Sinopsis de la suite para Cluster
Red Hat Cluster Suite para Red Hat Enterprise Linux 5
Edición 3
Resumen
Introducción
- Manual de instalación de Red Hat Enterprise Linux — Proporciona información relacionada con la instalación de Red Hat Enterprise Linux 5.
- Manual de implementación de Red Hat Enterprise Linux — Proporciona información sobre la implementación, configuración y administración de Red Hat Enterprise Linux 5.
- Configuración y administración de Red Hat Cluster — Proporciona información sobre la instalación, configuración y administración de componentes de Red Hat Cluster.
- LVM Administrator's Guide: Configuration and Administration — Provides a description of the Logical Volume Manager (LVM), including information on running LVM in a clustered environment.
- Sistema de archivos global: Configuración y administración — Proporciona información sobre la instalación, administración y mantenimiento de Sistemas de archivos global de Red Hat (Red Hat GFS).
- Sistema de archivos global: Configuración y administración — Proporciona información sobre la instalación, configuración y mantenimiento de Red Hat GFS2 (Red Hat Global File System 2).
- Cómo utilizar multirutas de mapeo de dispositivos — proporciona información sobre el uso de la función multirutas de mapeo de dispositivos de Red Hat Enterprise Linux 5.
- Como usar GNBD con GFS — Proporciona información sobre el uso de dispositivos de bloque de red global (GNBD) con GFS de Red Hat.
- Administración de servidores virtuales en Linux — Proporciona información sobre cómo configurar sistemas y servicios de alto rendimiento con el servidor virtual de Linux (LVS).
- Notas de lanzamiento de la Suite Red Hat Cluster — Proporciona información sobre el lanzamiento actual de Red Hat Cluster Suite.
1. Comentarios
Cluster_Suite_Overview(EN)-5 (2008-12-11T15:49)
Cluster_Suite_Overview(EN)-5 (2008-12-11T15:49)
Capítulo 1. Sinopsis de Red Hat Cluster Suite
1.1. Fundamentos sobre cluster
- Almacenamiento
- Alta disponibilidad
- Balance de carga
- Alto rendimiento
Nota
1.2. Red Hat Cluster Suite Introduction
- Infraestructura del cluster — proporciona funciones fundamentales para que los nodos trabajen juntos como un cluster: administración del archivo de configuración, administración de membresías, administración de cierres de exclusión y aislamiento.
- Administración de servicios de alta disponibilidad — Proporciona la transferencia de servicios de un cluster a otro en caso de que un nodo falle.
- Herramienta de administración de cluster — Herramientas de configuración y administración para configurar y administrar un cluster de Red Hat. Las herramientas se utilizan con los componentes de infraestructura del cluster, los componentes de alta disponibilidad, de administración de servicios y de almacenamiento.
- Servidor Virtual de Linux (LVS) — Software de encaminamiento que proporciona balance de carga de IP. LVS se ejecuta en un par de servidores pertinentes que distribuyen las peticiones de los clientes a los servidores reales que están tras los servidores LVS.
- Red Hat GFS (Sistema de archivos global) — Proporciona un sistema de archivos de cluster para utilizar con Red Hat Cluster Suite. GFS permite que los nodos compartan el almacenaje a nivel de bloque como si éste fuera conectado localmente en cada nodo.
- Administrador de volúmenes lógicos de cluster (CLVM) — Proporciona administración de volúmenes de almacenamiento en cluster.
Nota
When you create or modify a CLVM volume for a clustered environment, you must ensure that you are running theclvmddaemon. For further information, refer to Sección 1.6, “Administrador de volúmenes lógicos de cluster”. - Dispositivo de bloque de red global (GNBD) — Un componente complementario de GFS que exporta el almacenaje a nivel de bloque a través de Ethernet. Esta es una manera económica de hacer que el almacenaje de nivel de bloque esté disponible en Red Hat GFS.

Figura 1.1. Red Hat Cluster Suite Introduction
Nota
1.3. Cluster Infrastructure
- Administración de cluster
- Administración de los cierres de exclusión
- Fencing
- Administración de la configuración de cluster
1.3.1. Administración del cluster
Nota

Figura 1.2. CMAN/DLM Overview
1.3.2. Administración de cierres de exclusión
1.3.3. Fencing
fenced.
fenced ejecuta una acción de aislamiento sobre el nodo fallido cuando la comunicación es recibida. Otros componentes de la infraestructura de cluster determinan que acciones se deben tomar — los componentes ejecutan los procedimientos de recuperación que sean necesarios. Por ejemplo, DLM y GFS suspenden sus actividades hasta que detectan que fenced ha completado su tarea sobre el nodo fallido. Tras recibir la confirmación de que el nodo ha sido aislado, DLS y GFS ejecutan las tareas de recuperación. DLM libera los cierres del nodo fallido; GFS recupera el registro por diario (journal) del nodo fallido.
- Aislamiento de energía — Un método de aislamiento que utiliza un controlador de energía para apagar el nodo fallido.
- Aislamiento de interruptor de canal de fibra — Un método de aislamiento que desactiva el puerto del canal de fibra que conecta el almacenaje con el nodo fallido.
- GNBD fencing — A fencing method that disables an inoperable node's access to a GNBD server.
- Otros métodos de aislamiento — Hay otros métodos de aislamiento que desactivan la E/S o apagan el nodo fallido. Entre estos se incluye IBM Bladecenters, PAP, DRAC/MC, HP ILO, IPMI, IBM RSA II y otros.

Figura 1.3. Power Fencing Example

Figura 1.4. Fibre Channel Switch Fencing Example

Figura 1.5. Fencing a Node with Dual Power Supplies

Figura 1.6. Fencing a Node with Dual Fibre Channel Connections
1.3.4. Sistema de configuración del Cluster (CCS)

Figura 1.7. CCS Overview

Figura 1.8. Accessing Configuration Information
/etc/cluster/cluster.conf) es un archivo en XML que describe las siguientes características de cluster:
- Nombre de cluster — Muestra el nombre de cluster, el nivel de revisión del archivo de configuración de cluster y las propiedades de aislamiento básico que son utilizadas cuando un nodo entra al cluster o es aislado por el cluster.
- Cluster — Muestra cada nodo de cluster, especifica el nombre del nodo, el ID del nodo, el número de votos en el quórum y el método de aislamiento para el nodo.
- El dispositivo de aislamiento — Muestra el dispositivo de aislamiento en el cluster. Los parámetros pueden variar de acuerdo con el tipo de dispositivo de aislamiento. Por ejemplo, para un controlador de energía que es utilizado como dispositivo de aislamiento, la configuración de cluster define el nombre del controlador de poder, su dirección IP, el login y la contraseña.
- Recursos administrados — Muestra los recursos requeridos para crear los servicios de cluster. Entre los recursos administrados se encuentra la definición del dominio de recuperación contra fallas, los recursos (dirección IP por ejemplo) y los servicios. Los recursos administrados definen los servicios de cluster y el comportamiento de recuperación contra fallas de éstos.
1.4. Administración de servicios de alta disponibilidad
rgmanager. Este componente implementa recuperación contra fallos para aplicaciones. En un cluster de Red Hat, una aplicación es configurada con otros recursos del cluster para formar un servicio de cluster de alta disponibilidad. Un servicio de cluster de alta disponibilidad puede pasar de un nodo a otro sin ninguna interrupción aparente a los clientes de cluster. La recuperación contra fallos puede ocurrir si un nodo de cluster falla o si el administrador de sistema de cluster traslada el servicio de un nodo a otro (por ejemplo si el nodo necesita recibir tareas de mantenimiento).
Nota

Figura 1.9. Dominios de recuperación contra fallos
- recurso de dirección IP — dirección IP 10.10.10.201.
- An application resource named "httpd-content" — a web server application init script
/etc/init.d/httpd(specifyinghttpd). - A file system resource — Red Hat GFS named "gfs-content-webserver".

Figura 1.10. Web Server Cluster Service Example
1.5. Red Hat GFS
- Simplifica la infraestructura de sus datos
- Permite la instalación de aplicaciones para todo el cluster.
- Elimina la necesidad de copias innecesarias de los datos de la aplicación (duplicación)
- Permite acceso de lectura y escritura concurrente a los datos de varios clientes.
- Simplifica la creación de copias de seguridad y la recuperación contra desastres (sólo un sistema de archivos debe ser copiado o recuperado).
- Maximiza el uso de recursos de almacenaje; minimiza los costos de administración de almacenaje.
- Administra el almacenaje como un todo y no como particiones.
- Decrece el almacenamiento general al eliminar la necesidad de duplicación de datos.
- Escala el cluster al añadir servidores o almacenaje en la marcha.
- Evita el particionamiento de almacenaje a través de técnicas complicadas.
- Añade servidores al cluster montándolos en el sistema de archivos común.
Nota
1.5.1. Rendimiento y escalabilidad superior

Figura 1.11. GFS with a SAN
1.5.2. Rendimiento, escalabilidad y precio moderado

Figura 1.12. GFS and GNBD with a SAN
1.5.3. Economía y rendimiento

Figura 1.13. GFS y GNDB con un almacenaje conectado directamente
1.6. Administrador de volúmenes lógicos de cluster
clvmd. clvmd is a daemon that provides clustering extensions to the standard LVM2 tool set and allows LVM2 commands to manage shared storage. clvmd runs in each cluster node and distributes LVM metadata updates in a cluster, thereby presenting each cluster node with the same view of the logical volumes (refer to Figura 1.14, “CLVM Overview”). Logical volumes created with CLVM on shared storage are visible to all nodes that have access to the shared storage. CLVM allows a user to configure logical volumes on shared storage by locking access to physical storage while a logical volume is being configured. CLVM uses the lock-management service provided by the cluster infrastructure (refer to Sección 1.3, “Cluster Infrastructure”).
Nota
clvmd) o los agentes de administración de volúmenes lógicos de alta disponibilidad (HA-LVM). Si no puede utilizar ni el daemon clvmd ni HA-LVM por razones operativas o porque no tiene la debida autorización, no debe utilizar la instancia-única de LVM en el disco compartido porque se pueden dañar los datos. Si tiene dudas, por favor contacte al representante de servicio de Red Hat.
Nota
/etc/lvm/lvm.conf para el sistema de cierres de exclusión de cluster.

Figura 1.14. CLVM Overview

Figura 1.15. LVM Graphical User Interface

Figura 1.16. Conga LVM Graphical User Interface

Figura 1.17. Creating Logical Volumes
1.7. Dispositivo de bloque de red global (GNBD)

Figura 1.18. Sinopsis de GNBD
1.8. Servidor virtual de Linux
- Balancear la carga entre los servidores reales.
- Revisar la integridad de los servicios en cada servidor real.
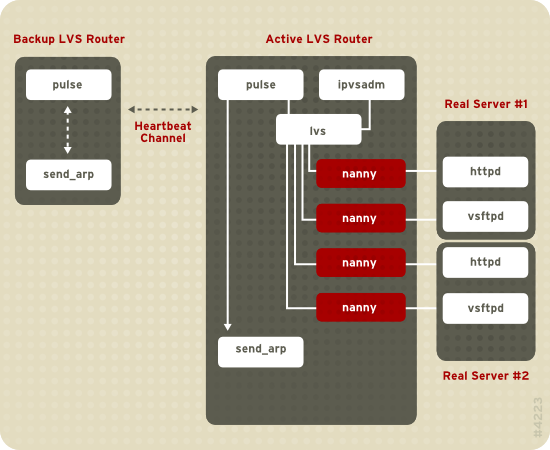
Figura 1.19. Components of a Running LVS Cluster
pulse se ejecuta tanto en el servidor LVS activo como en el pasivo. En el enrutador LVS de respaldo, pulse envía un latido a la interfaz pública del enrutador LVS activo para asegurarse de que éste esté funcionando apropiadamente. En el enrutador LVS activo, pulse inicia el daemon lvs y responde a los latidos que provienen del enrutador LVS de respaldo.
lvs llama a la utilidad ipvsadmin para configurar y mantener la tabla de rutas IPVS (IP Virtual Server) en el kernel e inicia un proceso nanny para cada servidor virtual configurado en cada servidor real. Cada proceso nanny revisa el estado de cada servidor configurado en un servidor real e informa al daemon lvs si el servicio en el servidor real no está funcionando. Si el servicio no está funcionando, el daemon lvs ordena a ipvsadm que remueva el servidor real de la tabla de rutas IPVS.
send_arp para que asigne nuevamente todas las direcciones IP virtuales a las direcciones de hardware NIC (direcciones MAC) del enrutador LVS de respaldo, envía un comando para activar el enrutador LVS activo a través de las interfaces de red pública y privada para apagar el daemon lvs en el enrutador LVS activo e inicia el daemon lvs en el enrutador LVS de respaldo para que acepte solicitudes para los servidores virtuales configurados.
- Sincronizar los datos entre los servidores reales.
- Añadir una tercera capa a la topología para el acceso de datos compartidos.
rsync para replicar los cambios de datos a lo largo de todos los nodos cada cierto intervalo de tiempo. Sin embargo, en los entornos donde los usuarios cargan archivos o ejecutan transacciones a la base de datos, el uso de scripts o del comando rsync para la sincronización de datos no funciona de forma óptima. Por lo cual, para servidores reales con una gran cantidad de cargas, transacciones a bases de datos o tráfico similar, una topología de tres capas es la opción más apropiada para la sincronización de datos.
1.8.1. Two-Tier LVS Topology

Figura 1.20. Two-Tier LVS Topology
eth0:1. Alternativamente, cada servidor virtual puede estar asociado con un dispositivo separado por servicio. Por ejemplo, el tráfico HTTP puede ser manejado en eth0:1 y el tráfico FTP puede ser manejado en eth0:2.
- Programador Round-Robin — Distribuye cada solicitud secuencialmente alrededor de los servidores reales. Al usar este algoritmo, todos los servidores reales son tratados del mismo modo, sin importar su capacidad o carga.
- Programador Weighted Round-Robin — Distribuye cada solicitud secuencialmente alrededor de los servidores reales dando más tareas a los servidores con mayor capacidad. La capacidad es indicada por el usuario y se ajusta gracias a la información de carga dinámica. Esta es la opción preferida si los servidores reales tienen distintas capacidades. Sin embargo, si la carga de solicitudes cambia dramáticamente, un servidor con gran capacidad podría responder a más solicitudes que las que debe.
- Least-Connection — Distribuye más solicitudes a los servidores reales que tienen menos conexiones activas. Este es un tipo de algoritmo de programación dinámico. Es una buena opción si hay altos grados de variación en las solicitudes. Es ideal en las infraestructuras donde cada servidor tiene aproximadamente la misma capacidad. Si los servidores reales tienen capacidades variadas, la programación weighted least-connection es una mejor opción.
- Weighted Least-Connections (predeterminado) — Distribuye más solicitudes a los servidores con menos conexiones activas en relación con sus capacidades. La capacidad es indicada por el usuario y es ajustada por la información de carga dinámica. La adición del parámetro de capacidad hace que este algoritmo sea ideal cuando la infraestructura tiene servidores reales con capacidades de hardware variado.
- Locality-Based Least-Connection Scheduling — Distribuye más solicitudes a los servidores con menos conexiones activas en relación con sus IP de destino. Este algoritmo se utiliza en cluster de servidores de caché proxy. Enruta el paquete para una dirección IP para el servidor con esa dirección a menos que el servidor esté sobrecargado, en dicho caso se asigna la dirección IP al servidor real con menos carga.
- Locality-Based Least-Connection Scheduling with Replication Scheduling — Distribuye más solicitudes a los servidores con menos conexiones activas de acuerdo con la IP de destino. Este algoritmo es usado en servidores de caché de proxy. Se diferencia de "Locality-Based Least-Connection Scheduling" al relacionar la dirección IP objetivo con un grupo de servidores reales. Las solicitudes son luego enviadas al servidor en el grupo con menos número de conexiones. Si la capacidad de todos los nodos para el IP de destino está sobre el límite, añade un nuevo servidor real del grupo general al grupo de servidores para el IP de destino. El nodo con mayor carga es desplazado fuera del grupo para evitar un exceso de replicación.
- Source Hash Scheduling — Distribuye todas las solicitudes de acuerdo con un diccionario estático de direcciones IP. Este algoritmo se utiliza en enrutadores LVS con varios cortafuegos.
1.8.2. Three-Tier LVS Topology
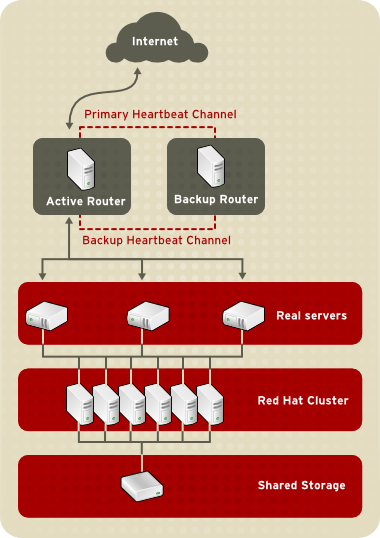
Figura 1.21. Three-Tier LVS Topology
1.8.3. Métodos de enrutado
1.8.3.1. Enrutado NAT
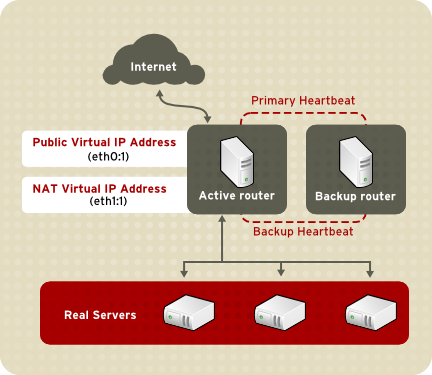
Figura 1.22. LVS Implemented with NAT Routing
1.8.3.2. Enrutado directo
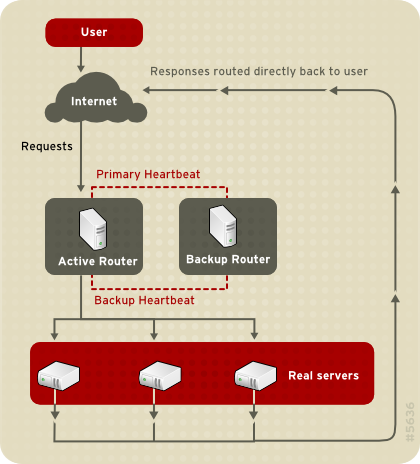
Figura 1.23. LVS Implemented with Direct Routing
arptables.
1.8.4. Marcas de cortafuego y persistencia
1.8.4.1. Persistence
1.8.4.2. Marcas de cortafuegos
1.9. Herramientas de administración de cluster
1.9.1. Conga
- Interfaz de web para administrar cluster y almacenaje
- Implementación automatizada de los datos del cluster y paquetes de soporte
- Integración fácil con los cluster existentes
- No hay necesidad de reautenticación
- Integración de los registros y estado del cluster
- Control detallado sobre los permisos de usuarios
- — Proporciona herramientas para añadir y borrar computadores, añadir y borrar usuarios y configurar privilegios de usuarios. Sólo un administrador de sistema puede acceder a esta pestaña.
- — Proporciona herramientas para crear y configurar los cluster. Cada instancia de luci lista los cluster que han sido establecidos con esa instancia de luci. Un administrador de sistema puede administrar todos los cluster listados en esta pestaña. Otros usuarios pueden administrar solo los cluster a los cuales tiene permiso de administrar (otorgados por el administrador).
- — proporciona herramientas para la administración remota del almacenamiento. Con las herramientas en esta pestaña, usted puede administrar el almacenaje en computadores (sin importar si estos pertenecen o no al cluster).

Figura 1.24. Pestaña de luci

Figura 1.25. Pestaña de luci

Figura 1.26. Pestaña de luci
1.9.2. Interfaz gráfica de administración de cluster
system-config-cluster cluster administration graphical user interface (GUI) available with Red Hat Cluster Suite. The GUI is for use with the cluster infrastructure and the high-availability service management components (refer to Sección 1.3, “Cluster Infrastructure” and Sección 1.4, “Administración de servicios de alta disponibilidad”). The GUI consists of two major functions: the Cluster Configuration Tool and the Cluster Status Tool. The Cluster Configuration Tool provides the capability to create, edit, and propagate the cluster configuration file (/etc/cluster/cluster.conf). The Cluster Status Tool provides the capability to manage high-availability services. The following sections summarize those functions.
1.9.2.1. Cluster Configuration Tool

Figura 1.27. Cluster Configuration Tool
/etc/cluster/cluster.conf) con una jerarquía gráfica que se muestra en el panel izquierdo. Un icono en forma de triángulo a la izquierda del nombre del componente indica que el componente tiene uno o más componentes subordinados asignados. Haga clic en el triángulo para expandir o cerrar la porción de árbol bajo el componente. Los componentes mostrados en la interfaz gráfica se resumen así:
- Nodo de cluster — Muestra los nodos de cluster. Los nodos se representan según el nombre como elementos subordinados bajo Nodos de cluster. Al usar los botones de configuración en la parte inferior del panel derecho (bajo Propiedades), usted puede añadir nodos, borrar nodos, editar nodos y configurar métodos de aislamiento para cada nodo.
- Dispositivos de aislamiento — Muestra los dispositivos de aislamiento. Los dispositivos de aislamiento se representan como elementos subordinados bajo Dispositivos de aislamiento. Con los botones de configuración en la parte inferior del panel derecho (bajo Propiedades), usted puede añadir dispositivos de aislamiento, borrar dispositivos de aislamiento y editar las propiedades de los dispositivos de aislamiento. Los dispositivos de aislamiento deben ser definidos antes de configurar el aislamiento (con el botón ) para cada nodo.
- Recursos administrados — Muestra los dominios de recuperación en contra de fallos, los recursos y servicios.
- Dominio de recuperación — Para configurar uno o más subgrupos de nodos de cluster utilizados para ejecutar un servicio de alta disponibilidad en caso de que un nodo falle. Los dominios de recuperación contra fallos se representan como elementos subordinados bajo Dominios de recuperación. Utilizando los botones de configuración en la parte inferior del panel derecho (bajo Propiedades), usted puede crear los dominios de recuperación contra fallos (cuando Dominios de recuperación está seleccionado) o editar las propiedades de un dominio de recuperación contra fallos (si el dominio está seleccionado).
- Recursos — Para configurar los recursos compartidos para que sean usados por servicios de alta disponibilidad. Los recursos compartidos consisten en sistemas de archivos, direcciones IP, recursos compartidos NFS y scripts creados por el usuario que están disponibles a cualquier servicio de alta disponibilidad en el cluster. Los recursos se representan como elementos subordinados bajo Recursos. Con los botones ubicados en la parte inferior del panel derecho (bajo Propiedades), se pueden crear recursos (cuando Recursos está seleccionado) o editar las propiedades del recurso (cuando éste está seleccionado).
Nota
La Cluster Configuration Tool permite también configurar los recursos privados. Un recurso privado es un recurso que es configurado para ser utilizado por un solo servicio. Se puede configurar un recurso privado con el componente Servicio en la interfaz gráfica. - Servicios — Para crear y configurar servicios de alta disponibilidad. Un servicio es configurado mediante la asignación de recursos (compartidos o privados), asignación de un dominio de recuperación contra fallos y la definición de una política de recuperación para el servicio. Los servicios se representan como elementos subordinados bajo Servicios. Con los botones ubicados en la parte inferior del panel derecho (bajo Propiedades), se puede crear servicios (cuando Servicios está seleccionado) o editar las propiedades de un servicio (cuando éste está seleccionado).
1.9.2.2. Cluster Status Tool

Figura 1.28. Cluster Status Tool
/etc/cluster/cluster.conf). Puede utilizar Cluster Status Tool para activar, desactivar, reiniciar o asignar los servicios de alta disponibilidad.
1.9.3. Herramientas de administración desde la línea de comandos
system-config-cluster Cluster Administration GUI, command line tools are available for administering the cluster infrastructure and the high-availability service management components. The command line tools are used by the Cluster Administration GUI and init scripts supplied by Red Hat. Tabla 1.1, “Herramientas de la línea de comandos” summarizes the command line tools.
| Herramienta de la línea de comando | Usado con | Propósito |
|---|---|---|
ccs_tool — Herramienta de sistema de configuración de cluster | Cluster Infrastructure | ccs_tool es un programa para realizar actualizaciones en línea al archivo de configuración del cluster. Con esta herramienta se puede crear y modificar componentes de la infraestructura del cluster (por ejemplo, crear un cluster o añadir y remover un nodo). Para obtener mayor información sobre esta herramienta, consulte las páginas man de ccs_tool(8). |
cman_tool — Herramienta de administración de cluster | Cluster Infrastructure | cman_tool es un programa que maneja el administrador de cluster CMAN. Se puede utilizar para unirse o abandonar un cluster, eliminar un nodo o cambiar los votos de quórum en un nodo. Para obtener mayor información sobre esta herramienta, consulte la página de cman_tool(8). |
fence_tool — Herramienta de aislamiento | Cluster Infrastructure | fence_tool es un programa utilizado para unirse o abandonar el dominio de aislamiento predeterminado. Específicamente, este programa inicia el daemon de aislamiento (fenced) para unirse al dominio y termina fenced para dejar el dominio. Para obtener mayor información sobre esta herramienta, consulte la página man fence_tool(8). |
clustat — Utilidad de estado del cluster | Componentes de administración de servicios de alta disponibilidad | El comando clustat muestra el estado del cluster. Muestra la información de membresía, la vista del quórum y el estado de todos los servicios de usuario configurados. Para mayor información sobre esta herramienta consulte la página man clustat(8). |
clusvcadm — Utilidad de administración de servicios de usuario del cluster | Componentes de administración de servicios de alta disponibilidad | Con el comando clusvcadm se pueden activar, desactivar, asignar y reiniciar los servicios de alta disponibilidad del cluster. Para mayor información sobre esta herramienta consulte la página man clusvcadm(8). |
1.10. Interfaz gráfica de administración del servidor virtual de Linux
/etc/sysconfig/ha/lvs.cf.
piranha-gui esté en ejecución en el enrutador LVS activo. Puede acceder a la Piranha Configuration Tool de forma local o remota con un navegador de web. Se puede utilizar esta URL: http://localhost:3636 para acceder a la interfaz de forma local. Para acceder remotamente, se puede utilizar el nombre de host o la dirección IP con :3636. Si está accediendo a la Piranha Configuration Tool de forma remota, se debe utilizar una conexión ssh al enrutador LVS activo como root.
Figura 1.29. The Welcome Panel
1.10.1. CONTROL/MONITORING
nanny creados por LVS.
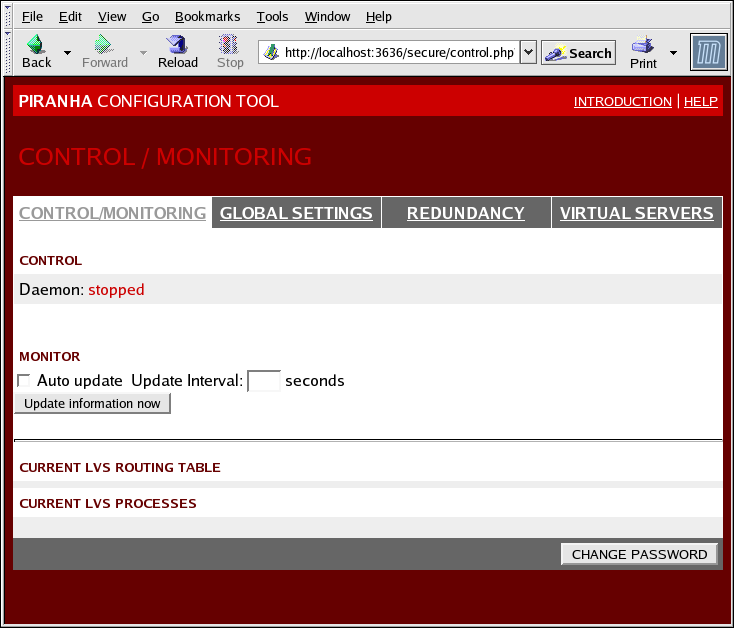
Figura 1.30. The CONTROL/MONITORING Panel
- Auto update
- Activa la visualización del estado para que sea actualizada de forma automática en intervalos de tiempo dados por el usuario en la casilla de texto Update frequency in seconds (el valor por defecto es 10 segundos).No se recomienda que el intervalo de tiempo sea menor de 10 segundos. Al hacerlo, puede llegar a ser difícil reconfigurar el intervalo Auto update porque la página se actualizará con demasiada frecuencia. Si se encuentra con este problema, simplemente haga clic en otro panel y luego regrese a CONTROL/MONITORING.
- Proporciona la actualización manual de la información de estado.
- Si se hace clic en este botón se tendrá acceso a una pantalla de ayuda con información sobre cómo cambiar la contraseña administrativa para la Piranha Configuration Tool.
1.10.2. GLOBAL SETTINGS
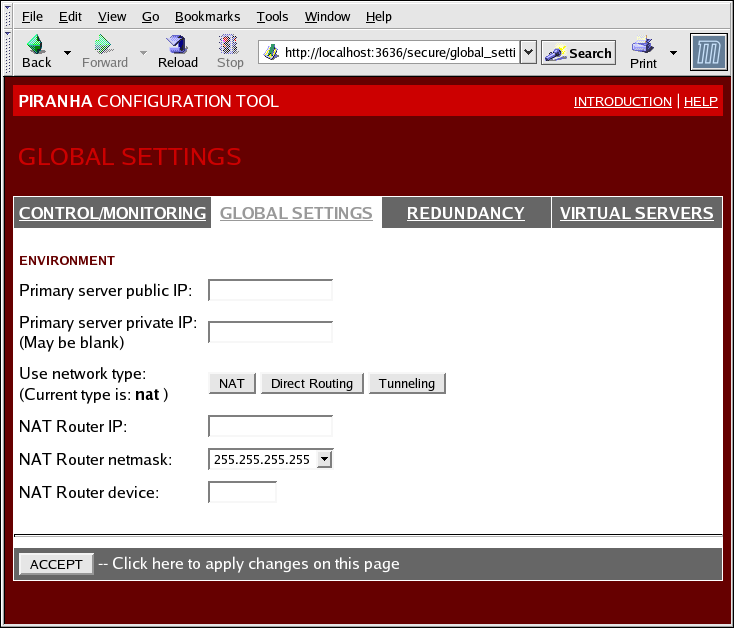
Figura 1.31. The GLOBAL SETTINGS Panel
- Primary server public IP
- La dirección IP real enrutable pública para el nodo LVS primario.
- Primary server private IP
- La dirección IP real para una interfaz de red alternativa en el nodo LVS primario. Esta dirección se utiliza únicamente como un canal alternativo de pulsos para el enrutador de respaldo.
- Use network type
- Selecciona el enrutado NAT
- NAT Router IP
- La IP flotante privada se define en este campo de texto. Esta IP flotante debe ser usada como puerta de enlace para los servidores reales.
- NAT Router netmask
- If the NAT router's floating IP needs a particular netmask, select it from drop-down list.
- NAT Router device
- Define el nombre del dispositivo de la interfaz de red para la dirección IP flotante, tal como
eth1:1.
1.10.3. REDUNDANCY
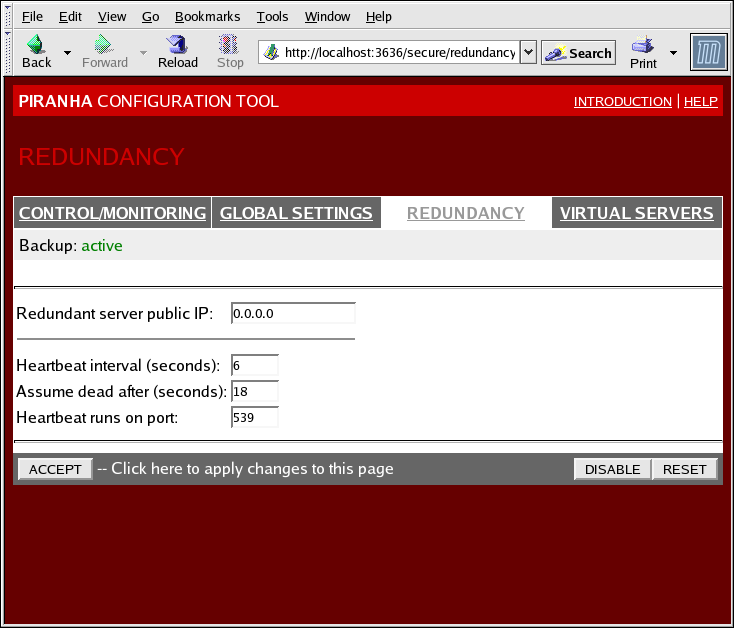
Figura 1.32. The REDUNDANCY Panel
- Redundant server public IP
- La dirección IP real pública para el enrutador LVS de respaldo.
- Redundant server private IP
- The backup router's private real IP address.
- Heartbeat Interval (seconds)
- Establece el intervalo de segundos entre pulsos — El nodo de respaldo utiliza este intervalo para revisar el estado del nodo LVS primario.
- Assume dead after (seconds)
- Si el nodo LVS primario no responde después de este intervalo de tiempo, el enrutador LVS de respaldo inicia el procedimiento de recuperación contra fallos.
- Heartbeat runs on port
- Establece el puerto utilizado para la comunicación de pulsos con el nodo LVS primario. El valor predeterminado es 539.
1.10.4. VIRTUAL SERVERS

Figura 1.33. The VIRTUAL SERVERS Panel
1.10.4.1. La subsección VIRTUAL SERVER

Figura 1.34. The VIRTUAL SERVERS Subsection
- Name
- Un nombre descriptivo para identificar el servidor virtual. Este nombre no es el nombre de host de la máquina, debe ser descriptivo y fácilmente identificable. Puede hacer referencia al protocolo usado por el servidor virtual (como por ejemplo HTTP).
- Application port
- El número de puerto a través del cual la aplicación escuchará.
- Permite elegir entre UDP y TCP.
- Virtual IP Address
- The virtual server's floating IP address.
- La máscara de red del servidor virtual en un menú desplegable.
- Firewall Mark
- Se puede introducir un valor entero de marca de cortafuego para el agrupamiento de protocolos o para crear un servidor virtual de varios puertos por separado pero con protocolos relacionados.
- Device
- El nombre del dispositivo de red en el cual desea vincular la dirección flotante definida en el campo Virtual IP Address.Se debe crear un alias de la dirección IP flotante a la interfaz de ethernet conectada a la red pública.
- Re-entry Time
- Un valor entero que define el número de segundos antes de que el enrutador LVS activo intente utilizar un servidor real después de que el servidor real falle.
- Service Timeout
- Un valor entero que define el número de segundos antes de que el servidor real sea considerado como no disponible.
- Quiesce server
- Si se selecciona el botón de radio Quiesce server, cada vez que un nuevo servidor entra en línea, la tabla de conexiones mínima se establece a cero para que el enrutador LVS activo enrute las solicitudes como si todos los servidores reales hubiesen sido recientemente añadidos. Esta opción previene que el nuevo servidor sea invadido por un alto número de conexiones tras entrar en el cluster.
- Load monitoring tool
- El enrutador LVS puede sondear la carga de los servidores reales utilizando
ruporuptime. Si seleccionarupdesde el menú desplegable, cada servidor real debe ejecutar el serviciorstatd. Si seleccionaruptime, cada servidor real debe ejecutar el serviciorwhod. - Scheduling
- Es el algoritmo de programación preferido. Por defecto es
Weighted least-connection. - Persistence
- Utilizado si se necesitan conexiones persistentes al servidor virtual durante las transacciones del cliente. En este campo de texto se deben especificar el número de segundos de inactividad antes de que la conexión expire.
- Para limitar la persistencia a una subred particular, seleccione la máscara apropiada de red desde el menú desplegable.
1.10.4.2. Subsección REAL SERVER
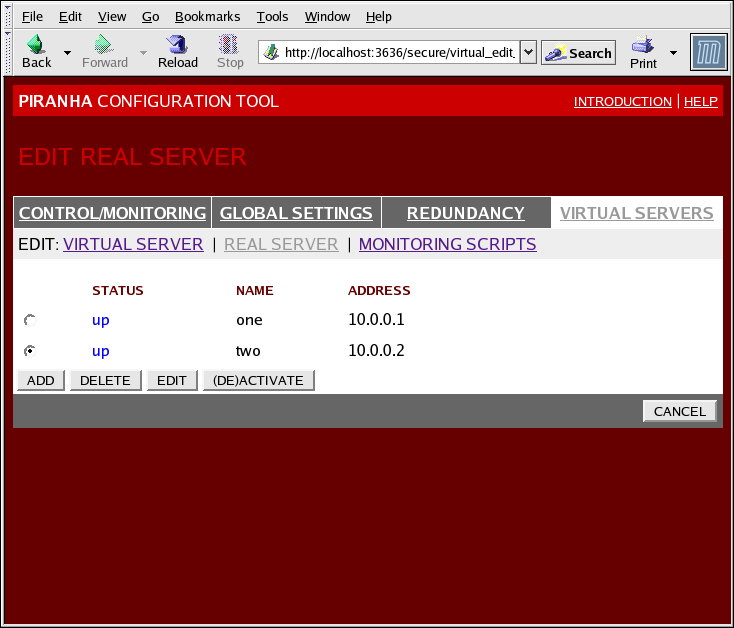
Figura 1.35. The REAL SERVER Subsection
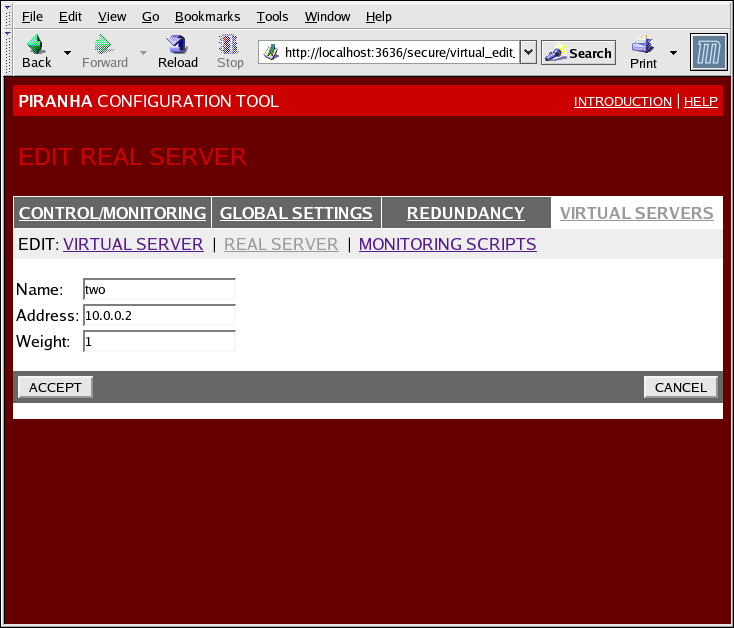
Figura 1.36. The REAL SERVER Configuration Panel
- Name
- Un nombre descriptivo para el servidor real.
Nota
Este nombre no es el nombre de host de la máquina. Utilice un nombre descriptivo y fácilmente identificable. - Address
- The real server's IP address. Since the listening port is already specified for the associated virtual server, do not add a port number.
- Weight
- An integer value indicating this host's capacity relative to that of other hosts in the pool. The value can be arbitrary, but treat it as a ratio in relation to other real servers.
1.10.4.3. EDIT MONITORING SCRIPTS Subsection

Figura 1.37. The EDIT MONITORING SCRIPTS Subsection
- Sending Program
- Se puede utilizar este campo para especificar un script para una verificación de servicios más avanzada. Esta función es especialmente útil para servicios que requieren cambios de datos de forma dinámica, como HTTPS o SSL.Para usar esta función, se debe escribir un script que retorne una respuesta textual. El script debe ser ejecutable y su ruta debe establecerse en el campo Sending Program.
Nota
Si se introduce un programa externo en el campo Sending Program, el campo Send será ignorado. - Send
- Una cadena para el daemon
nannyque será enviada a cada servidor real. Por defecto la entrada se completa para HTTP. Se puede alterar este valor dependiendo de sus necesidades. Si se deja este campo en blanco, el daemonnannyintentará abrir el puerto y, si lo logra, asumirá que el servicio está en ejecución.Solo una secuencia de envío es permitida en este campo y solo puede contener caracteres ASCII y los siguientes caracteres de escape:- \n para nueva línea.
- \r para retorno de línea.
- \t para tablatura.
- \ para escapar el siguiente caracter.
- Expect
- La respuesta textual que el servidor debe dar si está funcionando apropiadamente. Si escribió su propio programa de envío, introduzca la respuesta esperada.
Capítulo 2. Resumen de componentes de Red Hat Cluster Suite
2.1. Componentes de cluster
| Función | Componentes | Descripción |
|---|---|---|
| Conga | luci | Sistema de administración remota - estación de administración. |
ricci | Sistema de administración remota - estación administrada. | |
| Cluster Configuration Tool | system-config-cluster | Comando utilizado para administrar la configuración del cluster en un entorno gráfico. |
| Administrador de volúmenes lógicos de cluster (CLVM) | clvmd | El daemon que distribuye las actualizaciones de metadatos LVM en un cluster. Se debe ejecutar en todos los nodos del cluster. Si un nodo no está ejecutando este daemon se reportará un error. |
lvm | Herramientas LVM2. Proporciona las herramientas para la línea de comandos para LVM2. | |
system-config-lvm | Proporciona una interfaz gráfica para LVM2. | |
lvm.conf | El archivo de configuración de LVM. La ruta completa es /etc/lvm/lvm.conf. | |
| Sistema de configuración del Cluster (CCS) | ccs_tool | ccs_tool es parte del sistema de configuración del cluster (CCS). Se utiliza para hacer actualizaciones en línea de los archivos de configuración de CCS. Además puede ser utilizado para actualizar los archivos de configuración de cluster desde los archivos creados por GFS 6.0 (o anterior) al formato en XML utilizado en este lanzamiento de Red Hat Cluster Suite. |
ccs_test | Comando de diagnóstico y prueba utilizado para obtener información desde los archivos de configuración a través de ccsd. | |
ccsd | El daemon CCS que es ejecutado en todos los nodos de cluster y proporciona los datos del archivo de configuración al software de cluster. | |
cluster.conf | Este es el archivo de configuración del cluster. La ruta completa es /etc/cluster/cluster.conf. | |
| Administrador de cluster (CMAN) | cman.ko | El módulo de kernel para CMAN. |
cman_tool | Esta es la interfaz administrativa para CMAN. Inicia y detiene CMAN y puede cambiar algunos parámetros internos (por ejemplo los votos). | |
dlm_controld | Daemon iniciado por el script de inicio de cman para administrar dlm en el kernel. No utilizado por el usuario. | |
gfs_controld | Daemon iniciado por el script de inicio de cman para administrar gfs en el kernel. No utilizado por el usuario. | |
group_tool | Utilizado para obtener una lista de los grupos relacionados con el proceso de aislamiento, DLM, GFS y obtener información de depuración; incluye funcionalidades proporcionadas por cman_tool services en RHEL 4. | |
groupd | Daemon iniciado por el script de inicio de cman para servir de interfaz entre openais/cman y dlm_controld/gfs_controld/fenced. No utilizado por el usuario. | |
libcman.so.<version number> | Biblioteca para los programas que necesitan interactuar con cman.ko. | |
| Administrador de grupos de recursos (rgmanager) | clusvcadm | Comando utilizado para activar, desactivar, asignar y reiniciar manualmente los servicios de usuario en un cluster |
clustat | Comando utilizado para mostrar el estado del cluster, incluyendo la membresía de los nodos y los servicios en ejecución. | |
clurgmgrd | Daemon utilizado para manejar solicitudes a los servicios del usuario incluyendo el inicio, desactivación, asignación y reinicio de éstos. | |
clurmtabd | Daemon utilizado para manejar tablas de montaje NFS en clusters. | |
| Aislamiento | fence_apc | Agente de aislamiento para interruptores de energía APC. |
fence_bladecenter | Agente blende para IBM Bladecenters con interfaz Telnet. | |
fence_bullpap | Agente de aislamiento para la interfaz Bull Novascale Platform Administration Processor (PAP). | |
fence_drac | Agente de aislamiento para las tarjetas de acceso remoto de Dell | |
fence_ipmilan | Agente de aislamiento para máquinas controladas por IPMI (Intelligent Platform Management Interface) sobre una LAN. | |
fence_wti | Agente de aislamiento para el interruptor de energía WTI. | |
fence_brocade | Agente de aislamiento para el interruptor de canal de fibra Brocade. | |
fence_mcdata | Agente de aislamiento para el interruptor de canal de fibra McData. | |
fence_vixel | Agente de aislamiento para el interruptor de canal de fibra Vixel. | |
fence_sanbox2 | Agente de aislamiento para el interruptor de canal de fibra SANBox2. | |
fence_ilo | Agente de aislamiento para las interfaces HP ILO (anteriormente fence_rib). | |
fence_rsa | Agente de aislamiento de E/S para IBM RSA II. | |
fence_gnbd | Agente de aislamiento utilizado con almacenamiento GNDB. | |
fence_scsi | Agente de aislamiento de E/S para las reservaciones SCSI persistentes. | |
fence_egenera | Agente de aislamiento utilizado con sistemas Egenera BladeFrame. | |
fence_manual | Agente de aislamiento para interacción manual. NOTA Este componente no está soportado en entornos de producción. | |
fence_ack_manual | Interfaz de usuario para el agente fence_manual. | |
fence_node | Un programa que ejecuta procesos de aislamiento de E/S en un solo nodo. | |
fence_xvm | Agente de aislamiento de E/S para las máquinas virtuales Xen. | |
fence_xvmd | Agente anfitrión del proceso de aislamiento de E/S para máquinas virtuales Xen. | |
fence_tool | Un programa para unirse o separarse de un dominio de aislamiento. | |
fenced | El daemon de aislamiento de E/S. | |
| DLM | libdlm.so.<version number> | Biblioteca para el soporte de DLM (siglas en inglés de Distributed Lock Manager) |
| GFS | gfs.ko | Módulo del kernel que implementa el sistema de archivos GFS y se carga en los nodos de cluster GFS. |
gfs_fsck | Comando que repara un sistema de archivo GFS no montado. | |
gfs_grow | Comando que incrementa un sistema de archivo GFS montado. | |
gfs_jadd | Comando que añade el registro por diario (journal) en un sistema de archivo GFS. | |
gfs_mkfs | Comando que crea un sistema de archivos GFS en un dispositivo de almacenaje. | |
gfs_quota | Comando que administra quotas en un sistema de archivos GFS montado. | |
gfs_tool | Comando que configura o sintoniza un sistema de archivos GFS. Este comando puede también obtener información variada sobre el sistema de archivos. | |
mount.gfs | Ayudante de montaje que es llamado por mount(8); no utilizado por el usuario. | |
| GNBD | gnbd.ko | Módulo de kernel que implementa el controlador de dispositivos GNBD en clientes. |
gnbd_export | Comando para crear, exportar y administrar GNBDs en un servidor GNBD. | |
gnbd_import | Comando para importar y administrar GNBDs en un cliente GNBD. | |
gnbd_serv | Un daemon de servidor que le permite a un nodo exportar el almacenamiento local a través de la red. | |
| LVS | pulse | This is the controlling process which starts all other daemons related to LVS routers. At boot time, the daemon is started by the /etc/rc.d/init.d/pulse script. It then reads the configuration file /etc/sysconfig/ha/lvs.cf. On the active LVS router, pulse starts the LVS daemon. On the backup router, pulse determines the health of the active router by executing a simple heartbeat at a user-configurable interval. If the active LVS router fails to respond after a user-configurable interval, it initiates failover. During failover, pulse on the backup LVS router instructs the pulse daemon on the active LVS router to shut down all LVS services, starts the send_arp program to reassign the floating IP addresses to the backup LVS router's MAC address, and starts the lvs daemon. |
lvsd | El daemon lvs es ejecutado en el enrutador LVS activo una vez es llamado por pulse. Lee el archivo de configuración/etc/sysconfig/ha/lvs.cf, llama a la utilidad ipvsadm para construir y mantener la tabla de rutas IPVS y asignar un proceso nanny para cada servicio LVS configurado. Si nanny reporta que un servidor real ha sido apagado, lvs ordena a la utilidad ipvsadm remover el servidor real de la tabla de rutas IPVS. | |
ipvsadm | Este servicio actualiza la tabla de rutas IPVS en el kernel. El daemon lvs configura un administrador LVS llamando ipvsadm para añadir o borrar entradas en la tabla de rutas IPVS. | |
nanny | El daemon de sondeo nanny es ejecutado en el enrutador LVS activo. A través de este daemon, el enrutador LVS activo determina el estado de cada servidor real y,opcionalmente, sondea sus cargas de trabajo. Se ejecuta un proceso separado para cada servicio definido en cada servidor real. | |
lvs.cf | Este es el archivo de configuración LVS. La ruta completa del archivo es /etc/sysconfig/ha/lvs.cf. Directa o indirectamente, todos los daemons obtienen la información de configuración desde este archivo. | |
| Piranha Configuration Tool | Esta es la herramienta de web para monitorizar, configurar y administrar LVS. Ésta es la herramienta predeterminada para mantener el archivo de configuración LVS /etc/sysconfig/ha/lvs.cf | |
send_arp | Este programa envía señales ARP cuando la dirección IP de punto flotante cambia de un nodo a otro durante el proceso de recuperación contra fallos. | |
| Disco quórum | qdisk | Un daemon quórum basado en disco para Cluster de Linux / CMAN. |
mkqdisk | Utilidad de disco quórum de cluster | |
qdiskd | Daemon de disco quórum de cluster |
2.2. Páginas de manual (man)
- Infraestructura de cluster
- ccs_tool (8) - La herramienta para realizar actualizaciones en línea de los archivos de configuración CSS
- ccs_test (8) - La herramienta de diagnóstico para ejecutar el sistema de configuración de cluster
- ccsd (8) - El daemon usado para acceder a los archivos de configuración de cluster CCS
- ccs (7) - Sistema de configuración de cluster
- cman_tool (8) - Herramienta de administración de cluster
- cluster.conf [cluster] (5) - El archivo de configuración para los productos de cluster
- qdisk (5) - un daemon quórum basado en disco para Cluster de Linux / CMAN
- mkqdisk (8) - Utilidad de disco quórum de cluster
- qdiskd (8) - daemon de disco quórum de cluster
- fence_ack_manual (8) - programa ejecutado como operador como parte de la operación de aislamiento de E/S manual
- fence_apc (8) - agente de aislamiento de E/S para APC MasterSwitch
- fence_bladecenter (8) - agente de aislamiento de E/S para IBM Bladecenter
- fence_brocade (8) - Agente de proceso de aislamiento de E/S para interruptores Brocade FC
- fence_bullpap (8) - agente de aislamiento de E/S para la arquitectura Bull FAME controlada por una consola de administración PAP
- fence_drac (8) - agente de aislamiento para las tarjetas de acceso remoto de Dell
- fence_egenera (8) - agente de aislamiento de E/S para Egenera BladeFrame
- fence_gnbd (8) - agente de aislamiento de E/S para clusters GFS basados en GNBD
- fence_ilo (8) - agente de aislamiento de E/S para las tarjetas HP Integrated Lights Out
- fence_ipmilan (8) - agente de aislamiento de E/S para máquinas controladas por IPMI sobre LAN
- fence_manual (8) - programa ejecutado por fenced como parte de las operaciones de aislamiento de E/S manual
- fence_mcdata (8) - agente de aislamiento de E/S para los interruptores de canal de fibra McData
- fence_node (8) - un programa que ejecuta operaciones de aislamiento de E/S en un nodo único
- fence_rib (8) - agente de aislamiento de E/S para tarjetas Compaq Remote Insight Lights Out
- fence_rsa (8) - agente de aislamiento de E/S para IBM RSA II
- fence_sanbox2 (8) - agente de aislamiento de E/S para interruptores de canal de fibra QLogic SANBox2
- fence_scsi (8) - agente de aislamiento de E/S para las reservaciones SCSI persistentes
- fence_tool (8) - un programa para unirse o separarse de un dominio de aislamiento
- fence_vixel (8) - Agente de aislamiento de E/S para interruptores de canal de fibra Vixel
- fence_wti (8) - agente de aislamiento de E/S para interruptores de energía de red WTI
- fence_xvm (8) - agente de aislamiento de E/S para las máquinas virtuales Xen
- fence_xvmd (8) - agente anfitrión de aislamiento de E/S para máquinas virtuales Xen
- fenced (8) - el daemon de aislamiento de E/S
- Administración de servicios de alta disponibilidad
- clusvcadm (8) - utilidad de administración de servicios de usuario del cluster
- clustat (8) - utilidad de estado del cluster
- Clurgmgrd [clurgmgrd] (8) - daemon administrador de grupos de recursos (servicio de cluster)
- clurmtabd (8) - daemon de tabla de montaje remota NFS de cluster
- GFS
- gfs_fsck (8) - corrector del sistema de archivos GFS fuera de línea
- gfs_grow (8) - expande un sistema de archivos GFS
- gfs_jadd (8) - añade el registro por diario (journal) a un sistema de archivos GFS
- gfs_mount (8) - opciones de montaje GFS
- gfs_quota (8) - manipula las cuotas en los discos GFS
- gfs_tool (8) - interfaz para llamadas ioctl de gfs
- Administrador de volúmenes lógicos de cluster
- clvmd (8) - daemon LVM de cluster
- lvm (8) - herramientas LVM2
- lvm.conf [lvm] (5) - archivo de configuración para LVM2
- lvmchange (8) - cambia los atributos del administrador de volúmenes lógicos
- pvcreate (8) - inicializa un disco o partición para ser usado por LVM
- lvs (8) - reporta información sobre los volúmenes lógicos
- Dispositivo de bloque de red global (GNBD)
- gnbd_export (8) -la interfaz para exportar GNBDs
- gnbd_import (8) - manipula los dispositivos de bloque GNBD en un cliente
- gnbd_serv (8) - daemon de servidor gnbd
- LVS
- pulse (8) - daemon de pulsos para sondear el estado de los nodos del cluster
- lvs.cf [lvs] (5) - archivo de configuración para lvs
- lvscan (8) - explora (todos los discos) en busca de volúmenes lógicos
- lvsd (8) - daemon de control de los servicios de cluster de Red Hat
- ipvsadm (8) - administración del servidor virtual de Linux
- ipvsadm-restore (8) - restaura la tabla IPVS desde stdin
- ipvsadm-save (8) - guarda la tabla IPVS a stdout
- nanny (8) - herramienta para monitorizar el estado de los servicios en el cluster
- send_arp (8) - herramienta para notificar a la red sobre una nueva relación entre dirección IP y dirección MAC
2.3. Compatibilidad de hardware
Apéndice A. Historia de revisión
| Historial de revisiones | |||
|---|---|---|---|
| Revisión 3-7.400 | 2013-10-31 | ||
| |||
| Revisión 3-7 | 2012-07-18 | ||
| |||
| Revisión 1.0-0 | Tue Jan 20 2008 | ||
| |||
Índice
C
- cluster
- displaying status, Cluster Status Tool
- cluster administration
- displaying cluster and service status, Cluster Status Tool
- cluster component compatible hardware, Compatibilidad de hardware
- cluster component man pages, Páginas de manual (man)
- cluster components table, Componentes de cluster
- Cluster Configuration Tool
- accessing, Cluster Configuration Tool
- cluster service
- displaying status, Cluster Status Tool
- command line tools table, Herramientas de administración desde la línea de comandos
- compatible hardware
- cluster components, Compatibilidad de hardware
- Conga
- overview, Conga
- Conga overview, Conga
F
- feedback, Comentarios
I
- introduction, Introducción
- other Red Hat Enterprise Linux documents, Introducción
L
- LVS
- direct routing
- requirements, hardware, Enrutado directo
- requirements, network, Enrutado directo
- requirements, software, Enrutado directo
- routing methods
- NAT, Métodos de enrutado
- three tiered
- high-availability cluster, Three-Tier LVS Topology
M
- man pages
- cluster components, Páginas de manual (man)
N
- NAT
- routing methods, LVS, Métodos de enrutado
- network address translation (ver NAT)
O
- overview
- economy, Red Hat GFS
- performance, Red Hat GFS
- scalability, Red Hat GFS
P
- Piranha Configuration Tool
- CONTROL/MONITORING, CONTROL/MONITORING
- EDIT MONITORING SCRIPTS Subsection, EDIT MONITORING SCRIPTS Subsection
- GLOBAL SETTINGS, GLOBAL SETTINGS
- login panel, Interfaz gráfica de administración del servidor virtual de Linux
- necessary software, Interfaz gráfica de administración del servidor virtual de Linux
- REAL SERVER subsection, Subsección REAL SERVER
- REDUNDANCY, REDUNDANCY
- VIRTUAL SERVER subsection, VIRTUAL SERVERS
- Firewall Mark , La subsección VIRTUAL SERVER
- Persistence , La subsección VIRTUAL SERVER
- Scheduling , La subsección VIRTUAL SERVER
- Virtual IP Address , La subsección VIRTUAL SERVER
- VIRTUAL SERVERS, VIRTUAL SERVERS
R
- Red Hat Cluster Suite
- components, Componentes de cluster
T
- table
- cluster components, Componentes de cluster
- command line tools, Herramientas de administración desde la línea de comandos