Development Guide
For Use with Red Hat JBoss Enterprise Application Platform 7.1
Abstract
Chapter 1. Get Started Developing Applications
1.1. Introduction
1.1.1. About Red Hat JBoss Enterprise Application Platform 7
Red Hat JBoss Enterprise Application Platform 7 (JBoss EAP) is a middleware platform built on open standards and compliant with the Java Enterprise Edition 7 specification.
JBoss EAP includes a modular structure that allows service enabling only when required, improving startup speed.
The management console and management command-line interface (CLI) make editing XML configuration files unnecessary and add the ability to script and automate tasks.
JBoss EAP provides two operating modes for JBoss EAP instances: standalone server or managed domain. The standalone server operating mode represents running JBoss EAP as a single server instance. The managed domain operating mode allows for the management of multiple JBoss EAP instances from a single control point.
In addition, JBoss EAP includes APIs and development frameworks for quickly developing secure and scalable Java EE applications.
1.2. Become Familiar with Java Enterprise Edition 7
1.2.1. Overview of Java EE 7 Profiles
Java Enterprise Edition (Java EE) 7 includes support for profiles, which are subsets of APIs that represent configurations that are suited to specific classes of applications. The only profile that the Java EE 7 specification defines is the Web Profile. A product can choose to implement the full platform, the Web Profile, or one or more custom profiles, in any combination.
JBoss EAP 7.1 is a certified implementation of the Java Enterprise Edition 7 full platform and the Web Profile specifications.
Java Enterprise Edition 7 Web Profile
The Web Profile is the first and only profile defined by the Java Enterprise Edition 7 specification. It includes a selected subset of APIs that are designed to be useful for web application development. The Web Profile supports the following APIs:
Java EE 7 Web Profile Requirements:
- Java Platform, Enterprise Edition 7
Java Web Technologies:
- Servlet 3.1 (JSR 340)
- JSP 2.3
- Expression Language (EL) 3.0
- JavaServer Faces (JSF) 2.2 (JSR 344)
Java Standard Tag Library (JSTL) for JSP 1.2
NoteA known security risk in JBoss EAP exists where the Java Standard Tag Library (JSTL) allows the processing of external entity references in untrusted XML documents which could access resources on the host system and, potentially, allow arbitrary code execution.
To avoid this, the JBoss EAP server has to be run with system property
org.apache.taglibs.standard.xml.accessExternalEntitycorrectly set, usually with an empty string as value. This can be done in two ways:Configuring the system properties and restarting the server.
org.apache.taglibs.standard.xml.accessExternalEntity
org.apache.taglibs.standard.xml.accessExternalEntityCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
Passing
-Dorg.apache.taglibs.standard.xml.accessExternalEntity=""as an argument to thestandalone.shordomain.shscripts.
- Debugging Support for Other Languages 1.0 (JSR 45)
Enterprise Application Technologies:
- Contexts and Dependency Injection (CDI) 1.1 (JSR 346)
- Dependency Injection for Java 1.0 (JSR 330)
- Enterprise JavaBeans 3.2 Lite (JSR 345)
- Java Persistence API 2.1 (JSR 338)
- Common Annotations for the Java Platform 1.1 (JSR 250)
- Java Transaction API (JTA) 1.2 (JSR 907)
- Bean Validation 1.1 (JSR 349)
The full platform implementation defined by the Java EE 7 specification includes additional APIs.
Java Enterprise Edition 7 Full Platform
The Java EE 7 specification full platform includes all APIs and specifications included in the Java EE 7 specification. It supports the following APIs in addition to those supported in the Java Enterprise Edition 7 Web Profile:
Included in the Java EE 7 full platform:
- Batch 1.0
- JSON-P 1.0
- Concurrency 1.0
- WebSocket 1.1
- JMS 2.0
- JPA 2.1
- JCA 1.7
- JAX-RS 2.0
- JAX-WS 2.2
- Servlet 3.1
- JSF 2.2
- JSP 2.3
- EL 3.0
- CDI 1.1
- CDI Extensions
- JTA 1.2
- Interceptors 1.2
- Common Annotations 1.1
- Managed Beans 1.0
- EJB 3.2
- Bean Validation 1.1
1.3. Setting up the Development Environment
It is recommended to use JBoss Developer Studio 11.0 or later with JBoss EAP 7.1.
Download and install JBoss Developer Studio.
For instructions, see Installing JBoss Developer Studio Stand-alone Using the Installer in the JBoss Developer Studio Installation Guide.
Set up the JBoss EAP server in JBoss Developer Studio.
For instructions, see Using Runtime Detection to Set Up JBoss EAP from within the IDE in the Getting Started with JBoss Developer Studio Tools guide.
1.4. Configure Annotation Processing in JBoss Developer Studio
Annotation Processing (AP) is turned off by default in Eclipse. If your project generates implementation classes, this can result in java.lang.ExceptionInInitializerError exceptions, followed by CLASS_NAME (implementation not found) error messages when you deploy your project.
You can resolve these issues in one of the following ways. You can enable annotation processing for the individual project or you can enable annotation processing globally for all JBoss Developer Studio projects.
Enable Annotation Processing for an Individual Project
To enable annotation processing for a specific project, you must add the m2e.apt.activation property with a value of jdt_apt to the project’s pom.xml file.
<properties>
<m2e.apt.activation>jdt_apt</m2e.apt.activation>
</properties>
<properties>
<m2e.apt.activation>jdt_apt</m2e.apt.activation>
</properties>
You can find examples of this technique in the pom.xml files for the logging-tools and kitchensink-ml quickstarts that ship with JBoss EAP.
Enable Annotation Processing Globally in JBoss Developer Studio
- Select Window → Preferences.
- Expand Maven, and select Annotation Processing.
- Under Select Annotation Processing Mode, select Automatically configure JDT APT (builds faster , but outcome may differ from Maven builds), then click Apply and Close.
1.5. Configure the Default Welcome Web Application
JBoss EAP includes a default Welcome application, which displays at the root context on port 8080 by default.
This default Welcome application can be replaced with your own web application. This can be configured in one of two ways:
You can also disable the welcome content.
Change the welcome-content File Handler
Modify the existing
welcome-contentfile handler’s path to point to the new deployment./subsystem=undertow/configuration=handler/file=welcome-content:write-attribute(name=path,value="/path/to/content")
/subsystem=undertow/configuration=handler/file=welcome-content:write-attribute(name=path,value="/path/to/content")Copy to Clipboard Copied! Toggle word wrap Toggle overflow NoteAlternatively, you could create a different file handler to be used by the server’s root.
/subsystem=undertow/configuration=handler/file=NEW_FILE_HANDLER:add(path="/path/to/content") /subsystem=undertow/server=default-server/host=default-host/location=\/:write-attribute(name=handler,value=NEW_FILE_HANDLER)
/subsystem=undertow/configuration=handler/file=NEW_FILE_HANDLER:add(path="/path/to/content") /subsystem=undertow/server=default-server/host=default-host/location=\/:write-attribute(name=handler,value=NEW_FILE_HANDLER)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Reload the server for the changes to take effect.
reload
reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Change the default-web-module
Map a deployed web application to the server’s root.
/subsystem=undertow/server=default-server/host=default-host:write-attribute(name=default-web-module,value=hello.war)
/subsystem=undertow/server=default-server/host=default-host:write-attribute(name=default-web-module,value=hello.war)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Reload the server for the changes to take effect.
reload
reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Disable the Default Welcome Web Application
Disable the welcome application by removing the
locationentry/for thedefault-host./subsystem=undertow/server=default-server/host=default-host/location=\/:remove
/subsystem=undertow/server=default-server/host=default-host/location=\/:removeCopy to Clipboard Copied! Toggle word wrap Toggle overflow Reload the server for the changes to take effect.
reload
reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Chapter 2. Using Maven with JBoss EAP
2.1. Learn about Maven
2.1.1. About the Maven Repository
Apache Maven is a distributed build automation tool used in Java application development to create, manage, and build software projects. Maven uses standard configuration files called Project Object Model, or POM, files to define projects and manage the build process. POMs describe the module and component dependencies, build order, and targets for the resulting project packaging and output using an XML file. This ensures that the project is built in a correct and uniform manner.
Maven achieves this by using a repository. A Maven repository stores Java libraries, plug-ins, and other build artifacts. The default public repository is the Maven 2 Central Repository, but repositories can be private and internal within a company with a goal to share common artifacts among development teams. Repositories are also available from third-parties. JBoss EAP includes a Maven repository that contains many of the requirements that Java EE developers typically use to build applications on JBoss EAP. To configure your project to use this repository, see Configure the JBoss EAP Maven Repository.
For more information about Maven, see Welcome to Apache Maven.
For more information about Maven repositories, see Apache Maven Project - Introduction to Repositories.
2.1.2. About the Maven POM File
The Project Object Model, or POM, file is a configuration file used by Maven to build projects. It is an XML file that contains information about the project and how to build it, including the location of the source, test, and target directories, the project dependencies, plug-in repositories, and goals it can execute. It can also include additional details about the project including the version, description, developers, mailing list, license, and more. A pom.xml file requires some configuration options and will default all others.
The schema for the pom.xml file can be found at http://maven.apache.org/maven-v4_0_0.xsd.
For more information about POM files, see the Apache Maven Project POM Reference.
Minimum Requirements of a Maven POM File
The minimum requirements of a pom.xml file are as follows:
- project root
- modelVersion
- groupId - the ID of the project’s group
- artifactId - the ID of the artifact (project)
- version - the version of the artifact under the specified group
Example: Basic pom.xml File
A basic pom.xml file might look like this:
2.1.3. About the Maven Settings File
The Maven settings.xml file contains user-specific configuration information for Maven. It contains information that must not be distributed with the pom.xml file, such as developer identity, proxy information, local repository location, and other settings specific to a user.
There are two locations where the settings.xml can be found:
-
In the Maven installation: The settings file can be found in the
$M2_HOME/conf/directory. These settings are referred to asglobalsettings. The default Maven settings file is a template that can be copied and used as a starting point for the user settings file. -
In the user’s installation: The settings file can be found in the
${user.home}/.m2/directory. If both the Maven and usersettings.xmlfiles exist, the contents are merged. Where there are overlaps, the user’ssettings.xmlfile takes precedence.
Example: Maven Settings File
The schema for the settings.xml file can be found at http://maven.apache.org/xsd/settings-1.0.0.xsd.
2.1.4. About Maven Repository Managers
A repository manager is a tool that allows you to easily manage Maven repositories. Repository managers are useful in multiple ways:
- They provide the ability to configure proxies between your organization and remote Maven repositories. This provides a number of benefits, including faster and more efficient deployments and a better level of control over what is downloaded by Maven.
- They provide deployment destinations for your own generated artifacts, allowing collaboration between different development teams across an organization.
For more information about Maven repository managers, see Best Practice - Using a Repository Manager.
Commonly used Maven repository managers
- Sonatype Nexus
- See Sonatype Nexus documentation for more information about Nexus.
- Artifactory
- See JFrog Artifactory documentation for more information about Artifactory.
- Apache Archiva
- See Apache Archiva: The Build Artifact Repository Manager for more information about Apache Archiva.
In an enterprise environment, where a repository manager is usually used, Maven should query all artifacts for all projects using this manager. Because Maven uses all declared repositories to find missing artifacts, if it can not find what it is looking for, it will try and look for it in the repository central (defined in the built-in parent POM). To override this central location, you can add a definition with central so that the default repository central is now your repository manager as well. This works well for established projects, but for clean or 'new' projects it causes a problem as it creates a cyclic dependency.
2.2. Install Maven and the JBoss EAP Maven Repository
2.2.1. Download and Install Maven
If you plan to use Maven command line to build and deploy your applications to JBoss EAP, you must download and install Maven. If you plan to use Red Hat JBoss Developer Studio to build and deploy your applications, you can skip this procedure as Maven is distributed with Red Hat JBoss Developer Studio.
- Go to Apache Maven Project - Download Maven and download the latest distribution for your operating system.
- See the Maven documentation for information on how to download and install Apache Maven for your operating system.
2.2.2. Download the JBoss EAP Maven Repository
There are two ways to download the JBoss EAP Maven repository:
2.2.2.1. Download the JBoss EAP Maven Repository ZIP File from the Customer Portal
Follow these steps to download the JBoss EAP Maven repository.
- Open a web browser and access this URL: https://access.redhat.com/jbossnetwork/restricted/listSoftware.html?product=appplatform.
- Find Red Hat JBoss Enterprise Application Platform 7.1 Maven Repository in the list.
-
Click the Download button to download a
.zipfile containing the repository.
2.2.2.2. Download the JBoss EAP Maven Repository Using the Offliner Application
An Offliner application is now available as an alternate option to download the Maven artifacts from the Red Hat Maven repository for developing JBoss EAP 7.1 applications.
The process of downloading the JBoss EAP Maven repository using the Offliner application is provided as Technology Preview only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs), might not be functionally complete, and Red Hat does not recommend to use them for production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
See Technology Preview Features Support Scope on the Red Hat Customer Portal for information about the support scope for Technology Preview features.
Download the Maven Repository Offliner Content List text file,
jboss-eap-7.1.0-maven-repository-content-with-sha256-checksums.txt, from the JBoss EAP Software Downloads page. This serves as the input to the Offliner application.NoteThis file does not contain license information. The artifacts downloaded by the Offliner application have the same licenses as specified in the Maven repository ZIP file that is distributed with JBoss EAP.
- Download the Offliner application from the Maven Central Repository.
Run the Offliner application using the following command:
java -jar offliner.jar -r http://repository.redhat.com/ga/ -d FOLDER_TO_DOWNLOAD_TO jboss-eap-7.1.0-maven-repository-content-with-sha256-checksums.txt
$ java -jar offliner.jar -r http://repository.redhat.com/ga/ -d FOLDER_TO_DOWNLOAD_TO jboss-eap-7.1.0-maven-repository-content-with-sha256-checksums.txtCopy to Clipboard Copied! Toggle word wrap Toggle overflow The artifacts from the JBoss EAP Maven repository will be downloaded in the
FOLDER_TO_DOWNLOAD_TOdirectory.
See the Offliner documentation for more information on running the Offliner application.
The generated JBoss EAP Maven repository will have the same content that is currently available in the JBoss EAP Maven repository ZIP file. It will not contain artifacts available in Maven Central repository.
2.2.3. Install the JBoss EAP Maven Repository
There are three ways to install the JBoss EAP Maven repository.
- You can install the JBoss EAP Maven repository on your local file system. For detailed instructions, see Install the JBoss EAP Maven Repository Locally.
- You can install the JBoss EAP Maven repository on the Apache Web Server. For more information, see Install the JBoss EAP Maven Repository for Use with Apache httpd.
- You can install the JBoss EAP Maven repository using the Nexus Maven Repository Manager. For more information, see Repository Management Using Nexus Maven Repository Manager.
You can use the JBoss EAP Maven repository available online, or download and install it locally using any one of the three listed methods.
2.2.3.1. Install the JBoss EAP Maven Repository Locally
This section covers the steps to install the JBoss EAP Maven Repository to the local file system. This option is easy to configure and allows you to get up and running quickly on your local machine. It can help you become familiar with using Maven for development but is not recommended for team production environments.
Follow these steps to install the JBoss EAP Maven repository to the local file system.
- Make sure you have Download the JBoss EAP Maven Repository ZIP File from the Customer Portal to your local file system.
Unzip the file on the local file system into a directory of your choosing.
This creates a new
jboss-eap-7.1.0.GA-maven-repository/directory, which contains the Maven repository in a subdirectory namedmaven-repository/.
If you want to continue to use an older local repository, you must configure it separately in the Maven settings.xml configuration file. Each local repository must be configured within its own <repository> tag.
When downloading a new Maven repository, remove the cached repository/ subdirectory located under the .m2/ directory before attempting to use it.
2.2.3.2. Install the JBoss EAP Maven Repository for Use with Apache httpd
This section covers the steps to install the JBoss EAP Maven Repository for use with Apache httpd. This option is good for multi-user and cross-team development environments because any developer that can access the web server can also access the Maven repository.
You must first configure Apache httpd. See Apache HTTP Server Project documentation for instructions.
- Make sure you have Download the JBoss EAP Maven Repository ZIP File from the Customer Portal to your local file system.
- Unzip the file in a directory that is web accessible on the Apache server.
Configure Apache to allow read access and directory browsing in the created directory.
This configuration allows a multi-user environment to access the Maven repository on Apache httpd.
2.3. Use the Maven Repository
2.3.1. Configure the JBoss EAP Maven Repository
- Overview
There are two approaches to direct Maven to use the JBoss EAP Maven Repository in your project:
Configure the JBoss EAP Maven Repository Using the Maven Settings
This is the recommended approach. Maven settings used with a repository manager or repository on a shared server provide better control and manageability of projects. Settings also provide the ability to use an alternative mirror to redirect all lookup requests for a specific repository to your repository manager without changing the project files. For more information about mirrors, see http://maven.apache.org/guides/mini/guide-mirror-settings.html.
This method of configuration applies across all Maven projects, as long as the project POM file does not contain repository configuration.
This section describes how to configure the Maven settings. You can configure the Maven install global settings or the user’s install settings.
Configure the Maven Settings File
Locate the Maven
settings.xmlfile for your operating system. It is usually located in the${user.home}/.m2/directory.-
For Linux or Mac, this is
~/.m2/ -
For Windows, this is
\Documents and Settings\.m2\or\Users\.m2\
-
For Linux or Mac, this is
-
If you do not find a
settings.xmlfile, copy thesettings.xmlfile from the${user.home}/.m2/conf/directory into the${user.home}/.m2/directory. Copy the following XML into the
<profiles>element of thesettings.xmlfile. Determine the URL of the JBoss EAP repository and replace JBOSS_EAP_REPOSITORY_URL with it.Copy to Clipboard Copied! Toggle word wrap Toggle overflow The following is an example configuration that accesses the online JBoss EAP Maven repository.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy the following XML into the
<activeProfiles>element of thesettings.xmlfile.<activeProfile>jboss-enterprise-maven-repository</activeProfile>
<activeProfile>jboss-enterprise-maven-repository</activeProfile>Copy to Clipboard Copied! Toggle word wrap Toggle overflow If you modify the
settings.xmlfile while Red Hat JBoss Developer Studio is running, you must refresh the user settings.-
From the menu, choose
Window → Preferences. -
In the
Preferenceswindow, expandMavenand chooseUser Settings. Click the
Update Settingsbutton to refresh the Maven user settings in Red Hat JBoss Developer Studio.The Update Maven User Settings screen shot
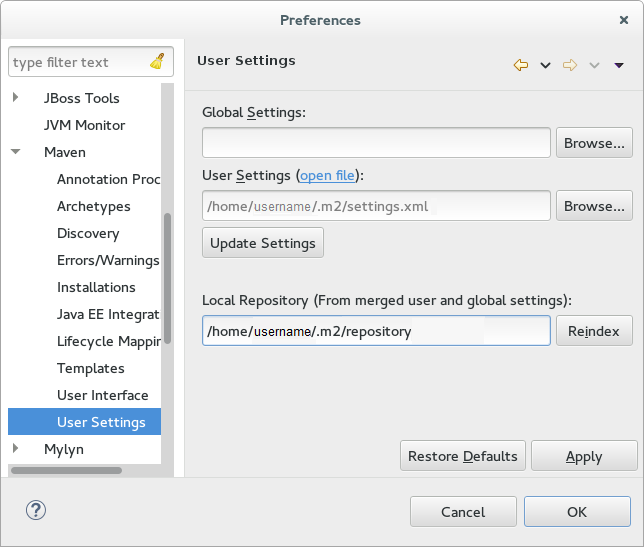
-
From the menu, choose
If your Maven repository contains outdated artifacts, you might encounter one of the following Maven error messages when you build or deploy your project:
- Missing artifact ARTIFACT_NAME
- [ERROR] Failed to execute goal on project PROJECT_NAME; Could not resolve dependencies for PROJECT_NAME
To resolve the issue, delete the cached version of your local repository to force a download of the latest Maven artifacts. The cached repository is located here: ${user.home}/.m2/repository/
Configure the JBoss EAP Maven Repository Using the Project POM
You should avoid this method of configuration as it overrides the global and user Maven settings for the configured project.
You must plan carefully if you decide to configure repositories using project POM file. Transitively included POMs are an issue with this type of configuration since Maven has to query the external repositories for missing artifacts and this slows the build process. It can also cause you to lose control over where your artifacts are coming from.
The URL of the repository will depend on where the repository is located: on the file system, or web server. For information on how to install the repository, see: Install the JBoss EAP Maven Repository. The following are examples for each of the installation options:
- File System
- file:///path/to/repo/jboss-eap-maven-repository
- Apache Web Server
- http://intranet.acme.com/jboss-eap-maven-repository/
- Nexus Repository Manager
- https://intranet.acme.com/nexus/content/repositories/jboss-eap-maven-repository
Configuring the Project’s POM File
-
Open your project’s
pom.xmlfile in a text editor. Add the following repository configuration. If there is already a
<repositories>configuration in the file, then add the<repository>element to it. Be sure to change the<url>to the actual repository location.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add the following plug-in repository configuration. If there is already a
<pluginRepositories>configuration in the file, then add the<pluginRepository>element to it.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Determine the URL of the JBoss EAP Repository
The repository URL depends on where the repository is located. You can configure Maven to use any of the following repository locations.
- To use the online JBoss EAP Maven repository, specify the following URL: https://maven.repository.redhat.com/ga/
- To use a JBoss EAP Maven repository installed on the local file system, you must download the repository and then use the local file path for the URL. For example: file:///path/to/repo/jboss-eap-7.1.0.GA-maven-repository/maven-repository/
- If you install the repository on an Apache Web Server, the repository URL will be similar to the following: http://intranet.acme.com/jboss-eap-7.1.0.GA-maven-repository/maven-repository/
- If you install the JBoss EAP Maven repository using the Nexus Repository Manager, the URL will look something like the following: https://intranet.acme.com/nexus/content/repositories/jboss-eap-7.1.0.GA-maven-repository/maven-repository/
Remote repositories are accessed using common protocols such as http:// for a repository on an HTTP server or file:// for a repository on a file server.
2.3.2. Configure Maven for Use with Red Hat JBoss Developer Studio
The artifacts and dependencies needed to build and deploy applications to Red Hat JBoss Enterprise Application Platform are hosted on a public repository. You must direct Maven to use this repository when you build your applications. This section covers the steps to configure Maven if you plan to build and deploy applications using Red Hat JBoss Developer Studio.
Maven is distributed with Red Hat JBoss Developer Studio, so it is not necessary to install it separately. However, you must configure Maven for use by the Java EE Web Project wizard for deployments to JBoss EAP. The procedure below demonstrates how to configure Maven for use with JBoss EAP by editing the Maven configuration file from within Red Hat JBoss Developer Studio.
Configure Maven in Red Hat JBoss Developer Studio
Click
Window → Preferences, expand JBoss Tools and select JBoss Maven Integration.JBoss Maven Integration Pane in the Preferences Window

- Click Configure Maven Repositories.
Click Add Repository to configure the JBoss Enterprise Maven repository. Complete the
Add Maven Repositorydialog as follows:-
Set the Profile ID, Repository ID, and Repository Name values to
jboss-ga-repository. -
Set the Repository URL value to
http://maven.repository.redhat.com/ga. - Click the Active by default checkbox to enable the Maven repository.
Click OK.
Add Maven Repository
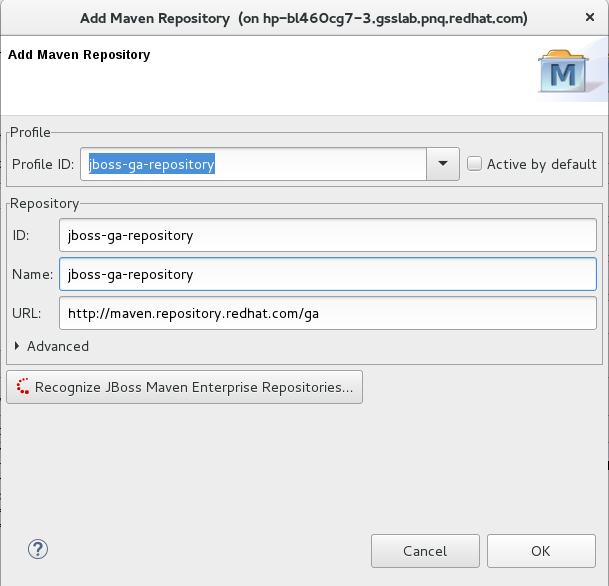
-
Set the Profile ID, Repository ID, and Repository Name values to
Review the repositories and click Finish.
Review Maven Repositories
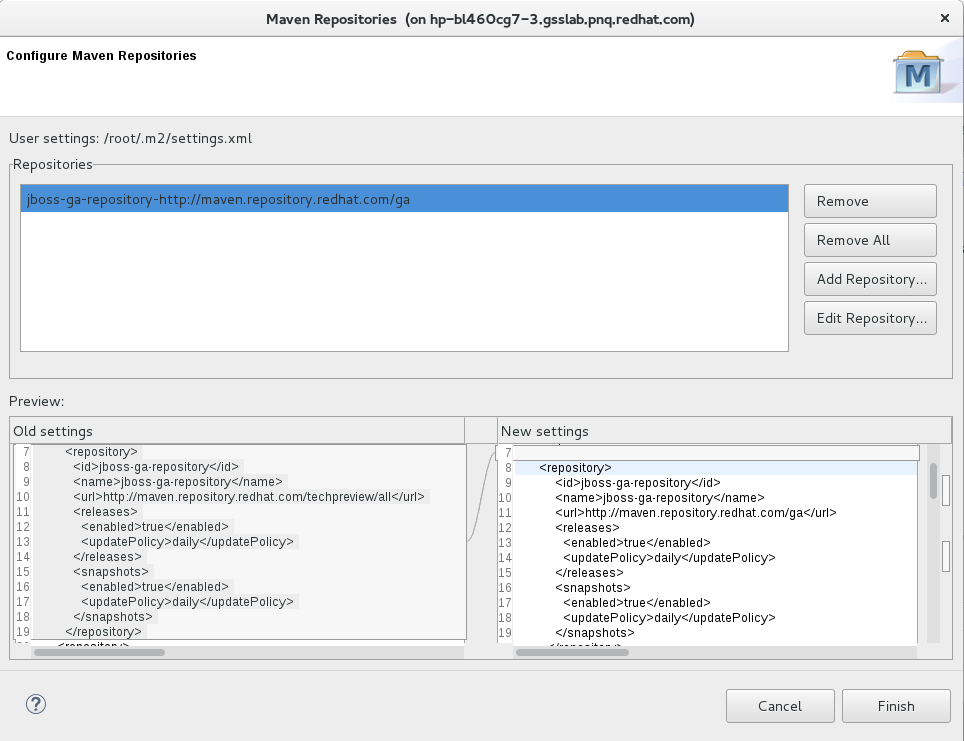
-
You are prompted with the message "Are you sure you want to update the file
MAVEN_HOME/settings.xml?". Click Yes to update the settings. Click OK to close the dialog.
The JBoss EAP Maven repository is now configured for use with Red Hat JBoss Developer Studio.
2.3.3. Manage Project Dependencies
This section describes the usage of Bill of Materials (BOM) POMs for Red Hat JBoss Enterprise Application Platform.
A BOM is a Maven pom.xml (POM) file that specifies the versions of all runtime dependencies for a given module. Version dependencies are listed in the dependency management section of the file.
A project uses a BOM by adding its groupId:artifactId:version (GAV) to the dependency management section of the project pom.xml file and specifying the <scope>import</scope> and <type>pom</type> element values.
In many cases, dependencies in project POM files use the provided scope. This is because these classes are provided by the application server at runtime and it is not necessary to package them with the user application.
Supported Maven Artifacts
As part of the product build process, all runtime components of JBoss EAP are built from source in a controlled environment. This helps to ensure that the binary artifacts do not contain any malicious code, and that they can be supported for the life of the product. These artifacts can be easily identified by the -redhat version qualifier, for example 1.0.0-redhat-1.
Adding a supported artifact to the build configuration pom.xml file ensures that the build is using the correct binary artifact for local building and testing. Note that an artifact with a -redhat version is not necessarily part of the supported public API, and might change in future revisions. For information about the public supported API, see the Javadoc documentation included in the release.
For example, to use the supported version of Hibernate, add something similar to the following to your build configuration.
Notice that the above example includes a value for the <version/> field. However, it is recommended to use Maven dependency management for configuring dependency versions.
Dependency Management
Maven includes a mechanism for managing the versions of direct and transitive dependencies throughout the build. For general information about using dependency management, see the Apache Maven Project: Introduction to the Dependency Mechanism.
Using one or more supported Red Hat dependencies directly in your build does not guarantee that all transitive dependencies of the build will be fully supported Red Hat artifacts. It is common for Maven builds to use a mix of artifact sources from the Maven central repository and other Maven repositories.
There is a dependency management BOM included in the JBoss EAP Maven repository, which specifies all the supported JBoss EAP binary artifacts. This BOM can be used in a build to ensure that Maven will prioritize supported JBoss EAP dependencies for all direct and transitive dependencies in the build. In other words, transitive dependencies will be managed to the correct supported dependency version where applicable. The version of this BOM matches the version of the JBoss EAP release.
In JBoss EAP 7 the name of this BOM was changed from eap6-supported-artifacts to eap-runtime-artifacts. The purpose of this change is to make it more clear that the artifacts in this POM are part of the JBoss EAP runtime, but are not necessarily part of the supported public API. Some of the jars contain internal API and functionality, which might change between releases.
JBoss EAP Java EE Specs BOM
The jboss-eap-javaee7 BOM contains the Java EE Specification API JARs used by JBoss EAP.
To use this BOM in a project, add a dependency for the GAV that contains the version of the JSP and Servlet API JARs needed to build and deploy the application.
The following example uses the 1.1.0.Final-redhat-1 version of the jboss-eap-javaee7 BOM.
JBoss EAP BOMs Available for Application Development
The following table lists the Maven BOMs that are available for application development.
| BOM Artifact ID | Use Case |
|---|---|
| jboss-eap-javaee7 | Supported JBoss EAP JavaEE 7 APIs plus additional JBoss EAP API JARs. |
| jboss-eap-javaee7-with-spring4 |
|
| jboss-eap-javaee7-with-tools |
|
These BOMs from JBoss EAP 6 have been consolidated into fewer BOMs to make usage simpler for most use cases. The Hibernate, logging, transactions, messaging, and other public API jars are now included in jboss-javaee7-eap instead of a requiring a separate BOM for each case.
The following example uses the 7.1.0.GA version of the jboss-eap-javaee7 BOM.
JBoss EAP Client BOMs
The client BOMs do not create a dependency management section or define dependencies. Instead, they are an aggregate of other BOMs and are used to package the set of dependencies necessary for a remote client use case.
The wildfly-ejb-client-bom and wildfly-jms-client-bom BOMs are managed by the jboss-eap-javaee7 BOM, so there is no need to manage the versions in your project dependencies.
The following is an example of how to add the wildfly-ejb-client-bom and wildfly-jms-client-bom client BOM dependencies to your project.
For more information about Maven Dependencies and BOM POM files, see Apache Maven Project - Introduction to the Dependency Mechanism.
Chapter 3. Class Loading and Modules
3.1. Introduction
3.1.1. Overview of Class Loading and Modules
JBoss EAP uses a modular class loading system for controlling the class paths of deployed applications. This system provides more flexibility and control than the traditional system of hierarchical class loaders. Developers have fine-grained control of the classes available to their applications, and can configure a deployment to ignore classes provided by the application server in favor of their own.
The modular class loader separates all Java classes into logical groups called modules. Each module can define dependencies on other modules in order to have the classes from that module added to its own class path. Because each deployed JAR and WAR file is treated as a module, developers can control the contents of their application’s class path by adding module configuration to their application.
3.1.2. Class Loading in Deployments
For the purposes of class loading, JBoss EAP treats all deployments as modules. These are called dynamic modules. Class loading behavior varies according to the deployment type.
- WAR Deployment
-
A WAR deployment is considered to be a single module. Classes in the
WEB-INF/libdirectory are treated the same as classes in theWEB-INF/classesdirectory. All classes packaged in the WAR will be loaded with the same class loader. - EAR Deployment
EAR deployments are made up of more than one module, and are defined by the following rules:
-
The
lib/directory of the EAR is a single module called the parent module. - Each WAR deployment within the EAR is a single module.
- Each EJB JAR deployment within the EAR is a single module.
-
The
Subdeployment modules, for example the WAR and JAR deployments within the EAR, have an automatic dependency on the parent module. However, they do not have automatic dependencies on each other. This is called subdeployment isolation and can be disabled per deployment or for the entire application server.
Explicit dependencies between subdeployment modules can be added by the same means as any other module.
3.1.3. Class Loading Precedence
The JBoss EAP modular class loader uses a precedence system to prevent class loading conflicts.
During deployment, a complete list of packages and classes is created for each deployment and each of its dependencies. The list is ordered according to the class loading precedence rules. When loading classes at runtime, the class loader searches this list, and loads the first match. This prevents multiple copies of the same classes and packages within the deployments class path from conflicting with each other.
The class loader loads classes in the following order, from highest to lowest:
Implicit dependencies: These dependencies are automatically added by JBoss EAP, such as the JAVA EE APIs. These dependencies have the highest class loader precedence because they contain common functionality and APIs that are supplied by JBoss EAP.
See Implicit Module Dependencies for complete details about each implicit dependency.
Explicit dependencies: These dependencies are manually added to the application configuration using the application’s
MANIFEST.MFfile or the new optional JBoss deployment descriptorjboss-deployment-structure.xmlfile.See Add an Explicit Module Dependency to a Deployment to learn how to add explicit dependencies.
-
Local resources: These are class files packaged up inside the deployment itself, for example in the
WEB-INF/classesorWEB-INF/libdirectories of a WAR file. -
Inter-deployment dependencies: These are dependencies on other deployments in a EAR deployment. This can include classes in the
libdirectory of the EAR or classes defined in other EJB jars.
3.1.4. jboss-deployment-structure.xml
The jboss-deployment-structure.xml file is an optional deployment descriptor for JBoss EAP. This deployment descriptor provides control over class loading in the deployment.
The XML schema for this deployment descriptor is located in the product install directory under EAP_HOME/docs/schema/jboss-deployment-structure-1_2.xsd.
The key tasks that can be performed using this deployment descriptor are:
- Defining explicit module dependencies.
- Preventing specific implicit dependencies from loading.
- Defining additional modules from the resources of that deployment.
- Changing the subdeployment isolation behavior in that EAR deployment.
- Adding additional resource roots to a module in an EAR.
3.2. Add an Explicit Module Dependency to a Deployment
Explicit module dependencies can be added to applications to add the classes of those modules to the class path of the application at deployment.
JBoss EAP automatically adds some dependencies to deployments. See Implicit Module Dependencies for details.
Prerequisites
- A working software project that you want to add a module dependency to.
- You must know the name of the module being added as a dependency. See Included Modules for the list of static modules included with JBoss EAP. If the module is another deployment, then see Dynamic Module Naming in the JBoss EAP Configuration Guide to determine the module name.
Dependencies can be configured using two methods:
-
Adding entries to the
MANIFEST.MFfile of the deployment. -
Adding entries to the
jboss-deployment-structure.xmldeployment descriptor.
Add a Dependency Configuration to MANIFEST.MF
Maven projects can be configured to create the required dependency entries in the MANIFEST.MF file.
-
If the project does not have one, create a file called
MANIFEST.MF. For a web application (WAR), add this file to theMETA-INF/directory. For an EJB archive (JAR), add it to theMETA-INF/directory. Add a dependencies entry to the
MANIFEST.MFfile with a comma-separated list of dependency module names:Dependencies: org.javassist, org.apache.velocity, org.antlr
Dependencies: org.javassist, org.apache.velocity, org.antlrCopy to Clipboard Copied! Toggle word wrap Toggle overflow To make a dependency optional, append
optionalto the module name in the dependency entry:Dependencies: org.javassist optional, org.apache.velocity
Dependencies: org.javassist optional, org.apache.velocityCopy to Clipboard Copied! Toggle word wrap Toggle overflow A dependency can be exported by appending
exportto the module name in the dependency entry:Dependencies: org.javassist, org.apache.velocity export
Dependencies: org.javassist, org.apache.velocity exportCopy to Clipboard Copied! Toggle word wrap Toggle overflow The
annotationsflag is needed when the module dependency contains annotations that need to be processed during annotation scanning, such as when declaring EJB interceptors. Without this, an EJB interceptor declared in a module cannot be used in a deployment. There are other situations involving annotation scanning when this is needed too.Dependencies: org.javassist, test.module annotations
Dependencies: org.javassist, test.module annotationsCopy to Clipboard Copied! Toggle word wrap Toggle overflow By default items in the
META-INFof a dependency are not accessible. Theservicesdependency makes items fromMETA-INF/servicesaccessible so thatservicesin the modules can be loaded.Dependencies: org.javassist, org.hibernate services
Dependencies: org.javassist, org.hibernate servicesCopy to Clipboard Copied! Toggle word wrap Toggle overflow To scan a
beans.xmlfile and make its resulting beans available to the application, themeta-infdependency can be used.Dependencies: org.javassist, test.module meta-inf
Dependencies: org.javassist, test.module meta-infCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Add a Dependency Configuration to the jboss-deployment-structure.xml
If the application does not have one, create a new file called
jboss-deployment-structure.xmland add it to the project. This file is an XML file with the root element of<jboss-deployment-structure>.<jboss-deployment-structure> </jboss-deployment-structure>
<jboss-deployment-structure> </jboss-deployment-structure>Copy to Clipboard Copied! Toggle word wrap Toggle overflow For a web application (WAR), add this file to the
WEB-INF/directory. For an EJB archive (JAR), add it to theMETA-INF/directory.-
Create a
<deployment>element within the document root and a<dependencies>element within that. Within the
<dependencies>node, add a module element for each module dependency. Set thenameattribute to the name of the module.<module name="org.javassist" />
<module name="org.javassist" />Copy to Clipboard Copied! Toggle word wrap Toggle overflow A dependency can be made optional by adding the
optionalattribute to the module entry with the value oftrue. The default value for this attribute isfalse.<module name="org.javassist" optional="true" />
<module name="org.javassist" optional="true" />Copy to Clipboard Copied! Toggle word wrap Toggle overflow A dependency can be exported by adding the
exportattribute to the module entry with the value oftrue. The default value for this attribute isfalse.<module name="org.javassist" export="true" />
<module name="org.javassist" export="true" />Copy to Clipboard Copied! Toggle word wrap Toggle overflow When the module dependency contains annotations that need to be processed during annotation scanning, the
annotationsflag is used.<module name="test.module" annotations="true" />
<module name="test.module" annotations="true" />Copy to Clipboard Copied! Toggle word wrap Toggle overflow The
servicesdependency specifies whether and howservicesfound in this dependency are used. The default isnone. Specifying a value ofimportfor this attribute is equivalent to adding a filter at the end of the import filter list which includes theMETA-INF/servicespath from the dependency module. Setting a value ofexportfor this attribute is equivalent to the same action on the export filter list.<module name="org.hibernate" services="import" />
<module name="org.hibernate" services="import" />Copy to Clipboard Copied! Toggle word wrap Toggle overflow The
META-INFdependency specifies whether and howMETA-INFentries in this dependency are used. The default isnone. Specifying a value ofimportfor this attribute is equivalent to adding a filter at the end of the import filter list which includes theMETA-INF/**path from the dependency module. Setting a value ofexportfor this attribute is equivalent to the same action on the export filter list.<module name="test.module" meta-inf="import" />
<module name="test.module" meta-inf="import" />Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Example: jboss-deployment-structure.xml File with Two Dependencies
JBoss EAP adds the classes from the specified modules to the class path of the application when it is deployed.
Creating a Jandex Index
The annotations flag requires that the module contain a Jandex index. In JBoss EAP 7.1, this is generated automatically. However, adding the index manually is still recommended for performance reasons because automatic scanning can be a long process that consumes the CPU and increases the deployment time.
To add the index manually, create a new "index JAR" to add to the module. Use the Jandex JAR to build the index, and then insert it into a new JAR file. In the current implementation, when an index is added to a JAR file inside a module, no scanning at all is executed.
Creating a Jandex index::
Create the index:
java -jar modules/system/layers/base/org/jboss/jandex/main/jandex-jandex-2.0.0.Final-redhat-1.jar $JAR_FILE
java -jar modules/system/layers/base/org/jboss/jandex/main/jandex-jandex-2.0.0.Final-redhat-1.jar $JAR_FILECopy to Clipboard Copied! Toggle word wrap Toggle overflow Create a temporary working space:
mkdir /tmp/META-INF
mkdir /tmp/META-INFCopy to Clipboard Copied! Toggle word wrap Toggle overflow Move the index file to the working directory
mv $JAR_FILE.ifx /tmp/META-INF/jandex.idx
mv $JAR_FILE.ifx /tmp/META-INF/jandex.idxCopy to Clipboard Copied! Toggle word wrap Toggle overflow Option 1: Include the index in a new JAR file
jar cf index.jar -C /tmp META-INF/jandex.idx
jar cf index.jar -C /tmp META-INF/jandex.idxCopy to Clipboard Copied! Toggle word wrap Toggle overflow Then place the JAR in the module directory and edit
module.xmlto add it to the resource roots.Option 2: Add the index to an existing JAR
java -jar /modules/org/jboss/jandex/main/jandex-1.0.3.Final-redhat-1.jar -m $JAR_FILE
java -jar /modules/org/jboss/jandex/main/jandex-1.0.3.Final-redhat-1.jar -m $JAR_FILECopy to Clipboard Copied! Toggle word wrap Toggle overflow
Tell the module import to utilize the annotation index, so that annotation scanning can find the annotations.
Option 1: If you are adding a module dependency using
MANIFEST.MF, addannotationsafter the module name. For example change:Dependencies: test.module, other.module
Dependencies: test.module, other.moduleCopy to Clipboard Copied! Toggle word wrap Toggle overflow to
Dependencies: test.module annotations, other.module
Dependencies: test.module annotations, other.moduleCopy to Clipboard Copied! Toggle word wrap Toggle overflow Option 2: If you are adding a module dependency using
jboss-deployment-structure.xmladdannotations="true"on the module dependency.NoteAn annotation index is required when an application wants to use annotated Java EE components defined in classes within the static module. In JBoss EAP 7.1, annotation indexes for static modules are automatically generated, so you do not need to create them. However, you must tell the module import to use the annotations by adding the dependencies to either the
MANIFEST.MFor thejboss-deployment-structure.xmlfile.
3.3. Generate MANIFEST.MF entries using Maven
Maven projects using the Maven JAR, EJB, or WAR packaging plug-ins can generate a MANIFEST.MF file with a Dependencies entry. This does not automatically generate the list of dependencies, but only creates the MANIFEST.MF file with the details specified in the pom.xml.
Before generating the MANIFEST.MF entries using Maven, you will require:
-
A working Maven project, which is using one of the JAR, EJB, or WAR plug-ins (
maven-jar-plugin,maven-ejb-plugin, ormaven-war-plugin). - You must know the name of the project’s module dependencies. Refer to Included Modules for the list of static modules included with JBoss EAP. If the module is another deployment, then refer to Dynamic Module Naming in the JBoss EAP Configuration Guide to determine the module name.
Generate a MANIFEST.MF File Containing Module Dependencies
Add the following configuration to the packaging plug-in configuration in the project’s
pom.xmlfile.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add the list of module dependencies to the
<Dependencies>element. Use the same format that is used when adding the dependencies to theMANIFEST.MFfile:<Dependencies>org.javassist, org.apache.velocity</Dependencies>
<Dependencies>org.javassist, org.apache.velocity</Dependencies>Copy to Clipboard Copied! Toggle word wrap Toggle overflow The
optionalandexportattributes can also be used here:<Dependencies>org.javassist optional, org.apache.velocity export</Dependencies>
<Dependencies>org.javassist optional, org.apache.velocity export</Dependencies>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Build the project using the Maven assembly goal:
mvn assembly:single
[Localhost ]$ mvn assembly:singleCopy to Clipboard Copied! Toggle word wrap Toggle overflow When the project is built using the assembly goal, the final archive contains a
MANIFEST.MFfile with the specified module dependencies.Example: Configured Module Dependencies in
pom.xmlNoteThe example here shows the WAR plug-in but it also works with the JAR and EJB plug-ins (maven-jar-plugin and maven-ejb-plugin).
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.4. Prevent a Module Being Implicitly Loaded
You can configure a deployable application to prevent implicit dependencies from being loaded. This can be useful when an application includes a different version of a library or framework than the one that will be provided by the application server as an implicit dependency.
Prerequisites
- A working software project that you want to exclude an implicit dependency from.
- You must know the name of the module to exclude. Refer to Implicit Module Dependencies for a list of implicit dependencies and their conditions.
Add dependency exclusion configuration to jboss-deployment-structure.xml
If the application does not have one, create a new file called
jboss-deployment-structure.xmland add it to the project. This is an XML file with the root element of<jboss-deployment-structure>.<jboss-deployment-structure> </jboss-deployment-structure>
<jboss-deployment-structure> </jboss-deployment-structure>Copy to Clipboard Copied! Toggle word wrap Toggle overflow For a web application (WAR), add this file to the
WEB-INF/directory. For an EJB archive (JAR), add it to theMETA-INF/directory.Create a
<deployment>element within the document root and an<exclusions>element within that.<deployment> <exclusions> </exclusions> </deployment>
<deployment> <exclusions> </exclusions> </deployment>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Within the exclusions element, add a
<module>element for each module to be excluded. Set thenameattribute to the name of the module.<module name="org.javassist" />
<module name="org.javassist" />Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example: Excluding Two Modules
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.5. Exclude a Subsystem from a Deployment
Excluding a subsystem provides the same effect as removing the subsystem, but it applies only to a single deployment. You can exclude a subsystem from a deployment by editing the jboss-deployment-structure.xml configuration file.
Exclude a Subsystem
-
Edit the
jboss-deployment-structure.xmlfile. Add the following XML inside the
<deployment>tags:<exclude-subsystems> <subsystem name="SUBSYSTEM_NAME" /> </exclude-subsystems>
<exclude-subsystems> <subsystem name="SUBSYSTEM_NAME" /> </exclude-subsystems>Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
Save the
jboss-deployment-structure.xmlfile.
The subsystem’s deployment unit processors will no longer run on the deployment.
Example: jboss-deployment-structure.xml File
3.6. Use the Class Loader Programmatically in a Deployment
3.6.1. Programmatically Load Classes and Resources in a Deployment
You can programmatically find or load classes and resources in your application code. The method you choose depends on a number of factors. This section describes the methods available and provides guidelines for when to use them.
Load a Class Using the Class.forName() Method
You can use the Class.forName() method to programmatically load and initialize classes. This method has two signatures:
Class.forName(String className):This signature takes only one parameter, the name of the class you need to load. With this method signature, the class is loaded by the class loader of the current class and initializes the newly loaded class by default.
Class.forName(String className, boolean initialize, ClassLoader loader):This signature expects three parameters: the class name, a boolean value that specifies whether to initialize the class, and the
ClassLoaderthat should load the class.
The three argument signature is the recommended way to programmatically load a class. This signature allows you to control whether you want the target class to be initialized upon load. It is also more efficient to obtain and provide the class loader because the JVM does not need to examine the call stack to determine which class loader to use. Assuming the class containing the code is named CurrentClass, you can obtain the class’s class loader using CurrentClass.class.getClassLoader() method.
The following example provides the class loader to load and initialize the TargetClass class:
Class<?> targetClass = Class.forName("com.myorg.util.TargetClass", true, CurrentClass.class.getClassLoader());
Class<?> targetClass = Class.forName("com.myorg.util.TargetClass", true, CurrentClass.class.getClassLoader());Find All Resources with a Given Name
If you know the name and path of a resource, the best way to load it directly is to use the standard Java Development Kit (JDK) Class or ClassLoader API.
Load a single resource.
To load a single resource located in the same directory as your class or another class in your deployment, you can use the
Class.getResourceAsStream()method.InputStream inputStream = CurrentClass.class.getResourceAsStream("targetResourceName");InputStream inputStream = CurrentClass.class.getResourceAsStream("targetResourceName");Copy to Clipboard Copied! Toggle word wrap Toggle overflow Load all instances of a single resource.
To load all instances of a single resource that are visible to your deployment’s class loader, use the
Class.getClassLoader().getResources(String resourceName)method, whereresourceNameis the fully qualified path of the resource. This method returns an Enumeration of allURLobjects for resources accessible by the class loader with the given name. You can then iterate through the array of URLs to open each stream using theopenStream()method.The following example loads all instances of a resource and iterates through the results.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow NoteBecause the URL instances are loaded from local storage, it is not necessary to use the
openConnection()or other related methods. Streams are much simpler to use and minimize the complexity of the code.Load a class file from the class loader.
If a class has already been loaded, you can load the class file that corresponds to that class using the following syntax:
InputStream inputStream = CurrentClass.class.getResourceAsStream(TargetClass.class.getSimpleName() + ".class");
InputStream inputStream = CurrentClass.class.getResourceAsStream(TargetClass.class.getSimpleName() + ".class");Copy to Clipboard Copied! Toggle word wrap Toggle overflow If the class is not yet loaded, you must use the class loader and translate the path:
String className = "com.myorg.util.TargetClass" InputStream inputStream = CurrentClass.class.getClassLoader().getResourceAsStream(className.replace('.', '/') + ".class");String className = "com.myorg.util.TargetClass" InputStream inputStream = CurrentClass.class.getClassLoader().getResourceAsStream(className.replace('.', '/') + ".class");Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.6.2. Programmatically Iterate Resources in a Deployment
The JBoss Modules library provides several APIs for iterating all deployment resources. The JavaDoc for the JBoss Modules API is located here: http://docs.jboss.org/jbossmodules/1.3.0.Final/api/. To use these APIs, you must add the following dependency to the MANIFEST.MF:
Dependencies: org.jboss.modules
Dependencies: org.jboss.modulesIt is important to note that while these APIs provide increased flexibility, they also run much more slowly than a direct path lookup.
This section describes some of the ways you can programmatically iterate through resources in your application code.
List resources within a deployment and within all imports.
There are times when it is not possible to look up resources by the exact path. For example, the exact path might not be known or you might need to examine more than one file in a given path. In this case, the JBoss Modules library provides several APIs for iterating all deployment resources. You can iterate through resources in a deployment by utilizing one of two methods.
Iterate all resources found in a single module.
The
ModuleClassLoader.iterateResources()method iterates all the resources within this module class loader. This method takes two arguments: the starting directory name to search and a boolean that specifies whether it should recurse into subdirectories.The following example demonstrates how to obtain the ModuleClassLoader and obtain the iterator for resources in the
bin/directory, recursing into subdirectories.ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = moduleClassLoader.iterateResources("bin",true);ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = moduleClassLoader.iterateResources("bin",true);Copy to Clipboard Copied! Toggle word wrap Toggle overflow The resultant iterator can be used to examine each matching resource and query its name and size (if available), open a readable stream, or acquire a URL for the resource.
Iterate all resources found in a single module and imported resources.
The
Module.iterateResources()method iterates all the resources within this module class loader, including the resources that are imported into the module. This method returns a much larger set than the previous method. This method requires an argument, which is a filter that narrows the result to a specific pattern. Alternatively, PathFilters.acceptAll() can be supplied to return the entire set.The following example demonstrates how to find the entire set of resources in this module, including imports.
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Module module = moduleClassLoader.getModule(); Iterator<Resource> moduleResources = module.iterateResources(PathFilters.acceptAll());
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Module module = moduleClassLoader.getModule(); Iterator<Resource> moduleResources = module.iterateResources(PathFilters.acceptAll());Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Find all resources that match a pattern.
If you need to find only specific resources within your deployment or within your deployment’s full import set, you need to filter the resource iteration. The JBoss Modules filtering APIs give you several tools to accomplish this.
Examine the full set of dependencies.
If you need to examine the full set of dependencies, you can use the
Module.iterateResources()method’sPathFilterparameter to check the name of each resource for a match.Examine deployment dependencies.
If you need to look only within the deployment, use the
ModuleClassLoader.iterateResources()method. However, you must use additional methods to filter the resultant iterator. ThePathFilters.filtered()method can provide a filtered view of a resource iterator this case. ThePathFiltersclass includes many static methods to create and compose filters that perform various functions, including finding child paths or exact matches, or matching an Ant-style "glob" pattern.
Additional code examples for filtering resources.
The following examples demonstrate how to filter resources based on different criteria.
Example: Find All Files Named
messages.propertiesin Your DeploymentModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = PathFilters.filtered(PathFilters.match("**/messages.properties"), moduleClassLoader.iterateResources("", true));ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = PathFilters.filtered(PathFilters.match("**/messages.properties"), moduleClassLoader.iterateResources("", true));Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example: Find All Files Named
messages.propertiesin Your Deployment and ImportsModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Module module = moduleClassLoader.getModule(); Iterator<Resource> moduleResources = module.iterateResources(PathFilters.match("**/message.properties"));ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Module module = moduleClassLoader.getModule(); Iterator<Resource> moduleResources = module.iterateResources(PathFilters.match("**/message.properties"));Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example: Find All Files Inside Any Directory Named
my-resourcesin Your DeploymentModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = PathFilters.filtered(PathFilters.match("**/my-resources/**"), moduleClassLoader.iterateResources("", true));ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = PathFilters.filtered(PathFilters.match("**/my-resources/**"), moduleClassLoader.iterateResources("", true));Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example: Find All Files Named
messagesorerrorsin Your Deployment and ImportsModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Module module = moduleClassLoader.getModule(); Iterator<Resource> moduleResources = module.iterateResources(PathFilters.any(PathFilters.match("**/messages"), PathFilters.match("**/errors"));ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Module module = moduleClassLoader.getModule(); Iterator<Resource> moduleResources = module.iterateResources(PathFilters.any(PathFilters.match("**/messages"), PathFilters.match("**/errors"));Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example: Find All Files in a Specific Package in Your Deployment
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = moduleClassLoader.iterateResources("path/form/of/packagename", false);ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = moduleClassLoader.iterateResources("path/form/of/packagename", false);Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.7. Class Loading and Subdeployments
3.7.1. Modules and Class Loading in Enterprise Archives
Enterprise Archives (EAR) are not loaded as a single module like JAR or WAR deployments. They are loaded as multiple unique modules.
The following rules determine what modules exist in an EAR:
-
The contents of the
lib/directory in the root of the EAR archive is a module. This is called the parent module. - Each WAR and EJB JAR subdeployment is a module. These modules have the same behavior as any other module as well as implicit dependencies on the parent module.
- Subdeployments have implicit dependencies on the parent module and any other non-WAR subdeployments.
The implicit dependencies on non-WAR subdeployments occur because JBoss EAP has subdeployment class loader isolation disabled by default. Dependencies on the parent module persist, regardless of subdeployment class loader isolation.
No subdeployment ever gains an implicit dependency on a WAR subdeployment. Any subdeployment can be configured with explicit dependencies on another subdeployment as would be done for any other module.
Subdeployment class loader isolation can be enabled if strict compatibility is required. This can be enabled for a single EAR deployment or for all EAR deployments. The Java EE specification recommends that portable applications should not rely on subdeployments being able to access each other unless dependencies are explicitly declared as Class-Path entries in the MANIFEST.MF file of each subdeployment.
3.7.2. Subdeployment Class Loader Isolation
Each subdeployment in an Enterprise Archive (EAR) is a dynamic module with its own class loader. By default, a subdeployment can access the resources of other subdeployments.
If a subdeployment is not to be allowed to access the resources of other subdeployments, strict subdeployment isolation can be enabled.
3.7.3. Enable Subdeployment Class Loader Isolation Within a EAR
This task shows you how to enable subdeployment class loader isolation in an EAR deployment by using a special deployment descriptor in the EAR. This does not require any changes to be made to the application server and does not affect any other deployments.
Even when subdeployment class loader isolation is disabled, it is not possible to add a WAR deployment as a dependency.
Add the deployment descriptor file.
Add the
jboss-deployment-structure.xmldeployment descriptor file to theMETA-INFdirectory of the EAR if it doesn’t already exist and add the following content:<jboss-deployment-structure> </jboss-deployment-structure>
<jboss-deployment-structure> </jboss-deployment-structure>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add the
<ear-subdeployments-isolated>element.Add the
<ear-subdeployments-isolated>element to thejboss-deployment-structure.xmlfile if it doesn’t already exist with the content oftrue.<ear-subdeployments-isolated>true</ear-subdeployments-isolated>
<ear-subdeployments-isolated>true</ear-subdeployments-isolated>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Subdeployment class loader isolation is now enabled for this EAR deployment. This means that the subdeployments of the EAR will not have automatic dependencies on each of the non-WAR subdeployments.
3.7.4. Configuring Session Sharing between Subdeployments in Enterprise Archives
JBoss EAP provides the ability to configure enterprise archives (EARs) to share sessions between WAR module subdeployments contained in the EAR. This functionality is disabled by default and must be explicitly enabled in the META-INF/jboss-all.xml file in the EAR.
Since this feature is not a standard servlet feature, your applications might not be portable if this functionality is enabled.
To enable session sharing between WARs within an EAR, you need to declare a shared-session-config element in the META-INF/jboss-all.xml of the EAR:
Example: META-INF/jboss-all.xml
The shared-session-config element is used to configure the shared session manager for all WARs within the EAR. If the shared-session-config element is present, all WARs within the EAR will share the same session manager. Changes made here will affect all the WARs contained within the EAR.
3.8. Deploy Tag Library Descriptors (TLDs) in a Custom Module
If you have multiple applications that use common Tag Library Descriptors (TLDs), it might be useful to separate the TLDs from the applications so that they are located in one central and unique location. This enables easier additions and updates to TLDs without necessarily having to update each individual application that uses them.
This can be done by creating a custom JBoss EAP module that contains the TLD JARs, and declaring a dependency on that module in the applications.
Ensure that at least one JAR contains TLDs and that the TLDs are packed in META-INF.
Deploy TLDs in a Custom Module
Using the management CLI, connect to your JBoss EAP instance and execute the following command to create the custom module containing the TLD JAR:
module add --name=MyTagLibs --resources=/path/to/TLDarchive.jar
module add --name=MyTagLibs --resources=/path/to/TLDarchive.jarCopy to Clipboard Copied! Toggle word wrap Toggle overflow ImportantUsing the
modulemanagement CLI command to add and remove modules is provided as Technology Preview only. This command is not appropriate for use in a managed domain or when connecting to the management CLI remotely. Modules should be added and removed manually in a production environment. For more information, see the Create a Custom Module Manually and Remove a Custom Module Manually sections of the JBoss EAP Configuration Guide.Technology Preview features are not supported with Red Hat production service level agreements (SLAs), might not be functionally complete, and Red Hat does not recommend to use them for production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
See Technology Preview Features Support Scope on the Red Hat Customer Portal for information about the support scope for Technology Preview features.
If the TLDs are packaged with classes that require dependencies, use the
--dependenciesoption to ensure that you specify those dependencies when creating the custom module.When creating the module, you can specify multiple JAR resources by separating each one with the file system-specific separator for your system.
-
For linux -
:. Example,--resources=<path-to-jar>:<path-to-another-jar> For Windows -
;. Example,--resources=<path-to-jar>;<path-to-another-jar>Note--resources-
It is required unless
--module-xmlis used. It lists file system paths, usually JAR files, separated by a file system-specific path separator, for examplejava.io.File.pathSeparatorChar. The files specified will be copied to the created module’s directory. --resource-delimiter-
It is an optional user-defined path separator for the resources argument. If this argument is present, the command parser will use the value here instead of the file system-specific path separator. This allows the
modulescommand to be used in cross-platform scripts.
-
For linux -
- In your applications, declare a dependency on the new MyTagLibs custom module using one of the methods described in Add an Explicit Module Dependency to a Deployment.
Ensure that you also import META-INF when declaring the dependency. For example, for MANIFEST.MF:
Dependencies: com.MyTagLibs meta-inf
Dependencies: com.MyTagLibs meta-inf
Or, for jboss-deployment-structure.xml, use the meta-inf attribute.
3.9. Class Loading Reference
3.9.1. Implicit Module Dependencies
The following table lists the modules that are automatically added to deployments as dependencies and the conditions that trigger the dependency.
| Subsystem Responsible for Adding the Dependency | Package Dependencies That Are Always Added | Package Dependencies That Are Conditionally Added | Conditions That Trigger the Addition of the Dependency |
|---|---|---|---|
| Application Client |
| ||
| Batch |
| ||
| Bean Validation |
| ||
| Core Server |
| ||
| DriverDependenciesProcessor |
| ||
| EE |
| ||
| EJB 3 |
|
| |
| IIOP |
| ||
| JAX-RS (RESTEasy) |
|
| The presence of JAX-RS annotations in the deployment. |
| JCA |
|
| The deployment of a resource adapter (RAR) archive. |
| JPA (Hibernate) |
|
|
The presence of an
JBoss EAP maps persistence provider names to module names. If you name a specific provider in the |
| JSF (Java Server Faces) |
| Added to EAR applications.
Added to WAR applications only if the | |
| JSR-77 |
| ||
| Logging |
| ||
| |
| ||
| Messaging |
|
| |
| PicketLink Federation |
| ||
| Pojo |
| ||
| SAR |
|
The deployment of a SAR archive that has a | |
| Seam2 |
| . | |
| Security |
| ||
| ServiceActivator |
| ||
| Transactions |
|
| |
| Undertow |
|
| |
| Web Services |
|
| If it is not application client type, then it will add the conditional dependencies. |
| Weld (CDI) |
|
|
The presence of a |
3.9.2. Included Modules
For the complete listing of the included modules and whether they are supported, see Red Hat JBoss Enterprise Application Platform 7 Included Modules on the Red Hat Customer Portal.
Chapter 4. Logging
4.1. About Logging
Logging is the practice of recording a series of messages from an application that provides a record, or log, of the application’s activities.
Log messages provide important information for developers when debugging an application and for system administrators maintaining applications in production.
Most modern Java logging frameworks also include details such as the exact time and the origin of the message.
4.1.1. Supported Application Logging Frameworks
JBoss LogManager supports the following logging frameworks:
- JBoss Logging (included with JBoss EAP)
- Apache Commons Logging
- Simple Logging Facade for Java (SLF4J)
- Apache log4j
- Java SE Logging (java.util.logging)
JBoss LogManager supports the following APIs:
- JBoss Logging
- commons-logging
- SLF4J
- Log4j
- java.util.logging
JBoss LogManager also supports the following SPIs:
- java.util.logging Handler
- Log4j Appender
If you are using the Log4j API and a Log4J Appender, then Objects will be converted to string before being passed.
4.2. Logging with the JBoss Logging Framework
4.2.1. About JBoss Logging
JBoss Logging is the application logging framework that is included in JBoss EAP. It provides an easy way to add logging to an application. You add code to your application that uses the framework to send log messages in a defined format. When the application is deployed to an application server, these messages can be captured by the server and displayed or written to file according to the server’s configuration.
JBoss Logging provides the following features:
-
An innovative, easy-to-use typed logger. A typed logger is a logger interface annotated with
org.jboss.logging.annotations.MessageLogger. For examples, see Creating Internationalized Loggers, Messages and Exceptions. - Full support for internationalization and localization. Translators work with message bundles in properties files while developers work with interfaces and annotations. For details, see Internationalization and Localization.
- Build-time tooling to generate typed loggers for production and runtime generation of typed loggers for development.
4.2.2. Add Logging to an Application with JBoss Logging
This procedure demonstrates how to add logging to an application using JBoss Logging.
If you use Maven to build your project, you must configure Maven to use the JBoss EAP Maven repository. For more information, see Configure the JBoss EAP Maven Repository.
The JBoss Logging JAR files must be in the build path for your application.
-
If you build using Red Hat JBoss Developer Studio, select
Propertiesfrom theProjectmenu, then selectTargeted Runtimesand ensure the runtime for JBoss EAP is checked. If you use Maven to build your project, make sure you add the
jboss-loggingdependency to your project’spom.xmlfile for access to the JBoss Logging framework:Copy to Clipboard Copied! Toggle word wrap Toggle overflow The
jboss-eap-javaee7BOM manages the version ofjboss-logging. For more details, see Manage Project Dependencies. See theloggingquickstart that ships with JBoss EAP for a working example of logging in an application.
You do not need to include the JARs in your built application because JBoss EAP provides them to deployed applications.
-
If you build using Red Hat JBoss Developer Studio, select
For each class to which you want to add logging:
Add the import statements for the JBoss Logging class namespaces that you will be using. At a minimum you will need the following import:
import org.jboss.logging.Logger;
import org.jboss.logging.Logger;Copy to Clipboard Copied! Toggle word wrap Toggle overflow Create an instance of
org.jboss.logging.Loggerand initialize it by calling the static methodLogger.getLogger(Class). It is recommended to create this as a single instance variable for each class.private static final Logger LOGGER = Logger.getLogger(HelloWorld.class);
private static final Logger LOGGER = Logger.getLogger(HelloWorld.class);Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Call the
Loggerobject methods in your code where you want to send log messages.The
Loggerhas many different methods with different parameters for different types of messages. Use the following methods to send a log message with the corresponding log level and themessageparameter as a string:LOGGER.debug("This is a debugging message."); LOGGER.info("This is an informational message."); LOGGER.error("Configuration file not found."); LOGGER.trace("This is a trace message."); LOGGER.fatal("A fatal error occurred.");LOGGER.debug("This is a debugging message."); LOGGER.info("This is an informational message."); LOGGER.error("Configuration file not found."); LOGGER.trace("This is a trace message."); LOGGER.fatal("A fatal error occurred.");Copy to Clipboard Copied! Toggle word wrap Toggle overflow For the complete list of JBoss Logging methods, see the Logging API documentation.
The following example loads customized configuration for an application from a properties file. If the specified file is not found, an ERROR level log message is recorded.
Example: Application Logging with JBoss Logging
4.3. Per-deployment Logging
Per-deployment logging allows a developer to configure the logging configuration for their application in advance. When the application is deployed, logging begins according to the defined configuration. The log files created through this configuration contain information only about the behavior of the application.
If the per-deployment logging configuration is not done, the configuration from logging subsystem is used for all the applications as well as the server.
This approach has advantages and disadvantages over using system-wide logging. An advantage is that the administrator of the JBoss EAP instance does not need to configure any other logging than the server logging. A disadvantage is that the per-deployment logging configuration is read only on server startup, and so cannot be changed at runtime.
4.3.1. Add Per-deployment Logging to an Application
To configure per-deployment logging for an application, add the logging.properties configuration file to your deployment. This configuration file is recommended because it can be used with any logging facade where JBoss Log Manager is the underlying log manager.
The directory into which the configuration file is added depends on the deployment method.
-
For EAR deployments, copy the logging configuration file to the
META-INF/directory. -
For WAR or JAR deployments, copy the logging configuration file to the
WEB-INF/classes/directory.
If you are using Simple Logging Facade for Java (SLF4J) or Apache log4j, the logging.properties configuration file is suitable. If you are using Apache log4j appenders then the configuration file log4j.properties is required. The configuration file jboss-logging.properties is supported only for legacy deployments.
Configuring logging.properties
The logging.properties file is used when the server boots, until the logging subsystem is started. If the logging subsystem is not included in your configuration, then the server uses the configuration in this file as the logging configuration for the entire server.
JBoss Log Manager Configuration Options
Logger options
-
loggers=<category>[,<category>,…]- Specify a comma-separated list of logger categories to be configured. Any categories not listed here will not be configured from the following properties. -
logger.<category>.level=<level>- Specify the level for a category. The level can be one of the valid levels. If unspecified, the level of the nearest parent will be inherited. -
logger.<category>.handlers=<handler>[,<handler>,…]- Specify a comma-separated list of the handler names to be attached to this logger. The handlers must be configured in the same properties file. -
logger.<category>.filter=<filter>- Specify a filter for a category. -
logger.<category>.useParentHandlers=(true|false)- Specify whether log messages should cascade up to parent handlers. The default value istrue.
Handler options
handler.<name>=<className>- Specify the class name of the handler to instantiate. This option is mandatory.NoteExpand Table 4.1. Possible Class Names: Name Associated Class Consoleorg.jboss.logmanager.handlers.ConsoleHandlerFileorg.jboss.logmanager.handlers.FileHandlerPeriodicorg.jboss.logmanager.handlers.PeriodicRotatingFileHandlerSizeorg.jboss.logmanager.handlers.SizeRotatingFileHandlerPeriodic Sizeorg.jboss.logmanager.handlers.PeriodicSizeRotatingFileHandlerSyslogorg.jboss.logmanager.handlers.SyslogHandlerAsyncorg.jboss.logmanager.handlers.AsyncHandlerThe
Customhandler can have any associated class or module. It is available in theloggingsubsystem for users to define their own log handlers.For further information, see Log Handlers in the JBoss EAP Configuration Guide.
-
handler.<name>.level=<level>- Restrict the level of this handler. If unspecified, the default value of ALL is retained. -
handler.<name>.encoding=<encoding>- Specify the character encoding, if it is supported by this handler type. If not specified, a handler-specific default is used. -
handler.<name>.errorManager=<name>- Specify the name of the error manager to use. The error manager must be configured in the same properties file. If unspecified, no error manager is configured. -
handler.<name>.filter=<name>- Specify a filter for a category. See the filter expressions for details on defining a filter. -
handler.<name>.formatter=<name>- Specify the name of the formatter to use, if it is supported by this handler type. The formatter must be configured in the same properties file. If not specified, messages will not be logged for most handler types. handler.<name>.properties=<property>[,<property>,…]- Specify a list of JavaBean-style properties to additionally configure. A rudimentary type introspection is done to ascertain the appropriate conversion for the given property.In case of all file handlers in JBoss Log Manager,
appendneeds to be set before thefileName. The order in which the properties appear inhandler.<name>.properties, is the order in which the properties will be set.-
handler.<name>.constructorProperties=<property>[,<property>,…]- Specify a list of properties that should be used as construction parameters. A rudimentary type introspection is done to ascertain the appropriate conversion for the given property. -
handler.<name>.<property>=<value>- Set the value of the named property. -
handler.<name>.module=<name>- Specify the name of the module the handler resides in.
For further information, see Log Handler Attributes in the JBoss EAP Configuration Guide.
Error manager options
-
errorManager.<name>=<className>- Specify the class name of the error manager to instantiate. This option is mandatory. -
errorManager.<name>.properties=<property>[,<property>,…]- Specify a list of JavaBean-style properties to additionally configure. A rudimentary type introspection is done to ascertain the appropriate conversion for the given property. -
errorManager.<name>.<property>=<value>- Set the value of the named property.
Formatter options
-
formatter.<name>=<className>- Specify the class name of the formatter to instantiate. This option is mandatory. -
formatter.<name>.properties=<property>[,<property>,…]- Specify a list of JavaBean-style properties to additionally configure. A rudimentary type introspection is done to ascertain the appropriate conversion for the given property. -
formatter.<name>.constructorProperties=<property>[,<property>,…]- Specify a list of properties that should be used as construction parameters. A rudimentary type introspection is done to ascertain the appropriate conversion for the given property. -
formatter.<name>.<property>=<value>- Set the value of the named property.
The following example shows the minimal configuration for logging.properties file that will log to the console.
Example: Minimal logging.properties Configuration
4.4. Logging Profiles
Logging profiles are independent sets of logging configurations that can be assigned to deployed applications. As with the regular logging subsystem, a logging profile can define handlers, categories, and a root logger, but it cannot refer to configurations in other profiles or the main logging subsystem. The design of logging profiles mimics the logging subsystem for ease of configuration.
Logging profiles allow administrators to create logging configurations that are specific to one or more applications without affecting any other logging configurations. Because each profile is defined in the server configuration, the logging configuration can be changed without requiring that the affected applications be redeployed. However, logging profiles cannot be configured using the management console. For more information, see Configure a Logging Profile in the JBoss EAP Configuration Guide.
Each logging profile can have:
- A unique name. This value is required.
- Any number of log handlers.
- Any number of log categories.
- Up to one root logger.
An application can specify a logging profile to use in its MANIFEST.MF file, using the Logging-Profile attribute.
4.4.1. Specify a Logging Profile in an Application
An application specifies the logging profile to use in its MANIFEST.MF file.
You must know the name of the logging profile that has been set up on the server for this application to use.
To add a logging profile configuration to an application, edit the MANIFEST.MF file.
If your application does not have a
MANIFEST.MFfile, create one with the following content to specify the logging profile name.Manifest-Version: 1.0 Logging-Profile: LOGGING_PROFILE_NAME
Manifest-Version: 1.0 Logging-Profile: LOGGING_PROFILE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow If your application already has a
MANIFEST.MFfile, add the following line to specify the logging profile name.Logging-Profile: LOGGING_PROFILE_NAME
Logging-Profile: LOGGING_PROFILE_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow
If you are using Maven and the maven-war-plugin, put your MANIFEST.MF file in src/main/resources/META-INF/ and add the following configuration to your pom.xml file:
When the application is deployed, it will use the configuration in the specified logging profile for its log messages.
For an example of how to configure a logging profile and the application using it, see Example Logging Profile Configuration in the JBoss EAP Configuration Guide.
4.5. Internationalization and Localization
4.5.1. Introduction
4.5.1.1. About Internationalization
Internationalization is the process of designing software so that it can be adapted to different languages and regions without engineering changes.
4.5.1.2. About Localization
Localization is the process of adapting internationalized software for a specific region or language by adding locale-specific components and translations of text.
4.5.2. JBoss Logging Tools Internationalization and Localization
JBoss Logging Tools is a Java API that provides support for the internationalization and localization of log messages, exception messages, and generic strings. In addition to providing a mechanism for translation, JBoss Logging Tools also provides support for unique identifiers for each log message.
Internationalized messages and exceptions are created as method definitions inside of interfaces annotated using org.jboss.logging.annotations annotations. Implementing the interfaces is not necessary; JBoss Logging Tools does this at compile time. Once defined, you can use these methods to log messages or obtain exception objects in your code.
Internationalized logging and exception interfaces created with JBoss Logging Tools can be localized by creating a properties file for each bundle containing the translations for a specific language and region. JBoss Logging Tools can generate template property files for each bundle that can then be edited by a translator.
JBoss Logging Tools creates an implementation of each bundle for each corresponding translations property file in your project. All you have to do is use the methods defined in the bundles and JBoss Logging Tools ensures that the correct implementation is invoked for your current regional settings.
Message IDs and project codes are unique identifiers that are prepended to each log message. These unique identifiers can be used in documentation to make it easy to find information about log messages. With adequate documentation, the meaning of a log message can be determined from the identifiers regardless of the language that the message was written in.
The JBoss Logging Tools includes support for the following features:
- MessageLogger
-
This interface in the
org.jboss.logging.annotationspackage is used to define internationalized log messages. A message logger interface is annotated with@MessageLogger. - MessageBundle
-
This interface can be used to define generic translatable messages and Exception objects with internationalized messages. A message bundle is not used for creating log messages. A message bundle interface is annotated with
@MessageBundle. - Internationalized Log Messages
These log messages are created by defining a method in a
MessageLogger. The method must be annotated with the@LogMessageand@Messageannotations and must specify the log message using the value attribute of@Message. Internationalized log messages are localized by providing translations in a properties file.JBoss Logging Tools generates the required logging classes for each translation at compile time and invokes the correct methods for the current locale at runtime.
- Internationalized Exceptions
- An internationalized exception is an exception object returned from a method defined in a MessageBundle. These message bundles can be annotated to define a default exception message. The default message is replaced with a translation if one is found in a matching properties file for the current locale. Internationalized exceptions can also have project codes and message IDs assigned to them.
- Internationalized Messages
-
An internationalized message is a string returned from a method defined in a
MessageBundle. Message bundle methods that return Java String objects can be annotated to define the default content of that string, known as the message. The default message is replaced with a translation if one is found in a matching properties file for the current locale. - Translation Properties Files
- Translation properties files are Java properties files that contain the translations of messages from one interface for one locale, country, and variant. Translation properties files are used by the JBoss Logging Tools to generate the classes that return the messages.
- JBoss Logging Tools Project Codes
Project codes are strings of characters that identify groups of messages. They are displayed at the beginning of each log message, prepended to the message ID. Project codes are defined with the projectCode attribute of the
@MessageLoggerannotation.NoteFor a complete list of the new log message project code prefixes, see the Project Codes used in JBoss EAP 7.1.
- JBoss Logging Tools Message IDs
-
Message IDs are numbers that uniquely identify a log message when combined with a project code. Message IDs are displayed at the beginning of each log message, appended to the project code for the message. Message IDs are defined with the ID attribute of the
@Messageannotation.
The logging-tools quickstart that ships with JBoss EAP is a simple Maven project that provides a working example of many of the features of JBoss Logging Tools. The code examples that follow are taken from the logging-tools quickstart.
4.5.3. Creating Internationalized Loggers, Messages and Exceptions
4.5.3.1. Create Internationalized Log Messages
You can use JBoss Logging Tools to create internationalized log messages by creating MessageLogger interfaces.
This section does not cover all optional features or the localization of the log messages.
If you have not yet done so, configure your Maven settings to use the JBoss EAP Maven repository.
For more information, see Configure the JBoss EAP Maven Repository Using the Maven Settings.
Configure the project’s
pom.xmlfile to use JBoss Logging Tools.For details, see JBoss Logging Tools Maven Configuration.
Create a message logger interface by adding a Java interface to your project to contain the log message definitions.
Name the interface to describe the log messages it will define. The log message interface has the following requirements:
-
It must be annotated with
@org.jboss.logging.annotations.MessageLogger. -
Optionally, it can extend
org.jboss.logging.BasicLogger. The interface must define a field that is a message logger of the same type as the interface. Do this with the
getMessageLogger()method of@org.jboss.logging.Logger.Example: Creating a Message Logger
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
It must be annotated with
Add a method definition to the interface for each log message.
Name each method descriptively for the log message that it represents. Each method has the following requirements:
-
The method must return
void. -
It must be annotated with the
@org.jboss.logging.annotation.LogMessageannotation. -
It must be annotated with the
@org.jboss.logging.annotations.Messageannotation. -
The default log level is
INFO. The value attribute of
@org.jboss.logging.annotations.Messagecontains the default log message, which is used if no translation is available.@LogMessage @Message(value = "Customer query failed, Database not available.") void customerQueryFailDBClosed();
@LogMessage @Message(value = "Customer query failed, Database not available.") void customerQueryFailDBClosed();Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
The method must return
Invoke the methods by adding the calls to the interface methods in your code where the messages must be logged from.
Creating implementations of the interfaces is not necessary, the annotation processor does this for you when the project is compiled.
AccountsLogger.LOGGER.customerQueryFailDBClosed();
AccountsLogger.LOGGER.customerQueryFailDBClosed();Copy to Clipboard Copied! Toggle word wrap Toggle overflow The custom loggers are subclassed from
BasicLogger, so the logging methods ofBasicLoggercan also be used. It is not necessary to create other loggers to log non-internationalized messages.AccountsLogger.LOGGER.error("Invalid query syntax.");AccountsLogger.LOGGER.error("Invalid query syntax.");Copy to Clipboard Copied! Toggle word wrap Toggle overflow - The project now supports one or more internationalized loggers that can be localized.
The logging-tools quickstart that ships with JBoss EAP is a simple Maven project that provides a working example of how to use JBoss Logging Tools.
4.5.3.2. Create and Use Internationalized Messages
This procedure demonstrates how to create and use internationalized messages.
This section does not cover all optional features or the process of localizing those messages.
- If you have not yet done so, configure your Maven settings to use the JBoss EAP Maven repository. For more information, see Configure the JBoss EAP Maven Repository Using the Maven Settings.
-
Configure the project’s
pom.xmlfile to use JBoss Logging Tools. For details, see JBoss Logging Tools Maven Configuration. Create an interface for the exceptions. JBoss Logging Tools defines internationalized messages in interfaces. Name each interface descriptively for the messages that it contains. The interface has the following requirements:
-
It must be declared as
public. -
It must be annotated with
@org.jboss.logging.annotations.MessageBundle. The interface must define a field that is a message bundle of the same type as the interface.
Example: Create a
MessageBundleInterface@MessageBundle(projectCode="") public interface GreetingMessageBundle { GreetingMessageBundle MESSAGES = Messages.getBundle(GreetingMessageBundle.class); }@MessageBundle(projectCode="") public interface GreetingMessageBundle { GreetingMessageBundle MESSAGES = Messages.getBundle(GreetingMessageBundle.class); }Copy to Clipboard Copied! Toggle word wrap Toggle overflow NoteCalling
Messages.getBundle(GreetingMessagesBundle.class)is equivalent to callingMessages.getBundle(GreetingMessagesBundle.class, Locale.getDefault()).Locale.getDefault()gets the current value of the default locale for this instance of the Java Virtual Machine. The Java Virtual Machine sets the default locale during startup, based on the host environment. It is used by many locale-sensitive methods if no locale is explicitly specified. It can be changed using thesetDefaultmethod.See Set the Default Locale of the Server in the JBoss EAP Configuration Guide for more information.
-
It must be declared as
Add a method definition to the interface for each message. Name each method descriptively for the message that it represents. Each method has the following requirements:
-
It must return an object of type
String. -
It must be annotated with the
@org.jboss.logging.annotations.Messageannotation. The value attribute of
@org.jboss.logging.annotations.Messagemust be set to the default message. This is the message that is used if no translation is available.@Message(value = "Hello world.") String helloworldString();
@Message(value = "Hello world.") String helloworldString();Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
It must return an object of type
Invoke the interface methods in your application where you need to obtain the message:
System.out.println(helloworldString());
System.out.println(helloworldString());Copy to Clipboard Copied! Toggle word wrap Toggle overflow
The project now supports internationalized message strings that can be localized.
See the logging-tools quickstart that ships with JBoss EAP for a complete working example.
4.5.3.3. Create Internationalized Exceptions
You can use JBoss Logging Tools to create and use internationalized exceptions.
The following instructions assume that you want to add internationalized exceptions to an existing software project that is built using either Red Hat JBoss Developer Studio or Maven.
This section does not cover all optional features or the process of localization of those exceptions.
-
Configure the project’s
pom.xmlfile to use JBoss Logging Tools. For details, see JBoss Logging Tools Maven Configuration. Create an interface for the exceptions. JBoss Logging Tools defines internationalized exceptions in interfaces. Name each interface descriptively for the exceptions that it defines. The interface has the following requirements:
-
It must be declared as
public. -
It must be annotated with
@MessageBundle. The interface must define a field that is a message bundle of the same type as the interface.
Example: Create an
ExceptionBundleInterface@MessageBundle(projectCode="") public interface ExceptionBundle { ExceptionBundle EXCEPTIONS = Messages.getBundle(ExceptionBundle.class); }@MessageBundle(projectCode="") public interface ExceptionBundle { ExceptionBundle EXCEPTIONS = Messages.getBundle(ExceptionBundle.class); }Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
It must be declared as
Add a method definition to the interface for each exception. Name each method descriptively for the exception that it represents. Each method has the following requirements:
-
It must return an
Exceptionobject, or a sub-type ofException. -
It must be annotated with the
@org.jboss.logging.annotations.Messageannotation. -
The value attribute of
@org.jboss.logging.annotations.Messagemust be set to the default exception message. This is the message that is used if no translation is available. If the exception being returned has a constructor that requires parameters in addition to a message string, then those parameters must be supplied in the method definition using the
@Paramannotation. The parameters must be the same type and order as they are in the constructor of the exception.@Message(value = "The config file could not be opened.") IOException configFileAccessError(); @Message(id = 13230, value = "Date string '%s' was invalid.") ParseException dateWasInvalid(String dateString, @Param int errorOffset);
@Message(value = "The config file could not be opened.") IOException configFileAccessError(); @Message(id = 13230, value = "Date string '%s' was invalid.") ParseException dateWasInvalid(String dateString, @Param int errorOffset);Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
It must return an
Invoke the interface methods in your code where you need to obtain one of the exceptions. The methods do not throw the exceptions, they return the exception object, which you can then throw.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
The project now supports internationalized exceptions that can be localized.
See the logging-tools quickstart that ships with JBoss EAP for a complete working example.
4.5.4. Localizing Internationalized Loggers, Messages and Exceptions
4.5.4.1. Generate New Translation Properties Files with Maven
Projects that are built using Maven can generate empty translation property files for each MessageLogger and MessageBundle it contains. These files can then be used as new translation property files.
The following procedure demonstrates how to configure a Maven project to generate new translation property files.
Prerequisites
- You must already have a working Maven project.
- The project must already be configured for JBoss Logging Tools.
- The project must contain one or more interfaces that define internationalized log messages or exceptions.
Generate the Translation Properties Files
Add the Maven configuration by adding the
-AgenereatedTranslationFilePathcompiler argument to the Maven compiler plug-in configuration, and assign it the path where the new files will be created.This configuration creates the new files in the
target/generated-translation-filesdirectory of your Maven project.Example: Define the Translation File Path
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Build the project using Maven:
mvn compile
$ mvn compileCopy to Clipboard Copied! Toggle word wrap Toggle overflow One properties file is created for each interface annotated with
@MessageBundleor@MessageLogger.- The new files are created in a subdirectory corresponding to the Java package in which each interface is declared.
Each new file is named using the following pattern where
INTERFACE_NAMEis the name of the interface used to generated the file.INTERFACE_NAME.i18n_locale_COUNTRY_VARIANT.properties
INTERFACE_NAME.i18n_locale_COUNTRY_VARIANT.propertiesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
The resulting files can now be copied into your project as the basis for new translations.
See the logging-tools quickstart that ships with JBoss EAP for a complete working example.
4.5.4.2. Translate an Internationalized Logger, Exception, or Message
Properties files can be used to provide translations for logging and exception messages defined in interfaces using JBoss Logging Tools.
The following procedure shows how to create and use a translation properties file, and assumes that you already have a project with one or more interfaces defined for internationalized exceptions or log messages.
Prerequisites
- You must already have a working Maven project.
- The project must already be configured for JBoss Logging Tools.
- The project must contain one or more interfaces that define internationalized log messages or exceptions.
- The project must be configured to generate template translation property files.
Translate an Internationalized Logger, Exception, or Message
Run the following command to create the template translation properties files:
mvn compile
$ mvn compileCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
Copy the template for the interfaces that you want to translate from the directory where they were created into the
src/main/resourcesdirectory of your project. The properties files must be in the same package as the interfaces they are translating. -
Rename the copied template file to indicate the language it will contain. For example:
GreeterLogger.i18n_fr_FR.properties. Edit the contents of the new translation properties file to contain the appropriate translation:
# Level: Logger.Level.INFO # Message: Hello message sent. logHelloMessageSent=Bonjour message envoyé.
# Level: Logger.Level.INFO # Message: Hello message sent. logHelloMessageSent=Bonjour message envoyé.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Repeat the process of copying the template and modifying it for each translation in the bundle.
The project now contains translations for one or more message or logger bundles. Building the project generates the appropriate classes to log messages with the supplied translations. It is not necessary to explicitly invoke methods or supply parameters for specific languages, JBoss Logging Tools automatically uses the correct class for the current locale of the application server.
The source code of the generated classes can be viewed under target/generated-sources/annotations/.
4.5.5. Customizing Internationalized Log Messages
4.5.5.1. Add Message IDs and Project Codes to Log Messages
This procedure demonstrates how to add message IDs and project codes to internationalized log messages created using JBoss Logging Tools. A log message must have both a project code and message ID to be displayed in the log. If a message does not have both a project code and a message ID, then neither is displayed.
Prerequisites
- You must already have a project with internationalized log messages. For details, see Create Internationalized Log Messages.
- You need to know the project code you will be using. You can use a single project code, or define different ones for each interface.
Add Message IDs and Project Codes to Log Messages
Specify the project code for the interface by using the projectCode attribute of the
@MessageLoggerannotation attached to a custom logger interface. All messages that are defined in the interface will use that project code.@MessageLogger(projectCode="ACCNTS") interface AccountsLogger extends BasicLogger { }@MessageLogger(projectCode="ACCNTS") interface AccountsLogger extends BasicLogger { }Copy to Clipboard Copied! Toggle word wrap Toggle overflow Specify a message ID for each message using the
idattribute of the@Messageannotation attached to the method that defines the message.@LogMessage @Message(id=43, value = "Customer query failed, Database not available.") void customerQueryFailDBClosed();
@LogMessage @Message(id=43, value = "Customer query failed, Database not available.") void customerQueryFailDBClosed();Copy to Clipboard Copied! Toggle word wrap Toggle overflow The log messages that have both a message ID and project code associated with them will prepend these to the logged message.
10:55:50,638 INFO [com.company.accounts.ejb] (MSC service thread 1-4) ACCNTS000043: Customer query failed, Database not available.
10:55:50,638 INFO [com.company.accounts.ejb] (MSC service thread 1-4) ACCNTS000043: Customer query failed, Database not available.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
4.5.5.2. Specify the Log Level for a Message
The default log level of a message defined by an interface by JBoss Logging Tools is INFO. A different log level can be specified with the level attribute of the @LogMessage annotation attached to the logging method. Use the following procedure to specify a different log level.
-
Add the
levelattribute to the@LogMessageannotation of the log message method definition. Assign the log level for this message using the
levelattribute. The valid values forlevelare the six enumerated constants defined inorg.jboss.logging.Logger.Level:DEBUG,ERROR,FATAL,INFO,TRACE, andWARN.import org.jboss.logging.Logger.Level; @LogMessage(level=Level.ERROR) @Message(value = "Customer query failed, Database not available.") void customerQueryFailDBClosed();
import org.jboss.logging.Logger.Level; @LogMessage(level=Level.ERROR) @Message(value = "Customer query failed, Database not available.") void customerQueryFailDBClosed();Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Invoking the logging method in the above example will produce a log message at the level of ERROR.
10:55:50,638 ERROR [com.company.app.Main] (MSC service thread 1-4) Customer query failed, Database not available.
10:55:50,638 ERROR [com.company.app.Main] (MSC service thread 1-4)
Customer query failed, Database not available.4.5.5.3. Customize Log Messages with Parameters
Custom logging methods can define parameters. These parameters are used to pass additional information to be displayed in the log message. Where the parameters appear in the log message is specified in the message itself using either explicit or ordinary indexing.
Customize Log Messages with Parameters
- Add parameters of any type to the method definition. Regardless of type, the String representation of the parameter is what is displayed in the message.
Add parameter references to the log message. References can use explicit or ordinary indexes.
-
To use ordinary indexes, insert
%scharacters in the message string where you want each parameter to appear. The first instance of%swill insert the first parameter, the second instance will insert the second parameter, and so on. -
To use explicit indexes, insert
%#$scharacters in the message, where # indicates the number of the parameter that you wish to appear.
-
To use ordinary indexes, insert
Using explicit indexes allows the parameter references in the message to be in a different order than they are defined in the method. This is important for translated messages that might require different ordering of parameters.
The number of parameters must match the number of references to the parameters in the specified message or the code will not compile. A parameter marked with the @Cause annotation is not included in the number of parameters.
The following is an example of message parameters using ordinary indexes:
@LogMessage(level=Logger.Level.DEBUG) @Message(id=2, value="Customer query failed, customerid:%s, user:%s") void customerLookupFailed(Long customerid, String username);
@LogMessage(level=Logger.Level.DEBUG)
@Message(id=2, value="Customer query failed, customerid:%s, user:%s")
void customerLookupFailed(Long customerid, String username);The following is an example of message parameters using explicit indexes:
@LogMessage(level=Logger.Level.DEBUG) @Message(id=2, value="Customer query failed, user:%2$s, customerid:%1$s") void customerLookupFailed(Long customerid, String username);
@LogMessage(level=Logger.Level.DEBUG)
@Message(id=2, value="Customer query failed, user:%2$s, customerid:%1$s")
void customerLookupFailed(Long customerid, String username);4.5.5.4. Specify an Exception as the Cause of a Log Message
JBoss Logging Tools allows one parameter of a custom logging method to be defined as the cause of the message. This parameter must be the Throwable type or any of its sub-classes, and is marked with the @Cause annotation. This parameter cannot be referenced in the log message like other parameters, and is displayed after the log message.
The following procedure shows how to update a logging method using the @Cause parameter to indicate the "causing" exception. It is assumed that you have already created internationalized logging messages to which you want to add this functionality.
Specify an Exception as the Cause of a Log Message
Add a parameter of the type
Throwableor its subclass to the method.@LogMessage @Message(id=404, value="Loading configuration failed. Config file:%s") void loadConfigFailed(Exception ex, File file);
@LogMessage @Message(id=404, value="Loading configuration failed. Config file:%s") void loadConfigFailed(Exception ex, File file);Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add the
@Causeannotation to the parameter.import org.jboss.logging.annotations.Cause @LogMessage @Message(value = "Loading configuration failed. Config file: %s") void loadConfigFailed(@Cause Exception ex, File file);
import org.jboss.logging.annotations.Cause @LogMessage @Message(value = "Loading configuration failed. Config file: %s") void loadConfigFailed(@Cause Exception ex, File file);Copy to Clipboard Copied! Toggle word wrap Toggle overflow Invoke the method. When the method is invoked in your code, an object of the correct type must be passed and will be displayed after the log message.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
The following is the output of the above code example if the code throws an exception of type FileNotFoundException:
4.5.6. Customizing Internationalized Exceptions
4.5.6.1. Add Message IDs and Project Codes to Exception Messages
Message IDs and project codes are unique identifiers that are prepended to each message displayed by internationalized exceptions. These identifying codes make it possible to create a reference for all the exception messages in an application. This allows someone to look up the meaning of an exception message written in language that they do not understand.
The following procedure demonstrates how to add message IDs and project codes to internationalized exception messages created using JBoss Logging Tools.
Prerequisites
- You must already have a project with internationalized exceptions. For details, see Create Internationalized Exceptions.
- You need to know the project code you will be using. You can use a single project code, or define different ones for each interface.
Add Message IDs and Project Codes to Exception Messages
Specify the project code using the
projectCodeattribute of the@MessageBundleannotation attached to a exception bundle interface. All messages that are defined in the interface will use that project code.@MessageBundle(projectCode="ACCTS") interface ExceptionBundle { ExceptionBundle EXCEPTIONS = Messages.getBundle(ExceptionBundle.class); }@MessageBundle(projectCode="ACCTS") interface ExceptionBundle { ExceptionBundle EXCEPTIONS = Messages.getBundle(ExceptionBundle.class); }Copy to Clipboard Copied! Toggle word wrap Toggle overflow Specify message IDs for each exception using the
idattribute of the@Messageannotation attached to the method that defines the exception.@Message(id=143, value = "The config file could not be opened.") IOException configFileAccessError();
@Message(id=143, value = "The config file could not be opened.") IOException configFileAccessError();Copy to Clipboard Copied! Toggle word wrap Toggle overflow
A message that has both a project code and message ID displays them prepended to the message. If a message does not have both a project code and a message ID, neither is displayed.
Example: Internationalized Exception
This exception bundle interface example uses the project code of "ACCTS". It contains a single exception method with the ID of "143".
The exception object can be obtained and thrown using the following code:
throw ExceptionBundle.EXCEPTIONS.configFileAccessError();
throw ExceptionBundle.EXCEPTIONS.configFileAccessError();This would display an exception message like the following:
Exception in thread "main" java.io.IOException: ACCTS000143: The config file could not be opened. at com.company.accounts.Main.openCustomProperties(Main.java:78) at com.company.accounts.Main.go(Main.java:53) at com.company.accounts.Main.main(Main.java:43)
Exception in thread "main" java.io.IOException: ACCTS000143: The config file could not be opened.
at com.company.accounts.Main.openCustomProperties(Main.java:78)
at com.company.accounts.Main.go(Main.java:53)
at com.company.accounts.Main.main(Main.java:43)4.5.6.2. Customize Exception Messages with Parameters
Exception bundle methods that define exceptions can specify parameters to pass additional information to be displayed in the exception message. The exact position of the parameters in the exception message is specified in the message itself using either explicit or ordinary indexing.
Customize Exception Messages with Parameters
- Add parameters of any type to the method definition. Regardless of type, the String representation of the parameter is what is displayed in the message.
Add parameter references to the exception message. References can use explicit or ordinary indexes.
-
To use ordinary indexes, insert
%scharacters in the message string where you want each parameter to appear. The first instance of%swill insert the first parameter, the second instance will insert the second parameter, and so on. -
To use explicit indexes, insert
%#$scharacters in the message, where # indicates the number of the parameter that you wish to appear.
-
To use ordinary indexes, insert
Using explicit indexes allows the parameter references in the message to be in a different order than they are defined in the method. This is important for translated messages that might require different ordering of parameters.
The number of parameters must match the number of references to the parameters in the specified message, or the code will not compile. A parameter marked with the @Cause annotation is not included in the number of parameters.
Example: Using Ordinary Indexes
@Message(id=2, value="Customer query failed, customerid:%s, user:%s") void customerLookupFailed(Long customerid, String username);
@Message(id=2, value="Customer query failed, customerid:%s, user:%s")
void customerLookupFailed(Long customerid, String username);Example: Using Explicit Indexes
@Message(id=2, value="Customer query failed, user:%2$s, customerid:%1$s") void customerLookupFailed(Long customerid, String username);
@Message(id=2, value="Customer query failed, user:%2$s, customerid:%1$s")
void customerLookupFailed(Long customerid, String username);4.5.6.3. Specify One Exception as the Cause of Another Exception
Exceptions returned by exception bundle methods can have another exception specified as the underlying cause. This is done by adding a parameter to the method and annotating the parameter with @Cause. This parameter is used to pass the causing exception, and cannot be referenced in the exception message.
The following procedure shows how to update a method from an exception bundle using the @Cause parameter to indicate the causing exception. It is assumed that you have already created an exception bundle to which you want to add this functionality.
Add a parameter of the type
Throwableor its subclass to the method.@Message(id=328, value = "Error calculating: %s.") ArithmeticException calculationError(Throwable cause, String msg);
@Message(id=328, value = "Error calculating: %s.") ArithmeticException calculationError(Throwable cause, String msg);Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add the
@Causeannotation to the parameter.import org.jboss.logging.annotations.Cause @Message(id=328, value = "Error calculating: %s.") ArithmeticException calculationError(@Cause Throwable cause, String msg);
import org.jboss.logging.annotations.Cause @Message(id=328, value = "Error calculating: %s.") ArithmeticException calculationError(@Cause Throwable cause, String msg);Copy to Clipboard Copied! Toggle word wrap Toggle overflow Invoke the interface method to obtain an exception object. The most common use case is to throw a new exception from a
catchblock, specifying the caught exception as the cause.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
The following is an example of specifying an exception as the cause of another exception. This exception bundle defines a single method that returns an exception of type ArithmeticException.
The following example demonstrates an operation that throws an exception because it attempts to divide an integer by zero. The exception is caught, and a new exception is created using the first one as the cause.
The following is the exception message generated from the previous example:
4.5.7. JBoss Logging Tools References
4.5.7.1. JBoss Logging Tools Maven Configuration
The following procedure configures a Maven project to use JBoss Logging and JBoss Logging Tools for internationalization.
If you have not yet done so, configure your Maven settings to use the JBoss EAP repository. For more information, see Configure the JBoss EAP Maven Repository Using the Maven Settings.
Include the
jboss-eap-javaee7BOM in the<dependencyManagement>section of the project’spom.xmlfile.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add the Maven dependencies to the project’s
pom.xmlfile:-
Add the
jboss-loggingdependency for access to JBoss Logging framework. If you plan to use the JBoss Logging Tools, also add the
jboss-logging-processordependency.Both of these dependencies are available in JBoss EAP BOM that was added in the previous step, so the scope element of each can be set to
providedas shown.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
Add the
The maven-compiler-plugin must be at least version
3.1and configured for target and generated sources of1.8.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
For a complete working example of a pom.xml file that is configured to use JBoss Logging Tools, see the logging-tools quickstart that ships with JBoss EAP.
4.5.7.2. Translation Property File Format
The property files used for the translation of messages in JBoss Logging Tools are standard Java property files. The format of the file is the simple line-oriented, key=value pair format described in the java.util.Properties class documentation.
The file name format has the following format:
InterfaceName.i18n_locale_COUNTRY_VARIANT.properties
InterfaceName.i18n_locale_COUNTRY_VARIANT.properties-
InterfaceNameis the name of the interface that the translations apply to. -
locale,COUNTRY, andVARIANTidentify the regional settings that the translation applies to. -
localeandCOUNTRYspecify the language and country using the ISO-639 and ISO-3166 Language and Country codes respectively.COUNTRYis optional. -
VARIANTis an optional identifier that can be used to identify translations that only apply to a specific operating system or browser.
The properties contained in the translation file are the names of the methods from the interface being translated. The assigned value of the property is the translation. If a method is overloaded, then this is indicated by appending a dot and then the number of parameters to the name. Methods for translation can only be overloaded by supplying a different number of parameters.
Example: Translation Properties File
File name: GreeterService.i18n_fr_FR_POSIX.properties.
# Level: Logger.Level.INFO # Message: Hello message sent. logHelloMessageSent=Bonjour message envoyé.
# Level: Logger.Level.INFO
# Message: Hello message sent.
logHelloMessageSent=Bonjour message envoyé.4.5.7.3. JBoss Logging Tools Annotations Reference
The following annotations are defined in JBoss Logging for use with internationalization and localization of log messages, strings, and exceptions.
| Annotation | Target | Description | Attributes |
|---|---|---|---|
| @MessageBundle | Interface | Defines the interface as a message bundle. | projectCode |
| @MessageLogger | Interface | Defines the interface as a message logger. | projectCode |
| @Message | Method | Can be used in message bundles and message loggers. In a message bundle it defines the method as being one that returns a localized String or Exception object. In a message logger it defines a method as being a localized logger. | value, id |
| @LogMessage | Method | Defines a method in a message logger as being a logging method. |
level (default |
| @Cause | Parameter | Defines a parameter as being one that passes an Exception as the cause of either a Log message or another Exception. | - |
| @Param | Parameter | Defines a parameter as being one that is passed to the constructor of the Exception. | - |
4.5.7.4. Project Codes Used in JBoss EAP
The following table lists all the project codes used in JBoss EAP 7.1, along with the Maven modules they belong to.
| Maven Module | Project Code |
|---|---|
| appclient | WFLYAC |
| batch/extension-jberet | WFLYBATCH |
| batch/extension | WFLYBATCH-DEPRECATED |
| batch/jberet | WFLYBAT |
| bean-validation | WFLYBV |
| controller-client | WFLYCC |
| controller | WFLYCTL |
| clustering/common | WFLYCLCOM |
| clustering/ejb/infinispan | WFLYCLEJBINF |
| clustering/infinispan/extension | WFLYCLINF |
| clustering/jgroups/extension | WFLYCLJG |
| clustering/server | WFLYCLSV |
| clustering/web/infinispan | WFLYCLWEBINF |
| connector | WFLYJCA |
| deployment-repository | WFLYDR |
| deployment-scanner | WFLYDS |
| domain-http | WFLYDMHTTP |
| domain-management | WFLYDM |
| ee | WFLYEE |
| ejb3 | WFLYEJB |
| embedded | WFLYEMB |
| host-controller | WFLYDC |
| host-controller | WFLYHC |
| iiop-openjdk | WFLYIIOP |
| io/subsystem | WFLYIO |
| jaxrs | WFLYRS |
| jdr | WFLYJDR |
| jmx | WFLYJMX |
| jpa/hibernate5 | JIPI |
| jpa/spi/src/main/java/org/jipijapa/JipiLogger.java | JIPI |
| jpa/subsystem | WFLYJPA |
| jsf/subsystem | WFLYJSF |
| jsr77 | WFLYEEMGMT |
| launcher | WFLYLNCHR |
| legacy/jacorb | WFLYORB |
| legacy/messaging | WFLYMSG |
| legacy/web | WFLYWEB |
| logging | WFLYLOG |
| | WFLYMAIL |
| management-client-content | WFLYCNT |
| messaging-activemq | WFLYMSGAMQ |
| mod_cluster/extension | WFLYMODCLS |
| naming | WFLYNAM |
| network | WFLYNET |
| patching | WFLYPAT |
| picketlink | WFLYPL |
| platform-mbean | WFLYPMB |
| pojo | WFLYPOJO |
| process-controller | WFLYPC |
| protocol | WFLYPRT |
| remoting | WFLYRMT |
| request-controller | WFLYREQCON |
| rts | WFLYRTS |
| sar | WFLYSAR |
| security-manager | WFLYSM |
| security | WFLYSEC |
| server | WFLYSRV |
| system-jmx | WFLYSYSJMX |
| threads | WFLYTHR |
| transactions | WFLYTX |
| undertow | WFLYUT |
| webservices/server-integration | WFLYWS |
| weld | WFLYWELD |
| xts | WFLYXTS |
Chapter 5. Remote JNDI lookup
5.1. Registering objects to JNDI
The Java Naming and Directory Interface (JNDI) is a Java API for a directory service that allows Java software clients to discover and look up objects using a name.
If an object registered to JNDI needs to be looked up by remote JNDI clients, for example clients that run in a separate JVM, then it must be registered under the java:jboss/exported context.
For example, if a JMS queue in the messaging-activemq subsystem must be exposed for remote JNDI clients, then it must be registered to JNDI using something like java:jboss/exported/jms/queue/myTestQueue. The remote JNDI client can then look it up by the name jms/queue/myTestQueue.
Example: Configuration of the Queue in standalone-full(-ha).xml
5.2. Configuring remote JNDI
A remote JNDI client can connect and lookup objects by name from JNDI. It must have the jboss-client.jar on its class path. The jboss-client.jar is available at EAP_HOME/bin/client/jboss-client.jar.
The following example shows how to look up the myTestQueue queue from JNDI in a remote JNDI client:
Example: Configuration for an MDB Resource Adapter
Properties properties = new Properties();
properties.put(Context.INITIAL_CONTEXT_FACTORY, "org.wildfly.naming.client.WildFlyInitialContextFactory");
properties.put(Context.PROVIDER_URL, "remote+http://HOST_NAME:8080");
context = new InitialContext(properties);
Queue myTestQueue = (Queue) context.lookup("jms/queue/myTestQueue");
Properties properties = new Properties();
properties.put(Context.INITIAL_CONTEXT_FACTORY, "org.wildfly.naming.client.WildFlyInitialContextFactory");
properties.put(Context.PROVIDER_URL, "remote+http://HOST_NAME:8080");
context = new InitialContext(properties);
Queue myTestQueue = (Queue) context.lookup("jms/queue/myTestQueue");5.3. JNDI Invocation Over HTTP
JNDI invocation over HTTP is provided as Technology Preview only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs), might not be functionally complete, and Red Hat does not recommend to use them for production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
See Technology Preview Features Support Scope on the Red Hat Customer Portal for information about the support scope for Technology Preview features.
JNDI invocation over HTTP includes two distinct parts: the client-side and the server-side implementations.
5.3.1. Client-side Implementation
The client-side implementation is similar to the remote naming implementation, but based on HTTP using the Undertow HTTP client.
Connection management is implicit rather than direct, using a caching approach similar to the one used in the existing remote naming implementation. Connection pools are cached based on connection parameters. If they are not used in the specified timeout period, they are discarded.
In order to configure a remote JNDI client application to use HTTP transport, you must add the following dependency on the HTTP transport implementation:
<dependency>
<groupId>org.wildfly.wildfly-http-client</groupId>
<artifactId>wildfly-http-naming-client</artifactId>
</dependency>
<dependency>
<groupId>org.wildfly.wildfly-http-client</groupId>
<artifactId>wildfly-http-naming-client</artifactId>
</dependency>
To perform the HTTP invocation, you must use the http URL scheme and include the context name of the HTTP invoker, wildfly-services. For example, if you are using remote+http://localhost:8080 as the target URL, in order to use HTTP transport, you must update this to http://localhost:8080/wildfly-services.
5.3.2. Server-side Implementation
The server-side implementation is similar to the existing remote naming implementation but with an HTTP transport.
In order to configure the server, you must enable the http-invoker on each of the virtual hosts that you wish to use in the undertow subsystem. This is enabled by default in the standard configurations. If it is disabled, you can re-enable it using the following management CLI command:
/subsystem=undertow/server=default-server/host=default-host/setting=http-invoker:add(http-authentication-factory=myfactory, path='/wildfly-services')
/subsystem=undertow/server=default-server/host=default-host/setting=http-invoker:add(http-authentication-factory=myfactory, path='/wildfly-services')
The http-invoker attribute takes two parameters: a path that defaults to /wildfly-services and an http-authentication-factory that must be a reference to an Elytron http-authentication-factory.
Any deployment that aims to use the http-authentication-factory must use Elytron security with the same security domain corresponding to the specified HTTP authentication factory.
Chapter 6. Clustering in Web Applications
6.1. Session Replication
6.1.1. About HTTP Session Replication
Session replication ensures that client sessions of distributable applications are not disrupted by failovers of nodes in a cluster. Each node in the cluster shares information about ongoing sessions, and can take over sessions if a node disappears.
Session replication is the mechanism by which mod_cluster, mod_jk, mod_proxy, ISAPI, and NSAPI clusters provide high availability.
6.1.2. Enable Session Replication in Your Application
To take advantage of JBoss EAP High Availability (HA) features and enable clustering of your web application, you must configure your application to be distributable. If your application is not marked as distributable, its sessions will never be distributed.
Make your Application Distributable
Add the
<distributable/>element inside the<web-app>tag of your application’sweb.xmldescriptor file:Example: Minimum Configuration for a Distributable Application
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Next, if desired, modify the default replication behavior. If you want to change any of the values affecting session replication, you can override them inside a
<replication-config>element inside<jboss-web>in an application’sWEB-INF/jboss-web.xmlfile. For a given element, only include it if you want to override the defaults.Example:
<replication-config>ValuesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
The <replication-granularity> parameter determines the granularity of data that is replicated. It defaults to SESSION, but can be set to ATTRIBUTE to increase performance on sessions where most attributes remain unchanged.
Valid values for <replication-granularity> can be :
-
SESSION: The default value. The entire session object is replicated if any attribute is dirty. This policy is required if an object reference is shared by multiple session attributes. The shared object references are maintained on remote nodes since the entire session is serialized in one unit. -
ATTRIBUTE: This is only for dirty attributes in the session and for some session data, such as the last-accessed timestamp.
Immutable Session Attributes
For JBoss EAP 7, session replication is triggered when the session is mutated or when any mutable attribute of the session is accessed. Session attributes are assumed to be mutable unless one of the following is true:
The value is a known immutable value:
-
null -
java.util.Collections.EMPTY_LIST,EMPTY_MAP,EMPTY_SET
-
The value type is or implements a known immutable type:
-
java.lang.Boolean,Character,Byte,Short,Integer,Long,Float,Double -
java.lang.Class,Enum,StackTraceElement,String -
java.io.File,java.nio.file.Path -
java.math.BigDecimal,BigInteger,MathContext -
java.net.Inet4Address,Inet6Address,InetSocketAddress,URI,URL -
java.security.Permission -
java.util.Currency,Locale,TimeZone,UUID -
java.time.Clock,Duration,Instant,LocalDate,LocalDateTime,LocalTime,MonthDay,Period,Year,YearMonth,ZoneId,ZoneOffset,ZonedDateTime -
java.time.chrono.ChronoLocalDate,Chronology,Era -
java.time.format.DateTimeFormatter,DecimalStyle -
java.time.temporal.TemporalField,TemporalUnit,ValueRange,WeekFields -
java.time.zone.ZoneOffsetTransition,ZoneOffsetTransitionRule,ZoneRules
-
The value type is annotated with:
-
@org.wildfly.clustering.web.annotation.Immutable -
@net.jcip.annotations.Immutable
-
6.2. HTTP Session Passivation and Activation
6.2.1. About HTTP Session Passivation and Activation
Passivation is the process of controlling memory usage by removing relatively unused sessions from memory while storing them in persistent storage.
Activation is when passivated data is retrieved from persisted storage and put back into memory.
Passivation occurs at different times in an HTTP session’s lifetime:
- When the container requests the creation of a new session, if the number of currently active sessions exceeds a configurable limit, the server attempts to passivate some sessions to make room for the new one.
- When a web application is deployed and a backup copy of sessions active on other servers is acquired by the newly deploying web application’s session manager, sessions might be passivated.
A session is passivated if the number of active sessions exceeds a configurable maximum.
Sessions are always passivated using a Least Recently Used (LRU) algorithm.
6.2.2. Configure HTTP Session Passivation in Your Application
HTTP session passivation is configured in your application’s WEB-INF/jboss-web.xml and META-INF/jboss-web.xml file.
Example: jboss-web.xml File
The <max-active-sessions> element dictates the maximum number of active sessions allowed, and is used to enable session passivation. If session creation would cause the number of active sessions to exceed <max-active-sessions>, then the oldest session known to the session manager will passivate to make room for the new session.
The total number of sessions in memory includes sessions replicated from other cluster nodes that are not being accessed on this node. Take this into account when setting <max-active-sessions>. The number of sessions replicated from other nodes also depends on whether REPL or DIST cache mode is enabled. In REPL cache mode, each session is replicated to each node. In DIST cache mode, each session is replicated only to the number of nodes specified by the owners parameter. See Configure the Cache Mode in the JBoss EAP Configuration Guide for information on configuring session cache modes. For example, consider an eight node cluster, where each node handles requests from 100 users. With REPL cache mode, each node would store 800 sessions in memory. With DIST cache mode enabled, and the default owners setting of 2, each node stores 200 sessions in memory.
6.3. Public API for Clustering Services
JBoss EAP 7 introduces a refined public clustering API for use by applications. The new services are designed to be lightweight, easily injectable, with no external dependencies.
org.wildfly.clustering.group.GroupThe group service provides a mechanism to view the cluster topology for a JGroups channel, and to be notified when the topology changes.
@Resource(lookup = "java:jboss/clustering/group/channel-name") private Group channelGroup;
@Resource(lookup = "java:jboss/clustering/group/channel-name") private Group channelGroup;Copy to Clipboard Copied! Toggle word wrap Toggle overflow org.wildfly.clustering.dispatcher.CommandDispatcherThe
CommandDispatcherFactoryservice provides a mechanism to create a dispatcher for executing commands on nodes in the cluster. The resultingCommandDispatcheris a command-pattern analog to the reflection-basedGroupRpcDispatcherfrom previous JBoss EAP releases.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.4. HA Singleton Service
A clustered singleton service, also known as a high-availability (HA) singleton, is a service deployed on multiple nodes in a cluster. The service is provided on only one of the nodes. The node running the singleton service is usually called the master node.
When the master node either fails or shuts down, another master is selected from the remaining nodes and the service is restarted on the new master. Other than a brief interval when one master has stopped and another has yet to take over, the service is provided by one, and only one, node.
HA Singleton ServiceBuilder API
JBoss EAP 7 introduces a new public API for building singleton services that simplifies the process significantly.
The SingletonServiceBuilder implementation installs its services so they will start asynchronously, preventing deadlocking of the Modular Service Container (MSC).
HA Singleton Service Election Policies
If there is a preference for which node should start the HA singleton, you can set the election policy in the ServiceActivator class.
JBoss EAP provides two election policies:
Simple election policy
The simple election policy selects a master node based on the relative age. The required age is configured in the position property, which is the index in the list of available nodes, where:
- position = 0 – refers to the oldest node. This is the default.
- position = 1 – refers to the 2nd oldest, and so on.
Position can also be negative to indicate the youngest nodes.
- position = -1 – refers to the youngest node.
- position = -2 – refers to the 2nd youngest node, and so on.
Random election policy
The random election policy elects a random member to be the provider of a singleton service.
HA Singleton Service Preferences
An HA singleton service election policy may optionally specify one or more preferred servers. This preferred server, when available, will be the master for all singleton applications under that policy.
You can define the preferences either through the node name or through the outbound socket binding name.
Node preferences always take precedence over the results of an election policy.
By default, JBoss EAP high availability configurations provide a simple election policy named default with no preferred server. You can set the preference by creating a custom policy and defining the preferred server.
Quorum
A potential issue with a singleton service arises when there is a network partition. In this situation, also known as the split-brain scenario, subsets of nodes cannot communicate with each other. Each set of servers consider all servers from the other set failed and continue to work as the surviving cluster. This might result in data consistency issues.
JBoss EAP allows you to specify a quorum in the election policy to prevent the split-brain scenario. The quorum specifies a minimum number of nodes to be present before a singleton provider election can take place.
A typical deployment scenario uses a quorum of N/2 + 1, where N is the anticipated cluster size. This value can be updated at runtime, and will immediately affect any active singleton services.
Create an HA Singleton Service Application
The following is an abbreviated example of the steps required to create and deploy an application as a cluster-wide singleton service. This example demonstrates a querying service that regularly queries a singleton service to get the name of the node on which it is running.
To see the singleton behavior, you must deploy the application to at least two servers. It is transparent whether the singleton service is running on the same node or whether the value is obtained remotely.
Create the
SingletonServiceclass. ThegetValue()method, which is called by the querying service, provides information about the node on which it is running.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Create the querying service. It calls the
getValue()method of the singleton service to get the name of the node on which it is running, and then writes the result to the server log.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Implement the
ServiceActivatorclass to build and install both the singleton service and the querying service.Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
Create a file in the
META-INF/services/directory namedorg.jboss.msc.service.ServiceActivatorthat contains the name of theServiceActivatorclass, for example,org.jboss.as.quickstarts.ha.singleton.service.primary.ServiceActivator.
See the ha-singleton-service quickstart that ships with JBoss EAP for the complete working example. This quickstart also provides a second example that demonstrates a singleton service that is installed with a backup service. The backup service is running on all nodes that are not elected to be running the singleton service. Finally, this quickstart also demonstrates how to configure a few different election policies.
6.5. HA Singleton Deployments
JBoss EAP 7 adds the ability to deploy a given application as a singleton deployment.
When deployed to a group of clustered servers, a singleton deployment will only deploy on a single node at any given time. If the node on which the deployment is active stops or fails, the deployment will automatically start on another node.
The policies for controlling HA singleton behavior are managed by a new singleton subsystem. A deployment can either specify a specific singleton policy or use the default subsystem policy. A deployment identifies itself as a singleton deployment by using a META-INF/singleton-deployment.xml deployment descriptor, which is most easily applied to an existing deployment as a deployment overlay. Alternatively, the requisite singleton configuration can be embedded within an existing jboss-all.xml file.
Defining or Choosing a Singleton Deployment
To define a deployment as a singleton deployment, include a
META-INF/singleton-deployment.xmldescriptor in your application archive.Example: Singleton Deployment Descriptor
<?xml version="1.0" encoding="UTF-8"?> <singleton-deployment xmlns="urn:jboss:singleton-deployment:1.0"/>
<?xml version="1.0" encoding="UTF-8"?> <singleton-deployment xmlns="urn:jboss:singleton-deployment:1.0"/>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example: Singleton Deployment Descriptor with a Specific Singleton Policy
<?xml version="1.0" encoding="UTF-8"?> <singleton-deployment policy="my-new-policy" xmlns="urn:jboss:singleton-deployment:1.0"/>
<?xml version="1.0" encoding="UTF-8"?> <singleton-deployment policy="my-new-policy" xmlns="urn:jboss:singleton-deployment:1.0"/>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Alternatively, you can also add a
singleton-deploymentelement to yourjboss-all.xmldescriptor file.Example: Defining
singleton-deploymentinjboss-all.xml<?xml version="1.0" encoding="UTF-8"?> <jboss xmlns="urn:jboss:1.0"> <singleton-deployment xmlns="urn:jboss:singleton-deployment:1.0"/> </jboss><?xml version="1.0" encoding="UTF-8"?> <jboss xmlns="urn:jboss:1.0"> <singleton-deployment xmlns="urn:jboss:singleton-deployment:1.0"/> </jboss>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example: Defining
singleton-deploymentinjboss-all.xmlwith a Specific Singleton Policy<?xml version="1.0" encoding="UTF-8"?> <jboss xmlns="urn:jboss:1.0"> <singleton-deployment policy="my-new-policy" xmlns="urn:jboss:singleton-deployment:1.0"/> </jboss><?xml version="1.0" encoding="UTF-8"?> <jboss xmlns="urn:jboss:1.0"> <singleton-deployment policy="my-new-policy" xmlns="urn:jboss:singleton-deployment:1.0"/> </jboss>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Creating a Singleton Deployment
JBoss EAP provides two election policies:
Simple election policy
The
simple-election-policychooses a specific member, indicated by thepositionattribute, on which a given application will be deployed. Thepositionattribute determines the index of the node to be elected from a list of candidates sorted by descending age, where0indicates the oldest node,1indicates the second oldest node,-1indicates the youngest node,-2indicates the second youngest node, and so on. If the specified position exceeds the number of candidates, a modulus operation is applied.Example: Create a New Singleton Policy with a
simple-election-policyand Position Set to-1, Using the Management CLIbatch /subsystem=singleton/singleton-policy=my-new-policy:add(cache-container=server) /subsystem=singleton/singleton-policy=my-new-policy/election- policy=simple:add(position=-1) run-batch
batch /subsystem=singleton/singleton-policy=my-new-policy:add(cache-container=server) /subsystem=singleton/singleton-policy=my-new-policy/election- policy=simple:add(position=-1) run-batchCopy to Clipboard Copied! Toggle word wrap Toggle overflow NoteTo set the newly created policy
my-new-policyas the default, run this command:/subsystem=singleton:write-attribute(name=default, value=my-new-policy)
/subsystem=singleton:write-attribute(name=default, value=my-new-policy)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example: Configure a
simple-election-policywith Position Set to-1Usingstandalone-ha.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Random election policy
The
random-election-policychooses a random member on which a given application will be deployed.Example: Creating a New Singleton Policy with a
random-election-policy, Using the Management CLIbatch /subsystem=singleton/singleton-policy=my-other-new-policy:add(cache-container=server) /subsystem=singleton/singleton-policy=my-other-new-policy/election-policy=random:add() run-batch
batch /subsystem=singleton/singleton-policy=my-other-new-policy:add(cache-container=server) /subsystem=singleton/singleton-policy=my-other-new-policy/election-policy=random:add() run-batchCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example: Configure a
random-election-policyUsingstandalone-ha.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow NoteThe
default-cacheattribute of thecache-containerneeds to be defined before trying to add the policy. Without this, if you are using a custom cache container, you might end up getting error messages.
Preferences
Additionally, any singleton election policy can indicate a preference for one or more members of a cluster. Preferences can be defined either by using the node name or by using the outbound socket binding name. Node preferences always take precedent over the results of an election policy.
Example: Indicate Preference in the Existing Singleton Policy Using the Management CLI
/subsystem=singleton/singleton-policy=foo/election-policy=simple:list-add(name=name-preferences, value=nodeA) /subsystem=singleton/singleton-policy=bar/election-policy=random:list-add(name=socket-binding-preferences, value=binding1)
/subsystem=singleton/singleton-policy=foo/election-policy=simple:list-add(name=name-preferences, value=nodeA)
/subsystem=singleton/singleton-policy=bar/election-policy=random:list-add(name=socket-binding-preferences, value=binding1)Example: Create a New Singleton Policy with a simple-election-policy and name-preferences, Using the Management CLI
batch /subsystem=singleton/singleton-policy=my-new-policy:add(cache-container=server) /subsystem=singleton/singleton-policy=my-new-policy/election-policy=simple:add(name-preferences=[node1, node2, node3, node4]) run-batch
batch
/subsystem=singleton/singleton-policy=my-new-policy:add(cache-container=server)
/subsystem=singleton/singleton-policy=my-new-policy/election-policy=simple:add(name-preferences=[node1, node2, node3, node4])
run-batch
To set the newly created policy my-new-policy as the default, run this command:
/subsystem=singleton:write-attribute(name=default, value=my-new-policy)
/subsystem=singleton:write-attribute(name=default, value=my-new-policy)Example: Configure a random-election-policy with socket-binding-preferences Using standalone-ha.xml
Define a Quorum
Network partitions are particularly problematic for singleton deployments, since they can trigger multiple singleton providers for the same deployment to run at the same time. To defend against this scenario, a singleton policy can define a quorum that requires a minimum number of nodes to be present before a singleton provider election can take place. A typical deployment scenario uses a quorum of N/2 + 1, where N is the anticipated cluster size. This value can be updated at runtime, and will immediately affect any singleton deployments using the respective singleton policy.
Example: Quorum Declaration in the standalone-ha.xml File
Example: Quorum Declaration Using the Management CLI
/subsystem=singleton/singleton-policy=foo:write-attribute(name=quorum, value=3)
/subsystem=singleton/singleton-policy=foo:write-attribute(name=quorum, value=3)
See the ha-singleton-deployment quickstart that ships with JBoss EAP for a complete working example of a service packaged in an application as a cluster-wide singleton using singleton deployments.
6.6. Apache mod_cluster-manager Application
6.6.1. About mod_cluster-manager Application
The mod_cluster-manager application is an administration web page, which is available on Apache HTTP Server. It is used for monitoring the connected worker nodes and performing various administration tasks, such as enabling or disabling contexts, and configuring the load-balancing properties of worker nodes in a cluster.
Exploring mod_cluster-manager Application
The mod_cluster-manager application can be used for performing various administration tasks on worker nodes.
 Figure - mod_cluster Administration Web Page
Figure - mod_cluster Administration Web Page
- [1] mod_cluster/1.3.1.Final: The version of the mod_cluster native library.
- [2] ajp://192.168.122.204:8099: The protocol used (either AJP, HTTP, or HTTPS), hostname or IP address of the worker node, and the port.
- [3] jboss-eap-7.0-2: The worker node’s JVMRoute.
- [4] Virtual Host 1: The virtual host(s) configured on the worker node.
- [5] Disable: An administration option that can be used to disable the creation of new sessions on the particular context. However, the ongoing sessions do not get disabled and remain intact.
-
[6] Stop: An administration option that can be used to stop the routing of session requests to the context. The remaining sessions will fail over to another node unless the
sticky-session-forceproperty is set totrue. - [7] Enable Contexts Disable Contexts Stop Contexts: The operations that can be performed on the whole node. Selecting one of these options affects all the contexts of a node in all its virtual hosts.
[8] Load balancing group (LBGroup): The
load-balancing-groupproperty is set in themodclustersubsystem in JBoss EAP configuration to group all worker nodes into custom load balancing groups. Load balancing group (LBGroup) is an informational field that gives information about all set load balancing groups. If this field is not set, then all worker nodes are grouped into a single default load balancing group.NoteThis is only an informational field and thus cannot be used to set
load-balancing-groupproperty. The property has to be set inmodclustersubsystem in JBoss EAP configuration.[9] Load (value): The load factor on the worker node. The load factors are evaluated as below:
-load > 0 : A load factor with value 1 indicates that the worker node is overloaded. A load factor of 100 denotes a free and not-loaded node. -load = 0 : A load factor of value 0 indicates that the worker node is in standby mode. This means that no session requests will be routed to this node until and unless the other worker nodes are unavailable. -load = -1 : A load factor of value -1 indicates that the worker node is in an error state. -load = -2 : A load factor of value -2 indicates that the worker node is undergoing CPing/CPong and is in a transition state.
-load > 0 : A load factor with value 1 indicates that the worker node is overloaded. A load factor of 100 denotes a free and not-loaded node. -load = 0 : A load factor of value 0 indicates that the worker node is in standby mode. This means that no session requests will be routed to this node until and unless the other worker nodes are unavailable. -load = -1 : A load factor of value -1 indicates that the worker node is in an error state. -load = -2 : A load factor of value -2 indicates that the worker node is undergoing CPing/CPong and is in a transition state.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
For JBoss EAP 7.1, it is also possible to use Undertow as load balancer.
Chapter 7. Contexts and Dependency Injection (CDI)
7.1. Introduction to CDI
7.1.1. About Contexts and Dependency Injection (CDI)
Contexts and Dependency Injection (CDI) 1.2 is a specification designed to enable Enterprise Java Beans (EJB) 3 components to be used as Java Server Faces (JSF) managed beans. CDI unifies the two component models and enables a considerable simplification to the programming model for web-based applications in Java. CDI 1.2 release is treated as a maintenance release of 1.1. Details about CDI 1.1 can be found in JSR 346: Contexts and Dependency Injection for Java™ EE 1.1.
JBoss EAP includes Weld, which is the reference implementation of JSR-346.
Benefits of CDI
The benefits of CDI include:
- Simplifying and shrinking your code base by replacing big chunks of code with annotations.
- Flexibility, allowing you to disable and enable injections and events, use alternative beans, and inject non-CDI objects easily.
-
Optionally, allowing you to include a
beans.xmlfile in yourMETA-INF/orWEB-INF/directory if you need to customize the configuration to differ from the default. The file can be empty. - Simplifying packaging and deployments and reducing the amount of XML you need to add to your deployments.
- Providing lifecycle management via contexts. You can tie injections to requests, sessions, conversations, or custom contexts.
- Providing type-safe dependency injection, which is safer and easier to debug than string-based injection.
- Decoupling interceptors from beans.
- Providing complex event notification.
7.1.2. Relationship Between Weld, Seam 2, and JavaServer Faces
Weld is the reference implementation of CDI, which is defined in JSR 346: Contexts and Dependency Injection for Java™ EE 1.1. Weld was inspired by Seam 2 and other dependency injection frameworks, and is included in JBoss EAP.
The goal of Seam 2 was to unify Enterprise Java Beans and JavaServer Faces managed beans.
JavaServer Faces 2.2 implements JSR-344: JavaServer™ Faces 2.2. It is an API for building server-side user interfaces.
7.2. Use CDI to Develop an Application
Contexts and Dependency Injection (CDI) gives you tremendous flexibility in developing applications, reusing code, adapting your code at deployment or runtime, and unit testing. JBoss EAP includes Weld, the reference implementation of CDI. These tasks show you how to use CDI in your enterprise applications.
Weld comes with a special mode for application development. When enabled, certain built-in tools, which facilitate the development of CDI applications, are available.
The development mode should not be used in production as it can have a negative impact on the performance of the application. Make sure to disable the development mode before deploying to production.
Enabling the Development Mode for a Web Application:
For a web application, set the servlet initialization parameter org.jboss.weld.development to true:
Enabling Development Mode for JBoss EAP Using the Management CLI:
It is possible to enable the Weld development mode globally for all the applications deployed by setting development-mode attribute to true:
/subsystem=weld:write-attribute(name=development-mode,value=true)
/subsystem=weld:write-attribute(name=development-mode,value=true)7.2.1. Default Bean Discovery Mode
The default bean discovery mode for a bean archive is annotated. Such a bean archive is said to be an implicit bean archive.
If the bean discovery mode is annotated, then:
-
Bean classes that do not have
bean defining annotationand are not bean classes of sessions beans are not discovered. - Producer methods that are not on a session bean and whose bean class does not have a bean defining annotation are not discovered.
- Producer fields that are not on a session bean and whose bean class does not have a bean defining annotation are not discovered.
- Disposer methods that are not on a session bean and whose bean class does not have a bean defining annotation are not discovered.
- Observer methods that are not on a session bean and whose bean class does not have a bean defining annotation are not discovered.
All examples in the CDI section are valid only when you have a discovery mode set to all.
Bean Defining Annotations
A bean class can have a bean defining annotation, allowing it to be placed anywhere in an application, as defined in bean archives. A bean class with a bean defining annotation is said to be an implicit bean.
The set of bean defining annotations contains:
-
@ApplicationScoped,@SessionScoped,@ConversationScopedand@RequestScopedannotations. - All other normal scope types.
-
@Interceptorand@Decoratorannotations. -
All stereotype annotations, i.e. annotations annotated with
@Stereotype. -
The
@Dependentscope annotation.
If one of these annotations is declared on a bean class, then the bean class is said to have a bean defining annotation.
Example: Bean Defining Annotation
To ensure compatibility with other JSR-330 implementations, all pseudo-scope annotations, except @Dependent, are not bean defining annotations. However, a stereotype annotation, including a pseudo-scope annotation, is a bean defining annotation.
7.2.2. Exclude Beans From the Scanning Process
Exclude filters are defined by <exclude> elements in the beans.xml file for the bean archive as children of the <scan> element. By default an exclude filter is active. The exclude filter becomes inactive, if its definition contains:
-
A child element named
<if-class-available>with anameattribute, and the class loader for the bean archive can not load a class for that name, or -
A child element named
<if-class-not-available>with anameattribute, and the class loader for the bean archive can load a class for that name, or -
A child element named
<if-system-property>with anameattribute, and there is no system property defined for that name, or -
A child element named
<if-system-property>with anameattribute and a value attribute, and there is no system property defined for that name with that value.
The type is excluded from discovery, if the filter is active, and:
- The fully qualified name of the type being discovered matches the value of the name attribute of the exclude filter, or
- The package name of the type being discovered matches the value of the name attribute with a suffix ".*" of the exclude filter, or
- The package name of the type being discovered starts with the value of the name attribute with a suffix ".**" of the exclude filter
Example 7.1. Example: beans.xml File
- 1
- The first exclude filter will exclude all classes in
com.acme.restpackage. - 2
- The second exclude filter will exclude all classes in the
com.acme.facespackage, and any subpackages, but only if JSF is not available. - 3
- The third exclude filter will exclude all classes in the
com.acme.verbosepackage if the system propertyverbosityhas the valuelow. - 4
- The fourth exclude filter will exclude all classes in the
com.acme.ejbpackage, and any subpackages, if the system propertyexclude-ejbsis set with any value and if at the same time, thejavax.enterprise.inject.Modelclass is also available to the classloader.
It is safe to annotate Java EE components with @Vetoed to prevent them being considered beans. An event is not fired for any type annotated with @Vetoed, or in a package annotated with @Vetoed. For more information, see @Vetoed.
7.2.3. Use an Injection to Extend an Implementation
You can use an injection to add or change a feature of your existing code.
The following example adds a translation ability to an existing class, and assumes you already have a Welcome class, which has a method buildPhrase. The buildPhrase method takes as an argument the name of a city, and outputs a phrase like "Welcome to Boston!".
This example injects a hypothetical Translator object into the Welcome class. The Translator object can be an EJB stateless bean or another type of bean, which can translate sentences from one language to another. In this instance, the Translator is used to translate the entire greeting, without modifying the original Welcome class. The Translator is injected before the buildPhrase method is called.
Example: Inject a Translator Bean into the Welcome Class
7.3. Ambiguous or Unsatisfied Dependencies
Ambiguous dependencies exist when the container is unable to resolve an injection to exactly one bean.
Unsatisfied dependencies exist when the container is unable to resolve an injection to any bean at all.
The container takes the following steps to try to resolve dependencies:
- It resolves the qualifier annotations on all beans that implement the bean type of an injection point.
-
It filters out disabled beans. Disabled beans are
@Alternativebeans which are not explicitly enabled.
In the event of an ambiguous or unsatisfied dependency, the container aborts deployment and throws an exception.
To fix an ambiguous dependency, see Use a Qualifier to Resolve an Ambiguous Injection.
7.3.1. Qualifiers
Qualifiers are annotations used to avoid ambiguous dependencies when the container can resolve multiple beans, which fit into an injection point. A qualifier declared at an injection point provides the set of eligible beans, which declare the same qualifier.
Qualifiers must be declared with a retention and target as shown in the example below.
Example: Define the @Synchronous and @Asynchronous Qualifiers
@Qualifier
@Retention(RUNTIME)
@Target({TYPE, METHOD, FIELD, PARAMETER})
public @interface Synchronous {}
@Qualifier
@Retention(RUNTIME)
@Target({TYPE, METHOD, FIELD, PARAMETER})
public @interface Synchronous {}@Qualifier
@Retention(RUNTIME)
@Target({TYPE, METHOD, FIELD, PARAMETER})
public @interface Asynchronous {}
@Qualifier
@Retention(RUNTIME)
@Target({TYPE, METHOD, FIELD, PARAMETER})
public @interface Asynchronous {}Example: Use the @Synchronous and @Asynchronous Qualifiers
@Synchronous
public class SynchronousPaymentProcessor implements PaymentProcessor {
public void process(Payment payment) { ... }
}
@Synchronous
public class SynchronousPaymentProcessor implements PaymentProcessor {
public void process(Payment payment) { ... }
}@Asynchronous
public class AsynchronousPaymentProcessor implements PaymentProcessor {
public void process(Payment payment) { ... }
}
@Asynchronous
public class AsynchronousPaymentProcessor implements PaymentProcessor {
public void process(Payment payment) { ... }
}'@Any'
Whenever a bean or injection point does not explicitly declare a qualifier, the container assumes the qualifier @Default. From time to time, you will need to declare an injection point without specifying a qualifier. There is a qualifier for that too. All beans have the qualifier @Any. Therefore, by explicitly specifying @Any at an injection point, you suppress the default qualifier, without otherwise restricting the beans that are eligible for injection.
This is especially useful if you want to iterate over all beans of a certain bean type.
Every bean has the qualifier @Any, even if it does not explicitly declare this qualifier.
Every event also has the qualifier @Any, even if it was raised without explicit declaration of this qualifier.
@Inject @Any Event<User> anyUserEvent;
@Inject @Any Event<User> anyUserEvent;
The @Any qualifier allows an injection point to refer to all beans or all events of a certain bean type.
@Inject @Delegate @Any Logger logger;
@Inject @Delegate @Any Logger logger;7.3.2. Use a Qualifier to Resolve an Ambiguous Injection
You can resolve an ambiguous injection using a qualifier. Read more about ambiguous injections at Ambiguous or Unsatisfied Dependencies.
The following example is ambiguous and features two implementations of Welcome, one which translates and one which does not. The injection needs to be specified to use the translating Welcome.
Example: Ambiguous Injection
Resolve an Ambiguous Injection with a Qualifier
To resolve the ambiguous injection, create a qualifier annotation called
@Translating:@Qualifier @Retention(RUNTIME) @Target({TYPE,METHOD,FIELD,PARAMETERS}) public @interface Translating{}@Qualifier @Retention(RUNTIME) @Target({TYPE,METHOD,FIELD,PARAMETERS}) public @interface Translating{}Copy to Clipboard Copied! Toggle word wrap Toggle overflow Annotate your translating
Welcomewith the@Translatingannotation:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Request the translating
Welcomein your injection. You must request a qualified implementation explicitly, similar to the factory method pattern. The ambiguity is resolved at the injection point.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.4. Managed Beans
Java EE establishes a common definition in the Managed Beans specification. Managed beans are defined as container-managed objects with minimal programming restrictions, otherwise known by the acronym POJO (Plain Old Java Object). They support a small set of basic services, such as resource injection, lifecycle callbacks, and interceptors. Companion specifications, such as EJB and CDI, build on this basic model.
With very few exceptions, almost every concrete Java class that has a constructor with no parameters, or a constructor designated with the annotation @Inject, is a bean. This includes every JavaBean and every EJB session bean.
7.4.1. Types of Classes That are Beans
A managed bean is a Java class. The basic lifecycle and semantics of a managed bean are defined by the Managed Beans specification. You can explicitly declare a managed bean by annotating the bean class @ManagedBean, but in CDI you do not need to. According to the specification, the CDI container treats any class that satisfies the following conditions as a managed bean:
- It is not a non-static inner class.
-
It is a concrete class or is annotated with
@Decorator. -
It is not annotated with an EJB component-defining annotation or declared as an EJB bean class in the
ejb-jar.xmlfile. -
It does not implement the interface
javax.enterprise.inject.spi.Extension. -
It has either a constructor with no parameters, or a constructor annotated with
@Inject. -
It is not annotated with
@Vetoedor in a package annotated with@Vetoed.
The unrestricted set of bean types for a managed bean contains the bean class, every superclass, and all interfaces it implements directly or indirectly.
If a managed bean has a public field, it must have the default scope @Dependent.
@Vetoed
CDI 1.1 introduces a new annotation, @Vetoed. You can prevent a bean from injection by adding this annotation:
@Vetoed
public class SimpleGreeting implements Greeting {
...
}
@Vetoed
public class SimpleGreeting implements Greeting {
...
}
In this code, the SimpleGreeting bean is not considered for injection.
All beans in a package can be prevented from injection:
@Vetoed package org.sample.beans; import javax.enterprise.inject.Vetoed;
@Vetoed
package org.sample.beans;
import javax.enterprise.inject.Vetoed;
This code in package-info.java in the org.sample.beans package will prevent all beans inside this package from injection.
Java EE components, such as stateless EJBs or JAX-RS resource endpoints, can be marked with @Vetoed to prevent them from being considered beans. Adding the @Vetoed annotation to all persistent entities prevents the BeanManager from managing an entity as a CDI Bean. When an entity is annotated with @Vetoed, no injections take place. The reasoning behind this is to prevent the BeanManager from performing the operations that might cause the JPA provider to break.
7.4.2. Use CDI to Inject an Object Into a Bean
CDI is activated automatically if CDI components are detected in an application. If you want to customize your configuration to differ from the default, you can include a META-INF/beans.xml file or a WEB-INF/beans.xml file in your deployment archive.
Inject Objects into Other Objects
To obtain an instance of a class, annotate the field with
@Injectwithin your bean:public class TranslateController { @Inject TextTranslator textTranslator; ...public class TranslateController { @Inject TextTranslator textTranslator; ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow Use your injected object’s methods directly. Assume that
TextTranslatorhas a methodtranslate:// in TranslateController class public void translate() { translation = textTranslator.translate(inputText); }// in TranslateController class public void translate() { translation = textTranslator.translate(inputText); }Copy to Clipboard Copied! Toggle word wrap Toggle overflow Use an injection in the constructor of a bean. You can inject objects into the constructor of a bean as an alternative to using a factory or service locator to create them:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Use the
Instance(<T>)interface to get instances programmatically. TheInstanceinterface can return an instance ofTextTranslatorwhen parameterized with the bean type.@Inject Instance<TextTranslator> textTranslatorInstance; ... public void translate() { textTranslatorInstance.get().translate(inputText); }@Inject Instance<TextTranslator> textTranslatorInstance; ... public void translate() { textTranslatorInstance.get().translate(inputText); }Copy to Clipboard Copied! Toggle word wrap Toggle overflow
When you inject an object into a bean, all of the object’s methods and properties are available to your bean. If you inject into your bean’s constructor, instances of the injected objects are created when your bean’s constructor is called, unless the injection refers to an instance that already exists. For instance, a new instance would not be created if you inject a session-scoped bean during the lifetime of the session.
7.5. Contexts and Scopes
A context, in terms of CDI, is a storage area that holds instances of beans associated with a specific scope.
A scope is the link between a bean and a context. A scope/context combination can have a specific lifecycle. Several predefined scopes exist, and you can create your own. Examples of predefined scopes are @RequestScoped, @SessionScoped, and @ConversationScope.
| Scope | Description |
|---|---|
|
|
The bean is bound to the lifecycle of the bean holding the reference. The default scope for an injected bean is |
|
| The bean is bound to the lifecycle of the application. |
|
| The bean is bound to the lifecycle of the request. |
|
| The bean is bound to the lifecycle of the session. |
|
| The bean is bound to the lifecycle of the conversation. The conversation scope is between the lengths of the request and the session, and is controlled by the application. |
| Custom scopes | If the above contexts do not meet your needs, you can define custom scopes. |
7.6. Named Beans
You can name a bean by using the @Named annotation. Naming a bean allows you to use it directly in Java Server Faces (JSF) and Expression Language (EL).
The @Named annotation takes an optional parameter, which is the bean name. If this parameter is omitted, the bean name defaults to the class name of the bean with its first letter converted to lowercase.
7.6.1. Use Named Beans
Configure Bean Names Using the @Named Annotation
Use the
@Namedannotation to assign a name to a bean.Copy to Clipboard Copied! Toggle word wrap Toggle overflow In the example above, the default name would be
greeterBeanif no name had been specified.Use the named bean in a JSF view.
<h:form> <h:commandButton value="Welcome visitors" action="#{greeter.welcomeVisitors}"/> </h:form><h:form> <h:commandButton value="Welcome visitors" action="#{greeter.welcomeVisitors}"/> </h:form>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.7. Bean Lifecycle
This task shows you how to save a bean for the life of a request.
The default scope for an injected bean is @Dependent. This means that the bean’s lifecycle is dependent upon the lifecycle of the bean that holds the reference. Several other scopes exist, and you can define your own scopes. For more information, see Contexts and Scopes.
Manage Bean Lifecycles
Annotate the bean with the desired scope.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow When your bean is used in the JSF view, it holds state.
<h:form> <h:inputText value="#{greeter.city}"/> <h:commandButton value="Welcome visitors" action="#{greeter.welcomeVisitors}"/> </h:form><h:form> <h:inputText value="#{greeter.city}"/> <h:commandButton value="Welcome visitors" action="#{greeter.welcomeVisitors}"/> </h:form>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Your bean is saved in the context relating to the scope that you specify, and lasts as long as the scope applies.
7.7.1. Use a Producer Method
A producer method is a method that acts as a source of bean instances. When no instance exists in the specified context, the method declaration itself describes the bean, and the container invokes the method to obtain an instance of the bean. A producer method lets the application take full control of the bean instantiation process.
This section shows how to use producer methods to produce a variety of different objects that are not beans for injection.
Example: Use a Producer Method
By using a producer method instead of an alternative, polymorphism after deployment is allowed.
The @Preferred annotation in the example is a qualifier annotation. For more information about qualifiers, see Qualifiers.
The following injection point has the same type and qualifier annotations as the producer method, so it resolves to the producer method using the usual CDI injection rules. The producer method is called by the container to obtain an instance to service this injection point.
@Inject @Preferred PaymentStrategy paymentStrategy;
@Inject @Preferred PaymentStrategy paymentStrategy;Example: Assign a Scope to a Producer Method
The default scope of a producer method is @Dependent. If you assign a scope to a bean, it is bound to the appropriate context. The producer method in this example is only called once per session.
@Produces @Preferred @SessionScoped
public PaymentStrategy getPaymentStrategy() {
...
}
@Produces @Preferred @SessionScoped
public PaymentStrategy getPaymentStrategy() {
...
}Example: Use an Injection Inside a Producer Method
Objects instantiated directly by an application cannot take advantage of dependency injection and do not have interceptors. However, you can use dependency injection into the producer method to obtain bean instances.
If you inject a request-scoped bean into a session-scoped producer, the producer method promotes the current request-scoped instance into session scope. This is almost certainly not the desired behavior, so use caution when you use a producer method in this way.
The scope of the producer method is not inherited from the bean that declares the producer method.
Producer methods allow you to inject non-bean objects and change your code dynamically.
7.8. Alternative Beans
Alternatives are beans whose implementation is specific to a particular client module or deployment scenario.
By default, @Alternative beans are disabled. They are enabled for a specific bean archive by editing its beans.xml file. However, this activation only applies to the beans in that archive. From CDI 1.1 onwards, the alternative can be enabled for the entire application using the @Priority annotation.
Example: Defining Alternatives
This alternative defines an implementation of the PaymentProcessor class using both @Synchronous and @Asynchronous alternatives:
Example: Enabling @Alternative Using beans.xml
Declaring Selected Alternatives
The @Priority annotation allows an alternative to be enabled for an entire application. An alternative can be given a priority for the application:
-
by placing the
@Priorityannotation on the bean class of a managed bean or session bean, or -
by placing the
@Priorityannotation on the bean class that declares the producer method, field or resource.
7.8.1. Override an Injection with an Alternative
You can use alternative beans to override existing beans. They can be thought of as a way to plug in a class which fills the same role, but functions differently. They are disabled by default.
This task shows you how to specify and enable an alternative.
Override an Injection
This task assumes that you already have a TranslatingWelcome class in your project, but you want to override it with a "mock" TranslatingWelcome class. This would be the case for a test deployment, where the true Translator bean cannot be used.
Define the alternative.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Activate the substitute implementation by adding the fully-qualified class name to your
META-INF/beans.xmlorWEB-INF/beans.xmlfile.<beans> <alternatives> <class>com.acme.MockTranslatingWelcome</class> </alternatives> </beans><beans> <alternatives> <class>com.acme.MockTranslatingWelcome</class> </alternatives> </beans>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
The alternative implementation is now used instead of the original one.
7.9. Stereotypes
In many systems, use of architectural patterns produces a set of recurring bean roles. A stereotype allows you to identify such a role and declare some common metadata for beans with that role in a central place.
A stereotype encapsulates any combination of:
- A default scope.
- A set of interceptor bindings.
A stereotype can also specify either:
- All beans where the stereotypes are defaulted bean EL names.
- All beans where the stereotypes are alternatives.
A bean can declare zero, one, or multiple stereotypes. A stereotype is an @Stereotype annotation that packages several other annotations. Stereotype annotations can be applied to a bean class, producer method, or field.
A class that inherits a scope from a stereotype can override that stereotype and specify a scope directly on the bean.
In addition, if a stereotype has a @Named annotation, any bean it is placed on has a default bean name. The bean can override this name if the @Named annotation is specified directly on the bean. For more information about named beans, see Named Beans.
7.9.1. Use Stereotypes
Without stereotypes, annotations can become cluttered. This task shows you how to use stereotypes to reduce the clutter and streamline your code.
Example: Annotation Clutter
Define and Use Stereotypes
Define the stereotype.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Use the stereotype.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.10. Observer Methods
Observer methods receive notifications when events occur.
CDI also provides transactional observer methods, which receive event notifications during the before completion or after completion phase of the transaction in which the event was fired.
7.10.1. Fire and Observe Events
Example: Fire an Event
The following code shows an event being injected and used in a method.
Example: Fire an Event with a Qualifier
You can annotate your event injection with a qualifier, to make it more specific. For more information about qualifiers, see Qualifiers.
Example: Observe an Event
To observe an event, use the @Observes annotation.
public class AccountObserver {
void checkTran(@Observes Withdrawal w) {
...
}
}
public class AccountObserver {
void checkTran(@Observes Withdrawal w) {
...
}
}You can use qualifiers to observe only specific types of events.
public class AccountObserver {
void checkTran(@Observes @Suspicious Withdrawal w) {
...
}
}
public class AccountObserver {
void checkTran(@Observes @Suspicious Withdrawal w) {
...
}
}7.10.2. Transactional Observers
Transactional observers receive the event notifications before or after the completion phase of the transaction in which the event was raised. Transactional observers are important in a stateful object model because state is often held for longer than a single atomic transaction.
There are five kinds of transactional observers:
-
IN_PROGRESS: By default, observers are invoked immediately. -
AFTER_SUCCESS: Observers are invoked after the completion phase of the transaction, but only if the transaction completes successfully. -
AFTER_FAILURE: Observers are invoked after the completion phase of the transaction, but only if the transaction fails to complete successfully. -
AFTER_COMPLETION: Observers are invoked after the completion phase of the transaction. -
BEFORE_COMPLETION: Observers are invoked before the completion phase of the transaction.
The following observer method refreshes a query result set cached in the application context, but only when transactions that update the Category tree are successful:
public void refreshCategoryTree(@Observes(during = AFTER_SUCCESS) CategoryUpdateEvent event) { ... }
public void refreshCategoryTree(@Observes(during = AFTER_SUCCESS) CategoryUpdateEvent event) { ... }Assume you have cached a JPA query result set in the application scope as shown in the following example:
Occasionally a Product is created or deleted. When this occurs, you need to refresh the Product catalog. But you must wait for the transaction to complete successfully before performing this refresh.
The following is an example of a bean that creates and deletes Products triggers events:
The Catalog can now observe the events after successful completion of the transaction:
7.11. Interceptors
Interceptors allow you to add functionality to the business methods of a bean without modifying the bean’s method directly. The interceptor is executed before any of the business methods of the bean. Interceptors are defined as part of the JSR 318: Enterprise JavaBeans™ 3.1 specification.
CDI enhances this functionality by allowing you to use annotations to bind interceptors to beans.
Interception points
- Business method interception: A business method interceptor applies to invocations of methods of the bean by clients of the bean.
- Lifecycle callback interception: A lifecycle callback interceptor applies to invocations of lifecycle callbacks by the container.
- Timeout method interception: A timeout method interceptor applies to invocations of the EJB timeout methods by the container.
Enabling Interceptors
By default, all interceptors are disabled. You can enable the interceptor by using the beans.xml descriptor of a bean archive. However, this activation only applies to the beans in that archive. From CDI 1.1 onwards the interceptor can be enabled for the whole application using the @Priority annotation.
Example: Enabling Interceptors in beans.xml
Having the XML declaration solves two problems:
- It enables you to specify an ordering for the interceptors in your system, ensuring deterministic behavior.
- It lets you enable or disable interceptor classes at deployment time.
Interceptors enabled using @Priority are called before interceptors enabled using the beans.xml file.
Having an interceptor enabled by @Priority and at the same time invoked by the beans.xml file leads to a nonportable behavior. This combination of enablement should therefore be avoided in order to maintain consistent behavior across different CDI implementations.
7.11.1. Use Interceptors with CDI
CDI can simplify your interceptor code and make it easier to apply to your business code.
Without CDI, interceptors have two problems:
- The bean must specify the interceptor implementation directly.
- Every bean in the application must specify the full set of interceptors in the correct order. This makes adding or removing interceptors on an application-wide basis time-consuming and error-prone.
Using Interceptors with CDI
Define the interceptor binding type.
@InterceptorBinding @Retention(RUNTIME) @Target({TYPE, METHOD}) public @interface Secure {}@InterceptorBinding @Retention(RUNTIME) @Target({TYPE, METHOD}) public @interface Secure {}Copy to Clipboard Copied! Toggle word wrap Toggle overflow Mark the interceptor implementation.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Use the interceptor in your development environment.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Enable the interceptor in your deployment, by adding it to the
META-INF/beans.xmlorWEB-INF/beans.xmlfile.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
The interceptors are applied in the order listed.
7.12. Decorators
A decorator intercepts invocations from a specific Java interface, and is aware of all the semantics attached to that interface. Decorators are useful for modeling some kinds of business concerns, but do not have the generality of interceptors. A decorator is a bean, or even an abstract class, that implements the type it decorates, and is annotated with @Decorator. To invoke a decorator in a CDI application, it must be specified in the beans.xml file.
Example: Invoke a Decorator Through beans.xml
This declaration serves two main purposes:
- It enables you to specify an ordering for decorators in your system, ensuring deterministic behavior.
- It lets you enable or disable decorator classes at deployment time.
A decorator must have exactly one @Delegate injection point to obtain a reference to the decorated object.
Example: Decorator Class
From CDI 1.1 onwards, the decorator can be enabled for the whole application using @Priority annotation.
Decorators enabled using @Priority are called before decorators enabled using the beans.xml file. The lower priority values are called first.
Having a decorator enabled by @Priority and at the same time invoked by beans.xml, leads to a nonportable behavior. This combination of enablement should therefore be avoided in order to maintain consistent behavior across different CDI implementations.
7.13. Portable Extensions
CDI is intended to be a foundation for frameworks, extensions, and for integration with other technologies. Therefore, CDI exposes a set of SPIs for the use of developers of portable extensions to CDI.
Extensions can provide the following types of functionality:
- Integration with Business Process Management engines.
- Integration with third-party frameworks, such as Spring, Seam, GWT, or Wicket.
- New technology based upon the CDI programming model.
According to the JSR-346 specification, a portable extension can integrate with the container in the following ways:
- Providing its own beans, interceptors, and decorators to the container.
- Injecting dependencies into its own objects using the dependency. injection service.
- Providing a context implementation for a custom scope.
- Augmenting or overriding the annotation-based metadata with metadata from another source.
For more information, see Portable extensions in the Weld documentation. You can also see the cdi-portable-extension quickstart that ships with JBoss EAP for a working example of using CDI portable extension.
7.14. Bean Proxies
Clients of an injected bean do not usually hold a direct reference to a bean instance. Unless the bean is a dependent object, scope @Dependent, the container must redirect all injected references to the bean using a proxy object.
A bean proxy, which can be referred to as client proxy, is responsible for ensuring the bean instance that receives a method invocation is the instance associated with the current context. The client proxy also allows beans bound to contexts, such as the session context, to be serialized to disk without recursively serializing other injected beans.
Due to Java limitations, some Java types cannot be proxied by the container. If an injection point declared with one of these types resolves to a bean with a scope other than @Dependent, the container aborts the deployment.
Certain Java types cannot be proxied by the container. These include:
- Classes that do not have a non-private constructor with no parameters.
-
Classes that are declared
finalor have afinalmethod. - Arrays and primitive types.
7.15. Use a Proxy in an Injection
A proxy is used for injection when the lifecycles of the beans are different from each other. The proxy is a subclass of the bean that is created at runtime, and overrides all the non-private methods of the bean class. The proxy forwards the invocation onto the actual bean instance.
In this example, the PaymentProcessor instance is not injected directly into Shop. Instead, a proxy is injected, and when the processPayment() method is called, the proxy looks up the current PaymentProcessor bean instance and calls the processPayment() method on it.
Example: Proxy Injection
Chapter 8. JBoss EAP MBean Services
A managed bean, sometimes simply referred to as an MBean, is a type of JavaBean that is created with dependency injection. MBean services are the core building blocks of the JBoss EAP server.
8.1. Writing JBoss MBean Services
Writing a custom MBean service that relies on a JBoss service requires the service interface method pattern. A JBoss MBean service interface method pattern consists of a set of life cycle operations that inform an MBean service when it can create, start, stop, and destroy itself.
You can manage the dependency state using any of the following approaches:
- If you want specific methods to be called on your MBean, declare those methods in your MBean interface. This approach allows your MBean implementation to avoid dependencies on JBoss specific classes.
-
If you are not bothered about dependencies on JBoss specific classes, then you can have your MBean interface extend the
ServiceMBeaninterface andServiceMBeanSupportclass. TheServiceMBeanSupportclass provides implementations of the service lifecycle methods like create, start, and stop. To handle a specific event like thestart()event, you need to overridestartService()method provided by theServiceMBeanSupportclass.
8.1.1. A Standard MBean Example
This section develops two example MBean services packaged together in a service archive (.sar).
ConfigServiceMBean interface declares specific methods like the start, getTimeout, and stop methods to start, hold, and stop the MBean correctly without using any JBoss specific classes. ConfigService class implements ConfigServiceMBean interface and consequently implements the methods used within that interface.
The PlainThread class extends the ServiceMBeanSupport class and implements the PlainThreadMBean interface. PlainThread starts a thread and uses ConfigServiceMBean.getTimeout() to determine how long the thread should sleep.
Example: MBean Services Class
The jboss-service.xml descriptor shows how the ConfigService class is injected into the PlainThread class using the inject tag. The inject tag establishes a dependency between PlainThreadMBean and ConfigServiceMBean, and thus allows PlainThreadMBean to use ConfigServiceMBean easily.
Example: jboss-service.xml Service Descriptor
After writing the MBeans example, you can package the classes and the jboss-service.xml descriptor in the META-INF/ folder of a service archive (.sar).
8.2. Deploying JBoss MBean Services
Example: Deploy and Test MBeans in a Managed Domain
Use the following command to deploy the example MBeans (ServiceMBeanTest.sar) in a managed domain:
deploy ~/Desktop/ServiceMBeanTest.sar --all-server-groups
deploy ~/Desktop/ServiceMBeanTest.sar --all-server-groupsExample: Deploy and Test MBeans on a Standalone Server
Use the following command to build and deploy the example MBeans (ServiceMBeanTest.sar) on a standalone server:
deploy ~/Desktop/ServiceMBeanTest.sar
deploy ~/Desktop/ServiceMBeanTest.sarExample: Undeploy the MBeans Archive
Use the following command to undeploy the MBeans example:
undeploy ServiceMBeanTest.sar
undeploy ServiceMBeanTest.sarChapter 9. Concurrency Utilities
Concurrency Utilities is an API that accommodates Java SE concurrency utilities into the Java EE application environment specifications. It is defined in JSR 236: Concurrency Utilities for Java™ EE. JBoss EAP allows you to create, edit, and delete instances of EE concurrency utilities, thus making these instances readily available for applications to use.
Concurrency Utilities help to extend the invocation context by pulling in the existing context’s application threads and using these in its own threads. This extending of invocation context includes class loading, JNDI, and security contexts, by default.
Types of Concurrency Utilities include:
- Context Service
- Managed Thread Factory
- Managed Executor Service
- Managed Scheduled Executor Service
Example: Concurrency Utilities in standalone.xml
9.1. Context Service
The context service (javax.enterprise.concurrent.ContextService) allows you to build contextual proxies from existing objects. Contextual proxy prepares the invocation context, which is used by other concurrency utilities when the context is created or invoked, before transferring the invocation to the original object.
Attributes of the context service concurrency utility include:
-
name: A unique name within all the context services. -
jndi-name: Defines where the context service should be placed in JNDI. -
use-transaction-setup-provider: Optional. Indicates if the contextual proxies built by the context service should suspend transactions in context when invoking the proxy objects. Its value defaults tofalse, but the default context service has the valuetrue.
See the example above for the usage of the context service concurrency utility.
Example: Add a New Context Service
/subsystem=ee/context-service=newContextService:add(jndi-name=java:jboss/ee/concurrency/contextservice/newContextService)
/subsystem=ee/context-service=newContextService:add(jndi-name=java:jboss/ee/concurrency/contextservice/newContextService)Example: Change a Context Service
/subsystem=ee/context-service=newContextService:write-attribute(name=jndi-name, value=java:jboss/ee/concurrency/contextservice/changedContextService)
/subsystem=ee/context-service=newContextService:write-attribute(name=jndi-name, value=java:jboss/ee/concurrency/contextservice/changedContextService)This operation requires reload.
Example: Remove a Context Service
/subsystem=ee/context-service=newContextService:remove()
/subsystem=ee/context-service=newContextService:remove()This operation requires reload.
9.2. Managed Thread Factory
The managed thread factory (javax.enterprise.concurrent.ManagedThreadFactory) concurrency utility allows Java EE applications to create Java threads. JBoss EAP handles the managed thread factory instances, hence Java EE applications cannot invoke any lifecycle related method.
Attributes of managed thread factory concurrency utility include:
-
context-service: A unique name within all managed thread factories. -
jndi-name: Defines where in JNDI the managed thread factory should be placed. -
priority: Optional. Indicates the priority for new threads created by the factory, and defaults to5.
Example: Add a New Managed Thread Factory
/subsystem=ee/managed-thread-factory=newManagedTF:add(context-service=newContextService, jndi-name=java:jboss/ee/concurrency/threadfactory/newManagedTF, priority=2)
/subsystem=ee/managed-thread-factory=newManagedTF:add(context-service=newContextService, jndi-name=java:jboss/ee/concurrency/threadfactory/newManagedTF, priority=2)Example: Change a Managed Thread Factory
/subsystem=ee/managed-thread-factory=newManagedTF:write-attribute(name=jndi-name, value=java:jboss/ee/concurrency/threadfactory/changedManagedTF)
/subsystem=ee/managed-thread-factory=newManagedTF:write-attribute(name=jndi-name, value=java:jboss/ee/concurrency/threadfactory/changedManagedTF)This operation requires reload. Similarly, you can change other attributes as well.
Example: Remove a Managed Thread Factory
/subsystem=ee/managed-thread-factory=newManagedTF:remove()
/subsystem=ee/managed-thread-factory=newManagedTF:remove()This operation requires reload.
9.3. Managed Executor Service
Managed executor service (javax.enterprise.concurrent.ManagedExecutorService) allows Java EE applications to submit tasks for asynchronous execution. JBoss EAP handles managed executor service instances, hence Java EE applications cannot invoke any lifecycle related method.
Attributes of managed executor service concurrency utility include:
-
context-service: Optional. References an existing context service by its name. If specified, then the referenced context service will capture the invocation context present when submitting a task to the executor, which will then be used when executing the task. -
jndi-name: Defines where the managed thread factory should be placed in JNDI. -
max-threads: Defines the maximum number of threads used by the executor. If undefined, the value fromcore-threadsis used. -
thread-factory: References an existing managed thread factory by its name, to handle the creation of internal threads. If not specified, then a managed thread factory with default configuration will be created and used internally. -
core-threads: Defines the minimum number of threads to be used by the executor. If this attribute is undefined, the default is calculated based on the number of processors. A value of0is not recommended. See thequeue-lengthattribute for details on how this value is used to determine the queuing strategy. -
keepalive-time: Defines the time, in milliseconds, that an internal thread can be idle. The attribute default value is60000. -
queue-length: Indicates the executor’s task queue capacity. A value of0means direct hand-off and possible rejection will occur. If this attribute is undefined or set toInteger.MAX_VALUE, this indicates that an unbounded queue should be used. All other values specify an exact queue size. If an unbounded queue or direct hand-off is used, acore-threadsvalue greater than0is required. -
hung-task-threshold: Defines the time, in milliseconds, after which tasks are considered hung by the managed executor service and forcefully aborted. If the value is0, which is the default, tasks are never considered hung. -
long-running-tasks: Suggests optimizing the execution of long running tasks, and defaults tofalse. -
reject-policy: Defines the policy to use when a task is rejected by the executor. The attribute value can be the defaultABORT, which means an exception should be thrown, orRETRY_ABORT, which means the executor will try to submit it once more, before throwing an exception
Example: Add a New Managed Executor Service
/subsystem=ee/managed-executor-service=newManagedExecutorService:add(jndi-name=java:jboss/ee/concurrency/executor/newManagedExecutorService, core-threads=7, thread-factory=default)
/subsystem=ee/managed-executor-service=newManagedExecutorService:add(jndi-name=java:jboss/ee/concurrency/executor/newManagedExecutorService, core-threads=7, thread-factory=default)Example: Change a Managed Executor Service
/subsystem=ee/managed-executor-service=newManagedExecutorService:write-attribute(name=core-threads,value=10)
/subsystem=ee/managed-executor-service=newManagedExecutorService:write-attribute(name=core-threads,value=10)This operation requires reload. Similarly, you can change other attributes too.
Example: Remove a Managed Executor Service
/subsystem=ee/managed-executor-service=newManagedExecutorService:remove()
/subsystem=ee/managed-executor-service=newManagedExecutorService:remove()This operation requires reload.
9.4. Managed Scheduled Executor Service
Managed scheduled executor service (javax.enterprise.concurrent.ManagedScheduledExecutorService) allows Java EE applications to schedule tasks for asynchronous execution. JBoss EAP handles managed scheduled executor service instances, hence Java EE applications cannot invoke any lifecycle related method.
Attributes of managed executor service concurrency utility include:
-
context-service: References an existing context service by its name. If specified then the referenced context service will capture the invocation context present when submitting a task to the executor, which will then be used when executing the task. -
hung-task-threshold: Defines the time, in milliseconds, after which tasks are considered hung by the managed scheduled executor service and forcefully aborted. If the value is0, which is the default, tasks are never considered hung. -
keepalive-time: Defines the time, in milliseconds, that an internal thread can be idle. The attribute default value is60000. -
reject-policy: Defines the policy to use when a task is rejected by the executor. The attribute value might be the defaultABORT, which means an exception should be thrown, orRETRY_ABORT, which means the executor will try to submit it once more, before throwing an exception. -
core-threads: Defines the minimum number of threads to be used by the scheduled executor. -
jndi-name: Defines where the managed scheduled executor service should be placed in JNDI . -
long-running-tasks: Suggests optimizing the execution of long running tasks, and defaults to false. -
thread-factory: References an existing managed thread factory by its name, to handle the creation of internal threads. If not specified, then a managed thread factory with default configuration will be created and used internally.
Example: Add a New Managed Scheduled Executor Service
/subsystem=ee/managed-scheduled-executor-service=newManagedScheduledExecutorService:add(jndi-name=java:jboss/ee/concurrency/scheduledexecutor/newManagedScheduledExecutorService, core-threads=7, context-service=default)
/subsystem=ee/managed-scheduled-executor-service=newManagedScheduledExecutorService:add(jndi-name=java:jboss/ee/concurrency/scheduledexecutor/newManagedScheduledExecutorService, core-threads=7, context-service=default)This operation requires reload.
Example: Changed a Managed Scheduled Executor Service
/subsystem=ee/managed-scheduled-executor-service=newManagedScheduledExecutorService:write-attribute(name=core-threads, value=10)
/subsystem=ee/managed-scheduled-executor-service=newManagedScheduledExecutorService:write-attribute(name=core-threads, value=10)This operation requires reload. Similarly, you can change other attributes.
Example: Remove a Managed Scheduled Executor Service
/subsystem=ee/managed-scheduled-executor-service=newManagedScheduledExecutorService:remove()
/subsystem=ee/managed-scheduled-executor-service=newManagedScheduledExecutorService:remove()This operation requires reload.
Chapter 10. Undertow
10.1. Introduction to Undertow Handler
Undertow is a web server designed to be used for both blocking and non-blocking tasks. It replaces JBoss Web in JBoss EAP 7. Some of its main features are:
- High Performance
- Embeddable
- Servlet 3.1
- Web Sockets
- Reverse Proxy
Request Lifecycle
When a client connects to the server, Undertow creates a io.undertow.server.HttpServerConnection. When the client sends a request, it is parsed by the Undertow parser, and then the resulting io.undertow.server.HttpServerExchange is passed to the root handler. When the root handler finishes, one of four things can happen:
The exchange is completed.
An exchange is considered complete if both request and response channels have been fully read or written. For requests with no content, such as GET and HEAD, the request side is automatically considered fully read. The read side is considered complete when a handler has written out the full response and has closed and fully flushed the response channel. If an exchange is already complete, then no action is taken.
The root handler returns normally without completing the exchange.
In this case the exchange is completed by calling
HttpServerExchange.endExchange().The root handler returns with an Exception.
In this case a response code of
500is set and the exchange is ended usingHttpServerExchange.endExchange().The root handler can return after
HttpServerExchange.dispatch()has been called, or after async IO has been started.In this case the dispatched task will be submitted to the dispatch executor, or if async IO has been started on either the request or response channels, then this will be started. In both of these cases, the exchange will not be finished. It is up to your async task to finish the exchange when it is done processing.
By far the most common use of HttpServerExchange.dispatch() is to move execution from an IO thread, where blocking is not allowed, into a worker thread, which does allow for blocking operations.
Example: Dispatching to a Worker Thread
Because the exchange is not actually dispatched until the call stack returns, you can be sure that more than one thread is never active in an exchange at once. The exchange is not thread safe. However, it can be passed between multiple threads as long as both threads do not attempt to modify it at once.
Ending the Exchange
There are two ways to end an exchange, either by fully reading the request channel and calling shutdownWrites() on the response channel and then flushing it, or by calling HttpServerExchange.endExchange(). When endExchange() is called, Undertow will check if the content has been generated yet. If it has, then it will simply drain the request channel and close and flush the response channel. If not and there are any default response listeners registered on the exchange, then Undertow will give each of them a chance to generate a default response. This mechanism is how default error pages are generated.
For more information on configuring Undertow, see Configuring the Web Server in the JBoss EAP Configuration Guide.
10.2. Using Existing Undertow Handlers with a Deployment
Undertow provides a default set of handlers that you can use with any application deployed to JBoss EAP.
To use a handler with a deployment, you need to add a WEB-INF/undertow-handlers.conf file.
Example: WEB-INF/undertow-handlers.conf File
allowed-methods(methods='GET')
allowed-methods(methods='GET')All handlers can also take an optional predicate to apply that handler in specific cases.
Example: WEB-INF/undertow-handlers.conf File with Optional Predicate
path('/my-path') -> allowed-methods(methods='GET')
path('/my-path') -> allowed-methods(methods='GET')
The above example will only apply the allowed-methods handler to the path /my-path.
Undertow Handler Default Parameter
Some handlers have a default parameter, which allows you to specify the value of that parameter in the handler definition without using the name.
Example: WEB-INF/undertow-handlers.conf File Using the Default Parameter
path('/a') -> redirect('/b')
path('/a') -> redirect('/b')
You can also update the WEB-INF/jboss-web.xml file to include the definition of one or more handlers, but using WEB-INF/undertow-handlers.conf is preferred.
Example: WEB-INF/jboss-web.xml File
A full list of the provided Undertow handlers can be found in the Provided Undertow Handlers reference.
10.3. Creating Custom Handlers
There are two ways to define custom handlers:
Defining Custom Handlers Using the WEB-INF/jboss-web.xml File
A custom handler can be defined in the WEB-INF/jboss-web.xml file.
Example: Define Custom Handler in WEB-INF/jboss-web.xml
<jboss-web>
<http-handler>
<class-name>org.jboss.example.MyHttpHandler</class-name>
</http-handler>
</jboss-web>
<jboss-web>
<http-handler>
<class-name>org.jboss.example.MyHttpHandler</class-name>
</http-handler>
</jboss-web>Example: HttpHandler Class
Parameters can also be set for the custom handler using the WEB-INF/jboss-web.xml file.
Example: Defining Parameters in WEB-INF/jboss-web.xml
For these parameters to work, the handler class needs to have corresponding setters.
Example: Defining Setter Methods in Handler
Defining Custom Handlers in the WEB-INF/undertow-handlers.conf File
Instead of using the WEB-INF/jboss-web.xml for defining the handler, it could also be defined in the WEB-INF/undertow-handlers.conf file.
myHttpHandler(myParam='foobar')
myHttpHandler(myParam='foobar')
For the handler defined in WEB-INF/undertow-handlers.conf to work, two things need to be created:
An implementation of
HandlerBuilder, which defines the corresponding syntax bits forundertow-handlers.confand is responsible for creating theHttpHandler, wrapped in aHandlerWrapper.Example:
HandlerBuilderClassCopy to Clipboard Copied! Toggle word wrap Toggle overflow An entry in the file.
META-INF/services/io.undertow.server.handlers.builder.HandlerBuilder. This file must be on the class path, for example, inWEB-INF/classes.org.jboss.example.MyHandlerBuilder
org.jboss.example.MyHandlerBuilderCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.4. Developing a Custom HTTP Mechanism
When Elytron is used to secure a web application, it is possible to implement custom HTTP authentication mechanisms that can be registered using the elytron subsystem. It is then also possible to override the configuration within the deployment to make use of this mechanism without requiring modifications to the deployment.
All custom HTTP mechanisms are required to implement the HttpServerAuthenticationMechanism interface.
In general, for an HTTP mechanism, the evaluateRequest method is called to handle the request passing in the HTTPServerRequest object. The mechanism processes the request and uses one of the following callback methods on the request to indicate the outcome:
-
authenticationComplete- The mechanism successfully authenticated the request. -
authenticationFailed- Authentication was attempted but failed. -
authenticationInProgress- Authentication started but an additional round trip is needed. -
badRequest- The authentication for this mechanism failed validation of the request. -
noAuthenticationInProgress- The mechanism did not attempt any stage of authentication.
After creating a custom HTTP mechanism that implements the HttpServerAuthenticationMechanism interface, the next step is to create a factory that returns instances of this mechanism. The factory must implement the HttpAuthenticationFactory interface. The most important step in the factory implementation is to double check the name of the mechanism requested. It is important for the factory to return null if it cannot create the required mechanism. The mechanism factory can also take into account properties in the map passed in to decide if it can create the requested mechanism.
There are two different approaches that can be used to advertise the availability of a mechanism factory.
-
The first approach is to implement a
java.security.Providerwith theHttpAuthenticationFactoryregistered as an available service once for each mechanism it supports. -
The second approach is to use a
java.util.ServiceLoaderto discover the factory instead. To achieve this, a file namedorg.wildfly.security.http.HttpServerAuthenticationMechanismFactoryshould be added underMETA-INF/services. The only content required in this file is the fully qualified class name of the factory implementation.
The mechanism can then be installed in the application server, as a module ready to be used:
module add --name=org.wildfly.security.examples.custom-http --resources=/path/to/custom-http-mechanism.jar --dependencies=org.wildfly.security.elytron,javax.api
module add --name=org.wildfly.security.examples.custom-http --resources=/path/to/custom-http-mechanism.jar --dependencies=org.wildfly.security.elytron,javax.apiUsing a Custom HTTP Mechanism
Add a custom module.
/subsystem=elytron/service-loader-http-server-mechanism-factory=custom-factory:add(module=org.wildfly.security.examples.custom-http)
/subsystem=elytron/service-loader-http-server-mechanism-factory=custom-factory:add(module=org.wildfly.security.examples.custom-http)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Add an
http-authentication-factoryto tie the mechanism factory to asecurity-domainthat will be used for the authentication./subsystem=elytron/http-authentication-factory=custom-mechanism:add(http-server-mechanism-factory=custom-factory,security-domain=ApplicationDomain,mechanism-configurations=[{mechanism-name=custom-mechanism}])/subsystem=elytron/http-authentication-factory=custom-mechanism:add(http-server-mechanism-factory=custom-factory,security-domain=ApplicationDomain,mechanism-configurations=[{mechanism-name=custom-mechanism}])Copy to Clipboard Copied! Toggle word wrap Toggle overflow Update the
application-security-domainresource to use the newhttp-authentication-factory.NoteWhen an application is deployed, it by default uses the
othersecurity domain. Thus, you need to add a mapping to the application to map it to an Elytron HTTP authentication factory./subsystem=undertow/application-security-domain=other:add(http-authentication-factory=application-http-authentication)
/subsystem=undertow/application-security-domain=other:add(http-authentication-factory=application-http-authentication)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The
application-security-domainresource can now be updated to use the newhttp-authentication-factory./subsystem=undertow/application-security-domain=other:write-attribute(name=http-authentication-factory,value=custom-mechanism) /subsystem=undertow/application-security-domain=other:write-attribute(name=override-deployment-config,value=true)
/subsystem=undertow/application-security-domain=other:write-attribute(name=http-authentication-factory,value=custom-mechanism) /subsystem=undertow/application-security-domain=other:write-attribute(name=override-deployment-config,value=true)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Notice that the command above overrides the deployment configuration. This means that the mechanisms from the
http-authentication-factorywill be used even if the deployment was configured to use a different mechanism. It is thus possible to override the configuration within a deployment to make use of a custom mechanism, without requiring modifications to the deployment itself.Reload the server
reload
reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Chapter 11. Java Transaction API (JTA)
11.1. Overview
11.1.1. Overview of Java Transaction API (JTA)
- Introduction
This section provides a foundational understanding of the Java Transaction API (JTA).
11.2. Transaction Concepts
11.2.1. About Transactions
A transaction consists of two or more actions, which must either all succeed or all fail. A successful outcome is a commit, and a failed outcome is a rollback. In a rollback, each member’s state is reverted to its state before the transaction attempted to commit.
The typical standard for a well-designed transaction is that it is Atomic, Consistent, Isolated, and Durable (ACID).
11.2.2. About ACID Properties for Transactions
ACID is an acronym which stands for Atomicity, Consistency, Isolation, and Durability. This terminology is usually used in the context of databases or transactional operations.
- Atomicity
- For a transaction to be atomic, all transaction members must make the same decision. Either they all commit, or they all roll back. If atomicity is broken, what results is termed a heuristic outcome.
- Consistency
- Consistency means that data written to the database is guaranteed to be valid data, in terms of the database schema. The database or other data source must always be in a consistent state. One example of an inconsistent state would be a field in which half of the data is written before an operation aborts. A consistent state would be if all the data were written, or the write were rolled back when it could not be completed.
- Isolation
- Isolation means that data being operated on by a transaction must be locked before modification, to prevent processes outside the scope of the transaction from modifying the data.
- Durability
- Durability means that in the event of an external failure after transaction members have been instructed to commit, all members will be able to continue committing the transaction when the failure is resolved. This failure can be related to hardware, software, network, or any other involved system.
11.2.3. About the Transaction Coordinator or Transaction Manager
The terms Transaction Coordinator and Transaction Manager (TM) are mostly interchangeable in terms of transactions with JBoss EAP. The term Transaction Coordinator is usually used in the context of distributed JTS transactions.
In JTA transactions, the TM runs within JBoss EAP and communicates with transaction participants during the two-phase commit protocol.
The TM tells transaction participants whether to commit or roll back their data, depending on the outcome of other transaction participants. In this way, it ensures that transactions adhere to the ACID standard.
11.2.4. About Transaction Participants
A transaction participant is any resource within a transaction that has the ability to commit or to roll back state. It is generally a database or a JMS broker, but by implementing the transaction interface, application code could also act as a transaction participant. Each participant of a transaction independently decides whether it is able to commit or roll back its state, and only if all participants can commit does the transaction as a whole succeed. Otherwise, each participant rolls back its state, and the transaction as a whole fails. The TM coordinates the commit or rollback operations and determines the outcome of the transaction.
11.2.5. About Java Transaction API (JTA)
Java Transaction API (JTA) is part of Java Enterprise Edition specification. It is defined in JSR 907: Java™ Transaction API (JTA).
Implementation of JTA is done using the TM, which is covered by project Narayana for JBoss EAP application server. The TM allows applications to assign various resources, for example, database or JMS brokers, through a single global transaction. The global transaction is referred as an XA transaction. Generally resources with XA capabilities are included in such transactions, but non-XA resources could also be part of global transactions. There are several optimizations which help non-XA resources to behave as XA capable resources. For more information, see LRCO Optimization for Single-phase Commit.
In this document, the term JTA refers to two things:
- The Java Transaction API, which is defined by Java EE specification.
- It indicates how the TM processes the transactions.
The TM works in JTA transactions mode, the data is shared in memory, and the transaction context is transferred by remote EJB calls. In JTS mode, the data is shared by sending Common Object Request Broker Architecture (CORBA) messages and the transaction context is transferred by IIOP calls. Both modes support distribution of transactions over multiple JBoss EAP servers.
11.2.6. About Java Transaction Service (JTS)
Java Transaction Service (JTS) is a mapping of the Object Transaction Service (OTS) to Java. Java EE applications use the JTA API to manage transactions. JTA API then interacts with a JTS transaction implementation when the transaction manager is switched to JTS mode. JTS works over the IIOP protocol. Transaction managers that use JTS communicate with each other using a process called an Object Request Broker (ORB), using a communication standard called Common Object Request Broker Architecture (CORBA). For more information, see ORB Configuration in the JBoss EAP Configuration Guide.
Using the JTA API from an application standpoint, a JTS transaction behaves in the same way as a JTA transaction.
The implementation of JTS included in JBoss EAP supports distributed transactions. The difference from fully-compliant JTS transactions is interoperability with external third-party ORBs. This feature is unsupported with JBoss EAP. Supported configurations distribute transactions across multiple JBoss EAP containers only.
11.2.7. About XML Transaction Service
The XML Transaction Service (XTS) component supports the coordination of private and public web services in a business transaction. Using XTS, you can coordinate complex business transactions in a controlled and reliable manner. The XTS API supports a transactional coordination model based on the WS-Coordination, WS-Atomic Transaction, and WS-Business Activity protocols.
11.2.7.1. Overview of Protocols Used by XTS
The WS-Coordination (WS-C) specification defines a framework that allows different coordination protocols to be plugged in to coordinate work between clients, services, and participants.
The WS-Transaction (WS-T) protocol comprises the pair of transaction coordination protocols, WS-Atomic Transaction (WS-AT) and WS-Business Activity (WS-BA), which utilize the coordination framework provided by WS-C. WS-T is developed to unify existing traditional transaction processing systems, allowing them to communicate reliably with one another.
11.2.7.2. Web Services-Atomic Transaction Process
An atomic transaction (AT) is designed to support short duration interactions where ACID semantics are appropriate. Within the scope of an AT, web services typically employ bridging to access XA resources, such as databases and message queues, under the control of the WS-T. When the transaction terminates, the participant propagates the outcome decision of the AT to the XA resources, and the appropriate commit or rollback actions are taken by each participant.
11.2.7.2.1. Atomic Transaction Process
- To initiate an AT, the client application first locates a WS-C Activation Coordinator web service that supports WS-T.
-
The client sends a WS-C
CreateCoordinationContextmessage to the service, specifying http://schemas.xmlsoap.org/ws/2004/10/wsat as its coordination type. - The client receives an appropriate WS-T context from the activation service.
-
The response to the
CreateCoordinationContextmessage, the transaction context, has itsCoordinationTypeelement set to the WS-AT namespace, http://schemas.xmlsoap.org/ws/2004/10/wsat. It also contains a reference to the atomic transaction coordinator endpoint, the WS-C Registration Service, where participants can be enlisted. - The client normally proceeds to invoke web services and complete the transaction, either committing all the changes made by the web services, or rolling them back. In order to be able to drive this completion, the client must register itself as a participant for the completion protocol, by sending a register message to the registration service whose endpoint was returned in the coordination context.
- Once registered for completion, the client application then interacts with web services to accomplish its business-level work. With each invocation of a business web service, the client inserts the transaction context into a SOAP header block, such that each invocation is implicitly scoped by the transaction. The toolkits that support WS-AT aware web services provide facilities to correlate contexts found in SOAP header blocks with back-end operations. This ensures that modifications made by the web service are done within the scope of the same transaction as the client and subject to commit or rollback by the Transaction Coordinator.
- Once all the necessary application work is complete, the client can terminate the transaction, with the intent of making any changes to the service state permanent. The completion participant instructs the coordinator to try to commit or roll back the transaction. When the commit or rollback operation completes, a status is returned to the participant to indicate the outcome of the transaction.
For more details, see WS-Coordination in the Naryana Project Documentation.
11.2.7.3. Web Services-Business Activity Process
Web Services-Business Activity (WS-BA) defines a protocol for web service applications to enable existing business processing and workflow systems to wrap their proprietary mechanisms and interoperate across implementations and business boundaries.
Unlike the WS-AT protocol model, where participants inform the transaction coordinator of their state only when asked, a child activity within a WS-BA can specify its outcome to the coordinator directly, without waiting for a request. A participant can choose to exit the activity or notify the coordinator of a failure at any point. This feature is useful when tasks fail because the notification can be used to modify the goals and drive processing forward, without waiting until the end of the transaction to identify failures.
11.2.7.3.1. WS-BA Process
- Services are requested to do work.
-
Wherever these services have the ability to undo any work, they inform the WS-BA, in case the WS-BA later decides the cancel the work. If the WS-BA suffers a failure. it can instruct the service to execute its
undobehavior.
The WS-BA protocols employ a compensation-based transaction model. When a participant in a business activity completes its work, it can choose to exit the activity. This choice does not allow any subsequent rollback. Alternatively, the participant can complete its activity, signaling to the coordinator that the work it has done can be compensated if, at some later point, another participant notifies a failure to the coordinator. In this latter case, the coordinator asks each non-exited participant to compensate for the failure, giving them the opportunity to execute whatever compensating action they consider appropriate. If all participants exit or complete without failure, the coordinator notifies each completed participant that the activity has been closed.
For more details, see WS-Coordination in the Naryana Project Documentation.
11.2.7.4. Transaction Bridging Overview
Transaction Bridging describes the process of linking the Java EE and WS-T domains. The transaction bridge component, txbridge, provides bi-directional linkage, such that either type of transaction can encompass business logic designed for use with the other type. The technique used by the bridge is a combination of interposition and protocol mapping.
In the transaction bridge, an interposed coordinator is registered into the existing transaction and performs the additional task of protocol mapping; that is, it appears to its parent coordinator to be a resource of its native transaction type, while appearing to its children to be a coordinator of their native transaction type, even though these transaction types differ.
The transaction bridge resides in the package org.jboss.jbossts.txbridge and its subpackages. It consists of two distinct sets of classes, one for bridging in each direction.
For more details, see TXBridge Guide in the Naryana Project Documentation.
11.2.8. About XA Resources and XA Transactions
XA stands for eXtended Architecture, which was developed by the X/Open Group to define a transaction that uses more than one back-end data store. The XA standard describes the interface between a global TM and a local resource manager. XA allows multiple resources, such as application servers, databases, caches, and message queues, to participate in the same transaction, while preserving all four ACID properties. One of the four ACID properties is atomicity, which means that if one of the participants fails to commit its changes, the other participants abort the transaction, and restore their state to the same status as before the transaction occurred. An XA resource is a resource that can participate in an XA global transaction.
An XA transaction is a transaction that can span multiple resources. It involves a coordinating TM, with one or more databases or other transactional resources, all involved in a single global XA transaction.
11.2.9. About XA Recovery
TM implements X/Open XA specification and supports XA transactions across multiple XA resources.
XA Recovery is the process of ensuring that all resources affected by a transaction are updated or rolled back, even if any of the resources that are transaction participants crash or become unavailable. Within the scope of JBoss EAP, the transactions subsystem provides the mechanisms for XA Recovery to any XA resources or subsystems that use them, such as XA datasources, JMS message queues, and JCA resource adapters.
XA Recovery happens without user intervention. In the event of an XA Recovery failure, errors are recorded in the log output. Contact Red Hat Global Support Services if you need assistance. The XA recovery process is driven by a periodic recovery thread which is launched by default every two minutes. The periodic recovery thread processes all unfinished transactions.
It can take four to eight minutes to complete the recovery for an in-doubt transaction because it might require multiple runs of the recovery process.
11.2.10. Limitations of the XA Recovery Process
XA recovery has the following limitations:
The transaction log might not be cleared from a successfully committed transaction.
If the JBoss EAP server crashes after an
XAResourcecommit method successfully completes and commits the transaction, but before the coordinator can update the log, you might see the following warning message in the log when you restart the server:ARJUNA016037: Could not find new XAResource to use for recovering non-serializable XAResource XAResourceRecord
ARJUNA016037: Could not find new XAResource to use for recovering non-serializable XAResource XAResourceRecordCopy to Clipboard Copied! Toggle word wrap Toggle overflow This is because upon recovery, the JBoss Transaction Manager (TM) sees the transaction participants in the log and attempts to retry the commit. Eventually the JBoss TM assumes the resources are committed and no longer retries the commit. In this situation, you can safely ignore this warning as the transaction is committed and there is no loss of data.
To prevent the warning, set the
com.arjuna.ats.jta.xaAssumeRecoveryCompleteproperty value totrue. This property is checked whenever a newXAResourceinstance cannot be located from any registeredXAResourceRecoveryinstance. When set totrue, the recovery assumes that a previous commit attempt succeeded and the instance can be removed from the log with no further recovery attempts. This property must be used with care because it is global and when used incorrectly could result inXAResourceinstances remaining in an uncommitted state.NoteJBoss EAP 7.1 has an implemented enhancement to clear transaction logs after a successfully committed transaction and the above situation should not occur frequently.
Rollback is not called for JTS transaction when a server crashes at the end of
XAResource.prepare().If the JBoss EAP server crashes after the completion of an
XAResource.prepare()method call, all of the participatingXAResourceinstances are locked in the prepared state and remain that way upon server restart. The transaction is not rolled back and the resources remain locked until the transaction times out or a database administrator manually rolls back the resources and clears the transaction log. For more information, see https://issues.jboss.org/browse/JBTM-2124Periodic recovery can occur on committed transactions.
When the server is under excessive load, the server log might contain the following warning message, followed by a stacktrace:
ARJUNA016027: Local XARecoveryModule.xaRecovery got XA exception XAException.XAER_NOTA: javax.transaction.xa.XAException
ARJUNA016027: Local XARecoveryModule.xaRecovery got XA exception XAException.XAER_NOTA: javax.transaction.xa.XAExceptionCopy to Clipboard Copied! Toggle word wrap Toggle overflow Under heavy load, the processing time taken by a transaction can overlap with the timing of the periodic recovery process’s activity. The periodic recovery process detects the transaction still in progress and attempts to initiate a rollback but in fact the transaction continues to completion. At the time the periodic recovery attempts but fails the rollback, it records the rollback failure in the server log. The underlying cause of this issue will be addressed in a future release, but in the meantime a workaround is available.
Increase the interval between the two phases of the recovery process by setting the
com.arjuna.ats.jta.orphanSafetyIntervalproperty to a value higher than the default value of10000milliseconds. A value of40000milliseconds is recommended. Note that this does not solve the issue. Instead it decreases the probability that it will occur and that the warning message will be shown in the log. For more information, see https://developer.jboss.org/thread/266729
11.2.11. About the 2-Phase Commit Protocol
The two-phase commit (2PC) protocol refers to an algorithm to determine the outcome of a transaction. 2PC is driven by the Transaction Manager (TM) as a process of finishing XA transactions.
Phase 1: Prepare
In the first phase, the transaction participants notify the transaction coordinator whether they are able to commit the transaction or must roll back.
Phase 2: Commit
In the second phase, the transaction coordinator makes the decision about whether the overall transaction should commit or roll back. If any one of the participants cannot commit, the transaction must roll back. Otherwise, the transaction can commit. The coordinator directs the resources about what to do, and they notify the coordinator when they have done it. At that point, the transaction is finished.
11.2.12. About Transaction Timeouts
In order to preserve atomicity and adhere to the ACID standard for transactions, some parts of a transaction can be long-running. Transaction participants need to lock an XA resource that is part of database table or message in a queue when they commit. The TM needs to wait to hear back from each transaction participant before it can direct them all whether to commit or roll back. Hardware or network failures can cause resources to be locked indefinitely.
Transaction timeouts can be associated with transactions in order to control their lifecycle. If a timeout threshold passes before the transaction commits or rolls back, the timeout causes the transaction to be rolled back automatically.
You can configure default timeout values for the entire transaction subsystem, or you can disable default timeout values and specify timeouts on a per-transaction basis.
11.2.13. About Distributed Transactions
A distributed transaction is a transaction with participants on multiple JBoss EAP servers. The Java Transaction Service (JTS) specification mandates that JTS transactions be able to be distributed across application servers from different vendors. The Java Transaction API (JTA) does not define that but JBoss EAP supports distributed JTA transactions among JBoss EAP servers.
Transaction distribution among servers from different vendors is not supported.
In other application server vendor documentation, you might find that the term distributed transaction means XA transaction. In the context of JBoss EAP documentation, the distributed transaction refers to transactions distributed among several JBoss EAP application servers. Transactions that consist of different resources, for example, database resources and JMS resources, are referred as XA transactions in this document. For more information, see About Java Transaction Service (JTS) and About XA Datasources and XA Transactions.
11.2.14. About the ORB Portability API
The Object Request Broker (ORB) is a process that sends and receives messages to transaction participants, coordinators, resources, and other services distributed across multiple application servers. An ORB uses a standardized Interface Description Language (IDL) to communicate and interpret messages. Common Object Request Broker Architecture (CORBA) is the IDL used by the ORB in JBoss EAP.
The main type of service that uses an ORB is a system of distributed Java Transactions, using the Java Transaction Service (JTS) specification. Other systems, especially legacy systems, can choose to use an ORB for communication rather than other mechanisms such as remote Enterprise JavaBeans or JAX-WS or JAX-RS web services.
The ORB Portability API provides mechanisms to interact with an ORB. This API provides methods for obtaining a reference to the ORB, as well as placing an application into a mode where it listens for incoming connections from an ORB. Some of the methods in the API are not supported by all ORBs. In those cases, an exception is thrown.
The API consists of two different classes:
-
com.arjuna.orbportability.orb -
com.arjuna.orbportability.oa
See the JBoss EAP Javadocs bundle available on the Red Hat Customer Portal for specific details about the methods and properties included in the ORB Portability API.
11.3. Transaction Optimizations
11.3.1. Overview of Transaction Optimizations
The Transaction Manager (TM) of JBoss EAP includes several optimizations that your application can take advantage of.
Optimizations serve to enhance the 2-phase commit protocol in particular cases. Generally, the TM starts a global transaction, which passes through the 2-phase commit. But when you optimize these transactions, in certain cases, the TM does not need to proceed with full 2-phased commits and thus the process gets faster.
Different optimizations used by the TM are described in detail below.
11.3.2. About the LRCO Optimization for Single-phase Commit (1PC)
Single-phase Commit (1PC)
Although the 2-phase commit protocol (2PC) is more commonly encountered with transactions, some situations do not require, or cannot accommodate, both phases. In these cases, you can use the single phase commit (1PC) protocol. The single phase commnit protocol is used when only one XA or non-XA resource is a part of the global transaction.
The prepare phase generally locks the resource until the second phase is processed. Single-phase commit means that the prepare phase is skipped and only the commit is processed on the resource. If not specified, the single-phase commit optimization is used automatically when the global transaction contains only one participant.
Last Resource Commit Optimization (LRCO)
In situations where non-XA datasource participate in XA transaction, an optimization known as the Last Resource Commit Optimization (LRCO) is employed. While this protocol allows for most transactions to complete normally, certain types of error can cause an inconsistent transaction outcome. Therefore, use this approach only as a last resort.
The non-XA resource is processed at the end of the prepare phase, and an attempt is made to commit it. If the commit succeeds, the transaction log is written and the remaining resources go through the commit phase. If the last resource fails to commit, the transaction is rolled back.
Where a single local TX datasource is used in a transaction, the LRCO is automatically applied to it.
Previously, adding non-XA resources to an XA transaction was achieved via the LRCO method. However, there is a window of failure in LRCO. The procedure for adding non-XA resources to an XA transaction using the LRCO method is as follows:
- Prepare the XA transaction.
- Commit LRCO.
- Write the transaction log.
- Commit the XA transaction.
If the procedure crashes between step 2 and step 3, this could lead to data inconsistency and you cannot commit the XA transaction. The data inconsistency is because the LRCO non-XA resource is committed but information about preparation of XA resource was not recorded. The recovery manager will rollback the resource after the server is up. Commit Markable Resource (CMR) eliminates this restriction and allows a non-XA resource to be reliably enlisted in an XA transaction.
CMR is a special case of LRCO optimization that should only be used for datasources. It is not suitable for all non-XA resources.
11.3.2.1. Commit Markable Resource
Summary
Configuring access to a resource manager using the Commit Markable Resource (CMR) interface ensures that a non-XA datasource can be reliably enlisted in an XA (2PC) transaction. It is an implementation of the LRCO algorithm, which makes non-XA resource fully recoverable.
To configure the CMR, you must:
- Create tables in a database.
- Enable the datasource to be connectable.
-
Add a reference to
transactionssubsystem.
Create Tables in Database
A transaction can contain only one CMR resource. You can create a table using SQL similar to the following example.
SELECT xid,actionuid FROM _tableName_ WHERE transactionManagerID IN (String[]) DELETE FROM _tableName_ WHERE xid IN (byte[[]]) INSERT INTO _tableName_ (xid, transactionManagerID, actionuid) VALUES (byte[],String,byte[])
SELECT xid,actionuid FROM _tableName_ WHERE transactionManagerID IN (String[])
DELETE FROM _tableName_ WHERE xid IN (byte[[]])
INSERT INTO _tableName_ (xid, transactionManagerID, actionuid) VALUES (byte[],String,byte[])The following are examples of the SQL syntax to create tables for various database management systems.
Example: Sybase Create Table Syntax
CREATE TABLE xids (xid varbinary(144), transactionManagerID varchar(64), actionuid varbinary(28))
CREATE TABLE xids (xid varbinary(144), transactionManagerID varchar(64), actionuid varbinary(28))Example: Oracle Create Table Syntax
CREATE TABLE xids (xid RAW(144), transactionManagerID varchar(64), actionuid RAW(28)) CREATE UNIQUE INDEX index_xid ON xids (xid)
CREATE TABLE xids (xid RAW(144), transactionManagerID varchar(64), actionuid RAW(28))
CREATE UNIQUE INDEX index_xid ON xids (xid)Example: IBM Create Table Syntax
CREATE TABLE xids (xid VARCHAR(255) for bit data not null, transactionManagerID varchar(64), actionuid VARCHAR(255) for bit data not null) CREATE UNIQUE INDEX index_xid ON xids (xid)
CREATE TABLE xids (xid VARCHAR(255) for bit data not null, transactionManagerID
varchar(64), actionuid VARCHAR(255) for bit data not null)
CREATE UNIQUE INDEX index_xid ON xids (xid)Example: SQL Server Create Table Syntax
CREATE TABLE xids (xid varbinary(144), transactionManagerID varchar(64), actionuid varbinary(28)) CREATE UNIQUE INDEX index_xid ON xids (xid)
CREATE TABLE xids (xid varbinary(144), transactionManagerID varchar(64), actionuid varbinary(28))
CREATE UNIQUE INDEX index_xid ON xids (xid)Example: PostgreSQL Create Table Syntax
CREATE TABLE xids (xid bytea, transactionManagerID varchar(64), actionuid bytea) CREATE UNIQUE INDEX index_xid ON xids (xid)
CREATE TABLE xids (xid bytea, transactionManagerID varchar(64), actionuid bytea)
CREATE UNIQUE INDEX index_xid ON xids (xid)Example: MariaDB Create Table Syntax
CREATE TABLE xids (xid BINARY(144), transactionManagerID varchar(64), actionuid BINARY(28)) CREATE UNIQUE INDEX index_xid ON xids (xid)
CREATE TABLE xids (xid BINARY(144), transactionManagerID varchar(64), actionuid BINARY(28))
CREATE UNIQUE INDEX index_xid ON xids (xid)Example: MySQL Create Table Syntax
CREATE TABLE xids (xid VARCHAR(255), transactionManagerID varchar(64), actionuid VARCHAR(255)) CREATE UNIQUE INDEX index_xid ON xids (xid)
CREATE TABLE xids (xid VARCHAR(255), transactionManagerID varchar(64), actionuid VARCHAR(255))
CREATE UNIQUE INDEX index_xid ON xids (xid)Enabling Datasource to be Connectable
By default, the CMR feature is disabled for datasources. To enable it, you must create or modify the datasource configuration and ensure that the connectable attribute is set to true. The following is an example of the datasources section of a server XML configuration file:
<datasource enabled="true" jndi-name="java:jboss/datasources/ConnectableDS" pool-name="ConnectableDS" jta="true" use-java-context="true" connectable="true"/>
<datasource enabled="true" jndi-name="java:jboss/datasources/ConnectableDS" pool-name="ConnectableDS" jta="true" use-java-context="true" connectable="true"/>This feature is not applicable to XA datasources.
You can also enable a resource manager as a CMR, using the management CLI, as follows:
/subsystem=datasources/data-source=ConnectableDS:add(enabled="true", jndi-name="java:jboss/datasources/ConnectableDS", jta="true", use-java-context="true", connectable="true", connection-url="validConnectionURL", exception-sorter-class-name="org.jboss.jca.adapters.jdbc.extensions.mssql.MSSQLExceptionSorter", driver-name="mssql")
/subsystem=datasources/data-source=ConnectableDS:add(enabled="true", jndi-name="java:jboss/datasources/ConnectableDS", jta="true", use-java-context="true", connectable="true", connection-url="validConnectionURL", exception-sorter-class-name="org.jboss.jca.adapters.jdbc.extensions.mssql.MSSQLExceptionSorter", driver-name="mssql")
This command generates the following XML in the datasources section of the server configuration file.
The datasource must have a valid driver defined. The example above uses mssql as the driver-name; however the mssql driver does not exist. For details, see Example MySQL Datasource in the JBoss EAP Configuration Guide.
Use the exception-sorter-class-name parameter in the datasource configuration. For details, see Example Datasource Configurations in the JBoss EAP Configuration Guide.
Updating an Existing Resource to Use the New CMR Feature
If you only need to update an existing datasource to use the CMR feature, then simply modify the connectable attribute:
/subsystem=datasources/data-source=ConnectableDS:write-attribute(name=connectable,value=true)
/subsystem=datasources/data-source=ConnectableDS:write-attribute(name=connectable,value=true)Add a Reference to the Transactions Subsystem
The transactions subsystem identifies the datasources that are CMR capable through an entry to the transactions subsystem configuration section as shown below:
The same result can be achieved using the management CLI:
/subsystem=transactions/commit-markable-resource=java\:jboss\/datasources\/ConnectableDS/:add(batch-size=100,immediate-cleanup=false,name=xids)
/subsystem=transactions/commit-markable-resource=java\:jboss\/datasources\/ConnectableDS/:add(batch-size=100,immediate-cleanup=false,name=xids)
You must restart the server after adding the CMR reference under the transactions subsystem.
11.3.3. About the Presumed-Abort Optimization
If a transaction is going to roll back, it can record this information locally and notify all enlisted participants. This notification is only a courtesy, and has no effect on the transaction outcome. After all participants have been contacted, the information about the transaction can be removed.
If a subsequent request for the status of the transaction occurs there will be no information available. In this case, the requester assumes that the transaction has aborted and rolled back. This presumed-abort optimization means that no information about participants needs to be made persistent until the transaction has decided to commit, since any failure prior to this point will be assumed to be an abort of the transaction.
11.3.4. About the Read-Only Optimization
When a participant is asked to prepare, it can indicate to the coordinator that it has not modified any data during the transaction. Such a participant does not need to be informed about the outcome of the transaction, since the fate of the participant has no affect on the transaction. This read-only participant can be omitted from the second phase of the commit protocol.
11.4. Transaction Outcomes
11.4.1. About Transaction Outcomes
There are three possible outcomes for a transaction.
- Commit
- If every transaction participant can commit, the transaction coordinator directs them to do so. See About Transaction Commit for more information.
- Rollback
- If any transaction participant cannot commit, or if the transaction coordinator cannot direct participants to commit, the transaction is rolled back. See About Transaction Rollback for more information.
- Heuristic outcome
- If some transaction participants commit and others roll back, it is termed a heuristic outcome. Heuristic outcomes require human intervention. See About Heuristic Outcomes for more information.
11.4.2. About Transaction Commit
When a transaction participant commits, it makes its new state durable. The new state is created by the participant doing the work involved in the transaction. The most common example is when a transaction member writes records to a database.
After a commit, information about the transaction is removed from the transaction coordinator, and the newly-written state is now the durable state.
11.4.3. About Transaction Rollback
A transaction participant rolls back by restoring its state to reflect the state before the transaction began. After a rollback, the state is the same as if the transaction had never been started.
11.4.4. About Heuristic Outcomes
A heuristic outcome, or non-atomic outcome, is a situation where the decisions of the participants in a transaction differ from that of the transaction manager. Heuristic outcomes can cause loss of integrity to the system, and usually require human intervention to resolve them. Do not write code which relies on them.
Heuristic outcomes typically occur during the second phase of the 2-phase commit (2PC) protocol. In rare cases, this outcome might occur in a 1PC. They are often caused by failures to the underlying hardware or communications subsystems of the underlying servers.
Heuristic outcomes are possible due to timeouts in various subsystems or resources even with transaction manager and full crash recovery. In any system that requires some form of distributed agreement, situations can arise where some parts of the system diverge in terms of the global outcome.
There are four different types of heuristic outcomes:
Heuristic rollback
The commit operation was not able to commit the resources but all of the participants were able to be rolled back and so an atomic outcome was still achieved.
Heuristic commit
An attempted rollback operation failed because all of the participants unilaterally committed. This can happen if, for example, the coordinator is able to successfully prepare the transaction but then decides to roll it back because of a failure on its side, such as a failure to update its log. In the interim, the participants might decide to commit.
Heuristic mixed
Some participants committed and others rolled back.
Heuristic hazard
The disposition of some of the updates is unknown. For those that are known, they have either all been committed or all rolled back.
11.4.5. JBoss Transactions Errors and Exceptions
For details about exceptions thrown by methods of the UserTransaction class, see the UserTransaction API Javadoc.
11.5. Overview of the Transaction Lifecycle
11.5.1. Transaction Lifecycle
See About Java Transaction API (JTA) for more information on Java Transaction API (JTA).
When a resource asks to participate in a transaction, a chain of events is set in motion. The Transaction Manager (TM) is a process that lives within the application server and manages transactions. Transaction participants are objects which participate in a transaction. Resources are datasources, JMS connection factories, or other JCA connections.
The application starts a new transaction.
To begin a transaction, the application obtains an instance of class
UserTransactionfrom JNDI or, if it is an EJB, from an annotation. TheUserTransactioninterface includes methods for beginning, committing, and rolling back top-level transactions. Newly created transactions are automatically associated with their invoking thread. Nested transactions are not supported in JTA, so all transactions are top-level transactions.An EJB starts a transaction when the
UserTransaction.begin()method is called. The default behavior of this transaction could be affected by use of theTransactionAttributeannotation or theejb.xmldescriptor. Any resource that is used after that point is associated with the transaction. If more than one resource is enlisted, the transaction becomes an XA transaction, and participates in the two-phase commit protocol at commit time.NoteBy default, transactions are driven by application containers in EJBs. This is called Container Managed Transaction (CMT). To make the transaction user driven, change the
Transaction Managementto Bean Managed Transaction (BMT). In BMT, theUserTransactionobject is available for the user to manage the transaction.The application modifies its state.
In the next step, the application performs its work and makes changes to its state, only on enlisted resources.
The application decides to commit or roll back.
When the application has finished changing its state, it decides whether to commit or roll back. It calls the appropriate method, either
UserTransaction.commit()orUserTransaction.rollback(). For a CMT, this process is driven automatically, whereas for a BMT, a method commit or rollback of theUserTransactionhas to be explicitly called.The TM removes the transaction from its records.
After the commit or rollback completes, the TM cleans up its records and removes information about the transaction from the transaction log.
Failure Recovery
If a resource, transaction participant, or the application server crashes or become unavailable, the Transaction Manager handles recovery when the underlying failure is resolved and the resource is available again. This process happens automatically. For more information, see XA Recovery.
11.6. Transaction Subsystem Configuration
The transactions subsystem allows you to configure transaction manager options such as statistics, timeout values, and transaction logging. You can also manage transactions and view transaction statistics.
For more information, see Configuring Transactions in the JBoss EAP Configuration Guide.
11.7. Transactions Usage In Practice
11.7.1. Transactions Usage Overview
The following procedures are useful when you need to use transactions in your application.
11.7.2. Control Transactions
Introduction
This list of procedures outlines the different ways to control transactions in your applications which use JTA APIs.
11.7.2.1. Begin a Transaction
This procedure shows how to begin a new transaction. The API is the same whether you run the Transaction Manager (TM) configured with JTA or JTS.
Get an instance of
UserTransaction.You can get the instance using JNDI, injection, or an EJB’s context if the EJB uses bean-managed transactions by means of a
@TransactionManagement(TransactionManagementType.BEAN)annotation.Get the instance using JNDI.
new InitialContext().lookup("java:comp/UserTransaction")new InitialContext().lookup("java:comp/UserTransaction")Copy to Clipboard Copied! Toggle word wrap Toggle overflow Get the instance using injection.
@Resource UserTransaction userTransaction;
@Resource UserTransaction userTransaction;Copy to Clipboard Copied! Toggle word wrap Toggle overflow Get the instance using the EJB context.
In a stateless/stateful bean:
@Resource SessionContext ctx; ctx.getUserTransaction();
@Resource SessionContext ctx; ctx.getUserTransaction();Copy to Clipboard Copied! Toggle word wrap Toggle overflow In a message-driven bean:
@Resource MessageDrivenContext ctx; ctx.getUserTransaction()
@Resource MessageDrivenContext ctx; ctx.getUserTransaction()Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Call
UserTransaction.begin()after you connect to your datasource.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Result
The transaction begins. All uses of your datasource are transactional until you commit or roll back the transaction.
For a full example, see JTA Transaction Example.
One of the benefits of EJBs (either used with CMT or BMT) is that the container manages all the internals of the transactional processing, that is, you are free from taking care of transaction being part of XA transaction or transaction distribution amongst JBoss EAP containers.
11.7.2.1.1. Nested Transactions
Nested transactions allow an application to create a transaction that is embedded in an existing transaction. In this model, multiple subtransactions can be embedded recursively in a transaction. Subtransactions can be committed or rolled back without committing or rolling back the parent transaction. However, the results of a commit operation are contingent upon the commitment of all the transaction’s ancestors.
For implementation specific information, see the Narayana Project Documentation.
Nested transactions are available only when used with the JTS specification. Nested transactions are not a supported feature of JBoss EAP application server. In addition, many database vendors do not support nested transactions, so consult your database vendor before you add nested transactions to your application.
11.7.2.2. Commit a Transaction
This procedure shows how to commit a transaction using the Java Transaction API (JTA).
Prerequisites
You must begin a transaction before you can commit it. For information on how to begin a transaction, see Begin a Transaction.
Call the
commit()method on theUserTransaction.When you call the commit() method on the
UserTransaction, the TM attempts to commit the transaction.Copy to Clipboard Copied! Toggle word wrap Toggle overflow If you use Container Managed Transactions (CMT), you do not need to manually commit.
If you configure your bean to use Container Managed Transactions, the container will manage the transaction lifecycle for you based on annotations you configure in the code.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Result
Your datasource commits and your transaction ends, or an exception is thrown.
For a full example, see JTA Transaction Example.
11.7.2.3. Roll Back a Transaction
This procedure shows how to roll back a transaction using the Java Transaction API (JTA).
Prerequisites
You must begin a transaction before you can roll it back. For information on how to begin a transaction, see Begin a Transaction.
Call the
rollback()method on theUserTransaction.When you call the
rollback()method on theUserTransaction, the TM attempts to roll back the transaction and return the data to its previous state.Copy to Clipboard Copied! Toggle word wrap Toggle overflow If you use Container Managed Transactions (CMT), you do not need to manually roll back the transaction.
If you configure your bean to use Container Managed Transactions, the container will manage the transaction lifecycle for you based on annotations you configure in the code.
Rollback for CMT occurs if RuntimeException is thrown. You can also explicitly call the setRollbackOnly method to gain the rollback. Or, use the @ApplicationException(rollback=true) for application exception to rollback.
Result
Your transaction is rolled back by the TM.
For a full example, see JTA Transaction Example.
11.7.3. Handle a Heuristic Outcome in a Transaction
Heuristic transaction outcomes are uncommon and usually have exceptional causes. The word heuristic means "by hand", and that is the way that these outcomes usually have to be handled. See About Heuristic Outcomes for more information about heuristic transaction outcomes.
This procedure shows how to handle a heuristic outcome of a transaction using the Java Transaction API (JTA).
Determine the cause: The over-arching cause of a heuristic outcome in a transaction is that a resource manager promised it could commit or rollback, and then failed to fulfill the promise. This could be due to a problem with a third-party component, the integration layer between the third-party component and JBoss EAP, or JBoss EAP itself.
By far, the most common two causes of heuristic errors are transient failures in the environment and coding errors dealing with resource managers.
Fix transient failures in the environment: Typically, if there is a transient failure in your environment, you will know about it before you find out about the heuristic error. This could be a network outage, hardware failure, database failure, power outage, or a host of other things.
If you experience a heuristic outcome in a test environment during stress testing, it provides information about weaknesses in your environment.
WarningJBoss EAP automatically recovers transactions that were in a non-heuristic state at the time of the failure, but it does not attempt to recover heuristic transactions.
- Contact resource manager vendors: If you have no obvious failure in your environment, or if the heuristic outcome is easily reproducible, it is probably due to a coding error. Contact third-party vendors to find out if a solution is available. If you suspect the problem is in the TM of JBoss EAP itself, contact Red Hat Global Support Services.
- Try to manually recover a transaction through the management CLI. For more information, see the Recover a Transaction Participant section of the JBoss EAP Configuration Guide.
In a test environment, delete the logs and restart JBoss EAP: In a test environment, or if you do not care about the integrity of the data, deleting the transaction logs and restarting JBoss EAP gets rid of the heuristic outcome. By default, the transaction logs are located in the
EAP_HOME/standalone/data/tx-object-store/directory for a standalone server, or theEAP_HOME/domain/servers/SERVER_NAME/data/tx-object-store/directory in a managed domain. In the case of a managed domain, SERVER_NAME refers to the name of the individual server participating in a server group.NoteThe location of the transaction log also depends on the object store in use and the values set for the
object-store-relative-toandobject-store-pathparameters. For file system logs, such as a standard shadow and Apache ActiveMQ Artemis logs, the default directory location is used, but when using a JDBC object store, the transaction logs are stored in a database.Resolve the outcome by hand: The process of resolving the transaction outcome by hand is very dependent on the exact circumstance of the failure. Typically, you need to take the following steps, applying them to your situation:
- Identify which resource managers were involved.
- Examine the state in the TM and the resource managers.
- Manually force log cleanup and data reconciliation in one or more of the involved components.
The details of how to perform these steps are out of the scope of this documentation.
11.7.4. JTA Transaction Error Handling
11.7.4.1. Handle Transaction Errors
Transaction errors are challenging to solve because they are often dependent on timing. Here are some common errors and ideas for troubleshooting them.
These guidelines do not apply to heuristic errors. If you experience heuristic errors, refer to Handle a Heuristic Outcome in a Transaction and contact Red Hat Global Support Services for assistance.
- The transaction timed out but the business logic thread did not notice
This type of error often manifests itself when Hibernate is unable to obtain a database connection for lazy loading. If it happens frequently, you can lengthen the timeout value. See the JBoss EAP Configuration Guide for information on configuring the transaction manager.
If that is not feasible, you might be able to tune your external environment to perform more quickly, or restructure your code to be more efficient. Contact Red Hat Global Support Services if you still have trouble with timeouts.
- The transaction is already running on a thread, or you receive a
NotSupportedExceptionexception The
NotSupportedExceptionexception usually indicates that you attempted to nest a JTA transaction, and this is not supported. If you were not attempting to nest a transaction, it is likely that another transaction was started in a thread pool task, but finished the task without suspending or ending the transaction.Applications typically use
UserTransaction, which handles this automatically. If so, there might be a problem with a framework.If your code does use
TransactionManagerorTransactionmethods directly, be aware of the following behavior when committing or rolling back a transaction. If your code usesTransactionManagermethods to control your transactions, committing or rolling back a transaction disassociates the transaction from the current thread. However, if your code usesTransactionmethods, the transaction might not be associated with the running thread, and you need to disassociate it from its threads manually, before returning it to the thread pool.- You are unable to enlist a second local resource
- This error happens if you try to enlist a second non-XA resource into a transaction. If you need multiple resources in a transaction, they must be XA.
11.8. Transaction References
11.8.1. JTA Transaction Example
This example illustrates how to begin, commit, and roll back a JTA transaction. You need to adjust the connection and datasource parameters to suit your environment, and set up two test tables in your database.
11.8.2. Transaction API Documentation
The transaction JTA API documentation is available as Javadoc at the following location:
If you use Red Hat JBoss Developer Studio to develop your applications, the API documentation is included in the Help menu.
Chapter 12. Java Persistence API (JPA)
12.1. About Java Persistence API (JPA)
The Java Persistence API (JPA) is a Java specification for accessing, persisting, and managing data between Java objects or classes and a relational database. The JPA specification recognizes the interest and the success of the transparent object or relational mapping paradigm. It standardizes the basic APIs and the metadata needed for any object or relational persistence mechanism.
JPA itself is just a specification, not a product; it cannot perform persistence or anything else by itself. JPA is just a set of interfaces, and requires an implementation.
12.2. Create a Simple JPA Application
Follow the procedure below to create a simple JPA application in Red Hat JBoss Developer Studio.
Create a JPA project in JBoss Developer Studio.
In Red Hat JBoss Developer Studio, click File-→ New -→ Project. Find JPA in the list, expand it, and select JPA Project. You are presented with the following dialog.
Figure 12.1. New JPA Project Dialog
- Enter a Project name.
- Select a Target runtime. If no target runtime is available, follow these instructions to define a new server and runtime: Using Runtime Detection to Set Up JBoss EAP from within the IDE in the Getting Started with JBoss Developer Studio Tools guide.
- Under JPA version, ensure 2.1 is selected.
- Under Configuration, choose Basic JPA Configuration.
- Click Finish.
- If prompted, choose whether you wish to associate this type of project with the JPA perspective window.
Create and configure a new persistence settings file.
- Open an EJB 3.x project in Red Hat JBoss Developer Studio.
- Right click the project root directory in the Project Explorer panel.
- Select New → Other….
- Select XML File from the XML folder and click Next.
-
Select the
ejbModule/META-INF/folder as the parent directory. -
Name the file
persistence.xmland click Next. - Select Create XML file from an XML schema file and click Next.
Select http://java.sun.com/xml/ns/persistence/persistence_2.0.xsd from the Select XML Catalog entry list and click Next.
Figure 12.2. Persistence XML Schema
Click Finish to create the file. The
persistence.xmlhas been created in theMETA-INF/folder and is ready to be configured.Example: Persistence Settings File
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12.3. JPA Entities
Once you have established the connection from your application to the database, you can start mapping the data in the database to Java objects. Java objects that are used to map against database tables are called entity objects.
Entities have relationships with other entities, which are expressed through object-relational metadata. The object-relational metadata can be specified either directly in the entity class file by using annotations, or in an XML descriptor file called persistence.xml included with the application.
The high-level mapping of Java objects to the database is as follows:
- Java classes map to the database tables.
- Java instances map to the database rows.
- Java fields map to the database columns.
12.4. Persistence Context
The JPA persistence context contains the entities managed by the persistence provider. The persistence context acts like a first level transactional cache for interacting with the datasource. It manages the entity instances and their lifecycle. Loaded entities are placed into the persistence context before being returned to the application. Entity changes are also placed into the persistence context to be saved in the database when the transaction commits.
The lifetime of a container-managed persistence context can either be scoped to a transaction, which is referred to as a transaction-scoped persistence context, or have a lifetime scope that extends beyond that of a single transaction, which is referred to as an extended persistence context. The PersistenceContextType property, which has the enum datatype, is used to define the persistence context lifetime scope for container-managed entity managers. The persistence context lifetime scope is defined when the EntityManager instance is created.
12.4.1. Transaction-Scoped Persistence Context
The transaction-scoped persistence context works with the active JTA transaction. When the transaction commits, the persistence context is flushed to the datasource; the entity objects are detached but might still be referenced by the application code. All the entity changes that are expected to be saved to the datasource must be made during a transaction. Entities that are read outside the transaction are detached when the EntityManager invocation completes.
12.4.2. Extended Persistence Context
The extended persistence context spans multiple transactions and allows data modifications to be queued without an active JTA transaction. The container-managed extended persistence context can only be injected into a stateful session bean.
12.5. JPA EntityManager
JPA entity manager represents a connection to the persistence context. You can read from and write to the database defined by the persistence context using the entity manager.
Persistence context is provided through the Java annotation @PersistenceContext in the javax.persistence package. The entity manager is provided through the Java class javax.persistence.EntityManager. In any managed bean, the EntityManager instance can be injected as shown below:
Example: Entity Manager Injection
12.5.1. Application-Managed EntityManager
Application-managed entity managers provide direct access to the underlying persistence provider, org.hibernate.ejb.HibernatePersistence. The scope of the application-managed entity manager is from when the application creates it and lasts until the application closes it. You can use the @PersistenceUnit annotation to inject a persistence unit into the javax.persistence.EntityManagerFactory interface, which returns an application-managed entity manager.
Application-managed entity managers can be used when your application needs to access a persistence context that is not propagated with the JTA transaction across EntityManager instances in a particular persistence unit. In this case, each EntityManager instance creates a new, isolated persistence context. The EntityManager instance and its associated PersistenceContext is created and destroyed explicitly by your application. Application-managed entity managers can also be used when you cannot inject EntityManager instances directly, because the EntityManager instances are not thread-safe. EntityManagerFactory instances are thread-safe.
Example: Application-Managed Entity Manager
12.5.2. Container-Managed EntityManager
Container-managed entity managers manage the underlying persistence provider for the application. They can use the transaction-scoped persistence contexts or the extended persistence contexts. The container-managed entity manager creates instances of the underlying persistence provider as needed. Every time a new underlying persistence provider org.hibernate.ejb.HibernatePersistence instance is created, a new persistence context is also created.
12.6. Working with the EntityManager
When you have the persistence.xml file located in the /META-INF directory, the entity manager is loaded and has an active connection to the database. The EntityManager property can be used to bind the entity manager to JNDI and to add, update, remove and query entities.
12.6.1. Binding the EntityManager to JNDI
By default, JBoss EAP does not bind the EntityManagerFactory to JNDI. You can explicitly configure this in the persistence.xml file of your application by setting the jboss.entity.manager.factory.jndi.name property. The value of this property should be the JNDI name to which you want to bind the EntityManagerFactory.
You can also bind a container-managed transaction-scoped entity manager to JNDI by using the jboss.entity.manager.jndi.name property.
Example: Binding the EntityManager and the EntityManagerFactory to JNDI
<property name="jboss.entity.manager.jndi.name" value="java:/MyEntityManager"/> <property name="jboss.entity.manager.factory.jndi.name" value="java:/MyEntityManagerFactory"/>
<property name="jboss.entity.manager.jndi.name" value="java:/MyEntityManager"/>
<property name="jboss.entity.manager.factory.jndi.name" value="java:/MyEntityManagerFactory"/>Example: Storing an Entity using the EntityManager
public User createUser(User user) {
entityManager.persist(user);
return user;
}
public User createUser(User user) {
entityManager.persist(user);
return user;
}Example: Updating an Entity using the EntityManager
public void updateUser(User user) {
entityManager.merge(user);
}
public void updateUser(User user) {
entityManager.merge(user);
}Example: Removing an Entity using the EntityManager
public void deleteUser(String user) {
User user = findUser(username);
if (user != null)
entityManager.remove(user);
}
public void deleteUser(String user) {
User user = findUser(username);
if (user != null)
entityManager.remove(user);
}Example: Querying an Entity using the EntityManager
12.7. Deploying the Persistence Unit
A persistence unit is a logical grouping that includes:
- Configuration information for an entity manager factory and its entity managers.
- Classes managed by the entity managers.
- Mapping metadata specifying the mapping of the classes to the database.
The persistence.xml file contains persistence unit configuration, including the datasource name. The JAR file or the directory whose /META-INF/ directory contains the persistence.xml file is termed as the root of the persistence unit.
In Java EE environments, the root of the persistence unit must be one of the following:
- An EJB-JAR file
-
The
/WEB-INF/classes/directory of a WAR file -
A JAR file in the
/WEB-INF/lib/directory of a WAR file - A JAR file in the EAR library directory
- An application client JAR file
Example: Persistence Settings File
12.8. Second-level Caches
12.8.1. About Second-level Caches
A second-level cache is a local data store that holds information persisted outside the application session. The cache is managed by the persistence provider, improving runtime by keeping the data separate from the application.
JBoss EAP supports caching for the following purposes:
- Web Session Clustering
- Stateful Session Bean Clustering
- SSO Clustering
- Hibernate/JPA Second-level Cache
Each cache container defines a repl and a dist cache. These caches should not be used directly by user applications.
12.8.1.1. Default Second-level Cache Provider
Infinispan is the default second-level cache provider for JBoss EAP. Infinispan is a distributed in-memory key/value data store with optional schema, available under the Apache License 2.0.
12.8.1.1.1. Configuring a Second-level Cache in the Persistence Unit
You can use the shared-cache-mode element of the persistence unit to configure the second-level cache.
-
See Create a Simple JPA Application to create the
persistence.xmlfile in Red Hat JBoss Developer Studio. Add the following to the
persistence.xmlfile:Copy to Clipboard Copied! Toggle word wrap Toggle overflow The
SHARED_CACHE_MODEelement can take the following values:-
ALL: All entities should be considered cacheable. -
NONE: No entities should be considered cacheable. -
ENABLE_SELECTIVE: Only entities marked as cacheable should be considered cacheable. -
DISABLE_SELECTIVE: All entities except the ones explicitly marked as not cacheable should be considered cacheable. -
UNSPECIFIED: Behavior is not defined. Provider-specific defaults are applicable.
-
Chapter 13. Bean Validation
13.1. About Bean Validation
Bean Validation, or JavaBeans Validation, is a model for validating data in Java objects. The model uses built-in and custom annotation constraints to ensure the integrity of application data. The specification is documented here: JSR 349: Bean Validation 1.1.
Hibernate Validator is the JBoss EAP implementation of Bean Validation. It is also the reference implementation of the JSR.
JBoss EAP is 100% compliant with JSR 349 Bean Validation 1.1 specification. Hibernate Validator also provides additional features to the specification.
To get started with Bean Validation, see the bean-validation quickstart that ships with JBoss EAP. For information about how to download and run the quickstarts, see Using the Quickstart Examples in the JBoss EAP Getting Started Guide.
JBoss EAP 7.1 now includes Hibernate Validator 5.3.x.
New Features of Hibernate Validator 5.3.x
Programmatic API for constraint definition and declaration.
Hibernate Validator introduces a new fluid API, more consistent than what existed in previous releases.
For example, if you want to define a new
ValidPassengerCountconstraint annotation which relies on aValidPassengerCountValidatorvalidator, you can use the API as follows:ConstraintMapping constraintMapping = configuration.createConstraintMapping(); constraintMapping .constraintDefinition( ValidPassengerCount.class ) .validatedBy( ValidPassengerCountValidator.class );ConstraintMapping constraintMapping = configuration.createConstraintMapping(); constraintMapping .constraintDefinition( ValidPassengerCount.class ) .validatedBy( ValidPassengerCountValidator.class );Copy to Clipboard Copied! Toggle word wrap Toggle overflow It can also be used to replace the implementation of the validator used for a given annotation constraint.
For more information on this, see Hibernate Validator 5.3.0.CR1 is out.
Constraint mapping contributors.
With the new
hibernate.validator.constraint_mapping_contributorsproperty you can now declare several constraint mapping contributors separated by a comma.NoteIn Hibernate Validator 5.3.x, the existing
hibernate.validator.constraint_mapping_contributorproperty is still supported, but has been deprecated.Dynamic payloads for constraints.
Hibernate Validator 5.3.x allows you to enrich custom constraint violations with additional context data. Code examining constraint violations can access and interpret this data in a safer way than by parsing string-based constraint violation messages. This is like a dynamic variant of the existing bean validation payload feature.
For more information on this, see Hibernate Validator 5.3.0.Alpha1 is out.
Email validation.
The way email validation is done has been changed. The domain of the email now needs to be a valid domain with each label being at most 63 characters long.
13.2. Validation Constraints
13.2.1. About Validation Constraints
Validation constraints are rules applied to a Java element, such as a field, property or bean. A constraint will usually have a set of attributes used to set its limits. There are predefined constraints, and custom ones can be created. Each constraint is expressed in the form of an annotation.
The built-in validation constraints for Hibernate Validator are listed here: Hibernate Validator Constraints.
13.2.2. Hibernate Validator Constraints
When applicable, the application-level constraints lead to creation of database-level constraints that are described in the Hibernate Metadata Impact column in the table below.
Java-specific Validation Constraints
The following table includes validation constraints defined in the Java specifications, which are included in the javax.validation.constraints package.
| Annotation | Property type | Runtime checking | Hibernate Metadata impact |
|---|---|---|---|
| @AssertFalse | Boolean | Check that the method evaluates to false. Useful for constraints expressed in code rather than annotations. | None. |
| @AssertTrue | Boolean | Check that the method evaluates to true. Useful for constraints expressed in code rather than annotations. | None. |
| @Digits(integerDigits=1) | Numeric or string representation of a numeric |
Check whether the property is a number having up to | Define column precision and scale. |
| @Future | Date or calendar | Check if the date is in the future. | None. |
| @Max(value=) | Numeric or string representation of a numeric | Check if the value is less than or equal to max. | Add a check constraint on the column. |
| @Min(value=) | Numeric or string representation of a numeric | Check if the value is more than or equal to Min. | Add a check constraint on the column. |
| @NotNull | Check if the value is not null. | Column(s) are not null. | |
| @Past | Date or calendar | Check if the date is in the past. | Add a check constraint on the column. |
| @Pattern(regexp="regexp", flag=) or @Patterns( {@Pattern(…)} ) | String |
Check if the property matches the regular expression given a match flag. See | None. |
| @Size(min=, max=) | Array, collection, map | Check if the element size is between min and max, both values included. | None. |
| @Valid | Object | Perform validation recursively on the associated object. If the object is a Collection or an array, the elements are validated recursively. If the object is a Map, the value elements are validated recursively. | None. |
The parameter @Valid is a part of the Bean Validation specification, even though it is located in the javax.validation.constraints package.
Hibernate Validator-specific Validation Constraints
The following table includes vendor-specific validation constraints, which are a part of the org.hibernate.validator.constraints package.
| Annotation | Property type | Runtime checking | Hibernate Metadata impact |
|---|---|---|---|
| @Length(min=, max=) | String | Check if the string length matches the range. | Column length will be set to max. |
| @CreditCardNumber | String | Check whether the string is a well formatted credit card number, derivative of the Luhn algorithm. | None. |
| @EAN | String | Check whether the string is a properly formatted EAN or UPC-A code. | None. |
| | String | Check whether the string is conform to the e-mail address specification. | None. |
| @NotEmpty | Check if the string is not null nor empty. Check if the connection is not null nor empty. | Columns are not null for String. | |
| @Range(min=, max=) | Numeric or string representation of a numeric | Check if the value is between min and max, both values included. | Add a check constraint on the column. |
13.2.3. Bean Validation Using Custom Constraints
Bean Validation API defines a set of standard constraint annotations, such as @NotNull, @Size, and so on. However, in cases where these predefined constraints are not sufficient, you can easily create custom constraints tailored to your specific validation requirements.
Creating a Bean Validation custom constraint requires that you create a constraint annotation and implement a constraint validator. The following abbreviated code examples are taken from the bean-validation-custom-constraint quickstart that ships with JBoss EAP. See that quickstart for a complete working example.
13.2.3.1. Creating A Constraint Annotation
The following example shows the personAddress field of entity Person is validated using a set of custom constraints defined in the class AddressValidator.
Create the entity
Person.Example:
PersonClassCopy to Clipboard Copied! Toggle word wrap Toggle overflow Create the constraint validator files.
Example:
AddressInterfaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow Example:
PersonAddressClassCopy to Clipboard Copied! Toggle word wrap Toggle overflow
13.2.3.2. Implementing A Constraint Validator
Having defined the annotation, you need to create a constraint validator that is able to validate elements with an @Address annotation. To do so, implement the interface ConstraintValidator as shown below:
Example: AddressValidator Class
13.3. Validation Configuration
You can configure bean validation using XML descriptors in the validation.xml file located in the /META-INF directory. If this file exists in the class path, its configuration is applied when the ValidatorFactory gets created.
Example: Validation Configuration File
The following example shows several configuration options of the validation.xml file. All the settings are optional. These options can also be configured using the javax.validation package.
The node default-provider allows to choose the bean validation provider. This is useful if there is more than one provider on the classpath. The message-interpolator and constraint-validator-factory properties are used to customize the used implementations for the interfaces MessageInterpolator and ConstraintValidatorFactory, which are defined in the javax.validation package. The constraint-mapping element lists additional XML files containing the actual constraint configuration.
Chapter 14. Creating WebSocket Applications
The WebSocket protocol provides two-way communication between web clients and servers. Communications between clients and the server are event-based, allowing for faster processing and smaller bandwidth compared with polling-based methods. WebSocket is available for use in web applications using a JavaScript API and by client WebSocket endpoints using the Java Websocket API.
A connection is first established between client and server as an HTTP connection. The client then requests a WebSocket connection using the Upgrade header. All communications are then full-duplex over the same TCP/IP connection, with minimal data overhead. Because each message does not include unnecessary HTTP header content, Websocket communications require smaller bandwidth. The result is a low latency communications path suited to applications, which require real-time responsiveness.
The JBoss EAP WebSocket implementation provides full dependency injection support for server endpoints, however, it does not provide CDI services for client endpoints.
A WebSocket application requires the following components and configuration changes:
- A Java client or a WebSocket enabled HTML client. You can verify HTML client browser support at this location: http://caniuse.com/#feat=websockets
- A WebSocket server endpoint class.
- Project dependencies configured to declare a dependency on the WebSocket API.
Create the WebSocket Application
The code examples that follow are taken from the websocket-hello quickstart that ships with JBoss EAP. It is a simple example of a WebSocket application that opens a connection, sends a message, and closes a connection. It does not implement any other functions or include any error handling, which would be required for a real world application.
Create the JavaScript HTML client.
The following is an example of a WebSocket client. It contains these JavaScript functions:
-
connect(): This function creates the WebSocket connection passing the WebSocket URI. The resource location matches the resource defined in the server endpoint class. This function also intercepts and handles the WebSocketonopen,onmessage,onerror, andonclose. -
sendMessage(): This function gets the name entered in the form, creates a message, and sends it using a WebSocket.send() command. -
disconnect(): This function issues the WebSocket.close() command. -
displayMessage(): This function sets the display message on the page to the value returned by the WebSocket endpoint method. displayStatus(): This function displays the WebSocket connection status.Example: Application
index.htmlCodeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
-
Create the WebSocket server endpoint.
You can create a WebSocket server endpoint using either of the following methods.
-
Programmatic Endpoint: The endpoint extends the Endpoint class. -
Annotated Endpoint: The endpoint class uses annotations to interact with the WebSocket events. It is simpler to code than the programmatic endpoint.
The code example below uses the annotated endpoint approach and handles the following events.
-
The
@ServerEndpointannotation identifies this class as a WebSocket server endpoint and specifies the path. -
The
@OnOpenannotation is triggered when the WebSocket connection is opened. -
The
@OnMessageannotation is triggered when a message is received. The
@OnCloseannotation is triggered when the WebSocket connection is closed.Example: WebSocket Endpoint Code
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
Declare the WebSocket API dependency in your project POM file.
If you use Maven, you add the following dependency to the project
pom.xmlfile.Example: Maven Dependency
<dependency> <groupId>org.jboss.spec.javax.websocket</groupId> <artifactId>jboss-websocket-api_1.1_spec</artifactId> <scope>provided</scope> </dependency>
<dependency> <groupId>org.jboss.spec.javax.websocket</groupId> <artifactId>jboss-websocket-api_1.1_spec</artifactId> <scope>provided</scope> </dependency>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
The quickstarts that ship with JBoss EAP include additional WebSocket client and endpoint code examples.
Chapter 15. Java Authorization Contract for Containers (JACC)
15.1. About Java Authorization Contract for Containers (JACC)
Java Authorization Contract for Containers (JACC) is a standard which defines a contract between containers and authorization service providers, which results in the implementation of providers for use by containers. It is defined in JSR-115 of the Java Community Process. For details about the specifications, see Java™ Authorization Contract for Containers.
JBoss EAP implements support for JACC within the security functionality of the security subsystem.
15.2. Configure Java Authorization Contract for Containers (JACC) Security
You can configure Java Authorization Contract for Containers (JACC) by configuring your security domain with the correct module, and then modifying your jboss-web.xml to include the required parameters.
Add JACC Support to the Security Domain
To add JACC support to the security domain, add the JACC authorization policy to the authorization stack of the security domain, with the required flag set. The following is an example of a security domain with JACC support. However, it is recommended to configure the security domain from the management console or the management CLI, rather than directly modifying the XML.
Example: Security Domain with JACC Support
Configure a Web Application to Use JACC
The jboss-web.xml file is located in the WEB-INF/ directory of your deployment, and contains overrides and additional JBoss-specific configuration for the web container. To use your JACC-enabled security domain, you need to include the <security-domain> element, and also set the <use-jboss-authorization> element to true. The following XML is configured to use the JACC security domain above.
Example: Utilize the JACC Security Domain
<jboss-web>
<security-domain>jacc</security-domain>
<use-jboss-authorization>true</use-jboss-authorization>
</jboss-web>
<jboss-web>
<security-domain>jacc</security-domain>
<use-jboss-authorization>true</use-jboss-authorization>
</jboss-web>Configure an EJB Application to Use JACC
Configuring EJBs to use a security domain and to use JACC differs from web applications. For an EJB, you can declare method permissions on a method or group of methods, in the ejb-jar.xml descriptor. Within the <ejb-jar> element, any child <method-permission> elements contain information about JACC roles. See the example configuration below for details. The EJBMethodPermission class is part of the Java EE 7 API, and is documented at http://docs.oracle.com/javaee/7/api/javax/security/jacc/EJBMethodPermission.html.
Example: JACC Method Permissions in an EJB
You can also constrain the authentication and authorization mechanisms for an EJB by using a security domain, just as you can do for a web application. Security domains are declared in the jboss-ejb3.xml descriptor, in the <security> child element. In addition to the security domain, you can also specify the <run-as-principal>, which changes the principal that the EJB runs as.
Example: Security Domain Declaration in an EJB
Enabling JACC Using the elytron Subsystem
Disable JACC in the Legacy Security Subsystem
By default, the application server uses the legacy security subsystem to configure the JACC policy provider and factory. The default configuration maps to implementations from PicketBox.
In order to use Elytron to manage JACC configuration, or any other policy you want to install to the application server, you must first disable JACC in the legacy security subsystem. For that, you can use the following management CLI command:
/subsystem=security:write-attribute(name=initialize-jacc, value=false)
/subsystem=security:write-attribute(name=initialize-jacc, value=false)
Failure to do so can result in the following error in the server log: MSC000004: Failure during stop of service org.wildfly.security.policy: java.lang.StackOverflowError.
Define a JACC Policy Provider
The elytron subsystem provides a built-in policy provider based on JACC specification. To create the policy provider you can execute the following management CLI command:
/subsystem=elytron/policy=jacc:add(jacc-policy={})
reload
/subsystem=elytron/policy=jacc:add(jacc-policy={})
reloadEnable JACC to a Web Deployment
Once a JACC policy provider is defined, you can enable JACC for web deployments by executing the following command:
/subsystem=undertow/application-security-domain=other:add(http-authentication-factory=application-http-authentication,enable-jacc=true)
/subsystem=undertow/application-security-domain=other:add(http-authentication-factory=application-http-authentication,enable-jacc=true)
The command above defines a default security domain for applications, if none is provided in the jboss-web.xml file. In case you already have a application-security-domain defined and just want to enable JACC you can execute the following command:
/subsystem=undertow/application-security-domain=my-security-domain:write-attribute(name=enable-jacc,value=true)
/subsystem=undertow/application-security-domain=my-security-domain:write-attribute(name=enable-jacc,value=true)Enable JACC to an EJB Deployment
Once a JACC policy provider is defined, you can enable JACC for EJB deployments by executing the following command:
/subsystem=ejb3/application-security-domain=other:add(security-domain=ApplicationDomain,enable-jacc=true)
/subsystem=ejb3/application-security-domain=other:add(security-domain=ApplicationDomain,enable-jacc=true)
The command above defines a default security domain for EJBs. In case you already have a application-security-domain defined and just want to enable JACC you can execute a command as follows:
/subsystem=ejb3/application-security-domain=my-security-domain:write-attribute(name=enable-jacc,value=true)
/subsystem=ejb3/application-security-domain=my-security-domain:write-attribute(name=enable-jacc,value=true)Creating a Custom Elytron Policy Provider
A custom policy provider is used when you need a custom java.security.Policy, like when you want to integrate with some external authorization service in order to check permissions. To create a custom policy provider, you will need to implement the java.security.Policy, create and plug in a custom module with the implementation and use the implementation from the module in the elytron subsystem.
/subsystem=elytron/policy=policy-provider-a:add(custom-policy={class-name=MyPolicyProviderA, module=x.y.z})
/subsystem=elytron/policy=policy-provider-a:add(custom-policy={class-name=MyPolicyProviderA, module=x.y.z})For more information, see the Policy Provider Properties.
In most cases, you can use the JACC policy provider as it is expected to be part of any Java EE compliant application server.
Chapter 16. Java Authentication SPI for Containers (JASPI)
16.1. About Java Authentication SPI for Containers (JASPI) Security
Java Authentication SPI for Containers (JASPI or JASPIC) is a pluggable interface for Java applications. It is defined in JSR-196 of the Java Community Process. Refer to http://www.jcp.org/en/jsr/detail?id=196 for details about the specification.
16.2. Configure Java Authentication SPI for Containers (JASPI) Security
You can authenticate a JASPI provider by adding <authentication-jaspi> element to your security domain. The configuration is similar to that of a standard authentication module, but login module elements are enclosed in a <login-module-stack> element. The structure of the configuration is:
Example: Structure of the authentication-jaspi Element
The login module itself is configured the same way as a standard authentication module.
The web-based management console does not expose the configuration of JASPI authentication modules. You must stop the JBoss EAP running instance completely before adding the configuration directly to the EAP_HOME/domain/configuration/domain.xml file or the EAP_HOME/standalone/configuration/standalone.xml file.
Chapter 17. Java Batch Application Development
Beginning with JBoss EAP 7, JBoss EAP supports Java batch applications as defined by JSR-352. The batch-jberet subsystem in JBoss EAP facilitates batch configuration and monitoring.
To configure your application to use batch processing on JBoss EAP, you must specify the required dependencies. Additional JBoss EAP features for batch processing include Job Specification Language (JSL) inheritance, and batch property injections.
17.1. Required Batch Dependencies
To deploy your batch application to JBoss EAP, some additional dependencies that are required for batch processing need to be declared in your application’s pom.xml. An example of these required dependencies is shown below. Most of the dependencies have the scope set to provided, as they are already included in JBoss EAP.
Example: pom.xml Batch Dependencies
17.2. Job Specification Language (JSL) Inheritance
A feature of the JBoss EAP batch-jberet subsystem is the ability to use Job Specification Language (JSL) inheritance to abstract out some common parts of your job definition. Although JSL inheritance is not included in the JSR-352 1.0 specification, the JBoss EAP batch-jberet subsystem implements JSL inheritance based on the JSL Inheritance v1 draft.
Inherit Step and Flow Within the Same Job XML File
Parent elements, for example step and flow, are marked with the attribute abstract="true" to exclude them from direct execution. Child elements contain a parent attribute, which points to the parent element.
Inherit a Step from a Different Job XML File
Child elements, for example step and job, contain:
-
A
jsl-nameattribute, which specifies the job XML file name, without the.xmlextension, containing the parent element. -
A
parentattribute, which points to the parent element in the job XML file specified byjsl-name.
Parent elements are marked with the attribute abstract="true" to exclude them from direct execution.
Example: chunk-child.xml
<job id="chunk-child" xmlns="http://xmlns.jcp.org/xml/ns/javaee" version="1.0">
<step id="chunk-child-step" parent="chunk-parent-step" jsl-name="chunk-parent">
</step>
</job>
<job id="chunk-child" xmlns="http://xmlns.jcp.org/xml/ns/javaee" version="1.0">
<step id="chunk-child-step" parent="chunk-parent-step" jsl-name="chunk-parent">
</step>
</job>Example: chunk-parent.xml
17.3. Batch Property Injections
A feature of the JBoss EAP batch-jberet subsystem is the ability to have properties defined in the job XML file injected into fields in the batch artifact class. Properties defined in the job XML file can be injected into fields using the @Inject and @BatchProperty annotations.
The injection field can be any of the following Java types:
-
java.lang.String -
java.lang.StringBuilder -
java.lang.StringBuffer any primitive type, and its wrapper type:
-
boolean,Boolean -
int,Integer -
double,Double -
long,Long -
char,Character -
float,Float -
short,Short -
byte,Byte
-
-
java.math.BigInteger -
java.math.BigDecimal -
java.net.URL -
java.net.URI -
java.io.File -
java.util.jar.JarFile -
java.util.Date -
java.lang.Class -
java.net.Inet4Address -
java.net.Inet6Address -
java.util.List,List<?>,List<String> -
java.util.Set,Set<?>,Set<String> -
java.util.Map,Map<?, ?>,Map<String, String>,Map<String, ?> -
java.util.logging.Logger -
java.util.regex.Pattern -
javax.management.ObjectName
The following array types are also supported:
-
java.lang.String[] any primitive type, and its wrapper type:
-
boolean[],Boolean[] -
int[],Integer[] -
double[],Double[] -
long[],Long[] -
char[],Character[] -
float[],Float[] -
short[],Short[] -
byte[],Byte[]
-
-
java.math.BigInteger[] -
java.math.BigDecimal[] -
java.net.URL[] -
java.net.URI[] -
java.io.File[] -
java.util.jar.JarFile[] -
java.util.zip.ZipFile[] -
java.util.Date[] -
java.lang.Class[]
Shown below are a few examples of using batch property injections:
Injecting a Number into a Batchlet Class as Various Types
Example: Job XML File
<batchlet ref="myBatchlet">
<properties>
<property name="number" value="10"/>
</properties>
</batchlet>
<batchlet ref="myBatchlet">
<properties>
<property name="number" value="10"/>
</properties>
</batchlet>Example: Artifact Class
Injecting a Number Sequence into a Batchlet Class as Various Arrays
Example: Job XML File
<batchlet ref="myBatchlet">
<properties>
<property name="weekDays" value="1,2,3,4,5,6,7"/>
</properties>
</batchlet>
<batchlet ref="myBatchlet">
<properties>
<property name="weekDays" value="1,2,3,4,5,6,7"/>
</properties>
</batchlet>Example: Artifact Class
Injecting a Class Property into a Batchlet Class
Example: Job XML File
<batchlet ref="myBatchlet">
<properties>
<property name="myClass" value="org.jberet.support.io.Person"/>
</properties>
</batchlet>
<batchlet ref="myBatchlet">
<properties>
<property name="myClass" value="org.jberet.support.io.Person"/>
</properties>
</batchlet>Example: Artifact Class
Assigning a Default Value to a Field Annotated for Property Injection
You can assign a default value to a field in an artifact Java class in the case where the target batch property is not defined in the job XML file. If the target property is resolved to a valid value, it is injected into that field; otherwise, no value is injected and the default field value is used.
Example: Artifact Class
Chapter 18. Configuring Clients
18.1. Client Configuration Using the wildfly-config.xml File
Prior to release 7.1, JBoss EAP client libraries, such as EJB and naming, used different configuration strategies. JBoss EAP 7.1 introduces the wildfly-config.xml file with the purpose of unifying all client configurations into one single configuration file, in a similar manner to the way the server configuration is handled.
The following table describes the clients and types of configuration that can be done using the wildfly-config.xml file in JBoss EAP 7.1 and a link to the reference schema link for each.
| Client Configuration | Schema Location / Configuration Information |
|---|---|
| Authentication client |
The schema reference is provided in the product installation at The schema is also published at http://www.jboss.org/schema/jbossas/elytron-1_0_1.xsd. |
|
See Client Authentication Configuration Using the Additional information can be found in Configure Client Authentication with Elytron Client in How to Configure Identity Management for JBoss EAP. | |
| EJB client |
The schema reference is provided in the product installation at The schema is also published at http://www.jboss.org/schema/jbossas/wildfly-client-ejb_3_0.xsd. |
|
See EJB Client Configuration Using the Another simple example is located in in the Migrate an EJB Client to Elytron section of the Migration Guide for JBoss EAP. | |
| HTTP client |
The schema reference is provided in the product installation at The schema is also published at http://www.jboss.org/schema/jbossas/wildfly-http-client_1_0.xsd. |
| Note This feature is provided as a Technology Preview only.
See HTTP Client Configuration Using the | |
| Remoting client |
The schema reference is provided in the product installation at The schema is also published at http://www.jboss.org/schema/jbossas/jboss-remoting_5_0.xsd. |
|
See Remoting Client Configuration Using the | |
| XNIO worker client |
The schema reference is provided in the product installation at The schema is also published at http://www.jboss.org/schema/jbossas/xnio_3_5.xsd. |
|
See Default XNIO Worker Configuration Using the |
18.1.1. Client Authentication Configuration Using the wildfly-config.xml File
You can use the authentication-client element, which is in the urn:elytron:1.0.1 namespace, to configure client authentication information using the wildfly-config.xml file. This section describes how to configure client authentication using this element.
authentication-client Elements and Attributes
The authentication-client element can optionally contain the following top level child elements, along with their child elements:
credential-storesThis optional element defines credential stores that are referenced from elsewhere in the configuration as an alternative to embedding credentials within the configuration.
It can contain any number of
credential-storeelements.Example:
credential-storesConfigurationCopy to Clipboard Copied! Toggle word wrap Toggle overflow
credential-storeThis element defines a credential store that is referenced from elsewhere in the configuration.
It has the following attributes.
Expand Attribute Name Attribute Description name
The name of the credential store. This attribute is required.
type
The type of credential store. This attribute is optional.
provider
The name of the
java.security.Providerto use to load the credential store. This attribute is optional.It can contain one and only one of each of the following child elements.
attributesThis element defines the configuration attributes used to initialize the credential store and can be repeated as many times as is required for the configuration.
Example:
attributesConfiguration<attributes> <attribute name="..." value="..." /> </attributes>
<attributes> <attribute name="..." value="..." /> </attributes>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
protection-parameter-credentialsThis element contains one or more credentials to be assembled into a protection parameter to be used when initializing the credential store.
It can contain one or more of the following child elements, which are dependent on the credential store implementation:
Example:
protection-parameter-credentialsConfigurationCopy to Clipboard Copied! Toggle word wrap Toggle overflow
key-store-referenceThis element, which is not currently used by any authentication mechanisms in JBoss EAP 7.1, defines a reference to a keystore.
It has the following attributes.
Expand Attribute Name Attribute Description key-store-name
The keystore name. This attribute is required.
alias
The alias of the entry to load from the referenced keystore. This can be omitted only for keystores that contain just a single entry.
It can contain one and only one of the following child elements.
Example:
key-store-referenceConfiguration<key-store-reference key-store-name="..." alias="..."> <key-store-clear-password password="..." /> <key-store-credential>...</key-store-credential> </key-store-reference>
<key-store-reference key-store-name="..." alias="..."> <key-store-clear-password password="..." /> <key-store-credential>...</key-store-credential> </key-store-reference>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
credential-store-referenceThis element defines a reference to a credential store.
It has the following attributes.
Expand Attribute Name Attribute Description store
The credential store name.
alias
The alias of the entry to load from the referenced credential store. This can be omitted only for keystores that contain just a single entry.
clear-text
The clear text password.
clear-password- This element defines a clear text password.
key-pairThis element, which is not currently used by any authentication mechanisms in JBoss EAP 7.1, defines a public and private key pair.
It can contain the following child elements.
public-key-pem- This element, which is not currently used by any authentication mechanisms in JBoss EAP 7.1, defines the PEM-encoded public key.
private-key-pem- This element defines the PEM-encoded private key.
certificateThis element, which is not currently used by any authentication mechanisms in JBoss EAP 7.1, specifies a certificate.
It has the following attributes.
Expand Attribute Name Attribute Description private-key-pem
A PEM-encoded private key.
pem
The corresponding certificate.
bearer-token- This element defines a bearer token.
oauth2-bearer-tokenThis element defines an OAuth 2 bearer token.
It has the following attribute.
Expand Attribute Name Attribute Description token-endpoint-uri
The URI of the token endpoint.
It can contain one and only one of each of the following child elements.
client-credentialsThis element defines the client credentials.
It has the following attributes.
Expand Attribute Name Attribute Description client-id
The client ID. This attribute is required.
client-secret
The client secret. This attribute is required.
resource-owner-credentialsThis element defines the resource owner credentials.
It has the following attributes.
Expand Attribute Name Attribute Description name
The resource name. This attribute is required.
pasword
The password. This attribute is required.
key-storesThis optional element defines keystores that are referenced from elsewhere in the configuration.
Example:
key-storesConfigurationCopy to Clipboard Copied! Toggle word wrap Toggle overflow
key-storeThis optional element defines a keystore that is referenced from elsewhere in the configuration.
The
key-storehas the following attributes.Expand Attribute Name Attribute Description name
The name of the keystore. This attribute is required.
type
The keystore type, for example,
JCEKS. This attribute is required.provider
The name of the
java.security.Providerto use to load the credential store. This attribute is optional.wrap-passwords
If true,
passwordswill wrap. The passwords are stored by taking the clear password contents, encoding them in UTF-8, and storing the resultant bytes as a secret key. Defaults tofalse.It must contain exactly one of the following elements, which define where to load the keystore from.
It must also contain one of the following elements, which specifies the protection parameter to use when initializing the keystore.
fileThis element specifies the name of the keystore file.
It has the following attribute.
Expand Attribute Name Attribute Description name
The fully qualified file path and name of the file.
load-fromThis element specifies the URI of the keystore file.
It has the following attribute.
Expand Attribute Name Attribute Description uri
The URI for the keystore file.
resourceThis element specifies the name of the resource to load from the
Threadcontext class loader.It has the following attribute.
Expand Attribute Name Attribute Description name
The name of the resource.
key-store-clear-passwordThis element specifies the clear text password.
It has the following attribute.
Expand Attribute Name Attribute Description password
The clear text password.
key-store-credentialThis element specifies a reference to another keystore that obtains an entry to use as the protection parameter to access this keystore.
The
key-store-credentialelement has the following attributes.Expand Attribute Name Attribute Description key-store-name
The keystore name. This attribute is required.
alias
The alias of the entry to load from the referenced keystore. This can be omitted only for keystores that contain just a single entry.
It can contain one and only one of the following child elements.
Example:
key-store-credentialConfiguration<key-store-credential key-store-name="..." alias="..."> <key-store-clear-password password="..." /> <key-store-credential>...</key-store-credential> </key-store-credential>
<key-store-credential key-store-name="..." alias="..."> <key-store-clear-password password="..." /> <key-store-credential>...</key-store-credential> </key-store-credential>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
authentication-rulesThis element defines the rules to match against the outbound connection to apply the appropriate authentication configuration. When an
authentication-configurationis required, the URI of the accessed resources as well as an optional abstract type and abstract type authority are matched against the rules defined in the configuration to identify whichauthentication-configurationshould be used.This element can contain one or more child
ruleelements.Example:
authentication-rulesConfigurationCopy to Clipboard Copied! Toggle word wrap Toggle overflow
ruleThis element defines the rules to match against the outbound connection to apply the appropriate authentication configuration.
It has the following attribute.
Expand Attribute Name Attribute Description use-configuration
The authentication configuration that is chosen when rules match.
Authentication configuration rule matching is independent of SSL context rule matching. The authentication rule structure is identical to the SSL context rule structure, except that it references an authentication configuration, while the SSL context rule references an SSL context.
It can contain the following child elements.
Example:
ruleConfiguration for AuthenticationCopy to Clipboard Copied! Toggle word wrap Toggle overflow
match-no-user-
This rule matches when there is no
user-infoembedded within the URI.
match-user-
This rule matches when the
user-infoembedded in the URI matches thenameattribute specified in this element.
match-protocol-
This rule matches when the protocol within the URI matches the protocol
nameattribute specified in this element.
match-host-
This rule matches when the host name specified within the URI matches the host
nameattribute specified in this element.
match-path-
This rule matches when the path specified within the URI matches the path
nameattribute specified in this element.
match-port-
This rule matches when the port number specified within the URI matches the port
numberattribute specified in this element. This only matches against the number specified within the URI and not against any default port number derived from the protocol.
match-urn-
This rule matches when the scheme specific part of the URI matches the
nameattribute specified in this element.
match-domain-name-
This rule matches when the protocol of the URI is
domainand the scheme specific part of the URI matches thenameattribute specified in this element.
match-abstract-type-
This rule matches when the abstract type matches the
nameattribute and the authority matches theauthorityattribute specified in this element.
authentication-configurationsThis element defines named authentication configurations that are to be chosen by the authentication rules.
It can contain one or more
configurationelements.Example:
authentication-configurationsConfigurationCopy to Clipboard Copied! Toggle word wrap Toggle overflow
configurationThis element defines named authentication configurations that are to be chosen by the authentication rules.
It can contain the following child elements.
-
The optional
set-host-name,set-port-number, andset-protocolelements can override the destination. -
The optional
set-user-nameandset-anonymouselements are mutually exclusive and can be used to set the name for authentication or switch to anonymous authentication. -
Next are the
set-mechanism-realm-name,rewrite-user-name-regex,sasl-mechanism-selector,set-mechanism-properties,credentials,set-authorization-name, andprovidersoptional elements. -
The final two optional
use-provider-sasl-factoryanduse-service-loader-sasl-factoryelements are mutually exclusive and define how the SASL mechanism factories are discovered for authentication.
-
The optional
set-host-nameThis element overrides the host name for the authenticated call.
It has the following attribute.
Expand Attribute Name Attribute Description name
The host name.
set-port-numberThis element overrides the port number for the authenticated call.
It has the following attribute.
Expand Attribute Name Attribute Description number
The port number.
set-protocolThis element overrides the protocol for the authenticated call.
It has the following attribute.
Expand Attribute Name Attribute Description name
The protocol.
set-user-nameThis element sets the user name to use for the authentication. It should not be used with the
set-anonymouselement.It has the following attribute.
Expand Attribute Name Attribute Description name
The user name to use for authentication.
set-anonymous-
The element is used to switch to anonymous authentication. It should not be used with the
set-user-nameelement.
set-mechanism-realm-nameThis element specifies the name of the realm that will be selected by the SASL mechanism if required.
It has the following attribute.
Expand Attribute Name Attribute Description name
The name of the realm.
rewrite-user-name-regexThis element defines a regular expression pattern and replacement to rewrite the user name used for authentication.
It has the following attributes.
Expand Attribute Name Attribute Description pattern
A regular expression pattern.
replacement
The replacement to use to rewrite the user name used for authentication.
sasl-mechanism-selectorThis element specifies a SASL mechanism selector using the syntax from the
org.wildfly.security.sasl.SaslMechanismSelector.fromString(string)method.It has the following attribute.
Expand Attribute Name Attribute Description selector
The SASL mechanism selector.
For more information about the grammar required for the
sasl-mechanism-selector, seesasl-mechanism-selectorGrammar in How to Configure Server Security for JBoss EAP.
set-mechanism-properties-
This element can contain one or more
propertyelements that are to be passed to the authentication mechanisms.
propertyThis element defines a property to be passed to the authentication mechanisms.
It has the following attributes.
Expand Attribute Name Attribute Description key
The property name.
value
The property value.
credentialsThis element defines one or more credentials available for use during authentication.
It can contain one or more of the following child elements, which are dependent on the credential store implementation:
These are the same child elements as those contained in the
protection-parameter-credentialselement. See theprotection-parameter-credentialselement for details and an example configuration.
set-authorization-nameThis element specifies the name that should be used for authorization if it is different from the authentication identity.
It has the following attributes.
Expand Attribute Name Attribute Description name
The name that should be used for authorization.
use-provider-sasl-factory-
This element specifies the
java.security.Providerinstances that are either inherited or defined in this configuration and that are to be used to locate the available SASL client factories. This element should not be used with theuse-service-loader-sasl-factoryelement.
use-service-loader-sasl-factoryThis element specifies the module that is to be used to discover the SASL client factories using the service loader discovery mechanism. If no module is specified, the class loader that loaded the configuration is used. This element should not be used with the
use-provider-sasl-factoryelement.It has the following attribute.
Expand Attribute Name Attribute Description module-name
The name of the module.
net-authenticatorThis element contains no configuration. If present, the
org.wildfly.security.auth.util.ElytronAuthenticatoris registered withjava.net.Authenticator.setDefault(Authenticator). This allows the Elytron authentication client configuration to be used for authentication when JDK APIs are used for HTTP calls that require authentication.NoteBecause the JDK caches the authentication on the first call across the JVM, it is better to use this approach only on standalone processes that do not require different credentials for different calls to the same URI.
ssl-context-rulesThis optional element defines the SSL context rules. When an
ssl-contextis required, the URI of the accessed resources as well as an optional abstract type and abstract type authority are matched against the rules defined in the configuration to identify whichssl-contextshould be used.This element can contain one or more child
ruleelements.Example:
ssl-context-rulesConfigurationCopy to Clipboard Copied! Toggle word wrap Toggle overflow
ruleThis element defines the rule to match on the SSL context definitions.
It has the following attribute.
Expand Attribute Name Attribute Description use-ssl-context
The SSL context definition that is chosen when rules match.
SSL context rule matching is independent of authentication rule matching. The SSL context rule structure is identical to the authentication configuration rule structure, except that it references an SSL context, while the authentication rule references an authentication configuration.
It can contain the following child elements.
Example:
ruleConfiguration for SSL ContextCopy to Clipboard Copied! Toggle word wrap Toggle overflow
ssl-contextsThis optional element defines SSL context definitions that are to be chosen by the SSL context rules.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
default-ssl-context-
This element takes the
SSLContextreturned byjavax.net.ssl.SSLContext.getDefault()and assigns it a name so it can referenced from thessl-context-rules. This element can be repeated, meaning the default SSL context can be referenced using different names.
ssl-contextThis element defines an SSL context to use for connections.
It can optionally contain one of each of the following child elements.
key-store-ssl-certificateThis element defines a reference to an entry within a keystore for the key and certificate to use for this SSL context.
It has the following attributes.
Expand Attribute Name Attribute Description key-store-name
The keystore name. This attribute is required.
alias
The alias of the entry to load from the referenced keystore. This can be omitted only for keystores that contain just a single entry.
It can contain the following child elements:
This structure is nearly identical to the structure used in the
key-store-credentialconfiguration with the exception that here it obtains the entry for the key and for the certificate. However, the nestedkey-store-clear-passwordandkey-store-credentialelements still provide the protection parameter to unlock the entry.Example:
key-store-ssl-certificateConfiguration<key-store-ssl-certificate key-store-name="..." alias="..."> <key-store-clear-password password="..." /> <key-store-credential>...</key-store-credential> </key-store-ssl-certificate>
<key-store-ssl-certificate key-store-name="..." alias="..."> <key-store-clear-password password="..." /> <key-store-credential>...</key-store-credential> </key-store-ssl-certificate>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
trust-storeThis element is a reference to the keystore that is to be used to initialize the
TrustManager.It has the following attribute.
Expand Attribute Name Attribute Description key-store-name
The keystore name. This attribute is required.
cipher-suiteThis element configures the filter for the enabled cipher suites.
It has the following attribute.
Expand Attribute Name Attribute Description selector
The selector to filter the cipher suites. The selector uses the format of the OpenSSL-style cipher list string created by the
org.wildfly.security.ssl.CipherSuiteSelector.fromString(selector)method.Example:
cipher-suiteConfiguration Using Default Filtering<cipher-suite selector="DEFAULT" />
<cipher-suite selector="DEFAULT" />Copy to Clipboard Copied! Toggle word wrap Toggle overflow
protocol-
This element defines a space separated list of the protocols to be supported. See the client-ssl-context Attributes table in How to Configure Server Security for JBoss EAP for the list of available protocols. Red Hat recommends that you use
TLSv1.2.
provider-name- Once the available providers have been identified, only the provider with the name defined on this element is used.
certificate-revocation-listThis element defines both the path to the certificate revocation list and the maximum number of non-self-issued intermediate certificates that can exist in a certification path. The presence of this element enables checking the peer’s certificate against the certificate revocation list.
It has the following attributes.
Expand Attribute Name Attribute Description path
The path to the certification list. This attribute is optional.
maximum-cert-path
The maximum number of non-self-issued intermediate certificates that can exist in a certification path. This attribute is optional.
providersThis element defines how
java.security.Providerinstances are located when required.It can contain the following child elements.
Because the configuration sections of
authentication-clientare independent of each other, this element can be configured in the following locations.Example: Locations of
providersConfigurationCopy to Clipboard Copied! Toggle word wrap Toggle overflow The
providersconfiguration applies to the element in which it is defined and to any of its child elements unless it is overridden. The specification of aprovidersin a child element overrides aprovidersspecified in any of its parent elements. If noprovidersconfiguration is specified, the default behavior is the equivalent of the following, which gives the Elytron provider priority over any globally registered providers, but also allows for the use of globally registered providers.Example:
providersConfiguration<providers> <use-service-loader /> <global /> </providers>
<providers> <use-service-loader /> <global /> </providers>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
global-
This empty element specifies to use the global providers loaded by the
java.security.Security.getProviders()method call.
use-service-loader- This empty element specifies to use the providers that are loaded by the specified module. If no module is specified, the class loader that loaded the authentication client is used.
Elements Not Currently Used By Any JBoss EAP 7.1 Authentication Mechanisms
The following child elements of the credentials element in the Elytron client configuration are not currently used by any authentication mechanisms in JBoss EAP. They can be used in your own custom implementations of authentication mechanism; however, they are not supported.
-
key-pair -
public-key-pem -
key-store-reference -
certificate
18.1.2. EJB Client Configuration Using the wildfly-config.xml File
You can use the jboss-ejb-client element, which is in the urn:jboss:wildfly-client-ejb:3.0 namespace, to configure EJB client connections, global interceptors, and invocation timeouts using the wildfly-config.xml file. This section describes how to configure an EJB client using this element.
jboss-ejb-client Elements and Attributes
The jboss-ejb-client element can optionally contain the following three top level child elements, along with their child elements:
invocation-timeoutThis optional element specifies the EJB invocation timeout. It has the following attribute.
Expand Attribute Name Attribute Description seconds
The timeout, in seconds, for the EJB handshake or the method invocation request/response cycle. This attribute is required.
If the execution of a method takes longer than the timeout period, the invocation throws a
java.util.concurrent.TimeoutException; however, the server side will not be interrupted.
global-interceptors-
This optional element specifies the global EJB client interceptors. It can contain any number of
interceptorelements.
interceptorThis element is used to specify an EJB client interceptor. It has the following attributes.
Expand Attribute Name Attribute Description class
The name of a class that implements the
org.jboss.ejb.client.EJBClientInterceptorinterface. This attribute is required.module
The name of the module that should be used to load the interceptor class. This attribute is optional.
connections-
This element is used to specify EJB client connections. It can contain any number of
connectionelements.
connectionThis element is used to specify an EJB client connection. It can optionally contain an
interceptorselement. It has the following attribute.Expand Attribute Name Attribute Description uri
The destination URI for the connection. This attribute is required.
interceptors-
This element is used to specify EJB client interceptors and can contain any number of
interceptorelements.
Example EJB Client Configuration in the wildfly-config.xml File
The following is an example that configures the EJB client connections, global interceptors, and invocation timeout using the jboss-ejb-client element in the wildfly-config.xml file.
18.1.3. HTTP Client Configuration Using the wildfly-config.xml File
The following is an example of how to configure HTTP clients using the wildfly-config.xml file.
HTTP client configuration using the wildfly-config.xml file is provided as Technology Preview only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs), might not be functionally complete, and Red Hat does not recommend to use them for production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
See Technology Preview Features Support Scope on the Red Hat Customer Portal for information about the support scope for Technology Preview features.
18.1.4. Remoting Client Configuration Using the wildfly-config.xml File
You can use the endpoint element, which is in the urn:jboss-remoting:5.0 namespace, to configure a remoting client using the wildfly-config.xml file. This section describes how to configure a remoting client using this element.
endpoint Elements and Attributes
The endpoint element can optionally contain the following two top level child elements, along with their child elements.
It also has the following attribute:
| Attribute Name | Attribute Description |
|---|---|
| name | The endpoint name. This attribute is optional. If not provided, an endpoint name is derived from the system’s host name, if possible. |
providers-
This optional element specifies transport providers for the remote endpoint. It can contain any number of
providerelements.
providerThis element defines a remote transport provider. It has the following attributes.
Expand Attribute Name Attribute Description scheme
The primary URI scheme that corresponds to this provider. This attribute is required.
aliases
The space-separated list of of other URI scheme names that are also recognized for this provider. This attribute is optional.
module
The name of the module that contains the provider implementation. This attribute is optional. If not provided, the class loader that loads JBoss Remoting searches for the provider class.
class
The name of the class that implements the transport provider. This attribute is optional. If not provided, the
java.util.ServiceLoaderfacility is used to search for the provider class.
connections-
This optional element specifies connections for the remote endpoint. It can contain any number of
connectionelements.
connectionThis element defines a connection for the remote endpoint. It has the following attributes.
Expand Attribute Name Attribute Description destination
The destination URI for the endpoint. This attribute is required.
read-timeout
The timeout, in seconds, for read operations on the corresponding socket. This attribute is optional; however, it should be provided only if a
heartbeat-intervalis defined.write-timeout
The timeout, in seconds, for a write operation. This attribute is optional; however, it should be provided only if a
heartbeat-intervalis defined.ip-traffic-class
Defines the numeric IP traffic class to use for this connection’s traffic. This attribute is optional.
tcp-keepalive
Boolean setting that determines whether to use TCP keepalive. This attribute is optional.
heartbeat-interval
The interval, in milliseconds, to use when checking for a connection heartbeat. This attribute is optional.
Example Remoting Client Configuration in the wildfly-config.xml File
The following is an example that configures a remoting client using the wildfly-config.xml file.
18.1.5. Default XNIO Worker Configuration Using the wildfly-config.xml File
You can use the worker element, which is in the urn:xnio:3.5 namespace, to configure an XNIO worker using the wildfly-config.xml file. This section describes how to configure an XNIO worker client using this element.
worker Elements and Attributes
The worker element can optionally contain the following top level child elements, along with their child elements:
daemon-threadsThis optional element specifies whether worker and task threads should be daemon threads. This element has no content. It has the following attribute.
Expand Attribute Name Attribute Description value
A boolean value that specifies whether worker and task threads should be daemon threads. A value of
trueindicates that worker and task threads should be daemon threads. A value offalseindicates that they should not be daemon threads. This attribute is required.If this element is not provided, a value of
trueis assumed.
worker-nameThis element defines the name of the worker. The worker name appears in thread dumps and in JMX. This element has no content. It has the following attribute.
Expand Attribute Name Attribute Description value
The name of the worker. This attribute is required.
pool-sizeThis optional element defines the maximum size of the worker’s task thread pool. This element has no content. It has the following attribute.
Expand Attribute Name Attribute Description max-threads
A positive integer that specifies the maximum number of threads that should be created. This attribute is required.
io-threadsThis optional element determines how many I/O selector threads should be maintained. Generally this number should be a small constant that is a multiple of the number of available cores. It has the following attribute.
Expand Attribute Name Attribute Description value
A positive integer that specifies the number of I/O threads. This attribute is required.
stack-sizeThis optional element establishes the desired minimum thread stack size for worker threads. This element should only be defined in very specialized situations where density is at a premium. It has the following attribute.
Expand Attribute Name Attribute Description value
A positive integer that specifies the requested stack size, in bytes. This attribute is required.
outbound-bind-addresses-
This optional element specifies the bind addresses to use for outbound connections. Each bind address mapping consists of a destination IP address block, and a bind address and optional port number to use for connections to destinations within that block. It can contain any number of
bind-addresselements.
bind-addressThis optional element defines an individual bind address mapping. It has the following attributes.
Expand Attribute Name Attribute Description match
The IP address block, in CIDR notation, to match.
bind-address
The IP address to bind to if the address block matches. This attribute is required.
bind-port
The port number to bind to if the address block matches. This value defauts to
0, meaning it binds to any port. This attribute is optional.
Example XNIO Worker Configuration in the wildfly-config.xml File
The following is an example of how to configure the default XNIO worker using the wildfly-config.xml file.
Appendix A. Reference Material
A.1. Provided Undertow Handlers
For the complete list of handlers, you must check the source JAR file of the Undertow core in the version that matches the Undertow core in your JBoss EAP installation. You can download the Undertow core source JAR file from the JBoss EAP Maven Repository, and then refer to the available handlers in the /io/undertow/server/handlers/ directory.
You can verify the Undertow core version used in your current installation of JBoss EAP by searching the server.log file for the INFO message that is printed during JBoss EAP server startup, similar to the one shown in the example below:
INFO [org.wildfly.extension.undertow] (MSC service thread 1-1) WFLYUT0003: Undertow 1.4.18.Final-redhat-1 starting
INFO [org.wildfly.extension.undertow] (MSC service thread 1-1) WFLYUT0003: Undertow 1.4.18.Final-redhat-1 startingAccessControlListHandler
Class Name: io.undertow.server.handlers.AccessControlListHandler
Name: access-control
Handler that can accept or reject a request based on an attribute of the remote peer.
| Name | Description |
|---|---|
| acl | ACL rules. This parameter is required. |
| attribute | Exchange attribute string. This parameter is required. |
| default-allow |
Boolean specifying whether handler accepts or rejects a request by default. Defaults to |
AccessLogHandler
Class Name: io.undertow.server.handlers.accesslog.AccessLogHandler
Name: access-log
Access log handler. This handler generates access log messages based on the provided format string and pass these messages into the provided AccessLogReceiver.
This handler can log any attribute that is provides via the ExchangeAttribute mechanism.
This factory produces token handlers for the following patterns.
| Pattern | Description |
|---|---|
| %a | Remote IP address |
| %A | Local IP address |
| %b |
Bytes sent, excluding HTTP headers or |
| %B | Bytes sent, excluding HTTP headers |
| %h | Remote host name |
| %H | Request protocol |
| %l |
Remote logical username from |
| %m | Request method |
| %p | Local port |
| %q |
Query string (excluding the |
| %r | First line of the request |
| %s | HTTP status code of the response |
| %t | Date and time, in Common Log Format format |
| %u | Remote user that was authenticated |
| %U | Requested URL path |
| %v | Local server name |
| %D | Time taken to process the request, in milliseconds |
| %T | Time taken to process the request, in seconds |
| %I | Current Request thread name (can compare later with stack traces) |
| common |
|
| combined |
|
There is also support to write information from the cookie, incoming header, or the session.
It is modeled after the Apache syntax:
-
%{i,xxx}for incoming headers -
%{o,xxx}for outgoing response headers -
%{c,xxx}for a specific cookie -
%{r,xxx}wherexxxis an attribute in theServletRequest -
%{s,xxx}wherexxxis an attribute in theHttpSession
| Name | Description |
|---|---|
| format | Format used to generate the log messages. This is the default parameter. |
AllowedMethodsHandler
Handler that whitelists certain HTTP methods. Only requests with a method in the allowed methods set are allowed to continue.
Class Name: io.undertow.server.handlers.AllowedMethodsHandler
Name: allowed-methods
| Name | Description |
|---|---|
| methods |
Methods to allow, for example |
BlockingHandler
An HttpHandler that initiates a blocking request. If the thread is currently running in the I/O thread it is dispatched.
Class Name: io.undertow.server.handlers.BlockingHandler
Name: blocking
This handler has no parameters.
ByteRangeHandler
Handler for range requests. This is a generic handler that can handle range requests to any resource of a fixed content length, for example, any resource where the content-length header has been set. This is not necessarily the most efficient way to handle range requests, as the full content is generated and then discarded. At present this handler can only handle simple, single range requests. If multiple ranges are requested the Range header is ignored.
Class Name: io.undertow.server.handlers.ByteRangeHandler
Name: byte-range
| Name | Description |
|---|---|
| send-accept-ranges | Boolean value on whether or not to send accept ranges. This is the default parameter. |
CanonicalPathHandler
This handler transforms a relative path to a canonical path.
Class Name: io.undertow.server.handlers.CanonicalPathHandler
Name: canonical-path
This handler has no parameters.
DisableCacheHandler
Handler that disables response caching by browsers and proxies.
Class Name: io.undertow.server.handlers.DisableCacheHandler
Name: disable-cache
This handler has no parameters.
DisallowedMethodsHandler
Handler that blacklists certain HTTP methods.
Class Name: io.undertow.server.handlers.DisallowedMethodsHandler
Name: disallowed-methods
| Name | Description |
|---|---|
| methods |
Methods to disallow, for example |
EncodingHandler
This handler serves as the basis for content encoding implementations. Encoding handlers are added as delegates to this handler, with a specified server side priority.
The q value will be used to determine the correct handler. If a request comes in with no q value then the server picks the handler with the highest priority as the encoding to use.
If no handler matches then the identity encoding is assumed. If the identity encoding has been specifically disallowed due to a q value of 0 then the handler sets the response code 406 (Not Acceptable) and returns.
Class Name: io.undertow.server.handlers.encoding.EncodingHandler
Name: compress
This handler has no parameters.
FileErrorPageHandler
Handler that serves up a file from disk to serve as an error page. This handler does not serve up any response codes by default, you must configure the response codes it responds to.
Class Name: io.undertow.server.handlers.error.FileErrorPageHandler
Name: error-file
| Name | Description |
|---|---|
| file | Location of file to serve up as an error page. |
| response-codes | List of response codes that result in a redirect to the defined error page file. |
HttpTraceHandler
A handler that handles HTTP trace requests.
Class Name: io.undertow.server.handlers.HttpTraceHandler
Name: trace
This handler has no parameters.
IPAddressAccessControlHandler
Handler that can accept or reject a request based on the IP address of the remote peer.
Class Name: io.undertow.server.handlers.IPAddressAccessControlHandler
Name: ip-access-control
| Name | Description |
|---|---|
| acl | String representing the access control list. This is the default parameter. |
| failure-status | Integer representing the status code to return on rejected requests. |
| default-allow | Boolean representing whether or not to allow by default. |
JDBCLogHandler
Class Name: io.undertow.server.handlers.JDBCLogHandler
Name: jdbc-access-log
| Name | Description |
|---|---|
| format |
Specifies the JDBC Log pattern. Default value is |
| datasource | Name of the datasource to log. This parameter is required and is the default parameter. |
| tableName | Table name. |
| remoteHostField | Remote Host address. |
| userField | Username. |
| timestampField | Timestamp. |
| virtualHostField | VirtualHost. |
| methodField | Method. |
| queryField | Query. |
| statusField | Status. |
| bytesField | Bytes. |
| refererField | Referrer. |
| userAgentField | UserAgent. |
LearningPushHandler
Handler that builds up a cache of resources that a browser requests, and uses server push to push them when supported.
Class Name: io.undertow.server.handlers.LearningPushHandler
Name: learning-push
| Name | Description |
|---|---|
| max-age | Integer representing the maximum time of a cache entry. |
| max-entries | Integer representing the maximum number of cache entries |
LocalNameResolvingHandler
A handler that performs DNS lookup to resolve a local address. Unresolved local address can be created when a front end server has sent a X-forwarded-host header or AJP is in use.
Class Name: io.undertow.server.handlers.LocalNameResolvingHandler
Name: resolve-local-name
This handler has no parameters.
PathSeparatorHandler
A handler that translates non-slash separator characters in the URL into a slash. In general this will translate backslash into slash on Windows systems.
Class Name: io.undertow.server.handlers.PathSeparatorHandler
Name: path-separator
This handler has no parameters.
PeerNameResolvingHandler
A handler that performs reverse DNS lookup to resolve a peer address.
Class Name: io.undertow.server.handlers.PeerNameResolvingHandler
Name: resolve-peer-name
This handler has no parameters.
ProxyPeerAddressHandler
Handler that sets the peer address to the value of the X-Forwarded-For header. This should only be used behind a proxy that always sets this header, otherwise it is possible for an attacker to forge their peer address.
Class Name: io.undertow.server.handlers.ProxyPeerAddressHandler
Name: proxy-peer-address
This handler has no parameters.
RedirectHandler
A redirect handler that redirects to the specified location via a 302 redirect. The location is specified as an exchange attribute string.
Class Name: io.undertow.server.handlers.RedirectHandler
Name: redirect
| Name | Description |
|---|---|
| value | Destination for the redirect. This is the default parameter. |
RequestBufferingHandler
Handler that buffers all request data.
Class Name: io.undertow.server.handlers.RequestBufferingHandler
Name: buffer-request
| Name | Description |
|---|---|
| buffers | Integer that defines the maximum number of buffers. This is the default parameter. |
RequestDumpingHandler
Handler that dumps an exchange to a log.
Class Name: io.undertow.server.handlers.RequestDumpingHandler
Name: dump-request
This handler has no parameters.
RequestLimitingHandler
A handler that limits the maximum number of concurrent requests. Requests beyond the limit will block until the previous request is complete.
Class Name: io.undertow.server.handlers.RequestLimitingHandler
Name: request-limit
| Name | Description |
|---|---|
| requests | Integer that represents the maximum number of concurrent requests. This is the default parameter and is required. |
ResourceHandler
A handler for serving resources.
Class Name: io.undertow.server.handlers.resource.ResourceHandler
Name: resource
| Name | Description |
|---|---|
| location | Location of resources. This is the default parameter and is required. |
| allow-listing | Boolean value to determine whether or not to allow directory listings. |
ResponseRateLimitingHandler
Handler that limits the download rate to a set number of bytes/time.
Class Name: io.undertow.server.handlers.ResponseRateLimitingHandler
Name: response-rate-limit
| Name | Description |
|---|---|
| bytes | Number of bytes to limit the download rate. This parameter is required. |
| time | Time in seconds to limit the download rate. This parameter is required. |
SetHeaderHandler
A handler that sets a fixed response header.
Class Name: io.undertow.server.handlers.SetHeaderHandler
Name: header
| Name | Description |
|---|---|
| header | Name of header attribute. This parameter is required. |
| value | Value of header attribute. This parameter is required. |
SSLHeaderHandler
Handler that sets SSL information on the connection based on the following headers:
- SSL_CLIENT_CERT
- SSL_CIPHER
- SSL_SESSION_ID
If this handler is present in the chain it always overrides the SSL session information, even if these headers are not present.
This handler must only be used on servers that are behind a reverse proxy, where the reverse proxy has been configured to always set these headers for every request or to strip existing headers with these names if no SSL information is present. Otherwise it might be possible for a malicious client to spoof an SSL connection.
Class Name: io.undertow.server.handlers.SSLHeaderHandler
Name: ssl-headers
This handler has no parameters.
StuckThreadDetectionHandler
This handler detects requests that take a long time to process, which might indicate that the thread that is processing it is stuck.
Class Name: io.undertow.server.handlers.StuckThreadDetectionHandler
Name: stuck-thread-detector
| Name | Description |
|---|---|
| threshhold |
Integer value in seconds that determines the threshold for how long a request should take to process. Default value is |
URLDecodingHandler
A handler that decodes the URL and query parameters to the specified charset. If you are using this handler you must set the UndertowOptions.DECODE_URL parameter to false.
This is not as efficient as using the parser’s built in UTF-8 decoder. Unless you need to decode to something other than UTF-8 you should rely on the parsers decoding instead.
Class Name: io.undertow.server.handlers.URLDecodingHandler
Name: url-decoding
| Name | Description |
|---|---|
| charset | Charset to decode. This is the default parameter and it is required. |
A.2. Persistence Unit Properties
Persistence unit definition supports the following properties, which can be configured from the persistence.xml file.
| Property | Description |
|---|---|
| jboss.as.jpa.providerModule |
Name of the persistence provider module. Default is |
| jboss.as.jpa.adapterModule | Name of the integration classes that help JBoss EAP to work with the persistence provider. |
| jboss.as.jpa.adapterClass | Class name of the integration adapter. |
| jboss.as.jpa.managed |
Set to |
| jboss.as.jpa.classtransformer |
Set to
Hibernate also needs persistence unit property |
| jboss.as.jpa.scopedname |
Specify the qualified application-scoped persistence unit name to be used. By default, this is set to the application name and persistence unit name, collectively. The |
| jboss.as.jpa.deferdetach |
Controls whether transaction-scoped persistence context used in non-JTA transaction thread, will detach loaded entities after each |
| wildfly.jpa.default-unit |
Set to |
| wildfly.jpa.twophasebootstrap |
Persistence providers allow a two-phase persistence unit bootstrap, which improves JPA integration with CDI. Setting the |
| wildfly.jpa.allowdefaultdatasourceuse |
Set to |
| wildfly.jpa.hibernate.search.module |
Controls which version of Hibernate Search to include on the classpath. The default is |
A.3. Policy Provider Properties
| Property | Description |
|---|---|
| custom-policy | A custom policy provider definition. |
| jacc-policy | A policy provider definition that sets up JACC and related services. |
| Property | Description |
|---|---|
| class-name |
The name of a |
| module | The name of the module to load the provider from. |
| Property | Description |
|---|---|
| policy |
The name of a |
| configuration-factory |
The name of a |
| module | The name of the module to load the provider from. |
Revised on 2018-10-11 12:31:33 UTC