Scaling storage
Instructions for scaling operations in OpenShift Data Foundation
Abstract
Making open source more inclusive
Red Hat is committed to replacing problematic language in our code, documentation, and web properties. We are beginning with these four terms: master, slave, blacklist, and whitelist. Because of the enormity of this endeavor, these changes will be implemented gradually over several upcoming releases. For more details, see our CTO Chris Wright’s message.
Providing feedback on Red Hat documentation
We appreciate your input on our documentation. Do let us know how we can make it better.
To give feedback, create a Bugzilla ticket:
- Go to the Bugzilla website.
- In the Component section, choose documentation.
- Fill in the Description field with your suggestion for improvement. Include a link to the relevant part(s) of documentation.
- Click Submit Bug.
Chapter 1. Introduction to scaling storage
Red Hat OpenShift Data Foundation is a highly scalable storage system. OpenShift Data Foundation allows you to scale by adding the disks in the multiple of three, or three or any number depending upon the deployment type.
- For internal (dynamic provisioning) deployment mode, you can increase the capacity by adding 3 disks at a time.
- For internal-attached (Local Storage Operator based) mode, you can deploy with less than 3 failure domains.
With flexible scale deployment enabled, you can scale up by adding any number of disks. For deployment with 3 failure domains, you will be able to scale up by adding disks in the multiple of 3.
For scaling your storage in external mode, see Red Hat Ceph Storage documentation.
You can use a maximum of twelve storage devices per node. The high number of storage devices will lead to a higher recovery time during the loss of a node. This recommendation ensures that nodes stay below the cloud provider dynamic storage device attachment limits, and limits the recovery time after node failure with local storage devices.
While scaling, you must ensure that there are enough CPU and Memory resources as per scaling requirement.
Supported storage classes by default
-
gp2-csion AWS -
thinon VMware -
managed_premiumon Microsoft Azure
1.1. Supported Deployments for Red Hat OpenShift Data Foundation
User-provisioned infrastructure:
- Amazon Web Services (AWS)
- VMware
- Bare metal
- IBM Power
- IBM Z or IBM® LinuxONE
Installer-provisioned infrastructure:
- Amazon Web Services (AWS)
- Microsoft Azure
- VMware
- Bare metal
Chapter 2. Requirements for scaling storage
Before you proceed to scale the storage nodes, refer to the following sections to understand the node requirements for your specific Red Hat OpenShift Data Foundation instance:
- Platform requirements
- Resource requirements
Storage device requirements
Always ensure that you have plenty of storage capacity.
If storage ever fills completely, it is not possible to add capacity or delete or migrate content away from the storage to free up space completely. Full storage is very difficult to recover.
Capacity alerts are issued when cluster storage capacity reaches 75% (near-full) and 85% (full) of total capacity. Always address capacity warnings promptly, and review your storage regularly to ensure that you do not run out of storage space.
If you do run out of storage space completely, contact Red Hat Customer Support.
Chapter 3. Scaling storage capacity of AWS OpenShift Data Foundation cluster
To scale the storage capacity of your configured Red Hat OpenShift Data Foundation worker nodes on AWS cluster, you can increase the capacity by adding three disks at a time. Three disks are needed since OpenShift Data Foundation uses a replica count of 3 to maintain the high availability. So the amount of storage consumed is three times the usable space.
Usable space might vary when encryption is enabled or replica 2 pools are being used.
3.1. Scaling up storage capacity on a cluster
To increase the storage capacity in a dynamically created storage cluster on an user-provisioned infrastructure, you can add storage capacity and performance to your configured Red Hat OpenShift Data Foundation worker nodes.
Prerequisites
- You have administrative privilege to the OpenShift Container Platform Console.
- You have a running OpenShift Data Foundation Storage Cluster.
- The disk should be of the same size and type as used during initial deployment.
Procedure
- Log in to the OpenShift Web Console.
- Click Operators → Installed Operators.
- Click OpenShift Data Foundation Operator.
Click the Storage Systems tab.
- Click the Action Menu (⋮) on the far right of the storage system name to extend the options menu.
- Select Add Capacity from the options menu.
- Select the Storage Class. Choose the storage class which you wish to use to provision new storage devices.
- Click Add.
-
To check the status, navigate to Storage → Data Foundation and verify that the
Storage Systemin the Status card has a green tick.
Verification steps
Verify the Raw Capacity card.
- In the OpenShift Web Console, click Storage → Data Foundation.
- In the Status card of the Overview tab, click Storage System and then click the storage system link from the pop up that appears.
In the Block and File tab, check the Raw Capacity card.
Note that the capacity increases based on your selections.
NoteThe raw capacity does not take replication into account and shows the full capacity.
Verify that the new object storage devices (OSDs) and their corresponding new Persistent Volume Claims (PVCs) are created.
To view the state of the newly created OSDs:
- Click Workloads → Pods from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
To view the state of the PVCs:
- Click Storage → Persistent Volume Claims from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
Optional: If cluster-wide encryption is enabled on the cluster, verify that the new OSD devices are encrypted.
Identify the nodes where the new OSD pods are running.
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/<OSD-pod-name><OSD-pod-name>Is the name of the OSD pod.
For example:
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/rook-ceph-osd-0-544db49d7f-qrgqmExample output:
NODE compute-1
For each of the nodes identified in the previous step, do the following:
Create a debug pod and open a chroot environment for the selected hosts.
$ oc debug node/<node-name><node-name>Is the name of the node.
$ chroot /host
Check for the
cryptkeyword beside theocs-devicesetnames.$ lsblk
Cluster reduction is supported only with the Red Hat Support Team’s assistance.
3.2. Scaling out storage capacity on a AWS cluster
OpenShift Data Foundation is highly scalable. It can be scaled out by adding new nodes with required storage and enough hardware resources in terms of CPU and RAM. Practically there is no limit on the number of nodes which can be added but from the support perspective 2000 nodes is the limit for OpenShift Data Foundation.
Scaling out storage capacity can be broken down into two steps
- Adding new node
- Scaling up the storage capacity
OpenShift Data Foundation does not support heterogeneous OSD/Disk sizes.
3.2.1. Adding a node
You can add nodes to increase the storage capacity when existing worker nodes are already running at their maximum supported OSDs or there are not enough resources to add new OSDs on the existing nodes. It is always recommended to add nodes in the multiple of three, each of them in different failure domains.
While it is recommended to add nodes in the multiple of three, you still have the flexibility to add one node at a time in the flexible scaling deployment. Refer to the Knowledgebase article Verify if flexible scaling is enabled.
OpenShift Data Foundation does not support heterogeneous disk size and types. The new nodes to be added should have the disk of the same type and size which was used during OpenShift Data Foundation deployment.
3.2.1.1. Adding a node to an installer-provisioned infrastructure
Prerequisites
- You have administrative privilege to the OpenShift Container Platform Console.
- You have a running OpenShift Data Foundation Storage Cluster.
Procedure
- Navigate to Compute → Machine Sets.
On the machine set where you want to add nodes, select Edit Machine Count.
- Add the amount of nodes, and click Save.
- Click Compute → Nodes and confirm if the new node is in Ready state.
Apply the OpenShift Data Foundation label to the new node.
- For the new node, click Action menu (⋮) → Edit Labels.
- Add cluster.ocs.openshift.io/openshift-storage, and click Save.
It is recommended to add 3 nodes, one each in different zones. You must add 3 nodes and perform this procedure for all of them. In case of bare metal installer-provisioned infrastructure deployment, you must expand the cluster first. For instructions, see Expanding the cluster.
Verification steps
Execute the following command in the terminal and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1On the OpenShift web console, click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
3.2.1.2. Adding a node to an user-provisioned infrastructure
Prerequisites
- You have administrative privilege to the OpenShift Container Platform Console.
- You have a running OpenShift Data Foundation Storage Cluster.
Procedure
Depending on the type of infrastructure, perform the following steps:
- Get a new machine with the required infrastructure. See Platform requirements.
- Create a new OpenShift Container Platform worker node using the new machine.
Check for certificate signing requests (CSRs) that are in
Pendingstate.$ oc get csrApprove all the required CSRs for the new node.
$ oc adm certificate approve <Certificate_Name><Certificate_Name>- Is the name of the CSR.
- Click Compute → Nodes, confirm if the new node is in Ready state.
Apply the OpenShift Data Foundation label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels.
-
Add
cluster.ocs.openshift.io/openshift-storage, and click Save.
- From Command line interface
Apply the OpenShift Data Foundation label to the new node.
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""<new_node_name>- Is the name of the new node.
Verification steps
Execute the following command in the terminal and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1On the OpenShift web console, click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
3.2.2. Scaling up storage capacity
To scale up storage capacity, see Scaling up storage capacity on a cluster.
Chapter 4. Scaling storage of bare metal OpenShift Data Foundation cluster
To scale the storage capacity of your configured Red Hat OpenShift Data Foundation worker nodes on your bare metal cluster, you can increase the capacity by adding three disks at a time. Three disks are needed since OpenShift Data Foundation uses a replica count of 3 to maintain the high availability. So the amount of storage consumed is three times the usable space.
Usable space might vary when encryption is enabled or replica 2 pools are being used.
4.1. Scaling up a cluster created using local storage devices
To scale up an OpenShift Data Foundation cluster which was created using local storage devices, you need to add a new disk to the storage node. The new disks size must be of the same size as the disks used during the deployment because OpenShift Data Foundation does not support heterogeneous disks/OSDs.
For deployments having three failure domains, you can scale up the storage by adding disks in the multiples of three, with the same number of disks coming from nodes in each of the failure domains. For example, if we scale by adding six disks, two disks are taken from nodes in each of the three failure domains. If the number of disks is not in multiples of three, it will only consume the disk to the maximum in the multiple of three while the remaining disks remain unused.
For deployments having less than three failure domains, there is a flexibility to add any number of disks. Make sure to verify that flexible scaling is enabled. For information, refer to the Knowledgebase article Verify if flexible scaling is enabled.
Flexible scaling features get enabled at the time of deployment and cannot be enabled or disabled later on.
Prerequisites
- Administrative privilege to the OpenShift Container Platform Console.
- A running OpenShift Data Foundation Storage Cluster.
- Make sure that the disks to be used for scaling are attached to the storage node
-
Make sure that
LocalVolumeDiscoveryandLocalVolumeSetobjects are created.
Procedure
To add capacity, you can either use a storage class that you provisioned during the deployment or any other storage class that matches the filter.
- In the OpenShift Web Console, click Operators → Installed Operators.
- Click OpenShift Data Foundation Operator.
Click the Storage Systems tab.
- Click the Action menu (⋮) next to the visible list to extend the options menu.
- Select Add Capacity from the options menu.
- Select the Storage Class for which you added disks or the new storage class depending on your requirement. Available Capacity displayed is based on the local disks available in storage class.
- Click Add.
- To check the status, navigate to Storage → Data Foundation and verify that the Storage System in the Status card has a green tick.
Verification steps
Verify the Raw Capacity card.
- In the OpenShift Web Console, click Storage → Data Foundation.
- In the Status card of the Overview tab, click Storage System and then click the storage system link from the pop up that appears.
In the Block and File tab, check the Raw Capacity card.
Note that the capacity increases based on your selections.
NoteThe raw capacity does not take replication into account and shows the full capacity.
Verify that the new OSDs and their corresponding new Persistent Volume Claims (PVCs) are created.
To view the state of the newly created OSDs:
- Click Workloads → Pods from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
To view the state of the PVCs:
- Click Storage → Persistent Volume Claims from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
Optional: If cluster-wide encryption is enabled on the cluster, verify that the new OSD devices are encrypted.
Identify the nodes where the new OSD pods are running.
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/<OSD-pod-name><OSD-pod-name>Is the name of the OSD pod.
For example:
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/rook-ceph-osd-0-544db49d7f-qrgqmExample output:
NODE compute-1
For each of the nodes identified in the previous step, do the following:
Create a debug pod and open a chroot environment for the selected host(s).
$ oc debug node/<node-name><node-name>Is the name of the node.
$ chroot /host
Check for the
cryptkeyword beside theocs-devicesetnames.$ lsblk
Cluster reduction is supported only with the Red Hat Support Team’s assistance.
4.2. Scaling out storage capacity on a bare metal cluster
OpenShift Data Foundation is highly scalable. It can be scaled out by adding new nodes with required storage and enough hardware resources in terms of CPU and RAM. There is no limit on the number of nodes which can be added. However, from the technical support perspective, 2000 nodes is the limit for OpenShift Data Foundation.
Scaling out storage capacity can be broken down into two steps
- Adding new node
- Scaling up the storage capacity
OpenShift Data Foundation does not support heterogeneous OSD/Disk sizes.
4.2.1. Adding a node
You can add nodes to increase the storage capacity when existing worker nodes are already running at their maximum supported OSDs or there are not enough resources to add new OSDs on the existing nodes. It is always recommended to add nodes in the multiple of three, each of them in different failure domains.
While it is recommended to add nodes in the multiple of three, you still have the flexibility to add one node at a time in the flexible scaling deployment. Refer to the Knowledgebase article Verify if flexible scaling is enabled.
OpenShift Data Foundation does not support heterogeneous disk size and types. The new nodes to be added should have the disk of the same type and size which was used during OpenShift Data Foundation deployment.
4.2.1.1. Adding a node to an installer-provisioned infrastructure
Prerequisites
- You have administrative privilege to the OpenShift Container Platform Console.
- You have a running OpenShift Data Foundation Storage Cluster.
Procedure
- Navigate to Compute → Machine Sets.
On the machine set where you want to add nodes, select Edit Machine Count.
- Add the amount of nodes, and click Save.
- Click Compute → Nodes and confirm if the new node is in Ready state.
Apply the OpenShift Data Foundation label to the new node.
- For the new node, click Action menu (⋮) → Edit Labels.
- Add cluster.ocs.openshift.io/openshift-storage, and click Save.
It is recommended to add 3 nodes, one each in different zones. You must add 3 nodes and perform this procedure for all of them. In case of bare metal installer-provisioned infrastructure deployment, you must expand the cluster first. For instructions, see Expanding the cluster.
Verification steps
Execute the following command in the terminal and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1On the OpenShift web console, click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
4.2.1.2. Adding a node using a local storage device
You can add nodes to increase the storage capacity when existing worker nodes are already running at their maximum supported OSDs or when there are not enough resources to add new OSDs on the existing nodes.
Add nodes in the multiple of 3, each of them in different failure domains. Though it is recommended to add nodes in multiples of 3 nodes, you have the flexibility to add one node at a time in flexible scaling deployment. See Knowledgebase article Verify if flexible scaling is enabled
OpenShift Data Foundation does not support heterogeneous disk size and types. The new nodes to be added should have the disk of the same type and size which was used during initial OpenShift Data Foundation deployment.
Prerequisites
- You have administrative privilege to the OpenShift Container Platform Console.
- You have a running OpenShift Data Foundation Storage Cluster.
Procedure
Depending on the type of infrastructure, perform the following steps:
- Get a new machine with the required infrastructure. See Platform requirements.
- Create a new OpenShift Container Platform worker node using the new machine.
Check for certificate signing requests (CSRs) that are in
Pendingstate.$ oc get csrApprove all the required CSRs for the new node.
$ oc adm certificate approve <Certificate_Name><Certificate_Name>- Is the name of the CSR.
- Click Compute → Nodes, confirm if the new node is in Ready state.
Apply the OpenShift Data Foundation label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels.
-
Add
cluster.ocs.openshift.io/openshift-storage, and click Save.
- From Command line interface
Apply the OpenShift Data Foundation label to the new node.
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""<new_node_name>- Is the name of the new node.
Click Operators → Installed Operators from the OpenShift Web Console.
From the Project drop-down list, make sure to select the project where the Local Storage Operator is installed.
- Click Local Storage.
Click the Local Volume Discovery tab.
-
Beside the
LocalVolumeDiscovery, click Action menu (⋮) → Edit Local Volume Discovery. -
In the YAML, add the hostname of the new node in the
valuesfield under the node selector. - Click Save.
-
Beside the
Click the Local Volume Sets tab.
-
Beside the
LocalVolumeSet, click Action menu (⋮) → Edit Local Volume Set. In the YAML, add the hostname of the new node in the
valuesfield under thenode selector.
- Click Save.
-
Beside the
It is recommended to add 3 nodes, one each in different zones. You must add 3 nodes and perform this procedure for all of them.
Verification steps
Execute the following command in the terminal and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1On the OpenShift web console, click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
4.2.2. Scaling up storage capacity
To scale up storage capacity, see Scaling up storage by adding capacity.
Chapter 5. Scaling storage of VMware OpenShift Data Foundation cluster
5.1. Scaling up storage on a dynamically provisioned VMware cluster
To increase the storage capacity in a dynamically created storage cluster on a VMware user-provisioned infrastructure, you can add storage capacity and performance to your configured Red Hat OpenShift Data Foundation worker nodes.
Prerequisites
- Administrative privilege to the OpenShift Container Platform Console.
- A running OpenShift Data Foundation Storage Cluster.
- Make sure that the disk is of the same size and type as the disk used during initial deployment.
Procedure
- Log in to the OpenShift Web Console.
- Click Operators → Installed Operators.
- Click OpenShift Data Foundation Operator.
Click the Storage Systems tab.
- Click the Action Menu (⋮) on the far right of the storage system name to extend the options menu.
- Select Add Capacity from the options menu.
- Select the Storage Class. Choose the storage class which you wish to use to provision new storage devices.
- Click Add.
-
To check the status, navigate to Storage → Data Foundation and verify that
Storage Systemin the Status card has a green tick.
Verification steps
Verify the Raw Capacity card.
- In the OpenShift Web Console, click Storage → Data Foundation.
- In the Status card of the Overview tab, click Storage System and then click the storage system link from the pop up that appears.
In the Block and File tab, check the Raw Capacity card.
Note that the capacity increases based on your selections.
NoteThe raw capacity does not take replication into account and shows the full capacity.
Verify that the new OSDs and their corresponding new Persistent Volume Claims (PVCs) are created.
To view the state of the newly created OSDs:
- Click Workloads → Pods from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
To view the state of the PVCs:
- Click Storage → Persistent Volume Claims from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
Optional: If cluster-wide encryption is enabled on the cluster, verify that the new OSD devices are encrypted.
Identify the nodes where the new OSD pods are running.
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/<OSD-pod-name><OSD-pod-name>Is the name of the OSD pod.
For example:
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/rook-ceph-osd-0-544db49d7f-qrgqmExample output:
NODE compute-1
For each of the nodes identified in the previous step, do the following:
Create a debug pod and open a chroot environment for the selected hosts.
$ oc debug node/<node-name><node-name>Is the name of the node.
$ chroot /host
Check for the
cryptkeyword beside theocs-devicesetnames.$ lsblk
Cluster reduction is supported only with the Red Hat Support Team’s assistance.
5.2. Scaling up a cluster created using local storage devices
To scale up an OpenShift Data Foundation cluster which was created using local storage devices, you need to add a new disk to the storage node. The new disks size must be of the same size as the disks used during the deployment because OpenShift Data Foundation does not support heterogeneous disks/OSDs.
For deployments having three failure domains, you can scale up the storage by adding disks in the multiples of three, with the same number of disks coming from nodes in each of the failure domains. For example, if we scale by adding six disks, two disks are taken from nodes in each of the three failure domains. If the number of disks is not in multiples of three, it will only consume the disk to the maximum in the multiple of three while the remaining disks remain unused.
For deployments having less than three failure domains, there is a flexibility to add any number of disks. Make sure to verify that flexible scaling is enabled. For information, refer to the Knowledgebase article Verify if flexible scaling is enabled.
Flexible scaling features get enabled at the time of deployment and cannot be enabled or disabled later on.
Prerequisites
- Administrative privilege to the OpenShift Container Platform Console.
- A running OpenShift Data Foundation Storage Cluster.
- Make sure that the disks to be used for scaling are attached to the storage node
-
Make sure that
LocalVolumeDiscoveryandLocalVolumeSetobjects are created.
Procedure
To add capacity, you can either use a storage class that you provisioned during the deployment or any other storage class that matches the filter.
- In the OpenShift Web Console, click Operators → Installed Operators.
- Click OpenShift Data Foundation Operator.
Click the Storage Systems tab.
- Click the Action menu (⋮) next to the visible list to extend the options menu.
- Select Add Capacity from the options menu.
- Select the Storage Class for which you added disks or the new storage class depending on your requirement. Available Capacity displayed is based on the local disks available in storage class.
- Click Add.
- To check the status, navigate to Storage → Data Foundation and verify that the Storage System in the Status card has a green tick.
Verification steps
Verify the Raw Capacity card.
- In the OpenShift Web Console, click Storage → Data Foundation.
- In the Status card of the Overview tab, click Storage System and then click the storage system link from the pop up that appears.
In the Block and File tab, check the Raw Capacity card.
Note that the capacity increases based on your selections.
NoteThe raw capacity does not take replication into account and shows the full capacity.
Verify that the new OSDs and their corresponding new Persistent Volume Claims (PVCs) are created.
To view the state of the newly created OSDs:
- Click Workloads → Pods from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
To view the state of the PVCs:
- Click Storage → Persistent Volume Claims from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
Optional: If cluster-wide encryption is enabled on the cluster, verify that the new OSD devices are encrypted.
Identify the nodes where the new OSD pods are running.
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/<OSD-pod-name><OSD-pod-name>Is the name of the OSD pod.
For example:
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/rook-ceph-osd-0-544db49d7f-qrgqmExample output:
NODE compute-1
For each of the nodes identified in the previous step, do the following:
Create a debug pod and open a chroot environment for the selected host(s).
$ oc debug node/<node-name><node-name>Is the name of the node.
$ chroot /host
Check for the
cryptkeyword beside theocs-devicesetnames.$ lsblk
Cluster reduction is supported only with the Red Hat Support Team’s assistance.
5.3. Scaling out storage capacity on a VMware cluster
5.3.1. Adding a node to an installer-provisioned infrastructure
Prerequisites
- You have administrative privilege to the OpenShift Container Platform Console.
- You have a running OpenShift Data Foundation Storage Cluster.
Procedure
- Navigate to Compute → Machine Sets.
On the machine set where you want to add nodes, select Edit Machine Count.
- Add the amount of nodes, and click Save.
- Click Compute → Nodes and confirm if the new node is in Ready state.
Apply the OpenShift Data Foundation label to the new node.
- For the new node, click Action menu (⋮) → Edit Labels.
- Add cluster.ocs.openshift.io/openshift-storage, and click Save.
It is recommended to add 3 nodes, one each in different zones. You must add 3 nodes and perform this procedure for all of them. In case of bare metal installer-provisioned infrastructure deployment, you must expand the cluster first. For instructions, see Expanding the cluster.
Verification steps
Execute the following command in the terminal and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1On the OpenShift web console, click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
5.3.2. Adding a node to an user-provisioned infrastructure
Prerequisites
- You have administrative privilege to the OpenShift Container Platform Console.
- You have a running OpenShift Data Foundation Storage Cluster.
Procedure
Depending on the type of infrastructure, perform the following steps:
- Get a new machine with the required infrastructure. See Platform requirements.
- Create a new OpenShift Container Platform worker node using the new machine.
Check for certificate signing requests (CSRs) that are in
Pendingstate.$ oc get csrApprove all the required CSRs for the new node.
$ oc adm certificate approve <Certificate_Name><Certificate_Name>- Is the name of the CSR.
- Click Compute → Nodes, confirm if the new node is in Ready state.
Apply the OpenShift Data Foundation label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels.
-
Add
cluster.ocs.openshift.io/openshift-storage, and click Save.
- From Command line interface
Apply the OpenShift Data Foundation label to the new node.
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""<new_node_name>- Is the name of the new node.
Verification steps
Execute the following command in the terminal and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1On the OpenShift web console, click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
5.3.3. Adding a node using a local storage device
You can add nodes to increase the storage capacity when existing worker nodes are already running at their maximum supported OSDs or when there are not enough resources to add new OSDs on the existing nodes.
Add nodes in the multiple of 3, each of them in different failure domains. Though it is recommended to add nodes in multiples of 3 nodes, you have the flexibility to add one node at a time in flexible scaling deployment. See Knowledgebase article Verify if flexible scaling is enabled
OpenShift Data Foundation does not support heterogeneous disk size and types. The new nodes to be added should have the disk of the same type and size which was used during initial OpenShift Data Foundation deployment.
Prerequisites
- You have administrative privilege to the OpenShift Container Platform Console.
- You have a running OpenShift Data Foundation Storage Cluster.
Procedure
Depending on the type of infrastructure, perform the following steps:
- Get a new machine with the required infrastructure. See Platform requirements.
- Create a new OpenShift Container Platform worker node using the new machine.
Check for certificate signing requests (CSRs) that are in
Pendingstate.$ oc get csrApprove all the required CSRs for the new node.
$ oc adm certificate approve <Certificate_Name><Certificate_Name>- Is the name of the CSR.
- Click Compute → Nodes, confirm if the new node is in Ready state.
Apply the OpenShift Data Foundation label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels.
-
Add
cluster.ocs.openshift.io/openshift-storage, and click Save.
- From Command line interface
Apply the OpenShift Data Foundation label to the new node.
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""<new_node_name>- Is the name of the new node.
Click Operators → Installed Operators from the OpenShift Web Console.
From the Project drop-down list, make sure to select the project where the Local Storage Operator is installed.
- Click Local Storage.
Click the Local Volume Discovery tab.
-
Beside the
LocalVolumeDiscovery, click Action menu (⋮) → Edit Local Volume Discovery. -
In the YAML, add the hostname of the new node in the
valuesfield under the node selector. - Click Save.
-
Beside the
Click the Local Volume Sets tab.
-
Beside the
LocalVolumeSet, click Action menu (⋮) → Edit Local Volume Set. In the YAML, add the hostname of the new node in the
valuesfield under thenode selector.
- Click Save.
-
Beside the
It is recommended to add 3 nodes, one each in different zones. You must add 3 nodes and perform this procedure for all of them.
Verification steps
Execute the following command in the terminal and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1On the OpenShift web console, click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
5.3.4. Scaling up storage capacity
To scale up storage capacity:
- For dynamic storage devices, see Scaling up storage capacity on a cluster.
- For local storage devices, see Scaling up a cluster created using local storage devices
Chapter 6. Scaling storage of Microsoft Azure OpenShift Data Foundation cluster
To scale the storage capacity of your configured Red Hat OpenShift Data Foundation worker nodes on Microsoft Azure cluster, you can increase the capacity by adding three disks at a time. Three disks are needed since OpenShift Data Foundation uses a replica count of 3 to maintain the high availability. So the amount of storage consumed is three times the usable space.
Usable space might vary when encryption is enabled or replica 2 pools are being used.
6.1. Scaling up storage capacity on a cluster
To increase the storage capacity in a dynamically created storage cluster on an user-provisioned infrastructure, you can add storage capacity and performance to your configured Red Hat OpenShift Data Foundation worker nodes.
Prerequisites
- You have administrative privilege to the OpenShift Container Platform Console.
- You have a running OpenShift Data Foundation Storage Cluster.
- The disk should be of the same size and type as used during initial deployment.
Procedure
- Log in to the OpenShift Web Console.
- Click Operators → Installed Operators.
- Click OpenShift Data Foundation Operator.
Click the Storage Systems tab.
- Click the Action Menu (⋮) on the far right of the storage system name to extend the options menu.
- Select Add Capacity from the options menu.
- Select the Storage Class. Choose the storage class which you wish to use to provision new storage devices.
- Click Add.
-
To check the status, navigate to Storage → Data Foundation and verify that the
Storage Systemin the Status card has a green tick.
Verification steps
Verify the Raw Capacity card.
- In the OpenShift Web Console, click Storage → Data Foundation.
- In the Status card of the Overview tab, click Storage System and then click the storage system link from the pop up that appears.
In the Block and File tab, check the Raw Capacity card.
Note that the capacity increases based on your selections.
NoteThe raw capacity does not take replication into account and shows the full capacity.
Verify that the new object storage devices (OSDs) and their corresponding new Persistent Volume Claims (PVCs) are created.
To view the state of the newly created OSDs:
- Click Workloads → Pods from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
To view the state of the PVCs:
- Click Storage → Persistent Volume Claims from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
Optional: If cluster-wide encryption is enabled on the cluster, verify that the new OSD devices are encrypted.
Identify the nodes where the new OSD pods are running.
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/<OSD-pod-name><OSD-pod-name>Is the name of the OSD pod.
For example:
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/rook-ceph-osd-0-544db49d7f-qrgqmExample output:
NODE compute-1
For each of the nodes identified in the previous step, do the following:
Create a debug pod and open a chroot environment for the selected hosts.
$ oc debug node/<node-name><node-name>Is the name of the node.
$ chroot /host
Check for the
cryptkeyword beside theocs-devicesetnames.$ lsblk
Cluster reduction is supported only with the Red Hat Support Team’s assistance.
6.2. Scaling out storage capacity on a Microsoft Azure cluster
OpenShift Data Foundation is highly scalable. It can be scaled out by adding new nodes with required storage and enough hardware resources in terms of CPU and RAM. Practically there is no limit on the number of nodes which can be added but from the support perspective 2000 nodes is the limit for OpenShift Data Foundation.
Scaling out storage capacity can be broken down into two steps
- Adding new node
- Scaling up the storage capacity
OpenShift Data Foundation does not support heterogeneous OSD/Disk sizes.
6.2.1. Adding a node to an installer-provisioned infrastructure
Prerequisites
- You have administrative privilege to the OpenShift Container Platform Console.
- You have a running OpenShift Data Foundation Storage Cluster.
Procedure
- Navigate to Compute → Machine Sets.
On the machine set where you want to add nodes, select Edit Machine Count.
- Add the amount of nodes, and click Save.
- Click Compute → Nodes and confirm if the new node is in Ready state.
Apply the OpenShift Data Foundation label to the new node.
- For the new node, click Action menu (⋮) → Edit Labels.
- Add cluster.ocs.openshift.io/openshift-storage, and click Save.
It is recommended to add 3 nodes, one each in different zones. You must add 3 nodes and perform this procedure for all of them. In case of bare metal installer-provisioned infrastructure deployment, you must expand the cluster first. For instructions, see Expanding the cluster.
Verification steps
Execute the following command in the terminal and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1On the OpenShift web console, click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
6.2.2. Scaling up storage capacity
To scale up storage capacity, see Scaling up storage capacity on a cluster.
Chapter 7. Scaling storage capacity of GCP OpenShift Data Foundation cluster
To scale the storage capacity of your configured Red Hat OpenShift Data Foundation worker nodes on GCP cluster, you can increase the capacity by adding three disks at a time. Three disks are needed since OpenShift Data Foundation uses a replica count of 3 to maintain the high availability. So the amount of storage consumed is three times the usable space.
Usable space might vary when encryption is enabled or replica 2 pools are being used.
7.1. Scaling up storage capacity on a cluster
To increase the storage capacity in a dynamically created storage cluster on an user-provisioned infrastructure, you can add storage capacity and performance to your configured Red Hat OpenShift Data Foundation worker nodes.
Prerequisites
- You have administrative privilege to the OpenShift Container Platform Console.
- You have a running OpenShift Data Foundation Storage Cluster.
- The disk should be of the same size and type as used during initial deployment.
Procedure
- Log in to the OpenShift Web Console.
- Click Operators → Installed Operators.
- Click OpenShift Data Foundation Operator.
Click the Storage Systems tab.
- Click the Action Menu (⋮) on the far right of the storage system name to extend the options menu.
- Select Add Capacity from the options menu.
- Select the Storage Class. Choose the storage class which you wish to use to provision new storage devices.
- Click Add.
-
To check the status, navigate to Storage → Data Foundation and verify that the
Storage Systemin the Status card has a green tick.
Verification steps
Verify the Raw Capacity card.
- In the OpenShift Web Console, click Storage → Data Foundation.
- In the Status card of the Overview tab, click Storage System and then click the storage system link from the pop up that appears.
In the Block and File tab, check the Raw Capacity card.
Note that the capacity increases based on your selections.
NoteThe raw capacity does not take replication into account and shows the full capacity.
Verify that the new object storage devices (OSDs) and their corresponding new Persistent Volume Claims (PVCs) are created.
To view the state of the newly created OSDs:
- Click Workloads → Pods from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
To view the state of the PVCs:
- Click Storage → Persistent Volume Claims from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
Optional: If cluster-wide encryption is enabled on the cluster, verify that the new OSD devices are encrypted.
Identify the nodes where the new OSD pods are running.
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/<OSD-pod-name><OSD-pod-name>Is the name of the OSD pod.
For example:
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/rook-ceph-osd-0-544db49d7f-qrgqmExample output:
NODE compute-1
For each of the nodes identified in the previous step, do the following:
Create a debug pod and open a chroot environment for the selected hosts.
$ oc debug node/<node-name><node-name>Is the name of the node.
$ chroot /host
Check for the
cryptkeyword beside theocs-devicesetnames.$ lsblk
Cluster reduction is supported only with the Red Hat Support Team’s assistance.
7.2. Scaling out storage capacity on a GCP cluster
OpenShift Data Foundation is highly scalable. It can be scaled out by adding new nodes with required storage and enough hardware resources in terms of CPU and RAM. Practically there is no limit on the number of nodes which can be added but from the support perspective 2000 nodes is the limit for OpenShift Data Foundation.
Scaling out storage capacity can be broken down into two steps
- Adding new node
- Scaling up the storage capacity
OpenShift Data Foundation does not support heterogeneous OSD/Disk sizes.
7.2.1. Adding a node
You can add nodes to increase the storage capacity when existing worker nodes are already running at their maximum supported OSDs or there are not enough resources to add new OSDs on the existing nodes. It is always recommended to add nodes in the multiple of three, each of them in different failure domains.
While it is recommended to add nodes in the multiple of three, you still have the flexibility to add one node at a time in the flexible scaling deployment. Refer to the Knowledgebase article Verify if flexible scaling is enabled.
OpenShift Data Foundation does not support heterogeneous disk size and types. The new nodes to be added should have the disk of the same type and size which was used during OpenShift Data Foundation deployment.
7.2.1.1. Adding a node to an installer-provisioned infrastructure
Prerequisites
- You have administrative privilege to the OpenShift Container Platform Console.
- You have a running OpenShift Data Foundation Storage Cluster.
Procedure
- Navigate to Compute → Machine Sets.
On the machine set where you want to add nodes, select Edit Machine Count.
- Add the amount of nodes, and click Save.
- Click Compute → Nodes and confirm if the new node is in Ready state.
Apply the OpenShift Data Foundation label to the new node.
- For the new node, click Action menu (⋮) → Edit Labels.
- Add cluster.ocs.openshift.io/openshift-storage, and click Save.
It is recommended to add 3 nodes, one each in different zones. You must add 3 nodes and perform this procedure for all of them. In case of bare metal installer-provisioned infrastructure deployment, you must expand the cluster first. For instructions, see Expanding the cluster.
Verification steps
Execute the following command in the terminal and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1On the OpenShift web console, click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
7.2.2. Scaling up storage capacity
To scale up storage capacity, see Scaling up storage capacity on a cluster.
Chapter 8. Scaling storage of IBM Z or IBM LinuxONE OpenShift Data Foundation cluster
8.1. Scaling up storage by adding capacity to your OpenShift Data Foundation nodes on IBM Z or IBM LinuxONE infrastructure
You can add storage capacity and performance to your configured Red Hat OpenShift Data Foundation worker nodes.
Flexible scaling features get enabled at the time of deployment and can not be enabled or disabled later on.
Prerequisites
- A running OpenShift Data Foundation Platform.
- Administrative privileges on the OpenShift Web Console.
- To scale using a storage class other than the one provisioned during deployment, first define an additional storage class. See Creating storage classes and pools for details.
Procedure
Add additional hardware resources with zFCP disks.
List all the disks.
$ lszdevExample output:
TYPE ID ON PERS NAMES zfcp-host 0.0.8204 yes yes zfcp-lun 0.0.8204:0x102107630b1b5060:0x4001402900000000 yes no sda sg0 zfcp-lun 0.0.8204:0x500407630c0b50a4:0x3002b03000000000 yes yes sdb sg1 qeth 0.0.bdd0:0.0.bdd1:0.0.bdd2 yes no encbdd0 generic-ccw 0.0.0009 yes noA SCSI disk is represented as a
zfcp-lunwith the structure<device-id>:<wwpn>:<lun-id>in the ID section. The first disk is used for the operating system. The device id for the new disk can be the same.Append a new SCSI disk.
$ chzdev -e 0.0.8204:0x400506630b1b50a4:0x3001301a00000000NoteThe device ID for the new disk must be the same as the disk to be replaced. The new disk is identified with its WWPN and LUN ID.
List all the FCP devices to verify the new disk is configured.
$ lszdev zfcp-lun TYPE ID ON PERS NAMES zfcp-lun 0.0.8204:0x102107630b1b5060:0x4001402900000000 yes no sda sg0 zfcp-lun 0.0.8204:0x500507630b1b50a4:0x4001302a00000000 yes yes sdb sg1 zfcp-lun 0.0.8204:0x400506630b1b50a4:0x3001301a00000000 yes yes sdc sg2
- Navigate to the OpenShift Web Console.
- Click Operators on the left navigation bar.
- Select Installed Operators.
- In the window, click OpenShift Data Foundation Operator.
In the top navigation bar, scroll right and click Storage Systems tab.
- Click the Action menu (⋮) next to the visible list to extend the options menu.
Select Add Capacity from the options menu.
The Raw Capacity field shows the size set during storage class creation. The total amount of storage consumed is three times this amount, because OpenShift Data Foundation uses a replica count of 3.
- Click Add.
- To check the status, navigate to Storage → Data Foundation and verify that Storage System in the Status card has a green tick.
Verification steps
Verify the Raw Capacity card.
- In the OpenShift Web Console, click Storage → Data Foundation.
- In the Status card of the Overview tab, click Storage System and then click the storage system link from the pop up that appears.
In the Block and File tab, check the Raw Capacity card.
Note that the capacity increases based on your selections.
NoteThe raw capacity does not take replication into account and shows the full capacity.
Verify that the new OSDs and their corresponding new Persistent Volume Claims (PVCs) are created.
To view the state of the newly created OSDs:
- Click Workloads → Pods from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
To view the state of the PVCs:
- Click Storage → Persistent Volume Claims from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
Optional: If cluster-wide encryption is enabled on the cluster, verify that the new OSD devices are encrypted.
Identify the nodes where the new OSD pods are running.
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/<OSD-pod-name><OSD-pod-name>Is the name of the OSD pod.
For example:
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/rook-ceph-osd-0-544db49d7f-qrgqmExample output:
NODE compute-1
For each of the nodes identified in the previous step, do the following:
Create a debug pod and open a chroot environment for the selected host(s).
$ oc debug node/<node-name><node-name>Is the name of the node.
$ chroot /host
Check for the
cryptkeyword beside theocs-devicesetnames.$ lsblk
Cluster reduction is supported only with the Red Hat Support Team’s assistance.
8.2. Scaling out storage capacity on a IBM Z or IBM LinuxONE cluster
8.2.1. Adding a node using a local storage device
You can add nodes to increase the storage capacity when existing worker nodes are already running at their maximum supported OSDs or when there are not enough resources to add new OSDs on the existing nodes.
Add nodes in the multiple of 3, each of them in different failure domains. Though it is recommended to add nodes in multiples of 3 nodes, you have the flexibility to add one node at a time in flexible scaling deployment. See Knowledgebase article Verify if flexible scaling is enabled
OpenShift Data Foundation does not support heterogeneous disk size and types. The new nodes to be added should have the disk of the same type and size which was used during initial OpenShift Data Foundation deployment.
Prerequisites
- You have administrative privilege to the OpenShift Container Platform Console.
- You have a running OpenShift Data Foundation Storage Cluster.
Procedure
Depending on the type of infrastructure, perform the following steps:
- Get a new machine with the required infrastructure. See Platform requirements.
- Create a new OpenShift Container Platform worker node using the new machine.
Check for certificate signing requests (CSRs) that are in
Pendingstate.$ oc get csrApprove all the required CSRs for the new node.
$ oc adm certificate approve <Certificate_Name><Certificate_Name>- Is the name of the CSR.
- Click Compute → Nodes, confirm if the new node is in Ready state.
Apply the OpenShift Data Foundation label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels.
-
Add
cluster.ocs.openshift.io/openshift-storage, and click Save.
- From Command line interface
Apply the OpenShift Data Foundation label to the new node.
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""<new_node_name>- Is the name of the new node.
Click Operators → Installed Operators from the OpenShift Web Console.
From the Project drop-down list, make sure to select the project where the Local Storage Operator is installed.
- Click Local Storage.
Click the Local Volume Discovery tab.
-
Beside the
LocalVolumeDiscovery, click Action menu (⋮) → Edit Local Volume Discovery. -
In the YAML, add the hostname of the new node in the
valuesfield under the node selector. - Click Save.
-
Beside the
Click the Local Volume Sets tab.
-
Beside the
LocalVolumeSet, click Action menu (⋮) → Edit Local Volume Set. In the YAML, add the hostname of the new node in the
valuesfield under thenode selector.
- Click Save.
-
Beside the
It is recommended to add 3 nodes, one each in different zones. You must add 3 nodes and perform this procedure for all of them.
Verification steps
Execute the following command in the terminal and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1On the OpenShift web console, click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
8.2.2. Scaling up storage capacity
To scale up storage capacity, see Scaling up storage capacity on a cluster.
Chapter 9. Scaling storage of IBM Power OpenShift Data Foundation cluster
To scale the storage capacity of your configured Red Hat OpenShift Data Foundation worker nodes on IBM Power cluster, you can increase the capacity by adding three disks at a time. Three disks are needed since OpenShift Data Foundation uses a replica count of 3 to maintain the high availability. So the amount of storage consumed is three times the usable space.
Usable space might vary when encryption is enabled or replica 2 pools are being used.
In order to scale up an OpenShift Data Foundation cluster which was created using local storage devices, a new disk needs to be added to the storage node. It is recommended to have the new disks of the same size as used earlier during the deployment as OpenShift Data Foundation does not support heterogeneous disks/OSD’s.
You can add storage capacity (additional storage devices) to your configured local storage based OpenShift Data Foundation worker nodes on IBM Power infrastructures.
Flexible scaling features get enabled at the time of deployment and can not be enabled or disabled later on.
Prerequisites
- You must be logged into the OpenShift Container Platform cluster.
You must have installed the local storage operator. Use the following procedure:
- You must have three OpenShift Container Platform worker nodes with the same storage type and size attached to each node (for example, 0.5TB SSD) as the original OpenShift Data Foundation StorageCluster was created with.
Procedure
To add storage capacity to OpenShift Container Platform nodes with OpenShift Data Foundation installed, you need to
Find the available devices that you want to add, that is, a minimum of one device per worker node. You can follow the procedure for finding available storage devices in the respective deployment guide.
NoteMake sure you perform this process for all the existing nodes (minimum of 3) for which you want to add storage.
Add the additional disks to the
LocalVolumecustom resource (CR).$ oc edit -n openshift-local-storage localvolume localblockExample output:
spec: logLevel: Normal managementState: Managed nodeSelector: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - worker-0 - worker-1 - worker-2 storageClassDevices: - devicePaths: - /dev/sda - /dev/sdx # newly added device storageClassName: localblock volumeMode: BlockMake sure to save the changes after editing the CR.
Example output:
localvolume.local.storage.openshift.io/localblock editedYou can see in this CR that new devices are added.
-
sdx
-
Display the newly created Persistent Volumes (PVs) with the
storageclassname used in thelocalVolumeCR.$ oc get pv | grep localblock | grep AvailableExample output:
local-pv-a04ffd8 500Gi RWO Delete Available localblock 24s local-pv-a0ca996b 500Gi RWO Delete Available localblock 23s local-pv-c171754a 500Gi RWO Delete Available localblock 23s- Navigate to the OpenShift Web Console.
- Click Operators on the left navigation bar.
- Select Installed Operators.
- In the window, click OpenShift Data Foundation Operator.
In the top navigation bar, scroll right and click Storage System tab.
- Click the Action menu (⋮) next to the visible list to extend the options menu.
Select Add Capacity from the options menu.
From this dialog box, set the Storage Class name to the name used in the
localVolumeCR. Available Capacity displayed is based on the local disks available in storage class.- Click Add.
- To check the status, navigate to Storage → Data Foundation and verify that the Storage System in the Status card has a green tick.
Verification steps
Verify the available Capacity.
- In the OpenShift Web Console, click Storage → Data Foundation.
-
Click the Storage Systems tab and then click on
ocs-storagecluster-storagesystem. Navigate to Overview → Block and File tab, then check the Raw Capacity card.
Note that the capacity increases based on your selections.
NoteThe raw capacity does not take replication into account and shows the full capacity.
Verify that the new OSDs and their corresponding new Persistent Volume Claims (PVCs) are created.
To view the state of the newly created OSDs:
- Click Workloads → Pods from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
To view the state of the PVCs:
- Click Storage → Persistent Volume Claims from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
Optional: If cluster-wide encryption is enabled on the cluster, verify that the new OSD devices are encrypted.
Identify the nodes where the new OSD pods are running.
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/<OSD-pod-name><OSD-pod-name>Is the name of the OSD pod.
For example:
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/rook-ceph-osd-0-544db49d7f-qrgqmExample output:
NODE compute-1
For each of the nodes identified in the previous step, do the following:
Create a debug pod and open a chroot environment for the selected host(s).
$ oc debug node/<node-name><node-name>Is the name of the node.
$ chroot /host
Check for the
cryptkeyword beside theocs-devicesetnames.$ lsblk
Cluster reduction is supported only with the Red Hat Support Team’s assistance.
9.2. Scaling out storage capacity on a IBM Power cluster
OpenShift Data Foundation is highly scalable. It can be scaled out by adding new nodes with required storage and enough hardware resources in terms of CPU and RAM. Practically there is no limit on the number of nodes which can be added but from the support perspective 2000 nodes is the limit for OpenShift Data Foundation.
Scaling out storage capacity can be broken down into two steps:
- Adding new node
- Scaling up the storage capacity
OpenShift Data Foundation does not support heterogeneous OSD/Disk sizes.
9.2.1. Adding a node using a local storage device on IBM Power
You can add nodes to increase the storage capacity when existing worker nodes are already running at their maximum supported OSDs or when there are not enough resources to add new OSDs on the existing nodes.
Add nodes in the multiple of 3, each of them in different failure domains. Though it is recommended to add nodes in multiples of 3 nodes, you have the flexibility to add one node at a time in flexible scaling deployment. See Knowledgebase article Verify if flexible scaling is enabled
OpenShift Data Foundation does not support heterogeneous disk size and types. The new nodes to be added should have the disk of the same type and size which was used during initial OpenShift Data Foundation deployment.
Prerequisites
- You must be logged into the OpenShift Container Platform cluster.
- You must have three OpenShift Container Platform worker nodes with the same storage type and size attached to each node (for example, 2TB SSD drive) as the original OpenShift Data Foundation StorageCluster was created with.
Procedure
- Get a new IBM Power machine with the required infrastructure. See Platform requirements.
Create a new OpenShift Container Platform node using the new IBM Power machine.
Check for certificate signing requests (CSRs) that are in
Pendingstate.$ oc get csrApprove all the required CSRs for the new node.
$ oc adm certificate approve <Certificate_Name><Certificate_Name>- Is the name of the CSR.
- Click Compute → Nodes, confirm if the new node is in Ready state.
Apply the OpenShift Data Foundation label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels.
-
Add
cluster.ocs.openshift.io/openshift-storageand click Save.
- From Command line interface
Apply the OpenShift Data Foundation label to the new node.
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""
<new_node_name>- Is the name of the new node.
Click Operators → Installed Operators from the OpenShift Web Console.
From the Project drop-down list, make sure to select the project where the Local Storage Operator is installed.
- Click Local Storage.
Click the Local Volume tab.
-
Beside the
LocalVolume, click Action menu (⋮) → Edit Local Volume. In the YAML, add the hostname of the new node in the
valuesfield under thenode selector.Figure 9.1. YAML showing the addition of new hostnames
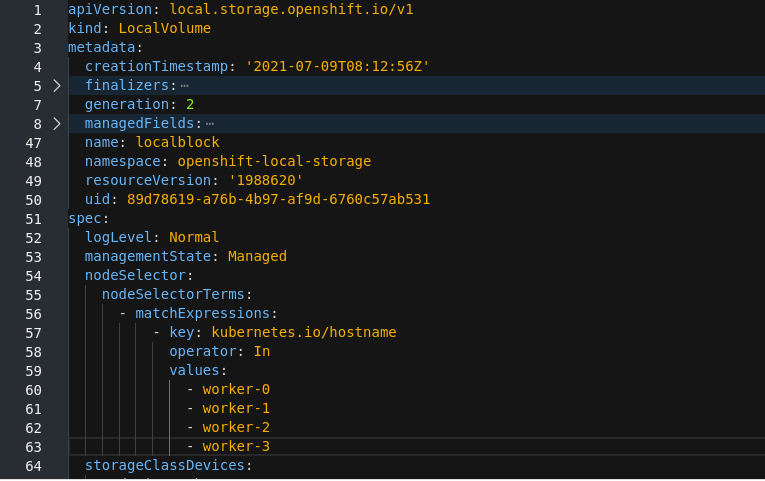
- Click Save.
-
Beside the
It is recommended to add 3 nodes, one each in different zones. You must add 3 nodes and perform this procedure for all of them.
Verification steps
Execute the following command in the terminal and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1On the OpenShift web console, click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
9.2.2. Scaling up storage capacity
To scale up storage capacity, see Scaling up storage capacity on a cluster.
Chapter 10. Scaling storage capacity of IBM FlashSystem cluster
To scale the storage capacity of your configured Red Hat OpenShift Data Foundation worker nodes on a cluster using external IBM FlashSystem, you can increase the capacity by adding three disks at a time. Three disks are needed since OpenShift Data Foundation uses a replica count of 3 to maintain the high availability. So the amount of storage consumed is three times the usable space.
Usable space might vary when encryption is enabled or replica 2 pools are being used.
10.1. Scaling up storage capacity on a cluster
To increase the storage capacity in a dynamically created storage cluster on an user-provisioned infrastructure, you can add storage capacity and performance to your configured Red Hat OpenShift Data Foundation worker nodes.
Prerequisites
- You have administrative privilege to the OpenShift Container Platform Console.
- You have a running OpenShift Data Foundation Storage Cluster.
- The disk should be of the same size and type as used during initial deployment.
Procedure
- Log in to the OpenShift Web Console.
- Click Operators → Installed Operators.
- Click OpenShift Data Foundation Operator.
Click the Storage Systems tab.
- Click the Action Menu (⋮) on the far right of the storage system name to extend the options menu.
- Select Add Capacity from the options menu.
- Select the Storage Class. Choose the storage class which you wish to use to provision new storage devices.
- Click Add.
-
To check the status, navigate to Storage → Data Foundation and verify that the
Storage Systemin the Status card has a green tick.
Verification steps
Verify the Raw Capacity card.
- In the OpenShift Web Console, click Storage → Data Foundation.
- In the Status card of the Overview tab, click Storage System and then click the storage system link from the pop up that appears.
In the Block and File tab, check the Raw Capacity card.
Note that the capacity increases based on your selections.
NoteThe raw capacity does not take replication into account and shows the full capacity.
Verify that the new object storage devices (OSDs) and their corresponding new Persistent Volume Claims (PVCs) are created.
To view the state of the newly created OSDs:
- Click Workloads → Pods from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
To view the state of the PVCs:
- Click Storage → Persistent Volume Claims from the OpenShift Web Console.
Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
Optional: If cluster-wide encryption is enabled on the cluster, verify that the new OSD devices are encrypted.
Identify the nodes where the new OSD pods are running.
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/<OSD-pod-name><OSD-pod-name>Is the name of the OSD pod.
For example:
$ oc get -n openshift-storage -o=custom-columns=NODE:.spec.nodeName pod/rook-ceph-osd-0-544db49d7f-qrgqmExample output:
NODE compute-1
For each of the nodes identified in the previous step, do the following:
Create a debug pod and open a chroot environment for the selected hosts.
$ oc debug node/<node-name><node-name>Is the name of the node.
$ chroot /host
Check for the
cryptkeyword beside theocs-devicesetnames.$ lsblk
Cluster reduction is supported only with the Red Hat Support Team’s assistance.
10.2. Scaling out storage capacity on an IBM FlashSystem cluster
OpenShift Data Foundation is highly scalable. It can be scaled out by adding new nodes with required storage and enough hardware resources in terms of CPU and RAM. Practically there is no limit on the number of nodes which can be added but from the support perspective 2000 nodes is the limit for OpenShift Data Foundation.
Scaling out storage capacity can be broken down into two steps
- Adding new node
- Scaling up the storage capacity
OpenShift Data Foundation does not support heterogeneous OSD/Disk sizes.
10.2.1. Adding a node
You can add nodes to increase the storage capacity when existing worker nodes are already running at their maximum supported OSDs or there are not enough resources to add new OSDs on the existing nodes. It is always recommended to add nodes in the multiple of three, each of them in different failure domains.
While we recommend adding nodes in the multiple of three, you still get the flexibility of adding one node at a time in the flexible scaling deployment. Refer to the Knowledgebase article Verify if flexible scaling is enabled.
OpenShift Data Foundation does not support heterogeneous disk size and types. The new nodes to be added should have the disk of the same type and size which was used during OpenShift Data Foundation deployment.
10.2.1.1. Adding a node to an installer-provisioned infrastructure
Prerequisites
- You have administrative privilege to the OpenShift Container Platform Console.
- You have a running OpenShift Data Foundation Storage Cluster.
Procedure
- Navigate to Compute → Machine Sets.
On the machine set where you want to add nodes, select Edit Machine Count.
- Add the amount of nodes, and click Save.
- Click Compute → Nodes and confirm if the new node is in Ready state.
Apply the OpenShift Data Foundation label to the new node.
- For the new node, click Action menu (⋮) → Edit Labels.
- Add cluster.ocs.openshift.io/openshift-storage, and click Save.
It is recommended to add 3 nodes, one each in different zones. You must add 3 nodes and perform this procedure for all of them. In case of bare metal installer-provisioned infrastructure deployment, you must expand the cluster first. For instructions, see Expanding the cluster.
Verification steps
Execute the following command in the terminal and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1On the OpenShift web console, click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
10.2.1.2. Adding a node to an user-provisioned infrastructure
Prerequisites
- You have administrative privilege to the OpenShift Container Platform Console.
- You have a running OpenShift Data Foundation Storage Cluster.
Procedure
Depending on the type of infrastructure, perform the following steps:
- Get a new machine with the required infrastructure. See Platform requirements.
- Create a new OpenShift Container Platform worker node using the new machine.
Check for certificate signing requests (CSRs) that are in
Pendingstate.$ oc get csrApprove all the required CSRs for the new node.
$ oc adm certificate approve <Certificate_Name><Certificate_Name>- Is the name of the CSR.
- Click Compute → Nodes, confirm if the new node is in Ready state.
Apply the OpenShift Data Foundation label to the new node using any one of the following:
- From User interface
- For the new node, click Action Menu (⋮) → Edit Labels.
-
Add
cluster.ocs.openshift.io/openshift-storage, and click Save.
- From Command line interface
Apply the OpenShift Data Foundation label to the new node.
$ oc label node <new_node_name> cluster.ocs.openshift.io/openshift-storage=""<new_node_name>- Is the name of the new node.
Verification steps
Execute the following command in the terminal and verify that the new node is present in the output:
$ oc get nodes --show-labels | grep cluster.ocs.openshift.io/openshift-storage= |cut -d' ' -f1On the OpenShift web console, click Workloads → Pods, confirm that at least the following pods on the new node are in Running state:
-
csi-cephfsplugin-* -
csi-rbdplugin-*
-
10.2.2. Scaling up storage capacity
To scale up storage capacity, see Scaling up a cluster.