Guía de diseño del sistema
Diseño de un sistema RHEL 8
Resumen
Hacer que el código abierto sea más inclusivo
Red Hat se compromete a sustituir el lenguaje problemático en nuestro código, documentación y propiedades web. Estamos empezando con estos cuatro términos: maestro, esclavo, lista negra y lista blanca. Debido a la enormidad de este esfuerzo, estos cambios se implementarán gradualmente a lo largo de varias versiones próximas. Para más detalles, consulte el mensaje de nuestro CTO Chris Wright.
Proporcionar comentarios sobre la documentación de Red Hat
Agradecemos su opinión sobre nuestra documentación. Por favor, díganos cómo podemos mejorarla. Para ello:
Para comentarios sencillos sobre pasajes concretos:
- Asegúrese de que está viendo la documentación en el formato Multi-page HTML. Además, asegúrese de ver el botón Feedback en la esquina superior derecha del documento.
- Utilice el cursor del ratón para resaltar la parte del texto que desea comentar.
- Haga clic en la ventana emergente Add Feedback que aparece debajo del texto resaltado.
- Siga las instrucciones mostradas.
Para enviar comentarios más complejos, cree un ticket de Bugzilla:
- Vaya al sitio web de Bugzilla.
- Como componente, utilice Documentation.
- Rellene el campo Description con su sugerencia de mejora. Incluya un enlace a la(s) parte(s) pertinente(s) de la documentación.
- Haga clic en Submit Bug.
Parte I. Diseño de la instalación
Capítulo 1. Introducción
Red Hat Enterprise Linux 8 ofrece una base estable, segura y consistente en las implementaciones de nube híbrida con las herramientas necesarias para entregar las cargas de trabajo más rápidamente con menos esfuerzo. Puede desplegarse como invitado en hipervisores y entornos de proveedores de nube compatibles, así como desplegarse en infraestructura física, para que sus aplicaciones puedan aprovechar las innovaciones de las principales plataformas de arquitectura de hardware.
1.1. Arquitecturas soportadas
Red Hat Enterprise Linux es compatible con las siguientes arquitecturas:
- Arquitecturas AMD, Intel y ARM de 64 bits
IBM Power Systems, Little Endian
- Servidores IBM Power System LC
- Servidores IBM Power System AC
- Servidores IBM Power System L
- IBM Z
1.2. Terminología de la instalación
Esta sección describe la terminología de instalación de Red Hat Enterprise Linux. Se puede utilizar diferente terminología para los mismos conceptos, dependiendo de su origen ascendente o descendente.
Anaconda: El instalador del sistema operativo utilizado en Fedora, Red Hat Enterprise Linux y sus derivados. Anaconda es un conjunto de módulos y scripts de Python con archivos adicionales como widgets Gtk (escritos en C), unidades systemd y bibliotecas dracut. Juntos, forman una herramienta que permite a los usuarios establecer los parámetros del sistema (objetivo) resultante. En este documento, el término installation program se refiere al aspecto de instalación de Anaconda.
Capítulo 2. Preparación de la instalación
Antes de comenzar a instalar Red Hat Enterprise Linux, revise las siguientes secciones para preparar su configuración para la instalación.
2.1. Pasos recomendados
La preparación de la instalación de RHEL consiste en los siguientes pasos:
Pasos
- Revise y determine el método de instalación.
- Comprueba los requisitos del sistema.
- Revise las opciones de medios de arranque de la instalación.
- Descargue la imagen ISO de instalación necesaria.
- Cree un medio de instalación de arranque.
- Preparar el origen de la instalación*
*Sólo se requiere para la imagen ISO de arranque (instalación mínima) si no se utiliza la red de distribución de contenidos (CDN) para descargar los paquetes de software necesarios.
2.2. Métodos de instalación disponibles
Puede instalar Red Hat Enterprise Linux utilizando cualquiera de los siguientes métodos:
- Instalaciones basadas en GUI
- Instalaciones basadas en imágenes del sistema o de la nube
- Instalaciones avanzadas
Este documento proporciona detalles sobre la instalación de RHEL utilizando las interfaces de usuario (GUI).
Instalaciones basadas en GUI
Existen los siguientes métodos de instalación basados en la GUI:
- Install RHEL using an ISO image from the Customer Portal: Instale Red Hat Enterprise Linux descargando el archivo de imagen Binary DVD ISO desde el Portal del Cliente. El registro se realiza una vez finalizada la instalación de la interfaz gráfica de usuario. Este método de instalación también es soportado por Kickstart.
Register and install RHEL from the Content Delivery Network: Registre su sistema, adjunte suscripciones e instale Red Hat Enterprise Linux desde la Red de Entrega de Contenido (CDN). Este método de instalación es soportado por los archivos de imagen Boot ISO y Binary DVD ISO; sin embargo, se recomienda que utilice el archivo de imagen Boot ISO ya que el origen de la instalación es por defecto CDN para el archivo de imagen Boot ISO. El registro se realiza antes de descargar e instalar los paquetes de instalación desde la CDN. Este método de instalación también es compatible con Kickstart.
ImportantePuede personalizar la instalación de RHEL para sus requisitos específicos utilizando la interfaz gráfica de usuario. Puede seleccionar opciones adicionales para requisitos específicos del entorno, por ejemplo, Conectar con Red Hat, selección de software, particionamiento, seguridad y muchos más. Para más información, consulte Capítulo 4, Personalización de la instalación.
Instalaciones basadas en imágenes del sistema o de la nube
Puede utilizar métodos de instalación basados en imágenes del sistema o de la nube sólo en entornos virtuales y de la nube.
Para realizar una instalación basada en imágenes de sistema o de nube, utilice Red Hat Image Builder. Image Builder crea imágenes de sistema personalizadas de Red Hat Enterprise Linux, incluyendo las imágenes de sistema para la implementación en la nube.
Para obtener más información sobre la instalación de RHEL mediante Image Builder, consulte el Composing a customized RHEL system image documento.
Instalaciones avanzadas
Existen los siguientes métodos avanzados de instalación:
- Perform an automated RHEL installation using Kickstart: Instalar Red Hat Enterprise Linux usando Kickstart. Kickstart es una instalación automatizada que le permite ejecutar tareas de instalación del sistema operativo sin supervisión.
- Perform a remote RHEL installation using VNC: El programa de instalación de RHEL ofrece dos modos de instalación de VNC: Directo y Conectado. Una vez establecida la conexión, los dos modos no difieren. El modo que seleccione depende de su entorno.
- Install RHEL from the network using PXE : Una instalación en red le permite instalar Red Hat Enterprise Linux en un sistema que tiene acceso a un servidor de instalación. Como mínimo, se requieren dos sistemas para una instalación en red.
Para más información sobre los métodos avanzados de instalación, consulte el Performing an advanced RHEL installation documento.
2.3. Requisitos del sistema
Si es la primera vez que instala Red Hat Enterprise Linux, se recomienda que revise las directrices proporcionadas para el sistema, el hardware, la seguridad, la memoria y el RAID antes de la instalación. Vea la referencia de los requisitos del sistema para más información.
2.4. Opciones de medios de arranque de la instalación
Hay varias opciones disponibles para arrancar el programa de instalación de Red Hat Enterprise Linux.
- DVD de instalación completa o unidad flash USB
- Cree un DVD de instalación completa o una unidad flash USB utilizando la imagen Binary DVD ISO. El DVD o la unidad flash USB pueden utilizarse como dispositivo de arranque y como fuente de instalación para instalar paquetes de software. Debido al tamaño de la imagen ISO del DVD binario, se recomienda utilizar un DVD o una unidad flash USB.
- Instalación mínima en DVD, CD o unidad flash USB
- Cree un CD, DVD o unidad flash USB de instalación mínima utilizando la imagen Boot ISO, que sólo contiene los archivos mínimos necesarios para arrancar el sistema e iniciar el programa de instalación.
Si no utiliza la red de distribución de contenidos (CDN) para descargar los paquetes de software necesarios, la imagen Boot ISO requiere una fuente de instalación que contenga los paquetes de software necesarios.
- Servidor PXE
- Un servidor preboot execution environment (PXE) permite que el programa de instalación arranque a través de la red. Después de un arranque del sistema, debe completar la instalación desde una fuente de instalación diferente, como un disco duro local o una ubicación de red.
- Constructor de imágenes
- Image Builder permite crear imágenes de sistema y de nube personalizadas para instalar Red Hat Enterprise Linux en un entorno virtual y de nube.
Recursos adicionales
- Para más información sobre los servidores PXE, consulte el Performing an advanced RHEL installation documento.
- Para más información sobre el Constructor de imágenes, consulte el Composing a customized RHEL system image documento.
2.5. Tipos de imágenes ISO de instalación
Hay dos tipos de imágenes ISO de instalación de Red Hat Enterprise Linux 8 disponibles en el Portal del Cliente de Red Hat.
- Archivo de imagen ISO de DVD binario
Un programa de instalación completo que contiene los repositorios de BaseOS y AppStream y permite completar la instalación sin repositorios adicionales.
ImportantePuede utilizar un DVD binario para IBM Z para arrancar el programa de instalación utilizando una unidad de DVD SCSI, o como fuente de instalación.
- Archivo de imagen ISO de arranque
La imagen Boot ISO es una instalación mínima que puede utilizarse para instalar RHEL de dos maneras diferentes:
- Al registrar e instalar RHEL desde la Red de Entrega de Contenidos (CDN).
- Como una imagen mínima que requiere acceso a los repositorios de BaseOS y AppStream para instalar paquetes de software. Los repositorios forman parte de la imagen ISO del DVD Binario que está disponible para su descarga en https://access.redhat.com/home. Descargue y descomprima la imagen ISO del DVD Binario para acceder a los repositorios.
La siguiente tabla contiene información sobre las imágenes disponibles para las arquitecturas soportadas.
| Arquitectura | DVD de instalación | DVD de arranque |
|---|---|---|
| AMD64 e Intel 64 | x86_64 Archivo de imagen ISO de DVD binario | archivo de imagen ISO de arranque x86_64 |
| ARM 64 | Archivo de imagen ISO de DVD binario AArch64 | Archivo de imagen ISO de arranque AArch64 |
| IBM POWER | ppc64le Archivo de imagen ISO de DVD binario | archivo de imagen ISO de arranque ppc64le |
| IBM Z | s390x Archivo de imagen ISO de DVD binario | archivo de imagen ISO de arranque s390x |
2.6. Descarga de la imagen ISO de instalación
Esta sección contiene instrucciones sobre cómo descargar una imagen de instalación de Red Hat Enterprise Linux desde el Portal del Cliente de Red Hat o mediante el comando curl.
2.6.1. Descarga de una imagen ISO desde el Portal del Cliente
Siga este procedimiento para descargar un archivo de imagen ISO de Red Hat Enterprise Linux 8 desde el Portal del Cliente de Red Hat.
- La imagen Boot ISO es un archivo de imagen mínimo que permite registrar el sistema, adjuntar suscripciones e instalar RHEL desde la red de distribución de contenidos (CDN).
- El archivo de imagen ISO del DVD binario contiene todos los repositorios y paquetes de software y no requiere ninguna configuración adicional.
Requisitos previos
- Tiene una suscripción activa a Red Hat.
- Ha iniciado la sesión en la sección Product Downloads del Portal del Cliente de Red Hat en https://access.redhat.com/downloads.
Procedimiento
- En la página Product Downloads, seleccione la pestaña By Category.
Haga clic en el enlace Red Hat Enterprise Linux 8.
Se abre la página web Download Red Hat Enterprise Linux.
En el menú desplegable Product Variant, seleccione la variante que desee.
- Opcional: Seleccione la pestaña Packages para ver los paquetes contenidos en la variante seleccionada. Para obtener información sobre los paquetes disponibles en Red Hat Enterprise Linux 8, consulte el documento Package Manifest.
- En el menú desplegable Version aparece por defecto la última versión de la variante seleccionada.
El menú desplegable Architecture muestra la arquitectura soportada.
La pestaña Product Software muestra los archivos de imagen, que incluyen:
- Red Hat Enterprise Linux Binary DVD imagen.
- Red Hat Enterprise Linux Boot ISO imagen.
Puede haber imágenes adicionales, por ejemplo, imágenes de máquinas virtuales preconfiguradas, pero están fuera del alcance de este documento.
- Haga clic en junto a la imagen ISO que necesita.
2.6.2. Descarga de una imagen ISO mediante curl
Utilice el comando curl para descargar imágenes de instalación directamente desde una URL específica.
Requisitos previos
Compruebe que el paquete curl está instalado:
Si su distribución utiliza el gestor de paquetes yum:
# yum install curlSi su distribución utiliza el gestor de paquetes dnf:
# dnf install curlSi su distribución utiliza el gestor de paquetes apt:
# apt update # apt install curl- Si su distribución de Linux no utiliza yum, dnf o apt, o si no utiliza Linux, descargue el paquete de software más apropiado del sitio web de curl.
- Ha navegado a la sección Product Downloads del Portal del Cliente de Red Hat en https://access.redhat.com/downloads, y ha seleccionado la variante, la versión y la arquitectura que necesita. Ha hecho clic con el botón derecho en el archivo de imagen ISO requerido y ha seleccionado Copy Link Location para copiar la URL del archivo de imagen ISO en su portapapeles.
Procedimiento
En la línea de comandos, introduzca un directorio adecuado y ejecute el siguiente comando para descargar el archivo:
$ curl --output directory-path/filename.iso 'copied_link_location'Sustituya directory-path por una ruta de acceso a la ubicación en la que desea guardar el archivo; sustituya filename.iso por el nombre de la imagen ISO que aparece en el Portal del Cliente; sustituya copied_link_location por el enlace que ha copiado del Portal del Cliente.
2.7. Creación de un medio de instalación de arranque
Esta sección contiene información sobre cómo utilizar el archivo de imagen ISO que descargó en Sección 2.6, “Descarga de la imagen ISO de instalación” para crear un medio de instalación físico de arranque, como un USB, un DVD o un CD.
Por defecto, la opción de arranque inst.stage2= se utiliza en el medio de instalación y se establece en una etiqueta específica, por ejemplo, inst.stage2=hd:LABEL=RHEL8\x86_64. Si se modifica la etiqueta por defecto del sistema de archivos que contiene la imagen de ejecución, o si se utiliza un procedimiento personalizado para arrancar el sistema de instalación, se debe verificar que la etiqueta está configurada con el valor correcto.
2.7.1. Creación de un DVD o CD de arranque
Puede crear un DVD o CD de instalación de arranque utilizando un software de grabación y una grabadora de CD/DVD. Los pasos exactos para producir un DVD o CD a partir de un archivo de imagen ISO varían mucho, dependiendo del sistema operativo y del software de grabación de discos instalado. Consulte la documentación del software de grabación de su sistema para conocer los pasos exactos para grabar un CD o DVD a partir de un archivo de imagen ISO.
Puedes crear un DVD o CD de arranque utilizando la imagen ISO de DVD binario (instalación completa) o la imagen ISO de arranque (instalación mínima). Sin embargo, la imagen ISO del DVD binario tiene un tamaño superior a 4,7 GB, por lo que es posible que no quepa en un DVD de una o dos capas. Compruebe el tamaño del archivo de imagen ISO de DVD binario antes de continuar. Se recomienda utilizar una llave USB cuando se utiliza la imagen ISO de DVD binario para crear medios de instalación de arranque.
2.7.2. Creación de un dispositivo USB de arranque en Linux
Siga este procedimiento para crear un dispositivo USB de arranque en un sistema Linux.
Este procedimiento es destructivo y los datos de la memoria USB se destruyen sin previo aviso.
Requisitos previos
- Ha descargado una imagen ISO de instalación como se describe en Sección 2.6, “Descarga de la imagen ISO de instalación”.
- La imagen ISO de Binary DVD tiene un tamaño superior a 4,7 GB, por lo que se necesita una unidad flash USB lo suficientemente grande como para contener la imagen ISO.
Procedimiento
- Conecte la unidad flash USB al sistema.
Abra una ventana de terminal y ejecute el comando
dmesg:$ dmesg|tailEl comando
dmesgdevuelve un registro que detalla todos los eventos recientes. Los mensajes resultantes de la unidad flash USB conectada se muestran en la parte inferior del registro. Registre el nombre del dispositivo conectado.Cambia a usuario root:
$ su -- Introduzca su contraseña de root cuando se le solicite.
Busque el nodo de dispositivo asignado a la unidad. En este ejemplo, el nombre de la unidad es
sdd.# dmesg|tail [288954.686557] usb 2-1.8: New USB device strings: Mfr=0, Product=1, SerialNumber=2 [288954.686559] usb 2-1.8: Product: USB Storage [288954.686562] usb 2-1.8: SerialNumber: 000000009225 [288954.712590] usb-storage 2-1.8:1.0: USB Mass Storage device detected [288954.712687] scsi host6: usb-storage 2-1.8:1.0 [288954.712809] usbcore: registered new interface driver usb-storage [288954.716682] usbcore: registered new interface driver uas [288955.717140] scsi 6:0:0:0: Direct-Access Generic STORAGE DEVICE 9228 PQ: 0 ANSI: 0 [288955.717745] sd 6:0:0:0: Attached scsi generic sg4 type 0 [288961.876382] sd 6:0:0:0: sdd Attached SCSI removable diskEjecute el comando
ddpara escribir la imagen ISO directamente en el dispositivo USB.# dd if=/directorio_de_imágenes/imagen.iso of=/dev/dispositivoSustituya /image_directory/image.iso por la ruta completa del archivo de imagen ISO que ha descargado, y sustituya device por el nombre del dispositivo que ha recuperado con el comando
dmesg. En este ejemplo, la ruta completa a la imagen ISO es/home/testuser/Downloads/rhel-8-x86_64-boot.iso, y el nombre del dispositivo essdd:# dd if=/home/testuser/Downloads/rhel-8-x86_64-boot.iso of=/dev/sddNotaAsegúrese de utilizar el nombre correcto del dispositivo, y no el nombre de una partición en el dispositivo. Los nombres de las particiones suelen ser nombres de dispositivos con un sufijo numérico. Por ejemplo,
sddes un nombre de dispositivo, ysdd1es el nombre de una partición en el dispositivosdd.-
Espere a que el comando
ddtermine de escribir la imagen en el dispositivo. La transferencia de datos se habrá completado cuando aparezca el mensaje #. Cuando aparezca el indicador, cierre la sesión de la cuenta raíz y desconecte la unidad USB. La unidad USB ya está lista para ser utilizada como dispositivo de arranque.
2.7.3. Creación de un dispositivo USB de arranque en Windows
Siga los pasos de este procedimiento para crear un dispositivo USB de arranque en un sistema Windows. El procedimiento varía dependiendo de la herramienta. Red Hat recomienda utilizar Fedora Media Writer, disponible para su descarga en https://github.com/FedoraQt/MediaWriter/releases.
- Fedora Media Writer es un producto de la comunidad y no está soportado por Red Hat. Puede informar de cualquier problema con la herramienta en https://github.com/FedoraQt/MediaWriter/issues.
- Este procedimiento es destructivo y los datos de la memoria USB se destruyen sin previo aviso.
Requisitos previos
- Ha descargado una imagen ISO de instalación como se describe en Sección 2.6, “Descarga de la imagen ISO de instalación”.
- La imagen ISO de Binary DVD tiene un tamaño superior a 4,7 GB, por lo que se necesita una unidad flash USB lo suficientemente grande como para contener la imagen ISO.
Procedimiento
Descargue e instale Fedora Media Writer desde https://github.com/FedoraQt/MediaWriter/releases.
NotaPara instalar Fedora Media Writer en Red Hat Enterprise Linux, utilice el paquete Flatpak pre-construido. Puede obtener el paquete desde el repositorio oficial de Flatpak Flathub.org en https://flathub.org/apps/details/org.fedoraproject.MediaWriter.
- Conecte la unidad flash USB al sistema.
- Abrir Fedora Media Writer.
- En la ventana principal, haga clic en y seleccione la imagen ISO de Red Hat Enterprise Linux previamente descargada.
- En la ventana Write Custom Image, seleccione la unidad que desea utilizar.
- Haga clic en . Se inicia el proceso de creación del medio de arranque. No desconecte la unidad hasta que se complete la operación. La operación puede tardar varios minutos, dependiendo del tamaño de la imagen ISO y de la velocidad de escritura de la unidad USB.
- Cuando la operación se complete, desmonte la unidad USB. La unidad USB ya está lista para ser utilizada como dispositivo de arranque.
2.7.4. Creación de un dispositivo USB de arranque en Mac OS X
Siga los pasos de este procedimiento para crear un dispositivo USB de arranque en un sistema Mac OS X.
Este procedimiento es destructivo y los datos de la memoria USB se destruyen sin previo aviso.
Requisitos previos
- Ha descargado una imagen ISO de instalación como se describe en Sección 2.6, “Descarga de la imagen ISO de instalación”.
- La imagen ISO de Binary DVD tiene un tamaño superior a 4,7 GB, por lo que se necesita una unidad flash USB lo suficientemente grande como para contener la imagen ISO.
Procedimiento
- Conecte la unidad flash USB al sistema.
Identifique la ruta del dispositivo con el comando
diskutil list. La ruta del dispositivo tiene el formato de /dev/disknumber, donde número es el número del disco. Los discos se numeran empezando por el cero (0). Normalmente, el disco 0 es el disco de recuperación de OS X, y el disco 1 es la instalación principal de OS X. En el siguiente ejemplo, el dispositivo USB esdisk2:$ diskutil list /dev/disk0 #: TYPE NAME SIZE IDENTIFIER 0: GUID_partition_scheme *500.3 GB disk0 1: EFI EFI 209.7 MB disk0s1 2: Apple_CoreStorage 400.0 GB disk0s2 3: Apple_Boot Recovery HD 650.0 MB disk0s3 4: Apple_CoreStorage 98.8 GB disk0s4 5: Apple_Boot Recovery HD 650.0 MB disk0s5 /dev/disk1 #: TYPE NAME SIZE IDENTIFIER 0: Apple_HFS YosemiteHD *399.6 GB disk1 Logical Volume on disk0s1 8A142795-8036-48DF-9FC5-84506DFBB7B2 Unlocked Encrypted /dev/disk2 #: TYPE NAME SIZE IDENTIFIER 0: FDisk_partition_scheme *8.1 GB disk2 1: Windows_NTFS SanDisk USB 8.1 GB disk2s1- Para identificar su unidad flash USB, compare las columnas NOMBRE, TIPO y TAMAÑO con su unidad flash. Por ejemplo, el NOMBRE debería ser el título del icono de la unidad flash en la herramienta Finder. También puede comparar estos valores con los del panel de información de la unidad flash.
Utilice el comando
diskutil unmountDiskpara desmontar los volúmenes del sistema de archivos de la unidad flash:$ diskutil unmountDisk /dev/disknumber Unmount of all volumes on disknumber was successfulCuando el comando se completa, el icono de la unidad flash desaparece del escritorio. Si el icono no desaparece, es posible que haya seleccionado el disco equivocado. Al intentar desmontar el disco del sistema accidentalmente se produce un error en failed to unmount.
Inicie sesión como root:
$ su -- Introduzca su contraseña de root cuando se le solicite.
Utilice el comando
ddcomo parámetro del comando sudo para escribir la imagen ISO en la unidad flash:# sudo dd if=/ruta/imagen.iso of=/dev/rdisknumberNotaMac OS X proporciona tanto un archivo de bloque (/dev/disk*) como un dispositivo de caracteres (/dev/rdisk*) para cada dispositivo de almacenamiento. Escribir una imagen en el dispositivo de caracteres /dev/rdisknumber es más rápido que escribir en el dispositivo de bloques /dev/disknumber.
Para escribir el archivo /Users/user_name/Downloads/rhel-8-x86_64-boot.iso en el dispositivo /dev/rdisk2, ejecute el siguiente comando:
# sudo dd if=/nombre_de_usuario/Descargas/rhel-8-x86_64-boot.iso of=/dev/rdisk2-
Espere a que el comando
ddtermine de escribir la imagen en el dispositivo. La transferencia de datos se habrá completado cuando aparezca el mensaje #. Cuando aparezca el indicador, cierre la sesión de la cuenta raíz y desconecte la unidad USB. La unidad USB ya está lista para ser utilizada como dispositivo de arranque.
2.8. Preparación de una fuente de instalación
El archivo de imagen Boot ISO no incluye ningún repositorio o paquete de software; sólo contiene el programa de instalación y las herramientas necesarias para arrancar el sistema e iniciar la instalación. Esta sección contiene información sobre cómo crear un origen de instalación para la imagen ISO de arranque utilizando la imagen ISO de DVD binario que contiene los repositorios y paquetes de software necesarios.
Se requiere una fuente de instalación para el archivo de imagen ISO de arranque sólo si decide no registrar e instalar RHEL desde la Red de Entrega de Contenido (CDN).
2.8.1. Tipos de fuente de instalación
Puede utilizar una de las siguientes fuentes de instalación para las imágenes de arranque mínimo:
- DVD: Grabe la imagen ISO del DVD binario en un DVD. El programa de instalación instalará automáticamente los paquetes de software desde el DVD.
Hard drive or USB drive: Copie la imagen ISO del DVD binario en la unidad y configure el programa de instalación para instalar los paquetes de software desde la unidad. Si utiliza una unidad USB, compruebe que está conectada al sistema antes de comenzar la instalación. El programa de instalación no puede detectar el soporte una vez iniciada la instalación.
-
Hard drive limitation: La imagen ISO del DVD binario en el disco duro debe estar en una partición con un sistema de archivos que el programa de instalación pueda montar. Los sistemas de archivos compatibles son
xfs,ext2,ext3,ext4yvfat (FAT32).
AvisoEn los sistemas Microsoft Windows, el sistema de archivos por defecto utilizado al formatear los discos duros es NTFS. También está disponible el sistema de archivos exFAT. Sin embargo, ninguno de estos sistemas de archivos puede montarse durante la instalación. Si está creando un disco duro o una unidad USB como fuente de instalación en Microsoft Windows, compruebe que ha formateado la unidad como FAT32. Tenga en cuenta que el sistema de archivos FAT32 no puede almacenar archivos de más de 4 GiB.
En Red Hat Enterprise Linux 8, puede habilitar la instalación desde un directorio en un disco duro local. Para hacerlo, necesita copiar el contenido de la imagen ISO del DVD a un directorio en un disco duro y luego especificar el directorio como la fuente de instalación en lugar de la imagen ISO. Por ejemplo
inst.repo=hd:<device>:<path to the directory>-
Hard drive limitation: La imagen ISO del DVD binario en el disco duro debe estar en una partición con un sistema de archivos que el programa de instalación pueda montar. Los sistemas de archivos compatibles son
Network location: Copie la imagen ISO del DVD binario o el árbol de instalación (contenido extraído de la imagen ISO del DVD binario) en una ubicación de red y realice la instalación a través de la red utilizando los siguientes protocolos:
- NFS: La imagen ISO del DVD binario está en un recurso compartido del sistema de archivos de red (NFS).
- HTTPS, HTTP or FTP: El árbol de instalación está en una ubicación de red que es accesible a través de HTTP, HTTPS o FTP.
2.8.2. Especifique el origen de la instalación
Puede especificar el origen de la instalación utilizando cualquiera de los siguientes métodos:
- Graphical installation: Seleccione el origen de la instalación en la ventana Installation Source de la instalación gráfica.
- Boot option: Configure una opción de arranque personalizada para especificar el origen de la instalación.
- Kickstart file: Utilice el comando install en un archivo Kickstart para especificar el origen de la instalación. Consulte el documento Performing an advanced RHEL installation para más información.
2.8.3. Puertos para la instalación en red
La siguiente tabla enumera los puertos que deben estar abiertos en el servidor que proporciona los archivos para cada tipo de instalación basada en la red.
| Protocolo utilizado | Puertos a abrir |
|---|---|
| HTTP | 80 |
| HTTPS | 443 |
| FTP | 21 |
| NFS | 2049, 111, 20048 |
| TFTP | 69 |
Recursos adicionales
- Consulte el Securing networks documento para más información.
2.8.4. Creación de un origen de instalación en un servidor NFS
Siga los pasos de este procedimiento para colocar el origen de la instalación en un servidor NFS. Utilice este método de instalación para instalar varios sistemas desde un único origen, sin tener que conectarse a medios físicos.
Requisitos previos
- Usted tiene acceso de nivel de administrador a un servidor con Red Hat Enterprise Linux 8, y este servidor está en la misma red que el sistema a ser instalado.
- Ha descargado una imagen binaria de DVD. Consulte Descarga de la imagen ISO de instalación en el documento Performing a standard RHEL installation para obtener más información.
- Ha creado un CD, DVD o dispositivo USB de arranque a partir del archivo de imagen. Consulte Creación de medios de instalación desde el documento Performing a standard RHEL installation para obtener más información.
- Ha verificado que su cortafuegos permite que el sistema que está instalando acceda al origen de la instalación remota. Consulte Puertos para la instalación basada en la red del documento Performing a standard RHEL installation para obtener más información.
Procedimiento
Instale el paquete
nfs-utils:# yum install nfs-utils- Copie la imagen ISO del DVD binario en un directorio del servidor NFS.
Abra el archivo
/etc/exportscon un editor de texto y añada una línea con la siguiente sintaxis:/exported_directory/ clientsSustituya /exported_directory/ por la ruta completa del directorio con la imagen ISO. Sustituya clients por el nombre de host o la dirección IP del sistema de destino, la subred que todos los sistemas de destino pueden utilizar para acceder a la imagen ISO, o el signo de asterisco (
*) si desea permitir que cualquier sistema con acceso de red al servidor NFS utilice la imagen ISO. Consulte la página de manualexports(5)para obtener información detallada sobre el formato de este campo.Una configuración básica que hace que el directorio
/rhel8-install/esté disponible como de sólo lectura para todos los clientes es:/rhel8-install *-
Guarde el archivo
/etc/exportsy salga del editor de texto. Inicie el servicio nfs:
# systemctl start nfs-server.serviceSi el servicio se estaba ejecutando antes de cambiar el archivo
/etc/exports, ejecute el siguiente comando para el servidor NFS en ejecución para recargar su configuración:# systemctl reload nfs-server.serviceLa imagen ISO es ahora accesible a través de NFS y está lista para ser utilizada como fuente de instalación.
Cuando configure el origen de la instalación, utilice nfs: como protocolo, el nombre del servidor o la dirección IP, el signo de dos puntos (:), y el directorio que contiene la imagen ISO. Por ejemplo, si el nombre del servidor es myserver.example.com y ha guardado la imagen ISO en /rhel8-install/, especifique nfs:myserver.example.com:/rhel8-install/ como origen de la instalación.
2.8.5. Creación de un origen de instalación mediante HTTP o HTTPS
Siga los pasos de este procedimiento para crear un origen de instalación para una instalación basada en red utilizando un árbol de instalación, que es un directorio que contiene el contenido extraído de la imagen ISO del DVD binario y un archivo válido .treeinfo. Se accede al origen de instalación a través de HTTP o HTTPS.
Requisitos previos
- Usted tiene acceso de nivel de administrador a un servidor con Red Hat Enterprise Linux 8, y este servidor está en la misma red que el sistema a ser instalado.
- Ha descargado una imagen binaria de DVD. Consulte Descarga de la imagen ISO de instalación en el documento Performing a standard RHEL installation para obtener más información.
- Ha creado un CD, DVD o dispositivo USB de arranque a partir del archivo de imagen. Consulte Creación de medios de instalación desde el documento Performing a standard RHEL installation para obtener más información.
- Ha verificado que su cortafuegos permite que el sistema que está instalando acceda al origen de la instalación remota. Consulte Puertos para la instalación basada en la red del documento Performing a standard RHEL installation para obtener más información.
Procedimiento
Instale el paquete
httpd:# yum install httpdAvisoSi la configuración de su servidor web Apache habilita la seguridad SSL, verifique que habilita solo el protocolo TLSv1 y deshabilita SSLv2 y SSLv3. Esto se debe a la vulnerabilidad POODLE SSL (CVE-2014-3566). Consulte https://access.redhat.com/solutions/1232413 para obtener más detalles.
ImportanteSi utiliza un servidor HTTPS con un certificado autofirmado, debe arrancar el programa de instalación con la opción
noverifyssl.- Copie la imagen ISO del DVD binario en el servidor HTTP(S).
Monte la imagen ISO del DVD binario, utilizando el comando
mount, en un directorio adecuado:# mkdir /mnt/rhel8-install/ # mount -o loop,ro -t iso9660 /image_directory/image.iso /mnt/rhel8-install/Sustituya /image_directory/image.iso por la ruta de acceso a la imagen ISO del DVD binario.
Copiar los archivos de la imagen montada a la raíz del servidor HTTP(S). Este comando crea el directorio
/var/www/html/rhel8-install/con el contenido de la imagen.# cp -r /mnt/rhel8-install/ /var/www/html/Este comando crea el directorio
/var/www/html/rhel8-install/con el contenido de la imagen. Tenga en cuenta que algunos métodos de copia pueden omitir el archivo.treeinfo, que es necesario para un origen de instalación válido. Si se ejecuta el comandocppara directorios enteros como se muestra en este procedimiento, se copiará.treeinfocorrectamente.Inicie el servicio
httpd:# systemctl start httpd.serviceEl árbol de instalación está ahora accesible y listo para ser utilizado como fuente de instalación.
NotaCuando configure el origen de la instalación, utilice
http://ohttps://como protocolo, el nombre de host del servidor o la dirección IP, y el directorio que contiene los archivos de la imagen ISO, en relación con la raíz del servidor HTTP. Por ejemplo, si utiliza HTTP, el nombre del servidor esmyserver.example.comy ha copiado los archivos de la imagen en/var/www/html/rhel8-install/, especifiquehttp://myserver.example.com/rhel8-install/como origen de la instalación.
Recursos adicionales
- Para más información sobre los servidores HTTP, consulte el documento Deploying different types of servers documento.
2.8.6. Creación de un origen de instalación mediante FTP
Siga los pasos de este procedimiento para crear un origen de instalación para una instalación basada en red utilizando un árbol de instalación, que es un directorio que contiene el contenido extraído de la imagen ISO del DVD binario y un archivo válido .treeinfo. Se accede al origen de la instalación a través de FTP.
Requisitos previos
- Usted tiene acceso de nivel de administrador a un servidor con Red Hat Enterprise Linux 8, y este servidor está en la misma red que el sistema a ser instalado.
- Ha descargado una imagen binaria de DVD. Consulte Descarga de la imagen ISO de instalación en el documento Performing a standard RHEL installation para obtener más información.
- Ha creado un CD, DVD o dispositivo USB de arranque a partir del archivo de imagen. Consulte Creación de medios de instalación desde el documento Performing a standard RHEL installation para obtener más información.
- Ha verificado que su cortafuegos permite que el sistema que está instalando acceda al origen de la instalación remota. Consulte Puertos para la instalación basada en la red del documento Performing a standard RHEL installation para obtener más información.
Procedimiento
Instale el paquete
vsftpdejecutando el siguiente comando como root:# yum install vsftpdAbra y edite el archivo de configuración
/etc/vsftpd/vsftpd.confen un editor de texto.-
Cambie la línea
anonymous_enable=NOporanonymous_enable=YES -
Cambie la línea
write_enable=YESporwrite_enable=NO. Añadir líneas
pasv_min_port=min_portypasv_max_port=max_port. Sustituya min_port y max_port por el rango de números de puerto utilizado por el servidor FTP en modo pasivo, por ejemplo10021y10031.Este paso puede ser necesario en entornos de red con varias configuraciones de firewall/NAT.
Opcionalmente, añada cambios personalizados a su configuración. Para conocer las opciones disponibles, consulte la página de manual vsftpd.conf(5). Este procedimiento asume que se utilizan las opciones por defecto.
AvisoSi ha configurado la seguridad SSL/TLS en su archivo
vsftpd.conf, asegúrese de habilitar sólo el protocolo TLSv1 y de desactivar SSLv2 y SSLv3. Esto se debe a la vulnerabilidad POODLE SSL (CVE-2014-3566). Consulte https://access.redhat.com/solutions/1234773 para obtener más detalles.
-
Cambie la línea
Configurar el cortafuegos del servidor.
Activa el cortafuegos:
# systemctl enable firewalld # systemctl start firewalldHabilite en su firewall el puerto FTP y el rango de puertos del paso anterior:
# firewall-cmd --add-port min_port-max_port/tcp --permanent # firewall-cmd --add-service ftp --permanent # firewall-cmd --reloadSustituya min_port-max_port por los números de puerto que introdujo en el archivo de configuración
/etc/vsftpd/vsftpd.conf.
- Copie la imagen ISO del DVD binario en el servidor FTP.
Monte la imagen ISO del DVD binario, utilizando el comando mount, en un directorio adecuado:
# mkdir /mnt/rhel8-install # mount -o loop,ro -t iso9660 /image-directory/image.iso /mnt/rhel8-installSustituya /image-directory/image.iso por la ruta de acceso a la imagen ISO del DVD binario.
Copie los archivos de la imagen montada a la raíz del servidor FTP:
# mkdir /var/ftp/rhel8-install # cp -r /mnt/rhel8-install/ /var/ftp/Este comando crea el directorio
/var/ftp/rhel8-install/con el contenido de la imagen. Tenga en cuenta que algunos métodos de copia pueden omitir el archivo.treeinfo, que es necesario para un origen de instalación válido. Si se ejecuta el comandocppara directorios enteros como se muestra en este procedimiento, se copiará.treeinfocorrectamente.Asegúrese de que el contexto SELinux y el modo de acceso correctos están establecidos en el contenido copiado:
# restorecon -r /var/ftp/rhel8-install # find /var/ftp/rhel8-install -type f -exec chmod 444 {} \; # find /var/ftp/rhel8-install -type d -exec chmod 755 {} \;Inicie el servicio
vsftpd:# systemctl start vsftpd.serviceSi el servicio estaba en marcha antes de cambiar el archivo
/etc/vsftpd/vsftpd.conf, reinicie el servicio para cargar el archivo editado:# systemctl restart vsftpd.serviceHabilite el servicio
vsftpdpara que se inicie durante el proceso de arranque:# systemctl enable vsftpdEl árbol de instalación está ahora accesible y listo para ser utilizado como fuente de instalación.
NotaCuando configure el origen de la instalación, utilice
ftp://como protocolo, el nombre del servidor o la dirección IP y el directorio en el que ha almacenado los archivos de la imagen ISO, en relación con la raíz del servidor FTP. Por ejemplo, si el nombre del servidor esmyserver.example.comy ha copiado los archivos de la imagen en/var/ftp/rhel8-install/, especifiqueftp://myserver.example.com/rhel8-install/como origen de la instalación.
Capítulo 3. Cómo empezar
Para comenzar con la instalación, primero revise el menú de arranque y las opciones de arranque disponibles. A continuación, en función de la elección que haga, proceda a arrancar la instalación.
3.1. Arranque de la instalación
Una vez que haya creado los medios de arranque, estará listo para arrancar la instalación de Red Hat Enterprise Linux.
3.1.1. Menú de arranque
El menú de arranque de Red Hat Enterprise Linux se muestra usando GRand Unified Bootloader version 2 (GRUB2) cuando su sistema ha completado la carga del medio de arranque.
Figura 3.1. Menú de arranque de Red Hat Enterprise Linux

El menú de arranque ofrece varias opciones además de lanzar el programa de instalación. Si no realiza una selección en 60 segundos, se ejecutará la opción de arranque por defecto (resaltada en blanco). Para seleccionar una opción diferente, utilice las teclas de flecha del teclado para hacer su selección y pulse la tecla Enter.
Puede personalizar las opciones de arranque para una entrada de menú concreta:
-
On BIOS-based systems: Pulse la tecla Tab y añada opciones de arranque personalizadas a la línea de comandos. También puede acceder al prompt
boot:presionando la tecla Esc pero no se preestablecen las opciones de arranque requeridas. En este escenario, siempre debe especificar la opción Linux antes de utilizar cualquier otra opción de arranque. - On UEFI-based systems: Pulse la tecla e y añada opciones de arranque personalizadas a la línea de comandos. Cuando esté listo pulse Ctrl X para arrancar la opción modificada.
| Opción de menú de arranque | Descripción |
|---|---|
| Install Red Hat Enterprise Linux 8.x | Utilice esta opción para instalar Red Hat Enterprise Linux utilizando el programa de instalación gráfica. Para más información, consulte Sección 3.2, “Instalación de RHEL mediante una imagen ISO desde el Portal del Cliente” |
| Test this media & install Red Hat Enterprise Linux 8.x | Utilice esta opción para comprobar la integridad de los medios de instalación. Para más información, consulte Sección A.1.4, “Verificación de los medios de arranque” |
| Troubleshooting > | Utilice esta opción para resolver diversos problemas de instalación. Pulse Intro para mostrar su contenido. |
| Opción de solución de problemas | Descripción |
|---|---|
| Troubleshooting > Install Red Hat Enterprise Linux 8.x in basic graphics mode | Utilice esta opción para instalar Red Hat Enterprise Linux en modo gráfico incluso si el programa de instalación no puede cargar el controlador correcto para su tarjeta de vídeo. Si su pantalla está distorsionada cuando utiliza la opción Instalar Red Hat Enterprise Linux 8.x, reinicie su sistema y utilice esta opción. Para más información, consulte Sección A.1.8, “No se puede arrancar en la instalación gráfica” |
| Troubleshooting > Rescue a Red Hat Enterprise Linux system | Utilice esta opción para reparar cualquier problema que le impida arrancar. Para más información, consulte Sección A.3.8, “Uso del modo de rescate” |
| Troubleshooting > Run a memory test | Utilice esta opción para ejecutar una prueba de memoria en su sistema. Pulse Intro para mostrar su contenido. Para más información, consulte Sección A.1.3, “Detección de fallos de memoria mediante la aplicación Memtest86” |
| Troubleshooting > Boot from local drive | Utilice esta opción para arrancar el sistema desde el primer disco instalado. Si arrancó este disco accidentalmente, utilice esta opción para arrancar desde el disco duro inmediatamente sin iniciar el programa de instalación. |
3.1.2. Tipos de opciones de arranque
Hay dos tipos de opciones de arranque: las que tienen el signo igual \ "=", y las que no tienen el signo igual \ "=". Las opciones de arranque se añaden a la línea de comandos de arranque y las opciones múltiples deben estar separadas por un solo espacio. Las opciones de arranque que son específicas del programa de instalación siempre comienzan con inst.
- Opciones con un signo de igualdad \ "="
-
Debe especificar un valor para las opciones de arranque que utilizan el símbolo
=. Por ejemplo, la opcióninst.vncpassword=debe contener un valor, en este caso, una contraseña. La sintaxis correcta para este ejemplo esinst.vncpassword=password. - Opciones sin signo de igualdad "="
-
Esta opción de arranque no acepta ningún valor o parámetro. Por ejemplo, la opción
rd.live.checkobliga al programa de instalación a verificar el medio de instalación antes de iniciar la instalación. Si esta opción de arranque está presente, se realiza la verificación; si la opción de arranque no está presente, se omite la verificación.
3.1.3. Edición de las opciones de arranque
Esta sección contiene información sobre las diferentes formas en que puede editar las opciones de arranque desde el menú de arranque. El menú de arranque se abre después de arrancar el medio de instalación.
Editar el indicador boot: en la BIOS
Cuando se utiliza el indicador boot:, la primera opción debe especificar siempre el archivo de imagen del programa de instalación que se desea cargar. En la mayoría de los casos, puede especificar la imagen utilizando la palabra clave. Puede especificar opciones adicionales según sus necesidades.
Requisitos previos
- Has creado un medio de instalación de arranque (USB, CD o DVD).
- Ha arrancado la instalación desde el medio, y el menú de arranque de la instalación está abierto.
Procedimiento
- Con el menú de arranque abierto, pulse la tecla Esc de su teclado.
-
Ahora se puede acceder a la página
boot:. - Pulse la tecla Tab del teclado para mostrar los comandos de ayuda.
-
Pulse la tecla Enter de su teclado para iniciar la instalación con sus opciones. Para volver de la indicación
boot:al menú de arranque, reinicie el sistema y vuelva a arrancar desde el medio de instalación.
El prompt boot: también acepta las opciones del kernel dracut. Una lista de opciones está disponible en la página man de dracut.cmdline(7).
Editar la indicación >
Puede utilizar el indicador > para editar las opciones de arranque predefinidas. Por ejemplo, seleccione Test this media and install Red Hat Enterprise Linux 8.1 en el menú de arranque para mostrar un conjunto completo de opciones.
Este procedimiento es para sistemas AMD64 e Intel 64 basados en BIOS.
Requisitos previos
- Has creado un medio de instalación de arranque (USB, CD o DVD).
- Ha arrancado la instalación desde el medio, y el menú de arranque de la instalación está abierto.
Procedimiento
-
En el menú de arranque, seleccione una opción y pulse la tecla Tab del teclado. El prompt
>es accesible y muestra las opciones disponibles. -
Añada las opciones que necesite a la consulta
>. - Pulse la tecla Enter de su teclado para iniciar la instalación.
- Pulse la tecla Esc de su teclado para cancelar la edición y volver al menú de arranque.
Editar el menú de GRUB2
El menú GRUB2 está disponible en sistemas AMD64, Intel 64 y ARM de 64 bits basados en UEFI.
Requisitos previos
- Has creado un medio de instalación de arranque (USB, CD o DVD).
- Ha arrancado la instalación desde el medio, y el menú de arranque de la instalación está abierto.
Procedimiento
- En la ventana del menú de arranque, seleccione la opción deseada y pulse la tecla e de su teclado.
-
Mueva el cursor a la línea de comandos del kernel. En los sistemas UEFI, la línea de comandos del kernel comienza con
linuxefi. -
Mueve el cursor al final de la línea de comandos del kernel
linuxefi. -
Edite los parámetros según sea necesario. Por ejemplo, para configurar una o más interfaces de red, añada el parámetro
ip=al final de la línea de comandos del kernellinuxefi, seguido del valor requerido. - Cuando termine de editar, pulse Ctrl X en su teclado para iniciar la instalación con las opciones especificadas.
3.1.4. Arranque de la instalación desde un USB, CD o DVD
Siga los pasos de este procedimiento para arrancar la instalación de Red Hat Enterprise Linux utilizando un USB, CD o DVD. Los pasos siguientes son genéricos. Consulte la documentación del fabricante de su hardware para obtener instrucciones específicas.
Requisito previo
Ha creado un medio de instalación de arranque (USB, CD o DVD). Consulte Sección 2.7, “Creación de un medio de instalación de arranque” para obtener más información.
Procedimiento
- Apague el sistema en el que está instalando Red Hat Enterprise Linux.
- Desconecte las unidades del sistema.
- Encienda el sistema.
- Inserte el medio de instalación de arranque (USB, DVD o CD).
- Apague el sistema pero no retire el medio de arranque.
Encienda el sistema.
NotaEs posible que tenga que pulsar una tecla o combinación de teclas específica para arrancar desde el soporte o configurar el sistema básico de entrada/salida (BIOS) de su sistema para arrancar desde el soporte. Para más información, consulte la documentación que acompaña a su sistema.
- La ventana Red Hat Enterprise Linux boot se abre y muestra información sobre una variedad de opciones de arranque disponibles.
Utilice las teclas de flecha de su teclado para seleccionar la opción de arranque que necesite y pulse Intro para seleccionar la opción de arranque. Se abre la ventana Welcome to Red Hat Enterprise Linux y puede instalar Red Hat Enterprise Linux utilizando la interfaz gráfica de usuario.
NotaEl programa de instalación se inicia automáticamente si no se realiza ninguna acción en la ventana de arranque en 60 segundos.
Opcionalmente, edite las opciones de arranque disponibles:
- UEFI-based systems: Pulse E para entrar en el modo de edición. Cambie la línea de comandos predefinida para añadir o eliminar opciones de arranque. Pulse Enter para confirmar su elección.
- BIOS-based systems: Pulse la tecla Tab de su teclado para entrar en el modo de edición. Cambie la línea de comandos predefinida para añadir o eliminar opciones de arranque. Pulse Enter para confirmar su elección.
3.1.5. Arranque de la instalación desde una red utilizando PXE
Cuando se instala Red Hat Enterprise Linux en un gran número de sistemas simultáneamente, el mejor enfoque es arrancar desde un servidor PXE e instalar desde una fuente en una ubicación de red compartida. Siga los pasos de este procedimiento para arrancar la instalación de Red Hat Enterprise Linux desde una red utilizando PXE.
Para arrancar el proceso de instalación desde una red utilizando PXE, debe utilizar una conexión de red física, por ejemplo, Ethernet. No se puede arrancar el proceso de instalación con una conexión inalámbrica.
Requisitos previos
- Ha configurado un servidor TFTP y hay una interfaz de red en su sistema que soporta PXE. Consulte Additional resources para obtener más información.
- Ha configurado su sistema para arrancar desde la interfaz de red. Esta opción está en la BIOS, y puede ser etiquetada como Network Boot o Boot Services.
- Ha comprobado que la BIOS está configurada para arrancar desde la interfaz de red especificada. Algunos sistemas BIOS especifican la interfaz de red como un posible dispositivo de arranque, pero no son compatibles con el estándar PXE. Consulte la documentación de su hardware para obtener más información. Cuando haya habilitado correctamente el arranque PXE, el sistema puede arrancar el programa de instalación de Red Hat Enterprise Linux sin ningún otro medio.
Procedimiento
- Compruebe que el cable de red está conectado. El indicador luminoso de enlace de la toma de red debe estar iluminado, aunque el ordenador no esté encendido.
Encienda el sistema.
Dependiendo de su hardware, se puede mostrar alguna información de configuración de red y de diagnóstico antes de que su sistema se conecte a un servidor PXE. Cuando se conecta, se muestra un menú según la configuración del servidor PXE.
Pulse la tecla numérica que corresponde a la opción que desea.
NotaEn algunos casos, las opciones de arranque no se muestran. Si esto ocurre, pulse la tecla Enter del teclado o espere a que se abra la ventana de arranque.
La ventana Red Hat Enterprise Linux boot se abre y muestra información sobre una variedad de opciones de arranque disponibles.
Utilice las teclas de flecha de su teclado para seleccionar la opción de arranque que necesite y pulse Intro para seleccionar la opción de arranque. Se abre la ventana Welcome to Red Hat Enterprise Linux y puede instalar Red Hat Enterprise Linux utilizando la interfaz gráfica de usuario.
NotaEl programa de instalación se inicia automáticamente si no se realiza ninguna acción en la ventana de arranque en 60 segundos.
Opcionalmente, edite las opciones de arranque disponibles:
- UEFI-based systems: Pulse E para entrar en el modo de edición. Cambie la línea de comandos predefinida para añadir o eliminar opciones de arranque. Pulse Enter para confirmar su elección.
- BIOS-based systems: Pulse la tecla Tab de su teclado para entrar en el modo de edición. Cambie la línea de comandos predefinida para añadir o eliminar opciones de arranque. Pulse Enter para confirmar su elección.
Recursos adicionales
- Para información sobre cómo preparar la instalación de Red Hat Enterprise Linux desde la red usando PXE, vea el Performing an advanced RHEL installation documento.
- Consulte la Referencia de opciones de arranque para obtener más información sobre la lista de opciones de arranque disponibles que puede utilizar en la línea de comandos de arranque.
3.2. Instalación de RHEL mediante una imagen ISO desde el Portal del Cliente
Utilice este procedimiento para instalar RHEL utilizando una imagen ISO de DVD binario que haya descargado del Portal del Cliente. Los pasos proporcionan instrucciones para seguir el programa de instalación de RHEL.
Cuando se realiza una instalación GUI utilizando el archivo de imagen ISO de DVD binario, una condición de carrera en el instalador puede a veces impedir que la instalación continúe hasta que se registre el sistema utilizando la función Conectar con Red Hat. Para más información, vea BZ#1823578 en la sección de Problemas Conocidos del RHEL 8.2 Release Notes documento.
Requisitos previos
- Ha descargado el archivo de imagen ISO de DVD binario desde el Portal del Cliente.
- Ha creado un medio de instalación de arranque.
- Ha arrancado el programa de instalación y se muestra el menú de arranque.
Procedimiento
- En el menú de arranque, seleccione Install Red Hat Enterprise Linux 8.x, y pulse Enter en su teclado.
- En la ventana Welcome to Red Hat Enterprise Linux 8.x, seleccione su idioma y ubicación, y haga clic en . La ventana Installation Summary se abre y muestra los valores por defecto para cada ajuste.
- Seleccione System > Installation Destination, y en el panel Local Standard Disks, seleccione el disco de destino y luego haga clic en . Se seleccionan los ajustes por defecto para la configuración del almacenamiento. Para obtener más información sobre la personalización de la configuración de almacenamiento, consulte Sección 4.4, “Configuración de las opciones de software”, Sección 4.5, “Configuración de los dispositivos de almacenamiento”, Sección 4.6, “Configuración de la partición manual”.
- Seleccione System > Network & Host Name. Se abre la ventana Network and Hostname.
- En la ventana Network and Hostname, cambie el interruptor de Ethernet a ON, y luego haga clic en . El instalador se conecta a una red disponible y configura los dispositivos disponibles en la red. Si es necesario, de la lista de redes disponibles, puede elegir una red deseada y configurar los dispositivos que están disponibles en esa red. Para obtener más información sobre la configuración de una red o de dispositivos de red, consulte Sección 4.3.3, “Configurar las opciones de red y de nombre de host”.
- Seleccione User Settings > Root Password. Se abre la ventana Root Password.
- En la ventana Root Password, escriba la contraseña que desea establecer para la cuenta de root y, a continuación, haga clic en . La contraseña de root es necesaria para finalizar el proceso de instalación y para acceder a la cuenta de usuario de administrador del sistema. Para más detalles sobre los requisitos y recomendaciones para crear una contraseña, consulte Sección 4.7, “Configurar una contraseña de root”.
- Opcional: Seleccione User Settings > User Creation para crear una cuenta de usuario para completar el proceso de instalación. En lugar de la cuenta raíz, puede utilizar esta cuenta de usuario para realizar cualquier tarea administrativa del sistema.
En la ventana Create User, realice lo siguiente, y luego haga clic en .
- Escriba un nombre y un nombre de usuario para la cuenta que desea crear.
- Seleccione las casillas Make this user administrator y Require a password to use this account. El programa de instalación añade el usuario al grupo de la rueda y crea una cuenta de usuario protegida por contraseña con la configuración predeterminada. Se recomienda crear una cuenta de usuario administrativa protegida con contraseña. Para más información sobre cómo editar la configuración por defecto de una cuenta de usuario, consulte Sección 4.8, “Crear una cuenta de usuario”.
- Haga clic en para comenzar la instalación.
- Cuando el proceso de instalación haya finalizado, haga clic en para reiniciar el sistema.
- Desde la ventana Initial Setup, acepte el acuerdo de licencia y registre su sistema.
Recursos adicionales
- Para saber más sobre cómo preparar su instalación, consulte Performing a standard RHEL installation para más información.
- Para obtener más información sobre cómo personalizar su red, conectarse a Red Hat, propósito del sistema, destino de la instalación, KDUMP y política de seguridad, consulte Performing a standard RHEL installation para más información.
- Para saber más sobre cómo completar la instalación, consulte Performing a standard RHEL installation para más información.
- Para saber más sobre cómo registrar su sistema, consulte Performing a standard RHEL installation para más información.
3.3. Registro e instalación de RHEL desde la CDN mediante la GUI
Esta sección contiene información sobre cómo registrar su sistema, adjuntar suscripciones a RHEL e instalar RHEL desde la Red Hat Content Delivery Network (CDN) utilizando la GUI.
3.3.1. Qué es la Red de Entrega de Contenidos
La Red de Entrega de Contenidos (CDN) de Red Hat, disponible en cdn.redhat.com, es una serie de servidores web estáticos distribuidos geográficamente que contienen contenidos y erratas que son consumidos por los sistemas. El contenido puede ser consumido directamente, por ejemplo, utilizando un sistema registrado en Red Hat Subscription Management. La CDN está protegida por la autenticación de certificados x.509 para garantizar que sólo los usuarios válidos tengan acceso. Cuando un sistema se registra en Red Hat Subscription Management, las suscripciones adjuntas regulan el subconjunto de la CDN al que puede acceder el sistema.
El registro y la instalación de RHEL desde la CDN proporciona las siguientes ventajas:
- El método de instalación CDN admite los archivos de imagen Boot ISO y Binary DVD ISO. Sin embargo, se recomienda el uso del archivo de imagen Boot ISO más pequeño, ya que consume menos espacio que el archivo de imagen Binary DVD ISO más grande.
- El CDN utiliza los últimos paquetes, lo que da como resultado un sistema totalmente actualizado justo después de la instalación. No es necesario instalar las actualizaciones de los paquetes inmediatamente después de la instalación, como suele ocurrir cuando se utiliza el archivo de imagen ISO del DVD binario.
- Soporte integrado para conectar con Red Hat Insights y habilitar System Purpose.
El registro y la instalación de RHEL desde la CDN están soportados por la GUI y Kickstart. Para obtener información sobre cómo registrar e instalar RHEL mediante la GUI, consulte el Performing a standard RHEL installation documento. Para obtener información sobre cómo registrar e instalar RHEL mediante Kickstart, consulte el documento Performing an advanced RHEL installation documento.
3.3.2. Registro e instalación de RHEL desde la CDN
Utilice este procedimiento para registrar su sistema, adjuntar suscripciones a RHEL e instalar RHEL desde la Red Hat Content Delivery Network (CDN) utilizando la GUI.
La función CDN es compatible con los archivos de imagen Boot ISO y Binary DVD ISO. Sin embargo, se recomienda utilizar el archivo de imagen Boot ISO, ya que el origen de la instalación es por defecto CDN para el archivo de imagen Boot ISO.
Requisitos previos
- Su sistema está conectado a una red que puede acceder a la CDN.
- Ha descargado el archivo de imagen Boot ISO desde el Portal del Cliente.
- Ha creado un medio de instalación de arranque.
- Ha arrancado el programa de instalación y se muestra el menú de arranque. Tenga en cuenta que el repositorio de instalación utilizado tras el registro del sistema depende de cómo se haya arrancado el sistema.
Procedimiento
- En el menú de arranque, seleccione Install Red Hat Enterprise Linux 8.x, y pulse Enter en su teclado.
- En la ventana Welcome to Red Hat Enterprise Linux 8.x, seleccione su idioma y ubicación, y haga clic en . La ventana Installation Summary se abre y muestra los valores por defecto para cada ajuste.
- Seleccione System > Installation Destination, y en el panel Local Standard Disks, seleccione el disco de destino y luego haga clic en . Se seleccionan los ajustes por defecto para la configuración del almacenamiento. Para obtener más información sobre la personalización de la configuración de almacenamiento, consulte Sección 4.4, “Configuración de las opciones de software”, Sección 4.5, “Configuración de los dispositivos de almacenamiento”, Sección 4.6, “Configuración de la partición manual”.
- Seleccione System > Network & Host Name. Se abre la ventana Network and Hostname.
- En la ventana Network and Hostname, cambie el interruptor de Ethernet a ON, y luego haga clic en . El instalador se conecta a una red disponible y configura los dispositivos disponibles en la red. Si es necesario, de la lista de redes disponibles, puede elegir una red deseada y configurar los dispositivos que están disponibles en esa red. Para obtener más información sobre la configuración de una red o de dispositivos de red, consulte Sección 4.3.3, “Configurar las opciones de red y de nombre de host”.
- Seleccione Software > Connect to Red Hat. Se abre la ventana Connect to Red Hat.
En la ventana Connect to Red Hat, realice los siguientes pasos:
Seleccione el método Authentication, y proporcione los detalles basados en el método que seleccione.
Para Account método de autenticación: Introduzca su nombre de usuario y contraseña del Portal del Cliente de Red Hat.
Para el método de autenticación Activation Key: Introduzca el ID de su organización y la clave de activación. Puede introducir más de una clave de activación, separadas por una coma, siempre que las claves de activación estén registradas en su suscripción.
Marque la casilla Set System Purpose y, a continuación, seleccione las opciones Role, SLA y Usage de las listas desplegables correspondientes.
Con el Propósito del sistema puede registrar el uso previsto de un sistema Red Hat Enterprise Linux 8 y asegurarse de que el servidor de asignación de derechos asigne automáticamente la suscripción más adecuada a su sistema.
La casilla Connect to Red Hat Insights está activada por defecto. Desactive la casilla si no desea conectarse a Red Hat Insights.
Red Hat Insights es una oferta de software como servicio (SaaS) que proporciona un análisis continuo y en profundidad de los sistemas registrados basados en Red Hat para identificar de forma proactiva las amenazas a la seguridad, el rendimiento y la estabilidad en entornos físicos, virtuales y de nube, así como en implementaciones de contenedores.
Opcionalmente, expanda Options, y seleccione el tipo de comunicación de red.
- Seleccione la casilla Use HTTP proxy si su entorno de red sólo permite el acceso externo a Internet o accede a los servidores de contenido a través de un proxy HTTP.
Si está ejecutando el Servidor Satélite o realizando pruebas internas, seleccione las casillas de verificación Custom server URL y Custom base URL e introduzca los datos necesarios.
El campo Custom server URL no requiere el protocolo HTTP, por ejemplo
nameofhost.com. Sin embargo, el campo Custom base URL requiere el protocolo HTTP. Para cambiar el Custom base URL después del registro, debe anular el registro, proporcionar los nuevos datos y volver a registrarse.
Haga clic en . Cuando el sistema se registra con éxito y se adjuntan las suscripciones, la ventana Connect to Red Hat muestra los detalles de la suscripción adjunta.
Dependiendo de la cantidad de suscripciones, el proceso de registro y fijación puede tardar hasta un minuto en completarse.
Haga clic en .
En Connect to Red Hat aparece un mensaje de Registered.
- Seleccione User Settings > Root Password. Se abre la ventana Root Password.
- En la ventana Root Password, escriba la contraseña que desea establecer para la cuenta de root y, a continuación, haga clic en . La contraseña de root es necesaria para finalizar el proceso de instalación y para acceder a la cuenta de usuario de administrador del sistema. Para más detalles sobre los requisitos y recomendaciones para crear una contraseña, consulte Sección 4.7, “Configurar una contraseña de root”.
- Opcional: Seleccione User Settings > User Creation para crear una cuenta de usuario para completar el proceso de instalación. En lugar de la cuenta raíz, puede utilizar esta cuenta de usuario para realizar cualquier tarea administrativa del sistema.
En la ventana Create User, realice lo siguiente, y luego haga clic en .
- Escriba un nombre y un nombre de usuario para la cuenta que desea crear.
- Seleccione las casillas Make this user administrator y Require a password to use this account. El programa de instalación añade el usuario al grupo de la rueda y crea una cuenta de usuario protegida por contraseña con la configuración predeterminada. Se recomienda crear una cuenta de usuario administrativa protegida con contraseña. Para más información sobre cómo editar la configuración por defecto de una cuenta de usuario, consulte Sección 4.8, “Crear una cuenta de usuario”.
- Haga clic en para comenzar la instalación.
- Cuando el proceso de instalación haya finalizado, haga clic en para reiniciar el sistema.
- Desde la ventana Initial Setup, acepte el acuerdo de licencia y registre su sistema.
Recursos adicionales
- Para saber más sobre cómo preparar su instalación, consulte Performing a standard RHEL installation para más información.
- Para saber más sobre cómo personalizar la red, la conexión a Red Hat, el propósito del sistema, el destino de la instalación, KDUMP y la política de seguridad, consulte Performing a standard RHEL installation para más información.
- Para obtener información sobre Red Hat Insights, consulte la página Red Hat Insights product documentation.
- Para obtener información sobre las claves de activación, consulte el Understanding Activation Keys capítulo del documento Using Red Hat Subscription Management.
- Para obtener información sobre cómo configurar un proxy HTTP para Subscription Manager, consulte el Using an HTTP proxy capítulo del documento Using and Configuring Red Hat Subscription Manager.
3.3.2.1. Repositorio de fuentes de instalación tras el registro del sistema
El repositorio de origen de la instalación utilizado tras el registro del sistema depende de cómo se haya arrancado el sistema.
- Sistema arrancado desde el archivo de imagen ISO de arranque o el DVD binario
-
Si ha arrancado la instalación de RHEL utilizando el archivo de imagen
Boot ISOoBinary DVD ISOcon los parámetros de arranque por defecto, el programa de instalación cambia automáticamente el repositorio de origen de la instalación al CDN después del registro. - El sistema arrancó con el parámetro de arranque
inst.repo=<URL> -
Si arrancó la instalación de RHEL con el parámetro de arranque
inst.repo=<URL>, el programa de instalación no cambia automáticamente el repositorio de origen de la instalación a la CDN después del registro. Si desea utilizar la CDN para instalar RHEL, debe cambiar manualmente el repositorio de origen de la instalación a la CDN seleccionando la opción Red Hat CDN en la ventana Installation Source de la instalación gráfica. Si no se cambia manualmente a la CDN, el programa de instalación instala los paquetes desde el repositorio especificado en la línea de comandos del kernel.
-
Puede cambiar el repositorio de origen de la instalación al CDN utilizando el comando Kickstart
rhsmsólo si no especifica un origen de instalación utilizandoinst.repo=en la línea de comandos del kernel o el comandourlen el archivo Kickstart. Debe utilizarinst.stage2=<URL>en la línea de comandos del kernel para obtener la imagen de instalación, pero sin especificar el origen de la instalación. -
Una URL de origen de instalación especificada mediante una opción de arranque o incluida en un archivo Kickstart tiene prioridad sobre la CDN, incluso si el archivo Kickstart contiene el comando
rhsmcon credenciales válidas. El sistema se registra, pero se instala desde la URL de origen de la instalación. Esto garantiza que los procesos de instalación anteriores funcionen con normalidad.
3.3.3. Verificar el registro de su sistema desde el CDN
Utilice este procedimiento para verificar que su sistema está registrado en el CDN utilizando la GUI.
not Sólo puede verificar su registro desde la CDN si ha hecho clic en el botón Begin Installation de la ventana Installation Summary. Una vez que haya hecho clic en el botón Begin Installation, no podrá volver a la ventana de resumen de la instalación para verificar su registro.
Requisito previo
- Ha completado el proceso de registro tal y como se documenta en Sección 3.3.2, “Registro e instalación de RHEL desde la CDN” y Registered aparece bajo Connect to Red Hat en la ventana Installation Summary.
Procedimiento
- En la ventana Installation Summary, seleccione Connect to Red Hat.
La ventana se abre y muestra un resumen del registro:
- Método
- Se muestra el nombre de la cuenta registrada o las claves de activación.
- Objetivo del sistema
- Si se establece, se muestra el rol, el SLA y los detalles de uso.
- Información
- Si se activa, se muestran los detalles de Insights.
- Número de suscripciones
- Se muestra el número de suscripciones adjuntas.
- Compruebe que el resumen del registro coincide con los datos introducidos.
3.3.4. Cómo anular el registro de su sistema en la CDN
Utilice este procedimiento para anular el registro de su sistema de la CDN utilizando la GUI.
- Puede anular el registro de la CDN si ha hecho clic en el botón la instalación de la ventana Installation Summary en not. Una vez que haya hecho clic en el botón la instalación, no podrá volver a la ventana Resumen de la instalación para anular el registro.
Al anular el registro, el programa de instalación pasa al primer repositorio disponible, en el siguiente orden:
- La URL utilizada en el parámetro de arranque inst.repo=<URL> en la línea de comandos del kernel.
- Un repositorio detectado automáticamente en el medio de instalación (USB o DVD).
Requisito previo
- Ha completado el proceso de registro tal y como se documenta en Sección 3.3.2, “Registro e instalación de RHEL desde la CDN” y Registered aparece bajo Connect to Red Hat en la ventana Installation Summary.
Procedimiento
- En la ventana Installation Summary, seleccione Connect to Red Hat.
La ventana Connect to Red Hat se abre y muestra un resumen del registro:
- Método
- Se muestra el nombre de la cuenta registrada o las claves de activación utilizadas.
- Objetivo del sistema
- Si se establece, se muestra el rol, el SLA y los detalles de uso.
- Información
- Si se activa, se muestran los detalles de Insights.
- Número de suscripciones
- Se muestra el número de suscripciones adjuntas.
- Haga clic en para eliminar el registro del CDN. Los detalles del registro original se muestran con un mensaje de Not registered que aparece en la parte media inferior de la ventana.
- Haga clic en para volver a la ventana Installation Summary.
- Connect to Red Hat muestra un mensaje Not registered, y Software Selection muestra un mensaje Red Hat CDN requires registration.
Después de anular el registro, es posible volver a registrar el sistema. Haga clic en Connect to Red Hat. Se rellenan los datos introducidos anteriormente. Edite los detalles originales o actualice los campos en función de la cuenta, el propósito y la conexión. Haga clic en para finalizar.
3.4. Completar la instalación
Espere a que se complete la instalación. Puede tardar unos minutos.
Una vez finalizada la instalación, retire cualquier medio de instalación si no se expulsa automáticamente al reiniciar.
Red Hat Enterprise Linux 8 se inicia después de que la secuencia normal de encendido de su sistema se haya completado. Si su sistema fue instalado en una estación de trabajo con el sistema X Window, se lanzan aplicaciones para configurar su sistema. Estas aplicaciones le guían a través de la configuración inicial y puede establecer la hora y la fecha de su sistema, registrar su sistema con Red Hat, etc. Si el sistema X Window no está instalado, se mostrará un prompt login:.
Para saber cómo completar la configuración inicial, el registro y la seguridad del sistema, consulte la sección Cómo completar las tareas posteriores a la instalación del documento Performing a standard RHEL installation.
Capítulo 4. Personalización de la instalación
Al instalar Red Hat Enterprise Linux, puede personalizar la ubicación, el software y los ajustes y parámetros del sistema, utilizando la ventana Installation Summary.
La ventana Installation Summary contiene las siguientes categorías:
- LOCALIZATION: Puede configurar el teclado, el soporte de idioma y la fecha y hora.
- SOFTWARE: Puede configurar la Conexión a Red Hat, la Fuente de Instalación y la Selección de Software.
- SYSTEM: Puede configurar el destino de la instalación, el KDUMP, el nombre de la red y del host, y la política de seguridad.
- USER SETTINGS: Puede configurar una contraseña de root para acceder a la cuenta de administrador que se utiliza para las tareas de administración del sistema, y crear una cuenta de usuario para acceder al sistema.
Una categoría tiene un estado diferente según el lugar donde se encuentre en el programa de instalación.
| Estado de la categoría | Estado | Descripción |
|---|---|---|
| Warning symbol type 1 | Triángulo amarillo con un signo de exclamación y texto rojo | Requiere atención antes de la instalación. Por ejemplo, la red & Nombre de host requiere atención antes de poder registrarse y descargar desde la red de entrega de contenidos (CDN). |
| Warning symbol type 2 | En gris y con un símbolo de advertencia (triángulo amarillo con un signo de exclamación) | El programa de instalación está configurando una categoría y debe esperar a que termine antes de acceder a la ventana. |
En la parte inferior de la ventana Installation Summary aparece un mensaje de advertencia y el botón Begin Installation se desactiva hasta que se configuren todas las categorías necesarias.
Esta sección contiene información sobre la personalización de su instalación de Red Hat Enterprise Linux utilizando la interfaz gráfica de usuario (GUI). La GUI es el método preferido para instalar Red Hat Enterprise Linux cuando arranca el sistema desde un CD, DVD o unidad flash USB, o desde una red usando PXE.
Puede haber alguna variación entre la ayuda en línea y el contenido que se publica en el Portal del Cliente. Para las últimas actualizaciones, consulte el contenido de la instalación en el Portal del Cliente.
4.1. Configuración de los ajustes de idioma y ubicación
El programa de instalación utiliza el idioma que ha seleccionado durante la instalación.
Requisitos previos
- Has creado un medio de instalación.
- Ha especificado una fuente de instalación si está utilizando el archivo de imagen Boot ISO.
- Has arrancado la instalación.
Procedimiento
En el panel izquierdo de la ventana Welcome to Red Hat Enterprise Linux, seleccione un idioma. Alternativamente, escriba su idioma preferido en el campo Search.
NotaUn idioma está preseleccionado por defecto. Si se configura el acceso a la red, es decir, si se arranca desde un servidor de red en lugar de un medio local, el idioma preseleccionado viene determinado por la función de detección automática de ubicación del módulo GeoIP. Si utilizó la opción
inst.lang=en la línea de comandos de arranque o en la configuración de su servidor PXE, entonces se selecciona el idioma que defina con la opción de arranque.- En el panel derecho de la ventana Welcome to Red Hat Enterprise Linux, seleccione una ubicación específica para su región.
Haga clic en para pasar a la ventana Capítulo 4, Personalización de la instalación.
ImportanteSi está instalando una versión preliminar de Red Hat Enterprise Linux, se mostrará un mensaje de advertencia sobre el estado preliminar del medio de instalación. Haga clic en para seguir con la instalación, o en para abandonar la instalación y reiniciar el sistema.
Recursos adicionales
Para obtener información sobre cómo cambiar la configuración de idioma y ubicación durante el programa de instalación, consulte Sección 4.2, “Configuración de las opciones de localización”
4.2. Configuración de las opciones de localización
Esta sección contiene información sobre la configuración del teclado, la compatibilidad con el idioma y la configuración de la fecha y la hora.
Si utiliza una disposición que no acepta caracteres latinos, como Russian, añada la disposición English (United States) y configure una combinación de teclado para cambiar entre las dos disposiciones. Si selecciona una disposición que no tiene caracteres latinos, es posible que no pueda introducir una contraseña válida de root ni las credenciales de usuario más adelante en el proceso de instalación. Esto podría impedirle completar la instalación.
4.2.1. Configurar el teclado, el idioma y la hora y la fecha
Los ajustes de teclado, idioma y fecha y hora están configurados por defecto como parte de Sección 4.1, “Configuración de los ajustes de idioma y ubicación”. Para cambiar cualquiera de las configuraciones, complete los siguientes pasos, de lo contrario proceda a Sección 4.4, “Configuración de las opciones de software”.
Procedimiento: Configurar los ajustes del teclado
En la ventana Installation Summary, haga clic en Keyboard. El diseño por defecto depende de la opción seleccionada en Sección 4.1, “Configuración de los ajustes de idioma y ubicación”.
- Haga clic en para abrir la ventana Add a Keyboard Layout y cambiar de diseño.
- Seleccione un diseño navegando por la lista o utilice el campo Search.
- Seleccione el diseño deseado y haga clic en . El nuevo diseño aparece debajo del diseño por defecto.
- Haga clic en para configurar opcionalmente un conmutador de teclado que puede utilizar para alternar entre las disposiciones disponibles. Se abre la ventana Layout Switching Options.
Para configurar las combinaciones de teclas para la conmutación, seleccione una o más combinaciones de teclas y haga clic en para confirmar su selección.
NotaCuando seleccione un diseño, haga clic en el botón Keyboard para abrir un nuevo cuadro de diálogo que muestra una representación visual del diseño seleccionado.
- Haga clic en para aplicar la configuración y volver a Capítulo 4, Personalización de la instalación.
Procedimiento: Configurar los ajustes de idioma
En la ventana Installation Summary, haga clic en Language Support. Se abre la ventana Language Support. En el panel izquierdo se enumeran los grupos de idiomas disponibles. Si se ha configurado al menos un idioma de un grupo, se muestra una marca de verificación y se resalta el idioma admitido.
- En el panel izquierdo, haga clic en un grupo para seleccionar otros idiomas y, en el panel derecho, seleccione las opciones regionales. Repita este proceso para los idiomas que necesite.
- Haga clic en para aplicar los cambios y volver a Capítulo 4, Personalización de la instalación.
Procedimiento: Configurar los ajustes de fecha y hora
En la ventana Installation Summary, haga clic en Time & Date. Se abre la ventana Time & Date.
NotaLos ajustes de Time & Date están configurados por defecto en función de los ajustes seleccionados en Sección 4.1, “Configuración de los ajustes de idioma y ubicación”.
La lista de ciudades y regiones procede de la base de datos de zonas horarias (
tzdata) de dominio público que mantiene la Autoridad de Asignación de Números de Internet (IANA). Red Hat no puede añadir ciudades o regiones a esta base de datos. Puede encontrar más información en el sitio web oficial de IANA.En el menú desplegable Region, seleccione una región.
NotaSeleccione Etc como región para configurar una zona horaria relativa a la hora de Greenwich (GMT) sin establecer su ubicación en una región específica.
- En el menú desplegable City, seleccione la ciudad, o la ciudad más cercana a su ubicación en la misma zona horaria.
Conmute el interruptor Network Time para activar o desactivar la sincronización de la hora de la red mediante el Protocolo de Hora de Red (NTP).
NotaLa activación del interruptor de la hora de la red mantiene la hora de su sistema correcta siempre que el sistema pueda acceder a Internet. Por defecto, un grupo NTP está configurado; puedes añadir una nueva opción, o desactivar o eliminar las opciones por defecto haciendo clic en el botón de junto al interruptor de Hora de .
Haga clic en para aplicar los cambios y volver a Capítulo 4, Personalización de la instalación.
NotaSi desactiva la sincronización de la hora de la red, los controles de la parte inferior de la ventana se activan y le permiten ajustar la hora y la fecha manualmente.
4.3. Configurar las opciones del sistema
Esta sección contiene información sobre la configuración del destino de la instalación, el KDUMP, el nombre de la red y del host, la política de seguridad y el propósito del sistema.
4.3.1. Configuración del destino de la instalación
Utilice la ventana Installation Destination para configurar las opciones de almacenamiento, por ejemplo, los discos que desea utilizar como destino de la instalación de su Red Hat Enterprise Linux. Debe seleccionar al menos un disco.
Haga una copia de seguridad de sus datos si planea utilizar un disco que ya contiene datos. Por ejemplo, si quiere reducir una partición existente de Microsoft Windows e instalar Red Hat Enterprise Linux como segundo sistema, o si está actualizando una versión anterior de Red Hat Enterprise Linux. La manipulación de particiones siempre conlleva un riesgo. Por ejemplo, si el proceso se interrumpe o falla por cualquier razón, los datos del disco pueden perderse.
Casos especiales
-
Algunos tipos de BIOS no admiten el arranque desde una tarjeta RAID. En estos casos, la partición
/bootdebe crearse en una partición fuera de la matriz RAID, como por ejemplo en un disco duro separado. Es necesario utilizar un disco duro interno para la creación de particiones con tarjetas RAID problemáticas. Una partición/boottambién es necesaria para las configuraciones RAID por software. Si elige particionar su sistema automáticamente, deberá editar manualmente su partición/boot. - Para configurar el gestor de arranque de Red Hat Enterprise Linux para chain load desde un gestor de arranque diferente, debe especificar la unidad de arranque manualmente haciendo clic en el enlace Full disk summary and bootloader desde la ventana Installation Destination.
- Cuando instala Red Hat Enterprise Linux en un sistema con dispositivos de almacenamiento multitrayectoria y no multitrayectoria, la distribución automática de particiones en el programa de instalación crea grupos de volúmenes que contienen una mezcla de dispositivos multitrayectoria y no multitrayectoria. Esto anula el propósito del almacenamiento multirruta. Se recomienda seleccionar dispositivos multipath o no multipath en la ventana Installation Destination. Alternativamente, proceda a la partición manual.
Requisito previo
La ventana Installation Summary está abierta.
Procedimiento
En la ventana Installation Summary, haga clic en Installation Destination. Se abre la ventana Installation Destination.
En la sección Local Standard Disks, seleccione el dispositivo de almacenamiento que necesita; una marca de verificación blanca indica su selección. Los discos sin marca blanca no se utilizan durante el proceso de instalación; se ignoran si se elige el particionamiento automático, y no están disponibles en el particionamiento manual.
NotaTodos los dispositivos de almacenamiento disponibles localmente (discos duros SATA, IDE y SCSI, memorias USB y discos externos) se muestran en Local Standard Disks. Cualquier dispositivo de almacenamiento conectado después de que se haya iniciado el programa de instalación no se detecta. Si utiliza una unidad extraíble para instalar Red Hat Enterprise Linux, su sistema quedará inutilizado si retira el dispositivo.
Opcional: Haga clic en el enlace Refresh en la parte inferior derecha de la ventana si desea configurar dispositivos de almacenamiento local adicionales para conectar nuevos discos duros. Se abre el cuadro de diálogo Rescan Disks.
NotaTodos los cambios de almacenamiento realizados durante la instalación se pierden al hacer clic en Rescan Disks.
- Haga clic en y espere hasta que el proceso de escaneo se complete.
- Haga clic en para volver a la ventana Installation Destination. Todos los discos detectados, incluidos los nuevos, aparecen en la sección Local Standard Disks.
Opcional: Para añadir un dispositivo de almacenamiento especializado, haga clic en
Se abre la ventana Storage Device Selection y enumera todos los dispositivos de almacenamiento a los que tiene acceso el programa de instalación. Para obtener información sobre cómo añadir un disco especializado, consulte Sección 4.5.3, “Uso de las opciones avanzadas de almacenamiento”.
Opcional: En Storage Configuration, seleccione el botón de opción Automatic.
ImportanteEl particionamiento automático es el método recommended para particionar su almacenamiento. También puede configurar un particionamiento personalizado, para más detalles vea Sección 4.6, “Configuración de la partición manual”
- Opcional: Para reclamar espacio de una distribución de particiones existente, seleccione la casilla I would like to make additional space available. Por ejemplo, si un disco que quiere usar ya contiene un sistema operativo diferente y quiere hacer las particiones de este sistema más pequeñas para permitir más espacio para Red Hat Enterprise Linux.
Opcional: Seleccione Encrypt my data para cifrar todas las particiones excepto las necesarias para arrancar el sistema (como
/boot) utilizando Linux Unified Key Setup (LUKS). Se recomienda cifrar el disco duro.Haga clic en . Se abre el cuadro de diálogo Disk Encryption Passphrase.
- Introduzca su frase de acceso en los campos Passphrase y Confirm.
Haga clic en para completar el cifrado del disco.
AvisoSi pierdes la frase de contraseña de LUKS, cualquier partición encriptada y sus datos son completamente inaccesibles. No hay forma de recuperar una frase de contraseña perdida. Sin embargo, si realiza una instalación Kickstart, puede guardar las frases de contraseña de cifrado y crear frases de contraseña de cifrado de reserva durante la instalación. Consulte el documento Performing an advanced RHEL installation para más información.
Opcional: Haga clic en el enlace Full disk summary and bootloader en la parte inferior izquierda de la ventana para seleccionar el dispositivo de almacenamiento que contiene el cargador de arranque. Para obtener más información, consulte Sección 4.3.1.1, “Configuración del gestor de arranque”.
NotaEn la mayoría de los casos es suficiente con dejar el gestor de arranque en la ubicación por defecto. Algunas configuraciones, por ejemplo, los sistemas que requieren la carga en cadena desde otro gestor de arranque, requieren que se especifique manualmente la unidad de arranque.
Haga clic en .
Si seleccionó automatic partitioning y I would like to make additional space available, o si no hay suficiente espacio libre en sus discos duros seleccionados para instalar Red Hat Enterprise Linux, la caja de diálogo Reclaim Disk Space se abre cuando hace clic en , y lista todos los dispositivos de disco configurados y todas las particiones en esos dispositivos. La caja de diálogo muestra información sobre cuánto espacio necesita el sistema para una instalación mínima y cuánto espacio ha recuperado.
AvisoSi delete una partición, todos los datos de esa partición se pierden. Si quiere conservar sus datos, utilice la opción Shrink, no la opción Delete.
- Revise la lista mostrada de dispositivos de almacenamiento disponibles. La columna Reclaimable Space muestra la cantidad de espacio que se puede recuperar de cada entrada.
Para recuperar espacio, seleccione un disco o una partición y haga clic en el botón para borrar esa partición, o todas las particiones de un disco seleccionado, o haga clic en para utilizar el espacio libre de una partición conservando los datos existentes.
NotaAlternativamente, puede hacer clic en , esto elimina todas las particiones existentes en todos los discos y hace que este espacio esté disponible para Red Hat Enterprise Linux. Los datos existentes en todos los discos se pierden.
- Haga clic en para aplicar los cambios y volver a Capítulo 4, Personalización de la instalación.
No se realiza ningún cambio en el disco hasta que se haga clic en en la ventana Installation Summary. El diálogo Reclaim Space sólo marca las particiones para su redimensionamiento o eliminación; no se realiza ninguna acción.
4.3.1.1. Configuración del gestor de arranque
Red Hat Enterprise Linux utiliza GRand Unified Bootloader versión 2 (GRUB2) como cargador de arranque para AMD64 e Intel 64, IBM Power Systems y ARM. Para IBM Z, se utiliza el gestor de arranque zipl.
El gestor de arranque es el primer programa que se ejecuta cuando se inicia el sistema y es responsable de cargar y transferir el control a un sistema operativo GRUB2 puede arrancar cualquier sistema operativo compatible (incluido Microsoft Windows) y también puede utilizar la carga en cadena para transferir el control a otros cargadores de arranque para sistemas operativos no compatibles.
La instalación de GRUB2 puede sobrescribir su cargador de arranque existente.
Si un sistema operativo ya está instalado, el programa de instalación de Red Hat Enterprise Linux intenta detectar y configurar automáticamente el gestor de arranque para iniciar el otro sistema operativo. Si el gestor de arranque no se detecta, puede configurar manualmente cualquier sistema operativo adicional después de terminar la instalación.
Si está instalando un sistema Red Hat Enterprise Linux con más de un disco, es posible que quiera especificar manualmente el disco donde quiere instalar el gestor de arranque.
Procedimiento
En la ventana Installation Destination, haga clic en el enlace Full disk summary and bootloader. Se abre el cuadro de diálogo Selected Disks.
El cargador de arranque se instala en el dispositivo de su elección, o en un sistema UEFI; el EFI system partition se crea en el dispositivo de destino durante el particionamiento guiado.
- Para cambiar el dispositivo de arranque, seleccione un dispositivo de la lista y haga clic en de arranque. Sólo se puede establecer un dispositivo como dispositivo de arranque.
- Para desactivar la instalación de un nuevo , seleccione el dispositivo actualmente marcado para el arranque y haga clic en . Esto asegura que GRUB2 no se instale en ningún dispositivo.
Si elige no instalar un gestor de arranque, no podrá arrancar el sistema directamente y deberá utilizar otro método de arranque, como una aplicación comercial independiente de gestor de arranque. Utilice esta opción sólo si tiene otra forma de arrancar el sistema.
El gestor de arranque también puede requerir la creación de una partición especial, dependiendo de si su sistema utiliza el firmware BIOS o UEFI, o si la unidad de arranque tiene una etiqueta GUID Partition Table (GPT) o una Master Boot Record (MBR, también conocida como msdos). Si utiliza el particionamiento automático, el programa de instalación crea la partición.
4.3.2. Configuración de Kdump
Kdump es un mecanismo de volcado del núcleo. En caso de caída del sistema, Kdump captura el contenido de la memoria del sistema en el momento del fallo. Esta memoria capturada puede ser analizada para encontrar la causa del fallo. Si Kdump está habilitado, debe tener una pequeña porción de la memoria del sistema (RAM) reservada para sí mismo. Esta memoria reservada no es accesible para el núcleo principal.
Procedimiento
- En la ventana Installation Summary, haga clic en Kdump. Se abre la ventana Kdump.
- Seleccione la casilla Enable kdump.
Seleccione el ajuste de reserva de memoria Automatic o Manual.
- Si selecciona Manual, introduzca la cantidad de memoria (en megabytes) que desea reservar en el campo Memory to be reserved utilizando los botones y -. La lectura de Usable System Memory debajo del campo de entrada de la reserva muestra la cantidad de memoria a la que puede acceder su sistema principal después de reservar la cantidad de RAM que seleccione.
- Haga clic en para aplicar la configuración y volver a Capítulo 4, Personalización de la instalación.
La cantidad de memoria que se reserva viene determinada por la arquitectura de su sistema (AMD64 e Intel 64 tienen requisitos diferentes a los de IBM Power), así como por la cantidad total de memoria del sistema. En la mayoría de los casos, la reserva automática es satisfactoria.
Otros ajustes, como la ubicación en la que se guardarán los volcados de fallos del kernel, sólo pueden configurarse después de la instalación utilizando la interfaz gráfica system-config-kdump interfaz gráfica, o manualmente en el archivo de configuración /etc/kdump.conf.
4.3.3. Configurar las opciones de red y de nombre de host
Utilice la ventana Network and Host name para configurar las interfaces de red. Las opciones que seleccione aquí estarán disponibles tanto durante la instalación para tareas como la descarga de paquetes desde una ubicación remota, como en el sistema instalado.
Siga los pasos de este procedimiento para configurar su red y su nombre de host.
Procedimiento
- En la ventana Installation Summary, haga clic en .
- En la lista del panel izquierdo, seleccione una interfaz. Los detalles se muestran en el panel derecho.
Activa el interruptor para activar o desactivar la interfaz seleccionada.
NotaEl programa de instalación detecta automáticamente las interfaces accesibles localmente, y no se pueden añadir o eliminar manualmente.
- Haga clic en para añadir una interfaz de red virtual, que puede ser: Equipo, Enlace, Puente o VLAN.
- Haga clic en para eliminar una interfaz virtual.
- Haga clic en para cambiar los ajustes como las direcciones IP, los servidores DNS o la configuración de enrutamiento para una interfaz existente (tanto virtual como física).
Introduzca un nombre de host para su sistema en el campo Host Name.
Nota-
Existen varios tipos de estándares de denominación de dispositivos de red que se utilizan para identificar los dispositivos de red con nombres persistentes, por ejemplo,
em1ywl3sp0. Para obtener información sobre estos estándares, consulte el Configuring and managing networking documento. -
El nombre de host puede ser un nombre de dominio completamente calificado (FQDN) en el formato hostname.domainname, o un nombre de host corto sin nombre de dominio. Muchas redes tienen un servicio de Protocolo de Configuración Dinámica de Host (DHCP) que proporciona automáticamente a los sistemas conectados un nombre de dominio. Para permitir que el servicio DHCP asigne el nombre de dominio a esta máquina, especifique sólo el nombre de host corto. El valor
localhost.localdomainsignifica que no se configura ningún nombre de host estático específico para el sistema de destino, y que el nombre de host real del sistema instalado se configura durante el proceso de configuración de la red, por ejemplo, medianteNetworkManagerutilizando DHCP o DNS.
-
Existen varios tipos de estándares de denominación de dispositivos de red que se utilizan para identificar los dispositivos de red con nombres persistentes, por ejemplo,
- Haga clic en para aplicar el nombre del host al entorno.
4.3.3.1. Añadir una interfaz de red virtual
Siga los pasos de este procedimiento para añadir una interfaz de red virtual.
Procedimiento
- En la ventana Network & Host name, pulse el botón para añadir una interfaz de red virtual. Se abre el cuadro de diálogo Add a device.
Seleccione uno de los cuatro tipos de interfaces virtuales disponibles:
- Bond: NIC (Network Interface Controller) Bonding, un método para unir varias interfaces de red físicas en un único canal enlazado.
- Bridge: Representa el NIC Bridging, un método para conectar múltiples redes separadas en una red agregada.
- Team: NIC Teaming, una nueva implementación para agregar enlaces, diseñada para proporcionar un pequeño controlador de núcleo para implementar el manejo rápido de los flujos de paquetes, y varias aplicaciones para hacer todo lo demás en el espacio de usuario.
- Vlan (Virtual LAN): Un método para crear múltiples dominios de difusión distintos que están mutuamente aislados.
- Seleccione el tipo de interfaz y haga clic en . Se abre un cuadro de diálogo de edición de la interfaz, que le permite editar cualquier configuración disponible para el tipo de interfaz elegido. Para más información, consulte Sección 4.3.3.2, “Edición de la configuración de la interfaz de red”.
- Haga clic en para confirmar la configuración de la interfaz virtual y volver a la ventana Network & Host name.
Si necesita cambiar la configuración de una interfaz virtual, seleccione la interfaz y haga clic en .
4.3.3.2. Edición de la configuración de la interfaz de red
Esta sección contiene información sobre los ajustes más importantes para una conexión típica por cable utilizada durante la instalación. La configuración de otros tipos de redes es, en líneas generales, similar, aunque los parámetros específicos de configuración pueden ser diferentes.
En IBM Z, no se puede añadir una nueva conexión, ya que los subcanales de red deben ser agrupados y puestos en línea de antemano, y esto se hace actualmente sólo en la fase de arranque.
Procedimiento
Para configurar una conexión de red manualmente, seleccione la interfaz en la ventana Network and Host name y haga clic en .
Se abre un diálogo de edición específico para la interfaz seleccionada.
Las opciones presentes dependen del tipo de conexión - las opciones disponibles son ligeramente diferentes dependiendo de si el tipo de conexión es una interfaz física (controlador de interfaz de red alámbrica o inalámbrica) o una interfaz virtual (Bond, Bridge, Team o Vlan) que fue previamente configurada en Sección 4.3.3.1, “Añadir una interfaz de red virtual”.
4.3.3.3. Activación o desactivación de la conexión de interfaz
Siga los pasos de este procedimiento para activar o desactivar una conexión de interfaz.
Procedimiento
- Haga clic en la pestaña General.
Seleccione la casilla Connect automatically with priority para activar la conexión por defecto. Mantenga el ajuste de prioridad por defecto en
0.Importante-
Cuando se activa en una conexión por cable, el sistema se conecta automáticamente durante el arranque o el reinicio. En una conexión inalámbrica, la interfaz intenta conectarse a cualquier red inalámbrica conocida que esté dentro del alcance. Para más información sobre NetworkManager, incluida la herramienta
nm-connection-editor, consulte el Configuring and managing networking documento. -
Puede habilitar o deshabilitar que todos los usuarios del sistema se conecten a esta red utilizando la opción All users may connect to this network. Si desactiva esta opción, sólo
rootpodrá conectarse a esta red. -
No es posible permitir que sólo un usuario específico distinto de
rootutilice esta interfaz, ya que no se crean otros usuarios en este momento durante la instalación. Si necesita una conexión para un usuario diferente, deberá configurarla después de la instalación.
-
Cuando se activa en una conexión por cable, el sistema se conecta automáticamente durante el arranque o el reinicio. En una conexión inalámbrica, la interfaz intenta conectarse a cualquier red inalámbrica conocida que esté dentro del alcance. Para más información sobre NetworkManager, incluida la herramienta
- Haga clic en para aplicar los cambios y volver a la ventana Network and Host name.
4.3.3.4. Configuración de IPv4 o IPv6 estática
Por defecto, tanto IPv4 como IPv6 se configuran de forma automática en función de la configuración actual de la red. Esto significa que direcciones como la dirección IP local, la dirección DNS y otras configuraciones se detectan automáticamente cuando la interfaz se conecta a una red. En muchos casos, esto es suficiente, pero también puede proporcionar una configuración estática en las pestañas IPv4 Settings y IPv6 Settings. Complete los siguientes pasos para configurar los ajustes de IPv4 o IPv6:
Procedimiento
Para establecer la configuración estática de la red, vaya a una de las pestañas de configuración de IPv y, en el menú desplegable Method, seleccione un método distinto de Automatic, por ejemplo, Manual. El panel Addresses se activa.
NotaEn la pestaña IPv6 Settings, también puede establecer el método a Ignore para desactivar IPv6 en esta interfaz.
- Haga clic en e introduzca la configuración de su dirección.
-
Introduzca las direcciones IP en el campo Additional DNS servers; acepta una o varias direcciones IP de servidores DNS, por ejemplo,
10.0.0.1,10.0.0.8. Seleccione la casilla Require IPvX addressing for this connection to complete casilla de verificación.
NotaSeleccione esta opción en las pestañas IPv4 Settings o IPv6 Settings para permitir esta conexión sólo si la configuración de IPv4 o IPv6 es correcta. Si esta opción permanece desactivada tanto para IPv4 como para IPv6, la interfaz podrá conectarse si la configuración tiene éxito en cualquiera de los dos protocolos IP.
- Haga clic en para aplicar los cambios y volver a la ventana Network & Host name.
4.3.3.5. Configuración de rutas
Complete los siguientes pasos para configurar las rutas.
Procedimiento
- En las pestañas IPv4 Settings y IPv6 Settings, haga clic en para configurar los ajustes de enrutamiento para un protocolo IP específico en una interfaz. Se abre un diálogo de edición de rutas específico para la interfaz.
- Haga clic en para añadir una ruta.
- Seleccione la casilla Ignore automatically obtained routes para configurar al menos una ruta estática y desactivar todas las rutas no configuradas específicamente.
Seleccione la casilla Use this connection only for resources on its network para evitar que la conexión se convierta en la ruta por defecto.
NotaEsta opción puede seleccionarse incluso si no se ha configurado ninguna ruta estática. Esta ruta se utiliza sólo para acceder a determinados recursos, como las páginas de la intranet que requieren una conexión local o VPN. Otra ruta (por defecto) se utiliza para los recursos disponibles públicamente. A diferencia de las rutas adicionales configuradas, esta configuración se transfiere al sistema instalado. Esta opción sólo es útil cuando se configura más de una interfaz.
- Haga clic en para guardar la configuración y volver al diálogo de edición de rutas específico de la interfaz.
- Haga clic en para aplicar la configuración y volver a la ventana Network and Host Name.
4.3.3.6. Recursos adicionales
- Para obtener más información sobre la configuración de la red después de la instalación, consulte el Configuring and managing networking documento.
4.3.4. Configuración de la conexión a Red Hat
La Red de Entrega de Contenidos (CDN) de Red Hat, disponible en cdn.redhat.com, es una serie de servidores web estáticos distribuidos geográficamente que contienen contenidos y erratas que son consumidos por los sistemas. El contenido puede ser consumido directamente, por ejemplo, utilizando un sistema registrado en Red Hat Subscription Management. La CDN está protegida por la autenticación de certificados x.509 para garantizar que sólo los usuarios válidos tengan acceso. Cuando un sistema se registra en Red Hat Subscription Management, las suscripciones adjuntas regulan el subconjunto de la CDN al que puede acceder el sistema.
El registro y la instalación de RHEL desde la CDN proporciona las siguientes ventajas:
- El método de instalación CDN admite los archivos de imagen Boot ISO y Binary DVD ISO. Sin embargo, se recomienda el uso del archivo de imagen Boot ISO más pequeño, ya que consume menos espacio que el archivo de imagen Binary DVD ISO más grande.
- El CDN utiliza los últimos paquetes, lo que da como resultado un sistema totalmente actualizado justo después de la instalación. No es necesario instalar las actualizaciones de los paquetes inmediatamente después de la instalación, como suele ocurrir cuando se utiliza el archivo de imagen ISO del DVD binario.
- Soporte integrado para conectar con Red Hat Insights y habilitar System Purpose.
4.3.4.1. Introducción a la finalidad del sistema
El propósito del sistema es una característica opcional pero recomendada de la instalación de Red Hat Enterprise Linux. Se utiliza el Propósito del Sistema para registrar el uso previsto de un sistema Red Hat Enterprise Linux 8, y asegurar que el servidor de asignación de derechos asigne automáticamente la suscripción más apropiada a su sistema.
Los beneficios incluyen:
- Información exhaustiva a nivel de sistema para los administradores de sistemas y las operaciones comerciales.
- Reducción de los gastos generales a la hora de determinar por qué se adquirió un sistema y su finalidad.
- Mejora de la experiencia del cliente en la conexión automática del Gestor de Suscripciones, así como la detección y conciliación automatizada del uso del sistema.
Puede introducir los datos del Propósito del Sistema de una de las siguientes maneras:
- Durante la creación de la imagen
- Durante la instalación de la GUI, cuando se utiliza Connect to Red Hat para registrar el sistema y adjuntar la suscripción a Red Hat
- Durante una instalación de Kickstart cuando se utilizan scripts de automatización de Kickstart
- Tras la instalación mediante la herramienta de línea de comandos (CLI) syspurpose
Para registrar el propósito de su sistema, puede configurar los siguientes componentes de Propósito del sistema. Los valores seleccionados son utilizados por el servidor de asignación de derechos al registrarse para adjuntar la suscripción más adecuada para su sistema.
Role
- Servidor Red Hat Enterprise Linux
- Estación de trabajo Red Hat Enterprise Linux
- Nodo informático de Red Hat Enterprise Linux
Service Level Agreement
- Premium
- Estándar
- Autoayuda
Usage
- Producción
- Desarrollo/prueba
- Recuperación de catástrofes
Recursos adicionales
- Para más información sobre el Constructor de imágenes, consulte el Composing a customized RHEL system image documento.
- Para más información sobre Kickstart, consulte el Performing an advanced RHEL installation documento.
- Para más información sobre el Gestor de Suscripciones, consulte el Using and Configuring Red Hat Subscription Manager documento.
4.3.4.2. Configuración de las opciones de Conexión a Red Hat
Utilice el siguiente procedimiento para configurar las opciones de Conectar con Red Hat en el GUI.
Puede registrarse en la CDN utilizando su cuenta de Red Hat o los datos de su clave de activación.
Procedimiento
Haga clic en Account.
- Introduzca su nombre de usuario y contraseña del Portal del Cliente de Red Hat.
Es opcional: Haga clic en Activation Key.
- Introduzca el ID de su organización y la clave de activación. Puede introducir más de una clave de activación, separadas por una coma, siempre que las claves de activación estén registradas en su suscripción.
Seleccione la casilla Set System Purpose. Propósito del sistema permite que el servidor de asignación de derechos determine y adjunte automáticamente la suscripción más adecuada para satisfacer el uso previsto de su sistema RHEL 8.
- Seleccione las direcciones Role, SLA, y Usage en las listas desplegables correspondientes.
La casilla Connect to Red Hat Insights está activada por defecto. Desactive la casilla si no desea conectarse a Red Hat Insights.
NotaRed Hat Insights es una oferta de software como servicio (SaaS) que proporciona un análisis continuo y en profundidad de los sistemas registrados basados en Red Hat para identificar de forma proactiva las amenazas a la seguridad, el rendimiento y la estabilidad en entornos físicos, virtuales y de nube, así como en implementaciones de contenedores.
Opcional: Ampliar Options.
- Seleccione la casilla Use HTTP proxy si su entorno de red sólo permite el acceso externo a Internet o el acceso a los servidores de contenido a través de un proxy HTTP. Desactive la casilla Use HTTP proxy si no se utiliza un proxy HTTP.
Si está ejecutando el Servidor Satélite o realizando pruebas internas, seleccione las casillas de verificación Custom server URL y Custom base URL e introduzca los datos necesarios.
Importante-
El campo Custom server URL no requiere el protocolo HTTP, por ejemplo
nameofhost.com. Sin embargo, el campo Custom base URL requiere el protocolo HTTP. - Para cambiar la dirección Custom base URL después del registro, debe anular el registro, proporcionar los nuevos datos y volver a registrarse.
-
El campo Custom server URL no requiere el protocolo HTTP, por ejemplo
Haga clic en para registrar el sistema. Cuando el sistema se registra con éxito y se adjuntan las suscripciones, la ventana Connect to Red Hat muestra los detalles de la suscripción adjunta.
NotaDependiendo de la cantidad de suscripciones, el proceso de registro y fijación puede tardar hasta un minuto en completarse.
Haga clic en para volver a la ventana Installation Summary.
- En Connect to Red Hat aparece un mensaje de Registered.
4.3.4.3. Repositorio de fuentes de instalación tras el registro del sistema
El repositorio de origen de la instalación utilizado tras el registro del sistema depende de cómo se haya arrancado el sistema.
- Sistema arrancado desde el archivo de imagen ISO de arranque o el DVD binario
-
Si ha arrancado la instalación de RHEL utilizando el archivo de imagen
Boot ISOoBinary DVD ISOcon los parámetros de arranque por defecto, el programa de instalación cambia automáticamente el repositorio de origen de la instalación al CDN después del registro. - El sistema arrancó con el parámetro de arranque
inst.repo=<URL> -
Si arrancó la instalación de RHEL con el parámetro de arranque
inst.repo=<URL>, el programa de instalación no cambia automáticamente el repositorio de origen de la instalación a la CDN después del registro. Si desea utilizar la CDN para instalar RHEL, debe cambiar manualmente el repositorio de origen de la instalación a la CDN seleccionando la opción Red Hat CDN en la ventana Installation Source de la instalación gráfica. Si no se cambia manualmente a la CDN, el programa de instalación instala los paquetes desde el repositorio especificado en la línea de comandos del kernel.
-
Puede cambiar el repositorio de origen de la instalación al CDN utilizando el comando Kickstart
rhsmsólo si no especifica un origen de instalación utilizandoinst.repo=en la línea de comandos del kernel o el comandourlen el archivo Kickstart. Debe utilizarinst.stage2=<URL>en la línea de comandos del kernel para obtener la imagen de instalación, pero sin especificar el origen de la instalación. -
Una URL de origen de instalación especificada mediante una opción de arranque o incluida en un archivo Kickstart tiene prioridad sobre la CDN, incluso si el archivo Kickstart contiene el comando
rhsmcon credenciales válidas. El sistema se registra, pero se instala desde la URL de origen de la instalación. Esto garantiza que los procesos de instalación anteriores funcionen con normalidad.
4.3.4.4. Verificar el registro de su sistema desde el CDN
Utilice este procedimiento para verificar que su sistema está registrado en el CDN utilizando la GUI.
not Sólo puede verificar su registro desde la CDN si ha hecho clic en el botón Begin Installation de la ventana Installation Summary. Una vez que haya hecho clic en el botón Begin Installation, no podrá volver a la ventana de resumen de la instalación para verificar su registro.
Requisito previo
- Ha completado el proceso de registro tal y como se documenta en Sección 3.3.2, “Registro e instalación de RHEL desde la CDN” y Registered aparece bajo Connect to Red Hat en la ventana Installation Summary.
Procedimiento
- En la ventana Installation Summary, seleccione Connect to Red Hat.
La ventana se abre y muestra un resumen del registro:
- Método
- Se muestra el nombre de la cuenta registrada o las claves de activación.
- Objetivo del sistema
- Si se establece, se muestra el rol, el SLA y los detalles de uso.
- Información
- Si se activa, se muestran los detalles de Insights.
- Número de suscripciones
- Se muestra el número de suscripciones adjuntas.
- Compruebe que el resumen del registro coincide con los datos introducidos.
4.3.4.5. Cómo anular el registro de su sistema en la CDN
Utilice este procedimiento para anular el registro de su sistema de la CDN utilizando la GUI.
- Puede anular el registro de la CDN si ha hecho clic en el botón la instalación de la ventana Installation Summary en not. Una vez que haya hecho clic en el botón la instalación, no podrá volver a la ventana Resumen de la instalación para anular el registro.
Al anular el registro, el programa de instalación pasa al primer repositorio disponible, en el siguiente orden:
- La URL utilizada en el parámetro de arranque inst.repo=<URL> en la línea de comandos del kernel.
- Un repositorio detectado automáticamente en el medio de instalación (USB o DVD).
Requisito previo
- Ha completado el proceso de registro tal y como se documenta en Sección 3.3.2, “Registro e instalación de RHEL desde la CDN” y Registered aparece bajo Connect to Red Hat en la ventana Installation Summary.
Procedimiento
- En la ventana Installation Summary, seleccione Connect to Red Hat.
La ventana Connect to Red Hat se abre y muestra un resumen del registro:
- Método
- Se muestra el nombre de la cuenta registrada o las claves de activación utilizadas.
- Objetivo del sistema
- Si se establece, se muestra el rol, el SLA y los detalles de uso.
- Información
- Si se activa, se muestran los detalles de Insights.
- Número de suscripciones
- Se muestra el número de suscripciones adjuntas.
- Haga clic en para eliminar el registro del CDN. Los detalles del registro original se muestran con un mensaje de Not registered que aparece en la parte media inferior de la ventana.
- Haga clic en para volver a la ventana Installation Summary.
- Connect to Red Hat muestra un mensaje Not registered, y Software Selection muestra un mensaje Red Hat CDN requires registration.
Después de anular el registro, es posible volver a registrar el sistema. Haga clic en Connect to Red Hat. Se rellenan los datos introducidos anteriormente. Edite los detalles originales o actualice los campos en función de la cuenta, el propósito y la conexión. Haga clic en para finalizar.
4.3.5. Configuración de la política de seguridad
Esta sección contiene información sobre la política de seguridad de Red Hat Enterprise Linux 8 y cómo configurarla para su uso en su sistema.
4.3.5.1. Sobre la política de seguridad
La política de seguridad de Red Hat Enterprise Linux se adhiere a las restricciones y recomendaciones (políticas de cumplimiento) definidas por el estándar Security Content Automation Protocol (SCAP). Los paquetes se instalan automáticamente. Sin embargo, por defecto, no se aplica ninguna política y, por tanto, no se realiza ninguna comprobación durante o después de la instalación, a menos que se configure específicamente.
La aplicación de una política de seguridad no es una característica obligatoria del programa de instalación. Si aplica una política de seguridad al sistema, éste se instala utilizando las restricciones y recomendaciones definidas en el perfil que haya seleccionado. El paquete openscap-scanner paquete se añade a su selección de paquetes, proporcionando una herramienta preinstalada para el cumplimiento y la exploración de vulnerabilidades. Una vez finalizada la instalación, el sistema se escanea automáticamente para verificar la conformidad. Los resultados de esta exploración se guardan en el directorio /root/openscap_data del sistema instalado. También puede cargar perfiles adicionales desde un servidor HTTP, HTTPS o FTP.
4.3.5.2. Configurar una política de seguridad
Complete los siguientes pasos para configurar una política de seguridad.
Requisito previo
La ventana Installation Summary está abierta.
Procedimiento
- En la ventana Installation Summary, haga clic en Security Policy. Se abre la ventana Security Policy.
- Para habilitar las políticas de seguridad en el sistema, cambie el interruptor Apply security policy a ON.
- Seleccione uno de los perfiles que aparecen en el panel superior.
Haga clic en .
Los cambios de perfil que debe aplicar antes de la instalación aparecen en el panel inferior.
NotaLos perfiles por defecto no requieren cambios antes de la instalación. Sin embargo, cargar un perfil personalizado puede requerir tareas previas a la instalación.
Haga clic en para utilizar un perfil personalizado. Se abre una ventana independiente que le permite introducir una URL para el contenido de seguridad válido.
- Haga clic en para recuperar la URL.
Haga clic en para volver a la ventana Security Policy.
NotaPuede cargar perfiles personalizados desde un servidor HTTP, HTTPS, o FTP. Utilice la dirección completa del contenido incluyendo el protocolo, como http://. Debe haber una conexión de red activa antes de poder cargar un perfil personalizado. El programa de instalación detecta el tipo de contenido automáticamente.
- Haga clic en para aplicar los ajustes y volver a la ventana Installation Summary.
4.4. Configuración de las opciones de software
Esta sección contiene información sobre la configuración del origen de la instalación y los ajustes de selección de software, y la activación de un repositorio.
4.4.1. Configurar el origen de la instalación
Complete los pasos de este procedimiento para configurar una fuente de instalación desde medios de instalación autodetectados, Red Hat CDN o la red.
Cuando la ventana Installation Summary se abre por primera vez, el programa de instalación intenta configurar una fuente de instalación basada en el tipo de medio que fue utilizado para arrancar el sistema. El DVD completo de Red Hat Enterprise Linux Server configura la fuente como medio local.
Requisitos previos
- Ha descargado la imagen de instalación completa.
- Has creado un medio físico de arranque.
- La ventana Installation Summary está abierta.
Procedimiento
En la ventana Installation Summary, haga clic en Installation Source. Se abre la ventana Installation Source.
- Revise la sección Auto-detected installation media para verificar los detalles. Esta opción está seleccionada por defecto si ha iniciado el programa de instalación desde un medio que contiene una fuente de instalación, por ejemplo, un DVD.
- Haga clic en para comprobar la integridad de los medios.
Revise la sección Additional repositories y observe que la casilla AppStream está seleccionada por defecto.
Importante- No additional configuration is necessary as the BaseOS and AppStream repositories are installed as part of the full installation image.
- Do not disable the AppStream repository check box if you want a full Red Hat Enterprise Linux 8 installation.
- Opcional: Seleccione la opción Red Hat CDN para registrar su sistema, adjuntar suscripciones a RHEL e instalar RHEL desde la Red Hat Content Delivery Network (CDN). Para más información, consulte la sección Registering and installing RHEL from the CDN.
Opcional: Seleccione la opción On the network para descargar e instalar los paquetes desde una ubicación de red en lugar de medios locales.
Nota- Si no desea descargar e instalar repositorios adicionales desde una ubicación de red, proceda a Sección 4.4.2, “Configuración de la selección de software”.
- Esta opción sólo está disponible cuando hay una conexión de red activa. Consulte Sección 4.3.3, “Configurar las opciones de red y de nombre de host” para obtener información sobre cómo configurar las conexiones de red en la GUI.
- Seleccione el menú desplegable On the network para especificar el protocolo de descarga de paquetes. Esta configuración depende del servidor que desee utilizar.
Escriba la dirección del servidor (sin el protocolo) en el campo de dirección. Si eliges NFS, se abre un segundo campo de entrada en el que puedes especificar un NFS mount options personalizado. Este campo acepta las opciones listadas en la página man
nfs(5).ImportanteAl seleccionar un origen de instalación NFS, debe especificar la dirección con dos puntos (
:) separando el nombre del host de la ruta. Por ejemplo:server.example.com:/path/to/directoryNotaLos siguientes pasos son opcionales y sólo son necesarios si se utiliza un proxy para el acceso a la red.
- Haga clic en .. para configurar un proxy para una fuente HTTP o HTTPS.
- Seleccione la casilla Enable HTTP proxy y escriba la URL en el campo Proxy Host.
- Seleccione la casilla Use Authentication si el servidor proxy requiere autenticación.
- Introduzca su nombre de usuario y su contraseña.
Haga clic en para finalizar la configuración y salir del cuadro de diálogo Proxy Setup….
NotaSi su URL HTTP o HTTPS hace referencia a un menú de réplica del repositorio, seleccione la opción requerida de la lista desplegable URL type. Todos los entornos y paquetes de software adicionales están disponibles para su selección cuando termine de configurar los orígenes.
- Haga clic en para añadir un repositorio.
- Haga clic en para eliminar un depósito.
- Haga clic en el icono de para revertir las entradas actuales a la configuración cuando abrió la ventana Installation Source.
Para activar o desactivar un repositorio, haga clic en la casilla de la columna Enabled de cada entrada de la lista.
NotaPuede nombrar y configurar su repositorio adicional de la misma manera que el repositorio principal en la red.
- Haga clic en para aplicar los ajustes y volver a la ventana Installation Summary.
4.4.2. Configuración de la selección de software
Utilice la ventana Software Selection para seleccionar los paquetes de software que necesite. Los paquetes están organizados por Entorno Base y Software Adicional.
- Base Environment contiene paquetes predefinidos. Sólo se puede seleccionar un entorno base, y la disponibilidad depende de la imagen ISO de instalación que se utilice como origen de la misma.
- Additional Software for Selected Environment contiene paquetes de software adicionales para el entorno base. Puede seleccionar varios paquetes de software.
Utilice un entorno predefinido y software adicional para personalizar su sistema. Sin embargo, en una instalación estándar, no puede seleccionar paquetes individuales para instalar. Para ver los paquetes contenidos en un entorno específico, consulte el archivo repository/repodata/*-comps-repository.architecture.xml de su medio de instalación (DVD, CD, USB). El archivo XML contiene detalles de los paquetes instalados como parte de un entorno base. Los entornos disponibles están marcados por la etiqueta <environment>, y los paquetes de software adicionales están marcados por la etiqueta <group>.
Si no está seguro de qué paquetes instalar, Red Hat le recomienda que seleccione el entorno base Minimal Install. La instalación mínima instala una versión básica de Red Hat Enterprise Linux con una cantidad mínima de software adicional. Después de que el sistema termine de instalarse y usted inicie la sesión por primera vez, puede utilizar el Yum package manager para instalar software adicional. Para más información sobre el gestor de paquetes Yum, consulte el Configuring basic system settings documento.
-
El comando
yum group listlista todos los grupos de paquetes de los repositorios de yum. Consulte el documento Configuring basic system settings para más información. -
Si necesita controlar qué paquetes se instalan, puede utilizar un archivo Kickstart y definir los paquetes en la sección
%packages. Consulte el documento Performing an advanced RHEL installation para obtener información sobre la instalación de Red Hat Enterprise Linux utilizando Kickstart.
Requisitos previos
- Ha configurado el origen de la instalación.
- El programa de instalación descargó los metadatos del paquete.
- La ventana Installation Summary está abierta.
Procedimiento
- En la ventana Installation Summary, haga clic en Software Selection. Se abre la ventana Software Selection.
En el panel Base Environment, seleccione un entorno base. Sólo puede seleccionar un entorno base.
NotaEl entorno base Server with GUI es el entorno base por defecto y lanza la aplicación Initial Setup después de que la instalación se complete y se reinicie el sistema.
- En el panel Additional Software for Selected Environment, seleccione una o varias opciones.
- Haga clic en para aplicar la configuración y volver a Capítulo 4, Personalización de la instalación.
4.5. Configuración de los dispositivos de almacenamiento
Puede instalar Red Hat Enterprise Linux en una gran variedad de dispositivos de almacenamiento. Puede configurar dispositivos de almacenamiento básicos, accesibles localmente, en la ventana Installation Destination. Los dispositivos de almacenamiento básicos conectados directamente al sistema local, tales como discos duros y unidades de estado sólido, se muestran en la sección Local Standard Disks de la ventana. En IBM Z, esta sección contiene dispositivos de almacenamiento de acceso directo (DASD) activados.
Un problema conocido impide que los DASD configurados como alias de HyperPAV se conecten automáticamente al sistema una vez finalizada la instalación. Estos dispositivos de almacenamiento están disponibles durante la instalación, pero no son accesibles inmediatamente después de terminar la instalación y reiniciar. Para adjuntar los dispositivos de alias de HyperPAV, agréguelos manualmente al archivo de configuración /etc/dasd.conf del sistema.
4.5.1. Selección del dispositivo de almacenamiento
La ventana de selección de dispositivos de almacenamiento enumera todos los dispositivos de almacenamiento a los que puede acceder el programa de instalación. Dependiendo de su sistema y del hardware disponible, es posible que algunas pestañas no se muestren. Los dispositivos se agrupan en las siguientes pestañas:
- Dispositivos multirruta
Dispositivos de almacenamiento accesibles a través de más de una ruta, como por ejemplo a través de varias controladoras SCSI o puertos Fiber Channel en el mismo sistema.
ImportanteEl programa de instalación sólo detecta los dispositivos de almacenamiento multirruta con números de serie de 16 o 32 caracteres.
- Otros dispositivos SAN
- Dispositivos disponibles en una red de área de almacenamiento (SAN).
- Firmware RAID
- Dispositivos de almacenamiento conectados a una controladora RAID de firmware.
- Dispositivos NVDIMM
- Bajo circunstancias específicas, Red Hat Enterprise Linux 8 puede arrancar y ejecutarse desde dispositivos (NVDIMM) en modo sectorial en las arquitecturas Intel 64 y AMD64.
- Dispositivos System z
- Dispositivos de almacenamiento, o unidades lógicas (LUNs), conectados a través del controlador FCP (Fiber Channel Protocol) de zSeries Linux.
4.5.2. Filtrado de dispositivos de almacenamiento
En la ventana de selección de dispositivos de almacenamiento puede filtrar los dispositivos de almacenamiento por su identificador mundial (WWID) o por el puerto, el objetivo o el número de unidad lógica (LUN).
Requisito previo
La ventana Installation Summary está abierta.
Procedimiento
- En la ventana Installation Summary, haga clic en Installation Destination. Se abre la ventana Installation Destination, con una lista de todas las unidades disponibles.
- En la sección Specialized & Network Disks, haga clic en Se abre la ventana de selección de dispositivos de almacenamiento.
Haga clic en la pestaña Search by para buscar por puerto, objetivo, LUN o WWID.
La búsqueda por WWID o LUN requiere valores adicionales en los campos de texto correspondientes.
- Seleccione la opción que desee en el menú desplegable Search.
- Haga clic en para iniciar la búsqueda. Cada dispositivo se presenta en una fila separada con su correspondiente casilla de verificación.
Seleccione la casilla para habilitar el dispositivo que necesite durante el proceso de instalación.
Más adelante en el proceso de instalación puede elegir instalar Red Hat Enterprise Linux en cualquiera de los dispositivos seleccionados y puede elegir montar cualquiera de los otros dispositivos seleccionados como parte del sistema instalado automáticamente.
Nota- Los dispositivos seleccionados no se borran automáticamente con el proceso de instalación y la selección de un dispositivo no pone en riesgo los datos almacenados en él.
-
Puede añadir dispositivos al sistema después de la instalación modificando el archivo
/etc/fstab.
- Haga clic en para volver a la ventana Installation Destination.
Los dispositivos de almacenamiento que no se seleccionen se ocultan por completo del programa de instalación. Para cargar en cadena el gestor de arranque desde un gestor de arranque diferente, seleccione todos los dispositivos presentes.
4.5.3. Uso de las opciones avanzadas de almacenamiento
Para utilizar un dispositivo de almacenamiento avanzado, puede configurar un objetivo iSCSI (SCSI sobre TCP/IP) o una SAN (red de área de almacenamiento) FCoE (canal de fibra sobre Ethernet).
Para utilizar dispositivos de almacenamiento iSCSI para la instalación, el programa de instalación debe ser capaz de descubrirlos como objetivos iSCSI y ser capaz de crear una sesión iSCSI para acceder a ellos. Cada uno de estos pasos puede requerir un nombre de usuario y una contraseña para la autenticación del Protocolo de Autenticación de Apretón de Manos (CHAP). Además, puede configurar un objetivo iSCSI para autenticar al iniciador iSCSI en el sistema al que está conectado el objetivo (CHAP inverso), tanto para el descubrimiento como para la sesión. Utilizados conjuntamente, CHAP y CHAP inverso se denominan CHAP mutuo o CHAP bidireccional. El CHAP mutuo proporciona el mayor nivel de seguridad para las conexiones iSCSI, especialmente si el nombre de usuario y la contraseña son diferentes para la autenticación CHAP y la autenticación CHAP inversa.
Repita los pasos de descubrimiento e inicio de sesión iSCSI para añadir todo el almacenamiento iSCSI necesario. No puede cambiar el nombre del iniciador iSCSI después de intentar la detección por primera vez. Para cambiar el nombre del iniciador iSCSI, debe reiniciar la instalación.
4.5.3.1. Descubrir e iniciar una sesión iSCSI
Complete los siguientes pasos para descubrir e iniciar una sesión iSCSI.
Requisitos previos
- La ventana Installation Summary está abierta.
Procedimiento
- En la ventana Installation Summary, haga clic en Installation Destination. Se abre la ventana Installation Destination, con una lista de todas las unidades disponibles.
- En la sección Specialized & Network Disks, haga clic en Se abre la ventana de selección de dispositivos de almacenamiento.
Haga clic en Se abre la ventana Add iSCSI Storage Target.
ImportanteNo puede colocar la partición
/booten objetivos iSCSI que haya añadido manualmente utilizando este método - un objetivo iSCSI que contenga una partición/bootdebe estar configurado para su uso con iBFT. Sin embargo, en los casos en los que se espera que el sistema instalado arranque desde iSCSI con la configuración de iBFT proporcionada por un método distinto al firmware iBFT, por ejemplo utilizando iPXE, puede eliminar la restricción de la partición/bootutilizando la opción de arranque del instaladorinst.nonibftiscsiboot.- Introduzca la dirección IP del objetivo iSCSI en el campo Target IP Address.
Introduzca un nombre en el campo iSCSI Initiator Name para el iniciador iSCSI en formato de nombre cualificado iSCSI (IQN). Una entrada IQN válida contiene la siguiente información:
-
La cadena
iqn.(nótese el punto). -
Un código de fecha que especifica el año y el mes en que se registró el nombre de dominio o subdominio de Internet de su organización, representado como cuatro dígitos para el año, un guión y dos dígitos para el mes, seguidos de un punto. Por ejemplo, represente septiembre de 2010 como
2010-09. -
El nombre del dominio o subdominio de Internet de su organización, presentado en orden inverso, con el dominio de nivel superior en primer lugar. Por ejemplo, represente el subdominio
storage.example.comcomocom.example.storage. Dos puntos seguidos de una cadena que identifica de forma exclusiva este iniciador iSCSI concreto dentro de su dominio o subdominio. Por ejemplo,
:diskarrays-sn-a8675309.El IQN completo es el siguiente:
iqn.2010-09.storage.example.com:diskarrays-sn-a8675309. El programa de instalación rellena previamente el campoiSCSI Initiator Namecon un nombre en este formato para ayudarle con la estructura. Para obtener más información sobre los IQN, consulte 3.2.6. iSCSI Names en RFC 3720 - Internet Small Computer Systems Interface (iSCSI) disponible en tools.ietf.org y 1. iSCSI Names and Addresses en RFC 3721 - Internet Small Computer Systems Interface (iSCSI) Naming and Discovery disponible en tools.ietf.org.
-
La cadena
Seleccione el menú desplegable
Discovery Authentication Typepara especificar el tipo de autenticación que se utilizará para la detección de iSCSI. Están disponibles las siguientes opciones:- Sin credenciales
- Pares CHAP
- Par CHAP y un par inverso
-
Si ha seleccionado
CHAP paircomo tipo de autenticación, introduzca el nombre de usuario y la contraseña del objetivo iSCSI en los camposCHAP UsernameyCHAP Password. -
Si ha seleccionado
CHAP pair and a reverse paircomo tipo de autenticación, introduzca el nombre de usuario y la contraseña del destino iSCSI en los camposCHAP UsernameyCHAP Password, y el nombre de usuario y la contraseña del iniciador iSCSI en los camposReverse CHAP UsernameyReverse CHAP Password.
-
Si ha seleccionado
-
Opcionalmente, seleccione la casilla
Bind targets to network interfaces. Haga clic en .
El programa de instalación intenta descubrir un objetivo iSCSI basándose en la información proporcionada. Si el descubrimiento tiene éxito, la ventana
Add iSCSI Storage Targetmuestra una lista de todos los nodos iSCSI descubiertos en el objetivo.Seleccione las casillas de verificación del nodo que desea utilizar para la instalación.
NotaEl menú
Node login authentication typecontiene las mismas opciones que el menúDiscovery Authentication Type. Sin embargo, si necesita credenciales para la autenticación de descubrimiento, utilice las mismas credenciales para iniciar sesión en un nodo descubierto.-
Haga clic en el menú desplegable
Use the credentials from discoveryadicional. Cuando proporcione las credenciales adecuadas, el botón de sesión estará disponible. - Haga clic en para iniciar una sesión iSCSI.
4.5.3.2. Configuración de los parámetros de FCoE
Complete los siguientes pasos para configurar los parámetros de FCoE.
Requisito previo
La ventana Installation Summary está abierta.
Procedimiento
- En la ventana Installation Summary, haga clic en Installation Destination. Se abre la ventana Installation Destination, con una lista de todas las unidades disponibles.
- En la sección Specialized & Network Disks, haga clic en Se abre la ventana de selección de dispositivos de almacenamiento.
- Haga clic en Se abre un cuadro de diálogo para que configure las interfaces de red para descubrir los dispositivos de almacenamiento FCoE.
-
Seleccione una interfaz de red que esté conectada a un switch FCoE en el menú desplegable
NIC. - Haga clic en para buscar dispositivos SAN en la red.
Seleccione las casillas necesarias:
- Use DCB: Data Center Bridging (DCB) es un conjunto de mejoras de los protocolos Ethernet diseñadas para aumentar la eficiencia de las conexiones Ethernet en las redes de almacenamiento y los clusters. Seleccione la casilla para activar o desactivar el conocimiento de DCB por parte del programa de instalación. Habilite esta opción sólo para las interfaces de red que requieren un cliente DCBX basado en el host. Para las configuraciones en interfaces que utilizan un cliente DCBX de hardware, desactive la casilla de verificación.
- Use auto vlan: Auto VLAN está activada por defecto e indica si se debe realizar el descubrimiento de la VLAN. Si esta casilla está activada, el protocolo de descubrimiento de VLAN FIP (FCoE Initiation Protocol) se ejecuta en la interfaz Ethernet cuando se ha validado la configuración del enlace. Si no están ya configuradas, se crean automáticamente interfaces de red para cualquier VLAN FCoE descubierta y se crean instancias FCoE en las interfaces VLAN.
-
Los dispositivos FCoE descubiertos se muestran en la pestaña
Other SAN Devicesde la ventana Installation Destination.
4.5.3.3. Configuración de dispositivos de almacenamiento DASD
Complete los siguientes pasos para configurar los dispositivos de almacenamiento DASD.
Requisito previo
La ventana Installation Summary está abierta.
Procedimiento
- En la ventana Installation Summary, haga clic en Installation Destination. Se abre la ventana Installation Destination, con una lista de todas las unidades disponibles.
- En la sección Specialized & Network Disks, haga clic en Se abre la ventana de selección de dispositivos de almacenamiento.
- Haga clic en . El cuadro de diálogo Add DASD Storage Target se abre y le pide que especifique un número de dispositivo, como 0.0.0204, y que adjunte los DASD adicionales que no se detectaron cuando se inició la instalación.
- Escriba el número de dispositivo del DASD que desea adjuntar en el campo Device number.
- Haga clic en .
-
Si se encuentra un DASD con el número de dispositivo especificado y si no está ya conectado, el cuadro de diálogo se cierra y las unidades recién descubiertas aparecen en la lista de unidades. A continuación, puede seleccionar las casillas de verificación de los dispositivos necesarios y hacer clic en . Los nuevos DASD están disponibles para su selección, marcados como
DASD device 0.0.xxxxen la sección Local Standard Disks de la ventana Installation Destination. - Si ha introducido un número de dispositivo no válido, o si el DASD con el número de dispositivo especificado ya está conectado al sistema, aparece un mensaje de error en el cuadro de diálogo, explicando el error y pidiéndole que lo intente de nuevo con un número de dispositivo diferente.
4.5.3.4. Configuración de los dispositivos FCP
Los dispositivos FCP permiten a IBM Z utilizar dispositivos SCSI en lugar de, o además de, dispositivos de almacenamiento de acceso directo (DASD). Los dispositivos FCP proporcionan una topología de tejido conmutado que permite a los sistemas IBM Z utilizar LUNs SCSI como dispositivos de disco además de los dispositivos DASD tradicionales.
Requisitos previos
- La ventana Installation Summary está abierta.
-
Para una instalación sólo de FCP, elimine la opción
DASD=del archivo de configuración de CMS o la opciónrd.dasd=del archivo de parámetros para indicar que no hay DASD.
Procedimiento
- En la ventana Installation Summary, haga clic en Installation Destination. Se abre la ventana Installation Destination, con una lista de todas las unidades disponibles.
- En la sección Specialized & Network Disks, haga clic en Se abre la ventana de selección de dispositivos de almacenamiento.
Haga clic en . Se abre el cuadro de diálogo Add zFCP Storage Target que permite añadir un dispositivo de almacenamiento FCP (Fibre Channel Protocol).
IBM Z requiere que introduzca cualquier dispositivo FCP manualmente para que el programa de instalación pueda activar los LUNs FCP. Puede introducir los dispositivos FCP en la instalación gráfica o como una entrada de parámetro única en el archivo de configuración de parámetros o CMS. Los valores que introduzca deben ser únicos para cada sitio que configure.
- Introduzca el número de dispositivo de 4 dígitos hexadecimales en el campo Device number.
- Introduzca los 16 dígitos hexadecimales del número de puerto mundial (WWPN) en el campo WWPN.
- Introduzca el identificador hexadecimal de 16 dígitos del LUN FCP en el campo LUN.
- Haga clic en para conectarse al dispositivo FCP.
Los dispositivos recién añadidos aparecen en la pestaña System z Devices de la ventana Installation Destination.
- La creación interactiva de un dispositivo FCP sólo es posible en modo gráfico. No es posible configurar un dispositivo FCP de forma interactiva en la instalación en modo texto.
- Utilice sólo letras minúsculas en los valores hexadecimales. Si introduce un valor incorrecto y hace clic en , el programa de instalación muestra una advertencia. Puede editar la información de configuración y volver a intentar la detección.
- Para obtener más información sobre estos valores, consulte la documentación del hardware y consulte al administrador del sistema.
4.5.4. Instalación en un dispositivo NVDIMM
Los dispositivos de módulo de memoria en línea doble no volátil (NVDIMM) combinan el rendimiento de la RAM con la persistencia de datos similar a la de un disco cuando no se suministra energía. Bajo circunstancias específicas, Red Hat Enterprise Linux 8 puede arrancar y ejecutarse desde dispositivos NVDIMM.
4.5.4.1. Criterios para utilizar un dispositivo NVDIMM como objetivo de instalación
Puede instalar Red Hat Enterprise Linux 8 en dispositivos de módulo de memoria en línea doble no volátil (NVDIMM) en modo sectorial en las arquitecturas Intel 64 y AMD64, con el apoyo del controlador nd_pmem.
Condiciones para utilizar un dispositivo NVDIMM como almacenamiento
Para utilizar un dispositivo NVDIMM como almacenamiento, deben cumplirse las siguientes condiciones:
- La arquitectura del sistema es Intel 64 o AMD64.
- El dispositivo NVDIMM está configurado en modo sectorial. El programa de instalación puede reconfigurar los dispositivos NVDIMM a este modo.
- El dispositivo NVDIMM debe ser compatible con el controlador nd_pmem.
Condiciones para arrancar desde un dispositivo NVDIMM
El arranque desde un dispositivo NVDIMM es posible bajo las siguientes condiciones:
- Se cumplen todas las condiciones para utilizar el dispositivo NVDIMM como almacenamiento.
- El sistema utiliza UEFI.
- El dispositivo NVDIMM debe ser compatible con el firmware disponible en el sistema, o con un controlador UEFI. El controlador UEFI puede cargarse desde una ROM opcional del propio dispositivo.
- El dispositivo NVDIMM debe estar disponible bajo un espacio de nombres.
Utilice el alto rendimiento de los dispositivos NVDIMM durante el arranque, coloque los directorios /boot y /boot/efi en el dispositivo. La función Execute-in-place (XIP) de los dispositivos NVDIMM no es compatible durante el arranque y el kernel se carga en la memoria convencional.
4.5.4.2. Configuración de un dispositivo NVDIMM mediante el modo de instalación gráfica
Un dispositivo de módulo de memoria en línea dual no volátil (NVDIMM) debe ser configurado correctamente para su uso por Red Hat Enterprise Linux 8 utilizando la instalación gráfica.
La reconfiguración de un proceso de dispositivo NVDIMM destruye cualquier dato almacenado en el dispositivo.
Requisitos previos
- Un dispositivo NVDIMM está presente en el sistema y satisface todas las demás condiciones para su uso como objetivo de instalación.
- La instalación ha arrancado y la ventana Installation Summary está abierta.
Procedimiento
- En la ventana Installation Summary, haga clic en Installation Destination. Se abre la ventana Installation Destination, con una lista de todas las unidades disponibles.
- En la sección Specialized & Network Disks, haga clic en Se abre la ventana de selección de dispositivos de almacenamiento.
- Haga clic en la pestaña NVDIMM Devices.
Para reconfigurar un dispositivo, selecciónelo en la lista.
Si un dispositivo no aparece en la lista, no está en modo sectorial.
- Haga clic en Se abre un diálogo de reconfiguración.
Introduzca el tamaño del sector que necesita y haga clic en .
Los tamaños de sector admitidos son 512 y 4096 bytes.
- Cuando se complete la reconfiguración, haga clic en .
- Seleccione la casilla de verificación del dispositivo.
Haga clic en para volver a la ventana Installation Destination.
El dispositivo NVDIMM que ha reconfigurado se muestra en la sección Specialized & Network Disks.
- Haga clic en para volver a la ventana Installation Summary.
El dispositivo NVDIMM está ahora disponible para que lo seleccione como destino de la instalación. Además, si el dispositivo cumple los requisitos para el arranque, puede establecerlo como dispositivo de arranque.
4.6. Configuración de la partición manual
Puede utilizar el particionamiento manual para configurar sus particiones de disco y puntos de montaje y definir el sistema de archivos en el que se instala Red Hat Enterprise Linux.
Antes de la instalación, debe considerar si desea utilizar dispositivos de disco con o sin particiones. Para obtener más información, consulte el artículo de la base de conocimientos en https://access.redhat.com/solutions/163853.
Una instalación de Red Hat Enterprise Linux requiere un mínimo de una partición pero Red Hat recomienda utilizar al menos las siguientes particiones o volúmenes: PReP, /, /home, /boot, y swap. También puede crear particiones y volúmenes adicionales según sus necesidades.
Una instalación de Red Hat Enterprise Linux en servidores IBM Power Systems requiere una partición de arranque PReP.
Para evitar la pérdida de datos, se recomienda hacer una copia de seguridad de los mismos antes de proceder. Si está actualizando o creando un sistema de arranque dual, debe hacer una copia de seguridad de los datos que desee conservar en sus dispositivos de almacenamiento.
4.6.1. Inicio de la partición manual
Requisitos previos
- Se muestra la pantalla Installation Summary.
- Todos los discos están disponibles para el programa de instalación.
Procedimiento
Seleccione los discos para la instalación:
- Haga clic en Installation Destination para abrir la ventana Installation Destination.
- Seleccione los discos que necesita para la instalación haciendo clic en el icono correspondiente. Un disco seleccionado tiene una marca de verificación en él.
- En Storage Configuration, seleccione el botón de radio Custom.
- Opcional: Para activar el cifrado de almacenamiento con LUKS, seleccione la casilla Encrypt my data.
- Haga clic en .
Si ha seleccionado cifrar el almacenamiento, se abre un cuadro de diálogo para introducir una frase de contraseña de cifrado del disco. Escriba la frase de contraseña LUKS:
Introduzca la frase de acceso en los dos campos de texto. Para cambiar la disposición del teclado, utilice el icono del teclado.
AvisoEn el cuadro de diálogo para introducir la frase de acceso, no se puede cambiar la disposición del teclado. Seleccione la disposición del teclado en inglés para introducir la frase de acceso en el programa de instalación.
- Haga clic en . Se abre la ventana Manual Partitioning.
Los puntos de montaje detectados aparecen en el panel izquierdo. Los puntos de montaje están organizados por instalaciones de sistemas operativos detectados. Como resultado, algunos sistemas de archivos pueden aparecer varias veces si una partición es compartida por varias instalaciones.
Seleccione los puntos de montaje en el panel izquierdo; las opciones que se pueden personalizar se muestran en el panel derecho.
NotaSi su sistema contiene sistemas de archivos existentes, asegúrese de que hay suficiente espacio disponible para la instalación. Para eliminar cualquier partición, selecciónela en la lista y haga clic en el botón .
El diálogo tiene una casilla de verificación que puede utilizar para eliminar todas las demás particiones utilizadas por el sistema al que pertenece la partición eliminada.
Si no hay particiones existentes y desea crear el conjunto recomendado de particiones como punto de partida, seleccione su esquema de particionamiento preferido en el panel izquierdo (el predeterminado para Red Hat Enterprise Linux es LVM) y haga clic en el enlace Click here to create them automatically.
Una partición
/boot, un volumen/(raíz) y un volumenswapproporcional al tamaño del almacenamiento disponible se crean y se enumeran en el panel izquierdo. Estos son los sistemas de archivos recomendados para una instalación típica, pero puede añadir sistemas de archivos y puntos de montaje adicionales.
- Haga clic en para confirmar los cambios y volver a la ventana Installation Summary.
4.6.2. Añadir un sistema de archivos de punto de montaje
Realice los siguientes pasos para añadir sistemas de archivos con múltiples puntos de montaje.
Requisitos previos
Planifique sus particiones:
-
Para evitar problemas con la asignación de espacio, cree primero particiones pequeñas con tamaños fijos conocidos, como
/boot, y luego cree las particiones restantes, dejando que el programa de instalación les asigne la capacidad restante. - Si desea instalar el sistema en varios discos, o si sus discos difieren en tamaño y una partición particular debe ser creada en el primer disco detectado por BIOS, entonces cree estas particiones primero.
-
Para evitar problemas con la asignación de espacio, cree primero particiones pequeñas con tamaños fijos conocidos, como
Procedimiento
- Haga clic en para crear un nuevo sistema de archivos de punto de montaje. Se abre el diálogo Add a New Mount Point.
-
Seleccione una de las rutas preestablecidas en el menú desplegable Mount Point o escriba la suya propia; por ejemplo, seleccione
/para la partición raíz o/bootpara la partición de arranque. Introduzca el tamaño del sistema de archivos en el campo Desired Capacity; por ejemplo,
2GiB.AvisoSi no especifica un valor en el campo Capacidad deseada, o si especifica un tamaño mayor que el espacio disponible, se utilizará todo el espacio libre restante.
- Haga clic en montaje para crear la partición y volver a la ventana Manual Partitioning.
4.6.3. Configuración de un sistema de archivos de punto de montaje
Este procedimiento describe cómo establecer el esquema de particionamiento para cada punto de montaje que se haya creado manualmente. Las opciones disponibles son Standard Partition, LVM, y LVM Thin Provisioning.
- El soporte de Btfrs ha sido eliminado en Red Hat Enterprise Linux 8.
-
La partición
/bootse encuentra siempre en una partición estándar, independientemente del valor seleccionado.
Procedimiento
- Para cambiar los dispositivos en los que debe ubicarse un punto de montaje que no sea LVM, seleccione el punto de montaje requerido en el panel de la izquierda.
- En el apartado Device(s), haga clic en Se abre el diálogo Configure Mount Point.
- Seleccione uno o más dispositivos y haga clic en para confirmar su selección y volver a la ventana Manual Partitioning.
Haga clic en para aplicar los cambios.
NotaHaga clic en el botón (botón de flecha circular) para actualizar todos los discos y particiones locales; esto sólo es necesario después de realizar la configuración avanzada de las particiones fuera del programa de instalación. Al hacer clic en el botón Volver a escanear , se restablecen todos los cambios de configuración realizados en el programa de instalación.
- En la parte inferior izquierda de la ventana Manual Partitioning, haga clic en el enlace storage device selected para abrir el diálogo Selected Disks y revisar la información del disco.
4.6.4. Personalizar una partición o un volumen
Puedes personalizar una partición o un volumen si quieres establecer una configuración específica.
Si /usr o /var se particionan por separado del resto del volumen raíz, el proceso de arranque se vuelve mucho más complejo ya que estos directorios contienen componentes críticos. En algunas situaciones, como cuando estos directorios se colocan en una unidad iSCSI o en una ubicación FCoE, el sistema no puede arrancar o se cuelga con un error Device is busy al apagar o reiniciar.
Esta limitación sólo se aplica a /usr o /var, no a los directorios que están por debajo de ellos. Por ejemplo, una partición separada para /var/www funciona con éxito.
Procedimiento
En el panel izquierdo, seleccione el punto de montaje.
Figura 4.1. Personalización de las particiones

En el panel derecho, puede personalizar las siguientes opciones:
-
Introduzca el punto de montaje del sistema de archivos en el campo Mount Point. Por ejemplo, si un sistema de archivos es el sistema de archivos raíz, introduzca
/; introduzca/bootpara el sistema de archivos/boot, y así sucesivamente. Para un sistema de archivos swap, no se debe establecer el punto de montaje, ya que es suficiente con establecer el tipo de sistema de archivos enswap. - Introduzca el tamaño del sistema de archivos en el campo Desired Capacity. Puede utilizar unidades de tamaño comunes como KiB o GiB. El valor por defecto es MiB si no se establece ninguna otra unidad.
Seleccione el tipo de dispositivo que necesita en el menú desplegable Device Type:
Standard Partition,LVM, oLVM Thin Provisioning.AvisoEl programa de instalación no es compatible con los thin pools LVM sobreaprovisionados.
NotaRAIDestá disponible sólo si se seleccionan dos o más discos para el particionamiento. Si seleccionaRAID, también puede establecer elRAID Level. Del mismo modo, si seleccionaLVM, puede especificar elVolume Group.- Seleccione la casilla Encrypt para cifrar la partición o el volumen. Deberá establecer una contraseña posteriormente en el programa de instalación. Aparece el menú desplegable LUKS Version.
- Seleccione la versión de LUKS que necesita en el menú desplegable.
Seleccione el tipo de sistema de archivos apropiado para esta partición o volumen en el menú desplegable File system.
NotaLa compatibilidad con el sistema de archivos
VFATno está disponible para las particiones del sistema Linux. Por ejemplo,/,/var,/usr, etc.- Seleccione la casilla Reformat para formatear una partición existente, o desactive la casilla Reformat para conservar sus datos. Las particiones y volúmenes recién creados deben ser reformateados, y la casilla de verificación no puede ser desactivada.
- Escriba una etiqueta para la partición en el campo Label. Utilice las etiquetas para reconocer y dirigir fácilmente las particiones individuales.
Escriba un nombre en el campo Name.
NotaTenga en cuenta que las particiones estándar se nombran automáticamente cuando se crean y no puede editar los nombres de las particiones estándar. Por ejemplo, no puede editar el nombre de
/bootsda1.
-
Introduzca el punto de montaje del sistema de archivos en el campo Mount Point. Por ejemplo, si un sistema de archivos es el sistema de archivos raíz, introduzca
Haga clic en para aplicar los cambios y, si es necesario, seleccione otra partición para personalizarla. Los cambios no se aplicarán hasta que haga clic en desde la ventana Installation Summary.
NotaHaga clic en para descartar los cambios de la partición.
Haga clic en cuando haya creado y personalizado todos los sistemas de archivos y puntos de montaje. Si elige cifrar un sistema de archivos, se le pedirá que cree una frase de contraseña.
Se abre un cuadro de diálogo Summary of Changes que muestra un resumen de todas las acciones de almacenamiento del programa de instalación.
- Haga clic en para aplicar los cambios y volver a la ventana Installation Summary.
4.6.5. Conservar el directorio /home
En una instalación gráfica de RHEL 8, puede conservar el directorio /home que se utilizaba en su sistema RHEL 7.
La conservación de /home sólo es posible si el directorio /home se encuentra en una partición separada de /home en su sistema RHEL 7.
Conservar el directorio /home que incluye varios ajustes de configuración, hace posible que el entorno de GNOME Shell en el nuevo sistema RHEL 8 esté configurado de la misma manera que lo estaba en su sistema RHEL 7. Tenga en cuenta que esto sólo se aplica a los usuarios en RHEL 8 con el mismo nombre de usuario y el mismo ID que en el sistema RHEL 7 anterior.
Complete este procedimiento para conservar el directorio /home de su sistema RHEL 7.
Requisitos previos
- El sistema RHEL 7 está instalado en su ordenador.
-
El directorio
/homese encuentra en una partición separada de/homeen su sistema RHEL 7. -
Se muestra la ventana de RHEL 8
Installation Summary.
Procedimiento
- Haga clic en Installation Destination para abrir la ventana Installation Destination.
- En Storage Configuration, seleccione el botón de opción Custom. Haga clic en Done.
- Haga clic en y se abrirá la ventana Manual Partitioning.
Elija la partición
/home, rellene/homeenMount Point:y desactive la casilla Reformat.Figura 4.2. Asegurarse de que /home no está formateado
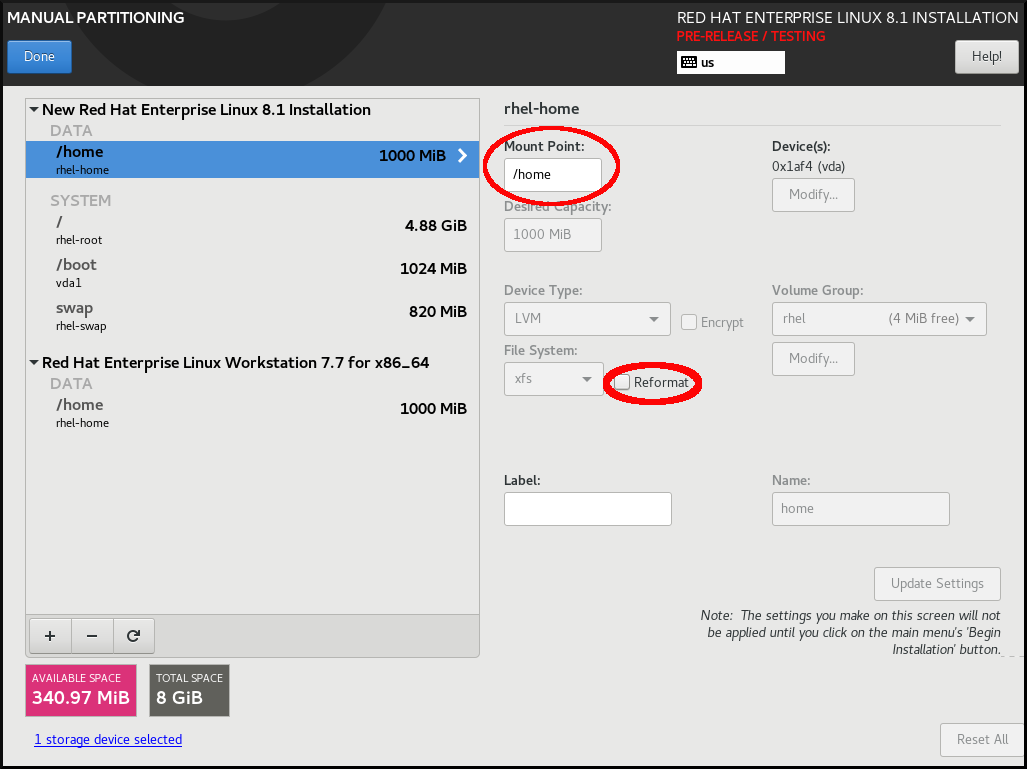
-
Opcional: También puede personalizar varios aspectos de la partición
/homenecesarios para su sistema RHEL 8 como se describe en Sección 4.6.4, “Personalizar una partición o un volumen”. Sin embargo, para conservar/homede su sistema RHEL 7, es necesario desactivar la casilla Reformat. - Después de personalizar todas las particiones de acuerdo con sus necesidades, haga clic en . Se abre el cuadro de diálogo Summary of changes.
-
Compruebe que el cuadro de diálogo Summary of changes no muestra ningún cambio para
/home. Esto significa que la partición/homese conserva. - Haga clic en para aplicarlos y volver a la ventana Installation Summary.
4.6.6. Creación de RAID por software
Siga los pasos de este procedimiento para crear un dispositivo RAID (Redundant Arrays of Independent Disks). Los dispositivos RAID se construyen a partir de varios dispositivos de almacenamiento que se organizan para proporcionar un mayor rendimiento y, en algunas configuraciones, una mayor tolerancia a los fallos.
Un dispositivo RAID se crea en un solo paso y los discos se añaden o eliminan según sea necesario. Puede configurar una partición RAID para cada disco físico de su sistema, por lo que el número de discos disponibles para el programa de instalación determina los niveles de dispositivo RAID disponibles. Por ejemplo, si su sistema tiene dos discos duros, no puede crear un dispositivo RAID 10, ya que requiere un mínimo de tres discos separados.
En IBM Z, el subsistema de almacenamiento utiliza RAID de forma transparente. No es necesario configurar manualmente el RAID por software.
Requisitos previos
- Si ha seleccionado dos o más discos para la instalación, las opciones de configuración de RAID serán visibles. Se necesitan al menos dos discos para crear un dispositivo RAID.
- Ha creado un punto de montaje. Al configurar un punto de montaje, se configura el dispositivo RAID.
-
Ha seleccionado el botón de radio
Customen la ventanaInstallation Destination.
Procedimiento
- En el panel izquierdo de la ventana Manual Partitioning, seleccione la partición deseada.
- En la sección Device(s), haga clic en . Se abre el cuadro de diálogo Configure Mount Point.
- Seleccione los discos que desea incluir en el dispositivo RAID y haga clic en .
- Haga clic en el menú desplegable Device Type y seleccione RAID.
- Haga clic en el menú desplegable File System y seleccione su tipo de sistema de archivos preferido.
- Haga clic en el menú desplegable RAID Level y seleccione su nivel preferido de RAID.
- Haga clic en para guardar los cambios.
- Haga clic en para aplicar los ajustes y volver a la ventana Installation Summary.
Se muestra un mensaje en la parte inferior de la ventana si el nivel RAID especificado requiere más discos.
4.6.7. Creación de un volumen lógico LVM
La gestión de volúmenes lógicos (LVM) presenta una visión lógica simple del espacio de almacenamiento físico subyacente, como los discos duros o los LUN. Las particiones en el almacenamiento físico se representan como volúmenes físicos que se pueden agrupar en grupos de volúmenes. Puedes dividir cada grupo de volúmenes en múltiples volúmenes lógicos, cada uno de los cuales es análogo a una partición de disco estándar. Por lo tanto, los volúmenes lógicos de LVM funcionan como particiones que pueden abarcar varios discos físicos.
La configuración de LVM sólo está disponible en el programa de instalación gráfica.
Durante la instalación en modo texto, la configuración LVM no está disponible. Para crear una configuración LVM, pulse Ctrl+Alt+F2 para utilizar una consola virtual diferente, y ejecute el comando lvm. Para volver a la instalación en modo texto, pulse Ctrl+Alt+F1.
Procedimiento
- En el panel izquierdo de la ventana Manual Partitioning, seleccione el punto de montaje.
Haga clic en el menú desplegable Device Type y seleccione
LVM. El menú desplegable Volume Group se muestra con el nombre del grupo de volumen recién creado.NotaNo se puede especificar el tamaño de los extensiones físicas del grupo de volúmenes en el diálogo de configuración. El tamaño siempre se establece en el valor por defecto de 4 MiB. Si quieres crear un grupo de volúmenes con diferentes extensiones físicas, debes crearlo manualmente cambiando a un shell interactivo y usando el comando
vgcreate, o usar un archivo Kickstart con el comandovolgroup --pesize=size. Consulte el documento Performing an advanced RHEL installation para más información sobre Kickstart.
Recursos adicionales
- Para más información sobre LVM, consulte el Configuring and managing logical volumes documento.
4.6.8. Configuración de un volumen lógico LVM
Siga los pasos de este procedimiento para configurar un volumen lógico LVM recién creado.
No es posible colocar la partición /boot en un volumen LVM.
Procedimiento
- En el panel izquierdo de la ventana Manual Partitioning, seleccione el punto de montaje.
-
Haga clic en el menú desplegable Device Type y seleccione
LVM. El menú desplegable Volume Group se muestra con el nombre del grupo de volumen recién creado. Haga clic en para configurar el grupo de volúmenes recién creado.
Se abre el cuadro de diálogo Configure Volume Group.
NotaNo se puede especificar el tamaño de los extensiones físicas del grupo de volúmenes en el diálogo de configuración. El tamaño siempre se establece en el valor por defecto de 4 MiB. Si quieres crear un grupo de volúmenes con diferentes extensiones físicas, debes crearlo manualmente cambiando a un shell interactivo y usando el comando
vgcreate, o usar un archivo Kickstart con el comandovolgroup --pesize=size. Consulte el documento Performing an advanced RHEL installation para más información sobre Kickstart.En el menú desplegable RAID Level, seleccione el nivel RAID que desee.
Los niveles RAID disponibles son los mismos que con los dispositivos RAID reales.
- Seleccione la casilla Encrypt para marcar el grupo de volúmenes para su encriptación.
En el menú desplegable Size policy, seleccione la política de tamaño para el grupo de volúmenes.
Las opciones políticas disponibles son:
- Automatic: El tamaño del grupo de volúmenes se establece automáticamente para que sea lo suficientemente grande como para contener los volúmenes lógicos configurados. Esto es óptimo si no necesita espacio libre dentro del grupo de volúmenes.
- As large as possible: El grupo de volúmenes se crea con el tamaño máximo, independientemente del tamaño de los volúmenes lógicos configurados que contiene. Esto es óptimo si planea mantener la mayoría de sus datos en LVM y más tarde necesita aumentar el tamaño de algunos volúmenes lógicos existentes, o si necesita crear volúmenes lógicos adicionales dentro de este grupo.
- Fixed: Puede establecer un tamaño exacto del grupo de volúmenes. Cualquier volumen lógico configurado debe encajar dentro de este tamaño fijo. Esto es útil si sabes exactamente el tamaño que necesitas que tenga el grupo de volúmenes.
- Haga clic en para aplicar la configuración y volver a la ventana Manual Partitioning.
- Haga clic en para guardar los cambios.
- Haga clic en para volver a la ventana Installation Summary.
4.7. Configurar una contraseña de root
Debe configurar una contraseña en root para finalizar el proceso de instalación y para acceder a la cuenta de administrador (también conocida como superusuario o raíz) que se utiliza para las tareas de administración del sistema. Estas tareas incluyen la instalación y actualización de paquetes de software y la modificación de la configuración de todo el sistema, como la configuración de la red y del cortafuegos, las opciones de almacenamiento y la adición o modificación de usuarios, grupos y permisos de archivos.
Utilice una o ambas de las siguientes formas para obtener privilegios de root en el sistema instalado:
- Utiliza una cuenta de root.
-
Cree una cuenta de usuario con privilegios administrativos (miembro del grupo wheel). La cuenta
rootse crea siempre durante la instalación. Cambie a la cuenta de administrador sólo cuando necesite realizar una tarea que requiera acceso de administrador.
La cuenta root tiene un control total sobre el sistema. Si personal no autorizado accede a la cuenta, puede acceder a los archivos personales de los usuarios o borrarlos.
Procedimiento
- En la ventana Installation Summary, seleccione User Settings > Root Password. Se abre la ventana Root Password.
Introduzca su contraseña en el campo Root Password.
Los requisitos y recomendaciones para crear una contraseña de root fuerte son:
- Must tener al menos ocho caracteres
- Puede contener números, letras (mayúsculas y minúsculas) y símbolos
- Distingue entre mayúsculas y minúsculas
- Introduzca la misma contraseña en el campo Confirm.
Haga clic en para confirmar su contraseña de root y volver a la ventana Installation Summary.
NotaSi ha procedido con una contraseña débil, debe hacer clic en dos veces.
4.8. Crear una cuenta de usuario
Se recomienda crear una cuenta de usuario para finalizar la instalación. Si no crea una cuenta de usuario, deberá iniciar la sesión en el sistema como root directamente, lo que se recomienda not.
Procedimiento
- En la ventana Installation Summary, seleccione User Settings > User Creation. Se abre la ventana Create User.
- Introduzca el nombre de la cuenta de usuario en el campo Full name, por ejemplo: Juan Pérez.
Introduzca el nombre de usuario en el campo User name, por ejemplo: jsmith.
NotaEl User name se utiliza para iniciar la sesión desde una línea de comandos; si se instala un entorno gráfico, el gestor de inicio de sesión gráfico utiliza el Full name.
Seleccione la casilla Make this user administrator si el usuario requiere derechos administrativos (el programa de instalación añade el usuario al grupo
wheel).ImportanteUn usuario administrador puede utilizar el comando
sudopara realizar tareas que sólo están disponibles pararootutilizando la contraseña del usuario, en lugar de la contraseña deroot. Esto puede ser más conveniente, pero también puede causar un riesgo de seguridad.Seleccione la casilla Require a password to use this account.
AvisoSi das privilegios de administrador a un usuario, verifica que la cuenta esté protegida por una contraseña. Nunca dé a un usuario privilegios de administrador sin asignar una contraseña a la cuenta.
- Introduzca una contraseña en el campo Password.
- Introduzca la misma contraseña en el campo Confirm password.
- Haga clic en para aplicar los cambios y volver a la ventana Installation Summary.
4.8.1. Edición de la configuración avanzada del usuario
Siga los pasos de este procedimiento para editar la configuración predeterminada de la cuenta de usuario en el cuadro de diálogo Advanced User Configuration.
Procedimiento
- En la ventana Create User, haga clic en .
-
Edite los detalles en el campo Home directory, si es necesario. El campo se rellena por defecto con
/home/username. En la sección User and Groups IDs puedes:
Seleccione la casilla Specify a user ID manually y utilice o para introducir el valor deseado.
NotaEl valor por defecto es 1000. Los ID de usuario (UID) 0-999 están reservados por el sistema, por lo que no pueden ser asignados a un usuario.
Seleccione la casilla Specify a group ID manually y utilice o para introducir el valor deseado.
NotaEl nombre de grupo por defecto es el mismo que el nombre de usuario, y el ID de grupo (GID) por defecto es 1000. Los GIDs 0-999 están reservados por el sistema por lo que no pueden ser asignados a un grupo de usuarios.
Especifique grupos adicionales como una lista separada por comas en el campo Group Membership. Se crean los grupos que aún no existen; puede especificar GIDs personalizados para grupos adicionales entre paréntesis. Si no especifica un GID personalizado para un nuevo grupo, el nuevo grupo recibe un GID automáticamente.
NotaLa cuenta de usuario creada siempre tiene una pertenencia a un grupo por defecto (el grupo por defecto del usuario con un ID establecido en el campo Specify a group ID manually ).
- Haga clic en para aplicar las actualizaciones y volver a la ventana Create User.
Capítulo 5. Completar las tareas posteriores a la instalación
Esta sección describe cómo completar las siguientes tareas posteriores a la instalación:
- Completar la configuración inicial
Registrar su sistema
NotaDependiendo de sus necesidades, existen varios métodos para registrar su sistema. La mayoría de estos métodos se completan como parte de las tareas posteriores a la instalación. Sin embargo, la Red Hat Content Delivery Network (CDN) registra su sistema y adjunta las suscripciones de RHEL before el proceso de instalación comienza. Consulte Sección 3.3.2, “Registro e instalación de RHEL desde la CDN” para más información.
- Asegurar su sistema
5.1. Completar la configuración inicial
Esta sección contiene información sobre cómo completar la configuración inicial en un sistema Red Hat Enterprise Linux 8.
- Si ha seleccionado el entorno base Server with GUI durante la instalación, la ventana Initial Setup se abrirá la primera vez que reinicie el sistema una vez finalizado el proceso de instalación.
- Si ha registrado e instalado RHEL desde la CDN, la opción del Gestor de suscripciones muestra una nota que indica que todos los productos instalados están cubiertos por derechos válidos.
La información mostrada en la ventana Initial Setup puede variar dependiendo de lo que se haya configurado durante la instalación. Como mínimo, se muestran las opciones Licensing y Subscription Manager.
Requisitos previos
- Ha completado la instalación gráfica según el flujo de trabajo recomendado descrito en Sección 3.2, “Instalación de RHEL mediante una imagen ISO desde el Portal del Cliente”.
- Tiene una suscripción activa a Red Hat Enterprise Linux sin evaluación.
Procedimiento
En la ventana Initial Setup, seleccione Licensing Information.
La ventana License Agreement se abre y muestra los términos de licencia de Red Hat Enterprise Linux.
Revise el acuerdo de licencia y seleccione la casilla I accept the license agreement.
NotaDebe aceptar el acuerdo de licencia. Salir de Initial Setup sin completar este paso provoca un reinicio del sistema. Cuando el proceso de reinicio se haya completado, se le pedirá que acepte el acuerdo de licencia de nuevo.
Haga clic en para aplicar los ajustes y volver a la ventana Initial Setup.
NotaSi no ha configurado los ajustes de red, no podrá registrar su sistema inmediatamente. En este caso, haga clic en . Red Hat Enterprise Linux 8 se inicia y puede iniciar sesión, activar el acceso a la red y registrar su sistema. Vea Sección 5.3, “Registro de su sistema mediante la interfaz de usuario del Gestor de Suscripciones” para más información. Si configuró los ajustes de red, como se describe en Sección 4.3.3, “Configurar las opciones de red y de nombre de host”, puede registrar su sistema inmediatamente, como se muestra en los pasos siguientes:
En la ventana Initial Setup, seleccione Subscription Manager.
ImportanteSi ha registrado e instalado RHEL desde la CDN, la opción del Gestor de suscripciones muestra una nota que indica que todos los productos instalados están cubiertos por derechos válidos.
- La interfaz gráfica Subscription Manager se abre y muestra la opción que va a registrar, que es subscription.rhsm.redhat.com.
- Haga clic en .
- Introduzca sus datos de Login y Password y haga clic en .
- Confirme los datos de la suscripción y haga clic en . Debe recibir el siguiente mensaje de confirmación Registration with Red Hat Subscription Management is Done!
- Haga clic en . Se abre la ventana Initial Setup.
- Haga clic en . Se abre la ventana de inicio de sesión.
- Configure su sistema. Consulte el Configuring basic system settings para más información.
Recursos adicionales
En función de sus necesidades, existen cinco métodos para registrar su sistema:
- Utilizar la Red Hat Content Delivery Network (CDN) para registrar su sistema, adjuntar suscripciones a RHEL e instalar Red Hat Enterprise Linux. Consulte Sección 3.3.2, “Registro e instalación de RHEL desde la CDN” para obtener más información.
- Durante la instalación mediante Initial Setup.
- Después de la instalación mediante la línea de comandos. Consulte Sección 5.2, “Registrar el sistema mediante la línea de comandos” para obtener más información.
- Después de la instalación mediante la interfaz de usuario del Gestor de Suscripciones. Consulte Sección 5.3, “Registro de su sistema mediante la interfaz de usuario del Gestor de Suscripciones” para obtener más información.
- Después de la instalación utilizando el Asistente de registro. El Asistente de registro está diseñado para ayudarle a elegir la opción de registro más adecuada para su entorno de Red Hat Enterprise Linux. Vea https://access.redhat.com/labs/registrationassistant/ para más información.
5.2. Registrar el sistema mediante la línea de comandos
Esta sección contiene información sobre cómo registrar su sistema Red Hat Enterprise Linux 8 utilizando la línea de comandos.
Cuando se autoadjunta un sistema, el servicio de suscripción comprueba si el sistema es físico o virtual, así como cuántos sockets hay en el sistema. Un sistema físico suele consumir dos derechos, un sistema virtual suele consumir uno. Se consume un derecho por cada dos sockets en un sistema.
Requisitos previos
- Tiene una suscripción activa a Red Hat Enterprise Linux sin evaluación.
- Su estado de suscripción a Red Hat está verificado.
- No ha recibido previamente una suscripción a Red Hat Enterprise Linux 8.
- Ha activado su suscripción antes de intentar descargar derechos desde el Portal del Cliente. Necesita una asignación de derechos para cada instancia que piense utilizar. El Servicio de Atención al Cliente de Red Hat está disponible si necesita ayuda para activar su suscripción.
- Ha instalado correctamente Red Hat Enterprise Linux 8 y ha iniciado la sesión en el sistema.
Procedimiento
Abra una ventana de terminal y registre una suscripción utilizando su nombre de usuario y contraseña del Portal del Cliente de Red Hat:
# subscription-manager register --username [nombre de usuario] --password [contraseña]Cuando la suscripción se registra con éxito, se muestra una salida similar a la siguiente:
# The system has been registered with ID: 123456abcdef # The registered system name is: localhost.localdomainEstablezca la función del sistema, por ejemplo:
# subscription-manager role --set="Red Hat Enterprise Linux Server"NotaLos roles disponibles dependen de las suscripciones que haya adquirido la organización y de la arquitectura del sistema RHEL 8. Puede establecer uno de los siguientes roles:
Red Hat Enterprise Linux Server,Red Hat Enterprise Linux Workstation, oRed Hat Enterprise Linux Compute Node.Establezca el nivel de servicio para el sistema, por ejemplo:
# subscription-manager service-level --set="Premium"Establezca el uso para el sistema, por ejemplo:
# subscription-manager usage --set="Production"Adjunte el sistema a una asignación de derechos que coincida con la arquitectura del sistema anfitrión:
# subscription-manager attachCuando la suscripción se adjunta con éxito, se muestra una salida similar a la siguiente:
Installed Product Current Status: Product Name: Red Hat Enterprise Linux for x86_64 Status: SubscribedNotaTambién puede registrar Red Hat Enterprise Linux 8 iniciando sesión en el sistema como usuario
rooty utilizando la interfaz gráfica de usuario del Gestor de suscripciones.
5.3. Registro de su sistema mediante la interfaz de usuario del Gestor de Suscripciones
Esta sección contiene información sobre cómo registrar su sistema Red Hat Enterprise Linux 8 utilizando la Interfaz de usuario del Gestor de suscripciones para recibir actualizaciones y acceder a los repositorios de paquetes.
Requisitos previos
- Ha completado la instalación gráfica según el flujo de trabajo recomendado descrito en Sección 3.2, “Instalación de RHEL mediante una imagen ISO desde el Portal del Cliente”.
- Tiene una suscripción activa a Red Hat Enterprise Linux sin evaluación.
- Su estado de suscripción a Red Hat está verificado.
Procedimiento
- Inicie sesión en su sistema.
- En la parte superior izquierda de la ventana, haga clic en Activities.
- En las opciones de menú, haga clic en el icono Show Applications.
- Haga clic en el icono Red Hat Subscription Manager, o introduzca Red Hat Subscription Manager en la búsqueda.
Introduzca su contraseña de administrador en el cuadro de diálogo Authentication Required.
NotaLa autenticación es necesaria para realizar tareas privilegiadas en el sistema.
- Se abre la ventana Subscriptions, que muestra el estado actual de las suscripciones, el propósito del sistema y los productos instalados. Los productos no registrados muestran una X roja.
- Haga clic en el botón de .
- Se abre el cuadro de diálogo Register System. Introduzca sus credenciales de Customer Portal y haga clic en el botón .
El botón Register de la ventana Subscriptions cambia a Unregister y los productos instalados muestran una X verde. Puede solucionar un registro fallido mediante el comando subscription-manager status.
Recursos adicionales
- Para obtener más información sobre el uso y la configuración de Subscription Manager, consulte el Using and Configuring Red Hat Subscription Manager documento.
- Para obtener información sobre la preparación de suscripciones en la gestión de suscripciones, la configuración de virt-who y el registro de máquinas virtuales para que hereden una suscripción de su hipervisor, consulte el documento Configuring Virtual Machine Subscriptions in Red Hat Subscription Management documento.
5.4. Asistente de registro
El Asistente de registro está diseñado para ayudarle a elegir la opción de registro más adecuada para su entorno de Red Hat Enterprise Linux. Consulte https://access.redhat.com/labs/registrationassistant/ para obtener más información.
5.5. Configuración de System Purpose mediante la herramienta de línea de comandos syspurpose
El propósito del sistema es una característica opcional pero recomendada de la instalación de Red Hat Enterprise Linux. Usted utiliza el Propósito del Sistema para registrar el uso previsto de un sistema Red Hat Enterprise Linux 8, y asegurar que el servidor de asignación de derechos asigne automáticamente la suscripción más apropiada a su sistema. La herramienta de línea de comandos syspurpose es parte del paquete python3_syspurpose.rpm. Si el Propósito del Sistema no fue configurado durante el proceso de instalación, puede utilizar la herramienta de línea de comandos syspurpose después de la instalación para establecer los atributos requeridos.
Requisitos previos
- Ha instalado y registrado su sistema Red Hat Enterprise Linux 8, pero el Propósito del Sistema no está configurado.
-
Está conectado como usuario de
root. El paquete
python3_syspurpose.rpmestá disponible en su sistema.NotaSi su sistema está registrado pero tiene suscripciones que no satisfacen el propósito requerido, puede ejecutar el comando
subscription-manager remove --allpara eliminar las suscripciones adjuntas. A continuación, puede utilizar la herramienta de línea de comandossyspurposepara establecer los atributos de propósito requeridos, y ejecutarsubscription-manager attach --autopara habilitar el sistema con los atributos actualizados.Procedimiento
Realice los pasos de este procedimiento para configurar el Propósito del Sistema tras la instalación mediante la herramienta de línea de comandos
syspurpose. Los valores seleccionados son utilizados por el servidor de asignación de derechos para adjuntar la suscripción más adecuada a su sistema.Desde una ventana de terminal, ejecute el siguiente comando para establecer el rol previsto del sistema:
# syspurpose set-role "VALUE"Sustituya
VALUEpor el rol que desea asignar:-
Red Hat Enterprise Linux Server -
Red Hat Enterprise Linux Workstation -
Red Hat Enterprise Linux Compute Node
Por ejemplo:
# syspurpose set-role \ "Red Hat Enterprise Linux Server"Es opcional: Ejecute el siguiente comando para desactivar el rol:
# syspurpose unset-role
-
Ejecute el siguiente comando para establecer el Acuerdo de Nivel de Servicio (SLA) previsto del sistema:
# syspurpose set-sla \ "VALUE"Sustituya
VALUEpor el SLA que desee asignar:-
Premium -
Standard -
Self-Support
Por ejemplo:
# syspurpose set-sla \N-"Standard"Opcional: Ejecute el siguiente comando para desajustar el SLA:
# syspurpose unset-sla
-
Ejecute el siguiente comando para establecer el uso previsto del sistema:
# syspurpose set-usage "VALUE"Sustituya
VALUEpor el uso que desee asignar:-
Production -
Disaster Recovery -
Development/Test
Por ejemplo:
# syspurpose set-usage \ "Production"Es opcional: Ejecute el siguiente comando para deshabilitar el uso:
# syspurpose unset-usage
-
Ejecute el siguiente comando para mostrar las propiedades actuales del propósito del sistema:
# syspurpose showEs opcional: Ejecute el siguiente comando para acceder a la página man de
syspurpose:# man syspurpose
5.6. Asegurar su sistema
Complete los siguientes pasos relacionados con la seguridad inmediatamente después de instalar Red Hat Enterprise Linux.
Requisitos previos
- Ha completado la instalación gráfica.
Procedimiento
Para actualizar su sistema, ejecute el siguiente comando como root:
# yum updateAunque el servicio de cortafuegos,
firewalld, se habilita automáticamente con la instalación de Red Hat Enterprise Linux, hay escenarios en los que podría estar explícitamente deshabilitado, por ejemplo en una configuración de Kickstart. En este caso, se recomienda volver a habilitar el cortafuegos.Para iniciar
firewalld, ejecute los siguientes comandos como root:# systemctl start firewalld # systemctl enable firewalldPara mejorar la seguridad, desactive los servicios que no necesite. Por ejemplo, si su sistema no tiene impresoras instaladas, desactive el servicio de tazas mediante el siguiente comando:
# systemctl mask cupsPara revisar los servicios activos, ejecute el siguiente comando:
$ systemctl list-units | grep service
5.7. Implantación de sistemas que cumplen con un perfil de seguridad inmediatamente después de una instalación
Puede utilizar el paquete OpenSCAP para desplegar sistemas RHEL que cumplan con un perfil de seguridad, como OSPP o PCI-DSS, inmediatamente después del proceso de instalación. Utilizando este método de despliegue, puede aplicar reglas específicas que no se pueden aplicar más tarde utilizando scripts de corrección, por ejemplo, una regla para la fuerza de la contraseña y la partición.
5.7.1. Implantación de sistemas RHEL compatibles con la línea de base mediante la instalación gráfica
Utilice este procedimiento para desplegar un sistema RHEL que esté alineado con una línea de base específica. Este ejemplo utiliza el perfil de protección para el sistema operativo de uso general (OSPP).
Requisitos previos
-
Ha iniciado el programa de instalación
graphical. Tenga en cuenta que el OSCAP Anaconda Add-on no admite la instalación de sólo texto. -
Ha accedido a la ventana
Installation Summary.
Procedimiento
-
En la ventana
Installation Summary, haga clic enSoftware Selection. Se abre la ventanaSoftware Selection. En el panel
Base Environment, seleccione el entornoServer. Sólo puede seleccionar un entorno base.AvisoNo utilice el entorno base de
Server with GUIsi desea desplegar un sistema compatible. Los perfiles de seguridad proporcionados como parte de SCAP Security Guide pueden no ser compatibles con el conjunto de paquetes extendidos deServer with GUI. Para más información, consulte, por ejemplo, BZ#1648162, BZ#1787156 o BZ#1816199.-
Haga clic en
Donepara aplicar la configuración y volver a la ventanaInstallation Summary. -
Haga clic en
Security Policy. Se abre la ventanaSecurity Policy. -
Para habilitar las políticas de seguridad en el sistema, cambie el interruptor
Apply security policyaON. -
Seleccione
Protection Profile for General Purpose Operating Systemsen el panel de perfiles. -
Haga clic en
Select Profilepara confirmar la selección. -
Confirme los cambios en el panel
Changes that were done or need to be doneque aparece en la parte inferior de la ventana. Complete los cambios manuales restantes. -
Dado que OSPP tiene estrictos requisitos de partición que deben cumplirse, cree particiones separadas para
/boot,/home,/var,/var/log,/var/tmpy/var/log/audit. Completa el proceso de instalación gráfica.
NotaEl programa de instalación gráfica crea automáticamente un archivo Kickstart correspondiente después de una instalación exitosa. Puede utilizar el archivo
/root/anaconda-ks.cfgpara instalar automáticamente sistemas compatibles con OSPP.
Pasos de verificación
Para comprobar el estado actual del sistema una vez finalizada la instalación, reinicie el sistema e inicie un nuevo análisis:
# oscap xccdf eval --profile ospp --report eval_postinstall_report.html /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
Recursos adicionales
- Para más detalles sobre la partición, consulte Configuración de la partición manual.
5.7.2. Implantación de sistemas RHEL compatibles con la línea de base mediante Kickstart
Utilice este procedimiento para desplegar sistemas RHEL que estén alineados con una línea de base específica. Este ejemplo utiliza el perfil de protección para el sistema operativo de uso general (OSPP).
Requisitos previos
-
El paquete
scap-security-guideestá instalado en su sistema RHEL 8.
Procedimiento
-
Abra el archivo
/usr/share/scap-security-guide/kickstart/ssg-rhel8-ospp-ks.cfgKickstart en un editor de su elección. Actualice el esquema de particiones para que se ajuste a sus requisitos de configuración. Para el cumplimiento de OSPP, las particiones separadas para
/boot,/home,/var,/var/log,/var/tmp, y/var/log/auditdeben ser preservadas, y sólo puede cambiar el tamaño de las particiones.AvisoDado que el plugin
OSCAP Anaconda Addonno admite la instalación de sólo texto, no utilice la opcióntexten su archivo Kickstart. Para más información, consulte RHBZ#1674001.- Inicie una instalación Kickstart como se describe en Realización de una instalación automatizada mediante Kickstart.
Las contraseñas en forma de hash no pueden ser verificadas para los requisitos de OSPP.
Pasos de verificación
Para comprobar el estado actual del sistema una vez finalizada la instalación, reinicie el sistema e inicie un nuevo análisis:
# oscap xccdf eval --profile ospp --report eval_postinstall_report.html /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
Recursos adicionales
- Para más detalles, consulte la página del proyecto OSCAP Anaconda Addon.
5.8. Próximos pasos
Cuando haya completado los pasos necesarios después de la instalación, puede configurar los ajustes básicos del sistema. Para obtener información sobre la realización de tareas como la instalación de software con yum, el uso de systemd para la gestión de servicios, la gestión de usuarios, grupos y permisos de archivos, el uso de chrony para configurar NTP y el trabajo con Python 3, consulte el documento Configuring basic system settings documento.
Apéndice A. Solución de problemas
Las siguientes secciones cubren varias informaciones de solución de problemas que pueden ser útiles para diagnosticar problemas durante las diferentes etapas del proceso de instalación.
A.1. Solución de problemas al inicio del proceso de instalación
La información de resolución de problemas de las siguientes secciones puede ser útil para diagnosticar problemas al inicio del proceso de instalación. Las siguientes secciones son para todas las arquitecturas soportadas. Sin embargo, si un problema es para una arquitectura en particular, se especifica al principio de la sección.
A.1.1. Dracut
Dracut es una herramienta que gestiona la imagen initramfs durante el proceso de arranque del sistema operativo Linux. El shell de emergencia dracut es un modo interactivo que puede iniciarse mientras se carga la imagen initramfs. Puede ejecutar comandos básicos de solución de problemas desde el shell de emergencia dracut. Para más información, consulte la sección Troubleshooting de la página man dracut.
A.1.2. Uso de los archivos de registro de la instalación
Para fines de depuración, el programa de instalación registra las acciones de instalación en archivos que se encuentran en el directorio /tmp. Estos archivos de registro se enumeran en la siguiente tabla.
| Archivo de registro | Contenido |
|---|---|
|
| Mensajes generales. |
|
| Todos los programas externos se ejecutan durante la instalación. |
|
| Amplia información del módulo de almacenamiento. |
|
| mensajes de instalación de paquetes yum y rpm. |
|
|
Información sobre la sesión de |
|
| Información sobre los scripts de red. |
|
| Información de configuración que no forma parte de otros registros y que no se copia en el sistema instalado. |
|
| Mensajes del sistema relacionados con el hardware. |
Si la instalación falla, los mensajes se consolidan en /tmp/anaconda-tb-identifier, donde el identificador es una cadena aleatoria. Después de una instalación exitosa, estos archivos se copian en el sistema instalado bajo el directorio /var/log/anaconda/. Sin embargo, si la instalación no tiene éxito, o si se utilizan las opciones inst.nosave=all o inst.nosave=logs al arrancar el sistema de instalación, estos registros sólo existen en el disco RAM del programa de instalación. Esto significa que los registros no se guardan permanentemente y se pierden cuando se apaga el sistema. Para almacenarlos permanentemente, copie los archivos a otro sistema en la red o cópielos en un dispositivo de almacenamiento montado, como una unidad flash USB.
A.1.2.1. Creación de archivos de registro de preinstalación
Utilice este procedimiento para configurar la opción inst.debug para crear archivos de registro antes de que se inicie el proceso de instalación. Estos archivos de registro contienen, por ejemplo, la configuración de almacenamiento actual.
Requisitos previos
- Se muestra el menú de arranque de Red Hat Enterprise Linux.
Procedimiento
- Seleccione la opción Install Red Hat Enterprise Linux en el menú de arranque.
- Pulse la tecla Tab en sistemas basados en BIOS o la tecla e en sistemas basados en UEFI para editar las opciones de arranque seleccionadas.
Añade
inst.debuga las opciones. Por ejemplo:vmlinuz ... inst.debug-
Pulse la tecla Enter de su teclado. El sistema almacena los archivos de registro de preinstalación en el directorio
/tmp/pre-anaconda-logs/antes de que se inicie el programa de instalación. - Para acceder a los archivos de registro, cambie a la consola.
Cambie al directorio
/tmp/pre-anaconda-logs/:# cd /tmp/pre-anaconda-logs/
A.1.2.2. Transferencia de archivos de registro de instalación a una unidad USB
Utilice este procedimiento para transferir los archivos de registro de la instalación a una unidad USB.
Requisitos previos
- Haga una copia de seguridad de los datos de la unidad USB antes de utilizar este procedimiento.
- Está conectado a una cuenta de root y tiene acceso al sistema de archivos temporales del programa de instalación.
Procedimiento
- Pulse Ctrl Alt F2 para acceder a un prompt de shell en el sistema que está instalando.
Conecte una unidad flash USB al sistema y ejecute el comando
dmesg:# dmesgSe muestra un registro que detalla todos los eventos recientes. Al final de este registro, se muestra un conjunto de mensajes. Por ejemplo:
[ 170.171135] sd 5:0:0:0: [sdb] Disco extraíble SCSI conectado-
Anote el nombre del dispositivo conectado. En el ejemplo anterior, es
sdb. Navegue hasta el directorio
/mnty cree un nuevo directorio que sirva como objetivo de montaje para la unidad USB. Este ejemplo utiliza el nombreusb:# mkdir usbMonte la unidad flash USB en el directorio recién creado. En la mayoría de los casos, no querrá montar toda la unidad, sino una partición de la misma. No utilice el nombre
sdb, utilice el nombre de la partición en la que desea escribir los archivos de registro. En este ejemplo, se utiliza el nombresdb1:# mount /dev/sdb1 /mnt/usbCompruebe que ha montado el dispositivo y la partición correctos accediendo a ellos y listando su contenido:
# cd /mnt/usb# lsCopie los archivos de registro en el dispositivo montado.
# cp /tmp/*log /mnt/usbDesmonte la unidad flash USB. Si recibe un mensaje de error indicando que el objetivo está ocupado, cambie su directorio de trabajo a otro fuera del montaje (por ejemplo, /).
# umount /mnt/usb
A.1.2.3. Transferencia de archivos de registro de instalación a través de la red
Utilice este procedimiento para transferir los archivos de registro de la instalación a través de la red.
Requisitos previos
- Está conectado a una cuenta de root y tiene acceso al sistema de archivos temporales del programa de instalación.
Procedimiento
- Pulse Ctrl Alt F2 para acceder a un prompt de shell en el sistema que está instalando.
Cambie al directorio
/tmpdonde se encuentran los archivos de registro:# cd /tmpCopie los archivos de registro en otro sistema de la red mediante el comando
scp:# scp *log usuario@dirección:rutaSustituya user por un nombre de usuario válido en el sistema de destino, address por la dirección o el nombre de host del sistema de destino y path por la ruta del directorio en el que desea guardar los archivos de registro. Por ejemplo, si desea iniciar sesión como
johnen un sistema con una dirección IP de 192.168.0.122 y colocar los archivos de registro en el directorio/home/john/logs/de ese sistema, el comando es el siguiente:# scp *log john@192.168.0.122:/home/john/logs/Cuando se conecta al sistema de destino por primera vez, el cliente SSH le pide que confirme que la huella digital del sistema remoto es correcta y que desea continuar:
The authenticity of host '192.168.0.122 (192.168.0.122)' can't be established. ECDSA key fingerprint is a4:60:76:eb:b2:d0:aa:23:af:3d:59:5c:de:bb:c4:42. Are you sure you want to continue connecting (yes/no)?- Escriba yes y pulse Enter para continuar. Proporcione una contraseña válida cuando se le solicite. Los archivos se transfieren al directorio especificado en el sistema de destino.
A.1.3. Detección de fallos de memoria mediante la aplicación Memtest86
Los fallos en los módulos de memoria (RAM) pueden hacer que su sistema falle de forma imprevisible. En ciertas situaciones, los fallos de memoria pueden causar errores sólo con determinadas combinaciones de software. Por esta razón, debería probar la memoria de su sistema antes de instalar Red Hat Enterprise Linux.
Red Hat Enterprise Linux incluye la aplicación de prueba de memoria Memtest86 sólo para sistemas BIOS. El soporte para sistemas UEFI no está disponible actualmente.
A.1.3.1. Ejecución de Memtest86
Utilice este procedimiento para ejecutar la aplicación Memtest86 para probar la memoria de su sistema en busca de fallos antes de instalar Red Hat Enterprise Linux.
Requisitos previos
- Ha accedido al menú de arranque de Red Hat Enterprise Linux.
Procedimiento
En el menú de arranque de Red Hat Enterprise Linux, seleccione Troubleshooting > Run a memory test. La ventana de la aplicación
Memtest86se muestra y las pruebas comienzan inmediatamente. Por defecto,Memtest86realiza diez pruebas en cada pasada. Una vez completada la primera pasada, se muestra un mensaje en la parte inferior de la ventana informando del estado actual. Otra pasada se inicia automáticamente.Si
Memtest86detecta un error, éste se muestra en el panel central de la ventana y se resalta en rojo. El mensaje incluye información detallada, como qué prueba ha detectado un problema, la ubicación de la memoria que está fallando, etc. En la mayoría de los casos, un solo pase exitoso de las 10 pruebas es suficiente para verificar que su memoria RAM está en buenas condiciones. Sin embargo, en raras circunstancias, los errores que no se detectaron durante la primera pasada pueden aparecer en las siguientes. Para realizar una prueba exhaustiva en sistemas importantes, ejecute las pruebas durante la noche o durante unos días para completar varias pasadas.NotaEl tiempo que se tarda en completar una sola pasada completa de
Memtest86varía en función de la configuración de tu sistema, especialmente del tamaño y la velocidad de la memoria RAM. Por ejemplo, en un sistema con 2 GiB de memoria DDR2 a 667 MHz, una sola pasada tarda 20 minutos en completarse.- Opcional: Siga las instrucciones en pantalla para acceder a la ventana Configuration y especificar una configuración diferente.
- Para detener las pruebas y reiniciar el ordenador, pulse la tecla Esc en cualquier momento.
Recursos adicionales
-
Para más información sobre el uso de
Memtest86, consulte el sitio web oficial en http://www.memtest.org/.
A.1.4. Verificación de los medios de arranque
La verificación de las imágenes ISO ayuda a evitar los problemas que a veces se encuentran durante la instalación. Estas fuentes incluyen DVD e imágenes ISO almacenadas en un disco duro o en un servidor NFS. Utilice este procedimiento para comprobar la integridad de una fuente de instalación basada en ISO antes de utilizarla para instalar Red Hat Enterprise Linux.
Requisitos previos
- Ha accedido al menú de arranque de Red Hat Enterprise Linux.
Procedimiento
- En el menú de arranque, seleccione Test this media & install Red Hat Enterprise Linux 8.1 para probar el medio de arranque.
- El proceso de arranque comprueba los soportes y pone de manifiesto cualquier problema.
-
Opcional: Puede iniciar el proceso de verificación añadiendo
rd.live.checka la línea de comandos de arranque.
A.1.5. Consolas y registro durante la instalación
El instalador de Red Hat Enterprise Linux utiliza el tmux para mostrar y controlar varias ventanas además de la interfaz principal. Cada una de estas ventanas tiene un propósito diferente; muestran varios registros diferentes, que pueden ser utilizados para solucionar problemas durante el proceso de instalación. Una de las ventanas proporciona un prompt de shell interactivo con privilegios root, a menos que este prompt haya sido específicamente desactivado usando una opción de arranque o un comando Kickstart.
En general, no hay razón para dejar el entorno gráfico de instalación por defecto a menos que necesite diagnosticar un problema de instalación.
El multiplexor de terminales se ejecuta en la consola virtual 1. Para pasar del entorno de instalación actual a tmuxpulse Ctrl+Alt+F1. Para volver a la interfaz de instalación principal que se ejecuta en la consola virtual 6, pulse Ctrl+Alt+F6.
Si elige la instalación en modo texto, comenzará en la consola virtual 1 (tmux), y al cambiar a la consola 6 se abrirá un prompt de shell en lugar de una interfaz gráfica.
La consola que se ejecuta tmux tiene cinco ventanas disponibles; su contenido se describe en la siguiente tabla, junto con los atajos de teclado. Tenga en cuenta que los atajos de teclado tienen dos partes: primero pulse Ctrl+b, luego suelte ambas teclas y pulse la tecla numérica de la ventana que desee utilizar.
También puede utilizar Ctrl+b n, Alt Tab y Ctrl+b p para pasar a la ventana siguiente o anterior tmux respectivamente.
| Atajo | Contenido |
|---|---|
| Ctrl+b 1 | Ventana principal del programa de instalación. Contiene indicaciones basadas en texto (durante la instalación en modo texto o si utiliza el modo directo VNC), y también alguna información de depuración. |
| Ctrl+b 2 |
Consigna de shell interactiva con privilegios de |
| Ctrl+b 3 |
Registro de la instalación; muestra los mensajes almacenados en |
| Ctrl+b 4 |
Registro de almacenamiento; muestra los mensajes relacionados con los dispositivos de almacenamiento y la configuración, almacenados en |
| Ctrl+b 5 |
Registro del programa; muestra los mensajes de las utilidades ejecutadas durante el proceso de instalación, almacenados en |
A.1.6. Cómo guardar las capturas de pantalla
Puede pulsar Turno+Imprimir pantalla en cualquier momento durante la instalación gráfica para capturar la pantalla actual. Las capturas de pantalla se guardan en /tmp/anaconda-screenshots.
A.1.7. Reanudar un intento de descarga interrumpido
Puede reanudar una descarga interrumpida mediante el comando curl.
Requisito previo
- Ha navegado a la sección Product Downloads del Portal del Cliente de Red Hat en https://access.redhat.com/downloads, y ha seleccionado la variante, versión y arquitectura requeridas.
- Ha hecho clic con el botón derecho del ratón en el archivo ISO deseado y ha seleccionado Copy Link Location para copiar la URL del archivo de imagen ISO en el portapapeles.
Procedimiento
Descargue la imagen ISO desde el nuevo enlace. Añade la opción
--continue-at -para reanudar automáticamente la descarga:$ curl --output directory-path/filename.iso 'new_copied_link_location' --continue-at -Utilice una utilidad de suma de comprobación como sha256sum para verificar la integridad del archivo de imagen una vez finalizada la descarga:
$ sha256sum rhel-8.1-x86_64-dvd.iso `85a...46c rhel-8.1-x86_64-dvd.iso`Compare el resultado con las sumas de comprobación de referencia proporcionadas en la página web de Red Hat Enterprise Linux Product Download.
Ejemplo A.1. Reanudar un intento de descarga interrumpido
El siguiente es un ejemplo de un comando curl para una imagen ISO parcialmente descargada:
$ curl --output _rhel-8.1-x86_64-dvd.iso 'https://access.cdn.redhat.com//content/origin/files/sha256/85/85a...46c/rhel-8.1-x86_64-dvd.iso?_auth=141...963' --continue-at -A.1.8. No se puede arrancar en la instalación gráfica
Algunas tarjetas de vídeo tienen problemas para arrancar el programa de instalación gráfica de Red Hat Enterprise Linux. Si el programa de instalación no se ejecuta utilizando su configuración por defecto, intenta ejecutarse en un modo de menor resolución. Si esto falla, el programa de instalación intenta ejecutarse en modo texto. Hay varias soluciones posibles para resolver los problemas de visualización, la mayoría de las cuales implican la especificación de opciones de arranque personalizadas. Para más información, consulte Sección D.3, “Opciones de arranque de la consola”.
| Solución | Descripción |
|---|---|
| Utilizar el modo gráfico básico | Puede intentar realizar la instalación utilizando el controlador gráfico básico. Para ello, seleccione Troubleshooting > Install Red Hat Enterprise Linux 8.1 in basic graphics mode en el menú de arranque o edite las opciones de arranque del programa de instalación y añada inst.xdriver=vesa al final de la línea de comandos. |
| Especificar manualmente la resolución de la pantalla | Si el programa de instalación no detecta su resolución de pantalla, puede anular la detección automática y especificarla manualmente. Para ello, añada la opción inst.resolution=x en el menú de arranque, donde x es la resolución de su pantalla, por ejemplo, 1024x768. |
| Utilizar un controlador de vídeo alternativo | Puede intentar especificar un controlador de vídeo personalizado, anulando la detección automática del programa de instalación. Para especificar un controlador, utilice la opción inst.xdriver=x, donde x es el controlador de dispositivo que desea utilizar (por ejemplo, nouveau)*. |
| Realice la instalación mediante VNC | Si las opciones anteriores fallan, puede utilizar un sistema independiente para acceder a la instalación gráfica a través de la red, utilizando el protocolo Virtual Network Computing (VNC). Para más detalles sobre la instalación mediante VNC, consulte la sección Performing a remote RHEL installation using VNC del documento Performing an advanced RHEL installation. |
*Si la especificación de un controlador de vídeo personalizado resuelve su problema, debería informar de ello como un error en https://bugzilla.redhat.com bajo el componente anaconda. El programa de instalación debería ser capaz de detectar su hardware automáticamente y utilizar el controlador apropiado sin intervención.
A.2. Solución de problemas durante la instalación
La información de resolución de problemas de las siguientes secciones puede ser útil para diagnosticar problemas durante el proceso de instalación. Las siguientes secciones son para todas las arquitecturas soportadas. Sin embargo, si un problema es para una arquitectura en particular, se especifica al principio de la sección.
A.2.1. No se detectan los discos
Si el programa de instalación no puede encontrar un dispositivo de almacenamiento con capacidad de escritura en el que instalar, devuelve el siguiente mensaje de error en la ventana Installation Destination No disks detected. Please shut down the computer, connect at least one disk, and restart to complete installation.
Compruebe los siguientes elementos:
- Su sistema tiene al menos un dispositivo de almacenamiento conectado.
- Si su sistema utiliza una controladora RAID por hardware, compruebe que la controladora está correctamente configurada y funciona como se espera. Consulte la documentación de su controlador para obtener instrucciones.
- Si está instalando en uno o más dispositivos iSCSI y no hay almacenamiento local presente en el sistema, verifique que todos los LUNs requeridos se presenten al adaptador de bus de host (HBA) apropiado.
Si el mensaje de error sigue apareciendo después de reiniciar el sistema e iniciar el proceso de instalación, el programa de instalación no ha detectado el almacenamiento. En muchos casos el mensaje de error es el resultado de intentar instalar en un dispositivo iSCSI que no es reconocido por el programa de instalación.
En este caso, debe realizar una actualización del controlador antes de iniciar la instalación. Consulte el sitio web de su proveedor de hardware para determinar si hay una actualización de controladores disponible. Para obtener más información general sobre las actualizaciones de los controladores, consulte la Updating drivers during installation del documento Performing an advanced RHEL installation.
También puede consultar la lista de compatibilidad de hardware de Red Hat, disponible en https://access.redhat.com/ecosystem/search/#/category/Server.
A.2.2. Informar de los mensajes de error al Servicio de Atención al Cliente de Red Hat
Si la instalación gráfica encuentra un error, muestra el cuadro de diálogo unknown error. Puede enviar información sobre el error al Servicio de Atención al Cliente de Red Hat. Para enviar un informe, debe introducir sus credenciales del Portal de Clientes. Si no tiene una cuenta en el Portal de Clientes, puede registrarse en https://www.redhat.com/wapps/ugc/register.html. La notificación automática de errores requiere una conexión de red.
Requisito previo
El programa de instalación gráfica encontró un error y mostró el cuadro de diálogo unknown error.
Procedimiento
En el cuadro de diálogo unknown error, haga clic en para notificar el problema, o en para abandonar la instalación.
-
Opcionalmente, haga clic en ... para mostrar una salida detallada que podría ayudar a determinar la causa del error. Si está familiarizado con la depuración, haga clic en . Esto muestra la terminal virtual
tty1, donde puede solicitar información adicional. Para volver a la interfaz gráfica desdetty1, utilice el comandocontinue.
-
Opcionalmente, haga clic en ... para mostrar una salida detallada que podría ayudar a determinar la causa del error. Si está familiarizado con la depuración, haga clic en . Esto muestra la terminal virtual
- Haga clic en Hat.
- Aparece el cuadro de diálogo Red Hat Customer Support - Reporting Configuration. En la pestaña Basic, introduzca su nombre de usuario y contraseña del Portal del Cliente. Si la configuración de su red requiere el uso de un proxy HTTP o HTTPS, puede configurarlo seleccionando la pestaña Advanced e introduciendo la dirección del servidor proxy.
- Complete todos los campos y haga clic en .
- Aparece un cuadro de texto. Explique cada paso que se dio antes de que apareciera el cuadro de diálogo unknown error.
- Seleccione una opción del menú desplegable How reproducible is this problem y proporcione información adicional en el cuadro de texto.
- Haga clic en .
- Comprueba que toda la información que has proporcionado está en la pestaña Comment. Las otras pestañas incluyen información como el nombre del host de su sistema y otros detalles sobre su entorno de instalación. Puede eliminar cualquier información que no desee enviar a Red Hat, pero tenga en cuenta que proporcionar menos detalles podría afectar a la investigación del problema.
- Haga clic en Forward cuando haya terminado de revisar todas las pestañas.
- Un cuadro de diálogo muestra todos los archivos que se enviarán a Red Hat. Desactive las casillas de verificación junto a los archivos que no desea enviar a Red Hat. Para añadir un archivo, haga clic en Attach a file.
- Seleccione la casilla I have reviewed the data and agree with submitting it.
- Haga clic en para enviar el informe y los archivos adjuntos a Red Hat.
- Haga clic en para ver los detalles del proceso de notificación o haga clic en para volver al cuadro de diálogo unknown error.
- Haga clic en para salir de la instalación.
A.2.3. Problemas de particionamiento para IBM Power Systems
Esta edición es para IBM Power Systems.
Si ha creado manualmente las particiones, pero no puede avanzar en el proceso de instalación, es posible que no haya creado todas las particiones necesarias para que la instalación siga adelante. Como mínimo, debe tener las siguientes particiones:
-
/ (root)partición -
PRePpartición de arranque -
/bootpartición (sólo si la partición raíz es un volumen lógico LVM)
Para más información, consulte Sección C.4, “Esquema de partición recomendado”.
A.3. Solución de problemas después de la instalación
La información de resolución de problemas de las siguientes secciones puede ser útil para diagnosticar problemas después del proceso de instalación. Las siguientes secciones son para todas las arquitecturas soportadas. Sin embargo, si un problema es para una arquitectura en particular, se especifica al principio de la sección.
A.3.1. No se puede arrancar con una tarjeta RAID
Si no puede arrancar su sistema después de la instalación, es posible que tenga que reinstalar y reparticionar el almacenamiento de su sistema. Algunos tipos de BIOS no soportan el arranque desde tarjetas RAID. Después de terminar la instalación y reiniciar el sistema por primera vez, una pantalla basada en texto muestra el prompt del cargador de arranque (por ejemplo, grub>) y puede aparecer un cursor parpadeante. Si este es el caso, debe reparticionar su sistema y mover su partición /boot y el cargador de arranque fuera de la matriz RAID. La partición /boot y el gestor de arranque deben estar en la misma unidad. Una vez realizados estos cambios, deberías poder terminar la instalación y arrancar el sistema correctamente.
A.3.2. La secuencia gráfica de arranque no responde
Al reiniciar el sistema por primera vez después de la instalación, es posible que el sistema no responda durante la secuencia gráfica de arranque. Si esto ocurre, es necesario reiniciar el sistema. En este caso, el menú del gestor de arranque se muestra correctamente, pero al seleccionar cualquier entrada e intentar arrancar el sistema se detiene. Esto suele indicar que hay un problema con la secuencia gráfica de arranque. Para resolver el problema, debe desactivar el arranque gráfico alterando temporalmente la configuración en el momento del arranque antes de cambiarla permanentemente.
Procedimiento: Desactivar el arranque gráfico temporalmente
-
Inicie su sistema y espere hasta que aparezca el menú del cargador de arranque. Si ha configurado el periodo de tiempo de espera de arranque en
0, pulse la tecla Esc para acceder a él. - En el menú del gestor de arranque, utilice las teclas del cursor para resaltar la entrada que desea arrancar. Pulse la tecla Tab en los sistemas basados en BIOS o la tecla e en los sistemas basados en UEFI para editar las opciones de entrada seleccionadas.
-
En la lista de opciones, busque la línea del núcleo, es decir, la línea que comienza con la palabra clave linux. En esta línea, localice y borre
rhgb. - Pulse F10 o Ctrl X para arrancar su sistema con las opciones editadas.
Si el sistema se ha iniciado con éxito, puede iniciar la sesión con normalidad. Sin embargo, si no desactiva el arranque gráfico de forma permanente, deberá realizar este procedimiento cada vez que el sistema arranque.
Procedimiento: Desactivar el arranque gráfico de forma permanente
- Acceda a la cuenta raíz de su sistema.
Utilice la herramienta grubby para encontrar el kernel GRUB2 por defecto:
# grubby --default-kernel /boot/vmlinuz-4.18.0-94.el8.x86_64Utilice la herramienta grubby para eliminar la opción de arranque
rhgbdel kernel por defecto en su configuración de GRUB2. Por ejemplo:# grubby --remove-args="rhgb" --update-kernel /boot/vmlinuz-4.18.0-94.el8.x86_64-
Reinicie el sistema. La secuencia gráfica de arranque ya no se utiliza. Si desea habilitar la secuencia gráfica de arranque, siga el mismo procedimiento, sustituyendo el parámetro
--remove-args="rhgb"por el parámetro--args="rhgb". Esto restablece la opción de arranquerhgbal kernel por defecto en su configuración de GRUB2.
A.3.3. El servidor X falla después de iniciar la sesión
Un servidor X es un programa del sistema X Window que se ejecuta en máquinas locales, es decir, en los ordenadores utilizados directamente por los usuarios. El servidor X gestiona todo el acceso a las tarjetas gráficas, las pantallas de visualización y los dispositivos de entrada, normalmente un teclado y un ratón en esos ordenadores. El sistema X Window, a menudo denominado X, es un sistema cliente-servidor completo, multiplataforma y gratuito para gestionar interfaces gráficas de usuario en ordenadores individuales y en redes de ordenadores. El modelo cliente-servidor es una arquitectura que divide el trabajo entre dos aplicaciones separadas pero vinculadas, denominadas clientes y servidores.*
Si el servidor X se bloquea tras el inicio de sesión, es posible que uno o varios de los sistemas de archivos estén llenos. Para solucionar el problema, ejecute el siguiente comando:
$ df -h
La salida verifica qué partición está llena - en la mayoría de los casos, el problema está en la partición /home. La siguiente es una muestra de la salida del comando df:
Filesystem Size Used Avail Use% Mounted on
devtmpfs 396M 0 396M 0% /dev
tmpfs 411M 0 411M 0% /dev/shm
tmpfs 411M 6.7M 405M 2% /run
tmpfs 411M 0 411M 0% /sys/fs/cgroup
/dev/mapper/rhel-root 17G 4.1G 13G 25% /
/dev/sda1 1014M 173M 842M 17% /boot
tmpfs 83M 20K 83M 1% /run/user/42
tmpfs 83M 84K 83M 1% /run/user/1000
/dev/dm-4 90G 90G 0 100% /home
En el ejemplo, puede ver que la partición /home está llena, lo que provoca el fallo. Elimine los archivos no deseados. Después de liberar algo de espacio en el disco, inicie X utilizando el comando startx. Para obtener información adicional sobre df y una explicación de las opciones disponibles, como la opción -h utilizada en este ejemplo, consulte la página de manual df(1).
*Fuente: http://www.linfo.org/x_server.html
A.3.4. No se reconoce la RAM
En algunos casos, el kernel no reconoce toda la memoria (RAM), lo que hace que el sistema utilice menos memoria de la instalada. Puede averiguar cuánta memoria RAM se está utilizando utilizando el comando free -m. Si la cantidad total de memoria no coincide con sus expectativas, es probable que al menos uno de sus módulos de memoria esté defectuoso. En los sistemas basados en la BIOS, puede utilizar la utilidad Memtest86 para comprobar la memoria de su sistema.
Algunas configuraciones de hardware tienen reservada parte de la memoria RAM del sistema y, por tanto, no está disponible para el sistema. Algunos ordenadores portátiles con tarjetas gráficas integradas reservan una parte de la memoria para la GPU. Por ejemplo, un portátil con 4 GiB de RAM y una tarjeta gráfica integrada de Intel muestra aproximadamente 3,7 GiB de memoria disponible. Adicionalmente, el mecanismo de volcado de kdump crash kernel, que está habilitado por defecto en la mayoría de los sistemas Red Hat Enterprise Linux, reserva algo de memoria para el kernel secundario utilizado en caso de un fallo del kernel primario. Esta memoria reservada no se muestra como disponible cuando se utiliza el comando free.
Procedimiento: Configurar manualmente la memoria
Utilice este procedimiento para establecer manualmente la cantidad de memoria utilizando la opción del kernel mem=.
- Inicie su sistema y espere hasta que aparezca el menú del cargador de arranque. Si ha configurado el periodo de tiempo de espera de arranque en 0, pulse la tecla Esc para acceder a él.
- En el menú del gestor de arranque, utilice las teclas del cursor para resaltar la entrada que desea arrancar y pulse la tecla Tab en los sistemas basados en BIOS o la tecla e en los sistemas basados en UEFI para editar las opciones de entrada seleccionadas.
En la lista de opciones, busque la línea del núcleo, es decir, la línea que comienza con la palabra clave linux. Añade la siguiente opción al final de esta línea:
mem=xxM- Sustituye xx por la cantidad de RAM que tienes en MiB.
- Pulse F10 o Ctrl X para arrancar su sistema con las opciones editadas.
- Espere a que el sistema se inicie y luego inicie la sesión.
Abra una línea de comandos y ejecute de nuevo el comando free
-m. Si la cantidad total de RAM mostrada por el comando coincide con sus expectativas, añada lo siguiente a la línea que comienza conGRUB_CMDLINE_LINUXen el archivo/etc/default/grubpara que el cambio sea permanente:# grub2-mkconfig --output=/boot/grub2/grub.cfg
A.3.5. El sistema muestra errores de la señal 11
Un error de señal 11, comúnmente conocido como fallo de segmentación, significa que un programa ha accedido a una ubicación de memoria que no tenía asignada. Un error de señal 11 puede ocurrir debido a un error en uno de los programas de software que se instalan, o a un hardware defectuoso. Si recibe un error de señal 11 durante el proceso de instalación, verifique que está utilizando las imágenes de instalación más recientes y pida al programa de instalación que las verifique para asegurarse de que no están corruptas. Para más información, consulte Sección A.1.4, “Verificación de los medios de arranque”.
Los medios de instalación defectuosos (como un disco óptico mal grabado o rayado) son una causa común de errores de la señal 11. Se recomienda verificar la integridad del medio de instalación antes de cada instalación. Para obtener información sobre cómo obtener los medios de instalación más recientes, consulte Sección 2.6, “Descarga de la imagen ISO de instalación”.
Para realizar una comprobación de medios antes de que se inicie la instalación, añada la opción de arranque rd.live.check en el menú de arranque. Si ha realizado una comprobación de medios sin ningún error y sigue teniendo problemas de fallos de segmentación, suele indicar que su sistema ha encontrado un error de hardware. En este escenario, lo más probable es que el problema esté en la memoria del sistema (RAM). Esto puede ser un problema incluso si anteriormente utilizó un sistema operativo diferente en el mismo ordenador sin ningún error.
Para arquitecturas AMD e Intel de 64 bits y ARM de 64 bits: En los sistemas basados en BIOS, puede utilizar el módulo de prueba de memoria Memtest86 incluido en el medio de instalación para realizar una prueba exhaustiva de la memoria de su sistema. Para obtener más información, consulte Sección A.1.3, “Detección de fallos de memoria mediante la aplicación Memtest86”.
Otras posibles causas están fuera del alcance de este documento. Consulte la documentación del fabricante de su hardware y también vea la Lista de compatibilidad de hardware de Red Hat, disponible en línea en https://access.redhat.com/ecosystem/search/#/category/Server.
A.3.6. No se puede IPL desde el espacio de almacenamiento de la red
Esta edición es para IBM Power Systems.
Si experimenta dificultades al intentar IPL desde el Espacio de Almacenamiento de Red (*NWSSTG), lo más probable es que se deba a la falta de una partición PReP. En este escenario, debe reinstalar el sistema y crear esta partición durante la fase de particionamiento o en el archivo Kickstart.
A.3.7. Uso de XDMCP
Hay escenarios en los que ha instalado el sistema X Window y desea iniciar la sesión en su sistema Red Hat Enterprise Linux utilizando un gestor de inicio de sesión gráfico. Utilice este procedimiento para habilitar el Protocolo de control de gestor de pantalla X (XDMCP) e iniciar sesión de forma remota en un entorno de escritorio desde cualquier cliente compatible con X, como una estación de trabajo conectada a la red o un terminal X11.
XDMCP no es compatible con el protocolo Wayland. Para más información, consulte el Using the desktop environment in RHEL 8 documento.
Esta edición es para IBM Z.
Procedimiento
-
Abra el archivo de configuración
/etc/gdm/custom.confen un editor de texto plano como vi o nano. En el archivo
custom.conf, localice la sección que comienza con[xdmcp]. En esta sección, añada la siguiente línea:Enable=true- Guarde el archivo y salga del editor de texto.
Reinicie el sistema X Window. Para hacer esto, reinicie el sistema, o reinicie el Gestor de Pantalla de GNOME usando el siguiente comando como root:
# systemctl restart gdm.serviceEspere a que aparezca el aviso de inicio de sesión y entre con su nombre de usuario y contraseña. El sistema X Window está ahora configurado para XDMCP. Puede conectarse a él desde otra estación de trabajo (cliente) iniciando una sesión X remota utilizando el comando X en la estación de trabajo cliente. Por ejemplo:
$ X :1 -consulta de la direcciónSustituye
addresspor el nombre del servidor X11 remoto. El comando se conecta al servidor X11 remoto utilizando XDMCP y muestra la pantalla gráfica de inicio de sesión remota en la pantalla :1 del sistema del servidor X11 (normalmente accesible pulsandoCtrl-Alt-F8). También puedes acceder a sesiones de escritorio remoto utilizando un servidor X11 anidado, que abre el escritorio remoto como una ventana en tu sesión X11 actual. Puedes utilizar Xnest para abrir un escritorio remoto anidado en una sesión X11 local. Por ejemplo, ejecute Xnest utilizando el siguiente comando, sustituyendo dirección por el nombre del servidor X11 remoto:$ Xnest :1 -consultar direcciónPara más información sobre XDMCP, consulte la documentación de X Window System en http://www.x.org/releases/X11R7.6/doc/libXdmcp/xdmcp.html.
A.3.8. Uso del modo de rescate
El modo de rescate del programa de instalación es un entorno Linux mínimo que puede ser arrancado desde el DVD de Red Hat Enterprise Linux o desde otros medios de arranque. Contiene utilidades de línea de comandos para reparar una amplia variedad de problemas. Se puede acceder al modo de rescate desde el menú Troubleshooting del menú de arranque. En este modo, puede montar sistemas de archivos como de sólo lectura, poner en la lista negra o añadir un controlador proporcionado en un disco de controladores, instalar o actualizar paquetes del sistema o gestionar particiones.
El modo de rescate del programa de instalación es diferente del modo de rescate (un equivalente al modo de usuario único) y del modo de emergencia, que se proporcionan como partes del sistema systemd y del gestor de servicios.
Para arrancar en modo de rescate, debe ser capaz de arrancar el sistema utilizando uno de los medios de arranque de Red Hat Enterprise Linux, como un disco de arranque mínimo o una unidad USB, o un DVD de instalación completa.
El almacenamiento avanzado, como los dispositivos iSCSI o zFCP, deben ser configurados usando las opciones de arranque dracut como rd.zfcp= o root=iscsi: options , o en el archivo de configuración CMS en IBM Z. No es posible configurar estos dispositivos de almacenamiento interactivamente después de arrancar en modo de rescate. Para obtener información sobre las opciones de arranque dracut, consulte la página man dracut.cmdline(7).
A.3.8.1. Arranque en modo de rescate
Utilice este procedimiento para arrancar en modo de rescate.
Procedimiento
- Inicie el sistema desde un medio de arranque mínimo o desde un DVD de instalación completa o una unidad USB, y espere a que aparezca el menú de arranque.
-
En el menú de arranque, seleccione Troubleshooting > Rescue a Red Hat Enterprise Linux system opción, o añada la opción
inst.rescuea la línea de comandos de arranque. Para entrar en la línea de comandos de arranque, pulse la tecla Tab en sistemas basados en BIOS o la tecla e en sistemas basados en UEFI. Opcional: Si su sistema requiere un controlador de terceros proporcionado en un disco de controladores para arrancar, añada el
inst.dd=driver_namea la línea de comandos de arranque:inst.rescue inst.dd=nombre_del_conductorOpcional: Si un controlador que forma parte de la distribución de Red Hat Enterprise Linux impide el arranque del sistema, añada la opción
modprobe.blacklist=a la línea de comandos de arranque:inst.rescue modprobe.blacklist=nombre_del_conductorPulse Enter (sistemas basados en BIOS) o Ctrl X (sistemas basados en UEFI) para arrancar la opción modificada. Espere hasta que aparezca el siguiente mensaje:
The rescue environment will now attempt to find your Linux installation and mount it under the directory: /mnt/sysroot/. You can then make any changes required to your system. Choose 1 to proceed with this step. You can choose to mount your file systems read-only instead of read-write by choosing 2. If for some reason this process does not work choose 3 to skip directly to a shell. 1) Continue 2) Read-only mount 3) Skip to shell 4) Quit (Reboot)Si selecciona 1, el programa de instalación intenta montar su sistema de archivos en el directorio
/mnt/sysroot/. Se le notificará si no consigue montar una partición. Si selecciona 2, el programa intenta montar su sistema de archivos en el directorio/mnt/sysroot/, pero en modo de sólo lectura. Si selecciona 3, su sistema de archivos no se monta.Para la raíz del sistema, el instalador admite dos puntos de montaje
/mnt/sysimagey/mnt/sysroot. La ruta/mnt/sysrootse utiliza para montar/del sistema de destino. Normalmente, la raíz física y la raíz del sistema son la misma, por lo que/mnt/sysrootse adjunta al mismo sistema de archivos que/mnt/sysimage. Las únicas excepciones son los sistemas rpm-ostree, en los que la raíz del sistema cambia en función de la implementación. Entonces,/mnt/sysrootse adjunta a un subdirectorio de/mnt/sysimage. Se recomienda utilizar/mnt/sysrootpara el chroot.Seleccione 1 para continuar. Una vez que su sistema esté en modo de rescate, aparecerá un aviso en la VC (consola virtual) 1 y en la VC 2. Utilice la combinación de teclas
Ctrl Alt F1para acceder a la VC 1 yCtrl Alt F2para acceder a la VC 2:sh-4.2#Incluso si su sistema de archivos está montado, la partición raíz por defecto mientras está en modo de rescate es una partición raíz temporal, no la partición raíz del sistema de archivos utilizada durante el modo de usuario normal (
multi-user.targetographical.target). Si seleccionó montar su sistema de archivos y se montó con éxito, puede cambiar la partición raíz del entorno del modo de rescate a la partición raíz de su sistema de archivos ejecutando el siguiente comando:sh-4.2# chroot /mnt/sysrootEsto es útil si necesitas ejecutar comandos, como
rpm, que requieren que tu partición raíz esté montada como/. Para salir del entorno chroot, escriba exit para volver al prompt.Si seleccionó 3, aún puede intentar montar una partición o volumen lógico LVM2 manualmente dentro del modo de rescate creando un directorio, como
/directory/, y escribiendo el siguiente comando:sh-4.2# mount -t xfs /dev/mapper/VolGroup00-LogVol02 /directoryEn el comando anterior,
/directory/es el directorio que has creado y/dev/mapper/VolGroup00-LogVol02es el volumen lógico LVM2 que quieres montar. Si la partición es de un tipo diferente a XFS, sustituye la cadena xfs por el tipo correcto (como ext4).Si no conoce los nombres de todas las particiones físicas, utilice el siguiente comando para listarlas:
sh-4.2# fdisk -lSi no conoce los nombres de todos los volúmenes físicos, grupos de volúmenes o volúmenes lógicos de LVM2, utilice los comandos
pvdisplay,vgdisplayolvdisplay.
A.3.8.2. Uso de un informe SOS en modo de rescate
La utilidad de línea de comandos sosreport recopila información de configuración y diagnóstico, como la versión del kernel en ejecución, los módulos cargados y los archivos de configuración del sistema y de los servicios del sistema. La salida de la utilidad se almacena en un archivo tar en el directorio /var/tmp/. La utilidad sosreport es útil para analizar los errores del sistema y solucionar problemas. Utilice este procedimiento para capturar una salida de sosreport en modo de rescate.
Requisitos previos
- Has arrancado en modo de rescate.
-
Ha montado la partición del sistema instalado
/ (root)en modo de lectura-escritura. - Ha contactado con el Soporte de Red Hat sobre su caso y ha recibido un número de caso.
Procedimiento
Cambie el directorio raíz por el directorio
/mnt/sysroot/:sh-4.2# chroot /mnt/sysroot/Ejecute
sosreportpara generar un archivo con la configuración del sistema y la información de diagnóstico:sh-4.2# sosreportImportantesosreportle pide que introduzca su nombre y el número de caso que recibió del Soporte de Red Hat. Utilice sólo letras y números, ya que si añade alguno de los siguientes caracteres o espacios, el informe podría quedar inutilizado:# % & { } \ < > > * ? / $ ~ ' " : @ + ` | =Opcional: Si desea transferir el archivo generado a una nueva ubicación utilizando la red, es necesario tener una interfaz de red configurada. En este caso, utilice el direccionamiento IP dinámico, ya que no se requieren otros pasos. Sin embargo, si utiliza el direccionamiento estático, introduzca el siguiente comando para asignar una dirección IP (por ejemplo 10.13.153.64/23) a una interfaz de red, por ejemplo dev eth0:
bash-4.2# ip addr add 10.13.153.64/23 dev eth0Salir del entorno chroot:
sh-4.2# exitGuarde el archivo generado en una nueva ubicación, desde la que se pueda acceder fácilmente:
sh-4.2# cp /mnt/sysroot/var/tmp/sosreport nueva_ubicaciónPara transferir el archivo a través de la red, utilice la utilidad
scp:sh-4.2# scp /mnt/sysroot/var/tmp/sosreport username@hostname:sosreportRecursos adicionales
- Para información general sobre sosreport, vea ¿Qué es un sosreport y cómo crear uno en Red Hat Enterprise Linux?
- Para obtener información sobre el uso de sosreport en modo de rescate, consulte Cómo generar sosreport desde el entorno de rescate.
- Para obtener información sobre cómo generar un sosreport en una ubicación diferente a /tmp, consulte ¿Cómo hago que sosreport escriba en una ubicación alternativa?
- Para obtener información sobre la recopilación de un sosreport manualmente, consulte Sosreport falla. ¿Qué datos debo proporcionar en su lugar?
A.3.8.3. Reinstalación del gestor de arranque GRUB2
En algunos escenarios, el gestor de arranque de GRUB2 se borra por error, se corrompe o se sustituye por otros sistemas operativos. Utilice este procedimiento para reinstalar GRUB2 en el registro maestro de arranque (MBR) en sistemas AMD64 e Intel 64 con BIOS, o en las variantes little-endian de IBM Power Systems con Open Firmware.
Requisitos previos
- Has arrancado en modo de rescate.
-
Ha montado la partición del sistema instalado
/ (root)en modo de lectura-escritura. -
Ha montado el punto de montaje
/booten modo de lectura-escritura.
Procedimiento
Cambia la partición raíz:
sh-4.2# chroot /mnt/sysroot/Vuelva a instalar el cargador de arranque GRUB2, donde se instaló el dispositivo de bloque
install_device:sh-4.2# /sbin/grub2-install install_deviceImportanteEjecutar el comando
grub2-installpuede hacer que la máquina no pueda arrancar si se dan todas las condiciones siguientes:- El sistema es un AMD64 o Intel 64 con Extensible Firmware Interface (EFI).
- El arranque seguro está activado.
Después de ejecutar el comando
grub2-install, no se pueden arrancar los sistemas AMD64 o Intel 64 que tienen activada la interfaz de firmware extensible (EFI) y el arranque seguro. Este problema se produce porque el comandogrub2-installinstala una imagen GRUB2 sin firma que arranca directamente en lugar de utilizar la aplicación shim. Cuando el sistema arranca, la aplicación shim valida la firma de la imagen, que cuando no se encuentra falla en el arranque del sistema.- Reinicie el sistema.
A.3.8.4. Uso de RPM para añadir o eliminar un controlador
Los controladores que faltan o funcionan mal causan problemas al arrancar el sistema. El modo de rescate proporciona un entorno en el que se puede añadir o eliminar un controlador incluso cuando el sistema no arranca. Siempre que sea posible, se recomienda utilizar el gestor de paquetes RPM para eliminar los controladores que funcionan mal o para añadir los controladores actualizados o que faltan. Utilice los siguientes procedimientos para añadir o eliminar un controlador.
Cuando se instala un controlador desde un disco de controladores, el disco de controladores actualiza todas las imágenes initramfs del sistema para que utilicen este controlador. Si un problema con un controlador impide que un sistema arranque, no puede confiar en que el sistema arranque desde otra imagen de initramfs.
Procedimiento: Añadir un controlador mediante RPM
Utilice este procedimiento para añadir un controlador.
Requisitos previos
- Has arrancado en modo de rescate.
Ha montado el sistema instalado en modo de lectura-escritura.
-
Ponga a disposición el paquete RPM que contiene el controlador. Por ejemplo, monte un CD o una unidad flash USB y copie el paquete RPM en una ubicación de su elección en
/mnt/sysroot/, por ejemplo:/mnt/sysroot/root/drivers/. Cambie el directorio raíz a
/mnt/sysroot/:sh-4.2# chroot /mnt/sysroot/Utilice el comando
rpm -ivhpara instalar el paquete de controladores. Por ejemplo, ejecute el siguiente comando para instalar el paquete de controladoresxorg-x11-drv-wacomdesde/root/drivers/:sh-4.2# rpm -ivh /root/drivers/xorg-x11-drv-wacom-0.23.0-6.el7.x86_64.rpmNotaEl directorio
/root/drivers/en este entorno chroot es el directorio/mnt/sysroot/root/drivers/en el entorno de rescate original.Salir del entorno chroot:
sh-4.2# exit
-
Ponga a disposición el paquete RPM que contiene el controlador. Por ejemplo, monte un CD o una unidad flash USB y copie el paquete RPM en una ubicación de su elección en
Procedimiento: Cómo eliminar un controlador mediante RPM
Utilice este procedimiento para eliminar un controlador.
Requisitos previos
- Has arrancado en modo de rescate.
Ha montado el sistema instalado en modo de lectura-escritura.
Cambie el directorio raíz por el directorio
/mnt/sysroot/:sh-4.2# chroot /mnt/sysroot/Utilice el comando
rpm -epara eliminar el paquete de controladores. Por ejemplo, para eliminar el paquete de controladoresxorg-x11-drv-wacom, ejecute:sh-4.2# rpm -e xorg-x11-drv-wacomSalir del entorno chroot:
sh-4.2# exitSi no puede eliminar un controlador que funciona mal por alguna razón, puede bloquear el controlador para que no se cargue durante el arranque.
- Cuando haya terminado de añadir y eliminar controladores, reinicie el sistema.
A.3.9. la opción ip= boot devuelve un error
Utilizando el formato de la opción de arranque ip= ip=[ip address] por ejemplo, ip=192.168.1.1 devuelve el mensaje de error Fatal for argument 'ip=[insert ip here]'\n sorry, unknown value [ip address] refusing to continue.
En versiones anteriores de Red Hat Enterprise Linux, el formato de la opción de arranque era:
--ip=192.168.1.15 --máscara de red=255.255.255.0 --gateway=192.168.1.254 --servidor de nombres=192.168.1.250 -nombre de host=mihost1Sin embargo, en Red Hat Enterprise Linux 8, el formato de la opción de arranque es:
ip=192.168.1.15::192.168.1.254:255.255.255.0:myhost1::none: nameserver=192.168.1.250
Para resolver el problema, utilice el formato: ip=ip::gateway:netmask:hostname:interface:none donde:
-
ipespecifica la dirección ip del cliente. Puede especificar direcciones IPv6 entre corchetes, por ejemplo,[2001:DB8::1]. -
gatewayes la puerta de enlace por defecto. También se aceptan direcciones IPv6. -
netmaskes la máscara de red que se utilizará. Puede ser una máscara de red completa, por ejemplo, 255.255.255.0, o un prefijo, por ejemplo,64. -
hostnamees el nombre del host del sistema cliente. Este parámetro es opcional.
Para más información, consulte Sección D.2, “Opciones de arranque en red”.
Apéndice B. Referencia de los requisitos del sistema
Esta sección proporciona información y directrices para el hardware, el objetivo de la instalación, el sistema, la memoria y el RAID cuando se instala Red Hat Enterprise Linux.
B.1. Compatibilidad de hardware
Red Hat colabora estrechamente con los proveedores de hardware en lo que respecta al hardware compatible.
- Para comprobar que su hardware es compatible, consulte la lista de compatibilidad de hardware de Red Hat, disponible en https://access.redhat.com/ecosystem/search/#/category/Server.
- Para ver los tamaños de memoria soportados o los recuentos de CPU, consulte https://access.redhat.com/articles/rhel-limits para obtener información.
B.2. Objetivos de instalación admitidos
Un objetivo de instalación es un dispositivo de almacenamiento que almacena Red Hat Enterprise Linux y arranca el sistema. Red Hat Enterprise Linux soporta los siguientes objetivos de instalación para sistemas AMD64, Intel 64 y ARM de 64 bits:
- Almacenamiento conectado por una interfaz interna estándar, como SCSI, SATA o SAS
- Dispositivos RAID BIOS/firmware
- Dispositivos NVDIMM en modo sectorial en las arquitecturas Intel64 y AMD64, soportados por el controlador nd_pmem.
- Adaptadores de bus de host de canal de fibra y dispositivos multirruta. Algunos pueden requerir controladores proporcionados por el proveedor.
- Dispositivos de bloque Xen en procesadores Intel en máquinas virtuales Xen.
- Dispositivos de bloque VirtIO en procesadores Intel en máquinas virtuales KVM.
Red Hat no soporta la instalación en unidades USB o tarjetas de memoria SD. Para obtener información sobre la compatibilidad con tecnologías de virtualización de terceros, consulte la Lista de compatibilidad de hardware de Red Hat.
B.3. Especificaciones del sistema
El programa de instalación de Red Hat Enterprise Linux detecta e instala automáticamente el hardware de su sistema, por lo que no debería tener que proporcionar ninguna información específica del sistema. Sin embargo, para ciertos escenarios de instalación de Red Hat Enterprise Linux, se recomienda que registre las especificaciones del sistema para futuras referencias. Estos escenarios incluyen:
Instalación de RHEL con una distribución de particiones personalizada
Record: Los números de modelo, tamaños, tipos e interfaces de los discos duros conectados al sistema. Por ejemplo, Seagate ST3320613AS 320 GB en SATA0, Western Digital WD7500AAKS 750 GB en SATA1.
Instalación de RHEL como sistema operativo adicional en un sistema existente
Record: Particiones utilizadas en el sistema. Esta información puede incluir tipos de sistemas de archivos, nombres de nodos de dispositivos, etiquetas de sistemas de archivos y tamaños, y le permite identificar particiones específicas durante el proceso de particionamiento. Si uno de los sistemas operativos es un sistema operativo Unix, Red Hat Enterprise Linux puede reportar los nombres de los dispositivos de forma diferente. Se puede encontrar información adicional ejecutando el equivalente del comando mount y el comando blkid, y en el archivo /etc/fstab.
Si se instalan varios sistemas operativos, el programa de instalación de Red Hat Enterprise Linux intenta detectarlos automáticamente y configurar el gestor de arranque para arrancarlos. Puede configurar manualmente los sistemas operativos adicionales si no son detectados automáticamente. Vea Configuring boot loader en Sección 4.4, “Configuración de las opciones de software” para más información.
Instalación de RHEL desde una imagen en un disco duro local
Record: El disco duro y el directorio que contiene la imagen.
Instalación de RHEL desde una ubicación de red
Si la red tiene que ser configurada manualmente, es decir, no se utiliza el DHCP.
Record:
- Dirección IP
- Máscara de red
- Dirección IP de la pasarela
- Direcciones IP del servidor, si es necesario
Póngase en contacto con su administrador de red si necesita ayuda con los requisitos de red.
Instalación de RHEL en un objetivo iSCSI
Record: La ubicación del objetivo iSCSI. Dependiendo de su red, puede necesitar un nombre de usuario y una contraseña CHAP, y un nombre de usuario y una contraseña CHAP inversos.
Instalación de RHEL si el sistema forma parte de un dominio
Compruebe que el nombre de dominio es suministrado por el servidor DHCP. Si no es así, introduzca el nombre de dominio durante la instalación.
B.4. Requisitos de disco y memoria
Si se instalan varios sistemas operativos, es importante que verifique que el espacio de disco asignado es independiente del espacio de disco requerido por Red Hat Enterprise Linux.
-
Para AMD64, Intel 64 y ARM de 64 bits, al menos dos particiones (
/yswap) deben estar dedicadas a Red Hat Enterprise Linux. -
Para los servidores IBM Power Systems, al menos tres particiones (
/,swap, y una partición de arranquePReP) deben estar dedicadas a Red Hat Enterprise Linux.
Debe tener un mínimo de 10 GiB de espacio disponible en el disco.
Para instalar Red Hat Enterprise Linux, debe tener un mínimo de 10 GiB de espacio en disco no particionado o en particiones que puedan ser eliminadas. Consulte Apéndice C, Referencia de partición para más información.
| Tipo de instalación | Memoria RAM mínima recomendada |
|---|---|
| Instalación en medios locales (USB, DVD) |
|
| Instalación de la red NFS |
|
| Instalación de red HTTP, HTTPS o FTP |
|
Es posible completar la instalación con menos memoria que los requisitos mínimos recomendados. Los requisitos exactos dependen de su entorno y de la ruta de instalación. Se recomienda que pruebe varias configuraciones para determinar la memoria RAM mínima requerida para su entorno. La instalación de Red Hat Enterprise Linux utilizando un archivo Kickstart tiene los mismos requisitos mínimos de RAM recomendados que una instalación estándar. Sin embargo, se puede requerir RAM adicional si su archivo Kickstart incluye comandos que requieren memoria adicional o escriben datos en el disco RAM. Consulte el documento Performing an advanced RHEL installation para obtener más información.
B.5. Requisitos de RAID
Es importante entender cómo se configuran las tecnologías de almacenamiento y cómo el soporte para ellas puede haber cambiado entre las principales versiones de Red Hat Enterprise Linux.
RAID por hardware
Cualquier función RAID proporcionada por la placa base de su ordenador, o las tarjetas controladoras conectadas, necesitan ser configuradas antes de comenzar el proceso de instalación. Cada matriz RAID activa aparece como una unidad dentro de Red Hat Enterprise Linux.
RAID por software
En sistemas con más de un disco duro, puede utilizar el programa de instalación de Red Hat Enterprise Linux para operar varias de las unidades como una matriz RAID por software de Linux. Con una matriz RAID por software, las funciones RAID son controladas por el sistema operativo en lugar del hardware dedicado.
Cuando los dispositivos miembros de una matriz RAID preexistente son todos discos/unidades sin particionar, el programa de instalación trata la matriz como un disco y no hay ningún método para eliminar la matriz.
Discos USB
Puede conectar y configurar el almacenamiento USB externo después de la instalación. La mayoría de los dispositivos son reconocidos por el kernel, pero algunos pueden no ser reconocidos. Si no es un requisito configurar estos discos durante la instalación, desconéctelos para evitar posibles problemas.
Dispositivos NVDIMM
Para utilizar un dispositivo de módulo de memoria en línea doble no volátil (NVDIMM) como almacenamiento, deben cumplirse las siguientes condiciones:
- La versión de Red Hat Enterprise Linux es la 7.6 o posterior.
- La arquitectura del sistema es Intel 64 o AMD64.
- El dispositivo está configurado en modo sectorial. Anaconda puede reconfigurar los dispositivos NVDIMM a este modo.
- El dispositivo debe ser compatible con el controlador nd_pmem.
El arranque desde un dispositivo NVDIMM es posible bajo las siguientes condiciones adicionales:
- El sistema utiliza UEFI.
- El dispositivo debe ser compatible con el firmware disponible en el sistema, o con un controlador UEFI. El controlador UEFI puede cargarse desde una ROM opcional del propio dispositivo.
- El dispositivo debe estar disponible bajo un espacio de nombres.
Para aprovechar el alto rendimiento de los dispositivos NVDIMM durante el arranque, coloque los directorios /boot y /boot/efi en el dispositivo.
La función de ejecución en el lugar (XIP) de los dispositivos NVDIMM no es compatible durante el arranque y el núcleo se carga en la memoria convencional.
Consideraciones sobre los conjuntos RAID de la BIOS de Intel
Red Hat Enterprise Linux utiliza mdraid para instalar en conjuntos RAID de Intel BIOS. Estos conjuntos se detectan automáticamente durante el proceso de arranque y sus rutas de nodos de dispositivos pueden cambiar a través de varios procesos de arranque. Por esta razón, las modificaciones locales a los archivos /etc/fstab, /etc/crypttab u otros archivos de configuración que se refieren a los dispositivos por sus rutas de nodos de dispositivos pueden no funcionar en Red Hat Enterprise Linux. Se recomienda que reemplace las rutas de nodos de dispositivos (como /dev/sda) con etiquetas de sistemas de archivos o UUIDs de dispositivos. Puede encontrar las etiquetas del sistema de archivos y los UUID de los dispositivos utilizando el comando blkid.
Apéndice C. Referencia de partición
C.1. Tipos de dispositivos compatibles
- Partición estándar
-
Una partición estándar puede contener un sistema de archivos o un espacio de intercambio. Las particiones estándar se utilizan más comúnmente para
/booty paraBIOS BootyEFI System partitions. Los volúmenes lógicos LVM se recomiendan para la mayoría de los demás usos. - LVM
-
Al elegir
LVM(o Logical Volume Management) como tipo de dispositivo se crea un volumen lógico LVM. Si no existe ningún grupo de volumen LVM, se crea uno automáticamente para contener el nuevo volumen; si ya existe un grupo de volumen LVM, se asigna el volumen. LVM puede mejorar el rendimiento cuando se utilizan discos físicos, y permite configuraciones avanzadas como el uso de múltiples discos físicos para un punto de montaje, y la configuración de RAID por software para aumentar el rendimiento, la fiabilidad, o ambos. - Aprovisionamiento ligero LVM
- Mediante el aprovisionamiento ligero, puede gestionar un pool de almacenamiento de espacio libre, conocido como thin pool, que puede asignarse a un número arbitrario de dispositivos cuando lo necesiten las aplicaciones. Puede ampliar dinámicamente el pool cuando sea necesario para una asignación rentable del espacio de almacenamiento.
El programa de instalación no es compatible con los thin pools LVM sobreaprovisionados.
C.2. Sistemas de archivos compatibles
Esta sección describe los sistemas de archivos disponibles en Red Hat Enterprise Linux.
- xfs
-
XFSes un sistema de archivos altamente escalable y de alto rendimiento que admite sistemas de archivos de hasta 16 exabytes (aproximadamente 16 millones de terabytes), archivos de hasta 8 exabytes (aproximadamente 8 millones de terabytes) y estructuras de directorios que contienen decenas de millones de entradas.XFStambién admite el registro en el diario de metadatos, lo que facilita una recuperación más rápida de los fallos. El tamaño máximo soportado de un único sistema de archivos XFS es de 500 TB.XFSes el sistema de archivos por defecto y recomendado en Red Hat Enterprise Linux. - ext4
-
El sistema de archivos
ext4se basa en el sistema de archivosext3y presenta una serie de mejoras. Entre ellas se encuentran la compatibilidad con sistemas de archivos y ficheros de mayor tamaño, una asignación más rápida y eficiente del espacio en disco, la ausencia de límites en el número de subdirectorios dentro de un directorio, una comprobación más rápida del sistema de archivos y un registro en el diario más sólido. El tamaño máximo de un sistema de archivosext4es de 50 TB. - ext3
-
El sistema de archivos
ext3está basado en el sistema de archivosext2y tiene una ventaja principal: el registro en el diario. El uso de un sistema de archivos con registro en el diario reduce el tiempo dedicado a la recuperación de un sistema de archivos después de que termine inesperadamente, ya que no hay necesidad de comprobar la consistencia de los metadatos del sistema de archivos ejecutando la utilidad fsck cada vez. - ext2
-
Un sistema de archivos
ext2admite los tipos de archivo estándar de Unix, incluidos los archivos normales, los directorios o los enlaces simbólicos. Ofrece la posibilidad de asignar nombres de archivo largos, de hasta 255 caracteres. - intercambiar
- Las particiones de intercambio se utilizan para apoyar la memoria virtual. En otras palabras, los datos se escriben en una partición de intercambio cuando no hay suficiente RAM para almacenar los datos que el sistema está procesando.
- vfat
El sistema de archivos
VFATes un sistema de archivos de Linux compatible con los nombres largos de archivos de Microsoft Windows en el sistema de archivos FAT.NotaLa compatibilidad con el sistema de archivos
VFATno está disponible para las particiones del sistema Linux. Por ejemplo,/,/var,/usry así sucesivamente.- Arranque de la BIOS
- Una partición muy pequeña necesaria para arrancar desde un dispositivo con una tabla de particiones GUID (GPT) en sistemas BIOS y sistemas UEFI en modo de compatibilidad BIOS.
- Partición del sistema EFI
- Una pequeña partición necesaria para arrancar un dispositivo con una tabla de particiones GUID (GPT) en un sistema UEFI.
- PReP
-
Esta pequeña partición de arranque se encuentra en la primera partición del disco duro. La partición de arranque
PRePcontiene el cargador de arranque GRUB2, que permite a otros servidores IBM Power Systems arrancar Red Hat Enterprise Linux.
C.3. Tipos de RAID soportados
RAID son las siglas de Redundant Array of Independent Disks, una tecnología que permite combinar varios discos físicos en unidades lógicas. Algunas configuraciones están diseñadas para mejorar el rendimiento a costa de la fiabilidad, mientras que otras mejoran la fiabilidad a costa de necesitar más discos para la misma cantidad de espacio disponible.
Esta sección describe los tipos de RAID por software compatibles que puede utilizar con LVM y LVM Thin Provisioning para configurar el almacenamiento en el sistema instalado.
- Ninguno
- No se ha configurado ninguna matriz RAID.
- RAID 0
- Rendimiento: Distribuye los datos entre varios discos. El RAID 0 ofrece un mayor rendimiento que las particiones estándar y puede utilizarse para agrupar el almacenamiento de varios discos en un gran dispositivo virtual. Tenga en cuenta que el RAID 0 no ofrece redundancia y que el fallo de un dispositivo de la matriz destruye los datos de toda la matriz. El RAID 0 requiere al menos dos discos.
- RAID 1
- Redundancia: Refleja todos los datos de una partición en otro u otros discos. Los dispositivos adicionales en la matriz proporcionan niveles crecientes de redundancia. RAID 1 requiere al menos dos discos.
- RAID 4
- Comprobación de errores: Distribuye los datos entre varios discos y utiliza un disco de la matriz para almacenar la información de paridad que protege la matriz en caso de que falle algún disco de la matriz. Como toda la información de paridad se almacena en un disco, el acceso a este disco crea un "cuello de botella" en el rendimiento de la matriz. El RAID 4 requiere al menos tres discos.
- RAID 5
- Comprobación de errores distribuida: Distribuye los datos y la información de paridad entre varios discos. RAID 5 ofrece las ventajas de rendimiento de la distribución de los datos entre varios discos, pero no comparte el cuello de botella de rendimiento de RAID 4, ya que la información de paridad también se distribuye por la matriz. El RAID 5 requiere al menos tres discos.
- RAID 6
- Comprobación de errores redundante: El RAID 6 es similar al RAID 5, pero en lugar de almacenar sólo un conjunto de datos de paridad, almacena dos conjuntos. El RAID 6 requiere al menos cuatro discos.
- RAID 10
- Rendimiento y redundancia: El RAID 10 es un RAID anidado o híbrido. Se construye distribuyendo los datos en conjuntos de discos en espejo. Por ejemplo, una matriz RAID 10 construida a partir de cuatro particiones RAID consta de dos pares de particiones en espejo. El RAID 10 requiere al menos cuatro discos.
C.4. Esquema de partición recomendado
Red Hat recomienda que cree sistemas de archivos separados en los siguientes puntos de montaje. Sin embargo, si es necesario, también puede crear los sistemas de archivos en los puntos de montaje /usr, /var, y /tmp.
-
/boot -
/(raíz) -
/home -
swap -
/boot/efi PReP/bootpartición - tamaño recomendado al menos 1 GiBLa partición montada en
/bootcontiene el kernel del sistema operativo, que permite a su sistema arrancar Red Hat Enterprise Linux 8, junto con los archivos utilizados durante el proceso de arranque. Debido a las limitaciones de la mayoría de los firmwares, se recomienda crear una pequeña partición para contenerlos. En la mayoría de los escenarios, una partición de arranque de 1 GiB es adecuada. A diferencia de otros puntos de montaje, el uso de un volumen LVM para/bootno es posible -/bootdebe estar ubicado en una partición de disco separada.AvisoNormalmente, la partición
/bootes creada automáticamente por el programa de instalación. Sin embargo, si la partición/(raíz) es mayor de 2 TiB y se utiliza (U)EFI para el arranque, es necesario crear una partición/bootseparada que sea menor de 2 TiB para arrancar la máquina con éxito.NotaSi tiene una tarjeta RAID, tenga en cuenta que algunos tipos de BIOS no admiten el arranque desde la tarjeta RAID. En tal caso, la partición
/bootdebe crearse en una partición fuera de la matriz RAID, como por ejemplo en un disco duro separado.root- tamaño recomendado de 10 GiBAquí es donde se encuentra "
/", o el directorio raíz. El directorio raíz es el nivel superior de la estructura de directorios. Por defecto, todos los archivos se escriben en este sistema de archivos a menos que se monte un sistema de archivos diferente en la ruta en la que se escribe, por ejemplo,/booto/home.Aunque un sistema de archivos raíz de 5 GiB le permite realizar una instalación mínima, se recomienda asignar al menos 10 GiB para poder instalar todos los grupos de paquetes que desee.
ImportanteNo confunda el directorio
/con el directorio/root. El directorio/rootes el directorio principal del usuario raíz. El directorio/rootse denomina a veces slash root para distinguirlo del directorio raíz./home- tamaño recomendado al menos 1 GiB-
Para almacenar los datos del usuario por separado de los datos del sistema, cree un sistema de archivos dedicado para el directorio
/home. Base el tamaño del sistema de archivos en la cantidad de datos que se almacenan localmente, el número de usuarios, etc. Puede actualizar o reinstalar Red Hat Enterprise Linux 8 sin borrar los archivos de datos de usuario. Si selecciona el particionamiento automático, se recomienda tener al menos 55 GiB de espacio en disco disponible para la instalación, para asegurar que se cree el sistema de archivos/home. swappartición - tamaño recomendado al menos 1 GBLos sistemas de archivos de intercambio soportan la memoria virtual; los datos se escriben en un sistema de archivos de intercambio cuando no hay suficiente memoria RAM para almacenar los datos que el sistema está procesando. El tamaño de la swap es una función de la carga de trabajo de la memoria del sistema, no de la memoria total del sistema y, por lo tanto, no es igual al tamaño total de la memoria del sistema. Es importante analizar qué aplicaciones va a ejecutar un sistema y la carga que van a tener esas aplicaciones para determinar la carga de trabajo de la memoria del sistema. Los proveedores y desarrolladores de aplicaciones pueden proporcionar orientación.
Cuando el sistema se queda sin espacio de intercambio, el núcleo termina los procesos al agotarse la memoria RAM del sistema. Configurar demasiado espacio de intercambio hace que los dispositivos de almacenamiento se asignen pero estén ociosos y es un mal uso de los recursos. Demasiado espacio de intercambio también puede ocultar fugas de memoria. El tamaño máximo de una partición de intercambio y otra información adicional se puede encontrar en la página del manual
mkswap(8).La siguiente tabla proporciona el tamaño recomendado de una partición de intercambio en función de la cantidad de RAM de su sistema y de si desea tener suficiente memoria para que su sistema hiberne. Si deja que el programa de instalación particione su sistema automáticamente, el tamaño de la partición de intercambio se establece utilizando estas directrices. La configuración del particionamiento automático asume que la hibernación no está en uso. El tamaño máximo de la partición de intercambio está limitado al 10 por ciento del tamaño total del disco duro, y el programa de instalación no puede crear particiones de intercambio de más de 128 GB de tamaño. Para establecer suficiente espacio de intercambio para permitir la hibernación, o si desea establecer el tamaño de la partición de intercambio a más del 10 por ciento del espacio de almacenamiento del sistema, o más de 128 GB, debe editar la disposición de las particiones manualmente.
/boot/efipartición - tamaño recomendado de 200 MiB- Los sistemas AMD64, Intel 64 y ARM de 64 bits basados en UEFI requieren una partición del sistema EFI de 200 MiB. El tamaño mínimo recomendado es de 200 MiB, el tamaño por defecto es de 600 MiB, y el tamaño máximo es de 600 MiB. Los sistemas BIOS no requieren una partición del sistema EFI.
| Cantidad de RAM en el sistema | Espacio de intercambio recomendado | Espacio de intercambio recomendado si se permite la hibernación |
|---|---|---|
| Menos de 2 GB | 2 veces la cantidad de RAM | 3 veces la cantidad de RAM |
| 2 GB - 8 GB | Igual a la cantidad de RAM | 2 veces la cantidad de RAM |
| 8 GB - 64 GB | 4 GB a 0,5 veces la cantidad de RAM | 1.5 veces la cantidad de RAM |
| Más de 64 GB | Depende de la carga de trabajo (al menos 4 GB) | No se recomienda la hibernación |
En el límite entre cada rango, por ejemplo, un sistema con 2 GB, 8 GB o 64 GB de RAM del sistema, se puede ejercer la discreción con respecto al espacio de intercambio elegido y el soporte de hibernación. Si los recursos de tu sistema lo permiten, aumentar el espacio de intercambio puede conducir a un mejor rendimiento.
Distribuir el espacio de intercambio en varios dispositivos de almacenamiento -sobre todo en sistemas con unidades, controladores e interfaces rápidos- también mejora el rendimiento del espacio de intercambio.
Muchos sistemas tienen más particiones y volúmenes que el mínimo requerido. Elija las particiones en función de las necesidades particulares de su sistema.
- Asigne sólo la capacidad de almacenamiento a las particiones que necesite inmediatamente. Puede asignar espacio libre en cualquier momento, para satisfacer las necesidades a medida que se produzcan.
- Si no está seguro de cómo configurar las particiones, acepte la distribución automática por defecto de las particiones que le proporciona el programa de instalación.
PRePpartición de arranque - tamaño recomendado de 4 a 8 MiB-
Cuando instale Red Hat Enterprise Linux en servidores IBM Power System, la primera partición del disco duro debe incluir una partición de arranque
PReP. Esta contiene el cargador de arranque GRUB2, que permite a otros servidores IBM Power Systems arrancar Red Hat Enterprise Linux.
C.5. Asesoramiento sobre tabiques
No existe la mejor manera de realizar una partición en cada sistema; la configuración óptima depende del uso que se le vaya a dar al sistema instalado. Sin embargo, los siguientes consejos pueden ayudarle a encontrar la distribución óptima para sus necesidades:
- Cree primero las particiones que tengan requisitos específicos, por ejemplo, si una partición concreta debe estar en un disco específico.
-
Considera la posibilidad de cifrar las particiones y volúmenes que puedan contener datos sensibles. El cifrado impide que personas no autorizadas accedan a los datos de las particiones, aunque tengan acceso al dispositivo de almacenamiento físico. En la mayoría de los casos, deberías cifrar al menos la partición
/home, que contiene los datos del usuario. -
En algunos casos, la creación de puntos de montaje separados para directorios distintos de
/,/booty/homepuede ser útil; por ejemplo, en un servidor que ejecuta una MySQL base de datos, tener un punto de montaje separado para/var/lib/mysqlle permitirá preservar la base de datos durante una reinstalación sin tener que restaurarla desde una copia de seguridad después. Sin embargo, tener puntos de montaje separados innecesarios dificultará la administración del almacenamiento. -
Algunas restricciones especiales se aplican a ciertos directorios con respecto a los diseños de partición que pueden ser colocados. En particular, el directorio
/bootdebe estar siempre en una partición física (no en un volumen LVM). - Si es nuevo en Linux, considere revisar la página Linux Filesystem Hierarchy Standard en http://refspecs.linuxfoundation.org/FHS_2.3/fhs-2.3.html para obtener información sobre los distintos directorios del sistema y su contenido.
Cada núcleo instalado en su sistema requiere aproximadamente 56 MB en la partición
/boot:- 32 MB initramfs
- 14 MB kdump initramfs
- 3.Mapa del sistema de 5 MB
6.6 MB vmlinuz
NotaPara el modo de rescate,
initramfsyvmlinuzrequieren 80 MB.El tamaño de la partición por defecto de 1 GB para
/bootdebería ser suficiente para los casos de uso más comunes. Sin embargo, se recomienda que aumente el tamaño de esta partición si planea conservar varias versiones del kernel o kernels con erratas.
-
El directorio
/varcontiene el contenido de una serie de aplicaciones, incluido el Apache servidor web, y es utilizado por el DNF para almacenar temporalmente las actualizaciones de los paquetes descargados. Asegúrate de que la partición o el volumen que contiene/vartiene al menos 3 GB. -
El contenido del directorio
/varsuele cambiar con mucha frecuencia. Esto puede causar problemas con las unidades de estado sólido (SSD) más antiguas, ya que pueden soportar un menor número de ciclos de lectura/escritura antes de quedar inservibles. Si la raíz de su sistema está en un SSD, considere la posibilidad de crear un punto de montaje separado para/varen un HDD clásico (de plato). -
El directorio
/usrcontiene la mayoría del software en una instalación típica de Red Hat Enterprise Linux. La partición o volumen que contiene este directorio debería por tanto tener al menos 5 GB para instalaciones mínimas y al menos 10 GB para instalaciones con un entorno gráfico. Si
/usro/varse particionan por separado del resto del volumen raíz, el proceso de arranque se vuelve mucho más complejo porque estos directorios contienen componentes críticos para el arranque. En algunas situaciones, como cuando estos directorios se colocan en una unidad iSCSI o en una ubicación FCoE, el sistema puede ser incapaz de arrancar, o puede colgarse con un errorDevice is busyal apagar o reiniciar.Esta limitación sólo se aplica a
/usro/var, no a los directorios que están por debajo de ellos. Por ejemplo, una partición separada para/var/wwwfuncionará sin problemas.-
Considere dejar una parte del espacio en un grupo de volúmenes LVM sin asignar. Este espacio no asignado le da flexibilidad si sus necesidades de espacio cambian pero no desea eliminar datos de otros volúmenes. También puede seleccionar el tipo de dispositivo
LVM Thin Provisioningpara la partición para que el espacio no utilizado sea manejado automáticamente por el volumen. - El tamaño de un sistema de archivos XFS no puede reducirse: si necesitas hacer más pequeña una partición o un volumen con este sistema de archivos, debes hacer una copia de seguridad de tus datos, destruir el sistema de archivos y crear uno nuevo más pequeño en su lugar. Por lo tanto, si esperas tener que manipular la distribución de tus particiones más adelante, deberías utilizar el sistema de archivos ext4 en su lugar.
-
Utilice la gestión de volúmenes lógicos (LVM) si prevé ampliar su almacenamiento añadiendo más discos duros o ampliando los discos duros de las máquinas virtuales después de la instalación. Con LVM, puedes crear volúmenes físicos en las nuevas unidades y luego asignarlos a cualquier grupo de volúmenes y volumen lógico que consideres oportuno; por ejemplo, puedes ampliar fácilmente el
/homede tu sistema (o cualquier otro directorio que resida en un volumen lógico). - Puede ser necesario crear una partición de arranque de la BIOS o una partición del sistema EFI, dependiendo del firmware de su sistema, del tamaño de la unidad de arranque y de la etiqueta del disco de la unidad de arranque. Consulte Sección C.4, “Esquema de partición recomendado” para obtener información sobre estas particiones. Tenga en cuenta que la instalación gráfica no le permitirá crear una partición de arranque BIOS o una partición de sistema EFI si su sistema not requiere una - en ese caso, se ocultarán del menú.
- Si necesita realizar algún cambio en la configuración del almacenamiento después de la instalación, los repositorios de Red Hat Enterprise Linux ofrecen varias herramientas diferentes que pueden ayudarle a hacerlo. Si prefiere una herramienta de línea de comandos, pruebe system-storage-manager.
Apéndice D. Referencia de las opciones de arranque
Esta sección contiene información sobre algunas de las opciones de arranque que puede utilizar para modificar el comportamiento por defecto del programa de instalación. Para las opciones de arranque avanzadas y de Kickstart, consulte el Performing an advanced RHEL installation documento.
D.1. Opciones de arranque de la fuente de instalación
Esta sección contiene información sobre las distintas opciones de arranque de la fuente de instalación.
- inst.repo=
La opción de arranque
inst.repo=especifica el origen de la instalación, es decir, la ubicación que proporciona los repositorios de paquetes y un archivo válido.treeinfoque los describe. Por ejemplo:inst.repo=cdrom. El destino de la opcióninst.repo=debe ser uno de los siguientes medios de instalación:-
un árbol instalable, que es una estructura de directorios que contiene las imágenes del programa de instalación, los paquetes y los datos del repositorio, así como un archivo válido
.treeinfo - un DVD (un disco físico presente en la unidad de DVD del sistema)
una imagen ISO del DVD de instalación completa de Red Hat Enterprise Linux, colocada en un disco duro o en una ubicación de red accesible al sistema.
Utilice la opción de arranque
inst.repo=para configurar diferentes métodos de instalación con distintos formatos. La siguiente tabla contiene detalles de la sintaxis de la opción de arranqueinst.repo=:Expand Tabla D.1. inst.repo= fuente de instalación opciones de arranque Tipo de fuente Formato de la opción de arranque Formato de la fuente Unidad de CD/DVD
inst.repo=cdrom:<device>DVD de instalación como disco físico [a]
Árbol instalable
inst.repo=hd:<device>:/<path>Archivo de imagen del DVD de instalación, o un árbol de instalación, que es una copia completa de los directorios y archivos del DVD de instalación.
Servidor NFS
inst.repo=nfs:[options:]<server>:/<path>Archivo de imagen del DVD de instalación, o un árbol de instalación, que es una copia completa de los directorios y archivos del DVD de instalación [b]
Servidor HTTP
inst.repo=http://<host>/<path>Árbol de instalación, que es una copia completa de los directorios y archivos del DVD de instalación.
Servidor HTTPS
inst.repo=https://<host>/<path>Servidor FTP
inst.repo=ftp://<username>:<password>@<host>/<path>HMC
inst.repo=hmc[a] Si se omite device, el programa de instalación busca automáticamente una unidad que contenga el DVD de instalación.[b] La opción Servidor NFS utiliza por defecto la versión 3 del protocolo NFS. Para utilizar una versión diferente, añadanfsvers=Xa options, sustituyendo X por el número de versión que desee utilizar.Establezca los nombres de los dispositivos de disco con los siguientes formatos:
-
Nombre del dispositivo del núcleo, por ejemplo
/dev/sda1osdb2 -
Etiqueta del sistema de archivos, por ejemplo
LABEL=FlashoLABEL=RHEL8 UUID del sistema de archivos, por ejemplo
UUID=8176c7bf-04ff-403a-a832-9557f94e61dbLos caracteres no alfanuméricos deben representarse como
\xNN, donde NN es la representación hexadecimal del carácter. Por ejemplo,\x20es un espacio en blanco(" ").
-
un árbol instalable, que es una estructura de directorios que contiene las imágenes del programa de instalación, los paquetes y los datos del repositorio, así como un archivo válido
- inst.addrepo=
Utilice la opción de arranque
inst.addrepo=para añadir un repositorio adicional que pueda ser utilizado como otra fuente de instalación junto con el repositorio principal (inst.repo=). Puede utilizar la opción de arranqueinst.addrepo=varias veces durante un arranque. La siguiente tabla contiene detalles de la sintaxis de la opción de arranqueinst.addrepo=.NotaEl
REPO_NAMEes el nombre del repositorio y es necesario en el proceso de instalación. Estos repositorios sólo se utilizan durante el proceso de instalación; no se instalan en el sistema instalado.Expand Tabla D.2. inst.addrepo fuente de instalación opciones de arranque Fuente de instalación Formato de la opción de arranque Información adicional Árbol instalable en una URL
inst.addrepo=REPO_NAME,[http,https,ftp]://<host>/<path>Busca el árbol instalable en una URL determinada.
Árbol instalable en una ruta NFS
inst.addrepo=REPO_NAME,nfs://<server>:/<path>Busca el árbol instalable en una ruta NFS dada. Se requieren dos puntos después del host. El programa de instalación pasa todo lo que hay después de
nfs://directamente al comando mount en lugar de analizar las URLs de acuerdo con el RFC 2224.Árbol instalable en el entorno de instalación
inst.addrepo=REPO_NAME,file://<path>Busca el árbol instalable en la ubicación dada en el entorno de instalación. Para utilizar esta opción, el repositorio debe estar montado antes de que el programa de instalación intente cargar los grupos de software disponibles. El beneficio de esta opción es que puede tener múltiples repositorios en una ISO de arranque, y puede instalar tanto el repositorio principal como los repositorios adicionales desde la ISO. La ruta de acceso a los repositorios adicionales es
/run/install/source/REPO_ISO_PATH. Adicionalmente, puede montar el directorio del repositorio en la sección%preen el archivo Kickstart. La ruta debe ser absoluta y comenzar con/, por ejemploinst.addrepo=REPO_NAME,file:///<path>Disco duro
inst.addrepo=REPO_NAME,hd:<device>:<path>Monta la partición dada <device> e instala desde la ISO que se especifica en <path>. Si no se especifica el <path>, el programa de instalación busca una ISO de instalación válida en el <device>. Este método de instalación requiere una ISO con un árbol instalable válido.
- inst.stage2=
Utilice la opción de arranque
inst.stage2=para especificar la ubicación de la imagen de ejecución del programa de instalación. Esta opción espera una ruta a un directorio que contenga un archivo.treeinfoválido. La ubicación de la imagen de ejecución se lee del archivo.treeinfo. Si el archivo.treeinfono está disponible, el programa de instalación intenta cargar la imagen desdeimages/install.img.Cuando no se especifica la opción
inst.stage2, el programa de instalación intenta utilizar la ubicación especificada con la opcióninst.repo.Utilice esta opción sólo cuando utilice el método de arranque PXE. El DVD de instalación y el Boot ISO ya contienen una opción correcta
inst.stage2para arrancar el programa de instalación desde ellos mismos.NotaPor defecto, la opción de arranque
inst.stage2=se utiliza en el medio de instalación y se establece en una etiqueta específica, por ejemplo,inst.stage2=hd:LABEL=RHEL-8-0-0-BaseOS-x86_64. Si modifica la etiqueta por defecto del sistema de archivos que contiene la imagen de ejecución, o si utiliza un procedimiento personalizado para arrancar el sistema de instalación, debe verificar que la opción de arranqueinst.stage2=esté configurada con el valor correcto.- inst.noverifyssl
Utilice la opción de arranque
inst.noverifysslpara evitar que el instalador verifique los certificados SSL para todas las conexiones HTTPS con la excepción de los repositorios adicionales de Kickstart, donde--noverifysslse puede establecer por repositorio.Por ejemplo, si el origen de la instalación remota utiliza certificados SSL autofirmados, la opción de arranque
inst.noverifysslpermite al instalador completar la instalación sin verificar los certificados SSL.Ejemplo cuando se especifica la fuente utilizando
inst.stage2=inst.stage2=https://hostname/path_to_install_image/ inst.noverifysslEjemplo cuando se especifica la fuente utilizando
inst.repo=inst.repo=https://hostname/path_to_install_repository/ inst.noverifyssl- inst.stage2.all
La opción de arranque
inst.stage2.allse utiliza para especificar varias fuentes HTTP, HTTPS o FTP. Puede utilizar la opción de arranqueinst.stage2=varias veces con la opcióninst.stage2.allpara obtener la imagen de las fuentes secuencialmente hasta que una tenga éxito. Por ejemplo:inst.stage2.all inst.stage2=http://hostname1/path_to_install_tree/ inst.stage2=http://hostname2/path_to_install_tree/ inst.stage2=http://hostname3/path_to_install_tree/- inst.dd=
-
La opción de arranque
inst.dd=se utiliza para realizar una actualización de los controladores durante la instalación. Para obtener más información sobre cómo actualizar los controladores durante la instalación, consulte el Performing an advanced RHEL installation documento. - inst.repo=hmc
-
Cuando se arranca desde un DVD binario, el programa de instalación le pide que introduzca parámetros adicionales del kernel. Para establecer el DVD como fuente de instalación, añada la opción
inst.repo=hmca los parámetros del kernel. El programa de instalación habilita entonces el acceso a los archivosSEyHMC, obtiene las imágenes para la etapa 2 desde el DVD y proporciona acceso a los paquetes del DVD para la selección del software. Esta opción elimina el requisito de una configuración de red externa y amplía las opciones de instalación. - inst.proxy=
La opción de arranque
inst.proxy=se utiliza cuando se realiza una instalación desde un protocolo HTTP, HTTPS y FTP. Por ejemplo:[PROTOCOLO://][NOMBRE DE USUARIO[:CONTRASEÑA]@]HOST[:PUERTO]- inst.nosave=
Utilice la opción de arranque
inst.nosave=para controlar los registros de instalación y los archivos relacionados que no se guardan en el sistema instalado, por ejemploinput_ks,output_ks,all_ks,logsyall. Se pueden combinar varios valores como una lista separada por comas, por ejemplo:input_ks,logs.NotaLa opción de arranque
inst.nosavese utiliza para excluir archivos del sistema instalado que no pueden ser eliminados por un script Kickstart %post, como los registros y los resultados de entrada/salida de Kickstart.Expand Tabla D.3. inst.nosave opciones de arranque Opción Descripción input_ks
Desactiva la posibilidad de guardar los resultados del Kickstart de entrada.
output_ks
Desactiva la posibilidad de guardar los resultados de Kickstart generados por el programa de instalación.
todos_los_más
Desactiva la posibilidad de guardar los resultados de entrada y salida de Kickstart.
registros
Desactiva la posibilidad de guardar todos los registros de instalación.
todo
Desactiva la capacidad de guardar todos los resultados de Kickstart, y todos los registros.
- inst.multilib
-
Utilice la opción de arranque
inst.multilibpara establecer el DNFmultilib_policyen all, en lugar de best. - inst.memcheck
-
La opción de arranque
inst.memcheckrealiza una comprobación para verificar que el sistema tiene suficiente RAM para completar la instalación. Si no hay suficiente RAM, el proceso de instalación se detiene. La comprobación del sistema es aproximada y el uso de la memoria durante la instalación depende de la selección del paquete, de la interfaz de usuario, por ejemplo gráfica o de texto, y de otros parámetros. - inst.nomemcheck
-
La opción de arranque
inst.nomemcheckno realiza una comprobación para verificar si el sistema tiene suficiente memoria RAM para completar la instalación. Cualquier intento de realizar la instalación con una cantidad de memoria inferior a la mínima recomendada no es compatible y puede hacer que el proceso de instalación falle.
D.2. Opciones de arranque en red
Esta sección contiene información sobre las opciones de arranque en red más utilizadas.
La inicialización de la red es manejada por dracut. Para obtener una lista completa, consulte la página de manual dracut.cmdline(7).
- ip=
Utilice la opción de arranque
ip=para configurar una o más interfaces de red. Para configurar varias interfaces, puede utilizar la opciónipvarias veces, una para cada interfaz; para ello, debe utilizar la opciónrd.neednet=1, y debe especificar una interfaz de arranque principal utilizando la opciónbootdev. Alternativamente, puede usar la opciónipuna vez, y luego usar Kickstart para configurar más interfaces. Esta opción acepta varios formatos diferentes. Las siguientes tablas contienen información sobre las opciones más comunes.NotaEn las siguientes tablas:
-
El parámetro
ipespecifica la dirección IP del cliente y requiere corchetes, por ejemplo [2001:db8::99]. -
El parámetro
gatewayes la puerta de enlace por defecto. También se aceptan direcciones IPv6. -
El parámetro
netmaskes la máscara de red que se va a utilizar. Puede ser una máscara de red completa (por ejemplo, 255.255.255.0) o un prefijo (por ejemplo, 64). -
El parámetro
hostnamees el nombre del host del sistema cliente. Este parámetro es opcional.
Expand Tabla D.4. Formatos de opciones de arranque de la configuración de la interfaz de red Método de configuración Formato de la opción de arranque Configuración automática de cualquier interfaz
ip=methodConfiguración automática de una interfaz específica
ip=interface:methodConfiguración estática
ip=ip::gateway:netmask:hostname:interface:noneConfiguración automática de una interfaz específica con una anulación
ip=ip::gateway:netmask:hostname:interface:method:mtuNotaEl método
automatic configuration of a specific interface with an overrideabre la interfaz utilizando el método de configuración automática especificado, comodhcp, pero anula la dirección IP, la puerta de enlace, la máscara de red, el nombre de host u otros parámetros especificados obtenidos automáticamente. Todos los parámetros son opcionales, así que especifique sólo los parámetros que desee anular.El parámetro
methodpuede ser cualquiera de los siguientes:Expand Tabla D.5. Métodos de configuración automática de interfaces Método de configuración automática Valor DHCP
dhcpIPv6 DHCP
dhcp6Configuración automática de IPv6
auto6tabla de Firmware de Arranque iSCSI (iBFT)
ibftNota-
Si utiliza una opción de arranque que requiere acceso a la red, como
inst.ks=http://host/path, sin especificar la opción ip, el programa de instalación utilizaip=dhcp. -
Para conectarse a un objetivo iSCSI automáticamente, debe activar un dispositivo de red para acceder al objetivo. La forma recomendada de activar una red es utilizar la opción de arranque
ip=ibft.
-
El parámetro
- servidor de nombres=
La opción
nameserver=especifica la dirección del servidor de nombres. Puede utilizar esta opción varias veces.NotaEl parámetro
ip=requiere corchetes. Sin embargo, una dirección IPv6 no funciona con corchetes. Un ejemplo de la sintaxis correcta a utilizar para una dirección IPv6 esnameserver=2001:db8::1.- bootdev=
-
La opción
bootdev=especifica la interfaz de arranque. Esta opción es obligatoria si se utiliza más de una opciónip. - ifname=
La opción
ifname=asigna un nombre de interfaz a un dispositivo de red con una dirección MAC determinada. Puede utilizar esta opción varias veces. La sintaxis esifname=interface:MAC. Por ejemplo:ifname=eth0:01:23:45:67:89:abNotaLa opción
ifname=es la única forma admitida para establecer nombres de interfaz de red personalizados durante la instalación.- inst.dhcpclass=
-
La opción
inst.dhcpclass=especifica el identificador de clase de proveedor DHCP. El serviciodhcpdve este valor comovendor-class-identifier. El valor por defecto esanaconda-$(uname -srm). - inst.waitfornet=
-
El uso de la opción de arranque
inst.waitfornet=SECONDShace que el sistema de instalación espere la conectividad de la red antes de la instalación. El valor indicado en el argumentoSECONDSespecifica el tiempo máximo de espera para la conectividad de red antes de que se agote el tiempo y se continúe el proceso de instalación, incluso si la conectividad de red no está presente.
Recursos adicionales
- Para más información sobre la conexión en red, consulte el Configuring and managing networking documento.
D.3. Opciones de arranque de la consola
Esta sección contiene información sobre la configuración de las opciones de arranque para la consola, la pantalla del monitor y el teclado.
- consola=
-
Utilice la opción
console=para especificar un dispositivo que desee utilizar como consola principal. Por ejemplo, para utilizar una consola en el primer puerto serie, utiliceconsole=ttyS0. Utilice esta opción junto con la opcióninst.text. Puede utilizar la opciónconsole=varias veces. Si lo hace, el mensaje de arranque se muestra en todas las consolas especificadas, pero sólo la última es utilizada por el programa de instalación. Por ejemplo, si especificaconsole=ttyS0 console=ttyS1, el programa de instalación utilizattyS1. - inst.lang=
-
Utilice la opción
inst.lang=para establecer el idioma que desea utilizar durante la instalación. Los comandoslocale -a | grep _olocalectl list-locales | grep _devuelven una lista de locales. - inst.singlelang
-
Utilice la opción
inst.singlelangpara instalar en modo de idioma único, lo que hace que no haya opciones interactivas disponibles para el idioma de instalación y la configuración de soporte de idiomas. Si se especifica un idioma mediante la opción de arranqueinst.lango el comando Kickstartlang, se utilizará. Si no se especifica ningún idioma, el programa de instalación utiliza por defectoen_US.UTF-8. - inst.geoloc=
Utilice la opción
inst.geoloc=para configurar el uso de la geolocalización en el programa de instalación. La geolocalización se utiliza para preestablecer el idioma y la zona horaria, y utiliza la siguiente sintaxis:inst.geoloc=value. Elvaluepuede ser cualquiera de los siguientes parámetros:Expand Tabla D.6. Valores para la opción de arranque inst.geoloc Valor Formato de la opción de arranque Desactivar la geolocalización
inst.geoloc=0Utilice la API GeoIP de Fedora
inst.geoloc=provider_fedora_geoipUtilice la API GeoIP de Hostip.info
inst.geoloc=provider_hostipSi no se especifica la opción
inst.geoloc=, el programa de instalación utilizaprovider_fedora_geoip.- inst.keymap=
-
Utilice la opción
inst.keymap=para especificar la distribución del teclado que desea utilizar para la instalación. - inst.cmdline
-
Utilice la opción
inst.cmdlinepara forzar que el programa de instalación se ejecute en modo de línea de comandos. Este modo no permite ninguna interacción, y debe especificar todas las opciones en un archivo Kickstart o en la línea de comandos. - inst.gráfica
-
Utilice la opción
inst.graphicalpara forzar que el programa de instalación se ejecute en modo gráfico. Este modo es el predeterminado. - texto.inst
-
Utilice la opción
inst.textpara forzar que el programa de instalación se ejecute en modo texto en lugar de en modo gráfico. - inst.nointeractivo
-
Utilice la opción de arranque
inst.noninteractivepara ejecutar el programa de instalación en modo no interactivo. No se permite la interacción del usuario en el modo no interactivo, yinst.noninteractivepuede utilizarse con una instalación gráfica o de texto. Cuando se utiliza la opcióninst.noninteractiveen modo texto se comporta igual que la opcióninst.cmdline. - inst.resolution=
-
Utilice la opción
inst.resolution=para especificar la resolución de la pantalla en modo gráfico. El formato esNxM, donde N es la anchura de la pantalla y M es la altura de la pantalla (en píxeles). La resolución más baja soportada es 1024x768. - inst.vnc
-
Utilice la opción
inst.vncpara ejecutar la instalación gráfica mediante VNC. Debe utilizar una aplicación cliente VNC para interactuar con el programa de instalación. Cuando el uso compartido de VNC está activado, pueden conectarse varios clientes. Un sistema instalado mediante VNC se inicia en modo texto. - inst.vncpassword=
-
Utilice la opción
inst.vncpassword=para establecer una contraseña en el servidor VNC que utiliza el programa de instalación. - inst.vncconnect=
-
Utilice la opción
inst.vncconnect=para conectarse a un cliente VNC a la escucha en la ubicación del host indicado. Por ejemploinst.vncconnect=<host>[:<port>]. El puerto por defecto es 5900. Esta opción puede utilizarse convncviewer -listen. - inst.xdriver=
-
Utilice la opción
inst.xdriver=para especificar el nombre del controlador X que desea utilizar tanto durante la instalación como en el sistema instalado. - inst.usefbx
-
Utilice la opción
inst.usefbxpara solicitar al programa de instalación que utilice el controlador X de la memoria intermedia en lugar de un controlador específico del hardware. Esta opción es equivalente ainst.xdriver=fbdev. - modprobe.blacklist=
Utilice la opción
modprobe.blacklist=para bloquear o desactivar completamente uno o varios controladores. Los controladores (mods) que deshabilite mediante esta opción no podrán cargarse cuando se inicie la instalación y, una vez finalizada ésta, el sistema instalado conservará esta configuración. Puede encontrar una lista de los controladores bloqueados en el directorio/etc/modprobe.d/. Utilice una lista separada por comas para desactivar varios controladores. Por ejemplo:modprobe.blacklist=ahci,firewire_ohci- inst.xtimeout=
-
Utilice la opción
inst.xtimeout=para especificar el tiempo de espera en segundos para iniciar el servidor X. - inst.sshd
Utilice la opción
inst.sshdpara iniciar el serviciosshddurante la instalación, de modo que pueda conectarse al sistema durante la instalación utilizando SSH, y supervisar el progreso de la instalación. Para más información sobre SSH, consulte la página manssh(1). Por defecto, la opciónsshdse inicia automáticamente sólo en la arquitectura IBM Z. En otras arquitecturas,sshdno se inicia a menos que se utilice la opcióninst.sshd.NotaDurante la instalación, la cuenta raíz no tiene contraseña por defecto. Puede establecer una contraseña de root durante la instalación con el comando
sshpwKickstart.- inst.kdump_addon=
-
Utilice la opción
inst.kdump_addon=para activar o desactivar la pantalla de configuración de Kdump (complemento) en el programa de instalación. Esta pantalla está activada por defecto; utiliceinst.kdump_addon=offpara desactivarla. Al deshabilitar el complemento se desactivan las pantallas de Kdump tanto en la interfaz gráfica como en la de texto, así como el comando Kickstart dedon com_redhat_kdump.
D.4. Opciones de arranque de depuración
Esta sección contiene información sobre las opciones que puede utilizar para depurar problemas.
- rescate.inst
-
Utilice la opción
inst.rescuepara ejecutar el entorno de rescate. Esta opción es útil para intentar diagnosticar y reparar sistemas. Por ejemplo, puede reparar un sistema de archivos en modo de rescate. - inst.updates=
Utilice la opción
inst.updates=para especificar la ubicación del archivoupdates.imgque desea aplicar durante la instalación. Hay varias fuentes para las actualizaciones.Expand Tabla D.7. inst.updates= actualizaciones de la fuente Fuente Descripción Ejemplo Actualizaciones de una red
La forma más sencilla de utilizar
inst.updates=es especificar la ubicación en red deupdates.img. Esto no requiere ninguna modificación del árbol de instalación. Para utilizar este método, edite la línea de comandos del kernel para incluirinst.updates.inst.updates=http://some.website.com/path/to/updates.img.Actualizaciones desde una imagen de disco
Puede guardar un
updates.imgen una unidad de disquete o en una llave USB. Esto sólo puede hacerse con un sistema de archivos de tipoext2deupdates.img. Para guardar el contenido de la imagen en su disquetera, inserte el disquete y ejecute el comandodd if=updates.img of=/dev/fd0 bs=72k count=20. Para utilizar una llave USB o un soporte flash, sustituya/dev/fd0por el nombre del dispositivo de su llave USB.Actualizaciones de un árbol de instalación
Si está utilizando una instalación en CD, disco duro, HTTP o FTP, puede guardar el
updates.imgen el árbol de instalación para que todas las instalaciones puedan detectar el archivo .img. Guarde el archivo en el directorioimages/. El nombre del archivo debe serupdates.img.Para las instalaciones NFS, hay dos opciones: Puede guardar la imagen en el directorio
images/, o en el directorioRHupdates/del árbol de instalación.- inst.loglevel=
-
Utilice la opción
inst.loglevel=para especificar el nivel mínimo de mensajes registrados en un terminal. Esto sólo afecta al registro de la terminal; los archivos de registro siempre contienen mensajes de todos los niveles. Los valores posibles para esta opción, de menor a mayor nivel, sondebug,info,warning,errorycritical. El valor por defecto esinfo, lo que significa que, por defecto, la terminal de registro muestra mensajes que van desdeinfohastacritical. - inst.syslog=
-
Cuando se inicia la instalación, la opción
inst.syslog=envía mensajes de registro al procesosyslogen el host especificado. El proceso remotosyslogdebe estar configurado para aceptar conexiones entrantes. - inst.virtiolog=
-
Utilice la opción
inst.virtiolog=para especificar el puerto de virtio (un dispositivo de caracteres en/dev/virtio-ports/name) que desea utilizar para el reenvío de registros. El valor por defecto esorg.fedoraproject.anaconda.log.0; si este puerto está presente, se utiliza. - inst.zram=
-
La opción
inst.zram=controla el uso de zRAM swap durante la instalación. La opción crea un dispositivo de bloque comprimido dentro de la RAM del sistema y lo utiliza como espacio de intercambio en lugar del disco duro. Esto permite que el programa de instalación se ejecute con menos memoria disponible de la que es posible sin compresión, y también puede hacer que la instalación sea más rápida. Por defecto, el intercambio en zRAM está activado en sistemas con 2 GiB o menos de RAM, y desactivado en sistemas con más de 2 GiB de memoria. Puede utilizar esta opción para cambiar este comportamiento; en un sistema con más de 2 GiB de RAM, utiliceinst.zram=1para activar la función, y en sistemas con 2 GiB o menos de memoria, utiliceinst.zram=0para desactivar la función. - rd.live.ram
-
Si se especifica la opción
rd.live.ram, la imagenstage 2se copia en la memoria RAM. El uso de esta opción cuando la imagenstage 2está en un servidor NFS aumenta la memoria mínima requerida por el tamaño de la imagen en aproximadamente 500 MiB. - inst.nokill
-
La opción
inst.nokilles una opción de depuración que evita que el programa de instalación se reinicie cuando se produce un error fatal, o al final del proceso de instalación. Utilice la opcióninst.nokillpara capturar los registros de instalación que se perderían al reiniciar. - inst.noshell
-
Utilice la opción
inst.noshellsi no desea un shell en la sesión de terminal 2 (tty2) durante la instalación. - inst.notmux
-
Utilice la opción
inst.notmuxsi no desea utilizar tmux durante la instalación. La salida se genera sin caracteres de control del terminal y está pensada para usos no interactivos. - inst.remotelog=
-
Puede utilizar la opción
inst.remotelog=para enviar todos los registros a unhost:portremoto utilizando una conexión TCP. La conexión se retira si no hay ningún oyente y la instalación prosigue con normalidad.
D.5. Opciones de arranque del almacenamiento
- inst.nodmraid
-
Utilice la opción
inst.nodmraidpara desactivar el soporte dedmraid.
Utilice esta opción con precaución. Si tiene un disco que se identifica incorrectamente como parte de un conjunto RAID con firmware, es posible que tenga algunos metadatos RAID obsoletos que deben eliminarse con la herramienta adecuada, por ejemplo, dmraid o wipefs.
- inst.nompath
-
Utilice la opción
inst.nompathpara desactivar la compatibilidad con los dispositivos multirruta. Esta opción se puede utilizar para sistemas en los que se encuentra un falso positivo que identifica incorrectamente un dispositivo de bloque normal como un dispositivo multitrayecto. No hay ninguna otra razón para utilizar esta opción.
Utilice esta opción con precaución. No debe utilizar esta opción con hardware multitrayectoria. No se admite el uso de esta opción para intentar instalar en una sola ruta de una ruta múltiple.
- inst.gpt
-
La opción de arranque
inst.gptobliga al programa de instalación a instalar la información de las particiones en una tabla de particiones GUID (GPT) en lugar de un registro de arranque maestro (MBR). Esta opción no es válida en sistemas basados en UEFI, a menos que estén en modo de compatibilidad con BIOS. Normalmente, los sistemas basados en BIOS y los sistemas basados en UEFI en modo de compatibilidad con BIOS intentan utilizar el esquema MBR para almacenar la información de las particiones, a menos que el disco tenga un tamaño de 2^32 sectores o más. Los sectores del disco suelen tener un tamaño de 512 bytes, lo que significa que esto suele equivaler a 2 TiB. El uso de la opción de arranqueinst.gptcambia este comportamiento, permitiendo escribir una GPT en discos más pequeños.
D.6. Opciones de arranque obsoletas
Esta sección contiene información sobre las opciones de arranque obsoletas. Estas opciones todavía son aceptadas por el programa de instalación pero están obsoletas y están programadas para ser eliminadas en una futura versión de Red Hat Enterprise Linux.
- método
-
La opción
methodes un alias deinst.repo. - dns
-
Utilice
nameserveren lugar dedns. Tenga en cuenta que nameserver no acepta listas separadas por comas; en su lugar, utilice varias opciones de nameserver. - máscara de red, puerta de enlace, nombre de host
-
Las opciones
netmask,gateway, yhostnamese proporcionan como parte de la opciónip. - ip=bootif
-
La opción
BOOTIFsuministrada por PXE se utiliza automáticamente, por lo que no es necesario utilizarip=bootif. - ksdevice
Expand Tabla D.8. Valores para la opción de arranque ksdevice Valor Información No está presente
N/A
ksdevice=linkSe ignora ya que esta opción es la misma que el comportamiento por defecto
ksdevice=bootifSe ignora ya que esta opción es la predeterminada si
BOOTIF=está presenteksdevice=ibftSustituido por
ip=ibft. Véaseippara más detallesksdevice=<MAC>Sustituido por
BOOTIF=${MAC/:/-}ksdevice=<DEV>Sustituido por
bootdev
D.7. Eliminación de las opciones de arranque
Esta sección contiene las opciones de arranque que han sido eliminadas de Red Hat Enterprise Linux.
dracut proporciona opciones avanzadas de arranque. Para más información sobre dracut, consulte la página de manual dracut.cmdline(7).
- askmethod, asknetwork
-
initramfses completamente no interactivo, por lo que se han eliminado las opcionesaskmethodyasknetwork. En su lugar, utiliceinst.repoo especifique las opciones de red adecuadas. - lista negra, nofirewire
-
La opción
modprobese encarga de bloquear los módulos del kernel; utilicemodprobe.blacklist=<mod1>,<mod2>. Puede bloquear el módulo firewire utilizandomodprobe.blacklist=firewire_ohci. - inst.headless=
-
La opción
headless=especifica que el sistema en el que se está instalando no tiene ningún hardware de pantalla, y que el programa de instalación no está obligado a buscar ningún hardware de pantalla. - inst.decorado
-
La opción
inst.decoratedse utiliza para especificar la instalación gráfica en una ventana decorada. Por defecto, la ventana no está decorada, por lo que no tiene barra de título, controles de redimensionamiento, etc. Esta opción ya no es necesaria. - repo=nfsiso
-
Utilice la opción
inst.repo=nfs:. - serie
-
Utilice la opción
console=ttyS0. - actualiza
-
Utilice la opción
inst.updates. - essid, wepkey, wpakey
- Dracut no admite redes inalámbricas.
- ethtool
- Esta opción ya no era necesaria.
- gdb
-
Esta opción se ha eliminado ya que hay muchas opciones disponibles para depurar el sistema basado en dracut
initramfs. - inst.mediacheck
-
Utilice la opción
dracut option rd.live.check. - ks=floppy
-
Utilice la opción
inst.ks=hd:<device>. - mostrar
-
Para una visualización remota de la interfaz de usuario, utilice la opción
inst.vnc. - utf8
- Esta opción ya no era necesaria, ya que la configuración por defecto de TERM se comporta como se espera.
- noipv6
-
ipv6 está integrado en el kernel y no puede ser eliminado por el programa de instalación. Puede desactivar ipv6 utilizando
ipv6.disable=1. Esta configuración es utilizada por el sistema instalado. - actualizar cualquier
- Esta opción ya no era necesaria porque el programa de instalación ya no gestiona las actualizaciones.
Apéndice E. Cambiar un servicio de suscripción
Para gestionar las suscripciones, puede registrar un sistema RHEL con Red Hat Subscription Management Server o Red Hat Satellite Server. Si es necesario, puede cambiar el servicio de suscripción en un momento posterior. Para cambiar el servicio de suscripción bajo el cual está registrado, desregistre el sistema del servicio actual y luego regístrelo con un nuevo servicio.
Esta sección contiene información sobre cómo anular el registro de su sistema RHEL desde el Servidor de gestión de suscripciones de Red Hat y el Servidor Satélite de Red Hat.
Requisitos previos
Ha registrado su sistema con cualquiera de los siguientes:
- Servidor de gestión de suscripciones de Red Hat
- Servidor Red Hat Satellite
Para recibir las actualizaciones del sistema, registre su sistema en cualquiera de los servidores de gestión.
E.1. Anulación del registro en el servidor de gestión de suscripciones
Esta sección contiene información sobre cómo desregistrar un sistema RHEL del Servidor de Gestión de Suscripciones de Red Hat, utilizando una línea de comandos y la interfaz de usuario del Gestor de Suscripciones.
E.1.1. Anulación del registro mediante la línea de comandos
Utilice el comando unregister para anular el registro de un sistema RHEL del Servidor de Gestión de Suscripciones de Red Hat.
Procedimiento
Ejecute el comando de desregistro como usuario root, sin ningún parámetro adicional.
# subscription-manager unregister- Cuando se le solicite, proporcione una contraseña de root.
El sistema no está registrado en el servidor de gestión de suscripciones, y se muestra el estado "El sistema no está registrado actualmente" con el botón de activado.
Para continuar con los servicios ininterrumpidos, vuelva a registrar el sistema en cualquiera de los servicios de gestión. Si no registra el sistema con un servicio de gestión, es posible que no reciba las actualizaciones del sistema. Para obtener más información sobre el registro de un sistema, consulte Registro del sistema mediante la línea de comandos
Para más información sobre el servidor de gestión de suscripciones de Red Hat, consulte el Using and Configuring Red Hat Subscription Manager documento.
E.1.2. Anulación del registro mediante la interfaz de usuario del Gestor de Suscripciones
Esta sección contiene información sobre cómo desregistrar un sistema RHEL del Servidor de Gestión de Suscripciones de Red Hat, utilizando la interfaz de usuario del Gestor de Suscripciones.
Procedimiento
- Inicie sesión en su sistema.
- En la parte superior izquierda de la ventana, haga clic en Activities.
- En las opciones de menú, haga clic en el icono Show Applications.
- Haga clic en el icono Red Hat Subscription Manager, o introduzca Red Hat Subscription Manager en la búsqueda.
Introduzca su contraseña de administrador en el cuadro de diálogo Authentication Required. Aparece la ventana Subscriptions y muestra el estado actual de las suscripciones, el propósito del sistema y los productos instalados. Los productos no registrados muestran una X roja.
NotaLa autenticación es necesaria para realizar tareas privilegiadas en el sistema.
- Haga clic en el botón de .
El sistema no está registrado en el servidor de gestión de suscripciones, y se muestra el estado "El sistema no está registrado actualmente" con el botón de activado.
Para continuar con los servicios ininterrumpidos, vuelva a registrar el sistema en cualquiera de los servicios de gestión. Si no registra el sistema en un servicio de gestión, es posible que no reciba las actualizaciones del sistema. Para obtener más información sobre el registro de un sistema, consulte Registro del sistema mediante la interfaz de usuario del gestor de suscripciones
Para más información sobre el servidor de gestión de suscripciones de Red Hat, consulte el Using and Configuring Red Hat Subscription Manager documento.
E.2. Desregulación del Servidor Satélite
Para anular el registro de un sistema Red Hat Enterprise Linux del Servidor Satélite, elimine el sistema del Servidor Satélite.
Para más información, consulte Eliminar un host de Red Hat Satellite en la guía Managing Hosts de la documentación del Servidor Satélite.
Apéndice F. discos iSCSI en el programa de instalación
El instalador de Red Hat Enterprise Linux puede descubrir y entrar en los discos iSCSI de dos maneras:
Cuando el instalador se inicia, comprueba si la BIOS o las ROMs de arranque adicionales del sistema soportan iSCSI Boot Firmware Table (iBFT), una extensión de la BIOS para sistemas que pueden arrancar desde iSCSI. Si la BIOS soporta iBFT, el instalador lee la información del destino iSCSI para el disco de arranque configurado desde la BIOS y se registra en este destino, haciéndolo disponible como un destino de instalación.
ImportantePara conectarse automáticamente a un objetivo iSCSI, active un dispositivo de red para acceder al objetivo. Para ello, utilice la opción de arranque
ip=ibft. Para más información, consulte Opciones de arranque en red.Puede descubrir y añadir objetivos iSCSI manualmente en la interfaz gráfica de usuario del instalador. Para obtener más información, consulte Configuración de dispositivos de almacenamiento.
ImportanteNo puede colocar la partición
/booten objetivos iSCSI que haya añadido manualmente utilizando este método - un objetivo iSCSI que contenga una partición/bootdebe estar configurado para su uso con iBFT. Sin embargo, en los casos en los que se espera que el sistema instalado arranque desde iSCSI con la configuración de iBFT proporcionada por un método distinto al firmware iBFT, por ejemplo utilizando iPXE, puede eliminar la restricción de la partición/bootutilizando la opción de arranque del instaladorinst.nonibftiscsiboot.
Mientras que el instalador utiliza iscsiadm para encontrar y entrar en los objetivos iSCSI, iscsiadm almacena automáticamente cualquier información sobre estos objetivos en la base de datos iSCSI iscsiadm. El instalador entonces copia esta base de datos al sistema instalado y marca cualquier objetivo iSCSI que no se utilice para la partición raíz, de modo que el sistema inicie automáticamente la sesión en ellos cuando se inicie. Si la partición raíz se coloca en un objetivo iSCSI, initrd inicia la sesión en este objetivo y el instalador no incluye este objetivo en los scripts de arranque para evitar múltiples intentos de iniciar la sesión en el mismo objetivo.
Capítulo 6. Composición de una imagen de sistema RHEL personalizada
6.1. Descripción de Image Builder
6.1.1. Introducción al constructor de imágenes
Puede utilizar Image Builder para crear imágenes de sistema personalizadas de Red Hat Enterprise Linux, incluyendo imágenes de sistema preparadas para su despliegue en plataformas de nube. Image Builder maneja automáticamente los detalles de la configuración para cada tipo de salida y por lo tanto es más fácil de usar y más rápido de trabajar que los métodos manuales de creación de imágenes. Puede acceder a la funcionalidad de Image Builder a través de una interfaz de línea de comandos en la herramienta composer-cli, o una interfaz gráfica de usuario en la consola web de RHEL 8.
A partir de Red Hat Enterprise Linux 8.3, el backend osbuild-composer sustituye a lorax-composer. El nuevo servicio proporciona APIs REST para la construcción de imágenes. Como resultado, los usuarios pueden beneficiarse de un backend más fiable y de imágenes de salida más predecibles.
El Generador de Imágenes se ejecuta como un servicio del sistema osbuild-composer. Puede interactuar con este servicio a través de dos interfaces:
-
Herramienta CLI
composer-clipara ejecutar comandos en el terminal. Este método es el preferido. - Plugin GUI para la consola web de RHEL 8.
6.1.2. Terminología del constructor de imágenes
- Plano
Los blueprints definen las imágenes personalizadas del sistema mediante una lista de paquetes y personalizaciones que formarán parte del sistema. Los blueprints pueden ser editados y son versionados. Cuando se crea una imagen del sistema a partir de un blueprint, la imagen se asocia al blueprint en la interfaz Image Builder de la consola web de RHEL 8.
Los planos se presentan al usuario como texto plano en el formato Tom's Obvious, Minimal Language (TOML).
- Componer
- Las composiciones son construcciones individuales de una imagen del sistema, basadas en una versión particular de un plano concreto. El término composición se refiere a la imagen del sistema, los registros de su creación, las entradas, los metadatos y el propio proceso.
- Personalizaciones
- Las personalizaciones son especificaciones para el sistema, que no son paquetes. Esto incluye usuarios, grupos y claves SSH.
6.1.3. Formatos de salida de Image Builder
El Generador de Imágenes puede crear imágenes en múltiples formatos de salida que se muestran en la siguiente tabla.
| Descripción | Nombre del CLI | extensión del archivo |
|---|---|---|
| Imagen QEMU QCOW2 |
|
|
| Archivo TAR |
|
|
| Disco de imagen de máquina de Amazon |
|
|
| Imagen de disco de Azure |
|
|
| Disco de máquina virtual VMware |
|
|
| Openstack |
|
|
| RHEL para Edge |
|
|
6.1.4. Requisitos del sistema de Image Builder
La herramienta osbuild-composer subyacente a Image Builder realiza una serie de acciones potencialmente inseguras y no seguras mientras crea las imágenes del sistema. Por este motivo, utilice una máquina virtual para ejecutar Image Builder.
El entorno en el que se ejecuta Image Builder, por ejemplo la máquina virtual, debe cumplir los requisitos que se indican en la siguiente tabla.
| Parámetro | Valor mínimo requerido |
|---|---|
| Tipo de sistema | Una máquina virtual dedicada |
| Procesador | 2 núcleos |
| Memoria | 4 GiB |
| Espacio en disco | 20 GiB |
| Privilegios de acceso | Nivel de administrador (root) |
| Red | Conectividad a Internet |
No hay soporte para la creación de imágenes en máquinas virtuales directamente instaladas en sistemas UEFI.
6.2. Instalación de Image Builder
Image Builder es una herramienta para crear imágenes de sistema personalizadas. Antes de utilizar Image Builder, debe instalar Image Builder en una máquina virtual.
6.2.1. Requisitos del sistema de Image Builder
La herramienta osbuild-composer subyacente a Image Builder realiza una serie de acciones potencialmente inseguras y no seguras mientras crea las imágenes del sistema. Por este motivo, utilice una máquina virtual para ejecutar Image Builder.
El entorno en el que se ejecuta Image Builder, por ejemplo la máquina virtual, debe cumplir los requisitos que se indican en la siguiente tabla.
| Parámetro | Valor mínimo requerido |
|---|---|
| Tipo de sistema | Una máquina virtual dedicada |
| Procesador | 2 núcleos |
| Memoria | 4 GiB |
| Espacio en disco | 20 GiB |
| Privilegios de acceso | Nivel de administrador (root) |
| Red | Conectividad a Internet |
No hay soporte para la creación de imágenes en máquinas virtuales directamente instaladas en sistemas UEFI.
6.2.2. Instalación de Image Builder en una máquina virtual
Para instalar Image Builder en una máquina virtual dedicada, siga estos pasos:
Requisitos previos
- Conéctese a la máquina virtual.
- La máquina virtual para Image Builder debe estar instalada, suscrita y funcionando.
Procedimiento
Instale el Image Builder y otros paquetes necesarios en la máquina virtual:
- osbuild-composer
- composer-cli
- cockpit-composer
- bash-completion
# yum install osbuild-composer composer-cli cockpit-composer bash-completionLa consola web se instala como una dependencia del paquete cockpit-composer.
Habilitar el generador de imágenes para que se inicie después de cada reinicio:
# systemctl enable --now osbuild-composer.socket # systemctl enable cockpit.socketLos servicios
osbuild-composerycockpitse inician automáticamente en el primer acceso.Configure el firewall del sistema para permitir el acceso a la consola web:
# firewall-cmd --add-service=cockpit && firewall-cmd --add-service=cockpit --permanentCargue el script de configuración del shell para que la función de autocompletar del comando
composer-clicomience a funcionar inmediatamente sin necesidad de reiniciar:$ source /etc/bash_completion.d/composer-cli
El osbuild-composer es el nuevo motor de backend que será el preferido por defecto y el foco de todas las nuevas funcionalidades a partir de Red Hat Enterprise Linux 8.3 y posteriores. El backend anterior lorax-composer se considera obsoleto, sólo recibirá arreglos selectos por el resto del ciclo de vida de Red Hat Enterprise Linux 8 y será omitido en futuros lanzamientos importantes. Se recomienda desinstalar lorax-composer en favor de osbuild-composer.
6.2.3. Volver a lorax-composer Image Builder backend
El backend osbuild-composer, aunque es mucho más extensible, no alcanza actualmente la paridad de características con el anterior backend lorax-composer.
Para volver al backend anterior, siga los pasos:
Requisitos previos
-
Ha instalado el paquete
osbuild-composer
Procedimiento
Eliminar el backend de osbuild-composer.
# yum remove osbuild-composerEn
/etc/yum.conf file, añada una entrada de exclusión para el paqueteosbuild-composer.# cat /etc/yum.conf [main] gpgcheck=1 installonly_limit=3 clean_requirements_on_remove=True best=True skip_if_unavailable=False exclude=osbuild-composerInstale el paquete "lorax-composer".
# yum install lorax-composer
6.3. Creación de imágenes del sistema con la interfaz de línea de comandos de Image Builder
Image Builder es una herramienta para crear imágenes de sistema personalizadas. Para controlar Image Builder y crear sus imágenes de sistema personalizadas, utilice la interfaz de línea de comandos, que es actualmente el método preferido para utilizar Image Builder.
6.3.1. Interfaz de línea de comandos de Image Builder
La interfaz de línea de comandos del Constructor de Imágenes es actualmente el método preferido para utilizar el Constructor de Imágenes. Ofrece más funcionalidad que la interfaz de la consola web. Para utilizar esta interfaz, ejecute el comando composer-cli con las opciones y subcomandos adecuados.
El flujo de trabajo de la interfaz de línea de comandos puede resumirse como sigue:
- Exportar (save) la definición del plano a un archivo de texto plano
- Edite este archivo en un editor de texto
- Importar (push) el archivo de texto del blueprint de vuelta a Image Builder
- Ejecutar una composición para construir una imagen a partir del plano
- Exportar el archivo de imagen para descargarlo
Además de los subcomandos básicos para realizar este procedimiento, el comando composer-cli ofrece muchos subcomandos para examinar el estado de los planos y composiciones configurados.
Para ejecutar el comando composer-cli como no root, el usuario debe estar en los grupos weldr o root.
6.3.2. Creación de un plano del Image Builder con interfaz de línea de comandos
Este procedimiento describe cómo crear un nuevo plano del Constructor de Imágenes utilizando la interfaz de línea de comandos.
Procedimiento
Cree un archivo de texto plano con el siguiente contenido:
name = "BLUEPRINT-NAME" description = "LONG FORM DESCRIPTION TEXT" version = "0.0.1" modules = [] groups = []Sustituya BLUEPRINT-NAME y LONG FORM DESCRIPTION TEXT por un nombre y una descripción para su plano.
Sustituir 0.0.1 por un número de versión según el esquema de Versionado Semántico.
Para cada paquete que desee incluir en el plano, añada las siguientes líneas al archivo:
[[packages]] name = "package-name" version = "package-version"Sustituya package-name por el nombre del paquete, por ejemplo httpd, gdb-doco coreutils.
Sustituya package-version por una versión a utilizar. Este campo admite las especificaciones de la versión
dnf:- Para una versión específica, utilice el número de versión exacto como 8.30.
- Para conocer la última versión disponible, utilice el asterisco *.
- Para la última versión menor, utilice el formato 8.*.
Los Blueprints pueden personalizarse de varias maneras. Para este ejemplo, se puede deshabilitar el Multihilo Simultáneo (SMT) realizando los siguientes pasos. Para conocer otras personalizaciones disponibles, consulte Personalizaciones de imágenes admitidas.
[customizations.kernel] append = "nosmt=force"- Guarde el archivo como BLUEPRINT-NAME.toml y cierre el editor de texto.
Empujar (importar) el plano:
# composer-cli blueprints push BLUEPRINT-NAME.tomlSustituya BLUEPRINT-NAME por el valor que utilizó en los pasos anteriores.
Para verificar que el plano ha sido empujado y existe, liste los planos existentes:
# composer-cli blueprints listCompruebe si los componentes y versiones que figuran en el plano y sus dependencias son válidos:
# composer-cli blueprints depsolve BLUEPRINT-NAME
Puedes crear imágenes utilizando el comando composer-cli como no-root. Para ello, añada su usuario a los grupos weldr o root. Para añadir tu usuario al grupo weldr, realiza los siguientes pasos:
# usermod -a -G weldr user
$ newgrp weldr6.3.3. Edición de un plano de Image Builder con la interfaz de línea de comandos
Este procedimiento describe cómo editar un plano de Image Builder existente en la interfaz de línea de comandos.
Procedimiento
Guardar (exportar) el plano a un archivo de texto local:
# composer-cli blueprints save BLUEPRINT-NAME- Edite el archivo BLUEPRINT-NAME.toml con un editor de texto de su elección y realice los cambios.
Antes de terminar con las ediciones, asegúrese de que el archivo es un plano válido:
Elimine esta línea, si está presente:
paquetes = []- Aumente el número de versión. Recuerde que las versiones de los planos del Constructor de Imágenes deben utilizar el esquema de Versionado Semántico. Tenga en cuenta también que si no cambia la versión, el componente patch de la versión se incrementa automáticamente.
Comprueba si el contenido es una especificación válida de TOML. Consulte la documentación de TOML para obtener más información.
NotaLa documentación de TOML es un producto de la comunidad y no está soportada por Red Hat. Puede informar de cualquier problema con la herramienta en https://github.com/toml-lang/toml/issues
- Guarde el archivo y cierre el editor.
Empuje (importe) el plano a Image Builder:
# composer-cli blueprints push BLUEPRINT-NAME.tomlTenga en cuenta que debe suministrar el nombre del archivo incluyendo la extensión
.toml, mientras que en otros comandos sólo se utiliza el nombre del plano.Para verificar que los contenidos cargados en el Generador de Imágenes coinciden con sus ediciones, liste los contenidos del blueprint:
# composer-cli blueprints show BLUEPRINT-NAMECompruebe si los componentes y versiones que figuran en el plano y sus dependencias son válidos:
# composer-cli blueprints depsolve BLUEPRINT-NAME
6.3.4. Creación de una imagen del sistema con Image Builder en la interfaz de línea de comandos
Este procedimiento muestra cómo construir una imagen personalizada utilizando la interfaz de línea de comandos del Constructor de Imágenes.
Requisitos previos
- Tienes un plano preparado para la imagen.
Procedimiento
Inicie la composición:
# composer-cli compose start BLUEPRINT-NAME IMAGE-TYPESustituya BLUEPRINT-NAME por el nombre del plano y IMAGE-TYPE por el tipo de imagen. Para ver los posibles valores, consulte la salida del comando
composer-cli compose types.El proceso de composición se inicia en segundo plano y se muestra el UUID de la composición.
Espere a que termine la composición. Tenga en cuenta que esto puede tardar varios minutos.
Para comprobar el estado de la composición:
# composer-cli compose statusUna composición terminada muestra un valor de estado FINISHED. Identifica la composición en la lista por su UUID.
Una vez terminada la composición, descargue el archivo de imagen resultante:
# composer-cli compose image UUIDSustituya UUID por el valor UUID indicado en los pasos anteriores.
También puede descargar los registros mediante el comando
composer-cli compose logs UUIDo los metadatos con el comandocomposer-cli compose metadata UUIDcomando.
6.3.5. Comandos básicos de la línea de comandos del Constructor de Imágenes
La interfaz de línea de comandos de Image Builder ofrece los siguientes subcomandos.
Manipulación de planos
- Lista de todos los planos disponibles
# composer-cli blueprints list- Mostrar el contenido de un plano en formato TOML
# composer-cli blueprints show BLUEPRINT-NAME- Guardar (exportar) el contenido de los planos en formato TOML en un archivo
BLUEPRINT-NAME.toml # composer-cli blueprints save BLUEPRINT-NAME- Eliminar un plano
# composer-cli blueprints delete BLUEPRINT-NAME- Introducir (importar) un archivo de planos en formato TOML en Image Builder
# composer-cli blueprints push BLUEPRINT-NAME
Composición de imágenes a partir de planos
- Iniciar una composición
# composer-cli compose start BLUEPRINT COMPOSE-TYPESustituya BLUEPRINT por el nombre del plano a construir y COMPOSE-TYPE por el tipo de imagen de salida.
- Lista de todas las composiciones
# composer-cli compose list- Lista de todas las composiciones y su estado
# composer-cli compose status- Cancelar una composición en curso
# composer-cli compose cancel COMPOSE-UUID- Borrar una composición terminada
# composer-cli compose delete COMPOSE-UUID- Mostrar información detallada sobre una composición
# composer-cli compose info COMPOSE-UUID- Descargar archivo de imagen de una composición
# composer-cli compose image COMPOSE-UUID
6.3.6. Formato de planos de Image Builder
Los planos de Image Builder se presentan al usuario como texto plano en el formato Tom's Obvious, Minimal Language (TOML).
Los elementos de un archivo típico de planos incluyen:
- Los metadatos del proyecto
name = "BLUEPRINT-NAME" description = "LONG FORM DESCRIPTION TEXT" version = "VERSION"Sustituya BLUEPRINT-NAME y LONG FORM DESCRIPTION TEXT por un nombre y una descripción para su plano.
Sustituir VERSION por un número de versión según el esquema de Versionado Semántico.
Esta parte está presente sólo una vez para todo el archivo de planos.
La entrada modules describe los nombres de los paquetes y el glob de la versión correspondiente que se instalará en la imagen.
La entrada group describe un grupo de paquetes a instalar en la imagen. Los grupos clasifican sus paquetes en:
- Obligatorio
- Por defecto
Opcional
Blueprints instala los paquetes obligatorios. No existe ningún mecanismo para seleccionar los paquetes opcionales.
- Grupos a incluir en la imagen
[[groups]] name = "group-name"Sustituya group-name por el nombre del grupo, por ejemplo anaconda-tools, widget, wheel o users.
- Paquetes a incluir en la imagen
[[packages]] name = "package-name" version = "package-version"Sustituya package-name por el nombre del paquete, por ejemplo httpd, gdb-doco coreutils.
Sustituya package-version por una versión a utilizar. Este campo admite las especificaciones de la versión
dnf:- Para una versión específica, utilice el número de versión exacto como 8.30.
- Para conocer la última versión disponible, utilice el asterisco *.
- Para la última versión menor, utilice el formato 8.*.
Repita este bloque para cada paquete que vaya a incluir.
6.3.7. Personalizaciones de imagen soportadas
En este momento se admiten varias personalizaciones de imágenes dentro de los planos. Para hacer uso de estas opciones, deben ser configuradas inicialmente en el plano e importadas (empujadas) a Image Builder.
Estas personalizaciones no son compatibles actualmente con la interfaz gráfica de usuario de la cabina de mando.
Procedimiento
Establezca el nombre de host de la imagen:
[customizations] hostname = "baseimage"Especificaciones del usuario para la imagen del sistema resultante:
[[customizations.user]] name = "USER-NAME" description = "USER-DESCRIPTION" password = "PASSWORD-HASH" key = "PUBLIC-SSH-KEY" home = "/home/USER-NAME/" shell = "/usr/bin/bash" groups = ["users", "wheel"] uid = NUMBER gid = NUMBERImportantePara generar el hash, debe instalar python3 en su sistema. El siguiente comando instalará el paquete python3.
# yum install python3Sustituya PASSWORD-HASH por el hash de la contraseña real. Para generar el hash, utilice un comando como:
$ python3 -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'Sustituya PUBLIC-SSH-KEY por la clave pública real.
Reemplace los otros marcadores de posición con valores adecuados.
Omita cualquiera de las líneas según sea necesario, sólo se requiere el nombre de usuario.
Repita este bloque para cada usuario a incluir.
Especificaciones del grupo para la imagen del sistema resultante:
[[customizations.group]] name = "GROUP-NAME" gid = NUMBERRepite este bloque para cada grupo a incluir.
Establecer la clave ssh de un usuario existente:
[[customizations.sshkey]] user = "root" key = "PUBLIC-SSH-KEY"NotaEsta opción sólo es aplicable a los usuarios existentes. Para crear un usuario y establecer una clave ssh, utilice la personalización User specifications for the resulting system image.
Añade una opción de parámetro de arranque del kernel a los valores por defecto:
[customizations.kernel] append = "KERNEL-OPTION"Establezca el nombre del host de la imagen:
[customizations] hostname = "BASE-IMAGE"Añade un grupo para la imagen del sistema resultante:
[[customizations.group]] name = "USER-NAME" gid = "NUMBER"Sólo se requiere el nombre y el GID es opcional.
Establezca la zona horaria y los servidores Network Time Protocol (NTP) para la imagen del sistema resultante:
[customizations.timezone] timezone = "TIMEZONE" ntpservers = "NTP_SERVER"Si no se establece una zona horaria, el sistema utiliza por defecto Universal Time, Coordinated (UTC) . La configuración de los servidores NTP es opcional.
Establezca la configuración regional para la imagen del sistema resultante:
[customizations.locale] languages = ["LANGUAGE"] keyboard = "KEYBOARD"La configuración de las opciones de idioma y teclado es obligatoria. Puedes añadir varios idiomas. El primer idioma que añadas será el principal y los demás serán secundarios.
Establezca el cortafuegos para la imagen del sistema resultante:
[customizations.firewall] port = ["PORTS"]Puede utilizar los puertos numéricos, o sus nombres del archivo
/etc/servicespara habilitar las listas.Personalizar los servicios del cortafuegos:
Revise los servicios de firewall disponibles.
$ firewall-cmd --get-servicesEn el plano, en la sección
customizations.firewall.service, especifique los servicios de firewall que desea personalizar.[customizations.firewall.services] enabled = ["SERVICES"] disabled = ["SERVICES"]Los servicios que aparecen en
firewall.servicesson diferentes de los nombres disponibles en el archivo/etc/services.Opcionalmente, puede personalizar los servicios del cortafuegos para la imagen del sistema que piensa crear.
NotaSi no desea personalizar los servicios del cortafuegos, omita las secciones
[customizations.firewall]y[customizations.firewall.services]del plano.Establece los servicios que se deben habilitar durante el arranque:
[customizations.services] enabled = ["SERVICES"] disabled = ["SERVICES"]Puede controlar los servicios que se activan durante el arranque. Algunos tipos de imagen ya tienen servicios habilitados o deshabilitados para que la imagen funcione correctamente y esta configuración no puede ser anulada.
Añade archivos de un repositorio git a tu plano:
[[repos.git]] rpmname = "RPM-NAME" rpmversion = "RPM-VERSION" rpmrelease = "RPM-RELEASE" summary = "RPM-SUMMARY" repo = "REPO-URL" ref = "GIT-REF" destination = "SERVICES"Puede utilizar entradas para añadir archivos de un repositorio git a la imagen creada.
Por ejemplo, para crear un paquete RPM llamado
server-config-1.0-1.noarch.rpm, añada la siguiente información a su proyecto:Sustituya _RPM-NAME por el nombre del paquete RPM a crear. Este es también el nombre del prefijo en el archivo tar resultante.
Sustituya RPM-VERSION por la versión del paquete RPM, por ejemplo, "1.0.0".
Sustituya RPM-RELEASE por la versión del paquete RPM, por ejemplo, \ "1".
Sustituya RPM-SUMMARY por la cadena de resumen del paquete RPM.
Sustituye REPO-URL por la URL del repositorio get para clonar y crear el archivo desde él.
Sustituya GIT-REF por la referencia git que desea consultar, por ejemplo,
origin/branch-name,git tag, ogit commit hash.Sustituya SERVICES por la ruta de instalación del directorio del repositorio git al instalar el paquete RPM.
Como consecuencia, se clona el repositorio git proporcionado, se comprueba la referencia git especificada y se crea un paquete RPM para instalar los archivos en una ruta de destino, por ejemplo,
/opt/server/. El RPM incluye un resumen con los detalles del repositorio y la referencia utilizada para crearlo. El paquete RPM también se incluye en los metadatos de construcción de la imagen.NotaCada vez que se inicia una compilación, se clona el repositorio. Si se refiere a un repositorio con una gran cantidad de historia, puede tomar un tiempo para clonar y utilizar una cantidad significativa de espacio en disco. Además, el clon es temporal y se elimina una vez que se crea el paquete RPM.
6.3.8. Paquetes instalados
Cuando se crea una imagen del sistema utilizando el Generador de Imágenes, por defecto, el sistema instala un conjunto de paquetes base. La lista de paquetes base son los miembros del grupo comps core. Por defecto, Image Builder utiliza el grupo core yum.
| Tipo de imagen | Paquetes por defecto |
|---|---|
| alibaba.ks | kernel, selinux-policy-targeted, cloud-init |
| ami.ks | kernel, selinux-policy-targeted, chrony, cloud-init |
| ext4-filesystem.ks | policycoreutils, selinux-policy-targeted, kernel |
| google.ks | kernel, selinux-policy-targeted |
| live-iso.ks | isomd5sum, kernel, dracut-config-generic, dracut-live, system-logos, selinux-policy-targeted |
| openstack.ks | kernel, selinux-policy-targeted |
| disco particionado.ks | kernel, selinux-policy-targeted |
| qcow2.ks | kernel, selinux-policy-targeted |
| tar.ks | policycoreutils, selinux-policy-targeted |
| vhd.ks | kernel, selinux-policy-targeted, chrony, WALinuxAgent, python3, net-tools, cloud-init, cloud-utils-growpart, gdisk |
| vmdk.ks | kernel, selinux-policy-targeted, chrony, open-vm-tools |
Cuando añada componentes adicionales a su plano, debe asegurarse de que los paquetes de los componentes que ha añadido no entran en conflicto con ningún otro paquete de componentes, ya que, de lo contrario, el sistema no resuelve las dependencias. Como consecuencia, no podrá crear su imagen personalizada.
6.3.9. Servicios habilitados
Cuando se configura la imagen personalizada, los servicios habilitados son los predeterminados para la versión de RHEL8 desde la que se ejecuta osbuild-composer, además de los servicios habilitados para tipos de imagen específicos.
Por ejemplo, el tipo de imagen .ami habilita los servicios sshd, chronyd y cloud-init y sin estos servicios, la imagen personalizada no arranca.
| Tipo de imagen | Servicios habilitados |
|---|---|
| alibaba.ks | sshd,cloud-init |
| ami.ks | No hay servicio por defecto |
| ext4-filesystem.ks | No hay servicio por defecto |
| google.ks | No hay servicio por defecto |
| live-iso.ks | NetworkManager |
| openstack.ks | sshd, cloud-init, cloud-init-local, cloud-config, cloud-final |
| disco particionado.ks | No hay servicio por defecto |
| qcow2.ks | No hay servicio por defecto |
| tar.ks | No hay servicio por defecto |
| vhd.ks | sshd, chronyd, waagent, cloud-init, cloud-init-local, cloud-config, cloud-final |
| vmdk.ks | sshd, chronyd, vmtoolsd |
Nota: Puede personalizar los servicios que se activan durante el arranque del sistema. Sin embargo, para los tipos de imagen con servicios habilitados por defecto, la personalización no anula esta característica.
6.3.10. Configuración de discos y particiones mediante Image Builder
Image Builder no permite que los discos estén particionados. Los tipos de salida que tienen un disco particionado tendrán una única partición y, además, cualquier partición específica de la plataforma que se requiera para arrancar la imagen del sistema. Por ejemplo, el tipo de imagen qcow2 tiene una única partición raíz, y posiblemente una partición de arranque específica de la plataforma - como PReP para el sistema PPC64 - que la imagen requiere para arrancar.
6.4. Creación de imágenes del sistema con la interfaz de la consola web de Image Builder
Image Builder es una herramienta para crear imágenes de sistema personalizadas. Para controlar el Constructor de Imágenes y crear sus imágenes de sistema personalizadas, puede utilizar la interfaz de la consola web. Tenga en cuenta que la interfaz de línea de comandos es la alternativa preferida actualmente, porque ofrece más funciones.
6.4.1. Acceso a la GUI de Image Builder en la consola web de RHEL 8
El plugin cockpit-composer para la consola web de RHEL 8 permite a los usuarios gestionar los planos y composiciones de Image Builder con una interfaz gráfica. Tenga en cuenta que el método preferido para controlar Image Builder es, por el momento, el uso de la interfaz de línea de comandos.
Requisitos previos
- Debe tener acceso a la raíz del sistema.
Procedimiento
Abra
https://localhost:9090/en un navegador web en el sistema donde está instalado el Generador de Imágenes.Para más información sobre cómo acceder de forma remota al Generador de Imágenes, consulte el Managing systems using the RHEL 8 web console documento.
- Acceda a la consola web con las credenciales de una cuenta de usuario con privilegios suficientes en el sistema.
Para mostrar los controles del Constructor de Imágenes, haga clic en el icono
Image Builder, que se encuentra en la esquina superior izquierda de la ventana.Se abre la vista del Constructor de Imágenes, con una lista de los planos existentes.
6.4.2. Creación de un plano del Constructor de Imágenes en la interfaz de la consola web
Para describir la imagen personalizada del sistema, cree primero un plano.
Requisitos previos
- Ha abierto la interfaz del Image Builder de la consola web de RHEL 8 en un navegador.
Procedimiento
Haga clic en en la esquina superior derecha.
Aparece una ventana emergente con campos para el nombre y la descripción del plano.
Introduzca el nombre del plano, su descripción y haga clic en .
La pantalla cambia al modo de edición de planos.
Añade los componentes que quieras incluir en la imagen del sistema:
A la izquierda, introduzca todo o parte del nombre del componente en el campo
Available Componentsy pulse .La búsqueda se añade a la lista de filtros bajo el campo de entrada de texto, y la lista de componentes de abajo se reduce a los que coinciden con la búsqueda.
Si la lista de componentes es demasiado larga, añada otros términos de búsqueda de la misma manera.
- La lista de componentes está paginada. Para desplazarse a otras páginas de resultados, utilice las flechas y el campo de entrada situados encima de la lista de componentes.
- Haga clic en el nombre del componente que desea utilizar para mostrar sus detalles. El panel derecho se llena de detalles de los componentes, como su versión y sus dependencias.
-
Seleccione la versión que desea utilizar en la casilla
Component Options, con el desplegableVersion Release. - Haga clic en en la parte superior izquierda.
-
Si ha añadido un componente por error, elimínelo haciendo clic en el botón situado en el extremo derecho de su entrada en el panel derecho, y seleccione
Removeen el menú.
NotaSi no tiene intención de seleccionar una versión para algunos componentes, puede omitir la pantalla de detalles del componente y la selección de la versión haciendo clic en los botones situados en la parte derecha de la lista de componentes.
Para guardar el plano, haga clic en en la parte superior derecha. Aparecerá un diálogo con un resumen de los cambios. Haga clic en .
Una pequeña ventana emergente a la derecha le informa del progreso de la grabación y luego del resultado.
Para salir de la pantalla de edición, haga clic en
Back to Blueprintsen la parte superior izquierda.Se abre la vista del Constructor de Imágenes, con una lista de los planos existentes.
6.4.3. Edición de un plano del Constructor de Imágenes en la interfaz de la consola web
Para cambiar las especificaciones de una imagen de sistema personalizada, edite el plano correspondiente.
Requisitos previos
- Ha abierto la interfaz del Image Builder de la consola web de RHEL 8 en un navegador.
- Existe un proyecto.
Procedimiento
Localice el plano que desea editar introduciendo su nombre o una parte del mismo en el cuadro de búsqueda de la parte superior izquierda y pulse .
La búsqueda se añade a la lista de filtros bajo el campo de entrada de texto, y la lista de planos de abajo se reduce a los que coinciden con la búsqueda.
Si la lista de planos es demasiado larga, añada otros términos de búsqueda de la misma manera.
En la parte derecha del plano, pulse el botón que pertenece al plano.
La vista cambia a la pantalla de edición de planos.
-
Elimine los componentes no deseados haciendo clic en su botón en el extremo derecho de su entrada en el panel derecho, y seleccione
Removeen el menú. Cambiar la versión de los componentes existentes:
En el campo de búsqueda de componentes de Blueprint, introduzca el nombre del componente o una parte del mismo en el campo situado bajo el título
Blueprint Componentsy pulse .La búsqueda se añade a la lista de filtros bajo el campo de entrada de texto, y la lista de componentes de abajo se reduce a los que coinciden con la búsqueda.
Si la lista de componentes es demasiado larga, añada otros términos de búsqueda de la misma manera.
Haga clic en el botón situado en el extremo derecho de la entrada del componente y seleccione
Viewen el menú.En el panel derecho se abre una pantalla de detalles del componente.
Seleccione la versión deseada en el menú desplegable
Version Releasey haga clic en en la parte superior derecha.El cambio se guarda y el panel derecho vuelve a enumerar los componentes del plano.
Añade nuevos componentes:
A la izquierda, introduzca el nombre del componente o una parte del mismo en el campo situado bajo el título
Available Componentsy pulse .La búsqueda se añade a la lista de filtros bajo el campo de entrada de texto, y la lista de componentes de abajo se reduce a los que coinciden con la búsqueda.
Si la lista de componentes es demasiado larga, añada otros términos de búsqueda de la misma manera.
- La lista de componentes está paginada. Para desplazarse a otras páginas de resultados, utilice las flechas y el campo de entrada situados encima de la lista de componentes.
- Haga clic en el nombre del componente que desea utilizar para mostrar sus detalles. El panel derecho se llena de detalles de los componentes, como su versión y sus dependencias.
-
Seleccione la versión que desea utilizar en la casilla
Component Options, con el menú desplegableVersion Release. - Haga clic en en la parte superior derecha.
Si ha añadido un componente por error, elimínelo haciendo clic en el botón situado en el extremo derecho de su entrada en el panel derecho, y seleccione
Removeen el menú.NotaSi no tiene intención de seleccionar una versión para algunos componentes, puede omitir la pantalla de detalles del componente y la selección de la versión haciendo clic en los botones situados en la parte derecha de la lista de componentes.
Confirme una nueva versión del plano con sus cambios:
Haga clic en el botón en la parte superior derecha.
Aparecerá una ventana emergente con un resumen de sus cambios.
Revise sus cambios y confírmelos haciendo clic en .
Una pequeña ventana emergente a la derecha le informa del progreso de guardado y de los resultados. Se crea una nueva versión del plano.
En la parte superior izquierda, haga clic en para salir de la pantalla de edición.
Se abre la vista del Constructor de Imágenes, con una lista de los planos existentes.
6.4.4. Añadir usuarios y grupos a un plano de Image Builder en la interfaz de la consola web
Actualmente no es posible añadir personalizaciones como usuarios y grupos a los planos en la interfaz de la consola web. Para evitar esta limitación, utilice la pestaña Terminal en la consola web para utilizar el flujo de trabajo de la interfaz de línea de comandos (CLI).
Requisitos previos
- Debe existir un proyecto.
Debe instalarse un editor de texto CLI como
vim,nano, oemacs. Para instalarlos:# yum install editor-name
Procedimiento
- Find out the name of the blueprint: Open the Image Builder (Image builder) tab on the left in the RHEL 8 web console to see the name of the blueprint.
- Navegue a la CLI en la consola web: Abra la pestaña de administración del sistema a la izquierda, luego seleccione el último elemento Terminal de la lista de la izquierda.
Entra en el modo de superusuario (root):
$ sudo bashProporcione sus credenciales cuando se le pida. Tenga en cuenta que el terminal no reutiliza las credenciales que introdujo al iniciar sesión en la consola web.
Un nuevo shell con privilegios de root se inicia en su directorio personal.
Exportar el plano a un archivo:
# composer-cli blueprints save BLUEPRINT-NAMEEdite el archivo BLUEPRINT-NAME.toml con un editor de texto CLI de su elección y añada los usuarios y grupos.
ImportanteLa consola web de RHEL 8 no tiene ninguna función incorporada para editar archivos de texto en el sistema, por lo que se requiere el uso de un editor de texto CLI para este paso.
Para cada usuario que se añada, añada este bloque al archivo:
[[customizations.user]] name = "USER-NAME" description = "USER-DESCRIPTION" password = "PASSWORD-HASH" key = "ssh-rsa (...) key-name" home = "/home/USER-NAME/" shell = "/usr/bin/bash" groups = ["users", "wheel"] uid = NUMBER gid = NUMBERSustituya PASSWORD-HASH por el hash de la contraseña real. Para generar el hash, utilice un comando como este:
$ python3 -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'Sustituya ssh-rsa (…) key-name por la clave pública real.
Reemplace los otros marcadores de posición con valores adecuados.
Omita cualquiera de las líneas según sea necesario, sólo se requiere el nombre de usuario.
Para cada grupo de usuarios que se agregue, añada este bloque al archivo:
[[customizations.group]] name = "GROUP-NAME" gid = NUMBER- Aumenta el número de la versión.
- Guarde el archivo y cierre el editor.
Importe de nuevo el plano en el Generador de Imágenes:
# composer-cli blueprints push BLUEPRINT-NAME.tomlTenga en cuenta que debe suministrar el nombre del archivo incluyendo la extensión
.toml, mientras que en otros comandos sólo se utiliza el nombre del plano.Para verificar que los contenidos cargados en el Generador de Imágenes coinciden con sus ediciones, liste los contenidos del blueprint:
# composer-cli blueprints show BLUEPRINT-NAMEComprueba si la versión coincide con la que pusiste en el archivo y si tus personalizaciones están presentes.
ImportanteLa consola web de Image Builder para RHEL 8 no muestra ninguna información que pueda utilizarse para verificar que los cambios se han aplicado, a menos que se hayan editado también los paquetes incluidos en el plano.
Salir del shell privilegiado:
# exitAbra la pestaña del Constructor de imágenes (Image builder) de la izquierda y actualice la página, en todos los navegadores y en todas las pestañas donde se haya abierto.
Esto evita que el estado cacheado en la página cargada revierta accidentalmente sus cambios.
6.4.5. Creación de una imagen del sistema con Image Builder en la interfaz de la consola web
Los siguientes pasos describen la creación de una imagen del sistema.
Requisitos previos
- Ha abierto la interfaz del Image Builder de la consola web de RHEL 8 en un navegador.
- Existe un proyecto.
Procedimiento
Localice el plano que desea construir una imagen introduciendo su nombre o una parte del mismo en el cuadro de búsqueda de la parte superior izquierda y pulse Intro.
La búsqueda se añade a la lista de filtros bajo el campo de entrada de texto, y la lista de planos de abajo se reduce a los que coinciden con la búsqueda.
Si la lista de planos es demasiado larga, añada otros términos de búsqueda de la misma manera.
En la parte derecha del plano, pulse el botón que pertenece al plano.
Aparece una ventana emergente.
Seleccione el tipo de imagen y pulse .
Una pequeña ventana emergente en la parte superior derecha le informa de que la creación de la imagen se ha añadido a la cola.
Haga clic en el nombre del plano.
Se abre una pantalla con los detalles del plano.
Haga clic en la pestaña para cambiar a ella. La imagen que se está creando aparece con el estado
In Progress.NotaLa creación de la imagen lleva más tiempo, medido en minutos. No hay indicación de progreso mientras se crea la imagen.
Para abortar la creación de la imagen, pulse su botón de a la derecha.
- Una vez que la imagen se ha creado con éxito, el botón de se sustituye por un botón de . Haga clic en este botón para descargar la imagen en su sistema.
6.4.6. Añadir una fuente a un plano
Las fuentes definidas en el Generador de Imágenes proporcionan los contenidos que puede añadir a los blueprints. Estas fuentes son globales y por lo tanto están disponibles para todos los blueprints. Los orígenes del sistema son repositorios que se configuran localmente en su ordenador y no pueden eliminarse del Constructor de imágenes. Puede añadir fuentes personalizadas adicionales y así poder acceder a otros contenidos distintos de las fuentes del Sistema disponibles en su sistema.
Los siguientes pasos describen cómo añadir una Fuente a su sistema local.
Requisitos previos
- Ha abierto la interfaz del Image Builder de la consola web de RHEL 8 en un navegador.
Procedimiento
Haz clic en el botón Manage Sources en la esquina superior derecha.
Aparece una ventana emergente con las fuentes disponibles, sus nombres y descripciones.
- En la parte derecha de la ventana emergente, haga clic en el botón .
Añada el Source name deseado, el Source path, y el Source Type. El campo Security es opcional.
- Haga clic en el botón . La pantalla muestra la ventana de fuentes disponibles y lista la fuente que ha añadido.
Como resultado, la nueva fuente del Sistema está disponible y lista para ser utilizada o editada.
6.4.7. Creación de una cuenta de usuario para un plano
Las imágenes creadas por el Generador de Imágenes tienen la cuenta raíz bloqueada y no incluyen otras cuentas. Esta configuración se proporciona para garantizar que no pueda construir e implementar accidentalmente una imagen sin una contraseña. El Generador de Imágenes le permite crear una cuenta de usuario con contraseña para un plano, de modo que pueda iniciar sesión en la imagen creada a partir del plano.
Requisitos previos
- Ha abierto la interfaz del Image Builder de la consola web de RHEL 8 en un navegador.
- Usted tiene un proyecto existente.
Procedimiento
Localice el plano para el que desea crear una cuenta de usuario introduciendo su nombre o una parte del mismo en el cuadro de búsqueda de la parte superior izquierda y pulse Intro.
La búsqueda se añade a la lista de filtros bajo el campo de entrada de texto, y la lista de planos que aparece a continuación se reduce a los que coinciden con la búsqueda.
Haga clic en el nombre del plano para mostrar los detalles del mismo.

Haga clic en .
Esto abrirá una ventana con campos para la creación de cuentas de usuario.

- Rellene los datos. Observe que al insertar el nombre, el campo User name se autocompleta, sugiriendo un nombre de usuario.
- Una vez que haya introducido todos los datos deseados, haga clic en .
La cuenta de usuario creada aparece mostrando toda la información que has insertado.
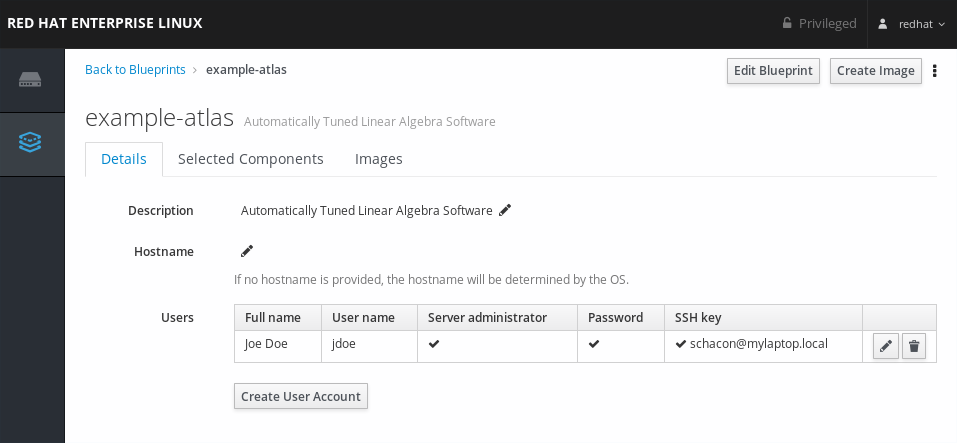
- Para crear más cuentas de usuario para el plano, repita el proceso.
6.4.8. Creación de una cuenta de usuario con clave SSH
Las imágenes creadas por el Generador de Imágenes tienen la cuenta raíz bloqueada y ninguna otra cuenta incluida. Esta configuración se proporciona para garantizar la seguridad de las imágenes, al no tener una contraseña por defecto. El Generador de Imágenes le permite crear una cuenta de usuario con clave SSH para un blueprint, de modo que pueda autenticarse en la imagen que ha creado a partir del blueprint. Para ello, primero, cree un blueprint. A continuación, cree una cuenta de usuario con una contraseña y una clave SSH. El siguiente ejemplo muestra cómo crear un usuario administrador del servidor con una clave SSH configurada.
Requisitos previos
- Ha creado una clave SSH que se emparejará con el usuario creado más adelante en el proceso.
- Ha abierto la interfaz del Image Builder de la consola web de RHEL 8 en un navegador.
- Usted tiene un proyecto existente
Procedimiento
Localice el plano para el que desea crear una cuenta de usuario introduciendo su nombre o una parte del mismo en el cuadro de búsqueda de la parte superior izquierda y pulse .
La búsqueda se añade a la lista de filtros bajo el campo de entrada de texto, y la lista de planos que aparece a continuación se reduce a los que coinciden con la búsqueda.
Haga clic en el nombre del plano para mostrar los detalles del mismo.
Haga clic en .
Esto abrirá una ventana con campos para la creación de cuentas de usuario
Rellene los datos. Observe que al insertar el nombre, el campo User name se autocompleta, sugiriendo un nombre de usuario.
Si desea proporcionar derechos de administrador a la cuenta de usuario que está creando, marque el campo Role.
Pegue el contenido de su archivo de clave pública SSH.
- Una vez que haya introducido todos los datos deseados, haga clic en .
La nueva cuenta de usuario aparecerá en la lista de usuarios, mostrando toda la información que ha insertado.
- Si quiere crear más cuentas de usuario para el plano, repita el proceso.
6.5. Preparación y carga de imágenes en la nube con Image Builder
Image Builder puede crear imágenes de sistema personalizadas listas para ser utilizadas en nubes de varios proveedores. Para utilizar su imagen personalizada del sistema RHEL en una nube, cree la imagen del sistema con Image Builder utilizando el tipo de salida respectivo, configure su sistema para subir la imagen y suba la imagen a su cuenta de nube. A partir de Red Hat Enterprise Linux 8.3, la capacidad de empujar imágenes personalizadas a las nubes a través de la aplicación Image Builder en la consola web de RHEL está disponible para un subconjunto de los proveedores de servicios que soportamos, como las nubes AWS y Azure. Ver Pushing images to AWS Cloud AMI y Pushing VHD imaged to Azure cloud.
6.5.1. Preparación para la carga de imágenes AWS AMI
Esto describe los pasos para configurar un sistema para cargar imágenes de AWS AMI.
Requisitos previos
- Debe tener un ID de clave de acceso configurado en el administrador de cuentas de AWS IAM.
- Debes tener preparado un bucket S3 con capacidad de escritura.
Procedimiento
Instale Python 3 y la herramienta
pip:# yum install python3 # yum install python3-pipInstale las herramientas de línea de comandos de AWS con
pip:# pip3 install awscliEjecute el siguiente comando para configurar su perfil. El terminal le pide que proporcione sus credenciales, la región y el formato de salida:
$ aws configure AWS Access Key ID [None]: AWS Secret Access Key [None]: Default region name [None]: Default output format [None]:Defina un nombre para su cubo y utilice el siguiente comando para crear un cubo:
$ BUCKET=bucketname $ aws s3 mb s3://$BUCKETSustituya bucketname por el nombre real del cubo. Debe ser un nombre único a nivel mundial. Como resultado, su cubo se ha creado.
A continuación, para conceder el permiso de acceso al cubo de S3, cree una función de S3
vmimporten IAM, si no lo ha hecho ya en el pasado:$ printf '{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "vmie.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": { "StringEquals":{ "sts:Externalid": "vmimport" } } } ] }' > trust-policy.json $ printf '{ "Version":"2012-10-17", "Statement":[ { "Effect":"Allow", "Action":[ "s3:GetBucketLocation", "s3:GetObject", "s3:ListBucket" ], "Resource":[ "arn:aws:s3:::%s", "arn:aws:s3:::%s/*" ] }, { "Effect":"Allow", "Action":[ "ec2:ModifySnapshotAttribute", "ec2:CopySnapshot", "ec2:RegisterImage", "ec2:Describe*" ], "Resource":"*" } ] }' $BUCKET $BUCKET > role-policy.json $ aws iam create-role --role-name vmimport --assume-role-policy-document file://trust-policy.json $ aws iam put-role-policy --role-name vmimport --policy-name vmimport --policy-document file://role-policy.json
6.5.2. Carga de una imagen AMI en AWS
Esta sección describe cómo subir una imagen AMI a AWS.
Requisitos previos
- Su sistema debe estar configurado para cargar imágenes de AWS.
-
Debe tener una imagen de AWS creada por Image Builder. Utilice el tipo de salida
amien CLI o Amazon Machine Image Disk (.ami) en la GUI al crear la imagen.
Procedimiento
Empuje la imagen a S3:
$ AMI=8db1b463-91ee-4fd9-8065-938924398428-disk.ami $ aws s3 cp $AMI s3://$BUCKET Completed 24.2 MiB/4.4 GiB (2.5 MiB/s) with 1 file(s) remaining ...Una vez finalizada la carga en S3, importe la imagen como una instantánea en EC2:
$ printf '{ "Description": "my-image", "Format": "raw", "UserBucket": { "S3Bucket": "%s", "S3Key": "%s" } }' $BUCKET $AMI > containers.json $ aws ec2 import-snapshot --disk-container file://containers.jsonSustituya my-image por el nombre de la imagen.
Para seguir el progreso de la importación, ejecute:
$ aws ec2 describe-import-snapshot-tasks --filters Name=task-state,Values=activeCree una imagen a partir de la instantánea cargada seleccionando la instantánea en la consola de EC2, haciendo clic con el botón derecho del ratón y seleccionando
Create Image:
Seleccione el
Virtualizationtype ofHardware-assisted virtualizationen la imagen creada:
-
Ahora puede ejecutar una instancia utilizando el mecanismo que desee (CLI o consola de AWS) desde la instantánea. Utilice su clave privada a través de SSH para acceder a la instancia EC2 resultante. Inicie sesión como
ec2-user.
6.5.3. Envío de imágenes a la AMI de la nube de AWS
La capacidad de empujar la imagen de salida que se crea a AWS Cloud AMI está disponible esta vez. Aquí se describen los pasos para transferir las imágenes de .ami creadas con el generador de imágenes al proveedor de servicios en la nube de Amazon AWS.
Requisitos previos
-
Debe tener acceso al sistema
rootowheelgrupo de usuarios. - Ha abierto la interfaz del Image Builder de la consola web de RHEL 8 en un navegador.
- Debe tener un ID de clave de acceso configurado en el administrador de cuentas de AWS IAM.
- Debes tener preparado un bucket S3 con capacidad de escritura.
Procedimiento
- Haga clic en para crear un plano. Consulte Crear un plano de Image Builder en la interfaz de la consola web.
- Seleccione los componentes y paquetes que desea que formen parte de la imagen que está creando.
Haga clic en para confirmar los cambios realizados en el plano.
Una pequeña ventana emergente en la parte superior derecha le informa del progreso de guardado y, a continuación, del resultado de los cambios realizados.
- Haga clic en el enlace blueprint name en el banner de la izquierda.
- Seleccione la pestaña .
Haga clic en para crear su imagen personalizada.
Se abre una ventana emergente.
- En la lista del menú desplegable "Type", seleccione la imagen "Amazon Machine Image Disk (.ami)".
- Marque la casilla "Upload to AWS" para subir su imagen a la nube de AWS y haga clic en .
Para autenticar su acceso a AWS, escriba su "ID de la clave de acceso de AWS" y su "clave de acceso secreta de AWS" en los campos correspondientes. Haga clic en .
NotaPuede ver su clave de acceso secreta de AWS solo cuando crea un nuevo ID de clave de acceso. Si no conoce su clave secreta, genere un nuevo ID de clave de acceso.
- Escriba el nombre de la imagen en el campo "Nombre de la imagen", escriba el nombre del cubo de Amazon en el campo "Nombre del cubo de Amazon S3" y escriba el campo "Región de AWS" para el cubo al que va a añadir su imagen personalizada. Haga clic en .
Revise la información que ha proporcionado y, una vez que esté satisfecho, haga clic en .
Opcionalmente, puede hacer clic en para modificar cualquier detalle incorrecto.
NotaDebe tener la configuración correcta de IAM para el cubo al que va a enviar su imagen personalizada. Estamos utilizando la Importación y Exportación de IAM, por lo que tiene que configurar a policy a su cubo antes de poder subir imágenes a él. Para más información, vea Permisos requeridos para los usuarios de IAM.
Una pequeña ventana emergente en la parte superior derecha le informa del progreso del guardado. También informa de que se ha iniciado la creación de la imagen, del progreso de dicha creación y de la posterior subida a la nube de AWS.
Una vez completado el proceso, podrá ver el estado de "Image build complete".
- Haga clic en Service→EC2 en el menú y elija la región correcta en la consola de AWS. La imagen debe tener el estado "Disponible", para indicar que está cargada.
- En el panel de control, seleccione su imagen y haga clic en .
- Se abre una nueva ventana. Elija un tipo de instancia según los recursos que necesite para lanzar su imagen. Haga clic en .
- Revise los detalles del lanzamiento de su instancia. Puede editar cada sección si necesita hacer algún cambio. Haga clic en
Antes de lanzar la instancia, debe seleccionar una clave pública para acceder a ella.
Puedes usar el par de claves que ya tienes o puedes crear un nuevo par de claves. También puede utilizar
Image Builderpara añadir un usuario a la imagen con una clave pública preestablecida. Consulte Crear una cuenta de usuario con clave SSH para obtener más detalles.Siga los siguientes pasos para crear un nuevo par de claves en EC2 y adjuntarlo a la nueva instancia.
- En la lista del menú desplegable, seleccione "Create a new key pair".
- Introduce el nombre del nuevo par de claves. Genera un nuevo par de claves.
- Haga clic en "Download Key Pair" para guardar el nuevo par de claves en su sistema local.
A continuación, puede hacer clic en para lanzar su instancia.
Puede comprobar el estado de la instancia, se muestra como "Initializing".
- Una vez que el estado de la instancia es "running", el botón pasa a estar disponible.
Haga clic en . Aparece una ventana emergente con instrucciones sobre cómo conectarse usando SSH.
- Seleccione el método de conexión preferido a "A standalone SSH client" y abra un terminal.
En la ubicación donde almacena su clave privada, asegúrese de que su clave es visible públicamente para que SSH funcione. Para ello, ejecute el comando
$ chmod 400 <su-nombre-de-instancia.pem>_Conéctese a su instancia utilizando su DNS público:
$ ssh -i \ "<_su-nombre-de-instancia.pem_"> ec2-user@<_su-dirección-IP-de-instancia_>Escriba "sí" para confirmar que quiere seguir conectándose.
Como resultado, usted está conectado a su instancia usando SSH.
Pasos de verificación
- Compruebe si puede realizar alguna acción mientras está conectado a su instancia mediante SSH.
6.5.4. Preparación para la carga de imágenes VHD de Azure
Esto describe los pasos para subir una imagen VHD a Azure.
Requisitos previos
- Debe tener un grupo de recursos de Azure y una cuenta de almacenamiento utilizables.
Procedimiento
Instalar python2:
# yum install python2Notapython2 paquete debe ser instalado porque desde el AZ CLI depende específicamente de python 2.7
Importe la clave de repositorio de Microsoft:
# rpm --import https://packages.microsoft.com/keys/microsoft.ascCrear una información de repositorio local azure-cli:
# sh -c 'echo -e \N "azure-cli]\Nname=Azure CLI\nbaseurl=https://packages.microsoft.com/yumrepos/azure-cli\nenabled=1\ngpgcheck=1\ngpgkey=https://packages.microsoft.com/keys/microsoft.asc" > /etc/yum.repos.d/azure-cli.repo'Instale la CLI de Azure:
# yumdownloader azure-cli # rpm -ivh --nodeps azure-cli-2.0.64-1.el7.x86_64.rpmNotaLa versión descargada del paquete de Azure CLI puede variar en función de la versión actual descargada.
Ejecute la CLI de Azure:
$ az loginEl terminal muestra el mensaje 'Nota, hemos lanzado un navegador para que pueda iniciar sesión. Para una experiencia antigua con el código del dispositivo, utilice \ "az login --use-device-code"' y abre un navegador donde puede iniciar la sesión.
NotaSi está ejecutando una sesión remota (SSH), el enlace no se abrirá en el navegador. En este caso, puede utilizar el enlace proporcionado y así poder iniciar sesión y autenticar su sesión remota. Para iniciar la sesión, utilice un navegador web para abrir la página https://microsoft.com/devicelogin e introduzca el código XXXXXXXXX para autenticarse.
Enumerar las claves de la cuenta de almacenamiento en Azure:
$ GROUP=resource-group-name $ ACCOUNT=storage-account-name $ az storage account keys list --resource-group $GROUP --account-name $ACCOUNTSustituya resource-group-name por el nombre del grupo de recursos de Azure y storage-account-name por el nombre de la cuenta de almacenamiento de Azure.
NotaPuedes listar los recursos disponibles utilizando el comando
Lista de recursos azAnote el valor
key1en la salida del comando anterior y asígnelo a una variable de entorno:$ KEY1=valueCrea un contenedor de almacenamiento:
$ CONTAINER=storage-account-name $ az storage container create --account-name $ACCOUNT \ --account-key $KEY1 --name $CONTAINERSustituya storage-account-name por el nombre de la cuenta de almacenamiento.
6.5.5. Carga de imágenes VHD a Azure
Esto describe los pasos para subir una imagen VHD a Azure.
Requisitos previos
- Su sistema debe estar configurado para cargar imágenes VHD de Azure.
-
Debe tener una imagen VHD de Azure creada por Image Builder. Utilice el tipo de salida
vhden CLI o Azure Disk Image (.vhd) en la GUI al crear la imagen.
Procedimiento
Empuje la imagen a Azure y cree una instancia a partir de ella:
$ VHD=25ccb8dd-3872-477f-9e3d-c2970cd4bbaf-disk.vhd $ az storage blob upload --account-name $ACCOUNT --container-name $CONTAINER --file $VHD --name $VHD --type page ...Una vez completada la carga al BLOB de Azure, cree una imagen de Azure a partir de ella:
$ az image create --resource-group $GROUP --name $VHD --os-type linux --location eastus --source https://$ACCOUNT.blob.core.windows.net/$CONTAINER/$VHD - Running ...Cree una instancia con el portal de Azure o con un comando similar al siguiente:
$ az vm create --resource-group $GROUP --location eastus --name $VHD --image $VHD --admin-username azure-user --generate-ssh-keys - Running ...-
Utilice su clave privada a través de SSH para acceder a la instancia resultante. Inicie sesión como
azure-user.
6.5.6. Carga de imágenes VMDK en vSphere
Image Builder puede generar imágenes adecuadas para cargarlas en un sistema VMware ESXi o vSphere. Esto describe los pasos para cargar una imagen VMDK a VMware vSphere.
Dado que los despliegues de VMWare no suelen tener configurado el cloud-init para inyectar las credenciales de usuario a las máquinas virtuales, debemos realizar esa tarea nosotros mismos en el blueprint.
Requisitos previos
-
Debe tener una imagen VMDK creada por Image Builder. Utilice el tipo de salida
vmdken CLI o VMware Virtual Machine Disk (.vmdk) en la GUI al crear la imagen.
Procedimiento
Cargue la imagen en vSphere a través de HTTP. Haga clic en
Upload Filesen el vCenter:
Cuando cree una VM, en la página
Device Configuration, elimine la página por defectoNew Hard Disky utilice el desplegable para seleccionar una imagen de discoExisting Hard Disk: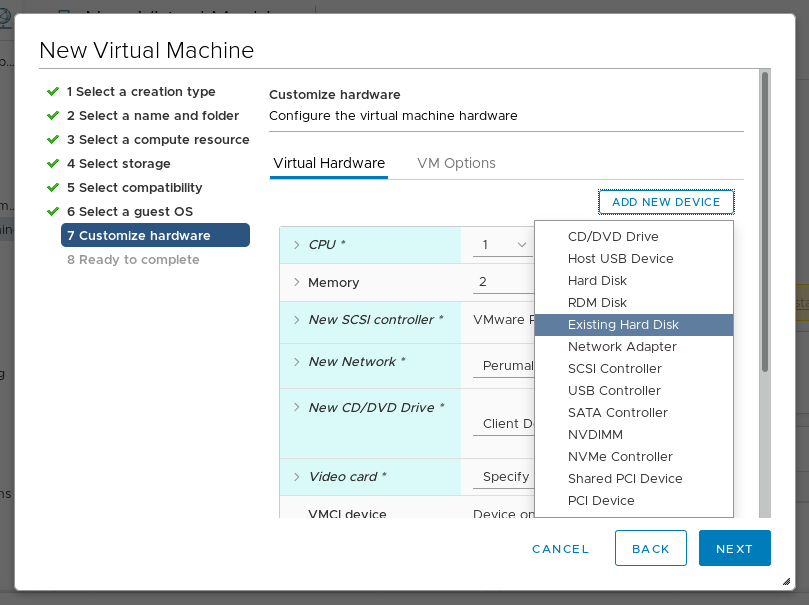
Asegúrese de utilizar un dispositivo
IDEcomoVirtual Device Nodepara el disco que cree. El valor por defectoSCSIda como resultado una máquina virtual que no puede arrancar.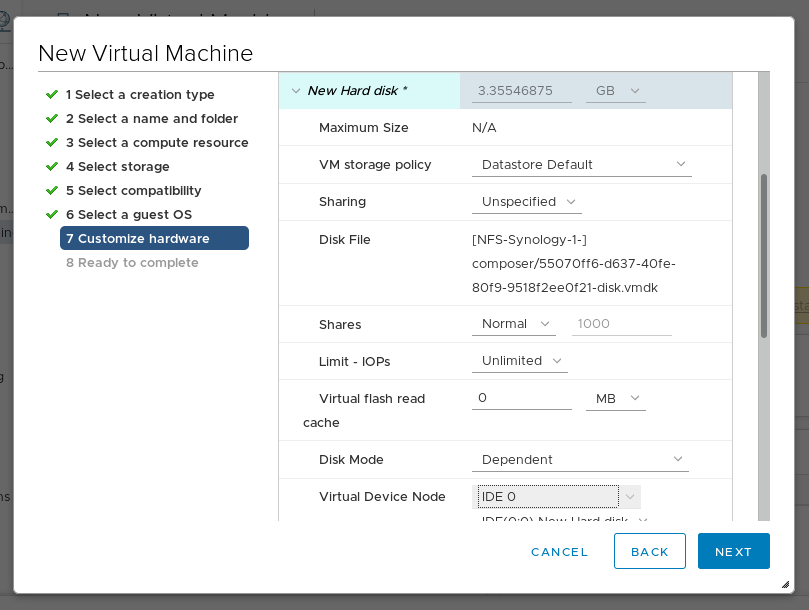
6.5.7. Envío de imágenes VHD a la nube de Azure
La capacidad de empujar la imagen de salida que usted crea al Azure Blob Storage está disponible. En esta sección se describen los pasos para transferir las imágenes de .vhd creadas con Image Builder al proveedor de servicios de Azure Cloud.
Requisitos previos
- Debe tener acceso a la raíz del sistema.
- Ha abierto la interfaz del Image Builder de la consola web de RHEL 8 en un navegador.
- Debe tener una cuenta de almacenamiento creada.
- Debe tener preparado un Blob Storage con capacidad de escritura.
Procedimiento
- Haga clic en para crear un plano. Vea más en Crear un plano de Image Builder en la interfaz de la consola web.
- Seleccione los componentes y paquetes que desea que formen parte de la imagen que está creando.
Haga clic en para confirmar los cambios realizados en el plano.
Una pequeña ventana emergente en la parte superior derecha le informa del progreso de guardado y, a continuación, del resultado de los cambios realizados.
- Haga clic en el enlace blueprint name en el banner de la izquierda.
- Seleccione la pestaña .
Haga clic en para crear su imagen personalizada.
Se abre una ventana emergente.
-
En la lista del menú desplegable "Type", seleccione la imagen
Azure Disk Image (.vhd). - Marque la casilla "Upload to Azure" para subir su imagen a la nube de Azure y haga clic en .
Para autenticar su acceso a Azure, escriba su "cuenta de almacenamiento" y su "clave de acceso al almacenamiento" en los campos correspondientes. Haga clic en .
Puede encontrar los detalles de su cuenta de almacenamiento en la lista del menú Configuración→Clave de acceso.
- Escriba un "Image name" que se utilizará para el archivo de imagen que se cargará y el Blob "contenedor de almacenamiento" en el que el archivo de imagen que desea empujar la imagen. Haga clic en .
Revise la información que ha proporcionado y, una vez que esté satisfecho, haga clic en .
Opcionalmente, puede hacer clic en para modificar cualquier detalle incorrecto.
-
En la lista del menú desplegable "Type", seleccione la imagen
Una pequeña ventana emergente en la parte superior derecha se muestra cuando se inicia el proceso de creación de la imagen con el mensaje "La creación de la imagen se ha añadido a la cola".
Una vez que el proceso de creación de la imagen haya finalizado, haga clic en el plano del que ha creado una imagen. Puede ver el estado de "Image build complete" para la imagen que creó dentro de la pestaña
Images.- Para acceder a la imagen que has introducido en Azure Cloud, accede a Azure Portal.
- En la barra de búsqueda, escriba Images y seleccione la primera entrada en Services. Se le redirige a la página Image dashboard.
Haga clic en . Se le redirige al panel de control de Create an Image.
Inserte los siguientes datos:
- Name: Elija un nombre para su nueva imagen.
- Resource Group: Seleccione un resource group.
- Location: Seleccione el location que coincida con las regiones asignadas a su cuenta de almacenamiento. De lo contrario, no podrás seleccionar una mancha.
- OS Type: Establece el tipo de sistema operativo en Linux.
- VM Generation: Mantenga la generación de VMs en Gen 1.
Storage Blob: Haga clic en Browse a la derecha de Storage blob input. Utiliza el cuadro de diálogo para encontrar la imagen que has subido antes.
Mantenga los campos restantes como en la opción por defecto.
- Haga clic en para crear la imagen. Una vez creada la imagen, podrá ver el mensaje "Successfully created image" en la esquina superior derecha.
- Haga clic en para ver su nueva imagen y abra la imagen recién creada.
- Haga clic en . Se le redirige al panel de control de Create a virtual machine.
En la pestaña Basic, en Project Details, your *Subscription y en Resource Group ya están preconfigurados.
Si desea crear un nuevo grupo de recursos
Haga clic en .
Una ventana emergente le pide que cree el contenedor Resource Group Name.
Introduzca un nombre y haga clic en .
Si quieres mantener los Resource Group que ya están preestablecidos.
En Instance Details, inserte:
- Virtual machine name
- Region
- Image: La imagen que ha creado está preseleccionada por defecto.
Size: Elija el tamaño de VM que mejor se adapte a sus necesidades.
Mantenga los campos restantes como en la opción por defecto.
En Administrator account, introduzca los siguientes datos:
- Username: el nombre del administrador de la cuenta.
SSH public key source: en el menú desplegable, seleccione Generate new key pair.
Puedes usar el par de claves que ya tienes o puedes crear un nuevo par de claves. También puede utilizar
Image Builderpara añadir un usuario a la imagen con una clave pública preestablecida. Consulte Crear una cuenta de usuario con clave SSH para obtener más detalles.- Key pair name: inserte un nombre para el par de claves.
En Inbound port rules, seleccione:
- Public inbound ports: Allow selected ports.
- Select inbound ports: Utiliza el conjunto por defecto SSH (22).
- Haga clic en . Se le redirige a la pestaña Review create y recibe una confirmación de que la validación ha sido aprobada.
Revise los detalles y haga clic en .
Opcionalmente, puede hacer clic en para fijar las opciones anteriores seleccionadas.
Se abre una ventana emergente generates new key pair. Haga clic en .
Guarde el archivo de claves como "yourKey.pem".
- Una vez que se haya completado el despliegue, haga clic en .
- Serás redirigido a una nueva ventana con los detalles de tu máquina virtual. Seleccione la dirección IP pública en la parte superior derecha de la página y cópiela en su portapapeles.
Ahora, para crear una conexión SSH con la VM para conectarse a la Máquina Virtual.
- Abre un terminal.
En el indicador, abra una conexión SSH a su máquina virtual. Sustituye la dirección IP por la de tu máquina virtual, y sustituye la ruta del .pem por la ruta donde se descargó el archivo de claves.
# ssh -i ./Downloads/yourKey.pem azureuser@10.111.12.123- Se le pedirá que confirme si quiere seguir conectándose. Escriba "sí" para continuar.
Como resultado, la imagen de salida que empujó al Azure Storage Blob está lista para ser aprovisionada.
6.5.8. Carga de la imagen QCOW2 en OpenStack
Image Builder puede generar imágenes adecuadas para subirlas a los despliegues de la nube OpenStack, y para iniciar instancias allí. Esto describe los pasos para subir una imagen QCOW2 a OpenStack.
Requisitos previos
Debe tener una imagen específica de OpenStack creada por Image Builder. Utilice el tipo de salida
openstacken CLI o OpenStack Image (.qcow2) en la GUI al crear la imagen.AvisoImage Builder también ofrece un formato de salida genérico de tipo de imagen QCOW2 como
qcow2o QEMU QCOW2 Image (.qcow2). No lo confunda con el tipo de imagen OpenStack que también está en el formato QCOW2, pero contiene más cambios específicos para OpenStack.
Procedimiento
Sube la imagen a OpenStack e inicia una instancia desde ella. Utilice la interfaz
Imagespara hacerlo: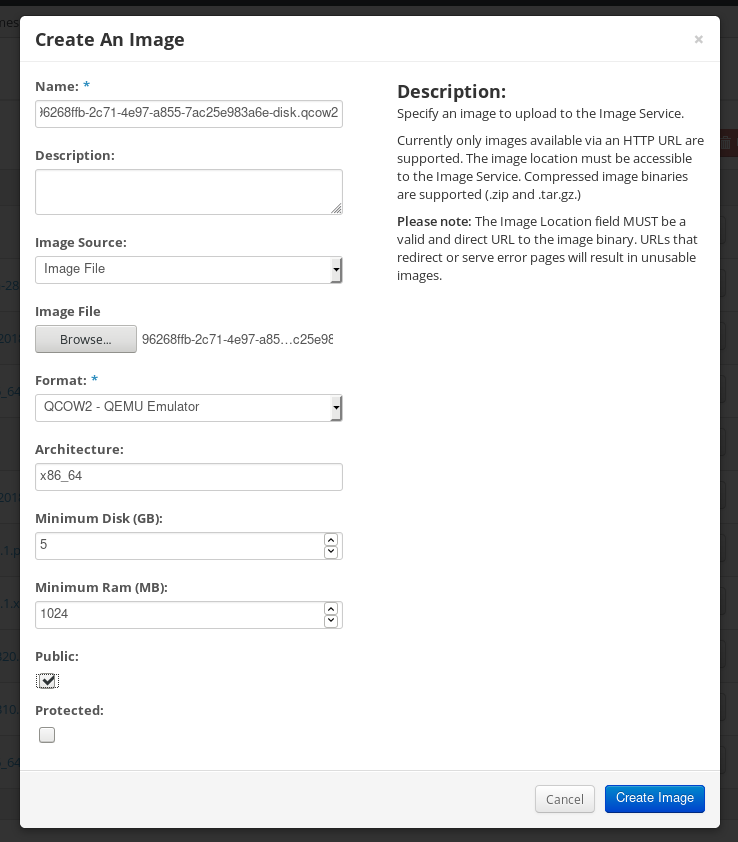
Inicie una instancia con esa imagen:
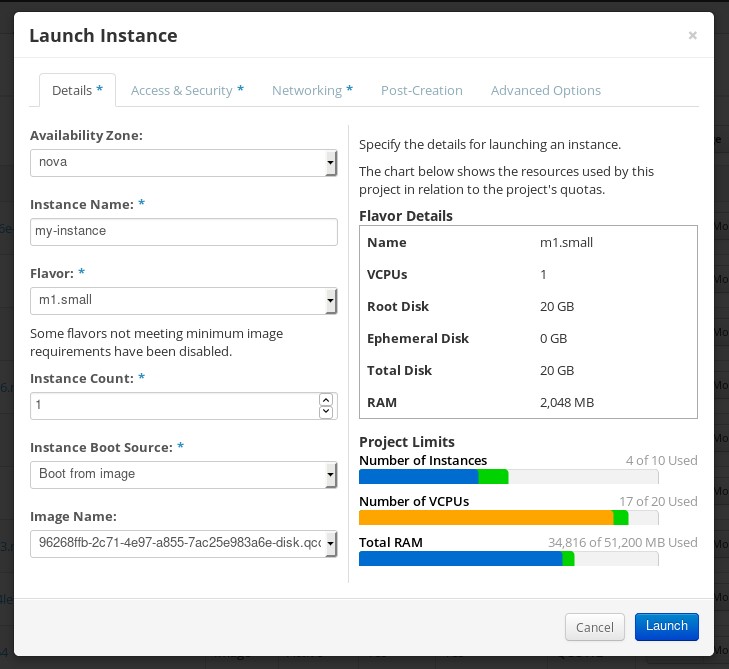
-
Puede ejecutar la instancia utilizando cualquier mecanismo (CLI o interfaz web de OpenStack) desde la instantánea. Utilice su clave privada a través de SSH para acceder a la instancia resultante. Inicie sesión como
cloud-user.
6.5.9. Preparación para subir imágenes a Alibaba
Esta sección describe los pasos para verificar las imágenes personalizadas que puede implementar en Alibaba Cloud. Las imágenes necesitarán una configuración específica para arrancar con éxito, ya que Alibaba Cloud solicita que las imágenes personalizadas cumplan con ciertos requisitos antes de su uso. Para ello, se recomienda utilizar la página web de Alibaba image_check tool.
La verificación de la imagen personalizada es una tarea opcional. Image Builder genera imágenes que se ajustan a los requisitos de Alibaba.
Requisitos previos
- Debe tener una imagen de Alibaba creada por Image Builder.
Procedimiento
- Conéctese al sistema que contiene la imagen que desea comprobar por medio de Alibaba image_check tool.
Descargue el sitio web image_check tool:
$ curl -O http://docs-aliyun.cn-hangzhou.oss.aliyun-inc.com/assets/attach/73848/cn_zh/1557459863884/image_checkCambiar el permiso de archivo de la herramienta de cumplimiento de la imagen:
# chmod x image_checkEjecute el comando para iniciar la comprobación de la herramienta de cumplimiento de la imagen:
# ./image_checkLa herramienta verifica la configuración del sistema y genera un informe que se muestra en su pantalla. La herramienta image_check guarda este informe en la misma carpeta en la que se ejecuta la herramienta de conformidad de la imagen.
- Si alguno de los Detection Items falla, siga las instrucciones para corregirlo. Para más información, consulte el enlace: Sección de elementos de detección.
6.5.10. Subir imágenes a Alibaba
Esta sección describe cómo cargar una imagen de Alibaba a Object Storage Service (OSS).
Requisitos previos
- Su sistema está configurado para cargar imágenes de Alibaba.
-
Debe tener una imagen Alibaba creada por Image Builder. Utilice el tipo de salida
amien RHEL 7 o Alibaba en RHEL 8 al crear la imagen. - Tiene un cubo. Véase Creación de un cubo.
- Tienes una cuenta de Alibaba activa.
- Has activado el OSS.
Procedimiento
- Inicie sesión en la consola de OSS.
- En el menú de cubos de la izquierda, seleccione el cubo al que desea cargar una imagen.
- En el menú superior derecho, haga clic en la pestaña Archivos.
Haga clic en . Se abre una ventana de diálogo en el lado derecho. Elija la siguiente información:
- Upload To: Elija si desea cargar el archivo en el directorio Current o en un directorio Specified.
- File ACL: Elija el tipo de permiso del archivo cargado.
- Haga clic en .
- Elige la imagen que quieres subir.
- Haga clic en .
Como resultado, la imagen personalizada se carga en la Consola OSS.
6.5.11. Importar imágenes a Alibaba
Esta sección describe cómo importar una imagen de Alibaba a Elastic Cloud Console (ECS).
Requisitos previos
- Has subido la imagen al Servicio de Almacenamiento de Objetos (OSS).
Procedimiento
Inicie sesión en la consola de ECS.
- En el menú de la izquierda, haga clic en .
- En la parte superior derecha, haga clic en . Se abre una ventana de diálogo.
Confirme que ha configurado la región correcta donde se encuentra la imagen. Introduzca la siguiente información:
- OSS Object Address: Vea cómo obtener la dirección del objeto OSS.
- Image Name:
- Operating System:
- System Disk Size:
- System Architecture:
- Platform: Red Hat
Opcionalmente, proporcione los siguientes detalles:
- Image Format: qcow2 o ami, según el formato de la imagen cargada.
- Image Description:
Add Images of Data Disks:
La dirección puede determinarse en la consola de gestión de OSS después de seleccionar el cubo requerido en el menú de la izquierda, seleccionar la sección Archivos y luego hacer clic en el enlace Detalles de la derecha para la imagen correspondiente. Aparecerá una ventana en la parte derecha de la pantalla, mostrando los detalles de la imagen. La dirección del objeto OSS está en el cuadro de la URL.
Haga clic en .
NotaEl tiempo del proceso de importación puede variar en función del tamaño de la imagen.
Como resultado, la imagen personalizada se importa a ECS Console. Puede crear una instancia a partir de la imagen personalizada.
6.5.12. Creación de una instancia de una imagen personalizada mediante Alibaba
Puede crear instancias de la imagen personalizada utilizando la Consola ECS de Alibaba.
Requisitos previos
- Has activado el OSS y has subido tu imagen personalizada.
- Ha importado con éxito su imagen a la Consola ECS.
Procedimiento
- Inicie sesión en la consola de ECS.
- En el menú de la izquierda, seleccione Instances.
- En la esquina superior, haga clic en Create Instance. Se le redirige a una nueva ventana.
- Rellene toda la información requerida. Consulte Crear una instancia mediante el asistente para obtener más detalles.
Haga clic en Create Instance y confirme el pedido.
NotaPuede ver la opción Create Order en lugar de Create Instace, dependiendo de su suscripción.
Como resultado, usted tiene una instancia activa lista para el despliegue.
Capítulo 7. Realización de una instalación automatizada mediante Kickstart
7.1. Conceptos básicos de la instalación de Kickstart
Lo siguiente proporciona información básica sobre Kickstart y cómo utilizarlo para automatizar la instalación de Red Hat Enterprise Linux.
7.1.1. Qué son las instalaciones Kickstart
Kickstart proporciona una forma de automatizar el proceso de instalación de RHEL, ya sea parcial o totalmente.
Los archivos Kickstart contienen algunas o todas las opciones de instalación de RHEL. Por ejemplo, la zona horaria, cómo se deben particionar las unidades o qué paquetes se deben instalar. Proporcionar un archivo Kickstart preparado permite una instalación sin la necesidad de ninguna intervención del usuario. Esto es especialmente útil cuando se implanta Red Hat Enterprise Linux en un gran número de sistemas a la vez.
Los archivos Kickstart también proporcionan más opciones en cuanto a la selección de software. Cuando se instala Red Hat Enterprise Linux manualmente utilizando la interfaz gráfica de instalación, la selección de software se limita a entornos predefinidos y complementos. Un archivo Kickstart le permite instalar o eliminar paquetes individuales también.
Los archivos Kickstart pueden mantenerse en un único sistema servidor y ser leídos por ordenadores individuales durante la instalación. Este método de instalación admite el uso de un único archivo Kickstart para instalar Red Hat Enterprise Linux en varias máquinas, lo que lo hace ideal para los administradores de redes y sistemas.
Todos los scripts de Kickstart y los archivos de registro de su ejecución se almacenan en el directorio /tmp del sistema recién instalado para ayudar a depurar los problemas de instalación.
En versiones anteriores de Red Hat Enterprise Linux, Kickstart podía utilizarse para actualizar sistemas. A partir de Red Hat Enterprise Linux 7, esta funcionalidad ha sido eliminada y las actualizaciones del sistema son manejadas por herramientas especializadas. Para más detalles sobre la actualización a Red Hat Enterprise Linux 8, consulte Actualización de RHEL 7 a RHEL 8 y Consideraciones para la adopción de RHEL 8.
7.1.2. Flujo de trabajo de instalación automatizado
Las instalaciones de Kickstart pueden realizarse utilizando un DVD local, un disco duro local o un servidor NFS, FTP, HTTP o HTTPS. Esta sección proporciona una visión general de alto nivel del uso de Kickstart.
- Cree un archivo Kickstart. Puede escribirlo a mano, copiar un archivo Kickstart guardado después de una instalación manual, o utilizar una herramienta generadora en línea para crear el archivo, y editarlo después. Consulte Creación de archivos Kickstart.
- Ponga el archivo Kickstart a disposición del programa de instalación en un soporte extraíble, un disco duro o una ubicación de red mediante un servidor HTTP(S), FTP o NFS. Consulte Cómo poner los archivos Kickstart a disposición del programa de instalación.
- Cree el medio de arranque que se utilizará para comenzar la instalación. Consulte Creación de un medio de instalación de arranque y Preparación de la instalación desde la red mediante PXE.
- Ponga el origen de la instalación a disposición del programa de instalación. Consulte Creación de fuentes de instalación para instalaciones Kickstart.
- Inicie la instalación utilizando el medio de arranque y el archivo Kickstart. Consulte Inicio de instalaciones Kickstart.
Si el archivo Kickstart contiene todos los comandos y secciones obligatorios, la instalación finaliza automáticamente. Si faltan una o varias de estas partes obligatorias, o si se produce un error, la instalación requiere una intervención manual para finalizar.
7.2. Creación de archivos Kickstart
Puede crear un archivo Kickstart utilizando los siguientes métodos:
- Utilice la herramienta de configuración Kickstart en línea.
- Copie el archivo Kickstart creado como resultado de una instalación manual.
- Escribir manualmente todo el archivo Kickstart. Tenga en cuenta que la edición de un archivo ya existente desde los otros métodos es más rápida, por lo que no se recomienda este método.
- Convierta el archivo Kickstart de Red Hat Enterprise Linux 7 para la instalación de Red Hat Enterprise Linux 8.
- En el caso del entorno virtual y de la nube, cree una imagen del sistema personalizada, utilizando Image Builder.
Tenga en cuenta que algunas opciones de instalación muy específicas sólo pueden configurarse mediante la edición manual del archivo Kickstart.
7.2.1. Creación de un archivo Kickstart con la herramienta de configuración Kickstart
Los usuarios con una cuenta en el Portal de Clientes de Red Hat pueden utilizar la herramienta Kickstart Generator en el Portal de Clientes Labs para generar archivos Kickstart en línea. Esta herramienta le guiará a través de la configuración básica y le permitirá descargar el archivo Kickstart resultante.
Actualmente, la herramienta no admite ningún tipo de partición avanzada.
Requisitos previos
- Debe tener una cuenta en el Portal del Cliente de Red Hat y una suscripción activa a Red Hat.
Procedimiento
- Abra la página de información del laboratorio del generador Kickstart en https://access.redhat.com/labsinfo/kickstartconfig
- Haga clic en el botón Go to Application a la izquierda del encabezamiento y espere a que se cargue la siguiente página.
- Seleccione Red Hat Enterprise Linux 8 en el menú desplegable y espere a que la página se actualice.
Describa el sistema que va a instalar utilizando los campos del formulario.
Puede utilizar los enlaces de la parte izquierda del formulario para navegar rápidamente entre las secciones del mismo.
Para descargar el archivo Kickstart generado, haga clic en el botón rojo Download en la parte superior de la página.
Su navegador web guarda el archivo.
7.2.2. Creación de un archivo Kickstart mediante una instalación manual
El enfoque recomendado para crear archivos Kickstart es utilizar el archivo creado por una instalación manual de Red Hat Enterprise Linux. Después de completar una instalación, todas las elecciones hechas durante la instalación se guardan en un archivo Kickstart llamado anaconda-ks.cfg, localizado en el directorio /root/ en el sistema instalado. Puede utilizar este archivo para reproducir la instalación de la misma manera que antes. También puede copiar este archivo, realizar los cambios que necesite y utilizar el archivo de configuración resultante para otras instalaciones.
Procedimiento
Instale RHEL. Para más detalles, consulte Realizar una instalación estándar de RHEL.
Durante la instalación, cree un usuario con privilegios de administrador.
- Finalice la instalación y reinicie el sistema instalado.
- Acceda al sistema con la cuenta de administrador.
Copie el archivo
/root/anaconda-ks.cfgen una ubicación de su elección.Para mostrar el contenido del archivo en el terminal:
# cat /root/anaconda-ks.cfgPuede copiar el resultado y guardarlo en otro archivo de su elección.
- Para copiar el archivo en otra ubicación, utilice el administrador de archivos. Recuerde cambiar los permisos de la copia, para que el archivo pueda ser leído por usuarios que no sean root.
ImportantEl archivo contiene información sobre los usuarios y las contraseñas.
Recursos adicionales
7.2.3. Conversión de un archivo Kickstart de RHEL 7 para la instalación de RHEL 8
Puede utilizar la herramienta Kickstart Converter para convertir un archivo Kickstart de RHEL 7 para utilizarlo en una nueva instalación de RHEL 8. Para obtener más información sobre la herramienta y cómo utilizarla para convertir un archivo Kickstart de RHEL 7, consulte https://access.redhat.com/labs/kickstartconvert/
7.2.4. Creación de una imagen personalizada con el Constructor de Imágenes
Puede utilizar Red Hat Image Builder para crear una imagen de sistema personalizada para implementaciones virtuales y de nube.
Para más información sobre la creación de imágenes personalizadas, utilizando el Constructor de Imágenes, consulte el Composing a customized RHEL system image documento.
7.3. Poner los archivos Kickstart a disposición del programa de instalación
A continuación se ofrece información sobre cómo poner el archivo Kickstart a disposición del programa de instalación en el sistema de destino.
7.3.1. Puertos para la instalación en red
La siguiente tabla enumera los puertos que deben estar abiertos en el servidor que proporciona los archivos para cada tipo de instalación basada en la red.
| Protocolo utilizado | Puertos a abrir |
|---|---|
| HTTP | 80 |
| HTTPS | 443 |
| FTP | 21 |
| NFS | 2049, 111, 20048 |
| TFTP | 69 |
Recursos adicionales
- Consulte el Securing networks documento para más información.
7.3.2. Hacer que un archivo Kickstart esté disponible en un servidor NFS
Este procedimiento describe cómo almacenar el archivo de script Kickstart en un servidor NFS. Este método le permite instalar varios sistemas desde una única fuente sin tener que utilizar medios físicos para el archivo Kickstart.
Requisitos previos
- Debe tener acceso de nivel de administrador a un servidor con Red Hat Enterprise Linux 8 en la red local.
- El sistema que se va a instalar debe poder conectarse al servidor.
- El cortafuegos del servidor debe permitir las conexiones desde el sistema en el que se está instalando.
Procedimiento
Instale el paquete
nfs-utilsejecutando el siguiente comando como root:# yum install nfs-utils- Copie el archivo Kickstart en un directorio del servidor NFS.
Abra el archivo
/etc/exportscon un editor de texto y añada una línea con la siguiente sintaxis:/exported_directory/ clientsSustituya /exported_directory/ por la ruta completa del directorio que contiene el archivo Kickstart. En lugar de clients, utilice el nombre de host o la dirección IP del ordenador que se va a instalar desde este servidor NFS, la subred desde la que todos los ordenadores van a tener acceso a la imagen ISO, o el signo de asterisco (
*) si desea permitir que cualquier ordenador con acceso a la red del servidor NFS utilice la imagen ISO. Consulte la página de manual exports(5) para obtener información detallada sobre el formato de este campo.Una configuración básica que hace que el directorio
/rhel8-install/esté disponible como de sólo lectura para todos los clientes es:/rhel8-install *-
Guarde el archivo
/etc/exportsy salga del editor de texto. Inicie el servicio nfs:
# systemctl start nfs-server.serviceSi el servicio se estaba ejecutando antes de cambiar el archivo
/etc/exports, introduzca el siguiente comando, para que el servidor NFS en ejecución recargue su configuración:# systemctl reload nfs-server.serviceEl archivo Kickstart es ahora accesible a través de NFS y está listo para ser utilizado para la instalación.
Cuando especifique el origen de Kickstart, utilice nfs: como protocolo, el nombre de host o la dirección IP del servidor, el signo de dos puntos (:) y la ruta dentro del directorio que contiene el archivo. Por ejemplo, si el nombre de host del servidor es myserver.example.com y ha guardado el archivo en /rhel8-install/my-ks.cfg, especifique inst.ks=nfs:myserver.example.com:/rhel8-install/my-ks.cfg como opción de arranque del origen de la instalación.
Recursos adicionales
- Para obtener detalles sobre la configuración del servidor TFTP para el arranque PXE desde la red, consulte la sección Preparación para la instalación desde la red mediante PXE en el documento Performing an advanced RHEL installation.
7.3.3. Hacer que un archivo Kickstart esté disponible en un servidor HTTP o HTTPS
Este procedimiento describe cómo almacenar el archivo de script Kickstart en un servidor HTTP o HTTPS. Este método le permite instalar varios sistemas desde una única fuente sin tener que utilizar medios físicos para el archivo Kickstart.
Requisitos previos
- Debe tener acceso de nivel de administrador a un servidor con Red Hat Enterprise Linux 8 en la red local.
- El sistema que se va a instalar debe poder conectarse al servidor.
- El cortafuegos del servidor debe permitir las conexiones desde el sistema en el que se está instalando.
Procedimiento
Instale el paquete
httpdejecutando el siguiente comando como root:# yum install httpdAvisoSi la configuración de su servidor web Apache habilita la seguridad SSL, verifique que solo habilita el protocolo TLSv1 y deshabilita SSLv2 y SSLv3. Esto se debe a la vulnerabilidad POODLE SSL (CVE-2014-3566). Consulte https://access.redhat.com/solutions/1232413 para obtener más detalles.
ImportanteSi utiliza un servidor HTTPS con un certificado autofirmado, debe arrancar el programa de instalación con la opción
inst.noverifyssl.-
Copie el archivo Kickstart en el servidor HTTP(S) en un subdirectorio del directorio
/var/www/html/. Inicie el servicio httpd:
# systemctl start httpd.serviceEl archivo Kickstart está ahora accesible y listo para ser utilizado para la instalación.
NotaCuando especifique la ubicación del archivo Kickstart, utilice
http://ohttps://como protocolo, el nombre de host del servidor o la dirección IP, y la ruta del archivo Kickstart, relativa a la raíz del servidor HTTP. Por ejemplo, si utiliza HTTP, el nombre de host del servidor esmyserver.example.com, y ha copiado el archivo Kickstart como/var/www/html/rhel8-install/my-ks.cfg, especifiquehttp://myserver.example.com/rhel8-install/my-ks.cfgcomo ubicación del archivo.
Recursos adicionales
- Para obtener más información sobre los servidores HTTP y FTP, consulte Implementación de diferentes tipos de servidores.
7.3.4. Hacer que un archivo Kickstart esté disponible en un servidor FTP
Este procedimiento describe cómo almacenar el archivo de script Kickstart en un servidor FTP. Este método le permite instalar varios sistemas desde una única fuente sin tener que utilizar medios físicos para el archivo Kickstart.
Requisitos previos
- Debe tener acceso de nivel de administrador a un servidor con Red Hat Enterprise Linux 8 en la red local.
- El sistema que se va a instalar debe poder conectarse al servidor.
- El cortafuegos del servidor debe permitir las conexiones desde el sistema en el que se está instalando.
Procedimiento
Instale el paquete
vsftpdejecutando el siguiente comando como root:# yum install vsftpdAbra y edite el archivo de configuración
/etc/vsftpd/vsftpd.confen un editor de texto.-
Cambie la línea
anonymous_enable=NOporanonymous_enable=YES -
Cambie la línea
write_enable=YESporwrite_enable=NO. Añadir líneas
pasv_min_port=min_portypasv_max_port=max_port. Sustituya min_port y max_port por el rango de números de puerto utilizado por el servidor FTP en modo pasivo, por ejemplo10021y10031.Este paso puede ser necesario en entornos de red con varias configuraciones de firewall/NAT.
Opcionalmente, añada cambios personalizados a su configuración. Para conocer las opciones disponibles, consulte la página de manual vsftpd.conf(5). Este procedimiento asume que se utilizan las opciones por defecto.
AvisoSi ha configurado la seguridad SSL/TLS en su archivo
vsftpd.conf, asegúrese de habilitar sólo el protocolo TLSv1 y de desactivar SSLv2 y SSLv3. Esto se debe a la vulnerabilidad POODLE SSL (CVE-2014-3566). Consulte https://access.redhat.com/solutions/1234773 para obtener más detalles.
-
Cambie la línea
Configurar el cortafuegos del servidor.
Activa el cortafuegos:
# systemctl enable firewalld # systemctl start firewalldHabilite en su firewall el puerto FTP y el rango de puertos del paso anterior:
# firewall-cmd --add-port min_port-max_port/tcp --permanent # firewall-cmd --add-service ftp --permanent # firewall-cmd --reloadSustituya min_port-max_port por los números de puerto que introdujo en el archivo de configuración
/etc/vsftpd/vsftpd.conf.
-
Copie el archivo Kickstart en el servidor FTP en el directorio
/var/ftp/o en su subdirectorio. Asegúrese de que el contexto de SELinux y el modo de acceso correctos están configurados en el archivo:
# restorecon -r /var/ftp/your-kickstart-file.ks # chmod 444 /var/ftp/your-kickstart-file.ksInicie el servicio
vsftpd:# systemctl start vsftpd.serviceSi el servicio estaba en marcha antes de cambiar el archivo
/etc/vsftpd/vsftpd.conf, reinicie el servicio para cargar el archivo editado:# systemctl restart vsftpd.serviceHabilite el servicio
vsftpdpara que se inicie durante el proceso de arranque:# systemctl enable vsftpdEl archivo Kickstart es ahora accesible y está listo para ser utilizado para las instalaciones de los sistemas en la misma red.
NotaCuando configure el origen de la instalación, utilice
ftp://como protocolo, el nombre de host o la dirección IP del servidor y la ruta del archivo Kickstart, relativa a la raíz del servidor FTP. Por ejemplo, si el nombre del servidor esmyserver.example.comy ha copiado el archivo en/var/ftp/my-ks.cfg, especifiqueftp://myserver.example.com/my-ks.cfgcomo origen de la instalación.
7.3.5. Hacer que un archivo Kickstart esté disponible en un volumen local
Este procedimiento describe cómo almacenar el archivo de script Kickstart en un volumen del sistema a instalar. Este método le permite evitar la necesidad de otro sistema.
Requisitos previos
- Debe tener una unidad que pueda ser trasladada a la máquina para ser instalada, como una memoria USB.
-
La unidad debe contener una partición que pueda ser leída por el programa de instalación. Los tipos admitidos son
ext2,ext3,ext4,xfsyfat. - La unidad debe estar ya conectada al sistema y sus volúmenes montados.
Procedimiento
Enumere la información del volumen y anote el UUID del volumen al que desea copiar el archivo Kickstart.
# lsblk -l -p -o name,rm,ro,hotplug,size,type,mountpoint,uuid- Navega hasta el sistema de archivos del volumen.
- Copie el archivo Kickstart en este sistema de archivos.
-
Anote la cadena para utilizarla posteriormente con la opción
inst.ks=. Esta cadena tiene la formahd:UUID=volume-UUID:path/to/kickstart-file.cfg. Tenga en cuenta que la ruta es relativa a la raíz del sistema de archivos, no a la raíz/de la jerarquía del sistema de archivos. Sustituya volume-UUID por el UUID que anotó anteriormente. Desmontar todos los volúmenes de las unidades:
# umount /dev/xyz...Añade todos los volúmenes al comando, separados por espacios.
7.3.6. Hacer que un archivo Kickstart esté disponible en un volumen local para su carga automática
Un archivo Kickstart con nombre especial puede estar presente en la raíz de un volumen con nombre especial en el sistema a instalar. Esto permite obviar la necesidad de otro sistema, y hace que el programa de instalación cargue el archivo automáticamente.
Requisitos previos
- Debe tener una unidad que pueda ser trasladada a la máquina para ser instalada, como una memoria USB.
-
La unidad debe contener una partición que pueda ser leída por el programa de instalación. Los tipos admitidos son
ext2,ext3,ext4,xfsyfat. - La unidad debe estar ya conectada al sistema y sus volúmenes montados.
Procedimiento
Enumere la información del volumen y anote el UUID del volumen al que desea copiar el archivo Kickstart.
# lsblk -l -p- Navega hasta el sistema de archivos del volumen.
- Copie el archivo Kickstart en la raíz de este sistema de archivos.
-
Cambie el nombre del archivo Kickstart a
ks.cfg. Renombra el volumen como
OEMDRV:Para los sistemas de archivos
ext2,ext3, yext4:# e2label /dev/xyz OEMDRVPara el sistema de archivos XFS:
# xfs_admin -L OEMDRV /dev/xyz
Sustituya /dev/xyz por la ruta del dispositivo de bloque del volumen.
Desmontar todos los volúmenes de las unidades:
# umount /dev/xyz...Añade todos los volúmenes al comando, separados por espacios.
7.4. Creación de fuentes de instalación para instalaciones Kickstart
Esta sección describe cómo crear un origen de instalación para la imagen ISO de arranque utilizando la imagen ISO del DVD binario que contiene los repositorios y paquetes de software necesarios.
7.4.1. Tipos de fuente de instalación
Puede utilizar una de las siguientes fuentes de instalación para las imágenes de arranque mínimo:
- DVD: Grabe la imagen ISO del DVD binario en un DVD. El programa de instalación instalará automáticamente los paquetes de software desde el DVD.
Hard drive or USB drive: Copie la imagen ISO del DVD binario en la unidad y configure el programa de instalación para instalar los paquetes de software desde la unidad. Si utiliza una unidad USB, compruebe que está conectada al sistema antes de comenzar la instalación. El programa de instalación no puede detectar el soporte una vez iniciada la instalación.
-
Hard drive limitation: La imagen ISO del DVD binario en el disco duro debe estar en una partición con un sistema de archivos que el programa de instalación pueda montar. Los sistemas de archivos compatibles son
xfs,ext2,ext3,ext4yvfat (FAT32).
AvisoEn los sistemas Microsoft Windows, el sistema de archivos por defecto utilizado al formatear los discos duros es NTFS. También está disponible el sistema de archivos exFAT. Sin embargo, ninguno de estos sistemas de archivos puede montarse durante la instalación. Si está creando un disco duro o una unidad USB como fuente de instalación en Microsoft Windows, compruebe que ha formateado la unidad como FAT32. Tenga en cuenta que el sistema de archivos FAT32 no puede almacenar archivos de más de 4 GiB.
En Red Hat Enterprise Linux 8, puede habilitar la instalación desde un directorio en un disco duro local. Para hacerlo, necesita copiar el contenido de la imagen ISO del DVD a un directorio en un disco duro y luego especificar el directorio como la fuente de instalación en lugar de la imagen ISO. Por ejemplo
inst.repo=hd:<device>:<path to the directory>-
Hard drive limitation: La imagen ISO del DVD binario en el disco duro debe estar en una partición con un sistema de archivos que el programa de instalación pueda montar. Los sistemas de archivos compatibles son
Network location: Copie la imagen ISO del DVD binario o el árbol de instalación (contenido extraído de la imagen ISO del DVD binario) en una ubicación de red y realice la instalación a través de la red utilizando los siguientes protocolos:
- NFS: La imagen ISO del DVD binario está en un recurso compartido del sistema de archivos de red (NFS).
- HTTPS, HTTP or FTP: El árbol de instalación está en una ubicación de red que es accesible a través de HTTP, HTTPS o FTP.
7.4.2. Puertos para la instalación en red
La siguiente tabla enumera los puertos que deben estar abiertos en el servidor que proporciona los archivos para cada tipo de instalación basada en la red.
| Protocolo utilizado | Puertos a abrir |
|---|---|
| HTTP | 80 |
| HTTPS | 443 |
| FTP | 21 |
| NFS | 2049, 111, 20048 |
| TFTP | 69 |
Recursos adicionales
- Consulte el Securing networks documento para más información.
7.4.3. Creación de un origen de instalación en un servidor NFS
Siga los pasos de este procedimiento para colocar el origen de la instalación en un servidor NFS. Utilice este método de instalación para instalar varios sistemas desde un único origen, sin tener que conectarse a medios físicos.
Requisitos previos
- Usted tiene acceso de nivel de administrador a un servidor con Red Hat Enterprise Linux 8, y este servidor está en la misma red que el sistema a ser instalado.
- Ha descargado una imagen binaria de DVD. Consulte Descarga de la imagen ISO de instalación en el documento Performing a standard RHEL installation para obtener más información.
- Ha creado un CD, DVD o dispositivo USB de arranque a partir del archivo de imagen. Consulte Creación de medios de instalación desde el documento Performing a standard RHEL installation para obtener más información.
- Ha verificado que su cortafuegos permite que el sistema que está instalando acceda al origen de la instalación remota. Consulte Puertos para la instalación basada en la red del documento Performing a standard RHEL installation para obtener más información.
Procedimiento
Instale el paquete
nfs-utils:# yum install nfs-utils- Copie la imagen ISO del DVD binario en un directorio del servidor NFS.
Abra el archivo
/etc/exportscon un editor de texto y añada una línea con la siguiente sintaxis:/exported_directory/ clientsSustituya /exported_directory/ por la ruta completa del directorio con la imagen ISO. Sustituya clients por el nombre de host o la dirección IP del sistema de destino, la subred que todos los sistemas de destino pueden utilizar para acceder a la imagen ISO, o el signo de asterisco (
*) si desea permitir que cualquier sistema con acceso de red al servidor NFS utilice la imagen ISO. Consulte la página de manualexports(5)para obtener información detallada sobre el formato de este campo.Una configuración básica que hace que el directorio
/rhel8-install/esté disponible como de sólo lectura para todos los clientes es:/rhel8-install *-
Guarde el archivo
/etc/exportsy salga del editor de texto. Inicie el servicio nfs:
# systemctl start nfs-server.serviceSi el servicio se estaba ejecutando antes de cambiar el archivo
/etc/exports, ejecute el siguiente comando para el servidor NFS en ejecución para recargar su configuración:# systemctl reload nfs-server.serviceLa imagen ISO es ahora accesible a través de NFS y está lista para ser utilizada como fuente de instalación.
Cuando configure el origen de la instalación, utilice nfs: como protocolo, el nombre del servidor o la dirección IP, el signo de dos puntos (:), y el directorio que contiene la imagen ISO. Por ejemplo, si el nombre del servidor es myserver.example.com y ha guardado la imagen ISO en /rhel8-install/, especifique nfs:myserver.example.com:/rhel8-install/ como origen de la instalación.
7.4.4. Creación de un origen de instalación mediante HTTP o HTTPS
Siga los pasos de este procedimiento para crear un origen de instalación para una instalación basada en red utilizando un árbol de instalación, que es un directorio que contiene el contenido extraído de la imagen ISO del DVD binario y un archivo válido .treeinfo. Se accede al origen de instalación a través de HTTP o HTTPS.
Requisitos previos
- Usted tiene acceso de nivel de administrador a un servidor con Red Hat Enterprise Linux 8, y este servidor está en la misma red que el sistema a ser instalado.
- Ha descargado una imagen binaria de DVD. Consulte Descarga de la imagen ISO de instalación en el documento Performing a standard RHEL installation para obtener más información.
- Ha creado un CD, DVD o dispositivo USB de arranque a partir del archivo de imagen. Consulte Creación de medios de instalación desde el documento Performing a standard RHEL installation para obtener más información.
- Ha verificado que su cortafuegos permite que el sistema que está instalando acceda al origen de la instalación remota. Consulte Puertos para la instalación basada en la red del documento Performing a standard RHEL installation para obtener más información.
Procedimiento
Instale el paquete
httpd:# yum install httpdAvisoSi la configuración de su servidor web Apache habilita la seguridad SSL, verifique que habilita solo el protocolo TLSv1 y deshabilita SSLv2 y SSLv3. Esto se debe a la vulnerabilidad POODLE SSL (CVE-2014-3566). Consulte https://access.redhat.com/solutions/1232413 para obtener más detalles.
ImportanteSi utiliza un servidor HTTPS con un certificado autofirmado, debe arrancar el programa de instalación con la opción
noverifyssl.- Copie la imagen ISO del DVD binario en el servidor HTTP(S).
Monte la imagen ISO del DVD binario, utilizando el comando
mount, en un directorio adecuado:# mkdir /mnt/rhel8-install/ # mount -o loop,ro -t iso9660 /image_directory/image.iso /mnt/rhel8-install/Sustituya /image_directory/image.iso por la ruta de acceso a la imagen ISO del DVD binario.
Copiar los archivos de la imagen montada a la raíz del servidor HTTP(S). Este comando crea el directorio
/var/www/html/rhel8-install/con el contenido de la imagen.# cp -r /mnt/rhel8-install/ /var/www/html/Este comando crea el directorio
/var/www/html/rhel8-install/con el contenido de la imagen. Tenga en cuenta que algunos métodos de copia pueden omitir el archivo.treeinfo, que es necesario para un origen de instalación válido. Si se ejecuta el comandocppara directorios enteros como se muestra en este procedimiento, se copiará.treeinfocorrectamente.Inicie el servicio
httpd:# systemctl start httpd.serviceEl árbol de instalación está ahora accesible y listo para ser utilizado como fuente de instalación.
NotaCuando configure el origen de la instalación, utilice
http://ohttps://como protocolo, el nombre de host del servidor o la dirección IP, y el directorio que contiene los archivos de la imagen ISO, en relación con la raíz del servidor HTTP. Por ejemplo, si utiliza HTTP, el nombre del servidor esmyserver.example.comy ha copiado los archivos de la imagen en/var/www/html/rhel8-install/, especifiquehttp://myserver.example.com/rhel8-install/como origen de la instalación.
Recursos adicionales
- Para más información sobre los servidores HTTP, consulte el documento Deploying different types of servers documento.
7.4.5. Creación de un origen de instalación mediante FTP
Siga los pasos de este procedimiento para crear un origen de instalación para una instalación basada en red utilizando un árbol de instalación, que es un directorio que contiene el contenido extraído de la imagen ISO del DVD binario y un archivo válido .treeinfo. Se accede al origen de la instalación a través de FTP.
Requisitos previos
- Usted tiene acceso de nivel de administrador a un servidor con Red Hat Enterprise Linux 8, y este servidor está en la misma red que el sistema a ser instalado.
- Ha descargado una imagen binaria de DVD. Consulte Descarga de la imagen ISO de instalación en el documento Performing a standard RHEL installation para obtener más información.
- Ha creado un CD, DVD o dispositivo USB de arranque a partir del archivo de imagen. Consulte Creación de medios de instalación desde el documento Performing a standard RHEL installation para obtener más información.
- Ha verificado que su cortafuegos permite que el sistema que está instalando acceda al origen de la instalación remota. Consulte Puertos para la instalación basada en la red del documento Performing a standard RHEL installation para obtener más información.
Procedimiento
Instale el paquete
vsftpdejecutando el siguiente comando como root:# yum install vsftpdAbra y edite el archivo de configuración
/etc/vsftpd/vsftpd.confen un editor de texto.-
Cambie la línea
anonymous_enable=NOporanonymous_enable=YES -
Cambie la línea
write_enable=YESporwrite_enable=NO. Añadir líneas
pasv_min_port=min_portypasv_max_port=max_port. Sustituya min_port y max_port por el rango de números de puerto utilizado por el servidor FTP en modo pasivo, por ejemplo10021y10031.Este paso puede ser necesario en entornos de red con varias configuraciones de firewall/NAT.
Opcionalmente, añada cambios personalizados a su configuración. Para conocer las opciones disponibles, consulte la página de manual vsftpd.conf(5). Este procedimiento asume que se utilizan las opciones por defecto.
AvisoSi ha configurado la seguridad SSL/TLS en su archivo
vsftpd.conf, asegúrese de habilitar sólo el protocolo TLSv1 y de desactivar SSLv2 y SSLv3. Esto se debe a la vulnerabilidad POODLE SSL (CVE-2014-3566). Consulte https://access.redhat.com/solutions/1234773 para obtener más detalles.
-
Cambie la línea
Configurar el cortafuegos del servidor.
Activa el cortafuegos:
# systemctl enable firewalld # systemctl start firewalldHabilite en su firewall el puerto FTP y el rango de puertos del paso anterior:
# firewall-cmd --add-port min_port-max_port/tcp --permanent # firewall-cmd --add-service ftp --permanent # firewall-cmd --reloadSustituya min_port-max_port por los números de puerto que introdujo en el archivo de configuración
/etc/vsftpd/vsftpd.conf.
- Copie la imagen ISO del DVD binario en el servidor FTP.
Monte la imagen ISO del DVD binario, utilizando el comando mount, en un directorio adecuado:
# mkdir /mnt/rhel8-install # mount -o loop,ro -t iso9660 /image-directory/image.iso /mnt/rhel8-installSustituya /image-directory/image.iso por la ruta de acceso a la imagen ISO del DVD binario.
Copie los archivos de la imagen montada a la raíz del servidor FTP:
# mkdir /var/ftp/rhel8-install # cp -r /mnt/rhel8-install/ /var/ftp/Este comando crea el directorio
/var/ftp/rhel8-install/con el contenido de la imagen. Tenga en cuenta que algunos métodos de copia pueden omitir el archivo.treeinfo, que es necesario para un origen de instalación válido. Si se ejecuta el comandocppara directorios enteros como se muestra en este procedimiento, se copiará.treeinfocorrectamente.Asegúrese de que el contexto SELinux y el modo de acceso correctos están establecidos en el contenido copiado:
# restorecon -r /var/ftp/rhel8-install # find /var/ftp/rhel8-install -type f -exec chmod 444 {} \; # find /var/ftp/rhel8-install -type d -exec chmod 755 {} \;Inicie el servicio
vsftpd:# systemctl start vsftpd.serviceSi el servicio estaba en marcha antes de cambiar el archivo
/etc/vsftpd/vsftpd.conf, reinicie el servicio para cargar el archivo editado:# systemctl restart vsftpd.serviceHabilite el servicio
vsftpdpara que se inicie durante el proceso de arranque:# systemctl enable vsftpdEl árbol de instalación está ahora accesible y listo para ser utilizado como fuente de instalación.
NotaCuando configure el origen de la instalación, utilice
ftp://como protocolo, el nombre del servidor o la dirección IP y el directorio en el que ha almacenado los archivos de la imagen ISO, en relación con la raíz del servidor FTP. Por ejemplo, si el nombre del servidor esmyserver.example.comy ha copiado los archivos de la imagen en/var/ftp/rhel8-install/, especifiqueftp://myserver.example.com/rhel8-install/como origen de la instalación.
7.5. Iniciar las instalaciones de Kickstart
Puede iniciar las instalaciones de Kickstart de múltiples maneras:
- Manualmente, entrando en el menú de arranque del programa de instalación y especificando allí las opciones, incluido el archivo Kickstart.
- Automáticamente mediante la edición de las opciones de arranque en el arranque PXE.
- Automáticamente proporcionando el archivo en un volumen con nombre específico.
Aprenda a realizar cada uno de estos métodos en las siguientes secciones.
7.5.1. Iniciar una instalación Kickstart manualmente
Esta sección explica cómo iniciar una instalación Kickstart manualmente, lo que significa que se requiere cierta interacción del usuario (añadiendo opciones de arranque en el prompt boot: ). Utilice la opción de arranque inst.ks=location al arrancar el sistema de instalación, sustituyendo location por la ubicación de su archivo Kickstart. La forma exacta de especificar la opción de arranque depende de la arquitectura de su sistema.
Requisitos previos
- Tiene un archivo Kickstart listo en una ubicación accesible desde el sistema a instalar
Procedimiento
- Inicie el sistema utilizando un medio local (un CD, DVD o una unidad flash USB).
En el indicador de arranque, especifique las opciones de arranque necesarias.
-
Si el archivo Kickstart o un repositorio necesario se encuentra en una ubicación de red, es posible que tenga que configurar la red utilizando la opción
ip=. El instalador intenta configurar todos los dispositivos de red utilizando el protocolo DHCP por defecto sin esta opción. -
Añade la opción de arranque
inst.ks=y la ubicación del archivo Kickstart. -
Para acceder a una fuente de software desde la que se instalarán los paquetes necesarios, puede ser necesario añadir la opción
inst.repo=. Si no especifica esta opción, deberá especificar la fuente de instalación en el archivo Kickstart.
Para obtener información sobre la edición de las opciones de arranque, consulte Sección 8.4.2, “Edición de las opciones de arranque”.
-
Si el archivo Kickstart o un repositorio necesario se encuentra en una ubicación de red, es posible que tenga que configurar la red utilizando la opción
Inicie la instalación confirmando las opciones de arranque añadidas.
La instalación comienza ahora, utilizando las opciones especificadas en el archivo Kickstart. Si el archivo Kickstart es válido y contiene todos los comandos necesarios, la instalación es completamente automática a partir de este momento.
7.5.2. Iniciar una instalación Kickstart automáticamente mediante PXE
Los sistemas AMD64, Intel 64 y ARM de 64 bits y los servidores IBM Power Systems tienen la capacidad de arrancar utilizando un servidor PXE. Cuando se configura el servidor PXE, se puede añadir la opción de arranque en el archivo de configuración del cargador de arranque, que a su vez permite iniciar la instalación automáticamente. Usando este enfoque, es posible automatizar la instalación completamente, incluyendo el proceso de arranque.
Este procedimiento pretende ser una referencia general; los pasos detallados difieren en función de la arquitectura de su sistema, y no todas las opciones están disponibles en todas las arquitecturas (por ejemplo, no puede utilizar el arranque PXE en IBM Z).
Requisitos previos
- Debe tener un archivo Kickstart listo en una ubicación accesible desde el sistema a instalar.
- Debe tener un servidor PXE que pueda utilizarse para arrancar el sistema y comenzar la instalación.
Procedimiento
Abra el archivo de configuración del cargador de arranque de su servidor PXE y añada la opción de arranque
inst.ks=en la línea correspondiente. El nombre del archivo y su sintaxis dependen de la arquitectura y el hardware de su sistema:En los sistemas AMD64 e Intel 64 con BIOS, el nombre del archivo puede ser el predeterminado o el basado en la dirección IP de su sistema. En este caso, añada la opción
inst.ks=a la línea append en la entrada de instalación. Un ejemplo de línea append en el archivo de configuración es similar al siguiente:append initrd=initrd.img inst.ks=http://10.32.5.1/mnt/archive/RHEL-8/8.x/x86_64/kickstarts/ks.cfgEn los sistemas que utilizan el cargador de arranque GRUB2 (sistemas AMD64, Intel 64 y ARM de 64 bits con firmware UEFI y servidores IBM Power Systems), el nombre del archivo será
grub.cfg. En este archivo, añada la opcióninst.ks=a la línea del kernel en la entrada de instalación. Un ejemplo de línea del kernel en el archivo de configuración será similar al siguiente:kernel vmlinuz inst.ks=http://10.32.5.1/mnt/archive/RHEL-8/8.x/x86_64/kickstarts/ks.cfg
Inicie la instalación desde el servidor de red.
La instalación comienza ahora, utilizando las opciones de instalación especificadas en el archivo Kickstart. Si el archivo Kickstart es válido y contiene todos los comandos necesarios, la instalación es completamente automática.
7.5.3. Iniciar una instalación Kickstart automáticamente utilizando un volumen local
Puede iniciar una instalación Kickstart poniendo un archivo Kickstart con un nombre específico en un volumen de almacenamiento específicamente etiquetado.
Requisitos previos
-
Debe tener un volumen preparado con la etiqueta
OEMDRVy el archivo Kickstart presente en su raíz comoks.cfg. - Una unidad que contenga este volumen debe estar disponible en el sistema cuando se inicie el programa de instalación.
Procedimiento
- Inicie el sistema utilizando un medio local (un CD, DVD o una unidad flash USB).
En el indicador de arranque, especifique las opciones de arranque necesarias.
-
Si un repositorio necesario se encuentra en una ubicación de red, es posible que tenga que configurar la red utilizando la opción
ip=. El instalador intenta configurar todos los dispositivos de red utilizando el protocolo DHCP por defecto sin esta opción. -
Para acceder a una fuente de software desde la que se instalarán los paquetes necesarios, puede ser necesario añadir la opción
inst.repo=. Si no especifica esta opción, deberá especificar la fuente de instalación en el archivo Kickstart.
-
Si un repositorio necesario se encuentra en una ubicación de red, es posible que tenga que configurar la red utilizando la opción
Inicie la instalación confirmando las opciones de arranque añadidas.
La instalación comienza ahora, y el archivo Kickstart se detecta automáticamente y se utiliza para iniciar una instalación Kickstart automatizada.
7.6. Consolas y registro durante la instalación
El instalador de Red Hat Enterprise Linux utiliza el tmux para mostrar y controlar varias ventanas además de la interfaz principal. Cada una de estas ventanas tiene un propósito diferente; muestran varios registros diferentes, que pueden ser utilizados para solucionar problemas durante el proceso de instalación. Una de las ventanas proporciona un prompt de shell interactivo con privilegios root, a menos que este prompt haya sido específicamente desactivado usando una opción de arranque o un comando Kickstart.
En general, no hay razón para dejar el entorno gráfico de instalación por defecto a menos que necesite diagnosticar un problema de instalación.
El multiplexor de terminales se ejecuta en la consola virtual 1. Para pasar del entorno de instalación actual a tmuxpulse Ctrl+Alt+F1. Para volver a la interfaz de instalación principal que se ejecuta en la consola virtual 6, pulse Ctrl+Alt+F6.
Si elige la instalación en modo texto, comenzará en la consola virtual 1 (tmux), y al cambiar a la consola 6 se abrirá un prompt de shell en lugar de una interfaz gráfica.
La consola que se ejecuta tmux tiene cinco ventanas disponibles; su contenido se describe en la siguiente tabla, junto con los atajos de teclado. Tenga en cuenta que los atajos de teclado tienen dos partes: primero pulse Ctrl+b, luego suelte ambas teclas y pulse la tecla numérica de la ventana que desee utilizar.
También puede utilizar Ctrl+b n, Alt Tab y Ctrl+b p para pasar a la ventana siguiente o anterior tmux respectivamente.
| Atajo | Contenido |
|---|---|
| Ctrl+b 1 | Ventana principal del programa de instalación. Contiene indicaciones basadas en texto (durante la instalación en modo texto o si utiliza el modo directo VNC), y también alguna información de depuración. |
| Ctrl+b 2 |
Consigna de shell interactiva con privilegios de |
| Ctrl+b 3 |
Registro de la instalación; muestra los mensajes almacenados en |
| Ctrl+b 4 |
Registro de almacenamiento; muestra los mensajes relacionados con los dispositivos de almacenamiento y la configuración, almacenados en |
| Ctrl+b 5 |
Registro del programa; muestra los mensajes de las utilidades ejecutadas durante el proceso de instalación, almacenados en |
7.7. Mantenimiento de los archivos Kickstart
Puede realizar comprobaciones automáticas de los archivos Kickstart. Normalmente, querrá verificar que un archivo Kickstart nuevo o problemático es válido.
7.7.1. Instalación de las herramientas de mantenimiento Kickstart
Para utilizar las herramientas de mantenimiento Kickstart, debe instalar el paquete que las contiene.
Procedimiento
Instale el pykickstart paquete:
# yum install pykickstart
7.7.2. Verificación de un archivo Kickstart
Utilice la utilidad de línea de comandos ksvalidator para verificar que su archivo Kickstart es válido. Esto es útil cuando se hacen cambios extensos en un archivo Kickstart.
Procedimiento
Ejecute
ksvalidatoren su archivo Kickstart:$ ksvalidator /path/to/kickstart.ksSustituya /path/to/kickstart.ks por la ruta del archivo Kickstart que desea verificar.
La herramienta de validación no puede garantizar que la instalación se realice correctamente. Sólo asegura que la sintaxis es correcta y que el archivo no incluye opciones obsoletas. No intenta validar las secciones %pre, %post y %packages del archivo Kickstart.
Recursos adicionales
- La página del manual ksvalidator(1).
7.8. Registro e instalación de RHEL desde la CDN mediante Kickstart
Esta sección contiene información sobre cómo registrar su sistema, adjuntar suscripciones a RHEL e instalar desde la Red Hat Content Delivery Network (CDN) utilizando Kickstart.
7.8.1. Registro e instalación de RHEL desde la CDN
Utilice este procedimiento para registrar su sistema, adjuntar suscripciones a RHEL e instalar desde la Red Hat Content Delivery Network (CDN) utilizando el comando rhsm Kickstart, que soporta el comando syspurpose así como Red Hat Insights. El comando rhsm Kickstart elimina el requisito de utilizar scripts personalizados %post al registrar el sistema.
La función CDN es compatible con los archivos de imagen Boot ISO y Binary DVD ISO. Sin embargo, se recomienda utilizar el archivo de imagen Boot ISO, ya que el origen de la instalación es por defecto CDN para el archivo de imagen Boot ISO.
Requisitos previos
- Su sistema está conectado a una red que puede acceder a la CDN.
- Ha creado un archivo Kickstart y lo ha puesto a disposición del programa de instalación en un soporte extraíble, un disco duro o una ubicación de red mediante un servidor HTTP(S), FTP o NFS.
- El archivo Kickstart se encuentra en una ubicación accesible para el sistema que se va a instalar.
- Ha creado el medio de arranque utilizado para iniciar la instalación y ha puesto el origen de la instalación a disposición del programa de instalación.
- El repositorio de origen de la instalación utilizado tras el registro del sistema depende de cómo se haya arrancado el sistema. Para más información, consulte la sección Installation source repository after system registration del Performing a standard RHEL installation documento.
- La configuración de los repositorios no es necesaria en un archivo Kickstart ya que su suscripción gobierna el subconjunto de CDN y los repositorios a los que el sistema puede acceder.
Procedimiento
- Abra el archivo Kickstart.
Edite el archivo para añadir el comando
rhsmKickstart y sus opciones al archivo:- Organización (obligatoria)
Introduzca el identificador de la organización. Un ejemplo es:
--organization=1234567NotaPor razones de seguridad, los detalles de la cuenta de usuario y contraseña de Red Hat no son soportados por Kickstart cuando se registra e instala desde la CDN.
- Clave de activación (necesaria)
Introduzca la clave de activación. Puede introducir varias claves siempre que las claves de activación estén registradas en su suscripción. Un ejemplo es:
--activation-key="Test_key_1" --activation-key="Test_key_2"- Red Hat Insights (opcional)
Conecte el sistema de destino a Red Hat Insights.
NotaRed Hat Insights es una oferta de software como servicio (SaaS) que proporciona un análisis continuo y en profundidad de los sistemas registrados basados en Red Hat para identificar de forma proactiva las amenazas a la seguridad, el rendimiento y la estabilidad en entornos físicos, virtuales y de nube, así como en implementaciones de contenedores. A diferencia de la configuración de la GUI, la conexión a Red Hat Insights no está habilitada por defecto cuando se utiliza Kickstart.
Un ejemplo es:
--conexión a la información- Proxy HTTP (opcional)
Establezca el proxy HTTP. Un ejemplo es:
--proxy="usuario:contraseña@hostname:9000"NotaSólo el nombre de host es obligatorio. Si se requiere que el proxy se ejecute en un puerto por defecto sin autenticación, entonces la opción es
--proxy="hostname"- Nombre del servidor (opcional)
- Nota
El nombre del servidor no requiere el protocolo HTTP, por ejemplo,
nameofhost.com.Establezca el nombre del servidor si está ejecutando el Servidor Satélite o realizando pruebas internas. Un ejemplo es:
--nombredelservidor="nombredelalojamiento.com" - rhsm baseurl (opcional)
- Nota
La baseurl de rhsm requiere el protocolo HTTP.
Establezca la opción rhsm baseurl si está ejecutando el Servidor Satélite o realizando pruebas internas. Un ejemplo es:
--rhsm-baseurl="http://nameofhost.com" - Propósito del sistema (opcional)
Establezca el rol de Propósito del Sistema, el SLA y el uso utilizando el comando:
syspurpose --role="Red Hat Enterprise Linux Server" --sla="Premium" --usage="Producción"- Ejemplo
El siguiente ejemplo muestra un archivo Kickstart mínimo con todas las opciones del comando Kickstart de
rhsm.graphical lang en_US.UTF-8 keyboard us rootpw 12345 timezone America/New_York zerombr clearpart --all --initlabel autopart syspurpose --role="Red Hat Enterprise Linux Server" --sla="Premium" --usage="Production" rhsm --organization="12345" --activation-key="test_key" --connect-to-insights --server-hostname="nameofhost.com" --rhsm-baseurl="http://nameofhost.com" --proxy="user:password@hostname:9000" %packages vim %end
- Guarde el archivo Kickstart e inicie el proceso de instalación.
Recursos adicionales
- Para más información sobre el propósito del sistema, consulte la sección Configuring System Purpose de este documento.
- Para obtener más información sobre cómo iniciar una instalación Kickstart, consulte Starting Kickstart installations.
- Para obtener información sobre Red Hat Insights, consulte la página Red Hat Insights product documentation.
- Para obtener información sobre las claves de activación, consulte el Understanding Activation Keys capítulo del documento Using Red Hat Subscription Management.
- Para obtener información sobre cómo configurar un proxy HTTP para Subscription Manager, consulte el Using an HTTP proxy capítulo del documento Using and Configuring Red Hat Subscription Manager.
7.8.2. Verificar el registro de su sistema desde el CDN
Utilice este procedimiento para verificar que su sistema está registrado en el CDN.
Requisitos previos
- Ha completado el proceso de registro e instalación como se documenta en Sección 7.8.1, “Registro e instalación de RHEL desde la CDN”
- Ha iniciado la instalación de Kickstart como se documenta en Starting Kickstart installations.
- El sistema instalado se ha reiniciado y se ha abierto una ventana de terminal.
Procedimiento
Desde la ventana del terminal, inicie sesión como usuario de
rooty verifique el registro:# lista de gestores de suscripciónLa salida muestra los detalles de la suscripción adjunta, por ejemplo:
Installed Product Status Product Name: Red Hat Enterprise Linux for x86_64 Product ID: 486 Version: 8.2 Arch: x86_64 Status: Subscribed Status Details Starts: 11/4/2019 Ends: 11/4/2020Para ver un informe detallado, ejecute el comando
# subscription-manager list --consumed
7.8.3. Cómo anular el registro de su sistema en la CDN
Utilice este procedimiento para anular el registro de su sistema del CDN de Red Hat.
Requisitos previos
- Ha completado el proceso de registro e instalación como se documenta en Sección 7.8.1, “Registro e instalación de RHEL desde la CDN”.
- Ha iniciado la instalación de Kickstart como se documenta en Starting Kickstart installations.
- El sistema instalado se ha reiniciado y se ha abierto una ventana de terminal.
Procedimiento
Desde la ventana de la terminal, inicie sesión como usuario de
rooty anule el registro:# subscription-manager unregisterLa suscripción adjunta se da de baja del sistema y se elimina la conexión a la CDN.
7.9. Realización de una instalación remota de RHEL mediante VNC
Esta sección describe cómo realizar una instalación remota de RHEL utilizando Virtual Network Computing (VNC).
7.9.1. Resumen
La interfaz gráfica de usuario es el método recomendado para instalar RHEL cuando se arranca el sistema desde un CD, DVD o unidad flash USB, o desde una red utilizando PXE. Sin embargo, muchos sistemas empresariales, por ejemplo, IBM Power Systems e IBM Z, se encuentran en entornos de centros de datos remotos que se ejecutan de forma autónoma y no están conectados a una pantalla, teclado y ratón. Estos sistemas suelen denominarse headless systems y suelen controlarse a través de una conexión de red. El programa de instalación de RHEL incluye una instalación de Virtual Network Computing (VNC) que ejecuta la instalación gráfica en la máquina de destino, pero el control de la instalación gráfica es manejado por otro sistema en la red. El programa de instalación de RHEL ofrece dos modos de instalación VNC: Direct y Connect. Una vez establecida la conexión, los dos modos no difieren. El modo que seleccione depende de su entorno.
- Modo directo
- En el modo Directo, el programa de instalación de RHEL está configurado para iniciarse en el sistema de destino y esperar un visor VNC que esté instalado en otro sistema antes de proceder. Como parte de la instalación en modo directo, la dirección IP y el puerto se muestran en el sistema de destino. Puede utilizar el visor VNC para conectarse al sistema de destino de forma remota utilizando la dirección IP y el puerto, y completar la instalación gráfica.
- Modo de conexión
- En el modo de conexión, el visor VNC se inicia en un sistema remoto en el modo listening. El visor VNC espera una conexión entrante desde el sistema de destino en un puerto especificado. Cuando el programa de instalación de RHEL se inicia en el sistema de destino, el nombre de host del sistema y el número de puerto se proporcionan mediante una opción de arranque o un comando Kickstart. A continuación, el programa de instalación establece una conexión con el visor VNC de escucha utilizando el nombre de host del sistema y el número de puerto especificados. Para utilizar el modo de conexión, el sistema con el visor VNC de escucha debe ser capaz de aceptar conexiones de red entrantes.
7.9.2. Consideraciones
Tenga en cuenta los siguientes elementos cuando realice una instalación remota de RHEL utilizando VNC:
VNC client application: Se necesita una aplicación cliente VNC para realizar una instalación de VNC Direct y Connect. Las aplicaciones cliente VNC están disponibles en los repositorios de la mayoría de las distribuciones de Linux, y también hay aplicaciones cliente VNC gratuitas para otros sistemas operativos como Windows. Las siguientes aplicaciones cliente VNC están disponibles en RHEL:
-
tigervnces independiente de su entorno de escritorio y se instala como parte del paquetetigervnc. -
vinagreforma parte del entorno de escritorio GNOME y se instala como parte del paquetevinagre.
-
Un servidor VNC está incluido en el programa de instalación y no necesita ser instalado.
Network and firewall:
- Si el sistema de destino no tiene permitidas las conexiones de entrada por un cortafuegos, deberá utilizar el modo Conectar o desactivar el cortafuegos. Desactivar un cortafuegos puede tener implicaciones de seguridad.
- Si el sistema que está ejecutando el visor VNC no tiene permitidas las conexiones entrantes por un cortafuegos, entonces debe utilizar el modo directo, o desactivar el cortafuegos. Desactivar un cortafuegos puede tener implicaciones de seguridad. Consulte el documento Security hardening para obtener más información sobre la configuración del cortafuegos.
- Custom Boot Options: Debe especificar las opciones de arranque personalizadas para iniciar una instalación de VNC y las instrucciones de instalación pueden diferir dependiendo de la arquitectura de su sistema.
-
VNC in Kickstart installations: Puede utilizar comandos específicos de VNC en instalaciones Kickstart. Utilizando sólo el comando
vncse ejecuta una instalación de RHEL en modo Directo. Existen opciones adicionales para configurar una instalación en modo Connect. Para obtener más información sobre las instalaciones Kickstart, consulte Sección 7.1.1, “Qué son las instalaciones Kickstart”.
7.9.3. Realizar una instalación remota de RHEL en modo VNC Direct
Utilice este procedimiento para realizar una instalación remota de RHEL en modo VNC Direct. El modo directo espera que el visor VNC inicie una conexión con el sistema de destino que se está instalando con RHEL. En este procedimiento, el sistema con el visor VNC se denomina sistema remote. El programa de instalación de RHEL le pedirá que inicie la conexión desde el visor VNC del sistema remoto al sistema de destino.
Este procedimiento utiliza TigerVNC como visor VNC. Las instrucciones específicas para otros visores pueden diferir, pero los principios generales se aplican.
Requisitos previos
Como root, has instalado un visor VNC en un sistema remoto, por ejemplo:
# yum install tigervnc- Ha configurado un servidor de arranque en red y ha arrancado la instalación en el sistema de destino. Para obtener más información, consulte Sección 8.3.1, “Resumen de la instalación de la red”.
Procedimiento
-
Desde el menú de arranque de RHEL en el sistema de destino, pulse la tecla
Tabde su teclado para editar las opciones de arranque. Añade la opción
inst.vncal final de la línea de comandos.Si desea restringir el acceso de VNC al sistema que se está instalando, añada la opción de arranque
inst.vncpassword=PASSWORDal final de la línea de comandos. Sustituya PASSWORD por la contraseña que desee utilizar para la instalación. La contraseña VNC debe tener entre 6 y 8 caracteres.ImportanteUtilice una contraseña temporal para la opción
inst.vncpassword=. No debe ser una contraseña existente o de root.
- Pulse Enter para iniciar la instalación. El sistema de destino inicializa el programa de instalación e inicia los servicios necesarios. Cuando el sistema está listo, aparece un mensaje que proporciona la dirección IP y el número de puerto del sistema.
- Abra el visor VNC en el sistema remoto.
- Introduzca la dirección IP y el número de puerto en el campo VNC server.
- Haga clic en Connect.
- Introduzca la contraseña de VNC y haga clic en OK. Una nueva ventana se abre con la conexión VNC establecida, mostrando el menú de instalación de RHEL. Desde esta ventana, puede instalar RHEL en el sistema de destino utilizando la interfaz gráfica de usuario.
Recursos adicionales
- Para más información sobre cómo realizar una instalación de RHEL utilizando la interfaz gráfica de usuario, consulte la sección Installing RHEL using the Graphical User Interface del Performing a standard RHEL installation documento.
7.9.4. Realizar una instalación remota de RHEL en modo VNC Connect
Utilice este procedimiento para realizar una instalación remota de RHEL en modo VNC Connect. En el modo Connect, el sistema de destino que se está instalando con RHEL inicia una conexión con el visor VNC que está instalado en otro sistema. En este procedimiento, el sistema con el visor VNC se denomina sistema remote.
Este procedimiento utiliza TigerVNC como visor VNC. Las instrucciones específicas para otros visores pueden diferir, pero los principios generales se aplican.
Requisitos previos
Como root, has instalado un visor VNC en un sistema remoto, por ejemplo:
# yum install tigervnc- Ha configurado un servidor de arranque en red para iniciar la instalación en el sistema de destino. Para obtener más información, consulte Sección 8.3.1, “Resumen de la instalación de la red”.
- Ha configurado el sistema de destino para utilizar las opciones de arranque para una instalación de VNC Connect.
- Ha verificado que el sistema remoto con el visor VNC está configurado para aceptar una conexión entrante en el puerto requerido. La verificación depende de la configuración de su red y del sistema. Para más información, consulte los documentos Security hardening y Securing networks.
Procedimiento
Inicie el visor VNC en el sistema remoto en listening mode ejecutando el siguiente comando:
$ vncviewer -listen PORT- Sustituya PORT por el número de puerto utilizado para la conexión.
El terminal muestra un mensaje que indica que está esperando una conexión entrante desde el sistema de destino.
TigerVNC Viewer 64-bit v1.8.0 Built on: 2017-10-12 09:20 Copyright (C) 1999-2017 TigerVNC Team and many others (see README.txt) See http://www.tigervnc.org for information on TigerVNC. Thu Jun 27 11:30:57 2019 main: Listening on port 5500- Arrancar el sistema de destino desde la red.
-
Desde el menú de arranque de RHEL en el sistema de destino, pulse la tecla
Tabde su teclado para editar las opciones de arranque. -
Añade la opción
inst.vnc inst.vncconnect=HOST:PORTal final de la línea de comandos. - Sustituya HOST por la dirección IP del sistema remoto que está ejecutando el visor VNC de escucha, y PORT por el número de puerto en el que está escuchando el visor VNC.
- Pulse Enter para iniciar la instalación. El sistema inicializa el programa de instalación e inicia los servicios necesarios. Una vez finalizado el proceso de inicialización, el programa de instalación intenta conectarse a la dirección IP y al puerto proporcionados.
- Cuando la conexión tiene éxito, se abre una nueva ventana con la conexión VNC establecida, mostrando el menú de instalación de RHEL. Desde esta ventana, puede instalar RHEL en el sistema de destino utilizando la interfaz gráfica de usuario.
Recursos adicionales
- Para más información sobre cómo realizar una instalación de RHEL utilizando la interfaz gráfica de usuario, consulte la sección Installing RHEL using the Graphical User Interface del Performing a standard RHEL installation documento.
Capítulo 8. Opciones de configuración avanzadas
8.1. Configuración del propósito del sistema
El propósito del sistema se utiliza para registrar el uso previsto de un sistema Red Hat Enterprise Linux 8. La configuración del Propósito del Sistema permite que el servidor de asignación de derechos asigne automáticamente la suscripción más apropiada. Esta sección describe cómo configurar el Propósito del Sistema utilizando Kickstart.
Los beneficios incluyen:
- Información exhaustiva a nivel de sistema para los administradores de sistemas y las operaciones comerciales.
- Reducción de los gastos generales a la hora de determinar por qué se adquirió un sistema y su finalidad.
- Mejora de la experiencia del cliente en la conexión automática del Gestor de Suscripciones, así como la detección y conciliación automatizada del uso del sistema.
8.1.1. Resumen
Puede introducir los datos del Propósito del Sistema de una de las siguientes maneras:
- Durante la creación de la imagen
- Durante la instalación de la GUI, cuando se utiliza Connect to Red Hat para registrar el sistema y adjuntar la suscripción a Red Hat
- Durante una instalación de Kickstart cuando se utilizan scripts de automatización de Kickstart
- Tras la instalación mediante la herramienta de línea de comandos (CLI) syspurpose
Para registrar el propósito de su sistema, puede configurar los siguientes componentes de Propósito del sistema. Los valores seleccionados son utilizados por el servidor de asignación de derechos al registrarse para adjuntar la suscripción más adecuada para su sistema.
Role
- Servidor Red Hat Enterprise Linux
- Estación de trabajo Red Hat Enterprise Linux
- Nodo informático de Red Hat Enterprise Linux
Service Level Agreement
- Premium
- Estándar
- Autoayuda
Usage
- Producción
- Desarrollo/prueba
- Recuperación de catástrofes
Recursos adicionales
- Para más información sobre el Constructor de imágenes, consulte el Composing a customized RHEL system image documento.
- Para más información sobre Kickstart, consulte el Performing an advanced RHEL installation documento.
- Para más información sobre el Gestor de Suscripciones, consulte el Using and Configuring Red Hat Subscription Manager documento.
8.1.2. Configuración del propósito del sistema en un archivo Kickstart
Siga los pasos de este procedimiento para utilizar el comando syspurpose para configurar el propósito del sistema en un archivo de configuración de Kickstart.
Aunque se recomienda encarecidamente que configure el Propósito del Sistema, es una característica opcional del programa de instalación de Red Hat Enterprise Linux. Si desea habilitar System Purpose después de que la instalación se haya completado, puede hacerlo utilizando la herramienta de línea de comandos syspurpose.
Están disponibles las siguientes acciones:
- papel
Establecer el rol previsto del sistema. Esta acción utiliza el siguiente formato:
syspurpose --role=El rol asignado puede ser:
-
Red Hat Enterprise Linux Server -
Red Hat Enterprise Linux Workstation -
Red Hat Enterprise Linux Compute Node
-
- SLA
Establezca el SLA previsto del sistema. Esta acción utiliza el siguiente formato:
syspurpose --sla=La esclavitud asignada puede ser:
-
Premium -
Standard -
Self-Support
-
- uso
Establece el uso previsto del sistema. Esta acción utiliza el siguiente formato:
syspurpose --usage=El uso asignado puede ser:
-
Production -
Development/Test -
Disaster Recovery
-
8.2. Actualización de los controladores durante la instalación
Esta sección describe cómo completar una actualización de controladores durante el proceso de instalación de Red Hat Enterprise Linux.
Este es un paso opcional del proceso de instalación. Red Hat recomienda no realizar una actualización de controladores a menos que sea necesario.
8.2.1. Requisito previo
Usted ha sido notificado por Red Hat, su proveedor de hardware o un proveedor de terceros de confianza que se requiere una actualización de controladores durante la instalación de Red Hat Enterprise Linux.
8.2.2. Resumen
Red Hat Enterprise Linux es compatible con los controladores de muchos dispositivos de hardware, pero es posible que algunos controladores recién lanzados no sean compatibles. Una actualización de controladores sólo debería realizarse si un controlador no soportado impide que la instalación se complete. La actualización de los controladores durante la instalación normalmente sólo es necesaria para soportar una configuración particular. Por ejemplo, la instalación de controladores para una tarjeta adaptadora de almacenamiento que proporciona acceso a los dispositivos de almacenamiento de su sistema.
Los discos de actualización de controladores pueden desactivar los controladores del kernel conflictivos. En raras ocasiones, la descarga de un módulo del kernel puede provocar errores de instalación.
8.2.3. Tipos de actualización de controladores
Red Hat, su proveedor de hardware o un tercero de confianza proporciona la actualización de los controladores como un archivo de imagen ISO. Una vez que reciba el archivo de imagen ISO, elija el tipo de actualización del controlador.
Tipos de actualización de controladores
- Automático
-
El método de actualización de controladores recomendado; se conecta físicamente al sistema un dispositivo de almacenamiento (incluido un CD, DVD o unidad flash USB) con la etiqueta
OEMDRV. Si el dispositivo de almacenamientoOEMDRVestá presente cuando se inicia la instalación, se trata como un disco de actualización de controladores y el programa de instalación carga automáticamente sus controladores. - Asistido
-
El programa de instalación le pedirá que localice una actualización del controlador. Puede utilizar cualquier dispositivo de almacenamiento local con una etiqueta distinta de
OEMDRV. La opción de arranqueinst.ddse especifica al iniciar la instalación. Si utiliza esta opción sin ningún parámetro, el programa de instalación muestra todos los dispositivos de almacenamiento conectados al sistema y le pide que seleccione un dispositivo que contenga una actualización del controlador. - Manual
-
Especifique manualmente una ruta a una imagen de actualización de controladores o a un paquete RPM. Puede utilizar cualquier dispositivo de almacenamiento local con una etiqueta distinta de
OEMDRV, o una ubicación de red accesible desde el sistema de instalación. La opción de arranqueinst.dd=locationse especifica al iniciar la instalación, donde location es la ruta a un disco de actualización de controladores o una imagen ISO. Cuando se especifica esta opción, el programa de instalación intenta cargar cualquier actualización de controladores que se encuentre en la ubicación especificada. En el caso de las actualizaciones manuales de controladores, puede especificar dispositivos de almacenamiento locales o una ubicación de red (servidor HTTP, HTTPS o FTP).
-
Puede utilizar simultáneamente
inst.dd=locationyinst.dd, donde location es la ruta a un disco de actualización de controladores o una imagen ISO. En este caso, el programa de instalación intenta cargar cualquier actualización de controladores disponible desde la ubicación y también le pide que seleccione un dispositivo que contenga la actualización de controladores. -
Inicialice la red utilizando el
ip= optioncuando cargue una actualización de controladores desde una ubicación de red.
Limitaciones
En los sistemas UEFI con la tecnología Secure Boot activada, todos los controladores deben estar firmados con un certificado válido. Los controladores de Red Hat están firmados por una de las claves privadas de Red Hat y autenticados por su correspondiente clave pública en el kernel. Si carga controladores adicionales por separado, verifique que estén firmados.
8.2.4. Preparación de una actualización de controladores
Este procedimiento describe cómo preparar una actualización de controladores en un CD y DVD.
Requisitos previos
- Ha recibido la imagen ISO de actualización de controladores de Red Hat, de su proveedor de hardware o de un tercero de confianza.
- Ha grabado la imagen ISO de actualización del controlador en un CD o DVD.
Si sólo hay un archivo de imagen ISO que termina en .iso en el CD o DVD, el proceso de grabación no ha tenido éxito. Consulte la documentación del software de grabación de su sistema para obtener instrucciones sobre cómo grabar imágenes ISO en un CD o DVD.
Procedimiento
- Inserte el CD o DVD de actualización de controladores en la unidad de CD/DVD de su sistema y examínelo con la herramienta de gestión de archivos del sistema.
-
Compruebe que existe un único archivo
rhdd3.rhdd3es un archivo de firma que contiene la descripción del controlador y un directorio llamadorpms, que contiene los paquetes RPM con los controladores reales para varias arquitecturas.
8.2.5. Realizar una actualización automática de los controladores
Este procedimiento describe cómo realizar una actualización automática del controlador durante la instalación.
Requisitos previos
-
Ha colocado la imagen de actualización del controlador en una partición de disco estándar con una etiqueta
OEMDRVo ha grabado la imagen de actualización del controladorOEMDRVen un CD o DVD. El almacenamiento avanzado, como los volúmenes RAID o LVM, puede no ser accesible durante el proceso de actualización del controlador. -
Ha conectado un dispositivo de bloque con una etiqueta de volumen
OEMDRVa su sistema, o ha insertado el CD o DVD preparado en la unidad de CD/DVD de su sistema antes de iniciar el proceso de instalación.
Procedimiento
- Una vez completados los pasos previos, los controladores se cargan automáticamente cuando se inicia el programa de instalación y se instalan en el sistema durante el proceso de instalación.
8.2.6. Realización de una actualización de controladores asistida
Este procedimiento describe cómo realizar una actualización asistida del controlador durante la instalación.
Requisitos previos
Ha conectado un dispositivo de bloque sin etiqueta de volumen OEMDRV a su sistema y ha copiado la imagen de disco del controlador en este dispositivo, o ha preparado un CD o DVD de actualización del controlador y lo ha insertado en la unidad de CD/DVD de su sistema antes de iniciar el proceso de instalación.
Si ha grabado un archivo de imagen ISO en un CD o DVD pero no tiene la etiqueta de volumen OEMDRV, puede utilizar la opción inst.dd sin argumentos. El programa de instalación ofrece una opción para escanear y seleccionar los controladores del CD o DVD. En este caso, el programa de instalación no le pedirá que seleccione una imagen ISO de actualización de controladores. Otro escenario es utilizar el CD o DVD con la opción de arranque inst.dd=location; esto permite que el programa de instalación analice automáticamente el CD o DVD en busca de actualizaciones de controladores. Para obtener más información, consulte Sección 8.2.7, “Realizar una actualización manual de los controladores”.
Procedimiento
- En la ventana del menú de arranque, pulse la tecla Tab de su teclado para mostrar la línea de comandos de arranque.
-
Añada la opción de arranque
inst.dda la línea de comandos y pulse Enter para ejecutar el proceso de arranque. - En el menú, seleccione una partición de disco local o un dispositivo de CD o DVD. El programa de instalación busca archivos ISO o paquetes RPM de actualización de controladores.
Opcional: Seleccione el archivo ISO de actualización del controlador.
NotaEste paso no es necesario si el dispositivo o la partición seleccionados contienen paquetes RPM de actualización de controladores en lugar de un archivo de imagen ISO, por ejemplo, una unidad óptica que contiene un CD o DVD de actualización de controladores.
Seleccione los controladores necesarios.
- Utilice las teclas numéricas de su teclado para alternar la selección de controladores.
- Pulse c para instalar el controlador seleccionado. El controlador seleccionado se carga y se inicia el proceso de instalación.
8.2.7. Realizar una actualización manual de los controladores
Este procedimiento describe cómo realizar una actualización manual del controlador durante la instalación.
Requisitos previos
- Coloque el archivo de imagen ISO de actualización del controlador en una unidad flash USB o en un servidor web, y conéctelo a su ordenador.
Procedimiento
- En la ventana del menú de arranque, pulse la tecla Tab de su teclado para mostrar la línea de comandos de arranque.
-
Añada la opción de arranque
inst.dd=locationa la línea de comandos, donde ubicación es una ruta de acceso a la actualización del controlador. Normalmente, el archivo de imagen se encuentra en un servidor web, por ejemplo, http://server.example.com/dd.iso, o en una unidad flash USB, por ejemplo,/dev/sdb1. También es posible especificar un paquete RPM que contenga la actualización del controlador, por ejemplo, http://server.example.com/dd.rpm. - Pulse Enter para ejecutar el proceso de arranque. Los controladores disponibles en la ubicación especificada se cargan automáticamente y se inicia el proceso de instalación.
Recursos adicionales
-
Para más información sobre la opción de arranque
inst.dd, consulte el contenido de la opción de arranque inst.dd. - Para obtener más información sobre todas las opciones de arranque, consulte el contenido de las opciones de arranque anteriores.
8.2.8. Desactivar un controlador
Este procedimiento describe cómo desactivar un controlador que funciona mal.
Requisitos previos
- Ha iniciado el menú de arranque del programa de instalación.
Procedimiento
- Desde el menú de arranque, pulse la tecla Tab de su teclado para mostrar la línea de comandos de arranque.
-
Añade la opción de arranque
modprobe.blacklist=driver_namea la línea de comandos. Sustituya driver_name por el nombre del controlador o controladores que desee desactivar, por ejemplo:
modprobe.blacklist=ahciLos controladores desactivados mediante la opción de arranque
modprobe.blacklist=permanecen desactivados en el sistema instalado y aparecen en el archivo/etc/modprobe.d/anaconda-blacklist.conf.- Pulse Enter para ejecutar el proceso de arranque.
8.3. Preparación de la instalación desde la red mediante PXE
Esta sección describe cómo configurar TFTP y DHCP en un servidor PXE para permitir el arranque PXE y la instalación en red.
8.3.1. Resumen de la instalación de la red
Una instalación en red le permite instalar Red Hat Enterprise Linux en un sistema que tenga acceso a un servidor de instalación. Como mínimo, se requieren dos sistemas para una instalación en red:
PXE Server: Un sistema que ejecuta un servidor DHCP, un servidor TFTP y un servidor HTTP, HTTPS, FTP o NFS. Aunque cada servidor puede ejecutarse en un sistema físico diferente, los procedimientos de esta sección asumen que un único sistema está ejecutando todos los servidores.
Client: El sistema en el que está instalando Red Hat Enterprise Linux. Una vez que se inicia la instalación, el cliente consulta al servidor DHCP, recibe los archivos de arranque desde el servidor TFTP y descarga la imagen de instalación desde el servidor HTTP, HTTPS, FTP o NFS. A diferencia de otros métodos de instalación, el cliente no requiere ningún medio físico de arranque para que la instalación se inicie.
Para arrancar un cliente desde la red, configúrelo en BIOS/UEFI o en un menú de arranque rápido. En algunos equipos, la opción de arrancar desde la red puede estar desactivada o no estar disponible.
Los pasos del flujo de trabajo para preparar la instalación de Red Hat Enterprise Linux desde una red utilizando PXE son los siguientes:
Pasos
- Exporte la imagen ISO de instalación o el árbol de instalación a un servidor NFS, HTTPS, HTTP o FTP.
- Configure el servidor TFTP y el servidor DHCP, e inicie el servicio TFTP en el servidor PXE.
- Inicie el cliente y comience la instalación.
El gestor de arranque GRUB2 soporta un arranque en red desde HTTP además de un servidor TFTP. El envío de los ficheros de arranque, que son el kernel y el disco RAM inicial vmlinuz y initrd, a través de este protocolo puede ser lento y provocar fallos de tiempo de espera. Un servidor HTTP no conlleva este riesgo, pero se recomienda utilizar un servidor TFTP cuando se envíen los archivos de arranque.
Recursos adicionales
- Para exportar la imagen ISO de instalación a una ubicación de red, consulte Sección 7.4, “Creación de fuentes de instalación para instalaciones Kickstart” para obtener información.
- Para configurar el servidor TFTP y el servidor DHCP, e iniciar el servicio TFTP, consulte Sección 8.3.2, “Configuración de un servidor TFTP para clientes basados en BIOS”, Sección 8.3.3, “Configuración de un servidor TFTP para clientes basados en UEFI”, y Sección 8.3.4, “Configuración de un servidor de red para sistemas IBM Power” para obtener información.
- Red Hat Satellite puede automatizar la configuración de un servidor PXE. Para más información, consulte la documentación del producto Red Hat Satellite.
8.3.2. Configuración de un servidor TFTP para clientes basados en BIOS
Utilice este procedimiento para configurar un servidor TFTP y un servidor DHCP e iniciar el servicio TFTP en el servidor PXE para sistemas AMD e Intel de 64 bits basados en BIOS.
Todos los archivos de configuración de esta sección son ejemplos. Los detalles de la configuración varían y dependen de la arquitectura y los requisitos específicos.
Procedimiento
Como root, instale los siguientes paquetes. Si ya tiene un servidor DHCP configurado en su red, excluya los paquetes
dhcp-server:# yum install tftp-server dhcp-serverPermitir las conexiones entrantes a la
tftp serviceen el cortafuegos:# firewall-cmd --add-service=tftpNota-
Este comando permite el acceso temporal hasta el próximo reinicio del servidor. Para habilitar el acceso permanente, añada la opción
--permanental comando. - Dependiendo de la ubicación del archivo ISO de instalación, es posible que tenga que permitir las conexiones entrantes para HTTP u otros servicios.
-
Este comando permite el acceso temporal hasta el próximo reinicio del servidor. Para habilitar el acceso permanente, añada la opción
Configure su servidor DHCP para utilizar las imágenes de arranque empaquetadas con SYSLINUX como se muestra en el siguiente archivo de ejemplo
/etc/dhcp/dhcpd.conf. Tenga en cuenta que si ya tiene un servidor DHCP configurado, entonces realice este paso en el servidor DHCP.option space pxelinux; option pxelinux.magic code 208 = string; option pxelinux.configfile code 209 = text; option pxelinux.pathprefix code 210 = text; option pxelinux.reboottime code 211 = unsigned integer 32; option architecture-type code 93 = unsigned integer 16; subnet 10.0.0.0 netmask 255.255.255.0 { option routers 10.0.0.254; range 10.0.0.2 10.0.0.253; class "pxeclients" { match if substring (option vendor-class-identifier, 0, 9) = "PXEClient"; next-server 10.0.0.1; if option architecture-type = 00:07 { filename "uefi/shim.efi"; } else { filename "pxelinux/pxelinux.0"; } } }Acceda al archivo
pxelinux.0desde el paqueteSYSLINUXen el archivo de imagen ISO del DVD Binario, donde my_local_directory es el nombre del directorio que se crea:# mount -t iso9660 /ruta_de_la_imagen/nombre_de_la_imagen.iso /punto_de_montaje -o loop,ro# cp -pr /punto_de_montaje/BaseOS/Packages/syslinux-tftpboot-version-architecture.rpm /mi_directorio_local# umount /mount_pointExtrae el paquete:
# rpm2cpio syslinux-tftpboot-version-architecture.rpm | cpio -dimvCree un directorio
pxelinux/entftpboot/y copie todos los archivos del directorio en el directoriopxelinux/:# mkdir /var/lib/tftpboot/pxelinux# cp mi_directorio_local/tftpboot/* /var/lib/tftpboot/pxelinuxCree el directorio
pxelinux.cfg/en el directoriopxelinux/:# mkdir /var/lib/tftpboot/pxelinux/pxelinux.cfgAñada un archivo de configuración por defecto al directorio
pxelinux.cfg/como se muestra en el siguiente ejemplo:default vesamenu.c32 prompt 1 timeout 600 display boot.msg label linux menu label ^Install system menu default kernel images/RHEL-8.1/vmlinuz append initrd=images/RHEL-8.1/initrd.img ip=dhcp inst.repo=http://10.32.5.1/RHEL-8.1/x86_64/iso-contents-root/ label vesa menu label Install system with ^basic video driver kernel images/RHEL-8.1/vmlinuz append initrd=images/RHEL-8.1/initrd.img ip=dhcp inst.xdriver=vesa nomodeset inst.repo=http://10.32.5.1/RHEL-8.1/x86_64/iso-contents-root/ label rescue menu label ^Rescue installed system kernel images/RHEL-8.1/vmlinuz append initrd=images/RHEL-8.1/initrd.img rescue label local menu label Boot from ^local drive localboot 0xffffNota-
El programa de instalación no puede arrancar sin su imagen de ejecución. Utilice la opción de arranque
inst.stage2para especificar la ubicación de la imagen. Alternativamente, puede utilizar la opcióninst.repo=para especificar la imagen así como el origen de la instalación. -
La ubicación de origen de la instalación utilizada con
inst.repodebe contener un archivo.treeinfoválido. -
Cuando se selecciona el DVD de instalación de RHEL8 como fuente de instalación, el archivo
.treeinfoapunta a los repositorios de BaseOS y AppStream. Puede utilizar una única opcióninst.repopara cargar ambos repositorios.
-
El programa de instalación no puede arrancar sin su imagen de ejecución. Utilice la opción de arranque
Cree un subdirectorio para almacenar los archivos de imagen de arranque en el directorio
/var/lib/tftpboot/, y copie los archivos de imagen de arranque en el directorio. En este ejemplo, el directorio es/var/lib/tftpboot/pxelinux/images/RHEL-8.1/:# mkdir -p /var/lib/tftpboot/pxelinux/images/RHEL-8.1/ # cp /path_to_x86_64_images/pxeboot/{vmlinuz,initrd.img} /var/lib/tftpboot/pxelinux/images/RHEL-8.1/En el servidor DHCP, inicie y habilite el servicio
dhcpd. Si ha configurado un servidor DHCP en el host local, inicie y habilite el serviciodhcpden el host local.# systemctl start dhcpd # systemctl enable dhcpdInicie y active el servicio
tftp.socket:# systemctl start tftp.socket # systemctl enable tftp.socketEl servidor de arranque PXE está ahora listo para servir a los clientes PXE. Puede iniciar el cliente, que es el sistema en el que está instalando Red Hat Enterprise Linux, seleccione PXE Boot cuando se le pida que especifique una fuente de arranque y comience la instalación en red.
8.3.3. Configuración de un servidor TFTP para clientes basados en UEFI
Utilice este procedimiento para configurar un servidor TFTP y un servidor DHCP e iniciar el servicio TFTP en el servidor PXE para sistemas AMD64, Intel 64 y ARM de 64 bits basados en UEFI.
- Todos los archivos de configuración de esta sección son ejemplos. Los detalles de la configuración varían y dependen de la arquitectura y los requisitos específicos.
-
El arranque UEFI PXE de Red Hat Enterprise Linux 8 soporta un formato de archivo en minúsculas para un archivo de menú grub basado en MAC. Por ejemplo, el formato de archivo de dirección MAC para grub2 es
grub.cfg-01-aa-bb-cc-dd-ee-ff
Procedimiento
Como root, instale los siguientes paquetes. Si ya tiene un servidor DHCP configurado en su red, excluya los paquetes dhcp-server.
# yum install tftp-server dhcp-serverPermitir las conexiones entrantes a la
tftp serviceen el cortafuegos:# firewall-cmd --add-service=tftpNota-
Este comando permite el acceso temporal hasta el próximo reinicio del servidor. Para habilitar el acceso permanente, añada la opción
--permanental comando. - Dependiendo de la ubicación del archivo ISO de instalación, es posible que tenga que permitir las conexiones entrantes para HTTP u otros servicios.
-
Este comando permite el acceso temporal hasta el próximo reinicio del servidor. Para habilitar el acceso permanente, añada la opción
Configure su servidor DHCP para utilizar las imágenes de arranque empaquetadas con shim como se muestra en el siguiente archivo de ejemplo
/etc/dhcp/dhcpd.conf. Tenga en cuenta que si ya tiene un servidor DHCP configurado, entonces realice este paso en el servidor DHCP.option space pxelinux; option pxelinux.magic code 208 = string; option pxelinux.configfile code 209 = text; option pxelinux.pathprefix code 210 = text; option pxelinux.reboottime code 211 = unsigned integer 32; option architecture-type code 93 = unsigned integer 16; subnet 10.0.0.0 netmask 255.255.255.0 { option routers 10.0.0.254; range 10.0.0.2 10.0.0.253; class "pxeclients" { match if substring (option vendor-class-identifier, 0, 9) = "PXEClient"; next-server 10.0.0.1; if option architecture-type = 00:07 { filename "BOOTX64.efi"; } else { filename "pxelinux/pxelinux.0"; } } }Acceda al archivo
BOOTX64.efidel paqueteshim, y al archivogrubx64.efidel paquetegrub2-efien el archivo de imagen ISO del DVD Binario, donde my_local_directory es el nombre del directorio que se crea:# mount -t iso9660 /ruta_de_la_imagen/nombre_de_la_imagen.iso /punto_de_montaje -o loop,ro# cp -pr /punto_de_montaje/BaseOS/Packages/shim-version-architecture.rpm /mi_directorio_local# cp -pr /punto_de_montaje/BaseOS/Packages/grub2-efi-version-architecture.rpm /mi_directorio_local# umount /mount_pointExtrae los paquetes:
# rpm2cpio shim-version-architecture.rpm | cpio -dimv# rpm2cpio grub2-efi-version-architecture.rpm | cpio -dimvCopie las imágenes de arranque EFI de su directorio de arranque. Sustituye ARCH por shim o grub seguido de la arquitectura, por ejemplo,
grubx64.# cp mi_directorio_local/boot/efi/EFI/redhat/ARCH.efi /var/lib/tftpboot/uefi/# cp mi_directorio_local/boot/efi/EFI/redhat/ARCH.efi /var/lib/tftpboot/uefiAñada un archivo de configuración llamado
grub.cfgal directoriotftpboot/como se muestra en el siguiente ejemplo:set timeout=60 menuentry 'RHEL 8' { linuxefi images/RHEL-8.1/vmlinuz ip=dhcp inst.repo=http://10.32.5.1/RHEL-8.1/x86_64/iso-contents-root/ initrdefi images/RHEL-8.1/initrd.img }Nota-
El programa de instalación no puede arrancar sin su imagen de ejecución. Utilice la opción de arranque
inst.stage2para especificar la ubicación de la imagen. Alternativamente, puede utilizar la opcióninst.repo=para especificar la imagen así como el origen de la instalación. -
La ubicación de origen de la instalación utilizada con
inst.repodebe contener un archivo.treeinfoválido. -
Cuando se selecciona el DVD de instalación de RHEL8 como fuente de instalación, el archivo
.treeinfoapunta a los repositorios de BaseOS y AppStream. Puede utilizar una única opcióninst.repopara cargar ambos repositorios.
-
El programa de instalación no puede arrancar sin su imagen de ejecución. Utilice la opción de arranque
Cree un subdirectorio para almacenar los archivos de imagen de arranque en el directorio
/var/lib/tftpboot/, y copie los archivos de imagen de arranque en el directorio. En este ejemplo, el directorio es/var/lib/tftpboot/images/RHEL-8.1/:# mkdir -p /var/lib/tftpboot/images/RHEL-8.1/ # cp /path_to_x86_64_images/pxeboot/{vmlinuz,initrd.img} /var/lib/tftpboot/images/RHEL-8.1/En el servidor DHCP, inicie y habilite el servicio
dhcpd. Si ha configurado un servidor DHCP en el host local, inicie y habilite el serviciodhcpden el host local.# systemctl start dhcpd # systemctl enable dhcpdInicie y active el servicio
tftp.socket:# systemctl start tftp.socket # systemctl enable tftp.socketEl servidor de arranque PXE está ahora listo para servir a los clientes PXE. Puede iniciar el cliente, que es el sistema en el que está instalando Red Hat Enterprise Linux, seleccione PXE Boot cuando se le pida que especifique una fuente de arranque y comience la instalación en red.
Recursos adicionales
-
Para obtener más información sobre
shim, consulte la documentación de la versión anterior: Uso del programa Shim.
8.3.4. Configuración de un servidor de red para sistemas IBM Power
Utilice este procedimiento para configurar un servidor de arranque en red para sistemas IBM Power utilizando GRUB2.
Todos los archivos de configuración de esta sección son ejemplos. Los detalles de la configuración varían y dependen de la arquitectura y los requisitos específicos.
Procedimiento
Como root, instale los siguientes paquetes. Si ya tiene un servidor DHCP configurado en su red, excluya los paquetes dhcp-server.
# yum install tftp-server dhcp-serverPermitir las conexiones entrantes a la
tftp serviceen el cortafuegos:# firewall-cmd --add-service=tftpNota-
Este comando permite el acceso temporal hasta el próximo reinicio del servidor. Para habilitar el acceso permanente, añada la opción
--permanental comando. - Dependiendo de la ubicación del archivo ISO de instalación, es posible que tenga que permitir las conexiones entrantes para HTTP u otros servicios.
-
Este comando permite el acceso temporal hasta el próximo reinicio del servidor. Para habilitar el acceso permanente, añada la opción
Cree un directorio de arranque de red
GRUB2dentro de la raíz tftp:# grub2-mknetdir --net-directory=/var/lib/tftpboot Netboot directory for powerpc-ieee1275 created. Configure your DHCP server to point to /boot/grub2/powerpc-ieee1275/core.elfNotaLa salida del comando le informa del nombre del archivo que necesita ser configurado en su configuración DHCP, descrita en este procedimiento.
Si el servidor PXE se ejecuta en una máquina x86, el
grub2-ppc64-modulesdebe ser instalado antes de crear un directorio de arranque de redGRUB2dentro de la raíz tftp:# yum install grub2-ppc64-modules
Cree un archivo de configuración
GRUB2:/var/lib/tftpboot/boot/grub2/grub.cfgcomo se muestra en el siguiente ejemplo:set default=0 set timeout=5 echo -e "\nWelcome to the Red Hat Enterprise Linux 8 installer!\n\n" menuentry 'Red Hat Enterprise Linux 8' { linux grub2-ppc64/vmlinuz ro ip=dhcp inst.repo=http://10.32.5.1/RHEL-8.1/x86_64/iso-contents-root/ initrd grub2-ppc64/initrd.img }Nota-
El programa de instalación no puede arrancar sin su imagen de ejecución. Utilice la opción de arranque
inst.stage2para especificar la ubicación de la imagen. Alternativamente, puede utilizar la opcióninst.repo=para especificar la imagen así como el origen de la instalación. -
La ubicación de origen de la instalación utilizada con
inst.repodebe contener un archivo.treeinfoválido. -
Cuando se selecciona el DVD de instalación de RHEL8 como fuente de instalación, el archivo
.treeinfoapunta a los repositorios de BaseOS y AppStream. Puede utilizar una única opcióninst.repopara cargar ambos repositorios.
-
El programa de instalación no puede arrancar sin su imagen de ejecución. Utilice la opción de arranque
Monte la imagen ISO del DVD binario utilizando el comando:
# mount -t iso9660 /ruta_de_imagen/nombre_de_iso/ /punto_de_montaje -o loop,roCree un directorio y copie en él los archivos
initrd.imgyvmlinuzde la imagen ISO del DVD binario, por ejemplo:# cp /punto_de_montaje/ppc/ppc64/{initrd.img,vmlinuz} /var/lib/tftpboot/grub2-ppc64/Configure su servidor DHCP para utilizar las imágenes de arranque empaquetadas con
GRUB2como se muestra en el siguiente ejemplo. Tenga en cuenta que si ya tiene un servidor DHCP configurado, entonces realice este paso en el servidor DHCP.subnet 192.168.0.1 netmask 255.255.255.0 { allow bootp; option routers 192.168.0.5; group { #BOOTP POWER clients filename "boot/grub2/powerpc-ieee1275/core.elf"; host client1 { hardware ethernet 01:23:45:67:89:ab; fixed-address 192.168.0.112; } } }-
Ajuste los parámetros de ejemplo
subnet,netmask,routers,fixed-addressyhardware ethernetpara que se ajusten a su configuración de red. Tenga en cuenta el parámetrofile name; se trata del nombre del archivo que se obtuvo con el comandogrub2-mknetdiranteriormente en este procedimiento. En el servidor DHCP, inicie y habilite el servicio
dhcpd. Si ha configurado un servidor DHCP en el host local, inicie y habilite el serviciodhcpden el host local.# systemctl start dhcpd # systemctl enable dhcpdInicie y active el servicio
tftp.socket:# systemctl start tftp.socket # systemctl enable tftp.socketEl servidor de arranque PXE está ahora listo para servir a los clientes PXE. Puede iniciar el cliente, que es el sistema en el que está instalando Red Hat Enterprise Linux, seleccione PXE Boot cuando se le pida que especifique una fuente de arranque y comience la instalación en red.
8.4. Opciones de arranque
Esta sección contiene información sobre algunas de las opciones de arranque que puede utilizar para modificar el comportamiento por defecto del programa de instalación. Para obtener una lista completa de las opciones de arranque, consulte el contenido de las opciones de arranque de aguas arriba.
8.4.1. Tipos de opciones de arranque
Hay dos tipos de opciones de arranque: las que tienen el signo igual \ "=", y las que no tienen el signo igual \ "=". Las opciones de arranque se añaden a la línea de comandos de arranque y las opciones múltiples deben estar separadas por un solo espacio. Las opciones de arranque que son específicas del programa de instalación siempre comienzan con inst.
- Opciones con un signo de igualdad \ "="
-
Debe especificar un valor para las opciones de arranque que utilizan el símbolo
=. Por ejemplo, la opcióninst.vncpassword=debe contener un valor, en este caso, una contraseña. La sintaxis correcta para este ejemplo esinst.vncpassword=password. - Opciones sin signo de igualdad "="
-
Esta opción de arranque no acepta ningún valor o parámetro. Por ejemplo, la opción
rd.live.checkobliga al programa de instalación a verificar el medio de instalación antes de iniciar la instalación. Si esta opción de arranque está presente, se realiza la verificación; si la opción de arranque no está presente, se omite la verificación.
8.4.2. Edición de las opciones de arranque
Esta sección contiene información sobre las diferentes formas en que puede editar las opciones de arranque desde el menú de arranque. El menú de arranque se abre después de arrancar el medio de instalación.
Editar el indicador boot: en la BIOS
Cuando se utiliza el indicador boot:, la primera opción debe especificar siempre el archivo de imagen del programa de instalación que se desea cargar. En la mayoría de los casos, puede especificar la imagen utilizando la palabra clave. Puede especificar opciones adicionales según sus necesidades.
Requisitos previos
- Has creado un medio de instalación de arranque (USB, CD o DVD).
- Ha arrancado la instalación desde el medio, y el menú de arranque de la instalación está abierto.
Procedimiento
- Con el menú de arranque abierto, pulse la tecla Esc de su teclado.
-
Ahora se puede acceder a la página
boot:. - Pulse la tecla Tab del teclado para mostrar los comandos de ayuda.
-
Pulse la tecla Enter de su teclado para iniciar la instalación con sus opciones. Para volver de la indicación
boot:al menú de arranque, reinicie el sistema y vuelva a arrancar desde el medio de instalación.
El prompt boot: también acepta las opciones del kernel dracut. Una lista de opciones está disponible en la página man de dracut.cmdline(7).
Editar la indicación >
Puede utilizar el indicador > para editar las opciones de arranque predefinidas. Por ejemplo, seleccione Test this media and install Red Hat Enterprise Linux 8.1 en el menú de arranque para mostrar un conjunto completo de opciones.
Este procedimiento es para sistemas AMD64 e Intel 64 basados en BIOS.
Requisitos previos
- Has creado un medio de instalación de arranque (USB, CD o DVD).
- Ha arrancado la instalación desde el medio, y el menú de arranque de la instalación está abierto.
Procedimiento
-
En el menú de arranque, seleccione una opción y pulse la tecla Tab del teclado. El prompt
>es accesible y muestra las opciones disponibles. -
Añada las opciones que necesite a la consulta
>. - Pulse la tecla Enter de su teclado para iniciar la instalación.
- Pulse la tecla Esc de su teclado para cancelar la edición y volver al menú de arranque.
Editar el menú de GRUB2
El menú GRUB2 está disponible en sistemas AMD64, Intel 64 y ARM de 64 bits basados en UEFI.
Requisitos previos
- Has creado un medio de instalación de arranque (USB, CD o DVD).
- Ha arrancado la instalación desde el medio, y el menú de arranque de la instalación está abierto.
Procedimiento
- En la ventana del menú de arranque, seleccione la opción deseada y pulse la tecla e de su teclado.
-
Mueva el cursor a la línea de comandos del kernel. En los sistemas UEFI, la línea de comandos del kernel comienza con
linuxefi. -
Mueve el cursor al final de la línea de comandos del kernel
linuxefi. -
Edite los parámetros según sea necesario. Por ejemplo, para configurar una o más interfaces de red, añada el parámetro
ip=al final de la línea de comandos del kernellinuxefi, seguido del valor requerido. - Cuando termine de editar, pulse Ctrl X en su teclado para iniciar la instalación con las opciones especificadas.
8.4.3. Opciones de arranque de la fuente de instalación
Esta sección contiene información sobre las distintas opciones de arranque de la fuente de instalación.
- inst.repo=
La opción de arranque
inst.repo=especifica el origen de la instalación, es decir, la ubicación que proporciona los repositorios de paquetes y un archivo válido.treeinfoque los describe. Por ejemplo:inst.repo=cdrom. El destino de la opcióninst.repo=debe ser uno de los siguientes medios de instalación:-
un árbol instalable, que es una estructura de directorios que contiene las imágenes del programa de instalación, los paquetes y los datos del repositorio, así como un archivo válido
.treeinfo - un DVD (un disco físico presente en la unidad de DVD del sistema)
una imagen ISO del DVD de instalación completa de Red Hat Enterprise Linux, colocada en un disco duro o en una ubicación de red accesible al sistema.
Utilice la opción de arranque
inst.repo=para configurar diferentes métodos de instalación con distintos formatos. La siguiente tabla contiene detalles de la sintaxis de la opción de arranqueinst.repo=:Expand Tabla 8.1. inst.repo= fuente de instalación opciones de arranque Tipo de fuente Formato de la opción de arranque Formato de la fuente Unidad de CD/DVD
inst.repo=cdrom:<device>DVD de instalación como disco físico [a]
Árbol instalable
inst.repo=hd:<device>:/<path>Archivo de imagen del DVD de instalación, o un árbol de instalación, que es una copia completa de los directorios y archivos del DVD de instalación.
Servidor NFS
inst.repo=nfs:[options:]<server>:/<path>Archivo de imagen del DVD de instalación, o un árbol de instalación, que es una copia completa de los directorios y archivos del DVD de instalación [b]
Servidor HTTP
inst.repo=http://<host>/<path>Árbol de instalación, que es una copia completa de los directorios y archivos del DVD de instalación.
Servidor HTTPS
inst.repo=https://<host>/<path>Servidor FTP
inst.repo=ftp://<username>:<password>@<host>/<path>HMC
inst.repo=hmc[a] Si se omite device, el programa de instalación busca automáticamente una unidad que contenga el DVD de instalación.[b] La opción Servidor NFS utiliza por defecto la versión 3 del protocolo NFS. Para utilizar una versión diferente, añadanfsvers=Xa options, sustituyendo X por el número de versión que desee utilizar.Establezca los nombres de los dispositivos de disco con los siguientes formatos:
-
Nombre del dispositivo del núcleo, por ejemplo
/dev/sda1osdb2 -
Etiqueta del sistema de archivos, por ejemplo
LABEL=FlashoLABEL=RHEL8 UUID del sistema de archivos, por ejemplo
UUID=8176c7bf-04ff-403a-a832-9557f94e61dbLos caracteres no alfanuméricos deben representarse como
\xNN, donde NN es la representación hexadecimal del carácter. Por ejemplo,\x20es un espacio en blanco(" ").
-
un árbol instalable, que es una estructura de directorios que contiene las imágenes del programa de instalación, los paquetes y los datos del repositorio, así como un archivo válido
- inst.addrepo=
Utilice la opción de arranque
inst.addrepo=para añadir un repositorio adicional que pueda ser utilizado como otra fuente de instalación junto con el repositorio principal (inst.repo=). Puede utilizar la opción de arranqueinst.addrepo=varias veces durante un arranque. La siguiente tabla contiene detalles de la sintaxis de la opción de arranqueinst.addrepo=.NotaEl
REPO_NAMEes el nombre del repositorio y es necesario en el proceso de instalación. Estos repositorios sólo se utilizan durante el proceso de instalación; no se instalan en el sistema instalado.Expand Tabla 8.2. inst.addrepo fuente de instalación opciones de arranque Fuente de instalación Formato de la opción de arranque Información adicional Árbol instalable en una URL
inst.addrepo=REPO_NAME,[http,https,ftp]://<host>/<path>Busca el árbol instalable en una URL determinada.
Árbol instalable en una ruta NFS
inst.addrepo=REPO_NAME,nfs://<server>:/<path>Busca el árbol instalable en una ruta NFS dada. Se requieren dos puntos después del host. El programa de instalación pasa todo lo que hay después de
nfs://directamente al comando mount en lugar de analizar las URLs de acuerdo con el RFC 2224.Árbol instalable en el entorno de instalación
inst.addrepo=REPO_NAME,file://<path>Busca el árbol instalable en la ubicación dada en el entorno de instalación. Para utilizar esta opción, el repositorio debe estar montado antes de que el programa de instalación intente cargar los grupos de software disponibles. El beneficio de esta opción es que puede tener múltiples repositorios en una ISO de arranque, y puede instalar tanto el repositorio principal como los repositorios adicionales desde la ISO. La ruta de acceso a los repositorios adicionales es
/run/install/source/REPO_ISO_PATH. Adicionalmente, puede montar el directorio del repositorio en la sección%preen el archivo Kickstart. La ruta debe ser absoluta y comenzar con/, por ejemploinst.addrepo=REPO_NAME,file:///<path>Disco duro
inst.addrepo=REPO_NAME,hd:<device>:<path>Monta la partición dada <device> e instala desde la ISO que se especifica en <path>. Si no se especifica el <path>, el programa de instalación busca una ISO de instalación válida en el <device>. Este método de instalación requiere una ISO con un árbol instalable válido.
- inst.stage2=
Utilice la opción de arranque
inst.stage2=para especificar la ubicación de la imagen de ejecución del programa de instalación. Esta opción espera una ruta a un directorio que contenga un archivo.treeinfoválido. La ubicación de la imagen de ejecución se lee del archivo.treeinfo. Si el archivo.treeinfono está disponible, el programa de instalación intenta cargar la imagen desdeimages/install.img.Cuando no se especifica la opción
inst.stage2, el programa de instalación intenta utilizar la ubicación especificada con la opcióninst.repo.Utilice esta opción sólo cuando utilice el método de arranque PXE. El DVD de instalación y el Boot ISO ya contienen una opción correcta
inst.stage2para arrancar el programa de instalación desde ellos mismos.NotaPor defecto, la opción de arranque
inst.stage2=se utiliza en el medio de instalación y se establece en una etiqueta específica, por ejemplo,inst.stage2=hd:LABEL=RHEL-8-0-0-BaseOS-x86_64. Si modifica la etiqueta por defecto del sistema de archivos que contiene la imagen de ejecución, o si utiliza un procedimiento personalizado para arrancar el sistema de instalación, debe verificar que la opción de arranqueinst.stage2=esté configurada con el valor correcto.- inst.noverifyssl
Utilice la opción de arranque
inst.noverifysslpara evitar que el instalador verifique los certificados SSL para todas las conexiones HTTPS con la excepción de los repositorios adicionales de Kickstart, donde--noverifysslse puede establecer por repositorio.Por ejemplo, si el origen de la instalación remota utiliza certificados SSL autofirmados, la opción de arranque
inst.noverifysslpermite al instalador completar la instalación sin verificar los certificados SSL.Ejemplo cuando se especifica la fuente utilizando
inst.stage2=inst.stage2=https://hostname/path_to_install_image/ inst.noverifysslEjemplo cuando se especifica la fuente utilizando
inst.repo=inst.repo=https://hostname/path_to_install_repository/ inst.noverifyssl- inst.stage2.all
La opción de arranque
inst.stage2.allse utiliza para especificar varias fuentes HTTP, HTTPS o FTP. Puede utilizar la opción de arranqueinst.stage2=varias veces con la opcióninst.stage2.allpara obtener la imagen de las fuentes secuencialmente hasta que una tenga éxito. Por ejemplo:inst.stage2.all inst.stage2=http://hostname1/path_to_install_tree/ inst.stage2=http://hostname2/path_to_install_tree/ inst.stage2=http://hostname3/path_to_install_tree/- inst.dd=
-
La opción de arranque
inst.dd=se utiliza para realizar una actualización de los controladores durante la instalación. Para obtener más información sobre cómo actualizar los controladores durante la instalación, consulte el Performing an advanced RHEL installation documento. - inst.repo=hmc
-
Cuando se arranca desde un DVD binario, el programa de instalación le pide que introduzca parámetros adicionales del kernel. Para establecer el DVD como fuente de instalación, añada la opción
inst.repo=hmca los parámetros del kernel. El programa de instalación habilita entonces el acceso a los archivosSEyHMC, obtiene las imágenes para la etapa 2 desde el DVD y proporciona acceso a los paquetes del DVD para la selección del software. Esta opción elimina el requisito de una configuración de red externa y amplía las opciones de instalación. - inst.proxy=
La opción de arranque
inst.proxy=se utiliza cuando se realiza una instalación desde un protocolo HTTP, HTTPS y FTP. Por ejemplo:[PROTOCOLO://][NOMBRE DE USUARIO[:CONTRASEÑA]@]HOST[:PUERTO]- inst.nosave=
Utilice la opción de arranque
inst.nosave=para controlar los registros de instalación y los archivos relacionados que no se guardan en el sistema instalado, por ejemploinput_ks,output_ks,all_ks,logsyall. Se pueden combinar varios valores como una lista separada por comas, por ejemplo:input_ks,logs.NotaLa opción de arranque
inst.nosavese utiliza para excluir archivos del sistema instalado que no pueden ser eliminados por un script Kickstart %post, como los registros y los resultados de entrada/salida de Kickstart.Expand Tabla 8.3. inst.nosave opciones de arranque Opción Descripción input_ks
Desactiva la posibilidad de guardar los resultados del Kickstart de entrada.
output_ks
Desactiva la posibilidad de guardar los resultados de Kickstart generados por el programa de instalación.
todos_los_más
Desactiva la posibilidad de guardar los resultados de entrada y salida de Kickstart.
registros
Desactiva la posibilidad de guardar todos los registros de instalación.
todo
Desactiva la capacidad de guardar todos los resultados de Kickstart, y todos los registros.
- inst.multilib
-
Utilice la opción de arranque
inst.multilibpara establecer el DNFmultilib_policyen all, en lugar de best. - inst.memcheck
-
La opción de arranque
inst.memcheckrealiza una comprobación para verificar que el sistema tiene suficiente RAM para completar la instalación. Si no hay suficiente RAM, el proceso de instalación se detiene. La comprobación del sistema es aproximada y el uso de la memoria durante la instalación depende de la selección del paquete, de la interfaz de usuario, por ejemplo gráfica o de texto, y de otros parámetros. - inst.nomemcheck
-
La opción de arranque
inst.nomemcheckno realiza una comprobación para verificar si el sistema tiene suficiente memoria RAM para completar la instalación. Cualquier intento de realizar la instalación con una cantidad de memoria inferior a la mínima recomendada no es compatible y puede hacer que el proceso de instalación falle.
8.4.4. Opciones de arranque en red
Esta sección contiene información sobre las opciones de arranque en red más utilizadas.
La inicialización de la red es manejada por dracut. Para obtener una lista completa, consulte la página de manual dracut.cmdline(7).
- ip=
Utilice la opción de arranque
ip=para configurar una o más interfaces de red. Para configurar varias interfaces, puede utilizar la opciónipvarias veces, una para cada interfaz; para ello, debe utilizar la opciónrd.neednet=1, y debe especificar una interfaz de arranque principal utilizando la opciónbootdev. Alternativamente, puede usar la opciónipuna vez, y luego usar Kickstart para configurar más interfaces. Esta opción acepta varios formatos diferentes. Las siguientes tablas contienen información sobre las opciones más comunes.NotaEn las siguientes tablas:
-
El parámetro
ipespecifica la dirección IP del cliente y requiere corchetes, por ejemplo [2001:db8::99]. -
El parámetro
gatewayes la puerta de enlace por defecto. También se aceptan direcciones IPv6. -
El parámetro
netmaskes la máscara de red que se va a utilizar. Puede ser una máscara de red completa (por ejemplo, 255.255.255.0) o un prefijo (por ejemplo, 64). -
El parámetro
hostnamees el nombre del host del sistema cliente. Este parámetro es opcional.
Expand Tabla 8.4. Formatos de opciones de arranque de la configuración de la interfaz de red Método de configuración Formato de la opción de arranque Configuración automática de cualquier interfaz
ip=methodConfiguración automática de una interfaz específica
ip=interface:methodConfiguración estática
ip=ip::gateway:netmask:hostname:interface:noneConfiguración automática de una interfaz específica con una anulación
ip=ip::gateway:netmask:hostname:interface:method:mtuNotaEl método
automatic configuration of a specific interface with an overrideabre la interfaz utilizando el método de configuración automática especificado, comodhcp, pero anula la dirección IP, la puerta de enlace, la máscara de red, el nombre de host u otros parámetros especificados obtenidos automáticamente. Todos los parámetros son opcionales, así que especifique sólo los parámetros que desee anular.El parámetro
methodpuede ser cualquiera de los siguientes:Expand Tabla 8.5. Métodos de configuración automática de interfaces Método de configuración automática Valor DHCP
dhcpIPv6 DHCP
dhcp6Configuración automática de IPv6
auto6tabla de Firmware de Arranque iSCSI (iBFT)
ibftNota-
Si utiliza una opción de arranque que requiere acceso a la red, como
inst.ks=http://host/path, sin especificar la opción ip, el programa de instalación utilizaip=dhcp. -
Para conectarse a un objetivo iSCSI automáticamente, debe activar un dispositivo de red para acceder al objetivo. La forma recomendada de activar una red es utilizar la opción de arranque
ip=ibft.
-
El parámetro
- servidor de nombres=
La opción
nameserver=especifica la dirección del servidor de nombres. Puede utilizar esta opción varias veces.NotaEl parámetro
ip=requiere corchetes. Sin embargo, una dirección IPv6 no funciona con corchetes. Un ejemplo de la sintaxis correcta a utilizar para una dirección IPv6 esnameserver=2001:db8::1.- bootdev=
-
La opción
bootdev=especifica la interfaz de arranque. Esta opción es obligatoria si se utiliza más de una opciónip. - ifname=
La opción
ifname=asigna un nombre de interfaz a un dispositivo de red con una dirección MAC determinada. Puede utilizar esta opción varias veces. La sintaxis esifname=interface:MAC. Por ejemplo:ifname=eth0:01:23:45:67:89:abNotaLa opción
ifname=es la única forma admitida para establecer nombres de interfaz de red personalizados durante la instalación.- inst.dhcpclass=
-
La opción
inst.dhcpclass=especifica el identificador de clase de proveedor DHCP. El serviciodhcpdve este valor comovendor-class-identifier. El valor por defecto esanaconda-$(uname -srm). - inst.waitfornet=
-
El uso de la opción de arranque
inst.waitfornet=SECONDShace que el sistema de instalación espere la conectividad de la red antes de la instalación. El valor indicado en el argumentoSECONDSespecifica el tiempo máximo de espera para la conectividad de red antes de que se agote el tiempo y se continúe el proceso de instalación, incluso si la conectividad de red no está presente.
Recursos adicionales
- Para más información sobre la conexión en red, consulte el Configuring and managing networking documento.
8.4.5. Opciones de arranque de la consola
Esta sección contiene información sobre la configuración de las opciones de arranque para la consola, la pantalla del monitor y el teclado.
- consola=
-
Utilice la opción
console=para especificar un dispositivo que desee utilizar como consola principal. Por ejemplo, para utilizar una consola en el primer puerto serie, utiliceconsole=ttyS0. Utilice esta opción junto con la opcióninst.text. Puede utilizar la opciónconsole=varias veces. Si lo hace, el mensaje de arranque se muestra en todas las consolas especificadas, pero sólo la última es utilizada por el programa de instalación. Por ejemplo, si especificaconsole=ttyS0 console=ttyS1, el programa de instalación utilizattyS1. - inst.lang=
-
Utilice la opción
inst.lang=para establecer el idioma que desea utilizar durante la instalación. Los comandoslocale -a | grep _olocalectl list-locales | grep _devuelven una lista de locales. - inst.singlelang
-
Utilice la opción
inst.singlelangpara instalar en modo de idioma único, lo que hace que no haya opciones interactivas disponibles para el idioma de instalación y la configuración de soporte de idiomas. Si se especifica un idioma mediante la opción de arranqueinst.lango el comando Kickstartlang, se utilizará. Si no se especifica ningún idioma, el programa de instalación utiliza por defectoen_US.UTF-8. - inst.geoloc=
Utilice la opción
inst.geoloc=para configurar el uso de la geolocalización en el programa de instalación. La geolocalización se utiliza para preestablecer el idioma y la zona horaria, y utiliza la siguiente sintaxis:inst.geoloc=value. Elvaluepuede ser cualquiera de los siguientes parámetros:Expand Tabla 8.6. Valores para la opción de arranque inst.geoloc Valor Formato de la opción de arranque Desactivar la geolocalización
inst.geoloc=0Utilice la API GeoIP de Fedora
inst.geoloc=provider_fedora_geoipUtilice la API GeoIP de Hostip.info
inst.geoloc=provider_hostipSi no se especifica la opción
inst.geoloc=, el programa de instalación utilizaprovider_fedora_geoip.- inst.keymap=
-
Utilice la opción
inst.keymap=para especificar la distribución del teclado que desea utilizar para la instalación. - inst.cmdline
-
Utilice la opción
inst.cmdlinepara forzar que el programa de instalación se ejecute en modo de línea de comandos. Este modo no permite ninguna interacción, y debe especificar todas las opciones en un archivo Kickstart o en la línea de comandos. - inst.gráfica
-
Utilice la opción
inst.graphicalpara forzar que el programa de instalación se ejecute en modo gráfico. Este modo es el predeterminado. - texto.inst
-
Utilice la opción
inst.textpara forzar que el programa de instalación se ejecute en modo texto en lugar de en modo gráfico. - inst.nointeractivo
-
Utilice la opción de arranque
inst.noninteractivepara ejecutar el programa de instalación en modo no interactivo. No se permite la interacción del usuario en el modo no interactivo, yinst.noninteractivepuede utilizarse con una instalación gráfica o de texto. Cuando se utiliza la opcióninst.noninteractiveen modo texto se comporta igual que la opcióninst.cmdline. - inst.resolution=
-
Utilice la opción
inst.resolution=para especificar la resolución de la pantalla en modo gráfico. El formato esNxM, donde N es la anchura de la pantalla y M es la altura de la pantalla (en píxeles). La resolución más baja soportada es 1024x768. - inst.vnc
-
Utilice la opción
inst.vncpara ejecutar la instalación gráfica mediante VNC. Debe utilizar una aplicación cliente VNC para interactuar con el programa de instalación. Cuando el uso compartido de VNC está activado, pueden conectarse varios clientes. Un sistema instalado mediante VNC se inicia en modo texto. - inst.vncpassword=
-
Utilice la opción
inst.vncpassword=para establecer una contraseña en el servidor VNC que utiliza el programa de instalación. - inst.vncconnect=
-
Utilice la opción
inst.vncconnect=para conectarse a un cliente VNC a la escucha en la ubicación del host indicado. Por ejemploinst.vncconnect=<host>[:<port>]. El puerto por defecto es 5900. Esta opción puede utilizarse convncviewer -listen. - inst.xdriver=
-
Utilice la opción
inst.xdriver=para especificar el nombre del controlador X que desea utilizar tanto durante la instalación como en el sistema instalado. - inst.usefbx
-
Utilice la opción
inst.usefbxpara solicitar al programa de instalación que utilice el controlador X de la memoria intermedia en lugar de un controlador específico del hardware. Esta opción es equivalente ainst.xdriver=fbdev. - modprobe.blacklist=
Utilice la opción
modprobe.blacklist=para bloquear o desactivar completamente uno o varios controladores. Los controladores (mods) que deshabilite mediante esta opción no podrán cargarse cuando se inicie la instalación y, una vez finalizada ésta, el sistema instalado conservará esta configuración. Puede encontrar una lista de los controladores bloqueados en el directorio/etc/modprobe.d/. Utilice una lista separada por comas para desactivar varios controladores. Por ejemplo:modprobe.blacklist=ahci,firewire_ohci- inst.xtimeout=
-
Utilice la opción
inst.xtimeout=para especificar el tiempo de espera en segundos para iniciar el servidor X. - inst.sshd
Utilice la opción
inst.sshdpara iniciar el serviciosshddurante la instalación, de modo que pueda conectarse al sistema durante la instalación utilizando SSH, y supervisar el progreso de la instalación. Para más información sobre SSH, consulte la página manssh(1). Por defecto, la opciónsshdse inicia automáticamente sólo en la arquitectura IBM Z. En otras arquitecturas,sshdno se inicia a menos que se utilice la opcióninst.sshd.NotaDurante la instalación, la cuenta raíz no tiene contraseña por defecto. Puede establecer una contraseña de root durante la instalación con el comando
sshpwKickstart.- inst.kdump_addon=
-
Utilice la opción
inst.kdump_addon=para activar o desactivar la pantalla de configuración de Kdump (complemento) en el programa de instalación. Esta pantalla está activada por defecto; utiliceinst.kdump_addon=offpara desactivarla. Al deshabilitar el complemento se desactivan las pantallas de Kdump tanto en la interfaz gráfica como en la de texto, así como el comando Kickstart dedon com_redhat_kdump.
8.4.6. Opciones de arranque de depuración
Esta sección contiene información sobre las opciones que puede utilizar para depurar problemas.
- rescate.inst
-
Utilice la opción
inst.rescuepara ejecutar el entorno de rescate. Esta opción es útil para intentar diagnosticar y reparar sistemas. Por ejemplo, puede reparar un sistema de archivos en modo de rescate. - inst.updates=
Utilice la opción
inst.updates=para especificar la ubicación del archivoupdates.imgque desea aplicar durante la instalación. Hay varias fuentes para las actualizaciones.Expand Tabla 8.7. inst.updates= actualizaciones de la fuente Fuente Descripción Ejemplo Actualizaciones de una red
La forma más sencilla de utilizar
inst.updates=es especificar la ubicación en red deupdates.img. Esto no requiere ninguna modificación del árbol de instalación. Para utilizar este método, edite la línea de comandos del kernel para incluirinst.updates.inst.updates=http://some.website.com/path/to/updates.img.Actualizaciones desde una imagen de disco
Puede guardar un
updates.imgen una unidad de disquete o en una llave USB. Esto sólo puede hacerse con un sistema de archivos de tipoext2deupdates.img. Para guardar el contenido de la imagen en su disquetera, inserte el disquete y ejecute el comandodd if=updates.img of=/dev/fd0 bs=72k count=20. Para utilizar una llave USB o un soporte flash, sustituya/dev/fd0por el nombre del dispositivo de su llave USB.Actualizaciones de un árbol de instalación
Si está utilizando una instalación en CD, disco duro, HTTP o FTP, puede guardar el
updates.imgen el árbol de instalación para que todas las instalaciones puedan detectar el archivo .img. Guarde el archivo en el directorioimages/. El nombre del archivo debe serupdates.img.Para las instalaciones NFS, hay dos opciones: Puede guardar la imagen en el directorio
images/, o en el directorioRHupdates/del árbol de instalación.- inst.loglevel=
-
Utilice la opción
inst.loglevel=para especificar el nivel mínimo de mensajes registrados en un terminal. Esto sólo afecta al registro de la terminal; los archivos de registro siempre contienen mensajes de todos los niveles. Los valores posibles para esta opción, de menor a mayor nivel, sondebug,info,warning,errorycritical. El valor por defecto esinfo, lo que significa que, por defecto, la terminal de registro muestra mensajes que van desdeinfohastacritical. - inst.syslog=
-
Cuando se inicia la instalación, la opción
inst.syslog=envía mensajes de registro al procesosyslogen el host especificado. El proceso remotosyslogdebe estar configurado para aceptar conexiones entrantes. - inst.virtiolog=
-
Utilice la opción
inst.virtiolog=para especificar el puerto de virtio (un dispositivo de caracteres en/dev/virtio-ports/name) que desea utilizar para el reenvío de registros. El valor por defecto esorg.fedoraproject.anaconda.log.0; si este puerto está presente, se utiliza. - inst.zram=
-
La opción
inst.zram=controla el uso de zRAM swap durante la instalación. La opción crea un dispositivo de bloque comprimido dentro de la RAM del sistema y lo utiliza como espacio de intercambio en lugar del disco duro. Esto permite que el programa de instalación se ejecute con menos memoria disponible de la que es posible sin compresión, y también puede hacer que la instalación sea más rápida. Por defecto, el intercambio en zRAM está activado en sistemas con 2 GiB o menos de RAM, y desactivado en sistemas con más de 2 GiB de memoria. Puede utilizar esta opción para cambiar este comportamiento; en un sistema con más de 2 GiB de RAM, utiliceinst.zram=1para activar la función, y en sistemas con 2 GiB o menos de memoria, utiliceinst.zram=0para desactivar la función. - rd.live.ram
-
Si se especifica la opción
rd.live.ram, la imagenstage 2se copia en la memoria RAM. El uso de esta opción cuando la imagenstage 2está en un servidor NFS aumenta la memoria mínima requerida por el tamaño de la imagen en aproximadamente 500 MiB. - inst.nokill
-
La opción
inst.nokilles una opción de depuración que evita que el programa de instalación se reinicie cuando se produce un error fatal, o al final del proceso de instalación. Utilice la opcióninst.nokillpara capturar los registros de instalación que se perderían al reiniciar. - inst.noshell
-
Utilice la opción
inst.noshellsi no desea un shell en la sesión de terminal 2 (tty2) durante la instalación. - inst.notmux
-
Utilice la opción
inst.notmuxsi no desea utilizar tmux durante la instalación. La salida se genera sin caracteres de control del terminal y está pensada para usos no interactivos. - inst.remotelog=
-
Puede utilizar la opción
inst.remotelog=para enviar todos los registros a unhost:portremoto utilizando una conexión TCP. La conexión se retira si no hay ningún oyente y la instalación prosigue con normalidad.
8.4.7. Opciones de arranque del almacenamiento
- inst.nodmraid
-
Utilice la opción
inst.nodmraidpara desactivar el soporte dedmraid.
Utilice esta opción con precaución. Si tiene un disco que se identifica incorrectamente como parte de un conjunto RAID con firmware, es posible que tenga algunos metadatos RAID obsoletos que deben eliminarse con la herramienta adecuada, por ejemplo, dmraid o wipefs.
- inst.nompath
-
Utilice la opción
inst.nompathpara desactivar la compatibilidad con los dispositivos multirruta. Esta opción se puede utilizar para sistemas en los que se encuentra un falso positivo que identifica incorrectamente un dispositivo de bloque normal como un dispositivo multitrayecto. No hay ninguna otra razón para utilizar esta opción.
Utilice esta opción con precaución. No debe utilizar esta opción con hardware multitrayectoria. No se admite el uso de esta opción para intentar instalar en una sola ruta de una ruta múltiple.
- inst.gpt
-
La opción de arranque
inst.gptobliga al programa de instalación a instalar la información de las particiones en una tabla de particiones GUID (GPT) en lugar de un registro de arranque maestro (MBR). Esta opción no es válida en sistemas basados en UEFI, a menos que estén en modo de compatibilidad con BIOS. Normalmente, los sistemas basados en BIOS y los sistemas basados en UEFI en modo de compatibilidad con BIOS intentan utilizar el esquema MBR para almacenar la información de las particiones, a menos que el disco tenga un tamaño de 2^32 sectores o más. Los sectores del disco suelen tener un tamaño de 512 bytes, lo que significa que esto suele equivaler a 2 TiB. El uso de la opción de arranqueinst.gptcambia este comportamiento, permitiendo escribir una GPT en discos más pequeños.
8.4.8. Opciones de arranque de Kickstart
Esta sección contiene información sobre las opciones de arranque del Kickstart.
- inst.ks=
Utilice la opción de arranque
inst.ks=para definir la ubicación de un archivo Kickstart que desee utilizar para automatizar la instalación. A continuación, puede especificar las ubicaciones utilizando cualquiera de los formatos deinst.repo. Si especifica un dispositivo y no una ruta, el programa de instalación busca el archivo Kickstart en/ks.cfgen el dispositivo que especifique. Si utiliza esta opción sin especificar un dispositivo, el programa de instalación utiliza la siguiente opción:inst.ks=nfs:siguiente-servidor:/nombre-de-ficheroEn el ejemplo anterior, next-server es la opción de siguiente servidor DHCP o la dirección IP del propio servidor DHCP, y filename es la opción de nombre de archivo DHCP, o /kickstart/. Si el nombre de archivo dado termina con el carácter
/, se añadeip-kickstart. La siguiente tabla contiene un ejemplo.Expand Tabla 8.8. Ubicación del archivo Kickstart por defecto Dirección del servidor DHCP Dirección del cliente Ubicación del archivo Kickstart 192.168.122.1
192.168.122.100
192.168.122.1:/kickstart/192.168.122.100-kickstart
Si un volumen con una etiqueta de
OEMDRVestá presente, el programa de instalación intenta cargar un archivo Kickstart llamadoks.cfg. Si su archivo Kickstart se encuentra en esta ubicación, no es necesario utilizar la opción de arranqueinst.ks=.- inst.ks.all
-
Especifique esta opción para probar secuencialmente varias ubicaciones de archivos Kickstart proporcionadas por varias opciones de
inst.ks. Se utilizará la primera ubicación que tenga éxito. Esto se aplica sólo a las ubicaciones de tipohttp,httpsoftp, las demás ubicaciones se ignoran. - inst.ks.sendmac
Utilice la opción
inst.ks.sendmacpara añadir cabeceras a las peticiones HTTP salientes que contengan las direcciones MAC de todas las interfaces de red. Por ejemplo:X-RHN-Provisioning-MAC-0: eth0 01:23:45:67:89:abEsto puede ser útil cuando se utiliza
inst.ks=httppara aprovisionar sistemas.- inst.ks.sendsn
Utilice la opción
inst.ks.sendsnpara añadir una cabecera a las peticiones HTTP salientes. Esta cabecera contiene el número de serie del sistema, leído de/sys/class/dmi/id/product_serial. La cabecera tiene la siguiente sintaxis:Número de serie del sistema X: R8VA23D
Recursos adicionales
- Para obtener una lista completa de las opciones de arranque, consulte el contenido de las opciones de arranque de la corriente principal.
8.4.9. Opciones avanzadas de arranque de la instalación
Esta sección contiene información sobre las opciones avanzadas de arranque de la instalación.
- inst.kexec
La opción
inst.kexecpermite al programa de instalación utilizar la llamada al sistemakexecal final de la instalación, en lugar de realizar un reinicio. La opcióninst.kexeccarga el nuevo sistema inmediatamente, y omite la inicialización del hardware que normalmente realiza la BIOS o el firmware.ImportanteEsta opción está obsoleta y sólo está disponible como Technology Preview. Para obtener información sobre el alcance del soporte de Red Hat para las funciones de Technology Preview, consulte el documento Alcance del soporte de las funciones de Technology Preview.
Cuando se utiliza
kexec, los registros de los dispositivos que normalmente se borrarían durante un reinicio completo del sistema, podrían permanecer llenos de datos, lo que podría crear problemas para algunos controladores de dispositivos.- inst.multilib
Utilice la opción de arranque
inst.multilibpara configurar el sistema para paquetes multilib, es decir, para permitir la instalación de paquetes de 32 bits en un sistema AMD64 o Intel 64 de 64 bits. Normalmente, en un sistema AMD64 o Intel 64, sólo se instalan paquetes para esta arquitectura (marcados como x86_64) y paquetes para todas las arquitecturas (marcados como noarch). Cuando se utiliza la opción de arranqueinst.multilib, se instalan automáticamente los paquetes para sistemas AMD o Intel de 32 bits (marcados como i686).Esto se aplica sólo a los paquetes especificados directamente en la sección
%packages. Si un paquete se instala como dependencia, sólo se instala la dependencia exacta especificada. Por ejemplo, si se instala el paquetebashque depende del paqueteglibc, el primero se instala en múltiples variantes, mientras que el segundo se instala sólo en las variantes que requiere el paquete bash.- selinux=0
Por defecto, la opción de arranque
selinux=0funciona en modo permisivo en el programa de instalación, y en modo reforzado en el sistema instalado. La opción de arranqueselinux=0desactiva el uso de SELinux en el programa de instalación y en el sistema instalado.NotaLas opciones
selinux=0yinst.selinux=0no son lo mismo. La opciónselinux=0desactiva el uso de SELinux en el programa de instalación y en el sistema instalado. La opcióninst.selinux=0desactiva SELinux sólo en el programa de instalación. Por defecto, SELinux funciona en modo permisivo en el programa de instalación, por lo que desactivar SELinux tiene poco efecto.- inst.noibftiscsiboot
-
Utilice la opción de arranque
inst.nonibftiscsibootpara colocar el cargador de arranque en dispositivos iSCSI que no fueron configurados en la Tabla de Firmware de Arranque iSCSI (iBFT).
8.4.10. Opciones de arranque obsoletas
Esta sección contiene información sobre las opciones de arranque obsoletas. Estas opciones todavía son aceptadas por el programa de instalación pero están obsoletas y están programadas para ser eliminadas en una futura versión de Red Hat Enterprise Linux.
- método
-
La opción
methodes un alias deinst.repo. - dns
-
Utilice
nameserveren lugar dedns. Tenga en cuenta que nameserver no acepta listas separadas por comas; en su lugar, utilice varias opciones de nameserver. - máscara de red, puerta de enlace, nombre de host
-
Las opciones
netmask,gateway, yhostnamese proporcionan como parte de la opciónip. - ip=bootif
-
La opción
BOOTIFsuministrada por PXE se utiliza automáticamente, por lo que no es necesario utilizarip=bootif. - ksdevice
Expand Tabla 8.9. Valores para la opción de arranque ksdevice Valor Información No está presente
N/A
ksdevice=linkSe ignora ya que esta opción es la misma que el comportamiento por defecto
ksdevice=bootifSe ignora ya que esta opción es la predeterminada si
BOOTIF=está presenteksdevice=ibftSustituido por
ip=ibft. Véaseippara más detallesksdevice=<MAC>Sustituido por
BOOTIF=${MAC/:/-}ksdevice=<DEV>Sustituido por
bootdev
8.4.11. Eliminación de las opciones de arranque
Esta sección contiene las opciones de arranque que han sido eliminadas de Red Hat Enterprise Linux.
dracut proporciona opciones avanzadas de arranque. Para más información sobre dracut, consulte la página de manual dracut.cmdline(7).
- askmethod, asknetwork
-
initramfses completamente no interactivo, por lo que se han eliminado las opcionesaskmethodyasknetwork. En su lugar, utiliceinst.repoo especifique las opciones de red adecuadas. - lista negra, nofirewire
-
La opción
modprobese encarga de bloquear los módulos del kernel; utilicemodprobe.blacklist=<mod1>,<mod2>. Puede bloquear el módulo firewire utilizandomodprobe.blacklist=firewire_ohci. - inst.headless=
-
La opción
headless=especifica que el sistema en el que se está instalando no tiene ningún hardware de pantalla, y que el programa de instalación no está obligado a buscar ningún hardware de pantalla. - inst.decorado
-
La opción
inst.decoratedse utiliza para especificar la instalación gráfica en una ventana decorada. Por defecto, la ventana no está decorada, por lo que no tiene barra de título, controles de redimensionamiento, etc. Esta opción ya no es necesaria. - repo=nfsiso
-
Utilice la opción
inst.repo=nfs:. - serie
-
Utilice la opción
console=ttyS0. - actualiza
-
Utilice la opción
inst.updates. - essid, wepkey, wpakey
- Dracut no admite redes inalámbricas.
- ethtool
- Esta opción ya no era necesaria.
- gdb
-
Esta opción se ha eliminado ya que hay muchas opciones disponibles para depurar el sistema basado en dracut
initramfs. - inst.mediacheck
-
Utilice la opción
dracut option rd.live.check. - ks=floppy
-
Utilice la opción
inst.ks=hd:<device>. - mostrar
-
Para una visualización remota de la interfaz de usuario, utilice la opción
inst.vnc. - utf8
- Esta opción ya no era necesaria, ya que la configuración por defecto de TERM se comporta como se espera.
- noipv6
-
ipv6 está integrado en el kernel y no puede ser eliminado por el programa de instalación. Puede desactivar ipv6 utilizando
ipv6.disable=1. Esta configuración es utilizada por el sistema instalado. - actualizar cualquier
- Esta opción ya no era necesaria porque el programa de instalación ya no gestiona las actualizaciones.
Capítulo 9. Referencias de Kickstart
Apéndice G. Referencia del formato de archivo de los scripts Kickstart
Esta referencia describe en detalle el formato de archivo kickstart.
G.1. Formato de archivo Kickstart
Los scripts Kickstart son archivos de texto plano que contienen palabras clave reconocidas por el programa de instalación, que sirven como instrucciones para la instalación. Cualquier editor de texto capaz de guardar archivos como texto ASCII, como Gedit o vim en sistemas Linux o Notepad en sistemas Windows, puede utilizarse para crear y editar archivos Kickstart. El nombre del archivo de configuración de Kickstart no importa; sin embargo, se recomienda utilizar un nombre sencillo, ya que tendrá que especificar este nombre más adelante en otros archivos de configuración o diálogos.
- Comandos
- Los comandos son palabras clave que sirven como instrucciones para la instalación. Cada comando debe estar en una sola línea. Los comandos pueden tener opciones. La especificación de comandos y opciones es similar al uso de comandos de Linux en el shell.
- Secciones
-
Algunos comandos especiales que comienzan con el carácter
%inician una sección. La interpretación de los comandos en las secciones es diferente de los comandos colocados fuera de las secciones. Cada sección debe terminar con el comando%end. - Tipos de secciones
Las secciones disponibles son:
-
Add-on sections. Estas secciones utilizan el
don addon_namecomando. -
Package selection sections. Comienza con
%packages. Se utiliza para listar los paquetes a instalar, incluyendo medios indirectos como grupos de paquetes o módulos. -
Script sections. Estos comienzan con
%pre,%pre-install,%post, y%onerror. Estas secciones no son obligatorias.
-
Add-on sections. Estas secciones utilizan el
- Sección de mando
-
La sección de comandos es un término utilizado para los comandos del archivo Kickstart que no forman parte de ninguna sección de script o de
%packages. - Recuento y ordenación de las secciones de los guiones
-
Todas las secciones, excepto la sección de comandos, son opcionales y pueden estar presentes varias veces. Cuando se debe evaluar un tipo particular de sección de script, todas las secciones de ese tipo presentes en el Kickstart se evalúan en orden de aparición: dos secciones
%postse evalúan una tras otra, en el orden en que aparecen. Sin embargo, no es necesario especificar los distintos tipos de secciones de script en ningún orden: no importa si hay secciones%postantes de las secciones%pre.
- Comentarios
-
Los comentarios Kickstart son líneas que comienzan con el carácter hash
#. Estas líneas son ignoradas por el programa de instalación.
Los elementos que no son necesarios pueden ser omitidos. La omisión de cualquier elemento requerido hace que el programa de instalación cambie al modo interactivo para que el usuario pueda proporcionar una respuesta al elemento relacionado, al igual que durante una instalación interactiva normal. También es posible declarar el script kickstart como no interactivo con el comando cmdline. En el modo no interactivo, cualquier respuesta que falte aborta el proceso de instalación.
G.2. Selección de paquetes en Kickstart
Kickstart utiliza las secciones iniciadas por el comando %packages para seleccionar los paquetes a instalar. Puede instalar paquetes, grupos, entornos, flujos de módulos y perfiles de módulos de esta manera.
G.2.1. Sección de selección de paquetes
Utilice el comando %packages para comenzar una sección Kickstart que describa los paquetes de software que se van a instalar. La sección %packages debe terminar con el comando %end.
Puede especificar los paquetes por entorno, grupo, flujo de módulos, perfil de módulos o por sus nombres de paquetes. Se definen varios entornos y grupos que contienen paquetes relacionados. Consulte el archivo repository/repodata/*-comps-repository.architecture.xml en el DVD de instalación de Red Hat Enterprise Linux 8 para una lista de entornos y grupos.
El archivo *-comps-repository.architecture.xml contiene una estructura que describe los entornos disponibles (marcados por la etiqueta <environment> ) y los grupos (la etiqueta <group> ). Cada entrada tiene un ID, un valor de visibilidad del usuario, un nombre, una descripción y una lista de paquetes. Si se selecciona el grupo para su instalación, los paquetes marcados con mandatory en la lista de paquetes se instalan siempre, los paquetes marcados con default se instalan si no se excluyen específicamente en otra parte, y los paquetes marcados con optional deben incluirse específicamente en otra parte incluso cuando se selecciona el grupo.
Puede especificar un grupo de paquetes o un entorno utilizando su ID (la etiqueta <id> ) o su nombre (la etiqueta <name> ).
Si no está seguro de qué paquete debe instalarse, Red Hat le recomienda que seleccione el Minimal Install entorno Minimal Install proporciona sólo los paquetes que son esenciales para ejecutar Red Hat Enterprise Linux 8. Esto reducirá sustancialmente la posibilidad de que el sistema sea afectado por una vulnerabilidad. Si es necesario, se pueden añadir paquetes adicionales después de la instalación. Para más detalles sobre Minimal Installconsulte la sección Instalación de la cantidad mínima de paquetes necesarios del documento Security Hardening. Tenga en cuenta que Initial Setup no puede ejecutarse después de la instalación de un sistema desde un archivo Kickstart a menos que se haya incluido un entorno de escritorio y el sistema X Window en la instalación y se haya habilitado el inicio de sesión gráfico.
Para instalar un paquete de 32 bits en un sistema de 64 bits:
-
especificar la opción
--multilibpara la sección%packages -
añadir al nombre del paquete la arquitectura de 32 bits para la que se ha creado el paquete; por ejemplo,
glibc.i686
G.2.2. Comandos de selección de paquetes
Estos comandos se pueden utilizar dentro de la sección %packages de un archivo Kickstart.
- Especificar un entorno
Especifique un entorno completo para ser instalado como una línea que comienza con los símbolos
@^:%packages @^Infrastructure Server %endEsto instala todos los paquetes que forman parte del entorno
Infrastructure Server. Todos los entornos disponibles se describen en el archivorepository/repodata/*-comps-repository.architecture.xmldel DVD de instalación de Red Hat Enterprise Linux 8.Sólo debe especificarse un único entorno en el archivo Kickstart. Si se especifican más entornos, sólo se utiliza el último entorno especificado.
- Especificación de grupos
Especifique los grupos, una entrada por línea, comenzando con un símbolo
@, y luego el nombre completo del grupo o el identificador del grupo como se indica en el archivo*-comps-repository.architecture.xmlarchivo. Por ejemplo:%packages @X Window System @Desktop @Sound and Video %endEl grupo
Coreestá siempre seleccionado - no es necesario especificarlo en la sección%packages.- Especificación de paquetes individuales
Especifique los paquetes individuales por nombre, una entrada por línea. Puede utilizar el carácter asterisco (
*) como comodín en los nombres de los paquetes. Por ejemplo:%packages sqlite curl aspell docbook* %endLa entrada
docbook*incluye los paquetesdocbook-dtdsydocbook-styleque coinciden con el patrón representado con el comodín.- Especificación de los perfiles de los flujos de módulos
Especifique los perfiles para los flujos de módulos, una entrada por línea, utilizando la sintaxis de los perfiles:
%packages @module:stream/profile %endEsto instala todos los paquetes listados en el perfil especificado del flujo de módulos.
- Cuando un módulo tiene un flujo por defecto especificado, puede omitirlo. Cuando el flujo por defecto no está especificado, debes especificarlo.
- Cuando un flujo de módulos tiene un perfil por defecto especificado, puede omitirlo. Cuando el perfil por defecto no está especificado, debes especificarlo.
- No es posible instalar un módulo varias veces con diferentes flujos.
- Es posible instalar varios perfiles del mismo módulo y flujo.
Los módulos y los grupos utilizan la misma sintaxis que comienza con el símbolo
@. Cuando existe un módulo y un grupo de paquetes con el mismo nombre, el módulo tiene prioridad.En Red Hat Enterprise Linux 8, los módulos están presentes sólo en el repositorio AppStream. Para listar los módulos disponibles, utilice el comando
yum module listen un sistema Red Hat Enterprise Linux 8 instalado.También es posible habilitar flujos de módulos utilizando el comando
moduleKickstart y luego instalar los paquetes contenidos en el flujo de módulos nombrándolos directamente.- Excluir entornos, grupos o paquetes
Utilice un guión inicial (
-) para especificar los paquetes o grupos que desea excluir de la instalación. Por ejemplo:%packages -@Graphical Administration Tools -autofs -ipa*compat %end
No es posible instalar todos los paquetes disponibles utilizando sólo * en un archivo Kickstart.
Puede cambiar el comportamiento por defecto de la sección %packages utilizando varias opciones. Algunas opciones funcionan para toda la selección de paquetes, otras se utilizan sólo con grupos específicos.
Recursos adicionales
- Para más información sobre el manejo de paquetes, consulte el capítulo Instalación de software del documento Configuring basic system settings.
- Para más información sobre módulos y flujos, consulte el documento Instalación, gestión y eliminación de componentes del espacio de usuario.
G.2.3. Opciones comunes de selección de paquetes
Las siguientes opciones están disponibles para las secciones de %packages. Para utilizar una opción, añádala al principio de la sección de selección de paquetes. Por ejemplo:
%packages --multilib --ignoremissing--default- Instalar el conjunto de paquetes por defecto. Esto corresponde al conjunto de paquetes que se instalaría si no se hicieran otras selecciones en la Package Selection pantalla durante una instalación interactiva.
--excludedocs-
No instalar ninguna documentación contenida en los paquetes. En la mayoría de los casos, esto excluye cualquier archivo que normalmente se instala en el directorio
/usr/share/doc, pero los archivos específicos que se excluyen dependen de los paquetes individuales. --ignoremissing- Ignora los paquetes, grupos, flujos de módulos, perfiles de módulos y entornos que faltan en el origen de la instalación, en lugar de detener la instalación para preguntar si se debe abortar o continuar la instalación.
--instLangs=- Especifique una lista de idiomas a instalar. Tenga en cuenta que esto es diferente de las selecciones a nivel de grupo de paquetes. Esta opción no describe qué grupos de paquetes deben instalarse; en su lugar, establece macros RPM que controlan qué archivos de traducción de paquetes individuales deben instalarse.
--multilibConfigure el sistema instalado para paquetes multilib, para permitir la instalación de paquetes de 32 bits en un sistema de 64 bits, e instale los paquetes especificados en esta sección como tales.
Normalmente, en un sistema AMD64 e Intel 64, puede instalar sólo los paquetes x86_64 y noarch. Sin embargo, con la opción --multilib, puede instalar automáticamente los paquetes de 32 bits de AMD y los paquetes del sistema i686 de Intel disponibles, si los hay.
Esto sólo se aplica a los paquetes especificados explícitamente en la sección
%packages. Los paquetes que sólo se instalan como dependencias sin estar especificados en el archivo Kickstart sólo se instalan en las versiones de la arquitectura en la que se necesitan, incluso si están disponibles para más arquitecturas.El usuario puede configurar Anaconda para que instale los paquetes en modo
multilibdurante la instalación del sistema. Utilice una de las siguientes opciones para activar el modomultilib:Configure el archivo Kickstart con las siguientes líneas:
%packages --multilib --default %end- Añade la opción de arranque inst.multilib durante el arranque de la imagen de instalación.
--nocoreDesactiva la instalación del grupo de paquetes
@Coreque, de otro modo, siempre se instala por defecto. La desactivación del grupo de paquetes@Corecon--nocoresólo debe utilizarse para crear contenedores ligeros; la instalación de un sistema de escritorio o servidor con--nocoredará lugar a un sistema inutilizable.Notas-
El uso de
-@Corepara excluir los paquetes del grupo de paquetes@Coreno funciona. La única forma de excluir el grupo de paquetes@Corees con la opción--nocore. -
El grupo de paquetes
@Corese define como un conjunto mínimo de paquetes necesarios para instalar un sistema en funcionamiento. No está relacionado de ninguna manera con los paquetes principales, tal y como se definen en el Manifiesto de paquetes y en los Detalles del alcance de la cobertura.
-
El uso de
--excludeWeakdeps- Desactiva la instalación de paquetes de dependencias débiles. Se trata de paquetes vinculados al conjunto de paquetes seleccionados por las banderas Recommends y Supplements. Por defecto se instalarán las dependencias débiles.
--retries=- Establece el número de veces que Yum intentará descargar paquetes (reintentos). El valor por defecto es 10. Esta opción sólo se aplica durante la instalación, y no afectará a la configuración de Yum en el sistema instalado.
--timeout=- Establece el tiempo de espera de Yum en segundos. El valor por defecto es 30. Esta opción sólo se aplica durante la instalación, y no afectará a la configuración de Yum en el sistema instalado.
G.2.4. Opciones para grupos de paquetes específicos
Las opciones de esta lista sólo se aplican a un único grupo de paquetes. En lugar de utilizarlas en el comando %packages del archivo Kickstart, añádelas al nombre del grupo. Por ejemplo:
%packages
@Graphical Administration Tools --optional
%end--nodefaults- Instale sólo los paquetes obligatorios del grupo, no las selecciones por defecto.
--optionalInstala los paquetes marcados como opcionales en la definición del grupo en el archivo
*-comps-repository.architecture.xmlademás de instalar las selecciones por defecto.Tenga en cuenta que algunos grupos de paquetes, como
Scientific Support, no tienen ningún paquete obligatorio o por defecto especificado - sólo paquetes opcionales. En este caso se debe utilizar siempre la opción--optional, de lo contrario no se instalará ningún paquete de este grupo.
G.3. Scripts en el archivo Kickstart
Un archivo kickstart puede incluir los siguientes scripts:
- %pre
- Preinstalación
- %post
Esta sección proporciona los siguientes detalles sobre los guiones:
- Tiempo de ejecución
- Tipos de comandos que se pueden incluir en el script
- Objetivo del guión
- Opciones de guión
G.3.1. %pre script
Las secuencias de comandos de %pre se ejecutan en el sistema inmediatamente después de que se haya cargado el archivo Kickstart, pero antes de que se analice por completo y comience la instalación. Cada una de estas secciones debe comenzar con %pre y terminar con %end.
El script %pre puede utilizarse para la activación y configuración de los dispositivos de red y de almacenamiento. También es posible ejecutar scripts, utilizando los intérpretes disponibles en el entorno de instalación. Añadir un script %pre puede ser útil si tienes una red y un almacenamiento que necesitan una configuración especial antes de proceder a la instalación, o tienes un script que, por ejemplo, configura parámetros de registro o variables de entorno adicionales.
La depuración de problemas con los scripts de %pre puede ser difícil, por lo que se recomienda utilizar un script de %pre sólo cuando sea necesario.
Los comandos relacionados con la red, el almacenamiento y los sistemas de archivos están disponibles para su uso en el script %pre, además de la mayoría de las utilidades en los directorios del entorno de instalación /sbin y /bin.
Puede acceder a la red en la sección %pre. Sin embargo, el servicio de nombres no se ha configurado en este punto, por lo que sólo funcionan las direcciones IP, no las URL.
El pre script no se ejecuta en el entorno chroot.
G.3.1.1. Opciones de la sección de preescritura
Las siguientes opciones pueden utilizarse para cambiar el comportamiento de los scripts de preinstalación. Para utilizar una opción, añádala a la línea %pre al principio del script. Por ejemplo:
%pre --interpreter=/usr/libexec/platform-python
-- Python script omitted --
%end--interpreter=Permite especificar un lenguaje de scripting diferente, como Python. Se puede utilizar cualquier lenguaje de scripting disponible en el sistema; en la mayoría de los casos, son
/usr/bin/sh,/usr/bin/bash, y/usr/libexec/platform-python.Tenga en cuenta que el intérprete
platform-pythonutiliza la versión 3.6 de Python. Debes cambiar tus scripts de Python de versiones anteriores de RHEL para la nueva ruta y versión. Además,platform-pythonestá destinado a las herramientas del sistema: Utilice el paquetepython36fuera del entorno de instalación. Para más detalles sobre Python en Red Hat Enterprise Linux 8, vea Introducción a Python en Configuring basic system settings.--erroronfail- Muestra un error y detiene la instalación si el script falla. El mensaje de error le indicará dónde se registra la causa del fallo.
--log=Registra la salida del script en el archivo de registro especificado. Por ejemplo:
%pre --log=/tmp/ks-pre.log
G.3.2. %script de preinstalación
Los comandos de la secuencia de comandos pre-install se ejecutan después de completar las siguientes tareas:
- El sistema está dividido
- Los sistemas de archivos se crean y montan en /mnt/sysimage
- La red se ha configurado según las opciones de arranque y los comandos kickstart
Cada una de las secciones de %pre-install debe comenzar con %pre-install y terminar con %end.
Los scripts de %pre-install se pueden utilizar para modificar la instalación, y para añadir usuarios y grupos con IDs garantizados antes de la instalación del paquete.
Se recomienda utilizar los scripts %post para cualquier modificación requerida en la instalación. Utilice el script %pre-install sólo si el script %post se queda corto para las modificaciones requeridas.
Nota: El script The pre-install no se ejecuta en un entorno chroot.
G.3.2.1. Opciones de la sección de script de preinstalación
Las siguientes opciones pueden utilizarse para cambiar el comportamiento de los scripts de pre-install. Para utilizar una opción, añádala a la línea %pre-install al principio del script. Por ejemplo:
%pre-install --interpreter=/usr/libexec/platform-python
-- Python script omitted --
%end
Tenga en cuenta que puede tener varias secciones de %pre-install, con intérpretes iguales o diferentes. Se evalúan en su orden de aparición en el archivo Kickstart.
--interpreter=Permite especificar un lenguaje de scripting diferente, como Python. Se puede utilizar cualquier lenguaje de scripting disponible en el sistema; en la mayoría de los casos, son
/usr/bin/sh,/usr/bin/bash, y/usr/libexec/platform-python.Tenga en cuenta que el intérprete
platform-pythonutiliza la versión 3.6 de Python. Debes cambiar tus scripts de Python de versiones anteriores de RHEL para la nueva ruta y versión. Además,platform-pythonestá destinado a las herramientas del sistema: Utilice el paquetepython36fuera del entorno de instalación. Para más detalles sobre Python en Red Hat Enterprise Linux 8, vea Introducción a Python en Configuring basic system settings.--erroronfail- Muestra un error y detiene la instalación si el script falla. El mensaje de error le indicará dónde se registra la causa del fallo.
--log=Registra la salida del script en el archivo de registro especificado. Por ejemplo:
%pre-install --log=/mnt/sysimage/root/ks-pre.log
G.3.3. %post script
El script %post es un script de post-instalación que se ejecuta después de la instalación, pero antes de reiniciar el sistema por primera vez. Puede utilizar esta sección para ejecutar tareas como la suscripción del sistema.
Tiene la opción de añadir comandos para ejecutar en el sistema una vez que la instalación se haya completado, pero antes de que el sistema se reinicie por primera vez. Esta sección debe comenzar con %post y terminar con %end.
La sección %post es útil para funciones como la instalación de software adicional o la configuración de un servidor de nombres adicional. El script de post-instalación se ejecuta en un entorno chroot, por lo tanto, la realización de tareas como la copia de scripts o paquetes RPM desde el medio de instalación no funcionan por defecto. Puede cambiar este comportamiento utilizando la opción --nochroot como se describe a continuación. Entonces el script %post se ejecutará en el entorno de instalación, no en chroot en el sistema de destino instalado.
Debido a que el script de post-instalación se ejecuta en un entorno chroot, la mayoría de los comandos de systemctl se negarán a realizar cualquier acción. Para más información, consulte la sección Comportamiento de systemctl en un entorno chroot del documento Configuring and managing system administration.
Tenga en cuenta que durante la ejecución de la sección %post, el medio de instalación debe estar todavía insertado.
G.3.3.1. Opciones de la sección de post script
Las siguientes opciones pueden utilizarse para cambiar el comportamiento de los scripts de post-instalación. Para utilizar una opción, añádala a la línea %post al principio del script. Por ejemplo:
%post --interpreter=/usr/libexec/platform-python
-- Python script omitted --
%end--interpreter=Permite especificar un lenguaje de scripting diferente, como Python. Por ejemplo:
%post --interpretación=/usr/libexec/plataforma-pythonSe puede utilizar cualquier lenguaje de scripting disponible en el sistema; en la mayoría de los casos, se trata de
/usr/bin/sh,/usr/bin/bash, y/usr/libexec/platform-python.Tenga en cuenta que el intérprete
platform-pythonutiliza la versión 3.6 de Python. Debes cambiar tus scripts de Python de versiones anteriores de RHEL para la nueva ruta y versión. Además,platform-pythonestá destinado a las herramientas del sistema: Utilice el paquetepython36fuera del entorno de instalación. Para más detalles sobre Python en Red Hat Enterprise Linux 8, vea Introducción a Python en Configuring basic system settings.--nochrootLe permite especificar los comandos que desea ejecutar fuera del entorno chroot.
El siguiente ejemplo copia el archivo /etc/resolv.conf al sistema de archivos que se acaba de instalar.
%post --nochroot cp /etc/resolv.conf /mnt/sysimage/etc/resolv.conf %end--erroronfail- Muestra un error y detiene la instalación si el script falla. El mensaje de error le indicará dónde se registra la causa del fallo.
--log=Registra la salida del script en el archivo de registro especificado. Tenga en cuenta que la ruta del archivo de registro debe tener en cuenta si utiliza o no la opción
--nochroot. Por ejemplo, sin--nochroot:%post --log=/root/ks-post.logy con
--nochroot:%post --nochroot --log=/mnt/sysimage/root/ks-post.log
G.3.3.2. Ejemplo: Montaje de NFS en un script de post-instalación
Este ejemplo de una sección %post monta un recurso compartido NFS y ejecuta un script llamado runme ubicado en /usr/new-machines/ en el recurso compartido. Tenga en cuenta que el bloqueo de archivos NFS no está soportado mientras se está en modo Kickstart, por lo que se requiere la opción -o nolock.
# Start of the %post section with logging into /root/ks-post.log
%post --log=/root/ks-post.log
# Mount an NFS share
mkdir /mnt/temp
mount -o nolock 10.10.0.2:/usr/new-machines /mnt/temp
openvt -s -w -- /mnt/temp/runme
umount /mnt/temp
# End of the %post section
%endG.3.3.3. Ejemplo: Ejecución de subscription-manager como un script post-instalación
Uno de los usos más comunes de los scripts de post-instalación en las instalaciones de Kickstart es el registro automático del sistema instalado utilizando el Red Hat Subscription Manager. El siguiente es un ejemplo de suscripción automática en un script %post:
%post --log=/root/ks-post.log
subscription-manager register --username=admin@example.com --password=secret --auto-attach
%end
El script de línea de comandos subscription-manager registra un sistema en un servidor de gestión de suscripciones de Red Hat (Customer Portal Subscription Management, Satellite 6 o CloudForms System Engine). Este script también se puede utilizar para asignar o adjuntar suscripciones automáticamente al sistema que mejor se adapte a ese sistema. Cuando se registre en el Portal del Cliente, utilice las credenciales de inicio de sesión de Red Hat Network. Cuando se registre en Satellite 6 o CloudForms System Engine, también puede necesitar especificar más opciones del gestor de suscripciones como --serverurl, --org, --environment así como las credenciales proporcionadas por su administrador local. Tenga en cuenta que las credenciales en forma de combinación --org --activationkey es una buena manera de evitar exponer los valores de --username --password en los archivos de kickstart compartidos.
Se pueden utilizar opciones adicionales con el comando de registro para establecer un nivel de servicio preferido para el sistema y para restringir las actualizaciones y las erratas a una versión menor específica de RHEL para los clientes con suscripciones de Soporte de Actualización Extendido que necesitan permanecer fijos en una corriente más antigua.
Consulte también el artículo ¿Cómo utilizo subscription-manager en un archivo kickstart? en el Portal del Cliente de Red Hat para obtener información adicional sobre el uso de subscription-manager en una sección Kickstart %post.
G.4. Sección de configuración de Anaconda
Se pueden configurar opciones adicionales de instalación en la sección aconda de su archivo Kickstart. Esta sección controla el comportamiento de la interfaz de usuario del sistema de instalación.
Esta sección debe colocarse hacia el final del archivo Kickstart, después de los comandos Kickstart, y debe comenzar con aconda y terminar con %end.
Actualmente, el único comando que se puede utilizar en la sección aconda es pwpolicy.
Ejemplo G.1. Ejemplo de script aconda
A continuación se presenta un ejemplo de sección de aconda:
%anaconda
pwpolicy root --minlen=10 --strict
%end
Esta sección de ejemplo aconda establece una política de contraseñas que requiere que la contraseña de root tenga al menos 10 caracteres, y prohíbe estrictamente las contraseñas que no cumplan este requisito.
G.5. Sección de gestión de errores de Kickstart
A partir de Red Hat Enterprise Linux 7, las instalaciones Kickstart pueden contener scripts personalizados que se ejecutan cuando el programa de instalación encuentra un error fatal. Por ejemplo, un error en un paquete que ha sido solicitado para la instalación, un fallo en el inicio de VNC cuando se especifica, o un error al escanear dispositivos de almacenamiento. La instalación no puede continuar si se produce un error de este tipo. El programa de instalación ejecutará todas las secuencias de comandos de %onerror en el orden en que aparecen en el archivo Kickstart. Además, se ejecutarán los scripts de %onerror en caso de que se produzca un error de rastreo.
Cada script de %onerror debe terminar con %end.
Las secciones de manejo de errores aceptan las siguientes opciones:
--erroronfail- Muestra un error y detiene la instalación si el script falla. El mensaje de error le indicará dónde se registra la causa del fallo.
--interpreter=Permite especificar un lenguaje de scripting diferente, como Python. Por ejemplo:
%onerror --interpreter=/usr/libexec/platform-pythonSe puede utilizar cualquier lenguaje de scripting disponible en el sistema; en la mayoría de los casos, se trata de
/usr/bin/sh,/usr/bin/bash, y/usr/libexec/platform-python.Tenga en cuenta que el intérprete
platform-pythonutiliza la versión 3.6 de Python. Debes cambiar tus scripts de Python de versiones anteriores de RHEL para la nueva ruta y versión. Además,platform-pythonestá destinado a las herramientas del sistema: Utilice el paquetepython36fuera del entorno de instalación. Para más detalles sobre Python en Red Hat Enterprise Linux 8, vea Introducción a Python en Configuring basic system settings.--log=- Registra la salida del script en el archivo de registro especificado.
G.6. Secciones complementarias de Kickstart
A partir de Red Hat Enterprise Linux 7, las instalaciones de Kickstart soportan complementos. Estos complementos pueden ampliar la funcionalidad básica de Kickstart (y de Anaconda) de muchas maneras.
Para utilizar un complemento en su archivo Kickstart, utilice el comando don addon_name options y termine el comando con una declaración %end, similar a las secciones de script de preinstalación y postinstalación. Por ejemplo, si desea utilizar el complemento Kdump, que se distribuye con Anaconda por defecto, utilice los siguientes comandos:
%addon com_redhat_kdump --enable --reserve-mb=auto
%end
El comando don no incluye ninguna opción propia - todas las opciones dependen del complemento actual.
Apéndice H. Referencia de comandos y opciones de Kickstart
Esta referencia es una lista completa de todos los comandos Kickstart soportados por el programa de instalación de Red Hat Enterprise Linux. Los comandos están ordenados alfabéticamente en algunas categorías generales. Si un comando puede caer bajo múltiples categorías, se lista en todas ellas.
H.1. Cambios en la puesta en marcha
Las siguientes secciones describen los cambios en los comandos y opciones de Kickstart en Red Hat Enterprise Linux 8.
H.1.1. auth o authconfig está obsoleto en RHEL 8
El comando auth o authconfig Kickstart está obsoleto en Red Hat Enterprise Linux 8 porque la herramienta y el paquete authconfig han sido eliminados.
De forma similar a los comandos authconfig emitidos en la línea de comandos, los comandos authconfig en los scripts Kickstart utilizan ahora la herramienta authselect-compat para ejecutar la nueva herramienta authselect. Para una descripción de esta capa de compatibilidad y sus problemas conocidos, consulte la página del manual authselect-migration(7). El programa de instalación detectará automáticamente el uso de los comandos obsoletos e instalará en el sistema el paquete authselect-compat para proporcionar la capa de compatibilidad.
H.1.2. Kickstart ya no soporta Btrfs
El sistema de archivos Btrfs no está soportado en Red Hat Enterprise Linux 8. Como resultado, la interfaz gráfica de usuario (GUI) y los comandos Kickstart ya no soportan Btrfs.
H.1.3. Uso de archivos Kickstart de versiones anteriores de RHEL
Si está utilizando archivos Kickstart de versiones anteriores de RHEL, vea la sección Repositories del documento Considerations in adopting RHEL 8 para más información sobre los repositorios de Red Hat Enterprise Linux 8 BaseOS y AppStream.
H.1.4. Comandos y opciones de Kickstart obsoletos
Los siguientes comandos y opciones de Kickstart han quedado obsoletos en Red Hat Enterprise Linux 8.
En los casos en que sólo se enumeran opciones específicas, el comando base y sus otras opciones siguen estando disponibles y no están obsoletos.
-
authoauthconfig- utiliceauthselect instead -
device -
deviceprobe -
dmraid -
install- utilizar los subcomandos o métodos directamente como comandos -
multipath -
bootloader --upgrade -
ignoredisk --interactive -
partition --active -
reboot --kexec
Excepto el comando auth o authconfig, el uso de los comandos en los archivos Kickstart imprime una advertencia en los registros.
Puede convertir las advertencias de los comandos obsoletos en errores con la opción de arranque inst.ksstrict, excepto para el comando auth o authconfig.
H.1.5. Eliminados los comandos y opciones de Kickstart
Los siguientes comandos y opciones de Kickstart han sido completamente eliminados en Red Hat Enterprise Linux 8. Su uso en los archivos Kickstart causará un error.
-
upgrade(Este comando ya había quedado obsoleto) -
btrfs -
part/partition btrfs -
part --fstype btrfsopartition --fstype btrfs -
logvol --fstype btrfs -
raid --fstype btrfs -
unsupported_hardware
Cuando sólo se enumeran opciones y valores específicos, el comando base y sus otras opciones siguen estando disponibles y no se eliminan.
H.1.6. Nuevos comandos y opciones de Kickstart
Los siguientes comandos y opciones fueron añadidos en Red Hat Enterprise Linux 8.2.
RHEL 8.2
-
rhsm -
zipl
Los siguientes comandos y opciones fueron añadidos en Red Hat Enterprise Linux 8.
RHEL 8.0
-
authselect -
module
H.2. Comandos Kickstart para la configuración del programa de instalación y el control de flujo
Los comandos Kickstart de esta lista controlan el modo y el curso de la instalación, y lo que ocurre al final de la misma.
H.2.1. paso automático
El comando autostep Kickstart es opcional. Esta opción hace que el programa de instalación pase por cada pantalla, mostrando cada una brevemente. Normalmente, las instalaciones Kickstart se saltan las pantallas innecesarias.
Sintaxis
autostep [--autoscreenshot]Opciones
--autoscreenshot- Realiza una captura de pantalla en cada paso de la instalación. Estas capturas de pantalla se almacenan en/tmp/anaconda-screenshots/durante la instalación, y una vez finalizada ésta, se pueden encontrar en/root/anaconda-screenshots.Cada pantalla sólo se captura justo antes de que el programa de instalación pase a la siguiente. Esto es importante, porque si usted no utiliza todas las opciones requeridas de Kickstart y la instalación por lo tanto no comienza automáticamente, usted puede ir a las pantallas que no fueron configuradas automáticamente, realizar cualquier configuración que desee. Luego, cuando haga clic en Done para continuar, se captura la pantalla incluyendo la configuración que acaba de proporcionar.
Notas
- Esta opción no debe utilizarse al desplegar un sistema porque puede interrumpir la instalación de los paquetes.
H.2.2. cdrom
El comando cdrom Kickstart es opcional. Realiza la instalación desde la primera unidad óptica del sistema.
Sintaxis
cdromNotas
-
Anteriormente, el comando
cdromtenía que utilizarse junto con el comandoinstall. El comandoinstallha quedado obsoleto ycdrompuede utilizarse por sí solo, ya que implicainstall. - Este comando no tiene opciones.
-
Para ejecutar la instalación, debe especificarse una de las siguientes opciones:
cdrom,harddrive,hmc,nfs,liveimg, ourl.
H.2.3. cmdline
El comando cmdline Kickstart es opcional. Realiza la instalación en un modo de línea de comandos completamente no interactivo. Cualquier solicitud de interacción detiene la instalación.
Sintaxis
cmdlineNotas
-
Para una instalación totalmente automática, debe especificar uno de los modos disponibles (
graphical,text, ocmdline) en el archivo Kickstart, o debe utilizar la opción de arranqueconsole=. Si no se especifica ningún modo, el sistema utilizará el modo gráfico si es posible, o le pedirá que elija entre VNC y el modo de texto. - Este comando no tiene opciones.
- Este modo es útil en los sistemas IBM Z con el terminal x3270.
H.2.4. driverdisk
El comando driverdisk Kickstart es opcional. Utilícelo para proporcionar controladores adicionales al programa de instalación.
Los discos de controladores pueden utilizarse durante las instalaciones Kickstart para proporcionar controladores adicionales no incluidos por defecto. Debe copiar el contenido de los discos de controladores en el directorio raíz de una partición del disco duro del sistema. A continuación, debe utilizar el comando driverdisk para especificar que el programa de instalación debe buscar un disco de controladores y su ubicación.
Sintaxis
driverdisk [partition|--source=url|--biospart=biospart]Opciones
Debe especificar la ubicación del disco del controlador de una manera de estas:
-
partition - Partición que contiene el disco del controlador. Tenga en cuenta que la partición debe especificarse como una ruta completa (por ejemplo,
/dev/sdb1), not sólo el nombre de la partición (por ejemplo,sdb1). --source=- URL del disco del controlador. Los ejemplos incluyen:driverdisk --source=ftp://path/to/dd.img driverdisk --source=http://path/to/dd.img driverdisk --source=nfs:host:/path/to/dd.img-
--biospart=- Partición de la BIOS que contiene el disco del controlador (por ejemplo,82p2).
Notas
Los discos de controladores también pueden cargarse desde una unidad de disco duro o un dispositivo similar en lugar de cargarse a través de la red o desde initrd. Siga este procedimiento:
- Cargue el disco del controlador en una unidad de disco duro, un USB o cualquier dispositivo similar.
- Establezca la etiqueta, por ejemplo, DD, para este dispositivo.
Añade la siguiente línea a tu archivo Kickstart:
driverdisk LABEL=DD:/e1000.rpm
Sustituya DD por una etiqueta específica y sustituya dd.rpm por un nombre específico. Utilice cualquier cosa que admita el comando inst.repo en lugar de LABEL para especificar su unidad de disco duro.
H.2.5. eula
El comando eula Kickstart es opcional. Utilice esta opción para aceptar el Acuerdo de Licencia de Usuario Final (EULA) sin la interacción del usuario. Al especificar esta opción se evita que la configuración inicial le pida que acepte el acuerdo de licencia después de terminar la instalación y reiniciar el sistema por primera vez. Para más información, consulte la sección Cómo completar la configuración inicial del documento Performing a standard RHEL installation.
Sintaxis
eulaOpciones
-
--agreed(obligatorio) - Aceptar el EULA. Esta opción debe usarse siempre, de lo contrario el comandoeulano tiene sentido. - Este comando no tiene opciones.
H.2.6. firstboot
El comando firstboot Kickstart es opcional. Determina si la aplicación Initial Setup se inicia la primera vez que se arranca el sistema. Si se activa, el paquete initial-setup paquete debe estar instalado. Si no se especifica, esta opción está desactivada por defecto.
Sintaxis
firstboot OPTIONSOpciones
-
--enableo--enabled- La configuración inicial se inicia la primera vez que el sistema arranca. -
--disableo--disabled- La configuración inicial no se inicia la primera vez que el sistema arranca. -
--reconfig- Habilita la configuración inicial para que se inicie en el momento del arranque en modo de reconfiguración. Este modo habilita las opciones de configuración de idioma, ratón, teclado, contraseña de root, nivel de seguridad, zona horaria y red, además de las predeterminadas.
H.2.7. gráfico
El comando graphical Kickstart es opcional. Realiza la instalación en modo gráfico. Es la opción por defecto.
Sintaxis
graphical [--non-interactive]Opciones
-
--non-interactive- Realiza la instalación en un modo completamente no interactivo. Este modo terminará la instalación cuando se requiera la interacción del usuario.
Notas
-
Para una instalación totalmente automática, debe especificar uno de los modos disponibles (
graphical,text, ocmdline) en el archivo Kickstart, o debe utilizar la opción de arranqueconsole=. Si no se especifica ningún modo, el sistema utilizará el modo gráfico si es posible, o le pedirá que elija entre VNC y el modo de texto.
H.2.8. detener
El comando halt Kickstart es opcional.
Detener el sistema después de que la instalación se haya completado con éxito. Esto es similar a una instalación manual, donde Anaconda muestra un mensaje y espera a que el usuario pulse una tecla antes de reiniciar. Durante una instalación Kickstart, si no se especifica ningún método de finalización, esta opción se utiliza por defecto.
Sintaxis
haltNotas
-
El comando
haltes equivalente al comandoshutdown -H. Para más detalles, consulte la página de manual shutdown(8). -
Para otros métodos de finalización, consulte los comandos
poweroff,rebootyshutdown. - Este comando no tiene opciones.
H.2.9. disco duro
El comando harddrive Kickstart es opcional. Realiza la instalación desde un árbol de instalación de Red Hat o una imagen ISO de instalación completa en una unidad local. La unidad debe contener un sistema de archivos que el programa de instalación pueda montar: ext2 , ext3, ext4, vfat, o xfs.
Sintaxis
harddrive OPTIONSOpciones
-
--partition=- Partición desde la que se va a instalar (comosdb2). -
--dir=- Directorio que contiene elvariantdirectorio del árbol de instalación, o la imagen ISO del DVD de instalación completa.
Ejemplo
harddrive --partition=hdb2 --dir=/tmp/install-treeNotas
-
Anteriormente, el comando
harddrivetenía que utilizarse junto con el comandoinstall. El comandoinstallha quedado obsoleto yharddrivepuede utilizarse por sí solo, ya que implicainstall. -
Para ejecutar la instalación, debe especificarse una de las siguientes opciones:
cdrom,harddrive,hmc,nfs,liveimg, ourl.
H.2.10. instalar (obsoleto)
El comando install Kickstart está obsoleto en Red Hat Enterprise Linux 8. Utilice sus métodos como comandos separados.
El comando install Kickstart es opcional. Especifica el modo de instalación por defecto.
Sintaxis
install
installation_methodNotas
-
El comando
installdebe ir seguido de un comando de método de instalación. El comando del método de instalación debe estar en una línea separada. Los métodos incluyen:
-
cdrom -
harddrive -
hmc -
nfs -
liveimg -
url
Para más detalles sobre los métodos, consulte las páginas de referencia correspondientes.
-
H.2.11. liveimg
El comando liveimg Kickstart es opcional. Realiza la instalación desde una imagen de disco en lugar de paquetes.
Sintaxis
liveimg--url=SOURCE [OPTIONS]Opciones obligatorias
-
--url=- La ubicación desde la que se va a instalar. Los protocolos soportados sonHTTP,HTTPS,FTP, yfile.
Opciones opcionales
-
--url=- La ubicación desde la que se va a instalar. Los protocolos soportados sonHTTP,HTTPS,FTP, yfile. -
--proxy=- Especifica un proxyHTTP,HTTPSoFTPque se utilizará al realizar la instalación. -
--checksum=- Un argumento opcional con la suma de comprobaciónSHA256del archivo de imagen, utilizado para la verificación. -
--noverifyssl- Desactivar la verificación SSL al conectarse a un servidorHTTPS.
Ejemplo
liveimg --url=file:///images/install/squashfs.img --checksum=03825f567f17705100de3308a20354b4d81ac9d8bed4bb4692b2381045e56197 --noverifysslNotas
-
La imagen puede ser el archivo
squashfs.imgde una imagen ISO en vivo, un archivo tar comprimido (.tar,.tbz,.tgz,.txz,.tar.bz2,.tar.gz, o.tar.xz.), o cualquier sistema de archivos que el medio de instalación pueda montar. Los sistemas de archivos compatibles sonext2,ext3,ext4,vfatyxfs. -
Cuando se utiliza el modo de instalación
liveimgcon un disco de controladores, los controladores del disco no se incluirán automáticamente en el sistema instalado. Si es necesario, estos controladores deben instalarse manualmente, o en la sección%postde un script kickstart. -
Anteriormente, el comando
liveimgtenía que utilizarse junto con el comandoinstall. El comandoinstallha quedado obsoleto yliveimgpuede utilizarse por sí solo, ya que implicainstall. -
Para ejecutar la instalación, debe especificarse una de las siguientes opciones:
cdrom,harddrive,hmc,nfs,liveimg, ourl.
H.2.12. registro
El comando logging Kickstart es opcional. Controla el registro de errores de Anaconda durante la instalación. No tiene ningún efecto sobre el sistema instalado.
El registro sólo es compatible con TCP. Para el registro remoto, asegúrese de que el número de puerto que especifica en la opción --port= está abierto en el servidor remoto. El puerto por defecto es el 514.
Sintaxis
logging OPTIONSOpciones opcionales
-
--host=- Envía información de registro al host remoto indicado, que debe estar ejecutando un proceso syslogd configurado para aceptar el registro remoto. -
--port=- Si el proceso remoto de syslogd utiliza un puerto distinto al predeterminado, establézcalo mediante esta opción. -
--level=- Especifica el nivel mínimo de mensajes que aparecen en tty3. Sin embargo, todos los mensajes se envían al archivo de registro independientemente de este nivel. Los valores posibles sondebug,info,warning,error, ocritical.
H.2.13. mediacheck
El comando mediacheck Kickstart es opcional. Este comando obliga al programa de instalación a realizar una comprobación de medios antes de iniciar la instalación. Este comando requiere que las instalaciones sean atendidas, por lo que está desactivado por defecto.
Sintaxis
mediacheckNotas
-
Este comando Kickstart es equivalente a la opción de arranque
rd.live.check. - Este comando no tiene opciones.
H.2.14. nfs
El comando nfs Kickstart es opcional. Realiza la instalación desde un servidor NFS especificado.
Sintaxis
nfs OPTIONSOpciones
-
--server=- Servidor desde el que instalar (nombre de host o IP). -
--dir=- Directorio que contiene elvariantdirectorio del árbol de instalación. -
--opts=- Opciones de montaje a utilizar para montar la exportación NFS. (opcional)
Ejemplo
nfs --server=nfsserver.example.com --dir=/tmp/install-treeNotas
-
Anteriormente, el comando
nfstenía que utilizarse junto con el comandoinstall. El comandoinstallha quedado obsoleto ynfspuede utilizarse por sí solo, ya que implicainstall. -
Para ejecutar la instalación, debe especificarse una de las siguientes opciones:
cdrom,harddrive,hmc,nfs,liveimg, ourl.
H.2.15. ostreesetup
El comando ostreesetup Kickstart es opcional. Se utiliza para configurar instalaciones basadas en OStree.
Sintaxis
ostreesetup --osname=OSNAME [--remote=REMOTE] --url=URL --ref=REF [--nogpg]Opciones obligatorias:
-
--osname=OSNAME- Raíz de gestión para la instalación del sistema operativo. -
--url=URL- URL del repositorio desde el que se va a instalar. -
--ref=REF- Nombre de la rama del repositorio que se utilizará para la instalación.
Opciones opcionales:
-
--remote=REMOTE- Raíz de gestión para la instalación del sistema operativo. -
--nogpg- Desactivar la verificación de la clave GPG.
Notas
- Para más información sobre las herramientas de OStree, consulte la documentación de la corriente principal: https://ostree.readthedocs.io/en/latest/
H.2.16. apagado
El comando poweroff Kickstart es opcional. Apaga el sistema después de que la instalación se haya completado con éxito. Normalmente, durante una instalación manual, Anaconda muestra un mensaje y espera a que el usuario pulse una tecla antes de reiniciar.
Sintaxis
poweroffNotas
-
La opción
poweroffes equivalente al comandoshutdown -P. Para más detalles, consulte la página de manual shutdown(8). -
Para otros métodos de finalización, consulte los comandos Kickstart
halt,rebootyshutdown. La opciónhaltes el método de finalización por defecto si no se especifican explícitamente otros métodos en el archivo Kickstart. -
El comando
poweroffdepende en gran medida del hardware del sistema en uso. En concreto, algunos componentes de hardware como la BIOS, APM (gestión avanzada de energía) y ACPI (interfaz avanzada de configuración y alimentación) deben poder interactuar con el núcleo del sistema. Consulte la documentación de su hardware para obtener más información sobre las capacidades APM/ACPI de su sistema. - Este comando no tiene opciones.
H.2.17. reiniciar
El comando reboot Kickstart es opcional. Indica al programa de instalación que se reinicie después de que la instalación se haya completado con éxito (sin argumentos). Normalmente, Kickstart muestra un mensaje y espera a que el usuario pulse una tecla antes de reiniciar.
Sintaxis
reboot OPTIONSOpciones
-
--eject- Intente expulsar el medio de arranque (DVD, USB u otro medio) antes de reiniciar. --kexec- Utiliza la llamada al sistemakexecen lugar de realizar un reinicio completo, que carga inmediatamente el sistema instalado en la memoria, omitiendo la inicialización del hardware que normalmente realiza la BIOS o el firmware.ImportanteEsta opción está obsoleta y sólo está disponible como Technology Preview. Para obtener información sobre el alcance del soporte de Red Hat para las funciones de Technology Preview, consulte el documento Alcance del soporte de las funciones de Technology Preview.
Cuando se utiliza
kexec, los registros de los dispositivos (que normalmente se borrarían durante un reinicio completo del sistema) podrían permanecer llenos de datos, lo que podría crear problemas para algunos controladores de dispositivos.
Notas
-
El uso de la opción
rebootmight da lugar a un bucle de instalación interminable, dependiendo del medio y el método de instalación. -
La opción
rebootes equivalente al comandoshutdown -r. Para más detalles, consulte la página de manual shutdown(8). -
Especifique
rebootpara automatizar completamente la instalación cuando se instala en modo de línea de comandos en IBM Z. -
Para otros métodos de finalización, consulte las opciones de Kickstart
halt,poweroff, yshutdown. La opciónhaltes el método de finalización por defecto si no se especifican explícitamente otros métodos en el archivo Kickstart.
H.2.18. rhsm
El comando rhsm Kickstart es opcional. Indica al programa de instalación que registre e instale RHEL desde el CDN.
El comando rhsm Kickstart elimina el requisito de utilizar scripts personalizados de %post al registrar el sistema.
Opciones
-
--organization=- Utiliza el ID de la organización para registrar e instalar RHEL desde la CDN. -
--activation-key=- Utiliza la clave de activación para registrar e instalar RHEL desde la CDN. Se pueden utilizar varias claves, siempre que las claves de activación estén registradas en su suscripción. -
--connect-to-insights- Conecta el sistema de destino a Red Hat Insights. -
--proxy=- Establece el proxy HTTP. -
--server-hostname=- Establece el nombre del servidor. Utilice esta opción si está ejecutando el Servidor Satélite o realizando pruebas internas. -
--rhsm-baseurl=- Establece la opción rhsm baseurl. Utilice esta opción si está ejecutando el Servidor Satélite o realizando pruebas internas.
El nombre del servidor no requiere el protocolo HTTP, por ejemplo --server-hostname="nameofhost.com". La baseurl de rhsm sí requiere el protocolo HTTP o HTTPS, por ejemplo --rhsm-baseurl="https://satellite.example.com/pulp/repos".
H.2.19. apagado
El comando shutdown Kickstart es opcional. Apaga el sistema después de que la instalación se haya completado con éxito.
Sintaxis
shutdownNotas
-
La opción
shutdownKickstart es equivalente al comandoshutdown. Para más detalles, consulte la página de manual shutdown(8). -
Para otros métodos de finalización, consulte las opciones de Kickstart
halt,poweroff, yreboot. La opciónhaltes el método de finalización por defecto si no se especifican explícitamente otros métodos en el archivo Kickstart. - Este comando no tiene opciones.
H.2.20. sshpw
El comando sshpw Kickstart es opcional.
Durante la instalación, puede interactuar con el programa de instalación y supervisar su progreso a través de una conexión SSH. Utilice el comando sshpw para crear cuentas temporales a través de las cuales iniciar sesión. Cada instancia del comando crea una cuenta independiente que sólo existe en el entorno de instalación. Estas cuentas no se transfieren al sistema instalado.
Sintaxis
sshpw --username=name [OPTIONS] passwordOpciones obligatorias
-
--username=name - Proporciona el nombre del usuario. Esta opción es necesaria. - password - La contraseña a utilizar para el usuario. Esta opción es necesaria.
Opciones opcionales
--iscrypted- Si esta opción está presente, se supone que el argumento de la contraseña ya está cifrado. Esta opción es mutuamente excluyente con--plaintext. Para crear una contraseña encriptada, puedes usar Python:$ python3 -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'Esto genera un hash compatible con la criptografía sha512 de su contraseña utilizando una sal aleatoria.
-
--plaintext- Si esta opción está presente, se asume que el argumento de la contraseña está en texto plano. Esta opción es mutuamente excluyente con--iscrypted -
--lock- Si esta opción está presente, esta cuenta está bloqueada por defecto. Esto significa que el usuario no podrá conectarse desde la consola. -
--sshkey- Si esta opción está presente, la cadena <password> se interpreta como un valor de clave ssh.
Notas
-
Por defecto, el servidor
sshno se inicia durante la instalación. Para quesshesté disponible durante la instalación, inicie el sistema con la opción de arranque del kernelinst.sshd. Si quieres desactivar el acceso de root a
ssh, mientras permites el acceso de otro usuario assh, utiliza lo siguiente:sshpw --username=example_username example_password --plaintext sshpw --username=root example_password --lockPara desactivar simplemente el acceso a la raíz
ssh, utilice lo siguiente:sshpw --username=root example_password --lock
H.2.21. texto
El comando text Kickstart es opcional. Realiza la instalación de Kickstart en modo texto. Las instalaciones de Kickstart se realizan por defecto en modo gráfico.
Sintaxis
text [--non-interactive]Opciones
-
--non-interactive- Realiza la instalación en un modo completamente no interactivo. Este modo terminará la instalación cuando se requiera la interacción del usuario.
Notas
-
Tenga en cuenta que para una instalación totalmente automática, debe especificar uno de los modos disponibles (
graphical,text, ocmdline) en el archivo Kickstart, o debe utilizar la opción de arranqueconsole=. Si no se especifica ningún modo, el sistema utilizará el modo gráfico si es posible, o le pedirá que elija entre VNC y el modo de texto.
H.2.22. url
El comando url Kickstart es opcional. Se utiliza para instalar desde una imagen de árbol de instalación en un servidor remoto utilizando el protocolo FTP, HTTP o HTTPS. Sólo se puede especificar una URL.
Sintaxis
url--url=FROM [OPTIONS]Opciones obligatorias
-
--url=FROM- Especifica la ubicación deHTTP,HTTPS,FTP, ofiledesde la que se va a instalar.
Opciones opcionales
-
--mirrorlist=- Especifica la URL de la réplica desde la que se va a instalar. -
--proxy=- Especifica un proxyHTTP,HTTPS, oFTPa utilizar durante la instalación. -
--noverifyssl- Desactiva la verificación SSL cuando se conecta a un servidorHTTPS. -
--metalink=URL- Especifica la URL del metalink desde la que se va a instalar. La sustitución de la variable se realiza para$releasevery$basearchen el URL.
Ejemplos
Para instalar desde un servidor HTTP:
url --url=http://server/pathPara instalar desde un servidor FTP:
url --url=ftp://username:password@server/pathPara instalar desde un archivo local:
liveimg --url=file:///images/install/squashfs.img --noverifyssl
Notas
-
Anteriormente, el comando
urltenía que utilizarse junto con el comandoinstall. El comandoinstallha quedado obsoleto yurlpuede utilizarse por sí solo, ya que implicainstall. -
Para ejecutar la instalación, debe especificarse una de las siguientes opciones:
cdrom,harddrive,hmc,nfs,liveimg, ourl.
H.2.23. vnc
El comando vnc Kickstart es opcional. Permite ver la instalación gráfica de forma remota a través de VNC.
Este método suele ser preferible al modo de texto, ya que existen algunas limitaciones de tamaño e idioma en las instalaciones de texto. Sin opciones adicionales, este comando inicia un servidor VNC en el sistema de instalación sin contraseña y muestra los detalles necesarios para conectarse a él.
Sintaxis
vnc [--host=host_name] [--port=port] [--password=password]Opciones
-
--host=- Conecta con el proceso de visualización VNC que escucha en el nombre de host dado. -
--port=- Proporciona un puerto en el que el proceso del visor VNC remoto está escuchando. Si no se proporciona, Anaconda utiliza el puerto por defecto de VNC, el 5900. -
--password=- Establece una contraseña que debe ser proporcionada para conectarse a la sesión VNC. Esto es opcional, pero se recomienda.
Recursos adicionales
- Para obtener más información sobre las instalaciones VNC, incluidas las instrucciones sobre cómo conectarse al sistema de instalación, consulte Realización de una instalación remota de RHEL mediante VNC.
H.2.24. %incluir
El comando %include Kickstart es opcional.
Utilice el comando %include para incluir el contenido de otro archivo en el archivo Kickstart como si el contenido estuviera en la ubicación del comando %include en el archivo Kickstart.
Esta inclusión se evalúa sólo después de las secciones de script %pre y, por lo tanto, puede utilizarse para incluir archivos generados por scripts en las secciones %pre. Para incluir archivos antes de la evaluación de las secciones %pre, utilice el comando %ksappend.
Sintaxis
%include path/to/fileH.2.25. %ksappend
El comando %ksappend Kickstart es opcional.
Utilice el comando %ksappend para incluir el contenido de otro archivo en el archivo Kickstart como si el contenido estuviera en la ubicación del comando %ksappend en el archivo Kickstart.
Esta inclusión se evalúa antes de las secciones del script %pre, a diferencia de la inclusión con el comando %include.
Sintaxis
%ksappend path/to/fileH.3. Comandos Kickstart para la configuración del sistema
Los comandos Kickstart de esta lista configuran más detalles del sistema resultante, como usuarios, repositorios o servicios.
H.3.1. auth o authconfig (obsoleto)
Utilice el nuevo comando authselect en lugar del comando Kickstart obsoleto auth o authconfig. auth y authconfig están disponibles sólo para una compatibilidad limitada con el pasado.
El comando auth o authconfig Kickstart es opcional. Configura las opciones de autenticación del sistema mediante la herramienta authconfig, que también puede ejecutarse en la línea de comandos una vez finalizada la instalación.
Sintaxis
authconfig [OPTIONS]Notas
-
Anteriormente, los comandos Kickstart
authoauthconfigllamaban a la herramientaauthconfig. Esta herramienta ha sido obviada en Red Hat Enterprise Linux 8. Estos comandos Kickstart ahora utilizan la herramientaauthselect-compatpara llamar a la nueva herramientaauthselect. Para una descripción de la capa de compatibilidad y sus problemas conocidos, vea la página del manual authselect-migration(7). El programa de instalación detectará automáticamente el uso de los comandos obsoletos e instalará en el sistema el paqueteauthselect-compatpara proporcionar la capa de compatibilidad. - Las contraseñas están sombreadas por defecto.
-
Cuando utilice OpenLDAP con el protocolo
SSLpara la seguridad, asegúrese de que los protocolosSSLv2ySSLv3están desactivados en la configuración del servidor. Esto se debe a la vulnerabilidad POODLE SSL (CVE-2014-3566). Consulte https://access.redhat.com/solutions/1234843 para obtener más detalles.
H.3.2. authselect
El comando authselect Kickstart es opcional. Configura las opciones de autenticación del sistema mediante el comando authselect, que también puede ejecutarse en la línea de comandos una vez finalizada la instalación.
Sintaxis
authselect [OPTIONS]Notas
-
Este comando pasa todas las opciones al comando
authselect. Consulte la página del manual authselect(8) y el comandoauthselect --helppara más detalles. -
Este comando sustituye a los comandos
authoauthconfig, obsoletos en Red Hat Enterprise Linux 8, junto con la herramientaauthconfig. - Las contraseñas están sombreadas por defecto.
-
Cuando utilice OpenLDAP con el protocolo
SSLpara la seguridad, asegúrese de que los protocolosSSLv2ySSLv3están desactivados en la configuración del servidor. Esto se debe a la vulnerabilidad POODLE SSL (CVE-2014-3566). Consulte https://access.redhat.com/solutions/1234843 para obtener más detalles.
H.3.3. cortafuegos
El comando firewall Kickstart es opcional. Especifica la configuración del cortafuegos para el sistema instalado.
Sintaxis
firewall --enabled|--disabled [incoming] [OPTIONS]Opciones obligatorias
-
--enabledo--enable- Rechazar las conexiones entrantes que no son en respuesta a las solicitudes salientes, como las respuestas de DNS o las solicitudes de DHCP. Si es necesario acceder a los servicios que se ejecutan en esta máquina, puede elegir permitir servicios específicos a través del cortafuegos. -
--disabledo--disable- No configure ninguna regla iptables.
Opciones opcionales
-
--trust- Enumerar un dispositivo aquí, comoem1, permite que todo el tráfico que entra y sale de ese dispositivo pase por el cortafuegos. Para enumerar más de un dispositivo, utilice la opción más veces, como--trust em1 --trust em2. No utilice un formato separado por comas, como--trust em1, em2. -
--remove-service- No permitir los servicios a través del firewall. incoming - Sustitúyase por una o varias de las siguientes opciones para permitir los servicios especificados a través del cortafuegos.
-
--ssh -
--smtp -
--http -
--ftp
-
-
--port=- Puede especificar que los puertos se permitan a través del cortafuegos utilizando el formato puerto:protocolo. Por ejemplo, para permitir el acceso a IMAP a través del cortafuegos, especifiqueimap:tcp. Los puertos numéricos también se pueden especificar explícitamente; por ejemplo, para permitir el paso de paquetes UDP en el puerto 1234, especifique1234:udp. Para especificar varios puertos, sepárelos con comas. --service=- Esta opción proporciona una forma de nivel superior para permitir servicios a través del cortafuegos. Algunos servicios (comocups,avahi, etc.) requieren que se abran varios puertos o una configuración especial para que el servicio funcione. Puede especificar cada puerto individual con la opción--port, o especificar--service=y abrirlos todos a la vez.Las opciones válidas son cualquier cosa reconocida por el programa
firewall-offline-cmden el firewalld paquete. Si el serviciofirewalldse está ejecutando,firewall-cmd --get-servicesproporciona una lista de nombres de servicios conocidos.-
--use-system-defaults- No configurar el cortafuegos en absoluto. Esta opción indica a anaconda que no haga nada y permite que el sistema confíe en los valores predeterminados que se proporcionaron con el paquete o con ostree. Si esta opción se utiliza con otras opciones, todas las demás opciones serán ignoradas.
H.3.4. grupo
El comando group Kickstart es opcional. Crea un nuevo grupo de usuarios en el sistema.
group --name=name [--gid=gid]Opciones obligatorias
-
--name=- Proporciona el nombre del grupo.
Opciones opcionales
-
--gid=- El GID del grupo. Si no se proporciona, el valor predeterminado es el siguiente GID disponible que no sea del sistema.
Notas
- Si un grupo con el nombre o GID dado ya existe, este comando falla.
-
El comando
userpuede utilizarse para crear un nuevo grupo para el usuario recién creado.
H.3.5. teclado (obligatorio)
El comando keyboard Kickstart es necesario. Establece una o más distribuciones de teclado disponibles para el sistema.
Sintaxis
keyboard --vckeymap|--xlayouts OPTIONSOpciones
-
--vckeymap=- Especifica un mapa de tecladoVConsoleque debe ser utilizado. Los nombres válidos corresponden a la lista de archivos del directorio/usr/lib/kbd/keymaps/xkb/, sin la extensión.map.gz. --xlayouts=- Especifica una lista de diseños X que deben ser utilizados como una lista separada por comas sin espacios. Acepta valores en el mismo formato quesetxkbmap(1), ya sea en el formatolayout(comocz), o en el formatolayout (variant)(comocz (qwerty)).Todos los diseños disponibles pueden verse en la página man
xkeyboard-config(7)enLayouts.--switch=- Especifica una lista de opciones de cambio de disposición (atajos para cambiar entre varias disposiciones de teclado). Las opciones múltiples deben estar separadas por comas sin espacios. Acepta valores en el mismo formato quesetxkbmap(1).Las opciones de conmutación disponibles pueden verse en la página man
xkeyboard-config(7)enOptions.
Notas
-
Debe utilizarse la opción
--vckeymap=o--xlayouts=.
Ejemplo
El siguiente ejemplo configura dos distribuciones de teclado (English (US) y Czech (qwerty)) utilizando la opción --xlayouts=, y permite cambiar entre ellas utilizando Alt+Shift:
keyboard --xlayouts=us,'cz (qwerty)' --switch=grp:alt_shift_toggleH.3.6. lang (obligatorio)
El comando lang Kickstart es necesario. Establece el idioma a utilizar durante la instalación y el idioma por defecto a utilizar en el sistema instalado.
Sintaxis
lang language [--addsupport=language,...]Opciones obligatorias
-
language- Instale el soporte para este idioma y establézcalo como predeterminado en el sistema.
Opciones opcionales
--addsupport=- Añade soporte para idiomas adicionales. Toma la forma de una lista separada por comas sin espacios. Por ejemplo:lang en_US --addsupport=cs_CZ,de_DE,en_UK
Notas
-
Los comandos
locale -a | grep _olocalectl list-locales | grep _devuelven una lista de las localizaciones soportadas. -
Algunos idiomas (por ejemplo, el chino, el japonés, el coreano y los idiomas índicos) no son compatibles con la instalación en modo texto. Si especifica uno de estos idiomas con el comando
lang, el proceso de instalación continúa en inglés, pero el sistema instalado utiliza su selección como idioma por defecto.
Ejemplo
Para establecer el idioma en inglés, el archivo Kickstart debe contener la siguiente línea:
lang en_USH.3.7. módulo
El comando module Kickstart es opcional. Utilice este comando para habilitar un flujo de módulo de paquete dentro de la secuencia de comandos kickstart.
Sintaxis
module --name=NAME [--stream=STREAM]Opciones obligatorias
-
--name=- Especifica el nombre del módulo a habilitar. Sustituya NAME por el nombre real.
Opciones opcionales
--stream=- Especifica el nombre del flujo del módulo a habilitar. Sustituya STREAM por el nombre real.No es necesario especificar esta opción para los módulos con un flujo por defecto definido. Para los módulos sin flujo por defecto, esta opción es obligatoria y omitirla da lugar a un error. No es posible habilitar un módulo varias veces con diferentes flujos.
Notas
-
El uso de una combinación de este comando y la sección
%packagesle permite instalar paquetes proporcionados por la combinación de módulos y flujos habilitados, sin especificar el módulo y el flujo explícitamente. Los módulos deben estar habilitados antes de la instalación de los paquetes. Después de habilitar un módulo con el comandomodule, puede instalar los paquetes habilitados por este módulo enumerándolos en la sección%packages. -
Un solo comando
modulepuede habilitar sólo una combinación de módulo y flujo. Para habilitar varios módulos, utilice varios comandosmodule. No es posible habilitar un módulo varias veces con diferentes flujos. -
En Red Hat Enterprise Linux 8, los módulos están presentes sólo en el repositorio de AppStream. Para listar los módulos disponibles, utilice el comando
yum module listen un sistema Red Hat Enterprise Linux 8 instalado con una suscripción válida.
Recursos adicionales
- Para más información sobre módulos y flujos, consulte el documento Instalación, gestión y eliminación de componentes del espacio de usuario.
H.3.8. repo
El comando repo Kickstart es opcional. Configura repositorios yum adicionales que pueden ser utilizados como fuentes para la instalación de paquetes. Puede añadir varias líneas repo.
Sintaxis
repo --name=repoid [--baseurl=url|--mirrorlist=url|--metalink=url] [OPTIONS]Opciones obligatorias
-
--name=- El id del repositorio. Esta opción es necesaria. Si un repositorio tiene un nombre que entra en conflicto con otro repositorio añadido previamente, se ignora. Como el programa de instalación utiliza una lista de repositorios preestablecidos, esto significa que no puede añadir repositorios con los mismos nombres que los preestablecidos.
Opciones de URL
Estas opciones son mutuamente excluyentes y opcionales. Las variables que se pueden utilizar en los archivos de configuración de los repositorios de yum no están soportadas aquí. Puede utilizar las cadenas $releasever y $basearch que se sustituyen por los valores respectivos en la URL.
-
--baseurl=- La URL del repositorio. -
--mirrorlist=- La URL que apunta a una lista de réplicas del repositorio. -
--metalink=- La URL con metalink para el repositorio.
Opciones opcionales
-
--install- Guarda la configuración del repositorio proporcionada en el sistema instalado en el directorio/etc/yum.repos.d/. Sin usar esta opción, un repositorio configurado en un archivo Kickstart sólo estará disponible durante el proceso de instalación, no en el sistema instalado. -
--cost=- Un valor entero para asignar un coste a este repositorio. Si varios repositorios proporcionan los mismos paquetes, este número se utiliza para priorizar qué repositorio se utilizará antes que otro. Los repositorios con un coste menor tienen prioridad sobre los repositorios con un coste mayor. -
--excludepkgs=- Una lista separada por comas de los nombres de los paquetes que deben not ser extraídos de este repositorio. Esto es útil si varios repositorios proporcionan el mismo paquete y quiere asegurarse de que proviene de un repositorio en particular. Se aceptan tanto nombres de paquetes completos (comopublican) como globos (comognome-*). -
--includepkgs=- Una lista separada por comas de los nombres de paquetes y globos que se pueden obtener de este repositorio. Cualquier otro paquete proporcionado por el repositorio será ignorado. Esto es útil si quiere instalar sólo un paquete o un conjunto de paquetes de un repositorio y excluir todos los demás paquetes que proporciona el repositorio. -
--proxy=[protocol://][username[:password]@]host[:port]- Especifique un proxy HTTP/HTTPS/FTP para usar sólo para este repositorio. Esta configuración no afecta a ningún otro repositorio, ni a la forma en que se obtieneinstall.imgen las instalaciones HTTP. -
--noverifyssl- Desactivar la verificación SSL al conectarse a un servidorHTTPS.
Notas
- Los repositorios utilizados para la instalación deben ser estables. La instalación puede fallar si un repositorio se modifica antes de que la instalación concluya.
H.3.9. rootpw (obligatorio)
El comando rootpw Kickstart es necesario. Establece la contraseña de root del sistema con el argumento password.
Sintaxis
rootpw [--iscrypted|--plaintext] [--lock] passwordOpciones obligatorias
-
password - Especificación de la contraseña. Texto plano o cadena cifrada. Véase
--iscryptedy--plaintextmás abajo.
Opciones
--iscrypted- Si esta opción está presente, se supone que el argumento de la contraseña ya está cifrado. Esta opción es mutuamente excluyente con--plaintext. Para crear una contraseña encriptada, puede utilizar python:$ python -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'Esto genera un hash compatible con la criptografía sha512 de su contraseña utilizando una sal aleatoria.
-
--plaintext- Si esta opción está presente, se asume que el argumento de la contraseña está en texto plano. Esta opción es mutuamente excluyente con--iscrypted. -
--lock- Si esta opción está presente, la cuenta de root está bloqueada por defecto. Esto significa que el usuario root no podrá iniciar sesión desde la consola. Esta opción también deshabilitará las Root Password pantallas de la instalación manual, tanto gráfica como de texto.
H.3.10. selinux
El comando selinux Kickstart es opcional. Establece el estado de SELinux en el sistema instalado. La política SELinux por defecto es enforcing.
Sintaxis
selinux [--disabled|--enforcing|--permissive]Opciones
-
--enforcing- Habilita SELinux con la política de destino por defectoenforcing. -
--permissive- Produce advertencias basadas en la política de SELinux, pero no aplica la política. -
--disabled- Desactiva SELinux completamente en el sistema.
Recursos adicionales
Para más información sobre SELinux, consulte el documento Uso de SElinux.
H.3.11. servicios
El comando services Kickstart es opcional. Modifica el conjunto de servicios por defecto que se ejecutarán bajo el objetivo systemd por defecto. La lista de servicios deshabilitados se procesa antes que la lista de servicios habilitados. Por lo tanto, si un servicio aparece en ambas listas, será habilitado.
Sintaxis
services [--disabled=list] [--enabled=list]Opciones
-
--disabled=- Desactivar los servicios indicados en la lista separada por comas. -
--enabled=- Habilitar los servicios indicados en la lista separada por comas.
Notas
No incluya espacios en la lista de servicios. Si lo hace, Kickstart activará o desactivará sólo los servicios hasta el primer espacio. Por ejemplo:
services --disabled=auditd, cups,smartd, nfslockEsto desactiva sólo el servicio
auditd. Para desactivar los cuatro servicios, esta entrada no debe incluir espacios:services --disabled=auditd,cups,smartd,nfslock
H.3.12. skipx
El comando skipx Kickstart es opcional. Si está presente, X no está configurado en el sistema instalado.
Si instala un gestor de pantalla entre sus opciones de selección de paquetes, este paquete crea una configuración X, y el sistema instalado por defecto es graphical.target. Esto anula el efecto de la opción skipx.
Sintaxis
skipxNotas
- Este comando no tiene opciones.
H.3.13. sshkey
El comando sshkey Kickstart es opcional. Añade una clave SSH al archivo authorized_keys del usuario especificado en el sistema instalado.
Sintaxis
sshkey --username=user KEYOpciones obligatorias
-
--username=- El usuario para el que se instalará la llave. - KEY - La clave SSH.
H.3.14. syspurpose
El comando syspurpose Kickstart es opcional. Se utiliza para establecer el propósito del sistema que describe cómo se utilizará el sistema después de la instalación. Esta información ayuda a aplicar el derecho de suscripción correcto al sistema.
Sintaxis
syspurpose [OPTIONS]Opciones
--role=- Establece el rol del sistema previsto. Los valores disponibles son:- Servidor Red Hat Enterprise Linux
- Estación de trabajo Red Hat Enterprise Linux
- Nodo informático de Red Hat Enterprise Linux
--sla=- Establezca el acuerdo de nivel de servicio. Los valores disponibles son:- Premium
- Estándar
- Autoayuda
--usage=- El uso previsto del sistema. Los valores disponibles son:- Producción
- Recuperación de catástrofes
- Desarrollo/prueba
-
--addon=- Especifica productos o características adicionales en capas. Puede utilizar esta opción varias veces.
Notas
Introduzca los valores con espacios y enciérrelos entre comillas dobles:
syspurpose --role="Red Hat Enterprise Linux Server"-
Aunque se recomienda encarecidamente que configure el Propósito del Sistema, es una característica opcional del programa de instalación de Red Hat Enterprise Linux. Si desea habilitar System Purpose después de que la instalación se haya completado, puede hacerlo utilizando la herramienta de línea de comandos
syspurpose.
H.3.15. zona horaria (obligatorio)
El comando timezone Kickstart es necesario. Establece la zona horaria del sistema.
Sintaxis
timezone timezone [OPTIONS]Opciones obligatorias
- timezone - la zona horaria a establecer para el sistema.
Opciones opcionales
-
--utc- Si está presente, el sistema asume que el reloj del hardware está ajustado a la hora UTC (media de Greenwich). -
--nontp- Desactivar el inicio automático del servicio NTP. -
--ntpservers=- Especifica una lista de servidores NTP a utilizar como una lista separada por comas sin espacios.
Notas
En Red Hat Enterprise Linux 8, los nombres de zonas horarias se validan utilizando la lista pytz.all_timezones, proporcionada por el paquete pytz paquete. En versiones anteriores, los nombres eran validados contra pytz.common_timezones, que es un subconjunto de la lista actualmente utilizada. Tenga en cuenta que las interfaces de modo gráfico y de texto todavía utilizan la lista pytz.common_timezones más restringida; debe utilizar un archivo Kickstart para utilizar definiciones de zona horaria adicionales.
H.3.16. usuario
El comando user Kickstart es opcional. Crea un nuevo usuario en el sistema.
Sintaxis
user --name=username [OPTIONS]Opciones obligatorias
-
--name=- Proporciona el nombre del usuario. Esta opción es necesaria.
Opciones opcionales
-
--gecos=- Proporciona la información de GECOS para el usuario. Es una cadena de varios campos específicos del sistema separados por una coma. Se utiliza frecuentemente para especificar el nombre completo del usuario, el número de oficina, etc. Consulte la página de manualpasswd(5)para obtener más detalles. -
--groups=- Además del grupo por defecto, una lista separada por comas de los nombres de los grupos a los que debe pertenecer el usuario. Los grupos deben existir antes de que se cree la cuenta de usuario. Consulte el comandogroup. -
--homedir=- El directorio principal del usuario. Si no se proporciona, el valor predeterminado es/home/username. -
--lock- Si esta opción está presente, esta cuenta está bloqueada por defecto. Esto significa que el usuario no podrá conectarse desde la consola. Esta opción también deshabilitará las Create User pantallas de la instalación manual, tanto gráfica como de texto. -
--password=- La contraseña del nuevo usuario. Si no se proporciona, la cuenta se bloqueará por defecto. --iscrypted- Si esta opción está presente, se supone que el argumento de la contraseña ya está cifrado. Esta opción es mutuamente excluyente con--plaintext. Para crear una contraseña encriptada, puede utilizar python:$ python -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'Esto genera un hash compatible con la criptografía sha512 de su contraseña utilizando una sal aleatoria.
-
--plaintext- Si esta opción está presente, se asume que el argumento de la contraseña está en texto plano. Esta opción es mutuamente excluyente con--iscrypted -
--shell=- El shell de inicio de sesión del usuario. Si no se proporciona, se utiliza el sistema por defecto. -
--uid=- El UID (ID de usuario) del usuario. Si no se proporciona, el valor predeterminado es el siguiente UID disponible que no sea del sistema. -
--gid=- El GID (ID de grupo) que se utilizará para el grupo del usuario. Si no se proporciona, el valor predeterminado es el siguiente ID de grupo no relacionado con el sistema.
Notas
Considere la posibilidad de utilizar las opciones
--uidy--gidpara establecer los ID de los usuarios regulares y sus grupos por defecto en un rango que comienza en5000en lugar de1000. Esto se debe a que el rango reservado para los usuarios y grupos del sistema,0-999, podría aumentar en el futuro y, por tanto, solaparse con los ID de los usuarios habituales.Para cambiar los límites mínimos de UID y GID después de la instalación, lo que garantiza que los rangos de UID y GID elegidos se apliquen automáticamente en la creación de usuarios, consulte la sección Configuración de permisos por defecto para los nuevos archivos mediante umask del documento Configuring basic system settings.
Los archivos y directorios se crean con varios permisos, dictados por la aplicación utilizada para crear el archivo o directorio. Por ejemplo, el comando
mkdircrea directorios con todos los permisos habilitados. Sin embargo, se impide que las aplicaciones concedan ciertos permisos a los archivos recién creados, según lo especificado por la configuraciónuser file-creation mask.El
user file-creation maskpuede ser controlado con el comandoumask. La configuración por defecto deuser file-creation maskpara los nuevos usuarios está definida por la variableUMASKen el archivo de configuración/etc/login.defsen el sistema instalado. Si no se establece, se pone por defecto022. Esto significa que, por defecto, cuando una aplicación crea un archivo, no puede conceder permisos de escritura a otros usuarios que no sean el propietario del archivo. Sin embargo, esto puede ser anulado por otras configuraciones o scripts. Puede encontrar más información en la sección Configuración de permisos por defecto para nuevos archivos usando umask del documento Configuring basic system settings.
H.3.17. xconfig
El comando xconfig Kickstart es opcional. Configura el sistema X Window.
Sintaxis
xconfig [--startxonboot]Opciones
-
--startxonboot- Utilice un inicio de sesión gráfico en el sistema instalado.
Notas
-
Debido a que Red Hat Enterprise Linux 8 no incluye el entorno de escritorio KDE, no utilice el
--defaultdesktop=documentado en upstream.
H.4. Comandos Kickstart para la configuración de la red
Los comandos Kickstart de esta lista le permiten configurar la red en el sistema.
H.4.1. red
El comando network Kickstart es opcional. Configura la información de red para el sistema de destino y activa los dispositivos de red en el entorno de instalación.
El dispositivo especificado en el primer comando network se activa automáticamente. La activación del dispositivo también puede requerirse explícitamente mediante la opción --activate.
Sintaxis
network OPTIONSOpciones
--activate- activar este dispositivo en el entorno de la instalación.Si utiliza la opción
--activateen un dispositivo que ya ha sido activado (por ejemplo, una interfaz que configuró con opciones de arranque para que el sistema pudiera recuperar el archivo Kickstart) el dispositivo se reactiva para utilizar los detalles especificados en el archivo Kickstart.Utilice la opción
--nodefroutepara evitar que el dispositivo utilice la ruta por defecto.--no-activate- no active este dispositivo en el entorno de la instalación.Por defecto, Anaconda activa el primer dispositivo de red en el archivo Kickstart independientemente de la opción
--activate. Puede desactivar la configuración por defecto utilizando la opción--no-activate.--bootproto=- Una de las opcionesdhcp,bootp,ibft, ostatic. La opción por defecto esdhcp; las opcionesdhcpybootpse tratan igual. Para desactivar la configuración deipv4del dispositivo, utilice la opción--noipv4.NotaEsta opción permite configurar el dispositivo en su versión ipv4. Para la configuración ipv6 utilice las opciones
--ipv6y--ipv6gateway.El método DHCP utiliza un sistema de servidor DHCP para obtener su configuración de red. El método BOOTP es similar, y requiere un servidor BOOTP para suministrar la configuración de red. Para indicar a un sistema que utilice DHCP:
network --bootproto=dhcpPara indicar a una máquina que utilice BOOTP para obtener su configuración de red, utilice la siguiente línea en el archivo Kickstart:
network --bootproto=bootpPara dirigir una máquina para utilizar la configuración especificada en iBFT, utilice:
network --bootproto=ibftEl método
staticrequiere que se especifique al menos la dirección IP y la máscara de red en el archivo Kickstart. Esta información es estática y se utiliza durante y después de la instalación.Toda la información de configuración de red estática debe especificarse en la línea one; no puede envolver las líneas utilizando una barra invertida (
\) como puede hacerlo en una línea de comandos.network --bootproto=static --ip=10.0.2.15 --netmask=255.255.255.0 --gateway=10.0.2.254 --nameserver=10.0.2.1También puede configurar varios servidores de nombres al mismo tiempo. Para ello, utilice la opción
--nameserver=una vez, y especifique cada una de sus direcciones IP, separadas por comas:network --bootproto=static --ip=10.0.2.15 --netmask=255.255.255.0 --gateway=10.0.2.254 --nameserver=192.168.2.1,192.168.3.1--device=- especifica el dispositivo que debe ser configurado (y eventualmente activado en Anaconda) con el comandonetwork.Si falta la opción
--device=en el uso de first del comandonetwork, se utiliza el valor de la opción de arranque de Anacondaksdevice=, si está disponible. Tenga en cuenta que esto se considera un comportamiento obsoleto; en la mayoría de los casos, siempre debe especificar un--device=para cada comandonetwork.El comportamiento de cualquier comando
networkposterior en el mismo archivo Kickstart no se especifica si falta su opción--device=. Asegúrese de especificar esta opción para cualquier comandonetworkmás allá del primero.Puede especificar un dispositivo para que se active de cualquiera de las siguientes maneras:
-
el nombre del dispositivo de la interfaz, por ejemplo,
em1 -
la dirección MAC de la interfaz, por ejemplo,
01:23:45:67:89:ab -
la palabra clave
link, que especifica la primera interfaz con su enlace en el estadoup -
la palabra clave
bootif, que utiliza la dirección MAC que pxelinux estableció en la variableBOOTIF. EstablezcaIPAPPEND 2en su archivopxelinux.cfgpara que pxelinux establezca la variableBOOTIF.
Por ejemplo:
network --bootproto=dhcp --device=em1-
el nombre del dispositivo de la interfaz, por ejemplo,
-
--ip=- Dirección IP del dispositivo. -
--ipv6=- Dirección IPv6 del dispositivo, en forma de address[/prefix length ] - por ejemplo,3ffe:ffff:0:1::1/128 `. If prefix is omitted, `64se utiliza. También se puede utilizarautopara la configuración automática, odhcppara la configuración sólo DHCPv6 (sin anuncios de router). -
--gateway=- Puerta de enlace por defecto como una única dirección IPv4. -
--ipv6gateway=- Pasarela por defecto como una única dirección IPv6. -
--nodefroute- Evita que la interfaz se establezca como ruta por defecto. Utilice esta opción cuando active dispositivos adicionales con la opción--activate=, por ejemplo, una NIC en una subred separada para un objetivo iSCSI. -
--nameserver=- Servidor de nombres DNS, como dirección IP. Para especificar más de un servidor de nombres, utilice esta opción una vez y separe cada dirección IP con una coma. -
--netmask=- Máscara de red para el sistema instalado. --hostname=- El nombre de host del sistema instalado. El nombre de host puede ser un nombre de dominio completamente calificado (FQDN) en el formatohost_name.domainnameo un nombre de host corto sin dominio. Muchas redes tienen un servicio de Protocolo de Configuración Dinámica de Host (DHCP) que suministra automáticamente a los sistemas conectados un nombre de dominio; para permitir que DHCP asigne el nombre de dominio, especifique sólo un nombre de host corto.ImportanteSi su red not proporciona un servicio DHCP, utilice siempre el FQDN como nombre de host del sistema.
-
--ethtool=- Especifica ajustes adicionales de bajo nivel para el dispositivo de red que se pasarán al programa ethtool. -
--onboot=- Habilitar o no el dispositivo en el momento del arranque. -
--dhcpclass=- La clase DHCP. -
--mtu=- La MTU del dispositivo. -
--noipv4- Desactivar IPv4 en este dispositivo. -
--noipv6- Desactivar IPv6 en este dispositivo. --bondslaves=- Cuando se utiliza esta opción, el dispositivo de enlace especificado por la opción--device=se crea utilizando dispositivos secundarios definidos en la opción--bondslaves=. Por ejemplo:network --device=bond0 --bondslaves=em1,em2El comando anterior crea un dispositivo de enlace llamado
bond0utilizando las interfacesem1yem2como sus dispositivos secundarios.--bondopts=- una lista de parámetros opcionales para una interfaz de enlace, que se especifica mediante las opciones--bondslaves=y--device=. Las opciones de esta lista deben estar separadas por comas (“,”) o punto y coma (“;”). Si una opción contiene una coma, utilice un punto y coma para separar las opciones. Por ejemplo:network --bondopts=mode=active-backup,balance-rr;primary=eth1ImportanteEl parámetro
--bondopts=mode=sólo admite nombres de modo completos comobalance-rrobroadcast, no sus representaciones numéricas como0o3.-
--vlanid=- Especifica el número de ID de la LAN virtual (VLAN) (etiqueta 802.1q) para el dispositivo creado utilizando el dispositivo especificado en--device=como padre. Por ejemplo,network --device=em1 --vlanid=171crea un dispositivo de LAN virtualem1.171. --interfacename=- Especifica un nombre de interfaz personalizado para un dispositivo LAN virtual. Esta opción debe utilizarse cuando el nombre por defecto generado por la opción--vlanid=no es deseable. Esta opción debe utilizarse junto con--vlanid=. Por ejemplo:network --device=em1 --vlanid=171 --interfacename=vlan171El comando anterior crea una interfaz LAN virtual llamada
vlan171en el dispositivoem1con un ID de171.El nombre de la interfaz puede ser arbitrario (por ejemplo,
my-vlan), pero en casos concretos deben seguirse las siguientes convenciones:-
Si el nombre contiene un punto (
.), debe tener la formaNAME.ID. El NAME es arbitrario, pero el ID debe ser el ID de la VLAN. Por ejemplo:em1.171omy-vlan.171. -
Los nombres que empiezan por
vlandeben tener la forma devlanID- por ejemplo,vlan171.
-
Si el nombre contiene un punto (
--teamslaves=- El dispositivo de equipo especificado por la opción--device=se creará utilizando los dispositivos secundarios especificados en esta opción. Los dispositivos secundarios están separados por comas. Un dispositivo secundario puede ir seguido de su configuración, que es una cadena JSON de comillas simples con comillas dobles escapadas por el carácter\. Por ejemplo:network --teamslaves="p3p1'{\"prio\": -10, \"sticky\": true}',p3p2'{\"prio\": 100}'"Véase también la opción
--teamconfig=.--teamconfig=- Configuración del dispositivo del equipo con comillas dobles que es una cadena JSON con comillas dobles escapadas por el carácter\. El nombre del dispositivo se especifica mediante la opción--device=y sus dispositivos secundarios y su configuración mediante la opción--teamslaves=. Por ejemplo:network --device team0 --activate --bootproto static --ip=10.34.102.222 --netmask=255.255.255.0 --gateway=10.34.102.254 --nameserver=10.34.39.2 --teamslaves="p3p1'{\"prio\": -10, \"sticky\": true}',p3p2'{\"prio\": 100}'" --teamconfig="{\"runner\": {\"name\": \"activebackup\"}}"--bridgeslaves=- Cuando se utiliza esta opción, se creará el puente de red con nombre de dispositivo especificado mediante la opción--device=y se añadirán al puente los dispositivos definidos en la opción--bridgeslaves=. Por ejemplo:network --device=bridge0 --bridgeslaves=em1--bridgeopts=- Una lista opcional separada por comas de parámetros para la interfaz puenteada. Los valores disponibles sonstp,priority,forward-delay,hello-time,max-ageyageing-time. Para obtener información sobre estos parámetros, consulte la tabla bridge setting tabla en la página mannm-settings(5)o en https://developer.gnome.org/NetworkManager/0.9/ref-settings.html.Consulte también el documento Configuración y gestión de redes para obtener información general sobre la conexión de redes.
-
--bindto=mac- Vincula el archivo de configuración del dispositivo (ifcfg) en el sistema instalado a la dirección MAC del dispositivo (HWADDR) en lugar de la vinculación por defecto al nombre de la interfaz (DEVICE). Tenga en cuenta que esta opción es independiente de la opción--device=---bindto=macse aplicará incluso si el mismo comandonetworktambién especifica un nombre de dispositivo,link, obootif.
Notas
-
Los nombres de dispositivos
ethNcomoeth0ya no están disponibles en Red Hat Enterprise Linux 8 debido a los cambios en el esquema de nomenclatura. Para más información sobre el esquema de nomenclatura de dispositivos, consulte el documento de aguas arriba Predictable Network Interface Names. - Si ha utilizado una opción Kickstart o una opción de arranque para especificar un repositorio de instalación en una red, pero no hay ninguna red disponible al inicio de la instalación, el programa de instalación muestra la ventana Network Configuration para configurar una conexión de red antes de mostrar la ventana Installation Summary ventana. Para más detalles, consulte la sección Configuración de las opciones de red y nombre de host del documento Performing a standard RHEL installation.
H.4.2. reino
El comando realm Kickstart es opcional. Utilícelo para unirse a un dominio de Active Directory o IPA. Para obtener más información sobre este comando, consulte la sección join de la página de manual realm(8).
Sintaxis
realm join [OPTIONS] domainOpciones obligatorias
-
domain- El dominio al que hay que unirse.
Opciones
-
--computer-ou=OU=- Proporcione el nombre distinguido de una unidad organizativa para crear la cuenta de ordenador. El formato exacto del nombre distinguido depende del software cliente y del software de afiliación. La parte del DSE raíz del nombre distinguido normalmente puede omitirse. -
--no-password- Únete automáticamente sin contraseña. -
--one-time-password=- Únase utilizando una contraseña de un solo uso. Esto no es posible con todos los tipos de reino. -
--client-software=- Sólo se une a los reinos que pueden ejecutar este software de cliente. Los valores válidos sonsssdywinbind. No todos los reinos admiten todos los valores. Por defecto, el software cliente se elige automáticamente. -
--server-software=- Únicamente se une a los reinos que pueden ejecutar este software de servidor. Los valores posibles sonactive-directoryofreeipa. -
--membership-software=- Utilice este programa cuando se una al reino. Los valores válidos sonsambayadcli. No todos los reinos admiten todos los valores. Por defecto, el software de afiliación se elige automáticamente.
H.5. Comandos Kickstart para el manejo del almacenamiento
Los comandos Kickstart de esta sección configuran aspectos del almacenamiento como dispositivos, discos, particiones, LVM y sistemas de archivos.
H.5.1. dispositivo (obsoleto)
El comando device Kickstart es opcional. Utilízalo para cargar módulos adicionales del kernel.
En la mayoría de los sistemas PCI, el programa de instalación detecta automáticamente las tarjetas Ethernet y SCSI. Sin embargo, en los sistemas más antiguos y en algunos sistemas PCI, Kickstart necesita una pista para encontrar los dispositivos adecuados. El comando device, que indica al programa de instalación que instale módulos adicionales, utiliza el siguiente formato:
Sintaxis
device moduleName --opts=optionsOpciones
- moduleName - Sustitúyase por el nombre del módulo del núcleo que debe instalarse.
--opts=- Opciones para pasar al módulo del núcleo. Por ejemplo:device --opts="aic152x=0x340 io=11"
H.5.2. autopartes
El comando autopart Kickstart es opcional. Crea automáticamente las particiones.
Las particiones creadas automáticamente son: una partición raíz (/) (1 GB o más), una partición swap y una partición /boot apropiada para la arquitectura. En unidades suficientemente grandes (50 GB o más), también se crea una partición /home.
Sintaxis
autopart OPTIONSOpciones
--type=- Selecciona uno de los esquemas de partición automática predefinidos que desea utilizar. Acepta los siguientes valores:-
lvm: El esquema de partición LVM. -
plain: Particiones normales sin LVM. -
thinp: El esquema de partición LVM Thin Provisioning.
-
-
--fstype=- Selecciona uno de los tipos de sistema de archivos disponibles. Los valores disponibles sonext2,ext3,ext4,xfsyvfat. El sistema de archivos por defecto esxfs. -
--nohome- Desactiva la creación automática de la partición/home. -
--nolvm- No utilizar LVM para el particionamiento automático. Esta opción es igual a--type=plain. -
--noboot- No cree una partición/boot. -
--noswap- No cree una partición de intercambio. --encrypted- Encripta todas las particiones con Linux Unified Key Setup (LUKS). Esto es equivalente a marcar la casilla Encrypt partitions en la pantalla inicial de particionamiento durante una instalación gráfica manual.NotaCuando se encriptan una o más particiones, Anaconda intenta reunir 256 bits de entropía para asegurar que las particiones están encriptadas de forma segura. La recopilación de entropía puede llevar algún tiempo - el proceso se detendrá después de un máximo de 10 minutos, independientemente de si se ha reunido suficiente entropía.
El proceso puede acelerarse interactuando con el sistema de instalación (escribiendo en el teclado o moviendo el ratón). Si está instalando en una máquina virtual, también puede adjuntar un dispositivo
virtio-rng(un generador virtual de números aleatorios) al huésped.-
--luks-version=LUKS_VERSION- Especifica qué versión del formato LUKS debe utilizarse para cifrar el sistema de archivos. Esta opción sólo tiene sentido si se especifica--encrypted. -
--passphrase=- Proporciona una frase de contraseña por defecto para todo el sistema para todos los dispositivos encriptados. -
--escrowcert=URL_of_X.509_certificate- Almacena las claves de encriptación de datos de todos los volúmenes encriptados como archivos en/root, encriptados utilizando el certificado X.509 de la URL especificada con URL_of_X.509_certificate. Las claves se almacenan como un archivo separado para cada volumen encriptado. Esta opción sólo tiene sentido si se especifica--encrypted. -
--backuppassphrase- Añade una frase de contraseña generada aleatoriamente a cada volumen cifrado. Almacena estas frases de contraseña en archivos separados en/root, encriptados usando el certificado X.509 especificado con--escrowcert. Esta opción sólo tiene sentido si se especifica--escrowcert. -
--cipher=- Especifica el tipo de encriptación a utilizar si el valor por defecto de Anacondaaes-xts-plain64no es satisfactorio. Debe utilizar esta opción junto con la opción--encrypted; por sí sola no tiene efecto. Los tipos de encriptación disponibles se enumeran en el documento Security hardening, pero Red Hat recomienda encarecidamente el uso deaes-xts-plain64oaes-cbc-essiv:sha256. -
--pbkdf=PBKDF- Establece el algoritmo de la Función de Derivación de Claves Basada en Contraseña (PBKDF) para la ranura de claves LUKS. Véase también la página de manual cryptsetup(8). Esta opción sólo tiene sentido si se especifica--encrypted. -
--pbkdf-memory=PBKDF_MEMORY- Establece el coste de memoria para PBKDF. Véase también la página de manual cryptsetup(8). Esta opción sólo tiene sentido si se especifica--encrypted. -
--pbkdf-time=PBKDF_TIME- Establece el número de milisegundos que se emplearán en el procesamiento de la frase de contraseña PBKDF. Véase también--iter-timeen la página de manual cryptsetup(8). Esta opción sólo tiene sentido si se especifica--encrypted, y es mutuamente excluyente con--pbkdf-iterations. -
--pbkdf-iterations=PBKDF_ITERATIONS- Establece el número de iteraciones directamente y evita el benchmark PBKDF. Véase también--pbkdf-force-iterationsen la página de manual cryptsetup(8). Esta opción sólo tiene sentido si se especifica--encrypted, y es mutuamente excluyente con--pbkdf-time.
Notas
-
La opción
autopartno puede utilizarse junto con las opcionespart/partition,raid,logvolovolgroupen el mismo archivo Kickstart. -
El comando
autopartno es obligatorio, pero debe incluirlo si no hay comandospartomounten su script Kickstart. -
Se recomienda utilizar la opción
autopart --nohomeKickstart cuando se instala en un solo DASD FBA del tipo CMS. Esto asegura que el programa de instalación no cree una partición separada/home. La instalación entonces procede con éxito. -
Si pierdes la frase de contraseña de LUKS, cualquier partición encriptada y sus datos son completamente inaccesibles. No hay forma de recuperar una frase de contraseña perdida. Sin embargo, puedes guardar las frases de contraseña de cifrado con la página
--escrowcerty crear frases de contraseña de cifrado de reserva con las opciones de--backuppassphrase.
H.5.3. cargador de arranque (obligatorio)
El comando bootloader Kickstart es necesario. Especifica cómo debe instalarse el gestor de arranque.
Sintaxis
bootloader [OPTIONS]Opciones
--append=- Especifica parámetros adicionales del núcleo. Para especificar varios parámetros, sepárelos con espacios. Por ejemplo:bootloader --location=mbr --append="hdd=ide-scsi ide=nodma"Los parámetros
rhgbyquietse añaden automáticamente cuando se instala el paqueteplymouth, aunque no los especifique aquí o no utilice el comando--append=. Para desactivar este comportamiento, desactive explícitamente la instalación deplymouth:%packages -plymouth %endEsta opción es útil para desactivar los mecanismos que se implementaron para mitigar las vulnerabilidades de ejecución especulativa Meltdown y Spectre encontradas en la mayoría de los procesadores modernos (CVE-2017-5754, CVE-2017-5753 y CVE-2017-5715). En algunos casos, estos mecanismos pueden ser innecesarios, y mantenerlos activados provoca una disminución del rendimiento sin mejorar la seguridad. Para desactivar estos mecanismos, añada las opciones para hacerlo en su archivo Kickstart - por ejemplo,
bootloader --append="nopti noibrs noibpb"en sistemas AMD64/Intel 64.AvisoAsegúrese de que su sistema no está en riesgo de ataque antes de desactivar cualquiera de los mecanismos de mitigación de vulnerabilidades. Consulte el artículo de respuesta a la vulnerabilidad de Red Hat para obtener información sobre las vulnerabilidades Meltdown y Spectre.
--boot-drive=- Especifica en qué unidad debe escribirse el gestor de arranque y, por tanto, desde qué unidad arrancará el ordenador. Si utiliza un dispositivo multipath como unidad de arranque, especifique el dispositivo utilizando su nombre disk/by-id/dm-uuid-mpath-WWID.ImportanteLa opción
--boot-drive=está siendo ignorada actualmente en las instalaciones de Red Hat Enterprise Linux en sistemas IBM Z que utilizan el cargador de arranquezipl. Cuando se instalazipl, éste determina la unidad de arranque por sí mismo.-
--leavebootorder- El programa de instalación añadirá Red Hat Enterprise Linux 8 al principio de la lista de sistemas instalados en el gestor de arranque y conservará todas las entradas existentes así como su orden. --driveorder=- Especifica qué unidad es la primera en el orden de arranque de la BIOS. Por ejemplo:bootloader --driveorder=sda,hda--location=- Especifica dónde se escribe el registro de arranque. Los valores válidos son los siguientes:mbr- La opción por defecto. Depende de si la unidad utiliza el esquema Master Boot Record (MBR) o GUID Partition Table (GPT):En un disco con formato GPT, esta opción instala la fase 1.5 del gestor de arranque en la partición de arranque de la BIOS.
En un disco con formato MBR, la etapa 1.5 se instala en el espacio vacío entre el MBR y la primera partición.
-
partition- Instala el gestor de arranque en el primer sector de la partición que contiene el kernel. -
none- No instale el gestor de arranque.
En la mayoría de los casos, no es necesario especificar esta opción.
-
--nombr- No instale el gestor de arranque en el MBR. --password=- Si utiliza GRUB2, establece la contraseña del cargador de arranque a la especificada con esta opción. Esto debería usarse para restringir el acceso al shell de GRUB2, donde se pueden pasar opciones arbitrarias del kernel.Si se especifica una contraseña, GRUB2 también pide un nombre de usuario. El nombre de usuario es siempre
root.--iscrypted- Normalmente, cuando se especifica una contraseña del gestor de arranque utilizando la opción--password=, ésta se almacena en el archivo Kickstart en texto plano. Si desea cifrar la contraseña, utilice esta opción y una contraseña cifrada.Para generar una contraseña encriptada, utilice el comando
grub2-mkpasswd-pbkdf2, introduzca la contraseña que desee utilizar y copie la salida del comando (el hash que comienza congrub.pbkdf2) en el archivo Kickstart. Un ejemplo de entrada de Kickstart enbootloadercon una contraseña encriptada se parece a lo siguiente:bootloader --iscrypted --password=grub.pbkdf2.sha512.10000.5520C6C9832F3AC3D149AC0B24BE69E2D4FB0DBEEDBD29CA1D30A044DE2645C4C7A291E585D4DC43F8A4D82479F8B95CA4BA4381F8550510B75E8E0BB2938990.C688B6F0EF935701FF9BD1A8EC7FE5BD2333799C98F28420C5CC8F1A2A233DE22C83705BB614EA17F3FDFDF4AC2161CEA3384E56EB38A2E39102F5334C47405E-
--timeout=- Especifica la cantidad de tiempo que el gestor de arranque espera antes de arrancar la opción por defecto (en segundos). -
--default=- Establece la imagen de arranque por defecto en la configuración del cargador de arranque. -
--extlinux- Utilizar el gestor de arranque extlinux en lugar de GRUB2. Esta opción sólo funciona en sistemas soportados por extlinux. -
--disabled- Esta opción es una versión más fuerte de--location=none. Mientras que--location=nonesimplemente desactiva la instalación del gestor de arranque,--disableddesactiva la instalación del gestor de arranque y también desactiva la instalación del paquete que contiene el gestor de arranque, ahorrando así espacio.
Notas
- Red Hat recomienda establecer una contraseña para el gestor de arranque en cada sistema. Un gestor de arranque desprotegido puede permitir a un potencial atacante modificar las opciones de arranque del sistema y obtener acceso no autorizado al mismo.
- En algunos casos, se requiere una partición especial para instalar el gestor de arranque en sistemas AMD64, Intel 64 y ARM de 64 bits. El tipo y tamaño de esta partición depende de si el disco en el que está instalando el gestor de arranque utiliza el esquema Master Boot Record (MBR) o una GUID Partition Table (GPT). Para más información, consulte la sección Configuración del gestor de arranque del documento Performing a standard RHEL installation.
Los nombres de los dispositivos en el
sdX(o/dev/sdX) no están garantizados para ser consistentes a través de los reinicios, lo que puede complicar el uso de algunos comandos de Kickstart. Cuando un comando pide un nombre de nodo de dispositivo, puede utilizar cualquier elemento de/dev/disk. Por ejemplo, en lugar de:part / --fstype=xfs --onpart=sda1Puede utilizar una entrada similar a una de las siguientes:
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1De este modo, el comando siempre se dirigirá al mismo dispositivo de almacenamiento. Esto es especialmente útil en entornos de almacenamiento grandes. Consulte el capítulo Visión general de los atributos de nomenclatura persistente en el documento Managing storage devices para obtener información más detallada sobre las diferentes formas de referirse de forma coherente a los dispositivos de almacenamiento.
-
La opción
--upgradeestá obsoleta en Red Hat Enterprise Linux 8.
H.5.4. zipl
El comando zipl Kickstart es opcional. Especifica la configuración de ZIPL para IBM Z.
Opciones
-
--secure-boot- Habilita el arranque seguro si es compatible con el sistema de instalación.
Cuando se instala en un sistema posterior a IBM z14, el sistema instalado no puede arrancarse desde un modelo IBM z14 o anterior.
-
--force-secure-boot- Activa el arranque seguro de forma incondicional.
La instalación no es compatible con IBM z14 y modelos anteriores.
-
--no-secure-boot- Desactiva el arranque seguro.
Secure Boot no es compatible con IBM z14 y modelos anteriores. Utilice --no-secure-boot si pretende arrancar el sistema instalado en IBM z14 y modelos anteriores.
H.5.5. clearpart
El comando clearpart Kickstart es opcional. Elimina las particiones del sistema, antes de la creación de nuevas particiones. Por defecto, no se elimina ninguna partición.
Sintaxis
clearpart OPTIONSOpciones
--all- Borra todas las particiones del sistema.Esta opción borrará todos los discos que puedan ser alcanzados por el programa de instalación, incluyendo cualquier almacenamiento de red conectado. Utilice esta opción con precaución.
Puede evitar que
clearpartborre el almacenamiento que desea conservar utilizando la opción--drives=y especificando sólo las unidades que desea borrar, adjuntando el almacenamiento de red más tarde (por ejemplo, en la sección%postdel archivo Kickstart), o bloqueando los módulos del kernel utilizados para acceder al almacenamiento de red.--drives=- Especifica de qué unidades se van a borrar las particiones. Por ejemplo, lo siguiente borra todas las particiones de las dos primeras unidades del controlador IDE primario:clearpart --drives=hda,hdb --allPara borrar un dispositivo multirruta, utilice el formato
disk/by-id/scsi-WWIDdonde WWID es el identificador mundial del dispositivo. Por ejemplo, para borrar un disco con WWID58095BEC5510947BE8C0360F604351918, utilice:clearpart --drives=disk/by-id/scsi-58095BEC5510947BE8C0360F604351918Este formato es preferible para todos los dispositivos multirruta, pero si surgen errores, los dispositivos multirruta que no utilizan la gestión de volúmenes lógicos (LVM) también pueden borrarse utilizando el formato
disk/by-id/dm-uuid-mpath-WWIDdonde WWID es el identificador mundial del dispositivo. Por ejemplo, para borrar un disco con WWID2416CD96995134CA5D787F00A5AA11017, utilice:clearpart --drives=disk/by-id/dm-uuid-mpath-2416CD96995134CA5D787F00A5AA11017Nunca especifique los dispositivos multipath con nombres de dispositivo como
mpatha. Este tipo de nombres de dispositivos no son específicos de un disco en particular. El disco llamado/dev/mpathadurante la instalación podría no ser el que usted espera que sea. Por lo tanto, el comandoclearpartpodría apuntar al disco equivocado.--initlabel- Inicializa un disco (o discos) creando una etiqueta de disco por defecto para todos los discos en su respectiva arquitectura que han sido designados para ser formateados (por ejemplo, msdos para x86). Dado que--initlabelpuede ver todos los discos, es importante asegurarse de que sólo se conecten las unidades que se van a formatear.clearpart --initlabel --drives=names_of_disksPor ejemplo:
clearpart --initlabel --drives=dasda,dasdb,dasdc--list=- Especifica qué particiones se van a borrar. Esta opción anula las opciones--ally--linuxsi se utilizan. Se puede utilizar en diferentes unidades. Por ejemplo:clearpart --list=sda2,sda3,sdb1-
--disklabel=LABEL- Establece la etiqueta de disco que se utilizará por defecto. Sólo se aceptarán las etiquetas de disco compatibles con la plataforma. Por ejemplo, en las arquitecturas Intel y AMD de 64 bits, se aceptan las etiquetas de discomsdosygpt, pero no se aceptadasd. -
--linux- Borra todas las particiones de Linux. -
--none(por defecto) - No eliminar ninguna partición. -
--cdl- Reformatea cualquier DASD LDL a formato CDL.
Notas
Los nombres de los dispositivos en el
sdX(o/dev/sdX) no están garantizados para ser consistentes a través de los reinicios, lo que puede complicar el uso de algunos comandos de Kickstart. Cuando un comando pide un nombre de nodo de dispositivo, puede utilizar cualquier elemento de/dev/disk. Por ejemplo, en lugar de:part / --fstype=xfs --onpart=sda1Podría utilizar una entrada similar a una de las siguientes:
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1De este modo, el comando siempre se dirigirá al mismo dispositivo de almacenamiento. Esto es especialmente útil en entornos de almacenamiento grandes. Consulte el capítulo Visión general de los atributos de nomenclatura persistente en el documento Managing storage devices para obtener información más detallada sobre las diferentes formas de referirse de forma coherente a los dispositivos de almacenamiento.
-
Si se utiliza el comando
clearpart, no se puede utilizar el comandopart --onparten una partición lógica.
H.5.6. fcoe
El comando fcoe Kickstart es opcional. Especifica qué dispositivos FCoE deben activarse automáticamente, además de los descubiertos por Enhanced Disk Drive Services (EDD).
Sintaxis
fcoe --nic=name [OPTIONS]Opciones
-
--nic=(obligatorio) - El nombre del dispositivo que se va a activar. -
--dcb=- Establecer la configuración del Data Center Bridging (DCB). -
--autovlan- Descubre las VLANs automáticamente. Esta opción está activada por defecto.
H.5.7. ignorado
El comando ignoredisk Kickstart es opcional. Hace que el programa de instalación ignore los discos especificados.
Esto es útil si usted utiliza el particionamiento automático y quiere estar seguro de que algunos discos son ignorados. Por ejemplo, sin ignoredisk, al intentar desplegar en un cluster SAN el Kickstart fallaría, ya que el programa de instalación detecta rutas pasivas a la SAN que no devuelven ninguna tabla de particiones.
Sintaxis
ignoredisk --drives=drive1,drive2,... | --only-use=driveOpciones
-
--drives=driveN,…- Sustituya driveN por uno de los siguientes:sda,sdb,...,hda,... y así sucesivamente. --only-use=driveN,…- Especifica una lista de discos para que el programa de instalación los utilice. Todos los demás discos se ignoran. Por ejemplo, para utilizar el discosdadurante la instalación e ignorar todos los demás discos:ignoredisk --only-use=sdaPara incluir un dispositivo multirruta que no utiliza LVM:
ignoredisk --only-use=disk/by-id/dm-uuid-mpath-2416CD96995134CA5D787F00A5AA11017Para incluir un dispositivo multirruta que utiliza LVM:
ignoredisk --only-use==/dev/disk/by-id/dm-uuid-mpath-bootloader --location=mbr
Debe especificar sólo uno de los --drives o --only-use.
Notas
-
La opción
--interactiveestá obsoleta en Red Hat Enterprise Linux 8. Esta opción permitía a los usuarios navegar manualmente por la pantalla de almacenamiento avanzado. Para ignorar un dispositivo multirruta que no utiliza la gestión de volúmenes lógicos (LVM), utilice el formato
disk/by-id/dm-uuid-mpath-WWID, donde WWID es el identificador mundial del dispositivo. Por ejemplo, para ignorar un disco con WWID2416CD96995134CA5D787F00A5AA11017, utilice:ignoredisk --drives=disk/by-id/dm-uuid-mpath-2416CD96995134CA5D787F00A5AA11017
-
Nunca especifique los dispositivos multipath con nombres de dispositivo como
mpatha. Este tipo de nombres de dispositivos no son específicos de un disco en particular. El disco llamado/dev/mpathadurante la instalación podría no ser el que usted espera que sea. Por lo tanto, el comandoclearpartpodría apuntar al disco equivocado. Los nombres de los dispositivos en el
sdX(o/dev/sdX) no están garantizados para ser consistentes a través de los reinicios, lo que puede complicar el uso de algunos comandos de Kickstart. Cuando un comando pide un nombre de nodo de dispositivo, puede utilizar cualquier elemento de/dev/disk. Por ejemplo, en lugar de:part / --fstype=xfs --onpart=sda1Puede utilizar una entrada similar a una de las siguientes:
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1De este modo, el comando siempre se dirigirá al mismo dispositivo de almacenamiento. Esto es especialmente útil en entornos de almacenamiento grandes. Consulte el capítulo Visión general de los atributos de nomenclatura persistente en el documento Managing storage devices para obtener información más detallada sobre las diferentes formas de referirse de forma coherente a los dispositivos de almacenamiento.
H.5.8. iscsi
El comando iscsi Kickstart es opcional. Especifica el almacenamiento iSCSI adicional que se debe conectar durante la instalación.
Sintaxis
iscsi --ipaddr=address [OPTIONS]Opciones obligatorias
-
--ipaddr=(obligatorio) - la dirección IP del objetivo a conectar.
Opciones opcionales
-
--port=(obligatorio) - el número de puerto. Si no está presente,--port=3260se utiliza automáticamente por defecto. -
--target=- el IQN de destino (iSCSI Qualified Name). -
--iface=- enlaza la conexión a una interfaz de red específica en lugar de utilizar la predeterminada determinada por la capa de red. Una vez utilizado, debe especificarse en todas las instancias del comandoiscsien todo el archivo Kickstart. -
--user=- el nombre de usuario requerido para autenticarse con el objetivo -
--password=- la contraseña que corresponde al nombre de usuario especificado para el objetivo -
--reverse-user=- el nombre de usuario requerido para autenticarse con el iniciador desde un objetivo que utiliza la autenticación CHAP inversa -
--reverse-password=- la contraseña que se corresponde con el nombre de usuario especificado para el iniciador
Notas
-
Si utiliza el comando
iscsi, también debe asignar un nombre al nodo iSCSI, utilizando el comandoiscsiname. El comandoiscsinamedebe aparecer antes del comandoiscsien el archivo Kickstart. -
Siempre que sea posible, configure el almacenamiento iSCSI en la BIOS o el firmware del sistema (iBFT para sistemas Intel) en lugar de utilizar el comando
iscsi. Anaconda detecta y utiliza automáticamente los discos configurados en la BIOS o el firmware y no es necesaria ninguna configuración especial en el archivo Kickstart. -
Si tiene que utilizar el comando
iscsi, asegúrese de que la conexión en red está activada al principio de la instalación y de que el comandoiscsiaparece en el archivo Kickstart before se refiere a los discos iSCSI con comandos comoclearpartoignoredisk.
H.5.9. iscsiname
El comando iscsiname Kickstart es opcional. Asigna un nombre a un nodo iSCSI especificado por el comando iscsi.
Sintaxis
iscsiname iqnameOpciones
-
iqname- Nombre a asignar al nodo iSCSI.
Notas
-
Si utiliza el comando
iscsien su archivo Kickstart, debe especificariscsinameearlier en el archivo Kickstart.
H.5.10. logvol
El comando logvol Kickstart es opcional. Crea un volumen lógico para Logical Volume Management (LVM).
Sintaxis
logvol mntpoint --vgname=name --name=name [OPTIONS]Opciones obligatorias
mntpoint- El punto de montaje donde se monta la partición. Debe ser de una de las siguientes formas:/pathPor ejemplo,
/o/homeswapLa partición se utiliza como espacio de intercambio.
Para determinar el tamaño de la partición de intercambio automáticamente, utilice la opción
--recommended:swap --recommendedPara determinar el tamaño de la partición de intercambio automáticamente y también dejar espacio extra para que su sistema hiberne, utilice la opción
--hibernation:swap --hibernationEl tamaño asignado será equivalente al espacio de intercambio asignado por
--recommendedmás la cantidad de RAM de su sistema.Para conocer los tamaños de swap asignados por estos comandos, consulte Sección C.4, “Esquema de partición recomendado” para sistemas AMD64, Intel 64 y ARM de 64 bits.
-
--vgname=name- nombre del grupo de volúmenes. -
--name=name- nombre del volumen lógico.
Opciones opcionales
-
--noformat- Utilice un volumen lógico existente y no lo formatee. -
--useexisting- Utilizar un volumen lógico existente y reformatearlo. -
--fstype=- Establece el tipo de sistema de archivos para el volumen lógico. Los valores válidos sonxfs,ext2,ext3,ext4,swapyvfat. -
--fsoptions=- Especifica una cadena de opciones de forma libre que se utilizará al montar el sistema de archivos. Esta cadena se copiará en el archivo/etc/fstabdel sistema instalado y debe ir entre comillas. -
--mkfsoptions=- Especifica los parámetros adicionales que se pasarán al programa que crea un sistema de archivos en esta partición. No se procesa la lista de argumentos, por lo que deben suministrarse en un formato que pueda pasarse directamente al programa mkfs. Esto significa que las opciones múltiples deben estar separadas por comas o rodeadas por comillas dobles, dependiendo del sistema de archivos. -
--fsprofile=- Especifica un tipo de uso que se pasa al programa que crea un sistema de archivos en esta partición. Un tipo de uso define una variedad de parámetros de ajuste que se utilizarán cuando se cree un sistema de archivos. Para que esta opción funcione, el sistema de archivos debe soportar el concepto de tipos de uso y debe haber un archivo de configuración que liste los tipos válidos. Paraext2,ext3, yext4, este archivo de configuración es/etc/mke2fs.conf. -
--label=- Establece una etiqueta para el volumen lógico. -
--grow- Amplía el volumen lógico para que ocupe el espacio disponible (si lo hay), o hasta el tamaño máximo especificado, si lo hay. Esta opción debe utilizarse sólo si se ha preasignado un espacio mínimo de almacenamiento en la imagen de disco, y se desea que el volumen crezca y ocupe el espacio disponible. En un entorno físico, se trata de una acción única. Sin embargo, en un entorno virtual, el tamaño del volumen aumenta a medida que la máquina virtual escribe cualquier dato en el disco virtual. -
--size=- El tamaño del volumen lógico en MiB. Esta opción no puede utilizarse junto con la opción--percent=. --percent=- El tamaño del volumen lógico, como porcentaje del espacio libre en el grupo de volúmenes después de tener en cuenta cualquier volumen lógico de tamaño estático. Esta opción no puede utilizarse junto con la opción--size=.ImportanteAl crear un nuevo volumen lógico, debes especificar su tamaño de forma estática utilizando la opción
--size=, o como un porcentaje del espacio libre restante utilizando la opción--percent=. No puedes utilizar ambas opciones en el mismo volumen lógico.-
--maxsize=- El tamaño máximo en MiB cuando el volumen lógico está configurado para crecer. Especifique aquí un valor entero como500(no incluya la unidad). -
--recommended- Use esta opción cuando cree un volumen lógico para determinar el tamaño de este volumen automáticamente, basado en el hardware de su sistema. Para obtener detalles sobre el esquema recomendado, consulte Sección C.4, “Esquema de partición recomendado” para sistemas AMD64, Intel 64 y ARM de 64 bits. -
--resize- Redimensiona un volumen lógico. Si utiliza esta opción, debe especificar también--useexistingy--size. --encrypted- Especifica que este volumen lógico debe ser encriptado con Linux Unified Key Setup (LUKS), utilizando la frase de contraseña proporcionada en la opción--passphrase=. Si no se especifica una frase de contraseña, el programa de instalación utiliza la frase de contraseña predeterminada para todo el sistema establecida con el comandoautopart --passphrase, o detiene la instalación y le pide que proporcione una frase de contraseña si no se establece ninguna predeterminada.NotaCuando se encriptan una o más particiones, Anaconda intenta reunir 256 bits de entropía para asegurar que las particiones están encriptadas de forma segura. La recopilación de entropía puede llevar algún tiempo - el proceso se detendrá después de un máximo de 10 minutos, independientemente de si se ha reunido suficiente entropía.
El proceso puede acelerarse interactuando con el sistema de instalación (escribiendo en el teclado o moviendo el ratón). Si está instalando en una máquina virtual, también puede adjuntar un dispositivo
virtio-rng(un generador virtual de números aleatorios) al huésped.-
--passphrase=- Especifica la frase de contraseña que se utilizará al cifrar este volumen lógico. Debe utilizar esta opción junto con la opción--encrypted; no tiene efecto por sí sola. -
--cipher=- Especifica el tipo de encriptación a utilizar si el valor por defecto de Anacondaaes-xts-plain64no es satisfactorio. Debe utilizar esta opción junto con la opción--encrypted; por sí sola no tiene efecto. Los tipos de encriptación disponibles se enumeran en el documento Security hardening, pero Red Hat recomienda encarecidamente el uso deaes-xts-plain64oaes-cbc-essiv:sha256. -
--escrowcert=URL_of_X.509_certificate- Almacena las claves de encriptación de datos de todos los volúmenes encriptados como archivos en/root, encriptados utilizando el certificado X.509 de la URL especificada con URL_of_X.509_certificate. Las claves se almacenan como un archivo separado para cada volumen encriptado. Esta opción sólo tiene sentido si se especifica--encrypted. -
--luks-version=LUKS_VERSION- Especifica qué versión del formato LUKS debe utilizarse para cifrar el sistema de archivos. Esta opción sólo tiene sentido si se especifica--encrypted. -
--backuppassphrase- Añade una frase de contraseña generada aleatoriamente a cada volumen cifrado. Almacene estas frases de contraseña en archivos separados en/root, encriptados usando el certificado X.509 especificado con--escrowcert. Esta opción sólo tiene sentido si se especifica--escrowcert. -
--pbkdf=PBKDF- Establece el algoritmo de la Función de Derivación de Claves Basada en Contraseña (PBKDF) para la ranura de claves LUKS. Véase también la página de manual cryptsetup(8). Esta opción sólo tiene sentido si se especifica--encrypted. -
--pbkdf-memory=PBKDF_MEMORY- Establece el coste de memoria para PBKDF. Véase también la página de manual cryptsetup(8). Esta opción sólo tiene sentido si se especifica--encrypted. -
--pbkdf-time=PBKDF_TIME- Establece el número de milisegundos que se emplearán en el procesamiento de la frase de contraseña PBKDF. Véase también--iter-timeen la página de manual cryptsetup(8). Esta opción sólo tiene sentido si se especifica--encrypted, y es mutuamente excluyente con--pbkdf-iterations. -
--pbkdf-iterations=PBKDF_ITERATIONS- Establece el número de iteraciones directamente y evita el benchmark PBKDF. Véase también--pbkdf-force-iterationsen la página de manual cryptsetup(8). Esta opción sólo tiene sentido si se especifica--encrypted, y es mutuamente excluyente con--pbkdf-time. -
--thinpool- Crea un volumen lógico de reserva delgada. (Utiliza un punto de montaje denone) -
--metadatasize=size- Especifique el tamaño del área de metadatos (en MiB) para un nuevo dispositivo thin pool. -
--chunksize=size- Especifica el tamaño del chunk (en KiB) para un nuevo dispositivo de thin pool. -
--thin- Crear un volumen lógico delgado. (Requiere el uso de--poolname) -
--poolname=name- Especifique el nombre de la reserva delgada en la que se va a crear un volumen lógico delgado. Requiere la opción--thin. -
--profile=name- Especifica el nombre del perfil de configuración que se utilizará con los volúmenes lógicos finos. Si se utiliza, el nombre también se incluirá en los metadatos del volumen lógico dado. Por defecto, los perfiles disponibles sondefaultythin-performancey están definidos en el directorio/etc/lvm/profile/. Consulte la página de manuallvm(8)para obtener información adicional. -
--cachepvs=- Una lista separada por comas de los volúmenes físicos que deben utilizarse como caché para este volumen. --cachemode=- Especifica el modo que se debe utilizar para almacenar en caché este volumen lógico - ya seawritebackowritethrough.NotaPara obtener más información sobre los volúmenes lógicos en caché y sus modos, consulte la página de manual
lvmcache(7).-
--cachesize=- Tamaño de la caché adjunta al volumen lógico, especificado en MiB. Esta opción requiere la opción--cachepvs=.
Notas
No utilice el carácter guión (
-) en los nombres de volúmenes lógicos y grupos de volúmenes cuando instale Red Hat Enterprise Linux utilizando Kickstart. Si se utiliza este carácter, la instalación termina normalmente, pero el directorio/dev/mapper/listará estos volúmenes y grupos de volúmenes con cada guión duplicado. Por ejemplo, un grupo de volúmenes llamadovolgrp-01que contiene un volumen lógico llamadologvol-01será listado como/dev/mapper/volgrp—01-logvol—01.Esta limitación sólo se aplica a los nombres de volúmenes lógicos y grupos de volúmenes recién creados. Si se reutilizan los existentes utilizando la opción
--noformat, sus nombres no se modificarán.-
Si pierdes la frase de contraseña de LUKS, cualquier partición encriptada y sus datos son completamente inaccesibles. No hay forma de recuperar una frase de contraseña perdida. Sin embargo, puedes guardar las frases de contraseña de cifrado con la página
--escrowcerty crear frases de contraseña de cifrado de reserva con las opciones de--backuppassphrase.
Ejemplos
Cree primero la partición, cree el grupo de volúmenes lógicos y luego cree el volumen lógico:
part pv.01 --size 3000 volgroup myvg pv.01 logvol / --vgname=myvg --size=2000 --name=rootvolCree primero la partición, cree el grupo de volúmenes lógicos y luego cree el volumen lógico para que ocupe el 90% del espacio restante en el grupo de volúmenes:
part pv.01 --size 1 --grow volgroup myvg pv.01 logvol / --vgname=myvg --name=rootvol --percent=90
Recursos adicionales
- Para más información sobre LVM, consulte el documento Configuración y gestión de volúmenes lógicos.
H.5.11. monte
El comando mount Kickstart es opcional. Asigna un punto de montaje a un dispositivo de bloque existente y, opcionalmente, lo reformatea a un formato determinado.
Sintaxis
mount [OPTIONS] device mountpointOpciones obligatorias:
-
device- El dispositivo de bloque a montar. -
mountpoint- Dónde montar eldevice. Debe ser un punto de montaje válido, como/o/usr, ononesi el dispositivo no es montable (por ejemploswap).
Opciones opcionales:
-
--reformat=- Especifica un nuevo formato (comoext4) al que se debe reformatear el dispositivo. -
--mkfsoptions=- Especifica las opciones adicionales que se pasarán al comando que crea el nuevo sistema de archivos especificado en--reformat=. La lista de opciones proporcionada aquí no se procesa, por lo que deben especificarse en un formato que pueda pasarse directamente al programamkfs. La lista de opciones debe estar separada por comas o rodeada por comillas dobles, dependiendo del sistema de archivos. Consulte la página de manualmkfspara el sistema de archivos que desee crear (por ejemplo,mkfs.ext4(8)omkfs.xfs(8)) para obtener detalles específicos. -
--mountoptions=- Especifica una cadena de forma libre que contiene las opciones que se utilizarán al montar el sistema de archivos. La cadena se copiará en el archivo/etc/fstabdel sistema instalado y debe ir entre comillas dobles. Consulte la página de manualmount(8)para obtener una lista completa de opciones de montaje, yfstab(5)para lo básico.
Notas
-
A diferencia de la mayoría de los otros comandos de configuración de almacenamiento en Kickstart,
mountno requiere que describa toda la configuración de almacenamiento en el archivo Kickstart. Sólo necesita asegurarse de que el dispositivo de bloque descrito existe en el sistema. Sin embargo, si desea create la pila de almacenamiento con todos los dispositivos montados, debe utilizar otros comandos comopartpara hacerlo. -
No puede utilizar
mountjunto con otros comandos relacionados con el almacenamiento, comopart,logvoloautoparten el mismo archivo Kickstart.
H.5.12. nvdimm
El comando nvdimm Kickstart es opcional. Realiza una acción en los dispositivos del módulo de memoria en línea doble no volátil (NVDIMM).
Sintaxis
nvdimm action [OPTIONS]Acciones
reconfigure- Reconfigura un dispositivo NVDIMM específico en un modo determinado. Además, el dispositivo especificado se marca implícitamente como a utilizar, por lo que un comandonvdimm useposterior para el mismo dispositivo es redundante. Esta acción utiliza el siguiente formato:nvdimm reconfigure [--namespace=NAMESPACE] [--mode=MODE] [--sectorsize=SECTORSIZE]--namespace=- La especificación del dispositivo por espacio de nombres. Por ejemplo:nvdimm reconfigure --namespace=namespace0.0 --mode=sector --sectorsize=512-
--mode=- La especificación del modo. Actualmente, sólo está disponible el valorsector. --sectorsize=- Tamaño de un sector para el modo de sector. Por ejemplo:nvdimm reconfigure --namespace=namespace0.0 --mode=sector --sectorsize=512Los tamaños de sector admitidos son 512 y 4096 bytes.
use- Especifica un dispositivo NVDIMM como objetivo de la instalación. El dispositivo debe estar ya configurado en modo sectorial mediante el comandonvdimm reconfigure. Esta acción utiliza el siguiente formato:nvdimm use [--namespace=NAMESPACE|--blockdevs=DEVICES]--namespace=- Especifica el dispositivo por espacio de nombres. Por ejemplo:nvdimm use --namespace=namespace0.0--blockdevs=- Especifica una lista separada por comas de dispositivos de bloque correspondientes a los dispositivos NVDIMM que se van a utilizar. Se admite el comodín asterisco*. Por ejemplo:nvdimm use --blockdevs=pmem0s,pmem1s nvdimm use --blockdevs=pmem*
Notas
-
Por defecto, todos los dispositivos NVDIMM son ignorados por el programa de instalación. Debe utilizar el comando
nvdimmpara habilitar la instalación en estos dispositivos.
H.5.13. parte o partición
Se requiere el comando part o partition Kickstart. Crea una partición en el sistema.
Sintaxis
part|partition mntpoint --name=name --device=device --rule=rule [OPTIONS]Opciones
mntpoint - Dónde está montada la partición. El valor debe ser de una de las siguientes formas:
/pathPor ejemplo,
/,/usr,/homeswapLa partición se utiliza como espacio de intercambio.
Para determinar el tamaño de la partición de intercambio automáticamente, utilice la opción
--recommended:swap --recommendedEl tamaño asignado será efectivo pero no estará calibrado con precisión para su sistema.
Para determinar el tamaño de la partición de intercambio de forma automática, pero también para dejar espacio extra para que su sistema pueda hibernar, utilice la opción
--hibernation:swap --hibernationEl tamaño asignado será equivalente al espacio de intercambio asignado por
--recommendedmás la cantidad de RAM de su sistema.Para conocer los tamaños de swap asignados por estos comandos, consulte Sección C.4, “Esquema de partición recomendado” para sistemas AMD64, Intel 64 y ARM de 64 bits.
raid.idLa partición se utiliza para el RAID por software (véase
raid).pv.idLa partición se utiliza para LVM (véase
logvol).biosbootLa partición se utilizará para una partición de arranque de la BIOS. Es necesaria una partición de arranque de la BIOS de 1 MiB en los sistemas AMD64 e Intel 64 basados en BIOS que utilizan una tabla de particiones GUID (GPT); el gestor de arranque se instalará en ella. No es necesario en sistemas UEFI. Consulte también el comando
bootloader./boot/efiUna partición del sistema EFI. Una partición EFI de 50 MiB es necesaria en sistemas UEFI basados en AMD64, Intel 64 y ARM de 64 bits; el tamaño recomendado es de 200 MiB. No es necesario en los sistemas BIOS. Consulte también el comando
bootloader.
--size=- El tamaño mínimo de la partición en MiB. Especifique aquí un valor entero como500(no incluya la unidad).ImportanteSi el valor de
--sizees demasiado pequeño, la instalación falla. Establezca el valor--sizecomo la cantidad mínima de espacio que necesita. Para conocer las recomendaciones de tamaño, consulte Sección C.4, “Esquema de partición recomendado”.--grow- Indica a la partición que crezca hasta llenar el espacio disponible (si lo hay), o hasta la configuración del tamaño máximo, si se especifica uno.NotaSi utiliza
--grow=sin configurar--maxsize=en una partición de intercambio, Anaconda limita el tamaño máximo de la partición de intercambio. Para los sistemas que tienen menos de 2 GB de memoria física, el límite impuesto es el doble de la cantidad de memoria física. Para sistemas con más de 2 GB, el límite impuesto es el tamaño de la memoria física más 2GB.-
--maxsize=- El tamaño máximo de la partición en MiB cuando la partición está configurada para crecer. Especifique aquí un valor entero como500(no incluya la unidad). -
--noformat- Especifica que la partición no debe ser formateada, para su uso con el comando--onpart. --onpart=o--usepart=- Especifica el dispositivo en el que colocar la partición. Utiliza un dispositivo existente en blanco y lo formatea al nuevo tipo especificado. Por ejemplo:partition /home --onpart=hda1pone
/homeen/dev/hda1.Estas opciones también pueden añadir una partición a un volumen lógico. Por ejemplo:
partition pv.1 --onpart=hda2El dispositivo debe existir ya en el sistema; la opción
--onpartno lo creará.También es posible especificar una unidad completa, en lugar de una partición, en cuyo caso Anaconda formateará y utilizará la unidad sin crear una tabla de particiones. Tenga en cuenta, sin embargo, que la instalación de GRUB2 no es compatible con un dispositivo formateado de esta manera, y debe ser colocado en una unidad con una tabla de particiones.
partition pv.1 --onpart=hdb--ondisk=o--ondrive=- Crea una partición (especificada por el comandopart) en un disco existente. Fuerza la creación de la partición en un disco en particular. Por ejemplo,--ondisk=sdbpone la partición en el segundo disco SCSI del sistema.Para especificar un dispositivo multirruta que no utiliza la gestión de volúmenes lógicos (LVM), utilice el formato
disk/by-id/dm-uuid-mpath-WWIDdonde WWID es el identificador mundial del dispositivo. Por ejemplo, para especificar un disco con WWID2416CD96995134CA5D787F00A5AA11017, utilice:part / --fstype=xfs --grow --asprimary --size=8192 --ondisk=disk/by-id/dm-uuid-mpath-2416CD96995134CA5D787F00A5AA11017AvisoNunca especifique los dispositivos multipath con nombres de dispositivo como
mpatha. Este tipo de nombres de dispositivos no son específicos de un disco en particular. El disco llamado/dev/mpathadurante la instalación podría no ser el que usted espera que sea. Por lo tanto, el comandoclearpartpodría apuntar al disco equivocado.-
--asprimary- Fuerza a la partición a ser asignada como una partición primary. Si la partición no se puede asignar como primaria (normalmente debido a que ya hay demasiadas particiones primarias asignadas), el proceso de particionado falla. Esta opción sólo tiene sentido cuando el disco utiliza un registro de arranque maestro (MBR); para los discos etiquetados con una tabla de particiones GUID (GPT) esta opción no tiene sentido. -
--fsprofile=- Especifica un tipo de uso que se pasa al programa que crea un sistema de archivos en esta partición. Un tipo de uso define una variedad de parámetros de ajuste que se utilizarán cuando se cree un sistema de archivos. Para que esta opción funcione, el sistema de archivos debe soportar el concepto de tipos de uso y debe haber un archivo de configuración que liste los tipos válidos. Paraext2,ext3,ext4, este archivo de configuración es/etc/mke2fs.conf. -
--mkfsoptions=- Especifica los parámetros adicionales que se pasarán al programa que hace un sistema de archivos en esta partición. Es similar a--fsprofilepero funciona para todos los sistemas de ficheros, no sólo para los que soportan el concepto de perfil. No se procesa la lista de argumentos, por lo que deben suministrarse en un formato que pueda pasarse directamente al programa mkfs. Esto significa que las opciones múltiples deben estar separadas por comas o rodeadas por comillas dobles, dependiendo del sistema de archivos. -
--fstype=- Establece el tipo de sistema de archivos para la partición. Los valores válidos sonxfs,ext2,ext3,ext4,swap,vfat,efiybiosboot. -
--fsoptions- Especifica una cadena de opciones de forma libre que se utilizará al montar el sistema de archivos. Esta cadena se copiará en el archivo/etc/fstabdel sistema instalado y debe ir entre comillas. -
--label=- asigna una etiqueta a una partición individual. --recommended- Determina el tamaño de la partición automáticamente. Para obtener detalles sobre el esquema recomendado, consulte Sección C.4, “Esquema de partición recomendado” para AMD64, Intel 64 y ARM de 64 bits.ImportanteEsta opción sólo se puede utilizar para las particiones que dan lugar a un sistema de archivos, como la partición
/booty el espacioswap. No se puede utilizar para crear volúmenes físicos LVM o miembros RAID.-
--onbiosdisk- Obliga a crear la partición en un disco concreto descubierto por la BIOS. --encrypted- Especifica que esta partición debe ser encriptada con Linux Unified Key Setup (LUKS), utilizando la frase de contraseña proporcionada en la opción--passphrase. Si no se especifica una frase de contraseña, Anaconda utiliza la frase de contraseña por defecto, para todo el sistema, establecida con el comandoautopart --passphrase, o detiene la instalación y le pide que proporcione una frase de contraseña si no se establece ninguna por defecto.NotaCuando se encriptan una o más particiones, Anaconda intenta reunir 256 bits de entropía para asegurar que las particiones están encriptadas de forma segura. La recopilación de entropía puede llevar algún tiempo - el proceso se detendrá después de un máximo de 10 minutos, independientemente de si se ha reunido suficiente entropía.
El proceso puede acelerarse interactuando con el sistema de instalación (escribiendo en el teclado o moviendo el ratón). Si está instalando en una máquina virtual, también puede adjuntar un dispositivo
virtio-rng(un generador virtual de números aleatorios) al huésped.-
--luks-version=LUKS_VERSION- Especifica qué versión del formato LUKS debe utilizarse para cifrar el sistema de archivos. Esta opción sólo tiene sentido si se especifica--encrypted. -
--passphrase=- Especifica la frase de contraseña que se utilizará al cifrar esta partición. Debe utilizar esta opción junto con la opción--encrypted; por sí sola no tiene efecto. -
--cipher=- Especifica el tipo de encriptación a utilizar si el valor por defecto de Anacondaaes-xts-plain64no es satisfactorio. Debe utilizar esta opción junto con la opción--encrypted; por sí sola no tiene efecto. Los tipos de encriptación disponibles se enumeran en el documento Security hardening, pero Red Hat recomienda encarecidamente el uso deaes-xts-plain64oaes-cbc-essiv:sha256. -
--escrowcert=URL_of_X.509_certificate- Almacena las claves de encriptación de datos de todas las particiones encriptadas como archivos en/root, encriptadas utilizando el certificado X.509 de la URL especificada con URL_of_X.509_certificate. Las claves se almacenan como un archivo separado para cada partición encriptada. Esta opción sólo tiene sentido si se especifica--encrypted. -
--backuppassphrase- Añade una frase de contraseña generada aleatoriamente a cada partición cifrada. Almacene estas frases de contraseña en archivos separados en/root, encriptadas usando el certificado X.509 especificado con--escrowcert. Esta opción sólo tiene sentido si se especifica--escrowcert. -
--pbkdf=PBKDF- Establece el algoritmo de la Función de Derivación de Claves Basada en Contraseña (PBKDF) para la ranura de claves LUKS. Véase también la página de manual cryptsetup(8). Esta opción sólo tiene sentido si se especifica--encrypted. -
--pbkdf-memory=PBKDF_MEMORY- Establece el coste de memoria para PBKDF. Véase también la página de manual cryptsetup(8). Esta opción sólo tiene sentido si se especifica--encrypted. -
--pbkdf-time=PBKDF_TIME- Establece el número de milisegundos que se emplearán en el procesamiento de la frase de contraseña PBKDF. Véase también--iter-timeen la página de manual cryptsetup(8). Esta opción sólo tiene sentido si se especifica--encrypted, y es mutuamente excluyente con--pbkdf-iterations. -
--pbkdf-iterations=PBKDF_ITERATIONS- Establece el número de iteraciones directamente y evita el benchmark PBKDF. Véase también--pbkdf-force-iterationsen la página de manual cryptsetup(8). Esta opción sólo tiene sentido si se especifica--encrypted, y es mutuamente excluyente con--pbkdf-time. -
--resize=- Redimensiona una partición existente. Cuando utilice esta opción, especifique el tamaño objetivo (en MiB) utilizando la opción--size=y la partición objetivo utilizando la opción--onpart=.
Notas
-
El comando
partno es obligatorio, pero debe incluirpart,autopartomounten su script Kickstart. -
La opción
--activeestá obsoleta en Red Hat Enterprise Linux 8. - Si la partición falla por cualquier motivo, aparecen mensajes de diagnóstico en la consola virtual 3.
-
Todas las particiones creadas se formatean como parte del proceso de instalación, a menos que se utilicen
--noformaty--onpart. Los nombres de los dispositivos en el
sdX(o/dev/sdX) no están garantizados para ser consistentes a través de los reinicios, lo que puede complicar el uso de algunos comandos de Kickstart. Cuando un comando pide un nombre de nodo de dispositivo, puede utilizar cualquier elemento de/dev/disk. Por ejemplo, en lugar de:part / --fstype=xfs --onpart=sda1Podría utilizar una entrada similar a una de las siguientes:
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1De este modo, el comando siempre se dirigirá al mismo dispositivo de almacenamiento. Esto es especialmente útil en entornos de almacenamiento grandes. Consulte el capítulo Visión general de los atributos de nomenclatura persistente en el documento Managing storage devices para obtener información más detallada sobre las diferentes formas de referirse de forma coherente a los dispositivos de almacenamiento.
-
Si pierdes la frase de contraseña de LUKS, cualquier partición encriptada y sus datos son completamente inaccesibles. No hay forma de recuperar una frase de contraseña perdida. Sin embargo, puedes guardar las frases de contraseña de cifrado con la página
--escrowcerty crear frases de contraseña de cifrado de reserva con las opciones de--backuppassphrase.
H.5.14. raid
El comando raid Kickstart es opcional. Monta un dispositivo RAID por software.
Sintaxis
raid mntpoint --level=level --device=device-name partitions*Opciones
mntpoint - Ubicación donde se monta el sistema de archivos RAID. Si es
/, el nivel RAID debe ser 1 a menos que haya una partición de arranque (/boot). Si hay una partición de arranque, la partición/bootdebe ser de nivel 1 y la partición raíz (/) puede ser de cualquiera de los tipos disponibles. El partitions* (que denota que se pueden listar múltiples particiones) enumera los identificadores RAID a añadir a la matriz RAID.ImportanteEn IBM Power Systems, si se ha preparado un dispositivo RAID y no se ha reformateado durante la instalación, asegúrese de que la versión de los metadatos RAID es
0.90si pretende poner las particiones/bootyPRePen el dispositivo RAID.La versión de metadatos por defecto de Red Hat Enterprise Linux 7
mdadmno es compatible con el dispositivo de arranque.-
--level=- Nivel RAID a utilizar (0, 1, 4, 5, 6 o 10). Consulte Sección C.3, “Tipos de RAID soportados” para obtener información sobre los distintos niveles RAID disponibles. --device=- Nombre del dispositivo RAID a utilizar - por ejemplo,--device=root.ImportanteNo utilice nombres de
mdraiden forma demd0- estos nombres no están garantizados para ser persistentes. En su lugar, utilice nombres significativos comorootoswap. El uso de nombres significativos crea un enlace simbólico desde/dev/md/namea cualquier nodo/dev/mdXnodo que se asigne a la matriz.Si tiene una matriz antigua (v0.90 de metadatos) a la que no puede asignar un nombre, puede especificar la matriz mediante una etiqueta de sistema de archivos o UUID (por ejemplo,
--device=rhel7-root --label=rhel7-root).-
--chunksize=- Establece el tamaño de los trozos de un almacenamiento RAID en KiB. En ciertas situaciones, el uso de un tamaño de chunk diferente al predeterminado (512 Kib) puede mejorar el rendimiento del RAID. -
--spares=- Especifica el número de unidades de repuesto asignadas a la matriz RAID. Las unidades de repuesto se utilizan para reconstruir la matriz en caso de fallo de la unidad. -
--fsprofile=- Especifica un tipo de uso que se pasa al programa que crea un sistema de archivos en esta partición. Un tipo de uso define una variedad de parámetros de ajuste que se utilizarán cuando se cree un sistema de archivos. Para que esta opción funcione, el sistema de archivos debe soportar el concepto de tipos de uso y debe haber un archivo de configuración que liste los tipos válidos. Para ext2, ext3 y ext4, este archivo de configuración es/etc/mke2fs.conf. -
--fstype=- Establece el tipo de sistema de archivos para la matriz RAID. Los valores válidos sonxfs,ext2,ext3,ext4,swap, yvfat. -
--fsoptions=- Especifica una cadena de opciones de forma libre que se utilizará al montar el sistema de archivos. Esta cadena se copiará en el archivo/etc/fstabdel sistema instalado y debe ir entre comillas. -
--mkfsoptions=- Especifica los parámetros adicionales que se pasarán al programa que crea un sistema de archivos en esta partición. No se procesa la lista de argumentos, por lo que deben suministrarse en un formato que pueda pasarse directamente al programa mkfs. Esto significa que las opciones múltiples deben estar separadas por comas o rodeadas por comillas dobles, dependiendo del sistema de archivos. -
--label=- Especifica la etiqueta que se va a dar al sistema de archivos que se va a crear. Si la etiqueta dada ya está en uso por otro sistema de archivos, se creará una nueva etiqueta. -
--noformat- Utilice un dispositivo RAID existente y no formatee la matriz RAID. -
--useexisting- Utilizar un dispositivo RAID existente y reformatearlo. --encrypted- Especifica que este dispositivo RAID debe ser encriptado con Linux Unified Key Setup (LUKS), utilizando la frase de contraseña proporcionada en la opción--passphrase. Si no se especifica una frase de contraseña, Anaconda utiliza la frase de contraseña por defecto, para todo el sistema, establecida con el comandoautopart --passphrase, o detiene la instalación y le pide que proporcione una frase de contraseña si no se establece ninguna por defecto.NotaCuando se encriptan una o más particiones, Anaconda intenta reunir 256 bits de entropía para asegurar que las particiones están encriptadas de forma segura. La recopilación de entropía puede llevar algún tiempo - el proceso se detendrá después de un máximo de 10 minutos, independientemente de si se ha reunido suficiente entropía.
El proceso puede acelerarse interactuando con el sistema de instalación (escribiendo en el teclado o moviendo el ratón). Si está instalando en una máquina virtual, también puede adjuntar un dispositivo
virtio-rng(un generador virtual de números aleatorios) al huésped.-
--luks-version=LUKS_VERSION- Especifica qué versión del formato LUKS debe utilizarse para cifrar el sistema de archivos. Esta opción sólo tiene sentido si se especifica--encrypted. -
--cipher=- Especifica el tipo de encriptación a utilizar si el valor por defecto de Anacondaaes-xts-plain64no es satisfactorio. Debe utilizar esta opción junto con la opción--encrypted; por sí sola no tiene efecto. Los tipos de encriptación disponibles se enumeran en el documento Security hardening, pero Red Hat recomienda encarecidamente el uso deaes-xts-plain64oaes-cbc-essiv:sha256. -
--passphrase=- Especifica la frase de contraseña que se utilizará al cifrar este dispositivo RAID. Debe utilizar esta opción junto con la opción--encrypted; por sí sola no tiene ningún efecto. -
--escrowcert=URL_of_X.509_certificate- Almacenar la clave de cifrado de datos para este dispositivo en un archivo en/root, cifrado utilizando el certificado X.509 de la URL especificada con URL_of_X.509_certificate. Esta opción sólo tiene sentido si se especifica--encrypted. -
--backuppassphrase- Añade una frase de contraseña generada aleatoriamente a este dispositivo. Almacena la frase de contraseña en un archivo en/root, cifrado utilizando el certificado X.509 especificado con--escrowcert. Esta opción sólo tiene sentido si se especifica--escrowcert. -
--pbkdf=PBKDF- Establece el algoritmo de la Función de Derivación de Claves Basada en Contraseña (PBKDF) para la ranura de claves LUKS. Véase también la página de manual cryptsetup(8). Esta opción sólo tiene sentido si se especifica--encrypted. -
--pbkdf-memory=PBKDF_MEMORY- Establece el coste de memoria para PBKDF. Véase también la página de manual cryptsetup(8). Esta opción sólo tiene sentido si se especifica--encrypted. -
--pbkdf-time=PBKDF_TIME- Establece el número de milisegundos que se emplearán en el procesamiento de la frase de contraseña PBKDF. Véase también--iter-timeen la página de manual cryptsetup(8). Esta opción sólo tiene sentido si se especifica--encrypted, y es mutuamente excluyente con--pbkdf-iterations. -
--pbkdf-iterations=PBKDF_ITERATIONS- Establece el número de iteraciones directamente y evita el benchmark PBKDF. Véase también--pbkdf-force-iterationsen la página de manual cryptsetup(8). Esta opción sólo tiene sentido si se especifica--encrypted, y es mutuamente excluyente con--pbkdf-time.
Ejemplo
El siguiente ejemplo muestra cómo crear una partición RAID de nivel 1 para /, y una RAID de nivel 5 para /home, asumiendo que hay tres discos SCSI en el sistema. También crea tres particiones de intercambio, una en cada disco.
part raid.01 --size=6000 --ondisk=sda
part raid.02 --size=6000 --ondisk=sdb
part raid.03 --size=6000 --ondisk=sdc
part swap --size=512 --ondisk=sda
part swap --size=512 --ondisk=sdb
part swap --size=512 --ondisk=sdc
part raid.11 --size=1 --grow --ondisk=sda
part raid.12 --size=1 --grow --ondisk=sdb
part raid.13 --size=1 --grow --ondisk=sdc
raid / --level=1 --device=rhel8-root --label=rhel8-root raid.01 raid.02 raid.03
raid /home --level=5 --device=rhel8-home --label=rhel8-home raid.11 raid.12 raid.13Notas
-
Si pierdes la frase de contraseña de LUKS, cualquier partición encriptada y sus datos son completamente inaccesibles. No hay forma de recuperar una frase de contraseña perdida. Sin embargo, puedes guardar las frases de contraseña de cifrado con la página
--escrowcerty crear frases de contraseña de cifrado de reserva con las opciones de--backuppassphrase.
H.5.15. reqpart
El comando reqpart Kickstart es opcional. Crea automáticamente las particiones requeridas por su plataforma de hardware. Estas incluyen una partición /boot/efi para sistemas con firmware UEFI, una partición biosboot para sistemas con firmware BIOS y GPT, y una partición PRePBoot para IBM Power Systems.
Sintaxis
reqpart [--add-boot]Opciones
-
--add-boot- Crea una partición separada/bootademás de la partición específica de la plataforma creada por el comando base.
Notas
-
Este comando no puede utilizarse junto con
autopart, porqueautoparthace todo lo que hace el comandoreqparty, además, crea otras particiones o volúmenes lógicos como/yswap. A diferencia deautopart, este comando sólo crea particiones específicas de la plataforma y deja el resto de la unidad vacía, lo que permite crear una disposición personalizada.
H.5.16. instantánea
El comando snapshot Kickstart es opcional. Se utiliza para crear instantáneas de volúmenes ligeros LVM durante el proceso de instalación. Esto le permite hacer una copia de seguridad de un volumen lógico antes o después de la instalación.
Para crear varias instantáneas, añada el comando snaphost Kickstart varias veces.
Sintaxis
snapshot vg_name/lv_name --name=snapshot_name --when=pre-install|post-installOpciones
-
vg_name/lv_name- Establece el nombre del grupo de volúmenes y del volumen lógico del que se creará la instantánea. -
--name=snapshot_name- Establece el nombre de la instantánea. Este nombre debe ser único dentro del grupo de volúmenes. -
--when=pre-install|post-install- Establece si la instantánea se crea antes de que comience la instalación o después de que ésta haya finalizado.
H.5.17. volgroup
El comando volgroup Kickstart es opcional. Crea un grupo de gestión de volúmenes lógicos (LVM).
Sintaxis
volgroup name [OPTIONS] [partition*]Opciones obligatorias
- name - Nombre del nuevo grupo de volúmenes.
Opciones
- partition - Particiones físicas de volumen a utilizar como almacenamiento de respaldo para el grupo de volúmenes.
-
--noformat- Utilice un grupo de volumen existente y no lo formatee. --useexisting- Utilizar un grupo de volúmenes existente y reformatearlo. Si utiliza esta opción, no especifique un partition. Por ejemplo:volgroup rhel00 --useexisting --noformat-
--pesize=- Establece el tamaño de los extensiones físicas del grupo de volúmenes en KiB. El valor por defecto es 4096 (4 MiB), y el valor mínimo es 1024 (1 MiB). -
--reserved-space=- Especifica una cantidad de espacio a dejar sin usar en un grupo de volumen en MiB. Aplicable sólo a los grupos de volumen recién creados. -
--reserved-percent=- Especifica un porcentaje del espacio total del grupo de volumen que se dejará sin utilizar. Aplicable sólo a los grupos de volumen recién creados.
Notas
Cree primero la partición, luego cree el grupo de volúmenes lógicos y después cree el volumen lógico. Por ejemplo:
part pv.01 --size 10000 volgroup my_volgrp pv.01 logvol / --vgname=my_volgrp --size=2000 --name=rootNo utilice el carácter guión (
-) en los nombres de volúmenes lógicos y grupos de volúmenes cuando instale Red Hat Enterprise Linux utilizando Kickstart. Si se utiliza este carácter, la instalación termina normalmente, pero el directorio/dev/mapper/listará estos volúmenes y grupos de volúmenes con cada guión duplicado. Por ejemplo, un grupo de volúmenes llamadovolgrp-01que contiene un volumen lógico llamadologvol-01será listado como/dev/mapper/volgrp--01-logvol--01.Esta limitación sólo se aplica a los nombres de volúmenes lógicos y grupos de volúmenes recién creados. Si se reutilizan los existentes utilizando la opción
--noformat, sus nombres no se modificarán.
H.5.18. zerombr
El comando zerombr Kickstart es opcional. El zerombr inicializa cualquier tabla de partición inválida que se encuentre en los discos y destruye todo el contenido de los discos con tablas de partición inválidas. Este comando es necesario cuando se realiza una instalación en un sistema IBM Z con discos de Dispositivo de Almacenamiento de Acceso Directo (DASD) no formateados, de lo contrario los discos no formateados no se formatean ni se utilizan durante la instalación.
Sintaxis
zerombrNotas
-
En IBM Z, si se especifica
zerombr, cualquier dispositivo de almacenamiento de acceso directo (DASD) visible para el programa de instalación que no esté ya formateado a bajo nivel se formatea automáticamente a bajo nivel con dasdfmt. El comando también evita la elección del usuario durante las instalaciones interactivas. -
Si no se especifica
zerombry hay al menos un DASD sin formatear visible para el programa de instalación, una instalación Kickstart no interactiva finaliza sin éxito. -
Si no se especifica
zerombry hay al menos un DASD no formateado visible para el programa de instalación, la instalación interactiva finaliza si el usuario no acepta formatear todos los DASD visibles y no formateados. Para evitar esto, active sólo los DASD que vaya a utilizar durante la instalación. Siempre puedes añadir más DASDs después de que la instalación se haya completado. - Este comando no tiene opciones.
H.5.19. zfcp
El comando zfcp Kickstart es opcional. Define un dispositivo de canal de fibra.
Esta opción sólo se aplica en IBM Z. Deben especificarse todas las opciones descritas a continuación.
Sintaxis
zfcp --devnum=devnum --wwpn=wwpn --fcplun=lunOpciones
-
--devnum=- El número de dispositivo (ID de bus de dispositivo del adaptador zFCP). -
--wwpn=- El nombre del puerto mundial del dispositivo (WWPN). Tiene la forma de un número de 16 dígitos, precedido por0x. -
--fcplun=- El número de unidad lógica (LUN) del dispositivo. Tiene la forma de un número de 16 dígitos, precedido por0x.
Ejemplo
zfcp --devnum=0.0.4000 --wwpn=0x5005076300C213e9 --fcplun=0x5022000000000000H.6. Comandos Kickstart para los complementos suministrados con el programa de instalación de RHEL
Los comandos Kickstart en esta sección están relacionados con los complementos suministrados por defecto con el programa de instalación de Red Hat Enterprise Linux: Kdump y OpenSCAP.
H.6.1. com_redhat_kdump
El comando don com_redhat_kdump Kickstart es opcional. Este comando configura el mecanismo de volcado de fallos del kernel kdump.
Sintaxis
%addon com_redhat_kdump [OPTIONS]
%endLa sintaxis de este comando es inusual porque se trata de un complemento en lugar de un comando Kickstart incorporado.
Notas
Kdump es un mecanismo de volcado de fallos del núcleo que permite guardar el contenido de la memoria del sistema para su posterior análisis. Se basa en kexec, que puede utilizarse para arrancar un núcleo de Linux desde el contexto de otro núcleo sin reiniciar el sistema, y preservar el contenido de la memoria del primer núcleo que, de otro modo, se perdería.
En caso de caída del sistema, kexec arranca en un segundo núcleo (un núcleo de captura). Este núcleo de captura reside en una parte reservada de la memoria del sistema. Kdump entonces captura el contenido de la memoria del kernel accidentado (un crash dump) y lo guarda en una ubicación especificada. La ubicación no puede ser configurada usando este comando Kickstart; debe ser configurada después de la instalación editando el archivo de configuración /etc/kdump.conf.
Para más información sobre Kdump, consulte el capítulo Instalación y configuración de kdump del documento Managing, monitoring and updating the kernel.
Opciones
-
--enable- Habilitar kdump en el sistema instalado. -
--disable- Desactivar kdump en el sistema instalado. --reserve-mb=- La cantidad de memoria que desea reservar para kdump, en MiB. Por ejemplo:%addon com_redhat_kdump --enable --reserve-mb=128 %endTambién puede especificar
autoen lugar de un valor numérico. En ese caso, el programa de instalación determinará la cantidad de memoria automáticamente basándose en los criterios descritos en la sección Requisitos de memoria para kdump del documento Managing, monitoring and updating the kernel.Si activa kdump y no especifica una opción
--reserve-mb=, se utilizará el valorauto.-
--enablefadump- Habilitar el volcado asistido por firmware en los sistemas que lo permiten (en particular, los servidores IBM Power Systems).
H.6.2. don org_fedora_oscap
El comando don org_fedora_oscap Kickstart es opcional.
El complemento del programa de instalación OpenSCAP se utiliza para aplicar el contenido SCAP (Protocolo de Automatización de Contenido de Seguridad) - políticas de seguridad - en el sistema instalado. Este complemento ha sido habilitado por defecto desde Red Hat Enterprise Linux 7.2. Cuando se habilita, los paquetes necesarios para proporcionar esta funcionalidad se instalan automáticamente. Sin embargo, por defecto, no se aplican políticas, lo que significa que no se realizan comprobaciones durante o después de la instalación a menos que se configure específicamente.
La aplicación de una política de seguridad no es necesaria en todos los sistemas. Este comando sólo debe utilizarse cuando las normas de su organización o las regulaciones gubernamentales exijan una política específica.
A diferencia de la mayoría de los otros comandos, este complemento no acepta opciones regulares, sino que utiliza pares clave-valor en el cuerpo de la definición de don. Estos pares son independientes del espacio en blanco. Los valores pueden ir opcionalmente entre comillas simples (') o dobles (").
Sintaxis
%addon org_fedora_oscap
key = value
%endClaves
El complemento reconoce las siguientes teclas:
content-type- Tipo de contenido de seguridad. Los valores posibles sondatastream,archive,rpm, yscap-security-guide.Si el
content-typeesscap-security-guide, el complemento utilizará el contenido proporcionado por el scap-security-guide que está presente en el soporte de arranque. Esto significa que todas las demás claves, exceptoprofile, no tendrán ningún efecto.-
content-url- Ubicación del contenido de seguridad. El contenido debe ser accesible mediante HTTP, HTTPS o FTP; actualmente no se admite el almacenamiento local. Debe haber una conexión de red disponible para llegar a las definiciones de contenido en una ubicación remota. -
datastream-id- ID del flujo de datos al que se hace referencia en el valorcontent-url. Sólo se utiliza sicontent-typeesdatastream. -
xccdf-id- ID del punto de referencia que desea utilizar. -
content-path- Ruta de acceso al flujo de datos o al archivo XCCDF que debe utilizarse, dada como ruta relativa en el archivo. -
profile- ID del perfil a aplicar. Utilicedefaultpara aplicar el perfil por defecto. -
fingerprint- Una suma de comprobación MD5, SHA1 o SHA2 del contenido referenciado porcontent-url. -
tailoring-path- Ruta de acceso a un archivo de adaptación que debe utilizarse, dada como ruta relativa en el archivo.
Ejemplos
El siguiente es un ejemplo de sección de
don org_fedora_oscapque utiliza el contenido del scap-security-guide en el medio de instalación:Ejemplo H.1. Ejemplo de definición del complemento OpenSCAP mediante la guía de seguridad SCAP
%addon org_fedora_oscap content-type = scap-security-guide profile = pci-dss %endEl siguiente es un ejemplo más complejo que carga un perfil personalizado desde un servidor web:
Ejemplo H.2. Ejemplo de definición de complemento de OpenSCAP utilizando un flujo de datos
%addon org_fedora_oscap content-type = datastream content-url = http://www.example.com/scap/testing_ds.xml datastream-id = scap_example.com_datastream_testing xccdf-id = scap_example.com_cref_xccdf.xml profile = xccdf_example.com_profile_my_profile fingerprint = 240f2f18222faa98856c3b4fc50c4195 %end
Recursos adicionales
- Encontrará más información sobre el complemento del programa de instalación OpenSCAP en https://www.open-scap.org/tools/oscap-anaconda-addon/.
- Para obtener más información sobre los perfiles disponibles en la guía de seguridad de SCAP y su función, consulte el portal OpenSCAP.
H.7. Comandos utilizados en Anaconda
El comando pwpolicy es un comando específico de la interfaz de usuario de Anaconda que sólo puede utilizarse en la sección aconda del archivo kickstart.
H.7.1. política de privacidad
El comando pwpolicy Kickstart es opcional. Utilice este comando para imponer una política de contraseñas personalizada durante la instalación. La política requiere que usted cree contraseñas para la raíz, los usuarios o las cuentas de usuario luks. Los factores como la longitud y la fuerza de la contraseña deciden la validez de una contraseña.
Sintaxis
pwpolicy name [--minlen=length] [--minquality=quality] [--strict|--nostrict] [--emptyok|--noempty] [--changesok|--nochanges]Opciones obligatorias
-
name - Sustitúyase por
root,userolukspara aplicar la política para la contraseñaroot, las contraseñas de usuario o la frase de contraseña LUKS, respectivamente.
Opciones opcionales
-
--minlen=- Establece la longitud mínima permitida de la contraseña, en caracteres. El valor por defecto es6. -
--minquality=- Establece la calidad mínima permitida de las contraseñas según lo definido por la bibliotecalibpwquality. El valor por defecto es1. -
--strict- Permite la aplicación estricta de la contraseña. Las contraseñas que no cumplan los requisitos especificados en--minquality=y--minlen=no serán aceptadas. Esta opción está desactivada por defecto. -
--notstrict- Las contraseñas que not cumplan con los requisitos mínimos de calidad especificados por las opciones--minquality=y-minlen=serán permitidas, después de que Done se pulse dos veces en la GUI. Para la interfaz en modo texto, se utiliza un mecanismo similar. -
--emptyok- Permite el uso de contraseñas vacías. Activado por defecto para las contraseñas de los usuarios. -
--notempty- Desactiva el uso de contraseñas vacías. Activado por defecto para la contraseña de root y la frase de contraseña de LUKS. -
--changesok- Permite cambiar la contraseña en la interfaz de usuario, incluso si el archivo Kickstart ya especifica una contraseña. Desactivado por defecto. -
--nochanges- No permite cambiar las contraseñas que ya están establecidas en el archivo Kickstart. Activado por defecto.
Notas
-
El comando
pwpolicyes un comando específico de Anaconda-UI que sólo puede utilizarse en la secciónacondadel archivo kickstart. -
La biblioteca
libpwqualityse utiliza para comprobar los requisitos mínimos de las contraseñas (longitud y calidad). Puede utilizar los comandospwscoreypwmakeproporcionados por el paquete libpwquality para comprobar la puntuación de calidad de una contraseña, o para crear una contraseña aleatoria con una puntuación determinada. Consulte la página de manualpwscore(1)ypwmake(1)para obtener detalles sobre estos comandos.
H.8. Comandos de arranque para la recuperación del sistema
El comando Kickstart de esta sección repara un sistema instalado.
H.8.1. rescate
El comando rescue Kickstart es opcional. Proporciona un entorno de shell con privilegios de root y un conjunto de herramientas de gestión del sistema para reparar la instalación y solucionar los problemas como:
- Montar los sistemas de archivos como de sólo lectura
- Bloquear o añadir un controlador proporcionado en un disco de controladores
- Instalar o actualizar los paquetes del sistema
- Gestionar las particiones
El modo de rescate Kickstart es diferente del modo de rescate y del modo de emergencia, que se proporcionan como parte del systemd y del gestor de servicios.
El comando rescue no modifica el sistema por sí mismo. Sólo configura el entorno de rescate montando el sistema bajo /mnt/sysimage en modo de lectura-escritura. Puedes elegir no montar el sistema, o montarlo en modo de sólo lectura.
Sintaxis
rescue [--nomount|--romount]Opciones
-
--nomounto--romount- Controla cómo se monta el sistema instalado en el entorno de rescate. Por defecto, el programa de instalación encuentra su sistema y lo monta en modo de lectura-escritura, indicándole dónde ha realizado este montaje. Puede seleccionar opcionalmente no montar nada (la opción--nomount) o montar en modo de sólo lectura (la opción--romount). Sólo se puede utilizar una de estas dos opciones.
Notas
Para ejecutar un modo de rescate, haga una copia del archivo Kickstart e incluya en él el comando rescue.
El uso del comando rescue hace que el instalador realice los siguientes pasos:
-
Ejecute el script
%pre. Configurar el entorno para el modo de rescate.
Los siguientes comandos de arranque tienen efecto:
- actualiza
- sshpw
- registro
- lang
- red
Configurar el entorno de almacenamiento avanzado.
Los siguientes comandos de arranque tienen efecto:
- fcoe
- iscsi
- iscsiname
- nvdimm
- zfcp
Montar el sistema
rescue [--nomount|--romount]Ejecutar el script %post
Este paso se ejecuta sólo si el sistema instalado está montado en modo de lectura-escritura.
- Inicio de la cáscara
- Reiniciar el sistema
Parte II. Diseño de la seguridad
Capítulo 10. Visión general del endurecimiento de la seguridad en RHEL
Debido a la creciente dependencia de los potentes ordenadores conectados en red para ayudar a dirigir las empresas y controlar nuestra información personal, se han formado industrias enteras en torno a la práctica de la seguridad de las redes y los ordenadores. Las empresas han solicitado los conocimientos y habilidades de los expertos en seguridad para auditar adecuadamente los sistemas y adaptar las soluciones a los requisitos de funcionamiento de su organización. Dado que la mayoría de las organizaciones son cada vez más dinámicas, sus trabajadores acceden a los recursos informáticos críticos de la empresa de forma local y remota, por lo que la necesidad de contar con entornos informáticos seguros se ha acentuado.
Por desgracia, muchas organizaciones, así como los usuarios individuales, consideran la seguridad más bien como una idea tardía, un proceso que se pasa por alto en favor de una mayor potencia, productividad, comodidad, facilidad de uso y preocupaciones presupuestarias. La implementación adecuada de la seguridad a menudo se lleva a cabo postmortem, cuando ya se ha producido una intrusión no autorizada. Tomar las medidas correctas antes de conectar un sitio a una red no fiable, como Internet, es un medio eficaz para frustrar muchos intentos de intrusión.
10.1. ¿Qué es la seguridad informática?
La seguridad informática es un término general que abarca un amplio ámbito de la informática y el procesamiento de la información. Las industrias que dependen de los sistemas y redes informáticos para llevar a cabo las transacciones comerciales diarias y acceder a información crítica consideran sus datos como una parte importante de sus activos generales. Varios términos y métricas han entrado en nuestro vocabulario empresarial diario, como el coste total de propiedad (TCO), el rendimiento de la inversión (ROI) y la calidad del servicio (QoS). Utilizando estas métricas, las industrias pueden calcular aspectos como la integridad de los datos y la alta disponibilidad (HA) como parte de sus costes de planificación y gestión de procesos. En algunos sectores, como el del comercio electrónico, la disponibilidad y fiabilidad de los datos puede significar la diferencia entre el éxito y el fracaso.
10.2. Normalización de la seguridad
Las empresas de todos los sectores se basan en normas y reglas establecidas por organismos de normalización como la Asociación Médica Americana (AMA) o el Instituto de Ingenieros Eléctricos y Electrónicos (IEEE). Los mismos conceptos son válidos para la seguridad de la información. Muchos consultores y proveedores de seguridad están de acuerdo con el modelo de seguridad estándar conocido como CIA, o Confidentiality, Integrity, and Availability. Este modelo de tres niveles es un componente generalmente aceptado para evaluar los riesgos de la información sensible y establecer una política de seguridad. A continuación se describe con más detalle el modelo CIA:
- Confidencialidad
- Integridad
- Disponibilidad
10.3. Software criptográfico y certificaciones
Red Hat Enterprise Linux se somete a varias certificaciones de seguridad, como FIPS 140-2 o Common Criteria (CC), para garantizar que se siguen las mejores prácticas del sector.
El artículo RHEL 8 core crypto components El artículo de la base de conocimientos proporciona una visión general de los componentes criptográficos del núcleo de Red Hat Enterprise Linux 8, documentando cuáles son, cómo se seleccionan, cómo se integran en el sistema operativo, cómo soportan los módulos de seguridad de hardware y las tarjetas inteligentes, y cómo se aplican las certificaciones criptográficas a ellos.
10.4. Controles de seguridad
La seguridad informática suele dividirse en tres categorías principales distintas, comúnmente denominadas controls:
- Físico
- Técnica
- Administrativo
Estas tres grandes categorías definen los principales objetivos de una correcta implementación de la seguridad. Dentro de estos controles hay subcategorías que detallan más los controles y la forma de aplicarlos.
10.4.1. Controles físicos
El control físico es la aplicación de medidas de seguridad en una estructura definida que se utiliza para disuadir o impedir el acceso no autorizado a material sensible. Ejemplos de controles físicos son:
- Cámaras de vigilancia en circuito cerrado
- Sistemas de alarma térmica o de movimiento
- Guardias de seguridad
- Identificaciones con foto
- Puertas de acero con cerradura y cerrojo
- Biometría (incluye las huellas dactilares, la voz, el rostro, el iris, la escritura a mano y otros métodos automatizados utilizados para reconocer a las personas)
10.4.2. Controles técnicos
Los controles técnicos utilizan la tecnología como base para controlar el acceso y la utilización de datos sensibles en toda una estructura física y en una red. Los controles técnicos tienen un gran alcance y abarcan tecnologías como:
- Codificación
- Tarjetas inteligentes
- Autenticación en red
- Listas de control de acceso (ACL)
- Software de auditoría de la integridad de los archivos
10.4.3. Controles administrativos
Los controles administrativos definen los factores humanos de la seguridad. Implican a todos los niveles del personal de una organización y determinan qué usuarios tienen acceso a qué recursos e información por medios como:
- Formación y sensibilización
- Planes de preparación y recuperación en caso de catástrofe
- Estrategias de contratación y separación de personal
- Registro y contabilidad del personal
10.5. Evaluación de la vulnerabilidad
Con tiempo, recursos y motivación, un atacante puede entrar en casi cualquier sistema. Todos los procedimientos y tecnologías de seguridad disponibles en la actualidad no pueden garantizar que ningún sistema esté completamente a salvo de las intrusiones. Los routers ayudan a asegurar las puertas de entrada a Internet. Los cortafuegos ayudan a asegurar el borde de la red. Las redes privadas virtuales transmiten los datos de forma segura en un flujo cifrado. Los sistemas de detección de intrusos avisan de las actividades maliciosas. Sin embargo, el éxito de cada una de estas tecnologías depende de una serie de variables, entre ellas:
- La experiencia del personal responsable de configurar, supervisar y mantener las tecnologías.
- La capacidad de parchear y actualizar servicios y núcleos de forma rápida y eficaz.
- La capacidad de los responsables de mantener una vigilancia constante sobre la red.
Dado el estado dinámico de los sistemas de datos y las tecnologías, asegurar los recursos corporativos puede ser bastante complejo. Debido a esta complejidad, a menudo es difícil encontrar recursos expertos para todos sus sistemas. Aunque es posible tener personal con conocimientos en muchas áreas de la seguridad de la información a un alto nivel, es difícil retener al personal que es experto en más de unas pocas áreas temáticas. Esto se debe principalmente a que cada área temática de la seguridad de la información requiere una atención y un enfoque constantes. La seguridad de la información no se detiene.
Una evaluación de la vulnerabilidad es una auditoría interna de la seguridad de su red y sistema, cuyos resultados indican la confidencialidad, integridad y disponibilidad de su red. Normalmente, la evaluación de la vulnerabilidad comienza con una fase de reconocimiento, durante la cual se recopilan datos importantes sobre los sistemas y recursos objetivo. Esta fase conduce a la fase de preparación del sistema, en la que se comprueba esencialmente que el objetivo no presenta ninguna vulnerabilidad conocida. La fase de preparación culmina con la fase de informe, en la que los hallazgos se clasifican en categorías de riesgo alto, medio y bajo; y se discuten los métodos para mejorar la seguridad (o mitigar el riesgo de vulnerabilidad) del objetivo
Si tuviera que realizar una evaluación de la vulnerabilidad de su hogar, probablemente comprobaría cada puerta de su casa para ver si están cerradas y bloqueadas. También comprobaría todas las ventanas, asegurándose de que se cierran por completo y de que se cierran correctamente. Este mismo concepto se aplica a los sistemas, redes y datos electrónicos. Los usuarios malintencionados son los ladrones y vándalos de sus datos. Concéntrese en sus herramientas, su mentalidad y sus motivaciones, y así podrá reaccionar rápidamente ante sus acciones.
10.5.1. Definir la evaluación y las pruebas
Las evaluaciones de la vulnerabilidad pueden ser de dos tipos: outside looking in y inside looking around.
Cuando se realiza una evaluación de la vulnerabilidad desde fuera, se intenta comprometer los sistemas desde el exterior. Ser externo a su empresa le proporciona el punto de vista del cracker. Usted ve lo que un cracker ve
Cuando realizas una evaluación de vulnerabilidad desde dentro, estás en ventaja ya que eres interno y tu estatus se eleva a confianza. Este es el punto de vista que usted y sus compañeros de trabajo tienen una vez que se conectan a sus sistemas. Usted ve los servidores de impresión, los servidores de archivos, las bases de datos y otros recursos.
Hay diferencias notables entre los dos tipos de evaluaciones de vulnerabilidad. El hecho de ser interno en su empresa le da más privilegios que a una persona externa. En la mayoría de las organizaciones, la seguridad está configurada para mantener a los intrusos fuera. Se hace muy poco para asegurar las partes internas de la organización (como cortafuegos departamentales, controles de acceso a nivel de usuario y procedimientos de autenticación para los recursos internos). Normalmente, hay muchos más recursos cuando se mira en el interior, ya que la mayoría de los sistemas son internos de una empresa. Una vez que se encuentra fuera de la empresa, su situación no es de confianza. Los sistemas y recursos disponibles en el exterior suelen ser muy limitados.
Considere la diferencia entre las evaluaciones de vulnerabilidad y penetration tests. Piensa en una evaluación de vulnerabilidad como el primer paso para una prueba de penetración. La información obtenida en la evaluación se utiliza para las pruebas. Mientras que la evaluación se lleva a cabo para comprobar los agujeros y las posibles vulnerabilidades, las pruebas de penetración realmente intentan explotar los hallazgos.
La evaluación de la infraestructura de red es un proceso dinámico. La seguridad, tanto informática como física, es dinámica. La realización de una evaluación muestra una visión general, que puede dar lugar a falsos positivos y falsos negativos. Un falso positivo es un resultado en el que la herramienta encuentra vulnerabilidades que en realidad no existen. Un falso negativo es cuando omite vulnerabilidades reales.
Los administradores de seguridad son tan buenos como las herramientas que utilizan y los conocimientos que conservan. Tome cualquiera de las herramientas de evaluación disponibles en la actualidad, ejecútelas contra su sistema y es casi una garantía de que hay algunos falsos positivos. Ya sea por fallo del programa o por error del usuario, el resultado es el mismo. La herramienta puede encontrar falsos positivos o, peor aún, falsos negativos.
Ahora que la diferencia entre una evaluación de la vulnerabilidad y una prueba de penetración está definida, tome las conclusiones de la evaluación y revíselas cuidadosamente antes de realizar una prueba de penetración como parte de su nuevo enfoque de mejores prácticas.
No intente explotar las vulnerabilidades en los sistemas de producción. Hacerlo puede tener efectos adversos en la productividad y eficiencia de sus sistemas y red.
La siguiente lista examina algunas de las ventajas de realizar evaluaciones de vulnerabilidad.
- Crea un enfoque proactivo en la seguridad de la información.
- Encuentra potenciales exploits antes de que los crackers los encuentren.
- Permite mantener los sistemas actualizados y con parches.
- Promueve el crecimiento y ayuda a desarrollar la experiencia del personal.
- Reduce las pérdidas financieras y la publicidad negativa.
10.5.2. Establecer una metodología para la evaluación de la vulnerabilidad
Para ayudar en la selección de herramientas para una evaluación de la vulnerabilidad, es útil establecer una metodología de evaluación de la vulnerabilidad. Desafortunadamente, no existe una metodología predefinida o aprobada por la industria en este momento; sin embargo, el sentido común y las mejores prácticas pueden actuar como una guía suficiente.
What is the target? Are we looking at one server, or are we looking at our entire network and everything within the network? Are we external or internal to the company? Las respuestas a estas preguntas son importantes, ya que ayudan a determinar no sólo qué herramientas seleccionar, sino también la forma de utilizarlas.
Para saber más sobre el establecimiento de metodologías, consulte el siguiente sitio web:
10.5.3. Herramientas de evaluación de la vulnerabilidad
Una evaluación puede comenzar utilizando algún tipo de herramienta de recopilación de información. Cuando se evalúa toda la red, primero hay que mapear la distribución para encontrar los hosts que están funcionando. Una vez localizado, examine cada host individualmente. Centrarse en estos hosts requiere otro conjunto de herramientas. Saber qué herramientas utilizar puede ser el paso más crucial para encontrar vulnerabilidades.
Las siguientes herramientas son sólo una pequeña muestra de las disponibles:
-
Nmapes una popular herramienta que puede ser usada para encontrar sistemas anfitriones y abrir puertos en esos sistemas. Para instalarNmapdesde el repositorioAppStream, introduzca el comandoyum install nmapcomo usuarioroot. Consulte la página de manualnmap(1)para obtener más información. -
Las herramientas del conjunto
OpenSCAP, como la utilidad de línea de comandososcapy la utilidad gráficascap-workbench, proporcionan una auditoría de cumplimiento totalmente automatizada. Para obtener más información, consulte la sección sobre la comprobación del cumplimiento de la seguridad y las vulnerabilidades del sistema. -
Advanced Intrusion Detection Environment (
AIDE) es una utilidad que crea una base de datos de archivos en el sistema, y luego utiliza esa base de datos para asegurar la integridad de los archivos y detectar intrusiones en el sistema. Consulte Comprobar la integridad con AIDE para obtener más información.
10.6. Amenazas a la seguridad
10.6.1. Amenazas a la seguridad de la red
Las malas prácticas a la hora de configurar los siguientes aspectos de una red pueden aumentar el riesgo de un ataque.
Arquitecturas inseguras
Una red mal configurada es un punto de entrada principal para usuarios no autorizados. Dejar una red local abierta y basada en la confianza, vulnerable a la altamente insegura Internet, es como dejar una puerta entreabierta en un vecindario plagado de delincuentes
Redes de difusión
Los administradores de sistemas a menudo no se dan cuenta de la importancia del hardware de red en sus esquemas de seguridad. El hardware simple, como los concentradores y routers, se basa en el principio de difusión o no conmutación; es decir, cada vez que un nodo transmite datos a través de la red a un nodo receptor, el concentrador o router envía una difusión de los paquetes de datos hasta que el nodo receptor recibe y procesa los datos. Este método es el más vulnerable a la suplantación de direcciones del protocolo de resolución de direcciones (ARP) o del control de acceso a los medios (MAC) tanto por parte de intrusos externos como de usuarios no autorizados en hosts locales.
Servidores centralizados
Otro posible escollo de la red es el uso de la informática centralizada. Una medida común de reducción de costes para muchas empresas es consolidar todos los servicios en una sola máquina potente. Esto puede ser conveniente, ya que es más fácil de gestionar y cuesta mucho menos que las configuraciones de varios servidores. Sin embargo, un servidor centralizado introduce un único punto de fallo en la red. Si el servidor central se ve comprometido, puede hacer que la red sea completamente inútil o, peor aún, propensa a la manipulación o el robo de datos. En estas situaciones, un servidor central se convierte en una puerta abierta que permite el acceso a toda la red.
10.6.2. Amenazas a la seguridad de los servidores
La seguridad de los servidores es tan importante como la seguridad de la red, ya que los servidores suelen contener gran parte de la información vital de una organización. Si un servidor se ve comprometido, todo su contenido puede estar disponible para que el cracker lo robe o manipule a voluntad. Las siguientes secciones detallan algunos de los principales problemas.
Servicios no utilizados y puertos abiertos
Una instalación completa de Red Hat Enterprise Linux 8 contiene más de 1000 aplicaciones y paquetes de biblioteca. Sin embargo, la mayoría de los administradores de servidores no optan por instalar todos los paquetes de la distribución, sino que prefieren instalar una instalación base de paquetes, que incluya varias aplicaciones de servidor.
Un hecho común entre los administradores de sistemas es instalar el sistema operativo sin prestar atención a qué programas se están instalando realmente. Esto puede ser problemático porque se pueden instalar servicios innecesarios, configurados con los parámetros por defecto y posiblemente activados. Esto puede hacer que servicios no deseados, como Telnet, DHCP o DNS, se ejecuten en un servidor o estación de trabajo sin que el administrador se dé cuenta, lo que a su vez puede provocar tráfico no deseado en el servidor o incluso una posible vía de acceso al sistema para los crackers.
Servicios sin parches
La mayoría de las aplicaciones de servidor que se incluyen en una instalación por defecto son piezas de software sólidas y ampliamente probadas. Al haber estado en uso en entornos de producción durante muchos años, su código se ha perfeccionado a fondo y se han encontrado y corregido muchos de los errores.
Sin embargo, no existe el software perfecto y siempre se puede perfeccionar. Además, el software más nuevo no suele ser probado tan rigurosamente como cabría esperar, debido a su reciente llegada a los entornos de producción o porque puede no ser tan popular como otro software de servidor.
Los desarrolladores y administradores de sistemas suelen encontrar fallos explotables en las aplicaciones de los servidores y publican la información en sitios web de seguimiento de fallos y relacionados con la seguridad, como la lista de correo Bugtraq (http://www.securityfocus.com) o el sitio web del Equipo de Respuesta a Emergencias Informáticas (CERT) (http://www.cert.org). Aunque estos mecanismos son una forma eficaz de alertar a la comunidad sobre las vulnerabilidades de seguridad, corresponde a los administradores de sistemas parchear sus sistemas con prontitud. Esto es especialmente cierto porque los crackers tienen acceso a estos mismos servicios de seguimiento de vulnerabilidades y utilizarán la información para crackear los sistemas no parcheados siempre que puedan. Una buena administración de sistemas requiere vigilancia, un seguimiento constante de los errores y un mantenimiento adecuado del sistema para garantizar un entorno informático más seguro.
Administración desatenta
Los administradores que no parchean sus sistemas son una de las mayores amenazas para la seguridad de los servidores. Esto se aplica tanto a los administradores inexpertos como a los administradores demasiado confiados o desmotivados.
Algunos administradores no parchean sus servidores y estaciones de trabajo, mientras que otros no vigilan los mensajes de registro del núcleo del sistema o el tráfico de red. Otro error común es cuando se dejan sin cambiar las contraseñas por defecto o las claves de los servicios. Por ejemplo, algunas bases de datos tienen contraseñas de administración por defecto porque los desarrolladores de la base de datos asumen que el administrador del sistema cambia estas contraseñas inmediatamente después de la instalación. Si el administrador de la base de datos no cambia esta contraseña, incluso un cracker inexperto puede utilizar una contraseña por defecto ampliamente conocida para obtener privilegios administrativos en la base de datos. Estos son sólo algunos ejemplos de cómo una administración desatenta puede llevar a servidores comprometidos.
Servicios intrínsecamente inseguros
Incluso la organización más vigilante puede ser víctima de vulnerabilidades si los servicios de red que elige son intrínsecamente inseguros. Por ejemplo, hay muchos servicios desarrollados bajo el supuesto de que se utilizan a través de redes de confianza; sin embargo, este supuesto falla tan pronto como el servicio está disponible en Internet
Una categoría de servicios de red inseguros son los que requieren nombres de usuario y contraseñas sin cifrar para la autenticación. Telnet y FTP son dos de estos servicios. Si el software de rastreo de paquetes está monitoreando el tráfico entre el usuario remoto y dicho servicio, los nombres de usuario y las contraseñas pueden ser fácilmente interceptados.
Intrínsecamente, estos servicios también pueden ser más fácilmente presa de lo que la industria de la seguridad denomina el ataque man-in-the-middle. En este tipo de ataque, un cracker redirige el tráfico de la red engañando a un servidor de nombres crackeado en la red para que apunte a su máquina en lugar del servidor previsto. Una vez que alguien abre una sesión remota al servidor, la máquina del atacante actúa como un conducto invisible, situándose tranquilamente entre el servicio remoto y el usuario desprevenido, capturando información. De este modo, un cracker puede recopilar contraseñas administrativas y datos en bruto sin que el servidor o el usuario se den cuenta.
Otra categoría de servicios inseguros son los sistemas de archivos de red y los servicios de información como NFS o NIS, desarrollados explícitamente para su uso en redes LAN pero que, desgraciadamente, se han extendido a las WAN (para usuarios remotos). NFS no tiene, por defecto, ningún mecanismo de autenticación o seguridad configurado para evitar que un cracker monte el recurso compartido NFS y acceda a cualquier cosa que contenga. NIS, además, tiene información vital que debe ser conocida por todos los ordenadores de una red, incluyendo contraseñas y permisos de archivos, dentro de una base de datos de texto plano ASCII o DBM (derivado de ASCII). Un cracker que consiga acceder a esta base de datos puede entonces acceder a todas las cuentas de usuario de una red, incluida la del administrador.
Por defecto, Red Hat Enterprise Linux 8 se publica con todos estos servicios desactivados. Sin embargo, dado que los administradores a menudo se ven obligados a utilizar estos servicios, una configuración cuidadosa es fundamental.
10.6.3. Amenazas para la seguridad de los puestos de trabajo y los ordenadores personales
Las estaciones de trabajo y los ordenadores domésticos pueden no ser tan propensos a los ataques como las redes o los servidores, pero como a menudo contienen datos sensibles, como la información de las tarjetas de crédito, son el objetivo de los crackers de sistemas. Las estaciones de trabajo también pueden ser cooptadas sin el conocimiento del usuario y utilizadas por los atacantes como máquinas "bot" en ataques coordinados. Por estas razones, conocer las vulnerabilidades de una estación de trabajo puede ahorrar a los usuarios el dolor de cabeza de reinstalar el sistema operativo, o peor aún, recuperarse del robo de datos.
Contraseñas incorrectas
Las contraseñas incorrectas son una de las formas más fáciles de que un atacante acceda a un sistema.
Aplicaciones cliente vulnerables
Aunque un administrador pueda tener un servidor totalmente seguro y parcheado, eso no significa que los usuarios remotos estén seguros al acceder a él. Por ejemplo, si el servidor ofrece servicios Telnet o FTP a través de una red pública, un atacante puede capturar los nombres de usuario y las contraseñas en texto plano mientras pasan por la red, y luego utilizar la información de la cuenta para acceder a la estación de trabajo del usuario remoto.
Incluso cuando se utilizan protocolos seguros, como SSH, un usuario remoto puede ser vulnerable a ciertos ataques si no mantiene sus aplicaciones cliente actualizadas. Por ejemplo, los clientes del protocolo SSH versión 1 son vulnerables a un ataque de reenvío de X desde servidores SSH maliciosos. Una vez conectado al servidor, el atacante puede capturar silenciosamente las pulsaciones de teclas y los clics del ratón realizados por el cliente a través de la red. Este problema se solucionó en la versión 2 del protocolo SSH, pero es responsabilidad del usuario estar al tanto de qué aplicaciones tienen esas vulnerabilidades y actualizarlas cuando sea necesario.
10.7. Ataques y exploits comunes
Tabla 10.1, “Héroes comunes” detalla algunos de los exploits y puntos de entrada más comunes utilizados por los intrusos para acceder a los recursos de la red de la organización. La clave de estos exploits comunes son las explicaciones de cómo se realizan y cómo los administradores pueden salvaguardar adecuadamente su red contra estos ataques.
| Explotar | Descripción | Notas |
|---|---|---|
| Contraseñas nulas o por defecto | Dejar las contraseñas administrativas en blanco o utilizar una contraseña por defecto establecida por el proveedor del producto. Esto es más común en hardware como routers y firewalls, pero algunos servicios que se ejecutan en Linux pueden contener contraseñas de administrador por defecto también (aunque Red Hat Enterprise Linux 8 no se entrega con ellos). | Se asocia habitualmente con el hardware de red, como los routers, los cortafuegos, las VPN y los dispositivos de almacenamiento en red (NAS). Común en muchos sistemas operativos heredados, especialmente los que agrupan servicios (como UNIX y Windows) Los administradores a veces crean cuentas de usuario privilegiadas con prisas y dejan la contraseña nula, creando un punto de entrada perfecto para los usuarios maliciosos que descubren la cuenta. |
| Claves compartidas por defecto | Los servicios de seguridad a veces empaquetan claves de seguridad por defecto para fines de desarrollo o pruebas de evaluación. Si estas claves no se modifican y se colocan en un entorno de producción en Internet, los usuarios de all con las mismas claves por defecto tienen acceso a ese recurso de clave compartida, y a cualquier información sensible que contenga. | Más común en los puntos de acceso inalámbricos y en los dispositivos de servidor seguro preconfigurados. |
| Suplantación de IP | Una máquina remota actúa como un nodo en su red local, encuentra vulnerabilidades en sus servidores e instala un programa de puerta trasera o un troyano para obtener el control de sus recursos de red. | La suplantación de identidad es bastante difícil, ya que implica que el atacante prediga los números de secuencia TCP/IP para coordinar una conexión con los sistemas objetivo, pero existen varias herramientas que ayudan a los crackers a realizar dicha vulnerabilidad.
Depende de que el sistema de destino ejecute servicios (como |
| Espionaje | Recogida de datos que pasan entre dos nodos activos de una red mediante la escucha de la conexión entre los dos nodos. | Este tipo de ataque funciona sobre todo con protocolos de transmisión de texto plano como Telnet, FTP y transferencias HTTP. El atacante remoto debe tener acceso a un sistema comprometido en una LAN para poder realizar dicho ataque; normalmente el cracker ha utilizado un ataque activo (como la suplantación de IP o el man-in-the-middle) para comprometer un sistema en la LAN. Las medidas preventivas incluyen servicios con intercambio de claves criptográficas, contraseñas de un solo uso o autenticación encriptada para evitar el espionaje de contraseñas; también se aconseja un fuerte cifrado durante la transmisión. |
| Vulnerabilidades del servicio | Un atacante encuentra un fallo o una laguna en un servicio que se ejecuta a través de Internet; a través de esta vulnerabilidad, el atacante compromete todo el sistema y los datos que pueda contener, y posiblemente podría comprometer otros sistemas de la red. | Los servicios basados en HTTP, como los CGI, son vulnerables a la ejecución remota de comandos e incluso al acceso interactivo al shell. Incluso si el servicio HTTP se ejecuta como un usuario sin privilegios, como "nadie", se puede leer información como archivos de configuración y mapas de red, o el atacante puede iniciar un ataque de denegación de servicio que agote los recursos del sistema o lo deje indisponible para otros usuarios. Los servicios a veces pueden tener vulnerabilidades que pasan desapercibidas durante el desarrollo y las pruebas; estas vulnerabilidades (como buffer overflows, donde los atacantes bloquean un servicio utilizando valores arbitrarios que llenan el buffer de memoria de una aplicación, dando al atacante un prompt de comando interactivo desde el que puede ejecutar comandos arbitrarios) pueden dar un control administrativo completo a un atacante. Los administradores deben asegurarse de que los servicios no se ejecutan como usuario raíz, y deben estar atentos a los parches y actualizaciones de erratas de las aplicaciones de los proveedores u organizaciones de seguridad como CERT y CVE. |
| Vulnerabilidades de las aplicaciones | Los atacantes encuentran fallos en las aplicaciones de escritorio y de estaciones de trabajo (como los clientes de correo electrónico) y ejecutan código arbitrario, implantan troyanos para comprometerlos en el futuro o bloquean los sistemas. La explotación puede ser mayor si la estación de trabajo comprometida tiene privilegios administrativos en el resto de la red. | Los puestos de trabajo y los ordenadores de sobremesa son más propensos a ser explotados, ya que los trabajadores no tienen los conocimientos o la experiencia necesarios para prevenir o detectar un compromiso; es imperativo informar a las personas de los riesgos que corren cuando instalan software no autorizado o abren archivos adjuntos de correo electrónico no solicitados. Se pueden implementar salvaguardas para que el software del cliente de correo electrónico no abra o ejecute automáticamente los archivos adjuntos. Además, la actualización automática del software de las estaciones de trabajo mediante Red Hat Network; u otros servicios de gestión de sistemas pueden aliviar las cargas de las implantaciones de seguridad en varios puestos. |
| Ataques de denegación de servicio (DoS) | El atacante o grupo de atacantes se coordinan contra los recursos de red o servidores de una organización enviando paquetes no autorizados al host objetivo (ya sea servidor, router o estación de trabajo). Esto hace que el recurso deje de estar disponible para los usuarios legítimos. | El caso de DoS más reportado en los Estados Unidos ocurrió en el año 2000. Varios sitios comerciales y gubernamentales muy frecuentados quedaron inutilizados por un ataque coordinado de inundación de ping que utilizaba varios sistemas comprometidos con conexiones de gran ancho de banda que actuaban como zombies, o nodos de difusión redirigidos. Los paquetes de origen suelen ser falsificados (así como retransmitidos), lo que dificulta la investigación del verdadero origen del ataque.
Los avances en el filtrado de entrada (IETF rfc2267) mediante |
Capítulo 11. Asegurar RHEL durante la instalación
La seguridad comienza incluso antes de iniciar la instalación de Red Hat Enterprise Linux. Configurar su sistema de forma segura desde el principio facilita la implementación de ajustes de seguridad adicionales más adelante.
11.1. Seguridad de la BIOS y la UEFI
La protección con contraseña de la BIOS (o su equivalente) y del gestor de arranque puede evitar que usuarios no autorizados que tengan acceso físico a los sistemas arranquen utilizando medios extraíbles u obtengan privilegios de root a través del modo de usuario único. Las medidas de seguridad que debe tomar para protegerse de estos ataques dependen tanto de la sensibilidad de la información en la estación de trabajo como de la ubicación de la máquina.
Por ejemplo, si una máquina se utiliza en una feria comercial y no contiene información sensible, entonces puede no ser crítico prevenir tales ataques. Sin embargo, si el portátil de un empleado con claves SSH privadas y sin cifrar para la red corporativa se deja sin vigilancia en esa misma feria, podría provocar una importante brecha de seguridad con ramificaciones para toda la empresa.
Sin embargo, si la estación de trabajo se encuentra en un lugar al que sólo tienen acceso personas autorizadas o de confianza, puede que no sea necesario asegurar la BIOS o el gestor de arranque.
11.1.1. Contraseñas de la BIOS
Las dos razones principales para proteger con contraseña la BIOS de un ordenador son[1]:
- Preventing changes to BIOS settings
- Preventing system booting
Dado que los métodos para configurar la contraseña de la BIOS varían entre los fabricantes de ordenadores, consulte el manual del ordenador para obtener instrucciones específicas.
Si olvida la contraseña de la BIOS, puede restablecerla con puentes en la placa base o desconectando la batería de la CMOS. Por esta razón, es una buena práctica bloquear la caja del ordenador si es posible. Sin embargo, consulte el manual del ordenador o de la placa base antes de intentar desconectar la batería del CMOS.
11.1.1.1. Seguridad de los sistemas no basados en BIOS
Otros sistemas y arquitecturas utilizan diferentes programas para realizar tareas de bajo nivel aproximadamente equivalentes a las de la BIOS en los sistemas x86. Por ejemplo, el shell Unified Extensible Firmware Interface (UEFI).
Para obtener instrucciones sobre la protección con contraseña de los programas tipo BIOS, consulte las instrucciones del fabricante.
11.2. Partición del disco
Red Hat recomienda crear particiones separadas para los directorios /boot, /, /home, /tmp, y /var/tmp/. Las razones para cada uno de ellos son diferentes, y nos ocuparemos de cada partición.
/boot- Esta partición es la primera que lee el sistema durante el arranque. El gestor de arranque y las imágenes del kernel que se utilizan para arrancar su sistema en Red Hat Enterprise Linux 8 se almacenan en esta partición. Esta partición no debería estar encriptada. Si esta partición está incluida en / y esa partición está encriptada o no está disponible, entonces su sistema no podrá arrancar.
/home-
Cuando los datos del usuario (
/home) se almacenan en/en lugar de en una partición separada, la partición puede llenarse causando que el sistema operativo se vuelva inestable. Además, cuando actualice su sistema a la siguiente versión de Red Hat Enterprise Linux 8 es mucho más fácil cuando puede mantener sus datos en la partición/homeya que no se sobrescribirán durante la instalación. Si la partición raíz (/) se corrompe sus datos podrían perderse para siempre. Al usar una partición separada hay un poco más de protección contra la pérdida de datos. También puedes destinar esta partición a realizar copias de seguridad frecuentes. /tmpy/var/tmp/-
Los directorios
/tmpy/var/tmp/se utilizan para almacenar datos que no necesitan ser almacenados durante un largo periodo de tiempo. Sin embargo, si una gran cantidad de datos inunda uno de estos directorios puede consumir todo su espacio de almacenamiento. Si esto ocurre y estos directorios se almacenan en/, su sistema podría volverse inestable y bloquearse. Por esta razón, mover estos directorios a sus propias particiones es una buena idea.
Durante el proceso de instalación, tienes la opción de cifrar las particiones. Debes proporcionar una frase de contraseña. Esta frase de contraseña sirve como clave para desbloquear la clave de encriptación masiva, que se utiliza para asegurar los datos de la partición.
11.3. Restricción de la conectividad a la red durante el proceso de instalación
Cuando se instala Red Hat Enterprise Linux 8, el medio de instalación representa una instantánea del sistema en un momento determinado. Debido a esto, puede que no esté actualizado con las últimas correcciones de seguridad y puede ser vulnerable a ciertos problemas que fueron corregidos sólo después de que el sistema proporcionado por el medio de instalación fuera lanzado.
Al instalar un sistema operativo potencialmente vulnerable, limite siempre la exposición sólo a la zona de red necesaria más cercana. La opción más segura es la zona "sin red", lo que significa dejar la máquina desconectada durante el proceso de instalación. En algunos casos, una conexión de LAN o intranet es suficiente, mientras que la conexión a Internet es la más arriesgada. Para seguir las mejores prácticas de seguridad, elija la zona más cercana a su repositorio mientras instala Red Hat Enterprise Linux 8 desde una red.
11.4. Instalar la cantidad mínima de paquetes necesarios
Es una buena práctica instalar sólo los paquetes que va a utilizar, ya que cada pieza de software en su ordenador podría contener una vulnerabilidad. Si está instalando desde el DVD, aproveche para seleccionar exactamente los paquetes que desea instalar durante la instalación. Si descubre que necesita otro paquete, siempre puede añadirlo al sistema más tarde.
11.5. Procedimientos posteriores a la instalación
Los siguientes pasos son los procedimientos relacionados con la seguridad que deberían realizarse inmediatamente después de la instalación de Red Hat Enterprise Linux 8.
Actualice su sistema. Introduzca el siguiente comando como root:
# yum updateAunque el servicio de cortafuegos,
firewalld, se habilita automáticamente con la instalación de Red Hat Enterprise Linux, hay escenarios en los que puede estar explícitamente deshabilitado, por ejemplo en la configuración de kickstart. En tal caso, se recomienda considerar la posibilidad de volver a habilitar el cortafuegos.Para iniciar
firewalldintroduzca los siguientes comandos como root:# systemctl start firewalld # systemctl enable firewalldPara mejorar la seguridad, desactive los servicios que no necesite. Por ejemplo, si no hay impresoras instaladas en su ordenador, desactive el servicio
cupsmediante el siguiente comando:# systemctl disable cupsPara revisar los servicios activos, introduzca el siguiente comando:
$ systemctl list-units | grep service
11.6. Instalación de un sistema RHEL 8 con el modo FIPS activado
Para habilitar las autocomprobaciones del módulo criptográfico exigidas por la Publicación 140-2 del Estándar Federal de Procesamiento de Información (FIPS), tiene que operar RHEL 8 en modo FIPS. Puede conseguirlo de la siguiente manera:
- Iniciar la instalación en modo FIPS.
- Pasar el sistema al modo FIPS después de la instalación.
Para evitar la regeneración de material de claves criptográficas y la reevaluación de la conformidad del sistema resultante asociada a la conversión de sistemas ya implantados, Red Hat recomienda iniciar la instalación en modo FIPS.
11.6.1. Norma Federal de Procesamiento de la Información (FIPS)
La publicación 140-2 de la Norma Federal de Procesamiento de la Información (FIPS) es una norma de seguridad informática desarrollada por el grupo de trabajo del Gobierno y la industria de Estados Unidos para validar la calidad de los módulos criptográficos. Consulte las publicaciones oficiales de FIPS en el Centro de Recursos de Seguridad Informática del NIST.
La norma FIPS 140-2 garantiza que las herramientas criptográficas implementen sus algoritmos correctamente. Uno de los mecanismos para ello es la autocomprobación en tiempo de ejecución. Consulte la norma FIPS 140-2 completa en FIPS PUB 140-2 para obtener más detalles y otras especificaciones de la norma FIPS.
Para conocer los requisitos de cumplimiento, consulte la página de normas gubernamentales de Red Hat.
11.6.2. Instalación del sistema con el modo FIPS activado
Para habilitar las autocomprobaciones del módulo criptográfico exigidas por la Publicación 140-2 del Estándar Federal de Procesamiento de Información (FIPS), habilite el modo FIPS durante la instalación del sistema.
Red Hat recomienda instalar Red Hat Enterprise Linux 8 con el modo FIPS activado, en lugar de activar el modo FIPS más tarde. La habilitación del modo FIPS durante la instalación garantiza que el sistema genere todas las claves con algoritmos aprobados por FIPS y pruebas de supervisión continua en el lugar.
Procedimiento
Añade la opción
fips=1a la línea de comandos del kernel durante la instalación del sistema.Durante la etapa de selección del software, no instale ningún software de terceros.
Tras la instalación, el sistema se inicia automáticamente en modo FIPS.
Pasos de verificación
Después de iniciar el sistema, compruebe que el modo FIPS está activado:
$ fips-mode-setup --check FIPS mode is enabled.
Capítulo 12. Uso de políticas criptográficas en todo el sistema
Crypto policies es un componente del sistema que configura los subsistemas criptográficos principales, cubriendo los protocolos TLS, IPSec, SSH, DNSSec y Kerberos. Proporciona un pequeño conjunto de políticas, que el administrador puede seleccionar.
12.1. Políticas criptográficas para todo el sistema
Una vez que se establece una política para todo el sistema, las aplicaciones en RHEL la siguen y se niegan a utilizar algoritmos y protocolos que no cumplan con la política, a menos que usted solicite explícitamente a la aplicación que lo haga. Es decir, la política se aplica al comportamiento por defecto de las aplicaciones cuando se ejecutan con la configuración proporcionada por el sistema, pero usted puede anularla si así lo requiere.
Red Hat Enterprise Linux 8 contiene los siguientes niveles de política:
|
| El nivel de política criptográfica por defecto en todo el sistema ofrece una configuración segura para los modelos de amenaza actuales. Permite los protocolos TLS 1.2 y 1.3, así como los protocolos IKEv2 y SSH2. Las claves RSA y los parámetros Diffie-Hellman se aceptan si tienen una longitud mínima de 2048 bits. |
|
|
Esta política garantiza la máxima compatibilidad con Red Hat Enterprise Linux 5 y anteriores; es menos segura debido a una mayor superficie de ataque. Además de los algoritmos y protocolos de nivel |
|
| Un nivel de seguridad conservador que se cree que resistirá cualquier ataque futuro a corto plazo. Este nivel no permite el uso de SHA-1 en los algoritmos de firma. Las claves RSA y los parámetros Diffie-Hellman se aceptan si tienen una longitud mínima de 3072 bits. |
|
|
Un nivel de política que se ajusta a los requisitos de FIPS 140-2. Lo utiliza internamente la herramienta |
Red Hat ajusta continuamente todos los niveles de políticas para que todas las bibliotecas, excepto cuando se utiliza la política LEGACY, proporcionen valores predeterminados seguros. Aunque el perfil LEGACY no proporciona valores predeterminados seguros, no incluye ningún algoritmo que sea fácilmente explotable. Como tal, el conjunto de algoritmos habilitados o los tamaños de clave aceptables en cualquier política proporcionada pueden cambiar durante la vida de RHEL 8.
Estos cambios reflejan los nuevos estándares de seguridad y las nuevas investigaciones en materia de seguridad. Si debe garantizar la interoperabilidad con un sistema específico durante toda la vida útil de RHEL 8, debe optar por no aplicar políticas criptográficas a los componentes que interactúan con ese sistema.
Debido a que una clave criptográfica utilizada por un certificado en la API del Portal del Cliente no cumple los requisitos de la política criptográfica de todo el sistema FUTURE, la utilidad redhat-support-tool no funciona con este nivel de política por el momento.
Para solucionar este problema, utilice la política de cifrado DEFAULT mientras se conecta a la API del Portal del Cliente.
Los algoritmos y cifrados específicos descritos en los niveles de política como permitidos sólo están disponibles si una aplicación los soporta.
Herramienta para la gestión de las criptopolíticas
Para ver o cambiar la política criptográfica actual de todo el sistema, utilice la herramienta update-crypto-policies, por ejemplo:
$ update-crypto-policies --show
DEFAULT
# update-crypto-policies --set FUTURE
Setting system policy to FUTUREPara asegurarse de que el cambio de la política criptográfica se aplica, reinicie el sistema.
Criptografía fuerte por defecto mediante la eliminación de suites de cifrado y protocolos inseguros
La siguiente lista contiene conjuntos de cifrado y protocolos eliminados de las bibliotecas criptográficas del núcleo en RHEL 8. No están presentes en las fuentes, o su soporte está deshabilitado durante la compilación, por lo que las aplicaciones no pueden utilizarlos.
- DES (desde RHEL 7)
- Todos los conjuntos de cifrado de grado de exportación (desde RHEL 7)
- MD5 en las firmas (desde RHEL 7)
- SSLv2 (desde RHEL 7)
- SSLv3 (desde RHEL 8)
- Todas las curvas ECC < 224 bits (desde RHEL 6)
- Todas las curvas ECC de campo binario (desde RHEL 6)
Suites de cifrado y protocolos desactivados en todos los niveles de política
Los siguientes conjuntos de cifrado y protocolos están deshabilitados en todos los niveles de la política de cifrado. Sólo se pueden habilitar mediante una configuración explícita de las aplicaciones individuales.
- DH con parámetros < 1024 bits
- RSA con tamaño de clave < 1024 bits
- Camelia
- ARIA
- SEED
- IDEA
- Suites de cifrado de sólo integridad
- Suites de cifrado en modo CBC de TLS con SHA-384 HMAC
- AES-CCM8
- Todas las curvas ECC incompatibles con TLS 1.3, incluida secp256k1
- IKEv1 (desde RHEL 8)
Suites de cifrado y protocolos habilitados en los niveles de criptopolíticas
La siguiente tabla muestra los conjuntos de cifrado y protocolos habilitados en los cuatro niveles de criptopolíticas.
LEGACY | DEFAULT | FIPS | FUTURE | |
|---|---|---|---|---|
| IKEv1 | no | no | no | no |
| 3DES | sí | no | no | no |
| RC4 | sí | no | no | no |
| DH | mínimo. 1024 bits | mínimo. 2048 bits | mínimo. 2048 bits | mínimo. 3072 bits |
| RSA | mínimo. 1024 bits | mínimo. 2048 bits | mínimo. 2048 bits | mínimo. 3072 bits |
| DSA | sí | no | no | no |
| TLS v1.0 | sí | no | no | no |
| TLS v1.1 | sí | no | no | no |
| SHA-1 in digital signatures | sí | sí | no | no |
| CBC mode ciphers | sí | sí | sí | no |
| Symmetric ciphers with keys < 256 bits | sí | sí | sí | no |
| SHA-1 and SHA-224 signatures in certificates | sí | sí | sí | no |
Recursos adicionales
-
Para más detalles, consulte la página de manual
update-crypto-policies(8).
12.2. Cambio de la política criptográfica de todo el sistema al modo compatible con versiones anteriores
La política criptográfica por defecto en todo el sistema en Red Hat Enterprise Linux 8 no permite la comunicación utilizando protocolos antiguos e inseguros. Para los entornos que requieren ser compatibles con Red Hat Enterprise Linux 5 y en algunos casos también con versiones anteriores, está disponible el nivel de política menos seguro LEGACY.
El cambio al nivel de política LEGACY resulta en un sistema y aplicaciones menos seguros.
Procedimiento
Para cambiar la política criptográfica de todo el sistema al nivel
LEGACY, introduzca el siguiente comando comoroot:# update-crypto-policies --set LEGACY Setting system policy to LEGACY
Recursos adicionales
-
Para ver la lista de niveles de políticas criptográficas disponibles, consulte la página de manual
update-crypto-policies(8).
12.3. Cambio del sistema al modo FIPS
Las políticas criptográficas de todo el sistema contienen un nivel de política que permite la autocomprobación de los módulos criptográficos de acuerdo con los requisitos de la Publicación 140-2 del Estándar Federal de Procesamiento de Información (FIPS). La herramienta fips-mode-setup que activa o desactiva el modo FIPS utiliza internamente el nivel de política criptográfica de todo el sistema FIPS.
Red Hat recomienda instalar Red Hat Enterprise Linux 8 con el modo FIPS activado, en lugar de activar el modo FIPS más tarde. La habilitación del modo FIPS durante la instalación garantiza que el sistema genere todas las claves con algoritmos aprobados por FIPS y pruebas de supervisión continua en el lugar.
Procedimiento
Para cambiar el sistema al modo FIPS en RHEL 8:
# fips-mode-setup --enable Setting system policy to FIPS FIPS mode will be enabled. Please reboot the system for the setting to take effect.Reinicie su sistema para permitir que el kernel cambie al modo FIPS:
# reboot
Pasos de verificación
Tras el reinicio, puede comprobar el estado actual del modo FIPS:
# fips-mode-setup --check FIPS mode is enabled.
Recursos adicionales
-
La página de manual
fips-mode-setup(8). - Lista de aplicaciones de RHEL 8 que utilizan criptografía y no cumplen con FIPS 140-2
- Para obtener más detalles sobre FIPS 140-2, consulte los requisitos de seguridad para los módulos criptográficos en el sitio web del Instituto Nacional de Normas y Tecnología (NIST).
12.4. Activación del modo FIPS en un contenedor
Permitir la autocomprobación de los módulos criptográficos de acuerdo con los requisitos de la Publicación 140-2 de la Norma Federal de Procesamiento de la Información (FIPS) en un contenedor:
Requisitos previos
- En primer lugar, el sistema anfitrión debe cambiarse al modo FIPS; consulte Cómo cambiar el sistema al modo FIPS.
Procedimiento
-
Monte el archivo
/etc/system-fipsen el contenedor desde el host. Establezca el nivel de política criptográfica FIPS en el contenedor:
$ update-crypto-policies --set FIPS
RHEL 8.2 introdujo un método alternativo para cambiar un contenedor al modo FIPS. Sólo requiere el uso del siguiente comando en el contenedor:
# mount --bind /usr/share/crypto-policies/back-ends/FIPS /etc/crypto-policies/back-ends
En RHEL 8, el comando fips-mode-setup no funciona correctamente en un contenedor y no se puede utilizar para activar o comprobar el modo FIPS en este escenario.
12.5. Lista de aplicaciones de RHEL que utilizan criptografía que no cumple con FIPS 140-2
Red Hat recomienda utilizar las librerías del conjunto de componentes criptográficos principales, ya que están garantizadas para pasar todas las certificaciones criptográficas relevantes, como FIPS 140-2, y también siguen las políticas criptográficas de todo el sistema RHEL.
Consulte el artículo sobre los componentes criptográficos del núcleo de RHEL 8 para obtener una visión general de los componentes criptográficos del núcleo de RHEL 8, la información sobre cómo se seleccionan, cómo se integran en el sistema operativo, cómo admiten los módulos de seguridad de hardware y las tarjetas inteligentes, y cómo se aplican las certificaciones criptográficas a ellos.
Además de la tabla siguiente, en algunas versiones de RHEL 8 Z-stream (por ejemplo, 8.1.1), se han actualizado los paquetes del navegador Firefox, que contienen una copia separada de la biblioteca de criptografía NSS. De este modo, Red Hat quiere evitar la interrupción que supone volver a basar un componente de tan bajo nivel en una versión de parche. Como resultado, estos paquetes de Firefox no utilizan un módulo validado por FIPS 140-2.
| Aplicación | Detalles |
|---|---|
| FreeRADIUS | El protocolo RADIUS utiliza MD5 |
| ghostscript | Criptografía propia (MD5, RC4, SHA-2, AES) para cifrar y descifrar documentos |
| ipxe | La pila criptográfica para TLS está compilada, pero no se utiliza |
| java-1.8.0-openjdk | Pila criptográfica completa[a] |
| libica | Software de respaldo para varios algoritmos como RSA y ECDH mediante instrucciones CPACF |
| Ovmf (firmware UEFI), Edk2, shim | Pila criptográfica completa (una copia incrustada de la biblioteca OpenSSL) |
| perl-Digest-HMAC | HMAC, HMAC-SHA1, HMAC-MD5 |
| perl-Digest-SHA | SHA-1, SHA-224, .. |
| pidgin | DES, RC4 |
| samba[b] | AES, DES, RC4 |
| valgrind | AES, hashes[c] |
[a]
En RHEL 8.1, java-1.8.0-openjdk requiere una configuración manual adicional para ser compatible con FIPS.
[b]
A partir de RHEL 8.3, samba utiliza criptografía compatible con FIPS.
[c]
Reimplementa en software operaciones de descarga de hardware, como AES-NI.
| |
12.6. Excluir una aplicación de seguir las políticas criptográficas de todo el sistema
Puedes personalizar la configuración criptográfica utilizada por tu aplicación preferentemente configurando los conjuntos de cifrado y protocolos soportados directamente en la aplicación.
También puede eliminar un enlace simbólico relacionado con su aplicación del directorio /etc/crypto-policies/back-ends y sustituirlo por su configuración criptográfica personalizada. Esta configuración impide el uso de políticas criptográficas en todo el sistema para las aplicaciones que utilizan el back end excluido. Además, esta modificación no está soportada por Red Hat.
12.6.1. Ejemplos de exclusión de las políticas criptográficas de todo el sistema
wget
Para personalizar la configuración criptográfica utilizada por el descargador de red wget, utilice las opciones --secure-protocol y --ciphers. Por ejemplo:
$ wget --secure-protocol=TLSv1_1 --ciphers="SECURE128" https://example.com
Consulte la sección Opciones HTTPS (SSL/TLS) de la página de manual wget(1) para obtener más información.
rizo
Para especificar los cifrados utilizados por la herramienta curl, utilice la opción --ciphers y proporcione una lista de cifrados separada por dos puntos como valor. Por ejemplo:
$ curl https://example.com --ciphers '@SECLEVEL=0:DES-CBC3-SHA:RSA-DES-CBC3-SHA'
Consulte la página de manual curl(1) para obtener más información.
Firefox
Aunque no se puede optar por las políticas criptográficas de todo el sistema en el navegador web Firefox, se pueden restringir aún más los cifrados y las versiones de TLS compatibles en el Editor de Configuración de Firefox. Escriba about:config en la barra de direcciones y cambie el valor de la opción security.tls.version.min según sea necesario. Configurar security.tls.version.min a 1 permite TLS 1.0 como mínimo requerido, security.tls.version.min 2 habilita TLS 1.1, y así sucesivamente.
OpenSSH
Para optar por las políticas criptográficas de todo el sistema para su servidor OpenSSH, descomente la línea con la variable CRYPTO_POLICY= en el archivo /etc/sysconfig/sshd. Después de este cambio, los valores que especifique en las secciones Ciphers, MACs, KexAlgoritms, y GSSAPIKexAlgorithms en el archivo /etc/ssh/sshd_config no serán anulados. Consulte la página man sshd_config(5) para obtener más información.
Libreswan
Consulte la sección Configuración de conexiones IPsec que se excluyen de las políticas criptográficas de todo el sistema en el documento Protección de redes para obtener información detallada.
Recursos adicionales
-
Para más detalles, consulte la página de manual
update-crypto-policies(8).
12.7. Personalización de las políticas criptográficas de todo el sistema con modificadores de políticas
Utilice este procedimiento para ajustar determinados algoritmos o protocolos de cualquier nivel de política criptográfica de todo el sistema o de una política personalizada completa.
La personalización de las políticas criptográficas de todo el sistema está disponible desde RHEL 8.2.
Procedimiento
Acceda al directorio
/etc/crypto-policies/policies/modules/:# cd /etc/crypto-policies/policies/modules/Cree módulos de política para sus ajustes, por ejemplo:
# touch MYCRYPTO1.pmod # touch NO-AES128.pmodImportanteUtilice letras mayúsculas en los nombres de archivo de los módulos de política.
Abra los módulos de política en un editor de texto de su elección e inserte las opciones que modifican la política criptográfica de todo el sistema, por ejemplo:
# vi MYCRYPTO1.pmodsha1_in_certs = 0 min_rsa_size = 3072# vi NO-AES128.pmodcifrado = -AES-128-GCM -AES-128-CCM -AES-128-CTR -AES-128-CBC- Guarde los cambios en los archivos del módulo.
Aplique sus ajustes de política al nivel de política criptográfica de todo el sistema
DEFAULT:# update-crypto-policies --set DEFAULT:MYCRYPTO1:NO-AES128Para que la configuración criptográfica sea efectiva para los servicios y aplicaciones que ya se están ejecutando, reinicie el sistema:
# reboot
Recursos adicionales
-
Para más detalles, consulte la sección
Custom Policiesen la página de manualupdate-crypto-policies(8)y la secciónCrypto Policy Definition Formaten la página de manualcrypto-policies(7). - El artículo Cómo personalizar las políticas criptográficas en RHEL 8.2 proporciona ejemplos adicionales de cómo personalizar las políticas criptográficas de todo el sistema.
12.8. Desactivación de SHA-1 mediante la personalización de una política criptográfica para todo el sistema
La función hash SHA-1 tiene un diseño inherentemente débil y el avance del criptoanálisis la ha hecho vulnerable a los ataques. Por defecto, RHEL 8 no utiliza SHA-1 pero algunas aplicaciones de terceros, por ejemplo las firmas públicas, siguen utilizando SHA-1. Para desactivar el uso de SHA-1 en los algoritmos de firma en su sistema, puede utilizar el módulo de políticas NO-SHA1.
El módulo para desactivar SHA-1 está disponible desde RHEL 8.3. La personalización de las políticas criptográficas de todo el sistema está disponible desde RHEL 8.2.
Procedimiento
Aplique sus ajustes de política al nivel de política criptográfica de todo el sistema
DEFAULT:# update-crypto-policies --set DEFAULT:NO-SHA1Para que la configuración criptográfica sea efectiva para los servicios y aplicaciones que ya se están ejecutando, reinicie el sistema:
# reboot
Recursos adicionales
-
Para más detalles, consulte la sección
Custom Policiesen la página de manualupdate-crypto-policies(8)y la secciónCrypto Policy Definition Formaten la página de manualcrypto-policies(7). - La entrada del blog Cómo personalizar las políticas criptográficas en RHEL 8.2 proporciona ejemplos adicionales de cómo personalizar las políticas criptográficas de todo el sistema.
12.9. Creación y configuración de una política criptográfica personalizada para todo el sistema
Los siguientes pasos demuestran la personalización de las políticas criptográficas de todo el sistema mediante un archivo de políticas completo.
La personalización de las políticas criptográficas de todo el sistema está disponible desde RHEL 8.2.
Procedimiento
Cree un archivo de políticas para sus personalizaciones:
# cd /etc/crypto-policies/policies/ # touch MYPOLICY.polTambién puede empezar copiando uno de los cuatro niveles de política predefinidos:
# cp /usr/share/crypto-policies/policies/DEFAULT.pol /etc/crypto-policies/policies/MYPOLICY.polEdite el archivo con su política criptográfica personalizada en un editor de texto de su elección para que se ajuste a sus necesidades, por ejemplo:
# vi /etc/crypto-policies/policies/MYPOLICY.polCambie la política criptográfica de todo el sistema a su nivel personalizado:
# update-crypto-policies --set MYPOLICYPara que la configuración criptográfica sea efectiva para los servicios y aplicaciones que ya se están ejecutando, reinicie el sistema:
# reboot
Recursos adicionales
-
Para más detalles, consulte la sección
Custom Policiesen la página de manualupdate-crypto-policies(8)y la secciónCrypto Policy Definition Formaten la página de manualcrypto-policies(7). - El artículo Cómo personalizar las políticas criptográficas en RHEL 8.2 proporciona ejemplos adicionales de cómo personalizar las políticas criptográficas de todo el sistema.
Capítulo 13. Configuración de aplicaciones para utilizar hardware criptográfico a través de PKCS #11
Separar partes de su información secreta en dispositivos criptográficos dedicados, tales como tarjetas inteligentes y tokens criptográficos para la autenticación del usuario final y módulos de seguridad de hardware (HSM) para aplicaciones de servidor, proporciona una capa adicional de seguridad. En Red Hat Enterprise Linux 8, el soporte para el hardware criptográfico a través de la API PKCS #11 es consistente en las diferentes aplicaciones, y el aislamiento de los secretos en el hardware criptográfico no es una tarea complicada.
13.1. Soporte de hardware criptográfico a través de PKCS #11
El PKCS #11 (Public-Key Cryptography Standard) define una interfaz de programación de aplicaciones (API) para los dispositivos criptográficos que contienen información criptográfica y realizan funciones criptográficas. Estos dispositivos se denominan tokens, y pueden implementarse en forma de hardware o software.
Un token PKCS #11 puede almacenar varios tipos de objetos, como un certificado, un objeto de datos y una clave pública, privada o secreta. Estos objetos son identificables de forma única a través del esquema PKCS #11 URI.
Un URI PKCS #11 es una forma estándar de identificar un objeto específico en un módulo PKCS #11 según los atributos del objeto. Esto permite configurar todas las bibliotecas y aplicaciones con la misma cadena de configuración en forma de URI.
Red Hat Enterprise Linux 8 proporciona por defecto el controlador OpenSC PKCS #11 para tarjetas inteligentes. Sin embargo, los tokens de hardware y los HSMs pueden tener sus propios módulos PKCS #11 que no tienen su contraparte en Red Hat Enterprise Linux. Puede registrar tales módulos PKCS #11 con la herramienta p11-kit, que actúa como una envoltura sobre los controladores de tarjetas inteligentes registrados en el sistema.
Para que su propio módulo PKCS #11 funcione en el sistema, añada un nuevo archivo de texto al directorio /etc/pkcs11/modules/
Puede añadir su propio módulo PKCS #11 en el sistema creando un nuevo archivo de texto en el directorio /etc/pkcs11/modules/. Por ejemplo, el archivo de configuración de OpenSC en p11-kit tiene el siguiente aspecto:
$ cat /usr/share/p11-kit/modules/opensc.module
module: opensc-pkcs11.so13.2. Uso de claves SSH almacenadas en una tarjeta inteligente
Red Hat Enterprise Linux 8 le permite utilizar claves RSA y ECDSA almacenadas en una tarjeta inteligente en clientes OpenSSH. Use este procedimiento para habilitar la autenticación usando una tarjeta inteligente en lugar de usar una contraseña.
Requisitos previos
-
En el lado del cliente, el paquete
openscestá instalado y el serviciopcscdestá funcionando.
Procedimiento
Enumerar todas las claves proporcionadas por el módulo PKCS #11 de OpenSC incluyendo sus URIs PKCS #11 y guardar el resultado en el archivo keys.pub:
$ ssh-keygen -D pkcs11: > keys.pub $ ssh-keygen -D pkcs11: ssh-rsa AAAAB3NzaC1yc2E...KKZMzcQZzx pkcs11:id=%02;object=SIGN%20pubkey;token=SSH%20key;manufacturer=piv_II?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so ecdsa-sha2-nistp256 AAA...J0hkYnnsM= pkcs11:id=%01;object=PIV%20AUTH%20pubkey;token=SSH%20key;manufacturer=piv_II?module-path=/usr/lib64/pkcs11/opensc-pkcs11.soPara habilitar la autenticación mediante una tarjeta inteligente en un servidor remoto (example.com), transfiera la clave pública al servidor remoto. Utilice el comando
ssh-copy-idcon keys.pub creado en el paso anterior:$ ssh-copy-id -f -i keys.pub username@example.comPara conectarse a example.com utilizando la clave ECDSA de la salida del comando
ssh-keygen -Den el paso 1, puede utilizar sólo un subconjunto de la URI, que hace referencia a su clave de forma exclusiva, por ejemplo:$ ssh -i "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" example.com Enter PIN for 'SSH key': [example.com] $Puede utilizar la misma cadena URI en el archivo
~/.ssh/configpara que la configuración sea permanente:$ cat ~/.ssh/config IdentityFile "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" $ ssh example.com Enter PIN for 'SSH key': [example.com] $Dado que OpenSSH utiliza el wrapper
p11-kit-proxyy el módulo PKCS #11 de OpenSC está registrado en PKCS#11 Kit, puede simplificar los comandos anteriores:$ ssh -i "pkcs11:id=%01" example.com Enter PIN for 'SSH key': [example.com] $
Si se omite la parte id= de un URI PKCS #11, OpenSSH carga todas las claves que están disponibles en el módulo proxy. Esto puede reducir la cantidad de escritura requerida:
$ ssh -i pkcs11: example.com
Enter PIN for 'SSH key':
[example.com] $Recursos adicionales
- Fedora 28: Mejor soporte para tarjetas inteligentes en OpenSSH
-
p11-kit(8)página de manual -
ssh(1)página de manual -
ssh-keygen(1)página de manual -
opensc.conf(5)página de manual -
pcscd(8)página de manual
13.3. Uso de HSM para proteger las claves privadas en Apache y Nginx
Los servidores HTTP Apache y Nginx pueden trabajar con claves privadas almacenadas en módulos de seguridad de hardware (HSM), lo que ayuda a evitar la divulgación de las claves y los ataques de intermediario. Tenga en cuenta que esto suele requerir HSMs de alto rendimiento para los servidores ocupados.
Apache Servidor HTTP
Para la comunicación segura en forma de protocolo HTTPS, el servidor HTTP Apache (httpd) utiliza la biblioteca OpenSSL. OpenSSL no soporta PKCS #11 de forma nativa. Para utilizar los HSM, tiene que instalar el paquete openssl-pkcs11, que proporciona acceso a los módulos PKCS #11 a través de la interfaz del motor. Puede utilizar un URI PKCS #11 en lugar de un nombre de archivo normal para especificar una clave de servidor y un certificado en el archivo de configuración /etc/httpd/conf.d/ssl.conf, por ejemplo:
SSLCertificateFile "pkcs11:id=%01;token=softhsm;type=cert"
SSLCertificateKeyFile "pkcs11:id=%01;token=softhsm;type=private?pin-value=111111"
Instale el paquete httpd-manual para obtener la documentación completa del servidor HTTP Apache, incluida la configuración de TLS. Las directivas disponibles en el archivo de configuración /etc/httpd/conf.d/ssl.conf se describen en detalle en /usr/share/httpd/manual/mod/mod_ssl.html.
Nginx Servidor HTTP y proxy
Dado que Nginx también utiliza OpenSSL para las operaciones criptográficas, el soporte para PKCS #11 debe pasar por el motor de openssl-pkcs11. Nginx actualmente sólo soporta la carga de claves privadas desde un HSM, y un certificado debe ser proporcionado por separado como un archivo regular. Modifique las opciones ssl_certificate y ssl_certificate_key en la sección server del archivo de configuración /etc/nginx/nginx.conf:
ssl_certificate /path/to/cert.pem
ssl_certificate_key "engine:pkcs11:pkcs11:token=softhsm;id=%01;type=private?pin-value=111111";
Tenga en cuenta que el prefijo engine:pkcs11: es necesario para el URI PKCS #11 en el archivo de configuración Nginx. Esto se debe a que el otro prefijo pkcs11 se refiere al nombre del motor.
13.4. Configurar las aplicaciones para que se autentifiquen mediante certificados de tarjetas inteligentes
El descargador de red
wgetle permite especificar URIs PKCS #11 en lugar de rutas a claves privadas almacenadas localmente, y así simplifica la creación de scripts para tareas que requieren claves privadas y certificados almacenados de forma segura. Por ejemplo:$ wget --private-key 'pkcs11:token=softhsm;id=;type=private?pin-value=111111' --certificate 'pkcs11:token=softhsm;id=;type=cert' https://example.com/Consulte la página de manual
wget(1)para obtener más información.La especificación de la URI PKCS #11 para su uso por la herramienta
curles análoga:$ curl --key 'pkcs11:token=softhsm;id=;type=private?pin-value=111111' --cert 'pkcs11:token=softhsm;id=;type=cert' https://example.com/Consulte la página de manual
curl(1)para obtener más información.-
El navegador web
Firefoxcarga automáticamente el módulop11-kit-proxy. Esto significa que se detectan automáticamente todas las tarjetas inteligentes compatibles con el sistema. Para utilizar la autenticación de cliente TLS, no se requiere ninguna configuración adicional y las claves de una tarjeta inteligente se utilizan automáticamente cuando un servidor las solicita.
Uso de URIs PKCS #11 en aplicaciones personalizadas
Si su aplicación utiliza la biblioteca GnuTLS o NSS, la compatibilidad con los URIs PKCS #11 está garantizada gracias a su soporte incorporado para PKCS #11. Además, las aplicaciones que dependen de la biblioteca OpenSSL pueden acceder a módulos de hardware criptográfico gracias al motor openssl-pkcs11.
En el caso de aplicaciones que requieran trabajar con claves privadas en tarjetas inteligentes y que no utilicen NSS, GnuTLS, o OpenSSL, utilice p11-kit para implementar el registro de módulos PKCS #11.
Consulte la página de manual p11-kit(8) para obtener más información.
Capítulo 15. Escanear el sistema para comprobar el cumplimiento de la seguridad y las vulnerabilidades
15.1. Herramientas de cumplimiento de la configuración en RHEL
Red Hat Enterprise Linux proporciona herramientas que le permiten realizar una auditoría de cumplimiento totalmente automatizada. Estas herramientas se basan en el estándar Security Content Automation Protocol (SCAP) y están diseñadas para la adaptación automatizada de las políticas de cumplimiento.
-
SCAP Workbench - La utilidad gráfica
scap-workbenchestá diseñada para realizar escaneos de configuración y vulnerabilidad en un solo sistema local o remoto. También puede utilizarla para generar informes de seguridad basados en estos escaneos y evaluaciones. -
OpenSCAP - La biblioteca
OpenSCAP, con la utilidad de línea de comandos que la acompañaoscap, está diseñada para realizar escaneos de configuración y vulnerabilidad en un sistema local, para validar el contenido de cumplimiento de la configuración y para generar informes y guías basados en estos escaneos y evaluaciones. -
SCAP Security Guide (SSG) - El paquete
scap-security-guideproporciona la última colección de políticas de seguridad para sistemas Linux. La guía consiste en un catálogo de consejos prácticos de endurecimiento, vinculados a los requisitos del gobierno cuando sea aplicable. El proyecto tiende un puente entre los requisitos políticos generalizados y las directrices de aplicación específicas. -
Script Check Engine (SCE) - SCE es una extensión del protocolo SCAP que permite a los administradores escribir su contenido de seguridad utilizando un lenguaje de scripting, como Bash, Python y Ruby. La extensión SCE se proporciona en el paquete
openscap-engine-sce. El SCE en sí no forma parte del estándar SCAP.
Para realizar auditorías de cumplimiento automatizadas en múltiples sistemas de forma remota, puede utilizar la solución OpenSCAP para Red Hat Satellite.
Recursos adicionales
-
oscap(8)- La página del manual de la utilidad de la línea de comandososcapofrece una lista completa de las opciones disponibles y explicaciones sobre su uso. - Demostraciones de seguridad de Red Hat: Creación de contenido de políticas de seguridad personalizadas para automatizar el cumplimiento de la seguridad - Un laboratorio práctico para obtener una experiencia inicial en la automatización del cumplimiento de la seguridad utilizando las herramientas que se incluyen en Red Hat Enterprise Linux para cumplir tanto con las políticas de seguridad estándar del sector como con las políticas de seguridad personalizadas. Si desea formación o acceso a estos ejercicios de laboratorio para su equipo, póngase en contacto con su equipo de cuentas de Red Hat para obtener más detalles.
- Demostraciones de seguridad de Red Hat: Defiéndase con las tecnologías de seguridad de RHEL - Un laboratorio práctico para aprender a implementar la seguridad en todos los niveles de su sistema RHEL, utilizando las principales tecnologías de seguridad disponibles en Red Hat Enterprise Linux, incluyendo OpenSCAP. Si desea formación o acceso a estos ejercicios de laboratorio para su equipo, póngase en contacto con su equipo de cuentas de Red Hat para obtener más detalles.
-
scap-workbench(8)- La página del manual de la aplicaciónSCAP Workbenchproporciona una información básica sobre la aplicación, así como algunos enlaces a posibles fuentes de contenido SCAP. -
scap-security-guide(8)- La página del manual del proyectoscap-security-guideproporciona más documentación sobre los distintos perfiles de seguridad SCAP disponibles. También se proporcionan ejemplos de cómo utilizar los puntos de referencia proporcionados utilizando la utilidad OpenSCAP. - Para más detalles sobre el uso de OpenSCAP con Red Hat Satellite, consulte Gestión del cumplimiento de la seguridad en el Manual de administración de Red Hat Satellite.
15.2. Avisos de seguridad de Red Hat Alimentación de OVAL
Las capacidades de auditoría de seguridad de Red Hat Enterprise Linux se basan en el estándar Security Content Automation Protocol (SCAP). SCAP es un marco de especificaciones polivalente que admite la configuración automatizada, la comprobación de vulnerabilidades y parches, las actividades de cumplimiento de controles técnicos y la medición de la seguridad.
Las especificaciones SCAP crean un ecosistema en el que el formato del contenido de seguridad es bien conocido y estandarizado, aunque la implementación del escáner o del editor de políticas no es obligatoria. Esto permite a las organizaciones construir su política de seguridad (contenido SCAP) una vez, sin importar cuántos proveedores de seguridad empleen.
El Lenguaje Abierto de Evaluación de Vulnerabilidades (OVAL) es el componente esencial y más antiguo de SCAP. A diferencia de otras herramientas y scripts personalizados, OVAL describe un estado requerido de los recursos de manera declarativa. El código de OVAL nunca se ejecuta directamente, sino que se utiliza una herramienta de interpretación de OVAL llamada escáner. La naturaleza declarativa de OVAL asegura que el estado del sistema evaluado no sea modificado accidentalmente.
Como todos los demás componentes de SCAP, OVAL se basa en XML. El estándar SCAP define varios formatos de documentos. Cada uno de ellos incluye un tipo de información diferente y sirve para un propósito distinto.
La Seguridad de Productos de Red Hat ayuda a los clientes a evaluar y gestionar los riesgos mediante el seguimiento y la investigación de todos los problemas de seguridad que afectan a los clientes de Red Hat. Proporciona parches y avisos de seguridad oportunos y concisos en el Portal del Cliente de Red Hat. Red Hat crea y soporta definiciones de parches OVAL, proporcionando versiones legibles por máquina de nuestros avisos de seguridad.
Debido a las diferencias entre plataformas, versiones y otros factores, las calificaciones cualitativas de gravedad de las vulnerabilidades de Red Hat Product Security no se alinean directamente con las calificaciones de referencia del Sistema Común de Puntuación de Vulnerabilidades (CVSS) proporcionadas por terceros. Por lo tanto, le recomendamos que utilice las definiciones de RHSA OVAL en lugar de las proporcionadas por terceros.
Las definiciones de RHSA OVAL están disponibles individualmente y como un paquete completo, y se actualizan una hora después de que un nuevo aviso de seguridad esté disponible en el Portal del Cliente de Red Hat.
Cada definición de parche de OVAL se corresponde con un aviso de seguridad de Red Hat (RHSA). Debido a que un RHSA puede contener correcciones para múltiples vulnerabilidades, cada vulnerabilidad es listada por separado por su nombre de Vulnerabilidades y Exposiciones Comunes (CVE) y tiene un enlace a su entrada en nuestra base de datos pública de errores.
Las definiciones de RHSA OVAL están diseñadas para buscar versiones vulnerables de los paquetes RPM instalados en un sistema. Es posible ampliar estas definiciones para incluir más comprobaciones, por ejemplo, para averiguar si los paquetes se están utilizando en una configuración vulnerable. Estas definiciones están diseñadas para cubrir el software y las actualizaciones enviadas por Red Hat. Se requieren definiciones adicionales para detectar el estado de los parches del software de terceros.
Para analizar los contenedores o las imágenes de contenedores en busca de vulnerabilidades de seguridad, consulte Análisis de contenedores e imágenes de contenedores en busca de vulnerabilidades.
15.3. Exploración de la vulnerabilidad
15.3.1. Avisos de seguridad de Red Hat Alimentación de OVAL
Las capacidades de auditoría de seguridad de Red Hat Enterprise Linux se basan en el estándar Security Content Automation Protocol (SCAP). SCAP es un marco de especificaciones polivalente que admite la configuración automatizada, la comprobación de vulnerabilidades y parches, las actividades de cumplimiento de controles técnicos y la medición de la seguridad.
Las especificaciones SCAP crean un ecosistema en el que el formato del contenido de seguridad es bien conocido y estandarizado, aunque la implementación del escáner o del editor de políticas no es obligatoria. Esto permite a las organizaciones construir su política de seguridad (contenido SCAP) una vez, sin importar cuántos proveedores de seguridad empleen.
El Lenguaje Abierto de Evaluación de Vulnerabilidades (OVAL) es el componente esencial y más antiguo de SCAP. A diferencia de otras herramientas y scripts personalizados, OVAL describe un estado requerido de los recursos de manera declarativa. El código de OVAL nunca se ejecuta directamente, sino que se utiliza una herramienta de interpretación de OVAL llamada escáner. La naturaleza declarativa de OVAL asegura que el estado del sistema evaluado no sea modificado accidentalmente.
Como todos los demás componentes de SCAP, OVAL se basa en XML. El estándar SCAP define varios formatos de documentos. Cada uno de ellos incluye un tipo de información diferente y sirve para un propósito distinto.
La Seguridad de Productos de Red Hat ayuda a los clientes a evaluar y gestionar los riesgos mediante el seguimiento y la investigación de todos los problemas de seguridad que afectan a los clientes de Red Hat. Proporciona parches y avisos de seguridad oportunos y concisos en el Portal del Cliente de Red Hat. Red Hat crea y soporta definiciones de parches OVAL, proporcionando versiones legibles por máquina de nuestros avisos de seguridad.
Debido a las diferencias entre plataformas, versiones y otros factores, las calificaciones cualitativas de gravedad de las vulnerabilidades de Red Hat Product Security no se alinean directamente con las calificaciones de referencia del Sistema Común de Puntuación de Vulnerabilidades (CVSS) proporcionadas por terceros. Por lo tanto, le recomendamos que utilice las definiciones de RHSA OVAL en lugar de las proporcionadas por terceros.
Las definiciones de RHSA OVAL están disponibles individualmente y como un paquete completo, y se actualizan una hora después de que un nuevo aviso de seguridad esté disponible en el Portal del Cliente de Red Hat.
Cada definición de parche de OVAL se corresponde con un aviso de seguridad de Red Hat (RHSA). Debido a que un RHSA puede contener correcciones para múltiples vulnerabilidades, cada vulnerabilidad es listada por separado por su nombre de Vulnerabilidades y Exposiciones Comunes (CVE) y tiene un enlace a su entrada en nuestra base de datos pública de errores.
Las definiciones de RHSA OVAL están diseñadas para buscar versiones vulnerables de los paquetes RPM instalados en un sistema. Es posible ampliar estas definiciones para incluir más comprobaciones, por ejemplo, para averiguar si los paquetes se están utilizando en una configuración vulnerable. Estas definiciones están diseñadas para cubrir el software y las actualizaciones enviadas por Red Hat. Se requieren definiciones adicionales para detectar el estado de los parches del software de terceros.
Para analizar los contenedores o las imágenes de contenedores en busca de vulnerabilidades de seguridad, consulte Análisis de contenedores e imágenes de contenedores en busca de vulnerabilidades.
15.3.2. Análisis del sistema en busca de vulnerabilidades
La utilidad de línea de comandos oscap permite escanear sistemas locales, validar el contenido de cumplimiento de la configuración y generar informes y guías basados en estos escaneos y evaluaciones. Esta utilidad sirve como front-end de la biblioteca OpenSCAP y agrupa sus funcionalidades en módulos (subcomandos) basados en el tipo de contenido SCAP que procesa.
Requisitos previos
-
El repositorio
AppStreamestá activado.
Procedimiento
Instale los paquetes
openscap-scannerybzip2:# yum install openscap-scanner bzip2Descargue las últimas definiciones de RHSA OVAL para su sistema:
# wget -O - https://www.redhat.com/security/data/oval/v2/RHEL8/rhel-8.oval.xml.bz2 | bzip2 --decompress > rhel-8.oval.xmlAnalice el sistema en busca de vulnerabilidades y guarde los resultados en el archivo vulnerability.html:
# oscap oval eval --report vulnerability.html rhel-8.oval.xml
Pasos de verificación
Compruebe los resultados en un navegador de su elección, por ejemplo:
$ firefox vulnerability.html &
Recursos adicionales
-
La página de manual
oscap(8). - La lista de definiciones de Red Hat OVAL.
15.3.3. Análisis de sistemas remotos en busca de vulnerabilidades
También puede comprobar las vulnerabilidades de los sistemas remotos con el escáner OpenSCAP utilizando la herramienta oscap-ssh a través del protocolo SSH.
Requisitos previos
-
El repositorio
AppStreamestá activado. -
El paquete
openscap-scannerestá instalado en los sistemas remotos. - El servidor SSH se está ejecutando en los sistemas remotos.
Procedimiento
Instale los paquetes
openscap-utilsybzip2:# yum install openscap-utils bzip2Descargue las últimas definiciones de RHSA OVAL para su sistema:
# wget -O - https://www.redhat.com/security/data/oval/v2/RHEL8/rhel-8.oval.xml.bz2 | bzip2 --decompress > rhel-8.oval.xmlAnalice un sistema remoto con el nombre de host machine1, SSH ejecutado en el puerto 22 y el nombre de usuario joesec en busca de vulnerabilidades y guarde los resultados en el archivo remote-vulnerability.html:
# oscap-ssh joesec@machine1 22 oval eval --report remote-vulnerability.html rhel-8.oval.xml
Recursos adicionales
-
La página de manual
oscap-ssh(8). - La lista de definiciones de Red Hat OVAL.
15.4. Escaneo del cumplimiento de la configuración
15.4.1. Cumplimiento de la configuración en RHEL 8
Puede utilizar el escaneo de cumplimiento de configuración para ajustarse a una línea de base definida por una organización específica. Por ejemplo, si trabaja con el gobierno de los Estados Unidos, puede que tenga que cumplir con el Perfil de Protección del Sistema Operativo (OSPP), y si es un procesador de pagos, puede que tenga que cumplir con el Estándar de Seguridad de Datos de la Industria de las Tarjetas de Pago (PCI-DSS). También puede realizar un análisis de cumplimiento de la configuración para reforzar la seguridad de su sistema.
Red Hat recomienda seguir el contenido del Protocolo de Automatización de Contenidos de Seguridad (SCAP) proporcionado en el paquete de la Guía de Seguridad SCAP porque está en línea con las mejores prácticas de Red Hat para los componentes afectados.
El paquete de la Guía de Seguridad SCAP proporciona contenido que se ajusta a los estándares SCAP 1.2 y SCAP 1.3. La utilidad openscap scanner es compatible con el contenido de SCAP 1.2 y SCAP 1.3 proporcionado en el paquete de la Guía de Seguridad SCAP.
La realización de un escaneo de conformidad de la configuración no garantiza que el sistema sea conforme.
El conjunto de guías de seguridad SCAP proporciona perfiles para varias plataformas en forma de documentos de flujo de datos. Un flujo de datos es un archivo que contiene definiciones, puntos de referencia, perfiles y reglas individuales. Cada regla especifica la aplicabilidad y los requisitos de cumplimiento. RHEL 8 proporciona varios perfiles para el cumplimiento de las políticas de seguridad. Además del estándar de la industria, los flujos de datos de Red Hat también contienen información para remediar las reglas fallidas.
Estructura de los recursos de exploración de la conformidad
Data stream
├── xccdf
| ├── benchmark
| ├── profile
| ├──rule
| ├── xccdf
| ├── oval reference
├── oval ├── ocil reference
├── ocil ├── cpe reference
└── cpe └── remediationUn perfil es un conjunto de reglas basadas en una política de seguridad, como el Perfil de Protección del Sistema Operativo (OSPP) o el Estándar de Seguridad de Datos de la Industria de las Tarjetas de Pago (PCI-DSS). Esto permite auditar el sistema de forma automatizada para comprobar el cumplimiento de las normas de seguridad.
Puede modificar (adaptar) un perfil para personalizar ciertas reglas, por ejemplo, la longitud de la contraseña. Para obtener más información sobre la adaptación del perfil, consulte Personalizar un perfil de seguridad con SCAP Workbench.
Para escanear contenedores o imágenes de contenedores en busca de cumplimiento de la configuración, consulte Escanear contenedores e imágenes de contenedores en busca de vulnerabilidades.
15.4.2. Posibles resultados de una exploración de OpenSCAP
Dependiendo de varias propiedades de su sistema y del flujo de datos y el perfil aplicado a una exploración de OpenSCAP, cada regla puede producir un resultado específico. Esta es una lista de posibles resultados con breves explicaciones de lo que significan.
| Resultado | Explicación |
|---|---|
| Pasar | La exploración no encontró ningún conflicto con esta norma. |
| Falla | El escáner encontró un conflicto con esta norma. |
| No se ha comprobado | OpenSCAP no realiza una evaluación automática de esta regla. Compruebe manualmente si su sistema se ajusta a esta regla. |
| No se aplica | Esta regla no se aplica a la configuración actual. |
| No seleccionado | Esta regla no forma parte del perfil. OpenSCAP no evalúa esta regla y no muestra estas reglas en los resultados. |
| Error |
El escaneo encontró un error. Para obtener información adicional, puede introducir el comando |
| Desconocido |
El escaneo encontró una situación inesperada. Para obtener información adicional, puede introducir el comando |
15.4.3. Visualización de perfiles para el cumplimiento de la configuración
Antes de decidirse a utilizar los perfiles para la exploración o la corrección, puede enumerarlos y comprobar sus descripciones detalladas mediante el subcomando oscap info.
Requisitos previos
-
Los paquetes
openscap-scanneryscap-security-guideestán instalados.
Procedimiento
Lista de todos los archivos disponibles con perfiles de cumplimiento de seguridad proporcionados por el proyecto de la Guía de Seguridad SCAP:
$ ls /usr/share/xml/scap/ssg/content/ ssg-firefox-cpe-dictionary.xml ssg-rhel6-ocil.xml ssg-firefox-cpe-oval.xml ssg-rhel6-oval.xml ... ssg-rhel6-ds-1.2.xml ssg-rhel8-oval.xml ssg-rhel8-ds.xml ssg-rhel8-xccdf.xml ...Muestra información detallada sobre un flujo de datos seleccionado utilizando el subcomando
oscap info. Los archivos XML que contienen flujos de datos se indican con la cadena-dsen sus nombres. En la secciónProfiles, puede encontrar una lista de perfiles disponibles y sus identificaciones:$ oscap info /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml ... Profiles: Title: PCI-DSS v3.2.1 Control Baseline for Red Hat Enterprise Linux 8 Id: xccdf_org.ssgproject.content_profile_pci-dss Title: OSPP - Protection Profile for General Purpose Operating Systems Id: xccdf_org.ssgproject.content_profile_ospp ...Seleccionar un perfil del archivo de flujo de datos y mostrar detalles adicionales sobre el perfil seleccionado. Para ello, utilice
oscap infocon la opción--profileseguida de la última sección del ID mostrado en la salida del comando anterior. Por ejemplo, el ID del perfil PCI-DSS es:xccdf_org.ssgproject.content_profile_pci-dss, y el valor de la opción--profileespci-dss:$ oscap info --profile pci-dss /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml ... Title: PCI-DSS v3.2.1 Control Baseline for Red Hat Enterprise Linux 8 Id: xccdf_org.ssgproject.content_profile_pci-dss Description: Ensures PCI-DSS v3.2.1 security configuration settings are applied. ...
Recursos adicionales
-
La página de manual
scap-security-guide(8).
15.4.4. Evaluar el cumplimiento de la configuración con una línea de base específica
Para determinar si su sistema se ajusta a una línea de base específica, siga estos pasos.
Requisitos previos
-
Los paquetes
openscap-scanneryscap-security-guideestán instalados - Usted conoce el ID del perfil dentro de la línea de base con el que el sistema debe cumplir. Para encontrar el ID, consulte Ver perfiles para el cumplimiento de la configuración.
Procedimiento
Evaluar la conformidad del sistema con el perfil seleccionado y guardar los resultados del escaneo en el archivo HTML report.html, por ejemplo:
$ sudo oscap xccdf eval --report report.html --profile ospp /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlOpcional: Escanee un sistema remoto con el nombre de host
machine1, SSH ejecutándose en el puerto22, y el nombre de usuariojoesecpara comprobar la conformidad y guarde los resultados en el archivoremote-report.html:$ oscap-ssh joesec@machine1 22 xccdf eval --report remote_report.html --profile ospp /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
Recursos adicionales
-
scap-security-guide(8)página de manual -
La documentación de
SCAP Security Guideinstalada en elfile:///usr/share/doc/scap-security-guide/directorio. -
El Manual de configuración segura de Red Hat Enterprise Linux 8 instalado con el paquete
scap-security-guide-doc.
15.5. Remediar el sistema para alinearlo con una línea de base específica
Utilice este procedimiento para remediar el sistema RHEL 8 para alinearlo con una línea de base específica. Este ejemplo utiliza el perfil de protección para sistemas operativos de uso general (OSPP).
Si no se utiliza con cuidado, la ejecución de la evaluación del sistema con la opción Remediate activada puede hacer que el sistema no funcione. Red Hat no proporciona ningún método automatizado para revertir los cambios realizados por las correcciones de seguridad. Las correcciones son compatibles con los sistemas RHEL en la configuración por defecto. Si su sistema ha sido alterado después de la instalación, la ejecución de la remediación podría hacer que no cumpla con el perfil de seguridad requerido.
Requisitos previos
-
El paquete
scap-security-guideestá instalado en su sistema RHEL 8.
Procedimiento
Utilice el comando
oscapcon la opción--remediate:$ sudo oscap xccdf eval --profile ospp --remediate /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml- Reinicie su sistema.
Paso de verificación
Evaluar la conformidad del sistema con el perfil OSPP, y guardar los resultados del escaneo en el archivo
ospp_report.html:$ oscap xccdf eval --report ospp_report.html --profile ospp /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
Recursos adicionales
-
scap-security-guide(8)yoscap(8)páginas man
15.6. Remediar el sistema para alinearlo con una línea de base específica utilizando el libro de jugadas de SSG Ansible
Utilice este procedimiento para remediar su sistema con una línea de base específica utilizando el archivo Ansible playbook del proyecto SCAP Security Guide. Este ejemplo utiliza el perfil de protección para sistemas operativos de uso general (OSPP).
Si no se utiliza con cuidado, la ejecución de la evaluación del sistema con la opción Remediate activada puede hacer que el sistema no funcione. Red Hat no proporciona ningún método automatizado para revertir los cambios realizados por las correcciones de seguridad. Las correcciones son compatibles con los sistemas RHEL en la configuración por defecto. Si su sistema ha sido alterado después de la instalación, la ejecución de la remediación podría hacer que no cumpla con el perfil de seguridad requerido.
Requisitos previos
-
El paquete
scap-security-guideestá instalado en su sistema RHEL 8. -
El paquete
ansibleestá instalado. Consulte la Guía de instalación de Ansible para obtener más información.
Procedimiento
Remedie su sistema para alinearlo con OSPP usando Ansible:
# ansible-playbook -i localhost, -c local /usr/share/scap-security-guide/ansible/rhel8-playbook-ospp.yml- Reinicia el sistema.
Pasos de verificación
Evaluar la conformidad del sistema con el perfil OSPP, y guardar los resultados del escaneo en el archivo
ospp_report.html:# oscap xccdf eval --profile ospp --report ospp_report.html /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
Recursos adicionales
-
scap-security-guide(8)yoscap(8)páginas man - Documentación de Ansible
15.7. Creación de un playbook Ansible de remediación para alinear el sistema con una línea de base específica
Utilice este procedimiento para crear un libro de jugadas de Ansible que contenga sólo las correcciones necesarias para alinear su sistema con una línea de base específica. Este ejemplo utiliza el perfil de protección para sistemas operativos de uso general (OSPP). Con este procedimiento, se crea un libro de jugadas más pequeño que no cubre los requisitos ya satisfechos. Siguiendo estos pasos, usted no modifica su sistema de ninguna manera, sólo prepara un archivo para su posterior aplicación.
Requisitos previos
-
El paquete
scap-security-guideestá instalado en su sistema RHEL 8.
Procedimiento
Escanee el sistema y guarde los resultados:
# oscap xccdf eval --profile ospp --results ospp-results.xml /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlGenere un playbook de Ansible basado en el archivo generado en el paso anterior:
# oscap xccdf generate fix --fix-type ansible --output ospp-remediations.yml ospp-results.xml-
El archivo
ospp-remediations.ymlcontiene las correcciones de Ansible para las reglas que fallaron durante el análisis realizado en el paso 1. Después de revisar este archivo generado, puede aplicarlo con el comandoansible-playbook ospp-remediations.yml.
Pasos de verificación
-
En un editor de texto de su elección, revise que el archivo
ospp-remediations.ymlcontenga las reglas que fallaron en el análisis realizado en el paso 1.
Recursos adicionales
-
scap-security-guide(8)yoscap(8)páginas man - Documentación de Ansible
15.8. Creación de un script Bash de remediación para una aplicación posterior
Utilice este procedimiento para crear un script Bash que contenga correcciones que alineen su sistema con un perfil de seguridad como PCI-DSS. Utilizando los siguientes pasos, no realiza ninguna modificación en su sistema, sólo prepara un archivo para su posterior aplicación.
Requisitos previos
-
El paquete
scap-security-guideestá instalado en su sistema RHEL 8.
Procedimiento
Utilice el comando
oscappara analizar el sistema y guardar los resultados en un archivo XML. En el siguiente ejemplo,oscapevalúa el sistema según el perfilpci-dss:# oscap xccdf eval --profile pci-dss --results pci-dss-results.xml /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlGenerar un script Bash basado en el archivo de resultados generado en el paso anterior:
# oscap xccdf generate fix --profile pci-dss --fix-type bash --output pci-dss-remediations.sh pci-dss-results.xml-
El archivo
pci-dss-remediations.shcontiene correcciones para las reglas que fallaron durante el análisis realizado en el paso 1. Después de revisar este archivo generado, puede aplicarlo con el comando./pci-dss-remediations.shcuando se encuentre en el mismo directorio que este archivo.
Pasos de verificación
-
En un editor de texto de su elección, revise que el archivo
pci-dss-remediations.shcontenga las reglas que fallaron en el análisis realizado en el paso 1.
Recursos adicionales
-
scap-security-guide(8),oscap(8), ybash(1)páginas de manual
15.9. Escanear el sistema con un perfil personalizado utilizando SCAP Workbench
SCAP Workbench, que está contenida en el paquete scap-workbench, es una utilidad gráfica que permite a los usuarios realizar escaneos de configuración y de vulnerabilidad en un solo sistema local o en uno remoto, realizar la corrección del sistema y generar informes basados en las evaluaciones de los escaneos. Tenga en cuenta que SCAP Workbench tiene una funcionalidad limitada en comparación con la utilidad de línea de comandos oscap. SCAP Workbench procesa el contenido de seguridad en forma de archivos de flujo de datos.
15.9.1. Uso de SCAP Workbench para escanear y remediar el sistema
Para evaluar su sistema con respecto a la política de seguridad seleccionada, utilice el siguiente procedimiento.
Requisitos previos
-
El paquete
scap-workbenchestá instalado en su sistema.
Procedimiento
Para ejecutar
SCAP Workbenchdesde el entorno de escritorioGNOME Classic, pulse la tecla Super para entrar enActivities Overview, escribascap-workbenchy pulse Enter. Como alternativa, utilice:$ scap-workbench &Seleccione una política de seguridad utilizando las siguientes opciones:
-
Load Contentbotón en la ventana de inicio -
Open content from SCAP Security Guide Open Other Contenten el menúFile, y busque el respectivo archivo XCCDF, SCAP RPM o de flujo de datos.
-
Puede permitir la corrección automática de la configuración del sistema seleccionando la casilla . Con esta opción activada,
SCAP Workbenchintenta cambiar la configuración del sistema de acuerdo con las reglas de seguridad aplicadas por la política. Este proceso debería corregir las comprobaciones relacionadas que fallan durante el análisis del sistema.AvisoSi no se utiliza con cuidado, la ejecución de la evaluación del sistema con la opción
Remediateactivada puede hacer que el sistema no funcione. Red Hat no proporciona ningún método automatizado para revertir los cambios realizados por las correcciones de seguridad. Las correcciones son compatibles con los sistemas RHEL en la configuración por defecto. Si su sistema ha sido alterado después de la instalación, la ejecución de la remediación podría hacer que no cumpla con el perfil de seguridad requerido.Analice su sistema con el perfil seleccionado haciendo clic en el botón .
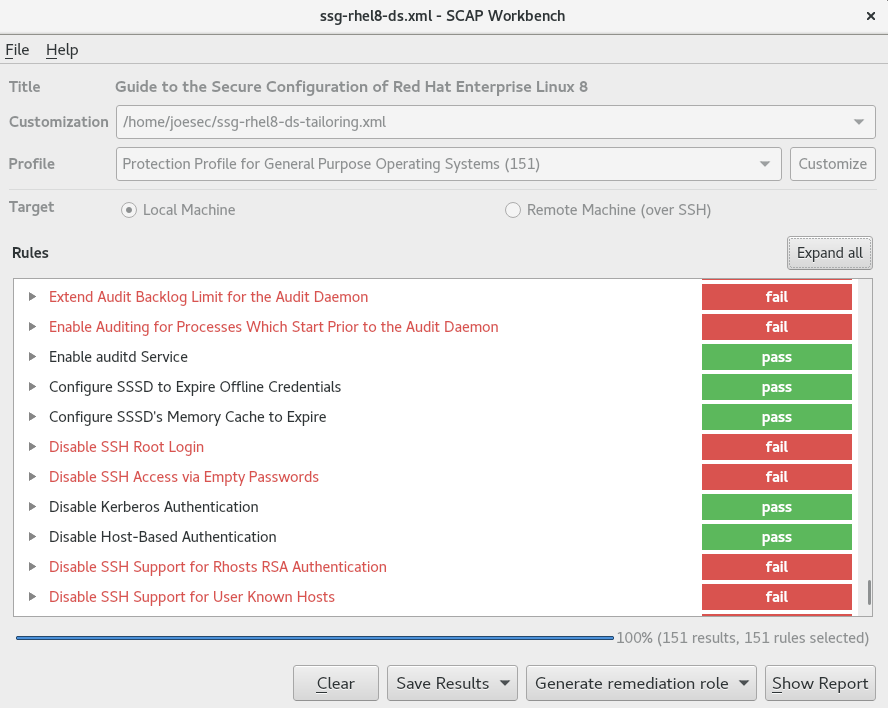
-
Para almacenar los resultados del escaneo en forma de archivo XCCDF, ARF o HTML, haga clic en el cuadro combinado . Elija la opción
HTML Reportpara generar el informe de escaneo en formato legible para el ser humano. Los formatos XCCDF y ARF (flujo de datos) son adecuados para su posterior procesamiento automático. Puede elegir repetidamente las tres opciones. - Para exportar las correcciones basadas en resultados a un archivo, utilice el menú emergente .
15.9.2. Personalización de un perfil de seguridad con SCAP Workbench
Puede personalizar un perfil de seguridad cambiando los parámetros de ciertas reglas (por ejemplo, la longitud mínima de la contraseña), eliminando las reglas que cubra de manera diferente y seleccionando reglas adicionales, para implementar políticas internas. No se pueden definir nuevas reglas al personalizar un perfil.
El siguiente procedimiento demuestra el uso de SCAP Workbench para personalizar (adaptar) un perfil. También puede guardar el perfil adaptado para utilizarlo con la utilidad de línea de comandos oscap.
Requisitos previos
-
El paquete
scap-workbenchestá instalado en su sistema.
Procedimiento
-
Ejecute
SCAP Workbench, y seleccione el perfil a personalizar medianteOpen content from SCAP Security GuideoOpen Other Contenten el menúFile. Para ajustar el perfil de seguridad seleccionado según sus necesidades, haga clic en el botón .
Esto abre la nueva ventana de personalización que le permite modificar el perfil actualmente seleccionado sin cambiar el archivo de flujo de datos original. Elija un nuevo ID de perfil.
- Encuentre una regla para modificar utilizando la estructura de árbol con reglas organizadas en grupos lógicos o el campo de .
Incluya o excluya reglas mediante casillas de verificación en la estructura de árbol, o modifique los valores de las reglas cuando corresponda.
- Confirme los cambios haciendo clic en el botón .
Para almacenar los cambios de forma permanente, utilice una de las siguientes opciones:
-
Guarde un archivo de personalización por separado utilizando
Save Customization Onlyen el menúFile. Guarde todo el contenido de seguridad a la vez en
Save Allen el menúFile.Si selecciona la opción
Into a directory,SCAP Workbenchguarda tanto el archivo de flujo de datos como el archivo de personalización en la ubicación especificada. Puede utilizarlo como solución de copia de seguridad.Seleccionando la opción
As RPM, puede ordenar aSCAP Workbenchque cree un paquete RPM que contenga el archivo de flujo de datos y el archivo de personalización. Esto es útil para distribuir el contenido de seguridad a sistemas que no pueden ser escaneados remotamente, y para entregar el contenido para su posterior procesamiento.
-
Guarde un archivo de personalización por separado utilizando
Dado que SCAP Workbench no admite correcciones basadas en resultados para perfiles adaptados, utilice las correcciones exportadas con la utilidad de línea de comandos oscap.
15.10. Escaneo de vulnerabilidades en contenedores e imágenes de contenedores
Utilice este procedimiento para encontrar vulnerabilidades de seguridad en un contenedor o una imagen de contenedor.
El comando oscap-podman está disponible a partir de RHEL 8.2. Para RHEL 8.1 y 8.0, utilice la solución descrita en el artículo de la base de conocimientos Using OpenSCAP for scanning containers in RHEL 8.
Requisitos previos
-
El paquete
openscap-utilsestá instalado.
Procedimiento
Descargue las últimas definiciones de RHSA OVAL para su sistema:
# wget -O - https://www.redhat.com/security/data/oval/v2/RHEL8/rhel-8.oval.xml.bz2 | bzip2 --decompress > rhel-8.oval.xmlObtiene el ID de un contenedor o de una imagen de contenedor, por ejemplo:
# podman images REPOSITORY TAG IMAGE ID CREATED SIZE registry.access.redhat.com/ubi8/ubi latest 096cae65a207 7 weeks ago 239 MBAnalice el contenedor o la imagen del contenedor en busca de vulnerabilidades y guarde los resultados en el archivo vulnerability.html:
# oscap-podman 096cae65a207 oval eval --report vulnerability.html rhel-8.oval.xmlTenga en cuenta que el comando
oscap-podmanrequiere privilegios de root, y el ID de un contenedor es el primer argumento.
Pasos de verificación
Compruebe los resultados en un navegador de su elección, por ejemplo:
$ firefox vulnerability.html &
Recursos adicionales
-
Para más información, consulte las páginas de manual
oscap-podman(8)yoscap(8).
15.11. Evaluación del cumplimiento de la seguridad de un contenedor o una imagen de contenedor con una línea de base específica
Siga estos pasos para evaluar el cumplimiento de su contenedor o de una imagen de contenedor con una línea base de seguridad específica, como el Perfil de Protección del Sistema Operativo (OSPP) o el Estándar de Seguridad de Datos de la Industria de las Tarjetas de Pago (PCI-DSS).
El comando oscap-podman está disponible a partir de RHEL 8.2. Para RHEL 8.1 y 8.0, utilice la solución descrita en el artículo de la base de conocimientos Using OpenSCAP for scanning containers in RHEL 8.
Requisitos previos
-
Los paquetes
openscap-utilsyscap-security-guideestán instalados.
Procedimiento
Obtiene el ID de un contenedor o de una imagen de contenedor, por ejemplo:
# podman images REPOSITORY TAG IMAGE ID CREATED SIZE registry.access.redhat.com/ubi8/ubi latest 096cae65a207 7 weeks ago 239 MBEvaluar la conformidad de la imagen del contenedor con el perfil OSPP y guardar los resultados del escaneo en el archivo HTML report.html
# oscap-podman 096cae65a207 xccdf eval --report report.html --profile ospp /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlSustituya 096cae65a207 por el ID de su imagen de contenedor y el valor ospp por pci-dss si evalúa el cumplimiento de la seguridad con la línea de base PCI-DSS. Tenga en cuenta que el comando
oscap-podmanrequiere privilegios de root.
Pasos de verificación
Compruebe los resultados en un navegador de su elección, por ejemplo:
$ firefox report.html &
Las reglas marcadas como notapplicable son reglas que no se aplican a los sistemas en contenedores. Estas reglas sólo se aplican a los sistemas bare-metal y virtualizados.
Recursos adicionales
-
Para más información, consulte las páginas de manual
oscap-podman(8)yscap-security-guide(8). -
La documentación de
SCAP Security Guideinstalada en elfile:///usr/share/doc/scap-security-guide/directorio.
15.12. Versiones soportadas de la Guía de Seguridad SCAP en RHEL
Las versiones oficialmente soportadas de la Guía de Seguridad SCAP son las versiones proporcionadas en la versión menor de RHEL relacionada o en la actualización por lotes de RHEL relacionada.
| Versión de Red Hat Enterprise Linux | Versión de la Guía de Seguridad SCAP |
|---|---|
| RHEL 6.6 | scap-security-guide-0.1.18-3.el6 |
| RHEL 6.9 | scap-security-guide-0.1.28-3.el6 |
| RHEL 6.10 | scap-security-guide-0.1.28-4.el6 |
| RHEL 7.2 AUS | scap-security-guide-0.1.25-3.el7 |
| RHEL 7.3 AUS | scap-security-guide-0.1.30-5.el7_3 |
| RHEL 7.4 AUS, E4S | scap-security-guide-0.1.33-6.el7_4 |
| RHEL 7.5 (actualización por lotes) | scap-security-guide-0.1.36-10.el7_5 |
| RHEL 7.6 EUS | scap-security-guide-0.1.40-13.el7_6 |
| RHEL 7.7 EUS | scap-security-guide-0.1.43-13.el7 |
| RHEL 7.8 (actualización por lotes) | scap-security-guide-0.1.46-11.el7 |
| RHEL 7.9 | scap-security-guide-0.1.52-2.el7_9 |
| RHEL 8.0 SAP | scap-security-guide-0.1.42-11.el8 |
| RHEL 8.1 EUS | scap-security-guide-0.1.47-8.el8_1 |
| RHEL 8.2 (actualización por lotes) | scap-security-guide-0.1.48-10.el8_2 |
| RHEL 8.3 | scap-security-guide-0.1.50-16.el8_3 |
15.13. Comprobación de la integridad con AIDE
Advanced Intrusion Detection Environment (AIDE) es una utilidad que crea una base de datos de archivos en el sistema, y luego utiliza esa base de datos para asegurar la integridad de los archivos y detectar intrusiones en el sistema.
15.13.1. Instalación de AIDE
Los siguientes pasos son necesarios para instalar AIDE e iniciar su base de datos.
Requisitos previos
-
El repositorio
AppStreamestá activado.
Procedimiento
Para instalar el paquete aide:
# yum install aidePara generar una base de datos inicial:
# aide --initNotaEn la configuración por defecto, el comando
aide --initcomprueba sólo un conjunto de directorios y archivos definidos en el archivo/etc/aide.conf. Para incluir directorios o archivos adicionales en la base de datosAIDE, y para cambiar sus parámetros observados, edite/etc/aide.confen consecuencia.Para empezar a utilizar la base de datos, elimine la subcadena
.newdel nombre inicial del archivo de la base de datos:# mv /var/lib/aide/aide.db.new.gz /var/lib/aide/aide.db.gz-
Para cambiar la ubicación de la base de datos
AIDE, edite el archivo/etc/aide.confy modifique el valorDBDIR. Para mayor seguridad, almacene la base de datos, la configuración y el archivo binario/usr/sbin/aideen una ubicación segura, como un soporte de sólo lectura.
15.13.2. Realización de comprobaciones de integridad con AIDE
Requisitos previos
-
AIDEestá correctamente instalado y su base de datos está inicializada. Véase Sección 15.13.1, “Instalación de AIDE”
Procedimiento
Para iniciar un control manual:
# aide --check Start timestamp: 2018-07-11 12:41:20 +0200 (AIDE 0.16) AIDE found differences between database and filesystem!! ... [trimmed for clarity]Como mínimo,
AIDEdebería estar configurado para ejecutar un escaneo semanal. Como máximo,AIDEdebería ejecutarse diariamente. Por ejemplo, para programar una ejecución diaria deAIDEa las 04:05 a.m. utilizando el comandocron, agregue la siguiente línea al archivo/etc/crontab:05 4 * * * root /usr/sbin/aide --check
15.13.3. Actualización de una base de datos AIDE
Después de verificar los cambios de su sistema, como las actualizaciones de los paquetes o los ajustes de los archivos de configuración, se recomienda actualizar su base de datos de referencia AIDE.
Requisitos previos
-
AIDEestá correctamente instalado y su base de datos está inicializada. Véase Sección 15.13.1, “Instalación de AIDE”
Procedimiento
Actualice su base de datos de referencia AIDE:
# aide --updateEl comando aide --update crea el archivo de base de datos
/var/lib/aide/aide.db.new.gz.-
Para empezar a utilizar la base de datos actualizada para las comprobaciones de integridad, elimine la subcadena
.newdel nombre del archivo.
15.14. Cifrado de dispositivos de bloque mediante LUKS
El cifrado de discos protege los datos de un dispositivo de bloque cifrándolos. Para acceder al contenido descifrado del dispositivo, el usuario debe proporcionar una frase de paso o una clave como autenticación. Esto es especialmente importante cuando se trata de ordenadores móviles y medios extraíbles: ayuda a proteger el contenido del dispositivo aunque se haya retirado físicamente del sistema. El formato LUKS es una implementación por defecto del cifrado de dispositivos en bloque en RHEL.
15.14.1. Cifrado de disco LUKS
El sistema Linux Unified Key Setup-on-disk-format (LUKS) permite cifrar dispositivos de bloque y proporciona un conjunto de herramientas que simplifica la gestión de los dispositivos cifrados. LUKS permite que varias claves de usuario descifren una clave maestra, que se utiliza para el cifrado masivo de la partición.
RHEL utiliza LUKS para realizar el cifrado del dispositivo de bloque. Por defecto, la opción de cifrar el dispositivo de bloque está desmarcada durante la instalación. Si selecciona la opción de cifrar el disco, el sistema le pedirá una frase de contraseña cada vez que arranque el ordenador. Esta frase de contraseña “desbloquea” la clave de cifrado masivo que descifra su partición. Si eliges modificar la tabla de particiones por defecto, puedes elegir qué particiones quieres cifrar. Esto se establece en la configuración de la tabla de particiones.
Qué hace LUKS
- LUKS encripta dispositivos de bloques enteros y, por tanto, es muy adecuado para proteger el contenido de dispositivos móviles, como medios de almacenamiento extraíbles o unidades de disco de ordenadores portátiles.
- El contenido subyacente del dispositivo de bloque cifrado es arbitrario, lo que lo hace útil para cifrar dispositivos de intercambio. También puede ser útil con ciertas bases de datos que utilizan dispositivos de bloque con un formato especial para el almacenamiento de datos.
- LUKS utiliza el subsistema del kernel de mapeo de dispositivos existente.
- LUKS proporciona un refuerzo de la frase de contraseña que protege contra los ataques de diccionario.
- Los dispositivos LUKS contienen varias ranuras para claves, lo que permite a los usuarios añadir claves de seguridad o frases de contraseña.
Qué hace LUKS not
- Las soluciones de cifrado de discos como LUKS protegen los datos sólo cuando el sistema está apagado. Una vez que el sistema está encendido y LUKS ha descifrado el disco, los archivos de ese disco están disponibles para cualquiera que normalmente tendría acceso a ellos.
- LUKS no es adecuado para escenarios que requieran que muchos usuarios tengan claves de acceso distintas para el mismo dispositivo. El formato LUKS1 proporciona ocho ranuras para llaves, LUKS2 hasta 32 ranuras para llaves.
- LUKS no es adecuado para aplicaciones que requieran encriptación a nivel de archivo.
Cifras
El cifrado por defecto utilizado para LUKS es aes-xts-plain64. El tamaño de la clave por defecto para LUKS es de 512 bits. El tamaño de la clave por defecto para LUKS con Anaconda (modo XTS) es de 512 bits. Los cifrados disponibles son:
- AES - Estándar de cifrado avanzado - FIPS PUB 197
- Twofish (un cifrado en bloque de 128 bits)
- Serpent
Recursos adicionales
15.14.2. Versiones de LUKS en RHEL 8
En RHEL 8, el formato por defecto para el cifrado LUKS es LUKS2. El formato heredado LUKS1 sigue siendo totalmente compatible y se proporciona como un formato compatible con las versiones anteriores de RHEL.
El formato LUKS2 está diseñado para permitir futuras actualizaciones de varias partes sin necesidad de modificar las estructuras binarias. LUKS2 utiliza internamente el formato de texto JSON para los metadatos, proporciona redundancia de metadatos, detecta la corrupción de metadatos y permite la reparación automática a partir de una copia de metadatos.
No utilice LUKS2 en sistemas que necesiten ser compatibles con sistemas heredados que sólo soporten LUKS1. Tenga en cuenta que RHEL 7 admite el formato LUKS2 desde la versión 7.6.
LUKS2 y LUKS1 utilizan diferentes comandos para cifrar el disco. Utilizar el comando incorrecto para una versión de LUKS podría causar la pérdida de datos.
| Versión LUKS | Comando de encriptación |
|---|---|
| LUKS2 |
|
| LUKS1 |
|
Reencriptación en línea
El formato LUKS2 permite volver a encriptar los dispositivos encriptados mientras éstos están en uso. Por ejemplo, no es necesario desmontar el sistema de archivos del dispositivo para realizar las siguientes tareas:
- Cambiar la tecla de volumen
- Cambiar el algoritmo de encriptación
Cuando se encripta un dispositivo no encriptado, hay que desmontar el sistema de archivos. Puedes volver a montar el sistema de archivos tras una breve inicialización del cifrado.
El formato LUKS1 no admite la recodificación en línea.
Conversión
El formato LUKS2 se inspira en LUKS1. En determinadas situaciones, se puede convertir LUKS1 en LUKS2. La conversión no es posible específicamente en los siguientes escenarios:
-
Un dispositivo LUKS1 está marcado como utilizado por una solución de descifrado basada en políticas (PBD - Clevis). La herramienta
cryptsetupse niega a convertir el dispositivo cuando se detectan algunos metadatos deluksmeta. - Un dispositivo está activo. El dispositivo debe estar en estado inactivo antes de que sea posible cualquier conversión.
15.14.3. Opciones de protección de datos durante la recodificación de LUKS2
LUKS2 ofrece varias opciones que priorizan el rendimiento o la protección de los datos durante el proceso de recodificación:
checksumEste es el modo por defecto. Equilibra la protección de los datos y el rendimiento.
Este modo almacena sumas de comprobación individuales de los sectores en el área de recodificación, por lo que el proceso de recuperación puede detectar los sectores que LUKS2 ya ha recodificado. El modo requiere que la escritura del sector del dispositivo de bloque sea atómica.
journal- Es el modo más seguro pero también el más lento. Este modo registra el área de recodificación en el área binaria, por lo que LUKS2 escribe los datos dos veces.
none-
Este modo da prioridad al rendimiento y no proporciona ninguna protección de datos. Protege los datos sólo contra la terminación segura del proceso, como la señal
SIGTERMo la pulsación por parte del usuario de Ctrl+C. Cualquier caída inesperada del sistema o de la aplicación puede provocar la corrupción de los datos.
Puede seleccionar el modo mediante la opción --resilience de cryptsetup.
Si un proceso de recodificación de LUKS2 termina inesperadamente por la fuerza, LUKS2 puede realizar la recuperación de una de las siguientes maneras:
-
Automáticamente, durante la siguiente acción de apertura del dispositivo LUKS2. Esta acción se desencadena mediante el comando
cryptsetup openo al adjuntar el dispositivo consystemd-cryptsetup. -
Manualmente, utilizando el comando
cryptsetup repairen el dispositivo LUKS2.
15.14.4. Cifrado de datos existentes en un dispositivo de bloques mediante LUKS2
Este procedimiento encripta los datos existentes en un dispositivo aún no encriptado utilizando el formato LUKS2. Se almacena una nueva cabecera LUKS en el cabezal del dispositivo.
Requisitos previos
- El dispositivo de bloque contiene un sistema de archivos.
Has hecho una copia de seguridad de tus datos.
AvisoPodrías perder tus datos durante el proceso de encriptación: debido a un fallo de hardware, del núcleo o humano. Asegúrate de tener una copia de seguridad fiable antes de empezar a encriptar los datos.
Procedimiento
Desmonte todos los sistemas de archivos del dispositivo que vaya a cifrar. Por ejemplo:
# umount /dev/sdb1Deje espacio libre para almacenar una cabecera LUKS. Elija una de las siguientes opciones que se adapte a su escenario:
En el caso de la encriptación de un volumen lógico, se puede ampliar el volumen lógico sin cambiar el tamaño del sistema de archivos. Por ejemplo:
# lvextend -L 32M vg00/lv00-
Amplíe la partición utilizando herramientas de gestión de particiones, como
parted. -
Reduzca el sistema de archivos del dispositivo. Puede utilizar la utilidad
resize2fspara los sistemas de archivos ext2, ext3 o ext4. Tenga en cuenta que no puede reducir el sistema de archivos XFS.
Inicializar la encriptación. Por ejemplo:
# cryptsetup reencrypt \ --encrypt \ --init-only \ --reduce-device-size 32M \ /dev/sdb1 sdb1_encryptedEl comando le pide una frase de contraseña y comienza el proceso de encriptación.
Monta el dispositivo:
# mount /dev/mapper/sdb1_encrypted /mnt/sdb1_encryptedInicie la codificación en línea:
# cryptsetup reencrypt --resume-only /dev/sdb1
Recursos adicionales
-
Para más detalles, consulte las páginas de manual
cryptsetup(8),lvextend(8),resize2fs(8), yparted(8).
15.14.5. Cifrado de datos existentes en un dispositivo de bloque mediante LUKS2 con una cabecera separada
Este procedimiento encripta los datos existentes en un dispositivo de bloque sin crear espacio libre para almacenar una cabecera LUKS. La cabecera se almacena en una ubicación independiente, lo que también sirve como capa adicional de seguridad. El procedimiento utiliza el formato de cifrado LUKS2.
Requisitos previos
- El dispositivo de bloque contiene un sistema de archivos.
Has hecho una copia de seguridad de tus datos.
AvisoPodrías perder tus datos durante el proceso de encriptación: debido a un fallo de hardware, del núcleo o humano. Asegúrate de tener una copia de seguridad fiable antes de empezar a encriptar los datos.
Procedimiento
Desmontar todos los sistemas de archivos del dispositivo. Por ejemplo:
# umount /dev/sdb1Inicializar la encriptación:
# cryptsetup reencrypt \ --encrypt \ --init-only \ --header /path/to/header \ /dev/sdb1 sdb1_encryptedSustituya /path/to/header por una ruta al archivo con una cabecera LUKS separada. La cabecera LUKS separada tiene que ser accesible para que el dispositivo encriptado pueda ser desbloqueado posteriormente.
El comando le pide una frase de contraseña y comienza el proceso de encriptación.
Monta el dispositivo:
# mount /dev/mapper/sdb1_encrypted /mnt/sdb1_encryptedInicie la codificación en línea:
# cryptsetup reencrypt --resume-only --header /path/to/header /dev/sdb1
Recursos adicionales
-
Para más detalles, consulte la página de manual
cryptsetup(8).
15.14.6. Cifrado de un dispositivo de bloque en blanco mediante LUKS2
Este procedimiento proporciona información sobre el cifrado de un dispositivo de bloque en blanco utilizando el formato LUKS2.
Requisitos previos
- Un dispositivo de bloque en blanco.
Procedimiento
Configurar una partición como una partición LUKS cifrada:
# cryptsetup luksFormat /dev/sdb1Abra una partición LUKS encriptada:
# cryptsetup open /dev/sdb1 sdb1_encryptedEsto desbloquea la partición y la asigna a un nuevo dispositivo utilizando el mapeador de dispositivos. Esto alerta al kernel de que
devicees un dispositivo encriptado y debe ser direccionado a través de LUKS usando el/dev/mapper/device_mapped_namepara no sobrescribir los datos encriptados.Para escribir datos encriptados en la partición, se debe acceder a ella a través del nombre mapeado del dispositivo. Para ello, debes crear un sistema de archivos. Por ejemplo:
# mkfs -t ext4 /dev/mapper/sdb1_encryptedMonta el dispositivo:
# montaje /dev/mapper/sdb1_encrypted
Recursos adicionales
-
Para más detalles, consulte la página de manual
cryptsetup(8).
15.14.7. Creación de un volumen encriptado LUKS utilizando el rol de almacenamiento
Puede utilizar el rol storage para crear y configurar un volumen encriptado con LUKS ejecutando un playbook de Ansible.
Requisitos previos
Tiene instalado Red Hat Ansible Engine en el sistema desde el que desea ejecutar el libro de jugadas.
NotaNo es necesario tener Red Hat Ansible Automation Platform instalado en los sistemas en los que se desea crear el volumen.
-
Tiene el paquete
rhel-system-rolesinstalado en el controlador Ansible. - Dispone de un archivo de inventario en el que se detallan los sistemas en los que desea desplegar un volumen encriptado LUKS mediante el rol de sistema de almacenamiento.
Procedimiento
Cree un nuevo
playbook.ymlarchivo con el siguiente contenido:- hosts: all vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs fs_label: label-name mount_point: /mnt/data encryption: true encryption_password: your-password roles: - rhel-system-roles.storageOpcional. Verificar la sintaxis del libro de jugadas:
# ansible-playbook --syntax-check playbook.ymlEjecute el libro de jugadas en su archivo de inventario:
# ansible-playbook -i inventory.file /path/to/file/playbook.yml
15.15. Configuración del desbloqueo automático de volúmenes encriptados mediante el descifrado basado en políticas
El descifrado basado en políticas (PBD) es un conjunto de tecnologías que permiten desbloquear los volúmenes raíz y secundarios cifrados de los discos duros de las máquinas físicas y virtuales. PBD utiliza diversos métodos de desbloqueo, como las contraseñas de los usuarios, un dispositivo Trusted Platform Module (TPM), un dispositivo PKCS #11 conectado a un sistema, por ejemplo, una tarjeta inteligente, o un servidor de red especial.
La PBD permite combinar diferentes métodos de desbloqueo en una política, lo que hace posible desbloquear el mismo volumen de diferentes maneras. La implementación actual de la PBD en Red Hat Enterprise Linux consiste en el marco de trabajo Clevis y en complementos llamados pins. Cada pin proporciona una capacidad de desbloqueo independiente. Actualmente, los siguientes pines están disponibles:
-
tang- permite desbloquear volúmenes mediante un servidor de red -
tpm2- permite desbloquear volúmenes mediante una política TPM2
El Network Bound Disc Encryption (NBDE) es una subcategoría de PBD que permite vincular volúmenes cifrados a un servidor de red especial. La implementación actual del NBDE incluye un pasador de horquilla para el servidor Tang y el propio servidor Tang.
15.15.1. Encriptación de discos en red
En Red Hat Enterprise Linux, NBDE se implementa a través de los siguientes componentes y tecnologías:
Figura 15.1. Esquema NBDE cuando se utiliza un volumen encriptado por LUKS1. El paquete luksmeta no se utiliza para los volúmenes LUKS2.
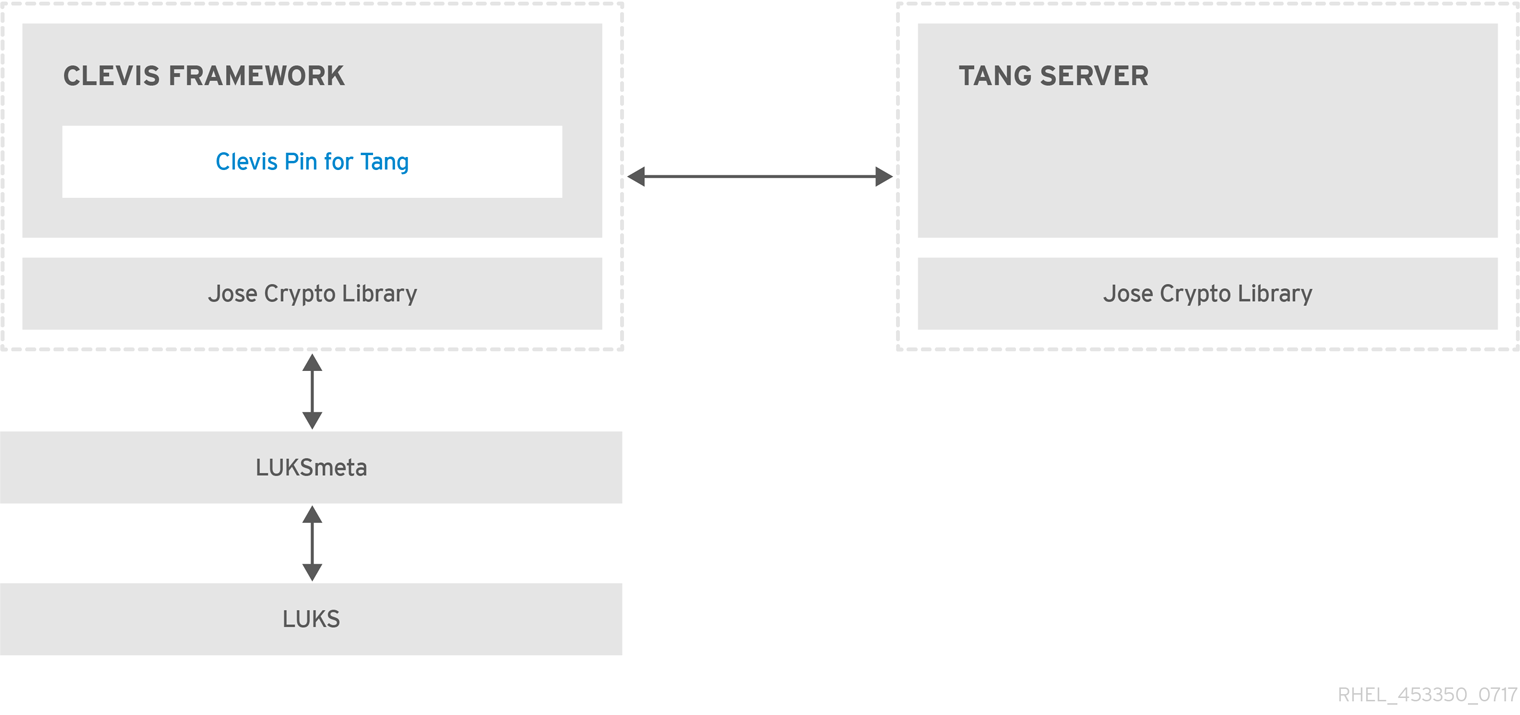
Tang es un servidor para vincular los datos a la presencia en la red. Hace que un sistema que contiene sus datos esté disponible cuando el sistema está vinculado a una determinada red segura. Tang no tiene estado y no requiere TLS ni autenticación. A diferencia de las soluciones basadas en escrow, en las que el servidor almacena todas las claves de cifrado y tiene conocimiento de todas las claves utilizadas, Tang nunca interactúa con ninguna clave del cliente, por lo que nunca obtiene ninguna información de identificación del cliente.
Clevis es un marco enchufable para el descifrado automatizado. En NBDE, Clevis proporciona el desbloqueo automatizado de volúmenes LUKS. El paquete clevis proporciona el lado del cliente de la función.
Un Clevis pin es un plug-in en el marco de Clevis. Uno de estos pines es un plug-in que implementa las interacciones con el servidor NBDE
Clevis y Tang son componentes genéricos de cliente y servidor que proporcionan encriptación ligada a la red. En Red Hat Enterprise Linux, se utilizan junto con LUKS para cifrar y descifrar los volúmenes de almacenamiento raíz y no raíz para lograr el cifrado de disco ligado a la red.
Tanto los componentes del lado del cliente como los del lado del servidor utilizan la biblioteca José para realizar operaciones de cifrado y descifrado.
Cuando se inicia el aprovisionamiento de NBDE, la clavija de Clevis para el servidor Tang obtiene una lista de las claves asimétricas anunciadas del servidor Tang. Como alternativa, dado que las claves son asimétricas, se puede distribuir una lista de las claves públicas de Tang fuera de banda para que los clientes puedan operar sin acceso al servidor Tang. Este modo se denomina offline provisioning.
El pasador de horquilla para Tang utiliza una de las claves públicas para generar una clave de cifrado única y criptográficamente fuerte. Una vez que los datos se encriptan utilizando esta clave, ésta se descarta. El cliente Clevis debe almacenar el estado producido por esta operación de aprovisionamiento en una ubicación conveniente. Este proceso de encriptación de datos es el provisioning step.
La versión 2 de LUKS (LUKS2) es el formato por defecto en Red Hat Enterprise Linux 8, por lo tanto, el estado de aprovisionamiento para NBDE se almacena como un token en una cabecera LUKS2. El aprovechamiento del estado de aprovisionamiento para NBDE por el paquete luksmeta sólo se utiliza para los volúmenes cifrados con LUKS1. El pasador de horquilla para Tang soporta tanto LUKS1 como LUKS2 sin necesidad de especificación.
Cuando el cliente está listo para acceder a sus datos, carga los metadatos producidos en el paso de aprovisionamiento y responde para recuperar la clave de cifrado. Este proceso es el recovery step.
En NBDE, Clevis vincula un volumen LUKS mediante un pin para que pueda ser desbloqueado automáticamente. Una vez completado con éxito el proceso de vinculación, el disco puede ser desbloqueado utilizando el desbloqueador Dracut proporcionado.
15.15.2. Instalación de un cliente de encriptación - Clevis
Utilice este procedimiento para desplegar y empezar a utilizar el marco enchufable de Clevis en su sistema.
Procedimiento
Para instalar Clevis y sus pines en un sistema con un volumen encriptado:
# yum install clevisPara descifrar los datos, utilice un comando
clevis decrypty proporcione un texto cifrado en el formato JSON Web Encryption (JWE), por ejemplo:$ clevis decrypt < secret.jwe
Recursos adicionales
Para una referencia rápida, consulte la ayuda de la CLI incorporada:
$ clevis Usage: clevis COMMAND [OPTIONS] clevis decrypt Decrypts using the policy defined at encryption time clevis encrypt sss Encrypts using a Shamir's Secret Sharing policy clevis encrypt tang Encrypts using a Tang binding server policy clevis encrypt tpm2 Encrypts using a TPM2.0 chip binding policy clevis luks bind Binds a LUKS device using the specified policy clevis luks list Lists pins bound to a LUKSv1 or LUKSv2 device clevis luks pass Returns the LUKS passphrase used for binding a particular slot. clevis luks regen Regenerate LUKS metadata clevis luks report Report any key rotation on the server side clevis luks unbind Unbinds a pin bound to a LUKS volume clevis luks unlock Unlocks a LUKS volume-
Para más información, consulte la página de manual
clevis(1).
15.15.3. Despliegue de un servidor Tang con SELinux en modo reforzado
Utilice este procedimiento para desplegar un servidor Tang que se ejecuta en un puerto personalizado como un servicio confinado en el modo de aplicación de SELinux.
Requisitos previos
-
El paquete
policycoreutils-python-utilsy sus dependencias están instalados.
Procedimiento
Para instalar el paquete
tangy sus dependencias, introduzca el siguiente comando comoroot:# yum install tangElija un puerto desocupado, por ejemplo, 7500/tcp, y permita que el servicio
tangdse vincule a ese puerto:# semanage port -a -t tangd_port_t -p tcp 7500Tenga en cuenta que un puerto sólo puede ser utilizado por un servicio a la vez, por lo que un intento de utilizar un puerto ya ocupado implica el mensaje de error
ValueError: Port already defined.Abre el puerto en el firewall:
# firewall-cmd --add-port=7500/tcp # firewall-cmd --runtime-to-permanentHabilite el servicio
tangd:# systemctl enable tangd.socketCrear un archivo de anulación:
# systemctl edit tangd.socketEn la siguiente pantalla del editor, que abre un archivo
override.confvacío situado en el directorio/etc/systemd/system/tangd.socket.d/, cambie el puerto por defecto del servidor Tang de 80 al número elegido anteriormente añadiendo las siguientes líneas:[Socket] ListenStream= ListenStream=7500Guarde el archivo y salga del editor.
Recarga la configuración modificada:
# systemctl daemon-reloadComprueba que tu configuración funciona:
# systemctl show tangd.socket -p Listen Listen=[::]:7500 (Stream)Inicie el servicio
tangd:# systemctl start tangd.socketDado que
tangdutiliza el mecanismo de activación de socketssystemd, el servidor se inicia en cuanto llega la primera conexión. En el primer arranque se genera automáticamente un nuevo juego de claves criptográficas. Para realizar operaciones criptográficas como la generación manual de claves, utilice la utilidadjose.
Recursos adicionales
-
tang(8)página de manual -
semanage(8)página de manual -
firewall-cmd(1)página de manual -
systemd.unit(5)ysystemd.socket(5)páginas man -
jose(1)página de manual
15.15.4. Rotación de las claves del servidor Tang y actualización de los enlaces en los clientes
Siga los siguientes pasos para rotar las claves del servidor Tang y actualizar los enlaces existentes en los clientes. El intervalo exacto con el que debe rotarlas depende de su aplicación, del tamaño de las claves y de la política institucional.
Requisitos previos
- Se está ejecutando un servidor Tang.
-
Los paquetes
clevisyclevis-luksestán instalados en sus clientes. -
Tenga en cuenta que
clevis luks list,clevis luks report, yclevis luks regense han introducido en RHEL 8.2.
Procedimiento
Para rotar las claves, genere nuevas claves utilizando el comando
/usr/libexec/tangd-keygenen el directorio de la base de datos de claves/var/db/tangen el servidor Tang:# ls /var/db/tang UV6dqXSwe1bRKG3KbJmdiR020hY.jwk y9hxLTQSiSB5jSEGWnjhY8fDTJU.jwk # /usr/libexec/tangd-keygen /var/db/tang # ls /var/db/tang UV6dqXSwe1bRKG3KbJmdiR020hY.jwk y9hxLTQSiSB5jSEGWnjhY8fDTJU.jwk 3ZWS6-cDrCG61UPJS2BMmPU4I54.jwk zyLuX6hijUy_PSeUEFDi7hi38.jwkCompruebe que su servidor Tang anuncia la clave de firma del nuevo par de claves, por ejemplo:
# tang-show-keys 7500 3ZWS6-cDrCG61UPJS2BMmPU4I54Cambie el nombre de las claves antiguas para que tengan un
.inicial para ocultarlas de la publicidad. Tenga en cuenta que los nombres de archivo en el siguiente ejemplo difieren de los nombres de archivo únicos en el directorio de la base de datos de claves de su servidor Tang:# cd /var/db/tang # ls -l -rw-r--r--. 1 root tang 354 Sep 23 16:08 3ZWS6-cDrCG61UPJS2BMmPU4I54.jwk -rw-r--r--. 1 root tang 349 Sep 23 16:08 I-zyLuX6hijUy_PSeUEFDi7hi38.jwk -rw-r--r--. 1 root root 349 Feb 7 14:55 UV6dqXSwe1bRKG3KbJmdiR020hY.jwk -rw-r--r--. 1 root root 354 Feb 7 14:55 y9hxLTQSiSB5jSEGWnjhY8fDTJU.jwk # mv UV6dqXSwe1bRKG3KbJmdiR020hY.jwk .UV6dqXSwe1bRKG3KbJmdiR020hY.jwk # mv y9hxLTQSiSB5jSEGWnjhY8fDTJU.jwk .y9hxLTQSiSB5jSEGWnjhY8fDTJU.jwkTang recoge inmediatamente todos los cambios. No es necesario reiniciar. En este momento, los nuevos enlaces de los clientes recogen las nuevas claves y los antiguos clientes pueden seguir utilizando las antiguas claves.
En sus clientes NBDE, utilice el comando
clevis luks reportpara comprobar si las claves anunciadas por el servidor Tang siguen siendo las mismas. Puede identificar las ranuras con el enlace correspondiente utilizando el comandoclevis luks list, por ejemplo:# clevis luks list -d /dev/sda2 1: tang '{"url":"http://tang.srv"}' # clevis luks report -d /dev/sda2 -s 1 ... Report detected that some keys were rotated. Do you want to regenerate luks metadata with "clevis luks regen -d /dev/sda2 -s 1"? [ynYN]Para regenerar los metadatos LUKS para las nuevas claves, pulse
yen el prompt del comando anterior, o utilice el comandoclevis luks regen:# clevis luks regen -d /dev/sda2 -s 1Cuando esté seguro de que todos los clientes antiguos utilizan las nuevas claves, puede eliminar las antiguas claves del servidor Tang, por ejemplo:
# cd /var/db/tang # rm .*.jwk
La eliminación de las claves antiguas mientras los clientes aún las utilizan puede provocar la pérdida de datos. Si elimina accidentalmente dichas claves, utilice el comando clevis luks regen en los clientes y proporcione su contraseña LUKS manualmente.
Recursos adicionales
-
tang-show-keys(1),clevis-luks-list(1),clevis-luks-report(1), yclevis-luks-regen(1)páginas de manual
15.15.5. Configuración del desbloqueo automático mediante una llave Tang en la consola web
Configure el desbloqueo automático de un dispositivo de almacenamiento cifrado con LUKS utilizando una clave proporcionada por un servidor Tang.
Requisitos previos
Se ha instalado la consola web de RHEL 8.
Para más detalles, véase Instalación de la consola web.
-
El paquete
cockpit-storagedestá instalado en su sistema. -
El servicio
cockpit.socketse ejecuta en el puerto 9090. -
Los paquetes
clevis,tang, yclevis-dracutestán instalados. - Se está ejecutando un servidor Tang.
Procedimiento
Abra la consola web de RHEL introduciendo la siguiente dirección en un navegador web:
https://localhost:9090Sustituya la parte localhost por el nombre del servidor remoto o la dirección IP cuando se conecte a un sistema remoto.
- Proporcione sus credenciales y haga clic en . Seleccione un dispositivo cifrado y haga clic en en la parte Content:
Haga clic en en la sección Keys para añadir una llave Tang:
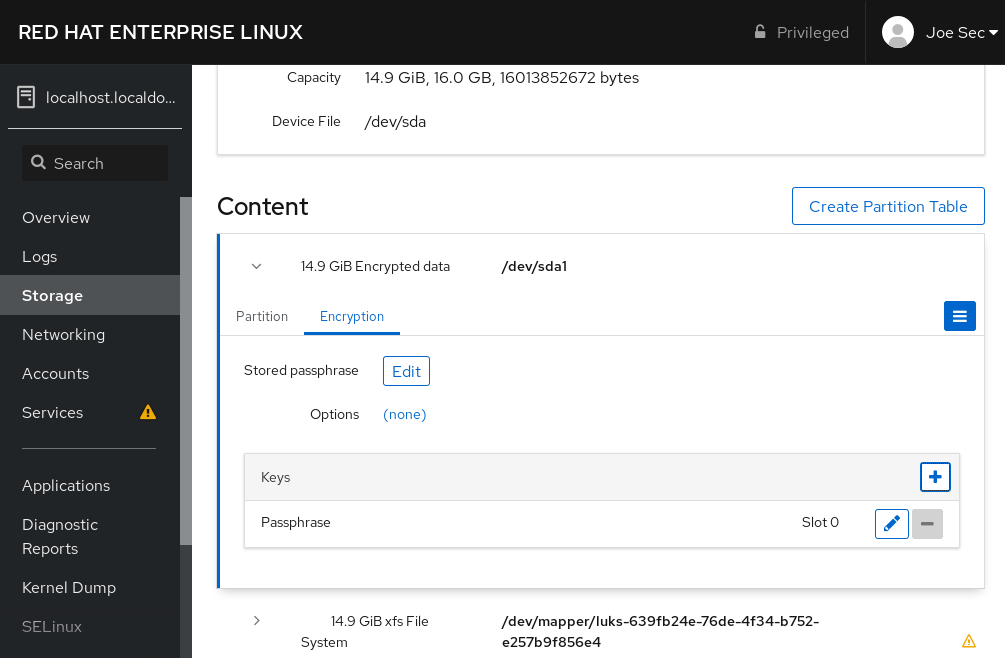
Proporcione la dirección de su servidor Tang y una contraseña que desbloquee el dispositivo cifrado con LUKS. Haz clic en para confirmar:
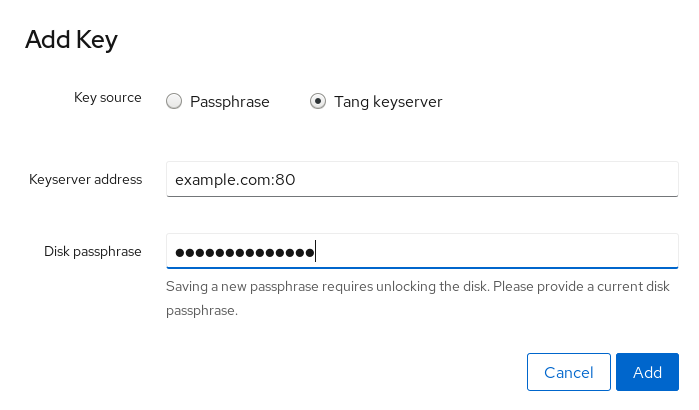
The following dialog window provides a command to verify that the key hash matches. RHEL 8.2 introduced the
tang-show-keysscript, and you can obtain the key hash using the following command on the Tang server running on the port 7500:# tang-show-keys 7500 3ZWS6-cDrCG61UPJS2BMmPU4I54En RHEL 8.1 y anteriores, obtenga el hash de la clave utilizando el siguiente comando:
# curl -s localhost:7500/adv | jose fmt -j- -g payload -y -o- | jose jwk use -i- -r -u verify -o- | jose jwk thp -i- 3ZWS6-cDrCG61UPJS2BMmPU4I54Haga clic en cuando los hashes de la clave en la consola web y en la salida de los comandos enumerados anteriormente sean iguales:
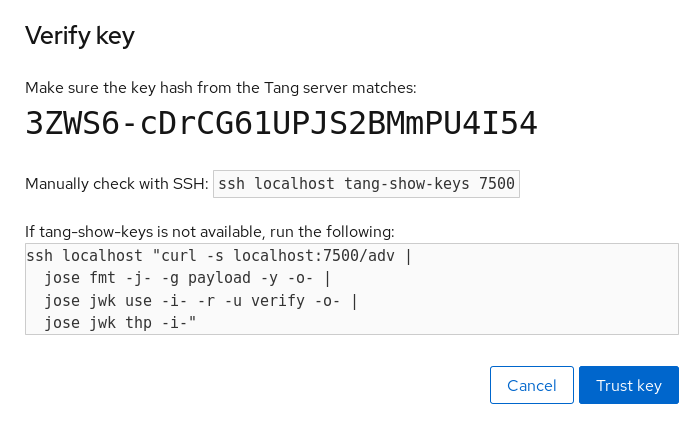
Para permitir que el sistema de arranque temprano procese la unión de discos, haga clic en en la parte inferior de la barra de navegación izquierda e introduzca los siguientes comandos:
# yum install clevis-dracut # dracut -fv --regenerate-all
Pasos de verificación
Compruebe que la clave Tang recién añadida aparece ahora en la sección Keys con el tipo
Keyserver: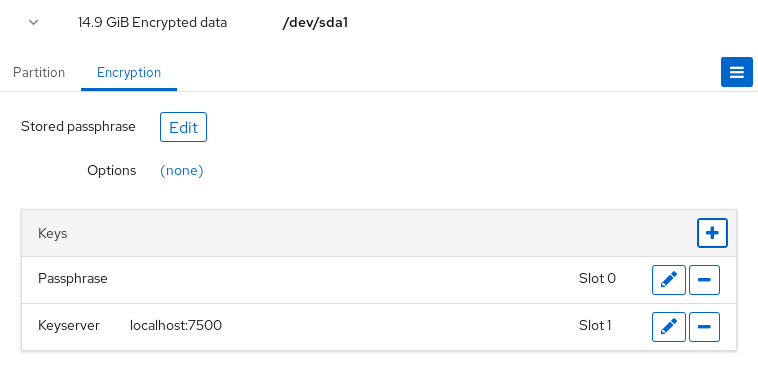
Comprueba que las fijaciones están disponibles para el arranque temprano, por ejemplo:
# lsinitrd | grep clevis clevis clevis-pin-sss clevis-pin-tang clevis-pin-tpm2 -rwxr-xr-x 1 root root 1600 Feb 11 16:30 usr/bin/clevis -rwxr-xr-x 1 root root 1654 Feb 11 16:30 usr/bin/clevis-decrypt ... -rwxr-xr-x 2 root root 45 Feb 11 16:30 usr/lib/dracut/hooks/initqueue/settled/60-clevis-hook.sh -rwxr-xr-x 1 root root 2257 Feb 11 16:30 usr/libexec/clevis-luks-askpass
15.15.6. Despliegue de un cliente de encriptación para un sistema NBDE con Tang
El siguiente procedimiento contiene los pasos para configurar el desbloqueo automático de un volumen cifrado con un servidor de red Tang.
Requisitos previos
- El marco de la horquilla está instalado.
- Hay un servidor Tang disponible.
Procedimiento
Para vincular un cliente de encriptación Clevis a un servidor Tang, utilice el subcomando
clevis encrypt tang:$ clevis encrypt tang '{"url":"http://tang.srv:port"}' < input-plain.txt > secret.jwe The advertisement contains the following signing keys: _OsIk0T-E2l6qjfdDiwVmidoZjA Do you wish to trust these keys? [ynYN] yCambie la URL de http://tang.srv:port en el ejemplo anterior para que coincida con la URL del servidor donde está instalado
tang. El archivo de salida secret.jwe contiene su texto cifrado en el formato JSON Web Encryption. Este texto cifrado se lee desde el archivo de entrada input-plain.txt.Alternativamente, si su configuración requiere una comunicación no interactiva con un servidor Tang sin acceso SSH, puede descargar un anuncio y guardarlo en un archivo:
$ curl -sfg http://tang.srv:port/adv -o adv.jwsUtilice el anuncio en el archivo adv.jws para cualquier tarea siguiente, como la encriptación de archivos o mensajes:
$ echo 'hello' | clevis encrypt tang '{"url":"http://tang.srv:port","adv":"adv.jws"}'Para descifrar los datos, utilice el comando
clevis decrypty proporcione el texto cifrado (JWE):$ clevis decrypt < secret.jwe > output-plain.txt
Recursos adicionales
Para obtener una referencia rápida, consulte la página man
clevis-encrypt-tang(1)o utilice la ayuda incorporada de la CLI:$ clevis $ clevis decrypt $ clevis encrypt tang Usage: clevis encrypt tang CONFIG < PLAINTEXT > JWE ...Para más información, consulte las siguientes páginas de manual:
-
clevis(1) -
clevis-luks-unlockers(7)
-
15.15.7. Extracción manual de un pasador de horquilla de un volumen cifrado con LUKS
Utilice el siguiente procedimiento para eliminar manualmente los metadatos creados por el comando clevis luks bind y también para borrar una ranura de llave que contenga una frase de contraseña añadida por Clevis.
La forma recomendada de eliminar un pasador de horquilla de un volumen cifrado con LUKS es a través del comando clevis luks unbind. El procedimiento de eliminación mediante clevis luks unbind consta de un solo paso y funciona tanto para volúmenes LUKS1 como LUKS2. El siguiente comando de ejemplo elimina los metadatos creados por el paso de vinculación y borra la ranura de la llave 1 en el dispositivo /dev/sda2:
# clevis luks unbind -d /dev/sda2 -s 1Requisitos previos
- Un volumen encriptado por LUKS con una encuadernación de horquilla.
Procedimiento
Compruebe con qué versión de LUKS está encriptado el volumen, por ejemplo /dev/sda2, e identifique una ranura y un token que esté vinculado a Clevis:
# cryptsetup luksDump /dev/sda2 LUKS header information Version: 2 ... Keyslots: 0: luks2 ... 1: luks2 Key: 512 bits Priority: normal Cipher: aes-xts-plain64 ... Tokens: 0: clevis Keyslot: 1 ...En el ejemplo anterior, la ficha de la horquilla se identifica con 0 y la ranura de la llave asociada es 1.
En el caso de la encriptación LUKS2, retire el token:
# cryptsetup token remove --token-id 0 /dev/sda2Si su dispositivo está encriptado por LUKS1, lo que se indica con la cadena
Version: 1en la salida del comandocryptsetup luksDump, realice este paso adicional con el comandoluksmeta wipe:# luksmeta wipe -d /dev/sda2 -s 1Limpie la ranura de la llave que contiene la frase de contraseña de la Clevis:
# cryptsetup luksKillSlot /dev/sda2 1
Recursos adicionales
-
Para más información, consulte las páginas de manual
clevis-luks-unbind(1),cryptsetup(8), yluksmeta(8).
15.15.8. Implementación de un cliente de cifrado con una política TPM 2.0
El siguiente procedimiento contiene los pasos para configurar el desbloqueo automático de un volumen cifrado con una política de Trusted Platform Module 2.0 (TPM 2.0).
Requisitos previos
- El marco de trabajo de Clevis está instalado. Ver Instalación de un cliente de encriptación - Clevis
- Un sistema con arquitectura Intel de 64 bits o AMD de 64 bits
Procedimiento
Para desplegar un cliente que cifre utilizando un chip TPM 2.0, utilice el subcomando
clevis encrypt tpm2con el único argumento en forma de objeto de configuración JSON:$ clevis encrypt tpm2 '{}' < input-plain.txt > secret.jwePara elegir una jerarquía, un hash y unos algoritmos de clave diferentes, especifique las propiedades de configuración, por ejemplo:
$ clevis encrypt tpm2 '{"hash":"sha1","key":"rsa"}' < input-plain.txt > secret.jwePara descifrar los datos, proporcione el texto cifrado en el formato JSON Web Encryption (JWE):
$ clevis decrypt < secret.jwe > output-plain.txt
El pin también admite el sellado de datos a un estado de los Registros de Configuración de la Plataforma (PCR). De este modo, los datos solo pueden desprecintarse si los valores de los hashes de los PCR coinciden con la política utilizada al sellarlos.
Por ejemplo, para sellar los datos al PCR con índice 0 y 1 para el banco SHA-1:
$ clevis encrypt tpm2 '{"pcr_bank":"sha1","pcr_ids":"0,1"}' < input-plain.txt > secret.jweRecursos adicionales
-
Para más información y la lista de posibles propiedades de configuración, consulte la página man
clevis-encrypt-tpm2(1).
15.15.9. Configuración de la inscripción manual de volúmenes cifrados con LUKS
Siga los siguientes pasos para configurar el desbloqueo de volúmenes cifrados con LUKS con NBDE.
Requisito previo
- Un servidor Tang está funcionando y está disponible.
Procedimiento
Para desbloquear automáticamente un volumen cifrado con LUKS, instale el subpaquete
clevis-luks:# yum install clevis-luksIdentifique el volumen cifrado por LUKS para PBD. En el siguiente ejemplo, el dispositivo de bloque se denomina /dev/sda2:
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 12G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 11G 0 part └─luks-40e20552-2ade-4954-9d56-565aa7994fb6 253:0 0 11G 0 crypt ├─rhel-root 253:0 0 9.8G 0 lvm / └─rhel-swap 253:1 0 1.2G 0 lvm [SWAP]Vincule el volumen a un servidor Tang utilizando el comando
clevis luks bind:# clevis luks bind -d /dev/sda2 tang '{"url":"http://tang.srv"}' The advertisement contains the following signing keys: _OsIk0T-E2l6qjfdDiwVmidoZjA Do you wish to trust these keys? [ynYN] y You are about to initialize a LUKS device for metadata storage. Attempting to initialize it may result in data loss if data was already written into the LUKS header gap in a different format. A backup is advised before initialization is performed. Do you wish to initialize /dev/sda2? [yn] y Enter existing LUKS password:Este comando realiza cuatro pasos:
- Crea una nueva clave con la misma entropía que la clave maestra LUKS.
- Cifra la nueva clave con la horquilla.
- Almacena el objeto Clevis JWE en el token de la cabecera LUKS2 o utiliza LUKSMeta si se utiliza la cabecera LUKS1 no predeterminada.
Habilita la nueva clave para su uso con LUKS.
NotaEl procedimiento de vinculación supone que hay al menos una ranura de contraseña LUKS libre. El comando
clevis luks bindtoma una de las ranuras.
- El volumen se puede desbloquear ahora con su contraseña existente, así como con la política de la horquilla.
Para permitir que el sistema de arranque temprano procese la unión de discos, introduzca los siguientes comandos en un sistema ya instalado:
# yum install clevis-dracut # dracut -fv --regenerate-all
Pasos de verificación
Para comprobar que el objeto JWE de la horquilla se ha colocado correctamente en una cabecera LUKS, utilice el comando
clevis luks list:# clevis luks list -d /dev/sda2 1: tang '{"url":"http://tang.srv:port"}'
Para utilizar NBDE para clientes con configuración IP estática (sin DHCP), pase su configuración de red a la herramienta dracut manualmente, por ejemplo:
# dracut -fv --regenerate-all --kernel-cmdline "ip=192.0.2.10::192.0.2.1:255.255.255.0::ens3:none:192.0.2.45"
Como alternativa, cree un archivo .conf en el directorio /etc/dracut.conf.d/ con la información de red estática. Por ejemplo:
# cat /etc/dracut.conf.d/static_ip.conf
kernel_cmdline="ip=192.0.2.10::192.0.2.1:255.255.255.0::ens3:none:192.0.2.45"Regenerar la imagen inicial del disco RAM:
# dracut -fv --regenerate-allRecursos adicionales
Para más información, consulte las siguientes páginas de manual:
-
clevis-luks-bind(1) -
dracut.cmdline(7)
15.15.10. Configuración de la inscripción automatizada de volúmenes cifrados con LUKS mediante Kickstart
Siga los pasos de este procedimiento para configurar un proceso de instalación automatizado que utilice Clevis para la inscripción de volúmenes cifrados con LUKS.
Procedimiento
Indique a Kickstart que particione el disco de forma que se habilite el cifrado LUKS para todos los puntos de montaje, excepto
/boot, con una contraseña temporal. La contraseña es temporal para este paso del proceso de inscripción.part /boot --fstype="xfs" --ondisk=vda --size=256 part / --fstype="xfs" --ondisk=vda --grow --encrypted --passphrase=temppassTenga en cuenta que los sistemas de reclamación OSPP requieren una configuración más compleja, por ejemplo:
part /boot --fstype="xfs" --ondisk=vda --size=256 part / --fstype="xfs" --ondisk=vda --size=2048 --encrypted --passphrase=temppass part /var --fstype="xfs" --ondisk=vda --size=1024 --encrypted --passphrase=temppass part /tmp --fstype="xfs" --ondisk=vda --size=1024 --encrypted --passphrase=temppass part /home --fstype="xfs" --ondisk=vda --size=2048 --grow --encrypted --passphrase=temppass part /var/log --fstype="xfs" --ondisk=vda --size=1024 --encrypted --passphrase=temppass part /var/log/audit --fstype="xfs" --ondisk=vda --size=1024 --encrypted --passphrase=temppassInstale los paquetes de la horquilla relacionados con ella, enumerándolos en la sección
%packages:%packages clevis-dracut %endLlame a
clevis luks bindpara realizar la vinculación en la sección%post. Después, elimine la contraseña temporal:%post curl -sfg http://tang.srv/adv -o adv.jws clevis luks bind -f -k- -d /dev/vda2 \ tang '{"url":"http://tang.srv","adv":"adv.jws"}' \ <<< "temppass" cryptsetup luksRemoveKey /dev/vda2 <<< "temppass" %endEn el ejemplo anterior, observe que descargamos el anuncio del servidor Tang como parte de nuestra configuración de vinculación, lo que permite que la vinculación sea completamente no interactiva.
AvisoEl comando
cryptsetup luksRemoveKeyimpide cualquier administración posterior de un dispositivo LUKS2 en el que se aplique. Puede recuperar una llave maestra eliminada utilizando el comandodmsetupsólo para dispositivos LUKS1.
Puede utilizar un procedimiento análogo cuando utilice una política TPM 2.0 en lugar de un servidor Tang.
Recursos adicionales
-
clevis(1),clevis-luks-bind(1),cryptsetup(8), ydmsetup(8)páginas de manual - Instalación de Red Hat Enterprise Linux 8 mediante Kickstart
15.15.11. Configuración del desbloqueo automático de un dispositivo de almacenamiento extraíble cifrado con LUKS
Utilice este procedimiento para configurar un proceso de desbloqueo automático de un dispositivo de almacenamiento USB cifrado con LUKS.
Procedimiento
Para desbloquear automáticamente un dispositivo de almacenamiento extraíble cifrado con LUKS, como una unidad USB, instale el paquete
clevis-udisks2:# yum install clevis-udisks2Reinicie el sistema y, a continuación, realice el paso de vinculación utilizando el comando
clevis luks bindcomo se describe en Configuring manual enrollment of LUKS-encrypted volumes, por ejemplo:# clevis luks bind -d /dev/sdb1 tang '{"url":"http://tang.srv"}'El dispositivo extraíble encriptado por LUKS puede ahora ser desbloqueado automáticamente en su sesión de escritorio GNOME. El dispositivo vinculado a una política de Clevis también puede desbloquearse mediante el comando
clevis luks unlock:# clevis luks unlock -d /dev/sdb1
Puede utilizar un procedimiento análogo cuando utilice una política TPM 2.0 en lugar de un servidor Tang.
Recursos adicionales
Para más información, consulte la siguiente página de manual:
-
clevis-luks-unlockers(7)
15.15.12. Implantación de sistemas NBDE de alta disponibilidad
Tang ofrece dos métodos para construir un despliegue de alta disponibilidad:
- Redundancia de clientes (recomendada)
-
Los clientes deben estar configurados con la capacidad de vincularse a múltiples servidores Tang. En esta configuración, cada servidor Tang tiene sus propias claves y los clientes pueden descifrar contactando con un subconjunto de estos servidores. Clevis ya soporta este flujo de trabajo a través de su plug-in
sss. Red Hat recomienda este método para un despliegue de alta disponibilidad. - Compartir las llaves
-
Por motivos de redundancia, se puede desplegar más de una instancia de Tang. Para configurar una segunda instancia o cualquier instancia posterior, instale los paquetes
tangy copie el directorio de claves al nuevo host utilizandorsyncsobreSSH. Tenga en cuenta que Red Hat no recomienda este método porque compartir claves aumenta el riesgo de compromiso de las mismas y requiere una infraestructura de automatización adicional.
15.15.12.1. NBDE de alta disponibilidad utilizando el secreto compartido de Shamir
La compartición de secretos de Shamir (SSS) es un esquema criptográfico que divide un secreto en varias partes únicas. Para reconstruir el secreto, se requiere un número de partes. El número se denomina umbral y el SSS también se conoce como esquema de umbralización.
Clevis proporciona una implementación de SSS. Crea una clave y la divide en un número de piezas. Cada trozo es encriptado usando otra clavija incluyendo incluso SSS recursivamente. Además, define el umbral t. Si un despliegue de NBDE descifra al menos t piezas, entonces recupera la clave de cifrado y el proceso de descifrado tiene éxito. Cuando Clevis detecta un número de piezas inferior al especificado en el umbral, imprime un mensaje de error.
15.15.12.1.1. Ejemplo 1: Redundancia con dos servidores Tang
El siguiente comando descifra un dispositivo cifrado con LUKS cuando al menos uno de los dos servidores Tang está disponible:
# clevis luks bind -d /dev/sda1 sss '{"t":1,"pins":{"tang":[{"url":"http://tang1.srv"},{"url":"http://tang2.srv"}]}}'El comando anterior utilizaba el siguiente esquema de configuración:
{
"t":1,
"pins":{
"tang":[
{
"url":"http://tang1.srv"
},
{
"url":"http://tang2.srv"
}
]
}
}
En esta configuración, el umbral de SSS t se establece en 1 y el comando clevis luks bind reconstruye con éxito el secreto si al menos uno de los dos servidores de la lista tang está disponible.
15.15.13. Despliegue de máquinas virtuales en una red NBDE
El comando clevis luks bind no cambia la clave maestra de LUKS. Esto implica que si creas una imagen cifrada con LUKS para usarla en una máquina virtual o en un entorno de nube, todas las instancias que ejecuten esta imagen compartirán una clave maestra. Esto es extremadamente inseguro y debe evitarse en todo momento.
Esto no es una limitación de Clevis sino un principio de diseño de LUKS. Si desea tener volúmenes raíz encriptados en una nube, necesita asegurarse de que realiza el proceso de instalación (normalmente usando Kickstart) para cada instancia de Red Hat Enterprise Linux en una nube también. Las imágenes no pueden ser compartidas sin compartir también una llave maestra LUKS.
Si pretende implementar el desbloqueo automatizado en un entorno virtualizado, Red Hat recomienda encarecidamente que utilice sistemas como lorax o virt-install junto con un archivo Kickstart (véase Configuring automated enrollment of LUKS-encrypted volumes using Kickstart) u otra herramienta de aprovisionamiento automatizado para garantizar que cada VM encriptada tenga una clave maestra única.
El desbloqueo automático con una política TPM 2.0 no es compatible con una máquina virtual.
Recursos adicionales
Para más información, consulte la siguiente página de manual:
-
clevis-luks-bind(1)
15.15.14. Creación de imágenes de máquinas virtuales automáticamente inscribibles para entornos de nube mediante NBDE
El despliegue de imágenes encriptadas automáticamente en un entorno de nube puede proporcionar un conjunto único de desafíos. Al igual que en otros entornos de virtualización, se recomienda reducir el número de instancias iniciadas a partir de una sola imagen para evitar compartir la clave maestra LUKS.
Por lo tanto, la mejor práctica es crear imágenes personalizadas que no se compartan en ningún repositorio público y que proporcionen una base para el despliegue de una cantidad limitada de instancias. El número exacto de instancias a crear debe ser definido por las políticas de seguridad del despliegue y basado en la tolerancia al riesgo asociado al vector de ataque de la llave maestra LUKS.
Para construir despliegues automatizados con LUKS, se deben utilizar sistemas como Lorax o virt-install junto con un archivo Kickstart para asegurar la unicidad de la llave maestra durante el proceso de construcción de la imagen.
Los entornos de nube permiten dos opciones de despliegue del servidor Tang que consideramos aquí. En primer lugar, el servidor Tang puede desplegarse dentro del propio entorno de la nube. En segundo lugar, el servidor Tang puede desplegarse fuera de la nube en una infraestructura independiente con un enlace VPN entre las dos infraestructuras.
El despliegue de Tang de forma nativa en la nube permite un fácil despliegue. Sin embargo, dado que comparte infraestructura con la capa de persistencia de datos de texto cifrado de otros sistemas, puede ser posible que tanto la clave privada del servidor Tang como los metadatos de Clevis se almacenen en el mismo disco físico. El acceso a este disco físico permite comprometer completamente los datos del texto cifrado.
Por esta razón, Red Hat recomienda encarecidamente mantener una separación física entre la ubicación donde se almacenan los datos y el sistema donde se ejecuta Tang. Esta separación entre la nube y el servidor Tang garantiza que la clave privada del servidor Tang no pueda combinarse accidentalmente con los metadatos de Clevis. También proporciona un control local del servidor Tang si la infraestructura de la nube está en peligro.
15.15.15. Introducción a las funciones del sistema de horquilla y Tang
RHEL System Roles es una colección de roles y módulos de Ansible que proporcionan una interfaz de configuración consistente para gestionar remotamente múltiples sistemas RHEL.
RHEL 8.3 introdujo los roles de Ansible para el despliegue automatizado de soluciones de descifrado basado en políticas (PBD) utilizando Clevis y Tang. El paquete rhel-system-roles contiene estos roles de sistema, los ejemplos relacionados y también la documentación de referencia.
El rol de sistema nbde_client le permite desplegar múltiples clientes Clevis de forma automatizada. Tenga en cuenta que el rol nbde_client sólo admite enlaces Tang, y no puede utilizarlo para enlaces TPM2 por el momento.
El rol nbde_client requiere volúmenes que ya están encriptados usando LUKS. Esta función permite vincular un volumen cifrado con LUKS a uno o más servidores vinculados a la red (NBDE) - servidores Tang. Puede conservar el cifrado del volumen existente con una frase de contraseña o eliminarla. Una vez eliminada la frase de contraseña, puede desbloquear el volumen sólo con NBDE. Esto es útil cuando un volumen está inicialmente encriptado utilizando una clave o contraseña temporal que debe eliminar después de aprovisionar el sistema.
Si proporciona tanto una frase de contraseña como un archivo de claves, el rol utiliza lo que ha proporcionado primero. Si no encuentra ninguno de ellos válido, intenta recuperar una frase de contraseña de un enlace existente.
PBD define una vinculación como una asignación de un dispositivo a una ranura. Esto significa que se pueden tener varios enlaces para el mismo dispositivo. La ranura por defecto es la ranura 1.
El rol nbde_client proporciona también la variable state. Utilice el valor present para crear un nuevo enlace o actualizar uno existente. Al contrario que el comando clevis luks bind, puede utilizar state: present también para sobrescribir un enlace existente en su ranura de dispositivo. El valor absent elimina un enlace especificado.
Utilizando el rol nbde_server, puede desplegar y gestionar un servidor Tang como parte de una solución de encriptación de disco automatizada. Este rol soporta las siguientes características:
- Llaves Tang giratorias
- Despliegue y copia de seguridad de las llaves Tang
Recursos adicionales
-
Para una referencia detallada sobre las variables de rol Network-Bound Disk Encryption (NBDE), instale el paquete
rhel-system-roles, y vea los archivosREADME.mdyREADME.htmlen los directorios/usr/share/doc/rhel-system-roles/nbde_client/y/usr/share/doc/rhel-system-roles/nbde_server/. -
Para ver ejemplos de playbooks de system-roles, instale el paquete
rhel-system-roles, y vea los directorios/usr/share/ansible/roles/rhel-system-roles.nbde_server/examples/. - Para obtener más información sobre las funciones del sistema RHEL, consulte Introducción a las funciones del sistema RHEL
15.15.16. Uso del rol de sistema nbde_server para configurar múltiples servidores Tang
Siga los pasos para preparar y aplicar un playbook de Ansible que contenga la configuración de su servidor Tang.
Requisitos previos
- Su suscripción a Red Hat Ansible Engine está conectada al sistema. Consulte el artículo Cómo descargar e instalar Red Hat Ansible Engine para obtener más información.
Procedimiento
Habilitar el repositorio RHEL Ansible, por ejemplo:
# subscription-manager repos --enable ansible-2-for-rhel-8-x86_64-rpmsInstale el motor Ansible:
# yum install ansibleInstalar los roles del sistema RHEL:
# yum install rhel-system-rolesPrepare su libro de jugadas con la configuración de los servidores Tang. Puede empezar desde cero o utilizar uno de los libros de juego de ejemplo del directorio
/usr/share/ansible/roles/rhel-system-roles.nbde_server/examples/.# cp /usr/share/ansible/roles/rhel-system-roles.nbde_server/examples/simple_deploy.yml ./my-tang-playbook.ymlEdite el libro de jugadas en un editor de texto de su elección, por ejemplo:
# vi my-tang-playbook.ymlAñada los parámetros necesarios. El siguiente ejemplo de libro de jugadas asegura el despliegue de su servidor Tang y una rotación de llaves:
--- - hosts: all vars: nbde_server_rotate_keys: yes roles: - linux-system-roles.nbde_serverAplicar el libro de jugadas terminado:
# ansible-playbook -i host1,host2,host3 my-tang-playbook.yml
Recursos adicionales
-
Para más información, instale el paquete
rhel-system-rolesy consulte los directorios/usr/share/doc/rhel-system-roles/nbde_server/yusr/share/ansible/roles/rhel-system-roles.nbde_server/.
15.15.17. Uso de la función del sistema nbde_client para configurar varios clientes Clevis
Siga los pasos para preparar y aplicar un libro de jugadas de Ansible que contenga su configuración de Clevis-client.
El rol de sistema nbde_client sólo admite enlaces Tang. Esto significa que, por el momento, no se puede utilizar para los enlaces TPM2.
Requisitos previos
- Su suscripción a Red Hat Ansible Engine está conectada al sistema. Consulte el artículo Cómo descargar e instalar Red Hat Ansible Engine para obtener más información.
- Sus volúmenes ya están encriptados por LUKS.
Procedimiento
Habilitar el repositorio RHEL Ansible, por ejemplo:
# subscription-manager repos --enable ansible-2-for-rhel-8-x86_64-rpmsInstale el motor Ansible:
# yum install ansibleInstalar los roles del sistema RHEL:
# yum install rhel-system-rolesPrepare su libro de jugadas con la configuración de los clientes de Clevis. Puede empezar desde cero o utilizar uno de los libros de juego de ejemplo del directorio
/usr/share/ansible/roles/rhel-system-roles.nbde_client/examples/.# cp /usr/share/ansible/roles/rhel-system-roles.nbde_client/examples/high_availability.yml ./my-clevis-playbook.ymlEdite el libro de jugadas en un editor de texto de su elección, por ejemplo:
# vi my-clevis-playbook.ymlAñada los parámetros necesarios. El siguiente ejemplo de libro de jugadas configura los clientes Clevis para el desbloqueo automático de dos volúmenes cifrados con LUKS cuando al menos uno de los dos servidores Tang está disponible:
--- - hosts: all vars: nbde_client_bindings: - device: /dev/rhel/root encryption_key_src: /etc/luks/keyfile servers: - http://server1.example.com - http://server2.example.com - device: /dev/rhel/swap encryption_key_src: /etc/luks/keyfile servers: - http://server1.example.com - http://server2.example.com roles: - linux-system-roles.nbde_clientAplicar el libro de jugadas terminado:
# ansible-playbook -i host1,host2,host3 my-clevis-playbook.yml
Recursos adicionales
-
Para obtener detalles sobre los parámetros e información adicional sobre la función
nbde_client, instale el paqueterhel-system-rolesy consulte los directorios/usr/share/doc/rhel-system-roles/nbde_client/y/usr/share/ansible/roles/rhel-system-roles.nbde_client/.
15.15.18. Recursos adicionales
-
Las páginas de manual
tang(8),clevis(1),jose(1), yclevis-luks-unlockers(7). - El artículo de la base de conocimientos Cómo configurar el cifrado de discos en red con varios dispositivos LUKS (desbloqueo de la horquilla).
Capítulo 16. Uso de SELinux
16.1. Introducción a SELinux
16.1.1. Introducción a SELinux
Security Enhanced Linux (SELinux) proporciona una capa adicional de seguridad del sistema. SELinux responde fundamentalmente a la pregunta: May <subject> do <action> to <object>?, por ejemplo May a web server access files in users' home directories?
La política de acceso estándar basada en el usuario, el grupo y otros permisos, conocida como Control de Acceso Discrecional (DAC), no permite a los administradores del sistema crear políticas de seguridad completas y de grano fino, como restringir aplicaciones específicas para que sólo vean los archivos de registro, mientras que se permite a otras aplicaciones añadir nuevos datos a los archivos de registro.
SELinux implementa el Control de Acceso Obligatorio (MAC). Cada proceso y recurso del sistema tiene una etiqueta de seguridad especial llamada SELinux context. Un contexto de SELinux, a veces denominado SELinux label, es un identificador que abstrae los detalles a nivel de sistema y se centra en las propiedades de seguridad de la entidad. Esto no sólo proporciona una forma consistente de referenciar objetos en la política de SELinux, sino que también elimina cualquier ambigüedad que pueda encontrarse en otros métodos de identificación. Por ejemplo, un archivo puede tener múltiples nombres de ruta válidos en un sistema que hace uso de montajes bind.
La política de SELinux utiliza estos contextos en una serie de reglas que definen cómo los procesos pueden interactuar entre sí y con los distintos recursos del sistema. Por defecto, la política no permite ninguna interacción a menos que una regla conceda explícitamente el acceso.
Recuerda que las reglas de política de SELinux se comprueban después de las reglas DAC. Las reglas de política de SELinux no se utilizan si las reglas DAC deniegan el acceso primero, lo que significa que no se registra ninguna denegación de SELinux si las reglas DAC tradicionales impiden el acceso.
Los contextos de SELinux tienen varios campos: usuario, rol, tipo y nivel de seguridad. La información del tipo de SELinux es quizás la más importante cuando se trata de la política de SELinux, ya que la regla de política más común que define las interacciones permitidas entre los procesos y los recursos del sistema utiliza los tipos de SELinux y no el contexto completo de SELinux. Los tipos de SELinux terminan con _t. Por ejemplo, el nombre del tipo para el servidor web es httpd_t. El contexto de tipo para los archivos y directorios que normalmente se encuentran en /var/www/html/ es httpd_sys_content_t. El contexto de tipo para los archivos y directorios que normalmente se encuentran en /tmp y /var/tmp/ es tmp_t. El contexto de tipo para los puertos del servidor web es http_port_t.
Hay una regla de política que permite a Apache (el proceso del servidor web que se ejecuta como httpd_t) acceder a los archivos y directorios con un contexto que normalmente se encuentra en /var/www/html/ y otros directorios del servidor web (httpd_sys_content_t). No hay ninguna regla de permiso en la política para los archivos que normalmente se encuentran en /tmp y /var/tmp/, por lo que el acceso no está permitido. Con SELinux, incluso si Apache está comprometido, y un script malicioso obtiene acceso, todavía no es capaz de acceder al directorio /tmp.
Figura 16.1. Un ejemplo de cómo SELinux puede ayudar a ejecutar Apache y MariaDB de forma segura.
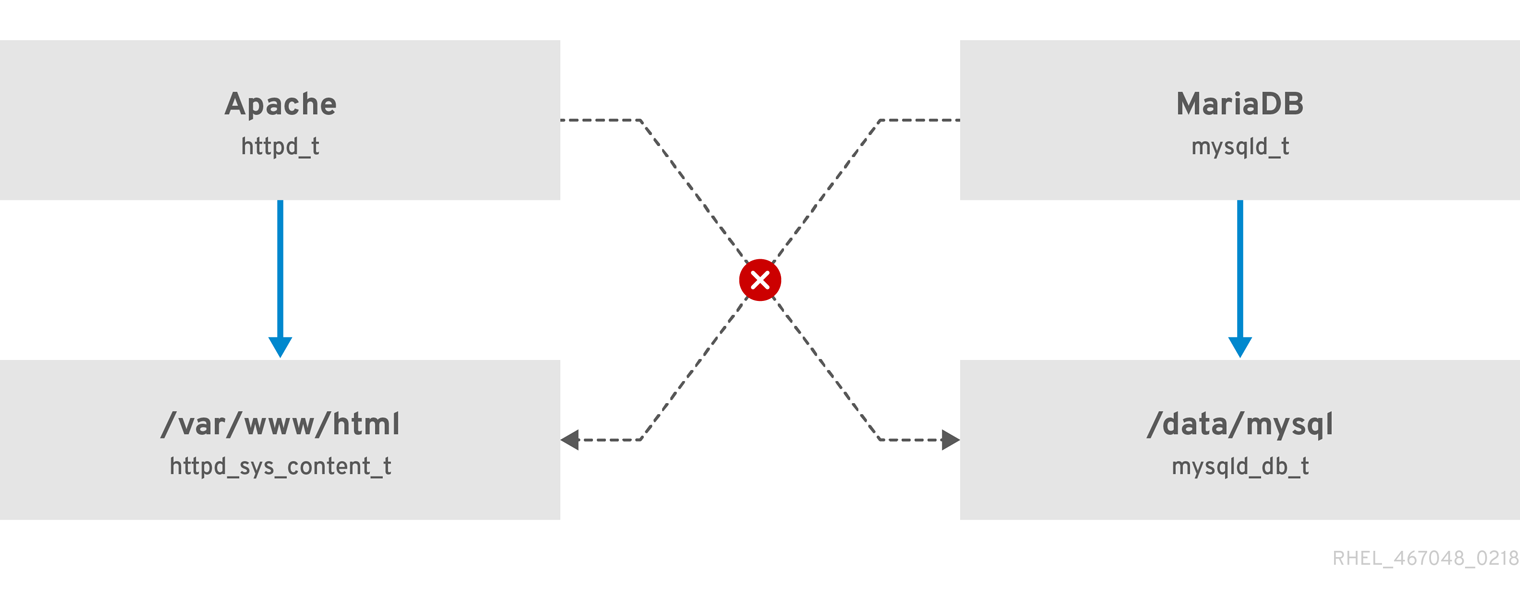
Como muestra el esquema anterior, SELinux permite que el proceso de Apache que se ejecuta como httpd_t acceda al directorio /var/www/html/ y le niega al mismo proceso el acceso al directorio /data/mysql/ porque no existe una regla de permiso para los contextos de tipo httpd_t y mysqld_db_t. Por otro lado, el proceso de MariaDB que se ejecuta como mysqld_t puede acceder al directorio /data/mysql/ y SELinux también deniega correctamente al proceso con el tipo mysqld_t el acceso al directorio /var/www/html/ etiquetado como httpd_sys_content_t.
Recursos adicionales
Para más información, consulte la siguiente documentación:
-
La página de manual
selinux(8)y las páginas de manual listadas por el comandoapropos selinux. -
Páginas de manual listadas por el comando
man -k _selinuxcuando el paqueteselinux-policy-docestá instalado. - El libro para colorear de SELinux le ayuda a entender mejor los conceptos básicos de SELinux.
- Preguntas frecuentes de la Wiki de SELinux
16.1.2. Ventajas de ejecutar SELinux
SELinux proporciona los siguientes beneficios:
- Todos los procesos y archivos están etiquetados. Las reglas de política de SELinux definen cómo los procesos interactúan con los archivos, así como cómo los procesos interactúan entre sí. Sólo se permite el acceso si existe una regla de política de SELinux que lo permita específicamente.
- Control de acceso detallado. Más allá de los permisos tradicionales de UNIX, que se controlan a discreción del usuario y se basan en los ID de usuario y grupo de Linux, las decisiones de acceso de SELinux se basan en toda la información disponible, como un usuario, un rol, un tipo y, opcionalmente, un nivel de seguridad de SELinux.
- La política de SELinux se define administrativamente y se aplica en todo el sistema.
- Mejora de la mitigación de los ataques de escalada de privilegios. Los procesos se ejecutan en dominios y, por tanto, están separados unos de otros. Las reglas de política de SELinux definen cómo los procesos acceden a los archivos y a otros procesos. Si un proceso se ve comprometido, el atacante sólo tiene acceso a las funciones normales de ese proceso, y a los archivos a los que el proceso ha sido configurado para tener acceso. Por ejemplo, si el Servidor HTTP Apache está comprometido, un atacante no puede usar ese proceso para leer archivos en los directorios personales de los usuarios, a menos que una regla de política SELinux específica haya sido agregada o configurada para permitir ese acceso.
- SELinux puede utilizarse para reforzar la confidencialidad e integridad de los datos, así como para proteger los procesos de las entradas no fiables.
Sin embargo, SELinux no lo es:
- software antivirus,
- reemplazo de contraseñas, cortafuegos y otros sistemas de seguridad,
- solución de seguridad todo en uno.
SELinux está diseñado para mejorar las soluciones de seguridad existentes, no para sustituirlas. Incluso cuando se ejecuta SELinux, es importante seguir las buenas prácticas de seguridad, como mantener el software actualizado, utilizar contraseñas difíciles de adivinar y cortafuegos.
16.1.3. Ejemplos de SELinux
Los siguientes ejemplos demuestran cómo SELinux aumenta la seguridad:
- La acción por defecto es denegar. Si no existe una regla de política de SELinux que permita el acceso, como por ejemplo para un proceso que abre un archivo, el acceso se deniega.
-
SELinux puede confinar a los usuarios de Linux. Existen varios usuarios confinados de SELinux en la política de SELinux. Los usuarios de Linux pueden ser asignados a usuarios confinados de SELinux para aprovechar las reglas y mecanismos de seguridad aplicados a ellos. Por ejemplo, mapear un usuario de Linux al usuario de SELinux
user_u, da como resultado un usuario de Linux que no es capaz de ejecutar, a menos que se configure de otra manera, aplicaciones con ID de usuario (setuid), comosudoysu, además de evitar que ejecuten archivos y aplicaciones potencialmente maliciosas en su directorio raíz. - Mayor separación de procesos y datos. El concepto de SELinux domains permite definir qué procesos pueden acceder a determinados archivos y directorios. Por ejemplo, cuando se ejecuta SELinux, a menos que se configure de otra manera, un atacante no puede comprometer un servidor Samba, y luego utilizar ese servidor Samba como un vector de ataque para leer y escribir en archivos utilizados por otros procesos, como las bases de datos MariaDB.
-
SELinux ayuda a mitigar los daños causados por los errores de configuración. Los servidores del Sistema de Nombres de Dominio (DNS) suelen replicar la información entre ellos en lo que se conoce como transferencia de zona. Los atacantes pueden utilizar las transferencias de zona para actualizar los servidores DNS con información falsa. Cuando se ejecuta el Berkeley Internet Name Domain (BIND) como un servidor DNS en Red Hat Enterprise Linux, incluso si un administrador se olvida de limitar qué servidores pueden realizar una transferencia de zona, la política SELinux por defecto evita que los archivos de zona [2] sean actualizados mediante transferencias de zona, por el propio demonio BIND
namedy por otros procesos.
16.1.4. Arquitectura y paquetes SELinux
SELinux es un módulo de seguridad de Linux (LSM) que está integrado en el núcleo de Linux. El subsistema de SELinux en el kernel está dirigido por una política de seguridad que es controlada por el administrador y cargada en el arranque. Todas las operaciones de acceso a nivel de kernel relevantes para la seguridad en el sistema son interceptadas por SELinux y examinadas en el contexto de la política de seguridad cargada. Si la política cargada permite la operación, ésta continúa. En caso contrario, la operación se bloquea y el proceso recibe un error.
Las decisiones de SELinux, como permitir o no el acceso, se almacenan en la caché. Esta caché se conoce como Access Vector Cache (AVC). Cuando se utilizan estas decisiones en caché, las reglas de política de SELinux necesitan ser comprobadas menos, lo que aumenta el rendimiento. Recuerda que las reglas de política de SELinux no tienen efecto si las reglas DAC deniegan el acceso primero. Los mensajes de auditoría sin procesar se registran en /var/log/audit/audit.log y comienzan con la cadena type=AVC.
En Red Hat Enterprise Linux 8, los servicios del sistema son controlados por el demonio systemd; systemd inicia y detiene todos los servicios, y los usuarios y procesos se comunican con systemd usando la utilidad systemctl. El demonio systemd puede consultar la política de SELinux y comprobar la etiqueta del proceso que llama y la etiqueta del archivo de la unidad que la persona que llama intenta gestionar, y luego preguntar a SELinux si la persona que llama tiene o no permiso de acceso. Este enfoque refuerza el control de acceso a las capacidades críticas del sistema, que incluyen el inicio y la detención de los servicios del sistema.
El demonio systemd también funciona como un gestor de acceso de SELinux. Recupera la etiqueta del proceso que ejecuta systemctl o el proceso que envió un mensaje D-Bus a systemd. El demonio busca entonces la etiqueta del archivo de unidad que el proceso quería configurar. Finalmente, systemd puede recuperar información del kernel si la política SELinux permite el acceso específico entre la etiqueta del proceso y la etiqueta del archivo de unidad. Esto significa que una aplicación comprometida que necesita interactuar con systemd para un servicio específico puede ahora ser confinada por SELinux. Los escritores de políticas también pueden utilizar estos controles de grano fino para confinar a los administradores.
Para evitar un etiquetado incorrecto de SELinux y los problemas subsiguientes, asegúrese de iniciar los servicios utilizando un comando systemctl start.
Red Hat Enterprise Linux 8 proporciona los siguientes paquetes para trabajar con SELinux:
-
políticas:
selinux-policy-targeted,selinux-policy-mls -
herramientas:
policycoreutils,policycoreutils-gui,libselinux-utils,policycoreutils-python-utils,setools-console,checkpolicy
16.1.5. Estados y modos de SELinux
SELinux puede ejecutarse en uno de los tres modos: reforzado, permisivo o deshabilitado.
- El modo de aplicación es el modo de operación por defecto, y el recomendado; en el modo de aplicación SELinux opera normalmente, aplicando la política de seguridad cargada en todo el sistema.
- En el modo permisivo, el sistema actúa como si SELinux estuviera aplicando la política de seguridad cargada, incluyendo el etiquetado de objetos y la emisión de entradas de denegación de acceso en los registros, pero en realidad no deniega ninguna operación. Aunque no se recomienda para sistemas de producción, el modo permisivo puede ser útil para el desarrollo y depuración de políticas de SELinux.
- Se desaconseja encarecidamente el modo deshabilitado; el sistema no sólo evita aplicar la política de SELinux, sino que también evita etiquetar cualquier objeto persistente, como los archivos, lo que dificulta la habilitación de SELinux en el futuro.
Utilice la utilidad setenforce para cambiar entre el modo de aplicación y el modo permisivo. Los cambios realizados con setenforce no persisten a través de los reinicios. Para cambiar al modo obligatorio, introduzca el comando setenforce 1 como usuario root de Linux. Para cambiar al modo permisivo, introduzca el comando setenforce 0. Utilice la utilidad getenforce para ver el modo SELinux actual:
# getenforce
Enforcing# setenforce 0
# getenforce
Permissive# setenforce 1
# getenforce
EnforcingEn Red Hat Enterprise Linux, puede poner dominios individuales en modo permisivo mientras el sistema se ejecuta en modo forzoso. Por ejemplo, para hacer que el dominio httpd_t sea permisivo:
# semanage permissive -a httpd_tTenga en cuenta que los dominios permisivos son una herramienta poderosa que puede comprometer la seguridad de su sistema. Red Hat recomienda utilizar los dominios permisivos con precaución, por ejemplo, al depurar un escenario específico.
16.2. Cambio de estados y modos de SELinux
Cuando está habilitado, SELinux puede funcionar en uno de los dos modos: enforcing o permissive. Las siguientes secciones muestran cómo cambiar permanentemente a estos modos.
16.2.1. Cambios permanentes en los estados y modos de SELinux
Como se discute en Estados y modos de SELinux, SELinux puede estar habilitado o deshabilitado. Cuando está habilitado, SELinux tiene dos modos: enforcing y permissive.
Utilice los comandos getenforce o sestatus para comprobar en qué modo se está ejecutando SELinux. El comando getenforce devuelve Enforcing, Permissive, o Disabled.
El comando sestatus devuelve el estado de SELinux y la política de SELinux que se está utilizando:
$ sestatus
SELinux status: enabled
SELinuxfs mount: /sys/fs/selinux
SELinux root directory: /etc/selinux
Loaded policy name: targeted
Current mode: enforcing
Mode from config file: enforcing
Policy MLS status: enabled
Policy deny_unknown status: allowed
Memory protection checking: actual (secure)
Max kernel policy version: 31Cuando los sistemas ejecutan SELinux en modo permisivo, los usuarios y los procesos pueden etiquetar varios objetos del sistema de archivos de forma incorrecta. Los objetos del sistema de archivos creados mientras SELinux está deshabilitado no son etiquetados en absoluto. Este comportamiento causa problemas cuando se cambia al modo de aplicación porque SELinux se basa en el etiquetado correcto de los objetos del sistema de archivos.
Para evitar que los archivos incorrectamente etiquetados y sin etiquetar causen problemas, los sistemas de archivos se vuelven a etiquetar automáticamente al cambiar del estado deshabilitado al modo permisivo o de aplicación. En el modo permisivo, utilice el comando fixfiles -F onboot como root para crear el archivo /.autorelabel que contiene la opción -F para garantizar que los archivos se vuelvan a etiquetar en el siguiente reinicio.
16.2.2. Cambio al modo permisivo
Utilice el siguiente procedimiento para cambiar permanentemente el modo de SELinux a permisivo. Cuando SELinux se ejecuta en modo permisivo, la política de SELinux no se aplica. El sistema permanece operativo y SELinux no deniega ninguna operación, sino que sólo registra los mensajes de CVA, que pueden utilizarse para la resolución de problemas, la depuración y la mejora de la política de SELinux. Cada CVA se registra sólo una vez en este caso.
Requisitos previos
-
Los paquetes
selinux-policy-targeted,libselinux-utils, ypolicycoreutilsestán instalados en su sistema. -
Los parámetros del núcleo
selinux=0oenforcing=0no se utilizan.
Procedimiento
Abra el archivo
/etc/selinux/configen un editor de texto de su elección, por ejemplo:# vi /etc/selinux/configConfigure la opción
SELINUX=permissive:# This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=permissive # SELINUXTYPE= can take one of these two values: # targeted - Targeted processes are protected, # mls - Multi Level Security protection. SELINUXTYPE=targetedReinicia el sistema:
# reboot
Pasos de verificación
Después de reiniciar el sistema, confirme que el comando
getenforcedevuelvePermissive:$ getenforce Permissive
16.2.3. Cambio al modo de aplicación
Utilice el siguiente procedimiento para cambiar SELinux al modo de aplicación. Cuando SELinux se ejecuta en modo de aplicación, aplica la política de SELinux y deniega el acceso basándose en las reglas de la política de SELinux. En RHEL, el modo de aplicación está activado por defecto cuando el sistema se instaló inicialmente con SELinux.
Requisitos previos
-
Los paquetes
selinux-policy-targeted,libselinux-utils, ypolicycoreutilsestán instalados en su sistema. -
Los parámetros del núcleo
selinux=0oenforcing=0no se utilizan.
Procedimiento
Abra el archivo
/etc/selinux/configen un editor de texto de su elección, por ejemplo:# vi /etc/selinux/configConfigure la opción
SELINUX=enforcing:# This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=enforcing # SELINUXTYPE= can take one of these two values: # targeted - Targeted processes are protected, # mls - Multi Level Security protection. SELINUXTYPE=targetedGuarde el cambio y reinicie el sistema:
# rebootEn el siguiente arranque, SELinux reetiqueta todos los archivos y directorios dentro del sistema y añade el contexto de SELinux para los archivos y directorios que fueron creados cuando SELinux estaba deshabilitado.
Pasos de verificación
Después de reiniciar el sistema, confirme que el comando
getenforcedevuelveEnforcing:$ getenforce Enforcing
Después de cambiar al modo de aplicación, SELinux puede denegar algunas acciones debido a reglas de política de SELinux incorrectas o ausentes. Para ver qué acciones deniega SELinux, introduzca el siguiente comando como root:
# ausearch -m AVC,USER_AVC,SELINUX_ERR,USER_SELINUX_ERR -ts today
Alternativamente, con el paquete setroubleshoot-server instalado, introduzca:
# grep "SELinux is preventing" /var/log/messages
Si SELinux está activo y el demonio de auditoría (auditd) no se está ejecutando en su sistema, entonces busque ciertos mensajes de SELinux en la salida del comando dmesg:
# dmesg | grep -i -e type=1300 -e type=1400Para más información, consulte Solución de problemas relacionados con SELinux.
16.2.4. Habilitación de SELinux en sistemas que anteriormente lo tenían deshabilitado
Cuando habilite SELinux en sistemas que lo tenían previamente deshabilitado, para evitar problemas, como que los sistemas no puedan arrancar o que se produzcan fallos en los procesos, siga este procedimiento:
Procedimiento
- Habilitar SELinux en modo permisivo. Para más información, consulte Cambiar al modo permisivo.
Reinicie su sistema:
# reboot- Compruebe si hay mensajes de denegación de SELinux. Para más información, consulte Identificación de denegaciones de SELinux.
- Si no hay denegaciones, cambie al modo de refuerzo. Para más información, consulte Cambio de los modos de SELinux en el arranque.
Pasos de verificación
Después de reiniciar el sistema, confirme que el comando
getenforcedevuelveEnforcing:$ getenforce Enforcing
Recursos adicionales
Para ejecutar aplicaciones personalizadas con SELinux en modo de refuerzo, elija uno de los siguientes escenarios:
-
Ejecute su aplicación en el dominio
unconfined_service_t. - Escriba una nueva política para su aplicación. Consulte el artículo de la base de conocimientos Escribir una política personalizada de SELinux para obtener más información.
-
Ejecute su aplicación en el dominio
- Los cambios temporales en los modos se tratan en Estados y modos de SELinux.
16.2.5. Desactivación de SELinux
Utilice el siguiente procedimiento para desactivar SELinux de forma permanente.
Cuando SELinux está deshabilitado, la política de SELinux no se carga en absoluto; no se aplica y los mensajes de AVC no se registran. Por lo tanto, se pierden todos los beneficios de ejecutar SEL inux.
Red Hat recomienda encarecidamente utilizar el modo permisivo en lugar de desactivar permanentemente SELinux. Vea Cambiar al modo permisivo para más información sobre el modo permisivo.
Desactivar SELinux usando la opción SELINUX=disabled en el /etc/selinux/config resulta en un proceso en el que el kernel arranca con SELinux activado y cambia al modo desactivado más tarde en el proceso de arranque. Debido a que pueden ocurrir fugas de memoria y condiciones de carrera que causen pánicos en el kernel, prefiera deshabilitar SELinux agregando el parámetro selinux=0 a la línea de comandos del kernel como se describe en Cambiar los modos de SELinux en el arranque si su escenario realmente requiere deshabilitar completamente SELinux.
Procedimiento
Abra el archivo
/etc/selinux/configen un editor de texto de su elección, por ejemplo:# vi /etc/selinux/configConfigure la opción
SELINUX=disabled:# This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled # SELINUXTYPE= can take one of these two values: # targeted - Targeted processes are protected, # mls - Multi Level Security protection. SELINUXTYPE=targetedGuarde el cambio y reinicie el sistema:
# reboot
Pasos de verificación
Después de reiniciar, confirme que el comando
getenforcedevuelveDisabled:$ getenforce Disabled
16.2.6. Cambio de los modos de SELinux en el arranque
En el arranque, puedes establecer varios parámetros del kernel para cambiar la forma en que SELinux se ejecuta:
- aplicación=0
La configuración de este parámetro hace que el sistema se inicie en modo permisivo, lo que resulta útil para solucionar problemas. El uso del modo permisivo puede ser la única opción para detectar un problema si su sistema de archivos está demasiado dañado. Además, en modo permisivo, el sistema sigue creando las etiquetas correctamente. Los mensajes AVC que se crean en este modo pueden ser diferentes que en el modo de aplicación.
En el modo permisivo, sólo se informa de la primera denegación de una serie de denegaciones iguales. Sin embargo, en el modo de aplicación, puede obtener una denegación relacionada con la lectura de un directorio, y una aplicación se detiene. En el modo permisivo, se obtiene el mismo mensaje de AVC, pero la aplicación continúa leyendo archivos en el directorio y se obtiene un AVC por cada denegación adicional.
- selinux=0
Este parámetro hace que el kernel no cargue ninguna parte de la infraestructura SELinux. Los scripts de init notan que el sistema arrancó con el parámetro
selinux=0y tocan el archivo/.autorelabel. Esto hace que el sistema se vuelva a etiquetar automáticamente la próxima vez que arranque con SELinux activado.ImportanteRed Hat no recomienda utilizar el parámetro
selinux=0. Para depurar su sistema, prefiera utilizar el modo permisivo.- autorelabel=1
Este parámetro obliga al sistema a reetiquetar de forma similar a los siguientes comandos:
# touch /.autorelabel # rebootSi un sistema de archivos contiene una gran cantidad de objetos mal etiquetados, inicie el sistema en modo permisivo para que el proceso de autoetiquetado tenga éxito.
Recursos adicionales
Para conocer otros parámetros de arranque del kernel relacionados con SELinux, como
checkreqprot, consulte el archivo/usr/share/doc/kernel-doc-<KERNEL_VER>/Documentation/admin-guide/kernel-parameters.txtinstalado con el paquetekernel-doc. Sustituya la cadena <KERNEL_VER> por el número de versión del kernel instalado, por ejemplo:# yum install kernel-doc $ less /usr/share/doc/kernel-doc-4.18.0/Documentation/admin-guide/kernel-parameters.txt
Parte III. Diseño de la red
Capítulo 17. Temas generales de la red RHEL
Esta sección proporciona detalles sobre temas generales de la red.
17.1. La diferencia entre redes IP y no IP
Una red es un sistema de dispositivos interconectados que pueden comunicarse compartiendo información y recursos, como archivos, impresoras, aplicaciones y conexión a Internet. Cada uno de estos dispositivos tiene una dirección IP única para enviar y recibir mensajes entre dos o más dispositivos utilizando un conjunto de reglas llamado protocolo.
Categorías de comunicación en red:
- Redes IP
- Redes que se comunican a través de direcciones IP. Una red IP está implementada en Internet y en la mayoría de las redes internas. Ethernet, las redes inalámbricas y las conexiones VPN son ejemplos típicos.
- Redes no IP
- Redes que se utilizan para comunicarse a través de una capa inferior en lugar de la capa de transporte. Hay que tener en cuenta que estas redes se utilizan raramente. Por ejemplo, InfiniBand es una red no IP.
17.2. La diferencia entre el direccionamiento IP estático y dinámico
- Direccionamiento IP estático
Cuando asignas una dirección IP estática a un dispositivo, la dirección no cambia con el tiempo a menos que la cambies manualmente. Utilice el direccionamiento IP estático si lo desea:
- Para asegurar la consistencia de las direcciones de red para servidores como DNS, y servidores de autenticación.
- Utilizar dispositivos de gestión fuera de banda que funcionen independientemente de otras infraestructuras de red.
- Direccionamiento IP dinámico
Cuando se configura un dispositivo para utilizar una dirección IP dinámica, la dirección puede cambiar con el tiempo. Por esta razón, las direcciones dinámicas se suelen utilizar para dispositivos que se conectan a la red ocasionalmente, ya que la dirección IP puede ser diferente después de reiniciar el host.
Las direcciones IP dinámicas son más flexibles, más fáciles de configurar y administrar. El Protocolo de Control Dinámico de Anfitriones (DHCP) es un método tradicional para asignar dinámicamente las configuraciones de red a los anfitriones.
No hay una regla estricta que defina cuándo utilizar direcciones IP estáticas o dinámicas. Depende de las necesidades del usuario, de sus preferencias y del entorno de la red.
Recursos adicionales
Para más detalles sobre la configuración de un servidor DHCP, consulte la sección Proporcionar servicios DHCP en la documentación de Configuring and managing networking.
17.3. Fases de la transacción DHCP
El DHCP funciona en cuatro fases: Descubrimiento, Oferta, Solicitud, Reconocimiento, también llamado proceso DORA. El DHCP utiliza este proceso para proporcionar direcciones IP a los clientes.
Descubrimiento
El cliente DHCP envía un mensaje para descubrir el servidor DHCP en la red. Este mensaje se emite en la capa de red y de enlace de datos.
Oferta
El servidor DHCP recibe mensajes del cliente y le ofrece una dirección IP. Este mensaje es unicast en la capa de enlace de datos pero broadcast en la capa de red.
Solicite
El cliente DHCP solicita al servidor DHCP la dirección IP ofrecida. Este mensaje es unicast en la capa de enlace de datos pero broadcast en la capa de red.
Acuse de recibo
El servidor DHCP envía un acuse de recibo al cliente DHCP. Este mensaje es unicast en la capa de enlace de datos pero broadcast en la capa de red. Es el mensaje final del proceso DHCP DORA.
17.4. Redes InfiniBand y RDMA
Para obtener más información sobre las redes InfiniBand y de Acceso Directo a la Memoria Remota (RDMA), consulte la documentación Configuración de redes InfiniBand y RDMA.
17.5. Soporte de scripts de red heredados en RHEL
Por defecto, RHEL utiliza NetworkManager para configurar y gestionar las conexiones de red, y los scripts /usr/sbin/ifup y /usr/sbin/ifdown utilizan NetworkManager para procesar los archivos ifcfg en el directorio /etc/sysconfig/network-scripts/.
Sin embargo, si necesita los scripts de red obsoletos que procesan la configuración de la red sin usar NetworkManager, puede instalarlos:
# yum install network-scripts
Una vez instalados los scripts de red heredados, los scripts /usr/sbin/ifup y /usr/sbin/ifdown enlazan con los scripts de shell obsoletos que gestionan la configuración de la red.
Los scripts heredados están obsoletos en RHEL 8 y serán eliminados en una futura versión mayor de RHEL. Si todavía utiliza los scripts de red heredados, por ejemplo, porque actualizó desde una versión anterior a RHEL 8, Red Hat recomienda que migre su configuración a NetworkManager.
17.6. Selección de los métodos de configuración de la red
Para configurar una interfaz de red mediante NetworkManager, utilice una de las siguientes herramientas:
-
la interfaz de usuario de texto,
nmtui. -
la utilidad de línea de comandos ,
nmcli. -
las herramientas de la interfaz gráfica de usuario,
GNOME GUI.
-
la interfaz de usuario de texto,
Para configurar una interfaz de red sin utilizar las herramientas y aplicaciones de NetworkManager:
-
editar manualmente los archivos de
ifcfg. Tenga en cuenta que incluso si edita los archivos directamente, NetworkManager es el predeterminado en RHEL y procesa estos archivos. Sólo si ha instalado y habilitado los scripts de red heredados obsoletos, entonces estos scripts procesan los archivosifcfg.
-
editar manualmente los archivos de
Para configurar los ajustes de red cuando el sistema de archivos raíz no es local:
- utilizar la línea de comandos del kernel.
Capítulo 18. Uso de netconsole para registrar los mensajes del kernel a través de una red
Utilizando el módulo del kernel netconsole y el servicio del mismo nombre, puede registrar los mensajes del kernel a través de una red para depurar el kernel cuando el registro en el disco falla o cuando no es posible utilizar una consola en serie.
18.1. Configurar el servicio netconsole para registrar los mensajes del kernel en un host remoto
Utilizando el módulo del kernel netconsole, puede registrar los mensajes del kernel en un servicio de registro del sistema remoto.
Requisitos previos
-
Un servicio de registro del sistema, como
rsyslogestá instalado en el host remoto. - El servicio de registro del sistema remoto está configurado para recibir entradas de registro de este host.
Procedimiento
Instale el paquete
netconsole-service:# yum install netconsole-serviceEdite el archivo
/etc/sysconfig/netconsoley configure el parámetroSYSLOGADDRcon la dirección IP del host remoto:# SYSLOGADDR=192.0.2.1Habilite e inicie el servicio
netconsole:# systemctl enable --now netconsole
Pasos de verificación
-
Muestra el archivo
/var/log/messagesen el servidor de registro del sistema remoto.
Recursos adicionales
-
Para más detalles sobre cómo habilitar el host remoto para que reciba los mensajes de registro, consulte la sección Configuración de una solución de registro remoto en la documentación de
Configuring basic system settings.
Capítulo 19. Introducción a NetworkManager
Por defecto, RHEL 8 utiliza NetworkManager para gestionar la configuración de la red y las conexiones.
19.1. Ventajas de utilizar NetworkManager
Las principales ventajas de utilizar NetworkManager son:
- Ofrece una API a través de D-Bus que permite consultar y controlar la configuración y el estado de la red. De este modo, la red puede ser comprobada y configurada por múltiples aplicaciones asegurando un estado de red sincronizado y actualizado. Por ejemplo, la consola web de RHEL, que supervisa y configura los servidores a través de un navegador web, utiliza la interfaz NetworkManager D-BUS para configurar la red, así como las herramientas Gnome GUI, nmcli y nm-connection-editor. Cada cambio realizado en una de estas herramientas es detectado por todas las demás.
- Facilitando la gestión de la red NetworkManager asegura que la conectividad de la red funciona. Cuando detecta que no hay configuración de red en un sistema pero sí hay dispositivos de red, NetworkManager crea conexiones temporales para proporcionar conectividad.
- Proporciona una fácil configuración de la conexión al usuario NetworkManager ofrece la gestión a través de diferentes herramientas - GUI, nmtui, nmcli.
- Soportar la flexibilidad de la configuración. Por ejemplo, la configuración de una interfaz WiFi NetworkManager escanea y muestra las redes wifi disponibles. Se puede seleccionar una interfaz, y NetworkManager muestra las credenciales requeridas proporcionando una conexión automática después del proceso de reinicio NetworkManager puede configurar alias de red, direcciones IP, rutas estáticas, información DNS y conexiones VPN, así como muchos parámetros específicos de la conexión. Puede modificar las opciones de configuración para reflejar sus necesidades.
- Mantener el estado de los dispositivos tras el proceso de reinicio y hacerse cargo de las interfaces que se ponen en modo gestionado durante el reinicio.
- Manejo de dispositivos que no están explícitamente establecidos como no gestionados, sino que son controlados manualmente por el usuario u otro servicio de red.
Recursos adicionales
- Para obtener más información sobre la instalación y el uso de la consola web de RHEL 8, consulte Administración de sistemas mediante la consola web de RHEL 8.
19.2. Una visión general de las utilidades y aplicaciones que puede utilizar para gestionar las conexiones de NetworkManager
Puede utilizar las siguientes utilidades y aplicaciones para gestionar las conexiones de NetworkManager:
-
nmcli: Una utilidad de línea de comandos para gestionar las conexiones. -
nmtui: Una interfaz de usuario de texto (TUI) basada en curses. Para utilizar esta aplicación, instale el paqueteNetworkManager-tui. -
nm-connection-editor: Una interfaz gráfica de usuario (GUI) para las tareas relacionadas con NetworkManager. Para iniciar esta aplicación, introduzcanm-connection-editoren un terminal de una sesión de GNOME. -
control-center: Una interfaz gráfica de usuario proporcionada por el shell de GNOME para los usuarios del escritorio. Tenga en cuenta que esta aplicación soporta menos características quenm-connection-editor. -
El
network connection iconen el shell de GNOME: Este icono representa los estados de la conexión de red y sirve como indicador visual del tipo de conexión que está utilizando.
19.3. Uso de los scripts de despacho de NetworkManager
Por defecto, el directorio /etc/NetworkManager/dispatcher.d/ existe y NetworkManager ejecuta los scripts allí, en orden alfabético. Cada script debe ser un archivo ejecutable owned by root y debe tener write permission sólo para el propietario del archivo.
NetworkManager ejecuta los scripts de los despachadores en /etc/NetworkManager/dispatcher.d/ en orden alfabético.
Recursos adicionales
- Para un ejemplo de un script despachador, vea la solución Cómo escribir un script despachador de NetworkManager para aplicar comandos de ethtool.
19.4. Carga de archivos ifcfg creados manualmente en NetworkManager
En Red Hat Enterprise Linux 8, si edita un archivo ifcfg, NetworkManager no es automáticamente consciente del cambio y tiene que ser solicitado para notar el cambio. Si utiliza una de las herramientas para actualizar NetworkManager la configuración del perfil, NetworkManager no implementa esos cambios hasta que usted se vuelva a conectar usando ese perfil. Por ejemplo, si se han modificado los archivos de configuración utilizando un editor, NetworkManager debe volver a leer los archivos de configuración.
El directorio /etc/sysconfig/ es una ubicación para archivos de configuración y scripts. La mayor parte de la información de configuración de la red se almacena allí, a excepción de la configuración de VPN, banda ancha móvil y PPPoE, que se almacenan en los subdirectorios /etc/NetworkManager/. Por ejemplo, la información específica de la interfaz se almacena en los archivos ifcfg del directorio /etc/sysconfig/network-scripts/.
La información de las VPN, la banda ancha móvil y las conexiones PPPoE se almacena en /etc/NetworkManager/system-connections/.
Por defecto, RHEL utiliza NetworkManager para configurar y gestionar las conexiones de red, y los scripts /usr/sbin/ifup y /usr/sbin/ifdown utilizan NetworkManager para procesar los archivos ifcfg en el directorio /etc/sysconfig/network-scripts/.
Si necesita los scripts de red heredados para gestionar su configuración de red, puede instalarlos manualmente. Para más detalles, consulte la sección [Soporte de scripts de red heredados en RHEL ] en la documentación de Configuring and managing networking. Sin embargo, tenga en cuenta que los scripts de red heredados están obsoletos y se eliminarán en una futura versión de RHEL.
Procedimiento
Para cargar un nuevo archivo de configuración:
# nmcli connection load /etc/sysconfig/network-scripts/ifcfg-connection_nameSi ha actualizado un archivo de conexión que ya ha sido cargado en NetworkManager, introduzca:
# nmcli connection up connection_name
Recursos adicionales
-
NetworkManager(8)- Describe el demonio de gestión de red. -
NetworkManager.conf(5)man page - Describe el archivo de configuraciónNetworkManager. -
/usr/share/doc/initscripts/sysconfig.txt- Describe los archivos de configuración deifcfgy sus directivas tal y como las entiende el servicio de red heredado. -
ifcfg(8)página de manual - Describe brevemente el comandoifcfg.
Capítulo 20. Cómo empezar con nmtui
La aplicación nmtui es una interfaz de usuario de texto (TUI) para NetworkManager. En la siguiente sección se explica cómo se puede configurar una interfaz de red mediante nmtui.
La aplicación nmtui aplicación no admite todos los tipos de conexión. En particular, no puede añadir o modificar conexiones VPN o conexiones Ethernet que requieran autenticación 802.1X.
20.1. Iniciar la utilidad nmtui
Este procedimiento describe cómo iniciar la interfaz de usuario de texto de NetworkManager, nmtui.
Requisitos previos
-
El paquete
NetworkManager-tuiestá instalado.
Procedimiento
Para iniciar
nmtui, introduzca:# nmtui
Para navegar:
- Utilice los cursores o pulse Tab para avanzar y pulse Shift+Tabulador para retroceder en las opciones.
- Utilice Enter para seleccionar una opción.
- Utilice la barra espaciadora para cambiar el estado de las casillas de verificación.
20.2. Añadir un perfil de conexión mediante nmtui
La aplicación nmtui proporciona una interfaz de usuario de texto para NetworkManager. Este procedimiento describe cómo añadir un nuevo perfil de conexión.
Requisitos previos
-
El paquete
NetworkManager-tuiestá instalado.
Procedimiento
Inicie la utilidad de interfaz de usuario de texto NetworkManager:
# nmtui-
Seleccione la entrada del menú
Edit a connectiony pulse Intro. - Seleccione el botón y pulse Intro.
-
Seleccione
Ethernety pulse Intro. Rellene los campos con los detalles de la conexión.
- Seleccione para guardar los cambios.
-
Seleccione
Backpara volver al menú principal. -
Seleccione
Activate a connectiony pulse Intro. - Seleccione la nueva entrada de conexión y pulse Enter para activar la conexión.
- Seleccione para volver al menú principal.
-
Seleccione
Quit.
Pasos de verificación
Muestra el estado de los dispositivos y las conexiones:
# nmcli device status DEVICE TYPE STATE CONNECTION enp1s0 ethernet connected Example-ConnectionPara mostrar todos los ajustes del perfil de conexión:
# nmcli connection show Example-Connection connection.id: Example-Connection connection.uuid: b6cdfa1c-e4ad-46e5-af8b-a75f06b79f76 connection.stable-id: -- connection.type: 802-3-ethernet connection.interface-name: enp1s0 ...
Recursos adicionales
-
Para obtener más información sobre la comprobación de las conexiones, consulte Prueba de la configuración básica de la red en
Configuring and managing networking. -
Para más detalles sobre la aplicación
nmtui, consulte la página mannmtui(1). - Si la configuración del disco no coincide con la del dispositivo, al iniciar o reiniciar NetworkManager se crea una conexión en memoria que refleja la configuración del dispositivo. Para más detalles y cómo evitar este problema, consulte NetworkManager duplica una conexión después de reiniciar el servicio NetworkManager.
20.3. Aplicación de cambios a una conexión modificada mediante nmtui
Después de modificar una conexión en nmtui, debe reactivar la conexión. Tenga en cuenta que la reactivación de una conexión en nmtui desactiva temporalmente la conexión.
Procedimiento
En el menú principal, seleccione la entrada del menú
Activate a connection:
- Seleccione la conexión modificada.
A la derecha, seleccione el botón
Deactivatey pulse Intro:
- Seleccione de nuevo la conexión.
A la derecha, seleccione el botón
Activatey pulse Intro:
Capítulo 21. Introducción a nmcli
Esta sección describe información general sobre la utilidad nmcli.
21.1. Los diferentes formatos de salida de nmcli
La utilidad nmcli admite diferentes opciones para modificar la salida de los comandos de nmcli. Utilizando estas opciones, puede mostrar sólo la información necesaria. Esto simplifica el procesamiento de la salida en los scripts.
Por defecto, la utilidad nmcli muestra su salida en un formato tipo tabla:
# nmcli device
DEVICE TYPE STATE CONNECTION
enp1s0 ethernet connected enp1s0
lo loopback unmanaged --
Utilizando la opción -f, puede mostrar columnas específicas en un orden personalizado. Por ejemplo, para mostrar sólo la columna DEVICE y STATE, introduzca:
# nmcli -f DEVICE,STATE device
DEVICE STATE
enp1s0 connected
lo unmanaged
La opción -t permite mostrar los campos individuales de la salida en un formato separado por dos puntos:
# nmcli -t device
enp1s0:ethernet:connected:enp1s0
lo:loopback:unmanaged:
La combinación de -f y -t para mostrar sólo campos específicos en formato separado por dos puntos puede ser útil cuando se procesa la salida en scripts:
# nmcli -f DEVICE,STATE -t device
enp1s0:connected
lo:unmanaged21.2. Uso de la finalización de tabulaciones en nmcli
Si el paquete bash-completion está instalado en su host, la utilidad nmcli admite la finalización de tabulaciones. Esto le permite autocompletar los nombres de las opciones e identificar posibles opciones y valores.
Por ejemplo, si se escribe nmcli con y se pulsa el tabulador, el intérprete de comandos completa automáticamente el comando a nmcli connection.
Para la finalización, las opciones o el valor que ha escrito deben ser únicos. Si no es único, entonces nmcli muestra todas las posibilidades. Por ejemplo, si escribe nmcli connection d y pulsa el tabulador, el comando muestra delete y down como posibles opciones.
También puede utilizar la función de completar el tabulador para mostrar todas las propiedades que puede establecer en un perfil de conexión. Por ejemplo, si escribe nmcli connection modify connection_name y pulsa el tabulador, el comando muestra la lista completa de propiedades disponibles.
21.3. Comandos nmcli frecuentes
A continuación se ofrece un resumen de los comandos más utilizados en nmcli.
Para mostrar la lista de perfiles de conexión, introduzca:
# nmcli connection show NAME UUID TYPE DEVICE enp1s0 45224a39-606f-4bf7-b3dc-d088236c15ee ethernet enp1s0Para mostrar la configuración de un perfil de conexión específico, introduzca:
# nmcli connection show connection_name connection.id: enp1s0 connection.uuid: 45224a39-606f-4bf7-b3dc-d088236c15ee connection.stable-id: -- connection.type: 802-3-ethernet ...Para modificar las propiedades de una conexión, introduzca:
# nmcli connection modify connection_name property valuePuede modificar varias propiedades con un solo comando si pasa varias
property valuecombinaciones al comando.Para mostrar la lista de dispositivos de red, su estado y qué perfiles de conexión utilizan el dispositivo, introduzca:
# nmcli device DEVICE TYPE STATE CONNECTION enp1s0 ethernet connected enp1s0 enp8s0 ethernet disconnected -- enp7s0 ethernet unmanaged -- ...Para activar una conexión, introduzca:
# nmcli connection up connection_namePara desactivar una conexión, introduzca:
# nmcli connection down connection_name
Capítulo 22. Introducción a la configuración de la red mediante la GUI de GNOME
Puede gestionar y configurar las conexiones de red utilizando las siguientes formas en GNOME:
- el icono de conexión de red de GNOME Shell en la parte superior derecha del escritorio
- la aplicación GNOME control-center aplicación
- la aplicación GNOME nm-connection-editor aplicación
22.1. Conectarse a una red utilizando el icono de conexión de red de GNOME Shell
Si utiliza la GUI de GNOME, puede utilizar el icono de conexión de red de GNOME Shell para conectarse a una red.
Requisitos previos
-
El grupo de paquetes
GNOMEestá instalado. - Ha iniciado sesión en GNOME.
- Si la red requiere una configuración específica, como una dirección IP estática o una configuración 802.1x, ya se ha creado un perfil de conexión.
Procedimiento
Haga clic en el icono de conexión de red en la esquina superior derecha de su escritorio.

Según el tipo de conexión, seleccione la entrada
WiredoWi-Fi.
-
Para una conexión por cable, seleccione
Connectpara conectarse a la red. -
Para una conexión Wi-Fi, haga clic en
Select network, seleccione la red a la que desea conectarse e introduzca la contraseña.
-
Para una conexión por cable, seleccione
Capítulo 23. Configuración de redes ip con archivos ifcfg
Esta sección describe cómo configurar una interfaz de red manualmente mediante la edición de los archivos ifcfg.
Los archivos de configuración de interfaz (ifcfg) controlan las interfaces de software para los dispositivos de red individuales. Cuando el sistema arranca, utiliza estos archivos para determinar qué interfaces deben aparecer y cómo configurarlas. Estos archivos suelen llamarse ifcfg-namedonde el sufijo name se refiere al nombre del dispositivo que controla el archivo de configuración. Por convención, el sufijo del archivo ifcfg es el mismo que la cadena dada por la directiva DEVICE en el propio archivo de configuración.
23.1. Configuración de una interfaz con ajustes de red estáticos mediante archivos ifcfg
Este procedimiento describe cómo configurar una interfaz de red utilizando los archivos ifcfg.
Procedimiento
Para configurar una interfaz con ajustes de red estáticos utilizando archivos
ifcfg, para una interfaz con el nombreenp1s0, cree un archivo con el nombreifcfg-enp1s0en el directorio/etc/sysconfig/network-scripts/que contenga:Para la configuración de
IPv4:DEVICE=enp1s0 BOOTPROTO=none ONBOOT=yes PREFIX=24 IPADDR=10.0.1.27 GATEWAY=10.0.1.1Para la configuración de
IPv6:DEVICE=enp1s0 BOOTPROTO=none ONBOOT=yes IPV6INIT=yes IPV6ADDR=2001:db8:1::2/64
Recursos adicionales
-
Para obtener más información sobre la comprobación de las conexiones, consulte Prueba de la configuración básica de la red en
Configuring and managing networking. -
Para obtener más información sobre las opciones de configuración de
IPv6ifcfg, consulte nm-settings-ifcfg-rh(5) página man.
23.2. Configuración de una interfaz con ajustes de red dinámicos mediante archivos ifcfg
Este procedimiento describe cómo configurar una interfaz de red con ajustes de red dinámicos utilizando los archivos ifcfg.
Procedimiento
Para configurar una interfaz denominada em1 con ajustes de red dinámicos mediante archivos
ifcfg, cree un archivo con el nombreifcfg-em1en el directorio/etc/sysconfig/network-scripts/que contenga:DEVICE=em1 BOOTPROTO=dhcp ONBOOT=yesPara configurar una interfaz para que envíe un nombre de host diferente al servidor
DHCP, añada la siguiente línea al archivoifcfg:DHCP_HOSTNAME=hostnamePara configurar una interfaz para que envíe un nombre de dominio completamente cualificado (FQDN) diferente al servidor
DHCP, añada la siguiente línea al archivoifcfg:DHCP_FQDN=fully.qualified.domain.nameNotaSólo debe utilizarse una directiva, ya sea
DHCP_HOSTNAMEoDHCP_FQDN, en un determinado archivoifcfg. En caso de que se especifique tantoDHCP_HOSTNAMEcomoDHCP_FQDN, sólo se utilizará esta última.Para configurar una interfaz para que utilice determinados servidores
DNS, añada las siguientes líneas al archivoifcfg:PEERDNS=no DNS1=ip-address DNS2=ip-addressdonde ip-address es la dirección de un servidor
DNS. Esto hará que el servicio de red actualice/etc/resolv.confcon los servidoresDNSespecificados. Sólo es necesaria una dirección de servidorDNS, la otra es opcional.
23.3. Gestión de perfiles de conexión privados y para todo el sistema con archivos ifcfg
Este procedimiento describe cómo configurar los archivos ifcfg para gestionar los perfiles de conexión privados y de todo el sistema.
Procedimiento
Los permisos corresponden a la directiva USERS en los archivos ifcfg. Si la directiva USERS no está presente, el perfil de red estará disponible para todos los usuarios.
Como ejemplo, modifique el archivo
ifcfgcon la siguiente fila, que hará que la conexión esté disponible sólo para los usuarios indicados:USERS="joe bob alice"
Capítulo 24. Introducción a la IPVLAN
Este documento describe el controlador IPVLAN.
24.1. Resumen de IPVLAN
IPVLAN es un controlador para un dispositivo de red virtual que puede utilizarse en un entorno de contenedor para acceder a la red del host. IPVLAN expone una única dirección MAC a la red externa independientemente del número de dispositivos IPVLAN creados dentro de la red host. Esto significa que un usuario puede tener varios dispositivos IPVLAN en varios contenedores y el switch correspondiente lee una única dirección MAC. El controlador IPVLAN es útil cuando el conmutador local impone restricciones al número total de direcciones MAC que puede gestionar.
24.2. Modos de IPVLAN
Los siguientes modos están disponibles para IPVLAN:
L2 mode
En IPVLAN L2 mode, los dispositivos virtuales reciben y responden a las solicitudes del Protocolo de Resolución de Direcciones (ARP). El marco
netfilterse ejecuta únicamente dentro del contenedor que posee el dispositivo virtual. No se ejecutan cadenas denetfilteren el espacio de nombres por defecto en el tráfico del contenedor. El uso de L2 mode proporciona un buen rendimiento, pero menos control sobre el tráfico de red.L3 mode
En L3 mode, los dispositivos virtuales sólo procesan el tráfico de L3 y superior. Los dispositivos virtuales no responden a las solicitudes ARP y los usuarios deben configurar manualmente las entradas de vecinos para las direcciones IPVLAN en los pares correspondientes. El tráfico de salida de un contenedor relevante es aterrizado en las cadenas
netfilterPOSTROUTING y OUTPUT en el espacio de nombres por defecto mientras que el tráfico de entrada es enhebrado de la misma manera que L2 mode. El uso de L3 mode proporciona un buen control pero disminuye el rendimiento del tráfico de red.L3S mode
En L3S mode, los dispositivos virtuales se procesan de la misma manera que en L3 mode, excepto que tanto el tráfico de salida como el de entrada de un contenedor relevante se aterrizan en la cadena
netfilteren el espacio de nombres por defecto. L3S mode se comporta de manera similar a L3 mode pero proporciona un mayor control de la red.
El dispositivo virtual IPVLAN no recibe tráfico de difusión y multidifusión en el caso de L3 y L3S modes.
24.3. Resumen de MACVLAN
El controlador MACVLAN permite crear múltiples dispositivos de red virtuales sobre una única NIC, cada uno de ellos identificado por su propia y única dirección MAC. Los paquetes que aterrizan en la NIC física se demultiplexan hacia el dispositivo MACVLAN correspondiente a través de la dirección MAC del destino. Los dispositivos MACVLAN no añaden ningún nivel de encapsulación.
24.4. Comparación de IPVLAN y MACVLAN
La siguiente tabla muestra las principales diferencias entre MACVLAN e IPVLAN.
| MACVLAN | IPVLAN |
|---|---|
| Utiliza la dirección MAC para cada dispositivo MACVLAN. El exceso de direcciones MAC en la tabla MAC del conmutador puede hacer que se pierda la conectividad. | Utiliza una única dirección MAC que no limita el número de dispositivos IPVLAN. |
| Las reglas de Netfilter para el espacio de nombres global no pueden afectar al tráfico hacia o desde el dispositivo MACVLAN en un espacio de nombres hijo. | Es posible controlar el tráfico hacia o desde el dispositivo IPVLAN en L3 mode y L3S mode. |
Tenga en cuenta que tanto la IPVLAN como la MACVLAN no requieren ningún nivel de encapsulación.
24.5. Creación y configuración del dispositivo IPVLAN mediante iproute2
Este procedimiento muestra cómo configurar el dispositivo IPVLAN utilizando iproute2.
Procedimiento
Para crear un dispositivo IPVLAN, introduzca el siguiente comando:
~]# ip link add link real_NIC_device name IPVLAN_device type ipvlan mode l2Tenga en cuenta que el controlador de interfaz de red (NIC) es un componente de hardware que conecta un ordenador a una red.
Ejemplo 24.1. Creación de un dispositivo IPVLAN
~]# ip link add link enp0s31f6 name my_ipvlan type ipvlan mode l2 ~]# ip link 47: my_ipvlan@enp0s31f6: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether e8:6a:6e:8a:a2:44 brd ff:ff:ff:ff:ff:ffPara asignar una dirección
IPv4oIPv6a la interfaz, introduzca el siguiente comando:~]# ip addr add dev IPVLAN_device IP_address/subnet_mask_prefixEn caso de configurar un dispositivo IPVLAN en L3 mode o L3S mode, realice las siguientes configuraciones:
Configura la configuración de vecinos para el peer remoto en el host remoto:
~]# ip neigh add dev peer_device IPVLAN_device_IP_address lladdr MAC_addressdonde MAC_address es la dirección MAC de la NIC real en la que se basa un dispositivo IPVLAN.
Configure un dispositivo IPVLAN para L3 mode con el siguiente comando:
~]# ip neigh add dev real_NIC_device peer_IP_address lladdr peer_MAC_addressPara L3S mode:
~]# ip route dev add real_NIC_device peer_IP_address/32donde la dirección IP representa la dirección del peer remoto.
Para activar un dispositivo IPVLAN, introduzca el siguiente comando:
~]# ip link set dev IPVLAN_device upPara comprobar si el dispositivo IPVLAN está activo, ejecute el siguiente comando en el host remoto:
~]# ping IP_addressdonde el IP_address utiliza la dirección IP del dispositivo IPVLAN.
Capítulo 25. Configuración del enrutamiento y reenvío virtual (VRF)
Con el enrutamiento y reenvío virtual (VRF), los administradores pueden utilizar varias tablas de enrutamiento simultáneamente en el mismo host. Para ello, VRF particiona una red en la capa 3. Esto permite al administrador aislar el tráfico utilizando tablas de rutas separadas e independientes por dominio VRF. Esta técnica es similar a las LAN virtuales (VLAN), que particionan una red en la capa 2, donde el sistema operativo utiliza diferentes etiquetas VLAN para aislar el tráfico que comparte el mismo medio físico.
Una de las ventajas de la VRF sobre la partición en la capa 2 es que el enrutamiento se escala mejor teniendo en cuenta el número de pares involucrados.
Red Hat Enterprise Linux utiliza un dispositivo virtual vrt para cada dominio VRF y añade rutas a un dominio VRF añadiendo dispositivos de red existentes a un dispositivo VRF. Las direcciones y rutas previamente adjuntadas al dispositivo original serán movidas dentro del dominio VRF.
Tenga en cuenta que cada dominio VRF está aislado de los demás.
25.1. Reutilización permanente de la misma dirección IP en diferentes interfaces
Este procedimiento describe cómo utilizar permanentemente la misma dirección IP en diferentes interfaces en un servidor utilizando la función VRF.
Para que los peers remotos puedan contactar con ambas interfaces VRF reutilizando la misma dirección IP, las interfaces de red deben pertenecer a diferentes dominios de difusión. Un dominio de difusión en una red es un conjunto de nodos que reciben el tráfico de difusión enviado por cualquiera de ellos. En la mayoría de las configuraciones, todos los nodos conectados al mismo switch pertenecen al mismo dominio de difusión.
Requisitos previos
-
Ha iniciado la sesión como usuario de
root. - Las interfaces de red no están configuradas.
Procedimiento
Cree y configure el primer dispositivo VRF:
Cree una conexión para el dispositivo VRF y asígnelo a una tabla de enrutamiento. Por ejemplo, para crear un dispositivo VRF llamado
vrf0que se asigna a la tabla de enrutamiento1001:# nmcli connection add type vrf ifname vrf0 con-name vrf0 table 1001 ipv4.method disabled ipv6.method disabledHabilite el dispositivo
vrf0:# nmcli connection up vrf0Asigne un dispositivo de red al VRF que acaba de crear. Por ejemplo, para añadir el dispositivo Ethernet
enp1s0al dispositivo VRFvrf0y asignar una dirección IP y la máscara de subred aenp1s0, introduzca:# nmcli connection add type ethernet con-name vrf.enp1s0 ifname enp1s0 master vrf0 ipv4.method manual ipv4.address 192.0.2.1/24Active la conexión
vrf.enp1s0:# nmcli connection up vrf.enp1s0
Cree y configure el siguiente dispositivo VRF:
Cree el dispositivo VRF y asígnelo a una tabla de enrutamiento. Por ejemplo, para crear un dispositivo VRF llamado
vrf1que se asigna a la tabla de enrutamiento1002, introduzca:# nmcli connection add type vrf ifname vrf1 con-name vrf1 table 1002 ipv4.method disabled ipv6.method disabledActive el dispositivo
vrf1:# nmcli connection up vrf1Asigne un dispositivo de red al VRF que acaba de crear. Por ejemplo, para añadir el dispositivo Ethernet
enp7s0al dispositivo VRFvrf1y asignar una dirección IP y la máscara de subred aenp7s0, introduzca:# nmcli connection add type ethernet con-name vrf.enp7s0 ifname enp7s0 master vrf1 ipv4.method manual ipv4.address 192.0.2.1/24Active el dispositivo
vrf.enp7s0:# nmcli connection up vrf.enp7s0
25.2. Reutilización temporal de la misma dirección IP en diferentes interfaces
El procedimiento en esta sección describe cómo utilizar temporalmente la misma dirección IP en diferentes interfaces en un servidor utilizando la función de enrutamiento y reenvío virtual (VRF). Utilice este procedimiento sólo con fines de prueba, ya que la configuración es temporal y se pierde después de reiniciar el sistema.
Para que los peers remotos puedan contactar con ambas interfaces VRF reutilizando la misma dirección IP, las interfaces de red deben pertenecer a diferentes dominios de difusión. Un dominio de difusión en una red es un conjunto de nodos que reciben el tráfico de difusión enviado por cualquiera de ellos. En la mayoría de las configuraciones, todos los nodos conectados al mismo switch pertenecen al mismo dominio de difusión.
Requisitos previos
-
Ha iniciado la sesión como usuario de
root. - Las interfaces de red no están configuradas.
Procedimiento
Cree y configure el primer dispositivo VRF:
Cree el dispositivo VRF y asígnelo a una tabla de enrutamiento. Por ejemplo, para crear un dispositivo VRF llamado
blueque se asigna a la tabla de enrutamiento1001:# ip link add dev blue type vrf table 1001Habilite el dispositivo
blue:# ip link set dev blue upAsigne un dispositivo de red al dispositivo VRF. Por ejemplo, para añadir el dispositivo Ethernet
enp1s0al dispositivo VRFblue:# ip link set dev enp1s0 master blueHabilite el dispositivo
enp1s0:# ip link set dev enp1s0 upAsigne una dirección IP y una máscara de subred al dispositivo
enp1s0. Por ejemplo, para configurarlo en192.0.2.1/24:# ip addr add dev enp1s0 192.0.2.1/24
Cree y configure el siguiente dispositivo VRF:
Cree el dispositivo VRF y asígnelo a una tabla de enrutamiento. Por ejemplo, para crear un dispositivo VRF llamado
redque se asigna a la tabla de enrutamiento1002:# ip link add dev red type vrf table 1002Habilite el dispositivo
red:# ip link set dev red upAsigne un dispositivo de red al dispositivo VRF. Por ejemplo, para añadir el dispositivo Ethernet
enp7s0al dispositivo VRFred:# ip link set dev enp7s0 master redHabilite el dispositivo
enp7s0:# ip link set dev enp7s0 upAsigne al dispositivo
enp7s0la misma dirección IP y máscara de subred que utilizó paraenp1s0en el dominioblueVRF:# ip addr add dev enp7s0 192.0.2.1/24
- Opcionalmente, cree más dispositivos VRF como se ha descrito anteriormente.
Capítulo 26. Asegurar las redes
26.1. Uso de comunicaciones seguras entre dos sistemas con OpenSSH
SSH (Secure Shell) es un protocolo que proporciona comunicaciones seguras entre dos sistemas utilizando una arquitectura cliente-servidor y permite a los usuarios iniciar la sesión en los sistemas anfitriones del servidor de forma remota. A diferencia de otros protocolos de comunicación remota, como FTP o Telnet, SSH cifra la sesión de inicio de sesión, lo que impide que los intrusos recojan las contraseñas no cifradas de la conexión.
Red Hat Enterprise Linux incluye los paquetes básicos OpenSSH: el paquete general openssh, el paquete openssh-server y el paquete openssh-clients. Tenga en cuenta que los paquetes OpenSSH requieren el paquete OpenSSL openssl-libs , que instala varias bibliotecas criptográficas importantes que permiten a OpenSSH proporcionar comunicaciones cifradas.
26.1.1. SSH y OpenSSH
SSH (Secure Shell) es un programa para entrar en una máquina remota y ejecutar comandos en esa máquina. El protocolo SSH proporciona comunicaciones seguras y encriptadas entre dos hosts no confiables a través de una red insegura. También puede reenviar conexiones X11 y puertos TCP/IP arbitrarios a través del canal seguro.
El protocolo SSH mitiga las amenazas de seguridad, como la interceptación de la comunicación entre dos sistemas y la suplantación de un determinado host, cuando se utiliza para el inicio de sesión de shell remoto o la copia de archivos. Esto se debe a que el cliente y el servidor SSH utilizan firmas digitales para verificar sus identidades. Además, toda la comunicación entre los sistemas cliente y servidor está cifrada.
OpenSSH es una implementación del protocolo SSH soportada por varios sistemas operativos Linux, UNIX y similares. Incluye los archivos centrales necesarios para el cliente y el servidor de OpenSSH. La suite OpenSSH consiste en las siguientes herramientas de espacio de usuario:
-
sshes un programa de acceso remoto (cliente SSH) -
sshdes un demonio SSHOpenSSH -
scpes un programa de copia remota segura de archivos -
sftpes un programa de transferencia segura de archivos -
ssh-agentes un agente de autenticación para el almacenamiento de claves privadas -
ssh-addañade identidades de clave privada assh-agent -
ssh-keygengenera, gestiona y convierte las claves de autenticación parassh -
ssh-copy-ides un script que añade claves públicas locales al archivoauthorized_keysen un servidor SSH remoto -
ssh-keyscan- recoge las claves públicas de host SSH
Actualmente existen dos versiones de SSH: la versión 1 y la versión 2, más reciente. La suite OpenSSH en Red Hat Enterprise Linux 8 sólo soporta la versión 2 de SSH, que tiene un algoritmo de intercambio de claves mejorado que no es vulnerable a los exploits conocidos de la versión 1.
OpenSSH, como uno de los subsistemas criptográficos centrales de RHEL, utiliza políticas criptográficas para todo el sistema. Esto asegura que los conjuntos de cifrado y los algoritmos criptográficos débiles están desactivados en la configuración por defecto. Para ajustar la política, el administrador debe utilizar el comando update-crypto-policies para hacer la configuración más estricta o más floja o excluir manualmente las políticas criptográficas de todo el sistema.
El conjunto OpenSSH utiliza dos conjuntos diferentes de archivos de configuración: los de los programas cliente (es decir, ssh, scp, y sftp), y los del servidor (el demonio sshd ). La información de configuración de SSH para todo el sistema se almacena en el directorio /etc/ssh/. La información de configuración SSH específica del usuario se almacena en ~/.ssh/ en el directorio de inicio del usuario. Para una lista detallada de los archivos de configuración de OpenSSH, vea la sección FILES en la página man sshd(8).
Recursos adicionales
-
Páginas de manual para el tema
sshlistadas por el comandoman -k ssh. - Uso de políticas criptográficas en todo el sistema.
26.1.2. Configurar e iniciar un servidor OpenSSH
Utilice el siguiente procedimiento para una configuración básica que puede ser necesaria para su entorno y para iniciar un servidor OpenSSH. Tenga en cuenta que después de la instalación por defecto de RHEL, el demonio sshd ya está iniciado y las claves del servidor se crean automáticamente.
Requisitos previos
-
El paquete
openssh-serverestá instalado.
Procedimiento
Inicie el demonio
sshden la sesión actual y configúrelo para que se inicie automáticamente al arrancar:# systemctl start sshd # systemctl enable sshdPara especificar direcciones diferentes a las predeterminadas
0.0.0.0(IPv4) o::(IPv6) para la directivaListenAddressen el archivo de configuración/etc/ssh/sshd_configy utilizar una configuración de red dinámica más lenta, añada la dependencia de la unidad de destinonetwork-online.targetal archivo de unidadsshd.service. Para ello, cree el archivo/etc/systemd/system/sshd.service.d/local.confcon el siguiente contenido:[Unit] Wants=network-online.target After=network-online.target-
Revise si la configuración del servidor
OpenSSHen el archivo de configuración/etc/ssh/sshd_configcumple con los requisitos de su escenario. Opcionalmente, cambie el mensaje de bienvenida que su servidor
OpenSSHmuestra antes de que un cliente se autentique editando el archivo/etc/issue, por ejemplo:Welcome to ssh-server.example.com Warning: By accessing this server, you agree to the referenced terms and conditions.Asegúrese de que la opción
Bannerno está comentada en/etc/ssh/sshd_configy su valor contiene/etc/issue:# less /etc/ssh/sshd_config | grep Banner Banner /etc/issueTenga en cuenta que para cambiar el mensaje que se muestra después de un inicio de sesión exitoso tiene que editar el archivo
/etc/motden el servidor. Consulte la página manpam_motdpara obtener más información.Vuelva a cargar la configuración de
systemdy reiniciesshdpara aplicar los cambios:# systemctl daemon-reload # systemctl restart sshd
Pasos de verificación
Compruebe que el demonio
sshdse está ejecutando:# systemctl status sshd ● sshd.service - OpenSSH server daemon Loaded: loaded (/usr/lib/systemd/system/sshd.service; enabled; vendor preset: enabled) Active: active (running) since Mon 2019-11-18 14:59:58 CET; 6min ago Docs: man:sshd(8) man:sshd_config(5) Main PID: 1149 (sshd) Tasks: 1 (limit: 11491) Memory: 1.9M CGroup: /system.slice/sshd.service └─1149 /usr/sbin/sshd -D -oCiphers=aes128-ctr,aes256-ctr,aes128-cbc,aes256-cbc -oMACs=hmac-sha2-256,> Nov 18 14:59:58 ssh-server-example.com systemd[1]: Starting OpenSSH server daemon... Nov 18 14:59:58 ssh-server-example.com sshd[1149]: Server listening on 0.0.0.0 port 22. Nov 18 14:59:58 ssh-server-example.com sshd[1149]: Server listening on :: port 22. Nov 18 14:59:58 ssh-server-example.com systemd[1]: Started OpenSSH server daemon.Conéctese al servidor SSH con un cliente SSH.
# ssh user@ssh-server-example.com ECDSA key fingerprint is SHA256:dXbaS0RG/UzlTTku8GtXSz0S1++lPegSy31v3L/FAEc. Are you sure you want to continue connecting (yes/no/[fingerprint])? yes Warning: Permanently added 'ssh-server-example.com' (ECDSA) to the list of known hosts. user@ssh-server-example.com's password:
Recursos adicionales
-
sshd(8)ysshd_config(5)páginas man
26.1.3. Uso de pares de claves en lugar de contraseñas para la autenticación SSH
Para mejorar aún más la seguridad del sistema, genere pares de claves SSH y luego aplique la autenticación basada en claves deshabilitando la autenticación por contraseña.
26.1.3.1. Configuración de un servidor OpenSSH para la autenticación basada en claves
Siga estos pasos para configurar su servidor OpenSSH para aplicar la autenticación basada en claves.
Requisitos previos
-
El paquete
openssh-serverestá instalado. -
El demonio
sshdse está ejecutando en el servidor.
Procedimiento
Abra la configuración de
/etc/ssh/sshd_configen un editor de texto, por ejemplo:# vi /etc/ssh/sshd_configCambie la opción
PasswordAuthenticationporno:PasswordAuthentication noEn un sistema que no sea una instalación nueva por defecto, compruebe que no se ha configurado
PubkeyAuthentication noy que la directivaChallengeResponseAuthenticationestá establecida enno. Si está conectado de forma remota, sin utilizar la consola o el acceso fuera de banda, pruebe el proceso de inicio de sesión basado en la clave antes de desactivar la autenticación por contraseña.Para utilizar la autenticación basada en claves con los directorios personales montados en NFS, active el booleano
use_nfs_home_dirsSELinux:# setsebool -P use_nfs_home_dirs 1Vuelva a cargar el demonio
sshdpara aplicar los cambios:# systemctl reload sshd
Recursos adicionales
-
sshd(8),sshd_config(5), ysetsebool(8)páginas de manual
26.1.3.2. Generación de pares de claves SSH
Utilice este procedimiento para generar un par de claves SSH en un sistema local y para copiar la clave pública generada en un servidor OpenSSH. Si el servidor está configurado como corresponde, podrá iniciar sesión en el servidor OpenSSH sin necesidad de proporcionar ninguna contraseña.
Si completa los siguientes pasos como root, sólo root podrá utilizar las llaves.
Procedimiento
Para generar un par de claves ECDSA para la versión 2 del protocolo SSH:
$ ssh-keygen -t ecdsa Generating public/private ecdsa key pair. Enter file in which to save the key (/home/joesec/.ssh/id_ecdsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/joesec/.ssh/id_ecdsa. Your public key has been saved in /home/joesec/.ssh/id_ecdsa.pub. The key fingerprint is: SHA256:Q/x+qms4j7PCQ0qFd09iZEFHA+SqwBKRNaU72oZfaCI joesec@localhost.example.com The key's randomart image is: +---[ECDSA 256]---+ |.oo..o=++ | |.. o .oo . | |. .. o. o | |....o.+... | |o.oo.o +S . | |.=.+. .o | |E.*+. . . . | |.=..+ +.. o | | . oo*+o. | +----[SHA256]-----+También puede generar un par de claves RSA utilizando la opción
-t rsacon el comandossh-keygeno un par de claves Ed25519 introduciendo el comandossh-keygen -t ed25519.Para copiar la clave pública en una máquina remota:
$ ssh-copy-id joesec@ssh-server-example.com /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed joesec@ssh-server-example.com's password: ... Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'joesec@ssh-server-example.com'" and check to make sure that only the key(s) you wanted were added.Si no utiliza el programa
ssh-agenten su sesión, el comando anterior copia la clave pública más recientemente modificada~/.ssh/id*.pubsi aún no está instalada. Para especificar otro archivo de clave pública o para dar prioridad a las claves en archivos sobre las claves almacenadas en la memoria porssh-agent, utilice el comandossh-copy-idcon la opción-i.
Si reinstalas tu sistema y quieres conservar los pares de claves generados anteriormente, haz una copia de seguridad del directorio ~/.ssh/. Después de reinstalar, cópialo de nuevo en tu directorio principal. Puedes hacer esto para todos los usuarios de tu sistema, incluyendo root.
Pasos de verificación
Inicie sesión en el servidor OpenSSH sin proporcionar ninguna contraseña:
$ ssh joesec@ssh-server-example.com Welcome message. ... Last login: Mon Nov 18 18:28:42 2019 from ::1
Recursos adicionales
-
ssh-keygen(1)yssh-copy-id(1)páginas man
26.1.4. Uso de claves SSH almacenadas en una tarjeta inteligente
Red Hat Enterprise Linux 8 le permite utilizar claves RSA y ECDSA almacenadas en una tarjeta inteligente en clientes OpenSSH. Use este procedimiento para habilitar la autenticación usando una tarjeta inteligente en lugar de usar una contraseña.
Requisitos previos
-
En el lado del cliente, el paquete
openscestá instalado y el serviciopcscdestá funcionando.
Procedimiento
Enumerar todas las claves proporcionadas por el módulo PKCS #11 de OpenSC incluyendo sus URIs PKCS #11 y guardar el resultado en el archivo keys.pub:
$ ssh-keygen -D pkcs11: > keys.pub $ ssh-keygen -D pkcs11: ssh-rsa AAAAB3NzaC1yc2E...KKZMzcQZzx pkcs11:id=%02;object=SIGN%20pubkey;token=SSH%20key;manufacturer=piv_II?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so ecdsa-sha2-nistp256 AAA...J0hkYnnsM= pkcs11:id=%01;object=PIV%20AUTH%20pubkey;token=SSH%20key;manufacturer=piv_II?module-path=/usr/lib64/pkcs11/opensc-pkcs11.soPara habilitar la autenticación mediante una tarjeta inteligente en un servidor remoto (example.com), transfiera la clave pública al servidor remoto. Utilice el comando
ssh-copy-idcon keys.pub creado en el paso anterior:$ ssh-copy-id -f -i keys.pub username@example.comPara conectarse a example.com utilizando la clave ECDSA de la salida del comando
ssh-keygen -Den el paso 1, puede utilizar sólo un subconjunto de la URI, que hace referencia a su clave de forma exclusiva, por ejemplo:$ ssh -i "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" example.com Enter PIN for 'SSH key': [example.com] $Puede utilizar la misma cadena URI en el archivo
~/.ssh/configpara que la configuración sea permanente:$ cat ~/.ssh/config IdentityFile "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" $ ssh example.com Enter PIN for 'SSH key': [example.com] $Dado que OpenSSH utiliza el wrapper
p11-kit-proxyy el módulo PKCS #11 de OpenSC está registrado en PKCS#11 Kit, puede simplificar los comandos anteriores:$ ssh -i "pkcs11:id=%01" example.com Enter PIN for 'SSH key': [example.com] $
Si se omite la parte id= de un URI PKCS #11, OpenSSH carga todas las claves que están disponibles en el módulo proxy. Esto puede reducir la cantidad de escritura requerida:
$ ssh -i pkcs11: example.com
Enter PIN for 'SSH key':
[example.com] $Recursos adicionales
- Fedora 28: Mejor soporte para tarjetas inteligentes en OpenSSH
-
p11-kit(8)página de manual -
ssh(1)página de manual -
ssh-keygen(1)página de manual -
opensc.conf(5)página de manual -
pcscd(8)página de manual
26.1.5. Cómo hacer que OpenSSH sea más seguro
Los siguientes consejos le ayudarán a aumentar la seguridad cuando utilice OpenSSH. Tenga en cuenta que los cambios en el archivo de configuración de /etc/ssh/sshd_config OpenSSH requieren la recarga del demonio sshd para que surtan efecto:
# systemctl reload sshdLa mayoría de los cambios en la configuración del refuerzo de la seguridad reducen la compatibilidad con los clientes que no admiten algoritmos o conjuntos de cifrado actualizados.
Desactivación de los protocolos de conexión inseguros
-
Para que SSH sea realmente eficaz, hay que evitar el uso de protocolos de conexión inseguros que sean sustituidos por el conjunto
OpenSSH. De lo contrario, la contraseña de un usuario podría estar protegida usando SSH para una sesión sólo para ser capturada más tarde cuando se conecte usando Telnet. Por esta razón, considere deshabilitar los protocolos inseguros, como telnet, rsh, rlogin y ftp.
Activación de la autenticación basada en clave y desactivación de la autenticación basada en contraseña
Desactivar las contraseñas para la autenticación y permitir sólo los pares de claves reduce la superficie de ataque y también podría ahorrar tiempo a los usuarios. En los clientes, genere pares de claves utilizando la herramienta
ssh-keygeny utilice la utilidadssh-copy-idpara copiar las claves públicas de los clientes en el servidorOpenSSH. Para desactivar la autenticación basada en contraseña en su servidor OpenSSH, edite/etc/ssh/sshd_configy cambie la opciónPasswordAuthenticationporno:PasswordAuthentication no
Tipos de claves
Aunque el comando
ssh-keygengenera un par de claves RSA por defecto, puedes indicarle que genere claves ECDSA o Ed25519 utilizando la opción-t. El ECDSA (Algoritmo de Firma Digital de Curva Elíptica) ofrece un mejor rendimiento que el RSA con una fuerza de clave simétrica equivalente. También genera claves más cortas. El algoritmo de clave pública Ed25519 es una implementación de curvas de Edwards retorcidas que es más segura y también más rápida que RSA, DSA y ECDSA.OpenSSH crea automáticamente las claves de host del servidor RSA, ECDSA y Ed25519 si no las tiene. Para configurar la creación de claves de host en RHEL 8, utilice el servicio instanciado
sshd-keygen@.service. Por ejemplo, para desactivar la creación automática del tipo de clave RSA:# systemctl mask sshd-keygen@rsa.service-
Para excluir determinados tipos de claves para las conexiones SSH, comente las líneas correspondientes en
/etc/ssh/sshd_configy vuelva a cargar el serviciosshd. Por ejemplo, para permitir sólo las claves de host Ed25519:
# HostKey /etc/ssh/ssh_host_rsa_key
# HostKey /etc/ssh/ssh_host_ecdsa_key
HostKey /etc/ssh/ssh_host_ed25519_keyPuerto no predeterminado
Por defecto, el demonio
sshdescucha en el puerto TCP 22. Cambiar el puerto reduce la exposición del sistema a ataques basados en el escaneo automático de la red y, por tanto, aumenta la seguridad a través de la oscuridad. Puede especificar el puerto utilizando la directivaPorten el archivo de configuración/etc/ssh/sshd_config.También tienes que actualizar la política de SELinux por defecto para permitir el uso de un puerto no predeterminado. Para ello, utilice la herramienta
semanagedel paquetepolicycoreutils-python-utils:# semanage port -a -t ssh_port_t -p tcp port_numberAdemás, actualice la configuración de
firewalld:# firewall-cmd --add-port port_number/tcp # firewall-cmd --runtime-to-permanentEn los comandos anteriores, sustituya port_number por el nuevo número de puerto especificado mediante la directiva
Port.
No hay acceso a la raíz
Si su caso de uso particular no requiere la posibilidad de iniciar sesión como usuario root, debería considerar establecer la directiva de configuración
PermitRootLoginanoen el archivo/etc/ssh/sshd_config. Al deshabilitar la posibilidad de iniciar sesión como usuario root, el administrador puede auditar qué usuarios ejecutan qué comandos privilegiados después de iniciar sesión como usuarios normales y luego obtener derechos de root.Como alternativa, configure
PermitRootLoginenprohibit-password:PermitRootLogin prohibir-contraseñaEsto refuerza el uso de la autenticación basada en claves en lugar del uso de contraseñas para iniciar la sesión como root y reduce los riesgos al evitar los ataques de fuerza bruta.
Uso de la extensión X Security
El servidor X en los clientes de Red Hat Enterprise Linux no proporciona la extensión X Security. Por lo tanto, los clientes no pueden solicitar otra capa de seguridad cuando se conectan a servidores SSH no confiables con el reenvío X11. La mayoría de las aplicaciones no pueden ejecutarse con esta extensión habilitada de todos modos.
Por defecto, la opción
ForwardX11Trusteden el archivo/etc/ssh/ssh_config.d/05-redhat.confse establece enyes, y no hay diferencia entre el comandossh -X remote_machine(host no confiable) yssh -Y remote_machine(host confiable).Si su escenario no requiere la función de reenvío de X11 en absoluto, establezca la directiva
X11Forwardingen el archivo de configuración/etc/ssh/sshd_configano.
Restringir el acceso a usuarios, grupos o dominios específicos
Las directivas
AllowUsersyAllowGroupsen el archivo de configuración del servidor/etc/ssh/sshd_configle permiten permitir sólo a ciertos usuarios, dominios o grupos conectarse a su servidor OpenSSH. Puede combinarAllowUsersyAllowGroupspara restringir el acceso con mayor precisión, por ejemplo:AllowUsers *@192.168.1.*,*@10.0.0.*,!*@192.168.1.2 AllowGroups example-groupLas líneas de configuración anteriores aceptan conexiones de todos los usuarios de los sistemas de las subredes 192.168.1.* y 10.0.0.*, excepto del sistema con la dirección 192.168.1.2. Todos los usuarios deben estar en el grupo
example-group. El servidor OpenSSH rechaza todas las demás conexiones.Tenga en cuenta que el uso de listas de permitidos (directivas que empiezan por Allow) es más seguro que el uso de listas de bloqueados (opciones que empiezan por Deny) porque las listas de permitidos bloquean también a nuevos usuarios o grupos no autorizados.
Cambiar las políticas criptográficas de todo el sistema
OpenSSHutiliza las políticas criptográficas de todo el sistema RHEL, y el nivel de política criptográfica por defecto de todo el sistema ofrece una configuración segura para los modelos de amenazas actuales. Para que la configuración criptográfica sea más estricta, cambie el nivel de política actual:# update-crypto-policies --set FUTURE Setting system policy to FUTURE-
Para optar por las políticas de criptografía de todo el sistema para su servidor
OpenSSH, descomente la línea con la variableCRYPTO_POLICY=en el archivo/etc/sysconfig/sshd. Después de este cambio, los valores que especifique en las seccionesCiphers,MACs,KexAlgoritms, yGSSAPIKexAlgorithmsen el archivo/etc/ssh/sshd_configno serán anulados. Tenga en cuenta que esta tarea requiere una gran experiencia en la configuración de opciones criptográficas. - Consulte Uso de políticas criptográficas en todo el sistema en el título de endurecimiento de la seguridad de RHEL 8 para obtener más información.
Recursos adicionales
-
sshd_config(5),ssh-keygen(1),crypto-policies(7), yupdate-crypto-policies(8)páginas de manual
26.1.6. Conectarse a un servidor remoto utilizando un host de salto SSH
Utilice este procedimiento para conectarse a un servidor remoto a través de un servidor intermediario, también llamado host de salto.
Requisitos previos
- Un host de salto acepta conexiones SSH desde su sistema.
- Un servidor remoto acepta conexiones SSH sólo desde el host de salto.
Procedimiento
Defina el host de salto editando el archivo
~/.ssh/config, por ejemplo:Host jump-server1 HostName jump1.example.comAñada la configuración de salto del servidor remoto con la directiva
ProxyJumpa~/.ssh/config, por ejemplo:Host remote-server HostName remote1.example.com ProxyJump jump-server1Conectar con el servidor remoto a través del servidor de salto:
$ ssh remote-serverEl comando anterior es equivalente al comando
ssh -J jump-server1 remote-serversi se omiten los pasos de configuración 1 y 2.
Puede especificar más servidores de salto y también puede omitir la adición de definiciones de host al archivo de configuraciones cuando proporciona sus nombres de host completos, por ejemplo:
$ ssh -J jump1.example.com,jump2.example.com,jump3.example.com remote1.example.comCambie la notación de sólo nombre de host en el comando anterior si los nombres de usuario o los puertos SSH en los servidores de salto difieren de los nombres y puertos en el servidor remoto, por ejemplo:
$ ssh -J johndoe@jump1.example.com:75,johndoe@jump2.example.com:75,johndoe@jump3.example.com:75 joesec@remote1.example.com:220Recursos adicionales
-
ssh_config(5)yssh(1)páginas man
26.1.7. Conexión a máquinas remotas con claves SSH usando ssh-agent
Para evitar la introducción de una frase de contraseña cada vez que inicie una conexión SSH, puede utilizar la utilidad ssh-agent para almacenar en caché la clave privada SSH. La clave privada y la frase de contraseña permanecen seguras.
Requisitos previos
- Tienes un host remoto con el demonio SSH en ejecución y accesible a través de la red.
- Conoce la dirección IP o el nombre de host y las credenciales para iniciar sesión en el host remoto.
- Ha generado un par de claves SSH con una frase de paso y ha transferido la clave pública a la máquina remota. Para más información, consulte Generación de pares de claves SSH.
Procedimiento
Opcional: Compruebe que puede utilizar la clave para autenticarse en el host remoto:
Conéctese al host remoto mediante SSH:
$ ssh example.user1@198.51.100.1 hostnameIntroduzca la frase de contraseña que estableció al crear la clave para dar acceso a la clave privada.
$ ssh example.user1@198.51.100.1 hostname host.example.com
Inicie el
ssh-agent.$ eval $(ssh-agent) Agent pid 20062Añade la clave a
ssh-agent.$ ssh-add ~/.ssh/id_rsa Enter passphrase for ~/.ssh/id_rsa: Identity added: ~/.ssh/id_rsa (example.user0@198.51.100.12)
Pasos de verificación
Opcional: Inicie sesión en el equipo anfitrión mediante SSH.
$ ssh example.user1@198.51.100.1 Last login: Mon Sep 14 12:56:37 2020Tenga en cuenta que no ha tenido que introducir la frase de contraseña.
26.1.8. Recursos adicionales
Para obtener más información sobre la configuración y la conexión a los servidores y clientes de OpenSSH en Red Hat Enterprise Linux, consulte los recursos enumerados a continuación.
Documentación instalada
-
sshd(8)La página de manual documenta las opciones disponibles en la línea de comandos y proporciona una lista completa de los archivos y directorios de configuración compatibles. -
la página de manual
ssh(1)proporciona una lista completa de las opciones disponibles en la línea de comandos y de los archivos y directorios de configuración admitidos. -
la página de manual
scp(1)proporciona una descripción más detallada de la utilidadscpy su uso. -
la página de manual
sftp(1)proporciona una descripción más detallada de la utilidadsftpy su uso. -
la página man
ssh-keygen(1)documenta en detalle el uso de la utilidadssh-keygenpara generar, gestionar y convertir las claves de autenticación utilizadas por ssh. -
la página de manual
ssh-copy-id(1)describe el uso del scriptssh-copy-id. -
ssh_config(5)La página de manual documenta las opciones de configuración del cliente SSH disponibles. -
la página de manual
sshd_config(5)proporciona una descripción completa de las opciones de configuración disponibles del demonio SSH. -
la página de manual
update-crypto-policies(8)proporciona orientación sobre la gestión de políticas criptográficas en todo el sistema -
la página de manual
crypto-policies(7)proporciona una visión general de los niveles de política criptográfica de todo el sistema
Documentación en línea
- Página principal de OpenSSH: contiene más documentación, preguntas frecuentes, enlaces a las listas de correo, informes de errores y otros recursos útiles.
- Configuración de SELinux para aplicaciones y servicios con configuraciones no estándar: puede aplicar procedimientos análogos para OpenSSH en una configuración no estándar con SELinux en modo de refuerzo.
-
Controlar el tráfico de la red utilizando firewalld - proporciona orientación sobre la actualización de la configuración de
firewallddespués de cambiar un puerto SSH
26.2. Planificación y aplicación de TLS
TLS (Transport Layer Security) es un protocolo criptográfico utilizado para asegurar las comunicaciones de red. A la hora de endurecer los ajustes de seguridad del sistema configurando los protocolos de intercambio de claves, los métodos de autenticación y los algoritmos de cifrado preferidos, es necesario tener en cuenta que cuanto más amplia sea la gama de clientes admitidos, menor será la seguridad resultante. A la inversa, una configuración de seguridad estricta conlleva una compatibilidad limitada con los clientes, lo que puede provocar que algunos usuarios se queden fuera del sistema. Asegúrese de apuntar a la configuración más estricta disponible y sólo relájela cuando sea necesario por razones de compatibilidad.
26.2.1. Protocolos SSL y TLS
El protocolo Secure Sockets Layer (SSL) fue desarrollado originalmente por Netscape Corporation para proporcionar un mecanismo de comunicación segura en Internet. Posteriormente, el protocolo fue adoptado por el Grupo de Trabajo de Ingeniería de Internet (IETF) y rebautizado como Transport Layer Security (TLS).
El protocolo TLS se sitúa entre una capa de protocolo de aplicación y una capa de transporte fiable, como TCP/IP. Es independiente del protocolo de aplicación y, por lo tanto, puede colocarse por debajo de muchos protocolos diferentes, por ejemplo: HTTP, FTP, SMTP, etc.
| Versión del protocolo | Recomendación de uso |
|---|---|
| SSL v2 | No utilizar. Tiene graves vulnerabilidades de seguridad. Eliminado de las bibliotecas criptográficas del núcleo desde RHEL 7. |
| SSL v3 | No utilizar. Tiene graves vulnerabilidades de seguridad. Eliminado de las bibliotecas criptográficas del núcleo desde RHEL 8. |
| TLS 1.0 |
No se recomienda su uso. Tiene problemas conocidos que no se pueden mitigar de forma que se garantice la interoperabilidad, y no admite suites de cifrado modernas. Habilitado sólo en el perfil de política criptográfica de todo el sistema |
| TLS 1.1 |
Utilícelo con fines de interoperabilidad cuando sea necesario. No admite suites de cifrado modernas. Habilitado sólo en la política |
| TLS 1.2 | Soporta las modernas suites de cifrado AEAD. Esta versión está habilitada en todas las políticas criptográficas del sistema, pero las partes opcionales de este protocolo contienen vulnerabilidades y TLS 1.2 también permite algoritmos obsoletos. |
| TLS 1.3 | Versión recomendada. TLS 1.3 elimina las opciones problemáticas conocidas, proporciona privacidad adicional al cifrar una mayor parte del apretón de manos de la negociación y puede ser más rápido gracias al uso de algoritmos criptográficos modernos más eficientes. TLS 1.3 también está habilitado en todas las políticas criptográficas del sistema. |
Recursos adicionales
26.2.2. Consideraciones de seguridad para TLS en RHEL 8
En RHEL 8, las consideraciones relacionadas con la criptografía se simplifican significativamente gracias a las políticas de criptografía de todo el sistema. La política criptográfica DEFAULT sólo permite TLS 1.2 y 1.3. Para permitir que su sistema negocie conexiones utilizando las versiones anteriores de TLS, debe optar por no seguir las políticas criptográficas en una aplicación o cambiar a la política LEGACY con el comando update-crypto-policies. Consulte Uso de políticas criptográficas en todo el sistema para obtener más información.
La configuración por defecto proporcionada por las bibliotecas incluidas en RHEL 8 es lo suficientemente segura para la mayoría de las implementaciones. Las implementaciones de TLS utilizan algoritmos seguros siempre que sea posible, sin impedir las conexiones desde o hacia clientes o servidores heredados. Aplique configuraciones reforzadas en entornos con requisitos de seguridad estrictos en los que no se espera ni se permite la conexión de clientes o servidores heredados que no soportan algoritmos o protocolos seguros.
La forma más directa de endurecer la configuración de TLS es cambiar el nivel de la política criptográfica de todo el sistema a FUTURE utilizando el comando update-crypto-policies --set FUTURE.
Si decide no seguir las políticas de cifrado de todo el sistema RHEL, utilice las siguientes recomendaciones para los protocolos, conjuntos de cifrado y longitudes de clave preferidos en su configuración personalizada:
26.2.2.1. Protocolos
La última versión de TLS proporciona el mejor mecanismo de seguridad. A menos que tenga una razón de peso para incluir el soporte de versiones anteriores de TLS, permita que sus sistemas negocien las conexiones utilizando al menos la versión 1.2 de TLS. Tenga en cuenta que, a pesar de que RHEL 8 soporta la versión 1.3 de TLS, no todas las características de este protocolo son totalmente compatibles con los componentes de RHEL 8. Por ejemplo, la función 0-RTT (Zero Round Trip Time), que reduce la latencia de la conexión, todavía no está totalmente soportada por los servidores web Apache o Nginx.
26.2.2.2. Suites de cifrado
Las suites de cifrado modernas y más seguras deben preferirse a las antiguas e inseguras. Desactive siempre el uso de las suites de cifrado eNULL y aNULL, que no ofrecen ningún tipo de cifrado o autenticación. Si es posible, las suites de cifrado basadas en RC4 o HMAC-MD5, que tienen serias deficiencias, también deberían deshabilitarse. Lo mismo se aplica a las llamadas suites de cifrado de exportación, que se han hecho intencionadamente más débiles y, por tanto, son fáciles de romper.
Aunque no son inmediatamente inseguras, las suites de cifrado que ofrecen menos de 128 bits de seguridad no deberían considerarse por su corta vida útil. Los algoritmos que utilizan 128 bits de seguridad o más pueden esperarse que sean indescifrables durante al menos varios años, por lo que se recomiendan encarecidamente. Tenga en cuenta que aunque los cifrados 3DES anuncian el uso de 168 bits, en realidad ofrecen 112 bits de seguridad.
Siempre hay que dar preferencia a las suites de cifrado que soportan el secreto (perfecto) hacia adelante (PFS), que garantiza la confidencialidad de los datos cifrados incluso en caso de que la clave del servidor se vea comprometida. Esto descarta el rápido intercambio de claves RSA, pero permite el uso de ECDHE y DHE. De los dos, ECDHE es el más rápido y, por tanto, la opción preferida.
También debe dar preferencia a los cifrados AEAD, como AES-GCM, antes que a los cifrados en modo CBC, ya que no son vulnerables a los ataques de oráculo de relleno. Además, en muchos casos, AES-GCM es más rápido que AES en modo CBC, especialmente cuando el hardware tiene aceleradores criptográficos para AES.
Tenga en cuenta también que cuando se utiliza el intercambio de claves ECDHE con certificados ECDSA, la transacción es incluso más rápida que el intercambio de claves RSA puro. Para dar soporte a los clientes antiguos, puedes instalar dos pares de certificados y claves en un servidor: uno con claves ECDSA (para los nuevos clientes) y otro con claves RSA (para los antiguos).
26.2.2.3. Longitud de la clave pública
Cuando utilice claves RSA, prefiera siempre longitudes de clave de al menos 3072 bits firmadas por al menos SHA-256, que es lo suficientemente grande para una seguridad real de 128 bits.
La seguridad de tu sistema es tan fuerte como el eslabón más débil de la cadena. Por ejemplo, un cifrado fuerte por sí solo no garantiza una buena seguridad. Las claves y los certificados son igual de importantes, así como las funciones hash y las claves utilizadas por la Autoridad de Certificación (CA) para firmar sus claves.
Recursos adicionales
- Políticas criptográficas para todo el sistema en RHEL 8.
-
update-crypto-policies(8)página de manual
26.2.3. Endurecimiento de la configuración de TLS en las aplicaciones
En Red Hat Enterprise Linux 8, las políticas criptográficas de todo el sistema proporcionan una manera conveniente de asegurar que sus aplicaciones que utilizan bibliotecas criptográficas no permiten protocolos, cifrados o algoritmos inseguros conocidos.
Si desea endurecer su configuración relacionada con TLS con sus ajustes criptográficos personalizados, puede utilizar las opciones de configuración criptográfica descritas en esta sección, y anular las políticas criptográficas de todo el sistema sólo en la cantidad mínima requerida.
Independientemente de la configuración que elija utilizar, asegúrese siempre de que su aplicación de servidor aplique server-side cipher order, de modo que el conjunto de cifrado que se utilice esté determinado por la orden que configure.
26.2.3.1. Configuración de la Apache HTTP server
El Apache HTTP Server puede utilizar las bibliotecas OpenSSL y NSS para sus necesidades de TLS. Red Hat Enterprise Linux 8 proporciona la funcionalidad de mod_ssl a través de paquetes epónimos:
# yum install mod_ssl
El paquete mod_ssl instala el archivo de configuración /etc/httpd/conf.d/ssl.conf, que puede utilizarse para modificar los ajustes relacionados con TLS de Apache HTTP Server.
Instale el paquete httpd-manual para obtener la documentación completa de Apache HTTP Server, incluida la configuración de TLS. Las directivas disponibles en el archivo de configuración /etc/httpd/conf.d/ssl.conf se describen en detalle en /usr/share/httpd/manual/mod/mod_ssl.html. Ejemplos de varias configuraciones están en /usr/share/httpd/manual/ssl/ssl_howto.html.
Al modificar los ajustes en el archivo de configuración /etc/httpd/conf.d/ssl.conf, asegúrese de tener en cuenta como mínimo las tres directivas siguientes:
SSLProtocol- Utilice esta directiva para especificar la versión de TLS o SSL que desea permitir.
SSLCipherSuite- Utilice esta directiva para especificar su conjunto de cifrado preferido o deshabilitar los que desee no permitir.
SSLHonorCipherOrder-
Descomente y establezca esta directiva en
onpara asegurarse de que los clientes que se conectan se adhieren al orden de cifrado que ha especificado.
Por ejemplo, para utilizar sólo el protocolo TLS 1.2 y 1.3:
SSLProtocol all -SSLv3 -TLSv1 -TLSv1.126.2.3.2. Configuración del servidor HTTP y proxy de Nginx
Para habilitar la compatibilidad con TLS 1.3 en Nginx, añada el valor TLSv1.3 a la opción ssl_protocols en la sección server del archivo de configuración /etc/nginx/nginx.conf:
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
....
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers
....
}26.2.3.3. Configuración del servidor de correo Dovecot
Para configurar su instalación del servidor de correo Dovecot para utilizar TLS, modifique el archivo de configuración /etc/dovecot/conf.d/10-ssl.conf. Puede encontrar una explicación de algunas de las directivas de configuración básicas disponibles en ese archivo en el archivo /usr/share/doc/dovecot/wiki/SSL.DovecotConfiguration.txt, que se instala junto con la instalación estándar de Dovecot.
Al modificar los ajustes en el archivo de configuración /etc/dovecot/conf.d/10-ssl.conf, asegúrese de tener en cuenta como mínimo las tres directivas siguientes:
ssl_protocols- Utilice esta directiva para especificar la versión de TLS o SSL que desea permitir o deshabilitar.
ssl_cipher_list- Utilice esta directiva para especificar sus suites de cifrado preferidas o deshabilitar las que desee no permitir.
ssl_prefer_server_ciphers-
Descomente y establezca esta directiva en
yespara asegurarse de que los clientes que se conectan se adhieren al orden de cifrado que ha especificado.
Por ejemplo, la siguiente línea en /etc/dovecot/conf.d/10-ssl.conf sólo permite TLS 1.1 y posteriores:
ssl_protocols = !SSLv2 !SSLv3 !TLSv1Recursos adicionales
Para obtener más información sobre la configuración de TLS y otros temas relacionados, consulte los recursos que se indican a continuación.
-
la página de manual
config(5)describe el formato del archivo de configuración/etc/ssl/openssl.conf. -
la página de manual
ciphers(1)incluye una lista de palabras clave y cadenas de cifrado disponibles enOpenSSL. - Recomendaciones para el uso seguro de la seguridad de la capa de transporte (TLS) y la seguridad de la capa de transporte de datagramas (DTLS)
-
El generador de configuración de Mozilla SSL puede ayudar a crear archivos de configuración para
ApacheoNginxcon configuraciones seguras que deshabilitan los protocolos, cifrados y algoritmos hash vulnerables conocidos. - Laprueba de servidor SSL verifica que su configuración cumple con los requisitos de seguridad modernos.
26.3. Configuración de una VPN con IPsec
En Red Hat Enterprise Linux 8, se puede configurar una red privada virtual (VPN) utilizando el protocolo IPsec, que es soportado por la aplicación Libreswan.
26.3.1. Libreswan como implementación de VPN IPsec
En Red Hat Enterprise Linux 8, se puede configurar una Red Privada Virtual (VPN) utilizando el protocolo IPsec, que es soportado por la aplicación Libreswan. Libreswan es una continuación de la aplicación Openswan, y muchos ejemplos de la documentación Openswan son intercambiables con Libreswan.
El protocolo IPsec para una VPN se configura utilizando el protocolo de intercambio de claves de Internet (IKE). Los términos IPsec e IKE se utilizan indistintamente. Una VPN IPsec también se denomina VPN IKE, VPN IKEv2, VPN XAUTH, VPN Cisco o VPN IKE/IPsec. Una variante de una VPN IPsec que también utiliza el Protocolo de Túnel de Nivel 2 (L2TP) suele llamarse VPN L2TP/IPsec, que requiere la aplicación del canal opcional xl2tpd.
Libreswan es una implementación de código abierto y espacio de usuario de IKE. IKE v1 y v2 se implementan como un demonio a nivel de usuario. El protocolo IKE también está cifrado. El protocolo IPsec es implementado por el kernel de Linux, y Libreswan configura el kernel para añadir y eliminar configuraciones de túneles VPN.
El protocolo IKE utiliza los puertos UDP 500 y 4500. El protocolo IPsec consta de dos protocolos:
-
Encapsulated Security Payload (
ESP), que tiene el número de protocolo 50. -
Authenticated Header (
AH), que tiene el número de protocolo 51.
No se recomienda el uso del protocolo AH. Se recomienda a los usuarios de AH que migren a ESP con cifrado nulo.
El protocolo IPsec ofrece dos modos de funcionamiento:
-
Tunnel Mode(por defecto) -
Transport Mode.
Se puede configurar el kernel con IPsec sin IKE. Esto se llama Manual Keying. También puede configurar la clave manual utilizando los comandos de ip xfrm, sin embargo, esto se desaconseja fuertemente por razones de seguridad. Libreswan interactúa con el kernel de Linux utilizando netlink. El cifrado y descifrado de paquetes se realiza en el kernel de Linux.
Libreswan utiliza la biblioteca criptográfica Network Security Services (NSS). Tanto Libreswan como NSS están certificados para su uso con la Publicación 140-2 de Federal Information Processing Standard (FIPS).
IKE/IPsec VPN, implementada por Libreswan y el kernel de Linux, es la única tecnología VPN recomendada para su uso en Red Hat Enterprise Linux 8. No utilice ninguna otra tecnología VPN sin entender los riesgos de hacerlo.
En Red Hat Enterprise Linux 8, Libreswan sigue a system-wide cryptographic policies por defecto. Esto asegura que Libreswan utiliza configuraciones seguras para los modelos de amenazas actuales, incluyendo IKEv2 como protocolo por defecto. Consulte Uso de políticas criptográficas en todo el sistema para obtener más información.
Libreswan no utiliza los términos "origen" y "destino" o "servidor" y "cliente" porque IKE/IPsec son protocolos peer to peer. En su lugar, utiliza los términos "izquierda" y "derecha" para referirse a los puntos finales (los hosts). Esto también permite utilizar la misma configuración en ambos puntos finales en la mayoría de los casos. Sin embargo, los administradores suelen optar por utilizar siempre "izquierda" para el host local y "derecha" para el host remoto.
26.3.2. Instalación de Libreswan
Este procedimiento describe los pasos para instalar e iniciar la implementación de la VPN IPsec/IKE de Libreswan.
Requisitos previos
-
El repositorio
AppStreamestá activado.
Procedimiento
Instale los paquetes de
libreswan:# yum install libreswanSi está reinstalando
Libreswan, elimine sus antiguos archivos de base de datos:# systemctl stop ipsec # rm /etc/ipsec.d/*dbInicie el servicio
ipsec, y habilite el servicio para que se inicie automáticamente al arrancar:# systemctl enable ipsec --nowConfigure el cortafuegos para permitir los puertos 500 y 4500/UDP para los protocolos IKE, ESP y AH añadiendo el servicio
ipsec:# firewall-cmd --add-service="ipsec" # firewall-cmd --runtime-to-permanent
26.3.3. Creación de una VPN de host a host
Para configurar Libreswan para crear una VPN de host a host IPsec entre dos hosts denominados left y right, introduzca los siguientes comandos en ambos hosts:
Procedimiento
Generar un par de claves RSA en cada host:
# ipsec newhostkey --output /etc/ipsec.d/hostkey.secretsEl paso anterior devolvió la clave generada
ckaid. Utilice eseckaidcon el siguiente comando en left, por ejemplo:# ipsec showhostkey --left --ckaid 2d3ea57b61c9419dfd6cf43a1eb6cb306c0e857dLa salida del comando anterior generó la línea
leftrsasigkey=necesaria para la configuración. Haga lo mismo en el segundo host (right):# ipsec showhostkey --right --ckaid a9e1f6ce9ecd3608c24e8f701318383f41798f03En el directorio
/etc/ipsec.d/, cree un nuevo archivomy_host-to-host.conf. Escriba en el nuevo archivo las claves de host RSA de la salida de los comandos deipsec showhostkeyen el paso anterior. Por ejemplo:conn mytunnel leftid=@west left=192.1.2.23 leftrsasigkey=0sAQOrlo+hOafUZDlCQmXFrje/oZm [...] W2n417C/4urYHQkCvuIQ== rightid=@east right=192.1.2.45 rightrsasigkey=0sAQO3fwC6nSSGgt64DWiYZzuHbc4 [...] D/v8t5YTQ== authby=rsasigDespués de importar las claves, reinicie el servicio
ipsec:# systemctl restart ipsecInicio
Libreswan:# ipsec setup startCargue la conexión:
# ipsec auto --add mytunnelEstablece el túnel:
# ipsec auto --up mytunnelPara iniciar automáticamente el túnel cuando se inicie el servicio
ipsec, añada la siguiente línea a la definición de la conexión:auto=inicio
26.3.4. Configuración de una VPN de sitio a sitio
Para crear una VPN de sitio a sitio IPsec, al unir dos redes, se crea un túnel IPsec entre los dos hosts. Los hosts actúan así como puntos finales, que están configurados para permitir el paso del tráfico de una o más subredes. Por lo tanto, se puede pensar en los hosts como puertas de enlace hacia la parte remota de la red.
La configuración de la VPN de sitio a sitio sólo difiere de la VPN de host a host en que hay que especificar una o más redes o subredes en el archivo de configuración.
Requisitos previos
- Una VPN de host a host ya está configurada.
Procedimiento
Copie el archivo con la configuración de su VPN de host a host en un nuevo archivo, por ejemplo:
# cp /etc/ipsec.d/my_host-to-host.conf /etc/ipsec.d/my_site-to-site.confAñada la configuración de la subred al archivo creado en el paso anterior, por ejemplo:
conn mysubnet also=mytunnel leftsubnet=192.0.1.0/24 rightsubnet=192.0.2.0/24 auto=start conn mysubnet6 also=mytunnel leftsubnet=2001:db8:0:1::/64 rightsubnet=2001:db8:0:2::/64 auto=start # the following part of the configuration file is the same for both host-to-host and site-to-site connections: conn mytunnel leftid=@west left=192.1.2.23 leftrsasigkey=0sAQOrlo+hOafUZDlCQmXFrje/oZm [...] W2n417C/4urYHQkCvuIQ== rightid=@east right=192.1.2.45 rightrsasigkey=0sAQO3fwC6nSSGgt64DWiYZzuHbc4 [...] D/v8t5YTQ== authby=rsasig
26.3.5. Configurar una VPN de acceso remoto
Los guerreros de la carretera son usuarios que viajan con clientes móviles con una dirección IP asignada dinámicamente, como los ordenadores portátiles. Los clientes móviles se autentican mediante certificados.
El siguiente ejemplo muestra la configuración para IKEv2, y evita el uso del protocolo IKEv1 XAUTH.
En el servidor:
conn roadwarriors
ikev2=insist
# Support (roaming) MOBIKE clients (RFC 4555)
mobike=yes
fragmentation=yes
left=1.2.3.4
# if access to the LAN is given, enable this, otherwise use 0.0.0.0/0
# leftsubnet=10.10.0.0/16
leftsubnet=0.0.0.0/0
leftcert=gw.example.com
leftid=%fromcert
leftxauthserver=yes
leftmodecfgserver=yes
right=%any
# trust our own Certificate Agency
rightca=%same
# pick an IP address pool to assign to remote users
# 100.64.0.0/16 prevents RFC1918 clashes when remote users are behind NAT
rightaddresspool=100.64.13.100-100.64.13.254
# if you want remote clients to use some local DNS zones and servers
modecfgdns="1.2.3.4, 5.6.7.8"
modecfgdomains="internal.company.com, corp"
rightxauthclient=yes
rightmodecfgclient=yes
authby=rsasig
# optionally, run the client X.509 ID through pam to allow/deny client
# pam-authorize=yes
# load connection, don't initiate
auto=add
# kill vanished roadwarriors
dpddelay=1m
dpdtimeout=5m
dpdaction=clearEn el cliente móvil, el dispositivo del guerrero de la carretera, utilice una ligera variación de la configuración anterior:
conn to-vpn-server
ikev2=insist
# pick up our dynamic IP
left=%defaultroute
leftsubnet=0.0.0.0/0
leftcert=myname.example.com
leftid=%fromcert
leftmodecfgclient=yes
# right can also be a DNS hostname
right=1.2.3.4
# if access to the remote LAN is required, enable this, otherwise use 0.0.0.0/0
# rightsubnet=10.10.0.0/16
rightsubnet=0.0.0.0/0
fragmentation=yes
# trust our own Certificate Agency
rightca=%same
authby=rsasig
# allow narrowing to the server’s suggested assigned IP and remote subnet
narrowing=yes
# Support (roaming) MOBIKE clients (RFC 4555)
mobike=yes
# Initiate connection
auto=start26.3.6. Configurar una VPN de malla
Una red VPN en malla, que también se conoce como VPN any-to-any, es una red en la que todos los nodos se comunican utilizando IPsec. La configuración permite excepciones para los nodos que no pueden utilizar IPsec. La red VPN en malla puede configurarse de dos maneras:
-
Requerir
IPsec. -
Para preferir
IPsec, pero permitir una vuelta a la comunicación en texto claro.
La autenticación entre los nodos puede basarse en certificados X.509 o en extensiones de seguridad DNS (DNSSEC).
El siguiente procedimiento utiliza certificados X.509. Estos certificados pueden generarse utilizando cualquier tipo de sistema de gestión de autoridades de certificación (CA), como el sistema de certificados Dogtag. Dogtag asume que los certificados de cada nodo están disponibles en el formato PKCS #12 (archivos .p12), que contienen la clave privada, el certificado del nodo y el certificado de la CA Raíz utilizado para validar los certificados X.509 de otros nodos.
Cada nodo tiene una configuración idéntica con la excepción de su certificado X.509. Esto permite añadir nuevos nodos sin reconfigurar ninguno de los existentes en la red. Los archivos PKCS #12 requieren un "nombre amistoso", para el que utilizamos el nombre "nodo", de modo que los archivos de configuración que hacen referencia al nombre amistoso pueden ser idénticos para todos los nodos.
Requisitos previos
-
se instala
Libreswany se inicia el servicioipsecen cada nodo.
Procedimiento
En cada nodo, importe los archivos PKCS #12. Este paso requiere la contraseña utilizada para generar los archivos PKCS #12:
# ipsec import nodeXXX.p12Cree las siguientes tres definiciones de conexión para los perfiles
IPsec required(privado),IPsec optional(privado o claro) yNo IPsec(claro):# cat /etc/ipsec.d/mesh.conf conn clear auto=ondemand type=passthrough authby=never left=%defaultroute right=%group conn private auto=ondemand type=transport authby=rsasig failureshunt=drop negotiationshunt=drop # left left=%defaultroute leftcert=nodeXXXX leftid=%fromcert leftrsasigkey=%cert # right rightrsasigkey=%cert rightid=%fromcert right=%opportunisticgroup conn private-or-clear auto=ondemand type=transport authby=rsasig failureshunt=passthrough negotiationshunt=passthrough # left left=%defaultroute leftcert=nodeXXXX leftid=%fromcert leftrsasigkey=%cert # right rightrsasigkey=%cert rightid=%fromcert right=%opportunisticgroupAñada la dirección IP de la red en la categoría adecuada. Por ejemplo, si todos los nodos residen en la red 10.15.0.0/16, y todos los nodos deben ordenar el cifrado
IPsec:# echo "10.15.0.0/16" >> /etc/ipsec.d/policies/privatePara permitir que ciertos nodos, por ejemplo, 10.15.34.0/24, trabajen con y sin
IPsec, añada esos nodos al grupo de privados o limpios mediante:# echo "10.15.34.0/24" >> /etc/ipsec.d/policies/private-or-clearPara definir un host, por ejemplo, 10.15.1.2, que no es capaz de
IPsecen el grupo claro, utilice:# echo "10.15.1.2/32" >> /etc/ipsec.d/policies/clearLos archivos del directorio
/etc/ipsec.d/policiesse pueden crear a partir de una plantilla para cada nuevo nodo, o se pueden aprovisionar utilizando Puppet o Ansible.Tenga en cuenta que cada nodo tiene la misma lista de excepciones o diferentes expectativas de flujo de tráfico. Por lo tanto, dos nodos podrían no ser capaces de comunicarse porque uno requiere
IPsecy el otro no puede utilizarIPsec.Reinicie el nodo para añadirlo a la malla configurada:
# systemctl restart ipsecUna vez que haya terminado con la adición de nodos, un comando
pinges suficiente para abrir un túnelIPsec. Para ver qué túneles ha abierto un nodo:# ipsec trafficstatus
26.3.7. Métodos de autentificación utilizados en Libreswan
Puede utilizar los siguientes métodos para la autenticación de los puntos finales:
- Pre-Shared Keys (PSK) es el método de autenticación más sencillo. Los PSK deben estar formados por caracteres aleatorios y tener una longitud de al menos 20 caracteres. En el modo FIPS, los PSKs deben cumplir con un requisito de fuerza mínima dependiendo del algoritmo de integridad utilizado. Se recomienda no utilizar PSKs de menos de 64 caracteres aleatorios.
-
Raw RSA keys se suele utilizar para configuraciones estáticas de host a host o de subred a subred
IPsec. Los hosts se configuran manualmente con la clave RSA pública de cada uno. Este método no se adapta bien cuando docenas o más hosts necesitan configurar túnelesIPsecentre sí. -
X.509 certificates se utiliza habitualmente para despliegues a gran escala en los que hay muchos hosts que necesitan conectarse a una pasarela común
IPsec. Se utiliza una certificate authority (CA) central para firmar certificados RSA para hosts o usuarios. Esta CA central es responsable de transmitir la confianza, incluyendo las revocaciones de hosts o usuarios individuales. -
NULL authentication se utiliza para obtener un cifrado de malla sin autenticación. Protege contra los ataques pasivos pero no protege contra los ataques activos. Sin embargo, como
IKEv2permite métodos de autenticación asimétricos, la autenticación NULL también puede utilizarse para IPsec oportunista a escala de Internet, donde los clientes autentican al servidor, pero los servidores no autentican al cliente. Este modelo es similar al de los sitios web seguros que utilizanTLS.
Protección contra los ordenadores cuánticos
Además de estos métodos de autenticación, puede utilizar el método Postquantum Preshared Keys (PPK) para protegerse de posibles ataques de ordenadores cuánticos. Los clientes individuales o los grupos de clientes pueden utilizar su propia PPK especificando un (PPKID) que corresponde a una clave precompartida configurada fuera de banda.
El uso de IKEv1 con claves precompartidas ofrecía protección contra los atacantes cuánticos. El rediseño de IKEv2 no ofrece esta protección de forma nativa. Libreswan ofrece el uso de Postquantum Preshared Keys (PPK) para proteger las conexiones de IKEv2 contra los ataques cuánticos.
Para activar el soporte opcional de PPK, añada ppk=yes a la definición de la conexión. Para exigir la PPK, añada ppk=insist. Entonces, a cada cliente se le puede dar un ID de PPK con un valor secreto que se comunica fuera de banda (y preferiblemente seguro desde el punto de vista cuántico). Las PPK deben ser muy fuertes en aleatoriedad y no estar basadas en palabras de diccionario. El ID PPK y los datos PPK en sí se almacenan en ipsec.secrets, por ejemplo:
@west @east : PPKS \ "user1" \N - "la cuerda es para llevarla a cabo"
La opción PPKS se refiere a los PPK estáticos. Una función experimental utiliza PPKs dinámicos basados en una almohadilla de un solo uso. En cada conexión, se utiliza una nueva parte de una almohadilla de un solo uso como PPK. Cuando se utiliza, esa parte del PPK dinámico dentro del archivo se sobrescribe con ceros para evitar su reutilización. Si no queda más material de la almohadilla de un solo uso, la conexión falla. Consulte la página de manual ipsec.secrets(5) para obtener más información.
La implementación de los PPK dinámicos se proporciona como una Muestra de Tecnología, y esta funcionalidad debe utilizarse con precaución.
26.3.8. Implementación de una VPN IPsec compatible con FIPS
Utilice este procedimiento para implementar una solución VPN IPsec compatible con FIPS basada en Libreswan. Los siguientes pasos también le permiten identificar qué algoritmos criptográficos están disponibles y cuáles están desactivados para Libreswan en modo FIPS.
Requisitos previos
-
El repositorio
AppStreamestá activado.
Procedimiento
Instale los paquetes de
libreswan:# yum install libreswanSi está reinstalando
Libreswan, elimine su antigua base de datos NSS:# systemctl stop ipsec # rm /etc/ipsec.d/*dbInicie el servicio
ipsec, y habilite el servicio para que se inicie automáticamente al arrancar:# systemctl enable ipsec --nowConfigure el cortafuegos para permitir los puertos 500 y 4500/UDP para los protocolos IKE, ESP y AH añadiendo el servicio
ipsec:# firewall-cmd --add-service="ipsec" # firewall-cmd --runtime-to-permanentCambie el sistema al modo FIPS en RHEL 8:
# fips-mode-setup --enableReinicie su sistema para permitir que el kernel cambie al modo FIPS:
# reboot
Pasos de verificación
Para confirmar que Libreswan funciona en modo FIPS:
# ipsec whack --fipsstatus 000 FIPS mode enabledTambién puede comprobar las entradas de la unidad
ipsecen el diariosystemd:$ journalctl -u ipsec ... Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Product: YES Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Kernel: YES Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Mode: YESPara ver los algoritmos disponibles en el modo FIPS:
# ipsec pluto --selftest 2>&1 | head -11 FIPS Product: YES FIPS Kernel: YES FIPS Mode: YES NSS DB directory: sql:/etc/ipsec.d Initializing NSS Opening NSS database "sql:/etc/ipsec.d" read-only NSS initialized NSS crypto library initialized FIPS HMAC integrity support [enabled] FIPS mode enabled for pluto daemon NSS library is running in FIPS mode FIPS HMAC integrity verification self-test passedPara consultar los algoritmos desactivados en el modo FIPS:
# ipsec pluto --selftest 2>&1 | grep disabled Encryption algorithm CAMELLIA_CTR disabled; not FIPS compliant Encryption algorithm CAMELLIA_CBC disabled; not FIPS compliant Encryption algorithm SERPENT_CBC disabled; not FIPS compliant Encryption algorithm TWOFISH_CBC disabled; not FIPS compliant Encryption algorithm TWOFISH_SSH disabled; not FIPS compliant Encryption algorithm NULL disabled; not FIPS compliant Encryption algorithm CHACHA20_POLY1305 disabled; not FIPS compliant Hash algorithm MD5 disabled; not FIPS compliant PRF algorithm HMAC_MD5 disabled; not FIPS compliant PRF algorithm AES_XCBC disabled; not FIPS compliant Integrity algorithm HMAC_MD5_96 disabled; not FIPS compliant Integrity algorithm HMAC_SHA2_256_TRUNCBUG disabled; not FIPS compliant Integrity algorithm AES_XCBC_96 disabled; not FIPS compliant DH algorithm MODP1024 disabled; not FIPS compliant DH algorithm MODP1536 disabled; not FIPS compliant DH algorithm DH31 disabled; not FIPS compliantPara listar todos los algoritmos y cifrados permitidos en el modo FIPS:
# ipsec pluto --selftest 2>&1 | grep ESP | grep FIPS | sed "s/^.*FIPS//" {256,192,*128} aes_ccm, aes_ccm_c {256,192,*128} aes_ccm_b {256,192,*128} aes_ccm_a [*192] 3des {256,192,*128} aes_gcm, aes_gcm_c {256,192,*128} aes_gcm_b {256,192,*128} aes_gcm_a {256,192,*128} aesctr {256,192,*128} aes {256,192,*128} aes_gmac sha, sha1, sha1_96, hmac_sha1 sha512, sha2_512, sha2_512_256, hmac_sha2_512 sha384, sha2_384, sha2_384_192, hmac_sha2_384 sha2, sha256, sha2_256, sha2_256_128, hmac_sha2_256 aes_cmac null null, dh0 dh14 dh15 dh16 dh17 dh18 ecp_256, ecp256 ecp_384, ecp384 ecp_521, ecp521
Recursos adicionales
26.3.9. Proteger la base de datos IPsec NSS con una contraseña
Por defecto, el servicio IPsec crea su base de datos de Servicios de Seguridad de Red (NSS) con una contraseña vacía durante el primer inicio. Añada la protección con contraseña siguiendo los siguientes pasos.
En las versiones anteriores de RHEL hasta la versión 6.6, había que proteger la base de datos de IPsec NSS con una contraseña para cumplir los requisitos de FIPS 140-2 porque las bibliotecas criptográficas de NSS estaban certificadas para el estándar FIPS 140-2 Nivel 2. En RHEL 8, el NIST certificó NSS para el nivel 1 de esta norma, y este estado no requiere la protección con contraseña de la base de datos.
Requisito previo
-
El directorio
/etc/ipsec.dcontiene los archivos de la base de datos NSS.
Procedimiento
Activar la protección por contraseña de la base de datos
NSSparaLibreswan:# certutil -N -d sql:/etc/ipsec.d Enter Password or Pin for "NSS Certificate DB": Enter a password which will be used to encrypt your keys. The password should be at least 8 characters long, and should contain at least one non-alphabetic character. Enter new password:Cree el archivo
/etc/ipsec.d/nsspasswordcon la contraseña que ha establecido en el paso anterior, por ejemplo:# cat /etc/ipsec.d/nsspassword NSS Certificate DB:MyStrongPasswordHereTenga en cuenta que el archivo
nsspasswordutiliza la siguiente sintaxis:token_1_name:the_password token_2_name:the_passwordEl token de software NSS por defecto es
NSS Certificate DB. Si su sistema funciona en modo FIPS, el nombre del token esNSS FIPS 140-2 Certificate DB.Dependiendo de su escenario, inicie o reinicie el servicio
ipsecdespués de terminar el archivonsspassword:# systemctl restart ipsec
Pasos de verificación
Compruebe que el servicio
ipsecestá funcionando después de haber añadido una contraseña no vacía a su base de datos NSS:# systemctl status ipsec ● ipsec.service - Internet Key Exchange (IKE) Protocol Daemon for IPsec Loaded: loaded (/usr/lib/systemd/system/ipsec.service; enabled; vendor preset: disable> Active: active (running)...Opcionalmente, compruebe que el registro
Journalcontiene entradas que confirman una inicialización exitosa:# journalctl -u ipsec ... pluto[23001]: NSS DB directory: sql:/etc/ipsec.d pluto[23001]: Initializing NSS pluto[23001]: Opening NSS database "sql:/etc/ipsec.d" read-only pluto[23001]: NSS Password from file "/etc/ipsec.d/nsspassword" for token "NSS Certificate DB" with length 20 passed to NSS pluto[23001]: NSS crypto library initialized ...
Recursos adicionales
-
La página de manual
certutil(1). - Para obtener más información sobre las certificaciones relacionadas con FIPS 140-2, consulte el artículo de la base de conocimientos sobre normas gubernamentales.
26.3.10. Configurar las conexiones IPsec que optan por las políticas criptográficas de todo el sistema
Anulación de las políticas criptográficas de todo el sistema para una conexión
Las políticas criptográficas de todo el sistema RHEL crean una conexión especial llamada fault. Esta conexión contiene los valores por defecto para las opciones ikev2, esp, y ike. Sin embargo, puede anular los valores por defecto especificando la opción mencionada en el archivo de configuración de la conexión.
Por ejemplo, la siguiente configuración permite conexiones que utilizan IKEv1 con AES y SHA-1 o SHA-2, e IPsec (ESP) con AES-GCM o AES-CBC:
conn MyExample
...
ikev2=never
ike=aes-sha2,aes-sha1;modp2048
esp=aes_gcm,aes-sha2,aes-sha1
...Tenga en cuenta que AES-GCM está disponible para IPsec (ESP) y para IKEv2, pero no para IKEv1.
Desactivación de las políticas criptográficas de todo el sistema para todas las conexiones
Para desactivar las políticas criptográficas de todo el sistema para todas las conexiones IPsec, comente la siguiente línea en el archivo /etc/ipsec.conf:
incluir /etc/crypto-policies/back-ends/libreswan.config
A continuación, añada la opción ikev2=never a su archivo de configuración de la conexión.
Recursos adicionales
- Para más información, consulte Uso de políticas criptográficas en todo el sistema.
26.3.11. Resolución de problemas de configuración de VPN IPsec
Los problemas relacionados con las configuraciones de VPN IPsec suelen producirse por varias razones principales. Si se encuentra con este tipo de problemas, puede comprobar si la causa del problema corresponde a alguno de los siguientes escenarios, y aplicar la solución correspondiente.
Solución de problemas básicos de conexión
La mayoría de los problemas con las conexiones VPN se producen en las nuevas implantaciones, en las que los administradores configuran los puntos finales con opciones de configuración que no coinciden. Además, una configuración que funciona puede dejar de hacerlo repentinamente, a menudo debido a valores incompatibles introducidos recientemente. Esto puede ser el resultado de que un administrador cambie la configuración. Alternativamente, un administrador puede haber instalado una actualización de firmware o una actualización de paquete con diferentes valores por defecto para ciertas opciones, como los algoritmos de cifrado.
Para confirmar que se ha establecido una conexión VPN IPsec:
# ipsec trafficstatus
006 #8: "vpn.example.com"[1] 192.0.2.1, type=ESP, add_time=1595296930, inBytes=5999, outBytes=3231, id='@vpn.example.com', lease=100.64.13.5/32Si la salida está vacía o no muestra una entrada con el nombre de la conexión, el túnel está roto.
Para comprobar que el problema está en la conexión:
Vuelva a cargar la conexión vpn.example.com:
# ipsec auto --add vpn.example.com 002 added connection description "vpn.example.com"A continuación, inicie la conexión VPN:
# ipsec auto --up vpn.example.com
Problemas relacionados con los cortafuegos
El problema más común es que un firewall en uno de los puntos finales de IPsec o en un router entre los puntos finales está dejando caer todos los paquetes de intercambio de claves de Internet (IKE).
Para IKEv2, una salida similar al siguiente ejemplo indica un problema con un firewall:
# ipsec auto --up vpn.example.com 181 "vpn.example.com"[1] 192.0.2.2 #15: initiating IKEv2 IKE SA 181 "vpn.example.com"[1] 192.0.2.2 #15: STATE_PARENT_I1: sent v2I1, expected v2R1 010 "vpn.example.com"[1] 192.0.2.2 #15: STATE_PARENT_I1: retransmission; will wait 0.5 seconds for response 010 "vpn.example.com"[1] 192.0.2.2 #15: STATE_PARENT_I1: retransmission; will wait 1 seconds for response 010 "vpn.example.com"[1] 192.0.2.2 #15: STATE_PARENT_I1: retransmission; will wait 2 seconds for ...Para IKEv1, la salida del comando de iniciación tiene el siguiente aspecto:
# ipsec auto --up vpn.example.com 002 "vpn.example.com" #9: initiating Main Mode 102 "vpn.example.com" #9: STATE_MAIN_I1: sent MI1, expecting MR1 010 "vpn.example.com" #9: STATE_MAIN_I1: retransmission; will wait 0.5 seconds for response 010 "vpn.example.com" #9: STATE_MAIN_I1: retransmission; will wait 1 seconds for response 010 "vpn.example.com" #9: STATE_MAIN_I1: retransmission; will wait 2 seconds for response ...
Dado que el protocolo IKE, que se utiliza para configurar IPsec, está encriptado, sólo puede solucionar un subconjunto limitado de problemas utilizando la herramienta tcpdump. Si un cortafuegos está dejando caer paquetes IKE o IPsec, puedes intentar encontrar la causa utilizando la utilidad tcpdump. Sin embargo, tcpdump no puede diagnosticar otros problemas con las conexiones VPN IPsec.
Para capturar la negociación de la VPN y todos los datos cifrados en la interfaz
eth0:# tcpdump -i eth0 -n -n esp or udp port 500 or udp port 4500 or tcp port 4500Algoritmos, protocolos y políticas no coincidentes
Las conexiones VPN requieren que los puntos finales tengan algoritmos IKE, algoritmos IPsec y rangos de direcciones IP que coincidan. Si se produce un desajuste, la conexión falla. Si identifica un desajuste mediante uno de los siguientes métodos, arréglelo alineando algoritmos, protocolos o políticas.
Si el extremo remoto no está ejecutando IKE/IPsec, puede ver un paquete ICMP indicándolo. Por ejemplo:
# ipsec auto --up vpn.example.com ... 000 "vpn.example.com"[1] 192.0.2.2 #16: ERROR: asynchronous network error report on wlp2s0 (192.0.2.2:500), complainant 198.51.100.1: Connection refused [errno 111, origin ICMP type 3 code 3 (not authenticated)] ...Ejemplo de algoritmos IKE no coincidentes:
# ipsec auto --up vpn.example.com ... 003 "vpn.example.com"[1] 193.110.157.148 #3: dropping unexpected IKE_SA_INIT message containing NO_PROPOSAL_CHOSEN notification; message payloads: N; missing payloads: SA,KE,NiEjemplo de algoritmos IPsec no coincidentes:
# ipsec auto --up vpn.example.com ... 182 "vpn.example.com"[1] 193.110.157.148 #5: STATE_PARENT_I2: sent v2I2, expected v2R2 {auth=IKEv2 cipher=AES_GCM_16_256 integ=n/a prf=HMAC_SHA2_256 group=MODP2048} 002 "vpn.example.com"[1] 193.110.157.148 #6: IKE_AUTH response contained the error notification NO_PROPOSAL_CHOSENUna versión de IKE que no coincida también puede hacer que el punto final remoto abandone la solicitud sin respuesta. Esto parece idéntico a un cortafuegos que abandona todos los paquetes IKE.
Ejemplo de rangos de direcciones IP no coincidentes para IKEv2 (llamados selectores de tráfico - TS):
# ipsec auto --up vpn.example.com ... 1v2 "vpn.example.com" #1: STATE_PARENT_I2: sent v2I2, expected v2R2 {auth=IKEv2 cipher=AES_GCM_16_256 integ=n/a prf=HMAC_SHA2_512 group=MODP2048} 002 "vpn.example.com" #2: IKE_AUTH response contained the error notification TS_UNACCEPTABLEEjemplo de rangos de direcciones IP no coincidentes para IKEv1:
# ipsec auto --up vpn.example.com ... 031 "vpn.example.com" #2: STATE_QUICK_I1: 60 second timeout exceeded after 0 retransmits. No acceptable response to our first Quick Mode message: perhaps peer likes no proposalCuando se utilizan PreSharedKeys (PSK) en IKEv1, si ambas partes no ponen la misma PSK, todo el mensaje IKE se vuelve ilegible:
# ipsec auto --up vpn.example.com ... 003 "vpn.example.com" #1: received Hash Payload does not match computed value 223 "vpn.example.com" #1: sending notification INVALID_HASH_INFORMATION to 192.0.2.23:500En IKEv2, el error de PSK no coincidente resulta en un mensaje AUTHENTICATION_FAILED:
# ipsec auto --up vpn.example.com ... 002 "vpn.example.com" #1: IKE SA authentication request rejected by peer: AUTHENTICATION_FAILED
Unidad máxima de transmisión
Aparte de los cortafuegos que bloquean los paquetes IKE o IPsec, la causa más común de los problemas de red está relacionada con el aumento del tamaño de los paquetes cifrados. El hardware de red fragmenta los paquetes más grandes que la unidad de transmisión máxima (MTU), por ejemplo, 1500 bytes. A menudo, los fragmentos se pierden y los paquetes no se vuelven a ensamblar. Esto provoca fallos intermitentes, cuando una prueba de ping, que utiliza paquetes de pequeño tamaño, funciona pero el resto del tráfico falla. En este caso, se puede establecer una sesión SSH pero el terminal se congela en cuanto se utiliza, por ejemplo, introduciendo el comando 'ls -al /usr' en el host remoto.
Para solucionar el problema, reduzca el tamaño de la MTU añadiendo la opción mtu=1400 al archivo de configuración del túnel.
Alternativamente, para las conexiones TCP, active una regla iptables que cambie el valor de MSS:
# iptables -I FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu
Si el comando anterior no resuelve el problema en su escenario, especifique directamente un tamaño menor en el parámetro set-mss:
# iptables -I FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --set-mss 1380Traducción de direcciones de red (NAT)
Cuando un host IPsec también sirve como router NAT, podría reasignar accidentalmente los paquetes. El siguiente ejemplo de configuración demuestra el problema:
conn myvpn
left=172.16.0.1
leftsubnet=10.0.2.0/24
right=172.16.0.2
rightsubnet=192.168.0.0/16
…El sistema con dirección 172.16.0.1 tiene una regla NAT:
iptables -t nat -I POSTROUTING -o eth0 -j MASQUERADESi el sistema en la dirección 10.0.2.33 envía un paquete a 192.168.0.1, el router traduce la fuente 10.0.2.33 a 172.16.0.1 antes de aplicar el cifrado IPsec.
Entonces, el paquete con la dirección de origen 10.0.2.33 ya no coincide con la configuración de conn myvpn, e IPsec no cifra este paquete.
Para resolver este problema, inserte reglas que excluyan NAT para los rangos de subred IPsec de destino en el router, en este ejemplo:
iptables -t nat -I POSTROUTING -s 10.0.2.0/24 -d 192.168.0.0/16 -j RETURNErrores en el subsistema IPsec del kernel
El subsistema IPsec del kernel puede fallar, por ejemplo, cuando un error provoca una desincronización del espacio de usuario de IKE y del kernel IPsec. Para comprobar este tipo de problemas:
$ cat /proc/net/xfrm_stat
XfrmInError 0
XfrmInBufferError 0
...Cualquier valor distinto de cero en la salida del comando anterior indica un problema. Si encuentra este problema, abra un nuevo caso de soporte, y adjunte la salida del comando anterior junto con los registros de IKE correspondientes.
Registros de Libreswan
Libreswan registra utilizando el protocolo syslog por defecto. Puedes utilizar el comando journalctl para encontrar entradas de registro relacionadas con IPsec. Como las entradas correspondientes al registro son enviadas por el demonio IKE de pluto, busque la palabra clave "pluto", por ejemplo:
$ journalctl -b | grep pluto
Para mostrar un registro en vivo para el servicio ipsec:
$ journalctl -f -u ipsec
Si el nivel de registro por defecto no revela su problema de configuración, active los registros de depuración añadiendo la opción plutodebug=all a la sección config setup del archivo /etc/ipsec.conf.
Tenga en cuenta que el registro de depuración produce muchas entradas, y es posible que el servicio journald o syslogd limite la velocidad de los mensajes syslog. Para asegurarse de que tiene registros completos, redirija el registro a un archivo. Edite el /etc/ipsec.conf, y añada el logfile=/var/log/pluto.log en la sección config setup.
Recursos adicionales
- Solución de problemas mediante archivos de registro
- Uso y configuración de firewalld
-
tcpdump(8)yipsec.conf(5)páginas man
26.4. Configuración de MACsec
La siguiente sección proporciona información sobre cómo configurar Media Control Access Security (MACsec), que es una tecnología de seguridad estándar 802.1AE IEEE para la comunicación segura en todo el tráfico de los enlaces Ethernet.
26.4.1. Introducción a MACsec
Media Access Control Security (MACsec, IEEE 802.1AE) cifra y autentifica todo el tráfico en las redes LAN con el algoritmo GCM-AES-128. MACsec puede proteger no sólo IP sino también el Protocolo de Resolución de Direcciones (ARP), el Descubrimiento de Vecinos (ND) o DHCP. Mientras que IPsec opera en la capa de red (capa 3) y SSL o TLS en la capa de aplicación (capa 7), MACsec opera en la capa de enlace de datos (capa 2). Combina MACsec con protocolos de seguridad para otras capas de red para aprovechar las diferentes características de seguridad que ofrecen estos estándares.
26.4.2. Uso de MACsec con la herramienta nmcli
Este procedimiento muestra cómo configurar MACsec con la herramienta nmcli.
Requisitos previos
- El NetworkManager debe estar en funcionamiento.
-
Ya tiene un CAK hexadecimal de 16 bytes (
$MKA_CAK) y un CKN hexadecimal de 32 bytes ($MKA_CKN).
Procedimiento
Para añadir una nueva conexión utilizando
nmcli, introduzca:~]# nmcli connection add type macsec \ con-name test-macsec+ ifname macsec0 \ connection.autoconnect no \ macsec.parent enp1s0 macsec.mode psk \ macsec.mka-cak $MKA_CAK \ macsec.mka-ckn $MKA_CKNSustituya macsec0 por el nombre del dispositivo que desea configurar.
Para activar la conexión, introduzca:
~]# nmcli connection up test-macsec
Después de este paso, el dispositivo macsec0 está configurado y puede utilizarse para la conexión en red.
26.4.3. Uso de MACsec con wpa_supplicant
Este procedimiento muestra cómo habilitar MACsec con un conmutador que realiza la autenticación utilizando un par precompartido de clave de asociación de conectividad/nombre CAK (CAK/CKN).
Procedimiento
Crea un par CAK/CKN. Por ejemplo, el siguiente comando genera una clave de 16 bytes en notación hexadecimal:
~]$ dd if=/dev/urandom count=16 bs=1 2> /dev/null | hexdump -e '1/2 "%02x"'Cree el archivo de configuración
wpa_supplicant.confy añada las siguientes líneas:ctrl_interface=/var/run/wpa_supplicant eapol_version=3 ap_scan=0 fast_reauth=1 network={ key_mgmt=NONE eapol_flags=0 macsec_policy=1 mka_cak=0011... # 16 bytes hexadecimal mka_ckn=2233... # 32 bytes hexadecimal }Utilice los valores del paso anterior para completar las líneas
mka_cakymka_cknen el archivo de configuraciónwpa_supplicant.conf.Para más información, consulte la página de manual
wpa_supplicant.conf(5).Asumiendo que está usando wlp61s0 para conectarse a su red, inicie wpa_supplicant utilizando el siguiente comando:
~]# wpa_supplicant -i wlp61s0 -Dmacsec_linux -c wpa_supplicant.conf
26.5. Uso y configuración de firewalld
Un firewall es una forma de proteger las máquinas de cualquier tráfico no deseado procedente del exterior. Permite a los usuarios controlar el tráfico de red entrante en las máquinas anfitrionas definiendo un conjunto de firewall rules. Estas reglas se utilizan para clasificar el tráfico entrante y bloquearlo o permitirlo.
Tenga en cuenta que firewalld con el backend nftables no admite el paso de reglas personalizadas nftables a firewalld, utilizando la opción --direct.
26.5.1. Cuándo utilizar firewalld, nftables o iptables
A continuación se presenta un breve resumen en el que se debe utilizar una de las siguientes utilidades:
-
firewalld: Utilice la utilidadfirewalldpara casos de uso de cortafuegos sencillos. La utilidad es fácil de usar y cubre los casos de uso típicos para estos escenarios. -
nftables: Utilice la utilidadnftablespara configurar cortafuegos complejos y de rendimiento crítico, como por ejemplo para toda una red. -
iptables: La utilidadiptablesen Red Hat Enterprise Linux 8 utiliza la API del kernelnf_tablesen lugar del back endlegacy. La APInf_tablesproporciona compatibilidad con versiones anteriores para que los scripts que utilizan comandosiptablessigan funcionando en Red Hat Enterprise Linux 8. Para los nuevos scripts de cortafuegos, Red Hat recomienda utilizarnftables.
Para evitar que los diferentes servicios de firewall se influyan mutuamente, ejecute sólo uno de ellos en un host RHEL y desactive los demás servicios.
26.5.2. Cómo empezar con firewalld
26.5.2.1. firewalld
firewalld es un demonio de servicio de cortafuegos que proporciona un cortafuegos dinámico personalizable basado en el host con una interfaz D-Bus. Al ser dinámico, permite crear, cambiar y eliminar las reglas sin necesidad de reiniciar el demonio del cortafuegos cada vez que se cambian las reglas.
firewalld utiliza los conceptos de zones y services, que simplifican la gestión del tráfico. Las zonas son conjuntos predefinidos de reglas. Se pueden asignar interfaces de red y fuentes a una zona. El tráfico permitido depende de la red a la que esté conectado el ordenador y del nivel de seguridad que tenga asignado esta red. Los servicios del cortafuegos son reglas predefinidas que cubren todos los ajustes necesarios para permitir el tráfico entrante para un servicio específico y se aplican dentro de una zona.
Los servicios utilizan uno o más ports o addresses para la comunicación en red. Los cortafuegos filtran la comunicación basándose en los puertos. Para permitir el tráfico de red para un servicio, sus puertos deben ser open. firewalld bloquea todo el tráfico en los puertos que no están explícitamente establecidos como abiertos. Algunas zonas, como trusted, permiten todo el tráfico por defecto.
26.5.2.2. Zonas
firewalld puede utilizarse para separar las redes en diferentes zonas según el nivel de confianza que el usuario haya decidido otorgar a las interfaces y al tráfico dentro de esa red. Una conexión sólo puede formar parte de una zona, pero una zona puede utilizarse para muchas conexiones de red.
NetworkManager notifica a firewalld la zona de una interfaz. Puede asignar zonas a las interfaces con:
-
NetworkManager -
firewall-configherramienta -
firewall-cmdherramienta de línea de comandos - La consola web de RHEL
Los tres últimos sólo pueden editar los archivos de configuración correspondientes de NetworkManager. Si se cambia la zona de la interfaz mediante la consola web, firewall-cmd o firewall-config, la solicitud se reenvía a NetworkManager y no es gestionada porfirewalld.
Las zonas predefinidas se almacenan en el directorio /usr/lib/firewalld/zones/ y pueden aplicarse instantáneamente a cualquier interfaz de red disponible. Estos archivos se copian en el directorio /etc/firewalld/zones/ sólo después de ser modificados. La configuración por defecto de las zonas predefinidas es la siguiente:
block-
Cualquier conexión de red entrante es rechazada con un mensaje icmp-host-prohibido para
IPv4e icmp6-adm-prohibido paraIPv6. Sólo son posibles las conexiones de red iniciadas desde dentro del sistema. dmz- Para los ordenadores de su zona desmilitarizada de acceso público con acceso limitado a su red interna. Sólo se aceptan las conexiones entrantes seleccionadas.
drop- Todos los paquetes de red entrantes se descartan sin ninguna notificación. Sólo son posibles las conexiones de red salientes.
external- Para usar en redes externas con el enmascaramiento activado, especialmente para los routers. No confía en que los otros ordenadores de la red no dañen su ordenador. Sólo se aceptan las conexiones entrantes seleccionadas.
home- Para usar en casa cuando se confía principalmente en los otros ordenadores de la red. Sólo se aceptan las conexiones entrantes seleccionadas.
internal- Para su uso en redes internas cuando se confía principalmente en los otros ordenadores de la red. Sólo se aceptan las conexiones entrantes seleccionadas.
public- Para su uso en áreas públicas donde no se confía en otros ordenadores de la red. Sólo se aceptan las conexiones entrantes seleccionadas.
trusted- Se aceptan todas las conexiones de red.
work- Para su uso en el trabajo, donde se confía principalmente en los otros ordenadores de la red. Sólo se aceptan las conexiones entrantes seleccionadas.
Una de estas zonas se establece como la zona default. Cuando se añaden conexiones de interfaz a NetworkManager, se asignan a la zona por defecto. En la instalación, la zona por defecto en firewalld se establece como la zona public. La zona por defecto se puede cambiar.
Los nombres de las zonas de red deben ser autoexplicativos y permitir a los usuarios tomar rápidamente una decisión razonable. Para evitar cualquier problema de seguridad, revise la configuración de la zona por defecto y desactive cualquier servicio innecesario según sus necesidades y evaluaciones de riesgo.
26.5.2.3. Servicios predefinidos
Un servicio puede ser una lista de puertos locales, protocolos, puertos de origen y destinos, así como una lista de módulos de ayuda del cortafuegos que se cargan automáticamente si el servicio está activado. El uso de servicios ahorra tiempo a los usuarios porque pueden realizar varias tareas, como abrir puertos, definir protocolos, habilitar el reenvío de paquetes, etc., en un solo paso, en lugar de configurar todo uno tras otro.
Las opciones de configuración de los servicios y la información genérica de los archivos se describen en la página man firewalld.service(5). Los servicios se especifican mediante archivos de configuración XML individuales, que se denominan con el siguiente formato service-name.xml. Se prefieren los nombres de los protocolos a los de los servicios o aplicaciones en firewalld.
Los servicios pueden añadirse y eliminarse mediante la herramienta gráfica firewall-config, firewall-cmd, y firewall-offline-cmd.
También puede editar los archivos XML en el directorio /etc/firewalld/services/. Si el usuario no añade o modifica un servicio, no se encuentra el archivo XML correspondiente en /etc/firewalld/services/. Los archivos del directorio /usr/lib/firewalld/services/ pueden utilizarse como plantillas si se desea añadir o modificar un servicio.
Recursos adicionales
-
firewalld.service(5)página de manual
26.5.3. Instalación de la herramienta de configuración GUI firewall-config
Para utilizar la herramienta de configuración GUI firewall-config, instale el paquete firewall-config.
Procedimiento
Introduzca el siguiente comando como
root:# yum install firewall-configAlternativamente, en
GNOME, use the Super key and type `Softwarepara iniciar la aplicaciónSoftware Sources. Escribafirewallen el cuadro de búsqueda, que aparece después de seleccionar el botón de búsqueda en la esquina superior derecha. Seleccione el elementoFirewallen los resultados de la búsqueda y haga clic en el botón .-
Para ejecutar
firewall-config, utilice el comandofirewall-configo pulse la tecla Super para entrar enActivities Overview, escribafirewally pulse Enter.
26.5.4. Ver el estado actual y la configuración de firewalld
26.5.4.1. Ver el estado actual de firewalld
El servicio de firewall, firewalld, está instalado en el sistema por defecto. Utilice la interfaz CLI de firewalld para comprobar que el servicio se está ejecutando.
Procedimiento
Para ver el estado del servicio:
# firewall-cmd --statePara obtener más información sobre el estado del servicio, utilice el subcomando
systemctl status:# systemctl status firewalld firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor pr Active: active (running) since Mon 2017-12-18 16:05:15 CET; 50min ago Docs: man:firewalld(1) Main PID: 705 (firewalld) Tasks: 2 (limit: 4915) CGroup: /system.slice/firewalld.service └─705 /usr/bin/python3 -Es /usr/sbin/firewalld --nofork --nopid
Recursos adicionales
Es importante saber cómo está configurado firewalld y qué reglas están en vigor antes de intentar editar la configuración. Para mostrar la configuración del cortafuegos, consulte Sección 26.5.4.2, “Ver la configuración actual de firewalld”
26.5.4.2. Ver la configuración actual de firewalld
26.5.4.2.1. Visualización de los servicios permitidos mediante la GUI
Para ver la lista de servicios mediante la herramienta gráfica firewall-config pulse la tecla Super para acceder a la vista general de actividades, escriba firewall y pulse Intro. Aparece la herramienta firewall-config aparece la herramienta. Ahora puede ver la lista de servicios en la pestaña Services.
Como alternativa, para iniciar la herramienta gráfica de configuración del cortafuegos mediante la línea de comandos, introduzca el siguiente comando:
$ firewall-config
Se abre la ventana Firewall Configuration. Tenga en cuenta que este comando se puede ejecutar como un usuario normal, pero ocasionalmente se le pedirá una contraseña de administrador.
26.5.4.2.2. Visualización de la configuración de firewalld mediante la CLI
Con el cliente CLI, es posible obtener diferentes vistas de la configuración actual del cortafuegos. La opción --list-all muestra una visión completa de la configuración de firewalld.
firewalld utiliza zonas para gestionar el tráfico. Si no se especifica una zona mediante la opción --zone, el comando es efectivo en la zona por defecto asignada a la interfaz de red y la conexión activas.
Para listar toda la información relevante para la zona por defecto:
# firewall-cmd --list-all
public
target: default
icmp-block-inversion: no
interfaces:
sources:
services: ssh dhcpv6-client
ports:
protocols:
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:
Para especificar la zona para la que se muestran los ajustes, añada el argumento --zone=zone-name al comando firewall-cmd --list-all, por ejemplo:
# firewall-cmd --list-all --zone=home
home
target: default
icmp-block-inversion: no
interfaces:
sources:
services: ssh mdns samba-client dhcpv6-client
... [trimmed for clarity]
Para ver la configuración de una información concreta, como los servicios o los puertos, utilice una opción específica. Consulte las páginas del manual firewalld u obtenga una lista de las opciones utilizando la ayuda del comando:
# firewall-cmd --help
Usage: firewall-cmd [OPTIONS...]
General Options
-h, --help Prints a short help text and exists
-V, --version Print the version string of firewalld
-q, --quiet Do not print status messages
Status Options
--state Return and print firewalld state
--reload Reload firewall and keep state information
... [trimmed for clarity]Por ejemplo, para ver qué servicios están permitidos en la zona actual:
# firewall-cmd --list-services
ssh dhcpv6-client
El listado de las configuraciones para una determinada subparte utilizando la herramienta CLI puede ser a veces difícil de interpretar. Por ejemplo, usted permite el servicio SSH y firewalld abre el puerto necesario (22) para el servicio. Más tarde, si se listan los servicios permitidos, la lista muestra el servicio SSH, pero si se listan los puertos abiertos, no muestra ninguno. Por lo tanto, se recomienda utilizar la opción --list-all para asegurarse de recibir una información completa.
26.5.5. Iniciando firewalld
Procedimiento
Para iniciar
firewalld, introduzca el siguiente comando comoroot:# systemctl unmask firewalld # systemctl start firewalldPara garantizar que
firewalldse inicie automáticamente al arrancar el sistema, introduzca el siguiente comando comoroot:# systemctl enable firewalld
26.5.6. Detención de firewalld
Procedimiento
Para detener
firewalld, introduzca el siguiente comando comoroot:# systemctl stop firewalldPara evitar que
firewalldse inicie automáticamente al arrancar el sistema:# systemctl disable firewalldPara asegurarse de que firewalld no se inicia accediendo a la interfaz
firewalldD-Busy también si otros servicios requierenfirewalld:# systemctl mask firewalld
26.5.7. Tiempo de ejecución y ajustes permanentes
Cualquier cambio realizado en el modo runtime sólo se aplica mientras firewalld está en funcionamiento. Cuando se reinicia firewalld, los ajustes vuelven a sus valores de permanent.
Para que los cambios persistan en los reinicios, aplíquelos de nuevo utilizando la opción --permanent. Alternativamente, para hacer que los cambios sean persistentes mientras se ejecuta firewalld, utilice la opción --runtime-to-permanent firewall-cmd .
Si establece las reglas mientras firewalld se está ejecutando utilizando sólo la opción --permanent, no se hacen efectivas antes de que se reinicie firewalld. Sin embargo, al reiniciar firewalld se cierran todos los puertos abiertos y se detiene el tráfico de red.
Modificación de ajustes en tiempo de ejecución y configuración permanente mediante CLI
Utilizando la CLI, no se modifica la configuración del cortafuegos en ambos modos al mismo tiempo. Sólo se modifica el modo de tiempo de ejecución o el modo permanente. Para modificar la configuración del cortafuegos en el modo permanente, utilice la opción --permanent con el comando firewall-cmd.
# firewall-cmd --permanent <other options>Sin esta opción, el comando modifica el modo de ejecución.
Para cambiar los ajustes en ambos modos, puedes utilizar dos métodos:
Cambie la configuración de tiempo de ejecución y luego hágala permanente de la siguiente manera:
# firewall-cmd <other options> # firewall-cmd --runtime-to-permanentEstablezca los ajustes permanentes y recargue los ajustes en el modo de ejecución:
# firewall-cmd --permanent <other options> # firewall-cmd --reload
El primer método permite probar los ajustes antes de aplicarlos al modo permanente.
Es posible, especialmente en los sistemas remotos, que una configuración incorrecta haga que un usuario se bloquee en una máquina. Para evitar estas situaciones, utilice la opción --timeout. Después de un tiempo determinado, cualquier cambio vuelve a su estado anterior. El uso de esta opción excluye la opción --permanent.
Por ejemplo, para añadir el servicio SSH durante 15 minutos:
# firewall-cmd --add-service=ssh --timeout 15m26.5.8. Verificación de la configuración permanente de firewalld
En ciertas situaciones, por ejemplo después de editar manualmente los archivos de configuración de firewalld, los administradores quieren verificar que los cambios son correctos. Esta sección describe cómo verificar la configuración permanente del servicio firewalld.
Requisitos previos
-
El servicio
firewalldestá funcionando.
Procedimiento
Verifique la configuración permanente del servicio
firewalld:# firewall-cmd --check-config successSi la configuración permanente es válida, el comando devuelve
success. En otros casos, el comando devuelve un error con más detalles, como el siguiente:# firewall-cmd --check-config Error: INVALID_PROTOCOL: 'public.xml': 'tcpx' not from {'tcp'|'udp'|'sctp'|'dccp'}
26.5.9. Controlar el tráfico de la red mediante firewalld
26.5.9.1. Desactivación de todo el tráfico en caso de emergencia mediante CLI
En una situación de emergencia, como un ataque al sistema, es posible desactivar todo el tráfico de la red y cortar al atacante.
Procedimiento
Para desactivar inmediatamente el tráfico de red, active el modo de pánico:
# firewall-cmd --panic-on
La activación del modo pánico detiene todo el tráfico de red. Por esta razón, sólo debe utilizarse cuando se tiene el acceso físico a la máquina o si se ha iniciado la sesión mediante una consola serie.
Al desactivar el modo de pánico, el cortafuegos vuelve a su configuración permanente. Para desactivar el modo de pánico:
# firewall-cmd --panic-offPara ver si el modo de pánico está activado o desactivado, utilice:
# firewall-cmd --query-panic26.5.9.2. Control del tráfico con servicios predefinidos mediante CLI
El método más sencillo para controlar el tráfico es añadir un servicio predefinido a firewalld. Así se abren todos los puertos necesarios y se modifican otras configuraciones según el service definition file.
Procedimiento
Compruebe que el servicio no está ya permitido:
# firewall-cmd --list-services ssh dhcpv6-clientEnumerar todos los servicios predefinidos:
# firewall-cmd --get-services RH-Satellite-6 amanda-client amanda-k5-client bacula bacula-client bitcoin bitcoin-rpc bitcoin-testnet bitcoin-testnet-rpc ceph ceph-mon cfengine condor-collector ctdb dhcp dhcpv6 dhcpv6-client dns docker-registry ... [trimmed for clarity]Añade el servicio a los servicios permitidos:
# firewall-cmd --add-service=<nombre-servicio>Haz que la nueva configuración sea persistente:
# firewall-cmd --runtime-to-permanent
26.5.9.3. Control del tráfico con servicios predefinidos mediante la interfaz gráfica de usuario
Para activar o desactivar un servicio predefinido o personalizado:
- Inicie la herramienta firewall-config herramienta y seleccione la zona de red cuyos servicios se van a configurar.
-
Seleccione la pestaña
Services. - Seleccione la casilla de cada tipo de servicio en el que desee confiar o desactive la casilla para bloquear un servicio.
Para editar un servicio:
- Inicie la firewall-config herramienta.
-
Seleccione
Permanenten el menú denominadoConfiguration. En la parte inferior de la ventana de aparecen otros iconos y botones de menú. - Seleccione el servicio que desea configurar.
Las pestañas Ports, Protocols, y Source Port permiten añadir, cambiar y eliminar puertos, protocolos y puerto de origen para el servicio seleccionado. La pestaña de módulos es para configurar Netfilter módulos de ayuda. La pestaña Destination permite limitar el tráfico a una dirección de destino y un protocolo de Internet concretos (IPv4 o IPv6).
No es posible modificar los ajustes de servicio en el modo Runtime.
26.5.9.4. Añadir nuevos servicios
Los servicios pueden añadirse y eliminarse utilizando la herramienta gráfica firewall-config firewall-cmd y firewall-offline-cmd. También se pueden editar los archivos XML en /etc/firewalld/services/. Si el usuario no añade o modifica un servicio, no se encuentra el archivo XML correspondiente en /etc/firewalld/services/. Los archivos /usr/lib/firewalld/services/ pueden utilizarse como plantillas si se desea añadir o modificar un servicio.
Los nombres de los servicios deben ser alfanuméricos y, además, sólo pueden incluir los caracteres _ (guión bajo) y - (guión).
Procedimiento
Para añadir un nuevo servicio en un terminal, utilice firewall-cmd, o firewall-offline-cmd en caso de que no esté activo firewalld.
Introduzca el siguiente comando para añadir un servicio nuevo y vacío:
$ firewall-cmd --new-service=service-name --permanentPara añadir un nuevo servicio utilizando un archivo local, utilice el siguiente comando:
$ firewall-cmd --new-service-from-file=service-name.xml --permanentPuede cambiar el nombre del servicio con la opción adicional
--name=service-nameadicional.En cuanto se modifican los ajustes del servicio, se coloca una copia actualizada del mismo en
/etc/firewalld/services/.Como
root, puede introducir el siguiente comando para copiar un servicio manualmente:# cp /usr/lib/firewalld/services/service-name.xml /etc/firewalld/services/service-name.xml
firewalld carga los archivos de /usr/lib/firewalld/services en primer lugar. Si los archivos se colocan en /etc/firewalld/services y son válidos, entonces estos anularán los archivos coincidentes de /usr/lib/firewalld/services. Los archivos anulados en /usr/lib/firewalld/services se utilizan tan pronto como los archivos coincidentes en /etc/firewalld/services se hayan eliminado o si se ha pedido a firewalld que cargue los valores predeterminados de los servicios. Esto se aplica sólo al entorno permanente. Se necesita una recarga para obtener estos fallbacks también en el entorno de ejecución.
26.5.9.5. Controlar los puertos mediante la CLI
Los puertos son dispositivos lógicos que permiten a un sistema operativo recibir y distinguir el tráfico de red y reenviarlo en consecuencia a los servicios del sistema. Suelen estar representados por un demonio que escucha en el puerto, es decir, que espera cualquier tráfico que llegue a este puerto.
Normalmente, los servicios del sistema escuchan en los puertos estándar que están reservados para ellos. El demonio httpd, por ejemplo, escucha en el puerto 80. Sin embargo, los administradores del sistema configuran por defecto los dæmons para que escuchen en diferentes puertos para mejorar la seguridad o por otras razones.
26.5.9.5.1. Abrir un puerto
A través de los puertos abiertos, el sistema es accesible desde el exterior, lo que representa un riesgo de seguridad. Por lo general, mantén los puertos cerrados y sólo ábrelos si son necesarios para determinados servicios.
Procedimiento
Para obtener una lista de puertos abiertos en la zona actual:
Lista de todos los puertos permitidos:
# firewall-cmd --list-portsAñade un puerto a los puertos permitidos para abrirlo al tráfico entrante:
# firewall-cmd --add-port=número de puerto/tipo de puertoHaz que la nueva configuración sea persistente:
# firewall-cmd --runtime-to-permanent
Los tipos de puerto son tcp, udp, sctp, o dccp. El tipo debe coincidir con el tipo de comunicación de red.
26.5.9.5.2. Cerrar un puerto
Cuando un puerto abierto ya no es necesario, cierre ese puerto en firewalld. Se recomienda encarecidamente cerrar todos los puertos innecesarios en cuanto no se utilicen, ya que dejar un puerto abierto representa un riesgo para la seguridad.
Procedimiento
Para cerrar un puerto, elimínelo de la lista de puertos permitidos:
Lista de todos los puertos permitidos:
# firewall-cmd --list-ports [WARNING] ==== This command will only give you a list of ports that have been opened as ports. You will not be able to see any open ports that have been opened as a service. Therefore, you should consider using the --list-all option instead of --list-ports. ====Elimina el puerto de los puertos permitidos para cerrarlo al tráfico entrante:
# firewall-cmd --remove-port=número de puerto/tipo de puertoHaz que la nueva configuración sea persistente:
# firewall-cmd --runtime-to-permanent
26.5.9.6. Abrir puertos mediante la GUI
Para permitir el tráfico a través del firewall a un determinado puerto:
- Inicie la firewall-config herramienta y seleccione la zona de red cuya configuración desea modificar.
-
Seleccione la pestaña
Portsy haga clic en el botón de la derecha. Se abre la ventanaPort and Protocol. - Introduzca el número de puerto o el rango de puertos a permitir.
-
Seleccione
tcpoudpde la lista.
26.5.9.7. Control del tráfico con protocolos mediante GUI
Para permitir el tráfico a través del cortafuegos utilizando un determinado protocolo:
- Inicie la firewall-config herramienta y seleccione la zona de red cuya configuración desea modificar.
-
Seleccione la pestaña
Protocolsy haga clic en el botónAddde la derecha. Se abre la ventanaProtocol. -
Seleccione un protocolo de la lista o marque la casilla
Other Protocole introduzca el protocolo en el campo.
26.5.9.8. Abrir puertos de origen mediante la GUI
Para permitir el tráfico a través del cortafuegos desde un determinado puerto:
- Inicie la herramienta de configuración del cortafuegos y seleccione la zona de red cuya configuración desea modificar.
-
Seleccione la pestaña
Source Porty haga clic en el botónAddde la derecha. Se abre la ventanaSource Port. -
Introduzca el número de puerto o el rango de puertos a permitir. Seleccione
tcpoudpde la lista.
26.5.10. Trabajar con zonas de firewalld
Las zonas representan un concepto para gestionar el tráfico entrante de forma más transparente. Las zonas están conectadas a interfaces de red o se les asigna un rango de direcciones de origen. Las reglas del cortafuegos se gestionan para cada zona de forma independiente, lo que permite definir configuraciones complejas del cortafuegos y aplicarlas al tráfico.
26.5.10.1. Zonas de cotización
Procedimiento
Para ver qué zonas están disponibles en su sistema:
# firewall-cmd --get-zonesEl comando
firewall-cmd --get-zonesmuestra todas las zonas que están disponibles en el sistema, pero no muestra ningún detalle de zonas concretas.Para ver información detallada de todas las zonas:
# firewall-cmd --list-all-zonesPara ver información detallada de una zona concreta:
# firewall-cmd --zone=nombre-de-la-zona --list-all
26.5.10.2. Modificación de la configuración de firewalld para una zona determinada
En Sección 26.5.9.2, “Control del tráfico con servicios predefinidos mediante CLI” y Sección 26.5.9.5, “Controlar los puertos mediante la CLI” se explica cómo añadir servicios o modificar puertos en el ámbito de la zona de trabajo actual. A veces, es necesario establecer reglas en una zona diferente.
Procedimiento
-
Para trabajar en una zona diferente, utilice la opción
--zone=zone-nameopción. Por ejemplo, para permitir el servicioSSHen la zona public:
# firewall-cmd --add-service=ssh --zone=public26.5.10.3. Cambiar la zona por defecto
Los administradores del sistema asignan una zona a una interfaz de red en sus archivos de configuración. Si una interfaz no está asignada a una zona específica, se asigna a la zona por defecto. Después de cada reinicio del servicio firewalld, firewalld carga la configuración de la zona por defecto y la activa.
Procedimiento
Para configurar la zona por defecto:
Muestra la zona actual por defecto:
# firewall-cmd --get-default-zoneEstablezca la nueva zona por defecto:
# firewall-cmd --set-default-zone zone-nameNotaSiguiendo este procedimiento, el ajuste es permanente, incluso sin la opción
--permanent.
26.5.10.4. Asignación de una interfaz de red a una zona
Es posible definir diferentes conjuntos de reglas para diferentes zonas y luego cambiar la configuración rápidamente cambiando la zona para la interfaz que se está utilizando. Con múltiples interfaces, se puede establecer una zona específica para cada una de ellas para distinguir el tráfico que llega a través de ellas.
Procedimiento
Para asignar la zona a una interfaz específica:
Enumera las zonas activas y las interfaces asignadas a ellas:
# firewall-cmd --get-active-zonesAsigne la interfaz a una zona diferente:
# firewall-cmd --zone=zone_name --change-interface=interface_name --permanent
26.5.10.5. Asignación de una zona a una conexión mediante nmcli
Este procedimiento describe cómo añadir una zona de firewalld a una conexión de NetworkManager utilizando la utilidad nmcli.
Procedimiento
Asigna la zona al perfil de conexión de NetworkManager:
# nmcli connection modify profile connection.zone zone_nameRecarga la conexión:
# nmcli connection up profile
26.5.10.6. Asignación manual de una zona a una conexión de red en un archivo ifcfg
Cuando la conexión es gestionada por NetworkManagerdebe conocer una zona que utiliza. Para cada conexión de red, se puede especificar una zona, lo que proporciona la flexibilidad de varias configuraciones de cortafuegos según la ubicación del ordenador con dispositivos portátiles. Así, se pueden especificar zonas y configuraciones para diferentes ubicaciones, como la empresa o el hogar.
Procedimiento
Para establecer una zona para una conexión, edite el archivo
/etc/sysconfig/network-scripts/ifcfg-connection_namey añada una línea que asigne una zona a esta conexión:ZONA=zone_name
26.5.10.7. Crear una nueva zona
Para utilizar zonas personalizadas, cree una nueva zona y utilícela igual que una zona predefinida. Las nuevas zonas requieren la opción --permanent, de lo contrario el comando no funciona.
Procedimiento
Para crear una nueva zona:
Crear una nueva zona:
# firewall-cmd --new-zone=nombre-de-zonaCompruebe si la nueva zona se ha añadido a su configuración permanente:
# firewall-cmd --get-zonesHaz que la nueva configuración sea persistente:
# firewall-cmd --runtime-to-permanent
26.5.10.8. Archivos de configuración de zona
Las zonas también pueden crearse utilizando un zone configuration file. Este enfoque puede ser útil cuando se necesita crear una nueva zona, pero se quiere reutilizar la configuración de otra zona y sólo alterarla un poco.
Un archivo de configuración de zona firewalld contiene la información de una zona. Se trata de la descripción de la zona, los servicios, los puertos, los protocolos, los bloqueos icmp, la mascarada, los puertos de reenvío y las reglas de lenguaje enriquecido en formato de archivo XML. El nombre del archivo debe ser zone-name.xml donde la longitud de zone-name está limitada actualmente a 17 caracteres. Los archivos de configuración de zona se encuentran en los directorios /usr/lib/firewalld/zones/ y /etc/firewalld/zones/.
El siguiente ejemplo muestra una configuración que permite un servicio (SSH) y un rango de puertos, tanto para los protocolos TCP como UDP:
<?xml version="1.0" encoding="utf-8"?>
<zone>
<short>My zone</short>
<description>Here you can describe the characteristic features of the zone.</description>
<service name="ssh"/>
<port port="1025-65535" protocol="tcp"/>
<port port="1025-65535" protocol="udp"/>
</zone>Para cambiar la configuración de esa zona, añada o elimine secciones para añadir puertos, reenviar puertos, servicios, etc.
Recursos adicionales
-
Para más información, consulte las páginas del manual
firewalld.zone.
26.5.10.9. Uso de objetivos de zona para establecer el comportamiento por defecto para el tráfico entrante
Para cada zona, se puede establecer un comportamiento por defecto que gestione el tráfico entrante que no se especifique más. Este comportamiento se define estableciendo el objetivo de la zona. Hay cuatro opciones - default, ACCEPT, REJECT, y DROP. Si se establece el objetivo en ACCEPT, se aceptan todos los paquetes entrantes excepto los deshabilitados por una regla específica. Si establece el objetivo en REJECT o DROP, deshabilita todos los paquetes entrantes excepto los que haya permitido en reglas específicas. Cuando los paquetes son rechazados, la máquina de origen es informada del rechazo, mientras que no se envía ninguna información cuando los paquetes son descartados.
Procedimiento
Para establecer un objetivo para una zona:
Enumerar la información de la zona específica para ver el objetivo por defecto:
$ firewall-cmd --zone=zone-name --list-allEstablece un nuevo objetivo en la zona:
# firewall-cmd --permanent --zone=nombre-de-zona --set-target=<default|ACCEPT|REJECT|DROP>
26.5.11. Uso de zonas para gestionar el tráfico entrante en función de una fuente
26.5.11.1. Uso de zonas para gestionar el tráfico entrante en función de una fuente
Puede utilizar las zonas para gestionar el tráfico entrante en función de su origen. Esto le permite clasificar el tráfico entrante y enrutarlo a través de diferentes zonas para permitir o rechazar los servicios que pueden ser alcanzados por ese tráfico.
Si añade una fuente a una zona, ésta se activa y todo el tráfico entrante procedente de esa fuente será dirigido a través de ella. Puede especificar diferentes configuraciones para cada zona, que se aplican al tráfico de las fuentes dadas en consecuencia. Puede utilizar más zonas aunque sólo tenga una interfaz de red.
26.5.11.2. Añadir una fuente
Para enrutar el tráfico entrante hacia una fuente específica, añada la fuente a esa zona. El origen puede ser una dirección IP o una máscara IP en la notación Classless Inter-domain Routing (CIDR).
En caso de que añada varias zonas con un rango de red superpuesto, se ordenan alfanuméricamente por nombre de zona y sólo se tiene en cuenta la primera.
Para fijar la fuente en la zona actual:
# firewall-cmd --add-source=<source>Para establecer la dirección IP de origen para una zona específica:
# firewall-cmd --zone=nombre-de-la-zona --add-source=<source>
El siguiente procedimiento permite todo el tráfico entrante de 192.168.2.15 en la zona trusted:
Procedimiento
Enumera todas las zonas disponibles:
# firewall-cmd --get-zonesAñade la IP de origen a la zona de confianza en el modo permanente:
# firewall-cmd --zone=trusted --add-source=192.168.2.15Haz que la nueva configuración sea persistente:
# firewall-cmd --runtime-to-permanent
26.5.11.3. Eliminar una fuente
Al eliminar una fuente de la zona se corta el tráfico procedente de ella.
Procedimiento
Lista de fuentes permitidas para la zona requerida:
# firewall-cmd --zone=nombre-de-la-zona --list-sourcesEliminar la fuente de la zona de forma permanente:
# firewall-cmd --zone=nombre-de-zona --remove-source=<source>Haz que la nueva configuración sea persistente:
# firewall-cmd --runtime-to-permanent
26.5.11.4. Añadir un puerto de origen
Para habilitar la clasificación del tráfico basada en un puerto de origen, especifique un puerto de origen utilizando la opción --add-source-port. También puede combinar esto con la opción --add-source para limitar el tráfico a una determinada dirección IP o rango de IP.
Procedimiento
Para añadir un puerto de origen:
# firewall-cmd --zone=nombre-de-la-zona --add-source-port=-nombre-de-puerto>/<tcp|udp|sctp|dccp>
26.5.11.5. Eliminación de un puerto de origen
Al eliminar un puerto de origen se desactiva la clasificación del tráfico en función de un puerto de origen.
Procedimiento
Para eliminar un puerto de origen:
# firewall-cmd --zone=nombre-de-la-zona --remove-source-port=-nombre-de-puerto>/<tcp|udp|sctp|dccp>
26.5.11.6. Uso de zonas y fuentes para permitir un servicio sólo para un dominio específico
Para permitir que el tráfico de una red específica utilice un servicio en una máquina, utilice las zonas y el origen. El siguiente procedimiento permite que el tráfico de 192.168.1.0/24 pueda llegar al servicio HTTP mientras que cualquier otro tráfico está bloqueado.
Procedimiento
Enumera todas las zonas disponibles:
# firewall-cmd --get-zones block dmz drop external home internal public trusted workAñade el origen a la zona de confianza para enrutar el tráfico originado por el origen a través de la zona:
# firewall-cmd --zone=trusted --add-source=192.168.1.0/24Añade el servicio http en la zona de confianza:
# firewall-cmd --zone=trusted --add-service=httpHaz que la nueva configuración sea persistente:
# firewall-cmd --runtime-to-permanentCompruebe que la zona de confianza está activa y que el servicio está permitido en ella:
# firewall-cmd --zone=trusted --list-all trusted (active) target: ACCEPT sources: 192.168.1.0/24 services: http
26.5.11.7. Configurar el tráfico aceptado por una zona en función de un protocolo
Puede permitir que el tráfico entrante sea aceptado por una zona basándose en un protocolo. Todo el tráfico que utiliza el protocolo especificado es aceptado por una zona, en la que puede aplicar más reglas y filtrado.
26.5.11.7.1. Añadir un protocolo a una zona
Al añadir un protocolo a una zona determinada, se permite que todo el tráfico con este protocolo sea aceptado por esta zona.
Procedimiento
Para añadir un protocolo a una zona:
# firewall-cmd --zone=nombre-de-zona --add-protocolo=nombre-de-puerto/tcp|udp|sctp|dccp|igmp
Para recibir tráfico de multidifusión, utilice el valor igmp con la opción --add-protocol.
26.5.11.7.2. Eliminar un protocolo de una zona
Al eliminar un protocolo de una zona determinada, se deja de aceptar todo el tráfico basado en este protocolo por la zona.
Procedimiento
Para eliminar un protocolo de una zona:
# firewall-cmd --zone=nombre-de-zona --remove-protocolo=nombre-de-puerto/tcp|udp|sctp|dccp|igmp
26.5.12. Configuración del enmascaramiento de direcciones IP
El siguiente procedimiento describe cómo habilitar el enmascaramiento de IP en su sistema. El enmascaramiento de IP oculta las máquinas individuales detrás de una puerta de enlace cuando se accede a Internet.
Procedimiento
Para comprobar si el enmascaramiento de IP está activado (por ejemplo, para la zona
external), introduzca el siguiente comando comoroot:# firewall-cmd --zone=external --query-masqueradeEl comando imprime
yescon el estado de salida0si está activado. Imprimenocon el estado de salida1en caso contrario. Si se omitezone, se utilizará la zona por defecto.Para activar el enmascaramiento de IP, introduzca el siguiente comando como
root:# firewall-cmd --zone=external --add-masquerade-
Para que esta configuración sea persistente, repita el comando añadiendo la opción
--permanent.
Para desactivar el enmascaramiento de IP, introduzca el siguiente comando como root:
# firewall-cmd --zone=external --remove-masquerade --permanent26.5.13. Reenvío de puertos
El redireccionamiento de puertos mediante este método sólo funciona para el tráfico basado en IPv4. Para la configuración de redireccionamiento de IPv6, debe utilizar reglas ricas.
Para redirigir a un sistema externo, es necesario habilitar el enmascaramiento. Para más información, consulte Configuración del enmascaramiento de direcciones IP.
26.5.13.1. Añadir un puerto para redirigir
Utilizando firewalld, puede configurar la redirección de puertos para que cualquier tráfico entrante que llegue a un determinado puerto de su sistema sea entregado a otro puerto interno de su elección o a un puerto externo de otra máquina.
Requisitos previos
- Antes de redirigir el tráfico de un puerto a otro puerto, o a otra dirección, hay que saber tres cosas: a qué puerto llegan los paquetes, qué protocolo se utiliza y a dónde se quiere redirigir.
Procedimiento
Para redirigir un puerto a otro puerto:
# firewall-cmd --add-forward-port=puerto=número de puerto:proto=tcp|udp|sctp|dccp:toport=número de puertoPara redirigir un puerto a otro puerto en una dirección IP diferente:
Añade el puerto a reenviar:
# firewall-cmd --add-forward-port=puerto=número de puerto:proto=tcp|udp:toport=número de puerto:toaddr=IPHabilitar la mascarada:
# firewall-cmd --add-masquerade
26.5.13.2. Redirigir el puerto TCP 80 al puerto 88 en la misma máquina
Siga los pasos para redirigir el puerto TCP 80 al puerto 88.
Procedimiento
Redirige el puerto 80 al puerto 88 para el tráfico TCP:
# firewall-cmd --add-forward-port=80:proto=tcp:toport=88Haz que la nueva configuración sea persistente:
# firewall-cmd --runtime-to-permanentCompruebe que el puerto está redirigido:
# firewall-cmd --list-all
26.5.13.3. Eliminación de un puerto redirigido
Para eliminar un puerto redirigido:
# firewall-cmd --remove-forward-port=puerto=número de puerto:proto=<tcp|udp>:toport=número de puerto:toaddr=<IP>Para eliminar un puerto redirigido a una dirección diferente, utilice el siguiente procedimiento.
Procedimiento
Elimina el puerto reenviado:
# firewall-cmd --remove-forward-port=puerto=número de puerto:proto=<tcp|udp>:toport=número de puerto:toaddr=<IP>Desactivar la mascarada:
# firewall-cmd --remove-masquerade
26.5.13.4. Eliminación del puerto TCP 80 reenviado al puerto 88 en la misma máquina
Para eliminar la redirección de puertos:
Procedimiento
Lista de puertos redirigidos:
~]# firewall-cmd --list-forward-ports port=80:proto=tcp:toport=88:toaddr=Elimine el puerto redirigido del cortafuegos::
~]# firewall-cmd --remove-forward-port=port=80:proto=tcp:toport=88:toaddr=Haz que la nueva configuración sea persistente:
~]# firewall-cmd --runtime-to-permanent
26.5.14. Gestión de peticiones ICMP
El Internet Control Message Protocol (ICMP) es un protocolo de apoyo que utilizan varios dispositivos de red para enviar mensajes de error e información operativa que indican un problema de conexión, por ejemplo, que un servicio solicitado no está disponible. ICMP se diferencia de los protocolos de transporte como TCP y UDP porque no se utiliza para intercambiar datos entre sistemas.
Lamentablemente, es posible utilizar los mensajes de ICMP, especialmente echo-request y echo-reply, para revelar información sobre su red y hacer un mal uso de dicha información para diversos tipos de actividades fraudulentas. Por lo tanto, firewalld permite bloquear las solicitudes de ICMP para proteger la información de su red.
26.5.14.1. Listado y bloqueo de peticiones ICMP
Listado ICMP solicitudes
Las solicitudes de ICMP se describen en archivos XML individuales que se encuentran en el directorio /usr/lib/firewalld/icmptypes/. Puede leer estos archivos para ver una descripción de la solicitud. El comando firewall-cmd controla la manipulación de las peticiones de ICMP.
Para listar todos los tipos disponibles de
ICMP:# firewall-cmd --get-icmptypesLa petición
ICMPpuede ser utilizada por IPv4, IPv6 o por ambos protocolos. Para ver para qué protocolo se utiliza la peticiónICMP:# firewall-cmd --info-icmptype=<icmptype>El estado de una solicitud
ICMPmuestrayessi la solicitud está actualmente bloqueada onosi no lo está. Para ver si una solicitud deICMPestá actualmente bloqueada:# firewall-cmd --query-icmp-block=<icmptype>
Bloqueo o desbloqueo de las solicitudes de ICMP
Cuando su servidor bloquea las solicitudes de ICMP, no proporciona la información que normalmente proporcionaría. Sin embargo, eso no significa que no se proporcione ninguna información. Los clientes reciben información de que la petición ICMP en particular está siendo bloqueada (rechazada). El bloqueo de las peticiones a ICMP debe considerarse cuidadosamente, porque puede causar problemas de comunicación, especialmente con el tráfico IPv6.
Para ver si una solicitud de
ICMPestá actualmente bloqueada:# firewall-cmd --query-icmp-block=<icmptype>Para bloquear una solicitud de
ICMP:# firewall-cmd --add-icmp-block=<icmptype>Para eliminar el bloqueo de una solicitud de
ICMP:# firewall-cmd --remove-icmp-block=<icmptype>
Bloqueo de las solicitudes de ICMP sin proporcionar ninguna información
Normalmente, si bloqueas las peticiones de ICMP, los clientes saben que lo estás bloqueando. Por lo tanto, un atacante potencial que esté husmeando en busca de direcciones IP activas todavía es capaz de ver que tu dirección IP está en línea. Para ocultar esta información por completo, tienes que eliminar todas las peticiones de ICMP.
-
Para bloquear y abandonar todas las solicitudes de
ICMP:
Establezca el objetivo de su zona en
DROP:# firewall-cmd --permanent --set-target=DROP
Ahora, todo el tráfico, incluyendo las solicitudes de ICMP, se descarta, excepto el tráfico que usted ha permitido explícitamente.
-
Para bloquear y eliminar ciertas solicitudes de
ICMPy permitir otras:
Establezca el objetivo de su zona en
DROP:# firewall-cmd --permanent --set-target=DROPAñade la inversión de bloque ICMP para bloquear todas las peticiones de
ICMPa la vez:# firewall-cmd --add-icmp-block-inversionAñade el bloqueo ICMP para aquellas peticiones de
ICMPque quieras permitir:# firewall-cmd --add-icmp-block=<icmptype>Haz que la nueva configuración sea persistente:
# firewall-cmd --runtime-to-permanent
El block inversion invierte la configuración de los bloqueos de las peticiones de ICMP, por lo que todas las peticiones, que antes no estaban bloqueadas, se bloquean debido a que el objetivo de su zona cambia a DROP. Las peticiones que estaban bloqueadas no lo están. Esto significa que si quiere desbloquear una petición, debe utilizar el comando de bloqueo.
- Para revertir la inversión de bloques a una configuración totalmente permisiva:
Establezca el objetivo de su zona en
defaultoACCEPT:# firewall-cmd --permanent --set-target=defaultEliminar todos los bloques añadidos para las solicitudes de
ICMP:# firewall-cmd --remove-icmp-block=<icmptype>Retire la inversión del bloque
ICMP:# firewall-cmd --remove-icmp-block-inversionHaz que la nueva configuración sea persistente:
# firewall-cmd --runtime-to-permanent
26.5.14.2. Configuración del filtro ICMP mediante la GUI
-
Para activar o desactivar un filtro
ICMP, inicie la herramienta firewall-config herramienta y seleccione la zona de red cuyos mensajes deben ser filtrados. Seleccione la pestañaICMP Filtery marque la casilla correspondiente a cada tipo de mensajeICMPque desee filtrar. Desactive la casilla para desactivar un filtro. Esta configuración es por dirección y el valor por defecto permite todo. -
Para editar un tipo de
ICMP, inicie la herramienta firewall-config herramienta y seleccione el modoPermanenten el menú denominadoConfiguration. Aparecen iconos adicionales en la parte inferior de la ventana de . Seleccione en el siguiente cuadro de diálogo para habilitar el enmascaramiento y hacer que funcione el reenvío a otra máquina. -
Para activar la inversión del
ICMP Filter, haga clic en la casillaInvert Filterde la derecha. Ahora sólo se aceptan los tipos deICMPmarcados, todos los demás se rechazan. En una zona que utilice el objetivo DROP, se descartan.
26.5.15. Ajuste y control de los conjuntos IP mediante firewalld
Para ver la lista de tipos de conjuntos de IP soportados por firewalld, introduzca el siguiente comando como root.
~]# firewall-cmd --get-ipset-types
hash:ip hash:ip,mark hash:ip,port hash:ip,port,ip hash:ip,port,net hash:mac hash:net hash:net,iface hash:net,net hash:net,port hash:net,port,net26.5.15.1. Configuración de las opciones del conjunto IP mediante la CLI
Los conjuntos de IP se pueden utilizar en las zonas de firewalld como fuentes y también como fuentes en reglas ricas. En Red Hat Enterprise Linux, el método preferido es utilizar los conjuntos de IP creados con firewalld en una regla directa.
Para listar los conjuntos de IP conocidos por
firewallden el entorno permanente, utilice el siguiente comando comoroot:# firewall-cmd --permanent --get-ipsetsPara añadir un nuevo conjunto de IP, utilice el siguiente comando utilizando el entorno permanente como
root:# firewall-cmd --permanent --new-ipset=test --type=hash:net successEl comando anterior crea un nuevo conjunto IP con el nombre test y el tipo
hash:netparaIPv4. Para crear un conjunto de IP para usar conIPv6, añada la opción--option=family=inet6. Para que la nueva configuración sea efectiva en el entorno de ejecución, vuelva a cargarfirewalld.Enumere el nuevo conjunto de IP con el siguiente comando como
root:# firewall-cmd --permanent --get-ipsets testPara obtener más información sobre el conjunto de IP, utilice el siguiente comando como
root:# firewall-cmd --permanent --info-ipset=test test type: hash:net options: entries:Tenga en cuenta que el conjunto de IP no tiene ninguna entrada en este momento.
Para añadir una entrada al conjunto de IP de test, utilice el siguiente comando como
root:# firewall-cmd --permanent --ipset=test --add-entry=192.168.0.1 successEl comando anterior añade la dirección IP 192.168.0.1 al conjunto de IP.
Para obtener la lista de entradas actuales en el conjunto de IP, utilice el siguiente comando como
root:# firewall-cmd --permanent --ipset=test --get-entries 192.168.0.1Generar un archivo con una lista de direcciones IP, por ejemplo:
# cat > iplist.txt <<EOL 192.168.0.2 192.168.0.3 192.168.1.0/24 192.168.2.254 EOLEl archivo con la lista de direcciones IP para un conjunto de IP debe contener una entrada por línea. Las líneas que comienzan con una almohadilla, un punto y coma o líneas vacías se ignoran.
Para añadir las direcciones del archivo iplist.txt, utilice el siguiente comando como
root:# firewall-cmd --permanent --ipset=test --add-entries-from-file=iplist.txt successPara ver la lista de entradas extendidas del conjunto de IP, utilice el siguiente comando como
root:# firewall-cmd --permanent --ipset=test --get-entries 192.168.0.1 192.168.0.2 192.168.0.3 192.168.1.0/24 192.168.2.254Para eliminar las direcciones del conjunto de IP y comprobar la lista de entradas actualizada, utilice los siguientes comandos como
root:# firewall-cmd --permanent --ipset=test --remove-entries-from-file=iplist.txt success # firewall-cmd --permanent --ipset=test --get-entries 192.168.0.1Puede añadir el conjunto de IPs como origen a una zona para gestionar todo el tráfico procedente de cualquiera de las direcciones listadas en el conjunto de IPs con una zona. Por ejemplo, para añadir el conjunto de IPs test como origen a la zona drop para descartar todos los paquetes procedentes de todas las entradas listadas en el conjunto de IPs test, utilice el siguiente comando como
root:# firewall-cmd --permanent --zone=drop --add-source=ipset:test successEl prefijo
ipset:en el origen muestra afirewalldque el origen es un conjunto de IP y no una dirección IP o un rango de direcciones.
Sólo la creación y eliminación de conjuntos de IP está limitada al entorno permanente, todas las demás opciones de conjuntos de IP pueden utilizarse también en el entorno de ejecución sin la opción --permanent.
Red Hat no recomienda el uso de conjuntos de IP que no sean gestionados a través de firewalld. Para usar tales conjuntos de IP, se requiere una regla directa permanente para referenciar el conjunto, y se debe agregar un servicio personalizado para crear estos conjuntos de IP. Este servicio debe iniciarse antes de que se inicie firewalld, de lo contrario firewalld no podrá añadir las reglas directas que utilizan estos conjuntos. Puede añadir reglas directas permanentes con el archivo /etc/firewalld/direct.xml.
26.5.16. Priorizar las reglas ricas
Por defecto, las reglas ricas se organizan en base a su acción de regla. Por ejemplo, las reglas de deny tienen prioridad sobre las de allow. El parámetro priority en las reglas ricas proporciona a los administradores un control detallado sobre las reglas ricas y su orden de ejecución.
26.5.16.1. Cómo el parámetro de prioridad organiza las reglas en diferentes cadenas
Puede establecer el parámetro priority en una regla rica en cualquier número entre -32768 y 32767, y los valores más bajos tienen mayor precedencia.
El servicio firewalld organiza las reglas en función de su valor de prioridad en diferentes cadenas:
-
Prioridad inferior a 0: la regla se redirige a una cadena con el sufijo
_pre. -
Prioridad superior a 0: la regla se redirige a una cadena con el sufijo
_post. -
Prioridad igual a 0: en función de la acción, la regla se redirige a una cadena con el
_log,_deny, o_allowla acción.
Dentro de estas subcadenas, firewalld ordena las reglas en función de su valor de prioridad.
26.5.16.2. Establecer la prioridad de una regla rica
El procedimiento describe un ejemplo de cómo crear una regla rica que utiliza el parámetro priority para registrar todo el tráfico no permitido o denegado por otras reglas. Puede utilizar esta regla para marcar el tráfico inesperado.
Procedimiento
Añade una regla rica con una precedencia muy baja para registrar todo el tráfico que no haya sido igualado por otras reglas:
# firewall-cmd --add-rich-rule='rule priority=32767 log prefix="UNEXPECTED: " limit value="5/m"'Además, el comando limita el número de entradas de registro a
5por minuto.Opcionalmente, visualice la regla
nftablesque el comando del paso anterior creó:# nft list chain inet firewalld filter_IN_public_post table inet firewalld { chain filter_IN_public_post { log prefix "UNEXPECTED: " limit rate 5/minute } }
26.5.17. Configuración del bloqueo del cortafuegos
Las aplicaciones o servicios locales pueden cambiar la configuración del cortafuegos si se ejecutan como root (por ejemplo, libvirt). Con esta función, el administrador puede bloquear la configuración del cortafuegos para que ninguna aplicación o sólo las aplicaciones añadidas a la lista de permisos de bloqueo puedan solicitar cambios en el cortafuegos. La configuración de bloqueo está desactivada por defecto. Si está activada, el usuario puede estar seguro de que no se realizan cambios de configuración no deseados en el cortafuegos por parte de aplicaciones o servicios locales.
26.5.17.1. Configuración del bloqueo mediante la CLI
Para consultar si el bloqueo está activado, utilice el siguiente comando como
root:# firewall-cmd --query-lockdownEl comando imprime
yescon el estado de salida0si el bloqueo está activado. Imprimenocon el estado de salida1en caso contrario.Para activar el bloqueo, introduzca el siguiente comando como
root:# firewall-cmd --lockdown-onPara desactivar el bloqueo, utilice el siguiente comando como
root:# firewall-cmd --lockdown-off
26.5.17.2. Configuración de las opciones de la lista de permisos de bloqueo mediante la CLI
La lista de permisos de bloqueo puede contener comandos, contextos de seguridad, usuarios e identificaciones de usuario. Si la entrada de un comando en la lista permitida termina con un asterisco "*", entonces todas las líneas de comando que comiencen con ese comando coincidirán. Si el asterisco "*" no está ahí, entonces el comando absoluto, incluyendo los argumentos, debe coincidir.
El contexto es el contexto de seguridad (SELinux) de una aplicación o servicio en ejecución. Para obtener el contexto de una aplicación en ejecución utilice el siguiente comando:
$ ps -e --contextEste comando devuelve todas las aplicaciones en ejecución. Pase la salida por la herramienta grep para obtener la aplicación que le interesa. Por ejemplo:
$ ps -e --context | grep ejemplo_programaPara listar todas las líneas de comandos que están en la lista de permitidos, introduzca el siguiente comando como
root:# firewall-cmd --list-lockdown-whitelist-commandsPara añadir un comando command a la lista de permitidos, introduzca el siguiente comando como
root:# firewall-cmd --add-lockdown-whitelist-command='/usr/bin/python3 -Es /usr/bin/command'Para eliminar un comando command de la lista permitida, introduzca el siguiente comando como
root:# firewall-cmd --remove-lockdown-whitelist-command='/usr/bin/python3 -Es /usr/bin/command'Para consultar si el comando command está en la lista permitida, introduzca el siguiente comando como
root:# firewall-cmd --query-lockdown-whitelist-command='/usr/bin/python3 -Es /usr/bin/command'El comando imprime
yescon el estado de salida0si es verdadero. Imprimenocon el estado de salida1en caso contrario.Para listar todos los contextos de seguridad que están en la lista de permitidos, introduzca el siguiente comando como
root:# firewall-cmd --list-lockdown-whitelist-contextsPara añadir un contexto context a la lista de permitidos, introduzca el siguiente comando como
root:# firewall-cmd --add-lockdown-whitelist-context=contextoPara eliminar un contexto context de la lista de permitidos, introduzca el siguiente comando como
root:# firewall-cmd --remove-lockdown-whitelist-context=contextoPara consultar si el contexto context está en la lista de permitidos, introduzca el siguiente comando como
root:# firewall-cmd --query-lockdown-whitelist-context=contextoImprime
yescon el estado de salida0, si es verdadero, imprimenocon el estado de salida1en caso contrario.Para listar todos los ID de usuario que están en la lista de permitidos, introduzca el siguiente comando como
root:# firewall-cmd --list-lockdown-whitelist-uidsPara añadir un ID de usuario uid a la lista de permitidos, introduzca el siguiente comando como
root:# firewall-cmd --add-lockdown-whitelist-uid=uidPara eliminar un ID de usuario uid de la lista de permitidos, introduzca el siguiente comando como
root:# firewall-cmd --remove-lockdown-whitelist-uid=uidPara consultar si el ID de usuario uid está en la lista de permitidos, introduzca el siguiente comando:
$ firewall-cmd --query-lockdown-whitelist-uid=uidImprime
yescon el estado de salida0, si es verdadero, imprimenocon el estado de salida1en caso contrario.Para listar todos los nombres de usuario que están en la lista de permitidos, introduzca el siguiente comando como
root:# firewall-cmd --list-lockdown-whitelist-usersPara añadir un nombre de usuario user a la lista de permitidos, introduzca el siguiente comando como
root:# firewall-cmd --add-lockdown-whitelist-user=userPara eliminar un nombre de usuario user de la lista de permitidos, introduzca el siguiente comando como
root:# firewall-cmd --remove-lockdown-whitelist-user=userPara consultar si el nombre de usuario user está en la lista de permitidos, introduzca el siguiente comando:
$ firewall-cmd --query-lockdown-whitelist-user=userImprime
yescon el estado de salida0, si es verdadero, imprimenocon el estado de salida1en caso contrario.
26.5.17.3. Configuración de las opciones de la lista de permisos de bloqueo mediante archivos de configuración
El archivo de configuración allowlist por defecto contiene el contexto NetworkManager y el contexto por defecto de libvirt. El ID de usuario 0 también está en la lista.
<?xml version="1.0" encoding="utf-8"?>
<whitelist>
<selinux context="system_u:system_r:NetworkManager_t:s0"/>
<selinux context="system_u:system_r:virtd_t:s0-s0:c0.c1023"/>
<user id="0"/>
</whitelist>
A continuación se muestra un ejemplo de archivo de configuración allowlist que habilita todos los comandos de la utilidad firewall-cmd, para un usuario llamado user cuyo ID de usuario es 815:
<?xml version="1.0" encoding="utf-8"?>
<whitelist>
<command name="/usr/libexec/platform-python -s /bin/firewall-cmd*"/>
<selinux context="system_u:system_r:NetworkManager_t:s0"/>
<user id="815"/>
<user name="user"/>
</whitelist>
Este ejemplo muestra tanto user id como user name, pero sólo se requiere una opción. Python es el intérprete y se antepone a la línea de comandos. También puede utilizar un comando específico, por ejemplo:
/usr/bin/python3 /bin/firewall-cmd --lockdown-on
En ese ejemplo, sólo se permite el comando --lockdown-on.
En Red Hat Enterprise Linux, todas las utilidades se colocan en el directorio /usr/bin/ y el directorio /bin/ está vinculado al directorio /usr/bin/. En otras palabras, aunque la ruta para firewall-cmd cuando se introduce como root podría resolver a /bin/firewall-cmd, ahora se puede utilizar /usr/bin/firewall-cmd. Todos los nuevos scripts deben utilizar la nueva ubicación. Pero tenga en cuenta que si los scripts que se ejecutan como root se escriben para utilizar la ruta /bin/firewall-cmd, entonces esa ruta de comandos debe añadirse en la lista de permisos además de la ruta /usr/bin/firewall-cmd que tradicionalmente sólo se utiliza para los usuarios que no son deroot.
El * al final del atributo name de un comando significa que todos los comandos que comienzan con esta cadena coinciden. Si el * no está ahí, entonces el comando absoluto, incluyendo los argumentos, debe coincidir.
26.5.18. Registro de paquetes rechazados
Con la opción LogDenied en firewalld, es posible añadir un mecanismo de registro sencillo para los paquetes rechazados. Estos son los paquetes que son rechazados o descartados. Para cambiar la configuración del registro, edite el archivo /etc/firewalld/firewalld.conf o utilice la herramienta de configuración de la línea de comandos o de la interfaz gráfica de usuario.
Si LogDenied está habilitado, las reglas de registro se añaden justo antes de las reglas de rechazo y eliminación en las cadenas INPUT, FORWARD y OUTPUT para las reglas por defecto y también las reglas finales de rechazo y eliminación en las zonas. Los valores posibles para esta configuración son: all , unicast, broadcast, multicast, y off. El valor por defecto es off. Con la configuración unicast, broadcast, y multicast, la coincidencia pkttype se utiliza para coincidir con el tipo de paquete de la capa de enlace. Con all, se registran todos los paquetes.
Para listar la configuración real de LogDenied con firewall-cmd, utilice el siguiente comando como root:
# firewall-cmd --get-log-denied
off
Para cambiar la configuración de LogDenied, utilice el siguiente comando como root:
# firewall-cmd --set-log-denied=all
success
Para cambiar la configuración de LogDenied con la herramienta de configuración de la GUI firewalld, inicie firewall-config, haga clic en el menú Options y seleccione Change Log Denied. Aparece la ventana LogDenied. Seleccione la nueva configuración de LogDenied en el menú y haga clic en Aceptar.
26.6. Introducción a nftables
El marco de trabajo nftables proporciona facilidades de clasificación de paquetes y es el sucesor designado de las herramientas iptables, ip6tables, arptables, y ebtables. Ofrece numerosas mejoras en cuanto a comodidad, características y rendimiento con respecto a las anteriores herramientas de filtrado de paquetes, sobre todo:
- tablas de búsqueda en lugar de procesamiento lineal
-
un único marco para los protocolos
IPv4yIPv6 - reglas aplicadas atómicamente en lugar de buscar, actualizar y almacenar un conjunto completo de reglas
-
soporte para la depuración y el rastreo en el conjunto de reglas (
nftrace) y la supervisión de los eventos de rastreo (en la herramientanft) - sintaxis más coherente y compacta, sin extensiones específicas de protocolo
- una API Netlink para aplicaciones de terceros
Al igual que iptables, nftables utiliza tablas para almacenar cadenas. Las cadenas contienen reglas individuales para realizar acciones. La herramienta nft sustituye a todas las herramientas de los anteriores marcos de filtrado de paquetes. La biblioteca libnftnl puede utilizarse para la interacción de bajo nivel con nftables Netlink API sobre la biblioteca libmnl.
El efecto de los módulos en el conjunto de reglas nftables puede observarse utilizando el comando nft list rule set. Dado que estas herramientas añaden tablas, cadenas, reglas, conjuntos y otros objetos al conjunto de reglas de nftables, tenga en cuenta que las operaciones del conjunto de reglas de nftables, como el comando nft flush ruleset, podrían afectar a los conjuntos de reglas instalados mediante los comandos heredados anteriormente separados.
26.6.1. Migración de iptables a nftables
Si ha actualizado su servidor a RHEL 8 o su configuración de cortafuegos todavía utiliza reglas de iptables, puede migrar sus reglas de iptables a nftables.
26.6.1.1. Cuándo utilizar firewalld, nftables o iptables
A continuación se presenta un breve resumen en el que se debe utilizar una de las siguientes utilidades:
-
firewalld: Utilice la utilidadfirewalldpara casos de uso de cortafuegos sencillos. La utilidad es fácil de usar y cubre los casos de uso típicos para estos escenarios. -
nftables: Utilice la utilidadnftablespara configurar cortafuegos complejos y de rendimiento crítico, como por ejemplo para toda una red. -
iptables: La utilidadiptablesen Red Hat Enterprise Linux 8 utiliza la API del kernelnf_tablesen lugar del back endlegacy. La APInf_tablesproporciona compatibilidad con versiones anteriores para que los scripts que utilizan comandosiptablessigan funcionando en Red Hat Enterprise Linux 8. Para los nuevos scripts de cortafuegos, Red Hat recomienda utilizarnftables.
Para evitar que los diferentes servicios de firewall se influyan mutuamente, ejecute sólo uno de ellos en un host RHEL y desactive los demás servicios.
26.6.1.2. Conversión de reglas iptables a reglas nftables
Red Hat Enterprise Linux 8 proporciona las herramientas iptables-translate y ip6tables-translate para convertir las reglas existentes iptables o ip6tables en las equivalentes para nftables.
Tenga en cuenta que algunas extensiones no tienen soporte de traducción. Si existe una extensión de este tipo, la herramienta imprime la regla no traducida con el prefijo #. Por ejemplo:
# iptables-translate -A INPUT -j CHECKSUM --checksum-fill
nft # -A INPUT -j CHECKSUM --checksum-fill
Además, los usuarios pueden utilizar las herramientas iptables-restore-translate y ip6tables-restore-translate para traducir un volcado de reglas. Tenga en cuenta que antes de eso, los usuarios pueden utilizar los comandos iptables-save o ip6tables-save para imprimir un volcado de las reglas actuales. Por ejemplo:
# iptables-save >/tmp/iptables.dump
# iptables-restore-translate -f /tmp/iptables.dump
# Translated by iptables-restore-translate v1.8.0 on Wed Oct 17 17:00:13 2018
add table ip nat
...
Para obtener más información y una lista de posibles opciones y valores, introduzca el comando iptables-translate --help.
26.6.2. Escritura y ejecución de scripts nftables
El marco de trabajo nftables proporciona un entorno de scripts nativo que aporta una gran ventaja sobre el uso de scripts de shell para mantener las reglas del cortafuegos: la ejecución de los scripts es atómica. Esto significa que el sistema aplica todo el script o impide la ejecución si se produce un error. Esto garantiza que el cortafuegos está siempre en un estado consistente.
Además, el entorno de scripts nftables permite a los administradores:
- añadir comentarios
- definir variables
- incluir otros archivos de conjuntos de reglas
En esta sección se explica cómo utilizar estas funciones, así como la creación y ejecución de los scripts de nftables.
Cuando se instala el paquete nftables, Red Hat Enterprise Linux crea automáticamente los scripts *.nft en el directorio /etc/nftables/. Estos scripts contienen comandos que crean tablas y cadenas vacías para diferentes propósitos. Usted puede extender estos archivos o escribir sus scripts.
26.6.2.1. La cabecera de script requerida en el script de nftables
Al igual que otros scripts, los scripts de nftables requieren una secuencia shebang en la primera línea del script que establece la directiva del intérprete.
Una secuencia de comandos nftables debe comenzar siempre con la siguiente línea:
# /usr/sbin/nft -f
Si omite el parámetro -f, la utilidad nft no lee el script y muestra Error: syntax error, unexpected newline, expecting string.
26.6.2.2. Formatos de script de nftables soportados
El entorno de scripting nftables admite scripts en los siguientes formatos:
Puede escribir una secuencia de comandos en el mismo formato que el comando
nft list rulesetmuestra el conjunto de reglas:#!/usr/sbin/nft -f # Flush the rule set flush ruleset table inet example_table { chain example_chain { # Chain for incoming packets that drops all packets that # are not explicitly allowed by any rule in this chain type filter hook input priority 0; policy drop; # Accept connections to port 22 (ssh) tcp dport ssh accept } }Puede utilizar la misma sintaxis para los comandos que en
nft:#!/usr/sbin/nft -f # Flush the rule set flush ruleset # Create a table add table inet example_table # Create a chain for incoming packets that drops all packets # that are not explicitly allowed by any rule in this chain add chain inet example_table example_chain { type filter hook input priority 0 ; policy drop ; } # Add a rule that accepts connections to port 22 (ssh) add rule inet example_table example_chain tcp dport ssh accept
26.6.2.3. Ejecución de scripts nftables
Para ejecutar un script de nftables, el script debe ser ejecutable. Sólo si el script está incluido en otro script, no es necesario que sea ejecutable. El procedimiento describe cómo hacer que un script sea ejecutable y ejecutar el script.
Requisitos previos
-
El procedimiento de esta sección asume que usted almacenó un script
nftablesen el archivo/etc/nftables/example_firewall.nft.
Procedimiento
Pasos que se requieren sólo una vez:
Opcionalmente, establezca el propietario del script en
root:# chown root /etc/nftables/example_firewall.nftHaz que el script sea ejecutable para el propietario:
# chmod u x /etc/nftables/example_firewall.nft
Ejecuta el script:
# /etc/nftables/example_firewall.nftSi no se muestra ninguna salida, el sistema ha ejecutado el script con éxito.
ImportanteIncluso si
nftejecuta la secuencia de comandos con éxito, las reglas mal colocadas, los parámetros que faltan u otros problemas en la secuencia de comandos pueden hacer que el cortafuegos no se comporte como se espera.
Recursos adicionales
-
Para más detalles sobre cómo establecer el propietario de un archivo, consulte la página de manual
chown(1). -
Para más detalles sobre cómo establecer los permisos de un archivo, consulte la página de manual
chmod(1). - Sección 26.6.2.7, “Carga automática de las reglas de nftables al arrancar el sistema”
26.6.2.4. Uso de comentarios en los scripts de nftables
El entorno de scripting nftables interpreta todo lo que está a la derecha de un carácter # como un comentario.
Ejemplo 26.1. Comentarios en un script de nftables
Los comentarios pueden comenzar al principio de una línea, así como junto a un comando:
...
# Flush the rule set
flush ruleset
add table inet example_table # Create a table
...26.6.2.5. Uso de variables en un script de nftables
Para definir una variable en un script nftables, utilice la palabra clave define. Puede almacenar valores individuales y conjuntos anónimos en una variable. Para escenarios más complejos, utilice conjuntos o mapas de veredicto.
Variables con un solo valor
El siguiente ejemplo define una variable llamada INET_DEV con el valor enp1s0:
define INET_DEV = enp1s0
Puede utilizar la variable en el script escribiendo el signo $ seguido del nombre de la variable:
...
add rule inet example_table example_chain iifname $INET_DEV tcp dport ssh accept
...Variables que contienen un conjunto anónimo
El siguiente ejemplo define una variable que contiene un conjunto anónimo:
define DNS_SERVERS = { 192.0.2.1, 192.0.2.2 }
Puede utilizar la variable en el script escribiendo el signo $ seguido del nombre de la variable:
add rule inet ejemplo_tabla ejemplo_cadena ip daddr $DNS_SERVERS acceptTenga en cuenta que las llaves tienen una semántica especial cuando las utiliza en una regla porque indican que la variable representa un conjunto.
Recursos adicionales
- Para más detalles sobre los conjuntos, véase Sección 26.6.5, “Uso de conjuntos en los comandos de nftables”.
- Para más detalles sobre los mapas de veredicto, consulte Sección 26.6.6, “Uso de mapas de veredicto en los comandos de nftables”.
26.6.2.6. Inclusión de archivos en un script de nftables
El entorno de scripting nftables permite a los administradores incluir otros scripts utilizando la sentencia include.
Si especifica sólo un nombre de archivo sin una ruta absoluta o relativa, nftables incluye los archivos de la ruta de búsqueda por defecto, que está configurada en /etc en Red Hat Enterprise Linux.
Ejemplo 26.2. Incluir archivos del directorio de búsqueda por defecto
Para incluir un archivo del directorio de búsqueda por defecto:
include "ejemplo.nft"Ejemplo 26.3. Incluir todos los archivos *.nft de un directorio
Para incluir todos los archivos que terminan en *.nft y que están almacenados en el directorio /etc/nftables/rulesets/:
include "/etc/nftables/rulesets/*.nft"
Tenga en cuenta que la sentencia include no coincide con los archivos que comienzan con un punto.
Recursos adicionales
-
Para más detalles, consulte la sección
Include filesen la página de manualnft(8).
26.6.2.7. Carga automática de las reglas de nftables al arrancar el sistema
El servicio nftables systemd carga los scripts del cortafuegos que se incluyen en el archivo /etc/sysconfig/nftables.conf. Esta sección explica cómo cargar las reglas del cortafuegos cuando el sistema se inicia.
Requisitos previos
-
Los scripts de
nftablesse almacenan en el directorio/etc/nftables/.
Procedimiento
Edite el archivo
/etc/sysconfig/nftables.conf.-
Si mejora los scripts
*.nftcreados en/etc/nftables/cuando instaló el paquetenftables, descomente la sentenciaincludepara estos scripts. Si escribe scripts desde cero, añada las declaraciones
includepara incluir estos scripts. Por ejemplo, para cargar el script/etc/nftables/example.nftcuando se inicie el servicionftables, añadainclude \ "/etc/nftables/example.nft"
-
Si mejora los scripts
Habilite el servicio
nftables.# systemctl enable nftablesOpcionalmente, inicie el servicio
nftablespara cargar las reglas del cortafuegos sin reiniciar el sistema:# systemctl start nftables
Recursos adicionales
26.6.3. Creación y gestión de tablas, cadenas y reglas nftables
En esta sección se explica cómo visualizar los conjuntos de reglas de nftables y cómo gestionarlos.
26.6.3.1. Valores estándar de prioridad de la cadena y nombres textuales
Cuando se crea una cadena, en priority se puede establecer un valor entero o un nombre estándar que especifique el orden en el que atraviesan las cadenas con el mismo valor hook.
Los nombres y valores se definen en función de las prioridades que utiliza xtables al registrar sus cadenas por defecto.
El comando nft list chains muestra por defecto valores de prioridad textuales. Puede ver el valor numérico pasando la opción -y al comando.
Ejemplo 26.4. Utilizar un valor textual para establecer la prioridad
El siguiente comando crea una cadena llamada example_chain en example_table utilizando el valor de prioridad estándar 50:
# nft add chain inet example_table example_chain { type filter hook input priority 50 \; policy accept \; }
Dado que la prioridad es un valor estándar, puede utilizar alternativamente el valor textual:
# nft add chain inet example_table example_chain { type filter hook input priority security \; policy accept \; }
| Nombre | Valor | Familias | Ganchos |
|---|---|---|---|
|
| -300 |
| todo |
|
| -150 |
| todo |
|
| -100 |
| prepago |
|
| 0 |
| todo |
|
| 50 |
| todo |
|
| 100 |
| post ruta |
Todas las familias utilizan los mismos valores, pero la familia bridge utiliza los siguientes valores:
| Nombre | Valor | Ganchos |
|---|---|---|
|
| -300 | prepago |
|
| -200 | todo |
|
| 100 | salida |
|
| 300 | post ruta |
Recursos adicionales
-
Para más detalles sobre otras acciones que puede ejecutar en las cadenas, consulte la sección
Chainsen la página de manualnft(8).
26.6.3.2. Visualización de conjuntos de reglas nftables
Los conjuntos de reglas de nftables contienen tablas, cadenas y reglas. En esta sección se explica cómo visualizar estos conjuntos de reglas.
Procedimiento
Para mostrar todos los conjuntos de reglas, introduzca:
# nft list ruleset table inet example_table { chain example_chain { type filter hook input priority filter; policy accept; tcp dport http accept tcp dport ssh accept } }NotaPor defecto,
nftablesno crea tablas previamente. Como consecuencia, al mostrar el conjunto de reglas en un host sin ninguna tabla, el comandonft list rulesetno muestra ninguna salida.
26.6.3.3. Creación de una tabla nftables
Una tabla en nftables es un espacio de nombres que contiene una colección de cadenas, reglas, conjuntos y otros objetos. Esta sección explica cómo crear una tabla.
Cada tabla debe tener definida una familia de direcciones. La familia de direcciones de una tabla define qué tipos de direcciones procesa la tabla. Puede establecer una de las siguientes familias de direcciones al crear una tabla:
-
ip: Coincide sólo con los paquetes IPv4. Este es el valor por defecto si no se especifica una familia de direcciones. -
ip6: Coincide sólo con los paquetes IPv6. -
inet: Coincide con los paquetes IPv4 e IPv6. -
arp: Coincide con los paquetes del protocolo de resolución de direcciones IPv4 (ARP). -
bridge: Coincide con los paquetes que atraviesan un dispositivo de puente. -
netdev: Coincide con los paquetes de entrada.
Procedimiento
Utilice el comando
nft add tablepara crear una nueva tabla. Por ejemplo, para crear una tabla llamadaexample_tableque procese paquetes IPv4 e IPv6:# nft add table inet example_tableOpcionalmente, se pueden listar todas las tablas del conjunto de reglas:
# nft list tables table inet example_table
Recursos adicionales
-
Para más detalles sobre las familias de direcciones, consulte la sección
Address familiesen la página mannft(8). -
Para más detalles sobre otras acciones que puede ejecutar en las tablas, consulte la sección
Tablesen la página de manualnft(8).
26.6.3.4. Creación de una cadena nftables
Las cadenas son contenedores de reglas. Existen los siguientes dos tipos de reglas:
- Cadena base: Puedes utilizar las cadenas base como punto de entrada para los paquetes de la pila de red.
-
Cadena regular: Puedes utilizar las cadenas regulares como objetivo de
jumpy para organizar mejor las reglas.
El procedimiento describe cómo añadir una cadena base a una tabla existente.
Requisitos previos
- La tabla a la que se quiere añadir la nueva cadena existe.
Procedimiento
Utilice el comando
nft add chainpara crear una nueva cadena. Por ejemplo, para crear una cadena llamadaexample_chainenexample_table:# nft add chain inet example_table example_chain { type filter hook input priority 0 \\N; policy accept \N; }ImportantePara evitar que el shell interprete los puntos y comas como el final del comando, debe escapar los puntos y comas con una barra invertida.
Esta cadena filtra los paquetes entrantes. El parámetro
priorityespecifica el orden en quenftablesprocesa las cadenas con el mismo valor de gancho. Un valor de prioridad más bajo tiene precedencia sobre los más altos. El parámetropolicyestablece la acción por defecto para las reglas de esta cadena. Tenga en cuenta que si está conectado al servidor de forma remota y establece la política por defecto endrop, se desconectará inmediatamente si ninguna otra regla permite el acceso remoto.Opcionalmente, mostrar todas las cadenas:
# nft list chains table inet example_table { chain example_chain { type filter hook input priority filter; policy accept; } }
Recursos adicionales
-
Para más detalles sobre las familias de direcciones, consulte la sección
Address familiesen la página mannft(8). -
Para más detalles sobre otras acciones que puede ejecutar en las cadenas, consulte la sección
Chainsen la página de manualnft(8).
26.6.3.5. Añadir una regla a una cadena nftables
Esta sección explica cómo añadir una regla a una cadena existente de nftables. Por defecto, el comando nftables add rule añade una nueva regla al final de la cadena.
Si, en cambio, desea insertar una regla al principio de la cadena, consulte Sección 26.6.3.6, “Insertar una regla en una cadena nftables”.
Requisitos previos
- La cadena a la que se quiere añadir la regla existe.
Procedimiento
Para añadir una nueva regla, utilice el comando
nft add rule. Por ejemplo, para añadir una regla alexample_chainen elexample_tableque permita el tráfico TCP en el puerto 22:# nft add rule inet example_table example_chain tcp dport 22 acceptEn lugar del número de puerto, puede especificar alternativamente el nombre del servicio. En el ejemplo, podría utilizar
sshen lugar del número de puerto22. Tenga en cuenta que un nombre de servicio se resuelve a un número de puerto basado en su entrada en el archivo/etc/services.Opcionalmente, mostrar todas las cadenas y sus reglas en
example_table:# nft list table inet example_table table inet example_table { chain example_chain { type filter hook input priority filter; policy accept; ... tcp dport ssh accept } }
Recursos adicionales
-
Para más detalles sobre las familias de direcciones, consulte la sección
Address familiesen la página mannft(8). -
Para más detalles sobre otras acciones que puede ejecutar en las reglas, consulte la sección
Rulesen la página de manualnft(8).
26.6.3.6. Insertar una regla en una cadena nftables
Esta sección explica cómo insertar una regla al principio de una cadena existente de nftables utilizando el comando nftables insert rule. Si, en cambio, desea añadir una regla al final de una cadena, consulte Sección 26.6.3.5, “Añadir una regla a una cadena nftables”.
Requisitos previos
- La cadena a la que se quiere añadir la regla existe.
Procedimiento
Para insertar una nueva regla, utilice el comando
nft insert rule. Por ejemplo, para insertar una regla a laexample_chainen elexample_tableque permite el tráfico TCP en el puerto 22:# nft insert rule inet example_table example_chain tcp dport 22 acceptTambién puede especificar el nombre del servicio en lugar del número de puerto. En el ejemplo, podría utilizar
sshen lugar del número de puerto22. Tenga en cuenta que un nombre de servicio se resuelve a un número de puerto basado en su entrada en el archivo/etc/services.Opcionalmente, mostrar todas las cadenas y sus reglas en
example_table:# nft list table inet example_table table inet example_table { chain example_chain { type filter hook input priority filter; policy accept; tcp dport ssh accept ... } }
Recursos adicionales
-
Para más detalles sobre las familias de direcciones, consulte la sección
Address familiesen la página mannft(8). -
Para más detalles sobre otras acciones que puede ejecutar en las reglas, consulte la sección
Rulesen la página de manualnft(8).
26.6.4. Configuración de NAT con nftables
Con nftables, puede configurar los siguientes tipos de traducción de direcciones de red (NAT):
- Enmascaramiento
- NAT de origen (SNAT)
- NAT de destino (DNAT)
26.6.4.1. Los diferentes tipos de NAT: enmascaramiento, NAT de origen y NAT de destino
Estos son los diferentes tipos de traducción de direcciones de red (NAT):
- Enmascaramiento y NAT de origen (SNAT)
Utilice uno de estos tipos de NAT para cambiar la dirección IP de origen de los paquetes. Por ejemplo, los proveedores de Internet no enrutan rangos de IP reservados, como
10.0.0.0/8. Si utiliza rangos de IP reservadas en su red y los usuarios deben poder llegar a los servidores de Internet, asigne la dirección IP de origen de los paquetes de estos rangos a una dirección IP pública.Tanto el enmascaramiento como el SNAT son muy similares. Las diferencias son:
- El enmascaramiento utiliza automáticamente la dirección IP de la interfaz saliente. Por lo tanto, utilice el enmascaramiento si la interfaz saliente utiliza una dirección IP dinámica.
- SNAT establece la dirección IP de origen de los paquetes a una IP especificada y no busca dinámicamente la IP de la interfaz de salida. Por lo tanto, SNAT es más rápido que el enmascaramiento. Utilice SNAT si la interfaz saliente utiliza una dirección IP fija.
- NAT de destino (DNAT)
- Utiliza este tipo de NAT para redirigir el tráfico entrante a un host diferente. Por ejemplo, si su servidor web utiliza una dirección IP de un rango IP reservado y, por tanto, no es accesible directamente desde Internet, puede establecer una regla DNAT en el router para redirigir el tráfico entrante a este servidor.
26.6.4.2. Configuración del enmascaramiento mediante nftables
El enmascaramiento permite a un router cambiar dinámicamente la IP de origen de los paquetes enviados a través de una interfaz por la dirección IP de la misma. Esto significa que si la interfaz recibe una nueva IP asignada, nftables utiliza automáticamente la nueva IP al sustituir la IP de origen.
El siguiente procedimiento describe cómo sustituir la IP de origen de los paquetes que salen del host a través de la interfaz ens3 por la IP establecida en ens3.
Procedimiento
Crea una tabla:
# nft add table natAñade las cadenas
preroutingypostroutinga la tabla:# nft -- add chain nat prerouting { type nat hook prerouting priority -100 \; } # nft add chain nat postrouting { type nat hook postrouting priority 100 \; }ImportanteIncluso si no se añade una regla a la cadena
prerouting, el marconftablesrequiere esta cadena para que coincida con las respuestas de los paquetes entrantes.Tenga en cuenta que debe pasar la opción
--al comandonftpara evitar que el shell interprete el valor de prioridad negativo como una opción del comandonft.Añada una regla a la cadena
postroutingque coincida con los paquetes salientes en la interfazens3:# nft add rule nat postrouting oifname "ens3" masquerade
26.6.4.3. Configuración del NAT de origen mediante nftables
En un router, Source NAT (SNAT) permite cambiar la IP de los paquetes enviados a través de una interfaz a una dirección IP específica.
El siguiente procedimiento describe cómo sustituir la IP de origen de los paquetes que salen del router a través de la interfaz ens3 a 192.0.2.1.
Procedimiento
Crea una tabla:
# nft add table natAñade las cadenas
preroutingypostroutinga la tabla:# nft -- add chain nat prerouting { type nat hook prerouting priority -100 \; } # nft add chain nat postrouting { type nat hook postrouting priority 100 \; }ImportanteIncluso si no se añade una regla a la cadena
postrouting, el marconftablesrequiere esta cadena para que coincida con las respuestas de los paquetes salientes.Tenga en cuenta que debe pasar la opción
--al comandonftpara evitar que el shell interprete el valor de prioridad negativo como una opción del comandonft.Añada una regla a la cadena
postroutingque sustituya la IP de origen de los paquetes salientes a través deens3por192.0.2.1:# nft add rule nat postrouting oifname "ens3" snat to 192.0.2.1
26.6.4.4. Configuración del NAT de destino mediante nftables
La NAT de destino permite redirigir el tráfico en un router a un host al que no se puede acceder directamente desde Internet.
El siguiente procedimiento describe cómo redirigir el tráfico entrante enviado al puerto 80 y 443 del router al host con la dirección IP 192.0.2.1.
Procedimiento
Crea una tabla:
# nft add table natAñade las cadenas
preroutingypostroutinga la tabla:# nft -- add chain nat prerouting { type nat hook prerouting priority -100 \; } # nft add chain nat postrouting { type nat hook postrouting priority 100 \; }ImportanteIncluso si no se añade una regla a la cadena
postrouting, el marconftablesrequiere esta cadena para que coincida con las respuestas de los paquetes salientes.Tenga en cuenta que debe pasar la opción
--al comandonftpara evitar que el shell interprete el valor de prioridad negativo como una opción del comandonft.Añada una regla a la cadena
preroutingque redirija el tráfico entrante en la interfazens3enviado al puerto80y443al host con la IP192.0.2.1:# nft add rule nat prerouting iifname ens3 tcp dport { 80, 443 } dnat to 192.0.2.1Dependiendo de su entorno, añada una regla SNAT o de enmascaramiento para cambiar la dirección de origen:
Si la interfaz
ens3utiliza direcciones IP dinámicas, añada una regla de enmascaramiento:# nft add rule nat postrouting oifname \ "ens3" masqueradeSi la interfaz
ens3utiliza una dirección IP estática, añada una regla SNAT. Por ejemplo, si elens3utiliza la dirección IP198.51.100.1:nft add rule nat postrouting oifname \ "ens3" snat to 198.51.100.1
26.6.5. Uso de conjuntos en los comandos de nftables
El marco de trabajo nftables admite de forma nativa los conjuntos. Puede utilizar conjuntos, por ejemplo, si una regla debe coincidir con varias direcciones IP, números de puerto, interfaces o cualquier otro criterio de coincidencia.
26.6.5.1. Uso de conjuntos anónimos en nftables
Un conjunto anónimo contiene valores separados por comas y encerrados entre corchetes, como { 22, 80, 443 }, que se utilizan directamente en una regla. También puede utilizar conjuntos anónimos para direcciones IP o cualquier otro criterio de coincidencia.
El inconveniente de los conjuntos anónimos es que si se quiere cambiar el conjunto, hay que sustituir la regla. Para una solución dinámica, utilice conjuntos con nombre como se describe en Sección 26.6.5.2, “Uso de conjuntos con nombre en nftables”.
Requisitos previos
-
Existe la cadena
example_chainy la tablaexample_tableen la familiainet.
Procedimiento
Por ejemplo, para añadir una regla a
example_chainenexample_tableque permita el tráfico entrante al puerto22,80y443:# nft add rule inet example_table example_chain tcp dport { 22, 80, 443 } acceptOpcionalmente, mostrar todas las cadenas y sus reglas en
example_table:# nft list table inet example_table table inet example_table { chain example_chain { type filter hook input priority filter; policy accept; tcp dport { ssh, http, https } accept } }
26.6.5.2. Uso de conjuntos con nombre en nftables
El marco nftables admite conjuntos con nombre mutables. Un conjunto con nombre es una lista o rango de elementos que se puede utilizar en múltiples reglas dentro de una tabla. Otra ventaja con respecto a los conjuntos anónimos es que se puede actualizar un conjunto con nombre sin sustituir las reglas que lo utilizan.
Cuando se crea un conjunto con nombre, se debe especificar el tipo de elementos que contiene el conjunto. Puede establecer los siguientes tipos:
-
ipv4_addrpara un conjunto que contiene direcciones o rangos IPv4, como192.0.2.1o192.0.2.0/24. -
ipv6_addrpara un conjunto que contiene direcciones o rangos IPv6, como2001:db8:1::1o2001:db8:1::1/64. -
ether_addrpara un conjunto que contiene una lista de direcciones de control de acceso al medio (MAC), como52:54:00:6b:66:42. -
inet_protopara un conjunto que contiene una lista de tipos de protocolo de Internet, comotcp. -
inet_servicepara un conjunto que contiene una lista de servicios de Internet, comossh. -
markpara un conjunto que contiene una lista de marcas de paquetes. Las marcas de paquetes pueden ser cualquier valor entero positivo de 32 bits (0a2147483647].
Requisitos previos
-
La cadena
example_chainy la tablaexample_tableexisten.
Procedimiento
Cree un conjunto vacío. Los siguientes ejemplos crean un conjunto para direcciones IPv4:
Para crear un conjunto que pueda almacenar varias direcciones IPv4 individuales:
# nft add set inet example_table example_set { type ipv4_addr \; }Para crear un conjunto que pueda almacenar rangos de direcciones IPv4:
# nft add set inet example_table example_set { type ipv4_addr \; flags interval \; }
ImportantePara evitar que el shell interprete los puntos y comas como el final del comando, debe escapar los puntos y comas con una barra invertida.
Opcionalmente, cree reglas que utilicen el conjunto. Por ejemplo, el siguiente comando agrega una regla a la
example_chainen elexample_tableque descartará todos los paquetes de las direcciones IPv4 enexample_set.# nft add rule inet example_table example_chain ip saddr @example_set dropComo
example_setestá todavía vacío, la regla no tiene actualmente ningún efecto.Añadir direcciones IPv4 a
example_set:Si crea un conjunto que almacena direcciones IPv4 individuales, introduzca:
# nft add element inet example_table example_set { 192.0.2.1, 192.0.2.2 }Si crea un conjunto que almacena rangos IPv4, introduzca:
# nft add element inet example_table example_set { 192.0.2.0-192.0.2.255 }Cuando se especifica un rango de direcciones IP, se puede utilizar alternativamente la notación Classless Inter-Domain Routing (CIDR), como
192.0.2.0/24en el ejemplo anterior.
26.6.6. Uso de mapas de veredicto en los comandos de nftables
Los mapas de veredicto, también conocidos como diccionarios, permiten a nft realizar una acción basada en la información del paquete mediante la asignación de criterios de coincidencia a una acción.
26.6.6.1. Uso de mapas literales en nftables
Un mapa literal es una { match_criteria : action } que se utiliza directamente en una regla. La sentencia puede contener múltiples mapeos separados por comas.
El inconveniente de un mapa literal es que si se quiere cambiar el mapa, hay que sustituir la regla. Para una solución dinámica, utilice mapas de veredicto con nombre como se describe en Sección 26.6.6.2, “Uso de mapas de veredicto mutables en nftables”.
El ejemplo describe cómo utilizar un mapa literal para enrutar paquetes TCP y UDP del protocolo IPv4 e IPv6 a diferentes cadenas para contar los paquetes TCP y UDP entrantes por separado.
Procedimiento
Cree la página web
example_table:# nft add table inet example_tableCree la cadena
tcp_packetsenexample_table:# nft add chain inet example_table tcp_packetsAgregue una regla a
tcp_packetsque cuente el tráfico en esta cadena:# nft add rule inet example_table tcp_packets counterCree la cadena
udp_packetsenexample_table# nft add chain inet example_table udp_packetsAgregue una regla a
udp_packetsque cuente el tráfico en esta cadena:# nft add rule inet example_table udp_packets counterCree una cadena para el tráfico entrante. Por ejemplo, para crear una cadena llamada
incoming_trafficenexample_tableque filtre el tráfico entrante:# nft add chain inet example_table incoming_traffic { type filter hook input priority 0 \; }Añade una regla con un mapa literal a
incoming_traffic:# nft add rule inet example_table incoming_traffic ip protocol vmap { tcp : jump tcp_packets, udp : jump udp_packets }El mapa literal distingue los paquetes y los envía a las diferentes cadenas de contadores en función de su protocolo.
Para listar los contadores de tráfico, visualice
example_table:# nft list table inet example_table table inet example_table { chain tcp_packets { counter packets 36379 bytes 2103816 } chain udp_packets { counter packets 10 bytes 1559 } chain incoming_traffic { type filter hook input priority filter; policy accept; ip protocol vmap { tcp : jump tcp_packets, udp : jump udp_packets } } }Los contadores de la cadena
tcp_packetsyudp_packetsmuestran tanto el número de paquetes como de bytes recibidos.
26.6.6.2. Uso de mapas de veredicto mutables en nftables
El marco nftables admite mapas de veredicto mutables. Puedes utilizar estos mapas en múltiples reglas dentro de una tabla. Otra ventaja con respecto a los mapas literales es que puedes actualizar un mapa mutable sin reemplazar las reglas que lo utilizan.
Cuando se crea un mapa de veredicto mutable, se debe especificar el tipo de elementos
-
ipv4_addrpara un mapa cuya parte coincidente contiene una dirección IPv4, como192.0.2.1. -
ipv6_addrpara un mapa cuya parte coincidente contiene una dirección IPv6, como2001:db8:1::1. -
ether_addrpara un mapa cuya parte coincidente contiene una dirección de control de acceso al medio (MAC), como52:54:00:6b:66:42. -
inet_protopara un mapa cuya parte coincidente contiene un tipo de protocolo de Internet, comotcp. -
inet_servicepara un mapa cuya parte de coincidencia contiene un número de puerto de nombre de servicios de Internet, comossho22. -
markpara un mapa cuya parte coincidente contiene una marca de paquete. Una marca de paquete puede ser cualquier valor entero positivo de 32 bits (0a2147483647. -
counterpara un mapa cuya parte de coincidencia contiene un valor de contador. El valor del contador puede ser cualquier valor entero positivo de 64 bits. -
quotapara un mapa cuya parte de coincidencia contiene un valor de cuota. El valor de la cuota puede ser cualquier valor entero positivo de 64 bits.
El ejemplo describe cómo permitir o descartar paquetes entrantes basándose en su dirección IP de origen. Utilizando un mapa de veredicto mutable, sólo se requiere una única regla para configurar este escenario, mientras que las direcciones IP y las acciones se almacenan dinámicamente en el mapa. El procedimiento también describe cómo añadir y eliminar entradas del mapa.
Procedimiento
Cree una tabla. Por ejemplo, para crear una tabla llamada
example_tableque procese paquetes IPv4:# nft add table ip example_tableCree una cadena. Por ejemplo, para crear una cadena llamada
example_chainenexample_table:# nft add chain ip example_table example_chain { type filter hook input priority 0 \_; }ImportantePara evitar que el shell interprete los puntos y comas como el final del comando, debe escapar los puntos y comas con una barra invertida.
Cree un mapa vacío. Por ejemplo, para crear un mapa de direcciones IPv4:
# nft add map ip example_table example_map { type ipv4_addr : verdict \; }Cree reglas que utilicen el mapa. Por ejemplo, el siguiente comando añade una regla a
example_chainenexample_tableque aplica acciones a las direcciones IPv4 que están definidas enexample_map:# nft add rule example_table example_chain ip saddr vmap @example_mapAgregue las direcciones IPv4 y las acciones correspondientes a
example_map:# nft add element ip example_table example_map { 192.0.2.1 : accept, 192.0.2.2 : drop }Este ejemplo define las asignaciones de direcciones IPv4 a acciones. En combinación con la regla creada anteriormente, el cortafuegos acepta los paquetes de
192.0.2.1y los descarta de192.0.2.2.Opcionalmente, puede mejorar el mapa añadiendo otra dirección IP y una declaración de acción:
# nft add element ip example_table example_map { 192.0.2.3 : accept }Opcionalmente, eliminar una entrada del mapa:
# nft delete element ip example_table example_map { 192.0.2.1 }Opcionalmente, mostrar el conjunto de reglas:
# nft list ruleset table ip example_table { map example_map { type ipv4_addr : verdict elements = { 192.0.2.2 : drop, 192.0.2.3 : accept } } chain example_chain { type filter hook input priority filter; policy accept; ip saddr vmap @example_map } }
26.6.7. Configuración del reenvío de puertos mediante nftables
El reenvío de puertos permite a los administradores reenviar los paquetes enviados a un puerto de destino específico a un puerto local o remoto diferente.
Por ejemplo, si su servidor web no tiene una dirección IP pública, puede establecer una regla de reenvío de puertos en su cortafuegos que reenvíe los paquetes entrantes en los puertos 80 y 443 del cortafuegos al servidor web. Con esta regla del cortafuegos, los usuarios de Internet pueden acceder al servidor web utilizando la IP o el nombre de host del cortafuegos.
26.6.7.1. Reenvío de paquetes entrantes a un puerto local diferente
Esta sección describe un ejemplo de cómo reenviar paquetes IPv4 entrantes en el puerto 8022 al puerto 22 en el sistema local.
Procedimiento
Cree una tabla llamada
natcon la familia de direccionesip:# nft add table ip natAñade las cadenas
preroutingypostroutinga la tabla:# nft -- add chain ip nat prerouting { type nat hook prerouting priority -100 \; }NotaPase la opción
--al comandonftpara evitar que el shell interprete el valor de prioridad negativo como una opción del comandonft.Añade una regla a la cadena
preroutingque redirige los paquetes entrantes en el puerto8022al puerto local22:# nft add rule ip nat prerouting tcp dport 8022 redirect to :22
26.6.7.2. Reenvío de paquetes entrantes en un puerto local específico a un host diferente
Puede utilizar una regla de traducción de direcciones de red de destino (DNAT) para reenviar los paquetes entrantes en un puerto local a un host remoto. Esto permite a los usuarios de Internet acceder a un servicio que se ejecuta en un host con una dirección IP privada.
El procedimiento describe cómo reenviar los paquetes IPv4 entrantes en el puerto local 443 al mismo número de puerto en el sistema remoto con la dirección IP 192.0.2.1.
Requisito previo
-
Usted está conectado como el usuario
rooten el sistema que debe reenviar los paquetes.
Procedimiento
Cree una tabla llamada
natcon la familia de direccionesip:# nft add table ip natAñade las cadenas
preroutingypostroutinga la tabla:# nft -- add chain ip nat prerouting { type nat hook prerouting priority -100 \; } # nft add chain ip nat postrouting { type nat hook postrouting priority 100 \; }NotaPase la opción
--al comandonftpara evitar que el shell interprete el valor de prioridad negativo como una opción del comandonft.Añade una regla a la cadena
preroutingque redirige los paquetes entrantes en el puerto443al mismo puerto en192.0.2.1:# nft add rule ip nat prerouting tcp dport 443 dnat to 192.0.2.1Añade una regla a la cadena
postroutingpara enmascarar el tráfico saliente:# nft add rule ip daddr 192.0.2.1 masqueradeActivar el reenvío de paquetes:
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
26.6.8. Uso de nftables para limitar la cantidad de conexiones
Puede utilizar nftables para limitar el número de conexiones o para bloquear las direcciones IP que intenten establecer una cantidad determinada de conexiones para evitar que utilicen demasiados recursos del sistema.
26.6.8.1. Limitación del número de conexiones mediante nftables
El parámetro ct count de la utilidad nft permite a los administradores limitar el número de conexiones. El procedimiento describe un ejemplo básico de cómo limitar las conexiones entrantes.
Requisitos previos
-
La base
example_chainenexample_tableexiste.
Procedimiento
Añade una regla que permita sólo dos conexiones simultáneas al puerto SSH (22) desde una dirección IPv4 y rechace todas las demás conexiones desde la misma IP:
# nft add rule ip example_table example_chain tcp dport ssh meter example_meter { ip saddr ct count over 2 } counter rejectOpcionalmente, visualice el contador creado en el paso anterior:
# nft list meter ip example_table example_meter table ip example_table { meter example_meter { type ipv4_addr size 65535 elements = { 192.0.2.1 : ct count over 2 , 192.0.2.2 : ct count over 2 } } }La entrada
elementsmuestra las direcciones que actualmente coinciden con la regla. En este ejemplo,elementsmuestra las direcciones IP que tienen conexiones activas al puerto SSH. Tenga en cuenta que la salida no muestra el número de conexiones activas o si las conexiones fueron rechazadas.
26.6.8.2. Bloqueo de direcciones IP que intentan más de diez nuevas conexiones TCP entrantes en un minuto
El marco nftables permite a los administradores actualizar dinámicamente los conjuntos. Esta sección explica cómo utilizar esta función para bloquear temporalmente los hosts que establecen más de diez conexiones TCP IPv4 en un minuto. Después de cinco minutos, nftables elimina automáticamente la dirección IP de la lista de denegación.
Procedimiento
Crear la tabla
filtercon la familia de direccionesip:# nft add table ip filterAñade la cadena
inputa la tablafilter:# nft add chain ip filter input { type filter hook input priority 0 \; }Añade un conjunto llamado
denylista la tablafilter:# nft add set ip filter denylist { type ipv4_addr \️; flags dynamic, timeout \️; timeout 5m \️; }Este comando crea un conjunto dinámico de direcciones IPv4. El parámetro
timeout 5mdefine quenftableselimine automáticamente las entradas después de 5 minutos del conjunto.Añada una regla que añada automáticamente la dirección IP de origen de los hosts que intenten establecer más de diez nuevas conexiones TCP en un minuto al conjunto
denylist:# nft add rule ip filter input ip protocol tcp ct state new, untracked limit rate over 10/minute add @denylist { ip saddr }Añada una regla que elimine todas las conexiones de las direcciones IP del conjunto
denylist:# nft add rule ip filter input ip saddr @denylist drop
Recursos adicionales
26.6.9. Depuración de las reglas de nftables
El marco nftables proporciona diferentes opciones para que los administradores puedan depurar las reglas y si los paquetes coinciden con ellas. Esta sección describe estas opciones.
26.6.9.1. Crear una regla con un contador
Para identificar si una regla coincide, puede utilizar un contador. Esta sección describe cómo crear una nueva regla con un contador.
Para un procedimiento que añade un contador a una regla existente, véase Sección 26.6.9.2, “Añadir un contador a una regla existente”.
Requisitos previos
- La cadena a la que se quiere añadir la regla existe.
Procedimiento
Añada una nueva regla con el parámetro
countera la cadena. El siguiente ejemplo añade una regla con un contador que permite el tráfico TCP en el puerto 22 y cuenta los paquetes y el tráfico que coinciden con esta regla:# nft add rule inet example_table example_chain tcp dport 22 counter acceptPara visualizar los valores del contador:
# nft list ruleset table inet example_table { chain example_chain { type filter hook input priority filter; policy accept; tcp dport ssh counter packets 6872 bytes 105448565 accept } }
26.6.9.2. Añadir un contador a una regla existente
Para identificar si una regla coincide, puede utilizar un contador. Esta sección describe cómo añadir un contador a una regla existente.
Para conocer el procedimiento para añadir una nueva regla con un contador, consulte Sección 26.6.9.1, “Crear una regla con un contador”.
Requisitos previos
- La regla a la que se quiere añadir el contador existe.
Procedimiento
Muestra las reglas de la cadena incluyendo sus asas:
# nft --handle list chain inet example_table example_chain table inet example_table { chain example_chain { # handle 1 type filter hook input priority filter; policy accept; tcp dport ssh accept # handle 4 } }Añada el contador sustituyendo la regla pero con el parámetro
counter. El siguiente ejemplo sustituye la regla mostrada en el paso anterior y añade un contador:# nft replace rule inet example_table example_chain handle 4 tcp dport 22 counter acceptPara visualizar los valores del contador:
# nft list ruleset table inet example_table { chain example_chain { type filter hook input priority filter; policy accept; tcp dport ssh counter packets 6872 bytes 105448565 accept } }
26.6.9.3. Supervisión de los paquetes que coinciden con una regla existente
La función de rastreo en nftables en combinación con el comando nft monitor permite a los administradores mostrar los paquetes que coinciden con una regla. El procedimiento describe cómo habilitar el rastreo para una regla, así como la supervisión de los paquetes que coinciden con esta regla.
Requisitos previos
- La regla a la que se quiere añadir el contador existe.
Procedimiento
Muestra las reglas de la cadena incluyendo sus asas:
# nft --handle list chain inet example_table example_chain table inet example_table { chain example_chain { # handle 1 type filter hook input priority filter; policy accept; tcp dport ssh accept # handle 4 } }Añada la función de rastreo sustituyendo la regla pero con los parámetros de
meta nftrace set 1. El siguiente ejemplo reemplaza la regla mostrada en el paso anterior y habilita el rastreo:# nft replace rule inet example_table example_chain handle 4 tcp dport 22 meta nftrace set 1 acceptUtilice el comando
nft monitorpara mostrar el rastreo. El siguiente ejemplo filtra la salida del comando para mostrar sólo las entradas que contieneninet example_table example_chain:# nft monitor | grep "inet example_table example_chain" trace id 3c5eb15e inet example_table example_chain packet: iif "enp1s0" ether saddr 52:54:00:17:ff:e4 ether daddr 52:54:00:72:2f:6e ip saddr 192.0.2.1 ip daddr 192.0.2.2 ip dscp cs0 ip ecn not-ect ip ttl 64 ip id 49710 ip protocol tcp ip length 60 tcp sport 56728 tcp dport ssh tcp flags == syn tcp window 64240 trace id 3c5eb15e inet example_table example_chain rule tcp dport ssh nftrace set 1 accept (verdict accept) ...AvisoDependiendo del número de reglas con el rastreo activado y de la cantidad de tráfico que coincida, el comando
nft monitorpuede mostrar una gran cantidad de salida. Utilicegrepu otras utilidades para filtrar la salida.
26.6.10. Copia de seguridad y restauración de conjuntos de reglas nftables
Esta sección describe cómo hacer una copia de seguridad de las reglas de nftables en un archivo, así como la restauración de las reglas desde un archivo.
Los administradores pueden utilizar un archivo con las reglas para, por ejemplo, transferirlas a un servidor diferente.
26.6.10.1. Copia de seguridad de los conjuntos de reglas de nftables en un archivo
Esta sección describe cómo hacer una copia de seguridad de los conjuntos de reglas de nftables en un archivo.
Procedimiento
Para hacer una copia de seguridad de las reglas de
nftables:En formato
nft list ruleset:# nft list ruleset > file.nftEn formato JSON:
# nft -j list ruleset > file.json
26.6.10.2. Restauración de conjuntos de reglas nftables desde un archivo
Esta sección describe cómo restaurar los conjuntos de reglas de nftables.
Procedimiento
Para restaurar las reglas de
nftables:Si el archivo a restaurar está en formato
nft list ruleseto contiene comandosnft:# nft -f file.nftSi el archivo a restaurar está en formato JSON:
# nft -j -f file.json
Parte IV. Diseño del disco duro
Capítulo 27. Resumen de los sistemas de archivos disponibles
La elección del sistema de archivos apropiado para su aplicación es una decisión importante debido al gran número de opciones disponibles y las compensaciones involucradas. Este capítulo describe algunos de los sistemas de archivos que se entregan con Red Hat Enterprise Linux 8 y proporciona antecedentes históricos y recomendaciones sobre el sistema de archivos adecuado para su aplicación.
27.1. Tipos de sistemas de archivos
Red Hat Enterprise Linux 8 soporta una variedad de sistemas de archivos (FS). Los diferentes tipos de sistemas de archivos resuelven diferentes tipos de problemas y su uso es específico de la aplicación. En el nivel más general, los sistemas de archivos disponibles pueden ser agrupados en los siguientes tipos principales:
| Tipo | Sistema de archivos | Atributos y casos de uso |
|---|---|---|
| Disco o FS local | XFS | XFS es el sistema de archivos por defecto en RHEL. Debido a que presenta los archivos como extensiones, es menos vulnerable a la fragmentación que ext4. Red Hat recomienda desplegar XFS como su sistema de archivos local a menos que haya razones específicas para hacer lo contrario: por ejemplo, compatibilidad o casos de esquina en torno al rendimiento. |
| ext4 | ext4 tiene la ventaja de la longevidad en Linux. Por lo tanto, es soportado por casi todas las aplicaciones de Linux. En la mayoría de los casos, rivaliza con XFS en cuanto a rendimiento. ext4 se utiliza habitualmente para los directorios personales. | |
| FS en red o cliente-servidor | NFS | Utilice NFS para compartir archivos entre varios sistemas de la misma red. |
| SMB | Utiliza SMB para compartir archivos con sistemas Microsoft Windows. | |
| Almacenamiento compartido o disco compartido FS | GFS2 | GFS2 proporciona acceso de escritura compartido a los miembros de un clúster informático. El énfasis está en la estabilidad y la fiabilidad, con la experiencia funcional de un sistema de archivos local como sea posible. SAS Grid, Tibco MQ, IBM Websphere MQ y Red Hat Active MQ se han implantado con éxito en GFS2. |
| FS de gestión de volumen | Stratis (avance tecnológico) | Stratis es un gestor de volúmenes construido sobre una combinación de XFS y LVM. El propósito de Stratis es emular las capacidades ofrecidas por los sistemas de archivos de gestión de volúmenes como Btrfs y ZFS. Es posible construir esta pila manualmente, pero Stratis reduce la complejidad de la configuración, implementa las mejores prácticas y consolida la información de errores. |
27.2. Sistemas de archivos locales
Los sistemas de archivos locales son sistemas de archivos que se ejecutan en un único servidor local y se conectan directamente al almacenamiento.
Por ejemplo, un sistema de archivos local es la única opción para los discos SATA o SAS internos, y se utiliza cuando su servidor tiene controladores RAID de hardware internos con unidades locales. Los sistemas de archivos locales son también los sistemas de archivos más comunes utilizados en el almacenamiento conectado a la SAN cuando el dispositivo exportado en la SAN no es compartido.
Todos los sistemas de archivos locales son compatibles con POSIX y son totalmente compatibles con todas las versiones de Red Hat Enterprise Linux. Los sistemas de archivos compatibles con POSIX proporcionan soporte para un conjunto bien definido de llamadas al sistema, tales como read(), write(), y seek().
Desde el punto de vista del programador de aplicaciones, hay relativamente pocas diferencias entre los sistemas de archivos locales. Las diferencias más notables desde la perspectiva del usuario están relacionadas con la escalabilidad y el rendimiento. Al considerar la elección de un sistema de archivos, hay que tener en cuenta el tamaño que debe tener el sistema de archivos, las características únicas que debe tener y el rendimiento bajo su carga de trabajo.
Sistemas de archivos locales disponibles
- XFS
- ext4
27.3. El sistema de archivos XFS
XFS es un sistema de archivos de 64 bits altamente escalable, de alto rendimiento, robusto y maduro que soporta archivos y sistemas de archivos muy grandes en un solo host. Es el sistema de archivos por defecto en Red Hat Enterprise Linux 8. XFS fue desarrollado originalmente a principios de los 90 por SGI y tiene una larga historia de funcionamiento en servidores y matrices de almacenamiento extremadamente grandes.
Las características de XFS incluyen:
- Fiabilidad
- El registro en el diario de los metadatos, que garantiza la integridad del sistema de archivos después de un fallo del sistema, ya que mantiene un registro de las operaciones del sistema de archivos que puede reproducirse cuando se reinicia el sistema y se vuelve a montar el sistema de archivos
- Amplia comprobación de la coherencia de los metadatos en tiempo de ejecución
- Utilidades de reparación escalables y rápidas
- Registro de cuotas. Esto evita la necesidad de largas comprobaciones de consistencia de cuotas después de una caída.
- Escalabilidad y rendimiento
- Tamaño del sistema de archivos soportado hasta 1024 TiB
- Capacidad para soportar un gran número de operaciones simultáneas
- Indexación del árbol B para la escalabilidad de la gestión del espacio libre
- Sofisticados algoritmos de lectura anticipada de metadatos
- Optimizaciones para cargas de trabajo de vídeo en streaming
- Regímenes de asignación
- Asignación basada en la extensión
- Políticas de asignación con conocimiento de las franjas
- Asignación retardada
- Pre-asignación de espacio
- Inodos asignados dinámicamente
- Otras características
- Copias de archivos basadas en Reflink (nuevo en Red Hat Enterprise Linux 8)
- Utilidades de copia de seguridad y restauración estrechamente integradas
- Desfragmentación en línea
- Crecimiento del sistema de archivos en línea
- Amplia capacidad de diagnóstico
-
Atributos extendidos (
xattr). Esto permite al sistema asociar varios pares nombre/valor adicionales por archivo. - Cuotas de proyectos o directorios. Esto permite restringir las cuotas sobre un árbol de directorios.
- Marcas de tiempo de subsegundos
Características de rendimiento
XFS tiene un alto rendimiento en sistemas grandes con cargas de trabajo empresariales. Un sistema grande es aquel con un número relativamente alto de CPUs, múltiples HBAs y conexiones a matrices de discos externas. XFS también tiene un buen rendimiento en sistemas más pequeños que tienen una carga de trabajo de E/S paralela y multihilo.
XFS tiene un rendimiento relativamente bajo para cargas de trabajo intensivas en metadatos de un solo hilo: por ejemplo, una carga de trabajo que crea o borra un gran número de archivos pequeños en un solo hilo.
27.4. El sistema de archivos ext4
El sistema de archivos ext4 es la cuarta generación de la familia de sistemas de archivos ext. Fue el sistema de archivos por defecto en Red Hat Enterprise Linux 6.
El controlador ext4 puede leer y escribir en los sistemas de archivos ext2 y ext3, pero el formato del sistema de archivos ext4 no es compatible con los controladores ext2 y ext3.
ext4 añade varias características nuevas y mejoradas, como:
- Tamaño del sistema de archivos soportado hasta 50 TiB
- Metadatos basados en el alcance
- Asignación retardada
- Suma de comprobación del diario
- Gran soporte de almacenamiento
Los metadatos basados en la extensión y las funciones de asignación retardada proporcionan una forma más compacta y eficiente de rastrear el espacio utilizado en un sistema de archivos. Estas características mejoran el rendimiento del sistema de archivos y reducen el espacio consumido por los metadatos. La asignación retardada permite que el sistema de archivos posponga la selección de la ubicación permanente para los datos de usuario recién escritos hasta que los datos se descarguen en el disco. Esto permite un mayor rendimiento, ya que puede permitir asignaciones más grandes y contiguas, lo que permite al sistema de archivos tomar decisiones con mucha más información.
El tiempo de reparación del sistema de archivos mediante la utilidad fsck en ext4 es mucho más rápido que en ext2 y ext3. Algunas reparaciones de sistemas de archivos han demostrado un aumento del rendimiento de hasta seis veces.
27.5. Comparación de XFS y ext4
XFS es el sistema de archivos por defecto en RHEL. Esta sección compara el uso y las características de XFS y ext4.
- Comportamiento de los errores de metadatos
-
En ext4, se puede configurar el comportamiento cuando el sistema de archivos encuentra errores de metadatos. El comportamiento por defecto es simplemente continuar la operación. Cuando XFS encuentra un error de metadatos irrecuperable, cierra el sistema de archivos y devuelve el error
EFSCORRUPTED. - Cuotas
En ext4, puedes habilitar las cuotas al crear el sistema de archivos o posteriormente en un sistema de archivos existente. A continuación, puede configurar la aplicación de cuotas mediante una opción de montaje.
Las cuotas XFS no son una opción remountable. Debes activar las cuotas en el montaje inicial.
La ejecución del comando
quotachecken un sistema de archivos XFS no tiene ningún efecto. La primera vez que se activa la contabilidad de cuotas, XFS comprueba las cuotas automáticamente.- Redimensionamiento del sistema de archivos
- XFS no tiene ninguna utilidad para reducir el tamaño de un sistema de archivos. Sólo se puede aumentar el tamaño de un sistema de archivos XFS. En comparación, ext4 permite tanto ampliar como reducir el tamaño de un sistema de archivos.
- Números de inodo
El sistema de archivos ext4 no admite más de232 inodos.
XFS asigna dinámicamente los inodos. Un sistema de archivos XFS no puede quedarse sin inodos mientras haya espacio libre en el sistema de archivos.
Algunas aplicaciones no pueden manejar correctamente números de inodo mayores que232 en un sistema de archivos XFS. Estas aplicaciones pueden provocar el fallo de las llamadas stat de 32 bits con el valor de retorno
EOVERFLOW. El número de inodo es superior a232 en las siguientes condiciones:- El sistema de archivos es mayor de 1 TiB con inodos de 256 bytes.
- El sistema de archivos es mayor de 2 TiB con inodos de 512 bytes.
Si su aplicación falla con números de inodo grandes, monte el sistema de archivos XFS con la opción
-o inode32para imponer números de inodo inferiores a232. Tenga en cuenta que el uso deinode32no afecta a los inodos que ya están asignados con números de 64 bits.ImportanteUtilice la opción
inode32en not a menos que un entorno específico lo requiera. La opcióninode32cambia el comportamiento de la asignación. Como consecuencia, podría producirse el errorENOSPCsi no hay espacio disponible para asignar inodos en los bloques de disco inferiores.
27.6. Elegir un sistema de archivos local
Para elegir un sistema de archivos que cumpla con los requisitos de su aplicación, necesita entender el sistema de destino en el que va a desplegar el sistema de archivos. Puede utilizar las siguientes preguntas para informar su decisión:
- ¿Tiene un servidor grande?
- ¿Tiene grandes necesidades de almacenamiento o tiene una unidad SATA local y lenta?
- ¿Qué tipo de carga de trabajo de E/S espera que presente su aplicación?
- ¿Cuáles son sus requisitos de rendimiento y latencia?
- ¿Cuál es la estabilidad de su servidor y hardware de almacenamiento?
- ¿Cuál es el tamaño típico de sus archivos y conjuntos de datos?
- Si el sistema falla, ¿cuánto tiempo de inactividad puede sufrir?
Si tanto tu servidor como tu dispositivo de almacenamiento son grandes, XFS es la mejor opción. Incluso con matrices de almacenamiento más pequeñas, XFS funciona muy bien cuando el tamaño medio de los archivos es grande (por ejemplo, de cientos de megabytes).
Si su carga de trabajo actual ha funcionado bien con ext4, permanecer con ext4 debería proporcionarle a usted y a sus aplicaciones un entorno muy familiar.
El sistema de archivos ext4 tiende a funcionar mejor en sistemas que tienen una capacidad de E/S limitada. Funciona mejor con un ancho de banda limitado (menos de 200MB/s) y hasta una capacidad de 1000 IOPS. Para cualquier cosa con mayor capacidad, XFS tiende a ser más rápido.
XFS consume aproximadamente el doble de CPU por operación de metadatos en comparación con ext4, por lo que si tienes una carga de trabajo limitada a la CPU con poca concurrencia, entonces ext4 será más rápido. En general, ext4 es mejor si una aplicación utiliza un único hilo de lectura/escritura y archivos pequeños, mientras que XFS brilla cuando una aplicación utiliza múltiples hilos de lectura/escritura y archivos más grandes.
No se puede reducir un sistema de archivos XFS. Si necesita poder reducir el sistema de archivos, considere utilizar ext4, que admite la reducción sin conexión.
En general, Red Hat recomienda que utilice XFS a menos que tenga un caso de uso específico para ext4. También debería medir el rendimiento de su aplicación específica en su servidor y sistema de almacenamiento de destino para asegurarse de que elige el tipo de sistema de archivos apropiado.
| Escenario | Sistema de archivos recomendado |
|---|---|
| Ningún caso de uso especial | XFS |
| Servidor grande | XFS |
| Dispositivos de almacenamiento de gran tamaño | XFS |
| Archivos grandes | XFS |
| E/S multihilo | XFS |
| E/S de un solo hilo | ext4 |
| Capacidad de E/S limitada (menos de 1000 IOPS) | ext4 |
| Ancho de banda limitado (menos de 200 MB/s) | ext4 |
| Carga de trabajo con CPU | ext4 |
| Apoyo a la contracción fuera de línea | ext4 |
27.7. Sistemas de archivos en red
Los sistemas de archivos en red, también denominados sistemas de archivos cliente/servidor, permiten a los sistemas cliente acceder a los archivos almacenados en un servidor compartido. Esto hace posible que varios usuarios en varios sistemas compartan archivos y recursos de almacenamiento.
Estos sistemas de archivos se construyen a partir de uno o varios servidores que exportan un conjunto de sistemas de archivos a uno o varios clientes. Los nodos clientes no tienen acceso al almacenamiento de bloques subyacente, sino que interactúan con el almacenamiento utilizando un protocolo que permite un mejor control de acceso.
Sistemas de archivos de red disponibles
- El sistema de archivos cliente/servidor más común para los clientes de RHEL es el sistema de archivos NFS. RHEL proporciona tanto un componente de servidor NFS para exportar un sistema de archivos local a través de la red como un cliente NFS para importar estos sistemas de archivos.
- RHEL también incluye un cliente CIFS que soporta los populares servidores de archivos SMB de Microsoft para la interoperabilidad con Windows. El servidor Samba del espacio de usuario proporciona a los clientes de Windows un servicio SMB de Microsoft desde un servidor RHEL.
27.10. Sistemas de archivos con gestión de volumen
Los sistemas de archivos con gestión de volumen integran toda la pila de almacenamiento con el fin de simplificar y optimizar la pila.
Sistemas de archivos de gestión de volumen disponibles
Red Hat Enterprise Linux 8 proporciona el gestor de volúmenes Stratis como una Muestra de Tecnología. Stratis utiliza XFS para la capa del sistema de archivos y lo integra con LVM, Device Mapper y otros componentes.
Stratis fue lanzado por primera vez en Red Hat Enterprise Linux 8.0. Fue concebido para llenar el vacío creado cuando Red Hat dejó de utilizar Btrfs. Stratis 1.0 es un gestor de volúmenes intuitivo, basado en la línea de comandos, que puede realizar importantes operaciones de gestión de almacenamiento ocultando la complejidad al usuario:
- Gestión del volumen
- Creación de piscinas
- Grupos de almacenamiento ligero
- Instantáneas
- Caché de lectura automatizada
Stratis ofrece potentes características, pero actualmente carece de ciertas capacidades de otras ofertas con las que podría compararse, como Btrfs o ZFS. La más notable es que no soporta CRCs con autocuración.
Capítulo 31. Visión general de los atributos de nomenclatura persistente
Como administrador del sistema, usted necesita referirse a los volúmenes de almacenamiento utilizando atributos de nomenclatura persistentes para construir configuraciones de almacenamiento que sean confiables a través de múltiples arranques del sistema.
31.1. Desventajas de los atributos de denominación no persistentes
Red Hat Enterprise Linux proporciona varias formas de identificar los dispositivos de almacenamiento. Es importante utilizar la opción correcta para identificar cada dispositivo cuando se utiliza para evitar acceder inadvertidamente al dispositivo equivocado, particularmente cuando se instalan o reformatean unidades.
Tradicionalmente, los nombres no persistentes en forma de /dev/sd(major number)(minor number) se utilizan en Linux para referirse a los dispositivos de almacenamiento. El rango de números mayores y menores y los nombres sd asociados se asignan a cada dispositivo cuando se detecta. Esto significa que la asociación entre el rango de números mayores y menores y los nombres sd asociados puede cambiar si el orden de detección del dispositivo cambia.
Este cambio en el ordenamiento podría ocurrir en las siguientes situaciones:
- La paralelización del proceso de arranque del sistema detecta los dispositivos de almacenamiento en un orden diferente con cada arranque del sistema.
-
Un disco no se enciende o no responde a la controladora SCSI. Esto hace que no sea detectado por la sonda normal de dispositivos. El disco no es accesible para el sistema y los dispositivos subsiguientes tendrán su rango de números mayores y menores, incluyendo los nombres asociados
sddesplazados hacia abajo. Por ejemplo, si un disco normalmente referido comosdbno es detectado, un disco normalmente referido comosdcaparecerá comosdb. -
Un controlador SCSI (adaptador de bus de host, o HBA) no se inicializa, lo que provoca que no se detecten todos los discos conectados a ese HBA. A todos los discos conectados a los HBA comprobados posteriormente se les asignan diferentes rangos de números mayores y menores, y diferentes nombres asociados
sd. - El orden de inicialización del controlador cambia si hay diferentes tipos de HBA en el sistema. Esto hace que los discos conectados a esos HBAs sean detectados en un orden diferente. Esto también puede ocurrir si los HBA se mueven a diferentes ranuras PCI en el sistema.
-
Los discos conectados al sistema con adaptadores de canal de fibra, iSCSI o FCoE pueden ser inaccesibles en el momento en que se comprueban los dispositivos de almacenamiento, debido a que una matriz de almacenamiento o un interruptor intermedio están apagados, por ejemplo. Esto puede ocurrir cuando un sistema se reinicia después de un fallo de alimentación, si la matriz de almacenamiento tarda más en ponerse en línea que el sistema en arrancar. Aunque algunos controladores de Canal de Fibra soportan un mecanismo para especificar un mapeo persistente de SCSI target ID a WWPN, esto no hace que se reserven los rangos de números mayores y menores, y los nombres asociados
sd; sólo proporciona números SCSI target ID consistentes.
Estas razones hacen que no sea deseable utilizar el rango de números mayores y menores o los nombres asociados de sd al referirse a los dispositivos, como en el archivo /etc/fstab. Existe la posibilidad de que se monte el dispositivo incorrecto y se produzca una corrupción de datos.
Ocasionalmente, sin embargo, sigue siendo necesario referirse a los nombres de sd incluso cuando se utiliza otro mecanismo, como cuando se informan errores de un dispositivo. Esto se debe a que el núcleo de Linux utiliza los nombres de sd (y también las tuplas SCSI host/channel/target/LUN) en los mensajes del núcleo relativos al dispositivo.
31.2. Sistema de archivos e identificadores de dispositivos
Esta sección explica la diferencia entre los atributos persistentes que identifican los sistemas de archivos y los dispositivos de bloque.
Identificadores del sistema de archivos
Los identificadores del sistema de archivos están vinculados a un sistema de archivos concreto creado en un dispositivo de bloques. El identificador también se almacena como parte del sistema de archivos. Si copias el sistema de archivos a un dispositivo diferente, sigue llevando el mismo identificador del sistema de archivos. Por otro lado, si reescribes el dispositivo, por ejemplo, formateándolo con la utilidad mkfs, el dispositivo pierde el atributo.
Los identificadores del sistema de archivos son:
- Identificador único (UUID)
- Etiqueta
Identificadores de dispositivos
Los identificadores de dispositivo están vinculados a un dispositivo de bloque: por ejemplo, un disco o una partición. Si se reescribe el dispositivo, por ejemplo, formateándolo con la utilidad mkfs, el dispositivo mantiene el atributo, porque no se almacena en el sistema de archivos.
Los identificadores de los dispositivos son:
- Identificador mundial (WWID)
- UUID de la partición
- Número de serie
Recomendaciones
- Algunos sistemas de archivos, como los volúmenes lógicos, abarcan varios dispositivos. Red Hat recomienda acceder a estos sistemas de archivos utilizando identificadores de sistemas de archivos en lugar de identificadores de dispositivos.
31.3. Nombres de dispositivos gestionados por el mecanismo udev en /dev/disk/
Esta sección enumera los diferentes tipos de atributos de nomenclatura persistente que el servicio udev proporciona en el directorio /dev/disk/.
El mecanismo udev se utiliza para todo tipo de dispositivos en Linux, no sólo para los dispositivos de almacenamiento. En el caso de los dispositivos de almacenamiento, Red Hat Enterprise Linux contiene reglas udev que crean enlaces simbólicos en el directorio /dev/disk/. Esto le permite referirse a los dispositivos de almacenamiento por:
- Su contenido
- Un identificador único
- Su número de serie.
Aunque los atributos de nomenclatura de udev son persistentes, en el sentido de que no cambian por sí solos en los reinicios del sistema, algunos también son configurables.
31.3.1. Identificadores del sistema de archivos
El atributo UUID en /dev/disk/by-uuid/
Las entradas de este directorio proporcionan un nombre simbólico que hace referencia al dispositivo de almacenamiento mediante un unique identifier (UUID) en el contenido (es decir, los datos) almacenado en el dispositivo. Por ejemplo:
/dev/disco/por-uuid/3e6be9de-8139-11d1-9106-a43f08d823a6
Puede utilizar el UUID para referirse al dispositivo en el archivo /etc/fstab utilizando la siguiente sintaxis:
UUID=3e6be9de-8139-11d1-9106-a43f08d823a6Puedes configurar el atributo UUID al crear un sistema de archivos, y también puedes cambiarlo posteriormente.
El atributo Label en /dev/disk/by-label/
Las entradas de este directorio proporcionan un nombre simbólico que hace referencia al dispositivo de almacenamiento mediante un label en el contenido (es decir, los datos) almacenado en el dispositivo.
Por ejemplo:
/dev/disco/por-etiqueta/Boot
Puede utilizar la etiqueta para referirse al dispositivo en el archivo /etc/fstab utilizando la siguiente sintaxis:
ETIQUETA=BootPuede configurar el atributo Etiqueta al crear un sistema de archivos, y también puede modificarlo posteriormente.
31.3.2. Identificadores de dispositivos
El atributo WWID en /dev/disk/by-id/
El World Wide Identifier (WWID) es un identificador persistente, system-independent identifier, que el estándar SCSI exige a todos los dispositivos SCSI. Se garantiza que el identificador WWID es único para cada dispositivo de almacenamiento, e independiente de la ruta que se utilice para acceder al dispositivo. El identificador es una propiedad del dispositivo, pero no se almacena en el contenido (es decir, los datos) de los dispositivos.
Este identificador puede obtenerse emitiendo una consulta SCSI para recuperar los datos vitales del producto de identificación del dispositivo (página 0x83) o el número de serie de la unidad (página 0x80).
Red Hat Enterprise Linux mantiene automáticamente el mapeo apropiado del nombre del dispositivo basado en WWID a un nombre actual de /dev/sd en ese sistema. Las aplicaciones pueden usar el nombre /dev/disk/by-id/ para referenciar los datos en el disco, incluso si la ruta al dispositivo cambia, e incluso cuando se accede al dispositivo desde diferentes sistemas.
Ejemplo 31.1. Asignaciones WWID
| Enlace simbólico WWID | Dispositivo no persistente | Nota |
|---|---|---|
|
|
|
Un dispositivo con un identificador de página |
|
|
|
Un dispositivo con un identificador de página |
|
|
| Una partición de disco |
Además de estos nombres persistentes proporcionados por el sistema, también puede utilizar las reglas de udev para implementar nombres persistentes propios, asignados al WWID del almacenamiento.
El atributo UUID de la partición en /dev/disk/by-partuuid
El atributo UUID de la partición (PARTUUID) identifica las particiones tal y como se definen en la tabla de particiones GPT.
Ejemplo 31.2. Asignaciones de UUID de partición
| PARTUUID symlink | Dispositivo no persistente |
|---|---|
|
|
|
|
|
|
|
|
|
El atributo Path en /dev/disk/by-path/
Este atributo proporciona un nombre simbólico que hace referencia al dispositivo de almacenamiento mediante la dirección hardware path utilizada para acceder al dispositivo.
El atributo Path falla si cualquier parte de la ruta de hardware (por ejemplo, el ID PCI, el puerto de destino o el número LUN) cambia. Por lo tanto, el atributo Path no es fiable. Sin embargo, el atributo Path puede ser útil en uno de los siguientes escenarios:
- Es necesario identificar un disco que se piensa sustituir más adelante.
- Usted planea instalar un servicio de almacenamiento en un disco en una ubicación específica.
31.4. El identificador mundial con DM Multipath
Esta sección describe el mapeo entre el World Wide Identifier (WWID) y los nombres de dispositivos no persistentes en una configuración de Device Mapper Multipath.
Si hay varias rutas desde un sistema a un dispositivo, DM Multipath utiliza el WWID para detectarlo. DM Multipath presenta entonces un único "pseudo-dispositivo" en el directorio /dev/mapper/wwid, como /dev/mapper/3600508b400105df70000e00000ac0000.
El comando multipath -l muestra la asignación a los identificadores no persistentes:
-
Host:Channel:Target:LUN -
/dev/sdnombre -
major:minornúmero
Ejemplo 31.3. Asignaciones WWID en una configuración multirruta
Un ejemplo de salida del comando multipath -l:
3600508b400105df70000e00000ac0000 dm-2 vendor,product
[size=20G][features=1 queue_if_no_path][hwhandler=0][rw]
\_ round-robin 0 [prio=0][active]
\_ 5:0:1:1 sdc 8:32 [active][undef]
\_ 6:0:1:1 sdg 8:96 [active][undef]
\_ round-robin 0 [prio=0][enabled]
\_ 5:0:0:1 sdb 8:16 [active][undef]
\_ 6:0:0:1 sdf 8:80 [active][undef]
DM Multipath mantiene automáticamente la asignación adecuada de cada nombre de dispositivo basado en WWID a su correspondiente nombre /dev/sd en el sistema. Estos nombres son persistentes a través de los cambios de ruta, y son consistentes cuando se accede al dispositivo desde diferentes sistemas.
Cuando se utiliza la función user_friendly_names de DM Multipath, el WWID se asigna a un nombre de la forma /dev/mapper/mpathN. Por defecto, esta asignación se mantiene en el archivo /etc/multipath/bindings. Estos nombres de mpathN nombres son persistentes mientras se mantenga ese archivo.
Si se utiliza user_friendly_names, se requieren pasos adicionales para obtener nombres consistentes en un clúster.
31.5. Limitaciones de la convención de nombres de dispositivos udev
Las siguientes son algunas limitaciones de la convención de nombres udev:
-
Es posible que el dispositivo no esté accesible en el momento en que se realiza la consulta porque el mecanismo de
udevpuede depender de la capacidad de consultar el dispositivo de almacenamiento cuando se procesan las reglas deudevpara un evento deudev. Esto es más probable que ocurra con los dispositivos de almacenamiento Fibre Channel, iSCSI o FCoE cuando el dispositivo no se encuentra en el chasis del servidor. -
El kernel puede enviar eventos
udeven cualquier momento, haciendo que las reglas sean procesadas y posiblemente haciendo que los enlaces/dev/disk/by-*/sean eliminados si el dispositivo no es accesible. -
Puede haber un retraso entre el momento en que se genera el evento
udevy el momento en que se procesa, como cuando se detecta un gran número de dispositivos y el servicioudevddel espacio de usuario tarda cierto tiempo en procesar las reglas de cada uno. Esto puede causar un retraso entre el momento en que el kernel detecta el dispositivo y cuando los nombres de/dev/disk/by-*/están disponibles. -
Los programas externos como
blkidinvocados por las reglas podrían abrir el dispositivo durante un breve período de tiempo, haciendo que el dispositivo sea inaccesible para otros usos. -
Los nombres de los dispositivos gestionados por el mecanismo
udeven /dev/disk/ pueden cambiar entre las principales versiones, lo que obliga a actualizar los enlaces.
31.6. Listado de atributos de nomenclatura persistente
Este procedimiento describe cómo averiguar los atributos de nomenclatura persistente de los dispositivos de almacenamiento no persistentes.
Procedimiento
Para listar los atributos UUID y Label, utilice la utilidad
lsblk:$ lsblk --fs storage-devicePor ejemplo:
Ejemplo 31.4. Ver el UUID y la etiqueta de un sistema de archivos
$ lsblk --fs /dev/sda1 NAME FSTYPE LABEL UUID MOUNTPOINT sda1 xfs Boot afa5d5e3-9050-48c3-acc1-bb30095f3dc4 /bootPara listar el atributo PARTUUID, utilice la utilidad
lsblkcon la opción--output PARTUUID:$ lsblk --output PARTUUIDPor ejemplo:
Ejemplo 31.5. Ver el atributo PARTUUID de una partición
$ lsblk --output +PARTUUID /dev/sda1 NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT PARTUUID sda1 8:1 0 512M 0 part /boot 4cd1448a-01Para listar el atributo WWID, examine los objetivos de los enlaces simbólicos en el directorio
/dev/disk/by-id/. Por ejemplo:Ejemplo 31.6. Ver el WWID de todos los dispositivos de almacenamiento del sistema
$ file /dev/disk/by-id/* /dev/disk/by-id/ata-QEMU_HARDDISK_QM00001 symbolic link to ../../sda /dev/disk/by-id/ata-QEMU_HARDDISK_QM00001-part1 symbolic link to ../../sda1 /dev/disk/by-id/ata-QEMU_HARDDISK_QM00001-part2 symbolic link to ../../sda2 /dev/disk/by-id/dm-name-rhel_rhel8-root symbolic link to ../../dm-0 /dev/disk/by-id/dm-name-rhel_rhel8-swap symbolic link to ../../dm-1 /dev/disk/by-id/dm-uuid-LVM-QIWtEHtXGobe5bewlIUDivKOz5ofkgFhP0RMFsNyySVihqEl2cWWbR7MjXJolD6g symbolic link to ../../dm-1 /dev/disk/by-id/dm-uuid-LVM-QIWtEHtXGobe5bewlIUDivKOz5ofkgFhXqH2M45hD2H9nAf2qfWSrlRLhzfMyOKd symbolic link to ../../dm-0 /dev/disk/by-id/lvm-pv-uuid-atlr2Y-vuMo-ueoH-CpMG-4JuH-AhEF-wu4QQm symbolic link to ../../sda2
31.7. Modificación de los atributos de nomenclatura persistente
Este procedimiento describe cómo cambiar el atributo de nomenclatura persistente UUID o Label de un sistema de archivos.
El cambio de los atributos de udev se produce en segundo plano y puede llevar mucho tiempo. El comando udevadm settle espera hasta que el cambio esté completamente registrado, lo que garantiza que su siguiente comando podrá utilizar el nuevo atributo correctamente.
En los siguientes comandos:
-
Sustituya new-uuid por el UUID que quieras establecer; por ejemplo,
1cdfbc07-1c90-4984-b5ec-f61943f5ea50. Puedes generar un UUID utilizando el comandouuidgen. -
Sustituya new-label por una etiqueta; por ejemplo,
backup_data.
Requisitos previos
- Si va a modificar los atributos de un sistema de archivos XFS, desmóntelo primero.
Procedimiento
Para cambiar los atributos UUID o Label de un sistema de archivos XFS, utilice la utilidad
xfs_admin:# xfs_admin -U new-uuid -L new-label storage-device # udevadm settlePara cambiar los atributos UUID o Label de un sistema de archivos ext4, ext3, o ext2, utilice la utilidad
tune2fs:# tune2fs -U new-uuid -L new-label storage-device # udevadm settlePara cambiar el UUID o los atributos de la etiqueta de un volumen de intercambio, utilice la utilidad
swaplabel:# swaplabel --uuid new-uuid --label new-label swap-device # udevadm settle
Capítulo 32. Cómo empezar con las particiones
Como administrador del sistema, puede utilizar los siguientes procedimientos para crear, eliminar y modificar varios tipos de particiones de disco.
Para obtener una visión general de las ventajas y desventajas de utilizar particiones en dispositivos de bloque, consulte el siguiente artículo de KBase: https://access.redhat.com/solutions/163853.
32.1. Visualización de la tabla de particiones
Como administrador del sistema, puede mostrar la tabla de particiones de un dispositivo de bloque para ver la disposición de las particiones y los detalles sobre las particiones individuales.
32.1.1. Visualización de la tabla de particiones con parted
Este procedimiento describe cómo ver la tabla de particiones en un dispositivo de bloque utilizando la utilidad parted.
Procedimiento
Inicie el shell interactivo
parted:# parted block-device-
Sustituya block-device por la ruta del dispositivo que desea examinar: por ejemplo,
/dev/sda.
-
Sustituya block-device por la ruta del dispositivo que desea examinar: por ejemplo,
Ver la tabla de particiones:
Impresión (parcial)Opcionalmente, utilice el siguiente comando para cambiar a otro dispositivo que desee examinar a continuación:
(separado) seleccionar block-device
Recursos adicionales
-
La página de manual
parted(8).
32.1.2. Ejemplo de salida de parted print
Esta sección proporciona un ejemplo de salida del comando print en el shell parted y describe los campos de la salida.
Ejemplo 32.1. Salida del comando print
Model: ATA SAMSUNG MZNLN256 (scsi)
Disk /dev/sda: 256GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 269MB 268MB primary xfs boot
2 269MB 34.6GB 34.4GB primary
3 34.6GB 45.4GB 10.7GB primary
4 45.4GB 256GB 211GB extended
5 45.4GB 256GB 211GB logicalA continuación se describen los campos:
Model: ATA SAMSUNG MZNLN256 (scsi)- El tipo de disco, el fabricante, el número de modelo y la interfaz.
Disk /dev/sda: 256GB- La ruta del archivo al dispositivo de bloque y la capacidad de almacenamiento.
Partition Table: msdos- El tipo de etiqueta del disco.
Number-
El número de la partición. Por ejemplo, la partición con número menor 1 corresponde a
/dev/sda1. StartyEnd- La ubicación en el dispositivo donde comienza y termina la partición.
Type- Los tipos válidos son metadatos, libre, primario, extendido o lógico.
File system-
El tipo de sistema de archivos. Si el campo
File systemde un dispositivo no muestra ningún valor, significa que su tipo de sistema de archivos es desconocido. La utilidadpartedno puede reconocer el sistema de archivos de los dispositivos cifrados. Flags-
Enumera las banderas establecidas para la partición. Las banderas disponibles son
boot,root,swap,hidden,raid,lvm, olba.
32.2. Creación de una tabla de particiones en un disco
Como administrador del sistema, puede formatear un dispositivo de bloque con diferentes tipos de tablas de partición para permitir el uso de particiones en el dispositivo.
Al formatear un dispositivo de bloque con una tabla de particiones se borran todos los datos almacenados en el dispositivo.
32.2.1. Consideraciones antes de modificar las particiones de un disco
Esta sección enumera los puntos clave a tener en cuenta antes de crear, eliminar o redimensionar las particiones.
Esta sección no cubre la tabla de particiones DASD, que es específica de la arquitectura IBM Z. Para obtener información sobre DASD, consulte:
- Configuración de una instancia de Linux en IBM Z
- El artículo Lo que debe saber sobre DASD en el Centro de Conocimiento de IBM
El número máximo de particiones
El número de particiones en un dispositivo está limitado por el tipo de tabla de particiones:
En un dispositivo formateado con la tabla de particiones Master Boot Record (MBR), puede tener cualquiera de los dos:
- Hasta cuatro particiones primarias, o
- Hasta tres particiones primarias, una partición extendida y múltiples particiones lógicas dentro de la extendida.
-
En un dispositivo formateado con el GUID Partition Table (GPT), el número máximo de particiones es 128. Aunque la especificación GPT permite más particiones aumentando el área reservada para la tabla de particiones, la práctica común utilizada por la utilidad
partedes limitarla a un área suficiente para 128 particiones.
Red Hat recomienda que, a menos que tenga una razón para hacer lo contrario, debería at least crear las siguientes particiones: swap, /boot/, y / (raíz).
El tamaño máximo de una partición
El tamaño de una partición en un dispositivo está limitado por el tipo de tabla de particiones:
- En un dispositivo formateado con la tabla de particiones Master Boot Record (MBR), el tamaño máximo es de 2TiB.
- En un dispositivo formateado con el GUID Partition Table (GPT), el tamaño máximo es de 8ZiB.
Si quieres crear una partición mayor de 2TiB, el disco debe estar formateado con GPT.
Alineación de tamaños
La utilidad parted le permite especificar el tamaño de la partición utilizando varios sufijos diferentes:
- MiB, GiB o TiB
Tamaño expresado en potencias de 2.
- El punto inicial de la partición se alinea con el sector exacto especificado por el tamaño.
- El punto final se alinea con el tamaño especificado menos 1 sector.
- MB, GB o TB
Tamaño expresado en potencias de 10.
El punto inicial y final se alinea dentro de la mitad de la unidad especificada: por ejemplo, ±500KB cuando se utiliza el sufijo MB.
32.2.2. Comparación de los tipos de tablas de partición
Esta sección compara las propiedades de los diferentes tipos de tablas de partición que se pueden crear en un dispositivo de bloque.
| Tabla de partición | Número máximo de particiones | Tamaño máximo de la partición |
|---|---|---|
| Registro de arranque maestro (MBR) | 4 primarios, o 3 primarios y 12 lógicos dentro de una partición extendida | 2TiB |
| Tabla de partición GUID (GPT) | 128 | 8ZiB |
32.2.3. Particiones de disco MBR
Los diagramas de este capítulo muestran que la tabla de particiones está separada del disco real. Sin embargo, esto no es del todo exacto. En realidad, la tabla de particiones se almacena al principio del disco, antes de cualquier sistema de archivos o datos de usuario, pero para mayor claridad, están separados en los siguientes diagramas.
Figura 32.1. Disco con tabla de partición MBR
Como muestra el diagrama anterior, la tabla de particiones se divide en cuatro secciones de cuatro particiones primarias. Una partición primaria es una partición en un disco duro que sólo puede contener una unidad lógica (o sección). Cada sección puede contener la información necesaria para definir una sola partición, lo que significa que la tabla de particiones no puede definir más de cuatro particiones.
Cada entrada de la tabla de particiones contiene varias características importantes de la partición:
- Los puntos del disco donde comienza y termina la partición.
- Si la partición es active. Sólo se puede marcar una partición como active.
- El tipo de partición.
Los puntos inicial y final definen el tamaño de la partición y su ubicación en el disco. El indicador "activo" es utilizado por los cargadores de arranque de algunos sistemas operativos. En otras palabras, el sistema operativo en la partición que está marcada como "activa" es arrancado, en este caso.
El tipo es un número que identifica el uso previsto de la partición. Algunos sistemas operativos utilizan el tipo de partición para denotar un tipo de sistema de archivos específico, para marcar la partición como asociada a un sistema operativo concreto, para indicar que la partición contiene un sistema operativo de arranque, o alguna combinación de las tres.
El siguiente diagrama muestra un ejemplo de una unidad con una sola partición:
Figura 32.2. Disco con una sola partición
La única partición en este ejemplo está etiquetada como DOS. Esta etiqueta muestra el tipo de partición, siendo DOS una de las más comunes.
32.2.4. Particiones MBR extendidas
En caso de que cuatro particiones sean insuficientes para sus necesidades, puede utilizar las particiones extendidas para crear particiones adicionales. Puede hacerlo configurando el tipo de partición como "Extendida".
Una partición extendida es como una unidad de disco en sí misma - tiene su propia tabla de particiones, que apunta a una o más particiones (ahora llamadas particiones lógicas, en contraposición a las cuatro particiones primarias), contenidas completamente dentro de la propia partición extendida. El siguiente diagrama muestra una unidad de disco con una partición primaria y una partición extendida que contiene dos particiones lógicas (junto con algo de espacio libre sin particionar):
Figura 32.3. Disco con una partición MBR primaria y otra extendida
Como esta figura implica, hay una diferencia entre las particiones primarias y las lógicas - sólo puede haber hasta cuatro particiones primarias y extendidas, pero no hay un límite fijo para el número de particiones lógicas que pueden existir. Sin embargo, debido a la forma en que se accede a las particiones en Linux, no se pueden definir más de 15 particiones lógicas en una sola unidad de disco.
32.2.5. Tipos de partición MBR
La siguiente tabla muestra una lista de algunos de los tipos de partición MBR más utilizados y los números hexadecimales utilizados para representarlos.
| MBR partition type | Value | MBR partition type | Value |
| Vacío | 00 | Novell Netware 386 | 65 |
| DOS 12-bit FAT | 01 | PIC/IX | 75 |
| Raíz de XENIX | O2 | Antiguo MINIX | 80 |
| XENIX usr | O3 | Linux/MINUX | 81 |
| DOS 16 bits ⇐32M | 04 | Intercambio en Linux | 82 |
| Extendido | 05 | Linux nativo | 83 |
| DOS 16 bits >=32 | 06 | Linux ampliado | 85 |
| OS/2 HPFS | 07 | Amoeba | 93 |
| AIX | 08 | Amoeba BBT | 94 |
| AIX de arranque | 09 | BSD/386 | a5 |
| Gestor de arranque de OS/2 | 0a | OpenBSD | a6 |
| Win95 FAT32 | 0b | NEXTSTEP | a7 |
| Win95 FAT32 (LBA) | 0c | BSDI fs | b7 |
| Win95 FAT16 (LBA) | 0e | Intercambio BSDI | b8 |
| Win95 Extended (LBA) | 0f | Syrinx | c7 |
| Venix 80286 | 40 | CP/M | db |
| Novell | 51 | Acceso al DOS | e1 |
| Bota PRep | 41 | DOS R/O | e3 |
| GNU HURD | 63 | DOS secundario | f2 |
| Novell Netware 286 | 64 | BBT | ff |
32.2.6. Tabla de partición GUID
La tabla de partición GUID (GPT) es un esquema de partición basado en el uso de un identificador único global (GUID). La GPT se desarrolló para hacer frente a las limitaciones de la tabla de partición MBR, especialmente con el limitado espacio de almacenamiento máximo direccionable de un disco. A diferencia de MBR, que no puede direccionar un almacenamiento mayor de 2 TiB (equivalente a unos 2,2 TB), GPT se utiliza con discos duros de mayor tamaño; el tamaño máximo direccionable del disco es de 2,2 ZiB. Además, GPT, por defecto, permite crear hasta 128 particiones primarias. Este número puede ampliarse asignando más espacio a la tabla de particiones.
Una GPT tiene tipos de partición basados en GUIDs. Tenga en cuenta que ciertas particiones requieren un GUID específico. Por ejemplo, la partición del sistema para los cargadores de arranque EFI requiere el GUID C12A7328-F81F-11D2-BA4B-00A0C93EC93B.
Los discos GPT utilizan el direccionamiento lógico de bloques (LBA) y la disposición de las particiones es la siguiente:
- Para mantener la compatibilidad con los discos MBR, el primer sector (LBA 0) de GPT está reservado para los datos de MBR y se llama "MBR protector".
- La cabecera GPT primaria comienza en el segundo bloque lógico (LBA 1) del dispositivo. La cabecera contiene el GUID del disco, la ubicación de la tabla de particiones primaria, la ubicación de la cabecera GPT secundaria, y las sumas de comprobación CRC32 de sí misma y de la tabla de particiones primaria. También especifica el número de entradas de partición en la tabla.
- La GPT primaria incluye, por defecto 128 entradas de partición, cada una con un tamaño de entrada de 128 bytes, su GUID de tipo de partición y su GUID de partición única.
- La GPT secundaria es idéntica a la GPT primaria. Se utiliza principalmente como una tabla de respaldo para la recuperación en caso de que la tabla de partición primaria se corrompa.
- La cabecera secundaria de GPT se encuentra en el último sector lógico del disco y puede utilizarse para recuperar la información de GPT en caso de que la cabecera primaria esté dañada. Contiene el GUID del disco, la ubicación de la tabla de particiones secundarias y la cabecera GPT primaria, las sumas de comprobación CRC32 de sí mismo y de la tabla de particiones secundarias, y el número de posibles entradas de partición.
Figura 32.4. Disco con una tabla de partición GUID
Debe haber una partición de arranque de la BIOS para que el gestor de arranque se instale con éxito en un disco que contenga una tabla de particiones GPT (GUID). Esto incluye los discos inicializados por Anaconda. Si el disco ya contiene una partición de arranque del BIOS, se puede reutilizar.
32.2.7. Creación de una tabla de particiones en un disco con partición
Este procedimiento describe cómo formatear un dispositivo de bloque con una tabla de particiones utilizando la utilidad parted.
Procedimiento
Inicie el shell interactivo
parted:# parted block-device-
Sustituya block-device por la ruta del dispositivo en el que desea crear una tabla de particiones: por ejemplo,
/dev/sda.
-
Sustituya block-device por la ruta del dispositivo en el que desea crear una tabla de particiones: por ejemplo,
Determine si ya existe una tabla de particiones en el dispositivo:
Impresión (parcial)Si el dispositivo ya contiene particiones, se eliminarán en los siguientes pasos.
Cree la nueva tabla de partición:
(parted) mklabel table-typeSustituya table-type por el tipo de tabla de partición deseado:
-
msdospara MBR -
gptpara GPT
-
Ejemplo 32.2. Creación de una tabla GPT
Por ejemplo, para crear una tabla GPT en el disco, utilice:
(parted) mklabel gptLos cambios empiezan a producirse en cuanto se introduce este comando, así que revísalo antes de ejecutarlo.
Ver la tabla de particiones para confirmar que la tabla de particiones existe:
Impresión (parcial)Salga del shell
parted:(separada) dejar de fumar
Recursos adicionales
-
La página de manual
parted(8).
Próximos pasos
- Crear particiones en el dispositivo. Consulte Sección 32.3, “Crear una partición” para obtener más detalles.
32.3. Crear una partición
Como administrador del sistema, puedes crear nuevas particiones en un disco.
32.3.1. Consideraciones antes de modificar las particiones de un disco
Esta sección enumera los puntos clave a tener en cuenta antes de crear, eliminar o redimensionar las particiones.
Esta sección no cubre la tabla de particiones DASD, que es específica de la arquitectura IBM Z. Para obtener información sobre DASD, consulte:
- Configuración de una instancia de Linux en IBM Z
- El artículo Lo que debe saber sobre DASD en el Centro de Conocimiento de IBM
El número máximo de particiones
El número de particiones en un dispositivo está limitado por el tipo de tabla de particiones:
En un dispositivo formateado con la tabla de particiones Master Boot Record (MBR), puede tener cualquiera de los dos:
- Hasta cuatro particiones primarias, o
- Hasta tres particiones primarias, una partición extendida y múltiples particiones lógicas dentro de la extendida.
-
En un dispositivo formateado con el GUID Partition Table (GPT), el número máximo de particiones es 128. Aunque la especificación GPT permite más particiones aumentando el área reservada para la tabla de particiones, la práctica común utilizada por la utilidad
partedes limitarla a un área suficiente para 128 particiones.
Red Hat recomienda que, a menos que tenga una razón para hacer lo contrario, debería at least crear las siguientes particiones: swap, /boot/, y / (raíz).
El tamaño máximo de una partición
El tamaño de una partición en un dispositivo está limitado por el tipo de tabla de particiones:
- En un dispositivo formateado con la tabla de particiones Master Boot Record (MBR), el tamaño máximo es de 2TiB.
- En un dispositivo formateado con el GUID Partition Table (GPT), el tamaño máximo es de 8ZiB.
Si quieres crear una partición mayor de 2TiB, el disco debe estar formateado con GPT.
Alineación de tamaños
La utilidad parted le permite especificar el tamaño de la partición utilizando varios sufijos diferentes:
- MiB, GiB o TiB
Tamaño expresado en potencias de 2.
- El punto inicial de la partición se alinea con el sector exacto especificado por el tamaño.
- El punto final se alinea con el tamaño especificado menos 1 sector.
- MB, GB o TB
Tamaño expresado en potencias de 10.
El punto inicial y final se alinea dentro de la mitad de la unidad especificada: por ejemplo, ±500KB cuando se utiliza el sufijo MB.
32.3.2. Tipos de partición
Esta sección describe diferentes atributos que especifican el tipo de una partición.
Tipos de partición o banderas
El tipo de partición, o bandera, es utilizado por un sistema en ejecución sólo en raras ocasiones. Sin embargo, el tipo de partición es importante para los generadores sobre la marcha, como systemd-gpt-auto-generator, que utilizan el tipo de partición para, por ejemplo, identificar y montar automáticamente los dispositivos.
-
La utilidad
partedproporciona cierto control de los tipos de partición mediante la asignación del tipo de partición a flags. La utilidad parted sólo puede manejar ciertos tipos de partición: por ejemplo LVM, swap o RAID. -
La utilidad
fdiskadmite toda la gama de tipos de partición especificando códigos hexadecimales.
Tipo de sistema de archivos de la partición
La utilidad parted acepta opcionalmente un argumento de tipo de sistema de archivos al crear una partición. El valor se utiliza para:
- Establecer las banderas de la partición en MBR, o
-
Establezca el tipo de UUID de la partición en GPT. Por ejemplo, los tipos de sistema de archivos
swap,fat, ohfsestablecen diferentes GUIDs. El valor por defecto es el GUID de datos de Linux.
El argumento no modifica el sistema de archivos de la partición de ninguna manera. Sólo diferencia entre las banderas o GUIDs soportados.
Se admiten los siguientes tipos de sistemas de archivos:
-
xfs -
ext2 -
ext3 -
ext4 -
fat16 -
fat32 -
hfs -
hfs -
linux-swap -
ntfs -
reiserfs
32.3.3. Esquema de nomenclatura de las particiones
Red Hat Enterprise Linux utiliza un esquema de nomenclatura basado en archivos, con nombres de archivos en forma de /dev/xxyN.
Los nombres de dispositivos y particiones tienen la siguiente estructura:
/dev/-
Este es el nombre del directorio en el que se encuentran todos los archivos del dispositivo. Como las particiones se colocan en los discos duros, y los discos duros son dispositivos, los archivos que representan todas las posibles particiones se encuentran en
/dev. xx-
Las dos primeras letras del nombre de las particiones indican el tipo de dispositivo en el que se encuentra la partición, normalmente
sd. y-
Esta letra indica en qué dispositivo se encuentra la partición. Por ejemplo,
/dev/sdapara el primer disco duro,/dev/sdbpara el segundo, y así sucesivamente. En sistemas con más de 26 discos, puede utilizar más letras. Por ejemplo,/dev/sdaa1. N-
La letra final indica el número que representa la partición. Las cuatro primeras particiones (primarias o extendidas) están numeradas de
1a4. Las particiones lógicas comienzan en5. Por ejemplo,/dev/sda3es la tercera partición primaria o extendida en el primer disco duro, y/dev/sdb6es la segunda partición lógica en el segundo disco duro. La numeración de las particiones de la unidad sólo se aplica a las tablas de partición MBR. Tenga en cuenta que N no siempre significa partición.
Incluso si Red Hat Enterprise Linux puede identificar y referirse a all tipos de particiones de disco, podría no ser capaz de leer el sistema de archivos y por lo tanto acceder a los datos almacenados en cada tipo de partición. Sin embargo, en muchos casos, es posible acceder con éxito a los datos de una partición dedicada a otro sistema operativo.
32.3.4. Puntos de montaje y particiones de disco
En Red Hat Enterprise Linux, cada partición se utiliza para formar parte del almacenamiento necesario para soportar un único conjunto de archivos y directorios. Esto se hace utilizando el proceso conocido como mounting, que asocia una partición con un directorio. El montaje de una partición hace que su almacenamiento esté disponible a partir del directorio especificado, conocido como mount point.
Por ejemplo, si la partición /dev/sda5 está montada en /usr/, eso significaría que todos los archivos y directorios bajo /usr/ residen físicamente en /dev/sda5. Así, el archivo /usr/share/doc/FAQ/txt/Linux-FAQ se almacenaría en /dev/sda5, mientras que el archivo /etc/gdm/custom.conf no.
Continuando con el ejemplo, también es posible que uno o más directorios por debajo de /usr/ sean puntos de montaje para otras particiones. Por ejemplo, una partición /dev/sda7 podría ser montada en /usr/local, lo que significa que /usr/local/man/whatis residiría entonces en /dev/sda7 en lugar de /dev/sda5.
32.3.5. Creación de una partición con parted
Este procedimiento describe cómo crear una nueva partición en un dispositivo de bloque utilizando la utilidad parted.
Requisitos previos
- Hay una tabla de particiones en el disco. Para obtener detalles sobre cómo formatear el disco, consulte Sección 32.2, “Creación de una tabla de particiones en un disco”.
- Si la partición que quiere crear es mayor de 2TiB, el disco debe estar formateado con la tabla de particiones GUID (GPT).
Procedimiento
Inicie el shell interactivo
parted:# parted block-device-
Sustituya block-device por la ruta del dispositivo en el que desea crear una partición: por ejemplo,
/dev/sda.
-
Sustituya block-device por la ruta del dispositivo en el que desea crear una partición: por ejemplo,
Vea la tabla de particiones actual para determinar si hay suficiente espacio libre:
Impresión (parcial)- Si no hay suficiente espacio libre, puede redimensionar una partición existente. Para más información, consulte Sección 32.5, “Cambiar el tamaño de una partición”.
A partir de la tabla de particiones, determinar:
- Los puntos inicial y final de la nueva partición
- En MBR, qué tipo de partición debe ser.
Crea la nueva partición:
(parted) mkpart part-type name fs-type start end-
Sustituya part-type con
primary,logical, oextendeden base a lo que haya decidido de la tabla de particiones. Esto se aplica sólo a la tabla de particiones MBR. - Sustituya name con un nombre de partición arbitrario. Esto es necesario para las tablas de partición GPT.
-
Sustituir fs-type por cualquiera de los siguientes:
xfs,ext2,ext3,ext4,fat16,fat32,hfs,hfs,linux-swap,ntfs, oreiserfs. El parámetro fs-type es opcional. Tenga en cuenta quepartedno crea el sistema de archivos en la partición. -
Sustituya start y end con los tamaños que determinan los puntos inicial y final de la partición, contando desde el principio del disco. Puede utilizar sufijos de tamaño, como
512MiB,20GiB, o1.5TiB. El tamaño por defecto es de megabytes.
Ejemplo 32.3. Creación de una pequeña partición primaria
Por ejemplo, para crear una partición primaria de 1024MiB hasta 2048MiB en una tabla MBR, utilice:
(parted) mkpart primary 1024MiB 2048MiBLos cambios empiezan a producirse en cuanto se introduce este comando, así que revísalo antes de ejecutarlo.
-
Sustituya part-type con
Vea la tabla de particiones para confirmar que la partición creada está en la tabla de particiones con el tipo de partición, el tipo de sistema de archivos y el tamaño correctos:
Impresión (parcial)Salga del shell
parted:(separada) dejar de fumarUtilice el siguiente comando para esperar a que el sistema registre el nuevo nodo de dispositivo:
# udevadm settleVerifique que el kernel reconoce la nueva partición:
# cat /proc/partitions
Recursos adicionales
-
La página de manual
parted(8).
32.3.6. Establecer un tipo de partición con fdisk
Este procedimiento describe cómo establecer un tipo de partición, o bandera, utilizando la utilidad fdisk.
Requisitos previos
- Hay una partición en el disco.
Procedimiento
Inicie el shell interactivo
fdisk:# fdisk block-device-
Sustituya block-device por la ruta del dispositivo en el que desea establecer un tipo de partición: por ejemplo,
/dev/sda.
-
Sustituya block-device por la ruta del dispositivo en el que desea establecer un tipo de partición: por ejemplo,
Ver la tabla de particiones actual para determinar el número de partición menor:
Comando (m de ayuda) printPuede ver el tipo de partición actual en la columna
Typey su correspondiente ID de tipo en la columnaId.Introduzca el comando de tipo de partición y seleccione una partición utilizando su número menor:
Command (m for help): type Partition number (1,2,3 default 3): 2Opcionalmente, enumera los códigos hexadecimales disponibles:
Código hexadecimal (escriba L para listar todos los códigos) LEstablezca el tipo de partición:
Código hexadecimal (escriba L para listar todos los códigos) 8eEscriba sus cambios y salga del shell
fdisk:Command (m for help): write The partition table has been altered. Syncing disks.Verifique los cambios:
# fdisk --list block-device
32.4. Eliminar una partición
Como administrador del sistema, puede eliminar una partición de disco que ya no se utilice para liberar espacio en el disco.
Al eliminar una partición se borran todos los datos almacenados en ella.
32.4.1. Consideraciones antes de modificar las particiones de un disco
Esta sección enumera los puntos clave a tener en cuenta antes de crear, eliminar o redimensionar las particiones.
Esta sección no cubre la tabla de particiones DASD, que es específica de la arquitectura IBM Z. Para obtener información sobre DASD, consulte:
- Configuración de una instancia de Linux en IBM Z
- El artículo Lo que debe saber sobre DASD en el Centro de Conocimiento de IBM
El número máximo de particiones
El número de particiones en un dispositivo está limitado por el tipo de tabla de particiones:
En un dispositivo formateado con la tabla de particiones Master Boot Record (MBR), puede tener cualquiera de los dos:
- Hasta cuatro particiones primarias, o
- Hasta tres particiones primarias, una partición extendida y múltiples particiones lógicas dentro de la extendida.
-
En un dispositivo formateado con el GUID Partition Table (GPT), el número máximo de particiones es 128. Aunque la especificación GPT permite más particiones aumentando el área reservada para la tabla de particiones, la práctica común utilizada por la utilidad
partedes limitarla a un área suficiente para 128 particiones.
Red Hat recomienda que, a menos que tenga una razón para hacer lo contrario, debería at least crear las siguientes particiones: swap, /boot/, y / (raíz).
El tamaño máximo de una partición
El tamaño de una partición en un dispositivo está limitado por el tipo de tabla de particiones:
- En un dispositivo formateado con la tabla de particiones Master Boot Record (MBR), el tamaño máximo es de 2TiB.
- En un dispositivo formateado con el GUID Partition Table (GPT), el tamaño máximo es de 8ZiB.
Si quieres crear una partición mayor de 2TiB, el disco debe estar formateado con GPT.
Alineación de tamaños
La utilidad parted le permite especificar el tamaño de la partición utilizando varios sufijos diferentes:
- MiB, GiB o TiB
Tamaño expresado en potencias de 2.
- El punto inicial de la partición se alinea con el sector exacto especificado por el tamaño.
- El punto final se alinea con el tamaño especificado menos 1 sector.
- MB, GB o TB
Tamaño expresado en potencias de 10.
El punto inicial y final se alinea dentro de la mitad de la unidad especificada: por ejemplo, ±500KB cuando se utiliza el sufijo MB.
32.4.2. Eliminación de una partición con parted
Este procedimiento describe cómo eliminar una partición de disco utilizando la utilidad parted.
Procedimiento
Inicie el shell interactivo
parted:# parted block-device-
Sustituya block-device por la ruta del dispositivo en el que desea eliminar una partición: por ejemplo,
/dev/sda.
-
Sustituya block-device por la ruta del dispositivo en el que desea eliminar una partición: por ejemplo,
Ver la tabla de particiones actual para determinar el número menor de la partición a eliminar:
Impresión (parcial)Retire la partición:
(separado) rm minor-number-
Sustituya minor-number por el número menor de la partición que desea eliminar: por ejemplo,
3.
Los cambios empiezan a producirse en cuanto se introduce este comando, así que revísalo antes de ejecutarlo.
-
Sustituya minor-number por el número menor de la partición que desea eliminar: por ejemplo,
Confirme que la partición se ha eliminado de la tabla de particiones:
Impresión (parcial)Salga del shell
parted:(separada) dejar de fumarVerifique que el kernel sabe que la partición ha sido eliminada:
# cat /proc/partitions-
Elimine la partición del archivo
/etc/fstabsi está presente. Encuentre la línea que declara la partición eliminada, y elimínela del archivo. Regenere las unidades de montaje para que su sistema registre la nueva configuración de
/etc/fstab:# systemctl daemon-reloadSi ha eliminado una partición swap o ha eliminado partes de LVM, elimine todas las referencias a la partición de la línea de comandos del kernel en el archivo
/etc/default/gruby regenere la configuración de GRUB:En un sistema basado en BIOS:
# grub2-mkconfig --output=/etc/grub2.cfgEn un sistema basado en UEFI:
# grub2-mkconfig --output=/etc/grub2-efi.cfg
Para registrar los cambios en el sistema de arranque temprano, reconstruya el sistema de archivos
initramfs:# dracut --force --verbose
Recursos adicionales
-
La página de manual
parted(8)
32.5. Cambiar el tamaño de una partición
Como administrador del sistema, puede ampliar una partición para utilizar el espacio de disco no utilizado, o reducir una partición para utilizar su capacidad para diferentes propósitos.
32.5.1. Consideraciones antes de modificar las particiones de un disco
Esta sección enumera los puntos clave a tener en cuenta antes de crear, eliminar o redimensionar las particiones.
Esta sección no cubre la tabla de particiones DASD, que es específica de la arquitectura IBM Z. Para obtener información sobre DASD, consulte:
- Configuración de una instancia de Linux en IBM Z
- El artículo Lo que debe saber sobre DASD en el Centro de Conocimiento de IBM
El número máximo de particiones
El número de particiones en un dispositivo está limitado por el tipo de tabla de particiones:
En un dispositivo formateado con la tabla de particiones Master Boot Record (MBR), puede tener cualquiera de los dos:
- Hasta cuatro particiones primarias, o
- Hasta tres particiones primarias, una partición extendida y múltiples particiones lógicas dentro de la extendida.
-
En un dispositivo formateado con el GUID Partition Table (GPT), el número máximo de particiones es 128. Aunque la especificación GPT permite más particiones aumentando el área reservada para la tabla de particiones, la práctica común utilizada por la utilidad
partedes limitarla a un área suficiente para 128 particiones.
Red Hat recomienda que, a menos que tenga una razón para hacer lo contrario, debería at least crear las siguientes particiones: swap, /boot/, y / (raíz).
El tamaño máximo de una partición
El tamaño de una partición en un dispositivo está limitado por el tipo de tabla de particiones:
- En un dispositivo formateado con la tabla de particiones Master Boot Record (MBR), el tamaño máximo es de 2TiB.
- En un dispositivo formateado con el GUID Partition Table (GPT), el tamaño máximo es de 8ZiB.
Si quieres crear una partición mayor de 2TiB, el disco debe estar formateado con GPT.
Alineación de tamaños
La utilidad parted le permite especificar el tamaño de la partición utilizando varios sufijos diferentes:
- MiB, GiB o TiB
Tamaño expresado en potencias de 2.
- El punto inicial de la partición se alinea con el sector exacto especificado por el tamaño.
- El punto final se alinea con el tamaño especificado menos 1 sector.
- MB, GB o TB
Tamaño expresado en potencias de 10.
El punto inicial y final se alinea dentro de la mitad de la unidad especificada: por ejemplo, ±500KB cuando se utiliza el sufijo MB.
32.5.2. Redimensionar una partición con parted
Este procedimiento redimensiona una partición de disco utilizando la utilidad parted.
Requisitos previos
Si quieres reducir una partición, haz una copia de seguridad de los datos que están almacenados en ella.
AvisoReducir una partición puede provocar la pérdida de datos en la partición.
- Si quiere redimensionar una partición para que sea mayor de 2TiB, el disco debe estar formateado con la tabla de particiones GUID (GPT). Para más detalles sobre cómo formatear el disco, consulte Sección 32.2, “Creación de una tabla de particiones en un disco”.
Procedimiento
- Si quiere reducir la partición, reduzca primero el sistema de archivos en ella para que no sea mayor que la partición redimensionada. Tenga en cuenta que XFS no admite la contracción.
Inicie el shell interactivo
parted:# parted block-device-
Sustituya block-device por la ruta del dispositivo en el que desea redimensionar una partición: por ejemplo,
/dev/sda.
-
Sustituya block-device por la ruta del dispositivo en el que desea redimensionar una partición: por ejemplo,
Ver la tabla de particiones actual:
Impresión (parcial)A partir de la tabla de particiones, determinar:
- El número menor de la partición
- La ubicación de la partición existente y su nuevo punto final tras el redimensionamiento
Redimensiona la partición:
(parted) resizepart minor-number new-end-
Sustituya minor-number por el número menor de la partición que está redimensionando: por ejemplo,
3. -
Sustituya new-end con el tamaño que determina el nuevo punto final de la partición redimensionada, contando desde el principio del disco. Puede utilizar sufijos de tamaño, como
512MiB,20GiB, o1.5TiB. El tamaño por defecto es de megabytes.
Ejemplo 32.4. Ampliar una partición
Por ejemplo, para ampliar una partición situada al principio del disco para que tenga un tamaño de 2GiB, utilice:
(parted) resizepart 1 2GiBLos cambios empiezan a producirse en cuanto se introduce este comando, así que revísalo antes de ejecutarlo.
-
Sustituya minor-number por el número menor de la partición que está redimensionando: por ejemplo,
Vea la tabla de particiones para confirmar que la partición redimensionada está en la tabla de particiones con el tamaño correcto:
Impresión (parcial)Salga del shell
parted:(separada) dejar de fumarVerifique que el kernel reconoce la nueva partición:
# cat /proc/partitions- Si ha ampliado la partición, amplíe también el sistema de archivos en ella. Consulte (referencia) para más detalles.
Recursos adicionales
-
La página de manual
parted(8).
32.6. Estrategias para reparticionar un disco
Hay varias maneras de reparticionar un disco. En esta sección se analizan los siguientes enfoques posibles:
- Hay espacio libre sin particionar
- Se dispone de una partición no utilizada
- Hay espacio libre en una partición utilizada activamente
Tenga en cuenta que esta sección discute los conceptos mencionados anteriormente sólo teóricamente y no incluye ningún paso de procedimiento sobre cómo realizar la repartición del disco paso a paso.
Las ilustraciones siguientes están simplificadas en aras de la claridad y no reflejan la disposición exacta de las particiones que encontrará cuando instale realmente Red Hat Enterprise Linux.
32.6.1. Uso del espacio libre no particionado
En esta situación, las particiones ya definidas no abarcan todo el disco duro, dejando espacio sin asignar que no forma parte de ninguna partición definida. El siguiente diagrama muestra cómo podría ser esto:
Figura 32.5. Disco con espacio libre no particionado
En el ejemplo anterior, el primer diagrama representa un disco con una partición primaria y una partición indefinida con espacio no asignado, y el segundo diagrama representa un disco con dos particiones definidas con espacio asignado.
Un disco duro no utilizado también entra en esta categoría. La única diferencia es que all el espacio no forma parte de ninguna partición definida.
En cualquier caso, puede crear las particiones necesarias a partir del espacio no utilizado. Este escenario es el más probable para un disco nuevo. La mayoría de los sistemas operativos preinstalados están configurados para ocupar todo el espacio disponible en una unidad de disco.
32.6.2. Utilizar el espacio de una partición no utilizada
En este caso, puede tener una o más particiones que ya no utilice. El siguiente diagrama ilustra esta situación.
Figura 32.6. Disco con una partición no utilizada
En el ejemplo anterior, el primer diagrama representa un disco con una partición no utilizada, y el segundo diagrama representa la reasignación de una partición no utilizada para Linux.
En esta situación, puede utilizar el espacio asignado a la partición no utilizada. Debe eliminar la partición y luego crear la(s) partición(es) Linux apropiada(s) en su lugar. Puede eliminar la partición no utilizada y crear manualmente nuevas particiones durante el proceso de instalación.
32.6.3. Utilizar el espacio libre de una partición activa
Esta es la situación más común. También es la más difícil de manejar, porque incluso si tiene suficiente espacio libre, actualmente está asignado a una partición que ya está en uso. Si has comprado un ordenador con software preinstalado, lo más probable es que el disco duro tenga una gran partición con el sistema operativo y los datos.
Además de añadir un nuevo disco duro a su sistema, puede elegir entre repartición destructiva y no destructiva.
32.6.3.1. Repartición destructiva
Esto elimina la partición y crea varias más pequeñas en su lugar. Debes hacer una copia de seguridad completa porque cualquier dato en la partición original se destruye. Cree dos copias de seguridad, utilice la verificación (si está disponible en su software de copia de seguridad) e intente leer los datos de la copia de seguridad before borrando la partición.
Si se instaló un sistema operativo en esa partición, deberá reinstalarlo si quiere utilizar también ese sistema. Tenga en cuenta que algunos ordenadores que se venden con sistemas operativos preinstalados pueden no incluir los medios de instalación para reinstalar el sistema operativo original. Debes comprobar si esto se aplica a tu sistema before y destruir la partición original y su instalación del sistema operativo.
Después de crear una partición más pequeña para su sistema operativo existente, puede reinstalar el software, restaurar sus datos e iniciar su instalación de Red Hat Enterprise Linux.
Figura 32.7. Acción destructiva de repartición en disco
Cualquier dato presente previamente en la partición original se pierde.
32.6.3.2. Repartición no destructiva
Con la repartición no destructiva se ejecuta un programa que hace más pequeña una partición grande sin perder ninguno de los archivos almacenados en esa partición. Este método suele ser fiable, pero puede llevar mucho tiempo en unidades grandes.
El proceso de repartición no destructiva es sencillo y consta de tres pasos:
- Compresión y copia de seguridad de los datos existentes
- Redimensionar la partición existente
- Crear nueva(s) partición(es)
Cada paso se describe con más detalle.
32.6.3.2.1. Compresión de datos existentes
El primer paso es comprimir los datos de la partición existente. La razón para hacer esto es reorganizar los datos para maximizar el espacio libre disponible en el "final" de la partición.
Figura 32.8. Compresión en disco
En el ejemplo anterior, el primer diagrama representa el disco antes de la compresión, y el segundo diagrama después de la compresión.
Este paso es crucial. Sin él, la ubicación de los datos podría impedir que la partición se redimensionara en la medida deseada. Tenga en cuenta que algunos datos no se pueden mover. En este caso, se restringe severamente el tamaño de sus nuevas particiones, y podría verse obligado a reparticionar destructivamente su disco.
32.6.3.2.2. Redimensionar la partición existente
La siguiente figura muestra el proceso real de redimensionamiento. Aunque el resultado real de la operación de redimensionamiento varía, dependiendo del software utilizado, en la mayoría de los casos el espacio recién liberado se utiliza para crear una partición sin formato del mismo tipo que la partición original.
Figura 32.9. Redimensionamiento de la partición en el disco
En el ejemplo anterior, el primer diagrama representa la partición antes del redimensionamiento, y el segundo diagrama después del redimensionamiento.
Es importante entender lo que el software de redimensionamiento que usas hace con el espacio recién liberado, para que puedas tomar los pasos apropiados. En el caso ilustrado aquí, lo mejor sería borrar la nueva partición DOS y crear la o las particiones Linux apropiadas.
32.6.3.2.3. Creación de nuevas particiones
Como se mencionó en el ejemplo Redimensionamiento de la partición existente, podría ser necesario o no crear nuevas particiones. Sin embargo, a menos que su software de redimensionamiento soporte sistemas con Linux instalado, es probable que deba eliminar la partición que se creó durante el proceso de redimensionamiento.
Figura 32.10. Disco con la configuración final de la partición
En el ejemplo anterior, el primer diagrama representa el disco antes de la configuración, y el segundo diagrama después de la configuración.
Capítulo 33. Introducción a XFS
Este es un resumen de cómo crear y mantener sistemas de archivos XFS.
33.1. El sistema de archivos XFS
XFS es un sistema de archivos de 64 bits altamente escalable, de alto rendimiento, robusto y maduro que soporta archivos y sistemas de archivos muy grandes en un solo host. Es el sistema de archivos por defecto en Red Hat Enterprise Linux 8. XFS fue desarrollado originalmente a principios de los 90 por SGI y tiene una larga historia de funcionamiento en servidores y matrices de almacenamiento extremadamente grandes.
Las características de XFS incluyen:
- Fiabilidad
- El registro en el diario de los metadatos, que garantiza la integridad del sistema de archivos después de un fallo del sistema, ya que mantiene un registro de las operaciones del sistema de archivos que puede reproducirse cuando se reinicia el sistema y se vuelve a montar el sistema de archivos
- Amplia comprobación de la coherencia de los metadatos en tiempo de ejecución
- Utilidades de reparación escalables y rápidas
- Registro de cuotas. Esto evita la necesidad de largas comprobaciones de consistencia de cuotas después de una caída.
- Escalabilidad y rendimiento
- Tamaño del sistema de archivos soportado hasta 1024 TiB
- Capacidad para soportar un gran número de operaciones simultáneas
- Indexación del árbol B para la escalabilidad de la gestión del espacio libre
- Sofisticados algoritmos de lectura anticipada de metadatos
- Optimizaciones para cargas de trabajo de vídeo en streaming
- Regímenes de asignación
- Asignación basada en la extensión
- Políticas de asignación con conocimiento de las franjas
- Asignación retardada
- Pre-asignación de espacio
- Inodos asignados dinámicamente
- Otras características
- Copias de archivos basadas en Reflink (nuevo en Red Hat Enterprise Linux 8)
- Utilidades de copia de seguridad y restauración estrechamente integradas
- Desfragmentación en línea
- Crecimiento del sistema de archivos en línea
- Amplia capacidad de diagnóstico
-
Atributos extendidos (
xattr). Esto permite al sistema asociar varios pares nombre/valor adicionales por archivo. - Cuotas de proyectos o directorios. Esto permite restringir las cuotas sobre un árbol de directorios.
- Marcas de tiempo de subsegundos
Características de rendimiento
XFS tiene un alto rendimiento en sistemas grandes con cargas de trabajo empresariales. Un sistema grande es aquel con un número relativamente alto de CPUs, múltiples HBAs y conexiones a matrices de discos externas. XFS también tiene un buen rendimiento en sistemas más pequeños que tienen una carga de trabajo de E/S paralela y multihilo.
XFS tiene un rendimiento relativamente bajo para cargas de trabajo intensivas en metadatos de un solo hilo: por ejemplo, una carga de trabajo que crea o borra un gran número de archivos pequeños en un solo hilo.
33.2. Creación de un sistema de archivos XFS
Como administrador del sistema, puede crear un sistema de archivos XFS en un dispositivo de bloque para que pueda almacenar archivos y directorios.
33.2.1. Creación de un sistema de archivos XFS con mkfs.xfs
Este procedimiento describe cómo crear un sistema de archivos XFS en un dispositivo de bloque.
Procedimiento
Para crear el sistema de archivos:
Si el dispositivo es una partición normal, un volumen LVM, un volumen MD, un disco o un dispositivo similar, utilice el siguiente comando:
# mkfs.xfs block-device-
Sustituya block-device por la ruta de acceso al dispositivo de bloque. Por ejemplo,
/dev/sdb1,/dev/disk/by-uuid/05e99ec8-def1-4a5e-8a9d-5945339ceb2a, o/dev/my-volgroup/my-lv. - En general, las opciones por defecto son óptimas para el uso común.
-
Cuando utilice
mkfs.xfsen un dispositivo de bloque que contenga un sistema de archivos existente, añada la opción-fpara sobrescribir ese sistema de archivos.
-
Sustituya block-device por la ruta de acceso al dispositivo de bloque. Por ejemplo,
Para crear el sistema de archivos en un dispositivo RAID por hardware, compruebe si el sistema detecta correctamente la geometría de las franjas del dispositivo:
Si la información de la geometría de la banda es correcta, no se necesitan opciones adicionales. Cree el sistema de archivos:
# mkfs.xfs block-deviceSi la información es incorrecta, especifique la geometría de la franja manualmente con los parámetros
suyswde la opción-d. El parámetrosuespecifica el tamaño de los trozos de RAID y el parámetroswespecifica el número de discos de datos en el dispositivo RAID.Por ejemplo:
# mkfs.xfs -d su=64k,sw=4 /dev/sda3
Utilice el siguiente comando para esperar a que el sistema registre el nuevo nodo de dispositivo:
# udevadm settle
Recursos adicionales
-
La página de manual
mkfs.xfs(8).
33.2.2. Creación de un sistema de archivos XFS en un dispositivo de bloque utilizando RHEL System Roles
Esta sección describe cómo crear un sistema de archivos XFS en un dispositivo de bloque en varias máquinas de destino utilizando el rol storage.
Requisitos previos
Existe un playbook de Ansible que utiliza el rol
storage.Para obtener información sobre cómo aplicar un libro de jugadas de este tipo, consulte Aplicar un rol.
33.2.2.1. Ejemplo de playbook de Ansible para crear un sistema de archivos XFS en un dispositivo de bloques
Esta sección proporciona un ejemplo de libro de jugadas de Ansible. Este libro de jugadas aplica el rol storage para crear un sistema de archivos XFS en un dispositivo de bloques utilizando los parámetros predeterminados.
El rol storage puede crear un sistema de archivos sólo en un disco entero no particionado o en un volumen lógico (LV). No puede crear el sistema de archivos en una partición.
Ejemplo 33.1. Un playbook que crea XFS en /dev/sdb
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: xfs
roles:
- rhel-system-roles.storage-
El nombre del volumen (
barefsen el ejemplo) es actualmente arbitrario. El rolstorageidentifica el volumen por el dispositivo de disco listado bajo el atributodisks:. -
Puede omitir la línea
fs_type: xfsporque XFS es el sistema de archivos por defecto en RHEL 8. Para crear el sistema de archivos en un LV, proporcione la configuración de LVM bajo el atributo
disks:, incluyendo el grupo de volúmenes que lo rodea. Para obtener más detalles, consulte Ejemplo de libro de jugadas de Ansible para gestionar volúmenes lógicos.No proporcione la ruta de acceso al dispositivo LV.
Recursos adicionales
-
Para más detalles sobre los parámetros utilizados en el rol de sistema
storage, consulte el archivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
33.3. Copia de seguridad de un sistema de archivos XFS
Como administrador del sistema, puede utilizar la página xfsdump para hacer una copia de seguridad de un sistema de archivos XFS en un archivo o en una cinta. Esto proporciona un mecanismo de copia de seguridad simple.
33.3.1. Características de la copia de seguridad XFS
En esta sección se describen los conceptos y las características principales de las copias de seguridad de un sistema de archivos XFS con la utilidad xfsdump.
Puede utilizar la utilidad xfsdump para:
Realiza copias de seguridad en imágenes de archivos regulares.
Sólo se puede escribir una copia de seguridad en un archivo normal.
Realiza copias de seguridad en unidades de cinta.
La utilidad
xfsdumptambién permite escribir varias copias de seguridad en la misma cinta. Una copia de seguridad puede abarcar varias cintas.Para hacer una copia de seguridad de varios sistemas de archivos en un solo dispositivo de cinta, simplemente escriba la copia de seguridad en una cinta que ya contenga una copia de seguridad XFS. Esto añade la nueva copia de seguridad a la anterior. Por defecto,
xfsdumpnunca sobrescribe las copias de seguridad existentes.Crear copias de seguridad incrementales.
La utilidad
xfsdumputiliza los niveles de volcado para determinar una copia de seguridad base a la que se refieren las demás copias de seguridad. Los números del 0 al 9 se refieren a niveles de volcado crecientes. Una copia de seguridad incremental sólo respalda los archivos que han cambiado desde el último volcado de un nivel inferior:- Para realizar una copia de seguridad completa, realice un volcado de nivel 0 en el sistema de archivos.
- Un volcado de nivel 1 es la primera copia de seguridad incremental después de una copia de seguridad completa. La siguiente copia de seguridad incremental sería la de nivel 2, que sólo hace una copia de seguridad de los archivos que han cambiado desde el último volcado de nivel 1; y así sucesivamente, hasta un máximo de nivel 9.
- Excluya archivos de una copia de seguridad utilizando banderas de tamaño, subárbol o inodo para filtrarlos.
Recursos adicionales
-
La página de manual
xfsdump(8).
33.3.2. Copia de seguridad de un sistema de archivos XFS con xfsdump
Este procedimiento describe cómo hacer una copia de seguridad del contenido de un sistema de archivos XFS en un archivo o en una cinta.
Requisitos previos
- Un sistema de archivos XFS del que se puede hacer una copia de seguridad.
- Otro sistema de archivos o una unidad de cinta donde almacenar la copia de seguridad.
Procedimiento
Utilice el siguiente comando para hacer una copia de seguridad de un sistema de archivos XFS:
# xfsdump -l level [-L label] \ -f backup-destination path-to-xfs-filesystem-
Sustituya level por el nivel de volcado de su copia de seguridad. Utilice
0para realizar una copia de seguridad completa o1a9para realizar copias de seguridad incrementales consecuentes. -
Sustituya backup-destination por la ruta en la que desea almacenar la copia de seguridad. El destino puede ser un archivo normal, una unidad de cinta o un dispositivo de cinta remoto. Por ejemplo,
/backup-files/Data.xfsdumppara un archivo o/dev/st0para una unidad de cinta. -
Sustituya path-to-xfs-filesystem por el punto de montaje del sistema de archivos XFS del que desea hacer una copia de seguridad. Por ejemplo,
/mnt/data/. El sistema de archivos debe estar montado. -
Cuando haga una copia de seguridad de varios sistemas de archivos y los guarde en un solo dispositivo de cinta, añada una etiqueta de sesión a cada copia de seguridad utilizando la opción
-L labelpara que sea más fácil identificarlas al restaurarlas. Sustituya label por cualquier nombre de la copia de seguridad: por ejemplo,backup_data.
-
Sustituya level por el nivel de volcado de su copia de seguridad. Utilice
Ejemplo 33.2. Copia de seguridad de varios sistemas de archivos XFS
Para hacer una copia de seguridad del contenido de los sistemas de archivos XFS montados en los directorios
/boot/y/data/y guardarlos como archivos en el directorio/backup-files/:# xfsdump -l 0 -f /backup-files/boot.xfsdump /boot # xfsdump -l 0 -f /backup-files/data.xfsdump /dataPara hacer una copia de seguridad de varios sistemas de archivos en un único dispositivo de cinta, añada una etiqueta de sesión a cada copia de seguridad utilizando la
-L labelopción:# xfsdump -l 0 -L "backup_boot" -f /dev/st0 /boot # xfsdump -l 0 -L "backup_data" -f /dev/st0 /data
Recursos adicionales
-
La página de manual
xfsdump(8).
33.3.3. Recursos adicionales
-
La página de manual
xfsdump(8).
33.4. Restauración de un sistema de archivos XFS a partir de una copia de seguridad
Como administrador del sistema, puede utilizar la utilidad xfsrestore para restaurar la copia de seguridad XFS creada con la utilidad xfsdump y almacenada en un archivo o en una cinta.
33.4.1. Características de la restauración de XFS a partir de una copia de seguridad
En esta sección se describen los conceptos y características clave de la restauración de un sistema de archivos XFS a partir de una copia de seguridad con la utilidad xfsrestore.
La utilidad xfsrestore restaura sistemas de archivos a partir de copias de seguridad producidas por xfsdump. La utilidad xfsrestore tiene dos modos:
- El modo simple permite a los usuarios restaurar un sistema de archivos completo a partir de un volcado de nivel 0. Este es el modo por defecto.
- El modo cumulative permite la restauración del sistema de archivos a partir de una copia de seguridad incremental: es decir, del nivel 1 al nivel 9.
Un único session ID o session label identifica cada copia de seguridad. La restauración de una copia de seguridad desde una cinta que contenga varias copias de seguridad requiere su correspondiente ID de sesión o etiqueta.
Para extraer, añadir o eliminar archivos específicos de una copia de seguridad, entre en el modo interactivo xfsrestore. El modo interactivo proporciona un conjunto de comandos para manipular los archivos de la copia de seguridad.
Recursos adicionales
-
La página de manual
xfsrestore(8).
33.4.2. Restauración de un sistema de archivos XFS a partir de una copia de seguridad con xfsrestore
Este procedimiento describe cómo restaurar el contenido de un sistema de archivos XFS a partir de una copia de seguridad de archivos o cintas.
Requisitos previos
- Una copia de seguridad de archivos o cintas de sistemas de archivos XFS, como se describe en Sección 33.3, “Copia de seguridad de un sistema de archivos XFS”.
- Un dispositivo de almacenamiento donde se puede restaurar la copia de seguridad.
Procedimiento
El comando para restaurar la copia de seguridad varía en función de si se está restaurando a partir de una copia de seguridad completa o de una incremental, o si se están restaurando varias copias de seguridad a partir de un único dispositivo de cinta:
# xfsrestore [-r] [-S session-id] [-L session-label] [-i] -f backup-location restoration-path-
Sustituya backup-location con la ubicación de la copia de seguridad. Puede ser un archivo normal, una unidad de cinta o un dispositivo de cinta remoto. Por ejemplo,
/backup-files/Data.xfsdumppara un archivo o/dev/st0para una unidad de cinta. -
Sustituya restoration-path por la ruta del directorio donde desea restaurar el sistema de archivos. Por ejemplo,
/mnt/data/. -
Para restaurar un sistema de archivos a partir de una copia de seguridad incremental (nivel 1 a nivel 9), añada la opción
-r. Para restaurar una copia de seguridad desde un dispositivo de cinta que contiene varias copias de seguridad, especifique la copia de seguridad utilizando las opciones
-So-L.La opción
-Spermite elegir una copia de seguridad por su ID de sesión, mientras que la opción-Lpermite elegir por la etiqueta de sesión. Para obtener el ID de sesión y las etiquetas de sesión, utilice el comandoxfsrestore -I.Sustituya session-id por el ID de sesión de la copia de seguridad. Por ejemplo,
b74a3586-e52e-4a4a-8775-c3334fa8ea2c. Sustituya session-label por la etiqueta de la sesión de la copia de seguridad. Por ejemplo,my_backup_session_label.Para utilizar
xfsrestorede forma interactiva, utilice la opción-i.El diálogo interactivo comienza después de que
xfsrestoretermine de leer el dispositivo especificado. Los comandos disponibles en el shell interactivoxfsrestoreincluyencd,ls,add,delete, yextract; para una lista completa de comandos, utilice el comandohelp.
-
Sustituya backup-location con la ubicación de la copia de seguridad. Puede ser un archivo normal, una unidad de cinta o un dispositivo de cinta remoto. Por ejemplo,
Ejemplo 33.3. Restauración de varios sistemas de archivos XFS
Para restaurar los archivos de la copia de seguridad XFS y guardar su contenido en directorios bajo
/mnt/:# xfsrestore -f /backup-files/boot.xfsdump /mnt/boot/ # xfsrestore -f /backup-files/data.xfsdump /mnt/data/Para restaurar desde un dispositivo de cinta que contenga varias copias de seguridad, especifique cada copia de seguridad por su etiqueta o ID de sesión:
# xfsrestore -L "backup_boot" -f /dev/st0 /mnt/boot/ # xfsrestore -S "45e9af35-efd2-4244-87bc-4762e476cbab" \ -f /dev/st0 /mnt/data/
Recursos adicionales
-
La página de manual
xfsrestore(8).
33.4.3. Mensajes informativos al restaurar una copia de seguridad XFS desde una cinta
Al restaurar una copia de seguridad de una cinta con copias de seguridad de varios sistemas de archivos, la utilidad xfsrestore puede emitir mensajes. Los mensajes le informan de si se ha encontrado una coincidencia de la copia de seguridad solicitada cuando xfsrestore examina cada copia de seguridad de la cinta en orden secuencial. Por ejemplo:
xfsrestore: preparing drive
xfsrestore: examining media file 0
xfsrestore: inventory session uuid (8590224e-3c93-469c-a311-fc8f23029b2a) does not match the media header's session uuid (7eda9f86-f1e9-4dfd-b1d4-c50467912408)
xfsrestore: examining media file 1
xfsrestore: inventory session uuid (8590224e-3c93-469c-a311-fc8f23029b2a) does not match the media header's session uuid (7eda9f86-f1e9-4dfd-b1d4-c50467912408)
[...]Los mensajes informativos siguen apareciendo hasta que se encuentra la copia de seguridad correspondiente.
33.4.4. Recursos adicionales
-
La página de manual
xfsrestore(8).
33.5. Aumentar el tamaño de un sistema de archivos XFS
Como administrador del sistema, puede aumentar el tamaño de un sistema de archivos XFS para utilizar una mayor capacidad de almacenamiento.
Actualmente no es posible disminuir el tamaño de los sistemas de archivos XFS.
33.5.1. Aumentar el tamaño de un sistema de archivos XFS con xfs_growfs
Este procedimiento describe cómo hacer crecer un sistema de archivos XFS utilizando la utilidad xfs_growfs.
Requisitos previos
- Asegúrese de que el dispositivo de bloque subyacente tiene un tamaño adecuado para albergar el sistema de archivos redimensionado posteriormente. Utilice los métodos de redimensionamiento adecuados para el dispositivo de bloque afectado.
- Monte el sistema de archivos XFS.
Procedimiento
Mientras el sistema de archivos XFS está montado, utilice la utilidad
xfs_growfspara aumentar su tamaño:# xfs_growfs file-system -D new-size- Sustituya file-system por el punto de montaje del sistema de archivos XFS.
Con la opción
-D, sustituya new-size por el nuevo tamaño deseado del sistema de archivos especificado en el número de bloques del sistema de archivos.Para averiguar el tamaño de bloque en kB de un determinado sistema de archivos XFS, utilice la utilidad
xfs_info:# xfs_info block-device ... data = bsize=4096 ...-
Sin la opción
-D,xfs_growfshace crecer el sistema de archivos hasta el tamaño máximo soportado por el dispositivo subyacente.
Recursos adicionales
-
La página de manual
xfs_growfs(8).
33.6. Comparación de las herramientas utilizadas con ext4 y XFS
Esta sección compara qué herramientas utilizar para realizar tareas comunes en los sistemas de archivos ext4 y XFS.
| Tarea | ext4 | XFS |
|---|---|---|
| Crear un sistema de archivos |
|
|
| Comprobación del sistema de archivos |
|
|
| Redimensionar un sistema de archivos |
|
|
| Guardar una imagen de un sistema de archivos |
|
|
| Etiquetar o ajustar un sistema de archivos |
|
|
| Copia de seguridad de un sistema de archivos |
|
|
| Gestión de cuotas |
|
|
| Asignación de archivos |
|
|
Capítulo 34. Montaje de sistemas de archivos
Como administrador del sistema, puedes montar sistemas de archivos en tu sistema para acceder a los datos que contienen.
34.1. El mecanismo de montaje de Linux
Esta sección explica los conceptos básicos del montaje de sistemas de archivos en Linux.
En Linux, UNIX y sistemas operativos similares, los sistemas de archivos en diferentes particiones y dispositivos extraíbles (CDs, DVDs o memorias USB, por ejemplo) se pueden montar en un punto determinado (el punto de montaje) en el árbol de directorios, y luego desprenderse de nuevo. Mientras un sistema de archivos está montado en un directorio, el contenido original del mismo no es accesible.
Tenga en cuenta que Linux no le impide montar un sistema de archivos en un directorio con un sistema de archivos ya adjunto.
Al montarlo, puedes identificar el dispositivo por:
-
un identificador único universal (UUID): por ejemplo,
UUID=34795a28-ca6d-4fd8-a347-73671d0c19cb -
una etiqueta de volumen: por ejemplo,
LABEL=home -
una ruta completa a un dispositivo de bloque no persistente: por ejemplo,
/dev/sda3
Cuando se monta un sistema de archivos utilizando el comando mount sin toda la información requerida, es decir, sin el nombre del dispositivo, el directorio de destino o el tipo de sistema de archivos, la utilidad mount lee el contenido del archivo /etc/fstab para comprobar si el sistema de archivos dado aparece en él. El archivo /etc/fstab contiene una lista de nombres de dispositivos y los directorios en los que los sistemas de archivos seleccionados están configurados para ser montados, así como el tipo de sistema de archivos y las opciones de montaje. Por lo tanto, cuando se monta un sistema de archivos especificado en /etc/fstab, la siguiente sintaxis de comando es suficiente:
Montaje por el punto de montaje:
# montaje directoryMontaje por el dispositivo de bloque:
# montaje device
Recursos adicionales
-
La página de manual
mount(8). - Para obtener información sobre cómo enumerar los atributos de nomenclatura persistente, como el UUID, consulte Sección 31.6, “Listado de atributos de nomenclatura persistente”.
34.2. Listado de los sistemas de archivos montados actualmente
Este procedimiento describe cómo listar todos los sistemas de archivos montados actualmente en la línea de comandos.
Procedimiento
Para listar todos los sistemas de archivos montados, utilice la utilidad
findmnt:$ findmntPara limitar los sistemas de archivos listados sólo a un determinado tipo de sistema de archivos, añada la opción
--types:$ findmnt --types fs-typePor ejemplo:
Ejemplo 34.1. Listado sólo de sistemas de archivos XFS
$ findmnt --types xfs TARGET SOURCE FSTYPE OPTIONS / /dev/mapper/luks-5564ed00-6aac-4406-bfb4-c59bf5de48b5 xfs rw,relatime ├─/boot /dev/sda1 xfs rw,relatime └─/home /dev/mapper/luks-9d185660-7537-414d-b727-d92ea036051e xfs rw,relatime
Recursos adicionales
-
La página de manual
findmnt(8).
34.3. Montaje de un sistema de archivos con mount
Este procedimiento describe cómo montar un sistema de archivos utilizando la utilidad mount.
Requisitos previos
Asegúrese de que no hay ningún sistema de archivos montado en el punto de montaje elegido:
$ findmnt mount-point
Procedimiento
Para adjuntar un determinado sistema de archivos, utilice la utilidad
mount:# montaje device mount-pointEjemplo 34.2. Montaje de un sistema de archivos XFS
Por ejemplo, para montar un sistema de archivos XFS local identificado por UUID:
# mount UUID=ea74bbec-536d-490c-b8d9-5b40bbd7545b /mnt/dataSi
mountno puede reconocer el tipo de sistema de archivos automáticamente, especifíquelo utilizando la opción--types:# mount --types type device mount-pointEjemplo 34.3. Montaje de un sistema de archivos NFS
Por ejemplo, para montar un sistema de archivos NFS remoto:
# mount --types nfs4 host:/remote-export /mnt/nfs
Recursos adicionales
-
La página de manual
mount(8).
34.4. Mover un punto de montaje
Este procedimiento describe cómo cambiar el punto de montaje de un sistema de archivos montado a un directorio diferente.
Procedimiento
Para cambiar el directorio en el que se monta un sistema de archivos:
# mount --move old-directory new-directoryEjemplo 34.4. Mover un sistema de archivos doméstico
Por ejemplo, para mover el sistema de archivos montado en el directorio
/mnt/userdirs/al punto de montaje/home/:# mount --move /mnt/userdirs /homeCompruebe que el sistema de archivos se ha movido como se esperaba:
$ findmnt $ ls old-directory $ ls new-directory
Recursos adicionales
-
La página de manual
mount(8).
34.5. Desmontaje de un sistema de archivos con umount
Este procedimiento describe cómo desmontar un sistema de archivos utilizando la utilidad umount.
Procedimiento
Intente desmontar el sistema de archivos utilizando cualquiera de los siguientes comandos:
Por punto de montaje:
# umount mount-pointPor dispositivo:
# umount device
Si el comando falla con un error similar al siguiente, significa que el sistema de archivos está en uso porque un proceso está utilizando recursos en él:
umount /run/media/user/FlashDrive: el objetivo está ocupado.Si el sistema de archivos está en uso, utilice la utilidad
fuserpara determinar qué procesos están accediendo a él. Por ejemplo:$ fuser --mount /run/media/user/FlashDrive /run/media/user/FlashDrive: 18351A continuación, finalice los procesos que utilizan el sistema de archivos e intente desmontarlo de nuevo.
34.6. Opciones de montaje habituales
Esta sección enumera algunas de las opciones más utilizadas de la utilidad mount.
Puede utilizar estas opciones en la siguiente sintaxis:
# mount --options option1,option2,option3 device mount-point| Opción | Descripción |
|---|---|
|
| Activa las operaciones asíncronas de entrada y salida en el sistema de archivos. |
|
|
Permite montar automáticamente el sistema de archivos mediante el comando |
|
|
Proporciona un alias para las opciones de |
|
| Permite la ejecución de archivos binarios en el sistema de archivos particular. |
|
| Monta una imagen como dispositivo de bucle. |
|
|
El comportamiento por defecto desactiva el montaje automático del sistema de archivos mediante el comando |
|
| Desactiva la ejecución de archivos binarios en el sistema de archivos concreto. |
|
| Impide que un usuario normal (es decir, que no sea root) monte y desmonte el sistema de archivos. |
|
| Vuelve a montar el sistema de archivos en caso de que ya esté montado. |
|
| Monta el sistema de archivos sólo para lectura. |
|
| Monta el sistema de archivos tanto para leer como para escribir. |
|
| Permite a un usuario normal (es decir, que no sea root) montar y desmontar el sistema de archivos. |
34.7. Compartir un montaje en varios puntos de montaje
Como administrador del sistema, puede duplicar los puntos de montaje para que los sistemas de archivos sean accesibles desde varios directorios.
34.7.2. Creación de un duplicado de punto de montaje privado
Este procedimiento duplica un punto de montaje como un montaje privado. Los sistemas de archivos que se monten posteriormente bajo el duplicado o el punto de montaje original no se reflejan en el otro.
Procedimiento
Cree un nodo de sistema de archivos virtual (VFS) a partir del punto de montaje original:
# mount --bind original-dir original-dirMarcar el punto de montaje original como privado:
# mount --make-private original-dirAlternativamente, para cambiar el tipo de montaje para el punto de montaje seleccionado y todos los puntos de montaje bajo él, utilice la opción
--make-rprivateen lugar de--make-private.Crea el duplicado:
# mount --bind original-dir duplicate-dir
Ejemplo 34.5. Duplicar /media en /mnt como punto de montaje privado
Cree un nodo VFS desde el directorio
/media:# mount --bind /media /mediaMarcar el directorio
/mediacomo privado:# mount --make-private /mediaCree su duplicado en
/mnt:# mount --bind /media /mntAhora es posible verificar que
/mediay/mntcomparten contenido pero ninguno de los montajes dentro de/mediaaparece en/mnt. Por ejemplo, si la unidad de CD-ROM contiene medios no vacíos y el directorio/media/cdrom/existe, utilice:# mount /dev/cdrom /media/cdrom # ls /media/cdrom EFI GPL isolinux LiveOS # ls /mnt/cdrom #También es posible comprobar que los sistemas de archivos montados en el directorio
/mntno se reflejan en/media. Por ejemplo, si se conecta una unidad flash USB no vacía que utiliza el dispositivo/dev/sdc1y el directorio/mnt/flashdisk/está presente, utilice:# mount /dev/sdc1 /mnt/flashdisk # ls /media/flashdisk # ls /mnt/flashdisk en-US publican.cfg
Recursos adicionales
-
La página de manual
mount(8).
34.7.4. Creación de un duplicado de punto de montaje esclavo
Este procedimiento duplica un punto de montaje como un montaje esclavo. Los sistemas de archivos que se monten posteriormente bajo el punto de montaje original se reflejan en el duplicado, pero no al revés.
Procedimiento
Cree un nodo de sistema de archivos virtual (VFS) a partir del punto de montaje original:
# mount --bind original-dir original-dirMarcar el punto de montaje original como compartido:
# mount --make-shared original-dirAlternativamente, para cambiar el tipo de montaje para el punto de montaje seleccionado y todos los puntos de montaje bajo él, utilice la opción
--make-rshareden lugar de--make-shared.Crea el duplicado y márcalo como esclavo:
# mount --bind original-dir duplicate-dir # mount --make-slave duplicate-dir
Ejemplo 34.7. Duplicación de /media en /mnt como punto de montaje esclavo
Este ejemplo muestra cómo conseguir que el contenido del directorio /media aparezca también en /mnt, pero sin que ningún montaje del directorio /mnt se refleje en /media.
Cree un nodo VFS desde el directorio
/media:# mount --bind /media /mediaMarque el directorio
/mediacomo compartido:# mount --make-shared /mediaCree su duplicado en
/mnty márquelo como esclavo:# mount --bind /media /mnt # mount --make-slave /mntCompruebe que un montaje dentro de
/mediatambién aparece en/mnt. Por ejemplo, si la unidad de CD-ROM contiene medios no vacíos y el directorio/media/cdrom/existe, utilice:# mount /dev/cdrom /media/cdrom # ls /media/cdrom EFI GPL isolinux LiveOS # ls /mnt/cdrom EFI GPL isolinux LiveOSCompruebe también que los sistemas de archivos montados en el directorio
/mntno se reflejan en/media. Por ejemplo, si se conecta una unidad flash USB no vacía que utiliza el dispositivo/dev/sdc1y el directorio/mnt/flashdisk/está presente, utilice:# mount /dev/sdc1 /mnt/flashdisk # ls /media/flashdisk # ls /mnt/flashdisk en-US publican.cfg
Recursos adicionales
-
La página de manual
mount(8).
34.7.5. Evitar que un punto de montaje se duplique
Este procedimiento marca un punto de montaje como no vinculable para que no sea posible duplicarlo en otro punto de montaje.
Procedimiento
Para cambiar el tipo de un punto de montaje a un montaje no vinculable, utilice
# mount --bind mount-point mount-point # mount --make-unbindable mount-pointAlternativamente, para cambiar el tipo de montaje para el punto de montaje seleccionado y todos los puntos de montaje bajo él, utilice la opción
--make-runbindableen lugar de--make-unbindable.Cualquier intento posterior de hacer un duplicado de este montaje falla con el siguiente error:
# mount --bind mount-point duplicate-dir mount: wrong fs type, bad option, bad superblock on mount-point, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg | tail or so
Ejemplo 34.8. Evitar la duplicación de /media
Para evitar que el directorio
/mediasea compartido, utilice:# mount --bind /media /media # mount --make-unbindable /media
Recursos adicionales
-
La página de manual
mount(8).
34.8. Montaje persistente de sistemas de archivos
Como administrador del sistema, puede montar de forma persistente sistemas de archivos para configurar el almacenamiento no extraíble.
34.8.1. El archivo /etc/fstab
Esta sección describe el archivo de configuración /etc/fstab, que controla los puntos de montaje persistentes de los sistemas de archivos. El uso de /etc/fstab es la forma recomendada para montar de forma persistente los sistemas de archivos.
Cada línea del archivo /etc/fstab define un punto de montaje de un sistema de archivos. Incluye seis campos separados por espacios en blanco:
-
El dispositivo de bloque identificado por un atributo persistente o una ruta en el directorio
/dev. - El directorio donde se montará el dispositivo.
- El sistema de archivos del dispositivo.
-
Opciones de montaje para el sistema de archivos. La opción
defaultssignifica que la partición se monta en el momento del arranque con las opciones por defecto. Esta sección también reconoce las opciones de la unidad de montajesystemden el formatox-systemd.optionformato. -
Opción de copia de seguridad para la utilidad
dump. -
Orden de comprobación de la utilidad
fsck.
Ejemplo 34.9. El sistema de archivos /boot en /etc/fstab
| Dispositivo en bloque | Punto de montaje | Sistema de archivos | Opciones | Copia de seguridad | Consulte |
|---|---|---|---|---|---|
|
|
|
|
|
|
|
El servicio systemd genera automáticamente unidades de montaje a partir de las entradas en /etc/fstab.
Recursos adicionales
-
La página de manual
fstab(5). -
La sección fstab de la página de manual
systemd.mount(5).
34.8.2. Añadir un sistema de archivos a /etc/fstab
Este procedimiento describe cómo configurar el punto de montaje persistente para un sistema de archivos en el archivo de configuración /etc/fstab.
Procedimiento
Averigua el atributo UUID del sistema de archivos:
$ lsblk --fs storage-devicePor ejemplo:
Ejemplo 34.10. Ver el UUID de una partición
$ lsblk --fs /dev/sda1 NAME FSTYPE LABEL UUID MOUNTPOINT sda1 xfs Boot ea74bbec-536d-490c-b8d9-5b40bbd7545b /bootSi el directorio del punto de montaje no existe, créelo:
# mkdir --parents mount-pointComo root, edite el archivo
/etc/fstaby añada una línea para el sistema de archivos, identificado por el UUID.Por ejemplo:
Ejemplo 34.11. El punto de montaje /boot en /etc/fstab
UUID=ea74bbec-536d-490c-b8d9-5b40bbd7545b /boot xfs defaults 0 0Regenere las unidades de montaje para que su sistema registre la nueva configuración:
# systemctl daemon-reloadIntente montar el sistema de archivos para verificar que la configuración funciona:
# montaje mount-point
Recursos adicionales
- Otros atributos persistentes que puede utilizar para identificar el sistema de archivos Sección 31.3, “Nombres de dispositivos gestionados por el mecanismo udev en /dev/disk/”
34.8.3. Montaje persistente de un sistema de archivos con RHEL System Roles
Esta sección describe cómo montar persistentemente un sistema de archivos utilizando el rol storage.
Requisitos previos
Existe un playbook de Ansible que utiliza el rol
storage.Para obtener información sobre cómo aplicar un libro de jugadas de este tipo, consulte Aplicar un rol.
34.8.3.1. Ejemplo de playbook de Ansible para montar persistentemente un sistema de archivos
Esta sección proporciona un ejemplo de libro de jugadas de Ansible. Este libro de jugadas aplica el rol storage para montar de forma inmediata y persistente un sistema de archivos XFS.
Ejemplo 34.12. Un playbook que monta un sistema de archivos en /dev/sdb a /mnt/data
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: xfs
mount_point: /mnt/data
roles:
- rhel-system-roles.storage-
Este libro de jugadas añade el sistema de archivos al archivo
/etc/fstab, y monta el sistema de archivos inmediatamente. -
Si el sistema de archivos del dispositivo
/dev/sdbo el directorio del punto de montaje no existen, el libro de jugadas los crea.
Recursos adicionales
-
Para más detalles sobre los parámetros utilizados en el rol de sistema
storage, consulte el archivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
34.9. Montaje de sistemas de archivos bajo demanda
Como administrador del sistema, puede configurar los sistemas de archivos, como NFS, para que se monten automáticamente bajo demanda.
34.9.1. El servicio autofs
Esta sección explica las ventajas y los conceptos básicos del servicio autofs, utilizado para montar sistemas de archivos bajo demanda.
Una desventaja del montaje permanente utilizando la configuración /etc/fstab es que, independientemente de la poca frecuencia con la que un usuario acceda al sistema de archivos montado, el sistema debe dedicar recursos para mantener el sistema de archivos montado en su lugar. Esto puede afectar al rendimiento del sistema cuando, por ejemplo, el sistema está manteniendo montajes NFS en muchos sistemas a la vez.
Una alternativa a /etc/fstab es utilizar el servicio autofs basado en el núcleo. Consta de los siguientes componentes:
- Un módulo del kernel que implementa un sistema de archivos, y
- Un servicio de espacio de usuario que realiza todas las demás funciones.
El servicio autofs puede montar y desmontar sistemas de archivos automáticamente (bajo demanda), ahorrando así recursos del sistema. Puede utilizarse para montar sistemas de archivos como NFS, AFS, SMBFS, CIFS y sistemas de archivos locales.
Recursos adicionales
-
La página de manual
autofs(8).
34.9.2. Los archivos de configuración de autofs
Esta sección describe el uso y la sintaxis de los archivos de configuración utilizados por el servicio autofs.
El archivo de mapa maestro
El servicio autofs utiliza /etc/auto.master (mapa maestro) como su archivo de configuración principal por defecto. Esto puede cambiarse para usar otra fuente de red y nombre soportados usando la configuración autofs en el archivo de configuración /etc/autofs.conf en conjunto con el mecanismo Name Service Switch (NSS).
Todos los puntos de montaje bajo demanda deben ser configurados en el mapa maestro. El punto de montaje, el nombre del host, el directorio exportado y las opciones pueden especificarse en un conjunto de archivos (u otras fuentes de red compatibles) en lugar de configurarlos manualmente para cada host.
El archivo de mapa maestro enumera los puntos de montaje controlados por autofs, y sus correspondientes archivos de configuración o fuentes de red conocidos como mapas de automontaje. El formato del mapa maestro es el siguiente:
mount-point map-name optionsLas variables utilizadas en este formato son:
- mount-point
-
El punto de montaje
autofs; por ejemplo,/mnt/data/. - map-file
- El archivo fuente del mapa, que contiene una lista de puntos de montaje y la ubicación del sistema de archivos desde la que se deben montar esos puntos de montaje.
- options
- Si se suministran, se aplican a todas las entradas del mapa dado, si no tienen ellas mismas opciones especificadas.
Ejemplo 34.13. El archivo /etc/auto.master
La siguiente es una línea de ejemplo del archivo /etc/auto.master:
/mnt/data /etc/auto.dataArchivos de mapas
Los archivos de mapa configuran las propiedades de los puntos de montaje individuales bajo demanda.
El contador automático crea los directorios si no existen. Si los directorios existen antes de que se inicie el contador automático, éste no los eliminará cuando salga. Si se especifica un tiempo de espera, el directorio se desmonta automáticamente si no se accede a él durante el periodo de tiempo de espera.
El formato general de los mapas es similar al del mapa maestro. Sin embargo, el campo de opciones aparece entre el punto de montaje y la ubicación en lugar de al final de la entrada como en el mapa maestro:
mount-point options locationLas variables utilizadas en este formato son:
- mount-point
-
Se refiere al punto de montaje de
autofs. Puede ser un solo nombre de directorio para un montaje indirecto o la ruta completa del punto de montaje para montajes directos. Cada clave de entrada del mapa directo e indirecto (mount-point) puede ir seguida de una lista separada por espacios de directorios de desplazamiento (nombres de subdirectorios que comienzan cada uno con/), lo que se conoce como una entrada de montaje múltiple. - options
- Cuando se suministran, son las opciones de montaje para las entradas del mapa que no especifican sus propias opciones. Este campo es opcional.
- location
-
Se refiere a la ubicación del sistema de archivos, como una ruta del sistema de archivos local (precedida por el carácter de escape del formato de mapa de Sun
:para los nombres de mapa que comienzan con/), un sistema de archivos NFS u otra ubicación válida del sistema de archivos.
Ejemplo 34.14. Un archivo de mapas
A continuación se muestra un ejemplo de un archivo de mapas; por ejemplo, /etc/auto.misc:
payroll -fstype=nfs4 personnel:/dev/disk/by-uuid/52b94495-e106-4f29-b868-fe6f6c2789b1
sales -fstype=xfs :/dev/disk/by-uuid/5564ed00-6aac-4406-bfb4-c59bf5de48b5
La primera columna del archivo de mapa indica el punto de montaje autofs: sales y payroll del servidor llamado personnel. La segunda columna indica las opciones para el montaje de autofs. La tercera columna indica el origen del montaje.
Siguiendo la configuración dada, los puntos de montaje autofs serán /home/payroll y /home/sales. La opción -fstype= suele omitirse y, por lo general, no es necesaria para su correcto funcionamiento.
Usando la configuración dada, si un proceso requiere acceso a un directorio no montado de autofs como /home/payroll/2006/July.sxc, el servicio autofs monta automáticamente el directorio.
El formato del mapa amd
El servicio autofs reconoce la configuración de mapas en el formato amd también. Esto es útil si desea reutilizar la configuración existente del contador automático escrita para el servicio am-utils, que ha sido eliminado de Red Hat Enterprise Linux.
Sin embargo, Red Hat recomienda utilizar el formato más sencillo autofs descrito en las secciones anteriores.
Recursos adicionales
-
Las páginas de manual
autofs(5),autofs.conf(5), yauto.master(5). -
Para más detalles sobre el formato del mapa
amd, véase el archivo/usr/share/doc/autofs/README.amd-maps, que proporciona el paqueteautofs.
34.9.3. Configuración de puntos de montaje autofs
Este procedimiento describe cómo configurar puntos de montaje bajo demanda utilizando el servicio autofs.
Requisitos previos
Instale el paquete
autofs:# yum install autofsInicie y active el servicio
autofs:# systemctl enable --now autofs
Procedimiento
-
Crear un archivo de mapa para el punto de montaje bajo demanda, ubicado en
/etc/auto.identifier. Sustituya identifier con un nombre que identifique el punto de montaje. - En el archivo de mapa, rellene los campos de punto de montaje, opciones y ubicación como se describe en Sección 34.9.2, “Los archivos de configuración de autofs”.
- Registre el archivo de mapas en el archivo de mapas maestro, como se describe en Sección 34.9.2, “Los archivos de configuración de autofs”.
Intenta acceder al contenido del directorio a la carta:
$ ls automounted-directory
34.9.4. Automatización de los directorios de usuario del servidor NFS con el servicio autofs
Este procedimiento describe cómo configurar el servicio autofs para que monte automáticamente los directorios personales de los usuarios.
Requisitos previos
- El paquete autofs paquete está instalado.
- El servicio autofs servicio está habilitado y funcionando.
Procedimiento
Especifique el punto de montaje y la ubicación del archivo de mapa editando el archivo
/etc/auto.masteren un servidor en el que necesite montar los directorios personales de los usuarios. Para ello, añada la siguiente línea en el archivo/etc/auto.master:/home /etc/auto.homeCree un archivo de mapa con el nombre de
/etc/auto.homeen un servidor en el que necesite montar los directorios personales de los usuarios, y edite el archivo con los siguientes parámetros:* -fstype=nfs,rw,sync host.example.com:/home/&iPuede omitir el parámetro
fstypeparámetro, ya que esnfspor defecto. Para más información, consulte la página de manualautofs(5).Recargue el servicio
autofs:# systemctl reload autofs
34.9.5. Anulación o aumento de los archivos de configuración del sitio autofs
A veces es útil anular los valores predeterminados del sitio para un punto de montaje específico en un sistema cliente.
Ejemplo 34.15. Condiciones iniciales
Por ejemplo, considere las siguientes condiciones:
Los mapas del contador automático se almacenan en NIS y el archivo
/etc/nsswitch.conftiene la siguiente directiva:automount: files nisEl archivo
auto.mastercontiene:auto.masterEl archivo de mapas NIS
auto.mastercontiene:/home auto.homeEl mapa NIS
auto.homecontiene:beth fileserver.example.com:/export/home/beth joe fileserver.example.com:/export/home/joe * fileserver.example.com:/export/home/&-
El mapa de archivos
/etc/auto.homeno existe.
Ejemplo 34.16. Montaje de directorios personales desde un servidor diferente
Dadas las condiciones anteriores, supongamos que el sistema cliente necesita anular el mapa NIS auto.home y montar los directorios iniciales desde un servidor diferente.
En este caso, el cliente debe utilizar el siguiente mapa
/etc/auto.master:/home /etc/auto.home +auto.masterEl mapa
/etc/auto.homecontiene la entrada:* host.example.com:/export/home/&
Como el contador automático sólo procesa la primera aparición de un punto de montaje, el directorio /home contiene el contenido de /etc/auto.home en lugar del mapa NIS auto.home.
Ejemplo 34.17. Aumentar auto.home sólo con las entradas seleccionadas
O bien, para aumentar el mapa de todo el sitio auto.home con sólo unas pocas entradas:
Cree un mapa de archivos
/etc/auto.home, y en él ponga las nuevas entradas. Al final, incluya el mapa NISauto.home. Entonces el mapa de archivos/etc/auto.hometiene un aspecto similar:mydir someserver:/export/mydir +auto.homeCon estas condiciones del mapa NIS
auto.home, el listado del contenido de las salidas del directorio/home:$ ls /home beth joe mydir
Este último ejemplo funciona como se esperaba porque autofs no incluye el contenido de un mapa de archivos del mismo nombre que el que está leyendo. Así, autofs pasa a la siguiente fuente de mapas en la configuración de nsswitch.
34.9.6. Uso de LDAP para almacenar mapas de contadores automáticos
Este procedimiento configura autofs para almacenar los mapas del contador automático en la configuración LDAP en lugar de en los archivos de mapas de autofs.
Requisitos previos
-
Las bibliotecas de cliente LDAP deben instalarse en todos los sistemas configurados para recuperar mapas de contadores automáticos desde LDAP. En Red Hat Enterprise Linux, el paquete
openldapdebería instalarse automáticamente como dependencia del paqueteautofs.
Procedimiento
-
Para configurar el acceso LDAP, modifique el archivo
/etc/openldap/ldap.conf. Asegúrese de que las opcionesBASE,URI, yschemaestán configuradas adecuadamente para su sitio. El esquema más recientemente establecido para el almacenamiento de mapas automáticos en LDAP se describe en el borrador
rfc2307bis. Para utilizar este esquema, establézcalo en el archivo de configuración/etc/autofs.confeliminando los caracteres de comentario de la definición del esquema. Por ejemplo:Ejemplo 34.18. Establecer la configuración de autofs
DEFAULT_MAP_OBJECT_CLASS="automountMap" DEFAULT_ENTRY_OBJECT_CLASS="automount" DEFAULT_MAP_ATTRIBUTE="automountMapName" DEFAULT_ENTRY_ATTRIBUTE="automountKey" DEFAULT_VALUE_ATTRIBUTE="automountInformation"Asegúrese de que todas las demás entradas del esquema están comentadas en la configuración. El atributo
automountKeysustituye al atributocnen el esquemarfc2307bis. A continuación se muestra un ejemplo de configuración del formato de intercambio de datos LDAP (LDIF):Ejemplo 34.19. Configuración de la LDF
# extended LDIF # # LDAPv3 # base <> with scope subtree # filter: (&(objectclass=automountMap)(automountMapName=auto.master)) # requesting: ALL # # auto.master, example.com dn: automountMapName=auto.master,dc=example,dc=com objectClass: top objectClass: automountMap automountMapName: auto.master # extended LDIF # # LDAPv3 # base <automountMapName=auto.master,dc=example,dc=com> with scope subtree # filter: (objectclass=automount) # requesting: ALL # # /home, auto.master, example.com dn: automountMapName=auto.master,dc=example,dc=com objectClass: automount cn: /home automountKey: /home automountInformation: auto.home # extended LDIF # # LDAPv3 # base <> with scope subtree # filter: (&(objectclass=automountMap)(automountMapName=auto.home)) # requesting: ALL # # auto.home, example.com dn: automountMapName=auto.home,dc=example,dc=com objectClass: automountMap automountMapName: auto.home # extended LDIF # # LDAPv3 # base <automountMapName=auto.home,dc=example,dc=com> with scope subtree # filter: (objectclass=automount) # requesting: ALL # # foo, auto.home, example.com dn: automountKey=foo,automountMapName=auto.home,dc=example,dc=com objectClass: automount automountKey: foo automountInformation: filer.example.com:/export/foo # /, auto.home, example.com dn: automountKey=/,automountMapName=auto.home,dc=example,dc=com objectClass: automount automountKey: / automountInformation: filer.example.com:/export/&
Recursos adicionales
-
El borrador de
rfc2307bis: https://tools.ietf.org/html/draft-howard-rfc2307bis.
34.10. Establecer permisos de sólo lectura para el sistema de archivos raíz
A veces, es necesario montar el sistema de archivos raíz (/) con permisos de sólo lectura. Algunos ejemplos de uso incluyen la mejora de la seguridad o la garantía de la integridad de los datos después de un apagado inesperado del sistema.
34.10.1. Archivos y directorios que siempre conservan los permisos de escritura
Para que el sistema funcione correctamente, algunos archivos y directorios deben conservar los permisos de escritura. Cuando el sistema de archivos raíz se monta en modo de sólo lectura, estos archivos se montan en la memoria RAM utilizando el sistema de archivos temporales tmpfs.
El conjunto por defecto de estos archivos y directorios se lee del archivo /etc/rwtab, que contiene:
dirs /var/cache/man
dirs /var/gdm
<content truncated>
empty /tmp
empty /var/cache/foomatic
<content truncated>
files /etc/adjtime
files /etc/ntp.conf
<content truncated>
Las entradas en el archivo /etc/rwtab siguen este formato:
copy-method pathEn esta sintaxis:
- Sustituya copy-method con una de las palabras clave que especifican cómo se copia el archivo o directorio en tmpfs.
- Sustituya path por la ruta del archivo o directorio.
El archivo /etc/rwtab reconoce las siguientes formas de copiar un archivo o directorio en tmpfs:
emptyUna ruta vacía se copia en
tmpfs. Por ejemplo:vaciar /tmpdirsSe copia un árbol de directorios en
tmpfs, vacío. Por ejemplo:dirs /var/runfilesUn archivo o un árbol de directorios se copia en
tmpfsintacto. Por ejemplo:archivos /etc/resolv.conf
El mismo formato se aplica al añadir rutas personalizadas a /etc/rwtab.d/.
34.10.2. Configurar el sistema de archivos raíz para que se monte con permisos de sólo lectura en el arranque
Con este procedimiento, el sistema de archivos raíz se monta de sólo lectura en todos los siguientes arranques.
Procedimiento
En el archivo
/etc/sysconfig/readonly-root, establezca la opciónREADONLYcomoyes:# Set to 'yes' to mount the file systems as read-only. READONLY=yesAñada la opción
roen la entrada raíz (/) en el archivo/etc/fstab:/dev/mapper/luks-c376919e... / xfs x-systemd.device-timeout=0,ro 1 1Añada la opción
roa la directivaGRUB_CMDLINE_LINUXen el archivo/etc/default/gruby asegúrese de que la directiva no contengarw:GRUB_CMDLINE_LINUX="rhgb quiet... ro"Vuelva a crear el archivo de configuración de GRUB2:
# grub2-mkconfig -o /boot/grub2/grub.cfgSi necesita añadir archivos y directorios para que se monten con permisos de escritura en el sistema de archivos
tmpfs, cree un archivo de texto en el directorio/etc/rwtab.d/y ponga la configuración allí.Por ejemplo, para montar el archivo
/etc/example/filecon permisos de escritura, añada esta línea al archivo/etc/rwtab.d/example:archivos /etc/ejemplo/archivoImportanteLos cambios realizados en los archivos y directorios en
tmpfsno persisten entre los arranques.- Reinicie el sistema para aplicar los cambios.
Solución de problemas
Si monta el sistema de archivos raíz con permisos de sólo lectura por error, puede volver a montarlo con permisos de lectura y escritura utilizando el siguiente comando:
# mount -o remount,rw /
Capítulo 35. Gestión de dispositivos de almacenamiento
35.1. Gestión del almacenamiento local en capas con Stratis
Podrá configurar y gestionar fácilmente complejas configuraciones de almacenamiento integradas por el sistema de alto nivel Stratis.
Stratis está disponible como Technology Preview. Para obtener información sobre el alcance del soporte de Red Hat para las características de la Technology Preview, consulte el documento sobre el alcance del soporte de las características de la Technology Preview.
Se anima a los clientes que implanten Stratis a que envíen sus comentarios a Red Hat.
35.1.1. Configuración de los sistemas de archivos Stratis
Como administrador del sistema, puede habilitar y configurar el sistema de archivos de gestión de volumen Stratis en su sistema para gestionar fácilmente el almacenamiento en capas.
35.1.1.1. Objetivo y características de Stratis
Stratis es una solución de gestión de almacenamiento local para Linux. Se centra en la simplicidad y la facilidad de uso, y le da acceso a funciones de almacenamiento avanzadas.
Stratis facilita las siguientes actividades:
- Configuración inicial del almacenamiento
- Realización de cambios a posteriori
- Uso de las funciones de almacenamiento avanzadas
Stratis es un sistema híbrido de gestión de almacenamiento local de usuario y de núcleo que admite funciones avanzadas de almacenamiento. El concepto central de Stratis es un pool de almacenamiento pool. Este pool se crea a partir de uno o más discos o particiones locales, y los volúmenes se crean a partir del pool.
La piscina permite muchas funciones útiles, como:
- Instantáneas del sistema de archivos
- Aprovisionamiento ligero
- Nivelación
35.1.1.2. Componentes de un volumen Stratis
Externamente, Stratis presenta los siguientes componentes de volumen en la interfaz de línea de comandos y en la API:
blockdev- Dispositivos de bloque, como un disco o una partición de disco.
poolCompuesto por uno o varios dispositivos en bloque.
Un pool tiene un tamaño total fijo, igual al tamaño de los dispositivos de bloque.
El pool contiene la mayoría de las capas de Stratis, como la caché de datos no volátil que utiliza el objetivo
dm-cache.Stratis crea un
/stratis/my-pool/directorio para cada pool. Este directorio contiene enlaces a dispositivos que representan sistemas de archivos Stratis en el pool.
filesystemCada pool puede contener uno o más sistemas de archivos, que almacenan archivos.
Los sistemas de archivos se aprovisionan de forma ligera y no tienen un tamaño total fijo. El tamaño real de un sistema de archivos crece con los datos almacenados en él. Si el tamaño de los datos se acerca al tamaño virtual del sistema de archivos, Stratis hace crecer el volumen delgado y el sistema de archivos automáticamente.
Los sistemas de archivos están formateados con XFS.
ImportanteStratis rastrea información sobre los sistemas de archivos creados con Stratis que XFS no conoce, y los cambios realizados con XFS no crean automáticamente actualizaciones en Stratis. Los usuarios no deben reformatear o reconfigurar los sistemas de archivos XFS que son administrados por Stratis.
Stratis crea enlaces a sistemas de archivos en la
/stratis/my-pool/my-fsruta de acceso.
Stratis utiliza muchos dispositivos Device Mapper, que aparecen en los listados de dmsetup y en el archivo /proc/partitions. Del mismo modo, la salida del comando lsblk refleja el funcionamiento interno y las capas de Stratis.
35.1.1.3. Dispositivos en bloque utilizables con Stratis
Esta sección enumera los dispositivos de almacenamiento que puede utilizar para Stratis.
Dispositivos compatibles
Las piscinas Stratis han sido probadas para funcionar en este tipo de dispositivos de bloque:
- LUKS
- Volúmenes lógicos LVM
- MD RAID
- DM Multipath
- iSCSI
- Discos duros y unidades de estado sólido (SSD)
- Dispositivos NVMe
En la versión actual, Stratis no maneja fallos en los discos duros u otro hardware. Si se crea un pool de Stratis sobre múltiples dispositivos de hardware, se incrementa el riesgo de pérdida de datos porque varios dispositivos deben estar operativos para acceder a los datos.
Dispositivos no compatibles
Debido a que Stratis contiene una capa de aprovisionamiento fino, Red Hat no recomienda colocar un pool de Stratis en dispositivos de bloque que ya están aprovisionados de forma fina.
Recursos adicionales
-
Para iSCSI y otros dispositivos de bloque que requieren red, consulte la página man
systemd.mount(5)para obtener información sobre la opción de montaje_netdev.
35.1.1.4. Instalación de Stratis
Este procedimiento instala todos los paquetes necesarios para utilizar Stratis.
Procedimiento
Instale los paquetes que proporcionan el servicio Stratis y las utilidades de línea de comandos:
# yum install stratisd stratis-cliAsegúrese de que el servicio
stratisdestá activado:# systemctl enable --now stratisd
35.1.1.5. Creación de un pool de Stratis
Este procedimiento describe cómo crear un pool Stratis encriptado o no encriptado a partir de uno o varios dispositivos de bloque.
Las siguientes notas se aplican a los pools Stratis encriptados:
-
Cada dispositivo de bloque se encripta utilizando la biblioteca
cryptsetupe implementa el formatoLUKS2. - Cada pool de Stratis puede tener una clave única o puede compartir la misma clave con otros pools. Estas claves se almacenan en el llavero del kernel.
- Todos los dispositivos de bloque que componen un pool Stratis están encriptados o sin encriptar. No es posible tener dispositivos de bloque encriptados y no encriptados en el mismo pool de Stratis.
- Los dispositivos de bloque añadidos al nivel de datos de un pool Stratis encriptado se encriptan automáticamente.
Requisitos previos
- Stratis v2.2.1 está instalado en su sistema. Consulte Sección 35.1.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Los dispositivos de bloque en los que está creando un pool de Stratis no están en uso y no están montados.
- Los dispositivos de bloque en los que está creando un pool de Stratis tienen un tamaño mínimo de 1 GiB cada uno.
En la arquitectura IBM Z, los dispositivos de bloque
/dev/dasd*deben ser particionados. Utilice la partición en el pool de Stratis.Para obtener información sobre la partición de dispositivos DASD, consulte Configuración de una instancia de Linux en IBM Z.
Procedimiento
Si el dispositivo de bloque seleccionado contiene firmas del sistema de archivos, de la tabla de particiones o del RAID, bórrelas con el siguiente comando:
# wipefs --all block-devicedonde
block-devicees la ruta de acceso al dispositivo de bloque; por ejemplo,/dev/sdb.Cree el nuevo pool de Stratis en el o los dispositivos de bloque seleccionados:
NotaEspecifique varios dispositivos de bloque en una sola línea, separados por un espacio:
# stratis pool create my-pool block-device-1 block-device-2Para crear un pool Stratis no encriptado, utilice el siguiente comando y vaya al paso 3:
# stratis pool create my-pool block-devicedonde
block-devicees la ruta a un dispositivo de bloque vacío o borrado.NotaNo se puede encriptar un pool Stratis no encriptado después de crearlo.
Para crear un pool Stratis encriptado, complete los siguientes pasos:
Si aún no ha creado un conjunto de claves, ejecute el siguiente comando y siga las indicaciones para crear un conjunto de claves que se utilizará para el cifrado:
# stratis key set --capture-key key-descriptiondonde
key-descriptiones la descripción o el nombre del conjunto de claves.Cree el pool Stratis encriptado y especifique la descripción de la clave a utilizar para la encriptación. También puede especificar la ruta de la clave utilizando el parámetro
--keyfile-pathen su lugar.# stratis pool create --key-desc key-description my-pool block-devicedonde
key-description- Especifica la descripción o el nombre del archivo de claves que se utilizará para el cifrado.
my-pool- Especifica el nombre del nuevo pool de Stratis.
block-device- Especifica la ruta de acceso a un dispositivo de bloque vacío o borrado.
Compruebe que se ha creado el nuevo pool de Stratis:
# lista de piscinas de stratis
Solución de problemas
Después de un reinicio del sistema, a veces puede que no vea su pool Stratis encriptado o los dispositivos de bloque que lo componen. Si se encuentra con este problema, debe desbloquear el pool Stratis para hacerlo visible.
Para desbloquear el pool de Stratis, complete los siguientes pasos:
Vuelva a crear el conjunto de claves utilizando la misma descripción de claves que se utilizó anteriormente:
# stratis key set --capture-key key-descriptionDesbloquea el pool de Stratis y el/los dispositivo/s de bloque:
# stratis pool unlockCompruebe que el pool de Stratis es visible:
# lista de piscinas de stratis
Recursos adicionales
-
La página de manual
stratis(8).
Próximos pasos
- Cree un sistema de archivos Stratis en el pool. Para más información, consulte Sección 35.1.1.6, “Creación de un sistema de archivos Stratis”.
35.1.1.6. Creación de un sistema de archivos Stratis
Este procedimiento crea un sistema de archivos Stratis en un pool Stratis existente.
Requisitos previos
- Stratis está instalado. Véase Sección 35.1.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado un pool de Stratis. Véase Sección 35.1.1.5, “Creación de un pool de Stratis”.
Procedimiento
Para crear un sistema de archivos Stratis en un pool, utilice:
# stratis fs create my-pool my-fs- Sustituya my-pool con el nombre de su pool Stratis existente.
- Sustituya my-fs con un nombre arbitrario para el sistema de archivos.
Para verificarlo, liste los sistemas de archivos dentro del pool:
# stratis fs list my-pool
Recursos adicionales
-
La página de manual
stratis(8)
Próximos pasos
- Monte el sistema de archivos Stratis. Véase Sección 35.1.1.7, “Montaje de un sistema de archivos Stratis”.
35.1.1.7. Montaje de un sistema de archivos Stratis
Este procedimiento monta un sistema de archivos Stratis existente para acceder al contenido.
Requisitos previos
- Stratis está instalado. Véase Sección 35.1.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado un sistema de archivos Stratis. Ver Sección 35.1.1.6, “Creación de un sistema de archivos Stratis”.
Procedimiento
Para montar el sistema de archivos, utilice las entradas que Stratis mantiene en el directorio
/stratis/:# mount /stratis/my-pool/my-fs mount-point
El sistema de archivos está ahora montado en el directorio mount-point y está listo para ser utilizado.
Recursos adicionales
-
La página de manual
mount(8)
35.1.1.8. Montaje persistente de un sistema de archivos Stratis
Este procedimiento monta persistentemente un sistema de archivos Stratis para que esté disponible automáticamente después de arrancar el sistema.
Requisitos previos
- Stratis está instalado. Véase Sección 35.1.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado un sistema de archivos Stratis. Ver Sección 35.1.1.6, “Creación de un sistema de archivos Stratis”.
Procedimiento
Determina el atributo UUID del sistema de archivos:
$ lsblk --output=UUID /stratis/my-pool/my-fsPor ejemplo:
Ejemplo 35.1. Ver el UUID del sistema de archivos Stratis
$ lsblk --output=UUID /stratis/my-pool/fs1 UUID a1f0b64a-4ebb-4d4e-9543-b1d79f600283Si el directorio del punto de montaje no existe, créelo:
# mkdir --parents mount-pointComo root, edita el archivo
/etc/fstaby añade una línea para el sistema de archivos, identificado por el UUID. Utilizaxfscomo tipo de sistema de archivos y añade la opciónx-systemd.requires=stratisd.service.Por ejemplo:
Ejemplo 35.2. El punto de montaje /fs1 en /etc/fstab
UUID=a1f0b64a-4ebb-4d4e-9543-b1d79f600283 /fs1 xfs defaults,x-systemd.requires=stratisd.service 0 0Regenere las unidades de montaje para que su sistema registre la nueva configuración:
# systemctl daemon-reloadIntente montar el sistema de archivos para verificar que la configuración funciona:
# montaje mount-point
Recursos adicionales
35.1.2. Ampliación de un volumen Stratis con dispositivos de bloque adicionales
Puede adjuntar dispositivos de bloque adicionales a un pool Stratis para proporcionar más capacidad de almacenamiento para los sistemas de archivos Stratis.
35.1.2.1. Componentes de un volumen Stratis
Externamente, Stratis presenta los siguientes componentes de volumen en la interfaz de línea de comandos y en la API:
blockdev- Dispositivos de bloque, como un disco o una partición de disco.
poolCompuesto por uno o varios dispositivos en bloque.
Un pool tiene un tamaño total fijo, igual al tamaño de los dispositivos de bloque.
El pool contiene la mayoría de las capas de Stratis, como la caché de datos no volátil que utiliza el objetivo
dm-cache.Stratis crea un
/stratis/my-pool/directorio para cada pool. Este directorio contiene enlaces a dispositivos que representan sistemas de archivos Stratis en el pool.
filesystemCada pool puede contener uno o más sistemas de archivos, que almacenan archivos.
Los sistemas de archivos se aprovisionan de forma ligera y no tienen un tamaño total fijo. El tamaño real de un sistema de archivos crece con los datos almacenados en él. Si el tamaño de los datos se acerca al tamaño virtual del sistema de archivos, Stratis hace crecer el volumen delgado y el sistema de archivos automáticamente.
Los sistemas de archivos están formateados con XFS.
ImportanteStratis rastrea información sobre los sistemas de archivos creados con Stratis que XFS no conoce, y los cambios realizados con XFS no crean automáticamente actualizaciones en Stratis. Los usuarios no deben reformatear o reconfigurar los sistemas de archivos XFS que son administrados por Stratis.
Stratis crea enlaces a sistemas de archivos en la
/stratis/my-pool/my-fsruta de acceso.
Stratis utiliza muchos dispositivos Device Mapper, que aparecen en los listados de dmsetup y en el archivo /proc/partitions. Del mismo modo, la salida del comando lsblk refleja el funcionamiento interno y las capas de Stratis.
35.1.2.2. Añadir dispositivos de bloque a un pool de Stratis
Este procedimiento añade uno o más dispositivos de bloque a un pool de Stratis para que puedan ser utilizados por los sistemas de archivos Stratis.
Requisitos previos
- Stratis está instalado. Véase Sección 35.1.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Los dispositivos de bloque que está añadiendo al pool de Stratis no están en uso y no están montados.
- Los dispositivos de bloque que está añadiendo al pool de Stratis tienen un tamaño mínimo de 1 GiB cada uno.
Procedimiento
Para añadir uno o más dispositivos de bloque al pool, utilice:
# stratis pool add-data my-pool device-1 device-2 device-n
Recursos adicionales
-
La página de manual
stratis(8)
35.1.3. Supervisión de los sistemas de archivos Stratis
Como usuario de Stratis, puede ver información sobre los volúmenes de Stratis en su sistema para controlar su estado y el espacio libre.
35.1.3.1. Tamaños de estratis reportados por diferentes empresas de servicios públicos
Esta sección explica la diferencia entre los tamaños de Stratis reportados por utilidades estándar como df y la utilidad stratis.
Las utilidades estándar de Linux como df reportan el tamaño de la capa del sistema de archivos XFS en Stratis, que es de 1 TiB. Esta información no es útil, porque el uso real de almacenamiento de Stratis es menor debido al thin provisioning, y también porque Stratis hace crecer automáticamente el sistema de archivos cuando la capa XFS está cerca de llenarse.
Supervise regularmente la cantidad de datos escritos en sus sistemas de archivos Stratis, que se reporta como el valor Total Physical Used. Asegúrese de que no supera el valor de Total Physical Size.
Recursos adicionales
-
La página de manual
stratis(8)
35.1.3.2. Visualización de información sobre los volúmenes de Stratis
Este procedimiento muestra las estadísticas de sus volúmenes Stratis, como el tamaño total, usado y libre, o los sistemas de archivos y dispositivos de bloques pertenecientes a un pool.
Requisitos previos
- Stratis está instalado. Véase Sección 35.1.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando.
Procedimiento
Para mostrar información sobre todos los block devices utilizados para Stratis en su sistema:
# stratis blockdev Pool Name Device Node Physical Size State Tier my-pool /dev/sdb 9.10 TiB In-use DataPara mostrar información sobre todos los Stratis pools en su sistema:
# stratis pool Name Total Physical Size Total Physical Used my-pool 9.10 TiB 598 MiBPara mostrar información sobre todos los Stratis file systems en su sistema:
# stratis filesystem Pool Name Name Used Created Device my-pool my-fs 546 MiB Nov 08 2018 08:03 /stratis/my-pool/my-fs
Recursos adicionales
-
La página de manual
stratis(8)
35.1.4. Uso de instantáneas en los sistemas de archivos Stratis
Puede utilizar instantáneas en los sistemas de archivos Stratis para capturar el estado del sistema de archivos en momentos arbitrarios y restaurarlo en el futuro.
35.1.4.1. Características de las instantáneas de Stratis
Esta sección describe las propiedades y limitaciones de las instantáneas del sistema de archivos en Stratis.
En Stratis, una instantánea es un sistema de archivos Stratis regular creado como una copia de otro sistema de archivos Stratis. La instantánea contiene inicialmente el mismo contenido de archivos que el sistema de archivos original, pero puede cambiar a medida que se modifica la instantánea. Cualquier cambio que se haga en la instantánea no se reflejará en el sistema de archivos original.
La implementación actual de la instantánea en Stratis se caracteriza por lo siguiente:
- Una instantánea de un sistema de archivos es otro sistema de archivos.
- Una instantánea y su origen no están vinculados en cuanto a su vida. Un sistema de archivos instantáneo puede vivir más tiempo que el sistema de archivos del que se creó.
- No es necesario montar un sistema de archivos para crear una instantánea a partir de él.
- Cada instantánea utiliza alrededor de medio gigabyte de almacenamiento de respaldo real, que es necesario para el registro XFS.
35.1.4.2. Creación de una instantánea de Stratis
Este procedimiento crea un sistema de archivos Stratis como una instantánea de un sistema de archivos Stratis existente.
Requisitos previos
- Stratis está instalado. Véase Sección 35.1.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado un sistema de archivos Stratis. Ver Sección 35.1.1.6, “Creación de un sistema de archivos Stratis”.
Procedimiento
Para crear una instantánea de Stratis, utilice:
# stratis fs snapshot my-pool my-fs my-fs-snapshot
Recursos adicionales
-
La página de manual
stratis(8)
35.1.4.3. Acceso al contenido de una instantánea de Stratis
Este procedimiento monta una instantánea de un sistema de archivos Stratis para que sea accesible para operaciones de lectura y escritura.
Requisitos previos
- Stratis está instalado. Véase Sección 35.1.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado una instantánea de Stratis. Véase Sección 35.1.4.2, “Creación de una instantánea de Stratis”.
Procedimiento
Para acceder a la instantánea, móntela como un sistema de archivos normal desde el directorio
/stratis/my-pool/directorio:# mount /stratis/my-pool/my-fs-snapshot mount-point
Recursos adicionales
- Sección 35.1.1.7, “Montaje de un sistema de archivos Stratis”
-
La página de manual
mount(8)
35.1.4.4. Revertir un sistema de archivos Stratis a una instantánea anterior
Este procedimiento revierte el contenido de un sistema de archivos Stratis al estado capturado en una instantánea Stratis.
Requisitos previos
- Stratis está instalado. Véase Sección 35.1.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado una instantánea de Stratis. Véase Sección 35.1.4.2, “Creación de una instantánea de Stratis”.
Procedimiento
Opcionalmente, haga una copia de seguridad del estado actual del sistema de archivos para poder acceder a él más tarde:
# stratis filesystem snapshot my-pool my-fs my-fs-backupDesmontar y eliminar el sistema de archivos original:
# umount /stratis/my-pool/my-fs # stratis filesystem destroy my-pool my-fsCree una copia de la instantánea con el nombre del sistema de archivos original:
# stratis filesystem snapshot my-pool my-fs-snapshot my-fsMonte la instantánea, que ahora es accesible con el mismo nombre que el sistema de archivos original:
# mount /stratis/my-pool/my-fs mount-point
El contenido del sistema de archivos llamado my-fs es ahora idéntico al de la instantánea my-fs-snapshot.
Recursos adicionales
-
La página de manual
stratis(8)
35.1.4.5. Eliminación de una instantánea de Stratis
Este procedimiento elimina una instantánea de Stratis de un pool. Los datos de la instantánea se pierden.
Requisitos previos
- Stratis está instalado. Véase Sección 35.1.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado una instantánea de Stratis. Véase Sección 35.1.4.2, “Creación de una instantánea de Stratis”.
Procedimiento
Desmontar la instantánea:
# umount /stratis/my-pool/my-fs-snapshotDestruye la instantánea:
# stratis filesystem destroy my-pool my-fs-snapshot
Recursos adicionales
-
La página de manual
stratis(8)
35.1.5. Eliminación de los sistemas de archivos Stratis
Puede eliminar un sistema de archivos Stratis existente o un pool Stratis, destruyendo los datos en ellos.
35.1.5.1. Componentes de un volumen Stratis
Externamente, Stratis presenta los siguientes componentes de volumen en la interfaz de línea de comandos y en la API:
blockdev- Dispositivos de bloque, como un disco o una partición de disco.
poolCompuesto por uno o varios dispositivos en bloque.
Un pool tiene un tamaño total fijo, igual al tamaño de los dispositivos de bloque.
El pool contiene la mayoría de las capas de Stratis, como la caché de datos no volátil que utiliza el objetivo
dm-cache.Stratis crea un
/stratis/my-pool/directorio para cada pool. Este directorio contiene enlaces a dispositivos que representan sistemas de archivos Stratis en el pool.
filesystemCada pool puede contener uno o más sistemas de archivos, que almacenan archivos.
Los sistemas de archivos se aprovisionan de forma ligera y no tienen un tamaño total fijo. El tamaño real de un sistema de archivos crece con los datos almacenados en él. Si el tamaño de los datos se acerca al tamaño virtual del sistema de archivos, Stratis hace crecer el volumen delgado y el sistema de archivos automáticamente.
Los sistemas de archivos están formateados con XFS.
ImportanteStratis rastrea información sobre los sistemas de archivos creados con Stratis que XFS no conoce, y los cambios realizados con XFS no crean automáticamente actualizaciones en Stratis. Los usuarios no deben reformatear o reconfigurar los sistemas de archivos XFS que son administrados por Stratis.
Stratis crea enlaces a sistemas de archivos en la
/stratis/my-pool/my-fsruta de acceso.
Stratis utiliza muchos dispositivos Device Mapper, que aparecen en los listados de dmsetup y en el archivo /proc/partitions. Del mismo modo, la salida del comando lsblk refleja el funcionamiento interno y las capas de Stratis.
35.1.5.2. Eliminación de un sistema de archivos Stratis
Este procedimiento elimina un sistema de archivos Stratis existente. Los datos almacenados en él se pierden.
Requisitos previos
- Stratis está instalado. Véase Sección 35.1.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado un sistema de archivos Stratis. Ver Sección 35.1.1.6, “Creación de un sistema de archivos Stratis”.
Procedimiento
Desmontar el sistema de archivos:
# umount /stratis/my-pool/my-fsDestruye el sistema de archivos:
# stratis filesystem destroy my-pool my-fsCompruebe que el sistema de archivos ya no existe:
# stratis filesystem list my-pool
Recursos adicionales
-
La página de manual
stratis(8)
35.1.5.3. Eliminación de una piscina Stratis
Este procedimiento elimina un pool de Stratis existente. Los datos almacenados en él se pierden.
Requisitos previos
- Stratis está instalado. Véase Sección 35.1.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado un pool de Stratis. Véase Sección 35.1.1.5, “Creación de un pool de Stratis”.
Procedimiento
Lista de sistemas de archivos en el pool:
# stratis filesystem list my-poolDesmontar todos los sistemas de archivos del pool:
# umount /stratis/my-pool/my-fs-1 \ /stratis/my-pool/my-fs-2 \ /stratis/my-pool/my-fs-nDestruye los sistemas de archivos:
# stratis filesystem destroy my-pool my-fs-1 my-fs-2Destruye la piscina:
# stratis pool destroy my-poolCompruebe que la piscina ya no existe:
# lista de piscinas de stratis
Recursos adicionales
-
La página de manual
stratis(8)
35.2. Empezar a usar el swap
Esta sección describe el espacio de intercambio y cómo utilizarlo.
35.2.1. Espacio de intercambio
Swap space en Linux se utiliza cuando la cantidad de memoria física (RAM) está llena. Si el sistema necesita más recursos de memoria y la RAM está llena, las páginas inactivas en la memoria se mueven al espacio de intercambio. Mientras que el espacio de intercambio puede ayudar a las máquinas con una pequeña cantidad de RAM, no debe ser considerado como un reemplazo de más RAM. El espacio de intercambio se encuentra en los discos duros, que tienen un tiempo de acceso más lento que la memoria física. El espacio de intercambio puede ser una partición de intercambio dedicada (recomendada), un archivo de intercambio, o una combinación de particiones de intercambio y archivos de intercambio.
En el pasado, la cantidad recomendada de espacio de intercambio aumentaba linealmente con la cantidad de RAM en el sistema. Sin embargo, los sistemas modernos suelen incluir cientos de gigabytes de RAM. Como consecuencia, el espacio de intercambio recomendado se considera una función de la carga de trabajo de la memoria del sistema, no de la memoria del sistema.
Sección 35.2.2, “Espacio de intercambio del sistema recomendado” ilustra el tamaño recomendado de una partición de intercambio en función de la cantidad de memoria RAM de su sistema y de si desea disponer de suficiente memoria para hibernar el sistema. El tamaño recomendado de la partición de intercambio se establece automáticamente durante la instalación. Sin embargo, para permitir la hibernación, es necesario editar el espacio de intercambio en la etapa de particionamiento personalizado.
Las recomendaciones de Sección 35.2.2, “Espacio de intercambio del sistema recomendado” son especialmente importantes en sistemas con poca memoria (1 GB o menos). No asignar suficiente espacio de intercambio en estos sistemas puede causar problemas como la inestabilidad o incluso hacer que el sistema instalado no pueda arrancar.
35.2.2. Espacio de intercambio del sistema recomendado
Esta sección ofrece recomendaciones sobre el espacio de intercambio.
| Cantidad de RAM en el sistema | Espacio de intercambio recomendado | Espacio de intercambio recomendado si se permite la hibernación |
|---|---|---|
| ࣘ 2 GB | 2 veces la cantidad de RAM | 3 veces la cantidad de RAM |
| > 2 GB | Igual a la cantidad de RAM | 2 veces la cantidad de RAM |
| > 8 GB | Al menos 4 GB | 1.5 veces la cantidad de RAM |
| > 64 GB | Al menos 4 GB | No se recomienda la hibernación |
En el límite entre cada rango enumerado en la tabla anterior, por ejemplo, un sistema con 2 GB, 8 GB o 64 GB de RAM del sistema, se puede ejercer la discreción con respecto al espacio de intercambio elegido y el soporte de hibernación. Si los recursos de su sistema lo permiten, aumentar el espacio de intercambio puede conducir a un mejor rendimiento. Se recomienda un espacio de intercambio de al menos 100 GB para sistemas con más de 140 procesadores lógicos o más de 3 TB de RAM.
Tenga en cuenta que la distribución del espacio de intercambio en varios dispositivos de almacenamiento también mejora el rendimiento del espacio de intercambio, especialmente en sistemas con unidades, controladores e interfaces rápidos.
Los sistemas de archivos y los volúmenes LVM2 asignados como espacio de intercambio should not están en uso cuando se modifican. Cualquier intento de modificar el swap falla si un proceso del sistema o el kernel está utilizando el espacio de swap. Utilice los comandos free y cat /proc/swaps para verificar la cantidad y el lugar de uso de la swap.
Debe modificar el espacio de intercambio mientras el sistema se inicia en el modo rescue, consulte las opciones de arranque de depuración en el Performing an advanced RHEL installation. Cuando se le pida que monte el sistema de archivos, seleccione .
35.2.3. Añadir espacio de intercambio
Esta sección describe cómo añadir más espacio de intercambio después de la instalación. Por ejemplo, puede aumentar la cantidad de RAM en su sistema de 1 GB a 2 GB, pero sólo hay 2 GB de espacio de intercambio. Podría ser ventajoso aumentar la cantidad de espacio de intercambio a 4 GB si realiza operaciones que requieren mucha memoria o ejecuta aplicaciones que requieren una gran cantidad de memoria.
Hay tres opciones: crear una nueva partición de intercambio, crear un nuevo archivo de intercambio o ampliar el intercambio en un volumen lógico LVM2 existente. Se recomienda ampliar un volumen lógico existente.
35.2.3.1. Ampliación del intercambio en un volumen lógico LVM2
Este procedimiento describe cómo ampliar el espacio de intercambio en un volumen lógico LVM2 existente. Suponiendo que /dev/VolGroup00/LogVol01 es el volumen que desea ampliar en 2 GB.
Requisitos previos
- Suficiente espacio en el disco.
Procedimiento
Desactivar el intercambio para el volumen lógico asociado:
# swapoff -v /dev/VolGroup00/LogVol01Redimensiona el volumen lógico LVM2 en 2 GB:
# lvresize /dev/VolGroup00/LogVol01 -L 2GFormatea el nuevo espacio de intercambio:
# mkswap /dev/VolGroup00/LogVol01Habilitar el volumen lógico extendido:
# swapon -v /dev/VolGroup00/LogVol01Para comprobar si el volumen lógico de intercambio se ha ampliado y activado correctamente, inspeccione el espacio de intercambio activo:
$ cat /proc/swaps $ free -h
35.2.3.2. Creación de un volumen lógico LVM2 para swap
Este procedimiento describe cómo crear un volumen lógico LVM2 para swap. Asumiendo que /dev/VolGroup00/LogVol02 es el volumen de swap que quieres añadir.
Requisitos previos
- Suficiente espacio en el disco.
Procedimiento
Cree el volumen lógico LVM2 de tamaño 2 GB:
# lvcreate VolGroup00 -n LogVol02 -L 2GFormatea el nuevo espacio de intercambio:
# mkswap /dev/VolGroup00/LogVol02Añada la siguiente entrada al archivo
/etc/fstab:/dev/VolGroup00/LogVol02 swap swap defaults 0 0Regenere las unidades de montaje para que su sistema registre la nueva configuración:
# systemctl daemon-reloadActivar el intercambio en el volumen lógico:
# swapon -v /dev/VolGroup00/LogVol02Para comprobar si el volumen lógico de intercambio se ha creado y activado correctamente, inspeccione el espacio de intercambio activo:
$ cat /proc/swaps $ free -h
35.2.3.3. Creación de un archivo de intercambio
Este procedimiento describe cómo crear un archivo de intercambio.
Requisitos previos
- Suficiente espacio en el disco.
Procedimiento
- Determine el tamaño del nuevo archivo de intercambio en megabytes y multiplique por 1024 para determinar el número de bloques. Por ejemplo, el tamaño de los bloques de un archivo de intercambio de 64 MB es de 65536.
Crear un archivo vacío:
# dd if=/dev/zero of=/swapfile bs=1024 count=65536Sustituya count por el valor equivalente al tamaño de bloque deseado.
Configure el archivo de intercambio con el comando
# mkswap /swapfileCambiar la seguridad del archivo de intercambio para que no sea legible por el mundo.
# chmod 0600 /swapfilePara habilitar el archivo de intercambio en el momento del arranque, edite
/etc/fstabcomo root para incluir la siguiente entrada:/swapfile swap swap defaults 0 0La próxima vez que el sistema arranque, activará el nuevo archivo de intercambio.
Regenere las unidades de montaje para que su sistema registre la nueva configuración de
/etc/fstab:# systemctl daemon-reloadPara activar el archivo de intercambio inmediatamente:
# swapon /swapfilePara comprobar si el nuevo archivo de intercambio se ha creado y activado correctamente, inspeccione el espacio de intercambio activo:
$ cat /proc/swaps $ free -h
35.2.4. Eliminación del espacio de intercambio
Esta sección describe cómo reducir el espacio de intercambio después de la instalación. Por ejemplo, usted ha reducido la cantidad de RAM en su sistema de 1 GB a 512 MB, pero todavía hay 2 GB de espacio de intercambio asignados. Podría ser ventajoso reducir la cantidad de espacio de intercambio a 1 GB, ya que los 2 GB más grandes podrían estar desperdiciando espacio en el disco.
Dependiendo de lo que necesite, puede elegir una de estas tres opciones: reducir el espacio de intercambio en un volumen lógico LVM2 existente, eliminar un volumen lógico LVM2 completo utilizado para el intercambio, o eliminar un archivo de intercambio.
35.2.4.1. Reducir el intercambio en un volumen lógico LVM2
Este procedimiento describe cómo reducir el swap en un volumen lógico LVM2. Asumiendo que /dev/VolGroup00/LogVol01 es el volumen que se quiere reducir.
Procedimiento
Desactivar el intercambio para el volumen lógico asociado:
# swapoff -v /dev/VolGroup00/LogVol01Reduzca el volumen lógico LVM2 en 512 MB:
# lvreduce /dev/VolGroup00/LogVol01 -L -512MFormatea el nuevo espacio de intercambio:
# mkswap /dev/VolGroup00/LogVol01Activar el intercambio en el volumen lógico:
# swapon -v /dev/VolGroup00/LogVol01Para comprobar si el volumen lógico de intercambio se redujo con éxito, inspeccione el espacio de intercambio activo:
$ cat /proc/swaps $ free -h
35.2.4.2. Eliminación de un volumen lógico LVM2 para swap
Este procedimiento describe cómo eliminar un volumen lógico LVM2 para swap. Asumiendo que /dev/VolGroup00/LogVol02 es el volumen de swap que desea eliminar.
Procedimiento
Desactivar el intercambio para el volumen lógico asociado:
# swapoff -v /dev/VolGroup00/LogVol02Eliminar el volumen lógico LVM2:
# lvremove /dev/VolGroup00/LogVol02Elimine la siguiente entrada asociada del archivo
/etc/fstab:/dev/VolGroup00/LogVol02 swap swap defaults 0 0Regenere las unidades de montaje para que su sistema registre la nueva configuración:
# systemctl daemon-reloadPara comprobar si el volumen lógico se ha eliminado correctamente, inspeccione el espacio de intercambio activo:
$ cat /proc/swaps $ free -h
35.2.4.3. Eliminación de un archivo de intercambio
Este procedimiento describe cómo eliminar un archivo de intercambio.
Procedimiento
En un prompt del shell, ejecute el siguiente comando para desactivar el archivo de intercambio (donde
/swapfilees el archivo de intercambio):# swapoff -v /swapfile-
Elimine su entrada del archivo
/etc/fstaben consecuencia. Regenere las unidades de montaje para que su sistema registre la nueva configuración:
# systemctl daemon-reloadEliminar el archivo actual:
# rm /swapfile
Capítulo 36. Deduplicar y comprimir el almacenamiento
36.1. Despliegue de VDO
Como administrador del sistema, puede utilizar VDO para crear pools de almacenamiento deduplicados y comprimidos.
36.1.1. Introducción a VDO
Virtual Data Optimizer (VDO) proporciona una reducción de datos en línea para Linux en forma de deduplicación, compresión y thin provisioning. Cuando se configura un volumen VDO, se especifica un dispositivo de bloques en el que construir el volumen VDO y la cantidad de almacenamiento lógico que se pretende presentar.
- Al alojar máquinas virtuales o contenedores activos, Red Hat recomienda aprovisionar el almacenamiento en una proporción de 10:1 lógica a física: es decir, si está utilizando 1 TB de almacenamiento físico, lo presentaría como 10 TB de almacenamiento lógico.
- Para el almacenamiento de objetos, como el tipo proporcionado por Ceph, Red Hat recomienda utilizar una proporción de 3:1 lógica a física: es decir, 1 TB de almacenamiento físico se presentaría como 3 TB de almacenamiento lógico.
En cualquiera de los dos casos, puede simplemente poner un sistema de archivos sobre el dispositivo lógico presentado por VDO y luego utilizarlo directamente o como parte de una arquitectura de almacenamiento distribuido en la nube.
Debido a que VDO tiene un aprovisionamiento ligero, el sistema de archivos y las aplicaciones sólo ven el espacio lógico en uso y no son conscientes del espacio físico real disponible. Utilice scripts para supervisar el espacio real disponible y generar una alerta si el uso supera un umbral: por ejemplo, cuando el volumen de VDO está a 80 de su capacidad.
36.1.2. Escenarios de implantación de VDO
Puede desplegar VDO de varias maneras para proporcionar almacenamiento deduplicado para:
- tanto el acceso a los bloques como a los archivos
- almacenamiento local y remoto
Dado que VDO expone su almacenamiento deduplicado como un dispositivo de bloques estándar de Linux, puede utilizarlo con sistemas de archivos estándar, controladores de destino iSCSI y FC, o como almacenamiento unificado.
El despliegue de VDO con Ceph Storage no está soportado actualmente.
KVM
Puede desplegar VDO en un servidor KVM configurado con Direct Attached Storage.

Sistemas de archivos
Puede crear sistemas de archivos sobre VDO y exponerlos a usuarios NFS o CIFS con el servidor NFS o Samba.

objetivo iSCSI
Puede exportar la totalidad del objetivo de almacenamiento VDO como objetivo iSCSI a iniciadores iSCSI remotos.

LVM
En los sistemas con más funciones, puede utilizar LVM para proporcionar varios números de unidades lógicas (LUN) que estén respaldados por el mismo grupo de almacenamiento deduplicado.
En el siguiente diagrama, el objetivo VDO se registra como un volumen físico para que pueda ser gestionado por LVM. Se crean múltiples volúmenes lógicos (LV1 a LV4) a partir del pool de almacenamiento deduplicado. De esta manera, VDO puede soportar el acceso a bloques o archivos unificados multiprotocolo al pool de almacenamiento deduplicado subyacente.
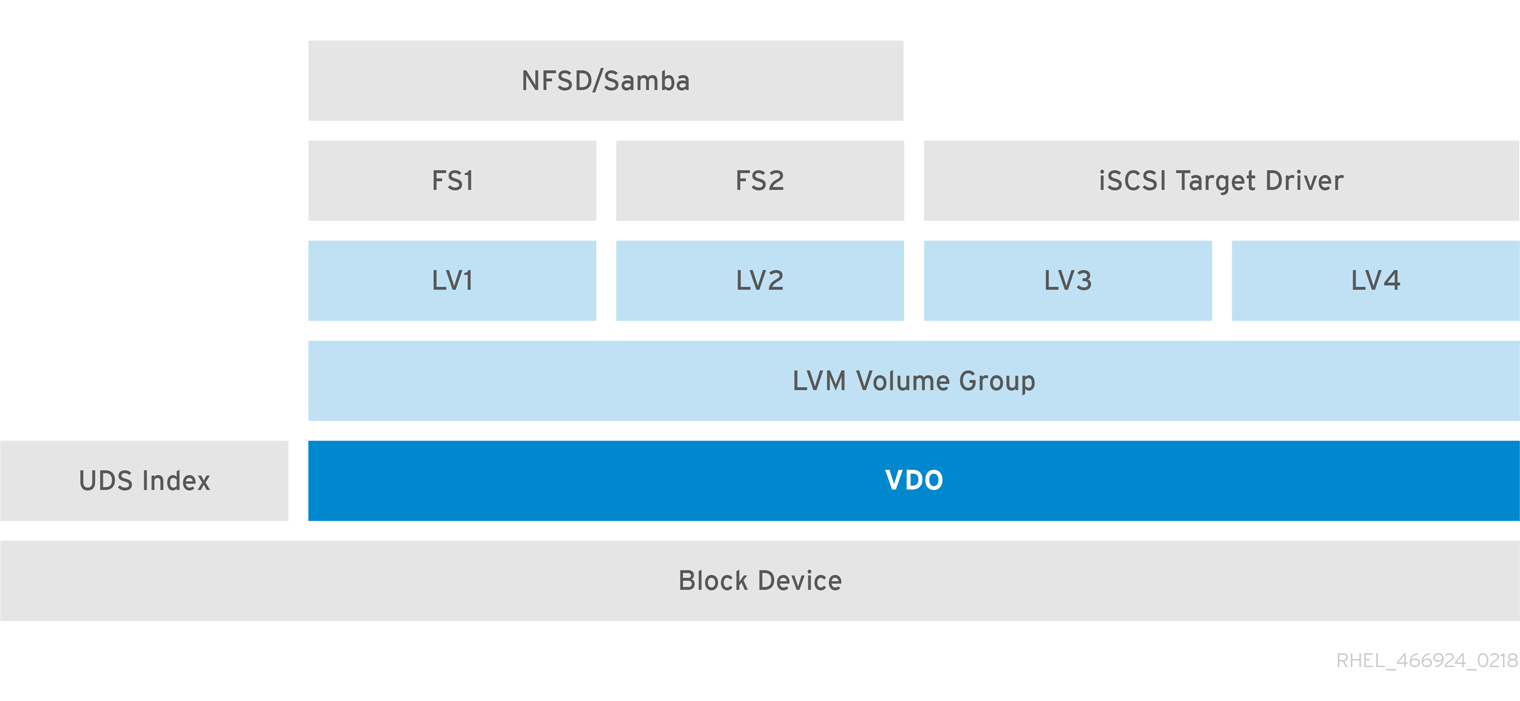
El diseño de almacenamiento unificado deduplicado permite que varios sistemas de archivos utilicen colectivamente el mismo dominio de deduplicación a través de las herramientas LVM. Además, los sistemas de archivos pueden aprovechar las funciones de instantáneas LVM, copia en escritura y contracción o crecimiento, todo ello sobre VDO.
Codificación
Los mecanismos de Device Mapper (DM) como DM Crypt son compatibles con VDO. El cifrado de los volúmenes de VDO ayuda a garantizar la seguridad de los datos, y cualquier sistema de archivos por encima de VDO se sigue deduplicando.

La aplicación de la capa de encriptación por encima de VDO da lugar a poca o ninguna deduplicación de datos. El cifrado hace que los bloques duplicados sean diferentes antes de que VDO pueda deduplicarlos.
Coloque siempre la capa de encriptación por debajo de VDO.
36.1.3. Componentes de un volumen VDO
VDO utiliza un dispositivo de bloque como almacén de respaldo, que puede incluir una agregación de almacenamiento físico consistente en uno o más discos, particiones o incluso archivos planos. Cuando una herramienta de gestión de almacenamiento crea un volumen VDO, VDO reserva espacio de volumen para el índice UDS y el volumen VDO. El índice UDS y el volumen VDO interactúan juntos para proporcionar almacenamiento de bloques deduplicado.
Figura 36.1. Organización del disco VDO

La solución de VDO consta de los siguientes componentes:
kvdoUn módulo del kernel que se carga en la capa de Linux Device Mapper proporciona un volumen de almacenamiento en bloque deduplicado, comprimido y con aprovisionamiento ligero.
El módulo
kvdoexpone un dispositivo de bloque. Puede acceder a este dispositivo de bloque directamente para el almacenamiento en bloque o presentarlo a través de un sistema de archivos Linux, como XFS o ext4.Cuando
kvdorecibe una solicitud para leer un bloque lógico de datos de un volumen VDO, mapea el bloque lógico solicitado al bloque físico subyacente y luego lee y devuelve los datos solicitados.Cuando
kvdorecibe una solicitud para escribir un bloque de datos en un volumen VDO, primero comprueba si la solicitud es una petición de DISCARD o TRIM o si los datos son uniformemente cero. Si cualquiera de estas condiciones es verdadera,kvdoactualiza su mapa de bloques y reconoce la solicitud. En caso contrario, VDO procesa y optimiza los datos.udsUn módulo del núcleo que se comunica con el índice del Servicio Universal de Deduplicación (UDS) en el volumen y analiza los datos en busca de duplicados. Para cada nueva pieza de datos, UDS determina rápidamente si esa pieza es idéntica a cualquier pieza de datos almacenada previamente. Si el índice encuentra una coincidencia, el sistema de almacenamiento puede entonces referenciar internamente el elemento existente para evitar almacenar la misma información más de una vez.
El índice UDS se ejecuta dentro del núcleo como el módulo del núcleo
uds.- Herramientas de línea de comandos
- Para configurar y gestionar el almacenamiento optimizado.
36.1.4. El tamaño físico y lógico de un volumen VDO
Esta sección describe el tamaño físico, el tamaño físico disponible y el tamaño lógico que puede utilizar VDO:
- Tamaño físico
Este es el mismo tamaño que el dispositivo de bloque subyacente. VDO utiliza este almacenamiento para:
- Los datos de los usuarios, que pueden estar deduplicados y comprimidos
- Metadatos VDO, como el índice UDS
- Tamaño físico disponible
Es la parte del tamaño físico que VDO puede utilizar para los datos del usuario
Equivale al tamaño físico menos el tamaño de los metadatos, menos el resto tras dividir el volumen en losas por el tamaño de losa dado.
- Tamaño lógico
Es el tamaño provisionado que el volumen VDO presenta a las aplicaciones. Normalmente es mayor que el tamaño físico disponible. Si no se especifica la opción
--vdoLogicalSize, entonces el aprovisionamiento del volumen lógico se aprovisiona en una proporción de1:1. Por ejemplo, si se coloca un volumen VDO sobre un dispositivo de bloques de 20 GB, entonces se reservan 2,5 GB para el índice UDS (si se utiliza el tamaño de índice por defecto). Los 17,5 GB restantes se destinan a los metadatos de VDO y a los datos del usuario. Como resultado, el almacenamiento disponible para consumir no es más de 17,5 GB, y puede ser menos debido a los metadatos que componen el volumen VDO real.Actualmente, VDO admite cualquier tamaño lógico hasta 254 veces el tamaño del volumen físico, con un tamaño lógico máximo absoluto de 4PB.
Figura 36.2. Organización del disco VDO
En esta figura, el objetivo de almacenamiento deduplicado VDO se sitúa completamente sobre el dispositivo de bloque, lo que significa que el tamaño físico del volumen VDO es del mismo tamaño que el dispositivo de bloque subyacente.
Recursos adicionales
- Para obtener más información sobre la cantidad de almacenamiento que requieren los metadatos VDO en dispositivos de bloque de diferentes tamaños, consulte Sección 36.1.6.4, “Ejemplos de requisitos VDO por tamaño físico”.
36.1.5. Tamaño de la losa en VDO
El almacenamiento físico del volumen VDO se divide en un número de losas. Cada tabla es una región contigua del espacio físico. Todos los bloques de un volumen determinado tienen el mismo tamaño, que puede ser cualquier potencia de 2 múltiplos de 128 MB hasta 32 GB.
El tamaño por defecto de los slabs es de 2 GB para facilitar la evaluación de VDO en sistemas de prueba más pequeños. Un solo volumen VDO puede tener hasta 8192 bloques. Por lo tanto, en la configuración por defecto con losas de 2 GB, el almacenamiento físico máximo permitido es de 16 TB. Cuando se utilizan placas de 32 GB, el máximo de almacenamiento físico permitido es de 256 TB. VDO siempre reserva al menos un slab entero para metadatos, y por lo tanto, el slab reservado no puede ser utilizado para almacenar datos de usuario.
El tamaño de la losa no influye en el rendimiento del volumen VDO.
| Tamaño del volumen físico | Tamaño de losa recomendado |
|---|---|
| 10-99 GB | 1 GB |
| 100 GB - 1 TB | 2 GB |
| 2-256 TB | 32 GB |
Puede controlar el tamaño de la losa proporcionando la opción --vdoSlabSize=megabytes al comando vdo create.
36.1.6. Requisitos de VDO
VDO tiene ciertos requisitos para su colocación y los recursos de su sistema.
36.1.6.1. Requisitos de memoria de VDO
Cada volumen VDO tiene dos requisitos de memoria distintos:
El módulo VDO
VDO requiere una cantidad fija de 38 MB de RAM y varias cantidades variables:
- 1.15 MB de RAM por cada 1 MB de tamaño de caché de mapa de bloques configurado. La caché del mapa de bloques requiere un mínimo de 150 MB de RAM.
- 1.6 MB de RAM por cada 1 TB de espacio lógico.
- 268 MB de RAM por cada 1 TB de almacenamiento físico gestionado por el volumen.
El índice UDS
El Servicio de Deduplicación Universal (UDS) requiere un mínimo de 250 MB de RAM, que es también la cantidad por defecto que utiliza la deduplicación. Puede configurar el valor al formatear un volumen VDO, ya que el valor también afecta a la cantidad de almacenamiento que necesita el índice.
La memoria necesaria para el índice UDS viene determinada por el tipo de índice y el tamaño requerido de la ventana de deduplicación:
| Tipo de índice | Ventana de deduplicación | Nota |
|---|---|---|
| Denso | 1 TB por cada 1 GB de RAM | Un índice denso de 1 GB suele ser suficiente para hasta 4 TB de almacenamiento físico. |
| Sparse | 10 TB por 1 GB de RAM | Un índice disperso de 1 GB suele ser suficiente para hasta 40 TB de almacenamiento físico. |
La función UDS Sparse Indexing es el modo recomendado para VDO. Se basa en la localidad temporal de los datos e intenta retener en memoria sólo las entradas de índice más relevantes. Con el índice disperso, UDS puede mantener una ventana de deduplicación diez veces mayor que con el denso, utilizando la misma cantidad de memoria.
Aunque el índice disperso proporciona la mayor cobertura, el índice denso ofrece más consejos de deduplicación. Para la mayoría de las cargas de trabajo, dada la misma cantidad de memoria, la diferencia en las tasas de deduplicación entre los índices densos y dispersos es insignificante.
Recursos adicionales
- Para ver ejemplos concretos de los requisitos de memoria del índice UDS, consulte Sección 36.1.6.4, “Ejemplos de requisitos VDO por tamaño físico”.
36.1.6.2. Requisitos de espacio de almacenamiento de VDO
Puede configurar un volumen VDO para utilizar hasta 256 TB de almacenamiento físico. Sólo una parte del almacenamiento físico es utilizable para almacenar datos. Esta sección proporciona los cálculos para determinar el tamaño utilizable de un volumen gestionado por VDO.
VDO requiere almacenamiento para dos tipos de metadatos VDO y para el índice UDS:
- El primer tipo de metadatos VDO utiliza aproximadamente 1 MB por cada 4 GB de physical storage más 1 MB adicional por cada losa.
- El segundo tipo de metadatos VDO consume aproximadamente 1,25 MB por cada 1 GB de logical storage, redondeado a la losa más cercana.
- La cantidad de almacenamiento necesaria para el índice UDS depende del tipo de índice y de la cantidad de RAM asignada al índice. Por cada 1 GB de RAM, un índice UDS denso utiliza 17 GB de almacenamiento, y un índice UDS disperso utilizará 170 GB de almacenamiento.
Recursos adicionales
- Para ver ejemplos concretos de necesidades de almacenamiento de VDO, consulte Ejemplos de necesidades de VDO por tamaño de volumen físico.
- Para una descripción de las losas, véase Tamaño de las losas en VDO.
36.1.6.3. Colocación de VDO en la pila de almacenamiento
Debe colocar ciertas capas de almacenamiento debajo de VDO y otras por encima de VDO.
Puede colocar capas de aprovisionamiento grueso encima de VDO, pero no puede confiar en las garantías del aprovisionamiento grueso en ese caso. Dado que la capa VDO es de aprovisionamiento fino, los efectos del aprovisionamiento fino se aplican a todas las capas por encima de ella. Si no supervisa el dispositivo VDO, podría quedarse sin espacio físico en los volúmenes de aprovisionamiento grueso por encima de VDO.
Configuraciones compatibles
Capas que sólo se pueden colocar bajo VDO:
- DM Multipath
- Cripta DM
- RAID por software (LVM o MD RAID)
Capas que sólo se pueden colocar encima de VDO:
- Caché LVM
- Instantáneas LVM
- Aprovisionamiento ligero LVM
Configuraciones no admitidas
- VDO sobre otros volúmenes VDO
- VDO sobre las instantáneas LVM
- VDO sobre la caché LVM
- VDO sobre un dispositivo de bucle de retorno
- VDO sobre el aprovisionamiento ligero de LVM
- Volúmenes encriptados sobre VDO
- Particiones en un volumen VDO
- RAID, como LVM RAID, MD RAID, o cualquier otro tipo, sobre un volumen VDO
Recursos adicionales
- Para más información sobre el apilamiento de VDO con capas LVM, consulte el artículo Apilar volúmenes LVM.
36.1.6.4. Ejemplos de requisitos VDO por tamaño físico
Las siguientes tablas proporcionan los requisitos aproximados del sistema de VDO basados en el tamaño físico del volumen subyacente. Cada tabla enumera los requisitos apropiados para el despliegue previsto, como el almacenamiento primario o el almacenamiento de copia de seguridad.
Los números exactos dependen de su configuración del volumen VDO.
Despliegue del almacenamiento primario
En el caso del almacenamiento primario, el índice UDS está entre el 0,01% y el 25% del tamaño físico.
| Tamaño físico | Uso de la RAM: UDS | Uso de la RAM: VDO | Uso del disco | Tipo de índice |
|---|---|---|---|---|
| 10GB-1TB | 250MB | 472MB | 2.5GB | Denso |
| 2-10TB | 1GB | 3GB | 10 GB | Denso |
| 250MB | 22 GB | Sparse | ||
| 11-50TB | 2GB | 14 GB | 170 GB | Sparse |
| 51-100TB | 3GB | 27 GB | 255 GB | Sparse |
| 101-256TB | 12 GB | 69 GB | 1020 GB | Sparse |
Despliegue del almacenamiento de seguridad
En el caso del almacenamiento de copias de seguridad, el índice UDS cubre el tamaño del conjunto de copias de seguridad pero no es mayor que el tamaño físico. Si espera que el conjunto de copias de seguridad o el tamaño físico crezcan en el futuro, téngalo en cuenta en el tamaño del índice.
| Tamaño físico | Uso de la RAM: UDS | Uso de la RAM: VDO | Uso del disco | Tipo de índice |
|---|---|---|---|---|
| 10GB-1TB | 250MB | 472MB | 2.5 GB | Denso |
| 2-10TB | 2GB | 3GB | 170 GB | Sparse |
| 11-50TB | 10 GB | 14 GB | 850 GB | Sparse |
| 51-100TB | 20 GB | 27 GB | 1700GB | Sparse |
| 101-256TB | 26 GB | 69 GB | 3400GB | Sparse |
36.1.7. Instalación de VDO
Este procedimiento instala el software necesario para crear, montar y gestionar volúmenes VDO.
Procedimiento
Instale los paquetes
vdoykmod-kvdo:# yum install vdo kmod-kvdo
36.1.8. Creación de un volumen VDO
Este procedimiento crea un volumen VDO en un dispositivo de bloque.
Requisitos previos
- Instale el software VDO. Consulte Sección 36.1.7, “Instalación de VDO”.
- Utilice el almacenamiento ampliable como dispositivo de bloque de respaldo. Para obtener más información, consulte Sección 36.1.6.3, “Colocación de VDO en la pila de almacenamiento”.
Procedimiento
En todos los pasos siguientes, sustituya vdo-name por el identificador que desee utilizar para su volumen VDO; por ejemplo, vdo1. Debe utilizar un nombre y un dispositivo diferentes para cada instancia de VDO en el sistema.
Busque un nombre persistente para el dispositivo de bloque donde desea crear el volumen VDO. Para más información sobre los nombres persistentes, consulte Capítulo 31, Visión general de los atributos de nomenclatura persistente.
Si utiliza un nombre de dispositivo no persistente, entonces VDO podría no iniciarse correctamente en el futuro si el nombre del dispositivo cambia.
Crea el volumen VDO:
# vdo create \ --name=vdo-name \ --device=block-device \ --vdoLogicalSize=logical-size-
Sustituya block-device por el nombre persistente del dispositivo de bloque en el que desea crear el volumen VDO. Por ejemplo,
/dev/disk/by-id/scsi-3600508b1001c264ad2af21e903ad031f. Sustituya logical-size con la cantidad de almacenamiento lógico que debe presentar el volumen VDO:
-
Para las máquinas virtuales activas o el almacenamiento en contenedores, utilice un tamaño lógico que sea ten veces el tamaño físico de su dispositivo de bloque. Por ejemplo, si su dispositivo de bloque tiene un tamaño de 1TB, utilice aquí
10T. -
Para el almacenamiento de objetos, utilice el tamaño lógico que es three veces el tamaño físico de su dispositivo de bloque. Por ejemplo, si su dispositivo de bloque tiene un tamaño de 1TB, utilice aquí
3T.
-
Para las máquinas virtuales activas o el almacenamiento en contenedores, utilice un tamaño lógico que sea ten veces el tamaño físico de su dispositivo de bloque. Por ejemplo, si su dispositivo de bloque tiene un tamaño de 1TB, utilice aquí
Si el dispositivo de bloque físico es mayor de 16TiB, añada la opción
--vdoSlabSize=32Gpara aumentar el tamaño de la losa en el volumen a 32GiB.Si se utiliza el tamaño de bloque por defecto de 2GiB en dispositivos de bloque de más de 16TiB, el comando
vdo createfalla con el siguiente error:vdo: ERROR - vdoformat: formatVDO failed on '/dev/device': Estado de VDO: Excede el número máximo de placas soportadas
Ejemplo 36.1. Creación de VDO para el almacenamiento de contenedores
Por ejemplo, para crear un volumen VDO para el almacenamiento de contenedores en un dispositivo de bloque de 1TB, podría utilizar:
# vdo create \ --name=vdo1 \ --device=/dev/disk/by-id/scsi-3600508b1001c264ad2af21e903ad031f \ --vdoLogicalSize=10TImportanteSi se produce un fallo al crear el volumen VDO, elimine el volumen para limpiarlo. Consulte Eliminar un volumen VDO creado sin éxito para obtener más detalles.
-
Sustituya block-device por el nombre persistente del dispositivo de bloque en el que desea crear el volumen VDO. Por ejemplo,
Cree un sistema de archivos sobre el volumen VDO:
Para el sistema de archivos XFS:
# mkfs.xfs -K /dev/mapper/vdo-namePara el sistema de archivos ext4:
# mkfs.ext4 -E nodiscard /dev/mapper/vdo-name
Utilice el siguiente comando para esperar a que el sistema registre el nuevo nodo de dispositivo:
# udevadm settle
Próximos pasos
- Montar el sistema de archivos. Consulte Sección 36.1.9, “Montaje de un volumen VDO” para obtener más detalles.
-
Habilite la función
discardpara el sistema de archivos de su dispositivo VDO. Consulte Sección 36.1.10, “Activación del descarte periódico de bloques” para obtener más detalles.
Recursos adicionales
-
La página de manual
vdo(8)
36.1.9. Montaje de un volumen VDO
Este procedimiento monta un sistema de archivos en un volumen VDO, de forma manual o persistente.
Requisitos previos
- Se ha creado un volumen VDO en su sistema. Para obtener instrucciones, consulte Sección 36.1.8, “Creación de un volumen VDO”.
Procedimiento
Para montar el sistema de archivos en el volumen VDO manualmente, utilice:
# montar /dev/mapper/vdo-name mount-pointPara configurar el sistema de archivos para que se monte automáticamente en el arranque, añada una línea al archivo
/etc/fstab:Para el sistema de archivos XFS:
/dev/mapper/vdo-name mount-point xfs defaults,_netdev,x-systemd.device-timeout=0,x-systemd.requires=vdo.service 0 0Para el sistema de archivos ext4:
/dev/mapper/vdo-name mount-point ext4 defaults,_netdev,x-systemd.device-timeout=0,x-systemd.requires=vdo.service 0 0
Recursos adicionales
-
La página de manual
vdo(8)
36.1.10. Activación del descarte periódico de bloques
Este procedimiento habilita un temporizador systemd que descarta regularmente los bloques no utilizados en todos los sistemas de archivos compatibles.
Procedimiento
Activar e iniciar el temporizador
systemd:# systemctl enable --now fstrim.timer
36.1.11. Control de VDO
Este procedimiento describe cómo obtener información de uso y eficiencia de un volumen VDO.
Requisitos previos
- Instale el software VDO. Consulte Instalación de VDO.
Procedimiento
Utilice la utilidad
vdostatspara obtener información sobre un volumen VDO:# vdostats --human-readable Device 1K-blocks Used Available Use% Space saving% /dev/mapper/node1osd1 926.5G 21.0G 905.5G 2% 73% /dev/mapper/node1osd2 926.5G 28.2G 898.3G 3% 64%
Recursos adicionales
-
La página de manual
vdostats(8).
36.2. Mantenimiento de VDO
Después de desplegar un volumen VDO, puede realizar ciertas tareas para mantenerlo u optimizarlo. Algunas de las siguientes tareas son necesarias para el correcto funcionamiento de los volúmenes VDO.
Requisitos previos
- VDO está instalado y desplegado. Véase Sección 36.1, “Despliegue de VDO”.
36.2.1. Gestión del espacio libre en los volúmenes VDO
VDO es un objetivo de almacenamiento en bloque poco aprovisionado. Por ello, debe supervisar y gestionar activamente el uso del espacio en los volúmenes de VDO.
36.2.1.1. El tamaño físico y lógico de un volumen VDO
Esta sección describe el tamaño físico, el tamaño físico disponible y el tamaño lógico que puede utilizar VDO:
- Tamaño físico
Este es el mismo tamaño que el dispositivo de bloque subyacente. VDO utiliza este almacenamiento para:
- Los datos de los usuarios, que pueden estar deduplicados y comprimidos
- Metadatos VDO, como el índice UDS
- Tamaño físico disponible
Es la parte del tamaño físico que VDO puede utilizar para los datos del usuario
Equivale al tamaño físico menos el tamaño de los metadatos, menos el resto tras dividir el volumen en losas por el tamaño de losa dado.
- Tamaño lógico
Es el tamaño provisionado que el volumen VDO presenta a las aplicaciones. Normalmente es mayor que el tamaño físico disponible. Si no se especifica la opción
--vdoLogicalSize, entonces el aprovisionamiento del volumen lógico se aprovisiona en una proporción de1:1. Por ejemplo, si se coloca un volumen VDO sobre un dispositivo de bloques de 20 GB, entonces se reservan 2,5 GB para el índice UDS (si se utiliza el tamaño de índice por defecto). Los 17,5 GB restantes se destinan a los metadatos de VDO y a los datos del usuario. Como resultado, el almacenamiento disponible para consumir no es más de 17,5 GB, y puede ser menos debido a los metadatos que componen el volumen VDO real.Actualmente, VDO admite cualquier tamaño lógico hasta 254 veces el tamaño del volumen físico, con un tamaño lógico máximo absoluto de 4PB.
Figura 36.3. Organización del disco VDO
En esta figura, el objetivo de almacenamiento deduplicado VDO se sitúa completamente sobre el dispositivo de bloque, lo que significa que el tamaño físico del volumen VDO es del mismo tamaño que el dispositivo de bloque subyacente.
Recursos adicionales
- Para obtener más información sobre la cantidad de almacenamiento que requieren los metadatos VDO en dispositivos de bloque de diferentes tamaños, consulte Sección 36.1.6.4, “Ejemplos de requisitos VDO por tamaño físico”.
36.2.1.2. Aprovisionamiento ligero en VDO
VDO es un objetivo de almacenamiento en bloque con aprovisionamiento ligero. La cantidad de espacio físico que utiliza un volumen VDO puede diferir del tamaño del volumen que se presenta a los usuarios del almacenamiento. Puede aprovechar esta disparidad para ahorrar en costes de almacenamiento.
Condiciones fuera del espacio
Tenga cuidado para evitar quedarse sin espacio de almacenamiento de forma inesperada, si los datos escritos no alcanzan la tasa de optimización esperada.
Cuando el número de bloques lógicos (almacenamiento virtual) supera el número de bloques físicos (almacenamiento real), es posible que los sistemas de archivos y las aplicaciones se queden inesperadamente sin espacio. Por esta razón, los sistemas de almacenamiento que utilizan VDO deben proporcionarle una forma de controlar el tamaño del pool libre en el volumen VDO.
Puede determinar el tamaño de este pool libre utilizando la utilidad vdostats. La salida por defecto de esta utilidad lista la información de todos los volúmenes VDO en ejecución en un formato similar al de la utilidad de Linux df. Por ejemplo:
Device 1K-blocks Used Available Use%
/dev/mapper/vdo-name 211812352 105906176 105906176 50%Cuando la capacidad de almacenamiento físico de un volumen VDO está casi llena, VDO informa de una advertencia en el registro del sistema, similar a la siguiente:
Oct 2 17:13:39 system lvm[13863]: Monitoring VDO pool vdo-name.
Oct 2 17:27:39 system lvm[13863]: WARNING: VDO pool vdo-name is now 80.69% full.
Oct 2 17:28:19 system lvm[13863]: WARNING: VDO pool vdo-name is now 85.25% full.
Oct 2 17:29:39 system lvm[13863]: WARNING: VDO pool vdo-name is now 90.64% full.
Oct 2 17:30:29 system lvm[13863]: WARNING: VDO pool vdo-name is now 96.07% full.
Estos mensajes de advertencia sólo aparecen cuando el servicio lvm2-monitor está en funcionamiento. Está activado por defecto.
Cómo prevenir las condiciones de fuera del espacio
Si el tamaño de la piscina libre desciende por debajo de un determinado nivel, puedes actuar:
- Eliminación de datos. Esto recupera espacio siempre que los datos borrados no se dupliquen. El borrado de datos libera el espacio sólo después de los descartes.
- Añadir almacenamiento físico
Supervise el espacio físico en sus volúmenes VDO para evitar situaciones de falta de espacio. Quedarse sin bloques físicos podría resultar en la pérdida de datos recientemente escritos y no reconocidos en el volumen VDO.
Aprovisionamiento delgado y los comandos TRIM y DISCARD
Para beneficiarse del ahorro de almacenamiento que supone el thin provisioning, la capa de almacenamiento físico necesita saber cuándo se eliminan los datos. Los sistemas de archivos que trabajan con el almacenamiento thinly provisioned envían comandos TRIM o DISCARD para informar al sistema de almacenamiento cuando un bloque lógico ya no es necesario.
Existen varios métodos para enviar los comandos TRIM o DISCARD:
-
Con la opción de montaje
discard, los sistemas de archivos pueden enviar estos comandos cada vez que se elimina un bloque. -
Puede enviar los comandos de forma controlada utilizando utilidades como
fstrim. Estas utilidades le dicen al sistema de archivos que detecte los bloques lógicos que no se utilizan y que envíe la información al sistema de almacenamiento en forma de comandoTRIMoDISCARD.
La necesidad de utilizar TRIM o DISCARD en los bloques no utilizados no es exclusiva de VDO. Cualquier sistema de almacenamiento con aprovisionamiento ligero tiene el mismo reto.
36.2.1.3. Control de VDO
Este procedimiento describe cómo obtener información de uso y eficiencia de un volumen VDO.
Requisitos previos
- Instale el software VDO. Consulte Instalación de VDO.
Procedimiento
Utilice la utilidad
vdostatspara obtener información sobre un volumen VDO:# vdostats --human-readable Device 1K-blocks Used Available Use% Space saving% /dev/mapper/node1osd1 926.5G 21.0G 905.5G 2% 73% /dev/mapper/node1osd2 926.5G 28.2G 898.3G 3% 64%
Recursos adicionales
-
La página de manual
vdostats(8).
36.2.1.4. Recuperación de espacio para VDO en los sistemas de archivos
Este procedimiento recupera el espacio de almacenamiento en un volumen VDO que alberga un sistema de archivos.
VDO no puede recuperar espacio a menos que los sistemas de archivos comuniquen que los bloques están libres utilizando los comandos DISCARD, TRIM, o UNMAP.
Procedimiento
- Si el sistema de archivos de su volumen VDO admite operaciones de descarte, habilítelas. Consulte Descartar bloques no utilizados.
-
Para los sistemas de archivos que no utilizan
DISCARD,TRIM, oUNMAP, puede recuperar manualmente el espacio libre. Almacene un archivo compuesto por ceros binarios para llenar el espacio libre y luego elimine ese archivo.
36.2.1.5. Recuperación de espacio para VDO sin sistema de archivos
Este procedimiento recupera el espacio de almacenamiento en un volumen VDO que se utiliza como destino de almacenamiento en bloque sin un sistema de archivos.
Procedimiento
Utilice la utilidad
blkdiscard.Por ejemplo, un único volumen VDO puede dividirse en múltiples subvolúmenes desplegando LVM sobre él. Antes de desaprovisionar un volumen lógico, utilice la utilidad
blkdiscardpara liberar el espacio utilizado previamente por ese volumen lógico.LVM soporta el comando
REQ_DISCARDy reenvía las peticiones a VDO en las direcciones lógicas de bloque apropiadas para liberar el espacio. Si se utilizan otros gestores de volumen, también deben soportarREQ_DISCARD, o, de forma equivalente,UNMAPpara dispositivos SCSI oTRIMpara dispositivos ATA.
Recursos adicionales
-
La página de manual
blkdiscard(8)
36.2.1.6. Recuperación de espacio para VDO en la red Fibre Channel o Ethernet
Este procedimiento reclama el espacio de almacenamiento en volúmenes VDO (o partes de volúmenes) que se aprovisionan a los hosts en una estructura de almacenamiento de canal de fibra o una red Ethernet utilizando marcos de destino SCSI como LIO o SCST.
Procedimiento
Los iniciadores SCSI pueden utilizar el comando
UNMAPpara liberar espacio en los objetivos de almacenamiento con aprovisionamiento ligero, pero el marco del objetivo SCSI necesita ser configurado para anunciar el soporte de este comando. Esto se hace normalmente habilitando el aprovisionamiento ligero en estos volúmenes.Verifique la compatibilidad con
UNMAPen los iniciadores SCSI basados en Linux ejecutando el siguiente comando:# sg_vpd --page=0xb0 /dev/deviceEn la salida, verifique que el valor de Maximum unmap LBA count es mayor que cero.
36.2.2. Iniciar o detener los volúmenes de VDO
Puede iniciar o detener un volumen VDO determinado, o todos los volúmenes VDO, y sus índices UDS asociados.
36.2.2.1. Inició y activó los volúmenes de VDO
Durante el arranque del sistema, la unidad vdo systemd automáticamente starts todos los dispositivos VDO que estén configurados como activated.
La unidad vdo systemd se instala y habilita por defecto cuando se instala el paquete vdo. Esta unidad ejecuta automáticamente el comando vdo start --all al iniciar el sistema para que aparezcan todos los volúmenes VDO activados.
También puede crear un volumen VDO que no se inicie automáticamente añadiendo la opción --activate=disabled al comando vdo create.
El orden de salida
Algunos sistemas pueden colocar los volúmenes LVM tanto por encima de los volúmenes VDO como por debajo de ellos. En estos sistemas, es necesario iniciar los servicios en el orden correcto:
- La capa inferior de LVM debe iniciarse primero. En la mayoría de los sistemas, el inicio de esta capa se configura automáticamente cuando se instala el paquete LVM.
-
La unidad
vdosystemddebe arrancar entonces. - Por último, deben ejecutarse scripts adicionales para iniciar volúmenes LVM u otros servicios sobre los volúmenes VDO en ejecución.
El tiempo que tarda en detenerse un volumen
Detener un volumen VDO lleva un tiempo basado en la velocidad de su dispositivo de almacenamiento y la cantidad de datos que el volumen necesita escribir:
- El volumen siempre escribe alrededor de 1GiB por cada 1GiB del índice UDS.
- El volumen escribe adicionalmente la cantidad de datos equivalente al tamaño de la caché del mapa de bloques más hasta 8MiB por losa.
- El volumen debe terminar de procesar todas las solicitudes de E/S pendientes.
36.2.2.2. Iniciar un volumen VDO
Este procedimiento inicia un volumen VDO determinado o todos los volúmenes VDO de su sistema.
Procedimiento
Para iniciar un determinado volumen VDO, utilice:
# vdo start --name=my-vdoPara iniciar todos los volúmenes VDO, utilice:
# vdo start --all
Recursos adicionales
-
La página de manual
vdo(8)
36.2.2.3. Detener un volumen VDO
Este procedimiento detiene un volumen VDO determinado o todos los volúmenes VDO de su sistema.
Procedimiento
Detener el volumen.
Para detener un determinado volumen VDO, utilice:
# vdo stop --name=my-vdoPara detener todos los volúmenes VDO, utilice:
# vdo stop --all
- Espere a que el volumen termine de escribir datos en el disco.
Recursos adicionales
-
La página de manual
vdo(8)
36.2.3. Inicio automático de los volúmenes VDO en el arranque del sistema
Puede configurar los volúmenes VDO para que se inicien automáticamente al arrancar el sistema. También puede desactivar el inicio automático.
36.2.3.1. Inició y activó los volúmenes de VDO
Durante el arranque del sistema, la unidad vdo systemd automáticamente starts todos los dispositivos VDO que estén configurados como activated.
La unidad vdo systemd se instala y habilita por defecto cuando se instala el paquete vdo. Esta unidad ejecuta automáticamente el comando vdo start --all al iniciar el sistema para que aparezcan todos los volúmenes VDO activados.
También puede crear un volumen VDO que no se inicie automáticamente añadiendo la opción --activate=disabled al comando vdo create.
El orden de salida
Algunos sistemas pueden colocar los volúmenes LVM tanto por encima de los volúmenes VDO como por debajo de ellos. En estos sistemas, es necesario iniciar los servicios en el orden correcto:
- La capa inferior de LVM debe iniciarse primero. En la mayoría de los sistemas, el inicio de esta capa se configura automáticamente cuando se instala el paquete LVM.
-
La unidad
vdosystemddebe arrancar entonces. - Por último, deben ejecutarse scripts adicionales para iniciar volúmenes LVM u otros servicios sobre los volúmenes VDO en ejecución.
El tiempo que tarda en detenerse un volumen
Detener un volumen VDO lleva un tiempo basado en la velocidad de su dispositivo de almacenamiento y la cantidad de datos que el volumen necesita escribir:
- El volumen siempre escribe alrededor de 1GiB por cada 1GiB del índice UDS.
- El volumen escribe adicionalmente la cantidad de datos equivalente al tamaño de la caché del mapa de bloques más hasta 8MiB por losa.
- El volumen debe terminar de procesar todas las solicitudes de E/S pendientes.
36.2.3.2. Activación de un volumen VDO
Este procedimiento activa un volumen VDO para que se ponga en marcha automáticamente.
Procedimiento
Para activar un volumen específico:
# vdo activate --name=my-vdoPara activar todos los volúmenes:
# vdo activate --all
Recursos adicionales
-
La página de manual
vdo(8)
36.2.3.3. Desactivación de un volumen VDO
Este procedimiento desactiva un volumen VDO para evitar que se inicie automáticamente.
Procedimiento
Para desactivar un volumen específico:
# vdo deactivate --name=my-vdoPara desactivar todos los volúmenes:
# vdo deactivate --all
Recursos adicionales
-
La página de manual
vdo(8)
36.2.4. Selección de un modo de escritura VDO
Puede configurar el modo de escritura para un volumen VDO, basándose en lo que requiere el dispositivo de bloque subyacente. Por defecto, VDO selecciona el modo de escritura automáticamente.
36.2.4.1. Modos de escritura VDO
VDO admite los siguientes modos de escritura:
syncCuando VDO está en modo
sync, las capas por encima de él asumen que un comando de escritura escribe datos en el almacenamiento persistente. Como resultado, no es necesario que el sistema de archivos o la aplicación, por ejemplo, emitan solicitudes FLUSH o de acceso forzado a la unidad (FUA) para hacer que los datos se vuelvan persistentes en los puntos críticos.VDO debe estar en modo
syncsólo cuando el almacenamiento subyacente garantiza que los datos se escriben en el almacenamiento persistente cuando el comando de escritura se completa. Es decir, el almacenamiento no debe tener una caché de escritura volátil, o debe tener una caché de escritura.asyncCuando VDO está en modo
async, VDO no garantiza que los datos se escriban en el almacenamiento persistente cuando se reconoce un comando de escritura. El sistema de archivos o la aplicación deben emitir peticiones FLUSH o FUA para asegurar la persistencia de los datos en los puntos críticos de cada transacción.VDO debe estar configurado en el modo
asyncsi el almacenamiento subyacente no garantiza que los datos se escriban en el almacenamiento persistente cuando el comando de escritura se completa; es decir, cuando el almacenamiento tiene una caché de escritura volátil.async-unsafeEste modo tiene las mismas propiedades que
asyncpero no cumple con Atomicidad, Consistencia, Aislamiento, Durabilidad (ACID). En comparación conasync,async-unsafetiene un mejor rendimiento.AvisoCuando una aplicación o un sistema de archivos que asume el cumplimiento de ACID opera sobre el volumen VDO, el modo
async-unsafepodría causar una pérdida de datos inesperada.auto-
El modo
autoselecciona automáticamentesyncoasyncen función de las características de cada dispositivo. Esta es la opción por defecto.
36.2.4.2. El procesamiento interno de los modos de escritura VDO
Esta sección proporciona detalles sobre el funcionamiento de los modos de escritura sync y async VDO.
Si el módulo kvdo funciona en modo síncrono:
- Escribe temporalmente los datos de la solicitud en el bloque asignado y luego acusa recibo de la solicitud.
- Una vez completado el acuse de recibo, se intenta desduplicar el bloque calculando una firma MurmurHash-3 de los datos del bloque, que se envía al índice VDO.
-
Si el índice VDO contiene una entrada para un bloque con la misma firma,
kvdolee el bloque indicado y hace una comparación byte a byte de los dos bloques para verificar que son idénticos. -
Si efectivamente son idénticos, entonces
kvdoactualiza su mapa de bloques para que el bloque lógico apunte al bloque físico correspondiente y libera el bloque físico asignado. -
Si el índice VDO no contiene una entrada para la firma del bloque que se está escribiendo, o el bloque indicado no contiene realmente los mismos datos,
kvdoactualiza su mapa de bloques para hacer permanente el bloque físico temporal.
Si kvdo funciona en modo asíncrono:
- En lugar de escribir los datos, acusará inmediatamente recibo de la solicitud.
- A continuación, intentará desduplicar el bloque de la misma manera que se ha descrito anteriormente.
-
Si el bloque resulta ser un duplicado,
kvdoactualiza su mapa de bloques y libera el bloque asignado. En caso contrario, escribe los datos de la solicitud en el bloque asignado y actualiza el mapa de bloques para que el bloque físico sea permanente.
36.2.4.3. Comprobación del modo de escritura en un volumen VDO
Este procedimiento muestra el modo de escritura activo en un volumen VDO seleccionado.
Procedimiento
Utilice el siguiente comando para ver el modo de escritura utilizado por un volumen VDO:
# vdo status --name=my-vdoLa lista de salida:
-
El configured write policy, que es la opción seleccionada entre
sync,async, oauto -
El write policy, que es el modo de escritura particular que VDO aplicó, es decir
syncoasync
-
El configured write policy, que es la opción seleccionada entre
36.2.4.4. Comprobación de un caché volátil
Este procedimiento determina si un dispositivo de bloque tiene una caché volátil o no. Puede utilizar la información para elegir entre los modos de escritura sync y async VDO.
Procedimiento
Utilice cualquiera de los siguientes métodos para determinar si un dispositivo tiene una caché de escritura:
Lea el
/sys/block/block-device/device/scsi_disk/identifier/cache_typesysfsarchivo. Por ejemplo:$ cat '/sys/block/sda/device/scsi_disk/7:0:0:0/cache_type' write back$ cat '/sys/block/sdb/device/scsi_disk/1:2:0:0/cache_type' NoneAlternativamente, puede encontrar si los dispositivos mencionados anteriormente tienen una caché de escritura o no en el registro de arranque del kernel:
sd 7:0:0:0: [sda] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA sd 1:2:0:0: [sdb] Write cache: disabled, read cache: disabled, supports DPO and FUA
En los ejemplos anteriores:
-
El dispositivo
sdaindica que has es una caché de escritura. Utilice el modoasyncpara ello. -
El dispositivo
sdbindica que does not have es una caché de escritura. Utilice el modosyncpara ello.
Debe configurar VDO para utilizar el modo de escritura
syncsi el valor decache_typeesNoneowrite through.-
El dispositivo
36.2.4.5. Configurar un modo de escritura VDO
Este procedimiento establece un modo de escritura para un volumen VDO, ya sea para uno existente o al crear un nuevo volumen.
El uso de un modo de escritura incorrecto puede provocar la pérdida de datos después de un fallo de alimentación, una caída del sistema o cualquier pérdida inesperada de contacto con el disco.
Requisitos previos
- Determine qué modo de escritura es el correcto para su dispositivo. Consulte Sección 36.2.4.4, “Comprobación de un caché volátil”.
Procedimiento
Puedes establecer un modo de escritura tanto en un volumen VDO existente como al crear un nuevo volumen:
Para modificar un volumen VDO existente, utilice:
# vdo changeWritePolicy --writePolicy=sync|async|async-unsafe|auto \ --name=vdo-name-
Para especificar un modo de escritura al crear un volumen VDO, añada la opción
--writePolicy=sync|async|async-unsafe|autoal comandovdo create.
36.2.5. Recuperación de un volumen VDO después de un cierre sucio
Puede recuperar un volumen VDO después de un apagado no limpio para que pueda seguir funcionando. La tarea es en su mayoría automatizada. Además, puede limpiar después de que un volumen VDO se haya creado sin éxito debido a un fallo en el proceso.
36.2.5.1. Modos de escritura VDO
VDO admite los siguientes modos de escritura:
syncCuando VDO está en modo
sync, las capas por encima de él asumen que un comando de escritura escribe datos en el almacenamiento persistente. Como resultado, no es necesario que el sistema de archivos o la aplicación, por ejemplo, emitan solicitudes FLUSH o de acceso forzado a la unidad (FUA) para hacer que los datos se vuelvan persistentes en los puntos críticos.VDO debe estar en modo
syncsólo cuando el almacenamiento subyacente garantiza que los datos se escriben en el almacenamiento persistente cuando el comando de escritura se completa. Es decir, el almacenamiento no debe tener una caché de escritura volátil, o debe tener una caché de escritura.asyncCuando VDO está en modo
async, VDO no garantiza que los datos se escriban en el almacenamiento persistente cuando se reconoce un comando de escritura. El sistema de archivos o la aplicación deben emitir peticiones FLUSH o FUA para asegurar la persistencia de los datos en los puntos críticos de cada transacción.VDO debe estar configurado en el modo
asyncsi el almacenamiento subyacente no garantiza que los datos se escriban en el almacenamiento persistente cuando el comando de escritura se completa; es decir, cuando el almacenamiento tiene una caché de escritura volátil.async-unsafeEste modo tiene las mismas propiedades que
asyncpero no cumple con Atomicidad, Consistencia, Aislamiento, Durabilidad (ACID). En comparación conasync,async-unsafetiene un mejor rendimiento.AvisoCuando una aplicación o un sistema de archivos que asume el cumplimiento de ACID opera sobre el volumen VDO, el modo
async-unsafepodría causar una pérdida de datos inesperada.auto-
El modo
autoselecciona automáticamentesyncoasyncen función de las características de cada dispositivo. Esta es la opción por defecto.
36.2.5.2. Recuperación de volumen VDO
Cuando un volumen VDO se reinicia después de un apagado no limpio, VDO realiza las siguientes acciones:
- Verifica la consistencia de los metadatos en el volumen.
- Reconstruye una parte de los metadatos para repararlos si es necesario.
Las reconstrucciones son automáticas y no requieren la intervención del usuario.
VDO puede reconstruir diferentes escrituras dependiendo del modo de escritura activo:
sync-
Si VDO se ejecutaba en un almacenamiento síncrono y la política de escritura estaba establecida en
sync, todos los datos escritos en el volumen se recuperan completamente. async-
Si la política de escritura era
async, algunas escrituras podrían no ser recuperadas si no se hicieron duraderas. Esto se hace enviando a VDO un comandoFLUSHo una E/S de escritura etiquetada con la bandera FUA (forzar acceso a la unidad). Puede lograr esto desde el modo de usuario invocando una operación de integridad de datos comofsync,fdatasync,sync, oumount.
En cualquiera de los dos modos, algunas escrituras que no fueron reconocidas o que no fueron seguidas de una descarga también podrían ser reconstruidas.
Recuperación automática y manual
Cuando un volumen VDO entra en el modo de funcionamiento recovering, VDO reconstruye automáticamente el volumen VDO sucio cuando vuelve a estar en línea. Esto se llama online recovery.
Si VDO no puede recuperar un volumen VDO con éxito, coloca el volumen en el modo de funcionamiento read-only que persiste a través de los reinicios del volumen. Es necesario arreglar el problema manualmente forzando una reconstrucción.
Recursos adicionales
- Para más información sobre la recuperación automática y manual y los modos de funcionamiento de VDO, consulte Sección 36.2.5.3, “Modos de funcionamiento de VDO”.
36.2.5.3. Modos de funcionamiento de VDO
Esta sección describe los modos que indican si un volumen VDO está funcionando normalmente o se está recuperando de un error.
Puede mostrar el modo de funcionamiento actual de un volumen VDO mediante el comando vdostats --verbose device comando. Consulte el atributo Operating mode en la salida.
normal-
Este es el modo de funcionamiento por defecto. Los volúmenes VDO están siempre en modo
normal, a menos que alguno de los siguientes estados fuerce un modo diferente. Un volumen VDO recién creado se inicia en modonormal. recoveringCuando un volumen VDO no guarda todos sus metadatos antes de apagarse, entra automáticamente en el modo
recoveringla próxima vez que se inicie. Las razones típicas para entrar en este modo son la pérdida repentina de energía o un problema del dispositivo de almacenamiento subyacente.En el modo
recovering, VDO está fijando los recuentos de referencias para cada bloque físico de datos en el dispositivo. La recuperación no suele llevar mucho tiempo. El tiempo depende de lo grande que sea el volumen VDO, de lo rápido que sea el dispositivo de almacenamiento subyacente y de cuántas otras peticiones esté gestionando VDO simultáneamente. El volumen VDO funciona normalmente con las siguientes excepciones:- Al principio, la cantidad de espacio disponible para las solicitudes de escritura en el volumen puede ser limitada. A medida que se recuperan más metadatos, se dispone de más espacio libre.
- Los datos escritos mientras el volumen VDO se está recuperando pueden fallar en la deduplicación contra los datos escritos antes de la caída si esos datos están en una porción del volumen que aún no se ha recuperado. VDO puede comprimir los datos mientras se recupera el volumen. Todavía puede leer o sobrescribir bloques comprimidos.
- Durante una recuperación en línea, algunas estadísticas no están disponibles: por ejemplo, blocks in use y blocks free. Estas estadísticas estarán disponibles cuando se complete la reconstrucción.
- Los tiempos de respuesta para las lecturas y escrituras podrían ser más lentos de lo habitual debido a los trabajos de recuperación en curso
Puede apagar el volumen VDO de forma segura en el modo
recovering. Si la recuperación no finaliza antes del apagado, el dispositivo vuelve a entrar en el modorecoveringla próxima vez que se inicie.El volumen VDO sale automáticamente del modo
recoveringy pasa al modonormalcuando ha fijado todos los recuentos de referencia. No es necesaria ninguna acción del administrador. Para más detalles, consulte Sección 36.2.5.4, “Recuperación de un volumen VDO en línea”.read-onlyCuando un volumen VDO encuentra un error interno fatal, entra en modo
read-only. Los eventos que pueden causar el modoread-onlyincluyen la corrupción de metadatos o que el dispositivo de almacenamiento de respaldo se vuelva de sólo lectura. Este modo es un estado de error.En el modo
read-only, las lecturas de datos funcionan normalmente pero las escrituras de datos siempre fallan. El volumen VDO permanece en modoread-onlyhasta que un administrador solucione el problema.Puede apagar con seguridad un volumen VDO en modo
read-only. El modo normalmente persiste después de reiniciar el volumen VDO. En raros casos, el volumen VDO no es capaz de grabar el estadoread-onlyen el dispositivo de almacenamiento de respaldo. En estos casos, VDO intenta hacer una recuperación en su lugar.Una vez que un volumen está en modo de sólo lectura, no hay garantía de que los datos del volumen no se hayan perdido o corrompido. En estos casos, Red Hat recomienda copiar los datos fuera del volumen de sólo lectura y posiblemente restaurar el volumen desde una copia de seguridad.
Si el riesgo de corrupción de datos es aceptable, es posible forzar una reconstrucción fuera de línea de los metadatos del volumen VDO para que el volumen pueda volver a estar en línea y disponible. No se puede garantizar la integridad de los datos reconstruidos. Para más detalles, consulte Sección 36.2.5.5, “Forzar una reconstrucción fuera de línea de los metadatos de un volumen VDO”.
36.2.5.4. Recuperación de un volumen VDO en línea
Este procedimiento realiza una recuperación en línea en un volumen VDO para recuperar los metadatos después de un cierre sucio.
Procedimiento
Si el volumen VDO no está ya iniciado, inícielo:
# vdo start --name=my-vdoNo son necesarios pasos adicionales. La recuperación se ejecuta en segundo plano.
- Si confía en estadísticas de volumen como blocks in use y blocks free, espere a que estén disponibles.
36.2.5.5. Forzar una reconstrucción fuera de línea de los metadatos de un volumen VDO
Este procedimiento realiza una reconstrucción forzada fuera de línea de los metadatos de un volumen VDO para recuperarse después de un cierre sucio.
Este procedimiento podría causar la pérdida de datos en el volumen.
Requisitos previos
- Se inicia el volumen VDO.
Procedimiento
Comprueba si el volumen está en modo de sólo lectura. Consulte el atributo operating mode en la salida del comando:
# vdo status --name=my-vdoSi el volumen no está en modo de sólo lectura, no es necesario forzar una reconstrucción fuera de línea. Realice una recuperación en línea como se describe en Sección 36.2.5.4, “Recuperación de un volumen VDO en línea”.
Detenga el volumen si está en funcionamiento:
# vdo stop --name=my-vdoReinicie el volumen con la opción
--forceRebuild:# vdo start --name=my-vdo --forceRebuild
36.2.5.6. Eliminación de un volumen VDO creado sin éxito
Este procedimiento limpia un volumen VDO en un estado intermedio. Un volumen queda en un estado intermedio si se produce un fallo al crear el volumen. Esto puede ocurrir cuando, por ejemplo:
- El sistema se bloquea
- El poder falla
-
El administrador interrumpe un comando
vdo createen ejecución
Procedimiento
Para limpiar, elimine el volumen creado sin éxito con la opción
--force:# vdo remove --force --name=my-vdoLa opción
--forcees necesaria porque el administrador podría haber causado un conflicto al cambiar la configuración del sistema desde que se creó el volumen sin éxito.Sin la opción
--force, el comandovdo removefalla con el siguiente mensaje:[...] A previous operation failed. Recovery from the failure either failed or was interrupted. Add '--force' to 'remove' to perform the following cleanup. Steps to clean up VDO my-vdo: umount -f /dev/mapper/my-vdo udevadm settle dmsetup remove my-vdo vdo: ERROR - VDO volume my-vdo previous operation (create) is incomplete
36.2.6. Optimización del índice UDS
Puede configurar ciertos ajustes del índice UDS para optimizarlo en su sistema.
No se pueden cambiar las propiedades del índice UDS after creando el volumen VDO.
36.2.6.1. Componentes de un volumen VDO
VDO utiliza un dispositivo de bloque como almacén de respaldo, que puede incluir una agregación de almacenamiento físico consistente en uno o más discos, particiones o incluso archivos planos. Cuando una herramienta de gestión de almacenamiento crea un volumen VDO, VDO reserva espacio de volumen para el índice UDS y el volumen VDO. El índice UDS y el volumen VDO interactúan juntos para proporcionar almacenamiento de bloques deduplicado.
Figura 36.4. Organización del disco VDO
La solución de VDO consta de los siguientes componentes:
kvdoUn módulo del kernel que se carga en la capa de Linux Device Mapper proporciona un volumen de almacenamiento en bloque deduplicado, comprimido y con aprovisionamiento ligero.
El módulo
kvdoexpone un dispositivo de bloque. Puede acceder a este dispositivo de bloque directamente para el almacenamiento en bloque o presentarlo a través de un sistema de archivos Linux, como XFS o ext4.Cuando
kvdorecibe una solicitud para leer un bloque lógico de datos de un volumen VDO, mapea el bloque lógico solicitado al bloque físico subyacente y luego lee y devuelve los datos solicitados.Cuando
kvdorecibe una solicitud para escribir un bloque de datos en un volumen VDO, primero comprueba si la solicitud es una petición de DISCARD o TRIM o si los datos son uniformemente cero. Si cualquiera de estas condiciones es verdadera,kvdoactualiza su mapa de bloques y reconoce la solicitud. En caso contrario, VDO procesa y optimiza los datos.udsUn módulo del núcleo que se comunica con el índice del Servicio Universal de Deduplicación (UDS) en el volumen y analiza los datos en busca de duplicados. Para cada nueva pieza de datos, UDS determina rápidamente si esa pieza es idéntica a cualquier pieza de datos almacenada previamente. Si el índice encuentra una coincidencia, el sistema de almacenamiento puede entonces referenciar internamente el elemento existente para evitar almacenar la misma información más de una vez.
El índice UDS se ejecuta dentro del núcleo como el módulo del núcleo
uds.- Herramientas de línea de comandos
- Para configurar y gestionar el almacenamiento optimizado.
36.2.6.2. El índice UDS
VDO utiliza un índice de deduplicación de alto rendimiento llamado UDS para detectar bloques de datos duplicados mientras se almacenan.
El índice UDS constituye la base del producto VDO. Para cada nuevo dato, determina rápidamente si ese dato es idéntico a cualquier dato almacenado anteriormente. Si el índice encuentra una coincidencia, el sistema de almacenamiento puede entonces referenciar internamente el elemento existente para evitar almacenar la misma información más de una vez.
El índice UDS se ejecuta dentro del núcleo como el módulo del núcleo uds.
El deduplication window es el número de bloques escritos previamente que el índice recuerda. El tamaño de la ventana de deduplicación es configurable. Para un tamaño de ventana determinado, el índice requiere una cantidad específica de memoria RAM y una cantidad específica de espacio en disco. El tamaño de la ventana suele determinarse especificando el tamaño de la memoria del índice mediante la opción --indexMem=size. VDO determina entonces la cantidad de espacio en disco a utilizar automáticamente.
El índice UDS consta de dos partes:
- En la memoria se utiliza una representación compacta que contiene como máximo una entrada por bloque único.
- Un componente en el disco que registra los nombres de los bloques asociados presentados al índice a medida que se producen, en orden.
UDS utiliza una media de 4 bytes por entrada en memoria, incluyendo la caché.
El componente en disco mantiene un historial acotado de los datos pasados a UDS. UDS proporciona consejos de deduplicación para los datos que caen dentro de esta ventana de deduplicación, conteniendo los nombres de los bloques vistos más recientemente. La ventana de deduplicación permite a UDS indexar los datos de la forma más eficiente posible, limitando al mismo tiempo la cantidad de memoria necesaria para indexar grandes depósitos de datos. A pesar de la naturaleza limitada de la ventana de deduplicación, la mayoría de los conjuntos de datos que tienen altos niveles de deduplicación también muestran un alto grado de localidad temporal, es decir, la mayor parte de la deduplicación se produce entre conjuntos de bloques que fueron escritos aproximadamente al mismo tiempo. Además, en general, es más probable que los datos que se escriben dupliquen los que se escribieron recientemente que los que se escribieron hace mucho tiempo. Por lo tanto, para una carga de trabajo determinada en un intervalo de tiempo determinado, los índices de deduplicación serán a menudo los mismos si UDS indexa sólo los datos más recientes o todos los datos.
Dado que los datos duplicados tienden a mostrar una localización temporal, rara vez es necesario indexar cada bloque en el sistema de almacenamiento. Si no fuera así, el coste de la memoria de los índices superaría el ahorro de los costes de almacenamiento derivados de la deduplicación. Los requisitos de tamaño de los índices están más relacionados con la tasa de ingestión de datos. Por ejemplo, consideremos un sistema de almacenamiento con 100 TB de capacidad total pero con una tasa de ingestión de 1 TB por semana. Con una ventana de deduplicación de 4 TB, UDS puede detectar la mayor parte de la redundancia entre los datos escritos en el último mes.
36.2.6.3. Configuración recomendada del índice UDS
Esta sección describe las opciones recomendadas para utilizar con el índice UDS, según el caso de uso previsto.
En general, Red Hat recomienda utilizar un índice UDS sparse para todos los casos de uso en producción. Esta es una estructura de datos de indexación extremadamente eficiente, que requiere aproximadamente una décima parte de un byte de RAM por bloque en su ventana de deduplicación. En el disco, requiere aproximadamente 72 bytes de espacio de disco por bloque. La configuración mínima de este índice utiliza 256 MB de RAM y aproximadamente 25 GB de espacio en disco.
Para utilizar esta configuración, especifique las opciones de --sparseIndex=enabled --indexMem=0.25 al comando vdo create. Esta configuración da como resultado una ventana de deduplicación de 2,5 TB (lo que significa que recordará un historial de 2,5 TB). En la mayoría de los casos, una ventana de deduplicación de 2,5 TB es adecuada para deduplicar pools de almacenamiento de hasta 10 TB.
Sin embargo, la configuración por defecto del índice es utilizar un índice dense. Este índice es considerablemente menos eficiente (por un factor de 10) en la memoria RAM, pero tiene un espacio mínimo requerido en el disco mucho menor (también por un factor de 10), lo que lo hace más conveniente para la evaluación en entornos restringidos.
En general, una ventana de deduplicación que es un cuarto del tamaño físico de un volumen VDO es una configuración recomendada. Sin embargo, esto no es un requisito real. Incluso ventanas de deduplicación pequeñas (comparadas con la cantidad de almacenamiento físico) pueden encontrar cantidades significativas de datos duplicados en muchos casos de uso. También se pueden utilizar ventanas más grandes, pero en la mayoría de los casos, habrá poco beneficio adicional al hacerlo.
Recursos adicionales
- Hable con su representante del Gestor Técnico de Cuentas de Red Hat para obtener directrices adicionales sobre el ajuste de este importante parámetro del sistema.
36.2.7. Activar o desactivar la deduplicación en VDO
En algunos casos, es posible que desee desactivar temporalmente la deduplicación de los datos que se están escribiendo en un volumen VDO mientras se mantiene la capacidad de leer y escribir en el volumen. Desactivar la deduplicación impide que las escrituras posteriores se dedupliquen, pero los datos que ya estaban deduplicados siguen estándolo.
36.2.7.1. Deduplicación en VDO
La deduplicación es una técnica para reducir el consumo de recursos de almacenamiento mediante la eliminación de múltiples copias de bloques duplicados.
En lugar de escribir los mismos datos más de una vez, VDO detecta cada bloque duplicado y lo registra como una referencia al bloque original. VDO mantiene un mapeo de las direcciones lógicas de bloque, que son utilizadas por la capa de almacenamiento por encima de VDO, a las direcciones físicas de bloque, que son utilizadas por la capa de almacenamiento por debajo de VDO.
Después de la deduplicación, se pueden asignar múltiples direcciones de bloques lógicos a la misma dirección de bloque físico. Estos se denominan bloques compartidos. La compartición de bloques es invisible para los usuarios del almacenamiento, que leen y escriben bloques como lo harían si VDO no estuviera presente.
Cuando se sobrescribe un bloque compartido, VDO asigna un nuevo bloque físico para almacenar los datos del nuevo bloque, para garantizar que no se modifiquen otras direcciones de bloques lógicos que están asignadas al bloque físico compartido.
36.2.7.2. Activación de la deduplicación en un volumen VDO
Este procedimiento reinicia el índice UDS asociado e informa al volumen VDO de que la deduplicación vuelve a estar activa.
La deduplicación está activada por defecto.
Procedimiento
Para reiniciar la deduplicación en un volumen VDO, utilice el siguiente comando:
# vdo enableDeduplication --name=my-vdo
36.2.7.3. Desactivación de la deduplicación en un volumen VDO
Este procedimiento detiene el índice UDS asociado e informa al volumen VDO de que la deduplicación ya no está activa.
Procedimiento
Para detener la deduplicación en un volumen VDO, utilice el siguiente comando:
# vdo disableDeduplication --name=my-vdo-
También puede desactivar la deduplicación al crear un nuevo volumen VDO añadiendo la opción
--deduplication=disabledal comandovdo create.
36.2.8. Activar o desactivar la compresión en VDO
VDO proporciona compresión de datos. Puede desactivarla para maximizar el rendimiento o para acelerar el procesamiento de datos que probablemente no se compriman, o volver a activarla para aumentar el ahorro de espacio.
36.2.8.1. Compresión en VDO
Además de la deduplicación a nivel de bloque, VDO también proporciona compresión en línea a nivel de bloque utilizando la tecnología HIOPS Compression™.
La compresión de volumen VDO está activada por defecto.
Mientras que la deduplicación es la solución óptima para entornos de máquinas virtuales y aplicaciones de copia de seguridad, la compresión funciona muy bien con formatos de archivo estructurados y no estructurados que no suelen presentar redundancia a nivel de bloque, como los archivos de registro y las bases de datos.
La compresión opera sobre bloques que no han sido identificados como duplicados. Cuando VDO ve datos únicos por primera vez, los comprime. Las copias posteriores de los datos que ya han sido almacenados se deduplican sin requerir un paso adicional de compresión.
La función de compresión se basa en un algoritmo de empaquetamiento paralelizado que permite manejar muchas operaciones de compresión a la vez. Después de almacenar primero el bloque y responder al solicitante, un algoritmo de empaquetamiento de mejor ajuste encuentra múltiples bloques que, cuando se comprimen, pueden caber en un solo bloque físico. Cuando se determina que es improbable que un bloque físico concreto contenga más bloques comprimidos, se escribe en el almacenamiento y los bloques no comprimidos se liberan y se reutilizan.
Al realizar las operaciones de compresión y empaquetado después de haber respondido al solicitante, el uso de la compresión impone una penalización de latencia mínima.
36.2.8.2. Activación de la compresión en un volumen VDO
Este procedimiento permite la compresión en un volumen VDO para aumentar el ahorro de espacio.
La compresión está activada por defecto.
Procedimiento
Para iniciarlo de nuevo, utilice el siguiente comando:
# vdo enableCompression --name=my-vdo
36.2.8.3. Desactivación de la compresión en un volumen VDO
Este procedimiento detiene la compresión en un volumen VDO para maximizar el rendimiento o para acelerar el procesamiento de datos que probablemente no se compriman.
Procedimiento
Para detener la compresión en un volumen VDO existente, utilice el siguiente comando:
# vdo disableCompression --name=my-vdo-
Como alternativa, puede desactivar la compresión añadiendo la opción
--compression=disabledal comandovdo createcuando cree un nuevo volumen.
36.2.9. Aumentar el tamaño de un volumen VDO
Puede aumentar el tamaño físico de un volumen VDO para utilizar más capacidad de almacenamiento subyacente, o el tamaño lógico para proporcionar más capacidad en el volumen.
36.2.9.1. El tamaño físico y lógico de un volumen VDO
Esta sección describe el tamaño físico, el tamaño físico disponible y el tamaño lógico que puede utilizar VDO:
- Tamaño físico
Este es el mismo tamaño que el dispositivo de bloque subyacente. VDO utiliza este almacenamiento para:
- Los datos de los usuarios, que pueden estar deduplicados y comprimidos
- Metadatos VDO, como el índice UDS
- Tamaño físico disponible
Es la parte del tamaño físico que VDO puede utilizar para los datos del usuario
Equivale al tamaño físico menos el tamaño de los metadatos, menos el resto tras dividir el volumen en losas por el tamaño de losa dado.
- Tamaño lógico
Es el tamaño provisionado que el volumen VDO presenta a las aplicaciones. Normalmente es mayor que el tamaño físico disponible. Si no se especifica la opción
--vdoLogicalSize, entonces el aprovisionamiento del volumen lógico se aprovisiona en una proporción de1:1. Por ejemplo, si se coloca un volumen VDO sobre un dispositivo de bloques de 20 GB, entonces se reservan 2,5 GB para el índice UDS (si se utiliza el tamaño de índice por defecto). Los 17,5 GB restantes se destinan a los metadatos de VDO y a los datos del usuario. Como resultado, el almacenamiento disponible para consumir no es más de 17,5 GB, y puede ser menos debido a los metadatos que componen el volumen VDO real.Actualmente, VDO admite cualquier tamaño lógico hasta 254 veces el tamaño del volumen físico, con un tamaño lógico máximo absoluto de 4PB.
Figura 36.5. Organización del disco VDO
En esta figura, el objetivo de almacenamiento deduplicado VDO se sitúa completamente sobre el dispositivo de bloque, lo que significa que el tamaño físico del volumen VDO es del mismo tamaño que el dispositivo de bloque subyacente.
Recursos adicionales
- Para obtener más información sobre la cantidad de almacenamiento que requieren los metadatos VDO en dispositivos de bloque de diferentes tamaños, consulte Sección 36.1.6.4, “Ejemplos de requisitos VDO por tamaño físico”.
36.2.9.2. Aprovisionamiento ligero en VDO
VDO es un objetivo de almacenamiento en bloque con aprovisionamiento ligero. La cantidad de espacio físico que utiliza un volumen VDO puede diferir del tamaño del volumen que se presenta a los usuarios del almacenamiento. Puede aprovechar esta disparidad para ahorrar en costes de almacenamiento.
Condiciones fuera del espacio
Tenga cuidado para evitar quedarse sin espacio de almacenamiento de forma inesperada, si los datos escritos no alcanzan la tasa de optimización esperada.
Cuando el número de bloques lógicos (almacenamiento virtual) supera el número de bloques físicos (almacenamiento real), es posible que los sistemas de archivos y las aplicaciones se queden inesperadamente sin espacio. Por esta razón, los sistemas de almacenamiento que utilizan VDO deben proporcionarle una forma de controlar el tamaño del pool libre en el volumen VDO.
Puede determinar el tamaño de este pool libre utilizando la utilidad vdostats. La salida por defecto de esta utilidad lista la información de todos los volúmenes VDO en ejecución en un formato similar al de la utilidad de Linux df. Por ejemplo:
Device 1K-blocks Used Available Use%
/dev/mapper/vdo-name 211812352 105906176 105906176 50%Cuando la capacidad de almacenamiento físico de un volumen VDO está casi llena, VDO informa de una advertencia en el registro del sistema, similar a la siguiente:
Oct 2 17:13:39 system lvm[13863]: Monitoring VDO pool vdo-name.
Oct 2 17:27:39 system lvm[13863]: WARNING: VDO pool vdo-name is now 80.69% full.
Oct 2 17:28:19 system lvm[13863]: WARNING: VDO pool vdo-name is now 85.25% full.
Oct 2 17:29:39 system lvm[13863]: WARNING: VDO pool vdo-name is now 90.64% full.
Oct 2 17:30:29 system lvm[13863]: WARNING: VDO pool vdo-name is now 96.07% full.
Estos mensajes de advertencia sólo aparecen cuando el servicio lvm2-monitor está en funcionamiento. Está activado por defecto.
Cómo prevenir las condiciones de fuera del espacio
Si el tamaño de la piscina libre desciende por debajo de un determinado nivel, puedes actuar:
- Eliminación de datos. Esto recupera espacio siempre que los datos borrados no se dupliquen. El borrado de datos libera el espacio sólo después de los descartes.
- Añadir almacenamiento físico
Supervise el espacio físico en sus volúmenes VDO para evitar situaciones de falta de espacio. Quedarse sin bloques físicos podría resultar en la pérdida de datos recientemente escritos y no reconocidos en el volumen VDO.
Aprovisionamiento delgado y los comandos TRIM y DISCARD
Para beneficiarse del ahorro de almacenamiento que supone el thin provisioning, la capa de almacenamiento físico necesita saber cuándo se eliminan los datos. Los sistemas de archivos que trabajan con el almacenamiento thinly provisioned envían comandos TRIM o DISCARD para informar al sistema de almacenamiento cuando un bloque lógico ya no es necesario.
Existen varios métodos para enviar los comandos TRIM o DISCARD:
-
Con la opción de montaje
discard, los sistemas de archivos pueden enviar estos comandos cada vez que se elimina un bloque. -
Puede enviar los comandos de forma controlada utilizando utilidades como
fstrim. Estas utilidades le dicen al sistema de archivos que detecte los bloques lógicos que no se utilizan y que envíe la información al sistema de almacenamiento en forma de comandoTRIMoDISCARD.
La necesidad de utilizar TRIM o DISCARD en los bloques no utilizados no es exclusiva de VDO. Cualquier sistema de almacenamiento con aprovisionamiento ligero tiene el mismo reto.
36.2.9.3. Aumentar el tamaño lógico de un volumen VDO
Este procedimiento aumenta el tamaño lógico de un determinado volumen VDO. Le permite crear inicialmente volúmenes VDO que tienen un tamaño lógico lo suficientemente pequeño como para estar a salvo de quedarse sin espacio. Después de algún tiempo, puede evaluar la tasa real de reducción de datos, y si es suficiente, puede aumentar el tamaño lógico del volumen VDO para aprovechar el ahorro de espacio.
No es posible disminuir el tamaño lógico de un volumen VDO.
Procedimiento
Para aumentar el tamaño lógico, utilice:
# vdo growLogical --name=my-vdo \ --vdoLogicalSize=new-logical-sizeCuando el tamaño lógico aumenta, VDO informa a cualquier dispositivo o sistema de archivos que se encuentre sobre el volumen del nuevo tamaño.
36.2.9.4. Aumentar el tamaño físico de un volumen VDO
Este procedimiento aumenta la cantidad de almacenamiento físico disponible para un volumen VDO.
No es posible reducir un volumen VDO de esta manera.
Requisitos previos
El dispositivo de bloque subyacente tiene una capacidad mayor que el tamaño físico actual del volumen VDO.
Si no lo hace, puede intentar aumentar el tamaño del dispositivo. El procedimiento exacto depende del tipo de dispositivo. Por ejemplo, para redimensionar una partición MBR o GPT, consulte la sección Redimensionar una partición en la guía Managing storage devices.
Procedimiento
Añade el nuevo espacio de almacenamiento físico al volumen VDO:
# vdo growPhysical --name=my-vdo
36.2.10. Eliminación de volúmenes VDO
Puede eliminar un volumen VDO existente en su sistema.
36.2.10.1. Eliminación de un volumen VDO en funcionamiento
Este procedimiento elimina un volumen VDO y su índice UDS asociado.
Procedimiento
- Desmonte los sistemas de archivos y detenga las aplicaciones que están utilizando el almacenamiento en el volumen VDO.
Para eliminar el volumen VDO de su sistema, utilice:
# vdo remove --name=my-vdo
36.2.10.2. Eliminación de un volumen VDO creado sin éxito
Este procedimiento limpia un volumen VDO en un estado intermedio. Un volumen queda en un estado intermedio si se produce un fallo al crear el volumen. Esto puede ocurrir cuando, por ejemplo:
- El sistema se bloquea
- El poder falla
-
El administrador interrumpe un comando
vdo createen ejecución
Procedimiento
Para limpiar, elimine el volumen creado sin éxito con la opción
--force:# vdo remove --force --name=my-vdoLa opción
--forcees necesaria porque el administrador podría haber causado un conflicto al cambiar la configuración del sistema desde que se creó el volumen sin éxito.Sin la opción
--force, el comandovdo removefalla con el siguiente mensaje:[...] A previous operation failed. Recovery from the failure either failed or was interrupted. Add '--force' to 'remove' to perform the following cleanup. Steps to clean up VDO my-vdo: umount -f /dev/mapper/my-vdo udevadm settle dmsetup remove my-vdo vdo: ERROR - VDO volume my-vdo previous operation (create) is incomplete
36.3. Descartar los bloques no utilizados
Puede realizar o programar operaciones de descarte en los dispositivos de bloque que las admitan.
36.3.1. Operaciones de descarte de bloques
Las operaciones de descarte de bloques descartan los bloques que ya no están en uso por un sistema de archivos montado. Son útiles en:
- Unidades de estado sólido (SSD)
- Almacenamiento con aprovisionamiento ligero
Requisitos
El dispositivo de bloque subyacente al sistema de archivos debe soportar operaciones de descarte físico.
Las operaciones de descarte físico se admiten si el valor del /sys/block/device/queue/discard_max_bytes es distinto de cero.
36.3.2. Tipos de operaciones de descarte de bloques
Se pueden ejecutar operaciones de descarte utilizando diferentes métodos:
- Descarte de lotes
- Son ejecutadas explícitamente por el usuario. Descartan todos los bloques no utilizados en los sistemas de archivos seleccionados.
- Descarte en línea
- Se especifican en el momento del montaje. Se ejecutan en tiempo real sin intervención del usuario. Las operaciones de descarte en línea sólo descartan los bloques que están pasando de usados a libres.
- Descarte periódico
-
Son operaciones por lotes que son ejecutadas regularmente por un servicio de
systemd.
Todos los tipos son compatibles con los sistemas de archivos XFS y ext4 y con VDO.
Recomendaciones
Red Hat recomienda utilizar el descarte por lotes o periódico.
Utilice el descarte en línea sólo si:
- la carga de trabajo del sistema es tal que el descarte por lotes no es factible, o
- las operaciones de descarte en línea son necesarias para mantener el rendimiento.
36.3.3. Realizar el descarte de bloques por lotes
Este procedimiento realiza una operación de descarte de bloques por lotes para descartar los bloques no utilizados en un sistema de archivos montado.
Requisitos previos
- El sistema de archivos está montado.
- El dispositivo de bloques subyacente al sistema de archivos admite operaciones de descarte físico.
Procedimiento
Utilice la utilidad
fstrim:Para realizar el descarte sólo en un sistema de archivos seleccionado, utilice:
# fstrim mount-pointPara realizar el descarte en todos los sistemas de archivos montados, utilice:
# fstrim --all
Si ejecuta el comando fstrim en:
- un dispositivo que no admite operaciones de descarte, o
- un dispositivo lógico (LVM o MD) compuesto por múltiples dispositivos, donde cualquiera de ellos no soporta operaciones de descarte,
aparece el siguiente mensaje:
# fstrim /mnt/non_discard
fstrim: /mnt/non_discard: the discard operation is not supportedRecursos adicionales
-
La página de manual
fstrim(8)
36.3.4. Activación del descarte de bloques en línea
Este procedimiento permite realizar operaciones de descarte de bloques en línea que descartan automáticamente los bloques no utilizados en todos los sistemas de archivos compatibles.
Procedimiento
Activar el descarte en línea en el momento del montaje:
Al montar un sistema de archivos manualmente, añada la opción de montaje
-o discard:# mount -o discard device mount-point-
Al montar un sistema de archivos de forma persistente, añada la opción
discarda la entrada de montaje en el archivo/etc/fstab.
Recursos adicionales
-
La página de manual
mount(8) -
La página de manual
fstab(5)
36.3.5. Habilitación del descarte de bloques en línea mediante RHEL System Roles
Esta sección describe cómo habilitar el descarte de bloques en línea utilizando el rol storage.
Requisitos previos
-
Existe un playbook de Ansible que incluye el rol
storage.
Para obtener información sobre cómo aplicar un libro de jugadas de este tipo, consulte Aplicar un rol.
36.3.5.1. Ejemplo de libro de jugadas de Ansible para activar el descarte de bloques en línea
Esta sección proporciona un ejemplo de libro de jugadas de Ansible. Este libro de jugadas aplica el rol storage para montar un sistema de archivos XFS con el descarte de bloques en línea activado.
Ejemplo 36.2. Un libro de jugadas que permite descartar bloques en línea en /mnt/data/
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: xfs
mount_point: /mnt/data
mount_options: discard
roles:
- rhel-system-roles.storageRecursos adicionales
- Este libro de jugadas también realiza todas las operaciones del ejemplo de montaje persistente descrito en Ejemplo de libro de jugadas de Ansible para montar persistentemente un sistema de archivos.
-
Para más detalles sobre los parámetros utilizados en el rol de sistema
storage, consulte el archivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
36.3.6. Activación del descarte periódico de bloques
Este procedimiento habilita un temporizador systemd que descarta regularmente los bloques no utilizados en todos los sistemas de archivos compatibles.
Procedimiento
Activar e iniciar el temporizador
systemd:# systemctl enable --now fstrim.timer
36.4. Uso de la consola web para gestionar los volúmenes del Optimizador de Datos Virtual
Configure el optimizador de datos virtual (VDO) mediante la consola web de RHEL 8.
Aprenderás a:
- Crear volúmenes VDO
- Formato de volúmenes VDO
- Ampliar los volúmenes de VDO
Requisitos previos
La consola web de RHEL 8 está instalada y accesible.
Para más detalles, véase Instalación de la consola web.
-
El paquete
cockpit-storagedestá instalado en su sistema.
36.4.1. Volúmenes VDO en la consola web
Red Hat Enterprise Linux 8 soporta Virtual Data Optimizer (VDO).
VDO es una tecnología de virtualización de bloques que combina:
- Compresión
- Para más detalles, consulte Activar o desactivar la compresión en VDO.
- Deduplicación
- Para más detalles, consulte Activar o desactivar la deduplicación en VDO.
- Aprovisionamiento ligero
- Para más detalles, consulte Volúmenes lógicos de aprovisionamiento fino (volúmenes finos).
Gracias a estas tecnologías, VDO:
- Ahorra espacio de almacenamiento en línea
- Comprime los archivos
- Elimina las duplicaciones
- Permite asignar más espacio virtual que el que proporciona el almacenamiento físico o lógico
- Permite ampliar el almacenamiento virtual mediante el crecimiento
VDO puede crearse sobre muchos tipos de almacenamiento. En la consola web de RHEL 8, puede configurar VDO sobre:
LVM
NotaNo es posible configurar VDO sobre volúmenes de aprovisionamiento ligero.
- Volumen físico
- RAID por software
Para más detalles sobre la colocación de VDO en la pila de almacenamiento, véase Requisitos del sistema.
36.4.2. Creación de volúmenes VDO en la consola web
Cree un volumen VDO en la consola web de RHEL.
Requisitos previos
- Unidades físicas, LVMs, o RAID de las que se quiere crear VDO.
Procedimiento
Inicie sesión en la consola web de RHEL 8.
Para más detalles, consulte Iniciar sesión en la consola web.
- Haga clic en Storage.
Haga clic en el icono en el cuadro VDO Devices.
- En el campo Name, introduzca el nombre de un volumen VDO sin espacios.
- Seleccione la unidad que desea utilizar.
En la barra Logical Size, configure el tamaño del volumen VDO. Puede ampliarlo más de diez veces, pero tenga en cuenta con qué fin está creando el volumen VDO:
- Para las máquinas virtuales activas o el almacenamiento en contenedores, utilice un tamaño lógico diez veces superior al tamaño físico del volumen.
- Para el almacenamiento de objetos, utilice un tamaño lógico que sea tres veces el tamaño físico del volumen.
Para más detalles, véase Despliegue de VDO.
En la barra Index Memory, asigne memoria para el volumen VDO.
Para más detalles sobre los requisitos del sistema VDO, consulte Requisitos del sistema.
Seleccione la opción Compression. Esta opción puede reducir eficazmente varios formatos de archivo.
Para más detalles, consulte Activar o desactivar la compresión en VDO.
Seleccione la opción Deduplication.
Esta opción reduce el consumo de recursos de almacenamiento al eliminar múltiples copias de bloques duplicados. Para más detalles, consulte Activar o desactivar la deduplicación en VDO.
- Opcional] Si desea utilizar el volumen VDO con aplicaciones que necesitan un tamaño de bloque de 512 bytes, seleccione Use 512 Byte emulation. Esto reduce el rendimiento del volumen VDO, pero debería ser necesario muy raramente. En caso de duda, déjelo desactivado.
Haga clic en Create.
Si el proceso de creación del volumen VDO tiene éxito, puede ver el nuevo volumen VDO en la sección Storage y formatearlo con un sistema de archivos.
36.4.3. Formateo de volúmenes VDO en la consola web
Los volúmenes VDO actúan como unidades físicas. Para utilizarlos, es necesario formatearlos con un sistema de archivos.
El formateo de VDO borrará todos los datos del volumen.
Los siguientes pasos describen el procedimiento para formatear volúmenes VDO.
Requisitos previos
- Se crea un volumen VDO. Para más detalles, consulte Creación de volúmenes VDO en la consola web.
Procedimiento
Inicie sesión en la consola web de RHEL 8.
Para más detalles, consulte Iniciar sesión en la consola web.
- Haga clic en Storage.
- Haz clic en el volumen VDO.
- Haga clic en la pestaña Unrecognized Data.
Haga clic en Format.

En el menú desplegable Erase, seleccione:
- Don’t overwrite existing data
- La consola web de RHEL sólo reescribe la cabecera del disco. La ventaja de esta opción es la velocidad de formateo.
- Overwrite existing data with zeros
- La consola web de RHEL reescribe todo el disco con ceros. Esta opción es más lenta porque el programa tiene que recorrer todo el disco. Utilice esta opción si el disco incluye algún dato y necesita reescribirlo.
En el menú desplegable Type, seleccione un sistema de archivos:
El sistema de archivos XFS soporta grandes volúmenes lógicos, el cambio de unidades físicas en línea sin interrupción, y el crecimiento. Deje este sistema de archivos seleccionado si no tiene una preferencia fuerte diferente.
XFS no admite la reducción de volúmenes. Por lo tanto, no podrá reducir el volumen formateado con XFS.
- El sistema de archivos ext4 admite volúmenes lógicos, el cambio de unidades físicas en línea sin interrupción, el crecimiento y la reducción.
También puede seleccionar una versión con el cifrado LUKS (Linux Unified Key Setup), que le permite cifrar el volumen con una frase de contraseña.
- En el campo Name, introduzca el nombre del volumen lógico.
En el menú desplegable Mounting, seleccione Custom.
La opción Default no asegura que el sistema de archivos se monte en el siguiente arranque.
- En el campo Mount Point, añada la ruta de montaje.
Seleccione Mount at boot.

Haga clic en Format.
El formateo puede tardar varios minutos dependiendo de las opciones de formateo utilizadas y del tamaño del volumen.
Después de terminar con éxito, puede ver los detalles del volumen VDO formateado en la pestaña Filesystem.

- Para utilizar el volumen VDO, haga clic en Mount.
En este punto, el sistema utiliza el volumen VDO montado y formateado.
36.4.4. Ampliación de volúmenes VDO en la consola web
Ampliar los volúmenes VDO en la consola web de RHEL 8.
Requisitos previos
-
El paquete
cockpit-storagedestá instalado en su sistema. - El volumen VDO creado.
Procedimiento
Inicie sesión en la consola web de RHEL 8.
Para más detalles, consulte Iniciar sesión en la consola web.
- Haga clic en Storage.
Haga clic en su volumen VDO en el cuadro VDO Devices.
- En los detalles del volumen VDO, haga clic en el botón Grow.
En el cuadro de diálogo Grow logical size of VDO, amplíe el tamaño lógico del volumen VDO.
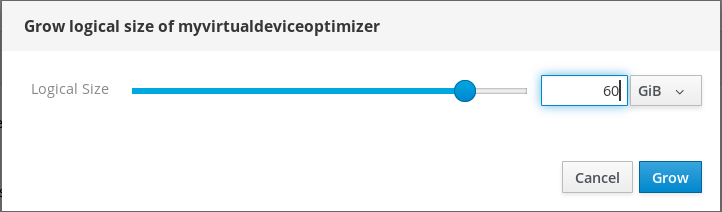
El tamaño original del volumen lógico de la captura de pantalla era de 6 GB. Como puede ver, la consola web de RHEL le permite hacer crecer el volumen a más de diez veces el tamaño y funciona correctamente debido a la compresión y deduplicación.
- Haga clic en Grow.
Si el proceso de crecimiento de VDO tiene éxito, puede ver el nuevo tamaño en los detalles del volumen VDO.
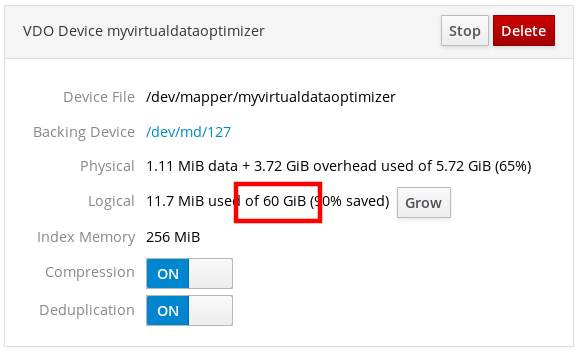
Parte V. Diseño del archivo de registro
Capítulo 37. Auditoría del sistema
La auditoría no proporciona seguridad adicional a su sistema; más bien, puede utilizarse para descubrir violaciones de las políticas de seguridad utilizadas en su sistema. Estas violaciones pueden evitarse además con medidas de seguridad adicionales como SELinux.
37.1. Auditoría Linux
El sistema de Auditoría de Linux proporciona una manera de rastrear la información relevante para la seguridad en su sistema. Basado en reglas preconfiguradas, Audit genera entradas de registro para registrar tanta información como sea posible sobre los eventos que están ocurriendo en su sistema. Esta información es crucial para que los entornos de misión crítica puedan determinar quién ha violado la política de seguridad y las acciones que ha realizado.
La siguiente lista resume parte de la información que Audit es capaz de registrar en sus archivos de registro:
- Fecha y hora, tipo y resultado de un evento.
- Etiquetas de sensibilidad de sujetos y objetos.
- Asociación de un evento con la identidad del usuario que lo ha provocado.
- Todas las modificaciones de la configuración de Auditoría y los intentos de acceso a los archivos de registro de Auditoría.
- Todos los usos de los mecanismos de autenticación, como SSH, Kerberos y otros.
-
Cambios en cualquier base de datos de confianza, como
/etc/passwd. - Intentos de importar o exportar información hacia o desde el sistema.
- Incluya o excluya eventos en función de la identidad del usuario, las etiquetas de sujetos y objetos, y otros atributos.
El uso del sistema Audit también es un requisito para una serie de certificaciones relacionadas con la seguridad. Audit está diseñado para cumplir o superar los requisitos de las siguientes certificaciones o guías de cumplimiento:
- Perfil de protección de acceso controlado (CAPP)
- Perfil de protección de seguridad etiquetado (LSPP)
- Control de acceso basado en conjuntos de reglas (RSBAC)
- Manual operativo del Programa Nacional de Seguridad Industrial (NISPOM)
- Ley Federal de Gestión de la Seguridad de la Información (FISMA)
- Industria de las tarjetas de pago
- Guías técnicas de aplicación de la seguridad (STIG)
La auditoría también lo ha sido:
- Evaluado por National Information Assurance Partnership (NIAP) y Best Security Industries (BSI).
- Certificado para LSPP/CAPP/RSBAC/EAL4 en Red Hat Enterprise Linux 5.
- Certificado para el Perfil de Protección del Sistema Operativo / Nivel de Garantía de Evaluación 4 (OSPP/EAL4 ) en Red Hat Enterprise Linux 6.
Casos de uso
- Vigilancia del acceso a los archivos
- La auditoría puede rastrear si se ha accedido a un archivo o a un directorio, si se ha modificado, si se ha ejecutado o si se han cambiado los atributos del archivo. Esto es útil, por ejemplo, para detectar el acceso a archivos importantes y tener un rastro de Auditoría disponible en caso de que uno de estos archivos se corrompa.
- Supervisión de las llamadas del sistema
-
La auditoría puede configurarse para generar una entrada de registro cada vez que se utiliza una llamada del sistema en particular. Esto puede utilizarse, por ejemplo, para rastrear los cambios en la hora del sistema mediante la supervisión de las llamadas al sistema
settimeofday,clock_adjtime, y otras relacionadas con la hora. - Grabación de los comandos ejecutados por un usuario
-
La auditoría puede rastrear si un archivo ha sido ejecutado, por lo que se pueden definir reglas para registrar cada ejecución de un comando en particular. Por ejemplo, se puede definir una regla para cada ejecutable en el directorio
/bin. Las entradas de registro resultantes pueden buscarse por ID de usuario para generar un registro de auditoría de los comandos ejecutados por usuario. - Grabación de la ejecución de los nombres de ruta del sistema
- Además de vigilar el acceso a los archivos que traduce una ruta a un inodo en la invocación de la regla, Auditoría puede ahora vigilar la ejecución de una ruta incluso si no existe en el momento de la invocación de la regla, o si el archivo es reemplazado después de la invocación de la regla. Esto permite que las reglas sigan funcionando después de actualizar el ejecutable de un programa o incluso antes de instalarlo.
- Registro de eventos de seguridad
-
El módulo de autenticación
pam_faillockes capaz de registrar los intentos fallidos de inicio de sesión. La auditoría puede configurarse para registrar también los intentos de inicio de sesión fallidos y proporciona información adicional sobre el usuario que intentó iniciar sesión. - Búsqueda de eventos
-
Audit proporciona la utilidad
ausearch, que se puede utilizar para filtrar las entradas del registro y proporcionar una pista de auditoría completa basada en varias condiciones. - Ejecución de informes de síntesis
-
La utilidad
aureportpuede utilizarse para generar, entre otras cosas, informes diarios de los eventos registrados. Un administrador del sistema puede entonces analizar estos informes e investigar más a fondo las actividades sospechosas. - Supervisión del acceso a la red
-
Las utilidades
iptablesyebtablespueden ser configuradas para desencadenar eventos de Auditoría, permitiendo a los administradores del sistema monitorear el acceso a la red.
El rendimiento del sistema puede verse afectado en función de la cantidad de información que recoja la Auditoría.
37.2. Arquitectura del sistema de auditoría
El sistema de auditoría consta de dos partes principales: las aplicaciones y utilidades del espacio de usuario y el procesamiento de las llamadas al sistema del lado del núcleo. El componente del núcleo recibe las llamadas al sistema de las aplicaciones del espacio del usuario y las filtra a través de uno de los siguientes filtros: user, task, fstype, o exit.
Una vez que una llamada al sistema pasa el filtro exclude, es enviada a través de uno de los filtros mencionados, el cual, basado en la configuración de la regla de Auditoría, la envía al demonio de Auditoría para su posterior procesamiento.
El demonio de Auditoría del espacio de usuario recoge la información del kernel y crea entradas en un archivo de registro. Otras utilidades de espacio de usuario de Auditoría interactúan con el demonio de Auditoría, el componente de Auditoría del kernel o los archivos de registro de Auditoría:
-
auditctl -
El resto de las utilidades de Auditoría toman el contenido de los archivos de registro de Auditoría como entrada y generan una salida basada en los requerimientos del usuario. Por ejemplo, la utilidad
aureportgenera un informe de todos los eventos registrados.
En RHEL 8, la funcionalidad del demonio despachador de Auditoría (audisp) está integrada en el demonio de Auditoría (auditd). Los archivos de configuración de los plugins para la interacción de los programas analíticos en tiempo real con los eventos de Audit se encuentran por defecto en el directorio /etc/audit/plugins.d/.
37.3. Configuración de auditd para un entorno seguro
La configuración por defecto de auditd debería ser adecuada para la mayoría de los entornos. Sin embargo, si su entorno tiene que cumplir con políticas de seguridad estrictas, se sugieren los siguientes ajustes para la configuración del demonio de auditoría en el archivo /etc/audit/auditd.conf:
- archivo_de_registro
-
El directorio que contiene los archivos de registro de Auditoría (normalmente
/var/log/audit/) debería residir en un punto de montaje separado. Esto evita que otros procesos consuman espacio en este directorio y proporciona una detección precisa del espacio restante para el demonio de Auditoría. - archivo_de_registro_máximo
- Especifica el tamaño máximo de un solo archivo de registro de Auditoría, debe establecerse para hacer uso completo del espacio disponible en la partición que contiene los archivos de registro de Auditoría.
- max_log_file_action
-
Decide qué acción se lleva a cabo una vez que se alcanza el límite establecido en
max_log_file, debería establecerse enkeep_logspara evitar que se sobrescriban los archivos de registro de auditoría. - espacio_izquierdo
-
Especifica la cantidad de espacio libre que queda en el disco para que se active una acción establecida en el parámetro
space_left_action. Debe establecerse un número que dé al administrador tiempo suficiente para responder y liberar espacio en el disco. El valor despace_leftdepende de la velocidad a la que se generan los archivos de registro de auditoría. - acción_espacio_izquierda
-
Se recomienda establecer el parámetro
space_left_actionenemailoexeccon un método de notificación apropiado. - espacio_administrador_izquierdo
-
Especifica la cantidad mínima absoluta de espacio libre para la cual se desencadena una acción establecida en el parámetro
admin_space_left_action, debe establecerse en un valor que deje suficiente espacio para registrar las acciones realizadas por el administrador. - admin_space_left_action
-
Se debe establecer en
singlepara poner el sistema en modo monopuesto y permitir al administrador liberar algo de espacio en el disco. - disk_full_action
-
Especifica una acción que se desencadena cuando no hay espacio libre disponible en la partición que contiene los archivos de registro de Auditoría, debe establecerse en
haltosingle. Esto asegura que el sistema se apague o funcione en modo monopuesto cuando Audit no pueda registrar más eventos. - acción_error_disco
-
Especifica una acción que se desencadena en caso de que se detecte un error en la partición que contiene los archivos de registro de auditoría, debe establecerse en
syslog,single, ohalt, dependiendo de sus políticas locales de seguridad en relación con el manejo de los fallos de hardware. - descarga
-
Debe establecerse en
incremental_async. Funciona en combinación con el parámetrofreq, que determina cuántos registros pueden enviarse al disco antes de forzar una sincronización con el disco duro. El parámetrofreqdebe ajustarse a100. Estos parámetros aseguran que los datos de los eventos de Auditoría estén sincronizados con los archivos de registro en el disco, manteniendo un buen rendimiento para las ráfagas de actividad.
El resto de las opciones de configuración deben establecerse de acuerdo con su política de seguridad local.
37.4. Inicio y control de la auditoría
Una vez configurado auditd, inicie el servicio para recoger la información de auditoría y almacenarla en los archivos de registro. Utiliza el siguiente comando como usuario root para iniciar auditd:
# service auditd start
Para configurar auditd para que se inicie en el momento del arranque:
# systemctl enable auditd
Se pueden realizar otras acciones en auditd utilizando el comando service auditd action donde action puede ser uno de los siguientes:
stop-
Para
auditd. restart-
Reinicia
auditd. reloadoforce-reload-
Recarga la configuración de
auditddesde el archivo/etc/audit/auditd.conf. rotate-
Rota los archivos de registro en el directorio
/var/log/audit/. resume- Reanuda el registro de eventos de Auditoría después de haber sido suspendido previamente, por ejemplo, cuando no hay suficiente espacio libre en la partición del disco que contiene los archivos de registro de Auditoría.
condrestartotry-restart-
Reinicia
auditdsólo si ya está en marcha. status-
Muestra el estado de funcionamiento de
auditd.
El comando service es la única manera de interactuar correctamente con el demonio auditd. Es necesario utilizar el comando service para que el valor de auid se registre correctamente. Puede utilizar el comando systemctl sólo para dos acciones: enable y status.
37.5. Comprensión de los archivos de registro de auditoría
Por defecto, el sistema de Auditoría almacena las entradas de registro en el archivo /var/log/audit/audit.log; si se activa la rotación de registros, los archivos audit.log rotados se almacenan en el mismo directorio.
Añada la siguiente regla de auditoría para registrar cada intento de lectura o modificación del archivo /etc/ssh/sshd_config:
# auditctl -w /etc/ssh/sshd_config -p warx -k sshd_config
Si el demonio auditd se está ejecutando, por ejemplo, el siguiente comando crea un nuevo evento en el archivo de registro de auditoría:
$ cat /etc/ssh/sshd_config
Este evento en el archivo audit.log tiene el siguiente aspecto:
type=SYSCALL msg=audit(1364481363.243:24287): arch=c000003e syscall=2 success=no exit=-13 a0=7fffd19c5592 a1=0 a2=7fffd19c4b50 a3=a items=1 ppid=2686 pid=3538 auid=1000 uid=1000 gid=1000 euid=1000 suid=1000 fsuid=1000 egid=1000 sgid=1000 fsgid=1000 tty=pts0 ses=1 comm="cat" exe="/bin/cat" subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 key="sshd_config"
type=CWD msg=audit(1364481363.243:24287): cwd="/home/shadowman"
type=PATH msg=audit(1364481363.243:24287): item=0 name="/etc/ssh/sshd_config" inode=409248 dev=fd:00 mode=0100600 ouid=0 ogid=0 rdev=00:00 obj=system_u:object_r:etc_t:s0 nametype=NORMAL cap_fp=none cap_fi=none cap_fe=0 cap_fver=0
type=PROCTITLE msg=audit(1364481363.243:24287) : proctitle=636174002F6574632F7373682F737368645F636F6E666967
El evento anterior consta de cuatro registros, que comparten el mismo sello de tiempo y número de serie. Los registros siempre comienzan con la palabra clave type=. Cada registro consta de varios name=value pares separados por un espacio en blanco o una coma. A continuación se presenta un análisis detallado del suceso anterior:
Primer disco
type=SYSCALL-
El campo
typecontiene el tipo de registro. En este ejemplo, el valorSYSCALLespecifica que este registro fue activado por una llamada del sistema al kernel.
msg=audit(1364481363.243:24287):El campo
msgregistra:-
un sello de tiempo y un ID único del registro en la forma
audit(time_stamp:ID). Varios registros pueden compartir la misma marca de tiempo e ID si se generaron como parte del mismo evento de auditoría. El sello de tiempo utiliza el formato de tiempo Unix - segundos desde las 00:00:00 UTC del 1 de enero de 1970. -
varios pares de eventos específicos
name=valueproporcionados por el kernel o las aplicaciones del espacio de usuario.
-
un sello de tiempo y un ID único del registro en la forma
arch=c000003e-
El campo
archcontiene información sobre la arquitectura de la CPU del sistema. El valor,c000003e, está codificado en notación hexadecimal. Cuando busque registros de auditoría con el comandoausearch, utilice la opción-io--interpretpara convertir automáticamente los valores hexadecimales en sus equivalentes legibles para el ser humano. El valorc000003ese interpreta comox86_64. syscall=2-
El campo
syscallregistra el tipo de llamada al sistema que se envió al kernel. El valor,2, puede ser comparado con su equivalente legible por humanos en el archivo/usr/include/asm/unistd_64.h. En este caso,2es la llamada al sistemaopen. Tenga en cuenta que la utilidadausyscallle permite convertir los números de las llamadas al sistema en sus equivalentes legibles para el ser humano. Utilice el comandoausyscall --dumppara mostrar un listado de todas las llamadas al sistema junto con sus números. Para más información, consulte la página de manualausyscall(8). success=no-
El campo
successregistra si la llamada al sistema registrada en ese evento concreto tuvo éxito o fracasó. En este caso, la llamada no tuvo éxito. exit=-13El campo
exitcontiene un valor que especifica el código de salida devuelto por la llamada al sistema. Este valor varía según la llamada al sistema. Puede interpretar el valor a su equivalente legible para humanos con el siguiente comando:# ausearch --interpret --exit -13Tenga en cuenta que el ejemplo anterior asume que su registro de auditoría contiene un evento que falló con el código de salida
-13.a0=7fffd19c5592,a1=0,a2=7fffd19c5592,a3=a-
Los campos
a0aa3registran los cuatro primeros argumentos, codificados en notación hexadecimal, de la llamada al sistema en este evento. Estos argumentos dependen de la llamada al sistema que se utilice; pueden ser interpretados por la utilidadausearch. items=1-
El campo
itemscontiene el número de registros auxiliares PATH que siguen al registro syscall. ppid=2686-
El campo
ppidregistra el ID del proceso padre (PPID). En este caso,2686era el PPID del proceso padre comobash. pid=3538-
El campo
pidregistra el ID del proceso (PID). En este caso,3538era el PID del procesocat. auid=1000-
El campo
auidregistra el ID de usuario de la auditoría, es decir, el loginuid. Este ID se asigna a un usuario al iniciar la sesión y es heredado por todos los procesos, incluso cuando la identidad del usuario cambia, por ejemplo, al cambiar de cuenta de usuario con el comandosu - john. uid=1000-
El campo
uidregistra el ID del usuario que inició el proceso analizado. El ID de usuario puede ser interpretado en nombres de usuario con el siguiente comandoausearch -i --uid UID. gid=1000-
El campo
gidregistra el ID del grupo del usuario que inició el proceso analizado. euid=1000-
El campo
euidregistra el ID de usuario efectivo del usuario que inició el proceso analizado. suid=1000-
En el campo
suidse registra el ID del usuario que inició el proceso analizado. fsuid=1000-
El campo
fsuidregistra el ID de usuario del sistema de archivos del usuario que inició el proceso analizado. egid=1000-
El campo
egidregistra el ID de grupo efectivo del usuario que inició el proceso analizado. sgid=1000-
En el campo
sgidse registra el ID del grupo del usuario que inició el proceso analizado. fsgid=1000-
El campo
fsgidregistra el ID del grupo del sistema de archivos del usuario que inició el proceso analizado. tty=pts0-
El campo
ttyregistra el terminal desde el que se invocó el proceso analizado. ses=1-
El campo
sesregistra el ID de la sesión desde la que se invocó el proceso analizado. comm="cat"-
El campo
commregistra el nombre de la línea de comandos que se utilizó para invocar el proceso analizado. En este caso, se utilizó el comandocatpara activar este evento de Auditoría. exe="/bin/cat"-
El campo
exeregistra la ruta del ejecutable que se utilizó para invocar el proceso analizado. subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023-
El campo
subjregistra el contexto SELinux con el que el proceso analizado fue etiquetado en el momento de la ejecución. key="sshd_config"-
El campo
keyregistra la cadena definida por el administrador asociada a la regla que generó este evento en el registro de auditoría.
Segundo disco
type=CWDEn el segundo registro, el valor del campo
typeesCWDEl propósito de este registro es registrar la ubicación del proceso actual en caso de que una ruta relativa termine siendo capturada en el registro PATH asociado. De esta manera se puede reconstruir la ruta absoluta.
msg=audit(1364481363.243:24287)-
El campo
msgcontiene la misma marca de tiempo y valor de identificación que el valor del primer registro. El sello de tiempo utiliza el formato de tiempo Unix - segundos desde las 00:00:00 UTC del 1 de enero de 1970. cwd="/home/user_name"-
El campo
cwdcontiene la ruta del directorio en el que se invocó la llamada al sistema.
Tercer disco
type=PATH-
En el tercer registro, el valor del campo
typeesPATH. Un evento de Auditoría contiene un registro de tipoPATHpara cada ruta que se pasa a la llamada del sistema como un argumento. En este evento de auditoría, sólo se utilizó una ruta (/etc/ssh/sshd_config) como argumento. msg=audit(1364481363.243:24287):-
El campo
msgcontiene el mismo sello de tiempo y valor de identificación que el valor del primer y segundo registro. item=0-
El campo
itemindica de qué artículo, del total de artículos referenciados en el registro de tipoSYSCALL, se trata el registro actual. Este número está basado en cero; un valor de0significa que es el primer elemento. name="/etc/ssh/sshd_config"-
El campo
nameregistra la ruta del archivo o directorio que se pasó a la llamada del sistema como argumento. En este caso, fue el archivo/etc/ssh/sshd_config. inode=409248El campo
inodecontiene el número de inodo asociado al archivo o directorio registrado en este evento. El siguiente comando muestra el archivo o directorio que está asociado con el número de inodo409248:# find / -inum 409248 -print /etc/ssh/sshd_configdev=fd:00-
El campo
devespecifica el ID menor y mayor del dispositivo que contiene el archivo o directorio registrado en este evento. En este caso, el valor representa el dispositivo/dev/fd/0. mode=0100600-
El campo
moderegistra los permisos de los archivos o directorios, codificados en notación numérica tal y como los devuelve el comandostaten el campost_mode. Consulte la página de manualstat(2)para obtener más información. En este caso,0100600puede interpretarse como-rw-------, lo que significa que sólo el usuario root tiene permisos de lectura y escritura en el archivo/etc/ssh/sshd_config. ouid=0-
El campo
ouidregistra el ID de usuario del propietario del objeto. ogid=0-
El campo
ogidregistra el ID del grupo del propietario del objeto. rdev=00:00-
El campo
rdevcontiene un identificador de dispositivo grabado sólo para archivos especiales. En este caso, no se utiliza ya que el archivo grabado es un archivo normal. obj=system_u:object_r:etc_t:s0-
El campo
objregistra el contexto SELinux con el que el archivo o directorio registrado fue etiquetado en el momento de la ejecución. nametype=NORMAL-
El campo
nametyperegistra la intención de la operación de cada registro de ruta en el contexto de una determinada syscall. cap_fp=none-
El campo
cap_fpregistra datos relacionados con la configuración de una capacidad permitida basada en el sistema de archivos del objeto de archivo o directorio. cap_fi=none-
El campo
cap_firegistra datos relacionados con la configuración de una capacidad heredada basada en el sistema de archivos del objeto de archivo o directorio. cap_fe=0-
El campo
cap_feregistra la configuración del bit efectivo de la capacidad basada en el sistema de archivos del objeto de archivo o directorio. cap_fver=0-
El campo
cap_fverregistra la versión de la capacidad basada en el sistema de archivos del objeto de archivo o directorio.
Cuarto disco
type=PROCTITLE-
El campo
typecontiene el tipo de registro. En este ejemplo, el valorPROCTITLEespecifica que este registro da la línea de comandos completa que desencadenó este evento de Auditoría, desencadenado por una llamada del sistema al kernel. proctitle=636174002F6574632F7373682F737368645F636F6E666967-
El campo
proctitleregistra la línea de comandos completa del comando que se utilizó para invocar el proceso analizado. El campo está codificado en notación hexadecimal para no permitir que el usuario influya en el analizador del registro de Auditoría. El texto se decodifica al comando que desencadenó este evento de Auditoría. Al buscar registros de Auditoría con el comandoausearch, utilice la opción-io--interpretpara convertir automáticamente los valores hexadecimales en sus equivalentes legibles para el ser humano. El valor636174002F6574632F7373682F737368645F636F6E666967se interpreta comocat /etc/ssh/sshd_config.
37.6. Uso de auditctl para definir y ejecutar reglas de auditoría
El sistema de auditoría funciona con un conjunto de reglas que definen lo que se captura en los archivos de registro. Las reglas de auditoría pueden establecerse en la línea de comandos mediante la utilidad auditctl o en el directorio /etc/audit/rules.d/.
El comando auditctl le permite controlar la funcionalidad básica del sistema de Auditoría y definir las reglas que deciden qué eventos de Auditoría se registran.
Ejemplos de reglas del sistema de archivos
Para definir una regla que registre todos los accesos de escritura y todos los cambios de atributos del archivo
/etc/passwd:# auditctl -w /etc/passwd -p wa -k passwd_changesPara definir una regla que registre todos los accesos de escritura y todos los cambios de atributos de todos los archivos del directorio
/etc/selinux/:# auditctl -w /etc/selinux/ -p wa -k selinux_changes
Ejemplos de reglas de llamada al sistema
Para definir una regla que cree una entrada de registro cada vez que las llamadas al sistema
adjtimexosettimeofdaysean utilizadas por un programa, y el sistema utilice la arquitectura de 64 bits:# auditctl -a always,exit -F arch=b64 -S adjtimex -S settimeofday -k time_changePara definir una regla que cree una entrada en el registro cada vez que un usuario del sistema cuyo ID es igual o superior a 1000 elimine o cambie el nombre de un archivo:
# auditctl -a always,exit -S unlink -S unlinkat -S rename -S renameat -F auid>=1000 -F auid!=4294967295 -k deleteTenga en cuenta que la opción
-F auid!=4294967295se utiliza para excluir a los usuarios cuyo UID de inicio de sesión no está establecido.
Reglas de los archivos ejecutables
Para definir una regla que registre toda la ejecución del programa /bin/id, ejecute el siguiente comando:
# auditctl -a always,exit -F exe=/bin/id -F arch=b64 -S execve -k execution_bin_idRecursos adicionales
-
Consulte la página man
audictl(8)para obtener más información, consejos de rendimiento y ejemplos adicionales de uso.
37.7. Definición de reglas de auditoría persistentes
Para definir reglas de Auditoría que sean persistentes a través de los reinicios, debe incluirlas directamente en el archivo /etc/audit/rules.d/audit.rules o utilizar el programa augenrules que lee las reglas ubicadas en el directorio /etc/audit/rules.d/.
Tenga en cuenta que el archivo /etc/audit/audit.rules se genera cada vez que se inicia el servicio auditd. Los archivos de /etc/audit/rules.d/ utilizan la misma sintaxis de la línea de comandos de auditctl para especificar las reglas. Las líneas vacías y el texto que sigue a un signo de almohadilla (#) se ignoran.
Además, puede utilizar el comando auditctl para leer las reglas de un archivo específico utilizando la opción -R, por ejemplo:
# auditctl -R /usr/share/audit/sample-rules/30-stig.rules37.8. Uso de archivos de reglas preconfigurados
En el directorio /usr/share/audit/sample-rules, el paquete audit proporciona un conjunto de archivos de reglas preconfiguradas según varias normas de certificación:
- 30-nispom.rules
- Configuración de la regla de auditoría que cumple con los requisitos especificados en el capítulo de Seguridad del Sistema de Información del Manual Operativo del Programa Nacional de Seguridad Industrial.
- 30-ospp-v42*.rules
- Configuración de la regla de auditoría que cumple con los requisitos definidos en el perfil OSPP (Protection Profile for General Purpose Operating Systems) versión 4.2.
- 30-pci-dss-v31.rules
- Configuración de la regla de auditoría que cumple los requisitos establecidos por la norma de seguridad de datos del sector de las tarjetas de pago (PCI DSS) v3.1.
- 30-reglas de la estigmatización
- Configuración de la regla de auditoría que cumple con los requisitos establecidos por las Guías Técnicas de Implementación de Seguridad (STIG).
Para utilizar estos archivos de configuración, cópielos en el directorio /usr/share/audit/sample-rules y utilice el comando augenrules --load, por ejemplo:
# cd /usr/share/audit/sample-rules/
# cp 10-base-config.rules 30-stig.rules 31-privileged.rules 99-finalize.rules /etc/audit/rules.d/
# augenrules --loadRecursos adicionales
-
Puede ordenar las reglas de auditoría utilizando un esquema de numeración. Consulte el archivo
/usr/share/audit/sample-rules/README-rulespara obtener más información. -
Consulte la página de manual
audit.rules(7)para obtener más información, solucionar problemas y obtener ejemplos adicionales de uso.
37.9. Uso de augenrules para definir reglas persistentes
El script augenrules lee las reglas ubicadas en el directorio /etc/audit/rules.d/ y las compila en un archivo audit.rules. Este script procesa todos los archivos que terminan en .rules en un orden específico basado en su orden natural de clasificación. Los archivos de este directorio están organizados en grupos con los siguientes significados:
- 10 - Configuración del kernel y auditctl
- 20 - Reglas que podrían coincidir con las reglas generales pero que usted quiere que coincidan de otra manera
- 30 - Normas principales
- 40 - Normas opcionales
- 50 - Reglas específicas del servidor
- 70 - Normas locales del sistema
- 90 - Finalizar (inmutable)
Las normas no están pensadas para ser utilizadas todas a la vez. Son piezas de una política que deben ser pensadas y copiadas individualmente en /etc/audit/rules.d/. Por ejemplo, para establecer un sistema en la configuración STIG, copie las reglas 10-base-config, 30-stig, 31-privileged, y 99-finalize.
Una vez que tenga las reglas en el directorio /etc/audit/rules.d/, cárguelas ejecutando el script augenrules con la directiva --load:
# augenrules --load
/sbin/augenrules: No change
No rules
enabled 1
failure 1
pid 742
rate_limit 0
...Recursos adicionales
-
Para más información sobre las reglas de auditoría y el script
augenrules, consulte las páginas de manualaudit.rules(8)yaugenrules(8).
37.10. Desactivación de augenrules
Siga los siguientes pasos para desactivar la utilidad augenrules. Esto cambia la Auditoría para utilizar las reglas definidas en el archivo /etc/audit/audit.rules.
Procedimiento
Copie el archivo
/usr/lib/systemd/system/auditd.serviceen el directorio/etc/systemd/system/:# cp -f /usr/lib/systemd/system/auditd.service /etc/systemd/system/Edite el archivo
/etc/systemd/system/auditd.serviceen un editor de texto de su elección, por ejemplo:# vi /etc/systemd/system/auditd.serviceComente la línea que contiene
augenrules, y descomente la línea que contiene el comandoauditctl -R:#ExecStartPost=-/sbin/augenrules --load ExecStartPost=-/sbin/auditctl -R /etc/audit/audit.rulesRecarga el demonio
systemdpara obtener los cambios en el archivoauditd.service:# systemctl daemon-reloadReinicie el servicio
auditd:# service auditd restart
Recursos adicionales
-
Las páginas de manual
augenrules(8)yaudit.rules(8). - El reinicio del servicio Auditd anula los cambios realizados en el artículo /etc/audit/audit.rules.
Parte VI. Diseño del núcleo
Capítulo 38. El RPM del núcleo de Linux
Las siguientes secciones describen el paquete RPM del kernel de Linux proporcionado y mantenido por Red Hat.
38.1. Qué es un RPM
Un paquete RPM es un archivo que contiene otros archivos y sus metadatos (información sobre los archivos que necesita el sistema).
En concreto, un paquete RPM consiste en el archivo cpio.
El archivo cpio contiene:
- Archivos
Cabecera del RPM (metadatos del paquete)
El gestor de paquetes
rpmutiliza estos metadatos para determinar las dependencias, dónde instalar los archivos y otra información.
Tipos de paquetes RPM
Existen dos tipos de paquetes RPM. Ambos tipos comparten el formato de archivo y las herramientas, pero tienen contenidos diferentes y sirven para fines distintos:
Fuente RPM (SRPM)
Un SRPM contiene el código fuente y un archivo SPEC, que describe cómo construir el código fuente en un RPM binario. Opcionalmente, también se incluyen los parches del código fuente.
RPM binario
Un RPM binario contiene los binarios construidos a partir de las fuentes y los parches.
38.2. Visión general del paquete RPM del núcleo de Linux
El RPM kernel es un metapaquete que no contiene ningún archivo, sino que asegura que los siguientes subpaquetes se instalen correctamente:
-
kernel-core- contiene un número mínimo de módulos del kernel necesarios para la funcionalidad principal. Este subpaquete por sí solo podría utilizarse en entornos virtualizados y de nube para proporcionar un kernel de Red Hat Enterprise Linux 8 con un tiempo de arranque rápido y un tamaño de disco reducido. -
kernel-modules- contiene más módulos del kernel. -
kernel-modules-extra- contiene módulos del kernel para hardware raro.
El pequeño conjunto de subpaquetes de kernel tiene como objetivo proporcionar una superficie de mantenimiento reducida a los administradores de sistemas, especialmente en entornos virtualizados y en la nube.
Los otros paquetes comunes del kernel son, por ejemplo:
-
kernel-debug- Contiene un núcleo con numerosas opciones de depuración habilitadas para el diagnóstico del núcleo, a expensas de un rendimiento reducido. -
kernel-tools- Contiene herramientas para manipular el núcleo de Linux y documentación de apoyo. -
kernel-devel- Contiene las cabeceras del kernel y los archivos makefiles suficientes para construir módulos contra el paquetekernel. -
kernel-abi-whitelists- Contiene información relativa a la ABI del kernel de Red Hat Enterprise Linux, incluyendo una lista de símbolos del kernel que necesitan los módulos externos del kernel de Linux y un complemento deyumpara ayudar a su aplicación. -
kernel-headers- Incluye los archivos de cabecera C que especifican la interfaz entre el núcleo de Linux y las bibliotecas y programas del espacio de usuario. Los archivos de cabecera definen estructuras y constantes que son necesarias para construir la mayoría de los programas estándar.
38.3. Visualización del contenido del paquete del núcleo
El siguiente procedimiento describe cómo ver el contenido del paquete del kernel y sus subpaquetes sin instalarlos utilizando el comando rpm.
Requisitos previos
-
Obtenido
kernel,kernel-core,kernel-modules,kernel-modules-extrapaquetes RPM para su arquitectura de CPU
Procedimiento
Lista de módulos para
kernel:$ rpm -qlp <kernel_rpm> (contains no files) …Lista de módulos para
kernel-core:$ rpm -qlp <kernel-core_rpm> … /lib/modules/4.18.0-80.el8.x86_64/kernel/fs/udf/udf.ko.xz /lib/modules/4.18.0-80.el8.x86_64/kernel/fs/xfs /lib/modules/4.18.0-80.el8.x86_64/kernel/fs/xfs/xfs.ko.xz /lib/modules/4.18.0-80.el8.x86_64/kernel/kernel /lib/modules/4.18.0-80.el8.x86_64/kernel/kernel/trace /lib/modules/4.18.0-80.el8.x86_64/kernel/kernel/trace/ring_buffer_benchmark.ko.xz /lib/modules/4.18.0-80.el8.x86_64/kernel/lib /lib/modules/4.18.0-80.el8.x86_64/kernel/lib/cordic.ko.xz …Lista de módulos para
kernel-modules:$ rpm -qlp <kernel-modules_rpm> … /lib/modules/4.18.0-80.el8.x86_64/kernel/drivers/infiniband/hw/mlx4/mlx4_ib.ko.xz /lib/modules/4.18.0-80.el8.x86_64/kernel/drivers/infiniband/hw/mlx5/mlx5_ib.ko.xz /lib/modules/4.18.0-80.el8.x86_64/kernel/drivers/infiniband/hw/qedr/qedr.ko.xz /lib/modules/4.18.0-80.el8.x86_64/kernel/drivers/infiniband/hw/usnic/usnic_verbs.ko.xz /lib/modules/4.18.0-80.el8.x86_64/kernel/drivers/infiniband/hw/vmw_pvrdma/vmw_pvrdma.ko.xz …Lista de módulos para
kernel-modules-extra:$ rpm -qlp <kernel-modules-extra_rpm> … /lib/modules/4.18.0-80.el8.x86_64/extra/net/sched/sch_cbq.ko.xz /lib/modules/4.18.0-80.el8.x86_64/extra/net/sched/sch_choke.ko.xz /lib/modules/4.18.0-80.el8.x86_64/extra/net/sched/sch_drr.ko.xz /lib/modules/4.18.0-80.el8.x86_64/extra/net/sched/sch_dsmark.ko.xz /lib/modules/4.18.0-80.el8.x86_64/extra/net/sched/sch_gred.ko.xz …
Recursos adicionales
-
Para obtener información sobre cómo utilizar el comando
rpmen el RPMkernelya instalado, incluidos sus subpaquetes, consulte la página del manualrpm(8). - Introducción a RPM packages
Capítulo 39. Actualización del kernel con yum
Las siguientes secciones aportan información sobre el kernel de Linux proporcionado y mantenido por Red Hat (kernel de Red Hat), y sobre cómo mantener el kernel de Red Hat actualizado. Como consecuencia, el sistema operativo tendrá todas las últimas correcciones de errores, mejoras de rendimiento y parches que garantizan la compatibilidad con el nuevo hardware.
39.1. Qué es el núcleo
El kernel es la parte central de un sistema operativo Linux, que gestiona los recursos del sistema y proporciona la interfaz entre el hardware y las aplicaciones de software. El kernel de Red Hat es un kernel personalizado basado en el kernel principal de Linux que los ingenieros de Red Hat desarrollan y endurecen con un enfoque en la estabilidad y la compatibilidad con las últimas tecnologías y hardware.
Antes de que Red Hat publique una nueva versión del kernel, éste debe pasar una serie de rigurosas pruebas de control de calidad.
Los kernels de Red Hat están empaquetados en el formato RPM para que sean fáciles de actualizar y verificar por el yum gestor de paquetes.
Los kernels que no han sido compilados por Red Hat son not soportados por Red Hat.
39.2. Qué es yum
Esta sección se refiere a la descripción del yum package manager.
Recursos adicionales
-
Para más información sobre
yum, consulte las secciones correspondientes de Configuring basic system settings.
39.3. Actualización del kernel
El siguiente procedimiento describe cómo actualizar el kernel utilizando el yum gestor de paquetes.
Procedimiento
Para actualizar el kernel, utilice lo siguiente:
# yum update kernelEste comando actualiza el kernel junto con todas las dependencias a la última versión disponible.
- Reinicie su sistema para que los cambios surtan efecto.
Cuando actualice de Red Hat Enterprise Linux 7 a Red Hat Enterprise Linux 8, siga las secciones relevantes del Upgrading from RHEL 7 to RHEL 8 documento.
39.4. Instalación del kernel
El siguiente procedimiento describe cómo instalar nuevos kernels utilizando el yum gestor de paquetes.
Procedimiento
Para instalar una versión específica del kernel, utilice lo siguiente:
# yum install kernel-{version}
Recursos adicionales
- Para obtener una lista de los núcleos disponibles, consulte Red Hat Code Browser.
- Para obtener una lista de las fechas de lanzamiento de versiones específicas del núcleo, consulte this article.
Capítulo 40. Configuración de los parámetros de la línea de comandos del kernel
Los parámetros de la línea de comandos del kernel son una forma de cambiar el comportamiento de ciertos aspectos del kernel de Red Hat Enterprise Linux en el momento del arranque. Como administrador del sistema, usted tiene el control total sobre las opciones que se establecen en el arranque. Ciertos comportamientos del kernel sólo pueden establecerse en el momento del arranque, por lo que entender cómo hacer estos cambios es una habilidad clave para la administración.
Optar por cambiar el comportamiento del sistema modificando los parámetros de la línea de comandos del kernel puede tener efectos negativos en su sistema. Por lo tanto, debería probar los cambios antes de desplegarlos en producción. Para obtener más orientación, póngase en contacto con el Soporte de Red Hat.
40.1. Comprender los parámetros de la línea de comandos del kernel
Los parámetros de la línea de comandos del kernel se utilizan para la configuración del tiempo de arranque de:
- El núcleo de Red Hat Enterprise Linux
- El disco RAM inicial
- Las características del espacio del usuario
Los parámetros del tiempo de arranque del kernel se utilizan a menudo para sobrescribir los valores por defecto y para establecer configuraciones específicas del hardware.
Por defecto, los parámetros de la línea de comandos del kernel para los sistemas que utilizan el gestor de arranque GRUB2 se definen en la variable kernelopts del archivo /boot/grub2/grubenv para todas las entradas de arranque del kernel.
Para IBM Z, los parámetros de la línea de comandos del kernel se almacenan en el archivo de configuración de la entrada de arranque porque el cargador de arranque zipl no admite variables de entorno. Por lo tanto, no se puede utilizar la variable de entorno kernelopts.
Recursos adicionales
-
Para más información sobre los parámetros de la línea de comandos del kernel que puede modificar, consulte las páginas de manual
kernel-command-line(7),bootparam(7)ydracut.cmdline(7). -
Para más información sobre la variable
kernelopts, consulte el artículo de la base de conocimientos, Cómo instalar y arrancar kernels personalizados en Red Hat Enterprise Linux 8.
40.2. Lo que es mugriento
grubby es una utilidad para manipular archivos de configuración específicos del cargador de arranque.
Puede utilizar grubby también para cambiar la entrada de arranque por defecto, y para añadir/eliminar argumentos de una entrada de menú de GRUB2.
Para más detalles, consulte la página del manual grubby(8).
40.3. Qué son las entradas de arranque
Una entrada de arranque es una colección de opciones que se almacenan en un archivo de configuración y están vinculadas a una versión particular del kernel. En la práctica, tiene al menos tantas entradas de arranque como núcleos instalados tenga su sistema. El archivo de configuración de la entrada de arranque se encuentra en el directorio /boot/loader/entries/ y puede tener el siguiente aspecto:
6f9cc9cb7d7845d49698c9537337cedc-4.18.0-5.el8.x86_64.conf
El nombre del archivo anterior consiste en un ID de máquina almacenado en el archivo /etc/machine-id, y una versión del kernel.
El archivo de configuración de la entrada de arranque contiene información sobre la versión del kernel, la imagen inicial del ramdisk y la variable de entorno kernelopts, que contiene los parámetros de la línea de comandos del kernel. El contenido de una configuración de entrada de arranque se puede ver a continuación:
title Red Hat Enterprise Linux (4.18.0-74.el8.x86_64) 8.0 (Ootpa)
version 4.18.0-74.el8.x86_64
linux /vmlinuz-4.18.0-74.el8.x86_64
initrd /initramfs-4.18.0-74.el8.x86_64.img $tuned_initrd
options $kernelopts $tuned_params
id rhel-20190227183418-4.18.0-74.el8.x86_64
grub_users $grub_users
grub_arg --unrestricted
grub_class kernel
La variable de entorno kernelopts se define en el archivo /boot/grub2/grubenv.
Recursos adicionales
Para más información sobre la variable kernelopts, consulte el artículo de la base de conocimientos Cómo instalar y arrancar kernels personalizados en Red Hat Enterprise Linux 8.
40.4. Configuración de los parámetros de la línea de comandos del kernel
Para ajustar el comportamiento de su sistema desde las primeras etapas del proceso de arranque, necesita establecer ciertos parámetros de la línea de comandos del kernel.
Esta sección explica cómo cambiar los parámetros de la línea de comandos del kernel en varias arquitecturas de CPU.
40.4.1. Cambio de los parámetros de la línea de comandos del kernel para todas las entradas de arranque
Este procedimiento describe cómo cambiar los parámetros de la línea de comandos del kernel para todas las entradas de arranque de su sistema.
Requisitos previos
-
Compruebe que las utilidades
grubbyyziplestán instaladas en su sistema.
Procedimiento
Para añadir un parámetro:
# grubby --update-kernel=ALL --args="<NEW_PARAMETER>"Para los sistemas que utilizan el gestor de arranque GRUB2, el comando actualiza el archivo
/boot/grub2/grubenvañadiendo un nuevo parámetro del kernel a la variablekerneloptsde ese archivo.En los IBM Z que utilizan el cargador de arranque zIPL, el comando añade un nuevo parámetro del kernel a cada
/boot/loader/entries/<ENTRY>.confarchivo.-
En IBM Z, ejecute el comando
ziplsin opciones para actualizar el menú de arranque.
-
En IBM Z, ejecute el comando
Para eliminar un parámetro:
# grubby --update-kernel=ALL --remove-args="<PARAMETER_TO_REMOVE>"-
En IBM Z, ejecute el comando
ziplsin opciones para actualizar el menú de arranque.
-
En IBM Z, ejecute el comando
Recursos adicionales
- Para más información sobre los parámetros de la línea de comandos del kernel, consulte Sección 40.1, “Comprender los parámetros de la línea de comandos del kernel”.
-
Para obtener información sobre la utilidad
grubby, consulte la página del manualgrubby(8). -
Para ver más ejemplos de cómo utilizar
grubby, consulte la página grubby tool. -
Para obtener información sobre la utilidad
zipl, consulte la página del manualzipl(8).
40.4.2. Cambio de los parámetros de la línea de comandos del kernel para una sola entrada de arranque
Este procedimiento describe cómo cambiar los parámetros de la línea de comandos del kernel para una sola entrada de arranque en su sistema.
Requisitos previos
-
Compruebe que las utilidades
grubbyyziplestán instaladas en su sistema.
Procedimiento
Para añadir un parámetro:
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="<NEW_PARAMETER>"-
En IBM Z, ejecute el comando
ziplsin opciones para actualizar el menú de arranque.
-
En IBM Z, ejecute el comando
Para eliminar un parámetro utilice lo siguiente:
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --remove-args="<PARAMETER_TO_REMOVE>"-
En IBM Z, ejecute el comando
ziplsin opciones para actualizar el menú de arranque.
-
En IBM Z, ejecute el comando
En los sistemas que utilizan el archivo grub.cfg, existe, por defecto, el parámetro options para cada entrada de arranque del kernel, que se establece en la variable kernelopts. Esta variable se define en el archivo de configuración /boot/grub2/grubenv.
En sistemas GRUB2:
-
Si los parámetros de la línea de comandos del kernel se modifican para todas las entradas de arranque, la utilidad
grubbyactualiza la variablekerneloptsen el archivo/boot/grub2/grubenv. -
Si los parámetros de la línea de comandos del kernel se modifican para una sola entrada de arranque, la variable
kerneloptsse expande, los parámetros del kernel se modifican y el valor resultante se almacena en el archivo/boot/loader/entries/<RELEVANT_KERNEL_BOOT_ENTRY.conf>de la entrada de arranque respectiva.
En los sistemas zIPL:
-
grubbymodifica y almacena los parámetros de la línea de comandos del kernel de una entrada individual de arranque del kernel en el archivo/boot/loader/entries/<ENTRY>.confarchivo.
Recursos adicionales
- Para más información sobre los parámetros de la línea de comandos del kernel, consulte Sección 40.1, “Comprender los parámetros de la línea de comandos del kernel”.
-
Para obtener información sobre la utilidad
grubby, consulte la página del manualgrubby(8). -
Para ver más ejemplos de cómo utilizar
grubby, consulte la página grubby tool. -
Para obtener información sobre la utilidad
zipl, consulte la página del manualzipl(8).
Capítulo 41. Configuración de los parámetros del núcleo en tiempo de ejecución
Como administrador del sistema, puede modificar muchas facetas del comportamiento del kernel de Red Hat Enterprise Linux en tiempo de ejecución. Esta sección describe cómo configurar los parámetros del kernel en tiempo de ejecución utilizando el comando sysctl y modificando los archivos de configuración en los directorios /etc/sysctl.d/ y /proc/sys/.
41.1. Qué son los parámetros del núcleo
Los parámetros del kernel son valores que se pueden ajustar mientras el sistema está en funcionamiento. No es necesario reiniciar o recompilar el kernel para que los cambios surtan efecto.
Es posible dirigirse a los parámetros del núcleo a través de:
-
El comando
sysctl -
El sistema de archivos virtual montado en el directorio
/proc/sys/ -
Los archivos de configuración en el directorio
/etc/sysctl.d/
Los sintonizables se dividen en clases según el subsistema del kernel. Red Hat Enterprise Linux tiene las siguientes clases de sintonizables:
| Clase ajustable | Subsistema |
|---|---|
| abi | Dominios de ejecución y personalidades |
| cripto | Interfaces criptográficas |
| depurar | Interfaces de depuración del núcleo |
| dev | Información específica del dispositivo |
| fs | Ajustes globales y específicos del sistema de archivos |
| núcleo | Ajustes globales del kernel |
| red | Redes sintonizables |
| sunrpc | Sun Remote Procedure Call (NFS) |
| usuario | Límites del espacio de nombres del usuario |
| vm | Ajuste y gestión de la memoria, los búferes y la caché |
Recursos adicionales
-
Para más información sobre
sysctl, consulte las páginas del manualsysctl(8). -
Para más información sobre
/etc/sysctl.d/, consulte las páginas del manualsysctl.d(5).
41.2. Configuración de los parámetros del kernel en tiempo de ejecución
La configuración de los parámetros del kernel en un sistema de producción requiere una planificación cuidadosa. Los cambios no planificados pueden hacer que el kernel sea inestable, requiriendo un reinicio del sistema. Verifique que está utilizando opciones válidas antes de cambiar cualquier valor del kernel.
41.2.1. Configurar temporalmente los parámetros del kernel con sysctl
El siguiente procedimiento describe cómo utilizar el comando sysctl para establecer temporalmente los parámetros del kernel en tiempo de ejecución. El comando también es útil para listar y filtrar sintonizables.
Requisitos previos
- Introducción a los parámetros del núcleo
- Permisos de la raíz
Procedimiento
Para listar todos los parámetros y sus valores, utilice lo siguiente:
# sysctl -aNotaEl comando
# sysctl -amuestra los parámetros del kernel, que pueden ajustarse en tiempo de ejecución y en tiempo de arranque.Para configurar un parámetro temporalmente, utilice el comando como en el siguiente ejemplo:
# sysctl <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>El comando de ejemplo anterior cambia el valor del parámetro mientras el sistema está en funcionamiento. Los cambios surten efecto inmediatamente, sin necesidad de reiniciar el sistema.
NotaLos cambios vuelven a ser por defecto después de reiniciar el sistema.
Recursos adicionales
-
Para más información sobre
sysctl, consulte la página del manualsysctl(8). -
Para modificar permanentemente los parámetros del kernel, utilice el comando
sysctlpara escribir los valores en el archivo/etc/sysctl.confo realice cambios manuales en los archivos de configuración en el directorio/etc/sysctl.d/.
41.2.2. Configurar los parámetros del kernel de forma permanente con sysctl
El siguiente procedimiento describe cómo utilizar el comando sysctl para establecer permanentemente los parámetros del kernel.
Requisitos previos
- Introducción a los parámetros del núcleo
- Permisos de la raíz
Procedimiento
Para listar todos los parámetros, utilice lo siguiente:
# sysctl -aEl comando muestra todos los parámetros del kernel que se pueden configurar en tiempo de ejecución.
Para configurar un parámetro de forma permanente:
# sysctl -w <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> >> /etc/sysctl.confEl comando de ejemplo cambia el valor sintonizable y lo escribe en el archivo
/etc/sysctl.conf, que anula los valores por defecto de los parámetros del kernel. Los cambios tienen efecto inmediato y persistente, sin necesidad de reiniciar.
Para modificar permanentemente los parámetros del kernel, también puede realizar cambios manuales en los archivos de configuración del directorio /etc/sysctl.d/.
Recursos adicionales
-
Para más información sobre
sysctl, consulte las páginas del manualsysctl(8)ysysctl.conf(5). -
Para más información sobre el uso de los archivos de configuración en el directorio
/etc/sysctl.d/para realizar cambios permanentes en los parámetros del kernel, consulte la sección Uso de los archivos de configuración en /etc/sysctl.d/ para ajustar los parámetros del kernel.
41.2.3. Uso de los archivos de configuración en /etc/sysctl.d/ para ajustar los parámetros del kernel
El siguiente procedimiento describe cómo modificar manualmente los archivos de configuración en el directorio /etc/sysctl.d/ para establecer permanentemente los parámetros del kernel.
Requisitos previos
- Introducción a los parámetros del núcleo
- Permisos de la raíz
Procedimiento
Cree un nuevo archivo de configuración en
/etc/sysctl.d/:# vim /etc/sysctl.d/<some_file.conf>Incluya los parámetros del núcleo, uno por línea, como sigue:
<TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>- Guarde el archivo de configuración.
Reinicie la máquina para que los cambios surtan efecto.
Alternativamente, para aplicar los cambios sin reiniciar, ejecute:
# sysctl -p /etc/sysctl.d/<some_file.conf>Este comando le permite leer los valores del archivo de configuración, que creó anteriormente.
Recursos adicionales
-
Para más información sobre
sysctl, consulte la página del manualsysctl(8). -
Para más información sobre
/etc/sysctl.d/, consulte la página del manualsysctl.d(5).
41.2.4. Configurar los parámetros del kernel temporalmente a través de /proc/sys/
El siguiente procedimiento describe cómo configurar los parámetros del kernel temporalmente a través de los archivos del directorio del sistema de archivos virtual /proc/sys/.
Requisitos previos
- Introducción a los parámetros del núcleo
- Permisos de la raíz
Procedimiento
Identifique un parámetro del núcleo que desee configurar:
# ls -l /proc/sys/<TUNABLE_CLASS>/Los archivos con permisos de escritura devueltos por el comando pueden utilizarse para configurar el kernel. Los archivos con permisos de sólo lectura proporcionan información sobre la configuración actual.
Asigna un valor objetivo al parámetro del núcleo:
# echo <TARGET_VALUE> > /proc/sys/<TUNABLE_CLASS>/<PARAMETER>El comando realiza cambios de configuración que desaparecerán una vez que se reinicie el sistema.
Opcionalmente, verifique el valor del parámetro del núcleo recién establecido:
# cat /proc/sys/<TUNABLE_CLASS>/<PARAMETER>
Recursos adicionales
-
Para modificar permanentemente los parámetros del kernel, utilice el comando
sysctlo realice cambios manuales en los archivos de configuración en el directorio/etc/sysctl.d/.
41.3. Mantener desactivados los parámetros de pánico del kernel en entornos virtualizados
Cuando configure un entorno virtualizado en Red Hat Enterprise Linux 8 (RHEL 8), no debe habilitar los parámetros del kernel softlockup_panic y nmi_watchdog, ya que el entorno virtualizado puede desencadenar un soft lockup espurio que no debería requerir un pánico del sistema.
En las siguientes secciones se explican las razones de este consejo resumiendo:
- Qué causa un bloqueo suave.
- Describe los parámetros del kernel que controlan el comportamiento de un sistema en un bloqueo suave.
- Explicación de cómo pueden activarse los bloqueos blandos en un entorno virtualizado.
41.3.1. ¿Qué es un bloqueo suave?
Un bloqueo suave es una situación causada normalmente por un error, cuando una tarea se ejecuta en el espacio del núcleo en una CPU sin reprogramar. La tarea tampoco permite que ninguna otra tarea se ejecute en esa CPU en particular. Como resultado, se muestra una advertencia al usuario a través de la consola del sistema. Este problema también se conoce como disparo de bloqueo suave.
Recursos adicionales
- Para conocer el motivo técnico de un bloqueo suave, ejemplos de mensajes de registro y otros detalles, consulte lo siguiente Knowledge Article.
41.3.2. Parámetros que controlan el pánico del núcleo
Los siguientes parámetros del kernel pueden establecerse para controlar el comportamiento del sistema cuando se detecta un bloqueo suave.
- softlockup_panic
Controla si el kernel entrará en pánico o no cuando se detecte un bloqueo suave.
Expand Tipo Valor Efecto Entero
0
el kernel no entra en pánico al bloquearse suavemente
Entero
1
el kernel entra en pánico al bloquearse suavemente
Por defecto, en RHEL8 este valor es 0.
Para entrar en pánico, el sistema necesita detectar primero un bloqueo duro. La detección se controla con el parámetro
nmi_watchdog.- nmi_watchdog
Controla si los mecanismos de detección de bloqueos (
watchdogs) están activos o no. Este parámetro es de tipo entero.Expand Valor Efecto 0
desactiva el detector de bloqueo
1
permite la detección de bloqueo
El detector de bloqueos duros supervisa cada CPU en cuanto a su capacidad de respuesta a las interrupciones.
- watchdog_thresh
Controla la frecuencia del watchdog
hrtimer, los eventos NMI y los umbrales de bloqueo suave/duro.Expand Umbral por defecto Umbral de bloqueo suave 10 segundos
2 *
watchdog_threshSi este parámetro se pone a cero, se desactiva la detección de bloqueos por completo.
Recursos adicionales
-
Para más información sobre
nmi_watchdogysoftlockup_panic, consulte el Softlockup detector and hardlockup detector documento. -
Para más detalles sobre
watchdog_thresh, consulte el Kernel sysctl documento.
41.3.3. Bloqueos suaves espurios en entornos virtualizados
El bloqueo suave que se produce en los hosts físicos, tal y como se describe en Sección 41.3.1, “¿Qué es un bloqueo suave?”, suele representar un fallo del kernel o del hardware. El mismo fenómeno que ocurre en los sistemas operativos invitados en entornos virtualizados puede representar una falsa advertencia.
Una gran carga de trabajo en un host o una alta contención sobre algún recurso específico, como la memoria, suele provocar un disparo de bloqueo suave espurio. Esto se debe a que el host puede programar la salida de la CPU del huésped durante un periodo superior a 20 segundos. Entonces, cuando la CPU del huésped se programa de nuevo para ejecutarse en el host, experimenta un time jump que dispara los temporizadores debidos. Los temporizadores incluyen también el watchdog hrtimer, que puede, en consecuencia, informar de un bloqueo suave en la CPU huésped.
Debido a que un soft lockup en un entorno virtualizado puede ser espurio, no debe habilitar los parámetros del kernel que causarían un pánico en el sistema cuando se reporta un soft lockup en una CPU huésped.
Para entender los bloqueos suaves en los invitados, es esencial saber que el anfitrión programa el invitado como una tarea, y el invitado entonces programa sus propias tareas.
Recursos adicionales
- Para conocer la definición de bloqueo suave y los tecnicismos de su funcionamiento, véase Sección 41.3.1, “¿Qué es un bloqueo suave?”.
- Para conocer los componentes de los entornos virtualizados de RHEL 8 y su interacción, consulte RHEL 8 virtual machine components and their interaction.
41.4. Ajuste de los parámetros del núcleo para los servidores de bases de datos
Existen diferentes conjuntos de parámetros del kernel que pueden afectar al rendimiento de determinadas aplicaciones de bases de datos. Las siguientes secciones explican qué parámetros del kernel hay que configurar para asegurar un funcionamiento eficiente de los servidores de bases de datos y de las bases de datos.
41.4.1. Introducción a los servidores de bases de datos
Un servidor de base de datos es un dispositivo de hardware que tiene una cierta cantidad de memoria principal, y una aplicación de base de datos (DB) instalada. Esta aplicación de base de datos proporciona servicios como medio para escribir los datos almacenados en la memoria principal, que suele ser pequeña y costosa, en archivos de base de datos (DB). Estos servicios se prestan a múltiples clientes en una red. Puede haber tantos servidores de BD como lo permita la memoria principal y el almacenamiento de una máquina.
Red Hat Enterprise Linux 8 proporciona las siguientes aplicaciones de bases de datos:
- MariaDB 10.3
- MySQL 8.0
- PostgreSQL 10
- PostgreSQL 9.6
- PostgreSQL 12 - disponible desde RHEL 8.1.1
41.4.2. Parámetros que afectan al rendimiento de las aplicaciones de bases de datos
Los siguientes parámetros del kernel afectan al rendimiento de las aplicaciones de bases de datos.
- fs.aio-max-nr
Define el número máximo de operaciones de E/S asíncronas que el sistema puede manejar en el servidor.
NotaAumentar el parámetro
fs.aio-max-nrno produce ningún cambio adicional más allá de aumentar el límite de aio.- fs.file-max
Define el número máximo de manejadores de archivos (nombres de archivos temporales o IDs asignados a archivos abiertos) que el sistema soporta en cualquier instancia.
El kernel asigna dinámicamente los manejadores de archivo cada vez que un manejador de archivo es solicitado por una aplicación. Sin embargo, el núcleo no libera estos manejadores de archivo cuando son liberados por la aplicación. El kernel recicla estos manejadores de archivo en su lugar. Esto significa que, con el tiempo, el número total de manejadores de archivo asignados aumentará aunque el número de manejadores de archivo utilizados actualmente sea bajo.
- kernel.shmall
-
Define el número total de páginas de memoria compartida que se pueden utilizar en todo el sistema. Para utilizar toda la memoria principal, el valor del parámetro
kernel.shmalldebe ser ≤ tamaño total de la memoria principal. - kernel.shmmax
- Define el tamaño máximo en bytes de un único segmento de memoria compartida que un proceso Linux puede asignar en su espacio de direcciones virtual.
- kernel.shmmni
- Define el número máximo de segmentos de memoria compartida que puede manejar el servidor de la base de datos.
- net.ipv4.ip_local_port_range
- Define el rango de puertos que el sistema puede utilizar para los programas que quieren conectarse a un servidor de base de datos sin un número de puerto específico.
- net.core.rmem_default
- Define la memoria del socket de recepción por defecto a través del Protocolo de Control de Transmisión (TCP).
- net.core.rmem_max
- Define la memoria máxima del socket de recepción a través del Protocolo de Control de Transmisión (TCP).
- net.core.wmem_default
- Define la memoria del socket de envío por defecto a través del Protocolo de Control de Transmisión (TCP).
- net.core.wmem_max
- Define la memoria máxima del socket de envío a través del Protocolo de Control de Transmisión (TCP).
- vm.dirty_bytes / vm.dirty_ratio
-
Define un umbral en bytes / en porcentaje de memoria sucia a partir del cual se inicia un proceso que genera datos sucios en la función
write().
Either vm.dirty_bytes or vm.dirty_ratio se puede especificar a la vez.
- vm.dirty_background_bytes / vm.dirty_background_ratio
- Define un umbral en bytes / en porcentaje de memoria sucia a partir del cual el núcleo intenta escribir activamente datos sucios en el disco duro.
Either vm.dirty_background_bytes or vm.dirty_background_ratio se puede especificar a la vez.
- vm.dirty_writeback_centisecs
Define un intervalo de tiempo entre los despertares periódicos de los hilos del kernel responsables de escribir los datos sucios en el disco duro.
Estos parámetros del núcleo se miden en centésimas de segundo.
- vm.dirty_expire_centisecs
Define el tiempo después del cual los datos sucios son lo suficientemente viejos para ser escritos en el disco duro.
Estos parámetros del núcleo se miden en centésimas de segundo.
Recursos adicionales
- Para la explicación de las devoluciones de datos sucios, cómo funcionan y qué parámetros del kernel se relacionan con ellos, vea el Dirty pagecache writeback and vm.dirty parameters documento.
Capítulo 42. Instalación y configuración de kdump
42.1. Qué es kdump
kdump es un servicio que proporciona un mecanismo de volcado de fallos. El servicio permite guardar el contenido de la memoria del sistema para su posterior análisis. kdump utiliza la llamada al sistema kexec para arrancar en el segundo núcleo (un capture kernel) sin reiniciar; y luego captura el contenido de la memoria del núcleo accidentado (un crash dump o un vmcore) y lo guarda. El segundo núcleo reside en una parte reservada de la memoria del sistema.
Un volcado del kernel puede ser la única información disponible en caso de fallo del sistema (un error crítico). Por lo tanto, asegurarse de que kdump está operativo es importante en entornos de misión crítica. Red Hat aconseja que los administradores de sistemas actualicen y prueben regularmente kexec-tools en su ciclo normal de actualización del kernel. Esto es especialmente importante cuando se implementan nuevas características del kernel.
42.2. Instalación de kdump
En muchos casos, el servicio kdump está instalado y activado por defecto en las nuevas instalaciones de Red Hat Enterprise Linux. El instalador de Anaconda instalador proporciona una pantalla para la configuración de kdump cuando se realiza una instalación interactiva utilizando la interfaz gráfica o de texto. La pantalla del instalador se titula Kdump y está disponible desde la pantalla principal Installation Summary, y sólo permite una configuración limitada - sólo puede seleccionar si kdump está activado y cuánta memoria está reservada.
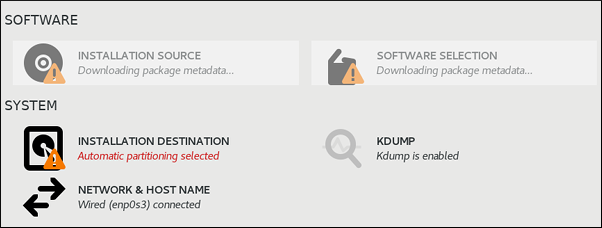
Algunas opciones de instalación, como las instalaciones Kickstart personalizadas, en algunos casos no instalan o habilitan kdump por defecto. Si este es el caso en su sistema, siga el procedimiento siguiente para instalar kdump.
Requisitos previos
- Una suscripción activa a Red Hat Enterprise Linux
- Un repositorio que contiene el kexec-tools para la arquitectura de la CPU de su sistema
-
Cumplió con los requisitos de
kdump
Procedimiento
Ejecute el siguiente comando para comprobar si
kdumpestá instalado en su sistema:$ rpm -q kexec-toolsSalida si el paquete está instalado:
kexec-tools-2.0.17-11.el8.x86_64Salida si el paquete no está instalado:
package kexec-tools is not installedInstalar
kdumpy otros paquetes necesarios por:# yum install kexec-tools
A partir de Red Hat Enterprise Linux 7.4 (kernel-3.10.0-693.el7) el controlador Intel IOMMU es soportado con kdump. Para versiones anteriores, Red Hat Enterprise Linux 7.3 (kernel-3.10.0-514[.XYZ].el7) y anteriores, se aconseja desactivar el soporte de Intel IOMMU, de lo contrario es probable que el kernel kdump no responda.
Recursos adicionales
-
La información sobre los requisitos de memoria de
kdumpestá disponible en Sección 42.5.1, “Requisitos de memoria para kdump”.
42.3. Configuración de kdump en la línea de comandos
42.3.1. Configuración del uso de la memoria de kdump
La memoria para kdump se reserva durante el arranque del sistema. El tamaño de la memoria se configura en el archivo de configuración del Grand Unified Bootloader (GRUB) 2 del sistema. El tamaño de la memoria depende del valor de crashkernel= especificado en el archivo de configuración y del tamaño de la memoria física del sistema.
La opción crashkernel= puede definirse de múltiples maneras. Puede especificar el valor crashkernel= o configurar la opción auto. La opción de arranque crashkernel=auto, reserva la memoria automáticamente, dependiendo de la cantidad total de la memoria física del sistema. Cuando se configura, el kernel reservará automáticamente una cantidad apropiada de memoria requerida para el kernel kdump. Esto ayuda a evitar que se produzcan errores de falta de memoria (OOM).
La asignación automática de memoria para kdump varía en función de la arquitectura del hardware del sistema y del tamaño de la memoria disponible.
Por ejemplo, en AMD64 e Intel 64, el parámetro crashkernel=auto sólo funciona cuando la memoria disponible es superior a 1GB y la arquitectura ARM de 64 bits e IBM Power Systems tienen una memoria disponible superior a 2GB.
Si el sistema tiene menos del umbral mínimo de memoria para la asignación automática, puede configurar la cantidad de memoria reservada manualmente.
Requisitos previos
-
Cumplió con los requisitos de
kdump
Procedimiento
-
Edite el archivo
/etc/default/grubutilizando los permisos de root. Ajuste la opción
crashkernel=al valor deseado.Por ejemplo, para reservar 128 MB de memoria, utilice lo siguiente:
crashkernel=128MAlternativamente, puede establecer la cantidad de memoria reservada en una variable en función de la cantidad total de memoria instalada. La sintaxis para la reserva de memoria en una variable es
crashkernel=<range1>:<size1>,<range2>:<size2>. Por ejemplo:crashkernel=512M-2G:64M,2G-:128MEl ejemplo anterior reserva 64 MB de memoria si la cantidad total de memoria del sistema es de 512 MB o superior e inferior a 2 GB. Si la cantidad total de memoria es superior a 2 GB, se reservan 128 MB para
kdump.Desplazar la memoria reservada.
Algunos sistemas requieren reservar la memoria con un cierto offset fijo ya que la reserva del crashkernel es muy temprana, y quiere reservar algún área para uso especial. Si se establece el offset, la memoria reservada comienza allí. Para compensar la memoria reservada, utilice la siguiente sintaxis:
crashkernel=128M@16MEl ejemplo anterior significa que
kdumpreserva 128 MB de memoria comenzando en 16 MB (dirección física 0x01000000). Si el parámetro offset se establece en 0 o se omite por completo,kdumpdesplaza la memoria reservada automáticamente. Esta sintaxis también se puede utilizar cuando se establece una reserva de memoria variable como se ha descrito anteriormente; en este caso, el offset siempre se especifica en último lugar (por ejemplo,crashkernel=512M-2G:64M,2G-:128M@16M).
Utilice el siguiente comando para actualizar el archivo de configuración de GRUB2:
# grub2-mkconfig -o /boot/grub2/grub.cfg
La forma alternativa de configurar la memoria para kdump es añadir el parámetro crashkernel=<SOME_VALUE> parámetro a la variable kernelopts con el grub2-editenv que actualizará todas sus entradas de arranque. O puede utilizar la utilidad grubby para actualizar los parámetros de la línea de comandos del kernel de una sola entrada.
Recursos adicionales
-
Para más información sobre las entradas de arranque,
kernelopts, y cómo trabajar congrub2-editenvygrubbyvea Configuración de los parámetros de la línea de comandos del kernel.
-
La opción
crashkernel=puede definirse de múltiples maneras. El valorautopermite la configuración automática de la memoria reservada en función de la cantidad total de memoria del sistema, siguiendo las pautas descritas en Requisitos de memoria para kdump. -
Para más información sobre las entradas de arranque,
kernelopts, y cómo trabajar congrub2-editenvygrubbyvea Configuración de los parámetros de la línea de comandos del kernel.
42.3.2. Configuración del objetivo kdump
Cuando se captura un fallo del kernel, el volcado del núcleo puede almacenarse como un archivo en un sistema de archivos local, escribirse directamente en un dispositivo o enviarse a través de una red utilizando el protocolo NFS (Network File System) o SSH (Secure Shell). Sólo se puede establecer una de estas opciones a la vez, y el comportamiento por defecto es almacenar el archivo vmcore en el directorio /var/crash/ del sistema de archivos local.
Requisitos previos
-
Cumplió con los requisitos de
kdump
Procedimiento
Para almacenar el archivo vmcore en el directorio /var/crash/ del sistema de archivos local:
Edite el archivo
/etc/kdump.confy especifique la ruta:ruta /var/crashLa opción
path /var/crashrepresenta la ruta del sistema de archivos en la quekdumpguarda el archivovmcore. Cuando se especifica un objetivo de volcado en el archivo/etc/kdump.conf, entonces elpathes relativo al objetivo de volcado especificado.Si no se especifica un objetivo de volcado en el archivo
/etc/kdump.conf, entonces elpathrepresenta la ruta absoluta desde el directorio raíz. Dependiendo de lo que esté montado en el sistema actual, el objetivo de volcado y la ruta de volcado ajustada se toman automáticamente.
kdump guarda el archivo vmcore en el directorio /var/crash/var/crash, cuando el objetivo de volcado está montado en /var/crash y la opción path también está configurada como /var/crash en el archivo /etc/kdump.conf. Por ejemplo, en el siguiente caso, el sistema de archivos ext4 ya está montado en /var/crash y la opción path está configurada como /var/crash:
grep -v ^# etc/kdump.conf | grep -v ^$
ext4 /dev/mapper/vg00-varcrashvol
path /var/crash
core_collector makedumpfile -c --message-level 1 -d 31
El resultado es la ruta /var/crash/var/crash. Para solucionar este problema, utilice la opción path / en lugar de path /var/crash
Para cambiar el directorio local en el que se debe guardar el volcado del núcleo, como root, edite el archivo de configuración /etc/kdump.conf como se describe a continuación.
-
Elimine el signo de almohadilla (\ "#") del principio de la línea
#path /var/crash. Sustituya el valor por la ruta del directorio deseado. Por ejemplo:
ruta /usr/local/coresImportanteEn Red Hat Enterprise Linux 8, el directorio definido como el objetivo de kdump utilizando la directiva
pathdebe existir cuando se inicia el serviciokdumpsystemd - de lo contrario el servicio falla. Este comportamiento es diferente de las versiones anteriores de Red Hat Enterprise Linux, donde el directorio se creaba automáticamente si no existía al iniciar el servicio.
Para escribir el archivo en una partición diferente, como root, edite el archivo de configuración /etc/kdump.conf como se describe a continuación.
Elimine el signo de almohadilla (\ "#") del principio de la línea
#ext4, según su elección.-
nombre del dispositivo (la línea
#ext4 /dev/vg/lv_kdump) -
etiqueta del sistema de archivos (la línea
#ext4 LABEL=/boot) -
UUID (la línea
#ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937)
-
nombre del dispositivo (la línea
Cambie el tipo de sistema de archivos así como el nombre del dispositivo, la etiqueta o el UUID a los valores deseados. Por ejemplo:
ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937ImportanteSe recomienda especificar los dispositivos de almacenamiento utilizando un
LABEL=oUUID=. No se garantiza que los nombres de los dispositivos de disco, como/dev/sda3, sean consistentes entre los reinicios.ImportanteAl volcar a un dispositivo de almacenamiento de acceso directo (DASD) en el hardware IBM Z, es esencial que los dispositivos de volcado se especifiquen correctamente en
/etc/dasd.confantes de proceder.
Para escribir el volcado directamente en un dispositivo:
-
Elimine el signo de almohadilla (\ "#") del principio de la línea
#raw /dev/vg/lv_kdump. Sustituya el valor por el nombre del dispositivo previsto. Por ejemplo:
raw /dev/sdb1
Para almacenar el volcado en una máquina remota utilizando el protocolo NFS:
-
Elimine el signo de almohadilla (\ "#") del principio de la línea
#nfs my.server.com:/export/tmp. Sustituya el valor por un nombre de host y una ruta de directorio válidos. Por ejemplo:
nfs pingüino.ejemplo.com:/exportar/núcleos
Para almacenar el volcado en una máquina remota utilizando el protocolo SSH:
-
Elimine el signo de almohadilla (\ "#") del principio de la
#ssh user@my.server.comlínea. - Sustituya el valor por un nombre de usuario y un nombre de host válidos.
Incluya su clave
SSHen la configuración.-
Elimine el signo de almohadilla del principio de la línea
#sshkey /root/.ssh/kdump_id_rsa. Cambie el valor por la ubicación de una clave válida en el servidor al que está intentando hacer el volcado. Por ejemplo:
ssh john@penguin.example.com sshkey /root/.ssh/mykey
-
Elimine el signo de almohadilla del principio de la línea
Recursos adicionales
- Para obtener una lista completa de los objetivos admitidos y no admitidos actualmente, ordenados por tipo, consulte Sección 42.5.3, “Objetivos de kdump compatibles”.
- Para obtener información sobre cómo configurar un servidor SSH y establecer una autenticación basada en claves, consulte Configuring basic system settings en Red Hat Enterprise Linux.
42.3.3. Configuración del colector central
El servicio kdump utiliza un programa core_collector para capturar la imagen vmcore. En RHEL, la utilidad makedumpfile es el recolector de núcleos por defecto.
makedumpfile es un programa de volcado que ayuda a comprimir el tamaño de un archivo de volcado y a copiar sólo las páginas necesarias utilizando varios niveles de volcado.
makedumpfile hace un archivo de volcado pequeño, ya sea comprimiendo los datos de volcado o excluyendo las páginas innecesarias, o ambas cosas. Necesita la primera información de depuración del kernel para entender cómo el primer kernel utiliza la memoria. Esto ayuda a detectar las páginas necesarias.
Sintaxis
core_collector makedumpfile -l --message-level 1 -d 31Opciones
-
-c,-lo-p: especifica el formato del archivo de volcado por cada página utilizando la opciónzlibpara-c,lzopara-losnappypara-p. -
-d(dump_level): excluye las páginas para que no se copien en el archivo de volcado. -
--message-level: especifica los tipos de mensajes. Puede restringir las salidas impresas especificandomessage_levelcon esta opción. Por ejemplo, especificando 7 comomessage_levelse imprimen los mensajes comunes y los mensajes de error. El valor máximo demessage_leveles 31
Requisitos previos
-
Cumplió con los requisitos de
kdump
Procedimiento
-
Como
root, edite el archivo de configuración/etc/kdump.confy elimine el signo de almohadilla ("#") del comienzo de#core_collector makedumpfile -l --message-level 1 -d 31. - Para activar la compresión del archivo de volcado, ejecute:
core_collector makedumpfile -l --message-level 1 -d 31donde,
-
-lespecifica el formato de archivo comprimidodump. -
-despecifica el nivel de volcado como 31. -
--message-levelespecifica el nivel del mensaje como 1.
Además, considere los siguientes ejemplos utilizando las opciones -c y -p:
-
Para comprimir el archivo de volcado utilizando
-c:
core_collector makedumpfile -c -d 31 --message-level 1-
Para comprimir el archivo de volcado utilizando
-p:
core_collector makedumpfile -p -d 31 --message-level 1Recursos adicionales
-
Consulte la página de manual
makedumpfile(8)para obtener una lista completa de las opciones disponibles.
42.3.4. Configuración de las respuestas a fallos por defecto de kdump
Por defecto, cuando kdump no consigue crear un archivo vmcore en la ubicación de destino especificada en Sección 42.3.2, “Configuración del objetivo kdump”, el sistema se reinicia y el volcado se pierde en el proceso. Para cambiar este comportamiento, siga el procedimiento siguiente.
Requisitos previos
-
Cumplió con los requisitos de
kdump
Procedimiento
-
Como
root, elimine el signo de almohadilla (\ "#") del comienzo de la línea#failure_actionen el archivo de configuración/etc/kdump.conf. Sustituya el valor por la acción deseada, como se describe en Sección 42.5.5, “Respuestas a fallos por defecto soportadas”. Por ejemplo:
failure_action poweroff
42.3.5. Activación y desactivación del servicio kdump
Para iniciar el servicio kdump en el momento del arranque, siga el siguiente procedimiento.
Requisitos previos
-
Cumplió los requisitos de
kdump. - Toda la configuración se establece de acuerdo con sus necesidades.
Procedimiento
Para activar el servicio
kdump, utilice el siguiente comando:# systemctl enable kdump.serviceEsto permite el servicio para
multi-user.target.Para iniciar el servicio en la sesión actual, utilice el siguiente comando:
# systemctl start kdump.servicePara detener el servicio
kdump, escriba el siguiente comando:# systemctl stop kdump.servicePara desactivar el servicio
kdump, ejecute el siguiente comando:# systemctl disable kdump.service
Se recomienda establecer kptr_restrict=1 como valor predeterminado. Cuando kptr_restrict se establece como (1) por defecto, el servicio kdumpctl carga el kernel de colisión incluso si Kernel Address Space Layout (KASLR) está habilitado o no.
Paso para la resolución de problemas
Cuando kptr_restrict no está configurado como (1), y si KASLR está activado, el contenido del archivo /proc/kore se genera como todos los ceros. En consecuencia, el servicio kdumpctl no puede acceder a /proc/kcore y cargar el kernel de colisión.
Para solucionar este problema, el archivo kexec-kdump-howto.txt muestra un mensaje de advertencia, en el que se especifica que se mantenga la configuración recomendada como kptr_restrict=1.
Para asegurarse de que el servicio kdumpctl carga el kernel de colisión, verifique que:
-
Kernel
kptr_restrict=1en el archivosysctl.conf.
Recursos adicionales
-
Para más información sobre
systemdy la configuración de servicios en general, consulte Configuring basic system settings en Red Hat Enterprise Linux.
42.4. Configuración de kdump en la consola web
Establezca y pruebe la configuración de kdump en la consola web de RHEL 8.
La consola web forma parte de la instalación por defecto de Red Hat Enterprise Linux 8 y activa o desactiva el servicio kdump en el momento del arranque. Además, la consola web le permite configurar convenientemente la memoria reservada para kdump; o seleccionar la ubicación de guardado de vmcore en un formato descomprimido o comprimido.
Requisitos previos
- Consulte Red Hat Enterprise Linux web console para más detalles.
42.4.1. Configurar el uso de memoria de kdump y la ubicación del objetivo en la consola web
El procedimiento siguiente le muestra cómo utilizar la pestaña Kernel Dump en la interfaz de la consola web de Red Hat Enterprise Linux para configurar la cantidad de memoria que se reserva para el kernel kdump. El procedimiento también describe cómo especificar la ubicación de destino del archivo de volcado de vmcore y cómo probar su configuración.
Requisitos previos
- Introducción al funcionamiento del web console
Procedimiento
-
Abra la pestaña
Kernel Dumpe inicie el serviciokdump. -
Configure el uso de la memoria de
kdumpa través del command line. Haga clic en el enlace junto a la opción
Crash dump location.
Seleccione la opción
Local Filesystemen el menú desplegable y especifique el directorio en el que desea guardar el volcado.
Alternativamente, seleccione la opción
Remote over SSHdel menú desplegable para enviar el vmcore a una máquina remota utilizando el protocolo SSH.Rellene los campos
Server,ssh key, yDirectorycon la dirección de la máquina remota, la ubicación de la clave ssh y un directorio de destino.Otra opción es seleccionar la opción
Remote over NFSen el desplegable y rellenar el campoMountpara enviar el vmcore a una máquina remota utilizando el protocolo NFS.NotaMarque la casilla
Compressionpara reducir el tamaño del archivo vmcore.
Pruebe su configuración haciendo fallar el kernel.
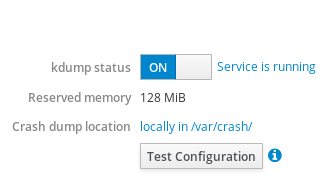 Aviso
AvisoEste paso interrumpe la ejecución del kernel y provoca la caída del sistema y la pérdida de datos.
42.5. Configuraciones y objetivos de kdump compatibles
42.5.1. Requisitos de memoria para kdump
Para que kdump pueda capturar un volcado del núcleo y guardarlo para su posterior análisis, una parte de la memoria del sistema tiene que estar permanentemente reservada para el núcleo de captura. Cuando se reserva, esta parte de la memoria del sistema no está disponible para el núcleo principal.
Los requisitos de memoria varían en función de ciertos parámetros del sistema. Uno de los principales factores es la arquitectura de hardware del sistema. Para averiguar la arquitectura exacta de la máquina (como Intel 64 y AMD64, también conocida como x86_64) e imprimirla en la salida estándar, utilice el siguiente comando:
$ uname -m
La siguiente tabla contiene una lista de requisitos mínimos de memoria para reservar automáticamente un tamaño de memoria para kdump. El tamaño cambia según la arquitectura del sistema y la memoria física total disponible.
| Arquitectura | Memoria disponible | Memoria mínima reservada |
|---|---|---|
|
AMD64 e Intel 64 ( | De 1 GB a 4 GB | 160 MB de RAM. |
| De 4 GB a 64 GB | 192 MB de RAM. | |
| De 64 GB a 1 TB | 256 MB de RAM. | |
| 1 TB y más | 512 MB de RAM. | |
|
Arquitectura ARM de 64 bits ( | 2 GB y más | 448 MB de RAM. |
|
IBM Power Systems ( | De 2 GB a 4 GB | 384 MB de RAM. |
| De 4 GB a 16 GB | 512 MB de RAM. | |
| De 16 GB a 64 GB | 1 GB de RAM. | |
| De 64 GB a 128 GB | 2 GB de RAM. | |
| 128 GB y más | 4 GB de RAM. | |
|
IBM Z ( | De 1 GB a 4 GB | 160 MB de RAM. |
| De 4 GB a 64 GB | 192 MB de RAM. | |
| De 64 GB a 1 TB | 256 MB de RAM. | |
| 1 TB y más | 512 MB de RAM. |
En muchos sistemas, kdump es capaz de estimar la cantidad de memoria necesaria y reservarla automáticamente. Este comportamiento está activado por defecto, pero sólo funciona en sistemas que tienen más de una determinada cantidad de memoria total disponible, que varía en función de la arquitectura del sistema.
La configuración automática de la memoria reservada basada en la cantidad total de memoria del sistema es una estimación del mejor esfuerzo. La memoria real requerida puede variar debido a otros factores como los dispositivos de E/S. Utilizar una cantidad insuficiente de memoria puede provocar que un kernel de depuración no sea capaz de arrancar como un kernel de captura en caso de pánico del kernel. Para evitar este problema, aumente suficientemente la memoria del kernel de captura.
Recursos adicionales
- Para obtener información sobre cómo cambiar la configuración de la memoria en la línea de comandos, consulte Sección 42.3.1, “Configuración del uso de la memoria de kdump”.
- Para obtener instrucciones sobre cómo configurar la cantidad de memoria reservada a través de la consola web, consulte Sección 42.4.1, “Configurar el uso de memoria de kdump y la ubicación del objetivo en la consola web”.
- Para más información sobre las diversas capacidades y límites de la tecnología de Red Hat Enterprise Linux, consulte el technology capabilities and limits tables.
42.5.2. Umbral mínimo para la reserva automática de memoria
En algunos sistemas, es posible asignar memoria para kdump automáticamente, ya sea utilizando el parámetro crashkernel=auto en el archivo de configuración del cargador de arranque, o habilitando esta opción en la utilidad de configuración gráfica. Sin embargo, para que esta reserva automática funcione, es necesario que haya una cierta cantidad de memoria total disponible en el sistema. Esta cantidad varía en función de la arquitectura del sistema.
La tabla siguiente enumera los umbrales para la asignación automática de memoria. Si el sistema tiene menos memoria que la especificada en la tabla, es necesario reservar la memoria manualmente.
| Arquitectura | Memoria necesaria |
|---|---|
|
AMD64 e Intel 64 ( | 2 GB |
|
IBM Power Systems ( | 2 GB |
|
IBM Z ( | 4 GB |
Recursos adicionales
- Para obtener información sobre cómo cambiar manualmente estos ajustes en la línea de comandos, consulte Sección 42.3.1, “Configuración del uso de la memoria de kdump”.
- Para obtener instrucciones sobre cómo cambiar manualmente la cantidad de memoria reservada a través de la consola web, consulte Sección 42.4.1, “Configurar el uso de memoria de kdump y la ubicación del objetivo en la consola web”.
42.5.3. Objetivos de kdump compatibles
Cuando se captura un fallo del kernel, el archivo de volcado de vmcore puede escribirse directamente en un dispositivo, almacenarse como un archivo en un sistema de archivos local o enviarse a través de una red. La siguiente tabla contiene una lista completa de los objetivos de volcado que actualmente son compatibles o que no son explícitamente compatibles con kdump.
| Tipo | Objetivos compatibles | Objetivos no compatibles |
|---|---|---|
| Dispositivo en bruto | Todos los discos y particiones raw conectados localmente. | |
| Sistema de archivos local |
|
Cualquier sistema de archivos local que no aparezca explícitamente en esta tabla, incluido el tipo |
| Directorio remoto |
Directorios remotos a los que se accede mediante el protocolo |
Directorios remotos en el sistema de archivos |
|
Directorios remotos a los que se accede mediante el protocolo |
Directorios remotos a los que se accede mediante el protocolo | Almacenes basados en la trayectoria múltiple. |
|
Directorios remotos a los que se accede a través de | ||
|
Directorios remotos a los que se accede mediante el protocolo | ||
|
Directorios remotos a los que se accede mediante el protocolo | ||
| Directorios remotos a los que se accede mediante interfaces de red inalámbricas. | ||
Utilizar el volcado asistido por el firmware (fadump) para capturar un vmcore y almacenarlo en una máquina remota utilizando el protocolo SSH o NFS provoca el cambio de nombre de la interfaz de red a kdump-<interface-name>. El cambio de nombre ocurre si el <interface-name> es genérico, por ejemplo *eth#, net#, y así sucesivamente. Este problema se produce porque los scripts de captura de vmcore en el disco RAM inicial (initrd) añaden el prefijo kdump- al nombre de la interfaz de red para asegurar la persistencia del nombre. Como el mismo initrd se utiliza también para un arranque normal, el nombre de la interfaz se cambia también para el kernel de producción.
Recursos adicionales
- Para obtener información sobre cómo configurar el tipo de destino en la línea de comandos, consulte Sección 42.3.2, “Configuración del objetivo kdump”.
- Para obtener información sobre cómo configurar el objetivo a través de la consola web, consulte Sección 42.4.1, “Configurar el uso de memoria de kdump y la ubicación del objetivo en la consola web”.
42.5.4. Niveles de filtrado de kdump soportados
Para reducir el tamaño del archivo de volcado, kdump utiliza el recopilador central makedumpfile para comprimir los datos y, opcionalmente, para omitir la información no deseada. La siguiente tabla contiene una lista completa de los niveles de filtrado que actualmente admite la utilidad makedumpfile.
| Opción | Descripción |
|---|---|
|
| Cero páginas |
|
| Páginas de caché |
|
| Caché privado |
|
| Páginas de usuarios |
|
| Páginas libres |
El comando makedumpfile soporta la eliminación de páginas enormes transparentes y páginas hugetlbfs. Considere estos dos tipos de páginas de usuario hugepages y elimínelos utilizando el nivel -8.
Recursos adicionales
- Para obtener instrucciones sobre cómo configurar el recopilador de núcleos en la línea de comandos, consulte Sección 42.3.3, “Configuración del colector central”.
42.5.5. Respuestas a fallos por defecto soportadas
Por defecto, cuando kdump no consigue crear un volcado de núcleo, el sistema operativo se reinicia. Sin embargo, puede configurar kdump para que realice una operación diferente en caso de que falle al guardar el volcado del núcleo en el objetivo primario. La siguiente tabla enumera todas las acciones por defecto que se admiten actualmente.
| Opción | Descripción |
|---|---|
|
| Intenta guardar el volcado del núcleo en el sistema de archivos raíz. Esta opción es especialmente útil en combinación con un objetivo de red: si el objetivo de red es inalcanzable, esta opción configura kdump para guardar el volcado del núcleo localmente. El sistema se reinicia después. |
|
| Reinicie el sistema, perdiendo el volcado del núcleo en el proceso. |
|
| Detener el sistema, perdiendo el volcado del núcleo en el proceso. |
|
| Apagar el sistema, perdiendo el volcado del núcleo en el proceso. |
|
| Ejecuta una sesión de shell desde el initramfs, permitiendo al usuario grabar el volcado del núcleo manualmente. |
Recursos adicionales
- Para obtener información detallada sobre cómo configurar las respuestas a fallos por defecto en la línea de comandos, consulte Sección 42.3.4, “Configuración de las respuestas a fallos por defecto de kdump”.
42.5.6. Estimación del tamaño del kdump
Cuando se planifica y se construye el entorno de kdump, es necesario saber cuánto espacio se necesita para el archivo de volcado antes de producir uno.
El comando makedumpfile --mem-usage proporciona un informe útil sobre las páginas excluibles, y puede utilizarse para determinar el nivel de volcado que desea asignar. Ejecute este comando cuando el sistema esté bajo una carga representativa, de lo contrario makedumpfile --mem-usage devuelve un valor menor del que se espera en su entorno de producción.
[root@hostname ~]# makedumpfile --mem-usage /proc/kcore
TYPE PAGES EXCLUDABLE DESCRIPTION
----------------------------------------------------------------------
ZERO 501635 yes Pages filled with zero
CACHE 51657 yes Cache pages
CACHE_PRIVATE 5442 yes Cache pages + private
USER 16301 yes User process pages
FREE 77738211 yes Free pages
KERN_DATA 1333192 no Dumpable kernel data
El comando makedumpfile --mem-usage informa en pages. Esto significa que tiene que calcular el tamaño de la memoria en uso contra el tamaño de página del kernel. Por defecto, el kernel de Red Hat Enterprise Linux utiliza páginas de 4 KB para las arquitecturas AMD64 e Intel 64, y páginas de 64 KB para las arquitecturas IBM POWER.
42.6. Probando la configuración de kdump
El siguiente procedimiento describe cómo probar que el proceso de volcado del núcleo funciona y es válido antes de que la máquina entre en producción.
Los siguientes comandos hacen que el kernel se bloquee. Tenga cuidado al seguir estos pasos, y nunca los use sin cuidado en un sistema de producción activo.
Procedimiento
-
Reinicie el sistema con
kdumpactivado. Asegúrese de que
kdumpestá funcionando:~]# systemctl is-active kdump activeForzar la caída del kernel de Linux:
echo 1 > /proc/sys/kernel/sysrq echo c > /proc/sysrq-triggerAvisoEl comando anterior bloquea el kernel y se requiere un reinicio.
Una vez arrancado de nuevo, el archivo
address-YYYY-MM-DD-HH:MM:SS/vmcorese crea en la ubicación que hayas especificado en/etc/kdump.conf(por defecto en/var/crash/).NotaAdemás de confirmar la validez de la configuración, es posible usar esta acción para registrar el tiempo que tarda en completarse un volcado de fallos, mientras se ejecuta una carga representativa.
42.7. Uso de kexec para reiniciar el kernel
La llamada al sistema kexec permite cargar y arrancar en otro kernel desde el kernel que se está ejecutando actualmente, realizando así una función de cargador de arranque desde el kernel.
La utilidad kexec carga el kernel y la imagen initramfs para que la llamada al sistema kexec arranque en otro kernel.
El siguiente procedimiento describe cómo invocar manualmente la llamada al sistema kexec cuando se utiliza la utilidad kexec para reiniciar en otro núcleo.
Procedimiento
Ejecute la utilidad
kexec:# kexec -l /boot/vmlinuz-3.10.0-1040.el7.x86_64 --initrd=/boot/initramfs-3.10.0-1040.el7.x86_64.img --reuse-cmdlineEl comando carga manualmente el kernel y la imagen initramfs para la llamada al sistema
kexec.Reinicia el sistema:
# rebootEl comando detecta el kernel, apaga todos los servicios y luego llama a la llamada del sistema
kexecpara reiniciar en el kernel que proporcionaste en el paso anterior.
Cuando se utiliza el comando kexec -e para reiniciar el kernel, el sistema no pasa por la secuencia de apagado estándar antes de iniciar el siguiente kernel, lo que puede provocar la pérdida de datos o que el sistema no responda.
42.8. Lista negra de controladores del kernel para kdump
Poner en la lista negra los controladores del kernel para kdump es un mecanismo para evitar que se carguen los controladores del kernel previstos. La inclusión en la lista negra de los controladores del kernel evita los fallos de oom killer u otros fallos del kernel.
Para poner en la lista negra los controladores del kernel, puede actualizar la variable KDUMP_COMMANDLINE_APPEND= en el archivo /etc/sysconfig/kdump y especificar una de las siguientes opciones de lista negra:
-
rd.driver.blacklist=<modules> -
modprobe.blacklist=<modules>
Cuando se incluye una lista negra de controladores en el archivo /etc/sysconfig/kdump, se impide que kdump initramfs cargue los módulos incluidos en la lista negra.
El siguiente procedimiento describe cómo poner en la lista negra un controlador del kernel para evitar fallos en el kernel.
Procedimiento
Seleccione el módulo del kernel que desea incluir en la lista negra:
$ lsmod Module Size Used by fuse 126976 3 xt_CHECKSUM 16384 1 ipt_MASQUERADE 16384 1 uinput 20480 1 xt_conntrack 16384 1El comando
lsmodmuestra una lista de los módulos que se cargan en el kernel que se está ejecutando actualmente.Actualice la línea
KDUMP_COMMANDLINE_APPEND=en el archivo/etc/sysconfig/kdumpcomo sigue:KDUMP_COMMANDLINE_APPEND="rd.driver.blacklist=hv_vmbus,hv_storvsc,hv_utils,hv_netvsc,hid-hyperv"También puede actualizar la línea
KDUMP_COMMANDLINE_APPEND=en el archivo/etc/sysconfig/kdumpde la siguiente manera:KDUMP_COMMANDLINE_APPEND="modprobe.blacklist=emcp modprobe.blacklist=bnx2fc modprobe.blacklist=libfcoe modprobe.blacklist=fcoe"Reinicie el servicio
kdump:$ systemctl restart kdump
Recursos adicionales
-
Para más información sobre la página web
oom killer, consulte el siguiente artículo de conocimiento. -
La página de manual
dracut.cmdlinepara las opciones de la lista negra de módulos.
42.9. Ejecución de kdump en sistemas con disco encriptado
Cuando se ejecuta una partición cifrada creada por la herramienta Logical Volume Manager (LVM), los sistemas requieren una cierta cantidad de memoria disponible. Si el sistema tiene menos de la cantidad requerida de memoria disponible, la utilidad cryptsetup falla al montar la partición. Como resultado, la captura del archivo vmcore a una ubicación de destino local kdump (con LVM y cifrado activado), falla en el segundo núcleo (núcleo de captura).
Este procedimiento describe el mecanismo de ejecución de kdump aumentando el valor de crashkernel=, utilizando un objetivo remoto kdump, o utilizando una función de derivación de claves (KDF).
Procedimiento
Ejecute el mecanismo kdump utilizando uno de los siguientes procedimientos:
Para ejecutar el
kdumpdefina una de las siguientes opciones:-
Configurar un objetivo remoto
kdump. - Definir el volcado a una partición no cifrada.
-
Especifique un valor incrementado de
crashkernel=hasta el nivel requerido.
-
Configurar un objetivo remoto
Añade una ranura de clave adicional utilizando una función de derivación de clave (KDF):
-
cryptsetup luksAddKey --pbkdf pbkdf2 /dev/vda2 -
cryptsetup config --key-slot 1 --priority prefer /dev/vda2 -
cryptsetup luksDump /dev/vda2
-
El uso del KDF por defecto de la partición cifrada puede consumir mucha memoria. Debe proporcionar manualmente la contraseña en el segundo kernel (captura), incluso si se encuentra con un mensaje de error de memoria insuficiente (OOM).
Añadir una ranura de llave adicional puede tener un efecto negativo en la seguridad, ya que varias llaves pueden descifrar un volumen cifrado. Esto puede causar un riesgo potencial para el volumen.
42.10. Mecanismos de volcado asistidos por el firmware
El volcado asistido por el firmware (fadump) es un mecanismo de captura de volcados, proporcionado como alternativa al mecanismo kdump en los sistemas IBM POWER. Los mecanismos kexec y kdump son útiles para capturar volcados de núcleo en sistemas AMD64 e Intel 64. Sin embargo, algunos hardware, como los minisistemas y los ordenadores centrales, aprovechan el firmware de la placa para aislar regiones de la memoria y evitar cualquier sobrescritura accidental de datos que sean importantes para el análisis del fallo. Esta sección cubre los mecanismos de fadump y cómo se integran con RHEL. La utilidad fadump está optimizada para estas funciones de volcado ampliadas en los sistemas IBM POWER.
42.10.1. Volcado asistido de firmware en hardware IBM PowerPC
La utilidad fadump captura el archivo vmcore de un sistema totalmente reiniciado con dispositivos PCI y de E/S. Este mecanismo utiliza el firmware para preservar las regiones de memoria durante un fallo y luego reutiliza los scripts de espacio de usuario kdump para guardar el archivo vmcore. Las regiones de memoria consisten en todo el contenido de la memoria del sistema, excepto la memoria de arranque, los registros del sistema y las entradas de la tabla de páginas del hardware (PTE).
El mecanismo fadump ofrece una mayor fiabilidad que el tipo de volcado tradicional, al reiniciar la partición y utilizar un nuevo núcleo para volcar los datos del fallo del núcleo anterior. El fadump requiere una plataforma de hardware basada en el procesador IBM POWER6 o una versión posterior.
Para más detalles sobre el mecanismo fadump, incluyendo los métodos específicos de PowerPC para restablecer el hardware, consulte el archivo /usr/share/doc/kexec-tools/fadump-howto.txt.
El área de memoria que no se conserva, conocida como memoria de arranque, es la cantidad de RAM necesaria para arrancar con éxito el kernel después de un evento de caída. Por defecto, el tamaño de la memoria de arranque es de 256MB o el 5% del total de la RAM del sistema, lo que sea mayor.
A diferencia del evento kexec-initiated, el mecanismo fadump utiliza el kernel de producción para recuperar un volcado de colisión. Al arrancar después de un fallo, el hardware PowerPC pone el nodo de dispositivo /proc/device-tree/rtas/ibm.kernel-dump a disposición del sistema de archivos proc (procfs). Los scripts fadump-aware kdump, comprueban el vmcore almacenado, y luego completan el reinicio del sistema limpiamente.
42.10.2. Habilitación del mecanismo de volcado asistido por el firmware
Las capacidades de volcado de fallos de los sistemas IBM POWER pueden mejorarse activando el mecanismo de volcado asistido por el firmware (fadump).
Procedimiento
-
Instale y configure
kdumpcomo se describe en el capítulo 7, "Instalación y configuración de kdump". Añada
fadump=ona la líneaGRUB_CMDLINE_LINUXen el archivo/etc/default/grub:GRUB_CMDLINE_LINUX="rd.lvm.lv=rhel/swap crashkernel=auto rd.lvm.lv=rhel/root rhgb quiet fadump=on"(Opcional) Si desea especificar la memoria de arranque reservada en lugar de utilizar los valores predeterminados, configure
crashkernel=xxMaGRUB_CMDLINE_LINUXen/etc/default/grub, dondexxes la cantidad de memoria necesaria en megabytes:GRUB_CMDLINE_LINUX="rd.lvm.lv=rhel/swap crashkernel=xxM rd.lvm.lv=rhel/root rhgb quiet fadump=on"ImportanteRed Hat recomienda probar todas las opciones de configuración de arranque antes de ejecutarlas. Si observa errores de falta de memoria (OOM) al arrancar desde el kernel de bloqueo, incremente el valor especificado en el argumento
crashkernel=hasta que el kernel de bloqueo pueda arrancar limpiamente. En este caso puede ser necesario un poco de prueba y error.
42.10.3. Mecanismos de volcado asistidos por el firmware en el hardware IBM Z
Los sistemas IBM Z soportan los siguientes mecanismos de volcado asistidos por firmware:
-
Stand-alone dump (sadump) -
VMDUMP
La infraestructura kdump es soportada y utilizada en sistemas IBM Z. Para configurar kdump desde RHEL, véase el capítulo 7, "Instalación y configuración de kdump".
Sin embargo, el uso de uno de los métodos de volcado asistido por firmware (fadump) para IBM Z puede proporcionar varios beneficios:
-
El mecanismo
sadumpse inicia y controla desde la consola del sistema, y se almacena en un dispositivo de arranqueIPL. -
El mecanismo de
VMDUMPes similar al desadump. Esta herramienta también se inicia desde la consola del sistema, pero recupera el volcado resultante del hardware y lo copia en el sistema para su análisis. -
Estos métodos (al igual que otros mecanismos de volcado basados en hardware) tienen la capacidad de capturar el estado de una máquina en la fase inicial de arranque, antes de que se inicie el servicio
kdump. -
Aunque
VMDUMPcontiene un mecanismo para recibir el archivo de volcado en un sistema Red Hat Enterprise Linux, la configuración y el control deVMDUMPse gestiona desde la consola de IBM Z Hardware.
IBM discute sadump en detalle en el artículo del programa de volcado autónomo y VMDUMP en el artículo Creación de volcados en z/VM con VMDUMP.
IBM también tiene un conjunto de documentación para usar las herramientas de volcado en Red Hat Enterprise Linux 7 en el artículo Uso de las herramientas de volcado en Red Hat Enterprise Linux 7.4.
42.10.4. Uso de sadump en los sistemas Fujitsu PRIMEQUEST
El mecanismo de Fujitsu sadump está diseñado para proporcionar una captura de volcado de fallback en caso de que kdump no pueda completarse con éxito. El mecanismo sadump se invoca manualmente desde la interfaz de la placa de gestión del sistema (MMB). Utilizando la MMB, configure kdump como para un servidor Intel 64 o AMD 64 y luego realice los siguientes pasos adicionales para habilitar sadump.
Procedimiento
Añada o edite las siguientes líneas en el archivo
/etc/sysctl.confpara asegurarse de quekdumpse inicie como se espera parasadump:kernel.panic=0 kernel.unknown_nmi_panic=1AvisoEn particular, asegúrese de que después de
kdump, el sistema no se reinicie. Si el sistema se reinicia después de quekdumpno haya guardado el archivovmcore, entonces no será posible invocar el programasadump.Establezca el parámetro
failure_actionen/etc/kdump.confadecuadamente comohaltoshell.shell failure_action
Recursos adicionales
Para obtener detalles sobre la configuración de su hardware para sadump, consulte el Manual de instalación del servidor FUJITSU PRIMEQUEST Serie 2000.
42.11. Analizar un volcado de núcleo
Para determinar la causa del fallo del sistema, puede utilizar la utilidad crash que proporciona un indicador interactivo muy similar al depurador de GNU (GDB). Esta utilidad le permite analizar interactivamente un volcado de núcleo creado por kdump, netdump, diskdump o xendump así como un sistema Linux en funcionamiento. Como alternativa, tiene la opción de utilizar el botón Kdump Helper o Kernel Oops Analyzer.
42.11.1. Instalación de la utilidad de choque
El siguiente procedimiento describe cómo instalar la crash herramienta de análisis.
Procedimiento
Habilite los repositorios correspondientes:
# subscription-manager repos --enable baseos repository# subscription-manager repos --enable appstream repository# subscription-manager repos --enable rhel-8-for-x86_64-baseos-debug-rpmsInstale el paquete
crash:# yum install crashInstale el paquete
kernel-debuginfo:# yum install kernel-debuginfoEl paquete corresponde a su núcleo en funcionamiento y proporciona los datos necesarios para el análisis del volcado.
Recursos adicionales
-
Para obtener más información sobre cómo trabajar con los repositorios utilizando la utilidad
subscription-manager, consulte Configuring basic system settings.
42.11.2. Ejecutar y salir de la utilidad de choque
El siguiente procedimiento describe cómo iniciar la utilidad de bloqueo para analizar la causa del bloqueo del sistema.
Requisitos previos
-
Identifica el núcleo que se está ejecutando actualmente (por ejemplo
4.18.0-5.el8.x86_64).
Procedimiento
Para iniciar la utilidad
crash, hay que pasar dos parámetros necesarios al comando:-
El debug-info (una imagen vmlinuz descomprimida), por ejemplo
/usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinuxproporcionada a través de un paquete específicokernel-debuginfo. El archivo vmcore real, por ejemplo
/var/crash/127.0.0.1-2018-10-06-14:05:33/vmcoreEl comando
crashresultante tiene el siguiente aspecto:# crash /usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinux /var/crash/127.0.0.1-2018-10-06-14:05:33/vmcoreUtilice la misma versión de <kernel> que fue capturada por
kdump.Ejemplo 42.1. Ejecución de la utilidad de choque
El siguiente ejemplo muestra el análisis de un volcado de núcleo creado el 6 de octubre de 2018 a las 14:05 PM, utilizando el kernel 4.18.0-5.el8.x86_64.
... WARNING: kernel relocated [202MB]: patching 90160 gdb minimal_symbol values KERNEL: /usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinux DUMPFILE: /var/crash/127.0.0.1-2018-10-06-14:05:33/vmcore [PARTIAL DUMP] CPUS: 2 DATE: Sat Oct 6 14:05:16 2018 UPTIME: 01:03:57 LOAD AVERAGE: 0.00, 0.00, 0.00 TASKS: 586 NODENAME: localhost.localdomain RELEASE: 4.18.0-5.el8.x86_64 VERSION: #1 SMP Wed Aug 29 11:51:55 UTC 2018 MACHINE: x86_64 (2904 Mhz) MEMORY: 2.9 GB PANIC: "sysrq: SysRq : Trigger a crash" PID: 10635 COMMAND: "bash" TASK: ffff8d6c84271800 [THREAD_INFO: ffff8d6c84271800] CPU: 1 STATE: TASK_RUNNING (SYSRQ) crash>
-
El debug-info (una imagen vmlinuz descomprimida), por ejemplo
Para salir del indicador interactivo y terminar
crash, escribaexitoq.Ejemplo 42.2. Salir de la utilidad de choque
crash> exit ~]#
El comando crash también puede utilizarse como una poderosa herramienta para depurar un sistema en vivo. Sin embargo, utilízalo con precaución para no romper tu sistema.
42.11.3. Visualización de varios indicadores en la utilidad de choque
Los siguientes procedimientos describen cómo utilizar la utilidad de bloqueo y mostrar varios indicadores, como un búfer de mensajes del kernel, un backtrace, un estado del proceso, información de la memoria virtual y archivos abiertos.
- Visualización del buffer de mensajes
-
Para mostrar el búfer de mensajes del kernel, escriba el comando
logen el indicador interactivo como se muestra en el ejemplo siguiente:
crash> log ... several lines omitted ... EIP: 0060:[<c068124f>] EFLAGS: 00010096 CPU: 2 EIP is at sysrq_handle_crash+0xf/0x20 EAX: 00000063 EBX: 00000063 ECX: c09e1c8c EDX: 00000000 ESI: c0a09ca0 EDI: 00000286 EBP: 00000000 ESP: ef4dbf24 DS: 007b ES: 007b FS: 00d8 GS: 00e0 SS: 0068 Process bash (pid: 5591, ti=ef4da000 task=f196d560 task.ti=ef4da000) Stack: c068146b c0960891 c0968653 00000003 00000000 00000002 efade5c0 c06814d0 <0> fffffffb c068150f b7776000 f2600c40 c0569ec4 ef4dbf9c 00000002 b7776000 <0> efade5c0 00000002 b7776000 c0569e60 c051de50 ef4dbf9c f196d560 ef4dbfb4 Call Trace: [<c068146b>] ? __handle_sysrq+0xfb/0x160 [<c06814d0>] ? write_sysrq_trigger+0x0/0x50 [<c068150f>] ? write_sysrq_trigger+0x3f/0x50 [<c0569ec4>] ? proc_reg_write+0x64/0xa0 [<c0569e60>] ? proc_reg_write+0x0/0xa0 [<c051de50>] ? vfs_write+0xa0/0x190 [<c051e8d1>] ? sys_write+0x41/0x70 [<c0409adc>] ? syscall_call+0x7/0xb Code: a0 c0 01 0f b6 41 03 19 d2 f7 d2 83 e2 03 83 e0 cf c1 e2 04 09 d0 88 41 03 f3 c3 90 c7 05 c8 1b 9e c0 01 00 00 00 0f ae f8 89 f6 <c6> 05 00 00 00 00 01 c3 89 f6 8d bc 27 00 00 00 00 8d 50 d0 83 EIP: [<c068124f>] sysrq_handle_crash+0xf/0x20 SS:ESP 0068:ef4dbf24 CR2: 0000000000000000Escriba
help logpara obtener más información sobre el uso del comando.NotaEl búfer de mensajes del kernel incluye la información más esencial sobre el fallo del sistema y, como tal, siempre se vuelca primero en el archivo
vmcore-dmesg.txt. Esto es útil cuando un intento de obtener el archivovmcorecompleto falla, por ejemplo, por falta de espacio en la ubicación de destino. Por defecto,vmcore-dmesg.txtse encuentra en el directorio/var/crash/.-
Para mostrar el búfer de mensajes del kernel, escriba el comando
- Visualización de un backtrace
-
Para mostrar el seguimiento de la pila del kernel, utilice el comando
bt.
crash> bt PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash" #0 [ef4dbdcc] crash_kexec at c0494922 #1 [ef4dbe20] oops_end at c080e402 #2 [ef4dbe34] no_context at c043089d #3 [ef4dbe58] bad_area at c0430b26 #4 [ef4dbe6c] do_page_fault at c080fb9b #5 [ef4dbee4] error_code (via page_fault) at c080d809 EAX: 00000063 EBX: 00000063 ECX: c09e1c8c EDX: 00000000 EBP: 00000000 DS: 007b ESI: c0a09ca0 ES: 007b EDI: 00000286 GS: 00e0 CS: 0060 EIP: c068124f ERR: ffffffff EFLAGS: 00010096 #6 [ef4dbf18] sysrq_handle_crash at c068124f #7 [ef4dbf24] __handle_sysrq at c0681469 #8 [ef4dbf48] write_sysrq_trigger at c068150a #9 [ef4dbf54] proc_reg_write at c0569ec2 #10 [ef4dbf74] vfs_write at c051de4e #11 [ef4dbf94] sys_write at c051e8cc #12 [ef4dbfb0] system_call at c0409ad5 EAX: ffffffda EBX: 00000001 ECX: b7776000 EDX: 00000002 DS: 007b ESI: 00000002 ES: 007b EDI: b7776000 SS: 007b ESP: bfcb2088 EBP: bfcb20b4 GS: 0033 CS: 0073 EIP: 00edc416 ERR: 00000004 EFLAGS: 00000246Escriba
bt <pid>para mostrar el backtrace de un proceso específico o escribahelp btpara obtener más información sobre el uso debt.-
Para mostrar el seguimiento de la pila del kernel, utilice el comando
- Visualización del estado de un proceso
-
Para mostrar el estado de los procesos en el sistema, utilice el comando
ps.
crash> ps PID PPID CPU TASK ST %MEM VSZ RSS COMM > 0 0 0 c09dc560 RU 0.0 0 0 [swapper] > 0 0 1 f7072030 RU 0.0 0 0 [swapper] 0 0 2 f70a3a90 RU 0.0 0 0 [swapper] > 0 0 3 f70ac560 RU 0.0 0 0 [swapper] 1 0 1 f705ba90 IN 0.0 2828 1424 init ... several lines omitted ... 5566 1 1 f2592560 IN 0.0 12876 784 auditd 5567 1 2 ef427560 IN 0.0 12876 784 auditd 5587 5132 0 f196d030 IN 0.0 11064 3184 sshd > 5591 5587 2 f196d560 RU 0.0 5084 1648 bashUtilice
ps <pid>para mostrar el estado de un solo proceso específico. Utilice help ps para obtener más información sobre el uso deps.-
Para mostrar el estado de los procesos en el sistema, utilice el comando
- Visualización de la información de la memoria virtual
-
Para mostrar la información básica de la memoria virtual, escriba el comando
vmen el indicador interactivo.
crash> vm PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash" MM PGD RSS TOTAL_VM f19b5900 ef9c6000 1648k 5084k VMA START END FLAGS FILE f1bb0310 242000 260000 8000875 /lib/ld-2.12.so f26af0b8 260000 261000 8100871 /lib/ld-2.12.so efbc275c 261000 262000 8100873 /lib/ld-2.12.so efbc2a18 268000 3ed000 8000075 /lib/libc-2.12.so efbc23d8 3ed000 3ee000 8000070 /lib/libc-2.12.so efbc2888 3ee000 3f0000 8100071 /lib/libc-2.12.so efbc2cd4 3f0000 3f1000 8100073 /lib/libc-2.12.so efbc243c 3f1000 3f4000 100073 efbc28ec 3f6000 3f9000 8000075 /lib/libdl-2.12.so efbc2568 3f9000 3fa000 8100071 /lib/libdl-2.12.so efbc2f2c 3fa000 3fb000 8100073 /lib/libdl-2.12.so f26af888 7e6000 7fc000 8000075 /lib/libtinfo.so.5.7 f26aff2c 7fc000 7ff000 8100073 /lib/libtinfo.so.5.7 efbc211c d83000 d8f000 8000075 /lib/libnss_files-2.12.so efbc2504 d8f000 d90000 8100071 /lib/libnss_files-2.12.so efbc2950 d90000 d91000 8100073 /lib/libnss_files-2.12.so f26afe00 edc000 edd000 4040075 f1bb0a18 8047000 8118000 8001875 /bin/bash f1bb01e4 8118000 811d000 8101873 /bin/bash f1bb0c70 811d000 8122000 100073 f26afae0 9fd9000 9ffa000 100073 ... several lines omitted ...Utilice
vm <pid>para mostrar información sobre un solo proceso específico, o utilicehelp vmpara obtener más información sobre el uso devm.-
Para mostrar la información básica de la memoria virtual, escriba el comando
- Visualización de expedientes abiertos
-
Para mostrar información sobre los archivos abiertos, utilice el comando
files.
crash> files PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash" ROOT: / CWD: /root FD FILE DENTRY INODE TYPE PATH 0 f734f640 eedc2c6c eecd6048 CHR /pts/0 1 efade5c0 eee14090 f00431d4 REG /proc/sysrq-trigger 2 f734f640 eedc2c6c eecd6048 CHR /pts/0 10 f734f640 eedc2c6c eecd6048 CHR /pts/0 255 f734f640 eedc2c6c eecd6048 CHR /pts/0Utilice
files <pid>para mostrar los archivos abiertos por un solo proceso seleccionado, o utilicehelp filespara obtener más información sobre el uso defiles.-
Para mostrar información sobre los archivos abiertos, utilice el comando
42.11.4. Uso de Kernel Oops Analyzer
El Kernel Oops Analyzer es una herramienta que analiza el volcado de fallos comparando los mensajes oops con los problemas conocidos en la base de conocimientos.
Requisitos previos
- Asegure un mensaje oops para alimentar el Kernel Oops Analyzer siguiendo las instrucciones en Red Hat Labs.
Procedimiento
- Siga el Kernel Oops Analyzer enlace para acceder a la herramienta.
Busque el mensaje oops pulsando el botón .
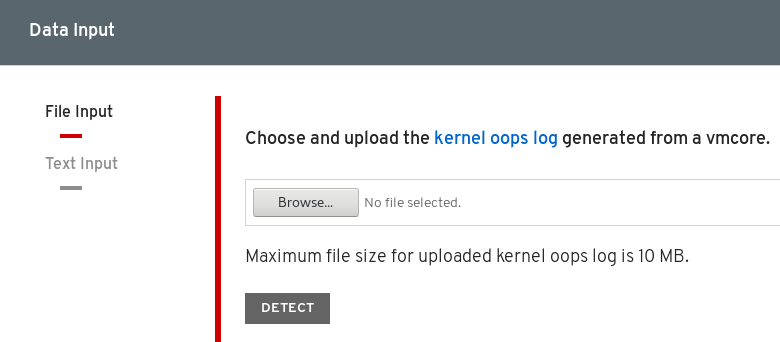
-
Haga clic en el botón para comparar el mensaje oops basado en la información de
makedumpfilecon las soluciones conocidas.
42.12. Uso de kdump temprano para capturar los fallos en el tiempo de arranque
Como administrador del sistema, puede utilizar el soporte de early kdump del servicio kdump para capturar un archivo vmcore del kernel que falla durante las primeras etapas del proceso de arranque. Esta sección describe qué es early kdump, cómo configurarlo y cómo comprobar el estado de este mecanismo.
42.12.1. Qué es el kdump temprano
Los fallos del kernel durante la fase de arranque se producen cuando el servicio kdump aún no se ha iniciado, y no puede facilitar la captura y el almacenamiento del contenido de la memoria del kernel accidentado. Por lo tanto, se pierde la información vital para la resolución de problemas.
Para solucionar este problema, RHEL 8 introdujo la función early kdump como parte del servicio kdump.
Recursos adicionales
-
Para más información sobre
early kdumpy su uso, consulte el archivo/usr/share/doc/kexec-tools/early-kdump-howto.txty la solución ¿Qué es el soporte de kdump temprano y cómo lo configuro? -
Para más información sobre el servicio
kdump, consulte la página web Sección 42.1, “Qué es kdump”.
42.12.2. Habilitación de kdump temprano
Esta sección describe cómo habilitar la función early kdump para eliminar el riesgo de perder información sobre los primeros fallos del kernel de arranque.
Requisitos previos
- Una suscripción activa a Red Hat Enterprise Linux
-
Un repositorio que contiene el paquete
kexec-toolspara la arquitectura de la CPU de su sistema -
Cumplió con los requisitos de
kdump
Procedimiento
Compruebe que el servicio
kdumpestá habilitado y activo:# systemctl is-enabled kdump.service && systemctl is-active kdump.service enabled activeSi
kdumpno está habilitado y en funcionamiento vea, Sección 42.3.5, “Activación y desactivación del servicio kdump”.Reconstruir la imagen
initramfsdel kernel de arranque con la funcionalidadearly kdump:dracut -f --add earlykdumpAñade el parámetro de línea de comandos del kernel
rd.earlykdump:grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="rd.earlykdump"Reinicie el sistema para reflejar los cambios
rebootOpcionalmente, verifique que
rd.earlykdumpfue agregado exitosamente y que la funciónearly kdumpfue habilitada:# cat /proc/cmdline BOOT_IMAGE=(hd0,msdos1)/vmlinuz-4.18.0-187.el8.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet rd.earlykdump # journalctl -x | grep early-kdump Mar 20 15:44:41 redhat dracut-cmdline[304]: early-kdump is enabled. Mar 20 15:44:42 redhat dracut-cmdline[304]: kexec: loaded early-kdump kernel
Recursos adicionales
-
Para más información sobre la activación de
early kdump, consulte el archivo/usr/share/doc/kexec-tools/early-kdump-howto.txty la solución ¿Qué es el soporte de kdump temprano y cómo lo configuro?
Capítulo 43. Aplicación de parches con kernel live patching
Puede utilizar la solución de parcheo en vivo del kernel de Red Hat Enterprise Linux para parchear un kernel en ejecución sin reiniciar o reiniciar ningún proceso.
Con esta solución, los administradores de sistemas:
- Puede aplicar inmediatamente los parches de seguridad críticos al kernel.
- No tenga que esperar a que se completen las tareas de larga duración, a que los usuarios se desconecten o al tiempo de inactividad programado.
- Controle más el tiempo de actividad del sistema y no sacrifique la seguridad ni la estabilidad.
Tenga en cuenta que no todas las CVE críticas o importantes se resolverán utilizando la solución de parches en vivo del kernel. Nuestro objetivo es reducir los reinicios necesarios para los parches relacionados con la seguridad, no eliminarlos por completo. Para obtener más detalles sobre el alcance de los parches en vivo, consulte la página Customer Portal Solutions article.
Existen algunas incompatibilidades entre el kernel live patching y otros subcomponentes del kernel. Lea atentamente la página Sección 43.1, “Limitaciones de kpatch” antes de utilizar el kernel live patching.
43.1. Limitaciones de kpatch
-
La función
kpatchno es un mecanismo de actualización del núcleo de uso general. Se utiliza para aplicar actualizaciones sencillas de seguridad y corrección de errores cuando no es posible reiniciar el sistema inmediatamente. -
No utilice las herramientas
SystemTapokprobedurante o después de cargar un parche. El parche podría no surtir efecto hasta después de haber eliminado dichas sondas.
43.2. Soporte para el live patching de terceros
La utilidad kpatch es la única utilidad de parcheo en vivo del kernel soportada por Red Hat con los módulos RPM proporcionados por los repositorios de Red Hat. Red Hat no soportará ningún parche en vivo que no haya sido proporcionado por la propia Red Hat.
Si necesita soporte para un problema que surja con un parche activo de terceros, Red Hat recomienda que abra un caso con el proveedor de parches activos al principio de cualquier investigación en la que sea necesario determinar la causa raíz. Esto permite que se suministre el código fuente si el proveedor lo permite, y que su organización de soporte proporcione asistencia en la determinación de la causa raíz antes de escalar la investigación al Soporte de Red Hat.
En el caso de cualquier sistema que funcione con parches activos de terceros, Red Hat se reserva el derecho de solicitar su reproducción con el software suministrado y soportado por Red Hat. En el caso de que esto no sea posible, requerimos que se implemente un sistema y una carga de trabajo similares en su entorno de prueba sin parches activos aplicados, para confirmar si se observa el mismo comportamiento.
Para más información sobre las políticas de soporte de software de terceros, consulte ¿Cómo maneja los Servicios de Soporte Global de Red Hat el software de terceros, los controladores y/o el hardware/hipervisores no certificados o los sistemas operativos invitados?
43.3. Acceso a los parches vivos del núcleo
La capacidad de parcheo en vivo del kernel se implementa como un módulo del kernel (kmod) que se entrega como un paquete RPM.
Todos los clientes tienen acceso a los parches del kernel en vivo, que se entregan a través de los canales habituales. Sin embargo, los clientes que no se suscriban a una oferta de soporte extendido perderán el acceso a los nuevos parches para la versión menor actual una vez que la siguiente versión menor esté disponible. Por ejemplo, los clientes con suscripciones estándar sólo podrán acceder a los parches en vivo del núcleo RHEL 8.2 hasta que se publique el núcleo RHEL 8.3.
43.4. Componentes de la aplicación de parches en el núcleo
Los componentes del kernel live patching son los siguientes:
- Módulo de parche del núcleo
- El mecanismo de entrega de los parches vivos del núcleo.
- Un módulo del kernel que se construye específicamente para el kernel que se parchea.
- El módulo de parches contiene el código de las correcciones deseadas para el kernel.
-
Los módulos de parche se registran en el subsistema del kernel
livepatchy proporcionan información sobre las funciones originales que se van a sustituir, con los correspondientes punteros a las funciones de reemplazo. Los módulos de parche del núcleo se entregan como RPM. -
La convención de nomenclatura es
kpatch_<kernel version>_<kpatch version>_<kpatch release>. La parte "versión del núcleo" del nombre tiene dots y dashes sustituida por underscores.
- La utilidad
kpatch - Una utilidad de línea de comandos para gestionar los módulos de parche.
- El servicio
kpatch -
Un servicio de
systemdrequerido pormultiuser.target. Este objetivo carga el módulo de parches del kernel en el momento del arranque.
43.5. Cómo funciona el kernel live patching
La solución de parcheo del kernel kpatch utiliza el subsistema del kernel livepatch para redirigir las funciones antiguas a las nuevas. Cuando se aplica un parche del kernel en vivo a un sistema, suceden las siguientes cosas:
-
El módulo de parche del kernel se copia en el directorio
/var/lib/kpatch/y se registra para su reaplicación en el kernel mediantesystemden el siguiente arranque. -
El módulo kpatch se carga en el núcleo en ejecución y las nuevas funciones se registran en el mecanismo
ftracecon un puntero a la ubicación en memoria del nuevo código. -
Cuando el núcleo accede a la función parcheada, es redirigido por el mecanismo
ftraceque pasa por alto las funciones originales y redirige el núcleo a la versión parcheada de la función.
Figura 43.1. Cómo funciona el kernel live patching

43.6. Activación de los parches en vivo del kernel
Un módulo de parche del kernel se entrega en un paquete RPM, específico para la versión del kernel que se parchea. Cada paquete RPM se actualizará de forma acumulativa a lo largo del tiempo.
Las siguientes secciones describen cómo asegurarse de recibir todas las futuras actualizaciones de parches acumulativos en vivo para un determinado kernel.
Red Hat no admite ningún parche activo de terceros aplicado a un sistema soportado por Red Hat.
43.6.1. Suscripción al flujo de parches en directo
Este procedimiento describe la instalación de un paquete de parches en vivo en particular. Al hacerlo, usted se suscribe al flujo de parches en vivo para un núcleo determinado y se asegura de recibir todas las futuras actualizaciones acumulativas de parches en vivo para ese núcleo.
Dado que los parches en vivo son acumulativos, no se puede seleccionar qué parches individuales se despliegan para un núcleo determinado.
Requisitos previos
- Permisos de la raíz
Procedimiento
Opcionalmente, compruebe la versión de su kernel:
# uname -r 4.18.0-94.el8.x86_64Busque un paquete de parches en vivo que corresponda a la versión de su kernel:
# yum search $(uname -r)Instale el paquete de parches en vivo:
# yum install "kpatch-patch = $(uname -r)"El comando anterior instala y aplica los últimos parches acumulativos en vivo sólo para ese núcleo específico.
El paquete de live patching contiene un módulo de parches, si la versión del paquete es 1-1 o superior. En ese caso, el kernel será parcheado automáticamente durante la instalación del paquete de parcheo en vivo.
El módulo de parche del kernel también se instala en el directorio
/var/lib/kpatch/para ser cargado por el sistemasystemdy el gestor de servicios durante los futuros reinicios.NotaSi todavía no hay parches vivos disponibles para el núcleo dado, se instalará un paquete de parches vivos vacío. Un paquete de parches en vivo vacío tendrá un kpatch_version-kpatch_release de 0-0, por ejemplo
kpatch-patch-4_18_0-94-0-0.el8.x86_64.rpm. La instalación del RPM vacío suscribe el sistema a todos los futuros parches en vivo para el núcleo dado.Opcionalmente, verifique que el kernel está parcheado:
# kpatch list Loaded patch modules: kpatch_4_18_0_94_1_1 [enabled] Installed patch modules: kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64) …La salida muestra que el módulo de parche del kernel se ha cargado en el kernel, que ahora está parcheado con las últimas correcciones del paquete
kpatch-patch-4_18_0-94-1-1.el8.x86_64.rpm.
Recursos adicionales
-
Para más información sobre la utilidad de línea de comandos
kpatch, consulte la página del manualkpatch(1). - Refiérase a las secciones relevantes del Configuring basic system settings para más información sobre la instalación de paquetes de software en Red Hat Enterprise Linux 8.
43.7. Actualización de los módulos de parche del kernel
Dado que los módulos de parche del núcleo se entregan y aplican a través de paquetes RPM, la actualización de un módulo de parche del núcleo acumulativo es como la actualización de cualquier otro paquete RPM.
Requisitos previos
- El sistema está suscrito al flujo de parches en vivo, como se describe en Sección 43.6.1, “Suscripción al flujo de parches en directo”.
Procedimiento
Actualizar a una nueva versión acumulativa para el kernel actual:
# yum update "kpatch-patch = $(uname -r)"El comando anterior instala y aplica automáticamente cualquier actualización que esté disponible para el kernel que se está ejecutando actualmente. Incluyendo cualquier parche acumulativo en vivo que se publique en el futuro.
Alternativamente, actualice todos los módulos de parche del kernel instalados:
# yum update "kpatch-patch\ ~ -"
Cuando el sistema se reinicia en el mismo kernel, el kernel es automáticamente parcheado en vivo de nuevo por el servicio kpatch.service systemd.
Recursos adicionales
- Para más información sobre la actualización de paquetes de software, vea las secciones relevantes de Configuring basic system settings en Red Hat Enterprise Linux 8.
43.8. Desactivación de los parches en vivo del kernel
En caso de que los administradores de sistemas encuentren algunos efectos negativos no anticipados relacionados con la solución de parcheo en vivo del kernel de Red Hat Enterprise Linux, tienen la opción de desactivar el mecanismo. Las siguientes secciones describen las formas de desactivar la solución de live patching.
Actualmente, Red Hat no permite revertir los parches en vivo sin reiniciar el sistema. En caso de cualquier problema, contacte con nuestro equipo de soporte.
43.8.1. Eliminación del paquete de parches en vivo
El siguiente procedimiento describe cómo desactivar la solución de parcheo en vivo del kernel de Red Hat Enterprise Linux eliminando el paquete de parcheo en vivo.
Requisitos previos
- Permisos de la raíz
- El paquete de parches en vivo está instalado.
Procedimiento
Seleccione el paquete de parches en vivo:
# yum list installed | grep kpatch-patch kpatch-patch-4_18_0-94.x86_64 1-1.el8 @@commandline …La salida del ejemplo anterior muestra los paquetes de parches vivos que ha instalado.
Retire el paquete de parches en vivo:
# yum remove kpatch-patch-4_18_0-94.x86_64Cuando se elimina un paquete de parcheo en vivo, el núcleo sigue parcheado hasta el siguiente reinicio, pero el módulo de parcheo del núcleo se elimina del disco. Tras el siguiente reinicio, el núcleo correspondiente dejará de estar parcheado.
- Reinicie su sistema.
Verifique que el paquete de parcheo en vivo haya sido eliminado:
# yum list installed | grep kpatch-patchEl comando no muestra ninguna salida si el paquete ha sido eliminado con éxito.
Opcionalmente, verifique que la solución de parcheo en vivo del kernel esté desactivada:
# kpatch list Loaded patch modules:La salida del ejemplo muestra que el kernel no está parcheado y que la solución de parcheo en vivo no está activa porque no hay módulos de parcheo cargados actualmente.
Recursos adicionales
-
Para más información sobre la utilidad de línea de comandos
kpatch, consulte la página del manualkpatch(1). - Para más información sobre la eliminación de paquetes de software en RHEL 8, consulte las secciones pertinentes de Configuring basic system settings.
43.8.2. Desinstalación del módulo de parches del kernel
El siguiente procedimiento describe cómo evitar que la solución de parcheo en vivo del kernel de Red Hat Enterprise Linux aplique un módulo de parcheo del kernel en los siguientes arranques.
Requisitos previos
- Permisos de la raíz
- Se instala un paquete de parches en vivo.
- Se instala y carga un módulo de parche del kernel.
Procedimiento
Seleccione un módulo de parche del kernel:
# kpatch list Loaded patch modules: kpatch_4_18_0_94_1_1 [enabled] Installed patch modules: kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64) …Desinstalar el módulo de parche del kernel seleccionado:
# kpatch uninstall kpatch_4_18_0_94_1_1 uninstalling kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64)Tenga en cuenta que el módulo de parche del kernel desinstalado sigue cargado:
# kpatch list Loaded patch modules: kpatch_4_18_0_94_1_1 [enabled] Installed patch modules: <NO_RESULT>Cuando se desinstala el módulo seleccionado, el núcleo permanece parcheado hasta el siguiente reinicio, pero el módulo de parche del núcleo se elimina del disco.
- Reinicie su sistema.
Opcionalmente, verifique que el módulo de parche del kernel ha sido desinstalado:
# kpatch list Loaded patch modules: …La salida del ejemplo anterior muestra que no hay módulos de parche del kernel cargados o instalados, por lo que el kernel no está parcheado y la solución de parcheo en vivo del kernel no está activa.
Recursos adicionales
-
Para más información sobre la utilidad de línea de comandos
kpatch, consulte la página del manualkpatch(1).
43.8.3. Desactivación de kpatch.service
El siguiente procedimiento describe cómo evitar que la solución de parcheo en vivo del kernel de Red Hat Enterprise Linux aplique todos los módulos de parcheo del kernel de forma global en los siguientes arranques.
Requisitos previos
- Permisos de la raíz
- Se instala un paquete de parches en vivo.
- Se instala y carga un módulo de parche del kernel.
Procedimiento
Compruebe que
kpatch.serviceestá activado:# systemctl is-enabled kpatch.service enabledDesactivar
kpatch.service:# systemctl disable kpatch.service Removed /etc/systemd/system/multi-user.target.wants/kpatch.service.Tenga en cuenta que el módulo de parche del kernel aplicado sigue cargado:
# kpatch list Loaded patch modules: kpatch_4_18_0_94_1_1 [enabled] Installed patch modules: kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64)
- Reinicie su sistema.
Opcionalmente, verifique el estado de
kpatch.service:# systemctl status kpatch.service ● kpatch.service - "Apply kpatch kernel patches" Loaded: loaded (/usr/lib/systemd/system/kpatch.service; disabled; vendor preset: disabled) Active: inactive (dead)La salida del ejemplo atestigua que
kpatch.servicese ha desactivado y no se está ejecutando. Por lo tanto, la solución de parcheo en vivo del kernel no está activa.Verifique que el módulo de parche del kernel ha sido descargado:
# kpatch list Loaded patch modules: <NO_RESULT> Installed patch modules: kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64)La salida del ejemplo anterior muestra que un módulo de parche del kernel sigue instalado pero el kernel no está parcheado.
Recursos adicionales
-
Para más información sobre la utilidad de línea de comandos
kpatch, consulte la página del manualkpatch(1). -
Para obtener más información sobre el sistema
systemdy el gestor de servicios, los archivos de configuración de las unidades, sus ubicaciones, así como una lista completa de los tipos de unidades desystemd, consulte las secciones correspondientes en Configuring basic system settings.
Capítulo 44. Fijar los límites de las aplicaciones
Como administrador del sistema, utilice la funcionalidad del kernel de grupos de control para establecer límites, priorizar o aislar los recursos de hardware de los procesos para que las aplicaciones de su sistema sean estables y no se queden sin memoria.
44.1. Entender los grupos de control
Control groups es una característica del kernel de Linux que permite organizar los procesos en grupos ordenados jerárquicamente - cgroups. La jerarquía (árbol de grupos de control) se define dotando de estructura a cgroups sistema de archivos virtual, montado por defecto en el directorio /sys/fs/cgroup/. Se hace manualmente creando y eliminando subdirectorios en /sys/fs/cgroup/. Alternativamente, utilizando el sistema systemd y el gestor de servicios.
Los controladores de recursos (un componente del kernel) modifican entonces el comportamiento de los procesos en cgroups limitando, priorizando o asignando los recursos del sistema, (como el tiempo de CPU, la memoria, el ancho de banda de la red o varias combinaciones) de esos procesos.
El valor añadido de cgroups es la agregación de procesos que permite dividir los recursos de hardware entre las aplicaciones y los usuarios. De este modo, se puede lograr un aumento de la eficiencia general, la estabilidad y la seguridad del entorno de los usuarios.
- Grupos de control versión 1
Control groups version 1 (
cgroups-v1) proporcionan una jerarquía de control por recurso. Esto significa que cada recurso, como la CPU, la memoria, la E/S, etc., tiene su propia jerarquía de grupos de control. Es posible combinar diferentes jerarquías de grupos de control de forma que un controlador pueda coordinarse con otro en la gestión de sus respectivos recursos. Sin embargo, los dos controladores pueden pertenecer a diferentes jerarquías de procesos, lo que no permite su correcta coordinación.Los controladores de
cgroups-v1se desarrollaron a lo largo de un amplio periodo de tiempo y, por tanto, el comportamiento y la denominación de sus archivos de control no son uniformes.- Grupos de control versión 2
Los problemas de coordinación de los controladores, derivados de la flexibilidad de las jerarquías, condujeron al desarrollo de control groups version 2.
Control groups version 2 (
cgroups-v2) proporciona una única jerarquía de grupo de control contra la que se montan todos los controladores de recursos.El comportamiento y la denominación de los archivos de control son coherentes entre los distintos controladores.
AvisoRHEL 8 proporciona
cgroups-v2como vista previa de la tecnología con un número limitado de controladores de recursos. Para obtener más información sobre los controladores de recursos pertinentes, consulte la página cgroups-v2 release note.
Esta subsección se basó en una presentación de Devconf.cz 2019.[3]
Recursos adicionales
-
Para más información sobre los controladores de recursos, consulte la sección Sección 44.2, “Qué son los controladores de recursos del núcleo” y las páginas del manual
cgroups(7). -
Para más información sobre las jerarquías de
cgroupsy las versiones decgroups, consulte las páginas del manualcgroups(7). -
Para más información sobre la cooperación en
systemdycgroups, véase la sección Papel de systemd en los grupos de control.
44.2. Qué son los controladores de recursos del núcleo
La funcionalidad de los grupos de control es habilitada por los controladores de recursos del kernel. RHEL 8 soporta varios controladores para control groups version 1 (cgroups-v1) y control groups version 2 (cgroups-v2).
Un controlador de recursos, también llamado subsistema de grupo de control, es un subsistema del kernel que representa un único recurso, como el tiempo de la CPU, la memoria, el ancho de banda de la red o la E/S del disco. El núcleo de Linux proporciona una serie de controladores de recursos que son montados automáticamente por el sistema systemd y el administrador de servicios. La lista de los controladores de recursos montados actualmente se encuentra en el archivo /proc/cgroups.
Los siguientes controladores están disponibles para cgroups-v1:
-
blkio- puede establecer límites en el acceso de entrada/salida a y desde los dispositivos de bloque. -
cpu- puede ajustar los parámetros del programador Completely Fair Scheduler (CFS) para las tareas del grupo de control. Se monta junto con el controladorcpuaccten el mismo montaje. -
cpuacct- crea informes automáticos sobre los recursos de la CPU utilizados por las tareas de un grupo de control. Se monta junto con el controladorcpuen el mismo montaje. -
cpuset- se puede utilizar para restringir las tareas del grupo de control para que se ejecuten sólo en un subconjunto especificado de CPUs y para dirigir las tareas para utilizar la memoria sólo en nodos de memoria especificados. -
devices- puede controlar el acceso a los dispositivos para las tareas de un grupo de control. -
freezer- se puede utilizar para suspender o reanudar las tareas en un grupo de control. -
memory- puede utilizarse para establecer límites en el uso de la memoria por parte de las tareas de un grupo de control y genera informes automáticos sobre los recursos de memoria utilizados por dichas tareas. -
net_cls- etiqueta los paquetes de red con un identificador de clase (classid) que permite al controlador de tráfico de Linux (el comandotc) identificar los paquetes que se originan en una tarea de grupo de control particular. Un subsistema denet_cls, elnet_filter(iptables), también puede utilizar esta etiqueta para realizar acciones sobre dichos paquetes. Elnet_filteretiqueta los sockets de red con un identificador de cortafuegos (fwid) que permite al cortafuegos de Linux (a través del comandoiptables) identificar los paquetes que se originan en una tarea de grupo de control particular. -
net_prio- establece la prioridad del tráfico de red. -
pids- puede establecer límites para un número de procesos y sus hijos en un grupo de control. -
perf_event- puede agrupar las tareas para su supervisión por la utilidad de supervisión e informes de rendimientoperf. -
rdma- puede establecer límites en los recursos específicos de Remote Direct Memory Access/InfiniBand en un grupo de control. -
hugetlb- puede utilizarse para limitar el uso de páginas de memoria virtual de gran tamaño por parte de las tareas de un grupo de control.
Los siguientes controladores están disponibles para cgroups-v2:
-
io- Un seguimiento deblkiodecgroups-v1. -
memory- Un seguimiento dememorydecgroups-v1. -
pids- Igual quepidsencgroups-v1. -
rdma- Igual querdmaencgroups-v1. -
cpu- Una continuación decpuycpuacctdecgroups-v1. -
cpuset- Sólo admite la funcionalidad principal (cpus{,.effective},mems{,.effective}) con una nueva función de partición. -
perf_event- El soporte es inherente, no hay un archivo de control explícito. Puede especificar unv2 cgroupcomo parámetro del comandoperfque perfilará todas las tareas dentro de esecgroup.
Un controlador de recursos puede utilizarse en una jerarquía cgroups-v1 o en una jerarquía cgroups-v2, pero no simultáneamente en ambas.
Recursos adicionales
-
Para más información sobre los controladores de recursos en general, consulte la página del manual
cgroups(7). -
Para obtener descripciones detalladas de los controladores de recursos específicos, consulte la documentación en el directorio
/usr/share/doc/kernel-doc-<kernel_version>/Documentation/cgroups-v1/. -
Para más información sobre
cgroups-v2, consulte la página del manualcgroups(7).
44.3. Uso de grupos de control a través de un sistema de archivos virtual
Puede utilizar control groups (cgroups) para establecer límites, priorizar o controlar el acceso a los recursos de hardware para grupos de procesos. Esto le permite controlar granularmente el uso de recursos de las aplicaciones para utilizarlos de forma más eficiente. Las siguientes secciones proporcionan una visión general de las tareas relacionadas con la gestión de cgroups tanto para la versión 1 como para la versión 2 utilizando un sistema de archivos virtual.
44.3.1. Establecimiento de límites de CPU a las aplicaciones mediante cgroups-v1
A veces una aplicación consume mucho tiempo de CPU, lo que puede afectar negativamente a la salud general de su entorno. Utilice el sistema de archivos virtuales /sys/fs/ para configurar los límites de CPU a una aplicación utilizando control groups version 1 (cgroups-v1).
Requisitos previos
- Una aplicación cuyo consumo de CPU se quiere restringir.
Verifique que los controladores de
cgroups-v1fueron montados:# mount -l | grep cgroup tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,seclabel,mode=755) cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd) cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpu,cpuacct) cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,perf_event) cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,pids) ...
Procedimiento
Identifique el ID del proceso (PID) de la aplicación que desea restringir en el consumo de la CPU:
# top top - 11:34:09 up 11 min, 1 user, load average: 0.51, 0.27, 0.22 Tasks: 267 total, 3 running, 264 sleeping, 0 stopped, 0 zombie %Cpu(s): 49.0 us, 3.3 sy, 0.0 ni, 47.5 id, 0.0 wa, 0.2 hi, 0.0 si, 0.0 st MiB Mem : 1826.8 total, 303.4 free, 1046.8 used, 476.5 buff/cache MiB Swap: 1536.0 total, 1396.0 free, 140.0 used. 616.4 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6955 root 20 0 228440 1752 1472 R 99.3 0.1 0:32.71 sha1sum 5760 jdoe 20 0 3603868 205188 64196 S 3.7 11.0 0:17.19 gnome-shell 6448 jdoe 20 0 743648 30640 19488 S 0.7 1.6 0:02.73 gnome-terminal- 1 root 20 0 245300 6568 4116 S 0.3 0.4 0:01.87 systemd 505 root 20 0 0 0 0 I 0.3 0.0 0:00.75 kworker/u4:4-events_unbound ...La salida de ejemplo del programa
toprevela quePID 6955(aplicación ilustrativasha1sum) consume muchos recursos de la CPU.Cree un subdirectorio en el directorio del controlador de recursos
cpu:# mkdir /sys/fs/cgroup/cpu/Example/El directorio anterior representa un grupo de control, donde se pueden colocar procesos específicos y aplicar ciertos límites de CPU a los procesos. Al mismo tiempo, se crearán en el directorio algunos archivos de la interfaz
cgroups-v1y archivos específicos del controladorcpu.Opcionalmente, inspeccione el grupo de control recién creado:
# ll /sys/fs/cgroup/cpu/Example/ -rw-r—r--. 1 root root 0 Mar 11 11:42 cgroup.clone_children -rw-r—r--. 1 root root 0 Mar 11 11:42 cgroup.procs -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.stat -rw-r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_all -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_percpu -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_percpu_sys -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_percpu_user -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_sys -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_user -rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.cfs_period_us -rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.cfs_quota_us -rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.rt_period_us -rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.rt_runtime_us -rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.shares -r—r—r--. 1 root root 0 Mar 11 11:42 cpu.stat -rw-r—r--. 1 root root 0 Mar 11 11:42 notify_on_release -rw-r—r--. 1 root root 0 Mar 11 11:42 tasksLa salida de ejemplo muestra archivos, como
cpuacct.usage,cpu.cfs._period_us, que representan configuraciones y/o límites específicos, que pueden establecerse para los procesos en el grupo de controlExample. Observe que los nombres de los archivos respectivos llevan como prefijo el nombre del controlador del grupo de control al que pertenecen.Por defecto, el grupo de control recién creado hereda el acceso a todos los recursos de la CPU del sistema sin límite.
Configurar los límites de la CPU para el grupo de control:
# echo "1000000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us # echo "200000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_usEl archivo
cpu.cfs_period_usrepresenta un periodo de tiempo en microsegundos (µs, representado aquí como \ "us") para la frecuencia con la que se debe reasignar el acceso de un grupo de control a los recursos de la CPU. El límite superior es de 1 segundo y el inferior de 1000 microsegundos.El archivo
cpu.cfs_quota_usrepresenta la cantidad total de tiempo en microsegundos que todos los procesos de un grupo de control pueden ejecutar durante un periodo (definido porcpu.cfs_period_us). Tan pronto como los procesos de un grupo de control, durante un solo período, utilizan todo el tiempo especificado por la cuota, son estrangulados para el resto del período y no se les permite ejecutar hasta el siguiente período. El límite inferior es de 1000 microsegundos.Los comandos de ejemplo anteriores establecen los límites de tiempo de la CPU para que todos los procesos colectivamente en el grupo de control
Examplepuedan ejecutarse sólo durante 0,2 segundos (definido porcpu.cfs_quota_us) de cada 1 segundo (definido porcpu.cfs_period_us).Opcionalmente, verifique los límites:
# cat /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_us 1000000 200000Añada el PID de la aplicación al grupo de control
Example:# echo "6955" > /sys/fs/cgroup/cpu/Example/cgroup.procs or # echo "6955" > /sys/fs/cgroup/cpu/Example/tasksEl comando anterior asegura que una aplicación deseada se convierta en miembro del grupo de control
Exampley por lo tanto no exceda los límites de CPU configurados para el grupo de controlExample. El PID debe representar un proceso existente en el sistema. ElPID 6955aquí fue asignado al procesosha1sum /dev/zero &, utilizado para ilustrar el caso de uso del controladorcpu.Compruebe que la aplicación se ejecuta en el grupo de control especificado:
# cat /proc/6955/cgroup 12:cpuset:/ 11:hugetlb:/ 10:net_cls,net_prio:/ 9:memory:/user.slice/user-1000.slice/user@1000.service 8:devices:/user.slice 7:blkio:/ 6:freezer:/ 5:rdma:/ 4:pids:/user.slice/user-1000.slice/user@1000.service 3:perf_event:/ 2:cpu,cpuacct:/Example 1:name=systemd:/user.slice/user-1000.slice/user@1000.service/gnome-terminal-server.serviceEl ejemplo anterior muestra que el proceso de la aplicación deseada se ejecuta en el grupo de control
Example, que aplica límites de CPU al proceso de la aplicación.Identifique el consumo actual de CPU de su aplicación estrangulada:
# top top - 12:28:42 up 1:06, 1 user, load average: 1.02, 1.02, 1.00 Tasks: 266 total, 6 running, 260 sleeping, 0 stopped, 0 zombie %Cpu(s): 11.0 us, 1.2 sy, 0.0 ni, 87.5 id, 0.0 wa, 0.2 hi, 0.0 si, 0.2 st MiB Mem : 1826.8 total, 287.1 free, 1054.4 used, 485.3 buff/cache MiB Swap: 1536.0 total, 1396.7 free, 139.2 used. 608.3 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6955 root 20 0 228440 1752 1472 R 20.6 0.1 47:11.43 sha1sum 5760 jdoe 20 0 3604956 208832 65316 R 2.3 11.2 0:43.50 gnome-shell 6448 jdoe 20 0 743836 31736 19488 S 0.7 1.7 0:08.25 gnome-terminal- 505 root 20 0 0 0 0 I 0.3 0.0 0:03.39 kworker/u4:4-events_unbound 4217 root 20 0 74192 1612 1320 S 0.3 0.1 0:01.19 spice-vdagentd ...Observe que el consumo de la CPU de
PID 6955ha disminuido del 99% al 20%.
Recursos adicionales
- Para obtener información sobre el concepto de grupos de control, consulte Sección 44.1, “Entender los grupos de control”.
-
Para más información sobre los controladores de recursos, consulte la sección Sección 44.2, “Qué son los controladores de recursos del núcleo” y la página del manual
cgroups(7). -
Para más información sobre el sistema de archivos virtual
/sys/fs/, consulte la página del manualsysfs(5).
44.3.2. Establecimiento de límites de CPU a las aplicaciones mediante cgroups-v2
A veces una aplicación utiliza mucho tiempo de CPU, lo que puede afectar negativamente a la salud general de su entorno. Utilice control groups version 2 (cgroups-v2) para configurar los límites de la CPU a la aplicación, y restringir su consumo.
Requisitos previos
- Una aplicación cuyo consumo de CPU se quiere restringir.
- Sección 44.1, “Entender los grupos de control”
Procedimiento
Evitar que
cgroups-v1se monte automáticamente durante el arranque del sistema:# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="cgroup_no_v1=all"El comando añade un parámetro de línea de comandos del kernel a la entrada de arranque actual. El parámetro
cgroup_no_v1=allevita quecgroups-v1se monte automáticamente.Como alternativa, utilice el parámetro de línea de comandos del kernel
systemd.unified_cgroup_hierarchy=1para montarcgroups-v2durante el arranque del sistema por defecto.NotaRHEL 8 soporta tanto
cgroups-v1comocgroups-v2. Sin embargo,cgroups-v1está activado y montado por defecto durante el proceso de arranque.- Reinicie el sistema para que los cambios surtan efecto.
Opcionalmente, verifique que la funcionalidad de
cgroups-v1ha sido desactivada:# mount -l | grep cgroup tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,seclabel,mode=755) cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)Si
cgroups-v1se ha desactivado con éxito, la salida no muestra ninguna referencia "tipo cgroup", excepto las que pertenecen asystemd.Monte
cgroups-v2en cualquier lugar del sistema de archivos:# mount -t cgroup2 none <MOUNT_POINT>Opcionalmente, verifique que la funcionalidad de
cgroups-v2ha sido montada:# mount -l | grep cgroup2 none on /cgroups-v2 type cgroup2 (rw,relatime,seclabel)La salida del ejemplo muestra que
cgroups-v2se ha montado en el directorio/cgroups-v2/.Opcionalmente, inspeccione el contenido del directorio
/cgroups-v2/:# ll /cgroups-v2/ -r—r—r--. 1 root root 0 Mar 13 11:57 cgroup.controllers -rw-r—r--. 1 root root 0 Mar 13 11:57 cgroup.max.depth -rw-r—r--. 1 root root 0 Mar 13 11:57 cgroup.max.descendants -rw-r—r--. 1 root root 0 Mar 13 11:57 cgroup.procs -r—r—r--. 1 root root 0 Mar 13 11:57 cgroup.stat -rw-r—r--. 1 root root 0 Mar 13 11:58 cgroup.subtree_control -rw-r—r--. 1 root root 0 Mar 13 11:57 cgroup.threads -rw-r—r--. 1 root root 0 Mar 13 11:57 cpu.pressure -r—r—r--. 1 root root 0 Mar 13 11:57 cpuset.cpus.effective -r—r—r--. 1 root root 0 Mar 13 11:57 cpuset.mems.effective -rw-r—r--. 1 root root 0 Mar 13 11:57 io.pressure -rw-r—r--. 1 root root 0 Mar 13 11:57 memory.pressureEl directorio
/cgroups-v2/, también llamado grupo de control raíz, contiene algunos archivos de interfaz (empezando porcgroup) y algunos archivos específicos del controlador comocpuset.cpus.effective.Identifique los ID de proceso (PID) de las aplicaciones que desea restringir en el consumo de la CPU:
# top top - 15:39:52 up 3:45, 1 user, load average: 0.79, 0.20, 0.07 Tasks: 265 total, 3 running, 262 sleeping, 0 stopped, 0 zombie %Cpu(s): 74.3 us, 6.1 sy, 0.0 ni, 19.4 id, 0.0 wa, 0.2 hi, 0.0 si, 0.0 st MiB Mem : 1826.8 total, 243.8 free, 1102.1 used, 480.9 buff/cache MiB Swap: 1536.0 total, 1526.2 free, 9.8 used. 565.6 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 5473 root 20 0 228440 1740 1456 R 99.7 0.1 0:12.11 sha1sum 5439 root 20 0 222616 3420 3052 R 60.5 0.2 0:27.08 cpu_load_generator 2170 jdoe 20 0 3600716 209960 67548 S 0.3 11.2 1:18.50 gnome-shell 3051 root 20 0 274424 3976 3092 R 0.3 0.2 1:01.25 top 1 root 20 0 245448 10256 5448 S 0.0 0.5 0:02.52 systemd ...La salida de ejemplo del programa
toprevela quePID 5473y5439(aplicación ilustrativasha1sumycpu_load_generator) consumen muchos recursos, concretamente la CPU. Ambas son aplicaciones de ejemplo utilizadas para demostrar la gestión de la funcionalidad decgroups-v2.Habilitar los controladores relacionados con la CPU:
# echo "+cpu" > /cgroups-v2/cgroup.subtree_control # echo "+cpuset" > /cgroups-v2/cgroup.subtree_controlLos comandos anteriores habilitan los controladores
cpuycpusetpara los grupos de subcontrol inmediatos del grupo de control raíz/cgroups-v2/.Cree un subdirectorio en el directorio
/cgroups-v2/creado anteriormente:# mkdir /cgroups-v2/Example/El directorio
/cgroups-v2/Example/representa un subgrupo de control, donde se pueden colocar procesos específicos y aplicar varios límites de CPU a los procesos. Además, el paso anterior habilitó los controladorescpuycpusetpara este grupo de subcontrol.En el momento de la creación de
/cgroups-v2/Example/, se crearán en el directorio algunos archivos de la interfazcgroups-v2y archivos específicos del controladorcpuycpuset.Opcionalmente, inspeccione el grupo de control recién creado:
# ll /cgroups-v2/Example/ -r—r—r--. 1 root root 0 Mar 13 14:48 cgroup.controllers -r—r—r--. 1 root root 0 Mar 13 14:48 cgroup.events -rw-r—r--. 1 root root 0 Mar 13 14:48 cgroup.freeze -rw-r—r--. 1 root root 0 Mar 13 14:48 cgroup.max.depth -rw-r—r--. 1 root root 0 Mar 13 14:48 cgroup.max.descendants -rw-r—r--. 1 root root 0 Mar 13 14:48 cgroup.procs -r—r—r--. 1 root root 0 Mar 13 14:48 cgroup.stat -rw-r—r--. 1 root root 0 Mar 13 14:48 cgroup.subtree_control -rw-r—r--. 1 root root 0 Mar 13 14:48 cgroup.threads -rw-r—r--. 1 root root 0 Mar 13 14:48 cgroup.type -rw-r—r--. 1 root root 0 Mar 13 14:48 cpu.max -rw-r—r--. 1 root root 0 Mar 13 14:48 cpu.pressure -rw-r—r--. 1 root root 0 Mar 13 14:48 cpuset.cpus -r—r—r--. 1 root root 0 Mar 13 14:48 cpuset.cpus.effective -rw-r—r--. 1 root root 0 Mar 13 14:48 cpuset.cpus.partition -rw-r—r--. 1 root root 0 Mar 13 14:48 cpuset.mems -r—r—r--. 1 root root 0 Mar 13 14:48 cpuset.mems.effective -r—r—r--. 1 root root 0 Mar 13 14:48 cpu.stat -rw-r—r--. 1 root root 0 Mar 13 14:48 cpu.weight -rw-r—r--. 1 root root 0 Mar 13 14:48 cpu.weight.nice -rw-r—r--. 1 root root 0 Mar 13 14:48 io.pressure -rw-r—r--. 1 root root 0 Mar 13 14:48 memory.pressureLa salida del ejemplo muestra archivos como
cpuset.cpusycpu.max. Los archivos son específicos de los controladorescpusetycpuque usted habilitó para los grupos de control hijos directos de la raíz (/cgroups-v2/) utilizando el archivo/cgroups-v2/cgroup.subtree_control. Además, hay archivos generales de interfaz de controlcgroupcomocgroup.procsocgroup.controllers, que son comunes a todos los grupos de control, independientemente de los controladores habilitados.Por defecto, el grupo de subcontrol recién creado hereda el acceso a todos los recursos de la CPU del sistema sin límite.
Asegúrese de que los procesos que desea limitar compiten por el tiempo de CPU en la misma CPU:
# echo "1" > /cgroups-v2/Example/cpuset.cpusEl comando anterior asegura los procesos que usted colocó en el grupo de subcontrol
Example, compiten en la misma CPU. Esta configuración es importante para que el controladorcpuse active.ImportanteEl controlador
cpusólo se activa si el grupo de subcontrol correspondiente tiene al menos 2 procesos, que compiten por el tiempo en una sola CPU.Configurar los límites de la CPU del grupo de control:
# echo "200000 1000000" > /cgroups-v2/Example/cpu.maxEl primer valor es la cuota de tiempo permitida en microsegundos para que todos los procesos colectivamente en un subgrupo de control puedan ejecutarse durante un período (especificado por el segundo valor). Durante un solo periodo, cuando los procesos de un grupo de control agotan colectivamente todo el tiempo especificado por esta cuota, se estrangulan durante el resto del periodo y no se les permite ejecutarse hasta el siguiente periodo.
El comando de ejemplo establece los límites de tiempo de la CPU para que todos los procesos colectivamente en el grupo de subcontrol
Examplepuedan funcionar en la CPU sólo durante 0,2 segundos de cada 1 segundo.Opcionalmente, verifique los límites:
# cat /cgroups-v2/Example/cpu.max 200000 1000000Añada los PID de las aplicaciones al grupo de subcontrol
Example:# echo "5473" > /cgroups-v2/Example/cgroup.procs # echo "5439" > /cgroups-v2/Example/cgroup.procsLos comandos de ejemplo garantizan que las aplicaciones deseadas se conviertan en miembros del grupo de subcontrol
Exampley, por tanto, no superen los límites de CPU configurados para el grupo de subcontrolExample.Compruebe que las aplicaciones se ejecutan en el grupo de control especificado:
# cat /proc/5473/cgroup /proc/5439/cgroup 1:name=systemd:/user.slice/user-1000.slice/user@1000.service/gnome-terminal-server.service 0::/Example 1:name=systemd:/user.slice/user-1000.slice/user@1000.service/gnome-terminal-server.service 0::/ExampleEl ejemplo anterior muestra que los procesos de las aplicaciones deseadas se ejecutan en el grupo de subcontrol
Example.Inspeccione el consumo actual de la CPU de sus aplicaciones estranguladas:
# top top - 15:56:27 up 4:02, 1 user, load average: 0.03, 0.41, 0.55 Tasks: 265 total, 4 running, 261 sleeping, 0 stopped, 0 zombie %Cpu(s): 9.6 us, 0.8 sy, 0.0 ni, 89.4 id, 0.0 wa, 0.2 hi, 0.0 si, 0.0 st MiB Mem : 1826.8 total, 243.4 free, 1102.1 used, 481.3 buff/cache MiB Swap: 1536.0 total, 1526.2 free, 9.8 used. 565.5 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 5439 root 20 0 222616 3420 3052 R 10.0 0.2 6:15.83 cpu_load_generator 5473 root 20 0 228440 1740 1456 R 10.0 0.1 9:20.65 sha1sum 2753 jdoe 20 0 743928 35328 20608 S 0.7 1.9 0:20.36 gnome-terminal- 2170 jdoe 20 0 3599688 208820 67552 S 0.3 11.2 1:33.06 gnome-shell 5934 root 20 0 274428 5064 4176 R 0.3 0.3 0:00.04 top ...Obsérvese que el consumo de CPU de
PID 5439yPID 5473ha disminuido al 10%. El subgrupo de controlExamplelimita sus procesos al 20% del tiempo de CPU de forma colectiva. Como hay 2 procesos en el grupo de control, cada uno puede utilizar el 10% del tiempo de CPU.
Recursos adicionales
- Para obtener información sobre el concepto de grupos de control, consulte Sección 44.1, “Entender los grupos de control”.
-
Para más información sobre los controladores de recursos, consulte la sección Sección 44.2, “Qué son los controladores de recursos del núcleo” y la página del manual
cgroups(7). -
Para más información sobre el sistema de archivos virtual
/sys/fs/, consulte la página del manualsysfs(5).
44.4. Función de systemd en los grupos de control versión 1
Red Hat Enterprise Linux 8 traslada la configuración de la gestión de recursos desde el nivel de proceso al nivel de aplicación vinculando el sistema de jerarquías cgroup con el árbol de unidades systemd. Por lo tanto, puede gestionar los recursos del sistema con el comando systemctl, o modificando los archivos de unidad systemd.
Por defecto, el gestor de sistemas y servicios systemd utiliza las unidades slice, scope y service para organizar y estructurar los procesos en los grupos de control. El comando systemctl permite modificar aún más esta estructura mediante la creación de slices personalizada. Además, systemd monta automáticamente jerarquías para los controladores de recursos importantes del kernel en el directorio /sys/fs/cgroup/.
Para el control de los recursos se utilizan tres tipos de unidades systemd:
Service - Un proceso o un grupo de procesos, que
systemdinició de acuerdo con un archivo de configuración de la unidad. Los servicios encapsulan los procesos especificados para que puedan iniciarse y detenerse como un conjunto. Los servicios se nombran de la siguiente manera:<name>.serviceScope - Un grupo de procesos creados externamente. Los ámbitos encapsulan procesos que son iniciados y detenidos por los procesos arbitrarios a través de la función
fork()y luego registrados porsystemden tiempo de ejecución. Por ejemplo, las sesiones de usuario, los contenedores y las máquinas virtuales se tratan como ámbitos. Los ámbitos se denominan como sigue:<name>.scopeSlice - Un grupo de unidades organizadas jerárquicamente. Las rebanadas organizan una jerarquía en la que se colocan ámbitos y servicios. Los procesos reales están contenidos en ámbitos o en servicios. Cada nombre de una unidad de slice corresponde a la ruta de acceso a una ubicación en la jerarquía. El carácter guión ("-") actúa como separador de los componentes de la ruta a una slice desde la slice raíz
-.slice. En el siguiente ejemplo:<parent-name>.sliceparent-name.slicees una subcorrida deparent.slice, que es una subcorrida de la rodaja raíz-.slice.parent-name.slicepuede tener su propia subcorrida llamadaparent-name-name2.slice, y así sucesivamente.
Las unidades service, scope y slice se asignan directamente a los objetos de la jerarquía del grupo de control. Cuando estas unidades se activan, se asignan directamente a las rutas de los grupos de control construidas a partir de los nombres de las unidades.
A continuación se presenta un ejemplo abreviado de la jerarquía de un grupo de control:
Control group /:
-.slice
├─user.slice
│ ├─user-42.slice
│ │ ├─session-c1.scope
│ │ │ ├─ 967 gdm-session-worker [pam/gdm-launch-environment]
│ │ │ ├─1035 /usr/libexec/gdm-x-session gnome-session --autostart /usr/share/gdm/greeter/autostart
│ │ │ ├─1054 /usr/libexec/Xorg vt1 -displayfd 3 -auth /run/user/42/gdm/Xauthority -background none -noreset -keeptty -verbose 3
│ │ │ ├─1212 /usr/libexec/gnome-session-binary --autostart /usr/share/gdm/greeter/autostart
│ │ │ ├─1369 /usr/bin/gnome-shell
│ │ │ ├─1732 ibus-daemon --xim --panel disable
│ │ │ ├─1752 /usr/libexec/ibus-dconf
│ │ │ ├─1762 /usr/libexec/ibus-x11 --kill-daemon
│ │ │ ├─1912 /usr/libexec/gsd-xsettings
│ │ │ ├─1917 /usr/libexec/gsd-a11y-settings
│ │ │ ├─1920 /usr/libexec/gsd-clipboard
…
├─init.scope
│ └─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 18
└─system.slice
├─rngd.service
│ └─800 /sbin/rngd -f
├─systemd-udevd.service
│ └─659 /usr/lib/systemd/systemd-udevd
├─chronyd.service
│ └─823 /usr/sbin/chronyd
├─auditd.service
│ ├─761 /sbin/auditd
│ └─763 /usr/sbin/sedispatch
├─accounts-daemon.service
│ └─876 /usr/libexec/accounts-daemon
├─example.service
│ ├─ 929 /bin/bash /home/jdoe/example.sh
│ └─4902 sleep 1
…El ejemplo anterior muestra que los servicios y los ámbitos contienen procesos y se colocan en rebanadas que no contienen procesos propios.
Recursos adicionales
-
Para obtener más información sobre
systemd, archivos de unidades y una lista completa de los tipos de unidades desystemd, consulte las secciones correspondientes en Configuring basic system settings. -
Para más información sobre los controladores de recursos, consulte la sección Qué son los controladores de recursos del kernel y las páginas del manual
systemd.resource-control(5),cgroups(7). -
Para más información sobre
fork(), consulte las páginas del manualfork(2).
44.5. Uso de grupos de control versión 1 con systemd
Las siguientes secciones proporcionan una visión general de las tareas relacionadas con la creación, modificación y eliminación de los grupos de control (cgroups). Las utilidades proporcionadas por el sistema systemd y el gestor de servicios son la forma preferida de la gestión de cgroups y serán apoyadas en el futuro.
44.5.1. Creación de grupos de control versión 1 con systemd
Puede utilizar el sistema systemd y el administrador de servicios para crear grupos de control transitorios y persistentes (cgroups) para establecer límites, priorizar o controlar el acceso a los recursos de hardware para grupos de procesos.
44.5.1.1. Creación de grupos de control transitorios
Los transitorios cgroups establecen límites a los recursos consumidos por una unidad (servicio o ámbito) durante su tiempo de ejecución.
Procedimiento
Para crear un grupo de control transitorio, utilice el comando
systemd-runcon el siguiente formato:# systemd-run --unit=<name> --slice=<name>.slice <command>Este comando crea e inicia un servicio transitorio o una unidad de alcance y ejecuta un comando personalizado en dicha unidad.
-
La opción
--unit=<name>da un nombre a la unidad. Si no se especifica--unit, el nombre se genera automáticamente. -
La opción
--slice=<name>.slicehace que su servicio o unidad de alcance sea miembro de una porción especificada. Sustituya<name>.slicecon el nombre de una porción existente (como se muestra en la salida desystemctl -t slice), o cree una nueva porción pasando un nombre único. Por defecto, los servicios y ámbitos se crean como miembros desystem.slice. Sustituya
<command>por el comando que desea ejecutar en el servicio o en la unidad de alcance.Se muestra el siguiente mensaje para confirmar que ha creado e iniciado el servicio o el ámbito de aplicación con éxito:
# Ejecutando como unidad <name>.service
-
La opción
Opcionalmente, mantenga la unidad en funcionamiento después de que sus procesos hayan finalizado para recopilar información en tiempo de ejecución:
# systemd-run --unit=<name> --slice=<name>.slice --remain-after-exit <command>El comando crea e inicia una unidad de servicio transitoria y ejecuta un comando personalizado en dicha unidad. La opción
--remain-after-exitasegura que el servicio siga funcionando después de que sus procesos hayan terminado.
Recursos adicionales
- Para más información sobre el concepto de grupos de control, véase Sección 44.1, “Entender los grupos de control”.
-
Para más información sobre el papel de
systemden los grupos de control, véase Sección 44.4, “Función de systemd en los grupos de control versión 1”. -
Para obtener más información sobre
systemd, los archivos de configuración de las unidades y sus ubicaciones, y una lista completa de los tipos de unidades desystemd, consulte las secciones correspondientes en Configuring basic system settings. -
Para una descripción detallada de
systemd-run, incluyendo otras opciones y ejemplos, consulte las páginas del manualsystemd-run(1).
44.5.1.2. Creación de grupos de control persistentes
Para asignar un grupo de control persistente a un servicio, es necesario editar su archivo de configuración de unidad. La configuración se conserva tras el reinicio del sistema, por lo que puede utilizarse para gestionar los servicios que se inician automáticamente.
Procedimiento
Para crear un grupo de control persistente, ejecute:
# systemctl enable <name>.serviceEl comando anterior crea automáticamente un archivo de configuración de la unidad en el directorio
/usr/lib/systemd/system/y, por defecto, asigna<name>.servicea la unidadsystem.slice.
Recursos adicionales
- Para más información sobre el concepto de grupos de control, véase Sección 44.1, “Entender los grupos de control”.
-
Para más información sobre el papel de
systemden los grupos de control, véase Sección 44.4, “Función de systemd en los grupos de control versión 1”. -
Para obtener más información sobre
systemd, los archivos de configuración de las unidades y sus ubicaciones, y una lista completa de los tipos de unidades desystemd, consulte las secciones correspondientes en Configuring basic system settings. -
Para una descripción detallada de
systemd-run, incluyendo otras opciones y ejemplos, consulte las páginas del manualsystemd-run(1).
44.5.2. Modificación de los grupos de control versión 1 con systemd
Cada unidad persistente está supervisada por el sistema systemd y el gestor de servicios, y tiene un archivo de configuración de la unidad en el directorio /usr/lib/systemd/system/. Para cambiar los ajustes de control de recursos de las unidades persistentes, modifique su archivo de configuración de unidades, ya sea manualmente en un editor de texto o desde la interfaz de línea de comandos.
44.5.2.1. Configuración de los ajustes de control de los recursos de memoria en la línea de comandos
La ejecución de comandos en la interfaz de línea de comandos es una de las formas de establecer límites, priorizar o controlar el acceso a los recursos de hardware para grupos de procesos.
Procedimiento
Para limitar el uso de memoria de un servicio, ejecute lo siguiente:
# systemctl set-property example.service MemoryLimit=1500KEl comando asigna instantáneamente el límite de memoria de 1.500 kilobytes a los procesos ejecutados en un grupo de control al que pertenece el servicio
example.service. El parámetroMemoryLimit, en esta variante de configuración, se define en el archivo/etc/systemd/system.control/example.service.d/50-MemoryLimit.confy controla el valor del archivo/sys/fs/cgroup/memory/system.slice/example.service/memory.limit_in_bytes.Opcionalmente, para limitar temporalmente el uso de memoria de un servicio, ejecute
# systemctl set-property --runtime example.service MemoryLimit=1500KEl comando asigna instantáneamente el límite de memoria al servicio
example.service. El parámetroMemoryLimitse define hasta el siguiente reinicio en el archivo/run/systemd/system.control/example.service.d/50-MemoryLimit.conf. Con un reinicio, se elimina todo el directorio/run/systemd/system.control/yMemoryLimit.
El archivo 50-MemoryLimit.conf almacena el límite de memoria como un múltiplo de 4096 bytes - un tamaño de página del kernel específico para AMD64 e Intel 64. El número real de bytes depende de la arquitectura de la CPU.
Recursos adicionales
- Para más información sobre el concepto de grupos de control, véase Sección 44.1, “Entender los grupos de control”.
-
Para más información sobre los controladores de recursos, consulte las páginas del manual Sección 44.2, “Qué son los controladores de recursos del núcleo” y
systemd.resource-control(5),cgroups(7). -
Para más información sobre el papel de
systemden los grupos de control, véase Sección 44.4, “Función de systemd en los grupos de control versión 1”.
44.5.2.2. Configuración de los ajustes de control de recursos de memoria con archivos de unidad
Modificar manualmente los archivos de unidad es una de las formas de establecer límites, priorizar o controlar el acceso a los recursos de hardware para grupos de procesos.
Procedimiento
Para limitar el uso de la memoria de un servicio, modifique el archivo
/usr/lib/systemd/system/example.servicecomo sigue:… [Service] MemoryLimit=1500K …La configuración anterior pone un límite al consumo máximo de memoria de los procesos ejecutados en un grupo de control, del que forma parte
example.service.NotaUtilice los sufijos K, M, G o T para identificar el Kilobyte, Megabyte, Gigabyte o Terabyte como unidad de medida.
Recarga todos los archivos de configuración de la unidad:
# systemctl daemon-reloadReinicie el servicio:
# systemctl restart example.service- Reinicie el sistema.
Opcionalmente, compruebe que los cambios surtieron efecto:
# cat /sys/fs/cgroup/memory/system.slice/example.service/memory.limit_in_bytes 1536000La salida del ejemplo muestra que el consumo de memoria se limitó a unos 1.500 Kilobytes.
NotaEl archivo
memory.limit_in_bytesalmacena el límite de memoria como un múltiplo de 4096 bytes - un tamaño de página del kernel específico para AMD64 e Intel 64. El número real de bytes depende de la arquitectura de la CPU.
Recursos adicionales
- Para más información sobre el concepto de grupos de control, véase Sección 44.1, “Entender los grupos de control”.
-
Para más información sobre los controladores de recursos, consulte las páginas del manual Sección 44.2, “Qué son los controladores de recursos del núcleo” y
systemd.resource-control(5),cgroups(7). -
Para obtener más información sobre
systemd, los archivos de configuración de las unidades y sus ubicaciones, así como una lista completa de los tipos de unidades desystemd, consulte las secciones correspondientes en Configuring basic system settings. -
Para más información sobre el papel de
systemden los grupos de control, véase Sección 44.4, “Función de systemd en los grupos de control versión 1”.
44.5.3. Eliminación de grupos de control versión 1 con systemd
Puede utilizar el sistema systemd y el gestor de servicios para eliminar los grupos de control transitorios y persistentes (cgroups) si ya no necesita limitar, priorizar o controlar el acceso a los recursos de hardware para grupos de procesos.
44.5.3.1. Eliminación de grupos de control transitorios
Los transitorios cgroups se liberan automáticamente una vez que terminan todos los procesos que contiene un servicio o una unidad de alcance.
Procedimiento
Para detener la unidad de servicio con todos sus procesos, ejecute:
# systemctl stop <name>.servicePara terminar uno o más procesos de la unidad, ejecute:
# systemctl kill <name>.service --kill-who=PID,… --signal=signalEl comando anterior utiliza la opción
--kill-whopara seleccionar los procesos del grupo de control que desea terminar. Para matar varios procesos al mismo tiempo, pase una lista de PIDs separada por comas. La opción--signaldetermina el tipo de señal POSIX que se enviará a los procesos especificados. La señal por defecto es SIGTERM.
Recursos adicionales
- Para más información sobre el concepto de grupos de control, véase Sección 44.1, “Entender los grupos de control”.
-
Para más información sobre los controladores de recursos, consulte las páginas del manual Sección 44.2, “Qué son los controladores de recursos del núcleo” y
systemd.resource-control(5),cgroups(7). -
Para más información sobre el papel de
systemden los grupos de control, véase Sección 44.4, “Función de systemd en los grupos de control versión 1”. -
Para obtener más información sobre
systemd, los archivos de configuración de las unidades y sus ubicaciones, así como una lista completa de los tipos de unidades desystemd, consulte las secciones correspondientes en Configuring basic system settings.
44.5.3.2. Eliminación de grupos de control persistentes
Los cgroups persistentes se liberan cuando un servicio o una unidad de ámbito se detiene o se desactiva y se borra su archivo de configuración.
Procedimiento
Detenga la unidad de servicio:
# systemctl stop <name>.serviceDesactivar la unidad de servicio:
# systemctl disable <name>.serviceEliminar el archivo de configuración de la unidad correspondiente:
# rm /usr/lib/systemd/system/<name>.serviceRecarga todos los archivos de configuración de las unidades para que los cambios surtan efecto:
# systemctl daemon-reload
Recursos adicionales
- Para más información sobre el concepto de grupos de control, véase Sección 44.1, “Entender los grupos de control”.
-
Para más información sobre los controladores de recursos, consulte las páginas del manual Sección 44.2, “Qué son los controladores de recursos del núcleo” y
systemd.resource-control(5),cgroups(7). -
Para más información sobre el papel de
systemden los grupos de control, véase Sección 44.4, “Función de systemd en los grupos de control versión 1”. -
Para obtener más información sobre
systemd, los archivos de configuración de las unidades y sus ubicaciones, así como una lista completa de los tipos de unidades desystemd, consulte las secciones correspondientes en Configuring basic system settings. -
Para más información sobre cómo matar procesos con
systemd, consulte la página del manualsystemd.kill(5).
44.6. Obtención de información sobre los grupos de control versión 1
Las siguientes secciones describen cómo visualizar diversas informaciones sobre los grupos de control (cgroups):
-
Listado de unidades de
systemdy visualización de su estado -
Visualización de la jerarquía
cgroups - Control del consumo de recursos en tiempo real
44.6.1. Listado de unidades systemd
El siguiente procedimiento describe cómo utilizar el sistema systemd y el gestor de servicios para listar sus unidades.
Requisitos previos
Procedimiento
Para listar todas las unidades activas en el sistema, ejecute el comando
# systemctly el terminal devolverá una salida similar al siguiente ejemplo:# systemctl UNIT LOAD ACTIVE SUB DESCRIPTION … init.scope loaded active running System and Service Manager session-2.scope loaded active running Session 2 of user jdoe abrt-ccpp.service loaded active exited Install ABRT coredump hook abrt-oops.service loaded active running ABRT kernel log watcher abrt-vmcore.service loaded active exited Harvest vmcores for ABRT abrt-xorg.service loaded active running ABRT Xorg log watcher … -.slice loaded active active Root Slice machine.slice loaded active active Virtual Machine and Container Slice system-getty.slice loaded active active system-getty.slice system-lvm2\x2dpvscan.slice loaded active active system-lvm2\x2dpvscan.slice system-sshd\x2dkeygen.slice loaded active active system-sshd\x2dkeygen.slice system-systemd\x2dhibernate\x2dresume.slice loaded active active system-systemd\x2dhibernate\x2dresume> system-user\x2druntime\x2ddir.slice loaded active active system-user\x2druntime\x2ddir.slice system.slice loaded active active System Slice user-1000.slice loaded active active User Slice of UID 1000 user-42.slice loaded active active User Slice of UID 42 user.slice loaded active active User and Session Slice …-
UNIT: nombre de una unidad que también refleja la posición de la unidad en una jerarquía de grupos de control. Las unidades relevantes para el control de recursos son un slice, un scope, y un service. -
LOAD- indica si el archivo de configuración de la unidad se cargó correctamente. Si el archivo de la unidad no se cargó, el campo contiene el estado error en lugar de loaded. Otros estados de carga de unidades son: stub , merged, y masked. -
ACTIVE- el estado de activación de la unidad de alto nivel, que es una generalización deSUB. -
SUB- el estado de activación de la unidad de bajo nivel. El rango de valores posibles depende del tipo de unidad. -
DESCRIPTION- la descripción del contenido y la funcionalidad de la unidad.
-
Para listar las unidades inactivas, ejecute:
# systemctl --allPara limitar la cantidad de información en la salida, ejecute:
# systemctl --type service,maskedLa opción
--typerequiere una lista separada por comas de tipos de unidades como service y slice, o estados de carga de unidades como loaded y masked.
Recursos adicionales
-
Para obtener más información sobre
systemd, archivos de unidades y una lista completa de los tipos de unidades desystemd, consulte las secciones correspondientes en Configuring basic system settings.
44.6.2. Visualización de una jerarquía de grupo de control versión 1
El siguiente procedimiento describe cómo mostrar la jerarquía de los grupos de control (cgroups) y los procesos que se ejecutan en un cgroups específico.
Requisitos previos
Procedimiento
Para mostrar toda la jerarquía de
cgroupsen su sistema, ejecute# systemd-cgls:# systemd-cgls Control group /: -.slice ├─user.slice │ ├─user-42.slice │ │ ├─session-c1.scope │ │ │ ├─ 965 gdm-session-worker [pam/gdm-launch-environment] │ │ │ ├─1040 /usr/libexec/gdm-x-session gnome-session --autostart /usr/share/gdm/greeter/autostart … ├─init.scope │ └─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 18 └─system.slice … ├─example.service │ ├─6882 /bin/bash /home/jdoe/example.sh │ └─6902 sleep 1 ├─systemd-journald.service └─629 /usr/lib/systemd/systemd-journald …La salida del ejemplo devuelve toda la jerarquía de
cgroups, donde el nivel más alto está formado por slices.Para mostrar la jerarquía
cgroupsfiltrada por un controlador de recursos, ejecute# systemd-cgls <resource_controller>:# systemd-cgls memory Controller memory; Control group /: ├─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 18 ├─user.slice │ ├─user-42.slice │ │ ├─session-c1.scope │ │ │ ├─ 965 gdm-session-worker [pam/gdm-launch-environment] … └─system.slice | … ├─chronyd.service │ └─844 /usr/sbin/chronyd ├─example.service │ ├─8914 /bin/bash /home/jdoe/example.sh │ └─8916 sleep 1 …El ejemplo de salida del comando anterior enumera los servicios que interactúan con el controlador seleccionado.
Para mostrar información detallada sobre una determinada unidad y su parte de la jerarquía
cgroups, ejecute# systemctl status <system_unit>:# systemctl status example.service ● example.service - My example service Loaded: loaded (/usr/lib/systemd/system/example.service; enabled; vendor preset: disabled) Active: active (running) since Tue 2019-04-16 12:12:39 CEST; 3s ago Main PID: 17737 (bash) Tasks: 2 (limit: 11522) Memory: 496.0K (limit: 1.5M) CGroup: /system.slice/example.service ├─17737 /bin/bash /home/jdoe/example.sh └─17743 sleep 1 Apr 16 12:12:39 redhat systemd[1]: Started My example service. Apr 16 12:12:39 redhat bash[17737]: The current time is Tue Apr 16 12:12:39 CEST 2019 Apr 16 12:12:40 redhat bash[17737]: The current time is Tue Apr 16 12:12:40 CEST 2019
Recursos adicionales
-
Para más información sobre los controladores de recursos, consulte la sección Sección 44.2, “Qué son los controladores de recursos del núcleo” y las páginas del manual
systemd.resource-control(5),cgroups(7).
44.6.3. Visualización de los controladores de recursos
El siguiente procedimiento describe cómo aprender qué procesos utilizan qué controladores de recursos.
Requisitos previos
Procedimiento
Para ver con qué controladores de recursos interactúa un proceso, ejecute el
# cat proc/<PID>/cgroupcomando:# cat /proc/11269/cgroup 12:freezer:/ 11:cpuset:/ 10:devices:/system.slice 9:memory:/system.slice/example.service 8:pids:/system.slice/example.service 7:hugetlb:/ 6:rdma:/ 5:perf_event:/ 4:cpu,cpuacct:/ 3:net_cls,net_prio:/ 2:blkio:/ 1:name=systemd:/system.slice/example.serviceEl ejemplo de salida se refiere a un proceso de interés. En este caso, se trata de un proceso identificado por
PID 11269, que pertenece a la unidadexample.service. Se puede determinar si el proceso fue colocado en un grupo de control correcto, tal como se define en las especificaciones del archivo de la unidadsystemd.NotaPor defecto, los elementos y su ordenación en la lista de controladores de recursos es la misma para todas las unidades iniciadas por
systemd, ya que monta automáticamente todos los controladores de recursos por defecto.
Recursos adicionales
-
Para más información sobre los controladores de recursos en general, consulte las páginas del manual
cgroups(7). -
Para una descripción detallada de los controladores de recursos específicos, consulte la documentación en el directorio
/usr/share/doc/kernel-doc-<kernel_version>/Documentation/cgroups-v1/.
44.6.4. Control del consumo de recursos
El siguiente procedimiento describe cómo ver una lista de los grupos de control que se están ejecutando (cgroups) y su consumo de recursos en tiempo real.
Requisitos previos
Procedimiento
Para ver una cuenta dinámica de la ejecución actual de
cgroups, ejecute el comando# systemd-cgtop:# systemd-cgtop Control Group Tasks %CPU Memory Input/s Output/s / 607 29.8 1.5G - - /system.slice 125 - 428.7M - - /system.slice/ModemManager.service 3 - 8.6M - - /system.slice/NetworkManager.service 3 - 12.8M - - /system.slice/accounts-daemon.service 3 - 1.8M - - /system.slice/boot.mount - - 48.0K - - /system.slice/chronyd.service 1 - 2.0M - - /system.slice/cockpit.socket - - 1.3M - - /system.slice/colord.service 3 - 3.5M - - /system.slice/crond.service 1 - 1.8M - - /system.slice/cups.service 1 - 3.1M - - /system.slice/dev-hugepages.mount - - 244.0K - - /system.slice/dev-mapper-rhel\x2dswap.swap - - 912.0K - - /system.slice/dev-mqueue.mount - - 48.0K - - /system.slice/example.service 2 - 2.0M - - /system.slice/firewalld.service 2 - 28.8M - - ...La salida del ejemplo muestra los
cgroupsque se están ejecutando actualmente ordenados por su uso de recursos (CPU, memoria, carga de E/S del disco). La lista se actualiza por defecto cada 1 segundo. Por lo tanto, ofrece una visión dinámica del uso real de recursos de cada grupo de control.
Recursos adicionales
-
Para más información sobre la supervisión dinámica del uso de los recursos, consulte las páginas del manual
systemd-cgtop(1).
44.7. Qué son los espacios de nombres
Los espacios de nombres son uno de los métodos más importantes para organizar e identificar los objetos de software.
Un espacio de nombres envuelve un recurso global del sistema (por ejemplo, un punto de montaje, un dispositivo de red o un nombre de host) en una abstracción que hace parecer a los procesos dentro del espacio de nombres que tienen su propia instancia aislada del recurso global. Una de las tecnologías más comunes que utilizan espacios de nombres son los contenedores.
Los cambios en un determinado recurso global sólo son visibles para los procesos de ese espacio de nombres y no afectan al resto del sistema ni a otros espacios de nombres.
Para inspeccionar de qué espacios de nombres es miembro un proceso, puedes comprobar los enlaces simbólicos en el directorio /proc/<PID>/ns/ del directorio.
La siguiente tabla muestra los espacios de nombres compatibles y los recursos que aíslan:
| Espacio de nombres | Aislados |
|---|---|
| Mount | Puntos de montaje |
| UTS | Nombre de host y nombre de dominio NIS |
| IPC | IPC de System V, colas de mensajes POSIX |
| PID | Identificación de procesos |
| Network | Dispositivos de red, pilas, puertos, etc |
| User | Identificación de usuarios y grupos |
| Control groups | Directorio raíz del grupo de control |
Recursos adicionales
-
Para más información sobre los espacios de nombres, consulte las páginas del manual
namespaces(7)ycgroup_namespaces(7). -
Para más información sobre
cgroups, véase Sección 44.1, “Entender los grupos de control”.
Capítulo 45. Análisis del rendimiento del sistema con BPF Compiler Collection
Como administrador del sistema, utilice la biblioteca BPF Compiler Collection (BCC) para crear herramientas que le permitan analizar el rendimiento de su sistema operativo Linux y recopilar información, que podría ser difícil de obtener a través de otras interfaces.
45.1. Una introducción a BCC
BPF Compiler Collection (BCC) es una biblioteca que facilita la creación de los programas Berkeley Packet Filter (eBPF) ampliados. La principal utilidad de los programas eBPF es analizar el rendimiento del sistema operativo y el rendimiento de la red sin experimentar problemas de sobrecarga o seguridad.
BCC elimina la necesidad de que los usuarios conozcan detalles técnicos profundos de eBPF, y proporciona muchos puntos de partida listos para usar, como el paquete bcc-tools con programas de eBPF precreados.
Los programas eBPF se activan en eventos, como la E/S de disco, las conexiones TCP y la creación de procesos. Es poco probable que los programas provoquen el bloqueo del kernel, bucles o que dejen de responder, ya que se ejecutan en una máquina virtual segura en el kernel.
45.2. Instalación del paquete bcc-tools
Esta sección describe cómo instalar el paquete bcc-tools, que también instala la biblioteca BPF Compiler Collection (BCC) como dependencia.
Requisitos previos
- Un activo Red Hat Enterprise Linux subscription
-
Un enabled repository que contiene el paquete
bcc-tools - Núcleo actualizado
- Permisos de raíz.
Procedimiento
Instalar
bcc-tools:# yum install bcc-toolsLas herramientas BCC se instalan en el directorio
/usr/share/bcc/tools/.Opcionalmente, inspeccione las herramientas:
# ll /usr/share/bcc/tools/ ... -rwxr-xr-x. 1 root root 4198 Dec 14 17:53 dcsnoop -rwxr-xr-x. 1 root root 3931 Dec 14 17:53 dcstat -rwxr-xr-x. 1 root root 20040 Dec 14 17:53 deadlock_detector -rw-r--r--. 1 root root 7105 Dec 14 17:53 deadlock_detector.c drwxr-xr-x. 3 root root 8192 Mar 11 10:28 doc -rwxr-xr-x. 1 root root 7588 Dec 14 17:53 execsnoop -rwxr-xr-x. 1 root root 6373 Dec 14 17:53 ext4dist -rwxr-xr-x. 1 root root 10401 Dec 14 17:53 ext4slower ...El directorio
docde la lista anterior contiene la documentación de cada herramienta.
45.3. Utilización de determinadas herramientas bcc para el análisis del rendimiento
Esta sección describe cómo utilizar ciertos programas precreados de la biblioteca BPF Compiler Collection (BCC) para analizar de forma eficiente y segura el rendimiento del sistema en base a cada evento. El conjunto de programas precreados en la biblioteca BCC puede servir de ejemplo para la creación de programas adicionales.
Requisitos previos
- Biblioteca BCC instalada
- Permisos de la raíz
Uso de execsnoop para examinar los procesos del sistema
Ejecute el programa
execsnoopen un terminal:# /usr/share/bcc/tools/execsnoopEn otro terminal ejecutar por ejemplo:
$ ls /usr/share/bcc/tools/doc/Lo anterior crea un proceso de corta duración del comando
ls.El terminal que ejecuta
execsnoopmuestra una salida similar a la siguiente:PCOMM PID PPID RET ARGS ls 8382 8287 0 /usr/bin/ls --color=auto /usr/share/bcc/tools/doc/ sed 8385 8383 0 /usr/bin/sed s/^ *[0-9]\+ *// ...El programa
execsnoopimprime una línea de salida por cada nuevo proceso, que consume recursos del sistema. Incluso detecta procesos de programas que se ejecutan muy poco tiempo, comols, y la mayoría de las herramientas de monitorización no los registrarían.La salida de
execsnoopmuestra los siguientes campos:-
PCOMM - El nombre del proceso padre. (
ls) -
PID - El ID del proceso. (
8382) -
PPID - El ID del proceso padre. (
8287) -
RET - El valor de retorno de la llamada al sistema
exec()(0), que carga el código del programa en nuevos procesos. - ARGS - La ubicación del programa iniciado con argumentos.
-
PCOMM - El nombre del proceso padre. (
Para ver más detalles, ejemplos y opciones de execsnoop, consulte el archivo /usr/share/bcc/tools/doc/execsnoop_example.txt.
Para más información sobre exec(), consulte las páginas del manual exec(3).
Uso de opensnoop para rastrear qué archivos abre un comando
Ejecute el programa
opensnoopen un terminal:# /usr/share/bcc/tools/opensnoop -n unameLo anterior imprime la salida para los archivos, que son abiertos sólo por el proceso del comando
uname.En otra terminal ejecutar:
$ unameEl comando anterior abre ciertos archivos, que se capturan en el siguiente paso.
El terminal que ejecuta
opensnoopmuestra una salida similar a la siguiente:PID COMM FD ERR PATH 8596 uname 3 0 /etc/ld.so.cache 8596 uname 3 0 /lib64/libc.so.6 8596 uname 3 0 /usr/lib/locale/locale-archive ...El programa
opensnoopvigila la llamada al sistemaopen()en todo el sistema, e imprime una línea de salida para cada archivo queunameintentó abrir en el camino.La salida de
opensnoopmuestra los siguientes campos:-
PID - El ID del proceso. (
8596) -
COMM - El nombre del proceso. (
uname) -
FD - El descriptor del archivo - un valor que
open()devuelve para referirse al archivo abierto. (3) - ERR - Cualquier error.
PATH - La ubicación de los archivos que
open()intentó abrir.Si un comando intenta leer un archivo inexistente, la columna
FDdevuelve-1y la columnaERRimprime un valor correspondiente al error en cuestión. Como resultado,opensnooppuede ayudarle a identificar una aplicación que no se comporta correctamente.
-
PID - El ID del proceso. (
Para ver más detalles, ejemplos y opciones de opensnoop, consulte el archivo /usr/share/bcc/tools/doc/opensnoop_example.txt.
Para más información sobre open(), consulte las páginas del manual open(2).
Uso de biotop para examinar las operaciones de E/S en el disco
Ejecute el programa
biotopen un terminal:# /usr/share/bcc/tools/biotop 30El comando permite supervisar los procesos principales, que realizan operaciones de E/S en el disco. El argumento asegura que el comando producirá un resumen de 30 segundos.
NotaSi no se proporciona ningún argumento, la pantalla de salida se actualiza por defecto cada 1 segundo.
En otro terminal ejecute por ejemplo :
# dd if=/dev/vda of=/dev/zeroEl comando anterior lee el contenido del dispositivo de disco duro local y escribe la salida en el archivo
/dev/zero. Este paso genera cierto tráfico de E/S para ilustrarbiotop.El terminal que ejecuta
biotopmuestra una salida similar a la siguiente:PID COMM D MAJ MIN DISK I/O Kbytes AVGms 9568 dd R 252 0 vda 16294 14440636.0 3.69 48 kswapd0 W 252 0 vda 1763 120696.0 1.65 7571 gnome-shell R 252 0 vda 834 83612.0 0.33 1891 gnome-shell R 252 0 vda 1379 19792.0 0.15 7515 Xorg R 252 0 vda 280 9940.0 0.28 7579 llvmpipe-1 R 252 0 vda 228 6928.0 0.19 9515 gnome-control-c R 252 0 vda 62 6444.0 0.43 8112 gnome-terminal- R 252 0 vda 67 2572.0 1.54 7807 gnome-software R 252 0 vda 31 2336.0 0.73 9578 awk R 252 0 vda 17 2228.0 0.66 7578 llvmpipe-0 R 252 0 vda 156 2204.0 0.07 9581 pgrep R 252 0 vda 58 1748.0 0.42 7531 InputThread R 252 0 vda 30 1200.0 0.48 7504 gdbus R 252 0 vda 3 1164.0 0.30 1983 llvmpipe-1 R 252 0 vda 39 724.0 0.08 1982 llvmpipe-0 R 252 0 vda 36 652.0 0.06 ...La salida de
biotopmuestra los siguientes campos:-
PID - El ID del proceso. (
9568) -
COMM - El nombre del proceso. (
dd) -
DISK - El disco que realiza las operaciones de lectura. (
vda) - I/O - El número de operaciones de lectura realizadas. (16294)
- Kbytes - La cantidad de Kbytes alcanzados por las operaciones de lectura. (14,440,636)
- AVGms - El tiempo medio de E/S de las operaciones de lectura. (3.69)
-
PID - El ID del proceso. (
Para ver más detalles, ejemplos y opciones de biotop, consulte el archivo /usr/share/bcc/tools/doc/biotop_example.txt.
Para más información sobre dd, consulte las páginas del manual dd(1).
Uso de xfsslower para exponer operaciones del sistema de archivos inesperadamente lentas
Ejecute el programa
xfssloweren un terminal:# /usr/share/bcc/tools/xfsslower 1El comando anterior mide el tiempo que el sistema de archivos XFS emplea en realizar operaciones de lectura, escritura, apertura o sincronización (
fsync). El argumento1asegura que el programa muestra sólo las operaciones que son más lentas que 1 ms.NotaCuando no se proporcionan argumentos,
xfsslowermuestra por defecto las operaciones más lentas de 10 ms.En otro terminal ejecute, por ejemplo, lo siguiente:
$ vim textEl comando anterior crea un archivo de texto en el editor
vimpara iniciar cierta interacción con el sistema de archivos XFS.El terminal que ejecuta
xfsslowermuestra algo similar al guardar el archivo del paso anterior:TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME 13:07:14 b'bash' 4754 R 256 0 7.11 b'vim' 13:07:14 b'vim' 4754 R 832 0 4.03 b'libgpm.so.2.1.0' 13:07:14 b'vim' 4754 R 32 20 1.04 b'libgpm.so.2.1.0' 13:07:14 b'vim' 4754 R 1982 0 2.30 b'vimrc' 13:07:14 b'vim' 4754 R 1393 0 2.52 b'getscriptPlugin.vim' 13:07:45 b'vim' 4754 S 0 0 6.71 b'text' 13:07:45 b'pool' 2588 R 16 0 5.58 b'text' ...Cada línea de arriba representa una operación en el sistema de archivos, que tomó más tiempo que un determinado umbral.
xfssloweres bueno para exponer posibles problemas del sistema de archivos, que pueden tomar la forma de operaciones inesperadamente lentas.La salida de
xfsslowermuestra los siguientes campos:-
COMM - El nombre del proceso. (
b’bash') T - El tipo de operación. (
R)- Read
- Write
- Sync
- OFF_KB - El desplazamiento del archivo en KB. (0)
- FILENAME - El archivo que se está leyendo, escribiendo o sincronizando.
-
COMM - El nombre del proceso. (
Para ver más detalles, ejemplos y opciones de xfsslower, consulte el archivo /usr/share/bcc/tools/doc/xfsslower_example.txt.
Para más información sobre fsync, consulte las páginas del manual fsync(2).
Parte VII. Diseño del sistema de alta disponibilidad
Capítulo 46. Descripción del complemento de alta disponibilidad
El complemento de alta disponibilidad es un sistema en clúster que proporciona fiabilidad, escalabilidad y disponibilidad a los servicios de producción críticos.
Un clúster son dos o más ordenadores (llamados nodes o members) que trabajan juntos para realizar una tarea. Los clústeres pueden utilizarse para proporcionar servicios o recursos de alta disponibilidad. La redundancia de múltiples máquinas se utiliza para protegerse de fallos de muchos tipos.
Los clústeres de alta disponibilidad proporcionan servicios de alta disponibilidad eliminando los puntos únicos de fallo y pasando los servicios de un nodo del clúster a otro en caso de que un nodo quede inoperativo. Normalmente, los servicios de un clúster de alta disponibilidad leen y escriben datos (mediante sistemas de archivos montados de lectura y escritura). Por lo tanto, un cluster de alta disponibilidad debe mantener la integridad de los datos cuando un nodo del cluster toma el control de un servicio de otro nodo del cluster. Los fallos de los nodos de un clúster de alta disponibilidad no son visibles para los clientes externos al clúster. (Los clústeres de alta disponibilidad se denominan a veces clústeres de conmutación por error). El complemento de alta disponibilidad proporciona clústeres de alta disponibilidad a través de su componente de gestión de servicios de alta disponibilidad, Pacemaker.
46.1. Componentes del complemento de alta disponibilidad
El complemento de alta disponibilidad consta de los siguientes componentes principales:
- Infraestructura de clústeres
- Gestión de servicios de alta disponibilidad
- Herramientas de administración de clústeres
Puede complementar el complemento de alta disponibilidad con los siguientes componentes:
- Red Hat GFS2 (Global File System 2)
-
Demonio de bloqueo LVM (
lvmlockd) - Complemento del equilibrador de carga
46.2. Visión general del marcapasos
Pacemaker es un gestor de recursos de clúster. Consigue la máxima disponibilidad para los servicios y recursos de su clúster haciendo uso de las capacidades de mensajería y afiliación de la infraestructura del clúster para disuadir y recuperarse de los fallos a nivel de nodos y recursos.
46.2.1. Componentes de la arquitectura del marcapasos
Un clúster configurado con Pacemaker está compuesto por demonios de componentes separados que supervisan la pertenencia al clúster, scripts que gestionan los servicios y subsistemas de gestión de recursos que supervisan los distintos recursos.
Los siguientes componentes forman la arquitectura de Pacemaker:
- Base de información de clusters (CIB)
- El demonio de información de Pacemaker, que utiliza XML internamente para distribuir y sincronizar la configuración actual y la información de estado del Coordinador Designado (DC)
- Demonio de gestión de recursos del clúster (CRMd)
Las acciones de los recursos del cluster Pacemaker se enrutan a través de este demonio. Los recursos gestionados por CRMd pueden ser consultados por los sistemas cliente, movidos, instanciados y modificados cuando sea necesario.
Cada nodo del clúster también incluye un demonio gestor de recursos local (LRMd) que actúa como interfaz entre CRMd y los recursos. LRMd pasa comandos de CRMd a los agentes, como el arranque y la parada y la transmisión de información de estado.
- Disparar al otro nodo en la cabeza (STONITH)
- STONITH es la implementación de cercado de Pacemaker. Actúa como un recurso de clúster en Pacemaker que procesa las solicitudes de vallado, apagando a la fuerza los nodos y retirándolos del clúster para garantizar la integridad de los datos. STONITH está configurado en el CIB y puede ser monitorizado como un recurso de cluster normal. Para una visión general de la esgrima, ver Sección 46.3, “Visión general de la esgrima”.
- corosync
corosynces el componente - y un demonio del mismo nombre - que sirve a las necesidades de membresía y comunicación de los miembros para los clusters de alta disponibilidad. Es necesario para que el complemento de alta disponibilidad funcione.Además de esas funciones de afiliación y mensajería,
corosynctambién:- Gestiona las normas de quórum y su determinación.
- Proporciona capacidades de mensajería para las aplicaciones que coordinan u operan a través de múltiples miembros del clúster y, por lo tanto, deben comunicar información de estado o de otro tipo entre las instancias.
-
Utiliza la librería
kronosnetcomo transporte de red para proporcionar múltiples enlaces redundantes y conmutación automática por error.
46.2.2. Herramientas de configuración y gestión
El complemento de alta disponibilidad cuenta con dos herramientas de configuración para el despliegue, la supervisión y la gestión del clúster.
pcsLa interfaz de línea de comandos
pcscontrola y configura Pacemaker y el demoniocorosyncheartbeat. Un programa basado en la línea de comandos,pcspuede realizar las siguientes tareas de gestión del clúster:- Crear y configurar un clúster Pacemaker/Corosync
- Modificar la configuración del clúster mientras se está ejecutando
- Configurar remotamente tanto Pacemaker como Corosync, así como iniciar, detener y mostrar la información de estado del clúster
pcsdWeb UI- Una interfaz gráfica de usuario para crear y configurar clusters Pacemaker/Corosync.
46.2.3. Los archivos de configuración del clúster y del marcapasos
Los archivos de configuración para el complemento de alta disponibilidad de Red Hat son corosync.conf y cib.xml.
El archivo corosync.conf proporciona los parámetros de cluster utilizados por corosync, el gestor de cluster en el que se basa Pacemaker. En general, no se debe editar el corosync.conf directamente sino, en su lugar, utilizar la interfaz pcs o pcsd.
El archivo cib.xml es un archivo XML que representa tanto la configuración del cluster como el estado actual de todos los recursos del cluster. Este archivo es utilizado por la Base de Información del Cluster (CIB) de Pacemaker. El contenido de la CIB se mantiene automáticamente sincronizado en todo el cluster. No edite el archivo cib.xml directamente; utilice la interfaz pcs o pcsd en su lugar.
46.3. Visión general de la esgrima
Si la comunicación con un solo nodo del clúster falla, los demás nodos del clúster deben ser capaces de restringir o liberar el acceso a los recursos a los que el nodo del clúster que ha fallado pueda tener acceso. Esto no puede lograrse contactando con el propio nodo del clúster, ya que éste puede no responder. En su lugar, debe proporcionar un método externo, que se denomina cercado con un agente de cercado. Un agente de valla es un dispositivo externo que puede ser utilizado por el clúster para restringir el acceso a los recursos compartidos por un nodo errante, o para emitir un reinicio duro en el nodo del clúster.
Sin un dispositivo de valla configurado, no tiene forma de saber que los recursos utilizados previamente por el nodo de clúster desconectado han sido liberados, y esto podría impedir que los servicios se ejecuten en cualquiera de los otros nodos de clúster. A la inversa, el sistema puede suponer erróneamente que el nodo del clúster ha liberado sus recursos y esto puede llevar a la corrupción y pérdida de datos. Sin un dispositivo de valla configurado no se puede garantizar la integridad de los datos y la configuración del clúster no será compatible.
Cuando el cercado está en curso, no se permite la ejecución de ninguna otra operación del clúster. El funcionamiento normal del clúster no se puede reanudar hasta que se haya completado el cercado o hasta que el nodo del clúster se reincorpore al clúster después de reiniciar el nodo del clúster.
Para más información sobre el cercado, consulte Cerrado en un cluster de alta disponibilidad de Red Hat.
46.4. Resumen del quórum
Para mantener la integridad y la disponibilidad del clúster, los sistemas de clúster utilizan un concepto conocido como quorum para evitar la corrupción y la pérdida de datos. Un clúster tiene quórum cuando más de la mitad de los nodos del clúster están en línea. Para mitigar la posibilidad de corrupción de datos debido a un fallo, Pacemaker detiene por defecto todos los recursos si el clúster no tiene quórum.
El quórum se establece mediante un sistema de votación. Cuando un nodo del clúster no funciona como debería o pierde la comunicación con el resto del clúster, la mayoría de los nodos que funcionan pueden votar para aislar y, si es necesario, cercar el nodo para su mantenimiento.
Por ejemplo, en un cluster de 6 nodos, el quórum se establece cuando al menos 4 nodos del cluster están funcionando. Si la mayoría de los nodos se desconectan o dejan de estar disponibles, el clúster deja de tener quórum y Pacemaker detiene los servicios en clúster.
Las características de quórum en Pacemaker previenen lo que también se conoce como split-brain, un fenómeno en el que el cluster se separa de la comunicación pero cada parte continúa trabajando como clusters separados, potencialmente escribiendo en los mismos datos y posiblemente causando corrupción o pérdida. Para más información sobre lo que significa estar en un estado de cerebro dividido, y sobre los conceptos de quórum en general, vea Explorando los conceptos de los clusters de alta disponibilidad de RHEL - Quórum.
Un cluster de Red Hat Enterprise Linux High Availability Add-On utiliza el servicio votequorum, en conjunto con fencing, para evitar situaciones de split brain. Se asigna un número de votos a cada sistema en el cluster, y las operaciones del cluster se permiten sólo cuando hay una mayoría de votos.
46.5. Resumen de recursos
Un cluster resource es una instancia de programa, datos o aplicación que debe ser gestionada por el servicio de cluster. Estos recursos se abstraen mediante agents que proporciona una interfaz estándar para gestionar el recurso en un entorno de clúster.
Para asegurarse de que los recursos se mantienen en buen estado, puede añadir una operación de supervisión a la definición de un recurso. Si no se especifica una operación de supervisión para un recurso, se añade una por defecto.
Puede determinar el comportamiento de un recurso en un cluster configurando constraints. Puede configurar las siguientes categorías de restricciones:
- limitaciones de ubicación
- restricciones de ordenación
- limitaciones de colocación
Uno de los elementos más comunes de un clúster es un conjunto de recursos que deben ubicarse juntos, iniciarse secuencialmente y detenerse en el orden inverso. Para simplificar esta configuración, Pacemaker admite el concepto de groups.
Capítulo 47. Cómo empezar con Pacemaker
Los siguientes procedimientos proporcionan una introducción a las herramientas y procesos que se utilizan para crear un cluster Pacemaker. Están destinados a los usuarios que están interesados en ver el aspecto del software de clúster y cómo se administra, sin necesidad de configurar un clúster en funcionamiento.
Estos procedimientos no crean un cluster Red Hat compatible, que requiere al menos dos nodos y la configuración de un dispositivo de cercado.
47.1. Aprender a usar el Marcapasos
Este ejemplo requiere un único nodo que ejecute RHEL 8 y requiere una dirección IP flotante que resida en la misma red que una de las direcciones IP asignadas estáticamente al nodo.
-
El nodo utilizado en este ejemplo es
z1.example.com. - La dirección IP flotante utilizada en este ejemplo es 192.168.122.120.
Asegúrese de que el nombre del nodo en el que se está ejecutando está en su archivo /etc/hosts.
Mediante este procedimiento, aprenderá a utilizar Pacemaker para configurar un clúster, a mostrar el estado del clúster y a configurar un servicio de clúster. Este ejemplo crea un servidor Apache HTTP como recurso de clúster y muestra cómo responde el clúster cuando el recurso falla.
Instale los paquetes de software de Red Hat High Availability Add-On desde el canal de Alta Disponibilidad, e inicie y habilite el servicio
pcsd.# yum install pcs pacemaker fence-agents-all ... # systemctl start pcsd.service # systemctl enable pcsd.serviceSi está ejecutando el demonio
firewalld, habilite los puertos requeridos por el complemento de alta disponibilidad de Red Hat.# firewall-cmd --permanent --add-service=high-availability # firewall-cmd --reloadEstablezca una contraseña para el usuario
haclusteren cada nodo del clúster y autentique el usuariohaclusterpara cada nodo del clúster en el nodo desde el que ejecutará los comandospcs. Este ejemplo está utilizando sólo un nodo, el nodo desde el cual está ejecutando los comandos, pero este paso se incluye aquí ya que es un paso necesario en la configuración de un cluster de alta disponibilidad de Red Hat soportado.# passwd hacluster ... # pcs host auth z1.example.comCrear un clúster llamado
my_clustercon un miembro y comprobar el estado del clúster. Este comando crea e inicia el clúster en un solo paso.# pcs cluster setup my_cluster --start z1.example.com ... # pcs cluster status Cluster Status: Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Thu Oct 11 16:11:18 2018 Last change: Thu Oct 11 16:11:00 2018 by hacluster via crmd on z1.example.com 1 node configured 0 resources configured PCSD Status: z1.example.com: OnlineUn cluster de Alta Disponibilidad de Red Hat requiere que se configure el cercado para el cluster. Las razones de este requisito se describen en Esgrima en un cluster de alta disponibilidad de Red Hat. Para esta introducción, sin embargo, que pretende mostrar sólo cómo usar los comandos básicos de Pacemaker, desactive el cercado estableciendo la opción de cluster
stonith-enabledafalse.AvisoEl uso de
stonith-enabled=falsees completamente inapropiado para un cluster de producción. Le dice al clúster que simplemente finja que los nodos que fallan están cercados de forma segura.# pcs property set stonith-enabled=falseConfigure un navegador web en su sistema y cree una página web para mostrar un simple mensaje de texto. Si está ejecutando el demonio
firewalld, habilite los puertos que requierehttpd.NotaNo utilice
systemctl enablepara habilitar cualquier servicio que vaya a ser gestionado por el clúster para que se inicie en el arranque del sistema.# yum install -y httpd wget ... # firewall-cmd --permanent --add-service=http # firewall-cmd --reload # cat <<-END >/var/www/html/index.html <html> <body>My Test Site - $(hostname)</body> </html> ENDPara que el agente de recursos de Apache obtenga el estado de Apache, cree la siguiente adición a la configuración existente para habilitar la URL del servidor de estado.
# cat <<-END > /etc/httpd/conf.d/status.conf <Location /server-status> SetHandler server-status Order deny,allow Deny from all Allow from 127.0.0.1 Allow from ::1 </Location> ENDCree los recursos
IPaddr2yapachepara que el clúster los gestione. El recurso 'IPaddr2' es una dirección IP flotante que no debe ser una ya asociada a un nodo físico. Si no se especifica el dispositivo NIC del recurso 'IPaddr2', la IP flotante debe residir en la misma red que la dirección IP asignada estáticamente y utilizada por el nodo.Puede mostrar una lista de todos los tipos de recursos disponibles con el comando
pcs resource list. Puede utilizar el comandopcs resource describe resourcetypepara mostrar los parámetros que puede establecer para el tipo de recurso especificado. Por ejemplo, el siguiente comando muestra los parámetros que puede establecer para un recurso del tipoapache:# pcs resource describe apache ...En este ejemplo, el recurso dirección IP y el recurso apache están configurados como parte de un grupo llamado
apachegroup, lo que asegura que los recursos se mantienen juntos para ejecutarse en el mismo nodo cuando se configura un clúster multinodal en funcionamiento.# pcs resource create ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.122.120 --group apachegroup # pcs resource create WebSite ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf statusurl="http://localhost/server-status" --group apachegroup # pcs status Cluster name: my_cluster Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Fri Oct 12 09:54:33 2018 Last change: Fri Oct 12 09:54:30 2018 by root via cibadmin on z1.example.com 1 node configured 2 resources configured Online: [ z1.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com WebSite (ocf::heartbeat:apache): Started z1.example.com PCSD Status: z1.example.com: Online ...Después de haber configurado un recurso de clúster, puede utilizar el comando
pcs resource configpara mostrar las opciones configuradas para ese recurso.# pcs resource config WebSite Resource: WebSite (class=ocf provider=heartbeat type=apache) Attributes: configfile=/etc/httpd/conf/httpd.conf statusurl=http://localhost/server-status Operations: start interval=0s timeout=40s (WebSite-start-interval-0s) stop interval=0s timeout=60s (WebSite-stop-interval-0s) monitor interval=1min (WebSite-monitor-interval-1min)- Dirija su navegador al sitio web que ha creado utilizando la dirección IP flotante que ha configurado. Esto debería mostrar el mensaje de texto que definiste.
Detenga el servicio web de apache y compruebe el estado del clúster. El uso de
killall -9simula un fallo a nivel de aplicación.# killall -9 httpdCompruebe el estado del clúster. Debería ver que la detención del servicio web provocó una acción fallida, pero que el software del clúster reinició el servicio y debería seguir pudiendo acceder al sitio web.
# pcs status Cluster name: my_cluster ... Current DC: z1.example.com (version 1.1.13-10.el7-44eb2dd) - partition with quorum 1 node and 2 resources configured Online: [ z1.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com WebSite (ocf::heartbeat:apache): Started z1.example.com Failed Resource Actions: * WebSite_monitor_60000 on z1.example.com 'not running' (7): call=13, status=complete, exitreason='none', last-rc-change='Thu Oct 11 23:45:50 2016', queued=0ms, exec=0ms PCSD Status: z1.example.com: OnlinePuede borrar el estado de fallo en el recurso que ha fallado una vez que el servicio esté en funcionamiento de nuevo y el aviso de acción fallida ya no aparecerá cuando vea el estado del clúster.
# pcs resource cleanup WebSiteCuando haya terminado de ver el clúster y el estado del mismo, detenga los servicios del clúster en el nodo. Aunque sólo haya iniciado los servicios en un nodo para esta introducción, se incluye el parámetro
--allya que detendría los servicios de clúster en todos los nodos de un clúster real de varios nodos.# pcs cluster stop --all
47.2. Aprender a configurar la conmutación por error
Este procedimiento proporciona una introducción a la creación de un cluster Pacemaker que ejecuta un servicio que fallará de un nodo a otro cuando el nodo en el que se ejecuta el servicio deje de estar disponible. Mediante este procedimiento, podrá aprender a crear un servicio en un cluster de dos nodos y podrá observar lo que ocurre con ese servicio cuando falla en el nodo en el que se está ejecutando.
Este procedimiento de ejemplo configura un cluster Pacemaker de dos nodos que ejecuta un servidor HTTP Apache. A continuación, puede detener el servicio Apache en un nodo para ver cómo el servicio sigue estando disponible.
Este procedimiento requiere como prerrequisito que tenga dos nodos ejecutando Red Hat Enterprise Linux 8 que puedan comunicarse entre sí, y requiere una dirección IP flotante que resida en la misma red que una de las direcciones IP asignadas estáticamente del nodo.
-
Los nodos utilizados en este ejemplo son
z1.example.comyz2.example.com. - La dirección IP flotante utilizada en este ejemplo es 192.168.122.120.
Asegúrese de que los nombres de los nodos que está utilizando están en el archivo /etc/hosts en cada nodo.
En ambos nodos, instale los paquetes de software Red Hat High Availability Add-On desde el canal de Alta Disponibilidad, e inicie y habilite el servicio
pcsd.# yum install pcs pacemaker fence-agents-all ... # systemctl start pcsd.service # systemctl enable pcsd.serviceSi está ejecutando el demonio
firewalld, en ambos nodos habilite los puertos requeridos por el complemento de alta disponibilidad de Red Hat.# firewall-cmd --permanent --add-service=high-availability # firewall-cmd --reloadEn ambos nodos del clúster, establezca una contraseña para el usuario
hacluster.# passwd haclusterAutentifique el usuario
haclusterpara cada nodo del clúster en el nodo desde el que va a ejecutar los comandospcs.# pcs host auth z1.example.com z2.example.comCree un clúster llamado
my_clustercon ambos nodos como miembros del clúster. Este comando crea e inicia el cluster en un solo paso. Sólo es necesario ejecutarlo desde un nodo del clúster porque los comandos de configuración depcstienen efecto para todo el clúster.En un nodo del clúster, ejecute el siguiente comando.
# pcs cluster setup my_cluster --start z1.example.com z2.example.comUn cluster de Alta Disponibilidad de Red Hat requiere que se configure el cercado para el cluster. Las razones de este requisito se describen en Esgrima en un cluster de alta disponibilidad de Red Hat. Para esta introducción, sin embargo, para mostrar solamente cómo funciona la conmutación por error en esta configuración, desactive el cercado estableciendo la opción de cluster
stonith-enabledafalseAvisoEl uso de
stonith-enabled=falsees completamente inapropiado para un cluster de producción. Le dice al clúster que simplemente finja que los nodos que fallan están cercados de forma segura.# pcs property set stonith-enabled=falseDespués de crear un clúster y desactivar el cercado, compruebe el estado del clúster.
NotaCuando ejecute el comando
pcs cluster status, es posible que la salida difiera temporalmente de los ejemplos mientras se inician los componentes del sistema.# pcs cluster status Cluster Status: Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Thu Oct 11 16:11:18 2018 Last change: Thu Oct 11 16:11:00 2018 by hacluster via crmd on z1.example.com 2 nodes configured 0 resources configured PCSD Status: z1.example.com: Online z2.example.com: OnlineEn ambos nodos, configure un navegador web y cree una página web para mostrar un simple mensaje de texto. Si está ejecutando el demonio
firewalld, habilite los puertos que requierehttpd.NotaNo utilice
systemctl enablepara habilitar cualquier servicio que vaya a ser gestionado por el clúster para que se inicie en el arranque del sistema.# yum install -y httpd wget ... # firewall-cmd --permanent --add-service=http # firewall-cmd --reload # cat <<-END >/var/www/html/index.html <html> <body>My Test Site - $(hostname)</body> </html> ENDPara que el agente de recursos de Apache obtenga el estado de Apache, en cada nodo del clúster cree la siguiente adición a la configuración existente para habilitar la URL del servidor de estado.
# cat <<-END > /etc/httpd/conf.d/status.conf <Location /server-status> SetHandler server-status Order deny,allow Deny from all Allow from 127.0.0.1 Allow from ::1 </Location> ENDCree los recursos
IPaddr2yapachepara que el clúster los gestione. El recurso 'IPaddr2' es una dirección IP flotante que no debe ser una ya asociada a un nodo físico. Si no se especifica el dispositivo NIC del recurso 'IPaddr2', la IP flotante debe residir en la misma red que la dirección IP asignada estáticamente y utilizada por el nodo.Puede mostrar una lista de todos los tipos de recursos disponibles con el comando
pcs resource list. Puede utilizar el comandopcs resource describe resourcetypepara mostrar los parámetros que puede establecer para el tipo de recurso especificado. Por ejemplo, el siguiente comando muestra los parámetros que puede establecer para un recurso del tipoapache:# pcs resource describe apache ...En este ejemplo, el recurso de la dirección IP y el recurso de apache están configurados como parte de un grupo llamado
apachegroup, que asegura que los recursos se mantienen juntos para ejecutarse en el mismo nodo.Ejecute los siguientes comandos desde un nodo del clúster:
# pcs resource create ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.122.120 --group apachegroup # pcs resource create WebSite ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf statusurl="http://localhost/server-status" --group apachegroup # pcs status Cluster name: my_cluster Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Fri Oct 12 09:54:33 2018 Last change: Fri Oct 12 09:54:30 2018 by root via cibadmin on z1.example.com 2 nodes configured 2 resources configured Online: [ z1.example.com z2.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com WebSite (ocf::heartbeat:apache): Started z1.example.com PCSD Status: z1.example.com: Online z2.example.com: Online ...Tenga en cuenta que en este caso, el servicio
apachegroupse está ejecutando en el nodo z1.ejemplo.com.Acceda al sitio web que ha creado, detenga el servicio en el nodo en el que se está ejecutando y observe cómo el servicio falla en el segundo nodo.
- Dirija un navegador al sitio web que ha creado utilizando la dirección IP flotante que ha configurado. Esto debería mostrar el mensaje de texto que definió, mostrando el nombre del nodo en el que se está ejecutando el sitio web.
Detener el servicio web de apache. El uso de
killall -9simula un fallo a nivel de aplicación.# killall -9 httpdCompruebe el estado del clúster. Debería ver que la detención del servicio web provocó una acción fallida, pero que el software del clúster reinició el servicio en el nodo en el que se había estado ejecutando y debería seguir pudiendo acceder al navegador web.
# pcs status Cluster name: my_cluster Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Fri Oct 12 09:54:33 2018 Last change: Fri Oct 12 09:54:30 2018 by root via cibadmin on z1.example.com 2 nodes configured 2 resources configured Online: [ z1.example.com z2.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com WebSite (ocf::heartbeat:apache): Started z1.example.com Failed Resource Actions: * WebSite_monitor_60000 on z1.example.com 'not running' (7): call=31, status=complete, exitreason='none', last-rc-change='Fri Feb 5 21:01:41 2016', queued=0ms, exec=0msBorre el estado de fallo una vez que el servicio esté de nuevo en funcionamiento.
# pcs resource cleanup WebSitePonga el nodo en el que se está ejecutando el servicio en modo de espera. Tenga en cuenta que, dado que hemos desactivado el cercado, no podemos simular eficazmente un fallo a nivel de nodo (como tirar de un cable de alimentación) porque el cercado es necesario para que el clúster se recupere de tales situaciones.
# pcs node standby z1.example.comCompruebe el estado del clúster y anote dónde se está ejecutando el servicio.
# pcs status Cluster name: my_cluster Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Fri Oct 12 09:54:33 2018 Last change: Fri Oct 12 09:54:30 2018 by root via cibadmin on z1.example.com 2 nodes configured 2 resources configured Node z1.example.com: standby Online: [ z2.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z2.example.com WebSite (ocf::heartbeat:apache): Started z2.example.com- Acceda al sitio web. No debería haber pérdida de servicio, aunque el mensaje de la pantalla debería indicar el nodo en el que se está ejecutando el servicio.
Para restaurar los servicios del clúster en el primer nodo, saque el nodo del modo de espera. Esto no necesariamente moverá el servicio de nuevo a ese nodo.
# pcs node unstandby z1.example.comPara la limpieza final, detenga los servicios del clúster en ambos nodos.
# pcs cluster stop --all
Capítulo 48. La interfaz de línea de comandos de pcs
La interfaz de línea de comandos pcs controla y configura servicios de clúster como corosync, pacemaker,booth y sbd proporcionando una interfaz más sencilla para sus archivos de configuración.
Tenga en cuenta que no debe editar directamente el archivo de configuración cib.xml. En la mayoría de los casos, Pacemaker rechazará un archivo cib.xml modificado directamente.
48.1. pantalla de ayuda de pcs
Puede utilizar la opción -h de pcs para mostrar los parámetros de un comando pcs y una descripción de dichos parámetros. Por ejemplo, el siguiente comando muestra los parámetros del comando pcs resource. Sólo se muestra una parte de la salida.
# pcs resource -h48.2. Visualización de la configuración bruta del clúster
Aunque no debe editar el archivo de configuración del clúster directamente, puede ver la configuración del clúster en bruto con el comando pcs cluster cib.
Puede guardar la configuración bruta del clúster en un archivo específico con el comando pcs cluster cib filename comando. Si ha configurado previamente un clúster y ya hay un CIB activo, utilice el siguiente comando para guardar el archivo xml sin procesar.
pcs cluster cib filename
Por ejemplo, el siguiente comando guarda el xml crudo del CIB en un archivo llamado testfile.
pcs cluster cib testfile48.3. Guardar un cambio de configuración en un archivo de trabajo
Al configurar un clúster, puede guardar los cambios de configuración en un archivo específico sin que ello afecte al CIB activo. Esto le permite especificar las actualizaciones de configuración sin actualizar inmediatamente la configuración del clúster que se está ejecutando actualmente con cada actualización individual.
Para obtener información sobre cómo guardar el CIB en un archivo, consulte Visualización de la configuración bruta del clúster. Una vez que haya creado ese archivo, puede guardar los cambios de configuración en ese archivo en lugar de en el CIB activo utilizando la opción -f del comando pcs. Cuando haya completado los cambios y esté listo para actualizar el archivo CIB activo, puede empujar esas actualizaciones del archivo con el comando pcs cluster cib-push.
El siguiente es el procedimiento recomendado para introducir cambios en el archivo CIB. Este procedimiento crea una copia del archivo CIB original guardado y realiza cambios en esa copia. Al transferir esos cambios al CIB activo, este procedimiento especifica la opción diff-against del comando pcs cluster cib-push para que sólo se transfieran al CIB los cambios entre el archivo original y el archivo actualizado. Esto permite a los usuarios realizar cambios en paralelo que no se sobrescriben entre sí, y reduce la carga de Pacemaker, que no necesita analizar todo el archivo de configuración.
Guardar el CIB activo en un archivo. Este ejemplo guarda el CIB en un archivo llamado
original.xml.# pcs cluster cib original.xmlCopie el archivo guardado en el archivo de trabajo que utilizará para las actualizaciones de configuración.
# cp original.xml updated.xmlActualice su configuración según sea necesario. El siguiente comando crea un recurso en el archivo
updated.xmlpero no añade ese recurso a la configuración del clúster que se está ejecutando actualmente.# pcs -f updated.xml resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 op monitor interval=30sEmpuje el archivo actualizado al CIB activo, especificando que está empujando sólo los cambios que ha hecho en el archivo original.
# pcs cluster cib-push updated.xml diff-against=original.xml
Alternativamente, puede empujar todo el contenido actual de un archivo CIB con el siguiente comando.
pcs cluster cib-push filename
Al empujar el archivo CIB completo, Pacemaker comprueba la versión y no permite empujar un archivo CIB que sea más antiguo que el que ya está en un cluster. Si necesita actualizar todo el archivo CIB con una versión más antigua que la que se encuentra actualmente en el clúster, puede utilizar la opción --config del comando pcs cluster cib-push.
pcs cluster cib-push --config filename48.4. Visualización del estado del clúster
Puede mostrar el estado del clúster y de los recursos del clúster con el siguiente comando.
estado de los pcs
Puede mostrar el estado de un componente concreto del clúster con el parámetro commands del comando pcs status, especificando resources, cluster, nodes o pcsd.
estado de los pcs commandsPor ejemplo, el siguiente comando muestra el estado de los recursos del cluster.
recursos del estado de los pcsEl siguiente comando muestra el estado del clúster, pero no los recursos del mismo.
estado del cluster pcs48.5. Visualización de la configuración completa del clúster
Utilice el siguiente comando para mostrar la configuración completa del clúster actual.
pcs configCapítulo 49. Creación de un cluster de alta disponibilidad de Red Hat con Pacemaker
El siguiente procedimiento crea un cluster de alta disponibilidad de Red Hat de dos nodos utilizando pcs.
La configuración del cluster en este ejemplo requiere que su sistema incluya los siguientes componentes:
-
2 nodos, que se utilizarán para crear el cluster. En este ejemplo, los nodos utilizados son
z1.example.comyz2.example.com. - Conmutadores de red para la red privada. Recomendamos, pero no exigimos, una red privada para la comunicación entre los nodos del clúster y otro hardware del clúster, como los conmutadores de alimentación de red y los conmutadores de canal de fibra.
-
Un dispositivo de cercado para cada nodo del clúster. Este ejemplo utiliza dos puertos del conmutador de potencia APC con un nombre de host de
zapc.example.com.
49.1. Instalación del software del clúster
El siguiente procedimiento instala el software del clúster y configura su sistema para la creación del clúster.
En cada nodo del cluster, instale los paquetes de software Red Hat High Availability Add-On junto con todos los agentes de valla disponibles en el canal de Alta Disponibilidad.
# yum install pcs pacemaker fence-agents-allAlternativamente, puede instalar los paquetes de software de Red Hat High Availability Add-On junto con sólo el agente de valla que necesite con el siguiente comando.
# yum install pcs pacemaker fence-agents-modelEl siguiente comando muestra una lista de los agentes de la valla disponibles.
# rpm -q -a | grep fence fence-agents-rhevm-4.0.2-3.el7.x86_64 fence-agents-ilo-mp-4.0.2-3.el7.x86_64 fence-agents-ipmilan-4.0.2-3.el7.x86_64 ...AvisoDespués de instalar los paquetes del complemento de alta disponibilidad de Red Hat, debe asegurarse de que sus preferencias de actualización de software estén configuradas para que no se instale nada automáticamente. La instalación en un cluster en funcionamiento puede causar comportamientos inesperados. Para obtener más información, consulte Prácticas recomendadas para aplicar actualizaciones de software a un cluster de alta disponibilidad o de almacenamiento resiliente de RHEL.
Si está ejecutando el demonio
firewalld, ejecute los siguientes comandos para habilitar los puertos requeridos por el complemento de alta disponibilidad de Red Hat.NotaPuede determinar si el demonio
firewalldestá instalado en su sistema con el comandorpm -q firewalld. Si está instalado, puede determinar si se está ejecutando con el comandofirewall-cmd --state.# firewall-cmd --permanent --add-service=high-availability # firewall-cmd --add-service=high-availabilityNotaLa configuración ideal del cortafuegos para los componentes del clúster depende del entorno local, en el que puede ser necesario tener en cuenta consideraciones como si los nodos tienen múltiples interfaces de red o si existe un cortafuegos fuera del host. El ejemplo que se presenta aquí, que abre los puertos que generalmente requiere un cluster Pacemaker, debe modificarse para adaptarse a las condiciones locales. Habilitación de puertos para el complemento de alta disponibilidad muestra los puertos que se deben habilitar para el complemento de alta disponibilidad de Red Hat y proporciona una explicación de para qué se utiliza cada puerto.
Para poder utilizar
pcspara configurar el cluster y comunicarse entre los nodos, debe establecer una contraseña en cada nodo para el usuariohacluster, que es la cuenta de administraciónpcs. Se recomienda que la contraseña del usuariohaclustersea la misma en cada nodo.# passwd hacluster Changing password for user hacluster. New password: Retype new password: passwd: all authentication tokens updated successfully.Antes de poder configurar el cluster, el demonio
pcsddebe ser iniciado y habilitado para arrancar en cada nodo. Este demonio funciona con el comandopcspara gestionar la configuración en todos los nodos del clúster.En cada nodo del clúster, ejecute los siguientes comandos para iniciar el servicio
pcsdy para habilitarpcsdal inicio del sistema.# systemctl start pcsd.service # systemctl enable pcsd.service
49.2. Instalación del paquete pcp-zeroconf (recomendado)
Cuando configure su cluster, se recomienda que instale el paquete pcp-zeroconf para la herramienta Performance Co-Pilot (PCP). PCP es la herramienta de monitorización de recursos recomendada por Red Hat para los sistemas RHEL. La instalación del paquete pcp-zeroconf le permite tener a PCP ejecutándose y recopilando datos de monitorización del rendimiento en beneficio de las investigaciones sobre cerramientos, fallos de recursos y otros eventos que perturban el cluster.
Los despliegues de clústeres en los que se habilita PCP necesitarán suficiente espacio disponible para los datos capturados por PCP en el sistema de archivos que contiene /var/log/pcp/. El uso típico de espacio por parte de PCP varía según las implementaciones, pero 10Gb suelen ser suficientes cuando se utiliza la configuración predeterminada de pcp-zeroconf, y algunos entornos pueden requerir menos. La supervisión del uso de este directorio durante un período de 14 días de actividad típica puede proporcionar una expectativa de uso más precisa.
Para instalar el paquete pcp-zeroconf, ejecute el siguiente comando.
# yum install pcp-zeroconf
Este paquete permite pmcd y establece la captura de datos a un intervalo de 10 segundos.
Para obtener información sobre la revisión de los datos del PCP, consulte ¿Por qué se ha reiniciado un nodo de cluster de alta disponibilidad de RHEL y cómo puedo evitar que vuelva a ocurrir? en el Portal del cliente de Red Hat.
49.3. Creación de un clúster de alta disponibilidad
Este procedimiento crea un cluster de Red Hat High Availability Add-On que consiste en los nodos z1.example.com y z2.example.com.
Autentifique el usuario
pcshaclusterpara cada nodo del clúster en el nodo desde el que va a ejecutarpcs.El siguiente comando autentifica al usuario
haclusterenz1.example.compara los dos nodos de un cluster de dos nodos que estará formado porz1.example.comyz2.example.com.[root@z1 ~]# pcs host auth z1.example.com z2.example.com Username: hacluster Password: z1.example.com: Authorized z2.example.com: AuthorizedEjecute el siguiente comando desde
z1.example.compara crear el cluster de dos nodosmy_clusterque consta de los nodosz1.example.comyz2.example.com. Esto propagará los archivos de configuración del cluster a ambos nodos del cluster. Este comando incluye la opción--start, que iniciará los servicios de cluster en ambos nodos del cluster.[root@z1 ~]# pcs cluster setup my_cluster --start z1.example.com z2.example.comHabilite los servicios del clúster para que se ejecuten en cada nodo del clúster cuando se inicie el nodo.
NotaPara su entorno particular, puede optar por dejar los servicios del clúster deshabilitados omitiendo este paso. Esto le permite asegurarse de que si un nodo se cae, cualquier problema con su clúster o sus recursos se resuelve antes de que el nodo se reincorpore al clúster. Si deja los servicios de clúster deshabilitados, tendrá que iniciar manualmente los servicios cuando reinicie un nodo ejecutando el comando
pcs cluster starten ese nodo.[root@z1 ~]# pcs cluster enable --all
Puede mostrar el estado actual del clúster con el comando pcs cluster status. Debido a que puede haber un ligero retraso antes de que el clúster esté en funcionamiento cuando inicie los servicios del clúster con la opción --start del comando pcs cluster setup, debe asegurarse de que el clúster esté en funcionamiento antes de realizar cualquier acción posterior en el clúster y su configuración.
[root@z1 ~]# pcs cluster status
Cluster Status:
Stack: corosync
Current DC: z2.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum
Last updated: Thu Oct 11 16:11:18 2018
Last change: Thu Oct 11 16:11:00 2018 by hacluster via crmd on z2.example.com
2 Nodes configured
0 Resources configured
...49.4. Creación de un cluster de alta disponibilidad con múltiples enlaces
Puede utilizar el comando pcs cluster setup para crear un cluster de Alta Disponibilidad de Red Hat con múltiples enlaces especificando todos los enlaces para cada nodo.
El formato del comando para crear un cluster de dos nodos con dos enlaces es el siguiente.
pcs cluster setup cluster_name node1_name addr=node1_link0_address addr=node1_link1_address node2_name addr=node2_link0_address addr=node2_link1_addressAl crear un clúster con múltiples enlaces, debe tener en cuenta lo siguiente.
-
El orden de los
addr=addresses importante. La primera dirección especificada después de un nombre de nodo es paralink0, la segunda paralink1, y así sucesivamente. - Es posible especificar hasta ocho enlaces utilizando el protocolo de transporte knet, que es el protocolo de transporte por defecto.
-
Todos los nodos deben tener el mismo número de parámetros
addr=. -
A partir de RHEL 8.1, es posible añadir, eliminar y cambiar enlaces en un clúster existente utilizando los comandos
pcs cluster link add,pcs cluster link remove,pcs cluster link deleteypcs cluster link update. - Al igual que con los clusters de un solo enlace, no mezcles direcciones IPv4 e IPv6 en un enlace, aunque puedes tener un enlace ejecutando IPv4 y el otro ejecutando IPv6.
- Al igual que con los clústeres de un solo enlace, puede especificar las direcciones como direcciones IP o como nombres siempre que los nombres se resuelvan con direcciones IPv4 o IPv6 para las que no se mezclen direcciones IPv4 e IPv6 en un enlace.
El siguiente ejemplo crea un cluster de dos nodos llamado my_twolink_cluster con dos nodos, rh80-node1 y rh80-node2. rh80-node1 tiene dos interfaces, la dirección IP 192.168.122.201 como link0 y 192.168.123.201 como link1. rh80-node2 tiene dos interfaces, la dirección IP 192.168.122.202 como link0 y 192.168.123.202 como link1.
# pcs cluster setup my_twolink_cluster rh80-node1 addr=192.168.122.201 addr=192.168.123.201 rh80-node2 addr=192.168.122.202 addr=192.168.123.202Para obtener información sobre cómo añadir nodos a un clúster existente con múltiples enlaces, consulte Añadir un nodo a un clúster con múltiples enlaces.
Para obtener información sobre la modificación de los enlaces en un clúster existente con múltiples enlaces, consulte Añadir y modificar enlaces en un clúster existente.
49.5. Configuración de las vallas
Debe configurar un dispositivo de cercado para cada nodo en el cluster. Para obtener información sobre los comandos y opciones de configuración de fencing, consulte Configuración de fencing en un cluster de Red Hat High Availability.
Para obtener información general sobre el cercado y su importancia en un cluster de alta disponibilidad de Red Hat, consulte Cerrado en un cluster de alta disponibilidad de Red Hat.
Al configurar un dispositivo de vallado, se debe prestar atención a si ese dispositivo comparte la energía con cualquier nodo o dispositivo del clúster. Si un nodo y su dispositivo de vallado comparten la alimentación, el clúster puede correr el riesgo de no poder vallar ese nodo si se pierde la alimentación de éste y de su dispositivo de vallado. Un clúster de este tipo debería tener fuentes de alimentación redundantes para los dispositivos de vallado y los nodos, o dispositivos de vallado redundantes que no compartan la energía. Los métodos alternativos de cercado, como el SBD o el cercado de almacenamiento, también pueden aportar redundancia en caso de pérdidas aisladas de energía.
Este ejemplo utiliza el conmutador de potencia APC con un nombre de host de zapc.example.com para cercar los nodos, y utiliza el agente de cercado fence_apc_snmp. Dado que ambos nodos serán cercados por el mismo agente de cercado, puede configurar ambos dispositivos de cercado como un único recurso, utilizando la opción pcmk_host_map.
Se crea un dispositivo de esgrima configurando el dispositivo como un recurso stonith con el comando pcs stonith create. El siguiente comando configura un recurso stonith llamado myapc que utiliza el agente de esgrima fence_apc_snmp para los nodos z1.example.com y z2.example.com. La opción pcmk_host_map asigna z1.example.com al puerto 1, y z2.example.com al puerto 2. El valor de inicio de sesión y la contraseña para el dispositivo APC son ambos apc. Por defecto, este dispositivo utilizará un intervalo de monitorización de sesenta segundos para cada nodo.
Tenga en cuenta que puede utilizar una dirección IP cuando especifique el nombre de host para los nodos.
[root@z1 ~]# pcs stonith create myapc fence_apc_snmp \
ipaddr="zapc.example.com" \
pcmk_host_map="z1.example.com:1;z2.example.com:2" \
login="apc" passwd="apc"El siguiente comando muestra los parámetros de un dispositivo STONITH existente.
[root@rh7-1 ~]# pcs stonith config myapc
Resource: myapc (class=stonith type=fence_apc_snmp)
Attributes: ipaddr=zapc.example.com pcmk_host_map=z1.example.com:1;z2.example.com:2 login=apc passwd=apc
Operations: monitor interval=60s (myapc-monitor-interval-60s)Después de configurar su dispositivo de valla, debe probar el dispositivo. Para obtener información sobre cómo probar un dispositivo de valla, consulte Probar un dispositivo de valla.
No pruebe su dispositivo de vallado desactivando la interfaz de red, ya que esto no probará correctamente el vallado.
Una vez que se ha configurado el cercado y se ha iniciado un clúster, un reinicio de la red desencadenará el cercado para el nodo que reinicie la red incluso cuando no se haya superado el tiempo de espera. Por este motivo, no reinicie el servicio de red mientras el servicio de clúster esté en funcionamiento, ya que activará el cercado involuntario en el nodo.
49.6. Copia de seguridad y restauración de la configuración de un clúster
Puede hacer una copia de seguridad de la configuración del clúster en un archivo tar con el siguiente comando. Si no especifica un nombre de archivo, se utilizará la salida estándar.
pcs config backup filename
El comando pcs config backup hace una copia de seguridad sólo de la configuración del clúster en sí, tal y como está configurada en el CIB; la configuración de los daemons de recursos está fuera del alcance de este comando. Por ejemplo, si ha configurado un recurso Apache en el clúster, se hará una copia de seguridad de la configuración del recurso (que está en el CIB), mientras que no se hará una copia de seguridad de la configuración del demonio Apache (como se establece en`/etc/httpd`) ni de los archivos que sirve. Del mismo modo, si hay un recurso de base de datos configurado en el clúster, la base de datos en sí no será respaldada, mientras que la configuración del recurso de base de datos (CIB) sí lo será.
Utilice el siguiente comando para restaurar los archivos de configuración del clúster en todos los nodos desde la copia de seguridad. Si no se especifica un nombre de archivo, se utilizará la entrada estándar. Si se especifica la opción --local, sólo se restaurarán los archivos del nodo actual.
pcs config restore [--local] [filename]49.7. Habilitación de puertos para el complemento de alta disponibilidad
La configuración ideal del cortafuegos para los componentes del clúster depende del entorno local, donde puede ser necesario tener en cuenta consideraciones tales como si los nodos tienen múltiples interfaces de red o si existe un cortafuegos fuera del host.
Si está ejecutando el demonio firewalld, ejecute los siguientes comandos para habilitar los puertos requeridos por el complemento de alta disponibilidad de Red Hat.
# firewall-cmd --permanent --add-service=high-availability
# firewall-cmd --add-service=high-availabilityEs posible que tenga que modificar qué puertos están abiertos para adaptarse a las condiciones locales.
Puede determinar si el demonio firewalld está instalado en su sistema con el comando rpm -q firewalld. Si el demonio firewalld está instalado, puede determinar si se está ejecutando con el comando firewall-cmd --state.
Tabla 49.1, “Puertos a habilitar para el complemento de alta disponibilidad” muestra los puertos a habilitar para el Complemento de Alta Disponibilidad de Red Hat y proporciona una explicación de para qué se utiliza el puerto.
| Puerto | Cuando sea necesario |
|---|---|
| TCP 2224 |
Puerto por defecto
Es crucial abrir el puerto 2224 de forma que |
| TCP 3121 | Requerido en todos los nodos si el cluster tiene nodos Pacemaker Remote
El demonio |
| TCP 5403 |
Se requiere en el host del dispositivo de quórum cuando se utiliza un dispositivo de quórum con |
| UDP 5404-5412 |
Se requiere en los nodos corosync para facilitar la comunicación entre nodos. Es crucial abrir los puertos 5404-5412 de forma que |
| TCP 21064 |
Se requiere en todos los nodos si el cluster contiene algún recurso que requiera DLM (como |
| TCP 9929, UDP 9929 | Se requiere que esté abierto en todos los nodos del clúster y en los nodos del árbitro de la cabina para las conexiones desde cualquiera de esos mismos nodos cuando se utiliza el gestor de tickets de la cabina para establecer un clúster multisitio. |
Capítulo 50. Configuración de un servidor HTTP Apache activo/pasivo en un cluster de alta disponibilidad de Red Hat
El siguiente procedimiento configura un servidor HTTP Apache activo/pasivo en un cluster de dos nodos de Red Hat Enterprise Linux High Availability Add-On utilizando pcs para configurar los recursos del cluster. En este caso de uso, los clientes acceden al servidor Apache HTTP a través de una dirección IP flotante. El servidor web se ejecuta en uno de los dos nodos del cluster. Si el nodo en el que se ejecuta el servidor web queda inoperativo, el servidor web vuelve a arrancar en el segundo nodo del cluster con una mínima interrupción del servicio.
Figura 50.1, “Apache en un cluster de alta disponibilidad de dos nodos de Red Hat” muestra una visión general de alto nivel del clúster en el que El clúster es un clúster de alta disponibilidad de Red Hat de dos nodos que está configurado con un interruptor de alimentación de red y con almacenamiento compartido. Los nodos del cluster están conectados a una red pública, para el acceso de los clientes al servidor Apache HTTP a través de una IP virtual. El servidor Apache se ejecuta en el Nodo 1 o en el Nodo 2, cada uno de los cuales tiene acceso al almacenamiento en el que se guardan los datos de Apache. En esta ilustración, el servidor web se ejecuta en el Nodo 1, mientras que el Nodo 2 está disponible para ejecutar el servidor si el Nodo 1 queda inoperativo.
Figura 50.1. Apache en un cluster de alta disponibilidad de dos nodos de Red Hat

Este caso de uso requiere que su sistema incluya los siguientes componentes:
- Un clúster de alta disponibilidad de Red Hat de dos nodos con un cercado de energía configurado para cada nodo. Recomendamos pero no requerimos una red privada. Este procedimiento utiliza el ejemplo de cluster proporcionado en Creación de un cluster de alta disponibilidad de Red Hat con Pacemaker.
- Una dirección IP virtual pública, necesaria para Apache.
- Almacenamiento compartido para los nodos del clúster, utilizando iSCSI, Fibre Channel u otro dispositivo de bloque de red compartido.
El clúster está configurado con un grupo de recursos Apache, que contiene los componentes del clúster que requiere el servidor web: un recurso LVM, un recurso de sistema de archivos, un recurso de dirección IP y un recurso de servidor web. Este grupo de recursos puede pasar de un nodo del clúster a otro, permitiendo que cualquiera de ellos ejecute el servidor web. Antes de crear el grupo de recursos para este clúster, usted realizará los siguientes procedimientos:
-
Configurar un sistema de archivos
ext4en el volumen lógicomy_lv. - Configurar un servidor web.
Después de realizar estos pasos, se crea el grupo de recursos y los recursos que contiene.
50.1. Configuración de un volumen LVM con un sistema de archivos ext4 en un cluster Pacemaker
Este caso de uso requiere que se cree un volumen lógico LVM en el almacenamiento que se comparte entre los nodos del clúster.
Los volúmenes LVM y las correspondientes particiones y dispositivos utilizados por los nodos del clúster deben estar conectados únicamente a los nodos del clúster.
El siguiente procedimiento crea un volumen lógico LVM y luego crea un sistema de archivos ext4 en ese volumen para utilizarlo en un cluster de Pacemaker. En este ejemplo, la partición compartida /dev/sdb1 se utiliza para almacenar el volumen físico LVM a partir del cual se creará el volumen lógico LVM.
En ambos nodos del clúster, realice los siguientes pasos para establecer el valor del ID del sistema LVM al valor del identificador
unamepara el sistema. El ID del sistema LVM se utilizará para garantizar que sólo el clúster sea capaz de activar el grupo de volúmenes.Establezca la opción de configuración
system_id_sourceen el archivo de configuración/etc/lvm/lvm.confcomouname.# Configuration option global/system_id_source. system_id_source = "uname"Verifique que el ID del sistema LVM en el nodo coincide con el
unamepara el nodo.# lvm systemid system ID: z1.example.com # uname -n z1.example.com
Cree el volumen LVM y cree un sistema de archivos ext4 en ese volumen. Como la partición
/dev/sdb1es un almacenamiento compartido, esta parte del procedimiento se realiza en un solo nodo.Crear un volumen físico LVM en la partición
/dev/sdb1.# pvcreate /dev/sdb1 Physical volume "/dev/sdb1" successfully createdCree el grupo de volúmenes
my_vgque consiste en el volumen físico/dev/sdb1.# vgcreate my_vg /dev/sdb1 Volume group "my_vg" successfully createdComprueba que el nuevo grupo de volúmenes tiene el ID del sistema del nodo en el que se está ejecutando y desde el que se creó el grupo de volúmenes.
# vgs -o+systemid VG #PV #LV #SN Attr VSize VFree System ID my_vg 1 0 0 wz--n- <1.82t <1.82t z1.example.comCrear un volumen lógico utilizando el grupo de volumen
my_vg.# lvcreate -L450 -n my_lv my_vg Rounding up size to full physical extent 452.00 MiB Logical volume "my_lv" createdPuede utilizar el comando
lvspara mostrar el volumen lógico.# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert my_lv my_vg -wi-a---- 452.00m ...Crear un sistema de archivos ext4 en el volumen lógico
my_lv.# mkfs.ext4 /dev/my_vg/my_lv mke2fs 1.44.3 (10-July-2018) Creating filesystem with 462848 1k blocks and 115824 inodes ...
50.2. Configuración de un servidor HTTP Apache
El siguiente procedimiento configura un servidor HTTP Apache.
Asegúrese de que el servidor HTTP Apache está instalado en cada nodo del clúster. También necesita la herramienta
wgetinstalada en el clúster para poder comprobar el estado del servidor HTTP Apache.En cada nodo, ejecute el siguiente comando.
# yum install -y httpd wgetSi está ejecutando el demonio
firewalld, en cada nodo del cluster habilite los puertos requeridos por el complemento de alta disponibilidad de Red Hat.# firewall-cmd --permanent --add-service=high-availability # firewall-cmd --reloadPara que el agente de recursos de Apache obtenga el estado del servidor HTTP Apache, asegúrese de que el siguiente texto está presente en el archivo
/etc/httpd/conf/httpd.confen cada nodo del clúster, y asegúrese de que no ha sido comentado. Si este texto no está ya presente, añádalo al final del archivo.<Location /server-status> SetHandler server-status Require local </Location>Cuando se utiliza el agente de recursos
apachepara gestionar Apache, no se utilizasystemd. Por ello, debe editar el scriptlogrotatesuministrado con Apache para que no utilicesystemctlpara recargar Apache.Elimine la siguiente línea en el archivo
/etc/logrotate.d/httpden cada nodo del clúster./bin/systemctl reload httpd.service > /dev/null 2>/dev/null || trueSustituya la línea que ha eliminado por las tres líneas siguientes.
/usr/bin/test -f /run/httpd.pid >/dev/null 2>/dev/null && /usr/bin/ps -q $(/usr/bin/cat /run/httpd.pid) >/dev/null 2>/dev/null && /usr/sbin/httpd -f /etc/httpd/conf/httpd.conf \ -c "PidFile /run/httpd.pid" -k graceful > /dev/null 2>/dev/null || trueCree una página web para que Apache la sirva. En un nodo del clúster, monte el sistema de archivos que creó en Configurar un volumen LVM con un sistema de archivos ext4, cree el archivo
index.htmlen ese sistema de archivos y luego desmonte el sistema de archivos.# mount /dev/my_vg/my_lv /var/www/ # mkdir /var/www/html # mkdir /var/www/cgi-bin # mkdir /var/www/error # restorecon -R /var/www # cat <<-END >/var/www/html/index.html <html> <body>Hello</body> </html> END # umount /var/www
50.3. Creación de los recursos y grupos de recursos
Este caso de uso requiere que se creen cuatro recursos de cluster. Para garantizar que todos estos recursos se ejecutan en el mismo nodo, se configuran como parte del grupo de recursos apachegroup. Los recursos a crear son los siguientes, listados en el orden en que se iniciarán.
-
Un recurso
LVMllamadomy_lvmque utiliza el grupo de volúmenes LVM que creó en Configuración de un volumen LVM con un sistema de archivos ext4. -
Un recurso
Filesystemllamadomy_fs, que utiliza el dispositivo del sistema de archivos/dev/my_vg/my_lvque creaste en Configuración de un volumen LVM con un sistema de archivos ext4. -
Un recurso
IPaddr2, que es una dirección IP flotante para el grupo de recursosapachegroup. La dirección IP no debe ser una ya asociada a un nodo físico. Si no se especifica el dispositivo NIC del recursoIPaddr2, la IP flotante debe residir en la misma red que una de las direcciones IP asignadas estáticamente del nodo, de lo contrario, el dispositivo NIC para asignar la dirección IP flotante no puede ser detectado correctamente. -
Un recurso
apachellamadoWebsiteque utiliza el archivoindex.htmly la configuración de Apache que definió en Configuración de un servidor HTTP Apache.
El siguiente procedimiento crea el grupo de recursos apachegroup y los recursos que contiene el grupo. Los recursos se iniciarán en el orden en que los añada al grupo y se detendrán en el orden inverso en que se añadan al grupo. Ejecute este procedimiento desde un solo nodo del clúster.
El siguiente comando crea el recurso
LVM-activatemy_lvm. Dado que el grupo de recursosapachegroupaún no existe, este comando crea el grupo de recursos.NotaNo configure más de un recurso
LVM-activateque utilice el mismo grupo de volúmenes LVM en una configuración de HA activa/pasiva, ya que esto podría causar la corrupción de los datos. Además, no configure un recursoLVM-activatecomo recurso clónico en una configuración de HA activa/pasiva.[root@z1 ~]# pcs resource create my_lvm ocf:heartbeat:LVM-activate vgname=my_vg vg_access_mode=system_id --group apachegroupCuando se crea un recurso, éste se inicia automáticamente. Puede utilizar el siguiente comando para confirmar que el recurso se ha creado y se ha iniciado.
# pcs resource status Resource Group: apachegroup my_lvm (ocf::heartbeat:LVM-activate): StartedPuede detener e iniciar manualmente un recurso individual con los comandos
pcs resource disableypcs resource enable.Los siguientes comandos crean los recursos restantes para la configuración, añadiéndolos al grupo de recursos existente
apachegroup.[root@z1 ~]# pcs resource create my_fs Filesystem \ device="/dev/my_vg/my_lv" directory="/var/www" fstype="ext4" \ --group apachegroup [root@z1 ~]# pcs resource create VirtualIP IPaddr2 ip=198.51.100.3 \ cidr_netmask=24 --group apachegroup [root@z1 ~]# pcs resource create Website apache \ configfile="/etc/httpd/conf/httpd.conf" \ statusurl="http://127.0.0.1/server-status" --group apachegroupDespués de crear los recursos y el grupo de recursos que los contiene, puede comprobar el estado del clúster. Observe que los cuatro recursos se ejecutan en el mismo nodo.
[root@z1 ~]# pcs status Cluster name: my_cluster Last updated: Wed Jul 31 16:38:51 2013 Last change: Wed Jul 31 16:42:14 2013 via crm_attribute on z1.example.com Stack: corosync Current DC: z2.example.com (2) - partition with quorum Version: 1.1.10-5.el7-9abe687 2 Nodes configured 6 Resources configured Online: [ z1.example.com z2.example.com ] Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: apachegroup my_lvm (ocf::heartbeat:LVM): Started z1.example.com my_fs (ocf::heartbeat:Filesystem): Started z1.example.com VirtualIP (ocf::heartbeat:IPaddr2): Started z1.example.com Website (ocf::heartbeat:apache): Started z1.example.comTenga en cuenta que si no ha configurado un dispositivo de cercado para su clúster, por defecto los recursos no se inician.
Una vez que el clúster esté en funcionamiento, puede dirigir un navegador a la dirección IP que definió como recurso
IPaddr2para ver la pantalla de muestra, que consiste en la simple palabra "Hola".HolaSi encuentra que los recursos que configuró no están funcionando, puede ejecutar el comando
pcs resource debug-start resourcepara probar la configuración de los recursos.
50.4. Probar la configuración de los recursos
En la pantalla de estado del clúster que se muestra en Creación de los recursos y grupos de recursos, todos los recursos se están ejecutando en el nodo z1.example.com. Puede probar si el grupo de recursos falla en el nodo z2.example.com utilizando el siguiente procedimiento para poner el primer nodo en modo standby, tras lo cual el nodo ya no podrá alojar recursos.
El siguiente comando pone el nodo
z1.example.comen modostandby.[root@z1 ~]# pcs node standby z1.example.comDespués de poner el nodo
z1en modostandby, compruebe el estado del clúster. Observe que los recursos deberían estar ahora todos funcionando enz2.[root@z1 ~]# pcs status Cluster name: my_cluster Last updated: Wed Jul 31 17:16:17 2013 Last change: Wed Jul 31 17:18:34 2013 via crm_attribute on z1.example.com Stack: corosync Current DC: z2.example.com (2) - partition with quorum Version: 1.1.10-5.el7-9abe687 2 Nodes configured 6 Resources configured Node z1.example.com (1): standby Online: [ z2.example.com ] Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: apachegroup my_lvm (ocf::heartbeat:LVM): Started z2.example.com my_fs (ocf::heartbeat:Filesystem): Started z2.example.com VirtualIP (ocf::heartbeat:IPaddr2): Started z2.example.com Website (ocf::heartbeat:apache): Started z2.example.comEl sitio web en la dirección IP definida debería seguir mostrándose, sin interrupción.
Para eliminar
z1del modostandby, introduzca el siguiente comando.[root@z1 ~]# pcs node unstandby z1.example.comNotaSacar un nodo del modo
standbyno provoca por sí mismo que los recursos vuelvan a fallar en ese nodo. Esto dependerá del valor deresource-stickinesspara los recursos. Para obtener información sobre el metaatributoresource-stickiness, consulte Configurar un recurso para que prefiera su nodo actual.
Capítulo 51. Configuración de un servidor NFS activo/pasivo en un cluster de Alta Disponibilidad de Red Hat
El siguiente procedimiento configura un servidor NFS activo/pasivo de alta disponibilidad en un cluster de dos nodos de Red Hat Enterprise Linux High Availability Add-On usando almacenamiento compartido. El procedimiento utiliza pcs para configurar los recursos del cluster Pacemaker. En este caso de uso, los clientes acceden al sistema de archivos NFS a través de una dirección IP flotante. El servidor NFS se ejecuta en uno de los dos nodos del clúster. Si el nodo en el que se ejecuta el servidor NFS deja de funcionar, el servidor NFS vuelve a arrancar en el segundo nodo del cluster con una mínima interrupción del servicio.
51.1. Requisitos previos
Este caso de uso requiere que su sistema incluya los siguientes componentes:
- Un clúster de alta disponibilidad de Red Hat de dos nodos con un cercado de energía configurado para cada nodo. Recomendamos pero no requerimos una red privada. Este procedimiento utiliza el ejemplo de cluster proporcionado en Creación de un cluster de alta disponibilidad de Red Hat con Pacemaker.
- Una dirección IP virtual pública, necesaria para el servidor NFS.
- Almacenamiento compartido para los nodos del clúster, utilizando iSCSI, Fibre Channel u otro dispositivo de bloque de red compartido.
51.2. Resumen del procedimiento
La configuración de un servidor NFS activo/pasivo de alta disponibilidad en un cluster de alta disponibilidad de dos nodos de Red Hat Enterprise Linux requiere que realice los siguientes pasos:
-
Configure un sistema de archivos
ext4en el volumen lógico LVMmy_lven el almacenamiento compartido para los nodos del clúster. - Configure un recurso compartido NFS en el almacenamiento compartido en el volumen lógico LVM.
- Crear los recursos del clúster.
- Pruebe el servidor NFS que ha configurado.
51.3. Configuración de un volumen LVM con un sistema de archivos ext4 en un cluster Pacemaker
Este caso de uso requiere que se cree un volumen lógico LVM en el almacenamiento que se comparte entre los nodos del clúster.
Los volúmenes LVM y las correspondientes particiones y dispositivos utilizados por los nodos del clúster deben estar conectados únicamente a los nodos del clúster.
El siguiente procedimiento crea un volumen lógico LVM y luego crea un sistema de archivos ext4 en ese volumen para utilizarlo en un cluster de Pacemaker. En este ejemplo, la partición compartida /dev/sdb1 se utiliza para almacenar el volumen físico LVM a partir del cual se creará el volumen lógico LVM.
En ambos nodos del clúster, realice los siguientes pasos para establecer el valor del ID del sistema LVM al valor del identificador
unamepara el sistema. El ID del sistema LVM se utilizará para garantizar que sólo el clúster sea capaz de activar el grupo de volúmenes.Establezca la opción de configuración
system_id_sourceen el archivo de configuración/etc/lvm/lvm.confcomouname.# Configuration option global/system_id_source. system_id_source = "uname"Verifique que el ID del sistema LVM en el nodo coincide con el
unamepara el nodo.# lvm systemid system ID: z1.example.com # uname -n z1.example.com
Cree el volumen LVM y cree un sistema de archivos ext4 en ese volumen. Como la partición
/dev/sdb1es un almacenamiento compartido, esta parte del procedimiento se realiza en un solo nodo.Crear un volumen físico LVM en la partición
/dev/sdb1.# pvcreate /dev/sdb1 Physical volume "/dev/sdb1" successfully createdCree el grupo de volúmenes
my_vgque consiste en el volumen físico/dev/sdb1.# vgcreate my_vg /dev/sdb1 Volume group "my_vg" successfully createdComprueba que el nuevo grupo de volúmenes tiene el ID del sistema del nodo en el que se está ejecutando y desde el que se creó el grupo de volúmenes.
# vgs -o+systemid VG #PV #LV #SN Attr VSize VFree System ID my_vg 1 0 0 wz--n- <1.82t <1.82t z1.example.comCrear un volumen lógico utilizando el grupo de volumen
my_vg.# lvcreate -L450 -n my_lv my_vg Rounding up size to full physical extent 452.00 MiB Logical volume "my_lv" createdPuede utilizar el comando
lvspara mostrar el volumen lógico.# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert my_lv my_vg -wi-a---- 452.00m ...Crear un sistema de archivos ext4 en el volumen lógico
my_lv.# mkfs.ext4 /dev/my_vg/my_lv mke2fs 1.44.3 (10-July-2018) Creating filesystem with 462848 1k blocks and 115824 inodes ...
51.5. Configuración de los recursos y del grupo de recursos para un servidor NFS en un clúster
Esta sección proporciona el procedimiento para configurar los recursos del clúster para este caso de uso.
Si no ha configurado un dispositivo de cercado para su clúster, por defecto los recursos no se inician.
Si encuentra que los recursos que configuró no están funcionando, puede ejecutar el comando pcs resource debug-start resource para probar la configuración de los recursos. Esto inicia el servicio fuera del control y conocimiento del cluster. En el momento en que los recursos configurados vuelvan a funcionar, ejecute pcs resource cleanup resource para que el clúster conozca las actualizaciones.
El siguiente procedimiento configura los recursos del sistema. Para garantizar que todos estos recursos se ejecutan en el mismo nodo, se configuran como parte del grupo de recursos nfsgroup. Los recursos se iniciarán en el orden en el que los añada al grupo, y se detendrán en el orden inverso en el que se añaden al grupo. Ejecute este procedimiento desde un solo nodo del clúster.
Crea el recurso LVM-activate llamado
my_lvm. Dado que el grupo de recursosnfsgroupaún no existe, este comando crea el grupo de recursos.AvisoNo configure más de un recurso
LVM-activateque utilice el mismo grupo de volúmenes LVM en una configuración de HA activa/pasiva, ya que se corre el riesgo de corromper los datos. Además, no configure un recursoLVM-activatecomo recurso clónico en una configuración de HA activa/pasiva.[root@z1 ~]# pcs resource create my_lvm ocf:heartbeat:LVM-activate vgname=my_vg vg_access_mode=system_id --group nfsgroupCompruebe el estado del clúster para verificar que el recurso está en funcionamiento.
root@z1 ~]# pcs status Cluster name: my_cluster Last updated: Thu Jan 8 11:13:17 2015 Last change: Thu Jan 8 11:13:08 2015 Stack: corosync Current DC: z2.example.com (2) - partition with quorum Version: 1.1.12-a14efad 2 Nodes configured 3 Resources configured Online: [ z1.example.com z2.example.com ] Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM): Started z1.example.com PCSD Status: z1.example.com: Online z2.example.com: Online Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledConfigurar un recurso
Filesystempara el cluster.El siguiente comando configura un recurso ext4
Filesystemllamadonfssharecomo parte del grupo de recursosnfsgroup. Este sistema de archivos utiliza el grupo de volúmenes LVM y el sistema de archivos ext4 que creó en Configuración de un volumen LVM con un sistema de archivos ext4 y se montará en el directorio/nfsshareque creó en Configuración de un recurso compartido NFS.[root@z1 ~]# pcs resource create nfsshare Filesystem \ device=/dev/my_vg/my_lv directory=/nfsshare \ fstype=ext4 --group nfsgroupPuede especificar las opciones de montaje como parte de la configuración de un recurso
Filesystemcon el parámetrooptions=optionsparámetro. Ejecute el comandopcs resource describe Filesystempara obtener las opciones de configuración completas.Compruebe que los recursos
my_lvmynfsshareestán en funcionamiento.[root@z1 ~]# pcs status ... Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM): Started z1.example.com nfsshare (ocf::heartbeat:Filesystem): Started z1.example.com ...Cree el recurso
nfsserverdenominadonfs-daemoncomo parte del grupo de recursosnfsgroup.NotaEl recurso
nfsserverpermite especificar un parámetronfs_shared_infodir, que es un directorio que los servidores NFS utilizan para almacenar información de estado relacionada con NFS.Se recomienda que este atributo se establezca en un subdirectorio de uno de los recursos
Filesystemcreados en esta colección de exportaciones. Esto asegura que los servidores NFS están almacenando su información de estado en un dispositivo que estará disponible para otro nodo si este grupo de recursos necesita reubicarse. En este ejemplo;-
/nfssharees el directorio de almacenamiento compartido gestionado por el recursoFilesystem -
/nfsshare/exports/export1y/nfsshare/exports/export2son los directorios de exportación -
/nfsshare/nfsinfoes el directorio de información compartida del recursonfsserver
[root@z1 ~]# pcs resource create nfs-daemon nfsserver \ nfs_shared_infodir=/nfsshare/nfsinfo nfs_no_notify=true \ --group nfsgroup [root@z1 ~]# pcs status ...-
Añada los recursos
exportfspara exportar el directorio/nfsshare/exports. Estos recursos forman parte del grupo de recursosnfsgroup. Esto construye un directorio virtual para los clientes NFSv4. Los clientes NFSv3 también pueden acceder a estas exportaciones.NotaLa opción
fsid=0sólo es necesaria si desea crear un directorio virtual para clientes NFSv4. Para más información, consulte ¿Cómo configuro la opción fsid en el archivo /etc/exports de un servidor NFS?[root@z1 ~]# pcs resource create nfs-root exportfs \ clientspec=192.168.122.0/255.255.255.0 \ options=rw,sync,no_root_squash \ directory=/nfsshare/exports \ fsid=0 --group nfsgroup [root@z1 ~]# # pcs resource create nfs-export1 exportfs \ clientspec=192.168.122.0/255.255.255.0 \ options=rw,sync,no_root_squash directory=/nfsshare/exports/export1 \ fsid=1 --group nfsgroup [root@z1 ~]# # pcs resource create nfs-export2 exportfs \ clientspec=192.168.122.0/255.255.255.0 \ options=rw,sync,no_root_squash directory=/nfsshare/exports/export2 \ fsid=2 --group nfsgroupAñada el recurso de dirección IP flotante que los clientes NFS utilizarán para acceder al recurso compartido NFS. Este recurso forma parte del grupo de recursos
nfsgroup. Para esta implementación de ejemplo, estamos usando 192.168.122.200 como dirección IP flotante.[root@z1 ~]# pcs resource create nfs_ip IPaddr2 \ ip=192.168.122.200 cidr_netmask=24 --group nfsgroupAñade un recurso
nfsnotifypara enviar notificaciones de reinicio de NFSv3 una vez que se haya inicializado todo el despliegue de NFS. Este recurso forma parte del grupo de recursosnfsgroup.NotaPara que la notificación NFS se procese correctamente, la dirección IP flotante debe tener un nombre de host asociado que sea consistente tanto en los servidores NFS como en el cliente NFS.
[root@z1 ~]# pcs resource create nfs-notify nfsnotify \ source_host=192.168.122.200 --group nfsgroupDespués de crear los recursos y las restricciones de recursos, puede comprobar el estado del clúster. Tenga en cuenta que todos los recursos se ejecutan en el mismo nodo.
[root@z1 ~]# pcs status ... Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM): Started z1.example.com nfsshare (ocf::heartbeat:Filesystem): Started z1.example.com nfs-daemon (ocf::heartbeat:nfsserver): Started z1.example.com nfs-root (ocf::heartbeat:exportfs): Started z1.example.com nfs-export1 (ocf::heartbeat:exportfs): Started z1.example.com nfs-export2 (ocf::heartbeat:exportfs): Started z1.example.com nfs_ip (ocf::heartbeat:IPaddr2): Started z1.example.com nfs-notify (ocf::heartbeat:nfsnotify): Started z1.example.com ...
51.6. Prueba de la configuración de los recursos NFS
Puede validar la configuración de su sistema con los siguientes procedimientos. Debería poder montar el sistema de archivos exportado con NFSv3 o NFSv4.
51.6.1. Prueba de la exportación NFS
En un nodo fuera del clúster, que resida en la misma red que el despliegue, verifique que el recurso compartido NFS puede ser visto montando el recurso compartido NFS. Para este ejemplo, estamos utilizando la red 192.168.122.0/24.
# showmount -e 192.168.122.200 Export list for 192.168.122.200: /nfsshare/exports/export1 192.168.122.0/255.255.255.0 /nfsshare/exports 192.168.122.0/255.255.255.0 /nfsshare/exports/export2 192.168.122.0/255.255.255.0Para verificar que puede montar el recurso compartido NFS con NFSv4, monte el recurso compartido NFS en un directorio del nodo cliente. Tras el montaje, compruebe que el contenido de los directorios de exportación es visible. Desmonte el recurso compartido después de la prueba.
# mkdir nfsshare # mount -o "vers=4" 192.168.122.200:export1 nfsshare # ls nfsshare clientdatafile1 # umount nfsshareCompruebe que puede montar el recurso compartido NFS con NFSv3. Tras el montaje, compruebe que el archivo de prueba
clientdatafile1es visible. A diferencia de NFSv4, como NFSv3 no utiliza el sistema de archivos virtual, debe montar una exportación específica. Desmonte el recurso compartido después de la prueba.# mkdir nfsshare # mount -o "vers=3" 192.168.122.200:/nfsshare/exports/export2 nfsshare # ls nfsshare clientdatafile2 # umount nfsshare
51.6.2. Pruebas de conmutación por error
En un nodo fuera del clúster, monte el recurso compartido NFS y verifique el acceso a la dirección
clientdatafile1que creamos en Configuración de un recurso compartido NFS# mkdir nfsshare # mount -o "vers=4" 192.168.122.200:export1 nfsshare # ls nfsshare clientdatafile1Desde un nodo del clúster, determine qué nodo del clúster está ejecutando
nfsgroup. En este ejemplo,nfsgroupse está ejecutando enz1.example.com.[root@z1 ~]# pcs status ... Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM): Started z1.example.com nfsshare (ocf::heartbeat:Filesystem): Started z1.example.com nfs-daemon (ocf::heartbeat:nfsserver): Started z1.example.com nfs-root (ocf::heartbeat:exportfs): Started z1.example.com nfs-export1 (ocf::heartbeat:exportfs): Started z1.example.com nfs-export2 (ocf::heartbeat:exportfs): Started z1.example.com nfs_ip (ocf::heartbeat:IPaddr2): Started z1.example.com nfs-notify (ocf::heartbeat:nfsnotify): Started z1.example.com ...Desde un nodo del clúster, ponga el nodo que está ejecutando
nfsgroupen modo de espera.[root@z1 ~]# pcs node standby z1.example.comCompruebe que
nfsgroupse inicia con éxito en el otro nodo del clúster.[root@z1 ~]# pcs status ... Full list of resources: Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM): Started z2.example.com nfsshare (ocf::heartbeat:Filesystem): Started z2.example.com nfs-daemon (ocf::heartbeat:nfsserver): Started z2.example.com nfs-root (ocf::heartbeat:exportfs): Started z2.example.com nfs-export1 (ocf::heartbeat:exportfs): Started z2.example.com nfs-export2 (ocf::heartbeat:exportfs): Started z2.example.com nfs_ip (ocf::heartbeat:IPaddr2): Started z2.example.com nfs-notify (ocf::heartbeat:nfsnotify): Started z2.example.com ...Desde el nodo externo al clúster en el que ha montado el recurso compartido NFS, verifique que este nodo externo sigue teniendo acceso al archivo de prueba dentro del montaje NFS.
# ls nfsshare clientdatafile1El servicio se perderá brevemente para el cliente durante la conmutación por error, pero el cliente debería recuperarlo sin intervención del usuario. Por defecto, los clientes que utilizan NFSv4 pueden tardar hasta 90 segundos en recuperar el montaje; estos 90 segundos representan el periodo de gracia de arrendamiento de archivos NFSv4 que observa el servidor al iniciarse. Los clientes NFSv3 deberían recuperar el acceso al montaje en cuestión de pocos segundos.
Desde un nodo del clúster, retire del modo de espera el nodo que inicialmente estaba ejecutando
nfsgroup.NotaSacar un nodo del modo
standbyno provoca por sí mismo que los recursos vuelvan a fallar en ese nodo. Esto dependerá del valor deresource-stickinesspara los recursos. Para obtener información sobre el metaatributoresource-stickiness, consulte Configurar un recurso para que prefiera su nodo actual.[root@z1 ~]# pcs node unstandby z1.example.com
Capítulo 52. Sistemas de archivos GFS2 en un clúster
Esta sección establece:
- Un procedimiento para configurar un clúster Pacemaker que incluya sistemas de archivos GFS2
- Un procedimiento para migrar volúmenes lógicos de RHEL 7 que contienen sistemas de archivos GFS2 a un clúster de RHEL 8
52.1. Configuración de un sistema de archivos GFS2 en un clúster
Este procedimiento es un resumen de los pasos necesarios para configurar un cluster Pacemaker que incluya sistemas de archivos GFS2. Este ejemplo crea tres sistemas de archivos GFS2 en tres volúmenes lógicos.
Como requisito previo a este procedimiento, debe instalar e iniciar el software de clúster en todos los nodos y crear un clúster básico de dos nodos. También debe configurar el cercado para el cluster. Para obtener información sobre la creación de un cluster Pacemaker y la configuración del cercado para el cluster, consulte Creación de un cluster de alta disponibilidad de Red Hat con Pacemaker.
Procedimiento
En ambos nodos del clúster, instale los paquetes
lvm2-lockd,gfs2-utilsydlm. El paquetelvm2-lockdforma parte del canal AppStream y los paquetesgfs2-utilsydlmforman parte del canal Resilient Storage.# yum install lvm2-lockd gfs2-utils dlmAjuste el parámetro global de Marcapasos
no_quorum_policyafreeze.NotaPor defecto, el valor de
no-quorum-policyse establece enstop, lo que indica que una vez que se pierde el quórum, todos los recursos de la partición restante se detendrán inmediatamente. Normalmente este valor por defecto es la opción más segura y óptima, pero a diferencia de la mayoría de los recursos, GFS2 requiere quórum para funcionar. Cuando se pierde el quórum, tanto las aplicaciones que utilizan los montajes de GFS2 como el propio montaje de GFS2 no pueden detenerse correctamente. Cualquier intento de detener estos recursos sin quórum fallará, lo que en última instancia provocará que todo el clúster quede vallado cada vez que se pierda el quórum.Para solucionar esta situación, configure
no-quorum-policyafreezecuando GFS2 esté en uso. Esto significa que cuando se pierde el quórum, la partición restante no hará nada hasta que se recupere el quórum.# pcs property set no-quorum-policy=freezeConfigure un recurso
dlm. Esta es una dependencia necesaria para configurar un sistema de archivos GFS2 en un clúster. Este ejemplo crea el recursodlmcomo parte de un grupo de recursos llamadolocking.[root@z1 ~]# pcs resource create dlm --group locking ocf:pacemaker:controld op monitor interval=30s on-fail=fenceClone el grupo de recursos
lockingpara que el grupo de recursos pueda estar activo en ambos nodos del clúster.[root@z1 ~]# pcs resource clone locking interleave=trueConfigure un recurso
lvmlockdcomo parte del grupolocking.[root@z1 ~]# pcs resource create lvmlockd --group locking ocf:heartbeat:lvmlockd op monitor interval=30s on-fail=fenceCompruebe el estado del clúster para asegurarse de que el grupo de recursos
lockingse ha iniciado en ambos nodos del clúster.[root@z1 ~]# pcs status --full Cluster name: my_cluster [...] Online: [ z1.example.com (1) z2.example.com (2) ] Full list of resources: smoke-apc (stonith:fence_apc): Started z1.example.com Clone Set: locking-clone [locking] Resource Group: locking:0 dlm (ocf::pacemaker:controld): Started z1.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z1.example.com Resource Group: locking:1 dlm (ocf::pacemaker:controld): Started z2.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z2.example.com Started: [ z1.example.com z2.example.com ]Compruebe que el demonio
lvmlockdse está ejecutando en ambos nodos del clúster.[root@z1 ~]# ps -ef | grep lvmlockd root 12257 1 0 17:45 ? 00:00:00 lvmlockd -p /run/lvmlockd.pid -A 1 -g dlm [root@z2 ~]# ps -ef | grep lvmlockd root 12270 1 0 17:45 ? 00:00:00 lvmlockd -p /run/lvmlockd.pid -A 1 -g dlmEn un nodo del clúster, cree dos grupos de volúmenes compartidos. Un grupo de volúmenes contendrá dos sistemas de archivos GFS2, y el otro grupo de volúmenes contendrá un sistema de archivos GFS2.
El siguiente comando crea el grupo de volúmenes compartidos
shared_vg1en/dev/vdb.[root@z1 ~]# vgcreate --shared shared_vg1 /dev/vdb Physical volume "/dev/vdb" successfully created. Volume group "shared_vg1" successfully created VG shared_vg1 starting dlm lockspace Starting locking. Waiting until locks are ready...El siguiente comando crea el grupo de volúmenes compartidos
shared_vg2en/dev/vdc.[root@z1 ~]# vgcreate --shared shared_vg2 /dev/vdc Physical volume "/dev/vdc" successfully created. Volume group "shared_vg2" successfully created VG shared_vg2 starting dlm lockspace Starting locking. Waiting until locks are ready...En el segundo nodo del clúster, inicie el gestor de bloqueos para cada uno de los grupos de volúmenes compartidos.
[root@z2 ~]# vgchange --lock-start shared_vg1 VG shared_vg1 starting dlm lockspace Starting locking. Waiting until locks are ready... [root@z2 ~]# vgchange --lock-start shared_vg2 VG shared_vg2 starting dlm lockspace Starting locking. Waiting until locks are ready...En un nodo del clúster, cree los volúmenes lógicos compartidos y formatee los volúmenes con un sistema de archivos GFS2. Se necesita un diario para cada nodo que monte el sistema de archivos. Asegúrese de crear suficientes diarios para cada uno de los nodos del clúster.
[root@z1 ~]# lvcreate --activate sy -L5G -n shared_lv1 shared_vg1 Logical volume "shared_lv1" created. [root@z1 ~]# lvcreate --activate sy -L5G -n shared_lv2 shared_vg1 Logical volume "shared_lv2" created. [root@z1 ~]# lvcreate --activate sy -L5G -n shared_lv1 shared_vg2 Logical volume "shared_lv1" created. [root@z1 ~]# mkfs.gfs2 -j2 -p lock_dlm -t my_cluster:gfs2-demo1 /dev/shared_vg1/shared_lv1 [root@z1 ~]# mkfs.gfs2 -j2 -p lock_dlm -t my_cluster:gfs2-demo2 /dev/shared_vg1/shared_lv2 [root@z1 ~]# mkfs.gfs2 -j2 -p lock_dlm -t my_cluster:gfs2-demo3 /dev/shared_vg2/shared_lv1Cree un recurso
LVM-activatepara cada volumen lógico para activar automáticamente ese volumen lógico en todos los nodos.Crea un recurso
LVM-activatellamadosharedlv1para el volumen lógicoshared_lv1en el grupo de volúmenesshared_vg1. Este comando también crea el grupo de recursosshared_vg1que incluye el recurso. En este ejemplo, el grupo de recursos tiene el mismo nombre que el grupo de volumen compartido que incluye el volumen lógico.[root@z1 ~]# pcs resource create sharedlv1 --group shared_vg1 ocf:heartbeat:LVM-activate lvname=shared_lv1 vgname=shared_vg1 activation_mode=shared vg_access_mode=lvmlockdCrea un recurso
LVM-activatellamadosharedlv2para el volumen lógicoshared_lv2en el grupo de volúmenesshared_vg1. Este recurso también formará parte del grupo de recursosshared_vg1.[root@z1 ~]# pcs resource create sharedlv2 --group shared_vg1 ocf:heartbeat:LVM-activate lvname=shared_lv2 vgname=shared_vg1 activation_mode=shared vg_access_mode=lvmlockdCrea un recurso
LVM-activatellamadosharedlv3para el volumen lógicoshared_lv1en el grupo de volúmenesshared_vg2. Este comando también crea el grupo de recursosshared_vg2que incluye el recurso.[root@z1 ~]# pcs resource create sharedlv3 --group shared_vg2 ocf:heartbeat:LVM-activate lvname=shared_lv1 vgname=shared_vg2 activation_mode=shared vg_access_mode=lvmlockd
Clona los dos nuevos grupos de recursos.
[root@z1 ~]# pcs resource clone shared_vg1 interleave=true [root@z1 ~]# pcs resource clone shared_vg2 interleave=trueConfigure las restricciones de ordenación para garantizar que el grupo de recursos
lockingque incluye los recursosdlmylvmlockdse inicie primero.[root@z1 ~]# pcs constraint order start locking-clone then shared_vg1-clone Adding locking-clone shared_vg1-clone (kind: Mandatory) (Options: first-action=start then-action=start) [root@z1 ~]# pcs constraint order start locking-clone then shared_vg2-clone Adding locking-clone shared_vg2-clone (kind: Mandatory) (Options: first-action=start then-action=start)Configure las restricciones de colocación para garantizar que los grupos de recursos
vg1yvg2se inicien en el mismo nodo que el grupo de recursoslocking.[root@z1 ~]# pcs constraint colocation add shared_vg1-clone with locking-clone [root@z1 ~]# pcs constraint colocation add shared_vg2-clone with locking-cloneEn ambos nodos del clúster, verifique que los volúmenes lógicos estén activos. Puede haber un retraso de unos segundos.
[root@z1 ~]# lvs LV VG Attr LSize shared_lv1 shared_vg1 -wi-a----- 5.00g shared_lv2 shared_vg1 -wi-a----- 5.00g shared_lv1 shared_vg2 -wi-a----- 5.00g [root@z2 ~]# lvs LV VG Attr LSize shared_lv1 shared_vg1 -wi-a----- 5.00g shared_lv2 shared_vg1 -wi-a----- 5.00g shared_lv1 shared_vg2 -wi-a----- 5.00gCree un recurso de sistema de archivos para montar automáticamente cada sistema de archivos GFS2 en todos los nodos.
No debe añadir el sistema de archivos al archivo
/etc/fstabporque se gestionará como un recurso de clúster de Pacemaker. Las opciones de montaje se pueden especificar como parte de la configuración del recurso conoptions=options. Ejecute el comandopcs resource describe Filesystempara obtener las opciones de configuración completas.Los siguientes comandos crean los recursos del sistema de archivos. Estos comandos añaden cada recurso al grupo de recursos que incluye el recurso de volumen lógico para ese sistema de archivos.
[root@z1 ~]# pcs resource create sharedfs1 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/shared_vg1/shared_lv1" directory="/mnt/gfs1" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence [root@z1 ~]# pcs resource create sharedfs2 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/shared_vg1/shared_lv2" directory="/mnt/gfs2" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence [root@z1 ~]# pcs resource create sharedfs3 --group shared_vg2 ocf:heartbeat:Filesystem device="/dev/shared_vg2/shared_lv1" directory="/mnt/gfs3" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fenceCompruebe que los sistemas de archivos GFS2 están montados en ambos nodos del clúster.
[root@z1 ~]# mount | grep gfs2 /dev/mapper/shared_vg1-shared_lv1 on /mnt/gfs1 type gfs2 (rw,noatime,seclabel) /dev/mapper/shared_vg1-shared_lv2 on /mnt/gfs2 type gfs2 (rw,noatime,seclabel) /dev/mapper/shared_vg2-shared_lv1 on /mnt/gfs3 type gfs2 (rw,noatime,seclabel) [root@z2 ~]# mount | grep gfs2 /dev/mapper/shared_vg1-shared_lv1 on /mnt/gfs1 type gfs2 (rw,noatime,seclabel) /dev/mapper/shared_vg1-shared_lv2 on /mnt/gfs2 type gfs2 (rw,noatime,seclabel) /dev/mapper/shared_vg2-shared_lv1 on /mnt/gfs3 type gfs2 (rw,noatime,seclabel)Comprueba el estado del clúster.
[root@z1 ~]# pcs status --full Cluster name: my_cluster [...1 Full list of resources: smoke-apc (stonith:fence_apc): Started z1.example.com Clone Set: locking-clone [locking] Resource Group: locking:0 dlm (ocf::pacemaker:controld): Started z2.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z2.example.com Resource Group: locking:1 dlm (ocf::pacemaker:controld): Started z1.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z1.example.com Started: [ z1.example.com z2.example.com ] Clone Set: shared_vg1-clone [shared_vg1] Resource Group: shared_vg1:0 sharedlv1 (ocf::heartbeat:LVM-activate): Started z2.example.com sharedlv2 (ocf::heartbeat:LVM-activate): Started z2.example.com sharedfs1 (ocf::heartbeat:Filesystem): Started z2.example.com sharedfs2 (ocf::heartbeat:Filesystem): Started z2.example.com Resource Group: shared_vg1:1 sharedlv1 (ocf::heartbeat:LVM-activate): Started z1.example.com sharedlv2 (ocf::heartbeat:LVM-activate): Started z1.example.com sharedfs1 (ocf::heartbeat:Filesystem): Started z1.example.com sharedfs2 (ocf::heartbeat:Filesystem): Started example.co Started: [ z1.example.com z2.example.com ] Clone Set: shared_vg2-clone [shared_vg2] Resource Group: shared_vg2:0 sharedlv3 (ocf::heartbeat:LVM-activate): Started z2.example.com sharedfs3 (ocf::heartbeat:Filesystem): Started z2.example.com Resource Group: shared_vg2:1 sharedlv3 (ocf::heartbeat:LVM-activate): Started z1.example.com sharedfs3 (ocf::heartbeat:Filesystem): Started z1.example.com Started: [ z1.example.com z2.example.com ] ...
Recursos adicionales
- Para obtener información sobre la configuración del almacenamiento en bloque compartido para un clúster de Red Hat High Availability con Microsoft Azure Shared Disks, consulte Configuración del almacenamiento en bloque compartido.
- Para obtener información sobre la configuración del almacenamiento en bloque compartido para un clúster de Red Hat High Availability con volúmenes de Amazon EBS Multi-Attach, consulte Configuración del almacenamiento en bloque compartido.
- Para obtener información sobre la configuración del almacenamiento en bloque compartido para un clúster de alta disponibilidad de Red Hat en Alibaba Cloud, consulte Configuración del almacenamiento en bloque compartido para un clúster de alta disponibilidad de Red Hat en Alibaba Cloud.
52.2. Migración de un sistema de archivos GFS2 de RHEL7 a RHEL8
En Red Hat Enterprise Linux 8, LVM utiliza el demonio de bloqueo de LVM lvmlockd en lugar de clvmd para gestionar los dispositivos de almacenamiento compartido en un cluster activo/activo. Esto requiere que configure los volúmenes lógicos que su cluster activo/activo requerirá como volúmenes lógicos compartidos. Además, esto requiere que utilice el recurso LVM-activate para gestionar un volumen LVM y que utilice el agente de recursos lvmlockd para gestionar el demonio lvmlockd. Consulte Configuración de un sistema de archivos GFS2 en un clúster para conocer el procedimiento completo para configurar un clúster Pacemaker que incluya sistemas de archivos GFS2 mediante volúmenes lógicos compartidos.
Para utilizar sus volúmenes lógicos existentes de Red Hat Enterprise Linux 7 cuando configure un cluster RHEL8 que incluya sistemas de archivos GFS2, realice el siguiente procedimiento desde el cluster RHEL8. En este ejemplo, el volumen lógico RHEL 7 en cluster es parte del grupo de volúmenes upgrade_gfs_vg.
El clúster RHEL8 debe tener el mismo nombre que el clúster RHEL7 que incluye el sistema de archivos GFS2 para que el sistema de archivos existente sea válido.
- Asegúrese de que los volúmenes lógicos que contienen los sistemas de archivos GFS2 están actualmente inactivos. Este procedimiento sólo es seguro si todos los nodos han dejado de utilizar el grupo de volúmenes.
Desde un nodo del clúster, cambie a la fuerza el grupo de volúmenes para que sea local.
[root@rhel8-01 ~]# vgchange --lock-type none --lock-opt force upgrade_gfs_vg Forcibly change VG lock type to none? [y/n]: y Volume group "upgrade_gfs_vg" successfully changedDesde un nodo del clúster, cambie el grupo de volumen local a un grupo de volumen compartido
[root@rhel8-01 ~]# vgchange --lock-type dlm upgrade_gfs_vg Volume group "upgrade_gfs_vg" successfully changedEn cada nodo del clúster, inicie el bloqueo del grupo de volúmenes.
[root@rhel8-01 ~]# vgchange --lock-start upgrade_gfs_vg VG upgrade_gfs_vg starting dlm lockspace Starting locking. Waiting until locks are ready... [root@rhel8-02 ~]# vgchange --lock-start upgrade_gfs_vg VG upgrade_gfs_vg starting dlm lockspace Starting locking. Waiting until locks are ready...
Después de realizar este procedimiento, puede crear un recurso LVM-activate para cada volumen lógico.
Capítulo 53. Configuración del cercado en un cluster de alta disponibilidad de Red Hat
Un nodo que no responde puede seguir accediendo a los datos. La única manera de estar seguro de que sus datos están a salvo es cercar el nodo utilizando STONITH. STONITH es un acrónimo de "Shoot The Other Node In The Head" (dispara al otro nodo en la cabeza) y protege tus datos de ser corrompidos por nodos deshonestos o accesos concurrentes. Usando STONITH, puedes estar seguro de que un nodo está realmente desconectado antes de permitir que se acceda a los datos desde otro nodo.
STONITH también tiene un papel que desempeñar en el caso de que un servicio en clúster no pueda ser detenido. En este caso, el clúster utiliza STONITH para forzar la desconexión de todo el nodo, lo que hace que sea seguro iniciar el servicio en otro lugar.
Para una información general más completa sobre el cercado y su importancia en un cluster de alta disponibilidad de Red Hat, consulte Cerrado en un cluster de alta disponibilidad de Red Hat.
La implementación de STONITH en un clúster Pacemaker se realiza mediante la configuración de dispositivos de valla para los nodos del clúster.
53.1. Visualización de los agentes de la valla disponibles y sus opciones
Utilice el siguiente comando para ver la lista de todos los agentes STONITH disponibles. Cuando se especifica un filtro, este comando muestra sólo los agentes STONITH que coinciden con el filtro.
lista de pcs stonith [filter]Utilice el siguiente comando para ver las opciones del agente STONITH especificado.
pcs stonith describir stonith_agentPor ejemplo, el siguiente comando muestra las opciones del agente de la valla para APC sobre telnet/SSH.
# pcs stonith describe fence_apc
Stonith options for: fence_apc
ipaddr (required): IP Address or Hostname
login (required): Login Name
passwd: Login password or passphrase
passwd_script: Script to retrieve password
cmd_prompt: Force command prompt
secure: SSH connection
port (required): Physical plug number or name of virtual machine
identity_file: Identity file for ssh
switch: Physical switch number on device
inet4_only: Forces agent to use IPv4 addresses only
inet6_only: Forces agent to use IPv6 addresses only
ipport: TCP port to use for connection with device
action (required): Fencing Action
verbose: Verbose mode
debug: Write debug information to given file
version: Display version information and exit
help: Display help and exit
separator: Separator for CSV created by operation list
power_timeout: Test X seconds for status change after ON/OFF
shell_timeout: Wait X seconds for cmd prompt after issuing command
login_timeout: Wait X seconds for cmd prompt after login
power_wait: Wait X seconds after issuing ON/OFF
delay: Wait X seconds before fencing is started
retry_on: Count of attempts to retry power on
Para los agentes de la valla que proporcionan una opción method, un valor de cycle no es compatible y no debe ser especificado, ya que puede causar la corrupción de datos.
53.2. Creación de un dispositivo de vallas
El formato del comando para crear un dispositivo stonith es el siguiente. Para ver un listado de las opciones de creación de stoniths disponibles, consulte la pantalla pcs stonith -h.
pcs stonith create stonith_id stonith_device_type [stonith_device_options] [op operation_action operation_options]El siguiente comando crea un único dispositivo de esgrima para un solo nodo.
# pcs stonith create MyStonith fence_virt pcmk_host_list=f1 op monitor interval=30sAlgunos dispositivos de cercado sólo pueden cercar un único nodo, mientras que otros dispositivos pueden cercar varios nodos. Los parámetros que se especifican al crear un dispositivo de vallado dependen de lo que el dispositivo de vallado admita y requiera.
- Algunos dispositivos de vallado pueden determinar automáticamente los nodos que pueden vallar.
-
Puede utilizar el parámetro
pcmk_host_listal crear un dispositivo de cercado para especificar todas las máquinas que están controladas por ese dispositivo de cercado. -
Algunos dispositivos de vallado requieren una asignación de nombres de host a las especificaciones que el dispositivo de vallado entiende. Puede asignar nombres de host con el parámetro
pcmk_host_mapal crear un dispositivo de vallado.
Para obtener información sobre los parámetros pcmk_host_list y pcmk_host_map, consulte Propiedades generales de los dispositivos de cercado.
Después de configurar un dispositivo de valla, es imprescindible que pruebe el dispositivo para asegurarse de que funciona correctamente. Para obtener información sobre cómo probar un dispositivo de valla, consulte Probar un dispositivo de valla.
53.3. Propiedades generales de los dispositivos de cercado
Cualquier nodo del clúster puede cercar cualquier otro nodo del clúster con cualquier dispositivo de cercado, independientemente de si el recurso de cercado está iniciado o detenido. El hecho de que el recurso esté iniciado sólo controla el monitor recurrente para el dispositivo, no si se puede utilizar, con las siguientes excepciones:
-
Puede desactivar un dispositivo de esgrima ejecutando el comando
pcs stonith disable stonith_idcomando. Esto evitará que cualquier nodo utilice ese dispositivo. -
Para evitar que un nodo específico utilice un dispositivo de esgrima, puede configurar las restricciones de ubicación para el recurso de esgrima con el comando
pcs constraint location … avoids. -
La configuración de
stonith-enabled=falsedeshabilitará el cercado por completo. Tenga en cuenta, sin embargo, que Red Hat no soporta clusters cuando el fencing está deshabilitado, ya que no es adecuado para un entorno de producción.
enTabla 53.1, “Propiedades generales de los dispositivos de esgrima” se describen las propiedades generales que se pueden establecer para los dispositivos de cercado.
| Campo | Tipo | Por defecto | Descripción |
|---|---|---|---|
|
| cadena |
Un mapeo de nombres de host a números de puerto para dispositivos que no soportan nombres de host. Por ejemplo: | |
|
| cadena |
Una lista de máquinas controladas por este dispositivo (Opcional a menos que | |
|
| cadena |
*
* En caso contrario,
* En caso contrario,
*En caso contrario, |
Cómo determinar qué máquinas controla el dispositivo. Valores permitidos: |
53.4. Opciones avanzadas de configuración del cercado
Tabla 53.2, “Propiedades avanzadas de los dispositivos de esgrima” resume las propiedades adicionales que puede configurar para los dispositivos de cercado. Tenga en cuenta que estas propiedades son sólo para uso avanzado.
| Campo | Tipo | Por defecto | Descripción |
|---|---|---|---|
|
| cadena | puerto |
Un parámetro alternativo para suministrar en lugar del puerto. Algunos dispositivos no admiten el parámetro de puerto estándar o pueden proporcionar otros adicionales. Utilícelo para especificar un parámetro alternativo, específico del dispositivo, que debe indicar la máquina que se va a cercar. Un valor de |
|
| cadena | reiniciar |
Un comando alternativo para ejecutar en lugar de |
|
| tiempo | 60s |
Especifique un tiempo de espera alternativo para utilizar en las acciones de reinicio en lugar de |
|
| entero | 2 |
El número máximo de veces para reintentar el comando |
|
| cadena | fuera de |
Un comando alternativo para ejecutar en lugar de |
|
| tiempo | 60s |
Especifique un tiempo de espera alternativo que se utilizará para las acciones de apagado en lugar de |
|
| entero | 2 | El número máximo de veces que se debe reintentar el comando de desconexión dentro del periodo de tiempo de espera. Algunos dispositivos no admiten conexiones múltiples. Las operaciones pueden fallar si el dispositivo está ocupado con otra tarea, por lo que Pacemaker reintentará automáticamente la operación, si queda tiempo. Utilice esta opción para modificar el número de veces que Pacemaker reintenta las acciones de desconexión antes de rendirse. |
|
| cadena | lista |
Un comando alternativo para ejecutar en lugar de |
|
| tiempo | 60s | Especifique un tiempo de espera alternativo para usar en las acciones de la lista. Algunos dispositivos necesitan mucho más o mucho menos tiempo de lo normal para completarse. Utilice esta opción para especificar un tiempo de espera alternativo, específico del dispositivo, para las acciones de la lista. |
|
| entero | 2 |
El número máximo de veces para reintentar el comando |
|
| cadena | monitor |
Un comando alternativo para ejecutar en lugar de |
|
| tiempo | 60s |
Especifique un tiempo de espera alternativo que se utilizará para las acciones del monitor en lugar de |
|
| entero | 2 |
El número máximo de veces para reintentar el comando |
|
| cadena | estado |
Un comando alternativo para ejecutar en lugar de |
|
| tiempo | 60s |
Especifique un tiempo de espera alternativo para utilizar en las acciones de estado en lugar de |
|
| entero | 2 | El número máximo de veces para reintentar el comando de estado dentro del periodo de tiempo de espera. Algunos dispositivos no admiten conexiones múltiples. Las operaciones pueden fallar si el dispositivo está ocupado con otra tarea, por lo que Pacemaker reintentará automáticamente la operación, si queda tiempo. Utilice esta opción para modificar el número de veces que Pacemaker reintenta las acciones de estado antes de rendirse. |
|
| tiempo | 0s |
Habilite un retardo base para las acciones de stonith y especifique un valor de retardo base. En un clúster con un número par de nodos, configurar un retardo puede ayudar a evitar que los nodos se cerquen entre sí al mismo tiempo en una división uniforme. Un retardo aleatorio puede ser útil cuando se utiliza el mismo dispositivo de vallado para todos los nodos, y diferentes retardos estáticos pueden ser útiles en cada dispositivo de vallado cuando se utiliza un dispositivo independiente para cada nodo. El retardo global se deriva de un valor de retardo aleatorio añadiendo este retardo estático para que la suma se mantenga por debajo del retardo máximo. Si se establece
Algunos agentes de vallas individuales implementan un parámetro de "retraso", que es independiente de los retrasos configurados con una propiedad |
|
| tiempo | 0s |
Habilite un retardo aleatorio para las acciones de stonith y especifique el máximo de retardo aleatorio. En un clúster con un número par de nodos, configurar un retardo puede ayudar a evitar que los nodos se cerquen entre sí al mismo tiempo en una división uniforme. Un retardo aleatorio puede ser útil cuando se utiliza el mismo dispositivo de vallado para todos los nodos, y diferentes retardos estáticos pueden ser útiles en cada dispositivo de vallado cuando se utiliza un dispositivo separado para cada nodo. El retardo global se deriva de este valor de retardo aleatorio añadiendo un retardo estático para que la suma se mantenga por debajo del retardo máximo. Si se establece
Algunos agentes de vallas individuales implementan un parámetro de "retraso", que es independiente de los retrasos configurados con una propiedad |
|
| entero | 1 |
El número máximo de acciones que se pueden realizar en paralelo en este dispositivo. Es necesario configurar primero la propiedad de clúster |
|
| cadena | en |
Sólo para uso avanzado: Un comando alternativo para ejecutar en lugar de |
|
| tiempo | 60s |
Sólo para uso avanzado: Especifique un tiempo de espera alternativo que se utilizará para las acciones de |
|
| entero | 2 |
Sólo para uso avanzado: El número máximo de veces para reintentar el comando |
Además de las propiedades que puede establecer para los dispositivos de vallado individuales, también hay propiedades de cluster que puede establecer que determinan el comportamiento del vallado, como se describe en Tabla 53.3, “Propiedades de los racimos que determinan el comportamiento del cercado”.
| Opción | Por defecto | Descripción |
|---|---|---|
|
| verdadero |
Indica que los nodos fallidos y los nodos con recursos que no pueden ser detenidos deben ser cercados. La protección de sus datos requiere que configure este
Si
Red Hat sólo admite clusters con este valor establecido en |
|
| reiniciar |
Acción a enviar al dispositivo STONITH. Valores permitidos: |
|
| 60s | Cuánto tiempo hay que esperar para que se complete una acción de STONITH. |
|
| 10 | Cuántas veces puede fallar el esgrima para un objetivo antes de que el clúster deje de reintentarlo inmediatamente. |
|
| El tiempo máximo de espera hasta que se pueda asumir que un nodo ha sido eliminado por el perro guardián del hardware. Se recomienda que este valor sea el doble del valor del tiempo de espera del perro guardián del hardware. Esta opción es necesaria sólo si se utiliza el SBD basado en watchdog para el fencing. | |
|
| true (RHEL 8.1 y posteriores) | Permitir que las operaciones de cercado se realicen en paralelo. |
|
| detener |
(Red Hat Enterprise Linux 8.2 y posterior) Determina cómo debe reaccionar un nodo del cluster si se le notifica su propio cercado. Un nodo de cluster puede recibir una notificación de su propio fencing si el fencing está mal configurado, o si el fabric fencing está en uso y no corta la comunicación del cluster. Los valores permitidos son
Aunque el valor por defecto para esta propiedad es |
Para obtener información sobre la configuración de las propiedades del clúster, consulte Configuración y eliminación de las propiedades del clúster.
53.5. Prueba de un dispositivo de valla
El cercado es una parte fundamental de la infraestructura de Red Hat Cluster y por lo tanto es importante validar o probar que el cercado funciona correctamente.
Utilice el siguiente procedimiento para probar un dispositivo de valla.
Utilice ssh, telnet, HTTP o cualquier protocolo remoto que se utilice para conectarse al dispositivo para iniciar sesión manualmente y probar el dispositivo de vallado o ver qué salida se da. Por ejemplo, si va a configurar el cercado para un dispositivo habilitado para IPMI, entonces intente iniciar la sesión de forma remota con
ipmitool. Tome nota de las opciones utilizadas al iniciar la sesión manualmente porque esas opciones podrían ser necesarias al utilizar el agente de cercado.Si no puede iniciar sesión en el dispositivo de vallado, verifique que el dispositivo es pingable, que no hay nada, como una configuración de cortafuegos, que esté impidiendo el acceso al dispositivo de vallado, que el acceso remoto está activado en el dispositivo de vallado y que las credenciales son correctas.
Ejecute el agente de vallas manualmente, utilizando el script del agente de vallas. Esto no requiere que los servicios del clúster se estén ejecutando, por lo que puede realizar este paso antes de que el dispositivo se configure en el clúster. Esto puede asegurar que el dispositivo de valla está respondiendo correctamente antes de proceder.
NotaLos ejemplos de esta sección utilizan el script
fence_ipmilanfence agent para un dispositivo iLO. El agente de valla real que utilizará y el comando que llama a ese agente dependerá del hardware de su servidor. Deberá consultar la página de manual del agente de vallas que esté utilizando para determinar qué opciones debe especificar. Normalmente necesitará conocer el nombre de usuario y la contraseña del dispositivo de valla y otra información relacionada con el dispositivo de valla.El siguiente ejemplo muestra el formato que se utilizaría para ejecutar el script del agente de vallado
fence_ipmilancon el parámetro-o statuspara comprobar el estado de la interfaz del dispositivo de vallado en otro nodo sin llegar a vallarlo. Esto le permite probar el dispositivo y hacerlo funcionar antes de intentar reiniciar el nodo. Cuando se ejecuta este comando, se especifica el nombre y la contraseña de un usuario iLO que tiene permisos de encendido y apagado para el dispositivo iLO.# fence_ipmilan -a ipaddress -l username -p password -o statusEl siguiente ejemplo muestra el formato que se utilizaría para ejecutar el script del agente de la valla
fence_ipmilancon el parámetro-o reboot. La ejecución de este comando en un nodo reinicia el nodo gestionado por este dispositivo iLO.# fence_ipmilan -a ipaddress -l username -p password -o rebootSi el agente de la valla no pudo realizar correctamente una acción de estado, apagado, encendido o reinicio, debe comprobar el hardware, la configuración del dispositivo de la valla y la sintaxis de sus comandos. Además, puede ejecutar el script del agente de valla con la salida de depuración activada. La salida de depuración es útil para algunos agentes de cercado para ver en qué parte de la secuencia de eventos el script del agente de cercado está fallando cuando se registra en el dispositivo de cercado.
# fence_ipmilan -a ipaddress -l username -p password -o status -D /tmp/$(hostname)-fence_agent.debugAl diagnosticar un fallo que se ha producido, debe asegurarse de que las opciones que especificó al iniciar sesión manualmente en el dispositivo de valla son idénticas a las que pasó al agente de valla con el script del agente de valla.
En el caso de los agentes de valla que admiten una conexión encriptada, es posible que aparezca un error debido a que falla la validación del certificado, lo que requiere que confíe en el host o que utilice el parámetro
ssl-insecuredel agente de valla. Del mismo modo, si SSL/TLS está deshabilitado en el dispositivo de destino, es posible que deba tenerlo en cuenta al configurar los parámetros SSL para el agente de valla.NotaSi el agente de cercado que se está probando es un
fence_drac,fence_ilo, o algún otro agente de cercado para un dispositivo de gestión de sistemas que sigue fallando, entonces vuelva a intentarfence_ipmilan. La mayoría de las tarjetas de gestión de sistemas soportan el inicio de sesión remoto IPMI y el único agente de cercado soportado esfence_ipmilan.Una vez que se ha configurado el dispositivo de vallado en el cluster con las mismas opciones que funcionaron manualmente y se ha iniciado el cluster, pruebe el vallado con el comando
pcs stonith fencedesde cualquier nodo (o incluso varias veces desde diferentes nodos), como en el siguiente ejemplo. El comandopcs stonith fencelee la configuración del cluster desde el CIB y llama al agente de vallado tal y como está configurado para ejecutar la acción de vallado. Esto verifica que la configuración del cluster es correcta.# pcs stonith fence node_nameSi el comando
pcs stonith fencefunciona correctamente, significa que la configuración de vallado del clúster debería funcionar cuando se produce un evento de vallado. Si el comando falla, significa que la administración del clúster no puede invocar el dispositivo de vallado a través de la configuración que ha recuperado. Compruebe los siguientes problemas y actualice la configuración del clúster según sea necesario.- Comprueba la configuración de tu valla. Por ejemplo, si ha utilizado un mapa de host, debe asegurarse de que el sistema puede encontrar el nodo utilizando el nombre de host que ha proporcionado.
- Comprueba si la contraseña y el nombre de usuario del dispositivo incluyen algún carácter especial que pueda ser malinterpretado por el shell bash. Asegurarse de introducir las contraseñas y los nombres de usuario entre comillas podría solucionar este problema.
-
Comprueba si puedes conectarte al dispositivo utilizando la dirección IP o el nombre de host exactos que has especificado en el comando
pcs stonith. Por ejemplo, si das el nombre de host en el comando stonith pero pruebas utilizando la dirección IP, esa no es una prueba válida. Si el protocolo que utiliza el dispositivo de la valla es accesible para usted, utilice ese protocolo para intentar conectarse al dispositivo. Por ejemplo, muchos agentes utilizan ssh o telnet. Debería intentar conectarse al dispositivo con las credenciales que proporcionó al configurar el dispositivo, para ver si obtiene un aviso válido y puede iniciar sesión en el dispositivo.
Si usted determina que todos sus parámetros son apropiados pero todavía tiene problemas para conectarse a su dispositivo de valla, puede comprobar el registro en el propio dispositivo de valla, si el dispositivo lo proporciona, que mostrará si el usuario se ha conectado y qué comando emitió el usuario. También puede buscar en el archivo
/var/log/messageslas instancias de stonith y error, que podrían dar alguna idea de lo que está ocurriendo, pero algunos agentes pueden proporcionar información adicional.
Una vez que las pruebas del dispositivo de la valla están funcionando y el clúster está en marcha, pruebe un fallo real. Para ello, realiza una acción en el clúster que debería iniciar una pérdida de tokens.
Desmontar una red. La forma de desmontar una red depende de su configuración específica. En muchos casos, puede sacar físicamente los cables de red o de alimentación del host. Para obtener información sobre la simulación de un fallo de red, consulte ¿Cuál es la forma adecuada de simular un fallo de red en un clúster RHEL?
NotaDesactivar la interfaz de red en el host local en lugar de desconectar físicamente los cables de red o de alimentación no se recomienda como prueba de cercado porque no simula con precisión un fallo típico del mundo real.
Bloquea el tráfico de corosync tanto de entrada como de salida utilizando el firewall local.
El siguiente ejemplo bloquea corosync, asumiendo que se utiliza el puerto por defecto de corosync,
firewalldse utiliza como firewall local, y la interfaz de red utilizada por corosync está en la zona de firewall por defecto:# firewall-cmd --direct --add-rule ipv4 filter OUTPUT 2 -p udp --dport=5405 -j DROP # firewall-cmd --add-rich-rule='rule family="ipv4" port port="5405" protocol="udp" drop'Simule un fallo y haga entrar en pánico a su máquina con
sysrq-trigger. Tenga en cuenta, sin embargo, que desencadenar un pánico del kernel puede causar la pérdida de datos; se recomienda que primero desactive los recursos de su clúster.# echo c > /proc/sysrq-trigger
53.6. Configuración de los niveles de vallado
Pacemaker admite nodos de esgrima con múltiples dispositivos a través de una función denominada topologías de esgrima. Para implementar topologías, cree los dispositivos individuales como lo haría normalmente y luego defina uno o más niveles de esgrima en la sección de topología de esgrima en la configuración.
- Cada nivel se intenta en orden numérico ascendente, empezando por el 1.
- Si un dispositivo falla, el proceso termina para el nivel actual. No se ejercitan más dispositivos en ese nivel y se intenta el siguiente nivel en su lugar.
- Si todos los dispositivos son cercados con éxito, entonces ese nivel ha tenido éxito y no se intentan otros niveles.
- La operación finaliza cuando se ha superado un nivel (éxito), o se han intentado todos los niveles (fracaso).
Utilice el siguiente comando para añadir un nivel de cercado a un nodo. Los dispositivos se dan como una lista separada por comas de ids de stoniths, que se intentan para el nodo en ese nivel.
pcs stonith level add level node devicesEl siguiente comando muestra todos los niveles de esgrima que están configurados actualmente.
pcs stonith level
En el siguiente ejemplo, hay dos dispositivos de valla configurados para el nodo rh7-2: un dispositivo de valla ilo llamado my_ilo y un dispositivo de valla apc llamado my_apc. Estos comandos configuran los niveles de vallado para que, si el dispositivo my_ilo falla y no puede vallar el nodo, Pacemaker intente utilizar el dispositivo my_apc. Este ejemplo también muestra la salida del comando pcs stonith level después de configurar los niveles.
# pcs stonith level add 1 rh7-2 my_ilo
# pcs stonith level add 2 rh7-2 my_apc
# pcs stonith level
Node: rh7-2
Level 1 - my_ilo
Level 2 - my_apcEl siguiente comando elimina el nivel de valla para el nodo y los dispositivos especificados. Si no se especifica ningún nodo o dispositivo, el nivel de valla que se especifique se eliminará de todos los nodos.
pcs stonith level remove level [node_id] [stonith_id] ... [stonith_id]El siguiente comando borra los niveles de valla en el nodo o id de piedra especificado. Si no se especifica un nodo o un id de stonith, se borran todos los niveles de valla.
pcs stonith level clear [node|stonith_id(s)]Si especifica más de un id de stonith, deben estar separados por una coma y sin espacios, como en el siguiente ejemplo.
# pcs stonith level clear dev_a,dev_bEl siguiente comando verifica que todos los dispositivos y nodos especificados en los niveles de la valla existen.
pcs stonith level verify
Puede especificar nodos en la topología de vallado mediante una expresión regular aplicada a un nombre de nodo y mediante un atributo de nodo y su valor. Por ejemplo, los siguientes comandos configuran los nodos node1, node2, y `node3 para utilizar los dispositivos de vallado apc1 y `apc2, y los nodos `node4, node5, y `node6 para utilizar los dispositivos de vallado apc3 y `apc4.
pcs stonith level add 1 "regexp%node[1-3]" apc1,apc2
pcs stonith level add 1 "regexp%node[4-6]" apc3,apc4Los siguientes comandos producen los mismos resultados utilizando la coincidencia de atributos de nodos.
pcs node attribute node1 rack=1
pcs node attribute node2 rack=1
pcs node attribute node3 rack=1
pcs node attribute node4 rack=2
pcs node attribute node5 rack=2
pcs node attribute node6 rack=2
pcs stonith level add 1 attrib%rack=1 apc1,apc2
pcs stonith level add 1 attrib%rack=2 apc3,apc453.7. Configurar el cercado para las fuentes de alimentación redundantes
Cuando se configura el cercado para las fuentes de alimentación redundantes, el clúster debe asegurarse de que cuando se intenta reiniciar un host, ambas fuentes de alimentación se apagan antes de que se vuelva a encender cualquiera de ellas.
Si el nodo nunca pierde completamente la energía, es posible que no libere sus recursos. Esto abre la posibilidad de que los nodos accedan a estos recursos simultáneamente y los corrompan.
Es necesario definir cada dispositivo sólo una vez y especificar que ambos son necesarios para cercar el nodo, como en el siguiente ejemplo.
# pcs stonith create apc1 fence_apc_snmp ipaddr=apc1.example.com login=user passwd='7a4D#1j!pz864' pcmk_host_map="node1.example.com:1;node2.example.com:2"
# pcs stonith create apc2 fence_apc_snmp ipaddr=apc2.example.com login=user passwd='7a4D#1j!pz864' pcmk_host_map="node1.example.com:1;node2.example.com:2"
# pcs stonith level add 1 node1.example.com apc1,apc2
# pcs stonith level add 1 node2.example.com apc1,apc253.8. Visualización de los dispositivos de vallas configurados
El siguiente comando muestra todos los dispositivos de valla actualmente configurados. Si se especifica un stonith_id, el comando muestra las opciones de ese dispositivo stonith configurado solamente. Si se especifica la opción --full, se muestran todas las opciones de stonith configuradas.
pcs stonith config [stonith_id] [--full]53.9. Modificación y supresión de los dispositivos de la valla
Utilice el siguiente comando para modificar o añadir opciones a un dispositivo de cercado actualmente configurado.
pcs stonith update stonith_id [stonith_device_options]Utilice el siguiente comando para eliminar un dispositivo de cercado de la configuración actual.
pcs stonith delete stonith_id53.10. Cercar manualmente un nodo del clúster
Puedes cercar un nodo manualmente con el siguiente comando. Si se especifica --off se utilizará la llamada de la API off a stonith que apagará el nodo en lugar de reiniciarlo.
pcs stonith fence node [--off]En una situación en la que ningún dispositivo stonith es capaz de cercar un nodo aunque ya no esté activo, es posible que el clúster no pueda recuperar los recursos del nodo. Si esto ocurre, después de asegurarse manualmente de que el nodo está apagado, puede introducir el siguiente comando para confirmar al clúster que el nodo está apagado y liberar sus recursos para su recuperación.
Si el nodo que especifica no está realmente apagado, sino que ejecuta el software del clúster o los servicios normalmente controlados por el clúster, se producirá una corrupción de datos/un fallo del clúster.
pcs stonith confirmar node53.11. Desactivación de un dispositivo de valla
Para desactivar un dispositivo/recurso de esgrima, se ejecuta el comando pcs stonith disable.
El siguiente comando desactiva el dispositivo de la valla myapc.
# pcs stonith disable myapc53.12. Impedir que un nodo utilice un dispositivo de valla
Para evitar que un nodo específico utilice un dispositivo de esgrima, puede configurar restricciones de ubicación para el recurso de esgrima.
El siguiente ejemplo evita que el dispositivo de valla node1-ipmi se ejecute en node1.
# pcs constraint location node1-ipmi avoids node153.13. Configuración de ACPI para su uso con dispositivos de valla integrados
Si su clúster utiliza dispositivos de cercado integrados, debe configurar ACPI (Advanced Configuration and Power Interface) para garantizar un cercado inmediato y completo.
Si un nodo del clúster está configurado para ser cercado por un dispositivo de cercado integrado, desactive el ACPI Soft-Off para ese nodo. La desactivación de ACPI Soft-Off permite que un dispositivo de valla integrado apague un nodo de forma inmediata y completa en lugar de intentar un apagado limpio (por ejemplo, shutdown -h now). De lo contrario, si el ACPI Soft-Off está habilitado, un dispositivo de barrera integrado puede tardar cuatro o más segundos en apagar un nodo (vea la nota que sigue). Además, si el ACPI Soft-Off está habilitado y un nodo entra en pánico o se congela durante el apagado, un dispositivo de cercado integrado puede no ser capaz de apagar el nodo. En esas circunstancias, el cercado se retrasa o no tiene éxito. En consecuencia, cuando un nodo está cercado con un dispositivo de cercado integrado y el ACPI Soft-Off está habilitado, un clúster se recupera lentamente o requiere la intervención administrativa para recuperarse.
El tiempo necesario para cercar un nodo depende del dispositivo de cercado integrado que se utilice. Algunos dispositivos de vallado integrados realizan el equivalente a pulsar y mantener el botón de encendido; por lo tanto, el dispositivo de vallado apaga el nodo en cuatro o cinco segundos. Otros dispositivos de valla integrados realizan el equivalente a pulsar el botón de encendido momentáneamente, confiando en el sistema operativo para apagar el nodo; por lo tanto, el dispositivo de valla apaga el nodo en un lapso de tiempo mucho mayor que cuatro o cinco segundos.
- La forma preferida de desactivar el ACPI Soft-Off es cambiar la configuración de la BIOS a "instant-off" o una configuración equivalente que apague el nodo sin demora, como se describe en Sección 53.13.1, “Desactivación de ACPI Soft-Off con la BIOS”.
La desactivación de ACPI Soft-Off con la BIOS puede no ser posible en algunos sistemas. Si la desactivación de ACPI con la BIOS no es satisfactoria para su clúster, puede desactivar ACPI Soft-Off con uno de los siguientes métodos alternativos:
-
Configurando
HandlePowerKey=ignoreen el archivo/etc/systemd/logind.confy verificando que el nodo se apague inmediatamente cuando sea cercado, como se describe en Sección 53.13.2, “Desactivación de ACPI Soft-Off en el archivo logind.conf”. Este es el primer método alternativo para desactivar el ACPI Soft-Off. Añadiendo
acpi=offa la línea de comandos de arranque del kernel, como se describe en Sección 53.13.3, “Desactivar completamente ACPI en el archivo GRUB 2”. Este es el segundo método alternativo para desactivar el ACPI Soft-Off, si el método preferido o el primer método alternativo no está disponible.ImportanteEste método desactiva completamente ACPI; algunos ordenadores no arrancan correctamente si ACPI está completamente desactivado. Utilice este método only si los otros métodos no son efectivos para su clúster.
53.13.1. Desactivación de ACPI Soft-Off con la BIOS
Puede desactivar el ACPI Soft-Off configurando la BIOS de cada nodo del cluster con el siguiente procedimiento.
El procedimiento para desactivar el ACPI Soft-Off con la BIOS puede variar entre los sistemas de servidor. Debe verificar este procedimiento con la documentación de su hardware.
-
Reinicie el nodo e inicie el programa
BIOS CMOS Setup Utility. - Navegue hasta el menú Power (o el menú de gestión de energía equivalente).
En el menú Power, ajuste la función
Soft-Off by PWR-BTTN(o su equivalente) aInstant-Off(o el ajuste equivalente que apague el nodo mediante el botón de encendido sin demora).BIOS CMOS Setup Utility: muestra un menú Power conACPI Functionajustado aEnabledySoft-Off by PWR-BTTNajustado aInstant-Off.NotaLos equivalentes a
ACPI Function,Soft-Off by PWR-BTTN, yInstant-Offpueden variar entre ordenadores. Sin embargo, el objetivo de este procedimiento es configurar la BIOS para que el ordenador se apague mediante el botón de encendido sin demora.-
Salga del programa
BIOS CMOS Setup Utility, guardando la configuración de la BIOS. - Compruebe que el nodo se apaga inmediatamente cuando se le pone una valla. Para obtener información sobre la comprobación de un dispositivo de vallado, consulte Probar un dispositivo de vallado.
BIOS CMOS Setup Utility:
`Soft-Off by PWR-BTTN` set to
`Instant-Off`+---------------------------------------------|-------------------+
| ACPI Function [Enabled] | Item Help |
| ACPI Suspend Type [S1(POS)] |-------------------|
| x Run VGABIOS if S3 Resume Auto | Menu Level * |
| Suspend Mode [Disabled] | |
| HDD Power Down [Disabled] | |
| Soft-Off by PWR-BTTN [Instant-Off | |
| CPU THRM-Throttling [50.0%] | |
| Wake-Up by PCI card [Enabled] | |
| Power On by Ring [Enabled] | |
| Wake Up On LAN [Enabled] | |
| x USB KB Wake-Up From S3 Disabled | |
| Resume by Alarm [Disabled] | |
| x Date(of Month) Alarm 0 | |
| x Time(hh:mm:ss) Alarm 0 : 0 : | |
| POWER ON Function [BUTTON ONLY | |
| x KB Power ON Password Enter | |
| x Hot Key Power ON Ctrl-F1 | |
| | |
| | |
+---------------------------------------------|-------------------+
Este ejemplo muestra ACPI Function ajustado a Enabled, y Soft-Off by PWR-BTTN ajustado a Instant-Off.
53.13.2. Desactivación de ACPI Soft-Off en el archivo logind.conf
Para desactivar el manejo de la tecla de encendido en el archivo /etc/systemd/logind.conf, utilice el siguiente procedimiento.
Defina la siguiente configuración en el archivo
/etc/systemd/logind.conf:HandlePowerKey=ignorarReinicie el servicio
systemd-logind:# systemctl restart systemd-logind.service- Compruebe que el nodo se apaga inmediatamente cuando se le pone una valla. Para obtener información sobre la comprobación de un dispositivo de vallado, consulte Probar un dispositivo de vallado.
53.13.3. Desactivar completamente ACPI en el archivo GRUB 2
Puede desactivar el ACPI Soft-Off añadiendo acpi=off a la entrada del menú GRUB para un kernel.
Este método desactiva completamente ACPI; algunos ordenadores no arrancan correctamente si ACPI está completamente desactivado. Utilice este método only si los otros métodos no son efectivos para su clúster.
Utilice el siguiente procedimiento para desactivar ACPI en el archivo GRUB 2:
Utilice la opción
--argsen combinación con la opción--update-kernelde la herramientagrubbypara cambiar el archivogrub.cfgde cada nodo del clúster de la siguiente manera:# grubby --args=acpi=off --update-kernel=ALL- Reinicia el nodo.
- Compruebe que el nodo se apaga inmediatamente cuando se le pone una valla. Para obtener información sobre la comprobación de un dispositivo de vallado, consulte Probar un dispositivo de vallado.
Capítulo 54. Configuración de los recursos del clúster
El formato del comando para crear un recurso de cluster es el siguiente:
pcs resource create resource_id [standard:[provider:]]type [resource_options] [op operation_action operation_options [operation_action operation options ]...] [meta meta_options...] [clone [clone_options] | master [master_options] | --group group_name [--before resource_id | --after resource_id] | [bundle bundle_id] [--disabled] [--wait[=n]]Las principales opciones de creación de recursos de clúster son las siguientes:
-
Cuando se especifica la opción
--group, el recurso se añade al grupo de recursos nombrado. Si el grupo no existe, se crea el grupo y se añade este recurso al grupo.
-
Las opciones
--beforey--afterespecifican la posición del recurso añadido en relación con un recurso que ya existe en un grupo de recursos. -
Especificar la opción
--disabledindica que el recurso no se inicia automáticamente.
Puede determinar el comportamiento de un recurso en un clúster configurando restricciones para ese recurso.
Ejemplos de creación de recursos
El siguiente comando crea un recurso con el nombre VirtualIP de estándar ocf, proveedor heartbeat, y tipo IPaddr2. La dirección flotante de este recurso es 192.168.0.120, y el sistema comprobará si el recurso está funcionando cada 30 segundos.
# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 cidr_netmask=24 op monitor interval=30s
Alternativamente, puede omitir los campos standard y provider y utilizar el siguiente comando. De este modo, el estándar será ocf y el proveedor heartbeat.
# pcs resource create VirtualIP IPaddr2 ip=192.168.0.120 cidr_netmask=24 op monitor interval=30sBorrar un recurso configurado
Utilice el siguiente comando para eliminar un recurso configurado.
supresión de recursos pcs resource_id
Por ejemplo, el siguiente comando elimina un recurso existente con un ID de recurso de VirtualIP.
# pcs resource delete VirtualIP54.1. Identificadores de agentes de recursos
Los identificadores que se definen para un recurso indican al clúster qué agente debe utilizar para el recurso, dónde encontrar ese agente y a qué estándares se ajusta. Tabla 54.1, “Identificadores de agentes de recursos”, describe estas propiedades.
| Campo | Descripción |
|---|---|
| estándar | La norma a la que se ajusta el agente. Valores permitidos y su significado:
*
*
*
*
* |
| tipo |
El nombre del agente de recursos que desea utilizar, por ejemplo |
| proveedor |
La especificación OCF permite que varios proveedores suministren el mismo agente de recursos. La mayoría de los agentes suministrados por Red Hat utilizan |
Tabla 54.2, “Comandos para mostrar las propiedades de los recursos” resume los comandos que muestran las propiedades de los recursos disponibles.
| comando de visualización de pcs | Salida |
|---|---|
|
| Muestra una lista de todos los recursos disponibles. |
|
| Muestra una lista de estándares de agentes de recursos disponibles. |
|
| Muestra una lista de proveedores de agentes de recursos disponibles. |
|
| Muestra una lista de recursos disponibles filtrados por la cadena especificada. Puede utilizar este comando para mostrar los recursos filtrados por el nombre de un estándar, un proveedor o un tipo. |
54.2. Visualización de los parámetros específicos de los recursos
Para cualquier recurso individual, puede utilizar el siguiente comando para mostrar una descripción del recurso, los parámetros que puede establecer para ese recurso y los valores por defecto que se establecen para el recurso.
pcs resource describe [standard:[provider:]]type
Por ejemplo, el siguiente comando muestra información de un recurso de tipo apache.
# pcs resource describe ocf:heartbeat:apache
This is the resource agent for the Apache Web server.
This resource agent operates both version 1.x and version 2.x Apache
servers.
...54.3. Configuración de las opciones meta de los recursos
Además de los parámetros específicos del recurso, puede configurar opciones adicionales para cualquier recurso. Estas opciones son utilizadas por el clúster para decidir cómo debe comportarse su recurso.
Tabla 54.3, “Meta opciones de recursos” describe las opciones meta de los recursos.
| Campo | Por defecto | Descripción |
|---|---|---|
|
|
| Si no todos los recursos pueden estar activos, el clúster detendrá los recursos de menor prioridad para mantener activos los de mayor prioridad. |
|
|
| ¿En qué estado debería el clúster intentar mantener este recurso? Valores permitidos: * Stopped - Forzar la detención del recurso * Started - Permitir que el recurso se inicie (y en el caso de los clones promocionables, que se promueva al rol de maestro si es apropiado) * Master - Permitir que el recurso se inicie y, en su caso, se promueva * Slave - Permite que el recurso se inicie, pero sólo en modo esclavo si el recurso es promocionable |
|
|
|
¿Tiene el clúster permiso para iniciar y detener el recurso? Valores permitidos: |
|
| 0 | Valor que indica cuánto prefiere el recurso quedarse donde está. |
|
| Calculado | Indica en qué condiciones se puede iniciar el recurso.
El valor por defecto es
*
*
*
* |
|
|
|
Cuántos fallos pueden ocurrir para este recurso en un nodo, antes de que este nodo sea marcado como inelegible para albergar este recurso. Un valor de 0 indica que esta función está deshabilitada (el nodo nunca se marcará como inelegible); por el contrario, el cluster trata |
|
|
|
Utilizado junto con la opción |
|
|
| Qué debe hacer el cluster si alguna vez encuentra el recurso activo en más de un nodo. Valores permitidos:
*
*
* |
54.3.1. Cambiar el valor por defecto de una opción de recurso
A partir de Red Hat Enterprise Linux 8.3, puede cambiar el valor por defecto de una opción de recurso para todos los recursos con el comando pcs resource defaults update. El siguiente comando restablece el valor por defecto de resource-stickiness a 100.
# pcs resource defaults update resource-stickiness=100
El comando original pcs resource defaults name=value que establecía los valores predeterminados para todos los recursos en las versiones anteriores de RHEL 8, sigue siendo compatible a menos que haya más de un conjunto de valores predeterminados configurados. Sin embargo, pcs resource defaults update es ahora la versión preferida del comando.
54.3.2. Cambio del valor por defecto de una opción de recurso para conjuntos de recursos (RHEL 8.3 y posteriores)
A partir de Red Hat Enterprise Linux 8.3, puede crear múltiples conjuntos de recursos por defecto con el comando pcs resource defaults set create, que le permite especificar una regla que contenga expresiones resource. Sólo las expresiones resource, incluyendo and, or y paréntesis, están permitidas en las reglas que usted especifica con este comando.
Con el comando pcs resource defaults set create, puede configurar un valor de recurso por defecto para todos los recursos de un tipo determinado. Si, por ejemplo, está ejecutando bases de datos que tardan mucho en detenerse, puede aumentar el valor por defecto de resource-stickiness para todos los recursos del tipo de base de datos para evitar que esos recursos se trasladen a otros nodos con más frecuencia de la deseada.
El siguiente comando establece el valor por defecto de resource-stickiness a 100 para todos los recursos de tipo pqsql.
-
La opción
id, que nombra el conjunto de recursos por defecto, no es obligatoria. Si no se establece esta opción,pcsgenerará un ID automáticamente. Si establece este valor, podrá proporcionar un nombre más descriptivo. En este ejemplo,
::pgsqlsignifica un recurso de cualquier clase, cualquier proveedor, del tipopgsql.-
Especificar
ocf:heartbeat:pgsqlindicaría la claseocf, el proveedorheartbeat, el tipopgsql, -
Especificando
ocf:pacemaker:se indicarían todos los recursos de la claseocf, proveedorpacemaker, de cualquier tipo.
-
Especificar
# pcs resource defaults set create id=pgsql-stickiness meta resource-stickiness=100 rule resource ::pgsql
Para cambiar los valores por defecto de un conjunto existente, utilice el comando pcs resource defaults set update.
54.3.3. Visualización de los valores predeterminados de los recursos configurados actualmente
El comando pcs resource defaults muestra una lista de los valores por defecto actualmente configurados para las opciones de recursos, incluyendo cualquier regla que haya especificado.
El siguiente ejemplo muestra la salida de este comando después de haber restablecido el valor por defecto de resource-stickiness a 100.
# pcs resource defaults
Meta Attrs: rsc_defaults-meta_attributes
resource-stickiness=100
El siguiente ejemplo muestra la salida de este comando después de haber restablecido el valor por defecto de resource-stickiness a 100 para todos los recursos de tipo pqsql y de haber establecido la opción id a id=pgsql-stickiness.
# pcs resource defaults
Meta Attrs: pgsql-stickiness
resource-stickiness=100
Rule: boolean-op=and score=INFINITY
Expression: resource ::pgsql54.3.4. Configuración de las opciones meta en la creación de recursos
Tanto si se ha restablecido el valor por defecto de una metaopción de recurso como si no, se puede establecer una opción de recurso para un determinado recurso con un valor distinto al predeterminado cuando se crea el recurso. A continuación se muestra el formato del comando pcs resource create que se utiliza al especificar un valor para una metaopción de recurso.
pcs resource create resource_id [standard:[provider:]]type [resource options] [meta meta_options...]
Por ejemplo, el siguiente comando crea un recurso con un valor resource-stickiness de 50.
# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 meta resource-stickiness=50También se puede establecer el valor de una metaopción de recurso para un recurso existente, un grupo o un recurso clonado con el siguiente comando.
pcs resource meta resource_id | group_id | clone_id meta_options
En el siguiente ejemplo, hay un recurso existente llamado dummy_resource. Este comando establece la opción meta failure-timeout a 20 segundos, para que el recurso pueda intentar reiniciarse en el mismo nodo en 20 segundos.
# pcs resource meta dummy_resource failure-timeout=20s
Después de ejecutar este comando, puede visualizar los valores del recurso para verificar que failure-timeout=20s está configurado.
# pcs resource config dummy_resource
Resource: dummy_resource (class=ocf provider=heartbeat type=Dummy)
Meta Attrs: failure-timeout=20s
...54.4. Configuración de los grupos de recursos
Uno de los elementos más comunes de un clúster es un conjunto de recursos que deben ubicarse juntos, iniciarse secuencialmente y detenerse en el orden inverso. Para simplificar esta configuración, Pacemaker admite el concepto de grupos de recursos.
54.4.1. Creación de un grupo de recursos
Se crea un grupo de recursos con el siguiente comando, especificando los recursos que se incluirán en el grupo. Si el grupo no existe, este comando crea el grupo. Si el grupo existe, este comando añade recursos adicionales al grupo. Los recursos se iniciarán en el orden que se especifique con este comando, y se detendrán en el orden inverso al de inicio.
pcs resource group add group_name resource_id [resource_id] ... [resource_id] [--before resource_id | --after resource_id]
Puede utilizar las opciones --before y --after de este comando para especificar la posición de los recursos añadidos en relación con un recurso que ya existe en el grupo.
También puede añadir un nuevo recurso a un grupo existente al crear el recurso, utilizando el siguiente comando. El recurso que se crea se añade al grupo denominado group_name. Si el grupo group_name no existe, se creará.
pcs resource create resource_id [standard:[provider:]]type [resource_options] [op operation_action operation_options ] --group group_nameNo hay límite en el número de recursos que puede contener un grupo. Las propiedades fundamentales de un grupo son las siguientes.
- Los recursos se colocan dentro de un grupo.
- Los recursos se inician en el orden en que se especifican. Si un recurso del grupo no puede ejecutarse en ningún sitio, ningún recurso especificado después de ese recurso podrá ejecutarse.
- Los recursos se detienen en el orden inverso al especificado.
El siguiente ejemplo crea un grupo de recursos denominado shortcut que contiene los recursos existentes IPaddr y Email.
# pcs resource group add shortcut IPaddr EmailEn este ejemplo:
-
Primero se pone en marcha el
IPaddry luego elEmail. -
Primero se detiene el recurso
Emaily luegoIPAddr. -
Si
IPaddrno puede correr en ningún sitio, tampocoEmail. -
Sin embargo, si
Emailno puede ejecutarse en ningún sitio, esto no afecta en absoluto aIPaddr.
54.4.2. Eliminar un grupo de recursos
Se elimina un recurso de un grupo con el siguiente comando. Si no quedan recursos en el grupo, este comando elimina el propio grupo.
pcs resource group remove group_name resource_id ...54.4.3. Visualización de los grupos de recursos
El siguiente comando muestra todos los grupos de recursos configurados actualmente.
lista de grupos de recursos pcs54.4.4. Opciones de grupo
Puede establecer las siguientes opciones para un grupo de recursos, y mantienen el mismo significado que cuando se establecen para un solo recurso: priority, target-role, is-managed. Para obtener información sobre las opciones meta de los recursos, consulte Configuración de las opciones meta de los recursos.
54.4.5. Adherencia al grupo
La pegajosidad, la medida de cuánto quiere un recurso quedarse donde está, es aditiva en los grupos. Cada recurso activo del grupo contribuirá con su valor de pegajosidad al total del grupo. Así, si el valor por defecto de resource-stickiness es 100, y un grupo tiene siete miembros, cinco de los cuales son activos, entonces el grupo en su conjunto preferirá su ubicación actual con una puntuación de 500.
54.5. Determinación del comportamiento de los recursos
Puede determinar el comportamiento de un recurso en un cluster configurando restricciones para ese recurso. Puede configurar las siguientes categorías de restricciones:
-
locationlimitaciones -
orderlimitaciones -
colocationlimitaciones
Pacemaker admite el concepto de grupos de recursos como una forma de abreviar la configuración de un conjunto de restricciones que ubicarán un conjunto de recursos juntos y garantizarán que los recursos se inicien de forma secuencial y se detengan en orden inverso. Una vez que haya creado un grupo de recursos, puede configurar las restricciones del propio grupo del mismo modo que configura las restricciones de los recursos individuales. Para obtener información sobre los grupos de recursos, consulte Configuración de grupos de recursos.
Capítulo 55. Determinación de los nodos en los que puede ejecutarse un recurso
Las restricciones de ubicación determinan en qué nodos puede ejecutarse un recurso. Puede configurar las restricciones de ubicación para determinar si un recurso preferirá o evitará un nodo específico.
Además de las restricciones de ubicación, el nodo en el que se ejecuta un recurso está influenciado por el valor resource-stickiness para ese recurso, que determina hasta qué punto un recurso prefiere permanecer en el nodo donde se está ejecutando actualmente. Para obtener información sobre la configuración del valor resource-stickiness, consulte Configuración de un recurso para que prefiera su nodo actual.
55.1. Configurar las restricciones de ubicación
Puede configurar una restricción de ubicación básica para especificar si un recurso prefiere o evita un nodo, con un valor opcional score para indicar el grado relativo de preferencia de la restricción.
El siguiente comando crea una restricción de ubicación para que un recurso prefiera el nodo o nodos especificados. Tenga en cuenta que es posible crear restricciones en un recurso concreto para más de un nodo con un solo comando.
pcs restricción ubicación rsc prefiere node[=score] [node[=score]] ...El siguiente comando crea una restricción de ubicación para que un recurso evite el nodo o nodos especificados.
pcs restricción ubicación rsc evita node[=score] [node[=score]] ...Tabla 55.1, “Opciones de restricción de ubicación” resume el significado de las opciones básicas para configurar las restricciones de ubicación.
| Campo | Descripción |
|---|---|
|
| Un nombre de recurso |
|
| El nombre de un nodo |
|
|
Valor entero positivo para indicar el grado de preferencia para que el recurso dado prefiera o evite el nodo dado.
Un valor de
Un valor de
Una puntuación numérica (es decir, no |
El siguiente comando crea una restricción de ubicación para especificar que el recurso Webserver prefiere el nodo node1.
pcs ubicación de la restricción El servidor web prefiere el nodo1
pcs admite expresiones regulares en las restricciones de ubicación en la línea de comandos. Estas restricciones se aplican a múltiples recursos basados en la expresión regular que coincide con el nombre del recurso. Esto le permite configurar múltiples restricciones de ubicación con una sola línea de comandos.
El siguiente comando crea una restricción de ubicación para especificar que los recursos dummy0 a dummy9 prefieren node1.
pcs ubicación de la restricción 'regexp mmy[0-9]' prefiere el nodo1Dado que Pacemaker utiliza expresiones regulares extendidas de POSIX, como se documenta en http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap09.html#tag_09_04puede especificar la misma restricción con el siguiente comando.
pcs constraint location 'regexp mmy[[:digit:]]' prefiere el nodo155.2. Limitación del descubrimiento de recursos a un subconjunto de nodos
Antes de que Pacemaker inicie un recurso en cualquier lugar, primero ejecuta una operación de monitorización única (a menudo denominada "sondeo") en cada nodo, para saber si el recurso ya se está ejecutando. Este proceso de descubrimiento de recursos puede dar lugar a errores en los nodos que no pueden ejecutar el monitor.
Al configurar una restricción de ubicación en un nodo, puede utilizar la opción resource-discovery del comando pcs constraint location para indicar una preferencia sobre si Pacemaker debe realizar el descubrimiento de recursos en este nodo para el recurso especificado. Limitar el descubrimiento de recursos a un subconjunto de nodos en los que el recurso puede ejecutarse físicamente puede aumentar significativamente el rendimiento cuando hay un gran conjunto de nodos. Cuando pacemaker_remote está en uso para ampliar el número de nodos en el rango de cientos de nodos, esta opción debe ser considerada.
El siguiente comando muestra el formato para especificar la opción resource-discovery del comando pcs constraint location. En este comando, un valor positivo para score corresponde a una restricción de ubicación básica que configura un recurso para preferir un nodo, mientras que un valor negativo para score corresponde a una restricción de ubicación básica que configura un recurso para evitar un nodo. Al igual que con las restricciones de ubicación básicas, también puedes utilizar expresiones regulares para los recursos con estas restricciones.
pcs constraint location add id rsc node score [resource-discovery=option]Tabla 55.2, “Parámetros de restricción de descubrimiento de recursos” resume los significados de los parámetros básicos para configurar las restricciones para el descubrimiento de recursos.
| Campo | Descripción |
|
| Un nombre elegido por el usuario para la propia restricción. |
|
| Un nombre de recurso |
|
| El nombre de un nodo |
|
| Valor entero para indicar el grado de preferencia para que el recurso dado prefiera o evite el nodo dado. Un valor positivo para la puntuación corresponde a una restricción de ubicación básica que configura un recurso para preferir un nodo, mientras que un valor negativo para la puntuación corresponde a una restricción de ubicación básica que configura un recurso para evitar un nodo.
Un valor de
Una puntuación numérica (es decir, no |
|
|
*
*
* |
Configurar resource-discovery como never o exclusive elimina la capacidad de Pacemaker de detectar y detener las instancias no deseadas de un servicio que se ejecuta donde no debe estar. Depende del administrador del sistema asegurarse de que el servicio nunca pueda estar activo en los nodos sin descubrimiento de recursos (por ejemplo, dejando desinstalado el software correspondiente).
55.3. Configurar una estrategia de restricción de ubicación
Cuando se utilizan restricciones de ubicación, se puede configurar una estrategia general para especificar en qué nodos puede ejecutarse un recurso:
- Agrupaciones Opt-In
- Agrupaciones Opt-Out
La elección de configurar su clúster como un clúster opt-in o opt-out depende tanto de sus preferencias personales como de la composición de su clúster. Si la mayoría de sus recursos pueden ejecutarse en la mayoría de los nodos, es probable que una disposición opt-out resulte en una configuración más sencilla. Por otro lado, si la mayoría de los recursos sólo pueden ejecutarse en un pequeño subconjunto de nodos, una configuración opt-in podría ser más sencilla.
55.3.1. Configuración de un clúster "Opt-In"
Para crear un clúster opcional, establezca la propiedad de clúster symmetric-cluster en false para evitar que los recursos se ejecuten en cualquier lugar por defecto.
# pcs property set symmetric-cluster=false
Habilitar nodos para recursos individuales. Los siguientes comandos configuran las restricciones de ubicación para que el recurso Webserver prefiera el nodo example-1, el recurso Database prefiera el nodo example-2, y ambos recursos puedan fallar en el nodo example-3 si su nodo preferido falla. Cuando se configuran las restricciones de ubicación para un cluster opt-in, establecer una puntuación de cero permite que un recurso se ejecute en un nodo sin indicar ninguna preferencia para preferir o evitar el nodo.
# pcs constraint location Webserver prefers example-1=200
# pcs constraint location Webserver prefers example-3=0
# pcs constraint location Database prefers example-2=200
# pcs constraint location Database prefers example-3=055.3.2. Configuración de un clúster "Opt-Out"
Para crear un clúster de exclusión, establezca la propiedad de clúster symmetric-cluster en true para permitir que los recursos se ejecuten en todas partes por defecto. Esta es la configuración por defecto si symmetric-cluster no se establece explícitamente.
# pcs property set symmetric-cluster=true
Los siguientes comandos darán lugar a una configuración equivalente al ejemplo de Sección 55.3.1, “Configuración de un clúster "Opt-In"”. Ambos recursos pueden fallar al nodo example-3 si su nodo preferido falla, ya que cada nodo tiene una puntuación implícita de 0.
# pcs constraint location Webserver prefers example-1=200
# pcs constraint location Webserver avoids example-2=INFINITY
# pcs constraint location Database avoids example-1=INFINITY
# pcs constraint location Database prefers example-2=200Tenga en cuenta que no es necesario especificar una puntuación de INFINITO en estos comandos, ya que ese es el valor por defecto para la puntuación.
55.4. Configurar un recurso para que prefiera su nodo actual
Los recursos tienen un valor resource-stickiness que puedes establecer como un meta atributo cuando creas el recurso, como se describe en Configuración de las opciones meta de los recursos. El valor resource-stickiness determina cuánto quiere permanecer un recurso en el nodo donde se está ejecutando actualmente. Pacemaker tiene en cuenta el valor de resource-stickiness junto con otros ajustes (por ejemplo, los valores de puntuación de las restricciones de ubicación) para determinar si se debe mover un recurso a otro nodo o dejarlo en su lugar.
Por defecto, un recurso se crea con un valor resource-stickiness de 0. El comportamiento predeterminado de Pacemaker cuando resource-stickiness se establece en 0 y no hay restricciones de ubicación es mover los recursos para que se distribuyan uniformemente entre los nodos del clúster. Esto puede dar lugar a que los recursos sanos se muevan con más frecuencia de la deseada. Para evitar este comportamiento, puede establecer el valor predeterminado de resource-stickiness en 1. Este valor predeterminado se aplicará a todos los recursos del clúster. Este pequeño valor puede ser fácilmente anulado por otras restricciones que usted cree, pero es suficiente para evitar que Pacemaker mueva innecesariamente los recursos sanos por el cluster.
El siguiente comando establece el valor por defecto de resource-stickiness en 1.
# pcs resource defaults resource-stickiness=1
Si se establece el valor resource-stickiness, no se moverá ningún recurso a un nodo recién añadido. Si se desea equilibrar los recursos en ese momento, se puede volver a establecer temporalmente el valor resource-stickiness a 0.
Tenga en cuenta que si la puntuación de una restricción de ubicación es mayor que el valor de resource-stickiness, el clúster puede seguir moviendo un recurso sano al nodo donde apunta la restricción de ubicación.
Para obtener más información sobre cómo Pacemaker determina dónde colocar un recurso, consulte Configuración de una estrategia de colocación de nodos.
Capítulo 56. Determinación del orden de ejecución de los recursos del clúster
Para determinar el orden de ejecución de los recursos, se configura una restricción de orden.
A continuación se muestra el formato del comando para configurar una restricción de ordenación.
pcs constraint order [action] resource_id then [action] resource_id [options]Tabla 56.1, “Propiedades de una restricción de orden”, resume las propiedades y opciones para configurar las restricciones de ordenación.
| Campo | Descripción |
|---|---|
| resource_id | El nombre de un recurso sobre el que se realiza una acción. |
| acción | La acción a realizar sobre un recurso. Los posibles valores de la propiedad action son los siguientes:
*
*
*
*
Si no se especifica ninguna acción, la acción por defecto es |
|
|
Cómo aplicar la restricción. Los posibles valores de la opción
*
*
* |
|
|
Si es verdadera, se aplica la inversa de la restricción para la acción opuesta (por ejemplo, si B comienza después de que A comience, entonces B se detiene antes Las restricciones de ordenación para las que |
Utilice el siguiente comando para eliminar los recursos de cualquier restricción de ordenación.
pcs constraint order remove resource1 [resourceN]...56.1. Configuración de la ordenación obligatoria
Una restricción de orden obligatoria indica que la segunda acción no debe iniciarse para el segundo recurso a menos que y hasta que la primera acción se complete con éxito para el primer recurso. Las acciones que pueden ordenarse son stop, start, y adicionalmente para los clones promocionables, demote y promote. Por ejemplo, \ "A entonces B" (que equivale a "iniciar A y luego iniciar B") significa que B no se iniciará a menos que A se inicie con éxito. Una restricción de ordenación es obligatoria si la opción kind de la restricción se establece en Mandatory o se deja por defecto.
Si la opción symmetrical se establece en true o se deja por defecto, las acciones opuestas se ordenarán de forma inversa. Las acciones start y stop son opuestas, y demote y promote son opuestas. Por ejemplo, una ordenación simétrica \ "promocionar A y luego iniciar B" implica \ "detener B y luego degradar A", lo que significa que A no puede ser degradado hasta que y a menos que B se detenga con éxito. Un ordenamiento simétrico significa que los cambios en el estado de A pueden causar acciones que se programen para B. Por ejemplo, dado "A entonces B", si A se reinicia debido a una falla, B se detendrá primero, luego A se detendrá, luego A se iniciará, luego B se iniciará.
Tenga en cuenta que el clúster reacciona a cada cambio de estado. Si el primer recurso se reinicia y vuelve a estar en estado de inicio antes de que el segundo recurso inicie una operación de parada, no será necesario reiniciar el segundo recurso.
56.2. Configurar la ordenación de los avisos
Cuando se especifica la opción kind=Optional para una restricción de ordenación, la restricción se considera opcional y sólo se aplica si ambos recursos están ejecutando las acciones especificadas. Cualquier cambio de estado del primer recurso especificado no tendrá efecto en el segundo recurso especificado.
El siguiente comando configura una restricción de ordenación de asesoramiento para los recursos denominados VirtualIP y dummy_resource.
# pcs constraint order VirtualIP then dummy_resource kind=Optional56.3. Configuración de conjuntos de recursos ordenados
Una situación común es que un administrador cree una cadena de recursos ordenados, donde, por ejemplo, el recurso A se inicia antes que el recurso B, que se inicia antes que el recurso C. Si su configuración requiere que cree un conjunto de recursos que se coloquen y se inicien en orden, puede configurar un grupo de recursos que contenga esos recursos, como se describe en Configuración de grupos de recursos.
Sin embargo, hay algunas situaciones en las que no es adecuado configurar los recursos que deben iniciarse en un orden determinado como un grupo de recursos:
- Es posible que tenga que configurar los recursos para que se inicien en orden y que los recursos no estén necesariamente colocados.
- Puede tener un recurso C que debe iniciarse después de que se haya iniciado el recurso A o el B, pero no hay ninguna relación entre A y B.
- Puede tener recursos C y D que deben iniciarse después de que se hayan iniciado los recursos A y B, pero no hay ninguna relación entre A y B o entre C y D.
En estas situaciones, puede crear una restricción de ordenación en un conjunto o conjuntos de recursos con el comando pcs constraint order set.
Puede establecer las siguientes opciones para un conjunto de recursos con el comando pcs constraint order set.
sequential, que puede establecerse comotrueofalsepara indicar si el conjunto de recursos debe estar ordenado de forma relativa. El valor por defecto estrue.Si se establece
sequentialenfalse, se puede ordenar un conjunto en relación con otros conjuntos en la restricción de ordenación, sin que sus miembros se ordenen entre sí. Por lo tanto, esta opción sólo tiene sentido si hay varios conjuntos en la restricción; en caso contrario, la restricción no tiene ningún efecto.-
require-all, que puede establecerse entrueofalsepara indicar si todos los recursos del conjunto deben estar activos antes de continuar. Establecerrequire-allafalsesignifica que sólo un recurso del conjunto debe iniciarse antes de continuar con el siguiente conjunto. Establecerrequire-allafalseno tiene ningún efecto a menos que se utilice junto con conjuntos desordenados, que son conjuntos para los quesequentialse establece enfalse. El valor por defecto estrue. -
action, que puede establecerse enstart,promote,demoteostop, como se describe en Propiedades de una restricción de orden. -
role, que puede ajustarse aStopped,Started,MasteroSlave.
Puede establecer las siguientes opciones de restricción para un conjunto de recursos siguiendo el parámetro setoptions del comando pcs constraint order set.
-
id, para dar un nombre a la restricción que está definiendo. -
kind, que indica cómo hacer cumplir la restricción, como se describe en Propiedades de una restricción de orden. -
symmetrical, para establecer si el reverso de la restricción se aplica para la acción opuesta, como se describe en Propiedades de una restricción de orden.
pcs constraint order set resource1 resource2 [resourceN]... [options] [set resourceX resourceY ... [options]] [setoptions [constraint_options]]
Si tiene tres recursos llamados D1, D2, y D3, el siguiente comando los configura como un conjunto de recursos ordenados.
# pcs constraint order set D1 D2 D3
Si tiene seis recursos denominados A, B, C, D, E, y F, este ejemplo configura una restricción de ordenación para el conjunto de recursos que comenzará de la siguiente manera:
-
AyBse inician de forma independiente -
Cse inicia una vez que se ha iniciadoAoB -
Dse pone en marcha una vez que se ha iniciadoC -
EyFse inician de forma independiente una vez que se ha iniciadoD
La detención de los recursos no se ve influida por esta restricción, ya que se establece symmetrical=false.
# pcs constraint order set A B sequential=false require-all=false set C D set E F sequential=false setoptions symmetrical=false56.4. Configuración del orden de inicio para las dependencias de recursos no gestionadas por Pacemaker
Es posible que un clúster incluya recursos con dependencias que no son gestionadas por el clúster. En este caso, debe asegurarse de que esas dependencias se inicien antes de iniciar Pacemaker y se detengan después de detenerlo.
Puede configurar su orden de inicio para tener en cuenta esta situación mediante el objetivo systemd resource-agents-deps . Puede crear una unidad de arranque systemd para este objetivo y Pacemaker se ordenará adecuadamente en relación con este objetivo.
Por ejemplo, si un clúster incluye un recurso que depende del servicio externo foo que no está gestionado por el clúster, realice el siguiente procedimiento.
Cree la unidad de entrega
/etc/systemd/system/resource-agents-deps.target.d/foo.confque contiene lo siguiente:[Unit] Requires=foo.service After=foo.service-
Ejecute el comando
systemctl daemon-reload.
Una dependencia del clúster especificada de esta manera puede ser algo distinto a un servicio. Por ejemplo, puede tener una dependencia para montar un sistema de archivos en /srv, en cuyo caso realizaría el siguiente procedimiento:
-
Asegúrese de que
/srvaparece en el archivo/etc/fstab. Esto se convertirá automáticamente en el archivosystemdsrv.mounten el arranque cuando se recargue la configuración del administrador del sistema. Para más información, consulte las páginas de manualsystemd.mount(5) ysystemd-fstab-generator(8). Para asegurarse de que Pacemaker se inicie después de montar el disco, cree la unidad drop-in
/etc/systemd/system/resource-agents-deps.target.d/srv.confque contiene lo siguiente.[Unit] Requires=srv.mount After=srv.mount-
Ejecute el comando
systemctl daemon-reload.
Capítulo 57. Colocación de los recursos del clúster
Para especificar que la ubicación de un recurso depende de la ubicación de otro recurso, se configura una restricción de colocación.
La creación de una restricción de colocación entre dos recursos tiene un efecto secundario importante: afecta al orden en que se asignan los recursos a un nodo. Esto se debe a que no se puede colocar el recurso A en relación con el recurso B a menos que se sepa dónde está el recurso B. Por lo tanto, cuando se crean restricciones de colocación, es importante considerar si se debe colocar el recurso A con el recurso B o el recurso B con el recurso A.
Otra cosa que hay que tener en cuenta al crear las restricciones de colocación es que, suponiendo que el recurso A esté colocado con el recurso B, el clúster también tendrá en cuenta las preferencias del recurso A a la hora de decidir qué nodo elegir para el recurso B.
El siguiente comando crea una restricción de colocación.
pcs constraint colocation add [master|slave] source_resource with [master|slave] target_resource [score] [options]Tabla 57.1, “Propiedades de una restricción de colocación”, resume las propiedades y opciones para configurar las restricciones de colocación.
| Campo | Descripción |
|---|---|
| recurso_fuente | La fuente de colocación. Si la restricción no puede ser satisfecha, el clúster puede decidir no permitir que el recurso se ejecute en absoluto. |
| recurso_objetivo | El objetivo de colocación. El clúster decidirá dónde colocar este recurso primero y luego decidirá dónde colocar el recurso de origen. |
| puntuación |
Los valores positivos indican que el recurso debe ejecutarse en el mismo nodo. Los valores negativos indican que los recursos no deben ejecutarse en el mismo nodo. Un valor de |
57.1. Especificación de la ubicación obligatoria de los recursos
La colocación obligatoria se produce cada vez que la puntuación de la restricción es INFINITY o -INFINITY. En estos casos, si la restricción no puede satisfacerse, no se permite la ejecución de source_resource. En el caso de score=INFINITY, esto incluye los casos en los que el target_resource no está activo.
Si necesita que myresource1 se ejecute siempre en la misma máquina que myresource2, deberá añadir la siguiente restricción:
# pcs constraint colocation add myresource1 with myresource2 score=INFINITY
Dado que se ha utilizado INFINITY, si myresource2 no puede ejecutarse en ninguno de los nodos del clúster (por la razón que sea), no se permitirá la ejecución de myresource1.
Alternativamente, puede querer configurar lo contrario, un cluster en el que myresource1 no pueda ejecutarse en la misma máquina que myresource2. En este caso, utilice score=-INFINITY
# pcs constraint colocation add myresource1 with myresource2 score=-INFINITY
De nuevo, al especificar -INFINITY, la restricción es vinculante. Así que si el único lugar que queda por ejecutar es donde ya está myresource2, entonces myresource1 no puede ejecutarse en ningún sitio.
57.2. Especificación de la colocación de los recursos con fines de asesoramiento
Si la colocación obligatoria se trata de \N "debe" y \N "no debe", entonces la colocación consultiva es la alternativa \N "preferiría si". Para las restricciones con puntuaciones superiores a -INFINITY e inferiores a INFINITY, el clúster intentará acomodar sus deseos pero puede ignorarlos si la alternativa es detener algunos de los recursos del clúster.
57.3. Colocación de conjuntos de recursos
Si su configuración requiere que cree un conjunto de recursos que se coloquen y se inicien en orden, puede configurar un grupo de recursos que contenga esos recursos, como se describe en Configuración de grupos de recursos. Sin embargo, hay algunas situaciones en las que no es apropiado configurar los recursos que deben colocarse como un grupo de recursos:
- Es posible que tenga que colocar un conjunto de recursos, pero los recursos no tienen que empezar necesariamente en orden.
- Puede tener un recurso C que debe estar colocado con el recurso A o B, pero no hay relación entre A y B.
- Es posible que haya recursos C y D que deban colocarse con los recursos A y B, pero no hay relación entre A y B ni entre C y D.
En estas situaciones, puede crear una restricción de colocación en un conjunto o conjuntos de recursos con el comando pcs constraint colocation set.
Puede establecer las siguientes opciones para un conjunto de recursos con el comando pcs constraint colocation set.
sequential, que puede establecerse comotrueofalsepara indicar si los miembros del conjunto deben estar colocados entre sí.Si se establece
sequentialenfalse, los miembros de este conjunto se colocan con otro conjunto que aparece más adelante en la restricción, independientemente de los miembros de este conjunto que estén activos. Por lo tanto, esta opción sólo tiene sentido si otro conjunto aparece después de éste en la restricción; de lo contrario, la restricción no tiene efecto.-
role, que puede ajustarse aStopped,Started,MasteroSlave.
Puede establecer la siguiente opción de restricción para un conjunto de recursos siguiendo el parámetro setoptions del comando pcs constraint colocation set.
-
id, para dar un nombre a la restricción que está definiendo. -
score, para indicar el grado de preferencia de esta restricción. Para obtener información sobre esta opción, consulte Opciones de restricción de ubicación.
Cuando se enumeran los miembros de un conjunto, cada miembro se coloca con el anterior. Por ejemplo, "conjunto A B" significa que "B está colocado con A". Sin embargo, cuando se enumeran varios conjuntos, cada conjunto se coloca con el que le sigue. Por ejemplo, \ "set C D sequential=false set A B" significa \ "set C D (donde C y D no tienen relación entre sí) está colocado con el set A B (donde B está colocado con A)".
El siguiente comando crea una restricción de colocación en un conjunto o conjuntos de recursos.
pcs constraint colocation set resource1 resource2 [resourceN]... [options] [set resourceX resourceY ... [options]] [setoptions [constraint_options]]57.4. Eliminación de las restricciones de colocación
Utilice el siguiente comando para eliminar las restricciones de colocación con source_resource.
pcs constraint colocation remove source_resource target_resourceCapítulo 58. Visualización de las limitaciones de recursos
Hay varios comandos que se pueden utilizar para mostrar las restricciones que se han configurado.
58.1. Visualización de todas las restricciones configuradas
El siguiente comando muestra todas las restricciones de ubicación, orden y colocación actuales. Si se especifica la opción --full, muestra los ID de las restricciones internas.
pcs constraint [list|show] [--full]
A partir de RHEL 8.2, el listado de restricciones de recursos ya no muestra por defecto las restricciones caducadas. Para incluir las restricciones caducadas, utilice la opción --all del comando pcs constraint. Esto listará las restricciones expiradas, anotando las restricciones y sus reglas asociadas como (expired) en la pantalla.
58.2. Visualización de las restricciones de ubicación
El siguiente comando muestra todas las restricciones de ubicación actuales.
-
Si se especifica
resources, las restricciones de ubicación se muestran por recurso. Este es el comportamiento por defecto. -
Si se especifica
nodes, las restricciones de ubicación se muestran por nodo. - Si se especifican recursos o nodos concretos, sólo se mostrará información sobre esos recursos o nodos.
pcs constraint location [show [resources [resource...]] | [nodos [node...]]] [--full]58.3. Visualización de las restricciones de ordenación
La siguiente orden enumera todas las restricciones de ordenación actuales.
pcs orden de restricción [mostrar]58.4. Visualización de las restricciones de colocación
El siguiente comando muestra todas las restricciones de colocación actuales.
pcs constraint colocation [show]58.5. Visualización de las restricciones específicas de los recursos
El siguiente comando enumera las restricciones que hacen referencia a recursos específicos.
pcs constraint ref resource...58.6. Visualización de las dependencias de recursos (Red Hat Enterprise Linux 8.2 y posteriores)
El siguiente comando muestra las relaciones entre los recursos del cluster en una estructura de árbol.
pcs resource relations resource [--full]
Si se utiliza la opción --full, el comando muestra información adicional, incluyendo los ID de las restricciones y los tipos de recursos.
En el siguiente ejemplo, hay 3 recursos configurados: C, D y E.
# pcs constraint order start C then start D
Adding C D (kind: Mandatory) (Options: first-action=start then-action=start)
# pcs constraint order start D then start E
Adding D E (kind: Mandatory) (Options: first-action=start then-action=start)
# pcs resource relations C
C
`- order
| start C then start D
`- D
`- order
| start D then start E
`- E
# pcs resource relations D
D
|- order
| | start C then start D
| `- C
`- order
| start D then start E
`- E
# pcs resource relations E
E
`- order
| start D then start E
`- D
`- order
| start C then start D
`- CEn el siguiente ejemplo, hay 2 recursos configurados: A y B. Los recursos A y B forman parte del grupo de recursos G.
# pcs resource relations A
A
`- outer resource
`- G
`- inner resource(s)
| members: A B
`- B
# pcs resource relations B
B
`- outer resource
`- G
`- inner resource(s)
| members: A B
`- A
# pcs resource relations G
G
`- inner resource(s)
| members: A B
|- A
`- BCapítulo 59. Determinación de la ubicación de los recursos con reglas
Para restricciones de ubicación más complicadas, puede utilizar las reglas de Pacemaker para determinar la ubicación de un recurso.
59.1. Reglas del marcapasos
Las reglas pueden ser utilizadas para hacer su configuración más dinámica. Un uso de las reglas podría ser asignar máquinas a diferentes grupos de procesamiento (utilizando un atributo de nodo) en función del tiempo y luego utilizar ese atributo al crear restricciones de ubicación.
Cada regla puede contener varias expresiones, expresiones de fecha e incluso otras reglas. Los resultados de las expresiones se combinan basándose en el campo boolean-op de la regla para determinar si la regla se evalúa finalmente como true o false. Lo que ocurre a continuación depende del contexto en el que se utiliza la regla.
| Campo | Descripción |
|---|---|
|
|
Limita la regla para que se aplique sólo cuando el recurso está en ese rol. Valores permitidos: |
|
|
La puntuación a aplicar si la regla se evalúa como |
|
|
El atributo del nodo que se busca y se utiliza como puntuación si la regla se evalúa como |
|
|
Cómo combinar el resultado de varios objetos de expresión. Valores permitidos: |
59.1.1. Expresiones de atributos de los nodos
Las expresiones de atributos de nodo se utilizan para controlar un recurso en función de los atributos definidos por un nodo o nodos.
| Campo | Descripción |
|---|---|
|
| El atributo del nodo a probar |
|
|
Determina cómo se deben comprobar los valores. Valores permitidos: |
|
| La comparación a realizar. Valores permitidos:
*
*
*
*
*
*
*
* |
|
|
Valor suministrado por el usuario para la comparación (obligatorio a menos que |
Además de los atributos añadidos por el administrador, el clúster define atributos de nodo especiales e incorporados para cada nodo que también pueden utilizarse, como se describe en Tabla 59.3, “Atributos de los nodos incorporados”.
| Nombre | Descripción |
|---|---|
|
| Nombre del nodo |
|
| ID de nodo |
|
|
Tipo de nodo. Los valores posibles son |
|
|
|
|
|
El valor de la propiedad |
|
|
El valor del atributo del nodo |
|
| La función que el clon promocionable correspondiente tiene en este nodo. Válido sólo dentro de una regla para una restricción de ubicación para un clon promocionable. |
59.1.2. Expresiones basadas en la fecha y la hora
Las expresiones de fecha se utilizan para controlar un recurso o una opción del clúster en función de la fecha/hora actual. Pueden contener una especificación de fecha opcional.
| Campo | Descripción |
|---|---|
|
| Una fecha/hora conforme a la especificación ISO8601. |
|
| Una fecha/hora conforme a la especificación ISO8601. |
|
| Compara la fecha/hora actual con la fecha de inicio o de finalización o con ambas, dependiendo del contexto. Valores permitidos:
*
*
*
* |
59.1.3. Especificaciones de fecha
Las especificaciones de fecha se utilizan para crear expresiones tipo cron relacionadas con el tiempo. Cada campo puede contener un solo número o un solo rango. En lugar de ponerlo a cero por defecto, cualquier campo no suministrado se ignora.
Por ejemplo, monthdays="1" coincide con el primer día de cada mes y hours="09-17" con las horas comprendidas entre las 9 y las 17 horas (inclusive). Sin embargo, no se puede especificar weekdays="1,2" o weekdays="1-2,5-6" ya que contienen múltiples rangos.
| Campo | Descripción |
|---|---|
|
| Un nombre único para la fecha |
|
| Valores permitidos: 0-23 |
|
| Valores permitidos: 0-31 (según el mes y el año) |
|
| Valores permitidos: 1-7 (1=lunes, 7=domingos) |
|
| Valores permitidos: 1-366 (dependiendo del año) |
|
| Valores permitidos: 1-12 |
|
|
Valores permitidos: 1-53 (dependiendo de |
|
| Año según el calendario gregoriano |
|
|
Puede diferir de los años gregorianos; por ejemplo, |
|
| Valores permitidos: 0-7 (0 es luna nueva, 4 es luna llena). |
59.2. Configuración de una restricción de ubicación de marcapasos mediante reglas
Utilice el siguiente comando para configurar una restricción de Pacemaker que utilice reglas. Si se omite score, el valor por defecto es INFINITO. Si se omite resource-discovery, el valor predeterminado es always.
Para obtener información sobre la opción resource-discovery, consulte Limitar el descubrimiento de recursos a un subconjunto de nodos.
Al igual que con las restricciones de ubicación básicas, también puede utilizar expresiones regulares para los recursos con estas restricciones.
Cuando se utilizan reglas para configurar las restricciones de ubicación, el valor de score puede ser positivo o negativo, con un valor positivo que indica "prefiere" y un valor negativo que indica "evita".
pcs constraint location rsc rule [resource-discovery=option] [role=master|slave] [score=score | score-attribute=attribute] expressionLa opción expression puede ser una de las siguientes, donde duration_options y date_spec_options son: horas, días del mes, días de la semana, días del año, meses, semanas, años, años de la semana, luna, como se describe en Propiedades de una especificación de fecha.
-
defined|not_defined attribute -
attribute lt|gt|lte|gte|eq|ne [string|integer|version] value -
date gt|lt date -
date in_range date to date -
date in_range date to duration duration_options … -
date-spec date_spec_options -
expression and|or expression -
(expression)
Tenga en cuenta que las duraciones son una forma alternativa de especificar un final para las operaciones de in_range mediante cálculos. Por ejemplo, puede especificar una duración de 19 meses.
La siguiente restricción de ubicación configura una expresión que es verdadera si ahora es cualquier momento del año 2018.
# pcs constraint location Webserver rule score=INFINITY date-spec years=2018El siguiente comando configura una expresión que es verdadera de 9 am a 5 pm, de lunes a viernes. Tenga en cuenta que el valor de horas de 16 coincide hasta las 16:59:59, ya que el valor numérico (hora) sigue coincidiendo.
# pcs constraint location Webserver rule score=INFINITY date-spec hours="9-16" weekdays="1-5"El siguiente comando configura una expresión que es verdadera cuando hay luna llena el viernes trece.
# pcs constraint location Webserver rule date-spec weekdays=5 monthdays=13 moon=4Para eliminar una regla, utilice el siguiente comando. Si la regla que está eliminando es la última regla de su restricción, la restricción será eliminada.
regla de restricción pcs eliminar rule_idCapítulo 60. Gestión de los recursos del clúster
Esta sección describe varios comandos que puede utilizar para gestionar los recursos del clúster.
60.1. Visualización de los recursos configurados
Para mostrar una lista de todos los recursos configurados, utilice el siguiente comando.
estado de los recursos pcs
Por ejemplo, si su sistema está configurado con un recurso llamado VirtualIP y un recurso llamado WebSite, el comando pcs resource show produce la siguiente salida.
# pcs resource status
VirtualIP (ocf::heartbeat:IPaddr2): Started
WebSite (ocf::heartbeat:apache): Started
Para mostrar una lista de todos los recursos configurados y los parámetros configurados para esos recursos, utilice la opción --full del comando pcs resource config, como en el siguiente ejemplo.
# pcs resource config
Resource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat)
Attributes: ip=192.168.0.120 cidr_netmask=24
Operations: monitor interval=30s
Resource: WebSite (type=apache class=ocf provider=heartbeat)
Attributes: statusurl=http://localhost/server-status configfile=/etc/httpd/conf/httpd.conf
Operations: monitor interval=1minPara mostrar los parámetros configurados para un recurso, utilice el siguiente comando.
pcs resource config resource_id
Por ejemplo, el siguiente comando muestra los parámetros actualmente configurados para el recurso VirtualIP.
# pcs resource config VirtualIP
Resource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat)
Attributes: ip=192.168.0.120 cidr_netmask=24
Operations: monitor interval=30s60.2. Modificación de los parámetros de los recursos
Para modificar los parámetros de un recurso configurado, utilice el siguiente comando.
pcs resource update resource_id [resource_options]
La siguiente secuencia de comandos muestra los valores iniciales de los parámetros configurados para el recurso VirtualIP, el comando para cambiar el valor del parámetro ip y los valores posteriores al comando de actualización.
# pcs resource config VirtualIP
Resource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat)
Attributes: ip=192.168.0.120 cidr_netmask=24
Operations: monitor interval=30s
# pcs resource update VirtualIP ip=192.169.0.120
# pcs resource config VirtualIP
Resource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat)
Attributes: ip=192.169.0.120 cidr_netmask=24
Operations: monitor interval=30s
Cuando se actualiza el funcionamiento de un recurso con el comando pcs resource update, cualquier opción que no se indique específicamente se restablece a sus valores por defecto.
60.3. Borrar el estado de fallo de los recursos del clúster
Si un recurso ha fallado, aparece un mensaje de fallo cuando se muestra el estado del cluster. Si resuelve ese recurso, puede borrar ese estado de fallo con el comando pcs resource cleanup. Este comando restablece el estado del recurso y failcount, indicando al clúster que olvide el historial de operaciones de un recurso y vuelva a detectar su estado actual.
El siguiente comando limpia el recurso especificado por resource_id.
limpieza de recursos pcs resource_id
Si no se especifica un resource_id, este comando restablece el estado del recurso y failcountpara todos los recursos.
El comando pcs resource cleanup sondea sólo los recursos que se muestran como una acción fallida. Para sondear todos los recursos en todos los nodos puede introducir el siguiente comando:
actualización de recursos pcs
Por defecto, el comando pcs resource refresh sondea sólo los nodos en los que se conoce el estado de un recurso. Para sondear todos los recursos aunque no se conozca su estado, introduzca el siguiente comando:
pcs resource refresh --full60.4. Desplazamiento de recursos en un clúster
Pacemaker proporciona una variedad de mecanismos para configurar un recurso para que se mueva de un nodo a otro y para mover manualmente un recurso cuando sea necesario.
Puede mover manualmente los recursos de un clúster con los comandos pcs resource move y pcs resource relocate, como se describe en Mover manualmente los recursos del clúster.
Además de estos comandos, también puede controlar el comportamiento de los recursos del clúster habilitando, deshabilitando y prohibiendo recursos, como se describe en Habilitación, deshabilitación y prohibición de recursos del clúster.
Puedes configurar un recurso para que se mueva a un nuevo nodo después de un número definido de fallos, y puedes configurar un clúster para que mueva los recursos cuando se pierda la conectividad externa.
60.4.1. Desplazamiento de recursos por avería
Cuando creas un recurso, puedes configurar el recurso para que se mueva a un nuevo nodo después de un número definido de fallos, estableciendo la opción migration-threshold para ese recurso. Una vez alcanzado el umbral, este nodo ya no podrá ejecutar el recurso fallido hasta:
-
El administrador restablece manualmente el recurso
failcountmediante el comandopcs resource cleanup. -
Se alcanza el valor del recurso
failure-timeout.
El valor de migration-threshold se establece por defecto en INFINITY. INFINITY se define internamente como un número muy grande pero finito. Un valor de 0 desactiva la función migration-threshold.
Configurar un migration-threshold para un recurso no es lo mismo que configurar un recurso para la migración, en la que el recurso se mueve a otra ubicación sin pérdida de estado.
El siguiente ejemplo añade un umbral de migración de 10 al recurso llamado dummy_resource, que indica que el recurso se moverá a un nuevo nodo después de 10 fallos.
# pcs resource meta dummy_resource migration-threshold=10Puede añadir un umbral de migración a los valores predeterminados para todo el clúster con el siguiente comando.
# pcs resource defaults migration-threshold=10
Para determinar el estado actual de los fallos y los límites del recurso, utilice el comando pcs resource failcount show.
Hay dos excepciones al concepto de umbral de migración; ocurren cuando un recurso falla al arrancar o falla al parar. Si la propiedad del clúster start-failure-is-fatal se establece en true (que es el valor predeterminado), los fallos de arranque hacen que failcount se establezca en INFINITY y, por lo tanto, siempre hacen que el recurso se mueva inmediatamente.
Los fallos de parada son ligeramente diferentes y cruciales. Si un recurso falla al detenerse y STONITH está habilitado, entonces el cluster cercará el nodo para poder iniciar el recurso en otro lugar. Si STONITH no está habilitado, entonces el cluster no tiene forma de continuar y no intentará iniciar el recurso en otro lugar, sino que intentará detenerlo de nuevo después del tiempo de espera del fallo.
60.4.2. Desplazamiento de recursos por cambios de conectividad
Configurar el clúster para mover los recursos cuando se pierde la conectividad externa es un proceso de dos pasos.
-
Añade un recurso
pingal cluster. El recursopingutiliza la utilidad del sistema del mismo nombre para comprobar si una lista de máquinas (especificadas por el nombre de host DNS o la dirección IPv4/IPv6) son alcanzables y utiliza los resultados para mantener un atributo de nodo llamadopingd. - Configure una restricción de ubicación para el recurso que lo trasladará a un nodo diferente cuando se pierda la conectividad.
Tabla 54.1, “Identificadores de agentes de recursos” describe las propiedades que se pueden establecer para un recurso ping.
| Campo | Descripción |
|---|---|
|
| El tiempo de espera (dampening) para que se produzcan más cambios. Esto evita que un recurso rebote por el clúster cuando los nodos del clúster notan la pérdida de conectividad en momentos ligeramente diferentes. |
|
| El número de nodos de ping conectados se multiplica por este valor para obtener una puntuación. Es útil cuando hay varios nodos de ping configurados. |
|
| Las máquinas con las que hay que contactar para determinar el estado actual de la conectividad. Los valores permitidos incluyen nombres de host DNS resolubles y direcciones IPv4 e IPv6. Las entradas de la lista de hosts están separadas por espacios. |
El siguiente comando de ejemplo crea un recurso ping que verifica la conectividad con gateway.example.com. En la práctica, usted verificaría la conectividad con su puerta de enlace/enrutador de red. Configure el recurso ping como un clon para que el recurso se ejecute en todos los nodos del clúster.
# pcs resource create ping ocf:pacemaker:ping dampen=5s multiplier=1000 host_list=gateway.example.com clone
El siguiente ejemplo configura una regla de restricción de ubicación para el recurso existente llamado Webserver. Esto hará que el recurso Webserver se mueva a un host que sea capaz de hacer ping a gateway.example.com si el host en el que se está ejecutando actualmente no puede hacer ping a gateway.example.com.
# pcs constraint location Webserver rule score=-INFINITY pingd lt 1 or not_defined pingd Module included in the following assemblies:
//
// <List assemblies here, each on a new line>
// rhel-8-docs/enterprise/assemblies/assembly_managing-cluster-resources.adoc60.5. Desactivación de una operación de monitorización
La forma más fácil de detener un monitor recurrente es eliminarlo. Sin embargo, puede haber ocasiones en las que sólo quiera desactivarlo temporalmente. En estos casos, añada enabled="false" a la definición de la operación. Cuando quiera restablecer la operación de monitorización, ponga enabled="true" en la definición de la operación.
Cuando se actualiza la operación de un recurso con el comando pcs resource update, cualquier opción que no se indique específicamente se restablece a sus valores por defecto. Por ejemplo, si ha configurado una operación de monitorización con un valor de tiempo de espera personalizado de 600, la ejecución de los siguientes comandos restablecerá el valor de tiempo de espera al valor predeterminado de 20 (o al que haya establecido el valor predeterminado con el comando pcs resource ops default ).
# pcs resource update resourceXZY op monitor enabled=false
# pcs resource update resourceXZY op monitor enabled=truePara mantener el valor original de 600 para esta opción, al restablecer la operación de supervisión debe especificar ese valor, como en el siguiente ejemplo.
# pcs resource update resourceXZY op monitor timeout=600 enabled=true60.6. Configuración y gestión de las etiquetas de recursos del clúster (RHEL 8.3 y posterior)
A partir de Red Hat Enterprise Linux 8.3, puede utilizar el comando pcs para etiquetar los recursos del cluster. Esto le permite habilitar, deshabilitar, gestionar o desgestionar un conjunto específico de recursos con un solo comando.
60.6.1. Etiquetado de los recursos del clúster para su administración por categorías
El siguiente procedimiento etiqueta dos recursos con una etiqueta de recurso y desactiva los recursos etiquetados. En este ejemplo, los recursos existentes que se van a etiquetar se llaman d-01 y d-02.
Cree una etiqueta denominada
special-resourcespara los recursosd-01yd-02.[root@node-01]# pcs tag create special-resources d-01 d-02Muestra la configuración de la etiqueta de recursos.
[root@node-01]# pcs tag config special-resources d-01 d-02Desactivar todos los recursos etiquetados con la etiqueta
special-resources.[root@node-01]# pcs resource disable special-resourcesMuestra el estado de los recursos para confirmar que los recursos
d-01yd-02están desactivados.[root@node-01]# pcs resource * d-01 (ocf::pacemaker:Dummy): Stopped (disabled) * d-02 (ocf::pacemaker:Dummy): Stopped (disabled)
Además del comando pcs resource disable, los comandos pcs resource enable, pcs resource manage, y pcs resource unmanage apoyan la administración de recursos etiquetados.
Después de haber creado una etiqueta de recurso:
-
Puede eliminar una etiqueta de recurso con el comando
pcs tag delete. -
Puede modificar la configuración de una etiqueta de recurso existente con el comando
pcs tag update.
60.6.2. Eliminar un recurso de clúster etiquetado
No se puede eliminar un recurso de cluster etiquetado con el comando pcs. Para eliminar un recurso etiquetado, utilice el siguiente procedimiento.
Eliminar la etiqueta de recurso.
El siguiente comando elimina la etiqueta de recurso
special-resourcesde todos los recursos con esa etiqueta,[root@node-01]# pcs tag remove special-resources [root@node-01]# pcs tag No tags definedEl siguiente comando elimina la etiqueta de recurso
special-resourcessólo del recursod-01.[root@node-01]# pcs tag update special-resources remove d-01
Eliminar el recurso.
[root@node-01]# pcs resource delete d-01 Attempting to stop: d-01... Stopped
Capítulo 61. Creación de recursos de cluster activos en varios nodos (recursos clonados)
Puede clonar un recurso de clúster para que el recurso pueda estar activo en varios nodos. Por ejemplo, puede utilizar los recursos clonados para configurar varias instancias de un recurso IP para distribuirlo en un clúster para el equilibrio de nodos. Puede clonar cualquier recurso siempre que el agente de recursos lo soporte. Un clon consiste en un recurso o un grupo de recursos.
Sólo los recursos que pueden estar activos en varios nodos al mismo tiempo son adecuados para la clonación. Por ejemplo, un recurso Filesystem que monte un sistema de archivos no agrupado como ext4 desde un dispositivo de memoria compartida no debe ser clonado. Dado que la partición ext4 no es consciente del clúster, este sistema de archivos no es adecuado para las operaciones de lectura/escritura que se producen desde varios nodos al mismo tiempo.
61.1. Creación y eliminación de un recurso clonado
Puedes crear un recurso y un clon de ese recurso al mismo tiempo con el siguiente comando.
pcs resource create resource_id [standard:[provider:]]type [resource options] [meta resource meta options] clone [clone options]
El nombre del clon será resource_id-clone.
No se puede crear un grupo de recursos y un clon de ese grupo de recursos en un solo comando.
Alternativamente, puede crear un clon de un recurso o grupo de recursos previamente creado con el siguiente comando.
pcs resource clone resource_id | group_name [clone options]...
El nombre del clon será resource_id-clone o group_name-clone.
Es necesario configurar los cambios de configuración de los recursos en un solo nodo.
Al configurar las restricciones, utilice siempre el nombre del grupo o del clon.
Cuando se crea un clon de un recurso, el clon toma el nombre del recurso con -clone añadido al nombre. Los siguientes comandos crean un recurso de tipo apache llamado webfarm y un clon de ese recurso llamado webfarm-clone.
# pcs resource create webfarm apache clone
Cuando se crea un clon de un recurso o grupo de recursos que se ordenará después de otro clon, casi siempre se debe establecer la opción interleave=true. Esto asegura que las copias del clon dependiente puedan detenerse o iniciarse cuando el clon del que depende se haya detenido o iniciado en el mismo nodo. Si no establece esta opción, si un recurso clonado B depende de un recurso clonado A y un nodo abandona el clúster, cuando el nodo regresa al clúster y el recurso A se inicia en ese nodo, entonces todas las copias del recurso B en todos los nodos se reiniciarán. Esto se debe a que cuando un recurso clonado dependiente no tiene la opción interleave establecida, todas las instancias de ese recurso dependen de cualquier instancia en ejecución del recurso del que depende.
Utilice el siguiente comando para eliminar un clon de un recurso o grupo de recursos. Esto no elimina el recurso o el grupo de recursos en sí.
pcs resource unclone resource_id | group_nameTabla 61.1, “Opciones de clonación de recursos” describe las opciones que puede especificar para un recurso clonado.
| Campo | Descripción |
|---|---|
|
| Opciones heredadas del recurso que se está clonando, como se describe en Tabla 54.3, “Meta opciones de recursos”. |
|
| Cuántas copias del recurso se van a iniciar. Por defecto, el número de nodos del clúster. |
|
|
Cuántas copias del recurso pueden iniciarse en un solo nodo; el valor por defecto es |
|
|
Cuando se detiene o se inicia una copia del clon, se informa a todas las demás copias de antemano y cuando la acción ha tenido éxito. Valores permitidos: |
|
|
¿Cada copia del clon realiza una función diferente? Valores permitidos:
Si el valor de esta opción es
Si el valor de esta opción es |
|
|
Si las copias se inician en serie (en lugar de en paralelo). Valores permitidos: |
|
|
Cambia el comportamiento de las restricciones de ordenación (entre clones) para que las copias del primer clon puedan iniciarse o detenerse tan pronto como la copia en el mismo nodo del segundo clon se haya iniciado o detenido (en lugar de esperar hasta que cada instancia del segundo clon se haya iniciado o detenido). Valores permitidos: |
|
|
Si se especifica un valor, cualquier clon que se ordene después de este clon no podrá iniciarse hasta que se ejecute el número especificado de instancias del clon original, incluso si la opción |
Para lograr un patrón de asignación estable, los clones son ligeramente pegajosos por defecto, lo que indica que tienen una ligera preferencia por permanecer en el nodo donde se están ejecutando. Si no se proporciona ningún valor para resource-stickiness, el clon utilizará un valor de 1. Al ser un valor pequeño, causa una perturbación mínima en los cálculos de puntuación de otros recursos, pero es suficiente para evitar que Pacemaker mueva innecesariamente las copias por el clúster. Para obtener información sobre la configuración de la meta-opción de recursos resource-stickiness, consulte Configuración de meta-opciones de recursos.
61.2. Configurar las limitaciones de recursos de los clones
En la mayoría de los casos, un clon tendrá una sola copia en cada nodo activo del clúster. Sin embargo, puede establecer clone-max para el clon de recursos a un valor que sea menor que el número total de nodos en el clúster. Si este es el caso, puedes indicar a qué nodos debe asignar preferentemente las copias el clúster con restricciones de ubicación de recursos. Estas restricciones no se escriben de forma diferente a las de los recursos normales, salvo que se debe utilizar el id del clon.
El siguiente comando crea una restricción de ubicación para que el clúster asigne preferentemente el clon de recursos webfarm-clone a node1.
# pcs constraint location webfarm-clone prefers node1
Las restricciones de orden se comportan de forma ligeramente diferente para los clones. En el ejemplo siguiente, como la opción de clon de interleave se deja por defecto como false, ninguna instancia de webfarm-stats se iniciará hasta que todas las instancias de webfarm-clone que necesiten iniciarse lo hayan hecho. Sólo si no se puede iniciar ninguna copia de webfarm-clone, se impedirá que webfarm-stats se active. Además, webfarm-clone esperará a que webfarm-stats se detenga antes de detenerse.
# pcs constraint order start webfarm-clone then webfarm-statsLa colocación de un recurso regular (o de grupo) con un clon significa que el recurso puede ejecutarse en cualquier máquina con una copia activa del clon. El clúster elegirá una copia en función de dónde se ejecute el clon y de las preferencias de ubicación del propio recurso.
También es posible la colocación entre clones. En estos casos, el conjunto de ubicaciones permitidas para el clon se limita a los nodos en los que el clon está (o estará) activo. La asignación se realiza entonces de forma normal.
El siguiente comando crea una restricción de colocación para garantizar que el recurso webfarm-stats se ejecute en el mismo nodo que una copia activa de webfarm-clone.
# pcs constraint colocation add webfarm-stats with webfarm-clone61.3. Creación de recursos clonados promocionables
Los recursos clónicos promocionables son recursos clónicos con el meta atributo promotable establecido en true. Permiten que las instancias estén en uno de los dos modos de funcionamiento; éstos se denominan Master y Slave. Los nombres de los modos no tienen significados específicos, excepto por la limitación de que cuando una instancia se inicia, debe aparecer en el estado Slave.
61.3.1. Crear un recurso promocionable
Puede crear un recurso como clon promocionable con el siguiente comando único.
pcs resource create resource_id [standard:[provider:]]type [resource options] promocionable [clone options]
El nombre del clon promocionable será resource_id-clone.
Alternativamente, puede crear un recurso promocionable a partir de un recurso o grupo de recursos creado previamente con el siguiente comando. El nombre del clon promocionable será resource_id-clone o group_name-clone.
recurso pcs promocionable resource_id [clone options]Tabla 61.2, “Opciones adicionales de clonación disponibles para los clones promocionables” describe las opciones adicionales de clonación que se pueden especificar para un recurso promocionable.
| Campo | Descripción |
|---|---|
|
| Cuántas copias del recurso se pueden promover; por defecto 1. |
|
| Cuántas copias del recurso pueden promoverse en un solo nodo; por defecto 1. |
61.3.2. Configuración de las limitaciones de los recursos promocionables
En la mayoría de los casos, un recurso promocionable tendrá una única copia en cada nodo activo del clúster. Si este no es el caso, puede indicar a qué nodos debe asignar preferentemente las copias el clúster con restricciones de ubicación de los recursos. Estas restricciones no se escriben de forma diferente a las de los recursos normales.
Puede crear una restricción de colocación que especifique si los recursos están operando en un rol de maestro o de esclavo. El siguiente comando crea una restricción de colocación de recursos.
pcs constraint colocation add [master|slave] source_resource with [master|slave] target_resource [score] [options]Para obtener información sobre las restricciones de colocación, consulte Colocación de los recursos del clúster.
Al configurar una restricción de ordenación que incluya recursos promocionables, una de las acciones que puede especificar para los recursos es promote, que indica que el recurso sea promocionado del rol esclavo al rol maestro. Además, puede especificar una acción de demote, que indica que el recurso sea degradado de rol maestro a rol esclavo.
El comando para configurar una restricción de orden es el siguiente.
pcs constraint order [action] resource_id then [action] resource_id [options]Determinación del orden de ejecución de los recursos del clúster.
61.4. Desplazamiento de un recurso promocionado en caso de fallo (RHEL 8.3 y posteriores)
Puede configurar un recurso promocionable para que cuando una acción de promote o monitor falle para ese recurso, o la partición en la que el recurso se está ejecutando pierda el quórum, el recurso se degradará pero no se detendrá completamente. Esto puede evitar la necesidad de una intervención manual en situaciones en las que sería necesario detener completamente el recurso.
Para configurar un recurso promocionable para que sea degradado cuando falle una acción de
promote, establezca la meta-opción de operaciónon-failademote, como en el siguiente ejemplo.# pcs resource op add my-rsc promote on-fail="demote"Para configurar un recurso promocionable para que sea degradado cuando una acción de
monitorfalle, establezcaintervala un valor no nulo, establezca la meta-opción de operaciónon-failademote, y establezcaroleaMaster, como en el siguiente ejemplo.# pcs resource op add my-rsc monitor interval="10s" on-fail="demote" role="Master"-
Para configurar un clúster de manera que cuando una partición del clúster pierda el quórum cualquier recurso promovido sea degradado pero se deje en funcionamiento y todos los demás recursos se detengan, establezca la propiedad del clúster
no-quorum-policyendemote
La especificación de un metaatributo demote para una operación no afecta al modo en que se determina la promoción de un recurso. Si el nodo afectado sigue teniendo la mayor puntuación de promoción, será seleccionado para ser promovido de nuevo.
Capítulo 62. Gestión de los nodos del clúster
Las siguientes secciones describen los comandos que se utilizan para gestionar los nodos del clúster, incluidos los comandos para iniciar y detener los servicios del clúster y para añadir y eliminar nodos del clúster.
62.1. Detención de los servicios del clúster
El siguiente comando detiene los servicios de cluster en el nodo o nodos especificados. Al igual que con pcs cluster start, la opción --all detiene los servicios de clúster en todos los nodos y, si no se especifica ningún nodo, los servicios de clúster se detienen únicamente en el nodo local.
pcs cluster stop [--all | node] [...]
Puede forzar una parada de los servicios del clúster en el nodo local con el siguiente comando, que realiza un comando kill -9.
pcs cluster kill62.2. Activación y desactivación de los servicios del clúster
Utilice el siguiente comando para habilitar los servicios del clúster, que configura los servicios del clúster para que se ejecuten al inicio en el nodo o nodos especificados. La habilitación permite que los nodos se reincorporen automáticamente al clúster después de que se hayan cercado, lo que minimiza el tiempo que el clúster está a menos de su capacidad. Si los servicios de clúster no están habilitados, un administrador puede investigar manualmente qué ha fallado antes de iniciar los servicios de clúster manualmente, de modo que, por ejemplo, no se permita que un nodo con problemas de hardware vuelva a entrar en el clúster cuando es probable que vuelva a fallar.
-
Si se especifica la opción
--all, el comando habilita los servicios de cluster en todos los nodos. - Si no se especifica ningún nodo, los servicios del clúster se activan sólo en el nodo local.
pcs cluster enable [--all | node] [...]Utilice el siguiente comando para configurar los servicios del clúster para que no se ejecuten al inicio en el nodo o nodos especificados.
-
Si se especifica la opción
--all, el comando desactiva los servicios de cluster en todos los nodos. - Si no se especifica ningún nodo, los servicios de cluster se desactivan sólo en el nodo local.
pcs cluster disable [--all | node] [...]62.3. Añadir nodos del clúster
Se recomienda encarecidamente añadir nodos a los clusters existentes sólo durante una ventana de mantenimiento de producción. Esto le permite realizar las pruebas de recursos y de despliegue adecuadas para el nuevo nodo y su configuración de cercado.
Utilice el siguiente procedimiento para añadir un nuevo nodo a un cluster existente. Este procedimiento añade nodos de clústeres estándar que ejecutan corosync. Para obtener información sobre la integración de nodos no corosync en un clúster, consulte Integración de nodos no corosync en un clúster: el servicio pacemaker_remote.
En este ejemplo, los nodos de cluster existentes son clusternode-01.example.com, clusternode-02.example.com, y clusternode-03.example.com. El nuevo nodo es newnode.example.com.
En el nuevo nodo a añadir al clúster, realice las siguientes tareas.
Instale los paquetes del clúster. Si el clúster utiliza SBD, el gestor de tickets de Booth o un dispositivo de quórum, debe instalar manualmente también los paquetes respectivos (
sbd,booth-site,corosync-qdevice) en el nuevo nodo.[root@newnode ~]# yum install -y pcs fence-agents-allAdemás de los paquetes del cluster, también necesitará instalar y configurar todos los servicios que esté ejecutando en el cluster, que haya instalado en los nodos existentes del cluster. Por ejemplo, si está ejecutando un servidor Apache HTTP en un cluster de alta disponibilidad de Red Hat, necesitará instalar el servidor en el nodo que está añadiendo, así como la herramienta
wgetque comprueba el estado del servidor.Si está ejecutando el demonio
firewalld, ejecute los siguientes comandos para habilitar los puertos requeridos por el complemento de alta disponibilidad de Red Hat.# firewall-cmd --permanent --add-service=high-availability # firewall-cmd --add-service=high-availabilityEstablezca una contraseña para el ID de usuario
hacluster. Se recomienda utilizar la misma contraseña para cada nodo del clúster.[root@newnode ~]# passwd hacluster Changing password for user hacluster. New password: Retype new password: passwd: all authentication tokens updated successfully.Ejecute los siguientes comandos para iniciar el servicio
pcsdy para habilitarpcsdal inicio del sistema.# systemctl start pcsd.service # systemctl enable pcsd.service
En un nodo del clúster existente, realice las siguientes tareas.
Autenticar al usuario
haclusteren el nuevo nodo del clúster.[root@clusternode-01 ~]# pcs host auth newnode.example.com Username: hacluster Password: newnode.example.com: AuthorizedAñade el nuevo nodo al clúster existente. Este comando también sincroniza el archivo de configuración del clúster
corosync.confcon todos los nodos del clúster, incluido el nuevo nodo que está añadiendo.[root@clusternode-01 ~]# pcs cluster node add newnode.example.com
En el nuevo nodo a añadir al clúster, realice las siguientes tareas.
Inicie y habilite los servicios del clúster en el nuevo nodo.
[root@newnode ~]# pcs cluster start Starting Cluster... [root@newnode ~]# pcs cluster enable- Asegúrese de configurar y probar un dispositivo de cercado para el nuevo nodo del clúster.
62.4. Eliminación de los nodos del clúster
El siguiente comando apaga el nodo especificado y lo elimina del archivo de configuración del clúster, corosync.conf, en todos los demás nodos del clúster.
pcs cluster node remove node62.5. Añadir un nodo a un cluster con múltiples enlaces
Al añadir un nodo a un cluster con múltiples enlaces, debe especificar las direcciones para todos los enlaces. El siguiente ejemplo añade el nodo rh80-node3 a un cluster, especificando la dirección IP 192.168.122.203 para el primer enlace y 192.168.123.203 como segundo enlace.
# pcs cluster node add rh80-node3 addr=192.168.122.203 addr=192.168.123.20362.6. Añadir y modificar enlaces en un clúster existente (RHEL 8.1 y posterior)
En la mayoría de los casos, puede añadir o modificar los enlaces de un clúster existente sin reiniciar el clúster.
62.6.1. Añadir y eliminar enlaces en un clúster existente
Para añadir un nuevo enlace a un clúster en funcionamiento, utilice el comando pcs cluster link add.
- Al añadir un enlace, debe especificar una dirección para cada nodo.
- Añadir y eliminar un enlace sólo es posible cuando se utiliza el protocolo de transporte knet.
- Al menos un enlace del clúster debe estar definido en todo momento.
- El número máximo de enlaces en un cluster es de 8, numerados del 0 al 7. No importa qué enlaces se definan, así que, por ejemplo, puedes definir sólo los enlaces 3, 6 y 7.
-
Cuando se añade un enlace sin especificar su número de enlace,
pcsutiliza el enlace más bajo disponible. -
Los números de los enlaces actualmente configurados se encuentran en el archivo
corosync.conf. Para mostrar el archivocorosync.conf, ejecute el comandopcs cluster corosync.
El siguiente comando añade el enlace número 5 a un cluster de tres nodos.
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=5
Para eliminar un enlace existente, utilice el comando pcs cluster link delete o pcs cluster link remove. Cualquiera de los siguientes comandos eliminará el enlace número 5 del clúster.
[root@node1 ~] # pcs cluster link delete 5
[root@node1 ~] # pcs cluster link remove 562.6.2. Modificación de un enlace en un cluster con múltiples enlaces
Si hay varios enlaces en el cluster y quiere cambiar uno de ellos, realice el siguiente procedimiento.
Elimina el enlace que quieres cambiar.
[root@node1 ~] # pcs cluster link remove 2Añade el enlace al clúster con las direcciones y opciones actualizadas.
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=2
62.6.3. Modificación de las direcciones de enlace en un clúster con un solo enlace
Si su clúster utiliza un solo enlace y quiere modificar ese enlace para utilizar diferentes direcciones, realice el siguiente procedimiento. En este ejemplo, el enlace original es el enlace 1.
Añade un nuevo enlace con las nuevas direcciones y opciones.
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=2Quite el enlace original.
[root@node1 ~] # pcs cluster link remove 1
Tenga en cuenta que no puede especificar direcciones que estén actualmente en uso al añadir enlaces a un clúster. Esto significa, por ejemplo, que si tienes un cluster de dos nodos con un enlace y quieres cambiar la dirección de un solo nodo, no puedes usar el procedimiento anterior para añadir un nuevo enlace que especifique una nueva dirección y una dirección existente. En su lugar, puede añadir un enlace temporal antes de eliminar el enlace existente y volver a añadirlo con la dirección actualizada, como en el siguiente ejemplo.
En este ejemplo:
- El enlace para el cluster existente es el enlace 1, que utiliza la dirección 10.0.5.11 para el nodo 1 y la dirección 10.0.5.12 para el nodo 2.
- Desea cambiar la dirección del nodo 2 a 10.0.5.31.
Para actualizar sólo una de las direcciones de un cluster de dos nodos con un único enlace, utilice el siguiente procedimiento.
Añade un nuevo enlace temporal al clúster existente, utilizando direcciones que no están actualmente en uso.
[root@node1 ~] # pcs cluster link add node1=10.0.5.13 node2=10.0.5.14 options linknumber=2Quite el enlace original.
[root@node1 ~] # pcs cluster link remove 1Añade el nuevo enlace modificado.
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.31 options linknumber=1Elimina el enlace temporal que has creado
[root@node1 ~] # pcs cluster link remove 2
62.6.4. Modificación de las opciones de enlace para un enlace en un cluster con un solo enlace
Si su clúster utiliza sólo un enlace y quiere modificar las opciones de ese enlace pero no quiere cambiar la dirección a utilizar, puede añadir un enlace temporal antes de eliminar y actualizar el enlace a modificar.
En este ejemplo:
- El enlace para el cluster existente es el enlace 1, que utiliza la dirección 10.0.5.11 para el nodo 1 y la dirección 10.0.5.12 para el nodo 2.
-
Desea cambiar la opción de enlace
link_prioritya 11.
Utilice el siguiente procedimiento para modificar la opción de enlace en un cluster con un solo enlace.
Añade un nuevo enlace temporal al clúster existente, utilizando direcciones que no están actualmente en uso.
[root@node1 ~] # pcs cluster link add node1=10.0.5.13 node2=10.0.5.14 options linknumber=2Quite el enlace original.
[root@node1 ~] # pcs cluster link remove 1Vuelve a añadir el enlace original con las opciones actualizadas.
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 options linknumber=1 link_priority=11Elimina el enlace temporal.
[root@node1 ~] # pcs cluster link remove 2
62.6.5. No es posible modificar un enlace cuando se añade uno nuevo
Si por alguna razón no es posible añadir un nuevo enlace en su configuración y su única opción es modificar un enlace existente, puede utilizar el siguiente procedimiento, que requiere que apague su cluster.
El siguiente procedimiento de ejemplo actualiza el enlace número 1 en el cluster y establece la opción link_priority para el enlace a 11.
Detenga los servicios de cluster para el cluster.
[root@node1 ~] # pcs cluster stop --allActualice las direcciones y opciones de los enlaces.
El comando
pcs cluster link updateno requiere que se especifiquen todas las direcciones y opciones de los nodos. En su lugar, puede especificar sólo las direcciones a modificar. Este ejemplo modifica las direcciones denode1ynode3y la opciónlink_prioritysolamente.[root@node1 ~] # pcs cluster link update 1 node1=10.0.5.11 node3=10.0.5.31 options link_priority=11Para eliminar una opción, puede establecer un valor nulo con el formato
option=formato.Reiniciar el clúster
[root@node1 ~] # pcs cluster start --all
62.7. Configuración de un gran clúster con muchos recursos
Si el clúster que va a desplegar está formado por un gran número de nodos y muchos recursos, es posible que tenga que modificar los valores por defecto de los siguientes parámetros para su clúster.
- La propiedad del clúster
cluster-ipc-limit La propiedad de clúster
cluster-ipc-limites la máxima acumulación de mensajes IPC antes de que un demonio de clúster desconecte a otro. Cuando un gran número de recursos se limpian o modifican simultáneamente en un cluster grande, un gran número de actualizaciones CIB llegan a la vez. Esto podría hacer que los clientes más lentos sean desalojados si el servicio Pacemaker no tiene tiempo de procesar todas las actualizaciones de configuración antes de que se alcance el umbral de la cola de eventos CIB.El valor recomendado de
cluster-ipc-limitpara su uso en clusters grandes es el número de recursos en el cluster multiplicado por el número de nodos. Este valor puede aumentarse si se ven mensajes de "desalojo de clientes" para PIDs de demonio de clúster en los registros.Puede aumentar el valor de
cluster-ipc-limitdesde su valor por defecto de 500 con el comandopcs property set. Por ejemplo, para un clúster de diez nodos con 200 recursos, puede establecer el valor decluster-ipc-limiten 2000 con el siguiente comando.# pcs property set cluster-ipc-limit=2000- El parámetro
PCMK_ipc_bufferMarcapasos En implementaciones muy grandes, los mensajes internos de Pacemaker pueden exceder el tamaño del búfer de mensajes. Cuando esto ocurra, verá un mensaje en los registros del sistema con el siguiente formato:
Compressed message exceeds X% of configured IPC limit (X bytes); consider setting PCMK_ipc_buffer to X or higherCuando vea este mensaje, puede aumentar el valor de
PCMK_ipc_bufferen el archivo de configuración/etc/sysconfig/pacemakeren cada nodo. Por ejemplo, para aumentar el valor dePCMK_ipc_bufferde su valor predeterminado a 13396332 bytes, cambie el campo no comentadoPCMK_ipc_bufferen el archivo/etc/sysconfig/pacemakeren cada nodo del clúster de la siguiente manera.PCMK_ipc_buffer=13396332Para aplicar este cambio, ejecute el siguiente comando.
# systemctl restart pacemaker
Capítulo 63. Propiedades de la agrupación de marcapasos
Las propiedades del clúster controlan cómo se comporta el clúster ante situaciones que pueden darse durante su funcionamiento.
63.1. Resumen de las propiedades y opciones del clúster
Tabla 63.1, “Propiedades del clúster” resume las propiedades del cluster Pacemaker, mostrando los valores por defecto de las propiedades y los posibles valores que puede establecer para esas propiedades.
Hay propiedades adicionales del clúster que determinan el comportamiento del cercado. Para obtener información sobre estas propiedades, consulte Opciones avanzadas de configuración de cercado.
Además de las propiedades descritas en esta tabla, existen otras propiedades del cluster que son expuestas por el software del cluster. Para estas propiedades, se recomienda no cambiar sus valores de los predeterminados.
| Opción | Por defecto | Descripción |
|---|---|---|
|
| 0 | El número de acciones de recursos que el clúster puede ejecutar en paralelo. El valor "correcto" dependerá de la velocidad y la carga de su red y de los nodos del clúster. El valor predeterminado de 0 significa que el clúster impondrá dinámicamente un límite cuando algún nodo tenga una carga elevada de CPU. |
|
| -1 (ilimitado) | El número de trabajos de migración que el clúster puede ejecutar en paralelo en un nodo. |
|
| detener | Qué hacer cuando el cluster no tiene quórum. Valores permitidos: * ignorar - continuar con la gestión de todos los recursos * congelar - continuar la gestión de los recursos, pero no recuperar los recursos de los nodos que no están en la partición afectada * detener - detener todos los recursos de la partición del clúster afectada * suicidio - valla todos los nodos de la partición del clúster afectado * degradar - si una partición del clúster pierde el quórum, degradar cualquier recurso promovido y detener todos los demás recursos |
|
| verdadero | Indica si los recursos pueden ejecutarse en cualquier nodo por defecto. |
|
| 60s | Retraso de ida y vuelta en la red (excluyendo la ejecución de la acción). El valor "correcto" dependerá de la velocidad y la carga de su red y de los nodos del clúster. |
|
| verdadero | Indica si los recursos eliminados deben ser detenidos. |
|
| verdadero | Indica si las acciones borradas deben ser canceladas. |
|
| verdadero |
Indica si un fallo en el arranque de un recurso en un nodo concreto impide nuevos intentos de arranque en ese nodo. Cuando se establece en
Si se establece |
|
| -1 (todos) | El número de entradas del programador que resultan en ERRORES para guardar. Se utiliza cuando se informa de los problemas. |
|
| -1 (todos) | El número de entradas del programador que resultan en ADVERTENCIAS para guardar. Se utiliza cuando se informa de los problemas. |
|
| -1 (todos) | El número de entradas "normales" del programador que hay que guardar. Se utiliza cuando se informa de los problemas. |
|
| La pila de mensajería en la que se está ejecutando actualmente Pacemaker. Se utiliza con fines informativos y de diagnóstico; no es configurable por el usuario. | |
|
| Versión de Pacemaker en el controlador designado (DC) del cluster. Se utiliza con fines de diagnóstico; no es configurable por el usuario. | |
|
| 15 minutos | Intervalo de sondeo para los cambios basados en el tiempo de las opciones, los parámetros de los recursos y las restricciones. Valores permitidos: Cero desactiva el sondeo, los valores positivos son un intervalo en segundos (a menos que se especifiquen otras unidades SI, como 5min). Tenga en cuenta que este valor es el tiempo máximo entre comprobaciones; si un evento del cluster ocurre antes del tiempo especificado por este valor, la comprobación se hará antes. |
|
| falso | El modo de mantenimiento indica al clúster que pase a un modo "sin manos" y que no inicie ni detenga ningún servicio hasta que se le indique lo contrario. Cuando el modo de mantenimiento se ha completado, el clúster realiza una comprobación del estado actual de los servicios y detiene o inicia los que lo necesiten. |
|
| 20min | El tiempo después del cual hay que renunciar a tratar de cerrar elegantemente y simplemente salir. Sólo para uso avanzado. |
|
| falso | En caso de que el clúster detenga todos los recursos. |
|
| falso |
Indica si el clúster puede utilizar listas de control de acceso, tal y como se establece con el comando |
|
|
| Indica si el clúster tendrá en cuenta los atributos de utilización a la hora de determinar la ubicación de los recursos en los nodos del clúster y cómo lo hará. |
|
| 0 (desactivado) | (RHEL 8.3 y posteriores) Permite configurar un cluster de dos nodos de forma que en una situación de división del cerebro el nodo con menos recursos en ejecución sea el que se valla.
La propiedad
Por ejemplo, si se establece El nodo que ejecuta el rol de maestro de un clon promocionable obtiene 1 punto extra si se ha configurado una prioridad para ese clon.
Cualquier retardo establecido con la propiedad
Sólo el cercado programado por el propio Marcapasos observará |
63.2. Establecer y eliminar las propiedades del clúster
Para establecer el valor de una propiedad del clúster, utilice el siguiente pcs comando.
pcs property set property=value
Por ejemplo, para establecer el valor de symmetric-cluster en false, utilice el siguiente comando.
# pcs property set symmetric-cluster=falsePuede eliminar una propiedad del clúster de la configuración con el siguiente comando.
propiedad pcs unset property
Alternativamente, puede eliminar una propiedad del clúster de una configuración dejando en blanco el campo de valor del comando pcs property set. Esto restablece esa propiedad a su valor por defecto. Por ejemplo, si ha establecido previamente la propiedad symmetric-cluster a false, el siguiente comando elimina el valor que ha establecido de la configuración y restaura el valor de symmetric-cluster a true, que es su valor por defecto.
# pcs property set symmetic-cluster=63.3. Consulta de la configuración de las propiedades del clúster
En la mayoría de los casos, cuando se utiliza el comando pcs para mostrar los valores de los distintos componentes del cluster, se puede utilizar pcs list o pcs show indistintamente. En los siguientes ejemplos, pcs list es el formato utilizado para mostrar una lista completa de todos los ajustes de más de una propiedad, mientras que pcs show es el formato utilizado para mostrar los valores de una propiedad específica.
Para mostrar los valores de la configuración de las propiedades que se han establecido para el clúster, utilice el siguiente pcs comando.
lista de propiedades de pcsPara mostrar todos los valores de las configuraciones de las propiedades del cluster, incluyendo los valores por defecto de las configuraciones de las propiedades que no se han establecido explícitamente, utilice el siguiente comando.
pcs property list --allPara mostrar el valor actual de una propiedad específica del clúster, utilice el siguiente comando.
pcs property show property
Por ejemplo, para mostrar el valor actual de la propiedad cluster-infrastructure, ejecute el siguiente comando:
# pcs property show cluster-infrastructure
Cluster Properties:
cluster-infrastructure: cmanCon fines informativos, puede mostrar una lista de todos los valores por defecto de las propiedades, tanto si se han establecido como si no, utilizando el siguiente comando.
propiedad pcs [list|show] --defaultsCapítulo 64. Configuración de un dominio virtual como recurso
Puede configurar un dominio virtual gestionado por el marco de virtualización libvirt como recurso de clúster con el comando pcs resource create, especificando VirtualDomain como tipo de recurso.
Al configurar un dominio virtual como recurso, tenga en cuenta las siguientes consideraciones:
- Un dominio virtual debe ser detenido antes de configurarlo como recurso de cluster.
- Una vez que un dominio virtual es un recurso del clúster, no debe iniciarse, detenerse o migrar, excepto a través de las herramientas del clúster.
- No configure un dominio virtual que haya configurado como recurso de cluster para que se inicie cuando su host arranque.
- Todos los nodos autorizados a ejecutar un dominio virtual deben tener acceso a los archivos de configuración y dispositivos de almacenamiento necesarios para ese dominio virtual.
Si desea que el clúster gestione servicios dentro del propio dominio virtual, puede configurar el dominio virtual como nodo invitado.
64.1. Opciones de recursos del dominio virtual
Tabla 64.1, “Opciones de recursos para los recursos del dominio virtual” describe las opciones de recursos que puede configurar para un recurso VirtualDomain.
| Campo | Por defecto | Descripción |
|---|---|---|
|
|
(obligatorio) Ruta absoluta al archivo de configuración | |
|
| Depende del sistema |
URI del hipervisor al que conectarse. Puede determinar la URI por defecto del sistema ejecutando el comando |
|
|
|
Siempre se apaga a la fuerza (\ "destruir") el dominio al detenerse. El comportamiento por defecto es recurrir a un apagado forzado sólo después de que un intento de apagado gracioso haya fallado. Debe configurar esta opción en |
|
| Depende del sistema |
Transporte utilizado para conectarse al hipervisor remoto durante la migración. Si se omite este parámetro, el recurso utilizará el transporte predeterminado de |
|
| Utilizar una red de migración dedicada. La URI de migración se compone añadiendo el valor de este parámetro al final del nombre del nodo. Si el nombre del nodo es un nombre de dominio completo (FQDN), inserte el sufijo inmediatamente antes del primer punto (.) en el FQDN. Asegúrese de que este nombre de host compuesto se puede resolver localmente y que la dirección IP asociada es accesible a través de la red favorecida. | |
|
|
Para supervisar adicionalmente los servicios dentro del dominio virtual, añada este parámetro con una lista de scripts a supervisar. Note: Cuando se utilizan scripts de supervisión, las operaciones | |
|
|
|
Si se establece en |
|
|
|
Si se establece como verdadero, el agente detectará el número de |
|
| puerto alto aleatorio |
Este puerto se utilizará en el URI de migración de |
|
|
Ruta al directorio de instantáneas donde se almacenará la imagen de la máquina virtual. Cuando se establece este parámetro, el estado RAM de la máquina virtual se guardará en un archivo en el directorio de instantáneas cuando se detenga. Si al iniciarse hay un archivo de estado para el dominio, éste se restaurará al mismo estado en el que estaba justo antes de detenerse por última vez. Esta opción es incompatible con la opción |
Además de las opciones del recurso VirtualDomain, puede configurar la opción de metadatos allow-migrate para permitir la migración en vivo del recurso a otro nodo. Cuando esta opción se establece en true, el recurso puede ser migrado sin pérdida de estado. Cuando esta opción se establece en false, que es el estado por defecto, el dominio virtual se apagará en el primer nodo y luego se reiniciará en el segundo nodo cuando se mueva de un nodo a otro.
64.2. Creación del recurso de dominio virtual
Utilice el siguiente procedimiento para crear un recurso VirtualDomain en un clúster para una máquina virtual que haya creado previamente:
Para crear el agente de recursos
VirtualDomainpara la gestión de la máquina virtual, Pacemaker requiere que el archivo de configuraciónxmlde la máquina virtual se vuelque a un archivo en el disco. Por ejemplo, si creó una máquina virtual llamadaguest1, vuelque el archivoxmla un archivo en algún lugar de uno de los nodos del clúster que podrá ejecutar el huésped. Puede utilizar un nombre de archivo de su elección; este ejemplo utiliza/etc/pacemaker/guest1.xml.# virsh dumpxml guest1 > /etc/pacemaker/guest1.xml-
Copie el archivo de configuración
xmlde la máquina virtual a todos los demás nodos del clúster que podrán ejecutar el invitado, en la misma ubicación de cada nodo. - Asegúrese de que todos los nodos autorizados a ejecutar el dominio virtual tienen acceso a los dispositivos de almacenamiento necesarios para ese dominio virtual.
- Compruebe por separado que el dominio virtual puede iniciarse y detenerse en cada nodo que ejecutará el dominio virtual.
- Si se está ejecutando, apague el nodo invitado. Pacemaker iniciará el nodo cuando esté configurado en el cluster. La máquina virtual no debe configurarse para que se inicie automáticamente al arrancar el host.
Configure el recurso
VirtualDomaincon el comandopcs resource create. Por ejemplo, el siguiente comando configura un recursoVirtualDomainllamadoVM. Dado que la opciónallow-migrateestá configurada comotrueunpcs move VM nodeXcomando se haría como una migración en vivo.En este ejemplo
migration_transportestá configurado comossh. Tenga en cuenta que para que la migración SSH funcione correctamente, el registro sin clave debe funcionar entre nodos.# pcs resource create VM VirtualDomain config=/etc/pacemaker/guest1.xml migration_transport=ssh meta allow-migrate=true
Capítulo 65. Quórum del clúster
Un cluster de Red Hat Enterprise Linux High Availability Add-On utiliza el servicio votequorum, en conjunto con fencing, para evitar situaciones de split brain. Se asigna un número de votos a cada sistema en el cluster y las operaciones del cluster se permiten sólo cuando hay una mayoría de votos. El servicio debe cargarse en todos los nodos o en ninguno; si se carga en un subconjunto de nodos del clúster, los resultados serán imprevisibles. Para obtener información sobre la configuración y el funcionamiento del servicio votequorum, consulte la página de manual votequorum(5).
65.1. Configuración de las opciones de quórum
Hay algunas características especiales de la configuración del quórum que puede establecer cuando crea un clúster con el comando pcs cluster setup. Tabla 65.1, “Opciones de quórum” resume estas opciones.
| Opción | Descripción |
|---|---|
|
|
Cuando se activa, el clúster puede sufrir hasta el 50% de los nodos que fallan al mismo tiempo, de forma determinista. La partición del clúster, o el conjunto de nodos que aún están en contacto con el
La opción
La opción |
|
| Cuando se habilita, el clúster será quórum por primera vez sólo después de que todos los nodos hayan sido visibles al menos una vez al mismo tiempo.
La opción
La opción |
|
|
Cuando se activa, el clúster puede recalcular dinámicamente |
|
|
El tiempo, en milisegundos, que se debe esperar antes de recalcular |
Para más información sobre la configuración y el uso de estas opciones, consulte la página de manual votequorum(5).
65.2. Modificación de las opciones de quórum
Puede modificar las opciones generales de quórum de su clúster con el comando pcs quorum update. La ejecución de este comando requiere que el clúster esté detenido. Para obtener información sobre las opciones de quórum, consulte la página de manual votequorum(5).
El formato del comando pcs quorum update es el siguiente.
pcs actualización del quórum [auto_tie_breaker=[0|1]] [last_man_standing=[0|1]] [last_man_standing_window=[time-in-ms] [wait_for_all=[0|1]]
La siguiente serie de comandos modifica la opción de quórum wait_for_all y muestra el estado actualizado de la opción. Tenga en cuenta que el sistema no permite ejecutar este comando mientras el clúster está en funcionamiento.
[root@node1:~]# pcs quorum update wait_for_all=1
Checking corosync is not running on nodes...
Error: node1: corosync is running
Error: node2: corosync is running
[root@node1:~]# pcs cluster stop --all
node2: Stopping Cluster (pacemaker)...
node1: Stopping Cluster (pacemaker)...
node1: Stopping Cluster (corosync)...
node2: Stopping Cluster (corosync)...
[root@node1:~]# pcs quorum update wait_for_all=1
Checking corosync is not running on nodes...
node2: corosync is not running
node1: corosync is not running
Sending updated corosync.conf to nodes...
node1: Succeeded
node2: Succeeded
[root@node1:~]# pcs quorum config
Options:
wait_for_all: 165.3. Visualización de la configuración y el estado del quórum
Una vez que el clúster está funcionando, puede introducir los siguientes comandos de quórum del clúster.
El siguiente comando muestra la configuración del quórum.
pcs quorum [config]El siguiente comando muestra el estado de ejecución del quórum.
estado del quórum del pcs65.4. Ejecución de clústeres inquemados
Si retira nodos de un clúster durante un largo período de tiempo y la pérdida de esos nodos provocaría la pérdida de quórum, puede cambiar el valor del parámetro expected_votes para el clúster en vivo con el comando pcs quorum expected-votes. Esto permite que el clúster siga funcionando cuando no tiene quórum.
El cambio de los votos esperados en un clúster en vivo debe hacerse con extrema precaución. Si menos del 50% del clúster se está ejecutando porque has cambiado manualmente los votos esperados, entonces los otros nodos del clúster podrían iniciarse por separado y ejecutar los servicios del clúster, causando corrupción de datos y otros resultados inesperados. Si cambia este valor, debe asegurarse de que el parámetro wait_for_all está activado.
El siguiente comando establece los votos esperados en el cluster en vivo al valor especificado. Esto afecta sólo al clúster en vivo y no cambia el archivo de configuración; el valor de expected_votes se restablece al valor del archivo de configuración en caso de recarga.
pcs quórum esperado-votos votes
En una situación en la que usted sabe que el clúster está inerme pero quiere que el clúster proceda a la gestión de recursos, puede utilizar el comando pcs quorum unblock para evitar que el clúster espere a todos los nodos al establecer el quórum.
Este comando debe utilizarse con extrema precaución. Antes de emitir este comando, es imprescindible asegurarse de que los nodos que no están actualmente en el clúster están apagados y no tienen acceso a los recursos compartidos.
# pcs quorum unblock65.5. Dispositivos de quórum
Puede permitir que un clúster soporte más fallos de nodo de los que permiten las reglas de quórum estándar configurando un dispositivo de quórum independiente que actúe como dispositivo de arbitraje de terceros para el clúster. Se recomienda un dispositivo de quórum para clusters con un número par de nodos. Con clusters de dos nodos, el uso de un dispositivo de quórum puede determinar mejor qué nodo sobrevive en una situación de cerebro dividido.
Al configurar un dispositivo de quórum hay que tener en cuenta lo siguiente.
- Se recomienda que un dispositivo de quórum se ejecute en una red física diferente en el mismo sitio que el clúster que utiliza el dispositivo de quórum. Lo ideal es que el host del dispositivo de quórum esté en un rack distinto al del clúster principal, o al menos en una fuente de alimentación distinta y no en el mismo segmento de red que el anillo o anillos de corosync.
- No se puede utilizar más de un dispositivo de quórum en un clúster al mismo tiempo.
-
Aunque no se puede utilizar más de un dispositivo de quórum en un clúster al mismo tiempo, un único dispositivo de quórum puede ser utilizado por varios clústeres al mismo tiempo. Cada clúster que utilice ese dispositivo de quórum puede utilizar diferentes algoritmos y opciones de quórum, ya que éstos se almacenan en los propios nodos del clúster. Por ejemplo, un único dispositivo de quórum puede ser utilizado por un cluster con un algoritmo
ffsplit(fifty/fifty split) y por un segundo cluster con un algoritmolms(last man standing). - Un dispositivo de quórum no debe ejecutarse en un nodo de clúster existente.
65.5.1. Instalación de paquetes de dispositivos de quórum
La configuración de un dispositivo de quórum para un clúster requiere la instalación de los siguientes paquetes:
Instale
corosync-qdeviceen los nodos de un clúster existente.[root@node1:~]# yum install corosync-qdevice [root@node2:~]# yum install corosync-qdeviceInstale
pcsycorosync-qnetden el host del dispositivo de quórum.[root@qdevice:~]# yum install pcs corosync-qnetdInicie el servicio
pcsdy habilitepcsdal iniciar el sistema en el host del dispositivo de quórum.[root@qdevice:~]# systemctl start pcsd.service [root@qdevice:~]# systemctl enable pcsd.service
65.5.2. Configuración de un dispositivo de quórum
El siguiente procedimiento configura un dispositivo de quórum y lo añade al clúster. En este ejemplo:
-
El nodo utilizado para un dispositivo de quórum es
qdevice. El modelo de dispositivo de quórum es
net, que es actualmente el único modelo soportado. El modelonetadmite los siguientes algoritmos:-
ffsplit: división al cincuenta por ciento. Esto proporciona exactamente un voto a la partición con el mayor número de nodos activos. lms: último hombre en pie. Si el nodo es el único que queda en el clúster que puede ver el servidorqnetd, entonces devuelve un voto.AvisoEl algoritmo LMS permite que el clúster siga siendo quórum incluso con un solo nodo restante, pero también significa que el poder de voto del dispositivo de quórum es grande, ya que es igual al número_de_nodos - 1. Perder la conexión con el dispositivo de quórum significa perder el número_de_nodos - 1 de votos, lo que significa que sólo un clúster con todos los nodos activos puede seguir siendo quórum (sobrevotando al dispositivo de quórum); cualquier otro clúster se convierte en no quórum.
Para obtener información más detallada sobre la implementación de estos algoritmos, consulte la página de manual
corosync-qdevice(8).
-
-
Los nodos del clúster son
node1ynode2.
El siguiente procedimiento configura un dispositivo de quórum y añade ese dispositivo de quórum a un clúster.
En el nodo que utilizará para alojar su dispositivo de quórum, configure el dispositivo de quórum con el siguiente comando. Este comando configura e inicia el modelo de dispositivo de quórum
nety configura el dispositivo para que se inicie al arrancar.[root@qdevice:~]# pcs qdevice setup model net --enable --start Quorum device 'net' initialized quorum device enabled Starting quorum device... quorum device startedDespués de configurar el dispositivo de quórum, puedes comprobar su estado. Esto debería mostrar que el demonio
corosync-qnetdse está ejecutando y, en este momento, no hay clientes conectados a él. La opción del comando--fullproporciona una salida detallada.[root@qdevice:~]# pcs qdevice status net --full QNetd address: *:5403 TLS: Supported (client certificate required) Connected clients: 0 Connected clusters: 0 Maximum send/receive size: 32768/32768 bytesHabilite los puertos del cortafuegos necesarios para el demonio
pcsdy el dispositivo de quórumnethabilitando el serviciohigh-availabilityenfirewalldcon los siguientes comandos.[root@qdevice:~]# firewall-cmd --permanent --add-service=high-availability [root@qdevice:~]# firewall-cmd --add-service=high-availabilityDesde uno de los nodos del clúster existente, autentique al usuario
haclusteren el nodo que aloja el dispositivo de quórum. Esto permite quepcsen el clúster se conecte apcsen el hostqdevice, pero no permite quepcsen el hostqdevicese conecte apcsen el clúster.[root@node1:~] # pcs host auth qdevice Username: hacluster Password: qdevice: AuthorizedAñade el dispositivo de quórum al clúster.
Antes de añadir el dispositivo de quórum, puede comprobar la configuración actual y el estado del dispositivo de quórum para su posterior comparación. La salida de estos comandos indica que el clúster aún no está utilizando un dispositivo de quórum, y el estado de pertenencia a
Qdevicepara cada nodo esNR(No registrado).[root@node1:~]# pcs quorum config Options:[root@node1:~]# pcs quorum status Quorum information ------------------ Date: Wed Jun 29 13:15:36 2016 Quorum provider: corosync_votequorum Nodes: 2 Node ID: 1 Ring ID: 1/8272 Quorate: Yes Votequorum information ---------------------- Expected votes: 2 Highest expected: 2 Total votes: 2 Quorum: 1 Flags: 2Node Quorate Membership information ---------------------- Nodeid Votes Qdevice Name 1 1 NR node1 (local) 2 1 NR node2El siguiente comando añade al clúster el dispositivo de quórum que ha creado previamente. No se puede utilizar más de un dispositivo de quórum en un clúster al mismo tiempo. Sin embargo, un dispositivo de quórum puede ser utilizado por varios clústeres al mismo tiempo. Este comando de ejemplo configura el dispositivo de quórum para utilizar el algoritmo
ffsplit. Para obtener información sobre las opciones de configuración del dispositivo de quórum, consulte la página de manualcorosync-qdevice(8).[root@node1:~]# pcs quorum device add model net host=qdevice \ algorithm=ffsplit Setting up qdevice certificates on nodes... node2: Succeeded node1: Succeeded Enabling corosync-qdevice... node1: corosync-qdevice enabled node2: corosync-qdevice enabled Sending updated corosync.conf to nodes... node1: Succeeded node2: Succeeded Corosync configuration reloaded Starting corosync-qdevice... node1: corosync-qdevice started node2: corosync-qdevice startedCompruebe el estado de configuración del dispositivo de quórum.
Desde el lado del clúster, puede ejecutar los siguientes comandos para ver cómo ha cambiado la configuración.
En
pcs quorum configse muestra el dispositivo de quórum que se ha configurado.[root@node1:~]# pcs quorum config Options: Device: Model: net algorithm: ffsplit host: qdeviceEl comando
pcs quorum statusmuestra el estado de ejecución del quórum, indicando que el dispositivo de quórum está en uso. Los significados de los valores de estado de la información de membresía deQdevicepara cada nodo del clúster son los siguientes:-
A/NA -
V/NV MW/NMW[root@node1:~]# pcs quorum status Quorum information ------------------ Date: Wed Jun 29 13:17:02 2016 Quorum provider: corosync_votequorum Nodes: 2 Node ID: 1 Ring ID: 1/8272 Quorate: Yes Votequorum information ---------------------- Expected votes: 3 Highest expected: 3 Total votes: 3 Quorum: 2 Flags: Quorate Qdevice Membership information ---------------------- Nodeid Votes Qdevice Name 1 1 A,V,NMW node1 (local) 2 1 A,V,NMW node2 0 1 QdeviceLa página
pcs quorum device statusmuestra el estado de ejecución del dispositivo de quórum.[root@node1:~]# pcs quorum device status Qdevice information ------------------- Model: Net Node ID: 1 Configured node list: 0 Node ID = 1 1 Node ID = 2 Membership node list: 1, 2 Qdevice-net information ---------------------- Cluster name: mycluster QNetd host: qdevice:5403 Algorithm: ffsplit Tie-breaker: Node with lowest node ID State: ConnectedDesde el lado del dispositivo de quórum, puede ejecutar el siguiente comando de estado, que muestra el estado del demonio
corosync-qnetd.[root@qdevice:~]# pcs qdevice status net --full QNetd address: *:5403 TLS: Supported (client certificate required) Connected clients: 2 Connected clusters: 1 Maximum send/receive size: 32768/32768 bytes Cluster "mycluster": Algorithm: ffsplit Tie-breaker: Node with lowest node ID Node ID 2: Client address: ::ffff:192.168.122.122:50028 HB interval: 8000ms Configured node list: 1, 2 Ring ID: 1.2050 Membership node list: 1, 2 TLS active: Yes (client certificate verified) Vote: ACK (ACK) Node ID 1: Client address: ::ffff:192.168.122.121:48786 HB interval: 8000ms Configured node list: 1, 2 Ring ID: 1.2050 Membership node list: 1, 2 TLS active: Yes (client certificate verified) Vote: ACK (ACK)
-
65.5.3. Gestión del servicio de dispositivos de quórum
PCS proporciona la capacidad de gestionar el servicio de dispositivo de quórum en el host local (corosync-qnetd), como se muestra en los siguientes comandos de ejemplo. Tenga en cuenta que estos comandos sólo afectan al servicio corosync-qnetd.
[root@qdevice:~]# pcs qdevice start net
[root@qdevice:~]# pcs qdevice stop net
[root@qdevice:~]# pcs qdevice enable net
[root@qdevice:~]# pcs qdevice disable net
[root@qdevice:~]# pcs qdevice kill net65.5.4. Gestión de la configuración del dispositivo de quórum en un clúster
Las siguientes secciones describen los comandos PCS que puede utilizar para gestionar la configuración de los dispositivos de quórum en un clúster.
65.5.4.1. Cambiar la configuración del dispositivo de quórum
Puede cambiar la configuración de un dispositivo de quórum con el comando pcs quorum device update.
Para cambiar la opción host del modelo de dispositivo de quórum net, utilice los comandos pcs quorum device remove y pcs quorum device add para establecer la configuración correctamente, a menos que el host antiguo y el nuevo sean la misma máquina.
El siguiente comando cambia el algoritmo del dispositivo de quórum a lms.
[root@node1:~]# pcs quorum device update model algorithm=lms
Sending updated corosync.conf to nodes...
node1: Succeeded
node2: Succeeded
Corosync configuration reloaded
Reloading qdevice configuration on nodes...
node1: corosync-qdevice stopped
node2: corosync-qdevice stopped
node1: corosync-qdevice started
node2: corosync-qdevice started65.5.4.2. Eliminación de un dispositivo de quórum
Utilice el siguiente comando para eliminar un dispositivo de quórum configurado en un nodo del clúster.
[root@node1:~]# pcs quorum device remove
Sending updated corosync.conf to nodes...
node1: Succeeded
node2: Succeeded
Corosync configuration reloaded
Disabling corosync-qdevice...
node1: corosync-qdevice disabled
node2: corosync-qdevice disabled
Stopping corosync-qdevice...
node1: corosync-qdevice stopped
node2: corosync-qdevice stopped
Removing qdevice certificates from nodes...
node1: Succeeded
node2: SucceededDespués de haber eliminado un dispositivo de quórum, debería ver el siguiente mensaje de error al mostrar el estado del dispositivo de quórum.
[root@node1:~]# pcs quorum device status
Error: Unable to get quorum status: corosync-qdevice-tool: Can't connect to QDevice socket (is QDevice running?): No such file or directory65.5.4.3. Destrucción de un dispositivo de quórum
Para desactivar y detener un dispositivo de quórum en el host del dispositivo de quórum y eliminar todos sus archivos de configuración, utilice el siguiente comando.
[root@qdevice:~]# pcs qdevice destroy net
Stopping quorum device...
quorum device stopped
quorum device disabled
Quorum device 'net' configuration files removedCapítulo 66. Integración de nodos no sincronizados en un clúster: el servicio pacemaker_remote
El servicio pacemaker_remote permite que los nodos que no ejecutan corosync se integren en el clúster y que éste gestione sus recursos como si fueran nodos reales del clúster.
Entre las capacidades que ofrece el servicio pacemaker_remote se encuentran las siguientes:
-
El servicio
pacemaker_remotele permite escalar más allá del límite de soporte de Red Hat de 32 nodos para RHEL 8.1. -
El servicio
pacemaker_remotepermite gestionar un entorno virtual como recurso de cluster y también gestionar servicios individuales dentro del entorno virtual como recursos de cluster.
Los siguientes términos se utilizan para describir el servicio pacemaker_remote.
- cluster node
- remote node
- guest node
- pacemaker_remote
Un cluster Pacemaker que ejecuta el servicio pacemaker_remote tiene las siguientes características.
-
Los nodos remotos y los nodos invitados ejecutan el servicio
pacemaker_remote(con muy poca configuración necesaria en el lado de la máquina virtual). -
La pila del clúster (
pacemakerycorosync), que se ejecuta en los nodos del clúster, se conecta al serviciopacemaker_remoteen los nodos remotos, lo que les permite integrarse en el clúster. -
La pila del clúster (
pacemakerycorosync), que se ejecuta en los nodos del clúster, lanza los nodos invitados y se conecta inmediatamente al serviciopacemaker_remoteen los nodos invitados, permitiéndoles integrarse en el clúster.
La diferencia clave entre los nodos del clúster y los nodos remotos e invitados que gestionan los nodos del clúster es que los nodos remotos e invitados no están ejecutando la pila del clúster. Esto significa que los nodos remotos e invitados tienen las siguientes limitaciones:
- no tienen lugar en el quórum
- no ejecutan las acciones del dispositivo de esgrima
- no son elegibles para ser el controlador designado (DC) del clúster
-
no ejecutan por sí mismos toda la gama de comandos de
pcs
Por otro lado, los nodos remotos y los nodos invitados no están sujetos a los límites de escalabilidad asociados a la pila del clúster.
Aparte de estas limitaciones, los nodos remotos e invitados se comportan igual que los nodos del clúster en lo que respecta a la gestión de recursos, y los propios nodos remotos e invitados pueden ser cercados. El clúster es totalmente capaz de gestionar y supervisar los recursos de cada nodo remoto e invitado: Puede crear restricciones contra ellos, ponerlos en espera o realizar cualquier otra acción que realice en los nodos del clúster con los comandos pcs. Los nodos remotos e invitados aparecen en la salida del estado del clúster igual que los nodos del clúster.
66.1. Autenticación de host y guest de los nodos pacemaker_remote
La conexión entre los nodos del clúster y pacemaker_remote está asegurada mediante Transport Layer Security (TLS) con cifrado de clave precompartida (PSK) y autenticación a través de TCP (utilizando el puerto 3121 por defecto). Esto significa que tanto el nodo del clúster como el nodo que ejecuta pacemaker_remote deben compartir la misma clave privada. Por defecto, esta clave debe colocarse en /etc/pacemaker/authkey tanto en los nodos del clúster como en los nodos remotos.
El comando pcs cluster node add-guest configura el authkey para los nodos invitados y el comando pcs cluster node add-remote configura el authkey para los nodos remotos.
66.2. Configuración de los nodos invitados KVM
Un nodo invitado de Pacemaker es un nodo invitado virtual que ejecuta el servicio pacemaker_remote. El nodo invitado virtual es gestionado por el clúster.
66.2.1. Opciones de recursos del nodo invitado
Al configurar una máquina virtual para que actúe como nodo invitado, se crea un recurso VirtualDomain, que gestiona la máquina virtual. Para ver las descripciones de las opciones que puede establecer para un recurso VirtualDomain, consulte Tabla 64.1, “Opciones de recursos para los recursos del dominio virtual”.
Además de las opciones del recurso VirtualDomain, las opciones de metadatos definen el recurso como nodo invitado y definen los parámetros de conexión. Estas opciones de recursos se establecen con el comando pcs cluster node add-guest. Tabla 66.1, “Opciones de metadatos para configurar recursos KVM como nodos remotos” describe estas opciones de metadatos.
| Campo | Por defecto | Descripción |
|---|---|---|
|
| <one> | El nombre del nodo invitado que define este recurso. Esto habilita el recurso como nodo invitado y define el nombre único utilizado para identificar el nodo invitado. WARNING: Este valor no puede solaparse con ningún recurso o ID de nodo. |
|
| 3121 |
Configura un puerto personalizado para utilizar la conexión de invitados a |
|
|
La dirección proporcionada en el comando | La dirección IP o el nombre de host al que conectarse |
|
| 60s | Cantidad de tiempo antes de que se agote el tiempo de una conexión pendiente de invitados |
66.2.2. Integración de una máquina virtual como nodo invitado
El siguiente procedimiento es un resumen de alto nivel de los pasos a realizar para que Pacemaker lance una máquina virtual e integre esa máquina como nodo invitado, utilizando libvirt y los invitados virtuales KVM.
-
Configure los recursos de
VirtualDomain. Introduzca los siguientes comandos en cada máquina virtual para instalar los paquetes de
pacemaker_remote, iniciar el serviciopcsdy permitir que se ejecute al inicio, y permitir el puerto TCP 3121 a través del cortafuegos.# yum install pacemaker-remote resource-agents pcs # systemctl start pcsd.service # systemctl enable pcsd.service # firewall-cmd --add-port 3121/tcp --permanent # firewall-cmd --add-port 2224/tcp --permanent # firewall-cmd --reload- Dé a cada máquina virtual una dirección de red estática y un nombre de host único, que debe ser conocido por todos los nodos. Para obtener información sobre la configuración de una dirección IP estática para la máquina virtual invitada, consulte la sección Virtualization Deployment and Administration Guide.
Si aún no lo has hecho, autentifica
pcsen el nodo que vas a integrar como nodo de búsqueda.# pcs host auth nodenameUtilice el siguiente comando para convertir un recurso existente de
VirtualDomainen un nodo invitado. Este comando debe ejecutarse en un nodo del clúster y no en el nodo invitado que se está añadiendo. Además de convertir el recurso, este comando copia el/etc/pacemaker/authkeyal nodo invitado e inicia y habilita el demoniopacemaker_remoteen el nodo invitado. El nombre del nodo invitado, que se puede definir de forma arbitraria, puede diferir del nombre del host del nodo.# pcs cluster node add-guest nodename resource_id [options]Después de crear el recurso
VirtualDomain, puede tratar el nodo invitado como trataría cualquier otro nodo del clúster. Por ejemplo, puede crear un recurso y colocar una restricción de recursos para que se ejecute en el nodo invitado, como en los siguientes comandos, que se ejecutan desde un nodo del clúster. Puede incluir nodos invitados en grupos, lo que le permite agrupar un dispositivo de almacenamiento, un sistema de archivos y una máquina virtual.# pcs resource create webserver apache configfile=/etc/httpd/conf/httpd.conf op monitor interval=30s # pcs constraint location webserver prefers nodename
66.3. Configuración de los nodos remotos de Pacemaker
Un nodo remoto se define como un recurso de cluster con ocf:pacemaker:remote como agente de recursos. Este recurso se crea con el comando pcs cluster node add-remote.
66.3.1. Opciones de recursos del nodo remoto
Tabla 66.2, “Opciones de recursos para nodos remotos” describe las opciones de recursos que puede configurar para un recurso remote.
| Campo | Por defecto | Descripción |
|---|---|---|
|
| 0 | Tiempo en segundos para esperar antes de intentar reconectarse a un nodo remoto después de que se haya cortado una conexión activa con el nodo remoto. Esta espera es recurrente. Si la reconexión falla después del período de espera, se realizará un nuevo intento de reconexión después de observar el tiempo de espera. Cuando se utiliza esta opción, Pacemaker seguirá intentando alcanzar y conectar con el nodo remoto indefinidamente después de cada intervalo de espera. |
|
|
Dirección especificada con el comando | Servidor al que conectarse. Puede ser una dirección IP o un nombre de host. |
|
| Puerto TCP al que conectarse. |
66.3.2. Resumen de la configuración del nodo remoto
Esta sección proporciona un resumen de alto nivel de los pasos a realizar para configurar un nodo Pacemaker Remote e integrar ese nodo en un entorno de cluster Pacemaker existente.
En el nodo que va a configurar como nodo remoto, permita los servicios relacionados con el cluster a través del firewall local.
# firewall-cmd --permanent --add-service=high-availability success # firewall-cmd --reload successNotaSi está usando
iptablesdirectamente, o alguna otra solución de firewall además defirewalld, simplemente abra los siguientes puertos: Puertos TCP 2224 y 3121.Instale el demonio
pacemaker_remoteen el nodo remoto.# yum install -y pacemaker-remote resource-agents pcsInicie y habilite
pcsden el nodo remoto.# systemctl start pcsd.service # systemctl enable pcsd.serviceSi aún no lo ha hecho, autentique
pcsen el nodo que va a añadir como nodo remoto.# pcs host auth remote1Añade el recurso del nodo remoto al clúster con el siguiente comando. Este comando también sincroniza todos los archivos de configuración relevantes con el nuevo nodo, arranca el nodo y lo configura para iniciar
pacemaker_remoteen el arranque. Este comando debe ejecutarse en un nodo del clúster y no en el nodo remoto que se está añadiendo.# pcs cluster node add-remote remote1Después de añadir el recurso
remoteal clúster, puede tratar el nodo remoto igual que trataría cualquier otro nodo del clúster. Por ejemplo, puede crear un recurso y colocar una restricción de recursos para que se ejecute en el nodo remoto, como en los siguientes comandos, que se ejecutan desde un nodo del clúster.# pcs resource create webserver apache configfile=/etc/httpd/conf/httpd.conf op monitor interval=30s # pcs constraint location webserver prefers remote1AvisoNunca incluya un recurso de conexión de nodo remoto en un grupo de recursos, restricción de colocación o restricción de orden.
- Configure los recursos de cercado para el nodo remoto. Los nodos remotos se cercan de la misma manera que los nodos de cluster. Configure los recursos de esgrima para su uso con los nodos remotos de la misma manera que lo haría con los nodos del clúster. Sin embargo, tenga en cuenta que los nodos remotos nunca pueden iniciar una acción de esgrima. Sólo los nodos del clúster son capaces de ejecutar una operación de cercado contra otro nodo.
66.4. Cambiar la ubicación del puerto por defecto
Si necesita cambiar la ubicación del puerto por defecto para Pacemaker o pacemaker_remote, puede establecer la variable de entorno PCMK_remote_port que afecta a ambos demonios. Esta variable de entorno se puede habilitar colocándola en el archivo /etc/sysconfig/pacemaker de la siguiente manera.
====# Pacemaker Remote
...
#
# Specify a custom port for Pacemaker Remote connections
PCMK_remote_port=3121
Cuando se cambia el puerto por defecto utilizado por un nodo invitado o un nodo remoto en particular, la variable PCMK_remote_port debe establecerse en el archivo /etc/sysconfig/pacemaker de ese nodo, y el recurso del clúster que crea la conexión del nodo invitado o del nodo remoto también debe configurarse con el mismo número de puerto (utilizando la opción de metadatos remote-port para los nodos invitados, o la opción port para los nodos remotos).
66.5. Actualización de sistemas con nodos pacemaker_remote
Si el servicio pacemaker_remote se detiene en un nodo activo de Pacemaker Remote, el clúster migrará con gracia los recursos del nodo antes de detenerlo. Esto le permite realizar actualizaciones de software y otros procedimientos de mantenimiento rutinarios sin retirar el nodo del clúster. Sin embargo, una vez que se apague pacemaker_remote, el clúster intentará reconectarse inmediatamente. Si pacemaker_remote no se reinicia dentro del tiempo de espera de monitorización del recurso, el clúster considerará la operación de monitorización como fallida.
Si desea evitar fallos de monitorización cuando el servicio pacemaker_remote se detiene en un nodo activo de Pacemaker Remote, puede utilizar el siguiente procedimiento para sacar el nodo del clúster antes de realizar cualquier administración del sistema que pueda detener pacemaker_remote
-
Detenga el recurso de conexión del nodo con el botón
pcs resource disable resourcenameque moverá todos los servicios fuera del nodo. Para los nodos invitados, esto también detendrá la VM, por lo que la VM debe iniciarse fuera del clúster (por ejemplo, utilizandovirsh) para realizar cualquier mantenimiento. - Realice el mantenimiento necesario.
-
Cuando esté listo para devolver el nodo al clúster, vuelva a habilitar el recurso con el botón
pcs resource enable.
Capítulo 67. Realizar el mantenimiento del clúster
Para realizar el mantenimiento de los nodos de su clúster, es posible que tenga que detener o mover los recursos y servicios que se ejecutan en ese clúster. O puede que tenga que detener el software del clúster dejando los servicios intactos. Pacemaker proporciona una variedad de métodos para realizar el mantenimiento del sistema.
- Si necesita detener un nodo de un clúster mientras continúa proporcionando los servicios que se ejecutan en ese clúster en otro nodo, puede poner el nodo del clúster en modo de espera. Un nodo que está en modo de espera ya no puede alojar recursos. Cualquier recurso actualmente activo en el nodo se moverá a otro nodo, o se detendrá si ningún otro nodo es elegible para ejecutar el recurso. Para obtener información sobre el modo de espera, consulte Poner un nodo en modo de espera.
Si necesita mover un recurso individual fuera del nodo en el que se está ejecutando actualmente sin detener ese recurso, puede utilizar el comando
pcs resource movepara mover el recurso a un nodo diferente. Para obtener información sobre el comandopcs resource move, consulte Mover manualmente los recursos del clúster.Cuando se ejecuta el comando
pcs resource move, se añade una restricción al recurso para evitar que se ejecute en el nodo en el que se está ejecutando actualmente. Cuando esté listo para volver a mover el recurso, puede ejecutar el comandopcs resource clearopcs constraint deletepara eliminar la restricción. Sin embargo, esto no necesariamente mueve los recursos de vuelta al nodo original, ya que el lugar donde los recursos pueden ejecutarse en ese momento depende de cómo hayas configurado tus recursos inicialmente. Puede reubicar un recurso en su nodo preferido con el comandopcs resource relocate run, como se describe en Mover un recurso a su nodo preferido.-
Si necesita detener un recurso en ejecución por completo y evitar que el clúster lo vuelva a iniciar, puede utilizar el comando
pcs resource disable. Para obtener información sobre el comandopcs resource disable, consulte Activación, desactivación y prohibición de recursos del clúster. -
Si desea evitar que Pacemaker realice alguna acción para un recurso (por ejemplo, si desea desactivar las acciones de recuperación mientras se realiza el mantenimiento del recurso, o si necesita recargar la configuración de
/etc/sysconfig/pacemaker), utilice el comandopcs resource unmanage, como se describe en Cómo poner un recurso en modo no gestionado. Los recursos de conexión de Pacemaker Remote nunca deben estar sin gestionar. -
Si necesita poner el clúster en un estado en el que no se inicie ni se detenga ningún servicio, puede establecer la propiedad de clúster
maintenance-mode. Al poner el clúster en modo de mantenimiento, se deshabilitan automáticamente todos los recursos. Para obtener información sobre cómo poner el clúster en modo de mantenimiento, consulte Poner un clúster en modo de mantenimiento. - Si necesita actualizar los paquetes que componen los complementos RHEL High Availability y Resilient Storage, puede actualizar los paquetes en un nodo a la vez o en todo el cluster en su conjunto, como se resume en Actualización de un cluster de alta disponibilidad de Red Hat Enterprise Linux.
- Si necesita realizar tareas de mantenimiento en un nodo remoto de Pacemaker, puede eliminar ese nodo del clúster desactivando el recurso del nodo remoto, como se describe en Actualización de nodos remotos y nodos invitados.
67.1. Poner un nodo en modo de espera
Cuando un nodo del clúster está en modo de espera, el nodo ya no puede albergar recursos. Cualquier recurso actualmente activo en el nodo será trasladado a otro nodo.
El siguiente comando pone el nodo especificado en modo de espera. Si se especifica el --all, este comando pone todos los nodos en modo de espera.
Puedes utilizar este comando cuando actualices los paquetes de un recurso. También se puede utilizar este comando al probar una configuración, para simular la recuperación sin apagar realmente un nodo.
pcs nodo standby node | --all
El siguiente comando elimina el nodo especificado del modo de espera. Después de ejecutar este comando, el nodo especificado podrá alojar recursos. Si se especifica el --all, este comando elimina todos los nodos del modo de espera.
pcs node unstandby node | --all
Tenga en cuenta que cuando ejecuta el comando pcs node standby, esto impide que los recursos se ejecuten en el nodo indicado. Cuando se ejecuta el comando pcs node unstandby, se permite que los recursos se ejecuten en el nodo indicado. Esto no mueve necesariamente los recursos de vuelta al nodo indicado; dónde pueden ejecutarse los recursos en ese momento depende de cómo hayas configurado tus recursos inicialmente.
67.2. Mover manualmente los recursos del clúster
Puede anular el clúster y forzar que los recursos se muevan de su ubicación actual. Hay dos ocasiones en las que querrás hacer esto:
- Cuando un nodo está en mantenimiento, y necesita mover todos los recursos que se ejecutan en ese nodo a un nodo diferente
- Cuando hay que mover recursos especificados individualmente
Para trasladar todos los recursos que se ejecutan en un nodo a otro nodo, se pone el nodo en modo de espera.
Puede mover los recursos especificados individualmente de cualquiera de las siguientes maneras.
-
Puede utilizar el comando
pcs resource movepara mover un recurso fuera de un nodo en el que se está ejecutando actualmente. -
Puede utilizar el comando
pcs resource relocate runpara mover un recurso a su nodo preferido, según el estado actual del clúster, las restricciones, la ubicación de los recursos y otras configuraciones.
67.2.1. Mover un recurso de su nodo actual
Para mover un recurso fuera del nodo en el que se está ejecutando actualmente, utilice el siguiente comando, especificando el resource_id del recurso tal y como está definido. Especifique la dirección destination_node si desea indicar en qué nodo debe ejecutarse el recurso que está moviendo.
pcs resource move resource_id [destination_node] [--master] [lifetime=lifetime]
Cuando se ejecuta el comando pcs resource move, se añade una restricción al recurso para evitar que se ejecute en el nodo en el que se está ejecutando actualmente. Puede ejecutar el comando pcs resource clear o pcs constraint delete para eliminar la restricción. Esto no necesariamente mueve los recursos de vuelta al nodo original; dónde pueden ejecutarse los recursos en ese momento depende de cómo hayas configurado tus recursos inicialmente.
Si especifica el parámetro --master del comando pcs resource move, el alcance de la restricción se limita al rol maestro y debe especificar master_id en lugar de resource_id.
Opcionalmente, puede configurar un parámetro lifetime para el comando pcs resource move para indicar un período de tiempo que la restricción debe permanecer. Las unidades de un parámetro lifetime se especifican según el formato definido en la norma ISO 8601, que requiere que se especifique la unidad como una letra mayúscula como Y (para años), M (para meses), W (para semanas), D (para días), H (para horas), M (para minutos) y S (para segundos).
Para distinguir una unidad de minutos(M) de una unidad de meses(M), debe especificar PT antes de indicar el valor en minutos. Por ejemplo, un parámetro lifetime de 5M indica un intervalo de cinco meses, mientras que un parámetro lifetime de PT5M indica un intervalo de cinco minutos.
El parámetro lifetime se comprueba a intervalos definidos por la propiedad de cluster cluster-recheck-interval. Por defecto este valor es de 15 minutos. Si su configuración requiere que compruebe este parámetro con más frecuencia, puede restablecer este valor con el siguiente comando.
pcs property set cluster-recheck-interval=value
Opcionalmente se puede configurar un parámetro --wait[=n] para el comando pcs resource move para indicar el número de segundos que se debe esperar para que el recurso se inicie en el nodo de destino antes de devolver 0 si el recurso se ha iniciado o 1 si el recurso aún no se ha iniciado. Si no se especifica n, se utilizará el tiempo de espera del recurso por defecto.
El siguiente comando mueve el recurso resource1 al nodo example-node2 y evita que vuelva al nodo en el que se estaba ejecutando originalmente durante una hora y treinta minutos.
pcs resource move resource1 example-node2 lifetime=PT1H30M
El siguiente comando mueve el recurso resource1 al nodo example-node2 y evita que vuelva al nodo en el que se estaba ejecutando originalmente durante treinta minutos.
pcs resource move resource1 example-node2 lifetime=PT30M67.2.2. Mover un recurso a su nodo preferido
Después de que un recurso se haya movido, ya sea debido a una conmutación por error o a que un administrador haya movido manualmente el nodo, no necesariamente se moverá de nuevo a su nodo original incluso después de que las circunstancias que causaron la conmutación por error se hayan corregido. Para reubicar los recursos en su nodo preferido, utilice el siguiente comando. El nodo preferido está determinado por el estado actual del clúster, las restricciones, la ubicación de los recursos y otras configuraciones, y puede cambiar con el tiempo.
pcs resource relocate run [resource1] [resource2] ...Si no se especifica ningún recurso, todos los recursos se reubican en sus nodos preferidos.
Este comando calcula el nodo preferido para cada recurso sin tener en cuenta la rigidez de los recursos. Después de calcular el nodo preferido, crea restricciones de ubicación que harán que los recursos se muevan a sus nodos preferidos. Una vez que los recursos se han movido, las restricciones se eliminan automáticamente. Para eliminar todas las restricciones creadas por el comando pcs resource relocate run, puede introducir el comando pcs resource relocate clear. Para mostrar el estado actual de los recursos y su nodo óptimo ignorando la adherencia de los recursos, introduzca el comando pcs resource relocate show.
67.3. Desactivación, activación y prohibición de los recursos del clúster
Además de los comandos pcs resource move y pcs resource relocate, hay una variedad de otros comandos que puede utilizar para controlar el comportamiento de los recursos del clúster.
Desactivación de un recurso del clúster
Puede detener manualmente un recurso en ejecución y evitar que el clúster lo inicie de nuevo con el siguiente comando. Dependiendo del resto de la configuración (restricciones, opciones, fallos, etc.), el recurso puede permanecer iniciado. Si se especifica la opción --wait, pcs esperará hasta 'n' segundos para que el recurso se detenga y luego devolverá 0 si el recurso está detenido o 1 si el recurso no se ha detenido. Si no se especifica 'n', el valor por defecto es de 60 minutos.
pcs resource disable resource_id [--wait[=n]]A partir de Red Hat Enterprise Linux 8.2, puede especificar que un recurso sea desactivado sólo si la desactivación del recurso no tendría un efecto sobre otros recursos. Asegurar que este sea el caso puede ser imposible de hacer a mano cuando se establecen relaciones complejas de recursos.
-
El comando
pcs resource disable --simulatemuestra los efectos de desactivar un recurso sin cambiar la configuración del cluster. -
El comando
pcs resource disable --safedeshabilita un recurso sólo si no hay otros recursos que se vean afectados de alguna manera, como por ejemplo, si se migra de un nodo a otro. El comandopcs resource safe-disablees un alias del comandopcs resource disable --safe. -
El comando
pcs resource disable --safe --no-strictdesactiva un recurso sólo si no se detienen o degradan otros recursos
Habilitación de un recurso de clúster
Utilice el siguiente comando para permitir que el clúster inicie un recurso. Dependiendo del resto de la configuración, el recurso puede permanecer detenido. Si especifica la opción --wait, pcs esperará hasta 'n' segundos para que el recurso se inicie y luego devolverá 0 si el recurso se ha iniciado o 1 si el recurso no se ha iniciado. Si no se especifica 'n', el valor por defecto es de 60 minutos.
pcs resource enable resource_id [--wait[=n]]Impedir que un recurso se ejecute en un nodo concreto
Utilice el siguiente comando para evitar que un recurso se ejecute en un nodo especificado, o en el nodo actual si no se especifica ningún nodo.
pcs resource ban resource_id [node] [--master] [lifetime=lifetime] [--wait[=n]]
Tenga en cuenta que cuando ejecuta el comando pcs resource ban, éste añade una restricción de ubicación -INFINITY al recurso para evitar que se ejecute en el nodo indicado. Puede ejecutar el comando pcs resource clear o pcs constraint delete para eliminar la restricción. Esto no necesariamente mueve los recursos de vuelta al nodo indicado; dónde pueden ejecutarse los recursos en ese momento depende de cómo haya configurado sus recursos inicialmente.
Si especifica el parámetro --master del comando pcs resource ban, el alcance de la restricción se limita al rol maestro y debe especificar master_id en lugar de resource_id.
Opcionalmente, puede configurar un parámetro lifetime para el comando pcs resource ban para indicar un período de tiempo que la restricción debe permanecer.
Opcionalmente se puede configurar un parámetro --wait[=n] para el comando pcs resource ban para indicar el número de segundos que se debe esperar para que el recurso se inicie en el nodo de destino antes de devolver 0 si el recurso se ha iniciado o 1 si el recurso aún no se ha iniciado. Si no se especifica n, se utilizará el tiempo de espera del recurso por defecto.
Forzar el inicio de un recurso en el nodo actual
Utilice el parámetro debug-start del comando pcs resource para forzar el inicio de un recurso especificado en el nodo actual, ignorando las recomendaciones del clúster e imprimiendo la salida del inicio del recurso. Esto se utiliza principalmente para depurar recursos; el arranque de recursos en un cluster se realiza (casi) siempre por Pacemaker y no directamente con un comando pcs. Si su recurso no se inicia, normalmente se debe a una mala configuración del recurso (que se depura en el registro del sistema), a restricciones que impiden que el recurso se inicie o a que el recurso está deshabilitado. Puede utilizar este comando para probar la configuración de los recursos, pero normalmente no debería utilizarse para iniciar recursos en un clúster.
El formato del comando debug-start es el siguiente.
pcs resource debug-start resource_id67.4. Poner un recurso en modo no gestionado
Cuando un recurso está en modo unmanaged, el recurso sigue en la configuración pero Pacemaker no gestiona el recurso.
El siguiente comando establece los recursos indicados en el modo unmanaged.
pcs resource unmanage resource1 [resource2] ...
El siguiente comando pone los recursos en modo managed, que es el estado por defecto.
pcs resource manage resource1 [resource2] ...
Puede especificar el nombre de un grupo de recursos con el comando pcs resource manage o pcs resource unmanage. El comando actuará sobre todos los recursos del grupo, de modo que puede poner todos los recursos de un grupo en modo managed o unmanaged con un solo comando y luego gestionar los recursos contenidos individualmente.
67.5. Poner un clúster en modo de mantenimiento
Cuando un clúster está en modo de mantenimiento, el clúster no inicia ni detiene ningún servicio hasta que se le indique lo contrario. Cuando el modo de mantenimiento finaliza, el clúster realiza una comprobación del estado actual de los servicios y, a continuación, detiene o inicia los que lo necesiten.
Para poner un clúster en modo de mantenimiento, utilice el siguiente comando para establecer la propiedad del clúster maintenance-mode en true.
# pcs property set maintenance-mode=true
Para eliminar un clúster del modo de mantenimiento, utilice el siguiente comando para establecer la propiedad del clúster maintenance-mode en false.
# pcs property set maintenance-mode=falsePuede eliminar una propiedad del clúster de la configuración con el siguiente comando.
propiedad pcs unset property
Alternativamente, puede eliminar una propiedad del clúster de una configuración dejando en blanco el campo de valor del comando pcs property set. Esto restablece esa propiedad a su valor por defecto. Por ejemplo, si ha establecido previamente la propiedad symmetric-cluster a false, el siguiente comando elimina el valor que ha establecido de la configuración y restaura el valor de symmetric-cluster a true, que es su valor por defecto.
# pcs property set symmetric-cluster=67.6. Actualización de un clúster de alta disponibilidad RHEL
La actualización de los paquetes que componen los complementos RHEL High Availability y Resilient Storage, ya sea de forma individual o en su conjunto, puede realizarse de dos formas generales:
- Rolling Updates: Retirar del servicio un nodo a la vez, actualizar su software y volver a integrarlo en el clúster. Esto permite que el clúster siga prestando servicio y gestionando recursos mientras se actualiza cada nodo.
- Entire Cluster Update: Detenga todo el clúster, aplique las actualizaciones a todos los nodos y vuelva a iniciar el clúster.
Es crítico que cuando se realicen procedimientos de actualización de software para los clusters de Red Hat Enterprise LInux High Availability y Resilient Storage, se asegure de que cualquier nodo que vaya a sufrir actualizaciones no sea un miembro activo del cluster antes de que se inicien dichas actualizaciones.
Para obtener una descripción completa de cada uno de estos métodos y los procedimientos a seguir para las actualizaciones, consulte Prácticas recomendadas para aplicar actualizaciones de software a un clúster de alta disponibilidad o de almacenamiento resistente de RHEL.
67.7. Actualización de nodos remotos y nodos invitados
Si el servicio pacemaker_remote se detiene en un nodo remoto activo o en un nodo invitado, el clúster migrará con gracia los recursos del nodo antes de detenerlo. Esto permite realizar actualizaciones de software y otros procedimientos de mantenimiento rutinarios sin necesidad de retirar el nodo del clúster. Sin embargo, una vez que se apague pacemaker_remote, el clúster intentará reconectarse inmediatamente. Si pacemaker_remote no se reinicia dentro del tiempo de espera de monitorización del recurso, el clúster considerará la operación de monitorización como fallida.
Si desea evitar fallos de monitorización cuando el servicio pacemaker_remote se detiene en un nodo activo de Pacemaker Remote, puede utilizar el siguiente procedimiento para sacar el nodo del clúster antes de realizar cualquier administración del sistema que pueda detener pacemaker_remote
-
Detenga el recurso de conexión del nodo con el botón
pcs resource disable resourcenameque moverá todos los servicios fuera del nodo. Para los nodos invitados, esto también detendrá la VM, por lo que la VM debe iniciarse fuera del clúster (por ejemplo, utilizandovirsh) para realizar cualquier mantenimiento. - Realice el mantenimiento necesario.
-
Cuando esté listo para devolver el nodo al clúster, vuelva a habilitar el recurso con el botón
pcs resource enable.
67.8. Migración de máquinas virtuales en un clúster RHEL
La información sobre las políticas de soporte para los clusters de alta disponibilidad de RHEL con miembros de clusters virtualizados se puede encontrar en Políticas de soporte para clusters de alta disponibilidad de RHEL - Condiciones generales con miembros de clusters virtualizados. Como se ha indicado, Red Hat no soporta la migración en vivo de nodos de cluster activos entre hipervisores o hosts. Si necesita realizar una migración en vivo, primero tendrá que detener los servicios de cluster en la VM para eliminar el nodo del cluster, y luego volver a iniciar el cluster después de realizar la migración. Los siguientes pasos describen el procedimiento para eliminar una máquina virtual de un clúster, migrar la máquina virtual y restaurar la máquina virtual en el clúster.
Este procedimiento se aplica a las máquinas virtuales que se utilizan como nodos de clúster completos, no a las máquinas virtuales gestionadas como recursos de clúster (incluidas las máquinas virtuales utilizadas como nodos invitados) que pueden migrarse en vivo sin precauciones especiales. Para obtener información general sobre el procedimiento más completo necesario para actualizar los paquetes que componen los complementos RHEL High Availability y Resilient Storage, ya sea individualmente o en conjunto, consulte Prácticas recomendadas para aplicar actualizaciones de software a un clúster RHEL High Availability o Resilient Storage.
Antes de realizar este procedimiento, considere el efecto que tiene la eliminación de un nodo del clúster sobre el quórum del mismo. Por ejemplo, si tiene un clúster de tres nodos y elimina un nodo, su clúster sólo puede soportar el fallo de un nodo más. Si un nodo de un clúster de tres nodos ya está caído, al eliminar un segundo nodo se perderá el quórum.
- Si es necesario realizar alguna preparación antes de detener o mover los recursos o el software que se ejecuta en la VM para migrar, realice esos pasos.
Ejecute el siguiente comando en la VM para detener el software de cluster en la VM.
# pcs cluster stop- Realice la migración en vivo de la VM.
Inicie los servicios de cluster en la VM.
# pcs cluster start
Capítulo 68. Configuración y gestión de volúmenes lógicos
68.1. Volúmenes lógicos
La gestión de volúmenes crea una capa de abstracción sobre el almacenamiento físico, lo que permite crear volúmenes de almacenamiento lógico. Esto proporciona una flexibilidad mucho mayor en varios aspectos que el uso del almacenamiento físico directamente. Además, la configuración del almacenamiento de hardware se oculta al software, por lo que se puede redimensionar y mover sin detener las aplicaciones ni desmontar los sistemas de archivos. Esto puede reducir los costes operativos.
Los volúmenes lógicos ofrecen las siguientes ventajas sobre el uso directo del almacenamiento físico:
Capacidad flexible
Cuando se utilizan volúmenes lógicos, los sistemas de archivos pueden extenderse a través de varios discos, ya que se pueden agregar discos y particiones en un único volumen lógico.
Grupos de almacenamiento redimensionables
Puede ampliar los volúmenes lógicos o reducir su tamaño con simples comandos de software, sin necesidad de reformatear y reparticionar los dispositivos de disco subyacentes.
Reubicación de datos en línea
Para implementar subsistemas de almacenamiento más nuevos, más rápidos o más resistentes, puede mover los datos mientras el sistema está activo. Los datos se pueden reorganizar en los discos mientras éstos están en uso. Por ejemplo, puede vaciar un disco intercambiable en caliente antes de retirarlo.
Una cómoda denominación de los dispositivos
Los volúmenes de almacenamiento lógico se pueden gestionar en grupos definidos por el usuario y con nombres personalizados.
Separación de discos
Puede crear un volumen lógico que reparta los datos entre dos o más discos. Esto puede aumentar drásticamente el rendimiento.
Volúmenes en espejo
Los volúmenes lógicos proporcionan una forma conveniente de configurar una réplica para sus datos.
Instantáneas de volumen
Mediante el uso de volúmenes lógicos, puede tomar instantáneas de dispositivos para realizar copias de seguridad consistentes o para probar el efecto de los cambios sin afectar a los datos reales.
Volúmenes finos
Los volúmenes lógicos pueden tener un aprovisionamiento ligero. Esto le permite crear volúmenes lógicos que son más grandes que los extensiones disponibles.
Volúmenes de caché
Un volumen lógico de caché utiliza un pequeño volumen lógico formado por dispositivos de bloques rápidos (como las unidades SSD) para mejorar el rendimiento de un volumen lógico más grande y lento, almacenando los bloques más utilizados en el volumen lógico más pequeño y rápido.
68.1.1. Visión general de la arquitectura LVM
La unidad de almacenamiento físico subyacente de un volumen lógico LVM es un dispositivo de bloque como una partición o un disco completo. Este dispositivo se inicializa como un LVM physical volume (PV).
Para crear un volumen lógico LVM, los volúmenes físicos se combinan en un volume group (VG). Esto crea una reserva de espacio en disco a partir de la cual se pueden asignar volúmenes lógicos LVM (LVs). Este proceso es análogo a la forma en que los discos se dividen en particiones. Un volumen lógico es utilizado por los sistemas de archivos y las aplicaciones (como las bases de datos).
Figura 68.1, “Componentes del volumen lógico LVM” muestra los componentes de un volumen lógico LVM simple:
Figura 68.1. Componentes del volumen lógico LVM

68.1.2. Volúmenes físicos
La unidad de almacenamiento físico subyacente de un volumen lógico LVM es un dispositivo de bloques, como una partición o un disco completo. Para utilizar el dispositivo para un volumen lógico LVM, el dispositivo debe ser inicializado como un volumen físico (PV). La inicialización de un dispositivo de bloque como volumen físico coloca una etiqueta cerca del inicio del dispositivo.
Por defecto, la etiqueta LVM se coloca en el segundo sector de 512 bytes. Puede sobrescribir este valor por defecto colocando la etiqueta en cualquiera de los primeros 4 sectores cuando cree el volumen físico. Esto permite que los volúmenes LVM coexistan con otros usuarios de estos sectores, si es necesario.
Una etiqueta LVM proporciona una correcta identificación y ordenación de dispositivos para un dispositivo físico, ya que los dispositivos pueden aparecer en cualquier orden al arrancar el sistema. Una etiqueta LVM permanece persistente a través de los reinicios y a través de un clúster.
La etiqueta LVM identifica el dispositivo como un volumen físico LVM. Contiene un identificador único aleatorio (el UUID) para el volumen físico. También almacena el tamaño del dispositivo de bloque en bytes, y registra dónde se almacenarán los metadatos LVM en el dispositivo.
Los metadatos LVM contienen los detalles de configuración de los grupos de volúmenes LVM en su sistema. Por defecto, se mantiene una copia idéntica de los metadatos en cada área de metadatos en cada volumen físico dentro del grupo de volúmenes. Los metadatos LVM son pequeños y se almacenan como ASCII.
Actualmente LVM permite almacenar 0, 1 o 2 copias idénticas de sus metadatos en cada volumen físico. El valor por defecto es 1 copia. Una vez que configure el número de copias de metadatos en el volumen físico, no podrá cambiar ese número posteriormente. La primera copia se almacena al principio del dispositivo, poco después de la etiqueta. Si hay una segunda copia, se coloca al final del dispositivo. Si accidentalmente sobrescribes el área al principio de tu disco escribiendo en un disco diferente al que pretendías, una segunda copia de los metadatos al final del dispositivo te permitirá recuperar los metadatos.
68.1.2.1. Disposición del volumen físico LVM
Figura 68.2, “Disposición del volumen físico” muestra la disposición de un volumen físico LVM. La etiqueta LVM está en el segundo sector, seguido por el área de metadatos, seguido por el espacio utilizable en el dispositivo.
En el núcleo de Linux (y a lo largo de este documento), se considera que los sectores tienen un tamaño de 512 bytes.
Figura 68.2. Disposición del volumen físico

68.1.2.2. Múltiples particiones en un disco
LVM le permite crear volúmenes físicos a partir de particiones de disco. Red Hat recomienda que cree una sola partición que cubra todo el disco para etiquetarlo como un volumen físico LVM por las siguientes razones:
Conveniencia administrativa
Es más fácil hacer un seguimiento del hardware de un sistema si cada disco real sólo aparece una vez. Esto es particularmente cierto si un disco falla. Además, múltiples volúmenes físicos en un solo disco pueden causar una advertencia del kernel sobre tipos de partición desconocidos en el arranque.
Rendimiento de las franjas
LVM no puede decir que dos volúmenes físicos están en el mismo disco físico. Si crea un volumen lógico rayado cuando dos volúmenes físicos están en el mismo disco físico, las rayas podrían estar en diferentes particiones del mismo disco. Esto resultaría en una disminución del rendimiento en lugar de un aumento.
Aunque no se recomienda, puede haber circunstancias específicas en las que necesite dividir un disco en volúmenes físicos LVM separados. Por ejemplo, en un sistema con pocos discos puede ser necesario mover los datos alrededor de las particiones cuando se está migrando un sistema existente a volúmenes LVM. Además, si tienes un disco muy grande y quieres tener más de un grupo de volúmenes para propósitos administrativos, entonces es necesario particionar el disco. Si tiene un disco con más de una partición y ambas particiones están en el mismo grupo de volúmenes, tenga cuidado de especificar qué particiones se incluirán en un volumen lógico al crear volúmenes rayados.
68.1.3. Grupos de volumen
Los volúmenes físicos se combinan en grupos de volúmenes (VG). Esto crea una reserva de espacio en disco a partir de la cual se pueden asignar volúmenes lógicos.
Dentro de un grupo de volúmenes, el espacio de disco disponible para la asignación se divide en unidades de tamaño fijo llamadas extensiones. Una extensión es la unidad más pequeña de espacio que se puede asignar. Dentro de un volumen físico, los extents se denominan extents físicos.
Un volumen lógico se asigna en extensiones lógicas del mismo tamaño que las extensiones físicas. El tamaño de la extensión es, por tanto, el mismo para todos los volúmenes lógicos del grupo de volúmenes. El grupo de volúmenes asigna las extensiones lógicas a extensiones físicas.
68.1.4. Volúmenes lógicos LVM
En LVM, un grupo de volúmenes se divide en volúmenes lógicos. Un administrador puede aumentar o reducir los volúmenes lógicos sin destruir los datos, a diferencia de las particiones de disco estándar. Si los volúmenes físicos de un grupo de volúmenes están en unidades separadas o en matrices RAID, los administradores también pueden repartir un volumen lógico entre los dispositivos de almacenamiento.
Puede perder datos si reduce un volumen lógico a una capacidad inferior a la que requieren los datos del volumen. Para garantizar la máxima flexibilidad, cree volúmenes lógicos que satisfagan sus necesidades actuales y deje el exceso de capacidad de almacenamiento sin asignar. Puede ampliar de forma segura los volúmenes lógicos para utilizar el espacio no asignado, en función de sus necesidades.
En los sistemas AMD, Intel, ARM y servidores IBM Power Systems, el gestor de arranque no puede leer volúmenes LVM. Debes hacer una partición de disco estándar, no LVM, para tu partición /boot. En IBM Z, el cargador de arranque zipl soporta /boot en volúmenes lógicos LVM con mapeo lineal. Por defecto, el proceso de instalación siempre crea las particiones / y swap dentro de volúmenes LVM, con una partición /boot separada en un volumen físico.
Las siguientes secciones describen los diferentes tipos de volúmenes lógicos.
68.1.4.1. Volúmenes lineales
Un volumen lineal agrega el espacio de uno o más volúmenes físicos en un volumen lógico. Por ejemplo, si tiene dos discos de 60 GB, puede crear un volumen lógico de 120 GB. El almacenamiento físico se concatena.
La creación de un volumen lineal asigna un rango de extensiones físicas a un área de un volumen lógico en orden. Por ejemplo, como se muestra en Figura 68.3, “Mapa de extensión” las extensiones lógicas 1 a 99 podrían asignarse a un volumen físico y las extensiones lógicas 100 a 198 podrían asignarse a un segundo volumen físico. Desde el punto de vista de la aplicación, hay un dispositivo que tiene 198 extensiones.
Figura 68.3. Mapa de extensión

Los volúmenes físicos que componen un volumen lógico no tienen que ser del mismo tamaño. Figura 68.4, “Volumen lineal con volúmenes físicos desiguales” muestra el grupo de volúmenes VG1 con un tamaño de extensión física de 4MB. Este grupo de volúmenes incluye 2 volúmenes físicos llamados PV1 y PV2. Los volúmenes físicos están divididos en unidades de 4MB, ya que ese es el tamaño de extensión. En este ejemplo, PV1 tiene un tamaño de 200 extensiones (800MB) y PV2 tiene un tamaño de 100 extensiones (400MB). Puedes crear un volumen lineal de cualquier tamaño entre 1 y 300 extensiones (4MB a 1200MB). En este ejemplo, el volumen lineal llamado LV1 tiene un tamaño de 300 extensiones.
Figura 68.4. Volumen lineal con volúmenes físicos desiguales

Puedes configurar más de un volumen lógico lineal del tamaño que necesites a partir del pool de extensiones físicas. Figura 68.5, “Múltiples volúmenes lógicos” muestra el mismo grupo de volúmenes que en Figura 68.4, “Volumen lineal con volúmenes físicos desiguales”, pero en este caso se han extraído dos volúmenes lógicos del grupo de volúmenes: LV1, que tiene un tamaño de 250 extensiones (1000MB) y LV2 que tiene un tamaño de 50 extensiones (200MB).
Figura 68.5. Múltiples volúmenes lógicos

68.1.4.2. Volúmenes lógicos rayados
Cuando se escriben datos en un volumen lógico LVM, el sistema de archivos distribuye los datos entre los volúmenes físicos subyacentes. Puedes controlar la forma en que se escriben los datos en los volúmenes físicos creando un volumen lógico dividido. Para grandes lecturas y escrituras secuenciales, esto puede mejorar la eficiencia de la E/S de los datos.
El striping mejora el rendimiento escribiendo los datos en un número predeterminado de volúmenes físicos en forma de round-robin. Con el striping, la E/S puede realizarse en paralelo. En algunas situaciones, esto puede resultar en una ganancia de rendimiento casi lineal por cada volumen físico adicional en la franja.
La siguiente ilustración muestra los datos que se están separando en tres volúmenes físicos. En esta figura:
- la primera franja de datos se escribe en el primer volumen físico
- la segunda franja de datos se escribe en el segundo volumen físico
- la tercera franja de datos se escribe en el tercer volumen físico
- la cuarta franja de datos se escribe en el primer volumen físico
En un volumen lógico rayado, el tamaño de la raya no puede superar el tamaño de una extensión.
Figura 68.6. Separación de datos en tres PV

Los volúmenes lógicos rayados pueden ampliarse concatenando otro conjunto de dispositivos al final del primer conjunto. Sin embargo, para ampliar un volumen lógico rayado, debe haber suficiente espacio libre en el conjunto de volúmenes físicos subyacentes que conforman el grupo de volúmenes para soportar la raya. Por ejemplo, si tienes una franja de dos direcciones que utiliza todo un grupo de volúmenes, añadir un solo volumen físico al grupo de volúmenes no te permitirá ampliar la franja. En su lugar, debes añadir al menos dos volúmenes físicos al grupo de volúmenes.
68.1.4.3. Volúmenes lógicos RAID
LVM soporta los niveles RAID 0, 1, 4, 5, 6 y 10.
Un volumen RAID LVM tiene las siguientes características:
- Los volúmenes lógicos RAID creados y gestionados por LVM aprovechan los controladores del kernel Multiple Devices (MD).
- Puede dividir temporalmente las imágenes RAID1 de la matriz y volver a fusionarlas en la matriz más tarde.
- Los volúmenes RAID de LVM admiten instantáneas.
Agrupaciones
Los volúmenes lógicos RAID no son conscientes del cluster.
Aunque puede crear y activar volúmenes lógicos RAID exclusivamente en una máquina, no puede activarlos simultáneamente en más de una máquina.
Subvolúmenes
Cuando se crea un volumen lógico RAID, LVM crea un subvolumen de metadatos de una extensión por cada subvolumen de datos o de paridad del array.
Por ejemplo, la creación de una matriz RAID1 de 2 vías da como resultado dos subvolúmenes de metadatos (lv_rmeta_0 y lv_rmeta_1) y dos subvolúmenes de datos (lv_rimage_0 y lv_rimage_1). Del mismo modo, la creación de una franja de 3 vías (más un dispositivo de paridad implícito) RAID4 da como resultado 4 subvolúmenes de metadatos (lv_rmeta_0, lv_rmeta_1, lv_rmeta_2, y lv_rmeta_3) y 4 subvolúmenes de datos (lv_rimage_0, lv_rimage_1, lv_rimage_2, y lv_rimage_3).
Integridad
Se pueden perder datos cuando falla un dispositivo RAID o cuando se produce una corrupción blanda. La corrupción blanda en el almacenamiento de datos implica que los datos recuperados de un dispositivo de almacenamiento son diferentes de los datos escritos en ese dispositivo. Añadir integridad a un RAID LV ayuda a mitigar o prevenir la corrupción blanda. Para saber más sobre la corrupción blanda y cómo añadir integridad a un RAID LV, consulte Sección 68.7.6, “Uso de la integridad de DM con RAID LV”.
68.1.4.4. Volúmenes lógicos de aprovisionamiento fino (volúmenes finos)
Los volúmenes lógicos pueden tener un aprovisionamiento ligero. Esto le permite crear volúmenes lógicos que son más grandes que los extensiones disponibles. Mediante el aprovisionamiento fino, puede gestionar un pool de almacenamiento de espacio libre, conocido como thin pool, que puede asignarse a un número arbitrario de dispositivos cuando lo necesiten las aplicaciones. A continuación, puede crear dispositivos que se pueden vincular al thin pool para su posterior asignación cuando una aplicación escriba realmente en el volumen lógico. El thin pool puede ampliarse dinámicamente cuando sea necesario para una asignación rentable del espacio de almacenamiento.
Los volúmenes ligeros no son compatibles con los nodos de un clúster. La reserva delgada y todos sus volúmenes delgados deben activarse exclusivamente en un solo nodo del clúster.
Al utilizar el thin provisioning, un administrador de almacenamiento puede sobrecomprometer el almacenamiento físico, evitando a menudo la necesidad de comprar almacenamiento adicional. Por ejemplo, si diez usuarios solicitan cada uno un sistema de archivos de 100 GB para su aplicación, el administrador de almacenamiento puede crear lo que parece ser un sistema de archivos de 100 GB para cada usuario, pero que está respaldado por menos almacenamiento real que se utiliza sólo cuando se necesita. Cuando se utiliza el thin provisioning, es importante que el administrador de almacenamiento supervise el pool de almacenamiento y añada más capacidad si empieza a llenarse.
Para asegurarse de que todo el espacio disponible puede ser utilizado, LVM soporta el descarte de datos. Esto permite reutilizar el espacio que antes utilizaba un archivo descartado u otro rango de bloques.
Los volúmenes delgados ofrecen soporte para una nueva implementación de volúmenes lógicos de copia en escritura (COW), que permiten que muchos dispositivos virtuales compartan los mismos datos en el grupo delgado.
68.1.4.5. Volúmenes de instantáneas
La función de instantáneas de LVM proporciona la capacidad de crear imágenes virtuales de un dispositivo en un instante determinado sin causar una interrupción del servicio. Cuando se realiza un cambio en el dispositivo original (el origen) después de tomar una instantánea, la función de instantánea hace una copia del área de datos modificada tal y como estaba antes del cambio para poder reconstruir el estado del dispositivo.
LVM soporta instantáneas de aprovisionamiento ligero.
Dado que una instantánea sólo copia las áreas de datos que cambian después de la creación de la instantánea, la función de instantánea requiere una cantidad mínima de almacenamiento. Por ejemplo, con un origen que se actualiza raramente, el 3-5 % de la capacidad del origen es suficiente para mantener la instantánea.
Las copias instantáneas de un sistema de archivos son copias virtuales, no una copia de seguridad real de un sistema de archivos. Las instantáneas no sustituyen a un procedimiento de copia de seguridad.
El tamaño de la instantánea gobierna la cantidad de espacio reservado para almacenar los cambios en el volumen de origen. Por ejemplo, si haces una instantánea y luego sobrescribes completamente el origen, la instantánea tendría que ser al menos tan grande como el volumen de origen para mantener los cambios. Es necesario dimensionar una instantánea de acuerdo con el nivel de cambio esperado. Así, por ejemplo, una instantánea de corta duración de un volumen de lectura, como /usr, necesitaría menos espacio que una instantánea de larga duración de un volumen que ve un mayor número de escrituras, como /home.
Si una instantánea se llena, la instantánea deja de ser válida, ya que no puede seguir los cambios en el volumen de origen. Debe controlar regularmente el tamaño de la instantánea. Sin embargo, las instantáneas son totalmente redimensionables, por lo que si tienes capacidad de almacenamiento puedes aumentar el tamaño del volumen de la instantánea para evitar que se pierda. A la inversa, si ves que el volumen de la instantánea es más grande de lo que necesitas, puedes reducir el tamaño del volumen para liberar espacio que necesitan otros volúmenes lógicos.
Cuando se crea un sistema de archivos de instantánea, el acceso de lectura y escritura completo al origen sigue siendo posible. Si se modifica un chunk en una instantánea, ese chunk se marca y nunca se copia del volumen original.
La función de instantáneas tiene varios usos:
- Normalmente, se toma una instantánea cuando se necesita realizar una copia de seguridad en un volumen lógico sin detener el sistema en vivo que está actualizando continuamente los datos.
-
Puede ejecutar el comando
fscken un sistema de archivos de instantánea para comprobar la integridad del sistema de archivos y determinar si el sistema de archivos original requiere una reparación del sistema de archivos. - Dado que la instantánea es de lectura/escritura, puede probar las aplicaciones contra los datos de producción tomando una instantánea y ejecutando pruebas contra la instantánea, dejando los datos reales intactos.
- Puede crear volúmenes LVM para utilizarlos con Red Hat Virtualization. Las instantáneas LVM se pueden utilizar para crear instantáneas de imágenes de huéspedes virtuales. Estas instantáneas pueden proporcionar una forma conveniente de modificar los huéspedes existentes o crear nuevos huéspedes con un mínimo de almacenamiento adicional.
Puedes utilizar la opción --merge del comando lvconvert para fusionar una instantánea con su volumen de origen. Una de las aplicaciones de esta función es realizar la reversión del sistema si has perdido datos o archivos o si necesitas restaurar tu sistema a un estado anterior. Después de fusionar el volumen de la instantánea, el volumen lógico resultante tendrá el nombre, el número menor y el UUID del volumen de origen y la instantánea fusionada se eliminará.
68.1.4.6. Volúmenes instantáneos de aprovisionamiento ligero
Red Hat Enterprise Linux proporciona soporte para volúmenes de instantáneas de aprovisionamiento delgado. Los volúmenes de instantáneas delgadas permiten que muchos dispositivos virtuales sean almacenados en el mismo volumen de datos. Esto simplifica la administración y permite compartir datos entre volúmenes de instantáneas.
Como para todos los volúmenes de instantánea LVM, así como para todos los volúmenes finos, los volúmenes finos de instantánea no son compatibles con los nodos de un clúster. El volumen de instantánea debe activarse exclusivamente en un solo nodo del clúster.
Los volúmenes de instantáneas delgadas proporcionan los siguientes beneficios:
- Un volumen delgado de instantáneas puede reducir el uso del disco cuando hay varias instantáneas del mismo volumen de origen.
- Si hay varias instantáneas del mismo origen, una escritura en el origen provocará una operación COW para conservar los datos. Aumentar el número de instantáneas del origen no debería suponer una ralentización importante.
- Los volúmenes finos de instantáneas pueden utilizarse como origen de volumen lógico para otra instantánea. Esto permite una profundidad arbitraria de instantáneas recursivas (instantáneas de instantáneas de instantáneas...).
- Una instantánea de un volumen lógico delgado también crea un volumen lógico delgado. Esto no consume espacio de datos hasta que se requiera una operación COW, o hasta que se escriba la propia instantánea.
- Un volumen delgado de instantáneas no necesita ser activado con su origen, por lo que un usuario puede tener sólo el origen activo mientras hay muchos volúmenes de instantáneas inactivos del origen.
- Cuando se elimina el origen de un volumen de instantáneas de aprovisionamiento ligero, cada instantánea de ese volumen de origen se convierte en un volumen de aprovisionamiento ligero independiente. Esto significa que, en lugar de fusionar una instantánea con su volumen de origen, puedes optar por eliminar el volumen de origen y luego crear una nueva instantánea con aprovisionamiento ligero utilizando ese volumen independiente como volumen de origen para la nueva instantánea.
Aunque hay muchas ventajas en el uso de volúmenes delgados de instantáneas, hay algunos casos de uso para los que la antigua función de volumen de instantáneas LVM puede ser más apropiada para sus necesidades:
- No se puede cambiar el tamaño del chunk de un thin pool. Si el thin pool tiene un tamaño de chunk grande (por ejemplo, 1MB) y necesita una instantánea de corta duración para la que un tamaño de chunk tan grande no es eficiente, puede optar por utilizar la función de instantáneas antiguas.
- No se puede limitar el tamaño de un volumen de instantánea delgada; la instantánea utilizará todo el espacio de la reserva delgada, si es necesario. Esto puede no ser apropiado para sus necesidades.
En general, debe tener en cuenta los requisitos específicos de su sitio web a la hora de decidir qué formato de instantánea utilizar.
68.1.4.7. Volúmenes de caché
LVM admite el uso de dispositivos de bloque rápidos (como las unidades SSD) como cachés de retroescritura o escritura para dispositivos de bloque más grandes y lentos. Los usuarios pueden crear volúmenes lógicos de caché para mejorar el rendimiento de sus volúmenes lógicos existentes o crear nuevos volúmenes lógicos de caché compuestos por un dispositivo pequeño y rápido acoplado a un dispositivo grande y lento.
68.2. Configuración de volúmenes lógicos LVM
Los siguientes procedimientos proporcionan ejemplos de tareas básicas de administración de LVM.
68.2.1. Uso de los comandos de la CLI
Las siguientes secciones describen algunas características operativas generales de los comandos de la CLI de LVM.
Especificación de unidades en un argumento de línea de comandos
Cuando se requieren tamaños en un argumento de la línea de comandos, las unidades siempre se pueden especificar explícitamente. Si no se especifica una unidad, se asume una por defecto, normalmente KB o MB. Los comandos de la CLI de LVM no aceptan fracciones.
Cuando se especifican unidades en un argumento de la línea de comandos, LVM no distingue entre mayúsculas y minúsculas; especificar M o m es equivalente, por ejemplo, y se utilizan potencias de 2 (múltiplos de 1024). Sin embargo, cuando se especifica el argumento --units en un comando, las minúsculas indican que las unidades están en múltiplos de 1024 mientras que las mayúsculas indican que las unidades están en múltiplos de 1000.
Especificación de grupos de volúmenes y volúmenes lógicos
Tenga en cuenta lo siguiente cuando especifique grupos de volúmenes o volúmenes lógicos en un comando CLI de LVM.
-
Cuando los comandos toman como argumento nombres de grupos de volúmenes o volúmenes lógicos, el nombre completo de la ruta es opcional. Un volumen lógico llamado
lvol0en un grupo de volúmenes llamadovg0puede ser especificado comovg0/lvol0. - Cuando se requiera una lista de grupos de volúmenes pero se deje vacía, se sustituirá por una lista de todos los grupos de volúmenes.
-
Cuando se requiere una lista de volúmenes lógicos pero se da un grupo de volúmenes, se sustituirá por una lista de todos los volúmenes lógicos de ese grupo de volúmenes. Por ejemplo, el comando
lvdisplay vg0mostrará todos los volúmenes lógicos del grupo de volúmenesvg0.
Aumentar la verbosidad de la salida
Todos los comandos LVM aceptan un argumento -v, que puede introducirse varias veces para aumentar la verbosidad de la salida. Los siguientes ejemplos muestran la salida por defecto del comando lvcreate.
# lvcreate -L 50MB new_vg
Rounding up size to full physical extent 52.00 MB
Logical volume "lvol0" created
El siguiente comando muestra la salida del comando lvcreate con el argumento -v.
# lvcreate -v -L 50MB new_vg
Rounding up size to full physical extent 52.00 MB
Archiving volume group "new_vg" metadata (seqno 1).
Creating logical volume lvol0
Creating volume group backup "/etc/lvm/backup/new_vg" (seqno 2).
Activating logical volume new_vg/lvol0.
activation/volume_list configuration setting not defined: Checking only host tags for new_vg/lvol0.
Creating new_vg-lvol0
Loading table for new_vg-lvol0 (253:0).
Resuming new_vg-lvol0 (253:0).
Wiping known signatures on logical volume "new_vg/lvol0"
Initializing 4.00 KiB of logical volume "new_vg/lvol0" with value 0.
Logical volume "lvol0" created
Los argumentos -vv, -vvv y -vvvv muestran cada vez más detalles sobre la ejecución del comando. El argumento -vvvv proporciona la máxima cantidad de información en este momento. El siguiente ejemplo muestra las primeras líneas de salida del comando lvcreate con el argumento -vvvv especificado.
# lvcreate -vvvv -L 50MB new_vg
#lvmcmdline.c:913 Processing: lvcreate -vvvv -L 50MB new_vg
#lvmcmdline.c:916 O_DIRECT will be used
#config/config.c:864 Setting global/locking_type to 1
#locking/locking.c:138 File-based locking selected.
#config/config.c:841 Setting global/locking_dir to /var/lock/lvm
#activate/activate.c:358 Getting target version for linear
#ioctl/libdm-iface.c:1569 dm version OF [16384]
#ioctl/libdm-iface.c:1569 dm versions OF [16384]
#activate/activate.c:358 Getting target version for striped
#ioctl/libdm-iface.c:1569 dm versions OF [16384]
#config/config.c:864 Setting activation/mirror_region_size to 512
...Visualización de la ayuda para los comandos de la CLI de LVM
Puede mostrar la ayuda para cualquiera de los comandos de la CLI de LVM con el argumento --help del comando.
# commandname --help
Para mostrar la página de manual de un comando, ejecute el comando man:
# man commandname
El comando man lvm proporciona información general en línea sobre LVM.
68.2.2. Creación de un volumen lógico LVM en tres discos
Este procedimiento de ejemplo crea un volumen lógico LVM llamado mylv que consiste en los discos en /dev/sda1, /dev/sdb1, y /dev/sdc1.
Para utilizar los discos en un grupo de volúmenes, etiquételos como volúmenes físicos LVM con el comando
pvcreate.AvisoEste comando destruye cualquier dato en
/dev/sda1,/dev/sdb1, y/dev/sdc1.# pvcreate /dev/sda1 /dev/sdb1 /dev/sdc1 Physical volume "/dev/sda1" successfully created Physical volume "/dev/sdb1" successfully created Physical volume "/dev/sdc1" successfully createdCrea un grupo de volúmenes que consiste en los volúmenes físicos LVM que has creado. El siguiente comando crea el grupo de volúmenes
myvg.# vgcreate myvg /dev/sda1 /dev/sdb1 /dev/sdc1 Volume group "myvg" successfully createdPuede utilizar el comando
vgspara mostrar los atributos del nuevo grupo de volúmenes.# vgs VG #PV #LV #SN Attr VSize VFree myvg 3 0 0 wz--n- 51.45G 51.45GCrea el volumen lógico a partir del grupo de volúmenes que has creado. El siguiente comando crea el volumen lógico
mylva partir del grupo de volumenmyvg. Este ejemplo crea un volumen lógico que utiliza 2 gigabytes del grupo de volúmenes.# lvcreate -L 2G -n mylv myvg Logical volume "mylv" createdCrea un sistema de archivos en el volumen lógico. El siguiente comando crea un sistema de archivos
ext4en el volumen lógico.# mkfs.ext4 /dev/myvg/mylv mke2fs 1.44.3 (10-July-2018) Creating filesystem with 524288 4k blocks and 131072 inodes Filesystem UUID: 616da032-8a48-4cd7-8705-bd94b7a1c8c4 Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912 Allocating group tables: done Writing inode tables: done Creating journal (16384 blocks): done Writing superblocks and filesystem accounting information: doneLos siguientes comandos montan el volumen lógico e informan del uso del espacio en disco del sistema de archivos.
# mount /dev/myvg/mylv /mnt # df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/myvg-mylv 1998672 6144 1871288 1% /mnt
68.2.3. Creación de un volumen lógico RAID0 (rayado)
Un volumen lógico RAID0 reparte los datos del volumen lógico entre varios subvolúmenes de datos en unidades de tamaño de franja.
El formato del comando para crear un volumen RAID0 es el siguiente.
lvcreate --type raid0[_meta] --stripes Stripes --stripesize StripeSize VolumeGroup [PhysicalVolumePath...]| Parámetro | Descripción |
|---|---|
|
|
Especificando |
|
| Especifica el número de dispositivos en los que se repartirá el volumen lógico. |
|
| Especifica el tamaño de cada franja en kilobytes. Es la cantidad de datos que se escribe en un dispositivo antes de pasar al siguiente. |
|
| Especifica el grupo de volúmenes a utilizar. |
|
| Especifica los dispositivos a utilizar. Si no se especifica, LVM elegirá el número de dispositivos especificados por la opción Stripes, uno para cada franja. |
Este procedimiento de ejemplo crea un volumen lógico RAID0 de LVM llamado mylv que separa los datos en los discos en /dev/sda1, /dev/sdb1, y /dev/sdc1.
Etiquete los discos que utilizará en el grupo de volúmenes como volúmenes físicos LVM con el comando
pvcreate.AvisoEste comando destruye cualquier dato en
/dev/sda1,/dev/sdb1, y/dev/sdc1.# pvcreate /dev/sda1 /dev/sdb1 /dev/sdc1 Physical volume "/dev/sda1" successfully created Physical volume "/dev/sdb1" successfully created Physical volume "/dev/sdc1" successfully createdCrear el grupo de volumen
myvg. El siguiente comando crea el grupo de volúmenesmyvg.# vgcreate myvg /dev/sda1 /dev/sdb1 /dev/sdc1 Volume group "myvg" successfully createdPuede utilizar el comando
vgspara mostrar los atributos del nuevo grupo de volúmenes.# vgs VG #PV #LV #SN Attr VSize VFree myvg 3 0 0 wz--n- 51.45G 51.45GCrea un volumen lógico RAID0 a partir del grupo de volúmenes que has creado. El siguiente comando crea el volumen RAID0
mylva partir del grupo de volúmenesmyvg. Este ejemplo crea un volumen lógico que tiene un tamaño de 2 gigabytes, con tres franjas y un tamaño de franja de 4 kilobytes.# lvcreate --type raid0 -L 2G --stripes 3 --stripesize 4 -n mylv myvg Rounding size 2.00 GiB (512 extents) up to stripe boundary size 2.00 GiB(513 extents). Logical volume "mylv" created.Cree un sistema de archivos en el volumen lógico RAID0. El siguiente comando crea un sistema de archivos
ext4en el volumen lógico.# mkfs.ext4 /dev/myvg/mylv mke2fs 1.44.3 (10-July-2018) Creating filesystem with 525312 4k blocks and 131376 inodes Filesystem UUID: 9d4c0704-6028-450a-8b0a-8875358c0511 Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912 Allocating group tables: done Writing inode tables: done Creating journal (16384 blocks): done Writing superblocks and filesystem accounting information: doneLos siguientes comandos montan el volumen lógico e informan del uso del espacio en disco del sistema de archivos.
# mount /dev/myvg/mylv /mnt # df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/myvg-mylv 2002684 6168 1875072 1% /mnt
68.2.4. Renombrar volúmenes lógicos LVM
Este procedimiento cambia el nombre de un volumen lógico existente utilizando la interfaz LVM de la línea de comandos.
Procedimiento
- Si el volumen lógico está actualmente montado, desmonte el volumen.
Si el volumen lógico existe en un entorno de clúster, desactive el volumen lógico en todos los nodos en los que esté activo. Utilice el siguiente comando en cada uno de esos nodos:
[root@node-n]# lvchange --activate n vg-name/lv-nameUtilice la utilidad
lvrenamepara renombrar un volumen lógico existente:# lvrename vg-name original-lv-name new-lv-nameOpcionalmente, puede especificar las rutas completas de los dispositivos:
# lvrename /dev/vg-name/original-lv-name /dev/vg-name/new-lv-name
Recursos adicionales
-
La página de manual
lvrename(8)
68.2.5. Eliminación de un disco de un volumen lógico
Estos procedimientos de ejemplo muestran cómo se puede eliminar un disco de un volumen lógico existente, ya sea para reemplazar el disco o para utilizar el disco como parte de un volumen diferente. Para eliminar un disco, primero debes mover los extensiones del volumen físico LVM a un disco o conjunto de discos diferente.
68.2.5.1. Mover extensiones a volúmenes físicos existentes
En este ejemplo, el volumen lógico se distribuye en cuatro volúmenes físicos en el grupo de volúmenes myvg.
# pvs -o+pv_used
PV VG Fmt Attr PSize PFree Used
/dev/sda1 myvg lvm2 a- 17.15G 12.15G 5.00G
/dev/sdb1 myvg lvm2 a- 17.15G 12.15G 5.00G
/dev/sdc1 myvg lvm2 a- 17.15G 12.15G 5.00G
/dev/sdd1 myvg lvm2 a- 17.15G 2.15G 15.00G
Estos ejemplos mueven los extensiones fuera de /dev/sdb1 para que pueda ser eliminado del grupo de volúmenes.
Si hay suficientes extensiones libres en los otros volúmenes físicos del grupo de volúmenes, puedes ejecutar el comando
pvmoveen el dispositivo que quieres eliminar sin otras opciones y las extensiones se distribuirán a los otros dispositivos.En un clúster, el comando
pvmovesólo puede mover el volumen lógico que está activo exclusivamente en un solo nodo.# pvmove /dev/sdb1 /dev/sdb1: Moved: 2.0% ... /dev/sdb1: Moved: 79.2% ... /dev/sdb1: Moved: 100.0%Después de que el comando
pvmovehaya terminado de ejecutarse, la distribución de extensiones es la siguiente:# pvs -o+pv_used PV VG Fmt Attr PSize PFree Used /dev/sda1 myvg lvm2 a- 17.15G 7.15G 10.00G /dev/sdb1 myvg lvm2 a- 17.15G 17.15G 0 /dev/sdc1 myvg lvm2 a- 17.15G 12.15G 5.00G /dev/sdd1 myvg lvm2 a- 17.15G 2.15G 15.00GUtilice el comando
vgreducepara eliminar el volumen físico/dev/sdb1del grupo de volúmenes.# vgreduce myvg /dev/sdb1 Removed "/dev/sdb1" from volume group "myvg" # pvs PV VG Fmt Attr PSize PFree /dev/sda1 myvg lvm2 a- 17.15G 7.15G /dev/sdb1 lvm2 -- 17.15G 17.15G /dev/sdc1 myvg lvm2 a- 17.15G 12.15G /dev/sdd1 myvg lvm2 a- 17.15G 2.15G
Ahora el disco puede ser eliminado físicamente o asignado a otros usuarios.
68.2.5.2. Mover extensiones a un nuevo disco
En este ejemplo, el volumen lógico se distribuye en tres volúmenes físicos en el grupo de volúmenes myvg como sigue:
# pvs -o+pv_used
PV VG Fmt Attr PSize PFree Used
/dev/sda1 myvg lvm2 a- 17.15G 7.15G 10.00G
/dev/sdb1 myvg lvm2 a- 17.15G 15.15G 2.00G
/dev/sdc1 myvg lvm2 a- 17.15G 15.15G 2.00G
Este procedimiento de ejemplo mueve las extensiones de /dev/sdb1 a un nuevo dispositivo, /dev/sdd1.
Crear un nuevo volumen físico desde
/dev/sdd1.# pvcreate /dev/sdd1 Physical volume "/dev/sdd1" successfully createdAñade el nuevo volumen físico
/dev/sdd1al grupo de volumen existentemyvg.# vgextend myvg /dev/sdd1 Volume group "myvg" successfully extended # pvs -o+pv_used PV VG Fmt Attr PSize PFree Used /dev/sda1 myvg lvm2 a- 17.15G 7.15G 10.00G /dev/sdb1 myvg lvm2 a- 17.15G 15.15G 2.00G /dev/sdc1 myvg lvm2 a- 17.15G 15.15G 2.00G /dev/sdd1 myvg lvm2 a- 17.15G 17.15G 0Utilice el comando
pvmovepara mover los datos de/dev/sdb1a/dev/sdd1.# pvmove /dev/sdb1 /dev/sdd1 /dev/sdb1: Moved: 10.0% ... /dev/sdb1: Moved: 79.7% ... /dev/sdb1: Moved: 100.0% # pvs -o+pv_used PV VG Fmt Attr PSize PFree Used /dev/sda1 myvg lvm2 a- 17.15G 7.15G 10.00G /dev/sdb1 myvg lvm2 a- 17.15G 17.15G 0 /dev/sdc1 myvg lvm2 a- 17.15G 15.15G 2.00G /dev/sdd1 myvg lvm2 a- 17.15G 15.15G 2.00GDespués de haber movido los datos fuera de
/dev/sdb1, puede eliminarlos del grupo de volúmenes.# vgreduce myvg /dev/sdb1 Removed "/dev/sdb1" from volume group "myvg"
Ahora puede reasignar el disco a otro grupo de volúmenes o eliminar el disco del sistema.
68.2.6. Configuración de números de dispositivos persistentes
Los números de dispositivo mayor y menor se asignan dinámicamente al cargar el módulo. Algunas aplicaciones funcionan mejor si el dispositivo de bloque se activa siempre con el mismo número de dispositivo (mayor y menor). Puede especificarlos con los comandos lvcreate y lvchange utilizando los siguientes argumentos:
--persistente y --mayor major --menor minorUtilice un número menor grande para estar seguro de que no se ha asignado ya a otro dispositivo de forma dinámica.
Si está exportando un sistema de archivos usando NFS, especificar el parámetro fsid en el archivo de exportación puede evitar la necesidad de establecer un número de dispositivo persistente dentro de LVM.
68.2.7. Especificación del tamaño de extensión de LVM
Cuando se utilizan volúmenes físicos para crear un grupo de volúmenes, su espacio de disco se divide en extensiones de 4MB, por defecto. Esta extensión es la cantidad mínima por la que el volumen lógico puede aumentar o disminuir su tamaño. Un gran número de extensiones no tendrá ningún impacto en el rendimiento de E/S del volumen lógico.
Puedes especificar el tamaño de extensión con la opción -s del comando vgcreate si el tamaño de extensión por defecto no es adecuado. Puedes poner límites al número de volúmenes físicos o lógicos que puede tener el grupo de volúmenes utilizando los argumentos -p y -l del comando vgcreate.
68.2.8. Gestión de los volúmenes lógicos LVM mediante los roles de sistema de RHEL
Esta sección describe cómo aplicar el rol storage para realizar las siguientes tareas:
- Crear un volumen lógico LVM en un grupo de volúmenes compuesto por varios discos.
- Crea un sistema de archivos ext4 con una etiqueta determinada en el volumen lógico.
- Montar persistentemente el sistema de archivos ext4.
Requisitos previos
-
Un libro de jugadas de Ansible que incluye el rol
storage
Para obtener información sobre cómo aplicar un libro de jugadas de Ansible, consulte Aplicar un rol.
68.2.8.1. Ejemplo de libro de jugadas de Ansible para gestionar volúmenes lógicos
Esta sección proporciona un ejemplo de libro de jugadas de Ansible. Este libro de jugadas aplica el rol storage para crear un volumen lógico LVM en un grupo de volúmenes.
Ejemplo 68.1. Un libro de jugadas que crea un volumen lógico mylv en el grupo de volúmenes myvg
- hosts: all
vars:
storage_pools:
- name: myvg
disks:
- sda
- sdb
- sdc
volumes:
- name: mylv
size: 2G
fs_type: ext4
mount_point: /mnt
roles:
- rhel-system-roles.storageEl grupo de volúmenes
myvgestá formado por los siguientes discos:-
/dev/sda -
/dev/sdb -
/dev/sdc
-
-
Si el grupo de volumen
myvgya existe, el libro de jugadas añade el volumen lógico al grupo de volumen. -
Si el grupo de volumen
myvgno existe, el libro de jugadas lo crea. -
El libro de jugadas crea un sistema de archivos Ext4 en el volumen lógico
mylv, y monta persistentemente el sistema de archivos en/mnt.
Recursos adicionales
-
Para más detalles sobre los parámetros utilizados en el rol de sistema
storage, consulte el archivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
68.2.8.2. Recursos adicionales
-
Para obtener más información sobre el rol
storage, consulte Gestión del almacenamiento local mediante los roles de sistema de RHEL.
68.2.9. Eliminación de volúmenes lógicos LVM
Este procedimiento elimina un volumen lógico existente utilizando la interfaz LVM de la línea de comandos.
Los siguientes comandos eliminan el volumen lógico /dev/vg-name/lv-name del grupo de volúmenes vg-name.
Procedimiento
- Si el volumen lógico está actualmente montado, desmonte el volumen.
Si el volumen lógico existe en un entorno de clúster, desactive el volumen lógico en todos los nodos en los que esté activo. Utilice el siguiente comando en cada uno de esos nodos:
[root@node-n]# lvchange --activate n vg-name/lv-nameElimine el volumen lógico utilizando la utilidad
lvremove:# lvremove /dev/vg-name/lv-name Do you really want to remove active logical volume "lv-name"? [y/n]: y Logical volume "lv-name" successfully removedNotaEn este caso, el volumen lógico no ha sido desactivado. Si se desactiva explícitamente el volumen lógico antes de eliminarlo, no se vería el aviso que verifica si se quiere eliminar un volumen lógico activo.
Recursos adicionales
-
La página de manual
lvremove(8)
68.3. Modificar el tamaño de un volumen lógico
Después de crear un volumen lógico, puedes modificar el tamaño del volumen.
68.3.1. Crecimiento de los volúmenes lógicos
Para aumentar el tamaño de un volumen lógico, utilice el comando lvextend.
Al ampliar el volumen lógico, puedes indicar cuánto quieres ampliar el volumen, o qué tamaño quieres que tenga después de ampliarlo.
El siguiente comando amplía el volumen lógico /dev/myvg/homevol a 12 gigabytes.
# lvextend -L12G /dev/myvg/homevol
lvextend -- extending logical volume "/dev/myvg/homevol" to 12 GB
lvextend -- doing automatic backup of volume group "myvg"
lvextend -- logical volume "/dev/myvg/homevol" successfully extended
El siguiente comando añade otro gigabyte al volumen lógico /dev/myvg/homevol.
# lvextend -L+1G /dev/myvg/homevol
lvextend -- extending logical volume "/dev/myvg/homevol" to 13 GB
lvextend -- doing automatic backup of volume group "myvg"
lvextend -- logical volume "/dev/myvg/homevol" successfully extended
Al igual que con el comando lvcreate, puedes utilizar el argumento -l del comando lvextend para especificar el número de extensiones en las que aumentar el tamaño del volumen lógico. También puedes utilizar este argumento para especificar un porcentaje del grupo de volúmenes, o un porcentaje del espacio libre restante en el grupo de volúmenes. El siguiente comando extiende el volumen lógico llamado testlv para llenar todo el espacio no asignado en el grupo de volumen myvg.
# lvextend -l +100%FREE /dev/myvg/testlv
Extending logical volume testlv to 68.59 GB
Logical volume testlv successfully resizedDespués de haber ampliado el volumen lógico es necesario aumentar el tamaño del sistema de archivos para que coincida.
Por defecto, la mayoría de las herramientas de redimensionamiento de sistemas de archivos aumentarán el tamaño del sistema de archivos hasta el tamaño del volumen lógico subyacente, por lo que no hay que preocuparse de especificar el mismo tamaño para cada uno de los dos comandos.
68.3.2. Crecimiento de un sistema de archivos en un volumen lógico
Para hacer crecer un sistema de archivos en un volumen lógico, realiza los siguientes pasos:
Determine si hay suficiente espacio sin asignar en el grupo de volúmenes existente para ampliar el volumen lógico. Si no es así, realice el siguiente procedimiento:
-
Cree un nuevo volumen físico con el comando
pvcreate. -
Utilice el comando
vgextendpara ampliar el grupo de volúmenes que contiene el volumen lógico con el sistema de archivos que está creciendo para incluir el nuevo volumen físico.
-
Cree un nuevo volumen físico con el comando
-
Una vez que el grupo de volúmenes sea lo suficientemente grande como para incluir el sistema de archivos más grande, amplíe el volumen lógico con el comando
lvresize. - Redimensiona el sistema de archivos del volumen lógico.
Tenga en cuenta que puede utilizar la opción -r del comando lvresize para ampliar el volumen lógico y redimensionar el sistema de archivos subyacente con un solo comando
68.3.3. Reducción de volúmenes lógicos
Puede reducir el tamaño de un volumen lógico con el comando lvreduce.
La reducción no es compatible con un sistema de archivos GFS2 o XFS, por lo que no se puede reducir el tamaño de un volumen lógico que contenga un sistema de archivos GFS2 o XFS.
Si el volumen lógico que está reduciendo contiene un sistema de archivos, para evitar la pérdida de datos debe asegurarse de que el sistema de archivos no está utilizando el espacio del volumen lógico que se está reduciendo. Por este motivo, se recomienda utilizar la opción --resizefs del comando lvreduce cuando el volumen lógico contenga un sistema de archivos. Cuando se utiliza esta opción, el comando lvreduce intenta reducir el sistema de archivos antes de reducir el volumen lógico. Si la reducción del sistema de archivos falla, como puede ocurrir si el sistema de archivos está lleno o el sistema de archivos no admite la reducción, el comando lvreduce fallará y no intentará reducir el volumen lógico.
En la mayoría de los casos, el comando lvreduce advierte sobre la posible pérdida de datos y pide una confirmación. Sin embargo, no debes confiar en estos avisos de confirmación para evitar la pérdida de datos porque en algunos casos no verás estos avisos, como cuando el volumen lógico está inactivo o no se utiliza la opción --resizefs.
Tenga en cuenta que el uso de la opción --test del comando lvreduce no indica si la operación es segura, ya que esta opción no comprueba el sistema de archivos ni prueba el redimensionamiento del sistema de archivos.
El siguiente comando reduce el volumen lógico lvol1 en el grupo de volúmenes vg00 a 64 megabytes. En este ejemplo, lvol1 contiene un sistema de archivos, que este comando redimensiona junto con el volumen lógico. Este ejemplo muestra la salida del comando.
# lvreduce --resizefs -L 64M vg00/lvol1
fsck from util-linux 2.23.2
/dev/mapper/vg00-lvol1: clean, 11/25688 files, 8896/102400 blocks
resize2fs 1.42.9 (28-Dec-2013)
Resizing the filesystem on /dev/mapper/vg00-lvol1 to 65536 (1k) blocks.
The filesystem on /dev/mapper/vg00-lvol1 is now 65536 blocks long.
Size of logical volume vg00/lvol1 changed from 100.00 MiB (25 extents) to 64.00 MiB (16 extents).
Logical volume vg00/lvol1 successfully resized.Especificar el signo - antes del valor de redimensionamiento indica que el valor se restará del tamaño real del volumen lógico. El siguiente ejemplo muestra el comando que utilizarías si, en lugar de reducir un volumen lógico a un tamaño absoluto de 64 megabytes, quisieras reducir el volumen en un valor de 64 megabytes.
# lvreduce --resizefs -L -64M vg00/lvol168.3.4. Ampliación de un volumen lógico rayado
Para aumentar el tamaño de un volumen lógico rayado, debe haber suficiente espacio libre en los volúmenes físicos subyacentes que componen el grupo de volúmenes para soportar la raya. Por ejemplo, si tienes una franja de dos direcciones que utiliza todo un grupo de volúmenes, añadir un solo volumen físico al grupo de volúmenes no te permitirá ampliar la franja. En su lugar, debes añadir al menos dos volúmenes físicos al grupo de volúmenes.
Por ejemplo, considere un grupo de volumen vg que consiste en dos volúmenes físicos subyacentes, como se muestra con el siguiente comando vgs.
# vgs
VG #PV #LV #SN Attr VSize VFree
vg 2 0 0 wz--n- 271.31G 271.31GPuedes crear una franja utilizando todo el espacio del grupo de volúmenes.
# lvcreate -n stripe1 -L 271.31G -i 2 vg
Using default stripesize 64.00 KB
Rounding up size to full physical extent 271.31 GB
Logical volume "stripe1" created
# lvs -a -o +devices
LV VG Attr LSize Origin Snap% Move Log Copy% Devices
stripe1 vg -wi-a- 271.31G /dev/sda1(0),/dev/sdb1(0)Observe que el grupo de volúmenes ya no tiene espacio libre.
# vgs
VG #PV #LV #SN Attr VSize VFree
vg 2 1 0 wz--n- 271.31G 0El siguiente comando agrega otro volumen físico al grupo de volúmenes, que entonces tiene 135 gigabytes de espacio adicional.
# vgextend vg /dev/sdc1
Volume group "vg" successfully extended
# vgs
VG #PV #LV #SN Attr VSize VFree
vg 3 1 0 wz--n- 406.97G 135.66GEn este punto no se puede ampliar el volumen lógico rayado hasta el tamaño completo del grupo de volúmenes, porque se necesitan dos dispositivos subyacentes para rayar los datos.
# lvextend vg/stripe1 -L 406G
Using stripesize of last segment 64.00 KB
Extending logical volume stripe1 to 406.00 GB
Insufficient suitable allocatable extents for logical volume stripe1: 34480
more requiredPara ampliar el volumen lógico rayado, añada otro volumen físico y luego amplíe el volumen lógico. En este ejemplo, habiendo añadido dos volúmenes físicos al grupo de volúmenes podemos ampliar el volumen lógico hasta el tamaño completo del grupo de volúmenes.
# vgextend vg /dev/sdd1
Volume group "vg" successfully extended
# vgs
VG #PV #LV #SN Attr VSize VFree
vg 4 1 0 wz--n- 542.62G 271.31G
# lvextend vg/stripe1 -L 542G
Using stripesize of last segment 64.00 KB
Extending logical volume stripe1 to 542.00 GB
Logical volume stripe1 successfully resized
Si no tiene suficientes dispositivos físicos subyacentes para ampliar el volumen lógico rayado, es posible ampliar el volumen de todas formas si no importa que la ampliación no esté rayada, lo que puede dar lugar a un rendimiento desigual. Cuando se añade espacio al volumen lógico, la operación por defecto es utilizar los mismos parámetros de striping del último segmento del volumen lógico existente, pero se pueden anular esos parámetros. El siguiente ejemplo amplía el volumen lógico rayado existente para utilizar el espacio libre restante después de que falle el comando inicial lvextend.
# lvextend vg/stripe1 -L 406G
Using stripesize of last segment 64.00 KB
Extending logical volume stripe1 to 406.00 GB
Insufficient suitable allocatable extents for logical volume stripe1: 34480
more required
# lvextend -i1 -l+100%FREE vg/stripe168.4. Gestión de volúmenes físicos LVM
Hay una variedad de comandos y procedimientos que puede utilizar para gestionar los volúmenes físicos LVM.
68.4.1. Búsqueda de dispositivos de bloque para utilizarlos como volúmenes físicos
Puede buscar dispositivos de bloque que puedan ser utilizados como volúmenes físicos con el comando lvmdiskscan, como se muestra en el siguiente ejemplo.
# lvmdiskscan
/dev/ram0 [ 16.00 MB]
/dev/sda [ 17.15 GB]
/dev/root [ 13.69 GB]
/dev/ram [ 16.00 MB]
/dev/sda1 [ 17.14 GB] LVM physical volume
/dev/VolGroup00/LogVol01 [ 512.00 MB]
/dev/ram2 [ 16.00 MB]
/dev/new_vg/lvol0 [ 52.00 MB]
/dev/ram3 [ 16.00 MB]
/dev/pkl_new_vg/sparkie_lv [ 7.14 GB]
/dev/ram4 [ 16.00 MB]
/dev/ram5 [ 16.00 MB]
/dev/ram6 [ 16.00 MB]
/dev/ram7 [ 16.00 MB]
/dev/ram8 [ 16.00 MB]
/dev/ram9 [ 16.00 MB]
/dev/ram10 [ 16.00 MB]
/dev/ram11 [ 16.00 MB]
/dev/ram12 [ 16.00 MB]
/dev/ram13 [ 16.00 MB]
/dev/ram14 [ 16.00 MB]
/dev/ram15 [ 16.00 MB]
/dev/sdb [ 17.15 GB]
/dev/sdb1 [ 17.14 GB] LVM physical volume
/dev/sdc [ 17.15 GB]
/dev/sdc1 [ 17.14 GB] LVM physical volume
/dev/sdd [ 17.15 GB]
/dev/sdd1 [ 17.14 GB] LVM physical volume
7 disks
17 partitions
0 LVM physical volume whole disks
4 LVM physical volumes68.4.2. Establecer el tipo de partición para un volumen físico
Si está utilizando un dispositivo de disco completo para su volumen físico, el disco no debe tener ninguna tabla de particiones. Para las particiones de disco de DOS, el id de la partición debe establecerse en 0x8e utilizando el comando fdisk o cfdisk o un equivalente. En el caso de los dispositivos de disco completo, sólo debe borrarse la tabla de particiones, lo que destruirá efectivamente todos los datos de ese disco. Puede eliminar una tabla de particiones existente poniendo a cero el primer sector con el siguiente comando:
# dd if=/dev/zero of=PhysicalVolume bs=512 count=168.4.3. Cambiar el tamaño de un volumen físico LVM
Si necesita cambiar el tamaño de un dispositivo de bloque subyacente por cualquier razón, utilice el comando pvresize para actualizar LVM con el nuevo tamaño. Puedes ejecutar este comando mientras LVM está utilizando el volumen físico.
68.4.4. Eliminación de volúmenes físicos
Si un dispositivo ya no es necesario para su uso por LVM, puedes eliminar la etiqueta LVM con el comando pvremove. La ejecución del comando pvremove pone a cero los metadatos LVM en un volumen físico vacío.
Si el volumen físico que quieres eliminar forma parte actualmente de un grupo de volúmenes, debes eliminarlo del grupo de volúmenes con el comando vgreduce.
# pvremove /dev/ram15
Labels on physical volume "/dev/ram15" successfully wiped68.4.5. Añadir volúmenes físicos a un grupo de volúmenes
Para añadir volúmenes físicos adicionales a un grupo de volúmenes existente, utilice el comando vgextend. El comando vgextend aumenta la capacidad de un grupo de volúmenes añadiendo uno o más volúmenes físicos libres.
El siguiente comando añade el volumen físico /dev/sdf1 al grupo de volúmenes vg1.
# vgextend vg1 /dev/sdf168.4.6. Eliminación de volúmenes físicos de un grupo de volúmenes
Para eliminar los volúmenes físicos no utilizados de un grupo de volúmenes, utilice el comando vgreduce. El comando vgreduce reduce la capacidad de un grupo de volúmenes eliminando uno o más volúmenes físicos vacíos. Esto libera esos volúmenes físicos para utilizarlos en otros grupos de volúmenes o para eliminarlos del sistema.
Antes de eliminar un volumen físico de un grupo de volúmenes, puedes asegurarte de que el volumen físico no es utilizado por ningún volumen lógico utilizando el comando pvdisplay.
# pvdisplay /dev/hda1
-- Physical volume ---
PV Name /dev/hda1
VG Name myvg
PV Size 1.95 GB / NOT usable 4 MB [LVM: 122 KB]
PV# 1
PV Status available
Allocatable yes (but full)
Cur LV 1
PE Size (KByte) 4096
Total PE 499
Free PE 0
Allocated PE 499
PV UUID Sd44tK-9IRw-SrMC-MOkn-76iP-iftz-OVSen7
Si el volumen físico sigue siendo utilizado, tendrás que migrar los datos a otro volumen físico utilizando el comando pvmove. A continuación, utilice el comando vgreduce para eliminar el volumen físico.
El siguiente comando elimina el volumen físico /dev/hda1 del grupo de volúmenes my_volume_group.
# vgreduce my_volume_group /dev/hda1
Si un volumen lógico contiene un volumen físico que falla, no podrás utilizar ese volumen lógico. Para eliminar los volúmenes físicos que faltan de un grupo de volúmenes, puede utilizar el parámetro --removemissing del comando vgreduce, si no hay volúmenes lógicos que estén asignados en los volúmenes físicos que faltan.
Si el volumen físico que falla contiene una imagen en espejo de un volumen lógico de un tipo de segmento mirror, puedes eliminar esa imagen del espejo con el comando vgreduce --removemissing --mirrorsonly --force. Esto elimina sólo los volúmenes lógicos que son imágenes en espejo del volumen físico.
68.5. Visualización de los componentes de LVM
LVM proporciona una variedad de formas para mostrar los componentes de LVM, así como para personalizar la pantalla. Esta sección resume el uso de los comandos básicos de visualización de LVM.
68.5.1. Visualización de la información de LVM con el comando lvm
El comando lvm proporciona varias opciones incorporadas que puede utilizar para mostrar información sobre el soporte y la configuración de LVM.
lvm devtypesMuestra los tipos de dispositivos de bloque incorporados reconocidos
lvm formatsMuestra los formatos de metadatos reconocidos.
lvm helpMuestra el texto de ayuda de LVM.
lvm segtypesMuestra los tipos de segmento de volumen lógico reconocidos.
lvm tagsMuestra cualquier etiqueta definida en este host.
lvm versionMuestra la información de la versión actual.
68.5.2. Visualización de los volúmenes físicos
Hay tres comandos que puede utilizar para mostrar las propiedades de los volúmenes físicos LVM: pvs, pvdisplay, y pvscan.
El comando pvs proporciona información sobre el volumen físico de forma configurable, mostrando una línea por volumen físico. El comando pvs proporciona un gran control del formato, y es útil para la creación de scripts.
El comando pvdisplay proporciona una salida verbosa de varias líneas para cada volumen físico. Muestra las propiedades físicas (tamaño, extensiones, grupo de volúmenes, etc.) en un formato fijo.
El siguiente ejemplo muestra la salida del comando pvdisplay para un solo volumen físico.
# pvdisplay
--- Physical volume ---
PV Name /dev/sdc1
VG Name new_vg
PV Size 17.14 GB / not usable 3.40 MB
Allocatable yes
PE Size (KByte) 4096
Total PE 4388
Free PE 4375
Allocated PE 13
PV UUID Joqlch-yWSj-kuEn-IdwM-01S9-XO8M-mcpsVe
El comando pvscan escanea todos los dispositivos de bloque LVM soportados en el sistema en busca de volúmenes físicos.
El siguiente comando muestra todos los dispositivos físicos encontrados:
# pvscan
PV /dev/sdb2 VG vg0 lvm2 [964.00 MB / 0 free]
PV /dev/sdc1 VG vg0 lvm2 [964.00 MB / 428.00 MB free]
PV /dev/sdc2 lvm2 [964.84 MB]
Total: 3 [2.83 GB] / in use: 2 [1.88 GB] / in no VG: 1 [964.84 MB]
Puede definir un filtro en el archivo lvm.conf para que este comando evite escanear volúmenes físicos específicos.
68.5.3. Visualización de los grupos de volumen
Hay dos comandos que puedes utilizar para mostrar las propiedades de los grupos de volumen LVM: vgs y vgdisplay. El comando vgscan, que escanea todos los dispositivos de bloque LVM soportados en el sistema en busca de grupos de volúmenes, también se puede utilizar para mostrar los grupos de volúmenes existentes.
El comando vgs proporciona información de grupos de volúmenes de forma configurable, mostrando una línea por grupo de volúmenes. El comando vgs proporciona un gran control del formato, y es útil para la creación de scripts.
El comando vgdisplay muestra las propiedades del grupo de volúmenes (como tamaño, extensiones, número de volúmenes físicos, etc.) de forma fija. El siguiente ejemplo muestra la salida del comando vgdisplay para el grupo de volumen new_vg. Si no se especifica un grupo de volúmenes, se muestran todos los grupos de volúmenes existentes.
# vgdisplay new_vg
--- Volume group ---
VG Name new_vg
System ID
Format lvm2
Metadata Areas 3
Metadata Sequence No 11
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 1
Open LV 0
Max PV 0
Cur PV 3
Act PV 3
VG Size 51.42 GB
PE Size 4.00 MB
Total PE 13164
Alloc PE / Size 13 / 52.00 MB
Free PE / Size 13151 / 51.37 GB
VG UUID jxQJ0a-ZKk0-OpMO-0118-nlwO-wwqd-fD5D32
El siguiente ejemplo muestra la salida del comando vgscan.
# vgscan
Reading all physical volumes. This may take a while...
Found volume group "new_vg" using metadata type lvm2
Found volume group "officevg" using metadata type lvm268.5.4. Visualización de volúmenes lógicos
Hay tres comandos que puede utilizar para mostrar las propiedades de los volúmenes lógicos LVM: lvs, lvdisplay, y lvscan.
El comando lvs proporciona información sobre el volumen lógico de forma configurable, mostrando una línea por volumen lógico. El comando lvs proporciona un gran control del formato, y es útil para la creación de scripts.
El comando lvdisplay muestra las propiedades del volumen lógico (como el tamaño, la distribución y la asignación) en un formato fijo.
El siguiente comando muestra los atributos de lvol2 en vg00. Si se han creado volúmenes lógicos instantáneos para este volumen lógico original, este comando muestra una lista de todos los volúmenes lógicos instantáneos y su estado (activo o inactivo) también.
# lvdisplay -v /dev/vg00/lvol2
El comando lvscan busca todos los volúmenes lógicos del sistema y los enumera, como en el siguiente ejemplo.
# lvscan
ACTIVE '/dev/vg0/gfslv' [1.46 GB] inherit68.6. Informes personalizados para LVM
LVM proporciona una amplia gama de opciones de configuración y de línea de comandos para producir informes personalizados y para filtrar la salida del informe. Para una descripción completa de las características y capacidades de los informes de LVM, consulte la página de manual lvmreport(7).
Puede producir informes concisos y personalizados de los objetos LVM con los comandos pvs, lvs, y vgs. Los informes que generan estos comandos incluyen una línea de salida para cada objeto. Cada línea contiene una lista ordenada de campos de propiedades relacionadas con el objeto. Hay cinco maneras de seleccionar los objetos a reportar: por volumen físico, grupo de volumen, volumen lógico, segmento de volumen físico y segmento de volumen lógico.
Puedes reportar información sobre volúmenes físicos, grupos de volúmenes, volúmenes lógicos, segmentos de volúmenes físicos y segmentos de volúmenes lógicos a la vez con el comando lvm fullreport. Para obtener información sobre este comando y sus capacidades, consulte la página de manual lvm-fullreport(8).
LVM admite informes de registro, que contienen un registro de operaciones, mensajes y el estado de cada objeto con la identificación completa del mismo, recogidos durante la ejecución de los comandos LVM. Para más información sobre el informe de registro de LVM. consulte la página de manual lvmreport(7).
68.6.1. Controlar el formato de la pantalla LVM
El uso de los comandos pvs, lvs, o vgs determina el conjunto de campos que se muestran por defecto y el orden de clasificación. Puede controlar la salida de estos comandos con los siguientes argumentos:
Puede cambiar los campos que se muestran a algo distinto de lo predeterminado utilizando el argumento
-o. Por ejemplo, el siguiente comando muestra sólo el nombre y el tamaño del volumen físico.# pvs -o pv_name,pv_size PV PSize /dev/sdb1 17.14G /dev/sdc1 17.14G /dev/sdd1 17.14GPuede añadir un campo a la salida con el signo más ( ), que se utiliza en combinación con el argumento -o.
El siguiente ejemplo muestra el UUID del volumen físico además de los campos por defecto.
# pvs -o +pv_uuid PV VG Fmt Attr PSize PFree PV UUID /dev/sdb1 new_vg lvm2 a- 17.14G 17.14G onFF2w-1fLC-ughJ-D9eB-M7iv-6XqA-dqGeXY /dev/sdc1 new_vg lvm2 a- 17.14G 17.09G Joqlch-yWSj-kuEn-IdwM-01S9-X08M-mcpsVe /dev/sdd1 new_vg lvm2 a- 17.14G 17.14G yvfvZK-Cf31-j75k-dECm-0RZ3-0dGW-UqkCSAñadir el argumento
-va un comando incluye algunos campos adicionales. Por ejemplo, el comandopvs -vmostrará los camposDevSizeyPV UUIDademás de los campos por defecto.# pvs -v Scanning for physical volume names PV VG Fmt Attr PSize PFree DevSize PV UUID /dev/sdb1 new_vg lvm2 a- 17.14G 17.14G 17.14G onFF2w-1fLC-ughJ-D9eB-M7iv-6XqA-dqGeXY /dev/sdc1 new_vg lvm2 a- 17.14G 17.09G 17.14G Joqlch-yWSj-kuEn-IdwM-01S9-XO8M-mcpsVe /dev/sdd1 new_vg lvm2 a- 17.14G 17.14G 17.14G yvfvZK-Cf31-j75k-dECm-0RZ3-0dGW-tUqkCSEl argumento
--noheadingssuprime la línea de encabezamiento. Esto puede ser útil para escribir scripts.El siguiente ejemplo utiliza el argumento
--noheadingsen combinación con el argumentopv_name, que generará una lista de todos los volúmenes físicos.# pvs --noheadings -o pv_name /dev/sdb1 /dev/sdc1 /dev/sdd1El argumento
--separator separatorutiliza separator para separar cada campo.El siguiente ejemplo separa los campos de salida por defecto del comando
pvscon un signo de igualdad (=).# pvs --separator = PV=VG=Fmt=Attr=PSize=PFree /dev/sdb1=new_vg=lvm2=a-=17.14G=17.14G /dev/sdc1=new_vg=lvm2=a-=17.14G=17.09G /dev/sdd1=new_vg=lvm2=a-=17.14G=17.14GPara mantener los campos alineados al utilizar el argumento
separator, utilice el argumentoseparatorjunto con el argumento--aligned.# pvs --separator = --aligned PV =VG =Fmt =Attr=PSize =PFree /dev/sdb1 =new_vg=lvm2=a- =17.14G=17.14G /dev/sdc1 =new_vg=lvm2=a- =17.14G=17.09G /dev/sdd1 =new_vg=lvm2=a- =17.14G=17.14G
Puede utilizar el argumento -P del comando lvs o vgs para mostrar información sobre un volumen que ha fallado y que de otro modo no aparecería en la salida.
Para obtener una lista completa de los argumentos de visualización, consulte las páginas de manual pvs(8), vgs(8) y lvs(8).
Los campos de los grupos de volúmenes pueden mezclarse con los campos de los volúmenes físicos (y los segmentos de los volúmenes físicos) o con los campos de los volúmenes lógicos (y los segmentos de los volúmenes lógicos), pero los campos de los volúmenes físicos y los volúmenes lógicos no pueden mezclarse. Por ejemplo, el siguiente comando mostrará una línea de salida para cada volumen físico.
# vgs -o +pv_name
VG #PV #LV #SN Attr VSize VFree PV
new_vg 3 1 0 wz--n- 51.42G 51.37G /dev/sdc1
new_vg 3 1 0 wz--n- 51.42G 51.37G /dev/sdd1
new_vg 3 1 0 wz--n- 51.42G 51.37G /dev/sdb168.6.2. Campos de visualización del objeto LVM
Esta sección proporciona una serie de tablas que enumeran la información que puedes mostrar sobre los objetos LVM con los comandos pvs, vgs, y lvs.
Por comodidad, se puede omitir el prefijo de un nombre de campo si coincide con el predeterminado para el comando. Por ejemplo, con el comando pvs, name significa pv_name, pero con el comando vgs, name se interpreta como vg_name.
Ejecutar el siguiente comando es el equivalente a ejecutar pvs -o pv_free.
# pvs -o free
PFree
17.14G
17.09G
17.14G
El número de caracteres en los campos de atributos en la salida de pvs, vgs, y lvs puede aumentar en versiones posteriores. Los campos de caracteres existentes no cambiarán de posición, pero es posible que se añadan nuevos campos al final. Debe tener esto en cuenta cuando escriba scripts que busquen determinados caracteres de atributos, buscando el carácter en función de su posición relativa al principio del campo, pero no por su posición relativa al final del campo. Por ejemplo, para buscar el carácter p en el noveno bit del campo lv_attr, podría buscar la cadena "^/........p/", pero no debería buscar la cadena "/*p$/".
Tabla 68.2, “Los campos de visualización del comando pvs” enumera los argumentos de visualización del comando pvs, junto con el nombre del campo tal y como aparece en la visualización de la cabecera y una descripción del campo.
| Argumento | Cabecera | Descripción |
|---|---|---|
|
| DevSize | El tamaño del dispositivo subyacente en el que se creó el volumen físico |
|
| 1er PE | Desplazamiento al inicio de la primera extensión física en el dispositivo subyacente |
|
| Attr | Estado del volumen físico: (a)locable o e(x)portado. |
|
| Fmt |
El formato de los metadatos del volumen físico ( |
|
| PFree | El espacio libre que queda en el volumen físico |
|
| PV | El nombre del volumen físico |
|
| Asignar | Número de extensiones físicas utilizadas |
|
| PE | Número de extensiones físicas |
|
| Tamaño de la SS | El tamaño del segmento del volumen físico |
|
| Inicie | La extensión física inicial del segmento de volumen físico |
|
| PSize | El tamaño del volumen físico |
|
| Etiquetas PV | Etiquetas LVM adjuntas al volumen físico |
|
| Usado | La cantidad de espacio utilizado actualmente en el volumen físico |
|
| PV UUID | El UUID del volumen físico |
El comando pvs muestra por defecto los siguientes campos: pv_name, vg_name, pv_fmt, pv_attr, pv_size, pv_free. La visualización está ordenada por pv_name.
# pvs
PV VG Fmt Attr PSize PFree
/dev/sdb1 new_vg lvm2 a- 17.14G 17.14G
/dev/sdc1 new_vg lvm2 a- 17.14G 17.09G
/dev/sdd1 new_vg lvm2 a- 17.14G 17.13G
El uso del argumento -v con el comando pvs añade los siguientes campos a la visualización por defecto: dev_size, pv_uuid.
# pvs -v
Scanning for physical volume names
PV VG Fmt Attr PSize PFree DevSize PV UUID
/dev/sdb1 new_vg lvm2 a- 17.14G 17.14G 17.14G onFF2w-1fLC-ughJ-D9eB-M7iv-6XqA-dqGeXY
/dev/sdc1 new_vg lvm2 a- 17.14G 17.09G 17.14G Joqlch-yWSj-kuEn-IdwM-01S9-XO8M-mcpsVe
/dev/sdd1 new_vg lvm2 a- 17.14G 17.13G 17.14G yvfvZK-Cf31-j75k-dECm-0RZ3-0dGW-tUqkCS
Puede utilizar el argumento --segments del comando pvs para mostrar información sobre cada segmento de volumen físico. Un segmento es un grupo de extensiones. Una vista de segmento puede ser útil si quieres ver si tu volumen lógico está fragmentado.
El comando pvs --segments muestra por defecto los siguientes campos: pv_name, vg_name, pv_fmt, pv_attr, pv_size, pv_free, pvseg_start, pvseg_size. La visualización está ordenada por pv_name y pvseg_size dentro del volumen físico.
# pvs --segments
PV VG Fmt Attr PSize PFree Start SSize
/dev/hda2 VolGroup00 lvm2 a- 37.16G 32.00M 0 1172
/dev/hda2 VolGroup00 lvm2 a- 37.16G 32.00M 1172 16
/dev/hda2 VolGroup00 lvm2 a- 37.16G 32.00M 1188 1
/dev/sda1 vg lvm2 a- 17.14G 16.75G 0 26
/dev/sda1 vg lvm2 a- 17.14G 16.75G 26 24
/dev/sda1 vg lvm2 a- 17.14G 16.75G 50 26
/dev/sda1 vg lvm2 a- 17.14G 16.75G 76 24
/dev/sda1 vg lvm2 a- 17.14G 16.75G 100 26
/dev/sda1 vg lvm2 a- 17.14G 16.75G 126 24
/dev/sda1 vg lvm2 a- 17.14G 16.75G 150 22
/dev/sda1 vg lvm2 a- 17.14G 16.75G 172 4217
/dev/sdb1 vg lvm2 a- 17.14G 17.14G 0 4389
/dev/sdc1 vg lvm2 a- 17.14G 17.14G 0 4389
/dev/sdd1 vg lvm2 a- 17.14G 17.14G 0 4389
/dev/sde1 vg lvm2 a- 17.14G 17.14G 0 4389
/dev/sdf1 vg lvm2 a- 17.14G 17.14G 0 4389
/dev/sdg1 vg lvm2 a- 17.14G 17.14G 0 4389
Puede utilizar el comando pvs -a para ver los dispositivos detectados por LVM que no han sido inicializados como volúmenes físicos LVM.
# pvs -a
PV VG Fmt Attr PSize PFree
/dev/VolGroup00/LogVol01 -- 0 0
/dev/new_vg/lvol0 -- 0 0
/dev/ram -- 0 0
/dev/ram0 -- 0 0
/dev/ram2 -- 0 0
/dev/ram3 -- 0 0
/dev/ram4 -- 0 0
/dev/ram5 -- 0 0
/dev/ram6 -- 0 0
/dev/root -- 0 0
/dev/sda -- 0 0
/dev/sdb -- 0 0
/dev/sdb1 new_vg lvm2 a- 17.14G 17.14G
/dev/sdc -- 0 0
/dev/sdc1 new_vg lvm2 a- 17.14G 17.09G
/dev/sdd -- 0 0
/dev/sdd1 new_vg lvm2 a- 17.14G 17.14G
Tabla 68.3, “campos de visualización de vgs” enumera los argumentos de visualización del comando vgs, junto con el nombre del campo tal y como aparece en la visualización de la cabecera y una descripción del campo.
| Argumento | Cabecera | Descripción |
|---|---|---|
|
| #LV | El número de volúmenes lógicos que contiene el grupo de volúmenes |
|
| MaxLV | El número máximo de volúmenes lógicos permitidos en el grupo de volúmenes (0 si es ilimitado) |
|
| MaxPV | El número máximo de volúmenes físicos permitidos en el grupo de volúmenes (0 si es ilimitado) |
|
| #PV | El número de volúmenes físicos que definen el grupo de volúmenes |
|
| #SN | El número de instantáneas que contiene el grupo de volúmenes |
|
| Attr | Estado del grupo de volumen: (w)riteable, (r)eadonly, resi(z)eable, e(x)ported, (p)artial y (c)lustered. |
|
| #Ext | El número de extensiones físicas en el grupo de volúmenes |
|
| Ext | El tamaño de las extensiones físicas del grupo de volúmenes |
|
| Fmt |
El formato de los metadatos del grupo de volúmenes ( |
|
| VFree | Tamaño del espacio libre que queda en el grupo de volúmenes |
|
| Gratis | Número de extensiones físicas libres en el grupo de volúmenes |
|
| VG | El nombre del grupo de volumen |
|
| Seq | Número que representa la revisión del grupo de volúmenes |
|
| VSize | El tamaño del grupo de volumen |
|
| IDENTIFICACIÓN DEL SISTEMA | ID del sistema LVM1 |
|
| Etiquetas VG | Etiquetas LVM adjuntas al grupo de volúmenes |
|
| VG UUID | El UUID del grupo de volúmenes |
El comando vgs muestra por defecto los siguientes campos: vg_name, pv_count, lv_count, snap_count, vg_attr, vg_size, vg_free. La visualización está ordenada por vg_name.
# vgs
VG #PV #LV #SN Attr VSize VFree
new_vg 3 1 1 wz--n- 51.42G 51.36G
El uso del argumento -v con el comando vgs añade los siguientes campos a la visualización por defecto: vg_extent_size, vg_uuid.
# vgs -v
Finding all volume groups
Finding volume group "new_vg"
VG Attr Ext #PV #LV #SN VSize VFree VG UUID
new_vg wz--n- 4.00M 3 1 1 51.42G 51.36G jxQJ0a-ZKk0-OpMO-0118-nlwO-wwqd-fD5D32
Tabla 68.4, “campos de visualización de lvs” enumera los argumentos de visualización del comando lvs, junto con el nombre del campo tal y como aparece en la visualización de la cabecera y una descripción del campo.
En versiones posteriores de Red Hat Enterprise Linux, la salida del comando lvs puede diferir, con campos adicionales en la salida. El orden de los campos, sin embargo, seguirá siendo el mismo y cualquier campo adicional aparecerá al final de la pantalla.
| Argumento | Cabecera | Descripción |
|---|---|---|
|
*
* | Chunk | Tamaño de la unidad en un volumen de instantáneas |
|
| Copiar% |
El porcentaje de sincronización de un volumen lógico reflejado; también se utiliza cuando se mueven extensiones físicas con el comando |
|
| Dispositivos | Los dispositivos subyacentes que componen el volumen lógico: los volúmenes físicos, los volúmenes lógicos y los extensiones físicas y lógicas de inicio |
|
| Ancestros | En el caso de las instantáneas del grupo ligero, los ancestros del volumen lógico |
|
| Descendientes | En el caso de las instantáneas del grupo ligero, los descendientes del volumen lógico |
|
| Attr | El estado del volumen lógico. Los bits de atributos del volumen lógico son los siguientes: * Bit 1: Tipo de volumen: (m)irrored, (M)irrored sin sincronización inicial, (o)rigin, (O)rigin con snapshot de fusión, (r)aid, ®aid sin sincronización inicial, (s)napshot, (S)napshot de fusión, (p)vmove, (v)irtual, mirror o raid (i)mage, mirror o raid (I)mage out-of-sync, mirror (l)og device, under (c)onversion, thin (V)olume, (t)hin pool, (T)hin pool data, raid o thin pool m(e)tadata o pool metadata spare, * Bit 2: Permisos: (w)riteable, (r)ead-only, ®ead-only activación del volumen de no-lectura
* Bit 3: Política de asignación: (a)nywhere, (c)ontiguous, (i)nherited, c(l)ing, (n)ormal. Se escribe con mayúsculas si el volumen está actualmente bloqueado contra los cambios de asignación, por ejemplo mientras se ejecuta el comando * Bit 4: (m)inor fijo * Bit 5: Estado: (a)ctivo, (s)uspendido, instantánea (I)nválida, instantánea (S)uspendida inválida, instantánea (m)erge fallada, instantánea suspendida (M)erge fallada, dispositivo (d)evice mapeado presente sin tablas, dispositivo mapeado presente con tabla (i)nactiva * Bit 6: dispositivo (o)pen * Bit 7: Tipo de objetivo: (m)irror, (r)aid, (s)napshot, (t)hin, (u)nknown, (v)irtual. Esto agrupa los volúmenes lógicos relacionados con el mismo objetivo del kernel. Así, por ejemplo, las imágenes de espejo, los registros de espejo así como los espejos mismos aparecen como (m) si usan el controlador original del kernel de espejo device-mapper, mientras que los equivalentes de raid que usan el controlador del kernel md raid aparecen todos como (r). Las instantáneas que utilizan el controlador original del mapeador de dispositivos aparecen como (s), mientras que las instantáneas de los volúmenes finos que utilizan el controlador de aprovisionamiento fino aparecen como (t). * Bit 8: Los bloques de datos recién asignados se sobrescriben con bloques de (z)eroes antes de su uso.
* Bit 9: Salud del volumen: (p)artificial, (r)efresh needed, (m)ismatches exist, (w)ritemostly. (p)artial significa que uno o más de los volúmenes físicos que utiliza este volumen lógico no está en el sistema. (r)efresh significa que uno o más de los volúmenes físicos que utiliza este volumen lógico RAID ha sufrido un error de escritura. El error de escritura puede deberse a un fallo temporal de ese Volumen Físico o una indicación de que está fallando. El dispositivo debe ser refrescado o reemplazado. (m)ismatches significa que el volumen lógico RAID tiene porciones del array que no son coherentes. Las incoherencias se descubren iniciando una operación * Bit 10: activación s(k)ip: este volumen está marcado para ser omitido durante la activación. |
|
| KMaj | Número de dispositivo principal real del volumen lógico (-1 si está inactivo) |
|
| KMIN | Número de dispositivo menor real del volumen lógico (-1 si está inactivo) |
|
| Mayor | El número de dispositivo mayor persistente del volumen lógico (-1 si no se especifica) |
|
| Min | El número de dispositivo menor persistente del volumen lógico (-1 si no se especifica) |
|
| LV | El nombre del volumen lógico |
|
| LSize | El tamaño del volumen lógico |
|
| Etiquetas LV | Etiquetas LVM adjuntas al volumen lógico |
|
| LV UUID | El UUID del volumen lógico. |
|
| Registro | Dispositivo en el que reside el registro de réplica |
|
| Módulos | El correspondiente objetivo del kernel device-mapper necesario para utilizar este volumen lógico |
|
| Mover |
Volumen físico de origen de un volumen lógico temporal creado con el comando |
|
| Origen | El dispositivo de origen de un volumen de instantáneas |
|
*
* | Región | El tamaño de la unidad de un volumen lógico reflejado |
|
| #Seg | El número de segmentos del volumen lógico |
|
| Tamaño de la SS | El tamaño de los segmentos del volumen lógico |
|
| Inicie | Desplazamiento del segmento en el volumen lógico |
|
| Seg Tags | Etiquetas LVM adjuntas a los segmentos del volumen lógico |
|
| Tipo | El tipo de segmento de un volumen lógico (por ejemplo: espejo, rayado, lineal) |
|
| Snap% | Porcentaje actual de un volumen de instantáneas que está en uso |
|
| #Str | Número de franjas o espejos en un volumen lógico |
|
*
* | Raya | Tamaño unitario de la franja en un volumen lógico rayado |
El comando lvs proporciona la siguiente visualización por defecto. La visualización por defecto está ordenada por vg_name y lv_name dentro del grupo de volúmenes.
# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
origin VG owi-a-s--- 1.00g
snap VG swi-a-s--- 100.00m origin 0.00
Un uso común del comando lvs es añadir devices al comando para mostrar los dispositivos subyacentes que componen el volumen lógico. Este ejemplo también especifica la opción -a para mostrar los volúmenes internos que son componentes de los volúmenes lógicos, como las réplicas RAID, encerradas entre paréntesis. Este ejemplo incluye un volumen RAID, un volumen rayado y un volumen thinly-pooled.
# lvs -a -o +devices
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices
raid1 VG rwi-a-r--- 1.00g 100.00 raid1_rimage_0(0),raid1_rimage_1(0)
[raid1_rimage_0] VG iwi-aor--- 1.00g /dev/sde1(7041)
[raid1_rimage_1] VG iwi-aor--- 1.00g /dev/sdf1(7041)
[raid1_rmeta_0] VG ewi-aor--- 4.00m /dev/sde1(7040)
[raid1_rmeta_1] VG ewi-aor--- 4.00m /dev/sdf1(7040)
stripe1 VG -wi-a----- 99.95g /dev/sde1(0),/dev/sdf1(0)
stripe1 VG -wi-a----- 99.95g /dev/sdd1(0)
stripe1 VG -wi-a----- 99.95g /dev/sdc1(0)
[lvol0_pmspare] rhel_host-083 ewi------- 4.00m /dev/vda2(0)
pool00 rhel_host-083 twi-aotz-- <4.79g 72.90 54.69 pool00_tdata(0)
[pool00_tdata] rhel_host-083 Twi-ao---- <4.79g /dev/vda2(1)
[pool00_tmeta] rhel_host-083 ewi-ao---- 4.00m /dev/vda2(1226)
root rhel_host-083 Vwi-aotz-- <4.79g pool00 72.90
swap rhel_host-083 -wi-ao---- 820.00m /dev/vda2(1227)
El uso del argumento -v con el comando lvs añade los siguientes campos a la visualización por defecto: seg_count, lv_major, lv_minor, lv_kernel_major, lv_kernel_minor, lv_uuid.
# lvs -v
Finding all logical volumes
LV VG #Seg Attr LSize Maj Min KMaj KMin Origin Snap% Move Copy% Log Convert LV UUID
lvol0 new_vg 1 owi-a- 52.00M -1 -1 253 3 LBy1Tz-sr23-OjsI-LT03-nHLC-y8XW-EhCl78
newvgsnap1 new_vg 1 swi-a- 8.00M -1 -1 253 5 lvol0 0.20 1ye1OU-1cIu-o79k-20h2-ZGF0-qCJm-CfbsIx
Puede utilizar el argumento --segments del comando lvs para mostrar información con columnas predeterminadas que enfatizan la información del segmento. Cuando se utiliza el argumento segments, el prefijo seg es opcional. El comando lvs --segments muestra por defecto los siguientes campos: lv_name, vg_name, lv_attr, stripes, segtype, seg_size. La visualización por defecto está ordenada por vg_name, lv_name dentro del grupo de volúmenes, y seg_start dentro del volumen lógico. Si los volúmenes lógicos estuvieran fragmentados, la salida de este comando lo mostraría.
# lvs --segments
LV VG Attr #Str Type SSize
LogVol00 VolGroup00 -wi-ao 1 linear 36.62G
LogVol01 VolGroup00 -wi-ao 1 linear 512.00M
lv vg -wi-a- 1 linear 104.00M
lv vg -wi-a- 1 linear 104.00M
lv vg -wi-a- 1 linear 104.00M
lv vg -wi-a- 1 linear 88.00M
El uso del argumento -v con el comando lvs --segments añade los siguientes campos a la visualización por defecto: seg_start, stripesize, chunksize.
# lvs -v --segments
Finding all logical volumes
LV VG Attr Start SSize #Str Type Stripe Chunk
lvol0 new_vg owi-a- 0 52.00M 1 linear 0 0
newvgsnap1 new_vg swi-a- 0 8.00M 1 linear 0 8.00K
El siguiente ejemplo muestra la salida por defecto del comando lvs en un sistema con un volumen lógico configurado, seguido de la salida por defecto del comando lvs con el argumento segments especificado.
# lvs
LV VG Attr LSize Origin Snap% Move Log Copy%
lvol0 new_vg -wi-a- 52.00M
# lvs --segments
LV VG Attr #Str Type SSize
lvol0 new_vg -wi-a- 1 linear 52.00M68.6.3. Clasificación de los informes LVM
Normalmente la salida completa del comando lvs, vgs, o pvs tiene que ser generada y almacenada internamente antes de que pueda ser ordenada y las columnas alineadas correctamente. Puede especificar el argumento --unbuffered para mostrar la salida sin clasificar tan pronto como se genere.
Para especificar una lista ordenada alternativa de columnas para ordenar, utilice el argumento -O de cualquiera de los comandos de informe. No es necesario incluir estos campos dentro de la propia salida.
El siguiente ejemplo muestra la salida del comando pvs que muestra el nombre del volumen físico, el tamaño y el espacio libre.
# pvs -o pv_name,pv_size,pv_free
PV PSize PFree
/dev/sdb1 17.14G 17.14G
/dev/sdc1 17.14G 17.09G
/dev/sdd1 17.14G 17.14GEl siguiente ejemplo muestra la misma salida, ordenada por el campo de espacio libre.
# pvs -o pv_name,pv_size,pv_free -O pv_free
PV PSize PFree
/dev/sdc1 17.14G 17.09G
/dev/sdd1 17.14G 17.14G
/dev/sdb1 17.14G 17.14GEl siguiente ejemplo muestra que no es necesario mostrar el campo en el que se está clasificando.
# pvs -o pv_name,pv_size -O pv_free
PV PSize
/dev/sdc1 17.14G
/dev/sdd1 17.14G
/dev/sdb1 17.14G
Para mostrar una ordenación inversa, preceda un campo que especifique después del argumento -O con el carácter -.
# pvs -o pv_name,pv_size,pv_free -O -pv_free
PV PSize PFree
/dev/sdd1 17.14G 17.14G
/dev/sdb1 17.14G 17.14G
/dev/sdc1 17.14G 17.09G68.6.4. Especificación de las unidades para la visualización de un informe LVM
Para especificar las unidades para la visualización del informe LVM, utilice el argumento --units del comando informe. Puede especificar (b)ytes, (k)ilobytes, (m)egabytes, (g)igabytes, (t)erabytes, (e)xabytes, (p)etabytes y (h)uman-readable. La visualización por defecto es legible para el ser humano. Puede anular el valor predeterminado estableciendo el parámetro units en la sección global del archivo /etc/lvm/lvm.conf.
El siguiente ejemplo especifica la salida del comando pvs en megabytes en lugar de los gigabytes por defecto.
# pvs --units m
PV VG Fmt Attr PSize PFree
/dev/sda1 lvm2 -- 17555.40M 17555.40M
/dev/sdb1 new_vg lvm2 a- 17552.00M 17552.00M
/dev/sdc1 new_vg lvm2 a- 17552.00M 17500.00M
/dev/sdd1 new_vg lvm2 a- 17552.00M 17552.00MPor defecto, las unidades se muestran en potencias de 2 (múltiplos de 1024). Puede especificar que las unidades se muestren en múltiplos de 1000 poniendo en mayúsculas la especificación de la unidad (B, K, M, G, T, H).
El siguiente comando muestra la salida como un múltiplo de 1024, el comportamiento por defecto.
# pvs
PV VG Fmt Attr PSize PFree
/dev/sdb1 new_vg lvm2 a- 17.14G 17.14G
/dev/sdc1 new_vg lvm2 a- 17.14G 17.09G
/dev/sdd1 new_vg lvm2 a- 17.14G 17.14GEl siguiente comando muestra la salida como un múltiplo de 1000.
# pvs --units G
PV VG Fmt Attr PSize PFree
/dev/sdb1 new_vg lvm2 a- 18.40G 18.40G
/dev/sdc1 new_vg lvm2 a- 18.40G 18.35G
/dev/sdd1 new_vg lvm2 a- 18.40G 18.40GTambién puede especificar (s)ectores (definidos como 512 bytes) o unidades personalizadas.
El siguiente ejemplo muestra la salida del comando pvs como un número de sectores.
# pvs --units s
PV VG Fmt Attr PSize PFree
/dev/sdb1 new_vg lvm2 a- 35946496S 35946496S
/dev/sdc1 new_vg lvm2 a- 35946496S 35840000S
/dev/sdd1 new_vg lvm2 a- 35946496S 35946496S
El siguiente ejemplo muestra la salida del comando pvs en unidades de 4 MB.
# pvs --units 4m
PV VG Fmt Attr PSize PFree
/dev/sdb1 new_vg lvm2 a- 4388.00U 4388.00U
/dev/sdc1 new_vg lvm2 a- 4388.00U 4375.00U
/dev/sdd1 new_vg lvm2 a- 4388.00U 4388.00U68.6.5. Visualización de la salida del comando LVM en formato JSON
Puede utilizar la opción --reportformat de los comandos de visualización de LVM para mostrar la salida en formato JSON.
El siguiente ejemplo muestra la salida del lvs en formato estándar por defecto.
# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
my_raid my_vg Rwi-a-r--- 12.00m 100.00
root rhel_host-075 -wi-ao---- 6.67g
swap rhel_host-075 -wi-ao---- 820.00mEl siguiente comando muestra la salida de la misma configuración LVM cuando se especifica el formato JSON.
# lvs --reportformat json
{
"report": [
{
"lv": [
{"lv_name":"my_raid", "vg_name":"my_vg", "lv_attr":"Rwi-a-r---", "lv_size":"12.00m", "pool_lv":"", "origin":"", "data_percent":"", "metadata_percent":"", "move_pv":"", "mirror_log":"", "copy_percent":"100.00", "convert_lv":""},
{"lv_name":"root", "vg_name":"rhel_host-075", "lv_attr":"-wi-ao----", "lv_size":"6.67g", "pool_lv":"", "origin":"", "data_percent":"", "metadata_percent":"", "move_pv":"", "mirror_log":"", "copy_percent":"", "convert_lv":""},
{"lv_name":"swap", "vg_name":"rhel_host-075", "lv_attr":"-wi-ao----", "lv_size":"820.00m", "pool_lv":"", "origin":"", "data_percent":"", "metadata_percent":"", "move_pv":"", "mirror_log":"", "copy_percent":"", "convert_lv":""}
]
}
]
}
También puede establecer el formato del informe como una opción de configuración en el archivo /etc/lvm/lvm.conf, utilizando el ajuste output_format. Sin embargo, el ajuste --reportformat de la línea de comandos tiene prioridad sobre este ajuste.
68.6.6. Visualización del registro de comandos LVM
Tanto los comandos LVM orientados al informe como los orientados al procesamiento pueden informar sobre el registro de comandos si esto se habilita con el ajuste de configuración log/report_command_log. Se puede determinar el conjunto de campos a mostrar y a ordenar para este informe.
Los siguientes ejemplos configuran LVM para generar un informe de registro completo para los comandos LVM. En este ejemplo, se puede ver que ambos volúmenes lógicos lvol0 y lvol1 fueron procesados con éxito, al igual que el grupo de volumen VG que contiene los volúmenes.
# lvmconfig --type full log/command_log_selection
command_log_selection="all"
# lvs
Logical Volume
==============
LV LSize Cpy%Sync
lvol1 4.00m 100.00
lvol0 4.00m
Command Log
===========
Seq LogType Context ObjType ObjName ObjGrp Msg Errno RetCode
1 status processing lv lvol0 vg success 0 1
2 status processing lv lvol1 vg success 0 1
3 status processing vg vg success 0 1
# lvchange -an vg/lvol1
Command Log
===========
Seq LogType Context ObjType ObjName ObjGrp Msg Errno RetCode
1 status processing lv lvol1 vg success 0 1
2 status processing vg vg success 0 1
Para más información sobre la configuración de los informes de LVM y los registros de comandos, consulte la página de manual lvmreport.
68.7. Configuración de volúmenes lógicos RAID
Puede crear, activar, modificar, eliminar, visualizar y utilizar volúmenes RAID LVM.
68.7.1. Volúmenes lógicos RAID
LVM soporta los niveles RAID 0, 1, 4, 5, 6 y 10.
Un volumen RAID LVM tiene las siguientes características:
- Los volúmenes lógicos RAID creados y gestionados por LVM aprovechan los controladores del kernel Multiple Devices (MD).
- Puede dividir temporalmente las imágenes RAID1 de la matriz y volver a fusionarlas en la matriz más tarde.
- Los volúmenes RAID de LVM admiten instantáneas.
Agrupaciones
Los volúmenes lógicos RAID no son conscientes del cluster.
Aunque puede crear y activar volúmenes lógicos RAID exclusivamente en una máquina, no puede activarlos simultáneamente en más de una máquina.
Subvolúmenes
Cuando se crea un volumen lógico RAID, LVM crea un subvolumen de metadatos de una extensión por cada subvolumen de datos o de paridad del array.
Por ejemplo, la creación de una matriz RAID1 de 2 vías da como resultado dos subvolúmenes de metadatos (lv_rmeta_0 y lv_rmeta_1) y dos subvolúmenes de datos (lv_rimage_0 y lv_rimage_1). Del mismo modo, la creación de una franja de 3 vías (más un dispositivo de paridad implícito) RAID4 da como resultado 4 subvolúmenes de metadatos (lv_rmeta_0, lv_rmeta_1, lv_rmeta_2, y lv_rmeta_3) y 4 subvolúmenes de datos (lv_rimage_0, lv_rimage_1, lv_rimage_2, y lv_rimage_3).
Integridad
Se pueden perder datos cuando falla un dispositivo RAID o cuando se produce una corrupción blanda. La corrupción blanda en el almacenamiento de datos implica que los datos recuperados de un dispositivo de almacenamiento son diferentes de los datos escritos en ese dispositivo. Añadir integridad a un RAID LV ayuda a mitigar o prevenir la corrupción blanda. Para saber más sobre la corrupción blanda y cómo añadir integridad a un RAID LV, consulte Sección 68.7.6, “Uso de la integridad de DM con RAID LV”.
68.7.2. Niveles RAID y soporte lineal
RAID soporta varias configuraciones, incluyendo los niveles 0, 1, 4, 5, 6, 10 y lineal. Estos tipos de RAID se definen como sigue:
- Nivel 0
El nivel 0 de RAID, a menudo llamado striping, es una técnica de asignación de datos en franjas orientada al rendimiento. Esto significa que los datos que se escriben en la matriz se dividen en franjas y se escriben en los discos miembros de la matriz, lo que permite un alto rendimiento de E/S con un bajo coste inherente, pero no proporciona redundancia.
Muchas implementaciones de RAID de nivel 0 sólo dividen los datos entre los dispositivos miembros hasta el tamaño del dispositivo más pequeño de la matriz. Esto significa que si tiene varios dispositivos con tamaños ligeramente diferentes, cada dispositivo se trata como si tuviera el mismo tamaño que la unidad más pequeña. Por lo tanto, la capacidad de almacenamiento común de un array de nivel 0 es igual a la capacidad del disco miembro más pequeño en un RAID de hardware o la capacidad de la partición miembro más pequeña en un RAID de software multiplicada por el número de discos o particiones del array.
- Nivel 1
El nivel 1 de RAID, o mirroring, proporciona redundancia escribiendo datos idénticos en cada disco miembro de la matriz, dejando una copia "en espejo" en cada disco. El mirroring sigue siendo popular debido a su simplicidad y a su alto nivel de disponibilidad de datos. El nivel 1 funciona con dos o más discos y proporciona una muy buena fiabilidad de los datos y mejora el rendimiento de las aplicaciones de lectura intensiva, pero a un coste relativamente alto.
El nivel RAID 1 tiene un coste elevado porque escribe la misma información en todos los discos de la matriz, lo que proporciona fiabilidad a los datos, pero de una forma mucho menos eficiente en cuanto a espacio que los niveles RAID basados en paridad, como el nivel 5. Sin embargo, esta ineficiencia de espacio viene acompañada de un beneficio de rendimiento: los niveles RAID basados en la paridad consumen considerablemente más potencia de la CPU para generar la paridad, mientras que el nivel RAID 1 simplemente escribe los mismos datos más de una vez en los múltiples miembros del RAID con muy poca sobrecarga de la CPU. Por ello, el nivel RAID 1 puede superar a los niveles RAID basados en la paridad en máquinas en las que se emplea el software RAID y los recursos de la CPU de la máquina se ven sometidos a una carga constante de operaciones distintas de las actividades RAID.
La capacidad de almacenamiento de la matriz de nivel 1 es igual a la capacidad del disco duro duplicado más pequeño en un RAID de hardware o de la partición duplicada más pequeña en un RAID de software. La redundancia de nivel 1 es la más alta posible entre todos los tipos de RAID, ya que la matriz puede funcionar con un solo disco presente.
- Nivel 4
El nivel 4 utiliza la paridad concentrada en una sola unidad de disco para proteger los datos. La información de paridad se calcula basándose en el contenido del resto de los discos miembros de la matriz. Esta información puede utilizarse para reconstruir los datos cuando falla un disco de la matriz. Los datos reconstruidos pueden utilizarse entonces para satisfacer las solicitudes de E/S al disco que ha fallado antes de que sea sustituido y para repoblar el disco que ha fallado después de que haya sido sustituido.
Debido a que el disco de paridad dedicado representa un cuello de botella inherente en todas las transacciones de escritura en la matriz RAID, el nivel 4 rara vez se utiliza sin tecnologías de acompañamiento como el almacenamiento en caché de escritura, o en circunstancias específicas en las que el administrador del sistema está diseñando intencionadamente el dispositivo RAID por software teniendo en cuenta este cuello de botella (como una matriz que tendrá pocas o ninguna transacción de escritura una vez que la matriz esté llena de datos). El nivel 4 de RAID se utiliza tan raramente que no está disponible como opción en Anaconda. Sin embargo, puede ser creado manualmente por el usuario si es realmente necesario.
La capacidad de almacenamiento del hardware RAID de nivel 4 es igual a la capacidad de la partición miembro más pequeña multiplicada por el número de particiones minus one. El rendimiento de una matriz RAID de nivel 4 es siempre asimétrico, lo que significa que las lecturas superan a las escrituras. Esto se debe a que las escrituras consumen un ancho de banda extra de la CPU y de la memoria principal cuando se genera la paridad, y también consumen un ancho de banda extra del bus cuando se escriben los datos reales en los discos, porque se están escribiendo no sólo los datos, sino también la paridad. Las lecturas sólo necesitan leer los datos y no la paridad, a menos que la matriz esté en un estado degradado. Como resultado, las lecturas generan menos tráfico en los discos y en los buses del ordenador para la misma cantidad de transferencia de datos en condiciones normales de funcionamiento.
- Nivel 5
Este es el tipo más común de RAID. Al distribuir la paridad entre todas las unidades de disco miembros de una matriz, el nivel RAID 5 elimina el cuello de botella de escritura inherente al nivel 4. El único cuello de botella en el rendimiento es el propio proceso de cálculo de la paridad. Con las CPUs modernas y el RAID por software, esto no suele ser un cuello de botella en absoluto, ya que las CPUs modernas pueden generar la paridad muy rápidamente. Sin embargo, si tiene un número suficientemente grande de dispositivos miembros en una matriz RAID 5 por software, de forma que la velocidad de transferencia de datos combinada entre todos los dispositivos sea lo suficientemente alta, entonces este cuello de botella puede empezar a entrar en juego.
Al igual que el nivel 4, el nivel 5 tiene un rendimiento asimétrico, y las lecturas superan sustancialmente a las escrituras. La capacidad de almacenamiento del nivel RAID 5 se calcula de la misma manera que la del nivel 4.
- Nivel 6
Este es un nivel común de RAID cuando la redundancia y la preservación de los datos, y no el rendimiento, son las principales preocupaciones, pero cuando la ineficiencia de espacio del nivel 1 no es aceptable. El nivel 6 utiliza un complejo esquema de paridad para poder recuperarse de la pérdida de dos unidades cualesquiera de la matriz. Este complejo esquema de paridad crea una carga de CPU significativamente mayor en los dispositivos RAID por software y también impone una mayor carga durante las transacciones de escritura. Como tal, el nivel 6 es considerablemente más asimétrico en rendimiento que los niveles 4 y 5.
La capacidad total de una matriz RAID de nivel 6 se calcula de forma similar a la de las matrices RAID de nivel 5 y 4, con la salvedad de que hay que restar 2 dispositivos (en lugar de 1) del recuento de dispositivos para el espacio de almacenamiento de paridad adicional.
- Nivel 10
Este nivel RAID intenta combinar las ventajas de rendimiento del nivel 0 con la redundancia del nivel 1. También ayuda a aliviar parte del espacio desperdiciado en las matrices de nivel 1 con más de 2 dispositivos. Con el nivel 10, es posible, por ejemplo, crear una matriz de 3 unidades configurada para almacenar sólo 2 copias de cada dato, lo que permite que el tamaño total de la matriz sea 1,5 veces el tamaño de los dispositivos más pequeños, en lugar de ser sólo igual al dispositivo más pequeño (como ocurriría con una matriz de 3 dispositivos de nivel 1). Esto evita el uso de procesos de la CPU para calcular la paridad como en el nivel 6 de RAID, pero es menos eficiente en cuanto a espacio.
La creación de un RAID de nivel 10 no es posible durante la instalación. Es posible crear uno manualmente después de la instalación.
- RAID lineal
El RAID lineal es una agrupación de unidades para crear una unidad virtual más grande.
En el RAID lineal, los trozos se asignan secuencialmente desde una unidad miembro, pasando a la siguiente unidad sólo cuando la primera está completamente llena. Esta agrupación no proporciona ninguna ventaja de rendimiento, ya que es poco probable que las operaciones de E/S se dividan entre las unidades miembro. El RAID lineal tampoco ofrece redundancia y disminuye la fiabilidad. Si una de las unidades miembro falla, no se puede utilizar toda la matriz. La capacidad es el total de todos los discos miembros.
68.7.3. Tipos de segmentos RAID de LVM
Para crear un volumen lógico RAID, se especifica un tipo de raid como argumento --type del comando lvcreate. La siguiente tabla describe los posibles tipos de segmento RAID.
Para la mayoría de los usuarios, especificar uno de los cinco tipos primarios disponibles (raid1, raid4, raid5, raid6, raid10) debería ser suficiente.
| Tipo de segmento | Descripción |
|---|---|
|
|
Espejo RAID1. Este es el valor por defecto para el argumento |
|
| Disco de paridad dedicado RAID4 |
|
|
Igual que |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Igual que |
|
|
|
|
|
|
|
|
|
|
|
|
|
| Striping. El RAID 0 reparte los datos del volumen lógico entre varios subvolúmenes de datos en unidades de tamaño de franja. Esto se utiliza para aumentar el rendimiento. Los datos del volumen lógico se perderán si alguno de los subvolúmenes de datos falla. |
68.7.4. Creación de volúmenes lógicos RAID
Esta sección proporciona ejemplos de comandos que crean diferentes tipos de volumen lógico RAID.
Puedes crear matrices RAID1 con diferentes números de copias según el valor que especifiques para el argumento -m. Del mismo modo, puedes especificar el número de franjas para un volumen lógico RAID 4/5/6 con el argumento -i argument. También puedes especificar el tamaño de las franjas con el argumento -I.
El siguiente comando crea una matriz RAID1 de 2 vías llamada my_lv en el grupo de volúmenes my_vg que tiene un tamaño de un gigabyte.
# lvcreate --type raid1 -m 1 -L 1G -n my_lv my_vg
El siguiente comando crea una matriz RAID5 (3 rayas 1 unidad de paridad implícita) llamada my_lv en el grupo de volumen my_vg que tiene un tamaño de un gigabyte. Tenga en cuenta que debe especificar el número de franjas tal y como lo hace para un volumen rayado LVM; el número correcto de unidades de paridad se añade automáticamente.
# lvcreate --type raid5 -i 3 -L 1G -n my_lv my_vg
El siguiente comando crea una matriz RAID6 (3 rayas 2 unidades de paridad implícita) llamada my_lv en el grupo de volumen my_vg que tiene un tamaño de un gigabyte.
# lvcreate --type raid6 -i 3 -L 1G -n my_lv my_vg68.7.5. Creación de un volumen lógico RAID0 (rayado)
Un volumen lógico RAID0 reparte los datos del volumen lógico entre varios subvolúmenes de datos en unidades de tamaño de franja.
El formato del comando para crear un volumen RAID0 es el siguiente.
lvcreate --type raid0[_meta] --stripes Stripes --stripesize StripeSize VolumeGroup [PhysicalVolumePath...]| Parámetro | Descripción |
|---|---|
|
|
Especificando |
|
| Especifica el número de dispositivos en los que se repartirá el volumen lógico. |
|
| Especifica el tamaño de cada franja en kilobytes. Es la cantidad de datos que se escribe en un dispositivo antes de pasar al siguiente. |
|
| Especifica el grupo de volúmenes a utilizar. |
|
| Especifica los dispositivos a utilizar. Si no se especifica, LVM elegirá el número de dispositivos especificados por la opción Stripes, uno para cada franja. |
Este procedimiento de ejemplo crea un volumen lógico RAID0 de LVM llamado mylv que separa los datos en los discos en /dev/sda1, /dev/sdb1, y /dev/sdc1.
Etiquete los discos que utilizará en el grupo de volúmenes como volúmenes físicos LVM con el comando
pvcreate.AvisoEste comando destruye cualquier dato en
/dev/sda1,/dev/sdb1, y/dev/sdc1.# pvcreate /dev/sda1 /dev/sdb1 /dev/sdc1 Physical volume "/dev/sda1" successfully created Physical volume "/dev/sdb1" successfully created Physical volume "/dev/sdc1" successfully createdCrear el grupo de volumen
myvg. El siguiente comando crea el grupo de volúmenesmyvg.# vgcreate myvg /dev/sda1 /dev/sdb1 /dev/sdc1 Volume group "myvg" successfully createdPuede utilizar el comando
vgspara mostrar los atributos del nuevo grupo de volúmenes.# vgs VG #PV #LV #SN Attr VSize VFree myvg 3 0 0 wz--n- 51.45G 51.45GCrea un volumen lógico RAID0 a partir del grupo de volúmenes que has creado. El siguiente comando crea el volumen RAID0
mylva partir del grupo de volúmenesmyvg. Este ejemplo crea un volumen lógico que tiene un tamaño de 2 gigabytes, con tres franjas y un tamaño de franja de 4 kilobytes.# lvcreate --type raid0 -L 2G --stripes 3 --stripesize 4 -n mylv myvg Rounding size 2.00 GiB (512 extents) up to stripe boundary size 2.00 GiB(513 extents). Logical volume "mylv" created.Cree un sistema de archivos en el volumen lógico RAID0. El siguiente comando crea un sistema de archivos
ext4en el volumen lógico.# mkfs.ext4 /dev/myvg/mylv mke2fs 1.44.3 (10-July-2018) Creating filesystem with 525312 4k blocks and 131376 inodes Filesystem UUID: 9d4c0704-6028-450a-8b0a-8875358c0511 Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912 Allocating group tables: done Writing inode tables: done Creating journal (16384 blocks): done Writing superblocks and filesystem accounting information: doneLos siguientes comandos montan el volumen lógico e informan del uso del espacio en disco del sistema de archivos.
# mount /dev/myvg/mylv /mnt # df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/myvg-mylv 2002684 6168 1875072 1% /mnt
68.7.6. Uso de la integridad de DM con RAID LV
Mientras que el RAID ayuda a prevenir la pérdida de datos cuando un dispositivo falla, el uso de la integridad del mapeador de dispositivos (DM) con un RAID LV reduce el riesgo de pérdida de datos cuando los datos de un dispositivo RAID se corrompen. Lea esta sección para saber más sobre cómo puede proteger sus datos de la corrupción suave con la integridad DM.
68.7.6.1. Proteger los datos con la integridad del DM
Según el tipo de configuración, un RAID LV evita la pérdida de datos cuando falla un dispositivo. Si un dispositivo que forma parte de una matriz RAID falla, los datos pueden recuperarse de otros dispositivos que forman parte de ese RAID LV. Sin embargo, una configuración RAID no asegura la integridad de los datos en sí. Corrupción blanda, corrupción silenciosa, errores blandos y errores silenciosos son términos que describen los datos que se han corrompido, aunque el diseño y el software del sistema sigan funcionando como se esperaba.
La corrupción blanda en el almacenamiento de datos implica que los datos recuperados de un dispositivo de almacenamiento son diferentes de los datos escritos en ese dispositivo. Los datos corruptos pueden existir indefinidamente en los dispositivos de almacenamiento. Es posible que no descubra estos datos corruptos hasta que los recupere e intente utilizarlos.
La integridad se utiliza con los niveles RAID 1, 4, 5, 6 y 10 para ayudar a mitigar o prevenir la pérdida de datos debido a la corrupción blanda. La capa RAID garantiza que una copia no corrupta de los datos pueda reparar los errores de corrupción blanda. La capa de integridad se sitúa por encima de cada imagen RAID, mientras que un sub LV adicional almacena los metadatos de integridad (sumas de comprobación de datos) para cada imagen RAID. Cuando se recuperan datos de un RAID LV con integridad, las sumas de comprobación de los datos de integridad analizan los datos en busca de corrupción. Si se detecta corrupción, la capa de integridad devuelve un mensaje de error y la capa RAID recupera una copia no corrupta de los datos de otra imagen RAID. La capa RAID reescribe automáticamente los datos no corruptos sobre los datos corruptos para reparar la corrupción blanda.
Puede añadir la integridad de DM a un RAID LV cuando lo crea, o puede añadir la integridad de DM a un RAID LV que ya existe. Cuando se crea un RAID LV con integridad, o se añade integridad a uno existente, se requiere espacio de almacenamiento adicional para los metadatos de integridad. Para cada imagen RAID, cada 500 MB de datos requiere 4 MB de espacio de almacenamiento adicional para guardar los metadatos de integridad.
68.7.6.1.1. Consideraciones al añadir la integridad del DM
Cuando se crea un nuevo RAID LV con integridad DM o se añade integridad a un RAID LV existente, se aplican ciertas consideraciones:
- La integridad DM requiere espacio de almacenamiento adicional porque añade sumas de comprobación a los datos.
- Aunque algunas configuraciones RAID se ven más afectadas que otras, añadir la integridad de la DM afecta al rendimiento debido a la latencia al acceder a los datos. Una configuración RAID1 suele ofrecer mejor rendimiento que RAID5 o sus variantes.
- El tamaño del bloque de integridad del RAID también afecta al rendimiento. Configurar un tamaño de bloque de integridad RAID mayor ofrece un mejor rendimiento. Sin embargo, un tamaño de bloque de integridad RAID menor ofrece una mayor compatibilidad con versiones anteriores.
- Hay dos modos de integridad disponibles: mapa de bits o diario. El modo de integridad de mapa de bits suele ofrecer un mejor rendimiento que el modo de diario.
Si experimenta problemas de rendimiento, le recomendamos que utilice RAID1 con integridad o que pruebe el rendimiento de una configuración RAID concreta para asegurarse de que cumple sus requisitos.
68.7.6.2. Creación de un RAID LV con integridad DM
Cuando se crea un RAID LV, la adición de la integridad DM ayuda a mitigar el riesgo de perder datos debido a la corrupción suave.
Requisitos previos
- Debes tener acceso a la raíz.
Procedimiento
Para crear un RAID LV con integridad DM, ejecute el siguiente comando:
# lvcreate --type <raid-level> --raidintegrity y -L <usable-size> -n <logical-volume> <volume-group>donde
<raid-level>- Especifica el nivel RAID del RAID LV que se quiere crear.
<usable-size>- Especifica el tamaño utilizable en MB.
<logical-volume>- Especifica el nombre del BT que quieres crear.
<volume-group>- Especifica el nombre del grupo de volúmenes bajo el que quieres crear el RAID LV.
En el siguiente ejemplo, creamos un RAID LV con integridad llamado test-lv en el grupo de volúmenes test-vg, con un tamaño utilizable de 256M y nivel RAID 1.
Ejemplo de RAID LV con integridad
# lvcreate --type raid1 --raidintegrity y -L256M -n test-lv test-vg
Creating integrity metadata LV test-lv_rimage_0_imeta with size 8.00 MiB.
Logical volume "test-lv_rimage_0_imeta" created.
Creating integrity metadata LV test-lv_rimage_1_imeta with size 8.00 MiB.
Logical volume "test-lv_rimage_1_imeta" created.
Logical volume "test-lv" created.68.7.6.3. Añadir integridad DM a un RAID LV existente
Puede añadir la integridad DM a un RAID LV existente para ayudar a mitigar el riesgo de perder datos debido a la corrupción suave.
Requisitos previos
- Debes tener acceso a la raíz.
Procedimiento
Para añadir la integridad DM a un RAID LV existente, ejecute el siguiente comando:
# lvconvert --raidintegrity y <volume-group>/<logical-volume>donde
<volume-group>- Especifica el nombre del grupo de volúmenes bajo el que quieres crear el RAID LV.
<logical-volume>- Especifica el nombre del BT que quieres crear.
68.7.6.5. Visualización de la información sobre la integridad del DM
Cuando cree un RAID LV con integridad o cuando añada integridad a un RAID LV existente, utilice el siguiente comando para ver información sobre la integridad:
# lvs -a <volume-group>
donde <volume-group> es el nombre del grupo de volúmenes que contiene el RAID LV con integridad.
El siguiente ejemplo muestra información sobre el LV RAID test-lv que fue creado en el grupo de volúmenes test-vg.
# lvs -a test-vg
LV VG Attr LSize Origin Cpy%Sync
test-lv test-vg rwi-a-r--- 256.00m 2.10
[test-lv_rimage_0] test-vg gwi-aor--- 256.00m [test-lv_rimage_0_iorig] 93.75
[test-lv_rimage_0_imeta] test-vg ewi-ao---- 8.00m
[test-lv_rimage_0_iorig] test-vg -wi-ao---- 256.00m
[test-lv_rimage_1] test-vg gwi-aor--- 256.00m [test-lv_rimage_1_iorig] 85.94
[test-lv_rimage_1_imeta] test-vg ewi-ao---- 8.00m
[test-lv_rimage_1_iorig] test-vg -wi-ao---- 256.00m
[test-lv_rmeta_0] test-vg ewi-aor--- 4.00m
[test-lv_rmeta_1] test-vg ewi-aor--- 4.00mSincronización
Cuando cree un RAID LV con integridad o añada integridad a un RAID LV existente, le recomendamos que espere a que se complete la sincronización de la integridad y los metadatos del RAID antes de utilizar el LV. De lo contrario, la inicialización en segundo plano podría afectar al rendimiento del RAID. La columna Cpy%Sync indica el progreso de la sincronización tanto para el RAID LV de nivel superior como para cada imagen RAID. La imagen RAID se indica en la columna LV mediante raid_image_N. Consulte la columna LV para asegurarse de que el progreso de la sincronización muestra 100% para el RAID LV de nivel superior y para cada imagen RAID.
Imágenes RAID con integridad
El atributo g en los atributos listados bajo la columna Attr indica que la imagen RAID está usando integridad. Las sumas de comprobación de la integridad se almacenan en el LV del RAID _imeta.
Para mostrar el tipo de cada RAID LV, añada la opción -o segtype al comando lvs:
# lvs -a my-vg -o+segtype
LV VG Attr LSize Origin Cpy%Sync Type
test-lv test-vg rwi-a-r--- 256.00m 87.96 raid1
[test-lv_rimage_0] test-vg gwi-aor--- 256.00m [test-lv_rimage_0_iorig] 100.00 integrity
[test-lv_rimage_0_imeta] test-vg ewi-ao---- 8.00m linear
[test-lv_rimage_0_iorig] test-vg -wi-ao---- 256.00m linear
[test-lv_rimage_1] test-vg gwi-aor--- 256.00m [test-lv_rimage_1_iorig] 100.00 integrity
[test-lv_rimage_1_imeta] test-vg ewi-ao---- 8.00m linear
[test-lv_rimage_1_iorig] test-vg -wi-ao---- 256.00m linear
[test-lv_rmeta_0] test-vg ewi-aor--- 4.00m linear
[test-lv_rmeta_1] test-vg ewi-aor--- 4.00m linearDesajustes de integridad
Hay un contador incremental que cuenta el número de desajustes detectados en cada imagen RAID. Para ver los desajustes de datos detectados por la integridad en una imagen RAID concreta, ejecute el siguiente comando:
# lvs -o integritymismatches <volume-group>/<logical-volume>_raid-image_<n>
donde
<volume-group>- Especifica el nombre del grupo de volúmenes bajo el que quieres crear el RAID LV.
<logical-volume>- Especifica el nombre del BT que quieres crear.
<n>- Especifica la imagen RAID de la que desea ver la información de desajuste de integridad.
Debe ejecutar el comando para cada imagen RAID que desee ver. En el siguiente ejemplo, veremos los desajustes de datos de rimage_0 en test-vg/test-lv.
# lvs -o+integritymismatches test-vg/test-lv_rimage_0
LV VG Attr LSize Origin Cpy%Sync IntegMismatches
[test-lv_rimage_0] test-vg gwi-aor--- 256.00m [test-lv_rimage_0_iorig] 100.00 0
Podemos ver que la integridad no ha detectado ninguna falta de coincidencia de datos y, por lo tanto, el contador IntegMismatches muestra cero (0).
Desajustes de integridad en los registros de mensajes del núcleo
También puede encontrar información sobre la integridad de los datos en los registros de mensajes del núcleo, como se muestra en los siguientes ejemplos.
Example of dm-integrity mismatches from the kernel message logs
device-mapper: integrity: dm-12: Checksum failed at sector 0x24e7Example of dm-integrity data corrections from the kernel message logs
md/raid1:mdX: error de lectura corregido (8 sectores en 9448 en dm-16)68.7.7. Control de la velocidad de inicialización de los volúmenes RAID
Cuando creas volúmenes lógicos RAID10, la E/S en segundo plano requerida para inicializar los volúmenes lógicos con una operación sync puede desplazar otras operaciones de E/S a los dispositivos LVM, como las actualizaciones de los metadatos del grupo de volúmenes, particularmente cuando estás creando muchos volúmenes lógicos RAID. Esto puede causar que las otras operaciones LVM se ralenticen.
Puedes controlar la velocidad a la que se inicializa un volumen lógico RAID implementando el estrangulamiento de la recuperación. Puede controlar la velocidad a la que se realizan las operaciones de sync estableciendo la velocidad de E/S mínima y máxima para dichas operaciones con las opciones --minrecoveryrate y --maxrecoveryrate del comando lvcreate. Estas opciones se especifican de la siguiente manera.
--maxrecoveryrate Rate[bBsSkKmMgG]Establece la tasa máxima de recuperación de un volumen lógico RAID para que no desborde las operaciones de E/S nominales. El Rate se especifica como una cantidad por segundo para cada dispositivo de la matriz. Si no se da ningún sufijo, se asume kiB/seg/dispositivo. Establecer la tasa de recuperación a 0 significa que será ilimitada.
--minrecoveryrate Rate[bBsSkKmMgG]Establece la tasa mínima de recuperación de un volumen lógico RAID para garantizar que la E/S de las operaciones de
syncalcance un rendimiento mínimo, incluso cuando haya una E/S nominal intensa. El Rate se especifica como una cantidad por segundo para cada dispositivo en el array. Si no se da ningún sufijo, se asume kiB/seg/dispositivo.
El siguiente comando crea un array RAID10 de 2 vías con 3 bandas que tiene un tamaño de 10 gigabytes con una tasa de recuperación máxima de 128 kiB/seg/dispositivo. El array se llama my_lv y está en el grupo de volúmenes my_vg.
# lvcreate --type raid10 -i 2 -m 1 -L 10G --maxrecoveryrate 128 -n my_lv my_vgTambién puede especificar las tasas de recuperación mínimas y máximas para una operación de depuración de RAID.
68.7.8. Convertir un dispositivo lineal en un dispositivo RAID
Puede convertir un volumen lógico lineal existente en un dispositivo RAID utilizando el argumento --type del comando lvconvert.
El siguiente comando convierte el volumen lógico lineal my_lv en el grupo de volumen my_vg en un array RAID1 de dos vías.
# lvconvert --type raid1 -m 1 my_vg/my_lvDado que los volúmenes lógicos RAID se componen de pares de subvolúmenes de metadatos y datos, cuando se convierte un dispositivo lineal en una matriz RAID1, se crea un nuevo subvolumen de metadatos y se asocia con el volumen lógico original en (uno de) los mismos volúmenes físicos en los que se encuentra el volumen lineal. Las imágenes adicionales se añaden en pares de subvolúmenes de metadatos/datos. Por ejemplo, si el dispositivo original es el siguiente
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv /dev/sde1(0)Tras la conversión a una matriz RAID1 de 2 vías, el dispositivo contiene los siguientes pares de subvolúmenes de datos y metadatos:
# lvconvert --type raid1 -m 1 my_vg/my_lv
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 6.25 my_lv_rimage_0(0),my_lv_rimage_1(0)
[my_lv_rimage_0] /dev/sde1(0)
[my_lv_rimage_1] /dev/sdf1(1)
[my_lv_rmeta_0] /dev/sde1(256)
[my_lv_rmeta_1] /dev/sdf1(0)
Si la imagen de metadatos que se empareja con el volumen lógico original no puede colocarse en el mismo volumen físico, el lvconvert fallará.
68.7.9. Convertir un volumen lógico RAID1 de LVM en un volumen lógico lineal de LVM
Puede convertir un volumen lógico RAID1 LVM existente en un volumen lógico lineal LVM con el comando lvconvert especificando el argumento -m0. Esto elimina todos los subvolúmenes de datos RAID y todos los subvolúmenes de metadatos RAID que componen el conjunto RAID, dejando la imagen RAID1 de nivel superior como volumen lógico lineal.
El siguiente ejemplo muestra un volumen lógico LVM RAID1 existente.
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0)
[my_lv_rimage_0] /dev/sde1(1)
[my_lv_rimage_1] /dev/sdf1(1)
[my_lv_rmeta_0] /dev/sde1(0)
[my_lv_rmeta_1] /dev/sdf1(0)
El siguiente comando convierte el volumen lógico RAID1 de LVM my_vg/my_lv en un dispositivo lineal de LVM.
# lvconvert -m0 my_vg/my_lv
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv /dev/sde1(1)
Cuando se convierte un volumen lógico RAID1 LVM en un volumen lineal LVM, se puede especificar qué volúmenes físicos eliminar. El siguiente ejemplo muestra la disposición de un volumen lógico RAID1 LVM compuesto por dos imágenes: /dev/sda1 y /dev/sdb1. En este ejemplo, el comando lvconvert especifica que se quiere eliminar /dev/sda1, dejando /dev/sdb1 como el volumen físico que compone el dispositivo lineal.
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0)
[my_lv_rimage_0] /dev/sda1(1)
[my_lv_rimage_1] /dev/sdb1(1)
[my_lv_rmeta_0] /dev/sda1(0)
[my_lv_rmeta_1] /dev/sdb1(0)
# lvconvert -m0 my_vg/my_lv /dev/sda1
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv /dev/sdb1(1)68.7.10. Convertir un dispositivo LVM en espejo en un dispositivo RAID1
Puede convertir un dispositivo LVM reflejado existente con un tipo de segmento de mirror a un dispositivo LVM RAID1 con el comando lvconvert especificando el argumento --type raid1. Esto cambia el nombre de los subvolúmenes en espejo (mimage) a subvolúmenes RAID (rimage). Además, se elimina el registro de réplica y se crean subvolúmenes de metadatos (rmeta) se crean para los subvolúmenes de datos en los mismos volúmenes físicos que los correspondientes subvolúmenes de datos.
El siguiente ejemplo muestra la disposición de un volumen lógico en espejo my_vg/my_lv.
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 15.20 my_lv_mimage_0(0),my_lv_mimage_1(0)
[my_lv_mimage_0] /dev/sde1(0)
[my_lv_mimage_1] /dev/sdf1(0)
[my_lv_mlog] /dev/sdd1(0)
El siguiente comando convierte el volumen lógico en espejo my_vg/my_lv en un volumen lógico RAID1.
# lvconvert --type raid1 my_vg/my_lv
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0)
[my_lv_rimage_0] /dev/sde1(0)
[my_lv_rimage_1] /dev/sdf1(0)
[my_lv_rmeta_0] /dev/sde1(125)
[my_lv_rmeta_1] /dev/sdf1(125)68.7.11. Redimensionar un volumen lógico RAID
Puede redimensionar un volumen lógico RAID de las siguientes maneras;
-
Puede aumentar el tamaño de un volumen lógico RAID de cualquier tipo con el comando
lvresizeolvextend. Esto no cambia el número de imágenes RAID. Para los volúmenes lógicos RAID rayados se aplican las mismas restricciones de redondeo de franjas que cuando se crea un volumen lógico RAID rayado.
-
Puede reducir el tamaño de un volumen lógico RAID de cualquier tipo con el comando
lvresizeolvreduce. Esto no cambia el número de imágenes RAID. Al igual que con el comandolvextend, se aplican las mismas restricciones de redondeo de franjas que cuando se crea un volumen lógico RAID en franjas.
-
Puede cambiar el número de franjas de un volumen lógico RAID rayado (
raid4/5/6/10) con el parámetro--stripes Ndel comandolvconvert. Esto aumenta o reduce el tamaño del volumen lógico RAID por la capacidad de las franjas añadidas o eliminadas. Tenga en cuenta que los volúmenes deraid10sólo pueden añadir franjas. Esta capacidad es parte de la función RAID reshaping que permite cambiar los atributos de un volumen lógico RAID manteniendo el mismo nivel RAID. Para obtener información sobre la remodelación de RAID y ejemplos de uso del comandolvconvertpara remodelar un volumen lógico RAID, consulte la página de manuallvmraid(7).
68.7.12. Cambio del número de imágenes en un dispositivo RAID1 existente
Puede cambiar el número de imágenes en una matriz RAID1 existente, al igual que puede cambiar el número de imágenes en la implementación anterior de la duplicación LVM. Utilice el comando lvconvert para especificar el número de pares de subvolúmenes de metadatos/datos adicionales que se van a añadir o eliminar.
Cuando se añaden imágenes a un dispositivo RAID1 con el comando lvconvert, se puede especificar el número total de imágenes para el dispositivo resultante, o se puede especificar cuántas imágenes se añadirán al dispositivo. También puede especificar opcionalmente en qué volúmenes físicos residirán los nuevos pares de imágenes de metadatos/datos.
Los subvolúmenes de metadatos (denominados rmeta) siempre existen en los mismos dispositivos físicos que sus homólogos de subvolumen de datos rimage). Los pares de subvolúmenes de metadatos/datos no se crearán en los mismos volúmenes físicos que los de otro par de subvolúmenes de metadatos/datos en la matriz RAID (a menos que especifique --alloc anywhere).
El formato del comando para añadir imágenes a un volumen RAID1 es el siguiente:
lvconvert -m new_absolute_count vg/lv [removable_PVs]
lvconvert -m +num_additional_images vg/lv [removable_PVs]
Por ejemplo, el siguiente comando muestra el dispositivo LVM my_vg/my_lv, que es una matriz RAID1 de 2 vías:
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 6.25 my_lv_rimage_0(0),my_lv_rimage_1(0)
[my_lv_rimage_0] /dev/sde1(0)
[my_lv_rimage_1] /dev/sdf1(1)
[my_lv_rmeta_0] /dev/sde1(256)
[my_lv_rmeta_1] /dev/sdf1(0)
El siguiente comando convierte el dispositivo RAID1 de 2 vías my_vg/my_lv en un dispositivo RAID1 de 3 vías:
# lvconvert -m 2 my_vg/my_lv
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 6.25 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0)
[my_lv_rimage_0] /dev/sde1(0)
[my_lv_rimage_1] /dev/sdf1(1)
[my_lv_rimage_2] /dev/sdg1(1)
[my_lv_rmeta_0] /dev/sde1(256)
[my_lv_rmeta_1] /dev/sdf1(0)
[my_lv_rmeta_2] /dev/sdg1(0)
Cuando añades una imagen a un array RAID1, puedes especificar qué volúmenes físicos utilizar para la imagen. El siguiente comando convierte el dispositivo RAID1 de 2 vías my_vg/my_lv en un dispositivo RAID1 de 3 vías, especificando que se utilice el volumen físico /dev/sdd1 para el array:
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 56.00 my_lv_rimage_0(0),my_lv_rimage_1(0)
[my_lv_rimage_0] /dev/sda1(1)
[my_lv_rimage_1] /dev/sdb1(1)
[my_lv_rmeta_0] /dev/sda1(0)
[my_lv_rmeta_1] /dev/sdb1(0)
# lvconvert -m 2 my_vg/my_lv /dev/sdd1
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 28.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0)
[my_lv_rimage_0] /dev/sda1(1)
[my_lv_rimage_1] /dev/sdb1(1)
[my_lv_rimage_2] /dev/sdd1(1)
[my_lv_rmeta_0] /dev/sda1(0)
[my_lv_rmeta_1] /dev/sdb1(0)
[my_lv_rmeta_2] /dev/sdd1(0)
Para eliminar imágenes de una matriz RAID1, utilice el siguiente comando. Cuando elimine imágenes de un dispositivo RAID1 con el comando lvconvert, puede especificar el número total de imágenes para el dispositivo resultante, o puede especificar cuántas imágenes eliminar del dispositivo. También puede especificar opcionalmente los volúmenes físicos de los que eliminar el dispositivo.
lvconvert -m new_absolute_count vg/lv [removable_PVs]
lvconvert -m -num_fewer_images vg/lv [removable_PVs]
Además, cuando se elimina una imagen y su volumen de subvolumen de metadatos asociado, cualquier imagen con un número superior se desplazará hacia abajo para llenar el hueco. Si elimina lv_rimage_1 de una matriz RAID1 de 3 vías que consiste en lv_rimage_0, lv_rimage_1, y lv_rimage_2, esto resulta en una matriz RAID1 que consiste en lv_rimage_0 y lv_rimage_1. El subvolumen lv_rimage_2 será renombrado y ocupará la ranura vacía, convirtiéndose en lv_rimage_1.
El siguiente ejemplo muestra la disposición de un volumen lógico RAID1 de 3 vías my_vg/my_lv.
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0)
[my_lv_rimage_0] /dev/sde1(1)
[my_lv_rimage_1] /dev/sdf1(1)
[my_lv_rimage_2] /dev/sdg1(1)
[my_lv_rmeta_0] /dev/sde1(0)
[my_lv_rmeta_1] /dev/sdf1(0)
[my_lv_rmeta_2] /dev/sdg1(0)El siguiente comando convierte el volumen lógico RAID1 de 3 vías en un volumen lógico RAID1 de 2 vías.
# lvconvert -m1 my_vg/my_lv
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0)
[my_lv_rimage_0] /dev/sde1(1)
[my_lv_rimage_1] /dev/sdf1(1)
[my_lv_rmeta_0] /dev/sde1(0)
[my_lv_rmeta_1] /dev/sdf1(0)
El siguiente comando convierte el volumen lógico RAID1 de 3 vías en un volumen lógico RAID1 de 2 vías, especificando el volumen físico que contiene la imagen a eliminar como /dev/sde1.
# lvconvert -m1 my_vg/my_lv /dev/sde1
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0)
[my_lv_rimage_0] /dev/sdf1(1)
[my_lv_rimage_1] /dev/sdg1(1)
[my_lv_rmeta_0] /dev/sdf1(0)
[my_lv_rmeta_1] /dev/sdg1(0)68.7.13. Dividir una imagen RAID como un volumen lógico separado
Puede dividir una imagen de un volumen lógico RAID para formar un nuevo volumen lógico.
El formato del comando para dividir una imagen RAID es el siguiente:
lvconvert --splitmirrors count -n splitname vg/lv [removable_PVs]Al igual que cuando se elimina una imagen RAID de un volumen lógico RAID1 existente, cuando se elimina un subvolumen de datos RAID (y su subvolumen de metadatos asociado) del centro del dispositivo, cualquier imagen con un número superior se desplazará hacia abajo para llenar el hueco. Los números de índice de los volúmenes lógicos que componen una matriz RAID serán, por tanto, una secuencia ininterrumpida de números enteros.
No se puede dividir una imagen RAID si la matriz RAID1 aún no está sincronizada.
El siguiente ejemplo divide un volumen lógico RAID1 de dos vías, my_lv, en dos volúmenes lógicos lineales, my_lv y new.
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 12.00 my_lv_rimage_0(0),my_lv_rimage_1(0)
[my_lv_rimage_0] /dev/sde1(1)
[my_lv_rimage_1] /dev/sdf1(1)
[my_lv_rmeta_0] /dev/sde1(0)
[my_lv_rmeta_1] /dev/sdf1(0)
# lvconvert --splitmirror 1 -n new my_vg/my_lv
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv /dev/sde1(1)
new /dev/sdf1(1)
El siguiente ejemplo divide un volumen lógico RAID1 de 3 vías, my_lv, en un volumen lógico RAID1 de 2 vías, my_lv, y un volumen lógico lineal, new
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0)
[my_lv_rimage_0] /dev/sde1(1)
[my_lv_rimage_1] /dev/sdf1(1)
[my_lv_rimage_2] /dev/sdg1(1)
[my_lv_rmeta_0] /dev/sde1(0)
[my_lv_rmeta_1] /dev/sdf1(0)
[my_lv_rmeta_2] /dev/sdg1(0)
# lvconvert --splitmirror 1 -n new my_vg/my_lv
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0)
[my_lv_rimage_0] /dev/sde1(1)
[my_lv_rimage_1] /dev/sdf1(1)
[my_lv_rmeta_0] /dev/sde1(0)
[my_lv_rmeta_1] /dev/sdf1(0)
new /dev/sdg1(1)68.7.14. Dividir y fusionar una imagen RAID
Puedes dividir temporalmente una imagen de una matriz RAID1 para uso de sólo lectura mientras mantienes el seguimiento de cualquier cambio utilizando el argumento --trackchanges junto con el argumento --splitmirrors del comando lvconvert. Esto le permite fusionar la imagen de nuevo en la matriz en un momento posterior mientras resincroniza sólo aquellas partes de la matriz que han cambiado desde que la imagen fue dividida.
El formato del comando lvconvert para dividir una imagen RAID es el siguiente.
lvconvert --splitmirrors count --trackchanges vg/lv [removable_PVs]
Cuando se divide una imagen RAID con el argumento --trackchanges, se puede especificar qué imagen se va a dividir, pero no se puede cambiar el nombre del volumen que se está dividiendo. Además, los volúmenes resultantes tienen las siguientes restricciones.
- El nuevo volumen creado es de sólo lectura.
- No se puede cambiar el tamaño del nuevo volumen.
- No se puede cambiar el nombre de la matriz restante.
- No se puede cambiar el tamaño de la matriz restante.
- Puedes activar el nuevo volumen y el resto del array de forma independiente.
Puede fusionar una imagen que se dividió con el argumento --trackchanges especificado ejecutando un comando posterior lvconvert con el argumento --merge. Cuando se fusiona la imagen, sólo se resincronizan las partes de la matriz que han cambiado desde que se dividió la imagen.
El formato del comando lvconvert para fusionar una imagen RAID es el siguiente.
lvconvert --merge raid_imageEl siguiente ejemplo crea un volumen lógico RAID1 y luego separa una imagen de ese volumen mientras rastrea los cambios en la matriz restante.
# lvcreate --type raid1 -m 2 -L 1G -n my_lv my_vg
Logical volume "my_lv" created
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0)
[my_lv_rimage_0] /dev/sdb1(1)
[my_lv_rimage_1] /dev/sdc1(1)
[my_lv_rimage_2] /dev/sdd1(1)
[my_lv_rmeta_0] /dev/sdb1(0)
[my_lv_rmeta_1] /dev/sdc1(0)
[my_lv_rmeta_2] /dev/sdd1(0)
# lvconvert --splitmirrors 1 --trackchanges my_vg/my_lv
my_lv_rimage_2 split from my_lv for read-only purposes.
Use 'lvconvert --merge my_vg/my_lv_rimage_2' to merge back into my_lv
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0)
[my_lv_rimage_0] /dev/sdb1(1)
[my_lv_rimage_1] /dev/sdc1(1)
my_lv_rimage_2 /dev/sdd1(1)
[my_lv_rmeta_0] /dev/sdb1(0)
[my_lv_rmeta_1] /dev/sdc1(0)
[my_lv_rmeta_2] /dev/sdd1(0)El siguiente ejemplo separa una imagen de un volumen RAID1 mientras rastrea los cambios en la matriz restante, y luego fusiona el volumen de nuevo en la matriz.
# lvconvert --splitmirrors 1 --trackchanges my_vg/my_lv
lv_rimage_1 split from my_lv for read-only purposes.
Use 'lvconvert --merge my_vg/my_lv_rimage_1' to merge back into my_lv
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0)
[my_lv_rimage_0] /dev/sdc1(1)
my_lv_rimage_1 /dev/sdd1(1)
[my_lv_rmeta_0] /dev/sdc1(0)
[my_lv_rmeta_1] /dev/sdd1(0)
# lvconvert --merge my_vg/my_lv_rimage_1
my_vg/my_lv_rimage_1 successfully merged back into my_vg/my_lv
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0)
[my_lv_rimage_0] /dev/sdc1(1)
[my_lv_rimage_1] /dev/sdd1(1)
[my_lv_rmeta_0] /dev/sdc1(0)
[my_lv_rmeta_1] /dev/sdd1(0)68.7.15. Establecimiento de una política de fallos en el RAID
El RAID LVM maneja los fallos de los dispositivos de forma automática basándose en las preferencias definidas por el campo raid_fault_policy en el archivo lvm.conf.
-
Si el campo
raid_fault_policyestá configurado comoallocate, el sistema intentará sustituir el dispositivo que ha fallado por un dispositivo de repuesto del grupo de volúmenes. Si no hay ningún dispositivo de repuesto disponible, se informará al registro del sistema. -
Si el campo
raid_fault_policyestá configurado comowarn, el sistema producirá una advertencia y el registro indicará que un dispositivo ha fallado. Esto permite al usuario determinar el curso de acción a seguir.
Mientras queden suficientes dispositivos para soportar la usabilidad, el volumen lógico RAID seguirá funcionando.
68.7.15.1. La política de fallos de RAID asignada
En el siguiente ejemplo, el campo raid_fault_policy se ha configurado como allocate en el archivo lvm.conf. El volumen lógico RAID está dispuesto de la siguiente manera.
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0)
[my_lv_rimage_0] /dev/sde1(1)
[my_lv_rimage_1] /dev/sdf1(1)
[my_lv_rimage_2] /dev/sdg1(1)
[my_lv_rmeta_0] /dev/sde1(0)
[my_lv_rmeta_1] /dev/sdf1(0)
[my_lv_rmeta_2] /dev/sdg1(0)
Si el dispositivo /dev/sde falla, el registro del sistema mostrará mensajes de error.
# grep lvm /var/log/messages
Jan 17 15:57:18 bp-01 lvm[8599]: Device #0 of raid1 array, my_vg-my_lv, has failed.
Jan 17 15:57:18 bp-01 lvm[8599]: /dev/sde1: read failed after 0 of 2048 at
250994294784: Input/output error
Jan 17 15:57:18 bp-01 lvm[8599]: /dev/sde1: read failed after 0 of 2048 at
250994376704: Input/output error
Jan 17 15:57:18 bp-01 lvm[8599]: /dev/sde1: read failed after 0 of 2048 at 0:
Input/output error
Jan 17 15:57:18 bp-01 lvm[8599]: /dev/sde1: read failed after 0 of 2048 at
4096: Input/output error
Jan 17 15:57:19 bp-01 lvm[8599]: Couldn't find device with uuid
3lugiV-3eSP-AFAR-sdrP-H20O-wM2M-qdMANy.
Jan 17 15:57:27 bp-01 lvm[8599]: raid1 array, my_vg-my_lv, is not in-sync.
Jan 17 15:57:36 bp-01 lvm[8599]: raid1 array, my_vg-my_lv, is now in-sync.
Dado que el campo raid_fault_policy se ha establecido en allocate, el dispositivo que ha fallado se sustituye por un nuevo dispositivo del grupo de volúmenes.
# lvs -a -o name,copy_percent,devices vg
Couldn't find device with uuid 3lugiV-3eSP-AFAR-sdrP-H20O-wM2M-qdMANy.
LV Copy% Devices
lv 100.00 lv_rimage_0(0),lv_rimage_1(0),lv_rimage_2(0)
[lv_rimage_0] /dev/sdh1(1)
[lv_rimage_1] /dev/sdf1(1)
[lv_rimage_2] /dev/sdg1(1)
[lv_rmeta_0] /dev/sdh1(0)
[lv_rmeta_1] /dev/sdf1(0)
[lv_rmeta_2] /dev/sdg1(0)
Tenga en cuenta que aunque el dispositivo fallado haya sido reemplazado, la pantalla sigue indicando que LVM no pudo encontrar el dispositivo fallado. Esto se debe a que, aunque el dispositivo fallido ha sido eliminado del volumen lógico RAID, el dispositivo fallido aún no ha sido eliminado del grupo de volúmenes. Para eliminar el dispositivo fallido del grupo de volúmenes, puede ejecutar vgreduce --removemissing VG.
Si el raid_fault_policy se ha establecido en allocate pero no hay dispositivos de repuesto, la asignación fallará, dejando el volumen lógico como está. Si la asignación falla, tienes la opción de arreglar la unidad y luego iniciar la recuperación del dispositivo fallido con la opción --refresh del comando lvchange. Alternativamente, puede reemplazar el dispositivo fallado.
68.7.15.2. El aviso de la política de fallos del RAID
En el siguiente ejemplo, el campo raid_fault_policy se ha configurado como warn en el archivo lvm.conf. El volumen lógico RAID está dispuesto de la siguiente manera.
# lvs -a -o name,copy_percent,devices my_vg
LV Copy% Devices
my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0)
[my_lv_rimage_0] /dev/sdh1(1)
[my_lv_rimage_1] /dev/sdf1(1)
[my_lv_rimage_2] /dev/sdg1(1)
[my_lv_rmeta_0] /dev/sdh1(0)
[my_lv_rmeta_1] /dev/sdf1(0)
[my_lv_rmeta_2] /dev/sdg1(0)
Si el dispositivo /dev/sdh falla, el registro del sistema mostrará mensajes de error. En este caso, sin embargo, LVM no intentará reparar automáticamente el dispositivo RAID reemplazando una de las imágenes. En su lugar, si el dispositivo ha fallado, puede reemplazar el dispositivo con el argumento --repair del comando lvconvert.
68.7.16. Sustitución de un dispositivo RAID en un volumen lógico
Puede sustituir un dispositivo RAID en un volumen lógico.
- Si no se ha producido ningún fallo en el dispositivo RAID, siga Sección 68.7.16.1, “Sustitución de un dispositivo RAID que no ha fallado”.
- Si el dispositivo RAID ha fallado, siga Sección 68.7.16.4, “Sustitución de un dispositivo RAID fallido en un volumen lógico”.
68.7.16.1. Sustitución de un dispositivo RAID que no ha fallado
Para sustituir un dispositivo RAID en un volumen lógico, utilice el argumento --replace del comando lvconvert.
Requisitos previos
- El dispositivo RAID no ha fallado. Los siguientes comandos no funcionarán si el dispositivo RAID ha fallado.
Procedimiento
Sustituya el dispositivo RAID:
# lvconvert --replace dev_to_remove vg/lv possible_replacements- Sustituya dev_to_remove con la ruta del volumen físico que desea reemplazar.
- Sustituya vg/lv con el grupo de volúmenes y el nombre del volumen lógico de la matriz RAID.
- Sustituya possible_replacements con la ruta del volumen físico que desea utilizar como reemplazo.
Ejemplo 68.2. Sustitución de un dispositivo RAID1
El siguiente ejemplo crea un volumen lógico RAID1 y luego reemplaza un dispositivo en ese volumen.
Cree la matriz RAID1:
# lvcreate --type raid1 -m 2 -L 1G -n my_lv my_vg Logical volume "my_lv" createdExamine la matriz RAID1:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sdb1(1) [my_lv_rimage_1] /dev/sdb2(1) [my_lv_rimage_2] /dev/sdc1(1) [my_lv_rmeta_0] /dev/sdb1(0) [my_lv_rmeta_1] /dev/sdb2(0) [my_lv_rmeta_2] /dev/sdc1(0)Sustituya el volumen físico
/dev/sdb2:# lvconvert --replace /dev/sdb2 my_vg/my_lvExamine la matriz RAID1 con el reemplazo:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 37.50 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sdb1(1) [my_lv_rimage_1] /dev/sdc2(1) [my_lv_rimage_2] /dev/sdc1(1) [my_lv_rmeta_0] /dev/sdb1(0) [my_lv_rmeta_1] /dev/sdc2(0) [my_lv_rmeta_2] /dev/sdc1(0)
Ejemplo 68.3. Especificación del volumen físico de sustitución
El siguiente ejemplo crea un volumen lógico RAID1 y luego reemplaza un dispositivo en ese volumen, especificando qué volumen físico usar para el reemplazo.
Cree la matriz RAID1:
# lvcreate --type raid1 -m 1 -L 100 -n my_lv my_vg Logical volume "my_lv" createdExamine la matriz RAID1:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sda1(1) [my_lv_rimage_1] /dev/sdb1(1) [my_lv_rmeta_0] /dev/sda1(0) [my_lv_rmeta_1] /dev/sdb1(0)Examine los volúmenes físicos:
# pvs PV VG Fmt Attr PSize PFree /dev/sda1 my_vg lvm2 a-- 1020.00m 916.00m /dev/sdb1 my_vg lvm2 a-- 1020.00m 916.00m /dev/sdc1 my_vg lvm2 a-- 1020.00m 1020.00m /dev/sdd1 my_vg lvm2 a-- 1020.00m 1020.00mSustituya el volumen físico
/dev/sdb1por/dev/sdd1:# lvconvert --replace /dev/sdb1 my_vg/my_lv /dev/sdd1Examine la matriz RAID1 con el reemplazo:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 28.00 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sda1(1) [my_lv_rimage_1] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sda1(0) [my_lv_rmeta_1] /dev/sdd1(0)
Ejemplo 68.4. Sustitución de varios dispositivos RAID
Puede reemplazar más de un dispositivo RAID a la vez especificando varios argumentos replace, como en el siguiente ejemplo.
Cree una matriz RAID1:
# lvcreate --type raid1 -m 2 -L 100 -n my_lv my_vg Logical volume "my_lv" createdExamine la matriz RAID1:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sda1(1) [my_lv_rimage_1] /dev/sdb1(1) [my_lv_rimage_2] /dev/sdc1(1) [my_lv_rmeta_0] /dev/sda1(0) [my_lv_rmeta_1] /dev/sdb1(0) [my_lv_rmeta_2] /dev/sdc1(0)Sustituya los volúmenes físicos
/dev/sdb1y/dev/sdc1:# lvconvert --replace /dev/sdb1 --replace /dev/sdc1 my_vg/my_lvExamine la matriz RAID1 con los reemplazos:
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 60.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sda1(1) [my_lv_rimage_1] /dev/sdd1(1) [my_lv_rimage_2] /dev/sde1(1) [my_lv_rmeta_0] /dev/sda1(0) [my_lv_rmeta_1] /dev/sdd1(0) [my_lv_rmeta_2] /dev/sde1(0)
68.7.16.2. Dispositivos fallidos en RAID LVM
RAID no es como el mirroring LVM tradicional. El mirroring LVM requería la eliminación de los dispositivos que fallaban o el volumen lógico reflejado se colgaba. Las matrices RAID pueden seguir funcionando con dispositivos fallidos. De hecho, para los tipos de RAID que no sean RAID1, eliminar un dispositivo significaría convertirlo a un nivel inferior de RAID (por ejemplo, de RAID6 a RAID5, o de RAID4 o RAID5 a RAID0).
Por lo tanto, en lugar de eliminar un dispositivo fallado incondicionalmente y potencialmente asignar un reemplazo, LVM le permite reemplazar un dispositivo fallado en un volumen RAID en una solución de un solo paso utilizando el argumento --repair del comando lvconvert.
68.7.16.3. Recuperación de un dispositivo RAID fallido en un volumen lógico
Si el fallo del dispositivo RAID LVM es un fallo transitorio o puede reparar el dispositivo que ha fallado, puede iniciar la recuperación del dispositivo que ha fallado.
Requisitos previos
- El dispositivo que antes fallaba ahora funciona.
Procedimiento
Actualiza el volumen lógico que contiene el dispositivo RAID:
# lvchange --refresh my_vg/my_lv
Pasos de verificación
Examine el volumen lógico con el dispositivo recuperado:
# lvs --all --options name,devices,lv_attr,lv_health_status my_vg
68.7.16.4. Sustitución de un dispositivo RAID fallido en un volumen lógico
Este procedimiento reemplaza un dispositivo fallado que sirve como volumen físico en un volumen lógico RAID LVM.
Requisitos previos
El grupo de volúmenes incluye un volumen físico que proporciona suficiente capacidad libre para reemplazar el dispositivo que ha fallado.
Si no hay ningún volumen físico con suficientes extensiones libres en el grupo de volúmenes, añada un nuevo volumen físico lo suficientemente grande utilizando la utilidad
vgextend.
Procedimiento
En el siguiente ejemplo, un volumen lógico RAID está dispuesto de la siguiente manera:
# lvs --all --options name,copy_percent,devices my_vg LV Cpy%Sync Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdc1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdc1(0) [my_lv_rmeta_2] /dev/sdd1(0)Si el dispositivo
/dev/sdcfalla, la salida del comandolvses la siguiente:# lvs --all --options name,copy_percent,devices my_vg /dev/sdc: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. WARNING: Couldn't find all devices for LV my_vg/my_lv_rimage_1 while checking used and assumed devices. WARNING: Couldn't find all devices for LV my_vg/my_lv_rmeta_1 while checking used and assumed devices. LV Cpy%Sync Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] [unknown](1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] [unknown](0) [my_lv_rmeta_2] /dev/sdd1(0)Sustituya el dispositivo que ha fallado y visualice el volumen lógico:
# lvconvert --repair my_vg/my_lv /dev/sdc: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. WARNING: Couldn't find all devices for LV my_vg/my_lv_rimage_1 while checking used and assumed devices. WARNING: Couldn't find all devices for LV my_vg/my_lv_rmeta_1 while checking used and assumed devices. Attempt to replace failed RAID images (requires full device resync)? [y/n]: y Faulty devices in my_vg/my_lv successfully replaced.Opcional: Para especificar manualmente el volumen físico que sustituye al dispositivo que ha fallado, añada el volumen físico al final del comando:
# lvconvert --repair my_vg/my_lv replacement_pvExamine el volumen lógico con la sustitución:
# lvs --all --options name,copy_percent,devices my_vg /dev/sdc: open failed: No such device or address /dev/sdc1: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. LV Cpy%Sync Devices my_lv 43.79 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdb1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdb1(0) [my_lv_rmeta_2] /dev/sdd1(0)Hasta que no elimine el dispositivo fallado del grupo de volúmenes, las utilidades LVM siguen indicando que LVM no puede encontrar el dispositivo fallado.
Elimine el dispositivo que ha fallado del grupo de volúmenes:
# vgreduce --removemissing VG
68.7.17. Comprobación de la coherencia de los datos en un volumen lógico RAID (RAID scrubbing)
LVM proporciona soporte de scrubbing para volúmenes lógicos RAID. El scrubbing de RAID es el proceso de lectura de todos los datos y bloques de paridad de un array y la comprobación de su coherencia.
Procedimiento
Opcional: Limitar el ancho de banda de E/S que utiliza el proceso de depuración.
Cuando se realiza una operación de depuración de RAID, la E/S en segundo plano requerida por las operaciones de
syncpuede desplazar otras E/S a los dispositivos LVM, como las actualizaciones de los metadatos del grupo de volúmenes. Esto puede hacer que las otras operaciones LVM se ralenticen. Se puede controlar la tasa de la operación de depuración implementando el estrangulamiento de la recuperación.Añade las siguientes opciones a los comandos de
lvchange --syncactionen los siguientes pasos:--maxrecoveryrate Rate[bBsSkKmMgG]- Establece la tasa de recuperación máxima para que la operación no desplace las operaciones de E/S nominales. Establecer la tasa de recuperación en 0 significa que la operación no tiene límites.
--minrecoveryrate Rate[bBsSkKmMgG]-
Establece la tasa de recuperación mínima para garantizar que la E/S de las operaciones de
syncalcance un rendimiento mínimo, incluso cuando haya una E/S nominal intensa.
Especifique el valor de Rate como una cantidad por segundo para cada dispositivo de la matriz. Si no proporciona ningún sufijo, las opciones asumen kiB por segundo por dispositivo.
Muestra el número de discrepancias en la matriz, sin repararlas:
# lvchange --syncaction check vg/raid_lvCorregir las discrepancias en la matriz:
# lvchange --syncaction repair vg/raid_lvNotaLa operación
lvchange --syncaction repairno realiza la misma función que la operaciónlvconvert --repair:-
La operación
lvchange --syncaction repairinicia una operación de sincronización en segundo plano en la matriz. -
La operación
lvconvert --repairrepara o sustituye los dispositivos que fallan en un espejo o volumen lógico RAID.
-
La operación
Opcional: Muestra información sobre la operación de lavado:
# lvs -o raid_sync_action,raid_mismatch_count vg/lvEl campo
raid_sync_actionmuestra la operación de sincronización actual que está realizando el volumen RAID. Puede ser uno de los siguientes valores:idle- Todas las operaciones de sincronización completadas (sin hacer nada)
resync- Inicialización de una matriz o recuperación tras un fallo de la máquina
recover- Sustitución de un dispositivo en la matriz
check- Buscar incoherencias en las matrices
repair- Buscar y reparar incoherencias
-
El campo
raid_mismatch_countmuestra el número de discrepancias encontradas durante una operación decheck. -
El campo
Cpy%Syncmuestra el progreso de las operaciones desync. El campo
lv_attrproporciona indicadores adicionales. El bit 9 de este campo muestra la salud del volumen lógico, y admite los siguientes indicadores:-
m(mismatches) indica que hay discrepancias en un volumen lógico RAID. Este carácter se muestra después de que una operación de depuración haya detectado que partes del RAID no son coherentes. -
r(refresh) indica que un dispositivo en un array RAID ha sufrido un fallo y el kernel lo considera como fallido, aunque LVM puede leer la etiqueta del dispositivo y considera que el dispositivo está operativo. Refresca el volumen lógico para notificar al kernel que el dispositivo está ahora disponible, o reemplaza el dispositivo si sospechas que ha fallado.
-
Recursos adicionales
-
Para más información, consulte las páginas de manual
lvchange(8)ylvmraid(7).
68.7.18. Conversión de un nivel RAID (absorción de RAID)
LVM soporta Raid takeover, lo que significa convertir un volumen lógico RAID de un nivel RAID a otro (como de RAID 5 a RAID 6). El cambio de nivel RAID se hace normalmente para aumentar o disminuir la resistencia a los fallos de los dispositivos o para restripear los volúmenes lógicos. Se utiliza la dirección lvconvert para la absorción de RAID. Para obtener información sobre la adquisición de RAID y para ver ejemplos de uso de lvconvert para convertir un volumen lógico RAID, consulte la página de manual lvmraid(7).
68.7.19. Cambio de atributos de un volumen RAID (RAID reshape)
RAID reshaping significa cambiar los atributos de un volumen lógico RAID manteniendo el mismo nivel RAID. Algunos de los atributos que se pueden cambiar son la disposición del RAID, el tamaño de las franjas y el número de franjas. Para obtener información sobre la remodelación de RAID y ejemplos de uso del comando lvconvert para remodelar un volumen lógico RAID, consulte la página de manual lvmraid(7).
68.7.20. Control de las operaciones de E/S en un volumen lógico RAID1
Puedes controlar las operaciones de E/S de un dispositivo en un volumen lógico RAID1 utilizando los parámetros --writemostly y --writebehind del comando lvchange. El formato para utilizar estos parámetros es el siguiente.
--[raid]writemostly PhysicalVolume[:{t|y|n}]Marca un dispositivo en un volumen lógico RAID1 como
write-mostly. Todas las lecturas a estas unidades se evitarán a menos que sean necesarias. La configuración de este parámetro mantiene el número de operaciones de E/S en la unidad al mínimo. Por defecto, el atributowrite-mostlyse establece en sí para el volumen físico especificado en el volumen lógico. Es posible eliminar la banderawrite-mostlyañadiendo:nal volumen físico o alternar el valor especificando:t. El argumento--writemostlyse puede especificar más de una vez en un solo comando, lo que hace posible alternar los atributos de sólo escritura para todos los volúmenes físicos en un volumen lógico a la vez.--[raid]writebehind IOCountEspecifica el número máximo de escrituras pendientes que se permiten en los dispositivos de un volumen lógico RAID1 que están marcados como
write-mostly. Una vez que se excede este valor, las escrituras se vuelven sincrónicas, haciendo que todas las escrituras en los dispositivos constituyentes se completen antes de que el array señale que la escritura se ha completado. Poner el valor a cero borra la preferencia y permite al sistema elegir el valor de forma arbitraria.
68.7.21. Cambiar el tamaño de la región en un volumen lógico RAID
Cuando se crea un volumen lógico RAID, el tamaño de la región para el volumen lógico será el valor del parámetro raid_region_size en el archivo /etc/lvm/lvm.conf. Puedes anular este valor por defecto con la opción -R del comando lvcreate.
Después de crear un volumen lógico RAID, puede cambiar el tamaño de la región del volumen con la opción -R del comando lvconvert. El siguiente ejemplo cambia el tamaño de región del volumen lógico vg/raidlv a 4096K. El volumen RAID debe estar sincronizado para poder cambiar el tamaño de la región.
# lvconvert -R 4096K vg/raid1
Do you really want to change the region_size 512.00 KiB of LV vg/raid1 to 4.00 MiB? [y/n]: y
Changed region size on RAID LV vg/raid1 to 4.00 MiB.68.8. Volúmenes lógicos instantáneos
La función de instantáneas LVM proporciona la capacidad de crear imágenes virtuales de un dispositivo en un instante determinado sin causar una interrupción del servicio.
68.8.1. Volúmenes de instantáneas
La función de instantáneas de LVM proporciona la capacidad de crear imágenes virtuales de un dispositivo en un instante determinado sin causar una interrupción del servicio. Cuando se realiza un cambio en el dispositivo original (el origen) después de tomar una instantánea, la función de instantánea hace una copia del área de datos modificada tal y como estaba antes del cambio para poder reconstruir el estado del dispositivo.
LVM soporta instantáneas de aprovisionamiento ligero.
Dado que una instantánea sólo copia las áreas de datos que cambian después de la creación de la instantánea, la función de instantánea requiere una cantidad mínima de almacenamiento. Por ejemplo, con un origen que se actualiza raramente, el 3-5 % de la capacidad del origen es suficiente para mantener la instantánea.
Las copias instantáneas de un sistema de archivos son copias virtuales, no una copia de seguridad real de un sistema de archivos. Las instantáneas no sustituyen a un procedimiento de copia de seguridad.
El tamaño de la instantánea gobierna la cantidad de espacio reservado para almacenar los cambios en el volumen de origen. Por ejemplo, si haces una instantánea y luego sobrescribes completamente el origen, la instantánea tendría que ser al menos tan grande como el volumen de origen para mantener los cambios. Es necesario dimensionar una instantánea de acuerdo con el nivel de cambio esperado. Así, por ejemplo, una instantánea de corta duración de un volumen de lectura, como /usr, necesitaría menos espacio que una instantánea de larga duración de un volumen que ve un mayor número de escrituras, como /home.
Si una instantánea se llena, la instantánea deja de ser válida, ya que no puede seguir los cambios en el volumen de origen. Debe controlar regularmente el tamaño de la instantánea. Sin embargo, las instantáneas son totalmente redimensionables, por lo que si tienes capacidad de almacenamiento puedes aumentar el tamaño del volumen de la instantánea para evitar que se pierda. A la inversa, si ves que el volumen de la instantánea es más grande de lo que necesitas, puedes reducir el tamaño del volumen para liberar espacio que necesitan otros volúmenes lógicos.
Cuando se crea un sistema de archivos de instantánea, el acceso de lectura y escritura completo al origen sigue siendo posible. Si se modifica un chunk en una instantánea, ese chunk se marca y nunca se copia del volumen original.
La función de instantáneas tiene varios usos:
- Normalmente, se toma una instantánea cuando se necesita realizar una copia de seguridad en un volumen lógico sin detener el sistema en vivo que está actualizando continuamente los datos.
-
Puede ejecutar el comando
fscken un sistema de archivos de instantánea para comprobar la integridad del sistema de archivos y determinar si el sistema de archivos original requiere una reparación del sistema de archivos. - Dado que la instantánea es de lectura/escritura, puede probar las aplicaciones contra los datos de producción tomando una instantánea y ejecutando pruebas contra la instantánea, dejando los datos reales intactos.
- Puede crear volúmenes LVM para utilizarlos con Red Hat Virtualization. Las instantáneas LVM se pueden utilizar para crear instantáneas de imágenes de huéspedes virtuales. Estas instantáneas pueden proporcionar una forma conveniente de modificar los huéspedes existentes o crear nuevos huéspedes con un mínimo de almacenamiento adicional.
Puedes utilizar la opción --merge del comando lvconvert para fusionar una instantánea con su volumen de origen. Una de las aplicaciones de esta función es realizar la reversión del sistema si has perdido datos o archivos o si necesitas restaurar tu sistema a un estado anterior. Después de fusionar el volumen de la instantánea, el volumen lógico resultante tendrá el nombre, el número menor y el UUID del volumen de origen y la instantánea fusionada se eliminará.
68.8.2. Creación de volúmenes de instantáneas
Utilice el argumento -s del comando lvcreate para crear un volumen de instantánea. Un volumen de instantánea es escribible.
Las instantáneas LVM no son compatibles con los nodos de un clúster. No se puede crear un volumen de instantánea en un grupo de volumen compartido. Sin embargo, si necesitas crear una copia de seguridad consistente de los datos de un volumen lógico compartido, puedes activar el volumen exclusivamente y luego crear la instantánea.
Las instantáneas son compatibles con los volúmenes lógicos RAID.
LVM no permite crear un volumen de instantánea que sea mayor que el tamaño del volumen de origen más los metadatos necesarios para el volumen. Si especifica un volumen de instantánea que es mayor que esto, el sistema creará un volumen de instantánea que es sólo tan grande como se necesitará para el tamaño del origen.
Por defecto, un volumen de instantánea se omite durante los comandos de activación normales.
El siguiente procedimiento crea un volumen lógico de origen llamado origin y un volumen instantáneo del volumen original llamado snap.
Cree un volumen lógico llamado
origina partir del grupo de volúmenesVG.# lvcreate -L 1G -n origin VG Logical volume "origin" created.Cree un volumen lógico de instantánea de
/dev/VG/originque tenga un tamaño de 100 MB llamadosnap. Si el volumen lógico original contiene un sistema de archivos, puedes montar el volumen lógico de instantánea en un directorio arbitrario para acceder al contenido del sistema de archivos y ejecutar una copia de seguridad mientras el sistema de archivos original sigue actualizándose.# lvcreate --size 100M --snapshot --name snap /dev/VG/origin Logical volume "snap" created.Muestra el estado del volumen lógico
/dev/VG/origin, mostrando todos los volúmenes lógicos instantáneos y su estado (activo o inactivo).# lvdisplay /dev/VG/origin --- Logical volume --- LV Path /dev/VG/origin LV Name origin VG Name VG LV UUID EsFoBp-CB9H-Epl5-pUO4-Yevi-EdFS-xtFnaF LV Write Access read/write LV Creation host, time host-083.virt.lab.msp.redhat.com, 2019-04-11 14:45:06 -0500 LV snapshot status source of snap [active] LV Status available # open 0 LV Size 1.00 GiB Current LE 256 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 8192 Block device 253:6-
El comando
lvs, por defecto, muestra el volumen de origen y el porcentaje actual del volumen de instantánea que se está utilizando. El siguiente ejemplo muestra la salida por defecto del comandolvsdespués de haber creado el volumen de instantánea, con una visualización que incluye los dispositivos que constituyen los volúmenes lógicos.
# lvs -a -o +devices
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices
origin VG owi-a-s--- 1.00g /dev/sde1(0)
snap VG swi-a-s--- 100.00m origin 0.00 /dev/sde1(256)
Dado que la instantánea aumenta de tamaño a medida que el volumen de origen cambia, es importante controlar el porcentaje del volumen de la instantánea regularmente con el comando lvs para asegurarse de que no se llena. Una instantánea que se llena 100 veces se pierde por completo, ya que una escritura en partes del origen que no han cambiado no podría tener éxito sin corromper la instantánea.
Además de que la propia instantánea se invalida cuando está llena, cualquier sistema de archivos montado en ese dispositivo de instantánea se desmonta a la fuerza, evitando los inevitables errores del sistema de archivos al acceder al punto de montaje. Además, puede especificar la opción snapshot_autoextend_threshold en el archivo lvm.conf. Esta opción permite la extensión automática de una instantánea siempre que el espacio restante de la instantánea caiga por debajo del umbral que hayas establecido. Esta función requiere que haya espacio sin asignar en el grupo de volúmenes.
LVM no permite crear un volumen de instantánea que sea mayor que el tamaño del volumen de origen más los metadatos necesarios para el volumen. Del mismo modo, la extensión automática de una instantánea no aumentará el tamaño de un volumen de instantánea más allá del tamaño máximo calculado que es necesario para la instantánea. Una vez que una instantánea ha crecido lo suficiente como para cubrir el origen, ya no se supervisa la extensión automática.
La información sobre la configuración de snapshot_autoextend_threshold y snapshot_autoextend_percent se proporciona en el propio archivo /etc/lvm/lvm.conf.
68.8.3. Fusión de volúmenes de instantáneas
Puedes utilizar la opción --merge del comando lvconvert para fusionar una instantánea con su volumen de origen. Si tanto el volumen de origen como el de la instantánea no están abiertos, la fusión se iniciará inmediatamente. En caso contrario, la fusión se iniciará la primera vez que el origen o la instantánea se activen y ambos se cierren. La fusión de una instantánea en un origen que no puede cerrarse, por ejemplo un sistema de archivos raíz, se aplaza hasta la próxima vez que se active el volumen de origen. Cuando se inicia la fusión, el volumen lógico resultante tendrá el nombre del origen, el número menor y el UUID. Mientras la fusión está en curso, las lecturas o escrituras en el origen aparecen como si fueran dirigidas a la instantánea que se está fusionando. Cuando la fusión termina, la instantánea fusionada se elimina.
El siguiente comando fusiona el volumen snapshot vg00/lvol1_snap en su origen.
# lvconvert --merge vg00/lvol1_snap
Puedes especificar múltiples instantáneas en la línea de comandos, o puedes usar etiquetas de objetos LVM para especificar que varias instantáneas se fusionen con sus respectivos orígenes. En el siguiente ejemplo, los volúmenes lógicos vg00/lvol1, vg00/lvol2, y vg00/lvol3 están todos etiquetados con la etiqueta @some_tag. El siguiente comando fusiona los volúmenes lógicos de instantáneas para los tres volúmenes en serie: vg00/lvol1, luego vg00/lvol2, luego vg00/lvol3. Si se utilizara la opción --background, todas las fusiones de volúmenes lógicos de instantáneas se iniciarían en paralelo.
# lvconvert --merge @some_tag
Para más información sobre el comando lvconvert --merge, consulte la página de manual lvconvert(8).
68.9. Creación y gestión de volúmenes lógicos de aprovisionamiento ligero (volúmenes ligeros)
Los volúmenes lógicos pueden tener un aprovisionamiento ligero. Esto le permite crear volúmenes lógicos que son más grandes que los extensiones disponibles.
68.9.1. Volúmenes lógicos de aprovisionamiento fino (volúmenes finos)
Los volúmenes lógicos pueden tener un aprovisionamiento ligero. Esto le permite crear volúmenes lógicos que son más grandes que los extensiones disponibles. Mediante el aprovisionamiento fino, puede gestionar un pool de almacenamiento de espacio libre, conocido como thin pool, que puede asignarse a un número arbitrario de dispositivos cuando lo necesiten las aplicaciones. A continuación, puede crear dispositivos que se pueden vincular al thin pool para su posterior asignación cuando una aplicación escriba realmente en el volumen lógico. El thin pool puede ampliarse dinámicamente cuando sea necesario para una asignación rentable del espacio de almacenamiento.
Los volúmenes ligeros no son compatibles con los nodos de un clúster. La reserva delgada y todos sus volúmenes delgados deben activarse exclusivamente en un solo nodo del clúster.
Al utilizar el thin provisioning, un administrador de almacenamiento puede sobrecomprometer el almacenamiento físico, evitando a menudo la necesidad de comprar almacenamiento adicional. Por ejemplo, si diez usuarios solicitan cada uno un sistema de archivos de 100 GB para su aplicación, el administrador de almacenamiento puede crear lo que parece ser un sistema de archivos de 100 GB para cada usuario, pero que está respaldado por menos almacenamiento real que se utiliza sólo cuando se necesita. Cuando se utiliza el thin provisioning, es importante que el administrador de almacenamiento supervise el pool de almacenamiento y añada más capacidad si empieza a llenarse.
Para asegurarse de que todo el espacio disponible puede ser utilizado, LVM soporta el descarte de datos. Esto permite reutilizar el espacio que antes utilizaba un archivo descartado u otro rango de bloques.
Los volúmenes delgados ofrecen soporte para una nueva implementación de volúmenes lógicos de copia en escritura (COW), que permiten que muchos dispositivos virtuales compartan los mismos datos en el grupo delgado.
68.9.2. Creación de volúmenes lógicos de aprovisionamiento ligero
Este procedimiento proporciona una visión general de los comandos básicos que se utilizan para crear y aumentar los volúmenes lógicos de aprovisionamiento ligero. Para obtener información detallada sobre el aprovisionamiento ligero de LVM, así como información sobre el uso de los comandos y utilidades de LVM con volúmenes lógicos de aprovisionamiento ligero, consulte la página de manual lvmthin(7).
Para crear un volumen ligero, realice las siguientes tareas:
-
Cree un grupo de volúmenes con el comando
vgcreate. -
Cree un grupo ligero con el comando
lvcreate. -
Cree un volumen delgado en la reserva delgada con el comando
lvcreate.
Puedes utilizar la opción -T (o --thin) del comando lvcreate para crear un pool delgado o un volumen delgado. También puedes utilizar la opción -T del comando lvcreate para crear un pool delgado y un volumen delgado en ese pool al mismo tiempo con un solo comando.
El siguiente comando utiliza la opción -T del comando lvcreate para crear un thin pool llamado mythinpool en el grupo de volúmenes vg001 y que tiene un tamaño de 100M. Ten en cuenta que como estás creando un pool de espacio físico, debes especificar el tamaño del pool. La opción -T del comando lvcreate no toma un argumento; deduce qué tipo de dispositivo se va a crear a partir de las otras opciones que especifica el comando.
# lvcreate -L 100M -T vg001/mythinpool
Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data.
Logical volume "mythinpool" created.
# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
mythinpool vg001 twi-a-tz-- 100.00m 0.00 10.84
El siguiente comando utiliza la opción -T del comando lvcreate para crear un volumen delgado llamado thinvolume en el pool delgado vg001/mythinpool. Ten en cuenta que en este caso estás especificando el tamaño virtual, y que estás especificando un tamaño virtual para el volumen que es mayor que el pool que lo contiene.
# lvcreate -V 1G -T vg001/mythinpool -n thinvolume
WARNING: Sum of all thin volume sizes (1.00 GiB) exceeds the size of thin pool vg001/mythinpool (100.00 MiB).
WARNING: You have not turned on protection against thin pools running out of space.
WARNING: Set activation/thin_pool_autoextend_threshold below 100 to trigger automatic extension of thin pools before they get full.
Logical volume "thinvolume" created.
# lvs
LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert
mythinpool vg001 twi-a-tz 100.00m 0.00
thinvolume vg001 Vwi-a-tz 1.00g mythinpool 0.00
El siguiente comando utiliza la opción -T del comando lvcreate para crear una reserva delgada y un volumen delgado en esa reserva especificando tanto un argumento de tamaño como de tamaño virtual para el comando lvcreate. Este comando crea una reserva delgada llamada mythinpool en el grupo de volúmenes vg001 y también crea un volumen delgado llamado thinvolume en esa reserva.
# lvcreate -L 100M -T vg001/mythinpool -V 1G -n thinvolume
Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data.
WARNING: Sum of all thin volume sizes (1.00 GiB) exceeds the size of thin pool vg001/mythinpool (100.00 MiB).
WARNING: You have not turned on protection against thin pools running out of space.
WARNING: Set activation/thin_pool_autoextend_threshold below 100 to trigger automatic extension of thin pools before they get full.
Logical volume "thinvolume" created.
# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
mythinpool vg001 twi-aotz-- 100.00m 0.00 10.94
thinvolume vg001 Vwi-a-tz-- 1.00g mythinpool 0.00
También puedes crear un thin pool especificando el parámetro --thinpool del comando lvcreate. A diferencia de la opción -T, el parámetro --thinpool requiere un argumento, que es el nombre del volumen lógico del thin pool que se está creando. El siguiente ejemplo especifica el parámetro --thinpool del comando lvcreate para crear un thin pool llamado mythinpool en el grupo de volúmenes vg001 y que tiene un tamaño de 100M:
# lvcreate -L 100M --thinpool mythinpool vg001
Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data.
Logical volume "mythinpool" created.
# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
mythinpool vg001 twi-a-tz-- 100.00m 0.00 10.84Utiliza los siguientes criterios para utilizar el tamaño de los trozos:
- Un tamaño de trozo más pequeño requiere más metadatos y dificulta el rendimiento, pero proporciona una mejor utilización del espacio con las instantáneas.
- Un tamaño de trozo mayor requiere menos manipulación de metadatos, pero hace que la instantánea sea menos eficiente en cuanto a espacio.
Por defecto, lvm2 comienza con un tamaño de chunk de 64KiB y aumenta su valor cuando el tamaño resultante del dispositivo de metadatos del thin pool crece por encima de los 128MiB, esto mantiene el tamaño de los metadatos compacto. Sin embargo, esto puede resultar en algunos valores de tamaño de chunk grandes, que son menos eficientes en cuanto a espacio para el uso de instantáneas. En estos casos, un tamaño de chunk más pequeño y un tamaño de metadatos más grande es una mejor opción.
Si el tamaño de los datos del volumen está en el rango de TiB, utilice ~15.8GiB como tamaño de los metadatos, que es el tamaño máximo soportado, y establezca el tamaño de los trozos según sus necesidades. Sin embargo, tenga en cuenta que no es posible aumentar el tamaño de los metadatos si necesita ampliar el tamaño de los datos del volumen y tiene un tamaño de trozo pequeño.
Red Hat no recomienda establecer un tamaño de chunk menor que el valor por defecto. Si el tamaño del chunk es demasiado pequeño y su volumen se queda sin espacio para los metadatos, el volumen no podrá crear datos. Supervise sus volúmenes lógicos para asegurarse de que se amplían, o cree más almacenamiento antes de que los volúmenes de metadatos se llenen por completo. Asegúrese de configurar su thin pool con un tamaño de trozo lo suficientemente grande como para que no se quede sin espacio para los metadatos.
El striping es soportado para la creación de pools. El siguiente comando crea una reserva delgada de 100M llamada pool en el grupo de volúmenes vg001 con dos franjas de 64 kB y un tamaño de trozo de 256 kB. También crea un volumen fino de 1T, vg00/thin_lv.
# lvcreate -i 2 -I 64 -c 256 -L 100M -T vg00/pool -V 1T --name thin_lv
Puede ampliar el tamaño de un volumen ligero con el comando lvextend. Sin embargo, no se puede reducir el tamaño de un thin pool.
El siguiente comando redimensiona un thin pool existente que tiene un tamaño de 100M ampliándolo otros 100M.
# lvextend -L+100M vg001/mythinpool
Extending logical volume mythinpool to 200.00 MiB
Logical volume mythinpool successfully resized
# lvs
LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert
mythinpool vg001 twi-a-tz 200.00m 0.00
thinvolume vg001 Vwi-a-tz 1.00g mythinpool 0.00
Al igual que con otros tipos de volúmenes lógicos, puedes renombrar el volumen con el comando lvrename, puedes eliminar el volumen con el comando lvremove, y puedes mostrar información sobre el volumen con los comandos lvs y lvdisplay.
By default, the lvcreate command sets the size of the thin pool’s metadata logical volume according to the formula (Pool_LV_size / Pool_LV_chunk_size * 64). If you will have large numbers of snapshots or if you have have small chunk sizes for your thin pool and thus expect significant growth of the size of the thin pool at a later time, you may need to increase the default value of the thin pool’s metadata volume with the --poolmetadatasize parameter of the lvcreate command. The supported value for the thin pool’s metadata logical volume is in the range between 2MiB and 16GiB.
Puede utilizar el parámetro --thinpool del comando lvconvert para convertir un volumen lógico existente en un volumen de reserva delgada. Cuando convierta un volumen lógico existente en un volumen de reserva delgada, debe utilizar el parámetro --poolmetadata junto con el parámetro --thinpool del comando lvconvert para convertir un volumen lógico existente en el volumen de metadatos del volumen de reserva delgada.
La conversión de un volumen lógico en un volumen thin pool o en un volumen de metadatos thin pool destruye el contenido del volumen lógico, ya que en este caso el lvconvert no conserva el contenido de los dispositivos, sino que lo sobrescribe.
El siguiente ejemplo convierte el volumen lógico existente lv1 en el grupo de volúmenes vg001 en un volumen thin pool y convierte el volumen lógico existente lv2 en el grupo de volúmenes vg001 en el volumen de metadatos para ese volumen thin pool.
# lvconvert --thinpool vg001/lv1 --poolmetadata vg001/lv2
Converted vg001/lv1 to thin pool.68.9.3. Volúmenes instantáneos de aprovisionamiento ligero
Red Hat Enterprise Linux proporciona soporte para volúmenes de instantáneas de aprovisionamiento delgado. Los volúmenes de instantáneas delgadas permiten que muchos dispositivos virtuales sean almacenados en el mismo volumen de datos. Esto simplifica la administración y permite compartir datos entre volúmenes de instantáneas.
Como para todos los volúmenes de instantánea LVM, así como para todos los volúmenes finos, los volúmenes finos de instantánea no son compatibles con los nodos de un clúster. El volumen de instantánea debe activarse exclusivamente en un solo nodo del clúster.
Los volúmenes de instantáneas delgadas proporcionan los siguientes beneficios:
- Un volumen delgado de instantáneas puede reducir el uso del disco cuando hay varias instantáneas del mismo volumen de origen.
- Si hay varias instantáneas del mismo origen, una escritura en el origen provocará una operación COW para conservar los datos. Aumentar el número de instantáneas del origen no debería suponer una ralentización importante.
- Los volúmenes finos de instantáneas pueden utilizarse como origen de volumen lógico para otra instantánea. Esto permite una profundidad arbitraria de instantáneas recursivas (instantáneas de instantáneas de instantáneas...).
- Una instantánea de un volumen lógico delgado también crea un volumen lógico delgado. Esto no consume espacio de datos hasta que se requiera una operación COW, o hasta que se escriba la propia instantánea.
- Un volumen delgado de instantáneas no necesita ser activado con su origen, por lo que un usuario puede tener sólo el origen activo mientras hay muchos volúmenes de instantáneas inactivos del origen.
- Cuando se elimina el origen de un volumen de instantáneas de aprovisionamiento ligero, cada instantánea de ese volumen de origen se convierte en un volumen de aprovisionamiento ligero independiente. Esto significa que, en lugar de fusionar una instantánea con su volumen de origen, puedes optar por eliminar el volumen de origen y luego crear una nueva instantánea con aprovisionamiento ligero utilizando ese volumen independiente como volumen de origen para la nueva instantánea.
Aunque hay muchas ventajas en el uso de volúmenes delgados de instantáneas, hay algunos casos de uso para los que la antigua función de volumen de instantáneas LVM puede ser más apropiada para sus necesidades:
- No se puede cambiar el tamaño del chunk de un thin pool. Si el thin pool tiene un tamaño de chunk grande (por ejemplo, 1MB) y necesita una instantánea de corta duración para la que un tamaño de chunk tan grande no es eficiente, puede optar por utilizar la función de instantáneas antiguas.
- No se puede limitar el tamaño de un volumen de instantánea delgada; la instantánea utilizará todo el espacio de la reserva delgada, si es necesario. Esto puede no ser apropiado para sus necesidades.
En general, debe tener en cuenta los requisitos específicos de su sitio web a la hora de decidir qué formato de instantánea utilizar.
68.9.4. Creación de volúmenes de instantáneas con aprovisionamiento ligero
Red Hat Enterprise Linux ofrece soporte para volúmenes de instantáneas de aprovisionamiento ligero.
Esta sección proporciona una visión general de los comandos básicos que se utilizan para crear y hacer crecer los volúmenes instantáneos de aprovisionamiento ligero. Para obtener información detallada sobre el aprovisionamiento ligero de LVM, así como información sobre el uso de los comandos y utilidades de LVM con volúmenes lógicos de aprovisionamiento ligero, consulte la página de manual lvmthin(7).
Cuando se crea un volumen de instantánea delgada, no se especifica el tamaño del volumen. Si se especifica un parámetro de tamaño, la instantánea que se creará no será un volumen de instantánea delgada y no utilizará el pool delgado para almacenar datos. Por ejemplo, el comando lvcreate -s vg/thinvolume -L10M no creará una instantánea delgada, aunque el volumen de origen sea un volumen delgado.
Las instantáneas delgadas pueden crearse para volúmenes de origen con aprovisionamiento delgado o para volúmenes de origen que no tienen aprovisionamiento delgado.
Puedes especificar un nombre para el volumen instantáneo con la opción --name del comando lvcreate. El siguiente comando crea un volumen de instantánea de aprovisionamiento ligero del volumen lógico de aprovisionamiento ligero vg001/thinvolume que se llama mysnapshot1.
# lvcreate -s --name mysnapshot1 vg001/thinvolume
Logical volume "mysnapshot1" created
# lvs
LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert
mysnapshot1 vg001 Vwi-a-tz 1.00g mythinpool thinvolume 0.00
mythinpool vg001 twi-a-tz 100.00m 0.00
thinvolume vg001 Vwi-a-tz 1.00g mythinpool 0.00Un volumen delgado de instantánea tiene las mismas características que cualquier otro volumen delgado. Puedes activar el volumen de forma independiente, ampliar el volumen, renombrar el volumen, eliminar el volumen e incluso hacer una instantánea del volumen.
Por defecto, un volumen instantáneo se omite durante los comandos de activación normales. Para obtener información sobre el control de la activación de un volumen lógico, consulte Activación de volúmenes lógicos en el documento Configuring and managing logical volumes.
También puede crear una instantánea con aprovisionamiento ligero de un volumen lógico sin aprovisionamiento ligero. Dado que el volumen lógico no aprovisionado en capa fina no está contenido en un fondo común, se denomina external origin. Los volúmenes de origen externo pueden ser utilizados y compartidos por muchos volúmenes instantáneos de aprovisionamiento fino, incluso de diferentes pools finos. El origen externo debe estar inactivo y ser de sólo lectura en el momento en que se crea la instantánea de aprovisionamiento fino.
Para crear una instantánea con aprovisionamiento ligero de un origen externo, debes especificar la opción --thinpool. El siguiente comando crea un volumen de instantánea delgada del volumen inactivo de sólo lectura origin_volume. El volumen thin snapshot se llama mythinsnap. El volumen lógico origin_volume se convierte entonces en el origen externo delgado para el volumen instantáneo delgado mythinsnap en el grupo de volúmenes vg001 que utilizará la reserva delgada existente vg001/pool. Debido a que el volumen de origen debe estar en el mismo grupo de volúmenes que el volumen de instantánea, no es necesario especificar el grupo de volúmenes cuando se especifica el volumen lógico de origen.
# lvcreate -s --thinpool vg001/pool origin_volume --name mythinsnapPuedes crear un segundo volumen de instantánea con aprovisionamiento ligero del primer volumen de instantánea, como en el siguiente comando.
# lvcreate -s vg001/mythinsnap --name my2ndthinsnap
Puedes mostrar una lista de todos los ancestros y descendientes de un volumen lógico de instantánea delgada especificando los campos de información lv_ancestors y lv_descendants del comando lvs.
En el siguiente ejemplo:
-
stack1es un volumen de origen en el grupo de volúmenesvg001. -
stack2es una instantánea destack1 -
stack3es una instantánea destack2 -
stack4es una instantánea destack3
Además:
-
stack5es también una instantánea destack2 -
stack6es una instantánea destack5
$ lvs -o name,lv_ancestors,lv_descendants vg001
LV Ancestors Descendants
stack1 stack2,stack3,stack4,stack5,stack6
stack2 stack1 stack3,stack4,stack5,stack6
stack3 stack2,stack1 stack4
stack4 stack3,stack2,stack1
stack5 stack2,stack1 stack6
stack6 stack5,stack2,stack1
pool
Los campos lv_ancestors y lv_descendants muestran las dependencias existentes, pero no hacen un seguimiento de las entradas eliminadas, lo que puede romper una cadena de dependencia si la entrada se eliminó de la mitad de la cadena. Por ejemplo, si se elimina el volumen lógico stack3 de esta configuración de ejemplo, la pantalla es la siguiente.
$ lvs -o name,lv_ancestors,lv_descendants vg001
LV Ancestors Descendants
stack1 stack2,stack5,stack6
stack2 stack1 stack5,stack6
stack4
stack5 stack2,stack1 stack6
stack6 stack5,stack2,stack1
pool
Puede configurar su sistema para rastrear y mostrar los volúmenes lógicos que han sido eliminados, y puede mostrar la cadena de dependencia completa que incluye esos volúmenes especificando los campos lv_ancestors_full y lv_descendants_full.
68.9.5. Seguimiento y visualización de los volúmenes finos de instantáneas que se han eliminado
Puede configurar su sistema para realizar un seguimiento de los volúmenes lógicos finos y de instantáneas finas que se han eliminado activando la opción de metadatos record_lvs_history en el archivo de configuración lvm.conf. Esto le permite mostrar una cadena de dependencia de instantáneas delgadas completa que incluye los volúmenes lógicos que se han eliminado de la cadena de dependencia original y se han convertido en volúmenes lógicos de historical.
Puede configurar su sistema para retener los volúmenes históricos durante un periodo de tiempo definido especificando el tiempo de retención, en segundos, con la opción de metadatos lvs_history_retention_time en el archivo de configuración lvm.conf.
Un volumen lógico histórico conserva una representación simplificada del volumen lógico que ha sido eliminado, incluyendo los siguientes campos de información para el volumen:
-
lv_time_removed: el tiempo de eliminación del volumen lógico -
lv_time: la hora de creación del volumen lógico -
lv_name: el nombre del volumen lógico -
lv_uuid: el UUID del volumen lógico -
vg_name: el grupo de volumen que contiene el volumen lógico.
Cuando se elimina un volumen, el nombre del volumen lógico histórico adquiere un guión como prefijo. Por ejemplo, cuando se elimina el volumen lógico lvol1, el nombre del volumen histórico es -lvol1. Un volumen lógico histórico no puede ser reactivado.
Incluso con la opción de metadatos record_lvs_history activada, puede evitar la retención de volúmenes lógicos históricos de forma individual cuando elimine un volumen lógico especificando la opción --nohistory del comando lvremove.
Para incluir los volúmenes lógicos históricos en la visualización del volumen, se especifica la opción -H|--history de un comando de visualización de LVM. Puede mostrar una cadena de dependencia de instantáneas delgadas completa que incluya volúmenes históricos especificando los campos de información lv_full_ancestors y lv_full_descendants junto con la opción -H.
La siguiente serie de comandos proporciona ejemplos de cómo puede visualizar y gestionar los volúmenes lógicos históricos.
-
Asegúrese de que los volúmenes lógicos históricos se conservan estableciendo
record_lvs_history=1en el archivolvm.conf. Esta opción de metadatos no está activada por defecto. Introduzca el siguiente comando para mostrar una cadena de instantáneas con aprovisionamiento ligero.
En este ejemplo:
-
lvol1es un volumen de origen, el primer volumen de la cadena. -
lvol2es una instantánea delvol1. -
lvol3es una instantánea delvol2. -
lvol4es una instantánea delvol3. lvol5es también una instantánea delvol3.Tenga en cuenta que, aunque el comando de visualización de
lvsde ejemplo incluye la opción-H, todavía no se ha eliminado ningún volumen delgado de instantáneas y no hay volúmenes lógicos históricos que mostrar.# lvs -H -o name,full_ancestors,full_descendants LV FAncestors FDescendants lvol1 lvol2,lvol3,lvol4,lvol5 lvol2 lvol1 lvol3,lvol4,lvol5 lvol3 lvol2,lvol1 lvol4,lvol5 lvol4 lvol3,lvol2,lvol1 lvol5 lvol3,lvol2,lvol1 pool
-
Elimine el volumen lógico
lvol3de la cadena de instantáneas y, a continuación, vuelva a ejecutar el siguiente comandolvspara ver cómo se muestran los volúmenes lógicos históricos, junto con sus ancestros y descendientes.# lvremove -f vg/lvol3 Logical volume "lvol3" successfully removed # lvs -H -o name,full_ancestors,full_descendants LV FAncestors FDescendants lvol1 lvol2,-lvol3,lvol4,lvol5 lvol2 lvol1 -lvol3,lvol4,lvol5 -lvol3 lvol2,lvol1 lvol4,lvol5 lvol4 -lvol3,lvol2,lvol1 lvol5 -lvol3,lvol2,lvol1 poolPuede utilizar el campo de informes
lv_time_removedpara mostrar la hora en que se eliminó un volumen histórico.# lvs -H -o name,full_ancestors,full_descendants,time_removed LV FAncestors FDescendants RTime lvol1 lvol2,-lvol3,lvol4,lvol5 lvol2 lvol1 -lvol3,lvol4,lvol5 -lvol3 lvol2,lvol1 lvol4,lvol5 2016-03-14 14:14:32 +0100 lvol4 -lvol3,lvol2,lvol1 lvol5 -lvol3,lvol2,lvol1 poolPuedes referenciar volúmenes lógicos históricos individualmente en un comando de visualización especificando el formato vgname/lvname, como en el siguiente ejemplo. Tenga en cuenta que el quinto bit del campo
lv_attrse establece enhpara indicar que el volumen es un volumen histórico.# lvs -H vg/-lvol3 LV VG Attr LSize -lvol3 vg ----h----- 0LVM no conserva los volúmenes lógicos históricos si el volumen no tiene ningún descendiente vivo. Esto significa que si se elimina un volumen lógico al final de una cadena de instantáneas, el volumen lógico no se conserva como volumen lógico histórico.
# lvremove -f vg/lvol5 Automatically removing historical logical volume vg/-lvol5. Logical volume "lvol5" successfully removed # lvs -H -o name,full_ancestors,full_descendants LV FAncestors FDescendants lvol1 lvol2,-lvol3,lvol4 lvol2 lvol1 -lvol3,lvol4 -lvol3 lvol2,lvol1 lvol4 lvol4 -lvol3,lvol2,lvol1 poolEjecute los siguientes comandos para eliminar el volumen
lvol1ylvol2y para ver cómo el comandolvsmuestra los volúmenes una vez eliminados.# lvremove -f vg/lvol1 vg/lvol2 Logical volume "lvol1" successfully removed Logical volume "lvol2" successfully removed # lvs -H -o name,full_ancestors,full_descendants LV FAncestors FDescendants -lvol1 -lvol2,-lvol3,lvol4 -lvol2 -lvol1 -lvol3,lvol4 -lvol3 -lvol2,-lvol1 lvol4 lvol4 -lvol3,-lvol2,-lvol1 poolPara eliminar un volumen lógico histórico por completo, puedes ejecutar el comando
lvremovede nuevo, especificando el nombre del volumen histórico que ahora incluye el guión, como en el siguiente ejemplo.# lvremove -f vg/-lvol3 Historical logical volume "lvol3" successfully removed # lvs -H -o name,full_ancestors,full_descendants LV FAncestors FDescendants -lvol1 -lvol2,lvol4 -lvol2 -lvol1 lvol4 lvol4 -lvol2,-lvol1 poolUn volumen lógico histórico se conserva mientras exista una cadena que incluya volúmenes vivos en sus descendientes. Esto significa que la eliminación de un volumen lógico histórico también elimina todos los volúmenes lógicos de la cadena si no hay ningún descendiente vinculado a ellos, como se muestra en el siguiente ejemplo.
# lvremove -f vg/lvol4 Automatically removing historical logical volume vg/-lvol1. Automatically removing historical logical volume vg/-lvol2. Automatically removing historical logical volume vg/-lvol4. Logical volume "lvol4" successfully removed
68.10. Activación de la caché para mejorar el rendimiento del volumen lógico
Puedes añadir caché a un volumen lógico LVM para mejorar el rendimiento. LVM almacena en caché las operaciones de E/S en el volumen lógico utilizando un dispositivo rápido, como un SSD.
Los siguientes procedimientos crean un LV especial del dispositivo rápido, y adjuntan este LV especial al LV original para mejorar el rendimiento.
68.10.1. Métodos de almacenamiento en caché en LVM
LVM proporciona los siguientes tipos de caché. Cada uno es adecuado para diferentes tipos de patrones de E/S en el volumen lógico.
dm-cacheEste método acelera el acceso a los datos de uso frecuente al almacenarlos en caché en el volumen más rápido. El método almacena en caché tanto las operaciones de lectura como las de escritura.
El método
dm-cachecrea volúmenes lógicos del tipocache.dm-writecacheEste método sólo almacena en caché las operaciones de escritura. El volumen más rápido almacena las operaciones de escritura y luego las migra al disco más lento en segundo plano. El volumen más rápido suele ser un SSD o un disco de memoria persistente (PMEM).
El método
dm-writecachecrea volúmenes lógicos del tipowritecache.
68.10.2. Componentes de caché LVM
Cuando se habilita el almacenamiento en caché para un volumen lógico, LVM renombra y oculta los volúmenes originales, y presenta un nuevo volumen lógico que está compuesto por los volúmenes lógicos originales. La composición del nuevo volumen lógico depende del método de almacenamiento en caché y de si se utiliza la opción cachevol o cachepool.
Las opciones cachevol y cachepool exponen diferentes niveles de control sobre la colocación de los componentes de la caché:
-
Con la opción
cachevol, el dispositivo más rápido almacena tanto las copias en caché de los bloques de datos como los metadatos para gestionar la caché. Con la opción
cachepool, dispositivos separados pueden almacenar las copias en caché de los bloques de datos y los metadatos para gestionar la caché.El método
dm-writecacheno es compatible concachepool.
En todas las configuraciones, LVM expone un único dispositivo resultante, que agrupa todos los componentes de la caché. El dispositivo resultante tiene el mismo nombre que el volumen lógico lento original.
68.10.3. Activación de la caché dm-cache para un volumen lógico
Este procedimiento permite almacenar en caché los datos más utilizados en un volumen lógico mediante el método dm-cache.
Requisitos previos
-
En su sistema existe un volumen lógico lento que desea acelerar utilizando
dm-cache. - El grupo de volumen que contiene el volumen lógico lento también contiene un volumen físico no utilizado en un dispositivo de bloque rápido.
Procedimiento
Cree un volumen
cachevolen el dispositivo rápido:# lvcreate --size cachevol-size --name fastvol vg /dev/fast-pvSustituya los siguientes valores:
cachevol-size-
El tamaño del volumen de
cachevol, como5G fastvol-
Un nombre para el volumen
cachevol vg- El nombre del grupo de volumen
/dev/fast-pv-
La ruta de acceso al dispositivo de bloque rápido, como
/dev/sdf1
Adjunte el volumen
cachevolal volumen lógico principal para comenzar el almacenamiento en caché:# lvconvert --type cache --cachevol fastvol vg /main-lvSustituya los siguientes valores:
fastvol-
El nombre del volumen
cachevol vg- El nombre del grupo de volumen
main-lv- El nombre del volumen lógico lento
Pasos de verificación
Examine los dispositivos recién creados:
# lvs --all --options +devices vg LV Pool Type Devices main-lv [fastvol_cvol] cache main-lv_corig(0) [fastvol_cvol] linear /dev/fast-pv [main-lv_corig] linear /dev/slow-pv
Recursos adicionales
-
Para obtener información sobre este procedimiento y otros detalles, incluyendo ejemplos administrativos, consulte la página man
lvmcache(7).
68.10.4. Activación de la caché dm-cache con un cachepool para un volumen lógico
Este procedimiento permite crear los volúmenes lógicos de datos de caché y de metadatos de caché individualmente y luego combinar los volúmenes en un pool de caché.
Requisitos previos
-
En su sistema existe un volumen lógico lento que desea acelerar utilizando
dm-cache. - El grupo de volumen que contiene el volumen lógico lento también contiene un volumen físico no utilizado en un dispositivo de bloque rápido.
Procedimiento
Cree un volumen
cachepoolen el dispositivo rápido:# lvcreate --type cache-pool --size cachepool-size --name fastpool vg /dev/fastSustituya los siguientes valores:
cachepool-size-
El tamaño de la
cachepool, como5G fastpool-
Un nombre para el volumen
cachepool vg- El nombre del grupo de volumen
/dev/fastLa ruta de acceso al dispositivo de bloque rápido, como
/dev/sdf1NotaPuede utilizar la opción
--poolmetadatapara especificar la ubicación de los metadatos del pool al crear el cache-pool.
Adjunte el
cachepoolal volumen lógico principal para comenzar a almacenar en caché:# lvconvert --type cache --cachepool fastpool vg/mainSustituya los siguientes valores:
fastpool-
El nombre del volumen
cachepool vg- El nombre del grupo de volumen
main- El nombre del volumen lógico lento
Pasos de verificación
Examine los dispositivos recién creados:
# lvs --all --options +devices vg LV Pool Type Devices [fastpool_cpool] cache-pool fastpool_pool_cdata(0) [fastpool_cpool_cdata] linear /dev/sdf1(4) [fastpool_cpool_cmeta] linear /dev/sdf1(2) [lvol0_pmspare] linear /dev/sdf1(0) main [fastpoool_cpool] cache main_corig(0) [main_corig] linear /dev/sdf1(O)
Recursos adicionales
-
La página de manual
lvcreate(8). -
La página de manual
lvmcache(7). -
La página de manual
lvconvert(8).
68.10.5. Activación de la caché dm-writecache para un volumen lógico
Este procedimiento permite almacenar en caché las operaciones de E/S de escritura en un volumen lógico utilizando el método dm-writecache.
Requisitos previos
-
En su sistema existe un volumen lógico lento que desea acelerar utilizando
dm-writecache. - El grupo de volumen que contiene el volumen lógico lento también contiene un volumen físico no utilizado en un dispositivo de bloque rápido.
Procedimiento
Si el volumen lógico lento está activo, desactívalo:
# lvchange --activate n vg/main-lvSustituya los siguientes valores:
vg- El nombre del grupo de volumen
main-lv- El nombre del volumen lógico lento
Cree un volumen
cachevoldesactivado en el dispositivo rápido:# lvcreate --activate n --size cachevol-size --name fastvol vg /dev/fast-pvSustituya los siguientes valores:
cachevol-size-
El tamaño del volumen de
cachevol, como5G fastvol-
Un nombre para el volumen
cachevol vg- El nombre del grupo de volumen
/dev/fast-pv-
La ruta de acceso al dispositivo de bloque rápido, como
/dev/sdf1
Adjunte el volumen
cachevolal volumen lógico principal para comenzar el almacenamiento en caché:# lvconvert --type writecache --cachevol fastvol vg /main-lvSustituya los siguientes valores:
fastvol-
El nombre del volumen
cachevol vg- El nombre del grupo de volumen
main-lv- El nombre del volumen lógico lento
Active el volumen lógico resultante:
# lvchange --activate y vg/main-lvSustituya los siguientes valores:
vg- El nombre del grupo de volumen
main-lv- El nombre del volumen lógico lento
Pasos de verificación
Examine los dispositivos recién creados:
# lvs --all --options +devices vg LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices main-lv vg Cwi-a-C--- 500.00m [fastvol_cvol] [main-lv_wcorig] 0.00 main-lv_wcorig(0) [fastvol_cvol] vg Cwi-aoC--- 252.00m /dev/sdc1(0) [main-lv_wcorig] vg owi-aoC--- 500.00m /dev/sdb1(0)
Recursos adicionales
-
Para obtener información, incluyendo ejemplos administrativos, consulte la página man
lvmcache(7).
68.10.6. Desactivación del almacenamiento en caché de un volumen lógico
Este procedimiento desactiva el almacenamiento en caché de dm-cache o dm-writecache que está actualmente activado en un volumen lógico.
Requisitos previos
- El almacenamiento en caché está activado en un volumen lógico.
Procedimiento
Desactivar el volumen lógico:
# lvchange --activate n vg/main-lvSustituya los siguientes valores:
vg- El nombre del grupo de volumen
main-lv- El nombre del volumen lógico en el que se ha habilitado el almacenamiento en caché
Separe el volumen
cachevolocachepool:# lvconvert --splitcache vg/main-lvSustituya los siguientes valores:
vg- El nombre del grupo de volumen
main-lv- El nombre del volumen lógico en el que se ha habilitado el almacenamiento en caché
Pasos de verificación
Compruebe que los volúmenes lógicos ya no están unidos:
# lvs --all --options +devices [replaceable]_vg_ LV Attr Type Devices fastvol -wi------- linear /dev/fast-pv main-lv -wi------- linear /dev/slow-pv
Recursos adicionales
-
La página de manual
lvmcache(7)
68.11. Activación del volumen lógico
Un volumen lógico en estado activo puede ser utilizado a través de un dispositivo de bloque. Un volumen lógico que está activado es accesible y está sujeto a cambios. Cuando se crea un volumen lógico se activa por defecto.
Hay varias circunstancias por las que necesitas hacer que un volumen lógico individual esté inactivo y por lo tanto sea desconocido para el kernel. Puede activar o desactivar un volumen lógico individual con la opción -a del comando lvchange.
El formato del comando para desactivar un volumen lógico individual es el siguiente.
lvchange -un vg/lvEl formato del comando para activar un volumen lógico individual es el siguiente.
lvchange -ay vg/lv
Puedes activar o desactivar todos los volúmenes lógicos de un grupo de volúmenes con la opción -a del comando vgchange. Esto es el equivalente a ejecutar el comando lvchange -a en cada volumen lógico individual del grupo de volúmenes.
El formato del comando para desactivar todos los volúmenes lógicos de un grupo de volúmenes es el siguiente.
vgchange -an vgEl formato del comando para activar todos los volúmenes lógicos de un grupo de volúmenes es el siguiente.
vgchange -ay vg68.11.1. Control de la autoactivación de los volúmenes lógicos
La autoactivación de un volumen lógico se refiere a la activación automática basada en eventos de un volumen lógico durante el inicio del sistema. A medida que los dispositivos están disponibles en el sistema (eventos de dispositivos en línea), systemd/udev ejecuta el servicio lvm2-pvscan para cada dispositivo. Este servicio ejecuta el comando pvscan --cache -aay device que lee el dispositivo nombrado. Si el dispositivo pertenece a un grupo de volúmenes, el comando pvscan comprobará si todos los volúmenes físicos de ese grupo de volúmenes están presentes en el sistema. Si es así, el comando activará los volúmenes lógicos de ese grupo de volúmenes.
Puede utilizar las siguientes opciones de configuración en el archivo de configuración /etc/lvm/lvm.conf para controlar la autoactivación de los volúmenes lógicos.
global/event_activationCuando
event_activationestá deshabilitado,systemd/udevautoactivará el volumen lógico sólo en los volúmenes físicos que estén presentes durante el arranque del sistema. Si aún no han aparecido todos los volúmenes físicos, es posible que algunos volúmenes lógicos no se autoactiven.activation/auto_activation_volume_listSi se establece
auto_activation_volume_listen una lista vacía, se desactiva la autoactivación por completo. Si se estableceauto_activation_volume_listen volúmenes lógicos y grupos de volúmenes específicos, se limita la autoactivación a esos volúmenes lógicos.
Para obtener información sobre la configuración de estas opciones, consulte el archivo de configuración /etc/lvm/lvm.conf.
68.11.2. Control de la activación del volumen lógico
Puede controlar la activación del volumen lógico de las siguientes maneras:
-
A través de la configuración de
activation/volume_listen el archivo/etc/lvm/conf. Esto permite especificar qué volúmenes lógicos se activan. Para obtener información sobre el uso de esta opción, consulte el archivo de configuración/etc/lvm/lvm.conf. - Mediante el indicador de omisión de activación para un volumen lógico. Cuando se establece este indicador para un volumen lógico, el volumen se omite durante los comandos de activación normales.
Puede establecer el indicador de omisión de activación en un volumen lógico de las siguientes maneras.
-
Puede desactivar el indicador de salto de activación al crear un volumen lógico especificando la opción
-kno--setactivationskip ndel comandolvcreate. -
Puede desactivar el indicador de salto de activación para un volumen lógico existente especificando la opción
-kno--setactivationskip ndel comandolvchange. -
Puede volver a activar el indicador de salto de activación para un volumen en el que se haya desactivado con la opción
-kyo--setactivationskip ydel comandolvchange.
Para determinar si el indicador de omisión de activación está establecido para un volumen lógico, ejecute el comando lvs, que muestra el atributo k como en el siguiente ejemplo.
# lvs vg/thin1s1
LV VG Attr LSize Pool Origin
thin1s1 vg Vwi---tz-k 1.00t pool0 thin1
Puede activar un volumen lógico con el atributo k establecido utilizando la opción -K o --ignoreactivationskip además de la opción estándar -ay o --activate y.
Por defecto, los volúmenes finos de instantáneas se marcan para omitir la activación cuando se crean. Puede controlar la configuración de omisión de activación por defecto en los nuevos volúmenes ligeros de instantáneas con la configuración auto_set_activation_skip en el archivo /etc/lvm/lvm.conf.
El siguiente comando activa un volumen lógico de instantánea delgada que tiene el indicador de omisión de activación establecido.
# lvchange -ay -K VG/SnapLVEl siguiente comando crea una instantánea fina sin el indicador de omisión de activación
# lvcreate --type thin -n SnapLV -kn -s ThinLV --thinpool VG/ThinPoolLVEl siguiente comando elimina el indicador de omisión de activación de un volumen lógico de instantánea.
# lvchange -kn VG/SnapLV68.11.3. Activación de volúmenes lógicos compartidos
Puedes controlar la activación de un volumen lógico compartido con la opción -a de los comandos lvchange y vgchange, de la siguiente manera.
| Comando | Activación |
|---|---|
|
| Activar el volumen lógico compartido en modo exclusivo, permitiendo que sólo un único host active el volumen lógico. Si la activación falla, como ocurriría si el volumen lógico está activo en otro host, se informa de un error. |
|
| Activar el volumen lógico compartido en modo compartido, permitiendo que varios hosts activen el volumen lógico simultáneamente. Si la activación falla, como sucedería si el volumen lógico está activo exclusivamente en otro host, se informa de un error. Si el tipo lógico prohíbe el acceso compartido, como una instantánea, el comando informará de un error y fallará. Los tipos de volúmenes lógicos que no pueden ser utilizados simultáneamente desde múltiples hosts incluyen thin, cache, raid y snapshot. |
|
| Desactivar el volumen lógico. |
68.11.4. Activación de un volumen lógico con dispositivos ausentes
Puede configurar qué volúmenes lógicos con dispositivos ausentes se activan estableciendo el parámetro activation_mode con el comando lvchange a uno de los siguientes valores.
| Modo de activación | Significado |
|---|---|
| completa | Permite activar sólo los volúmenes lógicos sin volúmenes físicos ausentes. Este es el modo más restrictivo. |
| degradado | Permite activar volúmenes lógicos RAID con volúmenes físicos ausentes. |
| parcial | Permite activar cualquier volumen lógico al que le falten volúmenes físicos. Esta opción debe utilizarse únicamente para la recuperación o reparación. |
El valor por defecto de activation_mode está determinado por la configuración de activation_mode en el archivo /etc/lvm/lvm.conf. Para más información, consulte la página de manual lvmraid(7).
68.12. Control de la exploración de dispositivos LVM
Puedes controlar el escaneo de dispositivos LVM configurando filtros en el archivo /etc/lvm/lvm.conf. Los filtros en el archivo lvm.conf consisten en una serie de expresiones regulares simples que se aplican a los nombres de los dispositivos en el directorio /dev para decidir si se acepta o rechaza cada dispositivo de bloque encontrado.
68.12.1. El filtro de dispositivos LVM
Las herramientas LVM escanean los dispositivos en el directorio /dev y comprueban cada uno de ellos en busca de metadatos LVM. Un filtro en el archivo /etc/lvm/lvm.conf controla qué dispositivos escanea LVM.
El filtro es una lista de patrones que LVM aplica a cada dispositivo encontrado por una exploración del directorio /dev, o el directorio especificado por la palabra clave dir en el archivo /etc/lvm/lvm.conf. Los patrones son expresiones regulares delimitadas por cualquier carácter y precedidas por a para accept o r para reject. La primera expresión regular de la lista que coincide con un dispositivo determina si LVM acepta o rechaza (ignora) el dispositivo. LVM acepta los dispositivos que no coinciden con ningún patrón.
La siguiente es la configuración por defecto del filtro, que escanea todos los dispositivos:
filtro = [ \ "a/.*/" ]68.12.2. Ejemplos de configuraciones de filtros de dispositivos LVM
Los siguientes ejemplos muestran el uso de filtros para controlar qué dispositivos escanea LVM.
Algunos de los ejemplos presentados aquí podrían coincidir involuntariamente con dispositivos adicionales en el sistema y podrían no representar la práctica recomendada para su sistema. Por ejemplo, a/loop/ es equivalente a a/.*loop.*/ y coincidiría con /dev/solooperation/lvol1.
El siguiente filtro añade todos los dispositivos descubiertos, que es el comportamiento por defecto porque no se ha configurado ningún filtro en el archivo de configuración:
filtro = [ \ "a/.*/" ]El siguiente filtro elimina el dispositivo
cdrompara evitar retrasos si la unidad no contiene medios:filter = [ "r|^/dev/cdrom$|" ]El siguiente filtro añade todos los dispositivos de bucle y elimina todos los demás dispositivos de bloque:
filter = [ \ "a/loop/", \ "r/.*/" ]El siguiente filtro añade todos los dispositivos de bucle e IDE y elimina todos los demás dispositivos de bloque:
filter = [ |"a|loop|\\\N-, |"a|/dev/hd.*|\N-, |"r|.*|\N- ]El siguiente filtro añade sólo la partición 8 en la primera unidad IDE y elimina todos los demás dispositivos de bloque:
filter = [ "a|^/dev/hda8$|", "r/.*/" ]
68.12.3. Aplicación de una configuración de filtro de dispositivos LVM
Este procedimiento cambia la configuración del filtro de dispositivos LVM, que controla los dispositivos que escanea LVM.
Requisitos previos
- Prepare el patrón de filtro del dispositivo que desea utilizar.
Procedimiento
Pruebe el patrón de filtrado de su dispositivo sin modificar el archivo
/etc/lvm/lvm.conf.Utilice un comando LVM con la opción
--config 'devices{ filter = [ your device filter pattern ] }'opción. Por ejemplo:# lvs --config 'devices{ filter = [ |"a|/dev/emcpower.*||\", "r|.*|" ]'-
Edite la opción
filteren el archivo de configuración/etc/lvm/lvm.confpara utilizar su nuevo patrón de filtrado de dispositivos. Compruebe que no faltan volúmenes físicos o grupos de volúmenes que desee utilizar con la nueva configuración:
# pvscan# vgscanReconstruya el sistema de archivos
initramfspara que LVM escanee sólo los dispositivos necesarios al reiniciar:# dracut --force --verbose
68.13. Control de la asignación de LVM
Por defecto, un grupo de volúmenes asigna extensiones físicas de acuerdo a reglas de sentido común como no colocar franjas paralelas en el mismo volumen físico. Esta es la política de asignación normal. Puedes usar el argumento --alloc del comando vgcreate para especificar una política de asignación de contiguous, anywhere, o cling. En general, las políticas de asignación diferentes a normal son requeridas sólo en casos especiales donde se necesita especificar una asignación de extensión inusual o no estándar.
68.13.1. Políticas de asignación de LVM
Cuando una operación LVM necesita asignar extensiones físicas para uno o más volúmenes lógicos, la asignación procede como sigue:
- Se genera el conjunto completo de extensiones físicas no asignadas en el grupo de volúmenes para su consideración. Si proporciona cualquier rango de extensiones físicas al final de la línea de comandos, sólo se considerarán las extensiones físicas no asignadas dentro de esos rangos en los volúmenes físicos especificados.
-
Cada política de asignación se intenta por turnos, empezando por la política más estricta (
contiguous) y terminando con la política de asignación especificada mediante la opción--alloco establecida por defecto para el volumen lógico o grupo de volúmenes concreto. Para cada política, trabajando desde la extensión lógica más baja del espacio del volumen lógico vacío que necesita ser llenado, se asigna tanto espacio como sea posible, de acuerdo con las restricciones impuestas por la política de asignación. Si se necesita más espacio, LVM pasa a la siguiente política.
Las restricciones de la política de asignación son las siguientes:
Una política de asignación de
contiguousrequiere que la ubicación física de cualquier extensión lógica que no sea la primera extensión lógica de un volumen lógico sea adyacente a la ubicación física de la extensión lógica inmediatamente anterior.Cuando un volumen lógico está dividido en franjas o en espejo, la restricción de asignación
contiguousse aplica independientemente a cada franja o imagen en espejo (pierna) que necesite espacio.Una política de asignación de
clingrequiere que el volumen físico utilizado para cualquier extensión lógica se añada a un volumen lógico existente que ya esté en uso por al menos una extensión lógica anterior en ese volumen lógico. Si se define el parámetro de configuraciónallocation/cling_tag_list, se considera que dos volúmenes físicos coinciden si alguna de las etiquetas enumeradas está presente en ambos volúmenes físicos. Esto permite que grupos de volúmenes físicos con propiedades similares (como su ubicación física) sean etiquetados y tratados como equivalentes a efectos de asignación.Cuando un Volumen Lógico es rayado o reflejado, la restricción de asignación
clingse aplica independientemente a cada raya o imagen reflejada (pierna) que necesite espacio.Una política de asignación de
normalno elegirá una extensión física que comparta el mismo volumen físico que una extensión lógica ya asignada a un volumen lógico paralelo (es decir, una franja o imagen espejo diferente) en el mismo desplazamiento dentro de ese volumen lógico paralelo.Cuando se asigna un registro en espejo al mismo tiempo que volúmenes lógicos para contener los datos en espejo, una política de asignación de
normalintentará primero seleccionar volúmenes físicos diferentes para el registro y los datos. Si eso no es posible y el parámetro de configuraciónallocation/mirror_logs_require_separate_pvsse establece en 0, entonces permitirá que el registro comparta volumen(s) físico(s) con parte de los datos.Del mismo modo, al asignar los metadatos del thin pool, una política de asignación de
normalseguirá las mismas consideraciones que para la asignación de un mirror log, basándose en el valor del parámetro de configuraciónallocation/thin_pool_metadata_require_separate_pvs.-
Si hay suficientes extensiones libres para satisfacer una solicitud de asignación pero una política de asignación de
normalno las utilizaría, la política de asignación deanywherelo hará, incluso si eso reduce el rendimiento al colocar dos franjas en el mismo volumen físico.
Las políticas de asignación pueden modificarse mediante el comando vgchange.
Si confía en cualquier comportamiento de distribución más allá de lo documentado en esta sección según las políticas de asignación definidas, debe tener en cuenta que esto podría cambiar en futuras versiones del código. Por ejemplo, si proporcionas en la línea de comandos dos volúmenes físicos vacíos que tienen un número idéntico de extensiones físicas libres disponibles para la asignación, LVM actualmente considera usar cada uno de ellos en el orden en que están listados; no hay garantía de que las futuras versiones mantengan esa propiedad. Si es importante obtener un diseño específico para un Volumen Lógico en particular, entonces deberías construirlo a través de una secuencia de pasos de lvcreate y lvconvert de tal manera que las políticas de asignación aplicadas a cada paso no dejen a LVM ninguna discreción sobre el diseño.
Para ver cómo funciona actualmente el proceso de asignación en cualquier caso específico, puede leer la salida del registro de depuración, por ejemplo, añadiendo la opción -vvvv a un comando.
68.13.2. Impedir la asignación en un volumen físico
Puede evitar la asignación de extensiones físicas en el espacio libre de uno o más volúmenes físicos con el comando pvchange. Esto puede ser necesario si hay errores de disco, o si va a eliminar el volumen físico.
El siguiente comando desactiva la asignación de extensiones físicas en /dev/sdk1.
# pvchange -x n /dev/sdk1
También puede utilizar los argumentos de -xy del comando pvchange para permitir la asignación donde antes no se permitía.
68.13.3. Ampliación de un volumen lógico con la política de asignación cling
Cuando se amplía un volumen LVM, se puede utilizar la opción --alloc cling del comando lvextend para especificar la política de asignación cling. Esta política elegirá espacio en los mismos volúmenes físicos que el último segmento del volumen lógico existente. Si no hay suficiente espacio en los volúmenes físicos y se define una lista de etiquetas en el archivo /etc/lvm/lvm.conf, LVM comprobará si alguna de las etiquetas está unida a los volúmenes físicos y tratará de hacer coincidir esas etiquetas de volúmenes físicos entre los extensiones existentes y las nuevas extensiones.
Por ejemplo, si tiene volúmenes lógicos que se reflejan entre dos sitios dentro de un mismo grupo de volúmenes, puede etiquetar los volúmenes físicos según su ubicación etiquetando los volúmenes físicos con las etiquetas @site1 y @site2. Entonces puede especificar la siguiente línea en el archivo lvm.conf:
cling_tag_list = [ \ "@site1", \ "@site2" ]
En el siguiente ejemplo, el archivo lvm.conf ha sido modificado para contener la siguiente línea:
cling_tag_list = [ \ "@A", \ "@B" ]
También en este ejemplo, se ha creado un grupo de volúmenes taft que consta de los volúmenes físicos /dev/sdb1, /dev/sdc1, /dev/sdd1, /dev/sde1, /dev/sdf1, /dev/sdg1, y /dev/sdh1. Estos volúmenes físicos han sido etiquetados con las etiquetas A, B, y C. El ejemplo no utiliza la etiqueta C, pero esto mostrará que LVM utiliza las etiquetas para seleccionar qué volúmenes físicos utilizar para las patas de la réplica.
# pvs -a -o +pv_tags /dev/sd[bcdefgh]
PV VG Fmt Attr PSize PFree PV Tags
/dev/sdb1 taft lvm2 a-- 15.00g 15.00g A
/dev/sdc1 taft lvm2 a-- 15.00g 15.00g B
/dev/sdd1 taft lvm2 a-- 15.00g 15.00g B
/dev/sde1 taft lvm2 a-- 15.00g 15.00g C
/dev/sdf1 taft lvm2 a-- 15.00g 15.00g C
/dev/sdg1 taft lvm2 a-- 15.00g 15.00g A
/dev/sdh1 taft lvm2 a-- 15.00g 15.00g A
El siguiente comando crea un volumen duplicado de 10 gigabytes a partir del grupo de volúmenes taft.
# lvcreate --type raid1 -m 1 -n mirror --nosync -L 10G taft
WARNING: New raid1 won't be synchronised. Don't read what you didn't write!
Logical volume "mirror" createdEl siguiente comando muestra qué dispositivos se utilizan para los tramos de réplica y los subvolúmenes de metadatos RAID.
# lvs -a -o +devices
LV VG Attr LSize Log Cpy%Sync Devices
mirror taft Rwi-a-r--- 10.00g 100.00 mirror_rimage_0(0),mirror_rimage_1(0)
[mirror_rimage_0] taft iwi-aor--- 10.00g /dev/sdb1(1)
[mirror_rimage_1] taft iwi-aor--- 10.00g /dev/sdc1(1)
[mirror_rmeta_0] taft ewi-aor--- 4.00m /dev/sdb1(0)
[mirror_rmeta_1] taft ewi-aor--- 4.00m /dev/sdc1(0)
El siguiente comando amplía el tamaño del volumen reflejado, utilizando la política de asignación cling para indicar que los tramos reflejados deben ampliarse utilizando volúmenes físicos con la misma etiqueta.
# lvextend --alloc cling -L +10G taft/mirror
Extending 2 mirror images.
Extending logical volume mirror to 20.00 GiB
Logical volume mirror successfully resized
El siguiente comando de visualización muestra que los tramos de réplica se han ampliado utilizando volúmenes físicos con la misma etiqueta que el tramo. Tenga en cuenta que los volúmenes físicos con una etiqueta de C fueron ignorados.
# lvs -a -o +devices
LV VG Attr LSize Log Cpy%Sync Devices
mirror taft Rwi-a-r--- 20.00g 100.00 mirror_rimage_0(0),mirror_rimage_1(0)
[mirror_rimage_0] taft iwi-aor--- 20.00g /dev/sdb1(1)
[mirror_rimage_0] taft iwi-aor--- 20.00g /dev/sdg1(0)
[mirror_rimage_1] taft iwi-aor--- 20.00g /dev/sdc1(1)
[mirror_rimage_1] taft iwi-aor--- 20.00g /dev/sdd1(0)
[mirror_rmeta_0] taft ewi-aor--- 4.00m /dev/sdb1(0)
[mirror_rmeta_1] taft ewi-aor--- 4.00m /dev/sdc1(0)68.13.4. Diferenciación de los objetos RAID de LVM mediante etiquetas
Puede asignar etiquetas a los objetos RAID de LVM para agruparlos, de modo que pueda automatizar el control del comportamiento de los RAID de LVM, como la activación, por grupo.
Las etiquetas de volumen físico (PV) son las responsables del control de la asignación en el raid LVM, a diferencia de las etiquetas de volumen lógico (LV) o de grupo de volúmenes (VG), ya que la asignación en lvm se produce a nivel de PV basándose en las políticas de asignación. Para distinguir los tipos de almacenamiento por sus diferentes propiedades, etiquételos apropiadamente (por ejemplo, NVMe, SSD, HDD). Red Hat recomienda que etiquete cada nuevo PV apropiadamente después de agregarlo a un VG.
Este procedimiento añade etiquetas de objeto a sus volúmenes lógicos, asumiendo que /dev/sda es un SSD, y /dev/sd[b-f] son HDDs con una partición.
Requisitos previos
-
El paquete
lvm2está instalado. - Existen dispositivos de almacenamiento para utilizar como FV.
Procedimiento
Crea un grupo de volúmenes.
# vgcreate MyVG /dev/sd[a-f]1Añade etiquetas a tus volúmenes físicos.
# pvchange --addtag ssds /dev/sda1 # pvchange --addtag hdds /dev/sd[b-f]1Cree un volumen lógico RAID6.
# lvcreate --type raid6 --stripes 3 -L1G -nr6 MyVG @hddsCree un volumen de reserva de caché lineal.
# lvcreate -nr6pool -L512m MyVG @ssdsConvierte el volumen RAID6 en caché.
# lvconvert --type cache --cachevol MyVG/r6pool MyVG/r6
68.14. Solución de problemas de LVM
Puede utilizar las herramientas de LVM para solucionar una variedad de problemas en los volúmenes y grupos de LVM.
68.14.1. Recogida de datos de diagnóstico en LVM
Si un comando LVM no está funcionando como se espera, puede reunir diagnósticos de las siguientes maneras.
Procedimiento
Utilice los siguientes métodos para reunir diferentes tipos de datos de diagnóstico:
-
Añade el argumento
-vvvva cualquier comando LVM para aumentar el nivel de verbosidad de la salida del comando. -
En la sección
logdel archivo de configuración/etc/lvm/lvm.conf, aumenta el valor de la opciónlevel. Esto hace que LVM proporcione más detalles en el registro del sistema. Si el problema está relacionado con la activación del volumen lógico, habilite a LVM para que registre los mensajes durante la activación:
-
Establezca la opción
activation = 1en la secciónlogdel archivo de configuración/etc/lvm/lvm.conf. -
Ejecute el comando LVM con la opción
-vvvv. - Examine la salida del comando.
Restablece la opción
activationen0.Si no restablece la opción a
0, el sistema podría dejar de responder en situaciones de poca memoria.
-
Establezca la opción
Muestra un volcado de información con fines de diagnóstico:
# lvmdumpMuestra información adicional del sistema:
# lvs -v# pvs --all# dmsetup info --columns-
Examine la última copia de seguridad de los metadatos LVM en el directorio
/etc/lvm/backup/y las versiones archivadas en el directorio/etc/lvm/archive/. Compruebe la información de configuración actual:
# lvmconfig-
Compruebe el archivo de caché
/run/lvm/hintspara obtener un registro de los dispositivos que tienen volúmenes físicos en ellos.
-
Añade el argumento
Recursos adicionales
-
La página de manual
lvmdump(8)
68.14.2. Visualización de información sobre dispositivos LVM fallidos
Puede mostrar información sobre un volumen LVM fallado que puede ayudarle a determinar por qué ha fallado el volumen.
Procedimiento
Visualice los volúmenes que han fallado utilizando la utilidad
vgsolvs.Ejemplo 68.5. Grupos de volumen fallidos
En este ejemplo, uno de los dispositivos que componen el grupo de volumen
vgha fallado. El grupo de volúmenes está inutilizado pero puedes ver información sobre el dispositivo que ha fallado.# vgs --options +devices /dev/sdb: open failed: No such device or address /dev/sdb: open failed: No such device or address WARNING: Couldn't find device with uuid 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s. WARNING: VG vg is missing PV 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s (last written to /dev/sdb1). WARNING: Couldn't find all devices for LV vg/linear while checking used and assumed devices. WARNING: Couldn't find all devices for LV vg/stripe while checking used and assumed devices. VG #PV #LV #SN Attr VSize VFree Devices vg 2 2 0 wz-pn- <3.64t <3.60t [unknown](0) vg 2 2 0 wz-pn- <3.64t <3.60t [unknown](5120),/dev/sdc1(0)Ejemplo 68.6. LV lineal y rayado fallido
En este ejemplo, el dispositivo que ha fallado ha provocado el fallo de un volumen lógico lineal y otro rayado en el grupo de volúmenes. La salida del comando muestra los volúmenes lógicos que han fallado.
# lvs --all --options +devices /dev/sdb: open failed: No such device or address /dev/sdb: open failed: No such device or address WARNING: Couldn't find device with uuid 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s. WARNING: VG vg is missing PV 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s (last written to /dev/sdb1). WARNING: Couldn't find all devices for LV vg/linear while checking used and assumed devices. WARNING: Couldn't find all devices for LV vg/stripe while checking used and assumed devices. LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices linear vg -wi-a---p- 20.00g [unknown](0) stripe vg -wi-a---p- 20.00g [unknown](5120),/dev/sdc1(0)Ejemplo 68.7. Fallo en el tramo de un volumen lógico reflejado
Los siguientes ejemplos muestran la salida de comandos de las utilidades
vgsylvscuando un tramo de un volumen lógico reflejado ha fallado.# vgs --all --options +devices VG #PV #LV #SN Attr VSize VFree Devices corey 4 4 0 rz-pnc 1.58T 1.34T my_mirror_mimage_0(0),my_mirror_mimage_1(0) corey 4 4 0 rz-pnc 1.58T 1.34T /dev/sdd1(0) corey 4 4 0 rz-pnc 1.58T 1.34T unknown device(0) corey 4 4 0 rz-pnc 1.58T 1.34T /dev/sdb1(0)# lvs --all --options +devices LV VG Attr LSize Origin Snap% Move Log Copy% Devices my_mirror corey mwi-a- 120.00G my_mirror_mlog 1.95 my_mirror_mimage_0(0),my_mirror_mimage_1(0) [my_mirror_mimage_0] corey iwi-ao 120.00G unknown device(0) [my_mirror_mimage_1] corey iwi-ao 120.00G /dev/sdb1(0) [my_mirror_mlog] corey lwi-ao 4.00M /dev/sdd1(0)
68.14.3. Eliminación de volúmenes físicos LVM perdidos de un grupo de volúmenes
Si un volumen físico falla, puedes activar los volúmenes físicos restantes en el grupo de volúmenes y eliminar del grupo de volúmenes todos los volúmenes lógicos que utilizaban ese volumen físico.
Procedimiento
Active los volúmenes físicos restantes en el grupo de volúmenes:
# vgchange --activate y --partial volume-groupCompruebe qué volúmenes lógicos se eliminarán:
# vgreduce --removemissing --test volume-groupEliminar del grupo de volúmenes todos los volúmenes lógicos que utilizaban el volumen físico perdido:
# vgreduce --removemissing --force volume-groupOpcional: Si ha eliminado accidentalmente volúmenes lógicos que quería conservar, puede revertir la operación
vgreduce:# vgcfgrestore volume-groupAvisoSi has eliminado un thin pool, LVM no puede revertir la operación.
68.14.4. Recuperación de un volumen físico LVM con metadatos dañados
Si el área de metadatos del grupo de volúmenes de un volumen físico se sobrescribe accidentalmente o se destruye de alguna manera, se obtiene un mensaje de error que indica que el área de metadatos es incorrecta, o que el sistema no pudo encontrar un volumen físico con un UUID particular. Es posible que puedas recuperar los datos del volumen físico reescribiendo el área de metadatos en el volumen físico.
68.14.4.1. Descubrir que un volumen LVM tiene metadatos perdidos o corruptos
El siguiente ejemplo muestra la salida del comando que podría ver si el área de metadatos de un volumen físico falta o está dañada.
Procedimiento
Intenta listar los volúmenes lógicos:
# lvs --all --options devicesEjemplo 68.8. Salida con metadatos faltantes o corruptos
En este ejemplo, algunos volúmenes lógicos se encuentran en un volumen físico al que le faltan metadatos o están corruptos.
Couldn't find device with uuid 'FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk'. Couldn't find all physical volumes for volume group VG. Couldn't find device with uuid 'FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk'. Couldn't find all physical volumes for volume group VG. ...
68.14.4.2. Encontrar los metadatos de un volumen físico LVM perdido
Este procedimiento encuentra los últimos metadatos archivados de un volumen físico que falta o está dañado.
Procedimiento
Busca el archivo de metadatos del grupo de volúmenes que contiene el volumen físico.
Los archivos de metadatos archivados se encuentran en la
/etc/lvm/archive/volume-group-name_backup-number.vgruta. Seleccione el último archivo de metadatos válido conocido, que tiene el número más alto para el grupo de volúmenes.Encuentre el UUID del volumen físico. Utilice uno de los siguientes métodos.
Enumerar los volúmenes lógicos:
# lvs --all --options +devices Couldn't find device with uuid 'FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk'.-
Examine el archivo de metadatos archivado. Encuentre el UUID como el valor etiquetado
id =en la secciónphysical_volumesde la configuración del grupo de volumen. Desactivar el grupo de volumen utilizando la opción
--partial:# vgchange --activate n --partial volume-group-name PARTIAL MODE. Incomplete logical volumes will be processed. WARNING: Couldn't find device with uuid 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s. WARNING: VG raid_sanity is missing PV 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s (last written to /dev/sdb1). 0 logical volume(s) in volume group "raid_sanity" now active
68.14.4.3. Restauración de metadatos en un volumen físico LVM
Este procedimiento restaura los metadatos de un volumen físico dañado o sustituido por un nuevo dispositivo.
No intente este procedimiento en un volumen lógico LVM en funcionamiento. Perderá sus datos si especifica el UUID incorrecto.
Requisitos previos
- Ha identificado los metadatos del volumen físico que falta. Para más detalles, consulte Sección 68.14.4.2, “Encontrar los metadatos de un volumen físico LVM perdido”.
Procedimiento
Restaurar los metadatos en el volumen físico:
# pvcreate --uuid physical-volume-uuid \ --restorefile /etc/lvm/archive/volume-group-name_backup-number.vg \ block-deviceNotaEl comando sólo sobrescribe las áreas de metadatos de LVM y no afecta a las áreas de datos existentes.
Ejemplo 68.9. Restauración de un volumen físico en /dev/sdh1
El siguiente ejemplo etiqueta el dispositivo
/dev/sdh1como un volumen físico con las siguientes propiedades:-
El UUID de
FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk -
La información de metadatos contenida en
VG_00050.vg, que son los metadatos buenos más recientes archivados para el grupo de volúmenes
# pvcreate --uuid "FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk" \ --restorefile /etc/lvm/archive/VG_00050.vg \ /dev/sdh1 ... Physical volume "/dev/sdh1" successfully created-
El UUID de
Restaurar los metadatos del grupo de volúmenes:
# vgcfgrestore volume-group-name Restored volume group volume-group-nameMuestra los volúmenes lógicos del grupo de volúmenes:
# lvs --all --options devices volume-group-nameLos volúmenes lógicos están actualmente inactivos. Por ejemplo:
LV VG Attr LSize Origin Snap% Move Log Copy% Devices stripe VG -wi--- 300.00G /dev/sdh1 (0),/dev/sda1(0) stripe VG -wi--- 300.00G /dev/sdh1 (34728),/dev/sdb1(0)Si el tipo de segmento de los volúmenes lógicos es RAID o espejo, resincronice los volúmenes lógicos:
# lvchange --resync volume-group-name/logical-volume-nameActivar los volúmenes lógicos:
# lvchange --activate y /dev/volume-group-name/logical-volume-name- Si los metadatos LVM en el disco ocupan al menos el mismo espacio que lo que los sobrepasó, este procedimiento puede recuperar el volumen físico. Si lo que anuló los metadatos fue más allá del área de metadatos, los datos en el volumen pueden haber sido afectados. Es posible que puedas utilizar el comando fsck para recuperar esos datos.
Pasos de verificación
Muestra los volúmenes lógicos activos:
# lvs --all --options +devices LV VG Attr LSize Origin Snap% Move Log Copy% Devices stripe VG -wi-a- 300.00G /dev/sdh1 (0),/dev/sda1(0) stripe VG -wi-a- 300.00G /dev/sdh1 (34728),/dev/sdb1(0)
68.14.5. Reemplazar un volumen físico LVM perdido
Si un volumen físico falla o necesita ser reemplazado, puedes etiquetar un nuevo volumen físico para reemplazar el que se ha perdido en el grupo de volumen existente.
Requisitos previos
Ha sustituido el volumen físico por un nuevo dispositivo de almacenamiento.
TODO: Reevaluar la ubicación de este paso.
68.14.5.1. Encontrar los metadatos de un volumen físico LVM perdido
Este procedimiento encuentra los últimos metadatos archivados de un volumen físico que falta o está dañado.
Procedimiento
Busca el archivo de metadatos del grupo de volúmenes que contiene el volumen físico.
Los archivos de metadatos archivados se encuentran en la
/etc/lvm/archive/volume-group-name_backup-number.vgruta. Seleccione el último archivo de metadatos válido conocido, que tiene el número más alto para el grupo de volúmenes.Encuentre el UUID del volumen físico. Utilice uno de los siguientes métodos.
Enumerar los volúmenes lógicos:
# lvs --all --options +devices Couldn't find device with uuid 'FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk'.-
Examine el archivo de metadatos archivado. Encuentre el UUID como el valor etiquetado
id =en la secciónphysical_volumesde la configuración del grupo de volumen. Desactivar el grupo de volumen utilizando la opción
--partial:# vgchange --activate n --partial volume-group-name PARTIAL MODE. Incomplete logical volumes will be processed. WARNING: Couldn't find device with uuid 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s. WARNING: VG raid_sanity is missing PV 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s (last written to /dev/sdb1). 0 logical volume(s) in volume group "raid_sanity" now active
68.14.5.2. Restauración de metadatos en un volumen físico LVM
Este procedimiento restaura los metadatos de un volumen físico dañado o sustituido por un nuevo dispositivo.
No intente este procedimiento en un volumen lógico LVM en funcionamiento. Perderá sus datos si especifica el UUID incorrecto.
Requisitos previos
- Ha identificado los metadatos del volumen físico que falta. Para más detalles, consulte Sección 68.14.5.1, “Encontrar los metadatos de un volumen físico LVM perdido”.
Procedimiento
Restaurar los metadatos en el volumen físico:
# pvcreate --uuid physical-volume-uuid \ --restorefile /etc/lvm/archive/volume-group-name_backup-number.vg \ block-deviceNotaEl comando sólo sobrescribe las áreas de metadatos de LVM y no afecta a las áreas de datos existentes.
Ejemplo 68.10. Restauración de un volumen físico en /dev/sdh1
El siguiente ejemplo etiqueta el dispositivo
/dev/sdh1como un volumen físico con las siguientes propiedades:-
El UUID de
FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk -
La información de metadatos contenida en
VG_00050.vg, que son los metadatos buenos más recientes archivados para el grupo de volúmenes
# pvcreate --uuid "FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk" \ --restorefile /etc/lvm/archive/VG_00050.vg \ /dev/sdh1 ... Physical volume "/dev/sdh1" successfully created-
El UUID de
Restaurar los metadatos del grupo de volúmenes:
# vgcfgrestore volume-group-name Restored volume group volume-group-nameMuestra los volúmenes lógicos del grupo de volúmenes:
# lvs --all --options devices volume-group-nameLos volúmenes lógicos están actualmente inactivos. Por ejemplo:
LV VG Attr LSize Origin Snap% Move Log Copy% Devices stripe VG -wi--- 300.00G /dev/sdh1 (0),/dev/sda1(0) stripe VG -wi--- 300.00G /dev/sdh1 (34728),/dev/sdb1(0)Si el tipo de segmento de los volúmenes lógicos es RAID o espejo, resincronice los volúmenes lógicos:
# lvchange --resync volume-group-name/logical-volume-nameActivar los volúmenes lógicos:
# lvchange --activate y /dev/volume-group-name/logical-volume-name- Si los metadatos LVM en el disco ocupan al menos el mismo espacio que lo que los sobrepasó, este procedimiento puede recuperar el volumen físico. Si lo que anuló los metadatos fue más allá del área de metadatos, los datos en el volumen pueden haber sido afectados. Es posible que puedas utilizar el comando fsck para recuperar esos datos.
Pasos de verificación
Muestra los volúmenes lógicos activos:
# lvs --all --options +devices LV VG Attr LSize Origin Snap% Move Log Copy% Devices stripe VG -wi-a- 300.00G /dev/sdh1 (0),/dev/sda1(0) stripe VG -wi-a- 300.00G /dev/sdh1 (34728),/dev/sdb1(0)
68.14.6. Solución de problemas de RAID LVM
Puede solucionar varios problemas en los dispositivos RAID LVM para corregir errores de datos, recuperar dispositivos o reemplazar dispositivos fallidos.
68.14.6.1. Comprobación de la coherencia de los datos en un volumen lógico RAID (RAID scrubbing)
LVM proporciona soporte de scrubbing para volúmenes lógicos RAID. El scrubbing de RAID es el proceso de lectura de todos los datos y bloques de paridad de un array y la comprobación de su coherencia.
Procedimiento
Opcional: Limitar el ancho de banda de E/S que utiliza el proceso de depuración.
Cuando se realiza una operación de depuración de RAID, la E/S en segundo plano requerida por las operaciones de
syncpuede desplazar otras E/S a los dispositivos LVM, como las actualizaciones de los metadatos del grupo de volúmenes. Esto puede hacer que las otras operaciones LVM se ralenticen. Se puede controlar la tasa de la operación de depuración implementando el estrangulamiento de la recuperación.Añade las siguientes opciones a los comandos de
lvchange --syncactionen los siguientes pasos:--maxrecoveryrate Rate[bBsSkKmMgG]- Establece la tasa de recuperación máxima para que la operación no desplace las operaciones de E/S nominales. Establecer la tasa de recuperación en 0 significa que la operación no tiene límites.
--minrecoveryrate Rate[bBsSkKmMgG]-
Establece la tasa de recuperación mínima para garantizar que la E/S de las operaciones de
syncalcance un rendimiento mínimo, incluso cuando haya una E/S nominal intensa.
Especifique el valor de Rate como una cantidad por segundo para cada dispositivo de la matriz. Si no proporciona ningún sufijo, las opciones asumen kiB por segundo por dispositivo.
Muestra el número de discrepancias en la matriz, sin repararlas:
# lvchange --syncaction check vg/raid_lvCorregir las discrepancias en la matriz:
# lvchange --syncaction repair vg/raid_lvNotaLa operación
lvchange --syncaction repairno realiza la misma función que la operaciónlvconvert --repair:-
La operación
lvchange --syncaction repairinicia una operación de sincronización en segundo plano en la matriz. -
La operación
lvconvert --repairrepara o sustituye los dispositivos que fallan en un espejo o volumen lógico RAID.
-
La operación
Opcional: Muestra información sobre la operación de lavado:
# lvs -o raid_sync_action,raid_mismatch_count vg/lvEl campo
raid_sync_actionmuestra la operación de sincronización actual que está realizando el volumen RAID. Puede ser uno de los siguientes valores:idle- Todas las operaciones de sincronización completadas (sin hacer nada)
resync- Inicialización de una matriz o recuperación tras un fallo de la máquina
recover- Sustitución de un dispositivo en la matriz
check- Buscar incoherencias en las matrices
repair- Buscar y reparar incoherencias
-
El campo
raid_mismatch_countmuestra el número de discrepancias encontradas durante una operación decheck. -
El campo
Cpy%Syncmuestra el progreso de las operaciones desync. El campo
lv_attrproporciona indicadores adicionales. El bit 9 de este campo muestra la salud del volumen lógico, y admite los siguientes indicadores:-
m(mismatches) indica que hay discrepancias en un volumen lógico RAID. Este carácter se muestra después de que una operación de depuración haya detectado que partes del RAID no son coherentes. -
r(refresh) indica que un dispositivo en un array RAID ha sufrido un fallo y el kernel lo considera como fallido, aunque LVM puede leer la etiqueta del dispositivo y considera que el dispositivo está operativo. Refresca el volumen lógico para notificar al kernel que el dispositivo está ahora disponible, o reemplaza el dispositivo si sospechas que ha fallado.
-
Recursos adicionales
-
Para más información, consulte las páginas de manual
lvchange(8)ylvmraid(7).
68.14.6.2. Dispositivos fallidos en RAID LVM
RAID no es como el mirroring LVM tradicional. El mirroring LVM requería la eliminación de los dispositivos que fallaban o el volumen lógico reflejado se colgaba. Las matrices RAID pueden seguir funcionando con dispositivos fallidos. De hecho, para los tipos de RAID que no sean RAID1, eliminar un dispositivo significaría convertirlo a un nivel inferior de RAID (por ejemplo, de RAID6 a RAID5, o de RAID4 o RAID5 a RAID0).
Por lo tanto, en lugar de eliminar un dispositivo fallado incondicionalmente y potencialmente asignar un reemplazo, LVM le permite reemplazar un dispositivo fallado en un volumen RAID en una solución de un solo paso utilizando el argumento --repair del comando lvconvert.
68.14.6.3. Recuperación de un dispositivo RAID fallido en un volumen lógico
Si el fallo del dispositivo RAID LVM es un fallo transitorio o puede reparar el dispositivo que ha fallado, puede iniciar la recuperación del dispositivo que ha fallado.
Requisitos previos
- El dispositivo que antes fallaba ahora funciona.
Procedimiento
Actualiza el volumen lógico que contiene el dispositivo RAID:
# lvchange --refresh my_vg/my_lv
Pasos de verificación
Examine el volumen lógico con el dispositivo recuperado:
# lvs --all --options name,devices,lv_attr,lv_health_status my_vg
68.14.6.4. Sustitución de un dispositivo RAID fallido en un volumen lógico
Este procedimiento reemplaza un dispositivo fallado que sirve como volumen físico en un volumen lógico RAID LVM.
Requisitos previos
El grupo de volúmenes incluye un volumen físico que proporciona suficiente capacidad libre para reemplazar el dispositivo que ha fallado.
Si no hay ningún volumen físico con suficientes extensiones libres en el grupo de volúmenes, añada un nuevo volumen físico lo suficientemente grande utilizando la utilidad
vgextend.
Procedimiento
En el siguiente ejemplo, un volumen lógico RAID está dispuesto de la siguiente manera:
# lvs --all --options name,copy_percent,devices my_vg LV Cpy%Sync Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdc1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdc1(0) [my_lv_rmeta_2] /dev/sdd1(0)Si el dispositivo
/dev/sdcfalla, la salida del comandolvses la siguiente:# lvs --all --options name,copy_percent,devices my_vg /dev/sdc: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. WARNING: Couldn't find all devices for LV my_vg/my_lv_rimage_1 while checking used and assumed devices. WARNING: Couldn't find all devices for LV my_vg/my_lv_rmeta_1 while checking used and assumed devices. LV Cpy%Sync Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] [unknown](1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] [unknown](0) [my_lv_rmeta_2] /dev/sdd1(0)Sustituya el dispositivo que ha fallado y visualice el volumen lógico:
# lvconvert --repair my_vg/my_lv /dev/sdc: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. WARNING: Couldn't find all devices for LV my_vg/my_lv_rimage_1 while checking used and assumed devices. WARNING: Couldn't find all devices for LV my_vg/my_lv_rmeta_1 while checking used and assumed devices. Attempt to replace failed RAID images (requires full device resync)? [y/n]: y Faulty devices in my_vg/my_lv successfully replaced.Opcional: Para especificar manualmente el volumen físico que sustituye al dispositivo que ha fallado, añada el volumen físico al final del comando:
# lvconvert --repair my_vg/my_lv replacement_pvExamine el volumen lógico con la sustitución:
# lvs --all --options name,copy_percent,devices my_vg /dev/sdc: open failed: No such device or address /dev/sdc1: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. LV Cpy%Sync Devices my_lv 43.79 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdb1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdb1(0) [my_lv_rmeta_2] /dev/sdd1(0)Hasta que no elimine el dispositivo fallado del grupo de volúmenes, las utilidades LVM siguen indicando que LVM no puede encontrar el dispositivo fallado.
Elimine el dispositivo que ha fallado del grupo de volúmenes:
# vgreduce --removemissing VG
68.14.7. Solución de problemas de insuficiencia de extensiones libres para un volumen lógico
Es posible que recibas el mensaje de error Insufficient free extents al intentar crear un volumen lógico, incluso cuando crees que el grupo de volúmenes tiene suficiente espacio libre. Puedes solucionar este error para poder crear un volumen lógico en el grupo de volúmenes.
68.14.7.1. Grupos de volumen
Los volúmenes físicos se combinan en grupos de volúmenes (VG). Esto crea una reserva de espacio en disco a partir de la cual se pueden asignar volúmenes lógicos.
Dentro de un grupo de volúmenes, el espacio de disco disponible para la asignación se divide en unidades de tamaño fijo llamadas extensiones. Una extensión es la unidad más pequeña de espacio que se puede asignar. Dentro de un volumen físico, los extents se denominan extents físicos.
Un volumen lógico se asigna en extensiones lógicas del mismo tamaño que las extensiones físicas. El tamaño de la extensión es, por tanto, el mismo para todos los volúmenes lógicos del grupo de volúmenes. El grupo de volúmenes asigna las extensiones lógicas a extensiones físicas.
68.14.7.2. Errores de redondeo en la salida de LVM
Los comandos de LVM que informan del uso de espacio en los grupos de volúmenes redondean el número informado a 2 decimales para proporcionar una salida legible para los humanos. Esto incluye las utilidades vgdisplay y vgs.
Como resultado del redondeo, el valor reportado de espacio libre podría ser mayor que el que proporcionan los extensiones físicas del grupo de volúmenes. Si intentas crear un volumen lógico del tamaño del espacio libre informado, podrías obtener el siguiente error:
Insuficientes extensiones libresPara solucionar el error, debe examinar el número de extensiones físicas libres en el grupo de volúmenes, que es el valor exacto del espacio libre. A continuación, puede utilizar el número de extensiones para crear el volumen lógico con éxito.
68.14.7.3. Evitar el error de redondeo al crear un volumen LVM
Al crear un volumen lógico LVM, puede especificar el tamaño del volumen lógico para que no se produzca un error de redondeo.
Procedimiento
Encuentre el número de extensiones físicas libres en el grupo de volúmenes:
# vgdisplay volume-group-nameEjemplo 68.11. Extensiones libres en un grupo de volúmenes
Por ejemplo, el siguiente grupo de volúmenes tiene 8780 extensiones físicas libres:
--- Volume group --- ... Free PE / Size 8780 / 34.30 GBCree el volumen lógico. Introduzca el tamaño del volumen en extensiones en lugar de bytes.
Ejemplo 68.12. Creación de un volumen lógico especificando el número de extensiones
# lvcreate --extents 8780 --name testlv testvgEjemplo 68.13. Creación de un volumen lógico para ocupar todo el espacio restante
Alternativamente, puedes ampliar el volumen lógico para utilizar un porcentaje del espacio libre restante en el grupo de volúmenes. Por ejemplo:
# lvcreate --extents 100EE --name testlv2 testvg
Pasos de verificación
Comprueba el número de extensiones que utiliza ahora el grupo de volúmenes:
# vgs --options +vg_free_count,vg_extent_count VG #PV #LV #SN Attr VSize VFree Free #Ext testvg 2 1 0 wz--n- 34.30G 0 0 8780
68.14.8. Solución de problemas de advertencias de volúmenes físicos duplicados para dispositivos LVM multipathed
Cuando se utiliza LVM con almacenamiento multipista, los comandos LVM que enumeran un grupo de volúmenes o un volumen lógico pueden mostrar mensajes como el siguiente:
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/dm-5 not /dev/sdd
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/emcpowerb not /dev/sde
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/sddlmab not /dev/sdfPuede solucionar estos avisos para entender por qué LVM los muestra, o para ocultar los avisos.
68.14.8.1. Causa de la duplicación de los avisos de FV
Cuando un software de multirruta como Device Mapper Multipath (DM Multipath), EMC PowerPath o Hitachi Dynamic Link Manager (HDLM) gestiona dispositivos de almacenamiento en el sistema, cada ruta a una unidad lógica (LUN) concreta se registra como un dispositivo SCSI diferente. A continuación, el software multipath crea un nuevo dispositivo que se asigna a esas rutas individuales. Como cada LUN tiene varios nodos de dispositivo en el directorio /dev que apuntan a los mismos datos subyacentes, todos los nodos de dispositivo contienen los mismos metadatos LVM.
| Software multitrayectoria | Rutas SCSI a un LUN | Asignación de dispositivos multirruta a las rutas |
|---|---|---|
| DM Multipath |
|
|
| EMC PowerPath |
| |
| HDLM |
|
Como resultado de los múltiples nodos de dispositivos, las herramientas LVM encuentran los mismos metadatos varias veces y los reportan como duplicados.
68.14.8.2. Casos de duplicación de avisos de FV
LVM muestra las advertencias de PV duplicado en cualquiera de los siguientes casos:
- Los dos dispositivos que se muestran en la salida son rutas únicas hacia el mismo dispositivo.
- Los dos dispositivos que se muestran en la salida son mapas multitrayectoria.
Caminos individuales hacia el mismo dispositivo
El siguiente ejemplo muestra una advertencia de PV duplicada en la que los dispositivos duplicados son ambos rutas únicas hacia el mismo dispositivo.
Encontrado duplicado PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: usando /dev/sdd no /dev/sdf
Si se lista la topología actual de DM Multipath usando el comando multipath -ll, se puede encontrar tanto /dev/sdd como /dev/sdf bajo el mismo mapa multipath.
Estos mensajes duplicados son sólo advertencias y no significan que la operación LVM haya fallado. Más bien, le están alertando de que LVM utiliza sólo uno de los dispositivos como volumen físico e ignora los otros.
Si los mensajes indican que LVM elige el dispositivo incorrecto o si las advertencias son molestas para los usuarios, puede aplicar un filtro. El filtro configura LVM para que busque sólo los dispositivos necesarios para los volúmenes físicos, y para que omita cualquier ruta subyacente a los dispositivos multipath. Como resultado, las advertencias ya no aparecen.
Mapas multitrayectoria
Los siguientes ejemplos muestran una advertencia de volúmenes físicos duplicados para dos dispositivos que son ambos mapas multirruta. Los volúmenes físicos duplicados se encuentran en dos dispositivos diferentes y no en dos rutas diferentes hacia el mismo dispositivo.
Encontrado duplicado PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: usando /dev/mapper/mpatha no /dev/mapper/mpathcEncontrado duplicado PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: usando /dev/emcpowera no /dev/emcpowerhEsta situación es más grave que las advertencias de duplicación de dispositivos que son ambas rutas únicas al mismo dispositivo. Estas advertencias suelen significar que la máquina está accediendo a dispositivos a los que no debería acceder: por ejemplo, clones LUN o réplicas.
A menos que sepa claramente qué dispositivos debe eliminar de la máquina, esta situación podría ser irrecuperable. Red Hat recomienda que se ponga en contacto con el Soporte Técnico de Red Hat para solucionar este problema.
68.14.8.3. El filtro de dispositivos LVM
Las herramientas LVM escanean los dispositivos en el directorio /dev y comprueban cada uno de ellos en busca de metadatos LVM. Un filtro en el archivo /etc/lvm/lvm.conf controla qué dispositivos escanea LVM.
El filtro es una lista de patrones que LVM aplica a cada dispositivo encontrado por una exploración del directorio /dev, o el directorio especificado por la palabra clave dir en el archivo /etc/lvm/lvm.conf. Los patrones son expresiones regulares delimitadas por cualquier carácter y precedidas por a para accept o r para reject. La primera expresión regular de la lista que coincide con un dispositivo determina si LVM acepta o rechaza (ignora) el dispositivo. LVM acepta los dispositivos que no coinciden con ningún patrón.
La siguiente es la configuración por defecto del filtro, que escanea todos los dispositivos:
filtro = [ \ "a/.*/" ]68.14.8.4. Ejemplo de filtros de dispositivos LVM que evitan los avisos de PV duplicados
Los siguientes ejemplos muestran filtros de dispositivos LVM que evitan las advertencias de volúmenes físicos duplicados que son causadas por múltiples rutas de almacenamiento a una sola unidad lógica (LUN).
El filtro que configure debe incluir todos los dispositivos que LVM necesita para comprobar los metadatos, como el disco duro local con el grupo de volumen raíz en él y cualquier dispositivo multipathed. Rechazando las rutas subyacentes a un dispositivo multirruta (como /dev/sdb, /dev/sdd, y así sucesivamente), puede evitar estas advertencias de PV duplicado, porque LVM encuentra cada área de metadatos única una vez en el propio dispositivo multirruta.
Este filtro acepta la segunda partición del primer disco duro y cualquier dispositivo DM Multipath, pero rechaza todo lo demás:
filter = [ \ "a|/dev/sda2$|\", \ "a|/dev/mapper/mpath.*|", \ "r|.*|" ]Este filtro acepta todos los controladores HP SmartArray y cualquier dispositivo EMC PowerPath:
filter = [ \ "a|/dev/cciss/.*||", \ "a|/dev/emcpower.*||", \ "r|.*||" ]Este filtro acepta cualquier partición en la primera unidad IDE y cualquier dispositivo multipath:
filter = [ |"a|/dev/hda.*|||", |"a|/dev/mapper/mpath.*|||", |"r|.*|||" ]
68.14.8.5. Aplicación de una configuración de filtro de dispositivos LVM
Este procedimiento cambia la configuración del filtro de dispositivos LVM, que controla los dispositivos que escanea LVM.
Requisitos previos
- Prepare el patrón de filtro del dispositivo que desea utilizar.
Procedimiento
Pruebe el patrón de filtrado de su dispositivo sin modificar el archivo
/etc/lvm/lvm.conf.Utilice un comando LVM con la opción
--config 'devices{ filter = [ your device filter pattern ] }'opción. Por ejemplo:# lvs --config 'devices{ filter = [ |"a|/dev/emcpower.*||\", "r|.*|" ]'-
Edite la opción
filteren el archivo de configuración/etc/lvm/lvm.confpara utilizar su nuevo patrón de filtrado de dispositivos. Compruebe que no faltan volúmenes físicos o grupos de volúmenes que desee utilizar con la nueva configuración:
# pvscan# vgscanReconstruya el sistema de archivos
initramfspara que LVM escanee sólo los dispositivos necesarios al reiniciar:# dracut --force --verbose