll | Whether bulk write operations can be executed. |
| LIFECYCLE | start, stop | Whether a cache can be started / stopped. |
| ADMIN | getVersion, addInterceptor*, removeInterceptor, getInterceptorChain, getEvictionManager, getComponentRegistry, getDistributionManager, getAuthorizationManager, evict, getRpcManager, getCacheConfiguration, getCacheManager, getInvocationContextContainer, setAvailability, getDataContainer, getStats, getXAResource | Whether access to the underlying components/internal structures is allowed. |
| ALL | A convenience permission which includes all of the above. | |
| ALL_READ | Combines READ and BULK_READ. | |
| ALL_WRITE | Combines WRITE and BULK_WRITE. |
Note
20.3. Role Mapping
PrincipalRoleMapper must be specified in the global configuration. Red Hat JBoss Data Grid ships with three mappers, and also allows you to provide a custom mapper.
| Mapper Name | Java | XML | Description |
|---|---|---|---|
| IdentityRoleMapper | org.infinispan.security.impl.IdentityRoleMapper | <identity-role-mapper /> | Uses the Principal name as the role name. |
| CommonNameRoleMapper | org.infinispan.security.impl.CommonRoleMapper | <common-name-role-mapper /> | If the Principal name is a Distinguished Name (DN), this mapper extracts the Common Name (CN) and uses it as a role name. For example the DN cn=managers,ou=people,dc=example,dc=com will be mapped to the role managers. |
| ClusterRoleMapper | org.infinispan.security.impl.ClusterRoleMapper | <cluster-role-mapper /> | Uses the ClusterRegistry to store principal to role mappings. This allows the use of the CLI’s GRANT and DENY commands to add/remove roles to a Principal. |
| Custom Role Mapper | <custom-role-mapper class="a.b.c" /> | Supply the fully-qualified class name of an implementation of org.infinispan.security.impl.PrincipalRoleMapper |
20.4. Configuring Authentication and Role Mapping using Login Modules
login-module for querying roles from LDAP, you must implement your own mapping of Principals to Roles, as custom classes are in use. The following example demonstrates how to map a principal obtained from a login-module to a role. It maps user principal name to a role, performing a similar action to the IdentityRoleMapper:
Example 20.1. Mapping a Principal
public class SimplePrincipalGroupRoleMapper implements PrincipalRoleMapper {
@Override
public Set<String> principalToRoles(Principal principal) {
if (principal instanceof SimpleGroup) {
Enumeration<Principal> members = ((SimpleGroup) principal).members();
if (members.hasMoreElements()) {
Set<String> roles = new HashSet<String>();
while (members.hasMoreElements()) {
Principal innerPrincipal = members.nextElement();
if (innerPrincipal instanceof SimplePrincipal) {
SimplePrincipal sp = (SimplePrincipal) innerPrincipal;
roles.add(sp.getName());
}
}
return roles;
}
}
return null;
}
}Important
20.5. Configuring Red Hat JBoss Data Grid for Authorization
- whether to use authorization.
- a class which will map principals to a set of roles.
- a set of named roles and the permissions they represent.
Roles may be applied on a cache-per-cache basis, using the roles defined at the cache-container level, as follows:
Important
The following example shows how to set up the same authorization parameters for Library mode using programmatic configuration:
Example 20.2. CacheManager Authorization Programmatic Configuration
GlobalConfigurationBuilder global = new GlobalConfigurationBuilder();
global
.security()
.authorization()
.principalRoleMapper(new IdentityRoleMapper())
.role("admin")
.permission(CachePermission.ALL)
.role("supervisor")
.permission(CachePermission.EXEC)
.permission(CachePermission.READ)
.permission(CachePermission.WRITE)
.role("reader")
.permission(CachePermission.READ);
ConfigurationBuilder config = new ConfigurationBuilder();
config
.security()
.enable()
.authorization()
.role("admin")
.role("supervisor")
.role("reader");Important
SecurityException.
20.6. Data Security for Library Mode
20.6.1. Subject and Principal Classes
Subject class is the central class in JAAS. A Subject represents information for a single entity, such as a person or service. It encompasses the entity's principals, public credentials, and private credentials. The JAAS APIs use the existing Java 2 java.security.Principal interface to represent a principal, which is a typed name.
public Set getPrincipals() {...}
public Set getPrincipals(Class c) {...}
getPrincipals() returns all principals contained in the subject. getPrincipals(Class c) returns only those principals that are instances of class c or one of its subclasses. An empty set is returned if the subject has no matching principals.
Note
java.security.acl.Group interface is a sub-interface of java.security.Principal, so an instance in the principals set may represent a logical grouping of other principals or groups of principals.
20.6.2. Obtaining a Subject
javax.security.auth.Subject. The Subject represents information for a single cache entity, such as a person or a service.
Subject subject = SecurityContextAssociation.getSubject();- Servlets:
ServletRequest.getUserPrincipal() - EJBs:
EJBContext.getCallerPrincipal() - MessageDrivenBeans:
MessageDrivenContext.getCallerPrincipal()
mapper is then used to identify the principals associated with the Subject and convert them into roles that correspond to those you have defined at the container level.
java.security.AccessControlContext. Either the container sets the Subject on the AccessControlContext, or the user must map the Principal to an appropriate Subject before wrapping the call to the JBoss Data Grid API using a Security.doAs() method.
Example 20.3. Obtaining a Subject
import org.infinispan.security.Security;
Security.doAs(subject, new PrivilegedExceptionAction<Void>() {
public Void run() throws Exception {
cache.put("key", "value");
}
});Security.doAs() method is in place of the typical Subject.doAs() method. Unless the AccessControlContext must be modified for reasons specific to your application's security model, using Security.doAs() provides a performance advantage.
Security.getSubject();, which will retrieve the Subject from either the JBoss Data Grid context, or from the AccessControlContext.
20.6.3. Subject Authentication
- An application instantiates a
LoginContextand passes in the name of the login configuration and aCallbackHandlerto populate theCallbackobjects, as required by the configurationLoginModules. - The
LoginContextconsults aConfigurationto load all theLoginModulesincluded in the named login configuration. If no such named configuration exists theotherconfiguration is used as a default. - The application invokes the
LoginContext.loginmethod. - The login method invokes all the loaded
LoginModules. As eachLoginModuleattempts to authenticate the subject, it invokes the handle method on the associatedCallbackHandlerto obtain the information required for the authentication process. The required information is passed to the handle method in the form of an array ofCallbackobjects. Upon success, theLoginModules associate relevant principals and credentials with the subject. - The
LoginContextreturns the authentication status to the application. Success is represented by a return from the login method. Failure is represented through a LoginException being thrown by the login method. - If authentication succeeds, the application retrieves the authenticated subject using the
LoginContext.getSubjectmethod. - After the scope of the subject authentication is complete, all principals and related information associated with the subject by the
loginmethod can be removed by invoking theLoginContext.logoutmethod.
LoginContext class provides the basic methods for authenticating subjects and offers a way to develop an application that is independent of the underlying authentication technology. The LoginContext consults a Configuration to determine the authentication services configured for a particular application. LoginModule classes represent the authentication services. Therefore, you can plug different login modules into an application without changing the application itself. The following code shows the steps required by an application to authenticate a subject.
CallbackHandler handler = new MyHandler();
LoginContext lc = new LoginContext("some-config", handler);
try {
lc.login();
Subject subject = lc.getSubject();
} catch(LoginException e) {
System.out.println("authentication failed");
e.printStackTrace();
}
// Perform work as authenticated Subject
// ...
// Scope of work complete, logout to remove authentication info
try {
lc.logout();
} catch(LoginException e) {
System.out.println("logout failed");
e.printStackTrace();
}
// A sample MyHandler class
class MyHandler
implements CallbackHandler
{
public void handle(Callback[] callbacks) throws
IOException, UnsupportedCallbackException
{
for (int i = 0; i < callbacks.length; i++) {
if (callbacks[i] instanceof NameCallback) {
NameCallback nc = (NameCallback)callbacks[i];
nc.setName(username);
} else if (callbacks[i] instanceof PasswordCallback) {
PasswordCallback pc = (PasswordCallback)callbacks[i];
pc.setPassword(password);
} else {
throw new UnsupportedCallbackException(callbacks[i],
"Unrecognized Callback");
}
}
}
}
LoginModule interface. This allows an administrator to plug different authentication technologies into an application. You can chain together multiple LoginModules to allow for more than one authentication technology to participate in the authentication process. For example, one LoginModule may perform user name/password-based authentication, while another may interface to hardware devices such as smart card readers or biometric authenticators.
LoginModule is driven by the LoginContext object against which the client creates and issues the login method. The process consists of two phases. The steps of the process are as follows:
- The
LoginContextcreates each configuredLoginModuleusing its public no-arg constructor. - Each
LoginModuleis initialized with a call to its initialize method. TheSubjectargument is guaranteed to be non-null. The signature of the initialize method is:public void initialize(Subject subject, CallbackHandler callbackHandler, Map sharedState, Map options) - The
loginmethod is called to start the authentication process. For example, a method implementation might prompt the user for a user name and password and then verify the information against data stored in a naming service such as NIS or LDAP. Alternative implementations might interface to smart cards and biometric devices, or simply extract user information from the underlying operating system. The validation of user identity by eachLoginModuleis considered phase 1 of JAAS authentication. The signature of theloginmethod isboolean login() throws LoginException. ALoginExceptionindicates failure. A return value of true indicates that the method succeeded, whereas a return value of false indicates that the login module should be ignored. - If the
LoginContext's overall authentication succeeds,commitis invoked on eachLoginModule. If phase 1 succeeds for aLoginModule, then the commit method continues with phase 2 and associates the relevant principals, public credentials, and/or private credentials with the subject. If phase 1 fails for aLoginModule, thencommitremoves any previously stored authentication state, such as user names or passwords. The signature of thecommitmethod is:boolean commit() throws LoginException. Failure to complete the commit phase is indicated by throwing aLoginException. A return of true indicates that the method succeeded, whereas a return of false indicates that the login module should be ignored. - If the
LoginContext's overall authentication fails, then theabortmethod is invoked on eachLoginModule. Theabortmethod removes or destroys any authentication state created by the login or initialize methods. The signature of theabortmethod isboolean abort() throws LoginException. Failure to complete theabortphase is indicated by throwing aLoginException. A return of true indicates that the method succeeded, whereas a return of false indicates that the login module should be ignored. - To remove the authentication state after a successful login, the application invokes
logouton theLoginContext. This in turn results in alogoutmethod invocation on eachLoginModule. Thelogoutmethod removes the principals and credentials originally associated with the subject during thecommitoperation. Credentials should be destroyed upon removal. The signature of thelogoutmethod is:boolean logout() throws LoginException. Failure to complete the logout process is indicated by throwing aLoginException. A return of true indicates that the method succeeded, whereas a return of false indicates that the login module should be ignored.
LoginModule must communicate with the user to obtain authentication information, it uses a CallbackHandler object. Applications implement the CallbackHandler interface and pass it to the LoginContext, which send the authentication information directly to the underlying login modules.
CallbackHandler both to gather input from users, such as a password or smart card PIN, and to supply information to users, such as status information. By allowing the application to specify the CallbackHandler, underlying LoginModules remain independent from the different ways applications interact with users. For example, a CallbackHandler's implementation for a GUI application might display a window to solicit user input. On the other hand, a CallbackHandler implementation for a non-GUI environment, such as an application server, might simply obtain credential information by using an application server API. The CallbackHandler interface has one method to implement:
void handle(Callback[] callbacks)
throws java.io.IOException,
UnsupportedCallbackException;
Callback interface is the last authentication class we will look at. This is a tagging interface for which several default implementations are provided, including the NameCallback and PasswordCallback used in an earlier example. A LoginModule uses a Callback to request information required by the authentication mechanism. LoginModules pass an array of Callbacks directly to the CallbackHandler.handle method during the authentication's login phase. If a callbackhandler does not understand how to use a Callback object passed into the handle method, it throws an UnsupportedCallbackException to abort the login call.
20.7. Securing Interfaces
20.7.1. Hot Rod Interface Security
20.7.1.1. Encryption of communication between Hot Rod Server and Hot Rod client
Example 20.4. Secure Hot Rod Using SSL/TLS
import javax.security.auth.callback.Callback;
import javax.security.auth.callback.CallbackHandler;
import javax.security.auth.callback.UnsupportedCallbackException;
import org.infinispan.client.hotrod.RemoteCache;
import org.infinispan.client.hotrod.RemoteCacheManager;
import org.infinispan.client.hotrod.configuration.ConfigurationBuilder;
import org.infinispan.client.hotrod.impl.ConfigurationProperties;
[...]
public class SslConfiguration {
public static final String ISPN_IP = "127.0.0.1";
public static final String SERVER_NAME = "node0";
public static final String SASL_MECH = "EXTERNAL";
private static final String KEYSTORE_PATH = "./keystore_client.jks";
private static final String KEYSTORE_PASSWORD = "secret";
private static final String TRUSTSTORE_PATH = "./truststore_client.jks";
private static final String TRUSTSTORE_PASSWORD = "secret";
SslConfiguration(boolean enabled,
String keyStoreFileName,
char[] keyStorePassword,
SSLContext sslContext,
String trustStoreFileName,
char[] trustStorePassword) {
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.addServer()
.host(ISPN_IP)
.port(ConfigurationProperties.DEFAULT_HOTROD_PORT);
//setup auth
builder.security()
.authentication()
.serverName(SERVER_NAME)
.saslMechanism(SASL_MECH)
.enable()
.callbackHandler(new VoidCallbackHandler());
//setup encrypt
builder.security()
.ssl()
.enable()
.keyStoreFileName(KEYSTORE_PATH)
.keyStorePassword(KEYSTORE_PASSWORD.toCharArray())
.trustStoreFileName(TRUSTSTORE_PATH)
.trustStorePassword(TRUSTSTORE_PASSWORD.toCharArray());
RemoteCacheManager cacheManager = new RemoteCacheManager(builder.build());
RemoteCache<Object, Object> cache = cacheManager.getCache(RemoteCacheManager.DEFAULT_CACHE_NAME);
}
private static class VoidCallbackHandler implements CallbackHandler {
@Override
public void handle(Callback[] clbcks) throws IOException, UnsupportedCallbackException {
}
}
}Important
20.7.1.2. Securing Hot Rod to LDAP Server using SSL
PLAIN authentication over SSL may be used for Hot Rod client authentication against an LDAP server. The Hot Rod client sends plain text credentials to the JBoss Data Grid server over SSL, and the server subsequently verifies the provided credentials against the specified LDAP server. In addition, a secure connection must be configured between the JBoss Data Grid server and the LDAP server. Refer to the JBoss Data Grid Administration and Configuration Guide for additional information on configuring the server to communicate to an LDAP backend. The example below demonstrates configuring PLAIN authentication over SSL on the Hot Rod client side:
Example 20.5. Hot Rod Client Authentication to LDAP Server
import static org.infinispan.demo.util.CacheOps.dumpCache;
import static org.infinispan.demo.util.CacheOps.onCache;
import static org.infinispan.demo.util.CacheOps.putTestKV;
import static org.infinispan.demo.util.CmdArgs.LOGIN_KEY;
import static org.infinispan.demo.util.CmdArgs.PASS_KEY;
import static org.infinispan.demo.util.CmdArgs.getCredentials;
import java.util.Map;
import javax.net.ssl.SSLContext;
import org.infinispan.client.hotrod.RemoteCache;
import org.infinispan.client.hotrod.RemoteCacheManager;
import org.infinispan.client.hotrod.configuration.ConfigurationBuilder;
import org.infinispan.client.hotrod.impl.ConfigurationProperties;
import org.infinispan.commons.util.SslContextFactory;
import org.infinispan.demo.util.SaslUtils.SimpleLoginHandler;
public class HotRodPlainAuthOverSSL {
public static final String ISPN_IP = "127.0.0.1";
public static final String SERVER_NAME = "node0";
public static final String SASL_MECH = "PLAIN";
private static final String SECURITY_REALM = "ApplicationRealm";
private static final String TRUSTSTORE_PATH = "./truststore_client.jks";
private static final String TRUSTSTORE_PASSWORD = "secret";
public static void main(String[] args) {
Map<String, String> userArgs = null;
try {
userArgs = getCredentials(args);
} catch (IllegalArgumentException e) {
System.err.println(e.getMessage());
System.err.println(
"Invalid credentials format, plase provide credentials (and optionally cache name) with --cache=<cache> --user=<user> --password=<password>");
System.exit(1);
}
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.addServer().host(ISPN_IP).port(ConfigurationProperties.DEFAULT_HOTROD_PORT);
//set up PLAIN auth
builder.security().authentication().serverName(SERVER_NAME).saslMechanism(SASL_MECH).enable().callbackHandler(
new SimpleLoginHandler(userArgs.get(LOGIN_KEY), userArgs.get(PASS_KEY), SECURITY_REALM));
//set up SSL
SSLContext cont = SslContextFactory.getContext(null, null, TRUSTSTORE_PATH, TRUSTSTORE_PASSWORD.toCharArray());
builder.security().ssl().sslContext(cont).enable();
RemoteCacheManager cacheManager = new RemoteCacheManager(builder.build());
RemoteCache<Object, Object> cache = cacheManager.getCache(RemoteCacheManager.DEFAULT_CACHE_NAME);
onCache(cache, putTestKV.andThen(dumpCache));
cacheManager.stop();
System.exit(0);
}
}Important
20.7.1.3. User Authentication over Hot Rod Using SASL
PLAINis the least secure mechanism because credentials are transported in plain text format. However, it is also the simplest mechanism to implement. This mechanism can be used in conjunction with encryption (SSL) for additional security.DIGEST-MD5is a mechanism than hashes the credentials before transporting them. As a result, it is more secure than thePLAINmechanism.GSSAPIis a mechanism that uses Kerberos tickets. As a result, it requires a correctly configured Kerberos Domain Controller (for example, Microsoft Active Directory).EXTERNALis a mechanism that obtains the required credentials from the underlying transport (for example, from aX.509client certificate) and therefore requires client certificate encryption to work correctly.
20.7.1.3.1. Configure Hot Rod Authentication (GSSAPI/Kerberos)
Procedure 20.1. Configure SASL GSSAPI/Kerberos Authentication - Client-side Configuration
- Ensure that the Server-Side configuration has been completed. As this is configured declaratively this configuration is found in the JBoss Data Grid Administration and Configuration Guide.
- Define a login module in a login configuration file (
gss.conf) on the client side:GssExample { com.sun.security.auth.module.Krb5LoginModule required client=TRUE; }; - Set up the following system properties:
java.security.auth.login.config=gss.conf java.security.krb5.conf=/etc/krb5.confNote
Thekrb5.conffile is dependent on the environment and must point to the Kerberos Key Distribution Center. - Implement the
CallbackHandler:public class MyCallbackHandler implements CallbackHandler { final private String username; final private char[] password; final private String realm; public MyCallbackHandler() { } public MyCallbackHandler (String username, String realm, char[] password) { this.username = username; this.password = password; this.realm = realm; } @Override public void handle(Callback[] callbacks) throws IOException, UnsupportedCallbackException { for (Callback callback : callbacks) { if (callback instanceof NameCallback) { NameCallback nameCallback = (NameCallback) callback; nameCallback.setName(username); } else if (callback instanceof PasswordCallback) { PasswordCallback passwordCallback = (PasswordCallback) callback; passwordCallback.setPassword(password); } else if (callback instanceof AuthorizeCallback) { AuthorizeCallback authorizeCallback = (AuthorizeCallback) callback; authorizeCallback.setAuthorized(authorizeCallback.getAuthenticationID().equals( authorizeCallback.getAuthorizationID())); } else if (callback instanceof RealmCallback) { RealmCallback realmCallback = (RealmCallback) callback; realmCallback.setText(realm); } else { throw new UnsupportedCallbackException(callback); } } } } - Configure the Hot Rod Client, as seen in the below snippet:
LoginContext lc = new LoginContext("GssExample", new MyCallbackHandler("krb_user", "krb_password".toCharArra())); lc.login(); Subject clientSubject = lc.getSubject(); ConfigurationBuilder clientBuilder = new ConfigurationBuilder(); clientBuilder.addServer() .host("127.0.0.1") .port(11222) .socketTimeout(1200000) .security() .authentication() .enable() .serverName("infinispan-server") .saslMechanism("GSSAPI") .clientSubject(clientSubject) .callbackHandler(new MyCallbackHandler()); remoteCacheManager = new RemoteCacheManager(clientBuilder.build()); RemoteCache<String, String> cache = remoteCacheManager.getCache("secured");
20.7.1.3.2. Configure Hot Rod Authentication (MD5)
- Ensure that the server has been configured for MD5 Authentication. Instructions for performing this configuration on the server are found in JBoss Data Grid's Administration and Configuration Guide.
- Implement the
CallbackHandler:public class MyCallbackHandler implements CallbackHandler { final private String username; final private char[] password; final private String realm; public MyCallbackHandler (String username, String realm, char[] password) { this.username = username; this.password = password; this.realm = realm; } @Override public void handle(Callback[] callbacks) throws IOException, UnsupportedCallbackException { for (Callback callback : callbacks) { if (callback instanceof NameCallback) { NameCallback nameCallback = (NameCallback) callback; nameCallback.setName(username); } else if (callback instanceof PasswordCallback) { PasswordCallback passwordCallback = (PasswordCallback) callback; passwordCallback.setPassword(password); } else if (callback instanceof AuthorizeCallback) { AuthorizeCallback authorizeCallback = (AuthorizeCallback) callback; authorizeCallback.setAuthorized(authorizeCallback.getAuthenticationID().equals( authorizeCallback.getAuthorizationID())); } else if (callback instanceof RealmCallback) { RealmCallback realmCallback = (RealmCallback) callback; realmCallback.setText(realm); } else { throw new UnsupportedCallbackException(callback); } } } } - Connect the client to the configured Hot Rod connector as seen below:
ConfigurationBuilder clientBuilder = new ConfigurationBuilder(); clientBuilder.addServer() .host("127.0.0.1") .port(11222) .socketTimeout(1200000) .security() .authentication() .enable() .serverName("myhotrodserver") .saslMechanism("DIGEST-MD5") .callbackHandler(new MyCallbackHandler("myuser", "ApplicationRealm", "qwer1234!".toCharArray())); remoteCacheManager = new RemoteCacheManager(clientBuilder.build()); RemoteCache<String, String> cache = remoteCacheManager.getCache("secured");
20.7.2. Hot Rod C++ Client Encryption
serverCAFile method on the SslConfigurationBuilder. Additionally, the client's certificate may be defined with the clientCertificateFile, allowing for client authentication.
Important
Example 20.6. Hot Rod C++ TLS Example
#include "infinispan/hotrod/ConfigurationBuilder.h"
#include "infinispan/hotrod/RemoteCacheManager.h"
#include "infinispan/hotrod/RemoteCache.h"
#include "infinispan/hotrod/Version.h"
#include "infinispan/hotrod/JBasicMarshaller.h"
#include <stdlib.h>
#include <iostream>
#include <memory>
#include <typeinfo>
using namespace infinispan::hotrod;
int main(int argc, char** argv) {
std::cout << "TLS Test" << std::endl;
if (argc < 2) {
std::cerr << "Usage: " << argv[0] << " server_ca_file [client_ca_file]" << std::endl;
return 1;
}
{
ConfigurationBuilder builder;
builder.addServer().host("127.0.0.1").port(11222).protocolVersion(Configuration::PROTOCOL_VERSION_24);
// Enable the TLS layer and install the server public key
// this ensure that the server is authenticated
builder.ssl().enable().serverCAFile(argv[1]);
if (argc > 2) {
// Send a client certificate for authentication (optional)
// without this the socket will only be encrypted
std::cout << "Using supplied client certificate for authentication against the server" << std::endl;
builder.ssl().clientCertificateFile(argv[2]);
}
// That's all. Now do business as usual
RemoteCacheManager cacheManager(builder.build(), false);
BasicMarshaller<std::string> *km = new BasicMarshaller<std::string>();
BasicMarshaller<std::string> *vm = new BasicMarshaller<std::string>();
RemoteCache<std::string, std::string> cache = cacheManager.getCache<std::string, std::string>(km,
&Marshaller<std::string>::destroy, vm, &Marshaller<std::string>::destroy );
cacheManager.start();
cache.clear();
std::string k1("key13");
std::string v1("boron");
cache.put(k1, v1);
std::unique_ptr<std::string> rv(cache.get(k1));
if (rv->compare(v1)) {
std::cerr << "get/put fail for " << k1 << " got " << *rv << " expected " << v1 << std::endl;
return 1;
}
cacheManager.stop();
}
return 0;
}20.7.3. Hot Rod C# Client Encryption
ServerCAFile method on the SslConfigurationBuilder. Additionally, the client's certificate may be defined with the ClientCertificateFile, allowing for client authentication.
Important
Example 20.7. Hot Rod C# TLS Example
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Infinispan.HotRod;
using Infinispan.HotRod.Config;
namespace TLS
{
/// <summary>
/// This sample code shows how to perform operations over TLS using the C# client
/// </summary>
class TLS
{
static void Main(string[] args)
{
// Cache manager setup
RemoteCacheManager remoteManager;
ConfigurationBuilder conf = new ConfigurationBuilder();
conf.AddServer().Host("127.0.0.1").Port(11222).ConnectionTimeout(90000).SocketTimeout(900);
SslConfigurationBuilder sslConfB = conf.Ssl();
// Retrieve the server public certificate, needed to do server authentication. Mandatory
if (!System.IO.File.Exists("resources/infinispan-ca.pem"))
{
Console.WriteLine("File not found: resources/infinispan-ca.pem.");
Environment.Exit(-1);
}
sslConfB.Enable().ServerCAFile("resources/infinispan-ca.pem");
// Retrieve the client public certificate, needed if the server requires client authentication. Optional
if (!System.IO.File.Exists("resources/client-ca.pem"))
{
Console.WriteLine("File not found: resources/client-ca.pem.");
Environment.Exit(-1);
}
sslConfB.ClientCertificateFile("resources/client-ca.pem");
// Usual business now
conf.Marshaller(new JBasicMarshaller());
remoteManager = new RemoteCacheManager(conf.Build(), true);
IRemoteCache<string, string> testCache = remoteManager.GetCache<string, string>();
testCache.Clear();
string k1 = "key13";
string v1 = "boron";
testCache.Put(k1, v1);
}
}
}20.8. The Security Audit Logger
org.infinispan.security.impl.DefaultAuditLogger. This logger outputs audit logs using the available logging framework (for example, JBoss Logging) and provides results at the TRACE level and the AUDIT category.
AUDIT category to either a log file, a JMS queue, or a database, use the appropriate log appender.
20.8.1. Configure the Security Audit Logger (Library Mode)
GlobalConfigurationBuilder global = new GlobalConfigurationBuilder();
global.security()
.authorization()
.auditLogger(new DefaultAuditLogger());20.8.2. Custom Audit Loggers
org.infinispan.security.AuditLogger interface. If no custom logger is provided, the default logger (DefaultAuditLogger) is used.
Chapter 21. Security for Cluster Traffic
21.1. Configure Node Security in Library Mode
SASL protocol to your JGroups XML configuration.
CallbackHandlers, to obtain certain information necessary for the authentication handshake. Users must supply their own CallbackHandlers on both client and server sides.
Important
JAAS API is only available when configuring user authentication and authorization, and is not available for node security.
CallbackHandler class. In this example, login and password are checked against values provided via Java properties when JBoss Data Grid is started, and authorization is checked against role which is defined in the class ("test_user").
Example 21.1. Callback Handler Class
public class SaslPropAuthUserCallbackHandler implements CallbackHandler {
private static final String APPROVED_USER = "test_user";
private final String name;
private final char[] password;
private final String realm;
public SaslPropAuthUserCallbackHandler() {
this.name = System.getProperty("sasl.username");
this.password = System.getProperty("sasl.password").toCharArray();
this.realm = System.getProperty("sasl.realm");
}
@Override
public void handle(Callback[] callbacks) throws IOException, UnsupportedCallbackException {
for (Callback callback : callbacks) {
if (callback instanceof PasswordCallback) {
((PasswordCallback) callback).setPassword(password);
} else if (callback instanceof NameCallback) {
((NameCallback) callback).setName(name);
} else if (callback instanceof AuthorizeCallback) {
AuthorizeCallback authorizeCallback = (AuthorizeCallback) callback;
if (APPROVED_USER.equals(authorizeCallback.getAuthorizationID())) {
authorizeCallback.setAuthorized(true);
} else {
authorizeCallback.setAuthorized(false);
}
} else if (callback instanceof RealmCallback) {
RealmCallback realmCallback = (RealmCallback) callback;
realmCallback.setText(realm);
} else {
throw new UnsupportedCallbackException(callback);
}
}
}
}
javax.security.auth.callback.NameCallback and javax.security.auth.callback.PasswordCallback callbacks
javax.security.sasl.AuthorizeCallback callback.
21.2. Node Authorization in Library Mode
SASL protocol in JGroups is concerned only with the authentication process. To implement node authorization, you can do so within the server callback handler by throwing an Exception.
Example 21.2. Implementing Node Authorization
public class AuthorizingServerCallbackHandler implements CallbackHandler {
@Override
public void handle(Callback[] callbacks) throws IOException,
UnsupportedCallbackException {
for (Callback callback : callbacks) {
<!-- Additional configuration information here -->
if (callback instanceof AuthorizeCallback) {
AuthorizeCallback acb = (AuthorizeCallback) callback;
if (!"myclusterrole".equals(acb.getAuthenticationID()))) {
throw new SecurityException("Unauthorized node " +user);
}
<!-- Additional configuration information here -->
}
}
}Part IV. Advanced Features in Red Hat JBoss Data Grid
- Transactions
- Marshalling
- Listeners and Notifications
- The Infinispan CDI Module
- MapReduce
- Distributed Execution
- Interoperability and Compatibility Mode
Chapter 22. Transactions
22.1. About Java Transaction API
- First, it retrieves the transactions currently associated with the thread.
- If not already done, it registers an
XAResourcewith the transaction manager to receive notifications when a transaction is committed or rolled back.
22.2. Configure Transactions (Library Mode)
TransactionManagerLookup interface. When initialized, the cache creates an instance of the specified class and invokes its getTransactionManager() method to locate and return a reference to the Transaction Manager.
Procedure 22.1. Configure Transactions in Library Mode (Programmatic Configuration)
Configuration config = new ConfigurationBuilder()/* ... */.transaction() .transactionMode(TransactionMode.TRANSACTIONAL) .transactionManagerLookup(new GenericTransactionManagerLookup()) .lockingMode(LockingMode.OPTIMISTIC) .useSynchronization(true) .recovery() .recoveryInfoCacheName("anotherRecoveryCacheName").build();- Set the transaction mode.
- Select and set a lookup class. See the table below this procedure for a list of available lookup classes.
- The
lockingModevalue determines whether optimistic or pessimistic locking is used. If the cache is non-transactional, the locking mode is ignored. The default value isOPTIMISTIC. - The
useSynchronizationvalue configures the cache to register a synchronization with the transaction manager, or register itself as an XA resource. The default value istrue(use synchronization). - The
recoveryparameter enables recovery for the cache when set totrue.TherecoveryInfoCacheNamesets the name of the cache where recovery information is held. The default name of the cache is specified byRecoveryConfiguration.DEFAULT_RECOVERY_INFO_CACHE.
Configure Write Skew Check
ThewriteSkewcheck determines if a modification to the entry from a different transaction should roll back the transaction. Write skew set totruerequiresisolation_levelset toREPEATABLE_READ. The default value forwriteSkewandisolation_levelarefalseandREAD_COMMITTEDrespectively.Configuration config = new ConfigurationBuilder()/* ... */.locking() .isolationLevel(IsolationLevel.REPEATABLE_READ).writeSkewCheck(true);Configure Entry Versioning
For clustered caches, enable write skew check by enabling entry versioning and setting its value toSIMPLE.Configuration config = new ConfigurationBuilder()/* ... */.versioning() .enable() .scheme(VersioningScheme.SIMPLE);
| Class Name | Details |
|---|---|
| org.infinispan.transaction.lookup.DummyTransactionManagerLookup | Used primarily for testing environments. This testing transaction manager is not for use in a production environment and is severely limited in terms of functionality, specifically for concurrent transactions and recovery. |
| org.infinispan.transaction.lookup.JBossStandaloneJTAManagerLookup | The default transaction manager when Red Hat JBoss Data Grid runs in a standalone environment. It is a fully functional JBoss Transactions based transaction manager that overcomes the functionality limits of the DummyTransactionManager. |
| org.infinispan.transaction.lookup.GenericTransactionManagerLookup | GenericTransactionManagerLookup is used by default when no transaction lookup class is specified. This lookup class is recommended when using JBoss Data Grid with Java EE-compatible environment that provides a TransactionManager interface, and is capable of locating the Transaction Manager in most Java EE application servers. If no transaction manager is located, it defaults to DummyTransactionManager. |
| org.infinispan.transaction.lookup.JBossTransactionManagerLookup | The JbossTransactionManagerLookup finds the standard transaction manager running in the application server. This lookup class uses JNDI to look up the TransactionManager instance, and is recommended when custom caches are being used in JTA transactions. |
Note
JBossStandaloneJTAManagerLookup, which uses JBoss Transactions.
22.3. Transactions Spanning Multiple Cache Instances
22.4. The Transaction Manager
TransactionManager tm = cache.getAdvancedCache().getTransactionManager();Example 22.1. Performing Operations
tm.begin();
Object value = cache.get("A");
cache.remove("A");
Object prev = cache.put("B", value);
if (prev == null)
tm.commit();
else
tm.rollback();Note
XAResource xar = cache.getAdvancedCache().getXAResource();Chapter 23. Marshalling
- transform data for relay to other JBoss Data Grid nodes within the cluster.
- transform data to be stored in underlying cache stores.
23.1. About Marshalling Framework
java.io.ObjectOutput and java.io.ObjectInput implementations compared to the standard java.io.ObjectOutputStream and java.io.ObjectInputStream.
23.2. Support for Non-Serializable Objects
Serializable or Externalizable support into your classes, you could (as an example) use XStream to convert the non-serializable objects into a String that can be stored in JBoss Data Grid.
Note
23.3. Hot Rod and Marshalling
- All data stored by clients on the JBoss Data Grid server are provided either as a byte array, or in a primitive format that is marshalling compatible for JBoss Data Grid.On the server side of JBoss Data Grid, marshalling occurs where the data stored in primitive format are converted into byte array and replicated around the cluster or stored to a cache store. No marshalling configuration is required on the server side of JBoss Data Grid.
- At the client level, marshalling must have a
Marshallerconfiguration element specified in the RemoteCacheManager configuration in order to serialize and deserialize POJOs.Due to Hot Rod's binary nature, it relies on marshalling to transform POJOs, specifically keys or values, into byte array.
23.4. Configuring the Marshaller using the RemoteCacheManager
marshaller configuration element in the RemoteCacheManager, the value of which must be the name of the class implementing the Marshaller interface. The default value for this property is org.infinispan.commons.marshall.jboss.GenericJBossMarshaller.
Procedure 23.1. Define a Marshaller
Create a ConfigurationBuilder
Create a ConfigurationBuilder and configure it with the required settings.ConfigurationBuilder builder = new ConfigurationBuilder(); //... (other configuration)Add a Marshaller Class
Add a Marshaller class specification within the Marshaller method.builder.marshaller(GenericJBossMarshaller.class);- Alternatively, specify a custom Marshaller instance.
builder.marshaller(new GenericJBossMarshaller());
Start the RemoteCacheManager
Build the configuration containing the Marshaller, and start a new RemoteCacheManager with it.Configuration configuration = builder.build(); RemoteCacheManager manager = new RemoteCacheManager(configuration);
Note
23.5. Troubleshooting
23.5.1. Marshalling Troubleshooting
Example 23.1. Exception Stack Trace
java.io.NotSerializableException: java.lang.Object
at org.jboss.marshalling.river.RiverMarshaller.doWriteObject(RiverMarshaller.java:857)
at org.jboss.marshalling.AbstractMarshaller.writeObject(AbstractMarshaller.java:407)
at org.infinispan.marshall.exts.ReplicableCommandExternalizer.writeObject(ReplicableCommandExternalizer.java:54)
at org.infinispan.marshall.jboss.ConstantObjectTable$ExternalizerAdapter.writeObject(ConstantObjectTable.java:267)
at org.jboss.marshalling.river.RiverMarshaller.doWriteObject(RiverMarshaller.java:143)
at org.jboss.marshalling.AbstractMarshaller.writeObject(AbstractMarshaller.java:407)
at org.infinispan.marshall.jboss.JBossMarshaller.objectToObjectStream(JBossMarshaller.java:167)
at org.infinispan.marshall.VersionAwareMarshaller.objectToBuffer(VersionAwareMarshaller.java:92)
at org.infinispan.marshall.VersionAwareMarshaller.objectToByteBuffer(VersionAwareMarshaller.java:170)
at org.infinispan.marshall.VersionAwareMarshallerTest.testNestedNonSerializable(VersionAwareMarshallerTest.java:415)
Caused by: an exception which occurred:
in object java.lang.Object@b40ec4
in object org.infinispan.commands.write.PutKeyValueCommand@df661da7
... Removed 22 stack framesin object and stack traces are read in the same way: the highest in object message is the innermost one and the outermost in object message is the lowest.
java.lang.Object instance within an org.infinispan.commands.write.PutKeyValueCommand instance cannot be serialized because java.lang.Object@b40ec4 is not serializable.
DEBUG or TRACE logging levels are enabled, marshalling exceptions will contain toString() representations of objects in the stack trace. The following is an example that depicts such a scenario:
Example 23.2. Exceptions with Logging Levels Enabled
java.io.NotSerializableException: java.lang.Object
...
Caused by: an exception which occurred:
in object java.lang.Object@b40ec4
-> toString = java.lang.Object@b40ec4
in object org.infinispan.commands.write.PutKeyValueCommand@df661da7
-> toString = PutKeyValueCommand{key=k, value=java.lang.Object@b40ec4, putIfAbsent=false, lifespanMillis=0, maxIdleTimeMillis=0}Example 23.3. Unmarshalling Exceptions
java.io.IOException: Injected failue!
at org.infinispan.marshall.VersionAwareMarshallerTest$1.readExternal(VersionAwareMarshallerTest.java:426)
at org.jboss.marshalling.river.RiverUnmarshaller.doReadNewObject(RiverUnmarshaller.java:1172)
at org.jboss.marshalling.river.RiverUnmarshaller.doReadObject(RiverUnmarshaller.java:273)
at org.jboss.marshalling.river.RiverUnmarshaller.doReadObject(RiverUnmarshaller.java:210)
at org.jboss.marshalling.AbstractUnmarshaller.readObject(AbstractUnmarshaller.java:85)
at org.infinispan.marshall.jboss.JBossMarshaller.objectFromObjectStream(JBossMarshaller.java:210)
at org.infinispan.marshall.VersionAwareMarshaller.objectFromByteBuffer(VersionAwareMarshaller.java:104)
at org.infinispan.marshall.VersionAwareMarshaller.objectFromByteBuffer(VersionAwareMarshaller.java:177)
at org.infinispan.marshall.VersionAwareMarshallerTest.testErrorUnmarshalling(VersionAwareMarshallerTest.java:431)
Caused by: an exception which occurred:
in object of type org.infinispan.marshall.VersionAwareMarshallerTest$1IOException was thrown when an instance of the inner class org.infinispan.marshall.VersionAwareMarshallerTest$1 is unmarshalled.
DEBUG or TRACE logging levels are enabled, the class type's classloader information is provided. An example of this classloader information is as follows:
Example 23.4. Classloader Information
java.io.IOException: Injected failue!
...
Caused by: an exception which occurred:
in object of type org.infinispan.marshall.VersionAwareMarshallerTest$1
-> classloader hierarchy:
-> type classloader = sun.misc.Launcher$AppClassLoader@198dfaf
->...file:/opt/eclipse/configuration/org.eclipse.osgi/bundles/285/1/.cp/eclipse-testng.jar
->...file:/opt/eclipse/configuration/org.eclipse.osgi/bundles/285/1/.cp/lib/testng-jdk15.jar
->...file:/home/galder/jboss/infinispan/code/trunk/core/target/test-classes/
->...file:/home/galder/jboss/infinispan/code/trunk/core/target/classes/
->...file:/home/galder/.m2/repository/org/testng/testng/5.9/testng-5.9-jdk15.jar
->...file:/home/galder/.m2/repository/net/jcip/jcip-annotations/1.0/jcip-annotations-1.0.jar
->...file:/home/galder/.m2/repository/org/easymock/easymockclassextension/2.4/easymockclassextension-2.4.jar
->...file:/home/galder/.m2/repository/org/easymock/easymock/2.4/easymock-2.4.jar
->...file:/home/galder/.m2/repository/cglib/cglib-nodep/2.1_3/cglib-nodep-2.1_3.jar
->...file:/home/galder/.m2/repository/javax/xml/bind/jaxb-api/2.1/jaxb-api-2.1.jar
->...file:/home/galder/.m2/repository/javax/xml/stream/stax-api/1.0-2/stax-api-1.0-2.jar
->...file:/home/galder/.m2/repository/javax/activation/activation/1.1/activation-1.1.jar
->...file:/home/galder/.m2/repository/jgroups/jgroups/2.8.0.CR1/jgroups-2.8.0.CR1.jar
->...file:/home/galder/.m2/repository/org/jboss/javaee/jboss-transaction-api/1.0.1.GA/jboss-transaction-api-1.0.1.GA.jar
->...file:/home/galder/.m2/repository/org/jboss/marshalling/river/1.2.0.CR4-SNAPSHOT/river-1.2.0.CR4-SNAPSHOT.jar
->...file:/home/galder/.m2/repository/org/jboss/marshalling/marshalling-api/1.2.0.CR4-SNAPSHOT/marshalling-api-1.2.0.CR4-SNAPSHOT.jar
->...file:/home/galder/.m2/repository/org/jboss/jboss-common-core/2.2.14.GA/jboss-common-core-2.2.14.GA.jar
->...file:/home/galder/.m2/repository/org/jboss/logging/jboss-logging-spi/2.0.5.GA/jboss-logging-spi-2.0.5.GA.jar
->...file:/home/galder/.m2/repository/log4j/log4j/1.2.14/log4j-1.2.14.jar
->...file:/home/galder/.m2/repository/com/thoughtworks/xstream/xstream/1.2/xstream-1.2.jar
->...file:/home/galder/.m2/repository/xpp3/xpp3_min/1.1.3.4.O/xpp3_min-1.1.3.4.O.jar
->...file:/home/galder/.m2/repository/com/sun/xml/bind/jaxb-impl/2.1.3/jaxb-impl-2.1.3.jar
-> parent classloader = sun.misc.Launcher$ExtClassLoader@1858610
->...file:/usr/java/jdk1.5.0_19/jre/lib/ext/localedata.jar
->...file:/usr/java/jdk1.5.0_19/jre/lib/ext/sunpkcs11.jar
->...file:/usr/java/jdk1.5.0_19/jre/lib/ext/sunjce_provider.jar
->...file:/usr/java/jdk1.5.0_19/jre/lib/ext/dnsns.jar
... Removed 22 stack frames23.5.2. Other Marshalling Related Issues
EOFException. During a state transfer, if an EOFException is logged that states that the state receiver has Read past end of file, this can be dealt with depending on whether the state provider encounters an error when generating the state. For example, if the state provider is currently providing a state to a node, when another node requests a state, the state generator log can contain:
Example 23.5. State Generator Log
2010-12-09 10:26:21,533 20267 ERROR [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (STREAMING_STATE_TRANSFER-sender-1,Infinispan-Cluster,NodeJ-2368:) Caught while responding to state transfer request
org.infinispan.statetransfer.StateTransferException: java.util.concurrent.TimeoutException: Could not obtain exclusive processing lock
at org.infinispan.statetransfer.StateTransferManagerImpl.generateState(StateTransferManagerImpl.java:175)
at org.infinispan.remoting.InboundInvocationHandlerImpl.generateState(InboundInvocationHandlerImpl.java:119)
at org.infinispan.remoting.transport.jgroups.JGroupsTransport.getState(JGroupsTransport.java:586)
at org.jgroups.blocks.MessageDispatcher$ProtocolAdapter.handleUpEvent(MessageDispatcher.java:691)
at org.jgroups.blocks.MessageDispatcher$ProtocolAdapter.up(MessageDispatcher.java:772)
at org.jgroups.JChannel.up(JChannel.java:1465)
at org.jgroups.stack.ProtocolStack.up(ProtocolStack.java:954)
at org.jgroups.protocols.pbcast.FLUSH.up(FLUSH.java:478)
at org.jgroups.protocols.pbcast.STREAMING_STATE_TRANSFER$StateProviderHandler.process(STREAMING_STATE_TRANSFER.java:653)
at org.jgroups.protocols.pbcast.STREAMING_STATE_TRANSFER$StateProviderThreadSpawner$1.run(STREAMING_STATE_TRANSFER.java:582)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
at java.lang.Thread.run(Thread.java:680)
Caused by: java.util.concurrent.TimeoutException: Could not obtain exclusive processing lock
at org.infinispan.remoting.transport.jgroups.JGroupsDistSync.acquireProcessingLock(JGroupsDistSync.java:71)
at org.infinispan.statetransfer.StateTransferManagerImpl.generateTransactionLog(StateTransferManagerImpl.java:202)
at org.infinispan.statetransfer.StateTransferManagerImpl.generateState(StateTransferManagerImpl.java:165)
... 12 more
EOFException, displayed as follows, when failing to read the transaction log that was not written by the sender:
Example 23.6. EOFException
2010-12-09 10:26:21,535 20269 TRACE [org.infinispan.marshall.VersionAwareMarshaller] (Incoming-2,Infinispan-Cluster,NodeI-38030:) Log exception reported
java.io.EOFException: Read past end of file
at org.jboss.marshalling.AbstractUnmarshaller.eofOnRead(AbstractUnmarshaller.java:184)
at org.jboss.marshalling.AbstractUnmarshaller.readUnsignedByteDirect(AbstractUnmarshaller.java:319)
at org.jboss.marshalling.AbstractUnmarshaller.readUnsignedByte(AbstractUnmarshaller.java:280)
at org.jboss.marshalling.river.RiverUnmarshaller.doReadObject(RiverUnmarshaller.java:207)
at org.jboss.marshalling.AbstractUnmarshaller.readObject(AbstractUnmarshaller.java:85)
at org.infinispan.marshall.jboss.GenericJBossMarshaller.objectFromObjectStream(GenericJBossMarshaller.java:175)
at org.infinispan.marshall.VersionAwareMarshaller.objectFromObjectStream(VersionAwareMarshaller.java:184)
at org.infinispan.statetransfer.StateTransferManagerImpl.processCommitLog(StateTransferManagerImpl.java:228)
at org.infinispan.statetransfer.StateTransferManagerImpl.applyTransactionLog(StateTransferManagerImpl.java:250)
at org.infinispan.statetransfer.StateTransferManagerImpl.applyState(StateTransferManagerImpl.java:320)
at org.infinispan.remoting.InboundInvocationHandlerImpl.applyState(InboundInvocationHandlerImpl.java:102)
at org.infinispan.remoting.transport.jgroups.JGroupsTransport.setState(JGroupsTransport.java:603)
...
Chapter 24. The Infinispan CDI Module
infinispan-cdi module. The infinispan-cdi module offers:
- Configuration and injection using the Cache API.
- A bridge between the cache listeners and the CDI event system.
- Partial support for the JCACHE caching annotations.
24.1. Using Infinispan CDI
24.1.1. Infinispan CDI Prerequisites
- Ensure that the most recent version of the infinispan-cdi module is used.
- Ensure that the correct dependency information is set.
24.1.2. Set the CDI Maven Dependency
In Library mode the infinispan-embedded artifact contains the CDI module, and should be added as a dependency as seen in the below example:
<dependency>
<groupId>org.infinispan</groupId>
<artifactId>infinispan-embedded</artifactId>
<version>${infinispan.version}</version>
</dependency>
In Remote Client-Server mode the infinispan-remote artifact contains the CDI module, and should be added as a dependency as seen in the below example:
<dependency>
<groupId>org.infinispan</groupId>
<artifactId>infinispan-remote</artifactId>
<version>${infinispan.version}</version>
</dependency>24.2. Using the Infinispan CDI Module
- To configure and inject Infinispan caches into CDI Beans and Java EE components.
- To configure cache managers.
- To control storage and retrieval using CDI annotations.
24.2.1. Configure and Inject Infinispan Caches
24.2.1.1. Inject an Infinispan Cache
public class MyCDIBean {
@Inject
Cache<String, String> cache;
}24.2.1.2. Inject a Remote Infinispan Cache
public class MyCDIBean {
@Inject
RemoteCache<String, String> remoteCache;
}24.2.1.3. Set the Injection's Target Cache
- Create a qualifier annotation.
- Add a producer class.
- Inject the desired class.
24.2.1.3.1. Create a Qualifier Annotation
Example 24.1. Custom Cache Qualifier
@javax.inject.Qualifier
@Target({ElementType.FIELD, ElementType.PARAMETER, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface SmallCache {}@SmallCache qualifier to specify how to create specific caches.
24.2.1.3.2. Add a Producer Class
@SmallCache qualifier (created in the previous step) specifies a way to create a cache:
Example 24.2. Using the @SmallCache Qualifier
import org.infinispan.configuration.cache.Configuration;
import org.infinispan.configuration.cache.ConfigurationBuilder;
import org.infinispan.cdi.ConfigureCache;
import javax.enterprise.inject.Produces;
public class CacheCreator {
@ConfigureCache("smallcache")
@SmallCache
@Produces
public Configuration specialCacheCfg() {
return new ConfigurationBuilder()
.eviction()
.strategy(EvictionStrategy.LRU)
.maxEntries(10)
.build();
}
}@ConfigureCachespecifies the name of the cache.@SmallCacheis the cache qualifier.
24.2.1.3.3. Inject the Desired Class
@SmallCache qualifier and the new producer class to inject a specific cache into the CDI bean as follows:
public class MyCDIBean {
@Inject @SmallCache
Cache<String, String> mySmallCache;
}24.2.2. Configure Cache Managers with CDI
24.2.2.1. Specify the Default Configuration
Example 24.3. Specifying the Default Configuration
public class Config {
@Produces
public Configuration defaultEmbeddedConfiguration () {
return new ConfigurationBuilder()
.eviction()
.strategy(EvictionStrategy.LRU)
.maxEntries(100)
.build();
}
}Note
@Default qualifier if no other qualifiers are provided.
@Produces annotation is placed in a method that returns a Configuration instance, the method is invoked when a Configuration object is required.
24.2.2.2. Override the Creation of the Embedded Cache Manager
After a producer method is annotated, this method will be called when creating an EmbeddedCacheManager, as follows:
Example 24.4. Create a Non Clustered Cache
public class Config {
@Produces
@ApplicationScoped
public EmbeddedCacheManager defaultEmbeddedCacheManager() {
Configuration cfg = new ConfigurationBuilder()
.eviction()
.strategy(EvictionStrategy.LRU)
.maxEntries(150)
.build();
return new DefaultCacheManager(cfg);
}
}@ApplicationScoped annotation specifies that the method is only called once.
The following configuration can be used to create an EmbeddedCacheManager that can create clustered caches.
Example 24.5. Create Clustered Caches
public class Config {
@Produces
@ApplicationScoped
public EmbeddedCacheManager defaultClusteredCacheManager() {
GlobalConfiguration g = new GlobalConfigurationBuilder()
.clusteredDefault()
.transport()
.clusterName("InfinispanCluster")
.build();
Configuration cfg = new ConfigurationBuilder()
.eviction()
.strategy(EvictionStrategy.LRU)
.maxEntries(150)
.build();
return new DefaultCacheManager(g, cfg);
}
}
The method annotated with @Produces in the non clustered method generates Configuration objects. The methods in the clustered cache example annonated with @Produces generate EmbeddedCacheManager objects.
EmbeddedCacheManager and injects it into the code at runtime.
Example 24.6. Generate an EmbeddedCacheManager
...
@Inject
EmbeddedCacheManager cacheManager;
...24.2.2.3. Configure a Remote Cache Manager
RemoteCacheManager is configured in a manner similar to EmbeddedCacheManagers, as follows:
Example 24.7. Configuring the Remote Cache Manager
public class Config {
@Produces
@ApplicationScoped
public RemoteCacheManager defaultRemoteCacheManager() {
Configuration conf = new ConfigurationBuilder().addServer().host(ADDRESS).port(PORT).build();
return new RemoteCacheManager(conf);
}
}}24.2.2.4. Configure Multiple Cache Managers with a Single Class
Example 24.8. Configure Multiple Cache Managers
public class Config {
@Produces
@ApplicationScoped
public org.infinispan.manager.EmbeddedCacheManager
defaultEmbeddedCacheManager() {
Configuration cfg = new ConfigurationBuilder()
.eviction()
.strategy(EvictionStrategy.LRU)
.maxEntries(150)
.build();
return new DefaultCacheManager(cfg);
}
@Produces
@ApplicationScoped
@DefaultClustered
public org.infinispan.manager.EmbeddedCacheManager
defaultClusteredCacheManager() {
GlobalConfiguration g = new GlobalConfigurationBuilder()
.clusteredDefault()
.transport()
.clusterName("InfinispanCluster")
.build();
Configuration cfg = new ConfigurationBuilder()
.eviction()
.strategy(EvictionStrategy.LRU)
.maxEntries(150)
.build();
return new DefaultCacheManager(g, cfg);
}
@Produces
@ApplicationScoped
@DefaultRemote
public RemoteCacheManager
defaultRemoteCacheManager() {
org.infinispan.client.hotrod.configuration.Configuration conf = new org.infinispan.client.hotrod.configuration.ConfigurationBuilder().addServer().host(ADDRESS).port(PORT).build();
return new RemoteCacheManager(conf);
}
@Produces
@ApplicationScoped
@RemoteCacheInDifferentDataCentre
public RemoteCacheManager newRemoteCacheManager() {
org.infinispan.client.hotrod.configuration.Configuration confid = new org.infinispan.client.hotrod.configuration.ConfigurationBuilder().addServer().host(ADDRESS_FAR_AWAY).port(PORT).build();
return new RemoteCacheManager(confid);
}
}24.2.3. Storage and Retrieval Using CDI Annotations
24.2.3.1. Configure Cache Annotations
javax.cache package.
Important
24.2.3.2. Enable Cache Annotations
beans.xml file.
Adding the following code adds interceptors such as the InjectedCacheResultInterceptor, InjectedCachePutInterceptor, InjectedCacheRemoveEntryInterceptor and the InjectedCacheRemoveAllInterceptor:
Example 24.9. Adding CDI Interceptors
<beans xmlns="http://java.sun.som/xml/ns/javaee"
xmlns:xsi="http://www/w3/org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/beans_1_0.xsd" >
<interceptors>
<class>org.infinispan.jcache.annotation.InjectedCacheResultInterceptor</class>
<class>org.infinispan.jcache.annotation.InjectedCachePutInterceptor</class>
<class>org.infinispan.jcache.annotation.InjectedCacheRemoveEntryInterceptor</class>
<class>org.infinispan.jcache.annotation.InjectedCacheRemoveAllInterceptor</class>
</interceptors>
</beans>
Adding the following code adds interceptors such as the CacheResultInterceptor, CachePutInterceptor, CacheRemoveEntryInterceptor and the CacheRemoveAllInterceptor:
Example 24.10. Adding JCache Interceptors
<beans xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/beans_1_0.xsd">
<interceptors>
<class>org.infinispan.jcache.annotation.CacheResultInterceptor</class>
<class>org.infinispan.jcache.annotation.CachePutInterceptor</class>
<class>org.infinispan.jcache.annotation.CacheRemoveEntryInterceptor</class>
<class>org.infinispan.jcache.annotation.CacheRemoveAllInterceptor</class>
</interceptors>
</beans>Note
beans.xml file for Red Hat JBoss Data Grid to use javax.cache annotations.
24.2.3.3. Caching the Result of a Method Invocation
public String toCelsiusFormatted(float fahrenheit) {
return
NumberFormat.getInstance()
.format((fahrenheit * 5 / 9) - 32)
+ " degrees Celsius";
}toCelsiusFormatted method again and stores the result in the cache.
float f = getTemperatureInFahrenheit();
Cache<Float, String>
fahrenheitToCelsiusCache = getCache();
String celsius =
fahrenheitToCelsiusCache = get(f);
if (celsius == null) {
celsius = toCelsiusFormatted(f);
fahrenheitToCelsiusCache.put(f, celsius);
}@CacheResult annotation instead, as follows:
@javax.cache.annotation.CacheResult
public String toCelsiusFormatted(float fahrenheit) {
return NumberFormat.getInstance()
.format((fahrenheit * 5 / 9) - 32)
+ " degrees Celsius";
}toCelsiusFormatted() method call.
Note
24.2.3.3.1. Specify the Cache Used
cacheName) to the @CacheResult annotation to specify the cache to check for results of the method call:
@CacheResult(cacheName = "mySpecialCache")
public String doSomething(String parameter) {
<!-- Additional configuration information here -->
}24.2.3.3.2. Cache Keys for Cached Results
@CacheResult annotation creates a key for the results fetched from a cache. The key consists of a combination of all parameters in the relevant method.
@CacheKey annotation as follows:
Example 24.11. Create a Custom Key
@CacheResult
public String doSomething
(@CacheKey String p1,
@CacheKey String p2,
String dontCare) {
<!-- Additional configuration information here -->
}p1 and p2 are used to create the cache key. The value of dontCare is not used when determining the cache key.
24.2.3.3.3. Generate a Custom Key
import javax.cache.annotation.CacheKey;
import javax.cache.annotation.CacheKeyGenerator;
import javax.cache.annotation.CacheKeyInvocationContext;
import java.lang.annotation.Annotation;
public class MyCacheKeyGenerator implements CacheKeyGenerator {
@Override
public CacheKey generateCacheKey(CacheKeyInvocationContext<? extends Annotation> ctx) {
return new MyCacheKey(
ctx.getAllParameters()[0].getValue()
);
}
}cacheKeyGenerator to the @CacheResult annotation as follows:
@CacheResult(cacheKeyGenerator = MyCacheKeyGenerator.class)
public void doSomething(String p1, String p2) {
<!-- Additional configuration information here -->
}p1 contains the custom key.
24.2.4. Cache Operations
24.2.4.1. Update a Cache Entry
@CachePut annotation is invoked, a parameter (normally passed to the method annotated with @CacheValue) is stored in the cache.
Example 24.12. Sample @CachePut Annotated Method
import javax.cache.annotation.CachePut;
import javax.cache.annotation.CacheKey;
import javax.cache.annotation.CacheValue;
@CachePut (cacheName = "personCache")
public void updatePerson
(@CacheKey long personId,
@CacheValue Person newPerson) {
<!-- Additional configuration information here -->
}cacheName and cacheKeyGenerator in the @CachePut method. Additionally, some parameters in the invoked method may be annotated with @CacheKey to control key generation.
24.2.4.2. Remove an Entry from the Cache
@CacheRemoveEntry annotated method that is used to remove an entry from the cache:
Example 24.13. Removing an Entry from the Cache
import javax.cache.annotation.CacheRemoveEntry;
import javax.cache.annotation.CacheKey;
@CacheRemoveEntry (cacheName = "cacheOfPeople")
public void changePersonName
(@CacheKey long personId,
string newName {
<!-- Additional configuration information here -->
}cacheName and cacheKeyGenerator attributes.
24.2.4.3. Clear the Cache
@CacheRemoveAll method to clear all entries from the cache.
Example 24.14. Clear All Entries from the Cache with @CacheRemoveAll
import javax.cache.annotation.CacheRemoveAll;
@CacheRemoveAll (cacheName = "statisticsCache")
public void resetStatistics() {
<!-- Additional configuration information here -->
}cacheName attribute.
Chapter 25. Integration with the Spring Framework
25.1. Defining the Spring Maven Dependency
Example 25.1. pom.xml for Spring 4 in Library Mode
<dependency>
<groupId>org.infinispan</groupId>
<artifactId>infinispan-spring4-embedded</artifactId>
<version>${infinispan.version}</version>
</dependency>Example 25.2. pom.xml for Spring 4 in Remote Client-Server Mode
<dependency>
<groupId>org.infinispan</groupId>
<artifactId>infinispan-spring4-remote</artifactId>
<version>${infinispan.version}</version>
</dependency>25.2. Enabling Spring Cache Support Programmatically (Library Mode)
- Add the
@EnableCachingannotation to the Spring configuration class in use. - Define a method returning a
SpringEmbeddedCacheManagerannotated with@Bean.
Example 25.3. Sample Programmatic Configuration
import org.infinispan.configuration.cache.Configuration;
import org.infinispan.configuration.cache.ConfigurationBuilder;
import org.infinispan.eviction.EvictionStrategy;
import org.infinispan.manager.DefaultCacheManager;
import org.infinispan.spring.provider.SpringEmbeddedCacheManager;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
[...]
@org.springframework.context.annotation.Configuration
@EnableCaching
public class Config {
[...]
@Bean
public SpringEmbeddedCacheManager cacheManager() throws Exception {
Configuration config = new ConfigurationBuilder()
.eviction()
.strategy(EvictionStrategy.LRU)
.maxEntries(150)
.build();
return SpringEmbeddedCacheManager(new DefaultCacheManager(config));
}
[...]25.3. Enabling Spring Cache Support Programmatically (Remote Client-Server Mode)
- Add the
@EnableCachingannotation to the Spring configuration class in use. - Define a method returning a
SpringRemoteCacheManagerannotated with@Bean.
Example 25.4. Sample Programmatic Configuration
import org.infinispan.client.hotrod.RemoteCacheManager;
import org.infinispan.client.hotrod.configuration.Configuration;
import org.infinispan.client.hotrod.configuration.ConfigurationBuilder;
import org.infinispan.spring.provider.SpringRemoteCacheManager;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
[...]
@org.springframework.context.annotation.Configuration
@EnableCaching
public class Config {
[...]
@Bean
public SpringRemoteCacheManager cacheManager() throws Exception {
Configuration config = new ConfigurationBuilder()
.addServer()
.host(ADDRESS)
.port(PORT)
.build();
return SpringRemoteCacheManager(new RemoteCacheManager(config));
}
[...]25.4. Adding Caching to Application Code
To add entries to the cache add the @Cacheable annotation to select methods. This annotation will add any returned values to the indicated cache. For instance, consider a method that returns a Book based on a particular key. By annotating this method with @Cacheable:
@Cacheable(value = "books", key = "#bookId")
public Book findBook(Integer bookId) {...}Book instances returned from findBook(Integer bookId) will be placed in a named cache books, using the bookId as the value's key.
Important
To remove entries from the cache annotate the desired methods with @CacheEvict. This annotation can be configured to evict all entries in a cache, or to only affect entries with the indicated key. Consider the following examples:
// Evict all entries in the "books" cache
@CacheEvict (value="books", key = "#bookId", allEntries = true)
public void deleteBookAllEntries() {...}
// Evict any entries in the "books" cache that match the passed in bookId
@CacheEvict (value="books", key = "#bookId")
public void deleteBook(Integer bookId) {...]}Chapter 26. Integration with Apache Spark
- Create an RDD from any cache
- Write a key/value RDD to a cache
- Create a DStream from cache-level events
- Write a key/value DStream to a cache
Note
26.1. Spark Dependencies
<dependency>
<groupId>org.infinispan</groupId>
<artifactId>infinispan-spark_2.10</artifactId>
<version>0.3.0.Final-redhat-1</version>
</dependency>26.2. Supported Spark Configuration Parameters
| Parameter Name | Description | Default Value |
|---|---|---|
infinispan.client.hotrod.server_list | List of JBoss Data Grid nodes | localhost:11222 |
infinispan.rdd.cacheName | The name of the cache that will back the RDD | default cache |
infinispan.rdd.read_batch_size | Batch size (number of entries) when reading from the cache | 10000 |
infinispan.rdd.write_batch_size | Batch size (number of entries) when writing to the cache | 500 |
infinispan.rdd.number_server_partitions | Numbers of partitions created per JBoss Data Grid server | 2 |
infinispan.rdd.query.proto.protofiles | Map with protobuf file names and contents | Can be omitted if entities are annotated with protobuf encoding information. Protobuf encoding is required to filter the RDD by Query. |
infinispan.rdd.query.proto.marshallers | List of protostream marshallers classes for the objects in the cache | Can be omitted if entities are annotated with protobuf encoding information. Protobuf encoding is required to filter the RDD by Query. |
26.3. Creating and Using RDDs
Properties instance with configurations described in the table 27.1, and then using it together with the Spark context to create a InfinispanRDD that is used with the normal Spark operations. An example of this is below in both Java and Scala:
Example 26.1. Creating a RDD (Java)
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.infinispan.spark.rdd.InfinispanJavaRDD;
import java.util.Properties;
[...]
// Begin by defining a new Spark configuration and creating a Spark context from this.
SparkConf conf = new SparkConf().setAppName("example-RDD");
JavaSparkContext jsc = new JavaSparkContext(conf);
// Create the Properties instance, containing the JBoss Data Grid node and cache name.
Properties properties = new Properties();
properties.put("infinispan.client.hotrod.server_list", "server:11222");
properties.put("infinispan.rdd.cacheName","exampleCache");
// Create the RDD
JavaPairRDD<Integer, Book> exampleRDD = InfinispanJavaRDD.createInfinispanRDD(jsc, properties);
JavaRDD<Book> booksRDD = exampleRDD.values();Example 26.2. Creating a RDD (Scala)
import java.util.Properties
import org.apache.spark.{SparkConf, SparkContext}
import org.infinispan.spark.rdd.InfinispanRDD
import org.infinispan.spark._
// Begin by defining a new Spark configuration and creating a Spark context from this.
val conf = new SparkConf().setAppName("example-RDD-scala")
val sc = new SparkContext(conf)
// Create the Properties instance, containing the JBoss Data Grid node and cache name.
val properties = new Properties
properties.put("infinispan.client.hotrod.server_list", "server:11222")
properties.put("infinispan.rdd.cacheName", "exampleCache")
// Create an RDD from the DataGrid cache
val exampleRDD = new InfinispanRDD[Integer, Book](sc, properties)
val booksRDD = exampleRDD.valuesExample 26.3. Querying with a RDD (Java)
// The following imports should be added to the list from the previous example
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
[...]
// Continuing the previous example
// Create a SQLContext, registering the data frame and table
SQLContext sqlContext = new SQLContext(jsc);
DataFrame dataFrame = sqlContext.createDataFrame(booksRDD, Book.class);
dataFrame.registerTempTable("books");
// Run the Query and collect results
List<Row> rows = sqlContext.sql("SELECT author, count(*) as a from books WHERE author != 'N/A' GROUP BY author ORDER BY a desc").collectAsList();Example 26.4. Querying with a RDD (Scala)
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
[...]
// Create a SQLContext, register a data frame and table
val sqlContext = new SQLContext(sc)
val dataFrame = sqlContext.createDataFrame(booksRDD, classOf[Book])
dataFrame.registerTempTable("books")
// Run the Query and collect the results
val rows = sqlContext.sql("SELECT author, count(*) as a from books WHERE author != 'N/A' GROUP BY author ORDER BY a desc").collect()
Any key/value based RDD can be written to the Data Grid cache by using the static InfinispanJavaRDD.write() method. This will copy the contents of the RDD to the cache:
Example 26.5. Writing with a RDD (Java)
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.infinispan.client.hotrod.RemoteCache;
import org.infinispan.spark.domain.Address;
import org.infinispan.spark.domain.Person;
import org.infinispan.spark.rdd.InfinispanJavaRDD;
import scala.Tuple2;
import java.util.List;
import java.util.Properties;
[...]
// Define the location of the JBoss Data Grid node
Properties properties = new Properties();
properties.put("infinispan.client.hotrod.server_list", "localhost:11222");
properties.put("infinispan.rdd.cacheName","exampleCache");
// Create the JavaSparkContext
SparkConf conf = new SparkConf().setAppName("write-example-RDD");
JavaSparkContext jsc = new JavaSparkContext(conf);
// Defining two entries to be stored in a RDD
// Each Book will contain the title, author, and publicationYear
Book bookOne = new Book("Linux Bible", "Negus, Chris", "2015");
Book bookTwo = new Book("Java 8 in Action", "Urma, Raoul-Gabriel", "2014");
List<Tuple2<Integer, Book>> pairs = Arrays.asList(
new Tuple2<>(1, bookOne),
new Tuple2<>(2, bookTwo)
);
// Create the RDD using the newly created List
JavaPairRDD<Integer, Book> pairsRDD = jsc.parallelizePairs(pairs);
// Write the entries into the cache
InfinispanJavaRDD.write(pairsRDD, config);
Example 26.6. Writing with a RDD (Scala)
import java.util.Properties
import org.infinispan.spark._
import org.infinispan.spark.rdd.InfinispanRDD
[...]
// Define the location of the JBoss Data Grid node
val properties = new Properties
properties.put("infinispan.client.hotrod.server_list", "localhost:11222")
properties.put("infinispan.rdd.cacheName", "exampleCache")
// Create the SparkContext
val conf = new SparkConf().setAppName("write-example-RDD-scala")
val sc = new SparkContext(conf)
// Create an RDD of Books
val bookOne = new Book("Linux Bible", "Negus, Chris", "2015")
val bookTwo = new Book("Java 8 in Action", "Urma, Raoul-Gabriel", "2014")
val sampleBookRDD = sc.parallelize(Seq(bookOne,bookTwo))
val pairsRDD = sampleBookRDD.zipWithIndex().map(_.swap)
// Write the Key/Value RDD to the Data Grid
pairsRDD.writeToInfinispan(properties)26.4. Creating and Using DStreams
StreamingContext will be passed in along with StorageLevel and the JBoss Data Grid RDD configuration, as seen in the below example:
Example 26.7. Creating a DStream (Scala)
import org.infinispan.spark.stream._
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.storage.StorageLevel
import java.util.Properties
// Spark context
val sc = ...
// java.util.Properties with Infinispan RDD configuration
val props = ...
val ssc = new StreamingContext(sc, Seconds(1))
val stream = new InfinispanInputDStream[String, Book](ssc, StorageLevel.MEMORY_ONLY, props)InfinispanInputDStream can be transformed using the many Spark's DStream operations, and the processing will occur after calling "start" in the StreamingContext. For example, to display every 10 seconds the number of books inserted in the cache in the last 30 seconds:
Example 26.8. Processing a DStream (Scala)
import org.infinispan.spark.stream._
val stream = ... // From previous sample
// Filter only created entries
val createdBooksRDD = stream.filter { case (_, _, t) => t == Type.CLIENT_CACHE_ENTRY_CREATED }
// Reduce last 30 seconds of data, every 10 seconds
val windowedRDD: DStream[Long] = createdBooksRDD.count().reduceByWindow(_ + _, Seconds(30), Seconds(10))
// Prints the results, couting the number of occurences in each individual RDD
windowedRDD.foreachRDD { rdd => println(rdd.reduce(_ + _)) }
// Start the processing
ssc.start()
ssc.awaitTermination()
Any DStream of Key/Value type can be written to JBoss Data Grid through the InfinispanJavaDStream.writeToInfinispan() Java method or in Scala using the implicit writeToInfinispan(properties) method directly on the DStream instance. Both methods take the JBoss Data Grid RDD configuration as input and will write each RDD contained within the DStream
26.5. Using the Infinispan Query DSL with Spark
Important
Doe:
Example 26.9. Filtering by a Query (Scala)
import org.infinispan.client.hotrod.impl.query.RemoteQuery
import org.infinispan.client.hotrod.{RemoteCacheManager, Search}
import org.infinispan.spark.domain._
[...]
val query = Search.getQueryFactory(remoteCacheManager.getCache(getCacheName))
.from(classOf[Book])
.having("author").like("Doe")
.toBuilder[RemoteQuery].build()
val rdd = createInfinispanRDD[Int, Book]
.filterByQuery[Book]](query, classOf[Book])Example 26.10. Filtering with a Projection (Scala)
import org.infinispan.client.hotrod.impl.query.RemoteQuery
import org.infinispan.client.hotrod.{RemoteCacheManager, Search}
import org.infinispan.spark.domain._
[...]
val query = Search.getQueryFactory(remoteCacheManager.getCache(getCacheName))
.select("title","publicationYear")
.from(classOf[Book])
.having("author").like("Doe")
.groupBy("publicationYear")
.toBuilder[RemoteQuery].build()
val rdd = createInfinispanRDD[Int, Book]
.filterByQuery[Array[AnyRef]](query, classOf[Book])
Example 26.11. Filtering with a Deployed Filter (Scala)
val rdd = InfinispanRDD[String,Book] = ....
// "my-filter-factory" filter and converts Book to a String, and has two parameters
val filteredRDD = rdd.filterByCustom[String]("my-filter-factory", "param1", "param2")
26.6. Spark Performance Considerations
Chapter 27. Integration with Apache Hadoop
InputFormat and OutputFormat, allowing applications to read and write data to a JBoss Data Grid server with best data locality. While JBoss Data Grid's implementation of the InputFormat and OutputFormat allow one to run traditional Hadoop Map/Reduce jobs, they may also be used with any tool or utility that supports Hadoop's InputFormat data source.
27.1. Hadoop Dependencies
<dependency>
<groupId>org.infinispan.hadoop</groupId>
<artifactId>infinispan-hadoop-core</artifactId>
<version>0.2.0.Final-redhat-1</version>
</dependency>27.2. Supported Hadoop Configuration Parameters
| Parameter Name | Description | Default Value |
|---|---|---|
hadoop.ispn.input.filter.factory | The name of the filter factory deployed on the server to pre-filter data before reading. | null (no filtering enabled) |
hadoop.ispn.input.cache.name | The name of cache where data will be read. | default |
hadoop.ispn.input.remote.cache.servers | List of servers of the input cache, in the format:
| localhost:11222 |
hadoop.ispn.output.cache.name | The name of cache where data will be written. | default |
hadoop.ispn.output.remote.cache.servers | List of servers of the output cache, in the format:
| null (no output cache) |
hadoop.ispn.input.read.batch | Batch size when reading from the cache. | 5000 |
hadoop.ispn.output.write.batch | Batch size when writing to the cache. | 500 |
hadoop.ispn.input.converter | Class name with an implementation of org.infinispan.hadoop.KeyValueConverter, applied after reading from the cache. | null (no converting enabled). |
hadoop.ispn.output.converter | Class name with an implementation of org.infinispan.hadoop.KeyValueConverter , applied before writing. | null (no converting enabled). |
27.3. Using the Hadoop Connector
InfinispanInputFormat and InfinispanOutputFormat
In Hadoop, the InputFormat interface indicates how a specific data source is partitioned, along with how to read data from each of the partitions, while the OutputFormat interface specifies how to write data.
InpoutFormat interface:
List<InputSplit> getSplits(JobContext context);RecordReader<K,V> createRecordReader(InputSplit split,TaskAttemptContext context);
getSplits method defines a data partitioner, returning one or more InputSplit instances that contain information regarding a certain section of the data. The InputSplit can then be used to obtain a RecordReader which will be used to iterate over the resulting dataset. These two operations allow for parallelization of data processing across multiple nodes, resulting in Hadoop's high throughput over large datasets.
Example of configuring a Map Reduce job targeting a JBoss Data Grid cluster:
import org.infinispan.hadoop.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.Job;
[...]
Configuration configuration = new Configuration();
configuration.set(InfinispanConfiguration.INPUT_REMOTE_CACHE_SERVER_LIST, "localhost:11222");
configuration.set(InfinispanConfiguration.INPUT_REMOTE_CACHE_NAME, "map-reduce-in");
configuration.set(InfinispanConfiguration.OUTPUT_REMOTE_CACHE_SERVER_LIST, "localhost:11222");
configuration.set(InfinispanConfiguration.OUTPUT_REMOTE_CACHE_NAME, "map-reduce-out");
Job job = Job.getInstance(configuration, "Infinispan Integration");
[...]InfinispanInputFormat and InfinispanOutputFormat classes:
[...]
// Define the Map and Reduce classes
job.setMapperClass(MapClass.class);
job.setReducerClass(ReduceClass.class);
// Define the JBoss Data Grid implementations
job.setInputFormatClass(InfinispanInputFormat.class);
job.setOutputFormatClass(InfinispanOutputFormat.class);
[...]Chapter 28. High Availability Using Server Hinting
machineId, rackId, or siteId in the transport configuration will trigger the use of TopologyAwareConsistentHashFactory, which is the equivalent of the DefaultConsistentHashFactory with Server Hinting enabled.
28.1. ConsistentHashFactories
DefaultConsistentHashFactory- keeps segments balanced evenly across all the nodes, however the key mapping is not guaranteed to be same across caches,as this depends on the history of each cache. If no consistentHashFactory is specified this is the class that will be used.SyncConsistentHashFactory- guarantees that the key mapping is the same for each cache, provided the current membership is the same. This has a drawback in that a node joining the cache can cause the existing nodes to also exchange segments, resulting in either additional state transfer traffic, the distribution of the data becoming less even, or both.TopologyAwareConsistentHashFactory- equivalent ofDefaultConsistentHashFactory, but automatically selected when the configuration includes server hinting.TopologyAwareSyncConsistentHashFactory- equivalent ofSyncConsistentHashFactory, but automatically selected when the configuration includes server hinting.
<hash consistent-hash-factory="org.infinispan.distribution.ch.SyncConsistentHashFactory"/>
machineId, rackId, or siteId attributes are specified in the transport configuration it also spreads backup copies across physical machines/racks/data centers.
SyncConsistentHashFactory and TopologyAwareSyncConsistentHashFactory both tend to reduce overhead in clustered environments, as neither of these calculate the hash based on the order that nodes have joined the cluster. In addition, both of these classes are typically faster than the default algorithms as both of these classes allow larger differences in the number of segments allocated to each node.
28.1.1. Implementing a ConsistentHashFactory
ConsistentHashFactory must implement the org.infinispan.distribution.ch.ConsistenHashFactory interface with the following methods (all of which return an implementation of org.infinispan.distribution.ch.ConsistentHash):
Example 28.1. ConsistentHashFactory Methods
create(Hash hashFunction, int numOwners, int numSegments, List<Address>
members,Map<Address, Float> capacityFactors)
updateMembers(ConsistentHash baseCH, List<Address> newMembers, Map<Address,
Float> capacityFactors)
rebalance(ConsistentHash baseCH)
union(ConsistentHash ch1, ConsistentHash ch2)ConsistentHashFactory implementations.
28.2. Key Affinity Service
Example 28.2. Key Affinity Service
EmbeddedCacheManager cacheManager = getCacheManager();
Cache cache = cacheManager.getCache();
KeyAffinityService keyAffinityService =
KeyAffinityServiceFactory.newLocalKeyAffinityService(
cache,
new RndKeyGenerator(),
Executors.newSingleThreadExecutor(),
100);
Object localKey = keyAffinityService.getKeyForAddress(cacheManager.getAddress());
cache.put(localKey, "yourValue");Procedure 28.1. Using the Key Affinity Service
- Obtain a reference to a cache manager and cache.
- This starts the service, then uses the supplied
Executorto generate and queue keys. - Obtain a key from the service which will be mapped to the local node (
cacheManager.getAddress()returns the local address). - The entry with a key obtained from the
KeyAffinityServiceis always stored on the node with the provided address. In this case, it is the local node.
28.2.1. Lifecycle
KeyAffinityService extends Lifecycle, which allows the key affinity service to be stopped, started, and restarted.
Example 28.3. Key Affinity Service Lifecycle Parameter
public interface Lifecycle {
void start();
void stop();
}KeyAffinityServiceFactory. All factory methods have an Executor, that is used for asynchronous key generation, so that this does not occur in the caller's thread. The user controls the shutting down of this Executor.
KeyAffinityService must be explicitly stopped when it is no longer required. This stops the background key generation, and releases other held resources. The KeyAffinityServce will only stop itself when the cache manager with which it is registered is shut down.
28.2.2. Topology Changes
KeyAffinityService key ownership may change when a topology change occurs. The key affinity service monitors topology changes and updates so that it doesn't return stale keys, or keys that would map to a different node than the one specified. However, this does not guarantee that a node affinity hasn't changed when a key is used. For example:
- Thread (
T1) reads a key (K1) that maps to a node (A). - A topology change occurs, resulting in
K1mapping to nodeB. T1usesK1to add something to the cache. At this point,K1maps toB, a different node to the one requested at the time of read.
KeyAffinityService provides an access proximity optimization for stable clusters, which does not apply during the instability of topology changes.
Chapter 29. Distributed Execution
ExecutorService interface. Tasks submitted for execution are executed on an entire cluster of JBoss Data Grid nodes, rather than being executed in a local JVM.
- Each
DistributedExecutorServiceis bound to a single cache. Tasks submitted have access to key/value pairs from that particular cache if the task submitted is an instance ofDistributedCallable. - Every
Callable,Runnable, and/orDistributedCallablesubmitted must be eitherSerializableorExternalizable, in order to prevent task migration to other nodes each time one of these tasks is performed. The value returned from aCallablemust also beSerializableorExternalizable.
29.1. Distributed Executor Service
DistributedExecutorService controls the execution of DistributedCallable, and other Callable and Runnable, classes on the cluster. These instances are tied to a specific cache that is passed in upon instantiation:
DistributedExecutorService des = new DefaultExecutorService(cache);DistributedTask against a subset of keys if DistributedCallable is extended, as discussed in Section 29.2, “DistributedCallable API”. If a task is submitted in this manner to a single node, then JBoss Data Grid will locate the nodes containing the indicated keys, migrate the DistributedCallable to this node, and return a CompletableFuture. Alternatively, if a task is submitted to all available nodes in this manner then only the nodes containing the indicated keys will receive the task.
DistributedTask has been created it may be submitted to the cluster using any of the below methods:
- The task can be submitted to all available nodes and key/value pairs on the cluster using the
submitEverywheremethod:des.submitEverywhere(task) - The
submitEverywheremethod can also take a set of keys as an argument. Passing in keys in this manner will submit the task only to available nodes that contain the indicated keys:des.submitEverywhere(task, $KEY) - If a key is specified, then the task will be executed on a single node that contains at least one of the specified keys. Any keys not present locally will be retrieved from the cluster. This version of the
submitmethod accepts one or more keys to be operated on, as seen in the following examples:des.submit(task, $KEY) des.submit(task, $KEY1, $KEY2, $KEY3) - A specific node can be instructed to execute the task by passing the node's
Addressto thesubmitmethod. The below will only be executed on the cluster'sCoordinator:des.submit(cache.getCacheManager().getCoordinator(), task)Note
By default tasks are automatically balanced, and there is typically no need to indicate a specific node to execute against.
29.2. DistributedCallable API
DistributedCallable interface is a subtype of the existing Callable from java.util.concurrent.package, and can be executed in a remote JVM and receive input from Red Hat JBoss Data Grid. The DistributedCallable interface is used to facilitate tasks that require access to JBoss Data Grid cache data.
DistributedCallable API to execute a task, the task's main algorithm remains unchanged, however the input source is changed.
Callable interface must extend DistributedCallable if access to the cache or the set of passed in keys is required.
Example 29.1. Using the DistributedCallable API
public interface DistributedCallable<K, V, T> extends Callable<T> {
/**
* Invoked by execution environment after DistributedCallable
* has been migrated for execution to a specific Infinispan node.
*
* @param cache
* cache whose keys are used as input data for this
* DistributedCallable task
* @param inputKeys
* keys used as input for this DistributedCallable task
*/
public void setEnvironment(Cache<K, V> cache, Set<K> inputKeys);
}29.3. Callable and CDI
DistributedCallable cannot be implemented or is not appropriate, and a reference to input cache used in DistributedExecutorService is still required, there is an option to inject the input cache by CDI mechanism.
Callable task arrives at a Red Hat JBoss Data Grid executing node, JBoss Data Grid's CDI mechanism provides an appropriate cache reference, and injects it to the executing Callable.
Callable:
- Declare a
Cachefield inCallableand annotate it withorg.infinispan.cdi.Input - Include the mandatory
@Injectannotation.
Example 29.2. Using Callable and the CDI
public class CallableWithInjectedCache implements Callable<Integer>, Serializable {
@Inject
@Input
private Cache<String, String> cache;
@Override
public Integer call() throws Exception {
//use injected cache reference
return 1;
}
}29.4. Distributed Task Failover
- Failover due to a node failure where a task is executing.
- Failover due to a task failure; for example, if a
Callabletask throws an exception.
Runnable, Callable, and DistributedCallable tasks fail without invoking any failover mechanism.
Distributed task on another random node if one is available.
Example 29.3. Random Failover Execution Policy
DistributedExecutorService des = new DefaultExecutorService(cache);
DistributedTaskBuilder<Boolean> taskBuilder = des.createDistributedTaskBuilder(new SomeCallable());
taskBuilder.failoverPolicy(DefaultExecutorService.RANDOM_NODE_FAILOVER);
DistributedTask<Boolean> distributedTask = taskBuilder.build();
Future<Boolean> future = des.submit(distributedTask);
Boolean r = future.get();DistributedTaskFailoverPolicy interface can also be implemented to provide failover management.
Example 29.4. Distributed Task Failover Policy Interface
/**
* DistributedTaskFailoverPolicy allows pluggable fail over target selection for a failed remotely
* executed distributed task.
*
*/
public interface DistributedTaskFailoverPolicy {
/**
* As parts of distributively executed task can fail due to the task itself throwing an exception
* or it can be an Infinispan system caused failure (e.g node failed or left cluster during task
* execution etc).
*
* @param failoverContext
* the FailoverContext of the failed execution
* @return result the Address of the Infinispan node selected for fail over execution
*/
Address failover(FailoverContext context);
/**
* Maximum number of fail over attempts permitted by this DistributedTaskFailoverPolicy
*
* @return max number of fail over attempts
*/
int maxFailoverAttempts();
}29.5. Distributed Task Execution Policy
DistributedTaskExecutionPolicy allows tasks to specify a custom execution policy across the Red Hat JBoss Data Grid cluster, by scoping execution of tasks to a subset of nodes.
DistributedTaskExecutionPolicy can be used to manage task execution in the following cases:
- where a task is to be exclusively executed on a local network site instead of a backup remote network center.
- where only a dedicated subset of a certain JBoss Data Grid rack nodes are required for specific task execution.
Example 29.5. Using Rack Nodes to Execute a Specific Task
DistributedExecutorService des = new DefaultExecutorService(cache);
DistributedTaskBuilder<Boolean> taskBuilder = des.createDistributedTaskBuilder(new SomeCallable());
taskBuilder.executionPolicy(DistributedTaskExecutionPolicy.SAME_RACK);
DistributedTask<Boolean> distributedTask = taskBuilder.build();
Future<Boolean> future = des.submit(distributedTask);
Boolean r = future.get();29.6. Distributed Execution and Locality
DistributionManager and ConsistentHash, is theoretical; neither of these classes have any knowledge if data is actively in the cache. Instead, these classes are used to determine which node should store the specified key.
- Option 1: Confirm that the key is both found in the cache and the
DistributionManagerindicates it is local, as seen in the following example:(cache.getAdvancedCache().withFlags(SKIP_REMOTE_LOOKUP).containsKey(key) && cache.getAdvancedCache().getDistributionManager().getLocality(key).isLocal()) - Option 2: Query the
DataContainerdirectly:cache.getAdvancedCache().getDataContainer().containsKey(key)Note
If the entry is passivated then theDataContainerwill returnFalse, regardless of the key's presence.
29.7. Distributed Execution Example
- As shown below, the area of a square is:Area of a Square (S) = 4r 2
- The following is an equation for the area of a circle:Area of a Circle (C) = π x r 2
- Isolate r 2 from the first equation:r 2 = S/4
- Inject this value of r 2 into the second equation to find a value for Pi:C = Sπ/4
- Isolating π in the equation results in:C = Sπ/44C = Sπ4C/S = π
Figure 29.1. Distributed Execution Example
Example 29.6. Distributed Execution Example
public class PiAppx {
public static void main (String [] arg){
List<Cache> caches = ...;
Cache cache = ...;
int numPoints = 10000000;
int numServers = caches.size();
int numberPerWorker = numPoints / numServers;
DistributedExecutorService des = new DefaultExecutorService(cache);
long start = System.currentTimeMillis();
CircleTest ct = new CircleTest(numberPerWorker);
List<Future<Integer>> results = des.submitEverywhere(ct);
int countCircle = 0;
for (Future<Integer> f : results) {
countCircle += f.get();
}
double appxPi = 4.0 * countCircle / numPoints;
System.out.println("Distributed PI appx is " + appxPi +
" completed in " + (System.currentTimeMillis() - start) + " ms");
}
private static class CircleTest implements Callable<Integer>, Serializable {
/** The serialVersionUID */
private static final long serialVersionUID = 3496135215525904755L;
private final int loopCount;
public CircleTest(int loopCount) {
this.loopCount = loopCount;
}
@Override
public Integer call() throws Exception {
int insideCircleCount = 0;
for (int i = 0; i < loopCount; i++) {
double x = Math.random();
double y = Math.random();
if (insideCircle(x, y))
insideCircleCount++;
}
return insideCircleCount;
}
private boolean insideCircle(double x, double y) {
return (Math.pow(x - 0.5, 2) + Math.pow(y - 0.5, 2))
<= Math.pow(0.5, 2);
}
}
}Chapter 30. Streams
Stream may be obtained by invoking the stream(), for a single-threaded stream, or parallelStream(), for a multi-threaded stream, methods on a given Map. Parallel streams are discussed in more detail at Section 30.4.2, “Parallelism”.
30.1. Using Streams on a Local/Invalidation/Replication Cache
Map<Object, String> jbossBooks = cache.entrySet().stream()
.filter(e -> e.getValue().getTitle().contains("JBoss"))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));30.2. Using Streams with a Distribution Cache
Once the stream has been created the data will be segmented so that each node will only perform operations upon the data that it owns as the primary owner. Assuming the segments are granular enough to provide an even distribution of data per node, this allows for even processing of data across the segments.
30.3. Setting Timeouts
timeout(long timeout, TimeUnit unit) method of the stream, as seen in the following example:
CacheStream<Object, String> stream = cache.entrySet().stream();
stream.timeout(1, TimeUnit.MINUTES);30.4. Distributed Streams
- The desired segments are grouped by which node is the primary owner of each given segment.
- A request is generated for each remote node. This request contains the intermediate and terminal operations, along with the segments to process.
- The thread where the terminal operation was initiated will perform the local operation directly.
- Each remote node will receive the generated request, run the operations on a remote thread, and then send the response back.
- Once all requests complete the user thread will gather all responses and perform any reductions specified by the operations.
- The final response is returned to the user.
30.4.1. Marshallability
Serializable or has an Externalizer registered; however, as the FunctionalInterface implements Serializable all lambdas are instantly serialized and thus no additional cast is required.
Note
Serializable. For instance, consider a cache that stores Book entries; the following would create a collection of Book instances that match a specific author:
List<Book> books = cache.keySet().stream()
.filter((Predicate<? super Book>) e -> e.getAuthor().equals("authorname"))
.collect(toList());Collectors are marshallable by default. JBoss Data Grid has included org.infinispan.stream.CacheCollectors as a convenient way to utilize any combination of Collectors that function properly when marshalling is required.
30.4.2. Parallelism
- Parallel Streams - causing each operation to be executed in parallel on a single node
- Parallel Distribution - parallelizing the request so that it involves multiple nodes
Stream, allowing concurrent operations executing across multiple nodes, with multiple threads on each node.
Stream as parallel it may either be obtained with parallelStream(), or it may be enabled after obtaining the Stream by invoking parallel(). The following example shows both methods:
// Obtain a parallel Stream initially
List<Book> books = cache.keySet().parallelStream()
[...]
// Create the initial stream and then invoke parallel
List<Book> books = cache.keySet().stream()
.parallel()
[...]Note
30.4.3. Distributed Operators
30.4.3.1. Terminal Operator Distributed Result Reductions
- allMatchThis operator is run on each node and then all results are combined using a logical AND operation locally to obtain the final value. If a normal stream operation returns early then these methods will complete early as well.
- noneMatch anyMatchThese operators are run on each node and then all results are combined using a logical OR operation locally to obtain the final value. If a normal stream operation returns early then these methods will complete early as well.
- collectThe collect method can perform a few extra steps. Similar to other methods the remote node will perform everything as expected; however, instead of performing the final finisher operator it sends back the fully combined results. The local thread will then combine all local and remote results into a value which then performs the finisher operator. In addition, the final value does not need to be serializable, but the values produced from the supplier and combiner methods must be serialized.
- countThe count method simply adds the numbers received from each node.
- findAny findFirstThe findAny method will return the first value found, regardless if it was from a remote or local node. This operation supports early termination, as once an initial value has been found no others will be processed. The findFirst method behaves similarly, but requires a sorted intermediate operation which is described in Section 30.4.3.3, “Intermediate Operation Exceptions”.
- max minThe max and min methods find the respective value on each node before a final reduction is performed locally to determine the true max or min across all nodes.
- reduceThe various reduce methods seralize the result as much as possible before accumulating the local and remote results together locally, combining if enabled. Due to this behavior a value returned from the combiner does not need to be serializable.
30.4.3.2. Key Based Rehash Aware Operators
iterator and spliterator operators, or at least once, for forEach, even if cluster membership changes.
- iterator spliteratorThese operators return batches of entries when run on a remote node, where the next batch is only sent after the previous is fully consumed. This behavior is to limit how many entries are retained in memory at any given time. The user node will keep track of which keys have been processed, and once a segment has completed those keys will be released from memory. Because of this behavior it is preferable to use sequential processing, allowing only a subset of segment keys to be held in memory instead of having keys from all nodes retained.
- forEachWhile
forEachreturns batches it only returns a batch after it has finished processing at least a batch worth of keys. This way the originating node knows which keys have been processed already, which reduces the possibility of processing the same entry again; however, it is possible to have the same set processed repeatedly if a node goes down unexpectedly. In this case the node could have been processing an uncompleted batch when it went down, resulting in the same batch to be ran again when the rehash failure operation occurs. Adding a node will not cause this issue, as the rehash failover does not occur until all responses are received.
distributedBatchSize, on the CacheStream. If no value is set then it will default to the chunkSize configured in state transfer. While larger values will allow for larger batches, resulting in fewer returns, this results in increased memory usage, and testing should be performed to determine an appropriate size for each application.
30.4.3.3. Intermediate Operation Exceptions
- SkipAn artificial iterator is implanted up to the skip operation, and then results are brought locally so that the appropriate number of elements may be skipped.
- PeekAn artificial iterator is implanted up to the peek operation. Only up to a number of peeked elements are returned to a remote node, and then results are brought locally so that it may peek at only the desired amount.
- SortedAn artificial iterator is implanted up to the sorted operation, and then all results are locally sorted.
Warning
This operation requires having all entries in memory on the local node. - DistinctDistinct is performed on each remote node and then an artificial iterator returns those distinct values, before all of those results have a distinct operation performed upon them.
Warning
This operation requires having all entries in memory on the local node.
30.4.4. Distributed Stream Examples
String for keys and values, and we need to count the occurrence of all words in all sentences, this could be implemented using the following:
Map<String, Integer> wordCountMap = cache.entrySet().parallelStream()
.map((Serializable & Function<Map.Entry<String, String>, String[]>) e -> e.getValue().split("\\s"))
.flatMap((Function<String[], Stream<String>>) Arrays::stream)
.collect(CacheCollectors.serializableCollector(() -> Collectors.groupingBy(Function.identity(), Collectors.counting())));String mostFrequentWord = cache.entrySet().parallelStream()
.map((Serializable & Function<Map.Entry<String, String>, String[]>) e -> e.getValue().split("\\s"))
.flatMap((Function<String[], Stream<String>>) Arrays::stream)
.collect(CacheCollectors.serializableCollector(() -> Collectors.collectingAndThen(
Collectors.groupingBy(Function.identity(), Collectors.counting()),
wordCountMap -> {
String mostFrequent = null;
long maxCount = 0;
for (Map.Entry<String, Long> e : wordCountMap.entrySet()) {
int count = e.getValue().intValue();
if (count > maxCount) {
maxCount = count;
mostFrequent = e.getKey();
}
}
return mostFrequent;
})));Map<String, Long> wordCount = cache.entrySet().parallelStream()
.map((Function<Map.Entry<String, String>, String[]>) e -> e.getValue().split("\\s"))
.flatMap((Function<String[], Stream<String>>) Arrays::stream)
.collect(CacheCollectors.serializableCollector(() -> Collectors.groupingBy(Function.identity(), Collectors.counting())));
Optional<Map.Entry<String, Long>> mostFrequent = wordCount.entrySet().parallelStream()
.reduce((e1, e2) -> e1.getValue() > e2.getValue() ? e1 : e2);Chapter 31. Scripting
javax.script.ScriptEngines. By default the JDK comes with Nashorn, capable of running JavaScript; however, this may be extended to run any JVM language that offers their own ScriptEngine.
31.1. Accessing the Script Cache
___script_cache. As this is a protected cache only loopback requests or connections with authorization enabled will be allowed to access the cache.
___script_cache remotely:
- A user has been defined with the
___script_managerrole. - The client has a secure connection to the server; this may be attained by following the instructions in Section 20.7, “Securing Interfaces”.
- Authorization has been enabled on the cache-container.
Example 31.1. Configuring the Server for Access the Script Cache
DIGEST-MD5 method of securing the Hot Rod connector.
- Add a user to the server as follows:
- Execute the
$JDG_HOME/bin/add-user.sh(Linux) or$JDG_HOME\bin\add-user.bat(Windows) script. - Enter
bat the first prompt to create anApplicationRealmuser.What type of user do you wish to add? a) Management User (mgmt-users.properties) b) Application User (application-users.properties) (a): b - Follow the prompts to define the desired username and password for the user.
- When prompted for the groups enter
___script_managerfor this user:What groups do you want this user to belong to? (Please enter a comma separated list, or leave blank for none)[ ]: ___script_manager
- Secure the communication between the client and server. As this example is using
DIGEST-MD5the instructions in will be followed. The following snippet demonstrates the necessary xml configuration:<cache-container name="local" default-cache="default" statistics="true"> <security> <authorization> <identity-role-mapper /> <role name="admin" permissions="ALL" /> <role name="reader" permissions="READ" /> <role name="writer" permissions="WRITE" /> <role name="supervisor" permissions="READ WRITE EXEC BULK" /> </authorization> </security> [...] <cache-container> [...] <hotrod-connector socket-binding="hotrod" cache-container="local"> <authentication security-realm="ApplicationRealm"> <sasl server-name="scriptserver" mechanisms="DIGEST-MD5" qop="auth" /> </authentication> </hotrod-connector> - Create the cache manager using the secured connection, as seen in the following code snippet:
Configuration config = new ConfigurationBuilder() .addServer() .host("localhost") .port(11222) .security() .authentication() .enable() .saslMechanism("DIGEST-MD5") .serverName("scriptserver") .callbackHandler(new MyCallbackHandler("user", "ApplicationRealm", "password".toCharArray())) .build(); cacheManager = new RemoteCacheManager(config);
31.2. Installing Scripts
script_cache by putting the script into the cache itself with the name of the script as the key, and the content of the script as the value. If the name of the script contains a filename extension, such as sample.js, then the extension will determine the engine used to execute the script. This behavior may be overridden by specifying metadata inside the script itself.
___script_cache this may either be loaded from a pre-existing file, or manually entered. The following examples demonstrate both of these options:
Example 31.2. Loading a Script From a File
private static final String SCRIPT_CACHE = "___script_cache";
private RemoteCache<String, String> scriptingCache;
[...]
scriptingCache = cacheManager.getCache(SCRIPT_CACHE);
[...]
private void loadScript(String filename) throws IOException{
StringBuilder sb = new StringBuilder();
BufferedReader reader = new BufferedReader(new FileReader(filename));
for (String line = reader.readLine(); line != null; line = reader.readLine()) {
sb.append(line);
sb.append("\n");
}
System.out.println(sb.toString());
scriptingCache.put(filename,sb.toString());
}Example 31.3. Defining the Contents of the Script
RemoteCache<String, String> scriptCache = cacheManager.getCache("___script_cache");
scriptCache.put("multiplication.js",
"// mode=local,language=javascript\n" +
"// parameters=[multiplicand,multiplier]"
"multiplicand * multiplier\n"31.3. Scripting Metadata
//, ;;, or #, depending on the scripting language in use. This information may be split over multiple lines if necessary, and single or double quotes may be used to delimit the values.
// name=test, language=javascript
// mode=local, parameters=[a,b,c]The following metadata properties are available:
mode: defines the mode of execution of a script. Can be one of the following values:local: the script will be executed only by the node handling the request. The script itself however can invoke clustered operations.distributed: runs the script using the Distributed Executor Service.
language: defines the script engine that will be used to execute the script, e.g. Javascript.extension: an alternative method of specifying the script engine that will be used to execute the script, e.g. js.role: a specific role which is required to execute the script.parameters: an array of valid parameter names for this script. Invocations which specify parameter names not included in this list will cause an exception.
31.4. Script Bindings
cache: the cache against which the script is being executed.cacheManager: the cacheManager for the cache.marshaller: the marshaller to use for marshalling/unmarshalling data to the cache.scriptingManager: the instance of the script manager which is being used to run the script. This can be used to run other scripts from a script.
31.5. Script Parameters
multiplicand and multiplier:
// mode=local,language=javascript
// parameters=[multiplicand,multiplier]
multiplicand * multiplier31.6. Script Execution Using the Hot Rod Java Client
EXEC permissions will be allowed to run previously installed scripts.
execute(scriptName, parameters) on the cache where the script should be executed. In this case the scriptName corresponds with the name of the script stored in the ___script_cache, and parameters is a Map<String,Object> of named parameters.
multiplication.js script through Hot Rod:
RemoteCache<String, Integer> cache = cacheManager.getCache();
// Create the parameters for script execution
Map<String, Object> params = new HashMap<>();
params.put("multiplicand", 10);
params.put("multiplier", 20);
// Run the script on the server, passing in the parameters
Object result = cache.execute("multiplication.js", params);31.7. Script Execution Using the Hot Rod C++ Client
Important
Tasks may be installed on the server by being using the put(std::string name, std::string script) method of the ___script_cache. The extension of the script name determines the engine used to execute the script; however, this may be overridden by metadata in the script itself.
Example 31.4. Installing a Task with the C++ Client
#include "infinispan/hotrod/ConfigurationBuilder.h"
#include "infinispan/hotrod/RemoteCacheManager.h"
#include "infinispan/hotrod/RemoteCache.h"
#include "infinispan/hotrod/Version.h"
#include "infinispan/hotrod/JBasicMarshaller.h"
using namespace infinispan::hotrod;
int main(int argc, char** argv) {
// Configure the client
ConfigurationBuilder builder;
builder.addServer().host("127.0.0.1").port(11222).protocolVersion(
Configuration::PROTOCOL_VERSION_24);
RemoteCacheManager cacheManager(builder.build(), false);
try {
// Create the cache with the given marshallers
auto *km = new JBasicMarshaller<std::string>();
auto *vm = new JBasicMarshaller<std::string>();
RemoteCache<std::string, std::string> cache = cacheManager.getCache<
std::string, std::string>(km, &Marshaller<std::string>::destroy,
vm, &Marshaller<std::string>::destroy,
std::string("namedCache"));
cacheManager.start();
// Obtain a reference to the ___script_cache
RemoteCache<std::string, std::string> scriptCache =
cacheManager.getCache<std::string, std::string>(
"___script_cache", false);
// Install on the server the getValue script
std::string getValueScript(
"// mode=local,language=javascript\n "
"var cache = cacheManager.getCache(\"namedCache\");\n "
"var ct = cache.get(\"accessCounter\");\n "
"var c = ct==null ? 0 : parseInt(ct);\n "
"cache.put(\"accessCounter\",(++c).toString());\n "
"cache.get(\"privateValue\") ");
std::string getValueScriptName("getValue.js");
std::string pGetValueScriptName =
JBasicMarshaller<std::string>::addPreamble(getValueScriptName);
std::string pGetValueScript =
JBasicMarshaller<std::string>::addPreamble(getValueScript);
scriptCache.put(pGetValueScriptName, pGetValueScript);
// Install on the server the get access counter script
std::string getAccessScript(
"// mode=local,language=javascript\n "
"var cache = cacheManager.getCache(\"namedCache\");\n "
"cache.get(\"accessCounter\")");
std::string getAccessScriptName("getAccessCounter.js");
std::string pGetAccessScriptName =
JBasicMarshaller<std::string>::addPreamble(getAccessScriptName);
std::string pGetAccessScript =
JBasicMarshaller<std::string>::addPreamble(getAccessScript);
scriptCache.put(pGetAccessScriptName, pGetAccessScript);
Once installed, a task may be executed by using the execute(std::string name, std::map<std::string, std::string> args) method, passing in the name of the script to execute, along with any arguments that are required for execution.
Example 31.5. Executing a Script with the C++ Client
// The following is a continuation of the above example
cache.put("privateValue", "Counted Access Value");
std::map<std::string, std::string> s;
// Execute the getValue script
std::vector<unsigned char> execValueResult = cache.execute(
getValueScriptName, s);
// Execute the getAccess script
std::vector<unsigned char> execAccessResult = cache.execute(
getAccessScriptName, s);
std::string value(
JBasicMarshallerHelper::unmarshall<std::string>(
(char*) execValueResult.data()));
std::string access(
JBasicMarshallerHelper::unmarshall<std::string>(
(char*) execAccessResult.data()));
std::cout << "Returned value is '" << value
<< "' and has been accessed: " << access << " times."
<< std::endl;
} catch (const Exception& e) {
std::cout << "is: " << typeid(e).name() << '\n';
std::cerr << "fail unexpected exception: " << e.what() << std::endl;
return 1;
}
cacheManager.stop();
return 0;
}31.8. Script Execution Using the Hot Rod C# Client
Important
Tasks may be installed on the server by being using the Put(string name, string script) method of the ___script_cache. The extension of the script name determines the engine used to execute the script; however, this may be overridden by metadata in the script itself.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Infinispan.HotRod;
using Infinispan.HotRod.Config;
namespace RemoteExec
{
/// <summary>
/// This sample code shows how to perform a server remote execution using the C# client
/// </summary>
class RemoteExec
{
static void Main(string[] args)
{
// Cache manager setup
RemoteCacheManager remoteManager;
IMarshaller marshaller;
ConfigurationBuilder conf = new ConfigurationBuilder();
conf.AddServer().Host("127.0.0.1").Port(11222).ConnectionTimeout(90000).SocketTimeout(6000);
marshaller = new JBasicMarshaller();
conf.Marshaller(marshaller);
remoteManager = new RemoteCacheManager(conf.Build(), true);
// Install the .js code into the Infinispan __script_cache
const string PROTOBUF_SCRIPT_CACHE_NAME = "___script_cache";
string valueScriptName = "getValue.js";
string valueScript = "// mode=local,language=javascript\n "
+ "var cache = cacheManager.getCache(\"namedCache\");\n "
+ "var ct = cache.get(\"accessCounter\");\n "
+ "var c = ct==null ? 0 : parseInt(ct);\n "
+ "cache.put(\"accessCounter\",(++c).toString());\n "
+ "cache.get(\"privateValue\") ";
string accessScriptName = "getAccess.js";
string accessScript = "// mode=local,language=javascript\n "
+ "var cache = cacheManager.getCache(\"namedCache\");\n "
+ "cache.get(\"accessCounter\")";
IRemoteCache<string, string> scriptCache = remoteManager.GetCache<string, string>(PROTOBUF_SCRIPT_CACHE_NAME);
IRemoteCache<string, string> testCache = remoteManager.GetCache<string, string>("namedCache");
scriptCache.Put(valueScriptName, valueScript);
scriptCache.Put(accessScriptName, accessScript);
Once installed, a task may be executed by using the execute(string name, Dictionary<string, string> scriptArgs method, passing in the name of the script to execute, along with any arguments that are required for execution.
// This example continues the previous codeblock
testCache.Put("privateValue", "Counted Access Value");
Dictionary<string, string> scriptArgs = new Dictionary<string, string>();
byte[] ret1 = testCache.Execute(valueScriptName, scriptArgs);
string value = (string)marshaller.ObjectFromByteBuffer(ret1);
byte[] ret2 = testCache.Execute(accessScriptName, scriptArgs);
string accessCount = (string)marshaller.ObjectFromByteBuffer(ret2);
Console.Write("Return value is '" + value + "' and has been accessed '" + accessCount + "' times.");
}
}
}31.9. Script Examples
Example 31.6. Distributed Execution
List to be returned to the client:
// mode:distributed,language=javascript
cacheManager.getAddress().toString();Example 31.7. Word Count Stream
// mode=local,language=javascript
var Function = Java.type("java.util.function.Function")
var Collectors = Java.type("java.util.stream.Collectors")
var Arrays = Java.type("org.infinispan.scripting.utils.JSArrays")
cache
.entrySet().stream()
.map(function(e) e.getValue())
.map(function(v) v.toLowerCase())
.map(function(v) v.split(/[\W]+/))
.flatMap(function(f) Arrays.stream(f))
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));31.10. Limitations when Executing Stored Scripts
It is not possible to use scripts that create a Stream in JavaScript when the cluster is in DIST mode. Any attempts to execute these scripts will result in a NotSerializableException, as the lambdas fail when attempting to be serialized. To workaround this issue it is recommended to manually iterate over data using an Iterator, or to execute lambdas after the data has been transferred from the script to the originator node.
Chapter 32. Remote Task Execution
32.1. Creating a Remote Task
org.infinispan.tasks.ServerTask. This interface contains the following methods that must be implemented:
void setTaskContext(TaskContext taskContext)- sets the task context; should be used to access caches and other resources necessary.String getName()- provides a unique name for the task. This is the name that will be used for execution by theTaskManager.
TaskExecutionMethod getExecutionMode()- Determines if the task is executed on one node,TaskExecutionMode.ONE_NODE, or on all nodes,TaskExecutionMode.ALL_NODES. Execution on one node is enabled by default.Optional<String> getAllowedRole()- Sets the role that may execute this task. By default no role is provided, indicating that no additional role is required for execution. Additional information on executing tasks is found in Section 32.4, “Running Remote Tasks”.Set<String> getParameters()- A collection of named parameters for use with the task.
32.2. Installing Remote Tasks
Procedure 32.1. Option 1: Using the Deployments Directory
- Copy the deployment into the
deployments/directory of the JBoss Data Grid server as seen in the following example:$] cp /path/to/sample_task.jar $JDG_HOME/standalone/deployments/
Procedure 32.2. Option 2: Using the CLI
- Connect to the JDG server by running the below command:
[$JDG_HOME] $ bin/cli.sh --connect --controller=$IP:$PORT - Deploy the .jar file by executing the following command:
deploy /path/to/sample_task.jarNote
When JBoss Data Grid is used in domain mode the server groups must be specified using either the--all-server-groupsor--server-groupsparameters.
32.3. Removing Remote Tasks
- Connect to the JDG server by running the below command:
[$JDG_HOME] $ bin/cli.sh --connect --controller=$IP:$PORT - Remove the .jar file by using the
undeploycommand, as seen below:undeploy /path/to/sample_task.jarNote
When JBoss Data Grid is used in domain mode the server groups must be specified using either the--all-relevant-server-groupsor--server-groupsparameters.
32.4. Running Remote Tasks
EXEC permissions will be allowed to run previously installed tasks. If a remote task has additional users specified, via the getAllowedRole method, then users must also belong to this role to execute the script.
execute(String taskName, Map parameters) on the desired cache. The following example demonstrates executing a task with the name sampleTask:
import org.infinispan.client.hotrod.*;
import java.util.*;
[...]
String TASK_NAME = "sampleTask";
RemoteCacheManager rcm = new RemoteCacheManager();
RemoteCache remoteCache = rcm.getCache();
// Assume the task takes a single parameter, and will return a result
Map<String, String> params = new HashMap<>();
params.put("name", "value");
String result = (String) remoteCache.execute(TASK_NAME, params);Chapter 33. Data Interoperability
33.1. Protocol Interoperability
For instructions on how to enable compatibility mode refer to the Administration and Configuration Guide.
33.1.1. Use Cases and Requirements
| Use Case | Client A (Reader or Writer) | Client B (Write/Read Counterpart of Client A) |
|---|---|---|
| 1 | Memcached | Hot Rod Java |
| 2 | REST | Hot Rod Java |
| 3 | Memcached | REST |
| 4 | Hot Rod Java | Hot Rod C++ |
| 5 | Hot Rod Java | Hot Rod C# |
| 6 | Memcached | Hot Rod C++ |
Person instance, it would use a String as a key.
Client A Side
- A uses a third-party marshaller, such as Protobuf or Avro, to serialize the
Personvalue into a byte[]. A UTF-8 encoded string must be used as the key (according to Memcached protocol requirements). - A writes a key-value pair to the server (key as UTF-8 string, the value as byte arrays).
Client B Side
- B must read a
Personfor a specific key (String). - B serializes the same UTF-8 key into the corresponding byte[].
- B invokes
get(byte[]) - B obtains a byte[] representing the serialized object.
- B uses the same marshaller as A to unmarshall the byte[] into the corresponding
Personobject.
Note
- In Use Case 4, the Protostream Marshaller, which is included with the Hot Rod Java client, is recommended. For the Hot Rod C++ client, the Protobuf Marshaller from Google (https://developers.google.com/protocol-buffers/docs/overview) is recommended.
- In Use Case 5, the default Hot Rod marshaller can be used.
33.1.2. Protocol Interoperability Over REST
application/x-java-serialized-object, application/xml, or application/json. Any other byte arrays are treated as application/octet-stream.
Chapter 34. Set Up Cross-Datacenter Replication
RELAY2 protocol.
34.1. Cross-Datacenter Replication Operations
Example 34.1. Cross-Datacenter Replication Example
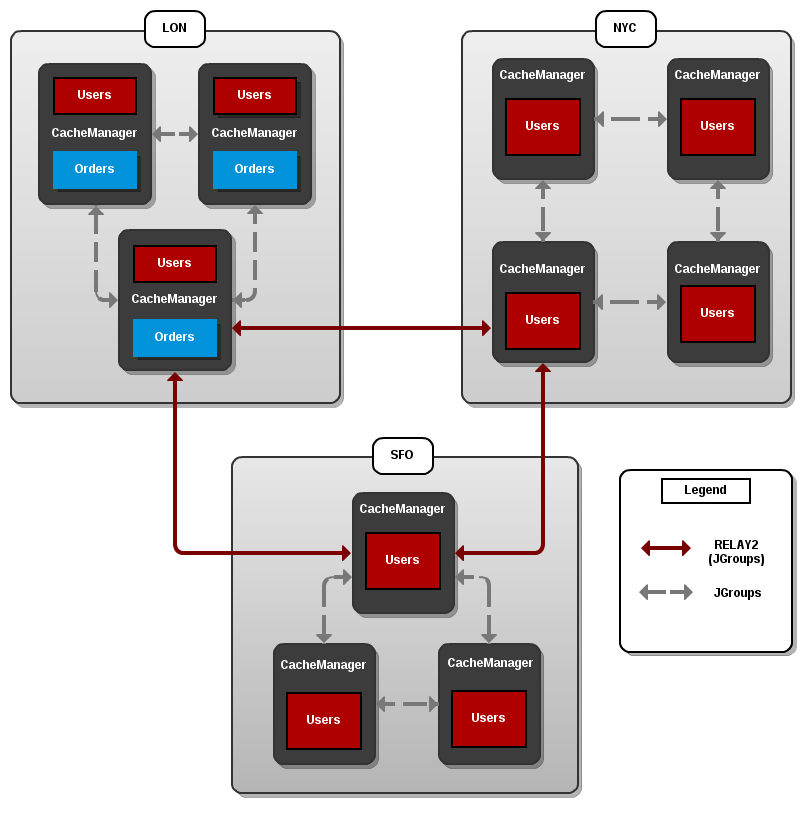
Figure 34.1. Cross-Datacenter Replication Example
LON, NYC and SFO. Each site hosts a running JBoss Data Grid cluster made up of three to four physical nodes.
Users cache is active in all three sites - LON, NYC and SFO. Changes to the Users cache at the any one of these sites will be replicated to the other two as long as the cache defines the other two sites as its backups through configuration. The Orders cache, however, is only available locally at the LON site because it is not replicated to the other sites.
Users cache can use different replication mechanisms each site. For example, it can back up data synchronously to SFO and asynchronously to NYC and LON.
Users cache can also have a different configuration from one site to another. For example, it can be configured as a distributed cache with owners set to 2 in the LON site, as a replicated cache in the NYC site and as a distributed cache with owners set to 1 in the SFO site.
RELAY2 facilitates communication between sites. For more information, refer to the RELAY2 section in the JBoss Data Grid Administration Guide.
34.2. Configure Cross-Datacenter Replication Programmatically
Procedure 34.1. Configure Cross-Datacenter Replication Programmatically
Identify the Node Location
Declare the site the node resides in:globalConfiguration.site().localSite("LON");Configure JGroups
Configure JGroups to use theRELAYprotocol:globalConfiguration.transport().addProperty("configurationFile", jgroups-with-relay.xml);Set Up the Remote Site
Set up JBoss Data Grid caches to replicate to the remote site:ConfigurationBuilder lon = new ConfigurationBuilder(); lon.sites().addBackup() .site("NYC") .backupFailurePolicy(BackupFailurePolicy.WARN) .strategy(BackupConfiguration.BackupStrategy.SYNC) .replicationTimeout(12000) .sites().addInUseBackupSite("NYC") .sites().addBackup() .site("SFO") .backupFailurePolicy(BackupFailurePolicy.IGNORE) .strategy(BackupConfiguration.BackupStrategy.ASYNC) .sites().addInUseBackupSite("SFO")Optional: Configure the Backup Caches
JBoss Data Grid implicitly replicates data to a cache with same name as the remote site. If a backup cache on the remote site has a different name, users must specify abackupForcache to ensure data is replicated to the correct cache.Note
This step is optional and only required if the remote site's caches are named differently from the original caches.- Configure the cache in site
NYCto receive backup data fromLON:ConfigurationBuilder NYCbackupOfLon = new ConfigurationBuilder(); NYCbackupOfLon.sites().backupFor().remoteCache("lon").remoteSite("LON"); - Configure the cache in site
SFOto receive backup data fromLON:ConfigurationBuilder SFObackupOfLon = new ConfigurationBuilder(); SFObackupOfLon.sites().backupFor().remoteCache("lon").remoteSite("LON");
Add the Contents of the Configuration File
As a default, Red Hat JBoss Data Grid includes JGroups configuration files such asdefault-configs/default-jgroups-tcp.xmlanddefault-configs/default-jgroups-udp.xmlin theinfinispan-embedded-{VERSION}.jarpackage.Copy the JGroups configuration to a new file (in this example, it is namedjgroups-with-relay.xml) and add the provided configuration information to this file. Note that therelay.RELAY2protocol configuration must be the last protocol in the configuration stack.<config> <!-- Additional configuration information here --> <relay.RELAY2 site="LON" config="relay.xml" relay_multicasts="false" /> </config>Configure the relay.xml File
Set up therelay.RELAY2configuration in therelay.xmlfile. This file describes the global cluster configuration.<RelayConfiguration> <sites> <site name="LON" id="0"> <bridges> <bridge config="jgroups-global.xml" name="global"/> </bridges> </site> <site name="NYC" id="1"> <bridges> <bridge config="jgroups-global.xml" name="global"/> </bridges> </site> <site name="SFO" id="2"> <bridges> <bridge config="jgroups-global.xml" name="global"/> </bridges> </site> </sites> </RelayConfiguration>Configure the Global Cluster
The filejgroups-global.xmlreferenced inrelay.xmlcontains another JGroups configuration which is used for the global cluster: communication between sites.The global cluster configuration is usuallyTCP-based and uses theTCPPINGprotocol (instead ofPINGorMPING) to discover members. Copy the contents ofdefault-configs/default-jgroups-tcp.xmlintojgroups-global.xmland add the following configuration in order to configureTCPPING:<config> <TCP bind_port="7800" <!-- Additional configuration information here --> /> <TCPPING initial_hosts="lon.hostname[7800],nyc.hostname[7800],sfo.hostname[7800]" ergonomics="false" /> <!-- Rest of the protocols --> </config>Replace the hostnames (or IP addresses) inTCPPING.initial_hostswith those used for your site masters. The ports (7800in this example) must match theTCP.bind_port.For more information about theTCPPINGprotocol, refer to the JBoss Data Grid Administration and Configuration Guide.
34.3. Taking a Site Offline
Example 34.2. Taking a Site Offline Programmatically
lon.sites().addBackup()
.site("NYC")
.backupFailurePolicy(BackupFailurePolicy.FAIL)
.strategy(BackupConfiguration.BackupStrategy.SYNC)
.takeOffline()
.afterFailures(500)
.minTimeToWait(10000);34.4. Hot Rod Cross Site Cluster Failover
If the main/primary cluster nodes are unavailable, the client application checks for alternatively defined clusters and will attempt to failover to them. Upon successful failover, the client will remain connected to the alternative cluster until it becomes unavailable. After that, the client will try to failover to other defined clusters and finally switch over to the main/primary cluster with the original server settings if the connectivity is restored.
Example 34.3. Configure Alternate Cluster
org.infinispan.client.hotrod.configuration.ConfigurationBuilder cb
= new org.infinispan.client.hotrod.configuration.ConfigurationBuilder();
cb.addCluster("remote-cluster").addClusterNode("remote-cluster-host", 11222);
RemoteCacheManager rcm = new RemoteCacheManager(cb.build());
Note
For manual site cluster switchover, call RemoteCacheManager’s switchToCluster(clusterName) or switchToDefaultCluster().
switchToCluster(clusterName), users can force a client to switch to one of the clusters predefined in the Hot Rod client configuration. To switch to the default cluster use switchToDefaultCluster() instead.
Chapter 35. Near Caching
get or getVersioned operations.
Important
Note
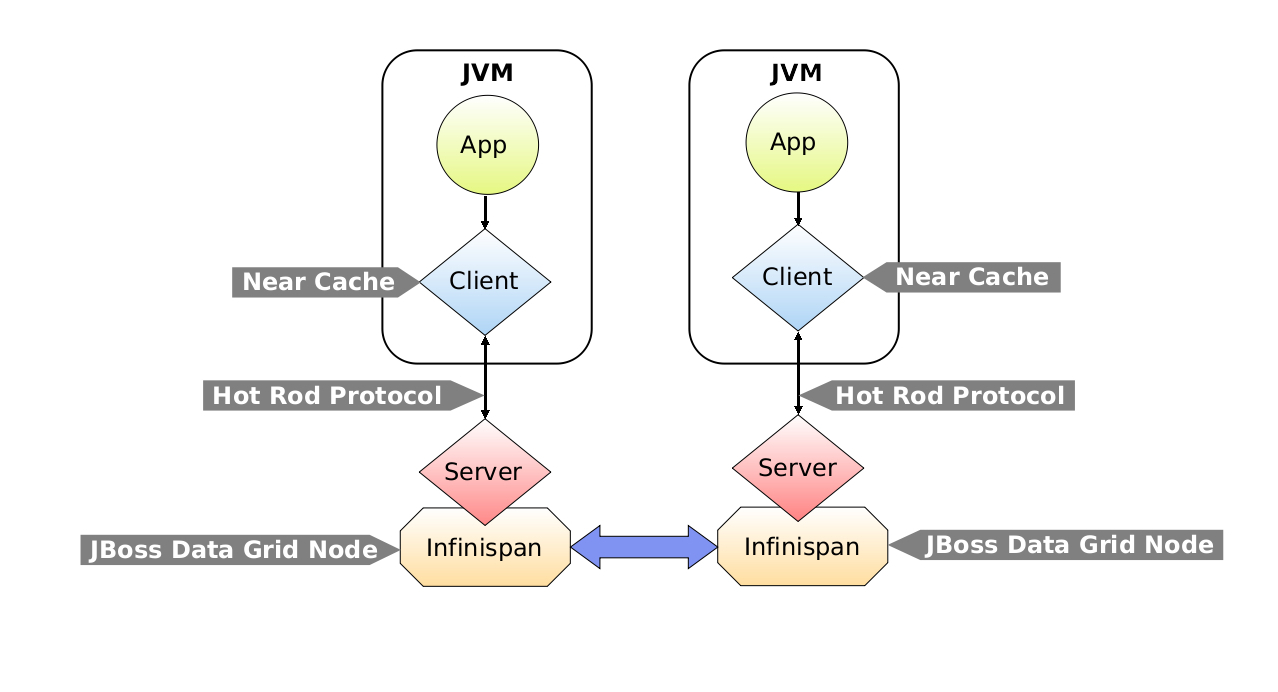
Figure 35.1. Near Caching Architecture
35.1. Lazy and Eager Near Caches
- Lazy Near Cache
- Entries are only added to lazy near caches when they are received remotely via
getorgetVersioned. If a cache entry is modified or removed on the server side, the Hot Rod client receives the events, which then invalidate the near cache entries by removing them from the near cache. This is an efficient way of maintaining near cache consistency as the events sent back to the client only contain key information. However, if a cache entry is retrieved after being modified the Hot Rod client must then retrieve it from the remote server. - Eager Near Cache
- Eager near caches are eagerly populated as entries are created on the server. When entries are modified, the latest value is sent along with the notification to the client, which stores it in the near cache. Eager caches are also populated when an entry is retrieved remotely, provided it is not already present. Eager near caches have the advantage of reducing the cost of accessing the server by having newly created entries present in the near cache before requests to retrieve them are received.Eager near caches also allow modified entries that are re-queried by the client to be fetched directly from the near cache. The drawback of using eager near caching is that events received from the server are larger in size due to shipping value information, and entries may be sent to the client that will not be queried.
Warning
Eager near caching is deprecated as of JBoss Data Grid 7.0.0. It is not supported for production use, as with high number of events, value sizes, or clients, eager near caching can generate a large amount of network traffic and potentially overload clients. For production use, it is recommended to use lazy near caches instead.
35.2. Configuring Near Caches
NearCacheMode enumeration.
Example 35.1. Configuring Lazy Near Cache Mode
import org.infinispan.client.hotrod.configuration.ConfigurationBuilder;
import org.infinispan.client.hotrod.configuration.NearCacheMode;
…
ConfigurationBuilder lazy = new ConfigurationBuilder();
lazy.nearCache().mode(NearCacheMode.LAZY).maxEntries(10);Example 35.2. Configuring Eager Near Cache Mode
import org.infinispan.client.hotrod.configuration.ConfigurationBuilder;
import org.infinispan.client.hotrod.configuration.NearCacheMode;
...
ConfigurationBuilder eager = new ConfigurationBuilder();
eager.nearCache().mode(NearCacheMode.EAGER)..maxEntries(10);Note
Example 35.3. Configuring Near Cache Maximum Size
import org.infinispan.client.hotrod.configuration.ConfigurationBuilder;
...
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.nearCache().maxEntries(100);Note
35.3. Near Caches in a Clustered Environment
Appendix A. References
A.1. The Externalizer
A.1.1. About Externalizer
Externalizer is a class that can:
- Marshall a given object type to a byte array.
- Unmarshall the contents of a byte array into an instance of the object type.
A.1.2. Internal Externalizer Implementation Access
public static class ABCMarshallingExternalizer implements AdvancedExternalizer<ABCMarshalling> {
@Override
public void writeObject(ObjectOutput output, ABCMarshalling object) throws IOException {
MapExternalizer ma = new MapExternalizer();
ma.writeObject(output, object.getMap());
}
@Override
public ABCMarshalling readObject(ObjectInput input) throws IOException, ClassNotFoundException {
ABCMarshalling hi = new ABCMarshalling();
MapExternalizer ma = new MapExternalizer();
hi.setMap((ConcurrentHashMap<Long, Long>) ma.readObject(input));
return hi;
}
<!-- Additional configuration information here -->public static class ABCMarshallingExternalizer implements AdvancedExternalizer<ABCMarshalling> {
@Override
public void writeObject(ObjectOutput output, ABCMarshalling object) throws IOException {
output.writeObject(object.getMap());
}
@Override
public ABCMarshalling readObject(ObjectInput input) throws IOException, ClassNotFoundException {
ABCMarshalling hi = new ABCMarshalling();
hi.setMap((ConcurrentHashMap<Long, Long>) input.readObject());
return hi;
}
<!-- Additional configuration information here -->
}A.2. Hash Space Allocation
A.2.1. About Hash Space Allocation
A.2.2. Locating a Key in the Hash Space
Appendix B. Revision History
| Revision History | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Revision 7.0.0-4 | Thur Jul 20 2017 | ||||||||
| |||||||||
| Revision 7.0.0-3 | Thur May 25 2017 | ||||||||
| |||||||||
| Revision 7.0.0-2 | Thu 23 Jun 2016 | ||||||||
| |||||||||
| Revision 7.0.0-1 | Tue 3 May 2016 | ||||||||
| |||||||||
| Revision 7.0.0-0 | Tue 19 Apr 2016 | ||||||||
| |||||||||