Audit AI apps to meet compliance goals
Deploy a financial audit system with insights into the performance, cost, and usage of your large language models in real time.
This content is authored by Red Hat experts, but has not yet been tested on every supported configuration.
Audit AI apps to meet compliance goals
Deploy a financial audit system with insights into the performance, cost, and usage of your large language models in real time.
Table of Contents
Detailed description
This quickstart features a Financial Services Industry (FSI) compliance demo that demonstrates auditability and traceability for AI-powered financial applications.
As AI workloads become more complex, organizations need robust telemetry and observability of Large Language Model (LLM) infrastructure. This quickstart demonstrates those needs by providing:
- AI observability for model performance, resource utilization, and distributed tracing
- Standardized deployment patterns for consistent, scalable AI service delivery
- Enterprise-grade monitoring using OpenShift-native observability tools
This repository provides helm charts for both the monitoring infrastructure and AI service deployments needed to run Llama Stack reliably in OpenShift AI.
Architecture
The proposed observability & telemetry architecture:
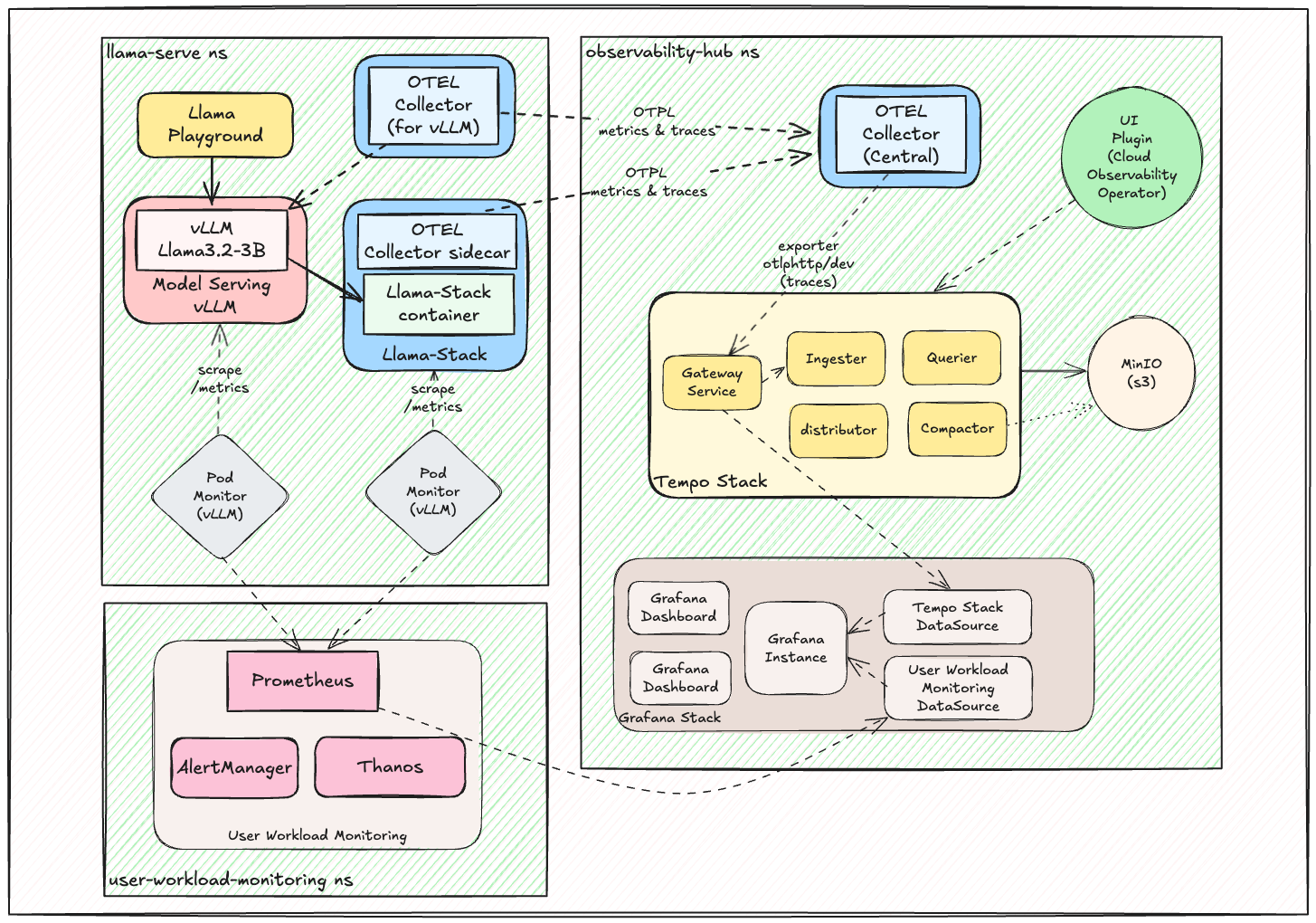
This architecture demonstrates the complete observability ecosystem, from AI workload telemetry collection through distributed tracing to comprehensive monitoring dashboards.
Components
All components are organized by dependency layers in the ./helm/ directory:
Phase 1: Operators (./helm/01-operators/)
cluster-observability-operator- PodMonitor/ServiceMonitor CRDs and UI pluginsgrafana-operator- Grafana operator for visualization and dashboard managementotel-operator- Red Hat Build of OpenTelemetry operatortempo-operator- Distributed tracing backend operator
Phase 2: Observability Infrastructure (./helm/02-observability/)
tempo- Distributed tracing backend with S3-compatible storageotel-collector- OpenTelemetry collector configurations for telemetry collection and processinggrafana- Visualization and dashboard management with pre-built dashboardsuwm- User Workload Monitoring with PodMonitors for VLLM and AI workloadsdistributed-tracing-ui-plugin- OpenShift console integration for tracing
Phase 3: AI Services (./helm/03-ai-services/)
llama-stack-instance- Complete Llama Stack Instance with configurable endpointsllama3.2-3b- Llama 3.2 3B model deployment on vLLMllama-stack-playground- Interactive Llama-Stack web interface for testingllama-guard- Llama Guard 1B for providing Safety / Shield mechanisms
Phase 4: MCP Servers (./helm/04-mcp-servers/)
mcp-weather- MCP weather servicehr-api- MCP HR API demonstration serviceopenshift-mcp- MCP OpenShift/Kubernetes operations service
Observability in Action
The telemetry and observability stack provides comprehensive visibility into AI workload performance and distributed system behavior.
Distributed Tracing Examples
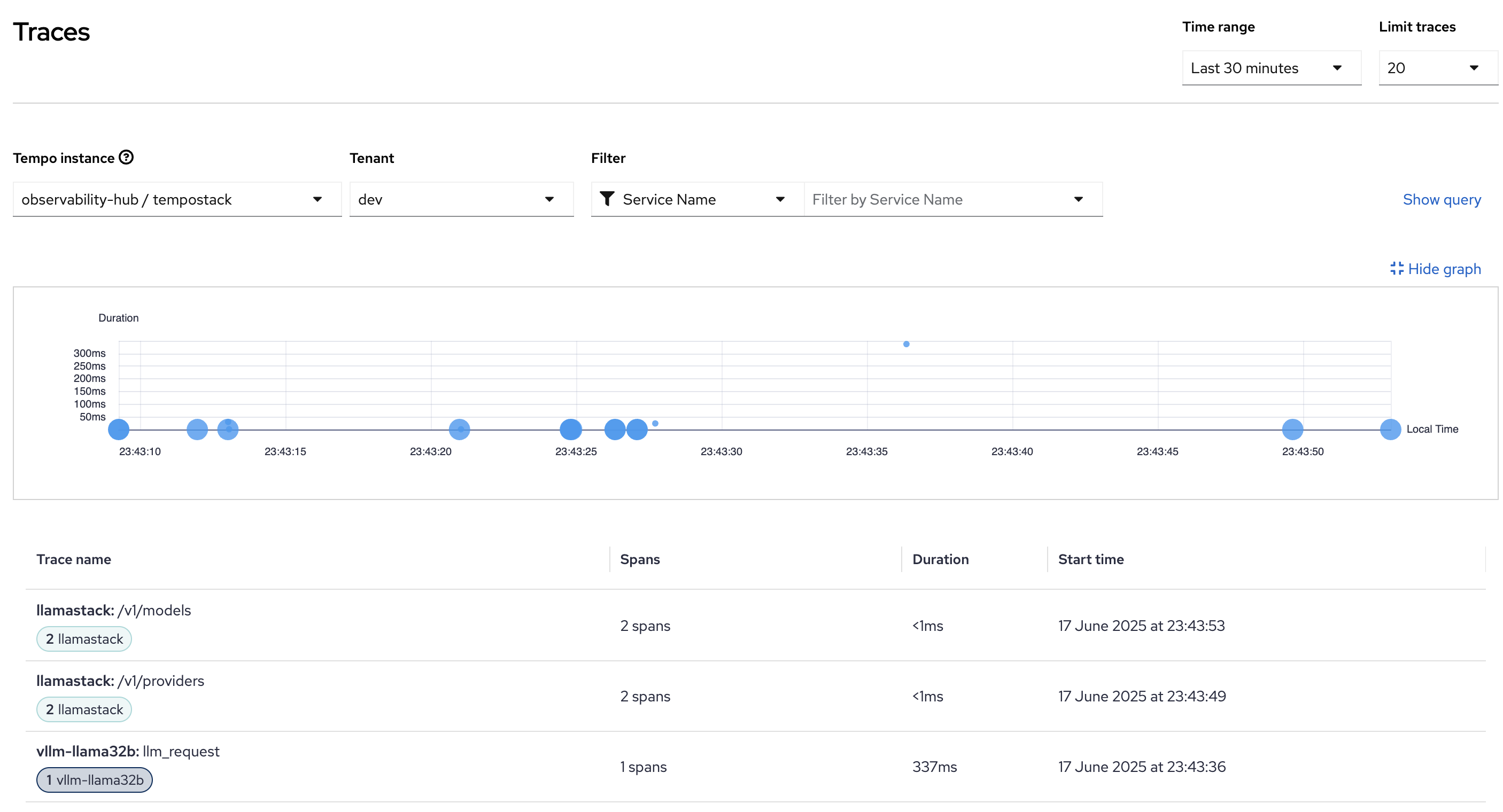
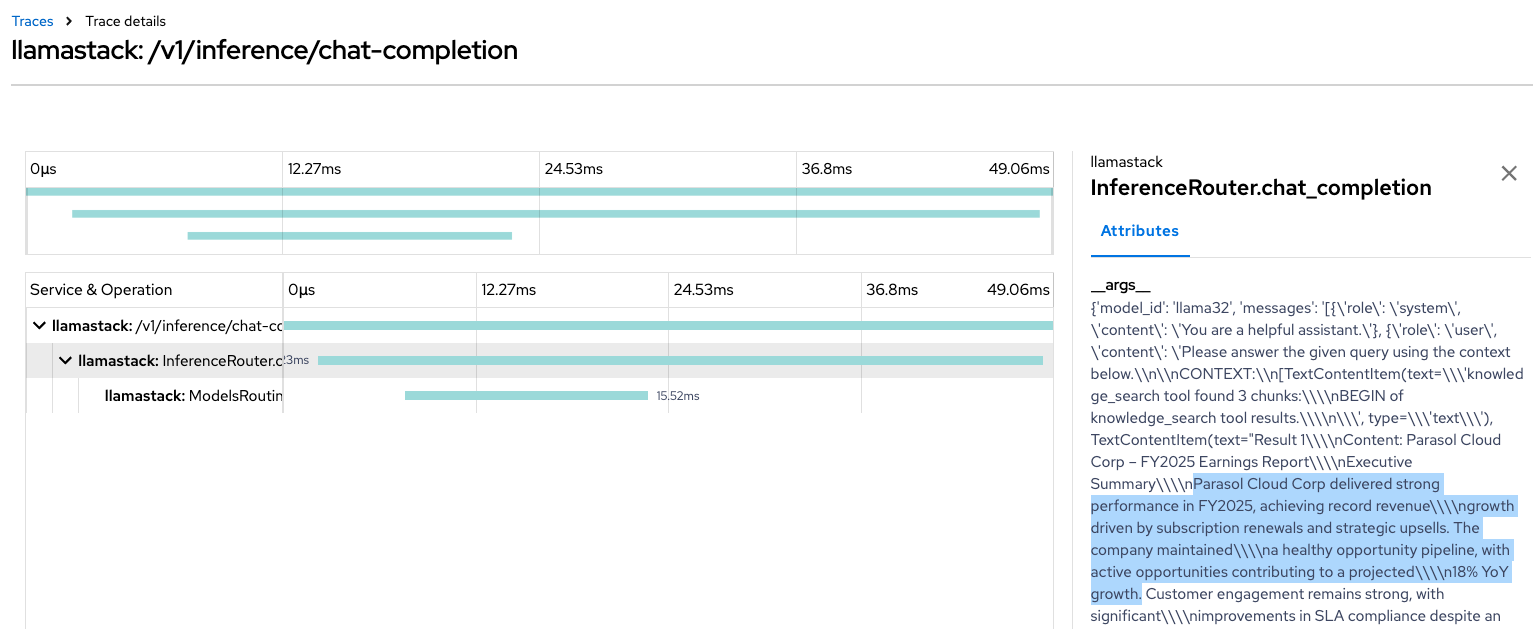
End-to-End Request Tracing: Complete visibility into AI inference request flows through the Llama Stack infrastructure.
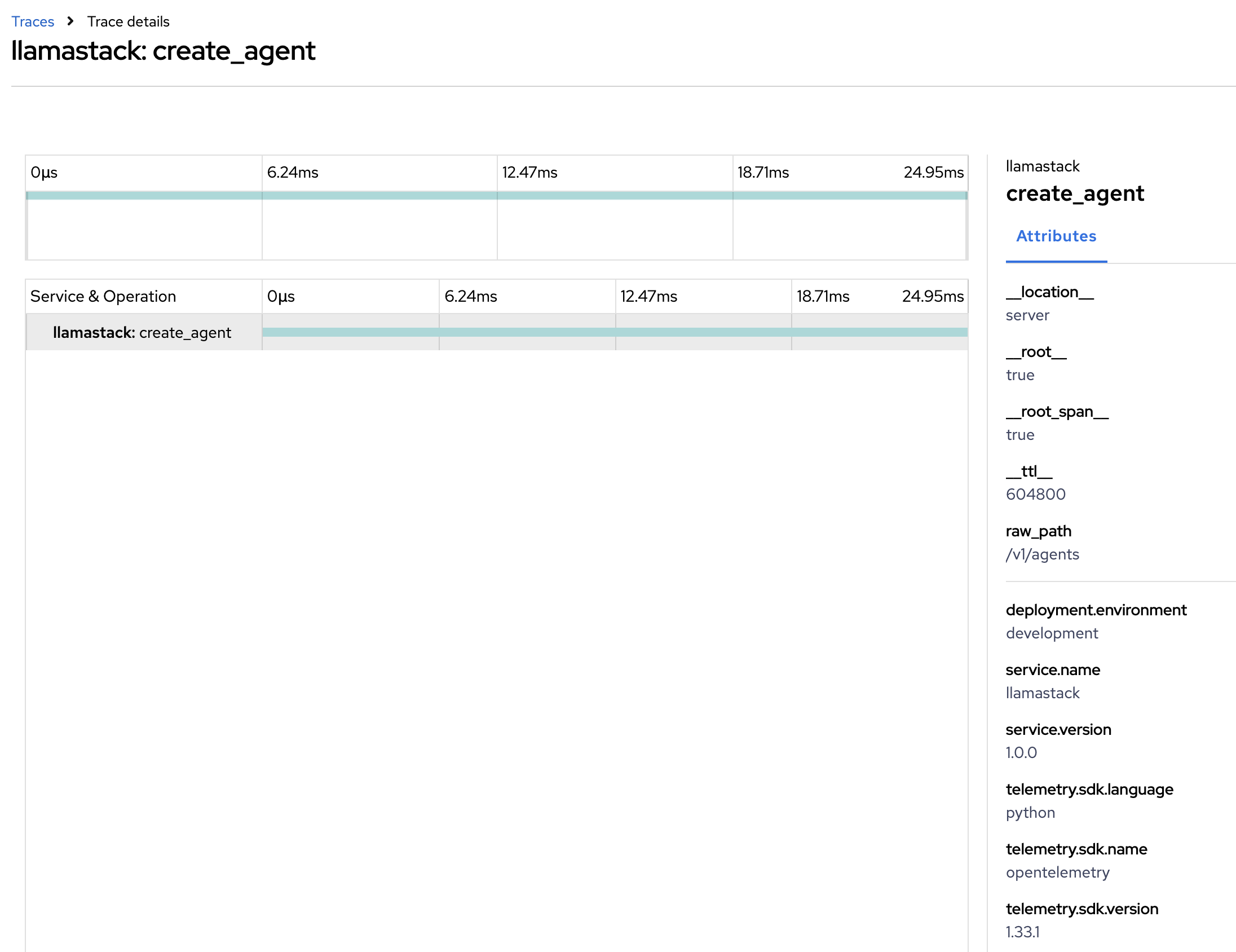
Create Agent from LlamaStack Tracing: Detailed trace view showing complex interactions between different services in the AI stack.
These traces provide insights into:
- Request latency and service dependencies
- Error tracking and performance bottlenecks
- Load distribution across model endpoints
Requirements
Minimum hardware requirements
- CPU: 8+ cores recommended for full stack deployment
- Memory: 16GB+ RAM for monitoring stack, additional memory based on AI workload requirements
- Storage: 100GB+ for observability data retention
- Inference Hardware
- GPU (Default): NVIDIA GPU required for AI model inference (varies by model size)
- Xeon:
- 2 worker nodes with Intel Xeon processor 4th gen or newer (SPR, EMR, GNR) with a minimum of 32vCPU and 64GB of RAM
- Llama3.2-3b requires at least 16vCPU and 32GB of memory
- Lllama-Guard (Llama-Guard-3-1B) requires at least 4vCPU and 16GB of memory
- for example: m8i.8xlarge, m7i.8xlarge, c8i.8xlarge
- 2 worker nodes with Intel Xeon processor 4th gen or newer (SPR, EMR, GNR) with a minimum of 32vCPU and 64GB of RAM
Minimum software requirements
- OpenShift 4.12+ or Kubernetes 1.24+
- OpenShift AI 2.19 onwards
- Helm 3.8+ for chart deployment
- oc CLI or kubectl for cluster management
Required user permissions
- Cluster Admin - Required for operator installation and observability stack setup
- GPU Access - Required for AI workload deployment on GPU
Deploy
# step 0
git clone https://github.com/rh-ai-quickstart/lls-observability.git && \
cd lls-observability
Prerequisites
Xeon deployment
- Build vllm-xeon-opentelemetry Image
# ImageStream
oc create imagestream vllm-xeon-opentelemetry -n openshift
# BuildConfig
oc apply -f helm/vllm-xeon-opentelemetry-build-config.yaml
# Wait ~5 minutes and check if image is present in OpenShift
oc get is -n openshift | grep vllm-xeon-opentelemetry
Quick Start - Automated Installation
Option 1: Complete Stack (Recommended)
# Run the full installation script
./scripts/install-full-stack.sh
# Xeon
DEVICE=xeon scripts/install-full-stack.sh
Option 2: Phase-by-Phase Installation
# For Xeon Deployments set DEVICE environment variable
# export DEVICE=xeon
# Phase 1: Install operators
./scripts/install-operators.sh
# Phase 2: Deploy observability infrastructure
./scripts/deploy-observability.sh
# Phase 3: Deploy AI workloads
./scripts/deploy-ai-workloads.sh
Option 3: Using Makefile (Optional)
# Xeon Deployments
# export DEVICE=xeon
# Install everything in one command
make install-all
# Or phase-by-phase
make install-operators # Phase 1
make deploy-observability # Phase 2
make deploy-ai # Phase 3
Advanced Usage
Manual Step-by-Step Installation
For users who prefer to understand each step or need to customize the installation.
Set these environment variables before running the installation commands:
export OBSERVABILITY_NAMESPACE="observability-hub"
export UWM_NAMESPACE="openshift-user-workload-monitoring"
export AI_SERVICES_NAMESPACE="llama-serve"
# Need to explicitly set DEVICE deployment
export DEVICE=GPU # or xeon
Launch this instructions:
# 1. Create required namespaces
oc create namespace ${OBSERVABILITY_NAMESPACE}
oc create namespace ${UWM_NAMESPACE}
oc create namespace ${AI_SERVICES_NAMESPACE}
# 2. Install required operators
helm install cluster-observability-operator ./helm/01-operators/cluster-observability-operator
helm install grafana-operator ./helm/01-operators/grafana-operator
helm install otel-operator ./helm/01-operators/otel-operator
helm install tempo-operator ./helm/01-operators/tempo-operator
# 3. Wait for operators to be ready
oc wait --for=condition=Ready pod -l app.kubernetes.io/name=cluster-observability-operator -n openshift-cluster-observability-operator --timeout=300s
oc wait --for=condition=Ready pod -l app.kubernetes.io/name=observability-operator -n openshift-cluster-observability-operator --timeout=300s
# 4. Deploy observability infrastructure
helm install tempo ./helm/02-observability/tempo -n ${OBSERVABILITY_NAMESPACE}
helm install otel-collector ./helm/02-observability/otel-collector -n ${OBSERVABILITY_NAMESPACE}
helm install grafana ./helm/02-observability/grafana -n ${OBSERVABILITY_NAMESPACE}
# 5. Enable User Workload Monitoring for AI workloads
helm template uwm ./helm/02-observability/uwm -n ${OBSERVABILITY_NAMESPACE} | oc apply -f-
# Verify UWM setup
oc get configmap user-workload-monitoring-config -n ${UWM_NAMESPACE}
oc get podmonitors -n ${OBSERVABILITY_NAMESPACE}
# 6. Deploy AI workloads
# Deploy MCP servers in AI services namespace
helm install mcp-weather ./helm/04-mcp-servers/mcp-weather -n ${AI_SERVICES_NAMESPACE}
helm install hr-api ./helm/04-mcp-servers/hr-api -n ${AI_SERVICES_NAMESPACE}
# Milvus vector database is configured inline within llama-stack-instance
# No external Milvus deployment needed
# Deploy AI services in AI services namespace
helm install llama3-2-3b ./helm/03-ai-services/llama3.2-3b -n ${AI_SERVICES_NAMESPACE} \
--set model.name="meta-llama/Llama-3.2-3B-Instruct" \
--set device="$DEVICE"
helm install llama-stack-instance ./helm/03-ai-services/llama-stack-instance -n ${AI_SERVICES_NAMESPACE} \
--set 'mcpServers[0].name=weather' \
--set 'mcpServers[0].uri=http://mcp-weather.${AI_SERVICES_NAMESPACE}.svc.cluster.local:80' \
--set 'mcpServers[0].description=Weather MCP Server for real-time weather data'
helm install llama-stack-playground ./helm/03-ai-services/llama-stack-playground -n ${AI_SERVICES_NAMESPACE}
helm install llama-guard ./helm/03-ai-services/llama-guard -n ${AI_SERVICES_NAMESPACE} \
--set device="$DEVICE"
# 7. Enable tracing UI
helm install distributed-tracing-ui-plugin ./helm/02-observability/distributed-tracing-ui-plugin
MaaS Integration (Optional)
Model-as-a-Service (MaaS) Remote Models
The Llama Stack can optionally integrate with external MaaS (Models as a Server) to access remote models without local GPU requirements.
Configuration Options:
maas:
enabled: true # Enable MaaS provider
apiToken: "your-api-token" # Authentication token
url: "https://endpoint.com/v1" # MaaS endpoint URL
maxTokens: 200000 # Maximum token limit
tlsVerify: false # TLS verification
modelId: "model-name" # Specific MaaS model identifier
Uninstall
Complete Stack Uninstall
# Uninstall everything in reverse order
make clean