Resource Management Guide
Managing system resources on Red Hat Enterprise Linux 6
Edition 6
Abstract
Chapter 1. Introduction to Control Groups (Cgroups)
cgconfig (control group config) service can be configured to start up at boot time and reestablish your predefined cgroups, thus making them persistent across reboots.
1.1. How Control Groups Are Organized
The Linux Process Model
init process, which is executed by the kernel at boot time and starts other processes (which may in turn start child processes of their own). Because all processes descend from a single parent, the Linux process model is a single hierarchy, or tree.
init inherits the environment (such as the PATH variable)[1] and certain other attributes (such as open file descriptors) of its parent process.
The Cgroup Model
- they are hierarchical, and
- child cgroups inherit certain attributes from their parent cgroup.
Available Subsystems in Red Hat Enterprise Linux
blkio— this subsystem sets limits on input/output access to and from block devices such as physical drives (disk, solid state, or USB).cpu— this subsystem uses the scheduler to provide cgroup tasks access to the CPU.cpuacct— this subsystem generates automatic reports on CPU resources used by tasks in a cgroup.cpuset— this subsystem assigns individual CPUs (on a multicore system) and memory nodes to tasks in a cgroup.devices— this subsystem allows or denies access to devices by tasks in a cgroup.freezer— this subsystem suspends or resumes tasks in a cgroup.memory— this subsystem sets limits on memory use by tasks in a cgroup and generates automatic reports on memory resources used by those tasks.net_cls— this subsystem tags network packets with a class identifier (classid) that allows the Linux traffic controller (tc) to identify packets originating from a particular cgroup task.net_prio— this subsystem provides a way to dynamically set the priority of network traffic per network interface.ns— the namespace subsystem.perf_event— this subsystem identifies cgroup membership of tasks and can be used for performance analysis.
Note
1.2. Relationships Between Subsystems, Hierarchies, Control Groups and Tasks
Rule 1
cpu and memory subsystems (or any number of subsystems) can be attached to a single hierarchy, as long as each one is not attached to any other hierarchy which has any other subsystems attached to it already (see Rule 2).
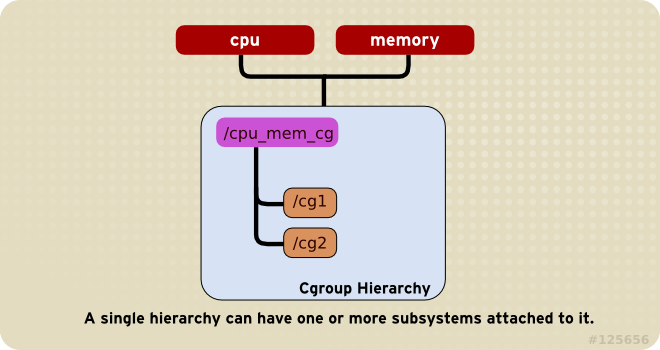
Figure 1.1. Rule 1
Rule 2
cpu) cannot be attached to more than one hierarchy if one of those hierarchies has a different subsystem attached to it already.
cpu subsystem can never be attached to two different hierarchies if one of those hierarchies already has the memory subsystem attached to it. However, a single subsystem can be attached to two hierarchies if both of those hierarchies have only that subsystem attached.
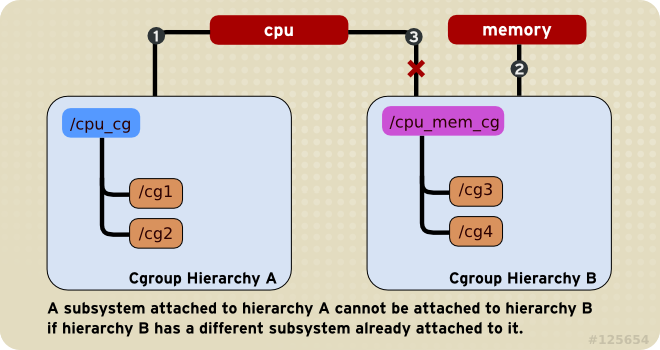
Figure 1.2. Rule 2—The numbered bullets represent a time sequence in which the subsystems are attached.
Rule 3
cpu and memory subsystems are attached to a hierarchy named cpu_mem_cg, and the net_cls subsystem is attached to a hierarchy named net, then a running httpd process could be a member of any one cgroup in cpu_mem_cg, and any one cgroup in net.
cpu_mem_cg that the httpd process is a member of might restrict its CPU time to half of that allotted to other processes, and limit its memory usage to a maximum of 1024 MB. Additionally, the cgroup in net that the httpd process is a member of might limit its transmission rate to 30 MB/s (megabytes per second).

Figure 1.3. Rule 3
Rule 4
httpd task that is a member of the cgroup named half_cpu_1gb_max in the cpu_and_mem hierarchy, and a member of the cgroup trans_rate_30 in the net hierarchy. When that httpd process forks itself, its child process automatically becomes a member of the half_cpu_1gb_max cgroup, and the trans_rate_30 cgroup. It inherits the exact same cgroups its parent task belongs to.
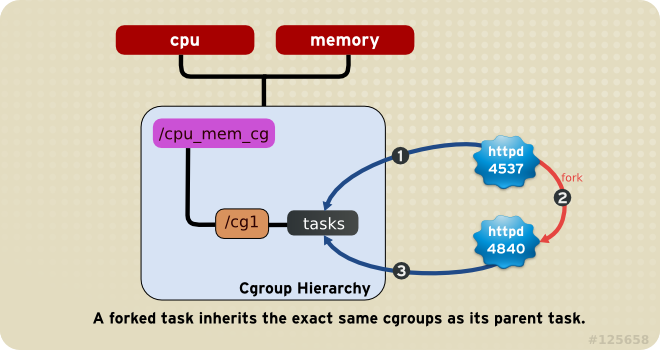
Figure 1.4. Rule 4—The numbered bullets represent a time sequence in which the task forks.
1.3. Implications for Resource Management
- Because a task can belong to only a single cgroup in any one hierarchy, there is only one way that a task can be limited or affected by any single subsystem. This is logical: a feature, not a limitation.
- You can group several subsystems together so that they affect all tasks in a single hierarchy. Because cgroups in that hierarchy have different parameters set, those tasks will be affected differently.
- It may sometimes be necessary to refactor a hierarchy. An example would be removing a subsystem from a hierarchy that has several subsystems attached, and attaching it to a new, separate hierarchy.
- Conversely, if the need for splitting subsystems among separate hierarchies is reduced, you can remove a hierarchy and attach its subsystems to an existing one.
- The design allows for simple cgroup usage, such as setting a few parameters for specific tasks in a single hierarchy, such as one with just the
cpuandmemorysubsystems attached. - The design also allows for highly specific configuration: each task (process) on a system could be a member of each hierarchy, each of which has a single attached subsystem. Such a configuration would give the system administrator absolute control over all parameters for every single task.
Chapter 2. Using Control Groups
Note
~]# yum install libcgroup2.1. The cgconfig Service
cgconfig service installed with the libcgroup package provides a convenient way to create hierarchies, attach subsystems to hierarchies, and manage cgroups within those hierarchies. It is recommended that you use cgconfig to manage hierarchies and cgroups on your system.
cgconfig service is not started by default on Red Hat Enterprise Linux 6. When you start the service with chkconfig, it reads the cgroup configuration file — /etc/cgconfig.conf. Cgroups are therefore recreated from session to session and remain persistent. Depending on the contents of the configuration file, cgconfig can create hierarchies, mount necessary file systems, create cgroups, and set subsystem parameters for each group.
/etc/cgconfig.conf file installed with the libcgroup package creates and mounts an individual hierarchy for each subsystem, and attaches the subsystems to these hierarchies. The cgconfig service also allows to create configuration files in the /etc/cgconfig.d/ directory and to invoke them from /etc/cgconfig.conf.
cgconfig service (with the service cgconfig stop command), it unmounts all the hierarchies that it mounted.
2.1.1. The /etc/cgconfig.conf File
/etc/cgconfig.conf file contains two major types of entries — mount and group. Mount entries create and mount hierarchies as virtual file systems, and attach subsystems to those hierarchies. Mount entries are defined using the following syntax:
mount {
subsystem = /cgroup/hierarchy;
…
}
/etc/cgconfig.conf file when it is installed. The default configuration file looks as follows:
mount {
cpuset = /cgroup/cpuset;
cpu = /cgroup/cpu;
cpuacct = /cgroup/cpuacct;
memory = /cgroup/memory;
devices = /cgroup/devices;
freezer = /cgroup/freezer;
net_cls = /cgroup/net_cls;
blkio = /cgroup/blkio;
}/cgroup/ directory. It is recommended to use these default hierarchies for specifying control groups. However, in certain cases you may need to create hierarchies manually, for example when they were deleted before, or it is beneficial to have a single hierarchy for multiple subsystems (as in Section 4.3, “Per-group Division of CPU and Memory Resources”). Note that multiple subsystems can be mounted to a single hierarchy, but each subsystem can be mounted only once. See Example 2.1, “Creating a mount entry” for an example of creating a hierarchy.
Example 2.1. Creating a mount entry
cpuset subsystem:
mount {
cpuset = /cgroup/red;
}
~]# mkdir /cgroup/red
~]# mount -t cgroup -o cpuset red /cgroup/redcpuset is already mounted.
group <name> {
[<permissions>]
<controller> {
<param name> = <param value>;
…
}
…
}
permissions section is optional. To define permissions for a group entry, use the following syntax:
perm {
task {
uid = <task user>;
gid = <task group>;
}
admin {
uid = <admin name>;
gid = <admin group>;
}
}
Example 2.2. Creating a group entry
sqladmin group to add tasks to the cgroup and the root user to modify subsystem parameters:
group daemons {
cpuset {
cpuset.mems = 0;
cpuset.cpus = 0;
}
}
group daemons/sql {
perm {
task {
uid = root;
gid = sqladmin;
} admin {
uid = root;
gid = root;
}
}
cpuset {
cpuset.mems = 0;
cpuset.cpus = 0;
}
}
~]# mkdir -p /cgroup/red/daemons/sql
~]# chown root:root /cgroup/red/daemons/sql/*
~]# chown root:sqladmin /cgroup/red/daemons/sql/tasks
~]# echo $(cgget -n -v -r cpuset.mems /) > /cgroup/red/daemons/cpuset.mems
~]# echo $(cgget -n -v -r cpuset.cpus /) > /cgroup/red/daemons/cpuset.cpus
~]# echo 0 > /cgroup/red/daemons/sql/cpuset.mems
~]# echo 0 > /cgroup/red/daemons/sql/cpuset.cpusNote
cgconfig service for the changes in the /etc/cgconfig.conf file to take effect. However, note that restarting this service causes the entire cgroup hierarchy to be rebuilt, which removes any previously existing cgroups (for example, any existing cgroups used by libvirtd). To restart the cgconfig service, use the following command:
~]# service cgconfig restart/etc/cgconfig.conf. The hash symbols ('#') at the start of each line comment that line out and make it invisible to the cgconfig service.
2.1.2. The /etc/cgconfig.d/ Directory
/etc/cgconfig.d/ directory is reserved for storing configuration files for specific applications and use cases. These files should be created with the .conf suffix and adhere to the same syntax rules as /etc/cgconfig.conf.
cgconfig service first parses the /etc/cgconfig.conf file and then continues with files in the /etc/cgconfig.d/ directory. Note that the order of file parsing is not defined, because it does not make a difference provided that each configuration file is unique. Therefore, do not define the same group or template in multiple configuration files, otherwise they would interfere with each other.
/etc/cgconfig.d/.
2.2. Creating a Hierarchy and Attaching Subsystems
Warning
cgconfig service) these commands fail unless you first unmount existing hierarchies, which affects the operation of the system. Do not experiment with these instructions on production systems.
mount section of the /etc/cgconfig.conf file as root. Entries in the mount section have the following format:
subsystem = /cgroup/hierarchy;cgconfig next starts, it will create the hierarchy and attach the subsystems to it.
cpu_and_mem and attaches the cpu, cpuset, cpuacct, and memory subsystems to it.
mount {
cpuset = /cgroup/cpu_and_mem;
cpu = /cgroup/cpu_and_mem;
cpuacct = /cgroup/cpu_and_mem;
memory = /cgroup/cpu_and_mem;
}Alternative method
~]# mkdir /cgroup/name~]# mkdir /cgroup/cpu_and_memmount command to mount the hierarchy and simultaneously attach one or more subsystems. For example:
~]# mount -t cgroup -o subsystems name /cgroup/nameExample 2.3. Using the mount command to attach subsystems
/cgroup/cpu_and_mem already exists and will serve as the mount point for the hierarchy that you create. Attach the cpu, cpuset, and memory subsystems to a hierarchy named cpu_and_mem, and mount the cpu_and_mem hierarchy on /cgroup/cpu_and_mem:
~]# mount -t cgroup -o cpu,cpuset,memory cpu_and_mem /cgroup/cpu_and_memlssubsys [3] command:
~]# lssubsys -am
cpu,cpuset,memory /cgroup/cpu_and_mem
net_cls
ns
cpuacct
devices
freezer
blkio- the
cpu,cpuset, andmemorysubsystems are attached to a hierarchy mounted on/cgroup/cpu_and_mem, and - the
net_cls,ns,cpuacct,devices,freezer, andblkiosubsystems are as yet unattached to any hierarchy, as illustrated by the lack of a corresponding mount point.
2.3. Attaching Subsystems to, and Detaching Them from, an Existing Hierarchy
mount section of the /etc/cgconfig.conf file as root, using the same syntax described in Section 2.2, “Creating a Hierarchy and Attaching Subsystems”. When cgconfig next starts, it will reorganize the subsystems according to the hierarchies that you specify.
Alternative method
mount command, together with the remount option.
Example 2.4. Remounting a hierarchy to add a subsystem
lssubsys command shows cpu, cpuset, and memory subsystems attached to the cpu_and_mem hierarchy:
~]# lssubsys -am
cpu,cpuset,memory /cgroup/cpu_and_mem
net_cls
ns
cpuacct
devices
freezer
blkiocpu_and_mem hierarchy, using the remount option, and include cpuacct in the list of subsystems:
~]# mount -t cgroup -o remount,cpu,cpuset,cpuacct,memory cpu_and_mem /cgroup/cpu_and_memlssubsys command now shows cpuacct attached to the cpu_and_mem hierarchy:
~]# lssubsys -am
cpu,cpuacct,cpuset,memory /cgroup/cpu_and_mem
net_cls
ns
devices
freezer
blkio-o options. For example, to then detach the cpuacct subsystem, simply remount and omit it:
~]# mount -t cgroup -o remount,cpu,cpuset,memory cpu_and_mem /cgroup/cpu_and_mem2.4. Unmounting a Hierarchy
umount command:
~]# umount /cgroup/name~]# umount /cgroup/cpu_and_memcgclear command which can deactivate a hierarchy even when it is not empty — refer to Section 2.12, “Unloading Control Groups”.
2.5. Creating Control Groups
cgcreate command to create cgroups. The syntax for cgcreate is:
cgcreate -t uid:gid -a uid:gid -g subsystems:path-t(optional) — specifies a user (by user ID, uid) and a group (by group ID, gid) to own thetaskspseudofile for this cgroup. This user can add tasks to the cgroup.Note
Note that the only way to remove a task from a cgroup is to move it to a different cgroup. To move a task, the user has to have write access to the destination cgroup; write access to the source cgroup is not necessary.-a(optional) — specifies a user (by user ID, uid) and a group (by group ID, gid) to own all pseudofiles other thantasksfor this cgroup. This user can modify access of the tasks in this cgroup to system resources.-g— specifies the hierarchy in which the cgroup should be created, as a comma‑separated list of subsystems associated with hierarchies. If the subsystems in this list are in different hierarchies, the group is created in each of these hierarchies. The list of hierarchies is followed by a colon and the path to the child group relative to the hierarchy. Do not include the hierarchy mount point in the path.For example, the cgroup located in the directory/cgroup/cpu_and_mem/lab1/is called justlab1— its path is already uniquely determined because there is at most one hierarchy for a given subsystem. Note also that the group is controlled by all the subsystems that exist in the hierarchies in which the cgroup is created, even though these subsystems have not been specified in thecgcreatecommand — refer to Example 2.5, “cgcreate usage”.
Example 2.5. cgcreate usage
cpu and memory subsystems are mounted together in the cpu_and_mem hierarchy, and the net_cls controller is mounted in a separate hierarchy called net. Run the following command:
~]# cgcreate -g cpu,net_cls:/test-subgroupcgcreate command creates two groups named test-subgroup, one in the cpu_and_mem hierarchy and one in the net hierarchy. The test-subgroup group in the cpu_and_mem hierarchy is controlled by the memory subsystem, even though it was not specified in the cgcreate command.
Alternative method
mkdir command:
~]# mkdir /cgroup/hierarchy/name/child_name~]# mkdir /cgroup/cpu_and_mem/group12.6. Removing Control Groups
cgdelete to remove cgroups. It has similar syntax as cgcreate. Run the following command:
cgdelete subsystems:path- subsystems is a comma‑separated list of subsystems.
- path is the path to the cgroup relative to the root of the hierarchy.
~]# cgdelete cpu,net_cls:/test-subgroupcgdelete can also recursively remove all subgroups with the option -r.
2.7. Setting Parameters
cgset command from a user account with permission to modify the relevant cgroup. For example, if cpuset is mounted to /cgroup/cpu_and_mem/ and the /cgroup/cpu_and_mem/group1 subdirectory exists, specify the CPUs to which this group has access with the following command:
cpu_and_mem]# cgset -r cpuset.cpus=0-1 group1cgset is:
cgset -r parameter=value path_to_cgroup- parameter is the parameter to be set, which corresponds to the file in the directory of the given cgroup.
- value is the value for the parameter.
- path_to_cgroup is the path to the cgroup relative to the root of the hierarchy. For example, to set the parameter of the root group (if the
cpuacctsubsystem is mounted to/cgroup/cpu_and_mem/), change to the/cgroup/cpu_and_mem/directory, and run:cpu_and_mem]# cgset -r cpuacct.usage=0 /Alternatively, because.is relative to the root group (that is, the root group itself) you could also run:cpu_and_mem]# cgset -r cpuacct.usage=0 .Note, however, that/is the preferred syntax.Note
Only a small number of parameters can be set for the root group (such as thecpuacct.usageparameter shown in the examples above). This is because a root group owns all of the existing resources, therefore, it would make no sense to limit all existing processes by defining certain parameters, for example thecpuset.cpuparameter.To set the parameter ofgroup1, which is a subgroup of the root group, run:cpu_and_mem]# cgset -r cpuacct.usage=0 group1A trailing slash after the name of the group (for example,cpuacct.usage=0 group1/) is optional.
cgset might depend on values set higher in a particular hierarchy. For example, if group1 is limited to use only CPU 0 on a system, you cannot set group1/subgroup1 to use CPUs 0 and 1, or to use only CPU 1.
cgset to copy the parameters of one cgroup into another existing cgroup. For example:
cpu_and_mem]# cgset --copy-from group1/ group2/cgset is:
cgset --copy-from path_to_source_cgroup path_to_target_cgroup- path_to_source_cgroup is the path to the cgroup whose parameters are to be copied, relative to the root group of the hierarchy.
- path_to_target_cgroup is the path to the destination cgroup, relative to the root group of the hierarchy.
Alternative method
echo command. In the following example, the echo command inserts the value of 0-1 into the cpuset.cpus pseudofile of the cgroup group1:
~]# echo 0-1 > /cgroup/cpu_and_mem/group1/cpuset.cpus2.8. Moving a Process to a Control Group
cgclassify command, for example:
~]# cgclassify -g cpu,memory:group1 1701cgclassify is:
cgclassify -g subsystems:path_to_cgroup pidlist- subsystems is a comma‑separated list of subsystems, or
*to launch the process in the hierarchies associated with all available subsystems. Note that if cgroups of the same name exist in multiple hierarchies, the-goption moves the processes in each of those groups. Ensure that the cgroup exists within each of the hierarchies whose subsystems you specify here. - path_to_cgroup is the path to the cgroup within its hierarchies.
- pidlist is a space-separated list of process identifier (PIDs).
-g option is not specified, cgclassify automatically searches the /etc/cgrules.conf file (see Section 2.8.1, “The cgred Service”) and uses the first applicable configuration line. According to this line, cgclassify determines the hierarchies and cgroups to move the process under. Note that for the move to be successful, the destination hierarchies must exist. The subsystems specified in /etc/cgrules.conf also have to be properly configured for the corresponding hierarchy in /etc/cgconfig.conf.
--sticky option before the pid to keep any child processes in the same cgroup. If you do not set this option and the cgred service is running, child processes are allocated to cgroups based on the settings found in /etc/cgrules.conf. However, the parent process remains in the cgroup in which it was first started.
cgclassify, you can move several processes simultaneously. For example, this command moves the processes with PIDs 1701 and 1138 into cgroup group1/:
~]# cgclassify -g cpu,memory:group1 1701 1138Alternative method
tasks file of the cgroup. For example, to move a process with the PID 1701 into a cgroup at /cgroup/cpu_and_mem/group1/:
~]# echo 1701 > /cgroup/cpu_and_mem/group1/tasks2.8.1. The cgred Service
cgrulesengd service) that moves tasks into cgroups according to parameters set in the /etc/cgrules.conf file. Entries in the /etc/cgrules.conf file can take one of these two forms:
user subsystems control_groupuser:command subsystems control_groupmaria devices /usergroup/staff
maria access the devices subsystem according to the parameters specified in the /usergroup/staff cgroup. To associate particular commands with particular cgroups, add the command parameter, as follows:
maria:ftp devices /usergroup/staff/ftp
maria uses the ftp command, the process is automatically moved to the /usergroup/staff/ftp cgroup in the hierarchy that contains the devices subsystem. Note, however, that the daemon moves the process to the cgroup only after the appropriate condition is fulfilled. Therefore, the ftp process might run for a short time in the wrong group. Furthermore, if the process quickly spawns children while in the wrong group, these children might not be moved.
/etc/cgrules.conf file can include the following extra notation:
@— indicates a group instead of an individual user. For example,@adminsare all users in theadminsgroup.*— represents "all". For example,*in thesubsystemfield represents all mounted subsystems.%— represents an item that is the same as the item on the line above.
/etc/cgrules.conf file can have the following form:
@adminstaff devices /admingroup
@labstaff % %
adminstaff and labstaff access the devices subsystem according to the limits set in the admingroup cgroup.
/etc/cgrules.conf can be linked to templates configured either in the /etc/cgconfig.conf file or in configuration files stored in the /etc/cgconfig.d/ directory, allowing for flexible cgroup assignment and creation.
/etc/cgconfig.conf:
template users/%g/%u {
cpuacct{
}
cpu {
cpu.shares = "1000";
}
}
/etc/cgrules.conf entry, which can look as follows:
peter:ftp cpu users/%g/%u
%g and %u variables used above are automatically replaced with group and user name depending on the owner of the ftp process. If the process belongs to peter from the adminstaff group, the above path is translated to users/adminstaff/peter. The cgred service then searches for this directory, and if it does not exist, cgred creates it and assigns the process to users/adminstaff/peter/tasks. Note that template rules apply only to definitions of templates in configuration files, so even if "group users/adminstaff/peter" was defined in /etc/cgconfig.conf, it would be ignored in favor of "template users/%g/%u".
%u— is replaced with the name of the user who owns the current process. If name resolution fails, UID is used instead.%U— is replaced with the UID of the specified user who owns the current process.%g— is replaced with the name of the user group that owns the current process, or with the GID if name resolution fails.%G— is replaced with the GID of the cgroup that owns the current process.%p— is replaced with the name of the current process. PID is used in case of name resolution failure.%P— is replaced with the PID of the current processes.
2.9. Starting a Process in a Control Group
Important
cpuset subsystem, the cpuset.cpus and cpuset.mems parameters must be defined for that cgroup.
cgexec command. For example, this command launches the firefox web browser within the group1 cgroup, subject to the limitations imposed on that group by the cpu subsystem:
~]# cgexec -g cpu:group1 firefox http://www.redhat.comcgexec is:
cgexec -g subsystems:path_to_cgroup command arguments- subsystems is a comma‑separated list of subsystems, or
*to launch the process in the hierarchies associated with all available subsystems. Note that, as withcgsetdescribed in Section 2.7, “Setting Parameters”, if cgroups of the same name exist in multiple hierarchies, the-goption creates processes in each of those groups. Ensure that the cgroup exists within each of the hierarchies whose subsystems you specify here. - path_to_cgroup is the path to the cgroup relative to the hierarchy.
- command is the command to run.
- arguments are any arguments for the command.
--sticky option before the command to keep any child processes in the same cgroup. If you do not set this option and the cgred service is running, child processes will be allocated to cgroups based on the settings found in /etc/cgrules.conf. The process itself, however, will remain in the cgroup in which you started it.
Alternative method
~]# echo $$ > /cgroup/cpu_and_mem/group1/tasks
~]# firefoxgroup1 cgroup. Therefore, an even better way would be:
~]# sh -c "echo \$$ > /cgroup/cpu_and_mem/group1/tasks && firefox"2.9.1. Starting a Service in a Control Group
- use a
/etc/sysconfig/servicenamefile - use the
daemon()function from/etc/init.d/functionsto start the service
/etc/sysconfig directory to include an entry in the form CGROUP_DAEMON="subsystem:control_group" where subsystem is a subsystem associated with a particular hierarchy, and control_group is a cgroup in that hierarchy. For example:
CGROUP_DAEMON="cpuset:group1"
cpuset is mounted to /cgroup/cpu_and_mem/, the above configuration translates to /cgroup/cpu_and_mem/group1.
2.9.2. Process Behavior in the Root Control Group
blkio and cpu configuration options affect processes (tasks) running in the root cgroup in a different way than those in a subgroup. Consider the following example:
- Create two subgroups under one root group:
/rootgroup/red/and/rootgroup/blue/ - In each subgroup and in the root group, define the
cpu.sharesconfiguration option and set it to1.
/rootgroup/tasks, /rootgroup/red/tasks and /rootgroup/blue/tasks) consumes 33.33% of the CPU:
/rootgroup/ process: 33.33%
/rootgroup/blue/ process: 33.33%
/rootgroup/red/ process: 33.33%
blue and red result in the 33.33% percent of the CPU assigned to that specific subgroup to be split among the multiple processes in that subgroup.
/rootgroup/ contains three processes, /rootgroup/red/ contains one process and /rootgroup/blue/ contains one process, and the cpu.shares option is set to 1 in all groups, the CPU resource is divided as follows:
/rootgroup/ processes: 20% + 20% + 20%
/rootgroup/blue/ process: 20%
/rootgroup/red/ process: 20%
blkio and cpu configuration options which divide an available resource based on a weight or a share (for example, cpu.shares or blkio.weight). To move all tasks from the root group into a specific subgroup, you can use the following commands:
rootgroup]# cat tasks >> red/tasks
rootgroup]# echo > tasks2.10. Generating the /etc/cgconfig.conf File
/etc/cgconfig.conf file can be generated from the current cgroup configuration using the cgsnapshot utility. This utility takes a snapshot of the current state of all subsystems and their cgroups and returns their configuration as it would appear in the /etc/cgconfig.conf file. Example 2.6, “Using the cgsnapshot utility” shows an example usage of the cgsnapshot utility.
Example 2.6. Using the cgsnapshot utility
~]# mkdir /cgroup/cpu
~]# mount -t cgroup -o cpu cpu /cgroup/cpu
~]# mkdir /cgroup/cpu/lab1
~]# mkdir /cgroup/cpu/lab2
~]# echo 2 > /cgroup/cpu/lab1/cpu.shares
~]# echo 3 > /cgroup/cpu/lab2/cpu.shares
~]# echo 5000000 > /cgroup/cpu/lab1/cpu.rt_period_us
~]# echo 4000000 > /cgroup/cpu/lab1/cpu.rt_runtime_us
~]# mkdir /cgroup/cpuacct
~]# mount -t cgroup -o cpuacct cpuacct /cgroup/cpuacctcpu subsystem, with specific values for some of their parameters. Executing the cgsnapshot command (with the -s option and an empty /etc/cgsnapshot_blacklist.conf file[4]) then produces the following output:
~]$ cgsnapshot -s
# Configuration file generated by cgsnapshot
mount {
cpu = /cgroup/cpu;
cpuacct = /cgroup/cpuacct;
}
group lab2 {
cpu {
cpu.rt_period_us="1000000";
cpu.rt_runtime_us="0";
cpu.shares="3";
}
}
group lab1 {
cpu {
cpu.rt_period_us="5000000";
cpu.rt_runtime_us="4000000";
cpu.shares="2";
}
}
-s option used in the example above tells cgsnapshot to ignore all warnings in the output file caused by parameters not being defined in the blacklist or whitelist of the cgsnapshot utility. For more information on parameter blacklisting, refer to Section 2.10.1, “Blacklisting Parameters”. For more information on parameter whitelisting, refer to Section 2.10.2, “Whitelisting Parameters”.
-f option to specify a file to which the output should be redirected. For example:
~]$ cgsnapshot -f ~/test/cgconfig_test.confWarning
-f option, note that it overwrites any content in the file you specify. Therefore, it is recommended not to direct the output straight to the /etc/cgconfig.conf file.
~]$ cgsnapshot cpuacct
# Configuration file generated by cgsnapshot
mount {
cpuacct = /cgroup/cpuacct;
}
2.10.1. Blacklisting Parameters
/etc/cgsnapshot_blacklist.conf file is checked for blacklisted parameters. If a parameter is not present in the blacklist, the whitelist is checked. To specify a different blacklist, use the -b option. For example:
~]$ cgsnapshot -b ~/test/my_blacklist.conf2.10.2. Whitelisting Parameters
~]$ cgsnapshot -f ~/test/cgconfig_test.conf
WARNING: variable cpu.rt_period_us is neither blacklisted nor whitelisted
WARNING: variable cpu.rt_runtime_us is neither blacklisted nor whitelisted
-w option. For example:
~]$ cgsnapshot -w ~/test/my_whitelist.conf-t option tells cgsnapshot to generate a configuration with parameters from the whitelist only.
2.11. Obtaining Information About Control Groups
2.11.1. Finding a Process
~]$ ps -O cgroup~]$ cat /proc/PID/cgroup2.11.2. Finding a Subsystem
~]$ cat /proc/cgroups
#subsys_name hierarchy num_cgroups enabled
cpuset 2 1 1
ns 0 1 1
cpu 3 1 1
cpuacct 4 1 1
memory 5 1 1
devices 6 1 1
freezer 7 1 1
net_cls 8 1 1
blkio 9 3 1
perf_event 0 1 1
net_prio 0 1 1
hierarchy column lists IDs of the existing hierarchies on the system. Subsystems with the same hierarchy ID are attached to the same hierarchy. The num_cgroup column lists the number of existing cgroups in the hierarchy that uses a particular subsystem. The enabled column reports the value of 1 if a particular subsystem is enabled, or 0 if it is not.
~]$ lssubsys -m subsystemslssubsys -m command returns only the top-level mount point per each hierarchy.
2.11.3. Finding Hierarchies
/cgroup/ directory. Assuming this is the case on your system, list or browse the contents of that directory to obtain a list of hierarchies. If the tree utility is installed on your system, run it to obtain an overview of all hierarchies and the cgroups within them:
~]$ tree /cgroup2.11.4. Finding Control Groups
~]$ lscgroupcontroller:path. For example:
~]$ lscgroup cpuset:group1group1 cgroup in the hierarchy to which the cpuset subsystem is attached.
2.11.5. Displaying Parameters of Control Groups
~]$ cgget -r parameter list_of_cgroups~]$ cgget -r cpuset.cpus -r memory.limit_in_bytes group1 group2cpuset.cpus and memory.limit_in_bytes for cgroups group1 and group2.
~]$ cgget -g cpuset /2.12. Unloading Control Groups
Warning
cgclear command destroys all cgroups in all hierarchies. If you do not have these hierarchies stored in a configuration file, you will not be able to readily reconstruct them.
cgclear command.
Note
mount command to create cgroups (as opposed to creating them using the cgconfig service) results in the creation of an entry in the /etc/mtab file (the mounted file systems table). This change is also reflected in the /proc/mounts file. However, the unloading of cgroups with the cgclear command, along with other cgconfig commands, uses a direct kernel interface which does not reflect its changes into the /etc/mtab file and only writes the new information into the /proc/mounts file. After unloading cgroups with the cgclear command, the unmounted cgroups can still be visible in the /etc/mtab file, and, consequently, displayed when the mount command is executed. Refer to the /proc/mounts file for an accurate listing of all mounted cgroups.
2.13. Using the Notification API
memory.oom_control. To create a notification handler, write a C program using the following instructions:
- Using the
eventfd()function, create a file descriptor for event notifications. For more information, refer to theeventfd(2)man page. - To monitor the
memory.oom_controlfile, open it using theopen()function. For more information, refer to theopen(2)man page. - Use the
write()function to write the following arguments to thecgroup.event_controlfile of the cgroup whosememory.oom_controlfile you are monitoring:<event_file_descriptor> <OOM_control_file_descriptor>where:- event_file_descriptor is used to open the
cgroup.event_controlfile, - and OOM_control_file_descriptor is used to open the respective
memory.oom_controlfile.
For more information on writing to a file, refer to thewrite(1)man page.
memory.oom_control tunable parameter, refer to Section 3.7, “memory”. For more information on configuring notifications for OOM control, refer to Example 3.3, “OOM Control and Notifications”.
2.14. Additional Resources
The libcgroup Man Pages
man 1 cgclassify— thecgclassifycommand is used to move running tasks to one or more cgroups.man 1 cgclear— thecgclearcommand is used to delete all cgroups in a hierarchy.man 5 cgconfig.conf— cgroups are defined in thecgconfig.conffile.man 8 cgconfigparser— thecgconfigparsercommand parses thecgconfig.conffile and mounts hierarchies.man 1 cgcreate— thecgcreatecommand creates new cgroups in hierarchies.man 1 cgdelete— thecgdeletecommand removes specified cgroups.man 1 cgexec— thecgexeccommand runs tasks in specified cgroups.man 1 cgget— thecggetcommand displays cgroup parameters.man 1 cgsnapshot— thecgsnapshotcommand generates a configuration file from existing subsystems.man 5 cgred.conf—cgred.confis the configuration file for thecgredservice.man 5 cgrules.conf—cgrules.confcontains the rules used for determining when tasks belong to certain cgroups.man 8 cgrulesengd— thecgrulesengdservice distributes tasks to cgroups.man 1 cgset— thecgsetcommand sets parameters for a cgroup.man 1 lscgroup— thelscgroupcommand lists the cgroups in a hierarchy.man 1 lssubsys— thelssubsyscommand lists the hierarchies containing the specified subsystems.
lssubsys command is one of the utilities provided by the libcgroup package. You have to install libcgroup to use it: refer to Chapter 2, Using Control Groups if you are unable to run lssubsys.
Chapter 3. Subsystems and Tunable Parameters
cgroups.txt in the kernel documentation, installed on your system at /usr/share/doc/kernel-doc-kernel-version/Documentation/cgroups/ (provided by the kernel-doc package). The latest version of the cgroups documentation is also available online at http://www.kernel.org/doc/Documentation/cgroup-v1/cgroups.txt. Note, however, that the features in the latest documentation might not match those available in the kernel installed on your system.
cpuset.cpus is a pseudofile that specifies which CPUs a cgroup is permitted to access. If /cgroup/cpuset/webserver is a cgroup for the web server that runs on a system, and the following command is executed,
~]# echo 0,2 > /cgroup/cpuset/webserver/cpuset.cpus0,2 is written to the cpuset.cpus pseudofile and therefore limits any tasks whose PIDs are listed in /cgroup/cpuset/webserver/tasks to use only CPU 0 and CPU 2 on the system.
3.1. blkio
blkio) subsystem controls and monitors access to I/O on block devices by tasks in cgroups. Writing values to some of these pseudofiles limits access or bandwidth, and reading values from some of these pseudofiles provides information on I/O operations.
blkio subsystem offers two policies for controlling access to I/O:
- Proportional weight division — implemented in the Completely Fair Queuing (CFQ) I/O scheduler, this policy allows you to set weights to specific cgroups. This means that each cgroup has a set percentage (depending on the weight of the cgroup) of all I/O operations reserved. For more information, refer to Section 3.1.1, “Proportional Weight Division Tunable Parameters”
- I/O throttling (Upper limit) — this policy is used to set an upper limit for the number of I/O operations performed by a specific device. This means that a device can have a limited rate of read or write operations. For more information, refer to Section 3.1.2, “I/O Throttling Tunable Parameters”
Important
3.1.1. Proportional Weight Division Tunable Parameters
- blkio.weight
- specifies the relative proportion (weight) of block I/O access available by default to a cgroup, in the range from
100to1000. This value is overridden for specific devices by theblkio.weight_deviceparameter. For example, to assign a default weight of500to a cgroup for access to block devices, run:~]# echo 500 > blkio.weight - blkio.weight_device
- specifies the relative proportion (weight) of I/O access on specific devices available to a cgroup, in the range from
100to1000. The value of this parameter overrides the value of theblkio.weightparameter for the devices specified. Values take the format of major:minor weight, where major and minor are device types and node numbers specified in Linux Allocated Devices, otherwise known as the Linux Devices List and available from https://www.kernel.org/doc/html/v4.11/admin-guide/devices.html. For example, to assign a weight of500to a cgroup for access to/dev/sda, run:~]# echo 8:0 500 > blkio.weight_deviceIn the Linux Allocated Devices notation,8:0represents/dev/sda.
3.1.2. I/O Throttling Tunable Parameters
- blkio.throttle.read_bps_device
- specifies the upper limit on the number of read operations a device can perform. The rate of the read operations is specified in bytes per second. Entries have three fields: major, minor, and bytes_per_second. Major and minor are device types and node numbers specified in Linux Allocated Devices, and bytes_per_second is the upper limit rate at which read operations can be performed. For example, to allow the
/dev/sdadevice to perform read operations at a maximum of 10 MBps, run:~]# echo "8:0 10485760" > /cgroup/blkio/test/blkio.throttle.read_bps_device - blkio.throttle.read_iops_device
- specifies the upper limit on the number of read operations a device can perform. The rate of the read operations is specified in operations per second. Entries have three fields: major, minor, and operations_per_second. Major and minor are device types and node numbers specified in Linux Allocated Devices, and operations_per_second is the upper limit rate at which read operations can be performed. For example, to allow the
/dev/sdadevice to perform a maximum of 10 read operations per second, run:~]# echo "8:0 10" > /cgroup/blkio/test/blkio.throttle.read_iops_device - blkio.throttle.write_bps_device
- specifies the upper limit on the number of write operations a device can perform. The rate of the write operations is specified in bytes per second. Entries have three fields: major, minor, and bytes_per_second. Major and minor are device types and node numbers specified in Linux Allocated Devices, and bytes_per_second is the upper limit rate at which write operations can be performed. For example, to allow the
/dev/sdadevice to perform write operations at a maximum of 10 MBps, run:~]# echo "8:0 10485760" > /cgroup/blkio/test/blkio.throttle.write_bps_device - blkio.throttle.write_iops_device
- specifies the upper limit on the number of write operations a device can perform. The rate of the write operations is specified in operations per second. Entries have three fields: major, minor, and operations_per_second. Major and minor are device types and node numbers specified in Linux Allocated Devices, and operations_per_second is the upper limit rate at which write operations can be performed. For example, to allow the
/dev/sdadevice to perform a maximum of 10 write operations per second, run:~]# echo "8:0 10" > /cgroup/blkio/test/blkio.throttle.write_iops_device - blkio.throttle.io_serviced
- reports the number of I/O operations performed on specific devices by a cgroup as seen by the throttling policy. Entries have four fields: major, minor, operation, and number. Major and minor are device types and node numbers specified in Linux Allocated Devices, operation represents the type of operation (
read,write,sync, orasync) and number represents the number of operations. - blkio.throttle.io_service_bytes
- reports the number of bytes transferred to or from specific devices by a cgroup. The only difference between
blkio.io_service_bytesandblkio.throttle.io_service_bytesis that the former is not updated when the CFQ scheduler is operating on a request queue. Entries have four fields: major, minor, operation, and bytes. Major and minor are device types and node numbers specified in Linux Allocated Devices, operation represents the type of operation (read,write,sync, orasync) and bytes is the number of transferred bytes.
3.1.3. blkio Common Tunable Parameters
- blkio.reset_stats
- resets the statistics recorded in the other pseudofiles. Write an integer to this file to reset the statistics for this cgroup.
- blkio.time
- reports the time that a cgroup had I/O access to specific devices. Entries have three fields: major, minor, and time. Major and minor are device types and node numbers specified in Linux Allocated Devices, and time is the length of time in milliseconds (ms).
- blkio.sectors
- reports the number of sectors transferred to or from specific devices by a cgroup. Entries have three fields: major, minor, and sectors. Major and minor are device types and node numbers specified in Linux Allocated Devices, and sectors is the number of disk sectors.
- blkio.avg_queue_size
- reports the average queue size for I/O operations by a cgroup, over the entire length of time of the group's existence. The queue size is sampled every time a queue for this cgroup receives a timeslice. Note that this report is available only if
CONFIG_DEBUG_BLK_CGROUP=yis set on the system. - blkio.group_wait_time
- reports the total time (in nanoseconds — ns) a cgroup spent waiting for a timeslice for one of its queues. The report is updated every time a queue for this cgroup gets a timeslice, so if you read this pseudofile while the cgroup is waiting for a timeslice, the report will not contain time spent waiting for the operation currently queued. Note that this report is available only if
CONFIG_DEBUG_BLK_CGROUP=yis set on the system. - blkio.empty_time
- reports the total time (in nanoseconds — ns) a cgroup spent without any pending requests. The report is updated every time a queue for this cgroup has a pending request, so if you read this pseudofile while the cgroup has no pending requests, the report will not contain time spent in the current empty state. Note that this report is available only if
CONFIG_DEBUG_BLK_CGROUP=yis set on the system. - blkio.idle_time
- reports the total time (in nanoseconds — ns) the scheduler spent idling for a cgroup in anticipation of a better request than the requests already in other queues or from other groups. The report is updated every time the group is no longer idling, so if you read this pseudofile while the cgroup is idling, the report will not contain time spent in the current idling state. Note that this report is available only if
CONFIG_DEBUG_BLK_CGROUP=yis set on the system. - blkio.dequeue
- reports the number of times requests for I/O operations by a cgroup were dequeued by specific devices. Entries have three fields: major, minor, and number. Major and minor are device types and node numbers specified in Linux Allocated Devices, and number is the number of times requests by the group were dequeued. Note that this report is available only if
CONFIG_DEBUG_BLK_CGROUP=yis set on the system. - blkio.io_serviced
- reports the number of I/O operations performed on specific devices by a cgroup as seen by the CFQ scheduler. Entries have four fields: major, minor, operation, and number. Major and minor are device types and node numbers specified in Linux Allocated Devices, operation represents the type of operation (
read,write,sync, orasync) and number represents the number of operations. - blkio.io_service_bytes
- reports the number of bytes transferred to or from specific devices by a cgroup as seen by the CFQ scheduler. Entries have four fields: major, minor, operation, and bytes. Major and minor are device types and node numbers specified in Linux Allocated Devices, operation represents the type of operation (
read,write,sync, orasync) and bytes is the number of transferred bytes. - blkio.io_service_time
- reports the total time between request dispatch and request completion for I/O operations on specific devices by a cgroup as seen by the CFQ scheduler. Entries have four fields: major, minor, operation, and time. Major and minor are device types and node numbers specified in Linux Allocated Devices, operation represents the type of operation (
read,write,sync, orasync) and time is the length of time in nanoseconds (ns). The time is reported in nanoseconds rather than a larger unit so that this report is meaningful even for solid-state devices. - blkio.io_wait_time
- reports the total time I/O operations on specific devices by a cgroup spent waiting for service in the scheduler queues. When you interpret this report, note:
- the time reported can be greater than the total time elapsed, because the time reported is the cumulative total of all I/O operations for the cgroup rather than the time that the cgroup itself spent waiting for I/O operations. To find the time that the group as a whole has spent waiting, use the
blkio.group_wait_timeparameter. - if the device has a
queue_depth> 1, the time reported only includes the time until the request is dispatched to the device, not any time spent waiting for service while the device reorders requests.
Entries have four fields: major, minor, operation, and time. Major and minor are device types and node numbers specified in Linux Allocated Devices, operation represents the type of operation (read,write,sync, orasync) and time is the length of time in nanoseconds (ns). The time is reported in nanoseconds rather than a larger unit so that this report is meaningful even for solid-state devices. - blkio.io_merged
- reports the number of BIOS requests merged into requests for I/O operations by a cgroup. Entries have two fields: number and operation. Number is the number of requests, and operation represents the type of operation (
read,write,sync, orasync). - blkio.io_queued
- reports the number of requests queued for I/O operations by a cgroup. Entries have two fields: number and operation. Number is the number of requests, and operation represents the type of operation (
read,write,sync, orasync).
3.1.4. Example Usage
dd threads in two different cgroups with various blkio.weight values.
Example 3.1. blkio proportional weight division
- Mount the
blkiosubsystem:~]# mount -t cgroup -o blkio blkio /cgroup/blkio/ - Create two cgroups for the
blkiosubsystem:~]# mkdir /cgroup/blkio/test1/ ~]# mkdir /cgroup/blkio/test2/ - Set
blkioweights in the previously created cgroups:~]# echo 1000 > /cgroup/blkio/test1/blkio.weight ~]# echo 500 > /cgroup/blkio/test2/blkio.weight - Create two large files:
~]# dd if=/dev/zero of=file_1 bs=1M count=4000 ~]# dd if=/dev/zero of=file_2 bs=1M count=4000The above commands create two files (file_1andfile_2) of size 4 GB. - For each of the test cgroups, execute a
ddcommand (which reads the contents of a file and outputs it to the null device) on one of the large files:~]# cgexec -g blkio:test1 time dd if=file_1 of=/dev/null ~]# cgexec -g blkio:test2 time dd if=file_2 of=/dev/nullBoth commands will output their completion time once they have finished. - Simultaneously with the two running
ddthreads, you can monitor the performance in real time by using the iotop utility. To install the iotop utility, execute, as root, theyum install iotopcommand. The following is an example of the output as seen in the iotop utility while running the previously startedddthreads:Total DISK READ: 83.16 M/s | Total DISK WRITE: 0.00 B/s TIME TID PRIO USER DISK READ DISK WRITE SWAPIN IO COMMAND 15:18:04 15071 be/4 root 27.64 M/s 0.00 B/s 0.00 % 92.30 % dd if=file_2 of=/dev/null 15:18:04 15069 be/4 root 55.52 M/s 0.00 B/s 0.00 % 88.48 % dd if=file_1 of=/dev/null
dd commands, flush all file system buffers and free pagecache, dentries and inodes using the following commands:
~]# sync
~]# echo 3 > /proc/sys/vm/drop_caches~]# echo 1 > /sys/block/<disk_device>/queue/iosched/group_isolationsda.
3.2. cpu
cpu subsystem schedules CPU access to cgroups. Access to CPU resources can be scheduled using two schedulers:
- Completely Fair Scheduler (CFS) — a proportional share scheduler which divides the CPU time (CPU bandwidth) proportionately between groups of tasks (cgroups) depending on the priority/weight of the task or shares assigned to cgroups. For more information about resource limiting using CFS, refer to Section 3.2.1, “CFS Tunable Parameters”.
- Real-Time scheduler (RT) — a task scheduler that provides a way to specify the amount of CPU time that real-time tasks can use. For more information about resource limiting of real-time tasks, refer to Section 3.2.2, “RT Tunable Parameters”.
3.2.1. CFS Tunable Parameters
Ceiling Enforcement Tunable Parameters
- cpu.cfs_period_us
- specifies a period of time in microseconds (µs, represented here as "
us") for how regularly a cgroup's access to CPU resources should be reallocated. If tasks in a cgroup should be able to access a single CPU for 0.2 seconds out of every 1 second, setcpu.cfs_quota_usto200000andcpu.cfs_period_usto1000000. The upper limit of thecpu.cfs_quota_usparameter is 1 second and the lower limit is 1000 microseconds. - cpu.cfs_quota_us
- specifies the total amount of time in microseconds (µs, represented here as "
us") for which all tasks in a cgroup can run during one period (as defined bycpu.cfs_period_us). As soon as tasks in a cgroup use up all the time specified by the quota, they are throttled for the remainder of the time specified by the period and not allowed to run until the next period. If tasks in a cgroup should be able to access a single CPU for 0.2 seconds out of every 1 second, setcpu.cfs_quota_usto200000andcpu.cfs_period_usto1000000. Note that the quota and period parameters operate on a CPU basis. To allow a process to fully utilize two CPUs, for example, setcpu.cfs_quota_usto200000andcpu.cfs_period_usto100000.Setting the value incpu.cfs_quota_usto-1indicates that the cgroup does not adhere to any CPU time restrictions. This is also the default value for every cgroup (except the root cgroup). - cpu.stat
- reports CPU time statistics using the following values:
nr_periods— number of period intervals (as specified incpu.cfs_period_us) that have elapsed.nr_throttled— number of times tasks in a cgroup have been throttled (that is, not allowed to run because they have exhausted all of the available time as specified by their quota).throttled_time— the total time duration (in nanoseconds) for which tasks in a cgroup have been throttled.
Relative Shares Tunable Parameters
- cpu.shares
- contains an integer value that specifies a relative share of CPU time available to the tasks in a cgroup. For example, tasks in two cgroups that have
cpu.sharesset to100will receive equal CPU time, but tasks in a cgroup that hascpu.sharesset to200receive twice the CPU time of tasks in a cgroup wherecpu.sharesis set to100. The value specified in thecpu.sharesfile must be2or higher.Note that shares of CPU time are distributed per all CPU cores on multi-core systems. Even if a cgroup is limited to less than 100% of CPU on a multi-core system, it may use 100% of each individual CPU core. Consider the following example: if cgroupAis configured to use 25% and cgroupB75% of the CPU, starting four CPU-intensive processes (one inAand three inB) on a system with four cores results in the following division of CPU shares:Expand Table 3.1. CPU share division PID cgroup CPU CPU share 100 A 0 100% of CPU0 101 B 1 100% of CPU1 102 B 2 100% of CPU2 103 B 3 100% of CPU3 Using relative shares to specify CPU access has two implications on resource management that should be considered:- Because the CFS does not demand equal usage of CPU, it is hard to predict how much CPU time a cgroup will be allowed to utilize. When tasks in one cgroup are idle and are not using any CPU time, the leftover time is collected in a global pool of unused CPU cycles. Other cgroups are allowed to borrow CPU cycles from this pool.
- The actual amount of CPU time that is available to a cgroup can vary depending on the number of cgroups that exist on the system. If a cgroup has a relative share of
1000and two other cgroups have a relative share of500, the first cgroup receives 50% of all CPU time in cases when processes in all cgroups attempt to use 100% of the CPU. However, if another cgroup is added with a relative share of1000, the first cgroup is only allowed 33% of the CPU (the rest of the cgroups receive 16.5%, 16.5%, and 33% of CPU).
3.2.2. RT Tunable Parameters
- cpu.rt_period_us
- applicable to real-time scheduling tasks only, this parameter specifies a period of time in microseconds (µs, represented here as "
us") for how regularly a cgroup's access to CPU resources is reallocated. - cpu.rt_runtime_us
- applicable to real-time scheduling tasks only, this parameter specifies a period of time in microseconds (µs, represented here as "
us") for the longest continuous period in which the tasks in a cgroup have access to CPU resources. Establishing this limit prevents tasks in one cgroup from monopolizing CPU time. As mentioned above, the access times are multiplied by the number of logical CPUs. For example, settingcpu.rt_runtime_usto200000andcpu.rt_period_usto1000000translates to the task being able to access a single CPU for 0.4 seconds out of every 1 second on systems with two CPUs (0.2 x 2), or 0.8 seconds on systems with four CPUs (0.2 x 4).
3.2.3. Example Usage
Example 3.2. Limiting CPU access
cpu subsystem mounted on your system:
- To allow one cgroup to use 25% of a single CPU and a different cgroup to use 75% of that same CPU, use the following commands:
~]# echo 250 > /cgroup/cpu/blue/cpu.shares ~]# echo 750 > /cgroup/cpu/red/cpu.shares - To limit a cgroup to fully utilize a single CPU, use the following commands:
~]# echo 10000 > /cgroup/cpu/red/cpu.cfs_quota_us ~]# echo 10000 > /cgroup/cpu/red/cpu.cfs_period_us - To limit a cgroup to utilize 10% of a single CPU, use the following commands:
~]# echo 10000 > /cgroup/cpu/red/cpu.cfs_quota_us ~]# echo 100000 > /cgroup/cpu/red/cpu.cfs_period_us - On a multi-core system, to allow a cgroup to fully utilize two CPU cores, use the following commands:
~]# echo 200000 > /cgroup/cpu/red/cpu.cfs_quota_us ~]# echo 100000 > /cgroup/cpu/red/cpu.cfs_period_us
3.3. cpuacct
cpuacct) subsystem generates automatic reports on CPU resources used by the tasks in a cgroup, including tasks in child groups. Three reports are available:
- cpuacct.usage
- reports the total CPU time (in nanoseconds) consumed by all tasks in this cgroup (including tasks lower in the hierarchy).
Note
To reset the value incpuacct.usage, execute the following command:~]# echo 0 > /cgroup/cpuacct/cpuacct.usageThe above command also resets values incpuacct.usage_percpu. - cpuacct.stat
- reports the user and system CPU time consumed by all tasks in this cgroup (including tasks lower in the hierarchy) in the following way:
user— CPU time consumed by tasks in user mode.system— CPU time consumed by tasks in system (kernel) mode.
CPU time is reported in the units defined by theUSER_HZvariable. - cpuacct.usage_percpu
- reports the CPU time (in nanoseconds) consumed on each CPU by all tasks in this cgroup (including tasks lower in the hierarchy).
3.4. cpuset
cpuset subsystem assigns individual CPUs and memory nodes to cgroups. Each cpuset can be specified according to the following parameters, each one in a separate pseudofile within the cgroup virtual file system:
Important
cpuset subsystem, the cpuset.cpus and cpuset.mems parameters must be defined for that cgroup.
- cpuset.cpus (mandatory)
- specifies the CPUs that tasks in this cgroup are permitted to access. This is a comma-separated list, with dashes ("
-") to represent ranges. For example,0-2,16represents CPUs 0, 1, 2, and 16. - cpuset.mems (mandatory)
- specifies the memory nodes that tasks in this cgroup are permitted to access. This is a comma-separated list in the ASCII format, with dashes ("
-") to represent ranges. For example,0-2,16represents memory nodes 0, 1, 2, and 16. - cpuset.memory_migrate
- contains a flag (
0or1) that specifies whether a page in memory should migrate to a new node if the values incpuset.memschange. By default, memory migration is disabled (0) and pages stay on the node to which they were originally allocated, even if the node is no longer among the nodes specified incpuset.mems. If enabled (1), the system migrates pages to memory nodes within the new parameters specified bycpuset.mems, maintaining their relative placement if possible — for example, pages on the second node on the list originally specified bycpuset.memsare allocated to the second node on the new list specified bycpuset.mems, if the place is available. - cpuset.cpu_exclusive
- contains a flag (
0or1) that specifies whether cpusets other than this one and its parents and children can share the CPUs specified for this cpuset. By default (0), CPUs are not allocated exclusively to one cpuset. - cpuset.mem_exclusive
- contains a flag (
0or1) that specifies whether other cpusets can share the memory nodes specified for the cpuset. By default (0), memory nodes are not allocated exclusively to one cpuset. Reserving memory nodes for the exclusive use of a cpuset (1) is functionally the same as enabling a memory hardwall with thecpuset.mem_hardwallparameter. - cpuset.mem_hardwall
- contains a flag (
0or1) that specifies whether kernel allocations of memory page and buffer data should be restricted to the memory nodes specified for the cpuset. By default (0), page and buffer data is shared across processes belonging to multiple users. With a hardwall enabled (1), each tasks' user allocation can be kept separate. - cpuset.memory_pressure
- a read-only file that contains a running average of the memory pressure created by the processes in the cpuset. The value in this pseudofile is automatically updated when
cpuset.memory_pressure_enabledis enabled, otherwise, the pseudofile contains the value0. - cpuset.memory_pressure_enabled
- contains a flag (
0or1) that specifies whether the system should compute the memory pressure created by the processes in the cgroup. Computed values are output tocpuset.memory_pressureand represent the rate at which processes attempt to free in-use memory, reported as an integer value of attempts to reclaim memory per second, multiplied by 1000. - cpuset.memory_spread_page
- contains a flag (
0or1) that specifies whether file system buffers should be spread evenly across the memory nodes allocated to the cpuset. By default (0), no attempt is made to spread memory pages for these buffers evenly, and buffers are placed on the same node on which the process that created them is running. - cpuset.memory_spread_slab
- contains a flag (
0or1) that specifies whether kernel slab caches for file input/output operations should be spread evenly across the cpuset. By default (0), no attempt is made to spread kernel slab caches evenly, and slab caches are placed on the same node on which the process that created them is running. - cpuset.sched_load_balance
- contains a flag (
0or1) that specifies whether the kernel will balance loads across the CPUs in the cpuset. By default (1), the kernel balances loads by moving processes from overloaded CPUs to less heavily used CPUs.Note, however, that setting this flag in a cgroup has no effect if load balancing is enabled in any parent cgroup, as load balancing is already being carried out at a higher level. Therefore, to disable load balancing in a cgroup, disable load balancing also in each of its parents in the hierarchy. In this case, you should also consider whether load balancing should be enabled for any siblings of the cgroup in question. - cpuset.sched_relax_domain_level
- contains an integer between
-1and a small positive value, which represents the width of the range of CPUs across which the kernel should attempt to balance loads. This value is meaningless ifcpuset.sched_load_balanceis disabled.The precise effect of this value varies according to system architecture, but the following values are typical:Values of cpuset.sched_relax_domain_levelValue Effect -1Use the system default value for load balancing 0Do not perform immediate load balancing; balance loads only periodically 1Immediately balance loads across threads on the same core 2Immediately balance loads across cores in the same package or book (in case of s390x architectures) 3Immediately balance loads across books in the same package (available only for s390x architectures) 4Immediately balance loads across CPUs on the same node or blade 5Immediately balance loads across several CPUs on architectures with non-uniform memory access (NUMA) 6Immediately balance loads across all CPUs on architectures with NUMA Note
With the release of Red Hat Enterprise Linux 6.1 the BOOK scheduling domain has been added to the list of supported domain levels. This change affected the meaning ofcpuset.sched_relax_domain_levelvalues. Please note that the effect of values from 3 to 5 changed. For example, to get the old effect of value 3, which was "Immediately balance loads across CPUs on the same node or blade" the value 4 needs to be selected. Similarly, the old 4 is now 5, and the old 5 is now 6.
3.5. devices
devices subsystem allows or denies access to devices by tasks in a cgroup.
Important
devices) subsystem is considered to be a Technology Preview in Red Hat Enterprise Linux 6.
- devices.allow
- specifies devices to which tasks in a cgroup have access. Each entry has four fields: type, major, minor, and access. The values used in the type, major, and minor fields correspond to device types and node numbers specified in Linux Allocated Devices, otherwise known as the Linux Devices List and available from https://www.kernel.org/doc/html/v4.11/admin-guide/devices.html.
- type
- type can have one of the following three values:
a— applies to all devices, both character devices and block devicesb— specifies a block devicec— specifies a character device
- major, minor
- major and minor are device node numbers specified by Linux Allocated Devices. The major and minor numbers are separated by a colon. For example,
8is the major number that specifies Small Computer System Interface (SCSI) disk drives, and the minor number1specifies the first partition on the first SCSI disk drive; therefore8:1fully specifies this partition, corresponding to a file system location of/dev/sda1.*can stand for all major or all minor device nodes, for example9:*(all RAID devices) or*:*(all devices). - access
- access is a sequence of one or more of the following letters:
r— allows tasks to read from the specified devicew— allows tasks to write to the specified devicem— allows tasks to create device files that do not yet exist
For example, when access is specified asr, tasks can only read from the specified device, but when access is specified asrw, tasks can read from and write to the device.
- devices.deny
- specifies devices that tasks in a cgroup cannot access. The syntax of entries is identical with
devices.allow. - devices.list
- reports the devices for which access controls have been set for tasks in this cgroup.
3.6. freezer
freezer subsystem suspends or resumes tasks in a cgroup.
- freezer.state
freezer.stateis only available in non-root cgroups and has three possible values:FROZEN— tasks in the cgroup are suspended.FREEZING— the system is in the process of suspending tasks in the cgroup.THAWED— tasks in the cgroup have resumed.
- Move that process to a cgroup in a hierarchy which has the
freezersubsystem attached to it. - Freeze that particular cgroup to suspend the process contained in it.
FROZEN and THAWED values can be written to freezer.state, FREEZING cannot be written, only read.
3.7. memory
memory subsystem generates automatic reports on memory resources used by the tasks in a cgroup, and sets limits on memory use of those tasks:
Note
memory subsystem uses 40 bytes of memory per physical page on x86_64 systems. These resources are consumed even if memory is not used in any hierarchy. If you do not plan to use the memory subsystem, you can disable it to reduce the resource consumption of the kernel.
memory subsystem, open the /boot/grub/grub.conf configuration file as root and append the following text to the line that starts with the kernel keyword:
cgroup_disable=memory/boot/grub/grub.conf, see the Configuring the GRUB Boot Loader chapter in the Red Hat Enterprise Linux 6 Deployment Guide.
memory subsystem for a single session, perform the following steps when starting the system:
- At the GRUB boot screen, press any key to enter the GRUB interactive menu.
- Select Red Hat Enterprise Linux with the version of the kernel that you want to boot and press the a key to modify the kernel parameters.
- Type
cgroup_disable=memoryat the end of the line and press Enter to exit GRUB edit mode.
cgroup_disable=memory enabled, memory is not visible as an individually mountable subsystem and it is not automatically mounted when mounting all cgroups in a single hierarchy. Please note that memory is currently the only subsystem that can be effectively disabled with cgroup_disable to save resources. Using this option with other subsystems only disables their usage, but does not cut their resource consumption. However, other subsystems do not consume as much resources as the memory subsystem.
memory subsystem:
- memory.stat
- reports a wide range of memory statistics, as described in the following table:
Expand Table 3.2. Values reported by memory.stat Statistic Description cachepage cache, including tmpfs(shmem), in bytesrssanonymous and swap cache, not including tmpfs(shmem), in bytesmapped_filesize of memory-mapped mapped files, including tmpfs(shmem), in bytespgpginnumber of pages paged into memory pgpgoutnumber of pages paged out of memory swapswap usage, in bytes active_anonanonymous and swap cache on active least-recently-used (LRU) list, including tmpfs(shmem), in bytesinactive_anonanonymous and swap cache on inactive LRU list, including tmpfs(shmem), in bytesactive_filefile-backed memory on active LRU list, in bytes inactive_filefile-backed memory on inactive LRU list, in bytes unevictablememory that cannot be reclaimed, in bytes hierarchical_memory_limitmemory limit for the hierarchy that contains the memorycgroup, in byteshierarchical_memsw_limitmemory plus swap limit for the hierarchy that contains the memorycgroup, in bytesAdditionally, each of these files other thanhierarchical_memory_limitandhierarchical_memsw_limithas a counterpart prefixedtotal_that reports not only on the cgroup, but on all its children as well. For example,swapreports the swap usage by a cgroup andtotal_swapreports the total swap usage by the cgroup and all its child groups.When you interpret the values reported bymemory.stat, note how the various statistics inter-relate:active_anon+inactive_anon= anonymous memory + file cache fortmpfs+ swap cacheTherefore,active_anon+inactive_anon≠rss, becauserssdoes not includetmpfs.active_file+inactive_file= cache - size oftmpfs
- memory.usage_in_bytes
- reports the total current memory usage by processes in the cgroup (in bytes).
- memory.memsw.usage_in_bytes
- reports the sum of current memory usage plus swap space used by processes in the cgroup (in bytes).
- memory.max_usage_in_bytes
- reports the maximum memory used by processes in the cgroup (in bytes).
- memory.memsw.max_usage_in_bytes
- reports the maximum amount of memory and swap space used by processes in the cgroup (in bytes).
- memory.limit_in_bytes
- sets the maximum amount of user memory (including file cache). If no units are specified, the value is interpreted as bytes. However, it is possible to use suffixes to represent larger units —
korKfor kilobytes,morMfor megabytes, andgorGfor gigabytes. For example, to set the limit to 1 gigabyte, execute:~]# echo 1G > /cgroup/memory/lab1/memory.limit_in_bytesYou cannot usememory.limit_in_bytesto limit the root cgroup; you can only apply values to groups lower in the hierarchy.Write-1tomemory.limit_in_bytesto remove any existing limits. - memory.memsw.limit_in_bytes
- sets the maximum amount for the sum of memory and swap usage. If no units are specified, the value is interpreted as bytes. However, it is possible to use suffixes to represent larger units —
korKfor kilobytes,morMfor megabytes, andgorGfor gigabytes.You cannot usememory.memsw.limit_in_bytesto limit the root cgroup; you can only apply values to groups lower in the hierarchy.Write-1tomemory.memsw.limit_in_bytesto remove any existing limits.Important
It is important to set thememory.limit_in_bytesparameter before setting thememory.memsw.limit_in_bytesparameter: attempting to do so in the reverse order results in an error. This is becausememory.memsw.limit_in_bytesbecomes available only after all memory limitations (previously set inmemory.limit_in_bytes) are exhausted.Consider the following example: settingmemory.limit_in_bytes = 2Gandmemory.memsw.limit_in_bytes = 4Gfor a certain cgroup will allow processes in that cgroup to allocate 2 GB of memory and, once exhausted, allocate another 2 GB of swap only. Thememory.memsw.limit_in_bytesparameter represents the sum of memory and swap. Processes in a cgroup that does not have thememory.memsw.limit_in_bytesparameter set can potentially use up all the available swap (after exhausting the set memory limitation) and trigger an Out Of Memory situation caused by the lack of available swap.The order in which thememory.limit_in_bytesandmemory.memsw.limit_in_bytesparameters are set in the/etc/cgconfig.conffile is important as well. The following is a correct example of such a configuration:memory { memory.limit_in_bytes = 1G; memory.memsw.limit_in_bytes = 1G; } - memory.failcnt
- reports the number of times that the memory limit has reached the value set in
memory.limit_in_bytes. - memory.memsw.failcnt
- reports the number of times that the memory plus swap space limit has reached the value set in
memory.memsw.limit_in_bytes. - memory.soft_limit_in_bytes
- enables flexible sharing of memory. Under normal circumstances, control groups are allowed to use as much of the memory as needed, constrained only by their hard limits set with the
memory.limit_in_bytesparameter. However, when the system detects memory contention or low memory, control groups are forced to restrict their consumption to their soft limits. To set the soft limit for example to 256 MB, execute:~]# echo 256M > /cgroup/memory/lab1/memory.soft_limit_in_bytesThis parameter accepts the same suffixes asmemory.limit_in_bytesto represent units. To have any effect, the soft limit must be set below the hard limit. If lowering the memory usage to the soft limit does not solve the contention, cgroups are pushed back as much as possible to make sure that one control group does not starve the others of memory. Note that soft limits take effect over a long period of time, since they involve reclaiming memory for balancing between memory cgroups. - memory.force_empty
- when set to
0, empties memory of all pages used by tasks in the cgroup. This interface can only be used when the cgroup has no tasks. If memory cannot be freed, it is moved to a parent cgroup if possible. Use thememory.force_emptyparameter before removing a cgroup to avoid moving out-of-use page caches to its parent cgroup. - memory.swappiness
- sets the tendency of the kernel to swap out process memory used by tasks in this cgroup instead of reclaiming pages from the page cache. This is the same tendency, calculated the same way, as set in
/proc/sys/vm/swappinessfor the system as a whole. The default value is60. Values lower than60decrease the kernel's tendency to swap out process memory, values greater than60increase the kernel's tendency to swap out process memory, and values greater than100permit the kernel to swap out pages that are part of the address space of the processes in this cgroup.Note that a value of0does not prevent process memory being swapped out; swap out might still happen when there is a shortage of system memory because the global virtual memory management logic does not read the cgroup value. To lock pages completely, usemlock()instead of cgroups.You cannot change the swappiness of the following groups:- the root cgroup, which uses the swappiness set in
/proc/sys/vm/swappiness. - a cgroup that has child groups below it.
- memory.move_charge_at_immigrate
- allows moving charges associated with a task along with task migration. Charging is a way of giving a penalty to cgroups which access shared pages too often. These penalties, also called charges, are by default not moved when a task migrates from one cgroup to another. The pages allocated from the original cgroup still remain charged to it; the charge is dropped when the page is freed or reclaimed.With
memory.move_charge_at_immigrateenabled, the pages associated with a task are taken from the old cgroup and charged to the new cgroup. The following example shows how to enablememory.move_charge_at_immigrate:~]# echo 1 > /cgroup/memory/lab1/memory.move_charge_at_immigrateCharges are moved only when the moved task is a leader of a thread group. If there is not enough memory for the task in the destination cgroup, an attempt to reclaim memory is performed. If the reclaim is not successful, the task migration is aborted.To disablememory.move_charge_at_immigrate, execute:~]# echo 0 > /cgroup/memory/lab1/memory.move_charge_at_immigrate - memory.use_hierarchy
- contains a flag (
0or1) that specifies whether memory usage should be accounted for throughout a hierarchy of cgroups. If enabled (1), the memory subsystem reclaims memory from the children of and process that exceeds its memory limit. By default (0), the subsystem does not reclaim memory from a task's children. - memory.oom_control
- contains a flag (
0or1) that enables or disables the Out of Memory killer for a cgroup. If enabled (0), tasks that attempt to consume more memory than they are allowed are immediately killed by the OOM killer. The OOM killer is enabled by default in every cgroup using thememorysubsystem; to disable it, write1to thememory.oom_controlfile:~]# echo 1 > /cgroup/memory/lab1/memory.oom_controlWhen the OOM killer is disabled, tasks that attempt to use more memory than they are allowed are paused until additional memory is freed.Thememory.oom_controlfile also reports the OOM status of the current cgroup under theunder_oomentry. If the cgroup is out of memory and tasks in it are paused, theunder_oomentry reports the value1.Thememory.oom_controlfile is capable of reporting an occurrence of an OOM situation using the notification API. For more information, refer to Section 2.13, “Using the Notification API” and Example 3.3, “OOM Control and Notifications”.
3.7.1. Example Usage
Example 3.3. OOM Control and Notifications
- Attach the
memorysubsystem to a hierarchy and create a cgroup:~]# mount -t cgroup -o memory memory /cgroup/memory ~]# mkdir /cgroup/memory/blue - Set the amount of memory which tasks in the
bluecgroup can use to 100 MB:~]# echo 104857600 > memory.limit_in_bytes - Change into the
bluedirectory and make sure the OOM killer is enabled:~]# cd /cgroup/memory/blue blue]# cat memory.oom_control oom_kill_disable 0 under_oom 0 - Move the current shell process into the
tasksfile of thebluecgroup so that all other processes started in this shell are automatically moved to thebluecgroup:blue]# echo $$ > tasks - Start a test program that attempts to allocate a large amount of memory exceeding the limit you set in step 2. As soon as the
bluecgroup runs out of free memory, the OOM killer kills the test program and reportsKilledto the standard output:blue]# ~/mem-hog KilledThe following is an example of such a test program[5]:#include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #define KB (1024) #define MB (1024 * KB) #define GB (1024 * MB) int main(int argc, char *argv[]) { char *p; again: while ((p = (char *)malloc(GB))) memset(p, 0, GB); while ((p = (char *)malloc(MB))) memset(p, 0, MB); while ((p = (char *)malloc(KB))) memset(p, 0, KB); sleep(1); goto again; return 0; } - Disable the OOM killer and rerun the test program. This time, the test program remains paused waiting for additional memory to be freed:
blue]# echo 1 > memory.oom_control blue]# ~/mem-hog - While the test program is paused, note that the
under_oomstate of the cgroup has changed to indicate that the cgroup is out of available memory:~]# cat /cgroup/memory/blue/memory.oom_control oom_kill_disable 1 under_oom 1Reenabling the OOM killer immediately kills the test program. - To receive notifications about every OOM situation, create a program as specified in Section 2.13, “Using the Notification API”. For example[6]:
#include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <sys/eventfd.h> #include <errno.h> #include <string.h> #include <stdio.h> #include <stdlib.h> static inline void die(const char *msg) { fprintf(stderr, "error: %s: %s(%d)\n", msg, strerror(errno), errno); exit(EXIT_FAILURE); } static inline void usage(void) { fprintf(stderr, "usage: oom_eventfd_test <cgroup.event_control> <memory.oom_control>\n"); exit(EXIT_FAILURE); } #define BUFSIZE 256 int main(int argc, char *argv[]) { char buf[BUFSIZE]; int efd, cfd, ofd, rb, wb; uint64_t u; if (argc != 3) usage(); if ((efd = eventfd(0, 0)) == -1) die("eventfd"); if ((cfd = open(argv[1], O_WRONLY)) == -1) die("cgroup.event_control"); if ((ofd = open(argv[2], O_RDONLY)) == -1) die("memory.oom_control"); if ((wb = snprintf(buf, BUFSIZE, "%d %d", efd, ofd)) >= BUFSIZE) die("buffer too small"); if (write(cfd, buf, wb) == -1) die("write cgroup.event_control"); if (close(cfd) == -1) die("close cgroup.event_control"); for (;;) { if (read(efd, &u, sizeof(uint64_t)) != sizeof(uint64_t)) die("read eventfd"); printf("mem_cgroup oom event received\n"); } return 0; }The above program detects OOM situations in a cgroup specified as an argument on the command line and reports them using themem_cgroup oom event receivedstring to the standard output. - Run the above notification handler program in a separate console, specifying the
bluecgroup's control files as arguments:~]$ ./oom_notification /cgroup/memory/blue/cgroup.event_control /cgroup/memory/blue/memory.oom_control - In a different console, run the
mem_hogtest program to create an OOM situation to see theoom_notificationprogram report it in the standard output:blue]# ~/mem-hog
3.8. net_cls
net_cls subsystem tags network packets with a class identifier (classid) that allows the Linux traffic controller (tc) to identify packets originating from a particular cgroup. The traffic controller can be configured to assign different priorities to packets from different cgroups.
- net_cls.classid
net_cls.classidcontains a single value that indicates a traffic control handle. The value ofclassidread from thenet_cls.classidfile is presented in the decimal format while the value to be written to the file is expected in the hexadecimal format. For example,0x100001represents the handle conventionally written as10:1in the format used by the ip utility. In thenet_cls.classidfile, it would be represented by the number1048577.The format for these handles is:0xAAAABBBB, where AAAA is the major number in hexadecimal and BBBB is the minor number in hexadecimal. You can omit any leading zeroes;0x10001is the same as0x00010001, and represents1:1. The following is an example of setting a10:1handle in thenet_cls.classidfile:~]# echo 0x100001 > /cgroup/net_cls/red/net_cls.classid ~]# cat /cgroup/net_cls/red/net_cls.classid 1048577
net_cls adds to network packets.
3.9. net_prio
net_prio) subsystem provides a way to dynamically set the priority of network traffic per each network interface for applications within various cgroups. A network's priority is a number assigned to network traffic and used internally by the system and network devices. Network priority is used to differentiate packets that are sent, queued, or dropped. The tc command may be used to set a network's priority (setting the network priority via the tc command is outside the scope of this guide; for more information, refer to the tc man page).
SO_PRIORITY socket option. However, applications are often not coded to set the priority value, or the application's traffic is site-specific and does not provide a defined priority.
net_prio subsystem in a cgroup allows the administrator to assign a process to a specific cgroup which defines the priority of outgoing traffic on a given network interface.
net_prio:
- net_prio.prioidx
- a read-only file which contains a unique integer value that the kernel uses as an internal representation of this cgroup.
- net_prio.ifpriomap
- contains a map of priorities assigned to traffic originating from processes in this group and leaving the system on various interfaces. This map is represented by a list of pairs in the form
<network_interface> <priority>:~]# cat /cgroup/net_prio/iscsi/net_prio.ifpriomap eth0 5 eth1 4 eth2 6Contents of thenet_prio.ifpriomapfile can be modified by echoing a string into the file using the above format, for example:~]# echo "eth0 5" > /cgroup/net_prio/iscsi/net_prio.ifpriomapThe above command forces any traffic originating from processes belonging to theiscsinet_priocgroup, and with traffic outgoing on theeth0network interface, to have the priority set to the value of5. The parent cgroup also has a writablenet_prio.ifpriomapfile that can be used to set a system default priority.
3.10. ns
ns subsystem provides a way to group processes into separate namespaces. Within a particular namespace, processes can interact with each other but are isolated from processes running in other namespaces. These separate namespaces are sometimes referred to as containers when used for operating-system-level virtualization.
3.11. perf_event
perf_event subsystem is attached to a hierarchy, all cgroups in that hierarchy can be used to group processes and threads which can then be monitored with the perf tool, as opposed to monitoring each process or thread separately or per-CPU. Cgroups which use the perf_event subsystem do not contain any special tunable parameters other than the common parameters listed in Section 3.12, “Common Tunable Parameters”.
3.12. Common Tunable Parameters
- tasks
- contains a list of processes, represented by their PIDs, that are running in a cgroup. The list of PIDs is not guaranteed to be ordered or unique (that is, it may contain duplicate entries). Writing a PID into the
tasksfile of a cgroup moves that process into that cgroup. - cgroup.procs
- contains a list of thread groups, represented by their TGIDs, that are running in a cgroup. The list of TGIDs is not guaranteed to be ordered or unique (that is, it may contain duplicate entries). Writing a TGID into the
cgroup.procsfile of a cgroup moves that thread group into that cgroup. - cgroup.event_control
- along with the cgroup notification API, allows notifications to be sent about a changing status of a cgroup.
- notify_on_release
- contains a Boolean value,
1or0, that either enables or disables the execution of the release agent. If thenotify_on_releaseparameter is enabled, the kernel executes the contents of therelease_agentfile when a cgroup no longer contains any tasks (that is, the cgroup'stasksfile contained some PIDs and those PIDs were removed, leaving the file empty). A path to the empty cgroup is provided as an argument to the release agent.The default value of thenotify_on_releaseparameter in the root cgroup is0. All non-root cgroups inherit the value innotify_on_releasefrom their parent cgroup. - release_agent (present in the root cgroup only)
- contains a command to be executed when a “notify on release” is triggered. Once a cgroup is emptied of all processes, and the
notify_on_releaseflag is enabled, the kernel runs the command in therelease_agentfile and supplies it with a relative path (relative to the root cgroup) to the emptied cgroup as an argument. The release agent can be used, for example, to automatically remove empty cgroups; for more information, see Example 3.4, “Automatically removing empty cgroups”.Example 3.4. Automatically removing empty cgroups
Follow these steps to configure automatic removal of any emptied cgroup from thecpucgroup:- Create a shell script that removes empty
cpucgroups, place it in, for example,/usr/local/bin, and make it executable.~]# cat /usr/local/bin/remove-empty-cpu-cgroup.sh #!/bin/sh rmdir /cgroup/cpu/$1 ~]# chmod +x /usr/local/bin/remove-empty-cpu-cgroup.shThe$1variable contains a relative path to the emptied cgroup. - In the
cpucgroup, enable thenotify_on_releaseflag:~]# echo 1 > /cgroup/cpu/notify_on_release - In the
cpucgroup, specify a release agent to be used:~]# echo "/usr/local/bin/remove-empty-cpu-cgroup.sh" > /cgroup/cpu/release_agent - Test your configuration to make sure emptied cgroups are properly removed:
cpu]# pwd; ls /cgroup/cpu cgroup.event_control cgroup.procs cpu.cfs_period_us cpu.cfs_quota_us cpu.rt_period_us cpu.rt_runtime_us cpu.shares cpu.stat libvirt notify_on_release release_agent tasks cpu]# cat notify_on_release 1 cpu]# cat release_agent /usr/local/bin/remove-empty-cpu-cgroup.sh cpu]# mkdir blue; ls blue cgroup.event_control cgroup.procs cpu.cfs_period_us cpu.cfs_quota_us cpu.rt_period_us cpu.rt_runtime_us cpu.shares cpu.stat libvirt notify_on_release release_agent tasks cpu]# cat blue/notify_on_release 1 cpu]# cgexec -g cpu:blue dd if=/dev/zero of=/dev/null bs=1024k & [1] 8623 cpu]# cat blue/tasks 8623 cpu]# kill -9 8623 cpu]# ls cgroup.event_control cgroup.procs cpu.cfs_period_us cpu.cfs_quota_us cpu.rt_period_us cpu.rt_runtime_us cpu.shares cpu.stat libvirt notify_on_release release_agent tasks
3.13. Additional Resources
Subsystem-Specific Kernel Documentation
/usr/share/doc/kernel-doc-<kernel_version>/Documentation/cgroups/ directory (provided by the kernel-doc package).
blkiosubsystem —blkio-controller.txtcpuacctsubsystem —cpuacct.txtcpusetsubsystem —cpusets.txtdevicessubsystem —devices.txtfreezersubsystem —freezer-subsystem.txtmemorysubsystem —memory.txtnet_priosubsystem —net_prio.txt
cpu subsystem:
- Real-Time scheduling —
/usr/share/doc/kernel-doc-<kernel_version>/Documentation/scheduler/sched-rt-group.txt - CFS scheduling —
/usr/share/doc/kernel-doc-<kernel_version>/Documentation/scheduler/sched-bwc.txt
Chapter 4. Control Group Application Examples
4.1. Prioritizing Database I/O
Figure 4.1. I/O throughput without resource allocation
Procedure 4.1. I/O throughput prioritization
- Attach the
blkiosubsystem to the/cgroup/blkiocgroup:~]# mkdir /cgroup/blkio ~]# mount -t cgroup -o blkio blkio /cgroup/blkio - Create a high and low priority cgroup:
~]# mkdir /cgroup/blkio/high_prio ~]# mkdir /cgroup/blkio/low_prio - Acquire the PIDs of the processes that represent both virtual guests (in which the database servers are running) and move them to their specific cgroup. In our example,
VM_highrepresents a virtual guest running a high priority database server, andVM_lowrepresents a virtual guest running a low priority database server. For example:~]# ps -eLf | grep qemu | grep VM_high | awk '{print $4}' | while read pid; do echo $pid >> /cgroup/blkio/high_prio/tasks; done ~]# ps -eLf | grep qemu | grep VM_low | awk '{print $4}' | while read pid; do echo $pid >> /cgroup/blkio/low_prio/tasks; done - Set a ratio of 10:1 for the
high_prioandlow_priocgroups. Processes in those cgroups (that is, processes running the virtual guests that have been added to those cgroups in the previous step) will immediately use only the resources made available to them.~]# echo 1000 > /cgroup/blkio/high_prio/blkio.weight ~]# echo 100 > /cgroup/blkio/low_prio/blkio.weightIn our example, the low priority cgroup permits the low priority database server to use only about 10% of the I/O operations, whereas the high priority cgroup permits the high priority database server to use about 90% of the I/O operations.
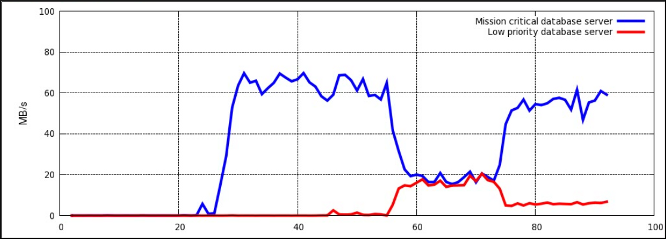
Figure 4.2. I/O throughput with resource allocation
blkio subsystem, refer to Section 3.1, “blkio”.
4.2. Prioritizing Network Traffic
net_prio subsystem can be used to set network priorities for processes in cgroups. These priorities are then translated into Type Of Service (TOS) bits and embedded into every packet. Follow the steps in Procedure 4.2, “Setting Network Priorities for File Sharing Services” to configure prioritization of two file sharing services (NFS and Samba).
Procedure 4.2. Setting Network Priorities for File Sharing Services
- The
net_priosubsystem is not compiled in the kernel, it is a module that must be loaded manually. To do so, type:~]# modprobe net_prio - Attach the
net_priosubsystem to the/cgroup/net_priocgroup:~]# mkdir /cgroup/net_prio ~]# mount -t cgroup -o net_prio net_prio /cgroup/net_prio - Create two cgroups, one for each service:
~]# mkdir /cgroup/net_prio/nfs_high ~]# mkdir /cgroup/net_prio/samba_low - To automatically move the
nfsservices to thenfs_highcgroup, add the following line to the/etc/sysconfig/nfsfile:CGROUP_DAEMON="net_prio:nfs_high"This configuration ensures thatnfsservice processes are moved to thenfs_highcgroup when thenfsservice is started or restarted. For more information about moving service processes to cgroups, refer to Section 2.9.1, “Starting a Service in a Control Group”. - The
smbddaemon does not have a configuration file in the/etc/sysconfigdirectory. To automatically move thesmbddaemon to thesamba_lowcgroup, add the following line to the/etc/cgrules.conffile:*:smbd net_prio samba_lowNote that this rule moves everysmbddaemon, not only/usr/sbin/smbd, into thesamba_lowcgroup.You can define rules for thenmbdandwinbindddaemons to be moved to thesamba_lowcgroup in a similar way. - Start the
cgredservice to load the configuration from the previous step:~]# service cgred start Starting CGroup Rules Engine Daemon: [ OK ] - For the purposes of this example, let us assume both services use the
eth1network interface. Define network priorities for each cgroup, where1denotes low priority and10denotes high priority:~]# echo "eth1 1" > /cgroup/net_prio/samba_low ~]# echo "eth1 10" > /cgroup/net_prio/nfs_high - Start the
nfsandsmbservices and check whether their processes have been moved into the correct cgroups:~]# service smb start Starting SMB services: [ OK ] ~]# cat /cgroup/net_prio/samba_low 16122 16124 ~]# service nfs start Starting NFS services: [ OK ] Starting NFS quotas: [ OK ] Starting NFS mountd: [ OK ] Stopping RPC idmapd: [ OK ] Starting RPC idmapd: [ OK ] Starting NFS daemon: [ OK ] ~]# cat /cgroup/net_prio/nfs_high 16321 16325 16376Network traffic originating from NFS now has higher priority than traffic originating from Samba.
net_prio subsystem can be used to set network priorities for client applications, for example, Firefox.
4.3. Per-group Division of CPU and Memory Resources
~]$ grep home /etc/passwd
martin:x:500:500::/home/martin:/bin/bash
john:x:501:501::/home/john:/bin/bash
mark:x:502:502::/home/mark:/bin/bash
peter:x:503:503::/home/peter:/bin/bash
jenn:x:504:504::/home/jenn:/bin/bash
mike:x:505:505::/home/mike:/bin/bash
~]$ grep -e "50[678]" /etc/group
finance:x:506:jenn,john
sales:x:507:mark,martin
engineering:x:508:peter,mike
/etc/cgconfig.conf and /etc/cgrules.conf files, you can create a hierarchy and a set of rules which determine the amount of resources for each user. To achieve this, follow the steps in Procedure 4.3, “Per-group CPU and memory resource management”.
Procedure 4.3. Per-group CPU and memory resource management
- In the
/etc/cgconfig.conffile, configure the following subsystems to be mounted and cgroups to be created:mount { cpu = /cgroup/cpu_and_mem; cpuacct = /cgroup/cpu_and_mem; memory = /cgroup/cpu_and_mem; } group finance { cpu { cpu.shares="250"; } cpuacct { cpuacct.usage="0"; } memory { memory.limit_in_bytes="2G"; memory.memsw.limit_in_bytes="3G"; } } group sales { cpu { cpu.shares="250"; } cpuacct { cpuacct.usage="0"; } memory { memory.limit_in_bytes="4G"; memory.memsw.limit_in_bytes="6G"; } } group engineering { cpu { cpu.shares="500"; } cpuacct { cpuacct.usage="0"; } memory { memory.limit_in_bytes="8G"; memory.memsw.limit_in_bytes="16G"; } }When loaded, the above configuration file mounts thecpu,cpuacct, andmemorysubsystems to a singlecpu_and_memcgroup. For more information on these subsystems, refer to Chapter 3, Subsystems and Tunable Parameters. Next, it creates a hierarchy incpu_and_memwhich contains three cgroups: sales, finance, and engineering. In each of these cgroups, custom parameters are set for each subsystem:cpu— thecpu.sharesparameter determines the share of CPU resources available to each process in all cgroups. Setting the parameter to250,250, and500in the finance, sales, and engineering cgroups respectively means that processes started in these groups will split the resources with a 1:1:2 ratio. Note that when a single process is running, it consumes as much CPU as necessary no matter which cgroup it is placed in. The CPU limitation only comes into effect when two or more processes compete for CPU resources.cpuacct— thecpuacct.usage="0"parameter is used to reset values stored in thecpuacct.usageandcpuacct.usage_percpufiles. These files report total CPU time (in nanoseconds) consumed by all processes in a cgroup.memory— thememory.limit_in_bytesparameter represents the amount of memory that is made available to all processes within a certain cgroup. In our example, processes started in the finance cgroup have 2 GB of memory available, processes in the sales group have 4 GB of memory available, and processes in the engineering group have 8 GB of memory available. Thememory.memsw.limit_in_bytesparameter specifies the total amount of memory and swap space processes may use. Should a process in the finance cgroup hit the 2 GB memory limit, it is allowed to use another 1 GB of swap space, thus totaling the configured 3 GB.
- To define the rules which the
cgrulesengddaemon uses to move processes to specific cgroups, configure the/etc/cgrules.confin the following way:#<user/group> <controller(s)> <cgroup> @finance cpu,cpuacct,memory finance @sales cpu,cpuacct,memory sales @engineering cpu,cpuacct,memory engineeringThe above configuration creates rules that assign a specific system group (for example,@finance) the resource controllers it may use (for example,cpu,cpuacct,memory) and a cgroup (for example,finance) which contains all processes originating from that system group.In our example, when thecgrulesengddaemon, started via theservice cgred startcommand, detects a process that is started by a user that belongs to the finance system group (for example,jenn), that process is automatically moved to the/cgroup/cpu_and_mem/finance/tasksfile and is subjected to the resource limitations set in the finance cgroup. - Start the
cgconfigservice to create the hierarchy of cgroups and set the needed parameters in all created cgroups:~]# service cgconfig start Starting cgconfig service: [ OK ]Start thecgredservice to let thecgrulesengddaemon detect any processes started in system groups configured in the/etc/cgrules.conffile:~]# service cgred start Starting CGroup Rules Engine Daemon: [ OK ]Note thatcgredis the name of the service that starts thecgrulesengddaemon. - To make all of the changes above persistent across reboots, configure the
cgconfigandcgredservices to be started by default:~]# chkconfig cgconfig on ~]# chkconfig cgred on
dd command under each user:
~]$ dd if=/dev/zero of=/dev/null bs=1024k/dev/zero and outputs it to the /dev/null in chunks of 1024 KB. When the top utility is launched, you can see results similar to these:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8201 peter 20 0 103m 1676 556 R 24.9 0.2 0:04.18 dd
8202 mike 20 0 103m 1672 556 R 24.9 0.2 0:03.47 dd
8199 jenn 20 0 103m 1676 556 R 12.6 0.2 0:02.87 dd
8200 john 20 0 103m 1676 556 R 12.6 0.2 0:02.20 dd
8197 martin 20 0 103m 1672 556 R 12.6 0.2 0:05.56 dd
8198 mark 20 0 103m 1672 556 R 12.3 0.2 0:04.28 dd
⋮
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8202 mike 20 0 103m 1676 556 R 66.4 0.2 0:06.35 dd
8200 john 20 0 103m 1672 556 R 33.2 0.2 0:05.08 dd
⋮
Alternative method
cgrulesengd daemon moves a process to a cgroup only after the appropriate conditions set by the rules in /etc/cgrules.conf have been fulfilled, that process may be running for a few milliseconds in an incorrect cgroup. An alternative way to move processes to their specified cgroups is to use the pam_cgroup.so PAM module. This module moves processes to available cgroups according to rules defined in the /etc/cgrules.conf file. Follow the steps in Procedure 4.4, “Using a PAM module to move processes to cgroups” to configure the pam_cgroup.so PAM module. Note that the libcgroup-pam package that provides this module is available form the Optional subscription channel. Before subscribing to this channel please see the Scope of Coverage Details. If you decide to install packages from the channel, follow the steps documented in the article called How to access Optional and Supplementary channels, and -devel packages using Red Hat Subscription Manager (RHSM)? on Red Hat Customer Portal.
Procedure 4.4. Using a PAM module to move processes to cgroups
- Install the libcgroup-pam package from the optional Red Hat Enterprise Linux Yum repository:
~]# yum install libcgroup-pam --enablerepo=rhel-6-server-optional-rpms - Ensure that the PAM module has been installed and exists:
~]# ls /lib64/security/pam_cgroup.so /lib64/security/pam_cgroup.soNote that on 32-bit systems, the module is placed in the/lib/securitydirectory. - Add the following line to the
/etc/pam.d/sufile to use thepam_cgroup.somodule each time thesucommand is executed:session optional pam_cgroup.so - Configure the
/etc/cgconfig.confand/etc/cgrules.conffiles as in Procedure 4.3, “Per-group CPU and memory resource management”. - Log out all users that are affected by the cgroup settings in the
/etc/cgrules.conffile to apply the above configuration.
pam_cgroup.so PAM module, you may disable the cgred service.
Appendix A. Revision History
| Revision History | |||
|---|---|---|---|
| Revision 1.0-31 | Thu Apr 28 2016 | ||
| |||
| Revision 1.0-29 | Tue May 12 2015 | ||
| |||
| Revision 1.0-26 | Thu Oct 10 2014 | ||
| |||
| Revision 1.0-16 | Thu Feb 21 2013 | ||
| |||
| Revision 1.0-7 | Wed Jun 20 2012 | ||
| |||
| Revision 1.0-6 | Tue Dec 6 2011 | ||
| |||
| Revision 1.0-5 | Thu May 19 2011 | ||
| |||
| Revision 1.0-0 | Tue Nov 9 2010 | ||
| |||