Chapter 4. Architecture Examples
This chapter contains references to architecture examples of Red Hat OpenStack Platform deployments.
All architecture examples in this guide assume that you deploy OpenStack Platform on Red Hat Enterprise Linux 7.2 with the KVM hypervisor.
4.1. Overview
Typically, deployments are based on performance or functionality. Deployments can also be based on deployed infrastructure.
| Example | Description |
|---|---|
| General high-availability cloud to use if you are unsure of specific technical or environmental needs. This architecture type is flexible, does not emphasize any single OpenStack component, and is not restricted to specific environments. | |
| Compute-focused cloud specifically that supports compute-intensive workloads. Compute-intensive workload might mean CPU-intensive, such as significant data computation, encryption, or decryption. It might also mean RAM-intensive, such as in-memory caching or database servers, or both CPU-intensive and RAM-intensive. It does not normally mean storage-intensive or network-intensive. You can choose this architecture type if you require high performance Compute resources. | |
| Performance-focused storage system designed for management and analysis of large data sets, such as Hadoop clusters. In this architecture type, OpenStack integrates with Hadoop to manage the Hadoop cluster with Ceph as the storage backend. | |
| High-performance storage system that assumes increased database IO requirements and utilizes a solid-state drive (SSD) to process data. You can use this architecture type for existing storage environments. | |
| Cloud-based file storage and sharing service, commonly used in OpenStack deployments. This architecture type uses a cloud backup application, where incoming data to the cloud traffic is higher than the outgoing data. | |
| Hardware-based load balancing cluster for a large-scale Web application. This architecture type provides SSL-offload functionality and connects to tenant networks to reduce address consumption and scale the Web application horizontally. |
4.2. General-Purpose Architecture
You can deploy a general high availability cloud if you are unsure of specific technical or environmental needs. This flexible architecture type does not emphasize any single OpenStack component, and it is not restricted to particular environments.
This architecture type covers 80% of potential use cases, including:
- Simple database
- Web application runtime environment
- Shared application development environment
- Test environment
- Environment requiring scale-out additions instead of than scale-up additions
This architecture type is not recommended for cloud domains that require increased security.
For installation and deployment documentation, see Chapter 5, Deployment Information.
4.2.1. Example Use Case
An online classified advertising company wants to run web applications that include Apache Tomcat, Nginx and MariaDB in a private cloud. To meet policy requirements, the cloud infrastructure will run inside the company data center.
The company has predictable load requirements, but requires scaling to cope with nightly increases in demand. The current environment does not have the flexibility to align with the company goal of running an open-source API environment.
The current environment consists of the following components:
- Between 120 and 140 installations of Nginx and Tomcat, each with 2 vCPUs and 4 GB of RAM
- A three-node MariaDB and Galera cluster, each with 4 vCPUs and 8 GB RAM. Pacemaker is used to manage the Galera nodes.
The company runs hardware load balancers and multiple web applications that serve the websites. Environment orchestration uses combinations of scripts and Puppet. The website generates large amounts of log data every day that need to be archived.
4.2.2. About the Design
The architecture for this example includes three controller nodes and at least eight Compute nodes. It uses OpenStack Object Storage for static objects and OpenStack Block Storage for all other storage needs.
To ensure that the OpenStack infrastructure components are highly available, nodes use the Pacemaker add-on for Red Hat Enterprise Linux together with HAProxy.
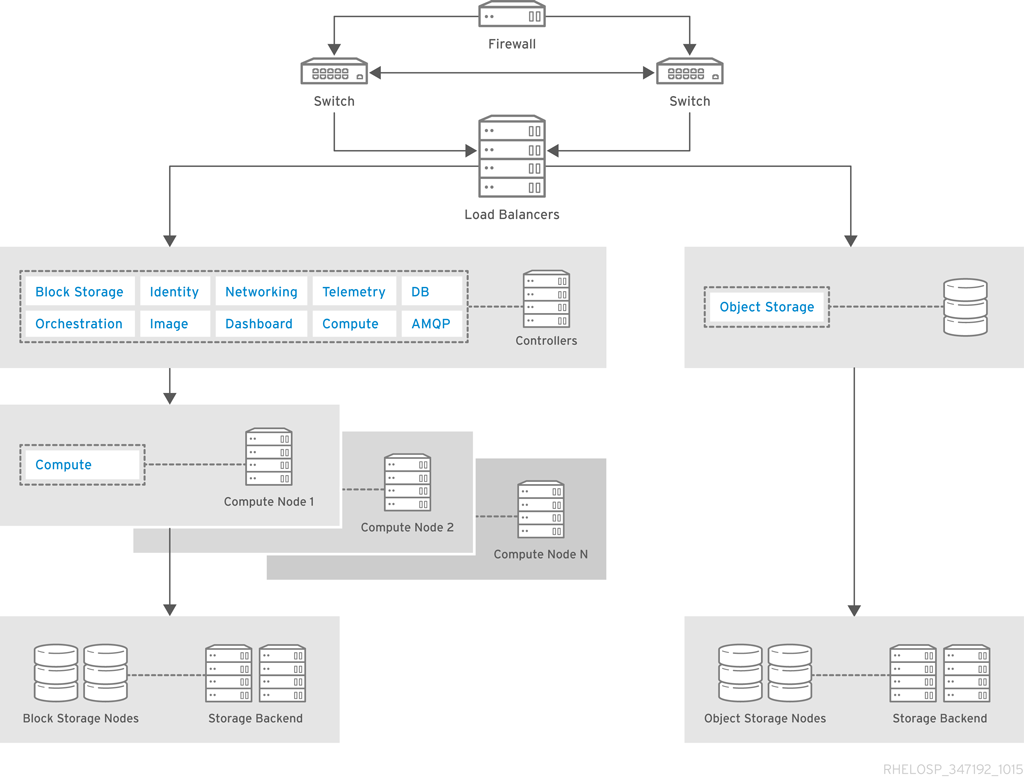
The architecture includes the following components:
- Firewall, switches, and hardware load balancers for the public-facing network connections.
- OpenStack controller service that run Image, Identity, and Networking, combined with the support services MariaDB and RabbitMQ. These services are configured for high availability on at least three controller nodes.
- Cloud nodes are configured for high availability with the Pacemaker add-on for Red Hat Enterprise Linux.
- Compute nodes use OpenStack Block Storage for instances that need persistent storage.
- OpenStack Object Storage to serve static objects, such as images.
4.2.3. Architecture Components
| Component | Description |
|---|---|
| Block Storage | Persistant storage for instances. |
| Compute controller services | Compute management and scheduling services that run on the controller. |
| Dashboard | Web console for OpenStack management. |
| Identity | Basic authentication and authorization for users and tenants. |
| Image | Stores images to be used for booting instances and managing snapshots. |
| MariaDB | Database for all OpenStack components. MariaDB server instances store data on shared enterprise storage, such as NetApp or Solidfire. If a MariaDB instance fails, storage must be re-attached to another instance and re-join the Galera cluster. |
| Networking | Controls hardware load balancers with plug-ins and the Networking API. If you increase OpenStack Object Storage, you must consider network bandwidth requirements. It is recommended to run OpenStack Object Storage on network connections with 10 GbE or higher. |
| Object Storage | Processes and archives logs from the web application servers. You can also use Object Storage to move static web content from OpenStack Object Storage containers or to back up images that are managed by OpenStack Image. |
| Telemetry | Monitoring and reporting for other OpenStack services. |
4.2.4. Compute Node Requirements
The Compute service is installed on each of the Compute nodes.
This general-purpose architecture can run up to 140 web instances, and the small number of MariaDB instances requires 292 vCPUs and 584 GB RAM. On a typical 1U server with dual-socket hex-core Intel CPUs with Hyperthreading, and assuming 2:1 CPU over-commit ratio, this architecture requires eight Compute nodes.
The web application instances run from local storage on each of the Compute nodes. The web application instances are stateless, so in case one of the instances fails, the application can continue to run.
4.2.5. Storage Requirements
For storage, use a scaled-out solution with directly-attached storage in the servers. For example, you can populate storage in the Compute hosts in a way that is similar to a grid-computing solution, or in dedicated hosts that provide block storage exclusively.
If you deploy storage in the Compute hosts, ensure that the hardware can handle the storage and compute services.
4.3. Compute-Focused Architecture
Cells are available in this release as a Technology Preview, and therefore are not fully supported by Red Hat. They should only be used for testing, and should not be deployed in a production environment. For more information about Technology Preview features, see Scope of Coverage Details.
A compute-focused cloud supports CPU-intensive workloads such as data computation or encryption and decryption, RAM-intensive workloads such as in-memory caching or database servers, or both. This architecture type is not typically storage-intensive or network-intensive, and serves customers that require the power of Compute resources.
Compute-focused workloads include the following use cases:
- High-performance computing (HPC)
- Big-data analytics using Hadoop or other distributed data stores
- Continuous integration or continuous deployment (CI/CD)
- Platform-as-a-Service (PaaS)
- Signal processing for network function virtualization (NFV)
A compute-focused OpenStack cloud does not typically use raw block storage services because the cloud does not generally host applications that require persistent block storage. Infrastructure components are not shared, so that the workloads can consume as many available resources as needed. Infrastructure components need to also be highly available. This design uses load balancers. You can also use HAProxy.
For installation and deployment documentation, see Chapter 5, Deployment Information.
4.3.1. Example Use Case
An organization provides HPC for research projects, and needs to add a third compute center to two existing compute centers in Europe.
The following table lists the requirements for each compute center to add:
| Data Center | Approximate capacity |
|---|---|
| Geneva, Switzerland |
|
| Budapest, Hungary |
|
4.3.2. About the Design
This architecture uses cells for segregation of compute resources and for transparent scaling between different data centers. This decision impacts support for security groups and live migration. In addition, it requires manual replication of some configuration elements, such as flavors, across cells. However, cells provide the required scale while exposing a single public API endpoint to users.
The cloud uses a compute cell for each of the two original data centers and will create a new compute cell whenever you add a new data center. Each cell contains three availability zones to further segregate compute resources and at least three RabbitMQ message brokers configured for clustering with mirrored queues for high availability.
The API cell, which resides behind an HAProxy load balancer, is in the data center in Switzerland. The API cell directs API calls to compute cells using a customized variation of the cell scheduler. The customizations allow certain workloads to route to a specific data center or to all data centers based on cell RAM availability.

You can also use filters to customize the Compute scheduler that handles placement in the cells. For example, ImagePropertiesFilter provides special handling based on the operating system that the guest runs, for example Linux or Windows.
A central database team manages the SQL database server in each cell in an active/passive configuration with a NetApp storage backend. Backups run every six hours.
4.3.3. Architecture Components
| Component | Description |
|---|---|
| Compute | Compute management and scheduling services run on the controller. The Compute service also runs on each compute node. |
| Dashboard Service | GUI for OpenStack management. |
| Identity Service | Basic authentication and authorization functionality. |
| Image Service | Runs in the API cell and maintains a small set of Linux images, onto which orchestration tools can place applications. |
| Networking | Networking services. For more information about OpenStack Networking, see Chapter 2, Networking In-Depth. |
| Monitoring | Telemetry service performs metering to adjust project quotas with a sharded, replicated MongoDB backend. To spread the API load, you must deploy instances of the openstack-nova-api service in the child cells that Telemetry can query. This deployment also requires configuration of supporting services, such as Identity and Image, in the child cells. Specific critical metrics to capture include Image disk utilization and response time to the Compute API. |
| Orchestration Service | Automatically deploys and tests new instances. |
| Telemetry Service | Supports the Orchestration auto-scaling feature. |
| Object Storage | Stores objects with a 3 PB Ceph cluster. |
4.3.4. Design Considerations
In addition to basic design considerations described in Chapter 3, Design and compute node design considerations described in Section 3.2, “Compute Resources”, the following items should be considered for a compute-intensive architecture.
- Workloads
Short-lived workloads can include continuous integration and continuous deployment (CI-CD) jobs, which create large numbers of compute instances simultaneously to perform a set of compute-intensive tasks. The environment then copies the results or the artifacts from each instance to long-term storage before it terminates the instances.
Long-lived workloads, such as a Hadoop cluster or an HPC cluster, typically receive large data sets, perform the computational work on those data sets, and then push the results to long-term storage. When the computational work ends, the instances are idle until they receive another job. Environments for long-lived workloads are often larger and more complex, but you can offset the cost of building these environments by keeping them active between jobs.
Workloads in a compute-focused OpenStack cloud generally do not require persistent block storage, except some uses of Hadoop with HDFS. A shared file system or object store maintains initial data sets and serves as the destination for saving the computational results. By avoiding input-output (IO) overhead, you can significantly enhance workload performance. Depending on the size of the data sets, you might need to scale the object store or the shared file system.
- Expansion Planning
Cloud users expect instant access to new resources as needed. Therefore, you must plan for typical usage and for sudden spikes in resource demand. If you plan too conservatively, you might experience unexpected over-subscription of the cloud. If you plan too aggressively, you might experience unexpected underutilization of the cloud unnecessary operations and maintenance costs.
The key factor in expansion planning is analytics of trends in cloud usage over time. Measure the consistency with which you deliver services instead of the average speed or capacity of the cloud. This information can help you model capacity performance and determine the current and future capacity of the cloud.
For information about monitoring software, see Section 3.9, “Additional Software”.
- CPU and RAM
Typical server offerings today include CPUs with up to 12 cores. In addition, some Intel CPUs support Hyper-Threading Technology (HTT), which doubles the core capacity. Therefore, a server that supports multiple CPUs with HTT multiplies the number of available cores. HTT is an Intel proprietary simultaneous multi-threading implementation that is used to improve parallelization on the Intel CPUs. Consider enabling HTT to improve the performance of multi-threaded applications.
The decision to enable HTT on a CPU depends on the use case. For example, disabling HTT can help intense computing environments. Running performance tests of local workloads with and without HTT can help determine which option is more appropriate for a particular case.
- Capacity Planning
You can add capacity to your compute environment with one or more of the following strategies:
Horizontally scale by adding extra capacity to the cloud. You should use the same, or similar CPUs in the extra nodes to reduce the chance of breaking any live-migration features. Scaling out hypervisor hosts also affects network and other data center resources. Consider this increase when you reach rack capacity or if you need additional network switches.
NoteBe aware of the additional work required to place the nodes in appropriate availability zones and host aggregates.
- Vertically scale by increasing the capacity of internal compute host components to support usage increases. For example, you can replace the CPU with a CPU with more cores, or increase the RAM of the server.
Assess your average workload, and if need be, increase the number of instances that can run in the compute environment by adjusting the over-commit ratio.
ImportantDo not increase the CPU over-commit ratio in a compute-focused OpenStack design architecture. Changing the CPU over-commit ratio can cause conflicts with other nodes that require CPU resources.
- Compute Hardware
A compute-focused OpenStack cloud is extremely demanding on processor and memory resources. Therefore, you should prioritize server hardware that can offer more CPU sockets, more CPU cores, and more RAM.
Network connectivity and storage capacity are less critical to this architecture. The hardware must provide enough network connectivity and storage capacity to meet minimum user requirements, but the storage and networking components primarily load data sets to the computational cluster and do not require consistent performance.
- Storage Hardware
You can build a storage array using commodity hardware with Open Source software, but you might need specialized expertise to deploy it. You can also use a scale-out storage solution with direct-attached storage in the servers, but you must ensure that the server hardware supports the storage solution.
Consider the following factors when you design your storage hardware:
- Availability. If instances must be highly available or capable of migration between hosts, use a shared storage file system for ephemeral instance data to ensure that compute services can run uninterrupted in the event of a node failure.
- Latency. Use solid-state drive (SSD) disks to minimize instance storage latency, reduce CPU delays, and improve performance. Consider using RAID controller cards in compute hosts to improve the performance of the underlying disk sub-system.
- Performance. Although a compute-focused cloud does not usually require major data I/O to and from storage, storage performance is still an important factor to consider. You can measure the storage hardware performance by observing the latency of storage I/O requests. In some compute-intensive workloads, minimizing the delays that the CPU experiences while fetching data from storage can significantly improve the overall performance of the application.
- Expandability. Decide the maximum capacity of the storage solution. For example, a solution that expands to 50 PB is more expandable than a solution that only expands to 10PB. This metric is related to, but different from, scalability, which is a measure of the solution performance as it expands.
- Connectivity. The connectivity must satisfy the storage solution requirements. If you select a centralized storage array, determine how to connect the hypervisors to the storage array. Connectivity can affect latency and performance. Therefore, ensure that the network characteristics minimize latency to boost the overall performance of the environment.
- Network Hardware
In addition to basic network considerations described in Chapter 2, Networking In-Depth, consider the following factors:
- The required port count affects the physical space that a network design requires. For example, a switch that provides 48 ports with 10 GbE capacity for each port in a 1U server has higher port density than a switch that provides 24 ports with 10 GbE capacity for each port in a 2U server. Higher port density allows more rack space for compute or storage components. You must also consider fault domains and power density. Although more expensive, you can also consider higher density switches as you should not design the network beyond functional requirements.
- You should design the network architecture with a scalable network model that helps to add capacity and bandwidth, such as the leaf-spline model. In this type of network design, you can add additional bandwidth as well as scale out to additional racks of gear.
- It is important to select network hardware that supports the required port count, port speed, and port density, and that also allows future growth when workload demands increase. It is also important to evaluate where in the network architecture it is valuable to provide redundancy. Increased network availability and redundancy can be expensive, so you should compare the extra cost with the benefits of redundant network switches and bonded interfaces at the host level.
4.4. Storage-Focused Architectures
Section 4.4.1, “Storage-Focused Architecture Types”
Section 4.4.2, “Data Analytics Architecture”
Section 4.4.3, “High-Performance Database Architecture”
Section 4.4.4, “Storage-Focused Architecture Considerations”
4.4.1. Storage-Focused Architecture Types
The cloud storage model stores data in logical pools on physical storage devices. This architecture is often referred to as an integrated storage cloud.
Cloud storage commonly refers to a hosted object storage service. However, the term can also include other types of data storage that are available as a service. OpenStack offers both Block Storage (cinder) and Object Storage (swift). Cloud storage typically runs on a virtual infrastructure and resembles broader cloud computing in interface accessibility, elasticity, scalability, multi-tenancy, and metered resources.
You can use cloud storage services on-premise or off-premises. Cloud storage is highly fault tolerant with redundancy and data distribution, is highly durable with versioned copies, and can perform consistent data replication.
Example cloud storage applications include:
- Active archive, backups and hierarchical storage management
- General content storage and synchronization such as a private DropBox service
- Data analytics with parallel file systems
- Unstructured data store for services such as social media backend storage
- Persistent block storage
- Operating system and application image store
- Media streaming
- Databases
- Content distribution
- Cloud storage peering
For more information about OpenStack storage services, see Section 1.2.2, “OpenStack Object Storage (swift)” and Section 1.2.1, “OpenStack Block Storage (cinder)”.
4.4.2. Data Analytics Architecture
Analysis of large data sets is highly dependent on the performance of the storage system. Parallel file systems can provide high-performance data processing and are recommended for large scale performance-focused systems.
For installation and deployment documentation, see Chapter 5, Deployment Information.
4.4.2.1. About the Design
OpenStack Data Processing (sahara) integrates with Hadoop to manage the Hadoop cluster inside the cloud. The following diagram shows an OpenStack store with a high-performance requirement.
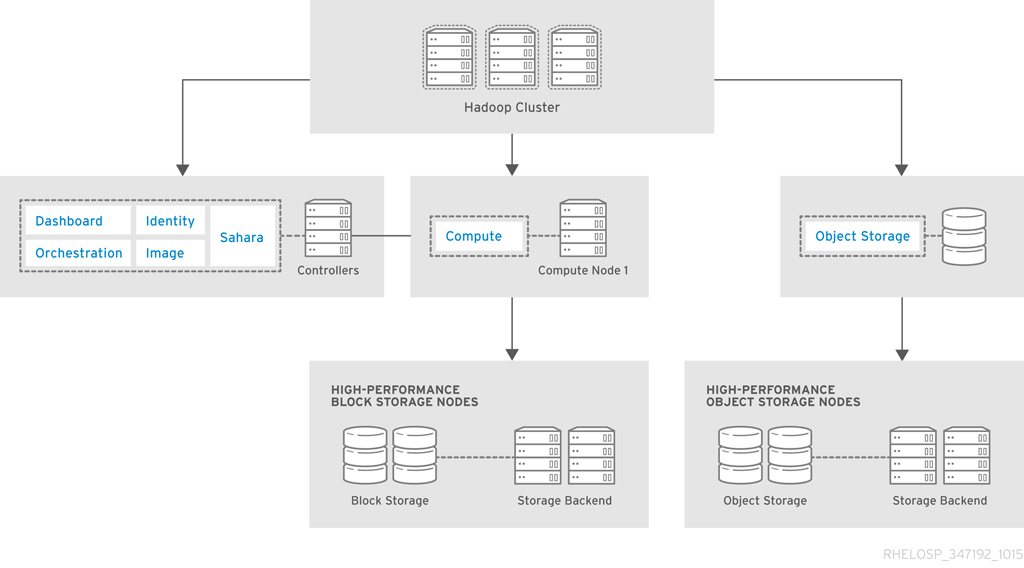
The hardware requirements and configuration are similar to the high-performance architecture described in Section 4.4.3, “High-Performance Database Architecture”. In this example, the architecture uses the Ceph Swift-compatible REST interface that connects to a caching pool and enables acceleration of the available pool.
4.4.2.2. Architecture Components
| Component | Description |
|---|---|
| Compute | Compute management and scheduling services run on the controller. The Compute service also runs on each compute node. |
| Dashboard | Web console for OpenStack management. |
| Identity | Basic authentication and authorization functionality. |
| Image | Stores images to be used for booting instances and managing snapshots. This service runs on the controller and offers a small set of images. |
| Networking | Networking services. For more information about OpenStack Networking, see Chapter 2, Networking In-Depth. |
| Telemetry | Monitoring and reporting for other OpenStack services. Use this service to monitor instance usage and adjust project quotas. |
| Object Storage | Stores data with the Hadoop backend. |
| Block Storage | Stores volumes with the Hadoop backend. |
| Orchestration | Manages templates for instances and block storage volume. Use this service to launch additional instances for storage-intensive processing, with Telemetry for auto-scaling. |
4.4.2.3. Cloud Requirements
| Requirement | Description |
|---|---|
| Performance | To boost performance, you can choose specialty solutions to cache disk activity. |
| Security | You must protect data both in transit and at rest. |
| Storage proximity | In order to provide high performance or large amounts of storage space, you might need to attach the storage to each hypervisor or serve it from a central storage device. |
4.4.2.4. Design Considerations
In addition to basic design considerations described in Chapter 3, Design, you should also follow the considerations described in Section 4.4.4, “Storage-Focused Architecture Considerations”.
4.4.3. High-Performance Database Architecture
Database architectures benefit from high performance storage backends. Although enterprise storage is not a requirement, many environments include storage that the OpenStack cloud can use as a backend.
You can create a storage pool to provide block devices with OpenStack Block Storage for instances and object interfaces. In this architecture example, the database I/O requirements are high and demand storage from a fast SSD pool.
4.4.3.1. About the Design
The storage system uses a LUN backed with a set of SSDs in a traditional storage array, and uses OpenStack Block Storage integration or a storage platform such as Ceph.
This system can provide additional performance capabilities. In the database example, a portion of the SSD pool can act as a block device to the database server. In the high performance analytics example, the inline SSD cache layer accelerates the REST interface.
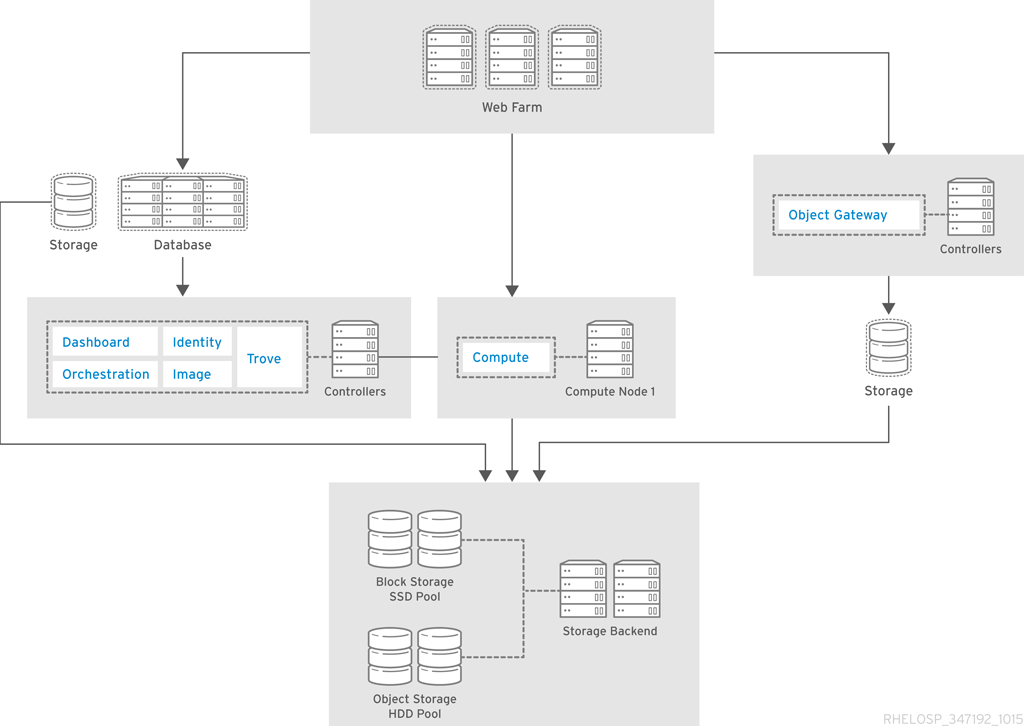
In this example, Ceph provides a Swift-compatible REST interface, as well as block-level storage from a distributed storage cluster. It is highly flexible and enables reduced cost of operations with features such as self-healing and auto-balancing. Erasure coded pools are recommended to maximize the amount of usable space.
Erasure coded pools require special considerations, such as higher computational requirements and limitations on which operations are allowed on an object. Erasure coded pools do not support partial writes.
4.4.3.2. Architecture Components
| Component | Description |
|---|---|
| Compute | Compute management and scheduling services run on the controller. The Compute service also runs on each compute node. |
| Dashboard | Web console for OpenStack management. |
| Identity | Basic authentication and authorization functionality. |
| Image | Stores images to be used for booting instances and managing snapshots. This service runs on the controller and offers a small set of images. |
| Networking | Networking services. For more information about OpenStack Networking, see Chapter 2, Networking In-Depth. |
| Telemetry | Monitoring and reporting for other OpenStack services. Use this service to monitor instance usage and adjust project quotas. |
| Monitoring | Use the Telemetry service to perform metering for the purposes of adjusting project quotas. |
| Object Storage | Stores data with the Ceph backend. |
| Block Storage | Stores volumes with the Ceph backend. |
| Orchestration | Manages templates for instances and block storage volume. Use this service to launch additional instances for storage-intensive processing, with Telemetry for auto-scaling. |
4.4.3.3. Hardware Requirements
You can use an SSD cache layer to link block devices directly to hypervisors or to instances. The REST interface can also use the SSD cache systems as an inline cache.
| Component | Requirement | Network |
|---|---|---|
| 10 GbE horizontally scalable spine-leaf backend storage and front-end network | Storage hardware | * 5 storage servers for caching layer 24x1 TB SSD * 10 storage servers with 12x4 TB disks for each server, which equals 480 TB total space with approximately 160 TB of usable space after 3 replicas |
4.4.3.4. Design Considerations
In addition to basic design considerations described in Chapter 3, Design, you should also follow the considerations described in Section 4.4.4, “Storage-Focused Architecture Considerations”.
4.4.4. Storage-Focused Architecture Considerations
In addition to basic design considerations described in Chapter 3, Design and to storage node design described in Section 3.3, “Storage Resources”, the following items should be considered for a storage-intensive architecture.
- Connectivity
- Ensure the connectivity matches the storage solution requirements. If you select a centralized storage array, determine how to connect the hypervisors to the array. Connectivity can affect latency and performance. Confirm that the network characteristics minimize latency to boost the overall performance of the design.
- Density
- Instance density. In a storage-focused architecture, instance density and CPU/RAM over-subscription are lower. You need more hosts to support the anticipated scale, especially if the design uses dual-socket hardware designs.
- Host density. You can address the higher host count with a quad-socket platform. This platform decreases host density and increases rack count. This configuration affects the number of power connections and also impacts network and cooling requirements.
- Power and cooling. The power and cooling density requirements might be lower with 2U, 3U, or 4U servers than with blade, sled, or 1U server designs. This configuration is recommended for data centers with older infrastructure.
- Flexibility
- Organizations need to have the flexibility to choose between off-premise and on-premise cloud storage options. For example, continuity of operations, disaster recovery, security, and records retention laws, regulations, and policies can impact the cost-effectiveness of the storage provider.
- Latency
- Solid-state drives (SSDs) can minimize latency for instance storage and reduce CPU delays that storage latency might cause. Evaluate the gains from using RAID controller cards in compute hosts to improve the performance of the underlying disk sub-system.
- Monitors and alerts
Monitoring and alerting services are critical in cloud environments with high demands on storage resources. These services provide a real-time view into the health and performance of the storage systems. An integrated management console, or other dashboards that visualize SNMP data, helps to discover and resolve issues with the storage cluster.
A storage-focused cloud design should include:
- Monitoring of physical hardware and environmental resources, such as temperature and humidity.
- Monitoring of storage resources, such as available storage, memory, and CPU.
- Monitoring of advanced storage performance data to ensure that storage systems are performing as expected.
- Monitoring of network resources for service disruptions which affect access to storage.
- Centralized log collection and log-analytics capabilities.
- Ticketing system, or integration with a ticketing system, to track issues.
- Alerting and notification of responsible teams or automated systems that can resolve problems with storage as they arise.
- Network Operations Center (NOC) staffed and always available to resolve issues.
- Scaling
- A storage-focused OpenStack architecture should focus on scaling up instead of scaling out. You should determine whether a smaller number of larger hosts or a larger number of smaller hosts based on factors such as cost, power, cooling, physical rack and floor space, support-warranty, and manageability.
4.5. Network-Focused Architectures
Section 4.5.1, “Network-Focused Architecture Types”
Section 4.5.2, “Cloud Storage and Backup Architecture”
Section 4.5.3, “Large-Scale Web-Application Architecture”
Section 4.5.4, “Network-Focused Architecture Considerations”
4.5.1. Network-Focused Architecture Types
All OpenStack deployments depend on network communication to function properly because of their service-based nature. However, in some cases the network configuration is more critical and requires additional design considerations.
The following table describes common network-focused architectures. These architectures depend on a reliable network infrastructure and on services that satisfy user and application requirements.
| Architecture | Description |
|---|---|
| Big data | Clouds used for the management and collection of big data create significant demand on network resources. Big data often uses partial replicas of the data to maintain integrity over large distributed clouds. Big data applications that require a large amount of network resources include Hadoop, Cassandra, NuoDB, Riak, or other NoSQL and distributed databases. |
| Content delivery network (CDN) | CDNs can be used to stream video, view photographs, host web conferences, or access any distributed cloud-based data repository by a large number of end-users. Network configuration affects latency, bandwidth, and distribution of instances. Other factors that affect content deliver and performance include network throughput of backend systems, resource locations, WAN architecture, and cache methodology. |
| High availability (HA) | HA environments are dependent on network sizing that maintains replication of data between sites. If one site becomes unavailable, additional sites can serve the increased load until the original site returns to service. It is important to size network capacity to handle the additional loads. |
| High performance computing (HPC) | HPC environments require additional consideration of traffic flows and usage patterns to address the needs of cloud clusters. HPC has high east-west traffic patterns for distributed computing within the network, but can also have substantial north-south traffic in and out of the network, depending on the application. |
| High-speed or high-volume transactional systems | These application types are sensitive to network jitter and latency. Example environments include financial systems, credit card transaction applications, and trading systems. These architectures must balance a high volume of east-west traffic with north-south traffic to maximize data delivery efficiency. Many of these systems must access large, high-performance database backends. |
| Network management functions | Environments that support delivery of backend network services such as DNS, NTP, or SNMP. You can use these services for internal network management. |
| Network service offerings | Environments that run customer-facing network tools to support services. Examples include VPNs, MPLS private networks, and GRE tunnels. |
| Virtual desktop infrastructure (VDI) | VDI systems are sensitive to network congestion, latency, and jitter. VDI requires upstream and downstream traffic, and cannot rely on caching to deliver the application to the end-user. |
| Voice over IP (VoIP) | VoIP systems are sensitive to network congestion, latency, and jitter. VoIP system have symmetrical traffic patterns and require network quality of service (QoS) for best performance. In addition, you can implement active queue management to deliver voice and multimedia content. Users are sensitive to latency and jitter fluctuations and can detect them at very low levels. |
| Video or web conference | Conferencing systems are sensitive to network congestion, latency, and jitter. Video conferencing systems have symmetrical traffic pattern, but if the network is not hosted on an MPLS private network, the system cannot use network quality of service (QoS) to improve performance. Similar to VoIP, users of these system notice network performance problems even at low levels. |
| Web portals or services | Web servers are common applications in cloud services, and require an understanding of the network requirements. The network must scale out to meet user demand and to deliver web pages with minimum latency. Depending on the details of the portal architecture, you should consider the internal east-west and north-south network bandwidth when you plan the architecture. |
4.5.2. Cloud Storage and Backup Architecture
This architecture is for a cloud that provides file storage and file-sharing. You might consider this a storage-focused use case, but the network-side requirements make it a network-focused use case.
For installation and deployment documentation, see Chapter 5, Deployment Information.
4.5.2.1. About the Design
The following cloud-backup application workload has two specific behaviors that impact the network.
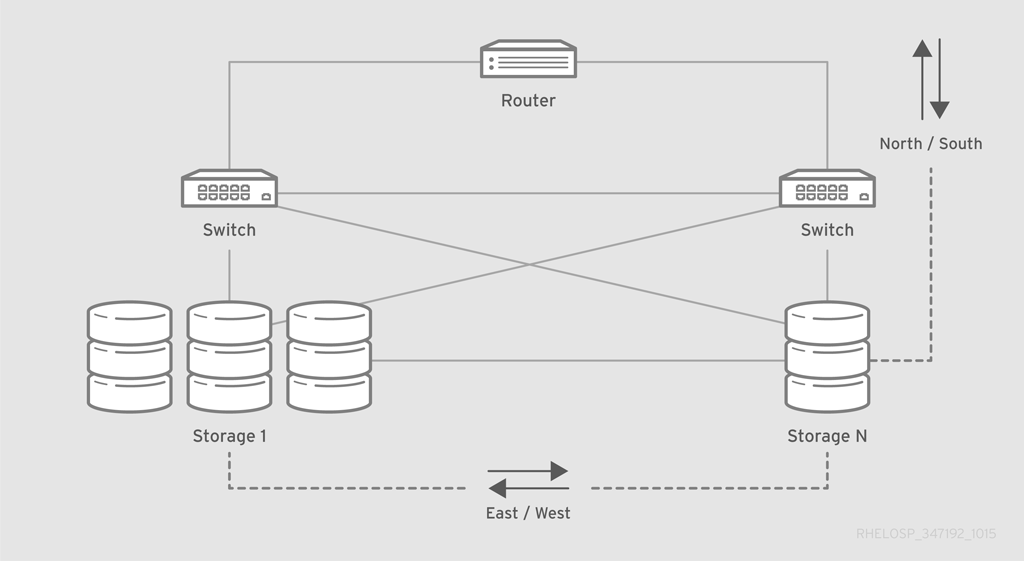
Because this workload includes an externally-facing service and an internally-replicating application, it requires north-south and east-west traffic considerations.
- North-south traffic
North-south traffic consists of data that moves in and out of the cloud. When a user uploads and stores content, that content moves southbound into the OpenStack environment. When users download content, that content moves northbound out of the OpenStack environment.
Because this service operates primarily as a backup service, most of the traffic moves southbound into the environment. In this situation, you should configure a network to be asymmetrically downstream, because the traffic that enters the OpenStack environment is greater than the traffic that leaves the environment.
- East-west traffic
- East-west traffic consists of data that moves inside the environment. This traffic is likely to be fully symmetric, because replication originates from any node and might target multiple nodes algorithmically. However, this traffic might interfere with north-south traffic.
4.5.2.2. Architecture Components
| Component | Description |
|---|---|
| Compute | Compute management and scheduling services run on the controller. The Compute service also runs on each compute node. |
| Dashboard | Web console for OpenStack management. |
| Identity | Basic authentication and authorization functionality. |
| Image | Stores images to be used for booting instances and managing snapshots. This service runs on the controller and offers a small set of images. |
| Networking | Networking services. For more information about OpenStack Networking, see Chapter 2, Networking In-Depth. |
| Object Storage | Stores backup content. |
| Telemetry | Monitoring and reporting for other OpenStack services. |
4.5.2.3. Design Considerations
In addition to basic design considerations described in Chapter 3, Design, you should also follow the considerations described in Section 4.5.4, “Network-Focused Architecture Considerations”.
4.5.3. Large-Scale Web-Application Architecture
This architecture is for a large-scale web application that scales horizontally in bursts and generates a high instance count. The application requires an SSL connection to secure data and must not lose connection to individual servers.
For installation and deployment documentation, see Chapter 5, Deployment Information.
4.5.3.1. About the Design
The following diagram shows an example design for this workload.
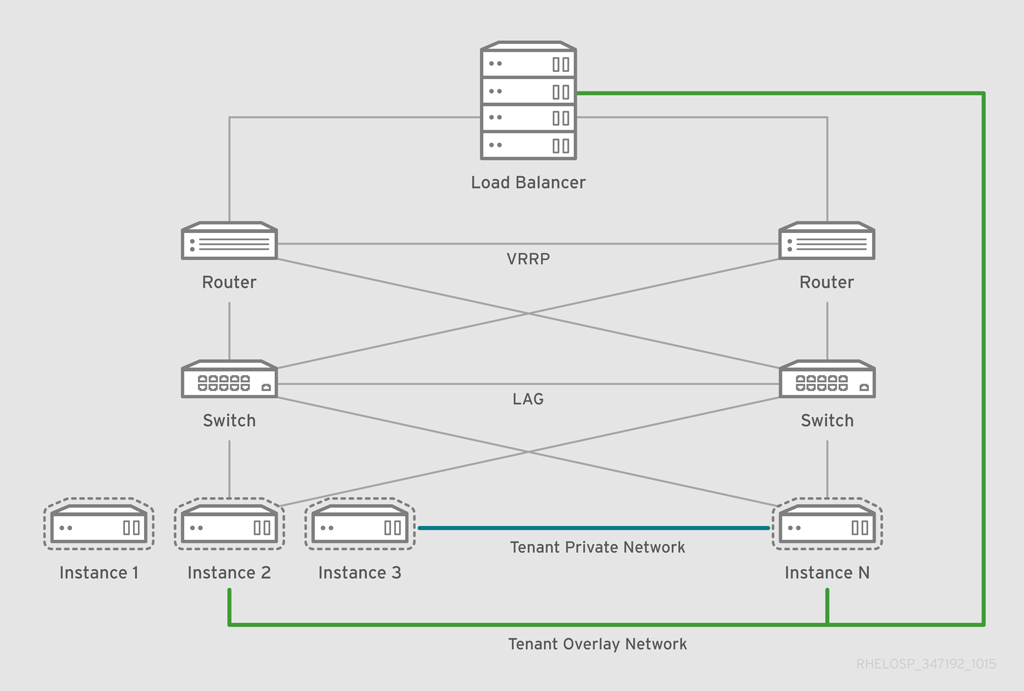
This design includes the following components and workflows:
- Hardware load balancer provides SSL offload functionality and connects to tenant networks to reduce address consumption.
- The load balancer links to the routing architecture while it services the virtual IP (VIP) for the application.
- The router and the load balancer use the GRE tunnel ID of the application tenant network, and an IP address that is located in the tenant subnet but outside of the address pool. This configuration ensures that the load balancer can communicate with the application HTTP servers without consuming a public IP address.
4.5.3.2. Architecture Components
A web service architecture can consist of many options and optional components. Therefore, this architecture can be used in multiple OpenStack designs. However, some key components must be deployed to handle most web-scale workloads.
| Component | Description |
|---|---|
| Compute | Compute management and scheduling services run on the controller. The Compute service also runs on each compute node. |
| Dashboard | Web console for OpenStack management. |
| Identity | Basic authentication and authorization functionality. |
| Image | Stores images to be used for booting instances and managing snapshots. This service runs on the controller and offers a small set of images. |
| Networking | Networking services. A split network configuration is compatible with databases that reside on private tenant networks, because the databases do not emit a large quantity of broadcast traffic and might need to interconnect to other databases for content. |
| Orchestration | Manages instance templates to use when scaling out and during traffic bursts. |
| Telemetry | Monitoring and reporting for other OpenStack services. Use this service to monitor instance usage and invoke instance templates from the Orchestration service. |
| Object Storage | Stores backup content. |
4.5.3.3. Design Considerations
In addition to basic design considerations described in Chapter 3, Design, you should also follow the considerations described in Section 4.5.4, “Network-Focused Architecture Considerations”.
4.5.4. Network-Focused Architecture Considerations
In addition to basic design considerations described in Chapter 3, Design and to network node design described in Chapter 2, Networking In-Depth, the following items should be considered for a network-intensive architecture.
- External dependencies
Consider using the following external network components:
- Hardware load balancers to distribute workloads or off-load certain functions
- External devices to implement dynamic routing
Although OpenStack Networking provides a tunneling feature, it is restricted to networking-managed regions. To extend a tunnel beyond the OpenStack regions to another region or to an external system, implement the tunnel outside OpenStack or use a tunnel-management system to map the tunnel or the overlay to an external tunnel.
- Maximum transmission unit (MTU)
Some workloads require a larger MTU due to the transfer of large blocks of data. When providing network service for applications such as video streaming or storage replication, configure the OpenStack hardware nodes and the supporting network equipment for jumbo frames wherever possible. This configuration maximizes available bandwidth usage.
Configure jumbo frames across the entire path that the packets traverse. If one network component cannot handle jumbo frames, the entire path reverts to the default MTU.
- NAT usage
If you need floating IPs instead of fixed public IPs, you must use NAT. For example, use a DHCP relay mapped to the DHCP server IP. In this case, it is easier to automate the infrastructure to apply the target IP to a new instance, instead of reconfiguring legacy or external systems for each new instance.
The NAT for floating IPs that is managed by OpenStack Networking resides in the hypervisor. However, other versions of NAT might be running elsewhere. If there is a shortage of IPv4 addresses, you can use the following methods to mitigate the shortage outside of OpenStack:
- Run a load balancer in OpenStack as an instance or externally as a service. The OpenStack Load-Balancer-as-a-Service (LBaaS) can manage load balancing software such as HAproxy internally. This service manages the Virtual IP (VIP) addresses while a dual-homed connection from the HAproxy instance connects the public network with the tenant private network that hosts all content servers.
- Use a load balancer to serve the VIP and also connect to the tenant overlay network with external methods or private addresses.
In some cases it may be desirable to use only IPv6 addresses on instances and operate either an instance or an external service to provide a NAT-based transition technology such as NAT64 and DNS64. This configuration provides a globally-routable IPv6 address, while consuming IPv4 addresses only as necessary.
- Quality of Service (QoS)
QoS impacts network-intensive workloads because it provides instant service to packets with high priority because of poor network performance. In applications such as Voice over IP (VoIP), differentiated service code points are usually required for continued operation.
You can also use QoS for mixed workloads to prevent low-priority, high-bandwidth applications such as backup services, video conferencing, or file sharing, from blocking bandwidth that is needed for the continued operation of other workloads.
You can tag file-storage traffic as lower class traffic, such as best effort or scavenger, to allow higher-priority traffic to move through the network. In cases where regions in a cloud are geographically distributed, you might also use WAN optimization to reduce latency or packet loss.
- Workloads
The routing and switching architecture should accommodate workdloads that require network-level redundancy. The configuration depends on your selected network hardware, on the selected hardware performance, and on your networking model. Examples include Link Aggregation (LAG) and Hot Standby Router Protocol (HSRP).
The workload also impacta the effectiveness of overlay networks. If application network connections are small, short lived, or bursty, running a dynamic overlay can generate as much bandwidth as the packets the network carries. Overlay can also induce enough latency to cause issues with the hypervisor, which causes performance degradation on packet-per-second and connection-per-second rates.
By default, overlays include a secondary full-mesh option that depends on the workload. For example, most web services applications do not have major issues with a full-mesh overlay network, and some network monitoring tools or storage replication workloads have performance issues with throughput or excessive broadcast traffic.