Managing OpenShift Container Storage
Instructions for cluster and storage administrators
Abstract
Chapter 1. Overview
Managing OpenShift Container Storage is written to help administrators understand how to manage and administer their Red Hat OpenShift Container Storage cluster.
Most management tasks focus on a single resource. This document is divided into chapters based on the resource that an administrator is trying to modify:
- Chapter 2, Configure storage for OpenShift Container Platform services shows you how to use OpenShift Container Storage for core OpenShift Container Platform services.
- Chapter 3, Backing OpenShift Container Platform applications with OpenShift Container Storage provides information about how to configure OpenShift Container Platform applications to use OpenShift Container Storage.
- Chapter 4, Scaling storage nodes provides information about scaling storage capacity of OpenShift Container Storage nodes.
- Chapter 5, Managing Persistent Volume Claims provides information about managing Persistent Volume Claim requests, and automating the fulfillment of those requests.
- Chapter 6, Managing container storage interface (CSI) component placements provides information about setting tolerations to bring up container storage interface component on the nodes.
- Chapter 7, Multicloud Object Gateway provides information about the Multicloud Object Gateway.
- Chapter 9, Replacing storage nodes for OpenShift Container Storage shows you how to replace an operational or failed node on AWS UPI, AWS IPI, and VMware UPI for OpenShift Container Storage.
- Chapter 10, Replacing a storage device provides instructions for replacing a device for OpenShift Container Storage deployed dynamically of VMware infrastructure and OpenShift Container Storage deployed using local storage devices.
- Chapter 11, Updating OpenShift Container Storage provides instructions for upgrading your OpenShift Container Storage cluster.
Chapter 2. Configure storage for OpenShift Container Platform services
You can use OpenShift Container Storage to provide storage for OpenShift Container Platform services such as image registry, monitoring, and logging.
The process for configuring storage for these services depends on the infrastructure used in your OpenShift Container Storage deployment.
Always ensure that you have plenty of storage capacity for these services. If the storage for these critical services runs out of space, the cluster becomes inoperable and very difficult to recover.
Red Hat recommends configuring shorter curation and retention intervals for these services. See Configuring the Curator schedule and the Modifying retention time for Prometheus metrics data sub section of Configuring persistent storage in the OpenShift Container Platform documentation for details.
If you do run out of storage space for these services, contact Red Hat Customer Support.
2.1. Configuring Image Registry to use OpenShift Container Storage
OpenShift Container Platform provides a built in Container Image Registry which runs as a standard workload on the cluster. A registry is typically used as a publication target for images built on the cluster as well as a source of images for workloads running on the cluster.
Follow the instructions in this section to configure OpenShift Container Storage as storage for the Container Image Registry. On AWS, it is not required to change the storage for the registry. However, it is recommended to change the storage to OpenShift Container Storage Persistent Volume for vSphere and Baremetal platforms.
This process does not migrate data from an existing image registry to the new image registry. If you already have container images in your existing registry, back up your registry before you complete this process, and re-register your images when this process is complete.
Prerequisites
- You have administrative access to OpenShift Web Console.
-
OpenShift Container Storage Operator is installed and running in the
openshift-storagenamespace. In OpenShift Web Console, click Operators → Installed Operators to view installed operators. -
Image Registry Operator is installed and running in the
openshift-image-registrynamespace. In OpenShift Web Console, click Administration → Cluster Settings → Cluster Operators to view cluster operators. -
A storage class with provisioner
openshift-storage.cephfs.csi.ceph.comis available. In OpenShift Web Console, click Storage → Storage Classes to view available storage classes.
Procedure
Create a Persistent Volume Claim for the Image Registry to use.
- In OpenShift Web Console, click Storage → Persistent Volume Claims.
-
Set the Project to
openshift-image-registry. Click Create Persistent Volume Claim.
-
From the list of available storage classes retrieved above, specify the Storage Class with the provisioner
openshift-storage.cephfs.csi.ceph.com. -
Specify the Persistent Volume Claim Name, for example,
ocs4registry. -
Specify an Access Mode of
Shared Access (RWX). - Specify a Size of at least 100 GB.
Click Create.
Wait until the status of the new Persistent Volume Claim is listed as
Bound.
-
From the list of available storage classes retrieved above, specify the Storage Class with the provisioner
Configure the cluster’s Image Registry to use the new Persistent Volume Claim.
- Click Administration →Custom Resource Definitions.
-
Click the
Configcustom resource definition associated with theimageregistry.operator.openshift.iogroup. - Click the Instances tab.
- Beside the cluster instance, click the Action Menu (⋮) → Edit Config.
Add the new Persistent Volume Claim as persistent storage for the Image Registry.
Add the following under
spec:, replacing the existingstorage:section if necessary.storage: pvc: claim: <new-pvc-name>For example:
storage: pvc: claim: ocs4registry- Click Save.
Verify that the new configuration is being used.
- Click Workloads → Pods.
-
Set the Project to
openshift-image-registry. -
Verify that the new
image-registry-*pod appears with a status ofRunning, and that the previousimage-registry-*pod terminates. -
Click the new
image-registry-*pod to view pod details. -
Scroll down to Volumes and verify that the
registry-storagevolume has a Type that matches your new Persistent Volume Claim, for example,ocs4registry.
2.2. Configuring monitoring to use OpenShift Container Storage
OpenShift Container Storage provides a monitoring stack that is comprised of Prometheus and AlertManager.
Follow the instructions in this section to configure OpenShift Container Storage as storage for the monitoring stack.
Monitoring will not function if it runs out of storage space. Always ensure that you have plenty of storage capacity for monitoring.
Red Hat recommends configuring a short retention intervals for this service. See the Modifying retention time for Prometheus metrics data sub section of Configuring persistent storage in the OpenShift Container Platform documentation for details.
Prerequisites
- You have administrative access to OpenShift Web Console.
-
OpenShift Container Storage Operator is installed and running in the
openshift-storagenamespace. In OpenShift Web Console, click Operators → Installed Operators to view installed operators. -
Monitoring Operator is installed and running in the
openshift-monitoringnamespace. In OpenShift Web Console, click Administration → Cluster Settings → Cluster Operators to view cluster operators. -
A storage class with provisioner
openshift-storage.rbd.csi.ceph.comis available. In OpenShift Web Console, click Storage → Storage Classes to view available storage classes.
Procedure
- In OpenShift Web Console, go to Workloads → Config Maps.
-
Set the Project dropdown to
openshift-monitoring. - Click Create Config Map.
Define a new
cluster-monitoring-configConfig Map using the following example.Replace the content in angle brackets (
<,>) with your own values, for example,retention: 24horstorage: 40Gi.Replace the storageClassName with the
storageclassthat uses the provisioneropenshift-storage.rbd.csi.ceph.com. In the example given below the name of the storageclass isocs-storagecluster-ceph-rbd.Example
cluster-monitoring-configConfig MapapiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: retention: <time to retain monitoring files, e.g. 24h> volumeClaimTemplate: metadata: name: ocs-prometheus-claim spec: storageClassName: ocs-storagecluster-ceph-rbd resources: requests: storage: <size of claim, e.g. 40Gi> alertmanagerMain: volumeClaimTemplate: metadata: name: ocs-alertmanager-claim spec: storageClassName: ocs-storagecluster-ceph-rbd resources: requests: storage: <size of claim, e.g. 40Gi>- Click Create to save and create the Config Map.
Verification steps
Verify that the Persistent Volume Claims are bound to the pods.
- Go to Storage → Persistent Volume Claims.
-
Set the Project dropdown to
openshift-monitoring. Verify that 5 Persistent Volume Claims are visible with a state of
Bound, attached to threealertmanager-main-*pods, and twoprometheus-k8s-*pods.Monitoring storage created and bound
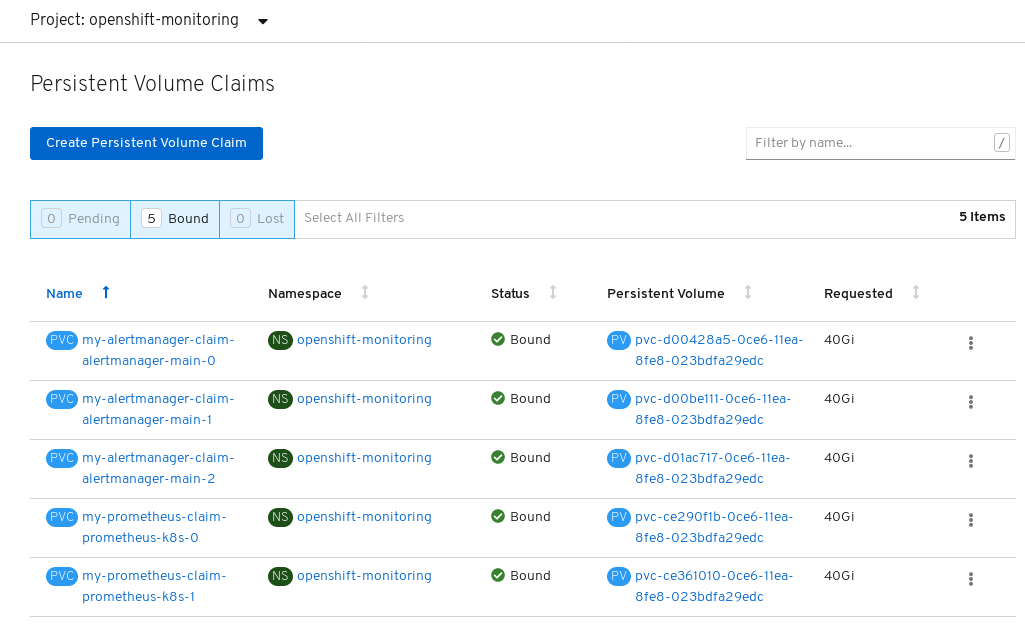
Verify that the new
alertmanager-main-*pods appear with a state ofRunning.-
Click the new
alertmanager-main-*pods to view the pod details. Scroll down to Volumes and verify that the volume has a Type,
ocs-alertmanager-claimthat matches one of your new Persistent Volume Claims, for example,ocs-alertmanager-claim-alertmanager-main-0.Persistent Volume Claims attached to
alertmanager-main-*pod
-
Click the new
Verify that the new
prometheus-k8s-*pods appear with a state ofRunning.-
Click the new
prometheus-k8s-*pods to view the pod details. Scroll down to Volumes and verify that the volume has a Type,
ocs-prometheus-claimthat matches one of your new Persistent Volume Claims, for example,ocs-prometheus-claim-prometheus-k8s-0.Persistent Volume Claims attached to
prometheus-k8s-*pod
-
Click the new
2.3. Cluster logging for OpenShift Container Storage
You can deploy cluster logging to aggregate logs for a range of OpenShift Container Platform services. For information about how to deploy cluster logging, see Deploying cluster logging.
Upon initial OpenShift Container Platform deployment, OpenShift Container Storage is not configured by default and the OpenShift Container Platform cluster will solely rely on default storage available from the nodes. You can edit the default configuration of OpenShift logging (ElasticSearch) to be backed by OpenShift Container Storage to have OpenShift Container Storage backed logging (Elasticsearch).
Always ensure that you have plenty of storage capacity for these services. If you run out of storage space for these critical services, the logging application becomes inoperable and very difficult to recover.
Red Hat recommends configuring shorter curation and retention intervals for these services. See Cluster logging curator in the OpenShift Container Platform documentation for details.
If you run out of storage space for these services, contact Red Hat Customer Support.
2.3.1. Configuring persistent storage
You can configure a persistent storage class and size for the Elasticsearch cluster using the storage class name and size parameters. The Cluster Logging Operator creates a Persistent Volume Claim for each data node in the Elasticsearch cluster based on these parameters. For example:
spec:
logStore:
type: "elasticsearch"
elasticsearch:
nodeCount: 3
storage:
storageClassName: "ocs-storagecluster-ceph-rbd”
size: "200G"
This example specifies that each data node in the cluster will be bound to a Persistent Volume Claim that requests 200GiB of ocs-storagecluster-ceph-rbd storage. Each primary shard will be backed by a single replica. A copy of the shard is replicated across all the nodes and are always available and the copy can be recovered if at least two nodes exist due to the single redundancy policy. For information about Elasticsearch replication policies, see Elasticsearch replication policy in About deploying and configuring cluster logging.
Omission of the storage block will result in a deployment backed by default storage. For example:
spec:
logStore:
type: "elasticsearch"
elasticsearch:
nodeCount: 3
storage: {}For more information, see Configuring cluster logging.
2.3.2. Configuring cluster logging to use OpenShift Container Storage
Follow the instructions in this section to configure OpenShift Container Storage as storage for the OpenShift cluster logging.
You can obtain all the logs when you configure logging for the first time in OpenShift Container Storage. However, after you uninstall and reinstall logging, the old logs are removed and only the new logs are processed.
Prerequisites
- You have administrative access to OpenShift Web Console.
-
OpenShift Container Storage Operator is installed and running in the
openshift-storagenamespace. -
Cluster logging Operator is installed and running in the
openshift-loggingnamespace.
Procedure
- Click Administration → Custom Resource Definitions from the left pane of the OpenShift Web Console.
- On the Custom Resource Definitions page, click ClusterLogging.
- On the Custom Resource Definition Overview page, select View Instances from the Actions menu or click the Instances Tab.
On the Cluster Logging page, click Create Cluster Logging.
You might have to refresh the page to load the data.
In the YAML, replace the storageClassName with the
storageclassthat uses the provisioneropenshift-storage.rbd.csi.ceph.com. In the example given below the name of the storageclass isocs-storagecluster-ceph-rbd:apiVersion: "logging.openshift.io/v1" kind: "ClusterLogging" metadata: name: "instance" namespace: "openshift-logging" spec: managementState: "Managed" logStore: type: "elasticsearch" elasticsearch: nodeCount: 3 storage: storageClassName: ocs-storagecluster-ceph-rbd size: 200G redundancyPolicy: "SingleRedundancy" visualization: type: "kibana" kibana: replicas: 1 curation: type: "curator" curator: schedule: "30 3 * * *" collection: logs: type: "fluentd" fluentd: {}- Click Save.
Verification steps
Verify that the Persistent Volume Claims are bound to the
elasticsearchpods.- Go to Storage → Persistent Volume Claims.
-
Set the Project dropdown to
openshift-logging. Verify that Persistent Volume Claims are visible with a state of
Bound, attached toelasticsearch-* pods.Figure 2.1. Cluster logging created and bound
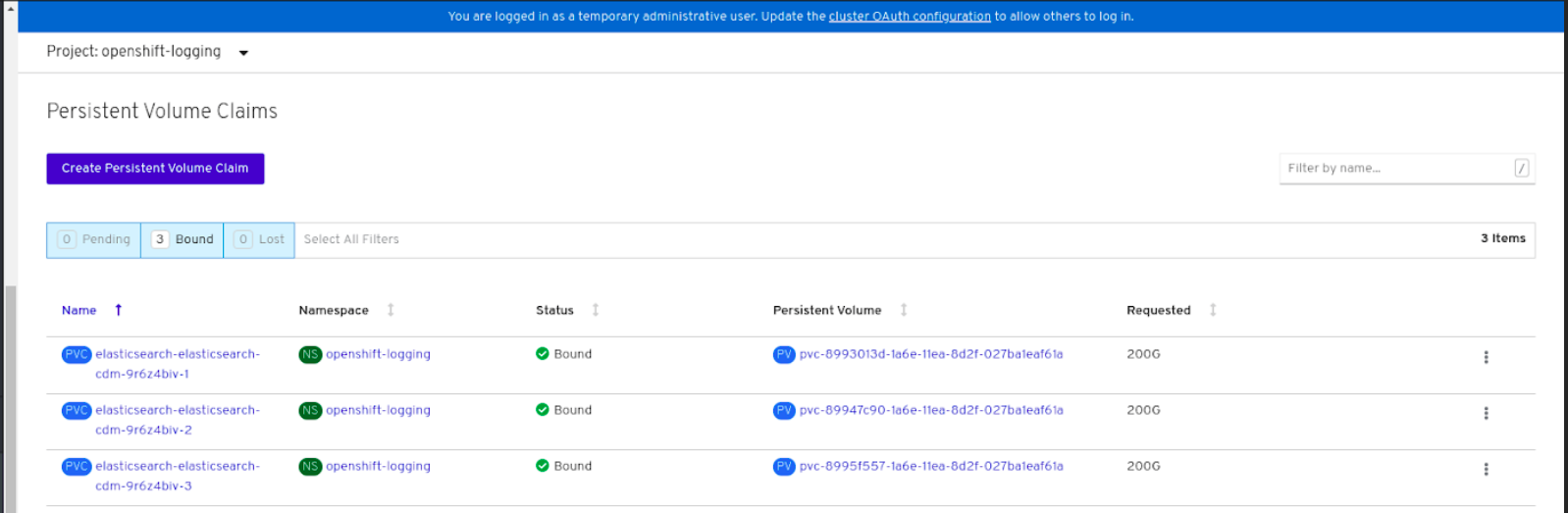
Verify that the new cluster logging is being used.
- Click Workload → Pods.
-
Set the Project to
openshift-logging. -
Verify that the new
elasticsearch-* pods appear with a state ofRunning. -
Click the new
elasticsearch-* pod to view pod details. -
Scroll down to Volumes and verify that the elasticsearch volume has a Type that matches your new Persistent Volume Claim, for example,
elasticsearch-elasticsearch-cdm-9r624biv-3. - Click the Persistent Volume Claim name and verify the storage class name in the PersistenVolumeClaim Overview page.
Make sure to use a shorter curator time to avoid PV full scenario on PVs attached to Elasticsearch pods.
You can configure Curator to delete Elasticsearch data based on retention settings. It is recommended that you set the following default index data retention of 5 days as a default.
config.yaml: |
openshift-storage:
delete:
days: 5For more details, see Curation of Elasticsearch Data.
To uninstall the cluster logging backed by Persistent Volume Claim, use the procedure removing the cluster logging operator from OpenShift Container Storage in the uninstall chapter of the respective deployment guide.
Chapter 3. Backing OpenShift Container Platform applications with OpenShift Container Storage
You cannot directly install OpenShift Container Storage during the OpenShift Container Platform installation. However, you can install OpenShift Container Storage on an existing OpenShift Container Platform by using the Operator Hub and then configure the OpenShift Container Platform applications to be backed by OpenShift Container Storage.
Prerequisites
- OpenShift Container Platform is installed and you have administrative access to OpenShift Web Console.
-
OpenShift Container Storage is installed and running in the
openshift-storagenamespace.
Procedure
In the OpenShift Web Console, perform one of the following:
Click Workloads → Deployments.
In the Deployments page, you can do one of the following:
- Select any existing deployment and click Add Storage option from the Action menu (⋮).
Create a new deployment and then add storage.
- Click Create Deployment to create a new deployment.
-
Edit the
YAMLbased on your requirement to create a deployment. - Click Create.
- Select Add Storage from the Actions drop down menu on the top right of the page.
Click Workloads → Deployment Configs.
In the Deployment Configs page, you can do one of the following:
- Select any existing deployment and click Add Storage option from the Action menu (⋮).
Create a new deployment and then add storage.
- Click Create Deployment Config to create a new deployment.
-
Edit the
YAMLbased on your requirement to create a deployment. - Click Create.
- Select Add Storage from the Actions drop down menu on the top right of the page.
In the Add Storage page, you can choose one of the following options:
- Click the Use existing claim option and select a suitable PVC from the drop down list.
Click the Create new claim option.
-
Select the appropriate
CephFSorRBDstorage class from the Storage Class drop down list. - Provide a name for the Persistent Volume Claim.
Select ReadWriteOnce (RWO) or ReadWriteMany (RWX) access mode.
NoteReadOnlyMany (ROX) is deactivated as it is not supported.
Select the size of the desired storage capacity.
NoteYou cannot resize the storage capacity after the creation of Persistent Volume Claim.
-
Select the appropriate
- Specify the mount path and subpath (if required) for the mount path volume inside the container.
- Click Save.
Verification steps
Depending on your configuration, perform one of the following:
- Click Workloads → Deployments.
- Click Workloads → Deployment Configs.
- Set the Project as required.
- Click the deployment for you which you added storage to view the deployment details.
- Scroll down to Volumes and verify that your deployment has a Type that matches the Persistent Volume Claim that you assigned.
- Click the Persistent Volume Claim name and verify the storage class name in the PersistenVolumeClaim Overview page.
Chapter 4. Scaling storage nodes
To scale the storage capacity of OpenShift Container Storage in internal mode, you can do either of the following:
- Scale up storage nodes - Add storage capacity to the existing Red Hat OpenShift Container Storage worker nodes
- Scale out storage nodes - Add new worker nodes containing storage capacity
For scaling your storage in external mode, see Red Hat Ceph Storage documentation.
4.1. Requirements for scaling storage nodes
Before you proceed to scale the storage nodes, refer to the following sections to understand the node requirements for your specific Red Hat OpenShift Container Storage instance:
- Platform requirements
Storage device requirements
Always ensure that you have plenty of storage capacity.
If storage ever fills completely, it is not possible to add capacity or delete or migrate content away from the storage to free up space. Completely full storage is very difficult to recover.
Capacity alerts are issued when cluster storage capacity reaches 75% (near-full) and 85% (full) of total capacity. Always address capacity warnings promptly, and review your storage regularly to ensure that you do not run out of storage space.
If you do run out of storage space completely, contact Red Hat Customer Support.
4.1.1. Supported Deployments for Red Hat OpenShift Container Storage
User-provisioned infrastructure:
- Amazon Web Services (AWS)
- VMware
- Bare metal
Installer-provisioned infrastructure:
- Amazon Web Services (AWS)
4.2. Scaling up storage capacity
Depending on the type of your deployment, you can choose one of the following procedures to scale up storage capacity.
- For AWS or VMware infrastructures using dynamic or automated provisioning of storage devices, see Section 4.2.1, “Scaling up storage by adding capacity to your OpenShift Container Storage nodes on AWS or VMware infrastructure”
- For bare metal, Amazon EC2 I3, or VMware infrastructures using local storage devices, see Section 4.2.2, “Scaling up storage by adding capacity to your OpenShift Container Storage nodes using local storage devices”
4.2.1. Scaling up storage by adding capacity to your OpenShift Container Storage nodes on AWS or VMware infrastructure
Use this procedure to add storage capacity and performance to your configured Red Hat OpenShift Container Storage worker nodes.
Prerequisites
- A running OpenShift Container Storage Platform
- Administrative privileges on the OpenShift Web Console
Procedure
- Navigate to the OpenShift Web Console.
- Click on Operators on the left navigation bar.
- Select Installed Operators.
In the window, click OpenShift Container Storage Operator:
In the top navigation bar, scroll right and click Storage Cluster tab.
- The visible list should have only one item. Click (⋮) on the far right to extend the options menu.
Select Add Capacity from the options menu.
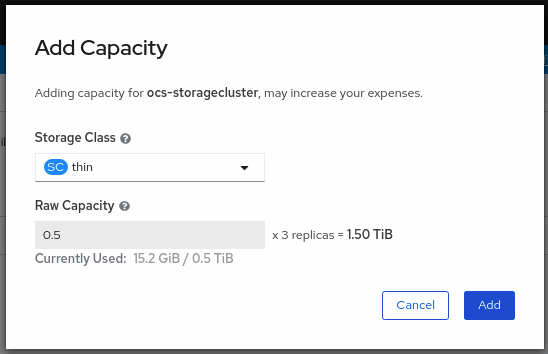
From this dialog box, you can set the requested additional capacity and the storage class. Add capacity will show the capacity selected at the time of installation and will allow to add the capacity only in this increment. On AWS, the storage class should be set to gp2. On VMware, the storage class should be set to thin.
NoteThe effectively provisioned capacity will be three times as much as what you see in the Raw Capacity field because OpenShift Container Storage uses a replica count of 3.
- Once you are done with your setting, click Add. You might need to wait a couple of minutes for the storage cluster to reach Ready state.
Verification steps
Navigate to Overview → Persistent Storage tab, then check the Capacity breakdown card.
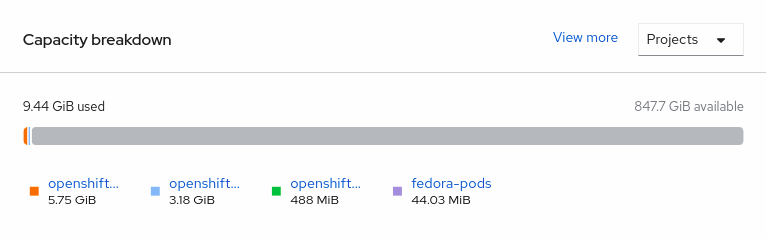
- Note that the capacity increases based on your selections.
As of OpenShift Container Storage 4.2, cluster reduction, whether by reducing OSDs or nodes, is not supported.
4.2.2. Scaling up storage by adding capacity to your OpenShift Container Storage nodes using local storage devices
Use this procedure to add storage capacity (additional storage devices) to your configured local storage based OpenShift Container Storage worker nodes on bare metal, and VMware infrastructures.
Scaling up storage on Amazon EC2 I3 is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
For Amazon EC2 I3 infrastructure, adding nodes is the only option for adding capacity, as deployment is done using both the available NVMe devices.
Prerequisites
- You must be logged into OpenShift Container Platform cluster.
You must have installed local storage operator. Use the following procedures, see
- You must have three OpenShift Container Platform worker nodes with the same storage type and size attached to each node (for example, 2TB NVMe drive) as the original OCS StorageCluster was created with.
Procedure
To add storage capacity to OpenShift Container Platform nodes with OpenShift Container Storage installed, you need to
Find the unique
by-ididentifier for available devices that you want to add, that is, a minimum of one device per worker node. You can follow the procedure for finding available storage devices in the respective deployment guide.NoteMake sure you perform this process for all the existing nodes (minimum of 3) for which you want to add storage.
Add the unique device ID to the
LocalVolumecustom resource (CR).$ oc edit -n local-storage localvolume local-blockExample output:
spec: logLevel: Normal managementState: Managed nodeSelector: nodeSelectorTerms: - matchExpressions: - key: cluster.ocs.openshift.io/openshift-storage operator: In values: - "" storageClassDevices: - devicePaths: - /dev/disk/by-id/nvme-INTEL_SSDPE2KX010T7_PHLF733402P51P0GGN - /dev/disk/by-id/nvme-INTEL_SSDPE2KX010T7_PHLF733402LM1P0GGN - /dev/disk/by-id/nvme-INTEL_SSDPE2KX010T7_PHLF733402M21P0GGN - /dev/disk/by-id/nvme-INTEL_SSDPE2KX010T7_PHLF733402B71P0GGN # newly added device by-id - /dev/disk/by-id/nvme-INTEL_SSDPE2KX010T7_PHLF733402A31P0GGN # newly added device by-id - /dev/disk/by-id/nvme-INTEL_SSDPE2KX010T7_PHLF733402Q71P0GGN # newly added device by-id storageClassName: localblock volumeMode: BlockMake sure to save the changes after editing the CR.
Example output:
localvolume.local.storage.openshift.io/local-block editedYou can see in this CR that new devices using
by-idhave been added. Each new device maps to one NVMe device on the three worker nodes.-
nvme-INTEL_SSDPE2KX010T7_PHLF733402B71P0GGN -
nvme-INTEL_SSDPE2KX010T7_PHLF733402A31P0GGN -
nvme-INTEL_SSDPE2KX010T7_PHLF733402Q71P0GGN
-
Display the newly created PVs with
storageclassname used inlocalVolumeCR.$ oc get pv | grep localblock | grep AvailableExample output:
local-pv-5ee61dcc 931Gi RWO Delete Available localblock 2m35s local-pv-b1fa607a 931Gi RWO Delete Available localblock 2m27s local-pv-e971c51d 931Gi RWO Delete Available localblock 2m22s ...There are three more available PVs of same size which will be used for new OSDs.
- Navigate to the OpenShift Web Console.
- Click on Operators on the left navigation bar.
- Select Installed Operators.
In the window, click OpenShift Container Storage Operator:
In the top navigation bar, scroll right and click Storage Cluster tab.
- The visible list should have only one item. Click (⋮) on the far right to extend the options menu.
Select Add Capacity from the options menu.

From this dialog box, set the Storage Class name to the name used in the
localVolumeCR. Available Capacity displayed is based on the local disks available in storage class.- Once you are done with your setting, click Add. You might need to wait a couple of minutes for the storage cluster to reach Ready state.
Verify that the new OSDs and their corresponding new PVCs are created.
$ oc get -n openshift-storage pods -l app=rook-ceph-osdExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-osd-0-77c4fdb758-qshw4 1/1 Running 0 1h rook-ceph-osd-1-8645c5fbb6-656ks 1/1 Running 0 1h rook-ceph-osd-2-86895b854f-r4gt6 1/1 Running 0 1h rook-ceph-osd-3-dc7f787dd-gdnsz 1/1 Running 0 10m rook-ceph-osd-4-554b5c46dd-hbf9t 1/1 Running 0 10m rook-ceph-osd-5-5cf94c4448-k94j6 1/1 Running 0 10mIn the above example, osd-3, osd-4, and osd-5 are the newly added pods to the OpenShift Container Storage cluster.
$ oc get pvc -n openshift-storage |grep localblockExample output:
ocs-deviceset-0-0-qc29m Bound local-pv-fc5562d3 931Gi RWO localblock 1h ocs-deviceset-0-1-qdmrl Bound local-pv-b1fa607a 931Gi RWO localblock 10m ocs-deviceset-1-0-mpwmk Bound local-pv-58cdd0bc 931Gi RWO localblock 1h ocs-deviceset-1-1-85892 Bound local-pv-e971c51d 931Gi RWO localblock 10m ocs-deviceset-2-0-rll47 Bound local-pv-29d8ad8d 931Gi RWO localblock 1h ocs-deviceset-2-1-cgth2 Bound local-pv-5ee61dcc 931Gi RWO localblock 10mIn the above example, we see three new PVCs are created.
Verification steps
Navigate to Overview → Persistent Storage tab, then check the Capacity breakdown card.
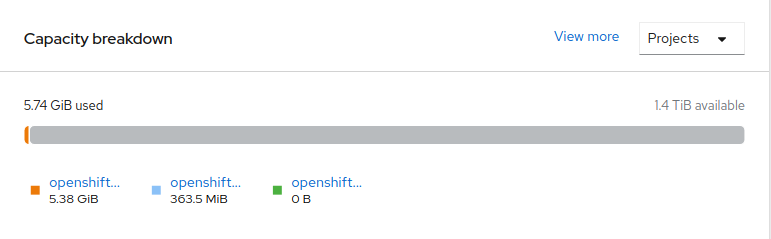
Note that the capacity increases based on your selections.
ImportantOpenShift Container Storage does not support cluster reduction either by reducing OSDs or reducing nodes.
4.3. Scaling out storage capacity
To scale out storage capacity, you need to perform the following steps:
- Add a new node
- Verify that the new node is added successfully
- Scale up the storage capacity
4.3.1. Adding a node
You can add nodes to increase the storage capacity when existing worker nodes are already running at their maximum supported OSDs, which is increment of 3 OSDs of the capacity selected during initial configuration.
Depending on the type of your deployment, you can choose one of the following procedures to add a storage node:
- For AWS installer-provisioned infrastructure, see Section 4.3.1.1, “Adding a node on an AWS installer-provisioned infrastructure”
- For AWS or VMware user-provisioned infrastructure, see Section 4.3.1.2, “Adding a node on an AWS or a VMware user-provisioned infrastructure”
- For bare metal, Amazon EC2 I3, or VMware infrastructures, see Section 4.3.1.3, “Adding a node using a local storage device”
4.3.1.1. Adding a node on an AWS installer-provisioned infrastructure
Prerequisites
- You must be logged into OpenShift Container Platform (OCP) cluster.
Procedure
- Navigate to Compute → Machine Sets.
- On the machine set where you want to add nodes, select Edit Machine Count.
- Add the amount of nodes, and click Save.
- Click Compute → Nodes and confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node.
- For the new node, Action menu (⋮) → Edit Labels.
- Add cluster.ocs.openshift.io/openshift-storage and click Save.
It is recommended to add 3 nodes each in different zones. You must add 3 nodes and perform this procedure for all of them.
Verification steps
To verify that the new node is added, see Section 4.3.2, “Verifying the addition of a new node”.
4.3.1.2. Adding a node on an AWS or a VMware user-provisioned infrastructure
Prerequisites
- You must be logged into OpenShift Container Platform (OCP) cluster.
Procedure
Depending on whether you are adding a node on an AWS user provisioned infrastructure or a VMware user-provisioned infrastructure, perform the following steps:
For AWS
- Create a new AWS machine instance with the required infrastructure. See Platform requirements.
- Create a new OpenShift Container Platform node using the new AWS machine instance.
For VMware:
- Create a new VM on vSphere with the required infrastructure. See Platform requirements.
- Create a new OpenShift Container Platform worker node using the new VM.
Check for certificate signing requests (CSRs) related to OpenShift Container Storage that are in
Pendingstate:$ oc get csrApprove all required OpenShift Container Storage CSRs for the new node:
$ oc adm certificate approve <Certificate_Name>- Click Compute → Nodes, confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
Execute the following command to apply the OpenShift Container Storage label to the new node:
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""NoteIt is recommended to add 3 nodes each in different zones. You must add 3 nodes and perform this procedure for all of them.
Verification steps
To verify that the new node is added, see Section 4.3.2, “Verifying the addition of a new node”.
4.3.1.3. Adding a node using a local storage device
Use this procedure to add a node on bare metal, Amazon EC2, and VMware infrastructures.
Scaling storage nodes for Amazon EC2 infrastructure is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
Prerequisites
- You must be logged into OpenShift Container Platform (OCP) cluster.
- You must have three OpenShift Container Platform worker nodes with the same storage type and size attached to each node (for example, 2TB NVMe drive) as the original OCS StorageCluster was created with.
Procedure
Depending on whether you are adding a node on bare metal, Amazon EC2, or VMware infrastructure, perform the following steps:
For Amazon EC2
- Create a new Amazon EC2 I3 machine instance with the required infrastructure. See Creating a MachineSet in AWS and Platform requirements.
- Create a new OpenShift Container Platform node using the new Amazon EC2 I3 machine instance.
For VMware:
- Create a new VM on vSphere with the required infrastructure. See Platform requirements.
- Create a new OpenShift Container Platform worker node using the new VM.
For bare metal:
- Get a new bare metal machine with the required infrastructure. See Platform requirements.
- Create a new OpenShift Container Platform node using the new bare metal machine.
Check for certificate signing requests (CSRs) related to OpenShift Container Storage that are in
Pendingstate:$ oc get csrApprove all required OpenShift Container Storage CSRs for the new node:
$ oc adm certificate approve <Certificate_Name>- Click Compute → Nodes, confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
Execute the following command to apply the OpenShift Container Storage label to the new node:
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""NoteIt is recommended to add 3 nodes each in different zones. You must add 3 nodes and perform this procedure for all of them.
Verification steps
To verify that the new node is added, see Section 4.3.2, “Verifying the addition of a new node”.
4.3.2. Verifying the addition of a new node
Execute the following command and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1Click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
4.3.3. Scaling up storage capacity
To scale up storage capacity, see Scaling up storage by adding capacity.
Chapter 5. Managing Persistent Volume Claims
5.1. Configuring application pods to use OpenShift Container Storage
Follow the instructions in this section to configure OpenShift Container Storage as storage for an application pod.
Prerequisites
- You have administrative access to OpenShift Web Console.
-
OpenShift Container Storage Operator is installed and running in the
openshift-storagenamespace. In OpenShift Web Console, click Operators → Installed Operators to view installed operators. - The default storage classes provided by OpenShift Container Storage are available. In OpenShift Web Console, click Storage → Storage Classes to view default storage classes.
Procedure
Create a Persistent Volume Claim (PVC) for the application to use.
- In OpenShift Web Console, click Storage → Persistent Volume Claims.
- Set the Project for the application pod.
Click Create Persistent Volume Claim.
- Specify a Storage Class provided by OpenShift Container Storage.
-
Specify the PVC Name, for example,
myclaim. - Select the required Access Mode.
- Specify a Size as per application requirement.
-
Click Create and wait until the PVC is in
Boundstatus.
Configure a new or existing application pod to use the new PVC.
For a new application pod, perform the following steps:
- Click Workloads →Pods.
- Create a new application pod.
Under the
spec:section, addvolume:section to add the new PVC as a volume for the application pod.volumes: - name: <volume_name> persistentVolumeClaim: claimName: <pvc_name>For example:
volumes: - name: mypd persistentVolumeClaim: claimName: myclaim
For an existing application pod, perform the following steps:
- Click Workloads →Deployment Configs.
- Search for the required deployment config associated with the application pod.
- Click on its Action menu (⋮) → Edit Deployment Config.
Under the
spec:section, addvolume:section to add the new PVC as a volume for the application pod and click Save.volumes: - name: <volume_name> persistentVolumeClaim: claimName: <pvc_name>For example:
volumes: - name: mypd persistentVolumeClaim: claimName: myclaim
Verify that the new configuration is being used.
- Click Workloads → Pods.
- Set the Project for the application pod.
-
Verify that the application pod appears with a status of
Running. - Click the application pod name to view pod details.
-
Scroll down to Volumes section and verify that the volume has a Type that matches your new Persistent Volume Claim, for example,
myclaim.
5.2. Viewing Persistent Volume Claim request status
Use this procedure to view the status of a PVC request.
Prerequisites
- Administrator access to OpenShift Container Storage.
Procedure
- Log in to OpenShift Web Console.
- Click Storage → Persistent Volume Claims
- Search for the required PVC name by using the Filter textbox. You can also filter the list of PVCs by Name or Label to narrow down the list
- Check the Status column corresponding to the required PVC.
- Click the required Name to view the PVC details.
5.3. Reviewing Persistent Volume Claim request events
Use this procedure to review and address Persistent Volume Claim (PVC) request events.
Prerequisites
- Administrator access to OpenShift Web Console.
Procedure
- Log in to OpenShift Web Console.
- Click Home → Overview → Persistent Storage
- Locate the Inventory card to see the number of PVCs with errors.
- Click Storage → Persistent Volume Claims
- Search for the required PVC using the Filter textbox.
- Click on the PVC name and navigate to Events
- Address the events as required or as directed.
5.4. Expanding Persistent Volume Claims
OpenShift Container Storage 4.5 introduces the ability to expand Persistent Volume Claims as a Technology Preview feature providing more flexibility in the management of persistent storage resources.
Expansion is supported for the following Persistent Volumes:
-
PVC with ReadWriteOnce (RWO) and ReadWriteMany (RWX) access that is based on Ceph File System (CephFS) for volume mode
Filesystem. -
PVC with ReadWriteOnce (RWO) access that is based on Ceph RADOS Block Devices (RBDs) with volume mode
Filesystem. -
PVC with ReadWriteOnce (RWO) access that is based on Ceph RADOS Block Devices (RBDs) with volume mode
Block.
Expanding Persistent Volumes is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
For more informaton, see Technology Preview Features Support Scope.
OSD and MON PVC expansion is not supported by Red Hat.
This Technology Preview feature is only available with fresh installations of OpenShift Container Storage version 4.5. It does not apply to clusters upgraded from previous OpenShift Container Storage releases.
Prerequisites
- Administrator access to OpenShift Web Console.
Procedure
-
In OpenShift Web Console, navigate to
Storage→Persistent Volume Claims. - Click the Action Menu (⋮) next to the Persistent Volume Claim you want to expand.
Click
Expand PVC:
Select the new size of the Persistent Volume Claim, then click
Expand: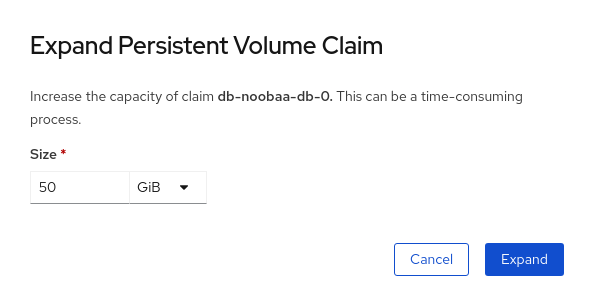
To verify the expansion, navigate to the PVC’s details page and verify the
Capacityfield has the correct size requested.NoteWhen expanding PVCs based on Ceph RADOS Block Devices (RBDs), if the PVC is not already attached to a pod the
Condition typeisFileSystemResizePendingin the PVC’s details page. Once the volume is mounted, Filesystem resize succeeds and the new size is reflected in theCapacityfield.
5.5. Dynamic provisioning
5.5.1. About dynamic provisioning
The StorageClass resource object describes and classifies storage that can be requested, as well as provides a means for passing parameters for dynamically provisioned storage on demand. StorageClass objects can also serve as a management mechanism for controlling different levels of storage and access to the storage. Cluster Administrators (cluster-admin) or Storage Administrators (storage-admin) define and create the StorageClass objects that users can request without needing any intimate knowledge about the underlying storage volume sources.
The OpenShift Container Platform persistent volume framework enables this functionality and allows administrators to provision a cluster with persistent storage. The framework also gives users a way to request those resources without having any knowledge of the underlying infrastructure.
Many storage types are available for use as persistent volumes in OpenShift Container Platform. While all of them can be statically provisioned by an administrator, some types of storage are created dynamically using the built-in provider and plug-in APIs.
5.5.2. Dynamic provisioning in OpenShift Container Storage
Red Hat OpenShift Container Storage is software-defined storage that is optimised for container environments. It runs as an operator on OpenShift Container Platform to provide highly integrated and simplified persistent storage management for containers.
OpenShift Container Storage supports a variety of storage types, including:
- Block storage for databases
- Shared file storage for continuous integration, messaging, and data aggregation
- Object storage for archival, backup, and media storage
Version 4.5 uses Red Hat Ceph Storage to provide the file, block, and object storage that backs persistent volumes, and Rook.io to manage and orchestrate provisioning of persistent volumes and claims. NooBaa provides object storage, and its Multicloud Gateway allows object federation across multiple cloud environments (available as a Technology Preview).
In OpenShift Container Storage 4.5, the Red Hat Ceph Storage Container Storage Interface (CSI) driver for RADOS Block Device (RBD) and Ceph File System (CephFS) handles the dynamic provisioning requests. When a PVC request comes in dynamically, the CSI driver has the following options:
-
Create a PVC with ReadWriteOnce (RWO) and ReadWriteMany (RWX) access that is based on Ceph RBDs with volume mode
Block -
Create a PVC with ReadWriteOnce (RWO) access that is based on Ceph RBDs with volume mode
Filesystem -
Create a PVC with ReadWriteOnce (RWO) and ReadWriteMany (RWX) access that is based on CephFS for volume mode
Filesystem
The judgement of which driver (RBD or CephFS) to use is based on the entry in the storageclass.yaml file.
5.5.3. Available dynamic provisioning plug-ins
OpenShift Container Platform provides the following provisioner plug-ins, which have generic implementations for dynamic provisioning that use the cluster’s configured provider’s API to create new storage resources:
| Storage type | Provisioner plug-in name | Notes |
|---|---|---|
| OpenStack Cinder |
| |
| AWS Elastic Block Store (EBS) |
|
For dynamic provisioning when using multiple clusters in different zones, tag each node with |
| AWS Elastic File System (EFS) | Dynamic provisioning is accomplished through the EFS provisioner pod and not through a provisioner plug-in. | |
| Azure Disk |
| |
| Azure File |
|
The |
| GCE Persistent Disk (gcePD) |
| In multi-zone configurations, it is advisable to run one OpenShift Container Platform cluster per GCE project to avoid PVs from being created in zones where no node in the current cluster exists. |
|
|
Any chosen provisioner plug-in also requires configuration for the relevant cloud, host, or third-party provider as per the relevant documentation.
Chapter 6. Managing container storage interface (CSI) component placements
Each cluster consists of a number of dedicated nodes such as infra and storage nodes. However, an infra node with a custom taint will not be able to use OpenShift Container Storage Persistent Volume Claims (PVCs) on the node. So, if you want to use such nodes, you can set tolerations to bring up csi-plugins on the nodes. For more information, see https://access.redhat.com/solutions/4827161.
Procedure
Edit the configmap to add the toleration for the custom taint. Remember to save before exiting the editor.
$ oc edit configmap rook-ceph-operator-config -n openshift-storageDisplay the
configmapto check the added toleration.$ oc get configmap rook-ceph-operator-config -n openshift-storage -o yamlExample output of the added toleration for the taint,
nodetype=infra:NoSchedule:apiVersion: v1 data: [...] CSI_PLUGIN_TOLERATIONS: | - effect: NoSchedule key: nodetype operator: Equal value: infra - effect: NoSchedule key: node.ocs.openshift.io/storage operator: Exists [...] kind: ConfigMap metadata: [...]Restart the
rook-ceph-operatorif thecsi-cephfsplugin-* andcsi-rbdplugin-* pods fail to come up on their own on the infra nodes.$ oc delete -n openshift-storage pod <name of the rook_ceph_operator pod>Example :
$ oc delete -n openshift-storage pod rook-ceph-operator-5446f9b95b-jrn2j pod "rook-ceph-operator-5446f9b95b-jrn2j" deleted
Verification step
Verify that the csi-cephfsplugin-* and csi-rbdplugin-* pods are running on the infra nodes.
Chapter 7. Multicloud Object Gateway
7.1. About the Multicloud Object Gateway
The Multicloud Object Gateway (MCG) is a lightweight object storage service for OpenShift, allowing users to start small and then scale as needed on-premise, in multiple clusters, and with cloud-native storage.
7.2. Accessing the Multicloud Object Gateway with your applications
You can access the object service with any application targeting AWS S3 or code that uses AWS S3 Software Development Kit (SDK). Applications need to specify the MCG endpoint, an access key, and a secret access key. You can use your terminal or the MCG CLI to retrieve this information.
For information on accessing the RADOS Object Gateway S3 endpoint, see Chapter 8, Accessing the RADOS Object Gateway S3 endpoint.
Prerequisites
- A running OpenShift Container Storage Platform
Download the MCG command-line interface for easier management:
# subscription-manager repos --enable=rh-ocs-4-for-rhel-8-x86_64-rpms # yum install mcg-
Alternatively, you can install the
mcgpackage from the OpenShift Container Storage RPMs found at Download RedHat OpenShift Container Storage page.
You can access the relevant endpoint, access key, and secret access key two ways:
7.2.1. Accessing the Multicloud Object Gateway from the terminal
Procedure
Run the describe command to view information about the MCG endpoint, including its access key (AWS_ACCESS_KEY_ID value) and secret access key (AWS_SECRET_ACCESS_KEY value):
# oc describe noobaa -n openshift-storageThe output will look similar to the following:
Name: noobaa
Namespace: openshift-storage
Labels: <none>
Annotations: <none>
API Version: noobaa.io/v1alpha1
Kind: NooBaa
Metadata:
Creation Timestamp: 2019-07-29T16:22:06Z
Generation: 1
Resource Version: 6718822
Self Link: /apis/noobaa.io/v1alpha1/namespaces/openshift-storage/noobaas/noobaa
UID: 019cfb4a-b21d-11e9-9a02-06c8de012f9e
Spec:
Status:
Accounts:
Admin:
Secret Ref:
Name: noobaa-admin
Namespace: openshift-storage
Actual Image: noobaa/noobaa-core:4.0
Observed Generation: 1
Phase: Ready
Readme:
Welcome to NooBaa!
-----------------
Welcome to NooBaa!
-----------------
NooBaa Core Version:
NooBaa Operator Version:
Lets get started:
1. Connect to Management console:
Read your mgmt console login information (email & password) from secret: "noobaa-admin".
kubectl get secret noobaa-admin -n openshift-storage -o json | jq '.data|map_values(@base64d)'
Open the management console service - take External IP/DNS or Node Port or use port forwarding:
kubectl port-forward -n openshift-storage service/noobaa-mgmt 11443:443 &
open https://localhost:11443
2. Test S3 client:
kubectl port-forward -n openshift-storage service/s3 10443:443 &
NOOBAA_ACCESS_KEY=$(kubectl get secret noobaa-admin -n openshift-storage -o json | jq -r '.data.AWS_ACCESS_KEY_ID|@base64d')
NOOBAA_SECRET_KEY=$(kubectl get secret noobaa-admin -n openshift-storage -o json | jq -r '.data.AWS_SECRET_ACCESS_KEY|@base64d')
alias s3='AWS_ACCESS_KEY_ID=$NOOBAA_ACCESS_KEY AWS_SECRET_ACCESS_KEY=$NOOBAA_SECRET_KEY aws --endpoint https://localhost:10443 --no-verify-ssl s3'
s3 ls
Services:
Service Mgmt:
External DNS:
https://noobaa-mgmt-openshift-storage.apps.mycluster-cluster.qe.rh-ocs.com
https://a3406079515be11eaa3b70683061451e-1194613580.us-east-2.elb.amazonaws.com:443
Internal DNS:
https://noobaa-mgmt.openshift-storage.svc:443
Internal IP:
https://172.30.235.12:443
Node Ports:
https://10.0.142.103:31385
Pod Ports:
https://10.131.0.19:8443
serviceS3:
External DNS:
https://s3-openshift-storage.apps.mycluster-cluster.qe.rh-ocs.com
https://a340f4e1315be11eaa3b70683061451e-943168195.us-east-2.elb.amazonaws.com:443
Internal DNS:
https://s3.openshift-storage.svc:443
Internal IP:
https://172.30.86.41:443
Node Ports:
https://10.0.142.103:31011
Pod Ports:
https://10.131.0.19:6443
The output from the oc describe noobaa command lists the internal and external DNS names that are available. When using the internal DNS, the traffic is free. The external DNS uses Load Balancing to process the traffic, and therefore has a cost per hour.
7.2.2. Accessing the Multicloud Object Gateway from the MCG command-line interface
Prerequisites
Download the MCG command-line interface:
# subscription-manager repos --enable=rh-ocs-4-for-rhel-8-x86_64-rpms # yum install mcg
Procedure
Run the status command to access the endpoint, access key, and secret access key:
noobaa status -n openshift-storageThe output will look similar to the following:
INFO[0000] Namespace: openshift-storage
INFO[0000]
INFO[0000] CRD Status:
INFO[0003] ✅ Exists: CustomResourceDefinition "noobaas.noobaa.io"
INFO[0003] ✅ Exists: CustomResourceDefinition "backingstores.noobaa.io"
INFO[0003] ✅ Exists: CustomResourceDefinition "bucketclasses.noobaa.io"
INFO[0004] ✅ Exists: CustomResourceDefinition "objectbucketclaims.objectbucket.io"
INFO[0004] ✅ Exists: CustomResourceDefinition "objectbuckets.objectbucket.io"
INFO[0004]
INFO[0004] Operator Status:
INFO[0004] ✅ Exists: Namespace "openshift-storage"
INFO[0004] ✅ Exists: ServiceAccount "noobaa"
INFO[0005] ✅ Exists: Role "ocs-operator.v0.0.271-6g45f"
INFO[0005] ✅ Exists: RoleBinding "ocs-operator.v0.0.271-6g45f-noobaa-f9vpj"
INFO[0006] ✅ Exists: ClusterRole "ocs-operator.v0.0.271-fjhgh"
INFO[0006] ✅ Exists: ClusterRoleBinding "ocs-operator.v0.0.271-fjhgh-noobaa-pdxn5"
INFO[0006] ✅ Exists: Deployment "noobaa-operator"
INFO[0006]
INFO[0006] System Status:
INFO[0007] ✅ Exists: NooBaa "noobaa"
INFO[0007] ✅ Exists: StatefulSet "noobaa-core"
INFO[0007] ✅ Exists: Service "noobaa-mgmt"
INFO[0008] ✅ Exists: Service "s3"
INFO[0008] ✅ Exists: Secret "noobaa-server"
INFO[0008] ✅ Exists: Secret "noobaa-operator"
INFO[0008] ✅ Exists: Secret "noobaa-admin"
INFO[0009] ✅ Exists: StorageClass "openshift-storage.noobaa.io"
INFO[0009] ✅ Exists: BucketClass "noobaa-default-bucket-class"
INFO[0009] ✅ (Optional) Exists: BackingStore "noobaa-default-backing-store"
INFO[0010] ✅ (Optional) Exists: CredentialsRequest "noobaa-cloud-creds"
INFO[0010] ✅ (Optional) Exists: PrometheusRule "noobaa-prometheus-rules"
INFO[0010] ✅ (Optional) Exists: ServiceMonitor "noobaa-service-monitor"
INFO[0011] ✅ (Optional) Exists: Route "noobaa-mgmt"
INFO[0011] ✅ (Optional) Exists: Route "s3"
INFO[0011] ✅ Exists: PersistentVolumeClaim "db-noobaa-core-0"
INFO[0011] ✅ System Phase is "Ready"
INFO[0011] ✅ Exists: "noobaa-admin"
#------------------#
#- Mgmt Addresses -#
#------------------#
ExternalDNS : [https://noobaa-mgmt-openshift-storage.apps.mycluster-cluster.qe.rh-ocs.com https://a3406079515be11eaa3b70683061451e-1194613580.us-east-2.elb.amazonaws.com:443]
ExternalIP : []
NodePorts : [https://10.0.142.103:31385]
InternalDNS : [https://noobaa-mgmt.openshift-storage.svc:443]
InternalIP : [https://172.30.235.12:443]
PodPorts : [https://10.131.0.19:8443]
#--------------------#
#- Mgmt Credentials -#
#--------------------#
email : admin@noobaa.io
password : HKLbH1rSuVU0I/souIkSiA==
#----------------#
#- S3 Addresses -#
#----------------#
ExternalDNS : [https://s3-openshift-storage.apps.mycluster-cluster.qe.rh-ocs.com https://a340f4e1315be11eaa3b70683061451e-943168195.us-east-2.elb.amazonaws.com:443]
ExternalIP : []
NodePorts : [https://10.0.142.103:31011]
InternalDNS : [https://s3.openshift-storage.svc:443]
InternalIP : [https://172.30.86.41:443]
PodPorts : [https://10.131.0.19:6443]
#------------------#
#- S3 Credentials -#
#------------------#
AWS_ACCESS_KEY_ID : jVmAsu9FsvRHYmfjTiHV
AWS_SECRET_ACCESS_KEY : E//420VNedJfATvVSmDz6FMtsSAzuBv6z180PT5c
#------------------#
#- Backing Stores -#
#------------------#
NAME TYPE TARGET-BUCKET PHASE AGE
noobaa-default-backing-store aws-s3 noobaa-backing-store-15dc896d-7fe0-4bed-9349-5942211b93c9 Ready 141h35m32s
#------------------#
#- Bucket Classes -#
#------------------#
NAME PLACEMENT PHASE AGE
noobaa-default-bucket-class {Tiers:[{Placement: BackingStores:[noobaa-default-backing-store]}]} Ready 141h35m33s
#-----------------#
#- Bucket Claims -#
#-----------------#
No OBC's found.You now have the relevant endpoint, access key, and secret access key in order to connect to your applications.
Example 7.1. Example
If AWS S3 CLI is the application, the following command will list buckets in OCS:
AWS_ACCESS_KEY_ID=<AWS_ACCESS_KEY_ID>
AWS_SECRET_ACCESS_KEY=<AWS_SECRET_ACCESS_KEY>
aws --endpoint <ENDPOINT> --no-verify-ssl s3 ls7.3. Allowing user access to the Multicloud Object Gateway Console
To allow access to the Multicloud Object Gateway Console to a user, ensure that the user meets the following conditions:
- User is in cluster-admins group.
- User is in system:cluster-admins virtual group.
Prerequisites
- A running OpenShift Container Storage Platform.
Procedure
Enable access to the Multicloud Object Gateway console.
Perform the following steps once on the cluster :
Create a
cluster-adminsgroup.# oc adm groups new cluster-adminsBind the group to the
cluster-adminrole.# oc adm policy add-cluster-role-to-group cluster-admin cluster-admins
Add or remove users from the
cluster-adminsgroup to control access to the Multicloud Object Gateway console.To add a set of users to the
cluster-adminsgroup :# oc adm groups add-users cluster-admins <user-name> <user-name> <user-name>...where
<user-name>is the name of the user to be added.NoteIf you are adding a set of users to the
cluster-adminsgroup, you do not need to bind the newly added users to the cluster-admin role to allow access to the OpenShift Container Storage dashboard.To remove a set of users from the
cluster-adminsgroup :# oc adm groups remove-users cluster-admins <user-name> <user-name> <user-name>...where
<user-name>is the name of the user to be removed.
Verification steps
- On the OpenShift Web Console, login as a user with access permission to Multicloud Object Gateway Console.
- Navigate to Home → Overview → Persistent Storage tab → select the noobaa link .
- On the Multicloud Object Gateway Console, login as the same user with access permission.
- Click Allow selected permissions.
7.4. Adding storage resources for hybrid or Multicloud
7.4.1. Creating a new backing store
Use this procedure to create a new backing store in OpenShift Container Storage.
Prerequisites
- Administrator access to OpenShift.
Procedure
- Click Operators → Installed Operators from the left pane of the OpenShift Web Console to view the installed operators.
- Click OpenShift Container Storage Operator.
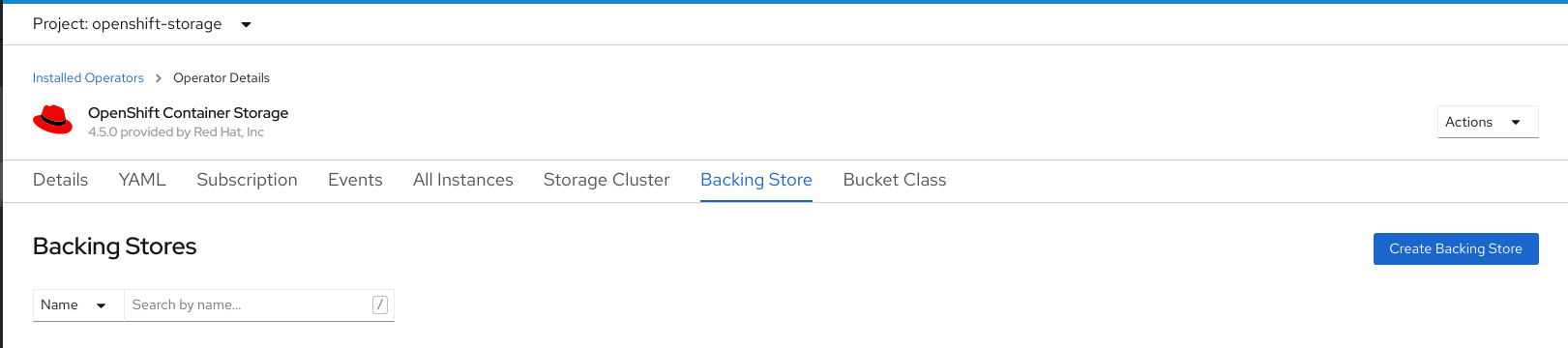
On the OpenShift Container Storage Operator page, scroll right and click the Backing Store tab.
Figure 7.1. OpenShift Container Storage Operator page with backing store tab
Click Create Backing Store.
Figure 7.2. Create Backing Store page
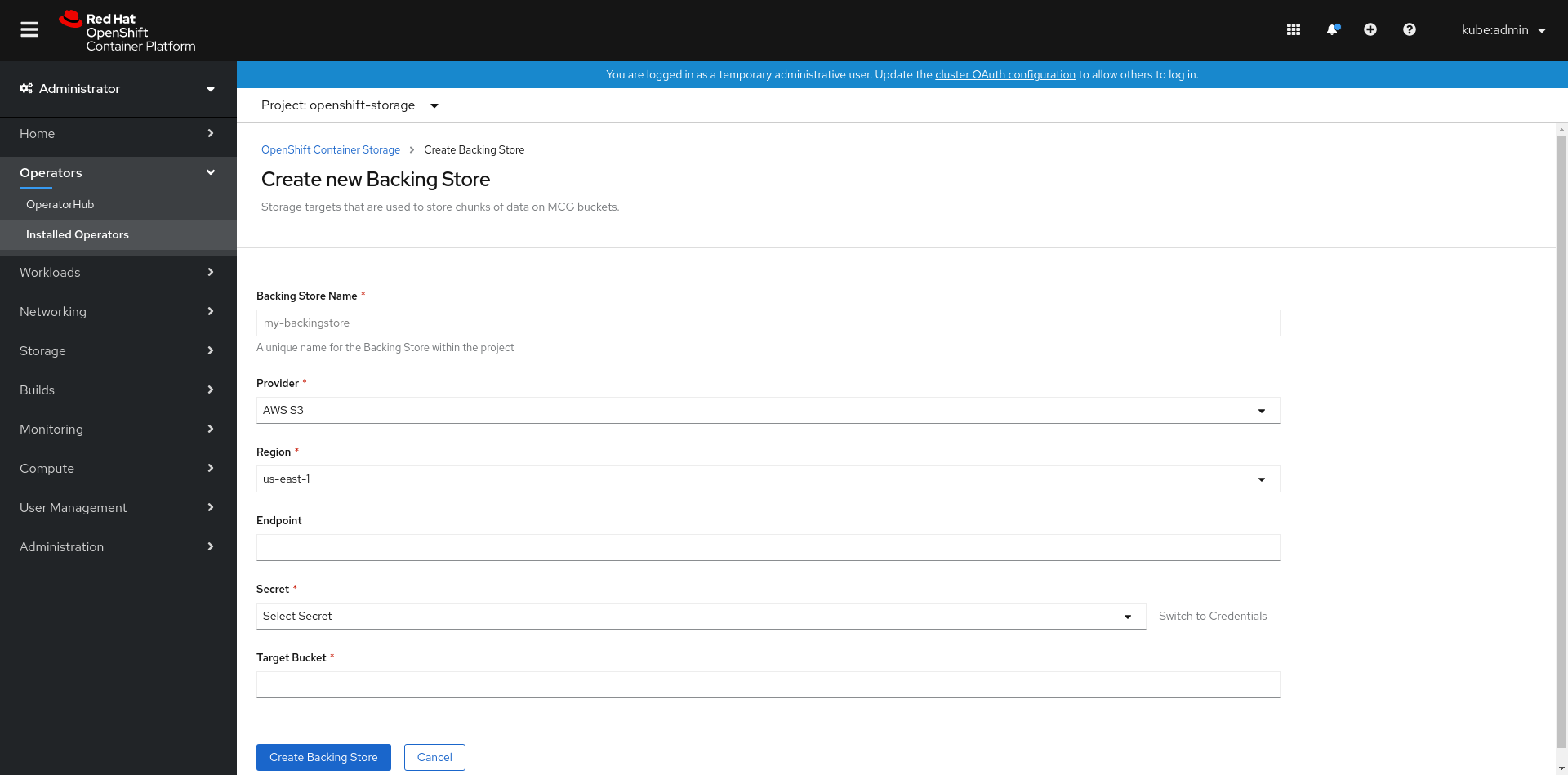
On the Create New Backing Store page, perform the following:
- Enter a Backing Store Name.
- Select a Provider.
- Select a Region.
- Enter an Endpoint. This is optional.
Select a Secret from drop down list, or create your own secret. Optionally, you can Switch to Credentials view which lets you fill in the required secrets.
For more information on creating an OCP secret, see the section Creating the secret in the Openshift Container Platform documentation.
Each backingstore requires a different secret. For more information on creating the secret for a particular backingstore, see the Section 7.4.2, “Adding storage resources for hybrid or Multicloud using the MCG command line interface” and follow the procedure for the addition of storage resources using a YAML.
NoteThis menu is relevant for all providers except Google Cloud and local PVC.
- Enter Target bucket. The target bucket is a container storage that is hosted on the remote cloud service. It allows you to create a connection that tells MCG that it can use this bucket for the system.
- Click Create Backing Store.
Verification steps
- Click Operators → Installed Operators.
- Click OpenShift Container Storage Operator.
- Search for the new backing store or click Backing Store tab to view all the backing stores.
7.4.2. Adding storage resources for hybrid or Multicloud using the MCG command line interface
The Multicloud Object Gateway (MCG) simplifies the process of spanning data across cloud provider and clusters.
You must add a backing storage that can be used by the MCG.
Depending on the type of your deployment, you can choose one of the following procedures to create a backing storage:
- For creating an AWS-backed backingstore, see Section 7.4.2.1, “Creating an AWS-backed backingstore”
- For creating an IBM COS-backed backingstore, see Section 7.4.2.2, “Creating an IBM COS-backed backingstore”
- For creating an Azure-backed backingstore, see Section 7.4.2.3, “Creating an Azure-backed backingstore”
- For creating a GCP-backed backingstore, see Section 7.4.2.4, “Creating a GCP-backed backingstore”
- For creating a local Persistent Volume-backed backingstore, see Section 7.4.2.5, “Creating a local Persistent Volume-backed backingstore”
For VMware deployments, skip to Section 7.4.3, “Creating an s3 compatible Multicloud Object Gateway backingstore” for further instructions.
7.4.2.1. Creating an AWS-backed backingstore
Prerequisites
Download the Multicloud Object Gateway (MCG) command-line interface:
# subscription-manager repos --enable=rh-ocs-4-for-rhel-8-x86_64-rpms # yum install mcg-
Alternatively, you can install the
mcgpackage from the OpenShift Container Storage RPMs found here https://access.redhat.com/downloads/content/547/ver=4/rhel---8/4/x86_64/packages
Procedure
From the MCG command-line interface, run the following command:
noobaa backingstore create <backingstore_name> --access-key=<AWS ACCESS KEY> --secret-key=<AWS SECRET ACCESS KEY> --target-bucket <bucket-name>
-
Replace
<backingstore_name>with the name of the backingstore. -
Replace
<AWS ACCESS KEY>and<AWS SECRET ACCESS KEY>with an AWS access key ID and secret access key you created for this purpose. Replace
<bucket-name>with an existing AWS bucket name. This argument tells Multicloud Object Gateway which bucket to use as a target bucket for its backing store, and subsequently, data storage and administration.The output will be similar to the following:
INFO[0001] ✅ Exists: NooBaa "noobaa" INFO[0002] ✅ Created: BackingStore "aws-resource" INFO[0002] ✅ Created: Secret "backing-store-secret-aws-resource"
You can also add storage resources using a YAML:
Create a secret with the credentials:
apiVersion: v1 kind: Secret metadata: name: <backingstore-secret-name> type: Opaque data: AWS_ACCESS_KEY_ID: <AWS ACCESS KEY ID ENCODED IN BASE64> AWS_SECRET_ACCESS_KEY: <AWS SECRET ACCESS KEY ENCODED IN BASE64>-
You must supply and encode your own AWS access key ID and secret access key using Base64, and use the results in place of
<AWS ACCESS KEY ID ENCODED IN BASE64>and<AWS SECRET ACCESS KEY ENCODED IN BASE64>. -
Replace
<backingstore-secret-name>with a unique name.
-
You must supply and encode your own AWS access key ID and secret access key using Base64, and use the results in place of
Apply the following YAML for a specific backing store:
apiVersion: noobaa.io/v1alpha1 kind: BackingStore metadata: finalizers: - noobaa.io/finalizer labels: app: noobaa name: bs namespace: openshift-storage spec: awsS3: secret: name: <backingstore-secret-name> namespace: noobaa targetBucket: <bucket-name> type: aws-s3-
Replace
<bucket-name>with an existing AWS bucket name. This argument tells Multicloud Object Gateway which bucket to use as a target bucket for its backing store, and subsequently, data storage and administration. -
Replace
<backingstore-secret-name>with the name of the secret created in the previous step.
-
Replace
7.4.2.2. Creating an IBM COS-backed backingstore
Prerequisites
Download the Multicloud Object Gateway (MCG) command-line interface:
# subscription-manager repos --enable=rh-ocs-4-for-rhel-8-x86_64-rpms # yum install mcg-
Alternatively, you can install the
mcgpackage from the OpenShift Container Storage RPMs found here https://access.redhat.com/downloads/content/547/ver=4/rhel---8/4/x86_64/packages
Procedure
From the MCG command-line interface, run the following command:
noobaa backingstore create ibm-cos <backingstore_name> --access-key=<IBM ACCESS KEY> --secret-key=<IBM SECRET ACCESS KEY> --endpoint=<IBM COS ENDPOINT> --target-bucket <bucket-name>-
Replace
<backingstore_name>with the name of the backingstore. Replace
<IBM ACCESS KEY>,<IBM SECRET ACCESS KEY>,<IBM COS ENDPOINT>with an IBM access key ID, secret access key and the appropriate regional endpoint that corresponds to the location of the existing IBM bucket.To generate the above keys on IBM cloud, you must include HMAC credentials while creating the service credentials for your target bucket.
Replace
<bucket-name>with an existing IBM bucket name. This argument tells Multicloud Object Gateway which bucket to use as a target bucket for its backing store, and subsequently, data storage and administration.The output will be similar to the following:
INFO[0001] ✅ Exists: NooBaa "noobaa" INFO[0002] ✅ Created: BackingStore "ibm-resource" INFO[0002] ✅ Created: Secret "backing-store-secret-ibm-resource"
-
Replace
You can also add storage resources using a YAML:
Create a secret with the credentials:
apiVersion: v1 kind: Secret metadata: name: <backingstore-secret-name> type: Opaque data: IBM_COS_ACCESS_KEY_ID: <IBM COS ACCESS KEY ID ENCODED IN BASE64> IBM_COS_SECRET_ACCESS_KEY: <IBM COS SECRET ACCESS KEY ENCODED IN BASE64>-
You must supply and encode your own IBM COS access key ID and secret access key using Base64, and use the results in place of
<IBM COS ACCESS KEY ID ENCODED IN BASE64>and<IBM COS SECRET ACCESS KEY ENCODED IN BASE64>. -
Replace
<backingstore-secret-name>with a unique name.
-
You must supply and encode your own IBM COS access key ID and secret access key using Base64, and use the results in place of
Apply the following YAML for a specific backing store:
apiVersion: noobaa.io/v1alpha1 kind: BackingStore metadata: finalizers: - noobaa.io/finalizer labels: app: noobaa name: bs namespace: openshift-storage spec: ibmCos: endpoint: <endpoint> secret: name: <backingstore-secret-name> namespace: openshift-storage targetBucket: <bucket-name> type: ibm-cos-
Replace
<bucket-name>with an existing IBM COS bucket name. This argument tells Multicloud Object Gateway which bucket to use as a target bucket for its backing store, and subsequently, data storage and administration. -
Replace
<endpoint>with a regional endpoint that corresponds to the location of the existing IBM bucket name. This argument tells Multicloud Object Gateway which endpoint to use for its backing store, and subsequently, data storage and administration. -
Replace
<backingstore-secret-name>with the name of the secret created in the previous step.
-
Replace
7.4.2.3. Creating an Azure-backed backingstore
Prerequisites
Download the Multicloud Object Gateway (MCG) command-line interface:
# subscription-manager repos --enable=rh-ocs-4-for-rhel-8-x86_64-rpms # yum install mcg-
Alternatively, you can install the
mcgpackage from the OpenShift Container Storage RPMs found here https://access.redhat.com/downloads/content/547/ver=4/rhel---8/4/x86_64/packages
Procedure
From the MCG command-line interface, run the following command:
noobaa backingstore create azure-blob <backingstore_name> --account-key=<AZURE ACCOUNT KEY> --account-name=<AZURE ACCOUNT NAME> --target-blob-container <blob container name>-
Replace
<backingstore_name>with the name of the backingstore. -
Replace
<AZURE ACCOUNT KEY>and<AZURE ACCOUNT NAME>with an AZURE account key and account name you created for this purpose. Replace
<blob container name>with an existing Azure blob container name. This argument tells Multicloud Object Gateway which bucket to use as a target bucket for its backing store, and subsequently, data storage and administration.The output will be similar to the following:
INFO[0001] ✅ Exists: NooBaa "noobaa" INFO[0002] ✅ Created: BackingStore "azure-resource" INFO[0002] ✅ Created: Secret "backing-store-secret-azure-resource"
-
Replace
You can also add storage resources using a YAML:
Create a secret with the credentials:
apiVersion: v1 kind: Secret metadata: name: <backingstore-secret-name> type: Opaque data: AccountName: <AZURE ACCOUNT NAME ENCODED IN BASE64> AccountKey: <AZURE ACCOUNT KEY ENCODED IN BASE64>-
You must supply and encode your own Azure Account Name and Account Key using Base64, and use the results in place of
<AZURE ACCOUNT NAME ENCODED IN BASE64>and<AZURE ACCOUNT KEY ENCODED IN BASE64>. -
Replace
<backingstore-secret-name>with a unique name.
-
You must supply and encode your own Azure Account Name and Account Key using Base64, and use the results in place of
Apply the following YAML for a specific backing store:
apiVersion: noobaa.io/v1alpha1 kind: BackingStore metadata: finalizers: - noobaa.io/finalizer labels: app: noobaa name: bs namespace: openshift-storage spec: azureBlob: secret: name: <backingstore-secret-name> namespace: openshift-storage targetBlobContainer: <blob-container-name> type: azure-blob-
Replace
<blob-container-name>with an existing Azure blob container name. This argument tells Multicloud Object Gateway which bucket to use as a target bucket for its backing store, and subsequently, data storage and administration. -
Replace
<backingstore-secret-name>with the name of the secret created in the previous step.
-
Replace
7.4.2.4. Creating a GCP-backed backingstore
Prerequisites
Download the Multicloud Object Gateway (MCG) command-line interface:
# subscription-manager repos --enable=rh-ocs-4-for-rhel-8-x86_64-rpms # yum install mcg-
Alternatively, you can install the
mcgpackage from the OpenShift Container Storage RPMs found here https://access.redhat.com/downloads/content/547/ver=4/rhel---8/4/x86_64/packages
Procedure
From the MCG command-line interface, run the following command:
noobaa backingstore create google-cloud-storage <backingstore_name> --private-key-json-file=<PATH TO GCP PRIVATE KEY JSON FILE> --target-bucket <GCP bucket name>-
Replace
<backingstore_name>with the name of the backingstore. -
Replace
<PATH TO GCP PRIVATE KEY JSON FILE>with a path to your GCP private key created for this purpose. Replace
<GCP bucket name>with an existing GCP object storage bucket name. This argument tells Multicloud Object Gateway which bucket to use as a target bucket for its backing store, and subsequently, data storage and administration.The output will be similar to the following:
INFO[0001] ✅ Exists: NooBaa "noobaa" INFO[0002] ✅ Created: BackingStore "google-gcp" INFO[0002] ✅ Created: Secret "backing-store-google-cloud-storage-gcp"
-
Replace
You can also add storage resources using a YAML:
Create a secret with the credentials:
apiVersion: v1 kind: Secret metadata: name: <backingstore-secret-name> type: Opaque data: GoogleServiceAccountPrivateKeyJson: <GCP PRIVATE KEY ENCODED IN BASE64>-
You must supply and encode your own GCP service account private key using Base64, and use the results in place of
<GCP PRIVATE KEY ENCODED IN BASE64>. - Replace <backingstore-secret-name> with a unique name.
-
You must supply and encode your own GCP service account private key using Base64, and use the results in place of
Apply the following YAML for a specific backing store:
apiVersion: noobaa.io/v1alpha1 kind: BackingStore metadata: finalizers: - noobaa.io/finalizer labels: app: noobaa name: bs namespace: openshift-storage spec: googleCloudStorage: secret: name: <backingstore-secret-name> namespace: openshift-storage targetBucket: <target bucket> type: google-cloud-storage-
Replace
<target bucket>with an existing Google storage bucket. This argument tells Multicloud Object Gateway which bucket to use as a target bucket for its backing store, and subsequently, data storage and administration. -
Replace
<backingstore-secret-name>with the name of the secret created in the previous step.
-
Replace
7.4.2.5. Creating a local Persistent Volume-backed backingstore
Prerequisites
Download the Multicloud Object Gateway (MCG) command-line interface:
# subscription-manager repos --enable=rh-ocs-4-for-rhel-8-x86_64-rpms # yum install mcg-
Alternatively, you can install the
mcgpackage from the OpenShift Container Storage RPMs found here https://access.redhat.com/downloads/content/547/ver=4/rhel---8/4/x86_64/packages
Procedure
From the MCG command-line interface, run the following command:
noobaa backingstore create pv-pool <backingstore_name> --num-volumes=<NUMBER OF VOLUMES> --pv-size-gb=<VOLUME SIZE> --storage-class=<LOCAL STORAGE CLASS>-
Replace
<backingstore_name>with the name of the backingstore. -
Replace
<NUMBER OF VOLUMES>with the number of volumes you would like to create. -
Replace
<VOLUME SIZE>with the required size, in GB, of each volume Replace
<LOCAL STORAGE CLASS>with the local storage class, recommended to use ocs-storagecluster-ceph-rbdThe output will be similar to the following:
INFO[0001] ✅ Exists: NooBaa "noobaa" INFO[0002] ✅ Exists: BackingStore "local-mcg-storage"
-
Replace
You can also add storage resources using a YAML:
Apply the following YAML for a specific backing store:
apiVersion: noobaa.io/v1alpha1 kind: BackingStore metadata: finalizers: - noobaa.io/finalizer labels: app: noobaa name: <backingstore_name> namespace: openshift-storage spec: pvPool: numVolumes: <NUMBER OF VOLUMES> resources: requests: storage: <VOLUME SIZE> storageClass: <LOCAL STORAGE CLASS> type: pv-pool-
Replace
<backingstore_name>with the name of the backingstore. -
Replace
<NUMBER OF VOLUMES>with the number of volumes you would like to create. -
Replace
<VOLUME SIZE>with the required size, in GB, of each volume. Note that the letter G should remain -
Replace
<LOCAL STORAGE CLASS>with the local storage class, recommended to use ocs-storagecluster-ceph-rbd
-
Replace
7.4.3. Creating an s3 compatible Multicloud Object Gateway backingstore
The Multicloud Object Gateway can use any S3 compatible object storage as a backing store, for example, Red Hat Ceph Storage’s RADOS Gateway (RGW). The following procedure shows how to create an S3 compatible Multicloud Object Gateway backing store for Red Hat Ceph Storage’s RADOS Gateway. Note that when RGW is deployed, Openshift Container Storage operator creates an S3 compatible backingstore for Multicloud Object Gateway automatically.
Procedure
From the Multicloud Object Gateway (MCG) command-line interface, run the following NooBaa command:
noobaa backingstore create s3-compatible rgw-resource --access-key=<RGW ACCESS KEY> --secret-key=<RGW SECRET KEY> --target-bucket=<bucket-name> --endpoint=http://rook-ceph-rgw-ocs-storagecluster-cephobjectstore.openshift-storage.svc.cluster.local:80To get the
<RGW ACCESS KEY>and<RGW SECRET KEY>, run the following command using your RGW user secret name:oc get secret <RGW USER SECRET NAME> -o yaml- Decode the access key ID and the access key from Base64 and keep them.
-
Replace
<RGW USER ACCESS KEY>and<RGW USER SECRET ACCESS KEY>with the appropriate, decoded data from the previous step. Replace
<bucket-name>with an existing RGW bucket name. This argument tells Multicloud Object Gateway which bucket to use as a target bucket for its backing store, and subsequently, data storage and administration.The output will be similar to the following:
INFO[0001] ✅ Exists: NooBaa "noobaa" INFO[0002] ✅ Created: BackingStore "rgw-resource" INFO[0002] ✅ Created: Secret "backing-store-secret-rgw-resource"
You can also create the backingstore using a YAML:
Create a
CephObjectStoreuser. This also creates a secret containing the RGW credentials:apiVersion: ceph.rook.io/v1 kind: CephObjectStoreUser metadata: name: <RGW-Username> namespace: openshift-storage spec: store: ocs-storagecluster-cephobjectstore displayName: "<Display-name>"-
Replace
<RGW-Username>and<Display-name>with a unique username and display name.
-
Replace
Apply the following YAML for an S3-Compatible backing store:
apiVersion: noobaa.io/v1alpha1 kind: BackingStore metadata: finalizers: - noobaa.io/finalizer labels: app: noobaa name: <backingstore-name> namespace: openshift-storage spec: s3Compatible: endpoint: http://rook-ceph-rgw-ocs-storagecluster-cephobjectstore.openshift-storage.svc.cluster.local:80 secret: name: <backingstore-secret-name> namespace: openshift-storage signatureVersion: v4 targetBucket: <RGW-bucket-name> type: s3-compatible-
Replace
<backingstore-secret-name>with the name of the secret that was created withCephObjectStorein the previous step. -
Replace
<bucket-name>with an existing RGW bucket name. This argument tells Multicloud Object Gateway which bucket to use as a target bucket for its backing store, and subsequently, data storage and administration.
-
Replace
7.4.4. Adding storage resources for hybrid and Multicloud using the user interface
Procedure
In your OpenShift Storage console, navigate to Overview → Object Service → select the noobaa link:

Select the Resources tab in the left, highlighted below. From the list that populates, select Add Cloud Resource:
Select Add new connection:
Select the relevant native cloud provider or S3 compatible option and fill in the details:
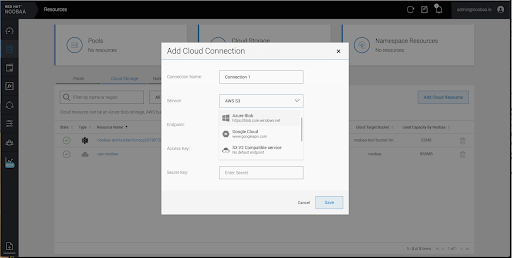
Select the newly created connection and map it to the existing bucket:

- Repeat these steps to create as many backing stores as needed.
Resources created in NooBaa UI cannot be used by OpenShift UI or MCG CLI.
7.4.5. Creating a new bucket class
Bucket class is a CRD representing a class of buckets that defines tiering policies and data placements for an Object Bucket Class (OBC).
Use this procedure to create a bucket class in OpenShift Container Storage.
Procedure
- Click Operators → Installed Operators from the left pane of the OpenShift Web Console to view the installed operators.
- Click OpenShift Container Storage Operator.
On the OpenShift Container Storage Operator page, scroll right and click the Bucket Class tab.
Figure 7.3. OpenShift Container Storage Operator page with Bucket Class tab
- Click Create Bucket Class.
On the Create new Bucket Class page, perform the following:
Enter a Bucket Class Name and click Next.
Figure 7.4. Create Bucket Class page

In Placement Policy, select Tier 1 - Policy Type and click Next. You can choose either one of the options as per your requirements.
- Spread allows spreading of the data across the chosen resources.
- Mirror allows full duplication of the data across the chosen resources.
Click Add Tier to add another policy tier.
Figure 7.5. Tier 1 - Policy Type selection page
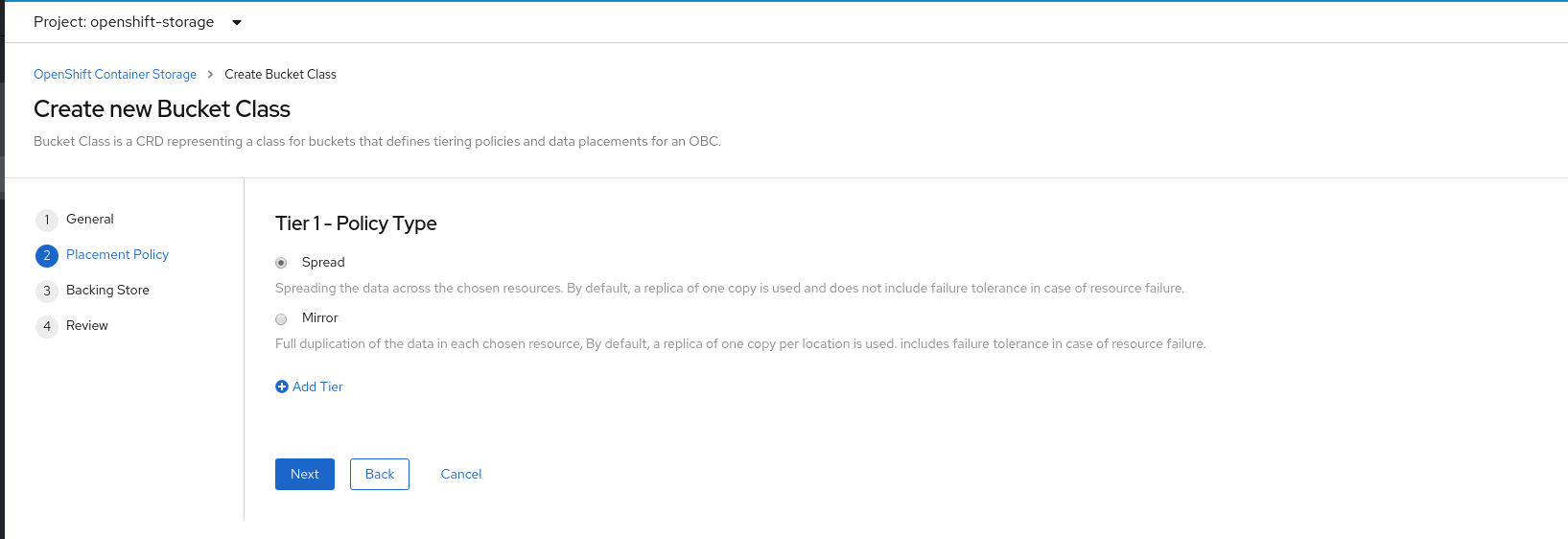
Select atleast one Backing Store resource from the available list if you have selected Tier 1 - Policy Type as Spread and click Next. Alternatively, you can also create a new backing store.
Figure 7.6. Tier 1 - Backing Store selection page

You need to select atleast 2 backing stores when you select Policy Type as Mirror in previous step.
Review and confirm Bucket Class settings.
Figure 7.7. Bucket class settings review page
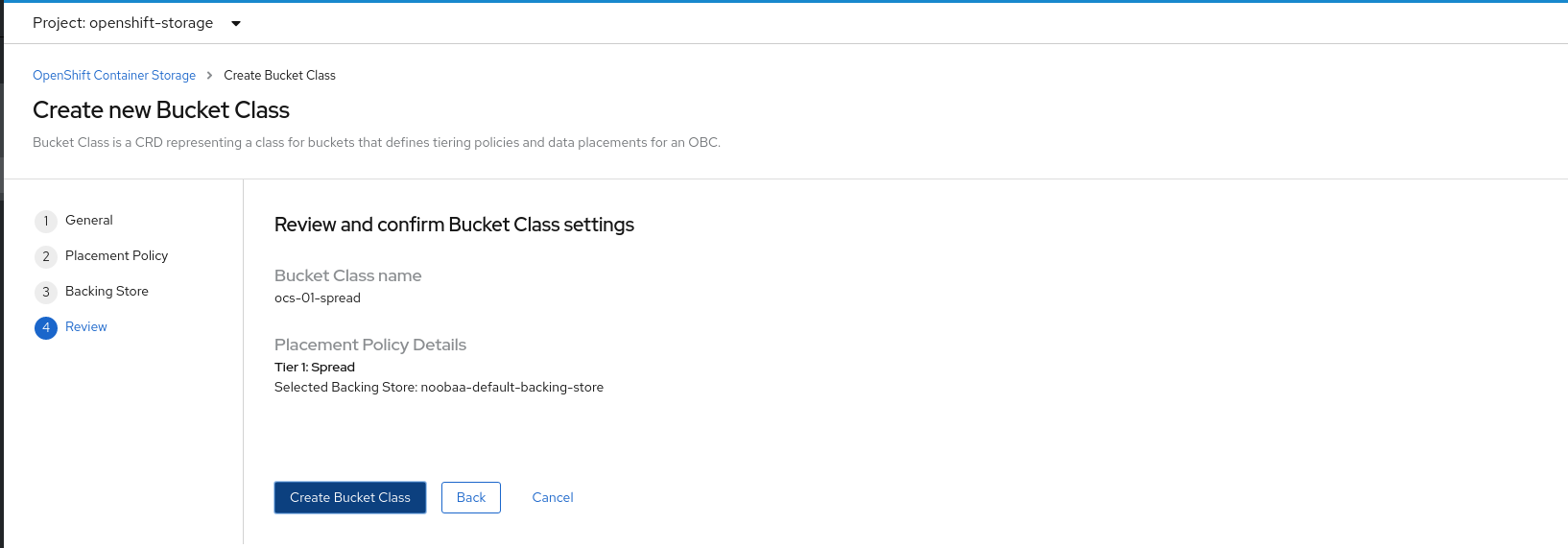
- Click Create Bucket Class.
Verification steps
- Click Operators → Installed Operators.
- Click OpenShift Container Storage Operator.
- Search for the new Bucket Class or click Bucket Class tab to view all the Bucket Classes.
7.5. Mirroring data for hybrid and Multicloud buckets
The Multicloud Object Gateway (MCG) simplifies the process of spanning data across cloud provider and clusters.
Prerequisites
- You must first add a backing storage that can be used by the MCG, see Section 7.4, “Adding storage resources for hybrid or Multicloud”.
Then you create a bucket class that reflects the data management policy, mirroring.
Procedure
You can set up mirroring data three ways:
7.5.1. Creating bucket classes to mirror data using the MCG command-line-interface
From the MCG command-line interface, run the following command to create a bucket class with a mirroring policy:
$ noobaa bucketclass create mirror-to-aws --backingstores=azure-resource,aws-resource --placement MirrorSet the newly created bucket class to a new bucket claim, generating a new bucket that will be mirrored between two locations:
$ noobaa obc create mirrored-bucket --bucketclass=mirror-to-aws
7.5.2. Creating bucket classes to mirror data using a YAML
Apply the following YAML. This YAML is a hybrid example that mirrors data between local Ceph storage and AWS:
apiVersion: noobaa.io/v1alpha1 kind: BucketClass metadata: name: hybrid-class labels: app: noobaa spec: placementPolicy: tiers: - tier: mirrors: - mirror: spread: - cos-east-us - mirror: spread: - noobaa-test-bucket-for-ocp201907291921-11247_resourceAdd the following lines to your standard Object Bucket Claim (OBC):
additionalConfig: bucketclass: mirror-to-awsFor more information about OBCs, see Section 7.7, “Object Bucket Claim”.
7.5.3. Configuring buckets to mirror data using the user interface
In your OpenShift Storage console, navigate to Overview → Object Service → select the noobaa link:
Click the buckets icon on the left side. You will see a list of your buckets:
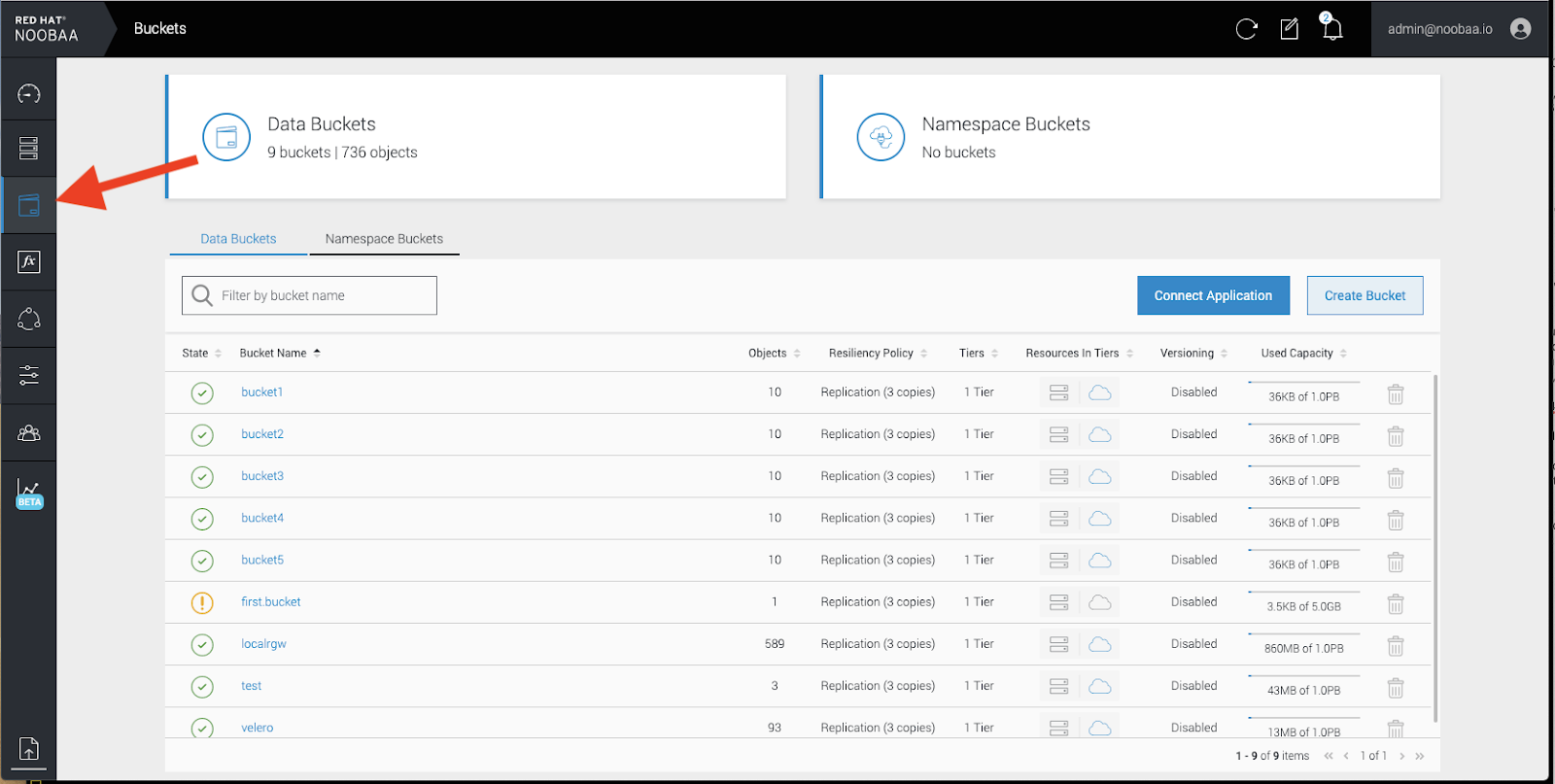
- Click the bucket you want to update.
Click Edit Tier 1 Resources:
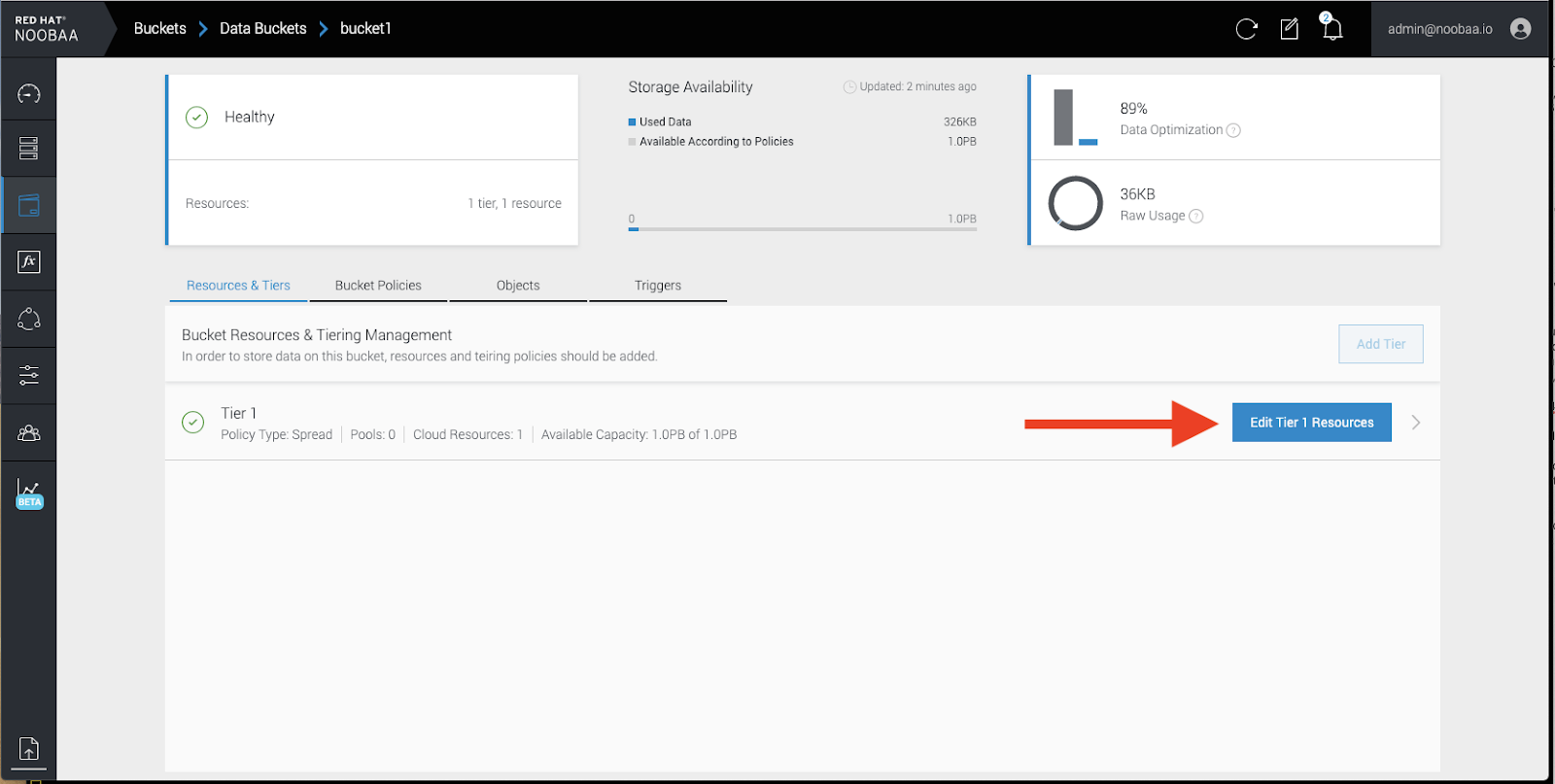
Select Mirror and check the relevant resources you want to use for this bucket. In the following example, we mirror data between on prem Ceph RGW to AWS:

- Click Save.
Resources created in NooBaa UI cannot be used by OpenShift UI or MCG CLI.
7.6. Bucket policies in the Multicloud Object Gateway
OpenShift Container Storage supports AWS S3 bucket policies. Bucket policies allow you to grant users access permissions for buckets and the objects in them.
7.6.1. About bucket policies
Bucket policies are an access policy option available for you to grant permission to your AWS S3 buckets and objects. Bucket policies use JSON-based access policy language. For more information about access policy language, see AWS Access Policy Language Overview.
7.6.2. Using bucket policies
Prerequisites
- A running OpenShift Container Storage Platform
- Access to the Multicloud Object Gateway, see Section 7.2, “Accessing the Multicloud Object Gateway with your applications”
Procedure
To use bucket policies in the Multicloud Object Gateway:
Create the bucket policy in JSON format. See the following example:
{ "Version": "NewVersion", "Statement": [ { "Sid": "Example", "Effect": "Allow", "Principal": [ "john.doe@example.com" ], "Action": [ "s3:GetObject" ], "Resource": [ "arn:aws:s3:::john_bucket" ] } ] }There are many available elements for bucket policies. For details on these elements and examples of how they can be used, see AWS Access Policy Language Overview.
For more examples of bucket policies, see AWS Bucket Policy Examples.
Instructions for creating S3 users can be found in Section 7.6.3, “Creating an AWS S3 user in the Multicloud Object Gateway”.
Using AWS S3 client, use the
put-bucket-policycommand to apply the bucket policy to your S3 bucket:# aws --endpoint ENDPOINT --no-verify-ssl s3api put-bucket-policy --bucket MyBucket --policy BucketPolicyReplace
ENDPOINTwith the S3 endpointReplace
MyBucketwith the bucket to set the policy onReplace
BucketPolicywith the bucket policy JSON fileAdd
--no-verify-sslif you are using the default self signed certificatesFor example:
# aws --endpoint https://s3-openshift-storage.apps.gogo44.noobaa.org --no-verify-ssl s3api put-bucket-policy -bucket MyBucket --policy file://BucketPolicyFor more information on the
put-bucket-policycommand, see the AWS CLI Command Reference for put-bucket-policy.
The principal element specifies the user that is allowed or denied access to a resource, such as a bucket. Currently, Only NooBaa accounts can be used as principals. In the case of object bucket claims, NooBaa automatically create an account obc-account.<generated bucket name>@noobaa.io.
Bucket policy conditions are not supported.
7.6.3. Creating an AWS S3 user in the Multicloud Object Gateway
Prerequisites
- A running OpenShift Container Storage Platform
- Access to the Multicloud Object Gateway, see Section 7.2, “Accessing the Multicloud Object Gateway with your applications”
Procedure
In your OpenShift Storage console, navigate to Overview → Object Service → select the noobaa link:
Under the Accounts tab, click Create Account:
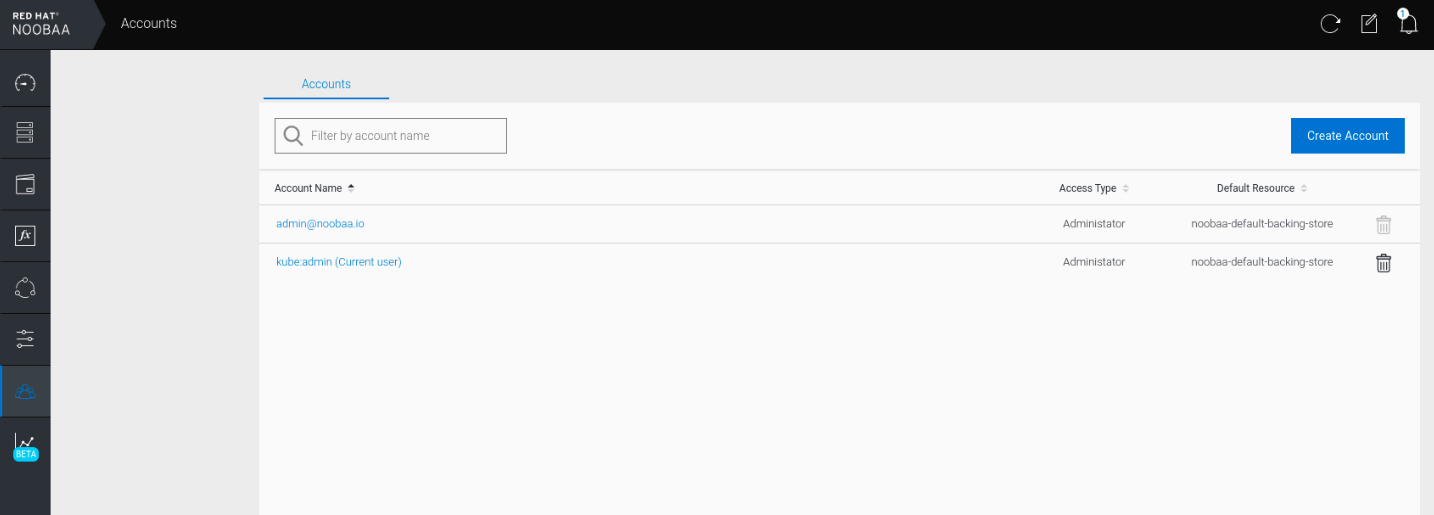
Select S3 Access Only, provide the Account Name, for example, john.doe@example.com. Click Next:
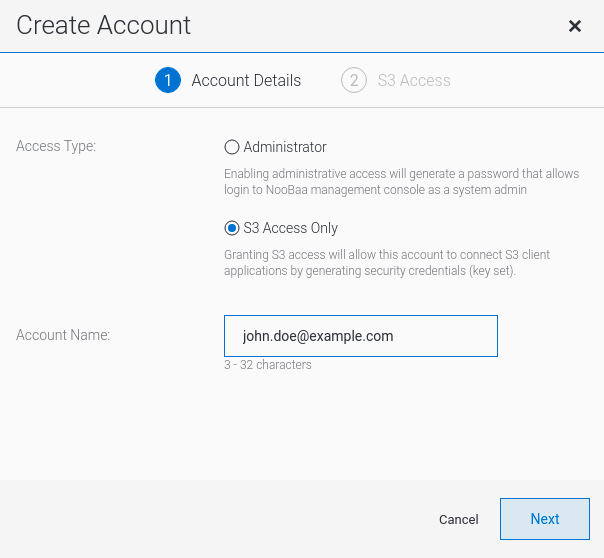
Select S3 default placement, for example, noobaa-default-backing-store. Select Buckets Permissions. A specific bucket or all buckets can be selected. Click Create:

7.7. Object Bucket Claim
An Object Bucket Claim can be used to request an S3 compatible bucket backend for your workloads.
You can create an Object Bucket Claim three ways:
An object bucket claim creates a new bucket and an application account in NooBaa with permissions to the bucket, including a new access key and secret access key. The application account is allowed to access only a single bucket and can’t create new buckets by default.
7.7.1. Dynamic Object Bucket Claim
Similar to Persistent Volumes, you can add the details of the Object Bucket claim to your application’s YAML, and get the object service endpoint, access key, and secret access key available in a configuration map and secret. It is easy to read this information dynamically into environment variables of your application.
Procedure
Add the following lines to your application YAML:
apiVersion: objectbucket.io/v1alpha1 kind: ObjectBucketClaim metadata: name: <obc-name> spec: generateBucketName: <obc-bucket-name> storageClassName: openshift-storage.noobaa.ioThese lines are the Object Bucket Claim itself.
-
Replace
<obc-name>with the a unique Object Bucket Claim name. -
Replace
<obc-bucket-name>with a unique bucket name for your Object Bucket Claim.
-
Replace
You can add more lines to the YAML file to automate the use of the Object Bucket Claim. The example below is the mapping between the bucket claim result, which is a configuration map with data and a secret with the credentials. This specific job will claim the Object Bucket from NooBaa, which will create a bucket and an account.
apiVersion: batch/v1 kind: Job metadata: name: testjob spec: template: spec: restartPolicy: OnFailure containers: - image: <your application image> name: test env: - name: BUCKET_NAME valueFrom: configMapKeyRef: name: <obc-name> key: BUCKET_NAME - name: BUCKET_HOST valueFrom: configMapKeyRef: name: <obc-name> key: BUCKET_HOST - name: BUCKET_PORT valueFrom: configMapKeyRef: name: <obc-name> key: BUCKET_PORT - name: AWS_ACCESS_KEY_ID valueFrom: secretKeyRef: name: <obc-name> key: AWS_ACCESS_KEY_ID - name: AWS_SECRET_ACCESS_KEY valueFrom: secretKeyRef: name: <obc-name> key: AWS_SECRET_ACCESS_KEY- Replace all instances of <obc-name> with your Object Bucket Claim name.
- Replace <your application image> with your application image.
Apply the updated YAML file:
# oc apply -f <yaml.file>-
Replace
<yaml.file>with the name of your YAML file.
-
Replace
To view the new configuration map, run the following:
# oc get cm <obc-name> -o yamlReplace
obc-namewith the name of your Object Bucket Claim.You can expect the following environment variables in the output:
-
BUCKET_HOST- Endpoint to use in the application BUCKET_PORT- The port available for the application-
The port is related to the
BUCKET_HOST. For example, if theBUCKET_HOSTis https://my.example.com, and theBUCKET_PORTis 443, the endpoint for the object service would be https://my.example.com:443.
-
The port is related to the
-
BUCKET_NAME- Requested or generated bucket name -
AWS_ACCESS_KEY_ID- Access key that is part of the credentials -
AWS_SECRET_ACCESS_KEY- Secret access key that is part of the credentials
-
7.7.2. Creating an Object Bucket Claim using the command line interface
When creating an Object Bucket Claim using the command-line interface, you get a configuration map and a Secret that together contain all the information your application needs to use the object storage service.
Prerequisites
Download the MCG command-line interface:
# subscription-manager repos --enable=rh-ocs-4-for-rhel-8-x86_64-rpms # yum install mcg
Procedure
Use the command-line interface to generate the details of a new bucket and credentials. Run the following command:
# noobaa obc create <obc-name> -n openshift-storageReplace
<obc-name>with a unique Object Bucket Claim name, for example,myappobc.Additionally, you can use the
--app-namespaceoption to specify the namespace where the Object Bucket Claim configuration map and secret will be created, for example,myapp-namespace.Example output:
INFO[0001] ✅ Created: ObjectBucketClaim "test21obc"The MCG command-line-interface has created the necessary configuration and has informed OpenShift about the new OBC.
Run the following command to view the Object Bucket Claim:
# oc get obc -n openshift-storageExample output:
NAME STORAGE-CLASS PHASE AGE test21obc openshift-storage.noobaa.io Bound 38sRun the following command to view the YAML file for the new Object Bucket Claim:
# oc get obc test21obc -o yaml -n openshift-storageExample output:
apiVersion: objectbucket.io/v1alpha1 kind: ObjectBucketClaim metadata: creationTimestamp: "2019-10-24T13:30:07Z" finalizers: - objectbucket.io/finalizer generation: 2 labels: app: noobaa bucket-provisioner: openshift-storage.noobaa.io-obc noobaa-domain: openshift-storage.noobaa.io name: test21obc namespace: openshift-storage resourceVersion: "40756" selfLink: /apis/objectbucket.io/v1alpha1/namespaces/openshift-storage/objectbucketclaims/test21obc uid: 64f04cba-f662-11e9-bc3c-0295250841af spec: ObjectBucketName: obc-openshift-storage-test21obc bucketName: test21obc-933348a6-e267-4f82-82f1-e59bf4fe3bb4 generateBucketName: test21obc storageClassName: openshift-storage.noobaa.io status: phase: BoundInside of your
openshift-storagenamespace, you can find the configuration map and the secret to use this Object Bucket Claim. The CM and the secret have the same name as the Object Bucket Claim. To view the secret:# oc get -n openshift-storage secret test21obc -o yamlExample output:
Example output: apiVersion: v1 data: AWS_ACCESS_KEY_ID: c0M0R2xVanF3ODR3bHBkVW94cmY= AWS_SECRET_ACCESS_KEY: Wi9kcFluSWxHRzlWaFlzNk1hc0xma2JXcjM1MVhqa051SlBleXpmOQ== kind: Secret metadata: creationTimestamp: "2019-10-24T13:30:07Z" finalizers: - objectbucket.io/finalizer labels: app: noobaa bucket-provisioner: openshift-storage.noobaa.io-obc noobaa-domain: openshift-storage.noobaa.io name: test21obc namespace: openshift-storage ownerReferences: - apiVersion: objectbucket.io/v1alpha1 blockOwnerDeletion: true controller: true kind: ObjectBucketClaim name: test21obc uid: 64f04cba-f662-11e9-bc3c-0295250841af resourceVersion: "40751" selfLink: /api/v1/namespaces/openshift-storage/secrets/test21obc uid: 65117c1c-f662-11e9-9094-0a5305de57bb type: OpaqueThe secret gives you the S3 access credentials.
To view the configuration map:
# oc get -n openshift-storage cm test21obc -o yamlExample output:
apiVersion: v1 data: BUCKET_HOST: 10.0.171.35 BUCKET_NAME: test21obc-933348a6-e267-4f82-82f1-e59bf4fe3bb4 BUCKET_PORT: "31242" BUCKET_REGION: "" BUCKET_SUBREGION: "" kind: ConfigMap metadata: creationTimestamp: "2019-10-24T13:30:07Z" finalizers: - objectbucket.io/finalizer labels: app: noobaa bucket-provisioner: openshift-storage.noobaa.io-obc noobaa-domain: openshift-storage.noobaa.io name: test21obc namespace: openshift-storage ownerReferences: - apiVersion: objectbucket.io/v1alpha1 blockOwnerDeletion: true controller: true kind: ObjectBucketClaim name: test21obc uid: 64f04cba-f662-11e9-bc3c-0295250841af resourceVersion: "40752" selfLink: /api/v1/namespaces/openshift-storage/configmaps/test21obc uid: 651c6501-f662-11e9-9094-0a5305de57bbThe configuration map contains the S3 endpoint information for your application.
7.7.3. Creating an Object Bucket Claim using the OpenShift Web Console
You can create an Object Bucket Claim (OBC) using the OpenShift Web Console.
Prerequisites
- Administrative access to the OpenShift Web Console.
- In order for your applications to communicate with the OBC, you need to use the configmap and secret. For more information about this, see Section 7.7.1, “Dynamic Object Bucket Claim”.
Procedure
- Log into the OpenShift Web Console.
- On the left navigation bar, click Storage → Object Bucket Claims.
Click Create Object Bucket Claim:

Enter a name for your object bucket claim and select the appropriate storage class based on your deployment, internal or external, from the dropdown menu:
Internal mode

The following storage classes, which were created after deployment, are available for use:
-
ocs-storagecluster-ceph-rgwuses the Ceph Object Gateway (RGW) -
openshift-storage.noobaa.iouses the Multicloud Object Gateway
External mode
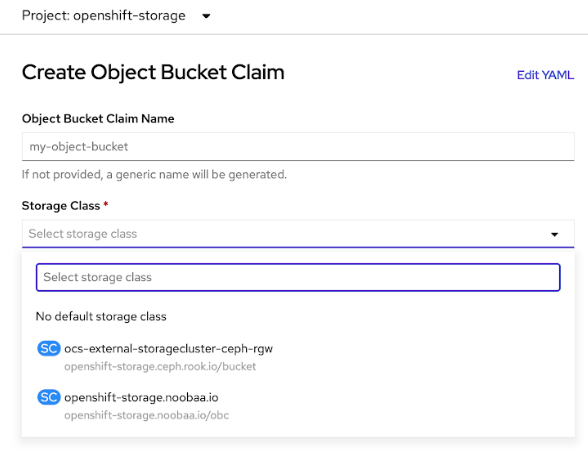
The following storage classes, which were created after deployment, are available for use:
-
ocs-external-storagecluster-ceph-rgwuses the Ceph Object Gateway (RGW) openshift-storage.noobaa.iouses the Multicloud Object GatewayNoteThe RGW OBC storage class is only available with fresh installations of OpenShift Container Storage version 4.5. It does not apply to clusters upgraded from previous OpenShift Container Storage releases.
-
Click Create.
Once you create the OBC, you are redirected to its detail page:
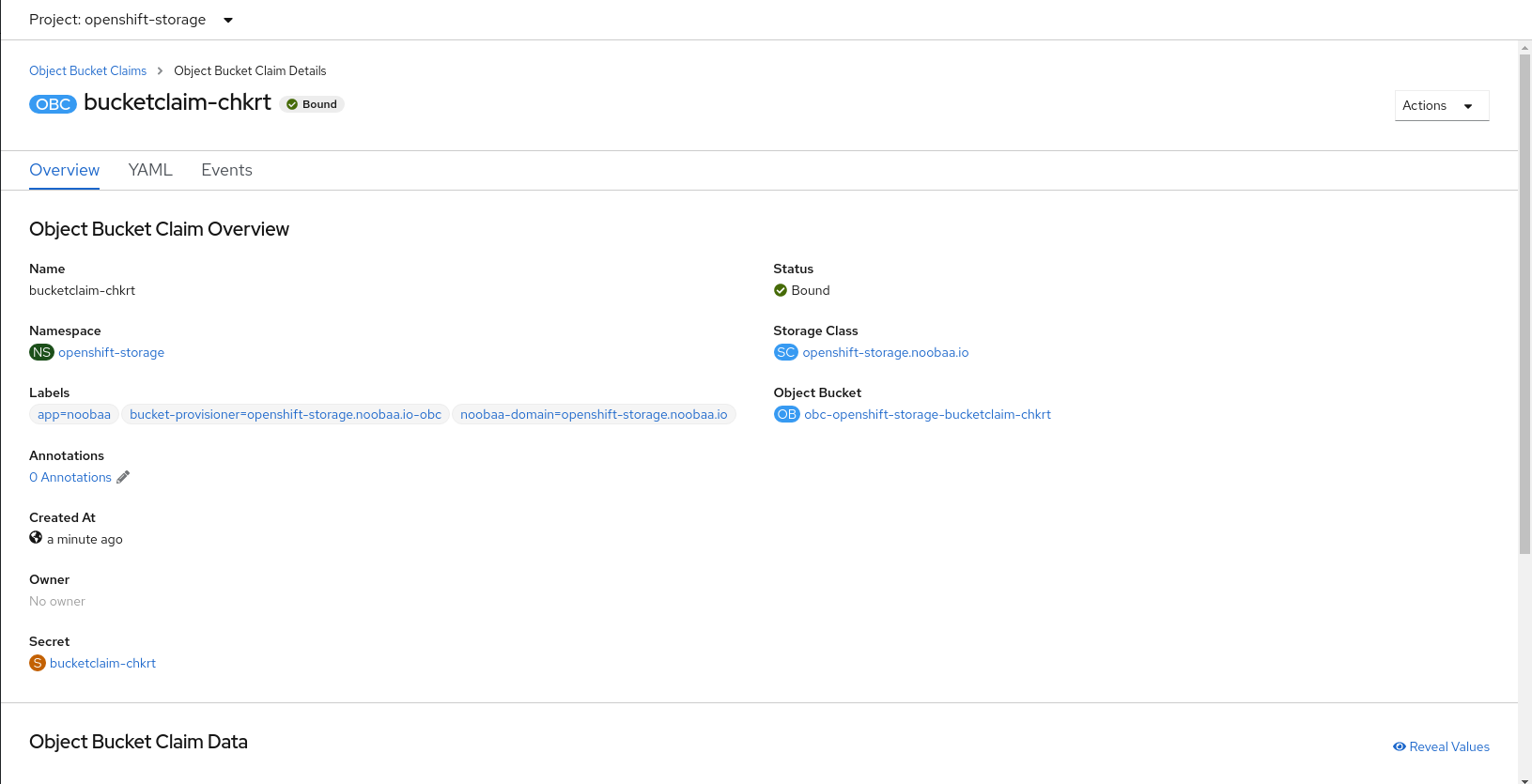
Additional Resources
7.7.4. Attaching an Object Bucket Claim to a deployment
Once created, Object Bucket Claims (OBCs) can be attached to specific deployments.
Prerequisites
- Administrative access to the OpenShift Web Console.
Procedure
- On the left navigation bar, click Storage → Object Bucket Claims.
- Click the action menu (⋮) next to the OBC you created.
From the drop down menu, select Attach to Deployment.

Select the desired deployment from the Deployment Name list, then click Attach:

Additional Resources
7.7.5. Viewing object buckets using the OpenShift Web Console
You can view the details of object buckets created for Object Bucket Claims (OBCs) using the OpenShift Web Console.
Prerequisites
- Administrative access to the OpenShift Web Console.
Procedure
To view the object bucket details:
- Log into the OpenShift Web Console.
On the left navigation bar, click Storage → Object Buckets:
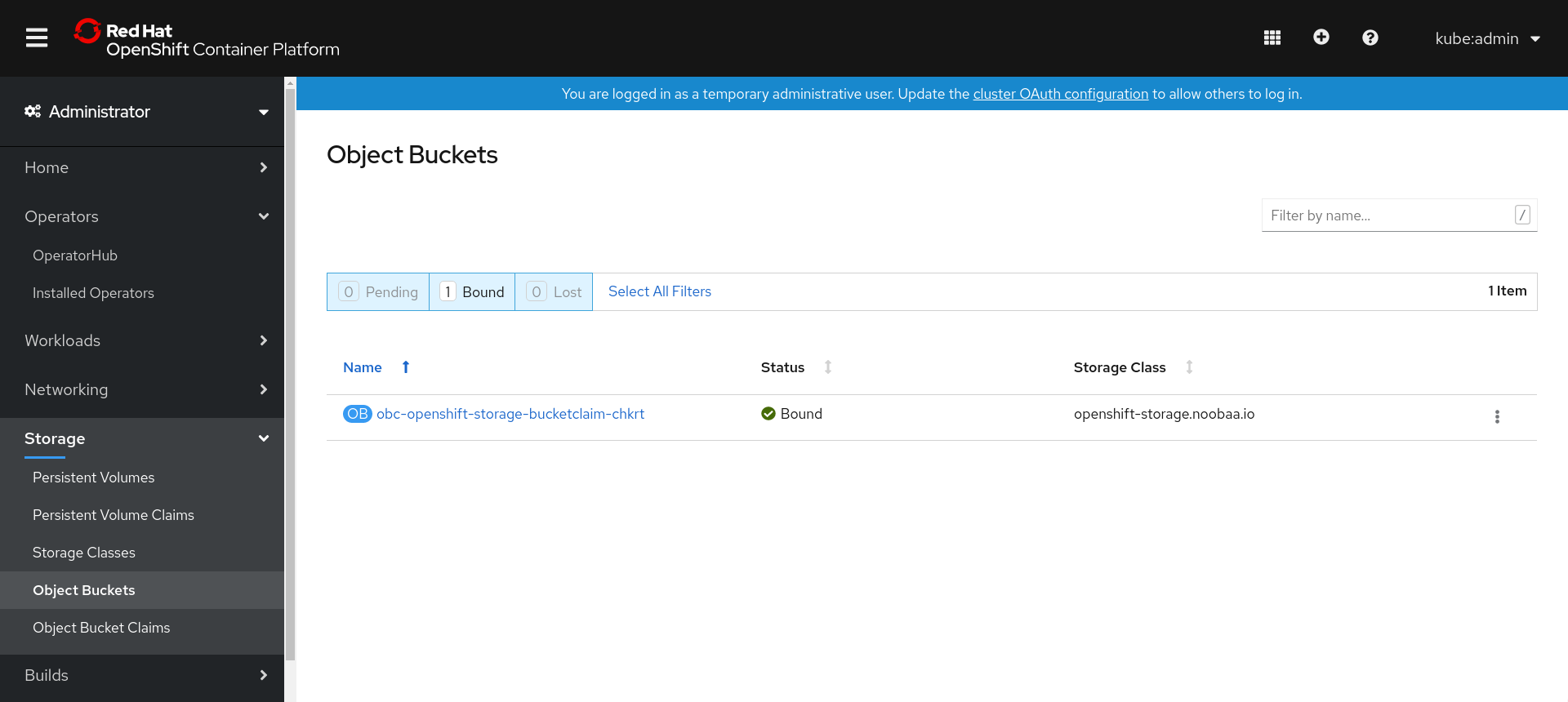
You can also navigate to the details page of a specific OBC and click the Resource link to view the object buckets for that OBC.
Select the object bucket you want to see details for. You are navigated to the object bucket’s details page:

Additional Resources
7.7.6. Deleting Object Bucket Claims
Prerequisites
- Administrative access to the OpenShift Web Console.
Procedure
- On the left navigation bar, click Storage → Object Bucket Claims.
click on the action menu (⋮) next to the Object Bucket Claim you want to delete.
Select Delete Object Bucket Claim from menu.
- Click Delete.
Additional Resources
7.8. Scaling Multicloud Object Gateway performance by adding endpoints
The Multicloud Object Gateway performance may vary from one environment to another. In some cases, specific applications require faster performance which can be easily addressed by scaling S3 endpoints, which is a Technology Preview feature.
The Multicloud Object Gateway resource pool is a group of NooBaa daemon containers that provide two types of services enabled by default:
- Storage service
- S3 endpoint service
Scaling Multicloud Object Gateway performance by adding endpoints is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
For more information, see Technology Preview Features Support Scope.
7.8.1. S3 endpoints in the Multicloud Object Gateway
The S3 endpoint is a service that every Multicloud Object Gateway provides by default that handles the heavy lifting data digestion in the Multicloud Object Gateway. The endpoint service handles the inline data chunking, deduplication, compression, and encryption, and it accepts data placement instructions from the Multicloud Object Gateway.
7.8.2. Scaling with storage nodes
Prerequisites
- A running OpenShift Container Storage cluster on OpenShift Container Platform with access to the Multicloud Object Gateway.
A storage node in the Multicloud Object Gateway is a NooBaa daemon container attached to one or more Persistent Volumes and used for local object service data storage. NooBaa daemons can be deployed on Kubernetes nodes. This can be done by creating a Kubernetes pool consisting of StatefulSet pods.
Procedure
In the Multicloud Object Gateway user interface, from the Overview page, click Add Storage Resources:
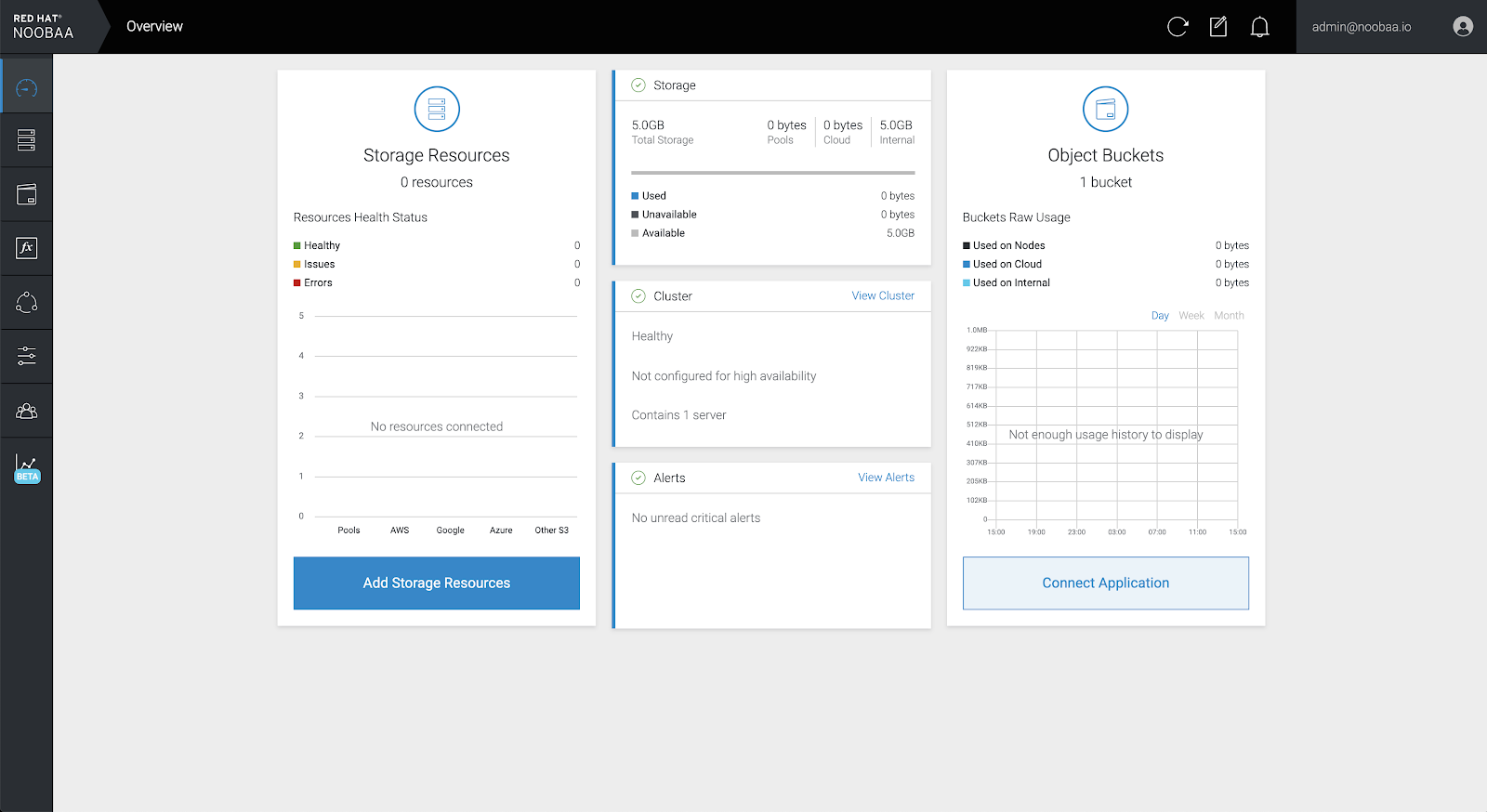
In the window, click Deploy Kubernetes Pool:
In the Create Pool step create the target pool for the future installed nodes.

In the Configure step, configure the number of requested pods and the size of each PV. For each new pod, one PV is be created.
- In the Review step, you can find the details of the new pool and select the deployment method you wish to use: local or external deployment. If local deployment is selected, the Kubernetes nodes will deploy within the cluster. If external deployment is selected, you will be provided with a YAML file to run externally.
All nodes will be assigned to the pool you chose in the first step, and can be found under Resources → Storage resources → Resource name:

Chapter 8. Accessing the RADOS Object Gateway S3 endpoint
Users can access the RADOS Object Gateway (RGW) endpoint directly.
Prerequisites
- A running OpenShift Container Storage Platform
Procedure
Run
oc get servicecommand to get the RGW service name.$ oc get service NAME TYPE rook-ceph-rgw-ocs-storagecluster-cephobjectstore ClusterIP CLUSTER-IP EXTERNAL-IP PORT(S) AGE 172.30.99.207 <none> 80/TCP 4d15hRun
oc exposecommand to expose the RGW service.$ oc expose svc/<RGW service name> --hostname=<route name>Replace
<RGW-service name>with the RGW service name from the previous step.Replace
<route name>with a route you want to create for the RGW service.For example:
$ oc expose svc/rook-ceph-rgw-ocs-storagecluster-cephobjectstore --hostname=rook-ceph-rgw-ocs.ocp.host.example.comRun
oc get routecommand to confirmoc exposeis successful and there is an RGW route.$ oc get route NAME HOST/PORT PATH rook-ceph-rgw-ocs-storagecluster-cephobjectstore rook-ceph-rgw-ocsocp.host.example.com SERVICES PORT TERMINATION WILDCARD rook-ceph-rgw-ocs-storagecluster-cephobjectstore http <none>
Verify
To verify the
ENDPOINT, run the following command:aws s3 --no-verify-ssl --endpoint <ENDPOINT> lsReplace
<ENDPOINT>with the route that you get from the command in the above step 3.For example:
$ aws s3 --no-verify-ssl --endpoint http://rook-ceph-rgw-ocs.ocp.host.example.com ls
To get the access key and secret of the default user ocs-storagecluster-cephobjectstoreuser, run the following commands:
Access key:
$ oc get secret rook-ceph-object-user-ocs-storagecluster-cephobjectstore-ocs-storagecluster-cephobjectstoreuser -o yaml | grep -w "AccessKey:" | head -n1 | awk '{print $2}' | base64 --decodeSecret key:
$ oc get secret rook-ceph-object-user-ocs-storagecluster-cephobjectstore-ocs-storagecluster-cephobjectstoreuser -o yaml | grep -w "SecretKey:" | head -n1 | awk '{print $2}' | base64 --decode
Chapter 9. Replacing storage nodes for OpenShift Container Storage
For OpenShift Container Storage, node replacement can be performed proactively for an operational node and reactively for a failed node for the following deployments:
For Amazon Web Services (AWS)
- User-provisioned infrastructure
- Installer-provisioned infrastructure
For VMware
- User-provisioned infrastructure
For local storage devices
- Bare metal
- Amazon EC2 I3
- VMware
- For replacing your storage nodes in external mode, see Red Hat Ceph Storage documentation.
9.1. OpenShift Container Storage deployed on AWS
9.1.1. Replacing an operational AWS node on user-provisioned infrastructure
Perform this procedure to replace an operational node on AWS user-provisioned infrastructure.
Procedure
- Identify the node that needs to be replaced.
Mark the node as unschedulable using the following command:
$ oc adm cordon <node_name>Drain the node using the following command:
$ oc adm drain <node_name> --force --delete-local-data --ignore-daemonsetsImportantThis activity may take at least 5-10 minutes or more. Ceph errors generated during this period are temporary and are automatically resolved when the new node is labeled and functional.
Delete the node using the following command:
$ oc delete nodes <node_name>- Create a new AWS machine instance with the required infrastructure. See Platform requirements.
- Create a new OpenShift Container Platform node using the new AWS machine instance.
Check for certificate signing requests (CSRs) related to OpenShift Container Platform that are in
Pendingstate:$ oc get csrApprove all required OpenShift Container Platform CSRs for the new node:
$ oc adm certificate approve <Certificate_Name>- Click Compute → Nodes, confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
Execute the following command to apply the OpenShift Container Storage label to the new node:
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""
Verification steps
Execute the following command and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1Click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
- Verify that all other required OpenShift Container Storage pods are in Running state.
- If verification steps fail, kindly contact Red Hat Support.
9.1.2. Replacing an operational AWS node on installer-provisioned infrastructure
Use this procedure to replace an operational node on AWS installer-provisioned infrastructure (IPI).
Procedure
- Log in to OpenShift Web Console and click Compute → Nodes.
- Identify the node that needs to be replaced. Take a note of its Machine Name.
Mark the node as unschedulable using the following command:
$ oc adm cordon <node_name>Drain the node using the following command:
$ oc adm drain <node_name> --force --delete-local-data --ignore-daemonsetsImportantThis activity may take at least 5-10 minutes or more. Ceph errors generated during this period are temporary and are automatically resolved when the new node is labeled and functional.
- Click Compute → Machines. Search for the required machine.
- Besides the required machine, click the Action menu (⋮) → Delete Machine.
- Click Delete to confirm the machine deletion. A new machine is automatically created.
Wait for new machine to start and transition into Running state.
ImportantThis activity may take at least 5-10 minutes or more.
- Click Compute → Nodes, confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
Execute the following command to apply the OpenShift Container Storage label to the new node:
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""
Verification steps
Execute the following command and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1Click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
- Verify that all other required OpenShift Container Storage pods are in Running state.
- If verification steps fail, kindly contact Red Hat Support.
9.1.3. Replacing a failed AWS node on user-provisioned infrastructure
Perform this procedure to replace a failed node which is not operational on AWS user-provisioned infrastructure (UPI) for OpenShift Container Storage.
Procedure
- Identify the AWS machine instance of the node that needs to be replaced.
- Log in to AWS and terminate the identified AWS machine instance.
- Create a new AWS machine instance with the required infrastructure. See platform requirements.
- Create a new OpenShift Container Platform node using the new AWS machine instance.
Check for certificate signing requests (CSRs) related to OpenShift Container Platform that are in
Pendingstate:$ oc get csrApprove all required OpenShift Container Platform CSRs for the new node:
$ oc adm certificate approve <Certificate_Name>- Click Compute → Nodes, confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
Execute the following command to apply the OpenShift Container Storage label to the new node:
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""
Verification steps
Execute the following command and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1Click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
- Verify that all other required OpenShift Container Storage pods are in Running state.
- If verification steps fail, contact Red Hat Support.
9.1.4. Replacing a failed AWS node on installer-provisioned infrastructure
Perform this procedure to replace a failed node which is not operational on AWS installer-provisioned infrastructure (IPI) for OpenShift Container Storage.
Procedure
- Log in to OpenShift Web Console and click Compute → Nodes.
- Identify the faulty node and click on its Machine Name.
- Click Actions → Edit Annotations, and click Add More.
-
Add
machine.openshift.io/exclude-node-drainingand click Save. - Click Actions → Delete Machine, and click Delete.
A new machine is automatically created, wait for new machine to start.
ImportantThis activity may take at least 5-10 minutes or more. Ceph errors generated during this period are temporary and are automatically resolved when the new node is labeled and functional.
- Click Compute → Nodes, confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
Execute the following command to apply the OpenShift Container Storage label to the new node:
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""
Execute the following command and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1Click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
- Verify that all other required OpenShift Container Storage pods are in Running state.
- If verification steps fail, kindly contact Red Hat Support.
9.2. OpenShift Container Storage deployed on VMware
9.2.1. Replacing an operational VMware node on user-provisioned infrastructure
Perform this procedure to replace an operational node on VMware user-provisioned infrastructure (UPI).
Procedure
- Identify the node and its VM that needs to be replaced.
Mark the node as unschedulable using the following command:
$ oc adm cordon <node_name>Drain the node using the following command:
$ oc adm drain <node_name> --force --delete-local-data --ignore-daemonsetsImportantThis activity may take at least 5-10 minutes or more. Ceph errors generated during this period are temporary and are automatically resolved when the new node is labeled and functional.
Delete the node using the following command:
$ oc delete nodes <node_name>Log in to vSphere and terminate the identified VM.
ImportantVM should be deleted only from the inventory and not from the disk.
- Create a new VM on vSphere with the required infrastructure. See Platform requirements.
- Create a new OpenShift Container Platform worker node using the new VM.
Check for certificate signing requests (CSRs) related to OpenShift Container Platform that are in
Pendingstate:$ oc get csrApprove all required OpenShift Container Platform CSRs for the new node:
$ oc adm certificate approve <Certificate_Name>- Click Compute → Nodes, confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
Execute the following command to apply the OpenShift Container Storage label to the new node:
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""
Verification steps
Execute the following command and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1Click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
- Verify that all other required OpenShift Container Storage pods are in Running state.
- If verification steps fail, kindly contact Red Hat Support.
9.2.2. Replacing a failed VMware node on user-provisioned infrastructure
Perform this procedure to replace a failed node on VMware user-provisioned infrastructure (UPI).
Procedure
- Identify the node and its VM that needs to be replaced.
Delete the node using the following command:
$ oc delete nodes <node_name>Log in to vSphere and terminate the identified VM.
ImportantVM should be deleted only from the inventory and not from the disk.
- Create a new VM on vSphere with the required infrastructure. See Platform requirements.
- Create a new OpenShift Container Platform worker node using the new VM.
Check for certificate signing requests (CSRs) related to OpenShift Container Platform that are in
Pendingstate:$ oc get csrApprove all required OpenShift Container Platform CSRs for the new node:
$ oc adm certificate approve <Certificate_Name>- Click Compute → Nodes, confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
Execute the following command to apply the OpenShift Container Storage label to the new node:
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""
Verification steps
Execute the following command and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1Click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
- Verify that all other required OpenShift Container Storage pods are in Running state.
- If verification steps fail, kindly contact Red Hat Support.
9.3. OpenShift Container Storage deployed using local storage devices
9.3.1. Replacing storage nodes on bare metal infrastructure
- To replace an operational node, see Section 9.3.1.1, “Replacing an operational node on bare metal user-provisioned infrastructure”
- To replace a failed node, see Section 9.3.1.2, “Replacing a failed node on bare metal user-provisioned infrastructure”
9.3.1.1. Replacing an operational node on bare metal user-provisioned infrastructure
Prerequisites
- You must be logged into the OpenShift Container Platform (OCP) cluster.
Procedure
Identify the node and get labels on the node to be replaced. Make a note of the rack label.
$ oc get nodes --show-labels | grep <node_name>Identify the mon (if any) and object storage device (OSD) pods that are running in the node to be replaced.
$ oc get pods -n openshift-storage -o wide | grep -i <node_name>Scale down the deployments of the pods identified in the previous step.
For example:
$ oc scale deployment rook-ceph-mon-c --replicas=0 -n openshift-storage $ oc scale deployment rook-ceph-osd-0 --replicas=0 -n openshift-storage $ oc scale deployment --selector=app=rook-ceph-crashcollector,node_name=<node_name> --replicas=0 -n openshift-storageMark the nodes as unschedulable.
$ oc adm cordon <node_name>Drain the node.
$ oc adm drain <node_name> --force --delete-local-data --ignore-daemonsetsDelete the node.
$ oc delete node <node_name>- Get a new bare metal machine with required infrastructure. See Installing a cluster on bare metal.
- Create a new OpenShift Container Platform node using the new bare metal machine.
Check for certificate signing requests (CSRs) related to OpenShift Container Storage that are in
Pendingstate:$ oc get csrApprove all required OpenShift Container Storage CSRs for the new node:
$ oc adm certificate approve <Certificate_Name>- Click Compute → Nodes in OpenShift Web Console, confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
- Execute the following command to apply the OpenShift Container Storage label to the new node:
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""
Add the local storage devices available in these worker nodes to the OpenShift Container Storage StorageCluster.
Add a new disk entry to
LocalVolumeCR.Edit
LocalVolumeCR and remove or comment out faileddevice /dev/disk/by-id/{id}and add the new/dev/disk/by-id/{id}. In this example, the new device is/dev/disk/by-id/nvme-INTEL_SSDPEKKA128G7_BTPYB89THF49128A.# oc get -n local-storage localvolume NAME AGE local-block 25h# oc edit -n local-storage localvolume local-blockExample output:
[...] storageClassDevices: - devicePaths: - /dev/disk/by-id/nvme-INTEL_SSDPEKKA128G7_BTPY81260978128A - /dev/disk/by-id/nvme-INTEL_SSDPEKKA128G7_BTPY80440W5U128A - /dev/disk/by-id/nvme-INTEL_SSDPEKKA128G7_BTPYB85AABDE128A - /dev/disk/by-id/nvme-INTEL_SSDPEKKA128G7_BTPYB89THF49128A storageClassName: localblock volumeMode: Block [...]Make sure to save the changes after editing the CR.
Display PVs with
localblock.$ oc get pv | grep localblockExample output:
local-pv-3e8964d3 931Gi RWO Delete Bound openshift-storage/ocs-deviceset-2-0-79j94 localblock 25h local-pv-414755e0 931Gi RWO Delete Bound openshift-storage/ocs-deviceset-1-0-959rp localblock 25h local-pv-b481410 931Gi RWO Delete Available localblock 3m24s local-pv-d9c5cbd6 931Gi RWO Delete Bound openshift-storage/ocs-deviceset-0-0-nvs68 localblock
Delete the PV associated with the failed node.
Identify the
DeviceSetassociated with the OSD to be replaced.# osd_id_to_remove=0 # oc get -n openshift-storage -o yaml deployment rook-ceph-osd-${osd_id_to_remove} | grep ceph.rook.io/pvcwhere,
osd_id_to_removeis the integer in the pod name immediately after therook-ceph-osd prefix. In this example, the deployment name isrook-ceph-osd-0.Example output:
ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68 ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68In this example, the PVC name is
ocs-deviceset-0-0-nvs68.Identify the PV associated with the PVC.
# oc get -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix>where,
x,y, andpvc-suffixare the values in theDeviceSetidentified in the previous step.Example output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ocs-deviceset-0-0-nvs68 Bound local-pv-d9c5cbd6 931Gi RWO localblock 24hIn this example, the associated PV is
local-pv-d9c5cbd6.Delete the PVC.
# oc delete pvc <pvc-name> -n openshift-storageDelete the PV.
# oc delete pv local-pv-d9c5cbd6Example output:
persistentvolume "local-pv-d9c5cbd6" deleted
Remove the failed OSD from the cluster.
# oc process -n openshift-storage ocs-osd-removal -p FAILED_OSD_ID=${osd_id_to_remove} | oc create -f -Verify that the OSD is removed successfully by checking the status of the
ocs-osd-removalpod. A status ofCompletedconfirms that the OSD removal job succeeded.# oc get pod -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storageNoteIf
ocs-osd-removalfails and the pod is not in the expectedCompletedstate, check the pod logs for further debugging. For example:# oc logs -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storage --tail=-1Delete OSD pod deployment and crashcollector pod deployment.
$ oc delete deployment rook-ceph-osd-${osd_id_to_remove} -n openshift-storage $ oc delete deployment --selector=app=rook-ceph-crashcollector,node_name=<old_node_name> -n openshift-storageDeploy the new OSD by restarting the
rook-ceph-operatorto force operator reconciliation.# oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-2d982 1/1 Running 0 1d20hDelete the
rook-ceph-operator.# oc delete -n openshift-storage pod rook-ceph-operator-6f74fb5bff-2d982Example output:
pod "rook-ceph-operator-6f74fb5bff-2d982" deletedVerify that the
rook-ceph-operatorpod is restarted.# oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-7mvrq 1/1 Running 0 66sCreation of the new OSD and
monmight take several minutes after the operator restarts.
Delete the
ocs-osd-removaljob.# oc delete job ocs-osd-removal-${osd_id_to_remove}Example output:
job.batch "ocs-osd-removal-0" deleted
Verification steps
Execute the following command and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1Click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
Verify that all other required OpenShift Container Storage pods are in Running state.
Make sure that the new incremental
monis created and is in the Running state.$ oc get pod -n openshift-storage | grep monExample output:
rook-ceph-mon-c-64556f7659-c2ngc 1/1 Running 0 6h14m rook-ceph-mon-d-7c8b74dc4d-tt6hd 1/1 Running 0 4h24m rook-ceph-mon-e-57fb8c657-wg5f2 1/1 Running 0 162mOSD and Mon might take several minutes to get to the
Runningstate.- If verification steps fail, contact Red Hat Support.
9.3.1.2. Replacing a failed node on bare metal user-provisioned infrastructure
Prerequisites
- You must be logged into the OpenShift Container Platform (OCP) cluster.
Procedure
Identify the node and get labels on the node to be replaced. Make a note of the rack label.
$ oc get nodes --show-labels | grep <node_name>Identify the mon (if any) and object storage device (OSD) pods that are running in the node to be replaced.
$ oc get pods -n openshift-storage -o wide | grep -i <node_name>Scale down the deployments of the pods identified in the previous step.
For example:
$ oc scale deployment rook-ceph-mon-c --replicas=0 -n openshift-storage $ oc scale deployment rook-ceph-osd-0 --replicas=0 -n openshift-storage $ oc scale deployment --selector=app=rook-ceph-crashcollector,node_name=<node_name> --replicas=0 -n openshift-storageMark the node as unschedulable.
$ oc adm cordon <node_name>Remove the pods which are in Terminating state
$ oc get pods -A -o wide | grep -i <node_name> | awk '{if ($4 == "Terminating") system ("oc -n " $1 " delete pods " $2 " --grace-period=0 " " --force ")}'Drain the node.
$ oc adm drain <node_name> --force --delete-local-data --ignore-daemonsetsDelete the node.
$ oc delete node <node_name>- Get a new bare metal machine with required infrastructure. See Installing a cluster on bare metal.
- Create a new OpenShift Container Platform node using the new bare metal machine.
Check for certificate signing requests (CSRs) related to OpenShift Container Storage that are in
Pendingstate:$ oc get csrApprove all required OpenShift Container Storage CSRs for the new node:
$ oc adm certificate approve <Certificate_Name>- Click Compute → Nodes in OpenShift Web Console, confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
- Execute the following command to apply the OpenShift Container Storage label to the new node:
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""
Add the local storage devices available in these worker nodes to the OpenShift Container Storage StorageCluster.
Add a new disk entry to
LocalVolumeCR.Edit
LocalVolumeCR and remove or comment out faileddevice /dev/disk/by-id/{id}and add the new/dev/disk/by-id/{id}. In this example, the new device is/dev/disk/by-id/nvme-INTEL_SSDPEKKA128G7_BTPYB89THF49128A.# oc get -n local-storage localvolume NAME AGE local-block 25h# oc edit -n local-storage localvolume local-blockExample output:
[...] storageClassDevices: - devicePaths: - /dev/disk/by-id/nvme-INTEL_SSDPEKKA128G7_BTPY81260978128A - /dev/disk/by-id/nvme-INTEL_SSDPEKKA128G7_BTPY80440W5U128A - /dev/disk/by-id/nvme-INTEL_SSDPEKKA128G7_BTPYB85AABDE128A - /dev/disk/by-id/nvme-INTEL_SSDPEKKA128G7_BTPYB89THF49128A storageClassName: localblock volumeMode: Block [...]Make sure to save the changes after editing the CR.
Display PVs with
localblock.$ oc get pv | grep localblockExample output:
local-pv-3e8964d3 931Gi RWO Delete Bound openshift-storage/ocs-deviceset-2-0-79j94 localblock 25h local-pv-414755e0 931Gi RWO Delete Bound openshift-storage/ocs-deviceset-1-0-959rp localblock 25h local-pv-b481410 931Gi RWO Delete Available localblock 3m24s local-pv-d9c5cbd6 931Gi RWO Delete Bound openshift-storage/ocs-deviceset-0-0-nvs68 localblock
Delete the PV associated with the failed node.
Identify the
DeviceSetassociated with the OSD to be replaced.# osd_id_to_remove=0 # oc get -n openshift-storage -o yaml deployment rook-ceph-osd-${osd_id_to_remove} | grep ceph.rook.io/pvcwhere,
osd_id_to_removeis the integer in the pod name immediately after therook-ceph-osd prefix. In this example, the deployment name isrook-ceph-osd-0.Example output:
ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68 ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68In this example, the PVC name is
ocs-deviceset-0-0-nvs68.Identify the PV associated with the PVC.
# oc get -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix>where,
x,y, andpvc-suffixare the values in theDeviceSetidentified in the previous step.Example output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ocs-deviceset-0-0-nvs68 Bound local-pv-d9c5cbd6 931Gi RWO localblock 24hIn this example, the associated PV is
local-pv-d9c5cbd6.Delete the PVC.
# oc delete pvc <pvc-name> -n openshift-storageDelete the PV.
# oc delete pv local-pv-d9c5cbd6Example output:
persistentvolume "local-pv-d9c5cbd6" deleted
Remove the failed OSD from the cluster.
# oc process -n openshift-storage ocs-osd-removal -p FAILED_OSD_ID=${osd_id_to_remove} | oc create -f -Verify that the OSD is removed successfully by checking the status of the
ocs-osd-removalpod. A status ofCompletedconfirms that the OSD removal job succeeded.# oc get pod -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storageNoteIf
ocs-osd-removalfails and the pod is not in the expectedCompletedstate, check the pod logs for further debugging. For example:# oc logs -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storage --tail=-1Delete OSD pod deployment and crashcollector pod deployment.
$ oc delete deployment rook-ceph-osd-${osd_id_to_remove} -n openshift-storage $ oc delete deployment --selector=app=rook-ceph-crashcollector,node_name=<old_node_name> -n openshift-storageDeploy the new OSD by restarting the
rook-ceph-operatorto force operator reconciliation.# oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-2d982 1/1 Running 0 1d20hDelete the
rook-ceph-operator.# oc delete -n openshift-storage pod rook-ceph-operator-6f74fb5bff-2d982Example output:
pod "rook-ceph-operator-6f74fb5bff-2d982" deletedVerify that the
rook-ceph-operatorpod is restarted.# oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-7mvrq 1/1 Running 0 66sCreation of the new OSD and
monmight take several minutes after the operator restarts.
Delete the
ocs-osd-removaljob.# oc delete job ocs-osd-removal-${osd_id_to_remove}Example output:
job.batch "ocs-osd-removal-0" deleted
Verification steps
Execute the following command and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1Click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
Verify that all other required OpenShift Container Storage pods are in Running state.
Make sure that the new incremental
monis created and is in the Running state.$ oc get pod -n openshift-storage | grep monExample output:
rook-ceph-mon-c-64556f7659-c2ngc 1/1 Running 0 6h14m rook-ceph-mon-d-7c8b74dc4d-tt6hd 1/1 Running 0 4h24m rook-ceph-mon-e-57fb8c657-wg5f2 1/1 Running 0 162mOSD and Mon might take several minutes to get to the
Runningstate.- If verification steps fail, contact Red Hat Support.
9.3.2. Replacing storage nodes on Amazon EC2 infrastructure
To replace an operational Amazon EC2 node on user-provisioned and installer provisioned infrastructures, see:
To replace a failed Amazon EC2 node on user-provisioned and installer provisioned infrastructures, see:
9.3.2.1. Replacing an operational Amazon EC2 node on user-provisioned infrastructure
Perform this procedure to replace an operational node on Amazon EC2 I3 user-provisioned infrastructure (UPI).
Replacing storage nodes in Amazon EC2 I3 infrastructure is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
Prerequisites
- You must be logged into the OpenShift Container Platform (OCP) cluster.
Procedure
Identify the node and get labels on the node to be replaced.
$ oc get nodes --show-labels | grep <node_name>Identify the mon (if any) and OSDs that are running in the node to be replaced.
$ oc get pods -n openshift-storage -o wide | grep -i <node_name>Scale down the deployments of the pods identified in the previous step.
For example:
$ oc scale deployment rook-ceph-mon-c --replicas=0 -n openshift-storage $ oc scale deployment rook-ceph-osd-0 --replicas=0 -n openshift-storage $ oc scale deployment --selector=app=rook-ceph-crashcollector,node_name=<node_name> --replicas=0 -n openshift-storageMark the nodes as unschedulable.
$ oc adm cordon <node_name>Drain the node.
$ oc adm drain <node_name> --force --delete-local-data --ignore-daemonsetsDelete the node.
$ oc delete node <node_name>- Create a new Amazon EC2 I3 machine instance with the required infrastructure. See Supported Infrastructure and Platforms.
- Create a new OpenShift Container Platform node using the new Amazon EC2 I3 machine instance.
Check for certificate signing requests (CSRs) related to OpenShift Container Platform that are in Pending state:
$ oc get csrApprove all required OpenShift Container Platform CSRs for the new node:
$ oc adm certificate approve <Certificate_Name>- Click Compute → Nodes in the OpenShift web console. Confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels.
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
- Execute the following command to apply the OpenShift Container Storage label to the new node:
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""
Add the local storage devices available in the new worker node to the OpenShift Container Storage StorageCluster.
Add the new disk entries to LocalVolume CR.
Edit
LocalVolumeCR. You can either remove or comment out the failed device/dev/disk/by-id/{id}and add the new/dev/disk/by-id/{id}.$ oc get -n local-storage localvolumeExample output:
NAME AGE local-block 25h$ oc edit -n local-storage localvolume local-blockExample output:
[...] storageClassDevices: - devicePaths: - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS10382E5D7441494EC - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS1F45C01D7E84FE3E9 - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS136BC945B4ECB9AE4 - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS10382E5D7441464EP # - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS1F45C01D7E84F43E7 # - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS136BC945B4ECB9AE8 - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS6F45C01D7E84FE3E9 - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS636BC945B4ECB9AE4 storageClassName: localblock volumeMode: Block [...]Make sure to save the changes after editing the CR.
You can see that in this CR the below two new devices using by-id have been added.
-
nvme-Amazon_EC2_NVMe_Instance_Storage_AWS6F45C01D7E84FE3E9 -
nvme-Amazon_EC2_NVMe_Instance_Storage_AWS636BC945B4ECB9AE4
-
Display PVs with
localblock.$ oc get pv | grep localblockExample output:
local-pv-3646185e 2328Gi RWO Delete Available localblock 9s local-pv-3933e86 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-2-1-v9jp4 localblock 5h1m local-pv-8176b2bf 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-0-0-nvs68 localblock 5h1m local-pv-ab7cabb3 2328Gi RWO Delete Available localblock 9s local-pv-ac52e8a 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-1-0-knrgr localblock 5h1m local-pv-b7e6fd37 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-2-0-rdm7m localblock 5h1m local-pv-cb454338 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-0-1-h9hfm localblock 5h1m local-pv-da5e3175 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-1-1-g97lq localblock 5h ...
Delete each PV and OSD associated with the failed node using the following steps.
Identify the DeviceSet associated with the OSD to be replaced.
$ osd_id_to_remove=0 $ oc get -n openshift-storage -o yaml deployment rook-ceph-osd-${osd_id_to_remove} | grep ceph.rook.io/pvcwhere,
osd_id_to_removeis the integer in the pod name immediately after therook-ceph-osdprefix. In this example, the deployment name isrook-ceph-osd-0.Example output:
ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68 ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68Identify the PV associated with the PVC.
$ oc get -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix>where,
x,y, andpvc-suffixare the values in the DeviceSet identified in an earlier step.Example output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ocs-deviceset-0-0-nvs68 Bound local-pv-8176b2bf 2328Gi RWO localblock 4h49mIn this example, the associated PV is
local-pv-8176b2bf.Delete the PVC which was identified in earlier steps. In this example, the PVC name is
ocs-deviceset-0-0-nvs68.$ oc delete pvc ocs-deviceset-0-0-nvs68 -n openshift-storageExample output:
persistentvolumeclaim "ocs-deviceset-0-0-nvs68" deletedDelete the PV which was identified in earlier steps. In this example, the PV name is
local-pv-8176b2bf.$ oc delete pv local-pv-8176b2bfExample output:
persistentvolume "local-pv-8176b2bf" deletedRemove the failed OSD from the cluster.
$ oc process -n openshift-storage ocs-osd-removal -p FAILED_OSD_ID=${osd_id_to_remove} | oc create -f -Verify that the OSD is removed successfully by checking the status of the
ocs-osd-removalpod. A status ofCompletedconfirms that the OSD removal job succeeded.# oc get pod -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storageNoteIf ocs-osd-removal fails and the pod is not in the expected Completed state, check the pod logs for further debugging. For example:
# oc logs -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storage --tail=-1Delete the OSD pod deployment.
$ oc delete deployment rook-ceph-osd-${osd_id_to_remove} -n openshift-storage
Delete
crashcollectorpod deployment identified in an earlier step.$ oc delete deployment --selector=app=rook-ceph-crashcollector,node_name=<old_node_name> -n openshift-storageDeploy the new OSD by restarting the
rook-ceph-operatorto force operator reconciliation.$ oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-2d982 1/1 Running 0 5h3mDelete the
rook-ceph-operator.$ oc delete -n openshift-storage pod rook-ceph-operator-6f74fb5bff-2d982Example output:
pod "rook-ceph-operator-6f74fb5bff-2d982" deletedVerify that the
rook-ceph-operatorpod is restarted.$ oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-7mvrq 1/1 Running 0 66sCreation of the new OSD may take several minutes after the operator starts.
Delete the
ocs-osd-removaljob(s).$ oc delete job ocs-osd-removal-${osd_id_to_remove}Example output:
job.batch "ocs-osd-removal-0" deleted
Verification steps
Execute the following command and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1Click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
Verify that all other required OpenShift Container Storage pods are in Running state.
Also, ensure that the new incremental mon is created and is in the Running state.
$ oc get pod -n openshift-storage | grep monExample output:
rook-ceph-mon-a-64556f7659-c2ngc 1/1 Running 0 5h1m rook-ceph-mon-b-7c8b74dc4d-tt6hd 1/1 Running 0 5h1m rook-ceph-mon-d-57fb8c657-wg5f2 1/1 Running 0 27mOSDs and mon’s might take several minutes to get to the Running state.
- If verification steps fail, contact Red Hat Support.
9.3.2.2. Replacing an operational Amazon EC2 node on installer-provisioned infrastructure
Use this procedure to replace an operational node on Amazon EC2 I3 installer-provisioned infrastructure (IPI).
Replacing storage nodes in Amazon EC2 I3 infrastructure is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
Prerequisites
- You must be logged into the OpenShift Container Platform (OCP) cluster.
Procedure
- Log in to OpenShift Web Console and click Compute → Nodes.
- Identify the node that needs to be replaced. Take a note of its Machine Name.
Get labels on the node to be replaced.
$ oc get nodes --show-labels | grep <node_name>Identify the mon (if any) and OSDs that are running in the node to be replaced.
$ oc get pods -n openshift-storage -o wide | grep -i <node_name>Scale down the deployments of the pods identified in the previous step.
For example:
$ oc scale deployment rook-ceph-mon-c --replicas=0 -n openshift-storage $ oc scale deployment rook-ceph-osd-0 --replicas=0 -n openshift-storage $ oc scale deployment --selector=app=rook-ceph-crashcollector,node_name=<node_name> --replicas=0 -n openshift-storageMark the nodes as unschedulable.
$ oc adm cordon <node_name>Drain the node.
$ oc adm drain <node_name> --force --delete-local-data --ignore-daemonsets- Click Compute → Machines. Search for the required machine.
- Besides the required machine, click the Action menu (⋮) → Delete Machine.
- Click Delete to confirm the machine deletion. A new machine is automatically created.
Wait for the new machine to start and transition into Running state.
ImportantThis activity may take at least 5-10 minutes or more.
- Click Compute → Nodes in the OpenShift web console. Confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels.
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
- Execute the following command to apply the OpenShift Container Storage label to the new node:
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""
Add the local storage devices available in the new worker node to the OpenShift Container Storage StorageCluster.
Add the new disk entries to LocalVolume CR.
Edit
LocalVolumeCR. You can either remove or comment out the failed device/dev/disk/by-id/{id}and add the new/dev/disk/by-id/{id}.$ oc get -n local-storage localvolumeExample output:
NAME AGE local-block 25h$ oc edit -n local-storage localvolume local-blockExample output:
[...] storageClassDevices: - devicePaths: - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS10382E5D7441494EC - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS1F45C01D7E84FE3E9 - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS136BC945B4ECB9AE4 - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS10382E5D7441464EP # - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS1F45C01D7E84F43E7 # - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS136BC945B4ECB9AE8 - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS6F45C01D7E84FE3E9 - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS636BC945B4ECB9AE4 storageClassName: localblock volumeMode: Block [...]Make sure to save the changes after editing the CR.
You can see that in this CR the below two new devices using by-id have been added.
-
nvme-Amazon_EC2_NVMe_Instance_Storage_AWS6F45C01D7E84FE3E9 -
nvme-Amazon_EC2_NVMe_Instance_Storage_AWS636BC945B4ECB9AE4
-
Display PVs with
localblock.$ oc get pv | grep localblockExample output:
local-pv-3646185e 2328Gi RWO Delete Available localblock 9s local-pv-3933e86 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-2-1-v9jp4 localblock 5h1m local-pv-8176b2bf 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-0-0-nvs68 localblock 5h1m local-pv-ab7cabb3 2328Gi RWO Delete Available localblock 9s local-pv-ac52e8a 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-1-0-knrgr localblock 5h1m local-pv-b7e6fd37 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-2-0-rdm7m localblock 5h1m local-pv-cb454338 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-0-1-h9hfm localblock 5h1m local-pv-da5e3175 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-1-1-g97lq localblock 5h ...
Delete each PV and OSD associated with the failed node using the following steps.
Identify the DeviceSet associated with the OSD to be replaced.
$ osd_id_to_remove=0 $ oc get -n openshift-storage -o yaml deployment rook-ceph-osd-${osd_id_to_remove} | grep ceph.rook.io/pvcwhere,
osd_id_to_removeis the integer in the pod name immediately after therook-ceph-osdprefix. In this example, the deployment name isrook-ceph-osd-0.Example output:
ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68 ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68Identify the PV associated with the PVC.
$ oc get -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix>where,
x,y, andpvc-suffixare the values in the DeviceSet identified in an earlier step.Example output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ocs-deviceset-0-0-nvs68 Bound local-pv-8176b2bf 2328Gi RWO localblock 4h49mIn this example, the associated PV is
local-pv-8176b2bf.Delete the PVC which was identified in earlier steps. In this example, the PVC name is
ocs-deviceset-0-0-nvs68.$ oc delete pvc ocs-deviceset-0-0-nvs68 -n openshift-storageExample output:
persistentvolumeclaim "ocs-deviceset-0-0-nvs68" deletedDelete the PV which was identified in earlier steps. In this example, the PV name is
local-pv-8176b2bf.$ oc delete pv local-pv-8176b2bfExample output:
persistentvolume "local-pv-8176b2bf" deletedRemove the failed OSD from the cluster.
$ oc process -n openshift-storage ocs-osd-removal -p FAILED_OSD_ID=${osd_id_to_remove} | oc create -f -Verify that the OSD is removed successfully by checking the status of the
ocs-osd-removalpod. A status ofCompletedconfirms that the OSD removal job succeeded.# oc get pod -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storageNoteIf ocs-osd-removal fails and the pod is not in the expected Completed state, check the pod logs for further debugging. For example:
# oc logs -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storage --tail=-1Delete the OSD pod deployment.
$ oc delete deployment rook-ceph-osd-${osd_id_to_remove} -n openshift-storage
Delete
crashcollectorpod deployment identified in an earlier step.$ oc delete deployment --selector=app=rook-ceph-crashcollector,node_name=<old_node_name> -n openshift-storageDeploy the new OSD by restarting the
rook-ceph-operatorto force operator reconciliation.$ oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-2d982 1/1 Running 0 5h3mDelete the
rook-ceph-operator.$ oc delete -n openshift-storage pod rook-ceph-operator-6f74fb5bff-2d982Example output:
pod "rook-ceph-operator-6f74fb5bff-2d982" deletedVerify that the
rook-ceph-operatorpod is restarted.$ oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-7mvrq 1/1 Running 0 66sCreation of the new OSD may take several minutes after the operator starts.
Delete the
ocs-osd-removaljob(s).$ oc delete job ocs-osd-removal-${osd_id_to_remove}Example output:
job.batch "ocs-osd-removal-0" deleted
Verification steps
Execute the following command and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1Click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
Verify that all other required OpenShift Container Storage pods are in Running state.
Also, ensure that the new incremental mon is created and is in the Running state.
$ oc get pod -n openshift-storage | grep monExample output:
rook-ceph-mon-a-64556f7659-c2ngc 1/1 Running 0 5h1m rook-ceph-mon-b-7c8b74dc4d-tt6hd 1/1 Running 0 5h1m rook-ceph-mon-d-57fb8c657-wg5f2 1/1 Running 0 27mOSDs and mon’s might take several minutes to get to the Running state.
- If verification steps fail, contact Red Hat Support.
9.3.2.3. Replacing a failed Amazon EC2 node on user-provisioned infrastructure
The ephemeral storage of Amazon EC2 I3 for OpenShift Container Storage might cause data loss when there is an instance power off. Use this procedure to recover from such an instance power off on Amazon EC2 infrastructure.
Replacing storage nodes in Amazon EC2 I3 infrastructure is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
Prerequisites
- You must be logged into the OpenShift Container Platform (OCP) cluster.
Procedure
Identify the node and get labels on the node to be replaced.
$ oc get nodes --show-labels | grep <node_name>Identify the mon (if any) and OSDs that are running in the node to be replaced.
$ oc get pods -n openshift-storage -o wide | grep -i <node_name>Scale down the deployments of the pods identified in the previous step.
For example:
$ oc scale deployment rook-ceph-mon-c --replicas=0 -n openshift-storage $ oc scale deployment rook-ceph-osd-0 --replicas=0 -n openshift-storage $ oc scale deployment --selector=app=rook-ceph-crashcollector,node_name=<node_name> --replicas=0 -n openshift-storageMark the nodes as unschedulable.
$ oc adm cordon <node_name>Remove the pods which are in Terminating state.
$ oc get pods -A -o wide | grep -i <node_name> | awk '{if ($4 == "Terminating") system ("oc -n " $1 " delete pods " $2 " --grace-period=0 " " --force ")}'Drain the node.
$ oc adm drain <node_name> --force --delete-local-data --ignore-daemonsetsDelete the node.
$ oc delete node <node_name>- Create a new Amazon EC2 I3 machine instance with the required infrastructure. See Supported Infrastructure and Platforms.
- Create a new OpenShift Container Platform node using the new Amazon EC2 I3 machine instance.
Check for certificate signing requests (CSRs) related to OpenShift Container Platform that are in Pending state:
$ oc get csrApprove all required OpenShift Container Platform CSRs for the new node:
$ oc adm certificate approve <Certificate_Name>- Click Compute → Nodes in the OpenShift web console. Confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels.
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
- Execute the following command to apply the OpenShift Container Storage label to the new node:
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""
Add the local storage devices available in the new worker node to the OpenShift Container Storage StorageCluster.
Add the new disk entries to LocalVolume CR.
Edit
LocalVolumeCR. You can either remove or comment out the failed device/dev/disk/by-id/{id}and add the new/dev/disk/by-id/{id}.$ oc get -n local-storage localvolumeExample output:
NAME AGE local-block 25h$ oc edit -n local-storage localvolume local-blockExample output:
[...] storageClassDevices: - devicePaths: - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS10382E5D7441494EC - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS1F45C01D7E84FE3E9 - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS136BC945B4ECB9AE4 - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS10382E5D7441464EP # - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS1F45C01D7E84F43E7 # - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS136BC945B4ECB9AE8 - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS6F45C01D7E84FE3E9 - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS636BC945B4ECB9AE4 storageClassName: localblock volumeMode: Block [...]Make sure to save the changes after editing the CR.
You can see that in this CR the below two new devices using by-id have been added.
-
nvme-Amazon_EC2_NVMe_Instance_Storage_AWS6F45C01D7E84FE3E9 -
nvme-Amazon_EC2_NVMe_Instance_Storage_AWS636BC945B4ECB9AE4
-
Display PVs with
localblock.$ oc get pv | grep localblockExample output:
local-pv-3646185e 2328Gi RWO Delete Available localblock 9s local-pv-3933e86 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-2-1-v9jp4 localblock 5h1m local-pv-8176b2bf 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-0-0-nvs68 localblock 5h1m local-pv-ab7cabb3 2328Gi RWO Delete Available localblock 9s local-pv-ac52e8a 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-1-0-knrgr localblock 5h1m local-pv-b7e6fd37 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-2-0-rdm7m localblock 5h1m local-pv-cb454338 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-0-1-h9hfm localblock 5h1m local-pv-da5e3175 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-1-1-g97lq localblock 5h ...
Delete each PV and OSD associated with the failed node using the following steps.
Identify the DeviceSet associated with the OSD to be replaced.
$ osd_id_to_remove=0 $ oc get -n openshift-storage -o yaml deployment rook-ceph-osd-${osd_id_to_remove} | grep ceph.rook.io/pvcwhere,
osd_id_to_removeis the integer in the pod name immediately after therook-ceph-osdprefix. In this example, the deployment name isrook-ceph-osd-0.Example output:
ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68 ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68Identify the PV associated with the PVC.
$ oc get -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix>where,
x,y, andpvc-suffixare the values in the DeviceSet identified in an earlier step.Example output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ocs-deviceset-0-0-nvs68 Bound local-pv-8176b2bf 2328Gi RWO localblock 4h49mIn this example, the associated PV is
local-pv-8176b2bf.Delete the PVC which was identified in earlier steps. In this example, the PVC name is
ocs-deviceset-0-0-nvs68.$ oc delete pvc ocs-deviceset-0-0-nvs68 -n openshift-storageExample output:
persistentvolumeclaim "ocs-deviceset-0-0-nvs68" deletedDelete the PV which was identified in earlier steps. In this example, the PV name is
local-pv-8176b2bf.$ oc delete pv local-pv-8176b2bfExample output:
persistentvolume "local-pv-8176b2bf" deletedRemove the failed OSD from the cluster.
$ oc process -n openshift-storage ocs-osd-removal -p FAILED_OSD_ID=${osd_id_to_remove} | oc create -f -Verify that the OSD is removed successfully by checking the status of the
ocs-osd-removalpod. A status ofCompletedconfirms that the OSD removal job succeeded.# oc get pod -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storageNoteIf ocs-osd-removal fails and the pod is not in the expected Completed state, check the pod logs for further debugging. For example:
# oc logs -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storage --tail=-1Delete the OSD pod deployment.
$ oc delete deployment rook-ceph-osd-${osd_id_to_remove} -n openshift-storage
Delete
crashcollectorpod deployment identified in an earlier step.$ oc delete deployment --selector=app=rook-ceph-crashcollector,node_name=<old_node_name> -n openshift-storageDeploy the new OSD by restarting the
rook-ceph-operatorto force operator reconciliation.$ oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-2d982 1/1 Running 0 5h3mDelete the
rook-ceph-operator.$ oc delete -n openshift-storage pod rook-ceph-operator-6f74fb5bff-2d982Example output:
pod "rook-ceph-operator-6f74fb5bff-2d982" deletedVerify that the
rook-ceph-operatorpod is restarted.$ oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-7mvrq 1/1 Running 0 66sCreation of the new OSD may take several minutes after the operator starts.
Delete the
ocs-osd-removaljob(s).$ oc delete job ocs-osd-removal-${osd_id_to_remove}Example output:
job.batch "ocs-osd-removal-0" deleted
Verification steps
Execute the following command and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1Click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
Verify that all other required OpenShift Container Storage pods are in Running state.
Also, ensure that the new incremental mon is created and is in the Running state.
$ oc get pod -n openshift-storage | grep monExample output:
rook-ceph-mon-a-64556f7659-c2ngc 1/1 Running 0 5h1m rook-ceph-mon-b-7c8b74dc4d-tt6hd 1/1 Running 0 5h1m rook-ceph-mon-d-57fb8c657-wg5f2 1/1 Running 0 27mOSDs and mon’s might take several minutes to get to the Running state.
- If verification steps fail, contact Red Hat Support.
9.3.2.4. Replacing a failed Amazon EC2 node on installer-provisioned infrastructure
The ephemeral storage of Amazon EC2 I3 for OpenShift Container Storage might cause data loss when there is an instance power off. Use this procedure to recover from such an instance power off on Amazon EC2 infrastructure.
Replacing storage nodes in Amazon EC2 I3 infrastructure is a Technology Preview feature. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
Prerequisites
- You must be logged into the OpenShift Container Platform (OCP) cluster.
Procedure
- Log in to OpenShift Web Console and click Compute → Nodes.
- Identify the node that needs to be replaced. Take a note of its Machine Name.
Get the labels on the node to be replaced.
$ oc get nodes --show-labels | grep <node_name>Identify the mon (if any) and OSDs that are running in the node to be replaced.
$ oc get pods -n openshift-storage -o wide | grep -i <node_name>Scale down the deployments of the pods identified in the previous step.
For example:
$ oc scale deployment rook-ceph-mon-c --replicas=0 -n openshift-storage $ oc scale deployment rook-ceph-osd-0 --replicas=0 -n openshift-storage $ oc scale deployment --selector=app=rook-ceph-crashcollector,node_name=<node_name> --replicas=0 -n openshift-storageMark the node as unschedulable.
$ oc adm cordon <node_name>Remove the pods which are in Terminating state.
$ oc get pods -A -o wide | grep -i <node_name> | awk '{if ($4 == "Terminating") system ("oc -n " $1 " delete pods " $2 " --grace-period=0 " " --force ")}'Drain the node.
$ oc adm drain <node_name> --force --delete-local-data --ignore-daemonsets- Click Compute → Machines. Search for the required machine.
- Besides the required machine, click the Action menu (⋮) → Delete Machine.
- Click Delete to confirm the machine deletion. A new machine is automatically created.
Wait for the new machine to start and transition into Running state.
ImportantThis activity may take at least 5-10 minutes or more.
- Click Compute → Nodes in the OpenShift web console. Confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels.
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
- Execute the following command to apply the OpenShift Container Storage label to the new node:
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""
Add the local storage devices available in the new worker node to the OpenShift Container Storage StorageCluster.
Add the new disk entries to LocalVolume CR.
Edit
LocalVolumeCR. You can either remove or comment out the failed device/dev/disk/by-id/{id}and add the new/dev/disk/by-id/{id}.$ oc get -n local-storage localvolumeExample output:
NAME AGE local-block 25h$ oc edit -n local-storage localvolume local-blockExample output:
[...] storageClassDevices: - devicePaths: - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS10382E5D7441494EC - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS1F45C01D7E84FE3E9 - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS136BC945B4ECB9AE4 - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS10382E5D7441464EP # - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS1F45C01D7E84F43E7 # - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS136BC945B4ECB9AE8 - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS6F45C01D7E84FE3E9 - /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_AWS636BC945B4ECB9AE4 storageClassName: localblock volumeMode: Block [...]Make sure to save the changes after editing the CR.
You can see that in this CR the below two new devices using by-id have been added.
-
nvme-Amazon_EC2_NVMe_Instance_Storage_AWS6F45C01D7E84FE3E9 -
nvme-Amazon_EC2_NVMe_Instance_Storage_AWS636BC945B4ECB9AE4
-
Display PVs with
localblock.$ oc get pv | grep localblockExample output:
local-pv-3646185e 2328Gi RWO Delete Available localblock 9s local-pv-3933e86 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-2-1-v9jp4 localblock 5h1m local-pv-8176b2bf 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-0-0-nvs68 localblock 5h1m local-pv-ab7cabb3 2328Gi RWO Delete Available localblock 9s local-pv-ac52e8a 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-1-0-knrgr localblock 5h1m local-pv-b7e6fd37 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-2-0-rdm7m localblock 5h1m local-pv-cb454338 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-0-1-h9hfm localblock 5h1m local-pv-da5e3175 2328Gi RWO Delete Bound openshift-storage/ocs-deviceset-1-1-g97lq localblock 5h ...
Delete each PV and OSD associated with the failed node using the following steps.
Identify the DeviceSet associated with the OSD to be replaced.
$ osd_id_to_remove=0 $ oc get -n openshift-storage -o yaml deployment rook-ceph-osd-${osd_id_to_remove} | grep ceph.rook.io/pvcwhere,
osd_id_to_removeis the integer in the pod name immediately after therook-ceph-osdprefix. In this example, the deployment name isrook-ceph-osd-0.Example output:
ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68 ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68Identify the PV associated with the PVC.
$ oc get -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix>where,
x,y, andpvc-suffixare the values in the DeviceSet identified in an earlier step.Example output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ocs-deviceset-0-0-nvs68 Bound local-pv-8176b2bf 2328Gi RWO localblock 4h49mIn this example, the associated PV is
local-pv-8176b2bf.Delete the PVC which was identified in earlier steps. In this example, the PVC name is
ocs-deviceset-0-0-nvs68.$ oc delete pvc ocs-deviceset-0-0-nvs68 -n openshift-storageExample output:
persistentvolumeclaim "ocs-deviceset-0-0-nvs68" deletedDelete the PV which was identified in earlier steps. In this example, the PV name is
local-pv-8176b2bf.$ oc delete pv local-pv-8176b2bfExample output:
persistentvolume "local-pv-8176b2bf" deletedRemove the failed OSD from the cluster.
$ oc process -n openshift-storage ocs-osd-removal -p FAILED_OSD_ID=${osd_id_to_remove} | oc create -f -Verify that the OSD is removed successfully by checking the status of the
ocs-osd-removalpod. A status ofCompletedconfirms that the OSD removal job succeeded.# oc get pod -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storageNoteIf ocs-osd-removal fails and the pod is not in the expected Completed state, check the pod logs for further debugging. For example:
# oc logs -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storage --tail=-1Delete the OSD pod deployment.
$ oc delete deployment rook-ceph-osd-${osd_id_to_remove} -n openshift-storage
Delete
crashcollectorpod deployment identified in an earlier step.$ oc delete deployment --selector=app=rook-ceph-crashcollector,node_name=<old_node_name> -n openshift-storageDeploy the new OSD by restarting the
rook-ceph-operatorto force operator reconciliation.$ oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-2d982 1/1 Running 0 5h3mDelete the
rook-ceph-operator.$ oc delete -n openshift-storage pod rook-ceph-operator-6f74fb5bff-2d982Example output:
pod "rook-ceph-operator-6f74fb5bff-2d982" deletedVerify that the
rook-ceph-operatorpod is restarted.$ oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-7mvrq 1/1 Running 0 66sCreation of the new OSD may take several minutes after the operator starts.
Delete the
ocs-osd-removaljob(s).$ oc delete job ocs-osd-removal-${osd_id_to_remove}Example output:
job.batch "ocs-osd-removal-0" deleted
Verification steps
Execute the following command and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1Click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
Verify that all other required OpenShift Container Storage pods are in Running state.
Also, ensure that the new incremental mon is created and is in the Running state.
$ oc get pod -n openshift-storage | grep monExample output:
rook-ceph-mon-a-64556f7659-c2ngc 1/1 Running 0 5h1m rook-ceph-mon-b-7c8b74dc4d-tt6hd 1/1 Running 0 5h1m rook-ceph-mon-d-57fb8c657-wg5f2 1/1 Running 0 27mOSDs and mon’s might take several minutes to get to the Running state.
- If verification steps fail, contact Red Hat Support.
9.3.3. Replacing storage nodes on VMware infrastructure
- To replace an operational node, see Section 9.3.3.1, “Replacing an operational node on VMware user-provisioned infrastructure”
- To replace a failed node, see Section 9.3.3.2, “Replacing a failed node on VMware user-provisioned infrastructure”
9.3.3.1. Replacing an operational node on VMware user-provisioned infrastructure
Prerequisites
- You must be logged into the OpenShift Container Platform (OCP) cluster.
Procedure
Identify the node and get labels on the node to be replaced.
$ oc get nodes --show-labels | grep <node_name>Identify the
mon(if any) and OSDs that are running in the node to be replaced.$ oc get pods -n openshift-storage -o wide | grep -i <node_name>Scale down the deployments of the pods identified in the previous step.
For example:
$ oc scale deployment rook-ceph-mon-c --replicas=0 -n openshift-storage $ oc scale deployment rook-ceph-osd-0 --replicas=0 -n openshift-storage $ oc scale deployment --selector=app=rook-ceph-crashcollector,node_name=<node_name> --replicas=0 -n openshift-storageMark the node as unschedulable.
$ oc adm cordon <node_name>Drain the node.
$ oc adm drain <node_name> --force --delete-local-data --ignore-daemonsetsDelete the node.
$ oc delete node <node_name>- Log in to vSphere and terminate the identified VM.
- Create a new VM on VMware with the required infrastructure. See Supported Infrastructure and Platforms.
- Create a new OpenShift Container Platform worker node using the new VM.
Check for certificate signing requests (CSRs) related to OpenShift Container Platform that are in Pending state:
$ oc get csrApprove all required OpenShift Container Platform CSRs for the new node:
$ oc adm certificate approve <Certificate_Name>- Click Compute → Nodes in OpenShift Web Console, confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels.
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
Execute the following command to apply the OpenShift Container Storage label to the new node:
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""
Add the local storage devices available in these worker nodes to the OpenShift Container Storage StorageCluster.
Add a new disk entry to
LocalVolumeCR.Edit
LocalVolumeCR and remove or comment out failed device/dev/disk/by-id/{id}and add the new/dev/disk/by-id/{id}. In this example, the new device is/dev/disk/by-id/nvme-eui.01000000010000005cd2e490020e5251.# oc get -n local-storage localvolumeExample output:
NAME AGE local-block 25h# oc edit -n local-storage localvolume local-blockExample output:
[...] storageClassDevices: - devicePaths: - /dev/disk/by-id/nvme-eui.01000000010000005cd2e4895e0e5251 - /dev/disk/by-id/nvme-eui.01000000010000005cd2e4ea2f0f5251 # - /dev/disk/by-id/nvme-eui.01000000010000005cd2e4de2f0f5251 - /dev/disk/by-id/nvme-eui.01000000010000005cd2e490020e5251 storageClassName: localblock volumeMode: Block [...]Make sure to save the changes after editing the CR.
Display PVs with
localblock.$ oc get pv | grep localblockExample output:
local-pv-3e8964d3 1490Gi RWO Delete Bound openshift-storage/ocs-deviceset-2-0-79j94 localblock 25h local-pv-414755e0 1490Gi RWO Delete Bound openshift-storage/ocs-deviceset-1-0-959rp localblock 25h local-pv-b481410 1490Gi RWO Delete Available localblock 3m24s local-pv-d9c5cbd6 1490Gi RWO Delete Bound openshift-storage/ocs-deviceset-0-0-nvs68 localblock
Delete the PV associated with the failed node.
Identify the
DeviceSetassociated with the OSD to be replaced.# osd_id_to_remove=0 # oc get -n openshift-storage -o yaml deployment rook-ceph-osd-${osd_id_to_remove} | grep ceph.rook.io/pvcwhere,
osd_id_to_removeis the integer in the pod name immediately after therook-ceph-osd prefix. In this example, the deployment name isrook-ceph-osd-0.Example output:
ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68 ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68In this example, the PVC name is
ocs-deviceset-0-0-nvs68.Identify the PV associated with the PVC.
# oc get -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix>where,
x,y, andpvc-suffixare the values in theDeviceSetidentified in the previous step.Example output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ocs-deviceset-0-0-nvs68 Bound local-pv-d9c5cbd6 1490Gi RWO localblock 24hIn this example, the associated PV is
local-pv-d9c5cbd6.Delete the PVC.
oc delete pvc <pvc-name> -n openshift-storageDelete the PV.
# oc delete pv local-pv-d9c5cbd6Example output:
persistentvolume "local-pv-d9c5cbd6" deleted
Remove the failed OSD from the cluster.
# oc process -n openshift-storage ocs-osd-removal -p FAILED_OSD_ID=${osd_id_to_remove} | oc create -f -Verify that the OSD is removed successfully by checking the status of the
ocs-osd-removalpod. A status ofCompletedconfirms that the OSD removal job succeeded.# oc get pod -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storageNoteIf ocs-osd-removal fails and the pod is not in the expected Completed state, check the pod logs for further debugging. For example:
# oc logs -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storage --tail=-1Delete OSD pod deployment and crashcollector pod deployment.
$ oc delete deployment rook-ceph-osd-${osd_id_to_remove} -n openshift-storage $ oc delete deployment --selector=app=rook-ceph-crashcollector,node_name=<old_node_name> -n openshift-storageDeploy the new OSD by restarting the
rook-ceph-operatorto force operator reconciliation.# oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-2d982 1/1 Running 0 1d20hDelete the
rook-ceph-operator.# oc delete -n openshift-storage pod rook-ceph-operator-6f74fb5bff-2d982Example output:
pod "rook-ceph-operator-6f74fb5bff-2d982" deletedVerify that the
rook-ceph-operatorpod is restarted.# oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-7mvrq 1/1 Running 0 66sCreation of the new OSD and
monmight take several minutes after the operator restarts.
Delete the
ocs-osd-removaljob.# oc delete job ocs-osd-removal-${osd_id_to_remove}Example output:
job.batch "ocs-osd-removal-0" deleted
Verification steps
Execute the following command and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1Click Workloads → Pods, confirm that at least the following pods on the new node are in
Runningstate:-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
Verify that all other required OpenShift Container Storage pods are in Running state.
Ensure that the new incremental
monis created and is in the Running state.$ oc get pod -n openshift-storage | grep monExample output:
rook-ceph-mon-c-64556f7659-c2ngc 1/1 Running 0 6h14m rook-ceph-mon-d-7c8b74dc4d-tt6hd 1/1 Running 0 4h24m rook-ceph-mon-e-57fb8c657-wg5f2 1/1 Running 0 162mOSD and Mon might take several minutes to get to the
Runningstate.- If verification steps fail, contact Red Hat Support.
9.3.3.2. Replacing a failed node on VMware user-provisioned infrastructure
Prerequisites
- You must be logged into the OpenShift Container Platform (OCP) cluster.
Procedure
Identify the node and get labels on the node to be replaced.
$ oc get nodes --show-labels | grep <node_name>Identify the
mon(if any) and OSDs that are running in the node to be replaced.$ oc get pods -n openshift-storage -o wide | grep -i <node_name>Scale down the deployments of the pods identified in the previous step.
For example:
$ oc scale deployment rook-ceph-mon-c --replicas=0 -n openshift-storage $ oc scale deployment rook-ceph-osd-0 --replicas=0 -n openshift-storage $ oc scale deployment --selector=app=rook-ceph-crashcollector,node_name=<node_name> --replicas=0 -n openshift-storageMark the node as unschedulable.
$ oc adm cordon <node_name>Remove the pods which are in Terminating state.
$ oc get pods -A -o wide | grep -i <node_name> | awk '{if ($4 == "Terminating") system ("oc -n " $1 " delete pods " $2 " --grace-period=0 " " --force ")}'Drain the node.
$ oc adm drain <node_name> --force --delete-local-data --ignore-daemonsetsDelete the node.
$ oc delete node <node_name>- Log in to vSphere and terminate the identified VM.
- Create a new VM on VMware with the required infrastructure. See Supported Infrastructure and Platforms.
- Create a new OpenShift Container Platform worker node using the new VM.
Check for certificate signing requests (CSRs) related to OpenShift Container Platform that are in Pending state:
$ oc get csrApprove all required OpenShift Container Platform CSRs for the new node:
$ oc adm certificate approve <Certificate_Name>- Click Compute → Nodes in OpenShift Web Console, confirm if the new node is in Ready state.
Apply the OpenShift Container Storage label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels.
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
- Execute the following command to apply the OpenShift Container Storage label to the new node:
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""
Add the local storage devices available in these worker nodes to the OpenShift Container Storage StorageCluster.
Add a new disk entry to
LocalVolumeCR.Edit
LocalVolumeCR and remove or comment out failed device/dev/disk/by-id/{id}and add the new/dev/disk/by-id/{id}. In this example, the new device is/dev/disk/by-id/nvme-eui.01000000010000005cd2e490020e5251.# oc get -n local-storage localvolumeExample output:
NAME AGE local-block 25h# oc edit -n local-storage localvolume local-blockExample output:
[...] storageClassDevices: - devicePaths: - /dev/disk/by-id/nvme-eui.01000000010000005cd2e4895e0e5251 - /dev/disk/by-id/nvme-eui.01000000010000005cd2e4ea2f0f5251 # - /dev/disk/by-id/nvme-eui.01000000010000005cd2e4de2f0f5251 - /dev/disk/by-id/nvme-eui.01000000010000005cd2e490020e5251 storageClassName: localblock volumeMode: Block [...]Make sure to save the changes after editing the CR.
Display PVs with
localblock.$ oc get pv | grep localblockExample output:
local-pv-3e8964d3 1490Gi RWO Delete Bound openshift-storage/ocs-deviceset-2-0-79j94 localblock 25h local-pv-414755e0 1490Gi RWO Delete Bound openshift-storage/ocs-deviceset-1-0-959rp localblock 25h local-pv-b481410 1490Gi RWO Delete Available localblock 3m24s local-pv-d9c5cbd6 1490Gi RWO Delete Bound openshift-storage/ocs-deviceset-0-0-nvs68 localblock
Delete the PV associated with the failed node.
Identify the
DeviceSetassociated with the OSD to be replaced.# osd_id_to_remove=0 # oc get -n openshift-storage -o yaml deployment rook-ceph-osd-${osd_id_to_remove} | grep ceph.rook.io/pvcwhere,
osd_id_to_removeis the integer in the pod name immediately after therook-ceph-osd prefix. In this example, the deployment name isrook-ceph-osd-0.Example output:
ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68 ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68In this example, the PVC name is
ocs-deviceset-0-0-nvs68.Identify the PV associated with the PVC.
# oc get -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix>where,
x,y, andpvc-suffixare the values in theDeviceSetidentified in the previous step.Example output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ocs-deviceset-0-0-nvs68 Bound local-pv-d9c5cbd6 1490Gi RWO localblock 24hIn this example, the associated PV is
local-pv-d9c5cbd6.Delete the PVC.
oc delete pvc <pvc-name> -n openshift-storageDelete the PV.
# oc delete pv local-pv-d9c5cbd6Example output:
persistentvolume "local-pv-d9c5cbd6" deleted
Remove the failed OSD from the cluster.
# oc process -n openshift-storage ocs-osd-removal -p FAILED_OSD_ID=${osd_id_to_remove} | oc create -f -Verify that the OSD is removed successfully by checking the status of the
ocs-osd-removalpod. A status ofCompletedconfirms that the OSD removal job succeeded.# oc get pod -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storageNoteIf ocs-osd-removal fails and the pod is not in the expected Completed state, check the pod logs for further debugging. For example:
# oc logs -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storage --tail=-1Delete OSD pod deployment and crashcollector pod deployment.
$ oc delete deployment rook-ceph-osd-${osd_id_to_remove} -n openshift-storage $ oc delete deployment --selector=app=rook-ceph-crashcollector,node_name=<old_node_name> -n openshift-storageDeploy the new OSD by restarting the
rook-ceph-operatorto force operator reconciliation.# oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-2d982 1/1 Running 0 1d20hDelete the
rook-ceph-operator.# oc delete -n openshift-storage pod rook-ceph-operator-6f74fb5bff-2d982Example output:
pod "rook-ceph-operator-6f74fb5bff-2d982" deletedVerify that the
rook-ceph-operatorpod is restarted.# oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-7mvrq 1/1 Running 0 66sCreation of the new OSD and
monmight take several minutes after the operator restarts.
Delete the`ocs-osd-removal` job.
# oc delete job ocs-osd-removal-${osd_id_to_remove}Example output:
job.batch "ocs-osd-removal-0" deleted
Verification steps
Execute the following command and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1Click Workloads → Pods, confirm that at least the following pods on the new node are in
Runningstate:-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
Verify that all other required OpenShift Container Storage pods are in Running state.
Ensure that the new incremental
monis created and is in the Running state.$ oc get pod -n openshift-storage | grep monExample output:
rook-ceph-mon-c-64556f7659-c2ngc 1/1 Running 0 6h14m rook-ceph-mon-d-7c8b74dc4d-tt6hd 1/1 Running 0 4h24m rook-ceph-mon-e-57fb8c657-wg5f2 1/1 Running 0 162mOSD and Mon might take several minutes to get to the
Runningstate.- If verification steps fail, contact Red Hat Support.
Chapter 10. Replacing a storage device
Depending on the type of your deployment, you can choose one of the following procedures to replace a storage device:
For dynamically created storage clusters deployed on AWS, see:
- For dynamically created storage clusters deployed on VMware, see Section 10.2.1, “Replacing operational or failed storage devices on VMware user-provisioned infrastructure”
For storage clusters deployed using local storage devices, see:
10.1. Dynamically provisioned OpenShift Container Storage deployed on AWS
10.1.1. Replacing operational or failed storage devices on AWS user-provisioned infrastructure
When you need to replace a device in a dynamically created storage cluster on an AWS user-provisioned infrastructure, you must replace the storage node. For information about how to replace nodes, see:
10.1.2. Replacing operational or failed storage devices on AWS installer-provisioned infrastructure
When you need to replace a device in a dynamically created storage cluster on an AWS installer-provisioned infrastructure, you must replace the storage node. For information about how to replace nodes, see:
10.2. Dynamically provisioned OpenShift Container Storage deployed on VMware
10.2.1. Replacing operational or failed storage devices on VMware user-provisioned infrastructure
Use this procedure when a virtual machine disk (VMDK) needs to be replaced in OpenShift Container Storage which is deployed dynamically on VMware infrastructure. This procedure helps to create a new Persistent Volume Claim (PVC) on a new volume and remove the old object storage device (OSD).
Procedure
Identify the OSD that needs to be replaced.
# oc get -n openshift-storage pods -l app=rook-ceph-osd -o wideExample output:
rook-ceph-osd-0-6d77d6c7c6-m8xj6 0/1 CrashLoopBackOff 0 24h 10.129.0.16 compute-2 <none> <none> rook-ceph-osd-1-85d99fb95f-2svc7 1/1 Running 0 24h 10.128.2.24 compute-0 <none> <none> rook-ceph-osd-2-6c66cdb977-jp542 1/1 Running 0 24h 10.131.2.32 compute-1 <none> <none>In this example,
rook-ceph-osd-0-6d77d6c7c6-m8xj6needs to be replaced.NoteIf the OSD to be replaced is healthy, the status of the pod will be Running.
Scale down the OSD deployment for the OSD to be replaced
# osd_id_to_remove=0 # oc scale -n openshift-storage deployment rook-ceph-osd-${osd_id_to_remove} --replicas=0where,
osd_id_to_removeis the integer in the pod name immediately after therook-ceph-osdprefix. In this example, the deployment name isrook-ceph-osd-0.Example output:
deployment.extensions/rook-ceph-osd-0 scaledVerify that the
rook-ceph-osdpod is terminated.# oc get -n openshift-storage pods -l ceph-osd-id=${osd_id_to_remove}Example output:
No resources found.NoteIf the
rook-ceph-osdpod is interminatingstate, use theforceoption to delete the pod.# oc delete pod rook-ceph-osd-0-6d77d6c7c6-m8xj6 --force --grace-period=0Example output:
warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely. pod "rook-ceph-osd-0-6d77d6c7c6-m8xj6" force deletedRemove the old OSD from the cluster so that a new OSD can be added.
# oc process -n openshift-storage ocs-osd-removal -p FAILED_OSD_ID=${osd_id_to_remove} | oc create -f -WarningThis step results in OSD being completely removed from the cluster. Make sure that the correct value of
osd_id_to_removeis provided.Verify that the OSD is removed successfully by checking the status of the
ocs-osd-removalpod. A status ofCompletedconfirms that the OSD removal job succeeded.# oc get pod -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storageNoteIf
ocs-osd-removalfails and the pod is not in the expectedCompletedstate, check the pod logs for further debugging. For example:# oc logs -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storage --tail=-1Delete the PVC resources associated with the OSD to be replaced.
Identify the
DeviceSetassociated with the OSD to be replaced.# oc get -n openshift-storage -o yaml deployment rook-ceph-osd-${osd_id_to_remove} | grep ceph.rook.io/pvcExample output:
ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68 ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68In this example, the PVC name is
ocs-deviceset-0-0-nvs68.Identify the PV associated with the PVC.
# oc get -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix>where,
x,y, andpvc-suffixare the values in theDeviceSetidentified in the previous step.Example output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ocs-deviceset-0-0-nvs68 Bound pvc-0e621d45-7d18-4d35-a282-9700c3cc8524 512Gi RWO thin 24hIn this example, the PVC is
ocs-deviceset-0-0-nvs68that is identified in the previous step and associated PV ispvc-0e621d45-7d18-4d35-a282-9700c3cc8524.Identify the
prepare-podassociated with the OSD to be replaced. Use the PVC name obtained in an earlier step.# oc describe -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix> | grep Mountedwhere,
x,y, andpvc-suffixare the values in theDeviceSetidentified in an earlier step.Example output:
Mounted By: rook-ceph-osd-prepare-ocs-deviceset-0-0-nvs68-zblp7Delete the
osd-preparepod before removing the associated PVC.# oc delete -n openshift-storage pod rook-ceph-osd-prepare-ocs-deviceset-<x>-<y>-<pvc-suffix>-<pod-suffix>where,
x,y,pvc-suffix, andpod-suffixare the values in theosd-preparepod name identified in the previous step.Example output:
pod "rook-ceph-osd-prepare-ocs-deviceset-0-0-nvs68-zblp7" deletedDelete the PVC associated with the device.
# oc delete -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix>where,
x,y, andpvc-suffixare the values in theDeviceSetidentified in an earlier step.Example output:
persistentvolumeclaim "ocs-deviceset-0-0-nvs68" deleted
Create new OSD for new device.
Delete the deployment for the OSD to be replaced.
# oc delete -n openshift-storage deployment rook-ceph-osd-${osd_id_to_remove}Example output:
deployment.extensions/rook-ceph-osd-0 deletedVerify that the PV for the device identified in an earlier step is deleted.
# oc get -n openshift-storage pv pvc-0e621d45-7d18-4d35-a282-9700c3cc8524Example output:
Error from server (NotFound): persistentvolumes "pvc-0e621d45-7d18-4d35-a282-9700c3cc8524" not foundIn this example, the PV name is
pvc-0e621d45-7d18-4d35-a282-9700c3cc8524.If the PV still exists, delete the PV associated with the device.
# oc delete pv pvc-0e621d45-7d18-4d35-a282-9700c3cc8524Example output:
persistentvolume "pvc-0e621d45-7d18-4d35-a282-9700c3cc8524" deletedIn this example, the PV name is
pvc-0e621d45-7d18-4d35-a282-9700c3cc8524.
Deploy the new OSD by restarting the
rook-ceph-operatorto force operator reconciliation.Identify the name of the
rook-ceph-operator.# oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-2d982 1/1 Running 0 1d20hDelete the
rook-ceph-operator.# oc delete -n openshift-storage pod rook-ceph-operator-6f74fb5bff-2d982Example output:
pod "rook-ceph-operator-6f74fb5bff-2d982" deletedIn this example, the rook-ceph-operator pod name is
rook-ceph-operator-6f74fb5bff-2d982.Verify that the
rook-ceph-operatorpod is restarted.# oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-7mvrq 1/1 Running 0 66sCreation of the new OSD may take several minutes after the operator restarts.
Delete the
ocs-osd-removaljob.# oc delete job ocs-osd-removal-${osd_id_to_remove}Example output:
job.batch "ocs-osd-removal-0" deleted
Verfication steps
Verify that there is a new OSD running and a new PVC created.
# oc get -n openshift-storage pods -l app=rook-ceph-osdExample output:
rook-ceph-osd-0-5f7f4747d4-snshw 1/1 Running 0 4m47s rook-ceph-osd-1-85d99fb95f-2svc7 1/1 Running 0 1d20h rook-ceph-osd-2-6c66cdb977-jp542 1/1 Running 0 1d20h# oc get -n openshift-storage pvcExample output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ocs-deviceset-0-0-2s6w4 Bound pvc-7c9bcaf7-de68-40e1-95f9-0b0d7c0ae2fc 512Gi RWO thin 5m ocs-deviceset-1-0-q8fwh Bound pvc-9e7e00cb-6b33-402e-9dc5-b8df4fd9010f 512Gi RWO thin 1d20h ocs-deviceset-2-0-9v8lq Bound pvc-38cdfcee-ea7e-42a5-a6e1-aaa6d4924291 512Gi RWO thin 1d20hLog in to OpenShift Web Console and view the storage dashboard.
Figure 10.1. OSD status in OpenShift Container Platform storage dashboard after device replacement

10.3. OpenShift Container Storage deployed using local storage devices
10.3.1. Replacing failed storage devices on Amazon EC2 infrastructure
When you need to replace a storage device on an Amazon EC2 (storage-optimized I3) infrastructure, you must replace the storage node. For information about how to replace nodes, see Replacing failed storage nodes on Amazon EC2 infrastructure.
10.3.2. Replacing operational or failed storage devices on VMware and bare metal infrastructures
You can replace an object storage device (OSD) in OpenShift Container Storage deployed using local storage devices on bare metal and VMware infrastructures. Use this procedure when an underlying storage device needs to be replaced.
Procedure
Identify the OSD that needs to be replaced and the OpenShift Container Platform node that has the OSD scheduled on it.
# oc get -n openshift-storage pods -l app=rook-ceph-osd -o wideExample output:
rook-ceph-osd-0-6d77d6c7c6-m8xj6 0/1 CrashLoopBackOff 0 24h 10.129.0.16 compute-2 <none> <none> rook-ceph-osd-1-85d99fb95f-2svc7 1/1 Running 0 24h 10.128.2.24 compute-0 <none> <none> rook-ceph-osd-2-6c66cdb977-jp542 1/1 Running 0 24h 10.130.0.18 compute-1 <none> <none>In this example,
rook-ceph-osd-0-6d77d6c7c6-m8xj6needs to be replaced andcompute-2is the OCP node on which the OSD is scheduled.NoteIf the OSD to be replaced is healthy, the status of the pod will be
Running.Scale down the OSD deployment for the OSD to be replaced.
# osd_id_to_remove=0 # oc scale -n openshift-storage deployment rook-ceph-osd-${osd_id_to_remove} --replicas=0where
osd_id_to_removeis the integer in the pod name immediately after therook-ceph-osdprefix. In this example, the deployment name isrook-ceph-osd-0.Example output:
deployment.extensions/rook-ceph-osd-0 scaledVerify that the
rook-ceph-osdpod is terminated.# oc get -n openshift-storage pods -l ceph-osd-id=${osd_id_to_remove}Example output:
No resources found in openshift-storage namespace.NoteIf the
rook-ceph-osdpod is interminatingstate, use theforceoption to delete the pod.# oc delete pod rook-ceph-osd-0-6d77d6c7c6-m8xj6 --grace-period=0 --forceExample output:
warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely. pod "rook-ceph-osd-0-6d77d6c7c6-m8xj6" force deletedRemove the old OSD from the cluster so that a new OSD can be added.
Delete any old
ocs-osd-removaljobs.# oc delete job ocs-osd-removal-${osd_id_to_remove}Example output:
job.batch "ocs-osd-removal-0" deletedRemove the old OSD from the cluster
# oc process -n openshift-storage ocs-osd-removal -p FAILED_OSD_ID=${osd_id_to_remove} | oc create -f -WarningThis step results in OSD being completely removed from the cluster. Make sure that the correct value of
osd_id_to_removeis provided.
Verify that the OSD is removed successfully by checking the status of the
ocs-osd-removalpod. A status ofCompletedconfirms that the OSD removal job succeeded.# oc get pod -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storageNoteIf
ocs-osd-removalfails and the pod is not in the expectedCompletedstate, check the pod logs for further debugging. For example:# oc logs -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storage --tail=-1Delete the Persistent Volume Claim (PVC) resources associated with the OSD to be replaced.
Identify the
DeviceSetassociated with the OSD to be replaced.# oc get -n openshift-storage -o yaml deployment rook-ceph-osd-${osd_id_to_remove} | grep ceph.rook.io/pvcExample output:
ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68 ceph.rook.io/pvc: ocs-deviceset-0-0-nvs68In this example, the PVC name is
ocs-deviceset-0-0-nvs68.Identify the PV associated with the PVC.
# oc get -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix>where,
x,y, andpvc-suffixare the values in theDeviceSetidentified in an earlier step.Example output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ocs-deviceset-0-0-nvs68 Bound local-pv-d9c5cbd6 1490Gi RWO localblock 24hIn this example, the associated PV is
local-pv-d9c5cbd6.Identify the name of the device to be replaced.
# oc get pv local-pv-<pv-suffix> -o yaml | grep pathwhere,
pv-suffixis the value in the PV name identified in an earlier step.Example output:
path: /mnt/local-storage/localblock/nvme0n1In this example, the device name is
nvme0n1.Identify the
prepare-podassociated with the OSD to be replaced.# oc describe -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix> | grep Mountedwhere,
x,y, andpvc-suffixare the values in theDeviceSetidentified in an earlier step.Example output:
Mounted By: rook-ceph-osd-prepare-ocs-deviceset-0-0-nvs68-zblp7In this example the
prepare-podname isrook-ceph-osd-prepare-ocs-deviceset-0-0-nvs68-zblp7.Delete the
osd-preparepod before removing the associated PVC.# oc delete -n openshift-storage pod rook-ceph-osd-prepare-ocs-deviceset-<x>-<y>-<pvc-suffix>-<pod-suffix>where,
x,y,pvc-suffix, andpod-suffixare the values in theosd-preparepod name identified in an earlier step.Example output:
pod "rook-ceph-osd-prepare-ocs-deviceset-0-0-nvs68-zblp7" deletedDelete the PVC associated with the OSD to be replaced.
# oc delete -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix>where,
x,y, andpvc-suffixare the values in theDeviceSetidentified in an earlier step.Example output:
persistentvolumeclaim "ocs-deviceset-0-0-nvs68" deleted
Replace the old device and use the new device to create a new OpenShift Container Platform PV.
Log in to OpenShift Container Platform node with the device to be replaced. In this example, the OpenShift Container Platform node is
compute-2.# oc debug node/compute-2Example output:
Starting pod/compute-2-debug ... To use host binaries, run `chroot /host` Pod IP: 10.70.56.66 If you don't see a command prompt, try pressing enter. # chroot /hostRecord the
/dev/disk/by-id/{id}that is to be replaced using the device name,nvme0n1, identified earlier.# ls -alh /mnt/local-storage/localblockExample output:
total 0 drwxr-xr-x. 2 root root 51 Aug 18 19:05 . drwxr-xr-x. 3 root root 24 Aug 18 19:05 .. lrwxrwxrwx. 1 root root 57 Aug 18 19:05 nvme0n1 -> /dev/disk/by-id/nvme-eui.01000000010000005cd2e4de2f0f5251Find the name of the
LocalVolumeCR, and remove or comment out the device/dev/disk/by-id/{id}that is to be replaced.# oc get -n local-storage localvolume NAME AGE local-block 25h# oc edit -n local-storage localvolume local-blockExample output:
[...] storageClassDevices: - devicePaths: - /dev/disk/by-id/nvme-eui.01000000010000005cd2e4895e0e5251 - /dev/disk/by-id/nvme-eui.01000000010000005cd2e4ea2f0f5251 # - /dev/disk/by-id/nvme-eui.01000000010000005cd2e4de2f0f5251 storageClassName: localblock volumeMode: Block [...]Make sure to save the changes after editing the CR.
Log in to OpenShift Container Platform node with the device to be replaced and remove the old
symlink.# oc debug node/compute-2Example output:
Starting pod/compute-2-debug ... To use host binaries, run `chroot /host` Pod IP: 10.70.56.66 If you don't see a command prompt, try pressing enter. # chroot /hostIdentify the old
symlinkfor the device name to be replaced. In this example, the device name isnvme0n1.# ls -alh /mnt/local-storage/localblockExample output:
total 0 drwxr-xr-x. 2 root root 51 Aug 18 19:05 . drwxr-xr-x. 3 root root 24 Aug 18 19:05 .. lrwxrwxrwx. 1 root root 57 Aug 18 19:05 nvme0n1 -> /dev/disk/by-id/nvme-eui.01000000010000005cd2e4de2f0f5251Remove the
symlink.# rm /mnt/local-storage/localblock/nvme0n1Verify that the
symlinkis removed.# ls -alh /mnt/local-storage/localblockExample output:
total 0 drwxr-xr-x. 2 root root 17 Apr 10 00:56 . drwxr-xr-x. 3 root root 24 Apr 8 23:03 ..ImportantFor new deployments of OpenShift Container Storage 4.5 or later, LVM is not in use,
ceph-volumeraw mode is in play instead. Therefore, additional validation is not needed and you can proceed to the next step.For OpenShift Container Storage 4.4, or if OpenShift Container Storage has been upgraded to version 4.5 from a prior version, then both
/dev/mapperand/dev/should be checked to see if there are orphans related tocephbefore moving on. Use the results ofvgdisplayto find these orphans. If there is anything in/dev/mapperor/dev/ceph-*withcephin the name that is not from the list of VG Names, usedmsetupto remove it.
Delete the PV associated with the device to be replaced, which was identified in earlier steps. In this example, the PV name is
local-pv-d9c5cbd6.# oc delete pv local-pv-d9c5cbd6Example output:
persistentvolume "local-pv-d9c5cbd6" deleted- Replace the device with the new device.
Log back into the correct OpenShift Container Platform node and identify the device name for the new drive. The device name can be the same as the old device, but the
by-idmust change unless you are reseating the same device.# lsblkExample output:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 120G 0 disk |-sda1 8:1 0 384M 0 part /boot |-sda2 8:2 0 127M 0 part /boot/efi |-sda3 8:3 0 1M 0 part `-sda4 8:4 0 119.5G 0 part `-coreos-luks-root-nocrypt 253:0 0 119.5G 0 dm /sysroot nvme0n1 259:0 0 1.5T 0 diskIn this example, the new device name is
nvme0n1.Identify the
/dev/disk/by-id/{id}for the new device and record it.# ls -alh /dev/disk/by-id | grep nvme0n1Example output:
lrwxrwxrwx. 1 root root 57 Aug 18 19:05 nvme0n1 -> /dev/disk/by-id/nvme-eui.01000000010000005cd2e4ce090e5251
After the new
/dev/disk/by-id/{id}is available a new disk entry can be added to theLocalVolumeCR.Find the name of the
LocalVolumeCR.# oc get -n local-storage localvolume NAME AGE local-block 25hEdit
LocalVolumeCR and add the new/dev/disk/by-id/{id}. In this example the new device is/dev/disk/by-id/nvme-eui.01000000010000005cd2e4ce090e5251.# oc edit -n local-storage localvolume local-blockExample output:
[...] storageClassDevices: - devicePaths: - /dev/disk/by-id/nvme-eui.01000000010000005cd2e4895e0e5251 - /dev/disk/by-id/nvme-eui.01000000010000005cd2e4ea2f0f5251 # - /dev/disk/by-id/nvme-eui.01000000010000005cd2e4de2f0f5251 - /dev/disk/by-id/nvme-eui.01000000010000005cd2e4ce090e5251 storageClassName: localblock volumeMode: Block [...]Make sure to save the changes after editing the CR.
Verify that there is a new PV in
Availablestate and of the correct size.# oc get pv | grep 1490GiExample output:
local-pv-3e8964d3 1490Gi RWO Delete Bound openshift-storage/ocs-deviceset-2-0-79j94 localblock 25h local-pv-414755e0 1490Gi RWO Delete Bound openshift-storage/ocs-deviceset-1-0-959rp localblock 25h local-pv-b481410 1490Gi RWO Delete AvailableCreate new OSD for new device.
Delete the deployment for the OSD to be replaced.
# osd_id_to_remove=0 # oc delete -n openshift-storage deployment rook-ceph-osd-${osd_id_to_remove}Example output:
deployment.extensions/rook-ceph-osd-0 deletedDeploy the new OSD by restarting the
rook-ceph-operatorto force operator reconciliation.Identify the name of the
rook-ceph-operator.# oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-2d982 1/1 Running 0 1d20hDelete the
rook-ceph-operator.# oc delete -n openshift-storage pod rook-ceph-operator-6f74fb5bff-2d982Example output:
pod "rook-ceph-operator-6f74fb5bff-2d982" deletedIn this example, the rook-ceph-operator pod name is
rook-ceph-operator-6f74fb5bff-2d982.Verify that the
rook-ceph-operatorpod is restarted.# oc get -n openshift-storage pod -l app=rook-ceph-operatorExample output:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-6f74fb5bff-7mvrq 1/1 Running 0 66sCreation of the new OSD may take several minutes after the operator restarts.
Verfication steps
Verify that there is a new OSD running and a new PVC created.
# oc get -n openshift-storage pods -l app=rook-ceph-osdExample output:
rook-ceph-osd-0-5f7f4747d4-snshw 1/1 Running 0 4m47s rook-ceph-osd-1-85d99fb95f-2svc7 1/1 Running 0 1d20h rook-ceph-osd-2-6c66cdb977-jp542 1/1 Running 0 1d20h# oc get -n openshift-storage pvc | grep localblockExample output:
ocs-deviceset-0-0-c2mqb Bound local-pv-b481410 1490Gi RWO localblock 5m ocs-deviceset-1-0-959rp Bound local-pv-414755e0 1490Gi RWO localblock 1d20h ocs-deviceset-2-0-79j94 Bound local-pv-3e8964d3 1490Gi RWO localblock 1d20hLog in to OpenShift Web Console and view the storage dashboard.
Figure 10.2. OSD status in OpenShift Container Platform storage dashboard after device replacement
Chapter 11. Updating OpenShift Container Storage
To update your cluster, you must first update Red Hat OpenShift Container Platform, and then, update Red Hat OpenShift Container Storage. It is recommended to use the same version of Red Hat OpenShift Container Platform with Red Hat OpenShift Container Storage. Refer to this Red Hat Knowledgebase article for a complete OpenShift Container Platform and OpenShift Container Storage supportability and compatibility matrix.
For updating Local Storage Operator:
- The Local Storage Operator version must match with the Red Hat OpenShift Container Platform version in order to have the Local Storage Operator fully supported with Red Hat OpenShift Container Storage.
- Local Storage Operator does not get updated when Red Hat OpenShift Container Platform is updated. To check if your OpenShift Container Storage cluster uses the Local Storage Operator, see the Checking for Local Storage Operator deployments section of the Troubleshooting Guide.
You can update OpenShift Container Storage in:
The update procedure is the same for proxy environment.
11.1. Updating OpenShift Container Storage in internal mode
Use the following procedures to update your OpenShift Container Storage cluster deployed in internal mode.
11.1.1. Enabling automatic updates for OpenShift Container Storage operator in internal mode
Use this procedure to enable automatic update approval for updating OpenShift Container Storage operator in OpenShift Container Platform.
Prerequisites
- Under Persistent Storage in Status card, confirm that the OCS cluster is healthy and data is resilient.
- Update the OpenShift Container Platform cluster to the latest stable release of version 4.4.X or 4.5.Y, see Updating Clusters.
Switch the Red Hat OpenShift Container Storage channel from
stable-4.4tostable-4.5. For details about channels, see OpenShift Container Platform upgrade channels and releases.NoteYou are required to switch channels only when you are updating minor versions (for example, updating from 4.4 to 4.5) and not when updating between batch updates of 4.5 (for example, updating from 4.5.0 to 4.5.1).
Ensure that all OpenShift Container Storage Pods, including the operator pods, are in
Runningstate in theopenshift-storage namespace.To view the state of the pods, click Workloads → Pods from the left pane of the OpenShift Web Console. Select openshift-storage from the Project drop down list.
- Ensure that you have sufficient time to complete the Openshift Container Storage (OCS) update process, as the update time varies depending on the number of OSDs that run in the cluster.
Procedure
- Log in to OpenShift Web Console.
- Click Operators → Installed Operators
-
Select the
openshift-storageproject. - Click on the OpenShift Container Storage operator name.
- Click Subscription tab and click the link under Approval.
- Select Automatic (default) and click Save.
Perform one of the following depending on the Upgrade Status:
Upgrade Status shows requires approval.
NoteUpgrade status shows requires approval if the new OpenShift Container Storage version is already detected in the channel, and approval strategy was changed from Manual to Automatic at the time of update.
- Click on the Install Plan link.
- On the InstallPlan Details page, click Preview Install Plan.
- Review the install plan and click Approve.
- Wait for the Status to change from Unknown to Created.
- Click Operators → Installed Operators
-
Select the
openshift-storageproject. - Wait for the Status to change to Up to date
Upgrade Status does not show requires approval:
- Wait for the update to initiate. This may take up to 20 minutes.
- Click Operators → Installed Operators
-
Select the
openshift-storageproject. - Wait for the Status to change to Up to date
Verification steps
- Click Overview → Persistent Storage tab and in Status card confirm that the OCS cluster has a green tick mark indicating it is healthy.
Click Operators → Installed Operators → OpenShift Container Storage Operator. Under Storage Cluster, verify that the cluster service status is
Ready.NoteOnce updated from OpenShift Container Storage version 4.4 to 4.5, the
Versionfield here will still display 4.4. This is because theocs-operatordoes not update the string represented in this field.Ensure that all OpenShift Container Storage Pods, including the operator pods, are in
Runningstate in theopenshift-storage namespace.To view the state of the pods, click Workloads → Pods from the left pane of the OpenShift Web Console. Select openshift-storage from the Project drop down list.
- If verification steps fail, kindly contact Red Hat Support.
Additional Resources
If you face any issues while updating OpenShift Container Storage, see the Commonly required logs for troubleshooting section in the Troubleshooting guide.
11.1.2. Manually updating OpenShift Container Storage operator in internal mode
Use this procedure to update OpenShift Container Storage operator by providing manual approval to the install plan.
Prerequisites
- Under Persistent Storage in Status card, confirm that the OCS cluster is healthy and data is resilient.
- Update the OpenShift Container Platform cluster to the latest stable release of version 4.4.X or 4.5.Y, see Updating Clusters.
Switch the Red Hat OpenShift Container Storage channel channel from
stable-4.4tostable-4.5. For details about channels, see OpenShift Container Platform upgrade channels and releases.NoteYou are required to switch channels only when you are updating minor versions (for example, updating from 4.4 to 4.5) and not when updating between batch updates of 4.5 (for example, updating from 4.5.0 to 4.5.1).
Ensure that all OpenShift Container Storage Pods, including the operator pods, are in
Runningstate in theopenshift-storage namespace.To view the state of the pods, click Workloads → Pods from the left pane of the OpenShift Web Console. Select openshift-storage from the Project drop down list.
- Ensure that you have sufficient time to complete the Openshift Container Storage (OCS) update process, as the update time varies depending on the number of OSDs that run in the cluster.
Procedure
- Log in to OpenShift Web Console.
- Click Operators → Installed Operators
-
Select the
openshift-storageproject. - Click on the OpenShift Container Storage operator name.
- Click Subscription tab and click the link under Approval.
- Select Manual and click Save.
- Wait for the Upgrade Status to change to Upgrading.
- If the Upgrade Status shows requires approval, click on requires approval.
- On the InstallPlan Details page, click Preview Install Plan.
- Review the install plan and click Approve.
- Wait for the Status to change from Unknown to Created.
- Click Operators → Installed Operators
-
Select the
openshift-storageproject. - Wait for the Status to change to Up to date
Verification steps
- Click Overview → Persistent Storage tab and in Status card confirm that the OCS cluster has a green tick mark indicating it is healthy.
Click Operators → Installed Operators → OpenShift Container Storage Operator. Under Storage Cluster, verify that the cluster service status is
Ready.NoteOnce updated from OpenShift Container Storage version 4.4 to 4.5, the
Versionfield here will still display 4.4. This is because theocs-operatordoes not update the string represented in this field.Ensure that all OpenShift Container Storage Pods, including the operator pods, are in
Runningstate in theopenshift-storage namespace.To view the state of the pods, click Workloads → Pods from the left pane of the OpenShift Web Console. Select openshift-storage from the Project drop down list.
- If verification steps fail, kindly contact Red Hat Support.
Additional Resources
If you face any issues while updating OpenShift Container Storage, see the Commonly required logs for troubleshooting section in the Troubleshooting guide.
11.2. Updating OpenShift Container Storage in external mode
Use the following procedures to update your OpenShift Container Storage cluster deployed in external mode.
Updating Red Hat OpenShift Container Storage Operator will not update the external Red Hat Ceph Storage cluster. It will only update the Red Hat OpenShift Container Storage Services running on the OpenShift Container Platform. To update the external Red Hat Ceph Storage cluster contact your Red Hat Ceph Storage administrator.
11.2.1. Enabling automatic updates for OpenShift Container Storage operator in external mode
Use this procedure to enable automatic update approval for updating OpenShift Container Storage operator in OpenShift Container Platform. Automatic Updates for Openshift Container Storage in external mode is supported from version 4.5 onwards.
Updating OpenShift Container Storage will not update the external Red Hat Ceph Storage cluster.
Prerequisites
- Update the OpenShift Container Platform cluster to the latest stable release of version 4.5.x, see Updating Clusters.
-
Ensure the Red Hat OpenShift Container Storage channel is set to
stable-4.5, see OpenShift Container Platform upgrade channels and releases.
You are not required to switch channels when updating between batch updates of 4.5 (for example, updating from 4.5.0 to 4.5.1).
Ensure that all OpenShift Container Storage Pods, including the operator pods, are in
Runningstate in theopenshift-storage namespace.To view the state of the pods, click Workloads → Pods from the left pane of the OpenShift Web Console. Select openshift-storage from the Project drop down list.
- Under Persistent Storage in Status card, confirm that the OCS cluster is healthy.
- Ensure that you have sufficient time to complete the Openshift Container Storage (OCS) update process.
Procedure
- Log in to OpenShift Web Console.
- Click Operators → Installed Operators.
-
Select the
openshift-storageproject. - Click on the OpenShift Container Storage operator name.
- Click Subscription tab and click the link under Approval.
- Select Automatic (default) and click Save.
Perform one of the following depending on the Upgrade Status:
Upgrade Status shows requires approval.
NoteUpgrade status shows requires approval if the new OpenShift Container Storage version is already detected in the channel, and approval strategy was changed from Manual to Automatic at the time of update.
- Click the Install Plan link.
- On the InstallPlan Details page, click Preview Install Plan.
- Review the install plan and click Approve.
- Wait for the Status to change from Unknown to Created.
- Click Operators → Installed Operators.
-
Select the
openshift-storageproject. - Wait for the Status to change to Up to date.
Upgrade Status does not show requires approval.
- Wait for the update to initiate. This may take up to 20 minutes.
- Click Operators → Installed Operators.
-
Select the
openshift-storageproject. - Wait for the Status to change to Up to date.
Verification steps
- Click Overview → Persistent Storage tab and in Status card confirm that the OCS cluster has a green tick mark indicating it is healthy.
-
Click Operators → Installed Operators → OpenShift Container Storage Operator. Under Storage Cluster, verify that the cluster service status in
Ready. Ensure that all OpenShift Container Storage Pods, including the operator pods, are in
Runningstate in theopenshift-storage namespace.To view the state of the pods, click Workloads → Pods from the left pane of the OpenShift Web Console. Select openshift-storage from the Project drop down list.
- If verification steps fail, kindly contact Red Hat Support.
Additional Resources
If you face any issues while updating OpenShift Container Storage, see the Commonly required logs for troubleshooting section in the Troubleshooting guide.
11.2.2. Manually updating OpenShift Container Storage operator in external mode
Use this procedure to update OpenShift Container Storage operator by providing manual approval to the install plan. Manual Updates for Openshift Container Storage in external mode is supported from version 4.5 onwards.
Updating OpenShift Container Storage will not update the external Red Hat Ceph Storage cluster.
Prerequisites
- Update the OpenShift Container Platform cluster to the latest stable release of version of 4.5.x, see Updating Clusters.
-
Ensure the Red Hat OpenShift Container Storage channel is set to
stable-4.5, see OpenShift Container Platform upgrade channels and releases.
You are not required to switch channels when updating between batch updates of 4.5 (for example, updating from 4.5.0 to 4.5.1).
Ensure that all OpenShift Container Storage Pods, including the operator pods, are in
Runningstate in theopenshift-storage namespace.To view the state of the pods, click Workloads → Pods from the left pane of the OpenShift Web Console. Select openshift-storage from the Project drop down list.
- Under Persistent Storage in Status card, confirm that the OCS cluster is healthy.
- Ensure that you have sufficient time to complete the Openshift Container Storage (OCS) update process.
Procedure
- Log in to OpenShift Web Console.
- Click Operators → Installed Operators.
-
Select the
openshift-storageproject. - Click on the OpenShift Container Storage operator name.
- Click Subscription tab and click the link under Approval.
- Select Manual and click Save.
- Wait for the Upgrade Status to change to Upgrading.
- If the Upgrade Status shows requires approval, click on requires approval.
- On the InstallPlan Details page, click Preview Install Plan.
- Review the install plan and click Approve.
- Wait for the Status to change from Unknown to Created.
- Click Operators → Installed Operators.
-
Select the
openshift-storageproject. - Wait for the Status to change to Up to date.
Verification steps
- Click Overview → Persistent Storage tab and in Status card confirm that the OCS cluster has a green tick mark indicating it is healthy.
-
Click Operators → Installed Operators → OpenShift Container Storage Operator. Under Storage Cluster, verify that the cluster service status in
Ready. Ensure that all OpenShift Container Storage Pods, including the operator pods, are in
Runningstate in theopenshift-storage namespace.To view the state of the pods, click Workloads → Pods from the left pane of the OpenShift Web Console. Select openshift-storage from the Project drop down list.
- If verification steps fail, kindly contact Red Hat Support.
Additional Resources
If you face any issues while updating OpenShift Container Storage, see the Commonly required logs for troubleshooting section in the Troubleshooting guide.
11.3. Preparing to update in a disconnected environment
When your Red Hat OpenShift Container Storage environment is not directly connected to the internet, some additional configuration is required to provide the Operator Lifecycle Manager (OLM) with alternatives to the default Operator Hub and image registries.
See the OpenShift Container Platform documentation for more general information: Updating an Operator catalog image.
To configure your cluster for disconnected update:
When these steps are complete, Continue with update as usual.
11.3.1. Adding mirror registry authentication details
Prerequisites
- Verify that your existing disconnected cluster uses OpenShift Container Platform 4.3 or higher.
-
Verify that you have an
oc clientversion of 4.4 or higher. - Prepare a mirror host with a mirror registry. See Preparing your mirror host for details.
Procedure
-
Log in to the OpenShift Container Platform cluster using the
cluster-adminrole. Locate your
auth.jsonfile.This file is generated when you use podman or docker to log in to a registry. It is located in one of the following locations:
-
~/.docker/auth.json -
/run/user/<UID>/containers/auth.json -
/var/run/containers/<UID>/auth.json
-
Obtain your unique Red Hat registry pull secret and paste it into your
auth.jsonfile. It will look something like this.{ "auths": { "cloud.openshift.com": { "auth": "*****************", "email": "user@example.com" }, "quay.io": { "auth": "*****************", "email": "user@example.com" }, "registry.connect.redhat.com": { "auth": "*****************", "email": "user@example.com" }, "registry.redhat.io": { "auth": "*****************", "email": "user@example.com" } } }Export environment variables with the appropriate details for your setup.
$ export AUTH_FILE="<location_of_auth.json>" $ export MIRROR_REGISTRY_DNS="<your_registry_url>:<port>"Use
podmanto log in to the mirror registry and store the credentials in the${AUTH_FILE}.$ podman login ${MIRROR_REGISTRY_DNS} --tls-verify=false --authfile ${AUTH_FILE}This adds the mirror registry to the
auth.jsonfile.{ "auths": { "cloud.openshift.com": { "auth": "*****************", "email": "user@example.com" }, "quay.io": { "auth": "*****************", "email": "user@example.com" }, "registry.connect.redhat.com": { "auth": "*****************", "email": "user@example.com" }, "registry.redhat.io": { "auth": "*****************", "email": "user@example.com" }, "<mirror_registry>": { "auth": "*****************", } } }
11.3.2. Building and mirroring the Red Hat operator catalog
Follow this process on a host that has access to Red Hat registries to create a mirror of those registries.
Prerequisites
- Run these commands as a cluster administrator.
-
Be aware that mirroring the
redhat-operatorcatalog can take hours to complete, and requires substantial available disk space on the mirror host.
Procedure
Build the catalog for
redhat-operators.Set
--fromto theose-operator-registrybase image using the tag that matches the target OpenShift Container Platform cluster major and minor version.$ oc adm catalog build --appregistry-org redhat-operators \ --from=registry.redhat.io/openshift4/ose-operator-registry:v4.5 \ --to=${MIRROR_REGISTRY_DNS}/olm/redhat-operators:v2 \ --registry-config=${AUTH_FILE} \ --filter-by-os="linux/amd64" --insecureMirror the catalog for
redhat-operators.This is a long operation and can take 1-5 hours. Make sure there is 100 GB available disk space on the mirror host.
$ oc adm catalog mirror ${MIRROR_REGISTRY_DNS}/olm/redhat-operators:v2 \ ${MIRROR_REGISTRY_DNS} --registry-config=${AUTH_FILE} --insecure
11.3.3. Creating Operator imageContentSourcePolicy
After the oc adm catalog mirror command is completed, the imageContentSourcePolicy.yaml file gets created. The output directory for this file is usually, ./[catalog image name]-manifests). Use this procedure to add any missing entries to the .yaml file and apply them to cluster.
Procedure
Check the content of this file for the mirrors mapping shown as follows:
spec: repositoryDigestMirrors: - mirrors: - <your_registry>/ocs4 source: registry.redhat.io/ocs4 - mirrors: - <your_registry>/rhceph source: registry.redhat.io/rhceph - mirrors: - <your_registry>/openshift4 source: registry.redhat.io/openshift4 - mirrors: - <your_registry>/rhscl source: registry.redhat.io/rhscl-
Add any missing entries to the end of the
imageContentSourcePolicy.yamlfile. Apply the imageContentSourcePolicy.yaml file to the cluster.
$ oc apply -f ./[output dir]/imageContentSourcePolicy.yamlOnce the Image Content Source Policy is updated, all the nodes (master, infra, and workers) in the cluster need to be updated and rebooted. This process is automatically handled through the Machine Config Pool operator and take up to 30 minutes although the exact elapsed time might vary based on the number of nodes in your OpenShift cluster. You can monitor the update process by using the
oc get mcpcommand or theoc get nodecommand.
11.3.4. Updating redhat-operator CatalogSource
Procedure
Recreate a
CatalogSourceobject that references the catalog image for Red Hat operators.NoteMake sure you have mirrored the correct catalog source with the correct version (that is,
v2).
+ Save the following in a redhat-operator-catalogsource.yaml file, remembering to replace <your_registry> with your mirror registry URL:
+
apiVersion: operators.coreos.com/v1alpha1
kind: CatalogSource
metadata:
name: redhat-operators
namespace: openshift-marketplace
spec:
sourceType: grpc
icon:
base64data: PHN2ZyBpZD0iTGF5ZXJfMSIgZGF0YS1uYW1lPSJMYXllciAxIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHZpZXdCb3g9IjAgMCAxOTIgMTQ1Ij48ZGVmcz48c3R5bGU+LmNscy0xe2ZpbGw6I2UwMDt9PC9zdHlsZT48L2RlZnM+PHRpdGxlPlJlZEhhdC1Mb2dvLUhhdC1Db2xvcjwvdGl0bGU+PHBhdGggZD0iTTE1Ny43Nyw2Mi42MWExNCwxNCwwLDAsMSwuMzEsMy40MmMwLDE0Ljg4LTE4LjEsMTcuNDYtMzAuNjEsMTcuNDZDNzguODMsODMuNDksNDIuNTMsNTMuMjYsNDIuNTMsNDRhNi40Myw2LjQzLDAsMCwxLC4yMi0xLjk0bC0zLjY2LDkuMDZhMTguNDUsMTguNDUsMCwwLDAtMS41MSw3LjMzYzAsMTguMTEsNDEsNDUuNDgsODcuNzQsNDUuNDgsMjAuNjksMCwzNi40My03Ljc2LDM2LjQzLTIxLjc3LDAtMS4wOCwwLTEuOTQtMS43My0xMC4xM1oiLz48cGF0aCBjbGFzcz0iY2xzLTEiIGQ9Ik0xMjcuNDcsODMuNDljMTIuNTEsMCwzMC42MS0yLjU4LDMwLjYxLTE3LjQ2YTE0LDE0LDAsMCwwLS4zMS0zLjQybC03LjQ1LTMyLjM2Yy0xLjcyLTcuMTItMy4yMy0xMC4zNS0xNS43My0xNi42QzEyNC44OSw4LjY5LDEwMy43Ni41LDk3LjUxLjUsOTEuNjkuNSw5MCw4LDgzLjA2LDhjLTYuNjgsMC0xMS42NC01LjYtMTcuODktNS42LTYsMC05LjkxLDQuMDktMTIuOTMsMTIuNSwwLDAtOC40MSwyMy43Mi05LjQ5LDI3LjE2QTYuNDMsNi40MywwLDAsMCw0Mi41Myw0NGMwLDkuMjIsMzYuMywzOS40NSw4NC45NCwzOS40NU0xNjAsNzIuMDdjMS43Myw4LjE5LDEuNzMsOS4wNSwxLjczLDEwLjEzLDAsMTQtMTUuNzQsMjEuNzctMzYuNDMsMjEuNzdDNzguNTQsMTA0LDM3LjU4LDc2LjYsMzcuNTgsNTguNDlhMTguNDUsMTguNDUsMCwwLDEsMS41MS03LjMzQzIyLjI3LDUyLC41LDU1LC41LDc0LjIyYzAsMzEuNDgsNzQuNTksNzAuMjgsMTMzLjY1LDcwLjI4LDQ1LjI4LDAsNTYuNy0yMC40OCw1Ni43LTM2LjY1LDAtMTIuNzItMTEtMjcuMTYtMzAuODMtMzUuNzgiLz48L3N2Zz4=
mediatype: image/svg+xml
image: <your_registry>/olm/redhat-operators:v2
displayName: Redhat Operators Catalog
publisher: Red HatCreate a catalogsource using the redhat-operator-catalogsource.yaml file:
$ oc apply -f redhat-operator-catalogsource.yamlVerify that the new
redhat-operatorpod is running.$ oc get pod -n openshift-marketplace | grep redhat-operators
11.3.5. Continue to update
After your alternative catalog source is configured, you can continue to the appropriate update process: