Debezium User Guide
For use with Debezium 1.7
Abstract
Preface
Debezium is a set of distributed services that capture row-level changes in your databases so that your applications can see and respond to those changes. Debezium records all row-level changes committed to each database table. Each application reads the transaction logs of interest to view all operations in the order in which they occurred.
This guide provides details about using the following Debezium topics:
- Chapter 1, High level overview of Debezium
- Chapter 2, Required custom resource upgrades
- Chapter 3, Debezium connector for Db2
- Chapter 4, Debezium connector for MongoDB
- Chapter 5, Debezium connector for MySQL
- Chapter 6, Debezium Connector for Oracle (Technology Preview)
- Chapter 7, Debezium connector for PostgreSQL
- Chapter 8, Debezium connector for SQL Server
- Chapter 9, Monitoring Debezium
- Chapter 10, Debezium logging
- Chapter 11, Configuring Debezium connectors for your application
- Chapter 12, Applying transformations to modify messages exchanged with Apache Kafka
Making open source more inclusive
Red Hat is committed to replacing problematic language in our code, documentation, and web properties. We are beginning with these four terms: master, slave, blacklist, and whitelist. Because of the enormity of this endeavor, these changes will be implemented gradually over several upcoming releases. For more details, see our CTO Chris Wright’s message.
Chapter 1. High level overview of Debezium
Debezium is a set of distributed services that capture changes in your databases. Your applications can consume and respond to those changes. Debezium captures each row-level change in each database table in a change event record and streams these records to Kafka topics. Applications read these streams, which provide the change event records in the same order in which they were generated.
More details are in the following sections:
1.1. Debezium Features
Debezium is a set of source connectors for Apache Kafka Connect. Each connector ingests changes from a different database by using that database’s features for change data capture (CDC). Unlike other approaches, such as polling or dual writes, log-based CDC as implemented by Debezium:
- Ensures that all data changes are captured.
- Produces change events with a very low delay while avoiding increased CPU usage required for frequent polling. For example, for MySQL or PostgreSQL, the delay is in the millisecond range.
- Requires no changes to your data model, such as a "Last Updated" column.
- Can capture deletes.
- Can capture old record state and additional metadata such as transaction ID and causing query, depending on the database’s capabilities and configuration.
Five Advantages of Log-Based Change Data Capture is a blog post that provides more details.
Debezium connectors capture data changes with a range of related capabilities and options:
- Snapshots: optionally, an initial snapshot of a database’s current state can be taken if a connector is started and not all logs still exist. Typically, this is the case when the database has been running for some time and has discarded trannsaction logs that are no longer needed for transaction recovery or replication. There are different modes for performing snapshots, including support for incremental snapshots, which can be triggered at connector runtime. For more details, see the documentation for the connector that you are using.
- Filters: you can configure the set of captured schemas, tables and columns with include/exclude list filters.
- Masking: the values from specific columns can be masked, for example, when they contain sensitive data.
- Monitoring: most connectors can be monitored by using JMX.
- Ready-to-use single message transformations (SMTs) for message routing, filtering, event flattening, and more. For more information about the SMTs that Debezium provides, see Applying transformations to modify messages exchanged with Apache Kafka.
The documentation for each connector provides details about the connectors features and configuration options.
1.2. Description of Debezium architecture
You deploy Debezium by means of Apache Kafka Connect. Kafka Connect is a framework and runtime for implementing and operating:
- Source connectors such as Debezium that send records into Kafka
- Sink connectors that propagate records from Kafka topics to other systems
The following image shows the architecture of a change data capture pipeline based on Debezium:
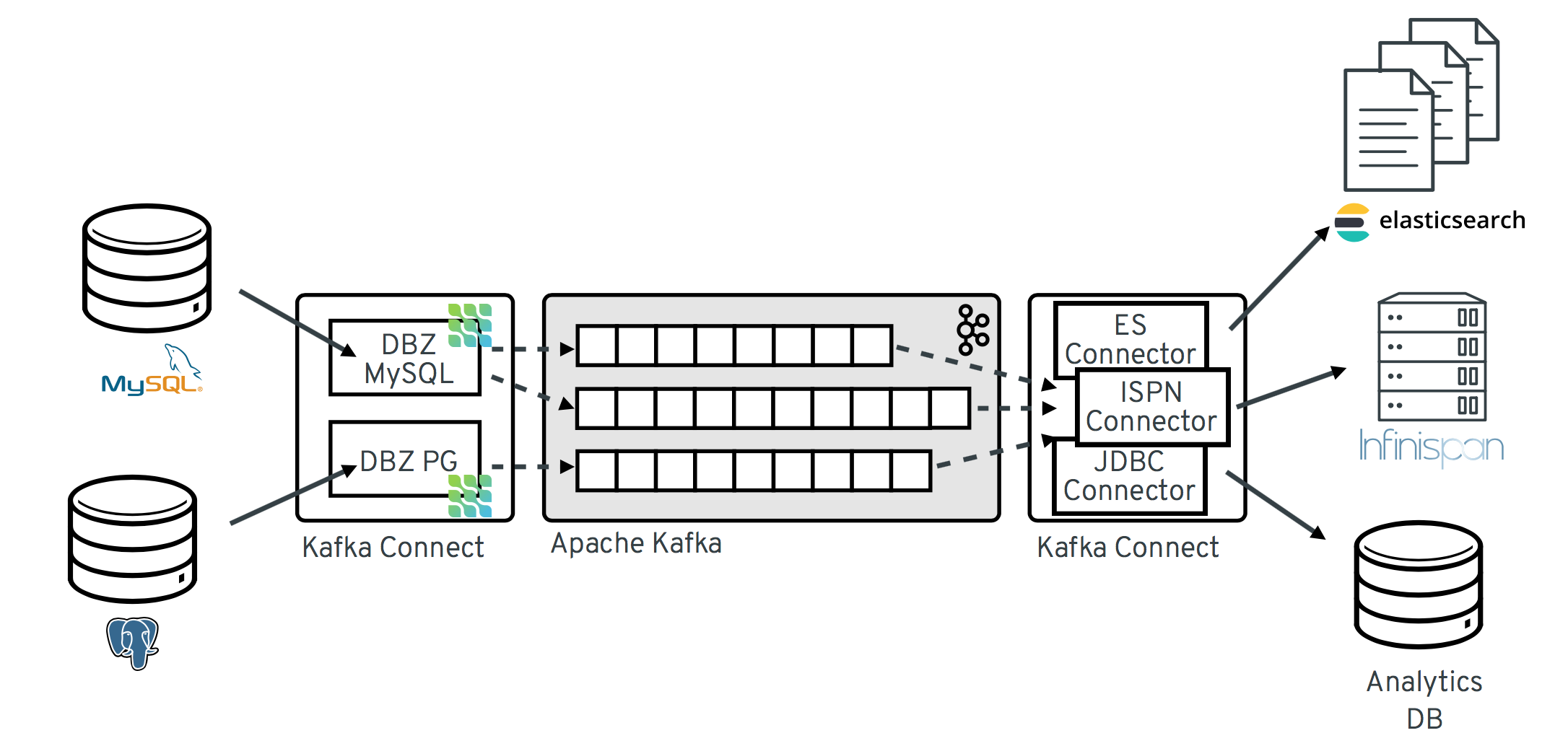
As shown in the image, the Debezium connectors for MySQL and PostgresSQL are deployed to capture changes to these two types of databases. Each Debezium connector establishes a connection to its source database:
-
The MySQL connector uses a client library for accessing the
binlog. - The PostgreSQL connector reads from a logical replication stream.
Kafka Connect operates as a separate service besides the Kafka broker.
By default, changes from one database table are written to a Kafka topic whose name corresponds to the table name. If needed, you can adjust the destination topic name by configuring Debezium’s topic routing transformation. For example, you can:
- Route records to a topic whose name is different from the table’s name
- Stream change event records for multiple tables into a single topic
After change event records are in Apache Kafka, different connectors in the Kafka Connect eco-system can stream the records to other systems and databases such as Elasticsearch, data warehouses and analytics systems, or caches such as Infinispan. Depending on the chosen sink connector, you might need to configure Debezium’s new record state extraction transformation. This Kafka Connect SMT propagates the after structure from Debezium’s change event to the sink connector. This is in place of the verbose change event record that is propagated by default.
Chapter 2. Required custom resource upgrades
Debezium is a Kafka connector plugin that is deployed to an Apache Kafka cluster that runs on AMQ Streams on OpenShift. To prepare for OpenShift CRD v1, in the current version of AMQ Streams the required version of the custom resource definitions (CRD) API is now set to v1beta2. The v1beta2 version of the API replaces the previously supported v1beta1 and v1alpha1 API versions. Support for the v1alpha1 and v1beta1 API versions is now deprecated in AMQ Streams. Those earlier versions are now removed from most AMQ Streams custom resources, including the KafkaConnect and KafkaConnector resources that you use to configure Debezium connectors.
The CRDs that are based on the v1beta2 API version use the OpenAPI structural schema. Custom resources based on the superseded v1alpha1 or v1beta1 APIs do not support structural schemas, and are incompatible with the current version of AMQ Streams. Before you upgrade to AMQ Streams2.0, you must upgrade existing custom resources to use API version kafka.strimzi.io/v1beta2. You can upgrade custom resources any time after you upgrade to AMQ Streams 1.7. You must complete the upgrade to the v1beta2 API before you upgrade to AMQ Streams2.0 or newer.
To facilitate the upgrade of CRDs and custom resources, AMQ Streams provides an API conversion tool that automatically upgrades them to a format that is compatible with v1beta2. For more information about the tool and for the complete instructions about how to upgrade AMQ Streams, see Deploying and Upgrading AMQ Streams on OpenShift.
The requirement to update custom resources applies only to Debezium deployments that run on AMQ Streams on OpenShift. The requirement does not apply to Debezium on Red Hat Enterprise Linux
Chapter 3. Debezium connector for Db2
Debezium’s Db2 connector can capture row-level changes in the tables of a Db2 database. For information about the Db2 Database versions that are compatible with this connector, see the Debezium Supported Configurations page.
This connector is strongly inspired by the Debezium implementation of SQL Server, which uses a SQL-based polling model that puts tables into "capture mode". When a table is in capture mode, the Debezium Db2 connector generates and streams a change event for each row-level update to that table.
A table that is in capture mode has an associated change-data table, which Db2 creates. For each change to a table that is in capture mode, Db2 adds data about that change to the table’s associated change-data table. A change-data table contains an entry for each state of a row. It also has special entries for deletions. The Debezium Db2 connector reads change events from change-data tables and emits the events to Kafka topics.
The first time a Debezium Db2 connector connects to a Db2 database, the connector reads a consistent snapshot of the tables for which the connector is configured to capture changes. By default, this is all non-system tables. There are connector configuration properties that let you specify which tables to put into capture mode, or which tables to exclude from capture mode.
When the snapshot is complete the connector begins emitting change events for committed updates to tables that are in capture mode. By default, change events for a particular table go to a Kafka topic that has the same name as the table. Applications and services consume change events from these topics.
The connector requires the use of the abstract syntax notation (ASN) libraries, which are available as a standard part of Db2 for Linux. To use the ASN libraries, you must have a license for IBM InfoSphere Data Replication (IIDR). You do not have to install IIDR to use the ASN libraries.
Information and procedures for using a Debezium Db2 connector is organized as follows:
- Section 3.1, “Overview of Debezium Db2 connector”
- Section 3.2, “How Debezium Db2 connectors work”
- Section 3.3, “Descriptions of Debezium Db2 connector data change events”
- Section 3.4, “How Debezium Db2 connectors map data types”
- Section 3.5, “Setting up Db2 to run a Debezium connector”
- Section 3.6, “Deployment of Debezium Db2 connectors”
- Section 3.7, “Monitoring Debezium Db2 connector performance”
- Section 3.8, “Managing Debezium Db2 connectors”
- Section 3.9, “Updating schemas for Db2 tables in capture mode for Debezium connectors”
3.1. Overview of Debezium Db2 connector
The Debezium Db2 connector is based on the ASN Capture/Apply agents that enable SQL Replication in Db2. A capture agent:
- Generates change-data tables for tables that are in capture mode.
- Monitors tables in capture mode and stores change events for updates to those tables in their corresponding change-data tables.
The Debezium connector uses a SQL interface to query change-data tables for change events.
The database administrator must put the tables for which you want to capture changes into capture mode. For convenience and for automating testing, there are Debezium user-defined functions (UDFs) in C that you can compile and then use to do the following management tasks:
- Start, stop, and reinitialize the ASN agent
- Put tables into capture mode
- Create the replication (ASN) schemas and change-data tables
- Remove tables from capture mode
Alternatively, you can use Db2 control commands to accomplish these tasks.
After the tables of interest are in capture mode, the connector reads their corresponding change-data tables to obtain change events for table updates. The connector emits a change event for each row-level insert, update, and delete operation to a Kafka topic that has the same name as the changed table. This is default behavior that you can modify. Client applications read the Kafka topics that correspond to the database tables of interest and can react to each row-level change event.
Typically, the database administrator puts a table into capture mode in the middle of the life of a table. This means that the connector does not have the complete history of all changes that have been made to the table. Therefore, when the Db2 connector first connects to a particular Db2 database, it starts by performing a consistent snapshot of each table that is in capture mode. After the connector completes the snapshot, the connector streams change events from the point at which the snapshot was made. In this way, the connector starts with a consistent view of the tables that are in capture mode, and does not drop any changes that were made while it was performing the snapshot.
Debezium connectors are tolerant of failures. As the connector reads and produces change events, it records the log sequence number (LSN) of the change-data table entry. The LSN is the position of the change event in the database log. If the connector stops for any reason, including communication failures, network problems, or crashes, upon restarting it continues reading the change-data tables where it left off. This includes snapshots. That is, if the snapshot was not complete when the connector stopped, upon restart the connector begins a new snapshot.
3.2. How Debezium Db2 connectors work
To optimally configure and run a Debezium Db2 connector, it is helpful to understand how the connector performs snapshots, streams change events, determines Kafka topic names, and handles schema changes.
Details are in the following topics:
- Section 3.2.1, “How Debezium Db2 connectors perform database snapshots”
- Section 3.2.2, “How Debezium Db2 connectors read change-data tables”
- Section 3.2.3, “Default names of Kafka topics that receive Debezium Db2 change event records”
- Section 3.2.4, “About the Debezium Db2 connector schema change topic”
- Section 3.2.5, “Debezium Db2 connector-generated events that represent transaction boundaries”
3.2.1. How Debezium Db2 connectors perform database snapshots
Db2`s replication feature is not designed to store the complete history of database changes. Consequently, when a Debezium Db2 connector connects to a database for the first time, it takes a consistent snapshot of tables that are in capture mode and streams this state to Kafka. This establishes the baseline for table content.
By default, when a Db2 connector performs a snapshot, it does the following:
-
Determines which tables are in capture mode, and thus must be included in the snapshot. By default, all non-system tables are in capture mode. Connector configuration properties, such as
table.exclude.listandtable.include.listlet you specify which tables should be in capture mode. -
Obtains a lock on each of the tables in capture mode. This ensures that no schema changes can occur in those tables during the snapshot. The level of the lock is determined by the
snapshot.isolation.modeconnector configuration property. - Reads the highest (most recent) LSN position in the server’s transaction log.
- Captures the schema of all tables that are in capture mode. The connector persists this information in its internal database history topic.
- Optional, releases the locks obtained in step 2. Typically, these locks are held for only a short time.
At the LSN position read in step 3, the connector scans the capture mode tables as well as their schemas. During the scan, the connector:
- Confirms that the table was created before the start of the snapshot. If it was not, the snapshot skips that table. After the snapshot is complete, and the connector starts emitting change events, the connector produces change events for any tables that were created during the snapshot.
- Produces a read event for each row in each table that is in capture mode. All read events contain the same LSN position, which is the LSN position that was obtained in step 3.
- Emits each read event to the Kafka topic that has the same name as the table.
- Records the successful completion of the snapshot in the connector offsets.
3.2.1.1. Ad hoc snapshots
The use of ad hoc snapshots is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service-level agreements (SLAs) and might not be functionally complete; therefore, Red Hat does not recommend implementing any Technology Preview features in production environments. This Technology Preview feature provides early access to upcoming product innovations, enabling you to test functionality and provide feedback during the development process. For more information about support scope, see Technology Preview Features Support Scope.
By default, a connector runs an initial snapshot operation only after it starts for the first time. Following this initial snapshot, under normal circumstances, the connector does not repeat the snapshot process. Any future change event data that the connector captures comes in through the streaming process only.
However, in some situations the data that the connector obtained during the initial snapshot might become stale, lost, or incomplete. To provide a mechanism for recapturing table data, Debezium includes an option to perform ad hoc snapshots. The following changes in a database might be cause for performing an ad hoc snapshot:
- The connector configuration is modified to capture a different set of tables.
- Kafka topics are deleted and must be rebuilt.
- Data corruption occurs due to a configuration error or some other problem.
You can re-run a snapshot for a table for which you previously captured a snapshot by initiating a so-called ad-hoc snapshot. Ad hoc snapshots require the use of signaling tables. You initiate an ad hoc snapshot by sending a signal request to the Debezium signaling table.
When you initiate an ad hoc snapshot of an existing table, the connector appends content to the topic that already exists for the table. If a previously existing topic was removed, Debezium can create a topic automatically if automatic topic creation is enabled.
Ad hoc snapshot signals specify the tables to include in the snapshot. The snapshot can capture the entire contents of the database, or capture only a subset of the tables in the database.
You specify the tables to capture by sending an execute-snapshot message to the signaling table. Set the type of the execute-snapshot signal to incremental, and provide the names of the tables to include in the snapshot, as described in the following table:
| Field | Default | Value |
|---|---|---|
|
|
|
Specifies the type of snapshot that you want to run. |
|
| N/A |
An array that contains the fully-qualified names of the table to be snapshotted. |
Triggering an ad hoc snapshot
You initiate an ad hoc snapshot by adding an entry with the execute-snapshot signal type to the signaling table. After the connector processes the message, it begins the snapshot operation. The snapshot process reads the first and last primary key values and uses those values as the start and end point for each table. Based on the number of entries in the table, and the configured chunk size, Debezium divides the table into chunks, and proceeds to snapshot each chunk, in succession, one at a time.
Currently, the execute-snapshot action type triggers incremental snapshots only. For more information, see Incremental snapshots.
3.2.1.2. Incremental snapshots
The use of incremental snapshots is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service-level agreements (SLAs) and might not be functionally complete; therefore, Red Hat does not recommend implementing any Technology Preview features in production environments. This Technology Preview feature provides early access to upcoming product innovations, enabling you to test functionality and provide feedback during the development process. For more information about support scope, see Technology Preview Features Support Scope.
To provide flexibility in managing snapshots, Debezium includes a supplementary snapshot mechanism, known as incremental snapshotting. Incremental snapshots rely on the Debezium mechanism for sending signals to a Debezium connector.
In an incremental snapshot, instead of capturing the full state of a database all at once, as in an initial snapshot, Debezium captures each table in phases, in a series of configurable chunks. You can specify the tables that you want the snapshot to capture and the size of each chunk. The chunk size determines the number of rows that the snapshot collects during each fetch operation on the database. The default chunk size for incremental snapshots is 1 KB.
As an incremental snapshot proceeds, Debezium uses watermarks to track its progress, maintaining a record of each table row that it captures. This phased approach to capturing data provides the following advantages over the standard initial snapshot process:
- You can run incremental snapshots in parallel with streamed data capture, instead of postponing streaming until the snapshot completes. The connector continues to capture near real-time events from the change log throughout the snapshot process, and neither operation blocks the other.
- If the progress of an incremental snapshot is interrupted, you can resume it without losing any data. After the process resumes, the snapshot begins at the point where it stopped, rather than recapturing the table from the beginning.
-
You can run an incremental snapshot on demand at any time, and repeat the process as needed to adapt to database updates. For example, you might re-run a snapshot after you modify the connector configuration to add a table to its
table.include.listproperty.
Incremental snapshot process
When you run an incremental snapshot, Debezium sorts each table by primary key and then splits the table into chunks based on the configured chunk size. Working chunk by chunk, it then captures each table row in a chunk. For each row that it captures, the snapshot emits a READ event. That event represents the value of the row when the snapshot for the chunk began.
As a snapshot proceeds, it’s likely that other processes continue to access the database, potentially modifying table records. To reflect such changes, INSERT, UPDATE, or DELETE operations are committed to the transaction log as per usual. Similarly, the ongoing Debezium streaming process continues to detect these change events and emits corresponding change event records to Kafka.
How Debezium resolves collisions among records with the same primary key
In some cases, the UPDATE or DELETE events that the streaming process emits are received out of sequence. That is, the streaming process might emit an event that modifies a table row before the snapshot captures the chunk that contains the READ event for that row. When the snapshot eventually emits the corresponding READ event for the row, its value is already superseded. To ensure that incremental snapshot events that arrive out of sequence are processed in the correct logical order, Debezium employs a buffering scheme for resolving collisions. Only after collisions between the snapshot events and the streamed events are resolved does Debezium emit an event record to Kafka.
Snapshot window
To assist in resolving collisions between late-arriving READ events and streamed events that modify the same table row, Debezium employs a so-called snapshot window. The snapshot windows demarcates the interval during which an incremental snapshot captures data for a specified table chunk. Before the snapshot window for a chunk opens, Debezium follows its usual behavior and emits events from the transaction log directly downstream to the target Kafka topic. But from the moment that the snapshot for a particular chunk opens, until it closes, Debezium performs a de-duplication step to resolve collisions between events that have the same primary key..
For each data collection, the Debezium emits two types of events, and stores the records for them both in a single destination Kafka topic. The snapshot records that it captures directly from a table are emitted as READ operations. Meanwhile, as users continue to update records in the data collection, and the transaction log is updated to reflect each commit, Debezium emits UPDATE or DELETE operations for each change.
As the snapshot window opens, and Debezium begins processing a snapshot chunk, it delivers snapshot records to a memory buffer. During the snapshot windows, the primary keys of the READ events in the buffer are compared to the primary keys of the incoming streamed events. If no match is found, the streamed event record is sent directly to Kafka. If Debezium detects a match, it discards the buffered READ event, and writes the streamed record to the destination topic, because the streamed event logically supersede the static snapshot event. After the snapshot window for the chunk closes, the buffer contains only READ events for which no related transaction log events exist. Debezium emits these remaining READ events to the table’s Kafka topic.
The connector repeats the process for each snapshot chunk.
Triggering an incremental snapshot
Currently, the only way to initiate an incremental snapshot is to send an ad hoc snapshot signal to the signaling table on the source database. You submit signals to the table as SQL INSERT queries. After Debezium detects the change in the signaling table, it reads the signal, and runs the requested snapshot operation.
The query that you submit specifies the tables to include in the snapshot, and, optionally, specifies the kind of snapshot operation. Currently, the only valid option for snapshots operations is the default value, incremental.
To specify the tables to include in the snapshot, provide a data-collections array that lists the tables, for example,{"data-collections": ["public.MyFirstTable", "public.MySecondTable"]}
The data-collections array for an incremental snapshot signal has no default value. If the data-collections array is empty, Debezium detects that no action is required and does not perform a snapshot.
Prerequisites
- A signaling data collection exists on the source database and the connector is configured to capture it.
-
The signaling data collection is specified in the
signal.data.collectionproperty.
Procedure
Send a SQL query to add the ad hoc incremental snapshot request to the signaling table:
INSERT INTO _<signalTable>_ (id, type, data) VALUES (_'<id>'_, _'<snapshotType>'_, '{"data-collections": ["_<tableName>_","_<tableName>_"],"type":"_<snapshotType>_"}');For example,
INSERT INTO myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["schema1.table1", "schema2.table2"],"type":"incremental"}');The values of the
id,type, anddataparameters in the command correspond to the fields of the signaling table.The following table describes the these parameters:
Expand Table 3.2. Descriptions of fields in a SQL command for sending an incremental snapshot signal to the signaling table Value Description myschema.debezium_signalSpecifies the fully-qualified name of the signaling table on the source database
ad-hoc-1The
idparameter specifies an arbitrary string that is assigned as theididentifier for the signal request.
Use this string to identify logging messages to entries in the signaling table. Debezium does not use this string. Rather, during the snapshot, Debezium generates its ownidstring as a watermarking signal.execute-snapshotSpecifies
typeparameter specifies the operation that the signal is intended to trigger.
data-collectionsA required component of the
datafield of a signal that specifies an array of table names to include in the snapshot.
The array lists tables by their fully-qualified names, using the same format as you use to specify the name of the connector’s signaling table in thesignal.data.collectionconfiguration property.incrementalAn optional
typecomponent of thedatafield of a signal that specifies the kind of snapshot operation to run.
Currently, the only valid option is the default value,incremental.
Specifying atypevalue in the SQL query that you submit to the signaling table is optional.
If you do not specify a value, the connector runs an incremental snapshot.
The following example, shows the JSON for an incremental snapshot event that is captured by a connector.
Example: Incremental snapshot event message
{
"before":null,
"after": {
"pk":"1",
"value":"New data"
},
"source": {
...
"snapshot":"incremental"
},
"op":"r",
"ts_ms":"1620393591654",
"transaction":null
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
Specifies the type of snapshot operation to run. |
| 2 |
|
Specifies the event type. |
The Debezium connector for Db2 does not support schema changes while an incremental snapshot is running.
3.2.2. How Debezium Db2 connectors read change-data tables
After a complete snapshot, when a Debezium Db2 connector starts for the first time, the connector identifies the change-data table for each source table that is in capture mode. The connector does the following for each change-data table:
- Reads change events that were created between the last stored, highest LSN and the current, highest LSN.
- Orders the change events according to the commit LSN and the change LSN for each event. This ensures that the connector emits the change events in the order in which the table changes occurred.
- Passes commit and change LSNs as offsets to Kafka Connect.
- Stores the highest LSN that the connector passed to Kafka Connect.
After a restart, the connector resumes emitting change events from the offset (commit and change LSNs) where it left off. While the connector is running and emitting change events, if you remove a table from capture mode or add a table to capture mode, the connector detects the change, and modifies its behavior accordingly.
3.2.3. Default names of Kafka topics that receive Debezium Db2 change event records
By default, the Db2 connector writes change events for all of the INSERT, UPDATE, and DELETE operations that occur in a table to a single Apache Kafka topic that is specific to that table. The connector uses the following convention to name change event topics:
databaseName.schemaName.tableName
The following list provides definitions for the components of the default name:
- databaseName
-
The logical name of the connector as specified by the
database.server.nameconnector configuration property. - schemaName
- The name of the schema in which the operation occurred.
- tableName
- The name of the table in which the operation occurred.
For example, consider a Db2 installation with the mydatabase database, which contains four tables: PRODUCTS, PRODUCTS_ON_HAND, CUSTOMERS, and ORDERS that are in the MYSCHEMA schema. The connector would emit events to these four Kafka topics:
-
mydatabase.MYSCHEMA.PRODUCTS -
mydatabase.MYSCHEMA.PRODUCTS_ON_HAND -
mydatabase.MYSCHEMA.CUSTOMERS -
mydatabase.MYSCHEMA.ORDERS
The connector applies similar naming conventions to label its internal database history topics, schema change topics, and transaction metadata topics.
If the default topic name do not meet your requirements, you can configure custom topic names. To configure custom topic names, you specify regular expressions in the logical topic routing SMT. For more information about using the logical topic routing SMT to customize topic naming, see Topic routing.
3.2.4. About the Debezium Db2 connector schema change topic
You can configure a Debezium Db2 connector to produce schema change events that describe schema changes that are applied to captured tables in the database.
Debezium emits a message to the schema change topic when:
- A new table goes into capture mode.
- A table is removed from capture mode.
- During a database schema update, there is a change in the schema for a table that is in capture mode.
The connector writes schema change events to a Kafka schema change topic that has the name <serverName> where <serverName> is the logical server name that is specified in the database.server.name connector configuration property. Messages that the connector sends to the schema change topic contain a payload that includes the following elements:
databaseName-
The name of the database to which the statements are applied. The value of
databaseNameserves as the message key. pos- The position in the binlog where the statements appear.
tableChanges-
A structured representation of the entire table schema after the schema change. The
tableChangesfield contains an array that includes entries for each column of the table. Because the structured representation presents data in JSON or Avro format, consumers can easily read messages without first processing them through a DDL parser.
For a table that is in capture mode, the connector not only stores the history of schema changes in the schema change topic, but also in an internal database history topic. The internal database history topic is for connector use only and it is not intended for direct use by consuming applications. Ensure that applications that require notifications about schema changes consume that information only from the schema change topic.
Never partition the database history topic. For the database history topic to function correctly, it must maintain a consistent, global order of the event records that the connector emits to it.
To ensure that the topic is not split among partitions, set the partition count for the topic by using one of the following methods:
-
If you create the database history topic manually, specify a partition count of
1. -
If you use the Apache Kafka broker to create the database history topic automatically, the topic is created, set the value of the Kafka
num.partitionsconfiguration option to1.
The format of messages that a connector emits to its schema change topic is in an incubating state and can change without notice.
Example: Message emitted to the Db2 connector schema change topic
The following example shows a message in the schema change topic. The message contains a logical representation of the table schema.
{
"schema": {
...
},
"payload": {
"source": {
"version": "1.7.2.Final",
"connector": "db2",
"name": "db2",
"ts_ms": 1588252618953,
"snapshot": "true",
"db": "testdb",
"schema": "DB2INST1",
"table": "CUSTOMERS",
"change_lsn": null,
"commit_lsn": "00000025:00000d98:00a2",
"event_serial_no": null
},
"databaseName": "TESTDB",
"schemaName": "DB2INST1",
"ddl": null,
"tableChanges": [
{
"type": "CREATE",
"id": "\"DB2INST1\".\"CUSTOMERS\"",
"table": {
"defaultCharsetName": null,
"primaryKeyColumnNames": [
"ID"
],
"columns": [
{
"name": "ID",
"jdbcType": 4,
"nativeType": null,
"typeName": "int identity",
"typeExpression": "int identity",
"charsetName": null,
"length": 10,
"scale": 0,
"position": 1,
"optional": false,
"autoIncremented": false,
"generated": false
},
{
"name": "FIRST_NAME",
"jdbcType": 12,
"nativeType": null,
"typeName": "varchar",
"typeExpression": "varchar",
"charsetName": null,
"length": 255,
"scale": null,
"position": 2,
"optional": false,
"autoIncremented": false,
"generated": false
},
{
"name": "LAST_NAME",
"jdbcType": 12,
"nativeType": null,
"typeName": "varchar",
"typeExpression": "varchar",
"charsetName": null,
"length": 255,
"scale": null,
"position": 3,
"optional": false,
"autoIncremented": false,
"generated": false
},
{
"name": "EMAIL",
"jdbcType": 12,
"nativeType": null,
"typeName": "varchar",
"typeExpression": "varchar",
"charsetName": null,
"length": 255,
"scale": null,
"position": 4,
"optional": false,
"autoIncremented": false,
"generated": false
}
]
}
}
]
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
| Identifies the database and the schema that contain the change. |
| 2 |
|
Always |
| 3 |
| An array of one or more items that contain the schema changes generated by a DDL command. |
| 4 |
| Describes the kind of change. The value is one of the following:
|
| 5 |
| Full identifier of the table that was created, altered, or dropped. |
| 6 |
| Represents table metadata after the applied change. |
| 7 |
| List of columns that compose the table’s primary key. |
| 8 |
| Metadata for each column in the changed table. |
In messages that the connector sends to the schema change topic, the message key is the name of the database that contains the schema change. In the following example, the payload field contains the key:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "databaseName"
}
],
"optional": false,
"name": "io.debezium.connector.db2.SchemaChangeKey"
},
"payload": {
"databaseName": "TESTDB"
}
}3.2.5. Debezium Db2 connector-generated events that represent transaction boundaries
Debezium can generate events that represent transaction boundaries and that enrich change data event messages.
Debezium registers and receives metadata only for transactions that occur after you deploy the connector. Metadata for transactions that occur before you deploy the connector is not available.
Debezium generates transaction boundary events for the BEGIN and END delimiters in every transaction. Transaction boundary events contain the following fields:
status-
BEGINorEND. id- String representation of the unique transaction identifier.
event_count(forENDevents)- Total number of events emitted by the transaction.
data_collections(forENDevents)-
An array of pairs of
data_collectionandevent_countelements. that indicates the number of events that the connector emits for changes that originate from a data collection.
Example
{
"status": "BEGIN",
"id": "00000025:00000d08:0025",
"event_count": null,
"data_collections": null
}
{
"status": "END",
"id": "00000025:00000d08:0025",
"event_count": 2,
"data_collections": [
{
"data_collection": "testDB.dbo.tablea",
"event_count": 1
},
{
"data_collection": "testDB.dbo.tableb",
"event_count": 1
}
]
}
The connector emits transaction events to the <database.server.name>.transaction topic.
Data change event enrichment
When transaction metadata is enabled the connector enriches the change event Envelope with a new transaction field. This field provides information about every event in the form of a composite of fields:
id- String representation of unique transaction identifier.
total_order- The absolute position of the event among all events generated by the transaction.
data_collection_order- The per-data collection position of the event among all events that were emitted by the transaction.
Following is an example of a message:
{
"before": null,
"after": {
"pk": "2",
"aa": "1"
},
"source": {
...
},
"op": "c",
"ts_ms": "1580390884335",
"transaction": {
"id": "00000025:00000d08:0025",
"total_order": "1",
"data_collection_order": "1"
}
}3.3. Descriptions of Debezium Db2 connector data change events
The Debezium Db2 connector generates a data change event for each row-level INSERT, UPDATE, and DELETE operation. Each event contains a key and a value. The structure of the key and the value depends on the table that was changed.
Debezium and Kafka Connect are designed around continuous streams of event messages. However, the structure of these events may change over time, which can be difficult for consumers to handle. To address this, each event contains the schema for its content or, if you are using a schema registry, a schema ID that a consumer can use to obtain the schema from the registry. This makes each event self-contained.
The following skeleton JSON shows the basic four parts of a change event. However, how you configure the Kafka Connect converter that you choose to use in your application determines the representation of these four parts in change events. A schema field is in a change event only when you configure the converter to produce it. Likewise, the event key and event payload are in a change event only if you configure a converter to produce it. If you use the JSON converter and you configure it to produce all four basic change event parts, change events have this structure:
{
"schema": {
...
},
"payload": {
...
},
"schema": {
...
},
"payload": {
...
},
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
The first |
| 2 |
|
The first |
| 3 |
|
The second |
| 4 |
|
The second |
By default, the connector streams change event records to topics with names that are the same as the event’s originating table. See topic names.
The Debezium Db2 connector ensures that all Kafka Connect schema names adhere to the Avro schema name format. This means that the logical server name must start with a Latin letter or an underscore, that is, a-z, A-Z, or _. Each remaining character in the logical server name and each character in the database and table names must be a Latin letter, a digit, or an underscore, that is, a-z, A-Z, 0-9, or \_. If there is an invalid character it is replaced with an underscore character.
This can lead to unexpected conflicts if the logical server name, a database name, or a table name contains invalid characters, and the only characters that distinguish names from one another are invalid and thus replaced with underscores.
Also, Db2 names for databases, schemas, and tables can be case sensitive. This means that the connector could emit event records for more than one table to the same Kafka topic.
Details are in the following topics:
3.3.1. About keys in Debezium db2 change events
A change event’s key contains the schema for the changed table’s key and the changed row’s actual key. Both the schema and its corresponding payload contain a field for each column in the changed table’s PRIMARY KEY (or unique constraint) at the time the connector created the event.
Consider the following customers table, which is followed by an example of a change event key for this table.
Example table
CREATE TABLE customers (
ID INTEGER IDENTITY(1001,1) NOT NULL PRIMARY KEY,
FIRST_NAME VARCHAR(255) NOT NULL,
LAST_NAME VARCHAR(255) NOT NULL,
EMAIL VARCHAR(255) NOT NULL UNIQUE
);Example change event key
Every change event that captures a change to the customers table has the same event key schema. For as long as the customers table has the previous definition, every change event that captures a change to the customers table has the following key structure. In JSON, it looks like this:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "ID"
}
],
"optional": false,
"name": "mydatabase.MYSCHEMA.CUSTOMERS.Key"
},
"payload": {
"ID": 1004
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
The schema portion of the key specifies a Kafka Connect schema that describes what is in the key’s |
| 2 |
|
Specifies each field that is expected in the |
| 3 |
|
Indicates whether the event key must contain a value in its |
| 4 |
|
Name of the schema that defines the structure of the key’s payload. This schema describes the structure of the primary key for the table that was changed. Key schema names have the format connector-name.database-name.table-name.
|
| 5 |
|
Contains the key for the row for which this change event was generated. In this example, the key, contains a single |
3.3.2. About values in Debezium Db2 change events
The value in a change event is a bit more complicated than the key. Like the key, the value has a schema section and a payload section. The schema section contains the schema that describes the Envelope structure of the payload section, including its nested fields. Change events for operations that create, update or delete data all have a value payload with an envelope structure.
Consider the same sample table that was used to show an example of a change event key:
Example table
CREATE TABLE customers (
ID INTEGER IDENTITY(1001,1) NOT NULL PRIMARY KEY,
FIRST_NAME VARCHAR(255) NOT NULL,
LAST_NAME VARCHAR(255) NOT NULL,
EMAIL VARCHAR(255) NOT NULL UNIQUE
);
The event value portion of every change event for the customers table specifies the same schema. The event value’s payload varies according to the event type:
create events
The following example shows the value portion of a change event that the connector generates for an operation that creates data in the customers table:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "ID"
},
{
"type": "string",
"optional": false,
"field": "FIRST_NAME"
},
{
"type": "string",
"optional": false,
"field": "LAST_NAME"
},
{
"type": "string",
"optional": false,
"field": "EMAIL"
}
],
"optional": true,
"name": "mydatabase.MYSCHEMA.CUSTOMERS.Value",
"field": "before"
},
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "ID"
},
{
"type": "string",
"optional": false,
"field": "FIRST_NAME"
},
{
"type": "string",
"optional": false,
"field": "LAST_NAME"
},
{
"type": "string",
"optional": false,
"field": "EMAIL"
}
],
"optional": true,
"name": "mydatabase.MYSCHEMA.CUSTOMERS.Value",
"field": "after"
},
{
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "version"
},
{
"type": "string",
"optional": false,
"field": "connector"
},
{
"type": "string",
"optional": false,
"field": "name"
},
{
"type": "int64",
"optional": false,
"field": "ts_ms"
},
{
"type": "boolean",
"optional": true,
"default": false,
"field": "snapshot"
},
{
"type": "string",
"optional": false,
"field": "db"
},
{
"type": "string",
"optional": false,
"field": "schema"
},
{
"type": "string",
"optional": false,
"field": "table"
},
{
"type": "string",
"optional": true,
"field": "change_lsn"
},
{
"type": "string",
"optional": true,
"field": "commit_lsn"
},
],
"optional": false,
"name": "io.debezium.connector.db2.Source",
"field": "source"
},
{
"type": "string",
"optional": false,
"field": "op"
},
{
"type": "int64",
"optional": true,
"field": "ts_ms"
}
],
"optional": false,
"name": "mydatabase.MYSCHEMA.CUSTOMERS.Envelope"
},
"payload": {
"before": null,
"after": {
"ID": 1005,
"FIRST_NAME": "john",
"LAST_NAME": "doe",
"EMAIL": "john.doe@example.org"
},
"source": {
"version": "1.7.2.Final",
"connector": "db2",
"name": "myconnector",
"ts_ms": 1559729468470,
"snapshot": false,
"db": "mydatabase",
"schema": "MYSCHEMA",
"table": "CUSTOMERS",
"change_lsn": "00000027:00000758:0003",
"commit_lsn": "00000027:00000758:0005",
},
"op": "c",
"ts_ms": 1559729471739
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
| The value’s schema, which describes the structure of the value’s payload. A change event’s value schema is the same in every change event that the connector generates for a particular table. |
| 2 |
|
In the |
| 3 |
|
|
| 4 |
|
|
| 5 |
|
The value’s actual data. This is the information that the change event is providing. |
| 6 |
|
An optional field that specifies the state of the row before the event occurred. When the |
| 7 |
|
An optional field that specifies the state of the row after the event occurred. In this example, the |
| 8 |
|
Mandatory field that describes the source metadata for the event. The
|
| 9 |
|
Mandatory string that describes the type of operation that caused the connector to generate the event. In this example,
|
| 10 |
|
Optional field that displays the time at which the connector processed the event. The time is based on the system clock in the JVM running the Kafka Connect task. |
update events
The value of a change event for an update in the sample customers table has the same schema as a create event for that table. Likewise, the update event value’s payload has the same structure. However, the event value payload contains different values in an update event. Here is an example of a change event value in an event that the connector generates for an update in the customers table:
{
"schema": { ... },
"payload": {
"before": {
"ID": 1005,
"FIRST_NAME": "john",
"LAST_NAME": "doe",
"EMAIL": "john.doe@example.org"
},
"after": {
"ID": 1005,
"FIRST_NAME": "john",
"LAST_NAME": "doe",
"EMAIL": "noreply@example.org"
},
"source": {
"version": "1.7.2.Final",
"connector": "db2",
"name": "myconnector",
"ts_ms": 1559729995937,
"snapshot": false,
"db": "mydatabase",
"schema": "MYSCHEMA",
"table": "CUSTOMERS",
"change_lsn": "00000027:00000ac0:0002",
"commit_lsn": "00000027:00000ac0:0007",
},
"op": "u",
"ts_ms": 1559729998706
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
An optional field that specifies the state of the row before the event occurred. In an update event value, the |
| 2 |
|
An optional field that specifies the state of the row after the event occurred. You can compare the |
| 3 |
|
Mandatory field that describes the source metadata for the event. The
|
| 4 |
|
Mandatory string that describes the type of operation. In an update event value, the |
| 5 |
|
Optional field that displays the time at which the connector processed the event. The time is based on the system clock in the JVM running the Kafka Connect task. |
Updating the columns for a row’s primary/unique key changes the value of the row’s key. When a key changes, Debezium outputs three events: a DELETE event and a tombstone event with the old key for the row, followed by an event with the new key for the row.
delete events
The value in a delete change event has the same schema portion as create and update events for the same table. The event value payload in a delete event for the sample customers table looks like this:
{
"schema": { ... },
},
"payload": {
"before": {
"ID": 1005,
"FIRST_NAME": "john",
"LAST_NAME": "doe",
"EMAIL": "noreply@example.org"
},
"after": null,
"source": {
"version": "1.7.2.Final",
"connector": "db2",
"name": "myconnector",
"ts_ms": 1559730445243,
"snapshot": false,
"db": "mydatabase",
"schema": "MYSCHEMA",
"table": "CUSTOMERS",
"change_lsn": "00000027:00000db0:0005",
"commit_lsn": "00000027:00000db0:0007"
},
"op": "d",
"ts_ms": 1559730450205
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
Optional field that specifies the state of the row before the event occurred. In a delete event value, the |
| 2 |
|
Optional field that specifies the state of the row after the event occurred. In a delete event value, the |
| 3 |
|
Mandatory field that describes the source metadata for the event. In a delete event value, the
|
| 4 |
|
Mandatory string that describes the type of operation. The |
| 5 |
|
Optional field that displays the time at which the connector processed the event. The time is based on the system clock in the JVM running the Kafka Connect task. |
A delete change event record provides a consumer with the information it needs to process the removal of this row. The old values are included because some consumers might require them in order to properly handle the removal.
Db2 connector events are designed to work with Kafka log compaction. Log compaction enables removal of some older messages as long as at least the most recent message for every key is kept. This lets Kafka reclaim storage space while ensuring that the topic contains a complete data set and can be used for reloading key-based state.
When a row is deleted, the delete event value still works with log compaction, because Kafka can remove all earlier messages that have that same key. However, for Kafka to remove all messages that have that same key, the message value must be null. To make this possible, after Debezium’s Db2 connector emits a delete event, the connector emits a special tombstone event that has the same key but a null value.
3.4. How Debezium Db2 connectors map data types
Db2’s data types are described in Db2 SQL Data Types.
The Db2 connector represents changes to rows with events that are structured like the table in which the row exists. The event contains a field for each column value. How that value is represented in the event depends on the Db2 data type of the column. This section describes these mappings.
Details are in the following sections:
Basic types
The following table describes how the connector maps each of the Db2 data types to a literal type and a semantic type in event fields.
-
literal type describes how the value is represented using Kafka Connect schema types:
INT8,INT16,INT32,INT64,FLOAT32,FLOAT64,BOOLEAN,STRING,BYTES,ARRAY,MAP, andSTRUCT. - semantic type describes how the Kafka Connect schema captures the meaning of the field using the name of the Kafka Connect schema for the field.
| Db2 data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
| Only snapshots can be taken from tables with BOOLEAN type columns. Currently SQL Replication on Db2 does not support BOOLEAN, so Debezium can not perform CDC on those tables. Consider using a different type. |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
|
|
|
|
|
|
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
|
|
If present, a column’s default value is propagated to the corresponding field’s Kafka Connect schema. Change events contain the field’s default value unless an explicit column value had been given. Consequently, there is rarely a need to obtain the default value from the schema.
Temporal types
Other than Db2’s DATETIMEOFFSET data type, which contains time zone information, how temporal types are mapped depends on the value of the time.precision.mode connector configuration property. The following sections describe these mappings:
time.precision.mode=adaptive
When the time.precision.mode configuration property is set to adaptive, the default, the connector determines the literal type and semantic type based on the column’s data type definition. This ensures that events exactly represent the values in the database.
| Db2 data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
time.precision.mode=connect
When the time.precision.mode configuration property is set to connect, the connector uses Kafka Connect logical types. This may be useful when consumers can handle only the built-in Kafka Connect logical types and are unable to handle variable-precision time values. However, since Db2 supports tenth of a microsecond precision, the events generated by a connector with the connect time precision results in a loss of precision when the database column has a fractional second precision value that is greater than 3.
| Db2 data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Timestamp types
The DATETIME, SMALLDATETIME and DATETIME2 types represent a timestamp without time zone information. Such columns are converted into an equivalent Kafka Connect value based on UTC. For example, the DATETIME2 value "2018-06-20 15:13:16.945104" is represented by an io.debezium.time.MicroTimestamp with the value "1529507596945104".
The timezone of the JVM running Kafka Connect and Debezium does not affect this conversion.
| Db2 data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.5. Setting up Db2 to run a Debezium connector
For Debezium to capture change events that are committed to Db2 tables, a Db2 database administrator with the necessary privileges must configure tables in the database for change data capture. After you begin to run Debezium you can adjust the configuration of the capture agent to optimize performance.
For details about setting up Db2 for use with the Debezium connector, see the following sections:
3.5.1. Configuring Db2 tables for change data capture
To put tables into capture mode, Debezium provides a set of user-defined functions (UDFs) for your convenience. The procedure here shows how to install and run these management UDFs. Alternatively, you can run Db2 control commands to put tables into capture mode. The administrator must then enable CDC for each table that you want Debezium to capture.
Prerequisites
-
You are logged in to Db2 as the
db2instluser. - On the Db2 host, the Debezium management UDFs are available in the $HOME/asncdctools/src directory. UDFs are available from the Debezium examples repository.
Procedure
Compile the Debezium management UDFs on the Db2 server host by using the
bldrtncommand provided with Db2:cd $HOME/asncdctools/src./bldrtn asncdcStart the database if it is not already running. Replace
DB_NAMEwith the name of the database that you want Debezium to connect to.db2 start db DB_NAMEEnsure that JDBC can read the Db2 metadata catalog:
cd $HOME/sqllib/bnddb2 bind db2schema.bnd blocking all grant public sqlerror continueEnsure that the database was recently backed-up. The ASN agents must have a recent starting point to read from. If you need to perform a backup, run the following commands, which prune the data so that only the most recent version is available. If you do not need to retain the older versions of the data, specify
dev/nullfor the backup location.Back up the database. Replace
DB_NAMEandBACK_UP_LOCATIONwith appropriate values:db2 backup db DB_NAME to BACK_UP_LOCATIONRestart the database:
db2 restart db DB_NAME
Connect to the database to install the Debezium management UDFs. It is assumed that you are logged in as the
db2instluser so the UDFs should be installed on thedb2inst1user.db2 connect to DB_NAMECopy the Debezium management UDFs and set permissions for them:
cp $HOME/asncdctools/src/asncdc $HOME/sqllib/functionchmod 777 $HOME/sqllib/functionEnable the Debezium UDF that starts and stops the ASN capture agent:
db2 -tvmf $HOME/asncdctools/src/asncdc_UDF.sqlCreate the ASN control tables:
$ db2 -tvmf $HOME/asncdctools/src/asncdctables.sqlEnable the Debezium UDF that adds tables to capture mode and removes tables from capture mode:
$ db2 -tvmf $HOME/asncdctools/src/asncdcaddremove.sqlAfter you set up the Db2 server, use the UDFs to control Db2 replication (ASN) with SQL commands. Some of the UDFs expect a return value in which case you use the SQL
VALUEstatement to invoke them. For other UDFs, use the SQLCALLstatement.Start the ASN agent:
VALUES ASNCDC.ASNCDCSERVICES('start','asncdc');The preceding statement returns one of the following results:
-
asncap is already running start --><COMMAND>In this case, enter the specified
<COMMAND>in the terminal window as shown in the following example:/database/config/db2inst1/sqllib/bin/asncap capture_schema=asncdc capture_server=SAMPLE &
-
Put tables into capture mode. Invoke the following statement for each table that you want to put into capture. Replace
MYSCHEMAwith the name of the schema that contains the table you want to put into capture mode. Likewise, replaceMYTABLEwith the name of the table to put into capture mode:CALL ASNCDC.ADDTABLE('MYSCHEMA', 'MYTABLE');Reinitialize the ASN service:
VALUES ASNCDC.ASNCDCSERVICES('reinit','asncdc');
Additional resources
3.5.2. Effect of Db2 capture agent configuration on server load and latency
When a database administrator enables change data capture for a source table, the capture agent begins to run. The agent reads new change event records from the transaction log and replicates the event records to a capture table. Between the time that a change is committed in the source table, and the time that the change appears in the corresponding change table, there is always a small latency interval. This latency interval represents a gap between when changes occur in the source table and when they become available for Debezium to stream to Apache Kafka.
Ideally, for applications that must respond quickly to changes in data, you want to maintain close synchronization between the source and capture tables. You might imagine that running the capture agent to continuously process change events as rapidly as possible might result in increased throughput and reduced latency — populating change tables with new event records as soon as possible after the events occur, in near real time. However, this is not necessarily the case. There is a performance penalty to pay in the pursuit of more immediate synchronization. Each time that the change agent queries the database for new event records, it increases the CPU load on the database host. The additional load on the server can have a negative effect on overall database performance, and potentially reduce transaction efficiency, especially during times of peak database use.
It’s important to monitor database metrics so that you know if the database reaches the point where the server can no longer support the capture agent’s level of activity. If you experience performance issues while running the capture agent, adjust capture agent settings to reduce CPU load.
3.5.3. Db2 capture agent configuration parameters
On Db2, the IBMSNAP_CAPPARMS table contains parameters that control the behavior of the capture agent. You can adjust the values for these parameters to balance the configuration of the capture process to reduce CPU load and still maintain acceptable levels of latency.
Specific guidance about how to configure Db2 capture agent parameters is beyond the scope of this documentation.
In the IBMSNAP_CAPPARMS table, the following parameters have the greatest effect on reducing CPU load:
COMMIT_INTERVAL- Specifies the number of seconds that the capture agent waits to commit data to the change data tables.
- A higher value reduces the load on the database host and increases latency.
-
The default value is
30.
SLEEP_INTERVAL- Specifies the number of seconds that the capture agent waits to start a new commit cycle after it reaches the end of the active transaction log.
- A higher value reduces the load on the server, and increases latency.
-
The default value is
5.
Additional resources
- For more information about capture agent parameters, see the Db2 documentation.
3.6. Deployment of Debezium Db2 connectors
You can use either of the following methods to deploy a Debezium Db2 connector:
The Debezium Db2 connector requires the Db2 JDBC driver to connect to Db2 databases. For information about how to obtain the driver, see Obtaining the Db2 JDBC driver.
Additional resources
3.6.1. Obtaining the Db2 JDBC driver
Due to licensing requirements, the Db2 JDBC driver file is not included in the Debezium Db2 connector archive. Regardless of the deployment method that you use, you must download the driver file to complete the deployment.
The following steps describe how to obtain the driver and use it your your environment.
Procedure
From a browser, navigate to the IBM Support site and download the JDBC driver that matches your version of Db2.
-
If you use a Dockerfile to build the connector, copy the downloaded file to the directory that contains the Debezium Db2 connector files, for example,
<kafka_home>/libsdirectory. If you use AMQ Streams to add the connector to your Kafka Connect image:
- Deploy the driver to a Maven repository or to another HTTP server that is available to your OpenShift cluster.
-
Add the artifact URL to the
KafkaConnectcustom resource.
-
If you use a Dockerfile to build the connector, copy the downloaded file to the directory that contains the Debezium Db2 connector files, for example,
After you apply the KafkaConnector resource to deploy the connector, the connector is configured to use the specified driver.
3.6.2. Db2 connector deployment using AMQ Streams
Beginning with Debezium 1.7, the preferred method for deploying a Debezium connector is to use AMQ Streams to build a Kafka Connect container image that includes the connector plug-in.
During the deployment process, you create and use the following custom resources (CRs):
-
A
KafkaConnectCR that defines your Kafka Connect instance and includes information about the connector artifacts needs to include in the image. -
A
KafkaConnectorCR that provides details that include information the connector uses to access the source database. After AMQ Streams starts the Kafka Connect pod, you start the connector by applying theKafkaConnectorCR.
In the build specification for the Kafka Connect image, you can specify the connectors that are available to deploy. For each connector plug-in, you can also specify other components that you want to make available for deployment. For example, you can add Service Registry artifacts, or the Debezium scripting component. When AMQ Streams builds the Kafka Connect image, it downloads the specified artifacts, and incorporates them into the image.
The spec.build.output parameter in the KafkaConnect CR specifies where to store the resulting Kafka Connect container image. Container images can be stored in a Docker registry, or in an OpenShift ImageStream. To store images in an ImageStream, you must create the ImageStream before you deploy Kafka Connect. ImageStreams are not created automatically.
If you use a KafkaConnect resource to create a cluster, afterwards you cannot use the Kafka Connect REST API to create or update connectors. You can still use the REST API to retrieve information.
Additional resources
- Configuring Kafka Connect in Using AMQ Streams on OpenShift.
- Creating a new container image automatically using AMQ Streams in Deploying and Upgrading AMQ Streams on OpenShift.
3.6.3. Using AMQ Streams to deploy a Debezium Db2 connector
With earlier versions of AMQ Streams, to deploy Debezium connectors on OpenShift, it was necessary to first build a Kafka Connect image for the connector. The current preferred method for deploying connectors on OpenShift is to use a build configuration in AMQ Streams to automatically build a Kafka Connect container image that includes the Debezium connector plug-ins that you want to use.
During the build process, the AMQ Streams Operator transforms input parameters in a KafkaConnect custom resource, including Debezium connector definitions, into a Kafka Connect container image. The build downloads the necessary artifacts from the Red Hat Maven repository or another configured HTTP server. The newly created container is pushed to the container registry that is specified in .spec.build.output, and is used to deploy a Kafka Connect pod. After AMQ Streams builds the Kafka Connect image, you create KafkaConnector custom resources to start the connectors that are included in the build.
Prerequisites
- You have access to an OpenShift cluster on which the cluster Operator is installed.
- The AMQ Streams Operator is running.
- An Apache Kafka cluster is deployed as documented in Deploying and Upgrading AMQ Streams on OpenShift.
- You have a Red Hat Integration license.
- Kafka Connect is deployed on AMQ Streams.
-
The OpenShift
ocCLI client is installed or you have access to the OpenShift Container Platform web console. Depending on how you intend to store the Kafka Connect build image, you need registry permissions or you must create an ImageStream resource:
- To store the build image in an image registry, such as Red Hat Quay.io or Docker Hub
- An account and permissions to create and manage images in the registry.
- To store the build image as a native OpenShift ImageStream
- An ImageStream resource is deployed to the cluster. You must explicitly create an ImageStream for the cluster. ImageStreams are not available by default.
Procedure
- Log in to the OpenShift cluster.
Create a Debezium
KafkaConnectcustom resource (CR) for the connector, or modify an existing one. For example, create aKafkaConnectCR that specifies themetadata.annotationsandspec.buildproperties, as shown in the following example. Save the file with a name such asdbz-connect.yaml.Example 3.1. A
dbz-connect.yamlfile that defines aKafkaConnectcustom resource that includes a Debezium connectorapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: debezium-kafka-connect-cluster annotations: strimzi.io/use-connector-resources: "true"1 spec: version: 3.00 build:2 output:3 type: imagestream4 image: debezium-streams-connect:latest plugins:5 - name: debezium-connector-db2 artifacts: - type: zip6 url: https://maven.repository.redhat.com/ga/io/debezium/debezium-connector-db2/1.7.2.Final-redhat-<build_number>/debezium-connector-db2-1.7.2.Final-redhat-<build_number>-plugin.zip7 - type: zip url: https://maven.repository.redhat.com/ga/io/apicurio/apicurio-registry-distro-connect-converter/2.0-redhat-<build-number>/apicurio-registry-distro-connect-converter-2.0-redhat-<build-number>.zip - type: zip url: https://maven.repository.redhat.com/ga/io/debezium/debezium-scripting/1.7.2.Final/debezium-scripting-1.7.2.Final.zip bootstrapServers: debezium-kafka-cluster-kafka-bootstrap:9093Expand Table 3.13. Descriptions of Kafka Connect configuration settings Item Description 1
Sets the
strimzi.io/use-connector-resourcesannotation to"true"to enable the Cluster Operator to useKafkaConnectorresources to configure connectors in this Kafka Connect cluster.2
The
spec.buildconfiguration specifies where to store the build image and lists the plug-ins to include in the image, along with the location of the plug-in artifacts.3
The
build.outputspecifies the registry in which the newly built image is stored.4
Specifies the name and image name for the image output. Valid values for
output.typearedockerto push into a container registry like Docker Hub or Quay, orimagestreamto push the image to an internal OpenShift ImageStream. To use an ImageStream, an ImageStream resource must be deployed to the cluster. For more information about specifying thebuild.outputin the KafkaConnect configuration, see the AMQ Streams Build schema reference documentation.5
The
pluginsconfiguration lists all of the connectors that you want to include in the Kafka Connect image. For each entry in the list, specify a plug-inname, and information for about the artifacts that are required to build the connector. Optionally, for each connector plug-in, you can include other components that you want to be available for use with the connector. For example, you can add Service Registry artifacts, or the Debezium scripting component.6
The value of
artifacts.typespecifies the file type of the artifact specified in theartifacts.url. Valid types arezip,tgz, orjar. Debezium connector archives are provided in.zipfile format. JDBC driver files are in.jarformat. Thetypevalue must match the type of the file that is referenced in theurlfield.7
The value of
artifacts.urlspecifies the address of an HTTP server, such as a Maven repository, that stores the file for the connector artifact. The OpenShift cluster must have access to the specified server.Apply the
KafkaConnectbuild specification to the OpenShift cluster by entering the following command:oc create -f dbz-connect.yamlBased on the configuration specified in the custom resource, the Streams Operator prepares a Kafka Connect image to deploy.
After the build completes, the Operator pushes the image to the specified registry or ImageStream, and starts the Kafka Connect cluster. The connector artifacts that you listed in the configuration are available in the cluster.Create a
KafkaConnectorresource to define an instance of each connector that you want to deploy.
For example, create the followingKafkaConnectorCR, and save it asdb2-inventory-connector.yamlExample 3.2. A
db2-inventory-connector.yamlfile that defines theKafkaConnectorcustom resource for a Debezium connectorapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: labels: strimzi.io/cluster: debezium-kafka-connect-cluster name: inventory-connector-db21 spec: class: io.debezium.connector.db2.Db2ConnectorConnector2 tasksMax: 13 config:4 database.history.kafka.bootstrap.servers: 'debezium-kafka-cluster-kafka-bootstrap.debezium.svc.cluster.local:9092' database.history.kafka.topic: schema-changes.inventory database.hostname: db2.debezium-db2.svc.cluster.local5 database.port: 33066 database.user: debezium7 database.password: dbz8 database.dbname: mydatabase9 database.server.name: inventory_connector_db210 database.include.list: public.inventory11 Expand Table 3.14. Descriptions of connector configuration settings Item Description 1
The name of the connector to register with the Kafka Connect cluster.
2
The name of the connector class.
3
The number of tasks that can operate concurrently.
4
The connector’s configuration.
5
The address of the host database instance.
6
The port number of the database instance.
7
The name of the user account through which Debezium connects to the database.
8
The password for the database user account.
9
The name of the database to capture changes from.
10
The logical name of the database instance or cluster.
The specified name must be formed only from alphanumeric characters or underscores.
Because the logical name is used as the prefix for any Kafka topics that receive change events from this connector, the name must be unique among the connectors in the cluster.
The namespace is also used in the names of related Kafka Connect schemas, and the namespaces of a corresponding Avro schema if you integrate the connector with the Avro connector.11
The list of tables from which the connector captures change events.
Create the connector resource by running the following command:
oc create -n <namespace> -f <kafkaConnector>.yamlFor example,
oc create -n debezium -f {context}-inventory-connector.yamlThe connector is registered to the Kafka Connect cluster and starts to run against the database that is specified by
spec.config.database.dbnamein theKafkaConnectorCR. After the connector pod is ready, Debezium is running.
You are now ready to verify the Debezium Db2 deployment.
3.6.4. Deploying a Debezium Db2 connector by building a custom Kafka Connect container image from a Dockerfile
To deploy a Debezium Db2 connector, you must build a custom Kafka Connect container image that contains the Debezium connector archive, and then push this container image to a container registry. You then need to create the following custom resources (CRs):
-
A
KafkaConnectCR that defines your Kafka Connect instance. Theimageproperty in the CR specifies the name of the container image that you create to run your Debezium connector. You apply this CR to the OpenShift instance where Red Hat AMQ Streams is deployed. AMQ Streams offers operators and images that bring Apache Kafka to OpenShift. -
A
KafkaConnectorCR that defines your Debezium Db2 connector. Apply this CR to the same OpenShift instance where you applied theKafkaConnectCR.
Prerequisites
- Db2 is running and you completed the steps to set up Db2 to work with a Debezium connector.
- AMQ Streams is deployed on OpenShift and is running Apache Kafka and Kafka Connect. For more information, see Deploying and Upgrading AMQ Streams on OpenShift.
- Podman or Docker is installed.
- You obtained the required JDBC driver for Db2.
-
You have an account and permissions to create and manage containers in the container registry (such as
quay.ioordocker.io) to which you plan to add the container that will run your Debezium connector.
Procedure
Create the Debezium Db2 container for Kafka Connect:
- Download the Debezium Db2 connector archive.
Extract the Debezium Db2 connector archive to create a directory structure for the connector plug-in, for example:
./my-plugins/ ├── debezium-connector-db2 │ ├── ...Create a Dockerfile that uses
registry.redhat.io/amq7/amq-streams-kafka-30-rhel8:2.0.0as the base image. For example, from a terminal window, enter the following, replacingmy-pluginswith the name of your plug-ins directory:cat <<EOF >debezium-container-for-db2.yaml1 FROM registry.redhat.io/amq7/amq-streams-kafka-30-rhel8:2.0.0 USER root:root COPY ./<my-plugins>/ /opt/kafka/plugins/2 USER 1001 EOFThe command creates a Dockerfile with the name
debezium-container-for-db2.yamlin the current directory.Build the container image from the
debezium-container-for-db2.yamlDocker file that you created in the previous step. From the directory that contains the file, open a terminal window and enter one of the following commands:podman build -t debezium-container-for-db2:latest .docker build -t debezium-container-for-db2:latest .The preceding commands build a container image with the name
debezium-container-for-db2.Push your custom image to a container registry, such as quay.io or an internal container registry. The container registry must be available to the OpenShift instance where you want to deploy the image. Enter one of the following commands:
podman push <myregistry.io>/debezium-container-for-db2:latestdocker push <myregistry.io>/debezium-container-for-db2:latestCreate a new Debezium Db2
KafkaConnectcustom resource (CR). For example, create aKafkaConnectCR with the namedbz-connect.yamlthat specifiesannotationsandimageproperties as shown in the following example:apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true"1 spec: #... image: debezium-container-for-db22 - 1
metadata.annotationsindicates to the Cluster Operator thatKafkaConnectorresources are used to configure connectors in this Kafka Connect cluster.- 2
spec.imagespecifies the name of the image that you created to run your Debezium connector. This property overrides theSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGEvariable in the Cluster Operator.
Apply the
KafkaConnectCR to the OpenShift Kafka Connect environment by entering the following command:oc create -f dbz-connect.yamlThe command adds a Kafka Connect instance that specifies the name of the image that you created to run your Debezium connector.
Create a
KafkaConnectorcustom resource that configures your Debezium Db2 connector instance.You configure a Debezium Db2 connector in a
.yamlfile that specifies the configuration properties for the connector. The connector configuration might instruct Debezium to produce events for a subset of the schemas and tables, or it might set properties so that Debezium ignores, masks, or truncates values in specified columns that are sensitive, too large, or not needed.The following example configures a Debezium connector that connects to a Db2 server host,
192.168.99.100, on port50000. This host has a database namedmydatabase, a table with the nameinventory, andfulfillmentis the server’s logical name.Db2
inventory-connector.yamlapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: inventory-connector1 labels: strimzi.io/cluster: my-connect-cluster annotations: strimzi.io/use-connector-resources: 'true' spec: class: io.debezium.connector.db2.Db2Connector2 tasksMax: 13 config:4 database.hostname: 192.168.99.1005 database.port: 500006 database.user: db2inst17 database.password: Password!8 database.dbname: mydatabase9 database.server.name: fullfillment10 database.include.list: public.inventory11 Expand Table 3.15. Descriptions of connector configuration settings Item Description 1
The name of the connector when we register it with a Kafka Connect cluster.
2
The name of this Db2 connector class.
3
Only one task should operate at any one time.
4
The connector’s configuration.
5
The database host, which is the address of the Db2 instance.
6
The port number of the Db2 instance.
7
The name of the Db2 user.
8
The password for the Db2 user.
9
The name of the database to capture changes from.
10
The logical name of the Db2 instance/cluster, which forms a namespace and is used in the names of the Kafka topics to which the connector writes, the names of Kafka Connect schemas, and the namespaces of the corresponding Avro schema when the Avro Connector is used.
11
A list of all tables whose changes Debezium should capture.
Create your connector instance with Kafka Connect. For example, if you saved your
KafkaConnectorresource in theinventory-connector.yamlfile, you would run the following command:oc apply -f inventory-connector.yamlThe preceding command registers
inventory-connectorand the connector starts to run against themydatabasedatabase as defined in theKafkaConnectorCR.
For the complete list of the configuration properties that you can set for the Debezium Db2 connector, see Db2 connector properties.
Results
After the connector starts, it performs a consistent snapshot of the Db2 database tables that the connector is configured to capture changes for. The connector then starts generating data change events for row-level operations and streaming change event records to Kafka topics.
3.6.5. Verifying that the Debezium Db2 connector is running
If the connector starts correctly without errors, it creates a topic for each table that the connector is configured to capture. Downstream applications can subscribe to these topics to retrieve information events that occur in the source database.
To verify that the connector is running, you perform the following operations from the OpenShift Container Platform web console, or through the OpenShift CLI tool (oc):
- Verify the connector status.
- Verify that the connector generates topics.
- Verify that topics are populated with events for read operations ("op":"r") that the connector generates during the initial snapshot of each table.
Prerequisites
- A Debezium connector is deployed to AMQ Streams on OpenShift.
-
The OpenShift
ocCLI client is installed. - You have access to the OpenShift Container Platform web console.
Procedure
Check the status of the
KafkaConnectorresource by using one of the following methods:From the OpenShift Container Platform web console:
- Navigate to Home → Search.
-
On the Search page, click Resources to open the Select Resource box, and then type
KafkaConnector. - From the KafkaConnectors list, click the name of the connector that you want to check, for example inventory-connector-db2.
- In the Conditions section, verify that the values in the Type and Status columns are set to Ready and True.
From a terminal window:
Enter the following command:
oc describe KafkaConnector <connector-name> -n <project>For example,
oc describe KafkaConnector inventory-connector-db2 -n debeziumThe command returns status information that is similar to the following output:
Example 3.3.
KafkaConnectorresource statusName: inventory-connector-db2 Namespace: debezium Labels: strimzi.io/cluster=debezium-kafka-connect-cluster Annotations: <none> API Version: kafka.strimzi.io/v1beta2 Kind: KafkaConnector ... Status: Conditions: Last Transition Time: 2021-12-08T17:41:34.897153Z Status: True Type: Ready Connector Status: Connector: State: RUNNING worker_id: 10.131.1.124:8083 Name: inventory-connector-db2 Tasks: Id: 0 State: RUNNING worker_id: 10.131.1.124:8083 Type: source Observed Generation: 1 Tasks Max: 1 Topics: inventory_connector_db2 inventory_connector_db2.inventory.addresses inventory_connector_db2.inventory.customers inventory_connector_db2.inventory.geom inventory_connector_db2.inventory.orders inventory_connector_db2.inventory.products inventory_connector_db2.inventory.products_on_hand Events: <none>
Verify that the connector created Kafka topics:
From the OpenShift Container Platform web console.
- Navigate to Home → Search.
-
On the Search page, click Resources to open the Select Resource box, and then type
KafkaTopic. - From the KafkaTopics list, click the name of the topic that you want to check, for example, inventory-connector-db2.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d.
- In the Conditions section, verify that the values in the Type and Status columns are set to Ready and True.
From a terminal window:
Enter the following command:
oc get kafkatopicsThe command returns status information that is similar to the following output:
Example 3.4.
KafkaTopicresource statusNAME CLUSTER PARTITIONS REPLICATION FACTOR READY connect-cluster-configs debezium-kafka-cluster 1 1 True connect-cluster-offsets debezium-kafka-cluster 25 1 True connect-cluster-status debezium-kafka-cluster 5 1 True consumer-offsets---84e7a678d08f4bd226872e5cdd4eb527fadc1c6a debezium-kafka-cluster 50 1 True inventory-connector-db2---a96f69b23d6118ff415f772679da623fbbb99421 debezium-kafka-cluster 1 1 True inventory-connector-db2.inventory.addresses---1b6beaf7b2eb57d177d92be90ca2b210c9a56480 debezium-kafka-cluster 1 1 True inventory-connector-db2.inventory.customers---9931e04ec92ecc0924f4406af3fdace7545c483b debezium-kafka-cluster 1 1 True inventory-connector-db2.inventory.geom---9f7e136091f071bf49ca59bf99e86c713ee58dd5 debezium-kafka-cluster 1 1 True inventory-connector-db2.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d debezium-kafka-cluster 1 1 True inventory-connector-db2.inventory.products---df0746db116844cee2297fab611c21b56f82dcef debezium-kafka-cluster 1 1 True inventory-connector-db2.inventory.products-on-hand---8649e0f17ffcc9212e266e31a7aeea4585e5c6b5 debezium-kafka-cluster 1 1 True schema-changes.inventory debezium-kafka-cluster 1 1 True strimzi-store-topic---effb8e3e057afce1ecf67c3f5d8e4e3ff177fc55 debezium-kafka-cluster 1 1 True strimzi-topic-operator-kstreams-topic-store-changelog---b75e702040b99be8a9263134de3507fc0cc4017b debezium-kafka-cluster 1 1 True
Check topic content.
- From a terminal window, enter the following command:
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>For example,
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory_connector_db2.inventory.products_on_handThe format for specifying the topic name is the same as the
oc describecommand returns in Step 1, for example,inventory_connector_db2.inventory.addresses.For each event in the topic, the command returns information that is similar to the following output:
Example 3.5. Content of a Debezium change event
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory_connector_db2.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory_connector_db2.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory_connector_db2.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.db2.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory_connector_db2.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"1.7.2.Final-redhat-00001","connector":"db2","name":"inventory_connector_db2","ts_ms":1638985247805,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"db2-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"transaction":null}}In the preceding example, the
payloadvalue shows that the connector snapshot generated a read ("op" ="r") event from the tableinventory.products_on_hand. The"before"state of theproduct_idrecord isnull, indicating that no previous value exists for the record. The"after"state shows aquantityof3for the item withproduct_id101.
3.6.6. Description of Debezium Db2 connector configuration properties
The Debezium Db2 connector has numerous configuration properties that you can use to achieve the right connector behavior for your application. Many properties have default values. Information about the properties is organized as follows:
- Required configuration properties
- Advanced configuration properties
Database history connector configuration properties that control how Debezium processes events that it reads from the database history topic.
- Pass-through database driver properties that control the behavior of the database driver.
Required Debezium Db2 connector configuration properties
The following configuration properties are required unless a default value is available.
| Property | Default | Description |
|---|---|---|
| No default | Unique name for the connector. Attempting to register again with the same name will fail. This property is required by all Kafka Connect connectors. | |
| No default |
The name of the Java class for the connector. Always use a value of | |
|
| The maximum number of tasks that should be created for this connector. The Db2 connector always uses a single task and therefore does not use this value, so the default is always acceptable. | |
| No default | IP address or hostname of the Db2 database server. | |
|
| Integer port number of the Db2 database server. | |
| No default | Name of the Db2 database user for connecting to the Db2 database server. | |
| No default | Password to use when connecting to the Db2 database server. | |
| No default | The name of the Db2 database from which to stream the changes | |
| No default | Logical name that identifies and provides a namespace for the particular Db2 database server that hosts the database for which Debezium is capturing changes. Only alphanumeric characters, hyphens, dots and underscores must be used in the database server logical name. The logical name should be unique across all other connectors, since it is used as a topic name prefix for all Kafka topics that receive records from this connector. | |
| No default |
An optional, comma-separated list of regular expressions that match fully-qualified table identifiers for tables whose changes you want the connector to capture. Any table not included in the include list does not have its changes captured. Each identifier is of the form schemaName.tableName. By default, the connector captures changes in every non-system table. Do not also set the | |
| No default |
An optional, comma-separated list of regular expressions that match fully-qualified table identifiers for tables whose changes you do not want the connector to capture. The connector captures changes in each non-system table that is not included in the exclude list. Each identifier is of the form schemaName.tableName. Do not also set the | |
| empty string | An optional, comma-separated list of regular expressions that match the fully-qualified names of columns to exclude from change event values. Fully-qualified names for columns are of the form schemaName.tableName.columnName. Primary key columns are always included in the event’s key, even if they are excluded from the value. | |
| n/a |
An optional, comma-separated list of regular expressions that match the fully-qualified names of character-based columns. Fully-qualified names for columns are of the form schemaName.tableName.columnName. In the resulting change event record, the values for the specified columns are replaced with pseudonyms.
A pseudonym consists of the hashed value that results from applying the specified hashAlgorithm and salt. Based on the hash function that is used, referential integrity is maintained, while column values are replaced with pseudonyms. Supported hash functions are described in the MessageDigest section of the Java Cryptography Architecture Standard Algorithm Name Documentation.
If necessary, the pseudonym is automatically shortened to the length of the column. The connector configuration can include multiple properties that specify different hash algorithms and salts. | |
|
|
Time, date, and timestamps can be represented with different kinds of precision: | |
|
|
Controls whether a delete event is followed by a tombstone event. | |
|
| Boolean value that specifies whether the connector should publish changes in the database schema to a Kafka topic with the same name as the database server ID. Each schema change is recorded with a key that contains the database name and a value that is a JSON structure that describes the schema update. This is independent of how the connector internally records database history. | |
| n/a |
An optional, comma-separated list of regular expressions that match the fully-qualified names of character-based columns. Fully-qualified names for columns are of the form schemaName.tableName.columnName. In change event records, values in these columns are truncated if they are longer than the number of characters specified by length in the property name. You can specify multiple properties with different lengths in a single configuration. Length must be a positive integer, for example, | |
| n/a |
An optional, comma-separated list of regular expressions that match the fully-qualified names of character-based columns. Fully-qualified names for columns are of the form schemaName.tableName.columnName. In change event values, the values in the specified table columns are replaced with length number of asterisk ( | |
| n/a |
An optional, comma-separated list of regular expressions that match the fully-qualified names of columns. Fully-qualified names for columns are of the form databaseName.tableName.columnName, or databaseName.schemaName.tableName.columnName. | |
| n/a |
An optional, comma-separated list of regular expressions that match the database-specific data type name for some columns. Fully-qualified data type names are of the form databaseName.tableName.typeName, or databaseName.schemaName.tableName.typeName. | |
| empty string | A list of expressions that specify the columns that the connector uses to form custom message keys for change event records that it publishes to the Kafka topics for specified tables.
By default, Debezium uses the primary key column of a table as the message key for records that it emits. In place of the default, or to specify a key for tables that lack a primary key, you can configure custom message keys based on one or more columns.
The property can list entries for multiple tables. Use a semicolon to separate entries for different tables in the list. |
Advanced connector configuration properties
The following advanced configuration properties have defaults that work in most situations and therefore rarely need to be specified in the connector’s configuration.
| Property | Default | Description |
|---|---|---|
|
|
Specifies the criteria for performing a snapshot when the connector starts: | |
|
|
During a snapshot, controls the transaction isolation level and how long the connector locks the tables that are in capture mode. The possible values are: | |
|
|
Specifies how the connector handles exceptions during processing of events. The possible values are: | |
|
| Positive integer value that specifies the number of milliseconds the connector should wait for new change events to appear before it starts processing a batch of events. Defaults to 1000 milliseconds, or 1 second. | |
|
|
Positive integer value for the maximum size of the blocking queue. The connector places change events that it reads from the database log into the blocking queue before writing them to Kafka. This queue can provide backpressure for reading change-data tables when, for example, writing records to Kafka is slower than it should be or Kafka is not available. Events that appear in the queue are not included in the offsets that are periodically recorded by the connector. The | |
|
| Positive integer value that specifies the maximum size of each batch of events that the connector processes. | |
|
| Long value for the maximum size in bytes of the blocking queue. The feature is disabled by default, it will be active if it’s set with a positive long value. | |
|
|
Controls how frequently the connector sends heartbeat messages to a Kafka topic. The default behavior is that the connector does not send heartbeat messages. | |
|
|
Specifies the prefix for the name of the topic to which the connector sends heartbeat messages. The format for this topic name is | |
| No default | An interval in milliseconds that the connector should wait before performing a snapshot when the connector starts. If you are starting multiple connectors in a cluster, this property is useful for avoiding snapshot interruptions, which might cause re-balancing of connectors. | |
|
| During a snapshot, the connector reads table content in batches of rows. This property specifies the maximum number of rows in a batch. | |
|
|
Positive integer value that specifies the maximum amount of time (in milliseconds) to wait to obtain table locks when performing a snapshot. If the connector cannot acquire table locks in this interval, the snapshot fails. How the connector performs snapshots provides details. Other possible settings are: | |
| No default | Specifies the table rows to include in a snapshot. Use the property if you want a snapshot to include only a subset of the rows in a table. This property affects snapshots only. It does not apply to events that the connector reads from the log.
The property contains a comma-separated list of fully-qualified table names in the form
From a
In the resulting snapshot, the connector includes only the records for which | |
|
| Indicates whether field names are sanitized to adhere to Avro naming requirements. | |
|
|
Determines whether the connector generates events with transaction boundaries and enriches change event envelopes with transaction metadata. Specify | |
| No default |
comma-separated list of operation types that will be skipped during streaming. The operations include: | |
| No default |
Fully-qualified name of the data collection that is used to send signals to the connector. Use the following format to specify the collection name: Signaling is a Technology Preview feature. | |
|
| The maximum number of rows that the connector fetches and reads into memory during an incremental snapshot chunk. Increasing the chunk size provides greater efficiency, because the snapshot runs fewer snapshot queries of a greater size. However, larger chunk sizes also require more memory to buffer the snapshot data. Adjust the chunk size to a value that provides the best performance in your environment. Incremental snapshots is a Technology Preview feature. |
Debezium connector database history configuration properties
Debezium provides a set of database.history.* properties that control how the connector interacts with the schema history topic.
The following table describes the database.history properties for configuring the Debezium connector.
| Property | Default | Description |
|---|---|---|
| The full name of the Kafka topic where the connector stores the database schema history. | ||
| A list of host/port pairs that the connector uses for establishing an initial connection to the Kafka cluster. This connection is used for retrieving the database schema history previously stored by the connector, and for writing each DDL statement read from the source database. Each pair should point to the same Kafka cluster used by the Kafka Connect process. | ||
|
| An integer value that specifies the maximum number of milliseconds the connector should wait during startup/recovery while polling for persisted data. The default is 100ms. | |
|
|
The maximum number of times that the connector should try to read persisted history data before the connector recovery fails with an error. The maximum amount of time to wait after receiving no data is | |
|
|
A Boolean value that specifies whether the connector should ignore malformed or unknown database statements or stop processing so a human can fix the issue. The safe default is | |
|
Deprecated and scheduled for removal in a future release; use |
|
A Boolean value that specifies whether the connector should record all DDL statements
The safe default is |
|
|
A Boolean value that specifies whether the connector should record all DDL statements
The safe default is |
Pass-through database history properties for configuring producer and consumer clients
Debezium relies on a Kafka producer to write schema changes to database history topics. Similarly, it relies on a Kafka consumer to read from database history topics when a connector starts. You define the configuration for the Kafka producer and consumer clients by assigning values to a set of pass-through configuration properties that begin with the database.history.producer.* and database.history.consumer.* prefixes. The pass-through producer and consumer database history properties control a range of behaviors, such as how these clients secure connections with the Kafka broker, as shown in the following example:
database.history.producer.security.protocol=SSL
database.history.producer.ssl.keystore.location=/var/private/ssl/kafka.server.keystore.jks
database.history.producer.ssl.keystore.password=test1234
database.history.producer.ssl.truststore.location=/var/private/ssl/kafka.server.truststore.jks
database.history.producer.ssl.truststore.password=test1234
database.history.producer.ssl.key.password=test1234
database.history.consumer.security.protocol=SSL
database.history.consumer.ssl.keystore.location=/var/private/ssl/kafka.server.keystore.jks
database.history.consumer.ssl.keystore.password=test1234
database.history.consumer.ssl.truststore.location=/var/private/ssl/kafka.server.truststore.jks
database.history.consumer.ssl.truststore.password=test1234
database.history.consumer.ssl.key.password=test1234Debezium strips the prefix from the property name before it passes the property to the Kafka client.
See the Kafka documentation for more details about Kafka producer configuration properties and Kafka consumer configuration properties.
Debezium connector pass-through database driver configuration properties
The Debezium connector provides for pass-through configuration of the database driver. Pass-through database properties begin with the prefix database.*. For example, the connector passes properties such as database.foobar=false to the JDBC URL.
As is the case with the pass-through properties for database history clients, Debezium strips the prefixes from the properties before it passes them to the database driver.
3.7. Monitoring Debezium Db2 connector performance
The Debezium Db2 connector provides three types of metrics that are in addition to the built-in support for JMX metrics that Apache ZooKeeper, Apache Kafka, and Kafka Connect provide.
- Snapshot metrics provide information about connector operation while performing a snapshot.
- Streaming metrics provide information about connector operation when the connector is capturing changes and streaming change event records.
- Schema history metrics provide information about the status of the connector’s schema history.
Debezium monitoring documentation provides details for how to expose these metrics by using JMX.
3.7.1. Monitoring Debezium during snapshots of Db2 databases
The MBean is debezium.db2:type=connector-metrics,context=snapshot,server=<db2.server.name>.
Snapshot metrics are not exposed unless a snapshot operation is active, or if a snapshot has occurred since the last connector start.
The following table lists the shapshot metrics that are available.
| Attributes | Type | Description |
|---|---|---|
|
| The last snapshot event that the connector has read. | |
|
| The number of milliseconds since the connector has read and processed the most recent event. | |
|
| The total number of events that this connector has seen since last started or reset. | |
|
| The number of events that have been filtered by include/exclude list filtering rules configured on the connector. | |
|
|
| The list of tables that are monitored by the connector. |
|
| The list of tables that are captured by the connector. | |
|
| The length the queue used to pass events between the snapshotter and the main Kafka Connect loop. | |
|
| The free capacity of the queue used to pass events between the snapshotter and the main Kafka Connect loop. | |
|
| The total number of tables that are being included in the snapshot. | |
|
| The number of tables that the snapshot has yet to copy. | |
|
| Whether the snapshot was started. | |
|
| Whether the snapshot was aborted. | |
|
| Whether the snapshot completed. | |
|
| The total number of seconds that the snapshot has taken so far, even if not complete. | |
|
| Map containing the number of rows scanned for each table in the snapshot. Tables are incrementally added to the Map during processing. Updates every 10,000 rows scanned and upon completing a table. | |
|
|
The maximum buffer of the queue in bytes. It will be enabled if | |
|
| The current data of records in the queue in bytes. |
The connector also provides the following additional snapshot metrics when an incremental snapshot is executed:
| Attributes | Type | Description |
|---|---|---|
|
| The identifier of the current snapshot chunk. | |
|
| The lower bound of the primary key set defining the current chunk. | |
|
| The upper bound of the primary key set defining the current chunk. | |
|
| The lower bound of the primary key set of the currently snapshotted table. | |
|
| The upper bound of the primary key set of the currently snapshotted table. |
Incremental snapshots is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process. For more information about the support scope of Red Hat Technology Preview features, see https://access.redhat.com/support/offerings/techpreview.
3.7.2. Monitoring Debezium Db2 connector record streaming
The MBean is debezium.db2:type=connector-metrics,context=streaming,server=<db2.server.name>.
The following table lists the streaming metrics that are available.
| Attributes | Type | Description |
|---|---|---|
|
| The last streaming event that the connector has read. | |
|
| The number of milliseconds since the connector has read and processed the most recent event. | |
|
| The total number of events that this connector has seen since last started or reset. | |
|
| The number of events that have been filtered by include/exclude list filtering rules configured on the connector. | |
|
|
| The list of tables that are monitored by the connector. |
|
| The list of tables that are captured by the connector. | |
|
| The length the queue used to pass events between the streamer and the main Kafka Connect loop. | |
|
| The free capacity of the queue used to pass events between the streamer and the main Kafka Connect loop. | |
|
| Flag that denotes whether the connector is currently connected to the database server. | |
|
| The number of milliseconds between the last change event’s timestamp and the connector processing it. The values will incoporate any differences between the clocks on the machines where the database server and the connector are running. | |
|
| The number of processed transactions that were committed. | |
|
| The coordinates of the last received event. | |
|
| Transaction identifier of the last processed transaction. | |
|
| The maximum buffer of the queue in bytes. | |
|
| The current data of records in the queue in bytes. |
3.7.3. Monitoring Debezium Db2 connector schema history
The MBean is debezium.db2:type=connector-metrics,context=schema-history,server=<db2.server.name>.
The following table lists the schema history metrics that are available.
| Attributes | Type | Description |
|---|---|---|
|
|
One of | |
|
| The time in epoch seconds at what recovery has started. | |
|
| The number of changes that were read during recovery phase. | |
|
| the total number of schema changes applied during recovery and runtime. | |
|
| The number of milliseconds that elapsed since the last change was recovered from the history store. | |
|
| The number of milliseconds that elapsed since the last change was applied. | |
|
| The string representation of the last change recovered from the history store. | |
|
| The string representation of the last applied change. |
3.8. Managing Debezium Db2 connectors
After you deploy a Debezium Db2 connector, use the Debezium management UDFs to control Db2 replication (ASN) with SQL commands. Some of the UDFs expect a return value in which case you use the SQL VALUE statement to invoke them. For other UDFs, use the SQL CALL statement.
| Task | Command and notes |
|---|---|
|
| |
|
| |
|
| |
|
| |
|
| |
|
|
3.9. Updating schemas for Db2 tables in capture mode for Debezium connectors
While a Debezium Db2 connector can capture schema changes, to update a schema, you must collaborate with a database administrator to ensure that the connector continues to produce change events. This is required by the way that Db2 implements replication.
For each table in capture mode, Db2’s replication feature creates a change-data table that contains all changes to that source table. However, change-data table schemas are static. If you update the schema for a table in capture mode then you must also update the schema of its corresponding change-data table. A Debezium Db2 connector cannot do this. A database administrator with elevated privileges must update schemas for tables that are in capture mode.
It is vital to execute a schema update procedure completely before there is a new schema update on the same table. Consequently, the recommendation is to execute all DDLs in a single batch so the schema update procedure is done only once.
There are generally two procedures for updating table schemas:
Each approach has advantages and disadvantages.
3.9.1. Performing offline schema updates for Debezium Db2 connectors
You stop the Debezium Db2 connector before you perform an offline schema update. While this is the safer schema update procedure, it might not be feasible for applications with high-availability requirements.
Prerequisites
- One or more tables that are in capture mode require schema updates.
Procedure
- Suspend the application that updates the database.
- Wait for the Debezium connector to stream all unstreamed change event records.
- Stop the Debezium connector.
- Apply all changes to the source table schema.
-
In the ASN register table, mark the tables with updated schemas as
INACTIVE. - Reinitialize the ASN capture service.
- Remove the source table with the old schema from capture mode by running the Debezium UDF for removing tables from capture mode.
- Add the source table with the new schema to capture mode by running the Debezium UDF for adding tables to capture mode.
-
In the ASN register table, mark the updated source tables as
ACTIVE. - Reinitialize the ASN capture service.
- Resume the application that updates the database.
- Restart the Debezium connector.
3.9.2. Performing online schema updates for Debezium Db2 connectors
An online schema update does not require application and data processing downtime. That is, you do not stop the Debezium Db2 connector before you perform an online schema update. Also, an online schema update procedure is simpler than the procedure for an offline schema update.
However, when a table is in capture mode, after a change to a column name, the Db2 replication feature continues to use the old column name. The new column name does not appear in Debezium change events. You must restart the connector to see the new column name in change events.
Prerequisites
- One or more tables that are in capture mode require schema updates.
Procedure when adding a column to the end of a table
- Lock the source tables whose schema you want to change.
-
In the ASN register table, mark the locked tables as
INACTIVE. - Reinitialize the ASN capture service.
- Apply all changes to the schemas for the source tables.
- Apply all changes to the schemas for the corresponding change-data tables.
-
In the ASN register table, mark the source tables as
ACTIVE. - Reinitialize the ASN capture service.
- Optional. Restart the connector to see updated column names in change events.
Procedure when adding a column to the middle of a table
- Lock the source table(s) to be changed.
-
In the ASN register table, mark the locked tables as
INACTIVE. - Reinitialize the ASN capture service.
For each source table to be changed:
- Export the data in the source table.
- Truncate the source table.
- Alter the source table and add the column.
- Load the exported data into the altered source table.
- Export the data in the source table’s corresponding change-data table.
- Truncate the change-data table.
- Alter the change-data table and add the column.
- Load the exported data into the altered change-data table.
-
In the ASN register table, mark the tables as
INACTIVE. This marks the old change-data tables as inactive, which allows the data in them to remain but they are no longer updated. - Reinitialize the ASN capture service.
- Optional. Restart the connector to see updated column names in change events.
Chapter 4. Debezium connector for MongoDB
Debezium’s MongoDB connector tracks a MongoDB replica set or a MongoDB sharded cluster for document changes in databases and collections, recording those changes as events in Kafka topics. The connector automatically handles the addition or removal of shards in a sharded cluster, changes in membership of each replica set, elections within each replica set, and awaiting the resolution of communications problems.
For information about the MongoDB versions that are compatible with this connector, see the Debezium Supported Configurations page.
Information and procedures for using a Debezium MongoDB connector is organized as follows:
- Section 4.1, “Overview of Debezium MongoDB connector”
- Section 4.2, “How Debezium MongoDB connectors work”
- Section 4.3, “Descriptions of Debezium MongoDB connector data change events”
- Section 4.4, “Setting up MongoDB to work with a Debezium connector”
- Section 4.5, “Deployment of Debezium MongoDB connectors”
- Section 4.6, “Monitoring Debezium MongoDB connector performance”
- Section 4.7, “How Debezium MongoDB connectors handle faults and problems”
4.1. Overview of Debezium MongoDB connector
MongoDB’s replication mechanism provides redundancy and high availability, and is the preferred way to run MongoDB in production. MongoDB connector captures the changes in a replica set or sharded cluster.
A MongoDB replica set consists of a set of servers that all have copies of the same data, and replication ensures that all changes made by clients to documents on the replica set’s primary are correctly applied to the other replica set’s servers, called secondaries. MongoDB replication works by having the primary record the changes in its oplog (or operation log), and then each of the secondaries reads the primary’s oplog and applies in order all of the operations to their own documents. When a new server is added to a replica set, that server first performs an snapshot of all of the databases and collections on the primary, and then reads the primary’s oplog to apply all changes that might have been made since it began the snapshot. This new server becomes a secondary (and able to handle queries) when it catches up to the tail of the primary’s oplog.
The MongoDB connector uses this same replication mechanism, though it does not actually become a member of the replica set. Just like MongoDB secondaries, however, the connector always reads the oplog of the replica set’s primary. And, when the connector sees a replica set for the first time, it looks at the oplog to get the last recorded transaction and then performs a snapshot of the primary’s databases and collections. When all the data is copied, the connector then starts streaming changes from the position it read earlier from the oplog. Operations in the MongoDB oplog are idempotent, so no matter how many times the operations are applied, they result in the same end state.
As the MongoDB connector processes changes, it periodically records the position in the oplog where the event originated. When the MongoDB connector stops, it records the last oplog position that it processed, so that upon restart it simply begins streaming from that position. In other words, the connector can be stopped, upgraded or maintained, and restarted some time later, and it will pick up exactly where it left off without losing a single event. Of course, MongoDB’s oplogs are usually capped at a maximum size, which means that the connector should not be stopped for too long, or else some of the operations in the oplog might be purged before the connector has a chance to read them. In this case, upon restart the connector will detect the missing oplog operations, perform a snapshot, and then proceed with streaming the changes.
The MongoDB connector is also quite tolerant of changes in membership and leadership of the replica sets, of additions or removals of shards within a sharded cluster, and network problems that might cause communication failures. The connector always uses the replica set’s primary node to stream changes, so when the replica set undergoes an election and a different node becomes primary, the connector will immediately stop streaming changes, connect to the new primary, and start streaming changes using the new primary node. Likewise, if connector experiences any problems communicating with the replica set primary, it will try to reconnect (using exponential backoff so as to not overwhelm the network or replica set) and continue streaming changes from where it last left off. In this way the connector is able to dynamically adjust to changes in replica set membership and to automatically handle communication failures.
Additional resources
4.2. How Debezium MongoDB connectors work
An overview of the MongoDB topologies that the connector supports is useful for planning your application.
When a MongoDB connector is configured and deployed, it starts by connecting to the MongoDB servers at the seed addresses, and determines the details about each of the available replica sets. Since each replica set has its own independent oplog, the connector will try to use a separate task for each replica set. The connector can limit the maximum number of tasks it will use, and if not enough tasks are available the connector will assign multiple replica sets to each task, although the task will still use a separate thread for each replica set.
When running the connector against a sharded cluster, use a value of tasks.max that is greater than the number of replica sets. This will allow the connector to create one task for each replica set, and will let Kafka Connect coordinate, distribute, and manage the tasks across all of the available worker processes.
The following topics provide details about how the Debezium MongoDB connector works:
- Section 4.2.1, “MongoDB topologies supported by Debezium connectors”
- Section 4.2.2, “How Debezium MongoDB connectors use logical names for replica sets and sharded clusters”
- Section 4.2.3, “How Debezium MongoDB connectors perform snapshots”
- Section 4.2.4, “How the Debezium MongoDB connector streams change event records”
- Section 4.2.5, “Default names of Kafka topics that receive Debezium MongoDB change event records”
- Section 4.2.6, “How event keys control topic partitioning for the Debezium MongoDB connector”
- Section 4.2.7, “Debezium MongoDB connector-generated events that represent transaction boundaries”
4.2.1. MongoDB topologies supported by Debezium connectors
The MongoDB connector supports the following MongoDB topologies:
- MongoDB replica set
The Debezium MongoDB connector can capture changes from a single MongoDB replica set. Production replica sets require a minimum of at least three members.
To use the MongoDB connector with a replica set, provide the addresses of one or more replica set servers as seed addresses through the connector’s
mongodb.hostsproperty. The connector will use these seeds to connect to the replica set, and then once connected will get from the replica set the complete set of members and which member is primary. The connector will start a task to connect to the primary and capture the changes from the primary’s oplog. When the replica set elects a new primary, the task will automatically switch over to the new primary.NoteWhen MongoDB is fronted by a proxy (such as with Docker on OS X or Windows), then when a client connects to the replica set and discovers the members, the MongoDB client will exclude the proxy as a valid member and will attempt and fail to connect directly to the members rather than go through the proxy.
In such a case, set the connector’s optional
mongodb.members.auto.discoverconfiguration property tofalseto instruct the connector to forgo membership discovery and instead simply use the first seed address (specified via themongodb.hostsproperty) as the primary node. This may work, but still make cause issues when election occurs.
- MongoDB sharded cluster
A MongoDB sharded cluster consists of:
- One or more shards, each deployed as a replica set;
- A separate replica set that acts as the cluster’s configuration server
One or more routers (also called
mongos) to which clients connect and that routes requests to the appropriate shardsTo use the MongoDB connector with a sharded cluster, configure the connector with the host addresses of the configuration server replica set. When the connector connects to this replica set, it discovers that it is acting as the configuration server for a sharded cluster, discovers the information about each replica set used as a shard in the cluster, and will then start up a separate task to capture the changes from each replica set. If new shards are added to the cluster or existing shards removed, the connector will automatically adjust its tasks accordingly.
- MongoDB standalone server
- The MongoDB connector is not capable of monitoring the changes of a standalone MongoDB server, since standalone servers do not have an oplog. The connector will work if the standalone server is converted to a replica set with one member.
MongoDB does not recommend running a standalone server in production. For more information, see the MongoDB documentation.
4.2.2. How Debezium MongoDB connectors use logical names for replica sets and sharded clusters
The connector configuration property mongodb.name serves as a logical name for the MongoDB replica set or sharded cluster. The connector uses the logical name in a number of ways: as the prefix for all topic names, and as a unique identifier when recording the oplog position of each replica set.
You should give each MongoDB connector a unique logical name that meaningfully describes the source MongoDB system. We recommend logical names begin with an alphabetic or underscore character, and remaining characters that are alphanumeric or underscore.
4.2.3. How Debezium MongoDB connectors perform snapshots
When a task starts up using a replica set, it uses the connector’s logical name and the replica set name to find an offset that describes the position where the connector previously stopped reading changes. If an offset can be found and it still exists in the oplog, then the task immediately proceeds with streaming changes, starting at the recorded offset position.
However, if no offset is found or if the oplog no longer contains that position, the task must first obtain the current state of the replica set contents by performing a snapshot. This process starts by recording the current position of the oplog and recording that as the offset (along with a flag that denotes a snapshot has been started). The task will then proceed to copy each collection, spawning as many threads as possible (up to the value of the snapshot.max.threads configuration property) to perform this work in parallel. The connector will record a separate read event for each document it sees, and that read event will contain the object’s identifier, the complete state of the object, and source information about the MongoDB replica set where the object was found. The source information will also include a flag that denotes the event was produced during a snapshot.
This snapshot will continue until it has copied all collections that match the connector’s filters. If the connector is stopped before the tasks' snapshots are completed, upon restart the connector begins the snapshot again.
Try to avoid task reassignment and reconfiguration while the connector is performing a snapshot of any replica sets. The connector does log messages with the progress of the snapshot. For utmost control, run a separate cluster of Kafka Connect for each connector.
4.2.4. How the Debezium MongoDB connector streams change event records
After the connector task for a replica set records an offset, it uses the offset to determine the position in the oplog where it should start streaming changes. The task then connects to the replica set’s primary node and start streaming changes from that position. It processes all of create, insert, and delete operations, and converts them into Debezium change events. Each change event includes the position in the oplog where the operation was found, and the connector periodically records this as its most recent offset. The interval at which the offset is recorded is governed by offset.flush.interval.ms, which is a Kafka Connect worker configuration property.
When the connector is stopped gracefully, the last offset processed is recorded so that, upon restart, the connector will continue exactly where it left off. If the connector’s tasks terminate unexpectedly, however, then the tasks may have processed and generated events after it last records the offset but before the last offset is recorded; upon restart, the connector begins at the last recorded offset, possibly generating some the same events that were previously generated just prior to the crash.
When everything is operating nominally, Kafka consumers will actually see every message exactly once. However, when things go wrong Kafka can only guarantee consumers will see every message at least once. Therefore, your consumers need to anticipate seeing messages more than once.
As mentioned above, the connector tasks always use the replica set’s primary node to stream changes from the oplog, ensuring that the connector sees the most up-to-date operations as possible and can capture the changes with lower latency than if secondaries were to be used instead. When the replica set elects a new primary, the connector immediately stops streaming changes, connects to the new primary, and starts streaming changes from the new primary node at the same position. Likewise, if the connector experiences any problems communicating with the replica set members, it tries to reconnect, by using exponential backoff so as to not overwhelm the replica set, and once connected it continues streaming changes from where it last left off. In this way, the connector is able to dynamically adjust to changes in replica set membership and automatically handle communication failures.
To summarize, the MongoDB connector continues running in most situations. Communication problems might cause the connector to wait until the problems are resolved.
4.2.5. Default names of Kafka topics that receive Debezium MongoDB change event records
The MongoDB connector writes events for all insert, update, and delete operations to documents in each collection to a single Kafka topic. The name of the Kafka topics always takes the form logicalName.databaseName.collectionName, where logicalName is the logical name of the connector as specified with the mongodb.name configuration property, databaseName is the name of the database where the operation occurred, and collectionName is the name of the MongoDB collection in which the affected document existed.
For example, consider a MongoDB replica set with an inventory database that contains four collections: products, products_on_hand, customers, and orders. If the connector monitoring this database were given a logical name of fulfillment, then the connector would produce events on these four Kafka topics:
-
fulfillment.inventory.products -
fulfillment.inventory.products_on_hand -
fulfillment.inventory.customers -
fulfillment.inventory.orders
Notice that the topic names do not incorporate the replica set name or shard name. As a result, all changes to a sharded collection (where each shard contains a subset of the collection’s documents) all go to the same Kafka topic.
You can set up Kafka to auto-create the topics as they are needed. If not, then you must use Kafka administration tools to create the topics before starting the connector.
4.2.6. How event keys control topic partitioning for the Debezium MongoDB connector
The MongoDB connector does not make any explicit determination about how to partition topics for events. Instead, it allows Kafka to determine how to partition topics based on event keys. You can change Kafka’s partitioning logic by defining the name of the Partitioner implementation in the Kafka Connect worker configuration.
Kafka maintains total order only for events written to a single topic partition. Partitioning the events by key does mean that all events with the same key always go to the same partition. This ensures that all events for a specific document are always totally ordered.
4.2.7. Debezium MongoDB connector-generated events that represent transaction boundaries
Debezium can generate events that represents transaction metadata boundaries and enrich change data event messages.
Debezium registers and receives metadata only for transactions that occur after you deploy the connector. Metadata for transactions that occur before you deploy the connector is not available.
For every transaction BEGIN and END, Debezium generates an event that contains the following fields:
status-
BEGINorEND id- String representation of unique transaction identifier.
event_count(forENDevents)- Total number of events emitted by the transaction.
data_collections(forENDevents)-
An array of pairs of
data_collectionandevent_countthat provides number of events emitted by changes originating from given data collection.
The following example shows a typical message:
{
"status": "BEGIN",
"id": "1462833718356672513",
"event_count": null,
"data_collections": null
}
{
"status": "END",
"id": "1462833718356672513",
"event_count": 2,
"data_collections": [
{
"data_collection": "rs0.testDB.collectiona",
"event_count": 1
},
{
"data_collection": "rs0.testDB.collectionb",
"event_count": 1
}
]
}
Unless overridden via the transaction.topic option, transaction events are written to the topic named database.server.name.transaction.
Change data event enrichment
When transaction metadata is enabled, the data message Envelope is enriched with a new transaction field. This field provides information about every event in the form of a composite of fields:
id- String representation of unique transaction identifier.
total_order- The absolute position of the event among all events generated by the transaction.
data_collection_order- The per-data collection position of the event among all events that were emitted by the transaction.
Following is an example of what a message looks like:
{
"patch": null,
"after": "{\"_id\" : {\"$numberLong\" : \"1004\"},\"first_name\" : \"Anne\",\"last_name\" : \"Kretchmar\",\"email\" : \"annek@noanswer.org\"}",
"source": {
...
},
"op": "c",
"ts_ms": "1580390884335",
"transaction": {
"id": "1462833718356672513",
"total_order": "1",
"data_collection_order": "1"
}
}4.3. Descriptions of Debezium MongoDB connector data change events
The Debezium MongoDB connector generates a data change event for each document-level operation that inserts, updates, or deletes data. Each event contains a key and a value. The structure of the key and the value depends on the collection that was changed.
Debezium and Kafka Connect are designed around continuous streams of event messages. However, the structure of these events may change over time, which can be difficult for consumers to handle. To address this, each event contains the schema for its content or, if you are using a schema registry, a schema ID that a consumer can use to obtain the schema from the registry. This makes each event self-contained.
The following skeleton JSON shows the basic four parts of a change event. However, how you configure the Kafka Connect converter that you choose to use in your application determines the representation of these four parts in change events. A schema field is in a change event only when you configure the converter to produce it. Likewise, the event key and event payload are in a change event only if you configure a converter to produce it. If you use the JSON converter and you configure it to produce all four basic change event parts, change events have this structure:
{
"schema": {
...
},
"payload": {
...
},
"schema": {
...
},
"payload": {
...
},
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
The first |
| 2 |
|
The first |
| 3 |
|
The second |
| 4 |
|
The second |
By default, the connector streams change event records to topics with names that are the same as the event’s originating collection. See topic names.
The MongoDB connector ensures that all Kafka Connect schema names adhere to the Avro schema name format. This means that the logical server name must start with a Latin letter or an underscore, that is, a-z, A-Z, or _. Each remaining character in the logical server name and each character in the database and collection names must be a Latin letter, a digit, or an underscore, that is, a-z, A-Z, 0-9, or \_. If there is an invalid character it is replaced with an underscore character.
This can lead to unexpected conflicts if the logical server name, a database name, or a collection name contains invalid characters, and the only characters that distinguish names from one another are invalid and thus replaced with underscores.
For more information, see the following topics:
4.3.1. About keys in Debezium MongoDB change events
A change event’s key contains the schema for the changed document’s key and the changed document’s actual key. For a given collection, both the schema and its corresponding payload contain a single id field. The value of this field is the document’s identifier represented as a string that is derived from MongoDB extended JSON serialization strict mode.
Consider a connector with a logical name of fulfillment, a replica set containing an inventory database, and a customers collection that contains documents such as the following.
Example document
{
"_id": 1004,
"first_name": "Anne",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
}Example change event key
Every change event that captures a change to the customers collection has the same event key schema. For as long as the customers collection has the previous definition, every change event that captures a change to the customers collection has the following key structure. In JSON, it looks like this:
{
"schema": {
"type": "struct",
"name": "fulfillment.inventory.customers.Key",
"optional": false,
"fields": [
{
"field": "id",
"type": "string",
"optional": false
}
]
},
"payload": {
"id": "1004"
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
The schema portion of the key specifies a Kafka Connect schema that describes what is in the key’s |
| 2 |
|
Name of the schema that defines the structure of the key’s payload. This schema describes the structure of the key for the document that was changed. Key schema names have the format connector-name.database-name.collection-name.
|
| 3 |
|
Indicates whether the event key must contain a value in its |
| 4 |
|
Specifies each field that is expected in the |
| 5 |
|
Contains the key for the document for which this change event was generated. In this example, the key contains a single |
This example uses a document with an integer identifier, but any valid MongoDB document identifier works the same way, including a document identifier. For a document identifier, an event key’s payload.id value is a string that represents the updated document’s original _id field as a MongoDB extended JSON serialization that uses strict mode. The following table provides examples of how different types of _id fields are represented.
| Type | MongoDB _id Value | Key’s payload |
|---|---|---|
| Integer | 1234 |
|
| Float | 12.34 |
|
| String | "1234" |
|
| Document |
|
|
| ObjectId |
|
|
| Binary |
|
|
4.3.2. About values in Debezium MongoDB change events
The value in a change event is a bit more complicated than the key. Like the key, the value has a schema section and a payload section. The schema section contains the schema that describes the Envelope structure of the payload section, including its nested fields. Change events for operations that create, update or delete data all have a value payload with an envelope structure.
Consider the same sample document that was used to show an example of a change event key:
Example document
{
"_id": 1004,
"first_name": "Anne",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
}The value portion of a change event for a change to this document is described for each event type:
create events
The following example shows the value portion of a change event that the connector generates for an operation that creates data in the customers collection:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "string",
"optional": true,
"name": "io.debezium.data.Json",
"version": 1,
"field": "after"
},
{
"type": "string",
"optional": true,
"name": "io.debezium.data.Json",
"version": 1,
"field": "patch"
},
{
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "version"
},
{
"type": "string",
"optional": false,
"field": "connector"
},
{
"type": "string",
"optional": false,
"field": "name"
},
{
"type": "int64",
"optional": false,
"field": "ts_ms"
},
{
"type": "boolean",
"optional": true,
"default": false,
"field": "snapshot"
},
{
"type": "string",
"optional": false,
"field": "db"
},
{
"type": "string",
"optional": false,
"field": "rs"
},
{
"type": "string",
"optional": false,
"field": "collection"
},
{
"type": "int32",
"optional": false,
"field": "ord"
},
{
"type": "int64",
"optional": true,
"field": "h"
}
],
"optional": false,
"name": "io.debezium.connector.mongo.Source",
"field": "source"
},
{
"type": "string",
"optional": true,
"field": "op"
},
{
"type": "int64",
"optional": true,
"field": "ts_ms"
}
],
"optional": false,
"name": "dbserver1.inventory.customers.Envelope"
},
"payload": {
"after": "{\"_id\" : {\"$numberLong\" : \"1004\"},\"first_name\" : \"Anne\",\"last_name\" : \"Kretchmar\",\"email\" : \"annek@noanswer.org\"}",
"patch": null,
"source": {
"version": "1.7.2.Final",
"connector": "mongodb",
"name": "fulfillment",
"ts_ms": 1558965508000,
"snapshot": false,
"db": "inventory",
"rs": "rs0",
"collection": "customers",
"ord": 31,
"h": 1546547425148721999
},
"op": "c",
"ts_ms": 1558965515240
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
| The value’s schema, which describes the structure of the value’s payload. A change event’s value schema is the same in every change event that the connector generates for a particular collection. |
| 2 |
|
In the |
| 3 |
|
|
| 4 |
|
|
| 5 |
|
The value’s actual data. This is the information that the change event is providing. |
| 6 |
|
An optional field that specifies the state of the document after the event occurred. In this example, the |
| 7 |
| Mandatory field that describes the source metadata for the event. This field contains information that you can use to compare this event with other events, with regard to the origin of the events, the order in which the events occurred, and whether events were part of the same transaction. The source metadata includes:
|
| 8 |
|
Mandatory string that describes the type of operation that caused the connector to generate the event. In this example,
|
| 9 |
|
Optional field that displays the time at which the connector processed the event. The time is based on the system clock in the JVM running the Kafka Connect task. |
update events
The value of a change event for an update in the sample customers collection has the same schema as a create event for that collection. Likewise, the event value’s payload has the same structure. However, the event value payload contains different values in an update event. An update event does not have an after value. Instead, it has these two fields:
-
patchis a string field that contains the JSON representation of the idempotent update operation -
filteris a string field that contains the JSON representation of the selection criteria for the update. Thefilterstring can include multiple shard key fields for sharded collections.
Here is an example of a change event value in an event that the connector generates for an update in the customers collection:
{
"schema": { ... },
"payload": {
"op": "u",
"ts_ms": 1465491461815,
"patch": "{\"$set\":{\"first_name\":\"Anne Marie\"}}",
"filter": "{\"_id\" : {\"$numberLong\" : \"1004\"}}",
"source": {
"version": "1.7.2.Final",
"connector": "mongodb",
"name": "fulfillment",
"ts_ms": 1558965508000,
"snapshot": true,
"db": "inventory",
"rs": "rs0",
"collection": "customers",
"ord": 6,
"h": 1546547425148721999
}
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
Mandatory string that describes the type of operation that caused the connector to generate the event. In this example, |
| 2 |
|
Optional field that displays the time at which the connector processed the event. The time is based on the system clock in the JVM running the Kafka Connect task. |
| 3 |
|
Contains the JSON string representation of the actual MongoDB idempotent change to the document. In this example, the update changed the |
| 4 |
| Contains the JSON string representation of the MongoDB selection criteria that was used to identify the document to be updated. |
| 5 |
| Mandatory field that describes the source metadata for the event. This field contains the same information as a create event for the same collection, but the values are different since this event is from a different position in the oplog. The source metadata includes:
|
In a Debezium change event, MongoDB provides the content of the patch field. The format of this field depends on the version of the MongoDB database. Consequently, be prepared for potential changes to the format when you upgrade to a newer MongoDB database version. Examples in this document were obtained from MongoDB 3.4, In your application, event formats might be different.
In MongoDB’s oplog, update events do not contain the before or after states of the changed document. Consequently, it is not possible for a Debezium connector to provide this information. However, a Debezium connector provides a document’s starting state in create and read events. Downstream consumers of the stream can reconstruct document state by keeping the latest state for each document and comparing the state in a new event with the saved state. Debezium connector’s are not able to keep this state.
delete events
The value in a delete change event has the same schema portion as create and update events for the same collection. The payload portion in a delete event contains values that are different from create and update events for the same collection. In particular, a delete event contains neither an after value nor a patch value. Here is an example of a delete event for a document in the customers collection:
{
"schema": { ... },
"payload": {
"op": "d",
"ts_ms": 1465495462115,
"filter": "{\"_id\" : {\"$numberLong\" : \"1004\"}}",
"source": {
"version": "1.7.2.Final",
"connector": "mongodb",
"name": "fulfillment",
"ts_ms": 1558965508000,
"snapshot": true,
"db": "inventory",
"rs": "rs0",
"collection": "customers",
"ord": 6,
"h": 1546547425148721999
}
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
Mandatory string that describes the type of operation. The |
| 2 |
|
Optional field that displays the time at which the connector processed the event. The time is based on the system clock in the JVM running the Kafka Connect task. |
| 3 |
| Contains the JSON string representation of the MongoDB selection criteria that was used to identify the document to be deleted. |
| 4 |
| Mandatory field that describes the source metadata for the event. This field contains the same information as a create or update event for the same collection, but the values are different since this event is from a different position in the oplog. The source metadata includes:
|
MongoDB connector events are designed to work with Kafka log compaction. Log compaction enables removal of some older messages as long as at least the most recent message for every key is kept. This lets Kafka reclaim storage space while ensuring that the topic contains a complete data set and can be used for reloading key-based state.
Tombstone events
All MongoDB connector events for a uniquely identified document have exactly the same key. When a document is deleted, the delete event value still works with log compaction because Kafka can remove all earlier messages that have that same key. However, for Kafka to remove all messages that have that key, the message value must be null. To make this possible, after Debezium’s MongoDB connector emits a delete event, the connector emits a special tombstone event that has the same key but a null value. A tombstone event informs Kafka that all messages with that same key can be removed.
4.4. Setting up MongoDB to work with a Debezium connector
The MongoDB connector uses MongoDB’s oplog to capture the changes, so the connector works only with MongoDB replica sets or with sharded clusters where each shard is a separate replica set. See the MongoDB documentation for setting up a replica set or sharded cluster. Also, be sure to understand how to enable access control and authentication with replica sets.
You must also have a MongoDB user that has the appropriate roles to read the admin database where the oplog can be read. Additionally, the user must also be able to read the config database in the configuration server of a sharded cluster and must have listDatabases privilege action.
4.5. Deployment of Debezium MongoDB connectors
You can use either of the following methods to deploy a Debezium MongoDB connector:
Additional resources
4.5.1. MongoDB connector deployment using AMQ Streams
Beginning with Debezium 1.7, the preferred method for deploying a Debezium connector is to use AMQ Streams to build a Kafka Connect container image that includes the connector plug-in.
During the deployment process, you create and use the following custom resources (CRs):
-
A
KafkaConnectCR that defines your Kafka Connect instance and includes information about the connector artifacts needs to include in the image. -
A
KafkaConnectorCR that provides details that include information the connector uses to access the source database. After AMQ Streams starts the Kafka Connect pod, you start the connector by applying theKafkaConnectorCR.
In the build specification for the Kafka Connect image, you can specify the connectors that are available to deploy. For each connector plug-in, you can also specify other components that you want to make available for deployment. For example, you can add Service Registry artifacts, or the Debezium scripting component. When AMQ Streams builds the Kafka Connect image, it downloads the specified artifacts, and incorporates them into the image.
The spec.build.output parameter in the KafkaConnect CR specifies where to store the resulting Kafka Connect container image. Container images can be stored in a Docker registry, or in an OpenShift ImageStream. To store images in an ImageStream, you must create the ImageStream before you deploy Kafka Connect. ImageStreams are not created automatically.
If you use a KafkaConnect resource to create a cluster, afterwards you cannot use the Kafka Connect REST API to create or update connectors. You can still use the REST API to retrieve information.
Additional resources
- Configuring Kafka Connect in Using AMQ Streams on OpenShift.
- Creating a new container image automatically using AMQ Streams in Deploying and Upgrading AMQ Streams on OpenShift.
4.5.2. Using AMQ Streams to deploy a Debezium MongoDB connector
With earlier versions of AMQ Streams, to deploy Debezium connectors on OpenShift, it was necessary to first build a Kafka Connect image for the connector. The current preferred method for deploying connectors on OpenShift is to use a build configuration in AMQ Streams to automatically build a Kafka Connect container image that includes the Debezium connector plug-ins that you want to use.
During the build process, the AMQ Streams Operator transforms input parameters in a KafkaConnect custom resource, including Debezium connector definitions, into a Kafka Connect container image. The build downloads the necessary artifacts from the Red Hat Maven repository or another configured HTTP server. The newly created container is pushed to the container registry that is specified in .spec.build.output, and is used to deploy a Kafka Connect pod. After AMQ Streams builds the Kafka Connect image, you create KafkaConnector custom resources to start the connectors that are included in the build.
Prerequisites
- You have access to an OpenShift cluster on which the cluster Operator is installed.
- The AMQ Streams Operator is running.
- An Apache Kafka cluster is deployed as documented in Deploying and Upgrading AMQ Streams on OpenShift.
- You have a Red Hat Integration license.
- Kafka Connect is deployed on AMQ Streams.
-
The OpenShift
ocCLI client is installed or you have access to the OpenShift Container Platform web console. Depending on how you intend to store the Kafka Connect build image, you need registry permissions or you must create an ImageStream resource:
- To store the build image in an image registry, such as Red Hat Quay.io or Docker Hub
- An account and permissions to create and manage images in the registry.
- To store the build image as a native OpenShift ImageStream
- An ImageStream resource is deployed to the cluster. You must explicitly create an ImageStream for the cluster. ImageStreams are not available by default.
Procedure
- Log in to the OpenShift cluster.
Create a Debezium
KafkaConnectcustom resource (CR) for the connector, or modify an existing one. For example, create aKafkaConnectCR that specifies themetadata.annotationsandspec.buildproperties, as shown in the following example. Save the file with a name such asdbz-connect.yaml.Example 4.1. A
dbz-connect.yamlfile that defines aKafkaConnectcustom resource that includes a Debezium connectorapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: debezium-kafka-connect-cluster annotations: strimzi.io/use-connector-resources: "true"1 spec: version: 3.00 build:2 output:3 type: imagestream4 image: debezium-streams-connect:latest plugins:5 - name: debezium-connector-mongodb artifacts: - type: zip6 url: https://maven.repository.redhat.com/ga/io/debezium/debezium-connector-mongodb/1.7.2.Final-redhat-<build_number>/debezium-connector-mongodb-1.7.2.Final-redhat-<build_number>-plugin.zip7 - type: zip url: https://maven.repository.redhat.com/ga/io/apicurio/apicurio-registry-distro-connect-converter/2.0-redhat-<build-number>/apicurio-registry-distro-connect-converter-2.0-redhat-<build-number>.zip - type: zip url: https://maven.repository.redhat.com/ga/io/debezium/debezium-scripting/1.7.2.Final/debezium-scripting-1.7.2.Final.zip bootstrapServers: debezium-kafka-cluster-kafka-bootstrap:9093Expand Table 4.7. Descriptions of Kafka Connect configuration settings Item Description 1
Sets the
strimzi.io/use-connector-resourcesannotation to"true"to enable the Cluster Operator to useKafkaConnectorresources to configure connectors in this Kafka Connect cluster.2
The
spec.buildconfiguration specifies where to store the build image and lists the plug-ins to include in the image, along with the location of the plug-in artifacts.3
The
build.outputspecifies the registry in which the newly built image is stored.4
Specifies the name and image name for the image output. Valid values for
output.typearedockerto push into a container registry like Docker Hub or Quay, orimagestreamto push the image to an internal OpenShift ImageStream. To use an ImageStream, an ImageStream resource must be deployed to the cluster. For more information about specifying thebuild.outputin the KafkaConnect configuration, see the AMQ Streams Build schema reference documentation.5
The
pluginsconfiguration lists all of the connectors that you want to include in the Kafka Connect image. For each entry in the list, specify a plug-inname, and information for about the artifacts that are required to build the connector. Optionally, for each connector plug-in, you can include other components that you want to be available for use with the connector. For example, you can add Service Registry artifacts, or the Debezium scripting component.6
The value of
artifacts.typespecifies the file type of the artifact specified in theartifacts.url. Valid types arezip,tgz, orjar. Debezium connector archives are provided in.zipfile format. JDBC driver files are in.jarformat. Thetypevalue must match the type of the file that is referenced in theurlfield.7
The value of
artifacts.urlspecifies the address of an HTTP server, such as a Maven repository, that stores the file for the connector artifact. The OpenShift cluster must have access to the specified server.Apply the
KafkaConnectbuild specification to the OpenShift cluster by entering the following command:oc create -f dbz-connect.yamlBased on the configuration specified in the custom resource, the Streams Operator prepares a Kafka Connect image to deploy.
After the build completes, the Operator pushes the image to the specified registry or ImageStream, and starts the Kafka Connect cluster. The connector artifacts that you listed in the configuration are available in the cluster.Create a
KafkaConnectorresource to define an instance of each connector that you want to deploy.
For example, create the followingKafkaConnectorCR, and save it asmongodb-inventory-connector.yamlExample 4.2. A
mongodb-inventory-connector.yamlfile that defines theKafkaConnectorcustom resource for a Debezium connectorapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: labels: strimzi.io/cluster: debezium-kafka-connect-cluster name: inventory-connector-mongodb1 spec: class: io.debezium.connector.mongodb.MongoDbConnector2 tasksMax: 13 config:4 database.history.kafka.bootstrap.servers: 'debezium-kafka-cluster-kafka-bootstrap.debezium.svc.cluster.local:9092' database.history.kafka.topic: schema-changes.inventory database.hostname: mongodb.debezium-mongodb.svc.cluster.local5 database.port: 33066 database.user: debezium7 database.password: dbz8 database.dbname: mydatabase9 database.server.name: inventory_connector_mongodb10 database.include.list: public.inventory11 Expand Table 4.8. Descriptions of connector configuration settings Item Description 1
The name of the connector to register with the Kafka Connect cluster.
2
The name of the connector class.
3
The number of tasks that can operate concurrently.
4
The connector’s configuration.
5
The address of the host database instance.
6
The port number of the database instance.
7
The name of the user account through which Debezium connects to the database.
8
The password for the database user account.
9
The name of the database to capture changes from.
10
The logical name of the database instance or cluster.
The specified name must be formed only from alphanumeric characters or underscores.
Because the logical name is used as the prefix for any Kafka topics that receive change events from this connector, the name must be unique among the connectors in the cluster.
The namespace is also used in the names of related Kafka Connect schemas, and the namespaces of a corresponding Avro schema if you integrate the connector with the Avro connector.11
The list of tables from which the connector captures change events.
Create the connector resource by running the following command:
oc create -n <namespace> -f <kafkaConnector>.yamlFor example,
oc create -n debezium -f {context}-inventory-connector.yamlThe connector is registered to the Kafka Connect cluster and starts to run against the database that is specified by
spec.config.database.dbnamein theKafkaConnectorCR. After the connector pod is ready, Debezium is running.
You are now ready to verify the Debezium MongoDB deployment.
4.5.3. Deploying a Debezium MongoDB connector by building a custom Kafka Connect container image from a Dockerfile
To deploy a Debezium MongoDB connector, you must build a custom Kafka Connect container image that contains the Debezium connector archive and then push this container image to a container registry. You then create two custom resources (CRs):
-
A
KafkaConnectCR that defines your Kafka Connect instance. Theimageproperty in the CR specifies the name of the container image that you create to run your Debezium connector. You apply this CR to the OpenShift instance where Red Hat AMQ Streams is deployed. AMQ Streams offers operators and images that bring Apache Kafka to OpenShift. -
A
KafkaConnectorCR that defines your Debezium MongoDB connector. Apply this CR to the same OpenShift instance where you apply theKafkaConnectCR.
Prerequisites
- MongoDB is running and you completed the steps to set up MongoDB to work with a Debezium connector.
- AMQ Streams is deployed on OpenShift and is running Apache Kafka and Kafka Connect. For more information, see Deploying and Upgrading AMQ Streams on OpenShift.
- Podman or Docker is installed.
-
You have an account and permissions to create and manage containers in the container registry (such as
quay.ioordocker.io) to which you plan to add the container that will run your Debezium connector.
Procedure
Create the Debezium MongoDB container for Kafka Connect:
- Download the Debezium MongoDB connector archive.
Extract the Debezium MongoDB connector archive to create a directory structure for the connector plug-in, for example:
./my-plugins/ ├── debezium-connector-mongodb │ ├── ...Create a Dockerfile that uses
registry.redhat.io/amq7/amq-streams-kafka-30-rhel8:2.0.0as the base image. For example, from a terminal window, enter the following, replacingmy-pluginswith the name of your plug-ins directory:cat <<EOF >debezium-container-for-mongodb.yaml1 FROM registry.redhat.io/amq7/amq-streams-kafka-30-rhel8:2.0.0 USER root:root COPY ./<my-plugins>/ /opt/kafka/plugins/2 USER 1001 EOFThe command creates a Dockerfile with the name
debezium-container-for-mongodb.yamlin the current directory.Build the container image from the
debezium-container-for-mongodb.yamlDocker file that you created in the previous step. From the directory that contains the file, open a terminal window and enter one of the following commands:podman build -t debezium-container-for-mongodb:latest .docker build -t debezium-container-for-mongodb:latest .The preceding commands build a container image with the name
debezium-container-for-mongodb.Push your custom image to a container registry, such as
quay.ioor an internal container registry. The container registry must be available to the OpenShift instance where you want to deploy the image. Enter one of the following commands:podman push <myregistry.io>/debezium-container-for-mongodb:latestdocker push <myregistry.io>/debezium-container-for-mongodb:latestCreate a new Debezium MongoDB
KafkaConnectcustom resource (CR). For example, create aKafkaConnectCR with the namedbz-connect.yamlthat specifiesannotationsandimageproperties as shown in the following example:apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true"1 spec: #... image: debezium-container-for-mongodb2 - 1
metadata.annotationsindicates to the Cluster Operator thatKafkaConnectorresources are used to configure connectors in this Kafka Connect cluster.- 2
spec.imagespecifies the name of the image that you created to run your Debezium connector. This property overrides theSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGEvariable in the Cluster Operator.
Apply the
KafkaConnectCR to the OpenShift Kafka Connect environment by entering the following command:oc create -f dbz-connect.yamlThe command adds a Kafka Connect instance that specifies the name of the image that you created to run your Debezium connector.
Create a
KafkaConnectorcustom resource that configures your Debezium MongoDB connector instance.You configure a Debezium MongoDB connector in a
.yamlfile that specifies the configuration properties for the connector. The connector configuration might instruct Debezium to produce change events for a subset of MongoDB replica sets or sharded clusters. Optionally, you can set properties that filter out collections that are not needed.The following example configures a Debezium connector that connects to a MongoDB replica set
rs0at port27017on192.168.99.100, and captures changes that occur in theinventorycollection.fullfillmentis the logical name of the replica set.MongoDB
inventory-connector.yamlapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: inventory-connector1 labels: strimzi.io/cluster: my-connect-cluster spec: class: io.debezium.connector.mongodb.MongoDbConnector2 config: mongodb.hosts: rs0/192.168.99.100:270173 mongodb.name: fulfillment4 collection.include.list: inventory[.]*5 - 1
- The name that is used to register the connector with Kafka Connect.
- 2
- The name of the MongoDB connector class.
- 3
- The host addresses to use to connect to the MongoDB replica set.
- 4
- The logical name of the MongoDB replica set, which forms a namespace for generated events and is used in all the names of the Kafka topics to which the connector writes, the Kafka Connect schema names, and the namespaces of the corresponding Avro schema when the Avro converter is used.
- 5
- An optional list of regular expressions that match the collection namespaces (for example, <dbName>.<collectionName>) of all collections to be monitored.
Create your connector instance with Kafka Connect. For example, if you saved your
KafkaConnectorresource in theinventory-connector.yamlfile, you would run the following command:oc apply -f inventory-connector.yamlThe preceding command registers
inventory-connectorand the connector starts to run against theinventorycollection as defined in theKafkaConnectorCR.
For the complete list of the configuration properties that you can set for the Debezium MongoDB connector, see MongoDB connector configuration properties.
Results
After the connector starts, it completes the following actions:
- Performs a consistent snapshot of the collections in your MongoDB replica sets.
- Reads the oplogs for the replica sets.
- Produces change events for every inserted, updated, and deleted document.
- Streams change event records to Kafka topics.
4.5.4. Verifying that the Debezium MongoDB connector is running
If the connector starts correctly without errors, it creates a topic for each table that the connector is configured to capture. Downstream applications can subscribe to these topics to retrieve information events that occur in the source database.
To verify that the connector is running, you perform the following operations from the OpenShift Container Platform web console, or through the OpenShift CLI tool (oc):
- Verify the connector status.
- Verify that the connector generates topics.
- Verify that topics are populated with events for read operations ("op":"r") that the connector generates during the initial snapshot of each table.
Prerequisites
- A Debezium connector is deployed to AMQ Streams on OpenShift.
-
The OpenShift
ocCLI client is installed. - You have access to the OpenShift Container Platform web console.
Procedure
Check the status of the
KafkaConnectorresource by using one of the following methods:From the OpenShift Container Platform web console:
- Navigate to Home → Search.
-
On the Search page, click Resources to open the Select Resource box, and then type
KafkaConnector. - From the KafkaConnectors list, click the name of the connector that you want to check, for example inventory-connector-mongodb.
- In the Conditions section, verify that the values in the Type and Status columns are set to Ready and True.
From a terminal window:
Enter the following command:
oc describe KafkaConnector <connector-name> -n <project>For example,
oc describe KafkaConnector inventory-connector-mongodb -n debeziumThe command returns status information that is similar to the following output:
Example 4.3.
KafkaConnectorresource statusName: inventory-connector-mongodb Namespace: debezium Labels: strimzi.io/cluster=debezium-kafka-connect-cluster Annotations: <none> API Version: kafka.strimzi.io/v1beta2 Kind: KafkaConnector ... Status: Conditions: Last Transition Time: 2021-12-08T17:41:34.897153Z Status: True Type: Ready Connector Status: Connector: State: RUNNING worker_id: 10.131.1.124:8083 Name: inventory-connector-mongodb Tasks: Id: 0 State: RUNNING worker_id: 10.131.1.124:8083 Type: source Observed Generation: 1 Tasks Max: 1 Topics: inventory_connector_mongodb inventory_connector_mongodb.inventory.addresses inventory_connector_mongodb.inventory.customers inventory_connector_mongodb.inventory.geom inventory_connector_mongodb.inventory.orders inventory_connector_mongodb.inventory.products inventory_connector_mongodb.inventory.products_on_hand Events: <none>
Verify that the connector created Kafka topics:
From the OpenShift Container Platform web console.
- Navigate to Home → Search.
-
On the Search page, click Resources to open the Select Resource box, and then type
KafkaTopic. - From the KafkaTopics list, click the name of the topic that you want to check, for example, inventory-connector-mongodb.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d.
- In the Conditions section, verify that the values in the Type and Status columns are set to Ready and True.
From a terminal window:
Enter the following command:
oc get kafkatopicsThe command returns status information that is similar to the following output:
Example 4.4.
KafkaTopicresource statusNAME CLUSTER PARTITIONS REPLICATION FACTOR READY connect-cluster-configs debezium-kafka-cluster 1 1 True connect-cluster-offsets debezium-kafka-cluster 25 1 True connect-cluster-status debezium-kafka-cluster 5 1 True consumer-offsets---84e7a678d08f4bd226872e5cdd4eb527fadc1c6a debezium-kafka-cluster 50 1 True inventory-connector-mongodb---a96f69b23d6118ff415f772679da623fbbb99421 debezium-kafka-cluster 1 1 True inventory-connector-mongodb.inventory.addresses---1b6beaf7b2eb57d177d92be90ca2b210c9a56480 debezium-kafka-cluster 1 1 True inventory-connector-mongodb.inventory.customers---9931e04ec92ecc0924f4406af3fdace7545c483b debezium-kafka-cluster 1 1 True inventory-connector-mongodb.inventory.geom---9f7e136091f071bf49ca59bf99e86c713ee58dd5 debezium-kafka-cluster 1 1 True inventory-connector-mongodb.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d debezium-kafka-cluster 1 1 True inventory-connector-mongodb.inventory.products---df0746db116844cee2297fab611c21b56f82dcef debezium-kafka-cluster 1 1 True inventory-connector-mongodb.inventory.products-on-hand---8649e0f17ffcc9212e266e31a7aeea4585e5c6b5 debezium-kafka-cluster 1 1 True schema-changes.inventory debezium-kafka-cluster 1 1 True strimzi-store-topic---effb8e3e057afce1ecf67c3f5d8e4e3ff177fc55 debezium-kafka-cluster 1 1 True strimzi-topic-operator-kstreams-topic-store-changelog---b75e702040b99be8a9263134de3507fc0cc4017b debezium-kafka-cluster 1 1 True
Check topic content.
- From a terminal window, enter the following command:
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>For example,
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory_connector_mongodb.inventory.products_on_handThe format for specifying the topic name is the same as the
oc describecommand returns in Step 1, for example,inventory_connector_mongodb.inventory.addresses.For each event in the topic, the command returns information that is similar to the following output:
Example 4.5. Content of a Debezium change event
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory_connector_mongodb.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory_connector_mongodb.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory_connector_mongodb.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.mongodb.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory_connector_mongodb.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"1.7.2.Final-redhat-00001","connector":"mongodb","name":"inventory_connector_mongodb","ts_ms":1638985247805,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"mongodb-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"transaction":null}}In the preceding example, the
payloadvalue shows that the connector snapshot generated a read ("op" ="r") event from the tableinventory.products_on_hand. The"before"state of theproduct_idrecord isnull, indicating that no previous value exists for the record. The"after"state shows aquantityof3for the item withproduct_id101.
4.5.5. Description of Debezium Db2 connector configuration properties
The Debezium MongoDB connector has numerous configuration properties that you can use to achieve the right connector behavior for your application. Many properties have default values. Information about the properties is organized as follows:
The following configuration properties are required unless a default value is available.
| Property | Default | Description |
|---|---|---|
| Unique name for the connector. Attempting to register again with the same name will fail. (This property is required by all Kafka Connect connectors.) | ||
|
The name of the Java class for the connector. Always use a value of | ||
|
The comma-separated list of hostname and port pairs (in the form 'host' or 'host:port') of the MongoDB servers in the replica set. The list can contain a single hostname and port pair. If | ||
| A unique name that identifies the connector and/or MongoDB replica set or sharded cluster that this connector monitors. Each server should be monitored by at most one Debezium connector, since this server name prefixes all persisted Kafka topics emanating from the MongoDB replica set or cluster. Only alphanumeric characters, hyphens, dots and underscores must be used. | ||
| Name of the database user to be used when connecting to MongoDB. This is required only when MongoDB is configured to use authentication. | ||
| Password to be used when connecting to MongoDB. This is required only when MongoDB is configured to use authentication. | ||
|
|
Database (authentication source) containing MongoDB credentials. This is required only when MongoDB is configured to use authentication with another authentication database than | |
|
| Connector will use SSL to connect to MongoDB instances. | |
|
|
When SSL is enabled this setting controls whether strict hostname checking is disabled during connection phase. If | |
| empty string |
An optional comma-separated list of regular expressions that match database names to be monitored; any database name not included in | |
| empty string |
An optional comma-separated list of regular expressions that match database names to be excluded from monitoring; any database name not included in | |
| empty string |
An optional comma-separated list of regular expressions that match fully-qualified namespaces for MongoDB collections to be monitored; any collection not included in | |
| empty string |
An optional comma-separated list of regular expressions that match fully-qualified namespaces for MongoDB collections to be excluded from monitoring; any collection not included in | |
|
| Specifies the criteria for running a snapshot upon startup of the connector. The default is initial, and specifies the connector reads a snapshot when either no offset is found or if the oplog no longer contains the previous offset. The never option specifies that the connector should never use snapshots, instead the connector should proceed to tail the log. | |
|
All collections specified in |
An optional, comma-separated list of regular expressions that match names of schemas specified in | |
| empty string | An optional comma-separated list of the fully-qualified names of fields that should be excluded from change event message values. Fully-qualified names for fields are of the form databaseName.collectionName.fieldName.nestedFieldName, where databaseName and collectionName may contain the wildcard (*) which matches any characters. | |
| empty string | An optional comma-separated list of the fully-qualified replacements of fields that should be used to rename fields in change event message values. Fully-qualified replacements for fields are of the form databaseName.collectionName.fieldName.nestedFieldName:newNestedFieldName, where databaseName and collectionName may contain the wildcard (*) which matches any characters, the colon character (:) is used to determine rename mapping of field. The next field replacement is applied to the result of the previous field replacement in the list, so keep this in mind when renaming multiple fields that are in the same path. | |
|
| The maximum number of tasks that should be created for this connector. The MongoDB connector will attempt to use a separate task for each replica set, so the default is acceptable when using the connector with a single MongoDB replica set. When using the connector with a MongoDB sharded cluster, we recommend specifying a value that is equal to or more than the number of shards in the cluster, so that the work for each replica set can be distributed by Kafka Connect. | |
|
| Positive integer value that specifies the maximum number of threads used to perform an intial sync of the collections in a replica set. Defaults to 1. | |
|
|
Controls whether a delete event is followed by a tombstone event. | |
|
An interval in milliseconds that the connector should wait before taking a snapshot after starting up; | ||
|
|
Specifies the maximum number of documents that should be read in one go from each collection while taking a snapshot. The connector will read the collection contents in multiple batches of this size. |
The following advanced configuration properties have good defaults that will work in most situations and therefore rarely need to be specified in the connector’s configuration.
| Property | Default | Description |
|---|---|---|
|
|
Positive integer value that specifies the maximum size of the blocking queue into which change events read from the database log are placed before they are written to Kafka. This queue can provide backpressure to the oplog reader when, for example, writes to Kafka are slower or if Kafka is not available. Events that appear in the queue are not included in the offsets periodically recorded by this connector. Defaults to 8192, and should always be larger than the maximum batch size specified in the | |
|
| Positive integer value that specifies the maximum size of each batch of events that should be processed during each iteration of this connector. Defaults to 2048. | |
|
| Long value for the maximum size in bytes of the blocking queue. The feature is disabled by default, it will be active if it’s set with a positive long value. | |
|
| Positive integer value that specifies the number of milliseconds the connector should wait during each iteration for new change events to appear. Defaults to 1000 milliseconds, or 1 second. | |
|
| Positive integer value that specifies the initial delay when trying to reconnect to a primary after the first failed connection attempt or when no primary is available. Defaults to 1 second (1000 ms). | |
|
| Positive integer value that specifies the maximum delay when trying to reconnect to a primary after repeated failed connection attempts or when no primary is available. Defaults to 120 seconds (120,000 ms). | |
|
|
Positive integer value that specifies the maximum number of failed connection attempts to a replica set primary before an exception occurs and task is aborted. Defaults to 16, which with the defaults for | |
|
|
Boolean value that specifies whether the addresses in 'mongodb.hosts' are seeds that should be used to discover all members of the cluster or replica set ( | |
|
|
Controls how frequently heartbeat messages are sent.
Set this parameter to | |
|
|
Controls the naming of the topic to which heartbeat messages are sent. | |
|
| Whether field names are sanitized to adhere to Avro naming requirements. | |
|
comma-separated list of operation types that will be skipped during streaming. The operations include: | ||
| Controls which collection items are included in snapshot. This property affects snapshots only. Specify a comma-separated list of collection names in the form databaseName.collectionName.
For each collection that you specify, also specify another configuration property: | ||
|
|
When set to See Transaction Metadata for additional details. | |
| 10000 (10 seconds) | The number of milliseconds to wait before restarting a connector after a retriable error occurs. | |
|
| The interval in which the connector polls for new, removed, or changed replica sets. | |
| 10000 (10 seconds) | The number of milliseconds the driver will wait before a new connection attempt is aborted. | |
| 0 |
The number of milliseconds before a send/receive on the socket can take before a timeout occurs. A value of | |
| 30000 (30 seconds) | The number of milliseconds the driver will wait to select a server before it times out and throws an error. | |
|
|
Specifies the maximum number of milliseconds the oplog cursor will wait for the server to produce a result before causing an execution timeout exception. A value of |
4.6. Monitoring Debezium MongoDB connector performance
The Debezium MongoDB connector has two metric types in addition to the built-in support for JMX metrics that Zookeeper, Kafka, and Kafka Connect have.
- Snapshot metrics provide information about connector operation while performing a snapshot.
- Streaming metrics provide information about connector operation when the connector is capturing changes and streaming change event records.
The Debezium monitoring documentation provides details about how to expose these metrics by using JMX.
4.6.1. Monitoring Debezium during MongoDB snapshots
The MBean is debezium.mongodb:type=connector-metrics,context=snapshot,server=<mongodb.server.name>.
Snapshot metrics are not exposed unless a snapshot operation is active, or if a snapshot has occurred since the last connector start.
The following table lists the shapshot metrics that are available.
| Attributes | Type | Description |
|---|---|---|
|
| The last snapshot event that the connector has read. | |
|
| The number of milliseconds since the connector has read and processed the most recent event. | |
|
| The total number of events that this connector has seen since last started or reset. | |
|
| The number of events that have been filtered by include/exclude list filtering rules configured on the connector. | |
|
|
| The list of tables that are monitored by the connector. |
|
| The list of tables that are captured by the connector. | |
|
| The length the queue used to pass events between the snapshotter and the main Kafka Connect loop. | |
|
| The free capacity of the queue used to pass events between the snapshotter and the main Kafka Connect loop. | |
|
| The total number of tables that are being included in the snapshot. | |
|
| The number of tables that the snapshot has yet to copy. | |
|
| Whether the snapshot was started. | |
|
| Whether the snapshot was aborted. | |
|
| Whether the snapshot completed. | |
|
| The total number of seconds that the snapshot has taken so far, even if not complete. | |
|
| Map containing the number of rows scanned for each table in the snapshot. Tables are incrementally added to the Map during processing. Updates every 10,000 rows scanned and upon completing a table. | |
|
|
The maximum buffer of the queue in bytes. It will be enabled if | |
|
| The current data of records in the queue in bytes. |
The Debezium MongoDB connector also provides the following custom snapshot metrics:
| Attribute | Type | Description |
|---|---|---|
|
|
| Number of database disconnects. |
4.6.2. Monitoring Debezium MongoDB connector record streaming
The MBean is debezium.mongodb:type=connector-metrics,context=streaming,server=<mongodb.server.name>.
The following table lists the streaming metrics that are available.
| Attributes | Type | Description |
|---|---|---|
|
| The last streaming event that the connector has read. | |
|
| The number of milliseconds since the connector has read and processed the most recent event. | |
|
| The total number of events that this connector has seen since last started or reset. | |
|
| The number of events that have been filtered by include/exclude list filtering rules configured on the connector. | |
|
|
| The list of tables that are monitored by the connector. |
|
| The list of tables that are captured by the connector. | |
|
| The length the queue used to pass events between the streamer and the main Kafka Connect loop. | |
|
| The free capacity of the queue used to pass events between the streamer and the main Kafka Connect loop. | |
|
| Flag that denotes whether the connector is currently connected to the database server. | |
|
| The number of milliseconds between the last change event’s timestamp and the connector processing it. The values will incoporate any differences between the clocks on the machines where the database server and the connector are running. | |
|
| The number of processed transactions that were committed. | |
|
| The coordinates of the last received event. | |
|
| Transaction identifier of the last processed transaction. | |
|
| The maximum buffer of the queue in bytes. | |
|
| The current data of records in the queue in bytes. |
The Debezium MongoDB connector also provides the following custom streaming metrics:
| Attribute | Type | Description |
|---|---|---|
|
|
| Number of database disconnects. |
|
|
| Number of primary node elections. |
4.7. How Debezium MongoDB connectors handle faults and problems
Debezium is a distributed system that captures all changes in multiple upstream databases, and will never miss or lose an event. When the system is operating normally and is managed carefully, then Debezium provides exactly once delivery of every change event.
If a fault occurs, the system does not lose any events. However, while it is recovering from the fault, it might repeat some change events. In such situations, Debezium, like Kafka, provides at least once delivery of change events.
The following topics provide details about how the Debezium MongoDB connector handles various kinds of faults and problems.
Configuration and startup errors
In the following situations, the connector fails when trying to start, reports an error or exception in the log, and stops running:
- The connector’s configuration is invalid.
- The connector cannot successfully connect to MongoDB by using the specified connection parameters.
After a failure, the connector attempts to reconnect by using exponential backoff. You can configure the maximum number of reconnection attempts.
In these cases, the error will have more details about the problem and possibly a suggested work around. The connector can be restarted when the configuration has been corrected or the MongoDB problem has been addressed.
The attempts to reconnect are controlled by three properties:
-
connect.backoff.initial.delay.ms- The delay before attempting to reconnect for the first time, with a default of 1 second (1000 milliseconds). -
connect.backoff.max.delay.ms- The maximum delay before attempting to reconnect, with a default of 120 seconds (120,000 milliseconds). -
connect.max.attempts- The maximum number of attempts before an error is produced, with a default of 16.
Each delay is double that of the prior delay, up to the maximum delay. Given the default values, the following table shows the delay for each failed connection attempt and the total accumulated time before failure.
| Reconnection attempt number | Delay before attempt, in seconds | Total delay before attempt, in minutes and seconds |
|---|---|---|
| 1 | 1 | 00:01 |
| 2 | 2 | 00:03 |
| 3 | 4 | 00:07 |
| 4 | 8 | 00:15 |
| 5 | 16 | 00:31 |
| 6 | 32 | 01:03 |
| 7 | 64 | 02:07 |
| 8 | 120 | 04:07 |
| 9 | 120 | 06:07 |
| 10 | 120 | 08:07 |
| 11 | 120 | 10:07 |
| 12 | 120 | 12:07 |
| 13 | 120 | 14:07 |
| 14 | 120 | 16:07 |
| 15 | 120 | 18:07 |
| 16 | 120 | 20:07 |
Kafka Connect process stops gracefully
If Kafka Connect is being run in distributed mode, and a Kafka Connect process is stopped gracefully, then prior to shutdown of that processes Kafka Connect will migrate all of the process' connector tasks to another Kafka Connect process in that group, and the new connector tasks will pick up exactly where the prior tasks left off. There is a short delay in processing while the connector tasks are stopped gracefully and restarted on the new processes.
If the group contains only one process and that process is stopped gracefully, then Kafka Connect will stop the connector and record the last offset for each replica set. Upon restart, the replica set tasks will continue exactly where they left off.
Kafka Connect process crashes
If the Kafka Connector process stops unexpectedly, then any connector tasks it was running will terminate without recording their most recently-processed offsets. When Kafka Connect is being run in distributed mode, it will restart those connector tasks on other processes. However, the MongoDB connectors will resume from the last offset recorded by the earlier processes, which means that the new replacement tasks may generate some of the same change events that were processed just prior to the crash. The number of duplicate events depends on the offset flush period and the volume of data changes just before the crash.
Because there is a chance that some events may be duplicated during a recovery from failure, consumers should always anticipate some events may be duplicated. Debezium changes are idempotent, so a sequence of events always results in the same state.
Debezium also includes with each change event message the source-specific information about the origin of the event, including the MongoDB event’s unique transaction identifier (h) and timestamp (sec and ord). Consumers can keep track of other of these values to know whether it has already seen a particular event.
Connector is stopped for a long interval
If the connector is gracefully stopped, the replica sets can continue to be used and any new changes are recorded in MongoDB’s oplog. When the connector is restarted, it will resume streaming changes for each replica set where it last left off, recording change events for all of the changes that were made while the connector was stopped. If the connector is stopped long enough such that MongoDB purges from its oplog some operations that the connector has not read, then upon startup the connector will perform a snapshot.
A properly configured Kafka cluster is capable of massive throughput. Kafka Connect is written with Kafka best practices, and given enough resources will also be able to handle very large numbers of database change events. Because of this, when a connector has been restarted after a while, it is very likely to catch up with the database, though how quickly will depend upon the capabilities and performance of Kafka and the volume of changes being made to the data in MongoDB.
If the connector remains stopped for long enough, MongoDB might purge older oplog files and the connector’s last position may be lost. In this case, when the connector configured with initial snapshot mode (the default) is finally restarted, the MongoDB server will no longer have the starting point and the connector will fail with an error.
MongoDB loses writes
In certain failure situations, MongoDB can lose commits, which results in the MongoDB connector being unable to capture the lost changes. For example, if the primary crashes suddenly after it applies a change and records the change to its oplog, the oplog might become unavailable before secondary nodes can read its contents. As a result, the secondary node that is elected as the new primary node might be missing the most recent changes from its oplog.
At this time, there is no way to prevent this side effect in MongoDB.
Chapter 5. Debezium connector for MySQL
This release of the Debezium MySQL connector includes a new default capturing implementation that is based on the common connector framework that is used by the other Debezium connectors. The revised capturing implementation is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service-level agreements (SLAs) and might not be functionally complete; therefore, Red Hat does not recommend implementing any Technology Preview features in production environments. This Technology Preview feature provides early access to upcoming product innovations, enabling you to test functionality and provide feedback during the development process. For more information about support scope, see Technology Preview Features Support Scope.
If the connector generates errors or unexpected behavior while running with the new capturing implementation, you can revert to the earlier implementation by setting the following configuration option:
internal.implementation=legacyMySQL has a binary log (binlog) that records all operations in the order in which they are committed to the database. This includes changes to table schemas as well as changes to the data in tables. MySQL uses the binlog for replication and recovery.
The Debezium MySQL connector reads the binlog, produces change events for row-level INSERT, UPDATE, and DELETE operations, and emits the change events to Kafka topics. Client applications read those Kafka topics.
As MySQL is typically set up to purge binlogs after a specified period of time, the MySQL connector performs an initial consistent snapshot of each of your databases. The MySQL connector reads the binlog from the point at which the snapshot was made.
For information about the MySQL Database versions that are compatible with this connector, see the Debezium Supported Configurations page.
Information and procedures for using a Debezium MySQL connector are organized as follows:
- Section 5.1, “How Debezium MySQL connectors work”
- Section 5.2, “Descriptions of Debezium MySQL connector data change events”
- Section 5.3, “How Debezium MySQL connectors map data types”
- Section 5.4, “Setting up MySQL to run a Debezium connector”
- Section 5.5, “Deployment of Debezium MySQL connectors”
- Section 5.6, “Monitoring Debezium MySQL connector performance”
- Section 5.7, “How Debezium MySQL connectors handle faults and problems”
5.1. How Debezium MySQL connectors work
An overview of the MySQL topologies that the connector supports is useful for planning your application. To optimally configure and run a Debezium MySQL connector, it is helpful to understand how the connector tracks the structure of tables, exposes schema changes, performs snapshots, and determines Kafka topic names.
Details are in the following topics:
- Section 5.1.1, “MySQL topologies supported by Debezium connectors”
- Section 5.1.2, “How Debezium MySQL connectors handle database schema changes”
- Section 5.1.3, “How Debezium MySQL connectors expose database schema changes”
- Section 5.1.4, “How Debezium MySQL connectors perform database snapshots”
- Section 5.1.5, “Default names of Kafka topics that receive Debezium MySQL change event records”
5.1.1. MySQL topologies supported by Debezium connectors
The Debezium MySQL connector supports the following MySQL topologies:
- Standalone
- When a single MySQL server is used, the server must have the binlog enabled (and optionally GTIDs enabled) so the Debezium MySQL connector can monitor the server. This is often acceptable, since the binary log can also be used as an incremental backup. In this case, the MySQL connector always connects to and follows this standalone MySQL server instance.
- Primary and replica
The Debezium MySQL connector can follow one of the primary servers or one of the replicas (if that replica has its binlog enabled), but the connector sees changes in only the cluster that is visible to that server. Generally, this is not a problem except for the multi-primary topologies.
The connector records its position in the server’s binlog, which is different on each server in the cluster. Therefore, the connector must follow just one MySQL server instance. If that server fails, that server must be restarted or recovered before the connector can continue.
- High available clusters
- A variety of high availability solutions exist for MySQL, and they make it significantly easier to tolerate and almost immediately recover from problems and failures. Most HA MySQL clusters use GTIDs so that replicas are able to keep track of all changes on any of the primary servers.
- Multi-primary
Network Database (NDB) cluster replication uses one or more MySQL replica nodes that each replicate from multiple primary servers. This is a powerful way to aggregate the replication of multiple MySQL clusters. This topology requires the use of GTIDs.
A Debezium MySQL connector can use these multi-primary MySQL replicas as sources, and can fail over to different multi-primary MySQL replicas as long as the new replica is caught up to the old replica. That is, the new replica has all transactions that were seen on the first replica. This works even if the connector is using only a subset of databases and/or tables, as the connector can be configured to include or exclude specific GTID sources when attempting to reconnect to a new multi-primary MySQL replica and find the correct position in the binlog.
- Hosted
There is support for the Debezium MySQL connector to use hosted options such as Amazon RDS and Amazon Aurora.
Because these hosted options do not allow a global read lock, table-level locks are used to create the consistent snapshot.
5.1.2. How Debezium MySQL connectors handle database schema changes
When a database client queries a database, the client uses the database’s current schema. However, the database schema can be changed at any time, which means that the connector must be able to identify what the schema was at the time each insert, update, or delete operation was recorded. Also, a connector cannot just use the current schema because the connector might be processing events that are relatively old that were recorded before the tables' schemas were changed.
To ensure correct processing of changes that occur after a schema change, MySQL includes in the binlog not only the row-level changes to the data, but also the DDL statements that are applied to the database. As the connector reads the binlog and comes across these DDL statements, it parses them and updates an in-memory representation of each table’s schema. The connector uses this schema representation to identify the structure of the tables at the time of each insert, update, or delete operation and to produce the appropriate change event. In a separate database history Kafka topic, the connector records all DDL statements along with the position in the binlog where each DDL statement appeared.
When the connector restarts after having crashed or been stopped gracefully, the connector starts reading the binlog from a specific position, that is, from a specific point in time. The connector rebuilds the table structures that existed at this point in time by reading the database history Kafka topic and parsing all DDL statements up to the point in the binlog where the connector is starting.
This database history topic is for connector use only. The connector can optionally emit schema change events to a different topic that is intended for consumer applications.
When the MySQL connector captures changes in a table to which a schema change tool such as gh-ost or pt-online-schema-change is applied, there are helper tables created during the migration process. The connector needs to be configured to capture change to these helper tables. If consumers do not need the records generated for helper tables, then a single message transform can be applied to filter them out.
See default names for topics that receive Debezium event records.
5.1.3. How Debezium MySQL connectors expose database schema changes
You can configure a Debezium MySQL connector to produce schema change events that describe schema changes that are applied to captured tables in the database. The connector writes schema change events to a Kafka topic named <serverName>, where serverName is the logical server name that is specified in the database.server.name connector configuration property. Messages that the connector sends to the schema change topic contain a payload, and, optionally, also contain the schema of the change event message.
The payload of a schema change event message includes the following elements:
ddl-
Provides the SQL
CREATE,ALTER, orDROPstatement that results in the schema change. databaseName-
The name of the database to which the DDL statements are applied. The value of
databaseNameserves as the message key. pos- The position in the binlog where the statements appear.
tableChanges-
A structured representation of the entire table schema after the schema change. The
tableChangesfield contains an array that includes entries for each column of the table. Because the structured representation presents data in JSON or Avro format, consumers can easily read messages without first processing them through a DDL parser.
For a table that is in capture mode, the connector not only stores the history of schema changes in the schema change topic, but also in an internal database history topic. The internal database history topic is for connector use only and it is not intended for direct use by consuming applications. Ensure that applications that require notifications about schema changes consume that information only from the schema change topic.
Never partition the database history topic. For the database history topic to function correctly, it must maintain a consistent, global order of the event records that the connector emits to it.
To ensure that the topic is not split among partitions, set the partition count for the topic by using one of the following methods:
-
If you create the database history topic manually, specify a partition count of
1. -
If you use the Apache Kafka broker to create the database history topic automatically, the topic is created, set the value of the Kafka
num.partitionsconfiguration option to1.
The format of the messages that a connector emits to its schema change topic is in an incubating state and is subject to change without notice.
Example: Message emitted to the MySQL connector schema change topic
The following example shows a typical schema change message in JSON format. The message contains a logical representation of the table schema.
{
"schema": {
...
},
"payload": {
"source": { // (1)
"version": "1.7.2.Final",
"connector": "mysql",
"name": "dbserver1",
"ts_ms": 0,
"snapshot": "false",
"db": "inventory",
"sequence": null,
"table": "customers",
"server_id": 0,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 219,
"row": 0,
"thread": null,
"query": null
},
"databaseName": "inventory", // (2)
"schemaName": null,
"ddl": "ALTER TABLE customers ADD COLUMN middle_name VARCHAR(2000)", // (3)
"tableChanges": [ // (4)
{
"type": "ALTER", // (5)
"id": "\"inventory\".\"customers\"", // (6)
"table": { // (7)
"defaultCharsetName": "latin1",
"primaryKeyColumnNames": [ // (8)
"id"
],
"columns": [ // (9)
{
"name": "id",
"jdbcType": 4,
"nativeType": null,
"typeName": "INT",
"typeExpression": "INT",
"charsetName": null,
"length": 11,
"scale": null,
"position": 1,
"optional": false,
"autoIncremented": true,
"generated": true
},
{
"name": "first_name",
"jdbcType": 12,
"nativeType": null,
"typeName": "VARCHAR",
"typeExpression": "VARCHAR",
"charsetName": "latin1",
"length": 255,
"scale": null,
"position": 2,
"optional": false,
"autoIncremented": false,
"generated": false
}, {
"name": "last_name",
"jdbcType": 12,
"nativeType": null,
"typeName": "VARCHAR",
"typeExpression": "VARCHAR",
"charsetName": "latin1",
"length": 255,
"scale": null,
"position": 3,
"optional": false,
"autoIncremented": false,
"generated": false
},
{
"name": "email",
"jdbcType": 12,
"nativeType": null,
"typeName": "VARCHAR",
"typeExpression": "VARCHAR",
"charsetName": "latin1",
"length": 255,
"scale": null,
"position": 4,
"optional": false,
"autoIncremented": false,
"generated": false
},
{
"name": "middle_name",
"jdbcType": 12,
"nativeType": null,
"typeName": "VARCHAR",
"typeExpression": "VARCHAR",
"charsetName": "latin1",
"length": 2000,
"scale": null,
"position": 5,
"optional": true,
"autoIncremented": false,
"generated": false
}
]
}
}
]
},
"payload": {
"databaseName": "inventory",
"ddl": "CREATE TABLE products ( id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY, name VARCHAR(255) NOT NULL, description VARCHAR(512), weight FLOAT ); ALTER TABLE products AUTO_INCREMENT = 101;",
"source" : {
"version": "1.7.2.Final",
"name": "mysql-server-1",
"server_id": 0,
"ts_ms": 0,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 154,
"row": 0,
"snapshot": true,
"thread": null,
"db": null,
"table": null,
"query": null
}
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
The |
| 2 |
|
Identifies the database and the schema that contains the change. The value of the |
| 3 |
|
This field contains the DDL that is responsible for the schema change. The |
| 4 |
| An array of one or more items that contain the schema changes generated by a DDL command. |
| 5 |
| Describes the kind of change. The value is one of the following:
|
| 6 |
|
Full identifier of the table that was created, altered, or dropped. In the case of a table rename, this identifier is a concatenation of |
| 7 |
| Represents table metadata after the applied change. |
| 8 |
| List of columns that compose the table’s primary key. |
| 9 |
| Metadata for each column in the changed table. |
See also: schema history topic.
5.1.4. How Debezium MySQL connectors perform database snapshots
When a Debezium MySQL connector is first started, it performs an initial consistent snapshot of your database. The following flow describes how the connector creates this snapshot. This flow is for the default snapshot mode, which is initial. For information about other snapshot modes, see the MySQL connector snapshot.mode configuration property.
| Step | Action |
|---|---|
| 1 |
Grabs a global read lock that blocks writes by other database clients. |
| 2 | Starts a transaction with repeatable read semantics to ensure that all subsequent reads within the transaction are done against the consistent snapshot. |
| 3 | Reads the current binlog position. |
| 4 | Reads the schema of the databases and tables for which the connector is configured to capture changes. |
| 5 | Releases the global read lock. Other database clients can now write to the database. |
| 6 |
If applicable, writes the DDL changes to the schema change topic, including all necessary |
| 7 |
Scans the database tables. For each row, the connector emits |
| 8 | Commits the transaction. |
| 9 | Records the completed snapshot in the connector offsets. |
- Connector restarts
If the connector fails, stops, or is rebalanced while performing the initial snapshot, then after the connector restarts, it performs a new snapshot. After that intial snapshot is completed, the Debezium MySQL connector restarts from the same position in the binlog so it does not miss any updates.
If the connector stops for long enough, MySQL could purge old binlog files and the connector’s position would be lost. If the position is lost, the connector reverts to the initial snapshot for its starting position. For more tips on troubleshooting the Debezium MySQL connector, see behavior when things go wrong.
- Global read locks not allowed
Some environments do not allow global read locks. If the Debezium MySQL connector detects that global read locks are not permitted, the connector uses table-level locks instead and performs a snapshot with this method. This requires the database user for the Debezium connector to have
LOCK TABLESprivileges.Expand Table 5.3. Workflow for performing an initial snapshot with table-level locks Step Action 1
Obtains table-level locks.
2
Starts a transaction with repeatable read semantics to ensure that all subsequent reads within the transaction are done against the consistent snapshot.
3
Reads and filters the names of the databases and tables.
4
Reads the current binlog position.
5
Reads the schema of the databases and tables for which the connector is configured to capture changes.
6
If applicable, writes the DDL changes to the schema change topic, including all necessary
DROP…andCREATE…DDL statements.7
Scans the database tables. For each row, the connector emits
CREATEevents to the relevant table-specific Kafka topics.8
Commits the transaction.
9
Releases the table-level locks.
10
Records the completed snapshot in the connector offsets.
5.1.4.1. Ad hoc snapshots
The use of ad hoc snapshots is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service-level agreements (SLAs) and might not be functionally complete; therefore, Red Hat does not recommend implementing any Technology Preview features in production environments. This Technology Preview feature provides early access to upcoming product innovations, enabling you to test functionality and provide feedback during the development process. For more information about support scope, see Technology Preview Features Support Scope.
By default, a connector runs an initial snapshot operation only after it starts for the first time. Following this initial snapshot, under normal circumstances, the connector does not repeat the snapshot process. Any future change event data that the connector captures comes in through the streaming process only.
However, in some situations the data that the connector obtained during the initial snapshot might become stale, lost, or incomplete. To provide a mechanism for recapturing table data, Debezium includes an option to perform ad hoc snapshots. The following changes in a database might be cause for performing an ad hoc snapshot:
- The connector configuration is modified to capture a different set of tables.
- Kafka topics are deleted and must be rebuilt.
- Data corruption occurs due to a configuration error or some other problem.
You can re-run a snapshot for a table for which you previously captured a snapshot by initiating a so-called ad-hoc snapshot. Ad hoc snapshots require the use of signaling tables. You initiate an ad hoc snapshot by sending a signal request to the Debezium signaling table.
When you initiate an ad hoc snapshot of an existing table, the connector appends content to the topic that already exists for the table. If a previously existing topic was removed, Debezium can create a topic automatically if automatic topic creation is enabled.
Ad hoc snapshot signals specify the tables to include in the snapshot. The snapshot can capture the entire contents of the database, or capture only a subset of the tables in the database.
You specify the tables to capture by sending an execute-snapshot message to the signaling table. Set the type of the execute-snapshot signal to incremental, and provide the names of the tables to include in the snapshot, as described in the following table:
| Field | Default | Value |
|---|---|---|
|
|
|
Specifies the type of snapshot that you want to run. |
|
| N/A |
An array that contains the fully-qualified names of the table to be snapshotted. |
Triggering an ad hoc snapshot
You initiate an ad hoc snapshot by adding an entry with the execute-snapshot signal type to the signaling table. After the connector processes the message, it begins the snapshot operation. The snapshot process reads the first and last primary key values and uses those values as the start and end point for each table. Based on the number of entries in the table, and the configured chunk size, Debezium divides the table into chunks, and proceeds to snapshot each chunk, in succession, one at a time.
Currently, the execute-snapshot action type triggers incremental snapshots only. For more information, see Incremental snapshots.
5.1.4.2. Incremental snapshots
The use of incremental snapshots is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service-level agreements (SLAs) and might not be functionally complete; therefore, Red Hat does not recommend implementing any Technology Preview features in production environments. This Technology Preview feature provides early access to upcoming product innovations, enabling you to test functionality and provide feedback during the development process. For more information about support scope, see Technology Preview Features Support Scope.
To provide flexibility in managing snapshots, Debezium includes a supplementary snapshot mechanism, known as incremental snapshotting. Incremental snapshots rely on the Debezium mechanism for sending signals to a Debezium connector.
In an incremental snapshot, instead of capturing the full state of a database all at once, as in an initial snapshot, Debezium captures each table in phases, in a series of configurable chunks. You can specify the tables that you want the snapshot to capture and the size of each chunk. The chunk size determines the number of rows that the snapshot collects during each fetch operation on the database. The default chunk size for incremental snapshots is 1 KB.
As an incremental snapshot proceeds, Debezium uses watermarks to track its progress, maintaining a record of each table row that it captures. This phased approach to capturing data provides the following advantages over the standard initial snapshot process:
- You can run incremental snapshots in parallel with streamed data capture, instead of postponing streaming until the snapshot completes. The connector continues to capture near real-time events from the change log throughout the snapshot process, and neither operation blocks the other.
- If the progress of an incremental snapshot is interrupted, you can resume it without losing any data. After the process resumes, the snapshot begins at the point where it stopped, rather than recapturing the table from the beginning.
-
You can run an incremental snapshot on demand at any time, and repeat the process as needed to adapt to database updates. For example, you might re-run a snapshot after you modify the connector configuration to add a table to its
table.include.listproperty.
Incremental snapshot process
When you run an incremental snapshot, Debezium sorts each table by primary key and then splits the table into chunks based on the configured chunk size. Working chunk by chunk, it then captures each table row in a chunk. For each row that it captures, the snapshot emits a READ event. That event represents the value of the row when the snapshot for the chunk began.
As a snapshot proceeds, it’s likely that other processes continue to access the database, potentially modifying table records. To reflect such changes, INSERT, UPDATE, or DELETE operations are committed to the transaction log as per usual. Similarly, the ongoing Debezium streaming process continues to detect these change events and emits corresponding change event records to Kafka.
How Debezium resolves collisions among records with the same primary key
In some cases, the UPDATE or DELETE events that the streaming process emits are received out of sequence. That is, the streaming process might emit an event that modifies a table row before the snapshot captures the chunk that contains the READ event for that row. When the snapshot eventually emits the corresponding READ event for the row, its value is already superseded. To ensure that incremental snapshot events that arrive out of sequence are processed in the correct logical order, Debezium employs a buffering scheme for resolving collisions. Only after collisions between the snapshot events and the streamed events are resolved does Debezium emit an event record to Kafka.
Snapshot window
To assist in resolving collisions between late-arriving READ events and streamed events that modify the same table row, Debezium employs a so-called snapshot window. The snapshot windows demarcates the interval during which an incremental snapshot captures data for a specified table chunk. Before the snapshot window for a chunk opens, Debezium follows its usual behavior and emits events from the transaction log directly downstream to the target Kafka topic. But from the moment that the snapshot for a particular chunk opens, until it closes, Debezium performs a de-duplication step to resolve collisions between events that have the same primary key..
For each data collection, the Debezium emits two types of events, and stores the records for them both in a single destination Kafka topic. The snapshot records that it captures directly from a table are emitted as READ operations. Meanwhile, as users continue to update records in the data collection, and the transaction log is updated to reflect each commit, Debezium emits UPDATE or DELETE operations for each change.
As the snapshot window opens, and Debezium begins processing a snapshot chunk, it delivers snapshot records to a memory buffer. During the snapshot windows, the primary keys of the READ events in the buffer are compared to the primary keys of the incoming streamed events. If no match is found, the streamed event record is sent directly to Kafka. If Debezium detects a match, it discards the buffered READ event, and writes the streamed record to the destination topic, because the streamed event logically supersede the static snapshot event. After the snapshot window for the chunk closes, the buffer contains only READ events for which no related transaction log events exist. Debezium emits these remaining READ events to the table’s Kafka topic.
The connector repeats the process for each snapshot chunk.
Triggering an incremental snapshot
Currently, the only way to initiate an incremental snapshot is to send an ad hoc snapshot signal to the signaling table on the source database. You submit signals to the table as SQL INSERT queries. After Debezium detects the change in the signaling table, it reads the signal, and runs the requested snapshot operation.
The query that you submit specifies the tables to include in the snapshot, and, optionally, specifies the kind of snapshot operation. Currently, the only valid option for snapshots operations is the default value, incremental.
To specify the tables to include in the snapshot, provide a data-collections array that lists the tables, for example,{"data-collections": ["public.MyFirstTable", "public.MySecondTable"]}
The data-collections array for an incremental snapshot signal has no default value. If the data-collections array is empty, Debezium detects that no action is required and does not perform a snapshot.
Prerequisites
- A signaling data collection exists on the source database and the connector is configured to capture it.
-
The signaling data collection is specified in the
signal.data.collectionproperty.
Procedure
Send a SQL query to add the ad hoc incremental snapshot request to the signaling table:
INSERT INTO _<signalTable>_ (id, type, data) VALUES (_'<id>'_, _'<snapshotType>'_, '{"data-collections": ["_<tableName>_","_<tableName>_"],"type":"_<snapshotType>_"}');For example,
INSERT INTO myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["schema1.table1", "schema2.table2"],"type":"incremental"}');The values of the
id,type, anddataparameters in the command correspond to the fields of the signaling table.The following table describes the these parameters:
Expand Table 5.5. Descriptions of fields in a SQL command for sending an incremental snapshot signal to the signaling table Value Description myschema.debezium_signalSpecifies the fully-qualified name of the signaling table on the source database
ad-hoc-1The
idparameter specifies an arbitrary string that is assigned as theididentifier for the signal request.
Use this string to identify logging messages to entries in the signaling table. Debezium does not use this string. Rather, during the snapshot, Debezium generates its ownidstring as a watermarking signal.execute-snapshotSpecifies
typeparameter specifies the operation that the signal is intended to trigger.
data-collectionsA required component of the
datafield of a signal that specifies an array of table names to include in the snapshot.
The array lists tables by their fully-qualified names, using the same format as you use to specify the name of the connector’s signaling table in thesignal.data.collectionconfiguration property.incrementalAn optional
typecomponent of thedatafield of a signal that specifies the kind of snapshot operation to run.
Currently, the only valid option is the default value,incremental.
Specifying atypevalue in the SQL query that you submit to the signaling table is optional.
If you do not specify a value, the connector runs an incremental snapshot.
The following example, shows the JSON for an incremental snapshot event that is captured by a connector.
Example: Incremental snapshot event message
{
"before":null,
"after": {
"pk":"1",
"value":"New data"
},
"source": {
...
"snapshot":"incremental"
},
"op":"r",
"ts_ms":"1620393591654",
"transaction":null
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
Specifies the type of snapshot operation to run. |
| 2 |
|
Specifies the event type. |
5.1.5. Default names of Kafka topics that receive Debezium MySQL change event records
By default, the MySQL connector writes change events for all of the INSERT, UPDATE, and DELETE operations that occur in a table to a single Apache Kafka topic that is specific to that table.
The connector uses the following convention to name change event topics:
serverName.databaseName.tableName
Suppose that fulfillment is the server name, inventory is the database name, and the database contains tables named orders, customers, and products. The Debezium MySQL connector emits events to three Kafka topics, one for each table in the database:
fulfillment.inventory.orders
fulfillment.inventory.customers
fulfillment.inventory.productsThe following list provides definitions for the components of the default name:
- serverName
-
The logical name of the server as specified by the
database.server.nameconnector configuration property. - schemaName
- The name of the schema in which the operation occurred.
- tableName
- The name of the table in which the operation occurred.
The connector applies similar naming conventions to label its internal database history topics, schema change topics, and transaction metadata topics.
If the default topic name do not meet your requirements, you can configure custom topic names. To configure custom topic names, you specify regular expressions in the logical topic routing SMT. For more information about using the logical topic routing SMT to customize topic naming, see Topic routing.
Transaction metadata
Debezium can generate events that represent transaction boundaries and that enrich data change event messages.
Debezium registers and receives metadata only for transactions that occur after you deploy the connector. Metadata for transactions that occur before you deploy the connector is not available.
Debezium generates transaction boundary events for the BEGIN and END delimiters in every transaction. Transaction boundary events contain the following fields:
status-
BEGINorEND. id- String representation of the unique transaction identifier.
event_count(forENDevents)- Total number of events emitted by the transaction.
data_collections(forENDevents)-
An array of pairs of
data_collectionandevent_countelements. that indicates the number of events that the connector emits for changes that originate from a data collection.
Example
{
"status": "BEGIN",
"id": "0e4d5dcd-a33b-11ea-80f1-02010a22a99e:10",
"event_count": null,
"data_collections": null
}
{
"status": "END",
"id": "0e4d5dcd-a33b-11ea-80f1-02010a22a99e:10",
"event_count": 2,
"data_collections": [
{
"data_collection": "s1.a",
"event_count": 1
},
{
"data_collection": "s2.a",
"event_count": 1
}
]
}
The connector emits transaction events to the <database.server.name>.transaction topic.
Change data event enrichment
When transaction metadata is enabled the data message Envelope is enriched with a new transaction field. This field provides information about every event in the form of a composite of fields:
-
id- string representation of unique transaction identifier -
total_order- absolute position of the event among all events generated by the transaction -
data_collection_order- the per-data collection position of the event among all events that were emitted by the transaction
Following is an example of a message:
{
"before": null,
"after": {
"pk": "2",
"aa": "1"
},
"source": {
...
},
"op": "c",
"ts_ms": "1580390884335",
"transaction": {
"id": "0e4d5dcd-a33b-11ea-80f1-02010a22a99e:10",
"total_order": "1",
"data_collection_order": "1"
}
}
For systems which don’t have GTID enabled, the transaction identifier is constructed using the combination of binlog filename and binlog position. For example, if the binlog filename and position corresponding to the transaction BEGIN event are mysql-bin.000002 and 1913 respectively then the Debezium constructed transaction identifier would be file=mysql-bin.000002,pos=1913.
5.2. Descriptions of Debezium MySQL connector data change events
The Debezium MySQL connector generates a data change event for each row-level INSERT, UPDATE, and DELETE operation. Each event contains a key and a value. The structure of the key and the value depends on the table that was changed.
Debezium and Kafka Connect are designed around continuous streams of event messages. However, the structure of these events may change over time, which can be difficult for consumers to handle. To address this, each event contains the schema for its content or, if you are using a schema registry, a schema ID that a consumer can use to obtain the schema from the registry. This makes each event self-contained.
The following skeleton JSON shows the basic four parts of a change event. However, how you configure the Kafka Connect converter that you choose to use in your application determines the representation of these four parts in change events. A schema field is in a change event only when you configure the converter to produce it. Likewise, the event key and event payload are in a change event only if you configure a converter to produce it. If you use the JSON converter and you configure it to produce all four basic change event parts, change events have this structure:
{
"schema": {
...
},
"payload": {
...
},
"schema": {
...
},
"payload": {
...
},
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
The first |
| 2 |
|
The first |
| 3 |
|
The second |
| 4 |
|
The second |
By default, the connector streams change event records to topics with names that are the same as the event’s originating table. See topic names.
The MySQL connector ensures that all Kafka Connect schema names adhere to the Avro schema name format. This means that the logical server name must start with a Latin letter or an underscore, that is, a-z, A-Z, or _. Each remaining character in the logical server name and each character in the database and table names must be a Latin letter, a digit, or an underscore, that is, a-z, A-Z, 0-9, or _. If there is an invalid character it is replaced with an underscore character.
This can lead to unexpected conflicts if the logical server name, a database name, or a table name contains invalid characters, and the only characters that distinguish names from one another are invalid and thus replaced with underscores.
More details are in the following topics:
5.2.1. About keys in Debezium MySQL change events
A change event’s key contains the schema for the changed table’s key and the changed row’s actual key. Both the schema and its corresponding payload contain a field for each column in the changed table’s PRIMARY KEY (or unique constraint) at the time the connector created the event.
Consider the following customers table, which is followed by an example of a change event key for this table.
CREATE TABLE customers (
id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(255) NOT NULL,
last_name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE KEY
) AUTO_INCREMENT=1001;
Every change event that captures a change to the customers table has the same event key schema. For as long as the customers table has the previous definition, every change event that captures a change to the customers table has the following key structure. In JSON, it looks like this:
{
"schema": {
"type": "struct",
"name": "mysql-server-1.inventory.customers.Key",
"optional": false,
"fields": [
{
"field": "id",
"type": "int32",
"optional": false
}
]
},
"payload": {
"id": 1001
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
The schema portion of the key specifies a Kafka Connect schema that describes what is in the key’s |
| 2 |
|
Name of the schema that defines the structure of the key’s payload. This schema describes the structure of the primary key for the table that was changed. Key schema names have the format connector-name.database-name.table-name.
|
| 3 |
|
Indicates whether the event key must contain a value in its |
| 4 |
|
Specifies each field that is expected in the |
| 5 |
|
Contains the key for the row for which this change event was generated. In this example, the key, contains a single |
5.2.2. About values in Debezium MySQL change events
The value in a change event is a bit more complicated than the key. Like the key, the value has a schema section and a payload section. The schema section contains the schema that describes the Envelope structure of the payload section, including its nested fields. Change events for operations that create, update or delete data all have a value payload with an envelope structure.
Consider the same sample table that was used to show an example of a change event key:
CREATE TABLE customers (
id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(255) NOT NULL,
last_name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE KEY
) AUTO_INCREMENT=1001;The value portion of a change event for a change to this table is described for:
create events
The following example shows the value portion of a change event that the connector generates for an operation that creates data in the customers table:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "first_name"
},
{
"type": "string",
"optional": false,
"field": "last_name"
},
{
"type": "string",
"optional": false,
"field": "email"
}
],
"optional": true,
"name": "mysql-server-1.inventory.customers.Value",
"field": "before"
},
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "first_name"
},
{
"type": "string",
"optional": false,
"field": "last_name"
},
{
"type": "string",
"optional": false,
"field": "email"
}
],
"optional": true,
"name": "mysql-server-1.inventory.customers.Value",
"field": "after"
},
{
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "version"
},
{
"type": "string",
"optional": false,
"field": "connector"
},
{
"type": "string",
"optional": false,
"field": "name"
},
{
"type": "int64",
"optional": false,
"field": "ts_ms"
},
{
"type": "boolean",
"optional": true,
"default": false,
"field": "snapshot"
},
{
"type": "string",
"optional": false,
"field": "db"
},
{
"type": "string",
"optional": true,
"field": "table"
},
{
"type": "int64",
"optional": false,
"field": "server_id"
},
{
"type": "string",
"optional": true,
"field": "gtid"
},
{
"type": "string",
"optional": false,
"field": "file"
},
{
"type": "int64",
"optional": false,
"field": "pos"
},
{
"type": "int32",
"optional": false,
"field": "row"
},
{
"type": "int64",
"optional": true,
"field": "thread"
},
{
"type": "string",
"optional": true,
"field": "query"
}
],
"optional": false,
"name": "io.debezium.connector.mysql.Source",
"field": "source"
},
{
"type": "string",
"optional": false,
"field": "op"
},
{
"type": "int64",
"optional": true,
"field": "ts_ms"
}
],
"optional": false,
"name": "mysql-server-1.inventory.customers.Envelope"
},
"payload": {
"op": "c",
"ts_ms": 1465491411815,
"before": null,
"after": {
"id": 1004,
"first_name": "Anne",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"source": {
"version": "1.7.2.Final",
"connector": "mysql",
"name": "mysql-server-1",
"ts_ms": 0,
"snapshot": false,
"db": "inventory",
"table": "customers",
"server_id": 0,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 154,
"row": 0,
"thread": 7,
"query": "INSERT INTO customers (first_name, last_name, email) VALUES ('Anne', 'Kretchmar', 'annek@noanswer.org')"
}
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
| The value’s schema, which describes the structure of the value’s payload. A change event’s value schema is the same in every change event that the connector generates for a particular table. |
| 2 |
|
In the |
| 3 |
|
|
| 4 |
|
|
| 5 |
|
The value’s actual data. This is the information that the change event is providing. |
| 6 |
|
Mandatory string that describes the type of operation that caused the connector to generate the event. In this example,
|
| 7 |
|
Optional field that displays the time at which the connector processed the event. The time is based on the system clock in the JVM running the Kafka Connect task. |
| 8 |
|
An optional field that specifies the state of the row before the event occurred. When the |
| 9 |
|
An optional field that specifies the state of the row after the event occurred. In this example, the |
| 10 |
| Mandatory field that describes the source metadata for the event. This field contains information that you can use to compare this event with other events, with regard to the origin of the events, the order in which the events occurred, and whether events were part of the same transaction. The source metadata includes:
If the |
update events
The value of a change event for an update in the sample customers table has the same schema as a create event for that table. Likewise, the event value’s payload has the same structure. However, the event value payload contains different values in an update event. Here is an example of a change event value in an event that the connector generates for an update in the customers table:
{
"schema": { ... },
"payload": {
"before": {
"id": 1004,
"first_name": "Anne",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"after": {
"id": 1004,
"first_name": "Anne Marie",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"source": {
"version": "1.7.2.Final",
"name": "mysql-server-1",
"connector": "mysql",
"name": "mysql-server-1",
"ts_ms": 1465581029100,
"snapshot": false,
"db": "inventory",
"table": "customers",
"server_id": 223344,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 484,
"row": 0,
"thread": 7,
"query": "UPDATE customers SET first_name='Anne Marie' WHERE id=1004"
},
"op": "u",
"ts_ms": 1465581029523
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
An optional field that specifies the state of the row before the event occurred. In an update event value, the |
| 2 |
|
An optional field that specifies the state of the row after the event occurred. You can compare the |
| 3 |
|
Mandatory field that describes the source metadata for the event. The
If the |
| 4 |
|
Mandatory string that describes the type of operation. In an update event value, the |
| 5 |
|
Optional field that displays the time at which the connector processed the event. The time is based on the system clock in the JVM running the Kafka Connect task. |
Updating the columns for a row’s primary/unique key changes the value of the row’s key. When a key changes, Debezium outputs three events: a DELETE event and a tombstone event with the old key for the row, followed by an event with the new key for the row. Details are in the next section.
Primary key updates
An UPDATE operation that changes a row’s primary key field(s) is known as a primary key change. For a primary key change, in place of an UPDATE event record, the connector emits a DELETE event record for the old key and a CREATE event record for the new (updated) key. These events have the usual structure and content, and in addition, each one has a message header related to the primary key change:
-
The
DELETEevent record has__debezium.newkeyas a message header. The value of this header is the new primary key for the updated row. -
The
CREATEevent record has__debezium.oldkeyas a message header. The value of this header is the previous (old) primary key that the updated row had.
delete events
The value in a delete change event has the same schema portion as create and update events for the same table. The payload portion in a delete event for the sample customers table looks like this:
{
"schema": { ... },
"payload": {
"before": {
"id": 1004,
"first_name": "Anne Marie",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"after": null,
"source": {
"version": "1.7.2.Final",
"connector": "mysql",
"name": "mysql-server-1",
"ts_ms": 1465581902300,
"snapshot": false,
"db": "inventory",
"table": "customers",
"server_id": 223344,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 805,
"row": 0,
"thread": 7,
"query": "DELETE FROM customers WHERE id=1004"
},
"op": "d",
"ts_ms": 1465581902461
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
Optional field that specifies the state of the row before the event occurred. In a delete event value, the |
| 2 |
|
Optional field that specifies the state of the row after the event occurred. In a delete event value, the |
| 3 |
|
Mandatory field that describes the source metadata for the event. In a delete event value, the
If the |
| 4 |
|
Mandatory string that describes the type of operation. The |
| 5 |
|
Optional field that displays the time at which the connector processed the event. The time is based on the system clock in the JVM running the Kafka Connect task. |
A delete change event record provides a consumer with the information it needs to process the removal of this row. The old values are included because some consumers might require them in order to properly handle the removal.
MySQL connector events are designed to work with Kafka log compaction. Log compaction enables removal of some older messages as long as at least the most recent message for every key is kept. This lets Kafka reclaim storage space while ensuring that the topic contains a complete data set and can be used for reloading key-based state.
Tombstone events
When a row is deleted, the delete event value still works with log compaction, because Kafka can remove all earlier messages that have that same key. However, for Kafka to remove all messages that have that same key, the message value must be null. To make this possible, after Debezium’s MySQL connector emits a delete event, the connector emits a special tombstone event that has the same key but a null value.
5.3. How Debezium MySQL connectors map data types
The Debezium MySQL connector represents changes to rows with events that are structured like the table in which the row exists. The event contains a field for each column value. The MySQL data type of that column dictates how Debezium represents the value in the event.
Columns that store strings are defined in MySQL with a character set and collation. The MySQL connector uses the column’s character set when reading the binary representation of the column values in the binlog events.
The connector can map MySQL data types to both literal and semantic types.
- Literal type: how the value is represented using Kafka Connect schema types
- Semantic type: how the Kafka Connect schema captures the meaning of the field (schema name)
Details are in the following sections:
Basic types
The following table shows how the connector maps basic MySQL data types.
| MySQL type | Literal type | Semantic type |
|---|---|---|
|
|
| n/a |
|
|
| n/a |
|
|
|
|
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
|
n/a |
|
|
|
n/a |
|
|
|
n/a |
|
|
| n/a |
|
|
|
n/a |
|
|
| n/a |
|
|
|
n/a |
|
|
| n/a |
|
|
|
n/a |
|
|
| n/a |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Temporal types
Excluding the TIMESTAMP data type, MySQL temporal types depend on the value of the time.precision.mode connector configuration property. For TIMESTAMP columns whose default value is specified as CURRENT_TIMESTAMP or NOW, the value 1970-01-01 00:00:00 is used as the default value in the Kafka Connect schema.
MySQL allows zero-values for DATE, DATETIME, and TIMESTAMP columns because zero-values are sometimes preferred over null values. The MySQL connector represents zero-values as null values when the column definition allows null values, or as the epoch day when the column does not allow null values.
Temporal values without time zones
The DATETIME type represents a local date and time such as "2018-01-13 09:48:27". As you can see, there is no time zone information. Such columns are converted into epoch milliseconds or microseconds based on the column’s precision by using UTC. The TIMESTAMP type represents a timestamp without time zone information. It is converted by MySQL from the server (or session’s) current time zone into UTC when writing and from UTC into the server (or session’s) current time zone when reading back the value. For example:
-
DATETIMEwith a value of2018-06-20 06:37:03becomes1529476623000. -
TIMESTAMPwith a value of2018-06-20 06:37:03becomes2018-06-20T13:37:03Z.
Such columns are converted into an equivalent io.debezium.time.ZonedTimestamp in UTC based on the server (or session’s) current time zone. The time zone will be queried from the server by default. If this fails, it must be specified explicitly by the database connectionTimeZone MySQL configuration option. For example, if the database’s time zone (either globally or configured for the connector by means of the connectionTimeZone option) is "America/Los_Angeles", the TIMESTAMP value "2018-06-20 06:37:03" is represented by a ZonedTimestamp with the value "2018-06-20T13:37:03Z".
The time zone of the JVM running Kafka Connect and Debezium does not affect these conversions.
More details about properties related to temporal values are in the documentation for MySQL connector configuration properties.
- time.precision.mode=adaptive_time_microseconds(default)
The MySQL connector determines the literal type and semantic type based on the column’s data type definition so that events represent exactly the values in the database. All time fields are in microseconds. Only positive
TIMEfield values in the range of00:00:00.000000to23:59:59.999999can be captured correctly.Expand Table 5.12. Mappings when time.precision.mode=adaptive_time_microseconds MySQL type Literal type Semantic type DATEINT32io.debezium.time.Date
Represents the number of days since the epoch.TIME[(M)]INT64io.debezium.time.MicroTime
Represents the time value in microseconds and does not include time zone information. MySQL allowsMto be in the range of0-6.DATETIME, DATETIME(0), DATETIME(1), DATETIME(2), DATETIME(3)INT64io.debezium.time.Timestamp
Represents the number of milliseconds past the epoch and does not include time zone information.DATETIME(4), DATETIME(5), DATETIME(6)INT64io.debezium.time.MicroTimestamp
Represents the number of microseconds past the epoch and does not include time zone information.- time.precision.mode=connect
The MySQL connector uses defined Kafka Connect logical types. This approach is less precise than the default approach and the events could be less precise if the database column has a fractional second precision value of greater than
3. Values in only the range of00:00:00.000to23:59:59.999can be handled. Settime.precision.mode=connectonly if you can ensure that theTIMEvalues in your tables never exceed the supported ranges. Theconnectsetting is expected to be removed in a future version of Debezium.Expand Table 5.13. Mappings when time.precision.mode=connect MySQL type Literal type Semantic type DATEINT32org.apache.kafka.connect.data.Date
Represents the number of days since the epoch.TIME[(M)]INT64org.apache.kafka.connect.data.Time
Represents the time value in microseconds since midnight and does not include time zone information.DATETIME[(M)]INT64org.apache.kafka.connect.data.Timestamp
Represents the number of milliseconds since the epoch, and does not include time zone information.
Decimal types
Debezium connectors handle decimals according to the setting of the decimal.handling.mode connector configuration property.
- decimal.handling.mode=precise
Expand Table 5.14. Mappings when decimal.handing.mode=precise MySQL type Literal type Semantic type NUMERIC[(M[,D])]BYTESorg.apache.kafka.connect.data.Decimal
Thescaleschema parameter contains an integer that represents how many digits the decimal point shifted.DECIMAL[(M[,D])]BYTESorg.apache.kafka.connect.data.Decimal
Thescaleschema parameter contains an integer that represents how many digits the decimal point shifted.- decimal.handling.mode=double
Expand Table 5.15. Mappings when decimal.handing.mode=double MySQL type Literal type Semantic type NUMERIC[(M[,D])]FLOAT64n/a
DECIMAL[(M[,D])]FLOAT64n/a
- decimal.handling.mode=string
Expand Table 5.16. Mappings when decimal.handing.mode=string MySQL type Literal type Semantic type NUMERIC[(M[,D])]STRINGn/a
DECIMAL[(M[,D])]STRINGn/a
Boolean values
MySQL handles the BOOLEAN value internally in a specific way. The BOOLEAN column is internally mapped to the TINYINT(1) data type. When the table is created during streaming then it uses proper BOOLEAN mapping as Debezium receives the original DDL. During snapshots, Debezium executes SHOW CREATE TABLE to obtain table definitions that return TINYINT(1) for both BOOLEAN and TINYINT(1) columns. Debezium then has no way to obtain the original type mapping and so maps to TINYINT(1).
Following is an example configuration:
converters=boolean
boolean.type=io.debezium.connector.mysql.converters.TinyIntOneToBooleanConverter
boolean.selector=db1.table1.*, db1.table2.column1Spatial types
Currently, the Debezium MySQL connector supports the following spatial data types.
| MySQL type | Literal type | Semantic type |
|---|---|---|
|
|
|
|
5.4. Setting up MySQL to run a Debezium connector
Some MySQL setup tasks are required before you can install and run a Debezium connector.
Details are in the following sections:
- Section 5.4.1, “Creating a MySQL user for a Debezium connector”
- Section 5.4.2, “Enabling the MySQL binlog for Debezium”
- Section 5.4.3, “Enabling MySQL Global Transaction Identifiers for Debezium”
- Section 5.4.4, “Configuring MySQL session timesouts for Debezium”
- Section 5.4.5, “Enabling query log events for Debezium MySQL connectors”
5.4.1. Creating a MySQL user for a Debezium connector
A Debezium MySQL connector requires a MySQL user account. This MySQL user must have appropriate permissions on all databases for which the Debezium MySQL connector captures changes.
Prerequisites
- A MySQL server.
- Basic knowledge of SQL commands.
Procedure
Create the MySQL user:
mysql> CREATE USER 'user'@'localhost' IDENTIFIED BY 'password';Grant the required permissions to the user:
mysql> GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user' IDENTIFIED BY 'password';The table below describes the permissions.
ImportantIf using a hosted option such as Amazon RDS or Amazon Aurora that does not allow a global read lock, table-level locks are used to create the consistent snapshot. In this case, you need to also grant
LOCK TABLESpermissions to the user that you create. See snapshots for more details.Finalize the user’s permissions:
mysql> FLUSH PRIVILEGES;
| Keyword | Description |
|---|---|
|
| Enables the connector to select rows from tables in databases. This is used only when performing a snapshot. |
|
|
Enables the connector the use of the |
|
|
Enables the connector to see database names by issuing the |
|
| Enables the connector to connect to and read the MySQL server binlog. |
|
| Enables the connector the use of the following statements:
The connector always requires this. |
|
| Identifies the database to which the permissions apply. |
|
| Specifies the user to grant the permissions to. |
|
| Specifies the user’s MySQL password. |
5.4.2. Enabling the MySQL binlog for Debezium
You must enable binary logging for MySQL replication. The binary logs record transaction updates for replication tools to propagate changes.
Prerequisites
- A MySQL server.
- Appropriate MySQL user privileges.
Procedure
Check whether the
log-binoption is already on:mysql> SELECT variable_value as "BINARY LOGGING STATUS (log-bin) ::" FROM information_schema.global_variables WHERE variable_name='log_bin';If it is
OFF, configure your MySQL server configuration file with the following properties, which are described in the table below:server-id = 223344 log_bin = mysql-bin binlog_format = ROW binlog_row_image = FULL expire_logs_days = 10Confirm your changes by checking the binlog status once more:
mysql> SELECT variable_value as "BINARY LOGGING STATUS (log-bin) ::" FROM information_schema.global_variables WHERE variable_name='log_bin';
| Property | Description |
|---|---|
|
|
The value for the |
|
|
The value of |
|
|
The |
|
|
The |
|
|
This is the number of days for automatic binlog file removal. The default is |
5.4.3. Enabling MySQL Global Transaction Identifiers for Debezium
Global transaction identifiers (GTIDs) uniquely identify transactions that occur on a server within a cluster. Though not required for a Debezium MySQL connector, using GTIDs simplifies replication and enables you to more easily confirm if primary and replica servers are consistent.
GTIDs are available in MySQL 5.6.5 and later. See the MySQL documentation for more details.
Prerequisites
- A MySQL server.
- Basic knowledge of SQL commands.
- Access to the MySQL configuration file.
Procedure
Enable
gtid_mode:mysql> gtid_mode=ONEnable
enforce_gtid_consistency:mysql> enforce_gtid_consistency=ONConfirm the changes:
mysql> show global variables like '%GTID%';
Result
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| enforce_gtid_consistency | ON |
| gtid_mode | ON |
+--------------------------+-------+| Option | Description |
|---|---|
|
| Boolean that specifies whether GTID mode of the MySQL server is enabled or not.
|
|
| Boolean that specifies whether the server enforces GTID consistency by allowing the execution of statements that can be logged in a transactionally safe manner. Required when using GTIDs.
|
5.4.4. Configuring MySQL session timesouts for Debezium
When an initial consistent snapshot is made for large databases, your established connection could timeout while the tables are being read. You can prevent this behavior by configuring interactive_timeout and wait_timeout in your MySQL configuration file.
Prerequisites
- A MySQL server.
- Basic knowledge of SQL commands.
- Access to the MySQL configuration file.
Procedure
Configure
interactive_timeout:mysql> interactive_timeout=<duration-in-seconds>Configure
wait_timeout:mysql> wait_timeout=<duration-in-seconds>
| Option | Description |
|---|---|
|
| The number of seconds the server waits for activity on an interactive connection before closing it. See MySQL’s documentation for more details. |
|
| The number of seconds the server waits for activity on a non-interactive connection before closing it. See MySQL’s documentation for more details. |
5.4.5. Enabling query log events for Debezium MySQL connectors
You might want to see the original SQL statement for each binlog event. Enabling the binlog_rows_query_log_events option in the MySQL configuration file allows you to do this.
This option is available in MySQL 5.6 and later.
Prerequisites
- A MySQL server.
- Basic knowledge of SQL commands.
- Access to the MySQL configuration file.
Procedure
Enable
binlog_rows_query_log_events:mysql> binlog_rows_query_log_events=ONbinlog_rows_query_log_eventsis set to a value that enables/disables support for including the originalSQLstatement in the binlog entry.-
ON= enabled -
OFF= disabled
-
5.5. Deployment of Debezium MySQL connectors
You can use either of the following methods to deploy a Debezium MySQL connector:
Additional resources
5.5.1. MySQL connector deployment using AMQ Streams
Beginning with Debezium 1.7, the preferred method for deploying a Debezium connector is to use AMQ Streams to build a Kafka Connect container image that includes the connector plug-in.
During the deployment process, you create and use the following custom resources (CRs):
-
A
KafkaConnectCR that defines your Kafka Connect instance and includes information about the connector artifacts needs to include in the image. -
A
KafkaConnectorCR that provides details that include information the connector uses to access the source database. After AMQ Streams starts the Kafka Connect pod, you start the connector by applying theKafkaConnectorCR.
In the build specification for the Kafka Connect image, you can specify the connectors that are available to deploy. For each connector plug-in, you can also specify other components that you want to make available for deployment. For example, you can add Service Registry artifacts, or the Debezium scripting component. When AMQ Streams builds the Kafka Connect image, it downloads the specified artifacts, and incorporates them into the image.
The spec.build.output parameter in the KafkaConnect CR specifies where to store the resulting Kafka Connect container image. Container images can be stored in a Docker registry, or in an OpenShift ImageStream. To store images in an ImageStream, you must create the ImageStream before you deploy Kafka Connect. ImageStreams are not created automatically.
If you use a KafkaConnect resource to create a cluster, afterwards you cannot use the Kafka Connect REST API to create or update connectors. You can still use the REST API to retrieve information.
Additional resources
- Configuring Kafka Connect in Using AMQ Streams on OpenShift.
- Creating a new container image automatically using AMQ Streams in Deploying and Upgrading AMQ Streams on OpenShift.
5.5.2. Using AMQ Streams to deploy a Debezium MySQL connector
With earlier versions of AMQ Streams, to deploy Debezium connectors on OpenShift, it was necessary to first build a Kafka Connect image for the connector. The current preferred method for deploying connectors on OpenShift is to use a build configuration in AMQ Streams to automatically build a Kafka Connect container image that includes the Debezium connector plug-ins that you want to use.
During the build process, the AMQ Streams Operator transforms input parameters in a KafkaConnect custom resource, including Debezium connector definitions, into a Kafka Connect container image. The build downloads the necessary artifacts from the Red Hat Maven repository or another configured HTTP server. The newly created container is pushed to the container registry that is specified in .spec.build.output, and is used to deploy a Kafka Connect pod. After AMQ Streams builds the Kafka Connect image, you create KafkaConnector custom resources to start the connectors that are included in the build.
Prerequisites
- You have access to an OpenShift cluster on which the cluster Operator is installed.
- The AMQ Streams Operator is running.
- An Apache Kafka cluster is deployed as documented in Deploying and Upgrading AMQ Streams on OpenShift.
- You have a Red Hat Integration license.
- Kafka Connect is deployed on AMQ Streams.
-
The OpenShift
ocCLI client is installed or you have access to the OpenShift Container Platform web console. Depending on how you intend to store the Kafka Connect build image, you need registry permissions or you must create an ImageStream resource:
- To store the build image in an image registry, such as Red Hat Quay.io or Docker Hub
- An account and permissions to create and manage images in the registry.
- To store the build image as a native OpenShift ImageStream
- An ImageStream resource is deployed to the cluster. You must explicitly create an ImageStream for the cluster. ImageStreams are not available by default.
Procedure
- Log in to the OpenShift cluster.
Create a Debezium
KafkaConnectcustom resource (CR) for the connector, or modify an existing one. For example, create aKafkaConnectCR that specifies themetadata.annotationsandspec.buildproperties, as shown in the following example. Save the file with a name such asdbz-connect.yaml.Example 5.1. A
dbz-connect.yamlfile that defines aKafkaConnectcustom resource that includes a Debezium connectorapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: debezium-kafka-connect-cluster annotations: strimzi.io/use-connector-resources: "true"1 spec: version: 3.00 build:2 output:3 type: imagestream4 image: debezium-streams-connect:latest plugins:5 - name: debezium-connector-mysql artifacts: - type: zip6 url: https://maven.repository.redhat.com/ga/io/debezium/debezium-connector-mysql/1.7.2.Final-redhat-<build_number>/debezium-connector-mysql-1.7.2.Final-redhat-<build_number>-plugin.zip7 - type: zip url: https://maven.repository.redhat.com/ga/io/apicurio/apicurio-registry-distro-connect-converter/2.0-redhat-<build-number>/apicurio-registry-distro-connect-converter-2.0-redhat-<build-number>.zip - type: zip url: https://maven.repository.redhat.com/ga/io/debezium/debezium-scripting/1.7.2.Final/debezium-scripting-1.7.2.Final.zip bootstrapServers: debezium-kafka-cluster-kafka-bootstrap:9093Expand Table 5.22. Descriptions of Kafka Connect configuration settings Item Description 1
Sets the
strimzi.io/use-connector-resourcesannotation to"true"to enable the Cluster Operator to useKafkaConnectorresources to configure connectors in this Kafka Connect cluster.2
The
spec.buildconfiguration specifies where to store the build image and lists the plug-ins to include in the image, along with the location of the plug-in artifacts.3
The
build.outputspecifies the registry in which the newly built image is stored.4
Specifies the name and image name for the image output. Valid values for
output.typearedockerto push into a container registry like Docker Hub or Quay, orimagestreamto push the image to an internal OpenShift ImageStream. To use an ImageStream, an ImageStream resource must be deployed to the cluster. For more information about specifying thebuild.outputin the KafkaConnect configuration, see the AMQ Streams Build schema reference documentation.5
The
pluginsconfiguration lists all of the connectors that you want to include in the Kafka Connect image. For each entry in the list, specify a plug-inname, and information for about the artifacts that are required to build the connector. Optionally, for each connector plug-in, you can include other components that you want to be available for use with the connector. For example, you can add Service Registry artifacts, or the Debezium scripting component.6
The value of
artifacts.typespecifies the file type of the artifact specified in theartifacts.url. Valid types arezip,tgz, orjar. Debezium connector archives are provided in.zipfile format. JDBC driver files are in.jarformat. Thetypevalue must match the type of the file that is referenced in theurlfield.7
The value of
artifacts.urlspecifies the address of an HTTP server, such as a Maven repository, that stores the file for the connector artifact. The OpenShift cluster must have access to the specified server.Apply the
KafkaConnectbuild specification to the OpenShift cluster by entering the following command:oc create -f dbz-connect.yamlBased on the configuration specified in the custom resource, the Streams Operator prepares a Kafka Connect image to deploy.
After the build completes, the Operator pushes the image to the specified registry or ImageStream, and starts the Kafka Connect cluster. The connector artifacts that you listed in the configuration are available in the cluster.Create a
KafkaConnectorresource to define an instance of each connector that you want to deploy.
For example, create the followingKafkaConnectorCR, and save it asmysql-inventory-connector.yamlExample 5.2. A
mysql-inventory-connector.yamlfile that defines theKafkaConnectorcustom resource for a Debezium connectorapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: labels: strimzi.io/cluster: debezium-kafka-connect-cluster name: inventory-connector-mysql1 spec: class: io.debezium.connector.mysql.MySqlConnector2 tasksMax: 13 config:4 database.history.kafka.bootstrap.servers: 'debezium-kafka-cluster-kafka-bootstrap.debezium.svc.cluster.local:9092' database.history.kafka.topic: schema-changes.inventory database.hostname: mysql.debezium-mysql.svc.cluster.local5 database.port: 33066 database.user: debezium7 database.password: dbz8 database.dbname: mydatabase9 database.server.name: inventory_connector_mysql10 database.include.list: public.inventory11 Expand Table 5.23. Descriptions of connector configuration settings Item Description 1
The name of the connector to register with the Kafka Connect cluster.
2
The name of the connector class.
3
The number of tasks that can operate concurrently.
4
The connector’s configuration.
5
The address of the host database instance.
6
The port number of the database instance.
7
The name of the user account through which Debezium connects to the database.
8
The password for the database user account.
9
The name of the database to capture changes from.
10
The logical name of the database instance or cluster.
The specified name must be formed only from alphanumeric characters or underscores.
Because the logical name is used as the prefix for any Kafka topics that receive change events from this connector, the name must be unique among the connectors in the cluster.
The namespace is also used in the names of related Kafka Connect schemas, and the namespaces of a corresponding Avro schema if you integrate the connector with the Avro connector.11
The list of tables from which the connector captures change events.
Create the connector resource by running the following command:
oc create -n <namespace> -f <kafkaConnector>.yamlFor example,
oc create -n debezium -f {context}-inventory-connector.yamlThe connector is registered to the Kafka Connect cluster and starts to run against the database that is specified by
spec.config.database.dbnamein theKafkaConnectorCR. After the connector pod is ready, Debezium is running.
You are now ready to verify the Debezium MySQL deployment.
5.5.3. Deploying Debezium MySQL connectors by building a custom Kafka Connect container image from a Dockerfile
To deploy a Debezium MySQL connector, you must build a custom Kafka Connect container image that contains the Debezium connector archive, and then push this container image to a container registry. You then need to create the following custom resources (CRs):
-
A
KafkaConnectCR that defines your Kafka Connect instance. Theimageproperty in the CR specifies the name of the container image that you create to run your Debezium connector. You apply this CR to the OpenShift instance where Red Hat AMQ Streams is deployed. AMQ Streams offers operators and images that bring Apache Kafka to OpenShift. -
A
KafkaConnectorCR that defines your Debezium MySQL connector. Apply this CR to the same OpenShift instance where you apply theKafkaConnectCR.
Prerequisites
- MySQL is running and you completed the steps to set up MySQL to work with a Debezium connector.
- AMQ Streams is deployed on OpenShift and is running Apache Kafka and Kafka Connect. For more information, see Deploying and Upgrading AMQ Streams on OpenShift.
- Podman or Docker is installed.
-
You have an account and permissions to create and manage containers in the container registry (such as
quay.ioordocker.io) to which you plan to add the container that will run your Debezium connector.
Procedure
Create the Debezium MySQL container for Kafka Connect:
- Download the Debezium MySQL connector archive.
Extract the Debezium MySQL connector archive to create a directory structure for the connector plug-in, for example:
./my-plugins/ ├── debezium-connector-mysql │ ├── ...Create a Dockerfile that uses
registry.redhat.io/amq7/amq-streams-kafka-30-rhel8:2.0.0as the base image. For example, from a terminal window, enter the following, replacingmy-pluginswith the name of your plug-ins directory:cat <<EOF >debezium-container-for-mysql.yaml1 FROM registry.redhat.io/amq7/amq-streams-kafka-30-rhel8:2.0.0 USER root:root COPY ./<my-plugins>/ /opt/kafka/plugins/2 USER 1001 EOFThe command creates a Dockerfile with the name
debezium-container-for-mysql.yamlin the current directory.Build the container image from the
debezium-container-for-mysql.yamlDocker file that you created in the previous step. From the directory that contains the file, open a terminal window and enter one of the following commands:podman build -t debezium-container-for-mysql:latest .docker build -t debezium-container-for-mysql:latest .The preceding commands build a container image with the name
debezium-container-for-mysql.Push your custom image to a container registry, such as
quay.ioor an internal container registry. The container registry must be available to the OpenShift instance where you want to deploy the image. Enter one of the following commands:podman push <myregistry.io>/debezium-container-for-mysql:latestdocker push <myregistry.io>/debezium-container-for-mysql:latestCreate a new Debezium MySQL
KafkaConnectcustom resource (CR). For example, create aKafkaConnectCR with the namedbz-connect.yamlthat specifiesannotationsandimageproperties as shown in the following example:apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true"1 spec: #... image: debezium-container-for-mysql2 - 1
metadata.annotationsindicates to the Cluster Operator that KafkaConnector resources are used to configure connectors in this Kafka Connect cluster.- 2
spec.imagespecifies the name of the image that you created to run your Debezium connector. This property overrides theSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGEvariable in the Cluster Operator.
Apply the
KafkaConnectCR to the OpenShift Kafka Connect environment by entering the following command:oc create -f dbz-connect.yamlThe command adds a Kafka Connect instance that specifies the name of the image that you created to run your Debezium connector.
Create a
KafkaConnectorcustom resource that configures your Debezium MySQL connector instance.You configure a Debezium MySQL connector in a
.yamlfile that specifies the configuration properties for the connector. The connector configuration might instruct Debezium to produce events for a subset of the schemas and tables, or it might set properties so that Debezium ignores, masks, or truncates values in specified columns that are sensitive, too large, or not needed.The following example configures a Debezium connector that connects to a MySQL host,
192.168.99.100, on port3306, and captures changes to theinventorydatabase.dbserver1is the server’s logical name.MySQL
inventory-connector.yamlapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: inventory-connector1 labels: strimzi.io/cluster: my-connect-cluster spec: class: io.debezium.connector.mysql.MySqlConnector tasksMax: 12 config:3 database.hostname: mysql4 database.port: 3306 database.user: debezium database.password: dbz database.server.id: 1840545 database.server.name: dbserver16 database.include.list: inventory7 database.history.kafka.bootstrap.servers: my-cluster-kafka-bootstrap:90928 database.history.kafka.topic: schema-changes.inventory9 Expand Table 5.24. Descriptions of connector configuration settings Item Description 1
The name of the connector.
2
Only one task should operate at any one time. Because the MySQL connector reads the MySQL server’s
binlog, using a single connector task ensures proper order and event handling. The Kafka Connect service uses connectors to start one or more tasks that do the work, and it automatically distributes the running tasks across the cluster of Kafka Connect services. If any of the services stop or crash, those tasks will be redistributed to running services.3
The connector’s configuration.
4
The database host, which is the name of the container running the MySQL server (
mysql).5
Unique ID of the connector.
6
Logical name of the MySQL server or cluster. This name is used as the prefix for all Kafka topics that receive change event records.
7
Changes in only the
inventorydatabase are captured.8
The list of Kafka brokers that this connector will use to write and recover DDL statements to the database history topic. Upon restart, the connector recovers the schemas of the database that existed at the point in time in the binlog when the connector should begin reading.
9
The name of the database history topic. This topic is for internal use only and should not be used by consumers.
Create your connector instance with Kafka Connect. For example, if you saved your
KafkaConnectorresource in theinventory-connector.yamlfile, you would run the following command:oc apply -f inventory-connector.yamlThe preceding command registers
inventory-connectorand the connector starts to run against theinventorydatabase as defined in theKafkaConnectorCR.
For the complete list of the configuration properties that you can set for the Debezium MySQL connector, see MySQL connector configuration properties.
Results
After the connector starts, it performs a consistent snapshot of the MySQL databases that the connector is configured for. The connector then starts generating data change events for row-level operations and streaming change event records to Kafka topics.
5.5.4. Verifying that the Debezium MySQL connector is running
If the connector starts correctly without errors, it creates a topic for each table that the connector is configured to capture. Downstream applications can subscribe to these topics to retrieve information events that occur in the source database.
To verify that the connector is running, you perform the following operations from the OpenShift Container Platform web console, or through the OpenShift CLI tool (oc):
- Verify the connector status.
- Verify that the connector generates topics.
- Verify that topics are populated with events for read operations ("op":"r") that the connector generates during the initial snapshot of each table.
Prerequisites
- A Debezium connector is deployed to AMQ Streams on OpenShift.
-
The OpenShift
ocCLI client is installed. - You have access to the OpenShift Container Platform web console.
Procedure
Check the status of the
KafkaConnectorresource by using one of the following methods:From the OpenShift Container Platform web console:
- Navigate to Home → Search.
-
On the Search page, click Resources to open the Select Resource box, and then type
KafkaConnector. - From the KafkaConnectors list, click the name of the connector that you want to check, for example inventory-connector-mysql.
- In the Conditions section, verify that the values in the Type and Status columns are set to Ready and True.
From a terminal window:
Enter the following command:
oc describe KafkaConnector <connector-name> -n <project>For example,
oc describe KafkaConnector inventory-connector-mysql -n debeziumThe command returns status information that is similar to the following output:
Example 5.3.
KafkaConnectorresource statusName: inventory-connector-mysql Namespace: debezium Labels: strimzi.io/cluster=debezium-kafka-connect-cluster Annotations: <none> API Version: kafka.strimzi.io/v1beta2 Kind: KafkaConnector ... Status: Conditions: Last Transition Time: 2021-12-08T17:41:34.897153Z Status: True Type: Ready Connector Status: Connector: State: RUNNING worker_id: 10.131.1.124:8083 Name: inventory-connector-mysql Tasks: Id: 0 State: RUNNING worker_id: 10.131.1.124:8083 Type: source Observed Generation: 1 Tasks Max: 1 Topics: inventory_connector_mysql inventory_connector_mysql.inventory.addresses inventory_connector_mysql.inventory.customers inventory_connector_mysql.inventory.geom inventory_connector_mysql.inventory.orders inventory_connector_mysql.inventory.products inventory_connector_mysql.inventory.products_on_hand Events: <none>
Verify that the connector created Kafka topics:
From the OpenShift Container Platform web console.
- Navigate to Home → Search.
-
On the Search page, click Resources to open the Select Resource box, and then type
KafkaTopic. - From the KafkaTopics list, click the name of the topic that you want to check, for example, inventory-connector-mysql.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d.
- In the Conditions section, verify that the values in the Type and Status columns are set to Ready and True.
From a terminal window:
Enter the following command:
oc get kafkatopicsThe command returns status information that is similar to the following output:
Example 5.4.
KafkaTopicresource statusNAME CLUSTER PARTITIONS REPLICATION FACTOR READY connect-cluster-configs debezium-kafka-cluster 1 1 True connect-cluster-offsets debezium-kafka-cluster 25 1 True connect-cluster-status debezium-kafka-cluster 5 1 True consumer-offsets---84e7a678d08f4bd226872e5cdd4eb527fadc1c6a debezium-kafka-cluster 50 1 True inventory-connector-mysql---a96f69b23d6118ff415f772679da623fbbb99421 debezium-kafka-cluster 1 1 True inventory-connector-mysql.inventory.addresses---1b6beaf7b2eb57d177d92be90ca2b210c9a56480 debezium-kafka-cluster 1 1 True inventory-connector-mysql.inventory.customers---9931e04ec92ecc0924f4406af3fdace7545c483b debezium-kafka-cluster 1 1 True inventory-connector-mysql.inventory.geom---9f7e136091f071bf49ca59bf99e86c713ee58dd5 debezium-kafka-cluster 1 1 True inventory-connector-mysql.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d debezium-kafka-cluster 1 1 True inventory-connector-mysql.inventory.products---df0746db116844cee2297fab611c21b56f82dcef debezium-kafka-cluster 1 1 True inventory-connector-mysql.inventory.products-on-hand---8649e0f17ffcc9212e266e31a7aeea4585e5c6b5 debezium-kafka-cluster 1 1 True schema-changes.inventory debezium-kafka-cluster 1 1 True strimzi-store-topic---effb8e3e057afce1ecf67c3f5d8e4e3ff177fc55 debezium-kafka-cluster 1 1 True strimzi-topic-operator-kstreams-topic-store-changelog---b75e702040b99be8a9263134de3507fc0cc4017b debezium-kafka-cluster 1 1 True
Check topic content.
- From a terminal window, enter the following command:
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>For example,
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory_connector_mysql.inventory.products_on_handThe format for specifying the topic name is the same as the
oc describecommand returns in Step 1, for example,inventory_connector_mysql.inventory.addresses.For each event in the topic, the command returns information that is similar to the following output:
Example 5.5. Content of a Debezium change event
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory_connector_mysql.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory_connector_mysql.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory_connector_mysql.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.mysql.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory_connector_mysql.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"1.7.2.Final-redhat-00001","connector":"mysql","name":"inventory_connector_mysql","ts_ms":1638985247805,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"mysql-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"transaction":null}}In the preceding example, the
payloadvalue shows that the connector snapshot generated a read ("op" ="r") event from the tableinventory.products_on_hand. The"before"state of theproduct_idrecord isnull, indicating that no previous value exists for the record. The"after"state shows aquantityof3for the item withproduct_id101.
5.5.5. Description of Debezium MySQL connector configuration properties
The Debezium MySQL connector has numerous configuration properties that you can use to achieve the right connector behavior for your application. Many properties have default values. Information about the properties is organized as follows:
- Required connector configuration properties
- Advanced connector configuration properties
Database history connector configuration properties that control how Debezium processes events that it reads from the database history topic.
- Pass-through database driver properties that control the behavior of the database driver.
The following configuration properties are required unless a default value is available.
| Property | Default | Description |
|---|---|---|
| No default | Unique name for the connector. Attempting to register again with the same name fails. This property is required by all Kafka Connect connectors. | |
| No default |
The name of the Java class for the connector. Always specify | |
|
| The maximum number of tasks that should be created for this connector. The MySQL connector always uses a single task and therefore does not use this value, so the default is always acceptable. | |
| No default | IP address or host name of the MySQL database server. | |
|
| Integer port number of the MySQL database server. | |
| No default | Name of the MySQL user to use when connecting to the MySQL database server. | |
| No default | Password to use when connecting to the MySQL database server. | |
| No default | Logical name that identifies and provides a namespace for the particular MySQL database server/cluster in which Debezium is capturing changes. The logical name should be unique across all other connectors, since it is used as a prefix for all Kafka topic names that receive events emitted by this connector. Only alphanumeric characters, hyphens, dots and underscores must be used in the database server logical name. | |
| random | A numeric ID of this database client, which must be unique across all currently-running database processes in the MySQL cluster. This connector joins the MySQL database cluster as another server (with this unique ID) so it can read the binlog. By default, a random number between 5400 and 6400 is generated, though the recommendation is to explicitly set a value. | |
| empty string |
An optional, comma-separated list of regular expressions that match the names of the databases for which to capture changes. The connector does not capture changes in any database whose name is not in | |
| empty string |
An optional, comma-separated list of regular expressions that match the names of databases for which you do not want to capture changes. The connector captures changes in any database whose name is not in the | |
| empty string |
An optional, comma-separated list of regular expressions that match fully-qualified table identifiers of tables whose changes you want to capture. The connector does not capture changes in any table not included in | |
| empty string |
An optional, comma-separated list of regular expressions that match fully-qualified table identifiers for tables whose changes you do not want to capture. The connector captures changes in any table not included in | |
| empty string | An optional, comma-separated list of regular expressions that match the fully-qualified names of columns to exclude from change event record values. Fully-qualified names for columns are of the form databaseName.tableName.columnName. | |
| empty string | An optional, comma-separated list of regular expressions that match the fully-qualified names of columns to include in change event record values. Fully-qualified names for columns are of the form databaseName.tableName.columnName. | |
| n/a | An optional, comma-separated list of regular expressions that match the fully-qualified names of character-based columns whose values should be truncated in the change event record values if the field values are longer than the specified number of characters. You can configure multiple properties with different lengths in a single configuration. The length must be a positive integer. Fully-qualified names for columns are of the form databaseName.tableName.columnName. | |
| n/a |
An optional, comma-separated list of regular expressions that match the fully-qualified names of character-based columns whose values should be replaced in the change event message values with a field value consisting of the specified number of asterisk ( | |
| n/a |
An optional, comma-separated list of regular expressions that match the fully-qualified names of character-based columns. Fully-qualified names for columns are of the form
A pseudonym consists of the hashed value that results from applying the specified hashAlgorithm and salt. Based on the hash function that is used, referential integrity is maintained, while column values are replaced with pseudonyms. Supported hash functions are described in the MessageDigest section of the Java Cryptography Architecture Standard Algorithm Name Documentation.
If necessary, the pseudonym is automatically shortened to the length of the column. The connector configuration can include multiple properties that specify different hash algorithms and salts. | |
| n/a | An optional, comma-separated list of regular expressions that match the fully-qualified names of columns whose original type and length should be added as a parameter to the corresponding field schemas in the emitted change event records. These schema parameters:
are used to propagate the original type name and length for variable-width types, respectively. This is useful to properly size corresponding columns in sink databases. Fully-qualified names for columns are of one of these forms: databaseName.tableName.columnName databaseName.schemaName.tableName.columnName | |
| n/a | An optional, comma-separated list of regular expressions that match the database-specific data type name of columns whose original type and length should be added as a parameter to the corresponding field schemas in the emitted change event records. These schema parameters:
are used to propagate the original type name and length for variable-width types, respectively. This is useful to properly size corresponding columns in sink databases. Fully-qualified data type names are of one of these forms: databaseName.tableName.typeName databaseName.schemaName.tableName.typeName See how MySQL connectors map data types for the list of MySQL-specific data type names. | |
|
|
Time, date, and timestamps can be represented with different kinds of precision, including: | |
|
|
Specifies how the connector should handle values for | |
|
|
Specifies how BIGINT UNSIGNED columns should be represented in change events. Possible settings are: | |
|
| Boolean value that specifies whether the connector should publish changes in the database schema to a Kafka topic with the same name as the database server ID. Each schema change is recorded by using a key that contains the database name and whose value includes the DDL statement(s). This is independent of how the connector internally records database history. | |
|
|
Boolean value that specifies whether the connector should include the original SQL query that generated the change event. | |
|
|
Specifies how the connector should react to exceptions during deserialization of binlog events. | |
|
|
Specifies how the connector should react to binlog events that relate to tables that are not present in internal schema representation. That is, the internal representation is not consistent with the database. | |
|
|
Positive integer value that specifies the maximum size of the blocking queue into which change events read from the database log are placed before they are written to Kafka. This queue can provide backpressure to the binlog reader when, for example, writes to Kafka are slow or if Kafka is not available. Events that appear in the queue are not included in the offsets periodically recorded by this connector. Defaults to 8192, and should always be larger than the maximum batch size specified by the | |
|
| Positive integer value that specifies the maximum size of each batch of events that should be processed during each iteration of this connector. Defaults to 2048. | |
|
| Long value for the maximum size in bytes of the blocking queue. The feature is disabled by default, it will be active if it’s set with a positive long value. | |
|
| Positive integer value that specifies the number of milliseconds the connector should wait for new change events to appear before it starts processing a batch of events. Defaults to 1000 milliseconds, or 1 second. | |
|
| A positive integer value that specifies the maximum time in milliseconds this connector should wait after trying to connect to the MySQL database server before timing out. Defaults to 30 seconds. | |
| No default |
A comma-separated list of regular expressions that match source UUIDs in the GTID set used to find the binlog position in the MySQL server. Only the GTID ranges that have sources that match one of these include patterns are used. Do not also specify a setting for | |
| No default |
A comma-separated list of regular expressions that match source UUIDs in the GTID set used to find the binlog position in the MySQL server. Only the GTID ranges that have sources that do not match any of these exclude patterns are used. Do not also specify a value for | |
|
|
Controls whether a delete event is followed by a tombstone event. | |
| n/a | A list of expressions that specify the columns that the connector uses to form custom message keys for change event records that it publishes to the Kafka topics for specified tables.
By default, Debezium uses the primary key column of a table as the message key for records that it emits. In place of the default, or to specify a key for tables that lack a primary key, you can configure custom message keys based on one or more columns.
Each fully-qualified table name is a regular expression in the following format: There is no limit to the number of columns that you use to create custom message keys. However, it’s best to use the minimum number that are required to specify a unique key. | |
| bytes |
Specifies how binary columns, for example, |
Advanced MySQL connector configuration properties
The following table describes advanced MySQL connector properties. The default values for these properties rarely need to be changed. Therefore, you do not need to specify them in the connector configuration.
| Property | Default | Description |
|---|---|---|
|
| A Boolean value that specifies whether a separate thread should be used to ensure that the connection to the MySQL server/cluster is kept alive. | |
|
| A Boolean value that specifies whether built-in system tables should be ignored. This applies regardless of the table include and exclude lists. By default, system tables are excluded from having their changes captured, and no events are generated when changes are made to any system tables. | |
|
|
Specifies whether to use an encrypted connection. Possible settings are: | |
|
|
Specifies the criteria for running a snapshot when the connector starts. Possible settings are: | |
|
|
Controls whether and how long the connector holds the global MySQL read lock, which prevents any updates to the database, while the connector is performing a snapshot. Possible settings are: | |
|
All tables specified in |
An optional, comma-separated list of regular expressions that match the fully-qualified names ( | |
| No default | Specifies the table rows to include in a snapshot. Use the property if you want a snapshot to include only a subset of the rows in a table. This property affects snapshots only. It does not apply to events that the connector reads from the log.
The property contains a comma-separated list of fully-qualified table names in the form
From a
In the resulting snapshot, the connector includes only the records for which | |
|
|
During a snapshot, the connector queries each table for which the connector is configured to capture changes. The connector uses each query result to produce a read event that contains data for all rows in that table. This property determines whether the MySQL connector puts results for a table into memory, which is fast but requires large amounts of memory, or streams the results, which can be slower but work for very large tables. The setting of this property specifies the minimum number of rows a table must contain before the connector streams results. | |
|
|
Controls how frequently the connector sends heartbeat messages to a Kafka topic. The default behavior is that the connector does not send heartbeat messages. | |
|
|
Controls the name of the topic to which the connector sends heartbeat messages. The topic name has this pattern: | |
| No default |
A semicolon separated list of SQL statements to be executed when a JDBC connection, not the connection that is reading the transaction log, to the database is established. To specify a semicolon as a character in a SQL statement and not as a delimiter, use two semicolons, ( | |
| No default | An interval in milliseconds that the connector should wait before performing a snapshot when the connector starts. If you are starting multiple connectors in a cluster, this property is useful for avoiding snapshot interruptions, which might cause re-balancing of connectors. | |
| No default | During a snapshot, the connector reads table content in batches of rows. This property specifies the maximum number of rows in a batch. | |
|
| Positive integer that specifies the maximum amount of time (in milliseconds) to wait to obtain table locks when performing a snapshot. If the connector cannot acquire table locks in this time interval, the snapshot fails. See how MySQL connectors perform database snapshots. | |
|
|
Boolean value that indicates whether the connector converts a 2-digit year specification to 4 digits. Set to | |
|
| Indicates whether field names are sanitized to adhere to Avro naming requirements. | |
| No default |
Comma-separated list of operation types to skip during streaming. The following values are possible: | |
| No default value |
Fully-qualified name of the data collection that is used to send signals to the connector. Signaling is a Technology Preview feature. | |
|
| The maximum number of rows that the connector fetches and reads into memory during an incremental snapshot chunk. Increasing the chunk size provides greater efficiency, because the snapshot runs fewer snapshot queries of a greater size. However, larger chunk sizes also require more memory to buffer the snapshot data. Adjust the chunk size to a value that provides the best performance in your environment. Incremental snapshots is a Technology Preview feature. | |
|
| Switch to alternative incremental snapshot watermarks implementation to avoid writes to signal data collection | |
|
|
Determines whether the connector generates events with transaction boundaries and enriches change event envelopes with transaction metadata. Specify |
Debezium connector database history configuration properties
Debezium provides a set of database.history.* properties that control how the connector interacts with the schema history topic.
The following table describes the database.history properties for configuring the Debezium connector.
| Property | Default | Description |
|---|---|---|
| The full name of the Kafka topic where the connector stores the database schema history. | ||
| A list of host/port pairs that the connector uses for establishing an initial connection to the Kafka cluster. This connection is used for retrieving the database schema history previously stored by the connector, and for writing each DDL statement read from the source database. Each pair should point to the same Kafka cluster used by the Kafka Connect process. | ||
|
| An integer value that specifies the maximum number of milliseconds the connector should wait during startup/recovery while polling for persisted data. The default is 100ms. | |
|
|
The maximum number of times that the connector should try to read persisted history data before the connector recovery fails with an error. The maximum amount of time to wait after receiving no data is | |
|
|
A Boolean value that specifies whether the connector should ignore malformed or unknown database statements or stop processing so a human can fix the issue. The safe default is | |
|
Deprecated and scheduled for removal in a future release; use |
|
A Boolean value that specifies whether the connector should record all DDL statements
The safe default is |
|
|
A Boolean value that specifies whether the connector should record all DDL statements
The safe default is |
Pass-through database history properties for configuring producer and consumer clients
Debezium relies on a Kafka producer to write schema changes to database history topics. Similarly, it relies on a Kafka consumer to read from database history topics when a connector starts. You define the configuration for the Kafka producer and consumer clients by assigning values to a set of pass-through configuration properties that begin with the database.history.producer.* and database.history.consumer.* prefixes. The pass-through producer and consumer database history properties control a range of behaviors, such as how these clients secure connections with the Kafka broker, as shown in the following example:
database.history.producer.security.protocol=SSL
database.history.producer.ssl.keystore.location=/var/private/ssl/kafka.server.keystore.jks
database.history.producer.ssl.keystore.password=test1234
database.history.producer.ssl.truststore.location=/var/private/ssl/kafka.server.truststore.jks
database.history.producer.ssl.truststore.password=test1234
database.history.producer.ssl.key.password=test1234
database.history.consumer.security.protocol=SSL
database.history.consumer.ssl.keystore.location=/var/private/ssl/kafka.server.keystore.jks
database.history.consumer.ssl.keystore.password=test1234
database.history.consumer.ssl.truststore.location=/var/private/ssl/kafka.server.truststore.jks
database.history.consumer.ssl.truststore.password=test1234
database.history.consumer.ssl.key.password=test1234Debezium strips the prefix from the property name before it passes the property to the Kafka client.
See the Kafka documentation for more details about Kafka producer configuration properties and Kafka consumer configuration properties.
Debezium connector Kafka signals configuration properties
When the MySQL connector is configured as read-only, the alternative for the signaling table is the signals Kafka topic.
Debezium provides a set of signal.* properties that control how the connector interacts with the Kafka signals topic.
The following table describes the signal properties.
| Property | Default | Description |
|---|---|---|
| The name of the Kafka topic that the connector monitors for ad hoc signals. | ||
| A list of host/port pairs that the connector uses for establishing an initial connection to the Kafka cluster. Each pair should point to the same Kafka cluster used by the Kafka Connect process. | ||
|
| An integer value that specifies the maximum number of milliseconds the connector should wait when polling signals. The default is 100ms. |
Debezium connector pass-through signals Kafka consumer client configuration properties
The Debezium connector provides for pass-through configuration of the signals Kafka consumer. Pass-through signals properties begin with the prefix signals.consumer.*. For example, the connector passes properties such as signal.consumer.security.protocol=SSL to the Kafka consumer.
As is the case with the pass-through properties for database history clients, Debezium strips the prefixes from the properties before it passes them to the Kafka signals consumer.
Debezium connector pass-through database driver configuration properties
The Debezium connector provides for pass-through configuration of the database driver. Pass-through database properties begin with the prefix database.*. For example, the connector passes properties such as database.foobar=false to the JDBC URL.
As is the case with the pass-through properties for database history clients, Debezium strips the prefixes from the properties before it passes them to the database driver.
5.6. Monitoring Debezium MySQL connector performance
The Debezium MySQL connector provides three types of metrics that are in addition to the built-in support for JMX metrics that Zookeeper, Kafka, and Kafka Connect provide.
- Snapshot metrics provide information about connector operation while performing a snapshot.
- Streaming metrics provide information about connector operation when the connector is reading the binlog.
- Schema history metrics provide information about the status of the connector’s schema history.
Debezium monitoring documentation provides details for how to expose these metrics by using JMX.
5.6.1. Monitoring Debezium during snapshots of MySQL databases
The MBean is debezium.mysql:type=connector-metrics,context=snapshot,server=<mysql.server.name>.
Snapshot metrics are not exposed unless a snapshot operation is active, or if a snapshot has occurred since the last connector start.
The following table lists the shapshot metrics that are available.
| Attributes | Type | Description |
|---|---|---|
|
| The last snapshot event that the connector has read. | |
|
| The number of milliseconds since the connector has read and processed the most recent event. | |
|
| The total number of events that this connector has seen since last started or reset. | |
|
| The number of events that have been filtered by include/exclude list filtering rules configured on the connector. | |
|
|
| The list of tables that are monitored by the connector. |
|
| The list of tables that are captured by the connector. | |
|
| The length the queue used to pass events between the snapshotter and the main Kafka Connect loop. | |
|
| The free capacity of the queue used to pass events between the snapshotter and the main Kafka Connect loop. | |
|
| The total number of tables that are being included in the snapshot. | |
|
| The number of tables that the snapshot has yet to copy. | |
|
| Whether the snapshot was started. | |
|
| Whether the snapshot was aborted. | |
|
| Whether the snapshot completed. | |
|
| The total number of seconds that the snapshot has taken so far, even if not complete. | |
|
| Map containing the number of rows scanned for each table in the snapshot. Tables are incrementally added to the Map during processing. Updates every 10,000 rows scanned and upon completing a table. | |
|
|
The maximum buffer of the queue in bytes. It will be enabled if | |
|
| The current data of records in the queue in bytes. |
The connector also provides the following additional snapshot metrics when an incremental snapshot is executed:
| Attributes | Type | Description |
|---|---|---|
|
| The identifier of the current snapshot chunk. | |
|
| The lower bound of the primary key set defining the current chunk. | |
|
| The upper bound of the primary key set defining the current chunk. | |
|
| The lower bound of the primary key set of the currently snapshotted table. | |
|
| The upper bound of the primary key set of the currently snapshotted table. |
Incremental snapshots is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process. For more information about the support scope of Red Hat Technology Preview features, see https://access.redhat.com/support/offerings/techpreview.
The Debezium MySQL connector also provides the HoldingGlobalLock custom snapshot metric. This metric is set to a Boolean value that indicates whether the connector currently holds a global or table write lock.
5.6.2. Monitoring Debezium MySQL connector record streaming
Transaction-related attributes are available only if binlog event buffering is enabled. See binlog.buffer.size in the advanced connector configuration properties for more details.
The MBean is debezium.mysql:type=connector-metrics,context=streaming,server=<mysql.server.name>.
The following table lists the streaming metrics that are available.
| Attributes | Type | Description |
|---|---|---|
|
| The last streaming event that the connector has read. | |
|
| The number of milliseconds since the connector has read and processed the most recent event. | |
|
| The total number of events that this connector has seen since last started or reset. | |
|
| The number of events that have been filtered by include/exclude list filtering rules configured on the connector. | |
|
|
| The list of tables that are monitored by the connector. |
|
| The list of tables that are captured by the connector. | |
|
| The length the queue used to pass events between the streamer and the main Kafka Connect loop. | |
|
| The free capacity of the queue used to pass events between the streamer and the main Kafka Connect loop. | |
|
| Flag that denotes whether the connector is currently connected to the database server. | |
|
| The number of milliseconds between the last change event’s timestamp and the connector processing it. The values will incoporate any differences between the clocks on the machines where the database server and the connector are running. | |
|
| The number of processed transactions that were committed. | |
|
| The coordinates of the last received event. | |
|
| Transaction identifier of the last processed transaction. | |
|
| The maximum buffer of the queue in bytes. | |
|
| The current data of records in the queue in bytes. |
The Debezium MySQL connector also provides the following additional streaming metrics:
| Attribute | Type | Description |
|---|---|---|
|
| The name of the binlog file that the connector has most recently read. | |
|
| The most recent position (in bytes) within the binlog that the connector has read. | |
|
| Flag that denotes whether the connector is currently tracking GTIDs from MySQL server. | |
|
| The string representation of the most recent GTID set processed by the connector when reading the binlog. | |
|
| The number of events that have been skipped by the MySQL connector. Typically events are skipped due to a malformed or unparseable event from MySQL’s binlog. | |
|
| The number of disconnects by the MySQL connector. | |
|
| The number of processed transactions that were rolled back and not streamed. | |
|
|
The number of transactions that have not conformed to the expected protocol of | |
|
|
The number of transactions that have not fit into the look-ahead buffer. For optimal performance, this value should be significantly smaller than |
5.6.3. Monitoring Debezium MySQL connector schema history
The MBean is debezium.mysql:type=connector-metrics,context=schema-history,server=<mysql.server.name>.
The following table lists the schema history metrics that are available.
| Attributes | Type | Description |
|---|---|---|
|
|
One of | |
|
| The time in epoch seconds at what recovery has started. | |
|
| The number of changes that were read during recovery phase. | |
|
| the total number of schema changes applied during recovery and runtime. | |
|
| The number of milliseconds that elapsed since the last change was recovered from the history store. | |
|
| The number of milliseconds that elapsed since the last change was applied. | |
|
| The string representation of the last change recovered from the history store. | |
|
| The string representation of the last applied change. |
5.7. How Debezium MySQL connectors handle faults and problems
Debezium is a distributed system that captures all changes in multiple upstream databases; it never misses or loses an event. When the system is operating normally or being managed carefully then Debezium provides exactly once delivery of every change event record.
If a fault does happen then the system does not lose any events. However, while it is recovering from the fault, it might repeat some change events. In these abnormal situations, Debezium, like Kafka, provides at least once delivery of change events.
Details are in the following sections:
Configuration and startup errors
In the following situations, the connector fails when trying to start, reports an error or exception in the log, and stops running:
- The connector’s configuration is invalid.
- The connector cannot successfully connect to the MySQL server by using the specified connection parameters.
- The connector is attempting to restart at a position in the binlog for which MySQL no longer has the history available.
In these cases, the error message has details about the problem and possibly a suggested workaround. After you correct the configuration or address the MySQL problem, restart the connector.
However, if GTIDs are enabled for a highly available MySQL cluster, you can restart the connector immediately. It will connect to a different MySQL server in the cluster, find the location in the server’s binlog that represents the last transaction, and begin reading the new server’s binlog from that specific location.
If GTIDs are not enabled, the connector records the binlog position of only the MySQL server to which it was connected. To restart from the correct binlog position, you must reconnect to that specific server.
Kafka Connect stops gracefully
When Kafka Connect stops gracefully, there is a short delay while the Debezium MySQL connector tasks are stopped and restarted on new Kafka Connect processes.
Kafka Connect process crashes
If Kafka Connect crashes, the process stops and any Debezium MySQL connector tasks terminate without their most recently-processed offsets being recorded. In distributed mode, Kafka Connect restarts the connector tasks on other processes. However, the MySQL connector resumes from the last offset recorded by the earlier processes. This means that the replacement tasks might generate some of the same events processed prior to the crash, creating duplicate events.
Each change event message includes source-specific information that you can use to identify duplicate events, for example:
- Event origin
- MySQL server’s event time
- The binlog file name and position
- GTIDs (if used)
MySQL purges binlog files
If the Debezium MySQL connector stops for too long, the MySQL server purges older binlog files and the connector’s last position may be lost. When the connector is restarted, the MySQL server no longer has the starting point and the connector performs another initial snapshot. If the snapshot is disabled, the connector fails with an error.
See snapshots for details about how MySQL connectors perform initial snapshots.
Chapter 6. Debezium Connector for Oracle (Technology Preview)
Debezium’s Oracle connector captures and records row-level changes that occur in databases on an Oracle server, including tables that are added while the connector is running. You can configure the connector to emit change events for specific subsets of schemas and tables, or to ignore, mask, or truncate values in specific columns.
For information about the Oracle Database versions that are compatible with this connector, see the Debezium Supported Configurations page.
Debezium ingests change events from Oracle by using the native LogMiner database package .
Debezium Oracle connector is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process. For more information about the support scope of Red Hat Technology Preview features, see https://access.redhat.com/support/offerings/techpreview.
Information and procedures for using a Debezium Oracle connector are organized as follows:
- Section 6.1, “How Debezium Oracle connectors work”
- Section 6.2, “Descriptions of Debezium Oracle connector data change events”
- Section 6.3, “How Debezium Oracle connectors map data types”
- Section 6.4, “Setting up Oracle to work with Debezium”
- Section 6.5, “Deployment of Debezium Oracle connectors”
- Section 6.7, “Monitoring Debezium Oracle connector performance”
- Section 6.8, “How Debezium Oracle connectors handle faults and problems”
6.1. How Debezium Oracle connectors work
To optimally configure and run a Debezium Oracle connector, it is helpful to understand how the connector performs snapshots, streams change events, determines Kafka topic names, and uses metadata.
Details are in the following topics:
- Section 6.1.1, “How Debezium Oracle connectors perform database snapshots”
- Section 6.1.2, “Default names of Kafka topics that receive Debezium Oracle change event records”
- Section 6.1.3, “How Debezium Oracle connectors expose database schema changes”
- Section 6.1.4, “Debezium Oracle connector-generated events that represent transaction boundaries”
6.1.1. How Debezium Oracle connectors perform database snapshots
Typically, the redo logs on an Oracle server are configured to not retain the complete history of the database. As a result, the Debezium Oracle connector cannot retrieve the entire history of the database from the logs. To enable the connector to establish a baseline for the current state of the database, the first time that the connector starts, it performs an initial consistent snapshot of the database.
You can customize the way that the connector creates snapshots by setting the value of the snapshot.mode connector configuration property. By default, the connector’s snapshot mode is set to initial.
Default connector workflow for creating an initial snapshot
When the snapshot mode is set to the default, the connector completes the following tasks to create a snapshot:
- Determines the tables to be captured
-
Obtains a
ROW SHARE MODElock on each of the monitored tables to prevent structural changes from occurring during creation of the snapshot. Debezium holds the locks for only a short time. - Reads the current system change number (SCN) position from the server’s redo log.
- Captures the structure of all relevant tables.
- Releases the locks obtained in Step 2.
-
Scans all of the relevant database tables and schemas as valid at the SCN position that was read in Step 3 (
SELECT * FROM … AS OF SCN 123), generates aREADevent for each row, and then writes the event records to the table-specific Kafka topic. - Records the successful completion of the snapshot in the connector offsets.
After the snapshot process begins, if the process is interrupted due to connector failure, rebalancing, or other reasons, the process restarts after the connector restarts. After the connector completes the initial snapshot, it continues streaming from the position that it read in Step 3 so that it does not miss any updates. If the connector stops again for any reason, after it restarts, it resumes streaming changes from where it previously left off.
| Setting | Description |
|---|---|
|
| The connector performs a database snapshot as described in the default workflow for creating an initial snapshot. After the snapshot completes, the connector begins to stream event records for subsequent database changes. |
|
|
The connector captures the structure of all relevant tables, performing all of the steps described in the default snapshot workflow, except that it does not create |
6.1.1.1. Ad hoc snapshots
The use of ad hoc snapshots is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service-level agreements (SLAs) and might not be functionally complete; therefore, Red Hat does not recommend implementing any Technology Preview features in production environments. This Technology Preview feature provides early access to upcoming product innovations, enabling you to test functionality and provide feedback during the development process. For more information about support scope, see Technology Preview Features Support Scope.
By default, a connector runs an initial snapshot operation only after it starts for the first time. Following this initial snapshot, under normal circumstances, the connector does not repeat the snapshot process. Any future change event data that the connector captures comes in through the streaming process only.
However, in some situations the data that the connector obtained during the initial snapshot might become stale, lost, or incomplete. To provide a mechanism for recapturing table data, Debezium includes an option to perform ad hoc snapshots. The following changes in a database might be cause for performing an ad hoc snapshot:
- The connector configuration is modified to capture a different set of tables.
- Kafka topics are deleted and must be rebuilt.
- Data corruption occurs due to a configuration error or some other problem.
You can re-run a snapshot for a table for which you previously captured a snapshot by initiating a so-called ad-hoc snapshot. Ad hoc snapshots require the use of signaling tables. You initiate an ad hoc snapshot by sending a signal request to the Debezium signaling table.
When you initiate an ad hoc snapshot of an existing table, the connector appends content to the topic that already exists for the table. If a previously existing topic was removed, Debezium can create a topic automatically if automatic topic creation is enabled.
Ad hoc snapshot signals specify the tables to include in the snapshot. The snapshot can capture the entire contents of the database, or capture only a subset of the tables in the database.
You specify the tables to capture by sending an execute-snapshot message to the signaling table. Set the type of the execute-snapshot signal to incremental, and provide the names of the tables to include in the snapshot, as described in the following table:
| Field | Default | Value |
|---|---|---|
|
|
|
Specifies the type of snapshot that you want to run. |
|
| N/A |
An array that contains the fully-qualified names of the table to be snapshotted. |
Triggering an ad hoc snapshot
You initiate an ad hoc snapshot by adding an entry with the execute-snapshot signal type to the signaling table. After the connector processes the message, it begins the snapshot operation. The snapshot process reads the first and last primary key values and uses those values as the start and end point for each table. Based on the number of entries in the table, and the configured chunk size, Debezium divides the table into chunks, and proceeds to snapshot each chunk, in succession, one at a time.
Currently, the execute-snapshot action type triggers incremental snapshots only. For more information, see Incremental snapshots.
6.1.1.2. Incremental snapshots
The use of incremental snapshots is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service-level agreements (SLAs) and might not be functionally complete; therefore, Red Hat does not recommend implementing any Technology Preview features in production environments. This Technology Preview feature provides early access to upcoming product innovations, enabling you to test functionality and provide feedback during the development process. For more information about support scope, see Technology Preview Features Support Scope.
To provide flexibility in managing snapshots, Debezium includes a supplementary snapshot mechanism, known as incremental snapshotting. Incremental snapshots rely on the Debezium mechanism for sending signals to a Debezium connector.
In an incremental snapshot, instead of capturing the full state of a database all at once, as in an initial snapshot, Debezium captures each table in phases, in a series of configurable chunks. You can specify the tables that you want the snapshot to capture and the size of each chunk. The chunk size determines the number of rows that the snapshot collects during each fetch operation on the database. The default chunk size for incremental snapshots is 1 KB.
As an incremental snapshot proceeds, Debezium uses watermarks to track its progress, maintaining a record of each table row that it captures. This phased approach to capturing data provides the following advantages over the standard initial snapshot process:
- You can run incremental snapshots in parallel with streamed data capture, instead of postponing streaming until the snapshot completes. The connector continues to capture near real-time events from the change log throughout the snapshot process, and neither operation blocks the other.
- If the progress of an incremental snapshot is interrupted, you can resume it without losing any data. After the process resumes, the snapshot begins at the point where it stopped, rather than recapturing the table from the beginning.
-
You can run an incremental snapshot on demand at any time, and repeat the process as needed to adapt to database updates. For example, you might re-run a snapshot after you modify the connector configuration to add a table to its
table.include.listproperty.
Incremental snapshot process
When you run an incremental snapshot, Debezium sorts each table by primary key and then splits the table into chunks based on the configured chunk size. Working chunk by chunk, it then captures each table row in a chunk. For each row that it captures, the snapshot emits a READ event. That event represents the value of the row when the snapshot for the chunk began.
As a snapshot proceeds, it’s likely that other processes continue to access the database, potentially modifying table records. To reflect such changes, INSERT, UPDATE, or DELETE operations are committed to the transaction log as per usual. Similarly, the ongoing Debezium streaming process continues to detect these change events and emits corresponding change event records to Kafka.
How Debezium resolves collisions among records with the same primary key
In some cases, the UPDATE or DELETE events that the streaming process emits are received out of sequence. That is, the streaming process might emit an event that modifies a table row before the snapshot captures the chunk that contains the READ event for that row. When the snapshot eventually emits the corresponding READ event for the row, its value is already superseded. To ensure that incremental snapshot events that arrive out of sequence are processed in the correct logical order, Debezium employs a buffering scheme for resolving collisions. Only after collisions between the snapshot events and the streamed events are resolved does Debezium emit an event record to Kafka.
Snapshot window
To assist in resolving collisions between late-arriving READ events and streamed events that modify the same table row, Debezium employs a so-called snapshot window. The snapshot windows demarcates the interval during which an incremental snapshot captures data for a specified table chunk. Before the snapshot window for a chunk opens, Debezium follows its usual behavior and emits events from the transaction log directly downstream to the target Kafka topic. But from the moment that the snapshot for a particular chunk opens, until it closes, Debezium performs a de-duplication step to resolve collisions between events that have the same primary key..
For each data collection, the Debezium emits two types of events, and stores the records for them both in a single destination Kafka topic. The snapshot records that it captures directly from a table are emitted as READ operations. Meanwhile, as users continue to update records in the data collection, and the transaction log is updated to reflect each commit, Debezium emits UPDATE or DELETE operations for each change.
As the snapshot window opens, and Debezium begins processing a snapshot chunk, it delivers snapshot records to a memory buffer. During the snapshot windows, the primary keys of the READ events in the buffer are compared to the primary keys of the incoming streamed events. If no match is found, the streamed event record is sent directly to Kafka. If Debezium detects a match, it discards the buffered READ event, and writes the streamed record to the destination topic, because the streamed event logically supersede the static snapshot event. After the snapshot window for the chunk closes, the buffer contains only READ events for which no related transaction log events exist. Debezium emits these remaining READ events to the table’s Kafka topic.
The connector repeats the process for each snapshot chunk.
Triggering an incremental snapshot
Currently, the only way to initiate an incremental snapshot is to send an ad hoc snapshot signal to the signaling table on the source database. You submit signals to the table as SQL INSERT queries. After Debezium detects the change in the signaling table, it reads the signal, and runs the requested snapshot operation.
The query that you submit specifies the tables to include in the snapshot, and, optionally, specifies the kind of snapshot operation. Currently, the only valid option for snapshots operations is the default value, incremental.
To specify the tables to include in the snapshot, provide a data-collections array that lists the tables, for example,{"data-collections": ["public.MyFirstTable", "public.MySecondTable"]}
The data-collections array for an incremental snapshot signal has no default value. If the data-collections array is empty, Debezium detects that no action is required and does not perform a snapshot.
Prerequisites
- A signaling data collection exists on the source database and the connector is configured to capture it.
-
The signaling data collection is specified in the
signal.data.collectionproperty.
Procedure
Send a SQL query to add the ad hoc incremental snapshot request to the signaling table:
INSERT INTO _<signalTable>_ (id, type, data) VALUES (_'<id>'_, _'<snapshotType>'_, '{"data-collections": ["_<tableName>_","_<tableName>_"],"type":"_<snapshotType>_"}');For example,
INSERT INTO myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["schema1.table1", "schema2.table2"],"type":"incremental"}');The values of the
id,type, anddataparameters in the command correspond to the fields of the signaling table.The following table describes the these parameters:
Expand Table 6.3. Descriptions of fields in a SQL command for sending an incremental snapshot signal to the signaling table Value Description myschema.debezium_signalSpecifies the fully-qualified name of the signaling table on the source database
ad-hoc-1The
idparameter specifies an arbitrary string that is assigned as theididentifier for the signal request.
Use this string to identify logging messages to entries in the signaling table. Debezium does not use this string. Rather, during the snapshot, Debezium generates its ownidstring as a watermarking signal.execute-snapshotSpecifies
typeparameter specifies the operation that the signal is intended to trigger.
data-collectionsA required component of the
datafield of a signal that specifies an array of table names to include in the snapshot.
The array lists tables by their fully-qualified names, using the same format as you use to specify the name of the connector’s signaling table in thesignal.data.collectionconfiguration property.incrementalAn optional
typecomponent of thedatafield of a signal that specifies the kind of snapshot operation to run.
Currently, the only valid option is the default value,incremental.
Specifying atypevalue in the SQL query that you submit to the signaling table is optional.
If you do not specify a value, the connector runs an incremental snapshot.
The following example, shows the JSON for an incremental snapshot event that is captured by a connector.
Example: Incremental snapshot event message
{
"before":null,
"after": {
"pk":"1",
"value":"New data"
},
"source": {
...
"snapshot":"incremental"
},
"op":"r",
"ts_ms":"1620393591654",
"transaction":null
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
Specifies the type of snapshot operation to run. |
| 2 |
|
Specifies the event type. |
The Debezium connector for Oracle does not support schema changes while an incremental snapshot is running.
6.1.2. Default names of Kafka topics that receive Debezium Oracle change event records
By default, the Oracle connector writes change events for all INSERT, UPDATE, and DELETE operations that occur in a table to a single Apache Kafka topic that is specific to that table. The connector uses the following convention to name change event topics:
serverName.schemaName.tableName
The following list provides definitions for the components of the default name:
- serverName
-
The logical name of the server as specified by the
database.server.nameconnector configuration property. - schemaName
- The name of the schema in which the operation occurred.
- tableName
- The name of the table in which the operation occurred.
For example, if fulfillment is the server name, inventory is the schema name, and the database contains tables with the names orders, customers, and products, the Debezium Oracle connector emits events to the following Kafka topics, one for each table in the database:
fulfillment.inventory.orders
fulfillment.inventory.customers
fulfillment.inventory.productsThe connector applies similar naming conventions to label its internal database history topics, schema change topics, and transaction metadata topics.
If the default topic name do not meet your requirements, you can configure custom topic names. To configure custom topic names, you specify regular expressions in the logical topic routing SMT. For more information about using the logical topic routing SMT to customize topic naming, see Topic routing.
6.1.3. How Debezium Oracle connectors expose database schema changes
You can configure a Debezium Oracle connector to produce schema change events that describe schema changes that are applied to captured tables in the database. The connector writes schema change events to a Kafka topic named <serverName>, where serverName is the logical server name that is specified in the database.server.name configuration property.
Debezium emits a new message to this topic whenever it streams data from a new table.
Messages that the connector sends to the schema change topic contain a payload, and, optionally, also contain the schema of the change event message. The payload of a schema change event message includes the following elements:
ddl-
Provides the SQL
CREATE,ALTER, orDROPstatement that results in the schema change. databaseName-
The name of the database to which the statements are applied. The value of
databaseNameserves as the message key. tableChanges-
A structured representation of the entire table schema after the schema change. The
tableChangesfield contains an array that includes entries for each column of the table. Because the structured representation presents data in JSON or Avro format, consumers can easily read messages without first processing them through a DDL parser.
When the connector is configured to capture a table, it stores the history of the table’s schema changes not only in the schema change topic, but also in an internal database history topic. The internal database history topic is for connector use only and it is not intended for direct use by consuming applications. Ensure that applications that require notifications about schema changes consume that information only from the schema change topic.
Never partition the database history topic. For the database history topic to function correctly, it must maintain a consistent, global order of the event records that the connector emits to it.
To ensure that the topic is not split among partitions, set the partition count for the topic by using one of the following methods:
-
If you create the database history topic manually, specify a partition count of
1. -
If you use the Apache Kafka broker to create the database history topic automatically, the topic is created, set the value of the Kafka
num.partitionsconfiguration option to1.
Example: Message emitted to the Oracle connector schema change topic
The following example shows a typical schema change message in JSON format. The message contains a logical representation of the table schema.
{
"schema": {
...
},
"payload": {
"source": {
"version": "1.7.2.Final",
"connector": "oracle",
"name": "server1",
"ts_ms": 1588252618953,
"snapshot": "true",
"db": "ORCLPDB1",
"schema": "DEBEZIUM",
"table": "CUSTOMERS",
"txId" : null,
"scn" : "1513734",
"commit_scn": "1513734",
"lcr_position" : null
},
"databaseName": "ORCLPDB1",
"schemaName": "DEBEZIUM", //
"ddl": "CREATE TABLE \"DEBEZIUM\".\"CUSTOMERS\" \n ( \"ID\" NUMBER(9,0) NOT NULL ENABLE, \n \"FIRST_NAME\" VARCHAR2(255), \n \"LAST_NAME" VARCHAR2(255), \n \"EMAIL\" VARCHAR2(255), \n PRIMARY KEY (\"ID\") ENABLE, \n SUPPLEMENTAL LOG DATA (ALL) COLUMNS\n ) SEGMENT CREATION IMMEDIATE \n PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 \n NOCOMPRESS LOGGING\n STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645\n PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1\n BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)\n TABLESPACE \"USERS\" ",
"tableChanges": [
{
"type": "CREATE",
"id": "\"ORCLPDB1\".\"DEBEZIUM\".\"CUSTOMERS\"",
"table": {
"defaultCharsetName": null,
"primaryKeyColumnNames": [
"ID"
],
"columns": [
{
"name": "ID",
"jdbcType": 2,
"nativeType": null,
"typeName": "NUMBER",
"typeExpression": "NUMBER",
"charsetName": null,
"length": 9,
"scale": 0,
"position": 1,
"optional": false,
"autoIncremented": false,
"generated": false
},
{
"name": "FIRST_NAME",
"jdbcType": 12,
"nativeType": null,
"typeName": "VARCHAR2",
"typeExpression": "VARCHAR2",
"charsetName": null,
"length": 255,
"scale": null,
"position": 2,
"optional": false,
"autoIncremented": false,
"generated": false
},
{
"name": "LAST_NAME",
"jdbcType": 12,
"nativeType": null,
"typeName": "VARCHAR2",
"typeExpression": "VARCHAR2",
"charsetName": null,
"length": 255,
"scale": null,
"position": 3,
"optional": false,
"autoIncremented": false,
"generated": false
},
{
"name": "EMAIL",
"jdbcType": 12,
"nativeType": null,
"typeName": "VARCHAR2",
"typeExpression": "VARCHAR2",
"charsetName": null,
"length": 255,
"scale": null,
"position": 4,
"optional": false,
"autoIncremented": false,
"generated": false
}
]
}
}
]
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
| Identifies the database and the schema that contains the change. |
| 2 |
| This field contains the DDL that is responsible for the schema change. |
| 3 |
| An array of one or more items that contain the schema changes generated by a DDL command. |
| 4 |
| Describes the kind of change. The value is one of the following:
|
| 5 |
|
Full identifier of the table that was created, altered, or dropped. In the case of a table rename, this identifier is a concatenation of |
| 6 |
| Represents table metadata after the applied change. |
| 7 |
| List of columns that compose the table’s primary key. |
| 8 |
| Metadata for each column in the changed table. |
In messages that the connector sends to the schema change topic, the message key is the name of the database that contains the schema change. In the following example, the payload field contains the key:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "databaseName"
}
],
"optional": false,
"name": "io.debezium.connector.oracle.SchemaChangeKey"
},
"payload": {
"databaseName": "ORCLPDB1"
}
}6.1.4. Debezium Oracle connector-generated events that represent transaction boundaries
Debezium can generate events that represent transaction metadata boundaries and that enrich data change event messages.
Debezium registers and receives metadata only for transactions that occur after you deploy the connector. Metadata for transactions that occur before you deploy the connector is not available.
Database transactions are represented by a statement block that is enclosed between the BEGIN and END keywords. Debezium generates transaction boundary events for the BEGIN and END delimiters in every transaction. Transaction boundary events contain the following fields:
status-
BEGINorEND id- String representation of unique transaction identifier.
event_count(forENDevents)- Total number of events emmitted by the transaction.
data_collections(forENDevents)-
An array of pairs of
data_collectionandevent_countelements that indicates number of events that the connector emits for changes that originate from a data collection.
The following example shows a typical transaction boundary message:
Example: Oracle connector transaction boundary event
{
"status": "BEGIN",
"id": "5.6.641",
"event_count": null,
"data_collections": null
}
{
"status": "END",
"id": "5.6.641",
"event_count": 2,
"data_collections": [
{
"data_collection": "ORCLPDB1.DEBEZIUM.CUSTOMER",
"event_count": 1
},
{
"data_collection": "ORCLPDB1.DEBEZIUM.ORDER",
"event_count": 1
}
]
}
The connector emits transaction events to the <database.server.name>.transaction topic.
6.1.4.1. Change data event enrichment
When transaction metadata is enabled, the data message Envelope is enriched with a new transaction field. This field provides information about every event in the form of a composite of fields:
id- String representation of unique transaction identifier.
total_order- The absolute position of the event among all events generated by the transaction.
data_collection_order- The per-data collection position of the event among all events that were emitted by the transaction.
The following example shows a typical transaction event message:
{
"before": null,
"after": {
"pk": "2",
"aa": "1"
},
"source": {
...
},
"op": "c",
"ts_ms": "1580390884335",
"transaction": {
"id": "5.6.641",
"total_order": "1",
"data_collection_order": "1"
}
}Event buffering
Oracle writes all changes to the redo logs in the order in which they occur, including changes that are later discarded by a rollback. As a result, concurrent changes from separate transactions are intertwined. When the connector first reads the stream of changes, because it cannot immediately determine which changes are committed or rolled back, it temporarily stores the change events in an internal buffer. After a change is committed, the connector writes the change event from the buffer to Kafka. The connector drops change events that are discarded by a rollback.
You can configure the buffering mechanism that the connector uses by setting the property log.mining.buffer.type.
Heap
The default buffer type is configured using memory. Under the default memory setting, the connector uses the heap memory of the JVM process to allocate and manage buffered event records. If you use the memory buffer setting, be sure that the amount of memory that you allocate to the Java process can accommodate long-running and large transactions in your environment.
6.1.5. Gaps between Oracle SCN values
When the Debezium Oracle connector is configured to use LogMiner, it collects change events from Oracle by using a start and end range that is based on system change numbers (SCNs). The connector manages this range automatically, increasing or decreasing the range depending on whether the connector is able to stream changes in near real-time, or must process a backlog because of large or bulk transactions in the database.
Under certain circumstances, the Oracle database advances the system change number by an unusually high amount, rather than increasing it at a constant rate. Such a jump in the SCN value can occur because of the way that a particular integration interacts with the database, or as a result of events such as hot backups.
The Debezium Oracle connector relies on the following configuration properties to detect the SCN gap and adjust the mining range.
log.mining.scn.gap.detection.gap.size.min- Specifies the minimum gap size.
log.mining.scn.gap.detection.time.interval.max.ms- Specifies the maximum time interval.
The connector first compares the difference in the number of changes between the current SCN and the highest SCN in the current mining range. If this difference is greater than the minimum gap size, then the connector has potentially detected a SCN gap. To confirm whether a gap exists, the connector next compares the timestamps of the current SCN and the SCN at the end of the previous mining range. If the difference between the timestamps is less than the maximum time interval, then the existence of an SCN gap is confirmed.
When an SCN gap occurs, the Debezium connector automatically uses the current SCN as the end point for the range of the current mining session. This allows the connector to quickly catch up to the real-time events without mining smaller ranges in between that return no changes because the SCN value was increased by an unexpectedly large number. Additionally, the connector will ignore the mining maximum batch size for this iteration only when this occurs.
SCN gap detection is available only if the large SCN increment occurs while the connector is running and processing near real-time events.
6.2. Descriptions of Debezium Oracle connector data change events
Every data change event that the Oracle connector emits has a key and a value. The structures of the key and value depend on the table from which the change events originate. For information about how Debezium constructs topic names, see Topic names).
The Debezium Oracle connector ensures that all Kafka Connect schema names are valid Avro schema names. This means that the logical server name must start with alphabetic characters or an underscore ([a-z,A-Z,_]), and the remaining characters in the logical server name and all characters in the schema and table names must be alphanumeric characters or an underscore ([a-z,A-Z,0-9,\_]). The connector automatically replaces invalid characters with an underscore character.
Unexpected naming conflicts can result when the only distinguishing characters between multiple logical server names, schema names, or table names are not valid characters, and those characters are replaced with underscores.
Debezium and Kafka Connect are designed around continuous streams of event messages. However, the structure of these events might change over time, which can be difficult for topic consumers to handle. To facilitate the processing of mutable event structures, each event in Kafka Connect is self-contained. Every message key and value has two parts: a schema and payload. The schema describes the structure of the payload, while the payload contains the actual data.
Changes that are performed by the SYS or SYSTEM user accounts are not captured by the connector.
The following topics contain more details about data change events:
6.2.1. About keys in Debezium Oracle connector change events
For each changed table, the change event key is structured such that a field exists for each column in the primary key (or unique key constraint) of the table at the time when the event is created.
For example, a customers table that is defined in the inventory database schema, might have the following change event key:
CREATE TABLE customers (
id NUMBER(9) GENERATED BY DEFAULT ON NULL AS IDENTITY (START WITH 1001) NOT NULL PRIMARY KEY,
first_name VARCHAR2(255) NOT NULL,
last_name VARCHAR2(255) NOT NULL,
email VARCHAR2(255) NOT NULL UNIQUE
);
If the value of the <database.server.name>.transaction configuration property is set to server1, the JSON representation for every change event that occurs in the customers table in the database features the following key structure:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "ID"
}
],
"optional": false,
"name": "server1.INVENTORY.CUSTOMERS.Key"
},
"payload": {
"ID": 1004
}
}
The schema portion of the key contains a Kafka Connect schema that describes the content of the key portion. In the preceding example, the payload value is not optional, the structure is defined by a schema named server1.DEBEZIUM.CUSTOMERS.Key, and there is one required field named id of type int32. The value of the key’s payload field indicates that it is indeed a structure (which in JSON is just an object) with a single id field, whose value is 1004.
Therefore, you can interpret this key as describing the row in the inventory.customers table (output from the connector named server1) whose id primary key column had a value of 1004.
6.2.2. About values in Debezium Oracle connector change events
Like the message key, the value of a change event message has a schema section and payload section. The payload section of every change event value produced by the Oracle connector has an envelope structure with the following fields:
op-
A mandatory field that contains a string value describing the type of operation. Values for the Oracle connector are
cfor create (or insert),ufor update,dfor delete, andrfor read (in the case of a snapshot). before-
An optional field that, if present, contains the state of the row before the event occurred. The structure is described by the
server1.INVENTORY.CUSTOMERS.ValueKafka Connect schema, which theserver1connector uses for all rows in theinventory.customerstable.
after-
An optional field that if present contains the state of the row after the event occurred. The structure is described by the same
server1.INVENTORY.CUSTOMERS.ValueKafka Connect schema used inbefore. source- A mandatory field that contains a structure describing the source metadata for the event, which in the case of Oracle contains these fields: the Debezium version, the connector name, whether the event is part of an ongoing snapshot or not, the transaction id (not while snapshotting), the SCN of the change, and a timestamp representing the point in time when the record was changed in the source database (during snapshotting, this is the point in time of snapshotting).
The commit_scn field is optional and describes the SCN of the transaction commit that the change event participates within. This field is only present when using the LogMiner connection adapter.
ts_ms- An optional field that, if present, contains the time (using the system clock in the JVM running the Kafka Connect task) at which the connector processed the event.
And of course, the schema portion of the event message’s value contains a schema that describes this envelope structure and the nested fields within it.
create events
Let’s look at what a create event value might look like for our customers table:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "ID"
},
{
"type": "string",
"optional": false,
"field": "FIRST_NAME"
},
{
"type": "string",
"optional": false,
"field": "LAST_NAME"
},
{
"type": "string",
"optional": false,
"field": "EMAIL"
}
],
"optional": true,
"name": "server1.DEBEZIUM.CUSTOMERS.Value",
"field": "before"
},
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "ID"
},
{
"type": "string",
"optional": false,
"field": "FIRST_NAME"
},
{
"type": "string",
"optional": false,
"field": "LAST_NAME"
},
{
"type": "string",
"optional": false,
"field": "EMAIL"
}
],
"optional": true,
"name": "server1.DEBEZIUM.CUSTOMERS.Value",
"field": "after"
},
{
"type": "struct",
"fields": [
{
"type": "string",
"optional": true,
"field": "version"
},
{
"type": "string",
"optional": false,
"field": "name"
},
{
"type": "int64",
"optional": true,
"field": "ts_ms"
},
{
"type": "string",
"optional": true,
"field": "txId"
},
{
"type": "string",
"optional": true,
"field": "scn"
},
{
"type": "string",
"optional": true,
"field": "commit_scn"
},
{
"type": "boolean",
"optional": true,
"field": "snapshot"
}
],
"optional": false,
"name": "io.debezium.connector.oracle.Source",
"field": "source"
},
{
"type": "string",
"optional": false,
"field": "op"
},
{
"type": "int64",
"optional": true,
"field": "ts_ms"
}
],
"optional": false,
"name": "server1.DEBEZIUM.CUSTOMERS.Envelope"
},
"payload": {
"before": null,
"after": {
"ID": 1004,
"FIRST_NAME": "Anne",
"LAST_NAME": "Kretchmar",
"EMAIL": "annek@noanswer.org"
},
"source": {
"version": "1.7.2.Final",
"name": "server1",
"ts_ms": 1520085154000,
"txId": "6.28.807",
"scn": "2122185",
"commit_scn": "2122185",
"snapshot": false
},
"op": "c",
"ts_ms": 1532592105975
}
}
Examining the schema portion of the preceding event’s value, we can see how the following schema are defined:
- The envelope
-
The
sourcestructure (which is specific to the Oracle connector and reused across all events). -
The table-specific schemas for the
beforeandafterfields.
The names of the schemas for the before and after fields are of the form <logicalName>.<schemaName>.<tableName>.Value, and thus are entirely independent from the schemas for all other tables. This means that when using the Avro Converter, the resulting Avro schems for each table in each logical source have their own evolution and history.
The payload portion of this event’s value, provides information about the event. It describes that a row was created (op=c), and shows that the after field value contains the values that were inserted into the ID, FIRST_NAME, LAST_NAME, and EMAIL columns of the row.
By default, the JSON representations of events are much larger than the rows they describe. This is true, because the JSON representation must include the schema and the payload portions of the message. You can use the Avro Converter to significantly decrease the size of the messages that the connector writes to Kafka topics.
update events
The value of an update change event on this table has the same schema as the create event. The payload uses the same structure, but it holds different values. Here’s an example:
{
"schema": { ... },
"payload": {
"before": {
"ID": 1004,
"FIRST_NAME": "Anne",
"LAST_NAME": "Kretchmar",
"EMAIL": "annek@noanswer.org"
},
"after": {
"ID": 1004,
"FIRST_NAME": "Anne",
"LAST_NAME": "Kretchmar",
"EMAIL": "anne@example.com"
},
"source": {
"version": "1.7.2.Final",
"name": "server1",
"ts_ms": 1520085811000,
"txId": "6.9.809",
"scn": "2125544",
"commit_scn": "2125544",
"snapshot": false
},
"op": "u",
"ts_ms": 1532592713485
}
}
Comparing the value of the update event to the create (insert) event, notice the following differences in the payload section:
-
The
opfield value is nowu, signifying that this row changed because of an update -
The
beforefield now has the state of the row with the values before the database commit -
The
afterfield now has the updated state of the row, and here was can see that theEMAILvalue is nowanne@example.com. -
The
sourcefield structure has the same fields as before, but the values are different since this event is from a different position in the redo log. -
The
ts_msshows the timestamp that Debezium processed this event.
The payload section reveals several other useful pieces of information. For example, by comparing the before and after structures, we can determine how a row changed as the result of a commit. The source structure provides information about Oracle’s record of this change, providing traceability. It also gives us insight into when this event occurred in relation to other events in this topic and in other topics. Did it occur before, after, or as part of the same commit as another event?
When the columns for a row’s primary/unique key are updated, the value of the row’s key changes. As a result, Debezium emits three events after such an update:
-
A
DELETEevent. - A tombstone event with the old key for the row.
-
An
INSERTevent that provides the new key for the row.
delete events
So far we’ve seen samples of create and update events. Now, let’s look at the value of a delete event for the same table. As is the case with create and update events, for a delete event, the schema portion of the value is exactly the same:
{
"schema": { ... },
"payload": {
"before": {
"ID": 1004,
"FIRST_NAME": "Anne",
"LAST_NAME": "Kretchmar",
"EMAIL": "anne@example.com"
},
"after": null,
"source": {
"version": "1.7.2.Final",
"name": "server1",
"ts_ms": 1520085153000,
"txId": "6.28.807",
"scn": "2122184",
"commit_scn": "2122184",
"snapshot": false
},
"op": "d",
"ts_ms": 1532592105960
}
}
If we look at the payload portion, we see a number of differences compared with the create or update event payloads:
-
The
opfield value is nowd, signifying that this row was deleted -
The
beforefield now has the state of the row that was deleted with the database commit. -
The
afterfield is null, signifying that the row no longer exists -
The
sourcefield structure has many of the same values as before, except thets_ms,scnandtxIdfields have changed -
The
ts_msshows the timestamp that Debezium processed this event.
This event gives a consumer all kinds of information that it can use to process the removal of this row.
The Oracle connector’s events are designed to work with Kafka log compaction, which allows for the removal of some older messages as long as at least the most recent message for every key is kept. This allows Kafka to reclaim storage space while ensuring the topic contains a complete dataset and can be used for reloading key-based state.
When a row is deleted, the delete event value listed above still works with log compaction, since Kafka can still remove all earlier messages with that same key. The message value must be set to null to instruct Kafka to remove all messages that share the same key. To make this possible, by default, Debezium’s Oracle connector always follows a delete event with a special tombstone event that has the same key but null value. You can change the default behavior by setting the connector property tombstones.on.delete.
6.3. How Debezium Oracle connectors map data types
To represent changes that occur in a table rows, the Debezium Oracle connector emits change events that are structured like the table in which the rows exists. The event contains a field for each column value. Column values are represented according to the Oracle data type of the column. The following sections describe how the connector maps oracle data types to a literal type and a semantic type in event fields.
- literal type
-
Describes how the value is literally represented using Kafka Connect schema types:
INT8,INT16,INT32,INT64,FLOAT32,FLOAT64,BOOLEAN,STRING,BYTES,ARRAY,MAP, andSTRUCT. - semantic type
- Describes how the Kafka Connect schema captures the meaning of the field using the name of the Kafka Connect schema for the field.
Details are in the following sections:
Character types
The following table describes how the connector maps basic character types.
| Oracle Data Type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
Binary and Character LOB types
The following table describes how the connector maps binary and character large object (LOB) data types.
| Oracle Data Type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
| The raw bytes. |
|
|
| n/a |
|
| n/a | This data type is not supported. |
|
| n/a | This data type is not supported. |
|
|
| n/a |
|
| n/a | This data type is not supported. |
Oracle only supplies column values for CLOB, NCLOB, and BLOB data types if they’re explicitly set or changed in a SQL statement. This means that change events will never contain the value of an unchanged CLOB, NCLOB, or BLOB column, but a placeholder as defined by the connector property, unavailable.value.placeholder.
If the value of a CLOB, NCLOB, or BLOB column gets updated, the new value will be contained in the after part of the corresponding update change events whereas the unavailable value placeholder will be used in the before part.
Numeric types
The following table describes how the connector maps numeric types.
| Oracle Data Type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
| n/a |
|
|
| n/a |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Boolean types
Oracle does not natively have support for a BOOLEAN data type; however, it is common practice to use other data types with certain semantics to simulate the concept of a logical BOOLEAN data type.
The operator can configure the out-of-the-box NumberOneToBooleanConverter custom converter that would either map all NUMBER(1) columns to a BOOLEAN or if the selector parameter is set, then a subset of columns could be enumerated using a comma-separated list of regular expressions.
Following is an example configuration:
converters=boolean
boolean.type=io.debezium.connector.oracle.converters.NumberOneToBooleanConverter
boolean.selector=.*MYTABLE.FLAG,.*.IS_ARCHIVEDDecimal types
The setting of the Oracle connector configuration property, decimal.handling.mode determines how the connector maps decimal types.
When the decimal.handling.mode property is set to precise, the connector uses Kafka Connect org.apache.kafka.connect.data.Decimal logical type for all DECIMAL and NUMERIC columns. This is the default mode.
However, when the decimal.handling.mode property is set to double, the connector represents the values as Java double values with schema type FLOAT64.
You can also set the decimal.handling.mode configuration property to use the string option. When the property is set to string, the connector represents DECIMAL and NUMERIC values as their formatted string representation with schema type STRING.
Temporal types
Other than Oracle’s INTERVAL, TIMESTAMP WITH TIME ZONE and TIMESTAMP WITH LOCAL TIME ZONE data types, the other temporal types depend on the value of the time.precision.mode configuration property.
When the time.precision.mode configuration property is set to adaptive (the default), then the connector determines the literal and semantic type for the temporal types based on the column’s data type definition so that events exactly represent the values in the database:
| Oracle data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
When the time.precision.mode configuration property is set to connect, then the connector uses the predefined Kafka Connect logical types. This can be useful when consumers only know about the built-in Kafka Connect logical types and are unable to handle variable-precision time values. Because the level of precision that Oracle supports exceeds the level that the logical types in Kafka Connect support, if you set time.precision.mode to connect, a loss of precision results when the fractional second precision value of a database column is greater than 3:
| Oracle data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
6.4. Setting up Oracle to work with Debezium
The following steps are necessary to set up Oracle for use with the Debezium Oracle connector. These steps assume the use of the multi-tenancy configuration with a container database and at least one pluggable database. If you do not intend to use a multi-tenant configuration, it might be necessary to adjust the following steps.
For information about using Vagrant to set up Oracle in a virtual machine, see the Debezium Vagrant Box for Oracle database GitHub repository.
For details about setting up Oracle for use with the Debezium connector, see the following sections:
6.4.1. Preparing Oracle databases for use with Debezium
Configuration needed for Oracle LogMiner
ORACLE_SID=ORACLCDB dbz_oracle sqlplus /nolog
CONNECT sys/top_secret AS SYSDBA
alter system set db_recovery_file_dest_size = 10G;
alter system set db_recovery_file_dest = '/opt/oracle/oradata/recovery_area' scope=spfile;
shutdown immediate
startup mount
alter database archivelog;
alter database open;
-- Should now "Database log mode: Archive Mode"
archive log list
exit;In addition, supplemental logging must be enabled for captured tables or the database in order for data changes to capture the before state of changed database rows. The following illustrates how to configure this on a specific table, which is the ideal choice to minimize the amount of information captured in the Oracle redo logs.
ALTER TABLE inventory.customers ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;Minimal supplemental logging must be enabled at the database level and can be configured as follows.
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;6.4.2. Redo log sizing
Depending on the database configuration, the size and number of redo logs might not be sufficient to achieve acceptable performance. Before you set up the Debezium Oracle connector, ensure that the capacity of the redo logs is sufficient to support the database.
The capacity of the redo logs for a database must be sufficient to store its data dictionary. In general, the size of the data dictionary increases with the number of tables and columns in the database. If the redo log lacks sufficient capacity, both the database and the Debezium connector might experience performance problems.
Consult with your database administrator to evaluate whether the database might require increased log capacity.
6.4.3. Creating an Oracle user for the Debezium Oracle connector
For the Debezium Oracle connector to capture change events, it must run as an Oracle LogMiner user that has specific permissions. The following example shows the SQL for creating an Oracle user account for the connector in a multi-tenant database model.
The connector captures database changes that are made by its own Oracle user account. However, it does not capture changes that are made by the SYS or SYSTEM user accounts.
Creating the connector’s LogMiner user
sqlplus sys/top_secret@//localhost:1521/ORCLCDB as sysdba
CREATE TABLESPACE logminer_tbs DATAFILE '/opt/oracle/oradata/ORCLCDB/logminer_tbs.dbf'
SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
exit;
sqlplus sys/top_secret@//localhost:1521/ORCLPDB1 as sysdba
CREATE TABLESPACE logminer_tbs DATAFILE '/opt/oracle/oradata/ORCLCDB/ORCLPDB1/logminer_tbs.dbf'
SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
exit;
sqlplus sys/top_secret@//localhost:1521/ORCLCDB as sysdba
CREATE USER c##dbzuser IDENTIFIED BY dbz
DEFAULT TABLESPACE logminer_tbs
QUOTA UNLIMITED ON logminer_tbs
CONTAINER=ALL;
GRANT CREATE SESSION TO c##dbzuser CONTAINER=ALL;
GRANT SET CONTAINER TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$DATABASE to c##dbzuser CONTAINER=ALL;
GRANT FLASHBACK ANY TABLE TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ANY TABLE TO c##dbzuser CONTAINER=ALL;
GRANT SELECT_CATALOG_ROLE TO c##dbzuser CONTAINER=ALL;
GRANT EXECUTE_CATALOG_ROLE TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ANY TRANSACTION TO c##dbzuser CONTAINER=ALL;
GRANT LOGMINING TO c##dbzuser CONTAINER=ALL;
GRANT CREATE TABLE TO c##dbzuser CONTAINER=ALL;
GRANT LOCK ANY TABLE TO c##dbzuser CONTAINER=ALL;
GRANT CREATE SEQUENCE TO c##dbzuser CONTAINER=ALL;
GRANT EXECUTE ON DBMS_LOGMNR TO c##dbzuser CONTAINER=ALL;
GRANT EXECUTE ON DBMS_LOGMNR_D TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOG TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOG_HISTORY TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOGMNR_LOGS TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOGMNR_CONTENTS TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOGMNR_PARAMETERS TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$LOGFILE TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$ARCHIVED_LOG TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO c##dbzuser CONTAINER=ALL;
exit;6.5. Deployment of Debezium Oracle connectors
You can use either of the following methods to deploy a Debezium Oracle connector:
The Debezium Oracle connector requires the Oracle JDBC driver (ojdbc8.jar) to connect to Oracle databases. For information about how to obtain the driver, see Obtaining the Oracle JDBC driver.
Additional resources
6.5.1. Debezium Oracle connector deployment using AMQ Streams
Beginning with Debezium 1.7, the preferred method for deploying a Debezium connector is to use AMQ Streams to build a Kafka Connect container image that includes the connector plug-in.
During the deployment process, you create and use the following custom resources (CRs):
-
A
KafkaConnectCR that defines your Kafka Connect instance and includes information about the connector artifacts needs to include in the image. -
A
KafkaConnectorCR that provides details that include information the connector uses to access the source database. After AMQ Streams starts the Kafka Connect pod, you start the connector by applying theKafkaConnectorCR.
In the build specification for the Kafka Connect image, you can specify the connectors that are available to deploy. For each connector plug-in, you can also specify other components that you want to make available for deployment. For example, you can add Service Registry artifacts, or the Debezium scripting component. When AMQ Streams builds the Kafka Connect image, it downloads the specified artifacts, and incorporates them into the image.
The spec.build.output parameter in the KafkaConnect CR specifies where to store the resulting Kafka Connect container image. Container images can be stored in a Docker registry, or in an OpenShift ImageStream. To store images in an ImageStream, you must create the ImageStream before you deploy Kafka Connect. ImageStreams are not created automatically.
If you use a KafkaConnect resource to create a cluster, afterwards you cannot use the Kafka Connect REST API to create or update connectors. You can still use the REST API to retrieve information.
Additional resources
- Configuring Kafka Connect in Using AMQ Streams on OpenShift.
- Creating a new container image automatically using AMQ Streams in Deploying and Upgrading AMQ Streams on OpenShift.
6.5.2. Using AMQ Streams to deploy a Debezium Oracle connector
With earlier versions of AMQ Streams, to deploy Debezium connectors on OpenShift, it was necessary to first build a Kafka Connect image for the connector. The current preferred method for deploying connectors on OpenShift is to use a build configuration in AMQ Streams to automatically build a Kafka Connect container image that includes the Debezium connector plug-ins that you want to use.
During the build process, the AMQ Streams Operator transforms input parameters in a KafkaConnect custom resource, including Debezium connector definitions, into a Kafka Connect container image. The build downloads the necessary artifacts from the Red Hat Maven repository or another configured HTTP server. The newly created container is pushed to the container registry that is specified in .spec.build.output, and is used to deploy a Kafka Connect pod. After AMQ Streams builds the Kafka Connect image, you create KafkaConnector custom resources to start the connectors that are included in the build.
Prerequisites
- You have access to an OpenShift cluster on which the cluster Operator is installed.
- The AMQ Streams Operator is running.
- An Apache Kafka cluster is deployed as documented in Deploying and Upgrading AMQ Streams on OpenShift.
- You have a Red Hat Integration license.
- Kafka Connect is deployed on AMQ Streams.
-
The OpenShift
ocCLI client is installed or you have access to the OpenShift Container Platform web console. Depending on how you intend to store the Kafka Connect build image, you need registry permissions or you must create an ImageStream resource:
- To store the build image in an image registry, such as Red Hat Quay.io or Docker Hub
- An account and permissions to create and manage images in the registry.
- To store the build image as a native OpenShift ImageStream
- An ImageStream resource is deployed to the cluster. You must explicitly create an ImageStream for the cluster. ImageStreams are not available by default.
Procedure
- Log in to the OpenShift cluster.
Create a Debezium
KafkaConnectcustom resource (CR) for the connector, or modify an existing one. For example, create aKafkaConnectCR that specifies themetadata.annotationsandspec.buildproperties, as shown in the following example. Save the file with a name such asdbz-connect.yaml.Example 6.1. A
dbz-connect.yamlfile that defines aKafkaConnectcustom resource that includes a Debezium connectorapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: debezium-kafka-connect-cluster annotations: strimzi.io/use-connector-resources: "true"1 spec: version: 3.00 build:2 output:3 type: imagestream4 image: debezium-streams-connect:latest plugins:5 - name: debezium-connector-oracle artifacts: - type: zip6 url: https://maven.repository.redhat.com/ga/io/debezium/debezium-connector-oracle/1.7.2.Final-redhat-<build_number>/debezium-connector-oracle-1.7.2.Final-redhat-<build_number>-plugin.zip7 - type: zip url: https://maven.repository.redhat.com/ga/io/apicurio/apicurio-registry-distro-connect-converter/2.0-redhat-<build-number>/apicurio-registry-distro-connect-converter-2.0-redhat-<build-number>.zip - type: zip url: https://maven.repository.redhat.com/ga/io/debezium/debezium-scripting/1.7.2.Final/debezium-scripting-1.7.2.Final.zip bootstrapServers: debezium-kafka-cluster-kafka-bootstrap:9093Expand Table 6.8. Descriptions of Kafka Connect configuration settings Item Description 1
Sets the
strimzi.io/use-connector-resourcesannotation to"true"to enable the Cluster Operator to useKafkaConnectorresources to configure connectors in this Kafka Connect cluster.2
The
spec.buildconfiguration specifies where to store the build image and lists the plug-ins to include in the image, along with the location of the plug-in artifacts.3
The
build.outputspecifies the registry in which the newly built image is stored.4
Specifies the name and image name for the image output. Valid values for
output.typearedockerto push into a container registry like Docker Hub or Quay, orimagestreamto push the image to an internal OpenShift ImageStream. To use an ImageStream, an ImageStream resource must be deployed to the cluster. For more information about specifying thebuild.outputin the KafkaConnect configuration, see the AMQ Streams Build schema reference documentation.5
The
pluginsconfiguration lists all of the connectors that you want to include in the Kafka Connect image. For each entry in the list, specify a plug-inname, and information for about the artifacts that are required to build the connector. Optionally, for each connector plug-in, you can include other components that you want to be available for use with the connector. For example, you can add Service Registry artifacts, or the Debezium scripting component.6
The value of
artifacts.typespecifies the file type of the artifact specified in theartifacts.url. Valid types arezip,tgz, orjar. Debezium connector archives are provided in.zipfile format. JDBC driver files are in.jarformat. Thetypevalue must match the type of the file that is referenced in theurlfield.7
The value of
artifacts.urlspecifies the address of an HTTP server, such as a Maven repository, that stores the file for the connector artifact. The OpenShift cluster must have access to the specified server.Apply the
KafkaConnectbuild specification to the OpenShift cluster by entering the following command:oc create -f dbz-connect.yamlBased on the configuration specified in the custom resource, the Streams Operator prepares a Kafka Connect image to deploy.
After the build completes, the Operator pushes the image to the specified registry or ImageStream, and starts the Kafka Connect cluster. The connector artifacts that you listed in the configuration are available in the cluster.Create a
KafkaConnectorresource to define an instance of each connector that you want to deploy.
For example, create the followingKafkaConnectorCR, and save it asoracle-inventory-connector.yamlExample 6.2. A
oracle-inventory-connector.yamlfile that defines theKafkaConnectorcustom resource for a Debezium connectorapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: labels: strimzi.io/cluster: debezium-kafka-connect-cluster name: inventory-connector-oracle1 spec: class: io.debezium.connector.oracle.MySqlConnector2 tasksMax: 13 config:4 database.history.kafka.bootstrap.servers: 'debezium-kafka-cluster-kafka-bootstrap.debezium.svc.cluster.local:9092' database.history.kafka.topic: schema-changes.inventory database.hostname: oracle.debezium-oracle.svc.cluster.local5 database.port: 33066 database.user: debezium7 database.password: dbz8 database.dbname: mydatabase9 database.server.name: inventory_connector_oracle10 database.include.list: public.inventory11 Expand Table 6.9. Descriptions of connector configuration settings Item Description 1
The name of the connector to register with the Kafka Connect cluster.
2
The name of the connector class.
3
The number of tasks that can operate concurrently.
4
The connector’s configuration.
5
The address of the host database instance.
6
The port number of the database instance.
7
The name of the user account through which Debezium connects to the database.
8
The password for the database user account.
9
The name of the database to capture changes from.
10
The logical name of the database instance or cluster.
The specified name must be formed only from alphanumeric characters or underscores.
Because the logical name is used as the prefix for any Kafka topics that receive change events from this connector, the name must be unique among the connectors in the cluster.
The namespace is also used in the names of related Kafka Connect schemas, and the namespaces of a corresponding Avro schema if you integrate the connector with the Avro connector.11
The list of tables from which the connector captures change events.
Create the connector resource by running the following command:
oc create -n <namespace> -f <kafkaConnector>.yamlFor example,
oc create -n debezium -f {context}-inventory-connector.yamlThe connector is registered to the Kafka Connect cluster and starts to run against the database that is specified by
spec.config.database.dbnamein theKafkaConnectorCR. After the connector pod is ready, Debezium is running.
You are now ready to verify the Debezium Oracle deployment.
6.5.3. Deploying a Debezium Oracle connector by building a custom Kafka Connect container image from a Dockerfile
To deploy a Debezium Oracle connector, you must build a custom Kafka Connect container image that contains the Debezium connector archive, and then push this container image to a container registry. You then need to create the following custom resources (CRs):
-
A
KafkaConnectCR that defines your Kafka Connect instance. Theimageproperty in the CR specifies the name of the container image that you create to run your Debezium connector. You apply this CR to the OpenShift instance where Red Hat AMQ Streams is deployed. AMQ Streams offers operators and images that bring Apache Kafka to OpenShift. -
A
KafkaConnectorCR that defines your Debezium Oracle connector. Apply this CR to the same OpenShift instance where you apply theKafkaConnectCR.
Prerequisites
- Oracle Database is running and you completed the steps to set up Oracle to work with a Debezium connector.
- AMQ Streams is deployed on OpenShift and is running Apache Kafka and Kafka Connect. For more information, see Deploying and Upgrading AMQ Streams on OpenShift
- Podman or Docker is installed.
-
You have an account and permissions to create and manage containers in the container registry (such as
quay.ioordocker.io) to which you plan to add the container that will run your Debezium connector. You have a copy of the Oracle JDBC driver. Due to licensing requirements, the Debezium Oracle connector does not include the required driver file.
For more information, see Obtaining the Oracle JDBC driver.
Procedure
Create the Debezium Oracle container for Kafka Connect:
- Download the Debezium Oracle connector archive.
Extract the Debezium Oracle connector archive to create a directory structure for the connector plug-in, for example:
./my-plugins/ ├── debezium-connector-oracle │ ├── ...Create a Dockerfile that uses
registry.redhat.io/amq7/amq-streams-kafka-30-rhel8:2.0.0as the base image. For example, from a terminal window, enter the following, replacingmy-pluginswith the name of your plug-ins directory:cat <<EOF >debezium-container-for-oracle.yaml1 FROM registry.redhat.io/amq7/amq-streams-kafka-30-rhel8:2.0.0 USER root:root COPY ./<my-plugins>/ /opt/kafka/plugins/2 USER 1001 EOFThe command creates a Dockerfile with the name
debezium-container-for-oracle.yamlin the current directory.Build the container image from the
debezium-container-for-oracle.yamlDocker file that you created in the previous step. From the directory that contains the file, open a terminal window and enter one of the following commands:podman build -t debezium-container-for-oracle:latest .docker build -t debezium-container-for-oracle:latest .The preceding commands build a container image with the name
debezium-container-for-oracle.Push your custom image to a container registry, such as quay.io or an internal container registry. The container registry must be available to the OpenShift instance where you want to deploy the image. Enter one of the following commands:
podman push <myregistry.io>/debezium-container-for-oracle:latestdocker push <myregistry.io>/debezium-container-for-oracle:latestCreate a new Debezium Oracle KafkaConnect custom resource (CR). For example, create a KafkaConnect CR with the name
dbz-connect.yamlthat specifiesannotationsandimageproperties as shown in the following example:apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true"1 spec: #... image: debezium-container-for-oracle2 - 1
metadata.annotationsindicates to the Cluster Operator that KafkaConnector resources are used to configure connectors in this Kafka Connect cluster.- 2
spec.imagespecifies the name of the image that you created to run your Debezium connector. This property overrides theSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGEvariable in the Cluster Operator
Apply the
KafkaConnectCR to the OpenShift Kafka Connect environment by entering the following command:oc create -f dbz-connect.yamlThe command adds a Kafka Connect instance that specifies the name of the image that you created to run your Debezium connector.
Create a
KafkaConnectorcustom resource that configures your Debezium Oracle connector instance.You configure a Debezium Oracle connector in a
.yamlfile that specifies the configuration properties for the connector. The connector configuration might instruct Debezium to produce events for a subset of the schemas and tables, or it might set properties so that Debezium ignores, masks, or truncates values in specified columns that are sensitive, too large, or not needed.The following example configures a Debezium connector that connects to an Oracle host IP address, on port
1521. This host has a database namedORCLCDB, andserver1is the server’s logical name.Oracle
inventory-connector.yamlapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: inventory-connector1 labels: strimzi.io/cluster: my-connect-cluster annotations: strimzi.io/use-connector-resources: 'true' spec: class: io.debezium.connector.oracle.OracleConnector2 config: database.hostname: <oracle_ip_address>3 database.port: 15214 database.user: c##dbzuser5 database.password: dbz6 database.dbname: ORCLCDB7 database.pdb.name : ORCLPDB1,8 database.server.name: server19 database.history.kafka.bootstrap.servers: kafka:909210 database.history.kafka.topic: schema-changes.inventory11 Expand Table 6.10. Descriptions of connector configuration settings Item Description 1
The name of our connector when we register it with a Kafka Connect service.
2
The name of this Oracle connector class.
3
The address of the Oracle instance.
4
The port number of the Oracle instance.
5
The name of the Oracle user, as specified in Creating users for the connector.
6
The password for the Oracle user, as specified in Creating users for the connector.
7
The name of the database to capture changes from.
8
The name of the Oracle pluggable database that the connector captures changes from. Used in container database (CDB) installations only.
9
Logical name that identifies and provides a namespace for the Oracle database server from which the connector captures changes.
10
The list of Kafka brokers that this connector uses to write and recover DDL statements to the database history topic.
11
The name of the database history topic where the connector writes and recovers DDL statements. This topic is for internal use only and should not be used by consumers.
Create your connector instance with Kafka Connect. For example, if you saved your
KafkaConnectorresource in theinventory-connector.yamlfile, you would run the following command:oc apply -f inventory-connector.yamlThe preceding command registers
inventory-connectorand the connector starts to run against theserver1database as defined in theKafkaConnectorCR.
6.5.4. Obtaining the Oracle JDBC driver
Due to licensing requirements, the required driver file is not included in the Debezium Oracle connector archive. Regardless of which deployment method that you use, you have obtain the Oracle JDBC driver to complete the deployment.
There are two methods for obtaining the driver, depending on the deployment method that you use.
-
If you use AMQ Streams to add the connector to your Kafka Connect image, add an artifact reference to the
KafkaConnectcustom resource and then add the location of the artifact as theurlvalue. - If you use a Dockerfile to build the connector, download the required driver file directly from Oracle and add it to your Kafka Connect environment.
The following steps describe how to make the driver and available in your environment.
Procedure
Complete one of the following procedures, depending on your deployment type:
If you use AMQ Streams to deploy the connector:
-
Navigate to Maven Central and locate the
ojdbc8.jarfile for your release of Oracle Database. In the YAML for the
KafkaConnectorcustom resource (CR), add the URL path for the driver to theartifacts.urlfield for thedebezium-connector-oracleartifact.For more information about the YAML file for the
KafkaConnectorCR, see Using AMQ Streams to deploy a Debezium Oracle connector.
-
Navigate to Maven Central and locate the
If you use a Dockerfile to deploy the connector:
- From a browser, navigate to the Oracle JDBC and UCP Downloads page.
-
Locate and download the
ojdbc8.jardriver file for your version of Oracle Database. Copy the downloaded file to the directory that stores the Debezium Oracle connector files, for example,
<kafka_home>/libs.When the connector starts, it is automatically configured to use the specified driver.
6.5.5. Configuration of container databases and non-container-databases
Oracle Database supports the following deployment types:
- Container database (CDB)
- A database that can contain multiple pluggable databases (PDBs). Database clients connect to each PDB as if it were a standard, non-CDB database.
- Non-container database (non-CDB)
- A standard Oracle database, which does not support the creation of pluggable databases.
For the complete list of the configuration properties that you can set for the Debezium Oracle connector, see Oracle connector properties.
Results
After the connector starts, it performs a consistent snapshot of the Oracle databases that the connector is configured for. The connector then starts generating data change events for row-level operations and streaming the change event records to Kafka topics.
6.5.6. Verifying that the Debezium Oracle connector is running
If the connector starts correctly without errors, it creates a topic for each table that the connector is configured to capture. Downstream applications can subscribe to these topics to retrieve information events that occur in the source database.
To verify that the connector is running, you perform the following operations from the OpenShift Container Platform web console, or through the OpenShift CLI tool (oc):
- Verify the connector status.
- Verify that the connector generates topics.
- Verify that topics are populated with events for read operations ("op":"r") that the connector generates during the initial snapshot of each table.
Prerequisites
- A Debezium connector is deployed to AMQ Streams on OpenShift.
-
The OpenShift
ocCLI client is installed. - You have access to the OpenShift Container Platform web console.
Procedure
Check the status of the
KafkaConnectorresource by using one of the following methods:From the OpenShift Container Platform web console:
- Navigate to Home → Search.
-
On the Search page, click Resources to open the Select Resource box, and then type
KafkaConnector. - From the KafkaConnectors list, click the name of the connector that you want to check, for example inventory-connector-oracle.
- In the Conditions section, verify that the values in the Type and Status columns are set to Ready and True.
From a terminal window:
Enter the following command:
oc describe KafkaConnector <connector-name> -n <project>For example,
oc describe KafkaConnector inventory-connector-oracle -n debeziumThe command returns status information that is similar to the following output:
Example 6.3.
KafkaConnectorresource statusName: inventory-connector-oracle Namespace: debezium Labels: strimzi.io/cluster=debezium-kafka-connect-cluster Annotations: <none> API Version: kafka.strimzi.io/v1beta2 Kind: KafkaConnector ... Status: Conditions: Last Transition Time: 2021-12-08T17:41:34.897153Z Status: True Type: Ready Connector Status: Connector: State: RUNNING worker_id: 10.131.1.124:8083 Name: inventory-connector-oracle Tasks: Id: 0 State: RUNNING worker_id: 10.131.1.124:8083 Type: source Observed Generation: 1 Tasks Max: 1 Topics: inventory_connector_oracle inventory_connector_oracle.inventory.addresses inventory_connector_oracle.inventory.customers inventory_connector_oracle.inventory.geom inventory_connector_oracle.inventory.orders inventory_connector_oracle.inventory.products inventory_connector_oracle.inventory.products_on_hand Events: <none>
Verify that the connector created Kafka topics:
From the OpenShift Container Platform web console.
- Navigate to Home → Search.
-
On the Search page, click Resources to open the Select Resource box, and then type
KafkaTopic. - From the KafkaTopics list, click the name of the topic that you want to check, for example, inventory-connector-oracle.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d.
- In the Conditions section, verify that the values in the Type and Status columns are set to Ready and True.
From a terminal window:
Enter the following command:
oc get kafkatopicsThe command returns status information that is similar to the following output:
Example 6.4.
KafkaTopicresource statusNAME CLUSTER PARTITIONS REPLICATION FACTOR READY connect-cluster-configs debezium-kafka-cluster 1 1 True connect-cluster-offsets debezium-kafka-cluster 25 1 True connect-cluster-status debezium-kafka-cluster 5 1 True consumer-offsets---84e7a678d08f4bd226872e5cdd4eb527fadc1c6a debezium-kafka-cluster 50 1 True inventory-connector-oracle---a96f69b23d6118ff415f772679da623fbbb99421 debezium-kafka-cluster 1 1 True inventory-connector-oracle.inventory.addresses---1b6beaf7b2eb57d177d92be90ca2b210c9a56480 debezium-kafka-cluster 1 1 True inventory-connector-oracle.inventory.customers---9931e04ec92ecc0924f4406af3fdace7545c483b debezium-kafka-cluster 1 1 True inventory-connector-oracle.inventory.geom---9f7e136091f071bf49ca59bf99e86c713ee58dd5 debezium-kafka-cluster 1 1 True inventory-connector-oracle.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d debezium-kafka-cluster 1 1 True inventory-connector-oracle.inventory.products---df0746db116844cee2297fab611c21b56f82dcef debezium-kafka-cluster 1 1 True inventory-connector-oracle.inventory.products-on-hand---8649e0f17ffcc9212e266e31a7aeea4585e5c6b5 debezium-kafka-cluster 1 1 True schema-changes.inventory debezium-kafka-cluster 1 1 True strimzi-store-topic---effb8e3e057afce1ecf67c3f5d8e4e3ff177fc55 debezium-kafka-cluster 1 1 True strimzi-topic-operator-kstreams-topic-store-changelog---b75e702040b99be8a9263134de3507fc0cc4017b debezium-kafka-cluster 1 1 True
Check topic content.
- From a terminal window, enter the following command:
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>For example,
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory_connector_oracle.inventory.products_on_handThe format for specifying the topic name is the same as the
oc describecommand returns in Step 1, for example,inventory_connector_oracle.inventory.addresses.For each event in the topic, the command returns information that is similar to the following output:
Example 6.5. Content of a Debezium change event
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory_connector_oracle.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory_connector_oracle.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory_connector_oracle.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.oracle.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory_connector_oracle.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"1.7.2.Final-redhat-00001","connector":"oracle","name":"inventory_connector_oracle","ts_ms":1638985247805,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"oracle-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"transaction":null}}In the preceding example, the
payloadvalue shows that the connector snapshot generated a read ("op" ="r") event from the tableinventory.products_on_hand. The"before"state of theproduct_idrecord isnull, indicating that no previous value exists for the record. The"after"state shows aquantityof3for the item withproduct_id101.
6.6. Descriptions of Debezium Oracle connector configuration properties
The Debezium Oracle connector has numerous configuration properties that you can use to achieve the right connector behavior for your application. Many properties have default values. Information about the properties is organized as follows:
- Required Debezium Oracle connector configuration properties
Database history connector configuration properties that control how Debezium processes events that it reads from the database history topic.
- Pass-through database driver properties that control the behavior of the database driver.
Required Debezium Oracle connector configuration properties
The following configuration properties are required unless a default value is available.
| Property | Default | Description |
| No default | Unique name for the connector. Attempting to register again with the same name will fail. (This property is required by all Kafka Connect connectors.) | |
| No default |
The name of the Java class for the connector. Always use a value of | |
|
| The maximum number of tasks that should be created for this connector. The Oracle connector always uses a single task and therefore does not use this value, so the default is always acceptable. | |
| No default | IP address or hostname of the Oracle database server. | |
| No default | Integer port number of the Oracle database server. | |
| No default | Name of the Oracle user account that the connector uses to connect to the Oracle database server. | |
| No default | Password to use when connecting to the Oracle database server. | |
| No default | Name of the database to connect to. Must be the CDB name when working with the CDB + PDB model. | |
| No default | Specifies the raw database JDBC URL. Use this property to provide flexibility in defining that database connection. Valid values include raw TNS names and RAC connection strings. | |
| No default | Name of the Oracle pluggable database to connect to. Use this property with container database (CDB) installations only. | |
| No default | Logical name that identifies and provides a namespace for the Oracle database server from which the connector captures changes. The value that you set is used as a prefix for all Kafka topic names that the connector emits. Specify a logical name that is unique among all connectors in your Debezium environment. The following characters are valid: alphanumeric characters, hyphens, dots, and underscores. | |
|
| The adapter implementation that the connector uses when it streams database changes. You can set the following values:
| |
| initial | Specifies the mode that the connector uses to take snapshots of a captured table. You can set the following values:
After the snapshot is complete, the connector continues to read change events from the database’s redo logs. | |
| shared | Controls whether and for how long the connector holds a table lock. Table locks prevent certain types of changes table operations from occurring while the connector performs a snapshot. You can set the following values:
| |
|
All tables specified in |
An optional, comma-separated list of regular expressions that match the fully-qualified names ( This property does not affect the behavior of incremental snapshots. | |
| No default | Specifies the table rows to include in a snapshot. Use the property if you want a snapshot to include only a subset of the rows in a table. This property affects snapshots only. It does not apply to events that the connector reads from the log.
The property contains a comma-separated list of fully-qualified table names in the form
From a
In the resulting snapshot, the connector includes only the records for which | |
| No default |
An optional, comma-separated list of regular expressions that match names of schemas for which you want to capture changes. Any schema name not included in | |
| No default |
An optional, comma-separated list of regular expressions that match names of schemas for which you do not want to capture changes. Any schema whose name is not included in | |
| No default |
An optional comma-separated list of regular expressions that match fully-qualified table identifiers for tables to be monitored. Tables that are not included in the include list are excluded from monitoring. Each table identifier uses the following format: | |
| No default |
An optional comma-separated list of regular expressions that match fully-qualified table identifiers for tables to be excluded from monitoring. The connector captures change events from any table that is not specified in the exclude list. Specify the identifier for each table using the following format:
Do not use this property in combination with | |
| No default |
An optional comma-separated list of regular expressions that match the fully-qualified names of columns that want to include in the change event message values. Fully-qualified names for columns use the following format: | |
| No default |
An optional comma-separated list of regular expressions that match the fully-qualified names of columns that you want to exclude from change event message values. Fully-qualified column names use the following format: | |
| No default |
An optional, comma-separated list of regular expressions that match the fully-qualified names of character-based columns. Fully-qualified names for columns are of the form
A pseudonym consists of the hashed value that results from applying the specified hashAlgorithm and salt. Based on the hash function that is used, referential integrity is maintained, while column values are replaced with pseudonyms. Supported hash functions are described in the MessageDigest section of the Java Cryptography Architecture Standard Algorithm Name Documentation.
If necessary, the pseudonym is automatically shortened to the length of the column. The connector configuration can include multiple properties that specify different hash algorithms and salts. | |
|
|
Specifies how the connector should handle floating point values for
| |
|
| Specifies how the connector should react to exceptions during processing of events. You can set one of the following options:
| |
|
|
A positive integer value that specifies the maximum size of the blocking queue. Change events read from the database log are placed in the blocking queue before they are written to Kafka. This queue can provide backpressure to the binlog reader when, for example, writes to Kafka are slow, or if Kafka is not available. Events that appear in the queue are not included in the offsets that the connector records periodically. Always specify a value that is larger than the maximum batch size that specified for the | |
|
| A positive integer value that specifies the maximum size of each batch of events to process during each iteration of this connector. | |
|
| Long value for the maximum size in bytes of the blocking queue. To activate the feature, set the value to a positive long data type. | |
|
| Positive integer value that specifies the number of milliseconds the connector should wait during each iteration for new change events to appear. | |
|
| Controls whether a delete event is followed by a tombstone event. The following values are possible:
After a source record is deleted, a tombstone event (the default behavior) enables Kafka to completely delete all events that share the key of the deleted row in topics that have log compaction enabled. | |
| No default | A list of expressions that specify the columns that the connector uses to form custom message keys for change event records that it publishes to the Kafka topics for specified tables.
By default, Debezium uses the primary key column of a table as the message key for records that it emits. In place of the default, or to specify a key for tables that lack a primary key, you can configure custom message keys based on one or more columns. | |
| No default |
An optional comma-separated list of regular expressions that match the fully-qualified names of character-based columns to be truncated in change event messages if their length exceeds the specified number of characters. Length is specified as a positive integer. A configuration can include multiple properties that specify different lengths. Specify the fully-qualified name for columns by using the following format: | |
| No default |
An optional comma-separated list of regular expressions for masking column names in change event messages by replacing characters with asterisks ( | |
| No default |
An optional comma-separated list of regular expressions that match the fully-qualified names of columns whose original type and length should be added as a parameter to the corresponding field schemas in the emitted change messages. The schema parameters | |
| No default |
An optional comma-separated list of regular expressions that match the database-specific data type name of columns whose original type and length should be added as a parameter to the corresponding field schemas in the emitted change messages. The schema parameters | |
|
|
Specifies, in milliseconds, how frequently the connector sends messages to a heartbeat topic. | |
|
|
Specifies the string that prefixes the name of the topic to which the connector sends heartbeat messages. | |
| No default |
Specifies an interval in milliseconds that the connector waits after it starts before it takes a snapshot. | |
|
| Specifies the maximum number of rows that should be read in one go from each table while taking a snapshot. The connector reads table contents in multiple batches of the specified size. | |
|
| Specifies whether field names are normalized to comply with Avro naming requirements. For more information, see Avro naming. | |
|
|
Set the property to See Transaction Metadata for additional details. | |
|
|
Specifies the mining strategy that controls how Oracle LogMiner builds and uses a given data dictionary for resolving table and column ids to names. | |
|
|
The buffer type controls how the connector manages buffering transaction data. | |
|
| The minimum SCN interval size that this connector attempts to read from redo/archive logs. Active batch size is also increased/decreased by this amount for tuning connector throughput when needed. | |
|
| The maximum SCN interval size that this connector uses when reading from redo/archive logs. | |
|
| The starting SCN interval size that the connector uses for reading data from redo/archive logs. | |
|
| The minimum amount of time that the connector sleeps after reading data from redo/archive logs and before starting reading data again. Value is in milliseconds. | |
|
| The maximum amount of time that the connector ill sleeps after reading data from redo/archive logs and before starting reading data again. Value is in milliseconds. | |
|
| The starting amount of time that the connector sleeps after reading data from redo/archive logs and before starting reading data again. Value is in milliseconds. | |
|
| The maximum amount of time up or down that the connector uses to tune the optimal sleep time when reading data from logminer. Value is in milliseconds. | |
|
| The number of content records that the connector fetches from the LogMiner content view. | |
|
|
The number of hours in the past from SYSDATE to mine archive logs. When the default setting ( | |
|
|
Controls whether or not the connector mines changes from just archive logs or a combination of the online redo logs and archive logs (the default). | |
|
|
The number of milliseconds the connector will sleep in between polling to determine if the starting system change number is in the archive logs. If | |
|
|
Positive integer value that specifies the number of hours to retain long running transactions between redo log switches. When set to The LogMiner adapter maintains an in-memory buffer of all running transactions. Because all of the DML operations that are part of a transaction are buffered until a commit or rollback is detected, long-running transactions should be avoided in order to not overflow that buffer. Any transaction that exceeds this configured value is discarded entirely, and the connector does not emit any messages for the operations that were part of the transaction. | |
| No default |
Specifies the configured Oracle archive destination to use when mining archive logs with LogMiner. | |
| No default | List of database users to exclude from the LogMiner query. It can be useful to set this property if you want the capturing process to always exclude the changes that specific users make. | |
|
|
Specifies a value that the connector compares to the difference between the current and previous SCN values to determine whether an SCN gap exists. If the difference between the SCN values is greater than the specified value, and the time difference is smaller than | |
|
|
Specifies a value, in milliseconds, that the connector compares to the difference between the current and previous SCN timestamps to determine whether an SCN gap exists. If the difference between the timestamps is less than the specified value, and the SCN delta is greater than | |
|
|
Controls whether or not large object (CLOB or BLOB) column values are emitted in change events. | |
|
| Specifies the constant that the connector provides to indicate that the original value is unchanged and not provided by the database. | |
| No default | A comma-separated list of Oracle Real Application Clusters (RAC) node host names or addresses. This field is required to enable Oracle RAC support. Specify the list of RAC nodes by using one of the following methods:
If you supply a raw JDBC URL for the database by using the | |
| No default | A comma-separated list of the operation types that you want the connector to skip during streaming. You can configure the connector to skip the following types of operations:
By default, no operations are skipped. | |
| No default value |
Fully-qualified name of the data collection that is used to send signals to the connector. | |
|
| The maximum number of rows that the connector fetches and reads into memory during an incremental snapshot chunk. Increasing the chunk size provides greater efficiency, because the snapshot runs fewer snapshot queries of a greater size. However, larger chunk sizes also require more memory to buffer the snapshot data. Adjust the chunk size to a value that provides the best performance in your environment. |
Debezium Oracle connector database history configuration properties
Debezium provides a set of database.history.* properties that control how the connector interacts with the schema history topic.
The following table describes the database.history properties for configuring the Debezium connector.
| Property | Default | Description |
|---|---|---|
| The full name of the Kafka topic where the connector stores the database schema history. | ||
| A list of host/port pairs that the connector uses for establishing an initial connection to the Kafka cluster. This connection is used for retrieving the database schema history previously stored by the connector, and for writing each DDL statement read from the source database. Each pair should point to the same Kafka cluster used by the Kafka Connect process. | ||
|
| An integer value that specifies the maximum number of milliseconds the connector should wait during startup/recovery while polling for persisted data. The default is 100ms. | |
|
|
The maximum number of times that the connector should try to read persisted history data before the connector recovery fails with an error. The maximum amount of time to wait after receiving no data is | |
|
|
A Boolean value that specifies whether the connector should ignore malformed or unknown database statements or stop processing so a human can fix the issue. The safe default is | |
|
Deprecated and scheduled for removal in a future release; use |
|
A Boolean value that specifies whether the connector should record all DDL statements
The safe default is |
|
|
A Boolean value that specifies whether the connector should record all DDL statements
The safe default is |
Pass-through database history properties for configuring producer and consumer clients
Debezium relies on a Kafka producer to write schema changes to database history topics. Similarly, it relies on a Kafka consumer to read from database history topics when a connector starts. You define the configuration for the Kafka producer and consumer clients by assigning values to a set of pass-through configuration properties that begin with the database.history.producer.* and database.history.consumer.* prefixes. The pass-through producer and consumer database history properties control a range of behaviors, such as how these clients secure connections with the Kafka broker, as shown in the following example:
database.history.producer.security.protocol=SSL
database.history.producer.ssl.keystore.location=/var/private/ssl/kafka.server.keystore.jks
database.history.producer.ssl.keystore.password=test1234
database.history.producer.ssl.truststore.location=/var/private/ssl/kafka.server.truststore.jks
database.history.producer.ssl.truststore.password=test1234
database.history.producer.ssl.key.password=test1234
database.history.consumer.security.protocol=SSL
database.history.consumer.ssl.keystore.location=/var/private/ssl/kafka.server.keystore.jks
database.history.consumer.ssl.keystore.password=test1234
database.history.consumer.ssl.truststore.location=/var/private/ssl/kafka.server.truststore.jks
database.history.consumer.ssl.truststore.password=test1234
database.history.consumer.ssl.key.password=test1234Debezium strips the prefix from the property name before it passes the property to the Kafka client.
See the Kafka documentation for more details about Kafka producer configuration properties and Kafka consumer configuration properties.
Debezium Oracle connector pass-through database driver configuration properties
The Debezium connector provides for pass-through configuration of the database driver. Pass-through database properties begin with the prefix database.*. For example, the connector passes properties such as database.foobar=false to the JDBC URL.
As is the case with the pass-through properties for database history clients, Debezium strips the prefixes from the properties before it passes them to the database driver.
6.7. Monitoring Debezium Oracle connector performance
The Debezium Oracle connector provides three metric types in addition to the built-in support for JMX metrics that Apache Zookeeper, Apache Kafka, and Kafka Connect have.
- snapshot metrics; for monitoring the connector when performing snapshots
- streaming metrics; for monitoring the connector when processing change events
- schema history metrics; for monitoring the status of the connector’s schema history
Please refer to the monitoring documentation for details of how to expose these metrics via JMX.
6.7.1. Debezium Oracle connector snapshot metrics
The MBean is debezium.oracle:type=connector-metrics,context=snapshot,server=<oracle.server.name>.
Snapshot metrics are not exposed unless a snapshot operation is active, or if a snapshot has occurred since the last connector start.
The following table lists the shapshot metrics that are available.
| Attributes | Type | Description |
|---|---|---|
|
| The last snapshot event that the connector has read. | |
|
| The number of milliseconds since the connector has read and processed the most recent event. | |
|
| The total number of events that this connector has seen since last started or reset. | |
|
| The number of events that have been filtered by include/exclude list filtering rules configured on the connector. | |
|
|
| The list of tables that are monitored by the connector. |
|
| The list of tables that are captured by the connector. | |
|
| The length the queue used to pass events between the snapshotter and the main Kafka Connect loop. | |
|
| The free capacity of the queue used to pass events between the snapshotter and the main Kafka Connect loop. | |
|
| The total number of tables that are being included in the snapshot. | |
|
| The number of tables that the snapshot has yet to copy. | |
|
| Whether the snapshot was started. | |
|
| Whether the snapshot was aborted. | |
|
| Whether the snapshot completed. | |
|
| The total number of seconds that the snapshot has taken so far, even if not complete. | |
|
| Map containing the number of rows scanned for each table in the snapshot. Tables are incrementally added to the Map during processing. Updates every 10,000 rows scanned and upon completing a table. | |
|
|
The maximum buffer of the queue in bytes. It will be enabled if | |
|
| The current data of records in the queue in bytes. |
The connector also provides the following additional snapshot metrics when an incremental snapshot is executed:
| Attributes | Type | Description |
|---|---|---|
|
| The identifier of the current snapshot chunk. | |
|
| The lower bound of the primary key set defining the current chunk. | |
|
| The upper bound of the primary key set defining the current chunk. | |
|
| The lower bound of the primary key set of the currently snapshotted table. | |
|
| The upper bound of the primary key set of the currently snapshotted table. |
Incremental snapshots is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process. For more information about the support scope of Red Hat Technology Preview features, see https://access.redhat.com/support/offerings/techpreview.
6.7.2. Debezium Oracle connector streaming metrics
The MBean is debezium.oracle:type=connector-metrics,context=streaming,server=<oracle.server.name>.
The following table lists the streaming metrics that are available.
| Attributes | Type | Description |
|---|---|---|
|
| The last streaming event that the connector has read. | |
|
| The number of milliseconds since the connector has read and processed the most recent event. | |
|
| The total number of events that this connector has seen since last started or reset. | |
|
| The number of events that have been filtered by include/exclude list filtering rules configured on the connector. | |
|
|
| The list of tables that are monitored by the connector. |
|
| The list of tables that are captured by the connector. | |
|
| The length the queue used to pass events between the streamer and the main Kafka Connect loop. | |
|
| The free capacity of the queue used to pass events between the streamer and the main Kafka Connect loop. | |
|
| Flag that denotes whether the connector is currently connected to the database server. | |
|
| The number of milliseconds between the last change event’s timestamp and the connector processing it. The values will incoporate any differences between the clocks on the machines where the database server and the connector are running. | |
|
| The number of processed transactions that were committed. | |
|
| The coordinates of the last received event. | |
|
| Transaction identifier of the last processed transaction. | |
|
| The maximum buffer of the queue in bytes. | |
|
| The current data of records in the queue in bytes. |
The Debezium Oracle connector also provides the following additional streaming metrics:
| Attributes | Type | Description |
|---|---|---|
|
| The most recent system change number that has been processed. | |
|
| The oldest system change number in the transaction buffer. | |
|
| The last committed system change number from the transaction buffer. | |
|
| The system change number currently written to the connector’s offsets. | |
|
| Array of the log files that are currently mined. | |
|
| The minimum number of logs specified for any LogMiner session. | |
|
| The maximum number of logs specified for any LogMiner session. | |
|
|
Array of the current state for each mined logfile with the format | |
|
| The number of times the database has performed a log switch for the last day. | |
|
| The number of DML operations observed in the last LogMiner session query. | |
|
| The maximum number of DML operations observed while processing a single LogMiner session query. | |
|
| The total number of DML operations observed. | |
|
| The total number of LogMiner session query (aka batches) performed. | |
|
| The duration of the last LogMiner session query’s fetch in milliseconds. | |
|
| The maximum duration of any LogMiner session query’s fetch in milliseconds. | |
|
| The duration for processing the last LogMiner query batch results in milliseconds. | |
|
| The time in milliseconds spent parsing DML event SQL statements. | |
|
| The duration in milliseconds to start the last LogMiner session. | |
|
| The longest duration in milliseconds to start a LogMiner session. | |
|
| The total duration in milliseconds spent by the connector starting LogMiner sessions. | |
|
| The minimum duration in milliseconds spent processing results from a single LogMiner session. | |
|
| The maximum duration in milliseconds spent processing results from a single LogMiner session. | |
|
| The total duration in milliseconds spent processing results from LogMiner sessions. | |
|
| The total duration in milliseconds spent by the JDBC driver fetching the next row to be processed from the log mining view. | |
|
| The total number of rows processed from the log mining view across all sessions. | |
|
| The number of entries fetched by the log mining query per database round-trip. | |
|
| The number of milliseconds the connector sleeps before fetching another batch of results from the log mining view. | |
|
| The maximum number of rows/second processed from the log mining view. | |
|
| The average number of rows/second processed from the log mining. | |
|
| The average number of rows/second processed from the log mining view for the last batch. | |
|
| The number of connection problems detected. | |
|
|
The number of hours that transactions are retained by the connector’s in-memory buffer without being committed or rolled back before being discarded. See | |
|
| The number of current active transactions in the transaction buffer. | |
|
| The number of committed transactions in the transaction buffer. | |
|
| The number of rolled back transactions in the transaction buffer. | |
|
| The average number of committed transactions per second in the transaction buffer. | |
|
| The number of registered DML operations in the transaction buffer. | |
|
| The time difference in milliseconds between when a change occurred in the transaction logs and when its added to the transaction buffer. | |
|
| The maximum time difference in milliseconds between when a change occurred in the transaction logs and when its added to the transaction buffer. | |
|
| The minimum time difference in milliseconds between when a change occurred in the transaction logs and when its added to the transaction buffer. | |
|
|
An array of abandoned transaction identifiers removed from the transaction buffer due to their age. See | |
|
| An array of transaction identifiers that have been mined and rolled back in the transaction buffer. | |
|
| The duration of the last transaction buffer commit operation in milliseconds. | |
|
| The duration of the longest transaction buffer commit operation in milliseconds. | |
|
| The number of errors detected. | |
|
| The number of warnings detected. | |
|
|
The number of times the system change number has been checked for advancement and remains unchanged. This is an indicator that long-running transaction(s) are ongoing and preventing the connector from flushing the latest processed system change number to the connector’s offsets. Under optimal operations, this should always be or remain close to | |
|
|
The number of DDL records that have been detected but could not be parsed by the DDL parser. This should always be | |
|
| The current mining session’s user global area (UGA) memory consumption in bytes. | |
|
| The maximum mining session’s user global area (UGA) memory consumption in bytes across all mining sessions. | |
|
| The current mining session’s process global area (PGA) memory consumption in bytes. | |
|
| The maximum mining session’s process global area (PGA) memory consumption in bytes across all mining sessions. |
6.7.3. Debezium Oracle connector schema history metrics
The MBean is debezium.oracle:type=connector-metrics,context=schema-history,server=<oracle.server.name>.
The following table lists the schema history metrics that are available.
| Attributes | Type | Description |
|---|---|---|
|
|
One of | |
|
| The time in epoch seconds at what recovery has started. | |
|
| The number of changes that were read during recovery phase. | |
|
| the total number of schema changes applied during recovery and runtime. | |
|
| The number of milliseconds that elapsed since the last change was recovered from the history store. | |
|
| The number of milliseconds that elapsed since the last change was applied. | |
|
| The string representation of the last change recovered from the history store. | |
|
| The string representation of the last applied change. |
6.8. How Debezium Oracle connectors handle faults and problems
Debezium is a distributed system that captures all changes in multiple upstream databases; it never misses or loses an event. When the system is operating normally or being managed carefully then Debezium provides exactly once delivery of every change event record.
If a fault occurs, Debezium does not lose any events. However, while it is recovering from the fault, it might repeat some change events. In these abnormal situations, Debezium, like Kafka, provides at least once delivery of change events.
The rest of this section describes how Debezium handles various kinds of faults and problems.
ORA-25191 - Cannot reference overflow table of an index-organized table
Oracle might issue this error during the snapshot phase when encountering an index-organized table (IOT). This error means that the connector has attempted to execute an operation that must be executed against the parent index-organized table that contains the specified overflow table.
To resolve this, the IOT name used in the SQL operation should be replaced with the parent index-organized table name. To determine the parent index-organized table name, use the following SQL:
SELECT IOT_NAME
FROM DBA_TABLES
WHERE OWNER='<tablespace-owner>'
AND TABLE_NAME='<iot-table-name-that-failed>'
The connector’s table.include.list or table.exclude.list configuration options should then be adjusted to explicitly include or exclude the appropriate tables to avoid the connector from attempting to capture changes from the child index-organized table.
LogMiner adapter does not capture changes made by SYS or SYSTEM
Oracle uses the SYS and SYSTEM accounts for lots of internal changes and therefore the connector automatically filters changes made by these users when fetching changes from LogMiner. Never use the SYS or SYSTEM user accounts for changes to be emitted by the Debezium Oracle connector.
Chapter 7. Debezium connector for PostgreSQL
The Debezium PostgreSQL connector captures row-level changes in the schemas of a PostgreSQL database. For information about the PostgreSQL versions that are compatible with the connector, see the Debezium Supported Configurations page.
The first time it connects to a PostgreSQL server or cluster, the connector takes a consistent snapshot of all schemas. After that snapshot is complete, the connector continuously captures row-level changes that insert, update, and delete database content and that were committed to a PostgreSQL database. The connector generates data change event records and streams them to Kafka topics. For each table, the default behavior is that the connector streams all generated events to a separate Kafka topic for that table. Applications and services consume data change event records from that topic.
Information and procedures for using a Debezium PostgreSQL connector is organized as follows:
- Section 7.1, “Overview of Debezium PostgreSQL connector”
- Section 7.2, “How Debezium PostgreSQL connectors work”
- Section 7.3, “Descriptions of Debezium PostgreSQL connector data change events”
- Section 7.4, “How Debezium PostgreSQL connectors map data types”
- Section 7.5, “Setting up PostgreSQL to run a Debezium connector”
- Section 7.6, “Deployment of Debezium PostgreSQL connectors”
- Section 7.7, “Monitoring Debezium PostgreSQL connector performance”
- Section 7.8, “How Debezium PostgreSQL connectors handle faults and problems”
7.1. Overview of Debezium PostgreSQL connector
PostgreSQL’s logical decoding feature was introduced in version 9.4. It is a mechanism that allows the extraction of the changes that were committed to the transaction log and the processing of these changes in a user-friendly manner with the help of an output plug-in. The output plug-in enables clients to consume the changes.
The PostgreSQL connector contains two main parts that work together to read and process database changes:
-
pgoutputis the standard logical decoding output plug-in in PostgreSQL 10+. This is the only supported logical decoding output plug-in in this Debezium release. This plug-in is maintained by the PostgreSQL community, and used by PostgreSQL itself for logical replication. This plug-in is always present so no additional libraries need to be installed. The Debezium connector interprets the raw replication event stream directly into change events. - Java code (the actual Kafka Connect connector) that reads the changes produced by the logical decoding output plug-in by using PostgreSQL’s streaming replication protocol and the PostgreSQL JDBC driver.
The connector produces a change event for every row-level insert, update, and delete operation that was captured and sends change event records for each table in a separate Kafka topic. Client applications read the Kafka topics that correspond to the database tables of interest, and can react to every row-level event they receive from those topics.
PostgreSQL normally purges write-ahead log (WAL) segments after some period of time. This means that the connector does not have the complete history of all changes that have been made to the database. Therefore, when the PostgreSQL connector first connects to a particular PostgreSQL database, it starts by performing a consistent snapshot of each of the database schemas. After the connector completes the snapshot, it continues streaming changes from the exact point at which the snapshot was made. This way, the connector starts with a consistent view of all of the data, and does not omit any changes that were made while the snapshot was being taken.
The connector is tolerant of failures. As the connector reads changes and produces events, it records the WAL position for each event. If the connector stops for any reason (including communication failures, network problems, or crashes), upon restart the connector continues reading the WAL where it last left off. This includes snapshots. If the connector stops during a snapshot, the connector begins a new snapshot when it restarts.
The connector relies on and reflects the PostgreSQL logical decoding feature, which has the following limitations:
- Logical decoding does not support DDL changes. This means that the connector is unable to report DDL change events back to consumers.
-
Logical decoding replication slots are supported on only
primaryservers. When there is a cluster of PostgreSQL servers, the connector can run on only the activeprimaryserver. It cannot run onhotorwarmstandby replicas. If theprimaryserver fails or is demoted, the connector stops. After theprimaryserver has recovered, you can restart the connector. If a different PostgreSQL server has been promoted toprimary, adjust the connector configuration before restarting the connector.
Behavior when things go wrong describes what the connector does when there is a problem.
Debezium currently supports databases with UTF-8 character encoding only. With a single byte character encoding, it is not possible to correctly process strings that contain extended ASCII code characters.
7.2. How Debezium PostgreSQL connectors work
To optimally configure and run a Debezium PostgreSQL connector, it is helpful to understand how the connector performs snapshots, streams change events, determines Kafka topic names, and uses metadata.
Details are in the following topics:
- Section 7.2.2, “How Debezium PostgreSQL connectors perform database snapshots”
- Section 7.2.3, “How Debezium PostgreSQL connectors stream change event records”
- Section 7.2.4, “Default names of Kafka topics that receive Debezium PostgreSQL change event records”
- Section 7.2.5, “Metadata in Debezium PostgreSQL change event records”
- Section 7.2.6, “Debezium PostgreSQL connector-generated events that represent transaction boundaries”
7.2.1. Security for PostgreSQL connector
To use the Debezium connector to stream changes from a PostgreSQL database, the connector must operate with specific privileges in the database. Although one way to grant the necessary privileges is to provide the user with superuser privileges, doing so potentially exposes your PostgreSQL data to unauthorized access. Rather than granting excessive privileges to the Debezium user, it is best to create a dedicated Debezium replication user to which you grant specific privileges.
For more information about configuring privileges for the Debezium PostgreSQL user, see Setting up permissions. For more information about PostgreSQL logical replication security, see the PostgreSQL documentation.
7.2.2. How Debezium PostgreSQL connectors perform database snapshots
Most PostgreSQL servers are configured to not retain the complete history of the database in the WAL segments. This means that the PostgreSQL connector would be unable to see the entire history of the database by reading only the WAL. Consequently, the first time that the connector starts, it performs an initial consistent snapshot of the database. The default behavior for performing a snapshot consists of the following steps. You can change this behavior by setting the snapshot.mode connector configuration property to a value other than initial.
-
Start a transaction with a SERIALIZABLE, READ ONLY, DEFERRABLE isolation level to ensure that subsequent reads in this transaction are against a single consistent version of the data. Any changes to the data due to subsequent
INSERT,UPDATE, andDELETEoperations by other clients are not visible to this transaction. - Read the current position in the server’s transaction log.
-
Scan the database tables and schemas, generate a
READevent for each row and write that event to the appropriate table-specific Kafka topic. - Commit the transaction.
- Record the successful completion of the snapshot in the connector offsets.
If the connector fails, is rebalanced, or stops after Step 1 begins but before Step 6 completes, upon restart the connector begins a new snapshot. After the connector completes its initial snapshot, the PostgreSQL connector continues streaming from the position that it read in step 3. This ensures that the connector does not miss any updates. If the connector stops again for any reason, upon restart, the connector continues streaming changes from where it previously left off.
| Setting | Description |
|---|---|
|
|
The connector always performs a snapshot when it starts. After the snapshot completes, the connector continues streaming changes from step 3 in the above sequence. This mode is useful in these situations:
|
|
|
The connector never performs snapshots. When a connector is configured this way, its behavior when it starts is as follows. If there is a previously stored LSN in the Kafka offsets topic, the connector continues streaming changes from that position. If no LSN has been stored, the connector starts streaming changes from the point in time when the PostgreSQL logical replication slot was created on the server. The |
|
| The connector performs a database snapshot and stops before streaming any change event records. If the connector had started but did not complete a snapshot before stopping, the connector restarts the snapshot process and stops when the snapshot completes. |
|
| Deprecated, all modes are lockless. |
7.2.2.1. Ad hoc snapshots
The use of ad hoc snapshots is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service-level agreements (SLAs) and might not be functionally complete; therefore, Red Hat does not recommend implementing any Technology Preview features in production environments. This Technology Preview feature provides early access to upcoming product innovations, enabling you to test functionality and provide feedback during the development process. For more information about support scope, see Technology Preview Features Support Scope.
By default, a connector runs an initial snapshot operation only after it starts for the first time. Following this initial snapshot, under normal circumstances, the connector does not repeat the snapshot process. Any future change event data that the connector captures comes in through the streaming process only.
However, in some situations the data that the connector obtained during the initial snapshot might become stale, lost, or incomplete. To provide a mechanism for recapturing table data, Debezium includes an option to perform ad hoc snapshots. The following changes in a database might be cause for performing an ad hoc snapshot:
- The connector configuration is modified to capture a different set of tables.
- Kafka topics are deleted and must be rebuilt.
- Data corruption occurs due to a configuration error or some other problem.
You can re-run a snapshot for a table for which you previously captured a snapshot by initiating a so-called ad-hoc snapshot. Ad hoc snapshots require the use of signaling tables. You initiate an ad hoc snapshot by sending a signal request to the Debezium signaling table.
When you initiate an ad hoc snapshot of an existing table, the connector appends content to the topic that already exists for the table. If a previously existing topic was removed, Debezium can create a topic automatically if automatic topic creation is enabled.
Ad hoc snapshot signals specify the tables to include in the snapshot. The snapshot can capture the entire contents of the database, or capture only a subset of the tables in the database.
You specify the tables to capture by sending an execute-snapshot message to the signaling table. Set the type of the execute-snapshot signal to incremental, and provide the names of the tables to include in the snapshot, as described in the following table:
| Field | Default | Value |
|---|---|---|
|
|
|
Specifies the type of snapshot that you want to run. |
|
| N/A |
An array that contains the fully-qualified names of the table to be snapshotted. |
Triggering an ad hoc snapshot
You initiate an ad hoc snapshot by adding an entry with the execute-snapshot signal type to the signaling table. After the connector processes the message, it begins the snapshot operation. The snapshot process reads the first and last primary key values and uses those values as the start and end point for each table. Based on the number of entries in the table, and the configured chunk size, Debezium divides the table into chunks, and proceeds to snapshot each chunk, in succession, one at a time.
Currently, the execute-snapshot action type triggers incremental snapshots only. For more information, see Incremental snapshots.
7.2.2.2. Incremental snapshots
The use of incremental snapshots is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service-level agreements (SLAs) and might not be functionally complete; therefore, Red Hat does not recommend implementing any Technology Preview features in production environments. This Technology Preview feature provides early access to upcoming product innovations, enabling you to test functionality and provide feedback during the development process. For more information about support scope, see Technology Preview Features Support Scope.
To provide flexibility in managing snapshots, Debezium includes a supplementary snapshot mechanism, known as incremental snapshotting. Incremental snapshots rely on the Debezium mechanism for sending signals to a Debezium connector.
In an incremental snapshot, instead of capturing the full state of a database all at once, as in an initial snapshot, Debezium captures each table in phases, in a series of configurable chunks. You can specify the tables that you want the snapshot to capture and the size of each chunk. The chunk size determines the number of rows that the snapshot collects during each fetch operation on the database. The default chunk size for incremental snapshots is 1 KB.
As an incremental snapshot proceeds, Debezium uses watermarks to track its progress, maintaining a record of each table row that it captures. This phased approach to capturing data provides the following advantages over the standard initial snapshot process:
- You can run incremental snapshots in parallel with streamed data capture, instead of postponing streaming until the snapshot completes. The connector continues to capture near real-time events from the change log throughout the snapshot process, and neither operation blocks the other.
- If the progress of an incremental snapshot is interrupted, you can resume it without losing any data. After the process resumes, the snapshot begins at the point where it stopped, rather than recapturing the table from the beginning.
-
You can run an incremental snapshot on demand at any time, and repeat the process as needed to adapt to database updates. For example, you might re-run a snapshot after you modify the connector configuration to add a table to its
table.include.listproperty.
Incremental snapshot process
When you run an incremental snapshot, Debezium sorts each table by primary key and then splits the table into chunks based on the configured chunk size. Working chunk by chunk, it then captures each table row in a chunk. For each row that it captures, the snapshot emits a READ event. That event represents the value of the row when the snapshot for the chunk began.
As a snapshot proceeds, it’s likely that other processes continue to access the database, potentially modifying table records. To reflect such changes, INSERT, UPDATE, or DELETE operations are committed to the transaction log as per usual. Similarly, the ongoing Debezium streaming process continues to detect these change events and emits corresponding change event records to Kafka.
How Debezium resolves collisions among records with the same primary key
In some cases, the UPDATE or DELETE events that the streaming process emits are received out of sequence. That is, the streaming process might emit an event that modifies a table row before the snapshot captures the chunk that contains the READ event for that row. When the snapshot eventually emits the corresponding READ event for the row, its value is already superseded. To ensure that incremental snapshot events that arrive out of sequence are processed in the correct logical order, Debezium employs a buffering scheme for resolving collisions. Only after collisions between the snapshot events and the streamed events are resolved does Debezium emit an event record to Kafka.
Snapshot window
To assist in resolving collisions between late-arriving READ events and streamed events that modify the same table row, Debezium employs a so-called snapshot window. The snapshot windows demarcates the interval during which an incremental snapshot captures data for a specified table chunk. Before the snapshot window for a chunk opens, Debezium follows its usual behavior and emits events from the transaction log directly downstream to the target Kafka topic. But from the moment that the snapshot for a particular chunk opens, until it closes, Debezium performs a de-duplication step to resolve collisions between events that have the same primary key..
For each data collection, the Debezium emits two types of events, and stores the records for them both in a single destination Kafka topic. The snapshot records that it captures directly from a table are emitted as READ operations. Meanwhile, as users continue to update records in the data collection, and the transaction log is updated to reflect each commit, Debezium emits UPDATE or DELETE operations for each change.
As the snapshot window opens, and Debezium begins processing a snapshot chunk, it delivers snapshot records to a memory buffer. During the snapshot windows, the primary keys of the READ events in the buffer are compared to the primary keys of the incoming streamed events. If no match is found, the streamed event record is sent directly to Kafka. If Debezium detects a match, it discards the buffered READ event, and writes the streamed record to the destination topic, because the streamed event logically supersede the static snapshot event. After the snapshot window for the chunk closes, the buffer contains only READ events for which no related transaction log events exist. Debezium emits these remaining READ events to the table’s Kafka topic.
The connector repeats the process for each snapshot chunk.
Triggering an incremental snapshot
Currently, the only way to initiate an incremental snapshot is to send an ad hoc snapshot signal to the signaling table on the source database. You submit signals to the table as SQL INSERT queries. After Debezium detects the change in the signaling table, it reads the signal, and runs the requested snapshot operation.
The query that you submit specifies the tables to include in the snapshot, and, optionally, specifies the kind of snapshot operation. Currently, the only valid option for snapshots operations is the default value, incremental.
To specify the tables to include in the snapshot, provide a data-collections array that lists the tables, for example,{"data-collections": ["public.MyFirstTable", "public.MySecondTable"]}
The data-collections array for an incremental snapshot signal has no default value. If the data-collections array is empty, Debezium detects that no action is required and does not perform a snapshot.
Prerequisites
- A signaling data collection exists on the source database and the connector is configured to capture it.
-
The signaling data collection is specified in the
signal.data.collectionproperty.
Procedure
Send a SQL query to add the ad hoc incremental snapshot request to the signaling table:
INSERT INTO _<signalTable>_ (id, type, data) VALUES (_'<id>'_, _'<snapshotType>'_, '{"data-collections": ["_<tableName>_","_<tableName>_"],"type":"_<snapshotType>_"}');For example,
INSERT INTO myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["schema1.table1", "schema2.table2"],"type":"incremental"}');The values of the
id,type, anddataparameters in the command correspond to the fields of the signaling table.The following table describes the these parameters:
Expand Table 7.3. Descriptions of fields in a SQL command for sending an incremental snapshot signal to the signaling table Value Description myschema.debezium_signalSpecifies the fully-qualified name of the signaling table on the source database
ad-hoc-1The
idparameter specifies an arbitrary string that is assigned as theididentifier for the signal request.
Use this string to identify logging messages to entries in the signaling table. Debezium does not use this string. Rather, during the snapshot, Debezium generates its ownidstring as a watermarking signal.execute-snapshotSpecifies
typeparameter specifies the operation that the signal is intended to trigger.
data-collectionsA required component of the
datafield of a signal that specifies an array of table names to include in the snapshot.
The array lists tables by their fully-qualified names, using the same format as you use to specify the name of the connector’s signaling table in thesignal.data.collectionconfiguration property.incrementalAn optional
typecomponent of thedatafield of a signal that specifies the kind of snapshot operation to run.
Currently, the only valid option is the default value,incremental.
Specifying atypevalue in the SQL query that you submit to the signaling table is optional.
If you do not specify a value, the connector runs an incremental snapshot.
The following example, shows the JSON for an incremental snapshot event that is captured by a connector.
Example: Incremental snapshot event message
{
"before":null,
"after": {
"pk":"1",
"value":"New data"
},
"source": {
...
"snapshot":"incremental"
},
"op":"r",
"ts_ms":"1620393591654",
"transaction":null
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
Specifies the type of snapshot operation to run. |
| 2 |
|
Specifies the event type. |
The Debezium connector for PostgreSQL does not support schema changes while an incremental snapshot is running. If a schema change is performed before the incremental snapshot start but after sending the signal then passthrough config option database.autosave is set to conservative to correctly process the schema change.
7.2.3. How Debezium PostgreSQL connectors stream change event records
The PostgreSQL connector typically spends the vast majority of its time streaming changes from the PostgreSQL server to which it is connected. This mechanism relies on PostgreSQL’s replication protocol. This protocol enables clients to receive changes from the server as they are committed in the server’s transaction log at certain positions, which are referred to as Log Sequence Numbers (LSNs).
Whenever the server commits a transaction, a separate server process invokes a callback function from the logical decoding plug-in. This function processes the changes from the transaction, converts them to a specific format (Protobuf or JSON in the case of Debezium plug-in) and writes them on an output stream, which can then be consumed by clients.
The Debezium PostgreSQL connector acts as a PostgreSQL client. When the connector receives changes it transforms the events into Debezium create, update, or delete events that include the LSN of the event. The PostgreSQL connector forwards these change events in records to the Kafka Connect framework, which is running in the same process. The Kafka Connect process asynchronously writes the change event records in the same order in which they were generated to the appropriate Kafka topic.
Periodically, Kafka Connect records the most recent offset in another Kafka topic. The offset indicates source-specific position information that Debezium includes with each event. For the PostgreSQL connector, the LSN recorded in each change event is the offset.
When Kafka Connect gracefully shuts down, it stops the connectors, flushes all event records to Kafka, and records the last offset received from each connector. When Kafka Connect restarts, it reads the last recorded offset for each connector, and starts each connector at its last recorded offset. When the connector restarts, it sends a request to the PostgreSQL server to send the events starting just after that position.
The PostgreSQL connector retrieves schema information as part of the events sent by the logical decoding plug-in. However, the connector does not retrieve information about which columns compose the primary key. The connector obtains this information from the JDBC metadata (side channel). If the primary key definition of a table changes (by adding, removing or renaming primary key columns), there is a tiny period of time when the primary key information from JDBC is not synchronized with the change event that the logical decoding plug-in generates. During this tiny period, a message could be created with an inconsistent key structure. To prevent this inconsistency, update primary key structures as follows:
- Put the database or an application into a read-only mode.
- Let Debezium process all remaining events.
- Stop Debezium.
- Update the primary key definition in the relevant table.
- Put the database or the application into read/write mode.
- Restart Debezium.
PostgreSQL 10+ logical decoding support (pgoutput)
As of PostgreSQL 10+, there is a logical replication stream mode, called pgoutput that is natively supported by PostgreSQL. This means that a Debezium PostgreSQL connector can consume that replication stream without the need for additional plug-ins. This is particularly valuable for environments where installation of plug-ins is not supported or not allowed.
See Setting up PostgreSQL for more details.
7.2.4. Default names of Kafka topics that receive Debezium PostgreSQL change event records
By default, the PostgreSQL connector writes change events for all INSERT, UPDATE, and DELETE operations that occur in a table to a single Apache Kafka topic that is specific to that table. The connector uses the following convention to name change event topics:
serverName.schemaName.tableName
The following list provides definitions for the components of the default name:
- serverName
-
The logical name of the connector, as specified by the
database.server.nameconfiguration property. - schemaName
- The name of the database schema in which the change event occurred.
- tableName
- The name of the database table in which the change event occurred.
For example, suppose that fulfillment is the logical server name in the configuration for a connector that is capturing changes in a PostgreSQL installation that has a postgres database and an inventory schema that contains four tables: products, products_on_hand, customers, and orders. The connector would stream records to these four Kafka topics:
-
fulfillment.inventory.products -
fulfillment.inventory.products_on_hand -
fulfillment.inventory.customers -
fulfillment.inventory.orders
Now suppose that the tables are not part of a specific schema but were created in the default public PostgreSQL schema. The names of the Kafka topics would be:
-
fulfillment.public.products -
fulfillment.public.products_on_hand -
fulfillment.public.customers -
fulfillment.public.orders
The connector applies similar naming conventions to label its transaction metadata topics.
If the default topic name do not meet your requirements, you can configure custom topic names. To configure custom topic names, you specify regular expressions in the logical topic routing SMT. For more information about using the logical topic routing SMT to customize topic naming, see Topic routing.
7.2.5. Metadata in Debezium PostgreSQL change event records
In addition to a database change event, each record produced by a PostgreSQL connector contains some metadata. Metadata includes where the event occurred on the server, the name of the source partition and the name of the Kafka topic and partition where the event should go, for example:
"sourcePartition": {
"server": "fulfillment"
},
"sourceOffset": {
"lsn": "24023128",
"txId": "555",
"ts_ms": "1482918357011"
},
"kafkaPartition": null-
sourcePartitionalways defaults to the setting of thedatabase.server.nameconnector configuration property. sourceOffsetcontains information about the location of the server where the event occurred:-
lsnrepresents the PostgreSQL Log Sequence Number oroffsetin the transaction log. -
txIdrepresents the identifier of the server transaction that caused the event. -
ts_msrepresents the server time at which the transaction was committed in the form of the number of milliseconds since the epoch.
-
-
kafkaPartitionwith a setting ofnullmeans that the connector does not use a specific Kafka partition. The PostgreSQL connector uses only one Kafka Connect partition and it places the generated events into one Kafka partition.
7.2.6. Debezium PostgreSQL connector-generated events that represent transaction boundaries
Debezium can generate events that represent transaction boundaries and that enrich data change event messages.
Debezium registers and receives metadata only for transactions that occur after you deploy the connector. Metadata for transactions that occur before you deploy the connector is not available.
For every transaction BEGIN and END, Debezium generates an event that contains the following fields:
-
status-BEGINorEND -
id- string representation of unique transaction identifier -
event_count(forENDevents) - total number of events emitted by the transaction -
data_collections(forENDevents) - an array of pairs ofdata_collectionandevent_countthat provides the number of events emitted by changes originating from given data collection
Example
{
"status": "BEGIN",
"id": "571",
"event_count": null,
"data_collections": null
}
{
"status": "END",
"id": "571",
"event_count": 2,
"data_collections": [
{
"data_collection": "s1.a",
"event_count": 1
},
{
"data_collection": "s2.a",
"event_count": 1
}
]
}
Transaction events are written to the topic named database.server.name.transaction.
Change data event enrichment
When transaction metadata is enabled the data message Envelope is enriched with a new transaction field. This field provides information about every event in the form of a composite of fields:
-
id- string representation of unique transaction identifier -
total_order- absolute position of the event among all events generated by the transaction -
data_collection_order- the per-data collection position of the event among all events that were emitted by the transaction
Following is an example of a message:
{
"before": null,
"after": {
"pk": "2",
"aa": "1"
},
"source": {
...
},
"op": "c",
"ts_ms": "1580390884335",
"transaction": {
"id": "571",
"total_order": "1",
"data_collection_order": "1"
}
}7.3. Descriptions of Debezium PostgreSQL connector data change events
The Debezium PostgreSQL connector generates a data change event for each row-level INSERT, UPDATE, and DELETE operation. Each event contains a key and a value. The structure of the key and the value depends on the table that was changed.
Debezium and Kafka Connect are designed around continuous streams of event messages. However, the structure of these events may change over time, which can be difficult for consumers to handle. To address this, each event contains the schema for its content or, if you are using a schema registry, a schema ID that a consumer can use to obtain the schema from the registry. This makes each event self-contained.
The following skeleton JSON shows the basic four parts of a change event. However, how you configure the Kafka Connect converter that you choose to use in your application determines the representation of these four parts in change events. A schema field is in a change event only when you configure the converter to produce it. Likewise, the event key and event payload are in a change event only if you configure a converter to produce it. If you use the JSON converter and you configure it to produce all four basic change event parts, change events have this structure:
{
"schema": {
...
},
"payload": {
...
},
"schema": {
...
},
"payload": {
...
},
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
The first |
| 2 |
|
The first |
| 3 |
|
The second |
| 4 |
|
The second |
By default behavior is that the connector streams change event records to topics with names that are the same as the event’s originating table.
Starting with Kafka 0.10, Kafka can optionally record the event key and value with the timestamp at which the message was created (recorded by the producer) or written to the log by Kafka.
The PostgreSQL connector ensures that all Kafka Connect schema names adhere to the Avro schema name format. This means that the logical server name must start with a Latin letter or an underscore, that is, a-z, A-Z, or _. Each remaining character in the logical server name and each character in the schema and table names must be a Latin letter, a digit, or an underscore, that is, a-z, A-Z, 0-9, or \_. If there is an invalid character it is replaced with an underscore character.
This can lead to unexpected conflicts if the logical server name, a schema name, or a table name contains invalid characters, and the only characters that distinguish names from one another are invalid and thus replaced with underscores.
Details are in the following topics:
7.3.1. About keys in Debezium PostgreSQL change events
For a given table, the change event’s key has a structure that contains a field for each column in the primary key of the table at the time the event was created. Alternatively, if the table has REPLICA IDENTITY set to FULL or USING INDEX there is a field for each unique key constraint.
Consider a customers table defined in the public database schema and the example of a change event key for that table.
Example table
CREATE TABLE customers (
id SERIAL,
first_name VARCHAR(255) NOT NULL,
last_name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
PRIMARY KEY(id)
);Example change event key
If the database.server.name connector configuration property has the value PostgreSQL_server, every change event for the customers table while it has this definition has the same key structure, which in JSON looks like this:
{
"schema": {
"type": "struct",
"name": "PostgreSQL_server.public.customers.Key",
"optional": false,
"fields": [
{
"name": "id",
"index": "0",
"schema": {
"type": "INT32",
"optional": "false"
}
}
]
},
"payload": {
"id": "1"
},
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
The schema portion of the key specifies a Kafka Connect schema that describes what is in the key’s |
| 2 |
|
Name of the schema that defines the structure of the key’s payload. This schema describes the structure of the primary key for the table that was changed. Key schema names have the format connector-name.database-name.table-name.
|
| 3 |
|
Indicates whether the event key must contain a value in its |
| 4 |
|
Specifies each field that is expected in the |
| 5 |
|
Contains the key for the row for which this change event was generated. In this example, the key, contains a single |
Although the column.exclude.list and column.include.list connector configuration properties allow you to capture only a subset of table columns, all columns in a primary or unique key are always included in the event’s key.
If the table does not have a primary or unique key, then the change event’s key is null. The rows in a table without a primary or unique key constraint cannot be uniquely identified.
7.3.2. About values in Debezium PostgreSQL change events
The value in a change event is a bit more complicated than the key. Like the key, the value has a schema section and a payload section. The schema section contains the schema that describes the Envelope structure of the payload section, including its nested fields. Change events for operations that create, update or delete data all have a value payload with an envelope structure.
Consider the same sample table that was used to show an example of a change event key:
CREATE TABLE customers (
id SERIAL,
first_name VARCHAR(255) NOT NULL,
last_name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
PRIMARY KEY(id)
);
The value portion of a change event for a change to this table varies according to the REPLICA IDENTITY setting and the operation that the event is for.
Details follow in these sections:
Replica identity
REPLICA IDENTITY is a PostgreSQL-specific table-level setting that determines the amount of information that is available to the logical decoding plug-in for UPDATE and DELETE events. More specifically, the setting of REPLICA IDENTITY controls what (if any) information is available for the previous values of the table columns involved, whenever an UPDATE or DELETE event occurs.
There are 4 possible values for REPLICA IDENTITY:
DEFAULT- The default behavior is thatUPDATEandDELETEevents contain the previous values for the primary key columns of a table if that table has a primary key. For anUPDATEevent, only the primary key columns with changed values are present.If a table does not have a primary key, the connector does not emit
UPDATEorDELETEevents for that table. For a table without a primary key, the connector emits only create events. Typically, a table without a primary key is used for appending messages to the end of the table, which means thatUPDATEandDELETEevents are not useful.-
NOTHING- Emitted events forUPDATEandDELETEoperations do not contain any information about the previous value of any table column. -
FULL- Emitted events forUPDATEandDELETEoperations contain the previous values of all columns in the table. -
INDEXindex-name - Emitted events forUPDATEandDELETEoperations contain the previous values of the columns contained in the specified index.UPDATEevents also contain the indexed columns with the updated values.
create events
The following example shows the value portion of a change event that the connector generates for an operation that creates data in the customers table:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "first_name"
},
{
"type": "string",
"optional": false,
"field": "last_name"
},
{
"type": "string",
"optional": false,
"field": "email"
}
],
"optional": true,
"name": "PostgreSQL_server.inventory.customers.Value",
"field": "before"
},
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "first_name"
},
{
"type": "string",
"optional": false,
"field": "last_name"
},
{
"type": "string",
"optional": false,
"field": "email"
}
],
"optional": true,
"name": "PostgreSQL_server.inventory.customers.Value",
"field": "after"
},
{
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "version"
},
{
"type": "string",
"optional": false,
"field": "connector"
},
{
"type": "string",
"optional": false,
"field": "name"
},
{
"type": "int64",
"optional": false,
"field": "ts_ms"
},
{
"type": "boolean",
"optional": true,
"default": false,
"field": "snapshot"
},
{
"type": "string",
"optional": false,
"field": "db"
},
{
"type": "string",
"optional": false,
"field": "schema"
},
{
"type": "string",
"optional": false,
"field": "table"
},
{
"type": "int64",
"optional": true,
"field": "txId"
},
{
"type": "int64",
"optional": true,
"field": "lsn"
},
{
"type": "int64",
"optional": true,
"field": "xmin"
}
],
"optional": false,
"name": "io.debezium.connector.postgresql.Source",
"field": "source"
},
{
"type": "string",
"optional": false,
"field": "op"
},
{
"type": "int64",
"optional": true,
"field": "ts_ms"
}
],
"optional": false,
"name": "PostgreSQL_server.inventory.customers.Envelope"
},
"payload": {
"before": null,
"after": {
"id": 1,
"first_name": "Anne",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"source": {
"version": "1.7.2.Final",
"connector": "postgresql",
"name": "PostgreSQL_server",
"ts_ms": 1559033904863,
"snapshot": true,
"db": "postgres",
"sequence": "[\"24023119\",\"24023128\"]"
"schema": "public",
"table": "customers",
"txId": 555,
"lsn": 24023128,
"xmin": null
},
"op": "c",
"ts_ms": 1559033904863
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
| The value’s schema, which describes the structure of the value’s payload. A change event’s value schema is the same in every change event that the connector generates for a particular table. |
| 2 |
|
In the |
| 3 |
|
|
| 4 |
|
|
| 5 |
|
The value’s actual data. This is the information that the change event is providing. |
| 6 |
|
An optional field that specifies the state of the row before the event occurred. When the Note
Whether or not this field is available is dependent on the |
| 7 |
|
An optional field that specifies the state of the row after the event occurred. In this example, the |
| 8 |
| Mandatory field that describes the source metadata for the event. This field contains information that you can use to compare this event with other events, with regard to the origin of the events, the order in which the events occurred, and whether events were part of the same transaction. The source metadata includes:
|
| 9 |
|
Mandatory string that describes the type of operation that caused the connector to generate the event. In this example,
|
| 10 |
|
Optional field that displays the time at which the connector processed the event. The time is based on the system clock in the JVM running the Kafka Connect task. |
update events
The value of a change event for an update in the sample customers table has the same schema as a create event for that table. Likewise, the event value’s payload has the same structure. However, the event value payload contains different values in an update event. Here is an example of a change event value in an event that the connector generates for an update in the customers table:
{
"schema": { ... },
"payload": {
"before": {
"id": 1
},
"after": {
"id": 1,
"first_name": "Anne Marie",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"source": {
"version": "1.7.2.Final",
"connector": "postgresql",
"name": "PostgreSQL_server",
"ts_ms": 1559033904863,
"snapshot": false,
"db": "postgres",
"schema": "public",
"table": "customers",
"txId": 556,
"lsn": 24023128,
"xmin": null
},
"op": "u",
"ts_ms": 1465584025523
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
An optional field that contains values that were in the row before the database commit. In this example, only the primary key column, |
| 2 |
|
An optional field that specifies the state of the row after the event occurred. In this example, the |
| 3 |
|
Mandatory field that describes the source metadata for the event. The
|
| 4 |
|
Mandatory string that describes the type of operation. In an update event value, the |
| 5 |
|
Optional field that displays the time at which the connector processed the event. The time is based on the system clock in the JVM running the Kafka Connect task. |
Updating the columns for a row’s primary/unique key changes the value of the row’s key. When a key changes, Debezium outputs three events: a DELETE event and a tombstone event with the old key for the row, followed by an event with the new key for the row. Details are in the next section.
Primary key updates
An UPDATE operation that changes a row’s primary key field(s) is known as a primary key change. For a primary key change, in place of sending an UPDATE event record, the connector sends a DELETE event record for the old key and a CREATE event record for the new (updated) key. These events have the usual structure and content, and in addition, each one has a message header related to the primary key change:
-
The
DELETEevent record has__debezium.newkeyas a message header. The value of this header is the new primary key for the updated row. -
The
CREATEevent record has__debezium.oldkeyas a message header. The value of this header is the previous (old) primary key that the updated row had.
delete events
The value in a delete change event has the same schema portion as create and update events for the same table. The payload portion in a delete event for the sample customers table looks like this:
{
"schema": { ... },
"payload": {
"before": {
"id": 1
},
"after": null,
"source": {
"version": "1.7.2.Final",
"connector": "postgresql",
"name": "PostgreSQL_server",
"ts_ms": 1559033904863,
"snapshot": false,
"db": "postgres",
"schema": "public",
"table": "customers",
"txId": 556,
"lsn": 46523128,
"xmin": null
},
"op": "d",
"ts_ms": 1465581902461
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
Optional field that specifies the state of the row before the event occurred. In a delete event value, the |
| 2 |
|
Optional field that specifies the state of the row after the event occurred. In a delete event value, the |
| 3 |
|
Mandatory field that describes the source metadata for the event. In a delete event value, the
|
| 4 |
|
Mandatory string that describes the type of operation. The |
| 5 |
|
Optional field that displays the time at which the connector processed the event. The time is based on the system clock in the JVM running the Kafka Connect task. |
A delete change event record provides a consumer with the information it needs to process the removal of this row.
For a consumer to be able to process a delete event generated for a table that does not have a primary key, set the table’s REPLICA IDENTITY to FULL. When a table does not have a primary key and the table’s REPLICA IDENTITY is set to DEFAULT or NOTHING, a delete event has no before field.
PostgreSQL connector events are designed to work with Kafka log compaction. Log compaction enables removal of some older messages as long as at least the most recent message for every key is kept. This lets Kafka reclaim storage space while ensuring that the topic contains a complete data set and can be used for reloading key-based state.
Tombstone events
When a row is deleted, the delete event value still works with log compaction, because Kafka can remove all earlier messages that have that same key. However, for Kafka to remove all messages that have that same key, the message value must be null. To make this possible, the PostgreSQL connector follows a delete event with a special tombstone event that has the same key but a null value.
truncate events
A truncate change event signals that a table has been truncated. The message key is null in this case, the message value looks like this:
{
"schema": { ... },
"payload": {
"source": {
"version": "1.7.2.Final",
"connector": "postgresql",
"name": "PostgreSQL_server",
"ts_ms": 1559033904863,
"snapshot": false,
"db": "postgres",
"schema": "public",
"table": "customers",
"txId": 556,
"lsn": 46523128,
"xmin": null
},
"op": "t",
"ts_ms": 1559033904961
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
Mandatory field that describes the source metadata for the event. In a truncate event value, the
|
| 2 |
|
Mandatory string that describes the type of operation. The |
| 3 |
|
Optional field that displays the time at which the connector processed the event. The time is based on the system clock in the JVM running the Kafka Connect task. |
In case a single TRUNCATE statement applies to multiple tables, one truncate change event record for each truncated table will be emitted.
Note that since truncate events represent a change made to an entire table and don’t have a message key, unless you’re working with topics with a single partition, there are no ordering guarantees for the change events pertaining to a table (create, update, etc.) and truncate events for that table. For instance a consumer may receive an update event only after a truncate event for that table, when those events are read from different partitions.
7.4. How Debezium PostgreSQL connectors map data types
The PostgreSQL connector represents changes to rows with events that are structured like the table in which the row exists. The event contains a field for each column value. How that value is represented in the event depends on the PostgreSQL data type of the column. The following sections describe how the connector maps PostgreSQL data types to a literal type and a semantic type in event fields.
-
literal type describes how the value is literally represented using Kafka Connect schema types:
INT8,INT16,INT32,INT64,FLOAT32,FLOAT64,BOOLEAN,STRING,BYTES,ARRAY,MAP, andSTRUCT. - semantic type describes how the Kafka Connect schema captures the meaning of the field using the name of the Kafka Connect schema for the field.
Details are in the following sections:
Basic types
The following table describes how the connector maps basic types.
| PostgreSQL data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
| n/a |
|
|
| n/a |
|
|
|
|
|
|
|
|
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n/a |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| n/a |
|
|
| n/a |
|
|
|
n/a |
|
|
|
n/a |
|
|
|
n/a |
|
|
|
n/a |
|
|
|
n/a |
|
|
|
n/a |
|
|
|
|
Temporal types
Other than PostgreSQL’s TIMESTAMPTZ and TIMETZ data types, which contain time zone information, how temporal types are mapped depends on the value of the time.precision.mode connector configuration property. The following sections describe these mappings:
time.precision.mode=adaptive
When the time.precision.mode property is set to adaptive, the default, the connector determines the literal type and semantic type based on the column’s data type definition. This ensures that events exactly represent the values in the database.
| PostgreSQL data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
time.precision.mode=adaptive_time_microseconds
When the time.precision.mode configuration property is set to adaptive_time_microseconds, the connector determines the literal type and semantic type for temporal types based on the column’s data type definition. This ensures that events exactly represent the values in the database, except all TIME fields are captured as microseconds.
| PostgreSQL data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
time.precision.mode=connect
When the time.precision.mode configuration property is set to connect, the connector uses Kafka Connect logical types. This may be useful when consumers can handle only the built-in Kafka Connect logical types and are unable to handle variable-precision time values. However, since PostgreSQL supports microsecond precision, the events generated by a connector with the connect time precision mode results in a loss of precision when the database column has a fractional second precision value that is greater than 3.
| PostgreSQL data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
TIMESTAMP type
The TIMESTAMP type represents a timestamp without time zone information. Such columns are converted into an equivalent Kafka Connect value based on UTC. For example, the TIMESTAMP value "2018-06-20 15:13:16.945104" is represented by an io.debezium.time.MicroTimestamp with the value "1529507596945104" when time.precision.mode is not set to connect.
The timezone of the JVM running Kafka Connect and Debezium does not affect this conversion.
PostgreSQL supports using +/-infinite values in TIMESTAMP columns. These special values are converted to timestamps with value 9223372036825200000 in case of positive infinity or -9223372036832400000 in case of negative infinity. This behaviour mimics the standard behaviour of PostgreSQL JDBC driver - see org.postgresql.PGStatement interface for reference.
Decimal types
The setting of the PostgreSQL connector configuration property, decimal.handling.mode determines how the connector maps decimal types.
When the decimal.handling.mode property is set to precise, the connector uses the Kafka Connect org.apache.kafka.connect.data.Decimal logical type for all DECIMAL and NUMERIC columns. This is the default mode.
| PostgreSQL data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
|
|
|
|
|
|
There is an exception to this rule. When the NUMERIC or DECIMAL types are used without scale constraints, the values coming from the database have a different (variable) scale for each value. In this case, the connector uses io.debezium.data.VariableScaleDecimal, which contains both the value and the scale of the transferred value.
| PostgreSQL data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
|
|
|
|
|
|
When the decimal.handling.mode property is set to double, the connector represents all DECIMAL and NUMERIC values as Java double values and encodes them as shown in the following table.
| PostgreSQL data type | Literal type (schema type) | Semantic type (schema name) |
|---|---|---|
|
|
| |
|
|
|
The last possible setting for the decimal.handling.mode configuration property is string. In this case, the connector represents DECIMAL and NUMERIC values as their formatted string representation, and encodes them as shown in the following table.
| PostgreSQL data type | Literal type (schema type) | Semantic type (schema name) |
|---|---|---|
|
|
| |
|
|
|
PostgreSQL supports NaN (not a number) as a special value to be stored in DECIMAL/NUMERIC values when the setting of decimal.handling.mode is string or double. In this case, the connector encodes NaN as either Double.NaN or the string constant NAN.
HSTORE type
When the hstore.handling.mode connector configuration property is set to json (the default), the connector represents HSTORE values as string representations of JSON values and encodes them as shown in the following table. When the hstore.handling.mode property is set to map, the connector uses the MAP schema type for HSTORE values.
| PostgreSQL data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
|
|
|
|
|
n/a |
Domain types
PostgreSQL supports user-defined types that are based on other underlying types. When such column types are used, Debezium exposes the column’s representation based on the full type hierarchy.
Capturing changes in columns that use PostgreSQL domain types requires special consideration. When a column is defined to contain a domain type that extends one of the default database types and the domain type defines a custom length or scale, the generated schema inherits that defined length or scale.
When a column is defined to contain a domain type that extends another domain type that defines a custom length or scale, the generated schema does not inherit the defined length or scale because that information is not available in the PostgreSQL driver’s column metadata.
Network address types
PostgreSQL has data types that can store IPv4, IPv6, and MAC addresses. It is better to use these types instead of plain text types to store network addresses. Network address types offer input error checking and specialized operators and functions.
| PostgreSQL data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
|
n/a |
|
|
|
n/a |
|
|
|
n/a |
|
|
|
n/a |
PostGIS types
The PostgreSQL connector supports all PostGIS data types.
| PostGIS data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
|
For format details, see Open Geospatial Consortium Simple Features Access specification. |
|
|
|
For format details, see Open Geospatial Consortium Simple Features Access specification. |
Toasted values
PostgreSQL has a hard limit on the page size. This means that values that are larger than around 8 KBs need to be stored by using TOAST storage. This impacts replication messages that are coming from the database. Values that were stored by using the TOAST mechanism and that have not been changed are not included in the message, unless they are part of the table’s replica identity. There is no safe way for Debezium to read the missing value out-of-bands directly from the database, as this would potentially lead to race conditions. Consequently, Debezium follows these rules to handle toasted values:
-
Tables with
REPLICA IDENTITY FULL- TOAST column values are part of thebeforeandafterfields in change events just like any other column. -
Tables with
REPLICA IDENTITY DEFAULT- When receiving anUPDATEevent from the database, any unchanged TOAST column value that is not part of the replica identity is not contained in the event. Similarly, when receiving aDELETEevent, no TOAST columns, if any, are in thebeforefield. As Debezium cannot safely provide the column value in this case, the connector returns a placeholder value as defined by the connector configuration property,unavailable.value.placeholder.
Default values
If a default value is specified for a column in the database schema, the PostgreSQL connector will attempt to propagate this value to the Kafka schema whenever possible. Most common data types are supported, including:
-
BOOLEAN -
Numeric types (
INT,FLOAT,NUMERIC, etc.) -
Text types (
CHAR,VARCHAR,TEXT, etc.) -
Temporal types (
DATE,TIME,INTERVAL,TIMESTAMP,TIMESTAMPTZ) -
JSON,JSONB,XML -
UUID
Note that for temporal types, parsing of the default value is provided by PostgreSQL libraries; therefore, any string representation which is normally supported by PostgreSQL should also be supported by the connector.
In the case that the default value is generated by a function rather than being directly specified in-line, the connector will instead export the equivalent of 0 for the given data type. These values include:
-
FALSEforBOOLEAN -
0with appropriate precision, for numeric types - Empty string for text/XML types
-
{}for JSON types -
1970-01-01forDATE,TIMESTAMP,TIMESTAMPTZtypes -
00:00forTIME -
EPOCHforINTERVAL -
00000000-0000-0000-0000-000000000000forUUID
This support currently extends only to explicit usage of functions. For example, CURRENT_TIMESTAMP(6) is supported with parentheses, but CURRENT_TIMESTAMP is not.
Support for the propagation of default values exists primarily to allow for safe schema evolution when using the PostgreSQL connector with a schema registry which enforces compatibility between schema versions. Due to this primary concern, as well as the refresh behaviours of the different plug-ins, the default value present in the Kafka schema is not guaranteed to always be in-sync with the default value in the database schema.
- Default values may appear 'late' in the Kafka schema, depending on when/how a given plugin triggers refresh of the in-memory schema. Values may never appear/be skipped in the Kafka schema if the default changes multiple times in-between refreshes
- Default values may appear 'early' in the Kafka schema, if a schema refresh is triggered while the connector has records waiting to be processed. This is due to the column metadata being read from the database at refresh time, rather than being present in the replication message. This may occur if the connector is behind and a refresh occurs, or on connector start if the connector was stopped for a time while updates continued to be written to the source database.
This behaviour may be unexpected, but it is still safe. Only the schema definition is affected, while the real values present in the message will remain consistent with what was written to the source database.
7.5. Setting up PostgreSQL to run a Debezium connector
This release of Debezium supports only the native pgoutput logical replication stream. To set up PostgreSQL so that it uses the pgoutput plug-in, you must enable a replication slot, and configure a user with sufficient privileges to perform the replication.
Details are in the following topics:
-
Section 7.5.1, “Configuring a replication slot for the Debezium
pgoutputplug-in” - Section 7.5.2, “Setting up PostgreSQL permissions for the Debezium connector”
- Section 7.5.3, “Setting privileges to enable Debezium to create PostgreSQL publications”
- Section 7.5.4, “Configuring PostgreSQL to allow replication with the Debezium connector host”
- Section 7.5.5, “Configuring PostgreSQL to manage Debezium WAL disk space consumption”
7.5.1. Configuring a replication slot for the Debezium pgoutput plug-in
PostgreSQL’s logical decoding uses replication slots. To configure a replication slot, specify the following in the postgresql.conf file:
wal_level=logical
max_wal_senders=1
max_replication_slots=1These settings instruct the PostgreSQL server as follows:
-
wal_level- Use logical decoding with the write-ahead log. -
max_wal_senders- Use a maximum of one separate process for processing WAL changes. -
max_replication_slots- Allow a maximum of one replication slot to be created for streaming WAL changes.
Replication slots are guaranteed to retain all WAL entries that are required for Debezium even during Debezium outages. Consequently, it is important to closely monitor replication slots to avoid:
- Too much disk consumption
- Any conditions, such as catalog bloat, that can happen if a replication slot stays unused for too long
For more information, see the PostgreSQL documentation for replication slots.
Familiarity with the mechanics and configuration of the PostgreSQL write-ahead log is helpful for using the Debezium PostgreSQL connector.
7.5.2. Setting up PostgreSQL permissions for the Debezium connector
Setting up a PostgreSQL server to run a Debezium connector requires a database user that can perform replications. Replication can be performed only by a database user that has appropriate permissions and only for a configured number of hosts.
Although, by default, superusers have the necessary REPLICATION and LOGIN roles, as mentioned in Security, it is best not to provide the Debezium replication user with elevated privileges. Instead, create a Debezium user that has the the minimum required privileges.
Prerequisites
- PostgreSQL administrative permissions.
Procedure
To provide a user with replication permissions, define a PostgreSQL role that has at least the
REPLICATIONandLOGINpermissions, and then grant that role to the user. For example:CREATE ROLE <name> REPLICATION LOGIN;
7.5.3. Setting privileges to enable Debezium to create PostgreSQL publications
Debezium streams change events for PostgreSQL source tables from publications that are created for the tables. Publications contain a filtered set of change events that are generated from one or more tables. The data in each publication is filtered based on the publication specification. The specification can be created by the PostgreSQL database administrator or by the Debezium connector. To permit the Debezium PostgreSQL connector to create publications and specify the data to replicate to them, the connector must operate with specific privileges in the database.
There are several options for determining how publications are created. In general, it is best to manually create publications for the tables that you want to capture, before you set up the connector. However, you can configure your environment in a way that permits Debezium to create publications automatically, and to specify the data that is added to them.
Debezium uses include list and exclude list properties to specify how data is inserted in the publication. For more information about the options for enabling Debezium to create publications, see publication.autocreate.mode.
For Debezium to create a PostgreSQL publication, it must run as a user that has the following privileges:
- Replication privileges in the database to add the table to a publication.
-
CREATEprivileges on the database to add publications. -
SELECTprivileges on the tables to copy the initial table data. Table owners automatically haveSELECTpermission for the table.
To add tables to a publication, the user be an owner of the table. But because the source table already exists, you need a mechanism to share ownership with the original owner. To enable shared ownership, you create a PostgreSQL replication group, and then add the existing table owner and the replication user to the group.
Procedure
Create a replication group.
CREATE ROLE <replication_group>;Add the original owner of the table to the group.
GRANT REPLICATION_GROUP TO <original_owner>;Add the Debezium replication user to the group.
GRANT REPLICATION_GROUP TO <replication_user>;Transfer ownership of the table to
<replication_group>.ALTER TABLE <table_name> OWNER TO REPLICATION_GROUP;
For Debezium to specify the capture configuration, the value of publication.autocreate.mode must be set to filtered.
7.5.4. Configuring PostgreSQL to allow replication with the Debezium connector host
To enable Debezium to replicate PostgreSQL data, you must configure the database to permit replication with the host that runs the PostgreSQL connector. To specify the clients that are permitted to replicate with the database, add entries to the PostgreSQL host-based authentication file, pg_hba.conf. For more information about the pg_hba.conf file, see the PostgreSQL documentation.
Procedure
Add entries to the
pg_hba.conffile to specify the Debezium connector hosts that can replicate with the database host. For example,pg_hba.conffile example:local replication <youruser> trust1 host replication <youruser> 127.0.0.1/32 trust2 host replication <youruser> ::1/128 trust3 - 1 1 1 1 1 1 1 1 1
- Instructs the server to allow replication for
<youruser>locally, that is, on the server machine. - 2 2 2 2 2 2 2 2 2
- Instructs the server to allow
<youruser>onlocalhostto receive replication changes usingIPV4. - 3 3 3 3 3 3 3 3
- Instructs the server to allow
<youruser>onlocalhostto receive replication changes usingIPV6.
For more information about network masks, see the PostgreSQL documentation.
7.5.5. Configuring PostgreSQL to manage Debezium WAL disk space consumption
In certain cases, it is possible for PostgreSQL disk space consumed by WAL files to spike or increase out of usual proportions. There are several possible reasons for this situation:
The LSN up to which the connector has received data is available in the
confirmed_flush_lsncolumn of the server’spg_replication_slotsview. Data that is older than this LSN is no longer available, and the database is responsible for reclaiming the disk space.Also in the
pg_replication_slotsview, therestart_lsncolumn contains the LSN of the oldest WAL that the connector might require. If the value forconfirmed_flush_lsnis regularly increasing and the value ofrestart_lsnlags then the database needs to reclaim the space.The database typically reclaims disk space in batch blocks. This is expected behavior and no action by a user is necessary.
-
There are many updates in a database that is being tracked but only a tiny number of updates are related to the table(s) and schema(s) for which the connector is capturing changes. This situation can be easily solved with periodic heartbeat events. Set the
heartbeat.interval.msconnector configuration property. The PostgreSQL instance contains multiple databases and one of them is a high-traffic database. Debezium captures changes in another database that is low-traffic in comparison to the other database. Debezium then cannot confirm the LSN as replication slots work per-database and Debezium is not invoked. As WAL is shared by all databases, the amount used tends to grow until an event is emitted by the database for which Debezium is capturing changes. To overcome this, it is necessary to:
-
Enable periodic heartbeat record generation with the
heartbeat.interval.msconnector configuration property. - Regularly emit change events from the database for which Debezium is capturing changes.
A separate process would then periodically update the table by either inserting a new row or repeatedly updating the same row. PostgreSQL then invokes Debezium, which confirms the latest LSN and allows the database to reclaim the WAL space. This task can be automated by means of the
heartbeat.action.queryconnector configuration property.-
Enable periodic heartbeat record generation with the
7.6. Deployment of Debezium PostgreSQL connectors
You can use either of the following methods to deploy a Debezium PostgreSQL connector:
Additional resources
7.6.1. PostgreSQL connector deployment using AMQ Streams
Beginning with Debezium 1.7, the preferred method for deploying a Debezium connector is to use AMQ Streams to build a Kafka Connect container image that includes the connector plug-in.
During the deployment process, you create and use the following custom resources (CRs):
-
A
KafkaConnectCR that defines your Kafka Connect instance and includes information about the connector artifacts needs to include in the image. -
A
KafkaConnectorCR that provides details that include information the connector uses to access the source database. After AMQ Streams starts the Kafka Connect pod, you start the connector by applying theKafkaConnectorCR.
In the build specification for the Kafka Connect image, you can specify the connectors that are available to deploy. For each connector plug-in, you can also specify other components that you want to make available for deployment. For example, you can add Service Registry artifacts, or the Debezium scripting component. When AMQ Streams builds the Kafka Connect image, it downloads the specified artifacts, and incorporates them into the image.
The spec.build.output parameter in the KafkaConnect CR specifies where to store the resulting Kafka Connect container image. Container images can be stored in a Docker registry, or in an OpenShift ImageStream. To store images in an ImageStream, you must create the ImageStream before you deploy Kafka Connect. ImageStreams are not created automatically.
If you use a KafkaConnect resource to create a cluster, afterwards you cannot use the Kafka Connect REST API to create or update connectors. You can still use the REST API to retrieve information.
Additional resources
- Configuring Kafka Connect in Using AMQ Streams on OpenShift.
- Creating a new container image automatically using AMQ Streams in Deploying and Upgrading AMQ Streams on OpenShift.
7.6.2. Using AMQ Streams to deploy a Debezium PostgreSQL connector
With earlier versions of AMQ Streams, to deploy Debezium connectors on OpenShift, it was necessary to first build a Kafka Connect image for the connector. The current preferred method for deploying connectors on OpenShift is to use a build configuration in AMQ Streams to automatically build a Kafka Connect container image that includes the Debezium connector plug-ins that you want to use.
During the build process, the AMQ Streams Operator transforms input parameters in a KafkaConnect custom resource, including Debezium connector definitions, into a Kafka Connect container image. The build downloads the necessary artifacts from the Red Hat Maven repository or another configured HTTP server. The newly created container is pushed to the container registry that is specified in .spec.build.output, and is used to deploy a Kafka Connect pod. After AMQ Streams builds the Kafka Connect image, you create KafkaConnector custom resources to start the connectors that are included in the build.
Prerequisites
- You have access to an OpenShift cluster on which the cluster Operator is installed.
- The AMQ Streams Operator is running.
- An Apache Kafka cluster is deployed as documented in Deploying and Upgrading AMQ Streams on OpenShift.
- You have a Red Hat Integration license.
- Kafka Connect is deployed on AMQ Streams.
-
The OpenShift
ocCLI client is installed or you have access to the OpenShift Container Platform web console. Depending on how you intend to store the Kafka Connect build image, you need registry permissions or you must create an ImageStream resource:
- To store the build image in an image registry, such as Red Hat Quay.io or Docker Hub
- An account and permissions to create and manage images in the registry.
- To store the build image as a native OpenShift ImageStream
- An ImageStream resource is deployed to the cluster. You must explicitly create an ImageStream for the cluster. ImageStreams are not available by default.
Procedure
- Log in to the OpenShift cluster.
Create a new Debezium
KafkaConnectcustom resource (CR) for the connector. For example, create aKafkaConnectCR that specifies themetadata.annotationsandspec.buildproperties, as shown in the following example. Save the file with a name such asdbz-connect.yaml.Example 7.1. A
dbz-connect.yamlfile that defines aKafkaConnectcustom resource that includes a Debezium connectorapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: debezium-kafka-connect-cluster annotations: strimzi.io/use-connector-resources: "true"1 spec: version: 3.00 build:2 output:3 type: imagestream4 image: debezium-streams-connect:latest plugins:5 - name: debezium-connector-postgres artifacts: - type: zip6 url: https://maven.repository.redhat.com/ga/io/debezium/debezium-connector-postgres/1.7.2.Final-redhat-<build_number>/debezium-connector-postgres-1.7.2.Final-redhat-<build_number>-plugin.zip7 - type: zip url: https://maven.repository.redhat.com/ga/io/apicurio/apicurio-registry-distro-connect-converter/2.0-redhat-<build-number>/apicurio-registry-distro-connect-converter-2.0-redhat-<build-number>.zip - type: zip url: https://maven.repository.redhat.com/ga/io/debezium/debezium-scripting/1.7.2.Final/debezium-scripting-1.7.2.Final.zip bootstrapServers: debezium-kafka-cluster-kafka-bootstrap:9093Expand Table 7.21. Descriptions of Kafka Connect configuration settings Item Description 1
Sets the
strimzi.io/use-connector-resourcesannotation to"true"to enable the Cluster Operator to useKafkaConnectorresources to configure connectors in this Kafka Connect cluster.2
The
spec.buildconfiguration specifies where to store the build image and lists the plug-ins to include in the image, along with the location of the plug-in artifacts.3
The
build.outputspecifies the registry in which the newly built image is stored.4
Specifies the name and image name for the image output. Valid values for
output.typearedockerto push into a container registry like Docker Hub or Quay, orimagestreamto push the image to an internal OpenShift ImageStream. To use an ImageStream, an ImageStream resource must be deployed to the cluster. For more information about specifying thebuild.outputin the KafkaConnect configuration, see the AMQ Streams Build schema reference documentation.5
The
pluginsconfiguration lists all of the connectors that you want to include in the Kafka Connect image. For each entry in the list, specify a plug-inname, and information for about the artifacts that are required to build the connector. Optionally, for each connector plug-in, you can include other components that you want to be available for use with the connector. For example, you can add Service Registry artifacts, or the Debezium scripting component.6
The value of
artifacts.typespecifies the file type of the artifact specified in theartifacts.url. Valid types arezip,tgz, orjar. Debezium connector archives are provided in.zipfile format. JDBC driver files are in.jarformat. Thetypevalue must match the type of the file that is referenced in theurlfield.7
The value of
artifacts.urlspecifies the address of an HTTP server, such as a Maven repository, that stores the file for the connector artifact. The OpenShift cluster must have access to the specified server.Apply the
KafkaConnectbuild specification to the OpenShift cluster by entering the following command:oc create -f dbz-connect.yamlBased on the configuration specified in the custom resource, the Streams Operator prepares a Kafka Connect image to deploy.
After the build completes, the Operator pushes the image to the specified registry or ImageStream, and starts the Kafka Connect cluster. The connector artifacts that you listed in the configuration are available in the cluster.Create a
KafkaConnectorresource to define an instance of each connector that you want to deploy.
For example, create the followingKafkaConnectorCR, and save it aspostgresql-inventory-connector.yamlExample 7.2. A
postgresql-inventory-connector.yamlfile that defines theKafkaConnectorcustom resource for a Debezium connectorapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: labels: strimzi.io/cluster: debezium-kafka-connect-cluster name: inventory-connector-postgresql1 spec: class: io.debezium.connector.postgresql.PostgresConnector2 tasksMax: 13 config:4 database.history.kafka.bootstrap.servers: 'debezium-kafka-cluster-kafka-bootstrap.debezium.svc.cluster.local:9092' database.history.kafka.topic: schema-changes.inventory database.hostname: postgresql.debezium-postgresql.svc.cluster.local5 database.port: 33066 database.user: debezium7 database.password: dbz8 database.dbname: mydatabase9 database.server.name: inventory_connector_postgresql10 database.include.list: public.inventory11 Expand Table 7.22. Descriptions of connector configuration settings Item Description 1
The name of the connector to register with the Kafka Connect cluster.
2
The name of the connector class.
3
The number of tasks that can operate concurrently.
4
The connector’s configuration.
5
The address of the host database instance.
6
The port number of the database instance.
7
The name of the user account through which Debezium connects to the database.
8
The password for the database user account.
9
The name of the database to capture changes from.
10
The logical name of the database instance or cluster.
The specified name must be formed only from alphanumeric characters or underscores.
Because the logical name is used as the prefix for any Kafka topics that receive change events from this connector, the name must be unique among the connectors in the cluster.
The namespace is also used in the names of related Kafka Connect schemas, and the namespaces of a corresponding Avro schema if you integrate the connector with the Avro connector.11
The list of tables from which the connector captures change events.
Create the connector resource by running the following command:
oc create -n <namespace> -f <kafkaConnector>.yamlFor example,
oc create -n debezium -f {context}-inventory-connector.yamlThe connector is registered to the Kafka Connect cluster and starts to run against the database that is specified by
spec.config.database.dbnamein theKafkaConnectorCR. After the connector pod is ready, Debezium is running.
You are now ready to verify the Debezium PostgreSQL deployment.
7.6.3. Deploying a Debezium PostgreSQL connector by building a custom Kafka Connect container image from a Dockerfile
To deploy a Debezium PostgreSQL connector, you need to build a custom Kafka Connect container image that contains the Debezium connector archive and push this container image to a container registry. You then need to create two custom resources (CRs):
-
A
KafkaConnectCR that defines your Kafka Connect instance. Theimageproperty in the CR specifies the name of the container image that you create to run your Debezium connector. You apply this CR to the OpenShift instance where Red Hat AMQ Streams is deployed. AMQ Streams offers operators and images that bring Apache Kafka to OpenShift. -
A
KafkaConnectorCR that defines your Debezium Db2 connector. Apply this CR to the same OpenShift instance where you applied theKafkaConnectCR.
Prerequisites
- PostgreSQL is running and you performed the steps to set up PostgreSQL to run a Debezium connector.
- AMQ Streams is deployed on OpenShift and is running Apache Kafka and Kafka Connect. For more information, see Deploying and Upgrading AMQ Streams on OpenShift.
- Podman or Docker is installed.
-
You have an account and permissions to create and manage containers in the container registry (such as
quay.ioordocker.io) to which you plan to add the container that will run your Debezium connector.
Procedure
Create the Debezium PostgreSQL container for Kafka Connect:
- Download the Debezium PostgreSQL connector archive.
Extract the Debezium PostgreSQL connector archive to create a directory structure for the connector plug-in, for example:
./my-plugins/ ├── debezium-connector-postgresql │ ├── ...Create a Dockerfile that uses
registry.redhat.io/amq7/amq-streams-kafka-30-rhel8:2.0.0as the base image. For example, from a terminal window, enter the following, replacingmy-pluginswith the name of your plug-ins directory:cat <<EOF >debezium-container-for-postgresql.yaml1 FROM registry.redhat.io/amq7/amq-streams-kafka-30-rhel8:2.0.0 USER root:root COPY ./<my-plugins>/ /opt/kafka/plugins/2 USER 1001 EOFThe command creates a Dockerfile with the name
debezium-container-for-postgresql.yamlin the current directory.Build the container image from the
debezium-container-for-postgresql.yamlDocker file that you created in the previous step. From the directory that contains the file, open a terminal window and enter one of the following commands:podman build -t debezium-container-for-postgresql:latest .docker build -t debezium-container-for-postgresql:latest .The
buildcommand builds a container image with the namedebezium-container-for-postgresql.Push your custom image to a container registry such as
quay.ioor an internal container registry. The container registry must be available to the OpenShift instance where you want to deploy the image. Enter one of the following commands:podman push <myregistry.io>/debezium-container-for-postgresql:latestdocker push <myregistry.io>/debezium-container-for-postgresql:latestCreate a new Debezium PostgreSQL
KafkaConnectcustom resource (CR). For example, create aKafkaConnectCR with the namedbz-connect.yamlthat specifiesannotationsandimageproperties as shown in the following example:apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true"1 spec: image: debezium-container-for-postgresql2 - 1
metadata.annotationsindicates to the Cluster Operator thatKafkaConnectorresources are used to configure connectors in this Kafka Connect cluster.- 2
spec.imagespecifies the name of the image that you created to run your Debezium connector. This property overrides theSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGEvariable in the Cluster Operator.
Apply your
KafkaConnectCR to the OpenShift Kafka instance by running the following command:oc create -f dbz-connect.yamlThis updates your Kafka Connect environment in OpenShift to add a Kafka Connector instance that specifies the name of the image that you created to run your Debezium connector.
Create a
KafkaConnectorcustom resource that configures your Debezium PostgreSQL connector instance.You configure a Debezium PostgreSQL connector in a
.yamlfile that specifies the configuration properties for the connector. The connector configuration might instruct Debezium to produce events for a subset of the schemas and tables, or it might set properties so that Debezium ignores, masks, or truncates values in specified columns that are sensitive, too large, or not needed. For the complete list of the configuration properties that you can set for the Debezium PostgreSQL connector, see PostgreSQL connector properties.The following example configures a Debezium connector that connects to a PostgreSQL server host,
192.168.99.100, on port5432. This host has a database namedsampledb, a schema namedpublic, andfulfillmentis the server’s logical name.fulfillment-connector.yamlapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: fulfillment-connector1 labels: strimzi.io/cluster: my-connect-cluster spec: class: io.debezium.connector.postgresql.PostgresConnector tasksMax: 12 config:3 database.hostname: 192.168.99.1004 database.port: 5432 database.user: debezium database.password: dbz database.dbname: sampledb database.server.name: fulfillment5 schema.include.list: public6 plugin.name: pgoutput7 - 1
- The name of the connector.
- 2
- Only one task should operate at any one time. Because the PostgreSQL connector reads the PostgreSQL server’s
binlog, using a single connector task ensures proper order and event handling. The Kafka Connect service uses connectors to start one or more tasks that do the work, and it automatically distributes the running tasks across the cluster of Kafka Connect services. If any of the services stop or crash, those tasks will be redistributed to running services. - 3
- The connector’s configuration.
- 4
- The name of the database host that is running the PostgreSQL server. In this example, the database host name is
192.168.99.100. - 5
- A unique server name. The server name is the logical identifier for the PostgreSQL server or cluster of servers. This name is used as the prefix for all Kafka topics that receive change event records.
- 6
- The connector captures changes in only the
publicschema. It is possible to configure the connector to capture changes in only the tables that you choose. Seetable.include.listconnector configuration property. - 7
- The name of the PostgreSQL logical decoding plug-in installed on the PostgreSQL server. While the only supported value for PostgreSQL 10 and later is
pgoutput, you must explicitly setplugin.nametopgoutput.
Create your connector instance with Kafka Connect. For example, if you saved your
KafkaConnectorresource in thefulfillment-connector.yamlfile, you would run the following command:oc apply -f fulfillment-connector.yamlThis registers
fulfillment-connectorand the connector starts to run against thesampledbdatabase as defined in theKafkaConnectorCR.
Results
After the connector starts, it performs a consistent snapshot of the PostgreSQL server databases that the connector is configured for. The connector then starts generating data change events for row-level operations and streaming change event records to Kafka topics.
7.6.4. Verifying that the Debezium PostgreSQL connector is running
If the connector starts correctly without errors, it creates a topic for each table that the connector is configured to capture. Downstream applications can subscribe to these topics to retrieve information events that occur in the source database.
To verify that the connector is running, you perform the following operations from the OpenShift Container Platform web console, or through the OpenShift CLI tool (oc):
- Verify the connector status.
- Verify that the connector generates topics.
- Verify that topics are populated with events for read operations ("op":"r") that the connector generates during the initial snapshot of each table.
Prerequisites
- A Debezium connector is deployed to AMQ Streams on OpenShift.
-
The OpenShift
ocCLI client is installed. - You have access to the OpenShift Container Platform web console.
Procedure
Check the status of the
KafkaConnectorresource by using one of the following methods:From the OpenShift Container Platform web console:
- Navigate to Home → Search.
-
On the Search page, click Resources to open the Select Resource box, and then type
KafkaConnector. - From the KafkaConnectors list, click the name of the connector that you want to check, for example inventory-connector-postgresql.
- In the Conditions section, verify that the values in the Type and Status columns are set to Ready and True.
From a terminal window:
Enter the following command:
oc describe KafkaConnector <connector-name> -n <project>For example,
oc describe KafkaConnector inventory-connector-postgresql -n debeziumThe command returns status information that is similar to the following output:
Example 7.3.
KafkaConnectorresource statusName: inventory-connector-postgresql Namespace: debezium Labels: strimzi.io/cluster=debezium-kafka-connect-cluster Annotations: <none> API Version: kafka.strimzi.io/v1beta2 Kind: KafkaConnector ... Status: Conditions: Last Transition Time: 2021-12-08T17:41:34.897153Z Status: True Type: Ready Connector Status: Connector: State: RUNNING worker_id: 10.131.1.124:8083 Name: inventory-connector-postgresql Tasks: Id: 0 State: RUNNING worker_id: 10.131.1.124:8083 Type: source Observed Generation: 1 Tasks Max: 1 Topics: inventory_connector_postgresql inventory_connector_postgresql.inventory.addresses inventory_connector_postgresql.inventory.customers inventory_connector_postgresql.inventory.geom inventory_connector_postgresql.inventory.orders inventory_connector_postgresql.inventory.products inventory_connector_postgresql.inventory.products_on_hand Events: <none>
Verify that the connector created Kafka topics:
From the OpenShift Container Platform web console.
- Navigate to Home → Search.
-
On the Search page, click Resources to open the Select Resource box, and then type
KafkaTopic. - From the KafkaTopics list, click the name of the topic that you want to check, for example, inventory-connector-postgresql.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d.
- In the Conditions section, verify that the values in the Type and Status columns are set to Ready and True.
From a terminal window:
Enter the following command:
oc get kafkatopicsThe command returns status information that is similar to the following output:
Example 7.4.
KafkaTopicresource statusNAME CLUSTER PARTITIONS REPLICATION FACTOR READY connect-cluster-configs debezium-kafka-cluster 1 1 True connect-cluster-offsets debezium-kafka-cluster 25 1 True connect-cluster-status debezium-kafka-cluster 5 1 True consumer-offsets---84e7a678d08f4bd226872e5cdd4eb527fadc1c6a debezium-kafka-cluster 50 1 True inventory-connector-postgresql---a96f69b23d6118ff415f772679da623fbbb99421 debezium-kafka-cluster 1 1 True inventory-connector-postgresql.inventory.addresses---1b6beaf7b2eb57d177d92be90ca2b210c9a56480 debezium-kafka-cluster 1 1 True inventory-connector-postgresql.inventory.customers---9931e04ec92ecc0924f4406af3fdace7545c483b debezium-kafka-cluster 1 1 True inventory-connector-postgresql.inventory.geom---9f7e136091f071bf49ca59bf99e86c713ee58dd5 debezium-kafka-cluster 1 1 True inventory-connector-postgresql.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d debezium-kafka-cluster 1 1 True inventory-connector-postgresql.inventory.products---df0746db116844cee2297fab611c21b56f82dcef debezium-kafka-cluster 1 1 True inventory-connector-postgresql.inventory.products-on-hand---8649e0f17ffcc9212e266e31a7aeea4585e5c6b5 debezium-kafka-cluster 1 1 True schema-changes.inventory debezium-kafka-cluster 1 1 True strimzi-store-topic---effb8e3e057afce1ecf67c3f5d8e4e3ff177fc55 debezium-kafka-cluster 1 1 True strimzi-topic-operator-kstreams-topic-store-changelog---b75e702040b99be8a9263134de3507fc0cc4017b debezium-kafka-cluster 1 1 True
Check topic content.
- From a terminal window, enter the following command:
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>For example,
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory_connector_postgresql.inventory.products_on_handThe format for specifying the topic name is the same as the
oc describecommand returns in Step 1, for example,inventory_connector_postgresql.inventory.addresses.For each event in the topic, the command returns information that is similar to the following output:
Example 7.5. Content of a Debezium change event
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory_connector_postgresql.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory_connector_postgresql.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory_connector_postgresql.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.postgresql.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory_connector_postgresql.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"1.7.2.Final-redhat-00001","connector":"postgresql","name":"inventory_connector_postgresql","ts_ms":1638985247805,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"postgresql-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"transaction":null}}In the preceding example, the
payloadvalue shows that the connector snapshot generated a read ("op" ="r") event from the tableinventory.products_on_hand. The"before"state of theproduct_idrecord isnull, indicating that no previous value exists for the record. The"after"state shows aquantityof3for the item withproduct_id101.
7.6.5. Description of Debezium PostgreSQL connector configuration properties
The Debezium PostgreSQL connector has many configuration properties that you can use to achieve the right connector behavior for your application. Many properties have default values. Information about the properties is organized as follows:
The following configuration properties are required unless a default value is available.
| Property | Default | Description |
|---|---|---|
| No default | Unique name for the connector. Attempting to register again with the same name will fail. This property is required by all Kafka Connect connectors. | |
| No default |
The name of the Java class for the connector. Always use a value of | |
|
| The maximum number of tasks that should be created for this connector. The PostgreSQL connector always uses a single task and therefore does not use this value, so the default is always acceptable. | |
|
| The name of the PostgreSQL logical decoding plug-in installed on the PostgreSQL server.
The only supported value is | |
|
| The name of the PostgreSQL logical decoding slot that was created for streaming changes from a particular plug-in for a particular database/schema. The server uses this slot to stream events to the Debezium connector that you are configuring. Slot names must conform to PostgreSQL replication slot naming rules, which state: "Each replication slot has a name, which can contain lower-case letters, numbers, and the underscore character." | |
|
| Whether or not to delete the logical replication slot when the connector stops in a graceful, expected way. The default behavior is that the replication slot remains configured for the connector when the connector stops. When the connector restarts, having the same replication slot enables the connector to start processing where it left off.
Set to | |
|
|
The name of the PostgreSQL publication created for streaming changes when using This publication is created at start-up if it does not already exist and it includes all tables. Debezium then applies its own include/exclude list filtering, if configured, to limit the publication to change events for the specific tables of interest. The connector user must have superuser permissions to create this publication, so it is usually preferable to create the publication before starting the connector for the first time. If the publication already exists, either for all tables or configured with a subset of tables, Debezium uses the publication as it is defined. | |
| No default | IP address or hostname of the PostgreSQL database server. | |
|
| Integer port number of the PostgreSQL database server. | |
| No default | Name of the PostgreSQL database user for connecting to the PostgreSQL database server. | |
| No default | Password to use when connecting to the PostgreSQL database server. | |
| No default | The name of the PostgreSQL database from which to stream the changes. | |
| No default | Logical name that identifies and provides a namespace for the particular PostgreSQL database server or cluster in which Debezium is capturing changes. Only alphanumeric characters, hyphens, dots and underscores must be used in the database server logical name. The logical name should be unique across all other connectors, since it is used as a topic name prefix for all Kafka topics that receive records from this connector. | |
| No default |
An optional, comma-separated list of regular expressions that match names of schemas for which you want to capture changes. Any schema name not included in | |
| No default |
An optional, comma-separated list of regular expressions that match names of schemas for which you do not want to capture changes. Any schema whose name is not included in | |
| No default |
An optional, comma-separated list of regular expressions that match fully-qualified table identifiers for tables whose changes you want to capture. Any table not included in | |
| No default |
An optional, comma-separated list of regular expressions that match fully-qualified table identifiers for tables whose changes you do not want to capture. Any table not included in | |
| No default |
An optional, comma-separated list of regular expressions that match the fully-qualified names of columns that should be included in change event record values. Fully-qualified names for columns are of the form schemaName.tableName.columnName. Do not also set the | |
| No default |
An optional, comma-separated list of regular expressions that match the fully-qualified names of columns that should be excluded from change event record values. Fully-qualified names for columns are of the form schemaName.tableName.columnName. Do not also set the | |
|
|
Time, date, and timestamps can be represented with different kinds of precision: | |
|
|
Specifies how the connector should handle values for | |
|
|
Specifies how the connector should handle values for | |
|
|
Specifies how the connector should handle values for | |
|
|
Whether to use an encrypted connection to the PostgreSQL server. Options include: | |
| No default | The path to the file that contains the SSL certificate for the client. See the PostgreSQL documentation for more information. | |
| No default | The path to the file that contains the SSL private key of the client. See the PostgreSQL documentation for more information. | |
| No default |
The password to access the client private key from the file specified by | |
| No default | The path to the file that contains the root certificate(s) against which the server is validated. See the PostgreSQL documentation for more information. | |
|
| Enable TCP keep-alive probe to verify that the database connection is still alive. See the PostgreSQL documentation for more information. | |
|
|
Controls whether a delete event is followed by a tombstone event. | |
| n/a |
An optional, comma-separated list of regular expressions that match the fully-qualified names of character-based columns. Fully-qualified names for columns are of the form schemaName.tableName.columnName. In change event records, values in these columns are truncated if they are longer than the number of characters specified by length in the property name. You can specify multiple properties with different lengths in a single configuration. Length must be a positive integer, for example, | |
| n/a |
An optional, comma-separated list of regular expressions that match the fully-qualified names of character-based columns. Fully-qualified names for columns are of the form schemaName.tableName.columnName. In change event values, the values in the specified table columns are replaced with length number of asterisk ( | |
| n/a |
An optional, comma-separated list of regular expressions that match the fully-qualified names of character-based columns. Fully-qualified names for columns are of the form <schemaName>.<tableName>.<columnName>. In the resulting change event record, the values for the specified columns are replaced with pseudonyms.
A pseudonym consists of the hashed value that results from applying the specified hashAlgorithm and salt. Based on the hash function that is used, referential integrity is maintained, while column values are replaced with pseudonyms. Supported hash functions are described in the MessageDigest section of the Java Cryptography Architecture Standard Algorithm Name Documentation.
If necessary, the pseudonym is automatically shortened to the length of the column. The connector configuration can include multiple properties that specify different hash algorithms and salts. | |
| n/a |
An optional, comma-separated list of regular expressions that match the fully-qualified names of columns. Fully-qualified names for columns are of the form databaseName.tableName.columnName, or databaseName.schemaName.tableName.columnName. | |
| n/a |
An optional, comma-separated list of regular expressions that match the database-specific data type name for some columns. Fully-qualified data type names are of the form databaseName.tableName.typeName, or databaseName.schemaName.tableName.typeName. | |
| empty string | A list of expressions that specify the columns that the connector uses to form custom message keys for change event records that it publishes to the Kafka topics for specified tables.
By default, Debezium uses the primary key column of a table as the message key for records that it emits. In place of the default, or to specify a key for tables that lack a primary key, you can configure custom message keys based on one or more columns.
Each fully-qualified table name is a regular expression in the following format: There is no limit to the number of columns that you use to create custom message keys. However, it’s best to use the minimum number that are required to specify a unique key. | |
| all_tables |
Applies only when streaming changes by using the | |
| bytes |
Specifies how binary ( | |
| bytes |
Specifies how whether |
The following advanced configuration properties have defaults that work in most situations and therefore rarely need to be specified in the connector’s configuration.
| Property | Default | Description |
|---|---|---|
|
|
Specifies the criteria for performing a snapshot when the connector starts: | |
|
All tables specified in |
An optional, comma-separated list of regular expressions that match the fully-qualified names ( This property does not affect the behavior of incremental snapshots. | |
|
| Positive integer value that specifies the maximum amount of time (in milliseconds) to wait to obtain table locks when performing a snapshot. If the connector cannot acquire table locks in this time interval, the snapshot fails. How the connector performs snapshots provides details. | |
| No default | Specifies the table rows to include in a snapshot. Use the property if you want a snapshot to include only a subset of the rows in a table. This property affects snapshots only. It does not apply to events that the connector reads from the log.
The property contains a comma-separated list of fully-qualified table names in the form
From a
In the resulting snapshot, the connector includes only the records for which | |
|
|
Specifies how the connector should react to exceptions during processing of events: | |
|
| Positive integer value for the maximum size of the blocking queue. The connector places change events received from streaming replication in the blocking queue before writing them to Kafka. This queue can provide backpressure when, for example, writing records to Kafka is slower that it should be or Kafka is not available. | |
|
| Positive integer value that specifies the maximum size of each batch of events that the connector processes. | |
|
| Long value for the maximum size in bytes of the blocking queue. The feature is disabled by default, it will be active if it’s set with a positive long value. | |
|
| Positive integer value that specifies the number of milliseconds the connector should wait for new change events to appear before it starts processing a batch of events. Defaults to 1000 milliseconds, or 1 second. | |
|
|
Specifies connector behavior when the connector encounters a field whose data type is unknown. The default behavior is that the connector omits the field from the change event and logs a warning. Note
Consumers risk backward compatibility issues when | |
| No default |
A semicolon separated list of SQL statements that the connector executes when it establishes a JDBC connection to the database. To use a semicolon as a character and not as a delimiter, specify two consecutive semicolons, | |
|
|
Frequency for sending replication connection status updates to the server, given in milliseconds. | |
|
|
Controls how frequently the connector sends heartbeat messages to a Kafka topic. The default behavior is that the connector does not send heartbeat messages. | |
|
|
Controls the name of the topic to which the connector sends heartbeat messages. The topic name has this pattern: | |
| No default |
Specifies a query that the connector executes on the source database when the connector sends a heartbeat message. | |
|
|
Specify the conditions that trigger a refresh of the in-memory schema for a table. | |
| No default | An interval in milliseconds that the connector should wait before performing a snapshot when the connector starts. If you are starting multiple connectors in a cluster, this property is useful for avoiding snapshot interruptions, which might cause re-balancing of connectors. | |
|
| During a snapshot, the connector reads table content in batches of rows. This property specifies the maximum number of rows in a batch. | |
| No default |
Semicolon separated list of parameters to pass to the configured logical decoding plug-in. For example, | |
|
| Indicates whether field names are sanitized to adhere to Avro naming requirements. | |
|
| If connecting to a replication slot fails, this is the maximum number of consecutive attempts to connect. | |
|
| The number of milliseconds to wait between retry attempts when the connector fails to connect to a replication slot. | |
|
|
Specifies the constant that the connector provides to indicate that the original value is a toasted value that is not provided by the database. If the setting of | |
|
|
Specifies the constant that the connector provides to indicate that the original value is a toasted value that is not provided by the database. If the setting of | |
|
|
Determines whether the connector generates events with transaction boundaries and enriches change event envelopes with transaction metadata. Specify | |
| 10000 (10 seconds) | The number of milliseconds to wait before restarting a connector after a retriable error occurs. | |
| No default |
A comma-separated list of operation types that will be skipped during streaming. The operations include: | |
| No default value |
Fully-qualified name of the data collection that is used to send signals to the connector. Signaling is a Technology Preview feature. | |
| 1024 | The maximum number of rows that the connector fetches and reads into memory during an incremental snapshot chunk. Increasing the chunk size provides greater efficiency, because the snapshot runs fewer snapshot queries of a greater size. However, larger chunk sizes also require more memory to buffer the snapshot data. Adjust the chunk size to a value that provides the best performance in your environment. Incremental snapshots is a Technology Preview feature. |
Pass-through connector configuration properties
The connector also supports pass-through configuration properties that are used when creating the Kafka producer and consumer.
Be sure to consult the Kafka documentation for all of the configuration properties for Kafka producers and consumers. The PostgreSQL connector does use the new consumer configuration properties.
7.7. Monitoring Debezium PostgreSQL connector performance
The Debezium PostgreSQL connector provides two types of metrics that are in addition to the built-in support for JMX metrics that Zookeeper, Kafka, and Kafka Connect provide.
- Snapshot metrics provide information about connector operation while performing a snapshot.
- Streaming metrics provide information about connector operation when the connector is capturing changes and streaming change event records.
Debezium monitoring documentation provides details for how to expose these metrics by using JMX.
7.7.1. Monitoring Debezium during snapshots of PostgreSQL databases
The MBean is debezium.postgres:type=connector-metrics,context=snapshot,server=<postgresql.server.name>.
Snapshot metrics are not exposed unless a snapshot operation is active, or if a snapshot has occurred since the last connector start.
The following table lists the shapshot metrics that are available.
| Attributes | Type | Description |
|---|---|---|
|
| The last snapshot event that the connector has read. | |
|
| The number of milliseconds since the connector has read and processed the most recent event. | |
|
| The total number of events that this connector has seen since last started or reset. | |
|
| The number of events that have been filtered by include/exclude list filtering rules configured on the connector. | |
|
|
| The list of tables that are monitored by the connector. |
|
| The list of tables that are captured by the connector. | |
|
| The length the queue used to pass events between the snapshotter and the main Kafka Connect loop. | |
|
| The free capacity of the queue used to pass events between the snapshotter and the main Kafka Connect loop. | |
|
| The total number of tables that are being included in the snapshot. | |
|
| The number of tables that the snapshot has yet to copy. | |
|
| Whether the snapshot was started. | |
|
| Whether the snapshot was aborted. | |
|
| Whether the snapshot completed. | |
|
| The total number of seconds that the snapshot has taken so far, even if not complete. | |
|
| Map containing the number of rows scanned for each table in the snapshot. Tables are incrementally added to the Map during processing. Updates every 10,000 rows scanned and upon completing a table. | |
|
|
The maximum buffer of the queue in bytes. It will be enabled if | |
|
| The current data of records in the queue in bytes. |
The connector also provides the following additional snapshot metrics when an incremental snapshot is executed:
| Attributes | Type | Description |
|---|---|---|
|
| The identifier of the current snapshot chunk. | |
|
| The lower bound of the primary key set defining the current chunk. | |
|
| The upper bound of the primary key set defining the current chunk. | |
|
| The lower bound of the primary key set of the currently snapshotted table. | |
|
| The upper bound of the primary key set of the currently snapshotted table. |
Incremental snapshots is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process. For more information about the support scope of Red Hat Technology Preview features, see https://access.redhat.com/support/offerings/techpreview.
7.7.2. Monitoring Debezium PostgreSQL connector record streaming
The MBean is debezium.postgres:type=connector-metrics,context=streaming,server=<postgresql.server.name>.
The following table lists the streaming metrics that are available.
| Attributes | Type | Description |
|---|---|---|
|
| The last streaming event that the connector has read. | |
|
| The number of milliseconds since the connector has read and processed the most recent event. | |
|
| The total number of events that this connector has seen since last started or reset. | |
|
| The number of events that have been filtered by include/exclude list filtering rules configured on the connector. | |
|
|
| The list of tables that are monitored by the connector. |
|
| The list of tables that are captured by the connector. | |
|
| The length the queue used to pass events between the streamer and the main Kafka Connect loop. | |
|
| The free capacity of the queue used to pass events between the streamer and the main Kafka Connect loop. | |
|
| Flag that denotes whether the connector is currently connected to the database server. | |
|
| The number of milliseconds between the last change event’s timestamp and the connector processing it. The values will incoporate any differences between the clocks on the machines where the database server and the connector are running. | |
|
| The number of processed transactions that were committed. | |
|
| The coordinates of the last received event. | |
|
| Transaction identifier of the last processed transaction. | |
|
| The maximum buffer of the queue in bytes. | |
|
| The current data of records in the queue in bytes. |
7.8. How Debezium PostgreSQL connectors handle faults and problems
Debezium is a distributed system that captures all changes in multiple upstream databases; it never misses or loses an event. When the system is operating normally or being managed carefully then Debezium provides exactly once delivery of every change event record.
If a fault does happen then the system does not lose any events. However, while it is recovering from the fault, it might repeat some change events. In these abnormal situations, Debezium, like Kafka, provides at least once delivery of change events.
Details are in the following sections:
Configuration and startup errors
In the following situations, the connector fails when trying to start, reports an error/exception in the log, and stops running:
- The connector’s configuration is invalid.
- The connector cannot successfully connect to PostgreSQL by using the specified connection parameters.
- The connector is restarting from a previously-recorded position in the PostgreSQL WAL (by using the LSN) and PostgreSQL no longer has that history available.
In these cases, the error message has details about the problem and possibly a suggested workaround. After you correct the configuration or address the PostgreSQL problem, restart the connector.
The PostgreSQL connector externally stores the last processed offset in the form of a PostgreSQL LSN. After a connector restarts and connects to a server instance, the connector communicates with the server to continue streaming from that particular offset. This offset is available as long as the Debezium replication slot remains intact. Never drop a replication slot on the primary server or you will lose data. See the next section for failure cases in which a slot has been removed.
Cluster failures
As of release 12, PostgreSQL allows logical replication slots only on primary servers. This means that you can point a Debezium PostgreSQL connector to only the active primary server of a database cluster. Also, replication slots themselves are not propagated to replicas. If the primary server goes down, a new primary must be promoted.
The new primary must have a replication slot that is configured for use by the pgoutput plug-in and the database in which you want to capture changes. Only then can you point the connector to the new server and restart the connector.
There are important caveats when failovers occur and you should pause Debezium until you can verify that you have an intact replication slot that has not lost data. After a failover:
- There must be a process that re-creates the Debezium replication slot before allowing the application to write to the new primary. This is crucial. Without this process, your application can miss change events.
- You might need to verify that Debezium was able to read all changes in the slot before the old primary failed.
One reliable method of recovering and verifying whether any changes were lost is to recover a backup of the failed primary to the point immediately before it failed. While this can be administratively difficult, it allows you to inspect the replication slot for any unconsumed changes.
Kafka Connect process stops gracefully
Suppose that Kafka Connect is being run in distributed mode and a Kafka Connect process is stopped gracefully. Prior to shutting down that process, Kafka Connect migrates the process’s connector tasks to another Kafka Connect process in that group. The new connector tasks start processing exactly where the prior tasks stopped. There is a short delay in processing while the connector tasks are stopped gracefully and restarted on the new processes.
Kafka Connect process crashes
If the Kafka Connector process stops unexpectedly, any connector tasks it was running terminate without recording their most recently processed offsets. When Kafka Connect is being run in distributed mode, Kafka Connect restarts those connector tasks on other processes. However, PostgreSQL connectors resume from the last offset that was recorded by the earlier processes. This means that the new replacement tasks might generate some of the same change events that were processed just prior to the crash. The number of duplicate events depends on the offset flush period and the volume of data changes just before the crash.
Because there is a chance that some events might be duplicated during a recovery from failure, consumers should always anticipate some duplicate events. Debezium changes are idempotent, so a sequence of events always results in the same state.
In each change event record, Debezium connectors insert source-specific information about the origin of the event, including the PostgreSQL server’s time of the event, the ID of the server transaction, and the position in the write-ahead log where the transaction changes were written. Consumers can keep track of this information, especially the LSN, to determine whether an event is a duplicate.
Connector is stopped for a duration
If the connector is gracefully stopped, the database can continue to be used. Any changes are recorded in the PostgreSQL WAL. When the connector restarts, it resumes streaming changes where it left off. That is, it generates change event records for all database changes that were made while the connector was stopped.
A properly configured Kafka cluster is able to handle massive throughput. Kafka Connect is written according to Kafka best practices, and given enough resources a Kafka Connect connector can also handle very large numbers of database change events. Because of this, after being stopped for a while, when a Debezium connector restarts, it is very likely to catch up with the database changes that were made while it was stopped. How quickly this happens depends on the capabilities and performance of Kafka and the volume of changes being made to the data in PostgreSQL.
Chapter 8. Debezium connector for SQL Server
The Debezium SQL Server connector captures row-level changes that occur in the schemas of a SQL Server database.
For information about the SQL Server versions that are compatible with this connector, see the Debezium Supported Configurations page.
For details about the Debezium SQL Server connector and its use, see following topics:
- Section 8.1, “Overview of Debezium SQL Server connector”
- Section 8.2, “How Debezium SQL Server connectors work”
- Section 8.2.5, “Descriptions of Debezium SQL Server connector data change events”
- Section 8.2.7, “How Debezium SQL Server connectors map data types”
- Section 8.3, “Setting up SQL Server to run a Debezium connector”
- Section 8.4, “Deployment of Debezium SQL Server connectors”
- Section 8.5, “Refreshing capture tables after a schema change”
- Section 8.6, “Monitoring Debezium SQL Server connector performance”
The first time that the Debezium SQL Server connector connects to a SQL Server database or cluster, it takes a consistent snapshot of the schemas in the database. After the initial snapshot is complete, the connector continuously captures row-level changes for INSERT, UPDATE, or DELETE operations that are committed to the SQL Server databases that are enabled for CDC. The connector produces events for each data change operation, and streams them to Kafka topics. The connector streams all of the events for a table to a dedicated Kafka topic. Applications and services can then consume data change event records from that topic.
8.1. Overview of Debezium SQL Server connector
The Debezium SQL Server connector is based on the change data capture feature that is available in SQL Server 2016 Service Pack 1 (SP1) and later Standard edition or Enterprise edition. The SQL Server capture process monitors designated databases and tables, and stores the changes into specifically created change tables that have stored procedure facades.
To enable the Debezium SQL Server connector to capture change event records for database operations, you must first enable change data capture on the SQL Server database. CDC must be enabled on both the database and on each table that you want to capture. After you set up CDC on the source database, the connector can capture row-level INSERT, UPDATE, and DELETE operations that occur in the database. The connector writes event records for each source table to a Kafka topic especially dedicated to that table. One topic exists for each captured table. Client applications read the Kafka topics for the database tables that they follow, and can respond to the row-level events they consume from those topics.
The first time that the connector connects to a SQL Server database or cluster, it takes a consistent snapshot of the schemas for all tables for which it is configured to capture changes, and streams this state to Kafka. After the snapshot is complete, the connector continuously captures subsequent row-level changes that occur. By first establishing a consistent view of all of the data, the connector can continue reading without having lost any of the changes that were made while the snapshot was taking place.
The Debezium SQL Server connector is tolerant of failures. As the connector reads changes and produces events, it periodically records the position of events in the database log (LSN / Log Sequence Number). If the connector stops for any reason (including communication failures, network problems, or crashes), after a restart the connector resumes reading the SQL Server CDC tables from the last point that it read.
Offsets are committed periodically. They are not committed at the time that a change event occurs. As a result, following an outage, duplicate events might be generated.
Fault tolerance also applies to snapshots. That is, if the connector stops during a snapshot, the connector begins a new snapshot when it restarts.
8.2. How Debezium SQL Server connectors work
To optimally configure and run a Debezium SQL Server connector, it is helpful to understand how the connector performs snapshots, streams change events, determines Kafka topic names, and uses metadata.
For details about how the connector works, see the following sections:
- Section 8.2.1, “How Debezium SQL Server connectors perform database snapshots”
- Section 8.2.2, “How Debezium SQL Server connectors read change data tables”
- Section 8.2.3, “Default names of Kafka topics that receive Debezium SQL Server change event records”
- Section 8.2.4, “How the Debezium SQL Server connector uses the schema change topic”
- Section 8.2.5, “Descriptions of Debezium SQL Server connector data change events”
- Section 8.2.6, “Debezium SQL Server connector-generated events that represent transaction boundaries”
8.2.1. How Debezium SQL Server connectors perform database snapshots
SQL Server CDC is not designed to store a complete history of database changes. For the Debezium SQL Server connector to establish a baseline for the current state of the database, it uses a process called snapshotting.
You can configure how the connector creates snapshots. By default, the connector’s snapshot mode is set to initial. Based on this initial snapshot mode, the first time that the connector starts, it performs an initial consistent snapshot of the database. This initial snapshot captures the structure and data for any tables that match the criteria defined by the include and exclude properties that are configured for the connector (for example, table.include.list, column.include.list, table.exclude.list, and so forth).
When the connector creates a snapshot, it completes the following tasks:
- Determines the tables to be captured.
-
Obtains a lock on the SQL Server tables for which CDC is enabled to prevent structural changes from occurring during creation of the snapshot. The level of the lock is determined by
snapshot.isolation.modeconfiguration option. - Reads the maximum log sequence number (LSN) position in the server’s transaction log.
- Captures the structure of all relevant tables.
- Releases the locks obtained in Step 2, if necessary. In most cases, locks are held for only a short period of time.
-
Scans the SQL Server source tables and schemas to be captured based on the LSN position that was read in Step 3, generates a
READevent for each row in the table, and writes the events to the Kafka topic for the table. - Records the successful completion of the snapshot in the connector offsets.
The resulting initial snapshot captures the current state of each row in the tables that are enabled for CDC. From this baseline state, the connector captures subsequent changes as they occur.
8.2.1.1. Ad hoc snapshots
The use of ad hoc snapshots is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service-level agreements (SLAs) and might not be functionally complete; therefore, Red Hat does not recommend implementing any Technology Preview features in production environments. This Technology Preview feature provides early access to upcoming product innovations, enabling you to test functionality and provide feedback during the development process. For more information about support scope, see Technology Preview Features Support Scope.
By default, a connector runs an initial snapshot operation only after it starts for the first time. Following this initial snapshot, under normal circumstances, the connector does not repeat the snapshot process. Any future change event data that the connector captures comes in through the streaming process only.
However, in some situations the data that the connector obtained during the initial snapshot might become stale, lost, or incomplete. To provide a mechanism for recapturing table data, Debezium includes an option to perform ad hoc snapshots. The following changes in a database might be cause for performing an ad hoc snapshot:
- The connector configuration is modified to capture a different set of tables.
- Kafka topics are deleted and must be rebuilt.
- Data corruption occurs due to a configuration error or some other problem.
You can re-run a snapshot for a table for which you previously captured a snapshot by initiating a so-called ad-hoc snapshot. Ad hoc snapshots require the use of signaling tables. You initiate an ad hoc snapshot by sending a signal request to the Debezium signaling table.
When you initiate an ad hoc snapshot of an existing table, the connector appends content to the topic that already exists for the table. If a previously existing topic was removed, Debezium can create a topic automatically if automatic topic creation is enabled.
Ad hoc snapshot signals specify the tables to include in the snapshot. The snapshot can capture the entire contents of the database, or capture only a subset of the tables in the database.
You specify the tables to capture by sending an execute-snapshot message to the signaling table. Set the type of the execute-snapshot signal to incremental, and provide the names of the tables to include in the snapshot, as described in the following table:
| Field | Default | Value |
|---|---|---|
|
|
|
Specifies the type of snapshot that you want to run. |
|
| N/A |
An array that contains the fully-qualified names of the table to be snapshotted. |
Triggering an ad hoc snapshot
You initiate an ad hoc snapshot by adding an entry with the execute-snapshot signal type to the signaling table. After the connector processes the message, it begins the snapshot operation. The snapshot process reads the first and last primary key values and uses those values as the start and end point for each table. Based on the number of entries in the table, and the configured chunk size, Debezium divides the table into chunks, and proceeds to snapshot each chunk, in succession, one at a time.
Currently, the execute-snapshot action type triggers incremental snapshots only. For more information, see Incremental snapshots.
8.2.1.2. Incremental snapshots
The use of incremental snapshots is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service-level agreements (SLAs) and might not be functionally complete; therefore, Red Hat does not recommend implementing any Technology Preview features in production environments. This Technology Preview feature provides early access to upcoming product innovations, enabling you to test functionality and provide feedback during the development process. For more information about support scope, see Technology Preview Features Support Scope.
To provide flexibility in managing snapshots, Debezium includes a supplementary snapshot mechanism, known as incremental snapshotting. Incremental snapshots rely on the Debezium mechanism for sending signals to a Debezium connector.
In an incremental snapshot, instead of capturing the full state of a database all at once, as in an initial snapshot, Debezium captures each table in phases, in a series of configurable chunks. You can specify the tables that you want the snapshot to capture and the size of each chunk. The chunk size determines the number of rows that the snapshot collects during each fetch operation on the database. The default chunk size for incremental snapshots is 1 KB.
As an incremental snapshot proceeds, Debezium uses watermarks to track its progress, maintaining a record of each table row that it captures. This phased approach to capturing data provides the following advantages over the standard initial snapshot process:
- You can run incremental snapshots in parallel with streamed data capture, instead of postponing streaming until the snapshot completes. The connector continues to capture near real-time events from the change log throughout the snapshot process, and neither operation blocks the other.
- If the progress of an incremental snapshot is interrupted, you can resume it without losing any data. After the process resumes, the snapshot begins at the point where it stopped, rather than recapturing the table from the beginning.
-
You can run an incremental snapshot on demand at any time, and repeat the process as needed to adapt to database updates. For example, you might re-run a snapshot after you modify the connector configuration to add a table to its
table.include.listproperty.
Incremental snapshot process
When you run an incremental snapshot, Debezium sorts each table by primary key and then splits the table into chunks based on the configured chunk size. Working chunk by chunk, it then captures each table row in a chunk. For each row that it captures, the snapshot emits a READ event. That event represents the value of the row when the snapshot for the chunk began.
As a snapshot proceeds, it’s likely that other processes continue to access the database, potentially modifying table records. To reflect such changes, INSERT, UPDATE, or DELETE operations are committed to the transaction log as per usual. Similarly, the ongoing Debezium streaming process continues to detect these change events and emits corresponding change event records to Kafka.
How Debezium resolves collisions among records with the same primary key
In some cases, the UPDATE or DELETE events that the streaming process emits are received out of sequence. That is, the streaming process might emit an event that modifies a table row before the snapshot captures the chunk that contains the READ event for that row. When the snapshot eventually emits the corresponding READ event for the row, its value is already superseded. To ensure that incremental snapshot events that arrive out of sequence are processed in the correct logical order, Debezium employs a buffering scheme for resolving collisions. Only after collisions between the snapshot events and the streamed events are resolved does Debezium emit an event record to Kafka.
Snapshot window
To assist in resolving collisions between late-arriving READ events and streamed events that modify the same table row, Debezium employs a so-called snapshot window. The snapshot windows demarcates the interval during which an incremental snapshot captures data for a specified table chunk. Before the snapshot window for a chunk opens, Debezium follows its usual behavior and emits events from the transaction log directly downstream to the target Kafka topic. But from the moment that the snapshot for a particular chunk opens, until it closes, Debezium performs a de-duplication step to resolve collisions between events that have the same primary key..
For each data collection, the Debezium emits two types of events, and stores the records for them both in a single destination Kafka topic. The snapshot records that it captures directly from a table are emitted as READ operations. Meanwhile, as users continue to update records in the data collection, and the transaction log is updated to reflect each commit, Debezium emits UPDATE or DELETE operations for each change.
As the snapshot window opens, and Debezium begins processing a snapshot chunk, it delivers snapshot records to a memory buffer. During the snapshot windows, the primary keys of the READ events in the buffer are compared to the primary keys of the incoming streamed events. If no match is found, the streamed event record is sent directly to Kafka. If Debezium detects a match, it discards the buffered READ event, and writes the streamed record to the destination topic, because the streamed event logically supersede the static snapshot event. After the snapshot window for the chunk closes, the buffer contains only READ events for which no related transaction log events exist. Debezium emits these remaining READ events to the table’s Kafka topic.
The connector repeats the process for each snapshot chunk.
Triggering an incremental snapshot
Currently, the only way to initiate an incremental snapshot is to send an ad hoc snapshot signal to the signaling table on the source database. You submit signals to the table as SQL INSERT queries. After Debezium detects the change in the signaling table, it reads the signal, and runs the requested snapshot operation.
The query that you submit specifies the tables to include in the snapshot, and, optionally, specifies the kind of snapshot operation. Currently, the only valid option for snapshots operations is the default value, incremental.
To specify the tables to include in the snapshot, provide a data-collections array that lists the tables, for example,{"data-collections": ["public.MyFirstTable", "public.MySecondTable"]}
The data-collections array for an incremental snapshot signal has no default value. If the data-collections array is empty, Debezium detects that no action is required and does not perform a snapshot.
Prerequisites
- A signaling data collection exists on the source database and the connector is configured to capture it.
-
The signaling data collection is specified in the
signal.data.collectionproperty.
Procedure
Send a SQL query to add the ad hoc incremental snapshot request to the signaling table:
INSERT INTO _<signalTable>_ (id, type, data) VALUES (_'<id>'_, _'<snapshotType>'_, '{"data-collections": ["_<tableName>_","_<tableName>_"],"type":"_<snapshotType>_"}');For example,
INSERT INTO myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["schema1.table1", "schema2.table2"],"type":"incremental"}');The values of the
id,type, anddataparameters in the command correspond to the fields of the signaling table.The following table describes the these parameters:
Expand Table 8.2. Descriptions of fields in a SQL command for sending an incremental snapshot signal to the signaling table Value Description myschema.debezium_signalSpecifies the fully-qualified name of the signaling table on the source database
ad-hoc-1The
idparameter specifies an arbitrary string that is assigned as theididentifier for the signal request.
Use this string to identify logging messages to entries in the signaling table. Debezium does not use this string. Rather, during the snapshot, Debezium generates its ownidstring as a watermarking signal.execute-snapshotSpecifies
typeparameter specifies the operation that the signal is intended to trigger.
data-collectionsA required component of the
datafield of a signal that specifies an array of table names to include in the snapshot.
The array lists tables by their fully-qualified names, using the same format as you use to specify the name of the connector’s signaling table in thesignal.data.collectionconfiguration property.incrementalAn optional
typecomponent of thedatafield of a signal that specifies the kind of snapshot operation to run.
Currently, the only valid option is the default value,incremental.
Specifying atypevalue in the SQL query that you submit to the signaling table is optional.
If you do not specify a value, the connector runs an incremental snapshot.
The following example, shows the JSON for an incremental snapshot event that is captured by a connector.
Example: Incremental snapshot event message
{
"before":null,
"after": {
"pk":"1",
"value":"New data"
},
"source": {
...
"snapshot":"incremental"
},
"op":"r",
"ts_ms":"1620393591654",
"transaction":null
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
Specifies the type of snapshot operation to run. |
| 2 |
|
Specifies the event type. |
The Debezium connector for SQL Server does not support schema changes while an incremental snapshot is running.
8.2.2. How Debezium SQL Server connectors read change data tables
When the connector first starts, it takes a structural snapshot of the structure of the captured tables and persists this information to its internal database history topic. The connector then identifies a change table for each source table, and completes the following steps.
- For each change table, the connector read all of the changes that were created between the last stored maximum LSN and the current maximum LSN.
- The connector sorts the changes that it reads in ascending order, based on the values of their commit LSN and change LSN. This sorting order ensures that the changes are replayed by Debezium in the same order in which they occurred in the database.
- The connector passes the commit and change LSNs as offsets to Kafka Connect.
- The connector stores the maximum LSN and restarts the process from Step 1.
After a restart, the connector resumes processing from the last offset (commit and change LSNs) that it read.
The connector is able to detect whether CDC is enabled or disabled for included source tables and adjust its behavior.
8.2.3. Default names of Kafka topics that receive Debezium SQL Server change event records
By default, the SQL Server connector writes events for all INSERT, UPDATE, and DELETE operations that occur in a table to a single Apache Kafka topic that is specific to that table. The connector uses the following convention to name change event topics: <serverName>.<schemaName>.<tableName>
The following list provides definitions for the components of the default name:
- serverName
-
The logical name of the server, as specified by the
database.server.nameconfiguration property. - schemaName
- The name of the database schema in which the change event occurred.
- tableName
- The name of the database table in which the change event occurred.
For example, if fulfillment is the server name, and dbo is the schema name, and the database contains tables with the names products, products_on_hand, customers, and orders, the connector would stream change event records to the following Kafka topics:
-
fulfillment.dbo.products -
fulfillment.dbo.products_on_hand -
fulfillment.dbo.customers -
fulfillment.dbo.orders
The connector applies similar naming conventions to label its internal database history topics, schema change topics, and transaction metadata topics.
If the default topic name do not meet your requirements, you can configure custom topic names. To configure custom topic names, you specify regular expressions in the logical topic routing SMT. For more information about using the logical topic routing SMT to customize topic naming, see Topic routing.
8.2.4. How the Debezium SQL Server connector uses the schema change topic
For each table for which CDC is enabled, the Debezium SQL Server connector stores a history of the schema change events that are applied to captured tables in the database. The connector writes schema change events to a Kafka topic named <serverName>, where serverName is the logical server name that is specified in the database.server.name configuration property.
Messages that the connector sends to the schema change topic contain a payload, and, optionally, also contain the schema of the change event message. The payload of a schema change event message includes the following elements:
databaseName-
The name of the database to which the statements are applied. The value of
databaseNameserves as the message key. tableChanges-
A structured representation of the entire table schema after the schema change. The
tableChangesfield contains an array that includes entries for each column of the table. Because the structured representation presents data in JSON or Avro format, consumers can easily read messages without first processing them through a DDL parser.
When the connector is configured to capture a table, it stores the history of the table’s schema changes not only in the schema change topic, but also in an internal database history topic. The internal database history topic is for connector use only and it is not intended for direct use by consuming applications. Ensure that applications that require notifications about schema changes consume that information only from the schema change topic.
The format of the messages that a connector emits to its schema change topic is in an incubating state and can change without notice.
Debezium emits a message to the schema change topic when the following events occur:
- You enable CDC for a table.
- You disable CDC for a table.
- You alter the structure of a table for which CDC is enabled by following the schema evolution procedure.
Example: Message emitted to the SQL Server connector schema change topic
The following example shows a message in the schema change topic. The message contains a logical representation of the table schema.
{
"schema": {
...
},
"payload": {
"source": {
"version": "1.7.2.Final",
"connector": "sqlserver",
"name": "server1",
"ts_ms": 1588252618953,
"snapshot": "true",
"db": "testDB",
"schema": "dbo",
"table": "customers",
"change_lsn": null,
"commit_lsn": "00000025:00000d98:00a2",
"event_serial_no": null
},
"databaseName": "testDB",
"schemaName": "dbo",
"ddl": null,
"tableChanges": [
{
"type": "CREATE",
"id": "\"testDB\".\"dbo\".\"customers\"",
"table": {
"defaultCharsetName": null,
"primaryKeyColumnNames": [
"id"
],
"columns": [
{
"name": "id",
"jdbcType": 4,
"nativeType": null,
"typeName": "int identity",
"typeExpression": "int identity",
"charsetName": null,
"length": 10,
"scale": 0,
"position": 1,
"optional": false,
"autoIncremented": false,
"generated": false
},
{
"name": "first_name",
"jdbcType": 12,
"nativeType": null,
"typeName": "varchar",
"typeExpression": "varchar",
"charsetName": null,
"length": 255,
"scale": null,
"position": 2,
"optional": false,
"autoIncremented": false,
"generated": false
},
{
"name": "last_name",
"jdbcType": 12,
"nativeType": null,
"typeName": "varchar",
"typeExpression": "varchar",
"charsetName": null,
"length": 255,
"scale": null,
"position": 3,
"optional": false,
"autoIncremented": false,
"generated": false
},
{
"name": "email",
"jdbcType": 12,
"nativeType": null,
"typeName": "varchar",
"typeExpression": "varchar",
"charsetName": null,
"length": 255,
"scale": null,
"position": 4,
"optional": false,
"autoIncremented": false,
"generated": false
}
]
}
}
]
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
| Identifies the database and the schema that contain the change. |
| 2 |
|
Always |
| 3 |
| An array of one or more items that contain the schema changes generated by a DDL command. |
| 4 |
| Describes the kind of change. The value is one of the following:
|
| 5 |
| Full identifier of the table that was created, altered, or dropped. |
| 6 |
| Represents table metadata after the applied change. |
| 7 |
| List of columns that compose the table’s primary key. |
| 8 |
| Metadata for each column in the changed table. |
In messages that the connector sends to the schema change topic, the key is the name of the database that contains the schema change. In the following example, the payload field contains the key:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "databaseName"
}
],
"optional": false,
"name": "io.debezium.connector.sqlserver.SchemaChangeKey"
},
"payload": {
"databaseName": "testDB"
}
}8.2.5. Descriptions of Debezium SQL Server connector data change events
The Debezium SQL Server connector generates a data change event for each row-level INSERT, UPDATE, and DELETE operation. Each event contains a key and a value. The structure of the key and the value depends on the table that was changed.
Debezium and Kafka Connect are designed around continuous streams of event messages. However, the structure of these events may change over time, which can be difficult for consumers to handle. To address this, each event contains the schema for its content or, if you are using a schema registry, a schema ID that a consumer can use to obtain the schema from the registry. This makes each event self-contained.
The following skeleton JSON shows the basic four parts of a change event. However, how you configure the Kafka Connect converter that you choose to use in your application determines the representation of these four parts in change events. A schema field is in a change event only when you configure the converter to produce it. Likewise, the event key and event payload are in a change event only if you configure a converter to produce it. If you use the JSON converter and you configure it to produce all four basic change event parts, change events have this structure:
{
"schema": {
...
},
"payload": {
...
},
"schema": {
...
},
"payload": {
...
},
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
The first |
| 2 |
|
The first |
| 3 |
|
The second |
| 4 |
|
The second |
By default, the connector streams change event records to topics with names that are the same as the event’s originating table. See topic names.
The SQL Server connector ensures that all Kafka Connect schema names adhere to the Avro schema name format. This means that the logical server name must start with a Latin letter or an underscore, that is, a-z, A-Z, or _. Each remaining character in the logical server name and each character in the database and table names must be a Latin letter, a digit, or an underscore, that is, a-z, A-Z, 0-9, or \_. If there is an invalid character it is replaced with an underscore character.
This can lead to unexpected conflicts if the logical server name, a database name, or a table name contains invalid characters, and the only characters that distinguish names from one another are invalid and thus replaced with underscores.
For details about change events, see the following topics:
8.2.5.1. About keys in Debezium SQL Server change events
A change event’s key contains the schema for the changed table’s key and the changed row’s actual key. Both the schema and its corresponding payload contain a field for each column in the changed table’s primary key (or unique key constraint) at the time the connector created the event.
Consider the following customers table, which is followed by an example of a change event key for this table.
Example table
CREATE TABLE customers (
id INTEGER IDENTITY(1001,1) NOT NULL PRIMARY KEY,
first_name VARCHAR(255) NOT NULL,
last_name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE
);Example change event key
Every change event that captures a change to the customers table has the same event key schema. For as long as the customers table has the previous definition, every change event that captures a change to the customers table has the following key structure, which in JSON, looks like this:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
}
],
"optional": false,
"name": "server1.dbo.customers.Key"
},
"payload": {
"id": 1004
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
The schema portion of the key specifies a Kafka Connect schema that describes what is in the key’s |
| 2 |
|
Specifies each field that is expected in the |
| 3 |
|
Indicates whether the event key must contain a value in its |
| 4 |
|
Name of the schema that defines the structure of the key’s payload. This schema describes the structure of the primary key for the table that was changed. Key schema names have the format connector-name.database-schema-name.table-name.
|
| 5 |
|
Contains the key for the row for which this change event was generated. In this example, the key, contains a single |
8.2.5.2. About values in Debezium SQL Server change events
The value in a change event is a bit more complicated than the key. Like the key, the value has a schema section and a payload section. The schema section contains the schema that describes the Envelope structure of the payload section, including its nested fields. Change events for operations that create, update or delete data all have a value payload with an envelope structure.
Consider the same sample table that was used to show an example of a change event key:
CREATE TABLE customers (
id INTEGER IDENTITY(1001,1) NOT NULL PRIMARY KEY,
first_name VARCHAR(255) NOT NULL,
last_name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE
);The value portion of a change event for a change to this table is described for each event type.
create events
The following example shows the value portion of a change event that the connector generates for an operation that creates data in the customers table:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "first_name"
},
{
"type": "string",
"optional": false,
"field": "last_name"
},
{
"type": "string",
"optional": false,
"field": "email"
}
],
"optional": true,
"name": "server1.dbo.customers.Value",
"field": "before"
},
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "first_name"
},
{
"type": "string",
"optional": false,
"field": "last_name"
},
{
"type": "string",
"optional": false,
"field": "email"
}
],
"optional": true,
"name": "server1.dbo.customers.Value",
"field": "after"
},
{
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "version"
},
{
"type": "string",
"optional": false,
"field": "connector"
},
{
"type": "string",
"optional": false,
"field": "name"
},
{
"type": "int64",
"optional": false,
"field": "ts_ms"
},
{
"type": "boolean",
"optional": true,
"default": false,
"field": "snapshot"
},
{
"type": "string",
"optional": false,
"field": "db"
},
{
"type": "string",
"optional": false,
"field": "schema"
},
{
"type": "string",
"optional": false,
"field": "table"
},
{
"type": "string",
"optional": true,
"field": "change_lsn"
},
{
"type": "string",
"optional": true,
"field": "commit_lsn"
},
{
"type": "int64",
"optional": true,
"field": "event_serial_no"
}
],
"optional": false,
"name": "io.debezium.connector.sqlserver.Source",
"field": "source"
},
{
"type": "string",
"optional": false,
"field": "op"
},
{
"type": "int64",
"optional": true,
"field": "ts_ms"
}
],
"optional": false,
"name": "server1.dbo.customers.Envelope"
},
"payload": {
"before": null,
"after": {
"id": 1005,
"first_name": "john",
"last_name": "doe",
"email": "john.doe@example.org"
},
"source": {
"version": "1.7.2.Final",
"connector": "sqlserver",
"name": "server1",
"ts_ms": 1559729468470,
"snapshot": false,
"db": "testDB",
"schema": "dbo",
"table": "customers",
"change_lsn": "00000027:00000758:0003",
"commit_lsn": "00000027:00000758:0005",
"event_serial_no": "1"
},
"op": "c",
"ts_ms": 1559729471739
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
| The value’s schema, which describes the structure of the value’s payload. A change event’s value schema is the same in every change event that the connector generates for a particular table. |
| 2 |
|
In the |
| 3 |
|
|
| 4 |
|
|
| 5 |
|
The value’s actual data. This is the information that the change event is providing. |
| 6 |
|
An optional field that specifies the state of the row before the event occurred. When the |
| 7 |
|
An optional field that specifies the state of the row after the event occurred. In this example, the |
| 8 |
| Mandatory field that describes the source metadata for the event. This field contains information that you can use to compare this event with other events, with regard to the origin of the events, the order in which the events occurred, and whether events were part of the same transaction. The source metadata includes:
|
| 9 |
|
Mandatory string that describes the type of operation that caused the connector to generate the event. In this example,
|
| 10 |
|
Optional field that displays the time at which the connector processed the event. In the event message envelope, the time is based on the system clock in the JVM running the Kafka Connect task. |
update events
The value of a change event for an update in the sample customers table has the same schema as a create event for that table. Likewise, the event value’s payload has the same structure. However, the event value payload contains different values in an update event. Here is an example of a change event value in an event that the connector generates for an update in the customers table:
{
"schema": { ... },
"payload": {
"before": {
"id": 1005,
"first_name": "john",
"last_name": "doe",
"email": "john.doe@example.org"
},
"after": {
"id": 1005,
"first_name": "john",
"last_name": "doe",
"email": "noreply@example.org"
},
"source": {
"version": "1.7.2.Final",
"connector": "sqlserver",
"name": "server1",
"ts_ms": 1559729995937,
"snapshot": false,
"db": "testDB",
"schema": "dbo",
"table": "customers",
"change_lsn": "00000027:00000ac0:0002",
"commit_lsn": "00000027:00000ac0:0007",
"event_serial_no": "2"
},
"op": "u",
"ts_ms": 1559729998706
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
An optional field that specifies the state of the row before the event occurred. In an update event value, the |
| 2 |
|
An optional field that specifies the state of the row after the event occurred. You can compare the |
| 3 |
|
Mandatory field that describes the source metadata for the event. The
The
|
| 4 |
|
Mandatory string that describes the type of operation. In an update event value, the |
| 5 |
|
Optional field that displays the time at which the connector processed the event. In the event message envelope, the time is based on the system clock in the JVM running the Kafka Connect task. |
Updating the columns for a row’s primary/unique key changes the value of the row’s key. When a key changes, Debezium outputs three events: a delete event and a tombstone event with the old key for the row, followed by a create event with the new key for the row.
delete events
The value in a delete change event has the same schema portion as create and update events for the same table. The payload portion in a delete event for the sample customers table looks like this:
{
"schema": { ... },
},
"payload": {
"before": { <>
"id": 1005,
"first_name": "john",
"last_name": "doe",
"email": "noreply@example.org"
},
"after": null,
"source": {
"version": "1.7.2.Final",
"connector": "sqlserver",
"name": "server1",
"ts_ms": 1559730445243,
"snapshot": false,
"db": "testDB",
"schema": "dbo",
"table": "customers",
"change_lsn": "00000027:00000db0:0005",
"commit_lsn": "00000027:00000db0:0007",
"event_serial_no": "1"
},
"op": "d",
"ts_ms": 1559730450205
}
}| Item | Field name | Description |
|---|---|---|
| 1 |
|
Optional field that specifies the state of the row before the event occurred. In a delete event value, the |
| 2 |
|
Optional field that specifies the state of the row after the event occurred. In a delete event value, the |
| 3 |
|
Mandatory field that describes the source metadata for the event. In a delete event value, the
|
| 4 |
|
Mandatory string that describes the type of operation. The |
| 5 |
|
Optional field that displays the time at which the connector processed the event. In the event message envelope, the time is based on the system clock in the JVM running the Kafka Connect task. |
SQL Server connector events are designed to work with Kafka log compaction. Log compaction enables removal of some older messages as long as at least the most recent message for every key is kept. This lets Kafka reclaim storage space while ensuring that the topic contains a complete data set and can be used for reloading key-based state.
Tombstone events
When a row is deleted, the delete event value still works with log compaction, because Kafka can remove all earlier messages that have that same key. However, for Kafka to remove all messages that have that same key, the message value must be null. To make this possible, after Debezium’s SQL Server connector emits a delete event, the connector emits a special tombstone event that has the same key but a null value.
8.2.6. Debezium SQL Server connector-generated events that represent transaction boundaries
Debezium can generate events that represent transaction boundaries and that enrich data change event messages.
Debezium registers and receives metadata only for transactions that occur after you deploy the connector. Metadata for transactions that occur before you deploy the connector is not available.
Database transactions are represented by a statement block that is enclosed between the BEGIN and END keywords. Debezium generates transaction boundary events for the BEGIN and END delimiters in every transaction. Transaction boundary events contain the following fields:
status-
BEGINorEND id- String representation of unique transaction identifier.
event_count(forENDevents)- Total number of events emitted by the transaction.
data_collections(forENDevents)-
An array of pairs of
data_collectionandevent_countthat provides the number of events emitted by changes originating from given data collection.
There is no way for Debezium to reliably identify when a transaction has ended. The transaction END marker is thus emitted only after the first event of another transaction arrives. This can lead to the delayed delivery of END marker in case of a low-traffic system.
The following example shows a typical transaction boundary message:
Example: SQL Server connector transaction boundary event
{
"status": "BEGIN",
"id": "00000025:00000d08:0025",
"event_count": null,
"data_collections": null
}
{
"status": "END",
"id": "00000025:00000d08:0025",
"event_count": 2,
"data_collections": [
{
"data_collection": "testDB.dbo.tablea",
"event_count": 1
},
{
"data_collection": "testDB.dbo.tableb",
"event_count": 1
}
]
}
The transaction events are written to the topic named <database.server.name>.transaction.
8.2.6.1. Change data event enrichment
When transaction metadata is enabled, the data message Envelope is enriched with a new transaction field. This field provides information about every event in the form of a composite of fields:
id- String representation of unique transaction identifier
total_order- The absolute position of the event among all events generated by the transaction
data_collection_order- The per-data collection position of the event among all events that were emitted by the transaction
The following example shows what a typical message looks like:
{
"before": null,
"after": {
"pk": "2",
"aa": "1"
},
"source": {
...
},
"op": "c",
"ts_ms": "1580390884335",
"transaction": {
"id": "00000025:00000d08:0025",
"total_order": "1",
"data_collection_order": "1"
}
}8.2.7. How Debezium SQL Server connectors map data types
The Debezium SQL Server connector represents changes to table row data by producing events that are structured like the table in which the row exists. Each event contains fields to represent the column values for the row. The way in which an event represents the column values for an operation depends on the SQL data type of the column. In the event, the connector maps the fields for each SQL Server data type to both a literal type and a semantic type.
The connector can map SQL Server data types to both literal and semantic types.
- Literal type
-
Describes how the value is literally represented by using Kafka Connect schema types, namely
INT8,INT16,INT32,INT64,FLOAT32,FLOAT64,BOOLEAN,STRING,BYTES,ARRAY,MAP, andSTRUCT. - Semantic type
- Describes how the Kafka Connect schema captures the meaning of the field using the name of the Kafka Connect schema for the field.
For more information about data type mappings, see the following sections:
Basic types
The following table shows how the connector maps basic SQL Server data types.
| SQL Server data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
| n/a |
|
|
|
|
|
|
|
|
Other data type mappings are described in the following sections.
If present, a column’s default value is propagated to the corresponding field’s Kafka Connect schema. Change messages will contain the field’s default value (unless an explicit column value had been given), so there should rarely be the need to obtain the default value from the schema.
Temporal values
Other than SQL Server’s DATETIMEOFFSET data type (which contain time zone information), the other temporal types depend on the value of the time.precision.mode configuration property. When the time.precision.mode configuration property is set to adaptive (the default), then the connector will determine the literal type and semantic type for the temporal types based on the column’s data type definition so that events exactly represent the values in the database:
| SQL Server data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
When the time.precision.mode configuration property is set to connect, then the connector will use the predefined Kafka Connect logical types. This may be useful when consumers only know about the built-in Kafka Connect logical types and are unable to handle variable-precision time values. On the other hand, since SQL Server supports tenth of microsecond precision, the events generated by a connector with the connect time precision mode will result in a loss of precision when the database column has a fractional second precision value greater than 3:
| SQL Server data type | Literal type (schema type) | Semantic type (schema name) and Notes |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Timestamp values
The DATETIME, SMALLDATETIME and DATETIME2 types represent a timestamp without time zone information. Such columns are converted into an equivalent Kafka Connect value based on UTC. So for instance the DATETIME2 value "2018-06-20 15:13:16.945104" is represented by a io.debezium.time.MicroTimestamp with the value "1529507596945104".
Note that the timezone of the JVM running Kafka Connect and Debezium does not affect this conversion.
Decimal values
Debezium connectors handle decimals according to the setting of the decimal.handling.mode connector configuration property.
- decimal.handling.mode=precise
Expand Table 8.10. Mappings when decimal.handing.mode=precise SQL Server type Literal type (schema type) Semantic type (schema name) NUMERIC[(P[,S])]BYTESorg.apache.kafka.connect.data.Decimal
Thescaleschema parameter contains an integer that represents how many digits the decimal point shifted.DECIMAL[(P[,S])]BYTESorg.apache.kafka.connect.data.Decimal
Thescaleschema parameter contains an integer that represents how many digits the decimal point shifted.SMALLMONEYBYTESorg.apache.kafka.connect.data.Decimal
Thescaleschema parameter contains an integer that represents how many digits the decimal point shifted.MONEYBYTESorg.apache.kafka.connect.data.Decimal
Thescaleschema parameter contains an integer that represents how many digits the decimal point shifted.- decimal.handling.mode=double
Expand Table 8.11. Mappings when decimal.handing.mode=double SQL Server type Literal type Semantic type NUMERIC[(M[,D])]FLOAT64n/a
DECIMAL[(M[,D])]FLOAT64n/a
SMALLMONEY[(M[,D])]FLOAT64n/a
MONEY[(M[,D])]FLOAT64n/a
- decimal.handling.mode=string
Expand Table 8.12. Mappings when decimal.handing.mode=string SQL Server type Literal type Semantic type NUMERIC[(M[,D])]STRINGn/a
DECIMAL[(M[,D])]STRINGn/a
SMALLMONEY[(M[,D])]STRINGn/a
MONEY[(M[,D])]STRINGn/a
8.3. Setting up SQL Server to run a Debezium connector
For Debezium to capture change events from SQL Server tables, a SQL Server administrator with the necessary privileges must first run a query to enable CDC on the database. The administrator must then enable CDC for each table that you want Debezium to capture.
For details about setting up SQL Server for use with the Debezium connector, see the following sections:
- Section 8.3.1, “Enabling CDC on the SQL Server database”
- Section 8.3.2, “Enabling CDC on a SQL Server table”
- Section 8.3.3, “Verifying that the user has access to the CDC table”
- Section 8.3.4, “SQL Server on Azure”
- Section 8.3.5, “Effect of SQL Server capture job agent configuration on server load and latency”
- Section 8.3.6, “SQL Server capture job agent configuration parameters”
After CDC is applied, it captures all of the INSERT, UPDATE, and DELETE operations that are committed to the tables for which CDD is enabled. The Debezium connector can then capture these events and emit them to Kafka topics.
8.3.1. Enabling CDC on the SQL Server database
Before you can enable CDC for a table, you must enable it for the SQL Server database. A SQL Server administrator enables CDC by running a system stored procedure. System stored procedures can be run by using SQL Server Management Studio, or by using Transact-SQL.
Prerequisites
- You are a member of the sysadmin fixed server role for the SQL Server.
- You are a db_owner of the database.
- The SQL Server Agent is running.
The SQL Server CDC feature processes changes that occur in user-created tables only. You cannot enable CDC on the SQL Server master database.
Procedure
- From the View menu in SQL Server Management Studio, click Template Explorer.
- In the Template Browser, expand SQL Server Templates.
- Expand Change Data Capture > Configuration and then click Enable Database for CDC.
-
In the template, replace the database name in the
USEstatement with the name of the database that you want to enable for CDC. Run the stored procedure
sys.sp_cdc_enable_dbto enable the database for CDC.After the database is enabled for CDC, a schema with the name
cdcis created, along with a CDC user, metadata tables, and other system objects.The following example shows how to enable CDC for the database
MyDB:Example: Enabling a SQL Server database for the CDC template
USE MyDB GO EXEC sys.sp_cdc_enable_db GO
8.3.2. Enabling CDC on a SQL Server table
A SQL Server administrator must enable change data capture on the source tables that you want to Debezium to capture. The database must already be enabled for CDC. To enable CDC on a table, a SQL Server administrator runs the stored procedure sys.sp_cdc_enable_table for the table. The stored procedures can be run by using SQL Server Management Studio, or by using Transact-SQL. SQL Server CDC must be enabled for every table that you want to capture.
Prerequisites
- CDC is enabled on the SQL Server database.
- The SQL Server Agent is running.
-
You are a member of the
db_ownerfixed database role for the database.
Procedure
- From the View menu in SQL Server Management Studio, click Template Explorer.
- In the Template Browser, expand SQL Server Templates.
- Expand Change Data Capture > Configuration, and then click Enable Table Specifying Filegroup Option.
-
In the template, replace the table name in the
USEstatement with the name of the table that you want to capture. Run the stored procedure
sys.sp_cdc_enable_table.The following example shows how to enable CDC for the table
MyTable:Example: Enabling CDC for a SQL Server table
USE MyDB GO EXEC sys.sp_cdc_enable_table @source_schema = N'dbo', @source_name = N'MyTable', //<.> @role_name = N'MyRole', //<.> @filegroup_name = N'MyDB_CT',//<.> @supports_net_changes = 0 GO<.> Specifies the name of the table that you want to capture. <.> Specifies a role
MyRoleto which you can add users to whom you want to grantSELECTpermission on the captured columns of the source table. Users in thesysadminordb_ownerrole also have access to the specified change tables. Set the value of@role_nametoNULL, to allow only members in thesysadminordb_ownerto have full access to captured information. <.> Specifies thefilegroupwhere SQL Server places the change table for the captured table. The namedfilegroupmust already exist. It is best not to locate change tables in the samefilegroupthat you use for source tables.
8.3.3. Verifying that the user has access to the CDC table
A SQL Server administrator can run a system stored procedure to query a database or table to retrieve its CDC configuration information. The stored procedures can be run by using SQL Server Management Studio, or by using Transact-SQL.
Prerequisites
-
You have
SELECTpermission on all of the captured columns of the capture instance. Members of thedb_ownerdatabase role can view information for all of the defined capture instances. - You have membership in any gating roles that are defined for the table information that the query includes.
Procedure
- From the View menu in SQL Server Management Studio, click Object Explorer.
- From the Object Explorer, expand Databases, and then expand your database object, for example, MyDB.
- Expand Programmability > Stored Procedures > System Stored Procedures.
Run the
sys.sp_cdc_help_change_data_capturestored procedure to query the table.Queries should not return empty results.
The following example runs the stored precedure
sys.sp_cdc_help_change_data_captureon the databaseMyDB:Example: Querying a table for CDC configuration information
USE MyDB; GO EXEC sys.sp_cdc_help_change_data_capture GOThe query returns configuration information for each table in the database that is enabled for CDC and that contains change data that the caller is authorized to access. If the result is empty, verify that the user has privileges to access both the capture instance and the CDC tables.
8.3.4. SQL Server on Azure
The Debezium SQL Server connector has not been tested with SQL Server on Azure.
8.3.5. Effect of SQL Server capture job agent configuration on server load and latency
When a database administrator enables change data capture for a source table, the capture job agent begins to run. The agent reads new change event records from the transaction log and replicates the event records to a change data table. Between the time that a change is committed in the source table, and the time that the change appears in the corresponding change table, there is always a small latency interval. This latency interval represents a gap between when changes occur in the source table and when they become available for Debezium to stream to Apache Kafka.
Ideally, for applications that must respond quickly to changes in data, you want to maintain close synchronization between the source and change tables. You might imagine that running the capture agent to continuously process change events as rapidly as possible might result in increased throughput and reduced latency — populating change tables with new event records as soon as possible after the events occur, in near real time. However, this is not necessarily the case. There is a performance penalty to pay in the pursuit of more immediate synchronization. Each time that the capture job agent queries the database for new event records, it increases the CPU load on the database host. The additional load on the server can have a negative effect on overall database performance, and potentially reduce transaction efficiency, especially during times of peak database use.
It’s important to monitor database metrics so that you know if the database reaches the point where the server can no longer support the capture agent’s level of activity. If you notice performance problems, there are SQL Server capture agent settings that you can modify to help balance the overall CPU load on the database host with a tolerable degree of latency.
8.3.6. SQL Server capture job agent configuration parameters
On SQL Server, parameters that control the behavior of the capture job agent are defined in the SQL Server table msdb.dbo.cdc_jobs. If you experience performance issues while running the capture job agent, adjust capture jobs settings to reduce CPU load by running the sys.sp_cdc_change_job stored procedure and supplying new values.
Specific guidance about how to configure SQL Server capture job agent parameters is beyond the scope of this documentation.
The following parameters are the most significant for modifying capture agent behavior for use with the Debezium SQL Server connector:
pollinginterval- Specifies the number of seconds that the capture agent waits between log scan cycles.
- A higher value reduces the load on the database host and increases latency.
-
A value of
0specifies no wait between scans. -
The default value is
5.
maxtrans-
Specifies the maximum number of transactions to process during each log scan cycle. After the capture job processes the specified number of transactions, it pauses for the length of time that the
pollingintervalspecifies before the next scan begins. - A lower value reduces the load on the database host and increases latency.
-
The default value is
500.
-
Specifies the maximum number of transactions to process during each log scan cycle. After the capture job processes the specified number of transactions, it pauses for the length of time that the
maxscans-
Specifies a limit on the number of scan cycles that the capture job can attempt in capturing the full contents of the database transaction log. If the
continuousparameter is set to1, the job pauses for the length of time that thepollingintervalspecifies before it resumes scanning. - A lower values reduces the load on the database host and increases latency.
-
The default value is
10.
-
Specifies a limit on the number of scan cycles that the capture job can attempt in capturing the full contents of the database transaction log. If the
Additional resources
- For more information about capture agent parameters, see the SQL Server documentation.
8.4. Deployment of Debezium SQL Server connectors
You can use either of the following methods to deploy a Debezium SQL Server connector:
Additional resources
8.4.1. SQL Server connector deployment using AMQ Streams
Beginning with Debezium 1.7, the preferred method for deploying a Debezium connector is to use AMQ Streams to build a Kafka Connect container image that includes the connector plug-in.
During the deployment process, you create and use the following custom resources (CRs):
-
A
KafkaConnectCR that defines your Kafka Connect instance and includes information about the connector artifacts needs to include in the image. -
A
KafkaConnectorCR that provides details that include information the connector uses to access the source database. After AMQ Streams starts the Kafka Connect pod, you start the connector by applying theKafkaConnectorCR.
In the build specification for the Kafka Connect image, you can specify the connectors that are available to deploy. For each connector plug-in, you can also specify other components that you want to make available for deployment. For example, you can add Service Registry artifacts, or the Debezium scripting component. When AMQ Streams builds the Kafka Connect image, it downloads the specified artifacts, and incorporates them into the image.
The spec.build.output parameter in the KafkaConnect CR specifies where to store the resulting Kafka Connect container image. Container images can be stored in a Docker registry, or in an OpenShift ImageStream. To store images in an ImageStream, you must create the ImageStream before you deploy Kafka Connect. ImageStreams are not created automatically.
If you use a KafkaConnect resource to create a cluster, afterwards you cannot use the Kafka Connect REST API to create or update connectors. You can still use the REST API to retrieve information.
Additional resources
- Configuring Kafka Connect in Using AMQ Streams on OpenShift.
- Creating a new container image automatically using AMQ Streams in Deploying and Upgrading AMQ Streams on OpenShift.
8.4.2. Using AMQ Streams to deploy a Debezium SQL Server connector
With earlier versions of AMQ Streams, to deploy Debezium connectors on OpenShift, it was necessary to first build a Kafka Connect image for the connector. The current preferred method for deploying connectors on OpenShift is to use a build configuration in AMQ Streams to automatically build a Kafka Connect container image that includes the Debezium connector plug-ins that you want to use.
During the build process, the AMQ Streams Operator transforms input parameters in a KafkaConnect custom resource, including Debezium connector definitions, into a Kafka Connect container image. The build downloads the necessary artifacts from the Red Hat Maven repository or another configured HTTP server. The newly created container is pushed to the container registry that is specified in .spec.build.output, and is used to deploy a Kafka Connect pod. After AMQ Streams builds the Kafka Connect image, you create KafkaConnector custom resources to start the connectors that are included in the build.
Prerequisites
- You have access to an OpenShift cluster on which the cluster Operator is installed.
- The AMQ Streams Operator is running.
- An Apache Kafka cluster is deployed as documented in Deploying and Upgrading AMQ Streams on OpenShift.
- You have a Red Hat Integration license.
- Kafka Connect is deployed on AMQ Streams.
-
The OpenShift
ocCLI client is installed or you have access to the OpenShift Container Platform web console. Depending on how you intend to store the Kafka Connect build image, you need registry permissions or you must create an ImageStream resource:
- To store the build image in an image registry, such as Red Hat Quay.io or Docker Hub
- An account and permissions to create and manage images in the registry.
- To store the build image as a native OpenShift ImageStream
- An ImageStream resource is deployed to the cluster. You must explicitly create an ImageStream for the cluster. ImageStreams are not available by default.
Procedure
- Log in to the OpenShift cluster.
Create a Debezium
KafkaConnectcustom resource (CR) for the connector, or modify an existing one. For example, create aKafkaConnectCR that specifies themetadata.annotationsandspec.buildproperties, as shown in the following example. Save the file with a name such asdbz-connect.yaml.Example 8.1. A
dbz-connect.yamlfile that defines aKafkaConnectcustom resource that includes a Debezium connectorapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: debezium-kafka-connect-cluster annotations: strimzi.io/use-connector-resources: "true"1 spec: version: 3.00 build:2 output:3 type: imagestream4 image: debezium-streams-connect:latest plugins:5 - name: debezium-connector-sqlserver artifacts: - type: zip6 url: https://maven.repository.redhat.com/ga/io/debezium/debezium-connector-sqlserver/1.7.2.Final-redhat-<build_number>/debezium-connector-sqlserver-1.7.2.Final-redhat-<build_number>-plugin.zip7 - type: zip url: https://maven.repository.redhat.com/ga/io/apicurio/apicurio-registry-distro-connect-converter/2.0-redhat-<build-number>/apicurio-registry-distro-connect-converter-2.0-redhat-<build-number>.zip - type: zip url: https://maven.repository.redhat.com/ga/io/debezium/debezium-scripting/1.7.2.Final/debezium-scripting-1.7.2.Final.zip bootstrapServers: debezium-kafka-cluster-kafka-bootstrap:9093Expand Table 8.13. Descriptions of Kafka Connect configuration settings Item Description 1
Sets the
strimzi.io/use-connector-resourcesannotation to"true"to enable the Cluster Operator to useKafkaConnectorresources to configure connectors in this Kafka Connect cluster.2
The
spec.buildconfiguration specifies where to store the build image and lists the plug-ins to include in the image, along with the location of the plug-in artifacts.3
The
build.outputspecifies the registry in which the newly built image is stored.4
Specifies the name and image name for the image output. Valid values for
output.typearedockerto push into a container registry like Docker Hub or Quay, orimagestreamto push the image to an internal OpenShift ImageStream. To use an ImageStream, an ImageStream resource must be deployed to the cluster. For more information about specifying thebuild.outputin the KafkaConnect configuration, see the AMQ Streams Build schema reference documentation.5
The
pluginsconfiguration lists all of the connectors that you want to include in the Kafka Connect image. For each entry in the list, specify a plug-inname, and information for about the artifacts that are required to build the connector. Optionally, for each connector plug-in, you can include other components that you want to be available for use with the connector. For example, you can add Service Registry artifacts, or the Debezium scripting component.6
The value of
artifacts.typespecifies the file type of the artifact specified in theartifacts.url. Valid types arezip,tgz, orjar. Debezium connector archives are provided in.zipfile format. JDBC driver files are in.jarformat. Thetypevalue must match the type of the file that is referenced in theurlfield.7
The value of
artifacts.urlspecifies the address of an HTTP server, such as a Maven repository, that stores the file for the connector artifact. The OpenShift cluster must have access to the specified server.Apply the
KafkaConnectbuild specification to the OpenShift cluster by entering the following command:oc create -f dbz-connect.yamlBased on the configuration specified in the custom resource, the Streams Operator prepares a Kafka Connect image to deploy.
After the build completes, the Operator pushes the image to the specified registry or ImageStream, and starts the Kafka Connect cluster. The connector artifacts that you listed in the configuration are available in the cluster.Create a
KafkaConnectorresource to define an instance of each connector that you want to deploy.
For example, create the followingKafkaConnectorCR, and save it assqlserver-inventory-connector.yamlExample 8.2. A
sqlserver-inventory-connector.yamlfile that defines theKafkaConnectorcustom resource for a Debezium connectorapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: labels: strimzi.io/cluster: debezium-kafka-connect-cluster name: inventory-connector-sqlserver1 spec: class: io.debezium.connector.sqlserver.SqlServerConnector2 tasksMax: 13 config:4 database.history.kafka.bootstrap.servers: 'debezium-kafka-cluster-kafka-bootstrap.debezium.svc.cluster.local:9092' database.history.kafka.topic: schema-changes.inventory database.hostname: sqlserver.debezium-sqlserver.svc.cluster.local5 database.port: 33066 database.user: debezium7 database.password: dbz8 database.dbname: mydatabase9 database.server.name: inventory_connector_sqlserver10 database.include.list: public.inventory11 Expand Table 8.14. Descriptions of connector configuration settings Item Description 1
The name of the connector to register with the Kafka Connect cluster.
2
The name of the connector class.
3
The number of tasks that can operate concurrently.
4
The connector’s configuration.
5
The address of the host database instance.
6
The port number of the database instance.
7
The name of the user account through which Debezium connects to the database.
8
The password for the database user account.
9
The name of the database to capture changes from.
10
The logical name of the database instance or cluster.
The specified name must be formed only from alphanumeric characters or underscores.
Because the logical name is used as the prefix for any Kafka topics that receive change events from this connector, the name must be unique among the connectors in the cluster.
The namespace is also used in the names of related Kafka Connect schemas, and the namespaces of a corresponding Avro schema if you integrate the connector with the Avro connector.11
The list of tables from which the connector captures change events.
Create the connector resource by running the following command:
oc create -n <namespace> -f <kafkaConnector>.yamlFor example,
oc create -n debezium -f {context}-inventory-connector.yamlThe connector is registered to the Kafka Connect cluster and starts to run against the database that is specified by
spec.config.database.dbnamein theKafkaConnectorCR. After the connector pod is ready, Debezium is running.
You are now ready to verify the Debezium SQL Server deployment.
8.4.3. Deploying a Debezium SQL Server connector by building a custom Kafka Connect container image from a Dockerfile
To deploy a Debezium SQL Server connector, you must build a custom Kafka Connect container image that contains the Debezium connector archive, and then push this container image to a container registry. You then need to create the following custom resources (CRs):
-
A
KafkaConnectCR that defines your Kafka Connect instance. Theimageproperty in the CR specifies the name of the container image that you create to run your Debezium connector. You apply this CR to the OpenShift instance where Red Hat AMQ Streams is deployed. AMQ Streams offers operators and images that bring Apache Kafka to OpenShift. -
A
KafkaConnectorCR that defines your Debezium SQL Server connector. Apply this CR to the same OpenShift instance where you apply theKafkaConnectCR.
Prerequisites
- SQL Server is running and you completed the steps to set up SQL Server to work with a Debezium connector.
- AMQ Streams is deployed on OpenShift and is running Apache Kafka and Kafka Connect. For more information, see Deploying and Upgrading AMQ Streams on OpenShift
- Podman or Docker is installed.
-
You have an account and permissions to create and manage containers in the container registry (such as
quay.ioordocker.io) to which you plan to add the container that will run your Debezium connector.
Procedure
Create the Debezium SQL Server container for Kafka Connect:
- Download the Debezium SQL Server connector archive.
Extract the Debezium SQL Server connector archive to create a directory structure for the connector plug-in, for example:
./my-plugins/ ├── debezium-connector-sqlserver │ ├── ...Create a Dockerfile that uses
registry.redhat.io/amq7/amq-streams-kafka-30-rhel8:2.0.0as the base image. For example, from a terminal window, enter the following, replacingmy-pluginswith the name of your plug-ins directory:cat <<EOF >debezium-container-for-sqlserver.yaml1 FROM registry.redhat.io/amq7/amq-streams-kafka-30-rhel8:2.0.0 USER root:root COPY ./<my-plugins>/ /opt/kafka/plugins/2 USER 1001 EOFThe command creates a Dockerfile with the name
debezium-container-for-sqlserver.yamlin the current directory.Build the container image from the
debezium-container-for-sqlserver.yamlDocker file that you created in the previous step. From the directory that contains the file, open a terminal window and enter one of the following commands:podman build -t debezium-container-for-sqlserver:latest .docker build -t debezium-container-for-sqlserver:latest .The preceding commands build a container image with the name
debezium-container-for-sqlserver.Push your custom image to a container registry, such as quay.io or an internal container registry. The container registry must be available to the OpenShift instance where you want to deploy the image. Enter one of the following commands:
podman push <myregistry.io>/debezium-container-for-sqlserver:latestdocker push <myregistry.io>/debezium-container-for-sqlserver:latestCreate a new Debezium SQL Server KafkaConnect custom resource (CR). For example, create a KafkaConnect CR with the name
dbz-connect.yamlthat specifiesannotationsandimageproperties as shown in the following example:apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true"1 spec: #... image: debezium-container-for-sqlserver2 - 1
metadata.annotationsindicates to the Cluster Operator that KafkaConnector resources are used to configure connectors in this Kafka Connect cluster.- 2
spec.imagespecifies the name of the image that you created to run your Debezium connector. This property overrides theSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGEvariable in the Cluster Operator
Apply the
KafkaConnectCR to the OpenShift Kafka Connect environment by entering the following command:oc create -f dbz-connect.yamlThe command adds a Kafka Connect instance that specifies the name of the image that you created to run your Debezium connector.
Create a
KafkaConnectorcustom resource that configures your Debezium SQL Server connector instance.You configure a Debezium SQL Server connector in a
.yamlfile that specifies the configuration properties for the connector. The connector configuration might instruct Debezium to produce events for a subset of the schemas and tables, or it might set properties so that Debezium ignores, masks, or truncates values in specified columns that are sensitive, too large, or not needed.The following example configures a Debezium connector that connects to a SQL server host,
192.168.99.100, on port1433. This host has a database namedtestDB, a table with the namecustomers, andfulfillmentis the server’s logical name.SQL Server
fulfillment-connector.yamlapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: fulfillment-connector1 labels: strimzi.io/cluster: my-connect-cluster annotations: strimzi.io/use-connector-resources: 'true' spec: class: io.debezium.connector.sqlserver.SqlServerConnector2 config: database.hostname: 192.168.99.1003 database.port: 14334 database.user: debezium5 database.password: dbz6 database.dbname: testDB7 database.server.name: fullfullment8 database.include.list: dbo.customers9 database.history.kafka.bootstrap.servers: my-cluster-kafka-bootstrap:909210 database.history.kafka.topic: dbhistory.fullfillment11 Expand Table 8.15. Descriptions of connector configuration settings Item Description 1
The name of our connector when we register it with a Kafka Connect service.
2
The name of this SQL Server connector class.
3
The address of the SQL Server instance.
4
The port number of the SQL Server instance.
5
The name of the SQL Server user.
6
The password for the SQL Server user.
7
The name of the database to capture changes from.
8
The logical name of the SQL Server instance/cluster, which forms a namespace and is used in all the names of the Kafka topics to which the connector writes, the Kafka Connect schema names, and the namespaces of the corresponding Avro schema when the Avro converter is used.
9
A list of all tables whose changes Debezium should capture.
10
The list of Kafka brokers that this connector will use to write and recover DDL statements to the database history topic.
11
The name of the database history topic where the connector will write and recover DDL statements. This topic is for internal use only and should not be used by consumers.
Create your connector instance with Kafka Connect. For example, if you saved your
KafkaConnectorresource in thefulfillment-connector.yamlfile, you would run the following command:oc apply -f fulfillment-connector.yamlThe preceding command registers
fulfillment-connectorand the connector starts to run against thetestDBdatabase as defined in theKafkaConnectorCR.
Verifying that the Debezium SQL Server connector is running
If the connector starts correctly without errors, it creates a topic for each table that the connector is configured to capture. Downstream applications can subscribe to these topics to retrieve information events that occur in the source database.
To verify that the connector is running, you perform the following operations from the OpenShift Container Platform web console, or through the OpenShift CLI tool (oc):
- Verify the connector status.
- Verify that the connector generates topics.
- Verify that topics are populated with events for read operations ("op":"r") that the connector generates during the initial snapshot of each table.
Prerequisites
- A Debezium connector is deployed to AMQ Streams on OpenShift.
-
The OpenShift
ocCLI client is installed. - You have access to the OpenShift Container Platform web console.
Procedure
Check the status of the
KafkaConnectorresource by using one of the following methods:From the OpenShift Container Platform web console:
- Navigate to Home → Search.
-
On the Search page, click Resources to open the Select Resource box, and then type
KafkaConnector. - From the KafkaConnectors list, click the name of the connector that you want to check, for example inventory-connector-sqlserver.
- In the Conditions section, verify that the values in the Type and Status columns are set to Ready and True.
From a terminal window:
Enter the following command:
oc describe KafkaConnector <connector-name> -n <project>For example,
oc describe KafkaConnector inventory-connector-sqlserver -n debeziumThe command returns status information that is similar to the following output:
Example 8.3.
KafkaConnectorresource statusName: inventory-connector-sqlserver Namespace: debezium Labels: strimzi.io/cluster=debezium-kafka-connect-cluster Annotations: <none> API Version: kafka.strimzi.io/v1beta2 Kind: KafkaConnector ... Status: Conditions: Last Transition Time: 2021-12-08T17:41:34.897153Z Status: True Type: Ready Connector Status: Connector: State: RUNNING worker_id: 10.131.1.124:8083 Name: inventory-connector-sqlserver Tasks: Id: 0 State: RUNNING worker_id: 10.131.1.124:8083 Type: source Observed Generation: 1 Tasks Max: 1 Topics: inventory_connector_sqlserver inventory_connector_sqlserver.inventory.addresses inventory_connector_sqlserver.inventory.customers inventory_connector_sqlserver.inventory.geom inventory_connector_sqlserver.inventory.orders inventory_connector_sqlserver.inventory.products inventory_connector_sqlserver.inventory.products_on_hand Events: <none>
Verify that the connector created Kafka topics:
From the OpenShift Container Platform web console.
- Navigate to Home → Search.
-
On the Search page, click Resources to open the Select Resource box, and then type
KafkaTopic. - From the KafkaTopics list, click the name of the topic that you want to check, for example, inventory-connector-sqlserver.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d.
- In the Conditions section, verify that the values in the Type and Status columns are set to Ready and True.
From a terminal window:
Enter the following command:
oc get kafkatopicsThe command returns status information that is similar to the following output:
Example 8.4.
KafkaTopicresource statusNAME CLUSTER PARTITIONS REPLICATION FACTOR READY connect-cluster-configs debezium-kafka-cluster 1 1 True connect-cluster-offsets debezium-kafka-cluster 25 1 True connect-cluster-status debezium-kafka-cluster 5 1 True consumer-offsets---84e7a678d08f4bd226872e5cdd4eb527fadc1c6a debezium-kafka-cluster 50 1 True inventory-connector-sqlserver---a96f69b23d6118ff415f772679da623fbbb99421 debezium-kafka-cluster 1 1 True inventory-connector-sqlserver.inventory.addresses---1b6beaf7b2eb57d177d92be90ca2b210c9a56480 debezium-kafka-cluster 1 1 True inventory-connector-sqlserver.inventory.customers---9931e04ec92ecc0924f4406af3fdace7545c483b debezium-kafka-cluster 1 1 True inventory-connector-sqlserver.inventory.geom---9f7e136091f071bf49ca59bf99e86c713ee58dd5 debezium-kafka-cluster 1 1 True inventory-connector-sqlserver.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d debezium-kafka-cluster 1 1 True inventory-connector-sqlserver.inventory.products---df0746db116844cee2297fab611c21b56f82dcef debezium-kafka-cluster 1 1 True inventory-connector-sqlserver.inventory.products-on-hand---8649e0f17ffcc9212e266e31a7aeea4585e5c6b5 debezium-kafka-cluster 1 1 True schema-changes.inventory debezium-kafka-cluster 1 1 True strimzi-store-topic---effb8e3e057afce1ecf67c3f5d8e4e3ff177fc55 debezium-kafka-cluster 1 1 True strimzi-topic-operator-kstreams-topic-store-changelog---b75e702040b99be8a9263134de3507fc0cc4017b debezium-kafka-cluster 1 1 True
Check topic content.
- From a terminal window, enter the following command:
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>For example,
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory_connector_sqlserver.inventory.products_on_handThe format for specifying the topic name is the same as the
oc describecommand returns in Step 1, for example,inventory_connector_sqlserver.inventory.addresses.For each event in the topic, the command returns information that is similar to the following output:
Example 8.5. Content of a Debezium change event
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory_connector_sqlserver.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory_connector_sqlserver.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory_connector_sqlserver.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.sqlserver.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory_connector_sqlserver.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"1.7.2.Final-redhat-00001","connector":"sqlserver","name":"inventory_connector_sqlserver","ts_ms":1638985247805,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"sqlserver-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"transaction":null}}In the preceding example, the
payloadvalue shows that the connector snapshot generated a read ("op" ="r") event from the tableinventory.products_on_hand. The"before"state of theproduct_idrecord isnull, indicating that no previous value exists for the record. The"after"state shows aquantityof3for the item withproduct_id101.
For the complete list of the configuration properties that you can set for the Debezium SQL Server connector, see SQL Server connector properties.
Results
When the connector starts, it performs a consistent snapshot of the SQL Server databases that the connector is configured for. The connector then starts generating data change events for row-level operations and streaming the change event records to Kafka topics.
8.4.4. Descriptions of Debezium SQL Server connector configuration properties
The Debezium SQL Server connector has numerous configuration properties that you can use to achieve the right connector behavior for your application. Many properties have default values.
Information about the properties is organized as follows:
- Required connector configuration properties
- Advanced connector configuration properties
Database history connector configuration properties that control how Debezium processes events that it reads from the database history topic.
- Pass-through database driver properties that control the behavior of the database driver.
Required Debezium SQL Server connector configuration properties
The following configuration properties are required unless a default value is available.
| Property | Default | Description |
|---|---|---|
| No default | Unique name for the connector. Attempting to register again with the same name will fail. (This property is required by all Kafka Connect connectors.) | |
| No default |
The name of the Java class for the connector. Always use a value of | |
|
| The maximum number of tasks that should be created for this connector. The SQL Server connector always uses a single task and therefore does not use this value, so the default is always acceptable. | |
| No default | IP address or hostname of the SQL Server database server. | |
|
| Integer port number of the SQL Server database server. | |
| No default | Username to use when connecting to the SQL Server database server. | |
| No default | Password to use when connecting to the SQL Server database server. | |
| No default |
The name of the SQL Server database from which to stream the changes Must not be used with | |
| No default |
The comma-separated list of the SQL Server database names from which to stream the changes. Currently, only one database name is supported. Must not be used with This option is experimental and must not be used in production. Using it will make the behavior of the connector incompatible with the default configuration with no upgrade or downgrade path:
| |
| No default | Logical name that identifies and provides a namespace for the SQL Server database server that you want Debezium to capture. The logical name should be unique across all other connectors, since it is used as a prefix for all Kafka topic names emanating from this connector. Only alphanumeric characters, hyphens, dots and underscores must be used. | |
| No default |
An optional comma-separated list of regular expressions that match fully-qualified table identifiers for tables that you want Debezium to capture; any table that is not included in | |
| No default |
An optional comma-separated list of regular expressions that match fully-qualified table identifiers for the tables that you want to exclude from being captured; Debezium captures all tables that are not included in | |
| empty string |
An optional comma-separated list of regular expressions that match the fully-qualified names of columns that should be included in the change event message values. Fully-qualified names for columns are of the form schemaName.tableName.columnName. Note that primary key columns are always included in the event’s key, even if not included in the value. Do not also set the | |
| empty string |
An optional comma-separated list of regular expressions that match the fully-qualified names of columns that should be excluded from change event message values. Fully-qualified names for columns are of the form schemaName.tableName.columnName. Note that primary key columns are always included in the event’s key, also if excluded from the value. Do not also set the | |
| n/a |
An optional, comma-separated list of regular expressions that match the fully-qualified names of character-based columns. Fully-qualified names for columns are of the form `<schemaName>.<tableName>._<columnName>`. In the resulting change event record, the values for the specified columns are replaced with pseudonyms.
A pseudonym consists of the hashed value that results from applying the specified hashAlgorithm and salt. Based on the hash function that is used, referential integrity is maintained, while column values are replaced with pseudonyms. Supported hash functions are described in the MessageDigest section of the Java Cryptography Architecture Standard Algorithm Name Documentation.
If necessary, the pseudonym is automatically shortened to the length of the column. The connector configuration can include multiple properties that specify different hash algorithms and salts. | |
|
|
Time, date, and timestamps can be represented with different kinds of precision, including: | |
|
|
Specifies how the connector should handle values for | |
|
|
Boolean value that specifies whether the connector should publish changes in the database schema to a Kafka topic with the same name as the database server ID. Each schema change is recorded with a key that contains the database name and a value that is a JSON structure that describes the schema update. This is independent of how the connector internally records database history. The default is | |
|
|
Controls whether a delete event is followed by a tombstone event. | |
| n/a | An optional comma-separated list of regular expressions that match the fully-qualified names of character-based columns whose values should be truncated in the change event message values if the field values are longer than the specified number of characters. Multiple properties with different lengths can be used in a single configuration, although in each the length must be a positive integer. Fully-qualified names for columns are of the form schemaName.tableName.columnName. | |
| n/a |
An optional comma-separated list of regular expressions that match the fully-qualified names of character-based columns whose values should be replaced in the change event message values with a field value consisting of the specified number of asterisk ( | |
| n/a |
An optional comma-separated list of regular expressions that match the fully-qualified names of columns whose original type and length should be added as a parameter to the corresponding field schemas in the emitted change messages. The schema parameters | |
| n/a |
An optional comma-separated list of regular expressions that match the database-specific data type name of columns whose original type and length should be added as a parameter to the corresponding field schemas in the emitted change messages. The schema parameters | |
| n/a | A list of expressions that specify the columns that the connector uses to form custom message keys for change event records that it publishes to the Kafka topics for specified tables.
By default, Debezium uses the primary key column of a table as the message key for records that it emits. In place of the default, or to specify a key for tables that lack a primary key, you can configure custom message keys based on one or more columns.
Each fully-qualified table name is a regular expression in the following format: There is no limit to the number of columns that you use to create custom message keys. However, it’s best to use the minimum number that are required to specify a unique key. | |
| bytes |
Specifies how binary ( |
Advanced SQL Server connector configuration properties
The following advanced configuration properties have good defaults that will work in most situations and therefore rarely need to be specified in the connector’s configuration.
| Property | Default | Description |
|---|---|---|
| initial | A mode for taking an initial snapshot of the structure and optionally data of captured tables. Once the snapshot is complete, the connector will continue reading change events from the database’s redo logs. The following values are supported:
| |
|
All tables specified in |
An optional, comma-separated list of regular expressions that match the fully-qualified names ( This property does not affect the behavior of incremental snapshots. | |
| repeatable_read | Mode to control which transaction isolation level is used and how long the connector locks tables that are designated for capture. The following values are supported:
The
Mode choice also affects data consistency. Only | |
|
|
Specifies how the connector should react to exceptions during processing of events. | |
|
| Positive integer value that specifies the number of milliseconds the connector should wait during each iteration for new change events to appear. Defaults to 1000 milliseconds, or 1 second. | |
|
|
Positive integer value that specifies the maximum size of the blocking queue into which change events read from the database log are placed before they are written to Kafka. This queue can provide backpressure to the CDC table reader when, for example, writes to Kafka are slower or if Kafka is not available. Events that appear in the queue are not included in the offsets periodically recorded by this connector. Defaults to 8192, and should always be larger than the maximum batch size specified in the | |
|
| Positive integer value that specifies the maximum size of each batch of events that should be processed during each iteration of this connector. Defaults to 2048. | |
|
|
Controls how frequently heartbeat messages are sent. | |
|
|
Controls the naming of the topic to which heartbeat messages are sent. | |
| No default |
An interval in milli-seconds that the connector should wait before taking a snapshot after starting up; | |
|
| Specifies the maximum number of rows that should be read in one go from each table while taking a snapshot. The connector will read the table contents in multiple batches of this size. Defaults to 2000. | |
| No default | Specifies the number of rows that will be fetched for each database round-trip of a given query. Defaults to the JDBC driver’s default fetch size. | |
|
|
An integer value that specifies the maximum amount of time (in milliseconds) to wait to obtain table locks when performing a snapshot. If table locks cannot be acquired in this time interval, the snapshot will fail (also see snapshots). | |
| No default | Specifies the table rows to include in a snapshot. Use the property if you want a snapshot to include only a subset of the rows in a table. This property affects snapshots only. It does not apply to events that the connector reads from the log.
The property contains a comma-separated list of fully-qualified table names in the form
From a
In the resulting snapshot, the connector includes only the records for which | |
|
| Whether field names are sanitized to adhere to Avro naming requirements. | |
|
|
When set to See Transaction Metadata for additional details. | |
| 10000 (10 seconds) | The number of milli-seconds to wait before restarting a connector after a retriable error occurs. | |
| No default |
comma-separated list of operation types that will be skipped during streaming. The operations include: | |
| No default value |
Fully-qualified name of the data collection that is used to send signals to the connector. Signaling is a Technology Preview feature. | |
|
| The maximum number of rows that the connector fetches and reads into memory during an incremental snapshot chunk. Increasing the chunk size provides greater efficiency, because the snapshot runs fewer snapshot queries of a greater size. However, larger chunk sizes also require more memory to buffer the snapshot data. Adjust the chunk size to a value that provides the best performance in your environment. | |
| 0 |
Specifies the maximum number of transactions per iteration to be used to reduce the memory footprint when streaming changes from multiple tables in a database. When set to |
Debezium SQL Server connector database history configuration properties
Debezium provides a set of database.history.* properties that control how the connector interacts with the schema history topic.
The following table describes the database.history properties for configuring the Debezium connector.
| Property | Default | Description |
|---|---|---|
| The full name of the Kafka topic where the connector stores the database schema history. | ||
| A list of host/port pairs that the connector uses for establishing an initial connection to the Kafka cluster. This connection is used for retrieving the database schema history previously stored by the connector, and for writing each DDL statement read from the source database. Each pair should point to the same Kafka cluster used by the Kafka Connect process. | ||
|
| An integer value that specifies the maximum number of milliseconds the connector should wait during startup/recovery while polling for persisted data. The default is 100ms. | |
|
|
The maximum number of times that the connector should try to read persisted history data before the connector recovery fails with an error. The maximum amount of time to wait after receiving no data is | |
|
|
A Boolean value that specifies whether the connector should ignore malformed or unknown database statements or stop processing so a human can fix the issue. The safe default is | |
|
Deprecated and scheduled for removal in a future release; use |
|
A Boolean value that specifies whether the connector should record all DDL statements
The safe default is |
|
|
A Boolean value that specifies whether the connector should record all DDL statements
The safe default is |
Pass-through database history properties for configuring producer and consumer clients
Debezium relies on a Kafka producer to write schema changes to database history topics. Similarly, it relies on a Kafka consumer to read from database history topics when a connector starts. You define the configuration for the Kafka producer and consumer clients by assigning values to a set of pass-through configuration properties that begin with the database.history.producer.* and database.history.consumer.* prefixes. The pass-through producer and consumer database history properties control a range of behaviors, such as how these clients secure connections with the Kafka broker, as shown in the following example:
database.history.producer.security.protocol=SSL
database.history.producer.ssl.keystore.location=/var/private/ssl/kafka.server.keystore.jks
database.history.producer.ssl.keystore.password=test1234
database.history.producer.ssl.truststore.location=/var/private/ssl/kafka.server.truststore.jks
database.history.producer.ssl.truststore.password=test1234
database.history.producer.ssl.key.password=test1234
database.history.consumer.security.protocol=SSL
database.history.consumer.ssl.keystore.location=/var/private/ssl/kafka.server.keystore.jks
database.history.consumer.ssl.keystore.password=test1234
database.history.consumer.ssl.truststore.location=/var/private/ssl/kafka.server.truststore.jks
database.history.consumer.ssl.truststore.password=test1234
database.history.consumer.ssl.key.password=test1234Debezium strips the prefix from the property name before it passes the property to the Kafka client.
See the Kafka documentation for more details about Kafka producer configuration properties and Kafka consumer configuration properties.
Debezium SQL Server connector pass-through database driver configuration properties
The Debezium connector provides for pass-through configuration of the database driver. Pass-through database properties begin with the prefix database.*. For example, the connector passes properties such as database.foobar=false to the JDBC URL.
As is the case with the pass-through properties for database history clients, Debezium strips the prefixes from the properties before it passes them to the database driver.
8.5. Refreshing capture tables after a schema change
When change data capture is enabled for a SQL Server table, as changes occur in the table, event records are persisted to a capture table on the server. If you introduce a change in the structure of the source table change, for example, by adding a new column, that change is not dynamically reflected in the change table. For as long as the capture table continues to use the outdated schema, the Debezium connector is unable to emit data change events for the table correctly. You must intervene to refresh the capture table to enable the connector to resume processing change events.
Because of the way that CDC is implemented in SQL Server, you cannot use Debezium to update capture tables. To refresh capture tables, one must be a SQL Server database operator with elevated privileges. As a Debezium user, you must coordinate tasks with the SQL Server database operator to complete the schema refresh and restore streaming to Kafka topics.
You can use one of the following methods to update capture tables after a schema change:
- Offline schema updates require you to stop the Debezium connector before you can update capture tables.
- Online schema updates can update capture tables while the Debezium connector is running.
There are advantages and disadvantages to using each type of procedure.
Whether you use the online or offline update method, you must complete the entire schema update process before you apply subsequent schema updates on the same source table. The best practice is to execute all DDLs in a single batch so the procedure can be run only once.
Some schema changes are not supported on source tables that have CDC enabled. For example, if CDC is enabled on a table, SQL Server does not allow you to change the schema of the table if you renamed one of its columns or changed the column type.
After you change a column in a source table from NULL to NOT NULL or vice versa, the SQL Server connector cannot correctly capture the changed information until after you create a new capture instance. If you do not create a new capture table after a change to the column designation, change event records that the connector emits do not correctly indicate whether the column is optional. That is, columns that were previously defined as optional (or NULL) continue to be, despite now being defined as NOT NULL. Similarly, columns that had been defined as required (NOT NULL), retain that designation, although they are now defined as NULL.
8.5.1. Running an offline update after a schema change
Offline schema updates provide the safest method for updating capture tables. However, offline updates might not be feasible for use with applications that require high-availability.
Prerequisites
- An update was committed to the schema of a SQL Server table that has CDC enabled.
- You are a SQL Server database operator with elevated privileges.
Procedure
- Suspend the application that updates the database.
- Wait for the Debezium connector to stream all unstreamed change event records.
- Stop the Debezium connector.
- Apply all changes to the source table schema.
-
Create a new capture table for the update source table using
sys.sp_cdc_enable_tableprocedure with a unique value for parameter@capture_instance. - Resume the application that you suspended in Step 1.
- Start the Debezium connector.
-
After the Debezium connector starts streaming from the new capture table, drop the old capture table by running the stored procedure
sys.sp_cdc_disable_tablewith the parameter@capture_instanceset to the old capture instance name.
8.5.2. Running an online update after a schema change
The procedure for completing an online schema updates is simpler than the procedure for running an offline schema update, and you can complete it without requiring any downtime in application and data processing. However, with online schema updates, a potential processing gap can occur after you update the schema in the source database, but before you create the new capture instance. During that interval, change events continue to be captured by the old instance of the change table, Q and the change data that is saved to the old table retains the structure of the earlier schema. So, for example, if you added a new column to a source table, change events that are produced before the new capture table is ready, do not contain a field for the new column. If your application does not tolerate such a transition period, it is best to use the offline schema update procedure.
Prerequisites
- An update was committed to the schema of a SQL Server table that has CDC enabled.
- You are a SQL Server database operator with elevated privileges.
Procedure
- Apply all changes to the source table schema.
-
Create a new capture table for the update source table by running the
sys.sp_cdc_enable_tablestored procedure with a unique value for the parameter@capture_instance. -
When Debezium starts streaming from the new capture table, you can drop the old capture table by running the
sys.sp_cdc_disable_tablestored procedure with the parameter@capture_instanceset to the old capture instance name.
Example: Running an online schema update after a database schema change
The following example shows how to complete an online schema update in the change table after the column phone_number is added to the customers source table.
Modify the schema of the
customerssource table by running the following query to add thephone_numberfield:ALTER TABLE customers ADD phone_number VARCHAR(32);Create the new capture instance by running the
sys.sp_cdc_enable_tablestored procedure.EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'customers', @role_name = NULL, @supports_net_changes = 0, @capture_instance = 'dbo_customers_v2'; GOInsert new data into the
customerstable by running the following query:INSERT INTO customers(first_name,last_name,email,phone_number) VALUES ('John','Doe','john.doe@example.com', '+1-555-123456'); GOThe Kafka Connect log reports on configuration updates through entries similar to the following message:
connect_1 | 2019-01-17 10:11:14,924 INFO || Multiple capture instances present for the same table: Capture instance "dbo_customers" [sourceTableId=testDB.dbo.customers, changeTableId=testDB.cdc.dbo_customers_CT, startLsn=00000024:00000d98:0036, changeTableObjectId=1525580473, stopLsn=00000025:00000ef8:0048] and Capture instance "dbo_customers_v2" [sourceTableId=testDB.dbo.customers, changeTableId=testDB.cdc.dbo_customers_v2_CT, startLsn=00000025:00000ef8:0048, changeTableObjectId=1749581271, stopLsn=NULL] [io.debezium.connector.sqlserver.SqlServerStreamingChangeEventSource] connect_1 | 2019-01-17 10:11:14,924 INFO || Schema will be changed for ChangeTable [captureInstance=dbo_customers_v2, sourceTableId=testDB.dbo.customers, changeTableId=testDB.cdc.dbo_customers_v2_CT, startLsn=00000025:00000ef8:0048, changeTableObjectId=1749581271, stopLsn=NULL] [io.debezium.connector.sqlserver.SqlServerStreamingChangeEventSource] ... connect_1 | 2019-01-17 10:11:33,719 INFO || Migrating schema to ChangeTable [captureInstance=dbo_customers_v2, sourceTableId=testDB.dbo.customers, changeTableId=testDB.cdc.dbo_customers_v2_CT, startLsn=00000025:00000ef8:0048, changeTableObjectId=1749581271, stopLsn=NULL] [io.debezium.connector.sqlserver.SqlServerStreamingChangeEventSource]Eventually, the
phone_numberfield is added to the schema and its value appears in messages written to the Kafka topic.... { "type": "string", "optional": true, "field": "phone_number" } ... "after": { "id": 1005, "first_name": "John", "last_name": "Doe", "email": "john.doe@example.com", "phone_number": "+1-555-123456" },Drop the old capture instance by running the
sys.sp_cdc_disable_tablestored procedure.EXEC sys.sp_cdc_disable_table @source_schema = 'dbo', @source_name = 'dbo_customers', @capture_instance = 'dbo_customers'; GO
8.6. Monitoring Debezium SQL Server connector performance
The Debezium SQL Server connector provides three types of metrics that are in addition to the built-in support for JMX metrics that Zookeeper, Kafka, and Kafka Connect provide. The connector provides the following metrics:
- Snapshot metrics for monitoring the connector when performing snapshots.
- Streaming metrics for monitoring the connector when reading CDC table data.
- Schema history metrics for monitoring the status of the connector’s schema history.
For information about how to expose the preceding metrics through JMX, see the Debezium monitoring documentation.
8.6.1. Debezium SQL Server connector snapshot metrics
The MBean is debezium.sql_server:type=connector-metrics,context=snapshot,server=<sqlserver.server.name>.
Snapshot metrics are not exposed unless a snapshot operation is active, or if a snapshot has occurred since the last connector start.
The following table lists the shapshot metrics that are available.
| Attributes | Type | Description |
|---|---|---|
|
| The last snapshot event that the connector has read. | |
|
| The number of milliseconds since the connector has read and processed the most recent event. | |
|
| The total number of events that this connector has seen since last started or reset. | |
|
| The number of events that have been filtered by include/exclude list filtering rules configured on the connector. | |
|
|
| The list of tables that are monitored by the connector. |
|
| The list of tables that are captured by the connector. | |
|
| The length the queue used to pass events between the snapshotter and the main Kafka Connect loop. | |
|
| The free capacity of the queue used to pass events between the snapshotter and the main Kafka Connect loop. | |
|
| The total number of tables that are being included in the snapshot. | |
|
| The number of tables that the snapshot has yet to copy. | |
|
| Whether the snapshot was started. | |
|
| Whether the snapshot was aborted. | |
|
| Whether the snapshot completed. | |
|
| The total number of seconds that the snapshot has taken so far, even if not complete. | |
|
| Map containing the number of rows scanned for each table in the snapshot. Tables are incrementally added to the Map during processing. Updates every 10,000 rows scanned and upon completing a table. | |
|
|
The maximum buffer of the queue in bytes. It will be enabled if | |
|
| The current data of records in the queue in bytes. |
The connector also provides the following additional snapshot metrics when an incremental snapshot is executed:
| Attributes | Type | Description |
|---|---|---|
|
| The identifier of the current snapshot chunk. | |
|
| The lower bound of the primary key set defining the current chunk. | |
|
| The upper bound of the primary key set defining the current chunk. | |
|
| The lower bound of the primary key set of the currently snapshotted table. | |
|
| The upper bound of the primary key set of the currently snapshotted table. |
Incremental snapshots is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process. For more information about the support scope of Red Hat Technology Preview features, see https://access.redhat.com/support/offerings/techpreview.
8.6.2. Debezium SQL Server connector streaming metrics
The MBean is debezium.sql_server:type=connector-metrics,context=streaming,server=<sqlserver.server.name>.
The following table lists the streaming metrics that are available.
| Attributes | Type | Description |
|---|---|---|
|
| The last streaming event that the connector has read. | |
|
| The number of milliseconds since the connector has read and processed the most recent event. | |
|
| The total number of events that this connector has seen since last started or reset. | |
|
| The number of events that have been filtered by include/exclude list filtering rules configured on the connector. | |
|
|
| The list of tables that are monitored by the connector. |
|
| The list of tables that are captured by the connector. | |
|
| The length the queue used to pass events between the streamer and the main Kafka Connect loop. | |
|
| The free capacity of the queue used to pass events between the streamer and the main Kafka Connect loop. | |
|
| Flag that denotes whether the connector is currently connected to the database server. | |
|
| The number of milliseconds between the last change event’s timestamp and the connector processing it. The values will incoporate any differences between the clocks on the machines where the database server and the connector are running. | |
|
| The number of processed transactions that were committed. | |
|
| The coordinates of the last received event. | |
|
| Transaction identifier of the last processed transaction. | |
|
| The maximum buffer of the queue in bytes. | |
|
| The current data of records in the queue in bytes. |
8.6.3. Debezium SQL Server connector schema history metrics
The MBean is debezium.sql_server:type=connector-metrics,context=schema-history,server=<sqlserver.server.name>.
The following table lists the schema history metrics that are available.
| Attributes | Type | Description |
|---|---|---|
|
|
One of | |
|
| The time in epoch seconds at what recovery has started. | |
|
| The number of changes that were read during recovery phase. | |
|
| the total number of schema changes applied during recovery and runtime. | |
|
| The number of milliseconds that elapsed since the last change was recovered from the history store. | |
|
| The number of milliseconds that elapsed since the last change was applied. | |
|
| The string representation of the last change recovered from the history store. | |
|
| The string representation of the last applied change. |
Chapter 9. Monitoring Debezium
You can use the JMX metrics provided by Apache Zookeeper, Apache Kafka, and Kafka Connect to monitor Debezium. To use these metrics, you must enable them when you start the Zookeeper, Kafka, and Kafka Connect services. Enabling JMX involves setting the correct environment variables.
If you are running multiple services on the same machine, be sure to use distinct JMX ports for each service.
9.1. Metrics for monitoring Debezium connectors
In addition to the built-in support for JMX metrics in Kafka, Zookeeper, and Kafka Connect, each connector provides additional metrics that you can use to monitor their activities.
9.2. Enabling JMX in local installations
With Zookeeper, Kafka, and Kafka Connect, you enable JMX by setting the appropriate environment variables when you start each service.
9.2.1. Zookeeper JMX environment variables
Zookeeper has built-in support for JMX. When running Zookeeper using a local installation, the zkServer.sh script recognizes the following environment variables:
JMXPORT-
Enables JMX and specifies the port number that will be used for JMX. The value is used to specify the JVM parameter
-Dcom.sun.management.jmxremote.port=$JMXPORT. JMXAUTH-
Whether JMX clients must use password authentication when connecting. Must be either
trueorfalse. The default isfalse. The value is used to specify the JVM parameter-Dcom.sun.management.jmxremote.authenticate=$JMXAUTH. JMXSSL-
Whether JMX clients connect using SSL/TLS. Must be either
trueorfalse. The default isfalse. The value is used to specify the JVM parameter-Dcom.sun.management.jmxremote.ssl=$JMXSSL. JMXLOG4J-
Whether the Log4J JMX MBeans should be disabled. Must be either
true(default) orfalse. The default istrue. The value is used to specify the JVM parameter-Dzookeeper.jmx.log4j.disable=$JMXLOG4J.
9.2.2. Kafka JMX environment variables
When running Kafka using a local installation, the kafka-server-start.sh script recognizes the following environment variables:
JMX_PORT-
Enables JMX and specifies the port number that will be used for JMX. The value is used to specify the JVM parameter
-Dcom.sun.management.jmxremote.port=$JMX_PORT. KAFKA_JMX_OPTSThe JMX options, which are passed directly to the JVM during startup. The default options are:
-
-Dcom.sun.management.jmxremote -
-Dcom.sun.management.jmxremote.authenticate=false -
-Dcom.sun.management.jmxremote.ssl=false
-
9.2.3. Kafka Connect JMX environment variables
When running Kafka using a local installation, the connect-distributed.sh script recognizes the following environment variables:
JMX_PORT-
Enables JMX and specifies the port number that will be used for JMX. The value is used to specify the JVM parameter
-Dcom.sun.management.jmxremote.port=$JMX_PORT. KAFKA_JMX_OPTSThe JMX options, which are passed directly to the JVM during startup. The default options are:
-
-Dcom.sun.management.jmxremote -
-Dcom.sun.management.jmxremote.authenticate=false -
-Dcom.sun.management.jmxremote.ssl=false
-
9.3. Monitoring Debezium on OpenShift
If you are using Debezium on OpenShift, you can obtain JMX metrics by opening a JMX port on 9999. For more information, see JMX Options in Using AMQ Streams on OpenShift.
In addition, you can use Prometheus and Grafana to monitor the JMX metrics. For more information, see Introducing Metrics to Kafka, in Deploying and Upgrading AMQ Streams on OpenShift.
Chapter 10. Debezium logging
Debezium has extensive logging built into its connectors, and you can change the logging configuration to control which of these log statements appear in the logs and where those logs are sent. Debezium (as well as Kafka, Kafka Connect, and Zookeeper) use the Log4j logging framework for Java.
By default, the connectors produce a fair amount of useful information when they start up, but then produce very few logs when the connector is keeping up with the source databases. This is often sufficient when the connector is operating normally, but may not be enough when the connector is behaving unexpectedly. In such cases, you can change the logging level so that the connector generates much more verbose log messages describing what the connector is doing and what it is not doing.
10.1. Debezium logging concepts
Before configuring logging, you should understand what Log4J loggers, log levels, and appenders are.
Loggers
Each log message produced by the application is sent to a specific logger (for example, io.debezium.connector.mysql). Loggers are arranged in hierarchies. For example, the io.debezium.connector.mysql logger is the child of the io.debezium.connector logger, which is the child of the io.debezium logger. At the top of the hierarchy, the root logger defines the default logger configuration for all of the loggers beneath it.
Log levels
Every log message produced by the application also has a specific log level:
-
ERROR- errors, exceptions, and other significant problems -
WARN- potential problems and issues -
INFO- status and general activity (usually low-volume) -
DEBUG- more detailed activity that would be useful in diagnosing unexpected behavior -
TRACE- very verbose and detailed activity (usually very high-volume)
Appenders
An appender is essentially a destination where log messages are written. Each appender controls the format of its log messages, giving you even more control over what the log messages look like.
To configure logging, you specify the desired level for each logger and the appender(s) where those log messages should be written. Since loggers are hierarchical, the configuration for the root logger serves as a default for all of the loggers below it, although you can override any child (or descendant) logger.
10.2. Default Debezium logging configuration
If you are running Debezium connectors in a Kafka Connect process, then Kafka Connect uses the Log4j configuration file (for example, /opt/kafka/config/connect-log4j.properties) in the Kafka installation. By default, this file contains the following configuration:
connect-log4j.properties
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=[%d] %p %m (%c)%n
...- 1 1
- The root logger, which defines the default logger configuration. By default, loggers include
INFO,WARN, andERRORmessages. These log messages are written to thestdoutappender. - 2 2
- The
stdoutappender writes log messages to the console (as opposed to a file). - 3 3
- The
stdoutappender uses a pattern matching algorithm to format the log messages. - 4 4
- The pattern for the
stdoutappender (see the Log4j documentation for details).
Unless you configure other loggers, all of the loggers that Debezium uses inherit the rootLogger configuration.
10.3. Configuring Debezium logging
By default, Debezium connectors write all INFO, WARN, and ERROR messages to the console. You can change the default logging configuration by using one of the following methods:
There are other methods that you can use to configure Debezium logging with Log4j. For more information, search for tutorials about setting up and using appenders to send log messages to specific destinations.
10.3.1. Changing the Debezium logging level by configuring loggers
The default Debezium logging level provides sufficient information to show whether a connector is healthy or not. However, if a connector is not healthy, you can change its logging level to troubleshoot the issue.
In general, Debezium connectors send their log messages to loggers with names that match the fully-qualified name of the Java class that is generating the log message. Debezium uses packages to organize code with similar or related functions. This means that you can control all of the log messages for a specific class or for all of the classes within or under a specific package.
Procedure
-
Open the
log4j.propertiesfile. Configure a logger for the connector.
This example configures loggers for the MySQL connector and the database history implementation used by the connector, and sets them to log
DEBUGlevel messages:log4j.properties
... log4j.logger.io.debezium.connector.mysql=DEBUG, stdout1 log4j.logger.io.debezium.relational.history=DEBUG, stdout2 log4j.additivity.io.debezium.connector.mysql=false3 log4j.additivity.io.debezium.relational.history=false4 ...- 1
- Configures the logger named
io.debezium.connector.mysqlto sendDEBUG,INFO,WARN, andERRORmessages to thestdoutappender. - 2
- Configures the logger named
io.debezium.relational.historyto sendDEBUG,INFO,WARN, andERRORmessages to thestdoutappender. - 3 4
- Turns off additivity, which results in log messages not being sent to the appenders of parent loggers (this can prevent seeing duplicate log messages when using multiple appenders).
If necessary, change the logging level for a specific subset of the classes within the connector.
Increasing the logging level for the entire connector increases the log verbosity, which can make it difficult to understand what is happening. In these cases, you can change the logging level just for the subset of classes that are related to the issue that you are troubleshooting.
-
Set the connector’s logging level to either
DEBUGorTRACE. Review the connector’s log messages.
Find the log messages that are related to the issue that you are troubleshooting. The end of each log message shows the name of the Java class that produced the message.
-
Set the connector’s logging level back to
INFO. Configure a logger for each Java class that you identified.
For example, consider a scenario in which you are unsure why the MySQL connector is skipping some events when it is processing the binlog. Rather than turn on
DEBUGorTRACElogging for the entire connector, you can keep the connector’s logging level atINFOand then configureDEBUGorTRACEon just the class that is reading the binlog:log4j.properties
... log4j.logger.io.debezium.connector.mysql=INFO, stdout log4j.logger.io.debezium.connector.mysql.BinlogReader=DEBUG, stdout log4j.logger.io.debezium.relational.history=INFO, stdout log4j.additivity.io.debezium.connector.mysql=false log4j.additivity.io.debezium.relational.history=false log4j.additivity.io.debezium.connector.mysql.BinlogReader=false ...
-
Set the connector’s logging level to either
10.3.2. Dynamically changing the Debezium logging level with the Kafka Connect API
You can use the Kafka Connect REST API to set logging levels for a connector dynamically at runtime. Unlike log level changes that you set in log4j.properties, changes that you make via the API take effect immediately, and do not require you to restart the worker.
The log level setting that you specify in the API applies only to the worker at the endpoint that receives the request. The log levels of other workers in the cluster remain unchanged.
The specified level is not persisted after the worker restarts. To make persistent changes to the logging level, set the log level in log4j.properties by configuring loggers or adding mapped diagnostic contexts.
Procedure
Set the log level by sending a PUT request to the
admin/loggersendpoint that specifies the following information:- The package for which you want to change the log level.
The log level that you want to set.
curl -s -X PUT -H "Content-Type:application/json" http://localhost:8083/admin/loggers/io.debezium.connector.<connector_package> -d '{"level": "<log_level>"}'For example, to log debug information for a Debezium MySQL connector, send the following request to Kafka Connect:
curl -s -X PUT -H "Content-Type:application/json" http://localhost:8083/admin/loggers/io.debezium.connector.mysql -d '{"level": "DEBUG"}'
10.3.3. Changing the Debezium logging levely by adding mapped diagnostic contexts
Most Debezium connectors (and the Kafka Connect workers) use multiple threads to perform different activities. This can make it difficult to look at a log file and find only those log messages for a particular logical activity. To make the log messages easier to find, Debezium provides several mapped diagnostic contexts (MDC) that provide additional information for each thread.
Debezium provides the following MDC properties:
dbz.connectorType-
A short alias for the type of connector. For example,
MySql,Mongo,Postgres, and so on. All threads associated with the same type of connector use the same value, so you can use this to find all log messages produced by a given type of connector. dbz.connectorName-
The name of the connector or database server as defined in the connector’s configuration. For example
products,serverA, and so on. All threads associated with a specific connector instance use the same value, so you can find all of the log messages produced by a specific connector instance. dbz.connectorContext-
A short name for an activity running as a separate thread running within the connector’s task. For example,
main,binlog,snapshot, and so on. In some cases, when a connector assigns threads to specific resources (such as a table or collection), the name of that resource could be used instead. Each thread associated with a connector would use a distinct value, so you can find all of the log messages associated with this particular activity.
To enable MDC for a connector, you configure an appender in the log4j.properties file.
Procedure
-
Open the
log4j.propertiesfile. Configure an appender to use any of the supported Debezium MDC properties.
In the following example, the
stdoutappender is configured to use these MDC properties:log4j.properties
... log4j.appender.stdout.layout.ConversionPattern=%d{ISO8601} %-5p %X{dbz.connectorType}|%X{dbz.connectorName}|%X{dbz.connectorContext} %m [%c]%n ...The configuration in the preceding example produces log messages similar to the ones in the following output:
... 2017-02-07 20:49:37,692 INFO MySQL|dbserver1|snapshot Starting snapshot for jdbc:mysql://mysql:3306/?useInformationSchema=true&nullCatalogMeansCurrent=false&useSSL=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8&zeroDateTimeBehavior=convertToNull with user 'debezium' [io.debezium.connector.mysql.SnapshotReader] 2017-02-07 20:49:37,696 INFO MySQL|dbserver1|snapshot Snapshot is using user 'debezium' with these MySQL grants: [io.debezium.connector.mysql.SnapshotReader] 2017-02-07 20:49:37,697 INFO MySQL|dbserver1|snapshot GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'debezium'@'%' [io.debezium.connector.mysql.SnapshotReader] ...Each line in the log includes the connector type (for example,
MySQL), the name of the connector (for example,dbserver1), and the activity of the thread (for example,snapshot).
10.4. Debezium logging on OpenShift
If you are using Debezium on OpenShift, you can use the Kafka Connect loggers to configure the Debezium loggers and logging levels. For more information about configuring logging properties in a Kafka Connect schema, see Using AMQ Streams on OpenShift.
Chapter 11. Configuring Debezium connectors for your application
When the default Debezium connector behavior is not right for your application, you can use the following Debezium features to configure the behavior you need.
- Kafka Connect automatic topic creation
- Enables Connect to create topics at runtime, and apply configuration settings to those topics based on their names.
- Avro serialization
- Support for configuring Debezium PostgreSQL, MongoDB, or SQL Server connectors to use Avro to serialize message keys and value, making it easier for change event record consumers to adapt to a changing record schema.
- CloudEvents converter
- Enables a Debezium connector to emit change event records that conform to the CloudEvents specification.
- Sending signals to a Debezium connector
- Provides a way to modify the behavior of a connector, or trigger an action, such as initiating an ad hoc snapshot.
11.1. Customization of Kafka Connect automatic topic creation
Kafka provides two mechanisms for creating topics automatically. You can enable automatic topic creation for the Kafka broker, and, beginning with Kafka 2.6.0, you can also enable Kafka Connect to create topics. The Kafka broker uses the auto.create.topics.enable property to control automatic topic creation. In Kafka Connect, the topic.creation.enable property specifies whether Kafka Connect is permitted to create topics. In both cases, the default settings for the properties enables automatic topic creation.
When automatic topic creation is enabled, if a Debezium source connector emits a change event record for a table for which no target topic already exists, the topic is created at runtime as the event record is ingested into Kafka.
Differences between automatic topic creation at the broker and in Kafka Connect
Topics that the broker creates are limited to sharing a single default configuration. The broker cannot apply unique configurations to different topics or sets of topics. By contrast, Kafka Connect can apply any of several configurations when creating topics, setting the replication factor, number of partitions, and other topic-specific settings as specified in the Debezium connector configuration. The connector configuration defines a set of topic creation groups, and associates a set of topic configuration properties with each group.
The broker configuration and the Kafka Connect configuration are independent of each other. Kafka Connect can create topics regardless of whether you disable topic creation at the broker. If you enable automatic topic creation at both the broker and in Kafka Connect, the Connect configuration takes precedence, and the broker creates topics only if none of the settings in the Kafka Connect configuration apply.
See the following topics for more information:
- Section 11.1.1, “Disabling automatic topic creation for the Kafka broker”
- Section 11.1.2, “Configuring automatic topic creation in Kafka Connect”
- Section 11.1.3, “Configuration of automatically created topics”
- Section 11.1.3.1, “Topic creation groups”
- Section 11.1.3.2, “Topic creation group configuration properties”
- Section 11.1.3.3, “Specifying the configuration for the Debezium default topic creation group”
- Section 11.1.3.4, “Specifying the configuration for Debezium custom topic creation groups”
- Section 11.1.3.5, “Registering Debezium custom topic creation groups”
11.1.1. Disabling automatic topic creation for the Kafka broker
By default, the Kafka broker configuration enables the broker to create topics at runtime if the topics do not already exist. Topics created by the broker cannot be configured with custom properties. If you use a Kafka version earlier than 2.6.0, and you want to create topics with specific configurations, you must to disable automatic topic creation at the broker, and then explicitly create the topics, either manually, or through a custom deployment process.
Procedure
-
In the broker configuration, set the value of
auto.create.topics.enabletofalse.
11.1.2. Configuring automatic topic creation in Kafka Connect
Automatic topic creation in Kafka Connect is controlled by the topic.creation.enable property. The default value for the property is true, enabling automatic topic creation, as shown in the following example:
topic.creation.enable = true
The setting for the topic.creation.enable property applies to all workers in the Connect cluster.
Kafka Connect automatic topic creation requires you to define the configuration properties that Kafka Connect applies when creating topics. You specify topic configuration properties in the Debezium connector configuration by defining topic groups, and then specifying the properties to apply to each group. The connector configuration defines a default topic creation group, and, optionally, one or more custom topic creation groups. Custom topic creation groups use lists of topic name patterns to specify the topics to which the group’s settings apply.
For details about how Kafka Connect matches topics to topic creation groups, see Topic creation groups. For more information about how configuration properties are assigned to groups, see Topic creation group configuration properties.
By default, topics that Kafka Connect creates are named based on the pattern server.schema.table, for example, dbserver.myschema.inventory.
Procedure
-
To prevent Kafka Connect from creating topics automatically, set the value of
topic.creation.enabletofalsein the Kafka Connect custom resource, as in the following example:
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-connect-cluster
...
spec:
config:
topic.creation.enable: "false"
Kafka Connect automatic topic creation requires the replication.factor and partitions properties to be set for at least the default topic creation group. It is valid for groups to obtain the values for the required properties from the default values for the Kafka broker.
11.1.3. Configuration of automatically created topics
For Kafka Connect to create topics automatically, it requires information from the source connector about the configuration properties to apply when creating topics. You define the properties that control topic creation in the configuration for each Debezium connector. As Kafka Connect creates topics for event records that a connector emits, the resulting topics obtain their configuration from the applicable group. The configuration applies to event records emitted by that connector only.
11.1.3.1. Topic creation groups
A set of topic properties is associated with a topic creation group. Minimally, you must define a default topic creation group and specify its configuration properties. Beyond that you can optionally define one or more custom topic creation groups and specify unique properties for each.
When you create custom topic creation groups, you define the member topics for each group based on topic name patterns. You can specify naming patterns that describe the topics to include or exclude from each group. The include and exclude properties contain comma-separated lists of regular expressions that define topic name patterns. For example, if you want a group to include all topics that start with the string dbserver1.inventory, set the value of its topic.creation.inventory.include property to dbserver1\\.inventory\\.*.
If you specify both include and exclude properties for a custom topic group, the exclusion rules take precedence, and override the inclusion rules.
11.1.3.2. Topic creation group configuration properties
The default topic creation group and each custom group is associated with a unique set of configuration properties. You can configure a group to include any of the Kafka topic-level configuration properties. For example, you can specify the cleanup policy for old topic segments, retention time, or the topic compression type for a topic group. You must define at least a minimum set of properties to describe the configuration of the topics to be created.
If no custom groups are registered, or if the include patterns for any registered groups don’t match the names of any topics to be created, then Kafka Connect uses the configuration of the default group to create topics.
For general information about configuring topics, see Kafka topic creation recommendations in Installing Debezium on OpenShift.
11.1.3.3. Specifying the configuration for the Debezium default topic creation group
Before you can use Kafka Connect automatic topic creation, you must create a default topic creation group and define a configuration for it. The configuration for the default topic creation group is applied to any topics with names that do not match the include list pattern of a custom topic creation group.
Prerequisites
In the Kafka Connect custom resource, the
use-connector-resourcesvalue inmetadata.annotationsspecifies that the cluster Operator uses KafkaConnector custom resources to configure connectors in the cluster. For example:... metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true" ...
Procedure
To define properties for the
topic.creation.defaultgroup, add them tospec.configin the connector custom resource, as shown in the following example:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnector metadata: name: inventory-connector labels: strimzi.io/cluster: my-connect-cluster spec: ... config: ... topic.creation.default.replication.factor: 31 topic.creation.default.partitions: 102 topic.creation.default.cleanup.policy: compact3 topic.creation.default.compression.type: lz44 ...You can include any Kafka topic-level configuration property in the configuration for the
defaultgroup.
| Item | Description |
|---|---|
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
Custom groups fall back to the default group settings only for the required replication.factor and partitions properties. If the configuration for a custom topic group leaves other properties undefined, the values specified in the default group are not applied.
11.1.3.4. Specifying the configuration for Debezium custom topic creation groups
You can define multiple custom topic groups, each with its own configuration.
Procedure
To define a custom topic group, add a
topic.creation.<group_name>.includeproperty tospec.configin the connector custom resource, followed by the configuration properties that you want to apply to topics in the custom group.The following example shows an excerpt of a custom resource that defines the custom topic creation groups
inventoryandapplicationlogs:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnector metadata: name: inventory-connector ... spec: ... config: ...1 topic.creation.inventory.include: dbserver1\\.inventory\\.*2 topic.creation.inventory.partitions: 20 topic.creation.inventory.cleanup.policy: compact topic.creation.inventory.delete.retention.ms: 77760000003 topic.creation.applicationlogs.include: dbserver1\\.logs\\.applog-.*4 topic.creation.applicationlogs.exclude": dbserver1\\.logs\\.applog-old-.*5 topic.creation.applicationlogs.replication.factor: 1 topic.creation.applicationlogs.partitions: 20 topic.creation.applicationlogs.cleanup.policy: delete topic.creation.applicationlogs.retention.ms: 7776000000 topic.creation.applicationlogs.compression.type: lz4 ... ...
| Item | Description |
|---|---|
| 1 |
Defines the configuration for the |
| 2 |
|
| 3 |
Defines the configuration for the |
| 4 |
|
| 5 |
|
11.1.3.5. Registering Debezium custom topic creation groups
After you specify the configuration for any custom topic creation groups, register the groups.
Procedure
Register custom groups by adding the
topic.creation.groupsproperty to the connector custom resource, and specifying a comma-separated list of custom topic creation groups.The following excerpt from a connector custom resource registers the custom topic creation groups
inventoryandapplicationlogs:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnector metadata: name: inventory-connector ... spec: ... config: topic.creation.groups: inventory,applicationlogs ...
Completed configuration
The following example shows a completed configuration that includes the configuration for a default topic group, along with the configurations for an inventory and an applicationlogs custom topic creation group:
Example: Configuration for a default topic creation group and two custom groups
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnector
metadata:
name: inventory-connector
...
spec:
...
config:
...
topic.creation.default.replication.factor: 3,
topic.creation.default.partitions: 10,
topic.creation.default.cleanup.policy: compact
topic.creation.default.compression.type: lz4
topic.creation.groups: inventory,applicationlogs
topic.creation.inventory.include: dbserver1\\.inventory\\.*
topic.creation.inventory.partitions: 20
topic.creation.inventory.cleanup.policy: compact
topic.creation.inventory.delete.retention.ms: 7776000000
topic.creation.applicationlogs.include: dbserver1\\.logs\\.applog-.*
topic.creation.applicationlogs.exclude": dbserver1\\.logs\\.applog-old-.*
topic.creation.applicationlogs.replication.factor: 1
topic.creation.applicationlogs.partitions: 20
topic.creation.applicationlogs.cleanup.policy: delete
topic.creation.applicationlogs.retention.ms: 7776000000
topic.creation.applicationlogs.compression.type: lz4
...11.2. Configuring Debezium connectors to use Avro serialization
A Debezium connector works in the Kafka Connect framework to capture each row-level change in a database by generating a change event record. For each change event record, the Debezium connector completes the following actions:
- Applies configured transformations.
- Serializes the record key and value into a binary form by using the configured Kafka Connect converters.
- Writes the record to the correct Kafka topic.
You can specify converters for each individual Debezium connector instance. Kafka Connect provides a JSON converter that serializes the record keys and values into JSON documents. The default behavior is that the JSON converter includes the record’s message schema, which makes each record very verbose. The Getting Started with Debezium guide shows what the records look like when both payload and schemas are included. If you want records to be serialized with JSON, consider setting the following connector configuration properties to false:
-
key.converter.schemas.enable -
value.converter.schemas.enable
Setting these properties to false excludes the verbose schema information from each record.
Alternatively, you can serialize the record keys and values by using Apache Avro. The Avro binary format is compact and efficient. Avro schemas make it possible to ensure that each record has the correct structure. Avro’s schema evolution mechanism enables schemas to evolve. This is essential for Debezium connectors, which dynamically generate each record’s schema to match the structure of the database table that was changed. Over time, change event records written to the same Kafka topic might have different versions of the same schema. Avro serialization makes it easier for the consumers of change event records to adapt to a changing record schema.
To use Apache Avro serialization, you must deploy a schema registry that manages Avro message schemas and their versions. For information about setting up this registry, see the Red Hat Integration - Service Registry documentation.
11.2.1. About the Service Registry
Red Hat Integration - Service Registry provides the following components that work with Avro:
- An Avro converter that you can specify in Debezium connector configurations. This converter maps Kafka Connect schemas to Avro schemas. The converter then uses the Avro schemas to serialize the record keys and values into Avro’s compact binary form.
An API and schema registry that tracks:
- Avro schemas that are used in Kafka topics.
- Where the Avro converter sends the generated Avro schemas.
Because the Avro schemas are stored in this registry, each record needs to contain only a tiny schema identifier. This makes each record even smaller. For an I/O bound system like Kafka, this means more total throughput for producers and consumers.
- Avro Serdes (serializers and deserializers) for Kafka producers and consumers. Kafka consumer applications that you write to consume change event records can use Avro Serdes to deserialize the change event records.
To use the Service Registry with Debezium, add Service Registry converters and their dependencies to the Kafka Connect container image that you are using for running a Debezium connector.
The Service Registry project also provides a JSON converter. This converter combines the advantage of less verbose messages with human-readable JSON. Messages do not contain the schema information themselves, but only a schema ID.
To use converters provided by Service Registry you need to provide apicurio.registry.url.
11.2.2. Overview of deploying a Debezium connector that uses Avro serialization
To deploy a Debezium connector that uses Avro serialization, you must complete three main tasks:
- Deploy a Red Hat Integration - Service Registry instance by following the instructions in Installing and deploying Service Registry on OpenShift.
- Install the Avro converter by downloading the Debezium Service Registry Kafka Connect zip file and extracting it into the Debezium connector’s directory.
Configure a Debezium connector instance to use Avro serialization by setting configuration properties as follows:
key.converter=io.apicurio.registry.utils.converter.AvroConverter key.converter.apicurio.registry.url=http://apicurio:8080/apis/registry/v2 key.converter.apicurio.registry.auto-register=true key.converter.apicurio.registry.find-latest=true value.converter=io.apicurio.registry.utils.converter.AvroConverter value.converter.apicurio.registry.url=http://apicurio:8080/apis/registry/v2 value.converter.apicurio.registry.auto-register=true value.converter.apicurio.registry.find-latest=true
Internally, Kafka Connect always uses JSON key/value converters for storing configuration and offsets.
11.2.3. Deploying connectors that use Avro in Debezium containers
In your environment, you might want to use a provided Debezium container to deploy Debezium connectors that use Avro serialization. Complete the following procedure to build a custom Kafka Connect container image for Debezium, and configure the Debezium connector to use the Avro converter.
Prerequisites
- You have Docker installed and sufficient rights to create and manage containers.
- You downloaded the Debezium connector plug-in(s) that you want to deploy with Avro serialization.
Procedure
Deploy an instance of Service Registry. See Installing and deploying Service Registry on OpenShift, which provides instructions for:
- Installing Service Registry
- Installing AMQ Streams
- Setting up AMQ Streams storage
Extract the Debezium connector archives to create a directory structure for the connector plug-ins. If you downloaded and extracted the archives for multiple Debezium connectors, the resulting directory structure looks like the one in the following example:
tree ./my-plugins/ ./my-plugins/ ├── debezium-connector-mongodb | ├── ... ├── debezium-connector-mysql │ ├── ... ├── debezium-connector-postgres │ ├── ... └── debezium-connector-sqlserver ├── ...Add the Avro converter to the directory that contains the Debezium connector that you want to configure to use Avro serialization:
- Go to the Red Hat Integration download site and download the Service Registry Kafka Connect zip file.
- Extract the archive into the desired Debezium connector directory.
To configure more than one type of Debezium connector to use Avro serialization, extract the archive into the directory for each relevant connector type. Although extracting the archive to each directory duplicates the files, by doing so you remove the possibility of conflicting dependencies.
Create and publish a custom image for running Debezium connectors that are configured to use the Avro converter:
Create a new
Dockerfileby usingregistry.redhat.io/amq7/amq-streams-kafka-30-rhel8:2.0.0as the base image. In the following example, replace my-plugins with the name of your plug-ins directory:FROM registry.redhat.io/amq7/amq-streams-kafka-30-rhel8:2.0.0 USER root:root COPY ./my-plugins/ /opt/kafka/plugins/ USER 1001Before Kafka Connect starts running the connector, Kafka Connect loads any third-party plug-ins that are in the
/opt/kafka/pluginsdirectory.Build the docker container image. For example, if you saved the docker file that you created in the previous step as
debezium-container-with-avro, then you would run the following command:docker build -t debezium-container-with-avro:latestPush your custom image to your container registry, for example:
docker push <myregistry.io>/debezium-container-with-avro:latestPoint to the new container image. Do one of the following:
Edit the
KafkaConnect.spec.imageproperty of theKafkaConnectcustom resource. If set, this property overrides theSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGEvariable in the Cluster Operator. For example:apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster spec: #... image: debezium-container-with-avro-
In the
install/cluster-operator/050-Deployment-strimzi-cluster-operator.yamlfile, edit theSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGEvariable to point to the new container image and reinstall the Cluster Operator. If you edit this file you will need to apply it to your OpenShift cluster.
Deploy each Debezium connector that is configured to use the Avro converter. For each Debezium connector:
Create a Debezium connector instance. The following
inventory-connector.yamlfile example creates aKafkaConnectorcustom resource that defines a MySQL connector instance that is configured to use the Avro converter:apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnector metadata: name: inventory-connector labels: strimzi.io/cluster: my-connect-cluster spec: class: io.debezium.connector.mysql.MySqlConnector tasksMax: 1 config: database.hostname: mysql database.port: 3306 database.user: debezium database.password: dbz database.server.id: 184054 database.server.name: dbserver1 database.include.list: inventory database.history.kafka.bootstrap.servers: my-cluster-kafka-bootstrap:9092 database.history.kafka.topic: schema-changes.inventory key.converter: io.apicurio.registry.utils.converter.AvroConverter key.converter.apicurio.registry.url: http://apicurio:8080/api key.converter.apicurio.registry.global-id: io.apicurio.registry.utils.serde.strategy.GetOrCreateIdStrategy value.converter: io.apicurio.registry.utils.converter.AvroConverter value.converter.apicurio.registry.url: http://apicurio:8080/api value.converter.apicurio.registry.global-id: io.apicurio.registry.utils.serde.strategy.GetOrCreateIdStrategyApply the connector instance, for example:
oc apply -f inventory-connector.yamlThis registers
inventory-connectorand the connector starts to run against theinventorydatabase.
Verify that the connector was created and has started to track changes in the specified database. You can verify the connector instance by watching the Kafka Connect log output as, for example,
inventory-connectorstarts.Display the Kafka Connect log output:
oc logs $(oc get pods -o name -l strimzi.io/name=my-connect-cluster-connect)Review the log output to verify that the initial snapshot has been executed. You should see something like the following lines:
... 2020-02-21 17:57:30,801 INFO Starting snapshot for jdbc:mysql://mysql:3306/?useInformationSchema=true&nullCatalogMeansCurrent=false&useSSL=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8&zeroDateTimeBehavior=CONVERT_TO_NULL&connectTimeout=30000 with user 'debezium' with locking mode 'minimal' (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] 2020-02-21 17:57:30,805 INFO Snapshot is using user 'debezium' with these MySQL grants: (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] ...Taking the snapshot involves a number of steps:
... 2020-02-21 17:57:30,822 INFO Step 0: disabling autocommit, enabling repeatable read transactions, and setting lock wait timeout to 10 (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] 2020-02-21 17:57:30,836 INFO Step 1: flush and obtain global read lock to prevent writes to database (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] 2020-02-21 17:57:30,839 INFO Step 2: start transaction with consistent snapshot (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] 2020-02-21 17:57:30,840 INFO Step 3: read binlog position of MySQL primary server (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] 2020-02-21 17:57:30,843 INFO using binlog 'mysql-bin.000003' at position '154' and gtid '' (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] ... 2020-02-21 17:57:34,423 INFO Step 9: committing transaction (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] 2020-02-21 17:57:34,424 INFO Completed snapshot in 00:00:03.632 (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] ...After completing the snapshot, Debezium begins tracking changes in, for example, the
inventorydatabase’sbinlogfor change events:... 2020-02-21 17:57:35,584 INFO Transitioning from the snapshot reader to the binlog reader (io.debezium.connector.mysql.ChainedReader) [task-thread-inventory-connector-0] 2020-02-21 17:57:35,613 INFO Creating thread debezium-mysqlconnector-dbserver1-binlog-client (io.debezium.util.Threads) [task-thread-inventory-connector-0] 2020-02-21 17:57:35,630 INFO Creating thread debezium-mysqlconnector-dbserver1-binlog-client (io.debezium.util.Threads) [blc-mysql:3306] Feb 21, 2020 5:57:35 PM com.github.shyiko.mysql.binlog.BinaryLogClient connect INFO: Connected to mysql:3306 at mysql-bin.000003/154 (sid:184054, cid:5) 2020-02-21 17:57:35,775 INFO Connected to MySQL binlog at mysql:3306, starting at binlog file 'mysql-bin.000003', pos=154, skipping 0 events plus 0 rows (io.debezium.connector.mysql.BinlogReader) [blc-mysql:3306] ...
11.2.4. About Avro name requirements
As stated in the Avro documentation, names must adhere to the following rules:
-
Start with
[A-Za-z_] -
Subsequently contains only
[A-Za-z0-9_]characters
Debezium uses the column’s name as the basis for the corresponding Avro field. This can lead to problems during serialization if the column name does not also adhere to the Avro naming rules. Each Debezium connector provides a configuration property, sanitize.field.names that you can set to true if you have columns that do not adhere to Avro rules for names. Setting sanitize.field.names to true allows serialization of non-conformant fields without having to actually modify your schema.
11.3. Emitting Debezium change event records in CloudEvents format
CloudEvents is a specification for describing event data in a common way. Its aim is to provide interoperability across services, platforms and systems. Debezium enables you to configure a MongoDB, MySQL, PostgreSQL, or SQL Server connector to emit change event records that conform to the CloudEvents specification.
Emitting change event records in CloudEvents format is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service-level agreements (SLAs) and might not be functionally complete; therefore, Red Hat does not recommend implementing any Technology Preview features in production environments. This Technology Preview feature provides early access to upcoming product innovations, enabling you to test functionality and provide feedback during the development process. For more information about support scope, see Technology Preview Features Support Scope.
The CloudEvents specification defines:
- A set of standardized event attributes
- Rules for defining custom attributes
- Encoding rules for mapping event formats to serialized representations such as JSON or Avro
- Protocol bindings for transport layers such as Apache Kafka, HTTP or AMQP
To configure a Debezium connector to emit change event records that conform to the CloudEvents specification, Debezium provides the io.debezium.converters.CloudEventsConverter, which is a Kafka Connect message converter.
Currently, only structured mapping mode is supported. The CloudEvents change event envelope can be JSON or Avro and each envelope type supports JSON or Avro as the data format. It is expected that a future Debezium release will support binary mapping mode.
Information about emitting change events in CloudEvents format is organized as follows:
For information about using Avro, see:
11.3.1. Example Debezium change event records in CloudEvents format
The following example shows what a CloudEvents change event record emitted by a PostgreSQL connector looks like. In this example, the PostgreSQL connector is configured to use JSON as the CloudEvents format envelope and also as the data format.
{
"id" : "name:test_server;lsn:29274832;txId:565",
"source" : "/debezium/postgresql/test_server",
"specversion" : "1.0",
"type" : "io.debezium.postgresql.datachangeevent",
"time" : "2020-01-13T13:55:39.738Z",
"datacontenttype" : "application/json",
"iodebeziumop" : "r",
"iodebeziumversion" : "1.7.2.Final",
"iodebeziumconnector" : "postgresql",
"iodebeziumname" : "test_server",
"iodebeziumtsms" : "1578923739738",
"iodebeziumsnapshot" : "true",
"iodebeziumdb" : "postgres",
"iodebeziumschema" : "s1",
"iodebeziumtable" : "a",
"iodebeziumtxId" : "565",
"iodebeziumlsn" : "29274832",
"iodebeziumxmin" : null,
"iodebeziumtxid": "565",
"iodebeziumtxtotalorder": "1",
"iodebeziumtxdatacollectionorder": "1",
"data" : {
"before" : null,
"after" : {
"pk" : 1,
"name" : "Bob"
}
}
}- 1 1 1
- Unique ID that the connector generates for the change event based on the change event’s content.
- 2 2 2
- The source of the event, which is the logical name of the database as specified by the
database.server.nameproperty in the connector’s configuration. - 3 3 3
- The CloudEvents specification version.
- 4 4 4
- Connector type that generated the change event. The format of this field is
io.debezium.CONNECTOR_TYPE.datachangeevent. The value ofCONNECTOR_TYPEismongodb,mysql,postgresql, orsqlserver. - 5 5
- Time of the change in the source database.
- 6
- Describes the content type of the
dataattribute, which is JSON in this example. The only alternative is Avro. - 7
- An operation identifier. Possible values are
rfor read,cfor create,ufor update, ordfor delete. - 8
- All
sourceattributes that are known from Debezium change events are mapped to CloudEvents extension attributes by using theiodebeziumprefix for the attribute name. - 9
- When enabled in the connector, each
transactionattribute that is known from Debezium change events is mapped to a CloudEvents extension attribute by using theiodebeziumtxprefix for the attribute name. - 10
- The actual data change itself. Depending on the operation and the connector, the data might contain
before,afterand/orpatchfields.
The following example also shows what a CloudEvents change event record emitted by a PostgreSQL connector looks like. In this example, the PostgreSQL connector is again configured to use JSON as the CloudEvents format envelope, but this time the connector is configured to use Avro for the data format.
{
"id" : "name:test_server;lsn:33227720;txId:578",
"source" : "/debezium/postgresql/test_server",
"specversion" : "1.0",
"type" : "io.debezium.postgresql.datachangeevent",
"time" : "2020-01-13T14:04:18.597Z",
"datacontenttype" : "application/avro",
"dataschema" : "http://my-registry/schemas/ids/1",
"iodebeziumop" : "r",
"iodebeziumversion" : "1.7.2.Final",
"iodebeziumconnector" : "postgresql",
"iodebeziumname" : "test_server",
"iodebeziumtsms" : "1578924258597",
"iodebeziumsnapshot" : "true",
"iodebeziumdb" : "postgres",
"iodebeziumschema" : "s1",
"iodebeziumtable" : "a",
"iodebeziumtxId" : "578",
"iodebeziumlsn" : "33227720",
"iodebeziumxmin" : null,
"iodebeziumtxid": "578",
"iodebeziumtxtotalorder": "1",
"iodebeziumtxdatacollectionorder": "1",
"data" : "AAAAAAEAAgICAg=="
}
It is also possible to use Avro for the envelope as well as the data attribute.
11.3.2. Example of configuring Debezium CloudEvents converter
Configure io.debezium.converters.CloudEventsConverter in your Debezium connector configuration. The following example shows how to configure the CloudEvents converter to emit change event records that have the following characteristics:
- Use JSON as the envelope.
-
Use the schema registry at
http://my-registry/schemas/ids/1to serialize thedataattribute as binary Avro data.
...
"value.converter": "io.debezium.converters.CloudEventsConverter",
"value.converter.serializer.type" : "json",
"value.converter.data.serializer.type" : "avro",
"value.converter.avro.schema.registry.url": "http://my-registry/schemas/ids/1"
...- 1
- Specifying the
serializer.typeis optional, becausejsonis the default.
The CloudEvents converter converts Kafka record values. In the same connector configuration, you can specify key.converter if you want to operate on record keys. For example, you might specify StringConverter, LongConverter, JsonConverter, or AvroConverter.
11.3.3. Debezium CloudEvents converter configuration options
When you configure a Debezium connector to use the CloudEvent converter you can specify the following options.
| Option | Default | Description |
|
|
The encoding type to use for the CloudEvents envelope structure. The value can be | |
|
|
The encoding type to use for the | |
| N/A |
Any configuration options to be passed through to the underlying converter when using JSON. The | |
| N/A |
Any configuration options to be passed through to the underlying converter when using Avro. The |
11.4. Sending signals to a Debezium connector
Signaling is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service-level agreements (SLAs) and might not be functionally complete; therefore, Red Hat does not recommend implementing any Technology Preview features in production environments. This Technology Preview feature provides early access to upcoming product innovations, enabling you to test functionality and provide feedback during the development process. For more information about support scope, see Technology Preview Features Support Scope.
The Debezium signaling mechanism provides a way to modify the behavior of a connector, or to trigger a one-time action, such as initiating an ad hoc snapshot of a table. To trigger a connector to perform a specified action, you issue a SQL command to add a signal message to a specialized signaling table, also referred to as a signaling data collection. The signaling table, which you create on the source database, is designated exclusively for communicating with Debezium. When Debezium detects that a new logging record or ad hoc snapshot record is added to the signaling table, it reads the signal, and initiates the requested operation.
Signaling is available for use with the following Debezium connectors:
- Db2
- MySQL
- Oracle
- PostgreSQL
- SQL Server
11.4.1. Enabling Debezium signaling
By default, the Debezium signaling mechanism is disabled. You must explicitly enable signaling for each connector that you want to use it with.
Procedure
- On the source database, create a signaling data collection table for sending signals to the connector. For information about the required structure of the signaling data collection, see Structure of a signaling data collection.
- For source databases such as Db2 or SQL Server that implement a native change data capture (CDC) mechanism, enable CDC for the signaling table.
Add the name of the signaling data collection to the Debezium connector configuration.
In the connector configuration, add the propertysignal.data.collection, and set its value to the fully-qualified name of the signaling data collection that you created in Step 1.
For example,signal.data.collection = inventory.debezium_signals.
The format for the fully-qualified name of the signaling collection depends on the connector.
The following example shows the naming formats to use for each connector:- Db2
-
<schemaName>.<tableName> - MySQL
-
<databaseName>.<tableName> - PostgreSQL
-
<schemaName>.<tableName> - SQL Server
-
<databaseName>.<schemaName>.<tableName>
For more information about setting thesignal.data.collectionproperty, see the table of configuration properties for your connector.
-
Add the signaling table to the list of tables to monitor.
In the configuration for the Debezium connector, add the name of the data collection that you created in Step 1 to thetable.include.listproperty.
For more information about thetable.include.listproperty, see the table of configuration properties for your connector.
11.4.1.1. Required structure of a Debezium signaling data collection
A signaling data collection, or signaling table, stores signals that you send to a connector to trigger a specified operation. The structure of the signaling table must conform to the following standard format.
- Contains three fields (columns).
- Fields are arranged in a specific order, as shown in Table 1.
| Field | Type | Description |
|---|---|---|
|
|
|
An arbitrary unique string that identifies a signal instance. |
|
|
|
Specifies the type of signal to send. |
|
|
|
Specifies JSON-formatted parameters to pass to a signal action. |
The field names in a data collection are arbitrary. The preceding table provides suggested names. If you use a different naming convention, ensure that the values in each field are consistent with the expected content.
11.4.1.2. Creating a Debezium signaling data collection
You create a signaling table by submitting a standard SQL DDL query to the source database.
Prerequisites
- You have sufficient access privileges to create a table on the target database.
Procedure
-
Submit a SQL query to the source database to create a table that is consistent with the required structure, as shown in the following example:
CREATE TABLE <tableName> (id VARCHAR(<varcharValue>) PRIMARY KEY, type VARCHAR(<varcharValue>) NOT NULL, data VARCHAR(<varcharValue>) NULL);
The amount of space that you allocate to the VARCHAR parameter of the id variable must be sufficient to accommodate the size of the ID strings of signals sent to the signaling table.
If the size of an ID exceeds the available space, the connector cannot process the signal.
The following example shows a CREATE TABLE command that creates a three-column debezium_signal table:
CREATE TABLE debezium_signal (id VARCHAR(42) PRIMARY KEY, type VARCHAR(32) NOT NULL, data VARCHAR(2048) NULL);11.4.2. Types of Debezium signal actions
You can use signaling to initiate the following actions:
Some signals are not compatible with all connectors.
11.4.2.1. Logging signals
You can request a connector to add an entry to the log by creating a signaling table entry with the log signal type. After processing the signal, the connector prints the specified message to the log. Optionally, you can configure the signal so that the resulting message includes the streaming coordinates.
| Column | Value | Description |
|---|---|---|
| id |
| |
| type |
| The action type of the signal. |
| data |
|
The |
11.4.2.2. Ad hoc snapshot signals
You can request a connector to initiate an ad hoc snapshot by creating a signaling table entry with the execute-snapshot signal type. After processing the signal, the connector runs the requested snapshot operation.
Unlike the initial snapshot that a connector runs after it first starts, an ad hoc snapshot occurs during runtime, after the connector has already begun to stream change events from a database. You can initiate ad hoc snapshots at any time.
Ad hoc snapshots are available for the following Debezium connectors:
- Db2
- MySQL
- PostgreSQL
- SQL Server
| Column | Value |
|---|---|
| id |
|
| type |
|
| data |
|
Currently, the execute-snapshot action triggers incremental snapshots only.
For more information about ad hoc snapshots, see the Snapshots topic in the documentation for your connector.
11.4.2.3. Incremental snapshots
Incremental snapshots are a specific type of ad hoc snapshot. In an incremental snapshot, the connector captures the baseline state of the tables that you specify, similar to an initial snapshot. However, unlike an initial snapshot, an incremental snapshot captures tables in chunks, rather than all at once. The connector uses a watermarking method to track the progress of the snapshot.
By capturing the initial state of the specified tables in chunks rather than in a single monolithic operation, incremental snapshots provide the following advantages over the initial snapshot process:
- While the connector captures the baseline state of the specified tables, streaming of near real-time events from the transaction log continues uninterrupted.
- If the incremental snapshot process is interrupted, it can be resumed from the point at which it stopped.
- You can initiate an incremental snapshot at any time.
For more information about incremental snapshots, see the Snapshots topic in the documentation for your connector.
Chapter 12. Applying transformations to modify messages exchanged with Apache Kafka
Debezium provides several single message transformations (SMTs) that you can use to modify change event records. You can configure a connector to apply a transformation that modifies records before its sends them to Apache Kafka. You can also apply the Debezium SMTs to a sink connector to modify records before the connector reads from a Kafka topic.
If you want to apply transformations selectively to specific messages only, you can configure a Kafka Connect predicate to define the conditions for applying the SMT.
Debezium provides the following SMTs:
- Topic router SMT
- Reroutes change event records to specific topics based on a regular expression that is applied to the original topic name.
- Content-based router SMT
- Reroutes specified change event records based on the event content.
- Message filtering SMT
- Enables you to propagate a subset of event records to the destination Kafka topic. The transformation applies a regular expression to the change event records that a connector emits, based on the content of the event record. Only records that match the expression are written to the target topic. Other records are ignored.
- New record state extraction SMT
- Flattens the complex structure of a Debezium change event record into a simplified format. The simplified structure enables processing by sink connectors that cannot consume the original structure.
- Outbox event router SMT
- Provides support for the outbox pattern to enable safe and reliable data exchange among multiple services.
- MongoDB outbox event router SMT
- Provides support for using the outbox pattern with the MongoDB connector to enable safe and reliable data exchange among multiple services.
12.1. Applying transformations selectively with SMT predicates
When you configure a single message transformation (SMT) for a connector, you can define a predicate for the transformation. The predicate specifies how to apply the transformation conditionally to a subset of the messages that the connector processes. You can assign predicates to transformations that you configure for source connectors, such as Debezium, or to sink connectors.
12.1.1. About SMT predicates
Debezium provides several single message transformations (SMTs) that you can use to modify event records before Kafka Connect saves the records to Kafka topics. By default, when you configure one of these SMTs for a Debezium connector, Kafka Connect applies that transformation to every record that the connector emits. However, there might be instances in which you want to apply a transformation selectively, so that it modifies only that subset of change event messages that share a common characteristic.
For example, for a Debezium connector, you might want to run the transformation only on event messages from a specific table or that include a specific header key. In environments that run Apache Kafka 2.6 or greater, you can append a predicate statement to a transformation to instruct Kafka Connect to apply the SMT only to certain records. In the predicate, you specify a condition that Kafka Connect uses to evaluate each message that it processes. When a Debezium connector emits a change event message, Kafka Connect checks the message against the configured predicate condition. If the condition is true for the event message, Kafka Connect applies the transformation, and then writes the message to a Kafka topic. Messages that do not match the condition are sent to Kafka unmodified.
The situation is similar for predicates that you define for a sink connector SMT. The connector reads messages from a Kafka topic and Kafka Connect evaluates the messages against the predicate condition. If a message matches the condition, Kafka Connect applies the transformation and then passes the messages to the sink connector.
After you define a predicate, you can reuse it and apply it to multiple transforms. Predicates also include a negate option that you can use to invert a predicate so that the predicate condition is applied only to records that do not match the condition that is defined in the predicate statement. You can use the negate option to pair the predicate with other transforms that are based on negating the condition.
Predicate elements
Predicates include the following elements:
-
predicatesprefix -
Alias (for example,
isOutboxTable) -
Type (for example,
org.apache.kafka.connect.transforms.predicates.TopicNameMatches). Kafka Connect provides a set of default predicate types, which you can supplement by defining your own custom predicates. - Condition statement and any additional configuration properties, depending on the type of predicate (for example, a regex naming pattern)
Default predicate types
The following predicate types are available by default:
- HasHeaderKey
- Specifies a key name in the header in the event message that you want Kafka Connect to evaluate. The predicate evaluates to true for any records that include a header key that has the specified name.
- RecordIsTombstone
Matches Kafka tombstone records. The predicate evaluates to
truefor any record that has anullvalue. Use this predicate in combination with a filter SMT to remove tombstone records. This predicate has no configuration parameters.A tombstone in Kafka is a record that has a key with a 0-byte,
nullpayload. When a Debezium connector processes a delete operation in the source database, the connector emits two change events for the delete operation:-
A delete operation (
"op" : "d") event that provides the previous value of the database record. A tombstone event that has the same key, but a
nullvalue.The tombstone represents a delete marker for the row. When log compaction is enabled for Kafka, during compaction Kafka removes all events that share the same key as the tombstone. Log compaction occurs periodically, with the compaction interval controlled by the
delete.retention.mssetting for the topic.Although it is possible to configure Debezium so that it does not emit tombstone events, it’s best to permit Debezium to emit tombstones to maintain the expected behavior during log compaction. Suppressing tombstones prevents Kafka from removing records for a deleted key during log compaction. If your environment includes sink connectors that cannot process tombstones, you can configure the sink connector to use an SMT with the
RecordIsTombstonepredicate to filter out the tombstone records.
-
A delete operation (
- TopicNameMatches
- A regular expression that specifies the name of a topic that you want Kafka Connect to match. The predicate is true for connector records in which the topic name matches the specified regular expression. Use this predicate to apply an SMT to records based on the name of the source table.
12.1.2. Defining SMT predicates
By default, Kafka Connect applies each single message transformation in the Debezium connector configuration to every change event record that it receives from Debezium. Beginning with Apache Kafka 2.6, you can define an SMT predicate for a transformation in the connector configuration that controls how Kafka Connect applies the transformation. The predicate statement defines the conditions under which Kafka Connect applies the transformation to event records emitted by Debezium. Kafka Connect evaluates the predicate statement and then applies the SMT selectively to the subset of records that match the condition that is defined in the predicate. Configuring Kafka Connect predicates is similar to configuring transforms. You specify a predicate alias, associate the alias with a transform, and then define the type and configuration for the predicate.
Prerequisites
- The Debezium environment runs Apache Kafka 2.6 or greater.
- An SMT is configured for the Debezium connector.
Procedure
-
In the Debezium connector configuration, specify a predicate alias for the
predicatesparameter, for example,IsOutboxTable. Associate the predicate alias with the transform that you want to apply conditionally, by appending the predicate alias to the transform alias in the connector configuration:
transforms.<TRANSFORM_ALIAS>.predicate=<PREDICATE_ALIAS>For example:
transforms.outbox.predicate=IsOutboxTableConfigure the predicate by specifying its type and providing values for configuration parameters.
For the type, specify one of the following default types that are available in Kafka Connect:
- HasHeaderKey
- RecordIsTombstone
TopicNameMatches
For example:
predicates.IsOutboxTable.type=org.apache.kafka.connect.predicates.TopicNameMatch
For the TopicNameMatch or
HasHeaderKeypredicates, specify a regular expression for the topic or header name that you want to match.For example:
predicates.IsOutboxTable.pattern=outbox.event.*
If you want to negate a condition, append the
negatekeyword to the transform alias and set it totrue.For example:
transforms.outbox.negate=trueThe preceding property inverts the set of records that the predicate matches, so that Kafka Connect applies the transform to any record that does not match the condition specified in the predicate.
Example: TopicNameMatch predicate for the outbox event router transformation
The following example shows a Debezium connector configuration that applies the outbox event router transformation only to messages that Debezium emits to the Kafka outbox.event.order topic.
Because the TopicNameMatch predicate evaluates to true only for messages from the outbox table (outbox.event.*), the transformation is not applied to messages that originate from other tables in the database.
transforms=outbox
transforms.outbox.predicate=IsOutboxTable
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
predicates=IsOutboxTable
predicates.IsOutboxTable.type=org.apache.kafka.connect.predicates.TopicNameMatch
predicates.IsOutboxTable.pattern=outbox.event.*12.1.3. Ignoring tombstone events
You can control whether Debezium emits tombstone events, and how long Kafka retains them. Depending on your data pipeline, you might want to set the tombstones.on.delete property for a connector so that Debezium does not emit tombstone events.
Whether you enable Debezium to emit tombstones depends on how topics are consumed in your environment and by the characteristics of the sink consumer. Some sink connectors rely on tombstone events to remove records from downstream data stores. In cases where sink connectors rely on tombstone records to indicate when to delete records in downstream data stores, configure Debezium to emit them.
When you configure Debezium to generate tombstones, further configuration is required to ensure that sink connectors receive the tombstone events. The retention policy for a topic must be set so that the connector has time to read event messages before Kafka removes them during log compaction. The length of time that a topic retains tombstones before compaction is controlled by the delete.retention.ms property for the topic.
By default, the tombstones.on.delete property for a connector is set to true so that the connector generates a tombstone after each delete event. If you set the property to false to prevent Debezium from saving tombstone records to Kafka topics, the absence of tombstone records might lead to unintended consequences. Kafka relies on tombstone during log compaction to remove records that are related to a deleted key.
If you need to support sink connectors or downstream Kafka consumers that cannot process records with null values, rather than preventing Debezium from emitting tombstones, consider configuring an SMT for the connector with a predicate that uses the RecordIsTombstone predicate type to remove tombstone messages before consumers read them.
Procedure
To prevent Debezium from emitting tombstone events for deleted database records, set the connector option
tombstones.on.deletetofalse.For example:
“tombstones.on.delete”: “false”
12.2. Routing Debezium event records to topics that you specify
Each Kafka record that contains a data change event has a default destination topic. If you need to, you can re-route records to topics that you specify before the records reach the Kafka Connect converter. To do this, Debezium provides the topic routing single message transformation (SMT). Configure this transformation in the Debezium connector’s Kafka Connect configuration. Configuration options enable you to specify the following:
- An expression for identifying the records to re-route
- An expression that resolves to the destination topic
- How to ensure a unique key among the records being re-routed to the destination topic
It is up to you to ensure that the transformation configuration provides the behavior that you want. Debezium does not validate the behavior that results from your configuration of the transformation.
The topic routing transformation is a Kafka Connect SMT.
The following topics provide details:
- Section 12.2.1, “Use case for routing Debezium records to topics that you specify”
- Section 12.2.2, “Example of routing Debezium records for multiple tables to one topic”
- Section 12.2.3, “Ensuring unique keys across Debezium records routed to the same topic”
- Section 12.2.5, “Options for configuring Debezium topic routing transformation”
12.2.1. Use case for routing Debezium records to topics that you specify
The default behavior is that a Debezium connector sends each change event record to a topic whose name is formed from the name of the database and the name of the table in which the change was made. In other words, a topic receives records for one physical table. When you want a topic to receive records for more than one physical table, you must configure the Debezium connector to re-route the records to that topic.
Logical tables
A logical table is a common use case for routing records for multiple physical tables to one topic. In a logical table, there are multiple physical tables that all have the same schema. For example, sharded tables have the same schema. A logical table might consist of two or more sharded tables: db_shard1.my_table and db_shard2.my_table. The tables are in different shards and are physically distinct but together they form a logical table. You can re-route change event records for tables in any of the shards to the same topic.
Partitioned PostgreSQL tables
When the Debezium PostgreSQL connector captures changes in a partitioned table, the default behavior is that change event records are routed to a different topic for each partition. To emit records from all partitions to one topic, configure the topic routing SMT. Because each key in a partitioned table is guaranteed to be unique, configure key.enforce.uniqueness=false so that the SMT does not add a key field to ensure unique keys. The addition of a key field is default behavior.
12.2.2. Example of routing Debezium records for multiple tables to one topic
To route change event records for multiple physical tables to the same topic, configure the topic routing transformation in the Kafka Connect configuration for the Debezium connector. Configuration of the topic routing SMT requires you to specify regular expressions that determine:
- The tables for which to route records. These tables must all have the same schema.
- The destination topic name.
For example, configuration in a .properties file looks like this:
transforms=Reroute
transforms.Reroute.type=io.debezium.transforms.ByLogicalTableRouter
transforms.Reroute.topic.regex=(.*)customers_shard(.*)
transforms.Reroute.topic.replacement=$1customers_all_shardstopic.regexSpecifies a regular expression that the transformation applies to each change event record to determine if it should be routed to a particular topic.
In the example, the regular expression,
(.*)customers_shard(.*)matches records for changes to tables whose names include thecustomers_shardstring. This would re-route records for tables with the following names:myserver.mydb.customers_shard1myserver.mydb.customers_shard2myserver.mydb.customers_shard3topic.replacement-
Specifies a regular expression that represents the destination topic name. The transformation routes each matching record to the topic identified by this expression. In this example, records for the three sharded tables listed above would be routed to the
myserver.mydb.customers_all_shardstopic.
12.2.3. Ensuring unique keys across Debezium records routed to the same topic
A Debezium change event key uses the table columns that make up the table’s primary key. To route records for multiple physical tables to one topic, the event key must be unique across all of those tables. However, it is possible for each physical table to have a primary key that is unique within only that table. For example, a row in the myserver.mydb.customers_shard1 table might have the same key value as a row in the myserver.mydb.customers_shard2 table.
To ensure that each event key is unique across the tables whose change event records go to the same topic, the topic routing transformation inserts a field into change event keys. By default, the name of the inserted field is __dbz__physicalTableIdentifier. The value of the inserted field is the default destination topic name.
If you want to, you can configure the topic routing transformation to insert a different field into the key. To do this, specify the key.field.name option and set it to a field name that does not clash with existing primary key field names. For example:
transforms=Reroute
transforms.Reroute.type=io.debezium.transforms.ByLogicalTableRouter
transforms.Reroute.topic.regex=(.*)customers_shard(.*)
transforms.Reroute.topic.replacement=$1customers_all_shards
transforms.Reroute.key.field.name=shard_id
This example adds the shard_id field to the key structure in routed records.
If you want to adjust the value of the key’s new field, configure both of these options:
key.field.regex- Specifies a regular expression that the transformation applies to the default destination topic name to capture one or more groups of characters.
key.field.replacement- Specifies a regular expression for determining the value of the inserted key field in terms of those captured groups.
For example:
transforms.Reroute.key.field.regex=(.*)customers_shard(.*)
transforms.Reroute.key.field.replacement=$2With this configuration, suppose that the default destination topic names are:
myserver.mydb.customers_shard1myserver.mydb.customers_shard2myserver.mydb.customers_shard3
The transformation uses the values in the second captured group, the shard numbers, as the value of the key’s new field. In this example, the inserted key field’s values would be 1, 2, or 3.
If your tables contain globally unique keys and you do not need to change the key structure, you can set the key.enforce.uniqueness option to false:
...
transforms.Reroute.key.enforce.uniqueness=false
...12.2.4. Options for applying the topic routing transformation selectively
In addition to the change event messages that a Debezium connector emits when a database change occurs, the connector also emits other types of messages, including heartbeat messages, and metadata messages about schema changes and transactions. Because the structure of these other messages differs from the structure of the change event messages that the SMT is designed to process, it’s best to configure the connector to selectively apply the SMT, so that it processes only the intended data change messages.
You can use one of the following methods to configure the connector to apply the SMT selectively:
- Configure an SMT predicate for the transformation.
- Use the topic.regex configuration option for the SMT.
12.2.5. Options for configuring Debezium topic routing transformation
The following table describes topic routing SMT configuration options.
| Option | Default | Description |
|---|---|---|
| Specifies a regular expression that the transformation applies to each change event record to determine if it should be routed to a particular topic. | ||
|
Specifies a regular expression that represents the destination topic name. The transformation routes each matching record to the topic identified by this expression. This expression can refer to groups captured by the regular expression that you specify for | ||
|
|
Indicates whether to add a field to the record’s change event key. Adding a key field ensures that each event key is unique across the tables whose change event records go to the same topic. This helps to prevent collisions of change events for records that have the same key but that originate from different source tables. | |
|
|
Name of a field to be added to the change event key. The value of this field identifies the original table name. For the SMT to add this field, | |
|
Specifies a regular expression that the transformation applies to the default destination topic name to capture one or more groups of characters. For the SMT to apply this expression, | ||
|
Specifies a regular expression for determining the value of the inserted key field in terms of the groups captured by the expression specified for |
12.3. Routing change event records to topics according to event content
By default, Debezium streams all of the change events that it reads from a table to a single static topic. However, there might be situations in which you might want to reroute selected events to other topics, based on the event content. The process of routing messages based on their content is described in the Content-based routing messaging pattern. To apply this pattern in Debezium, you use the content-based routing single message transform (SMT) to write expressions that are evaluated for each event. Depending how an event is evaluated, the SMT either routes the event message to the original destination topic, or reroutes it to the topic that you specify in the expression.
The Debezium content-based routing SMT is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service-level agreements (SLAs) and might not be functionally complete; therefore, Red Hat does not recommend implementing any Technology Preview features in production environments. This Technology Preview feature provides early access to upcoming product innovations, enabling you to test functionality and provide feedback during the development process. For more information about support scope, see Technology Preview Features Support Scope.
While it is possible to use Java to create a custom SMT to encode routing logic, using a custom-coded SMT has its drawbacks. For example:
- It is necessary to compile the transformation up front and deploy it to Kafka Connect.
- Every change needs code recompilation and redeployment, leading to inflexible operations.
The content-based routing SMT supports scripting languages that integrate with JSR 223 (Scripting for the Java™ Platform).
Debezium does not come with any implementations of the JSR 223 API. To use an expression language with Debezium, you must download the JSR 223 script engine implementation for the language, and add to your Debezium connector plug-in directories, along any other JAR files used by the language implementation. For example, for Groovy 3, you can download its JSR 223 implementation from https://groovy-lang.org/. The JSR 223 implementation for GraalVM JavaScript is available at https://github.com/graalvm/graaljs.
12.3.1. Setting up the Debezium content-based-routing SMT
For security reasons, the content-based routing SMT is not included with the Debezium connector archives. Instead, it is provided in a separate artifact, debezium-scripting-1.7.2.Final.tar.gz. To use the content-based routing SMT with a Debezium connector plug-in, you must explicitly add the SMT artifact to your Kafka Connect environment.
After the routing SMT is present in a Kafka Connect instance, any user who is allowed to add a connector to the instance can run scripting expressions. To ensure that scripting expressions can be run only by authorized users, be sure to secure the Kafka Connect instance and its configuration interface before you add the routing SMT.
Procedure
-
From a browser, open the Red Hat Integration download site, and download the Debezium scripting SMT archive (
debezium-scripting-1.7.2.Final.tar.gz). - Extract the contents of the archive into the Debezium plug-in directories of your Kafka Connect environment.
- Obtain a JSR-223 script engine implementation and add its contents to the Debezium plug-in directories of your Kafka Connect environment.
- Restart the Kafka Connect process to pick up the new JAR files.
The Groovy language needs the following libraries on the classpath:
-
groovy -
groovy-json(optional) -
groovy-jsr223
The JavaScript language needs the following libraries on the classpath:
-
graalvm.js -
graalvm.js.scriptengine
12.3.2. Example: Debezium basic content-based routing configuration
To configure a Debezium connector to route change event records based on the event content, you configure the ContentBasedRouter SMT in the Kafka Connect configuration for the connector.
Configuration of the content-based routing SMT requires you to specify a regular expression that defines the filtering criteria. In the configuration, you create a regular expression that defines routing criteria. The expression defines a pattern for evaluating event records. It also specifies the name of a destination topic where events that match the pattern are routed. The pattern that you specify might designate an event type, such as a table insert, update, or delete operation. You might also define a pattern that matches a value in a specific column or row.
For example, to reroute all update (u) records to an updates topic, you might add the following configuration to your connector configuration:
...
transforms=route
transforms.route.type=io.debezium.transforms.ContentBasedRouter
transforms.route.language=jsr223.groovy
transforms.route.topic.expression=value.op == 'u' ? 'updates' : null
...
The preceding example specifies the use of the Groovy expression language.
Records that do not match the pattern are routed to the default topic.
12.3.3. Variables for use in Debezium content-based routing expressions
Debezium binds certain variables into the evaluation context for the SMT. When you create expressions to specify conditions to control the routing destination, the SMT can look up and interpret the values of these variables to evaluate conditions in an expression.
The following table lists the variables that Debezium binds into the evaluation context for the content-based routing SMT:
| Name | Description | Type |
|---|---|---|
|
| A key of the message. |
|
|
| A value of the message. |
|
|
| Schema of the message key. |
|
|
| Schema of the message value. |
|
|
| Name of the target topic. | String |
|
|
A Java map of message headers. The key field is the header name. The
|
|
An expression can invoke arbitrary methods on its variables. Expressions should resolve to a Boolean value that determines how the SMT dispositions the message. When the routing condition in an expression evaluates to true, the message is retained. When the routing condition evaluates to false, the message is removed.
Expressions should not result in any side-effects. That is, they should not modify any variables that they pass.
12.3.4. Options for applying the content-based routing transformation selectively
In addition to the change event messages that a Debezium connector emits when a database change occurs, the connector also emits other types of messages, including heartbeat messages, and metadata messages about schema changes and transactions. Because the structure of these other messages differs from the structure of the change event messages that the SMT is designed to process, it’s best to configure the connector to selectively apply the SMT, so that it processes only the intended data change messages. You can use one of the following methods to configure the connector to apply the SMT selectively:
- Configure an SMT predicate for the transformation.
- Use the topic.regex configuration option for the SMT.
12.3.5. Configuration of content-based routing conditions for other scripting languages
The way that you express content-based routing conditions depends on the scripting language that you use. For example, as shown in the basic configuration example, when you use Groovy as the expression language, the following expression reroutes all update (u) records to the updates topic, while routing other records to the default topic:
value.op == 'u' ? 'updates' : nullOther languages use different methods to express the same condition.
The Debezium MongoDB connector emits the after and patch fields as serialized JSON documents rather than as structures. To use the ContentBasedRouting SMT with the MongoDB connector, you must first unwind the fields by applying the ExtractNewDocumentState SMT.
You could also take the approach of using a JSON parser within the expression. For example, if you use Groovy as the expression language, add the groovy-json artifact to the classpath, and then add an expression such as (new groovy.json.JsonSlurper()).parseText(value.after).last_name == 'Kretchmar'.
Javascript
When you use JavaScript as the expression language, you can call the Struct#get() method to specify the content-based routing condition, as in the following example:
value.get('op') == 'u' ? 'updates' : nullJavascript with Graal.js
When you create content-based routing conditions by using JavaScript with Graal.js, you use an approach that is similar to the one use with Groovy. For example:
value.op == 'u' ? 'updates' : null12.3.6. Options for configuring the content-based routing transformation
| Property | Default | Description |
|
An optional regular expression that evaluates the name of the destination topic for an event to determine whether to apply the condition logic. If the name of the destination topic matches the value in | ||
|
The language in which the expression is written. Must begin with | ||
|
The expression to be evaluated for every message. Must evaluate to a | ||
|
|
Specifies how the transformation handles
|
12.4. Filtering Debezium change event records
By default, Debezium delivers every data change event that it receives to the Kafka broker. However, in many cases, you might be interested in only a subset of the events emitted by the producer. To enable you to process only the records that are relevant to you, Debezium provides the filter single message transform (SMT).
The Debezium filter SMT is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service-level agreements (SLAs) and might not be functionally complete; therefore, Red Hat does not recommend implementing any Technology Preview features in production environments. This Technology Preview feature provides early access to upcoming product innovations, enabling you to test functionality and provide feedback during the development process. For more information about support scope, see Technology Preview Features Support Scope.
While it is possible to use Java to create a custom SMT to encode filtering logic, using a custom-coded SMT has its drawbacks. For example:
- It is necessary to compile the transformation up front and deploy it to Kafka Connect.
- Every change needs code recompilation and redeployment, leading to inflexible operations.
The filter SMT supports scripting languages that integrate with JSR 223 (Scripting for the Java™ Platform).
Debezium does not come with any implementations of the JSR 223 API. To use an expression language with Debezium, you must download the JSR 223 script engine implementation for the language, and add to your Debezium connector plug-in directories, along any other JAR files used by the language implementation. For example, for Groovy 3, you can download its JSR 223 implementation from https://groovy-lang.org/. The JSR223 implementation for GraalVM JavaScript is available at https://github.com/graalvm/graaljs.
12.4.1. Setting up the Debezium filter SMT
For security reasons, the filter SMT is not included with the Debezium connector archives. Instead, it is provided in a separate artifact, debezium-scripting-1.7.2.Final.tar.gz. To use the filter SMT with a Debezium connector plug-in, you must explicitly add the SMT artifact to your Kafka Connect environment.
After the filter SMT is present in a Kafka Connect instance, any user who is allowed to add a connector to the instance can run scripting expressions. To ensure that scripting expressions can be run only by authorized users, be sure to secure the Kafka Connect instance and its configuration interface before you add the filter SMT.
Procedure
-
From a browser, open the Red Hat Integration download site, and download the Debezium scripting SMT archive (
debezium-scripting-1.7.2.Final.tar.gz). - Extract the contents of the archive into the Debezium plug-in directories of your Kafka Connect environment.
- Obtain a JSR-223 script engine implementation and add its contents to the Debezium plug-in directories of your Kafka Connect environment.
- Restart the Kafka Connect process to pick up the new JAR files.
The Groovy language needs the following libraries on the classpath:
-
groovy -
groovy-json(optional) -
groovy-jsr223
The JavaScript language needs the following libraries on the classpath:
-
graalvm.js -
graalvm.js.scriptengine
12.4.2. Example: Debezium basic filter SMT configuration
You configure the filter transformation in the Debezium connector’s Kafka Connect configuration. In the configuration, you specify the events that you are interested in by defining filter conditions that are based on business rules. As the filter SMT processes the event stream, it evaluates each event against the configured filter conditions. Only events that meet the criteria of the filter conditions are passed to the broker.
To configure a Debezium connector to filter change event records, configure the Filter SMT in the Kafka Connect configuration for the Debezium connector. Configuration of the filter SMT requires you to specify a regular expression that defines the filtering criteria.
For example, you might add the following configuration in your connector configuration.
...
transforms=filter
transforms.filter.type=io.debezium.transforms.Filter
transforms.filter.language=jsr223.groovy
transforms.filter.condition=value.op == 'u' && value.before.id == 2
...
The preceding example specifies the use of the Groovy expression language. The regular expression value.op == 'u' && value.before.id == 2 removes all messages, except those that represent update (u) records with id values that are equal to 2.
12.4.3. Variables for use in filter expressions
Debezium binds certain variables into the evaluation context for the filter SMT. When you create expressions to specify filter conditions, you can use the variables that Debezium binds into the evaluation context. By binding variables, Debezium enables the SMT to look up and interpret their values as it evaluates the conditions in an expression.
The following table lists the variables that Debezium binds into the evaluation context for the filter SMT:
| Name | Description | Type |
|---|---|---|
|
| A key of the message. |
|
|
| A value of the message. |
|
|
| Schema of the message key. |
|
|
| Schema of the message value. |
|
|
| Name of the target topic. | String |
|
|
A Java map of message headers. The key field is the header name. The
|
|
An expression can invoke arbitrary methods on its variables. Expressions should resolve to a Boolean value that determines how the SMT dispositions the message. When the filter condition in an expression evaluates to true, the message is retained. When the filter condition evaluates to false, the message is removed.
Expressions should not result in any side-effects. That is, they should not modify any variables that they pass.
12.4.4. Options for applying the filter transformation selectively
In addition to the change event messages that a Debezium connector emits when a database change occurs, the connector also emits other types of messages, including heartbeat messages, and metadata messages about schema changes and transactions. Because the structure of these other messages differs from the structure of the change event messages that the SMT is designed to process, it’s best to configure the connector to selectively apply the SMT, so that it processes only the intended data change messages. You can use one of the following methods to configure the connector to apply the SMT selectively:
- Configure an SMT predicate for the transformation.
- Use the topic.regex configuration option for the SMT.
12.4.5. Filter condition configuration for other scripting languages
The way that you express filtering conditions depends on the scripting language that you use.
For example, as shown in the basic configuration example, when you use Groovy as the expression language, the following expression removes all messages, except for update records that have id values set to 2:
value.op == 'u' && value.before.id == 2Other languages use different methods to express the same condition.
The Debezium MongoDB connector emits the after and patch fields as serialized JSON documents rather than as structures. To use the filter SMT with the MongoDB connector, you must first unwind the fields by applying the ExtractNewDocumentState SMT.
You could also take the approach of using a JSON parser within the expression. For example, if you use Groovy as the expression language, add the groovy-json artifact to the classpath, and then add an expression such as (new groovy.json.JsonSlurper()).parseText(value.after).last_name == 'Kretchmar'.
Javascript
If you use JavaScript as the expression language, you can call the Struct#get() method to specify the filtering condition, as in the following example:
value.get('op') == 'u' && value.get('before').get('id') == 2Javascript with Graal.js
If you use JavaScript with Graal.js to define filtering conditions, you use an approach that is similar to the one that you use with Groovy. For example:
value.op == 'u' && value.before.id == 212.4.6. Options for configuring filter transformation
The following table lists the configuration options that you can use with the filter SMT.
| Property | Default | Description |
|
An optional regular expression that evaluates the name of the destination topic for an event to determine whether to apply filtering logic. If the name of the destination topic matches the value in | ||
|
The language in which the expression is written. Must begin with | ||
|
The expression to be evaluated for every message. Must evaluate to a Boolean value where a result of | ||
|
|
Specifies how the transformation handles
|
12.5. Extracting source record after state from Debezium change events
A Debezium data change event has a complex structure that provides a wealth of information. Kafka records that convey Debezium change events contain all of this information. However, parts of a Kafka ecosystem might expect Kafka records that provide a flat structure of field names and values. To provide this kind of record, Debezium provides the event flattening single message transformation (SMT). Configure this transformation when consumers need Kafka records that have a format that is simpler than Kafka records that contain Debezium change events.
The event flattening transformation is a Kafka Connect SMT.
This transformation is available to only SQL database connectors.
The following topics provide details:
- Section 12.5.1, “Description of Debezium change event structure”
- Section 12.5.2, “Behavior of Debezium event flattening transformation”
- Section 12.5.3, “Configuration of Debezium event flattening transformation”
- Section 12.5.4, “Example of adding Debezium metadata to the Kafka record”
- Section 12.5.6, “Options for configuring Debezium event flattening transformation”
12.5.1. Description of Debezium change event structure
Debezium generates data change events that have a complex structure. Each event consists of three parts:
Metadata, which includes but is not limited to:
- The operation that made the change
- Source information such as the names of the database and table where the change was made
- Time stamp for when the change was made
- Optional transaction information
- Row data before the change
- Row data after the change
For example, part of the structure of an UPDATE change event looks like this:
{
"op": "u",
"source": {
...
},
"ts_ms" : "...",
"before" : {
"field1" : "oldvalue1",
"field2" : "oldvalue2"
},
"after" : {
"field1" : "newvalue1",
"field2" : "newvalue2"
}
}This complex format provides the most information about changes happening in the system. However, other connectors or other parts of the Kafka ecosystem usually expect the data in a simple format like this:
{
"field1" : "newvalue1",
"field2" : "newvalue2"
}To provide the needed Kafka record format for consumers, configure the event flattening SMT.
12.5.2. Behavior of Debezium event flattening transformation
The event flattening SMT extracts the after field from a Debezium change event in a Kafka record. The SMT replaces the original change event with only its after field to create a simple Kafka record.
You can configure the event flattening SMT for a Debezium connector or for a sink connector that consumes messages emitted by a Debezium connector. The advantage of configuring event flattening for a sink connector is that records stored in Apache Kafka contain whole Debezium change events. The decision to apply the SMT to a source or sink connector depends on your particular use case.
You can configure the transformation to do any of the following:
- Add metadata from the change event to the simplified Kafka record. The default behavior is that the SMT does not add metadata.
-
Keep Kafka records that contain change events for
DELETEoperations in the stream. The default behavior is that the SMT drops Kafka records forDELETEoperation change events because most consumers cannot yet handle them.
A database DELETE operation causes Debezium to generate two Kafka records:
-
A record that contains
"op": "d",thebeforerow data, and some other fields. -
A tombstone record that has the same key as the deleted row and a value of
null. This record is a marker for Apache Kafka. It indicates that log compaction can remove all records that have this key.
Instead of dropping the record that contains the before row data, you can configure the event flattening SMT to do one of the following:
-
Keep the record in the stream and edit it to have only the
"value": "null"field. -
Keep the record in the stream and edit it to have a
valuefield that contains the key/value pairs that were in thebeforefield with an added"__deleted": "true"entry.
Similary, instead of dropping the tombstone record, you can configure the event flattening SMT to keep the tombstone record in the stream.
12.5.3. Configuration of Debezium event flattening transformation
Configure the Debezium event flattening SMT in a Kafka Connect source or sink connector by adding the SMT configuration details to your connector’s configuration. To obtain the default behavior, in a .properties file, you would specify something like the following:
transforms=unwrap,...
transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
As for any Kafka Connect connector configuration, you can set transforms= to multiple, comma-separated, SMT aliases in the order in which you want Kafka Connect to apply the SMTs.
The following .properties example sets several event flattening SMT options:
transforms=unwrap,...
transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
transforms.unwrap.drop.tombstones=false
transforms.unwrap.delete.handling.mode=rewrite
transforms.unwrap.add.fields=table,lsndrop.tombstones=false-
Keeps tombstone records for
DELETEoperations in the event stream. delete.handling.mode=rewriteFor
DELETEoperations, edits the Kafka record by flattening thevaluefield that was in the change event. Thevaluefield directly contains the key/value pairs that were in thebeforefield. The SMT adds__deletedand sets it totrue, for example:"value": { "pk": 2, "cola": null, "__deleted": "true" }add.fields=table,lsn-
Adds change event metadata for the
tableandlsnfields to the simplified Kafka record.
12.5.4. Example of adding Debezium metadata to the Kafka record
The event flattening SMT can add original, change event metadata to the simplified Kafka record. For example, you might want the simplified record’s header or value to contain any of the following:
- The type of operation that made the change
- The name of the database or table that was changed
- Connector-specific fields such as the Postgres LSN field
To add metadata to the simplified Kafka record’s header, specify the add.header option. To add metadata to the simplified Kafka record’s value, specify the add.fields option. Each of these options takes a comma separated list of change event field names. Do not specify spaces. When there are duplicate field names, to add metadata for one of those fields, specify the struct as well as the field. For example:
transforms=unwrap,...
transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
transforms.unwrap.add.fields=op,table,lsn,source.ts_ms
transforms.unwrap.add.headers=db
transforms.unwrap.delete.handling.mode=rewriteWith that configuration, a simplified Kafka record would contain something like the following:
{
...
"__op" : "c",
"__table": "MY_TABLE",
"__lsn": "123456789",
"__source_ts_ms" : "123456789",
...
}
Also, simplified Kafka records would have a __db header.
In the simplified Kafka record, the SMT prefixes the metadata field names with a double underscore. When you specify a struct, the SMT also inserts an underscore between the struct name and the field name.
To add metadata to a simplified Kafka record that is for a DELETE operation, you must also configure delete.handling.mode=rewrite.
12.5.5. Options for applying the event flattening transformation selectively
In addition to the change event messages that a Debezium connector emits when a database change occurs, the connector also emits other types of messages, including heartbeat messages, and metadata messages about schema changes and transactions. Because the structure of these other messages differs from the structure of the change event messages that the SMT is designed to process, it’s best to configure the connector to selectively apply the SMT, so that it processes only the intended data change messages.
For more information about how to apply the SMT selectively, see Configure an SMT predicate for the transformation.
12.5.6. Options for configuring Debezium event flattening transformation
The following table describes the options that you can specify to configure the event flattening SMT.
| Option | Default | Description |
|---|---|---|
|
|
Debezium generates a tombstone record for each | |
|
|
Debezium generates a change event record for each | |
|
To use row data to determine the topic to route the record to, set this option to an | ||
| __ (double-underscore) | Set this optional string to prefix a field. | |
|
Set this option to a comma-separated list, with no spaces, of metadata fields to add to the simplified Kafka record’s value. When there are duplicate field names, to add metadata for one of those fields, specify the struct as well as the field, for example | ||
| __ (double-underscore) | Set this optional string to prefix a header. | |
|
Set this option to a comma-separated list, with no spaces, of metadata fields to add to the header of the simplified Kafka record. When there are duplicate field names, to add metadata for one of those fields, specify the struct as well as the field, for example |
12.6. Configuring Debezium connectors to use the outbox pattern
The outbox pattern is a way to safely and reliably exchange data between multiple (micro) services. An outbox pattern implementation avoids inconsistencies between a service’s internal state (as typically persisted in its database) and state in events consumed by services that need the same data.
To implement the outbox pattern in a Debezium application, configure a Debezium connector to:
- Capture changes in an outbox table
- Apply the Debezium outbox event router single message transformation (SMT)
A Debezium connector that is configured to apply the outbox SMT should capture changes that occur in an outbox table only. For more information, see Options for applying the transformation selectively.
A connector can capture changes in more than one outbox table only if each outbox table has the same structure.
See Reliable Microservices Data Exchange With the Outbox Pattern to learn about why the outbox pattern is useful and how it works.
The outbox event router SMT is not compatible with the MongoDB connector.
MongoDB users can run the MongoDB outbox event router SMT.
The following topics provide details:
- Section 12.6.1, “Example of a Debezium outbox message”
- Section 12.6.2, “Outbox table structure expected by Debezium outbox event router SMT”
- Section 12.6.3, “Basic Debezium outbox event router SMT configuration”
- Section 12.6.4, “Options for applying the Outbox event router transformation selectively”
- Section 12.6.5, “Using Avro as the payload format in Debezium outbox messages”
- Section 12.6.6, “Emitting additional fields in Debezium outbox messages”
- Section 12.6.7, “Expanding escaped JSON String as JSON”
- Section 12.6.8, “Options for configuring outbox event router transformation”
12.6.1. Example of a Debezium outbox message
To understand how the Debezium outbox event router SMT is configured, review the following example of a Debezium outbox message:
# Kafka Topic: outbox.event.order
# Kafka Message key: "1"
# Kafka Message Headers: "id=4d47e190-0402-4048-bc2c-89dd54343cdc"
# Kafka Message Timestamp: 1556890294484
{
"{\"id\": 1, \"lineItems\": [{\"id\": 1, \"item\": \"Debezium in Action\", \"status\": \"ENTERED\", \"quantity\": 2, \"totalPrice\": 39.98}, {\"id\": 2, \"item\": \"Debezium for Dummies\", \"status\": \"ENTERED\", \"quantity\": 1, \"totalPrice\": 29.99}], \"orderDate\": \"2019-01-31T12:13:01\", \"customerId\": 123}"
}A Debezium connector that is configured to apply the outbox event router SMT generates the above message by transforming a Debezium raw message like this:
# Kafka Message key: "406c07f3-26f0-4eea-a50c-109940064b8f"
# Kafka Message Headers: ""
# Kafka Message Timestamp: 1556890294484
{
"before": null,
"after": {
"id": "406c07f3-26f0-4eea-a50c-109940064b8f",
"aggregateid": "1",
"aggregatetype": "Order",
"payload": "{\"id\": 1, \"lineItems\": [{\"id\": 1, \"item\": \"Debezium in Action\", \"status\": \"ENTERED\", \"quantity\": 2, \"totalPrice\": 39.98}, {\"id\": 2, \"item\": \"Debezium for Dummies\", \"status\": \"ENTERED\", \"quantity\": 1, \"totalPrice\": 29.99}], \"orderDate\": \"2019-01-31T12:13:01\", \"customerId\": 123}",
"timestamp": 1556890294344,
"type": "OrderCreated"
},
"source": {
"version": "1.7.2.Final",
"connector": "postgresql",
"name": "dbserver1-bare",
"db": "orderdb",
"ts_usec": 1556890294448870,
"txId": 584,
"lsn": 24064704,
"schema": "inventory",
"table": "outboxevent",
"snapshot": false,
"last_snapshot_record": null,
"xmin": null
},
"op": "c",
"ts_ms": 1556890294484
}This example of a Debezium outbox message is based on the default outbox event router configuration, which assumes an outbox table structure and event routing based on aggregates. To customize behavior, the outbox event router SMT provides numerous configuration options.
12.6.2. Outbox table structure expected by Debezium outbox event router SMT
To apply the default outbox event router SMT configuration, your outbox table is assumed to have the following columns:
Column | Type | Modifiers
--------------+------------------------+-----------
id | uuid | not null
aggregatetype | character varying(255) | not null
aggregateid | character varying(255) | not null
type | character varying(255) | not null
payload | jsonb || Column | Effect |
|---|---|
|
|
Contains the unique ID of the event. In an outbox message, this value is a header. You can use this ID, for example, to remove duplicate messages. |
|
|
Contains a value that the SMT appends to the name of the topic to which the connector emits an outbox message. The default behavior is that this value replaces the default |
|
|
Contains the event key, which provides an ID for the payload. The SMT uses this value as the key in the emitted outbox message. This is important for maintaining correct order in Kafka partitions. |
|
|
A representation of the outbox change event. The default structure is JSON. By default, the Kafka message value is solely comprised of the |
| Additional custom columns |
Any additional columns from the outbox table can be added to outbox events either within the payload section or as a message header. |
12.6.3. Basic Debezium outbox event router SMT configuration
To configure a Debezium connector to support the outbox pattern, configure the outbox.EventRouter SMT. For example, the basic configuration in a .properties file looks like this:
transforms=outbox,...
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter12.6.4. Options for applying the Outbox event router transformation selectively
In addition to the change event messages that a Debezium connector emits when a database change occurs, the connector also emits other types of messages, including heartbeat messages, and metadata messages about schema changes and transactions. Because the structure of these other messages differs from the structure of the change event messages that the SMT is designed to process, it’s best to configure the connector to selectively apply the SMT, so that it processes only the intended data change messages. You can use one of the following methods to configure the connector to apply the SMT selectively:
- Configure an SMT predicate for the transformation.
-
Use the
route.topic.regexconfiguration option for the SMT.
12.6.5. Using Avro as the payload format in Debezium outbox messages
The outbox event router SMT supports arbitrary payload formats. The payload column value in an outbox table is passed on transparently. An alternative to working with JSON is to use Avro. This can be beneficial for message format governance and for ensuring that outbox event schemas evolve in a backwards-compatible way.
How a source application produces Avro formatted content for outbox message payloads is out of the scope of this documentation. One possibility is to leverage the KafkaAvroSerializer class to serialize GenericRecord instances. To ensure that the Kafka message value is the exact Avro binary data, apply the following configuration to the connector:
transforms=outbox,...
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
value.converter=io.debezium.converters.ByteBufferConverter
By default, the payload column value (the Avro data) is the only message value. Configuration of ByteBufferConverter as the value converter propagates the payload column value as-is into the Kafka message value.
The Debezium connectors may be configured to emit heartbeat, transaction metadata, or schema change events (support varies by connector). These events cannot be serialized by the ByteBufferConverter so additional configuration must be provided so the converter knows how to serialize these events. As an example, the following configuration illustrates using the Apache Kafka JsonConverter with no schemas:
transforms=outbox,...
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
value.converter=io.debezium.converters.ByteBufferConverter
value.converter.delegate.converter.type=org.apache.kafka.connect.json.JsonConverter
value.converter.delegate.converter.type.schemas.enable=false
The delegate Converter implementation is specified by the delegate.converter.type option. If any extra configuration options are needed by the converter, they can also be specified, such as the disablement of schemas shown above using schemas.enable=false.
12.6.6. Emitting additional fields in Debezium outbox messages
Your outbox table might contain columns whose values you want to add to the emitted outbox messages. For example, consider an outbox table that has a value of purchase-order in the aggregatetype column and another column, eventType, whose possible values are order-created and order-shipped. To emit the eventType column value in the outbox message header, configure the SMT like this:
transforms=outbox,...
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
transforms.outbox.table.fields.additional.placement=type:header:eventType
To emit the eventType column value in the outbox message envelope, configure the SMT like this:
transforms=outbox,...
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
transforms.outbox.table.fields.additional.placement=type:envelope:eventType12.6.7. Expanding escaped JSON String as JSON
You may have noticed that the Debezium outbox message contains the payload represented as a String. So when this string, is actually JSON, it appears as escaped in the result Kafka message like shown below:
# Kafka Topic: outbox.event.order
# Kafka Message key: "1"
# Kafka Message Headers: "id=4d47e190-0402-4048-bc2c-89dd54343cdc"
# Kafka Message Timestamp: 1556890294484
{
"{\"id\": 1, \"lineItems\": [{\"id\": 1, \"item\": \"Debezium in Action\", \"status\": \"ENTERED\", \"quantity\": 2, \"totalPrice\": 39.98}, {\"id\": 2, \"item\": \"Debezium for Dummies\", \"status\": \"ENTERED\", \"quantity\": 1, \"totalPrice\": 29.99}], \"orderDate\": \"2019-01-31T12:13:01\", \"customerId\": 123}"
}The outbox event router allows you to expand this message content to "real" JSON with the companion schema being deduced from the JSON document itself. That way the result in Kafka message looks like:
# Kafka Topic: outbox.event.order
# Kafka Message key: "1"
# Kafka Message Headers: "id=4d47e190-0402-4048-bc2c-89dd54343cdc"
# Kafka Message Timestamp: 1556890294484
{
"id": 1, "lineItems": [{"id": 1, "item": "Debezium in Action", "status": "ENTERED", "quantity": 2, "totalPrice": 39.98}, {"id": 2, "item": "Debezium for Dummies", "status": "ENTERED", "quantity": 1, "totalPrice": 29.99}], "orderDate": "2019-01-31T12:13:01", "customerId": 123
}
To enable this transformation, you have to set the table.expand.json.payload to true and use the StringConverter like below:
transforms=outbox,...
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
transforms.outbox.table.expand.json.payload=true
value.converter=org.apache.kafka.connect.storage.StringConverter12.6.8. Options for configuring outbox event router transformation
The following table describes the options that you can specify for the outbox event router SMT. In the table, the Group column indicates a configuration option classification for Kafka.
| Option | Default | Group | Description |
|---|---|---|---|
|
| Table |
Determines the behavior of the SMT when there is an
All changes in an outbox table are expected to be | |
|
| Table |
Specifies the outbox table column that contains the unique event ID. This ID will be stored in the emitted event’s headers under the | |
|
| Table | Specifies the outbox table column that contains the event key. When this column contains a value, the SMT uses that value as the key in the emitted outbox message. This is important for maintaining correct order in Kafka partitions. | |
| Table | By default, the timestamp in the emitted outbox message is the Debezium event timestamp. To use a different timestamp in outbox messages, set this option to an outbox table column that contains the timestamp that you want to be in emitted outbox messages. | ||
|
| Table | Specifies the outbox table column that contains the event payload. | |
|
| Table |
Specifies the outbox table column that contains the payload ID. This ID will be used as the emitted event’s key. | |
|
| Table |
Specifies whether the JSON expansion of a String payload should be done. If no content found or in case of parsing error, the content is kept "as is". | |
| Table, Envelope | Specifies one or more outbox table columns that you want to add to outbox message headers or envelopes. Specify a comma-separated list of pairs. In each pair, specify the name of a column and whether you want the value to be in the header or the envelope. Separate the values in the pair with a colon, for example:
To specify an alias for the column, specify a trio with the alias as the third value, for example:
The second value is the placement and it must always be Configuration examples are in emitting additional fields in Debezium outbox messages. | ||
| Table, Schema | When set, this value is used as the schema version as described in the Kafka Connect Schema Javadoc. | ||
|
| Router | Specifies the name of a column in the outbox table. The default behavior is that the value in this column becomes a part of the name of the topic to which the connector emits the outbox messages. An example is in the description of the expected outbox table. | |
|
| Router |
Specifies a regular expression that the outbox SMT applies in the RegexRouter to outbox table records. This regular expression is part of the setting of the | |
|
| Router |
Specifies the name of the topic to which the connector emits outbox messages. The default topic name is
| |
|
| Router |
Indicates whether an empty or |
12.7. Configuring Debezium MongoDB connectors to use the outbox pattern
This SMT is for use with the Debezium MongoDB connector only. For information about using the outbox event router SMT for relational databases, see Outbox event router.
The outbox pattern is a way to safely and reliably exchange data between multiple (micro) services. An outbox pattern implementation avoids inconsistencies between a service’s internal state (as typically persisted in its database) and state in events consumed by services that need the same data.
To implement the outbox pattern in a Debezium application, configure a Debezium connector to:
- Capture changes in an outbox collection
- Apply the Debezium MongoDB outbox event router single message transformation (SMT)
A Debezium connector that is configured to apply the MongoDB outbox SMT should capture changes that occur in an outbox collection only. For more information, see Options for applying the transformation selectively.
A connector can capture changes in more than one outbox collection only if each outbox collection has the same structure.
To use this SMT, operations on the actual business collection(s) and the insert into the outbox collection must be done as part of a multi-document transaction, which have been being supported since MongoDB 4.0, to prevent potential data inconsistencies between business collection(s) and outbox collection. For future update, to enable updating existing data and inserting outbox event in an ACID transaction without multi-document transactions, we have planned to support additional configurations for storing outbox events in a form of a sub-document of the existing collection, rather than an independent outbox collection.
For more information about the outbox pattern, see Reliable Microservices Data Exchange With the Outbox Pattern.
The following topics provide details:
- Section 12.7.1, “Example of a Debezium MongoDB outbox message”
- Section 12.7.2, “Outbox collection structure expected by Debezium mongodb outbox event router SMT”
- Section 12.7.3, “Basic Debezium MongoDB outbox event router SMT configuration”
- Section 12.7.5, “Using Avro as the payload format in Debezium MongoDB outbox messages”
- Section 12.7.6, “Emitting additional fields in Debezium MongoDB outbox messages”
- Section 12.7.8, “Options for configuring outbox event router transformation”
12.7.1. Example of a Debezium MongoDB outbox message
To understand how to configure the Debezium MongoDB outbox event router SMT, consider the following example of a Debezium outbox message:
# Kafka Topic: outbox.event.order
# Kafka Message key: "b2730779e1f596e275826f08"
# Kafka Message Headers: "id=596e275826f08b2730779e1f"
# Kafka Message Timestamp: 1556890294484
{
"{\"id\": {\"$oid\": \"da8d6de63b7745ff8f4457db\"}, \"lineItems\": [{\"id\": 1, \"item\": \"Debezium in Action\", \"status\": \"ENTERED\", \"quantity\": 2, \"totalPrice\": 39.98}, {\"id\": 2, \"item\": \"Debezium for Dummies\", \"status\": \"ENTERED\", \"quantity\": 1, \"totalPrice\": 29.99}], \"orderDate\": \"2019-01-31T12:13:01\", \"customerId\": 123}"
}A Debezium connector that is configured to apply the MongoDB outbox event router SMT generates the preceding message by transforming a raw Debezium change event message as in the following example:
# Kafka Message key: { "id": "{\"$oid\": \"596e275826f08b2730779e1f\"}" }
# Kafka Message Headers: ""
# Kafka Message Timestamp: 1556890294484
{
"patch": null,
"after": "{\"_id\": {\"$oid\": \"596e275826f08b2730779e1f\"}, \"aggregateid\": {\"$oid\": \"b2730779e1f596e275826f08\"}, \"aggregatetype\": \"Order\", \"type\": \"OrderCreated\", \"payload\": {\"_id\": {\"$oid\": \"da8d6de63b7745ff8f4457db\"}, \"lineItems\": [{\"id\": 1, \"item\": \"Debezium in Action\", \"status\": \"ENTERED\", \"quantity\": 2, \"totalPrice\": 39.98}, {\"id\": 2, \"item\": \"Debezium for Dummies\", \"status\": \"ENTERED\", \"quantity\": 1, \"totalPrice\": 29.99}], \"orderDate\": \"2019-01-31T12:13:01\", \"customerId\": 123}}",
"source": {
"version": "1.7.2.Final",
"connector": "mongodb",
"name": "fulfillment",
"ts_ms": 1558965508000,
"snapshot": false,
"db": "inventory",
"rs": "rs0",
"collection": "customers",
"ord": 31,
"h": 1546547425148721999
},
"op": "c",
"ts_ms": 1556890294484
}This example of a Debezium outbox message is based on the default outbox event router configuration, which assumes an outbox collection structure and event routing based on aggregates. To customize behavior, the outbox event router SMT provides numerous configuration options.
12.7.2. Outbox collection structure expected by Debezium mongodb outbox event router SMT
To apply the default MongoDB outbox event router SMT configuration, your outbox collection is assumed to have the following fields:
{
"_id": "objectId",
"aggregatetype": "string",
"aggregateid": "objectId",
"type": "string",
"payload": "object"
}| Field | Effect |
|---|---|
|
|
Contains the unique ID of the event. In an outbox message, this value is a header. You can use this ID, for example, to remove duplicate messages. |
|
|
Contains a value that the SMT appends to the name of the topic to which the connector emits an outbox message. The default behavior is that this value replaces the default |
|
|
Contains the event key, which provides an ID for the payload. The SMT uses this value as the key in the emitted outbox message. This is important for maintaining correct order in Kafka partitions. |
|
|
A representation of the outbox change event. The default structure is JSON. By default, the Kafka message value is solely comprised of the |
| Additional custom fields |
Any additional fields from the outbox collection can be added to outbox events either within the payload section or as a message header. |
12.7.3. Basic Debezium MongoDB outbox event router SMT configuration
To configure a Debezium connector to support the outbox pattern, configure the outbox.EventRouter SMT. The following example shows the basic configuration for the SMT in a .properties file:
transforms=outbox,...
transforms.outbox.type=io.debezium.connector.mongodb.transforms.outbox.MongoEventRouter12.7.4. Options for applying the MongoDB outbox event router transformation selectively
In addition to the change event messages that a Debezium connector emits when a database change occurs, the connector also emits other types of messages, including heartbeat messages, and metadata messages about schema changes and transactions. Because the structure of these other messages differs from the structure of the change event messages that the SMT is designed to process, it’s best to configure the connector to selectively apply the SMT, so that it processes only the intended data change messages. You can use one of the following methods to configure the connector to apply the SMT selectively:
- Configure an SMT predicate for the transformation.
-
Use the
route.topic.regexconfiguration option for the SMT.
12.7.5. Using Avro as the payload format in Debezium MongoDB outbox messages
The MongoDB outbox event router SMT supports arbitrary payload formats. The payload field value in an outbox collection is passed on transparently. An alternative to working with JSON is to use Avro. This can be beneficial for message format governance and for ensuring that outbox event schemas evolve in a backwards-compatible way.
How a source application produces Avro formatted content for outbox message payloads is out of the scope of this documentation. One possibility is to leverage the KafkaAvroSerializer class to serialize GenericRecord instances. To ensure that the Kafka message value is the exact Avro binary data, apply the following configuration to the connector:
transforms=outbox,...
transforms.outbox.type=io.debezium.connector.mongodb.transforms.outbox.MongoEventRouter
value.converter=io.debezium.converters.ByteBufferConverter
By default, the payload field value (the Avro data) is the only message value. Configuration of ByteBufferConverter as the value converter propagates the payload field value as-is into the Kafka message value.
The Debezium connectors may be configured to emit heartbeat, transaction metadata, or schema change events (support varies by connector). These events cannot be serialized by the ByteBufferConverter so additional configuration must be provided so the converter knows how to serialize these events. As an example, the following configuration illustrates using the Apache Kafka JsonConverter with no schemas:
transforms=outbox,...
transforms.outbox.type=io.debezium.connector.mongodb.transforms.outbox.MongoEventRouter
value.converter=io.debezium.converters.ByteBufferConverter
value.converter.delegate.converter.type=org.apache.kafka.connect.json.JsonConverter
value.converter.delegate.converter.type.schemas.enable=false
The delegate Converter implementation is specified by the delegate.converter.type option. If any extra configuration options are needed by the converter, they can also be specified, such as the disablement of schemas shown above using schemas.enable=false.
12.7.6. Emitting additional fields in Debezium MongoDB outbox messages
Your outbox collection might contain fields whose values you want to add to the emitted outbox messages. For example, consider an outbox collection that has a value of purchase-order in the aggregatetype field and another field, eventType, whose possible values are order-created and order-shipped. To emit the eventType field value in the outbox message header, configure the SMT like this:
transforms=outbox,...
transforms.outbox.type=io.debezium.connector.mongodb.transforms.outbox.MongoEventRouter
transforms.outbox.collection.fields.additional.placement=type:header:eventType
To emit the eventType field value in the outbox message envelope, configure the SMT like this:
transforms=outbox,...
transforms.outbox.type=io.debezium.connector.mongodb.transforms.outbox.MongoEventRouter
transforms.outbox.collection.fields.additional.placement=type:envelope:eventType12.7.7. Expanding escaped JSON String as JSON
By default, the payload of the Debezium outbox message is represented as a string. When the original source of the string is in JSON format, the resulting Kafka message uses escape sequences to represent the string, as shown in the following example:
# Kafka Topic: outbox.event.order
# Kafka Message key: "1"
# Kafka Message Headers: "id=596e275826f08b2730779e1f"
# Kafka Message Timestamp: 1556890294484
{
"{\"id\": {\"$oid\": \"da8d6de63b7745ff8f4457db\"}, \"lineItems\": [{\"id\": 1, \"item\": \"Debezium in Action\", \"status\": \"ENTERED\", \"quantity\": 2, \"totalPrice\": 39.98}, {\"id\": 2, \"item\": \"Debezium for Dummies\", \"status\": \"ENTERED\", \"quantity\": 1, \"totalPrice\": 29.99}], \"orderDate\": \"2019-01-31T12:13:01\", \"customerId\": 123}"
}You can configure the outbox event router to expand the message content, converting the escaped JSON back to its original, unescaped JSON format. In the converted string, the companion schema is deduced from the original JSON document. The following examples shows the expanded JSON in the resulting Kafka message:
# Kafka Topic: outbox.event.order
# Kafka Message key: "1"
# Kafka Message Headers: "id=596e275826f08b2730779e1f"
# Kafka Message Timestamp: 1556890294484
{
"id": "da8d6de63b7745ff8f4457db", "lineItems": [{"id": 1, "item": "Debezium in Action", "status": "ENTERED", "quantity": 2, "totalPrice": 39.98}, {"id": 2, "item": "Debezium for Dummies", "status": "ENTERED", "quantity": 1, "totalPrice": 29.99}], "orderDate": "2019-01-31T12:13:01", "customerId": 123
}
To enable string conversion in the transformation, set the value of collection.expand.json.payload to true and use the StringConverter as shown in the following example:
transforms=outbox,...
transforms.outbox.type=io.debezium.connector.mongodb.transforms.outbox.MongoEventRouter
transforms.outbox.collection.expand.json.payload=true
value.converter=org.apache.kafka.connect.storage.StringConverter12.7.8. Options for configuring outbox event router transformation
The following table describes the options that you can specify for the outbox event router SMT. In the table, the Group column indicates a configuration option classification for Kafka.
| Option | Default | Group | Description |
|---|---|---|---|
|
| Collection | Determines the behavior of the SMT when there is an update operation on the outbox collection. Possible settings are:
All changes in an outbox collection are expected to be an insert or delete operation. That is, an outbox collection functions as a queue; updates to documents in an outbox collection are not allowed. The SMT automatically filters out delete operations (for removing proceeded outbox events) on an outbox collection. | |
|
| Collection |
Specifies the outbox collection field that contains the unique event ID. This ID will be stored in the emitted event’s headers under the | |
|
| Collection | Specifies the outbox collection field that contains the event key. When this field contains a value, the SMT uses that value as the key in the emitted outbox message. This is important for maintaining correct order in Kafka partitions. | |
| Collection | By default, the timestamp in the emitted outbox message is the Debezium event timestamp. To use a different timestamp in outbox messages, set this option to an outbox collection field that contains the timestamp that you want to be in emitted outbox messages. | ||
|
| Collection | Specifies the outbox collection field that contains the event payload. | |
|
| Collection |
Specifies whether the JSON expansion of a String payload should be done. If no content found or in case of parsing error, the content is kept "as is". | |
| Collection, Envelope | Specifies one or more outbox collection fields that you want to add to outbox message headers or envelopes. Specify a comma-separated list of pairs. In each pair, specify the name of a field and whether you want the value to be in the header or the envelope. Separate the values in the pair with a colon, for example:
To specify an alias for the field, specify a trio with the alias as the third value, for example:
The second value is the placement and it must always be Configuration examples are in emitting additional fields in Debezium outbox messages. | ||
| Collection, Schema | When set, this value is used as the schema version as described in the Kafka Connect Schema Javadoc. | ||
|
| Router | Specifies the name of a field in the outbox collection. By default, the value specified in this field becomes a part of the name of the topic to which the connector emits the outbox messages. For an example, see the description of the expected outbox collection. | |
|
| Router |
Specifies a regular expression that the outbox SMT applies in the RegexRouter to outbox collection documents. This regular expression is part of the setting of the
+ The default behavior is that the SMT replaces the default | |
|
| Router |
Specifies the name of the topic to which the connector emits outbox messages. The default topic name is
+ To change the topic name, you can:
| |
|
| Router |
Indicates whether an empty or |
Revised on 2022-04-13 09:46:09 UTC