Chapter 18. Availability
One of the most basic elements for monitoring is knowing whether your server or application is running. Availability monitoring tells administrators that a certain process is running and minimally responsive.
18.1. Core "Up and Down" Monitoring
Copy linkLink copied to clipboard!
The first question with monitoring is is the resource running? A resource's availability is the first thing to check for overall performance, for determining service levels, and for maintaining infrastructure.
Availability (sometimes called up or down monitoring) determines whether a resource is up or whether it is in some other state.
Up means that the resource is running and that it responds to the agent within a prescribed time.
How availability is determined depends on the resource; it could be checking a process ID or a JVM or something else. Availability for a resource type is defined in its plug-in descriptor. Therefore, the plug-in container is the intermediary between the resource and the agent. The agent checks the plug-in container for resource availability; the container obtains it from the resource component.
Usually, an availability check takes a fraction of a second; for certain types of resources or in certain environments, it could take longer. There is a timeout period for availability scans, set to five (5) seconds by default. If a resource is running and responds to the availability scan within that five-second window, the resource is up.
Because availability — or "up and down" — monitoring is so critical to IT administrators, availability states in JBoss ON are highly visible. Availability is displayed on resource details pages, in every list of resources, in groups, and in monitoring reports. The idea is that it should only take a glance to be able to determine whether your resource is up.
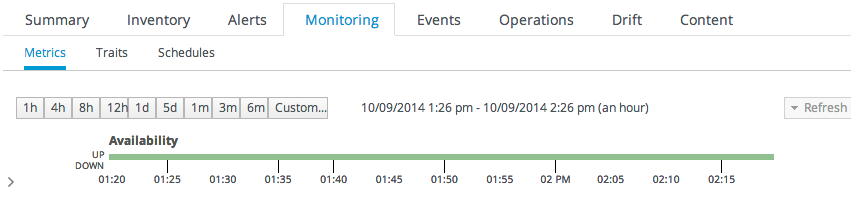
Figure 18.1. Resource Availability

Even though availability is not a true monitoring metric, the Monitoring > Metrics page even shows the percentage of time, within the display time period, that the resource has been in an up state. This is because availability (and concomitant uptime) impacts every other metric collected by the agent.
Figure 18.2. Availability Uptime Percentage
Note
Often, if a resource shows down availability even when it is running, it is a problem with the connection settings. The agent may not have information it requires, such as a username or new port number, that it requires to connect to the resource. Since the agent cannot connect to the resource, it assumes it is down.
18.1.1. Long Scan Times and Async Availability Collection
Copy linkLink copied to clipboard!
Availability scans are performed by a resource plug-in itself, for its defined resource types, and then reported to the plug-in container.
Availability checks are typically very fast, fractions of a second, but there can be situations where an availability check takes longer. The plug-in container limits how long an availability check can run to five seconds, to prevent a rogue plug-in from delaying availability reporting for all other resources managed by the agent.
There can be instances where a certain plug-in or resource type consistently has scans longer than the five-second timeout period.
For custom plug-ins, plug-in writers can configure asynchronous availability checking. Basically, with async availability checks, the resource component creates its own, independent thread to run availability checks. Within that thread, the availability checks can take as long as they need to complete. The availability checks can also be run fairly frequently, every minute by default, to make sure that the availability state is current, even if the full check takes longer to complete.
The component caches and then reports the most recent availability result to the plug-in container. That stored last availability can be delivered very quickly, in the fractions of a second that the plug-in container expects.
Async availability checks are implemented through the
AvailabilityCollectorRunnable class in the JBoss ON plug-in API. Details for this class are available in the Plug-in API and Writing Custom Plug-ins Guides.
Note
It is also possible to address long availability check times by extending the scan timeout period in the agent configuration itself. For example, add a new timeout period to the ADDITIONAL_JAVA_OPTIONS parameters in the
rhq-agent-env.sh file:
RHQ_AGENT_ADDITIONAL_JAVA_OPTS="$RHQ_AGENT_ADDITIONAL_JAVA_OPTS -Drhq.agent.plugins.availability-scan.timeout=15000"
However, that timeout period applies to the entire plug-in container, not just one specific, slow-running plug-in. If there are several plug-ins that are running sluggish availability checks, then the availability report may take too long to complete, causing the agent to delay or even miss sending availability reports to the JBoss ON server.
Generally, it is preferable to configure async availability on a custom plug-in, rather than trying to reset the scan interval for all plug-ins.
18.1.2. Synchronous Availability
Copy linkLink copied to clipboard!
Availability scans are run on defined schedules, anywhere from every minute to every 20 minutes by default. This means that most availability data is asynchronous — it is displayed in the availability timeline, in reports, and in most of the UI based on the most recent (but not necessarily current) value.
There is one way to get synchronous, near-real time availability information: by viewing the resource's Monitoring tab. As long as the Monitoring tab is open, the availability reading is checked every 15 seconds, rather than their configured collection schedule. This is as close as possible to real-time availability information.
Note
This altered schedule for collecting availability could impact dampening rules for any alerts for a resource.
For example, if availability is scheduled to be checked every 10 minutes with dampening set to fire an alert after three (3) occurrances of a certain state, then an alert could fire after less than a minute if a certain state is read — even though the intent of the alert is to fire only after half an hour of the condition persisting.
18.1.3. Availability States
Copy linkLink copied to clipboard!
There is a gray area between up and not up. While a resource may not be up, it may be not up for different reasons. For instance, an agent could have been restarted, so no resource states are known. Or a resource may have been taken offline for maintenance, so no availability reports are being sent.
The different resource states are listed in Table 18.1, “Availability States”.
| State | Description | Icon |
|---|---|---|
| Available (UP) | The resource is running and responding to availability status checks. | 
|
| Down | The resource is not responding to availability checks. | 
|
| Unknown | The agent does not have a record of the resource's state. This could be because the resource has been newly added to the inventory and has not had its first availability check or because the agent is down. | 
|
| Disabled | The resource has been administratively marked as unavailable. The resource (in reality) could be running or stopped. Disabling a resource means that the server ignores the availability reports from the agent to prevent unnecessary alerts based on a (known) down or cycling state. | 
|
|
Mixed (For groups only.) [a]
| The resources in a group have different availability states. | 
|
[a]
A similar warning sign can be displayed next to the resource availability at the top of the resource details page. That warning indicates that an error message or suspect metric has been returned for that resource, not that the resource's availability is in a warning state.
| ||
18.1.4. Parent-Child States and Backfilling
Copy linkLink copied to clipboard!
Availability is assessed from the top of the resource tree downward. For example, if an application server is down, it is safe to assume that all of its dependent webapp children are also down.
This is called backfilling. The parent's state is propagated to its children without running additional availability scans for each child. Backfilling can set children to down, unknown, or disabled states.
In some cases, backfilling even includes up states. Some dependent child resources (low priority services that only run if the parent is running) may not even have their own availability assessed independently by default. When a child's availability checking is disabled, the child presumptively uses its parent's state. If the parent is up, those children are assumed to be up.
There is one slight variation on backfilling — if a platform is marked as down. A platform being down is the same as the agent being down. It means that the agent has not reported to the server. There could be a number of reasons for that, apart from any servers or services actually being offline. In this case, the platform (functionally, the agent) is set to down, but its children are set to unknown.
18.1.5. Collection Intervals and Agent Scan Periods
Copy linkLink copied to clipboard!
As alluded to, an availability reading is not the same as a metric collection. There are some superficial similarities, mainly in that they both are collected on schedules and that they both relate to resource performance.
Internally, availability and metrics are treated differently. Availability is called through different functions and reported separately, and, more important, availability reports are prioritized higher than other reports sent by the agent, including monitoring reports.
While availability reports are sent as first priority messages, resources themselves have different priorities for availability scans. Higher priority (more critical) resources are, by default, checked for availability more frequently:
- An agent heartbeat ping (analogous to the platform's availability) is sent to the server every minute.
- Server availability is checked every minute.
- Service availability is checked every 10 minutes.
The agent itself runs an availability scan at 30-second intervals. Not every resource is checked with every scan. When the agent scan runs, only those resources scheduled to be checked are checked. So, there are functionally two availability schedules working together in tandem, the agent scan interval and the resource collection schedule. For example, if a server is configured with a 60-second interval for availability checks and the agent scan period is 30 seconds, the server is eligible to be checked every two scans. That means that the server is checked roughly every 60 seconds, but that is a best effort estimate; if the agent is under a heavy load or if there are a large number of resources, the agent may run its scans longer than every 30 seconds, so the actual interval between checks for a specific resource would be longer.
The agent only sends an availability report to the server if there is an availability state change for one of its managed resources.
If an agent goes down suddenly, it shows a down state within five minutes, the (default) agent quiet period. If the agent shuts down gracefully, the JBoss ON server recognizes the state change within about a minute. Once the server recognizes the agent is down, it begins backfilling the states of all of the resources in that agent's inventory (Section 18.1.4, “Parent-Child States and Backfilling”).
Down servers typically record a down state between one and two minutes after going down. This is not exactly real-time, but it is close enough for most infrastructure to be able to establish a reliable baseline of performance and even calculate service levels and uptime. A short window of 90 seconds can catch most resource cycling.
The default agent scan interval is 30 seconds, but, depending on a resource schedule, it could be over 10 minutes before some services are detected as down. If an administrator suspects that there has been a state change, it is possible to force an immediate availability scan for all resources for the agent through the interactive agent prompt:
> avail -- force
Using simply the avail command runs the check for the next scheduled resources, not all resources.
Additionally, resource plug-ins can be written so that any operation which could cause a state change (such as start, stop, and restart operations) automatically requests an availability check for the resource when the operation ends.