Development Guide
For Use with Red Hat JBoss Enterprise Application Platform 6
Abstract
Chapter 1. Get Started Developing Applications
1.1. Introduction
1.1.1. About Red Hat JBoss Enterprise Application Platform 6
1.2. Prerequisites
1.2.1. Become Familiar with Java Enterprise Edition 6
1.2.1.1. Overview of EE 6 Profiles
1.2.1.2. Java Enterprise Edition 6 Web Profile
Java EE 6 Web Profile Requirements
- Java Platform, Enterprise Edition 6
Java Web Technologies
- Servlet 3.0 (JSR 315)
- JSP 2.2 and Expression Language (EL) 1.2
- JavaServer Faces (JSF) 2.1 (JSR 314)
- Java Standard Tag Library (JSTL) for JSP 1.2
- Debugging Support for Other Languages 1.0 (JSR 45)
Enterprise Application Technologies
- Contexts and Dependency Injection (CDI) (JSR 299)
- Dependency Injection for Java (JSR 330)
- Enterprise JavaBeans 3.1 Lite (JSR 318)
- Java Persistence API 2.0 (JSR 317)
- Common Annotations for the Java Platform 1.1 (JSR 250)
- Java Transaction API (JTA) 1.1 (JSR 907)
- Bean Validation (JSR 303)
1.2.1.3. Java Enterprise Edition 6 Full Profile
Items Included in the EE 6 Full Profile
- EJB 3.1 (not Lite) (JSR 318)
- Java EE Connector Architecture 1.6 (JSR 322)
- Java Message Service (JMS) API 1.1 (JSR 914)
- JavaMail 1.4 (JSR 919)
Web Service Technologies
- Jax-RS RESTful Web Services 1.1 (JSR 311)
- Implementing Enterprise Web Services 1.3 (JSR 109)
- JAX-WS Java API for XML-Based Web Services 2.2 (JSR 224)
- Java Architecture for XML Binding (JAXB) 2.2 (JSR 222)
- Web Services Metadata for the Java Platform (JSR 181)
- Java APIs for XML-based RPC 1.1 (JSR 101)
- Java APIs for XML Messaging 1.3 (JSR 67)
- Java API for XML Registries (JAXR) 1.0 (JSR 93)
Management and Security Technologies
- Java Authentication Service Provider Interface for Containers 1.0 (JSR 196)
- Java Authentication Contract for Containers 1.3 (JSR 115)
- Java EE Application Deployment 1.2 (JSR 88)
- J2EE Management 1.1 (JSR 77)
1.2.2. About Modules and the New Modular Class Loading System used in JBoss EAP 6
1.2.2.1. Modules
- Static Modules
- Static Modules are predefined in the
EAP_HOME/modules/directory of the application server. Each sub-directory represents one module and defines amain/subdirectory that contains a configuration file (module.xml) and any required JAR files. The name of the module is defined in themodule.xmlfile. All the application server provided APIs are provided as static modules, including the Java EE APIs as well as other APIs such as JBoss Logging.Example 1.1. Example module.xml file
Copy to Clipboard Copied! Toggle word wrap Toggle overflow The module name,com.mysql, should match the directory structure for the module, excluding themain/subdirectory name.The modules provided in JBoss EAP distributions are located in asystemdirectory within theJBOSS_HOME/modulesdirectory. This keeps them separate from any modules provided by third parties.Any Red Hat provided layered products that layer on top of JBoss EAP 6.1 or later will also install their modules within thesystemdirectory.Creating custom static modules can be useful if many applications are deployed on the same server that use the same third party libraries. Instead of bundling those libraries with each application, a module containing these libraries can be created and installed by the JBoss administrator. The applications can then declare an explicit dependency on the custom static modules.Users must ensure that custom modules are installed into theJBOSS_HOME/modulesdirectory, using a one directory per module layout. This ensures that custom versions of modules that already exist in thesystemdirectory are loaded instead of the shipped versions. In this way, user provided modules will take precedence over system modules.If you use theJBOSS_MODULEPATHenvironment variable to change the locations in which JBoss EAP searches for modules, then the product will look for asystemsubdirectory structure within one of the locations specified. Asystemstructure must exist somewhere in the locations specified withJBOSS_MODULEPATH. - Dynamic Modules
- Dynamic Modules are created and loaded by the application server for each JAR or WAR deployment (or subdeployment in an EAR). The name of a dynamic module is derived from the name of the deployed archive. Because deployments are loaded as modules, they can configure dependencies and be used as dependencies by other deployments.
1.3. Set Up the Development Environment
1.3.1. Download and Install Red Hat JBoss Developer Studio
1.3.1.1. Setup Red Hat JBoss Developer Studio
1.3.1.2. Download Red Hat JBoss Developer Studio 7.1
- Go to https://access.redhat.com/.
- Select from the menu at the top of the page.
- Find
Red Hat JBoss Developer Studioin the list and click on it. - Select the appropriate version and click .
1.3.1.3. Install Red Hat JBoss Developer Studio 7.1
Procedure 1.1. Install Red Hat JBoss Developer Studio 7.1
- Open a terminal.
- Move into the directory containing the downloaded
.jarfile. - Run the following command to launch the GUI installer:
java -jar jbdevstudio-build_version.jar
java -jar jbdevstudio-build_version.jarCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Click to start the installation process.
- Select I accept the terms of this license agreement and click .
- Adjust the installation path and click .
Note
If the installation path folder does not exist, a prompt will appear. Click to create the folder. - Choose a JVM, or leave the default JVM selected, and click .
- Add any application platforms available, and click .
- Review the installation details, and click .
- Click when the installation process is complete.
- Configure the desktop shortcuts for Red Hat JBoss Developer Studio, and click .
- Click .
1.3.1.4. Start Red Hat JBoss Developer Studio
Procedure 1.2. Command to start Red Hat JBoss Developer Studio
- Open a terminal.
- Change into the installation directory.
- Run the following command to start Red Hat JBoss Developer Studio:
./jbdevstudio
[localhost]$ ./jbdevstudioCopy to Clipboard Copied! Toggle word wrap Toggle overflow
1.3.1.5. Add the JBoss EAP Server Using Define New Server
Procedure 1.3. Add the server
- Open the Servers tab. If there is no Servers tab, add it to the panel as follows:
- Click → → .
- Select Servers from the Server folder and click .
- Click on the link to create a new server or right-click within the blank Server panel and select → .
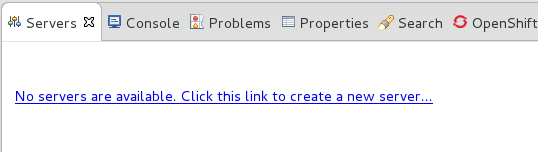
Figure 1.1. Add a new server - No servers available
- Expand JBoss Enterprise Middleware and choose . Click to create the JBoss runtime and define the server. The next time you define a new server, this dialog displays a Server runtime environment selection with the new runtime definition.
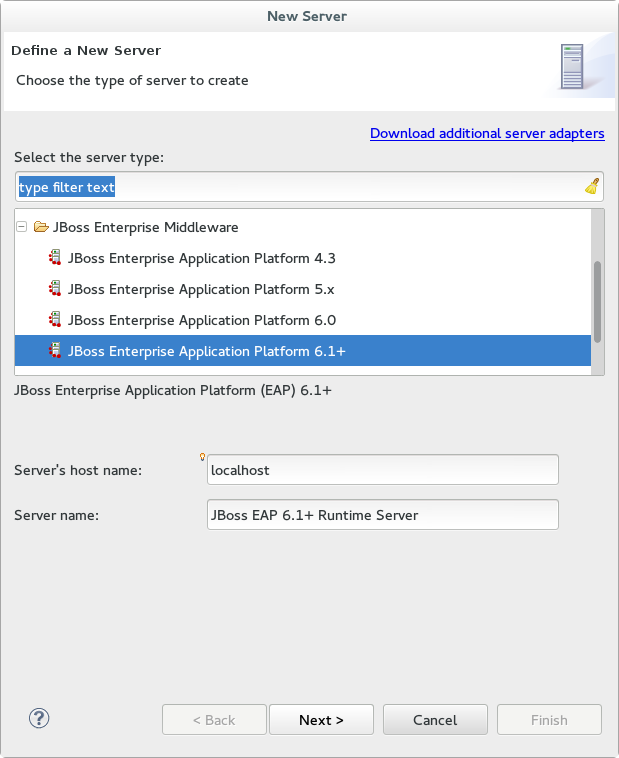
Figure 1.2. Define a New Server
- Enter a name, for example "JBoss EAP 6.3 Runtime". Under Home Directory, click and navigate to your JBoss EAP install location. Then click .
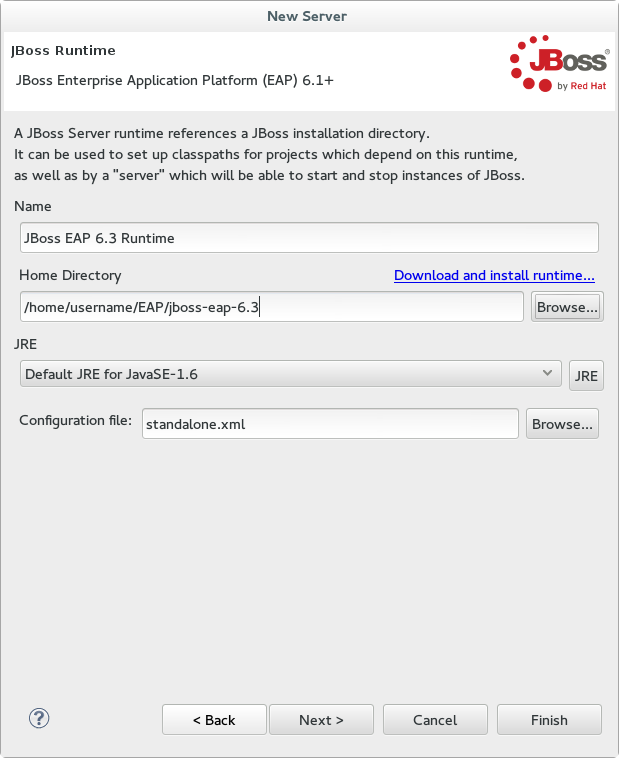
Figure 1.3. Add New Server Runtime Environment
Note
Some quickstarts require that you run the server with a different profile or additional arguments. To deploy a quickstart that requires thefullprofile, you must define a new server and add a Server Runtime Environment that specifiesstandalone-full.xmlfor the Configuration file. Be sure to give the new server a descriptive name. - On this screen you define the server behavior. You can start the server manually or let Red Hat JBoss Developer Studio manage it for you. You can also define a remote server for deployment and determine if you want to expose the management port for that server, for example, if you need connect to it using JMX. In this example, we assume the server is local and you want Red Hat JBoss Developer Studio to manage your server so you do not need to check anything. Click .
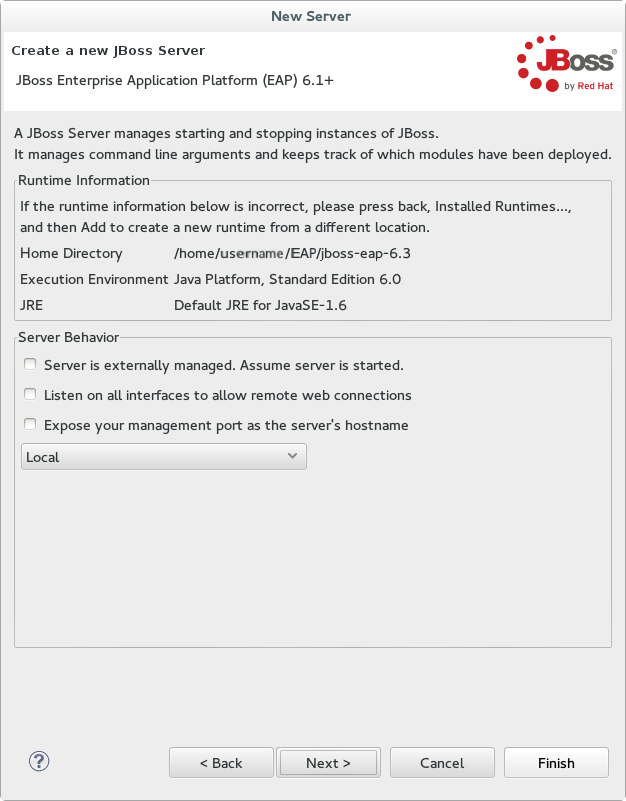
Figure 1.4. Define the New JBoss Server Behavior
- This screen allows you to configure existing projects for the new server. Because you do not have any projects at this point, click .
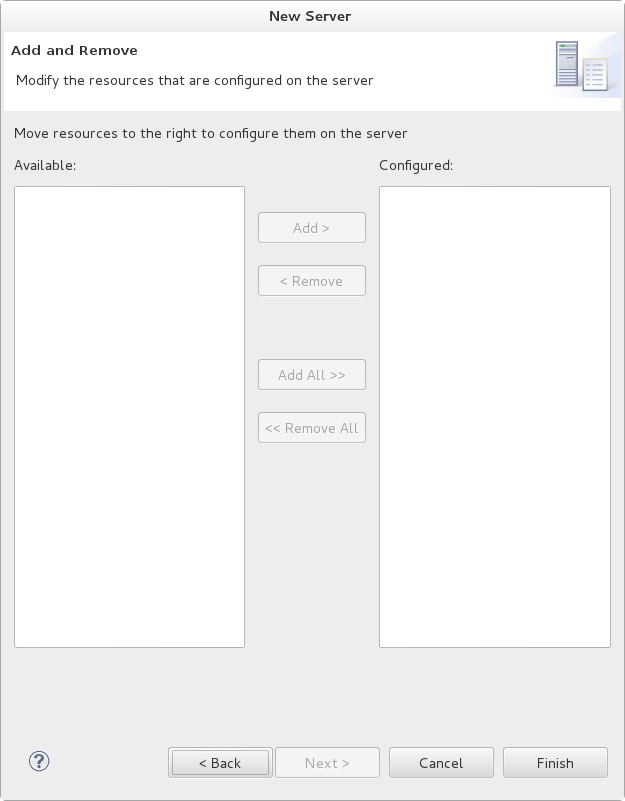
Figure 1.5. Modify resources for the new JBoss server
The JBoss EAP Runtime Server is listed in the Servers tab.
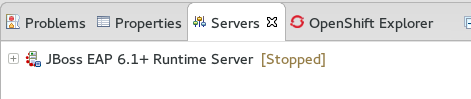
Figure 1.6. Server appears in the server list
1.4. Run Your First Application
1.4.1. Download the Quickstart Code Examples
1.4.1.1. Access the Quickstarts
JBoss EAP 6 comes with a series of quickstart examples designed to help users begin writing applications using the Java EE 6 technologies.
Prerequisites
- Maven 3.0.0 or higher. For more information on installing Maven, refer to http://maven.apache.org/download.html.
- The JBoss EAP 6.3 Maven respository is available online, so it is not necessary to download and install it locally. If you plan to use the online repository, you can skip to the next step. If you prefer to install a local repository, see: Section 2.2.3, “Install the JBoss EAP 6 Maven Repository Locally”.
Procedure 1.4. Download the Quickstarts
- Open a web browser and access this URL: https://access.redhat.com/jbossnetwork/restricted/listSoftware.html?product=appplatform.
- Find "Quickstarts" in the list.
- Click the button to download a Zip archive containing the examples.
- Unzip the archive in a directory of your choosing.
The JBoss EAP Quickstarts have been downloaded and unzipped. Refer to the README.md file in the top-level directory of the Quickstart archive for instructions about deploying each quickstart.
1.4.2. Run the Quickstarts
1.4.2.1. Run the Quickstarts in Red Hat JBoss Developer Studio
Procedure 1.5. Import the quickstarts into Red Hat JBoss Developer Studio
Important
- If you have not yet done so, Section 2.3.2, “Configure the JBoss EAP 6 Maven Repository Using the Maven Settings”.
- Start Red Hat JBoss Developer Studio.
- From the menu, select → .
- In the selection list, choose → , then click .
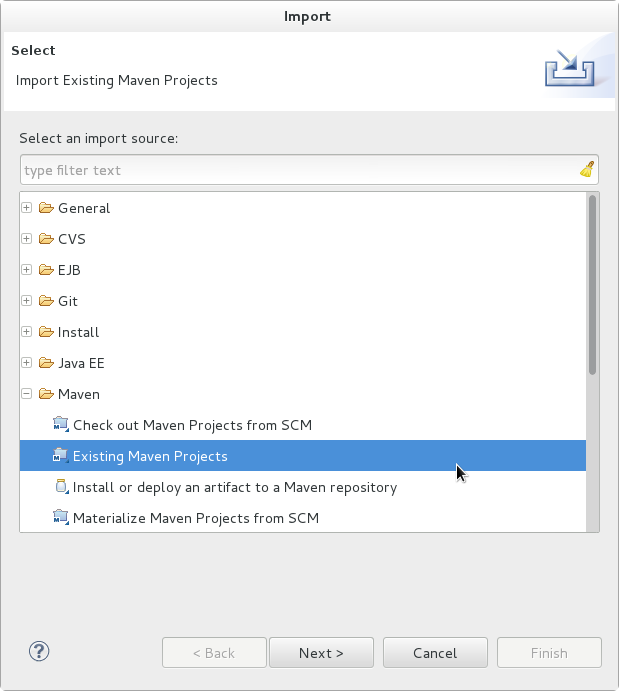
Figure 1.7. Import Existing Maven Projects
- Browse to the directory of the quickstart you plan to test, for example the
helloworldquickstart, and click . The Projects list box is populated with thepom.xmlfile of the selected quickstart project.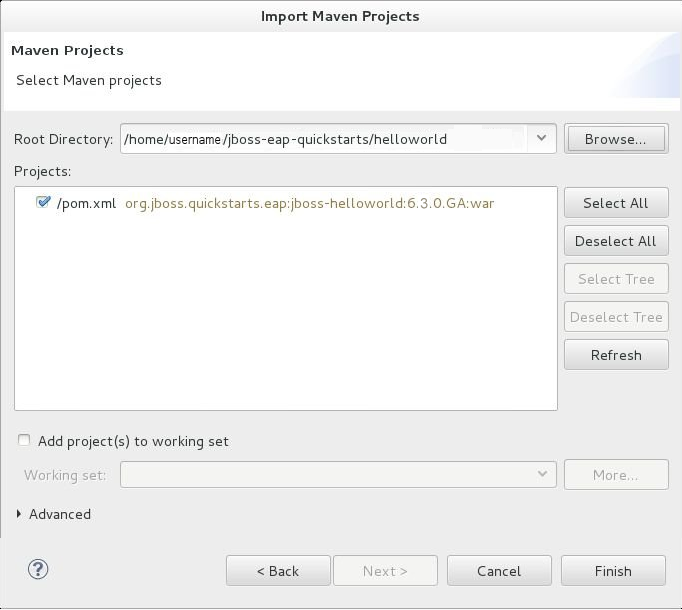
Figure 1.8. Select Maven Projects
- Click .
Procedure 1.6. Build and Deploy the helloworld quickstart
helloworld quickstart is one of the simplest quickstarts and is a good way to verify that the JBoss server is configured and running correctly.
- If you do not see a Servers tab or have not yet defined a server, follow the instructions here: Section 1.3.1.5, “Add the JBoss EAP Server Using Define New Server”. If you plan to deploy a quickstart that requires the
fullprofile or additional startup arguments, be sure to create the server runtime environment as noted in the quickstart instructions. - Right-click on the
jboss-helloworldproject in the Project Explorer tab and select . You are provided with a list of choices. Select .
Figure 1.9. Run As - Run on Server
- Select JBoss EAP 6.1+ Runtime Server from the server list and click .
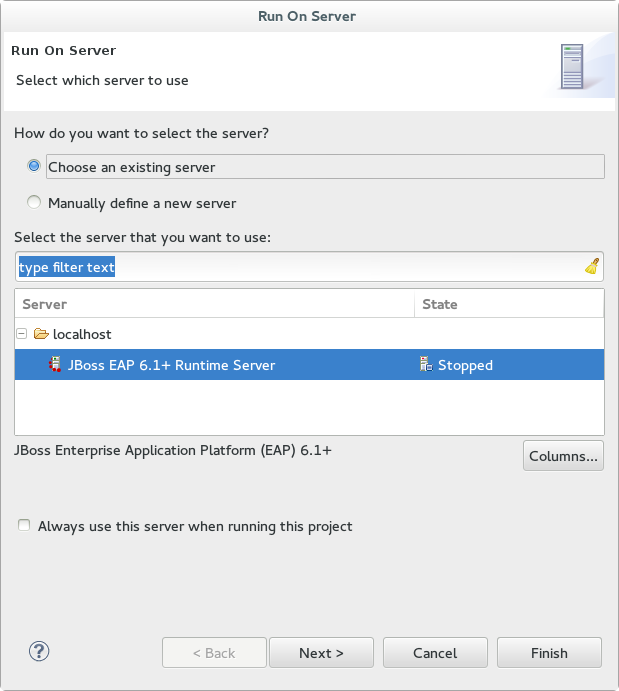
Figure 1.10. Run on Server
- The next screen displays the resources that are configured on the server. The
jboss-helloworldquickstart is configured for you. Click to deploy the quickstart.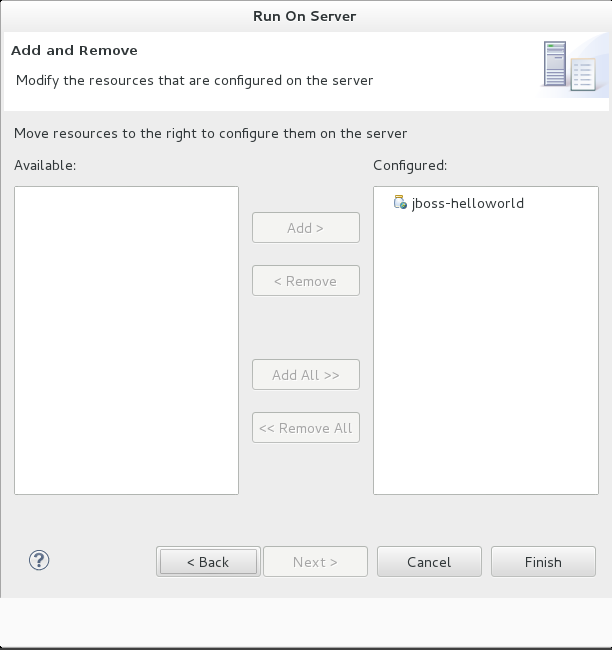
Figure 1.11. Modify Resources Configured on the Server
- Review the results.
- In the
Servertab, the JBoss EAP 6.3 Runtime Server status changes to[Started, Republish]. - The server Console tab shows messages detailing the JBoss EAP 6.3 server start and the helloworld quickstart deployment.
- A helloworld tab appears displaying the URL http://localhost:8080/jboss-helloworld/HelloWorld and the text "Hello World!".
- The following messages in the Console confirm deployment of the
jboss-helloworld.warfile:The registered web context is appended toJBAS018210: Register web context: /jboss-helloworld JBAS018559: Deployed "jboss-helloworld.war" (runtime-name : "jboss-helloworld.war")
JBAS018210: Register web context: /jboss-helloworld JBAS018559: Deployed "jboss-helloworld.war" (runtime-name : "jboss-helloworld.war")Copy to Clipboard Copied! Toggle word wrap Toggle overflow http://localhost:8080to provide the URL used to access the deployed application.
- To verify the
helloworldquickstart deployed successfully to the JBoss server, open a web browser and access the application at this URL: http://localhost:8080/jboss-helloworld
Procedure 1.7. Run the bean-validation quickstart Arquillian tests
bean-validation quickstart is an example of a quickstart that provides Arquillian tests.
- Follow the procedure above to import the
bean-validationquickstart into Red Hat JBoss Developer Studio. - If you do not see a Servers tab or have not yet defined a server, follow the instructions here: Section 1.3.1.5, “Add the JBoss EAP Server Using Define New Server”
- Right-click on the
jboss-bean-validationproject in the Project Explorer tab and select . You are provided with a list of choices. Select . - In the Goals input field of the Edit Configuration dialog, type:
clean test -Parq-jbossas-remoteThen click .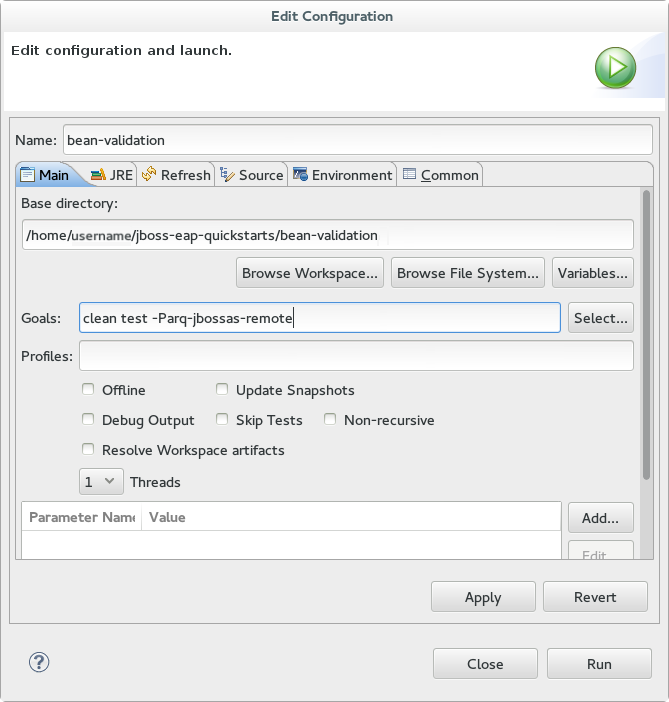
Figure 1.12. Edit Configuration
- Review the results.The server Console tab shows messages detailing the JBoss EAP server start and the output of the
bean-validationquickstart Arquillian tests.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
1.4.2.2. Run the Quickstarts Using a Command Line
Procedure 1.8. Build and Deploy the Quickstarts Using a Command Line
- If you have not yet done so, Section 2.3.2, “Configure the JBoss EAP 6 Maven Repository Using the Maven Settings”.
- Review the
README.htmlfile in the root directory of the quickstarts.This file contains general information about system requirements, how to configure Maven, how to add users, and how to run the Quickstarts. Be sure to read through it before you get started.It also contains a table listing the available quickstarts. The table lists each quickstart name and the technologies it demonstrates. It gives a brief description of each quickstart and the level of experience required to set it up. For more detailed information about a quickstart, click on the quickstart name.Some quickstarts are designed to enhance or extend other quickstarts. These are noted in thePrerequisitescolumn. If a quickstart lists prerequisites, you must install them first before working with the quickstart.Some quickstarts require the installation and configuration of optional components. Do not install these components unless the quickstart requires them. - Run the
helloworldquickstart.Thehelloworldquickstart is one of the simplest quickstarts and is a good way to verify that the JBoss server is configured and running correctly. Open theREADME.htmlfile in the root of thehelloworldquickstart. It contains detailed instructions on how to build and deploy the quickstart and access the running application - Run the other quickstarts.Follow the instructions in the
README.htmlfile located in the root folder of each quickstart to run the example.
1.4.3. Review the Quickstart Tutorials
1.4.3.1. Explore the helloworld Quickstart
The helloworld quickstart shows you how to deploy a simple Servlet to JBoss EAP 6. The business logic is encapsulated in a service which is provided as a CDI (Contexts and Dependency Injection) bean and injected into the Servlet. This quickstart is very simple. All it does is print "Hello World" onto a web page. It is a good starting point to be sure you have configured and started your server properly.
helloworld quickstart.
- Install Red Hat JBoss Developer Studio following the procedure here: Section 1.3.1.3, “Install Red Hat JBoss Developer Studio 7.1”.
- Configure Maven for use with Red Hat JBoss Developer Studio following the procedure here: Section 2.3.3, “Configure Maven for Use with Red Hat JBoss Developer Studio”.
- Follow the procedures here to import, build, and deploy the
helloworldquickstart in Red Hat JBoss Developer Studio: Section 1.4.2.1, “Run the Quickstarts in Red Hat JBoss Developer Studio” - Verify the
helloworldquickstart was deployed successfully to JBoss EAP by opening a web browser and accessing the application at this URL: http://localhost:8080/jboss-helloworld
Procedure 1.9. Examine the Directory Structure
QUICKSTART_HOME/helloworld directory. The helloworld quickstart is comprised a Servlet and a CDI bean. It also includes an empty beans.xml file which tells JBoss EAP 6 to look for beans in this application and to activate the CDI.
- The
beans.xmlfile is located in theWEB-INF/folder in thesrc/main/webapp/directory of the quickstart. - The
src/main/webapp/directory also includes anindex.htmlfile which uses a simple meta refresh to redirect the user's browser to the Servlet, which is located at http://localhost:8080/jboss-helloworld/HelloWorld. - All the configuration files for this example are located in
WEB-INF/, which can be found in thesrc/main/webapp/directory of the example. - Notice that the quickstart doesn't even need a
web.xmlfile!
Procedure 1.10. Examine the Code
Review the HelloWorldServlet code
TheHelloWorldServlet.javafile is located in thesrc/main/java/org/jboss/as/quickstarts/helloworld/directory. This Servlet sends the information to the browser.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand Table 1.1. HelloWorldServlet Details Line Note 43 Before Java EE 6, an XML file was used to register Servlets. It is now much cleaner. All you need to do is add the @WebServletannotation and provide a mapping to a URL used to access the servlet.46-48 Every web page needs correctly formed HTML. This quickstart uses static Strings to write the minimum header and footer output. 50-51 These lines inject the HelloService CDI bean which generates the actual message. As long as we don't alter the API of HelloService, this approach allows us to alter the implementation of HelloService at a later date without changing the view layer. 58 This line calls into the service to generate the message "Hello World", and write it out to the HTTP request. Review the HelloService code
TheHelloService.javafile is located in thesrc/main/java/org/jboss/as/quickstarts/helloworld/directory. This service is very simple. It returns a message. No XML or annotation registration is required.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
1.4.3.2. Explore the numberguess Quickstart
This quickstart shows you how to create and deploy a simple application to JBoss EAP 6. This application does not persist any information. Information is displayed using a JSF view, and business logic is encapsulated in two CDI (Contexts and Dependency Injection) beans. In the numberguess quickstart, you get 10 attempts to guess a number between 1 and 100. After each attempt, you're told whether your guess was too high or too low.
QUICKSTART_HOME/numberguess directory. The numberguess quickstart is comprised of a number of beans, configuration files and Facelets (JSF) views, packaged as a WAR module.
numberguess quickstart.
- Install Red Hat JBoss Developer Studio following the procedure here: Section 1.3.1.3, “Install Red Hat JBoss Developer Studio 7.1”.
- Configure Maven for use with Red Hat JBoss Developer Studio following the procedure here: Section 2.3.3, “Configure Maven for Use with Red Hat JBoss Developer Studio”.
- Follow the procedures here to import, build, and deploy the
numberguessquickstart in Red Hat JBoss Developer Studio: Section 1.4.2.1, “Run the Quickstarts in Red Hat JBoss Developer Studio” - Verify the
numberguessquickstart was deployed successfully to JBoss EAP by opening a web browser and accessing the application at this URL: http://localhost:8080/jboss-numberguess
Procedure 1.11. Examine the Configuration Files
WEB-INF/ directory which can be found in the src/main/webapp/ directory of the quickstart.
- Examine the
faces-config.xmlfile.This quickstart uses the JSF 2.0 version offaces-config.xmlfilename. A standardized version of Facelets is the default view handler in JSF 2.0, so there's really nothing that you have to configure. JBoss EAP 6 goes above and beyond Java EE here. It will automatically configure the JSF for you if you include this configuration file. As a result, the configuration consists of only the root element:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Examine the
beans.xmlfile.There's also an emptybeans.xmlfile, which tells JBoss EAP 6 to look for beans in this application and to activate the CDI. - There is no
web.xmlfileNotice that the quickstart doesn't even need aweb.xmlfile!
Procedure 1.12. Examine the JSF Code
.xhtml file extension for source files, but serves up the rendered views with the .jsf extension.
- Examine the
home.xhtmlcode.Thehome.xhtmlfile is located in thesrc/main/webapp/directory.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand Table 1.2. JSF Details Line Note 36-40 These are the messages which can be sent to the user: "Higher!" and "Lower!" 45-48 As the user guesses, the range of numbers they can guess gets smaller. This sentence changes to make sure they know the number range of a valid guess. 55-58 This input field is bound to a bean property using a value expression. 58 A validator binding is used to make sure the user does not accidentally input a number outside of the range in which they can guess. If the validator was not here, the user might use up a guess on an out of bounds number. 59-61 There must be a way for the user to send their guess to the server. Here we bind to an action method on the bean.
Procedure 1.13. Examine the Class Files
src/main/java/org/jboss/as/quickstarts/numberguess/ directory. The package declaration and imports have been excluded from these listings. The complete listing is available in the quickstart source code.
- Review the
Random.javaqualifier code.A qualifier is used to remove ambiguity between two beans, both of which are eligible for injection based on their type. For more information on qualifiers, refer to Section 10.2.3.3, “Use a Qualifier to Resolve an Ambiguous Injection”The@Randomqualifier is used for injecting a random number.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Review the
MaxNumber.javaqualifier code.The@MaxNumberqualifieris used for injecting the maximum number allowed.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Review the
Generator.javacode.TheGeneratorclass is responsible for creating the random number via a producer method. It also exposes the maximum possible number via a producer method. This class is application scoped so you don't get a different random each time.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Review the
Game.javacode.The session scoped classGameis the primary entry point of the application. It is responsible for setting up or resetting the game, capturing and validating the user's guess, and providing feedback to the user with aFacesMessage. It uses the post-construct lifecycle method to initialize the game by retrieving a random number from the@Random Instance<Integer>bean.Notice the @Named annotation in the class. This annotation is only required when you want to make the bean accessible to a JSF view via Expression Language (EL), in this case#{game}.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
1.4.4. Replace the Default Welcome Web Application
Procedure 1.14. Replace the Default Welcome Web Application With Your Own Web Application
Disable the Welcome application.
Use the Management CLI scriptEAP_HOME/bin/jboss-cli.shto run the following command. You may need to change the profile to modify a different managed domain profile, or remove the/profile=defaultportion of the command for a standalone server./profile=default/subsystem=web/virtual-server=default-host:write-attribute(name=enable-welcome-root,value=false)
/profile=default/subsystem=web/virtual-server=default-host:write-attribute(name=enable-welcome-root,value=false)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Configure your Web application to use the root context.
To configure your web application to use the root context (/) as its URL address, modify itsjboss-web.xml, which is located in theMETA-INF/orWEB-INF/directory. Replace its<context-root>directive with one that looks like the following.<jboss-web> <context-root>/</context-root> </jboss-web><jboss-web> <context-root>/</context-root> </jboss-web>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Deploy your application.
Deploy your application to the server group or server you modified in the first step. The application is now available onhttp://SERVER_URL:PORT/.
Chapter 2. Maven Guide
2.1. Learn about Maven
2.1.1. About the Maven Repository
http:// for a repository on an HTTP server or file:// for a repository on a file server.
2.1.2. About the Maven POM File
pom.xml file requires some configuration options and will default all others. See Section 2.1.3, “Minimum Requirements of a Maven POM File” for details.
pom.xml file can be found at http://maven.apache.org/maven-v4_0_0.xsd.
2.1.3. Minimum Requirements of a Maven POM File
The minimum requirements of a pom.xml file are as follows:
- project root
- modelVersion
- groupId - the id of the project's group
- artifactId - the id of the artifact (project)
- version - the version of the artifact under the specified group
A basic pom.xml file might look like this:
2.1.4. About the Maven Settings File
settings.xml file contains user-specific configuration information for Maven. It contains information that should not be distributed with the pom.xml file, such as developer identity, proxy information, local repository location, and other settings specific to a user.
settings.xml can be found.
- In the Maven install
- The settings file can be found in the
M2_HOME/conf/directory. These settings are referred to asglobalsettings. The default Maven settings file is a template that can be copied and used as a starting point for the user settings file. - In the user's install
- The settings file can be found in the
USER_HOME/.m2/directory. If both the Maven and usersettings.xmlfiles exist, the contents are merged. Where there are overlaps, the user'ssettings.xmlfile takes precedence.
settings.xml file:
settings.xml file can be found at http://maven.apache.org/xsd/settings-1.0.0.xsd.
2.2. Install Maven and the JBoss Maven Repository
2.2.1. Download and Install Maven
- Go to Apache Maven Project - Download Maven and download the latest distribution for your operating system.
- See the Maven documentation for information on how to download and install Apache Maven for your operating system.
2.2.2. Install the JBoss EAP 6 Maven Repository
2.2.3. Install the JBoss EAP 6 Maven Repository Locally
The JBoss EAP 6.3 Maven repository is available online, so it is not necessary to download and install it locally. However, if you prefer to install the JBoss EAP Maven repository locally, there are three ways to do it: on your local file system, on Apache Web Server, or with a Maven repository manager. This example covers the steps to download the JBoss EAP 6 Maven Repository to the local file system. This option is easy to configure and allows you to get up and running quickly on your local machine. It can help you become familiar with using Maven for development but is not recommended for team production environments.
Procedure 2.1. Download and Install the JBoss EAP 6 Maven Repository to the Local File System
- Open a web browser and access this URL: https://access.redhat.com/jbossnetwork/restricted/listSoftware.html?product=appplatform.
- Find "Red Hat JBoss Enterprise Application Platform 6.3.0 Maven Repository" in the list.
- Click the button to download a
.zipfile containing the repository. - Unzip the file on the local file system into a directory of your choosing.
This creates a Maven repository directory called jboss-eap-6.3.0.GA-maven-repository.
Important
settings.xml configuration file. Each local repository must be configured within its own <repository> tag.
Important
repository/ subdirectory located under the .m2/directory before attempting to use the new Maven repository.
2.2.4. Install the JBoss EAP 6 Maven Repository for Use with Apache httpd
You must configure Apache httpd. See Apache HTTP Server Project documentation for instructions.
Procedure 2.2. Download the JBoss EAP 6 Maven Repository ZIP archive
- Open a web browser and access this URL: https://access.redhat.com/jbossnetwork/restricted/listSoftware.html?product=appplatform.
- Find "Red Hat JBoss Enterprise Application Platform 6.3.0 Maven Repository" in the list.
- Click the button to download a
.zipfile containing the repository. - Unzip the files in a directory that is web accessible on the Apache server.
- Configure Apache to allow read access and directory browsing in the created directory.
This allows a multi-user environment to access the Maven repository on Apache httpd.
Note
2.2.5. Install the JBoss EAP 6 Maven Repository Using Nexus Maven Repository Manager
Procedure 2.3. Download the JBoss EAP 6 Maven Repository ZIP archive
- Open a web browser and access this URL: https://access.redhat.com/jbossnetwork/restricted/listSoftware.html?product=appplatform.
- Find "Red Hat JBoss Enterprise Application Platform 6.3.0 Maven Repository" in the list.
- Click the button to download a
.zipfile containing the repository. - Unzip the files into a directory of your choosing on the server hosting Nexus.
Procedure 2.4. Add the JBoss EAP 6 Maven Repository using Nexus Maven Repository Manager
- Log into Nexus as an Administrator.
- Select the Repositories section from the → menu to the left of your repository manager.
- Click the Add... dropdown, then select Hosted Repository.
- Give the new repository a name and ID.
- Enter the path on disk to the unzipped repository in the field Override Local Storage Location.
- Continue if you want the artifact to be available in a repository group. Do not continue with this procedure if this is not what you want.
- Select the repository group.
- Click on the Configure tab.
- Drag the new JBoss Maven repository from the Available Repositories list to the Ordered Group Repositories list on the left.
Note
Note that the order of this list determines the priority for searching Maven artifacts.
The repository is configured using Nexus Maven Repository Manager.
2.2.6. About Maven Repository Managers
- They provide the ability to configure proxies between your organization and remote Maven repositories. This provides a number of benefits, including faster and more efficient deployments and a better level of control over what is downloaded by Maven.
- They provide deployment destinations for your own generated artifacts, allowing collaboration between different development teams across an organization.
Commonly used Maven repository managers
- Sonatype Nexus
- See Sonatype Nexus: Manage Artifacts for more information about Nexus.
- Artifactory
- See Artifactory Open Source for more information about Artifactory.
- Apache Archiva
- See Apache Archiva: The Build Artifact Repository Manager for more information about Apache Archiva.
2.3. Use the Maven Repository
2.3.1. Configure the JBoss EAP Maven 6 Repository
There are two approaches to direct Maven to use the JBoss EAP 6 Maven Repository in your project:
- You can configure the repositories in the Maven global or user settings.
- You can configure the repositories in the project's POM file.
Procedure 2.5. Configure Maven Settings to Use the JBoss EAP 6 Maven Repository
Configure the Maven repository using Maven settings
This is the recommended approach. Maven settings used with a repository manager or repository on a shared server provide better control and manageability of projects. Settings also provide the ability to use an alternative mirror to redirect all lookup requests for a specific repository to your repository manager without changing the project files. For more information about mirrors, see http://maven.apache.org/guides/mini/guide-mirror-settings.html.This method of configuration applies across all Maven projects, as long as the project POM file does not contain repository configuration.Configure the Maven repository using the project POM
This method of configuration is generally not recommended. If you decide to configure repositories in your project POM file, plan carefully and be aware that it can slow down your build and you may even end up with artifacts that are not from the expected repository.Note
In an Enterprise environment, where a repository manager is usually used, Maven should query all artifacts for all projects using this manager. Because Maven uses all declared repositories to find missing artifacts, if it can't find what it's looking for, it will try and look for it in the repository central (defined in the built-in parent POM). To override this central location, you can add a definition withcentralso that the default repository central is now your repository manager as well. This works well for established projects, but for clean or 'new' projects it causes a problem as it creates a cyclic dependency.Transitively included POMs are also an issue with this type of configuration. Maven has to query these external repositories for missing artifacts. This not only slows down your build, it also causes you to lose control over where your artifacts are coming from and likely to cause broken builds.This method of configuration overrides the global and user Maven settings for the configured project.
2.3.2. Configure the JBoss EAP 6 Maven Repository Using the Maven Settings
- You can modify the Maven settings. This directs Maven to use the configuration across all projects.
- You can configure the project's POM file. This limits the configuration to the specific project.
Note
- File System
- file:///path/to/repo/jboss-eap-6.x-maven-repository
- Apache Web Server
- http://intranet.acme.com/jboss-eap-6.x-maven-repository/
- Nexus Repository Manager
- https://intranet.acme.com/nexus/content/repositories/jboss-eap-6.x-maven-repository
Procedure 2.6. Configure Maven Using the Settings Shipped with the Quickstart Examples
settings.xml file that is configured to use the online JBoss EAP 6 Maven repository. This is the simplest approach.
- This procedure overwrites the existing Maven settings file, so you must back up the existing Maven
settings.xmlfile.- Locate the Maven install directory for your operating system. It is usually installed in
USER_HOME/.m2/directory.- For Linux or Mac, this is:
~/.m2/ - For Windows, this is:
\Documents and Settings\USER_NAME\.m2\or\Users\USER_NAME\.m2\
- If you have an existing
USER_HOME/.m2/settings.xmlfile, rename it or make a backup copy so you can restore it later.
- Download and unzip the quickstart examples that ship with JBoss EAP 6. For more information, see Section 1.4.1.1, “Access the Quickstarts”
- Copy the
QUICKSTART_HOME/settings.xmlfile to theUSER_HOME/.m2/directory. - If you modify the
settings.xmlfile while Red Hat JBoss Developer Studio is running, follow the procedure below entitled Refresh the Red Hat JBoss Developer Studio User Settings.
Procedure 2.7. Manually Edit and Configure the Maven Settings To Use the Online JBoss EAP 6 Maven Repository
- Locate the Maven install directory for your operating system. It is usually installed in
USER_HOME/.m2/directory.- For Linux or Mac, this is
~/.m2/ - For Windows, this is
\Documents and Settings\USER_NAME\.m2\or\Users\USER_NAME\.m2\
- If you do not find a
settings.xmlfile, copy thesettings.xmlfile from theUSER_HOME/.m2/conf/directory into theUSER_HOME/.m2/directory. - Copy the following XML into the
<profiles>element of the file.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy the following XML into the<activeProfiles>element of thesettings.xmlfile.<activeProfile>jboss-ga-repository</activeProfile> <activeProfile>jboss-earlyaccess-repository</activeProfile>
<activeProfile>jboss-ga-repository</activeProfile> <activeProfile>jboss-earlyaccess-repository</activeProfile>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - If you modify the
settings.xmlfile while Red Hat JBoss Developer Studio is running, follow the procedure below entitled Refresh the Red Hat JBoss Developer Studio User Settings.
Procedure 2.8. Configure the Settings to Use a Locally Installed JBoss EAP Repository
- Locate the Maven install directory for your operating system. It is usually installed in
USER_HOME/.m2/directory.- For Linux or Mac, this is
~/.m2/ - For Windows, this is
\Documents and Settings\USER_NAME\.m2\or\Users\USER_NAME\.m2\
- If you do not find a
settings.xmlfile, copy thesettings.xmlfile from theUSER_HOME/.m2/conf/directory into theUSER_HOME/.m2/directory. - Copy the following XML into the
<profiles>element of thesettings.xmlfile. Be sure to change the<url>to the actual repository location.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy the following XML into the<activeProfiles>element of thesettings.xmlfile.<activeProfile>jboss-eap-repository</activeProfile>
<activeProfile>jboss-eap-repository</activeProfile>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - If you modify the
settings.xmlfile while Red Hat JBoss Developer Studio is running, follow the procedure below entitled Refresh the Red Hat JBoss Developer Studio User Settings.
Procedure 2.9. Refresh the Red Hat JBoss Developer Studio User Settings
settings.xml file while Red Hat JBoss Developer Studio is running, you must refresh the user settings.
- From the menu, choose → .
- In the Preferences Window, expand Maven and choose User Settings.
- Click the button to refresh the Maven user settings in Red Hat JBoss Developer Studio.
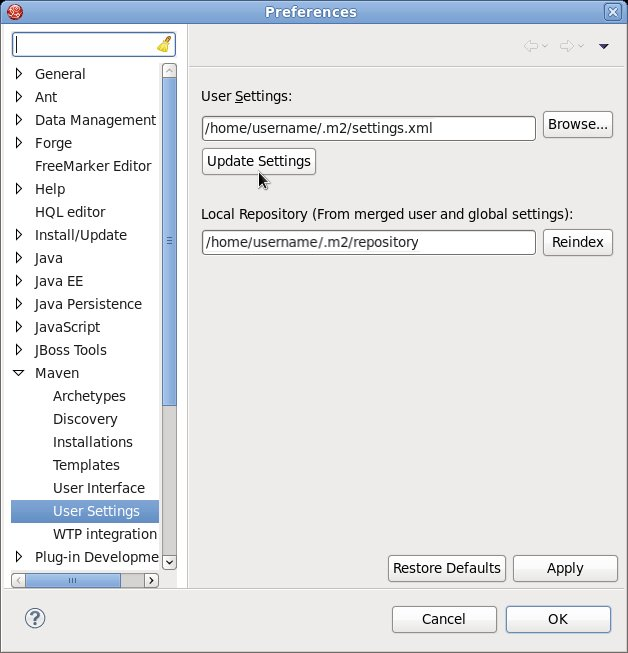
Figure 2.1. Update Maven User Settings
Important
- Missing artifact ARTIFACT_NAME
- [ERROR] Failed to execute goal on project PROJECT_NAME; Could not resolve dependencies for PROJECT_NAME
~/.m2/repository/ subdirectory on Linux, or the %SystemDrive%\Users\USERNAME\.m2\repository\ subdirectory on Windows.
2.3.3. Configure Maven for Use with Red Hat JBoss Developer Studio
Procedure 2.10. Configure Maven in Red Hat JBoss Developer Studio
- Click →, expand JBoss Tools and select JBoss Maven Integration.
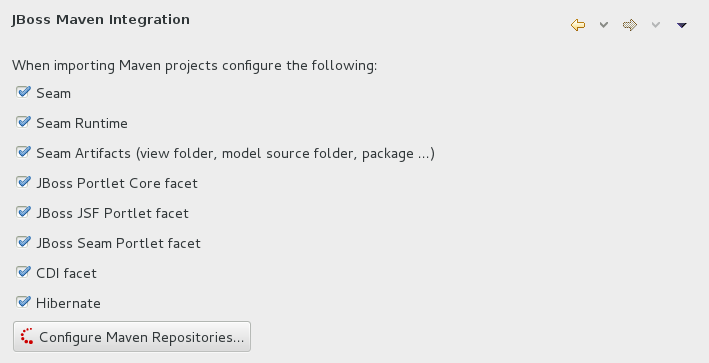
Figure 2.2. JBoss Maven Integration Pane in the Preferences Window
- Click .
- Click to configure the JBoss GA Tech Preview Maven repository. Complete the
Add Maven Repositorydialog as follows:- Set the Profile ID, Repository ID, and Repository Name values to
jboss-ga-repository. - Set the Repository URL value to
http://maven.repository.redhat.com/techpreview/all. - Click the checkbox to enable the Maven repository.
- Click
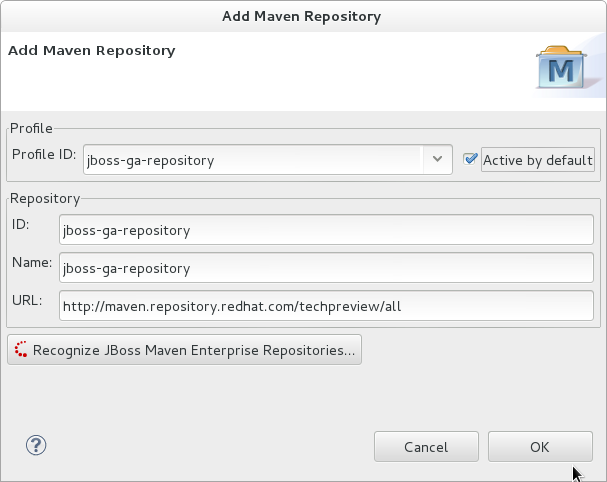
Figure 2.3. Add Maven Repository - JBoss Tech Preview
- Click to configure the JBoss Early Access Maven repository. Complete the
Add Maven Repositorydialog as follows:- Set the Profile ID, Repository ID, and Repository Name values to
jboss-earlyaccess-repository. - Set the Repository URL value to
http://maven.repository.redhat.com/earlyaccess/all/. - Click the checkbox to enable the Maven repository.
- Click
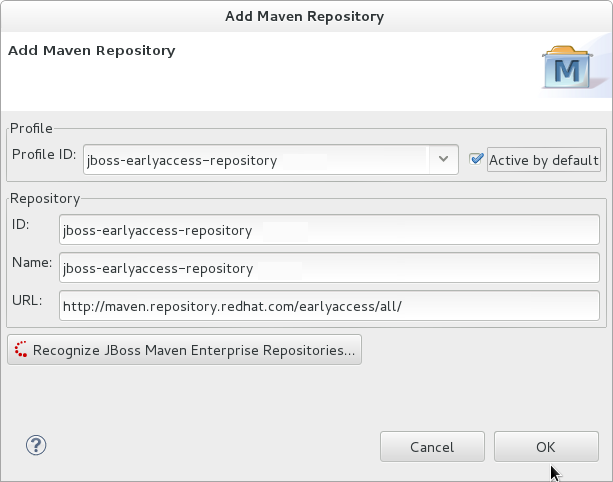
Figure 2.4. Add Maven Repository - JBoss Early Access
- Review the repositories and click .
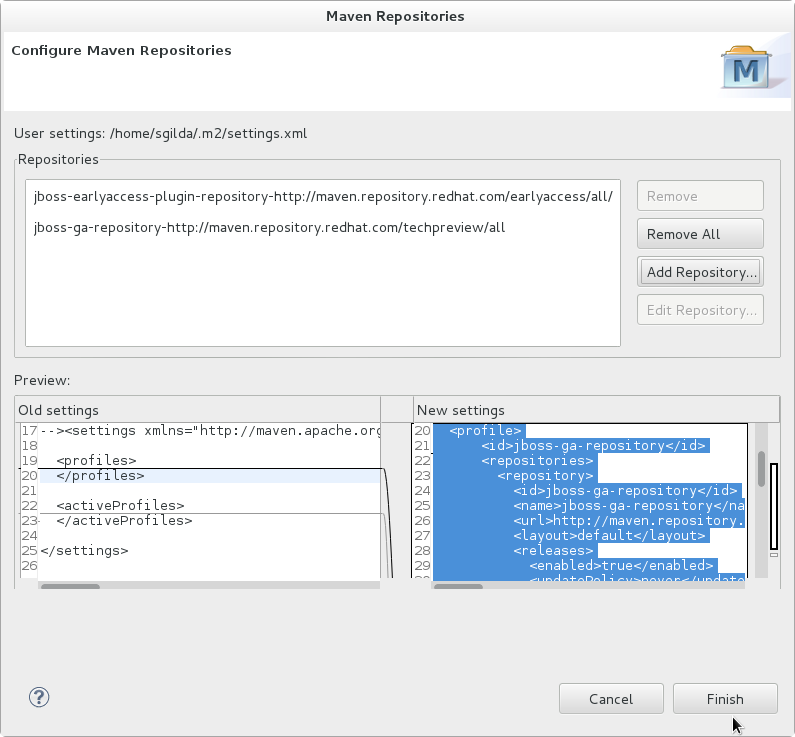
Figure 2.5. Review Maven Repositories
- You are prompted with the message "Are you sure you want to update the file 'MAVEN_HOME/settings.xml'?". Click to update the settings. Click to close the dialog.The JBoss EAP Maven repository is now configured for use with Red Hat JBoss Developer Studio.
2.3.4. Configure the JBoss EAP 6 Maven Repository Using the Project POM
- You can modify the Maven settings.
- You can configure the project's POM file.
pom.xml. This configuration method supercedes and overrides the global and user settings configurations.
Note
central so that the default repository central is now your repository manager as well. This works well for established projects, but for clean or 'new' projects it causes a problem as it creates a cyclic dependency.
Note
- File System
- file:///path/to/repo/jboss-eap-6.x-maven-repository
- Apache Web Server
- http://intranet.acme.com/jboss-eap-6.x-maven-repository/
- Nexus Repository Manager
- https://intranet.acme.com/nexus/content/repositories/jboss-eap-6.x-maven-repository
- Open your project's
pom.xmlfile in a text editor. - Add the following repository configuration. If there is already a
<repositories>configuration in the file, then add the<repository>element to it. Be sure to change the<url>to the actual repository location.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Add the following plug-in repository configuration. If there is already a
<pluginRepositories>configuration in the file, then add the<pluginRepository>element to it.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.3.5. Manage Project Dependencies
pom.xml (POM) file that specifies the versions of all runtime dependencies for a given module. Version dependencies are listed in the dependency management section of the file.
groupId:artifactId:version (GAV) to the dependency management section of the project pom.xml file and specifying the <scope>import</scope> and <type>pom</type> element values.
Note
provided scope. This is because these classes are provided by the application server at runtime and it is not necessary to package them with the user application.
Supported Maven Artifacts
-redhat version qualifier, for example 1.0.0-redhat-1.
pom.xml file ensures that the build is using the correct binary artifact for local building and testing. Note that an artifact with a -redhat version is not necessarily part of the supported public API, and may change in future revisions. For information about the public supported API, see the JavaDoc documentation included in the release.
<version/> field. However, it is recommended to use Maven dependency management for configuring dependency versions.
Dependency Management
JBoss JavaEE Specs Bom
jboss-javaee-6.0 BOM contains the Java EE Specification API JARs used by JBoss EAP.
3.0.2.Final-redhat-x version of the jboss-javaee-6.0 BOM.
JBoss EAP BOMs and Quickstarts
| Maven artifactId | Description |
|---|---|
| jboss-javaee-6.0-with-hibernate | This BOM builds on the Java EE full profile BOM, adding Hibernate Community projects including Hibernate ORM, Hibernate Search and Hibernate Validator. It also provides tool projects such as Hibernate JPA Model Gen and Hibernate Validator Annotation Processor. |
| jboss-javaee-6.0-with-hibernate3 | This BOM builds on the Java EE full profile BOM, adding Hibernate Community projects including Hibernate 3 ORM, Hibernate Entity Manager (JPA 1.0) and Hibernate Validator. |
| jboss-javaee-6.0-with-logging | This BOM builds on the Java EE full profile BOM, adding the JBoss Logging Tools and Log4j framework. |
| jboss-javaee-6.0-with-osgi | This BOM builds on the Java EE full profile BOM, adding OSGI. |
| jboss-javaee-6.0-with-resteasy | This BOM builds on the Java EE full profile BOM, adding RESTEasy |
| jboss-javaee-6.0-with-security | This BOM builds on the Java EE full profile BOM, adding Picketlink. |
| jboss-javaee-6.0-with-tools | This BOM builds on the Java EE full profile BOM, adding Arquillian to the mix. It also provides a version of JUnit and TestNG recommended for use with Arquillian. |
| jboss-javaee-6.0-with-transactions | This BOM includes a world class transaction manager. Use the JBossTS APIs to access its full capabilities. |
6.3.0.GA version of the jboss-javaee-6.0-with-hibernate BOM.
JBoss Client BOMs
jboss-as-ejb-client-bom and jboss-as-jms-client-bom.
7.4.0.Final-redhat-x version of the jboss-as-ejb-client-bom client BOM.
7.4.0.Final-redhat-x version of the jboss-as-jms-client-bom client BOM.
2.4. Upgrade the Maven Repository
2.4.1. Apply a Patch to the Local Maven Repository
A Maven repository stores Java libraries, plug-ins, and other artifacts required to build and deploy applications to JBoss EAP. The JBoss EAP repository is available online or as a downloaded ZIP file. If you use the publicly hosted repository, updates are applied automatically for you. However, if you download and install the Maven repository locally, you are responsible for applying any updates. Whenever a patch is available for JBoss EAP, a corresponding patch is provided for the JBoss EAP Maven repository. This patch is available in the form of an incremental ZIP file that is unzipped into the existing local repository. The ZIP file contains new JAR and POM files. It does not overwrite any existing JARs nor does it remove JARs, so there is no rollback requirement.
unzip command.
Prerequisites
- Valid access and subscription to the Red Hat Customer Portal.
- The Red Hat JBoss Enterprise Application Platform 6.3.0 Maven Repository ZIP file, downloaded and installed locally.
Procedure 2.11. Update the Maven Repository
- Open a browser and log into https://access.redhat.com.
- Select from the menu at the top of the page.
- Find
Red Hat JBoss Enterprise Application Platformin the list and click on it. - Select the correct version of JBoss EAP from the Version drop-down menu that appears on this screen, then click on Patches.
- Find
Red Hat JBoss Enterprise Application Platform 6.3 CPx Incremental Maven Repositoryin the list and click . - You are prompted to save the ZIP file to a directory of your choice. Choose a directory and save the file.
- Locate the path to JBoss EAP Maven repository, referred to in the commands below as EAP_MAVEN_REPOSITORY_PATH, for your operating system. For more information about how to install the Maven repository on the local file system, see Section 2.2.3, “Install the JBoss EAP 6 Maven Repository Locally”.
- Unzip the Maven patch file directly into the installation directory of the JBoss EAP 6.3.x Maven repository.
- For Linux, open a terminal and type the following command:
[standalone@localhost:9999 /] unzip -o jboss-eap-6.3.x-incremental-maven-repository.zip -d EAP_MAVEN_REPOSITORY_PATH
[standalone@localhost:9999 /] unzip -o jboss-eap-6.3.x-incremental-maven-repository.zip -d EAP_MAVEN_REPOSITORY_PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow - For Windows, use the Windows extraction utility to extract the ZIP file into the root of the
EAP_MAVEN_REPOSITORY_PATHdirectory.
The locally installed Maven repository is updated with the latest patch.
Chapter 3. Class Loading and Modules
3.1. Introduction
3.1.1. Overview of Class Loading and Modules
3.1.2. Class Loading
3.1.3. Modules
- Static Modules
- Static Modules are predefined in the
EAP_HOME/modules/directory of the application server. Each sub-directory represents one module and defines amain/subdirectory that contains a configuration file (module.xml) and any required JAR files. The name of the module is defined in themodule.xmlfile. All the application server provided APIs are provided as static modules, including the Java EE APIs as well as other APIs such as JBoss Logging.Example 3.1. Example module.xml file
Copy to Clipboard Copied! Toggle word wrap Toggle overflow The module name,com.mysql, should match the directory structure for the module, excluding themain/subdirectory name.The modules provided in JBoss EAP distributions are located in asystemdirectory within theJBOSS_HOME/modulesdirectory. This keeps them separate from any modules provided by third parties.Any Red Hat provided layered products that layer on top of JBoss EAP 6.1 or later will also install their modules within thesystemdirectory.Creating custom static modules can be useful if many applications are deployed on the same server that use the same third party libraries. Instead of bundling those libraries with each application, a module containing these libraries can be created and installed by the JBoss administrator. The applications can then declare an explicit dependency on the custom static modules.Users must ensure that custom modules are installed into theJBOSS_HOME/modulesdirectory, using a one directory per module layout. This ensures that custom versions of modules that already exist in thesystemdirectory are loaded instead of the shipped versions. In this way, user provided modules will take precedence over system modules.If you use theJBOSS_MODULEPATHenvironment variable to change the locations in which JBoss EAP searches for modules, then the product will look for asystemsubdirectory structure within one of the locations specified. Asystemstructure must exist somewhere in the locations specified withJBOSS_MODULEPATH. - Dynamic Modules
- Dynamic Modules are created and loaded by the application server for each JAR or WAR deployment (or subdeployment in an EAR). The name of a dynamic module is derived from the name of the deployed archive. Because deployments are loaded as modules, they can configure dependencies and be used as dependencies by other deployments.
3.1.4. Module Dependencies
Example 3.2. Module dependencies
- Module A declares an explicit dependency on Module C, or
- Module B exports its dependency on Module C.
3.1.5. Class Loading in Deployments
- WAR Deployment
- A WAR deployment is considered to be a single module. Classes in the
WEB-INF/libdirectory are treated the same as classes inWEB-INF/classesdirectory. All classes packaged in the war will be loaded with the same class loader. - EAR Deployment
- EAR deployments are made up more than one module. The definition of these modules follows these rules:
- The
lib/directory of the EAR is a single module called the parent module. - Each WAR deployment within the EAR is a single module.
- Each EJB JAR deployment within the EAR is a single module.
Subdeployment modules (the WAR and JAR deployments within the EAR) have an automatic dependency on the parent module. However they do not have automatic dependencies on each other. This is called subdeployment isolation and can be disabled on a per deployment basis or for the entire application server.Explicit dependencies between subdeployment modules can be added by the same means as any other module.
3.1.6. Class Loading Precedence
- Implicit dependencies.These are the dependencies that are added automatically by JBoss EAP 6, such as the JAVA EE APIs. These dependencies have the highest class loader precedence because they contain common functionality and APIs that are supplied by JBoss EAP 6.Refer to Section 3.8.1, “Implicit Module Dependencies” for complete details about each implicit dependency.
- Explicit dependencies.These are dependencies that are manually added in the application configuration. This can be done using the application's
MANIFEST.MFfile or the new optional JBoss deployment descriptorjboss-deployment-structure.xmlfile.Refer to Section 3.2, “Add an Explicit Module Dependency to a Deployment” to learn how to add explicit dependencies. - Local resources.Class files packaged up inside the deployment itself, e.g. from the
WEB-INF/classesorWEB-INF/libdirectories of a WAR file. - Inter-deployment dependencies.These are dependencies on other deployments in a EAR deployment. This can include classes in the
libdirectory of the EAR or classes defined in other EJB jars.
3.1.7. Dynamic Module Naming
- Deployments of WAR and JAR files are named with the following format:
deployment.DEPLOYMENT_NAME
deployment.DEPLOYMENT_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow For example,inventory.warandstore.jarwill have the module names ofdeployment.inventory.waranddeployment.store.jarrespectively. - Subdeployments within an Enterprise Archive are named with the following format:
deployment.EAR_NAME.SUBDEPLOYMENT_NAME
deployment.EAR_NAME.SUBDEPLOYMENT_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow For example, the subdeployment ofreports.warwithin the enterprise archiveaccounts.earwill have the module name ofdeployment.accounts.ear.reports.war.
3.1.8. jboss-deployment-structure.xml
jboss-deployment-structure.xml is a new optional deployment descriptor for JBoss EAP 6. This deployment descriptor provides control over class loading in the deployment.
EAP_HOME/docs/schema/jboss-deployment-structure-1_2.xsd
3.2. Add an Explicit Module Dependency to a Deployment
Prerequisites
- You must already have a working software project that you want to add a module dependency to.
- You must know the name of the module being added as a dependency. See Section 3.8.2, “Included Modules” for the list of static modules included with JBoss EAP 6. If the module is another deployment then see Section 3.1.7, “Dynamic Module Naming” to determine the module name.
- Adding entries to the
MANIFEST.MFfile of the deployment. - Adding entries to the
jboss-deployment-structure.xmldeployment descriptor.
Procedure 3.1. Add dependency configuration to MANIFEST.MF
MANIFEST.MF file. See Section 3.3, “Generate MANIFEST.MF entries using Maven”.
Add
MANIFEST.MFfileIf the project has noMANIFEST.MFfile, create a file calledMANIFEST.MF. For a web application (WAR) add this file to theMETA-INFdirectory. For an EJB archive (JAR) add it to theMETA-INFdirectory.Add dependencies entry
Add a dependencies entry to theMANIFEST.MFfile with a comma-separated list of dependency module names.Dependencies: org.javassist, org.apache.velocity
Dependencies: org.javassist, org.apache.velocityCopy to Clipboard Copied! Toggle word wrap Toggle overflow Optional: Make a dependency optional
A dependency can be made optional by appendingoptionalto the module name in the dependency entry.Dependencies: org.javassist optional, org.apache.velocity
Dependencies: org.javassist optional, org.apache.velocityCopy to Clipboard Copied! Toggle word wrap Toggle overflow Optional: Export a dependency
A dependency can be exported by appendingexportto the module name in the dependency entry.Dependencies: org.javassist, org.apache.velocity export
Dependencies: org.javassist, org.apache.velocity exportCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Procedure 3.2. Add dependency configuration to jboss-deployment-structure.xml
Add
jboss-deployment-structure.xmlIf the application has nojboss-deployment-structure.xmlfile then create a new file calledjboss-deployment-structure.xmland add it to the project. This file is an XML file with the root element of<jboss-deployment-structure>.<jboss-deployment-structure> </jboss-deployment-structure>
<jboss-deployment-structure> </jboss-deployment-structure>Copy to Clipboard Copied! Toggle word wrap Toggle overflow For a web application (WAR) add this file to theWEB-INFdirectory. For an EJB archive (JAR) add it to theMETA-INFdirectory.Add dependencies section
Create a<deployment>element within the document root and a<dependencies>element within that.Add module elements
Within the dependencies node, add a module element for each module dependency. Set thenameattribute to the name of the module.<module name="org.javassist" />
<module name="org.javassist" />Copy to Clipboard Copied! Toggle word wrap Toggle overflow Optional: Make a dependency optional
A dependency can be made optional by adding theoptionalattribute to the module entry with the value oftrue. The default value for this attribute isfalse.<module name="org.javassist" optional="true" />
<module name="org.javassist" optional="true" />Copy to Clipboard Copied! Toggle word wrap Toggle overflow Optional: Export a dependency
A dependency can be exported by adding theexportattribute to the module entry with the value oftrue. The default value for this attribute isfalse.<module name="org.javassist" export="true" />
<module name="org.javassist" export="true" />Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Example 3.3. jboss-deployment-structure.xml with two dependencies
3.3. Generate MANIFEST.MF entries using Maven
MANIFEST.MF file with a Dependencies entry. This does not automatically generate the list of dependencies, this process only creates the MANIFEST.MF file with the details specified in the pom.xml.
Prerequisites
- You must already have a working Maven project.
- The Maven project must be using one of the JAR, EJB, or WAR plug-ins (
maven-jar-plugin,maven-ejb-plugin,maven-war-plugin). - You must know the name of the project's module dependencies. Refer to Section 3.8.2, “Included Modules” for the list of static modules included with JBoss EAP 6. If the module is another deployment , then refer to Section 3.1.7, “Dynamic Module Naming” to determine the module name.
Procedure 3.3. Generate a MANIFEST.MF file containing module dependencies
Add Configuration
Add the following configuration to the packaging plug-in configuration in the project'spom.xmlfile.Copy to Clipboard Copied! Toggle word wrap Toggle overflow List Dependencies
Add the list of the module dependencies in the <Dependencies> element. Use the same format that is used when adding the dependencies to theMANIFEST.MF. Refer to Section 3.2, “Add an Explicit Module Dependency to a Deployment” for details about that format.<Dependencies>org.javassist, org.apache.velocity</Dependencies>
<Dependencies>org.javassist, org.apache.velocity</Dependencies>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Build the Project
Build the project using the Maven assembly goal.mvn assembly:assembly
[Localhost ]$ mvn assembly:assemblyCopy to Clipboard Copied! Toggle word wrap Toggle overflow
MANIFEST.MF file with the specified module dependencies.
Example 3.4. Configured Module Dependencies in pom.xml
3.4. Prevent a Module Being Implicitly Loaded
Prerequisites
- You must already have a working software project that you want to exclude an implicit dependency from.
- You must know the name of the module to exclude. Refer to Section 3.8.1, “Implicit Module Dependencies” for a list of implicit dependencies and their conditions.
Procedure 3.4. Add dependency exclusion configuration to jboss-deployment-structure.xml
- If the application has no
jboss-deployment-structure.xmlfile, create a new file calledjboss-deployment-structure.xmland add it to the project. This file is an XML file with the root element of<jboss-deployment-structure>.<jboss-deployment-structure> </jboss-deployment-structure>
<jboss-deployment-structure> </jboss-deployment-structure>Copy to Clipboard Copied! Toggle word wrap Toggle overflow For a web application (WAR) add this file to theWEB-INFdirectory. For an EJB archive (JAR) add it to theMETA-INFdirectory. - Create a
<deployment>element within the document root and an<exclusions>element within that.<deployment> <exclusions> </exclusions> </deployment>
<deployment> <exclusions> </exclusions> </deployment>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Within the exclusions element, add a
<module>element for each module to be excluded. Set thenameattribute to the name of the module.<module name="org.javassist" />
<module name="org.javassist" />Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Example 3.5. Excluding two modules
3.5. Exclude a Subsystem from a Deployment
This topic covers the steps required to exclude a subsystem from a deployment. This is done by editing the jboss-deployment-structure.xml configuration file. Excluding a subsystem provides the same effect as removing the subsystem, but it applies only to a single deployment.
Procedure 3.5. Exclude a Subsystem
- Open the
jboss-deployment-structure.xmlfile in a text editor. - Add the following XML inside the <deployment> tags:
<exclude-subsystems> <subsystem name="SUBSYSTEM_NAME" /> </exclude-subsystems>
<exclude-subsystems> <subsystem name="SUBSYSTEM_NAME" /> </exclude-subsystems>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Save the
jboss-deployment-structure.xmlfile.
The subsystem has been successfully excluded. The subsystem's deployment unit processors will no longer run on the deployment.
Example 3.6. Example jboss-deployment-structure.xml file.
3.6. Use the Class Loader Programmatically in a Deployment
3.6.1. Programmatically Load Classes and Resources in a Deployment
- Load a Class Using the Class.forName() Method
- You can use the
Class.forName()method to programmatically load and initialize classes. This method has two signatures.The three argument signature is the recommended way to programmatically load a class. This signature allows you to control whether you want the target class to be initialized upon load. It is also more efficient to obtain and provide the class loader because the JVM does not need to examine the call stack to determine which class loader to use. Assuming the class containing the code is named- Class.forName(String className)
- This signature takes only one parameter, the name of the class you need to load. With this method signature, the class is loaded by the class loader of the current class and initializes the newly loaded class by default.
- Class.forName(String className, boolean initialize, ClassLoader loader)
- This signature expects three parameters: the class name, a boolean value that specifies whether to initialize the class, and the ClassLoader that should load the class.
CurrentClass, you can obtain the class's class loader usingCurrentClass.class.getClassLoader()method.The following example provides the class loader to load and initialize theTargetClassclass:Example 3.7. Provide a class loader to load and initialize the TargetClass.
Class<?> targetClass = Class.forName("com.myorg.util.TargetClass", true, CurrentClass.class.getClassLoader());Class<?> targetClass = Class.forName("com.myorg.util.TargetClass", true, CurrentClass.class.getClassLoader());Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Find All Resources with a Given Name
- If you know the name and path of a resource, the best way to load it directly is to use the standard JDK Class or ClassLoader API.
- Load a Single Resource
- To load a single resource located in the same directory as your class or another class in your deployment, you can use the
Class.getResourceAsStream()method.Example 3.8. Load a single resource in your deployment.
InputStream inputStream = CurrentClass.class.getResourceAsStream("targetResourceName");InputStream inputStream = CurrentClass.class.getResourceAsStream("targetResourceName");Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Load All Instances of a Single Resource
- To load all instances of a single resource that are visible to your deployment's class loader, use the
Class.getClassLoader().getResources(String resourceName)method, whereresourceNameis the fully qualified path of the resource. This method returns an Enumeration of allURLobjects for resources accessible by the class loader with the given name. You can then iterate through the array of URLs to open each stream using theopenStream()method.Example 3.9. Load all instances of a resource and iterate through the result.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Note
Because the URL instances are loaded from local storage, it is not necessary to use theopenConnection()or other related methods. Streams are much simpler to use and minimize the complexity of the code.
- Load a Class File From the Class Loader
- If a class has already been loaded, you can load the class file that corresponds to that class using the following syntax:If the class is not yet loaded, you must use the class loader and translate the path:
Example 3.10. Load a class file for a class that has been loaded.
InputStream inputStream = CurrentClass.class.getResourceAsStream(TargetClass.class.getSimpleName() + ".class");
InputStream inputStream = CurrentClass.class.getResourceAsStream(TargetClass.class.getSimpleName() + ".class");Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example 3.11. Load a class file for a class that has not been loaded.
String className = "com.myorg.util.TargetClass" InputStream inputStream = CurrentClass.class.getClassLoader().getResourceAsStream(className.replace('.', '/') + ".class");String className = "com.myorg.util.TargetClass" InputStream inputStream = CurrentClass.class.getClassLoader().getResourceAsStream(className.replace('.', '/') + ".class");Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.6.2. Programmatically Iterate Resources in a Deployment
MANIFEST.MF:
Dependencies: org.jboss.modules
Dependencies: org.jboss.modules- List Resources Within a Deployment and Within All Imports
- There are times when it is not possible to look up resources by the exact path. For example, the exact path may not be known or you may need to examine more than one file in a given path. In this case, the JBoss Modules library provides several APIs for iterating all deployment resources. You can iterate through resources in a deployment by utilizing one of two methods.
- Iterate All Resources Found in a Single Module
- The
ModuleClassLoader.iterateResources()method iterates all the resources within this module class loader. This method takes two arguments: the starting directory name to search and a boolean that specifies whether it should recurse into subdirectories.The following example demonstrates how to obtain the ModuleClassLoader and obtain the iterator for resources in thebin/directory, recursing into subdirectories.The resultant iterator may be used to examine each matching resource and query its name and size (if available), open a readable stream, or acquire a URL for the resource.Example 3.12. Find resources in the "bin" directory, recursing into subdirectories.
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = moduleClassLoader.iterateResources("bin",true);ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = moduleClassLoader.iterateResources("bin",true);Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Iterate All Resources Found in a Single Module and Imported Resources
- The
Module.iterateResources()method iterates all the resources within this module class loader, including the resources that are imported into the module. This method returns a much larger set than the previous method. This method requires an argument, which is a filter that narrows the result to a specific pattern. Alternatively, PathFilters.acceptAll() can be supplied to return the entire set.Example 3.13. Find the entire set of resources in this module, including imports.
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Module module = moduleClassLoader.getModule(); Iterator<Resource> moduleResources = module.iterateResources(PathFilters.acceptAll());
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Module module = moduleClassLoader.getModule(); Iterator<Resource> moduleResources = module.iterateResources(PathFilters.acceptAll());Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- Find All Resources That Match a Pattern
- If you need to find only specific resources within your deployment or within your deployment's full import set, you need to filter the resource iteration. The JBoss Modules filtering APIs give you several tools to accomplish this.
- Examine the Full Set of Dependencies
- If you need to examine the full set of dependencies, you can use the
Module.iterateResources()method'sPathFilterparameter to check the name of each resource for a match. - Examine Deployment Dependencies
- If you need to look only within the deployment, use the
ModuleClassLoader.iterateResources()method. However, you must use additional methods to filter the resultant iterator. ThePathFilters.filtered()method can provide a filtered view of a resource iterator this case. ThePathFiltersclass includes many static methods to create and compose filters that perform various functions, including finding child paths or exact matches, or matching an Ant-style "glob" pattern.
- Additional Code Examples For Filtering Resouces
- The following examples demonstrate how to filter resources based on different criteria.
Example 3.14. Find all files named "messages.properties" in your deployment.
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = PathFilters.filtered(PathFilters.match("**/messages.properties"), moduleClassLoader.iterateResources("", true));ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = PathFilters.filtered(PathFilters.match("**/messages.properties"), moduleClassLoader.iterateResources("", true));Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example 3.15. Find all files named "messages.properties" in your deployment and imports.
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Module module = moduleClassLoader.getModule(); Iterator<Resource> moduleResources = module.iterateResources(PathFilters.match("**/message.properties));ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Module module = moduleClassLoader.getModule(); Iterator<Resource> moduleResources = module.iterateResources(PathFilters.match("**/message.properties));Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example 3.16. Find all files inside any directory named "my-resources" in your deployment.
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = PathFilters.filtered(PathFilters.match("**/my-resources/**"), moduleClassLoader.iterateResources("", true));ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = PathFilters.filtered(PathFilters.match("**/my-resources/**"), moduleClassLoader.iterateResources("", true));Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example 3.17. Find all files named "messages" or "errors" in your deployment and imports.
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Module module = moduleClassLoader.getModule(); Iterator<Resource> moduleResources = module.iterateResources(PathFilters.any(PathFilters.match("**/messages"), PathFilters.match("**/errors"));ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Module module = moduleClassLoader.getModule(); Iterator<Resource> moduleResources = module.iterateResources(PathFilters.any(PathFilters.match("**/messages"), PathFilters.match("**/errors"));Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example 3.18. Find all files in a specific package in your deployment.
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = moduleClassLoader.iterateResources("path/form/of/packagename", false);ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = moduleClassLoader.iterateResources("path/form/of/packagename", false);Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.7. Class Loading and Subdeployments
3.7.1. Modules and Class Loading in Enterprise Archives
- Each WAR and EJB JAR subdeployment is a module.
- The contents of the
lib/directory in the root of the EAR archive is a module. This is called the parent module.
- WAR subdeployments have implicit dependencies on the parent module and any EJB JAR subdeployments.
- EJB JAR subdeployments have implicit dependencies on the parent module and any other EJB JAR subdeployments.
Important
Class-Path entries in the MANIFEST.MF file of each subdeployment.
3.7.2. Subdeployment Class Loader Isolation
3.7.3. Disable Subdeployment Class Loader Isolation Within a EAR
Important
Add the deployment descriptor file
Add thejboss-deployment-structure.xmldeployment descriptor file to theMETA-INFdirectory of the EAR if it doesn't already exist and add the following content:<jboss-deployment-structure> </jboss-deployment-structure>
<jboss-deployment-structure> </jboss-deployment-structure>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add the
<ear-subdeployments-isolated>elementAdd the<ear-subdeployments-isolated>element to thejboss-deployment-structure.xmlfile if it doesn't already exist with the content offalse.<ear-subdeployments-isolated>false</ear-subdeployments-isolated>
<ear-subdeployments-isolated>false</ear-subdeployments-isolated>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Subdeployment class loader isolation will now be disabled for this EAR deployment. This means that the subdeployments of the EAR will have automatic dependencies on each of the non-WAR subdeployments.
3.8. Reference
3.8.1. Implicit Module Dependencies
| Subsystem Responsible for Adding the Dependency | Dependencies That Are Always Added | Dependencies That Are Conditionally Added | Conditions That Trigger the Addition of the Dependency |
|---|---|---|---|
| Core Server |
| | |
| EE subsystem |
| | |
| EJB 3 subsystem | |
|
The presence of an
ejb-jar.xml file within a valid location in the deployment, as described in the Java EE 6 specification.
The presence of annotation-based EJBs, for example:
@Stateless, @Stateful, @MessageDriven
|
| JAX-RS (RESTEasy) subsystem |
|
| The presence of JAX-RS annotations in the deployment. |
| JCA subsystem |
|
| The deployment of a resource adapter (RAR) archive. |
| JPA (Hibernate) subsystem |
|
|
The presence of an
@PersistenceUnit or @PersistenceContext annotation, or a <persistence-unit-ref> or <persistence-context-ref> element in a deployment descriptor.
JBoss EAP 6 maps persistence provider names to module names. If you name a specific provider in the
persistence.xml file, a dependency is added for the appropriate module. If this not the desired behavior, you can exclude it using a jboss-deployment-structure.xml file.
|
| Logging subsystem |
| |
These dependencies are always added unless the
add-logging-api-dependencies attribute is set to false.
|
| SAR subsystem | |
| The deployment of a SAR archive. |
| Security subsystem |
| | |
| Web subsystem | |
| The deployment of a WAR archive. JavaServer Faces (JSF) is added only if it is used. |
| Web Services subsystem |
| | |
| Weld (CDI) Subsystem | |
| The presence of a beans.xml file in the deployment. |
3.8.2. Included Modules
3.8.3. JBoss Deployment Structure Deployment Descriptor Reference
- Defining explicit module dependencies.
- Preventing specific implicit dependencies from loading.
- Defining additional modules from the resources of that deployment.
- Changing the subdeployment isolation behavior in that EAR deployment.
- Adding additional resource roots to a module in an EAR.
Chapter 4. Valves
4.1. About Valves
- Global Valves are configured at the server level and apply to all applications deployed to the server. Instructions to configure Global Valves are located in the Administration and Configuration Guide for JBoss EAP.
- Valves configured at the application level are packaged with the application deployment and only affect the specific application. Instructions to configure Valves at the application level are located in the Development Guide for JBoss EAP.
4.2. About Global Valves
4.3. About Authenticator Valves
org.apache.catalina.authenticator.AuthenticatorBase and overrides the authenticate(Request request, Response response, LoginConfig config) method.
4.4. Configure a Web Application to use a Valve
jboss-web.xml deployment descriptor.
Important
Prerequisites
- The valve must be created and included in your application's classpath. This can be done by either including it in the application's WAR file or any module that is added as a dependency. Examples of such modules include a static module installed on the server or a JAR file in the
lib/directory of an EAR archive if the WAR is deployed in an EAR. - The application must include a
jboss-web.xmldeployment descriptor.
Procedure 4.1. Configure an application for a local valve
Configure a Valve
Create avalveelement containing theclass-namechild element in the application'sjboss-web.xmlfile. Theclass-nameis the name of the valve class.<valve> <class-name>VALVE_CLASS_NAME</class-name> </valve><valve> <class-name>VALVE_CLASS_NAME</class-name> </valve>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example 4.1. Example of a valve element configured in the jboss-web.xml file
<valve> <class-name>org.jboss.security.negotiation.NegotiationAuthenticator</class-name> </valve><valve> <class-name>org.jboss.security.negotiation.NegotiationAuthenticator</class-name> </valve>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Configure a Custom Valve
If the valve has configurable parameters, add aparamchild element to thevalveelement for each parameter, specifying theparam-nameandparam-valuefor each.Example 4.2. Example of a custom valve element configured in the jboss-web.xml file
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Example 4.3. jboss-web.xml valve configuration
4.5. Configure a Web Application to use an Authenticator Valve
web.xml deployment descriptor of the application to be configured. In the simplest case, the web.xml configuration is the same as using BASIC authentication except the auth-method child element of login-config is set to the name of the valve performing the configuration.
Prerequisites
- Authentication valve must already be created.
- If the authentication valve is a global valve then it must already be installed and configured, and you must know the name that it was configured as.
- You need to know the realm name of the security realm that the application will use.
Procedure 4.2. Configure an Application to use an Authenticator Valve
Configure the valve
When using a local valve, it must be configured in the applicationsjboss-web.xmldeployment descriptor. Refer to Section 4.4, “Configure a Web Application to use a Valve”.When using a global valve, this is unnecessary.Add security configuration to web.xml
Add the security configuration to the web.xml file for your application, using the standard elements such as security-constraint, login-config, and security-role. In the login-config element, set the value of auth-method to the name of the authenticator valve. The realm-name element also needs to be set to the name of the JBoss security realm being used by the application.<login-config> <auth-method>VALVE_NAME</auth-method> <realm-name>REALM_NAME</realm-name> </login-config>
<login-config> <auth-method>VALVE_NAME</auth-method> <realm-name>REALM_NAME</realm-name> </login-config>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
4.6. Create a Custom Valve
Procedure 4.3. Create a Custom Valve
Create the Valve class
Create a subclass oforg.apache.catalina.valves.ValveBase.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Implement the invoke method
Theinvoke()method is called when this valve is executed in the pipeline. The request and response objects are passed as parameters. Perform any processing and modification of the request and response here.public void invoke(Request request, Response response) { }public void invoke(Request request, Response response) { }Copy to Clipboard Copied! Toggle word wrap Toggle overflow Invoke the next pipeline step
The last thing the invoke method must do is invoke the next step of the pipeline and pass the modified request and response objects along. This is done using thegetNext().invoke()methodgetNext().invoke(request, response);
getNext().invoke(request, response);Copy to Clipboard Copied! Toggle word wrap Toggle overflow Optional: Specify parameters
If the valve must be configurable, enable this by adding a parameter. Do this by adding an instance variable and a setter method for each parameter.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Example 4.4. Sample Custom Valve
Chapter 5. Logging for Developers
5.1. Introduction
5.1.1. About Logging
5.1.2. Application Logging Frameworks Supported By JBoss LogManager
- JBoss Logging - included with JBoss EAP 6
- Apache Commons Logging - http://commons.apache.org/logging/
- Simple Logging Facade for Java (SLF4J) - http://www.slf4j.org/
- Apache log4j - http://logging.apache.org/log4j/1.2/
- Java SE Logging (java.util.logging) - http://download.oracle.com/javase/6/docs/api/java/util/logging/package-summary.html
5.1.3. About Log Levels
TRACE, DEBUG, INFO, WARN, ERROR and FATAL.
WARN will only record messages of the levels WARN, ERROR and FATAL.
5.1.4. Supported Log Levels
| Log Level | Value | Description |
|---|---|---|
| FINEST | 300 |
-
|
| FINER | 400 |
-
|
| TRACE | 400 |
Use for messages that provide detailed information about the running state of an application. Log messages of
TRACE are usually only captured when debugging an application.
|
| DEBUG | 500 |
Use for messages that indicate the progress individual requests or activities of an application. Log messages of
DEBUG are usually only captured when debugging an application.
|
| FINE | 500 |
-
|
| CONFIG | 700 |
-
|
| INFO | 800 |
Use for messages that indicate the overall progress of the application. Often used for application startup, shutdown and other major lifecycle events.
|
| WARN | 900 |
Use to indicate a situation that is not in error but is not considered ideal. May indicate circumstances that may lead to errors in the future.
|
| WARNING | 900 |
-
|
| ERROR | 1000 |
Use to indicate an error that has occurred that could prevent the current activity or request from completing but will not prevent the application from running.
|
| SEVERE | 1000 |
-
|
| FATAL | 1100 |
Use to indicate events that could cause critical service failure and application shutdown and possibly cause JBoss EAP 6 to shutdown.
|
5.1.5. Default Log File Locations
| Log File | Description |
|---|---|
EAP_HOME/standalone/log/server.log |
Server Log. Contains all server log messages, including server startup messages.
|
EAP_HOME/standalone/log/gc.log |
Garbage collection log. Contains details of all garbage collection.
|
| Log File | Description |
|---|---|
EAP_HOME/domain/log/host-controller.log |
Host Controller boot log. Contains log messages related to the startup of the host controller.
|
EAP_HOME/domain/log/process-controller.log |
Process controller boot log. Contains log messages related to the startup of the process controller.
|
EAP_HOME/domain/servers/SERVERNAME/log/server.log |
The server log for the named server. Contains all log messages for that server, including server startup messages.
|
5.2. Logging with the JBoss Logging Framework
5.2.1. About JBoss Logging
5.2.2. Features of JBoss Logging
- Provides an innovative, easy to use "typed" logger.
- Full support for internationalization and localization. Translators work with message bundles in properties files while developers can work with interfaces and annotations.
- Build-time tooling to generate typed loggers for production, and runtime generation of typed loggers for development.
5.2.3. Add Logging to an Application with JBoss Logging
org.jboss.logging.Logger) and call the appropriate methods of that object. This task describes the steps required to add support for this to your application.
Prerequisites
- If you are using Maven as your build system, the project must already be configured to include the JBoss Maven Repository. Refer to Section 2.3.2, “Configure the JBoss EAP 6 Maven Repository Using the Maven Settings”
- The JBoss Logging JAR files must be in the build path for your application. How you do this depends on whether you build your application using Red Hat JBoss Developer Studio or with Maven.
- When building using Red Hat JBoss Developer Studio this can be done selecting Project -> Properties from the Red Hat JBoss Developer Studio menu, selecting Targeted Runtimes and ensuring the runtime for JBoss EAP 6 is checked.
- When building using Maven this can be done by adding the following dependency configuration to your project's
pom.xmlfile.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
You do not need to include the JARs in your built application because JBoss EAP 6 provides them to deployed applications.
Add imports
Add the import statements for the JBoss Logging class namespaces that you will be using. At a minimum you will need to importimport org.jboss.logging.Logger.import org.jboss.logging.Logger;
import org.jboss.logging.Logger;Copy to Clipboard Copied! Toggle word wrap Toggle overflow Create a Logger object
Create an instance oforg.jboss.logging.Loggerand initialize it by calling the static methodLogger.getLogger(Class). Red Hat recommends creating this as a single instance variable for each class.private static final Logger LOGGER = Logger.getLogger(HelloWorld.class);
private static final Logger LOGGER = Logger.getLogger(HelloWorld.class);Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add logging messages
Add calls to the methods of theLoggerobject to your code where you want it to send log messages. TheLoggerobject has many different methods with different parameters for different types of messages. The easiest to use are:debug(Object message)info(Object message)error(Object message)trace(Object message)fatal(Object message)These methods send a log message with the corresponding log level and themessageparameter as a string.LOGGER.error("Configuration file not found.");LOGGER.error("Configuration file not found.");Copy to Clipboard Copied! Toggle word wrap Toggle overflow For the complete list of JBoss Logging methods refer to theorg.jboss.loggingpackage in the JBoss EAP 6 API Documentation.
Example 5.1. Using JBoss Logging when opening a properties file
5.3. Per-deployment Logging
5.3.1. About Per-deployment Logging
5.3.2. Add Per-deployment Logging to an Application
logging.properties into the deployment. This configuration file is recommended because it can be used with any logging facade as the JBoss Log Manager is the underlying log manager used.
Simple Logging Facade for Java (SLF4J) or Apache log4j, the logging.properties configuration file is suitable. If you are using Apache log4j appenders then the configuration file log4j.properties is required. The configuration file jboss-logging.properties is supported only for legacy deployments.
Procedure 5.1. Add Configuration File to the Application
The directory into which the configuration file is added depends on the deployment method:
EAR,WARorJAR.EARdeploymentCopy the logging configuration file to theMETA-INFdirectory.WARorJARdeploymentCopy the logging configuration file to either theMETA-INForWEB-INF/classesdirectory.
5.3.3. Example logging.properties File
5.4. Logging Profiles
5.4.1. About Logging Profiles
Important
- A unique name. This is required.
- Any number of log handlers.
- Any number of log categories.
- Up to one root logger.
MANIFEST.MF file, using the logging-profile attribute.
5.4.2. Specify a Logging Profile in an Application
MANIFEST.MF file.
Prerequisites:
- You must know the name of the logging profile that has been setup on the server for this application to use. Ask your server administrator for the name of the profile to use.
Procedure 5.2. Add Logging Profile configuration to an Application
Edit
MANIFEST.MFIf your application does not have aMANIFEST.MFfile: create one with the following content, replacing NAME with the required profile name.Manifest-Version: 1.0 Logging-Profile: NAME
Manifest-Version: 1.0 Logging-Profile: NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow If your application already has aMANIFEST.MFfile: add the following line to it, replacing NAME with the required profile name.Logging-Profile: NAME
Logging-Profile: NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow
Note
maven-war-plugin, you can put your MANIFEST.MF file in src/main/resources/META-INF/ and add the following configuration to your pom.xml file.
Chapter 6. Internationalization and Localization
6.1. Introduction
6.1.1. About Internationalization
6.1.2. About Localization
6.2. JBoss Logging Tools
6.2.1. Overview
6.2.1.1. JBoss Logging Tools Internationalization and Localization
org.jboss.logging annotations. It is not necessary to implement the interfaces, JBoss Logging Tools does this at compile time. Once defined you can use these methods to log messages or obtain exception objects in your code.
6.2.1.2. JBoss Logging Tools Quickstart
logging-tools, contains a simple Maven project that demonstrates the features of JBoss Logging Tools. It has been used extensively in this documentation for code samples.
6.2.1.3. Message Logger
@org.jboss.logging.MessageLogger.
6.2.1.4. Message Bundle
@org.jboss.logging.MessageBundle.
6.2.1.5. Internationalized Log Messages
@LogMessage and @Message annotations and specify the log message using the value attribute of @Message. Internationalized log messages are localized by providing translations in a properties file.
6.2.1.6. Internationalized Exceptions
6.2.1.7. Internationalized Messages
6.2.1.8. Translation Properties Files
6.2.1.9. JBoss Logging Tools Project Codes
projectCode attribute of the @MessageLogger annotation.
6.2.1.10. JBoss Logging Tools Message Ids
id attribute of the @Message annotation.
6.2.2. Creating Internationalized Loggers, Messages and Exceptions
6.2.2.1. Create Internationalized Log Messages
logging-tools quick start for a complete example.
Prerequisites:
- You must already have a working Maven project. Refer to Section 6.2.6.1, “JBoss Logging Tools Maven Configuration”.
- The project must have the required maven configuration for JBoss Logging Tools.
Procedure 6.1. Create an Internationalized Log Message Bundle
Create an Message Logger interface
Add a Java interface to your project to contain the log message definitions. Name the interface descriptively for the log messages that will be defined in it.The log message interface has the following requirements:- It must be annotated with
@org.jboss.logging.MessageLogger. - It must extend
org.jboss.logging.BasicLogger. - The interface must define a field of that is a typed logger that implements this interface. Do this with the
getMessageLogger()method oforg.jboss.logging.Logger.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add method definitions
Add a method definition to the interface for each log message. Name each method descriptively for the log message that it represents.Each method has the following requirements:- The method must return
void. - It must be annotated with the
@org.jboss.logging.LogMessageannotation. - It must be annotated with the
@org.jboss.logging.Messageannotation. - The value attribute of
@org.jboss.logging.Messagecontains the default log message. This is the message that is used if no translation is available.
@LogMessage @Message(value = "Customer query failed, Database not available.") void customerQueryFailDBClosed();
@LogMessage @Message(value = "Customer query failed, Database not available.") void customerQueryFailDBClosed();Copy to Clipboard Copied! Toggle word wrap Toggle overflow The default log level isINFO.Invoke the methods
Add the calls to the interface methods in your code where the messages must be logged from. It is not necessary to create implementations of the interfaces, the annotation processor does this for you when the project is compiled.AccountsLogger.LOGGER.customerQueryFailDBClosed();
AccountsLogger.LOGGER.customerQueryFailDBClosed();Copy to Clipboard Copied! Toggle word wrap Toggle overflow The custom loggers are sub-classed from BasicLogger so the logging methods ofBasicLogger(debug(),error()etc) can also be used. It is not necessary to create other loggers to log non-internationalized messages.AccountsLogger.LOGGER.error("Invalid query syntax.");AccountsLogger.LOGGER.error("Invalid query syntax.");Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.2.2.2. Create and Use Internationalized Messages
logging-tools quickstart for a complete example.
Prerequisites
- You have a working Maven project using the JBoss EAP 6 repository. Refer to Section 2.3.2, “Configure the JBoss EAP 6 Maven Repository Using the Maven Settings”.
- The required Maven configuration for JBoss Logging Tools has been added. Refer to Section 6.2.6.1, “JBoss Logging Tools Maven Configuration”.
Procedure 6.2. Create and Use Internationalized Messages
Create an interface for the exceptions
JBoss Logging Tools defines internationalized messages in interfaces. Name each interface descriptively for the messages that will be defined in it.The interface has the following requirements:- It must be declared as public
- It must be annotated with
@org.jboss.logging.MessageBundle. - The interface must define a field that is a message bundle of the same type as the interface.
@MessageBundle(projectCode="") public interface GreetingMessageBundle { GreetingMessageBundle MESSAGES = Messages.getBundle(GreetingMessageBundle.class); }@MessageBundle(projectCode="") public interface GreetingMessageBundle { GreetingMessageBundle MESSAGES = Messages.getBundle(GreetingMessageBundle.class); }Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add method definitions
Add a method definition to the interface for each message. Name each method descriptively for the message that it represents.Each method has the following requirements:- It must return an object of type
String. - It must be annotated with the
@org.jboss.logging.Messageannotation. - The value attribute of
@org.jboss.logging.Messagemust be set to the default message. This is the message that is used if no translation is available.
@Message(value = "Hello world.") String helloworldString();
@Message(value = "Hello world.") String helloworldString();Copy to Clipboard Copied! Toggle word wrap Toggle overflow Invoke methods
Invoke the interface methods in your application where you need to obtain the message.System.console.out.println(helloworldString());
System.console.out.println(helloworldString());Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.2.2.3. Create Internationalized Exceptions
logging-tools quick start for a complete example.
Procedure 6.3. Create and use Internationalized Exceptions
Add JBoss Logging Tools configuration
Add the required project configuration to support JBoss Logging Tools. Refer to Section 6.2.6.1, “JBoss Logging Tools Maven Configuration”Create an interface for the exceptions
JBoss Logging Tools defines internationalized exceptions in interfaces. Name each interface descriptively for the exceptions that will be defined in it.The interface has the following requirements:- It must be declared as
public. - It must be annotated with
@org.jboss.logging.MessageBundle. - The interface must define a field that is a message bundle of the same type as the interface.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add method definitions
Add a method definition to the interface for each exception. Name each method descriptively for the exception that it represents.Each method has the following requirements:- It must return an object of type
Exceptionor a sub-type ofException. - It must be annotated with the
@org.jboss.logging.Messageannotation. - The value attribute of
@org.jboss.logging.Messagemust be set to the default exception message. This is the message that is used if no translation is available. - If the exception being returned has a constructor that requires parameters in addition to a message string, then those parameters must be supplied in the method definition using the
@Paramannotation. The parameters must be the same type and order as the constructor.
@Message(value = "The config file could not be opened.") IOException configFileAccessError(); @Message(id = 13230, value = "Date string '%s' was invalid.") ParseException dateWasInvalid(String dateString, @Param int errorOffset);
@Message(value = "The config file could not be opened.") IOException configFileAccessError(); @Message(id = 13230, value = "Date string '%s' was invalid.") ParseException dateWasInvalid(String dateString, @Param int errorOffset);Copy to Clipboard Copied! Toggle word wrap Toggle overflow Invoke methods
Invoke the interface methods in your code where you need to obtain one of the exceptions. The methods do not throw the exceptions, they return the exception object which you can then throw.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.2.3. Localizing Internationalized Loggers, Messages and Exceptions
6.2.3.1. Generate New Translation Properties Files with Maven
logging-tools quick start for a complete example.
Prerequisites:
- You must already have a working Maven project.
- The project must already be configured for JBoss Logging Tools.
- The project must contain one or more interfaces that define internationalized log messages or exceptions.
Procedure 6.4. Generate New Translation Properties Files with Maven
Add Maven configuration
Add the-AgenereatedTranslationFilePathcompiler argument to the Maven compiler plug-in configuration and assign it the path where the new files will be created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow The above configuration will create the new files in thetarget/generated-translation-filesdirectory of your Maven project.Build the project
Build the project using Maven.mvn compile
[Localhost]$ mvn compileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
@MessageBundle or @MessageLogger. The new files are created in a subdirectory corresponding to the Java package that each interface is declared in.
InterfaceName is the name of the interface that this file was generated for: InterfaceName.i18n_locale_COUNTRY_VARIANT.properties.
6.2.3.2. Translate an Internationalized Logger, Exception or Message
logging-tools quick start for a complete example.
Prerequisites
- You must already have a working Maven project.
- The project must already be configured for JBoss Logging Tools.
- The project must contain one or interfaces that define internationalized log messages or exceptions.
- The project must be configured to generate template translation property files.
Procedure 6.5. Translate an internationalized logger, exception or message
Generate the template properties files
Run themvn compilecommand to create the template translation properties files.Add the template file to your project
Copy the template for the interfaces that you want to translate from the directory where they were created into thesrc/main/resourcesdirectory of your project. The properties files must be in the same package as the interfaces they are translating.Rename the copied template file
Rename the copy of the template file according to the translation it will contain. E.g.GreeterLogger.i18n_fr_FR.properties.Translate the contents of the template.
Edit the new translation properties file to contain the appropriate translation.# Level: Logger.Level.INFO # Message: Hello message sent. logHelloMessageSent=Bonjour message envoyé.
# Level: Logger.Level.INFO # Message: Hello message sent. logHelloMessageSent=Bonjour message envoyé.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Repeat steps two, three, and four for each translation of each bundle being performed.
target/generated-sources/annotations/.
6.2.4. Customizing Internationalized Log Messages
6.2.4.1. Add Message Ids and Project Codes to Log Messages
logging-tools quick start for a complete example.
Prerequisites
- You must already have a project with internationalized log messages. Refer to Section 6.2.2.1, “Create Internationalized Log Messages”.
- You need to know what the project code you will be using is. You can use a single project code, or define different ones for each interface.
Procedure 6.6. Add message Ids and Project Codes to Log Messages
Specify the project code for the interface.
Specify the project code using the projectCode attribute of the@MessageLoggerannotation attached to a custom logger interface. All messages that are defined in the interface will use that project code.@MessageLogger(projectCode="ACCNTS") interface AccountsLogger extends BasicLogger { }@MessageLogger(projectCode="ACCNTS") interface AccountsLogger extends BasicLogger { }Copy to Clipboard Copied! Toggle word wrap Toggle overflow Specify Message Ids
Specify a message ID for each message using theidattribute of the@Messageannotation attached to the method that defines the message.@LogMessage @Message(id=43, value = "Customer query failed, Database not available.") void customerQueryFailDBClosed();
@LogMessage @Message(id=43, value = "Customer query failed, Database not available.") void customerQueryFailDBClosed();Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10:55:50,638 INFO [com.company.accounts.ejb] (MSC service thread 1-4) ACCNTS000043: Customer query failed, Database not available.
10:55:50,638 INFO [com.company.accounts.ejb] (MSC service thread 1-4) ACCNTS000043: Customer query failed, Database not available.6.2.4.2. Specify the Log Level for a Message
INFO. A different log level can be specified with the level attribute of the @LogMessage annotation attached to the logging method.
Procedure 6.7. Specify the log level for a message
Specify level attribute
Add thelevelattribute to the@LogMessageannotation of the log message method definition.Assign log level
Assign thelevelattribute the value of the log level for this message. The valid values forlevelare the six enumerated constants defined inorg.jboss.logging.Logger.Level:DEBUG,ERROR,FATAL,INFO,TRACE, andWARN.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
ERROR.
10:55:50,638 ERROR [com.company.app.Main] (MSC service thread 1-4) Customer query failed, Database not available.
10:55:50,638 ERROR [com.company.app.Main] (MSC service thread 1-4)
Customer query failed, Database not available.6.2.4.3. Customize Log Messages with Parameters
Procedure 6.8. Customize log messages with parameters
Add parameters to method definition
Parameters of any type can be added to the method definition. Regardless of type, the String representation of the parameter is what is displayed in the message.Add parameter references to the log message
References can use explicit or ordinary indexes.- To use ordinary indexes, insert the characters
%sin the message string where you want each parameter to appear. The first instance of%swill insert the first parameter, the second instance will insert the second parameter, and so on. - To use explicit indexes, insert the characters
%{#}in the message where # is the number of the parameter you want to appear.
Important
@Cause annotation is not included in the number of parameters.
Example 6.1. Message parameters using ordinary indexes
@LogMessage(level=Logger.Level.DEBUG) @Message(id=2, value="Customer query failed, customerid:%s, user:%s") void customerLookupFailed(Long customerid, String username);
@LogMessage(level=Logger.Level.DEBUG)
@Message(id=2, value="Customer query failed, customerid:%s, user:%s")
void customerLookupFailed(Long customerid, String username);Example 6.2. Message parameters using explicit indexes
@LogMessage(level=Logger.Level.DEBUG)
@Message(id=2, value="Customer query failed, customerid:%{1}, user:%{2}")
void customerLookupFailed(Long customerid, String username);
@LogMessage(level=Logger.Level.DEBUG)
@Message(id=2, value="Customer query failed, customerid:%{1}, user:%{2}")
void customerLookupFailed(Long customerid, String username);6.2.4.4. Specify an Exception as the Cause of a Log Message
Throwable or any of its sub-classes and is marked with the @Cause annotation. This parameter cannot be referenced in the log message like other parameters and is displayed after the log message.
@Cause parameter to indicate the "causing" exception. It is assumed that you have already created internationalized logging messages to which you want to add this functionality.
Procedure 6.9. Specify an exception as the cause of a log message
Add the parameter
Add a parameter of the typeThrowableor a sub-class to the method.@LogMessage @Message(id=404, value="Loading configuration failed. Config file:%s") void loadConfigFailed(Exception ex, File file);
@LogMessage @Message(id=404, value="Loading configuration failed. Config file:%s") void loadConfigFailed(Exception ex, File file);Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add the annotation
Add the@Causeannotation to the parameter.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Invoke the method
When the method is invoked in your code, an object of the correct type must be passed and will be displayed after the log message.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Below is the output of the above code samples if the code threw an exception of typeFileNotFoundException.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.2.5. Customizing Internationalized Exceptions
6.2.5.1. Add Message Ids and Project Codes to Exception Messages
Prerequisites
- You must already have a project with internationalized exceptions. Refer to Section 6.2.2.3, “Create Internationalized Exceptions”.
- You need to know what the project code you will be using is. You can use a single project code, or define different ones for each interface.
Procedure 6.10. Add message IDs and project codes to exception messages
Specify a project code
Specify the project code using theprojectCodeattribute of the@MessageBundleannotation attached to a exception bundle interface. All messages that are defined in the interface will use that project code.@MessageBundle(projectCode="ACCTS") interface ExceptionBundle { ExceptionBundle EXCEPTIONS = Messages.getBundle(ExceptionBundle.class); }@MessageBundle(projectCode="ACCTS") interface ExceptionBundle { ExceptionBundle EXCEPTIONS = Messages.getBundle(ExceptionBundle.class); }Copy to Clipboard Copied! Toggle word wrap Toggle overflow Specify message IDs
Specify a message id for each exception using theidattribute of the@Messageannotation attached to the method that defines the exception.@Message(id=143, value = "The config file could not be opened.") IOException configFileAccessError();
@Message(id=143, value = "The config file could not be opened.") IOException configFileAccessError();Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Important
Example 6.3. Creating internationalized exceptions
throw ExceptionBundle.EXCEPTIONS.configFileAccessError();
throw ExceptionBundle.EXCEPTIONS.configFileAccessError();Exception in thread "main" java.io.IOException: ACCTS000143: The config file could not be opened. at com.company.accounts.Main.openCustomProperties(Main.java:78) at com.company.accounts.Main.go(Main.java:53) at com.company.accounts.Main.main(Main.java:43)
Exception in thread "main" java.io.IOException: ACCTS000143: The config file could not be opened.
at com.company.accounts.Main.openCustomProperties(Main.java:78)
at com.company.accounts.Main.go(Main.java:53)
at com.company.accounts.Main.main(Main.java:43)6.2.5.2. Customize Exception Messages with Parameters
Procedure 6.11. Customize an exception message with parameters
Add parameters to method definition
Parameters of any type can be added to the method definition. Regardless of type, theStringrepresentation of the parameter is what is displayed in the message.Add parameter references to the exception message
References can use explicit or ordinary indexes.- To use ordinary indexes, insert the characters
%sin the message string where you want each parameter to appear. The first instance of%swill insert the first parameter, the second instance will insert the second parameter, and so on. - To use explicit indexes, insert the characters
%{#}in the message where#is the number of the parameter you want to appear.
Using explicit indexes allows the parameter references in the message to be in a different order than they are defined in the method. This is important for translated messages which may require different ordering of parameters.
Important
@Cause annotation is not included in the number of parameters.
Example 6.4. Using ordinary indexes
@Message(id=143, value = "The config file %s could not be opened.") IOException configFileAccessError(File config);
@Message(id=143, value = "The config file %s could not be opened.")
IOException configFileAccessError(File config);Example 6.5. Using explicit indexes
@Message(id=143, value = "The config file %{1} could not be opened.")
IOException configFileAccessError(File config);
@Message(id=143, value = "The config file %{1} could not be opened.")
IOException configFileAccessError(File config);6.2.5.3. Specify One Exception as the Cause of Another Exception
@Cause. This parameter is used to pass the causing exception. This parameter cannot be referenced in the exception message.
@Cause parameter to indicate the causing exception. It is assumed that you have already created an exception bundle to which you want to add this functionality.
Procedure 6.12. Specify one exception as the cause of another exception
Add the parameter
Add the a parameter of the typeThrowableor a sub-class to the method.@Message(id=328, value = "Error calculating: %s.") ArithmeticException calculationError(Throwable cause, String msg);
@Message(id=328, value = "Error calculating: %s.") ArithmeticException calculationError(Throwable cause, String msg);Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add the annotation
Add the@Causeannotation to the parameter.import org.jboss.logging.Cause @Message(id=328, value = "Error calculating: %s.") ArithmeticException calculationError(@Cause Throwable cause, String msg);
import org.jboss.logging.Cause @Message(id=328, value = "Error calculating: %s.") ArithmeticException calculationError(@Cause Throwable cause, String msg);Copy to Clipboard Copied! Toggle word wrap Toggle overflow Invoke the method
Invoke the interface method to obtain an exception object. The most common use case is to throw a new exception from a catch block using the caught exception as the cause.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Example 6.6. Specify one exception as the cause of another exception
6.2.6. Reference
6.2.6.1. JBoss Logging Tools Maven Configuration
pom.xml file.
logging-tools quick start for an example of a complete working pom.xml file.
- JBoss Maven Repository must be enabled for the project. Refer to Section 2.3.2, “Configure the JBoss EAP 6 Maven Repository Using the Maven Settings”.
- The Maven dependencies for
jboss-loggingandjboss-logging-processormust be added. Both of dependencies are available in JBoss EAP 6 so the scope element of each can be set toprovidedas shown.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - The
maven-compiler-pluginmust be at least version2.2and be configured for target and generated sources of1.6.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.2.6.2. Translation Property File Format
key=value pair format described in the documentation for the java.util.Properties class, http://docs.oracle.com/javase/6/docs/api/java/util/Properties.html.
InterfaceName.i18n_locale_COUNTRY_VARIANT.properties
InterfaceName.i18n_locale_COUNTRY_VARIANT.properties InterfaceNameis the name of the interface that the translations apply to.locale,COUNTRY, andVARIANTidentify the regional settings that the translation applies to.localeandCOUNTRYspecify the language and country using the ISO-639 and ISO-3166 Language and Country codes respectively.COUNTRYis optional.VARIANTis an optional identifier that can be used to identify translations that only apply to a specific operating system or browser.
Example 6.7. Sample Translation Properties File
GreeterService.i18n_fr_FR_POSIX.properties.
# Level: Logger.Level.INFO # Message: Hello message sent. logHelloMessageSent=Bonjour message envoyé.
# Level: Logger.Level.INFO
# Message: Hello message sent.
logHelloMessageSent=Bonjour message envoyé.6.2.6.3. JBoss Logging Tools Annotations Reference
| Annotation | Target | Description | Attributes |
|---|---|---|---|
@MessageBundle | Interface |
Defines the interface as a Message Bundle.
| projectCode |
@MessageLogger | Interface |
Defines the interface as a Message Logger.
| projectCode |
@Message | Method |
Can be used in Message Bundles and Message Loggers. In a Message Logger it defines a method as being a localized logger. In a Message Bundle it defines the method as being one that returns a localized String or Exception object.
| value, id |
@LogMessage | Method |
Defines a method in a Message Logger as being a logging method.
| level (default INFO) |
@Cause | Parameter |
Defines a parameter as being one that passes an Exception as the cause of either a Log message or another Exception.
| - |
@Param | Parameter |
Defines a parameter as being one that is passed to the constructor of the Exception.
| - |
Chapter 7. Enterprise JavaBeans
7.1. Introduction
7.1.1. Overview of Enterprise JavaBeans
7.1.2. EJB 3.1 Feature Set
- Session Beans
- Message Driven Beans
- No-interface views
- local interfaces
- remote interfaces
- JAX-WS web services
- JAX-RS web services
- Timer Service
- Asynchronous Calls
- Interceptors
- RMI/IIOP interoperability
- Transaction support
- Security
- Embeddable API
- Entity Beans (container and bean-managed persistence)
- EJB 2.1 Entity Bean client views
- EJB Query Language (EJB QL)
- JAX-RPC based Web Services (endpoints and client views)
7.1.3. EJB 3.1 Lite
- Only supporting the features that make sense for web-applications, and
- allowing EJBs to be deployed in the same WAR file as a web-application.
7.1.4. EJB 3.1 Lite Features
- Stateless, stateful, and singleton session beans
- Local business interfaces and "no interface" beans
- Interceptors
- Container-managed and bean-managed transactions
- Declarative and programmatic security
- Embeddable API
- Remote interfaces
- RMI-IIOP Interoperability
- JAX-WS Web Service Endpoints
- EJB Timer Service
- Asynchronous session bean invocations
- Message-driven beans
7.1.5. Enterprise Beans
Important
7.1.6. Overview of Writing Enterprise Beans
7.1.7. Session Bean Business Interfaces
7.1.7.1. Enterprise Bean Business Interfaces
7.1.7.2. EJB Local Business Interfaces
7.1.7.3. EJB Remote Business Interfaces
7.1.7.4. EJB No-interface Beans
7.2. Creating Enterprise Bean Projects
7.2.1. Create an EJB Archive Project Using Red Hat JBoss Developer Studio
Prerequisites
- A server and server runtime for JBoss EAP 6 has been set up.
Procedure 7.1. Create an EJB Project in Red Hat JBoss Developer Studio
Create new project
To open the New EJB Project wizard, navigate to the menu, select , and then .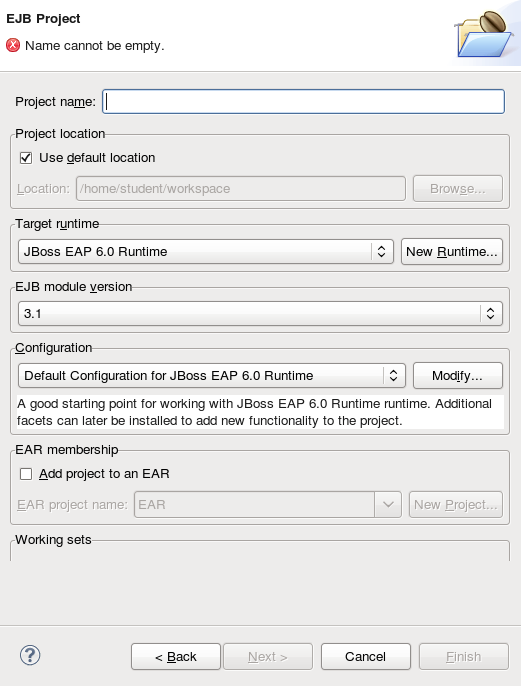
Figure 7.1. New EJB Project wizard
Specify Details
Supply the following details:- Project name.As well as the being the name of the project that appears in Red Hat JBoss Developer Studio this is also the default filename for the deployed JAR file.
- Project location.The directory where the project's files will be saved. The default is a directory in the current workspace.
- Target Runtime.This is the server runtime used for the project. This will need to be set to the same JBoss EAP 6 runtime used by the server that you will be deploying to.
- EJB module version. This is the version of the EJB specification that your enterprise beans will comply with. Red Hat recommends using
3.1. - Configuration. This allows you to adjust the supported features in your project. Use the default configuration for your selected runtime.
Click to continue.Java Build Configuration
This screen allows you to customize the directories will contain Java source files and the directory where the built output is placed.Leave this configuration unchanged and click .EJB Module settings
Check the Generate ejb-jar.xml deployment descriptor checkbox if a deployment descriptor is required. The deployment descriptor is optional in EJB 3.1 and can be added later if required.Click and the project is created and will be displayed in the Project Explorer.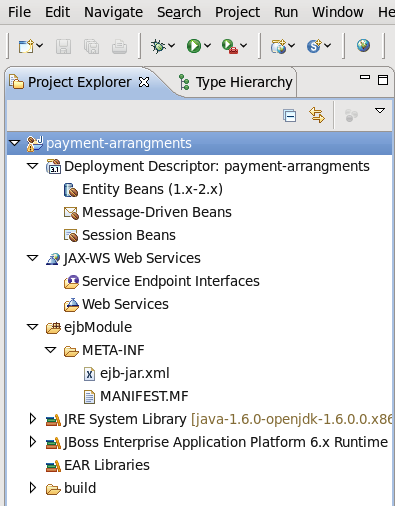
Figure 7.2. Newly created EJB Project in the Project Explorer
Add Build Artifact to Server for Deployment
Open the Add and Remove dialog by right-clicking on the server you want to deploy the built artifact to in the server tab, and select "Add and Remove".Select the resource to deploy from the Available column and click the button. The resource will be moved to the Configured column. Click to close the dialog.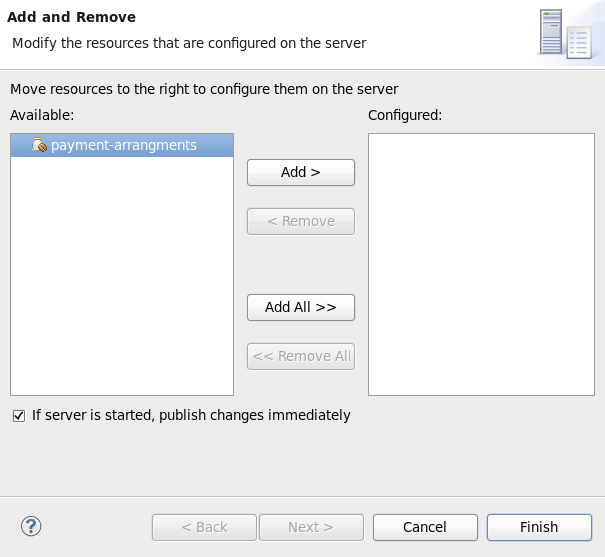
Figure 7.3. Add and Remove dialog
You now have an EJB Project in Red Hat JBoss Developer Studio that can build and deploy to the specified server.
7.2.2. Create an EJB Archive Project in Maven
Prerequisites:
- Maven is already installed.
- You understand the basic usage of Maven.
Procedure 7.2. Create an EJB Archive project in Maven
Create the Maven project
An EJB project can be created using Maven's archetype system and theejb-javaee6archetype. To do this run themvncommand with parameters as shown:mvn archetype:generate -DarchetypeGroupId=org.codehaus.mojo.archetypes -DarchetypeArtifactId=ejb-javaee6
mvn archetype:generate -DarchetypeGroupId=org.codehaus.mojo.archetypes -DarchetypeArtifactId=ejb-javaee6Copy to Clipboard Copied! Toggle word wrap Toggle overflow Maven will prompt you for thegroupId,artifactId,versionandpackagefor your project.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add your enterprise beans
Write your enterprise beans and add them to the project under thesrc/main/javadirectory in the appropriate sub-directory for the bean's package.Build the project
To build the project, run themvn packagecommand in the same directory as thepom.xmlfile. This will compile the Java classes and package the JAR file. The built JAR file is namedartifactId-version.jarand is placed in thetarget/directory.
7.2.3. Create an EAR Project containing an EJB Project
Prerequisites
- A server and server runtime for JBoss EAP 6 has been set up. Refer to Section 1.3.1.5, “Add the JBoss EAP Server Using Define New Server”.
Procedure 7.3. Create an EAR Project containing an EJB Project
Open the New EAR Application Project Wizard
Navigate to the menu, select , then and the New Project wizard appears. Select and click .
Figure 7.4. New EAR Application Project Wizard
Supply details
Supply the following details:- Project name.As well as the being the name of the project that appears in Red Hat JBoss Developer Studio this is also the default filename for the deployed EAR file.
- Project location.The directory where the project's files will be saved. The default is a directory in the current workspace.
- Target Runtime.This is the server runtime used for the project. This will need to be set to the same JBoss EAP 6 runtime used by the server that you will be deploying to.
- EAR version.This is the version of the Java Enterprise Edition specification that your project will comply with. Red Hat recommends using
6. - Configuration. This allows you to adjust the supported features in your project. Use the default configuration for your selected runtime.
Click to continue.Add a new EJB Module
New Modules can be added from the Enterprise Application page of the wizard. To add a new EJB Project as a module follow the steps below:Add new EJB Module
Click , uncheck Create Default Modules checkbox, select the Enterprise Java Bean and click . The New EJB Project wizard appears.Create EJB Project
New EJB Project wizard is the same as the wizard used to create new standalone EJB Projects and is described in Section 7.2.1, “Create an EJB Archive Project Using Red Hat JBoss Developer Studio”.The minimal details required to create the project are:- Project name
- Target Runtime
- EJB Module version
- Configuration
All the other steps of the wizard are optional. Click to complete creating the EJB Project.
The newly created EJB project is listed in the Java EE module dependencies and the checkbox is checked.Optional: add an application.xml deployment descriptor
Check the Generate application.xml deployment descriptor checkbox if one is required.Click Finish
Two new project will appear, the EJB project and the EAR projectAdd Build Artifact to Server for Deployment
Open the Add and Remove dialog by right-clicking in the Servers tab on the server you want to deploy the built artifact to in the server tab, and select .Select the EAR resource to deploy from the Available column and click the button. The resource will be moved to the Configured column. Click to close the dialog.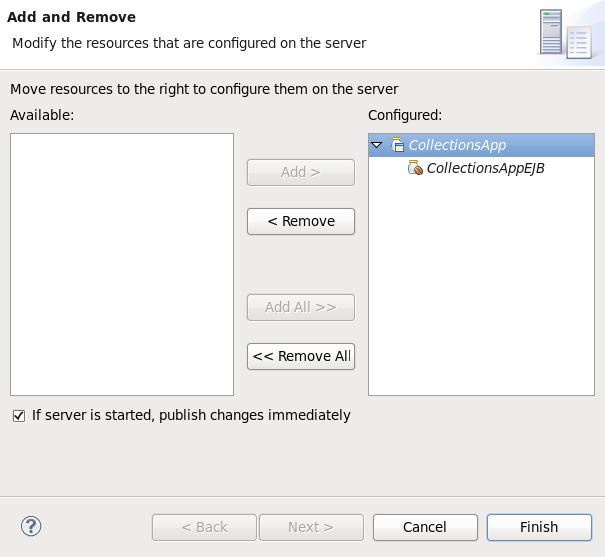
Figure 7.5. Add and Remove dialog
You now have an Enterprise Application Project with a member EJB Project. This will build and deploy to the specified server as a single EAR deployment containing an EJB subdeployment.
7.2.4. Add a Deployment Descriptor to an EJB Project
Perquisites:
- You have a EJB Project in Red Hat JBoss Developer Studio to which you want to add an EJB deployment descriptor.
Procedure 7.4. Add an Deployment Descriptor to an EJB Project
Open the Project
Open the project in Red Hat JBoss Developer Studio.Add Deployment Descriptor
Right-click on the Deployment Descriptor folder in the project view and select .
Figure 7.6. Adding a Deployment Descriptor
ejb-jar.xml, is created in ejbModule/META-INF/. Double-clicking on the Deployment Descriptor folder in the project view will also open this file.
7.3. Session Beans
7.3.1. Session Beans
7.3.2. Stateless Session Beans
7.3.3. Stateful Session Beans
7.3.4. Singleton Session Beans
7.3.5. Add Session Beans to a Project in Red Hat JBoss Developer Studio
Prerequisites:
- You have a EJB or Dynamic Web Project in Red Hat JBoss Developer Studio to which you want to add one or more session beans.
Procedure 7.5. Add Session Beans to a Project in Red Hat JBoss Developer Studio
Open the Project
Open the project in Red Hat JBoss Developer Studio.Open the "Create EJB 3.x Session Bean" wizard
To open the Create EJB 3.x Session Bean wizard, navigate to the menu, select , and then .
Figure 7.7. Create EJB 3.x Session Bean wizard
Specify class information
Supply the following details:- ProjectVerify the correct project is selected.
- Source folderThis is the folder that the Java source files will be created in. This should not usually need to be changed.
- PackageSpecify the package that the class belongs to.
- Class nameSpecify the name of the class that will be the session bean.
- SuperclassThe session bean class can inherit from a super class. Specify that here if your session has a super class.
- State typeSpecify the state type of the session bean: stateless, stateful, or singleton.
- Business InterfacesBy default the No-interface box is checked so no interfaces will be created. Check the boxes for the interfaces you wish to define and adjust the names if necessary.Remember that enterprise beans in a web archive (WAR) only support EJB 3.1 Lite and this does not include remote business interfaces.
Click .Session Bean Specific Information
You can enter in additional information here to further customize the session bean. It is not required to change any of the information here.Items that you can change are:- Bean name.
- Mapped name.
- Transaction type (Container managed or Bean managed).
- Additional interfaces can be supplied that the bean must implement.
- You can also specify EJB 2.x Home and Component interfaces if required.
Finish
Click and the new session bean will be created and added to the project. The files for any new business interfaces will also be created if they were specified.
Figure 7.8. New Session Bean in Red Hat JBoss Developer Studio
7.4. Message-Driven Beans
7.4.1. Message-Driven Beans
7.4.2. Resource Adapters
7.4.3. Create a JMS-based Message-Driven Bean in Red Hat JBoss Developer Studio
Prerequisites:
- You must have an existing project open in Red Hat JBoss Developer Studio.
- You must know the name and type of the JMS destination that the bean will be listening to.
- Support for Java Messaging Service (JMS) must be enabled in the JBoss EAP 6 configuration to which this bean will be deployed.
Procedure 7.6. Add a JMS-based Message-Driven Bean in Red Hat JBoss Developer Studio
Open the Create EJB 3.x Message-Driven Bean Wizard
Go to → → . Select EJB/Message-Driven Bean (EJB 3.x) and click the button.
Figure 7.9. Create EJB 3.x Message-Driven Bean Wizard
Specify class file destination details
There are three sets of details to specify for the bean class here: Project, Java class, and message destination.- Project
- If multiple projects exist in the Workspace, ensure that the correct one is selected in the menu.
- The folder where the source file for the new bean will be created is
ejbModuleunder the selected project's directory. Only change this if you have a specific requirement.
- Java class
- The required fields are: Java package and class name.
- It is not necessary to supply a Superclass unless the business logic of your application requires it.
- Message Destination
- These are the details you must supply for a JMS-based Message-Driven Bean:
- Destination name. This is the queue or topic name that contains the messages that the bean will respond to.
- By default the JMS checkbox is selected. Do not change this.
- Set Destination type to Queue or Topic as required.
Click the button.Enter Message-Driven Bean specific information
The default values here are suitable for a JMS-based Message-Driven bean using Container-managed transactions.- Change the Transaction type to Bean if the Bean will use Bean-managed transactions.
- Change the Bean name if a different bean name than the class name is required.
- The JMS Message Listener interface will already be listed. You do not need to add or remove any interfaces unless they are specific to your applications business logic.
- Leave the checkboxes for creating method stubs selected.
Click the button.
onMessage() method. A Red Hat JBoss Developer Studio editor window opened with the corresponding file.
7.4.4. Enable EJB and MDB Property Substitution in an Application
@ActivationConfigProperty and @Resource annotations. Property substitution requires the following configuration and code changes.
- You must enable property substitution in the JBoss EAP server configuration file.
- You must define the system properties in the server configuration file or pass them as arguments when you start the JBoss EAP server.
- You must modify the code to use the substitution variables.
Procedure 7.7. Implement Property Substitution in an MDB Application
helloworld-mdb quickstart that ships with JBoss EAP 6.3 or later. This topic shows you how to modify that quickstart to enable property substitution.
Configure the JBoss EAP server to enable property substitution.
The JBoss EAP server must be configured to enable property substitution. To do this, set the<annotation-property-replacement>attribute in theeesubsystem of the server configuration file totrue.- Back up the server configuration file. The
helloworld-mdbquickstart example requires the full profile for a standalone server, so this is thestandalone/configuration/standalone-full.xmlfile. If you are running your server in a managed domain, this is thedomain/configuration/domain.xmlfile. - Start the JBoss EAP server with the full profile.For Linux:For Windows:
EAP_HOME/bin/standalone.sh -c standalone-full.xml
EAP_HOME/bin/standalone.sh -c standalone-full.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow EAP_HOMEbin\standalone.bat -c standalone-full.xml
EAP_HOMEbin\standalone.bat -c standalone-full.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Launch the Management CLI using the command for your operating system.For Linux:For Windows:
EAP_HOME/bin/jboss-cli.sh --connect
EAP_HOME/bin/jboss-cli.sh --connectCopy to Clipboard Copied! Toggle word wrap Toggle overflow EAP_HOME\bin\jboss-cli.bat --connect
EAP_HOME\bin\jboss-cli.bat --connectCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Type the following command to enable annotation property substitution.
/subsystem=ee:write-attribute(name=annotation-property-replacement,value=true)
/subsystem=ee:write-attribute(name=annotation-property-replacement,value=true)Copy to Clipboard Copied! Toggle word wrap Toggle overflow - You should see the following result:
{"outcome" => "success"}{"outcome" => "success"}Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Review the changes to the JBoss EAP server configuration file. The
eesubsystem should now contain the following XML.<subsystem xmlns="urn:jboss:domain:ee:1.2"> <spec-descriptor-property-replacement>false</spec-descriptor-property-replacement> <jboss-descriptor-property-replacement>true</jboss-descriptor-property-replacement> <annotation-property-replacement>true</annotation-property-replacement> </subsystem><subsystem xmlns="urn:jboss:domain:ee:1.2"> <spec-descriptor-property-replacement>false</spec-descriptor-property-replacement> <jboss-descriptor-property-replacement>true</jboss-descriptor-property-replacement> <annotation-property-replacement>true</annotation-property-replacement> </subsystem>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Define the system properties.
You can specify the system properties in the server configuration file or you can pass them as command line arguments when you start the JBoss EAP server. System properties defined in the server configuration file take precedence over those passed on the command line when you start the server.- Define the system properties in the server configuration file.
- Start the JBoss EAP server and Management API as described in the previous step.
- Use the following command syntax to configure a system property in the JBoss EAP server:
/system-property=PROPERTY_NAME:add(value=PROPERTY_VALUE)
/system-property=PROPERTY_NAME:add(value=PROPERTY_VALUE)Copy to Clipboard Copied! Toggle word wrap Toggle overflow For thehelloworld-mdbquickstart, we configure the following system properties:/system-property=property.helloworldmdb.queue:add(value=java:/queue/HELLOWORLDMDBPropQueue) /system-property=property.helloworldmdb.topic:add(value=java:/topic/HELLOWORLDMDBPropTopic) /system-property=property.connection.factory:add(value=java:/ConnectionFactory)
/system-property=property.helloworldmdb.queue:add(value=java:/queue/HELLOWORLDMDBPropQueue) /system-property=property.helloworldmdb.topic:add(value=java:/topic/HELLOWORLDMDBPropTopic) /system-property=property.connection.factory:add(value=java:/ConnectionFactory)Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Review the changes to the JBoss EAP server configuration file. The following system properties should now appear in the after the
<extensions>.<system-properties> <property name="property.helloworldmdb.queue" value="java:/queue/HELLOWORLDMDBPropQueue"/> <property name="property.helloworldmdb.topic" value="java:/topic/HELLOWORLDMDBPropTopic"/> <property name="property.connection.factory" value="java:/ConnectionFactory"/> </system-properties><system-properties> <property name="property.helloworldmdb.queue" value="java:/queue/HELLOWORLDMDBPropQueue"/> <property name="property.helloworldmdb.topic" value="java:/topic/HELLOWORLDMDBPropTopic"/> <property name="property.connection.factory" value="java:/ConnectionFactory"/> </system-properties>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- Pass the system properties as arguments on the command line when you start the JBoss EAP server in the form of
-DPROPERTY_NAME=PROPERTY_VALUE. The following is an example of how to pass the arguments for the system properties defined in the previous step.EAP_HOME/bin/standalone.sh -c standalone-full.xml -Dproperty.helloworldmdb.queuejava:/queue/HELLOWORLDMDBPropQueue -Dproperty.helloworldmdb.topic=java:/topic/HELLOWORLDMDBPropTopic -Dproperty.connection.factory=java:/ConnectionFactory
EAP_HOME/bin/standalone.sh -c standalone-full.xml -Dproperty.helloworldmdb.queuejava:/queue/HELLOWORLDMDBPropQueue -Dproperty.helloworldmdb.topic=java:/topic/HELLOWORLDMDBPropTopic -Dproperty.connection.factory=java:/ConnectionFactoryCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Modify the code to use the system property substitutions.
Replace hard-coded@ActivationConfigPropertyand@Resourceannotation values with substitutions for the newly defined system properties. The following are examples of how to change thehelloworld-mdbquickstart to use the newly defined system property substitutions within the annotations in the source code.- Change the
@ActivationConfigPropertydestinationproperty value in theHelloWorldQueueMDBclass to use the substitution for the system property. The@MessageDrivenannotation should now look like this:@MessageDriven(name = "HelloWorldQueueMDB", activationConfig = { @ActivationConfigProperty(propertyName = "destinationType", propertyValue = "javax.jms.Queue"), @ActivationConfigProperty(propertyName = "destination", propertyValue = "${property.helloworldmdb.queue}"), @ActivationConfigProperty(propertyName = "acknowledgeMode", propertyValue = "Auto-acknowledge") })@MessageDriven(name = "HelloWorldQueueMDB", activationConfig = { @ActivationConfigProperty(propertyName = "destinationType", propertyValue = "javax.jms.Queue"), @ActivationConfigProperty(propertyName = "destination", propertyValue = "${property.helloworldmdb.queue}"), @ActivationConfigProperty(propertyName = "acknowledgeMode", propertyValue = "Auto-acknowledge") })Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Change the
@ActivationConfigPropertydestinationproperty value in theHelloWorldTopicMDBclass to use the substitution for the system property. The@MessageDrivenannotation should now look like this:@MessageDriven(name = "HelloWorldQTopicMDB", activationConfig = { @ActivationConfigProperty(propertyName = "destinationType", propertyValue = "javax.jms.Topic"), @ActivationConfigProperty(propertyName = "destination", propertyValue = "${property.helloworldmdb.topic}"), @ActivationConfigProperty(propertyName = "acknowledgeMode", propertyValue = "Auto-acknowledge") })@MessageDriven(name = "HelloWorldQTopicMDB", activationConfig = { @ActivationConfigProperty(propertyName = "destinationType", propertyValue = "javax.jms.Topic"), @ActivationConfigProperty(propertyName = "destination", propertyValue = "${property.helloworldmdb.topic}"), @ActivationConfigProperty(propertyName = "acknowledgeMode", propertyValue = "Auto-acknowledge") })Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Change the
@Resourceannotations in theHelloWorldMDBServletClientclass to use the system property substitutions. The code should now look like this:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Modify the
hornetq-jms.xmlfile to use the system property substitution values.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- Deploy the application. The application will now use the values specified by the system properties for the
@Resourceand@ActivationConfigPropertyproperty values.
7.5. Invoking Session Beans
7.5.1. Invoke a Session Bean Remotely using JNDI
ejb-remote quickstart contains working Maven projects that demonstrate this functionality. The quickstart contains projects for both the session beans to deploy and the remote client. The code samples below are taken from the remote client project.
Warning
Prerequisites
- You must already have a Maven project created ready to use.
- Configuration for the JBoss EAP 6 Maven repository has already been added.
- The session beans that you want to invoke are already deployed.
- The deployed session beans implement remote business interfaces.
- The remote business interfaces of the session beans are available as a Maven dependency. If the remote business interfaces are only available as a JAR file then it is recommended to add the JAR to your Maven repository as an artifact. Refer to the Maven documentation for the
install:install-filegoal for directions, http://maven.apache.org/plugins/maven-install-plugin/usage.html - You need to know the hostname and JNDI port of the server hosting the session beans.
Procedure 7.8. Add Maven Project Configuration for Remote Invocation of Session Beans
Add the required project dependencies
Thepom.xmlfor the project must be updated to include the necessary dependencies.Add the
jboss-ejb-client.propertiesfileThe JBoss EJB client API expects to find a file in the root of the project namedjboss-ejb-client.propertiesthat contains the connection information for the JNDI service. Add this file to thesrc/main/resources/directory of your project with the following content.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Change the host name and port to match your server.4447is the default port number. For a secure connection, set theSSL_ENABLEDline totrueand uncomment theSSL_STARTTLSline. The Remoting interface in the container supports secured and unsecured connections using the same port.Add dependencies for the remote business interfaces
Add the Maven dependencies to thepom.xmlfor the remote business interfaces of the session beans.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Procedure 7.9. Obtain a Bean Proxy using JNDI and Invoke Methods of the Bean
Handle checked exceptions
Two of the methods used in the following code (InitialContext()andlookup()) have a checked exception of typejavax.naming.NamingException. These method calls must either be enclosed in a try/catch block that catchesNamingExceptionor in a method that is declared to throwNamingException. Theejb-remotequickstart uses the second technique.Create a JNDI Context
A JNDI Context object provides the mechanism for requesting resources from the server. Create a JNDI context using the following code:final Hashtable jndiProperties = new Hashtable(); jndiProperties.put(Context.URL_PKG_PREFIXES, "org.jboss.ejb.client.naming"); final Context context = new InitialContext(jndiProperties);
final Hashtable jndiProperties = new Hashtable(); jndiProperties.put(Context.URL_PKG_PREFIXES, "org.jboss.ejb.client.naming"); final Context context = new InitialContext(jndiProperties);Copy to Clipboard Copied! Toggle word wrap Toggle overflow The connection properties for the JNDI service are read from thejboss-ejb-client.propertiesfile.Use the JNDI Context's lookup() method to obtain a bean proxy
Invoke thelookup()method of the bean proxy and pass it the JNDI name of the session bean you require. This will return an object that must be cast to the type of the remote business interface that contains the methods you want to invoke.final RemoteCalculator statelessRemoteCalculator = (RemoteCalculator) context.lookup( "ejb:/jboss-ejb-remote-server-side//CalculatorBean!" + RemoteCalculator.class.getName());final RemoteCalculator statelessRemoteCalculator = (RemoteCalculator) context.lookup( "ejb:/jboss-ejb-remote-server-side//CalculatorBean!" + RemoteCalculator.class.getName());Copy to Clipboard Copied! Toggle word wrap Toggle overflow Session bean JNDI names are defined using a special syntax. For more information, see Section 7.8.1, “EJB JNDI Naming Reference” .Invoke methods
Now that you have a proxy bean object you can invoke any of the methods contained in the remote business interface.int a = 204; int b = 340; System.out.println("Adding " + a + " and " + b + " via the remote stateless calculator deployed on the server"); int sum = statelessRemoteCalculator.add(a, b); System.out.println("Remote calculator returned sum = " + sum);int a = 204; int b = 340; System.out.println("Adding " + a + " and " + b + " via the remote stateless calculator deployed on the server"); int sum = statelessRemoteCalculator.add(a, b); System.out.println("Remote calculator returned sum = " + sum);Copy to Clipboard Copied! Toggle word wrap Toggle overflow The proxy bean passes the method invocation request to the session bean on the server, where it is executed. The result is returned to the proxy bean which then returns it to the caller. The communication between the proxy bean and the remote session bean is transparent to the caller.
7.5.2. About EJB Client Contexts
- A remote client, which runs as a standalone Java application.
- A remote client, which runs within another JBoss EAP 6 instance.
7.5.3. Considerations When Using a Single EJB Context
You must consider your application requirements when using a single EJB client context with standalone remote clients. For more information about the different types of remote clients, refer to: Section 7.5.2, “About EJB Client Contexts” .
A remote standalone client typically has just one EJB client context backed by any number of EJB receivers. The following is an example of a standalone remote client application:
jboss-ejb-client.properties file, which is used to set up the EJB client context and the EJB receivers. This configuration also includes the security credentials, which are then used to create the EJB receiver that connects to the JBoss EAP 6 server. When the above code is invoked, the EJB client API looks for the EJB client context, which is then used to select the EJB receiver that will receive and process the EJB invocation request. In this case, there is just the single EJB client context, so that context is used by the above code to invoke the bean. The procedure to invoke a session bean remotely using JNDI is described in greater detail here: Section 7.5.1, “Invoke a Session Bean Remotely using JNDI” .
A user application may want to invoke a bean more than once, but connect to the JBoss EAP 6 server using different security credentials. The following is an example of a standalone remote client application that invokes the same bean twice:
Scoped EJB client contexts offer a solution to this issue. They provide a way to have more control over the EJB client contexts and their associated JNDI contexts, which are typically used for EJB invocations. For more information about scoped EJB client contexts, refer to Section 7.5.4, “Using Scoped EJB Client Contexts” and Section 7.5.5, “Configure EJBs Using a Scoped EJB Client Context” .
7.5.4. Using Scoped EJB Client Contexts
To invoke an EJB In earlier versions of JBoss EAP 6, you would typically create a JNDI context and pass it the PROVIDER_URL, which would point to the target server. Any invocations done on EJB proxies that were looked up using that JNDI context, would end up on that server. With scoped EJB client contexts, user applications have control over which EJB receiver is used for a specific invocation.
Prior to the introduction of scoped EJB client contexts, the context was typically scoped to the client application. Scoped client contexts now allow the EJB client contexts to be scoped with the JNDI contexts. The following is an example of a standalone remote client application that invokes the same bean twice using a scoped EJB client context:
jboss-ejb-client.properties file. To scope the EJB client context to the JNDI context, you must also specify the org.jboss.ejb.client.scoped.context property and set its value to true. This property notifies the EJB client API that it must create an EJB client context, which is backed by EJB receivers, and that the created context is then scoped or visible only to the JNDI context that created it. Any EJB proxies looked up or invoked using this JNDI context will only know of the EJB client context associated with this JNDI context. Other JNDI contexts used by the application to lookup and invoke EJBs will not know about the other scoped EJB client contexts.
org.jboss.ejb.client.scoped.context property and aren't scoped to an EJB client context will use the default behavior, which is to use the existing EJB client context that is typically tied to the entire application.
Note
InitialContext when it is no longer needed. When the InitialContext is closed, the resources are released immediately. The proxies that are bound to it are no longer valid and any invocation will throw an Exception. Failure to close the InitialContext may result in resource and performance issues.
7.5.5. Configure EJBs Using a Scoped EJB Client Context
EJBs can be configured using a map-based scoped context. This is achieved by programmatically populating a Properties map using the standard properties found in the jboss-ejb-client.properties, specifying true for the org.jboss.ejb.client.scoped.context property, and passing the properties on the InitialContext creation.
Procedure 7.10. Configure an EJB Using a Map-Based Scoped Context
Set the Properties
Configure the EJB client properties programmatically, specifying the same set of properties that are used in the standardjboss-ejb-client.propertiesfile. To enable the scoped context, you must specify theorg.jboss.ejb.client.scoped.contextproperty and set its value totrue. The following is an example that configures the properties programmatically.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Pass the Properties on the Context Creation
// Create the context using the configured properties InitialContext ic = new InitialContext(ejbClientContextProps); MySLSB bean = ic.lookup("ejb:myapp/ejb//MySLSBBean!" + MySLSB.class.getName());// Create the context using the configured properties InitialContext ic = new InitialContext(ejbClientContextProps); MySLSB bean = ic.lookup("ejb:myapp/ejb//MySLSBBean!" + MySLSB.class.getName());Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- Contexts generated by lookup EJB proxies are bound by this scoped context and use only the relevant connection parameters. This makes it possible to create different contexts to access data within a client application or to independently access servers using different logins.
- In the client, both the scoped
InitialContextand the scoped proxy are passed to threads, allowing each thread to work with the given context. It is also possible to pass the proxy to multiple threads that can use it concurrently. - The scoped context EJB proxy is serialized on the remote call and then deserialized on the server. When it is deserialized, the scoped context information is removed and it returns to its default state. If the deserialized proxy is used on the remote server, because it no longer has the scoped context that was used when it was created, this can result in an
EJBCLIENT000025error or possibly call an unwanted target by using the EJB name.
7.5.6. EJB Client Properties
The following tables list properties that can be configured programmatically or in the jboss-ejb-client.properties file.
The following table lists properties that are valid for the whole library within the same scope.
| Property Name | Description |
|---|---|
endpoint.name |
Name of the client endpoint. If not set, the default value is
client-endpoint
This can be helpful to distinguish different endpoint settings because the thread name contains this property.
|
remote.connectionprovider.create.options.org.xnio.Options.SSL_ENABLED |
Boolean value that specifies whether the SSL protocol is enabled for all connections.
Warning
Red Hat recommends that you explicitly disable SSL in favor of TLSv1.1 or TLSv1.2 in all affected packages.
|
deployment.node.selector |
The fully qualified name of the implementation of
org.jboss.ejb.client.DeploymentNodeSelector.
This is used to load balance the invocation for the EJBs.
|
invocation.timeout |
The timeout for the EJB handshake or method invocation request/response cycle. The value is in milliseconds.
The invocation of any method throws a
java.util.concurrent.TimeoutException if the execution takes longer than the timeout period. The execution completes and the server is not interrupted.
|
reconnect.tasks.timeout |
The timeout for the background reconnect tasks. The value is in milliseconds.
If a number of connections are down, the next client EJB invocation will use an algorithm to decide if a reconnect is necessary to find the right node.
|
org.jboss.ejb.client.scoped.context |
Boolean value that specifies whether to enable the scoped EJB client context. The default value is
false.
If set to
true, the EJB Client will use the scoped context that is tied to the JNDI context. Otherwise the EJB client context will use the global selector in the JVM to determine the properties used to call the remote EJB and host.
|
The connection properties start with the prefix remote.connection.CONNECTION_NAME where the CONNECTION_NAME is a local identifier only used to uniquely identify the connection.
| Property Name | Description |
|---|---|
remote.connections |
A comma-separated list of active
connection-names. Each connection is configured by using this name.
|
|
The host name or IP for the connection.
|
|
The port for the connection. The default value is 4447.
|
|
The user name used to authenticate connection security.
|
|
The password used to authenticate the user.
|
|
The timeout period for the initial connection. After that, the reconnect task will periodically check whether the connection can be established. The value is in milliseconds.
|
|
Full qualified name of the
CallbackHandler class. It will be used to establish the connection and can not changed as long as the connection is open.
|
channel.options.org.jboss.remoting3.RemotingOptions.MAX_OUTBOUND_MESSAGES
|
Integer value specifying the maximum number of outbound requests. The default is 80.
There is only one connection from the client (JVM) to the server to handle all invocations.
|
connect.options.org.xnio.Options.SASL_POLICY_NOANONYMOUS
|
Boolean value that determines whether credentials must be provided by the client to connect successfully. The default value is
true.
If set to
true, the client must provide credentials. If set to false, invocation is allowed as long as the remoting connector does not request a security realm.
|
connect.options.org.xnio.Options.SASL_DISALLOWED_MECHANISMS
|
Disables certain SASL mechanisms used for authenticating during connection creation.
JBOSS_LOCAL_USER means the silent authentication mechanism, used when the client and server are on the same machine, is disabled.
|
connect.options.org.xnio.Options.SASL_POLICY_NOPLAINTEXT
|
Boolean value that enables or disables the use of plain text messages during the authentication. If using JAAS, it must be set to false to allow a plain text password.
|
connect.options.org.xnio.Options.SSL_ENABLED
|
Boolean value that specifies whether the SSL protocol is enabled for this connection.
Warning
Red Hat recommends that you explicitly disable SSL in favor of TLSv1.1 or TLSv1.2 in all affected packages.
|
connect.options.org.jboss.remoting3.RemotingOptions.HEARTBEAT_INTERVAL
|
t automatic close, for example, in the case of a firewall. The value is in milliseconds.
|
If the initial connection connects to a clustered environment, the topology of the cluster is received automatically and asynchronously. These properties are used to connect to each received member. Each property starts with the prefix remote.cluster.CLUSTER_NAME where the CLUSTER_NAME refers to the related to the servers Infinispan subsystem configuration.
| Property Name | Description |
|---|---|
clusternode.selector
|
The fully qualified name of the implementation of
org.jboss.ejb.client.ClusterNodeSelector.
This class, rather than
org.jboss.ejb.clientDeploymentNodeSelector, is used to load balance EJB invocations in a clustered environment. If the cluster is completely down, the invocation will fail with No ejb receiver available.
|
channel.options.org.jboss.remoting3.RemotingOptions.MAX_OUTBOUND_MESSAGES
|
Integer value specifying the maximum number of outbound requests that can be made to the entire cluster.
|
node.NODE_NAME. channel.options.org.jboss.remoting3.RemotingOptions.MAX_OUTBOUND_MESSAGES
|
Integer value specifying the maximum number of outbound requests that can be made to this specific cluster-node.
|
7.6. Container Interceptors
7.6.1. About Container Interceptors
ejb-jar.xml file for the 3.1 version of the ejb-jar deployment descriptor.
The container interceptors configured for an EJB are guaranteed to be run before the JBoss EAP provided security interceptors, transaction management interceptors, and other server provided interceptors. This allows specific application container interceptors to process or configure relevant context data before the invocation proceeds.
Although container interceptors are modeled to be similar to Java EE interceptors, there are some differences in the semantics of the API. For example, it is illegal for container interceptors to invoke the javax.interceptor.InvocationContext.getTarget() method because these interceptors are invoked long before the EJB components are setup or instantiated.
7.6.2. Create a Container Interceptor Class
Container interceptor classes are simple Plain Old Java Objects (POJOs). They use the @javax.annotation.AroundInvoke to mark the method that is invoked during the invocation on the bean.
iAmAround method for invocation:
Example 7.1. Container Interceptor Class Example
jboss-ejb3.xml file described here: Section 7.6.3, “Configure a Container Interceptor”.
7.6.3. Configure a Container Interceptor
Container interceptors use the standard Java EE interceptor libraries, meaning they use the same XSD elements that are allowed in ejb-jar.xml file for the 3.1 version of the ejb-jar deployment descriptor. Because they are based on the standard Jave EE interceptor libraries, container interceptors may only be configured using deployment descriptors. This was done by design so applications would not require any JBoss specific annotation or other library dependencies. For more information about container interceptors, refer to: Section 7.6.1, “About Container Interceptors”.
Procedure 7.11. Create the Descriptor File to Configure the Container Interceptor
- Create a
jboss-ejb3.xmlfile in theMETA-INFdirectory of the EJB deployment. - Configure the container interceptor elements in the descriptor file.
- Use the
urn:container-interceptors:1.0namespace to specify configuration of container interceptor elements. - Use the
<container-interceptors>element to specify the container interceptors. - Use the
<interceptor-binding>elements to bind the container interceptor to the EJBs. The interceptors can be bound in either of the following ways:- Bind the interceptor to all the EJBs in the deployment using the
*wildcard. - Bind the interceptor at the individual bean level using the specific EJB name.
- Bind the interceptor at the specific method level for the EJBs.
Note
These elements are configured using the EJB 3.1 XSD in the same way it is done for Java EE interceptors.
- Review the following descriptor file for examples of the above elements.
Example 7.2. jboss-ejb3.xml
Copy to Clipboard Copied! Toggle word wrap Toggle overflow The XSD for theurn:container-interceptors:1.0namespace is available atEAP_HOME/docs/schema/jboss-ejb-container-interceptors_1_0.xsd.
7.6.4. Change the Security Context Identity
By default, when you make a remote call to an EJB deployed to the application server, the connection to the server is authenticated and any request received over this connection is executed as the identity that authenticated the connection. This is true for both client-to-server and server-to-server calls. If you need to use different identities from the same client, you normally need to open multiple connections to the server so that each one is authenticated as a different identity. Rather than open multiple client connections, you can give permission to the authenticated user to execute a request as a different user.
ejb-security-interceptors quickstart for a complete working example.
Procedure 7.12. Change the Identity of the Security Context
Create the client side interceptor
The client side interceptor must implement theorg.jboss.ejb.client.EJBClientInterceptorinterface. The interceptor must pass the requested identity through the context data map, which can be obtained via a call toEJBClientInvocationContext.getContextData(). The following is an example of client side interceptor code:Copy to Clipboard Copied! Toggle word wrap Toggle overflow User applications can insert the interceptor into the interceptor chain in theEJBClientContextin one of the following ways:Programmatically
With this approach, you call theorg.jboss.ejb.client.EJBClientContext.registerInterceptor(int order, EJBClientInterceptor interceptor)method and pass theorderand theinterceptorinstance. Theorderdetermines where this client interceptor is placed in the interceptor chain.ServiceLoader Mechanism
With this approach, you create aMETA-INF/services/org.jboss.ejb.client.EJBClientInterceptorfile and place or package it in the classpath of the client application. The rules for the file are dictated by the Java ServiceLoader Mechanism. This file is expected to contain a separate line for each fully qualified class name of the EJB client interceptor implementation. The EJB client interceptor classes must be available in the classpath. EJB client interceptors added using theServiceLoadermechanism are added to the end of the client interceptor chain, in the order they are found in the classpath. Theejb-security-interceptorsquickstart uses this approach.
Create and configure the server side container interceptor
Container interceptor classes are simple Plain Old Java Objects (POJOs). They use the@javax.annotation.AroundInvoketo mark the method that will be invoked during the invocation on the bean. For more information about container interceptors, refer to: Section 7.6.1, “About Container Interceptors”.Create the container interceptor
This interceptor receives theInvocationContextwith the identity and requests the switch to that new identity. The following is an abridged version of the actual code example:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Configure the container interceptor
For information on how to configure server side container interceptors, refer to: Section 7.6.3, “Configure a Container Interceptor”.
Create the JAAS LoginModule
This component is responsible for verifying that user is allowed to execute requests as the requested identity. The following abridged code examples show the methods that peform the login and validation:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
ejb-security-interceptors quickstart README.html file for complete instructions and more detailed information about the code.
7.6.5. Pass Additional Security For EJB Authentication
By default, when you make a remote call to an EJB deployed to the application server, the connection to the server is authenticated and any request received over this connection is executed using the credentials that authenticated the connection. Authentication at the connection level is dependent on the capabilities of the underlying SASL (Simple Authentication and Security Layer) mechanisms. Rather than write custom SASL mechanisms, you can open and authenticate a connection to the server, then later add additional security tokens prior to invoking an EJB. This topic describes how to pass additional information on the existing client connection for EJB authentication.
Procedure 7.13. Pass Security Information for EJB Authentication
Create the client side interceptor
This interceptor must implement theorg.jboss.ejb.client.EJBClientInterceptor. The interceptor is expected to pass the additional security token through the context data map, which can be obtained via a call toEJBClientInvocationContext.getContextData(). The following is an example of client side interceptor code that creates an additional security token:Copy to Clipboard Copied! Toggle word wrap Toggle overflow For information on how to plug the client interceptor into an application, refer to Section 7.6.6, “Use a Client Side Interceptor in an Application”.Create and configure the server side container interceptor
Container interceptor classes are simple Plain Old Java Objects (POJOs). They use the@javax.annotation.AroundInvoketo mark the method that is invoked during the invocation on the bean. For more information about container interceptors, refer to: Section 7.6.1, “About Container Interceptors”.Create the container interceptor
This interceptor retrieves the security authentication token from the context and passes it to the JAAS (Java Authentication and Authorization Service) domain for verification. The following is an example of container interceptor code:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Configure the container interceptor
For information on how to configure server side container interceptors, refer to: Section 7.6.3, “Configure a Container Interceptor”.
Create the JAAS LoginModule
This custom module performs the authentication using the existing authenticated connection information plus any additional security token. The following is a shortened example of code that uses the additional security token and performs the authentication. The complete code example can be viewed in theejb-security-interceptorsquickstart that ships with JBoss EAP 6.3 or later.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add the Custom LoginModule to the Chain
You must add the new custom LoginModule to the correct location the chain so that it is invoked in the correct order. In this example, theSaslPlusLoginModulemust be chained before the LoginModule that loads the roles with thepassword-stackingoption set.Configure the LoginModule Order using the Management CLI
The following is an example of Management CLI commands that chain the customSaslPlusLoginModulebefore theRealmDirectLoginModule that sets thepassword-stackingoption.For more information about the Management CLI, refer to the chapter entitled Management Interfaces in the Administration and Configuration Guide for JBoss EAP 6 located on the Customer Portal at https://access.redhat.com/site/documentation/JBoss_Enterprise_Application_Platform//subsystem=security/security-domain=quickstart-domain:add(cache-type=default) /subsystem=security/security-domain=quickstart-domain/authentication=classic:add /subsystem=security/security-domain=quickstart-domain/authentication=classic/login-module=DelegationLoginModule:add(code=org.jboss.as.quickstarts.ejb_security_plus.SaslPlusLoginModule,flag=optional,module-options={password-stacking=useFirstPass}) /subsystem=security/security-domain=quickstart-domain/authentication=classic/login-module=RealmDirect:add(code=RealmDirect,flag=required,module-options={password-stacking=useFirstPass})/subsystem=security/security-domain=quickstart-domain:add(cache-type=default) /subsystem=security/security-domain=quickstart-domain/authentication=classic:add /subsystem=security/security-domain=quickstart-domain/authentication=classic/login-module=DelegationLoginModule:add(code=org.jboss.as.quickstarts.ejb_security_plus.SaslPlusLoginModule,flag=optional,module-options={password-stacking=useFirstPass}) /subsystem=security/security-domain=quickstart-domain/authentication=classic/login-module=RealmDirect:add(code=RealmDirect,flag=required,module-options={password-stacking=useFirstPass})Copy to Clipboard Copied! Toggle word wrap Toggle overflow Configure the LoginModule Order Manually
The following is an example of XML that configures the LoginModule order in thesecuritysubsystem of the server configuration file. The customSaslPlusLoginModulemust precede theRealmDirectLoginModule so that it can verify the remote user before the user roles are loaded and thepassword-stackingoption is set.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Create the Remote Client
In the following code example, assume theadditional-secret.propertiesfile accessed by the JAAS LoginModule above contains the following property:quickstartUser=7f5cc521-5061-4a5b-b814-bdc37f021acc
quickstartUser=7f5cc521-5061-4a5b-b814-bdc37f021accCopy to Clipboard Copied! Toggle word wrap Toggle overflow The following code demonstrates how create the security token and set it before the EJB call. The secret token is hard-coded for demonstration purposes only. This client simply prints the results to the console.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.6.6. Use a Client Side Interceptor in an Application
You can plug a client-side interceptor into an application programmatically or using a ServiceLoader mechanism. The following procedure describes the two methods.
Procedure 7.14. Plug the Interceptor into
Programmatically
With this approach, you call theorg.jboss.ejb.client.EJBClientContext.registerInterceptor(int order, EJBClientInterceptor interceptor)API and pass theorderand theinterceptorinstance. Theorderis used to determine where exactly in the client interceptor chain thisinterceptoris placed.ServiceLoader Mechanism
With this approach, you create aMETA-INF/services/org.jboss.ejb.client.EJBClientInterceptorfile and place or package it in the classpath of the client application. The rules for the file are dictated by the Java ServiceLoader Mechanism. This file is expected to contain a separate line for each fully qualified class name of the EJB client interceptor implementation. The EJB client interceptor classes must be available in the classpath. EJB client interceptors added using theServiceLoadermechanism are added to the end of the client interceptor chain, in the order they are found in the classpath. Theejb-security-interceptorsquickstart uses this approach.
7.7. Clustered Enterprise JavaBeans
7.7.1. About Clustered Enterprise JavaBeans (EJBs)
Note
7.7.2. Standalone and In-server Client Configuration
jboss-ejb-client.properties for standalone EJB client, or even jboss-ejb-client.xml file for a server-side application must be expanded to include a cluster configuration.
jboss-ejb-client.xml file) shows the complete configuration:
Example 7.3. Standalone client with jboss-ejb-client.properties configuration
jboss-ejb-client.xml file and add cluster configuration as shown in the following example:
Example 7.4. Client application which is deployed in another EAP 6 instance (Configuring jboss-ejb-client.xml file)
Note
7.7.3. Implementing a Custom Load Balancing Policy for EJB Calls
AllClusterNodeSelector for EJB calls. The node selection behavior of AllClusterNodeSelector is similar to default selector except that AllClusterNodeSelector uses all available cluster nodes even in case of a large cluster (number of nodes>20). If an unconnected cluster node is returned it is opened automatically. The following example shows AllClusterNodeSelector implementation:
SimpleLoadFactorNodeSelector for EJB calls. Load balancing in SimpleLoadFactorNodeSelector happens based on a load factor. The load factor (2/3/4) is calculated based on the names of nodes (A/B/C) irrespective of the load on each node. The following example shows SimpleLoadFactorNodeSelector implementation:
jboss-ejb-client.properties
You need to add the property remote.cluster.ejb.clusternode.selector with the name of your implementation class (AllClusterNodeSelector or SimpleLoadFactorNodeSelector). The selector will see all configured servers which are available at the invocation time. The following example uses AllClusterNodeSelector as the deployment node selector:
You need to add the property remote.cluster.ejb.clusternode.selector to the list for the PropertiesBasedEJBClientConfiguration constructor. The following example uses AllClusterNodeSelector as the deployment node selector:
jboss-ejb-client.xml
To use the load balancing policy for server to server communication; package the class together with the application and configure it within the jboss-ejb-client.xml settings(located in META-INF folder). The following example uses AllClusterNodeSelector as the deployment node selector:
ejb-security-realm-1 to client-server configuration. The following example shows the CLI commands for adding security realm (ejb-security-realm-1) the value is the base64 encoded password for the user "test"":
core-service=management/security-realm=ejb-security-realm-1:add() core-service=management/security-realm=ejb-security-realm-1/server-identity=secret:add(value=cXVpY2sxMjMr)
core-service=management/security-realm=ejb-security-realm-1:add()
core-service=management/security-realm=ejb-security-realm-1/server-identity=secret:add(value=cXVpY2sxMjMr)
Note
-Djboss.node.name= or the server configuration file standalone.xml to configure the server name (server name=""). Ensure that the server name is unique. In domain mode, the controller automatically validates that the names are unique.
7.7.4. Transaction Behavior of EJB Invocations
Transaction attributes for distributed EAP applications need to be handled in a way as if the application is called on the same server. To discontinue a transaction, the destination method must be marked REQUIRES_NEW using different interfaces.
Note
To invoke EJB session beans with an EAP 6 standalone client, the client must have a reference to the InitialContext object while the EJB proxies or UserTransaction are used. It is also important to keep the InitialContext object open while EJB proxies or UserTransaction are being used. Control of the connections will be inside the classes created by the InitialContext with the properties.
InitialContext object:
Note
UserTransaction reference on the client is unsupported for scenarios with a scoped EJB client context and for invocations which use the remote-naming protocol. This is because in these scenarios, InitialContext encapsulates its own EJB client context instance; which cannot be accessed using the static methods of the EJBClient class. When EJBClient.getUserTransaction() is called, it returns a transaction from default (global) EJB client context (which might not be initialized) and not from the desired one.
The following example shows how to get UserTransaction reference on a standalone client:
Note
UserTransaction reference on the client side; start your server with the following system property -Djboss.node.name=yourServerName and then use it on client side as following:
tx=EJBClient.getUserTransaction("yourServerName");
tx=EJBClient.getUserTransaction("yourServerName");UserTransaction with remote-naming protocol and scoped-context.
7.8. Reference
7.8.1. EJB JNDI Naming Reference
ejb:<appName>/<moduleName>/<distinctName>/<beanName>!<viewClassName>?stateful
ejb:<appName>/<moduleName>/<distinctName>/<beanName>!<viewClassName>?stateful <appName>- If the session bean's JAR file has been deployed within an enterprise archive (EAR) then this is the name of that EAR. By default, the name of an EAR is its filename without the
.earsuffix. The application name can also be overridden in itsapplication.xmlfile. If the session bean is not deployed in an EAR then leave this blank. <moduleName>- The module name is the name of the JAR file that the session bean is deployed in. By the default, the name of the JAR file is its filename without the
.jarsuffix. The module name can also be overridden in the JAR'sejb-jar.xmlfile. <distinctName>- JBoss EAP 6 allows each deployment to specify an optional distinct name. If the deployment does not have a distinct name then leave this blank.
<beanName>- The bean name is the classname of the session bean to be invoked.
<viewClassName>- The view class name is the fully qualified classname of the remote interface. This includes the package name of the interface.
?stateful- The
?statefulsuffix is required when the JNDI name refers to a stateful session bean. It is not included for other bean types.
7.8.2. EJB Reference Resolution
@EJB and @Resource. Please note that XML always overrides annotations but the same rules apply.
Rules for the @EJB annotation
- The
@EJBannotation also has amappedName()attribute. The specification leaves this as vendor specific metadata, but JBoss recognizesmappedName()as the global JNDI name of the EJB you are referencing. If you have specified amappedName(), then all other attributes are ignored and this global JNDI name is used for binding. - If you specify
@EJBwith no attributes defined:@EJB ProcessPayment myEjbref;
@EJB ProcessPayment myEjbref;Copy to Clipboard Copied! Toggle word wrap Toggle overflow Then the following rules apply:- The EJB jar of the referencing bean is searched for an EJB with the interface used in the
@EJBinjection. If there are more than one EJB that publishes same business interface, then an exception is thrown. If there is only one bean with that interface then that one is used. - Search the EAR for EJBs that publish that interface. If there are duplicates, then an exception is thrown. Otherwise the matching bean is returned.
- Search globally in JBoss runtime for an EJB of that interface. Again, if duplicates are found, an exception is thrown.
@EJB.beanName()corresponds to<ejb-link>. If thebeanName()is defined, then use the same algorithm as@EJBwith no attributes defined except use thebeanName()as a key in the search. An exception to this rule is if you use the ejb-link '#' syntax. The '#' syntax allows you to put a relative path to a jar in the EAR where the EJB you are referencing is located. Refer to the EJB 3.1 specification for more details.
7.8.3. Project dependencies for Remote EJB Clients
| GroupID | ArtifactID |
|---|---|
| org.jboss.spec | jboss-javaee-6.0 |
| org.jboss.as | jboss-as-ejb-client-bom |
| org.jboss.spec.javax.transaction | jboss-transaction-api_1.1_spec |
| org.jboss.spec.javax.ejb | jboss-ejb-api_3.1_spec |
| org.jboss | jboss-ejb-client |
| org.jboss.xnio | xnio-api |
| org.jboss.xnio | xnio-nio |
| org.jboss.remoting3 | jboss-remoting |
| org.jboss.sasl | jboss-sasl |
| org.jboss.marshalling | jboss-marshalling-river |
jboss-javaee-6.0 and jboss-as-ejb-client-bom, these dependencies must be added to the <dependencies> section of the pom.xml file.
jboss-javaee-6.0 and jboss-as-ejb-client-bom dependencies should be added to the <dependencyManagement> section of your pom.xml with the scope of import.
Note
artifactID's versions are subject to change. Refer to the Maven repository for the relevant version.
ejb-remote/client/pom.xml in the quickstart files for a complete example of dependency configuration for remote session bean invocation.
7.8.4. jboss-ejb3.xml Deployment Descriptor Reference
jboss-ejb3.xml is a custom deployment descriptor that can be used in either EJB JAR or WAR archives. In an EJB JAR archive it must be located in the META-INF/ directory. In a WAR archive it must be located in the WEB-INF/ directory.
ejb-jar.xml, using some of the same namespaces and providing some other additional namespaces. The contents of jboss-ejb3.xml are merged with the contents of ejb-jar.xml, with the jboss-ejb3.xml items taking precedence.
jboss-ejb3.xml. Refer to http://java.sun.com/xml/ns/javaee/ for documentation on the standard namespaces.
http://www.jboss.com/xml/ns/javaee.
Assembly descriptor namespaces
<assembly-descriptor> element. They can be used to apply their configuration to a single bean, or to all beans in the deployment by using \* as the ejb-name.
- The clustering namespace:
urn:clustering:1.0 xmlns:c="urn:clustering:1.0"
xmlns:c="urn:clustering:1.0"Copy to Clipboard Copied! Toggle word wrap Toggle overflow This allows you to mark EJB's as clustered. It is the deployment descriptor equivalent to@org.jboss.ejb3.annotation.Clustered.<c:clustering> <ejb-name>DDBasedClusteredSFSB</ejb-name> <c:clustered>true</c:clustered> </c:clustering>
<c:clustering> <ejb-name>DDBasedClusteredSFSB</ejb-name> <c:clustered>true</c:clustered> </c:clustering>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - The security namespace (
urn:security) xmlns:s="urn:security"
xmlns:s="urn:security"Copy to Clipboard Copied! Toggle word wrap Toggle overflow This allows you to set the security domain and the run-as principal for an EJB.<s:security> <ejb-name>*</ejb-name> <s:security-domain>myDomain</s:security-domain> <s:run-as-principal>myPrincipal</s:run-as-principal> </s:security>
<s:security> <ejb-name>*</ejb-name> <s:security-domain>myDomain</s:security-domain> <s:run-as-principal>myPrincipal</s:run-as-principal> </s:security>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - The resource adapter namespace:
urn:resource-adapter-binding xmlns:r="urn:resource-adapter-binding"
xmlns:r="urn:resource-adapter-binding"Copy to Clipboard Copied! Toggle word wrap Toggle overflow This allows you to set the resource adapter for a Message-Driven Bean.<r:resource-adapter-binding> <ejb-name>*</ejb-name> <r:resource-adapter-name>myResourceAdapter</r:resource-adapter-name> </r:resource-adapter-binding>
<r:resource-adapter-binding> <ejb-name>*</ejb-name> <r:resource-adapter-name>myResourceAdapter</r:resource-adapter-name> </r:resource-adapter-binding>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - The IIOP namespace:
urn:iiop xmlns:u="urn:iiop"
xmlns:u="urn:iiop"Copy to Clipboard Copied! Toggle word wrap Toggle overflow The IIOP namespace is where IIOP settings are configured.- The pool namespace:
urn:ejb-pool:1.0 xmlns:p="urn:ejb-pool:1.0"
xmlns:p="urn:ejb-pool:1.0"Copy to Clipboard Copied! Toggle word wrap Toggle overflow This allows you to select the pool that is used by the included stateless session beans or Message-Driven Beans. Pools are defined in the server configuration.<p:pool> <ejb-name>*</ejb-name> <p:bean-instance-pool-ref>my-pool</p:bean-instance-pool-ref> </p:pool>
<p:pool> <ejb-name>*</ejb-name> <p:bean-instance-pool-ref>my-pool</p:bean-instance-pool-ref> </p:pool>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - The cache namespace:
urn:ejb-cache:1.0 xmlns:c="urn:ejb-cache:1.0"
xmlns:c="urn:ejb-cache:1.0"Copy to Clipboard Copied! Toggle word wrap Toggle overflow This allows you to select the cache that is used by the included stateful session beans. Caches are defined in the server configuration.<c:cache> <ejb-name>*</ejb-name> <c:cache-ref>my-cache</c:cache-ref> </c:cache>
<c:cache> <ejb-name>*</ejb-name> <c:cache-ref>my-cache</c:cache-ref> </c:cache>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Example 7.5. Example jboss-ejb3.xml file
Chapter 8. JBoss MBean Services
8.1. Writing JBoss MBean Services
create, start, stop, and destroy itself.
- If you want specific methods to be called on your MBean, declare those methods in your MBean interface. This approach allows your MBean implementation to avoid dependencies on JBoss specific classes
- If you are not bothered about dependencies on JBoss specific classes then you may have your MBean interface extend the
ServiceMBeaninterface andServiceMBeanSupportclass. TheServiceMBeanSupportclass provides implementations of the service lifecycle methods likecreate,startandstop. To handle a specific event like thestart()event, you need to overridestartService()method provided by the ServiceMBeanSupport class.
8.2. A Standard MBean Example
.sar).
ConfigServiceMBean interface declares specific methods like the start, getTimeout and stop methods to start, hold and stop the MBean correctly without using any JBoss specific classes. ConfigService class implements ConfigServiceMBean interface and consequently implements the methods used within that interface.
PlainThread class extends ServiceMBeanSupport class and implements PlainThreadMBean interface. PlainThread starts a thread and uses ConfigServiceMBean.getTimeout() to determine how long the thread should sleep.
Example 8.1. Sample MBean services
jboss-service.xml descriptor shows how ConfigService class is injected into PlainThread class using inject tag. The inject tag establishes a dependency between PlainThreadMBean and ConfigServiceMBean and thus allows PlainThreadMBean use ConfigServiceMBean easily.
Example 8.2. JBoss-service.xml Service Descriptor
jboss-service.xml descriptor in the META-INF folder of a service archive (.sar).
8.3. Deploying JBoss MBean Services
ServiceMBeanTest.sar) in Domain mode use the following commands:
[domain@localhost:9999 /] deploy ~/Desktop/ServiceMBeanTest.sar
[domain@localhost:9999 /] deploy ~/Desktop/ServiceMBeanTest.sar[domain@localhost:9999 /] deploy ~/Desktop/ServiceMBeanTest.sar --all-server-groups
[domain@localhost:9999 /] deploy ~/Desktop/ServiceMBeanTest.sar --all-server-groupsServiceMBeanTest.sar) in Standalone mode use the following command:
[standalone@localhost:9999 /] deploy ~/Desktop/ServiceMBeanTest.sar
[standalone@localhost:9999 /] deploy ~/Desktop/ServiceMBeanTest.sar[standalone@localhost:9999 /] undeploy ServiceMBeanTest.sar
[standalone@localhost:9999 /] undeploy ServiceMBeanTest.sarChapter 9. Clustering in Web Applications
9.1. Session Replication
9.1.1. About HTTP Session Replication
9.1.2. About the Web Session Cache
standalone-ha.xml profile, or the managed domain profiles ha or full-ha. The most commonly configured elements are the cache mode and the number of cache owners for a distributed cache.
The cache mode can either be REPL (the default) or DIST.
- REPL
- The
REPLmode replicates the entire cache to every other node in the cluster. This is the safest option, but introduces more overhead. - DIST
- The
DISTmode is similar to the buddy mode provided in previous implementations. It reduces overhead by distributing the cache to the number of nodes specified in theownersparameter. This number of owners defaults to2.
The owners parameter controls how many cluster nodes hold replicated copies of the session. The default is 2.
9.1.3. Configure the Web Session Cache
REPL. If you wish to use DIST mode, run the following two commands in the Management CLI. If you use a different profile, change the profile name in the commands. If you use a standalone server, remove the /profile=ha portion of the commands.
Procedure 9.1. Configure the Web Session Cache
Change the default cache mode to
DIST./profile=ha/subsystem=infinispan/cache-container=web/:write-attribute(name=default-cache,value=dist)
/profile=ha/subsystem=infinispan/cache-container=web/:write-attribute(name=default-cache,value=dist)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Set the number of owners for a distributed cache.
The following command sets5owners. The default is2./profile=ha/subsystem=infinispan/cache-container=web/distributed-cache=dist/:write-attribute(name=owners,value=5)
/profile=ha/subsystem=infinispan/cache-container=web/distributed-cache=dist/:write-attribute(name=owners,value=5)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Change the default cache mode back to
REPL./profile=ha/subsystem=infinispan/cache-container=web/:write-attribute(name=default-cache,value=repl)
/profile=ha/subsystem=infinispan/cache-container=web/:write-attribute(name=default-cache,value=repl)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Restart the Server
After changing the web cache mode, you must restart the server.
Your server is configured for session replication. To use session replication in your own applications, refer to the following topic: Section 9.1.4, “Enable Session Replication in Your Application”.
9.1.4. Enable Session Replication in Your Application
To take advantage of JBoss EAP 6 High Availability (HA) features, you must configure your application to be distributable. This procedure shows how to do that, and then explains some of the advanced configuration options you can use.
Procedure 9.2. Make your Application Distributable
Required: Indicate that your application is distributable.
If your application is not marked as distributable, its sessions will never be distributed. Add the<distributable/>element inside the<web-app>tag of your application'sweb.xmldescriptor file. Here is an example.Example 9.1. Minimum Configuration for a Distributable Application
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Modify the default replication behavior if desired.
If you want to change any of the values affecting session replication, you can override them inside a<replication-config>element which is a child element of the<jboss-web>element of your application'sjboss-web.xmlfile. For a given element, only include it if you want to override the defaults. The following example lists all of the default settings, and is followed by a table which explains the most commonly changed options.Example 9.2. Default
<replication-config>ValuesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
|
Option
|
Description
|
|---|---|
<replication-trigger>
|
Controls which conditions should trigger session data replication across the cluster. This option is necessary because after a mutable object stored as a session attribute is accessed from the session, the container has no clear way to know if the object has been modified and needs to be replicated, unless method
setAttribute() is called directly.
Regardless of the setting, you can always trigger session replication by calling
setAttribute().
|
<replication-granularity>
|
Determines the granularity of data that is replicated. It defaults to
SESSION, but can be set to ATTRIBUTE instead, to increase performance on sessions where most attributes remain unchanged.
|
|
Option
|
Description
|
|---|---|
<use-jk>
|
Whether to assume that a load balancer such as
mod_cluster, mod_jk, or mod_proxy is in use. The default is false. If set to true, the container examines the session ID associated with each request and replaces the jvmRoute portion of the session ID if there is a failover.
|
<max-unreplicated-interval>
|
The maximum interval (in seconds) to wait after a session was accessed before triggering a replication of a session's timestamp, even if it is considered to be unchanged. This ensures that cluster nodes are aware of each session's timestamp and that an unreplicated session will not expire incorrectly during a failover. It also ensures that you can rely on a correct value for calls to method
HttpSession.getLastAccessedTime()during a failover.
By default, no value is specified. A value of
0 causes the timestamp to be replicated whenever the session is accessed. A value of -1 causes the timestamp to be replicated only if other activity during the request triggers a replication. A positive value greater than HttpSession.getMaxInactiveInterval() is treated as a misconfiguration and converted to 0.
|
<snapshot-mode>
|
Specifies when sessions are replicated to other nodes. The default is
INSTANT and the other possible value is INTERVAL.
In
INSTANT mode, changes are replicated at the end of a request, by means of the request processing thread. The <snapshot-interval> option is ignored.
In
INTERVAL mode, a background task runs at the interval specified by <snapshot-interval>, and replicates modified sessions.
|
<snapshot-interval>
|
The interval, in milliseconds, at which modified sessions should be replicated when using
INTERVAL for the value of <snapshot-mode>.
|
<session-notification-policy>
|
The fully-qualified class name of the implementation of interface
ClusteredSessionNotificationPolicy which governs whether servlet specification notifications are emitted to any registered HttpSessionListener, HttpSessionAttributeListener, or HttpSessionBindingListener.
|
9.2. HttpSession Passivation and Activation
9.2.1. About HTTP Session Passivation and Activation
- When the container requests the creation of a new session, if the number of currently active session exceeds a configurable limit, the server attempts to passivate some sessions to make room for the new one.
- Periodically, at a configured interval, a background task checks to see if sessions should be passivated.
- When a web application is deployed and a backup copy of sessions active on other servers is acquired by the newly deploying web application's session manager, sessions may be passivated.
- The session has not been in use for longer than a configurable maximum idle time.
- The number of active sessions exceeds a configurable maximum and the session has not been in use for longer than a configurable minimum idle time.
9.2.2. Configure HttpSession Passivation in Your Application
HttpSession passivation is configured in your application's WEB_INF/jboss-web.xml or META_INF/jboss-web.xml file.
Example 9.3. Example jboss-web.xml File
Passivation Configuration Elements
<max-active-sessions>- The maximum number of active sessions allowed. If the number of sessions managed by the session manager exceeds this value and passivation is enabled, the excess will be passivated based on the configured
<passivation-min-idle-time>. Then, if the number of active sessions still exceeds this limit, attempts to create new sessions will fail. The default value of-1sets no limit on the maximum number of active sessions. <passivation-config>- This element holds the rest of the passivation configuration parameters, as child elements.
<passivation-config> Child Elements
<use-session-passivation>- Whether or not to use session passivation. The default value is
false. <passivation-min-idle-time>- The minimum time, in seconds, that a session must be inactive before the container will consider passivating it in order to reduce the active session count to conform to value defined by max-active-sessions. The default value of
-1disables passivating sessions before<passivation-max-idle-time>has elapsed. Neither a value of -1 nor a high value are recommended if<max-active-sessions>is set. <passivation-max-idle-time>- The maximum time, in seconds, that a session can be inactive before the container attempts to passivate it to save memory. Passivation of such sessions takes place regardless of whether the active session count exceeds
<max-active-sessions>. This value should be less than the<session-timeout>setting in theweb.xml. The default value of-1disables passivation based on maximum inactivity.
Note
<max-active-sessions>. The number of sessions replicated from other nodes also depends on whether REPL or DIST cache mode is enabled. In REPL cache mode, each session is replicated to each node. In DIST cache mode, each session is replicated only to the number of nodes specified by the owners parameter. See Section 9.1.2, “About the Web Session Cache” and Section 9.1.3, “Configure the Web Session Cache” for information on configuring session cache modes.
REPL cache mode, each node would store 800 sessions in memory. With DIST cache mode enabled, and the default owners setting of 2, each node stores 200 sessions in memory.
9.3. Cookie Domain
9.3.1. About the Cookie Domain
/. This means that only the issuing host can read the contents of a cookie. Setting a specific cookie domain makes the contents of the cookie available to a wider range of hosts. To set the cookie domain, refer to Section 9.3.2, “Configure the Cookie Domain”.
9.3.2. Configure the Cookie Domain
http://app1.xyz.com and http://app2.xyz.com to share an SSO context, even if these applications run on different servers in a cluster or the virtual host with which they are associated has multiple aliases.
Example 9.4. Example Cookie Domain Configuration
<Valve className="org.jboss.web.tomcat.service.sso.ClusteredSingleSignOn"
cookieDomain="xyz.com" />
<Valve className="org.jboss.web.tomcat.service.sso.ClusteredSingleSignOn"
cookieDomain="xyz.com" />
9.4. Implement an HA Singleton
The following procedure demonstrates how to deploy of a Service that is wrapped with the SingletonService decorator and used as a cluster-wide singleton service. The service activates a scheduled timer, which is started only once in the cluster.
Procedure 9.3. Implement an HA Singleton Service
Write the HA singleton service application.
The following is a simple example of aServicethat is wrapped with theSingletonServicedecorator to be deployed as a singleton service. A complete example can be found in thecluster-ha-singletonquickstart that ships with Red Hat JBoss Enterprise Application Platform 6. This quickstart contains all the instructions to build and deploy the application.Create a service.
The following listing is an example of a service:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Create an activator that installs the
Serviceas a clustered singleton.The following listing is an example of a Service activator that installs theHATimerServiceas a clustered singleton service:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Note
The above code example uses a class,org.jboss.as.clustering.singleton.SingletonService, that is part of the JBoss EAP private API. A public API will become available in the EAP 7 release and the private class will be deprecated, but this classes will be maintained and available for the duration of the EAP 6.x release cycle.Create a ServiceActivator File
Create a file namedorg.jboss.msc.service.ServiceActivatorin the application'sresources/META-INF/services/directory. Add a line containing the fully qualified name of the ServiceActivator class created in the previous step.org.jboss.as.quickstarts.cluster.hasingleton.service.ejb.HATimerServiceActivator
org.jboss.as.quickstarts.cluster.hasingleton.service.ejb.HATimerServiceActivatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow Create a Singleton bean that implements a timer to be used as a cluster-wide singleton timer.
This Singleton bean must not have a remote interface and you must not reference its local interface from another EJB in any application. This prevents a lookup by a client or other component and ensures the SingletonService has total control of the Singleton.Create the Scheduler interface
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Create the Singleton bean that implements the cluster-wide singleton timer.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Start each JBoss EAP 6 instance with clustering enabled.
To enable clustering for standalone servers, you must start each server with theHAprofile, using a unique node name and port offset for each instance.- For Linux, use the following command syntax to start the servers:
EAP_HOME/bin/standalone.sh --server-config=standalone-ha.xml -Djboss.node.name=UNIQUE_NODE_NAME -Djboss.socket.binding.port-offset=PORT_OFFSET
EAP_HOME/bin/standalone.sh --server-config=standalone-ha.xml -Djboss.node.name=UNIQUE_NODE_NAME -Djboss.socket.binding.port-offset=PORT_OFFSETCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example 9.5. Start multiple standalone servers on Linux
EAP_HOME/bin/standalone.sh --server-config=standalone-ha.xml -Djboss.node.name=node1 EAP_HOME/bin/standalone.sh --server-config=standalone-ha.xml -Djboss.node.name=node2 -Djboss.socket.binding.port-offset=100
$ EAP_HOME/bin/standalone.sh --server-config=standalone-ha.xml -Djboss.node.name=node1 $ EAP_HOME/bin/standalone.sh --server-config=standalone-ha.xml -Djboss.node.name=node2 -Djboss.socket.binding.port-offset=100Copy to Clipboard Copied! Toggle word wrap Toggle overflow - For Microsoft Windows, use the following command syntax to start the servers:
EAP_HOME\bin\standalone.bat --server-config=standalone-ha.xml -Djboss.node.name=UNIQUE_NODE_NAME -Djboss.socket.binding.port-offset=PORT_OFFSET
EAP_HOME\bin\standalone.bat --server-config=standalone-ha.xml -Djboss.node.name=UNIQUE_NODE_NAME -Djboss.socket.binding.port-offset=PORT_OFFSETCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example 9.6. Start multiple standalone servers on Microsoft Windows
C:> EAP_HOME\bin\standalone.bat --server-config=standalone-ha.xml -Djboss.node.name=node1 C:> EAP_HOME\bin\standalone.bat --server-config=standalone-ha.xml -Djboss.node.name=node2 -Djboss.socket.binding.port-offset=100
C:> EAP_HOME\bin\standalone.bat --server-config=standalone-ha.xml -Djboss.node.name=node1 C:> EAP_HOME\bin\standalone.bat --server-config=standalone-ha.xml -Djboss.node.name=node2 -Djboss.socket.binding.port-offset=100Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Note
If you prefer not to use command line arguments, you can configure thestandalone-ha.xmlfile for each server instance to bind on a separate interface.Deploy the application to the servers
The following Maven command deploys the application to a standalone server running on the default ports.mvn clean install jboss-as:deploy
mvn clean install jboss-as:deployCopy to Clipboard Copied! Toggle word wrap Toggle overflow To deploy to additional servers, pass the server name. if it is on a different host, pass the host name and port number on the command line:mvn clean package jboss-as:deploy -Djboss-as.hostname=localhost -Djboss-as.port=10099
mvn clean package jboss-as:deploy -Djboss-as.hostname=localhost -Djboss-as.port=10099Copy to Clipboard Copied! Toggle word wrap Toggle overflow See thecluster-ha-singletonquickstart that ships with JBoss EAP 6 for Maven configuration and deployment details.
9.5. Apache mod_cluster-manager Application
9.5.1. About mod_cluster-manager Application
9.5.2. Exploring mod_cluster-manager Application
Figure 9.1. mod_cluster Administration Web Page
- [1] mod_cluster/1.2.8.Final: This denotes the version of the mod_cluster native library
- [2] ajp://192.168.122.204:8099: This denotes the protocol used (either one of AJP, HTTP, HTTPS), hostname or IP address of the worker node and the port
- [3] jboss-eap-6.3-2: This denotes the worker node's JVMRoute.
- [4] Virtual Host 1: This denotes the virtual host(s) configured on the worker node
- : This is an administration option which can be used to disable the creation of new sessions on the particular context. However the ongoing sessions do not get disabled and remain intact
- : This is an administration option which can be used to stop the routing of session requests to the context. The remaining sessions will failover to another node unless the property
sticky-session-forceis set to "true" - : These denote operations which can be performed on the whole node. Selecting one of these options affects all the contexts of a node in all its virtual hosts.
- [8] Load balancing group (LBGroup): The
load-balancing-groupproperty is set in the mod_cluster subsystem in EAP configuration to group all worker nodes into custom load balancing groups. Load balancing group (LBGroup) is an informational field which gives information about all set load balancing groups. If this field is not set, then all worker nodes are grouped into a single default load balancing groupNote
This is only an informational field and thus cannot be used to setload-balancing-groupproperty. The property has to be set in mod_cluster subsystem in EAP configuration. - [9] Load (value): This indicates the load factor on the worker node. The load factor(s) are evaluated as below:
-load > 0 : A load factor with value 1 indicates that the worker node is overloaded. A load factor of 100 denotes a free and not-loaded node. -load = 0 :A load factor of value 0 indicates that the worker node is in a standby mode. This means that no session requests will be routed to this node until and unless the other worker nodes are unavailable -load = -1 : A load factor of value -1 indicates that the worker node is in an error state. -load = -2 : A load factor of value -2 indicates that the worker node is undergoing CPing/CPong and is in a transition state
-load > 0 : A load factor with value 1 indicates that the worker node is overloaded. A load factor of 100 denotes a free and not-loaded node. -load = 0 :A load factor of value 0 indicates that the worker node is in a standby mode. This means that no session requests will be routed to this node until and unless the other worker nodes are unavailable -load = -1 : A load factor of value -1 indicates that the worker node is in an error state. -load = -2 : A load factor of value -2 indicates that the worker node is undergoing CPing/CPong and is in a transition stateCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Chapter 10. CDI
10.1. Overview of CDI
10.1.1. Overview of CDI
10.1.2. About Contexts and Dependency Injection (CDI)
10.1.3. Benefits of CDI
- CDI simplifies and shrinks your code base by replacing big chunks of code with annotations.
- CDI is flexible, allowing you to disable and enable injections and events, use alternative beans, and inject non-CDI objects easily.
- It is easy to use your old code with CDI. You only need to include a
beans.xmlin yourMETA-INF/orWEB-INF/directory. The file can be empty. - CDI simplifies packaging and deployments and reduces the amount of XML you need to add to your deployments.
- CDI provides lifecycle management via contexts. You can tie injections to requests, sessions, conversations, or custom contexts.
- CDI provides type-safe dependency injection, which is safer and easier to debug than string-based injection.
- CDI decouples interceptors from beans.
- CDI provides complex event notification.
10.1.4. About Type-safe Dependency Injection
10.1.5. Relationship Between Weld, Seam 2, and JavaServer Faces
10.2. Use CDI
10.2.1. First Steps
10.2.1.1. Enable CDI
Contexts and Dependency Injection (CDI) is one of the core technologies in JBoss EAP 6, and is enabled by default. If for some reason it is disabled and you need to enable it, follow this procedure.
Procedure 10.1. Enable CDI in JBoss EAP 6
Check to see if the CDI subsystem details are commented out of the configuration file.
A subsystem can be disabled by commenting out the relevant section of thedomain.xmlorstandalone.xmlconfiguration files, or by removing the relevant section altogether.To find the CDI subsystem inEAP_HOME/domain/configuration/domain.xmlorEAP_HOME/standalone/configuration/standalone.xml, search them for the following string. If it exists, it is located inside the <extensions> section.<extension module="org.jboss.as.weld"/>
<extension module="org.jboss.as.weld"/>Copy to Clipboard Copied! Toggle word wrap Toggle overflow The following line must also be present in the profile you are using. Profiles are in individual <profile> elements within the <profiles> section.<subsystem xmlns="urn:jboss:domain:weld:1.0"/>
<subsystem xmlns="urn:jboss:domain:weld:1.0"/>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Before editing any files, stop JBoss EAP 6.
JBoss EAP 6 modifies the configuration files during the time it is running, so you must stop the server before you edit the configuration files directly.Edit the configuration file to restore the CDI subsystem.
If the CDI subsystem was commented out, remove the comments.If it was removed entirely, restore it by adding this line to the file in a new line directly above the </extensions> tag:<extension module="org.jboss.as.weld"/>
<extension module="org.jboss.as.weld"/>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - You also need to add the following line to the relevant profile in the <profiles> section.
<subsystem xmlns="urn:jboss:domain:weld:1.0"/>
<subsystem xmlns="urn:jboss:domain:weld:1.0"/>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Restart JBoss EAP 6.
Start JBoss EAP 6 with your updated configuration.
JBoss EAP 6 starts with the CDI subsystem enabled.
10.2.2. Use CDI to Develop an Application
10.2.2.1. Use CDI to Develop an Application
Contexts and Dependency Injection (CDI) gives you tremendous flexibility in developing applications, reusing code, adapting your code at deployment or run-time, and unit testing. JBoss EAP 6 includes Weld, the reference implementation of CDI. These tasks show you how to use CDI in your enterprise applications.
10.2.2.2. Use CDI with Existing Code
beans.xml in the META-INF/ or WEB-INF/ directory of your archive. The file can be empty.
Procedure 10.2. Use legacy beans in CDI applications
Package your beans into an archive.
Package your beans into a JAR or WAR archive.Include a
beans.xmlfile in your archive.Place abeans.xmlfile into your JAR archive'sMETA-INF/or your WAR archive'sWEB-INF/directory. The file can be empty.
You can use these beans with CDI. The container can create and destroy instances of your beans and associate them with a designated context, inject them into other beans, use them in EL expressions, specialize them with qualifier annotations, and add interceptors and decorators to them, without any modifications to your existing code. In some circumstances, you may need to add some annotations.
10.2.2.3. Exclude Beans From the Scanning Process
One of the features of Weld, the JBoss EAP 6 implementation of CDI, is the ability to exclude classes in your archive from scanning, having container lifecycle events fired, and being deployed as beans. This is not part of the JSR-299 specification.
Example 10.1. Exclude packages from your bean
- The first one excludes all Swing classes.
- The second excludes Google Web Toolkit classes if Google Web Toolkit is not installed.
- The third excludes classes which end in the string
Blether(using a regular expression), if the system property verbosity is set tolow. - The fourth excludes Java Server Faces (JSF) classes if Wicket classes are present and the viewlayer system property is not set.
10.2.2.4. Use an Injection to Extend an Implementation
You can use an injection to add or change a feature of your existing code. This example shows you how to add a translation ability to an existing class. The translation is a hypothetical feature and the way it is implemented in the example is pseudo-code, and only provided for illustration.
buildPhrase. The buildPhrase method takes as an argument the name of a city, and outputs a phrase like "Welcome to Boston." Your goal is to create a version of the Welcome class which can translate the greeting into a different language.
Example 10.2. Inject a Translator Bean Into the Welcome Class
Translator object into the Welcome class. The Translator object may be an EJB stateless bean or another type of bean, which can translate sentences from one language to another. In this instance, the Translator is used to translate the entire greeting, without actually modifying the original Welcome class at all. The Translator is injected before the buildPhrase method is implemented.
10.2.3. Ambiguous or Unsatisfied Dependencies
10.2.3.1. About Ambiguous or Unsatisfied Dependencies
- It resolves the qualifier annotations on all beans that implement the bean type of an injection point.
- It filters out disabled beans. Disabled beans are @Alternative beans which are not explicitly enabled.
10.2.3.2. About Qualifiers
Example 10.3. Define the @Synchronous and @Asynchronous Qualifiers
@Qualifier
@Retention(RUNTIME)
@Target({TYPE, METHOD, FIELD, PARAMETER})
public @interface Synchronous {}
@Qualifier
@Retention(RUNTIME)
@Target({TYPE, METHOD, FIELD, PARAMETER})
public @interface Synchronous {}
@Qualifier
@Retention(RUNTIME)
@Target({TYPE, METHOD, FIELD, PARAMETER})
public @interface Asynchronous {}
@Qualifier
@Retention(RUNTIME)
@Target({TYPE, METHOD, FIELD, PARAMETER})
public @interface Asynchronous {}
Example 10.4. Use the @Synchronous and @Asynchronous Qualifiers
10.2.3.3. Use a Qualifier to Resolve an Ambiguous Injection
This task shows an ambiguous injection and removes the ambiguity with a qualifier. Read more about ambiguous injections at Section 10.2.3.1, “About Ambiguous or Unsatisfied Dependencies”.
Example 10.5. Ambiguous injection
Welcome, one which translates and one which does not. In that situation, the injection below is ambiguous and needs to be specified to use the translating Welcome.
Procedure 10.3. Resolve an Ambiguous Injection with a Qualifier
Create a qualifier annotation called
@Translating.@Qualifier @Retention(RUNTIME) @Target({TYPE,METHOD,FIELD,PARAMETERS}) public @interface Translating{}@Qualifier @Retention(RUNTIME) @Target({TYPE,METHOD,FIELD,PARAMETERS}) public @interface Translating{}Copy to Clipboard Copied! Toggle word wrap Toggle overflow Annotate your translating
Welcomewith the@Translatingannotation.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Request the translating
Welcomein your injection.You must request a qualified implementation explicitly, similar to the factory method pattern. The ambiguity is resolved at the injection point.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
The TranslatingWelcome is used, and there is no ambiguity.
10.2.4. Managed Beans
10.2.4.1. About Managed Beans
bean.
@Inject) is a bean. This includes every JavaBean and every EJB session bean. The only requirement to enable the mentioned services in beans is that they reside in an archive (a JAR, or a Java EE module such as a WAR or EJB JAR) that contains a special marker file: META-INF/beans.xml.
10.2.4.2. Types of Classes That are Beans
@ManagedBean, but in CDI you do not need to. According to the specification, the CDI container treats any class that satisfies the following conditions as a managed bean:
- It is not a non-static inner class.
- It is a concrete class, or is annotated
@Decorator. - It is not annotated with an EJB component-defining annotation or declared as an EJB bean class in
ejb-jar.xml. - It does not implement interface
javax.enterprise.inject.spi.Extension. - It has either a constructor with no parameters, or a constructor annotated with
@Inject.
10.2.4.3. Use CDI to Inject an Object Into a Bean
META-INF/beans.xml or WEB-INF/beans.xml file, each object in your deployment can be injected using CDI.
Inject an object into any part of a bean with the
@Injectannotation.To obtain an instance of a class, within your bean, annotate the field with@Inject.Example 10.6. Injecting a
TextTranslatorinstance into aTranslateControllerpublic class TranslateController { @Inject TextTranslator textTranslator; ...public class TranslateController { @Inject TextTranslator textTranslator; ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow Use your injected object's methods
You can use your injected object's methods directly. Assume thatTextTranslatorhas a methodtranslate.Example 10.7. Use your injected object's methods
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Use injection in the constructor of a bean
You can inject objects into the constructor of a bean, as an alternative to using a factory or service locator to create them.Example 10.8. Using injection in the constructor of a bean
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Use the
Instance(<T>)interface to get instances programmatically.TheInstanceinterface can return an instance of TextTranslator when parameterized with the bean type.Example 10.9. Obtaining an instance programmatically
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
When you inject an object into a bean all of the object's methods and properties are available to your bean. If you inject into your bean's constructor, instances of the injected objects are created when your bean's constructor is called, unless the injection refers to an instance which already exists. For instance, a new instance would not be created if you inject a session-scoped bean during the lifetime of the session.
10.2.5. Contexts, Scopes, and Dependencies
10.2.5.1. Contexts and Scopes
@RequestScoped, @SessionScoped, and @ConversationScope.
10.2.5.2. Available Contexts
| Context | Description |
|---|---|
| @Dependent | The bean is bound to the lifecycle of the bean holding the reference. |
| @ApplicationScoped | Bound to the lifecycle of the application. |
| @RequestScoped | Bound to the lifecycle of the request. |
| @SessionScoped | Bound to the lifecycle of the session. |
| @ConversationScoped | Bound to the lifecycle of the conversation. The conversation scope is between the lengths of the request and the session, and is controlled by the application. |
| Custom scopes | If the above contexts do not meet your needs, you can define custom scopes. |
10.2.6. Bean Lifecycle
10.2.6.1. Manage the Lifecycle of a Bean
This task shows you how to save a bean for the life of a request. Several other scopes exist, and you can define your own scopes.
@Dependent. This means that the bean's lifecycle is dependent upon the lifecycle of the bean which holds the reference. For more information, see Section 10.2.5.1, “Contexts and Scopes”.
Procedure 10.4. Manage Bean Lifecycles
Annotate the bean with the scope corresponding to your desired scope.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow When your bean is used in the JSF view, it holds state.
<h:form> <h:inputText value="#{greeter.city}"/> <h:commandButton value="Welcome visitors" action="#{greeter.welcomeVisitors}"/> </h:form><h:form> <h:inputText value="#{greeter.city}"/> <h:commandButton value="Welcome visitors" action="#{greeter.welcomeVisitors}"/> </h:form>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Your bean is saved in the context relating to the scope that you specify, and lasts as long as the scope applies.
10.2.6.2. Use a Producer Method
This task shows how to use producer methods to produce a variety of different objects which are not beans for injection.
Example 10.10. Use a producer method instead of an alternative, to allow polymorphism after deployment
@Preferred annotation in the example is a qualifier annotation. For more information about qualifiers, refer to: Section 10.2.3.2, “About Qualifiers”.
@Inject @Preferred PaymentStrategy paymentStrategy;
@Inject @Preferred PaymentStrategy paymentStrategy;
Example 10.11. Assign a scope to a producer method
@Dependent. If you assign a scope to a bean, it is bound to the appropriate context. The producer method in this example is only called once per session.
@Produces @Preferred @SessionScoped
public PaymentStrategy getPaymentStrategy() {
...
}
@Produces @Preferred @SessionScoped
public PaymentStrategy getPaymentStrategy() {
...
}
Example 10.12. Use an injection inside a producer method
Note
Producer methods allow you to inject non-bean objects and change your code dynamically.
10.2.7. Named Beans and Alternative Beans
10.2.7.1. About Named Beans
@Named annotation. Naming a bean allows you to use it directly in Java Server Faces (JSF).
@Named annotation takes an optional parameter, which is the bean name. If this parameter is omitted, the lower-cased bean name is used as the name.
10.2.7.2. Use Named Beans
Use the
@Namedannotation to assign a name to a bean.Copy to Clipboard Copied! Toggle word wrap Toggle overflow The bean name itself is optional. If it is omitted, the bean is named after the class name, with the first letter decapitalized. In the example above, the default name would begreeterBean.Use the named bean in a JSF view.
<h:form> <h:commandButton value="Welcome visitors" action="#{greeter.welcomeVisitors}"/> </h:form><h:form> <h:commandButton value="Welcome visitors" action="#{greeter.welcomeVisitors}"/> </h:form>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Your named bean is assigned as an action to the control in your JSF view, with a minimum of coding.
10.2.7.3. About Alternative Beans
Example 10.13. Defining Alternatives
beans.xml file.
10.2.7.4. Override an Injection with an Alternative
Alternative beans let you override existing beans. They can be thought of as a way to plug in a class which fills the same role, but functions differently. They are disabled by default. This task shows you how to specify and enable an alternative.
Procedure 10.5. Override an Injection
TranslatingWelcome class in your project, but you want to override it with a "mock" TranslatingWelcome class. This would be the case for a test deployment, where the true Translator bean cannot be used.
Define the alternative.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Substitute the alternative.
To activate the substitute implementation, add the fully-qualified class name to yourMETA-INF/beans.xmlorWEB-INF/beans.xmlfile.<beans> <alternatives> <class>com.acme.MockTranslatingWelcome</class> </alternatives> </beans><beans> <alternatives> <class>com.acme.MockTranslatingWelcome</class> </alternatives> </beans>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
The alternative implementation is now used instead of the original one.
10.2.8. Stereotypes
10.2.8.1. About Stereotypes
- default scope
- a set of interceptor bindings
- all beans with the stereotype have defaulted bean EL names
- all beans with the stereotype are alternatives
@Named annotation, any bean it is placed on has a default bean name. The bean may override this name if the @Named annotation is specified directly on the bean. For more information about named beans, see Section 10.2.7.1, “About Named Beans”.
10.2.8.2. Use Stereotypes
Without stereotypes, annotations can become cluttered. This task shows you how to use stereotypes to reduce the clutter and streamline your code. For more information about what stereotypes are, see Section 10.2.8.1, “About Stereotypes”.
Example 10.14. Annotation clutter
Procedure 10.6. Define and Use Stereotypes
Define the stereotype,
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Use the stereotype.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Stereotypes streamline and simplify your code.
10.2.9. Observer Methods
10.2.9.1. About Observer Methods
10.2.9.2. Fire and Observe Events
Example 10.15. Fire an event
Example 10.16. Fire an event with a qualifier
Example 10.17. Observe an event
@Observes annotation.
Example 10.18. Observe a qualified event
10.2.10. Interceptors
10.2.10.1. About Interceptors
Interception points
- business method interception
- A business method interceptor applies to invocations of methods of the bean by clients of the bean.
- lifecycle callback interception
- A lifecycle callback interceptor applies to invocations of lifecycle callbacks by the container.
- timeout method interception
- A timeout method interceptor applies to invocations of the EJB timeout methods by the container.
10.2.10.2. Use Interceptors with CDI
Example 10.19. Interceptors without CDI
- The bean must specify the interceptor implementation directly.
- Every bean in the application must specify the full set of interceptors in the correct order. This makes adding or removing interceptors on an application-wide basis time-consuming and error-prone.
Procedure 10.7. Use interceptors with CDI
Define the interceptor binding type.
@InterceptorBinding @Retention(RUNTIME) @Target({TYPE, METHOD}) public @interface Secure {}@InterceptorBinding @Retention(RUNTIME) @Target({TYPE, METHOD}) public @interface Secure {}Copy to Clipboard Copied! Toggle word wrap Toggle overflow Mark the interceptor implementation.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Use the interceptor in your business code.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Enable the interceptor in your deployment, by adding it to
META-INF/beans.xmlorWEB-INF/beans.xml.Copy to Clipboard Copied! Toggle word wrap Toggle overflow The interceptors are applied in the order listed.
CDI simplifies your interceptor code and makes it easier to apply to your business code.
10.2.11. About Decorators
@Decorator.
Example 10.20. Example Decorator
10.2.12. About Portable Extensions
- integration with Business Process Management engines
- integration with third-party frameworks such as Spring, Seam, GWT or Wicket
- new technology based upon the CDI programming model
- Providing its own beans, interceptors and decorators to the container
- Injecting dependencies into its own objects using the dependency injection service
- Providing a context implementation for a custom scope
- Augmenting or overriding the annotation-based metadata with metadata from some other source
10.2.13. Bean Proxies
10.2.13.1. About Bean Proxies
Problems of dependency injection, which are solved by using proxies
- Performance - Proxies are much faster than dependency injection, so you can use them in beans which need good performance.
- Thread safety - Proxies forward requests to the correct bean instance, even when multiple threads access a bean at the same time. Dependency injection does not guarantee thread safety.
Types of classes that cannot be proxied
- Primitive types or array types
- Classes that are
finalor havefinalmethods - Classes which have a non-private default constructor
10.2.13.2. Use a Proxy in an Injection
A proxy is used for injection when the lifecycles of the beans are different from each other. The proxy is a subclass of the bean that is created at run-time, and overrides all the non-private methods of the bean class. The proxy forwards the invocation onto the actual bean instance.
PaymentProcessor instance is not injected directly into Shop. Instead, a proxy is injected, and when the processPayment() method is called, the proxy looks up the current PaymentProcessor bean instance and calls the processPayment() method on it.
Example 10.21. Proxy Injection
Chapter 11. Java Transaction API (JTA)
11.1. Overview
11.1.1. Overview of Java Transactions API (JTA)
These topics provide a foundational understanding of the Java Transactions API (JTA).
11.2. Transaction Concepts
11.2.1. About Transactions
11.2.2. About ACID Properties for Transactions
Atomicity, Consistency, Isolation, and Durability. This terminology is usually used in the context of databases or transactional operations.
ACID Definitions
- Atomicity
- For a transaction to be atomic, all transaction members must make the same decision. Either they all commit, or they all roll back. If atomicity is broken, what results is termed a heuristic outcome.
- Consistency
- Consistency means that data written to the database is guaranteed to be valid data, in terms of the database schema. The database or other data source must always be in a consistent state. One example of an inconsistent state would be a field in which half of the data is written before an operation aborts. A consistent state would be if all the data were written, or the write were rolled back when it could not be completed.
- Isolation
- Isolation means that data being operated on by a transaction must be locked before modification, to prevent processes outside the scope of the transaction from modifying the data.
- Durability
- Durability means that in the event of an external failure after transaction members have been instructed to commit, all members will be able to continue committing the transaction when the failure is resolved. This failure may be related to hardware, software, network, or any other involved system.
11.2.3. About the Transaction Coordinator or Transaction Manager
11.2.4. About Transaction Participants
11.2.5. About Java Transactions API (JTA)
11.2.6. About Java Transaction Service (JTS)
Note
11.2.7. About XA Datasources and XA Transactions
11.2.8. About XA Recovery
11.2.9. About the 2-Phase Commit Protocol
In the first phase, the transaction participants notify the transaction coordinator whether they are able to commit the transaction or must roll back.
In the second phase, the transaction coordinator makes the decision about whether the overall transaction should commit or roll back. If any one of the participants cannot commit, the transaction must roll back. Otherwise, the transaction can commit. The coordinator directs the transactions about what to do, and they notify the coordinator when they have done it. At that point, the transaction is finished.
11.2.10. About Transaction Timeouts
11.2.11. About Distributed Transactions
Note
11.2.12. About the ORB Portability API
ORB Portability API Classes
com.arjuna.orbportability.orbcom.arjuna.orbportability.oa
11.2.13. About Nested Transactions
Benefits of Nested Transactions
- Fault Isolation
- If a subtransaction rolls back, perhaps because an object it is using fails, the enclosing transaction does not need to roll back.
- Modularity
- If a transaction is already associated with a call when a new transaction begins, the new transaction is nested within it. Therefore, if you know that an object requires transactions, you can create them within the object. If the object's methods are invoked without a client transaction, then the object's transactions are top-level. Otherwise, they are nested within the scope of the client's transactions. Likewise, a client does not need to know whether an object is transactional. It can begin its own transaction.
11.3. Transaction Optimizations
11.3.1. Overview of Transaction Optimizations
The Transactions subsystem of JBoss EAP 6 includes several optimizations which you can take advantage of in your applications.
11.3.2. About the LRCO Optimization for Single-phase Commit (1PC)
11.3.2.1. Commit Markable Resource
Configuring access to a resource manager via the Commit Markable Resource (CMR) interface ensures that a 1PC resource manager can be reliably enlisted in a 2PC transaction. It is an implementation of the LRCO algorithm, which makes non-XA resource fully recoverable.
- Prepare 2PC
- Commit LRCO
- Write tx log
- Commit 2PC
A transaction may contain only one CMR resource.
You must have a table created for which the following SQL would work:
SELECT xid,actionuid FROM _tableName_ WHERE transactionManagerID IN (String[]) DELETE FROM _tableName_ WHERE xid IN (byte[[]]) INSERT INTO _tableName_ (xid, transactionManagerID, actionuid) VALUES (byte[],String,byte[])
SELECT xid,actionuid FROM _tableName_ WHERE transactionManagerID IN (String[])
DELETE FROM _tableName_ WHERE xid IN (byte[[]])
INSERT INTO _tableName_ (xid, transactionManagerID, actionuid) VALUES (byte[],String,byte[])Example 11.1. Some examples of the SQL query
CREATE TABLE xids (xid varbinary(144), transactionManagerID varchar(64), actionuid varbinary(28))
CREATE TABLE xids (xid varbinary(144), transactionManagerID varchar(64), actionuid varbinary(28))CREATE TABLE xids (xid RAW(144), transactionManagerID varchar(64), actionuid RAW(28)) CREATE UNIQUE INDEX index_xid ON xids (xid)
CREATE TABLE xids (xid RAW(144), transactionManagerID varchar(64), actionuid RAW(28))
CREATE UNIQUE INDEX index_xid ON xids (xid)CREATE TABLE xids (xid VARCHAR(255) for bit data not null, transactionManagerID varchar(64), actionuid VARCHAR(255) for bit data not null) CREATE UNIQUE INDEX index_xid ON xids (xid)
CREATE TABLE xids (xid VARCHAR(255) for bit data not null, transactionManagerID
varchar(64), actionuid VARCHAR(255) for bit data not null)
CREATE UNIQUE INDEX index_xid ON xids (xid)CREATE TABLE xids (xid varbinary(144), transactionManagerID varchar(64), actionuid varbinary(28)) CREATE UNIQUE INDEX index_xid ON xids (xid)
CREATE TABLE xids (xid varbinary(144), transactionManagerID varchar(64), actionuid varbinary(28))
CREATE UNIQUE INDEX index_xid ON xids (xid)CREATE TABLE xids (xid bytea, transactionManagerID varchar(64), actionuid bytea) CREATE UNIQUE INDEX index_xid ON xids (xid)
CREATE TABLE xids (xid bytea, transactionManagerID varchar(64), actionuid bytea)
CREATE UNIQUE INDEX index_xid ON xids (xid)By default, the CMR feature is disabled for datasources. To enable it, you must create or modify the datasource configuration and ensure that the connectible attribute is set to true. An example configuration entry in the datasources section of a server xml configuration file could be as follows:
<datasource enabled="true" jndi-name="java:jboss/datasources/ConnectableDS" pool-name="ConnectableDS" jta="true" use-java-context="true" spy="false" use-ccm="true" connectable="true"/>
<datasource enabled="true" jndi-name="java:jboss/datasources/ConnectableDS" pool-name="ConnectableDS" jta="true" use-java-context="true" spy="false" use-ccm="true" connectable="true"/>Note
/subsystem=datasources/data-source=ConnectableDS:add(enabled="true", jndi-name="java:jboss/datasources/ConnectableDS", jta="true", use-java-context="true", spy="false", use-ccm="true", connectable="true", connection-url="validConnectionURL", driver-name="h2")
/subsystem=datasources/data-source=ConnectableDS:add(enabled="true", jndi-name="java:jboss/datasources/ConnectableDS", jta="true", use-java-context="true", spy="false", use-ccm="true", connectable="true", connection-url="validConnectionURL", driver-name="h2")If you only need to update an existing resource to use the new CMR feature, then simply modifiy the connectable attribute:
/subsystem=datasources/data-source=ConnectableDS:write-attribute(name=connectable,value=true)
/subsystem=datasources/data-source=ConnectableDS:write-attribute(name=connectable,value=true)The transaction subsystem identifies the datasources that are CMR capable through an entry to the transaction subsystem config section as shown below:
Note
11.3.3. About the Presumed-Abort Optimization
11.3.4. About the Read-Only Optimization
11.4. Transaction Outcomes
11.4.1. About Transaction Outcomes
- Roll-back
- If any transaction participant cannot commit, or the transaction coordinator cannot direct participants to commit, the transaction is rolled back. See Section 11.4.3, “About Transaction Roll-Back” for more information.
- Commit
- If every transaction participant can commit, the transaction coordinator directs them to do so. See Section 11.4.2, “About Transaction Commit” for more information.
- Heuristic outcome
- If some transaction participants commit and others roll back. it is termed a heuristic outcome. Heuristic outcomes require human intervention. See Section 11.4.4, “About Heuristic Outcomes” for more information.
11.4.2. About Transaction Commit
11.4.3. About Transaction Roll-Back
11.4.4. About Heuristic Outcomes
- Heuristic rollback
- The commit operation failed because some or all of the participants unilaterally rolled back the transaction.
- Heuristic commit
- An attempted rollback operation failed because all of the participants unilaterally committed. This may happen if, for example, the coordinator is able to successfully prepare the transaction but then decides to roll it back because of a failure on its side, such as a failure to update its log. In the interim, the participants may decide to commit.
- Heuristic mixed
- Some participants committed and others rolled back.
- Heuristic hazard
- The outcome of some of the updates is unknown. For the ones that are known, they have either all committed or all rolled back.
11.4.5. JBoss Transactions Errors and Exceptions
UserTransaction class, see the UserTransaction API specification at http://docs.oracle.com/javaee/6/api/javax/transaction/UserTransaction.html.
11.5. Overview of JTA Transactions
11.5.1. About Java Transactions API (JTA)
11.5.2. Lifecycle of a JTA Transaction
Your application starts a new transaction
To begin a transaction, your application obtains an instance of classUserTransactionfrom JNDI or, if it is an EJB, from an annotation. TheUserTransactioninterface includes methods for beginning, committing, and rolling back top-level transactions. Newly-created transactions are automatically associated with their invoking thread. Nested transactions are not supported in JTA, so all transactions are top-level transactions.CallingUserTransaction.begin()using annotations starts a transaction when an EJB method is called (driven by TransactionAttribute rules). Any resource that is used after that point is associated with the transaction. If more than one resource is enlisted, your transaction becomes an XA transaction, and participates in the two-phase commit protocol at commit time.Note
TheUserTransactionobject is used only for BMT transactions. In CMT, the UserTransaction object is not permitted.Your application modifies its state.
In the next step, your application performs its work and makes changes to its state.Your application decides to commit or roll back
When your application has finished changing its state, it decides whether to commit or roll back. It calls the appropriate method. It callsUserTransaction.commit()orUserTransaction.rollback().The transaction manager removes the transaction from its records.
After the commit or rollback completes, the transaction manager cleans up its records and removes information about your transaction from the transaction log.
Failure recovery happens automatically. If a resource, transaction participant, or the application server become unavailable, the Transaction Manager handles recovery when the underlying failure is resolved and the resource is available again.
11.6. Transaction Subsystem Configuration
11.6.1. Transactions Configuration Overview
The following procedures show you how to configure the transactions subsystem of JBoss EAP 6.
11.6.2. Transactional Datasource Configuration
11.6.2.1. Configure Your Datasource to Use JTA Transaction API
This task shows you how to enable Java Transaction API (JTA) on your datasource.
You must meet the following conditions before continuing with this task:
- Your database or other resource must support Java Transaction API. If in doubt, consult the documentation for your database or other resource.
- Create a datasource. Refer to Section 11.6.2.4, “Create a Non-XA Datasource with the Management Interfaces”.
- Stop JBoss EAP 6.
- Have access to edit the configuration files directly, in a text editor.
Procedure 11.1. Configure the Datasource to use Java Transaction API
Open the configuration file in a text editor.
Depending on whether you run JBoss EAP 6 in a managed domain or standalone server, your configuration file will be in a different location.Managed domain
The default configuration file for a managed domain is inEAP_HOME/domain/configuration/domain.xmlfor Red Hat Enterprise Linux, andEAP_HOME\domain\configuration\domain.xmlfor Microsoft Windows Server.Standalone server
The default configuration file for a standalone server is inEAP_HOME/standalone/configuration/standalone.xmlfor Red Hat Enterprise Linux, andEAP_HOME\standalone\configuration\standalone.xmlfor Microsoft Windows Server.
Locate the
<datasource>tag that corresponds to your datasource.The datasource will have thejndi-nameattribute set to the one you specified when you created it. For example, the ExampleDS datasource looks like this:<datasource jndi-name="java:jboss/datasources/ExampleDS" pool-name="H2DS" enabled="true" jta="true" use-java-context="true" use-ccm="true">
<datasource jndi-name="java:jboss/datasources/ExampleDS" pool-name="H2DS" enabled="true" jta="true" use-java-context="true" use-ccm="true">Copy to Clipboard Copied! Toggle word wrap Toggle overflow Set the
jtaattribute totrue.Add the following to the contents of your<datasource>tag, as they appear in the previous step:jta="true"Save the configuration file.
Save the configuration file and exit the text editor.Start JBoss EAP 6.
Relaunch the JBoss EAP 6 server.
JBoss EAP 6 starts, and your datasource is configured to use Java Transaction API.
11.6.2.2. Configure an XA Datasource
In order to add an XA Datasource, you need to log into the Management Console. See Section 11.6.2.3, “Log in to the Management Console” for more information.
Add a new datasource.
Add a new datasource to JBoss EAP 6. Follow the instructions in Section 11.6.2.4, “Create a Non-XA Datasource with the Management Interfaces”, but click the XA Datasource tab at the top.Configure additional properties as appropriate.
All datasource parameters are listed in Section 11.6.2.6, “Datasource Parameters”.
Your XA Datasource is configured and ready to use.
11.6.2.3. Log in to the Management Console
Prerequisites
- You must create an administrative user. For complete instructions, see Add the User for the Management Interfaces in the Administration and Configuration Guide for JBoss Enterprise Application Platform.JBoss EAP 6 must be running.
Navigate to the Management Console start page
Launch your web browser and navigate to the Management Console in your web browser at http://localhost:9990/console/App.htmlNote
Port 9990 is predefined as the Management Console socket binding.- Enter the username and password of the account that you created previously to log in to the Management Console login screen.
Figure 11.1. Log in screen for the Management Console
Once logged in, you are redirected to the following address and the the Management Console landing page appears: http://localhost:9990/console/App.html#home
11.6.2.4. Create a Non-XA Datasource with the Management Interfaces
This topic covers the steps required to create a non-XA datasource, using either the Management Console or the Management CLI.
Prerequisites
- The JBoss EAP 6 server must be running.
Note
Procedure 11.2. Create a Datasource using either the Management CLI or the Management Console
Management CLI
- Launch the CLI tool and connect to your server.
- Run the following command to create a non-XA datasource, configuring the variables as appropriate:
data-source add --name=DATASOURCE_NAME --jndi-name=JNDI_NAME --driver-name=DRIVER_NAME --connection-url=CONNECTION_URL
data-source add --name=DATASOURCE_NAME --jndi-name=JNDI_NAME --driver-name=DRIVER_NAME --connection-url=CONNECTION_URLCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Enable the datasource:
data-source enable --name=DATASOURCE_NAME
data-source enable --name=DATASOURCE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow
Management Console
- Login to the Management Console.
Navigate to the Datasources panel in the Management Console
- Select the Configuration tab from the top of the console.
- For Domain mode only, select a profile from the drop-down box in the top left.
- Expand the menu on the left of the console, then expand the menu.
- Select from the menu on the left of the console.
Create a new datasource
- Click at the top of the Datasources panel.
- Enter the new datasource attributes in the Create Datasource wizard and proceed with the button.
- Enter the JDBC driver details in the Create Datasource wizard and click to continue.
- Enter the connection settings in the Create Datasource wizard.
- Click the button to test the connection to the datasource and verify the settings are correct.
- Click to finish
The non-XA datasource has been added to the server. It is now visible in either the standalone.xml or domain.xml file, as well as the management interfaces.
11.6.2.5. Configure Database Connection Validation Settings
Database maintenance, network problems, or other outage events may cause JBoss EAP 6 to lose the connection to the database. You enable database connection validation using the <validation> element within the <datasource> section of the server configuration file. Follow the steps below to configure the datasource settings to enable database connection validation in JBoss EAP 6.
Procedure 11.3. Configure Database Connection Validation Settings
Choose a Validation Method
Select one of the following validation methods.<validate-on-match>true</validate-on-match>
When the<validate-on-match>option is set totrue, the database connection is validated every time it is checked out from the connection pool using the validation mechanism specified in the next step.If a connection is not valid, a warning is written to the log and it retrieves the next connection in the pool. This process continues until a valid connection is found. If you prefer not to cycle through every connection in the pool, you can use the<use-fast-fail>option. If a valid connection is not found in the pool, a new connection is created. If the connection creation fails, an exception is returned to the requesting application.This setting results in the quickest recovery but creates the highest load on the database. However, this is the safest selection if the minimal performance hit is not a concern.<background-validation>true</background-validation>
When the<background-validation>option is set totrue, it is used in combination with the<background-validation-millis>value to determine how often background validation runs. The default value for the<background-validation-millis>parameter is 0 milliseconds, meaning it is disabled by default. This value should not be set to the same value as your<idle-timeout-minutes>setting.It is a balancing act to determine the optimum<background-validation-millis>value for a particular system. The lower the value, the more frequently the pool is validated and the sooner invalid connections are removed from the pool. However, lower values take more database resources. Higher values result in less frequent connection validation checks and use less database resources, but dead connections are undetected for longer periods of time.
Note
If the<validate-on-match>option is set totrue, the<background-validation>option should be set tofalse. The reverse is also true. If the<background-validation>option is set totrue, the<validate-on-match>option should be set tofalse.Choose a Validation Mechanism
Select one of the following validation mechanisms.Specify a <valid-connection-checker> Class Name
This is the preferred mechanism as it optimized for the particular RDBMS in use. JBoss EAP 6 provides the following connection checkers:- org.jboss.jca.adapters.jdbc.extensions.db2.DB2ValidConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.mssql.MSSQLValidConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLReplicationValidConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLValidConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.novendor.JDBC4ValidConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.novendor.NullValidConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.oracle.OracleValidConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.postgres.PostgreSQLValidConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.sybase.SybaseValidConnectionChecker
Specify SQL for <check-valid-connection-sql>
You provide the SQL statement used to validate the connection.The following is an example of how you might specify a SQL statement to validate a connection for Oracle:For MySQL or PostgreSQL, you might specify the following SQL statement:<check-valid-connection-sql>select 1 from dual</check-valid-connection-sql>
<check-valid-connection-sql>select 1 from dual</check-valid-connection-sql>Copy to Clipboard Copied! Toggle word wrap Toggle overflow <check-valid-connection-sql>select 1</check-valid-connection-sql>
<check-valid-connection-sql>select 1</check-valid-connection-sql>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Set the <exception-sorter> Class Name
When an exception is marked as fatal, the connection is closed immediately, even if the connection is participating in a transaction. Use the exception sorter class option to properly detect and clean up after fatal connection exceptions. JBoss EAP 6 provides the following exception sorters:- org.jboss.jca.adapters.jdbc.extensions.db2.DB2ExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.informix.InformixExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.novendor.NullExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.oracle.OracleExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.postgres.PostgreSQLExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.sybase.SybaseExceptionSorter
11.6.2.6. Datasource Parameters
| Parameter | Description |
|---|---|
| jndi-name | The unique JNDI name for the datasource. |
| pool-name | The name of the management pool for the datasource. |
| enabled | Whether or not the datasource is enabled. |
| use-java-context |
Whether to bind the datasource to global JNDI.
|
| spy |
Enable
spy functionality on the JDBC layer. This logs all JDBC traffic to the datasource. Note that the logging category jboss.jdbc.spy must also be set to the log level DEBUG in the logging subsystem.
|
| use-ccm | Enable the cached connection manager. |
| new-connection-sql | A SQL statement which executes when the connection is added to the connection pool. |
| transaction-isolation |
One of the following:
|
| url-selector-strategy-class-name | A class that implements interface org.jboss.jca.adapters.jdbc.URLSelectorStrategy. |
| security |
Contains child elements which are security settings. See Table 11.6, “Security parameters”.
|
| validation |
Contains child elements which are validation settings. See Table 11.7, “Validation parameters”.
|
| timeout |
Contains child elements which are timeout settings. See Table 11.8, “Timeout parameters”.
|
| statement |
Contains child elements which are statement settings. See Table 11.9, “Statement parameters”.
|
| Parameter | Description |
|---|---|
| jta | Enable JTA integration for non-XA datasources. Does not apply to XA datasources. |
| connection-url | The JDBC driver connection URL. |
| driver-class | The fully-qualified name of the JDBC driver class. |
| connection-property |
Arbitrary connection properties passed to the method
Driver.connect(url,props). Each connection-property specifies a string name/value pair. The property name comes from the name, and the value comes from the element content.
|
| pool |
Contains child elements which are pooling settings. See Table 11.4, “Pool parameters common to non-XA and XA datasources”.
|
| url-delimiter |
The delimiter for URLs in a connection-url for High Availability (HA) clustered databases.
|
| Parameter | Description |
|---|---|
| xa-datasource-property |
A property to assign to implementation class
XADataSource. Specified by name=value. If a setter method exists, in the format setName, the property is set by calling a setter method in the format of setName(value).
|
| xa-datasource-class |
The fully-qualified name of the implementation class
javax.sql.XADataSource.
|
| driver |
A unique reference to the classloader module which contains the JDBC driver. The accepted format is driverName#majorVersion.minorVersion.
|
| xa-pool |
Contains child elements which are pooling settings. See Table 11.4, “Pool parameters common to non-XA and XA datasources” and Table 11.5, “XA pool parameters”.
|
| recovery |
Contains child elements which are recovery settings. See Table 11.10, “Recovery parameters”.
|
| Parameter | Description |
|---|---|
| min-pool-size | The minimum number of connections a pool holds. |
| max-pool-size | The maximum number of connections a pool can hold. |
| prefill | Whether to try to prefill the connection pool. An empty element denotes a true value. The default is false. |
| use-strict-min | Whether the pool-size is strict. Defaults to false. |
| flush-strategy |
Whether the pool is flushed in the case of an error. Valid values are:
The default is
FailingConnectionOnly.
|
| allow-multiple-users | Specifies if multiple users will access the datasource through the getConnection(user, password) method, and whether the internal pool type accounts for this behavior. |
| Parameter | Description |
|---|---|
| is-same-rm-override | Whether the javax.transaction.xa.XAResource.isSameRM(XAResource) class returns true or false. |
| interleaving | Whether to enable interleaving for XA connection factories. |
| no-tx-separate-pools |
Whether to create separate sub-pools for each context. This is required for Oracle datasources, which do not allow XA connections to be used both inside and outside of a JTA transaction.
Using this option will cause your total pool size to be twice
max-pool-size, because two actual pools will be created.
|
| pad-xid | Whether to pad the Xid. |
| wrap-xa-resource |
Whether to wrap the XAResource in an
org.jboss.tm.XAResourceWrapper instance.
|
| Parameter | Description |
|---|---|
| user-name | The username to use to create a new connection. |
| password | The password to use to create a new connection. |
| security-domain | Contains the name of a JAAS security-manager which handles authentication. This name correlates to the application-policy/name attribute of the JAAS login configuration. |
| reauth-plugin | Defines a reauthentication plug-in to use to reauthenticate physical connections. |
| Parameter | Description |
|---|---|
| valid-connection-checker |
An implementation of interface
org.jboss.jca.adaptors.jdbc.ValidConnectionChecker which provides a SQLException.isValidConnection(Connection e) method to validate a connection. An exception means the connection is destroyed. This overrides the parameter check-valid-connection-sql if it is present.
|
| check-valid-connection-sql | An SQL statement to check validity of a pool connection. This may be called when a managed connection is taken from a pool for use. |
| validate-on-match |
Indicates whether connection level validation is performed when a connection factory attempts to match a managed connection for a given set.
Specifying "true" for
validate-on-match is typically not done in conjunction with specifying "true" for background-validation. Validate-on-match is needed when a client must have a connection validated prior to use. This parameter is false by default.
|
| background-validation |
Specifies that connections are validated on a background thread. Background validation is a performance optimization when not used with
validate-on-match. If validate-on-match is true, using background-validation could result in redundant checks. Background validation does leave open the opportunity for a bad connection to be given to the client for use (a connection goes bad between the time of the validation scan and prior to being handed to the client), so the client application must account for this possibility.
|
| background-validation-millis | The amount of time, in milliseconds, that background validation runs. |
| use-fast-fail |
If true, fail a connection allocation on the first attempt, if the connection is invalid. Defaults to
false.
|
| stale-connection-checker |
An instance of
org.jboss.jca.adapters.jdbc.StaleConnectionChecker which provides a Boolean isStaleConnection(SQLException e) method. If this method returns true, the exception is wrapped in an org.jboss.jca.adapters.jdbc.StaleConnectionException, which is a subclass of SQLException.
|
| exception-sorter |
An instance of
org.jboss.jca.adapters.jdbc.ExceptionSorter which provides a Boolean isExceptionFatal(SQLException e) method. This method validates whether an exception is broadcast to all instances of javax.resource.spi.ConnectionEventListener as a connectionErrorOccurred message.
|
| Parameter | Description |
|---|---|
| use-try-lock | Uses tryLock() instead of lock(). This attempts to obtain the lock for the configured number of seconds, before timing out, rather than failing immediately if the lock is unavailable. Defaults to 60 seconds. As an example, to set a timeout of 5 minutes, set <use-try-lock>300</use-try-lock>. |
| blocking-timeout-millis | The maximum time, in milliseconds, to block while waiting for a connection. After this time is exceeded, an exception is thrown. This blocks only while waiting for a permit for a connection, and does not throw an exception if creating a new connection takes a long time. Defaults to 30000, which is 30 seconds. |
| idle-timeout-minutes |
The maximum time, in minutes, before an idle connection is closed. The actual maximum time depends upon the idleRemover scan time, which is half of the smallest
idle-timeout-minutes of any pool.
|
| set-tx-query-timeout |
Whether to set the query timeout based on the time remaining until transaction timeout. Any configured query timeout is used if no transaction exists. Defaults to
false.
|
| query-timeout | Timeout for queries, in seconds. The default is no timeout. |
| allocation-retry | The number of times to retry allocating a connection before throwing an exception. The default is 0, so an exception is thrown upon the first failure. |
| allocation-retry-wait-millis |
How long, in milliseconds, to wait before retrying to allocate a connection. The default is 5000, which is 5 seconds.
|
| xa-resource-timeout |
If non-zero, this value is passed to method
XAResource.setTransactionTimeout.
|
| Parameter | Description |
|---|---|
| track-statements |
Whether to check for unclosed statements when a connection is returned to a pool and a statement is returned to the prepared statement cache. If false, statements are not tracked.
|
| prepared-statement-cache-size | The number of prepared statements per connection, in a Least Recently Used (LRU) cache. |
| share-prepared-statements |
Whether asking for the same statement twice without closing it uses the same underlying prepared statement. The default is
false.
|
| Parameter | Description |
|---|---|
| recover-credential | A username/password pair or security domain to use for recovery. |
| recover-plugin |
An implementation of the
org.jboss.jca.core.spi.recoveryRecoveryPlugin class, to be used for recovery.
|
11.6.3. Transaction Logging
11.6.3.1. About Transaction Log Messages
DEBUG log level for the transaction logger. For detailed debugging, use the TRACE log level. Refer to Section 11.6.3.2, “Configure Logging for the Transaction Subsystem” for information on configuring the transaction logger.
TRACE log level. Following are some of the most commonly-seen messages. This list is not comprehensive, so you may see other messages than these.
| Transaction Begin |
When a transaction begins, the following code is executed:
com.arjuna.ats.arjuna.coordinator.BasicAction::Begin:1342 tsLogger.logger.trace("BasicAction::Begin() for action-id "+ get_uid());
|
| Transaction Commit |
When a transaction commits, the following code is executed:
com.arjuna.ats.arjuna.coordinator.BasicAction::End:1342 tsLogger.logger.trace("BasicAction::End() for action-id "+ get_uid());
|
| Transaction Rollback |
When a transaction rolls back, the following code is executed:
com.arjuna.ats.arjuna.coordinator.BasicAction::Abort:1575 tsLogger.logger.trace("BasicAction::Abort() for action-id "+ get_uid());
|
| Transaction Timeout |
When a transaction times out, the following code is executed:
com.arjuna.ats.arjuna.coordinator.TransactionReaper::doCancellations:349 tsLogger.logger.trace("Reaper Worker " + Thread.currentThread() + " attempting to cancel " + e._control.get_uid());
You will then see the same thread rolling back the transaction as shown above.
|
11.6.3.2. Configure Logging for the Transaction Subsystem
Use this procedure to control the amount of information logged about transactions, independent of other logging settings in JBoss EAP 6. The main procedure shows how to do this in the web-based Management Console. The Management CLI command is given afterward.
Procedure 11.4. Configure the Transaction Logger Using the Management Console
Navigate to the Logging configuration area.
In the Management Console, click the Configuration tab. If you use a managed domain, choose the server profile you wish to configure, from the Profile selection box at the top left.Expand the Core menu, and select Logging.Edit the
com.arjunaattributes.Select the Log Categories tab. Selectcom.arjunaand lick Edit in the Details section. This is where you can add class-specific logging information. Thecom.arjunaclass is already present. You can change the log level and whether to use parent handlers.- Log Level
- The log level is
WARNby default. Because transactions can produce a large quantity of logging output, the meaning of the standard logging levels is slightly different for the transaction logger. In general, messages tagged with levels at a lower severity than the chosen level are discarded.Transaction Logging Levels, from Most to Least Verbose
- TRACE
- DEBUG
- INFO
- WARN
- ERROR
- FAILURE
- Use Parent Handlers
- Whether the logger should send its output to its parent logger. The default behavior is
true.
- Changes take effect immediately.
11.6.3.3. Browse and Manage Transactions
log-store. An API operation called probe reads the transaction logs and creates a node for each log. You can call the probe command manually, whenever you need to refresh the log-store. It is normal for transaction logs to appear and disappear quickly.
Example 11.2. Refresh the Log Store
default in a managed domain. For a standalone server, remove the profile=default from the command.
/profile=default/subsystem=transactions/log-store=log-store/:probe
/profile=default/subsystem=transactions/log-store=log-store/:probeExample 11.3. View All Prepared Transactions
ls command.
ls /profile=default/subsystem=transactions/log-store=log-store/transactions
ls /profile=default/subsystem=transactions/log-store=log-store/transactionsManage a Transaction
- View a transaction's attributes.
- To view information about a transaction, such as its JNDI name, EIS product name and version, or its status, use the
:read-resourceCLI command./profile=default/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9:read-resource
/profile=default/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9:read-resourceCopy to Clipboard Copied! Toggle word wrap Toggle overflow - View the participants of a transaction.
- Each transaction log contains a child element called
participants. Use theread-resourceCLI command on this element to see the participants of the transaction. Participants are identified by their JNDI names./profile=default/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9/participants=java\:\/JmsXA:read-resource
/profile=default/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9/participants=java\:\/JmsXA:read-resourceCopy to Clipboard Copied! Toggle word wrap Toggle overflow The result may look similar to this:Copy to Clipboard Copied! Toggle word wrap Toggle overflow The outcome status shown here is in aHEURISTICstate and is eligible for recover. See Recover a transaction. for more details. - Delete a transaction.
- Each transaction log supports a
:deleteoperation, to delete the transaction log representing the transaction./profile=default/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9:delete
/profile=default/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9:deleteCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Recover a transaction.
- Each transaction log supports recovery via the
:recoverCLI command.Recovery of Heuristic Transactions and Participants
- If the transaction's status is
HEURISTIC, the recovery operation changes the state toPREPAREand triggers a recovery. - If one of the transaction's participants is heuristic, the recovery operation tries to replay the
commitoperation. If successful, the participant is removed from the transaction log. You can verify this by re-running the:probeoperation on thelog-storeand checking that the participant is no longer listed. If this is the last participant, the transaction is also deleted.
- Refresh the status of a transaction which needs recovery.
- If a transaction needs recovery, you can use the
:refreshCLI command to be sure it still requires recovery, before attempting the recovery./profile=default/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9/participants=2:refresh
/profile=default/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9/participants=2:refreshCopy to Clipboard Copied! Toggle word wrap Toggle overflow
If Transaction Manager statistics are enabled, you can view statistics about the Transaction Manager and transaction subsystem. See Section 11.7.8.2, “Configure the Transaction Manager” for information about how to enable Transaction Manager statistics.
| Statistic | Description | CLI Command |
|---|---|---|
| Total |
The total number of transactions processed by the Transaction Manager on this server.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-transactions,include-defaults=true) |
| Committed |
The number of committed transactions processed by the Transaction Manager on this server.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-committed-transactions,include-defaults=true) |
| Aborted |
The number of aborted transactions processed by the Transaction Manager on this server.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-aborted-transactions,include-defaults=true) |
| Timed Out |
The number of timed out transactions processed by the Transaction Manager on this server.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-timed-out-transactions,include-defaults=true) |
| Heuristics |
Not available in the Management Console. Number of transactions in a heuristic state.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-heuristics,include-defaults=true) |
| In-Flight Transactions |
Not available in the Management Console. Number of transactions which have begun but not yet terminated.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-inflight-transactions,include-defaults=true) |
| Failure Origin - Applications |
The number of failed transactions whose failure origin was an application.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-application-rollbacks,include-defaults=true) |
| Failure Origin - Resources |
The number of failed transactions whose failure origin was a resource.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-resource-rollbacks,include-defaults=true) |
| Participant ID |
The ID of the participant.
|
/host=master/server=server-one/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9:read-children-names(child-type=participants) |
| List of all transactions |
The complete list of transactions.
|
/host=master/server=server-one/subsystem=transactions/log-store=log-store:read-children-names(child-type=transactions) |
11.7. Use JTA Transactions
11.7.1. Transactions JTA Task Overview
The following procedures are useful when you need to use transactions in your application.
11.7.2. Control Transactions
This list of procedures outlines the different ways to control transactions in your applications which use JTA or JTS APIs.
11.7.3. Begin a Transaction
Get an instance of
UserTransaction.You can get the instance using JNDI, injection, or an EJB's context, if the EJB uses bean-managed transactions, by means of a@TransactionManagement(TransactionManagementType.BEAN)annotation.JNDI
new InitialContext().lookup("java:comp/UserTransaction")new InitialContext().lookup("java:comp/UserTransaction")Copy to Clipboard Copied! Toggle word wrap Toggle overflow Injection
@Resource UserTransaction userTransaction;
@Resource UserTransaction userTransaction;Copy to Clipboard Copied! Toggle word wrap Toggle overflow Context
- In a stateless/stateful bean:
@Resource SessionContext ctx; ctx.getUserTransaction();
@Resource SessionContext ctx; ctx.getUserTransaction();Copy to Clipboard Copied! Toggle word wrap Toggle overflow - In a message-driven bean:
@Resource MessageDrivenContext ctx; ctx.getUserTransaction()
@Resource MessageDrivenContext ctx; ctx.getUserTransaction()Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Call
UserTransaction.begin()after you connect to your datasource.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
One of the benefits of EJBs is that the container manages all of the transactions. If you have set up the ORB and activated JTS transactions, the container will manage distributed transactions for you.
The transaction begins. All uses of your datasource until you commit or roll back the transaction are transactional.
Note
11.7.4. Nested Transactions
11.7.5. Commit a Transaction
You must begin a transaction before you can commit it. For information on how to begin a transaction, refer to Section 11.7.3, “Begin a Transaction”.
Call the
commit()method on theUserTransaction.When you call thecommit()method on theUserTransaction, the Transaction Manager attempts to commit the transaction.Copy to Clipboard Copied! Toggle word wrap Toggle overflow If you use Container Managed Transactions (CMT), you do not need to manually commit.
If you configure your bean to use Container Managed Transactions, the container will manage the transaction lifecycle for you based on annotations you configure in the code.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Your datasource commits and your transaction ends, or an exception is thrown.
Note
11.7.6. Roll Back a Transaction
You must begin a transaction before you can roll it back. For information on how to begin a transaction, refer to Section 11.7.3, “Begin a Transaction”.
Call the
rollback()method on theUserTransaction.When you call therollback()method on theUserTransaction, the Transaction Manager attempts to roll back the transaction and return the data to its previous state.Copy to Clipboard Copied! Toggle word wrap Toggle overflow If you use Container Managed Transactions (CMT), you do not need to manually roll back the transaction.
If you configure your bean to use Container Managed Transactions, the container will manage the transaction lifecycle for you based on annotations you configure in the code.
Your transaction is rolled back by the Transaction Manager.
Note
11.7.7. Handle a Heuristic Outcome in a Transaction
Procedure 11.5. Handle a heuristic outcome in a transaction
Determine the cause
The over-arching cause of a heuristic outcome in a transaction is that a resource manager promised it could commit or roll-back, and then failed to fulfill the promise. This could be due to a problem with a third-party component, the integration layer between the third-party component and JBoss EAP 6, or JBoss EAP 6 itself.By far, the most common two causes of heuristic errors are transient failures in the environment and coding errors in the code dealing with resource managers.Fix transient failures in the environment
Typically, if there is a transient failure in your environment, you will know about it before you find out about the heuristic error. This could be a network outage, hardware failure, database failure, power outage, or a host of other things.If you experienced the heuristic outcome in a test environment, during stress testing, it provides information about weaknesses in your environment.Warning
JBoss EAP 6 will automatically recover transactions that were in a non-heuristic state at the time of the failure, but it does not attempt to recover heuristic transactions.Contact resource manager vendors
If you have no obvious failure in your environment, or the heuristic outcome is easily reproducible, it is probably a coding error. Contact third-party vendors to find out if a solution is available. If you suspect the problem is in the transaction manager of JBoss EAP 6 itself, contact Red Hat Global Support Services.In a test environment, delete the logs and restart JBoss EAP 6.
In a test environment, or if you do not care about the integrity of the data, deleting the transaction logs and restarting JBoss EAP 6 gets rid of the heuristic outcome. The transaction logs are located inEAP_HOME/standalone/data/tx-object-store/for a standalone server, orEAP_HOME/domain/servers/SERVER_NAME/data/tx-object-storein a managed domain, by default. In the case of a managed domain, SERVER_NAME refers to the name of the individual server participating in a server group.Note
The location of the transaction log also depends on the object store in use and the values set for theoject-store-relative-toandobject-store-pathparameters. For file system logs (such as a standard shadow and HornetQ logs) the default direction location is used, but when using a JDBC object store, the transaction logs are stored in a database.Resolve the outcome by hand
The process of resolving the transaction outcome by hand is very dependent on the exact circumstance of the failure. Typically, you need to take the following steps, applying them to your situation:- Identify which resource managers were involved.
- Examine the state in the transaction manager and the resource managers.
- Manually force log cleanup and data reconciliation in one or more of the involved components.
The details of how to perform these steps are out of the scope of this documentation.
11.7.8. Transaction Timeouts
11.7.8.1. About Transaction Timeouts
11.7.8.2. Configure the Transaction Manager
default, you may need to modify the steps and commands in the following ways.
Notes about the Example Commands
- For the Management Console, the
defaultprofile is the one which is selected when you first log into the console. If you need to modify the Transaction Manager's configuration in a different profile, select your profile instead ofdefault, in each instruction.Similarly, substitute your profile for thedefaultprofile in the example CLI commands. - If you use a Standalone Server, only one profile exists. Ignore any instructions to choose a specific profile. In CLI commands, remove the
/profile=defaultportion of the sample commands.
Note
transactions subsystem must be enabled. It is enabled by default, and required for many other subsystems to function properly, so it is very unlikely that it would be disabled.
To configure the TM using the web-based Management Console, select the Configuration tab from the top of the screen. If you use a managed domain, choose the correct profile from the Profile selection box at the top left. Expand the Container menu and select Transactions.
In the Management CLI, you can configure the TM using a series of commands. The commands all begin with /profile=default/subsystem=transactions/ for a managed domain with profile default, or /subsystem=transactions for a Standalone Server.
Important
| Option | Description | CLI Command |
|---|---|---|
|
Enable Statistics
|
Whether to enable transaction statistics. These statistics can be viewed in the Management Console in the Subsystem Metrics section of the Runtime tab.
| /profile=default/subsystem=transactions/:write-attribute(name=enable-statistics,value=true)
|
|
Default Timeout
|
The default transaction timeout. This defaults to
300 seconds. You can override this programmatically, on a per-transaction basis.
| /profile=default/subsystem=transactions/:write-attribute(name=default-timeout,value=300)
|
|
Object Store Path
|
A relative or absolute filesystem path where the TM object store stores data. By default relative to the
object-store-relative-to parameter's value.
| /profile=default/subsystem=transactions/:write-attribute(name=object-store-path,value=tx-object-store)
|
|
Object Store Path Relative To
|
References a global path configuration in the domain model. The default value is the data directory for JBoss EAP 6, which is the value of the property
jboss.server.data.dir, and defaults to EAP_HOME/domain/data/ for a Managed Domain, or EAP_HOME/standalone/data/ for a Standalone Server instance. The value of the object store object-store-path TM attribute is relative to this path.
| /profile=default/subsystem=transactions/:write-attribute(name=object-store-relative-to,value=jboss.server.data.dir)
|
|
Socket Binding
|
Specifies the name of the socket binding used by the Transaction Manager for recovery and generating transaction identifiers, when the socket-based mechanism is used. Refer to
process-id-socket-max-ports for more information on unique identifier generation. Socket bindings are specified per server group in the Server tab of the Management Console.
| /profile=default/subsystem=transactions/:write-attribute(name=socket-binding,value=txn-recovery-environment)
|
|
Recovery Listener
|
Whether or not the Transaction Recovery process should listen on a network socket. Defaults to
false.
| /profile=default/subsystem=transactions/:write-attribute(name=recovery-listener,value=false)
|
| Option | Description | CLI Command |
|---|---|---|
|
jts
|
Whether to use Java Transaction Service (JTS) transactions. Defaults to
false, which uses JTA transactions only.
| /profile=default/subsystem=transactions/:write-attribute(name=jts,value=false)
|
|
node-identifier
|
The node identifier for the Transaction Manager. This option is required in the following situations:
node-identifier must be unique for each Transaction Manager as it is required to enforce data integrity during recovery. The node-identifier must also be unique for JTA because multiple nodes may interact with the same resource manager or share a transaction object store.
| /profile=default/subsystem=transactions/:write-attribute(name=node-identifier,value=1)
|
|
process-id-socket-max-ports
|
The Transaction Manager creates a unique identifier for each transaction log. Two different mechanisms are provided for generating unique identifiers: a socket-based mechanism and a mechanism based on the process identifier of the process.
In the case of the socket-based identifier, a socket is opened and its port number is used for the identifier. If the port is already in use, the next port is probed, until a free one is found. The
process-id-socket-max-ports represents the maximum number of sockets the TM will try before failing. The default value is 10.
| /profile=default/subsystem=transactions/:write-attribute(name=process-id-socket-max-ports,value=10)
|
|
process-id-uuid
|
Set to
true to use the process identifier to create a unique identifier for each transaction. Otherwise, the socket-based mechanism is used. Defaults to true. Refer to process-id-socket-max-ports for more information.
| /profile=default/subsystem=transactions/:write-attribute(name=process-id-uuid,value=true)
|
|
use-hornetq-store
|
Use HornetQ's journaled storage mechanisms instead of file-based storage, for the transaction logs. This is disabled by default, but can improve I/O performance. It is not recommended for JTS transactions on separate Transaction Managers. When changing this option, the server has to be restarted using the
shutdown command for the change to take effect.
| /profile=default/subsystem=transactions/:write-attribute(name=use-hornetq-store,value=false)
|
11.7.9. JTA Transaction Error Handling
11.7.9.1. Handle Transaction Errors
Note
This type of error often manifests itself when Hibernate is unable to obtain a database connection for lazy loading. If it happens frequently, you can lengthen the timeout value. Refer to Section 11.7.8.2, “Configure the Transaction Manager”.
NotSupportedException exception
The NotSupportedException exception usually indicates that you attempted to nest a JTA transaction, and this is not supported. If you were not attempting to nest a transaction, it is likely that another transaction was started in a thread pool task, but finished the task without suspending or ending the transaction.
UserTransaction, which handles this automatically. If so, there may be a problem with a framework.
TransactionManager or Transaction methods directly, be aware of the following behavior when committing or rolling back a transaction. If your code uses TransactionManager methods to control your transactions, committing or rolling back a transaction disassociates the transaction from the current thread. However, if your code uses Transaction methods, the transaction may not be associated with the running thread, and you need to disassociate it from its threads manually, before returning it to the thread pool.
This error happens if you try to enlist a second non-XA resource into a transaction. If you need multiple resources in a transaction, they must be XA.
11.8. ORB Configuration
11.8.1. About Common Object Request Broker Architecture (CORBA)
11.8.2. Configure the ORB for JTS Transactions
Note
full and full-ha profiles only. In a standalone server, it is available when you use the standalone-full.xml or standalone-full-ha.xml configurations.
Procedure 11.6. Configure the ORB using the Management Console
View the profile settings.
Select Configuration from the top of the management console. If you use a managed domain, select either the full or full-ha profile from the selection box at the top left.Modify the Initializers Settings
Expand the Subsystems menu. Expand the Container menu and select JacORB.In the form that appears in the main screen, select the Initializers tab and click the Edit button.Enable the security interceptors by setting the value of Security toon.To enable the ORB for JTS, set the Transaction Interceptors value toon, rather than the defaultspec.Refer to the Need Help? link in the form for detailed explanations about these values. Click Save when you have finished editing the values.Advanced ORB Configuration
Refer to the other sections of the form for advanced configuration options. Each section includes a Need Help? link with detailed information about the parameters.
You can configure each aspect of the ORB using the Management CLI. The following commands configure the initializers to the same values as the procedure above, for the Management Console. This is the minimum configuration for the ORB to be used with JTS.
/profile=full portion of the commands.
Example 11.4. Enable the Security Interceptors
/profile=full/subsystem=jacorb/:write-attribute(name=security,value=on)
/profile=full/subsystem=jacorb/:write-attribute(name=security,value=on)Example 11.5. Enable Transactions in the JacORB Subsystem
/profile=full/subsystem=jacorb/:write-attribute(name=transactions,value=on)
/profile=full/subsystem=jacorb/:write-attribute(name=transactions,value=on)Example 11.6. Enable JTS in the Transaction Subsystem
/profile=full/subsystem=transactions:write-attribute(name=jts,value=true)
/profile=full/subsystem=transactions:write-attribute(name=jts,value=true)Note
11.9. Transaction References
11.9.1. JBoss Transactions Errors and Exceptions
UserTransaction class, see the UserTransaction API specification at http://docs.oracle.com/javaee/6/api/javax/transaction/UserTransaction.html.
11.9.2. Limitations on JTA Transactions
11.9.3. JTA Transaction Example
Example 11.7. JTA Transaction example
11.9.4. API Documentation for JBoss Transactions JTA
11.9.5. Limitations of the XA Recovery Process
- The transaction log may not be cleared from a successfully committed transaction.
- If the JBoss EAP server crashes after an
XAResourcecommit method successfully completes and commits the transaction, but before the coordinator can update the log, you may see the following warning message in the log when you restart the server:This is because upon recovery, the JBoss Transaction Manager sees the transaction participants in the log and attempts to retry the commit. Eventually the JBoss Transaction Manager assumes the resources are committed and no longer retries the commit. In this situation, can safely ignore this warning as the transaction is committed and there is no loss of data.ARJUNA016037: Could not find new XAResource to use for recovering non-serializable XAResource XAResourceRecord
ARJUNA016037: Could not find new XAResource to use for recovering non-serializable XAResource XAResourceRecordCopy to Clipboard Copied! Toggle word wrap Toggle overflow To prevent the warning, set the com.arjuna.ats.jta.xaAssumeRecoveryComplete property value totrue. This property is checked whenever a newXAResourceinstance cannot be located from any registeredXAResourceRecoveryinstance. When set totrue, the recovery assumes that a previous commit attempt succeeded and the instance can be removed from the log with no further recovery attempts. This property must be used with care because it is global and when used incorrectly could result inXAResourceinstances remaining in an uncommitted state. - Rollback is not called for JTS transaction when a server crashes at the end of XAResource.prepare().
- If the JBoss EAP server crashes after the completion of an
XAResourceprepare()method call, all of the participating XAResources are locked in the prepared state and remain that way upon server restart, The transaction is not rolled back and the resources remain locked until the transaction times out or a DBA manually rolls back the resources and clears the transaction log. - Periodic recovery can occur on committed transactions.
- When the server is under excessive load, the server log may contain the following warning message, followed by a stacktrace:
ARJUNA016027: Local XARecoveryModule.xaRecovery got XA exception XAException.XAER_NOTA: javax.transaction.xa.XAException
ARJUNA016027: Local XARecoveryModule.xaRecovery got XA exception XAException.XAER_NOTA: javax.transaction.xa.XAExceptionCopy to Clipboard Copied! Toggle word wrap Toggle overflow Under heavy load, the processing time taken by a transaction can overlap with the timing of the periodic recovery process’s activity. The periodic recovery process detects the transaction still in progress and attempts to initiate a rollback but in fact the transaction continues to completion. At the time the periodic recovery attempts but fails the rollback, it records the rollback failure in the server log. The underlying cause of this issue will be addressed in a future release, but in the meantime a workaround is available.Increase the interval between the two phases of the recovery process by setting the com.arjuna.ats.jta.orphanSafetyInterval property to a value higher than the default value of 10000 milliseconds. A value of 40000 milliseconds is recommended. Please note that this does not solve the issue, instead it decreases the probability that it will occur and that the warning message will be shown in the log.
Chapter 12. Hibernate
12.1. About Hibernate Core
12.2. Java Persistence API (JPA)
12.2.1. About JPA
bean-validation, greeter, and kitchensink quickstarts: Section 1.4.1.1, “Access the Quickstarts”.
12.2.2. Hibernate EntityManager
12.2.3. Getting Started
12.2.3.1. Create a JPA project in Red Hat JBoss Developer Studio
This example covers the steps required to create a JPA project in Red Hat JBoss Developer Studio.
Procedure 12.1. Create a JPA project in Red Hat JBoss Developer Studio
- In the Red Hat JBoss Developer Studio window, click → → .
- In the project dialog, type the name of the project.
- Select a Target runtime from the dropdown box.
- If no Target runtime is available, click .
- Find the JBoss Community Folder in the list.
- Select JBoss Enterprise Application Platform 6.x Runtime
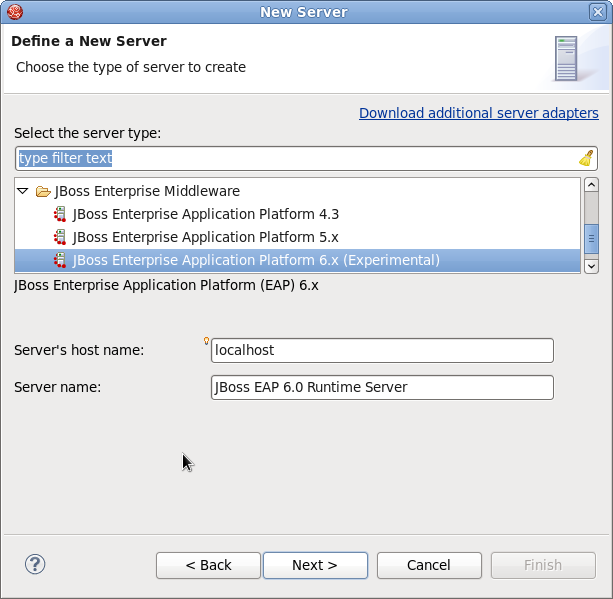
- Click .
- In the Home Directory field, click to set the JBoss EAP source folder as the Home Directory.
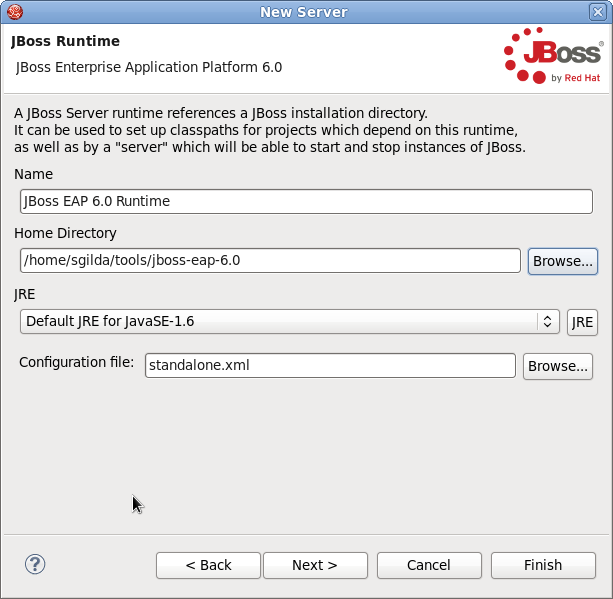
- Click .
- Click .
- Leave the source folders on build path window as default, and click .
- In the Platform dropdown, ensure Hibernate (JPA 2.x) is selected.
- Click .
- If prompted, choose whether you wish to open the JPA perspective window.
12.2.3.2. Create the Persistence Settings File in Red Hat JBoss Developer Studio
This topic covers the process for creating the persistence.xml file in a Java project using Red Hat JBoss Developer Studio.
Prerequisites
Procedure 12.2. Create and Configure a new Persistence Settings File
- Open an EJB 3.x project in Red Hat JBoss Developer Studio.
- Right click the project root directory in the Project Explorer panel.
- Select → .
- Select XML File from the XML folder and click .
- Select the
ejbModule/META-INFfolder as the parent directory. - Name the file
persistence.xmland click . - Select Create XML file from an XML schema file and click .
- Select http://java.sun.com/xml/ns/persistence/persistence_2.0.xsd from the Select XML Catalog entry list and click .
- Click to create the file.
- Result:
- The
persistence.xmlhas been created in theMETA-INF/folder and is ready to be configured. An example file is available here: Section 12.2.3.3, “Example Persistence Settings File”
12.2.3.3. Example Persistence Settings File
Example 12.1. persistence.xml
12.2.3.4. Create the Hibernate Configuration File in Red Hat JBoss Developer Studio
Prerequisites
This topic covers the process for creating the hibernate.cfg.xml file in a Java project using Red Hat JBoss Developer Studio.
Procedure 12.3. Create a New Hibernate Configuration File
- Open a Java project in Red Hat JBoss Developer Studio.
- Right click the project root directory in the Project Explorer panel.
- Select → .
- Select Hibernate Configuration File from the Hibernate folder and click .
- Select the
src/directory and click . - Configure the following:
- Session factory name
- Database dialect
- Driver class
- Connection URL
- Username
- Password
- Click to create the file.
- Result:
- The
hibernate.cfg.xmlhas been created in thesrc/folder. An example file is available here: Section 12.2.3.5, “Example Hibernate Configuration File”.
12.2.3.5. Example Hibernate Configuration File
Example 12.2. hibernate.cfg.xml
12.2.4. Configuration
12.2.4.1. Hibernate Configuration Properties
| Property Name | Description |
|---|---|
| hibernate.dialect |
The classname of a Hibernate
org.hibernate.dialect.Dialect. Allows Hibernate to generate SQL optimized for a particular relational database.
In most cases Hibernate will be able to choose the correct
org.hibernate.dialect.Dialect implementation, based on the JDBC metadata returned by the JDBC driver.
|
| hibernate.show_sql |
Boolean. Writes all SQL statements to console. This is an alternative to setting the log category
org.hibernate.SQL to debug.
|
| hibernate.format_sql |
Boolean. Pretty print the SQL in the log and console.
|
| hibernate.default_schema |
Qualify unqualified table names with the given schema/tablespace in generated SQL.
|
| hibernate.default_catalog |
Qualifies unqualified table names with the given catalog in generated SQL.
|
| hibernate.session_factory_name |
The
org.hibernate.SessionFactory will be automatically bound to this name in JNDI after it has been created. For example, jndi/composite/name.
|
| hibernate.max_fetch_depth |
Sets a maximum "depth" for the outer join fetch tree for single-ended associations (one-to-one, many-to-one). A
0 disables default outer join fetching. The recommended value is between 0 and 3.
|
| hibernate.default_batch_fetch_size |
Sets a default size for Hibernate batch fetching of associations. The recommended values are
4, 8, and 16.
|
| hibernate.default_entity_mode |
Sets a default mode for entity representation for all sessions opened from this
SessionFactory. Values include: dynamic-map, dom4j, pojo.
|
| hibernate.order_updates |
Boolean. Forces Hibernate to order SQL updates by the primary key value of the items being updated. This will result in fewer transaction deadlocks in highly concurrent systems.
|
| hibernate.generate_statistics |
Boolean. If enabled, Hibernate will collect statistics useful for performance tuning.
|
| hibernate.use_identifier_rollback |
Boolean. If enabled, generated identifier properties will be reset to default values when objects are deleted.
|
| hibernate.use_sql_comments |
Boolean. If turned on, Hibernate will generate comments inside the SQL, for easier debugging. Default value is
false.
|
| hibernate.id.new_generator_mappings |
Boolean. This property is relevant when using
@GeneratedValue. It indicates whether or not the new IdentifierGenerator implementations are used for javax.persistence.GenerationType.AUTO, javax.persistence.GenerationType.TABLE and javax.persistence.GenerationType.SEQUENCE. Default value is true.
|
Important
hibernate.id.new_generator_mappings, new applications should keep the default value of true. Existing applications that used Hibernate 3.3.x may need to change it to false to continue using a sequence object or table based generator, and maintain backward compatibility.
12.2.4.2. Hibernate JDBC and Connection Properties
| Property Name | Description |
|---|---|
| hibernate.jdbc.fetch_size |
A non-zero value that determines the JDBC fetch size (calls
Statement.setFetchSize()).
|
| hibernate.jdbc.batch_size |
A non-zero value enables use of JDBC2 batch updates by Hibernate. The recommended values are between
5 and 30.
|
| hibernate.jdbc.batch_versioned_data |
Boolean. Set this property to
true if the JDBC driver returns correct row counts from executeBatch(). Hibernate will then use batched DML for automatically versioned data. Default value is to false.
|
| hibernate.jdbc.factory_class |
Select a custom
org.hibernate.jdbc.Batcher. Most applications will not need this configuration property.
|
| hibernate.jdbc.use_scrollable_resultset |
Boolean. Enables use of JDBC2 scrollable resultsets by Hibernate. This property is only necessary when using user-supplied JDBC connections. Hibernate uses connection metadata otherwise.
|
| hibernate.jdbc.use_streams_for_binary |
Boolean. This is a system-level property. Use streams when writing/reading
binary or serializable types to/from JDBC.
|
| hibernate.jdbc.use_get_generated_keys |
Boolean. Enables use of JDBC3
PreparedStatement.getGeneratedKeys() to retrieve natively generated keys after insert. Requires JDBC3+ driver and JRE1.4+. Set to false if JDBC driver has problems with the Hibernate identifier generators. By default, it tries to determine the driver capabilities using connection metadata.
|
| hibernate.connection.provider_class |
The classname of a custom
org.hibernate.connection.ConnectionProvider which provides JDBC connections to Hibernate.
|
| hibernate.connection.isolation |
Sets the JDBC transaction isolation level. Check
java.sql.Connection for meaningful values, but note that most databases do not support all isolation levels and some define additional, non-standard isolations. Standard values are 1, 2, 4, 8.
|
| hibernate.connection.autocommit |
Boolean. This property is not recommended for use. Enables autocommit for JDBC pooled connections.
|
| hibernate.connection.release_mode |
Specifies when Hibernate should release JDBC connections. By default, a JDBC connection is held until the session is explicitly closed or disconnected. The default value
auto will choose after_statement for the JTA and CMT transaction strategies, and after_transaction for the JDBC transaction strategy.
Available values are
auto (default) | on_close | after_transaction | after_statement.
This setting only affects
Sessions returned from SessionFactory.openSession. For Sessions obtained through SessionFactory.getCurrentSession, the CurrentSessionContext implementation configured for use controls the connection release mode for those Sessions.
|
| hibernate.connection.<propertyName> |
Pass the JDBC property <propertyName> to
DriverManager.getConnection().
|
| hibernate.jndi.<propertyName> |
Pass the property <propertyName> to the JNDI
InitialContextFactory.
|
12.2.4.3. Hibernate Cache Properties
| Property Name | Description |
|---|---|
hibernate.cache.region.factory_class |
The classname of a custom
CacheProvider.
|
hibernate.cache.use_minimal_puts |
Boolean. Optimizes second-level cache operation to minimize writes, at the cost of more frequent reads. This setting is most useful for clustered caches and, in Hibernate3, is enabled by default for clustered cache implementations.
|
hibernate.cache.use_query_cache |
Boolean. Enables the query cache. Individual queries still have to be set cacheable.
|
hibernate.cache.use_second_level_cache |
Boolean. Used to completely disable the second level cache, which is enabled by default for classes that specify a
<cache> mapping.
|
hibernate.cache.query_cache_factory |
The classname of a custom
QueryCache interface. The default value is the built-in StandardQueryCache.
|
hibernate.cache.region_prefix |
A prefix to use for second-level cache region names.
|
hibernate.cache.use_structured_entries |
Boolean. Forces Hibernate to store data in the second-level cache in a more human-friendly format.
|
hibernate.cache.default_cache_concurrency_strategy |
Setting used to give the name of the default
org.hibernate.annotations.CacheConcurrencyStrategy to use when either @Cacheable or @Cache is used. @Cache(strategy="..") is used to override this default.
|
12.2.4.4. Hibernate Transaction Properties
| Property Name | Description |
|---|---|
hibernate.transaction.factory_class |
The classname of a
TransactionFactory to use with Hibernate Transaction API. Defaults to JDBCTransactionFactory).
|
jta.UserTransaction |
A JNDI name used by
JTATransactionFactory to obtain the JTA UserTransaction from the application server.
|
hibernate.transaction.manager_lookup_class |
The classname of a
TransactionManagerLookup. It is required when JVM-level caching is enabled or when using hilo generator in a JTA environment.
|
hibernate.transaction.flush_before_completion |
Boolean. If enabled, the session will be automatically flushed during the before completion phase of the transaction. Built-in and automatic session context management is preferred.
|
hibernate.transaction.auto_close_session |
Boolean. If enabled, the session will be automatically closed during the after completion phase of the transaction. Built-in and automatic session context management is preferred.
|
12.2.4.5. Miscellaneous Hibernate Properties
| Property Name | Description |
|---|---|
hibernate.current_session_context_class |
Supply a custom strategy for the scoping of the "current"
Session. Values include jta | thread | managed | custom.Class.
|
hibernate.query.factory_class |
Chooses the HQL parser implementation:
org.hibernate.hql.internal.ast.ASTQueryTranslatorFactory or org.hibernate.hql.internal.classic.ClassicQueryTranslatorFactory.
|
hibernate.query.substitutions |
Used to map from tokens in Hibernate queries to SQL tokens (tokens might be function or literal names). For example,
hqlLiteral=SQL_LITERAL, hqlFunction=SQLFUNC.
|
hibernate.hbm2ddl.auto |
Automatically validates or exports schema DDL to the database when the
SessionFactory is created. With create-drop, the database schema will be dropped when the SessionFactory is closed explicitly. Property value options are validate | update | create | create-drop
|
hibernate.hbm2ddl.import_files |
Comma-separated names of the optional files containing SQL DML statements executed during the
SessionFactory creation. This is useful for testing or demonstrating. For example, by adding INSERT statements, the database can be populated with a minimal set of data when it is deployed. An example value is /humans.sql,/dogs.sql.
File order matters, as the statements of a given file are executed before the statements of the following files. These statements are only executed if the schema is created (i.e. if
hibernate.hbm2ddl.auto is set to create or create-drop).
|
hibernate.hbm2ddl.import_files_sql_extractor |
The classname of a custom
ImportSqlCommandExtractor. Defaults to the built-in SingleLineSqlCommandExtractor. This is useful for implementing a dedicated parser that extracts a single SQL statement from each import file. Hibernate also provides MultipleLinesSqlCommandExtractor, which supports instructions/comments and quoted strings spread over multiple lines (mandatory semicolon at the end of each statement).
|
hibernate.bytecode.use_reflection_optimizer |
Boolean. This is a system-level property, which cannot be set in the
hibernate.cfg.xml file. Enables the use of bytecode manipulation instead of runtime reflection. Reflection can sometimes be useful when troubleshooting. Hibernate always requires either CGLIB or javassist even if the optimizer is turned off.
|
hibernate.bytecode.provider |
Both javassist or cglib can be used as byte manipulation engines. The default is
javassist. Property value is either javassist or cglib
|
12.2.4.6. Hibernate SQL Dialects
Important
hibernate.dialect property should be set to the correct org.hibernate.dialect.Dialect subclass for the application database. If a dialect is specified, Hibernate will use sensible defaults for some of the other properties. This means that they do not have to be specified manually.
| RDBMS | Dialect |
|---|---|
| DB2 | org.hibernate.dialect.DB2Dialect |
| DB2 AS/400 | org.hibernate.dialect.DB2400Dialect |
| DB2 OS390 | org.hibernate.dialect.DB2390Dialect |
| Firebird | org.hibernate.dialect.FirebirdDialect |
| FrontBase | org.hibernate.dialect.FrontbaseDialect |
| H2 Database | org.hibernate.dialect.H2Dialect |
| HypersonicSQL | org.hibernate.dialect.HSQLDialect |
| Informix | org.hibernate.dialect.InformixDialect |
| Ingres | org.hibernate.dialect.IngresDialect |
| Interbase | org.hibernate.dialect.InterbaseDialect |
| Mckoi SQL | org.hibernate.dialect.MckoiDialect |
| Microsoft SQL Server 2000 | org.hibernate.dialect.SQLServerDialect |
| Microsoft SQL Server 2005 | org.hibernate.dialect.SQLServer2005Dialect |
| Microsoft SQL Server 2008 | org.hibernate.dialect.SQLServer2008Dialect |
| Microsoft SQL Server 2012 | org.hibernate.dialect.SQLServer2008Dialect |
| MySQL5 | org.hibernate.dialect.MySQL5Dialect |
| MySQL5 with InnoDB | org.hibernate.dialect.MySQL5InnoDBDialect |
| MySQL with MyISAM | org.hibernate.dialect.MySQLMyISAMDialect |
| Oracle (any version) | org.hibernate.dialect.OracleDialect |
| Oracle 9i | org.hibernate.dialect.Oracle9iDialect |
| Oracle 10g | org.hibernate.dialect.Oracle10gDialect |
| Oracle 11g | org.hibernate.dialect.Oracle10gDialect |
| Pointbase | org.hibernate.dialect.PointbaseDialect |
| PostgreSQL | org.hibernate.dialect.PostgreSQLDialect |
| PostgreSQL 9.2 | org.hibernate.dialect.PostgreSQL82Dialect |
| Postgres Plus Advanced Server | org.hibernate.dialect.PostgresPlusDialect |
| Progress | org.hibernate.dialect.ProgressDialect |
| SAP DB | org.hibernate.dialect.SAPDBDialect |
| Sybase | org.hibernate.dialect.SybaseASE15Dialect |
| Sybase 15.7 | org.hibernate.dialect.SybaseASE157Dialect |
| Sybase Anywhere | org.hibernate.dialect.SybaseAnywhereDialect |
12.2.5. Second-Level Caches
12.2.5.1. About Second-Level Caches
- Web Session Clustering
- Stateful Session Bean Clustering
- SSO Clustering
- Hibernate Second Level Cache
12.2.5.2. Configure a Second Level Cache for Hibernate
Procedure 12.4. Create and Edit the hibernate.cfg.xml file
Create the hibernate.cfg.xml file
Create thehibernate.cfg.xmlin the deployment's classpath. For specifics, refer to Section 12.2.3.4, “Create the Hibernate Configuration File in Red Hat JBoss Developer Studio” .- Add these lines of XML to the
hibernate.cfg.xmlfile in your application. The XML needs to be inside the <session-factory> tags:<property name="hibernate.cache.use_second_level_cache">true</property> <property name="hibernate.cache.use_query_cache">true</property>
<property name="hibernate.cache.use_second_level_cache">true</property> <property name="hibernate.cache.use_query_cache">true</property>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Add one of the following to the <session-factory> section of the
hibernate.cfg.xmlfile:If the Infinispan CacheManager is bound to JNDI:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow If the Infinispan CacheManager is standalone:
<property name="hibernate.cache.region.factory_class"> org.hibernate.cache.infinispan.InfinispanRegionFactory </property><property name="hibernate.cache.region.factory_class"> org.hibernate.cache.infinispan.InfinispanRegionFactory </property>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Infinispan is configured as the Second Level Cache for Hibernate.
12.3. Hibernate Annotations
12.3.1. Hibernate Annotations
| Annotation | Description |
|---|---|
| AccessType | Property Access type. |
| Any | Defines a ToOne association pointing to several entity types. Matching the according entity type is done through a metadata discriminator column. This kind of mapping should be only marginal. |
| AnyMetaDef | Defines @Any and @manyToAny metadata. |
| AnyMedaDefs | Defines @Any and @ManyToAny set of metadata. Can be defined at the entity level or the package level. |
| BatchSize | Batch size for SQL loading. |
| Cache | Add caching strategy to a root entity or a collection. |
| Cascade | Apply a cascade strategy on an association. |
| Check | Arbitrary SQL check constraints which can be defined at the class, property or collection level. |
| Columns | Support an array of columns. Useful for component user type mappings. |
| ColumnTransformer | Custom SQL expression used to read the value from and write a value to a column. Use for direct object loading/saving as well as queries. The write expression must contain exactly one '?' placeholder for the value. |
| ColumnTransformers | Plural annotation for @ColumnTransformer. Useful when more than one column is using this behavior. |
| DiscriminatorFormula | Discriminator formula to be placed at the root entity. |
| DiscriminatorOptions | Optional annotation to express Hibernate specific discriminator properties. |
| Entity | Extends Entity with Hibernate features. |
| Fetch | Defines the fetching strategy used for the given association. |
| FetchProfile | Defines the fetching strategy profile. |
| FetchProfiles | Plural annotation for @FetchProfile. |
| Filter | Adds filters to an entity or a target entity of a collection. |
| FilterDef | Filter definition. |
| FilterDefs | Array of filter definitions. |
| FilterJoinTable | Adds filters to a join table collection. |
| FilterJoinTables | Adds multiple @FilterJoinTable to a collection. |
| Filters | Adds multiple @Filters. |
| Formula | To be used as a replacement for @Column in most places. The formula has to be a valid SQL fragment. |
| Generated | This annotated property is generated by the database. |
| GenericGenerator | Generator annotation describing any kind of Hibernate generator in a detyped manner. |
| GenericGenerators | Array of generic generator definitions. |
| Immutable |
Mark an Entity or a Collection as immutable. No annotation means the element is mutable.
An immutable entity may not be updated by the application. Updates to an immutable entity will be ignored, but no exception is thrown.
@Immutable placed on a collection makes the collection immutable, meaning additions and deletions to and from the collection are not allowed. A HibernateException is thrown in this case.
|
| Index | Defines a database index. |
| JoinFormula | To be used as a replacement for @JoinColumn in most places. The formula has to be a valid SQL fragment. |
| LazyCollection | Defines the lazy status of a collection. |
| LazyToOne | Defines the lazy status of a ToOne association (i.e. OneToOne or ManyToOne). |
| Loader | Overwrites Hibernate default FIND method. |
| ManyToAny | Defines a ToMany association pointing to different entity types. Matching the according entity type is done through a metadata discriminator column. This kind of mapping should be only marginal. |
| MapKeyType | Defines the type of key of a persistent map. |
| MetaValue | Represents a discriminator value associated to a given entity type. |
| NamedNativeQueries | Extends NamedNativeQueries to hold Hibernate NamedNativeQuery objects. |
| NamedNativeQuery | Extends NamedNativeQuery with Hibernate features. |
| NamedQueries | Extends NamedQueries to hold Hibernate NamedQuery objects. |
| NamedQuery | Extends NamedQuery with Hibernate features. |
| NaturalId | Specifies that a property is part of the natural id of the entity. |
| NotFound | Action to do when an element is not found on an association. |
| OnDelete | Strategy to use on collections, arrays and on joined subclasses delete. OnDelete of secondary tables is currently not supported. |
| OptimisticLock | Whether or not a change of the annotated property will trigger an entity version increment. If the annotation is not present, the property is involved in the optimistic lock strategy (default). |
| OptimisticLocking | Used to define the style of optimistic locking to be applied to an entity. In a hierarchy, only valid on the root entity. |
| OrderBy | Order a collection using SQL ordering (not HQL ordering). |
| ParamDef | A parameter definition. |
| Parameter | Key/value pattern. |
| Parent | Reference the property as a pointer back to the owner (generally the owning entity). |
| Persister | Specify a custom persister. |
| Polymorphism | Used to define the type of polymorphism Hibernate will apply to entity hierarchies. |
| Proxy | Lazy and proxy configuration of a particular class. |
| RowId | Support for ROWID mapping feature of Hibernate. |
| Sort | Collection sort (Java level sorting). |
| Source | Optional annotation in conjunction with Version and timestamp version properties. The annotation value decides where the timestamp is generated. |
| SQLDelete | Overwrites the Hibernate default DELETE method. |
| SQLDeleteAll | Overwrites the Hibernate default DELETE ALL method. |
| SQLInsert | Overwrites the Hibernate default INSERT INTO method. |
| SQLUpdate | Overwrites the Hibernate default UPDATE method. |
| Subselect | Maps an immutable and read-only entity to a given SQL subselect expression. |
| Synchronize | Ensures that auto-flush happens correctly and that queries against the derived entity do not return stale data. Mostly used with Subselect. |
| Table | Complementary information to a table either primary or secondary. |
| Tables | Plural annotation of Table. |
| Target | Defines an explicit target, avoiding reflection and generics resolving. |
| Tuplizer | Defines a tuplizer for an entity or a component. |
| Tuplizers | Defines a set of tuplizers for an entity or a component. |
| Type | Hibernate Type. |
| TypeDef | Hibernate Type definition. |
| TypeDefs | Hibernate Type definition array. |
| Where | Where clause to add to the element Entity or target entity of a collection. The clause is written in SQL. |
| WhereJoinTable | Where clause to add to the collection join table. The clause is written in SQL. |
Note
12.4. Hibernate Query Language
12.4.1. About Hibernate Query Language
12.4.2. HQL Statements
SELECT, UPDATE, DELETE, and INSERT statements. The HQL INSERT statement has no equivalent in JPQL.
Important
UPDATE or DELETE statement is executed.
| Statement | Description |
|---|---|
SELECT |
The BNF for
SELECT statements in HQL is:
The simplest possible HQL
SELECT statement is of the form:
from com.acme.Cat |
UDPATE | The BNF for UPDATE statement in HQL is the same as it is in JPQL |
DELETE | The BNF for DELETE statements in HQL is the same as it is in JPQL |
12.4.3. About the INSERT Statement
INSERT statements. There is no JPQL equivalent to this. The BNF for an HQL INSERT statement is:
attribute_list is analogous to the column specification in the SQL INSERT statement. For entities involved in mapped inheritance, only attributes directly defined on the named entity can be used in the attribute_list. Superclass properties are not allowed and subclass properties do not make sense. In other words, INSERT statements are inherently non-polymorphic.
Warning
select_statement can be any valid HQL select query, with the caveat that the return types must match the types expected by the insert. Currently, this is checked during query compilation rather than allowing the check to relegate to the database. This may cause problems between Hibernate Types which are equivalent as opposed to equal. For example, this might cause lead to issues with mismatches between an attribute mapped as a org.hibernate.type.DateType and an attribute defined as a org.hibernate.type.TimestampType, even though the database might not make a distinction or might be able to handle the conversion.
attribute_list, in which case its value is taken from the corresponding select expression, or omit it from the attribute_list in which case a generated value is used. This latter option is only available when using id generators that operate "in the database"; attempting to use this option with any "in memory" type generators will cause an exception during parsing.
attribute_list in which case its value is taken from the corresponding select expressions, or omit it from the attribute_list in which case the seed value defined by the corresponding org.hibernate.type.VersionType is used.
Example 12.3. Example INSERT Query Statements
String hqlInsert = "insert into DelinquentAccount (id, name) select c.id, c.name from Customer c where ..."; int createdEntities = s.createQuery( hqlInsert ).executeUpdate();
String hqlInsert = "insert into DelinquentAccount (id, name) select c.id, c.name from Customer c where ...";
int createdEntities = s.createQuery( hqlInsert ).executeUpdate();
12.4.4. About the FROM Clause
FROM clause is responsible defining the scope of object model types available to the rest of the query. It also is responsible for defining all the "identification variables" available to the rest of the query.
12.4.5. About the WITH Clause
WITH clause to qualify the join conditions. This is specific to HQL; JPQL does not define this feature.
Example 12.4. with-clause Join Example
select distinct c
from Customer c
left join c.orders o
with o.value > 5000.00
select distinct c
from Customer c
left join c.orders o
with o.value > 5000.00
with clause are made part of the on clause in the generated SQL as opposed to the other queries in this section where the HQL/JPQL conditions are made part of the where clause in the generated SQL. The distinction in this specific example is probably not that significant. The with clause is sometimes necessary in more complicated queries.
12.4.6. About Bulk Update, Insert and Delete
Warning
( UPDATE | DELETE ) FROM? EntityName (WHERE where_conditions)?.
Note
FROM keyword and the WHERE Clause are optional.
Example 12.5. Example of a Bulk Update Statement
Example 12.6. Example of a Bulk Delete statement
int value returned by the Query.executeUpdate() method indicates the number of entities within the database that were affected by the operation.
Company table for companies that are named with oldName, but also against joined tables. Thus, a Company table in a BiDirectional ManyToMany relationship with an Employee table, would lose rows from the corresponding join table Company_Employee as a result of the successful execution of the previous example.
int deletedEntries value above will contain a count of all the rows affected due to this operation, including the rows in the join tables.
INSERT INTO EntityName properties_list select_statement.
Note
Example 12.7. Example of a Bulk Insert statement
id attribute via the SELECT statement, an ID is generated for you, as long as the underlying database supports auto-generated keys. The return value of this bulk insert operation is the number of entries actually created in the database.
12.4.7. About Collection Member References
Example 12.8. Collection References Example
o actually refers to the object model type Order which is the type of the elements of the Customer#orders association.
IN syntax. Both forms are equivalent. Which form an application chooses to use is simply a matter of taste.
12.4.8. About Qualified Path Expressions
| Expression | Description |
|---|---|
VALUE |
Refers to the collection value. Same as not specifying a qualifier. Useful to explicitly show intent. Valid for any type of collection-valued reference.
|
INDEX |
According to HQL rules, this is valid for both Maps and Lists which specify a
javax.persistence.OrderColumn annotation to refer to the Map key or the List position (aka the OrderColumn value). JPQL however, reserves this for use in the List case and adds KEY for the MAP case. Applications interested in JPA provider portability should be aware of this distinction.
|
KEY |
Valid only for Maps. Refers to the map's key. If the key is itself an entity, can be further navigated.
|
ENTRY |
Only valid only for Maps. Refers to the Map's logical
java.util.Map.Entry tuple (the combination of its key and value). ENTRY is only valid as a terminal path and only valid in the select clause.
|
Example 12.9. Qualified Collection References Example
12.4.9. About Scalar Functions
12.4.10. HQL Standardized Functions
| Function | Description |
|---|---|
BIT_LENGTH |
Returns the length of binary data.
|
CAST |
Performs a SQL cast. The cast target should name the Hibernate mapping type to use. See the chapter on data types for more information.
|
EXTRACT |
Performs a SQL extraction on datetime values. An extraction extracts parts of the datetime (the year, for example). See the abbreviated forms below.
|
SECOND |
Abbreviated extract form for extracting the second.
|
MINUTE |
Abbreviated extract form for extracting the minute.
|
HOUR |
Abbreviated extract form for extracting the hour.
|
DAY |
Abbreviated extract form for extracting the day.
|
MONTH |
Abbreviated extract form for extracting the month.
|
YEAR |
Abbreviated extract form for extracting the year.
|
STR |
Abbreviated form for casting a value as character data.
|
addSqlFunction method of org.hibernate.cfg.Configuration
12.4.11. About the Concatenation Operation
CONCAT) function. This is not defined by JPQL, so portable applications should avoid using it. The concatenation operator is taken from the SQL concatenation operator - ||.
Example 12.10. Concatenation Operation Example
select 'Mr. ' || c.name.first || ' ' || c.name.last from Customer c where c.gender = Gender.MALE
select 'Mr. ' || c.name.first || ' ' || c.name.last
from Customer c
where c.gender = Gender.MALE
12.4.12. About Dynamic Instantiation
Example 12.11. Dynamic Instantiation Example - Constructor
select new Family( mother, mate, offspr )
from DomesticCat as mother
join mother.mate as mate
left join mother.kittens as offspr
select new Family( mother, mate, offspr )
from DomesticCat as mother
join mother.mate as mate
left join mother.kittens as offspr
Example 12.12. Dynamic Instantiation Example - List
select new list(mother, offspr, mate.name)
from DomesticCat as mother
inner join mother.mate as mate
left outer join mother.kittens as offspr
select new list(mother, offspr, mate.name)
from DomesticCat as mother
inner join mother.mate as mate
left outer join mother.kittens as offspr
Example 12.13. Dynamic Instantiation Example - Map
12.4.13. About HQL Predicates
TRUE or FALSE, although boolean comparisons involving NULLs generally resolve to UNKNOWN.
HQL Predicates
- Nullness Predicate
- Check a value for nullness. Can be applied to basic attribute references, entity references and parameters. HQL additionally allows it to be applied to component/embeddable types.
Example 12.14. Nullness Checking Examples
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Like Predicate
- Performs a like comparison on string values. The syntax is:
like_expression ::= string_expression [NOT] LIKE pattern_value [ESCAPE escape_character]
like_expression ::= string_expression [NOT] LIKE pattern_value [ESCAPE escape_character]Copy to Clipboard Copied! Toggle word wrap Toggle overflow The semantics follow that of the SQL like expression. Thepattern_valueis the pattern to attempt to match in thestring_expression. Just like SQL,pattern_valuecan use "_" and "%" as wildcards. The meanings are the same. "_" matches any single character. "%" matches any number of characters.The optionalescape_characteris used to specify an escape character used to escape the special meaning of "_" and "%" in thepattern_value. This is useful when needing to search on patterns including either "_" or "%".Example 12.15. Like Predicate Examples
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Between Predicate
- Analogous to the SQL
BETWEENexpression. Perform a evaluation that a value is within the range of 2 other values. All the operands should have comparable types.Example 12.16. Between Predicate Examples
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12.4.14. About Relational Comparisons
Example 12.17. Relational Comparison Examples
ALL, ANY, SOME. SOME and ANY are synonymous.
ALL qualifier resolves to true if the comparison is true for all of the values in the result of the subquery. It resolves to false if the subquery result is empty.
Example 12.18. ALL Subquery Comparison Qualifier Example
ANY/SOME qualifier resolves to true if the comparison is true for some of (at least one of) the values in the result of the subquery. It resolves to false if the subquery result is empty.
12.4.15. About the IN Predicate
IN predicate performs a check that a particular value is in a list of values. Its syntax is:
single_valued_expression and the individual values in the single_valued_list must be consistent. JPQL limits the valid types here to string, numeric, date, time, timestamp, and enum types. In JPQL, single_valued_expression can only refer to:
- "state fields", which is its term for simple attributes. Specifically this excludes association and component/embedded attributes.
- entity type expressions.
single_valued_expression can refer to a far more broad set of expression types. Single-valued association are allowed. So are component/embedded attributes, although that feature depends on the level of support for tuple or "row value constructor syntax" in the underlying database. Additionally, HQL does not limit the value type in any way, though application developers should be aware that different types may incur limited support based on the underlying database vendor. This is largely the reason for the JPQL limitations.
constructor_expression and collection_valued_input_parameter, the list of values must not be empty; it must contain at least one value.
Example 12.19. In Predicate Examples
12.4.16. About HQL Ordering
ORDER BY clause is used to specify the selected values to be used to order the result. The types of expressions considered valid as part of the order-by clause include:
- state fields
- component/embeddable attributes
- scalar expressions such as arithmetic operations, functions, etc.
- identification variable declared in the select clause for any of the previous expression types
ASC (ascending) or DESC (descending) to indicated the desired ordering direction.
Example 12.20. Order-by Examples
12.5. Hibernate Services
12.5.1. About Hibernate Services
12.5.2. About Service Contracts
org.hibernate.service.Service. Hibernate uses this internally for some basic type safety.
org.hibernate.service.spi.Startable and org.hibernate.service.spi.Stoppable interfaces to receive notifications of being started and stopped. Another optional service contract is org.hibernate.service.spi.Manageable which marks the service as manageable in JMX provided the JMX integration is enabled.
12.5.3. Types of Service Dependencies
- @
org.hibernate.service.spi.InjectService - Any method on the service implementation class accepting a single parameter and annotated with @
InjectServiceis considered requesting injection of another service.By default the type of the method parameter is expected to be the service role to be injected. If the parameter type is different than the service role, theserviceRoleattribute of theInjectServiceshould be used to explicitly name the role.By default injected services are considered required, that is the start up will fail if a named dependent service is missing. If the service to be injected is optional, therequiredattribute of theInjectServiceshould be declared asfalse(default istrue). org.hibernate.service.spi.ServiceRegistryAwareService- The second approach is a pull approach where the service implements the optional service interface
org.hibernate.service.spi.ServiceRegistryAwareServicewhich declares a singleinjectServicesmethod.During startup, Hibernate will inject theorg.hibernate.service.ServiceRegistryitself into services which implement this interface. The service can then use theServiceRegistryreference to locate any additional services it needs.
12.5.4. The ServiceRegistry
12.5.4.1. About the ServiceRegistry
org.hibernate.service.ServiceRegistry interface. The main purpose of a service registry is to hold, manage and provide access to services.
org.hibernate.service.ServiceRegistryBuilder to build a org.hibernate.service.ServiceRegistry instance.
Example 12.21. Use ServiceRegistryBuilder to create a ServiceRegistry
ServiceRegistryBuilder registryBuilder = new ServiceRegistryBuilder( bootstrapServiceRegistry );
ServiceRegistry serviceRegistry = registryBuilder.buildServiceRegistry();
ServiceRegistryBuilder registryBuilder = new ServiceRegistryBuilder( bootstrapServiceRegistry );
ServiceRegistry serviceRegistry = registryBuilder.buildServiceRegistry();
12.5.5. Custom Services
12.5.5.1. About Custom Services
org.hibernate.service.ServiceRegistry is built it is considered immutable; the services themselves might accept re-configuration, but immutability here means adding/replacing services. So another role provided by the org.hibernate.service.ServiceRegistryBuilder is to allow tweaking of the services that will be contained in the org.hibernate.service.ServiceRegistry generated from it.
org.hibernate.service.ServiceRegistryBuilder about custom services.
- Implement a
org.hibernate.service.spi.BasicServiceInitiatorclass to control on-demand construction of the service class and add it to theorg.hibernate.service.ServiceRegistryBuildervia itsaddInitiatormethod. - Just instantiate the service class and add it to the
org.hibernate.service.ServiceRegistryBuildervia itsaddServicemethod.
Example 12.22. Use ServiceRegistryBuilder to Replace an Existing Service with a Custom Service
12.5.6. The Bootstrap Registry
12.5.6.1. About the Boot-strap Registry
ClassLoaderService which is a perfect example. Even resolving configuration files needs access to class loading services (resource look ups). This is the root registry (no parent) in normal use.
org.hibernate.service.BootstrapServiceRegistryBuilder class.
12.5.6.2. Using BootstrapServiceRegistryBuilder
Example 12.23. Using BootstrapServiceRegistryBuilder
12.5.6.3. BootstrapRegistry Services
org.hibernate.service.classloading.spi.ClassLoaderService
- the ability to locate application classes
- the ability to locate integration classes
- the ability to locate resources (properties files, xml files, etc)
- the ability to load
java.util.ServiceLoader
Note
org.hibernate.integrator.spi.IntegratorService
java.util.ServiceLoader capability provided by the org.hibernate.service.classloading.spi.ClassLoaderService in order to discover implementations of the org.hibernate.integrator.spi.Integrator contract.
/META-INF/services/org.hibernate.integrator.spi.Integrator and make it available on the classpath. java.util.ServiceLoader covers the format of this file in detail, but essentially it list classes by FQN that implement the org.hibernate.integrator.spi.Integrator one per line.
12.5.7. The SessionFactory Registry
12.5.7.1. SessionFactory Registry
org.hibernate.SessionFactory, the instances of services in this group explicitly belong to a single org.hibernate.SessionFactory.
org.hibernate.SessionFactory to be initiated. This special registry is org.hibernate.service.spi.SessionFactoryServiceRegistry
12.5.7.2. SessionFactory Services
org.hibernate.event.service.spi.EventListenerRegistry
- Description
- Service for managing event listeners.
- Initiator
org.hibernate.event.service.internal.EventListenerServiceInitiator- Implementations
org.hibernate.event.service.internal.EventListenerRegistryImpl
12.5.8. Integrators
12.5.8.1. Integrators
org.hibernate.integrator.spi.Integrator is intended to provide a simple means for allowing developers to hook into the process of building a functioning SessionFactory. The org.hibernate.integrator.spi.Integrator interface defines 2 methods of interest: integrate allows us to hook into the building process; disintegrate allows us to hook into a SessionFactory shutting down.
Note
org.hibernate.integrator.spi.Integrator, an overloaded form of integrate accepting a org.hibernate.metamodel.source.MetadataImplementor instead of org.hibernate.cfg.Configuration. This form is intended for use with the new metamodel code scheduled for completion in 5.0.
12.5.8.2. Integrator use-cases
org.hibernate.integrator.spi.Integrator right now are registering event listeners and providing services (see org.hibernate.integrator.spi.ServiceContributingIntegrator). With 5.0 we plan on expanding that to allow altering the metamodel describing the mapping between object and relational models.
Example 12.24. Registering event listeners
12.6. Bean Validation
12.6.1. About Bean Validation
bean-validation quickstart example: Section 1.4.1.1, “Access the Quickstarts”.
12.6.2. Hibernate Validator
12.6.3. Validation Constraints
12.6.3.1. About Validation Constraints
12.6.3.2. Create a Constraint Annotation in Red Hat JBoss Developer Studio
This task covers the process of creating a constraint annotation in Red Hat JBoss Developer Studio, for use within a Java application.
Prerequisites
Procedure 12.5. Create a Constraint Annotation
- Open a Java project in Red Hat JBoss Developer Studio.
Create a Data Set
A constraint annotation requires a data set that defines the acceptable values.- Right click on the project root folder in the Project Explorer panel.
- Select → .
- Configure the following elements:
- Package:
- Name:
- Click the button to add any required interfaces.
- Click to create the file.
- Add a set of values to the data set and click .
Example 12.25. Example Data Set
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Create the Annotation File
Create a new Java class. For more information, refer to Section 12.6.3.3, “Create a New Java Class in Red Hat JBoss Developer Studio”.- Configure the constraint annotation and click .
Example 12.26. Example Constraint Annotation File
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- Result
- A custom constraint annotation with a set of possible values has been created, ready to be used in the Java project.
12.6.3.3. Create a New Java Class in Red Hat JBoss Developer Studio
Prerequisites
This topic covers the process of creating a Java class for an existing Java project, using Red Hat JBoss Developer Studio.
Procedure 12.6. Create a New Java Class
- Right click on the project root folder in the Project Explorer panel.
- Select → .
- Configure the following elements:
- Package:
- Name:
Optional: Add an Interface
- Click
- Search for the interface name
- Select the correct interface
- Repeat steps 2 and 3 for each required interface
- Click .
- Click to create the file.
- Result
- A new Java class has been created within the project, ready for configuration.
12.6.3.4. Hibernate Validator Constraints
| Annotation | Apply on | Runtime checking | Hibernate Metadata impact |
|---|---|---|---|
| @Length(min=, max=) | property (String) | Check if the string length matches the range. | Column length will be set to max. |
| @Max(value=) | property (numeric or string representation of a numeric) | Check if the value is less than or equal to max. | Add a check constraint on the column. |
| @Min(value=) | property (numeric or string representation of a numeric) | Check if the value is more than or equal to Min. | Add a check constraint on the column. |
| @NotNull | property | Check if the value is not null. | Column(s) are not null. |
| @NotEmpty | property | Check if the string is not null nor empty. Check if the connection is not null nor empty. | Column(s) are not null (for String). |
| @Past | property (date or calendar) | Check if the date is in the past. | Add a check constraint on the column. |
| @Future | property (date or calendar) | Check if the date is in the future. | None. |
| @Pattern(regex="regexp", flag=) or @Patterns( {@Pattern(...)} ) | property (string) | Check if the property matches the regular expression given a match flag (see java.util.regex.Pattern). | None. |
| @Range(min=, max=) | property (numeric or string representation of a numeric) | Check if the value is between min and max (included). | Add a check constraint on the column. |
| @Size(min=, max=) | property (array, collection, map) | Check if the element size is between min and max (included). | None. |
| @AssertFalse | property | Check that the method evaluates to false (useful for constraints expressed in code rather than annotations). | None. |
| @AssertTrue | property | Check that the method evaluates to true (useful for constraints expressed in code rather than annotations). | None. |
| @Valid | property (object) | Perform validation recursively on the associated object. If the object is a Collection or an array, the elements are validated recursively. If the object is a Map, the value elements are validated recursively. | None. |
| property (String) | Check whether the string is conform to the e-mail address specification. | None. | |
| @CreditCardNumber | property (String) | Check whether the string is a well formatted credit card number (derivative of the Luhn algorithm). | None. |
| @Digits(integerDigits=1) | property (numeric or string representation of a numeric) | Check whether the property is a number having up to integerDigits integer digits and fractionalDigits fractional digits. | Define column precision and scale. |
| @EAN | property (string) | Check whether the string is a properly formatted EAN or UPC-A code. | None. |
12.6.4. Configuration
12.6.4.1. Example Validation Configuration File
Example 12.27. validation.xml
12.7. Envers
12.7.1. About Hibernate Envers
@Audited, which store the history of changes made to the entity. The data can then be retrieved and queried.
- audit all mappings defined by the JPA specification,
- audit all hibernate mappings that extend the JPA specification,
- audit entities mapped by or using the native Hibernate API
- log data for each revision using a revision entity, and
- query historical data.
12.7.2. About Auditing Persistent Classes
@Audited annotation. When the annotation is applied to a class, a table is created, which stores the revision history of the entity.
12.7.3. Auditing Strategies
12.7.3.1. About Auditing Strategies
- Default Audit Strategy
- This strategy persists the audit data together with a start revision. For each row that is inserted, updated or deleted in an audited table, one or more rows are inserted in the audit tables, along with the start revision of its validity.Rows in the audit tables are never updated after insertion. Queries of audit information use subqueries to select the applicable rows in the audit tables, which are slow and difficult to index.
- Validity Audit Strategy
- This strategy stores the start revision, as well as the end revision of the audit information. For each row that is inserted, updated or deleted in an audited table, one or more rows are inserted in the audit tables, along with the start revision of its validity.At the same time, the end revision field of the previous audit rows (if available) is set to this revision. Queries on the audit information can then use between start and end revision, instead of subqueries. This means that persisting audit information is a little slower because of the extra updates, but retrieving audit information is a lot faster.This can also be improved by adding extra indexes.
12.7.3.2. Set the Auditing Strategy
There are two audit strategies supported by JBoss EAP 6: the default and validity audit strategies. This task covers the steps required to define the auditing strategy for an application.
Procedure 12.7. Define a Auditing Strategy
- Configure the
org.hibernate.envers.audit_strategyproperty in thepersistence.xmlfile of the application. If the property is not set in thepersistence.xmlfile, then the default audit strategy is used.Example 12.28. Set the Default Audit Strategy
<property name="org.hibernate.envers.audit_strategy" value="org.hibernate.envers.strategy.DefaultAuditStrategy"/>
<property name="org.hibernate.envers.audit_strategy" value="org.hibernate.envers.strategy.DefaultAuditStrategy"/>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example 12.29. Set the Validity Audit Strategy
<property name="org.hibernate.envers.audit_strategy" value="org.hibernate.envers.strategy.ValidityAuditStrategy"/>
<property name="org.hibernate.envers.audit_strategy" value="org.hibernate.envers.strategy.ValidityAuditStrategy"/>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12.7.4. Getting Started with Entity Auditing
12.7.4.1. Add Auditing Support to a JPA Entity
Procedure 12.8. Add Auditing Support to a JPA Entity
- Configure the available auditing parameters to suit the deployment: Section 12.7.5.1, “Configure Envers Parameters”.
- Open the JPA entity to be audited.
- Import the
org.hibernate.envers.Auditedinterface. - Apply the
@Auditedannotation to each field or property to be audited, or apply it once to the whole class.Example 12.30. Audit Two Fields
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example 12.31. Audit an entire Class
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
The JPA entity has been configured for auditing. A table called Entity_AUD will be created to store the historical changes.
12.7.5. Configuration
12.7.5.1. Configure Envers Parameters
Procedure 12.9. Configure Envers Parameters
- Open the
persistence.xmlfile for the application. - Add, remove or configure Envers properties as required. For a list of available properties, refer to Section 12.7.5.4, “Envers Configuration Properties”.
Example 12.32. Example Envers Parameters
- Result
- Auditing has been configured for all JPA entities in the application.
12.7.5.2. Enable or Disable Auditing at Runtime
This task covers the configuration steps required to enable/disable entity version auditing at runtime.
Procedure 12.10. Enable/Disable Auditing
- Subclass the
AuditEventListenerclass. - Override the following methods that are called on Hibernate events:
- onPostInsert
- onPostUpdate
- onPostDelete
- onPreUpdateCollection
- onPreRemoveCollection
- onPostRecreateCollection
- Specify the subclass as the listener for the events.
- Determine if the change should be audited.
- Pass the call to the superclass if the change should be audited.
12.7.5.3. Configure Conditional Auditing
Hibernate Envers persists audit data in reaction to various Hibernate events, using a series of event listeners. These listeners are registered automatically if the Envers jar is in the class path. This task covers the steps required to implement conditional auditing, by overriding some of the Envers event listeners.
Procedure 12.11. Implement Conditional Auditing
- Set the
hibernate.listeners.envers.autoRegisterHibernate property to false in thepersistence.xmlfile. - Subclass each event listener to be overridden. Place the conditional auditing logic in the subclass, and call the super method if auditing should be performed.
- Create a custom implementation of
org.hibernate.integrator.spi.Integrator, similar toorg.hibernate.envers.event.EnversIntegrator. Use the event listener subclasses created in step two, rather than the default classes. - Add a
META-INF/services/org.hibernate.integrator.spi.Integratorfile to the jar. This file should contain the fully qualified name of the class implementing the interface.
Conditional auditing has been configured, overriding the default Envers event listeners.
12.7.5.4. Envers Configuration Properties
| Property Name | Default Value | Description |
|---|---|---|
|
org.hibernate.envers.audit_table_prefix
| |
A string that is prepended to the name of an audited entity, to create the name of the entity that will hold the audit information.
|
|
org.hibernate.envers.audit_table_suffix
|
_AUD
|
A string that is appended to the name of an audited entity to create the name of the entity that will hold the audit information. For example, if an entity with a table name of
Person is audited, Envers will generate a table called Person_AUD to store the historical data.
|
|
org.hibernate.envers.revision_field_name
|
REV
|
The name of the field in the audit entity that holds the revision number.
|
|
org.hibernate.envers.revision_type_field_name
|
REVTYPE
|
The name of the field in the audit entity that holds the type of revision. The current types of revisions possible are:
add, mod and del.
|
|
org.hibernate.envers.revision_on_collection_change
|
true
|
This property determines if a revision should be generated if a relation field that is not owned changes. This can either be a collection in a one-to-many relation, or the field using the
mappedBy attribute in a one-to-one relation.
|
|
org.hibernate.envers.do_not_audit_optimistic_locking_field
|
true
|
When true, properties used for optimistic locking (annotated with
@Version) will automatically be excluded from auditing.
|
|
org.hibernate.envers.store_data_at_delete
|
false
|
This property defines whether or not entity data should be stored in the revision when the entity is deleted, instead of only the ID, with all other properties marked as null. This is not usually necessary, as the data is present in the last-but-one revision. Sometimes, however, it is easier and more efficient to access it in the last revision. However, this means the data the entity contained before deletion is stored twice.
|
|
org.hibernate.envers.default_schema
|
null (same as normal tables)
|
The default schema name used for audit tables. Can be overridden using the
@AuditTable(schema="...") annotation. If not present, the schema will be the same as the schema of the normal tables.
|
|
org.hibernate.envers.default_catalog
|
null (same as normal tables)
|
The default catalog name that should be used for audit tables. Can be overridden using the
@AuditTable(catalog="...") annotation. If not present, the catalog will be the same as the catalog of the normal tables.
|
|
org.hibernate.envers.audit_strategy
|
org.hibernate.envers.strategy.DefaultAuditStrategy
|
This property defines the audit strategy that should be used when persisting audit data. By default, only the revision where an entity was modified is stored. Alternatively,
org.hibernate.envers.strategy.ValidityAuditStrategy stores both the start revision and the end revision. Together, these define when an audit row was valid.
|
|
org.hibernate.envers.audit_strategy_validity_end_rev_field_name
|
REVEND
|
The column name that will hold the end revision number in audit entities. This property is only valid if the validity audit strategy is used.
|
|
org.hibernate.envers.audit_strategy_validity_store_revend_timestamp
|
false
|
This property defines whether the timestamp of the end revision, where the data was last valid, should be stored in addition to the end revision itself. This is useful to be able to purge old audit records out of a relational database by using table partitioning. Partitioning requires a column that exists within the table. This property is only evaluated if the
ValidityAuditStrategy is used.
|
|
org.hibernate.envers.audit_strategy_validity_revend_timestamp_field_name
|
REVEND_TSTMP
|
Column name of the timestamp of the end revision at which point the data was still valid. Only used if the
ValidityAuditStrategy is used, and org.hibernate.envers.audit_strategy_validity_store_revend_timestamp evaluates to true.
|
12.7.6. Queries
12.7.6.1. Retrieve Auditing Information
Hibernate Envers provides the functionality to retrieve audit information through queries. This topic provides examples of those queries.
Note
live data, as they involve correlated subselects.
Example 12.33. Querying for Entities of a Class at a Given Revision
AuditQuery query = getAuditReader()
.createQuery()
.forEntitiesAtRevision(MyEntity.class, revisionNumber);
AuditQuery query = getAuditReader()
.createQuery()
.forEntitiesAtRevision(MyEntity.class, revisionNumber);AuditEntity factory class. The query below only selects entities where the name property is equal to John:
query.add(AuditEntity.property("name").eq("John"));
query.add(AuditEntity.property("name").eq("John"));query.add(AuditEntity.property("address").eq(relatedEntityInstance));
// or
query.add(AuditEntity.relatedId("address").eq(relatedEntityId));
query.add(AuditEntity.property("address").eq(relatedEntityInstance));
// or
query.add(AuditEntity.relatedId("address").eq(relatedEntityId));Example 12.34. Query Revisions where Entities of a Given Class Changed
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true);
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true);AuditEntity.revisionNumber()- Specify constraints, projections and order on the revision number in which the audited entity was modified.
AuditEntity.revisionProperty(propertyName)- Specify constraints, projections and order on a property of the revision entity, corresponding to the revision in which the audited entity was modified.
AuditEntity.revisionType()- Provides accesses to the type of the revision (ADD, MOD, DEL).
MyEntity class, with the entityId ID has changed, after revision number 42:
actualDate for a given entity was larger than a given value, but as small as possible:
minimize() and maximize() methods return a criteria, to which constraints can be added, which must be met by the entities with the maximized/minimized properties.
selectEntitiesOnly- This parameter is only valid when an explicit projection is not set.If true, the result of the query will be a list of entities that changed at revisions satisfying the specified constraints.If false, the result will be a list of three element arrays. The first element will be the changed entity instance. The second will be an entity containing revision data. If no custom entity is used, this will be an instance of
DefaultRevisionEntity. The third element array will be the type of the revision (ADD, MOD, DEL). selectDeletedEntities- This parameter specified if revisions in which the entity was deleted should be included in the results. If true, the entities will have the revision type
DEL, and all fields, except id, will have the valuenull.
Example 12.35. Query Revisions of an Entity that Modified a Given Property
MyEntity with a given id, where the actualDate property has been changed.
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true)
.add(AuditEntity.id().eq(id));
.add(AuditEntity.property("actualDate").hasChanged())
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true)
.add(AuditEntity.id().eq(id));
.add(AuditEntity.property("actualDate").hasChanged())hasChanged condition can be combined with additional criteria. The query below will return a horizontal slice for MyEntity at the time the revisionNumber was generated. It will be limited to the revisions that modified prop1, but not prop2.
AuditQuery query = getAuditReader().createQuery()
.forEntitiesAtRevision(MyEntity.class, revisionNumber)
.add(AuditEntity.property("prop1").hasChanged())
.add(AuditEntity.property("prop2").hasNotChanged());
AuditQuery query = getAuditReader().createQuery()
.forEntitiesAtRevision(MyEntity.class, revisionNumber)
.add(AuditEntity.property("prop1").hasChanged())
.add(AuditEntity.property("prop2").hasNotChanged());MyEntities changed in revisionNumber with prop1 modified and prop2 untouched."
forEntitiesModifiedAtRevision query:
AuditQuery query = getAuditReader().createQuery()
.forEntitiesModifiedAtRevision(MyEntity.class, revisionNumber)
.add(AuditEntity.property("prop1").hasChanged())
.add(AuditEntity.property("prop2").hasNotChanged());
AuditQuery query = getAuditReader().createQuery()
.forEntitiesModifiedAtRevision(MyEntity.class, revisionNumber)
.add(AuditEntity.property("prop1").hasChanged())
.add(AuditEntity.property("prop2").hasNotChanged());Example 12.36. Query Entities Modified in a Given Revision
Set<Pair<String, Class>> modifiedEntityTypes = getAuditReader()
.getCrossTypeRevisionChangesReader().findEntityTypes(revisionNumber);
Set<Pair<String, Class>> modifiedEntityTypes = getAuditReader()
.getCrossTypeRevisionChangesReader().findEntityTypes(revisionNumber); org.hibernate.envers.CrossTypeRevisionChangesReader:
List<Object> findEntities(Number)- Returns snapshots of all audited entities changed (added, updated and removed) in a given revision.Executes
n+1SQL queries, wherenis a number of different entity classes modified within the specified revision. List<Object> findEntities(Number, RevisionType)- Returns snapshots of all audited entities changed (added, updated or removed) in a given revision filtered by modification type. Executes
n+1SQL queries, wherenis a number of different entity classes modified within specified revision. Map<RevisionType, List<Object>> findEntitiesGroupByRevisionType(Number)- Returns a map containing lists of entity snapshots grouped by modification operation (e.g. addition, update and removal). Executes
3n+1SQL queries, wherenis a number of different entity classes modified within specified revision.
12.8. Performance Tuning
12.8.1. Alternative Batch Loading Algorithms
- Per-Class LevelWhen Hibernate loads data on a per-class level, it requires the batch size of the association to pre-load when queried. For example, consider that at runtime you have 30 instances of a
carobject loaded in session. Eachcarobject belongs to anownerobject. If you were to iterate through all thecarobjects and request their owners, withlazyloading, Hibernate will issue 30 select statements - one for each owner. This is a performance bottleneck.You can instead, tell Hiberante to pre-load the data for the next batch of owners before they have been sought via a query. When anownerobject has been queried, Hibernate will query many more of these objects in the same SELECT statement.The number ofownerobjects to query in advance depends upon thebatch-sizeparameter specified at configuration time:<class name="owner" batch-size="10"></class>
<class name="owner" batch-size="10"></class>Copy to Clipboard Copied! Toggle word wrap Toggle overflow This tells Hibernate to query at least 10 moreownerobjects in expectation of them being needed in the near future. When a user queries theownerofcar A, theownerofcar Bmay already have been loaded as part of batch loading. When the user actually needs theownerofcar B, instead of going to the database (and issuing a SELECT statement), the value can be retrieved from the current session.In addition to thebatch-sizeparameter, Hibernate 4.2.0 has introduced a new configuration item to improve in batch loading performance. The configuration item is calledBatch Fetch Styleconfiguration and specified by thehibernate.batch_fetch_styleparameter.Three different batch fetch styles are supported: LEGACY, PADDED and DYNAMIC. To specify which style to use, useorg.hibernate.cfg.AvailableSettings#BATCH_FETCH_STYLE.- LEGACY: In the legacy style of loading, a set of pre-built batch sizes based on
ArrayHelper.getBatchSizes(int)are utilized. Batches are loaded using the next-smaller pre-built batch size from the number of existing batchable identifiers.Continuing with the above example, with abatch-sizesetting of 30, the pre-built batch sizes would be [30, 15, 10, 9, 8, 7, .., 1]. An attempt to batch load 29 identifiers would result in batches of 15, 10, and 4. There will be 3 corresponding SQL queries, each loading 15, 10 and 4 owners from the database. - PADDED - Padded is similar to LEGACY style of batch loading. It still utilizes pre-built batch sizes, but uses the next-bigger batch size and pads the extra identifier placeholders.As with the example above, if 30 owner objects are to be initialized, there will only be one query executed against the database.However, if 29 owner objects are to be initialized, Hibernate will still execute only 1 SQL select statement of batch size 30, with the extra space padded with a repeated identifier.
- Dynamic - While still conforming to batch-size restrictions, this style of batch loading dynamically builds its SQL SELECT statement using the actual number of objects to be loaded.For example, for 30 owner objects, and a maximum batch size of 30, a call to retrieve 30 owner objects will result in one SQL SELECT statement. A call to retrieve 35 will result in two SQL statements, of batch sizes 30 and 5 respectively. Hibernate will dynamically alter the second SQL statement to keep at 5, the required number, while still remaining under the restriction of 30 as the batch-size. This is different to the PADDED version, as the second SQL will not get PADDED, and unlike the LEGACY style, there is no fixed size for the second SQL statement - the second SQL is created dynamically.For a query of less than 30 identifiers, this style will dynamically only load the number of identifiers requested.
- Per-Collection LevelHibernate can also batch load collections honoring the batch fetch size and styles as listed in the per-class section above.To reverse the example used in the previous section, consider that you need to load all the
carobjects owned by eachownerobject. If 10ownerobjects are loaded in the current session iterating through all owners will generate 10 SELECT statements, one for every call togetCars()method. If you enable batch fetching for the cars collection in the mapping of Owner, Hibernate can pre-fetch these collections, as shown below.<class name="Owner"><set name="cars" batch-size="5"></set></class>
<class name="Owner"><set name="cars" batch-size="5"></set></class>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Thus, with abatch-sizeof 5 and using legacy batch style, Hibernate will load 5, 5 collections in two SELECT statements.
12.8.2. Second Level Caching of Object References for Non-mutable Data
hibernate.cache.use_reference_entries to true. By default, hibernate.cache.use_reference_entries is set to false.
hibernate.cache.use_reference_entries is set to true, an immutable data object that does not have any associations is not copied into the second-level cache, and only a reference to it is stored.
Warning
hibernate.cache.use_reference_entries is set to true, immutable data objects with associations are still deep copied into the second-level cache.
Chapter 13. JAX-RS Web Services
13.1. About JAX-RS
helloworld-rs, jax-rs-client, and kitchensink quickstart: Section 1.4.1.1, “Access the Quickstarts”.
13.2. About RESTEasy
13.3. About RESTful Web Services
13.4. RESTEasy Defined Annotations
| Annotation | Usage |
|---|---|
ClientResponseType | This is an annotation that you can add to a RESTEasy client interface that has a return type of Response. |
ContentEncoding | Meta annotation that specifies a Content-Encoding to be applied via the annotated annotation. |
DecorateTypes | Must be placed on a DecoratorProcessor class to specify the supported types. |
Decorator | Meta-annotation to be placed on another annotation that triggers decoration. |
Form | This can be used as a value object for incoming/outgoing request/responses. |
StringParameterUnmarshallerBinder | Meta-annotation to be placed on another annotation that triggers a StringParameterUnmarshaller to be applied to a string based annotation injector. |
Cache | Set response Cache-Control header automatically. |
NoCache | Set Cache-Control response header of "nocache". |
ServerCached | Specifies that the response to this jax-rs method should be cached on the server. |
ClientInterceptor | Identifies an interceptor as a client-side interceptor. |
DecoderPrecedence | This interceptor is an Content-Encoding decoder. |
EncoderPrecedence | This interceptor is an Content-Encoding encoder. |
HeaderDecoratorPrecedence | HeaderDecoratorPrecedence interceptors should always come first as they decorate a response (on the server), or an outgoing request (on the client) with special, user-defined, headers. |
RedirectPrecedence | Should be placed on a PreProcessInterceptor. |
SecurityPrecedence | Should be placed on a PreProcessInterceptor. |
ServerInterceptor | Identifies an interceptor as a server-side interceptor. |
NoJackson | Placed on class, parameter, field or method when you don't want the Jackson provider to be triggered. |
ImageWriterParams | An annotation that a resource class can use to pass parameters to the IIOImageProvider. |
DoNotUseJAXBProvider | Put this on a class or parameter when you do not want the JAXB MessageBodyReader/Writer used but instead have a more specific provider you want to use to marshall the type. |
Formatted | Format XML output with indentations and newlines. This is a JAXB Decorator. |
IgnoreMediaTypes | Placed on a type, method, parameter, or field to tell JAXRS not to use JAXB provider for a certain media type |
Stylesheet | Specifies an XML stylesheet header. |
Wrapped | Put this on a method or parameter when you want to marshal or unmarshal a collection or array of JAXB objects. |
WrappedMap | Put this on a method or parameter when you want to marshal or unmarshal a map of JAXB objects. |
XmlHeader | Sets an XML header for the returned document. |
BadgerFish | A JSONConfig. |
Mapped | A JSONConfig. |
XmlNsMap | A JSONToXml. |
MultipartForm | This can be used as a value object for incoming/outgoing request/responses of the multipart/form-data mime type. |
PartType | Must be used in conjunction with Multipart providers when writing out a List or Map as a multipart/* type. |
XopWithMultipartRelated | This annotation can be used to process/produce incoming/outgoing XOP messages (packaged as multipart/related) to/from JAXB annotated objects. |
After | Used to add an expiration attribute when signing or as a stale check for verification. |
Signed | Convenience annotation that triggers the signing of a request or response using the DOSETA specification. |
Verify | Verification of input signature specified in a signature header. |
13.5. RESTEasy Configuration
13.5.1. RESTEasy Configuration Parameters
| Option Name | Default Value | Description |
|---|---|---|
| resteasy.servlet.mapping.prefix | No default | If the url-pattern for the Resteasy servlet-mapping is not /*. |
| resteasy.scan | false | Automatically scan WEB-INF/lib jars and WEB-INF/classes directory for both @Provider and JAX-RS resource classes (@Path, @GET, @POST etc..) and register them. |
| resteasy.scan.providers | false | Scan for @Provider classes and register them. |
| resteasy.scan.resources | false | Scan for JAX-RS resource classes. |
| resteasy.providers | no default | A comma delimited list of fully qualified @Provider class names you want to register. |
| resteasy.use.builtin.providers | true | Whether or not to register default, built-in @Provider classes. |
| resteasy.resources | No default | A comma delimited list of fully qualified JAX-RS resource class names you want to register. |
| resteasy.jndi.resources | No default | A comma delimited list of JNDI names which reference objects you want to register as JAX-RS resources. |
| javax.ws.rs.Application | No default | Fully qualified name of Application class to bootstrap in a spec portable way. |
| resteasy.media.type.mappings | No default | Replaces the need for an Accept header by mapping file name extensions (like .xml or .txt) to a media type. Used when the client is unable to use a Accept header to choose a representation (i.e. a browser). |
| resteasy.language.mappings | No default | Replaces the need for an Accept-Language header by mapping file name extensions (like .en or .fr) to a language. Used when the client is unable to use a Accept-Language header to choose a language (i.e. a browser). |
| resteasy.document.expand.entity.references | false | Whether to expand external entities or replace them with an empty string. In JBoss EAP 6.3, this parameter defaults to false, so it replaces them with an empty string. |
Important
resteasy.scan.* configurations in the web.xml file are ignored, and all JAX-RS annotated components will be automatically scanned.
13.6. JAX-RS Web Service Security
13.6.1. Enable Role-Based Security for a RESTEasy JAX-RS Web Service
RESTEasy supports the @RolesAllowed, @PermitAll, and @DenyAll annotations on JAX-RS methods. However, it does not recognize these annotations by default. Follow these steps to configure the web.xml file and enable role-based security.
Warning
Procedure 13.1. Enable Role-Based Security for a RESTEasy JAX-RS Web Service
- Open the
web.xmlfile for the application in a text editor. - Add the following <context-param> to the file, within the
web-apptags:<context-param> <param-name>resteasy.role.based.security</param-name> <param-value>true</param-value> </context-param><context-param> <param-name>resteasy.role.based.security</param-name> <param-value>true</param-value> </context-param>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Declare all roles used within the RESTEasy JAX-RS WAR file, using the <security-role> tags:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Authorize access to all URLs handled by the JAX-RS runtime for all roles:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Role-based security has been enabled within the application, with a set of defined roles.
Example 13.1. Example Role-Based Security Configuration
13.6.2. Secure a JAX-RS Web Service using Annotations
This topic covers the steps to secure a JAX-RS web service using the supported security annotations
Procedure 13.2. Secure a JAX-RS Web Service using Supported Security Annotations
- Enable role-based security. For more information, refer to: Section 13.6.1, “Enable Role-Based Security for a RESTEasy JAX-RS Web Service”
- Add security annotations to the JAX-RS web service. RESTEasy supports the following annotations:
- @RolesAllowed
- Defines which roles can access the method. All roles should be defined in the
web.xmlfile. - @PermitAll
- Allows all roles defined in the
web.xmlfile to access the method. - @DenyAll
- Denies all access to the method.
13.7. RESTEasy Logging
13.7.1. About JAX-RS Web Service Logging
- If log4j is in the application's classpath, log4j will be used.
- If slf4j is in the application's classpath, slf4j will be used.
- java.util.logging is the default if neither log4j or slf4j is in the classpath.
- If the servlet context param resteasy.logger.type is set to java.util.logging, log4j, or slf4j will override this default behavior
13.7.2. Logging Categories Defined in RESTEasy
| Category | Function |
|---|---|
org.jboss.resteasy.core | Logs all activity by the core RESTEasy implementation. |
org.jboss.resteasy.plugins.providers | Logs all activity by RESTEasy entity providers. |
org.jboss.resteasy.plugins.server | Logs all activity by the RESTEasy server implementation. |
org.jboss.resteasy.specimpl | Logs all activity by JAX-RS implementing classes. |
org.jboss.resteasy.mock | Logs all activity by the RESTEasy mock framework. |
13.8. Exception Handling
13.8.1. Create an Exception Mapper
Exception mappers are custom, application provided components that catch thrown exceptions and write specific HTTP responses.
Example 13.2. Exception Mapper
ExceptionMapper interface.
web.xml file under the resteasy.providers context-param, or register it programmatically through the ResteasyProviderFactory class.
13.8.2. RESTEasy Internally Thrown Exceptions
| Exception | HTTP Code | Description |
|---|---|---|
| BadRequestException | 400 | Bad Request. The request was not formatted correctly, or there was a problem processing the request input. |
| UnauthorizedException | 401 | Unauthorized. Security exception thrown if you are using RESTEasy's annotation-based role-based security. |
| InternalServerErrorException | 500 | Internal Server Error. |
| MethodNotAllowedException | 405 | There is no JAX-RS method for the resource that can handle the invoked HTTP operation. |
| NotAcceptableException | 406 | There is no JAX-RS method that can produce the media types listed in the Accept header. |
| NotFoundException | 404 | There is no JAX-RS method that serves the request path/resource. |
| ReaderException | 400 | All exceptions thrown from MessageBodyReaders are wrapped within this exception. If there is no ExceptionMapper for the wrapped exception, or if the exception is not a WebApplicationException, then RESTEasy will return a 400 code by default. |
| WriterException | 500 | All exceptions thrown from MessageBodyWriters are wrapped within this exception. If there is no ExceptionMapper for the wrapped exception, or if the exception is not a WebApplicationException, then RESTEasy will return a 400 code by default. |
| JAXBUnmarshalException | 400 | The JAXB providers (XML and Jettison) throw this exception on reads. They may be wrapping JAXBExceptions. This class extends ReaderException. |
| JAXBMarshalException | 500 | The JAXB providers (XML and Jettison) throw this exception on writes. They may be wrapping JAXBExceptions. This class extends WriterException. |
| ApplicationException | N/A | Wraps all exceptions thrown from application code. It functions in the same way as InvocationTargetException. If there is an ExceptionMapper for wrapped exception, then that is used to handle the request. |
| Failure | N/A | Internal RESTEasy error. Not logged. |
| LoggableFailure | N/A | Internal RESTEasy error. Logged. |
| DefaultOptionsMethodException | N/A | If the user invokes HTTP OPTIONS and no JAX-RS method for it, RESTEasy provides a default behavior by throwing this exception. |
13.9. RESTEasy Interceptors
13.9.1. Intercept JAX-RS Invocations
RESTEasy can intercept JAX-RS invocations and route them through listener-like objects called interceptors. This topic covers descriptions of the four types of interceptors.
Example 13.3. MessageBodyReader/Writer Interceptors
@Provider, as well as either @ServerInterceptor or @ClientInterceptor so that RESTEasy knows whether or not to add them to the interceptor list.
MessageBodyReader.readFrom() or MessageBodyWriter.writeTo(). They can be used to wrap the Output or Input streams.
MessageBodyReaderContext.proceed() or MessageBodyWriterContext.proceed() is called in order to go to the next interceptor or, if there are no more interceptors to invoke, the readFrom() or writeTo() method of the MessageBodyReader or MessageBodyWriter. This wrapping allows objects to be modified before they get to the Reader or Writer, and then cleaned up after proceed() returns.
Example 13.4. PreProcessInterceptor
public interface PreProcessInterceptor
{
ServerResponse preProcess(HttpRequest request, ResourceMethod method) throws Failure, WebApplicationException;
}
public interface PreProcessInterceptor
{
ServerResponse preProcess(HttpRequest request, ResourceMethod method) throws Failure, WebApplicationException;
}
preProcess() method returns a ServerResponse then the underlying JAX-RS method will not get invoked, and the runtime will process the response and return to the client. If the preProcess() method does not return a ServerResponse, the underlying JAX-RS method will be invoked.
Example 13.5. PostProcessInterceptors
public interface PostProcessInterceptor
{
void postProcess(ServerResponse response);
}
public interface PostProcessInterceptor
{
void postProcess(ServerResponse response);
}
Example 13.6. ClientExecutionInterceptors
@ClientInterceptor and @Provider. These interceptors run after the MessageBodyWriter, and after the ClientRequest has been built on the client side.
13.9.2. Bind an Interceptor to a JAX-RS Method
All registered interceptors are invoked for every request by default. The AcceptedByMethod interface can be implemented to fine tune this behavior.
Example 13.7. Binding Interceptors Example
accept() method for interceptors that implement the AcceptedByMethod interface. If the method returns true, the interceptor will be added to the JAX-RS method's call chain; otherwise it will be ignored for that method.
accept() determines if the @GET annotation is present on the JAX-RS method. If it is, the interceptor will be applied to the method's call chain.
13.9.3. Register an Interceptor
This topic covers how to register a RESTEasy JAX-RS interceptor in an application.
Procedure 13.3. Register an Interceptor
- To register an interceptor, list it in the
web.xmlfile under theresteasy.providerscontext-param, or return it as a class or as an object in theApplication.getClasses()orApplication.getSingletons()method.
13.9.4. Interceptor Precedence Families
13.9.4.1. About Interceptor Precedence Families
Interceptors can be sensitive to the order they are invoked. RESTEasy groups interceptors in families to make ordering them simpler. This reference topic covers the built-in interceptor precedence families and the interceptors associated with each.
- SECURITY
- SECURITY interceptors are usually PreProcessInterceptors. They are invoked first because as little as possible should be done before the invocation is authorized.
- HEADER_DECORATOR
- HEADER_DECORATOR interceptors add headers to a response or an outgoing request. They follow the security interceptors as the added headers may affect the behavior of other interceptor families.
- ENCODER
- ENCODER interceptors change the OutputStream. For example, the GZIP interceptor creates a GZIPOutputStream to wrap the real OutputStream for compression.
- REDIRECT
- REDIRECT interceptors are usually used in PreProcessInterceptors, as they may reroute the request and totally bypass the JAX-RS method.
- DECODER
- DECODER interceptors wrap the InputStream. For example, the GZIP interceptor decoder wraps the InputStream in a GzipInputStream instance.
13.9.4.2. Define a Custom Interceptor Precedence Family
Custom precedence families can be created and registered in the web.xml file. This topic covers examples of the context params available for defining interceptor precedence families.
Example 13.8. resteasy.append.interceptor.precedence
resteasy.append.interceptor.precedence context param appends the new precedence family to the default precedence family list.
<context-param>
<param-name>resteasy.append.interceptor.precedence</param-name>
<param-value>CUSTOM_PRECEDENCE_FAMILY</param-value>
</context-param>
<context-param>
<param-name>resteasy.append.interceptor.precedence</param-name>
<param-value>CUSTOM_PRECEDENCE_FAMILY</param-value>
</context-param>
Example 13.9. resteasy.interceptor.before.precedence
resteasy.interceptor.before.precedence context param defines the default precedence family that the custom family is executed before. The parameter value takes the form DEFAULT_PRECEDENCE_FAMILY/CUSTOM_PRECEDENCE_FAMILY, delimited by a ':'.
<context-param>
<param-name>resteasy.interceptor.before.precedence</param-name>
<param-value>DEFAULT_PRECEDENCE_FAMILY : CUSTOM_PRECEDENCE_FAMILY</param-value>
</context-param>
<context-param>
<param-name>resteasy.interceptor.before.precedence</param-name>
<param-value>DEFAULT_PRECEDENCE_FAMILY : CUSTOM_PRECEDENCE_FAMILY</param-value>
</context-param>
Example 13.10. resteasy.interceptor.after.precedence
resteasy.interceptor.after.precedence context param defines the default precedence family that the custom family is executed after. The parameter value takes the form DEFAULT_PRECEDENCE_FAMILY/CUSTOM_PRECEDENCE_FAMILY, delimited by a :.
<context-param>
<param-name>resteasy.interceptor.after.precedence</param-name>
<param-value>DEFAULT_PRECEDENCE_FAMILY : CUSTOM_PRECEDENCE_FAMILY</param-value>
</context-param>
<context-param>
<param-name>resteasy.interceptor.after.precedence</param-name>
<param-value>DEFAULT_PRECEDENCE_FAMILY : CUSTOM_PRECEDENCE_FAMILY</param-value>
</context-param>
13.10. String Based Annotations
13.10.1. Convert String Based @*Param Annotations to Objects
@*Param annotations, including @PathParam and @FormParam, are represented as strings in a raw HTTP request. These types of injected parameters can be converted to objects if these objects have a valueOf(String) static method or a constructor that takes one String parameter.
@Provider interfaces to handle this conversion for classes that don't have either a valueOf(String) static method, or a string constructor.
Example 13.11. StringConverter
Example 13.12. StringParameterUnmarshaller
StringParameterUnmarshaller interface is sensitive to the annotations placed on the parameter or field you are injecting into. It is created per injector. The setAnnotations() method is called by resteasy to initialize the unmarshaller.
org.jboss.resteasy.annotations.StringsParameterUnmarshallerBinder.
java.util.Date based @PathParam.
13.11. Configure File Extensions
13.11.1. Map File Extensions to Media Types in the web.xml File
Some clients, like browsers, cannot use the Accept and Accept-Language headers to negotiate the representation's media type or language. RESTEasy can map file name suffixes to media types and languages to deal with this issue. Follow these steps to map media types to file extensions, in the web.xml file.
Procedure 13.4. Map Media Types to File Extensions
- Open the
web.xmlfile for the application in a text editor. - Add the context-param
resteasy.media.type.mappingsto the file, inside theweb-apptags:<context-param> <param-name>resteasy.media.type.mappings</param-name> </context-param><context-param> <param-name>resteasy.media.type.mappings</param-name> </context-param>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Configure the parameter values. The mappings form a comma delimited list. Each mapping is delimited by a
::Example 13.13. Example Mapping
<context-param> <param-name>resteasy.media.type.mappings</param-name> <param-value>html : text/html, json : application/json, xml : application/xml</param-value> </context-param><context-param> <param-name>resteasy.media.type.mappings</param-name> <param-value>html : text/html, json : application/json, xml : application/xml</param-value> </context-param>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
13.11.2. Map File Extensions to Languages in the web.xml File
Some clients, like browsers, cannot use the Accept and Accept-Language headers to negotiate the representation's media type or language. RESTEasy can map file name suffixes to media types and languages to deal with this issue. Follow these steps to map languages to file extensions, in the web.xml file.
Procedure 13.5. Map File Extensions to Languages in the web.xml File
- Open the
web.xmlfile for the application in a text editor. - Add the context-param
resteasy.language.mappingsto the file, inside theweb-apptags:<context-param> <param-name>resteasy.language.mappings</param-name> </context-param><context-param> <param-name>resteasy.language.mappings</param-name> </context-param>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Configure the parameter values. The mappings form a comma delimited list. Each mapping is delimited by a
::Example 13.14. Example Mapping
<context-param> <param-name>resteasy.language.mappings</param-name> <param-value> en : en-US, es : es, fr : fr</param-name> </context-param><context-param> <param-name>resteasy.language.mappings</param-name> <param-value> en : en-US, es : es, fr : fr</param-name> </context-param>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
13.11.3. RESTEasy Supported Media Types
| Media Type | Java Type |
|---|---|
| application/*+xml, text/*+xml, application/*+json, application/*+fastinfoset, application/atom+* | JaxB annotated classes |
| application/*+xml, text/*+xml | org.w3c.dom.Document |
| */* | java.lang.String |
| */* | java.io.InputStream |
| text/plain | primitives, java.lang.String, or any type that has a String constructor, or static valueOf(String) method for input, toString() for output |
| */* | javax.activation.DataSource |
| */* | byte[] |
| */* | java.io.File |
| application/x-www-form-urlencoded | javax.ws.rs.core.MultivaluedMap |
13.12. RESTEasy JavaScript API
13.12.1. About the RESTEasy JavaScript API
Example 13.15. Simple JAX-RS JavaScript API Example
var X = {
Y : function(params){...},
Z : function(params){...}
};
var X = {
Y : function(params){...},
Z : function(params){...}
};
13.12.2. Enable the RESTEasy JavaScript API Servlet
The RESTEasy JavaScript API is not enabled by default. Follow these steps to enable it using the web.xml file.
Procedure 13.6. Edit web.xml to enable RESTEasy JavaScript API
- Open the
web.xmlfile of the application in a text editor. - Add the following configuration to the file, inside the
web-apptags:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
13.12.3. RESTEasy Javascript API Parameters
| Property | Default Value | Description |
|---|---|---|
| $entity | The entity to send as a PUT, POST request. | |
| $contentType | The MIME type of the body entity sent as the Content-Type header. Determined by the @Consumes annotation. | |
| $accepts | */* | The accepted MIME types sent as the Accept header. Determined by the @Provides annotation. |
| $callback | Set to a function (httpCode, xmlHttpRequest, value) for an asynchronous call. If not present, the call will be synchronous and return the value. | |
| $apiURL | Set to the base URI of the JAX-RS endpoint, not including the last slash. | |
| $username | If username and password are set, they will be used for credentials for the request. | |
| $password | If username and password are set, they will be used for credentials for the request. |
13.12.4. Build AJAX Queries with the JavaScript API
The RESTEasy JavaScript API can be used to manually construct requests. This topic covers examples of this behavior.
Example 13.16. The REST Object
- apiURL
- Set by default to the JAX-RS root URL. Used by every JavaScript client API functions when constructing the requests.
- log
- Set to a function(string) in order to receive RESTEasy client API logs. This is useful if you want to debug your client API and place the logs where you can see them.
Example 13.17. The REST.Request Class
13.12.5. REST.Request Class Members
| Member | Description |
|---|---|
| execute(callback) | Executes the request with all the information set in the current object. The value is passed to the optional argument callback, not returned. |
| setAccepts(acceptHeader) | Sets the Accept request header. Defaults to */*. |
| setCredentials(username, password) | Sets the request credentials. |
| setEntity(entity) | Sets the request entity. |
| setContentType(contentTypeHeader) | Sets the Content-Type request header. |
| setURI(uri) | Sets the request URI. This should be an absolute URI. |
| setMethod(method) | Sets the request method. Defaults to GET. |
| setAsync(async) | Controls whether the request should be asynchronous. Defaults to true. |
| addCookie(name, value) | Sets the given cookie in the current document when executing the request. This will be persistent in the browser. |
| addQueryParameter(name, value) | Adds a query parameter to the URI query part. |
| addMatrixParameter(name, value) | Adds a matrix parameter (path parameter) to the last path segment of the request URI. |
| addHeader(name, value) | Adds a request header. |
13.13. RESTEasy Asynchronous Job Service
13.13.1. About the RESTEasy Asynchronous Job Service
13.13.2. Enable the Asynchronous Job Service
Procedure 13.7. Modify the web.xml file
- Enable the asynchronous job service in the
web.xmlfile:<context-param> <param-name>resteasy.async.job.service.enabled</param-name> <param-value>true</param-value> </context-param><context-param> <param-name>resteasy.async.job.service.enabled</param-name> <param-value>true</param-value> </context-param>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
The asynchronous job service has been enabled. For configuration options, refer to: Section 13.13.4, “Asynchronous Job Service Configuration Parameters”.
13.13.3. Configure Asynchronous Jobs for RESTEasy
This topic covers examples of the query parameters for asynchronous jobs with RESTEasy.
Warning
web.xml file instead.
Important
Example 13.18. The Asynch Parameter
asynch query parameter is used to run invocations in the background. A 202 Accepted response is returned, as well as a Location header with a URL pointing to where the response of the background method is located.
POST http://example.com/myservice?asynch=true
POST http://example.com/myservice?asynch=trueHTTP/1.1 202 Accepted Location: http://example.com/asynch/jobs/3332334
HTTP/1.1 202 Accepted
Location: http://example.com/asynch/jobs/3332334
/asynch/jobs/{job-id}?wait={millisconds}|nowait=true
/asynch/jobs/{job-id}?wait={millisconds}|nowait=true- GET returns the JAX-RS resource method invoked as a response if the job was completed. If the job has not been completed, this GET will return a 202 Accepted response code. Invoking GET does not remove the job, so it can be called multiple times.
- POST does a read of the job response and removes the job if it has been completed.
- DELETE is called to manually clean up the job queue.
Note
When the Job queue is full, it will evict the earliest job from memory automatically, without needing to call DELETE.
Example 13.19. Wait / Nowait
wait and nowait query parameters. If the wait parameter is not specified, the operation will default to nowait=true, and will not wait at all if the job is not complete. The wait parameter is defined in milliseconds.
POST http://example.com/asynch/jobs/122?wait=3000
POST http://example.com/asynch/jobs/122?wait=3000Example 13.20. The Oneway Parameter
oneway query parameter.
POST http://example.com/myservice?oneway=true
POST http://example.com/myservice?oneway=true13.13.4. Asynchronous Job Service Configuration Parameters
The table below details the configurable context-params for the Asynchronous Job Service. These parameters can be configured in the web.xml file.
| Parameter | Description |
|---|---|
| resteasy.async.job.service.max.job.results | Number of job results that can be held in the memory at any one time. Default value is 100. |
| resteasy.async.job.service.max.wait | Maximum wait time on a job when a client is querying for it. Default value is 300000. |
| resteasy.async.job.service.thread.pool.size | Thread pool size of the background threads that run the job. Default value is 100. |
| resteasy.async.job.service.base.path | Sets the base path for the job URIs. Default value is /asynch/jobs |
Example 13.21. Example Asynchronous Jobs Configuration
13.14. RESTEasy JAXB
13.14.1. Create a JAXB Decorator
RESTEasy's JAXB providers have a pluggable way to decorate Marshaller and Unmarshaller instances. An annotation is created that can trigger either a Marshaller or Unmarshaller instance. This topic covers the steps to create a JAXB decorator with RESTEasy.
Procedure 13.8. Create a JAXB Decorator with RESTEasy
Create the Processor Class
- Create a class that implements DecoratorProcessor<Target, Annotation>. The target is either the JAXB Marshaller or Unmarshaller class. The annotation is created in step two.
- Annotate the class with @DecorateTypes, and declare the MIME Types the decorator should decorate.
- Set properties or values within the
decoratefunction.
Example 13.22. Example Processor Class
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Create the Annotation
- Create a custom interface that is annotated with the @Decorator annotation.
- Declare the processor and target for the @Decorator annotation. The processor is created in step one. The target is either the JAXB Marshaller or Unmarshaller class.
Example 13.23. Example Annotation
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Add the annotation created in step two to a function so that either the input or output is decorated when it is marshalled.
The JAXB decorator has been created and applied within the JAX-RS web service.
13.15. RESTEasy Atom Support
13.15.1. About the Atom API and Provider
org.jboss.resteasy.plugins.providers.atom package. RESTEasy uses JAXB to marshal and unmarshal the API. The provider is JAXB based, and is not limited to sending atom objects using XML. All JAXB providers that RESTEasy has can be reused by the Atom API and provider, including JSON. Refer to the javadocs for more information on the API.
13.16. RESTEasy/Spring Integration
13.16.1. RESTEasy/Spring integration
Prerequisites
- Your application must have an existing JAX-WS service and client configuration.
Procedure 13.9. Enable the RESTEasy/Spring integration functionality
- RESTEasy integrates with Spring 3.0.x.Maven users must use the resteasy-spring artifact. Alternatively, the jar is available as a module in JBoss EAP 6.RESTEasy comes with its own Spring ContextLoaderListener that registers a RESTEasy specific BeanPostProcessor that processes JAX-RS annotations when a bean is created by a BeanFactory.This means that RESTEasy will automatically scan for @Provider and JAX-RS resource annotations on your bean class and register them as JAX-RS resources.
Example 13.24. Edit web.xml
Add the following to your web.xml file to enable the RESTEasy/Spring integration functionality:Copy to Clipboard Copied! Toggle word wrap Toggle overflow The SpringContextLoaderListener must be declared after ResteasyBootstrap as it uses ServletContext attributes initialized by it.
Chapter 14. JAX-WS Web Services
14.1. About JAX-WS Web Services
WS-Notification, WS-Addressing, WS-Policy, WS-Security, and WS-Trust. They communicate using a specialized XML language called Simple Object Access Protocol (SOAP), which defines a message architecture and message formats.
WebService and WebMethod interfaces.
webservices subsystem.
The JBoss EAP Quickstarts include several fully-functioning JAX-WS Web Service applications. These examples include:
- wsat-simple
- wsba-coordinator-completion-simple
- wsba-participant-completion-simple
14.2. Configure the webservices Subsystem
webservices subsystem, which controls the behavior of Web Services deployed into JBoss EAP 6. The command to modify each element in the Management CLI script (EAP_HOME/bin/jboss-cli.sh or EAP_HOME/bin/jboss-cli.bat) is provided. Remove the /profile=default portion of the command for a standalone server, or replace default with the name of profile to configure.
You can rewrite the <soap:address> element in endpoint-published WSDL contracts. This ability can be used to control the server address that is advertised to clients for each endpoint. Each of the following optional elements can be modified to suit your needs. Modification of any of these elements requires a server restart.
| Element | Description | CLI Command |
|---|---|---|
| modify-wsdl-address |
Whether to always modify the WSDL address. If true, the content of
<soap:address> will always be overwritten. If false, the content of <soap:address> will only be overwritten if it is not a valid URL. The values used will be the wsdl-host, wsdl-port, and wsdl-secure-port described below.
| /profile=default/subsystem=webservices/:write-attribute(name=modify-wsdl-address,value=true)
|
| wsdl-host |
The hostname / IP address to be used for rewriting
<soap:address>. If wsdl-host is set to the string jbossws.undefined.host, the requester's host is used when rewriting the <soap:address>.
| /profile=default/subsystem=webservices/:write-attribute(name=wsdl-host,value=10.1.1.1) |
| wsdl-port | An integer which explicitly defines the HTTP port that will be used for rewriting the SOAP address. If undefined, the HTTP port is identified by querying the list of installed HTTP connectors. | /profile=default/subsystem=webservices/:write-attribute(name=wsdl-port,value=8080)
|
| wsdl-secure-port | An integer which explicitly defines the HTTPS port that will be used for rewriting the SOAP address. If undefined, the HTTPS port is identified by querying the list of installed HTTPS connectors. | /profile=default/subsystem=webservices/:write-attribute(name=wsdl-secure-port,value=8443)
|
You can define endpoint configurations which can be referenced by endpoint implementations. One way this might be used is to add a given handler to any WS endpoint that is marked with a given endpoint configuration with the annotation @org.jboss.ws.api.annotation.EndpointConfig.
Standard-Endpoint-Config. An example of a custom configuration, Recording-Endpoint-Config, is also included. This provides an example of a recording handler. The Standard-Endpoint-Config is automatically used for any endpoint which is not associated with any other configuration.
Standard-Endpoint-Config using the Management CLI, use the following command:
/profile=default/subsystem=webservices/endpoint-config=Standard-Endpoint-Config/:read-resource(recursive=true,proxies=false,include-runtime=false,include-defaults=true)
/profile=default/subsystem=webservices/endpoint-config=Standard-Endpoint-Config/:read-resource(recursive=true,proxies=false,include-runtime=false,include-defaults=true)
An endpoint configuration, referred to as an endpoint-config in the Management API, includes a pre-handler-chain, post-handler-chain and some properties, which are applied to a particular endpoint. The following commands read and add and endpoint config.
Example 14.1. Read an Endpoint Config
/profile=default/subsystem=webservices/endpoint-config=Recording-Endpoint-Config:read-resource
/profile=default/subsystem=webservices/endpoint-config=Recording-Endpoint-Config:read-resourceExample 14.2. Add an Endpoint Config
/profile=default/subsystem=webservices/endpoint-config=My-Endpoint-Config:add
/profile=default/subsystem=webservices/endpoint-config=My-Endpoint-Config:add
Each endpoint config may be associated with PRE and POST handler chains. Each handler chain may include JAXWS-compliant handlers. For outbound messages, PRE handler chain handlers are executed before any handler attached to the endpoints using standard JAXWS means, such as the @HandlerChain annotation. POST handler chain handlers are executed after usual endpoint handlers. For inbound messages, the opposite applies. JAX-WS is a standard API for XML-based web services, and is documented at http://jcp.org/en/jsr/detail?id=224.
protocol-bindings attribute, which sets the protocols which trigger the chain to start.
Example 14.3. Read a Handler Chain
/profile=default/subsystem=webservices/endpoint-config=Recording-Endpoint-Config/pre-handler-chain=recording-handlers:read-resource
/profile=default/subsystem=webservices/endpoint-config=Recording-Endpoint-Config/pre-handler-chain=recording-handlers:read-resourceExample 14.4. Add a Handler Chain
/profile=default/subsystem=webservices/endpoint-config=My-Endpoint-Config/post-handler-chain=my-handlers:add(protocol-bindings="##SOAP11_HTTP")
/profile=default/subsystem=webservices/endpoint-config=My-Endpoint-Config/post-handler-chain=my-handlers:add(protocol-bindings="##SOAP11_HTTP")
A JAXWS handler is a child element handler within a handler chain. The handler takes a class attribute, which is the fully-qualified classname of the handler class. When the endpoint is deployed, an instance of that class is created for each referencing deployment. Either the deployment classloader or the classloader for module org.jboss.as.webservices.server.integration must be able to load the handler class.
Example 14.5. Read a Handler
/profile=default/subsystem=webservices/endpoint-config=Recording-Endpoint-Config/pre-handler-chain=recording-handlers/handler=RecordingHandler:read-resource
/profile=default/subsystem=webservices/endpoint-config=Recording-Endpoint-Config/pre-handler-chain=recording-handlers/handler=RecordingHandler:read-resourceExample 14.6. Add a Handler
/profile=default/subsystem=webservices/endpoint-config=My-Endpoint-Config/post-handler-chain=my-handlers/handler=foo-handler:add(class="org.jboss.ws.common.invocation.RecordingServerHandler")
/profile=default/subsystem=webservices/endpoint-config=My-Endpoint-Config/post-handler-chain=my-handlers/handler=foo-handler:add(class="org.jboss.ws.common.invocation.RecordingServerHandler")
You can view runtime information about Web Services, such as the web context and the WSDL URL, by querying the endpoints themselves. You can use the * character to query all endpoints at once. The following examples show the command for a both a server in a managed domain and for a standalone server.
Example 14.7. View Runtime Information about All Web Service Endpoints on A Server in a Managed Domain
server-one, which is hosted on physical host master and running in a managed domain.
/host=master/server=server-one/deployment="*"/subsystem=webservices/endpoint="*":read-resource
/host=master/server=server-one/deployment="*"/subsystem=webservices/endpoint="*":read-resourceExample 14.8. View Runtime Information about All Web Service Endpoints on a Standalone Server
/deployment="*"/subsystem=webservices/endpoint="*":read-resource
/deployment="*"/subsystem=webservices/endpoint="*":read-resourceExample 14.9. Example Endpoint Information
14.3. JAX-WS Web Service Endpoints
14.3.1. About JAX-WS Web Service Endpoints
- You can write WSDL descriptors manually.
- You can use JAX-WS annotations that create the WSDL descriptors automatically for you. This is the most common method for creating WSDL descriptors.
A Web Service must fulfill the requirements of the JAX-WS API and the Web Services metadata specification at http://www.jcp.org/en/jsr/summary?id=181. A valid implementation meets the following requirements:
- It contains a
javax.jws.WebServiceannotation. - All method parameters and return types are compatible with the JAXB 2.0 specification, JSR-222. Refer to http://www.jcp.org/en/jsr/summary?id=222 for more information.
Example 14.10. Example POJO Endpoint
Example 14.11. Example Web Services Endpoint
Example 14.12. Exposing an Endpoint in an EJB
JAX-WS services typically implement a Java service endpoint interface (SEI), which may be mapped from a WSDL port type, either directly or using annotations. This SEI provides a high-level abstraction which hides the details between Java objects and their XML representations. However, in some cases, services need the ability to operate at the XML message level. The endpoint Provider interface provides this functionality to Web Services which implement it.
After you deploy your Web Service, you can consume the WSDL to create the component stubs which will be the basis for your application. Your application can then access the endpoint to do its work.
The JBoss EAP Quickstarts include several fully-functioning JAX-WS Web Service applications. These examples include:
- wsat-simple
- wsba-coordinator-completion-simple
- wsba-participant-completion-simple
14.3.2. Write and Deploy a JAX-WS Web Service Endpoint
This topic discusses the development of a simple JAX-WS service endpoint, which is the server-side component, which responds to requests from JAX-WS clients and publishes the WSDL definition for itself. For more in-depth information about JAX-WS service endpoints, refer to Section 14.5.2, “JAX-WS Common API Reference” and the API documentation bundle in Javadoc format, distributed with JBoss EAP 6.
A Web Service must fulfill the requirements of the JAXWS API and the Web Services meta data specification at http://www.jcp.org/en/jsr/summary?id=181. A valid implementation meets the following requirements:
- It contains a
javax.jws.WebServiceannotation. - All method parameters and return types are compatible with the JAXB 2.0 specification, JSR-222. Refer to http://www.jcp.org/en/jsr/summary?id=222 for more information.
Example 14.13. Example Service Implementation
Example 14.14. Example XML Payload
DiscountRequest class which is used by the ProfileMgmtBean bean in the previous example. The annotations are included for verbosity. Typically, the JAXB defaults are reasonable and do not need to be specified.
The implementation class is wrapped in a JAR deployment. Any metadata required for deployment is taken from the annotations on the implementation class and the service endpoint interface. Deploy the JAR using the Management CLI or the Management Interface, and the HTTP endpoint is created automatically.
Example 14.15. Example JAR Structure for a Web Service Deployment
14.4. JAX-WS Web service Clients
14.4.1. Consume and Access a JAX-WS Web Service
- Create the client artifacts.
- Construct a service stub.
- Access the endpoint.
Before you can create client artifacts, you need to create your WSDL contract. The following WSDL contract is used for the examples presented in the rest of this topic.
Example 14.16. Example WSDL Contract
Note
wsconsume.sh or wsconsume.bat tool is used to consume the abstract contract (WSDL) and produce annotated Java classes and optional sources that define it. The command is located in the EAP_HOME/bin/ directory of the JBoss EAP 6 installation.
Example 14.17. Syntax of the wsconsume.sh Command
.java files listed in the output, from the ProfileMgmtService.wsdl file. The sources use the directory structure of the package, which is specified with the -p switch.
.java source files and compiled .class files are generated into the output/ directory within the directory where you run the command.
| File | Description |
|---|---|
ProfileMgmt.java
|
Service endpoint interface.
|
Customer.java
|
Custom data type.
|
Discount*.java
|
Custom data types.
|
ObjectFactory.java
|
JAXB XML registry.
|
package-info.java
|
JAXB package annotations.
|
ProfileMgmtService.java
|
Service factory.
|
wsconsume.sh command generates all custom data types (JAXB annotated classes), the service endpoint interface and a service factory class. These artifacts are used the build web service client implementations.
Web service clients use service stubs to abstract the details of a remote web service invocation. To a client application, a WS invocation looks like an invocation of any other business component. In this case the service endpoint interface acts as the business interface, and a service factory class is not used to construct it as a service stub.
Example 14.18. Constructing a Service Stub and Accessing the Endpoint
wsconsume.sh command to build the service stub. Finally, the stub can be used just as any other business interface would be.
14.4.2. Develop a JAX-WS Client Application
Service
- Overview
- A
Serviceis an abstraction which represents a WSDL service. A WSDL service is a collection of related ports, each of which includes a port type bound to a particular protocol and a particular endpoint address.Usually, the Service is generated when the rest of the component stubs are generated from an existing WSDL contract. The WSDL contract is available via the WSDL URL of the deployed endpoint, or can be created from the endpoint source using thewsprovide.shcommand in theEAP_HOME/bin/directory.This type of usage is referred to as the static use case. In this case, you create instances of theServiceclass which is created as one of the component stubs.You can also create the service manually, using theService.createmethod. This is referred to as the dynamic use case. - Usage
- Static Use Case
- The static use case for a JAX-WS client assumes that you already have a WSDL contract. This may be generated by an external tool or generated by using the correct JAX-WS annotations when you create your JAX-WS endpoint.To generate your component stubs, you use the
wsconsume.shorwsconsume.batscript which is included inEAP_HOME/bin/. The script takes the WSDL URL or file as a parameter, and generates multiple of files, structured in a directory tree. The source and class files representing yourServiceare namedCLASSNAME_Service.javaandCLASSNAME_Service.class, respectively.The generated implementation class has two public constructors, one with no arguments and one with two arguments. The two arguments represent the WSDL location (ajava.net.URL) and the service name (ajavax.xml.namespace.QName) respectively.The no-argument constructor is the one used most often. In this case the WSDL location and service name are those found in the WSDL. These are set implicitly from the@WebServiceClientannotation that decorates the generated class.Example 14.19. Example Generated Service Class
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Dynamic Use Case
- In the dynamic case, no stubs are generated automatically. Instead, a web service client uses the
Service.createmethod to createServiceinstances. The following code fragment illustrates this process.Example 14.20. Creating Services Manually
URL wsdlLocation = new URL("http://example.org/my.wsdl"); QName serviceName = new QName("http://example.org/sample", "MyService"); Service service = Service.create(wsdlLocation, serviceName);URL wsdlLocation = new URL("http://example.org/my.wsdl"); QName serviceName = new QName("http://example.org/sample", "MyService"); Service service = Service.create(wsdlLocation, serviceName);Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- Handler Resolver
- JAX-WS provides a flexible plug-in framework for message processing modules, known as handlers. These handlers extend the capabilities of a JAX-WS runtime system. A
Serviceinstance provides access to aHandlerResolvervia a pair ofgetHandlerResolverandsetHandlerResolvermethods that can configure a set of handlers on a per-service, per-port or per-protocol binding basis.When aServiceinstance creates a proxy or aDispatchinstance, the handler resolver currently registered with the service creates the required handler chain. Subsequent changes to the handler resolver configured for aServiceinstance do not affect the handlers on previously created proxies orDispatchinstances. - Executor
Serviceinstances can be configured with ajava.util.concurrent.Executor. TheExecutorinvokes any asynchronous callbacks requested by the application. ThesetExecutorandgetExecutormethods ofServicecan modify and retrieve theExecutorconfigured for a service.
A dynamic proxy is an instance of a client proxy using one of the getPort methods provided in the Service. The portName specifies the name of the WSDL port the service uses. The serviceEndpointInterface specifies the service endpoint interface supported by the created dynamic proxy instance.
Example 14.21. getPort Methods
public <T> T getPort(QName portName, Class<T> serviceEndpointInterface) public <T> T getPort(Class<T> serviceEndpointInterface)
public <T> T getPort(QName portName, Class<T> serviceEndpointInterface)
public <T> T getPort(Class<T> serviceEndpointInterface)
wsconsume.sh command, which parses the WSDL and creates Java classes from it.
Example 14.22. Returning the Port of a Service
@WebServiceRef
The @WebServiceRef annotation declares a reference to a Web Service. It follows the resource pattern shown by the javax.annotation.Resource annotation defined in http://www.jcp.org/en/jsr/summary?id=250.
Use Cases for @WebServiceRef
- You can use it to define a reference whose type is a generated
Serviceclass. In this case, the type and value element each refer to the generatedServiceclass type. Moreover, if the reference type can be inferred by the field or method declaration the annotation is applied to, the type and value elements may (but are not required to) have the default value ofObject.class. If the type cannot be inferred, then at least the type element must be present with a non-default value. - You can use it to define a reference whose type is an SEI. In this case, the type element may (but is not required to) be present with its default value if the type of the reference can be inferred from the annotated field or method declaration. However, the value element must always be present and refer to a generated service class type, which is a subtype of
javax.xml.ws.Service. ThewsdlLocationelement, if present, overrides the WSDL location information specified in the@WebServiceannotation of the referenced generated service class.Example 14.23.
@WebServiceRefExamplesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
XML Web Services use XML messages for communication between the endpoint, which is deployed in the Java EE container, and any clients. The XML messages use an XML language called Simple Object Access Protocol (SOAP). The JAX-WS API provides the mechanisms for the endpoint and clients to each be able to send and receive SOAP messages. Marshalling is the process of converting a Java Object into a SOAP XML message. Unmarshalling is the process of converting the SOAP XML message back into a Java Object.
Dispatch class provides this functionality. Dispatch operates in one of two usage modes, which are identified by one of the following constants.
javax.xml.ws.Service.Mode.MESSAGE- This mode directs client applications to work directly with protocol-specific message structures. When used with a SOAP protocol binding, a client application works directly with a SOAP message.javax.xml.ws.Service.Mode.PAYLOAD- This mode causes the client to work with the payload itself. For instance, if it is used with a SOAP protocol binding, a client application would work with the contents of the SOAP body rather than the entire SOAP message.
Dispatch is a low-level API which requires clients to structure messages or payloads as XML, with strict adherence to the standards of the individual protocol and a detailed knowledge of message or payload structure. Dispatch is a generic class which supports input and output of messages or message payloads of any type.
Example 14.24. Dispatch Usage
The BindingProvider interface represents a component that provides a protocol binding which clients can use. It is implemented by proxies and is extended by the Dispatch interface.
BindingProvider instances may provide asynchronous operation capabilities.Asynchronous operation invocations are decoupled from the BindingProvider instance at invocation time. The response context is not updated when the operation completes. Instead, a separate response context is made available using the Response interface.
Example 14.25. Example Asynchronous Invocation
@Oneway Invocations
The @Oneway annotation indicates that the given web method takes an input message but returns no output message. Usually, a @Oneway method returns the thread of control to the calling application before the business method is executed.
Example 14.26. Example @Oneway Invocation
Two different properties control the timeout behavior of the HTTP connection and the timeout of a client which is waiting to receive a message. The first is javax.xml.ws.client.connectionTimeout and the second is javax.xml.ws.client.receiveTimeout. Each is expressed in milliseconds, and the correct syntax is shown below.
Example 14.27. JAX-WS Timeout Configuration
14.5. JAX-WS Development Reference
14.5.1. Enable Web Services Addressing (WS-Addressing)
Prerequisites
- Your application must have an existing JAX-WS service and client configuration.
Procedure 14.1. Annotate and Update client code
Annotate the service endpoint
Add the@Addressingannotation to the application's endpoint code.Example 14.28.
@AddressingannotationThis example demonstrates a regular JAX-WS endpoint with the@Addressingannotation added.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Update client code
Update the client code in the application so that it configures WS-Addressing.Example 14.29. Client configuration for WS-Addressing
This example demonstrates a regular JAX-WS client updated to configure WS-Addressing.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
The client and endpoint are now communicating using WS-Addressing.
14.5.2. JAX-WS Common API Reference
The handler framework is implemented by a JAX-WS protocol binding in the runtime of the client and the endpoint, which is the server component. Proxies and Dispatch instances, known collectively as binding providers, each use protocol bindings to bind their abstract functionality to specific protocols.
Types of Message Handlers
- Logical Handler
- Logical handlers only operate on message context properties and message payloads. Logical handlers are protocol-independent and cannot affect protocol-specific parts of a message. Logical handlers implement interface
javax.xml.ws.handler.LogicalHandler. - Protocol Handler
- Protocol handlers operate on message context properties and protocol-specific messages. Protocol handlers are specific to a particular protocol and may access and change protocol-specific aspects of a message. Protocol handlers implement any interface derived from
javax.xml.ws.handler.Handler except javax.xml.ws.handler.LogicalHandler. - Service Endpoint Handler
- On a service endpoint, handlers are defined using the
@HandlerChainannotation. The location of the handler chain file can be either an absolutejava.net.URLinexternalFormor a relative path from the source file or class file.Example 14.30. Example Service Endpoint Handler
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Service Client Handler
- On a JAX-WS client, handlers are defined either by using the
@HandlerChainannotation, as in service endpoints, or dynamically, using the JAX-WS API.Example 14.31. Defining a Service Client Handler Using the API
Copy to Clipboard Copied! Toggle word wrap Toggle overflow The call to thesetHandlerChainmethod is required.
The MessageContext interface is the super interface for all JAX-WS message contexts. It extends Map<String,Object> with additional methods and constants to manage a set of properties that enable handlers in a handler chain to share processing related state. For example, a handler may use the put method to insert a property into the message context. One or more other handlers in the handler chain may subsequently obtain the message via the get method.
APPLICATION or HANDLER. All properties are available to all handlers for an instance of a message exchange pattern (MEP) of a particular endpoint. For instance, if a logical handler puts a property into the message context, that property is also available to any protocol handlers in the chain during the execution of an MEP instance.
Note
APPLICATION level are also made available to client applications and service endpoint implementations. The defaultscope for a property is HANDLER.
- Logical Message Context
- When logical handlers are invoked, they receive a message context of type
LogicalMessageContext.LogicalMessageContextextendsMessageContextwith methods which obtain and modify the message payload. It does not provide access to the protocol-specific aspects of a message. A protocol binding defines which components of a message are available via a logical message context. A logical handler deployed in a SOAP binding can access the contents of the SOAP body but not the SOAP headers. On the other hand, the XML/HTTP binding defines that a logical handler can access the entire XML payload of a message. - SOAP Message Context
- When SOAP handlers are invoked, they receive a
SOAPMessageContext.SOAPMessageContextextendsMessageContextwith methods which obtain and modify the SOAP message payload.
An application may throw a SOAPFaultException or an application-specific user exception. In the case of the latter, the required fault wrapper beans are generated at run-time if they are not already part of the deployment.
Example 14.32. Fault Handling Examples
public void throwApplicationException() throws UserException
{
throw new UserException("validation", 123, "Some validation error");
}
public void throwApplicationException() throws UserException
{
throw new UserException("validation", 123, "Some validation error");
}
The annotations available via the JAX-WS API are defined in JSR-224, which can be found at http://www.jcp.org/en/jsr/detail?id=224. These annotations are in package javax.xml.ws.
javax.jws.
Chapter 15. WebSockets
15.1. About WebSockets
Upgrade header. All communications are then full-duplex over the same TCP/IP connection, with minimal data overhead. Because each message does not include unnecessary HTTP header content, Websocket communications require smaller bandwidth. The result is a low latency communications path, suited to applications which require real-time responsiveness.
15.2. Create a WebSocket Application
- A Java client or a WebSocket enabled HTML client. You can verify HTML client browser support at this location: http://caniuse.com/websockets
- A WebSocket server endpoint class.
- A
jboss-web.xmlfile configured to enable WebSockets. - Project dependencies configured to declare a dependency on the WebSocket API.
- Enable the
NIO2connector in thewebsubsystem of the JBoss EAP server configuration file. If you installed the Native Components for your operating system with the JBoss EAP installation and have also installed Apache Portability Runtime (APR), you can instead choose to enable theAPRconnector.
Note
Procedure 15.1. Create the WebSocket Application
Create the JavaScript HTML client.
The following is an example of a WebSocket client. It contains these JavaScript functions:lconnect(): This function creates the WebSocket connection passing the WebSocket URI. The resource location matches the resource defined in the server endpoint class. This function also intercepts and handles the WebSocketonopen,onmessage,onerror, andonclose.sendMessage(): This function gets the name entered in the form, creates a message, and sends it using a WebSocket.send() command.disconnect(): This function issues the WebSocket.close() command.displayMessage(): This function sets the display message on the page to the value returned by the WebSocket endpoint method.displayStatus(): This function displays the WebSocket connection status.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Create the WebSocket server endpoint.
You can create a WebSocket server endpoint using either of the following methods.The code example below uses the annotated endpoint approach and handles the following events.Programmatic Endpoint: The endpoint extends the Endpoint class.Annotated Endpoint: The endpoint class uses annotations to interact with the WebSocket events. It is simpler to code than the programmatic endpoint
- The
@ServerEndpointannotation identifies this class as a WebSocket server endpoint and specifies the path. - The
@OnOpenannotation is triggered when the WebSocket connection is opened. - The
@OnMessageannotation is triggered when a message is sent to the WebSocket connection. - The
@OnCloseannotation is triggered when the WebSocket connection is closed.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Configure the jboss-web.xml file.
You must create the<enable-websockets>element in the applicationWEB-INF/jboss-web.xmland set it totrue.<?xml version="1.0" encoding="UTF-8"?> <!--Enable WebSockets --> <jboss-web> <enable-websockets>true</enable-websockets> </jboss-web>
<?xml version="1.0" encoding="UTF-8"?> <!--Enable WebSockets --> <jboss-web> <enable-websockets>true</enable-websockets> </jboss-web>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Declare the WebSocket API dependency in your project POM file.
If you use Maven, you add the following dependency to the projectpom.xmlfile.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Configure the JBoss EAP server.
Configure thehttp<connector>in thewebsubsystem of the server configuration file to use theNIO2protocol.- Start the JBoss EAP server.
- Launch the Management CLI using the command for your operating system.For Linux:For Windows:
EAP_HOME/bin/jboss-cli.sh --connect
EAP_HOME/bin/jboss-cli.sh --connectCopy to Clipboard Copied! Toggle word wrap Toggle overflow EAP_HOME\bin\jboss-cli.bat --connect
EAP_HOME\bin\jboss-cli.bat --connectCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Enable the
NIO2or theAPRconnector in thewebsubsystem of the JBoss EAP server configuration file.- Type the following command to use the non blocking Java
NIO2connector protocol:/subsystem=web/connector=http/:write-attribute(name=protocol,value=org.apache.coyote.http11.Http11NioProtocol)
/subsystem=web/connector=http/:write-attribute(name=protocol,value=org.apache.coyote.http11.Http11NioProtocol)Copy to Clipboard Copied! Toggle word wrap Toggle overflow - If you have installed the Apache Portability Runtime (APR), you can type the following commands to use the Apache Portable Runtime
APRnative connector protocol:/subsystem=web:write-attribute(name=native,value=true) /subsystem=web/connector=http/:write-attribute(name=protocol,value=org.apache.coyote.http11.Http11AprProtocol)
/subsystem=web:write-attribute(name=native,value=true) /subsystem=web/connector=http/:write-attribute(name=protocol,value=org.apache.coyote.http11.Http11AprProtocol)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
For either command, you should see the following result:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Notify the server to reload the configuration.
:reload
:reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow You should see the following result:{ "outcome" => "success", "result" => undefined }{ "outcome" => "success", "result" => undefined }Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Review the changes to the JBoss EAP server configuration file. The
websubsystem should now contain the following XML for thehttp<connector>.For theNIO2connector configuration:Copy to Clipboard Copied! Toggle word wrap Toggle overflow For theAPRconnector configuration:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Chapter 16. Identity Within Applications
16.1. Foundational Concepts
16.1.1. About Encryption
16.1.2. About Security Domains
16.1.3. About SSL Encryption
Warning
16.1.4. About Declarative Security
16.2. Role-Based Security in Applications
16.2.1. About Application Security
16.2.2. About Authentication
16.2.3. About Authorization
16.2.4. About Security Auditing
16.2.5. About Security Mapping
16.2.6. Java Authentication and Authorization Service (JAAS)
16.2.7. About Java Authentication and Authorization Service (JAAS)
Server groups (in a managed domain) and servers (in a standalone server) include the configuration for security domains. A security domain includes information about a combination of authentication, authorization, mapping, and auditing modules, with configuration details. An application specifies which security domain it requires, by name, in its jboss-web.xml.
Application-specific configuration takes place in one or more of the following four files.
| File | Description |
|---|---|
| ejb-jar.xml |
The deployment descriptor for an Enterprise JavaBean (EJB) application, located in the
META-INF directory of the archive. Use the ejb-jar.xml to specify roles and map them to principals, at the application level. You can also limit specific methods and classes to certain roles. It is also used for other EJB-specific configuration not related to security.
|
| web.xml |
The deployment descriptor for a Java Enterprise Edition (EE) web application. Use the
web.xml to declare the resource and transport constraints for the application, such as limiting the type of HTTP requests that are allowed. You can also configure simple web-based authentication in this file. It is also used for other application-specific configuration not related to security. The security domain the application uses for authentication and authorization is defined in jboss-web.xml.
|
| jboss-ejb3.xml |
Contains JBoss-specific extensions to the
ejb-jar.xml descriptor.
|
| jboss-web.xml |
Contains JBoss-specific extensions to the
web.xml descriptor.
|
Note
ejb-jar.xml and web.xml are defined in the Java Enterprise Edition (Java EE) specification. The jboss-ejb3.xml provides JBoss-specific extensions for the ejb-jar.xml, and the jboss-web.xml provides JBoss-specific extensions for the web.xml.
16.2.8. Use a Security Domain in Your Application
To use a security domain in your application, first you need to define the security domain in the server's configuration and then enable it for an application in the application's deployment descriptor. Then you must add the required annotations to the EJB that uses it. This topic covers the steps required to use a security domain in your application.
Warning
Procedure 16.1. Configure Your Application to Use a Security Domain
Define the Security Domain
You need to define the security domain in the server's configuration file, and then enable it for an application in the application's descriptor file.Configure the security domain in the server's configuration file
The security domain is configured in thesecuritysubsystem of the server's configuration file. If the JBoss EAP 6 instance is running in a managed domain, this is thedomain/configuration/domain.xmlfile. If the JBoss EAP 6 instance is running as a standalone server, this is thestandalone/configuration/standalone.xmlfile.Theother,jboss-web-policy, andjboss-ejb-policysecurity domains are provided by default in JBoss EAP 6. The following XML example was copied from thesecuritysubsystem in the server's configuration file.Thecache-typeattribute of a security domain specifies a cache for faster authentication checks. Allowed values aredefaultto use a simple map as the cache, orinfinispanto use an Infinispan cache.Copy to Clipboard Copied! Toggle word wrap Toggle overflow You can configure additional security domains as needed using the Management Console or CLI.Enable the security domain in the application's descriptor file
The security domain is specified in the<security-domain>child element of the<jboss-web>element in the application'sWEB-INF/jboss-web.xmlfile. The following example configures a security domain namedmy-domain.<jboss-web> <security-domain>my-domain</security-domain> </jboss-web><jboss-web> <security-domain>my-domain</security-domain> </jboss-web>Copy to Clipboard Copied! Toggle word wrap Toggle overflow This is only one of many settings which you can specify in theWEB-INF/jboss-web.xmldescriptor.
Add the Required Annotation to the EJB
You configure security in the EJB using the@SecurityDomainand@RolesAllowedannotations. The following EJB code example limits access to theothersecurity domain by users in theguestrole.Copy to Clipboard Copied! Toggle word wrap Toggle overflow For more code examples, see theejb-securityquickstart in the JBoss EAP 6 Quickstarts bundle, which is available from the Red Hat Customer Portal.
16.2.9. Use Role-Based Security In Servlets
jboss-web.xml.
Before you use role-based security in a servlet, the security domain used to authenticate and authorize access needs to be configured in the JBoss EAP 6 container.
Procedure 16.2. Add Role-Based Security to Servlets
Add mappings between servlets and URL patterns.
Use<servlet-mapping>elements in theweb.xmlto map individual servlets to URL patterns. The following example maps the servlet calledDisplayOpResultto the URL pattern/DisplayOpResult.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add security constraints to the URL patterns.
To map the URL pattern to a security constraint, use a<security-constraint>. The following example constrains access from the URL pattern/DisplayOpResultto be accessed by principals with the roleeap_admin. The role needs to be present in the security domain.Copy to Clipboard Copied! Toggle word wrap Toggle overflow You need to specify the authentication method, which can be any of the following:BASIC, FORM, DIGEST, CLIENT-CERT, SPNEGO.This example usesBASICauthentication.Specify the security domain in the WAR's
jboss-web.xmlAdd the security domain to the WAR'sjboss-web.xmlin order to connect the servlets to the configured security domain, which knows how to authenticate and authorize principals against the security constraints. The following example uses the security domain calledacme_domain.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Example 16.1. Example web.xml with Role-Based Security Configured
16.2.10. Use A Third-Party Authentication System In Your Application
Note
context.xml deployment descriptor. Valves are configured directly in the jboss-web.xml descriptor instead. The context.xml is now ignored.
Example 16.2. Basic Authentication Valve
Example 16.3. Custom Valve With Header Attributes Set
Writing your own authenticator is out of scope of this document. However, the following Java code is provided as an example.
Example 16.4. GenericHeaderAuthenticator.java
16.3. Security Realms
16.3.1. About Security Realms
ManagementRealmstores authentication information for the Management API, which provides the functionality for the Management CLI and web-based Management Console. It provides an authentication system for managing JBoss EAP 6 itself. You could also use theManagementRealmif your application needed to authenticate with the same business rules you use for the Management API.ApplicationRealmstores user, password, and role information for Web Applications and EJBs.
REALM-users.propertiesstores usernames and hashed passwords.REALM-roles.propertiesstores user-to-role mappings.mgmt-groups.propertiesstores user-to-group mapping file forManagementRealm. Only used when Role-based Access Control (RBAC) is enabled.
domain/configuration/ and standalone/configuration/ directories. The files are written simultaneously by the add-user.sh or add-user.bat command. When you run the command, the first decision you make is which realm to add your new user to.
16.3.2. Add a New Security Realm
Run the Management CLI.
Start thejboss-cli.shorjboss-cli.batcommand and connect to the server.Create the new security realm itself.
Run the following command to create a new security realm namedMyDomainRealmon a domain controller or a standalone server.For a domain instance, use this command:/host=master/core-service=management/security-realm=MyDomainRealm:add()
/host=master/core-service=management/security-realm=MyDomainRealm:add()Copy to Clipboard Copied! Toggle word wrap Toggle overflow For a standalone instance, use this command:/core-service=management/security-realm=MyDomainRealm:add()
/core-service=management/security-realm=MyDomainRealm:add()Copy to Clipboard Copied! Toggle word wrap Toggle overflow Create the references to the properties file which will store information about the new role.
Run the following command to create a pointer a file namedmyfile.properties, which will contain the properties pertaining to the new role.Note
The newly created properties file is not managed by the includedadd-user.shandadd-user.batscripts. It must be managed externally.For a domain instance, use this command:/host=master/core-service=management/security-realm=MyDomainRealm/authentication=properties:add(path=myfile.properties)
/host=master/core-service=management/security-realm=MyDomainRealm/authentication=properties:add(path=myfile.properties)Copy to Clipboard Copied! Toggle word wrap Toggle overflow For a standalone instance, use this command:/core-service=management/security-realm=MyDomainRealm/authentication=properties:add(path=myfile.properties)
/core-service=management/security-realm=MyDomainRealm/authentication=properties:add(path=myfile.properties)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Your new security realm is created. When you add users and roles to this new realm, the information will be stored in a separate file from the default security realms. You can manage this new file using your own applications or procedures.
16.3.3. Add a User to a Security Realm
Run the
add-user.shoradd-user.batcommand.Open a terminal and change directories to theEAP_HOME/bin/directory. If you run Red Hat Enterprise Linux or another UNIX-like operating system, runadd-user.sh. If you run Microsoft Windows Server, runadd-user.bat.Choose whether to add a Management User or Application User.
For this procedure, typebto add an Application User.Choose the realm the user will be added to.
By default, the only available realm isApplicationRealm. If you have added a custom realm, you can type its name instead.Type the username, password, and roles, when prompted.
Type the desired username, password, and optional roles when prompted. Verify your choice by typingyes, or typenoto cancel the changes. The changes are written to each of the properties files for the security realm.
16.4. EJB Application Security
16.4.1. Security Identity
16.4.1.1. About EJB Security Identity
16.4.1.2. Set the Security Identity of an EJB
<security-identity> tag in the security configuration.
<security-identity> tag is present - the EJB's own caller identity is used.
Example 16.5. Set the security identity of an EJB to be the same as its caller
<security-identity> element declaration.
Example 16.6. Set the security identity of an EJB to a specific role
<run-as> and <role-name> tags inside the <security-identity> tag.
<run-as>, a principal named anonymous is assigned to outgoing calls. To assign a different principal, uses the <run-as-principal>.
Note
<run-as> and <run-as-principal> elements inside a servlet element.
See also:
16.4.2. EJB Method Permissions
16.4.2.1. About EJB Method Permissions
<method-permission> element declaration specifies the roles that can invoke the EJB's interface methods. You can specify permissions for the following combinations:
- All home and component interface methods of the named EJB
- A specified method of the home or component interface of the named EJB
- A specified method within a set of methods with an overloaded name
16.4.2.2. Use EJB Method Permissions
The <method-permission> element defines the logical roles that are allowed to access the EJB methods defined by <method> elements. Several examples demonstrate the syntax of the XML. Multiple method permission statements may be present, and they have a cumulative effect. The <method-permission> element is a child of the <assembly-descriptor> element of the <ejb-jar> descriptor.
Example 16.7. Allow roles to access all methods of an EJB
Example 16.8. Allow roles to access only specific methods of an EJB, and limiting which method parameters can be passed.
Example 16.9. Allow any authenticated user to access methods of EJBs
<unchecked/> element allows any authenticated user to use the specified methods.
Example 16.10. Completely exclude specific EJB methods from being used
Example 16.11. A complete <assembly-descriptor> containing several <method-permission> blocks
16.4.3. EJB Security Annotations
16.4.3.1. About EJB Security Annotations
javax.annotation.security annotations are defined in JSR250.
- @DeclareRoles
- Declares which roles are available.
- @RunAs
- Configures the propagated security identity of a component.
16.4.3.2. Use EJB Security Annotations
You can use either XML descriptors or annotations to control which security roles are able to call methods in your Enterprise JavaBeans (EJBs). For information on using XML descriptors, refer to Section 16.4.2.2, “Use EJB Method Permissions”.
Annotations for Controlling Security Permissions of EJBs
- @DeclareRoles
- Use @DeclareRoles to define which security roles to check permissions against. If no @DeclareRoles is present, the list is built automatically from the @RolesAllowed annotation. For information about configuring roles, refer to the Java EE 6 Tutorial Specifying Authorized Users by Declaring Security Roles.
- @RolesAllowed, @PermitAll, @DenyAll
- Use
@RolesAllowedto list which roles are allowed to access a method or methods. Use@PermitAllor@DenyAllto either permit or deny all roles from using a method or methods. For information about configuring annotation method permissions, refer to the Java EE 6 Tutorial Specifying Authorized Users by Declaring Security Roles. - @RunAs
- Use
@RunAsto specify a role a method uses when making calls from the annotated method. For information about configuring propagated security identities using annotations, refer to the Java EE 6 Tutorial Propagating a Security Identity (Run-As).
Example 16.12. Security Annotations Example
WelcomeEveryone. The GoodBye method uses the tempemployee role when making calls. Only the admin role can access method GoodbyeAdmin, and any other methods with no security annotation.
16.4.4. Remote Access to EJBs
16.4.4.1. About Remote Method Access
Supported Transport Types
- Socket / Secure Socket
- RMI / RMI over SSL
- HTTP / HTTPS
- Servlet / Secure Servlet
- Bisocket / Secure Bisocket
Warning
The Remoting system also provides data marshalling and unmarshalling services. Data marshalling refers to the ability to safely move data across network and platform boundaries, so that a separate system can perform work on it. The work is then sent back to the original system and behaves as though it were handled locally.
When you design a client application which uses Remoting, you direct your application to communicate with the server by configuring it to use a special type of resource locator called an InvokerLocator, which is a simple String with a URL-type format. The server listens for requests for remote resources on a connector, which is configured as part of the remoting subsystem. The connector hands the request off to a configured ServerInvocationHandler. Each ServerInvocationHandler implements a method invoke(InvocationRequest), which knows how to handle the request.
JBoss Remoting Framework Layers
- The user interacts with the outer layer. On the client side, the outer layer is the
Clientclass, which sends invocation requests. On the server side, it is the InvocationHandler, which is implemented by the user and receives invocation requests. - The transport is controlled by the invoker layer.
- The lowest layer contains the marshaller and unmarshaller, which convert data formats to wire formats.
16.4.4.2. About Remoting Callbacks
InvocationRequest to the client. Your server-side code works the same regardless of whether the callback is synchronous or asynchronous. Only the client needs to know the difference. The server's InvocationRequest sends a responseObject to the client. This is the payload that the client has requested. This may be a direct response to a request or an event notification.
m_listeners object. It contains a list of all listeners that have been added to your server handler. The ServerInvocationHandler interface includes methods that allow you to manage this list.
org.jboss.remoting.InvokerCallbackHandler, which processes the callback data. After implementing the callback handler, you either add yourself as a listener for a pull callback, or implement a callback server for a push callback.
For a pull callback, your client adds itself to the server's list of listeners using the Client.addListener() method. It then polls the server periodically for synchronous delivery of callback data. This poll is performed using the Client.getCallbacks().
A push callback requires your client application to run its own InvocationHandler. To do this, you need to run a Remoting service on the client itself. This is referred to as a callback server. The callback server accepts incoming requests asynchronously and processes them for the requester (in this case, the server). To register your client's callback server with the main server, pass the callback server's InvokerLocator as the second argument to the addListener method.
16.4.4.3. About Remoting Server Detection
16.4.4.4. Configure the Remoting Subsystem
JBoss Remoting has three top-level configurable elements: the worker thread pool, one or more connectors, and a series of local and remote connection URIs. This topic presents an explanation of each configurable item, example CLI commands for how to configure each item, and an XML example of a fully-configured subsystem. This configuration only applies to the server. Most people will not need to configure the Remoting subsystem at all, unless they use custom connectors for their own applications. Applications which act as Remoting clients, such as EJBs, need separate configuration to connect to a specific connector.
Note
The CLI commands are formulated for a managed domain, when configuring the default profile. To configure a different profile, substitute its name. For a standalone server, omit the /profile=default part of the command.
There are a few configuration aspects which are outside of the remoting subsystem:
- Network Interface
- The network interface used by the
remotingsubsystem is theunsecureinterface defined in thedomain/configuration/domain.xmlorstandalone/configuration/standalone.xml.Copy to Clipboard Copied! Toggle word wrap Toggle overflow The per-host definition of theunsecureinterface is defined in thehost.xmlin the same directory as thedomain.xmlorstandalone.xml. This interface is also used by several other subsystems. Exercise caution when modifying it.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - socket-binding
- The default socket-binding used by the
remotingsubsystem binds to TCP port 4777. Refer to the documentation about socket bindings and socket binding groups for more information if you need to change this. - Remoting Connector Reference for EJB
- The EJB subsystem contains a reference to the remoting connector for remote method invocations. The following is the default configuration:
<remote connector-ref="remoting-connector" thread-pool-name="default"/>
<remote connector-ref="remoting-connector" thread-pool-name="default"/>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Secure Transport Configuration
- Remoting transports use StartTLS to use a secure (HTTPS, Secure Servlet, etc) connection if the client requests it. The same socket binding (network port) is used for secured and unsecured connections, so no additional server-side configuration is necessary. The client requests the secure or unsecured transport, as its needs dictate. JBoss EAP 6 components which use Remoting, such as EJBs, the ORB, and the JMS provider, request secured interfaces by default.
Warning
The worker thread pool is the group of threads which are available to process work which comes in through the Remoting connectors. It is a single element <worker-thread-pool>, and takes several attributes. Tune these attributes if you get network timeouts, run out of threads, or need to limit memory usage. Specific recommendations depend on your specific situation. Contact Red Hat Global Support Services for more information.
| Attribute | Description | CLI Command |
|---|---|---|
| read-threads |
The number of read threads to create for the remoting worker. Defaults to
1.
| /profile=default/subsystem=remoting/:write-attribute(name=worker-read-threads,value=1)
|
| write-threads |
The number of write threads to create for the remoting worker. Defaults to
1.
| /profile=default/subsystem=remoting/:write-attribute(name=worker-write-threads,value=1)
|
| task-keepalive |
The number of milliseconds to keep non-core remoting worker task threads alive. Defaults to
60.
| /profile=default/subsystem=remoting/:write-attribute(name=worker-task-keepalive,value=60)
|
| task-max-threads |
The maximum number of threads for the remoting worker task thread pool. Defaults to
16.
| /profile=default/subsystem=remoting/:write-attribute(name=worker-task-max-threads,value=16)
|
| task-core-threads |
The number of core threads for the remoting worker task thread pool. Defaults to
4.
| /profile=default/subsystem=remoting/:write-attribute(name=worker-task-core-threads,value=4)
|
| task-limit |
The maximum number of remoting worker tasks to allow before rejecting. Defaults to
16384.
| /profile=default/subsystem=remoting/:write-attribute(name=worker-task-limit,value=16384)
|
The connector is the main Remoting configuration element. Multiple connectors are allowed. Each consists of a element <connector> element with several sub-elements, as well as a few possible attributes. The default connector is used by several subsystems of JBoss EAP 6. Specific settings for the elements and attributes of your custom connectors depend on your applications, so contact Red Hat Global Support Services for more information.
| Attribute | Description | CLI Command |
|---|---|---|
| socket-binding | The name of the socket binding to use for this connector. | /profile=default/subsystem=remoting/connector=remoting-connector/:write-attribute(name=socket-binding,value=remoting)
|
| authentication-provider |
The Java Authentication Service Provider Interface for Containers (JASPIC) module to use with this connector. The module must be in the classpath.
| /profile=default/subsystem=remoting/connector=remoting-connector/:write-attribute(name=authentication-provider,value=myProvider)
|
| security-realm |
Optional. The security realm which contains your application's users, passwords, and roles. An EJB or Web Application can authenticate against a security realm.
ApplicationRealm is available in a default JBoss EAP 6 installation.
| /profile=default/subsystem=remoting/connector=remoting-connector/:write-attribute(name=security-realm,value=ApplicationRealm)
|
| Attribute | Description | CLI Command |
|---|---|---|
| sasl |
Enclosing element for Simple Authentication and Security Layer (SASL) authentication mechanisms
| N/A
|
| properties |
Contains one or more
<property> elements, each with a name attribute and an optional value attribute.
| /profile=default/subsystem=remoting/connector=remoting-connector/property=myProp/:add(value=myPropValue)
|
You can specify three different types of outbound connection:
- Outbound connection to a URI.
- Local outbound connection – connects to a local resource such as a socket.
- Remote outbound connection – connects to a remote resource and authenticates using a security realm.
<outbound-connections> element. Each of these connection types takes an outbound-socket-binding-ref attribute. The outbound-connection takes a uri attribute. The remote outbound connection takes optional username and security-realm attributes to use for authorization.
| Attribute | Description | CLI Command |
|---|---|---|
| outbound-connection | Generic outbound connection. | /profile=default/subsystem=remoting/outbound-connection=my-connection/:add(uri=http://my-connection)
|
| local-outbound-connection | Outbound connection with a implicit local:// URI scheme. | /profile=default/subsystem=remoting/local-outbound-connection=my-connection/:add(outbound-socket-binding-ref=remoting2)
|
| remote-outbound-connection |
Outbound connections for remote:// URI scheme, using basic/digest authentication with a security realm.
| /profile=default/subsystem=remoting/remote-outbound-connection=my-connection/:add(outbound-socket-binding-ref=remoting,username=myUser,security-realm=ApplicationRealm)
|
Before defining the SASL child elements, you need to create the initial SASL element. Use the following command:
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl:add
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl:add| Attribute | Description | CLI Command |
|---|---|---|
| include-mechanisms |
Contains a
value attribute, which is a space-separated list of SASL mechanisms.
|
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl:write-attribute(name=include-mechanisms,value=["DIGEST","PLAIN","GSSAPI"]) |
| qop |
Contains a
value attribute, which is a space-separated list of SASL Quality of protection values, in decreasing order of preference.
|
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl:write-attribute(name=qop,value=["auth"]) |
| strength |
Contains a
value attribute, which is a space-separated list of SASL cipher strength values, in decreasing order of preference.
|
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl:write-attribute(name=strength,value=["medium"]) |
| reuse-session |
Contains a
value attribute which is a boolean value. If true, attempt to reuse sessions.
|
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl:write-attribute(name=reuse-session,value=false) |
| server-auth |
Contains a
value attribute which is a boolean value. If true, the server authenticates to the client.
|
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl:write-attribute(name=server-auth,value=false) |
| policy |
An enclosing element which contains zero or more of the following elements, which each take a single
value.
|
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/sasl-policy=policy:add /profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/sasl-policy=policy:write-attribute(name=forward-secrecy,value=true) /profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/sasl-policy=policy:write-attribute(name=no-active,value=false) /profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/sasl-policy=policy:write-attribute(name=no-anonymous,value=false) /profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/sasl-policy=policy:write-attribute(name=no-dictionary,value=true) /profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/sasl-policy=policy:write-attribute(name=no-plain-text,value=false) /profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/sasl-policy=policy:write-attribute(name=pass-credentials,value=true) |
| properties |
Contains one or more
<property> elements, each with a name attribute and an optional value attribute.
|
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/property=myprop:add(value=1) /profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/property=myprop2:add(value=2) |
Example 16.13. Example Configurations
<subsystem xmlns="urn:jboss:domain:remoting:1.1">
<connector name="remoting-connector" socket-binding="remoting" security-realm="ApplicationRealm"/>
</subsystem>
<subsystem xmlns="urn:jboss:domain:remoting:1.1">
<connector name="remoting-connector" socket-binding="remoting" security-realm="ApplicationRealm"/>
</subsystem>
Configuration Aspects Not Yet Documented
- JNDI and Multicast Automatic Detection
16.4.4.5. Use Security Realms with Remote EJB Clients
- Add a new security realm to the domain controller or standalone server.
- Add the following parameters to the
jboss-ejb-client.propertiesfile, which is in the classpath of the application. This example assumes the connection is referred to asdefaultby the other parameters in the file.remote.connection.default.username=appuser remote.connection.default.password=apppassword
remote.connection.default.username=appuser remote.connection.default.password=apppasswordCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Create a custom Remoting connector on the domain or standalone server, which uses your new security realm.
- Deploy your EJB to the server group which is configured to use the profile with the custom Remoting connector, or to your standalone server if you are not using a managed domain.
16.4.4.6. Add a New Security Realm
Run the Management CLI.
Start thejboss-cli.shorjboss-cli.batcommand and connect to the server.Create the new security realm itself.
Run the following command to create a new security realm namedMyDomainRealmon a domain controller or a standalone server.For a domain instance, use this command:/host=master/core-service=management/security-realm=MyDomainRealm:add()
/host=master/core-service=management/security-realm=MyDomainRealm:add()Copy to Clipboard Copied! Toggle word wrap Toggle overflow For a standalone instance, use this command:/core-service=management/security-realm=MyDomainRealm:add()
/core-service=management/security-realm=MyDomainRealm:add()Copy to Clipboard Copied! Toggle word wrap Toggle overflow Create the references to the properties file which will store information about the new role.
Run the following command to create a pointer a file namedmyfile.properties, which will contain the properties pertaining to the new role.Note
The newly created properties file is not managed by the includedadd-user.shandadd-user.batscripts. It must be managed externally.For a domain instance, use this command:/host=master/core-service=management/security-realm=MyDomainRealm/authentication=properties:add(path=myfile.properties)
/host=master/core-service=management/security-realm=MyDomainRealm/authentication=properties:add(path=myfile.properties)Copy to Clipboard Copied! Toggle word wrap Toggle overflow For a standalone instance, use this command:/core-service=management/security-realm=MyDomainRealm/authentication=properties:add(path=myfile.properties)
/core-service=management/security-realm=MyDomainRealm/authentication=properties:add(path=myfile.properties)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Your new security realm is created. When you add users and roles to this new realm, the information will be stored in a separate file from the default security realms. You can manage this new file using your own applications or procedures.
16.4.4.7. Add a User to a Security Realm
Run the
add-user.shoradd-user.batcommand.Open a terminal and change directories to theEAP_HOME/bin/directory. If you run Red Hat Enterprise Linux or another UNIX-like operating system, runadd-user.sh. If you run Microsoft Windows Server, runadd-user.bat.Choose whether to add a Management User or Application User.
For this procedure, typebto add an Application User.Choose the realm the user will be added to.
By default, the only available realm isApplicationRealm. If you have added a custom realm, you can type its name instead.Type the username, password, and roles, when prompted.
Type the desired username, password, and optional roles when prompted. Verify your choice by typingyes, or typenoto cancel the changes. The changes are written to each of the properties files for the security realm.
16.4.4.8. About Remote EJB Access Using SSL Encryption
Warning
16.5. JAX-RS Application Security
16.5.1. Enable Role-Based Security for a RESTEasy JAX-RS Web Service
RESTEasy supports the @RolesAllowed, @PermitAll, and @DenyAll annotations on JAX-RS methods. However, it does not recognize these annotations by default. Follow these steps to configure the web.xml file and enable role-based security.
Warning
Procedure 16.3. Enable Role-Based Security for a RESTEasy JAX-RS Web Service
- Open the
web.xmlfile for the application in a text editor. - Add the following <context-param> to the file, within the
web-apptags:<context-param> <param-name>resteasy.role.based.security</param-name> <param-value>true</param-value> </context-param><context-param> <param-name>resteasy.role.based.security</param-name> <param-value>true</param-value> </context-param>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Declare all roles used within the RESTEasy JAX-RS WAR file, using the <security-role> tags:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Authorize access to all URLs handled by the JAX-RS runtime for all roles:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Role-based security has been enabled within the application, with a set of defined roles.
Example 16.14. Example Role-Based Security Configuration
16.5.2. Secure a JAX-RS Web Service using Annotations
This topic covers the steps to secure a JAX-RS web service using the supported security annotations
Procedure 16.4. Secure a JAX-RS Web Service using Supported Security Annotations
- Enable role-based security. For more information, refer to: Section 16.5.1, “Enable Role-Based Security for a RESTEasy JAX-RS Web Service”
- Add security annotations to the JAX-RS web service. RESTEasy supports the following annotations:
- @RolesAllowed
- Defines which roles can access the method. All roles should be defined in the
web.xmlfile. - @PermitAll
- Allows all roles defined in the
web.xmlfile to access the method. - @DenyAll
- Denies all access to the method.
16.6. Secure Remote Password Protocol
16.6.1. About Secure Remote Password Protocol (SRP)
This document describes a cryptographically strong network authentication mechanism known as the Secure Remote Password (SRP) protocol. This mechanism is suitable for negotiating secure connections using a user-supplied password, while eliminating the security problems traditionally associated with reusable passwords. This system also performs a secure key exchange in the process of authentication, allowing security layers (privacy and/or integrity protection) to be enabled during the session. Trusted key servers and certificate infrastructures are not required, and clients are not required to store or manage any long-term keys. SRP offers both security and deployment advantages over existing challenge-response techniques, making it an ideal drop-in replacement where secure password authentication is needed.
16.6.2. Configure Secure Remote Password (SRP) Protocol
SRPVerifierStore interface. Information about the implementation is provided in The SRPVerifierStore Implementation.
Procedure 16.5. Integrate the Existing Password Store
Create the hashed password information store.
If your passwords are already stored in an irreversible hashed form, you need to do this on a per-user basis.You can implementsetUserVerifier(String, VerifierInfo)as a noOp method, or a method that throws an exception stating that the store is read-only.Create the SRPVerifierStore interface.
Create a customSRPVerifierStoreinterface implementation that can obtain theVerifierInfofrom the store you created.TheverifyUserChallenge(String, Object)can be used to integrate existing hardware token based schemes like SafeWord or Radius into the SRP algorithm. This interface method is called only when the client SRPLoginModule configuration specifies the hasAuxChallenge option.Create the JNDI MBean.
Create a MBean that exposes theSRPVerifierStoreinterface available to JNDI, and exposes any configurable parameters required.The defaultorg.jboss.security.srp.SRPVerifierStoreServiceallows you to implement this. You can also implement the MBean using a Java properties file implementation ofSRPVerifierStore.
The default implementation of the SRPVerifierStore interface is not recommended for production systems, because it requires all password hash information to be available as a file of serialized objects.
SRPVerifierStore implementation provides access to the SRPVerifierStore.VerifierInfo object for a given username. The getUserVerifier(String) method is called by the SRPService at the start of a user SRP session to obtain the parameters needed by the SRP algorithm.
Elements of a VerifierInfo Object
- username
- The username or user ID used to authenticate
- verifier
- A one-way hash of the password the user enters as proof of identity. The
org.jboss.security.Utilclass includes acalculateVerifiermethod which performs the password hashing algorithm. The output password takes the formH(salt | H(username | ':' | password)), whereHis the SHA secure hash function as defined by RFC2945. The username is converted from a string to a byte[] using UTF-8 encoding. - salt
- A random number used to increase the difficulty of a brute force dictionary attack on the verifier password database in the event that the database is compromised. The value should be generated from a cryptographically strong random number algorithm when the user's existing clear-text password is hashed.
- g
- The SRP algorithm primitive generator. This can be a well known fixed parameter rather than a per-user setting. The
org.jboss.security.srp.SRPConfutility class provides several settings forg, including a suitable default obtained viaSRPConf.getDefaultParams().g(). - N
- The SRP algorithm safe-prime modulus. This can be a well-known fixed parameter rather than a per-user setting. The
org.jboss.security.srp.SRPConfutility class provides several settings for N including a good default obtained viaSRPConf.getDefaultParams().N().
Example 16.15. The SRPVerifierStore Interface
16.7. Password Vaults for Sensitive Strings
16.7.1. Password Vault System
16.7.2. Create a Java Keystore to Store Sensitive Strings
Prerequisites
- The
keytoolcommand must be available to use. It is provided by the Java Runtime Environment (JRE). Locate the path for the file. In Red Hat Enterprise Linux, it is installed to/usr/bin/keytool.
Warning
vault.keystore using the keytool from the same vendor as the JDK you use.
keytool from one vendor's JDK in an EAP instance running on a JDK from a different vendor results in the following exception:
java.io.IOException: com.sun.crypto.provider.SealedObjectForKeyProtector
java.io.IOException: com.sun.crypto.provider.SealedObjectForKeyProtectorProcedure 16.6. Setup a Java Keystore
Create a directory to store your keystore and other encrypted information.
Create a directory to hold your keystore and other important information. The rest of this procedure assumes that the directory isEAP_HOME/vault/. Since this directory will contain sensitive information it should be accessible to only limited users. At a minimum the user account under which JBoss EAP is running requires read-write access.Determine the parameters to use with
keytool.Determine the following parameters:- alias
- The alias is a unique identifier for the vault or other data stored in the keystore. The alias in the example command at the end of this procedure is
vault. Aliases are case-insensitive. - keyalg
- The algorithm to use for encryption. The example in this procedure uses
AES. Use the documentation for your JRE and operating system to see which other choices may be available to you. - keysize
- The size of an encryption key impacts how difficult it is to decrypt through brute force. The example in this procedure uses
128. For information on appropriate values, see the documentation distributed with thekeytool. - keystore
- The keystore is a database which holds encrypted information and the information about how to decrypt it. If you do not specify a keystore, the default keystore to use is a file called
.keystorein your home directory. The first time you add data to a keystore, it is created. The example in this procedure uses thevault.keystorekeystore.
Thekeytoolcommand has many other options. See the documentation for your JRE or your operating system for more details.Determine the answers to questions the
keystorecommand will ask.Thekeystoreneeds the following information in order to populate the keystore entry:- Keystore password
- When you create a keystore, you must set a password. In order to work with the keystore in the future, you need to provide the password. Create a strong password that you will remember. The keystore is only as secure as its password and the security of the file system and operating system where it resides.
- Key password (optional)
- In addition to the keystore password, you can specify a password for each key it holds. In order to use such a key, the password needs to be given each time it is used. Usually, this facility is not used.
- First name (given name) and last name (surname)
- This, and the rest of the information in the list, helps to uniquely identify the key and place it into a hierarchy of other keys. It does not necessarily need to be a name at all, but it should be two words, and must be unique to the key. The example in this procedure uses
Accounting Administrator. In directory terms, this becomes the common name of the certificate. - Organizational unit
- This is a single word that identifies who uses the certificate. It may be the application or the business unit. The example in this procedure uses
AccountingServices. Typically, all keystores used by a group or application use the same organizational unit. - Organization
- This is usually a single-word representation of your organization's name. This typically remains the same across all certificates used by an organization. This example uses
MyOrganization. - City or municipality
- Your city.
- State or province
- Your state or province, or the equivalent for your locality.
- Country
- The two-letter code for your country.
All of this information together will create a hierarchy for your keystores and certificates, ensuring that they use a consistent naming structure but are unique.Run the
keytoolcommand, supplying the information that you gathered.Example 16.16. Example input and output of
keystorecommandCopy to Clipboard Copied! Toggle word wrap Toggle overflow
A file named vault.keystore is created in the EAP_HOME/vault/ directory. It stores a single key, called vault, which will be used to store encrypted strings, such as passwords, for JBoss EAP 6.
16.7.3. Mask the Keystore Password and Initialize the Password Vault
Run the
vault.shcommand.RunEAP_HOME/bin/vault.sh. Start a new interactive session by typing0.Enter the directory where encrypted files will be stored.
This directory should be accessible to only limited users. At a minimum the user account under which JBoss EAP is running requires read-write access. If you followed Section 16.7.2, “Create a Java Keystore to Store Sensitive Strings”, your keystore is in a directory calledEAP_HOME/vault/.Note
Do not forget to include the trailing slash on the directory name. Either use/or\, depending on your operating system.Enter the path to the keystore.
Enter the full path to the keystore file. This example usesEAP_HOME/vault/vault.keystore.Encrypt the keystore password.
The following steps encrypt the keystore password, so that you can use it in configuration files and applications securely.Enter the keystore password.
When prompted, enter the keystore password.Enter a salt value.
Enter an 8-character salt value. The salt value, together with the iteration count (below), are used to create the hash value.Enter the iteration count.
Enter a number for the iteration count.Make a note of the masked password information.
The masked password, the salt, and the iteration count are printed to standard output. Make a note of them in a secure location. An attacker could use them to decrypt the password.Enter the alias of the vault.
When prompted, enter the alias of the vault. If you followed Section 16.7.2, “Create a Java Keystore to Store Sensitive Strings” to create your vault, the alias isvault.
Exit the interactive console.
Type2to exit the interactive console.
Your keystore password has been masked for use in configuration files and deployments. In addition, your vault is fully configured and ready to use.
16.7.4. Configure JBoss EAP 6 to Use the Password Vault
Before you can mask passwords and other sensitive attributes in configuration files, you need to make JBoss EAP 6 aware of the password vault which stores and decrypts them. Follow this procedure to enable this functionality.
Prerequisites
Procedure 16.7. Setup a Password Vault
Determine the correct values for the command.
Determine the values for the following parameters, which are determined by the commands used to create the keystore itself. For information on creating a keystore, refer the following topics: Section 16.7.2, “Create a Java Keystore to Store Sensitive Strings” and Section 16.7.3, “Mask the Keystore Password and Initialize the Password Vault”.Expand Parameter Description KEYSTORE_URL The file system path or URI of the keystore file, usually called something likevault.keystoreKEYSTORE_PASSWORD The password used to access the keystore. This value should be masked.KEYSTORE_ALIAS The name of the keystore alias.SALT The salt used to encrypt and decrypt keystore values.ITERATION_COUNT The number of times the encryption algorithm is run.ENC_FILE_DIR The path to the directory from which the keystore commands are run. Typically the directory containing the password vault.host (managed domain only) The name of the host you are configuringUse the Management CLI to enable the password vault.
Run one of the following commands, depending on whether you use a managed domain or standalone server configuration. Substitute the values in the command with the ones from the first step of this procedure.Note
If you use Microsoft Windows Server, in the CLI command, escape each\character in a directory path with an additional\character. For example,C:\\data\\vault\\vault.keystore. This is because single\character is used for character escaping.Managed Domain
/host=YOUR_HOST/core-service=vault:add(vault-options=[("KEYSTORE_URL" => "PATH_TO_KEYSTORE"), ("KEYSTORE_PASSWORD" => "MASKED_PASSWORD"), ("KEYSTORE_ALIAS" => "ALIAS"), ("SALT" => "SALT"),("ITERATION_COUNT" => "ITERATION_COUNT"), ("ENC_FILE_DIR" => "ENC_FILE_DIR")])/host=YOUR_HOST/core-service=vault:add(vault-options=[("KEYSTORE_URL" => "PATH_TO_KEYSTORE"), ("KEYSTORE_PASSWORD" => "MASKED_PASSWORD"), ("KEYSTORE_ALIAS" => "ALIAS"), ("SALT" => "SALT"),("ITERATION_COUNT" => "ITERATION_COUNT"), ("ENC_FILE_DIR" => "ENC_FILE_DIR")])Copy to Clipboard Copied! Toggle word wrap Toggle overflow Standalone Server
/core-service=vault:add(vault-options=[("KEYSTORE_URL" => "PATH_TO_KEYSTORE"), ("KEYSTORE_PASSWORD" => "MASKED_PASSWORD"), ("KEYSTORE_ALIAS" => "ALIAS"), ("SALT" => "SALT"),("ITERATION_COUNT" => "ITERATION_COUNT"), ("ENC_FILE_DIR" => "ENC_FILE_DIR")])/core-service=vault:add(vault-options=[("KEYSTORE_URL" => "PATH_TO_KEYSTORE"), ("KEYSTORE_PASSWORD" => "MASKED_PASSWORD"), ("KEYSTORE_ALIAS" => "ALIAS"), ("SALT" => "SALT"),("ITERATION_COUNT" => "ITERATION_COUNT"), ("ENC_FILE_DIR" => "ENC_FILE_DIR")])Copy to Clipboard Copied! Toggle word wrap Toggle overflow
The following is an example of the command with hypothetical values:/core-service=vault:add(vault-options=[("KEYSTORE_URL" => "/home/user/vault/vault.keystore"), ("KEYSTORE_PASSWORD" => "MASK-3y28rCZlcKR"), ("KEYSTORE_ALIAS" => "vault"), ("SALT" => "12438567"),("ITERATION_COUNT" => "50"), ("ENC_FILE_DIR" => "/home/user/vault/")])/core-service=vault:add(vault-options=[("KEYSTORE_URL" => "/home/user/vault/vault.keystore"), ("KEYSTORE_PASSWORD" => "MASK-3y28rCZlcKR"), ("KEYSTORE_ALIAS" => "vault"), ("SALT" => "12438567"),("ITERATION_COUNT" => "50"), ("ENC_FILE_DIR" => "/home/user/vault/")])Copy to Clipboard Copied! Toggle word wrap Toggle overflow
JBoss EAP 6 is configured to decrypt masked strings using the password vault. To add strings to the vault and use them in your configuration, refer to the following topic: Section 16.7.6, “Store and Retrieve Encrypted Sensitive Strings in the Java Keystore”.
16.7.5. Configure JBoss EAP 6 to Use a Custom Implementation of the Password Vault
You can use your own implementation of SecurityVault to mask passwords and other sensitive attributes in configuration files.
Procedure 16.8. Use a Custom Implementation of the Password Vault
- Create a class that implements the interface
SecurityVault. - Create a module containing the class from the previous step, and specify a dependency on
org.picketboxwhere the interface isSecurityVault. - Enable the custom Password Vault in the JBoss EAP server configuration by adding the vault element with the following attributes:
- code
- The fully qualified name of class that implements
SecurityVault. - module
- The name of the module that contains the custom class.
Optionally, you can usevault-optionsparameters to initialize the custom class for a Password Vault. For example:/core-service=vault:add(code="custom.vault.implementation.CustomSecurityVault", module="custom.vault.module", vault-options=[("KEYSTORE_URL" => "PATH_TO_KEYSTORE"), ("KEYSTORE_PASSWORD" => "MASKED_PASSWORD"), ("KEYSTORE_ALIAS" => "ALIAS"), ("SALT" => "SALT"),("ITERATION_COUNT" => "ITERATION_COUNT"), ("ENC_FILE_DIR" => "ENC_FILE_DIR")])/core-service=vault:add(code="custom.vault.implementation.CustomSecurityVault", module="custom.vault.module", vault-options=[("KEYSTORE_URL" => "PATH_TO_KEYSTORE"), ("KEYSTORE_PASSWORD" => "MASKED_PASSWORD"), ("KEYSTORE_ALIAS" => "ALIAS"), ("SALT" => "SALT"),("ITERATION_COUNT" => "ITERATION_COUNT"), ("ENC_FILE_DIR" => "ENC_FILE_DIR")])Copy to Clipboard Copied! Toggle word wrap Toggle overflow
JBoss EAP 6 is configured to decrypt masked strings using a custom implementation of the password vault.
16.7.6. Store and Retrieve Encrypted Sensitive Strings in the Java Keystore
Including passwords and other sensitive strings in plain-text configuration files is insecure. JBoss EAP 6 includes the ability to store and mask these sensitive strings in an encrypted keystore, and use masked values in configuration files.
Prerequisites
- The
EAP_HOME/bin/vault.shapplication must be accessible via a command-line interface.
Procedure 16.9. Setup the Java Keystore
Run the
vault.shcommand.RunEAP_HOME/bin/vault.sh. Start a new interactive session by typing0.Enter the directory where encrypted files will be stored.
If you followed Section 16.7.2, “Create a Java Keystore to Store Sensitive Strings”, your keystore is in the directoryEAP_HOME/vault. In most cases, it makes sense to store all of your encrypted information in the same place as the key store. Since this directory will contain sensitive information it should be accessible to only limited users. At a minimum the user account under which JBoss EAP is running requires read-write access.Note
Do not forget to include the trailing slash on the directory name. Either use/or\, depending on your operating system.Enter the path to the keystore.
Enter the full path to the keystore file. This example usesEAP_HOME/vault/vault.keystore.Enter the keystore password, vault name, salt, and iteration count.
When prompted, enter the keystore password, vault name, salt, and iteration count. A handshake is performed.Select the option to store a password.
Select option0to store a password or other sensitive string.Enter the value.
When prompted, enter the value twice. If the values do not match, you are prompted to try again.Enter the vault block.
Enter the vault block, which is a container for attributes which pertain to the same resource. An example of an attribute name would beds_ExampleDS. This will form part of the reference to the encrypted string, in your datasource or other service definition.Enter the attribute name.
Enter the name of the attribute you are storing. An example attribute name would bepassword.ResultA message such as the one below shows that the attribute has been saved.
Secured attribute value has been stored in vault.
Secured attribute value has been stored in vault.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Make note of the information about the encrypted string.
A message prints to standard output, showing the vault block, attribute name, shared key, and advice about using the string in your configuration. Make note of this information in a secure location. Example output is shown below.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Use the encrypted string in your configuration.
Use the string from the previous step in your configuration, in place of a plain-text string. A datasource using the encrypted password above is shown below.Copy to Clipboard Copied! Toggle word wrap Toggle overflow You can use an encrypted string anywhere in your domain or standalone configuration file where expressions are allowed.Note
To check if expressions are allowed within a particular subsystem, run the following CLI command against that subsystem:/host=master/core-service=management/security-realm=TestRealm:read-resource-description(recursive=true)
/host=master/core-service=management/security-realm=TestRealm:read-resource-description(recursive=true)Copy to Clipboard Copied! Toggle word wrap Toggle overflow From the output of running this command, look for the value for theexpressions-allowedparameter. If this is true, then you can use expressions within the configuration of this particular subsystem.After you store your string in the keystore, use the following syntax to replace any clear-text string with an encrypted one.${VAULT::VAULT_BLOCK::ATTRIBUTE_NAME::ENCRYPTED_VALUE}${VAULT::VAULT_BLOCK::ATTRIBUTE_NAME::ENCRYPTED_VALUE}Copy to Clipboard Copied! Toggle word wrap Toggle overflow Here is a sample real-world value, where the vault block isds_ExampleDSand the attribute ispassword.<password>${VAULT::ds_ExampleDS::password::1}</password><password>${VAULT::ds_ExampleDS::password::1}</password>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
16.7.7. Store and Resolve Sensitive Strings In Your Applications
Configuration elements of JBoss EAP 6 support the ability to resolve encrypted strings against values stored in a Java Keystore, via the Security Vault mechanism. You can add support for this feature to your own applications.
Before performing this procedure, make sure that the directory for storing your vault files exists. It does not matter where you place them, as long as the user who executes JBoss EAP 6 has permission to read and write the files. This example places the vault/ directory into the /home/USER/vault/ directory. The vault itself is a file called vault.keystore inside the vault/ directory.
Example 16.17. Adding the Password String to the Vault
EAP_HOME/bin/vault.sh command. The full series of commands and responses is included in the following screen output. Values entered by the user are emphasized. Some output is removed for formatting. In Microsoft Windows, the name of the command is vault.bat. Note that in Microsoft Windows, file paths use the \ character as a directory separator, rather than the / character.
VAULT.
Example 16.18. Servlet Using a Vaulted Password
16.8. Java Authorization Contract for Containers (JACC)
16.8.1. About Java Authorization Contract for Containers (JACC)
16.8.2. Configure Java Authorization Contract for Containers (JACC) Security
jboss-web.xml to include the correct parameters.
To add JACC support to the security domain, add the JACC authorization policy to the authorization stack of the security domain, with the required flag set. The following is an example of a security domain with JACC support. However, the security domain is configured in the Management Console or Management CLI, rather than directly in the XML.
The jboss-web.xml is located in the WEB-INF/ directory of your deployment, and contains overrides and additional JBoss-specific configuration for the web container. To use your JACC-enabled security domain, you need to include the <security-domain> element, and also set the <use-jboss-authorization> element to true. The following application is properly configured to use the JACC security domain above.
<jboss-web>
<security-domain>jacc</security-domain>
<use-jboss-authorization>true</use-jboss-authorization>
</jboss-web>
<jboss-web>
<security-domain>jacc</security-domain>
<use-jboss-authorization>true</use-jboss-authorization>
</jboss-web>
Configuring EJBs to use a security domain and to use JACC differs from Web Applications. For an EJB, you can declare method permissions on a method or group of methods, in the ejb-jar.xml descriptor. Within the <ejb-jar> element, any child <method-permission> elements contain information about JACC roles. Refer to the example configuration for more details. The EJBMethodPermission class is part of the Java Enterprise Edition 6 API, and is documented at http://docs.oracle.com/javaee/6/api/javax/security/jacc/EJBMethodPermission.html.
Example 16.19. Example JACC Method Permissions in an EJB
jboss-ejb3.xml descriptor, in the <security> child element. In addition to the security domain, you can also specify the run-as principal, which changes the principal the EJB runs as.
Example 16.20. Example Security Domain Declaration in an EJB
16.9. Java Authentication SPI for Containers (JASPI)
16.9.1. About Java Authentication SPI for Containers (JASPI) Security
16.9.2. Configure Java Authentication SPI for Containers (JASPI) Security
<authentication-jaspi> element to your security domain. The configuration is similar to a standard authentication module, but login module elements are enclosed in a <login-module-stack> element. The structure of the configuration is:
Example 16.21. Structure of the authentication-jaspi element
EAP_HOME/domain/configuration/domain.xml or EAP_HOME/standalone/configuration/standalone.xml.
Chapter 17. Single Sign On (SSO)
17.1. About Single Sign On (SSO) for Web Applications
Single Sign On (SSO) allows authentication to one resource to implicitly authorize access to other resources.
Non-clustered SSO limits the sharing of authorization information to applications on the same virtual host. In addition, there is no resiliency in the event of a host failure. Clustered SSO data can be shared between applications in multiple virtual hosts, and is resilient to failover. In addition, clustered SSO is able to receive requests from a load balancer.
If a resource is unprotected, a user is not challenged to authenticate at all. If a user accesses a protected resource, the user is required to authenticate.
17.2. About Clustered Single Sign On (SSO) for Web Applications
jboss-web.xml.
- Apache Tomcat ClusteredSingleSignOn
- Apache Tomcat IDPWebBrowserSSOValve
- SPNEGO-based SSO provided by PicketLink
17.3. Choose the Right SSO Implementation
web.xml deployment descriptor. Clustered SSO allows for replication of security context and identity information, regardless of whether or not the applications are themselves clustered. Although these technologies may be used together they are separate concepts.
If your organization already uses a Kerberos-based authentication and authorization system, such as Microsoft Active Directory, you can use the same systems to transparently authenticate to your enterprise applications running on JBoss EAP 6.
If you are running multiple applications on a single instance and need to enable SSO session replication for those applications, non-clustered SSO will meet your requirements.
If you are running either a single application, or multiple applications, across a cluster and need to enable SSO session replication for those applications, clustered SSO will meet your requirements.
17.4. Use Single Sign On (SSO) In A Web Application
Single Sign On (SSO) capabilities are provided by the web and Infinispan subsystems. Use this procedure to configure SSO in web applications.
Prerequisites
- A configured security domain which handles authentication and authorization.
- The
infinispansubsystem. It is present in thefull-haprofile for a managed domain, or by using thestandalone-full-ha.xmlconfiguration in a standalone server. - The
webcache-containerand SSO replicated-cache. The initial configuration files already contain thewebcache-container, and some of the configurations already contain the SSO replicated-cache as well. Use the following commands to check for and enable the SSO replicated-cache. Note that these commands modify thehaprofile of a managed domain. You can change the commands to use a different profile, or remove the/profile=haportion of the command, for a standalone server.Example 17.1. Check for the
webcache-containerThe profiles and configurations mentioned above include thewebcache-container by default. Use the following command to verify its presence. If you use a different profile, substitute its name instead ofha./profile=ha/subsystem=infinispan/cache-container=web/:read-resource(recursive=false,proxies=false,include-runtime=false,include-defaults=true)
/profile=ha/subsystem=infinispan/cache-container=web/:read-resource(recursive=false,proxies=false,include-runtime=false,include-defaults=true)Copy to Clipboard Copied! Toggle word wrap Toggle overflow If the result issuccessthe subsystem is present. Otherwise, you need to add it.Example 17.2. Add the
webcache-containerUse the following three commands to enable thewebcache-container to your configuration. Modify the name of the profile as appropriate, as well as the other parameters. The parameters here are the ones used in a default configuration./profile=ha/subsystem=infinispan/cache-container=web:add(aliases=["standard-session-cache"],default-cache="repl",module="org.jboss.as.clustering.web.infinispan")
/profile=ha/subsystem=infinispan/cache-container=web:add(aliases=["standard-session-cache"],default-cache="repl",module="org.jboss.as.clustering.web.infinispan")Copy to Clipboard Copied! Toggle word wrap Toggle overflow /profile=ha/subsystem=infinispan/cache-container=web/transport=TRANSPORT:add(lock-timeout=60000)
/profile=ha/subsystem=infinispan/cache-container=web/transport=TRANSPORT:add(lock-timeout=60000)Copy to Clipboard Copied! Toggle word wrap Toggle overflow /profile=ha/subsystem=infinispan/cache-container=web/replicated-cache=repl:add(mode="ASYNC",batching=true)
/profile=ha/subsystem=infinispan/cache-container=web/replicated-cache=repl:add(mode="ASYNC",batching=true)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example 17.3. Check for the
SSOreplicated-cacheRun the following Management CLI command:/profile=ha/subsystem=infinispan/cache-container=web/:read-resource(recursive=true,proxies=false,include-runtime=false,include-defaults=true)
/profile=ha/subsystem=infinispan/cache-container=web/:read-resource(recursive=true,proxies=false,include-runtime=false,include-defaults=true)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Look for output like the following:"sso" => {If you do not find it, the SSO replicated-cache is not present in your configuration.Example 17.4. Add the
SSOreplicated-cache/profile=ha/subsystem=infinispan/cache-container=web/replicated-cache=sso:add(mode="SYNC", batching=true)
/profile=ha/subsystem=infinispan/cache-container=web/replicated-cache=sso:add(mode="SYNC", batching=true)Copy to Clipboard Copied! Toggle word wrap Toggle overflow - The
websubsystem needs to be configured to use SSO. The following command enables SSO on the virtual server calleddefault-host, and the cookie domaindomain.com. The cache name issso, and reauthentication is disabled./profile=ha/subsystem=web/virtual-server=default-host/sso=configuration:add(cache-container="web",cache-name="sso",reauthenticate="false",domain="domain.com")
/profile=ha/subsystem=web/virtual-server=default-host/sso=configuration:add(cache-container="web",cache-name="sso",reauthenticate="false",domain="domain.com")Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Each application which will share the SSO information must be configured to use the same <security-domain> in its
jboss-web.xmldeployment descriptor and the same Realm in itsweb.xmlconfiguration file.
Configure sso under the web subsystem in the server profile. The ClusteredSingleSignOn version is used when attribute cache-container is present, otherwise standard SingleSignOn class is used.
Example 17.5. Example Clustered SSO Configuration
/subsystem=web/virtual-server=default-host/sso=configuration:add(cache-container="web",cache-name="sso",reauthenticate="false",domain="domain.com")
/subsystem=web/virtual-server=default-host/sso=configuration:add(cache-container="web",cache-name="sso",reauthenticate="false",domain="domain.com")Example 17.6. Example Non-Clustered SSO Configuration
/subsystem=web/virtual-server=default-host/sso=configuration:add(reauthenticate="false")
/subsystem=web/virtual-server=default-host/sso=configuration:add(reauthenticate="false")
An application can programmatically invalidate a session by invoking method javax.servlet.http.HttpSession.invalidate().
17.5. About Kerberos
17.6. About SPNEGO
17.7. About Microsoft Active Directory
- Lightweight Directory Access Protocol (LDAP), for storing information about users, computers, passwords, and other resources.
- Kerberos, for providing secure authentication over the network.
- Domain Name Service (DNS) for providing mappings between IP addresses and host names of computers and other devices on the network.
17.8. Configure Kerberos or Microsoft Active Directory Desktop SSO for Web Applications
To authenticate your web or EJB applications using your organization's existing Kerberos-based authentication and authorization infrastructure, such as Microsoft Active Directory, you can use the JBoss Negotiation capabilities built into JBoss EAP 6. If you configure your web application properly, a successful desktop or network login is sufficient to transparently authenticate against your web application, so no additional login prompt is required.
There are a few noticeable differences between JBoss EAP 6 and earlier versions:
- Security domains are configured for each profile of a managed domain, or for each standalone server. They are not part of the deployment itself. The security domain a deployment should use is named in the deployment's
jboss-web.xmlorjboss-ejb3.xmlfile. - Security properties are configured as part of a security domain. They are not part of the deployment.
- You can no longer override the authenticators as part of your deployment. However, you can add a NegotiationAuthenticator valve to your
jboss-web.xmldescriptor to achieve the same effect. The valve still requires the<security-constraint>and<login-config>elements to be defined in theweb.xml. These are used to decide which resources are secured. However, the chosen auth-method will be overridden by the NegotiationAuthenticator valve in thejboss-web.xml. - The
CODEattributes in security domains now use a simple name instead of a fully-qualified class name. The following table shows the mappings between the classes used for JBoss Negotiation, and their classes.
| Simple Name | Class Name | Purpose |
|---|---|---|
| Kerberos |
com.sun.security.auth.module.Krb5LoginModule
com.ibm.security.auth.module.Krb5LoginModule
|
Kerberos login module when using the Oracle JDK
Kerberos login module when using the IBM JDK
|
| SPNEGO | org.jboss.security.negotiation.spnego.SPNEGOLoginModule | The mechanism which enables your Web applications to authenticate to your Kerberos authentication server. |
| AdvancedLdap | org.jboss.security.negotiation.AdvancedLdapLoginModule | Used with LDAP servers other than Microsoft Active Directory. |
| AdvancedAdLdap | org.jboss.security.negotiation.AdvancedADLoginModule | Used with Microsoft Active Directory LDAP servers. |
The JBoss Negotiation Toolkit is a debugging tool which is available for download from https://community.jboss.org/servlet/JiveServlet/download/16876-2-34629/jboss-negotiation-toolkit.war. It is provided as an extra tool to help you to debug and test the authentication mechanisms before introducing your application into production. It is an unsupported tool, but is considered to be very helpful, as SPNEGO can be difficult to configure for web applications.
Procedure 17.1. Setup SSO Authentication for your Web or EJB Applications
Configure one security domain to represent the identity of the server. Set system properties if necessary.
The first security domain authenticates the container itself to the directory service. It needs to use a login module which accepts some type of static login mechanism, because a real user is not involved. This example uses a static principal and references a keytab file which contains the credential.The XML code is given here for clarity, but you should use the Management Console or Management CLI to configure your security domains.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Configure a second security domain to secure the web application or applications. Set system properties if necessary.
The second security domain is used to authenticate the individual user to the Kerberos or SPNEGO authentication server. You need at least one login module to authenticate the user, and another to search for the roles to apply to the user. The following XML code shows an example SPNEGO security domain. It includes an authorization module to map roles to individual users. You can also use a module which searches for the roles on the authentication server itself.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Specify the security-constraint and login-config in the
web.xmlTheweb.xmldescriptor contain information about security constraints and login configuration. The following are example values for each.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Specify the security domain and other settings in the
jboss-web.xmldescriptor.Specify the name of the client-side security domain (the second one in this example) in thejboss-web.xmldescriptor of your deployment, to direct your application to use this security domain.You can no longer override authenticators directly. Instead, you can add the NegotiationAuthenticator as a valve to yourjboss-web.xmldescriptor, if you need to. The<jacc-star-role-allow>allows you to use the asterisk (*) character to match multiple role names, and is optional.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add a dependency to your application's
MANIFEST.MF, to locate the Negotiation classes.The web application needs a dependency on classorg.jboss.security.negotiationto be added to the deployment'sMETA-INF/MANIFEST.MFmanifest, in order to locate the JBoss Negotiation classes. The following shows a properly-formatted entry.Manifest-Version: 1.0 Build-Jdk: 1.6.0_24 Dependencies: org.jboss.security.negotiation
Manifest-Version: 1.0 Build-Jdk: 1.6.0_24 Dependencies: org.jboss.security.negotiationCopy to Clipboard Copied! Toggle word wrap Toggle overflow - As an alternative, add a dependency to your application by editing the
META-INF/jboss-deployment-structure.xmlfile:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Your web application accepts and authenticates credentials against your Kerberos, Microsoft Active Directory, or other SPNEGO-compatible directory service. If the user runs the application from a system which is already logged into the directory service, and where the required roles are already applied to the user, the web application does not prompt for authentication, and SSO capabilities are achieved.
17.9. Configure SPNEGO Fall Back to Form Authentication
Procedure 17.2. SPNEGO security with fall back to form authentication
Set up SPNEGO
Refer the procedure described in Section 17.8, “Configure Kerberos or Microsoft Active Directory Desktop SSO for Web Applications”Modify
web.xmlAdd alogin-configelement to your application and setup the login and error pages in web.xml:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add web content
Add references oflogin.htmlanderror.htmltoweb.xml. These files are added to web application archive to the place specified inform-login-configconfiguration. For more information refer Enable Form-based Authentication section in the Security Guide for JBoss EAP 6. A typicallogin.htmllooks like this:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Note
Chapter 18. Development Security References
18.1. jboss-web.xml Configuration Reference
The jboss-web.xml is a file within your deployment's WEB-INF directory. It contains configuration information about features the JBoss Web container adds to the Servlet 3.0 specification. Settings specific to the Servlet 3.0 specification are placed into web.xml in the same directory.
jboss-web.xml file is the <jboss-web> element.
Many of the available settings map requirements set in the application's web.xml to local resources. The explanations of the web.xml settings can be found at http://docs.oracle.com/cd/E13222_01/wls/docs81/webapp/web_xml.html.
web.xml requires jdbc/MyDataSource, the jboss-web.xml may map the global datasource java:/DefaultDS to fulfill this need. The WAR uses the global datasource to fill its need for jdbc/MyDataSource.
| Attribute | Description |
|---|---|
| env-entry |
A mapping to an
env-entry required by the web.xml.
|
| ejb-ref |
A mapping to an
ejb-ref required by the web.xml.
|
| ejb-local-ref |
A mapping to an
ejb-local-ref required by the web.xml.
|
| service-ref |
A mapping to a
service-ref required by the web.xml.
|
| resource-ref |
A mapping to a
resource-ref required by the web.xml.
|
| resource-env-ref |
A mapping to a
resource-env-ref required by the web.xml.
|
| message-destination-ref |
A mapping to a
message-destination-ref required by the web.xml.
|
| persistence-context-ref |
A mapping to a
persistence-context-ref required by the web.xml.
|
| persistence-unit-ref |
A mapping to a
persistence-unit-ref required by the web.xml.
|
| post-construct |
A mapping to a
post-context required by the web.xml.
|
| pre-destroy |
A mapping to a
pre-destroy required by the web.xml.
|
| data-source |
A mapping to a
data-source required by the web.xml.
|
| context-root | The root context of the application. The default value is the name of the deployment without the .war suffix. |
| virtual-host | The name of the HTTP virtual-host the application accepts requests from. It refers to the contents of the HTTP Host header. |
| annotation | Describes an annotation used by the application. Refer to <annotation> for more information. |
| listener | Describes a listener used by the application. Refer to <listener> for more information. |
| session-config | This element fills the same function as the <session-config> element of the web.xml and is included for compatibility only. |
| valve | Describes a valve used by the application. Refer to <valve> for more information. |
| overlay | The name of an overlay to add to the application. |
| security-domain | The name of the security domain used by the application. The security domain itself is configured in the web-based management console or the management CLI. |
| security-role | This element fills the same function as the <security-role> element of the web.xml and is included for compatibility only. |
| use-jboss-authorization | If this element is present and contains the case insensitive value "true", the JBoss web authorization stack is used. If it is not present or contains any value that is not "true", then only the authorization mechanisms specified in the Java Enterprise Edition specifications are used. This element is new to JBoss EAP 6. |
| disable-audit | Set this boolean element to false to enable and true to disable web auditing. Web security auditing is not part of the Java EE specification. This element is new to JBoss EAP 6. |
| disable-cross-context | If false, the application is able to call another application context. Defaults to true. |
Describes an annotation used by the application. The following table lists the child elements of an <annotation>.
| Attribute | Description |
|---|---|
| class-name |
Name of the class of the annotation
|
| servlet-security |
The element, such as
@ServletSecurity, which represents servlet security.
|
| run-as |
The element, such as
@RunAs, which represents the run-as information.
|
| multipart-config |
The element, such as
@MultiPart, which represents the multipart-config information.
|
Describes a listener. The following table lists the child elements of a <listener>.
| Attribute | Description |
|---|---|
| class-name |
Name of the class of the listener
|
| listener-type |
List of
condition elements, which indicate what kind of listener to add to the Context of the application. Valid choices are:
|
| module |
The name of the module containing the listener class.
|
| param |
A parameter. Contains two child elements,
<param-name> and <param-value>.
|
Describes a valve of the application. Similar to the <listener>, has class-name, module and param elements.
18.2. EJB Security Parameter Reference
| Element | Description |
|---|---|
<security-identity>
|
Contains child elements pertaining to the security identity of an EJB.
|
<use-caller-identity />
|
Indicates that the EJB uses the same security identity as the caller.
|
<run-as>
|
Contains a
<role-name> element.
|
<run-as-principal>
|
If present, indicates the principal assigned to outgoing calls. If not present, outgoing calls are assigned to a principal named
anonymous.
|
<role-name>
|
Specifies the role the EJB should run as.
|
<description>
|
Describes the role named in
. <role-name>
|
Example 18.1. Security identity examples
<session>.
Chapter 19. Supplemental References
19.1. Types of Java Archives
| Archive Type | Extension | Purpose | Directory structure requirements |
|---|---|---|---|
| Java Archive | .jar | Contains Java class libraries. | META-INF/MANIFEST.MF file (optional), which specifies information such as which class is the main class.
|
| Web Archive | .war |
Contains Java Server Pages (JSP) files, servlets, and XML files, in addition to Java classes and libraries. The Web Archive's contents are also referred to as a Web Application.
| WEB-INF/web.xml file, which contains information about the structure of the web application. Other files may also be present in WEB-INF/.
|
| Resource Adapter Archive | .rar |
The directory structure is specified by the JCA specification.
|
Contains a Java Connector Architecture (JCA) resource adapter. Also called a connector.
|
| Enterprise Archive | .ear |
Used by Java Enterprise Edition (EE) to package one or more modules into a single archive, so that the modules can be deployed onto the application server simultaneously. Maven and Ant are the most common tools used to build EAR archives.
| META-INF/ directory, which contains one or more XML deployment descriptor files.
|
|
Any of the following types of modules.
| |||
| Service Archive | .sar |
Similar to an Enterprise Archive, but specific to the JBoss EAP.
| META-INF/ directory containing jboss-service.xml or jboss-beans.xml file.
|
Appendix A. Revision History
| Revision History | |||
|---|---|---|---|
| Revision 6.3.0-50 | Tuesday November 18 2014 | ||
| |||
| Revision 6.3.0-29 | Friday August 8 2014 | ||
| |||
| Revision 6.3.0-28 | Friday July 25 2014 | ||
| |||