Authentification et autorisation
Configuration de l'authentification des utilisateurs et des contrôles d'accès pour les utilisateurs et les services
Résumé
Chapitre 1. Aperçu de l'authentification et de l'autorisation
1.1. Glossaire des termes courants pour l'authentification et l'autorisation de OpenShift Container Platform
Ce glossaire définit les termes communs utilisés dans l'authentification et l'autorisation de OpenShift Container Platform.
- l'authentification
- Une authentification détermine l'accès à un cluster OpenShift Container Platform et garantit que seuls les utilisateurs authentifiés accèdent au cluster OpenShift Container Platform.
- autorisation
- L'autorisation détermine si l'utilisateur identifié a le droit d'effectuer l'action demandée.
- jeton au porteur
-
Le jeton du porteur est utilisé pour s'authentifier auprès de l'API avec l'en-tête
Authorization: Bearer <token>. - Opérateur de certificats dans le nuage
- Le Cloud Credential Operator (CCO) gère les informations d'identification des fournisseurs de cloud sous forme de définitions de ressources personnalisées (CRD).
- carte de configuration
-
Une carte de configuration permet d'injecter des données de configuration dans les pods. Vous pouvez référencer les données stockées dans une carte de configuration dans un volume de type
ConfigMap. Les applications fonctionnant dans un pod peuvent utiliser ces données. - conteneurs
- Images légères et exécutables composées de logiciels et de toutes leurs dépendances. Comme les conteneurs virtualisent le système d'exploitation, vous pouvez les exécuter dans un centre de données, un nuage public ou privé, ou votre hôte local.
- Ressource personnalisée (CR)
- Un CR est une extension de l'API Kubernetes.
- groupe
- Un groupe est un ensemble d'utilisateurs. Un groupe est utile pour accorder des autorisations à plusieurs utilisateurs en même temps.
- HTPasswd
- HTPasswd met à jour les fichiers qui stockent les noms d'utilisateur et les mots de passe pour l'authentification des utilisateurs HTTP.
- Keystone
- Keystone est un projet de Red Hat OpenStack Platform (RHOSP) qui fournit des services d'identité, de jeton, de catalogue et de politique.
- Protocole d'accès à l'annuaire léger (LDAP)
- LDAP est un protocole qui permet d'interroger les informations sur les utilisateurs.
- mode manuel
- En mode manuel, c'est un utilisateur qui gère les informations d'identification dans le nuage à la place de l'opérateur d'informations d'identification dans le nuage (Cloud Credential Operator, CCO).
- mode menthe
- Le mode Mint est le paramètre par défaut et la meilleure pratique recommandée pour le Cloud Credential Operator (CCO) sur les plates-formes pour lesquelles il est pris en charge. Dans ce mode, le CCO utilise le justificatif d'identité cloud de niveau administrateur fourni pour créer de nouveaux justificatifs d'identité pour les composants du cluster avec uniquement les autorisations spécifiques requises.
- espace de noms
- Un espace de noms isole des ressources système spécifiques qui sont visibles par tous les processus. À l'intérieur d'un espace de noms, seuls les processus membres de cet espace peuvent voir ces ressources.
- nœud
- Un nœud est une machine de travail dans le cluster OpenShift Container Platform. Un nœud est soit une machine virtuelle (VM), soit une machine physique.
- Client OAuth
- Le client OAuth est utilisé pour obtenir un jeton de porteur.
- Serveur OAuth
- Le plan de contrôle d'OpenShift Container Platform comprend un serveur OAuth intégré qui détermine l'identité de l'utilisateur à partir du fournisseur d'identité configuré et crée un jeton d'accès.
- OpenID Connect
- OpenID Connect est un protocole qui permet d'authentifier les utilisateurs afin d'utiliser l'authentification unique (SSO) pour accéder aux sites qui utilisent les fournisseurs OpenID.
- mode passthrough
- En mode passthrough, le Cloud Credential Operator (CCO) transmet le justificatif d'identité cloud fourni aux composants qui demandent des justificatifs d'identité cloud.
- nacelle
- Un pod est la plus petite unité logique de Kubernetes. Un pod est composé d'un ou plusieurs conteneurs à exécuter dans un nœud de travailleur.
- utilisateurs réguliers
- Utilisateurs créés automatiquement dans le cluster lors de la première connexion ou via l'API.
- en-tête de la demande
- Un en-tête de requête est un en-tête HTTP utilisé pour fournir des informations sur le contexte de la requête HTTP, afin que le serveur puisse suivre la réponse à la requête.
- le contrôle d'accès basé sur les rôles (RBAC)
- Un contrôle de sécurité clé pour s'assurer que les utilisateurs et les charges de travail des clusters n'ont accès qu'aux ressources nécessaires à l'exécution de leurs rôles.
- comptes de service
- Les comptes de service sont utilisés par les composants ou les applications du cluster.
- les utilisateurs du système
- Utilisateurs créés automatiquement lors de l'installation du cluster.
- utilisateurs
- L'utilisateur est une entité qui peut faire des demandes à l'API.
1.2. À propos de l'authentification dans OpenShift Container Platform
Pour contrôler l'accès à un cluster OpenShift Container Platform, un administrateur de cluster peut configurer l'authentification des utilisateurs et s'assurer que seuls les utilisateurs approuvés accèdent au cluster.
Pour interagir avec un cluster OpenShift Container Platform, les utilisateurs doivent d'abord s'authentifier auprès de l'API OpenShift Container Platform d'une manière ou d'une autre. Vous pouvez vous authentifier en fournissant un jeton d'accès OAuth ou un certificat client X.509 dans vos demandes à l'API OpenShift Container Platform.
Si vous ne présentez pas de jeton d'accès ou de certificat valide, votre demande n'est pas authentifiée et vous recevez une erreur HTTP 401.
Un administrateur peut configurer l'authentification en effectuant les tâches suivantes :
- Configuration d'un fournisseur d'identité : Vous pouvez définir n'importe quel fournisseur d'identité pris en charge dans OpenShift Container Platform et l'ajouter à votre cluster.
Configuration du serveur OAuth interne: Le plan de contrôle d'OpenShift Container Platform comprend un serveur OAuth intégré qui détermine l'identité de l'utilisateur à partir du fournisseur d'identité configuré et crée un jeton d'accès. Vous pouvez configurer la durée du jeton et le délai d'inactivité, et personnaliser l'URL du serveur OAuth interne.
NoteLes utilisateurs peuvent consulter et gérer les jetons OAuth dont ils sont propriétaires.
Enregistrement d'un client OAuth : OpenShift Container Platform inclut plusieurs clients OAuth par défaut. Vous pouvez enregistrer et configurer des clients OAuth supplémentaires.
NoteLorsque les utilisateurs envoient une demande de jeton OAuth, ils doivent spécifier un client OAuth par défaut ou personnalisé qui reçoit et utilise le jeton.
- Gestion des informations d'identification du fournisseur de cloud à l'aide de l'opérateur d'informations d'identification du cloud: Les composants du cluster utilisent les informations d'identification du fournisseur de cloud pour obtenir les autorisations nécessaires à l'exécution des tâches liées au cluster.
- Usurpation d'identité d'un utilisateur administrateur système : Vous pouvez accorder des droits d'administrateur de cluster à un utilisateur en vous faisant passer pour un utilisateur administrateur système.
1.3. À propos de l'autorisation dans OpenShift Container Platform
L'autorisation consiste à déterminer si l'utilisateur identifié a le droit d'effectuer l'action demandée.
Les administrateurs peuvent définir les autorisations et les attribuer aux utilisateurs à l'aide des objets RBAC, tels que les règles, les rôles et les liaisons. Pour comprendre comment fonctionne l'autorisation dans OpenShift Container Platform, voir Évaluation de l'autorisation.
Vous pouvez également contrôler l'accès à un cluster OpenShift Container Platform par le biais de projets et d'espaces de noms.
Outre le contrôle de l'accès des utilisateurs à un cluster, vous pouvez également contrôler les actions qu'un pod peut effectuer et les ressources auxquelles il peut accéder à l'aide de contraintes de contexte de sécurité (SCC).
Vous pouvez gérer l'autorisation pour OpenShift Container Platform en effectuant les tâches suivantes :
- Visualisation des rôles et des liens locaux et de cluster.
- Créer un rôle local et l'attribuer à un utilisateur ou à un groupe.
- Créer un rôle de cluster et l'attribuer à un utilisateur ou à un groupe : OpenShift Container Platform inclut un ensemble de rôles de cluster par défaut. Vous pouvez créer des rôles de cluster supplémentaires et les ajouter à un utilisateur ou à un groupe.
Création d'un utilisateur cluster-admin : Par défaut, votre cluster n'a qu'un seul administrateur de cluster appelé
kubeadmin. Vous pouvez créer un autre administrateur de cluster. Avant de créer un administrateur de cluster, assurez-vous que vous avez configuré un fournisseur d'identité.NoteAprès avoir créé l'utilisateur administrateur du cluster, supprimez l'utilisateur kubeadmin existant afin d'améliorer la sécurité du cluster.
- Création de comptes de service : Les comptes de service constituent un moyen souple de contrôler l'accès à l'API sans partager les informations d'identification d'un utilisateur normal. Un utilisateur peut créer et utiliser un compte de service dans des applications et également en tant que client OAuth.
- Jetons de portée: Un jeton de portée est un jeton qui identifie un utilisateur spécifique qui ne peut effectuer que des opérations spécifiques. Vous pouvez créer des jetons de portée pour déléguer certaines de vos autorisations à un autre utilisateur ou à un compte de service.
- Synchronisation des groupes LDAP : Vous pouvez gérer les groupes d'utilisateurs en un seul endroit en synchronisant les groupes stockés dans un serveur LDAP avec les groupes d'utilisateurs d'OpenShift Container Platform.
Chapitre 2. Comprendre l'authentification
Pour que les utilisateurs puissent interagir avec OpenShift Container Platform, ils doivent d'abord s'authentifier auprès du cluster. La couche d'authentification identifie l'utilisateur associé aux demandes de l'API OpenShift Container Platform. La couche d'autorisation utilise ensuite des informations sur l'utilisateur demandeur pour déterminer si la demande est autorisée.
En tant qu'administrateur, vous pouvez configurer l'authentification pour OpenShift Container Platform.
2.1. Utilisateurs
Un user dans OpenShift Container Platform est une entité qui peut faire des requêtes à l'API OpenShift Container Platform. Un objet User dans OpenShift Container Platform représente un acteur à qui l'on peut accorder des permissions dans le système en lui ajoutant des rôles ou des groupes. Typiquement, cela représente le compte d'un développeur ou d'un administrateur qui interagit avec OpenShift Container Platform.
Plusieurs types d'utilisateurs peuvent exister :
| Type d'utilisateur | Description |
|---|---|
|
|
C'est ainsi que sont représentés la plupart des utilisateurs interactifs d'OpenShift Container Platform. Les utilisateurs réguliers sont créés automatiquement dans le système lors de la première connexion ou peuvent être créés via l'API. Les utilisateurs réguliers sont représentés par l'objet |
|
|
Nombre d'entre eux sont créés automatiquement lors de la définition de l'infrastructure, principalement dans le but de permettre à l'infrastructure d'interagir avec l'API en toute sécurité. Il s'agit notamment d'un administrateur de cluster (qui a accès à tout), d'un utilisateur par nœud, d'utilisateurs pour les routeurs et les registres, et de divers autres. Enfin, il existe un utilisateur système |
|
|
Il s'agit d'utilisateurs spéciaux du système associés à des projets ; certains sont créés automatiquement lors de la création du projet, tandis que les administrateurs de projet peuvent en créer d'autres afin de définir l'accès au contenu de chaque projet. Les comptes de service sont représentés par l'objet |
Chaque utilisateur doit s'authentifier d'une manière ou d'une autre pour accéder à OpenShift Container Platform. Les demandes d'API sans authentification ou avec une authentification non valide sont authentifiées comme des demandes par l'utilisateur du système anonymous. Après l'authentification, la politique détermine ce que l'utilisateur est autorisé à faire.
2.2. Groupes
Un utilisateur peut être affecté à un ou plusieurs groups, chacun d'entre eux représentant un certain ensemble d'utilisateurs. Les groupes sont utiles pour gérer les politiques d'autorisation afin d'accorder des permissions à plusieurs utilisateurs à la fois, par exemple en autorisant l'accès à des objets au sein d'un projet, plutôt qu'en les accordant à des utilisateurs individuels.
En plus des groupes explicitement définis, il existe également des groupes système, ou virtual groups, qui sont automatiquement provisionnés par le cluster.
Les groupes virtuels par défaut suivants sont les plus importants :
| Groupe virtuel | Description |
|---|---|
|
| Automatiquement associé à tous les utilisateurs authentifiés. |
|
| Automatiquement associé à tous les utilisateurs authentifiés avec un jeton d'accès OAuth. |
|
| Automatiquement associé à tous les utilisateurs non authentifiés. |
2.3. Authentification de l'API
Les requêtes adressées à l'API OpenShift Container Platform sont authentifiées à l'aide des méthodes suivantes :
- Jetons d'accès OAuth
-
Obtenu à partir du serveur OAuth de OpenShift Container Platform à l'aide des paramètres
<namespace_route>/oauth/authorizeet<namespace_route>/oauth/token. -
Envoyé en tant qu'en-tête
Authorization: Bearer…. -
Envoyé en tant qu'en-tête du sous-protocole websocket sous la forme
base64url.bearer.authorization.k8s.io.<base64url-encoded-token>pour les requêtes websocket.
-
Obtenu à partir du serveur OAuth de OpenShift Container Platform à l'aide des paramètres
- Certificats clients X.509
- Nécessite une connexion HTTPS au serveur de l'API.
- Vérifié par le serveur API par rapport à un ensemble d'autorités de certification de confiance.
- Le serveur API crée et distribue des certificats aux contrôleurs pour qu'ils s'authentifient.
Toute demande comportant un jeton d'accès ou un certificat non valide est rejetée par la couche d'authentification avec une erreur 401.
Si aucun jeton d'accès ou certificat n'est présenté, la couche d'authentification attribue l'utilisateur virtuel system:anonymous et le groupe virtuel system:unauthenticated à la demande. Cela permet à la couche d'autorisation de déterminer quelles demandes, le cas échéant, un utilisateur anonyme est autorisé à faire.
2.3.1. Serveur OAuth de OpenShift Container Platform
Le master OpenShift Container Platform comprend un serveur OAuth intégré. Les utilisateurs obtiennent des jetons d'accès OAuth pour s'authentifier auprès de l'API.
Lorsqu'une personne demande un nouveau jeton OAuth, le serveur OAuth utilise le fournisseur d'identité configuré pour déterminer l'identité de la personne qui fait la demande.
Il détermine ensuite à quel utilisateur correspond cette identité, crée un jeton d'accès pour cet utilisateur et renvoie le jeton pour utilisation.
2.3.1.1. Demandes de jetons OAuth
Chaque demande de jeton OAuth doit spécifier le client OAuth qui recevra et utilisera le jeton. Les clients OAuth suivants sont automatiquement créés lors du démarrage de l'API OpenShift Container Platform :
| Client OAuth | Utilisation |
|---|---|
|
|
Demande des jetons à |
|
|
Demande de jetons avec un user-agent qui peut gérer les défis |
<namespace_route>fait référence à la route de l'espace de noms. On le trouve en exécutant la commande suivante :$ oc get route oauth-openshift -n openshift-authentication -o json | jq .spec.host
Toutes les demandes de jetons OAuth impliquent une requête à <namespace_route>/oauth/authorize. La plupart des intégrations d'authentification placent un proxy d'authentification devant ce point de terminaison, ou configurent OpenShift Container Platform pour valider les informations d'identification par rapport à un fournisseur d'identité de soutien. Les demandes adressées à <namespace_route>/oauth/authorize peuvent provenir d'agents utilisateurs qui ne peuvent pas afficher de pages de connexion interactives, telles que la CLI. Par conséquent, OpenShift Container Platform prend en charge l'authentification à l'aide d'un défi WWW-Authenticate en plus des flux de connexion interactifs.
Si un proxy d'authentification est placé devant le point de terminaison <namespace_route>/oauth/authorize, il envoie aux agents utilisateurs non authentifiés, qui ne sont pas des navigateurs, des défis WWW-Authenticate au lieu d'afficher une page de connexion interactive ou de rediriger vers un flux de connexion interactif.
Pour éviter les attaques de type cross-site request forgery (CSRF) contre les clients des navigateurs, n'envoyez des défis d'authentification de base que si un en-tête X-CSRF-Token figure sur la demande. Les clients qui s'attendent à recevoir des défis Basic WWW-Authenticate doivent attribuer à cet en-tête une valeur non vide.
Si le proxy d'authentification ne prend pas en charge les défis WWW-Authenticate ou si OpenShift Container Platform est configuré pour utiliser un fournisseur d'identité qui ne prend pas en charge les défis WWW-Authenticate, vous devez utiliser un navigateur pour obtenir manuellement un jeton à partir de <namespace_route>/oauth/token/request.
2.3.1.2. L'usurpation d'identité de l'API
Vous pouvez configurer une requête à l'API OpenShift Container Platform pour qu'elle agisse comme si elle provenait d'un autre utilisateur. Pour plus d'informations, voir User impersonation dans la documentation Kubernetes.
2.3.1.3. Mesures d'authentification pour Prometheus
OpenShift Container Platform capture les métriques système Prometheus suivantes lors des tentatives d'authentification :
-
openshift_auth_basic_password_countcompte le nombre de tentatives de saisie du nom d'utilisateur et du mot de passe suroc login. -
openshift_auth_basic_password_count_resultcompte le nombre de tentatives d'utilisation du nom d'utilisateur et du mot de passeoc loginpar résultat,successouerror. -
openshift_auth_form_password_countcompte le nombre de tentatives de connexion à la console web. -
openshift_auth_form_password_count_resultcompte le nombre de tentatives de connexion à la console web par résultat,successouerror. -
openshift_auth_password_totalcompte le nombre total de tentatives de connexion àoc loginet à la console web.
Chapitre 3. Configuration du serveur OAuth interne
3.1. Serveur OAuth de OpenShift Container Platform
Le master OpenShift Container Platform comprend un serveur OAuth intégré. Les utilisateurs obtiennent des jetons d'accès OAuth pour s'authentifier auprès de l'API.
Lorsqu'une personne demande un nouveau jeton OAuth, le serveur OAuth utilise le fournisseur d'identité configuré pour déterminer l'identité de la personne qui fait la demande.
Il détermine ensuite à quel utilisateur correspond cette identité, crée un jeton d'accès pour cet utilisateur et renvoie le jeton pour utilisation.
3.2. Flux de demandes de jetons OAuth et réponses
Le serveur OAuth prend en charge le code d' autorisation standard et les flux d'autorisation OAuth implicites.
Lors d'une demande de jeton OAuth utilisant le flux d'octroi implicite (response_type=token) avec un identifiant client configuré pour demander WWW-Authenticate challenges (comme openshift-challenging-client), voici les réponses possibles du serveur à partir de /oauth/authorize, et la façon dont elles doivent être traitées :
| Statut | Contenu | Réponse du client |
|---|---|---|
| 302 |
|
Utilisez la valeur |
| 302 |
|
Échouer, en faisant éventuellement apparaître à l'utilisateur les valeurs de la requête |
| 302 |
Autre en-tête | Suivez la redirection et traitez le résultat à l'aide de ces règles. |
| 401 |
|
Répondre au défi si le type est reconnu (par exemple |
| 401 |
| Aucune authentification par défi n'est possible. Échec et affichage du corps de la réponse (qui peut contenir des liens ou des détails sur d'autres méthodes pour obtenir un jeton OAuth). |
| Autres | Autres | Échec, éventuellement en faisant apparaître le corps de la réponse à l'utilisateur. |
3.3. Options pour le serveur OAuth interne
Plusieurs options de configuration sont disponibles pour le serveur OAuth interne.
3.3.1. Options de durée du jeton OAuth
Le serveur OAuth interne génère deux types de jetons :
| Jeton | Description |
|---|---|
| Jetons d'accès | Jetons à durée de vie plus longue qui permettent d'accéder à l'API. |
| Autoriser les codes | Jetons de courte durée dont la seule utilité est d'être échangés contre un jeton d'accès. |
Vous pouvez configurer la durée par défaut pour les deux types de jetons. Si nécessaire, vous pouvez remplacer la durée du jeton d'accès en utilisant une définition d'objet OAuthClient.
3.3.2. Options d'octroi d'OAuth
Lorsque le serveur OAuth reçoit des demandes de jetons pour un client auquel l'utilisateur n'a pas accordé d'autorisation au préalable, l'action du serveur OAuth dépend de la stratégie d'octroi du client OAuth.
Le client OAuth qui demande le jeton doit fournir sa propre stratégie d'octroi.
Vous pouvez appliquer les méthodes par défaut suivantes :
| Option d'attribution | Description |
|---|---|
|
| Approuver automatiquement la subvention et réessayer la demande. |
|
| Inviter l'utilisateur à approuver ou à refuser la subvention. |
3.4. Configuration de la durée du jeton du serveur OAuth interne
Vous pouvez configurer des options par défaut pour la durée du jeton du serveur OAuth interne.
Par défaut, les jetons ne sont valables que 24 heures. Les sessions existantes expirent à l'issue de cette période.
Si la durée par défaut est insuffisante, elle peut être modifiée en suivant la procédure suivante.
Procédure
Créez un fichier de configuration contenant les options relatives à la durée du jeton. Le fichier suivant fixe cette durée à 48 heures, soit le double de la valeur par défaut.
apiVersion: config.openshift.io/v1 kind: OAuth metadata: name: cluster spec: tokenConfig: accessTokenMaxAgeSeconds: 1728001 - 1
- Définissez
accessTokenMaxAgeSecondspour contrôler la durée de vie des jetons d'accès. La durée de vie par défaut est de 24 heures, soit 86400 secondes. Cet attribut ne peut pas être négatif. S'il est défini à zéro, la durée de vie par défaut est utilisée.
Appliquer le nouveau fichier de configuration :
NoteComme vous mettez à jour le serveur OAuth existant, vous devez utiliser la commande
oc applypour appliquer la modification.$ oc apply -f </path/to/file.yaml>Confirmez que les modifications sont effectives :
$ oc describe oauth.config.openshift.io/clusterExemple de sortie
... Spec: Token Config: Access Token Max Age Seconds: 172800 ...
3.5. Configuration du délai d'inactivité du jeton pour le serveur OAuth interne
Vous pouvez configurer les jetons OAuth pour qu'ils expirent après une période d'inactivité donnée. Par défaut, aucun délai d'inactivité n'est défini.
Si le délai d'inactivité du jeton est également configuré dans votre client OAuth, cette valeur remplace le délai défini dans la configuration interne du serveur OAuth.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. - Vous avez configuré un fournisseur d'identité (IDP).
Procédure
Mettre à jour la configuration de
OAuthpour définir un délai d'inactivité des jetons.Modifiez l'objet
OAuth:$ oc edit oauth clusterAjoutez le champ
spec.tokenConfig.accessTokenInactivityTimeoutet définissez la valeur de votre délai d'attente :apiVersion: config.openshift.io/v1 kind: OAuth metadata: ... spec: tokenConfig: accessTokenInactivityTimeout: 400s1 - 1
- Définissez une valeur avec les unités appropriées, par exemple
400spour 400 secondes, ou30mpour 30 minutes. La valeur minimale autorisée pour le délai d'attente est300s.
- Enregistrez le fichier pour appliquer les modifications.
Vérifier que les pods du serveur OAuth ont redémarré :
$ oc get clusteroperators authenticationNe passez pas à l'étape suivante tant que
PROGRESSINGn'est pas répertorié commeFalse, comme le montre le résultat suivant :Exemple de sortie
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE authentication 4.12.0 True False False 145mVérifiez qu'une nouvelle révision des pods du serveur Kubernetes API a été déployée. Cela prendra plusieurs minutes.
$ oc get clusteroperators kube-apiserverNe passez pas à l'étape suivante tant que
PROGRESSINGn'est pas répertorié commeFalse, comme le montre le résultat suivant :Exemple de sortie
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE kube-apiserver 4.12.0 True False False 145mSi
PROGRESSINGafficheTrue, attendez quelques minutes et réessayez.
Vérification
- Connectez-vous au cluster avec l'identité de votre IDP.
- Exécuter une commande et vérifier qu'elle a abouti.
- Attendre plus longtemps que le délai configuré sans utiliser l'identité. Dans l'exemple de cette procédure, il faut attendre plus de 400 secondes.
Essayer d'exécuter une commande à partir de la session de la même identité.
Cette commande doit échouer car le jeton doit avoir expiré en raison d'une inactivité plus longue que le délai d'attente configuré.
Exemple de sortie
error: You must be logged in to the server (Unauthorized)
3.6. Personnaliser l'URL interne du serveur OAuth
Vous pouvez personnaliser l'URL du serveur OAuth interne en définissant le nom d'hôte personnalisé et le certificat TLS dans le champ spec.componentRoutes de la configuration du cluster Ingress.
Si vous mettez à jour l'URL du serveur OAuth interne, vous risquez de perdre la confiance des composants du cluster qui ont besoin de communiquer avec le serveur OpenShift OAuth pour récupérer les jetons d'accès OAuth. Les composants qui ont besoin de faire confiance au serveur OAuth devront inclure le bundle CA approprié lors de l'appel des endpoints OAuth. Par exemple :
$ oc login -u <username> -p <password> --certificate-authority=<path_to_ca.crt> - 1
- Pour les certificats auto-signés, le fichier
ca.crtdoit contenir le certificat personnalisé de l'autorité de certification, sinon la connexion n'aboutira pas.
L'opérateur d'authentification de cluster publie le certificat de service du serveur OAuth dans la carte de configuration oauth-serving-cert dans l'espace de noms openshift-config-managed. Vous pouvez trouver le certificat dans la clé data.ca-bundle.crt de la carte de configuration.
Conditions préalables
- Vous vous êtes connecté au cluster en tant qu'utilisateur disposant de privilèges administratifs.
Vous avez créé un secret dans l'espace de noms
openshift-configcontenant le certificat et la clé TLS. Cela est nécessaire si le domaine du suffixe du nom d'hôte personnalisé ne correspond pas au suffixe du domaine du cluster. Le secret est facultatif si le suffixe correspond.AstuceVous pouvez créer un secret TLS à l'aide de la commande
oc create secret tls.
Procédure
Modifiez la configuration du cluster
Ingress:$ oc edit ingress.config.openshift.io clusterDéfinir le nom d'hôte personnalisé et, éventuellement, le certificat et la clé de service :
apiVersion: config.openshift.io/v1 kind: Ingress metadata: name: cluster spec: componentRoutes: - name: oauth-openshift namespace: openshift-authentication hostname: <custom_hostname>1 servingCertKeyPairSecret: name: <secret_name>2 - 1
- Le nom d'hôte personnalisé.
- 2
- Référence à un secret dans l'espace de noms
openshift-configqui contient un certificat TLS (tls.crt) et une clé (tls.key). Cette référence est obligatoire si le domaine du suffixe du nom d'hôte personnalisé ne correspond pas au suffixe du domaine du cluster. Le secret est facultatif si le suffixe correspond.
- Enregistrez le fichier pour appliquer les modifications.
3.7. Métadonnées du serveur OAuth
Les applications fonctionnant sur OpenShift Container Platform peuvent avoir à découvrir des informations sur le serveur OAuth intégré. Par exemple, elles peuvent avoir à découvrir l'adresse du site <namespace_route> sans configuration manuelle. Pour les aider, OpenShift Container Platform met en œuvre le projet de spécification IETF OAuth 2.0 Authorization Server Metadata.
Ainsi, toute application s'exécutant au sein du cluster peut envoyer une requête GET à https://openshift.default.svc/.well-known/oauth-authorization-server pour obtenir les informations suivantes :
{
"issuer": "https://<namespace_route>",
"authorization_endpoint": "https://<namespace_route>/oauth/authorize",
"token_endpoint": "https://<namespace_route>/oauth/token",
"scopes_supported": [
"user:full",
"user:info",
"user:check-access",
"user:list-scoped-projects",
"user:list-projects"
],
"response_types_supported": [
"code",
"token"
],
"grant_types_supported": [
"authorization_code",
"implicit"
],
"code_challenge_methods_supported": [
"plain",
"S256"
]
}- 1
- L'identifiant de l'émetteur du serveur d'autorisation, qui est une URL utilisant le schéma
httpset ne comportant aucun élément de requête ou de fragment. Il s'agit de l'emplacement où sont publiées les ressources.well-knownRFC 5785 contenant des informations sur le serveur d'autorisation. - 2
- URL du point final d'autorisation du serveur d'autorisation. Voir RFC 6749.
- 3
- URL du point de terminaison du jeton du serveur d'autorisation. Voir RFC 6749.
- 4
- Tableau JSON contenant une liste des valeurs d'étendue OAuth 2.0 RFC 6749 prises en charge par ce serveur d'autorisation. Notez que toutes les valeurs d'étendue prises en charge ne sont pas annoncées.
- 5
- Tableau JSON contenant une liste des valeurs OAuth 2.0
response_typeprises en charge par ce serveur d'autorisation. Les valeurs de tableau utilisées sont les mêmes que celles utilisées avec le paramètreresponse_typesdéfini par "OAuth 2.0 Dynamic Client Registration Protocol" dans la RFC 7591. - 6
- Tableau JSON contenant une liste des valeurs de type de subvention OAuth 2.0 prises en charge par ce serveur d'autorisation. Les valeurs du tableau utilisées sont les mêmes que celles utilisées avec le paramètre
grant_typesdéfini parOAuth 2.0 Dynamic Client Registration Protocoldans la RFC 7591. - 7
- Tableau JSON contenant une liste des méthodes de contestation de code PKCE RFC 7636 prises en charge par ce serveur d'autorisation. Les valeurs de ces méthodes sont utilisées dans le paramètre
code_challenge_methoddéfini dans la section 4.3 de la RFC 7636. Les valeurs valides de la méthode de contestation de code sont celles qui sont enregistrées dans le registrePKCE Code Challenge Methodsde l'IANA. Voir les paramètres OAuth de l'IANA.
3.8. Dépannage des événements de l'API OAuth
Dans certains cas, le serveur API renvoie un message d'erreur unexpected condition qui est difficile à déboguer sans accès direct au journal principal de l'API. La raison sous-jacente de l'erreur est volontairement masquée afin d'éviter de fournir à un utilisateur non authentifié des informations sur l'état du serveur.
Un sous-ensemble de ces erreurs est lié à des problèmes de configuration du compte de service OAuth. Ces problèmes sont capturés dans des événements qui peuvent être visualisés par des utilisateurs qui ne sont pas administrateurs. Lorsque vous rencontrez une erreur du serveur unexpected condition pendant OAuth, exécutez oc get events pour afficher ces événements sous ServiceAccount.
L'exemple suivant signale un compte de service dont l'URI de redirection OAuth n'est pas correct :
$ oc get events | grep ServiceAccountExemple de sortie
1m 1m 1 proxy ServiceAccount Warning NoSAOAuthRedirectURIs service-account-oauth-client-getter system:serviceaccount:myproject:proxy has no redirectURIs; set serviceaccounts.openshift.io/oauth-redirecturi.<some-value>=<redirect> or create a dynamic URI using serviceaccounts.openshift.io/oauth-redirectreference.<some-value>=<reference>
L'exécution de oc describe sa/<service_account_name> rapporte tous les événements OAuth associés au nom du compte de service donné.
$ oc describe sa/proxy | grep -A5 EventsExemple de sortie
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
3m 3m 1 service-account-oauth-client-getter Warning NoSAOAuthRedirectURIs system:serviceaccount:myproject:proxy has no redirectURIs; set serviceaccounts.openshift.io/oauth-redirecturi.<some-value>=<redirect> or create a dynamic URI using serviceaccounts.openshift.io/oauth-redirectreference.<some-value>=<reference>Voici une liste des erreurs d'événements possibles :
No redirect URI annotations or an invalid URI is specified
Reason Message
NoSAOAuthRedirectURIs system:serviceaccount:myproject:proxy has no redirectURIs; set serviceaccounts.openshift.io/oauth-redirecturi.<some-value>=<redirect> or create a dynamic URI using serviceaccounts.openshift.io/oauth-redirectreference.<some-value>=<reference>Invalid route specified
Reason Message
NoSAOAuthRedirectURIs [routes.route.openshift.io "<name>" not found, system:serviceaccount:myproject:proxy has no redirectURIs; set serviceaccounts.openshift.io/oauth-redirecturi.<some-value>=<redirect> or create a dynamic URI using serviceaccounts.openshift.io/oauth-redirectreference.<some-value>=<reference>]Invalid reference type specified
Reason Message
NoSAOAuthRedirectURIs [no kind "<name>" is registered for version "v1", system:serviceaccount:myproject:proxy has no redirectURIs; set serviceaccounts.openshift.io/oauth-redirecturi.<some-value>=<redirect> or create a dynamic URI using serviceaccounts.openshift.io/oauth-redirectreference.<some-value>=<reference>]Missing SA tokens
Reason Message
NoSAOAuthTokens system:serviceaccount:myproject:proxy has no tokensChapitre 4. Configuration des clients OAuth
Plusieurs clients OAuth sont créés par défaut dans OpenShift Container Platform. Vous pouvez également enregistrer et configurer des clients OAuth supplémentaires.
4.1. Clients OAuth par défaut
Les clients OAuth suivants sont automatiquement créés lors du démarrage de l'API OpenShift Container Platform :
| Client OAuth | Utilisation |
|---|---|
|
|
Demande des jetons à |
|
|
Demande de jetons avec un user-agent qui peut gérer les défis |
<namespace_route>fait référence à la route de l'espace de noms. On le trouve en exécutant la commande suivante :$ oc get route oauth-openshift -n openshift-authentication -o json | jq .spec.host
4.2. Enregistrement d'un client OAuth supplémentaire
Si vous avez besoin d'un client OAuth supplémentaire pour gérer l'authentification de votre cluster OpenShift Container Platform, vous pouvez en enregistrer un.
Procédure
Pour enregistrer des clients OAuth supplémentaires :
$ oc create -f <(echo ' kind: OAuthClient apiVersion: oauth.openshift.io/v1 metadata: name: demo1 secret: "..."2 redirectURIs: - "http://www.example.com/"3 grantMethod: prompt4 ')- 1
- L'adresse
namedu client OAuth est utilisée comme paramètreclient_idlors des demandes adressées à<namespace_route>/oauth/authorizeet<namespace_route>/oauth/token. - 2
- L'adresse
secretest utilisée comme paramètre de l'adresseclient_secretlors des demandes adressées à l'adresse<namespace_route>/oauth/token. - 3
- Le paramètre
redirect_urispécifié dans les demandes adressées à<namespace_route>/oauth/authorizeet<namespace_route>/oauth/tokendoit être égal ou préfixé par l'un des URI énumérés dans la valeur du paramètreredirectURIs. - 4
- L'adresse
grantMethodest utilisée pour déterminer l'action à entreprendre lorsque ce client demande des jetons et que l'utilisateur ne lui a pas encore accordé l'accès. Indiquezautopour approuver automatiquement l'autorisation et relancer la demande, oupromptpour demander à l'utilisateur d'approuver ou de refuser l'autorisation.
4.3. Configuration du délai d'inactivité du jeton pour un client OAuth
Vous pouvez configurer les clients OAuth pour qu'ils expirent les jetons OAuth après une période d'inactivité donnée. Par défaut, aucun délai d'inactivité n'est défini.
Si le délai d'inactivité du jeton est également configuré dans la configuration interne du serveur OAuth, le délai défini dans le client OAuth remplace cette valeur.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. - Vous avez configuré un fournisseur d'identité (IDP).
Procédure
Mettre à jour la configuration de
OAuthClientpour définir un délai d'inactivité des jetons.Modifiez l'objet
OAuthClient:oc edit oauthclient <oauth_client>1 - 1
- Remplacez
<oauth_client>par le client OAuth à configurer, par exempleconsole.
Ajoutez le champ
accessTokenInactivityTimeoutSecondset définissez la valeur de votre délai d'attente :apiVersion: oauth.openshift.io/v1 grantMethod: auto kind: OAuthClient metadata: ... accessTokenInactivityTimeoutSeconds: 6001 - 1
- La valeur minimale autorisée du délai d'attente en secondes est de
300.
- Enregistrez le fichier pour appliquer les modifications.
Vérification
- Connectez-vous au cluster avec une identité provenant de votre IDP. Veillez à utiliser le client OAuth que vous venez de configurer.
- Effectuer une action et vérifier qu'elle a réussi.
- Attendre plus longtemps que le délai configuré sans utiliser l'identité. Dans l'exemple de cette procédure, attendez plus de 600 secondes.
Essayer d'effectuer une action à partir de la session de la même identité.
Cette tentative doit échouer car le jeton doit avoir expiré en raison d'une inactivité plus longue que le délai configuré.
Chapitre 5. Gestion des jetons d'accès OAuth appartenant à l'utilisateur
Les utilisateurs peuvent consulter leurs propres jetons d'accès OAuth et supprimer ceux qui ne sont plus nécessaires.
5.1. Liste des jetons d'accès OAuth appartenant à l'utilisateur
Vous pouvez dresser la liste des jetons d'accès OAuth appartenant à l'utilisateur. Les noms des jetons ne sont pas sensibles et ne peuvent pas être utilisés pour se connecter.
Procédure
Liste de tous les jetons d'accès OAuth appartenant à l'utilisateur :
$ oc get useroauthaccesstokensExemple de sortie
NAME CLIENT NAME CREATED EXPIRES REDIRECT URI SCOPES <token1> openshift-challenging-client 2021-01-11T19:25:35Z 2021-01-12 19:25:35 +0000 UTC https://oauth-openshift.apps.example.com/oauth/token/implicit user:full <token2> openshift-browser-client 2021-01-11T19:27:06Z 2021-01-12 19:27:06 +0000 UTC https://oauth-openshift.apps.example.com/oauth/token/display user:full <token3> console 2021-01-11T19:26:29Z 2021-01-12 19:26:29 +0000 UTC https://console-openshift-console.apps.example.com/auth/callback user:fullListe des jetons d'accès OAuth appartenant à l'utilisateur pour un client OAuth particulier :
$ oc get useroauthaccesstokens --field-selector=clientName="console"Exemple de sortie
NAME CLIENT NAME CREATED EXPIRES REDIRECT URI SCOPES <token3> console 2021-01-11T19:26:29Z 2021-01-12 19:26:29 +0000 UTC https://console-openshift-console.apps.example.com/auth/callback user:full
5.2. Afficher les détails d'un jeton d'accès OAuth appartenant à un utilisateur
Vous pouvez afficher les détails d'un jeton d'accès OAuth appartenant à un utilisateur.
Procédure
Décrire les détails d'un jeton d'accès OAuth appartenant à un utilisateur :
oc describe useroauthaccesstokens <token_name>Exemple de sortie
Name: <token_name>1 Namespace: Labels: <none> Annotations: <none> API Version: oauth.openshift.io/v1 Authorize Token: sha256~Ksckkug-9Fg_RWn_AUysPoIg-_HqmFI9zUL_CgD8wr8 Client Name: openshift-browser-client2 Expires In: 864003 Inactivity Timeout Seconds: 3174 Kind: UserOAuthAccessToken Metadata: Creation Timestamp: 2021-01-11T19:27:06Z Managed Fields: API Version: oauth.openshift.io/v1 Fields Type: FieldsV1 fieldsV1: f:authorizeToken: f:clientName: f:expiresIn: f:redirectURI: f:scopes: f:userName: f:userUID: Manager: oauth-server Operation: Update Time: 2021-01-11T19:27:06Z Resource Version: 30535 Self Link: /apis/oauth.openshift.io/v1/useroauthaccesstokens/<token_name> UID: f9d00b67-ab65-489b-8080-e427fa3c6181 Redirect URI: https://oauth-openshift.apps.example.com/oauth/token/display Scopes: user:full5 User Name: <user_name>6 User UID: 82356ab0-95f9-4fb3-9bc0-10f1d6a6a345 Events: <none>- 1
- Le nom du jeton, qui est le hachage sha256 du jeton. Les noms de jetons ne sont pas sensibles et ne peuvent pas être utilisés pour se connecter.
- 2
- Le nom du client, qui décrit l'origine du jeton.
- 3
- La valeur en secondes à partir de l'heure de création avant que ce jeton n'expire.
- 4
- Si le serveur OAuth a défini un délai d'inactivité pour le jeton, il s'agit de la valeur en secondes à partir de l'heure de création avant que ce jeton ne puisse plus être utilisé.
- 5
- Les champs d'application de ce jeton.
- 6
- Le nom d'utilisateur associé à ce jeton.
5.3. Suppression des jetons d'accès OAuth appartenant à l'utilisateur
La commande oc logout invalide uniquement le jeton OAuth de la session active. Vous pouvez utiliser la procédure suivante pour supprimer tous les jetons OAuth appartenant à l'utilisateur qui ne sont plus nécessaires.
La suppression d'un jeton d'accès OAuth déconnecte l'utilisateur de toutes les sessions qui utilisent le jeton.
Procédure
Supprimer le jeton d'accès OAuth appartenant à l'utilisateur :
oc delete useroauthaccesstokens <token_name>Exemple de sortie
useroauthaccesstoken.oauth.openshift.io "<token_name>" supprimé
Chapitre 6. Comprendre la configuration du fournisseur d'identité
Le master OpenShift Container Platform comprend un serveur OAuth intégré. Les développeurs et les administrateurs obtiennent des jetons d'accès OAuth pour s'authentifier auprès de l'API.
En tant qu'administrateur, vous pouvez configurer OAuth pour qu'il spécifie un fournisseur d'identité après l'installation de votre cluster.
6.1. À propos des fournisseurs d'identité dans OpenShift Container Platform
Par défaut, seul un utilisateur kubeadmin existe sur votre cluster. Pour spécifier un fournisseur d'identité, vous devez créer une ressource personnalisée (CR) qui décrit ce fournisseur d'identité et l'ajouter au cluster.
Les noms d'utilisateur OpenShift Container Platform contenant /, :, et % ne sont pas pris en charge.
6.2. Fournisseurs d'identité pris en charge
Vous pouvez configurer les types de fournisseurs d'identité suivants :
| Fournisseur d'identité | Description |
|---|---|
|
Configurer le fournisseur d'identité | |
|
Configurez le fournisseur d'identité | |
|
Configurer le fournisseur d'identité | |
|
Configurer un fournisseur d'identité | |
|
Configurez un fournisseur d'identité | |
|
Configurez un fournisseur d'identité | |
|
Configurer un fournisseur d'identité | |
|
Configurer un fournisseur d'identité | |
|
Configurer un fournisseur d'identité |
Une fois qu'un fournisseur d'identité a été défini, vous pouvez utiliser RBAC pour définir et appliquer des autorisations.
6.3. Suppression de l'utilisateur kubeadmin
Après avoir défini un fournisseur d'identité et créé un nouvel utilisateur cluster-admin, vous pouvez supprimer le site kubeadmin pour améliorer la sécurité du cluster.
Si vous suivez cette procédure avant qu'un autre utilisateur ne soit cluster-admin, OpenShift Container Platform doit être réinstallé. Il n'est pas possible d'annuler cette commande.
Conditions préalables
- Vous devez avoir configuré au moins un fournisseur d'identité.
-
Vous devez avoir ajouté le rôle
cluster-adminà un utilisateur. - Vous devez être connecté en tant qu'administrateur.
Procédure
Supprimez les secrets de
kubeadmin:$ oc delete secrets kubeadmin -n kube-system
6.4. Paramètres du fournisseur d'identité
Les paramètres suivants sont communs à tous les fournisseurs d'identité :
| Paramètres | Description |
|---|---|
|
| Le nom du fournisseur est préfixé aux noms des utilisateurs du fournisseur pour former un nom d'identité. |
|
| Définit la manière dont les nouvelles identités sont associées aux utilisateurs lorsqu'ils se connectent. Entrez l'une des valeurs suivantes :
|
Lorsque vous ajoutez ou modifiez des fournisseurs d'identité, vous pouvez faire correspondre les identités du nouveau fournisseur aux utilisateurs existants en définissant le paramètre mappingMethod sur add.
6.5. Exemple de CR de fournisseur d'identité
La ressource personnalisée (CR) suivante montre les paramètres et les valeurs par défaut que vous utilisez pour configurer un fournisseur d'identité. Cet exemple utilise le fournisseur d'identité htpasswd.
Exemple de CR de fournisseur d'identité
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: my_identity_provider
mappingMethod: claim
type: HTPasswd
htpasswd:
fileData:
name: htpass-secret Chapitre 7. Configuration des fournisseurs d'identité
7.1. Configuration d'un fournisseur d'identité htpasswd
Configurez le fournisseur d'identité htpasswd pour permettre aux utilisateurs de se connecter à OpenShift Container Platform avec des informations d'identification provenant d'un fichier htpasswd.
Pour définir un fournisseur d'identité htpasswd, effectuez les tâches suivantes :
-
Créez un fichier
htpasswdpour stocker les informations relatives à l'utilisateur et au mot de passe. -
Créer un secret pour représenter le fichier
htpasswd. - Définir une ressource fournisseur d'identité htpasswd qui référence le secret.
- Appliquer la ressource à la configuration OAuth par défaut pour ajouter le fournisseur d'identité.
7.1.1. À propos des fournisseurs d'identité dans OpenShift Container Platform
Par défaut, seul un utilisateur kubeadmin existe sur votre cluster. Pour spécifier un fournisseur d'identité, vous devez créer une ressource personnalisée (CR) qui décrit ce fournisseur d'identité et l'ajouter au cluster.
Les noms d'utilisateur OpenShift Container Platform contenant /, :, et % ne sont pas pris en charge.
7.1.2. A propos de l'authentification htpasswd
L'utilisation de l'authentification htpasswd dans OpenShift Container Platform vous permet d'identifier les utilisateurs sur la base d'un fichier htpasswd. Un fichier htpasswd est un fichier plat qui contient le nom d'utilisateur et le mot de passe haché de chaque utilisateur. Vous pouvez utiliser l'utilitaire htpasswd pour créer ce fichier.
7.1.3. Création du fichier htpasswd
Consultez l'une des sections suivantes pour savoir comment créer le fichier htpasswd :
7.1.3.1. Création d'un fichier htpasswd sous Linux
Pour utiliser le fournisseur d'identité htpasswd, vous devez générer un fichier plat contenant les noms d'utilisateur et les mots de passe de votre cluster à l'aide de la commande htpasswd.
Conditions préalables
-
Avoir accès à l'utilitaire
htpasswd. Sur Red Hat Enterprise Linux, cet utilitaire est disponible en installant le paquetagehttpd-tools.
Procédure
Créez ou mettez à jour votre fichier plat avec un nom d'utilisateur et un mot de passe haché :
$ htpasswd -c -B -b </path/to/users.htpasswd> <user_name> <password>La commande génère une version hachée du mot de passe.
Par exemple :
$ htpasswd -c -B -b users.htpasswd user1 MyPassword!Exemple de sortie
Adding password for user user1Continuez à ajouter ou à mettre à jour les informations d'identification dans le fichier :
$ htpasswd -B -b </path/to/users.htpasswd> <user_name> <password>
7.1.3.2. Création d'un fichier htpasswd sous Windows
Pour utiliser le fournisseur d'identité htpasswd, vous devez générer un fichier plat contenant les noms d'utilisateur et les mots de passe de votre cluster à l'aide de la commande htpasswd.
Conditions préalables
-
Avoir accès à
htpasswd.exe. Ce fichier est inclus dans le répertoire\binde nombreuses distributions d'Apache httpd.
Procédure
Créez ou mettez à jour votre fichier plat avec un nom d'utilisateur et un mot de passe haché :
> htpasswd.exe -c -B -b <\path\to\users.htpasswd> < nom_utilisateur> <mot_de_passe>La commande génère une version hachée du mot de passe.
Par exemple :
> htpasswd.exe -c -B -b users.htpasswd user1 MyPassword !Exemple de sortie
Adding password for user user1Continuez à ajouter ou à mettre à jour les informations d'identification dans le fichier :
> htpasswd.exe -b <\pathto\users.htpasswd> < nom_utilisateur> <mot_de_passe>
7.1.4. Création du secret htpasswd
Pour utiliser le fournisseur d'identité htpasswd, vous devez définir un secret contenant le fichier utilisateur htpasswd.
Conditions préalables
- Créer un fichier htpasswd.
Procédure
Créez un objet
Secretqui contient le fichier htpasswd users :$ oc create secret generic htpass-secret --from-file=htpasswd=<path_to_users.htpasswd> -n openshift-config1 - 1
- La clé secrète contenant le fichier des utilisateurs pour l'argument
--from-filedoit être nomméehtpasswd, comme indiqué dans la commande ci-dessus.
AstuceVous pouvez également appliquer le code YAML suivant pour créer le secret :
apiVersion: v1 kind: Secret metadata: name: htpass-secret namespace: openshift-config type: Opaque data: htpasswd: <base64_encoded_htpasswd_file_contents>
7.1.5. Exemple de CR htpasswd
La ressource personnalisée (CR) suivante présente les paramètres et les valeurs acceptables pour un fournisseur d'identité htpasswd.
htpasswd CR
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: my_htpasswd_provider
mappingMethod: claim
type: HTPasswd
htpasswd:
fileData:
name: htpass-secret 7.1.6. Ajouter un fournisseur d'identité à votre cluster
Après avoir installé votre cluster, ajoutez-y un fournisseur d'identité pour que vos utilisateurs puissent s'authentifier.
Conditions préalables
- Créer un cluster OpenShift Container Platform.
- Créez la ressource personnalisée (CR) pour vos fournisseurs d'identité.
- Vous devez être connecté en tant qu'administrateur.
Procédure
Appliquer le CR défini :
$ oc apply -f </path/to/CR>NoteSi un CR n'existe pas,
oc applycrée un nouveau CR et peut déclencher l'avertissement suivant :Warning: oc apply should be used on resources created by either oc create --save-config or oc apply. Dans ce cas, vous pouvez ignorer cet avertissement.Connectez-vous au cluster en tant qu'utilisateur de votre fournisseur d'identité, en saisissant le mot de passe lorsque vous y êtes invité.
$ oc login -u <nom d'utilisateur>Confirmez que l'utilisateur s'est connecté avec succès et affichez le nom de l'utilisateur.
$ oc whoami
7.1.7. Mise à jour des utilisateurs d'un fournisseur d'identité htpasswd
Vous pouvez ajouter ou supprimer des utilisateurs d'un fournisseur d'identité htpasswd existant.
Conditions préalables
-
Vous avez créé un objet
Secretqui contient le fichier utilisateur htpasswd. Cette procédure suppose qu'il est nomméhtpass-secret. -
Vous avez configuré un fournisseur d'identité htpasswd. Cette procédure suppose qu'il s'appelle
my_htpasswd_provider. -
Vous avez accès à l'utilitaire
htpasswd. Sur Red Hat Enterprise Linux, cet utilitaire est disponible en installant le paquetagehttpd-tools. - Vous avez des privilèges d'administrateur de cluster.
Procédure
Récupérez le fichier htpasswd de l'objet
htpass-secretSecretet enregistrez le fichier sur votre système de fichiers :$ oc get secret htpass-secret -ojsonpath={.data.htpasswd} -n openshift-config | base64 --decode > users.htpasswdAjouter ou supprimer des utilisateurs du fichier
users.htpasswd.Pour ajouter un nouvel utilisateur :
$ htpasswd -bB users.htpasswd <nom d'utilisateur> <mot de passe>Exemple de sortie
Ajout d'un mot de passe pour l'utilisateur <nom d'utilisateur>Pour supprimer un utilisateur existant :
$ htpasswd -D users.htpasswd <username>Exemple de sortie
Suppression du mot de passe de l'utilisateur <nom d'utilisateur>
Remplacez l'objet
htpass-secretSecretpar les utilisateurs mis à jour dans le fichierusers.htpasswd:$ oc create secret generic htpass-secret --from-file=htpasswd=users.htpasswd --dry-run=client -o yaml -n openshift-config | oc replace -f -AstuceVous pouvez également appliquer le YAML suivant pour remplacer le secret :
apiVersion: v1 kind: Secret metadata: name: htpass-secret namespace: openshift-config type: Opaque data: htpasswd: <base64_encoded_htpasswd_file_contents>Si vous avez supprimé un ou plusieurs utilisateurs, vous devez également supprimer les ressources existantes pour chaque utilisateur.
Supprimer l'objet
User:$ oc delete user <username>Exemple de sortie
user.user.openshift.io "<username>" suppriméVeillez à supprimer l'utilisateur, sinon il pourra continuer à utiliser son jeton tant qu'il n'aura pas expiré.
Supprimer l'objet
Identitypour l'utilisateur :oc delete identity my_htpasswd_provider:<username> $ oc delete identity my_htpasswd_provider:<username>Exemple de sortie
identity.user.openshift.io "my_htpasswd_provider:<username>" supprimé
7.1.8. Configuration des fournisseurs d'identité à l'aide de la console web
Configurez votre fournisseur d'identité (IDP) via la console web au lieu de l'interface CLI.
Conditions préalables
- Vous devez être connecté à la console web en tant qu'administrateur de cluster.
Procédure
- Naviguez jusqu'à Administration → Cluster Settings.
- Sous l'onglet Configuration, cliquez sur OAuth.
- Dans la section Identity Providers, sélectionnez votre fournisseur d'identité dans le menu déroulant Add.
Vous pouvez spécifier plusieurs IDP via la console web sans écraser les IDP existants.
7.2. Configuration d'un fournisseur d'identité Keystone
Configurez le fournisseur d'identité keystone pour intégrer votre cluster OpenShift Container Platform avec Keystone afin d'activer l'authentification partagée avec un serveur OpenStack Keystone v3 configuré pour stocker les utilisateurs dans une base de données interne. Cette configuration permet aux utilisateurs de se connecter à OpenShift Container Platform avec leurs informations d'identification Keystone.
7.2.1. À propos des fournisseurs d'identité dans OpenShift Container Platform
Par défaut, seul un utilisateur kubeadmin existe sur votre cluster. Pour spécifier un fournisseur d'identité, vous devez créer une ressource personnalisée (CR) qui décrit ce fournisseur d'identité et l'ajouter au cluster.
Les noms d'utilisateur OpenShift Container Platform contenant /, :, et % ne sont pas pris en charge.
7.2.2. À propos de l'authentification Keystone
Keystone est un projet OpenStack qui fournit des services d'identité, de jeton, de catalogue et de politique.
Vous pouvez configurer l'intégration avec Keystone pour que les nouveaux utilisateurs d'OpenShift Container Platform soient basés sur les noms d'utilisateurs Keystone ou les identifiants uniques Keystone. Avec les deux méthodes, les utilisateurs se connectent en entrant leur nom d'utilisateur et leur mot de passe Keystone. Baser les utilisateurs d'OpenShift Container Platform sur l'ID Keystone est plus sûr car si vous supprimez un utilisateur Keystone et créez un nouvel utilisateur Keystone avec ce nom d'utilisateur, le nouvel utilisateur pourrait avoir accès aux ressources de l'ancien utilisateur.
7.2.3. Création du secret
Les fournisseurs d'identité utilisent des objets OpenShift Container Platform Secret dans l'espace de noms openshift-config pour contenir le secret du client, les certificats du client et les clés.
Procédure
Créez un objet
Secretcontenant la clé et le certificat à l'aide de la commande suivante :$ oc create secret tls <secret_name> --key=key.pem --cert=cert.pem -n openshift-configAstuceVous pouvez également appliquer le code YAML suivant pour créer le secret :
apiVersion: v1 kind: Secret metadata: name: <secret_name> namespace: openshift-config type: kubernetes.io/tls data: tls.crt: <base64_encoded_cert> tls.key: <base64_encoded_key>
7.2.4. Création d'une carte de configuration
Les fournisseurs d'identité utilisent les objets OpenShift Container Platform ConfigMap dans l'espace de noms openshift-config pour contenir le paquet de l'autorité de certification. Ces objets sont principalement utilisés pour contenir les paquets de certificats nécessaires au fournisseur d'identité.
Procédure
Définissez un objet OpenShift Container Platform
ConfigMapcontenant l'autorité de certification en utilisant la commande suivante. L'autorité de certification doit être stockée dans la cléca.crtde l'objetConfigMap.$ oc create configmap ca-config-map --from-file=ca.crt=/path/to/ca -n openshift-configAstuceVous pouvez également appliquer le YAML suivant pour créer la carte de configuration :
apiVersion: v1 kind: ConfigMap metadata: name: ca-config-map namespace: openshift-config data: ca.crt: | <CA_certificate_PEM>
7.2.5. Exemple de Keystone CR
La ressource personnalisée (CR) suivante présente les paramètres et les valeurs acceptables pour un fournisseur d'identité Keystone.
Keystone CR
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: keystoneidp
mappingMethod: claim
type: Keystone
keystone:
domainName: default
url: https://keystone.example.com:5000
ca:
name: ca-config-map
tlsClientCert:
name: client-cert-secret
tlsClientKey:
name: client-key-secret- 1
- Ce nom de fournisseur est préfixé aux noms d'utilisateurs du fournisseur pour former un nom d'identité.
- 2
- Contrôle la manière dont les correspondances sont établies entre les identités de ce fournisseur et les objets
User. - 3
- Nom de domaine Keystone. Dans Keystone, les noms d'utilisateur sont spécifiques à un domaine. Un seul domaine est pris en charge.
- 4
- L'URL à utiliser pour se connecter au serveur Keystone (obligatoire). Elle doit utiliser https.
- 5
- Facultatif : Référence à un objet OpenShift Container Platform
ConfigMapcontenant le bundle de l'autorité de certification codé en PEM à utiliser pour valider les certificats du serveur pour l'URL configurée. - 6
- Facultatif : Référence à un objet OpenShift Container Platform
Secretcontenant le certificat client à présenter lors des requêtes à l'URL configurée. - 7
- Référence à un objet OpenShift Container Platform
Secretcontenant la clé du certificat client. Requis sitlsClientCertest spécifié.
7.2.6. Ajouter un fournisseur d'identité à votre cluster
Après avoir installé votre cluster, ajoutez-y un fournisseur d'identité pour que vos utilisateurs puissent s'authentifier.
Conditions préalables
- Créer un cluster OpenShift Container Platform.
- Créez la ressource personnalisée (CR) pour vos fournisseurs d'identité.
- Vous devez être connecté en tant qu'administrateur.
Procédure
Appliquer le CR défini :
$ oc apply -f </path/to/CR>NoteSi un CR n'existe pas,
oc applycrée un nouveau CR et peut déclencher l'avertissement suivant :Warning: oc apply should be used on resources created by either oc create --save-config or oc apply. Dans ce cas, vous pouvez ignorer cet avertissement.Connectez-vous au cluster en tant qu'utilisateur de votre fournisseur d'identité, en saisissant le mot de passe lorsque vous y êtes invité.
$ oc login -u <nom d'utilisateur>Confirmez que l'utilisateur s'est connecté avec succès et affichez le nom de l'utilisateur.
$ oc whoami
7.3. Configuration d'un fournisseur d'identité LDAP
Configurer le fournisseur d'identité ldap pour valider les noms d'utilisateur et les mots de passe par rapport à un serveur LDAPv3, en utilisant l'authentification par liaison simple.
7.3.1. À propos des fournisseurs d'identité dans OpenShift Container Platform
Par défaut, seul un utilisateur kubeadmin existe sur votre cluster. Pour spécifier un fournisseur d'identité, vous devez créer une ressource personnalisée (CR) qui décrit ce fournisseur d'identité et l'ajouter au cluster.
Les noms d'utilisateur OpenShift Container Platform contenant /, :, et % ne sont pas pris en charge.
7.3.2. À propos de l'authentification LDAP
Lors de l'authentification, l'annuaire LDAP est parcouru à la recherche d'une entrée correspondant au nom d'utilisateur fourni. Si une correspondance unique est trouvée, une liaison simple est tentée en utilisant le nom distinctif (DN) de l'entrée et le mot de passe fourni.
Telles sont les mesures prises :
-
Générer un filtre de recherche en combinant l'attribut et le filtre dans le site
urlconfiguré avec le nom d'utilisateur fourni par l'utilisateur. - Effectuez une recherche dans le répertoire à l'aide du filtre généré. Si la recherche ne renvoie pas exactement une entrée, l'accès est refusé.
- Tentative de connexion au serveur LDAP à l'aide du DN de l'entrée récupérée lors de la recherche et du mot de passe fourni par l'utilisateur.
- Si la liaison n'aboutit pas, l'accès est refusé.
- Si la liaison est réussie, créez une identité en utilisant les attributs configurés comme identité, adresse électronique, nom d'affichage et nom d'utilisateur préféré.
L'adresse url configurée est une URL RFC 2255, qui spécifie l'hôte LDAP et les paramètres de recherche à utiliser. La syntaxe de l'URL est la suivante :
ldap://host:port/basedn?attribute?scope?filterPour cette URL :
| Composant URL | Description |
|---|---|
|
|
Pour le LDAP normal, utilisez la chaîne |
|
|
Le nom et le port du serveur LDAP. La valeur par défaut est |
|
| Le DN de la branche du répertoire à partir de laquelle toutes les recherches doivent commencer. Au minimum, il doit s'agir du sommet de l'arborescence de votre répertoire, mais il peut également s'agir d'une sous-arborescence du répertoire. |
|
|
L'attribut à rechercher. Bien que la RFC 2255 autorise une liste d'attributs séparés par des virgules, seul le premier attribut sera utilisé, quel que soit le nombre d'attributs fournis. Si aucun attribut n'est fourni, la valeur par défaut est |
|
|
L'étendue de la recherche. Il peut s'agir de |
|
|
Un filtre de recherche LDAP valide. S'il n'est pas fourni, la valeur par défaut est |
Lors des recherches, l'attribut, le filtre et le nom d'utilisateur fourni sont combinés pour créer un filtre de recherche qui se présente comme suit :
(&(<filtre>)(<attribut>=<nom d'utilisateur>)))Prenons l'exemple d'une URL de :
ldap://ldap.example.com/o=Acme?cn?sub?(enabled=true)
Lorsqu'un client tente de se connecter en utilisant le nom d'utilisateur bob, le filtre de recherche résultant sera (&(enabled=true)(cn=bob)).
Si l'annuaire LDAP nécessite une authentification pour la recherche, indiquez un bindDN et un bindPassword à utiliser pour effectuer la recherche d'entrée.
7.3.3. Création du secret LDAP
Pour utiliser le fournisseur d'identité, vous devez définir un objet OpenShift Container Platform Secret qui contient le champ bindPassword.
Procédure
Créez un objet
Secretqui contient le champbindPassword:$ oc create secret generic ldap-secret --from-literal=bindPassword=<secret> -n openshift-config1 - 1
- La clé secrète contenant le mot de passe de liaison pour l'argument
--from-literaldoit être appeléebindPassword.
AstuceVous pouvez également appliquer le code YAML suivant pour créer le secret :
apiVersion: v1 kind: Secret metadata: name: ldap-secret namespace: openshift-config type: Opaque data: bindPassword: <base64_encoded_bind_password>
7.3.4. Création d'une carte de configuration
Les fournisseurs d'identité utilisent les objets OpenShift Container Platform ConfigMap dans l'espace de noms openshift-config pour contenir le paquet de l'autorité de certification. Ces objets sont principalement utilisés pour contenir les paquets de certificats nécessaires au fournisseur d'identité.
Procédure
Définissez un objet OpenShift Container Platform
ConfigMapcontenant l'autorité de certification en utilisant la commande suivante. L'autorité de certification doit être stockée dans la cléca.crtde l'objetConfigMap.$ oc create configmap ca-config-map --from-file=ca.crt=/path/to/ca -n openshift-configAstuceVous pouvez également appliquer le YAML suivant pour créer la carte de configuration :
apiVersion: v1 kind: ConfigMap metadata: name: ca-config-map namespace: openshift-config data: ca.crt: | <CA_certificate_PEM>
7.3.5. Exemple de CR LDAP
La ressource personnalisée (CR) suivante présente les paramètres et les valeurs acceptables pour un fournisseur d'identité LDAP.
LDAP CR
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: ldapidp
mappingMethod: claim
type: LDAP
ldap:
attributes:
id:
- dn
email:
- mail
name:
- cn
preferredUsername:
- uid
bindDN: ""
bindPassword:
name: ldap-secret
ca:
name: ca-config-map
insecure: false
url: "ldaps://ldaps.example.com/ou=users,dc=acme,dc=com?uid" - 1
- Ce nom de fournisseur est préfixé à l'identifiant de l'utilisateur renvoyé pour former un nom d'identité.
- 2
- Contrôle la manière dont les correspondances sont établies entre les identités de ce fournisseur et les objets
User. - 3
- Liste des attributs à utiliser comme identité. Le premier attribut non vide est utilisé. Au moins un attribut est requis. Si aucun des attributs énumérés n'a de valeur, l'authentification échoue. Les attributs définis sont récupérés sous forme brute, ce qui permet d'utiliser des valeurs binaires.
- 4
- Liste des attributs à utiliser comme adresse électronique. Le premier attribut non vide est utilisé.
- 5
- Liste des attributs à utiliser comme nom d'affichage. Le premier attribut non vide est utilisé.
- 6
- Liste d'attributs à utiliser comme nom d'utilisateur préféré lors du provisionnement d'un utilisateur pour cette identité. Le premier attribut non vide est utilisé.
- 7
- DN facultatif à utiliser pour se lier pendant la phase de recherche. Doit être défini si
bindPasswordest défini. - 8
- Référence optionnelle à un objet OpenShift Container Platform
Secretcontenant le mot de passe de liaison. Doit être défini sibindDNest défini. - 9
- Facultatif : Référence à un objet OpenShift Container Platform
ConfigMapcontenant le paquet d'autorité de certification codé PEM à utiliser dans la validation des certificats de serveur pour l'URL configurée. Utilisé uniquement lorsqueinsecureestfalse. - 10
- Lorsque
true, aucune connexion TLS n'est établie avec le serveur. Lorsquefalse, les URLldaps://se connectent en utilisant TLS, et les URLldap://sont mis à niveau vers TLS. Ce paramètre doit être défini surfalselorsque les URLldaps://sont utilisées, car ces URL tentent toujours de se connecter à l'aide de TLS. - 11
- URL RFC 2255 qui spécifie l'hôte LDAP et les paramètres de recherche à utiliser.
Pour établir une liste blanche d'utilisateurs pour une intégration LDAP, utilisez la méthode de mappage lookup. Avant d'autoriser une connexion à partir de LDAP, un administrateur de cluster doit créer un objet Identity et un objet User pour chaque utilisateur LDAP.
7.3.6. Ajouter un fournisseur d'identité à votre cluster
Après avoir installé votre cluster, ajoutez-y un fournisseur d'identité pour que vos utilisateurs puissent s'authentifier.
Conditions préalables
- Créer un cluster OpenShift Container Platform.
- Créez la ressource personnalisée (CR) pour vos fournisseurs d'identité.
- Vous devez être connecté en tant qu'administrateur.
Procédure
Appliquer le CR défini :
$ oc apply -f </path/to/CR>NoteSi un CR n'existe pas,
oc applycrée un nouveau CR et peut déclencher l'avertissement suivant :Warning: oc apply should be used on resources created by either oc create --save-config or oc apply. Dans ce cas, vous pouvez ignorer cet avertissement.Connectez-vous au cluster en tant qu'utilisateur de votre fournisseur d'identité, en saisissant le mot de passe lorsque vous y êtes invité.
$ oc login -u <nom d'utilisateur>Confirmez que l'utilisateur s'est connecté avec succès et affichez le nom de l'utilisateur.
$ oc whoami
7.4. Configuration d'un fournisseur d'identité pour l'authentification de base
Configurer le fournisseur d'identité basic-authentication pour que les utilisateurs puissent se connecter à OpenShift Container Platform avec des informations d'identification validées par rapport à un fournisseur d'identité distant. L'authentification de base est un mécanisme d'intégration générique.
7.4.1. À propos des fournisseurs d'identité dans OpenShift Container Platform
Par défaut, seul un utilisateur kubeadmin existe sur votre cluster. Pour spécifier un fournisseur d'identité, vous devez créer une ressource personnalisée (CR) qui décrit ce fournisseur d'identité et l'ajouter au cluster.
Les noms d'utilisateur OpenShift Container Platform contenant /, :, et % ne sont pas pris en charge.
7.4.2. A propos de l'authentification de base
L'authentification de base est un mécanisme d'intégration générique qui permet aux utilisateurs de se connecter à OpenShift Container Platform avec des informations d'identification validées par un fournisseur d'identité distant.
L'authentification de base étant générique, vous pouvez utiliser ce fournisseur d'identité pour des configurations d'authentification avancées.
L'authentification de base doit utiliser une connexion HTTPS avec le serveur distant afin d'éviter que l'identifiant et le mot de passe de l'utilisateur ne soient espionnés et que des attaques de type "man-in-the-middle" ne se produisent.
Lorsque l'authentification de base est configurée, les utilisateurs envoient leur nom d'utilisateur et leur mot de passe à OpenShift Container Platform, qui valide ensuite ces informations d'identification auprès d'un serveur distant en effectuant une requête de serveur à serveur, en transmettant les informations d'identification en tant qu'en-tête d'authentification de base. Les utilisateurs doivent donc envoyer leurs informations d'identification à OpenShift Container Platform lors de la connexion.
Cela ne fonctionne que pour les mécanismes de connexion par nom d'utilisateur/mot de passe, et OpenShift Container Platform doit être en mesure de faire des demandes de réseau au serveur d'authentification distant.
Les noms d'utilisateur et les mots de passe sont validés par rapport à une URL distante qui est protégée par une authentification de base et renvoie du JSON.
Une réponse 401 indique que l'authentification a échoué.
Un état non200 ou la présence d'une clé "error" non vide indique une erreur :
{"error":"Error message"}
Un statut 200 avec une clé sub (sujet) indique un succès :
{\i1}"sub":\N-"userid" } - 1
- Le sujet doit être unique pour l'utilisateur authentifié et ne doit pas pouvoir être modifié.
Une réponse positive peut éventuellement fournir des données supplémentaires, telles que
Un nom d'affichage à l'aide de la touche
name. Par exemple :{"sub":"userid", "name": "User Name", ...}Une adresse électronique à l'aide de la clé
email. Par exemple :{"sub":"userid", "email":"user@example.com", ...}Un nom d'utilisateur préféré utilisant la clé
preferred_username. Ceci est utile lorsque le sujet unique et immuable est une clé de base de données ou un UID, et qu'il existe un nom plus lisible par l'homme. Ceci est utilisé comme un indice lors du provisionnement de l'utilisateur OpenShift Container Platform pour l'identité authentifiée. Par exemple :{"sub":"014fbff9a07c", "preferred_username":"bob", ...}
7.4.3. Création du secret
Les fournisseurs d'identité utilisent des objets OpenShift Container Platform Secret dans l'espace de noms openshift-config pour contenir le secret du client, les certificats du client et les clés.
Procédure
Créez un objet
Secretcontenant la clé et le certificat à l'aide de la commande suivante :$ oc create secret tls <secret_name> --key=key.pem --cert=cert.pem -n openshift-configAstuceVous pouvez également appliquer le code YAML suivant pour créer le secret :
apiVersion: v1 kind: Secret metadata: name: <secret_name> namespace: openshift-config type: kubernetes.io/tls data: tls.crt: <base64_encoded_cert> tls.key: <base64_encoded_key>
7.4.4. Création d'une carte de configuration
Les fournisseurs d'identité utilisent les objets OpenShift Container Platform ConfigMap dans l'espace de noms openshift-config pour contenir le paquet de l'autorité de certification. Ces objets sont principalement utilisés pour contenir les paquets de certificats nécessaires au fournisseur d'identité.
Procédure
Définissez un objet OpenShift Container Platform
ConfigMapcontenant l'autorité de certification en utilisant la commande suivante. L'autorité de certification doit être stockée dans la cléca.crtde l'objetConfigMap.$ oc create configmap ca-config-map --from-file=ca.crt=/path/to/ca -n openshift-configAstuceVous pouvez également appliquer le YAML suivant pour créer la carte de configuration :
apiVersion: v1 kind: ConfigMap metadata: name: ca-config-map namespace: openshift-config data: ca.crt: | <CA_certificate_PEM>
7.4.5. Exemple de CR d'authentification de base
La ressource personnalisée (CR) suivante présente les paramètres et les valeurs acceptables pour un fournisseur d'identité d'authentification de base.
Authentification de base CR
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: basicidp
mappingMethod: claim
type: BasicAuth
basicAuth:
url: https://www.example.com/remote-idp
ca:
name: ca-config-map
tlsClientCert:
name: client-cert-secret
tlsClientKey:
name: client-key-secret- 1
- Ce nom de fournisseur est préfixé à l'identifiant de l'utilisateur renvoyé pour former un nom d'identité.
- 2
- Contrôle la manière dont les correspondances sont établies entre les identités de ce fournisseur et les objets
User. - 3
- URL acceptant les informations d'identification dans les en-têtes d'authentification de base.
- 4
- Facultatif : Référence à un objet OpenShift Container Platform
ConfigMapcontenant le bundle de l'autorité de certification codé en PEM à utiliser pour valider les certificats du serveur pour l'URL configurée. - 5
- Facultatif : Référence à un objet OpenShift Container Platform
Secretcontenant le certificat client à présenter lors des requêtes à l'URL configurée. - 6
- Référence à un objet OpenShift Container Platform
Secretcontenant la clé du certificat client. Requis sitlsClientCertest spécifié.
7.4.6. Ajouter un fournisseur d'identité à votre cluster
Après avoir installé votre cluster, ajoutez-y un fournisseur d'identité pour que vos utilisateurs puissent s'authentifier.
Conditions préalables
- Créer un cluster OpenShift Container Platform.
- Créez la ressource personnalisée (CR) pour vos fournisseurs d'identité.
- Vous devez être connecté en tant qu'administrateur.
Procédure
Appliquer le CR défini :
$ oc apply -f </path/to/CR>NoteSi un CR n'existe pas,
oc applycrée un nouveau CR et peut déclencher l'avertissement suivant :Warning: oc apply should be used on resources created by either oc create --save-config or oc apply. Dans ce cas, vous pouvez ignorer cet avertissement.Connectez-vous au cluster en tant qu'utilisateur de votre fournisseur d'identité, en saisissant le mot de passe lorsque vous y êtes invité.
$ oc login -u <nom d'utilisateur>Confirmez que l'utilisateur s'est connecté avec succès et affichez le nom de l'utilisateur.
$ oc whoami
7.4.7. Exemple de configuration Apache HTTPD pour les fournisseurs d'identité de base
La configuration de base du fournisseur d'identification (IDP) dans OpenShift Container Platform 4 exige que le serveur IDP réponde avec JSON pour les succès et les échecs. Vous pouvez utiliser un script CGI dans Apache HTTPD pour y parvenir. Cette section fournit des exemples.
Exemple /etc/httpd/conf.d/login.conf
<VirtualHost *:443>
# CGI Scripts in here
DocumentRoot /var/www/cgi-bin
# SSL Directives
SSLEngine on
SSLCipherSuite PROFILE=SYSTEM
SSLProxyCipherSuite PROFILE=SYSTEM
SSLCertificateFile /etc/pki/tls/certs/localhost.crt
SSLCertificateKeyFile /etc/pki/tls/private/localhost.key
# Configure HTTPD to execute scripts
ScriptAlias /basic /var/www/cgi-bin
# Handles a failed login attempt
ErrorDocument 401 /basic/fail.cgi
# Handles authentication
<Location /basic/login.cgi>
AuthType Basic
AuthName "Please Log In"
AuthBasicProvider file
AuthUserFile /etc/httpd/conf/passwords
Require valid-user
</Location>
</VirtualHost>Exemple /var/www/cgi-bin/login.cgi
#!/bin/bash
echo "Content-Type: application/json"
echo ""
echo '{"sub":"userid", "name":"'$REMOTE_USER'"}'
exit 0Exemple /var/www/cgi-bin/fail.cgi
#!/bin/bash
echo "Content-Type: application/json"
echo ""
echo '{"error": "Login failure"}'
exit 07.4.7.1. Exigences en matière de fichiers
Voici les conditions requises pour les fichiers que vous créez sur un serveur web Apache HTTPD :
-
login.cgietfail.cgidoivent être exécutables (chmod x). -
login.cgietfail.cgidoivent avoir des contextes SELinux appropriés si SELinux est activé :restorecon -RFv /var/www/cgi-binou s'assurer que le contexte esthttpd_sys_script_exec_ten utilisantls -laZ. -
login.cgin'est exécuté que si l'utilisateur se connecte avec succès, conformément aux directives deRequire and Auth. -
fail.cgiest exécuté si l'utilisateur ne parvient pas à se connecter, ce qui entraîne une réponseHTTP 401.
7.4.8. Dépannage de l'authentification de base
Le problème le plus courant est lié à la connectivité réseau avec le serveur backend. Pour un débogage simple, exécutez les commandes curl sur le maître. Pour tester une connexion réussie, remplacez <user> et <password> dans l'exemple de commande suivant par des informations d'identification valides. Pour tester une connexion non valide, remplacez-les par de fausses informations d'identification.
$ curl --cacert /path/to/ca.crt --cert /path/to/client.crt --key /path/to/client.key -u <user>:<password> -v https://www.example.com/remote-idpSuccessful responses
Un statut 200 avec une clé sub (sujet) indique un succès :
{"sub":"userid"}Le sujet doit être unique pour l'utilisateur authentifié et ne doit pas pouvoir être modifié.
Une réponse positive peut éventuellement fournir des données supplémentaires, telles que
Un nom d'affichage à l'aide de la touche
name:{"sub":"userid", "name": "User Name", ...}Une adresse électronique à l'aide de la touche
email:{"sub":"userid", "email":"user@example.com", ...}Un nom d'utilisateur préféré à l'aide de la touche
preferred_username:{"sub":"014fbff9a07c", "preferred_username":"bob", ...}La clé
preferred_usernameest utile lorsque le sujet unique et immuable est une clé de base de données ou un UID, et qu'il existe un nom plus lisible par l'homme. Elle est utilisée comme indice lors du provisionnement de l'utilisateur OpenShift Container Platform pour l'identité authentifiée.
Failed responses
-
Une réponse
401indique que l'authentification a échoué. -
Un état non
200ou la présence d'une clé "error" non vide indique une erreur :{"error":"Error message"}
7.5. Configuration d'un fournisseur d'identité d'en-tête de requête
Configurez le fournisseur d'identité request-header pour qu'il identifie les utilisateurs à partir des valeurs d'en-tête des requêtes, telles que X-Remote-User. Il est généralement utilisé en combinaison avec un proxy d'authentification, qui définit la valeur de l'en-tête de la requête.
7.5.1. À propos des fournisseurs d'identité dans OpenShift Container Platform
Par défaut, seul un utilisateur kubeadmin existe sur votre cluster. Pour spécifier un fournisseur d'identité, vous devez créer une ressource personnalisée (CR) qui décrit ce fournisseur d'identité et l'ajouter au cluster.
Les noms d'utilisateur OpenShift Container Platform contenant /, :, et % ne sont pas pris en charge.
7.5.2. À propos de l'authentification de l'en-tête de la requête
Un fournisseur d'identité d'en-tête de requête identifie les utilisateurs à partir des valeurs d'en-tête de requête, telles que X-Remote-User. Il est généralement utilisé en combinaison avec un proxy d'authentification, qui définit la valeur de l'en-tête de la requête. Le fournisseur d'identité d'en-tête de requête ne peut pas être combiné avec d'autres fournisseurs d'identité qui utilisent des connexions directes par mot de passe, comme htpasswd, Keystone, LDAP ou l'authentification de base.
Vous pouvez également utiliser le fournisseur d'identité de l'en-tête de la requête pour des configurations avancées telles que l'authentification SAML supportée par la communauté. Notez que cette solution n'est pas prise en charge par Red Hat.
Pour que les utilisateurs puissent s'authentifier à l'aide de ce fournisseur d'identité, ils doivent accéder à https://<namespace_route>/oauth/authorize (et aux sous-chemins) via un proxy d'authentification. Pour ce faire, configurez le serveur OAuth pour qu'il redirige les demandes non authentifiées de jetons OAuth vers le point d'extrémité du proxy qui fait office de proxy vers https://<namespace_route>/oauth/authorize.
Pour rediriger les demandes non authentifiées des clients qui attendent des flux de connexion basés sur un navigateur :
-
Attribuez au paramètre
provider.loginURLl'URL du proxy d'authentification qui authentifiera les clients interactifs et transmettra ensuite la requête àhttps://<namespace_route>/oauth/authorize.
Pour rediriger les demandes non authentifiées des clients qui s'attendent à être confrontés à WWW-Authenticate:
-
Définissez le paramètre
provider.challengeURLà l'URL du proxy d'authentification qui authentifiera les clients qui attendent des défisWWW-Authenticate, puis transmettra la demande àhttps://<namespace_route>/oauth/authorize.
Les paramètres provider.challengeURL et provider.loginURL peuvent inclure les jetons suivants dans la partie requête de l'URL :
${url}est remplacé par l'URL actuelle, échappée pour être sûre dans un paramètre de requête.Par exemple :
https://www.example.com/sso-login?then=${url}${query}est remplacée par la chaîne de requête actuelle, non codée.Par exemple :
https://www.example.com/auth-proxy/oauth/authorize?${query}
Depuis OpenShift Container Platform 4.1, votre proxy doit prendre en charge TLS mutuel.
7.5.2.1. Prise en charge de la connexion SSPI sous Microsoft Windows
L'utilisation de la prise en charge de la connexion SSPI sur Microsoft Windows est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes d'un point de vue fonctionnel. Red Hat ne recommande pas leur utilisation en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
L'OpenShift CLI (oc) prend en charge la Security Support Provider Interface (SSPI) pour permettre les flux SSO sur Microsft Windows. Si vous utilisez le fournisseur d'identité d'en-tête de demande avec un proxy compatible GSSAPI pour connecter un serveur Active Directory à OpenShift Container Platform, les utilisateurs peuvent s'authentifier automatiquement à OpenShift Container Platform en utilisant l'interface de ligne de commande oc à partir d'un ordinateur Microsoft Windows connecté à un domaine.
7.5.3. Création d'une carte de configuration
Les fournisseurs d'identité utilisent les objets OpenShift Container Platform ConfigMap dans l'espace de noms openshift-config pour contenir le paquet de l'autorité de certification. Ces objets sont principalement utilisés pour contenir les paquets de certificats nécessaires au fournisseur d'identité.
Procédure
Définissez un objet OpenShift Container Platform
ConfigMapcontenant l'autorité de certification en utilisant la commande suivante. L'autorité de certification doit être stockée dans la cléca.crtde l'objetConfigMap.$ oc create configmap ca-config-map --from-file=ca.crt=/path/to/ca -n openshift-configAstuceVous pouvez également appliquer le YAML suivant pour créer la carte de configuration :
apiVersion: v1 kind: ConfigMap metadata: name: ca-config-map namespace: openshift-config data: ca.crt: | <CA_certificate_PEM>
7.5.4. Exemple d'en-tête de requête CR
La ressource personnalisée (CR) suivante indique les paramètres et les valeurs acceptables pour un fournisseur d'identité d'en-tête de requête.
En-tête de requête CR
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: requestheaderidp
mappingMethod: claim
type: RequestHeader
requestHeader:
challengeURL: "https://www.example.com/challenging-proxy/oauth/authorize?${query}"
loginURL: "https://www.example.com/login-proxy/oauth/authorize?${query}"
ca:
name: ca-config-map
clientCommonNames:
- my-auth-proxy
headers:
- X-Remote-User
- SSO-User
emailHeaders:
- X-Remote-User-Email
nameHeaders:
- X-Remote-User-Display-Name
preferredUsernameHeaders:
- X-Remote-User-Login- 1
- Ce nom de fournisseur est préfixé au nom d'utilisateur dans l'en-tête de la demande pour former un nom d'identité.
- 2
- Contrôle la manière dont les correspondances sont établies entre les identités de ce fournisseur et les objets
User. - 3
- Facultatif : URL vers laquelle rediriger les requêtes
/oauth/authorizenon authentifiées, qui authentifiera les clients basés sur un navigateur et transmettra leur requête par proxy àhttps://<namespace_route>/oauth/authorize. L'URL qui redirige vershttps://<namespace_route>/oauth/authorizedoit se terminer par/authorize(sans barre oblique à la fin), ainsi que les sous-chemins de proxy, afin que les flux d'approbation OAuth fonctionnent correctement.${url}est remplacé par l'URL actuelle, échappée pour être sûre dans un paramètre de requête.${query}est remplacé par la chaîne de requête actuelle. Si cet attribut n'est pas défini,loginURLdoit être utilisé. - 4
- Facultatif : URL vers laquelle rediriger les requêtes
/oauth/authorizenon authentifiées, qui authentifiera les clients qui attendent des défisWWW-Authenticate, puis les redirigera vershttps://<namespace_route>/oauth/authorize.${url}est remplacé par l'URL actuelle, échappée pour être sûre dans un paramètre de requête.${query}est remplacé par la chaîne de requête actuelle. Si cet attribut n'est pas défini, il faut utiliserchallengeURL. - 5
- Référence à un objet OpenShift Container Platform
ConfigMapcontenant un paquet de certificats codé en PEM. Utilisé comme ancre de confiance pour valider les certificats TLS présentés par le serveur distant.ImportantDepuis OpenShift Container Platform 4.1, le champ
caest obligatoire pour ce fournisseur d'identité. Cela signifie que votre proxy doit prendre en charge TLS mutuel. - 6
- Facultatif : liste de noms communs (
cn). S'il est défini, un certificat client valide avec un nom commun (cn) figurant dans la liste spécifiée doit être présenté avant que les en-têtes de la demande ne soient vérifiés pour les noms d'utilisateur. S'il est vide, n'importe quel nom commun est autorisé. Ne peut être utilisé qu'en combinaison avecca. - 7
- Noms des en-têtes à vérifier, dans l'ordre, pour l'identité de l'utilisateur. Le premier en-tête contenant une valeur est utilisé comme identité. Obligatoire, insensible à la casse.
- 8
- Noms des en-têtes à vérifier, dans l'ordre, pour une adresse électronique. Le premier en-tête contenant une valeur est utilisé comme adresse électronique. Facultatif, insensible à la casse.
- 9
- Noms d'en-tête à vérifier, dans l'ordre, pour un nom d'affichage. Le premier en-tête contenant une valeur est utilisé comme nom d'affichage. Facultatif, insensible à la casse.
- 10
- Noms des en-têtes à vérifier, dans l'ordre, pour un nom d'utilisateur préféré, s'il est différent de l'identité immuable déterminée à partir des en-têtes spécifiés à l'adresse
headers. Le premier en-tête contenant une valeur est utilisé comme nom d'utilisateur préféré lors du provisionnement. Facultatif, insensible à la casse.
7.5.5. Ajouter un fournisseur d'identité à votre cluster
Après avoir installé votre cluster, ajoutez-y un fournisseur d'identité pour que vos utilisateurs puissent s'authentifier.
Conditions préalables
- Créer un cluster OpenShift Container Platform.
- Créez la ressource personnalisée (CR) pour vos fournisseurs d'identité.
- Vous devez être connecté en tant qu'administrateur.
Procédure
Appliquer le CR défini :
$ oc apply -f </path/to/CR>NoteSi un CR n'existe pas,
oc applycrée un nouveau CR et peut déclencher l'avertissement suivant :Warning: oc apply should be used on resources created by either oc create --save-config or oc apply. Dans ce cas, vous pouvez ignorer cet avertissement.Connectez-vous au cluster en tant qu'utilisateur de votre fournisseur d'identité, en saisissant le mot de passe lorsque vous y êtes invité.
$ oc login -u <nom d'utilisateur>Confirmez que l'utilisateur s'est connecté avec succès et affichez le nom de l'utilisateur.
$ oc whoami
7.5.6. Exemple de configuration de l'authentification Apache à l'aide de l'en-tête de requête
Cet exemple configure un proxy d'authentification Apache pour OpenShift Container Platform en utilisant le fournisseur d'identité de l'en-tête de requête.
Configuration personnalisée du proxy
L'utilisation du module mod_auth_gssapi est un moyen courant de configurer le proxy d'authentification Apache en utilisant le fournisseur d'identité de l'en-tête de requête ; cependant, ce n'est pas obligatoire. D'autres mandataires peuvent facilement être utilisés si les conditions suivantes sont remplies :
-
Bloquer l'en-tête
X-Remote-Userdans les requêtes des clients pour empêcher l'usurpation d'identité. -
Renforcer l'authentification du certificat du client dans la configuration de
RequestHeaderIdentityProvider. -
Exiger que l'en-tête
X-Csrf-Tokensoit défini pour toutes les demandes d'authentification utilisant le flux de défi. -
Veillez à ce que seuls le point d'accès
/oauth/authorizeet ses sous-chemins soient protégés ; les redirections doivent être réécrites pour permettre au serveur dorsal d'envoyer le client au bon endroit. -
L'URL qui fait office de proxy vers
https://<namespace_route>/oauth/authorizedoit se terminer par/authorizesans barre oblique de fin. Par exemple,https://proxy.example.com/login-proxy/authorize?…doit se substituer àhttps://<namespace_route>/oauth/authorize?…. -
Les sous-chemins de l'URL qui fait office de proxy vers
https://<namespace_route>/oauth/authorizedoivent faire office de proxy vers les sous-chemins dehttps://<namespace_route>/oauth/authorize. Par exemple,https://proxy.example.com/login-proxy/authorize/approve?…doit faire office de proxy vershttps://<namespace_route>/oauth/authorize/approve?….
L'adresse https://<namespace_route> est la route vers le serveur OAuth et peut être obtenue en exécutant oc get route -n openshift-authentication.
Configuration de l'authentification Apache à l'aide de l'en-tête de requête
Cet exemple utilise le module mod_auth_gssapi pour configurer un proxy d'authentification Apache en utilisant le fournisseur d'identité de l'en-tête de requête.
Conditions préalables
Obtenez le module
mod_auth_gssapià partir du canal optionnel. Les paquets suivants doivent être installés sur votre machine locale :-
httpd -
mod_ssl -
mod_session -
apr-util-openssl -
mod_auth_gssapi
-
Générer une autorité de certification pour valider les demandes qui soumettent l'en-tête de confiance. Définir un objet OpenShift Container Platform
ConfigMapcontenant l'AC. Cette opération s'effectue en exécutant :$ oc create configmap ca-config-map --from-file=ca.crt=/path/to/ca -n openshift-config1 - 1
- L'autorité de certification doit être stockée dans la clé
ca.crtde l'objetConfigMap.
AstuceVous pouvez également appliquer le YAML suivant pour créer la carte de configuration :
apiVersion: v1 kind: ConfigMap metadata: name: ca-config-map namespace: openshift-config data: ca.crt: | <CA_certificate_PEM>- Générer un certificat client pour le proxy. Vous pouvez générer ce certificat en utilisant n'importe quel outil de certificat x509. Le certificat client doit être signé par l'autorité de certification que vous avez générée pour valider les demandes qui soumettent l'en-tête de confiance.
- Créez la ressource personnalisée (CR) pour vos fournisseurs d'identité.
Procédure
Ce proxy utilise un certificat client pour se connecter au serveur OAuth, qui est configuré pour faire confiance à l'en-tête X-Remote-User.
-
Créez le certificat pour la configuration Apache. Le certificat que vous spécifiez comme valeur du paramètre
SSLProxyMachineCertificateFileest le certificat client du proxy qui est utilisé pour authentifier le proxy auprès du serveur. Il doit utiliserTLS Web Client Authenticationcomme type de clé étendue. Créez la configuration d'Apache. Utilisez le modèle suivant pour fournir les paramètres et les valeurs nécessaires :
ImportantExaminez attentivement le modèle et adaptez son contenu à votre environnement.
LoadModule request_module modules/mod_request.so LoadModule auth_gssapi_module modules/mod_auth_gssapi.so # Some Apache configurations might require these modules. # LoadModule auth_form_module modules/mod_auth_form.so # LoadModule session_module modules/mod_session.so # Nothing needs to be served over HTTP. This virtual host simply redirects to # HTTPS. <VirtualHost *:80> DocumentRoot /var/www/html RewriteEngine On RewriteRule ^(.*)$ https://%{HTTP_HOST}$1 [R,L] </VirtualHost> <VirtualHost *:443> # This needs to match the certificates you generated. See the CN and X509v3 # Subject Alternative Name in the output of: # openssl x509 -text -in /etc/pki/tls/certs/localhost.crt ServerName www.example.com DocumentRoot /var/www/html SSLEngine on SSLCertificateFile /etc/pki/tls/certs/localhost.crt SSLCertificateKeyFile /etc/pki/tls/private/localhost.key SSLCACertificateFile /etc/pki/CA/certs/ca.crt SSLProxyEngine on SSLProxyCACertificateFile /etc/pki/CA/certs/ca.crt # It is critical to enforce client certificates. Otherwise, requests can # spoof the X-Remote-User header by accessing the /oauth/authorize endpoint # directly. SSLProxyMachineCertificateFile /etc/pki/tls/certs/authproxy.pem # To use the challenging-proxy, an X-Csrf-Token must be present. RewriteCond %{REQUEST_URI} ^/challenging-proxy RewriteCond %{HTTP:X-Csrf-Token} ^$ [NC] RewriteRule ^.* - [F,L] <Location /challenging-proxy/oauth/authorize> # Insert your backend server name/ip here. ProxyPass https://<namespace_route>/oauth/authorize AuthName "SSO Login" # For Kerberos AuthType GSSAPI Require valid-user RequestHeader set X-Remote-User %{REMOTE_USER}s GssapiCredStore keytab:/etc/httpd/protected/auth-proxy.keytab # Enable the following if you want to allow users to fallback # to password based authentication when they do not have a client # configured to perform kerberos authentication. GssapiBasicAuth On # For ldap: # AuthBasicProvider ldap # AuthLDAPURL "ldap://ldap.example.com:389/ou=People,dc=my-domain,dc=com?uid?sub?(objectClass=*)" </Location> <Location /login-proxy/oauth/authorize> # Insert your backend server name/ip here. ProxyPass https://<namespace_route>/oauth/authorize AuthName "SSO Login" AuthType GSSAPI Require valid-user RequestHeader set X-Remote-User %{REMOTE_USER}s env=REMOTE_USER GssapiCredStore keytab:/etc/httpd/protected/auth-proxy.keytab # Enable the following if you want to allow users to fallback # to password based authentication when they do not have a client # configured to perform kerberos authentication. GssapiBasicAuth On ErrorDocument 401 /login.html </Location> </VirtualHost> RequestHeader unset X-Remote-UserNoteL'adresse
https://<namespace_route>est la route vers le serveur OAuth et peut être obtenue en exécutantoc get route -n openshift-authentication.Mettez à jour la strophe
identityProvidersdans la ressource personnalisée (CR) :identityProviders: - name: requestheaderidp type: RequestHeader requestHeader: challengeURL: "https://<namespace_route>/challenging-proxy/oauth/authorize?${query}" loginURL: "https://<namespace_route>/login-proxy/oauth/authorize?${query}" ca: name: ca-config-map clientCommonNames: - my-auth-proxy headers: - X-Remote-UserVérifier la configuration.
Confirmez que vous pouvez contourner le proxy en demandant un jeton en fournissant le certificat client et l'en-tête corrects :
# curl -L -k -H "X-Remote-User: joe" \ --cert /etc/pki/tls/certs/authproxy.pem \ https://<namespace_route>/oauth/token/requestConfirmez que les demandes qui ne fournissent pas le certificat du client échouent en demandant un jeton sans le certificat :
# curl -L -k -H "X-Remote-User: joe" \ https://<namespace_route>/oauth/token/requestConfirmez que la redirection
challengeURLest active :# curl -k -v -H 'X-Csrf-Token: 1' \ https://<namespace_route>/oauth/authorize?client_id=openshift-challenging-client&response_type=tokenCopiez la redirection
challengeURLpour l'utiliser dans l'étape suivante.Exécutez cette commande pour afficher une réponse
401avec un défi de baseWWW-Authenticate, un défi de négociation ou les deux défis :# curl -k -v -H 'X-Csrf-Token: 1' \ <challengeURL_redirect + query>Tester la connexion à l'OpenShift CLI (
oc) avec et sans l'utilisation d'un ticket Kerberos :Si vous avez généré un ticket Kerberos en utilisant
kinit, détruisez-le :# kdestroy -c nom_du_cache1 - 1
- Veillez à indiquer le nom de votre cache Kerberos.
Connectez-vous à l'outil
ocen utilisant vos identifiants Kerberos :# oc login -u <nom d'utilisateur>Saisissez votre mot de passe Kerberos à l'invite.
Déconnectez-vous de l'outil
oc:# oc logoutUtilisez vos identifiants Kerberos pour obtenir un ticket :
# kinitSaisissez votre nom d'utilisateur et votre mot de passe Kerberos à l'invite.
Confirmez que vous pouvez vous connecter à l'outil
oc:# oc loginSi votre configuration est correcte, vous êtes connecté sans avoir à saisir d'informations d'identification distinctes.
7.6. Configuration d'un fournisseur d'identité GitHub ou GitHub Enterprise
Configurez le fournisseur d'identité github pour valider les noms d'utilisateur et les mots de passe par rapport au serveur d'authentification OAuth de GitHub ou GitHub Enterprise. OAuth facilite l'échange de jetons entre OpenShift Container Platform et GitHub ou GitHub Enterprise.
Vous pouvez utiliser l'intégration GitHub pour vous connecter à GitHub ou à GitHub Enterprise. Pour les intégrations GitHub Enterprise, vous devez fournir le site hostname de votre instance et pouvez éventuellement fournir un paquet de certificats ca à utiliser dans les demandes adressées au serveur.
Les étapes suivantes s'appliquent à la fois à GitHub et à GitHub Enterprise, sauf indication contraire.
7.6.1. À propos des fournisseurs d'identité dans OpenShift Container Platform
Par défaut, seul un utilisateur kubeadmin existe sur votre cluster. Pour spécifier un fournisseur d'identité, vous devez créer une ressource personnalisée (CR) qui décrit ce fournisseur d'identité et l'ajouter au cluster.
Les noms d'utilisateur OpenShift Container Platform contenant /, :, et % ne sont pas pris en charge.
7.6.2. À propos de l'authentification GitHub
La configuration de l'authentification GitHub permet aux utilisateurs de se connecter à OpenShift Container Platform avec leurs identifiants GitHub. Pour empêcher toute personne possédant un identifiant GitHub de se connecter à votre cluster OpenShift Container Platform, vous pouvez restreindre l'accès aux seules personnes appartenant à des organisations GitHub spécifiques.
7.6.3. Enregistrer une application GitHub
Pour utiliser GitHub ou GitHub Enterprise comme fournisseur d'identité, vous devez enregistrer une application à utiliser.
Procédure
Enregistrer une application sur GitHub :
- Pour GitHub, cliquez sur Settings → Developer settings → OAuth Apps → Register a new OAuth application.
- Pour GitHub Enterprise, allez sur la page d'accueil de GitHub Enterprise et cliquez sur Settings → Developer settings → Register a new application.
-
Saisissez un nom d'application, par exemple
My OpenShift Install. -
Saisissez l'URL d'une page d'accueil, par exemple
https://oauth-openshift.apps.<cluster-name>.<cluster-domain>. - Optionnel : Saisissez une description de l'application.
Entrez l'URL de rappel d'autorisation, où la fin de l'URL contient le fournisseur d'identité
name:https://oauth-openshift.apps.<cluster-name>.<cluster-domain>/oauth2callback/<idp-provider-name>Par exemple :
https://oauth-openshift.apps.openshift-cluster.example.com/oauth2callback/github- Cliquez sur Register application. GitHub fournit un identifiant et un secret client. Vous avez besoin de ces valeurs pour terminer la configuration du fournisseur d'identité.
7.6.4. Création du secret
Les fournisseurs d'identité utilisent des objets OpenShift Container Platform Secret dans l'espace de noms openshift-config pour contenir le secret du client, les certificats du client et les clés.
Procédure
Créez un objet
Secretcontenant une chaîne de caractères à l'aide de la commande suivante :$ oc create secret generic <secret_name> --from-literal=clientSecret=<secret> -n openshift-configAstuceVous pouvez également appliquer le code YAML suivant pour créer le secret :
apiVersion: v1 kind: Secret metadata: name: <secret_name> namespace: openshift-config type: Opaque data: clientSecret: <base64_encoded_client_secret>Vous pouvez définir un objet
Secretcontenant le contenu d'un fichier, tel qu'un fichier de certificat, à l'aide de la commande suivante :oc create secret generic <secret_name> --from-file=<path_to_file> -n openshift-config
7.6.5. Création d'une carte de configuration
Les fournisseurs d'identité utilisent les objets OpenShift Container Platform ConfigMap dans l'espace de noms openshift-config pour contenir le paquet de l'autorité de certification. Ces objets sont principalement utilisés pour contenir les paquets de certificats nécessaires au fournisseur d'identité.
Cette procédure n'est nécessaire que pour GitHub Enterprise.
Procédure
Définissez un objet OpenShift Container Platform
ConfigMapcontenant l'autorité de certification en utilisant la commande suivante. L'autorité de certification doit être stockée dans la cléca.crtde l'objetConfigMap.$ oc create configmap ca-config-map --from-file=ca.crt=/path/to/ca -n openshift-configAstuceVous pouvez également appliquer le YAML suivant pour créer la carte de configuration :
apiVersion: v1 kind: ConfigMap metadata: name: ca-config-map namespace: openshift-config data: ca.crt: | <CA_certificate_PEM>
7.6.6. Exemple de CR GitHub
La ressource personnalisée (CR) suivante présente les paramètres et les valeurs acceptables pour un fournisseur d'identité GitHub.
GitHub CR
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: githubidp
mappingMethod: claim
type: GitHub
github:
ca:
name: ca-config-map
clientID: {...}
clientSecret:
name: github-secret
hostname: ...
organizations:
- myorganization1
- myorganization2
teams:
- myorganization1/team-a
- myorganization2/team-b- 1
- Ce nom de fournisseur est préfixé à l'identifiant numérique de l'utilisateur GitHub pour former un nom d'identité. Il est également utilisé pour construire l'URL de rappel.
- 2
- Contrôle la manière dont les correspondances sont établies entre les identités de ce fournisseur et les objets
User. - 3
- Facultatif : Référence à un objet OpenShift Container Platform
ConfigMapcontenant le paquet d'autorité de certification encodé PEM à utiliser dans la validation des certificats de serveur pour l'URL configurée. A utiliser uniquement dans GitHub Enterprise avec un certificat racine non publiquement fiable. - 4
- L'identifiant client d'une application GitHub OAuth enregistrée. L'application doit être configurée avec une URL de rappel de
https://oauth-openshift.apps.<cluster-name>.<cluster-domain>/oauth2callback/<idp-provider-name>. - 5
- Référence à un objet OpenShift Container Platform
Secretcontenant le secret client émis par GitHub. - 6
- Pour GitHub Enterprise, vous devez fournir le nom d'hôte de votre instance, par exemple
example.com. Cette valeur doit correspondre à la valeurhostnamede GitHub Enterprise dans le fichier/setup/settingset ne peut pas inclure de numéro de port. Si cette valeur n'est pas définie, il faut définirteamsouorganizations. Pour GitHub, omettez ce paramètre. - 7
- La liste des organisations. Le champ
organizationsouteamsdoit être activé si le champhostnamene l'est pas ou simappingMethodest associé àlookup. Ne peut être utilisé en combinaison avec le champteams. - 8
- La liste des équipes. Le champ
teamsouorganizationsdoit être activé si le champhostnamen'est pas activé ou simappingMethodest remplacé parlookup. Ne peut être utilisé en combinaison avec le champorganizations.
Si organizations ou teams est spécifié, seuls les utilisateurs de GitHub qui sont membres d'au moins une des organisations répertoriées seront autorisés à se connecter. Si l'application GitHub OAuth configurée dans clientID n'appartient pas à l'organisation, un propriétaire de l'organisation doit accorder un accès à un tiers pour utiliser cette option. Cela peut être fait lors de la première connexion à GitHub par l'administrateur de l'organisation, ou à partir des paramètres de l'organisation GitHub.
7.6.7. Ajouter un fournisseur d'identité à votre cluster
Après avoir installé votre cluster, ajoutez-y un fournisseur d'identité pour que vos utilisateurs puissent s'authentifier.
Conditions préalables
- Créer un cluster OpenShift Container Platform.
- Créez la ressource personnalisée (CR) pour vos fournisseurs d'identité.
- Vous devez être connecté en tant qu'administrateur.
Procédure
Appliquer le CR défini :
$ oc apply -f </path/to/CR>NoteSi un CR n'existe pas,
oc applycrée un nouveau CR et peut déclencher l'avertissement suivant :Warning: oc apply should be used on resources created by either oc create --save-config or oc apply. Dans ce cas, vous pouvez ignorer cet avertissement.Obtenir un jeton du serveur OAuth.
Tant que l'utilisateur
kubeadmina été supprimé, la commandeoc loginfournit des instructions sur la manière d'accéder à une page web où vous pouvez récupérer le jeton.Vous pouvez également accéder à cette page à partir de la console web en naviguant vers (?) Help → Command Line Tools → Copy Login Command.
Se connecter au cluster en transmettant le jeton d'authentification.
$ oc login --token=<token>NoteCe fournisseur d'identité ne permet pas de se connecter avec un nom d'utilisateur et un mot de passe.
Confirmez que l'utilisateur s'est connecté avec succès et affichez le nom de l'utilisateur.
$ oc whoami
7.7. Configuration d'un fournisseur d'identité GitLab
Configurer le fournisseur d'identité gitlab en utilisant GitLab.com ou toute autre instance de GitLab comme fournisseur d'identité.
7.7.1. À propos des fournisseurs d'identité dans OpenShift Container Platform
Par défaut, seul un utilisateur kubeadmin existe sur votre cluster. Pour spécifier un fournisseur d'identité, vous devez créer une ressource personnalisée (CR) qui décrit ce fournisseur d'identité et l'ajouter au cluster.
Les noms d'utilisateur OpenShift Container Platform contenant /, :, et % ne sont pas pris en charge.
7.7.2. À propos de l'authentification GitLab
La configuration de l'authentification GitLab permet aux utilisateurs de se connecter à OpenShift Container Platform avec leurs identifiants GitLab.
Si vous utilisez GitLab version 7.7.0 à 11.0, vous vous connectez en utilisant l'intégration OAuth. Si vous utilisez GitLab version 11.1 ou ultérieure, vous pouvez utiliser OpenID Connect (OIDC) pour vous connecter au lieu d'OAuth.
7.7.3. Création du secret
Les fournisseurs d'identité utilisent des objets OpenShift Container Platform Secret dans l'espace de noms openshift-config pour contenir le secret du client, les certificats du client et les clés.
Procédure
Créez un objet
Secretcontenant une chaîne de caractères à l'aide de la commande suivante :$ oc create secret generic <secret_name> --from-literal=clientSecret=<secret> -n openshift-configAstuceVous pouvez également appliquer le code YAML suivant pour créer le secret :
apiVersion: v1 kind: Secret metadata: name: <secret_name> namespace: openshift-config type: Opaque data: clientSecret: <base64_encoded_client_secret>Vous pouvez définir un objet
Secretcontenant le contenu d'un fichier, tel qu'un fichier de certificat, à l'aide de la commande suivante :oc create secret generic <secret_name> --from-file=<path_to_file> -n openshift-config
7.7.4. Création d'une carte de configuration
Les fournisseurs d'identité utilisent les objets OpenShift Container Platform ConfigMap dans l'espace de noms openshift-config pour contenir le paquet de l'autorité de certification. Ces objets sont principalement utilisés pour contenir les paquets de certificats nécessaires au fournisseur d'identité.
Cette procédure n'est nécessaire que pour GitHub Enterprise.
Procédure
Définissez un objet OpenShift Container Platform
ConfigMapcontenant l'autorité de certification en utilisant la commande suivante. L'autorité de certification doit être stockée dans la cléca.crtde l'objetConfigMap.$ oc create configmap ca-config-map --from-file=ca.crt=/path/to/ca -n openshift-configAstuceVous pouvez également appliquer le YAML suivant pour créer la carte de configuration :
apiVersion: v1 kind: ConfigMap metadata: name: ca-config-map namespace: openshift-config data: ca.crt: | <CA_certificate_PEM>
7.7.5. Exemple de CR GitLab
La ressource personnalisée (CR) suivante présente les paramètres et les valeurs acceptables pour un fournisseur d'identité GitLab.
GitLab CR
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: gitlabidp
mappingMethod: claim
type: GitLab
gitlab:
clientID: {...}
clientSecret:
name: gitlab-secret
url: https://gitlab.com
ca:
name: ca-config-map- 1
- Ce nom de fournisseur est préfixé à l'identifiant numérique de l'utilisateur GitLab pour former un nom d'identité. Il est également utilisé pour construire l'URL de rappel.
- 2
- Contrôle la manière dont les correspondances sont établies entre les identités de ce fournisseur et les objets
User. - 3
- L'identifiant client d'une application GitLab OAuth enregistrée. L'application doit être configurée avec une URL de rappel de
https://oauth-openshift.apps.<cluster-name>.<cluster-domain>/oauth2callback/<idp-provider-name>. - 4
- Référence à un objet OpenShift Container Platform
Secretcontenant le secret client émis par GitLab. - 5
- L'URL de l'hôte d'un fournisseur de GitLab. Il peut s'agir de
https://gitlab.com/ou de toute autre instance auto-hébergée de GitLab. - 6
- Facultatif : Référence à un objet OpenShift Container Platform
ConfigMapcontenant le bundle de l'autorité de certification codé en PEM à utiliser pour valider les certificats du serveur pour l'URL configurée.
7.7.6. Ajouter un fournisseur d'identité à votre cluster
Après avoir installé votre cluster, ajoutez-y un fournisseur d'identité pour que vos utilisateurs puissent s'authentifier.
Conditions préalables
- Créer un cluster OpenShift Container Platform.
- Créez la ressource personnalisée (CR) pour vos fournisseurs d'identité.
- Vous devez être connecté en tant qu'administrateur.
Procédure
Appliquer le CR défini :
$ oc apply -f </path/to/CR>NoteSi un CR n'existe pas,
oc applycrée un nouveau CR et peut déclencher l'avertissement suivant :Warning: oc apply should be used on resources created by either oc create --save-config or oc apply. Dans ce cas, vous pouvez ignorer cet avertissement.Connectez-vous au cluster en tant qu'utilisateur de votre fournisseur d'identité, en saisissant le mot de passe lorsque vous y êtes invité.
$ oc login -u <nom d'utilisateur>Confirmez que l'utilisateur s'est connecté avec succès et affichez le nom de l'utilisateur.
$ oc whoami
7.8. Configuration d'un fournisseur d'identité Google
Configurez le fournisseur d'identité google à l'aide de l'intégration Google OpenID Connect.
7.8.1. À propos des fournisseurs d'identité dans OpenShift Container Platform
Par défaut, seul un utilisateur kubeadmin existe sur votre cluster. Pour spécifier un fournisseur d'identité, vous devez créer une ressource personnalisée (CR) qui décrit ce fournisseur d'identité et l'ajouter au cluster.
Les noms d'utilisateur OpenShift Container Platform contenant /, :, et % ne sont pas pris en charge.
7.8.2. À propos de l'authentification Google
L'utilisation de Google comme fournisseur d'identité permet à tout utilisateur de Google de s'authentifier sur votre serveur. Vous pouvez limiter l'authentification aux membres d'un domaine hébergé spécifique à l'aide de l'attribut de configuration hostedDomain.
Pour utiliser Google comme fournisseur d'identité, les utilisateurs doivent obtenir un jeton à l'aide de <namespace_route>/oauth/token/request afin de pouvoir l'utiliser avec des outils en ligne de commande.
7.8.3. Création du secret
Les fournisseurs d'identité utilisent des objets OpenShift Container Platform Secret dans l'espace de noms openshift-config pour contenir le secret du client, les certificats du client et les clés.
Procédure
Créez un objet
Secretcontenant une chaîne de caractères à l'aide de la commande suivante :$ oc create secret generic <secret_name> --from-literal=clientSecret=<secret> -n openshift-configAstuceVous pouvez également appliquer le code YAML suivant pour créer le secret :
apiVersion: v1 kind: Secret metadata: name: <secret_name> namespace: openshift-config type: Opaque data: clientSecret: <base64_encoded_client_secret>Vous pouvez définir un objet
Secretcontenant le contenu d'un fichier, tel qu'un fichier de certificat, à l'aide de la commande suivante :oc create secret generic <secret_name> --from-file=<path_to_file> -n openshift-config
7.8.4. Exemple de Google CR
La ressource personnalisée (CR) suivante présente les paramètres et les valeurs acceptables pour un fournisseur d'identité Google.
Google CR
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: googleidp
mappingMethod: claim
type: Google
google:
clientID: {...}
clientSecret:
name: google-secret
hostedDomain: "example.com" - 1
- Ce nom de fournisseur est préfixé à l'identifiant numérique de l'utilisateur Google pour former un nom d'identité. Il est également utilisé pour construire l'URL de redirection.
- 2
- Contrôle la manière dont les correspondances sont établies entre les identités de ce fournisseur et les objets
User. - 3
- L'identifiant client d'un projet Google enregistré. Le projet doit être configuré avec un URI de redirection de
https://oauth-openshift.apps.<cluster-name>.<cluster-domain>/oauth2callback/<idp-provider-name>. - 4
- Référence à un objet OpenShift Container Platform
Secretcontenant le secret client émis par Google. - 5
- Un domaine hébergé utilisé pour restreindre les comptes de connexion. Facultatif si l'adresse
lookupmappingMethodest utilisée. S'il est vide, tout compte Google est autorisé à s'authentifier.
7.8.5. Ajouter un fournisseur d'identité à votre cluster
Après avoir installé votre cluster, ajoutez-y un fournisseur d'identité pour que vos utilisateurs puissent s'authentifier.
Conditions préalables
- Créer un cluster OpenShift Container Platform.
- Créez la ressource personnalisée (CR) pour vos fournisseurs d'identité.
- Vous devez être connecté en tant qu'administrateur.
Procédure
Appliquer le CR défini :
$ oc apply -f </path/to/CR>NoteSi un CR n'existe pas,
oc applycrée un nouveau CR et peut déclencher l'avertissement suivant :Warning: oc apply should be used on resources created by either oc create --save-config or oc apply. Dans ce cas, vous pouvez ignorer cet avertissement.Obtenir un jeton du serveur OAuth.
Tant que l'utilisateur
kubeadmina été supprimé, la commandeoc loginfournit des instructions sur la manière d'accéder à une page web où vous pouvez récupérer le jeton.Vous pouvez également accéder à cette page à partir de la console web en naviguant vers (?) Help → Command Line Tools → Copy Login Command.
Se connecter au cluster en transmettant le jeton d'authentification.
$ oc login --token=<token>NoteCe fournisseur d'identité ne permet pas de se connecter avec un nom d'utilisateur et un mot de passe.
Confirmez que l'utilisateur s'est connecté avec succès et affichez le nom de l'utilisateur.
$ oc whoami
7.9. Configuration d'un fournisseur d'identité OpenID Connect
Configurer le fournisseur d'identité oidc pour qu'il s'intègre à un fournisseur d'identité OpenID Connect à l'aide d'un flux de code d'autorisation.
7.9.1. À propos des fournisseurs d'identité dans OpenShift Container Platform
Par défaut, seul un utilisateur kubeadmin existe sur votre cluster. Pour spécifier un fournisseur d'identité, vous devez créer une ressource personnalisée (CR) qui décrit ce fournisseur d'identité et l'ajouter au cluster.
Les noms d'utilisateur OpenShift Container Platform contenant /, :, et % ne sont pas pris en charge.
7.9.2. À propos de l'authentification OpenID Connect
L'opérateur d'authentification dans OpenShift Container Platform exige que le fournisseur d'identité OpenID Connect configuré mette en œuvre la spécification OpenID Connect Discovery.
ID Token et UserInfo ne sont pas pris en charge.
Par défaut, le champ d'application openid est demandé. Si nécessaire, des portées supplémentaires peuvent être spécifiées dans le champ extraScopes.
Les revendications sont lues à partir du JWT id_token renvoyé par le fournisseur d'identité OpenID et, si cela est spécifié, à partir du JSON renvoyé par l'URL UserInfo.
Au moins une revendication doit être configurée pour être utilisée comme identité de l'utilisateur. La revendication d'identité standard est sub.
Vous pouvez également indiquer les revendications à utiliser comme nom d'utilisateur, nom d'affichage et adresse électronique préférés de l'utilisateur. Si plusieurs revendications sont spécifiées, c'est la première dont la valeur n'est pas vide qui est utilisée. Le tableau suivant répertorie les revendications standard :
| Réclamation | Description |
|---|---|
|
| Abréviation de "subject identifier." L'identité à distance de l'utilisateur auprès de l'émetteur. |
|
|
Le nom d'utilisateur préféré lors du provisionnement d'un utilisateur. Un nom abrégé sous lequel l'utilisateur souhaite être désigné, tel que |
|
| Adresse électronique. |
|
| Nom d'affichage. |
Voir la documentation sur les réclamations OpenID pour plus d'informations.
À moins que votre fournisseur d'identité OpenID Connect ne prenne en charge le flux d'octroi ROPC (resource owner password credentials), les utilisateurs doivent obtenir un jeton auprès de <namespace_route>/oauth/token/request pour l'utiliser avec les outils en ligne de commande.
7.9.3. Fournisseurs de l'OIDC soutenus
Les fournisseurs OpenID Connect (OIDC) suivants sont testés et pris en charge par OpenShift Container Platform :
Services de fédération Active Directory pour Windows Server
NoteActuellement, il n'est pas possible d'utiliser Active Directory Federation Services for Windows Server avec OpenShift Container Platform lorsque des réclamations personnalisées sont utilisées.
- GitLab
- Keycloak
Plate-forme d'identité Microsoft (Azure Active Directory v2.0)
NoteActuellement, il n'est pas possible d'utiliser la plateforme d'identité Microsoft lorsque des noms de groupes doivent être synchronisés.
- Okta
- Identité de Ping
- Red Hat Single Sign-On
7.9.4. Création du secret
Les fournisseurs d'identité utilisent des objets OpenShift Container Platform Secret dans l'espace de noms openshift-config pour contenir le secret du client, les certificats du client et les clés.
Procédure
Créez un objet
Secretcontenant une chaîne de caractères à l'aide de la commande suivante :$ oc create secret generic <secret_name> --from-literal=clientSecret=<secret> -n openshift-configAstuceVous pouvez également appliquer le code YAML suivant pour créer le secret :
apiVersion: v1 kind: Secret metadata: name: <secret_name> namespace: openshift-config type: Opaque data: clientSecret: <base64_encoded_client_secret>Vous pouvez définir un objet
Secretcontenant le contenu d'un fichier, tel qu'un fichier de certificat, à l'aide de la commande suivante :oc create secret generic <secret_name> --from-file=<path_to_file> -n openshift-config
7.9.5. Création d'une carte de configuration
Les fournisseurs d'identité utilisent les objets OpenShift Container Platform ConfigMap dans l'espace de noms openshift-config pour contenir le paquet de l'autorité de certification. Ces objets sont principalement utilisés pour contenir les paquets de certificats nécessaires au fournisseur d'identité.
Cette procédure n'est nécessaire que pour GitHub Enterprise.
Procédure
Définissez un objet OpenShift Container Platform
ConfigMapcontenant l'autorité de certification en utilisant la commande suivante. L'autorité de certification doit être stockée dans la cléca.crtde l'objetConfigMap.$ oc create configmap ca-config-map --from-file=ca.crt=/path/to/ca -n openshift-configAstuceVous pouvez également appliquer le YAML suivant pour créer la carte de configuration :
apiVersion: v1 kind: ConfigMap metadata: name: ca-config-map namespace: openshift-config data: ca.crt: | <CA_certificate_PEM>
7.9.6. Exemples de CR OpenID Connect
Les ressources personnalisées (CR) suivantes indiquent les paramètres et les valeurs acceptables pour un fournisseur d'identité OpenID Connect.
Si vous devez spécifier un paquet de certificats personnalisé, des champs d'application supplémentaires, des paramètres de demande d'autorisation supplémentaires ou une URL userInfo, utilisez le CR OpenID Connect complet.
Standard OpenID Connect CR
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: oidcidp
mappingMethod: claim
type: OpenID
openID:
clientID: ...
clientSecret:
name: idp-secret
claims:
preferredUsername:
- preferred_username
name:
- name
email:
- email
groups:
- groups
issuer: https://www.idp-issuer.com - 1
- Ce nom de fournisseur est préfixé à la valeur de la revendication d'identité pour former un nom d'identité. Il est également utilisé pour construire l'URL de redirection.
- 2
- Contrôle la manière dont les correspondances sont établies entre les identités de ce fournisseur et les objets
User. - 3
- L'identifiant d'un client enregistré auprès du fournisseur OpenID. Le client doit être autorisé à rediriger vers
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name>. - 4
- Une référence à un objet OpenShift Container Platform
Secretcontenant le secret du client. - 5
- La liste des revendications à utiliser comme identité. La première revendication non vide est utilisée.
- 6
- L'identifiant de l'émetteur décrit dans la spécification OpenID. Doit utiliser
httpssans composante de requête ou de fragment.
OpenID Connect CR complet
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: oidcidp
mappingMethod: claim
type: OpenID
openID:
clientID: ...
clientSecret:
name: idp-secret
ca:
name: ca-config-map
extraScopes:
- email
- profile
extraAuthorizeParameters:
include_granted_scopes: "true"
claims:
preferredUsername:
- preferred_username
- email
name:
- nickname
- given_name
- name
email:
- custom_email_claim
- email
groups:
- groups
issuer: https://www.idp-issuer.com- 1
- Facultatif : Référence à une carte de configuration OpenShift Container Platform contenant le paquet d'autorité de certification encodé PEM à utiliser dans la validation des certificats de serveur pour l'URL configurée.
- 2
- Facultatif : La liste des champs d'application à demander, en plus du champ d'application
openid, lors de la demande de jeton d'autorisation. - 3
- Facultatif : Une liste de paramètres supplémentaires à ajouter à la demande de jeton d'autorisation.
- 4
- La liste des revendications à utiliser comme nom d'utilisateur préféré lors du provisionnement d'un utilisateur pour cette identité. La première revendication non vide est utilisée.
- 5
- La liste des revendications à utiliser comme nom d'affichage. La première revendication non vide est utilisée.
- 6
- La liste des créances à utiliser comme adresse électronique. La première demande non vide est utilisée.
- 7
- La liste des réclamations à utiliser pour synchroniser les groupes du fournisseur OpenID Connect à OpenShift Container Platform lors de la connexion de l'utilisateur. Le premier claim non vide est utilisé.
7.9.7. Ajouter un fournisseur d'identité à votre cluster
Après avoir installé votre cluster, ajoutez-y un fournisseur d'identité pour que vos utilisateurs puissent s'authentifier.
Conditions préalables
- Créer un cluster OpenShift Container Platform.
- Créez la ressource personnalisée (CR) pour vos fournisseurs d'identité.
- Vous devez être connecté en tant qu'administrateur.
Procédure
Appliquer le CR défini :
$ oc apply -f </path/to/CR>NoteSi un CR n'existe pas,
oc applycrée un nouveau CR et peut déclencher l'avertissement suivant :Warning: oc apply should be used on resources created by either oc create --save-config or oc apply. Dans ce cas, vous pouvez ignorer cet avertissement.Obtenir un jeton du serveur OAuth.
Tant que l'utilisateur
kubeadmina été supprimé, la commandeoc loginfournit des instructions sur la manière d'accéder à une page web où vous pouvez récupérer le jeton.Vous pouvez également accéder à cette page à partir de la console web en naviguant vers (?) Help → Command Line Tools → Copy Login Command.
Se connecter au cluster en transmettant le jeton d'authentification.
$ oc login --token=<token>NoteSi votre fournisseur d'identité OpenID Connect prend en charge le flux d'attribution des identifiants ROPC (resource owner password credentials), vous pouvez vous connecter avec un nom d'utilisateur et un mot de passe. Il se peut que vous deviez prendre des mesures pour activer le flux d'octroi ROPC pour votre fournisseur d'identité.
Une fois le fournisseur d'identité OIDC configuré dans OpenShift Container Platform, vous pouvez vous connecter à l'aide de la commande suivante, qui vous demande votre nom d'utilisateur et votre mot de passe :
$ oc login -u <identity_provider_username> --server=<api_server_url_and_port>Confirmez que l'utilisateur s'est connecté avec succès et affichez le nom de l'utilisateur.
$ oc whoami
7.9.8. Configuration des fournisseurs d'identité à l'aide de la console web
Configurez votre fournisseur d'identité (IDP) via la console web au lieu de l'interface CLI.
Conditions préalables
- Vous devez être connecté à la console web en tant qu'administrateur de cluster.
Procédure
- Naviguez jusqu'à Administration → Cluster Settings.
- Sous l'onglet Configuration, cliquez sur OAuth.
- Dans la section Identity Providers, sélectionnez votre fournisseur d'identité dans le menu déroulant Add.
Vous pouvez spécifier plusieurs IDP via la console web sans écraser les IDP existants.
Chapitre 8. Utilisation de RBAC pour définir et appliquer des autorisations
8.1. Vue d'ensemble de RBAC
Les objets de contrôle d'accès basé sur les rôles (RBAC) déterminent si un utilisateur est autorisé à effectuer une action donnée au sein d'un projet.
Les administrateurs de cluster peuvent utiliser les rôles de cluster et les bindings pour contrôler qui a différents niveaux d'accès à la plateforme OpenShift Container Platform elle-même et à tous les projets.
Les développeurs peuvent utiliser des rôles et des liens locaux pour contrôler qui a accès à leurs projets. Notez que l'autorisation est une étape distincte de l'authentification, qui consiste plutôt à déterminer l'identité de la personne qui effectue l'action.
L'autorisation est gérée à l'aide de :
| Objet d'autorisation | Description |
|---|---|
| Règles |
Ensemble de verbes autorisés sur un ensemble d'objets. Par exemple, si un compte d'utilisateur ou de service peut |
| Rôles | Collections de règles. Vous pouvez associer, ou lier, des utilisateurs et des groupes à plusieurs rôles. |
| Fixations | Associations entre des utilisateurs et/ou des groupes ayant un rôle. |
Il existe deux niveaux de rôles et de liaisons RBAC qui contrôlent l'autorisation :
| Niveau RBAC | Description |
|---|---|
| Cluster RBAC | Rôles et liaisons applicables à tous les projets. Cluster roles existe à l'échelle du cluster, et cluster role bindings ne peut faire référence qu'à des rôles du cluster. |
| RBAC local | Rôles et liaisons qui sont liés à un projet donné. Alors que local roles n'existe que dans un seul projet, les liaisons de rôles locaux peuvent faire référence à both et aux rôles locaux. |
Un lien de rôle de cluster est un lien qui existe au niveau du cluster. Un lien de rôle existe au niveau du projet. Le rôle de cluster view doit être lié à un utilisateur à l'aide d'une liaison de rôle locale pour que cet utilisateur puisse consulter le projet. Ne créez des rôles locaux que si un rôle de cluster ne fournit pas l'ensemble des autorisations nécessaires dans une situation particulière.
Cette hiérarchie à deux niveaux permet la réutilisation dans plusieurs projets grâce aux rôles de groupe, tout en permettant la personnalisation au sein des projets individuels grâce aux rôles locaux.
Lors de l'évaluation, on utilise à la fois les liaisons de rôles de la grappe et les liaisons de rôles locales. Par exemple :
- Les règles d'autorisation à l'échelle du groupe sont vérifiées.
- Les règles locales d'autorisation sont vérifiées.
- Refusé par défaut.
8.1.1. Rôles par défaut des clusters
OpenShift Container Platform inclut un ensemble de rôles de cluster par défaut que vous pouvez lier à des utilisateurs et des groupes à l'échelle du cluster ou localement.
Il n'est pas recommandé de modifier manuellement les rôles par défaut des clusters. La modification de ces rôles système peut empêcher le bon fonctionnement d'un cluster.
| Rôle de la grappe par défaut | Description |
|---|---|
|
|
Un chef de projet. S'il est utilisé dans un lien local, un |
|
| Un utilisateur qui peut obtenir des informations de base sur les projets et les utilisateurs. |
|
| Un super-utilisateur qui peut effectuer n'importe quelle action dans n'importe quel projet. Lorsqu'il est lié à un utilisateur avec un lien local, il a le contrôle total des quotas et de toutes les actions sur toutes les ressources du projet. |
|
| Un utilisateur qui peut obtenir des informations de base sur l'état de la grappe. |
|
| Un utilisateur qui peut obtenir ou visualiser la plupart des objets mais ne peut pas les modifier. |
|
| Un utilisateur qui peut modifier la plupart des objets d'un projet mais qui n'a pas le pouvoir de visualiser ou de modifier les rôles ou les liaisons. |
|
| Un utilisateur qui peut créer ses propres projets. |
|
| Un utilisateur qui ne peut effectuer aucune modification, mais qui peut voir la plupart des objets d'un projet. Il ne peut pas voir ou modifier les rôles ou les liaisons. |
Soyez attentif à la différence entre les liaisons locales et les liaisons de grappe. Par exemple, si vous liez le rôle cluster-admin à un utilisateur à l'aide d'une liaison de rôle locale, il peut sembler que cet utilisateur dispose des privilèges d'un administrateur de cluster. Ce n'est pas le cas. La liaison du rôle cluster-admin à un utilisateur dans un projet accorde à l'utilisateur des privilèges de super administrateur pour ce projet uniquement. Cet utilisateur dispose des autorisations du rôle de cluster admin, ainsi que de quelques autorisations supplémentaires, comme la possibilité de modifier les limites de taux, pour ce projet. Cette liaison peut être déroutante via l'interface utilisateur de la console Web, qui ne répertorie pas les liaisons de rôles de cluster qui sont liées à de véritables administrateurs de cluster. Cependant, elle répertorie les liaisons de rôles locaux que vous pouvez utiliser pour lier localement cluster-admin.
Les relations entre les rôles de grappe, les rôles locaux, les liaisons de rôles de grappe, les liaisons de rôles locaux, les utilisateurs, les groupes et les comptes de service sont illustrées ci-dessous.
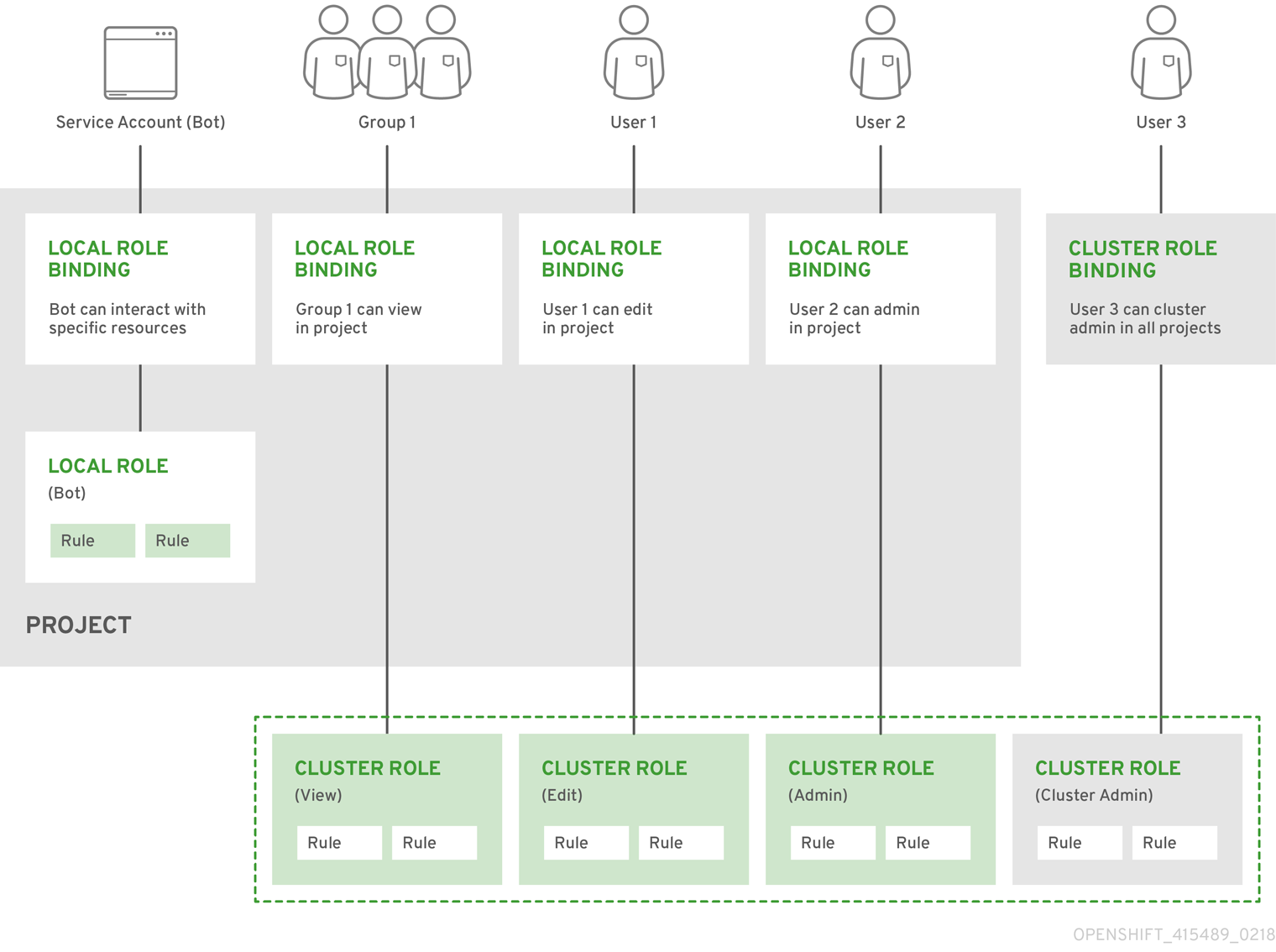
Les règles get pods/exec, get pods/* et get * accordent des privilèges d'exécution lorsqu'elles sont appliquées à un rôle. Appliquez le principe du moindre privilège et n'attribuez que les droits RBAC minimaux requis pour les utilisateurs et les agents. Pour plus d'informations, voir Règles RBAC autorisant les privilèges d'exécution.
8.1.2. Évaluation de l'autorisation
OpenShift Container Platform évalue l'autorisation en utilisant :
- Identité
- Le nom de l'utilisateur et la liste des groupes auxquels il appartient.
- Action
L'action que vous effectuez. Dans la plupart des cas, il s'agit de
- Project: Le projet auquel vous accédez. Un projet est un espace de noms Kubernetes avec des annotations supplémentaires qui permet à une communauté d'utilisateurs d'organiser et de gérer leur contenu de manière isolée par rapport à d'autres communautés.
-
Verb: L'action elle-même :
get,list,create,update,delete,deletecollection, ouwatch. - Resource name: Le point de terminaison de l'API auquel vous accédez.
- Fixations
- La liste complète des liens, les associations entre les utilisateurs ou les groupes avec un rôle.
OpenShift Container Platform évalue l'autorisation en utilisant les étapes suivantes :
- L'identité et l'action à l'échelle du projet sont utilisées pour trouver toutes les liaisons qui s'appliquent à l'utilisateur ou à ses groupes.
- Les liaisons sont utilisées pour localiser tous les rôles qui s'appliquent.
- Les rôles sont utilisés pour trouver toutes les règles qui s'appliquent.
- L'action est comparée à chaque règle pour trouver une correspondance.
- Si aucune règle correspondante n'est trouvée, l'action est alors refusée par défaut.
N'oubliez pas que les utilisateurs et les groupes peuvent être associés ou liés à plusieurs rôles à la fois.
Les administrateurs de projet peuvent utiliser l'interface de programmation pour visualiser les rôles locaux et les liaisons, y compris une matrice des verbes et des ressources associés à chacun d'entre eux.
Le rôle de cluster lié à l'administrateur de projet est limité dans un projet par un lien local. Il n'est pas lié à l'ensemble du cluster comme les rôles de cluster accordés à cluster-admin ou system:admin.
Les rôles de cluster sont des rôles définis au niveau du cluster, mais qui peuvent être liés soit au niveau du cluster, soit au niveau du projet.
8.1.2.1. Agrégation des rôles des clusters
Les rôles de cluster par défaut admin, edit, view et cluster-reader prennent en charge l'agrégation des rôles de cluster, où les règles de cluster pour chaque rôle sont mises à jour dynamiquement au fur et à mesure que de nouvelles règles sont créées. Cette fonctionnalité n'est pertinente que si vous étendez l'API Kubernetes en créant des ressources personnalisées.
8.2. Projets et espaces de noms
Un espace de noms Kubernetes namespace fournit un mécanisme permettant de délimiter les ressources dans un cluster. La documentation de Kubernetes contient plus d'informations sur les espaces de noms.
Les espaces de noms fournissent un champ d'application unique pour les :
- Ressources nommées pour éviter les collisions de noms de base.
- Délégation de l'autorité de gestion à des utilisateurs de confiance.
- La possibilité de limiter la consommation des ressources communautaires.
La plupart des objets du système sont délimités par l'espace de noms, mais certains sont exclus et n'ont pas d'espace de noms, notamment les nœuds et les utilisateurs.
Un project est un espace de noms Kubernetes avec des annotations supplémentaires et est le véhicule central par lequel l'accès aux ressources pour les utilisateurs réguliers est géré. Un projet permet à une communauté d'utilisateurs d'organiser et de gérer son contenu indépendamment des autres communautés. Les utilisateurs doivent se voir accorder l'accès aux projets par les administrateurs ou, s'ils sont autorisés à créer des projets, ont automatiquement accès à leurs propres projets.
Les projets peuvent avoir des name, displayName et description distincts.
-
Le nom obligatoire
nameest un identifiant unique pour le projet et est le plus visible lors de l'utilisation des outils CLI ou de l'API. La longueur maximale du nom est de 63 caractères. -
L'option
displayNameindique comment le projet est affiché dans la console web (la valeur par défaut estname). -
Le site optionnel
descriptionpeut être une description plus détaillée du projet et est également visible dans la console web.
Chaque projet a son propre ensemble d'objectifs :
| Objet | Description |
|---|---|
|
| Pods, services, contrôleurs de réplication, etc. |
|
| Règles selon lesquelles les utilisateurs peuvent ou ne peuvent pas effectuer des actions sur les objets. |
|
| Quotas pour chaque type d'objet pouvant être limité. |
|
| Les comptes de service agissent automatiquement avec un accès désigné aux objets du projet. |
Les administrateurs de clusters peuvent créer des projets et déléguer les droits d'administration du projet à n'importe quel membre de la communauté des utilisateurs. Les administrateurs de clusters peuvent également autoriser les développeurs à créer leurs propres projets.
Les développeurs et les administrateurs peuvent interagir avec les projets en utilisant le CLI ou la console web.
8.3. Projets par défaut
OpenShift Container Platform est livré avec un certain nombre de projets par défaut, et les projets commençant par openshift- sont les plus essentiels pour les utilisateurs. Ces projets hébergent des composants maîtres qui s'exécutent sous forme de pods et d'autres composants d'infrastructure. Les pods créés dans ces espaces de noms qui ont une annotation de pod critique sont considérés comme critiques, et leur admission est garantie par kubelet. Les pods créés pour les composants maîtres dans ces espaces de noms sont déjà marqués comme critiques.
Vous ne pouvez pas attribuer de SCC aux pods créés dans l'un des espaces de noms par défaut : default kube-system , kube-public, openshift-node, openshift-infra et openshift. Vous ne pouvez pas utiliser ces espaces de noms pour exécuter des pods ou des services.
8.4. Visualisation des rôles et des liaisons des clusters
Vous pouvez utiliser l'interface CLI de oc pour visualiser les rôles et les liaisons des clusters à l'aide de la commande oc describe.
Conditions préalables
-
Installez le CLI
oc. - Obtenir l'autorisation de visualiser les rôles et les liaisons du cluster.
Les utilisateurs ayant le rôle de cluster par défaut cluster-admin lié à l'ensemble du cluster peuvent effectuer n'importe quelle action sur n'importe quelle ressource, y compris la visualisation des rôles de cluster et des liaisons.
Procédure
Pour afficher les rôles de la grappe et les ensembles de règles qui leur sont associés :
$ oc describe clusterrole.rbacExemple de sortie
Name: admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- .packages.apps.redhat.com [] [] [* create update patch delete get list watch] imagestreams [] [] [create delete deletecollection get list patch update watch create get list watch] imagestreams.image.openshift.io [] [] [create delete deletecollection get list patch update watch create get list watch] secrets [] [] [create delete deletecollection get list patch update watch get list watch create delete deletecollection patch update] buildconfigs/webhooks [] [] [create delete deletecollection get list patch update watch get list watch] buildconfigs [] [] [create delete deletecollection get list patch update watch get list watch] buildlogs [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs/scale [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamimages [] [] [create delete deletecollection get list patch update watch get list watch] imagestreammappings [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamtags [] [] [create delete deletecollection get list patch update watch get list watch] processedtemplates [] [] [create delete deletecollection get list patch update watch get list watch] routes [] [] [create delete deletecollection get list patch update watch get list watch] templateconfigs [] [] [create delete deletecollection get list patch update watch get list watch] templateinstances [] [] [create delete deletecollection get list patch update watch get list watch] templates [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs.apps.openshift.io/scale [] [] [create delete deletecollection get list patch update watch get list watch] deploymentconfigs.apps.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] buildconfigs.build.openshift.io/webhooks [] [] [create delete deletecollection get list patch update watch get list watch] buildconfigs.build.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] buildlogs.build.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamimages.image.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] imagestreammappings.image.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] imagestreamtags.image.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] routes.route.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] processedtemplates.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] templateconfigs.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] templateinstances.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] templates.template.openshift.io [] [] [create delete deletecollection get list patch update watch get list watch] serviceaccounts [] [] [create delete deletecollection get list patch update watch impersonate create delete deletecollection patch update get list watch] imagestreams/secrets [] [] [create delete deletecollection get list patch update watch] rolebindings [] [] [create delete deletecollection get list patch update watch] roles [] [] [create delete deletecollection get list patch update watch] rolebindings.authorization.openshift.io [] [] [create delete deletecollection get list patch update watch] roles.authorization.openshift.io [] [] [create delete deletecollection get list patch update watch] imagestreams.image.openshift.io/secrets [] [] [create delete deletecollection get list patch update watch] rolebindings.rbac.authorization.k8s.io [] [] [create delete deletecollection get list patch update watch] roles.rbac.authorization.k8s.io [] [] [create delete deletecollection get list patch update watch] networkpolicies.extensions [] [] [create delete deletecollection patch update create delete deletecollection get list patch update watch get list watch] networkpolicies.networking.k8s.io [] [] [create delete deletecollection patch update create delete deletecollection get list patch update watch get list watch] configmaps [] [] [create delete deletecollection patch update get list watch] endpoints [] [] [create delete deletecollection patch update get list watch] persistentvolumeclaims [] [] [create delete deletecollection patch update get list watch] pods [] [] [create delete deletecollection patch update get list watch] replicationcontrollers/scale [] [] [create delete deletecollection patch update get list watch] replicationcontrollers [] [] [create delete deletecollection patch update get list watch] services [] [] [create delete deletecollection patch update get list watch] daemonsets.apps [] [] [create delete deletecollection patch update get list watch] deployments.apps/scale [] [] [create delete deletecollection patch update get list watch] deployments.apps [] [] [create delete deletecollection patch update get list watch] replicasets.apps/scale [] [] [create delete deletecollection patch update get list watch] replicasets.apps [] [] [create delete deletecollection patch update get list watch] statefulsets.apps/scale [] [] [create delete deletecollection patch update get list watch] statefulsets.apps [] [] [create delete deletecollection patch update get list watch] horizontalpodautoscalers.autoscaling [] [] [create delete deletecollection patch update get list watch] cronjobs.batch [] [] [create delete deletecollection patch update get list watch] jobs.batch [] [] [create delete deletecollection patch update get list watch] daemonsets.extensions [] [] [create delete deletecollection patch update get list watch] deployments.extensions/scale [] [] [create delete deletecollection patch update get list watch] deployments.extensions [] [] [create delete deletecollection patch update get list watch] ingresses.extensions [] [] [create delete deletecollection patch update get list watch] replicasets.extensions/scale [] [] [create delete deletecollection patch update get list watch] replicasets.extensions [] [] [create delete deletecollection patch update get list watch] replicationcontrollers.extensions/scale [] [] [create delete deletecollection patch update get list watch] poddisruptionbudgets.policy [] [] [create delete deletecollection patch update get list watch] deployments.apps/rollback [] [] [create delete deletecollection patch update] deployments.extensions/rollback [] [] [create delete deletecollection patch update] catalogsources.operators.coreos.com [] [] [create update patch delete get list watch] clusterserviceversions.operators.coreos.com [] [] [create update patch delete get list watch] installplans.operators.coreos.com [] [] [create update patch delete get list watch] packagemanifests.operators.coreos.com [] [] [create update patch delete get list watch] subscriptions.operators.coreos.com [] [] [create update patch delete get list watch] buildconfigs/instantiate [] [] [create] buildconfigs/instantiatebinary [] [] [create] builds/clone [] [] [create] deploymentconfigrollbacks [] [] [create] deploymentconfigs/instantiate [] [] [create] deploymentconfigs/rollback [] [] [create] imagestreamimports [] [] [create] localresourceaccessreviews [] [] [create] localsubjectaccessreviews [] [] [create] podsecuritypolicyreviews [] [] [create] podsecuritypolicyselfsubjectreviews [] [] [create] podsecuritypolicysubjectreviews [] [] [create] resourceaccessreviews [] [] [create] routes/custom-host [] [] [create] subjectaccessreviews [] [] [create] subjectrulesreviews [] [] [create] deploymentconfigrollbacks.apps.openshift.io [] [] [create] deploymentconfigs.apps.openshift.io/instantiate [] [] [create] deploymentconfigs.apps.openshift.io/rollback [] [] [create] localsubjectaccessreviews.authorization.k8s.io [] [] [create] localresourceaccessreviews.authorization.openshift.io [] [] [create] localsubjectaccessreviews.authorization.openshift.io [] [] [create] resourceaccessreviews.authorization.openshift.io [] [] [create] subjectaccessreviews.authorization.openshift.io [] [] [create] subjectrulesreviews.authorization.openshift.io [] [] [create] buildconfigs.build.openshift.io/instantiate [] [] [create] buildconfigs.build.openshift.io/instantiatebinary [] [] [create] builds.build.openshift.io/clone [] [] [create] imagestreamimports.image.openshift.io [] [] [create] routes.route.openshift.io/custom-host [] [] [create] podsecuritypolicyreviews.security.openshift.io [] [] [create] podsecuritypolicyselfsubjectreviews.security.openshift.io [] [] [create] podsecuritypolicysubjectreviews.security.openshift.io [] [] [create] jenkins.build.openshift.io [] [] [edit view view admin edit view] builds [] [] [get create delete deletecollection get list patch update watch get list watch] builds.build.openshift.io [] [] [get create delete deletecollection get list patch update watch get list watch] projects [] [] [get delete get delete get patch update] projects.project.openshift.io [] [] [get delete get delete get patch update] namespaces [] [] [get get list watch] pods/attach [] [] [get list watch create delete deletecollection patch update] pods/exec [] [] [get list watch create delete deletecollection patch update] pods/portforward [] [] [get list watch create delete deletecollection patch update] pods/proxy [] [] [get list watch create delete deletecollection patch update] services/proxy [] [] [get list watch create delete deletecollection patch update] routes/status [] [] [get list watch update] routes.route.openshift.io/status [] [] [get list watch update] appliedclusterresourcequotas [] [] [get list watch] bindings [] [] [get list watch] builds/log [] [] [get list watch] deploymentconfigs/log [] [] [get list watch] deploymentconfigs/status [] [] [get list watch] events [] [] [get list watch] imagestreams/status [] [] [get list watch] limitranges [] [] [get list watch] namespaces/status [] [] [get list watch] pods/log [] [] [get list watch] pods/status [] [] [get list watch] replicationcontrollers/status [] [] [get list watch] resourcequotas/status [] [] [get list watch] resourcequotas [] [] [get list watch] resourcequotausages [] [] [get list watch] rolebindingrestrictions [] [] [get list watch] deploymentconfigs.apps.openshift.io/log [] [] [get list watch] deploymentconfigs.apps.openshift.io/status [] [] [get list watch] controllerrevisions.apps [] [] [get list watch] rolebindingrestrictions.authorization.openshift.io [] [] [get list watch] builds.build.openshift.io/log [] [] [get list watch] imagestreams.image.openshift.io/status [] [] [get list watch] appliedclusterresourcequotas.quota.openshift.io [] [] [get list watch] imagestreams/layers [] [] [get update get] imagestreams.image.openshift.io/layers [] [] [get update get] builds/details [] [] [update] builds.build.openshift.io/details [] [] [update] Name: basic-user Labels: <none> Annotations: openshift.io/description: A user that can get basic information about projects. rbac.authorization.kubernetes.io/autoupdate: true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- selfsubjectrulesreviews [] [] [create] selfsubjectaccessreviews.authorization.k8s.io [] [] [create] selfsubjectrulesreviews.authorization.openshift.io [] [] [create] clusterroles.rbac.authorization.k8s.io [] [] [get list watch] clusterroles [] [] [get list] clusterroles.authorization.openshift.io [] [] [get list] storageclasses.storage.k8s.io [] [] [get list] users [] [~] [get] users.user.openshift.io [] [~] [get] projects [] [] [list watch] projects.project.openshift.io [] [] [list watch] projectrequests [] [] [list] projectrequests.project.openshift.io [] [] [list] Name: cluster-admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- *.* [] [] [*] [*] [] [*] ...Pour afficher l'ensemble actuel des liaisons de rôles de cluster, qui montre les utilisateurs et les groupes liés à divers rôles :
$ oc describe clusterrolebinding.rbacExemple de sortie
Name: alertmanager-main Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: alertmanager-main Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount alertmanager-main openshift-monitoring Name: basic-users Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: basic-user Subjects: Kind Name Namespace ---- ---- --------- Group system:authenticated Name: cloud-credential-operator-rolebinding Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: cloud-credential-operator-role Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount default openshift-cloud-credential-operator Name: cluster-admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: cluster-admin Subjects: Kind Name Namespace ---- ---- --------- Group system:masters Name: cluster-admins Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: cluster-admin Subjects: Kind Name Namespace ---- ---- --------- Group system:cluster-admins User system:admin Name: cluster-api-manager-rolebinding Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: cluster-api-manager-role Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount default openshift-machine-api ...
8.5. Visualisation des rôles et des liens locaux
Vous pouvez utiliser l'interface de gestion de oc pour afficher les rôles et les liens locaux à l'aide de la commande oc describe.
Conditions préalables
-
Installez le CLI
oc. Obtenir l'autorisation de visualiser les rôles et les liens locaux :
-
Les utilisateurs ayant le rôle de cluster par défaut
cluster-admin, lié à l'ensemble du cluster, peuvent effectuer n'importe quelle action sur n'importe quelle ressource, y compris la visualisation des rôles locaux et des liaisons. -
Les utilisateurs ayant le rôle de cluster par défaut
adminlié localement peuvent voir et gérer les rôles et les liaisons dans ce projet.
-
Les utilisateurs ayant le rôle de cluster par défaut
Procédure
Pour afficher l'ensemble actuel des liaisons de rôle locales, qui montrent les utilisateurs et les groupes liés à divers rôles pour le projet en cours :
$ oc describe rolebinding.rbacPour afficher les rôles locaux d'un autre projet, ajoutez le drapeau
-nà la commande :$ oc describe rolebinding.rbac -n joe-projectExemple de sortie
Name: admin Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User kube:admin Name: system:deployers Labels: <none> Annotations: openshift.io/description: Allows deploymentconfigs in this namespace to rollout pods in this namespace. It is auto-managed by a controller; remove subjects to disa... Role: Kind: ClusterRole Name: system:deployer Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount deployer joe-project Name: system:image-builders Labels: <none> Annotations: openshift.io/description: Allows builds in this namespace to push images to this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-builder Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount builder joe-project Name: system:image-pullers Labels: <none> Annotations: openshift.io/description: Allows all pods in this namespace to pull images from this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-puller Subjects: Kind Name Namespace ---- ---- --------- Group system:serviceaccounts:joe-project
8.6. Ajouter des rôles aux utilisateurs
Vous pouvez utiliser le CLI de l'administrateur oc adm pour gérer les rôles et les liaisons.
Le fait de lier ou d'ajouter un rôle à des utilisateurs ou à des groupes donne à l'utilisateur ou au groupe l'accès accordé par le rôle. Vous pouvez ajouter et supprimer des rôles à des utilisateurs et à des groupes à l'aide des commandes oc adm policy.
Vous pouvez lier n'importe lequel des rôles de cluster par défaut à des utilisateurs ou groupes locaux dans votre projet.
Procédure
Ajouter un rôle à un utilisateur dans un projet spécifique :
$ oc adm policy add-role-to-user <role> <user> -n <project>Par exemple, vous pouvez ajouter le rôle
adminà l'utilisateuralicedans le projetjoeen exécutant :$ oc adm policy add-role-to-user admin alice -n joeAstuceVous pouvez également appliquer le code YAML suivant pour ajouter le rôle à l'utilisateur :
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: admin-0 namespace: joe roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: admin subjects: - apiGroup: rbac.authorization.k8s.io kind: User name: aliceAffichez les liaisons de rôle locales et vérifiez l'ajout dans la sortie :
$ oc describe rolebinding.rbac -n <projet>Par exemple, pour afficher les attributions de rôles locaux pour le projet
joe:$ oc describe rolebinding.rbac -n joeExemple de sortie
Name: admin Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User kube:admin Name: admin-0 Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User alice1 Name: system:deployers Labels: <none> Annotations: openshift.io/description: Allows deploymentconfigs in this namespace to rollout pods in this namespace. It is auto-managed by a controller; remove subjects to disa... Role: Kind: ClusterRole Name: system:deployer Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount deployer joe Name: system:image-builders Labels: <none> Annotations: openshift.io/description: Allows builds in this namespace to push images to this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-builder Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount builder joe Name: system:image-pullers Labels: <none> Annotations: openshift.io/description: Allows all pods in this namespace to pull images from this namespace. It is auto-managed by a controller; remove subjects to disable. Role: Kind: ClusterRole Name: system:image-puller Subjects: Kind Name Namespace ---- ---- --------- Group system:serviceaccounts:joe- 1
- L'utilisateur
alicea été ajouté à l'utilisateuradminsRoleBinding.
8.7. Création d'un rôle local
Vous pouvez créer un rôle local pour un projet et le lier à un utilisateur.
Procédure
Pour créer un rôle local pour un projet, exécutez la commande suivante :
$ oc create role <name> --verb=<verb> --resource=<resource> -n <project>Dans cette commande, spécifiez :
-
<name>le nom du rôle local -
<verb>une liste de verbes à appliquer au rôle, séparés par des virgules -
<resource>les ressources auxquelles le rôle s'applique -
<project>, le nom du projet
Par exemple, pour créer un rôle local permettant à un utilisateur de visualiser les pods du projet
blue, exécutez la commande suivante :$ oc create role podview --verb=get --resource=pod -n blue-
Pour lier le nouveau rôle à un utilisateur, exécutez la commande suivante :
$ oc adm policy add-role-to-user podview user2 --role-namespace=blue -n blue
8.8. Création d'un rôle de cluster
Vous pouvez créer un rôle de cluster.
Procédure
Pour créer un rôle de cluster, exécutez la commande suivante :
oc create clusterrole <name> --verb=<verb> --resource=<resource> $ oc create clustersrole <name> --verb=<verb>Dans cette commande, spécifiez :
-
<name>le nom du rôle local -
<verb>une liste de verbes à appliquer au rôle, séparés par des virgules -
<resource>les ressources auxquelles le rôle s'applique
Par exemple, pour créer un rôle de cluster permettant à un utilisateur de visualiser les pods, exécutez la commande suivante :
$ oc create clusterrole podviewonly --verb=get --resource=pod-
8.9. Commandes de liaison des rôles locaux
Lorsque vous gérez les rôles associés à un utilisateur ou à un groupe pour les liaisons de rôles locales à l'aide des opérations suivantes, un projet peut être spécifié à l'aide de l'indicateur -n. S'il n'est pas spécifié, c'est le projet actuel qui est utilisé.
Vous pouvez utiliser les commandes suivantes pour la gestion locale de RBAC.
| Commandement | Description |
|---|---|
|
| Indique quels utilisateurs peuvent effectuer une action sur une ressource. |
|
| Associe un rôle spécifique à des utilisateurs spécifiques dans le projet en cours. |
|
| Supprime un rôle donné aux utilisateurs spécifiés dans le projet en cours. |
|
| Supprime les utilisateurs spécifiés et tous leurs rôles dans le projet en cours. |
|
| Relie un rôle donné aux groupes spécifiés dans le projet en cours. |
|
| Supprime un rôle donné des groupes spécifiés dans le projet en cours. |
|
| Supprime les groupes spécifiés et tous leurs rôles dans le projet en cours. |
8.10. Commandes de liaison des rôles de cluster
Vous pouvez également gérer les liaisons de rôles de cluster à l'aide des opérations suivantes. L'indicateur -n n'est pas utilisé pour ces opérations car les liaisons de rôles de cluster utilisent des ressources non espacées.
| Commandement | Description |
|---|---|
|
| Lie un rôle donné aux utilisateurs spécifiés pour tous les projets du cluster. |
|
| Supprime un rôle donné aux utilisateurs spécifiés pour tous les projets du cluster. |
|
| Lie un rôle donné aux groupes spécifiés pour tous les projets du cluster. |
|
| Supprime un rôle donné des groupes spécifiés pour tous les projets du cluster. |
8.11. Création d'un administrateur de cluster
Le rôle cluster-admin est nécessaire pour effectuer des tâches de niveau administrateur sur le cluster OpenShift Container Platform, telles que la modification des ressources du cluster.
Conditions préalables
- Vous devez avoir créé un utilisateur à définir comme administrateur du cluster.
Procédure
Définir l'utilisateur comme administrateur de cluster :
$ oc adm policy add-cluster-role-to-user cluster-admin <user>
Chapitre 9. Suppression de l'utilisateur kubeadmin
9.1. L'utilisateur kubeadmin
OpenShift Container Platform crée un administrateur de cluster, kubeadmin, une fois le processus d'installation terminé.
Cet utilisateur a le rôle cluster-admin automatiquement appliqué et est traité comme l'utilisateur racine pour le cluster. Le mot de passe est généré dynamiquement et unique à votre environnement OpenShift Container Platform. Une fois l'installation terminée, le mot de passe est fourni dans la sortie du programme d'installation. Par exemple, le mot de passe est généré dynamiquement et est unique à votre environnement OpenShift Container Platform :
INFO Install complete!
INFO Run 'export KUBECONFIG=<your working directory>/auth/kubeconfig' to manage the cluster with 'oc', the OpenShift CLI.
INFO The cluster is ready when 'oc login -u kubeadmin -p <provided>' succeeds (wait a few minutes).
INFO Access the OpenShift web-console here: https://console-openshift-console.apps.demo1.openshift4-beta-abcorp.com
INFO Login to the console with user: kubeadmin, password: <provided>9.2. Suppression de l'utilisateur kubeadmin
Après avoir défini un fournisseur d'identité et créé un nouvel utilisateur cluster-admin, vous pouvez supprimer le site kubeadmin pour améliorer la sécurité du cluster.
Si vous suivez cette procédure avant qu'un autre utilisateur ne soit cluster-admin, OpenShift Container Platform doit être réinstallé. Il n'est pas possible d'annuler cette commande.
Conditions préalables
- Vous devez avoir configuré au moins un fournisseur d'identité.
-
Vous devez avoir ajouté le rôle
cluster-adminà un utilisateur. - Vous devez être connecté en tant qu'administrateur.
Procédure
Supprimez les secrets de
kubeadmin:$ oc delete secrets kubeadmin -n kube-system
Chapitre 10. Comprendre et créer des comptes de service
10.1. Vue d'ensemble des comptes de service
Un compte de service est un compte OpenShift Container Platform qui permet à un composant d'accéder directement à l'API. Les comptes de service sont des objets API qui existent dans chaque projet. Les comptes de service offrent un moyen flexible de contrôler l'accès à l'API sans partager les informations d'identification d'un utilisateur normal.
Lorsque vous utilisez le CLI ou la console web de OpenShift Container Platform, votre jeton API vous authentifie auprès de l'API. Vous pouvez associer un composant à un compte de service afin qu'il puisse accéder à l'API sans utiliser les informations d'identification d'un utilisateur normal. Par exemple, les comptes de service peuvent permettre :
- Contrôleurs de réplication pour effectuer des appels API afin de créer ou de supprimer des pods.
- Applications à l'intérieur des conteneurs pour effectuer des appels d'API à des fins de découverte.
- Des applications externes pour effectuer des appels d'API à des fins de surveillance ou d'intégration.
Le nom d'utilisateur de chaque compte de service est dérivé de son projet et de son nom :
system:serviceaccount:<project>:<name>Chaque compte de service est également membre de deux groupes :
| Groupe | Description |
|---|---|
| système:comptes de service | Comprend tous les comptes de service du système. |
| system:serviceaccounts:<project> | Inclut tous les comptes de service du projet spécifié. |
Chaque compte de service contient automatiquement deux secrets :
- Un jeton API
- Informations d'identification pour le registre de conteneurs OpenShift
Le jeton API et les informations d'identification du registre générés n'expirent pas, mais vous pouvez les révoquer en supprimant le secret. Lorsque vous supprimez le secret, un nouveau est automatiquement généré pour le remplacer.
10.2. Création de comptes de service
Vous pouvez créer un compte de service dans un projet et lui accorder des autorisations en le liant à un rôle.
Procédure
Optionnel : Pour afficher les comptes de service du projet en cours :
$ oc get saExemple de sortie
NAME SECRETS AGE builder 2 2d default 2 2d deployer 2 2dPour créer un nouveau compte de service dans le projet en cours :
oc create sa <service_account_name> $ oc create sa <service_account_name>1 - 1
- Pour créer un compte de service dans un autre projet, spécifiez
-n <project_name>.
Exemple de sortie
serviceaccount "robot" createdAstuceVous pouvez également appliquer le code YAML suivant pour créer le compte de service :
apiVersion: v1 kind: ServiceAccount metadata: name: <service_account_name> namespace: <current_project>Facultatif : Affichez les secrets du compte de service :
$ oc describe sa robotExemple de sortie
Name: robot Namespace: project1 Labels: <none> Annotations: <none> Image pull secrets: robot-dockercfg-qzbhb Mountable secrets: robot-dockercfg-qzbhb Tokens: robot-token-f4khf Events: <none>
10.3. Exemples d'attribution de rôles aux comptes de service
Vous pouvez attribuer des rôles aux comptes de service de la même manière que vous attribuez des rôles à un compte d'utilisateur normal.
Vous pouvez modifier les comptes de service du projet en cours. Par exemple, pour ajouter le rôle
viewau compte de servicerobotdans le projettop-secret:$ oc policy add-role-to-user view system:serviceaccount:top-secret:robotAstuceVous pouvez également appliquer le code YAML suivant pour ajouter le rôle :
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: view namespace: top-secret roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: view subjects: - kind: ServiceAccount name: robot namespace: top-secretVous pouvez également accorder l'accès à un compte de service spécifique dans un projet. Par exemple, à partir du projet auquel le compte de service appartient, utilisez l'indicateur
-zet spécifiez l'option<service_account_name>$ oc policy add-role-to-user <role_name> -z <service_account_name>ImportantSi vous souhaitez accorder l'accès à un compte de service spécifique dans un projet, utilisez l'option
-z. L'utilisation de cet indicateur permet d'éviter les fautes de frappe et garantit que l'accès n'est accordé qu'au compte de service spécifié.AstuceVous pouvez également appliquer le code YAML suivant pour ajouter le rôle :
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: <rolebinding_name> namespace: <current_project_name> roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: <role_name> subjects: - kind: ServiceAccount name: <service_account_name> namespace: <current_project_name>Pour modifier un autre espace de noms, vous pouvez utiliser l'option
-npour indiquer l'espace de noms du projet auquel elle s'applique, comme le montrent les exemples suivants.Par exemple, pour permettre à tous les comptes de service de tous les projets de visualiser les ressources du projet
my-project:$ oc policy add-role-to-group view system:serviceaccounts -n my-projectAstuceVous pouvez également appliquer le code YAML suivant pour ajouter le rôle :
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: view namespace: my-project roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: view subjects: - apiGroup: rbac.authorization.k8s.io kind: Group name: system:serviceaccountsPour permettre à tous les comptes de service du projet
managersde modifier les ressources du projetmy-project:$ oc policy add-role-to-group edit system:serviceaccounts:managers -n my-projectAstuceVous pouvez également appliquer le code YAML suivant pour ajouter le rôle :
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: edit namespace: my-project roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: edit subjects: - apiGroup: rbac.authorization.k8s.io kind: Group name: system:serviceaccounts:managers
Chapitre 11. Utilisation des comptes de service dans les applications
11.1. Vue d'ensemble des comptes de service
Un compte de service est un compte OpenShift Container Platform qui permet à un composant d'accéder directement à l'API. Les comptes de service sont des objets API qui existent dans chaque projet. Les comptes de service offrent un moyen flexible de contrôler l'accès à l'API sans partager les informations d'identification d'un utilisateur normal.
Lorsque vous utilisez le CLI ou la console web de OpenShift Container Platform, votre jeton API vous authentifie auprès de l'API. Vous pouvez associer un composant à un compte de service afin qu'il puisse accéder à l'API sans utiliser les informations d'identification d'un utilisateur normal. Par exemple, les comptes de service peuvent permettre :
- Contrôleurs de réplication pour effectuer des appels API afin de créer ou de supprimer des pods.
- Applications à l'intérieur des conteneurs pour effectuer des appels d'API à des fins de découverte.
- Des applications externes pour effectuer des appels d'API à des fins de surveillance ou d'intégration.
Le nom d'utilisateur de chaque compte de service est dérivé de son projet et de son nom :
system:serviceaccount:<project>:<name>Chaque compte de service est également membre de deux groupes :
| Groupe | Description |
|---|---|
| système:comptes de service | Comprend tous les comptes de service du système. |
| system:serviceaccounts:<project> | Inclut tous les comptes de service du projet spécifié. |
Chaque compte de service contient automatiquement deux secrets :
- Un jeton API
- Informations d'identification pour le registre de conteneurs OpenShift
Le jeton API et les informations d'identification du registre générés n'expirent pas, mais vous pouvez les révoquer en supprimant le secret. Lorsque vous supprimez le secret, un nouveau est automatiquement généré pour le remplacer.
11.2. Comptes de service par défaut
Votre cluster OpenShift Container Platform contient des comptes de service par défaut pour la gestion du cluster et génère d'autres comptes de service pour chaque projet.
11.2.1. Comptes de service de cluster par défaut
Plusieurs contrôleurs d'infrastructure fonctionnent en utilisant les informations d'identification des comptes de service. Les comptes de service suivants sont créés dans le projet d'infrastructure OpenShift Container Platform (openshift-infra) au démarrage du serveur et se voient attribuer les rôles suivants à l'échelle du cluster :
| Compte de service | Description |
|---|---|
|
|
Le rôle de |
|
|
Le rôle de |
|
|
Le rôle |
11.2.2. Comptes et rôles de service de projet par défaut
Trois comptes de service sont automatiquement créés dans chaque projet :
| Compte de service | Utilisation |
|---|---|
|
|
Utilisé par les pods de construction. Le rôle |
|
|
Utilisé par les pods de déploiement et doté du rôle |
|
| Utilisé pour exécuter tous les autres pods à moins qu'ils ne spécifient un compte de service différent. |
Tous les comptes de service d'un projet se voient attribuer le rôle system:image-puller, qui permet d'extraire des images de n'importe quel flux d'images du projet à l'aide du registre interne d'images de conteneurs.
11.2.3. À propos des secrets de jetons de compte de service générés automatiquement
Dans la version 4.12, OpenShift Container Platform adopte une amélioration de Kubernetes en amont, qui active la fonctionnalité LegacyServiceAccountTokenNoAutoGeneration par défaut. Par conséquent, lors de la création de nouveaux comptes de service (SA), un secret de jeton de compte de service n'est plus automatiquement généré. Auparavant, OpenShift Container Platform ajoutait automatiquement un jeton de compte de service à un secret pour chaque nouveau SA.
Cependant, certaines fonctionnalités et charges de travail ont besoin de secrets de jetons de compte de service pour communiquer avec le serveur API Kubernetes, par exemple, OpenShift Controller Manager. Cette exigence sera modifiée dans une prochaine version, mais elle demeure dans OpenShift Container Platform 4.12. Par conséquent, si vous avez besoin d'un secret de jeton de compte de service, vous devez utiliser manuellement l'API TokenRequest pour demander des jetons de compte de service liés ou créer un secret de jeton de compte de service.
Après la mise à jour vers la version 4.12, les secrets de jetons de compte de service existants ne sont pas supprimés et continuent de fonctionner comme prévu.
Dans la version 4.12, les secrets des jetons des comptes de service sont toujours générés automatiquement. Au lieu de créer deux secrets par compte de service, OpenShift Container Platform n'en crée plus qu'un. Dans une prochaine version, ce nombre sera encore réduit à zéro. Notez que les secrets dockercfg sont toujours générés et qu'aucun secret n'est supprimé lors des mises à jour.
Ressources complémentaires
- Pour plus d'informations sur la demande de jetons de compte de service lié, voir Configuration des jetons de compte de service lié à l'aide de la projection en volume
- Pour plus d'informations sur la création d'un jeton secret de compte de service, voir Création d'un jeton secret de compte de service.
11.3. Création de comptes de service
Vous pouvez créer un compte de service dans un projet et lui accorder des autorisations en le liant à un rôle.
Procédure
Optionnel : Pour afficher les comptes de service du projet en cours :
$ oc get saExemple de sortie
NAME SECRETS AGE builder 2 2d default 2 2d deployer 2 2dPour créer un nouveau compte de service dans le projet en cours :
oc create sa <service_account_name> $ oc create sa <service_account_name>1 - 1
- Pour créer un compte de service dans un autre projet, spécifiez
-n <project_name>.
Exemple de sortie
serviceaccount "robot" createdAstuceVous pouvez également appliquer le code YAML suivant pour créer le compte de service :
apiVersion: v1 kind: ServiceAccount metadata: name: <service_account_name> namespace: <current_project>Facultatif : Affichez les secrets du compte de service :
$ oc describe sa robotExemple de sortie
Name: robot Namespace: project1 Labels: <none> Annotations: <none> Image pull secrets: robot-dockercfg-qzbhb Mountable secrets: robot-dockercfg-qzbhb Tokens: robot-token-f4khf Events: <none>
Chapitre 12. Utiliser un compte de service comme client OAuth
12.1. Comptes de service en tant que clients OAuth
Vous pouvez utiliser un compte de service comme une forme limitée de client OAuth. Les comptes de service ne peuvent demander qu'un sous-ensemble de champs d'application permettant d'accéder à certaines informations de base sur l'utilisateur et à des pouvoirs basés sur le rôle à l'intérieur de l'espace de noms propre au compte de service :
-
user:info -
user:check-access -
role:<any_role>:<service_account_namespace> -
role:<any_role>:<service_account_namespace>:!
Lors de l'utilisation d'un compte de service en tant que client OAuth :
-
client_idestsystem:serviceaccount:<service_account_namespace>:<service_account_name>. client_secretpeut être n'importe quel jeton d'API pour ce compte de service. Par exemple, il peut s'agir de n'importe quel jeton d'API pour ce compte de service :oc sa get-token <service_account_name>-
Pour obtenir les défis
WWW-Authenticate, définissez une annotationserviceaccounts.openshift.io/oauth-want-challengessur le compte de service àtrue. -
redirect_uridoit correspondre à une annotation sur le compte de service.
12.1.1. Redirection des URI pour les comptes de service en tant que clients OAuth
Les clés d'annotation doivent avoir le préfixe serviceaccounts.openshift.io/oauth-redirecturi. ou serviceaccounts.openshift.io/oauth-redirectreference., comme par exemple :
serviceaccounts.openshift.io/oauth-redirecturi.<name>Dans sa forme la plus simple, l'annotation peut être utilisée pour spécifier directement des URI de redirection valides. Par exemple, l'annotation suivante peut être utilisée pour spécifier directement des URI de redirection valides :
"serviceaccounts.openshift.io/oauth-redirecturi.first": "https://example.com"
"serviceaccounts.openshift.io/oauth-redirecturi.second": "https://other.com"
Les postfixes first et second dans l'exemple ci-dessus sont utilisés pour séparer les deux URI de redirection valides.
Dans les configurations plus complexes, les URI de redirection statiques peuvent ne pas suffire. Par exemple, vous souhaitez peut-être que tous les Ingresses d'une route soient considérés comme valides. C'est là que les URI de redirection dynamique via le préfixe serviceaccounts.openshift.io/oauth-redirectreference. entrent en jeu.
Par exemple :
"serviceaccounts.openshift.io/oauth-redirectreference.first": "{\"kind\":\"OAuthRedirectReference\",\"apiVersion\":\"v1\",\"reference\":{\"kind\":\"Route\",\"name\":\"jenkins\"}}"Comme la valeur de cette annotation contient des données JSON sérialisées, elle est plus facile à voir dans un format développé :
{
"kind": "OAuthRedirectReference",
"apiVersion": "v1",
"reference": {
"kind": "Route",
"name": "jenkins"
}
}
Vous pouvez maintenant voir qu'un OAuthRedirectReference nous permet de référencer la route nommée jenkins. Ainsi, toutes les entrées pour cette route seront désormais considérées comme valides. La spécification complète d'un OAuthRedirectReference est la suivante :
{
"kind": "OAuthRedirectReference",
"apiVersion": "v1",
"reference": {
"kind": ...,
"name": ...,
"group": ...
}
}- 1
kindfait référence au type de l'objet référencé. Actuellement, seulrouteest pris en charge.- 2
namefait référence au nom de l'objet. L'objet doit se trouver dans le même espace de noms que le compte de service.- 3
groupfait référence au groupe de l'objet. Laissez ce champ vide, car le groupe d'un itinéraire est la chaîne vide.
Les deux préfixes d'annotation peuvent être combinés pour remplacer les données fournies par l'objet de référence. Par exemple :
"serviceaccounts.openshift.io/oauth-redirecturi.first": "custompath"
"serviceaccounts.openshift.io/oauth-redirectreference.first": "{\"kind\":\"OAuthRedirectReference\",\"apiVersion\":\"v1\",\"reference\":{\"kind\":\"Route\",\"name\":\"jenkins\"}}"
Le postfixe first est utilisé pour relier les annotations entre elles. En supposant que la route jenkins ait une entrée de https://example.com, https://example.com/custompath est maintenant considéré comme valide, mais https://example.com ne l'est pas. Le format pour fournir partiellement des données d'annulation est le suivant :
| Type | Syntaxe |
|---|---|
| Régime | "https://" |
| Nom d'hôte | "//website.com" |
| Port | "//:8000" |
| Chemin d'accès | \N- "examplepath\N" |
La spécification d'un remplacement de nom d'hôte remplacera les données de nom d'hôte de l'objet référencé, ce qui n'est probablement pas le comportement souhaité.
Toute combinaison de la syntaxe ci-dessus peut être combinée en utilisant le format suivant :
<scheme:>//<hostname><:port>/<path>
Le même objet peut être référencé plusieurs fois pour plus de flexibilité :
"serviceaccounts.openshift.io/oauth-redirecturi.first": "custompath"
"serviceaccounts.openshift.io/oauth-redirectreference.first": "{\"kind\":\"OAuthRedirectReference\",\"apiVersion\":\"v1\",\"reference\":{\"kind\":\"Route\",\"name\":\"jenkins\"}}"
"serviceaccounts.openshift.io/oauth-redirecturi.second": "//:8000"
"serviceaccounts.openshift.io/oauth-redirectreference.second": "{\"kind\":\"OAuthRedirectReference\",\"apiVersion\":\"v1\",\"reference\":{\"kind\":\"Route\",\"name\":\"jenkins\"}}"
En supposant que la route nommée jenkins a une entrée de https://example.com, alors les deux https://example.com:8000 et https://example.com/custompath sont considérés comme valides.
Des annotations statiques et dynamiques peuvent être utilisées en même temps pour obtenir le comportement souhaité :
"serviceaccounts.openshift.io/oauth-redirectreference.first": "{\"kind\":\"OAuthRedirectReference\",\"apiVersion\":\"v1\",\"reference\":{\"kind\":\"Route\",\"name\":\"jenkins\"}}"
"serviceaccounts.openshift.io/oauth-redirecturi.second": "https://other.com"Chapitre 13. Jetons de cadrage
13.1. À propos des jetons de cadrage
Vous pouvez créer des jetons de portée pour déléguer certaines de vos autorisations à un autre utilisateur ou compte de service. Par exemple, un administrateur de projet peut vouloir déléguer le pouvoir de créer des pods.
Un jeton à portée limitée est un jeton qui s'identifie comme un utilisateur donné mais qui est limité à certaines actions par sa portée. Seul un utilisateur ayant le rôle cluster-admin peut créer des jetons à portée limitée.
Les champs d'application sont évalués en convertissant l'ensemble des champs d'application d'un jeton en un ensemble de PolicyRules. La demande est ensuite comparée à ces règles. Les attributs de la demande doivent correspondre à au moins une des règles de portée pour être transmis à l'autorisateur "normal" pour d'autres contrôles d'autorisation.
13.1.1. Portée de l'utilisateur
Les champs d'application utilisateur visent à obtenir des informations sur un utilisateur donné. Elles sont basées sur l'intention, de sorte que les règles sont automatiquement créées pour vous :
-
user:full- Permet un accès complet en lecture/écriture à l'API avec toutes les autorisations de l'utilisateur. -
user:info- Permet d'accéder en lecture seule aux informations relatives à l'utilisateur, telles que son nom et ses groupes. -
user:check-access- Permet l'accès àself-localsubjectaccessreviewsetself-subjectaccessreviews. Il s'agit des variables pour lesquelles vous passez un utilisateur et des groupes vides dans votre objet de requête. -
user:list-projects- Permet un accès en lecture seule à la liste des projets auxquels l'utilisateur a accès.
13.1.2. Champ d'application du rôle
L'étendue du rôle vous permet d'avoir le même niveau d'accès qu'un rôle donné filtré par l'espace de noms.
role:<cluster-role name>:<namespace or * for all>- Limits the scope to the rules specified by the cluster-role, but only in the specified namespace .NoteMise en garde : cela empêche l'escalade de l'accès. Même si le rôle autorise l'accès à des ressources telles que les secrets, les attributions de rôles et les rôles, cette portée interdira l'accès à ces ressources. Cela permet d'éviter les escalades inattendues. Beaucoup de gens ne pensent pas qu'un rôle comme
editest un rôle d'escalade, mais avec l'accès à un secret, c'est le cas.-
role:<cluster-role name>:<namespace or * for all>:!- This is similar to the example above, except that including the bang causes this scope to allow escalating access.
Chapitre 14. Utilisation de jetons de compte de service liés
Vous pouvez utiliser des jetons de compte de service lié, ce qui améliore la capacité d'intégration avec les services de gestion de l'accès aux identités (IAM) des fournisseurs de services en nuage, tels que AWS IAM.
14.1. À propos des jetons de compte de service lié
Vous pouvez utiliser des jetons de compte de service liés pour limiter l'étendue des autorisations pour un jeton de compte de service donné. Ces jetons sont liés à l'audience et à la durée. Cela facilite l'authentification d'un compte de service auprès d'un rôle IAM et la génération d'informations d'identification temporaires montées sur un pod. Vous pouvez demander des jetons de compte de service liés en utilisant la projection de volume et l'API TokenRequest.
14.2. Configuration des jetons de compte de service lié à l'aide de la projection de volume
Vous pouvez configurer les modules pour qu'ils demandent des jetons de compte de service liés en utilisant la projection de volume.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé un compte de service. Cette procédure suppose que le compte de service s'appelle
build-robot.
Procédure
Optionnel : Définir l'émetteur du compte de service.
Cette étape n'est généralement pas nécessaire si les jetons liés ne sont utilisés qu'au sein du cluster.
ImportantSi vous remplacez l'émetteur du compte de service par un émetteur personnalisé, l'émetteur précédent du compte de service reste fiable pendant les 24 heures suivantes.
Vous pouvez forcer tous les détenteurs à demander un nouveau jeton lié soit en redémarrant manuellement tous les pods dans le cluster, soit en effectuant un redémarrage continu des nœuds. Avant d'effectuer l'une ou l'autre de ces actions, attendez qu'une nouvelle révision des pods du serveur API Kubernetes soit déployée avec les modifications de l'émetteur de votre compte de service.
Modifier l'objet
clusterAuthentication:$ oc edit authentications clusterRéglez le champ
spec.serviceAccountIssuersur la valeur de l'émetteur du compte de service souhaité :spec: serviceAccountIssuer: https://test.default.svc1 - 1
- Cette valeur doit être une URL à partir de laquelle le destinataire d'un jeton lié peut obtenir les clés publiques nécessaires pour vérifier la signature du jeton. La valeur par défaut est
https://kubernetes.default.svc.
- Enregistrez le fichier pour appliquer les modifications.
Attendez qu'une nouvelle révision des pods de serveur de l'API Kubernetes soit déployée. La mise à jour de tous les nœuds vers la nouvelle révision peut prendre plusieurs minutes. Exécutez la commande suivante :
$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Examinez la condition d'état
NodeInstallerProgressingpour le serveur API Kubernetes afin de vérifier que tous les nœuds sont à la dernière révision. La sortie indiqueAllNodesAtLatestRevisionlorsque la mise à jour est réussie :AllNodesAtLatestRevision 3 nodes are at revision 121 - 1
- Dans cet exemple, le dernier numéro de révision est
12.
Si la sortie affiche un message similaire à l'un des messages suivants, la mise à jour est toujours en cours. Attendez quelques minutes et réessayez.
-
3 nodes are at revision 11; 0 nodes have achieved new revision 12 -
2 nodes are at revision 11; 1 nodes are at revision 12
Facultatif : Forcer le détenteur à demander un nouveau jeton lié, soit en effectuant un redémarrage continu des nœuds, soit en redémarrant manuellement tous les pods du cluster.
Effectuer un redémarrage progressif du nœud :
AvertissementIl n'est pas recommandé d'effectuer un redémarrage progressif des nœuds si des charges de travail personnalisées sont exécutées sur votre cluster, car cela peut entraîner une interruption de service. Au lieu de cela, redémarrez manuellement tous les pods du cluster.
Redémarrer les nœuds de manière séquentielle. Attendez que le nœud soit entièrement disponible avant de redémarrer le nœud suivant. Voir Rebooting a node gracefully pour savoir comment drainer, redémarrer et marquer un nœud comme étant à nouveau planifiable.
Redémarrer manuellement tous les pods du cluster :
AvertissementSachez que l'exécution de cette commande entraîne une interruption de service, car elle supprime tous les modules en cours d'exécution dans chaque espace de noms. Ces modules redémarreront automatiquement après avoir été supprimés.
Exécutez la commande suivante :
$ for I in $(oc get ns -o jsonpath='{range .items[*]} {.metadata.name}{"\n"} {end}'); \ do oc delete pods --all -n $I; \ sleep 1; \ done
Configurer un pod pour utiliser un jeton de compte de service lié en utilisant la projection de volume.
Créez un fichier appelé
pod-projected-svc-token.yamlavec le contenu suivant :apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: - image: nginx name: nginx volumeMounts: - mountPath: /var/run/secrets/tokens name: vault-token serviceAccountName: build-robot1 volumes: - name: vault-token projected: sources: - serviceAccountToken: path: vault-token2 expirationSeconds: 72003 audience: vault4 - 1
- Une référence à un compte de service existant.
- 2
- Le chemin relatif au point de montage du fichier dans lequel le jeton doit être projeté.
- 3
- Il est possible de définir l'expiration du jeton de compte de service, en secondes. La valeur par défaut est de 3600 secondes (1 heure) et doit être d'au moins 600 secondes (10 minutes). Le kubelet commencera à essayer de faire pivoter le jeton s'il a dépassé 80 % de sa durée de vie ou s'il a dépassé 24 heures.
- 4
- Le destinataire du jeton doit vérifier que l'identité du destinataire correspond à la déclaration du jeton. Le destinataire d'un jeton doit vérifier que l'identité du destinataire correspond à l'audience déclarée du jeton, sinon il doit rejeter le jeton. Par défaut, l'audience est l'identifiant du serveur API.
Créer la capsule :
$ oc create -f pod-projected-svc-token.yamlLe kubelet demande et stocke le jeton au nom du pod, met le jeton à la disposition du pod dans un chemin d'accès configurable et rafraîchit le jeton à l'approche de son expiration.
L'application qui utilise le jeton lié doit gérer le rechargement du jeton lorsqu'il tourne.
Le kubelet fait pivoter le jeton s'il a dépassé 80 % de sa durée de vie ou s'il a plus de 24 heures.
14.3. Création de jetons de compte de service lié en dehors du pod
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez créé un compte de service. Cette procédure suppose que le compte de service s'appelle
build-robot.
Procédure
Créez le jeton de compte de service lié à l'extérieur du module en exécutant la commande suivante :
$ oc create token build-robotExemple de sortie
eyJhbGciOiJSUzI1NiIsImtpZCI6IkY2M1N4MHRvc2xFNnFSQlA4eG9GYzVPdnN3NkhIV0tRWmFrUDRNcWx4S0kifQ.eyJhdWQiOlsiaHR0cHM6Ly9pc3N1ZXIyLnRlc3QuY29tIiwiaHR0cHM6Ly9pc3N1ZXIxLnRlc3QuY29tIiwiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjIl0sImV4cCI6MTY3OTU0MzgzMCwiaWF0IjoxNjc5NTQwMjMwLCJpc3MiOiJodHRwczovL2lzc3VlcjIudGVzdC5jb20iLCJrdWJlcm5ldGVzLmlvIjp7Im5hbWVzcGFjZSI6ImRlZmF1bHQiLCJzZXJ2aWNlYWNjb3VudCI6eyJuYW1lIjoidGVzdC1zYSIsInVpZCI6ImM3ZjA4MjkwLWIzOTUtNGM4NC04NjI4LTMzMTM1NTVhNWY1OSJ9fSwibmJmIjoxNjc5NTQwMjMwLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6ZGVmYXVsdDp0ZXN0LXNhIn0.WyAOPvh1BFMUl3LNhBCrQeaB5wSynbnCfojWuNNPSilT4YvFnKibxwREwmzHpV4LO1xOFZHSi6bXBOmG_o-m0XNDYL3FrGHd65mymiFyluztxa2lgHVxjw5reIV5ZLgNSol3Y8bJqQqmNg3rtQQWRML2kpJBXdDHNww0E5XOypmffYkfkadli8lN5QQD-MhsCbiAF8waCYs8bj6V6Y7uUKTcxee8sCjiRMVtXKjQtooERKm-CH_p57wxCljIBeM89VdaR51NJGued4hVV5lxvVrYZFu89lBEAq4oyQN_d6N1vBWGXQMyoihnt_fQjn-NfnlJWk-3NSZDIluDJAv7e-MTEk3geDrHVQKNEzDei2-Un64hSzb-n1g1M0Vn0885wQBQAePC9UlZm8YZlMNk1tq6wIUKQTMv3HPfi5HtBRqVc2eVs0EfMX4-x-PHhPCasJ6qLJWyj6DvyQ08dP4DW_TWZVGvKlmId0hzwpg59TTcLR0iCklSEJgAVEEd13Aa_M0-faD11L3MhUGxw0qxgOsPczdXUsolSISbefs7OKymzFSIkTAn9sDQ8PHMOsuyxsK8vzfrR-E0z7MAeguZ2kaIY7cZqbN6WFy0caWgx46hrKem9vCKALefElRYbCg3hcBmowBcRTOqaFHLNnHghhU1LaRpoFzH7OUarqX9SGQ
Chapitre 15. Gestion des contraintes liées au contexte de sécurité
Dans OpenShift Container Platform, vous pouvez utiliser des contraintes de contexte de sécurité (SCC) pour contrôler les permissions des pods dans votre cluster.
Les SCC par défaut sont créés lors de l'installation et lorsque vous installez certains opérateurs ou d'autres composants. En tant qu'administrateur de cluster, vous pouvez également créer vos propres SCC en utilisant la CLI OpenShift (oc).
Ne modifiez pas les SCC par défaut. La personnalisation des SCC par défaut peut entraîner des problèmes lors du déploiement de certains pods de la plateforme ou lors de la mise à jour d'OpenShift Container Platform. De plus, les valeurs par défaut des SCC sont réinitialisées lors de certaines mises à niveau de clusters, ce qui annule toutes les personnalisations de ces SCC.
Au lieu de modifier les SCC par défaut, créez et modifiez vos propres SCC si nécessaire. Pour plus d'informations, voir Création de contraintes de contexte de sécurité.
15.1. A propos des contraintes du contexte de sécurité
De la même manière que les ressources RBAC contrôlent l'accès des utilisateurs, les administrateurs peuvent utiliser des contraintes de contexte de sécurité (SCC) pour contrôler les autorisations des modules. Ces autorisations déterminent les actions qu'un module peut effectuer et les ressources auxquelles il peut accéder. Vous pouvez utiliser les SCC pour définir un ensemble de conditions qu'un module doit respecter pour être accepté dans le système.
Les contraintes liées au contexte de sécurité permettent à l'administrateur de contrôler :
-
Si un pod peut exécuter des conteneurs privilégiés avec le drapeau
allowPrivilegedContainer -
Si un pod est contraint par le drapeau
allowPrivilegeEscalation - Les capacités qu'un conteneur peut demander
- L'utilisation de répertoires d'hôtes en tant que volumes
- Le contexte SELinux du conteneur
- L'identifiant de l'utilisateur du conteneur
- L'utilisation des espaces de noms d'hôtes et des réseaux
-
L'attribution d'un
FSGroupqui possède les volumes de pods - La configuration des groupes supplémentaires autorisés
- Si un conteneur nécessite un accès en écriture à son système de fichiers racine
- L'utilisation des types de volumes
-
La configuration des profils autorisés
seccomp
Ne définissez pas l'étiquette openshift.io/run-level sur les espaces de noms dans OpenShift Container Platform. Ce label est utilisé par les composants internes d'OpenShift Container Platform pour gérer le démarrage des principaux groupes d'API, tels que le serveur d'API Kubernetes et le serveur d'API OpenShift. Si le label openshift.io/run-level est défini, aucun SCC n'est appliqué aux pods dans cet espace de noms, ce qui fait que toutes les charges de travail s'exécutant dans cet espace de noms sont hautement privilégiées.
15.1.1. Contraintes de contexte de sécurité par défaut
Le cluster contient plusieurs contraintes de contexte de sécurité (SCC) par défaut, comme décrit dans le tableau ci-dessous. Des SCC supplémentaires peuvent être installées lorsque vous installez des opérateurs ou d'autres composants sur OpenShift Container Platform.
Ne modifiez pas les SCC par défaut. La personnalisation des SCC par défaut peut entraîner des problèmes lors du déploiement de certains pods de la plateforme ou lors de la mise à jour d'OpenShift Container Platform. De plus, les valeurs par défaut des SCC sont réinitialisées lors de certaines mises à niveau de clusters, ce qui annule toutes les personnalisations de ces SCC.
Au lieu de modifier les SCC par défaut, créez et modifiez vos propres SCC selon vos besoins. Pour connaître les étapes détaillées, voir Creating security context constraints.
| Contrainte du contexte de sécurité | Description |
|---|---|
|
|
Fournit toutes les fonctionnalités du SCC |
|
| Permet l'accès à tous les espaces de noms d'hôtes, mais exige toujours que les pods soient exécutés avec un UID et un contexte SELinux alloués à l'espace de noms. Avertissement Ce SCC permet à l'hôte d'accéder aux espaces de noms, aux systèmes de fichiers et aux PID. Il ne doit être utilisé que par des pods de confiance. Accordez-le avec prudence. |
|
|
Fournit toutes les fonctionnalités du SCC Avertissement Ce SCC autorise l'accès au système de fichiers de l'hôte sous n'importe quel UID, y compris l'UID 0. A accorder avec prudence. |
|
| Permet d'utiliser le réseau et les ports de l'hôte, mais exige toujours que les pods soient exécutés avec un UID et un contexte SELinux alloués à l'espace de noms. Avertissement
Si d'autres charges de travail sont exécutées sur des hôtes du plan de contrôle, soyez prudent lorsque vous donnez accès à |
|
|
Comme le
|
|
| Utilisé pour l'exportateur de nœuds Prometheus. Avertissement Ce SCC autorise l'accès au système de fichiers de l'hôte sous n'importe quel UID, y compris l'UID 0. A accorder avec prudence. |
|
|
Fournit toutes les fonctionnalités de |
|
|
Comme le
|
|
| Permet d'accéder à toutes les fonctions privilégiées et hôtes et de s'exécuter en tant qu'utilisateur, groupe, FSGroup et dans n'importe quel contexte SELinux. Avertissement Il s'agit du SCC le plus souple et il ne doit être utilisé que pour l'administration de clusters. Il doit être accordé avec prudence.
Le site
Note
Le fait de définir |
|
| Refuse l'accès à toutes les fonctionnalités de l'hôte et exige que les pods soient exécutés avec un UID et un contexte SELinux qui sont alloués à l'espace de noms.
Le
Dans les clusters qui ont été mis à niveau depuis OpenShift Container Platform 4.10 ou une version antérieure, ce SCC est disponible pour être utilisé par tout utilisateur authentifié. Le SCC |
|
|
Comme le
Il s'agit du CSC le plus restrictif fourni par une nouvelle installation et il sera utilisé par défaut pour les utilisateurs authentifiés. Note
Le SCC |
15.1.2. Paramètres des contraintes du contexte de sécurité
Les contraintes du contexte de sécurité (SCC) sont composées de paramètres et de stratégies qui contrôlent les fonctions de sécurité auxquelles un pod a accès. Ces paramètres se répartissent en trois catégories :
| Catégorie | Description |
|---|---|
| Contrôlé par un booléen |
Les champs de ce type prennent par défaut la valeur la plus restrictive. Par exemple, |
| Contrôlé par un ensemble autorisé | Les champs de ce type sont vérifiés par rapport à l'ensemble pour s'assurer que leur valeur est autorisée. |
| Contrôlé par une stratégie | Les éléments qui ont une stratégie pour générer une valeur ajoutée :
|
Le CRI-O dispose de la liste suivante de capacités par défaut qui sont autorisées pour chaque conteneur d'un pod :
-
CHOWN -
DAC_OVERRIDE -
FSETID -
FOWNER -
SETGID -
SETUID -
SETPCAP -
NET_BIND_SERVICE -
KILL
Les conteneurs utilisent les capacités de cette liste par défaut, mais les auteurs de manifestes de pods peuvent modifier la liste en demandant des capacités supplémentaires ou en supprimant certains comportements par défaut. Utilisez les paramètres allowedCapabilities, defaultAddCapabilities, et requiredDropCapabilities pour contrôler ces demandes de la part des modules. Ces paramètres permettent de spécifier les capacités qui peuvent être demandées, celles qui doivent être ajoutées à chaque conteneur et celles qui doivent être interdites ou supprimées de chaque conteneur.
Vous pouvez supprimer toutes les capacités des conteneurs en réglant le paramètre requiredDropCapabilities sur ALL. C'est ce que fait le CCN restricted-v2.
15.1.3. Contexte de sécurité contraintes stratégies
Exécuter en tant qu'utilisateur
MustRunAs- Nécessite la configuration derunAsUser. Utilise le siterunAsUserconfiguré comme valeur par défaut. Valide par rapport à l'adresserunAsUserconfigurée.Exemple
MustRunAssnippet... runAsUser: type: MustRunAs uid: <id> ...MustRunAsRange- Nécessite la définition des valeurs minimale et maximale si l'on n'utilise pas de valeurs pré-allouées. Utilise le minimum comme valeur par défaut. Valide par rapport à l'ensemble de la plage autorisée.Exemple
MustRunAsRangesnippet... runAsUser: type: MustRunAsRange uidRangeMax: <maxvalue> uidRangeMin: <minvalue> ...MustRunAsNonRoot- Nécessite que le pod soit soumis avec unrunAsUsernon nul ou que la directiveUSERsoit définie dans l'image. Aucune valeur par défaut n'est fournie.Exemple
MustRunAsNonRootsnippet... runAsUser: type: MustRunAsNonRoot ...RunAsAny- Aucune valeur par défaut n'est fournie. Permet de spécifier n'importe quellerunAsUser.Exemple
RunAsAnysnippet... runAsUser: type: RunAsAny ...
SELinuxContext
-
MustRunAs- Nécessite la configuration deseLinuxOptionssi l'on n'utilise pas de valeurs pré-allouées. UtiliseseLinuxOptionscomme valeur par défaut. Valide par rapport àseLinuxOptions. -
RunAsAny- Aucune valeur par défaut n'est fournie. Permet de spécifier n'importe quelleseLinuxOptions.
Groupes supplémentaires
-
MustRunAs- Nécessite la spécification d'au moins une plage si l'on n'utilise pas de valeurs pré-allouées. Utilise la valeur minimale de la première plage comme valeur par défaut. Valide toutes les plages. -
RunAsAny- Aucune valeur par défaut n'est fournie. Permet de spécifier n'importe quellesupplementalGroups.
FSGroup
-
MustRunAs- Nécessite la spécification d'au moins une plage si l'on n'utilise pas de valeurs pré-allouées. Utilise par défaut la valeur minimale de la première plage. Valide par rapport au premier ID de la première plage. -
RunAsAny- Aucune valeur par défaut n'est fournie. Permet de spécifier n'importe quel identifiantfsGroup.
15.1.4. Contrôle des volumes
L'utilisation de types de volumes spécifiques peut être contrôlée en définissant le champ volumes du SCC.
Les valeurs autorisées de ce champ correspondent aux sources de volume définies lors de la création d'un volume :
-
awsElasticBlockStore -
azureDisk -
azureFile -
cephFS -
cinder -
configMap -
downwardAPI -
emptyDir -
fc -
flexVolume -
flocker -
gcePersistentDisk -
gitRepo -
glusterfs -
hostPath -
iscsi -
nfs -
persistentVolumeClaim -
photonPersistentDisk -
portworxVolume -
projected -
quobyte -
rbd -
scaleIO -
secret -
storageos -
vsphereVolume - * (Une valeur spéciale pour permettre l'utilisation de tous les types de volumes)
-
none(Une valeur spéciale pour interdire l'utilisation de tous les types de volumes. N'existe que pour la compatibilité ascendante)
L'ensemble minimal recommandé de volumes autorisés pour les nouveaux CCN est le suivant : configMap, downwardAPI, emptyDir, persistentVolumeClaim, secret, et projected.
Cette liste de types de volumes autorisés n'est pas exhaustive car de nouveaux types sont ajoutés à chaque version d'OpenShift Container Platform.
Pour des raisons de compatibilité ascendante, l'utilisation de allowHostDirVolumePlugin est prioritaire sur les paramètres du champ volumes. Par exemple, si allowHostDirVolumePlugin est défini comme faux mais autorisé dans le champ volumes, la valeur hostPath sera supprimée de volumes.
15.1.5. Contrôle d'admission
Admission control avec les CSC permet de contrôler la création de ressources en fonction des capacités accordées à un utilisateur.
En ce qui concerne les SCC, cela signifie qu'un contrôleur d'admission peut inspecter les informations sur l'utilisateur mises à disposition dans le contexte afin de récupérer un ensemble approprié de SCC. Ce faisant, il s'assure que le module est autorisé à formuler des demandes concernant son environnement opérationnel ou à générer un ensemble de contraintes à appliquer au module.
L'ensemble des CSC que l'admission utilise pour autoriser un module est déterminé par l'identité de l'utilisateur et les groupes auxquels il appartient. En outre, si le module spécifie un compte de service, l'ensemble des CSC autorisées comprend toutes les contraintes accessibles au compte de service.
Admission utilise l'approche suivante pour créer le contexte de sécurité final pour le module :
- Récupérer tous les CCN disponibles pour utilisation.
- Génère des valeurs de champ pour les paramètres du contexte de sécurité qui n'ont pas été spécifiés dans la demande.
- Valider les paramètres finaux en fonction des contraintes disponibles.
Si un ensemble de contraintes correspondantes est trouvé, le module est accepté. Si la demande ne peut être associée à une CSC, le module est rejeté.
Un pod doit valider chaque champ par rapport au CCN. Les exemples suivants ne concernent que deux des champs qui doivent être validés :
Ces exemples s'inscrivent dans le cadre d'une stratégie utilisant les valeurs préallouées.
An FSGroup SCC strategy of MustRunAs
Si le pod définit un ID fsGroup, cet ID doit être égal à l'ID par défaut fsGroup. Dans le cas contraire, le pod n'est pas validé par ce CSC et le CSC suivant est évalué.
Si le champ SecurityContextConstraints.fsGroup a la valeur RunAsAny et que la spécification du module omet Pod.spec.securityContext.fsGroup, ce champ est considéré comme valide. Notez qu'il est possible qu'au cours de la validation, d'autres paramètres du CCN rejettent d'autres champs du module et fassent ainsi échouer le module.
A SupplementalGroups SCC strategy of MustRunAs
Si la spécification du module définit un ou plusieurs identifiants supplementalGroups, les identifiants du module doivent correspondre à l'un des identifiants figurant dans l'annotation openshift.io/sa.scc.supplemental-groups de l'espace de noms. Dans le cas contraire, le pod n'est pas validé par ce SCC et le SCC suivant est évalué.
Si le champ SecurityContextConstraints.supplementalGroups a la valeur RunAsAny et que la spécification du module omet Pod.spec.securityContext.supplementalGroups, ce champ est considéré comme valide. Notez qu'il est possible qu'au cours de la validation, d'autres paramètres du CCN rejettent d'autres champs du module et fassent ainsi échouer le module.
15.1.6. Priorité aux contraintes liées au contexte de sécurité
Les contraintes de contexte de sécurité (SCC) ont un champ de priorité qui affecte l'ordre lors de la tentative de validation d'une demande par le contrôleur d'admission.
Une valeur de priorité de 0 est la priorité la plus basse possible. Une priorité nulle est considérée comme une priorité 0, c'est-à-dire la plus basse. Les CSC ayant une priorité plus élevée sont déplacés vers l'avant de l'ensemble lors du tri.
Lorsque l'ensemble des CCN disponibles est déterminé, les CCN sont classés de la manière suivante :
- Les CSC les plus prioritaires sont commandés en premier.
- Si les priorités sont égales, les CSC sont classées de la plus restrictive à la moins restrictive.
- Si les priorités et les restrictions sont égales, les CSC sont triés par nom.
Par défaut, le SCC anyuid accordé aux administrateurs de clusters est prioritaire dans leur jeu de SCC. Cela permet aux administrateurs de cluster d'exécuter des pods en tant que n'importe quel utilisateur en spécifiant RunAsUser dans le SCC du pod SecurityContext.
15.2. A propos des valeurs de contraintes de contexte de sécurité pré-allouées
Le contrôleur d'admission est conscient de certaines conditions dans les contraintes du contexte de sécurité (SCC) qui l'amènent à rechercher des valeurs pré-allouées à partir d'un espace de noms et à remplir le SCC avant de traiter le module. Chaque stratégie SCC est évaluée indépendamment des autres stratégies, les valeurs pré-allouées, lorsqu'elles sont autorisées, pour chaque politique étant agrégées avec les valeurs de spécification du pod afin d'obtenir les valeurs finales pour les différents ID définis dans le pod en cours d'exécution.
Les SCC suivants amènent le contrôleur d'admission à rechercher des valeurs pré-allouées lorsqu'aucune plage n'est définie dans la spécification du pod :
-
Une stratégie
RunAsUserdeMustRunAsRangesans minimum ni maximum. Admission recherche l'annotationopenshift.io/sa.scc.uid-rangepour remplir les champs de l'intervalle. -
Une stratégie
SELinuxContextdeMustRunAssans niveau défini. Admission recherche l'annotationopenshift.io/sa.scc.mcspour remplir le niveau. -
Une stratégie
FSGroupdeMustRunAs. L'admission recherche l'annotationopenshift.io/sa.scc.supplemental-groups. -
Une stratégie
SupplementalGroupsdeMustRunAs. L'admission recherche l'annotationopenshift.io/sa.scc.supplemental-groups.
Pendant la phase de génération, le fournisseur de contexte de sécurité utilise des valeurs par défaut pour toutes les valeurs de paramètres qui ne sont pas spécifiquement définies dans le pod. Les valeurs par défaut sont basées sur la stratégie sélectionnée :
-
RunAsAnyetMustRunAsNonRootne fournissent pas de valeurs par défaut. Si le module a besoin d'une valeur de paramètre, telle qu'un identifiant de groupe, vous devez définir la valeur dans la spécification du module. -
MustRunAs(valeur unique) fournissent une valeur par défaut qui est toujours utilisée. Par exemple, pour les ID de groupe, même si la spécification du pod définit sa propre valeur d'ID, la valeur du paramètre par défaut de l'espace de noms apparaît également dans les groupes du pod. -
MustRunAsRangeetMustRunAs(basées sur une fourchette) fournissent la valeur minimale de la fourchette. Comme pour la stratégieMustRunAsà valeur unique, la valeur par défaut du paramètre de l'espace de noms apparaît dans le pod en cours d'exécution. Si une stratégie basée sur une plage est configurable avec plusieurs plages, elle fournit la valeur minimale de la première plage configurée.
FSGroup et SupplementalGroups reviennent à l'annotation openshift.io/sa.scc.uid-range si l'annotation openshift.io/sa.scc.supplemental-groups n'existe pas pour l'espace de noms. Si aucune des deux n'existe, le CCN n'est pas créé.
Par défaut, la stratégie FSGroup basée sur l'annotation se configure avec une seule plage basée sur la valeur minimale de l'annotation. Par exemple, si votre annotation est 1/3, la stratégie FSGroup se configure avec une valeur minimale et maximale de 1. Si vous voulez permettre à davantage de groupes d'être acceptés pour le champ FSGroup, vous pouvez configurer un CSC personnalisé qui n'utilise pas l'annotation.
L'annotation openshift.io/sa.scc.supplemental-groups accepte une liste de blocs délimitée par des virgules au format <start>/<length ou <start>-<end>. L'annotation openshift.io/sa.scc.uid-range n'accepte qu'un seul bloc.
15.3. Exemple de contraintes liées au contexte de sécurité
Les exemples suivants montrent le format et les annotations des contraintes du contexte de sécurité (SCC) :
privileged SCC annoté
allowHostDirVolumePlugin: true
allowHostIPC: true
allowHostNetwork: true
allowHostPID: true
allowHostPorts: true
allowPrivilegedContainer: true
allowedCapabilities:
- '*'
apiVersion: security.openshift.io/v1
defaultAddCapabilities: []
fsGroup:
type: RunAsAny
groups:
- system:cluster-admins
- system:nodes
kind: SecurityContextConstraints
metadata:
annotations:
kubernetes.io/description: 'privileged allows access to all privileged and host
features and the ability to run as any user, any group, any fsGroup, and with
any SELinux context. WARNING: this is the most relaxed SCC and should be used
only for cluster administration. Grant with caution.'
creationTimestamp: null
name: privileged
priority: null
readOnlyRootFilesystem: false
requiredDropCapabilities:
- KILL
- MKNOD
- SETUID
- SETGID
runAsUser:
type: RunAsAny
seLinuxContext:
type: RunAsAny
seccompProfiles:
- '*'
supplementalGroups:
type: RunAsAny
users:
- system:serviceaccount:default:registry
- system:serviceaccount:default:router
- system:serviceaccount:openshift-infra:build-controller
volumes:
- '*'- 1
- Liste des capacités qu'un pod peut demander. Une liste vide signifie qu'aucune capacité ne peut être demandée, tandis que le symbole spécial
*autorise toutes les capacités. - 2
- Liste des capacités supplémentaires qui sont ajoutées à un pod.
- 3
- La stratégie
FSGroup, qui dicte les valeurs autorisées pour le contexte de sécurité. - 4
- Les groupes qui peuvent accéder à ce CCN.
- 5
- Une liste de capacités à supprimer d'un module. Vous pouvez également spécifier
ALLpour supprimer toutes les capacités. - 6
- Le type de stratégie
runAsUser, qui dicte les valeurs autorisées pour le contexte de sécurité. - 7
- Le type de stratégie
seLinuxContext, qui dicte les valeurs autorisées pour le contexte de sécurité. - 8
- La stratégie
supplementalGroups, qui dicte les groupes supplémentaires autorisés pour le contexte de sécurité. - 9
- Les utilisateurs qui peuvent accéder à ce CCN.
- 10
- Les types de volumes autorisés pour le contexte de sécurité. Dans l'exemple,
*autorise l'utilisation de tous les types de volumes.
Les champs users et groups du SCC contrôlent les utilisateurs qui peuvent accéder au SCC. Par défaut, les administrateurs de cluster, les nœuds et le contrôleur de construction ont accès au SCC privilégié. Tous les utilisateurs authentifiés ont accès au SCC restricted-v2.
Sans réglage explicite de runAsUser
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo
spec:
securityContext:
containers:
- name: sec-ctx-demo
image: gcr.io/google-samples/node-hello:1.0- 1
- Lorsqu'un conteneur ou un pod ne demande pas d'identifiant sous lequel il doit être exécuté, l'UID effectif dépend du SCC qui émet ce pod. Comme le SCC
restricted-v2est accordé par défaut à tous les utilisateurs authentifiés, il sera disponible pour tous les utilisateurs et comptes de service et utilisé dans la plupart des cas. Le SCCrestricted-v2utilise la stratégieMustRunAsRangepour contraindre et définir par défaut les valeurs possibles du champsecurityContext.runAsUser. Le plugin d'admission recherchera l'annotationopenshift.io/sa.scc.uid-rangesur le projet actuel pour remplir les champs de la plage, car il ne fournit pas cette plage. Au final, un conteneur aurarunAsUserégal à la première valeur de l'intervalle, ce qui est difficile à prévoir car chaque projet a des intervalles différents.
Avec un réglage explicite de runAsUser
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo
spec:
securityContext:
runAsUser: 1000
containers:
- name: sec-ctx-demo
image: gcr.io/google-samples/node-hello:1.0- 1
- Un conteneur ou un pod qui demande un identifiant spécifique sera accepté par OpenShift Container Platform seulement si un compte de service ou un utilisateur a accès à un SCC qui autorise un tel identifiant. Le SCC peut autoriser des identifiants arbitraires, un identifiant compris dans une fourchette, ou l'identifiant exact spécifique à la demande.
Cette configuration est valable pour SELinux, fsGroup et Supplemental Groups.
15.4. Création de contraintes de contexte de sécurité
Vous pouvez créer des contraintes de contexte de sécurité (SCC) à l'aide de la CLI OpenShift (oc).
La création et la modification de vos propres SCC sont des opérations avancées qui peuvent entraîner une instabilité de votre cluster. Si vous avez des questions concernant l'utilisation de vos propres SCC, contactez l'assistance Red Hat. Pour plus d'informations sur la manière de contacter l'assistance Red Hat, consultez Getting support.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Définir le SCC dans un fichier YAML nommé
scc-admin.yaml:kind: SecurityContextConstraints apiVersion: security.openshift.io/v1 metadata: name: scc-admin allowPrivilegedContainer: true runAsUser: type: RunAsAny seLinuxContext: type: RunAsAny fsGroup: type: RunAsAny supplementalGroups: type: RunAsAny users: - my-admin-user groups: - my-admin-groupEn option, vous pouvez supprimer des capacités spécifiques pour un SCC en définissant le champ
requiredDropCapabilitiesavec les valeurs souhaitées. Toutes les capacités spécifiées sont supprimées du conteneur. Pour supprimer toutes les capacités, indiquezALL. Par exemple, pour créer un SCC qui supprime les capacitésKILL,MKNOD, etSYS_CHROOT, ajoutez ce qui suit à l'objet SCC :requiredDropCapabilities: - KILL - MKNOD - SYS_CHROOTNoteVous ne pouvez pas répertorier une capacité à la fois sur
allowedCapabilitieset surrequiredDropCapabilities.CRI-O prend en charge la même liste de valeurs de capacités que celle figurant dans la documentation de Docker.
Créez le CCN en lui transmettant le fichier :
$ oc create -f scc-admin.yamlExemple de sortie
securitycontextconstraints "scc-admin" created
Vérification
Vérifiez que le SCC a été créé :
$ oc get scc scc-adminExemple de sortie
NAME PRIV CAPS SELINUX RUNASUSER FSGROUP SUPGROUP PRIORITY READONLYROOTFS VOLUMES scc-admin true [] RunAsAny RunAsAny RunAsAny RunAsAny <none> false [awsElasticBlockStore azureDisk azureFile cephFS cinder configMap downwardAPI emptyDir fc flexVolume flocker gcePersistentDisk gitRepo glusterfs iscsi nfs persistentVolumeClaim photonPersistentDisk quobyte rbd secret vsphere]
15.5. Accès aux contraintes du contexte de sécurité en fonction des rôles
Vous pouvez spécifier les SCC en tant que ressources gérées par RBAC. Cela vous permet de limiter l'accès à vos SCC à un certain projet ou à l'ensemble du cluster. L'affectation d'utilisateurs, de groupes ou de comptes de service directement à un SCC conserve la portée de l'ensemble du cluster.
Vous ne pouvez pas attribuer de SCC aux pods créés dans l'un des espaces de noms par défaut : default, kube-system, kube-public, openshift-node, openshift-infra, openshift. Ces espaces de noms ne doivent pas être utilisés pour l'exécution de pods ou de services.
Pour inclure l'accès aux SCC dans votre rôle, spécifiez la ressource scc lors de la création d'un rôle.
$ oc create role <role-name> --verb=use --resource=scc --resource-name=<scc-name> -n <namespace>Il en résulte la définition de rôle suivante :
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
...
name: role-name
namespace: namespace
...
rules:
- apiGroups:
- security.openshift.io
resourceNames:
- scc-name
resources:
- securitycontextconstraints
verbs:
- use- 1
- Le nom du rôle.
- 2
- Espace de noms du rôle défini. La valeur par défaut est
defaultsi elle n'est pas spécifiée. - 3
- Le groupe API qui inclut la ressource
SecurityContextConstraints. Défini automatiquement lorsquesccest spécifié comme ressource. - 4
- Un exemple de nom pour un CCN auquel vous voulez avoir accès.
- 5
- Nom du groupe de ressources qui permet aux utilisateurs de spécifier des noms de CSC dans le champ
resourceNames. - 6
- Une liste de verbes à appliquer au rôle.
Un rôle local ou de groupe doté d'une telle règle permet aux sujets qui lui sont liés par une liaison de rôle ou une liaison de rôle de groupe d'utiliser le CCS défini par l'utilisateur appelé scc-name.
Parce que RBAC est conçu pour empêcher l'escalade, même les administrateurs de projet ne sont pas en mesure d'accorder l'accès à un SCC. Par défaut, ils ne sont pas autorisés à utiliser le verbe use sur les ressources du SCC, y compris le SCC restricted-v2.
15.6. Référence des commandes de contraintes de contexte de sécurité
Vous pouvez gérer les contraintes de contexte de sécurité (SCC) dans votre instance en tant qu'objets API normaux à l'aide de l'OpenShift CLI (oc).
Vous devez disposer des privilèges cluster-admin pour gérer les SCC.
15.6.1. Liste des contraintes du contexte de sécurité
Pour obtenir une liste actualisée des CCN :
$ oc get sccExemple de sortie
NAME PRIV CAPS SELINUX RUNASUSER FSGROUP SUPGROUP PRIORITY READONLYROOTFS VOLUMES
anyuid false <no value> MustRunAs RunAsAny RunAsAny RunAsAny 10 false ["configMap","downwardAPI","emptyDir","persistentVolumeClaim","projected","secret"]
hostaccess false <no value> MustRunAs MustRunAsRange MustRunAs RunAsAny <no value> false ["configMap","downwardAPI","emptyDir","hostPath","persistentVolumeClaim","projected","secret"]
hostmount-anyuid false <no value> MustRunAs RunAsAny RunAsAny RunAsAny <no value> false ["configMap","downwardAPI","emptyDir","hostPath","nfs","persistentVolumeClaim","projected","secret"]
hostnetwork false <no value> MustRunAs MustRunAsRange MustRunAs MustRunAs <no value> false ["configMap","downwardAPI","emptyDir","persistentVolumeClaim","projected","secret"]
hostnetwork-v2 false ["NET_BIND_SERVICE"] MustRunAs MustRunAsRange MustRunAs MustRunAs <no value> false ["configMap","downwardAPI","emptyDir","persistentVolumeClaim","projected","secret"]
node-exporter true <no value> RunAsAny RunAsAny RunAsAny RunAsAny <no value> false ["*"]
nonroot false <no value> MustRunAs MustRunAsNonRoot RunAsAny RunAsAny <no value> false ["configMap","downwardAPI","emptyDir","persistentVolumeClaim","projected","secret"]
nonroot-v2 false ["NET_BIND_SERVICE"] MustRunAs MustRunAsNonRoot RunAsAny RunAsAny <no value> false ["configMap","downwardAPI","emptyDir","persistentVolumeClaim","projected","secret"]
privileged true ["*"] RunAsAny RunAsAny RunAsAny RunAsAny <no value> false ["*"]
restricted false <no value> MustRunAs MustRunAsRange MustRunAs RunAsAny <no value> false ["configMap","downwardAPI","emptyDir","persistentVolumeClaim","projected","secret"]
restricted-v2 false ["NET_BIND_SERVICE"] MustRunAs MustRunAsRange MustRunAs RunAsAny <no value> false ["configMap","downwardAPI","emptyDir","persistentVolumeClaim","projected","secret"]15.6.2. Examen des contraintes liées au contexte de sécurité
Vous pouvez afficher des informations sur un SCC particulier, y compris les utilisateurs, les comptes de service et les groupes auxquels le SCC s'applique.
Par exemple, pour examiner le site restricted SCC :
$ oc describe scc restrictedExemple de sortie
Name: restricted
Priority: <none>
Access:
Users: <none>
Groups: <none>
Settings:
Allow Privileged: false
Allow Privilege Escalation: true
Default Add Capabilities: <none>
Required Drop Capabilities: KILL,MKNOD,SETUID,SETGID
Allowed Capabilities: <none>
Allowed Seccomp Profiles: <none>
Allowed Volume Types: configMap,downwardAPI,emptyDir,persistentVolumeClaim,projected,secret
Allowed Flexvolumes: <all>
Allowed Unsafe Sysctls: <none>
Forbidden Sysctls: <none>
Allow Host Network: false
Allow Host Ports: false
Allow Host PID: false
Allow Host IPC: false
Read Only Root Filesystem: false
Run As User Strategy: MustRunAsRange
UID: <none>
UID Range Min: <none>
UID Range Max: <none>
SELinux Context Strategy: MustRunAs
User: <none>
Role: <none>
Type: <none>
Level: <none>
FSGroup Strategy: MustRunAs
Ranges: <none>
Supplemental Groups Strategy: RunAsAny
Ranges: <none>Pour préserver les SCC personnalisés lors des mises à niveau, ne modifiez pas les paramètres des SCC par défaut.
15.6.3. Suppression des contraintes du contexte de sécurité
Pour supprimer une CSC :
oc delete scc <scc_name>Si vous supprimez un SCC par défaut, il sera régénéré lorsque vous redémarrerez le cluster.
15.6.4. Mise à jour des contraintes du contexte de sécurité
Pour mettre à jour une CSC existante :
$ oc edit scc <scc_name>Pour préserver les SCC personnalisés lors des mises à niveau, ne modifiez pas les paramètres des SCC par défaut.
Chapitre 16. Comprendre et gérer l'admission à la sécurité des pods
L'admission à la sécurité des pods est une mise en œuvre des normes de sécurité des pods de Kubernetes. Utilisez l'admission de sécurité des pods pour restreindre le comportement des pods.
16.1. Synchronisation des contraintes du contexte de sécurité avec les normes de sécurité des pods
OpenShift Container Platform inclut l'admission de sécurité des pods Kubernetes. Globalement, le profil privileged est appliqué et le profil restricted est utilisé pour les avertissements et les audits.
En plus de la configuration globale du contrôle d'admission à la sécurité des pods, il existe un contrôleur qui applique les étiquettes de contrôle d'admission à la sécurité des pods warn et audit aux espaces de noms en fonction des autorisations SCC des comptes de service qui se trouvent dans un espace de noms donné.
La synchronisation de l'admission à la sécurité des pods est désactivée en permanence pour les espaces de noms définis comme faisant partie de la charge utile du cluster. Vous pouvez activer la synchronisation de l'admission à la sécurité des pods sur d'autres espaces de noms si nécessaire. Si un opérateur est installé dans un espace de noms openshift-* créé par l'utilisateur, la synchronisation est activée par défaut après la création d'une version de service de cluster (CSV) dans l'espace de noms.
Le contrôleur examine les autorisations de l'objet ServiceAccount pour utiliser les contraintes de contexte de sécurité dans chaque espace de noms. Les contraintes de contexte de sécurité (SCC) sont converties en profils de sécurité de pods en fonction de leurs valeurs de champ ; le contrôleur utilise ces profils traduits. Les étiquettes d'admission à la sécurité des modules warn et audit sont définies sur le profil de sécurité de module le plus privilégié trouvé dans l'espace de noms afin d'éviter les avertissements et la journalisation d'audit lors de la création des modules.
L'étiquetage de l'espace de nommage est basé sur la prise en compte des privilèges du compte de service local de l'espace de nommage.
L'application directe des pods peut utiliser les privilèges SCC de l'utilisateur qui exécute le pod. Cependant, les privilèges de l'utilisateur ne sont pas pris en compte lors de l'étiquetage automatique.
16.2. Contrôle de la synchronisation des admissions à la sécurité des pods
Vous pouvez activer ou désactiver la synchronisation automatique de l'admission à la sécurité des pods pour la plupart des espaces de noms.
Les espaces de noms définis comme faisant partie de la charge utile du cluster ont une synchronisation d'admission de sécurité des pods désactivée de façon permanente. Ces espaces de noms sont les suivants
-
default -
kube-node-lease -
kube-system -
kube-public -
openshift -
Tous les espaces de noms créés par le système et préfixés par
openshift-, à l'exception deopenshift-operators
Par défaut, tous les espaces de noms ayant un préfixe openshift- ne sont pas synchronisés. Vous pouvez activer la synchronisation pour tous les espaces de noms openshift-* créés par l'utilisateur. Vous ne pouvez pas activer la synchronisation pour les espaces de noms openshift-* créés par le système, à l'exception de openshift-operators.
Si un opérateur est installé dans un espace de noms openshift-* créé par l'utilisateur, la synchronisation est activée par défaut après la création d'une version de service de cluster (CSV) dans l'espace de noms. L'étiquette synchronisée hérite des autorisations des comptes de service de l'espace de noms.
Procédure
Pour chaque espace de noms que vous souhaitez configurer, définissez une valeur pour l'étiquette
security.openshift.io/scc.podSecurityLabelSync:Pour désactiver la synchronisation des étiquettes d'admission à la sécurité des pods dans un espace de noms, définissez la valeur de l'étiquette
security.openshift.io/scc.podSecurityLabelSyncsurfalse.Exécutez la commande suivante :
oc label namespace <namespace> security.openshift.io/scc.podSecurityLabelSync=falsePour activer la synchronisation des étiquettes d'admission à la sécurité des pods dans un espace de noms, définissez la valeur de l'étiquette
security.openshift.io/scc.podSecurityLabelSyncsurtrue.Exécutez la commande suivante :
oc label namespace <namespace> security.openshift.io/scc.podSecurityLabelSync=true
16.3. À propos des alertes d'admission à la sécurité des pods
Une alerte PodSecurityViolation est déclenchée lorsque le serveur API Kubernetes signale un déni de pod au niveau de l'audit du contrôleur d'admission à la sécurité des pods. Cette alerte persiste pendant un jour.
Consultez les journaux d'audit du serveur API Kubernetes pour étudier les alertes qui ont été déclenchées. Par exemple, une charge de travail est susceptible d'échouer à l'admission si l'application globale est définie sur le niveau de sécurité du pod restricted.
Pour obtenir de l'aide dans l'identification des événements d'audit de violation de l'admission à la sécurité des pods, voir Annotations d'audit dans la documentation Kubernetes.
16.3.1. Identifier les violations de la sécurité des pods
L'alerte PodSecurityViolation ne fournit pas de détails sur les charges de travail à l'origine des violations de sécurité des pods. Vous pouvez identifier les charges de travail concernées en examinant les journaux d'audit du serveur API Kubernetes. Cette procédure utilise l'outil must-gather pour rassembler les journaux d'audit, puis recherche l'annotation pod-security.kubernetes.io/audit-violations.
Conditions préalables
-
Vous avez installé
jq. -
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Pour rassembler les journaux d'audit, entrez la commande suivante :
$ oc adm must-gather -- /usr/bin/gather_audit_logsPour afficher les détails de la charge de travail affectée, entrez la commande suivante :
$ zgrep -h pod-security.kubernetes.io/audit-violations must-gather.local.<archive_id>/quay*/audit_logs/kube-apiserver/*log.gz \ | jq -r 'select((.annotations["pod-security.kubernetes.io/audit-violations"] != null) and (.objectRef.resource=="pods")) | .objectRef.namespace + " " + .objectRef.name + " " + .objectRef.resource' \ | sort | uniq -cRemplacez
must-gather.local.<archive_id>par le nom du répertoire.Exemple de sortie
15 ci namespace-ttl-controller deployments 1 ci-op-k5whzrsh rpm-repo-546f98d8b replicasets 1 ci-op-k5whzrsh rpm-repo deployments
Chapitre 17. Usurpation d'identité de l'utilisateur system:admin
17.1. L'usurpation d'identité de l'API
Vous pouvez configurer une requête à l'API OpenShift Container Platform pour qu'elle agisse comme si elle provenait d'un autre utilisateur. Pour plus d'informations, voir User impersonation dans la documentation Kubernetes.
17.2. Usurpation d'identité de l'utilisateur system:admin
Vous pouvez autoriser un utilisateur à se faire passer pour system:admin, ce qui lui confère des droits d'administrateur de cluster.
Procédure
Pour autoriser un utilisateur à se faire passer pour
system:admin, exécutez la commande suivante :oc create clusterrolebinding <any_valid_name> --clusterrole=sudoer --user=<username>AstuceVous pouvez également appliquer le langage YAML suivant pour accorder l'autorisation de se faire passer pour
system:admin:apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: <any_valid_name> roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: sudoer subjects: - apiGroup: rbac.authorization.k8s.io kind: User name: <username>
17.3. Usurpation d'identité du groupe system:admin
Lorsqu'un utilisateur system:admin se voit accorder des droits d'administration de cluster par l'intermédiaire d'un groupe, vous devez inclure les paramètres --as=<user> --as-group=<group1> --as-group=<group2> dans la commande pour vous faire passer pour les groupes associés.
Procédure
Pour autoriser un utilisateur à se faire passer pour un utilisateur de
system:adminen se faisant passer pour les groupes d'administration de clusters associés, exécutez la commande suivante :$ oc create clusterrolebinding <any_valid_name> --clusterrole=sudoer --as=<user> \ --as-group=<group1> --as-group=<group2>
Chapitre 18. Synchronisation des groupes LDAP
En tant qu'administrateur, vous pouvez utiliser les groupes pour gérer les utilisateurs, modifier leurs autorisations et améliorer la collaboration. Votre organisation a peut-être déjà créé des groupes d'utilisateurs et les a stockés dans un serveur LDAP. OpenShift Container Platform peut synchroniser ces enregistrements LDAP avec les enregistrements internes d'OpenShift Container Platform, ce qui vous permet de gérer vos groupes en un seul endroit. OpenShift Container Platform prend actuellement en charge la synchronisation des groupes avec les serveurs LDAP en utilisant trois schémas communs pour définir l'appartenance à un groupe : RFC 2307, Active Directory et Active Directory augmenté.
Pour plus d'informations sur la configuration de LDAP, voir Configuration d'un fournisseur d'identité LDAP.
Vous devez disposer des privilèges cluster-admin pour synchroniser les groupes.
18.1. À propos de la configuration de la synchronisation LDAP
Avant de pouvoir exécuter la synchronisation LDAP, vous avez besoin d'un fichier de configuration de la synchronisation. Ce fichier contient les informations suivantes sur la configuration du client LDAP :
- Configuration de la connexion à votre serveur LDAP.
- Options de configuration de la synchronisation qui dépendent du schéma utilisé dans votre serveur LDAP.
- Une liste définie par l'administrateur de correspondances de noms qui associe les noms de groupes de OpenShift Container Platform aux groupes de votre serveur LDAP.
Le format du fichier de configuration dépend du schéma utilisé : RFC 2307, Active Directory ou Active Directory augmenté.
- Configuration du client LDAP
- La section de configuration du client LDAP de la configuration définit les connexions à votre serveur LDAP.
La section de configuration du client LDAP de la configuration définit les connexions à votre serveur LDAP.
Configuration du client LDAP
url: ldap://10.0.0.0:389
bindDN: cn=admin,dc=example,dc=com
bindPassword: password
insecure: false
ca: my-ldap-ca-bundle.crt - 1
- Le protocole de connexion, l'adresse IP du serveur LDAP hébergeant votre base de données et le port auquel se connecter, formaté comme
scheme://host:port. - 2
- Nom distinctif (DN) facultatif à utiliser comme DN de liaison. OpenShift Container Platform l'utilise si des privilèges élevés sont nécessaires pour récupérer les entrées pour l'opération de synchronisation.
- 3
- Mot de passe facultatif à utiliser pour la liaison. OpenShift Container Platform l'utilise si des privilèges élevés sont nécessaires pour récupérer les entrées pour l'opération de synchronisation. Cette valeur peut également être fournie dans une variable d'environnement, un fichier externe ou un fichier crypté.
- 4
- Lorsque
false, les URL LDAP sécurisées (ldaps://) se connectent en utilisant TLS, et les URL LDAP non sécurisées (ldap://) sont mises à niveau vers TLS. Lorsquetrue, aucune connexion TLS n'est établie avec le serveur et vous ne pouvez pas utiliser les schémas d'URLldaps://. - 5
- Le paquet de certificats à utiliser pour valider les certificats de serveur pour l'URL configurée. S'il est vide, OpenShift Container Platform utilise les racines de confiance du système. Cela ne s'applique que si
insecureest défini surfalse.
- Définition d'une requête LDAP
- Les configurations de synchronisation consistent en des définitions de requêtes LDAP pour les entrées nécessaires à la synchronisation. La définition spécifique d'une requête LDAP dépend du schéma utilisé pour stocker les informations sur les membres dans le serveur LDAP.
Définition d'une requête LDAP
baseDN: ou=users,dc=example,dc=com
scope: sub
derefAliases: never
timeout: 0
filter: (objectClass=person)
pageSize: 0 - 1
- Le nom distinctif (DN) de la branche du répertoire à partir de laquelle toutes les recherches seront effectuées. Vous devez spécifier le sommet de l'arborescence de votre répertoire, mais vous pouvez également spécifier une sous-arborescence du répertoire.
- 2
- L'étendue de la recherche. Les valeurs valables sont
base,oneousub. Si cette valeur n'est pas définie, l'étendue desubest prise en compte. Les descriptions des options d'étendue se trouvent dans le tableau ci-dessous. - 3
- Comportement de la recherche par rapport aux alias dans l'arbre LDAP. Les valeurs valides sont
never,search,base, oualways. Si cette valeur n'est pas définie, le déréférencement des alias se fait par défaut à l'aide dealways. Les descriptions des comportements de déréférencement se trouvent dans le tableau ci-dessous. - 4
- La limite de temps autorisée pour la recherche par le client, en secondes. Une valeur de
0n'impose aucune limite côté client. - 5
- Un filtre de recherche LDAP valide. Si ce paramètre n'est pas défini, la valeur par défaut est
(objectClass=*). - 6
- Taille maximale facultative des pages de réponse du serveur, mesurée en entrées LDAP. Si la valeur est
0, aucune restriction de taille ne sera appliquée aux pages de réponses. La définition de la taille des pages est nécessaire lorsque les requêtes renvoient plus d'entrées que le client ou le serveur n'en autorise par défaut.
| Étendue de la recherche LDAP | Description |
|---|---|
|
| Ne prendre en compte que l'objet spécifié par le DN de base donné pour la requête. |
|
| Tous les objets situés au même niveau de l'arbre sont considérés comme le DN de base de la requête. |
|
| Considérer le sous-arbre entier enraciné dans le DN de base donné pour la requête. |
| Comportement de déréférencement | Description |
|---|---|
|
| Ne jamais déréférencer les alias trouvés dans l'arbre LDAP. |
|
| Ne déréférencer que les alias trouvés lors de la recherche. |
|
| Ne déréférencer que les alias lors de la recherche de l'objet de base. |
|
| Toujours déréférencer tous les alias trouvés dans l'arbre LDAP. |
- Mappage de noms définis par l'utilisateur
- Un mappage de nom défini par l'utilisateur fait explicitement correspondre les noms des groupes OpenShift Container Platform à des identifiants uniques qui trouvent les groupes sur votre serveur LDAP. Le mappage utilise la syntaxe YAML normale. Un mappage défini par l'utilisateur peut contenir une entrée pour chaque groupe dans votre serveur LDAP ou seulement un sous-ensemble de ces groupes. S'il y a des groupes sur le serveur LDAP qui n'ont pas de mappage de nom défini par l'utilisateur, le comportement par défaut pendant la synchronisation est d'utiliser l'attribut spécifié comme nom du groupe OpenShift Container Platform.
Mappage de noms définis par l'utilisateur
groupUIDNameMapping:
"cn=group1,ou=groups,dc=example,dc=com": firstgroup
"cn=group2,ou=groups,dc=example,dc=com": secondgroup
"cn=group3,ou=groups,dc=example,dc=com": thirdgroup18.1.1. À propos du fichier de configuration RFC 2307
Le schéma RFC 2307 exige que vous fournissiez une définition de requête LDAP pour les entrées d'utilisateurs et de groupes, ainsi que les attributs avec lesquels les représenter dans les enregistrements internes d'OpenShift Container Platform.
Pour plus de clarté, le groupe que vous créez dans OpenShift Container Platform devrait utiliser des attributs autres que le nom distinctif dans la mesure du possible pour les champs orientés vers l'utilisateur ou l'administrateur. Par exemple, identifiez les utilisateurs d'un groupe OpenShift Container Platform par leur e-mail et utilisez le nom du groupe comme nom commun. Le fichier de configuration suivant crée ces relations :
Si vous utilisez des correspondances de noms définies par l'utilisateur, votre fichier de configuration sera différent.
Configuration de la synchronisation LDAP qui utilise le schéma RFC 2307 : rfc2307_config.yaml
kind: LDAPSyncConfig
apiVersion: v1
url: ldap://LDAP_SERVICE_IP:389
insecure: false
rfc2307:
groupsQuery:
baseDN: "ou=groups,dc=example,dc=com"
scope: sub
derefAliases: never
pageSize: 0
groupUIDAttribute: dn
groupNameAttributes: [ cn ]
groupMembershipAttributes: [ member ]
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
pageSize: 0
userUIDAttribute: dn
userNameAttributes: [ mail ]
tolerateMemberNotFoundErrors: false
tolerateMemberOutOfScopeErrors: false- 1
- L'adresse IP et l'hôte du serveur LDAP où l'enregistrement de ce groupe est stocké.
- 2
- Lorsque
false, les URL LDAP sécurisées (ldaps://) se connectent en utilisant TLS, et les URL LDAP non sécurisées (ldap://) sont mises à niveau vers TLS. Lorsquetrue, aucune connexion TLS n'est établie avec le serveur et vous ne pouvez pas utiliser les schémas d'URLldaps://. - 3
- L'attribut qui identifie de manière unique un groupe sur le serveur LDAP. Vous ne pouvez pas spécifier de filtres
groupsQuerylorsque vous utilisez DN pourgroupUIDAttribute. Pour un filtrage plus fin, utilisez la méthode whitelist / blacklist. - 4
- L'attribut à utiliser comme nom du groupe.
- 5
- L'attribut du groupe qui stocke les informations relatives à l'appartenance.
- 6
- L'attribut qui identifie de manière unique un utilisateur sur le serveur LDAP. Vous ne pouvez pas spécifier de filtres
usersQuerylorsque vous utilisez DN pour userUIDAttribute. Pour un filtrage plus fin, utilisez la méthode whitelist / blacklist. - 7
- L'attribut à utiliser comme nom de l'utilisateur dans l'enregistrement du groupe OpenShift Container Platform.
18.1.2. A propos du fichier de configuration d'Active Directory
Le schéma Active Directory exige que vous fournissiez une définition de requête LDAP pour les entrées utilisateur, ainsi que les attributs pour les représenter dans les enregistrements de groupe internes d'OpenShift Container Platform.
Pour plus de clarté, le groupe que vous créez dans OpenShift Container Platform devrait utiliser des attributs autres que le nom distinctif chaque fois que possible pour les champs orientés vers l'utilisateur ou l'administrateur. Par exemple, identifiez les utilisateurs d'un groupe OpenShift Container Platform par leur e-mail, mais définissez le nom du groupe par le nom du groupe sur le serveur LDAP. Le fichier de configuration suivant crée ces relations :
Configuration de la synchronisation LDAP qui utilise le schéma Active Directory : active_directory_config.yaml
kind: LDAPSyncConfig
apiVersion: v1
url: ldap://LDAP_SERVICE_IP:389
activeDirectory:
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
filter: (objectclass=person)
pageSize: 0
userNameAttributes: [ mail ]
groupMembershipAttributes: [ memberOf ] 18.1.3. À propos du fichier de configuration Active Directory augmenté
Le schéma Active Directory augmenté vous oblige à fournir une définition de requête LDAP pour les entrées d'utilisateurs et de groupes, ainsi que les attributs avec lesquels les représenter dans les enregistrements de groupes internes d'OpenShift Container Platform.
Pour plus de clarté, le groupe que vous créez dans OpenShift Container Platform devrait utiliser des attributs autres que le nom distinctif dans la mesure du possible pour les champs orientés vers l'utilisateur ou l'administrateur. Par exemple, identifiez les utilisateurs d'un groupe OpenShift Container Platform par leur e-mail et utilisez le nom du groupe comme nom commun. Le fichier de configuration suivant crée ces relations.
Configuration de la synchronisation LDAP qui utilise le schéma Active Directory augmenté : augmented_active_directory_config.yaml
kind: LDAPSyncConfig
apiVersion: v1
url: ldap://LDAP_SERVICE_IP:389
augmentedActiveDirectory:
groupsQuery:
baseDN: "ou=groups,dc=example,dc=com"
scope: sub
derefAliases: never
pageSize: 0
groupUIDAttribute: dn
groupNameAttributes: [ cn ]
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
filter: (objectclass=person)
pageSize: 0
userNameAttributes: [ mail ]
groupMembershipAttributes: [ memberOf ] - 1
- L'attribut qui identifie de manière unique un groupe sur le serveur LDAP. Vous ne pouvez pas spécifier de filtres
groupsQuerylorsque vous utilisez DN pour groupUIDAttribute. Pour un filtrage plus fin, utilisez la méthode whitelist / blacklist. - 2
- L'attribut à utiliser comme nom du groupe.
- 3
- L'attribut à utiliser comme nom de l'utilisateur dans l'enregistrement du groupe OpenShift Container Platform.
- 4
- L'attribut de l'utilisateur qui stocke les informations relatives à l'adhésion.
18.2. Exécution de la synchronisation LDAP
Une fois que vous avez créé un fichier de configuration de synchronisation, vous pouvez commencer à synchroniser. OpenShift Container Platform permet aux administrateurs d'effectuer un certain nombre de types de synchronisation différents avec le même serveur.
18.2.1. Synchroniser le serveur LDAP avec OpenShift Container Platform
Vous pouvez synchroniser tous les groupes du serveur LDAP avec OpenShift Container Platform.
Conditions préalables
- Créer un fichier de configuration de la synchronisation.
Procédure
Pour synchroniser tous les groupes du serveur LDAP avec OpenShift Container Platform :
$ oc adm groups sync --sync-config=config.yaml --confirmNotePar défaut, toutes les opérations de synchronisation de groupe sont effectuées à sec, vous devez donc activer l'option
--confirmsur la commandeoc adm groups syncpour apporter des modifications aux enregistrements de groupe d'OpenShift Container Platform.
18.2.2. Synchronisation des groupes OpenShift Container Platform avec le serveur LDAP
Vous pouvez synchroniser tous les groupes déjà présents dans OpenShift Container Platform qui correspondent aux groupes du serveur LDAP spécifié dans le fichier de configuration.
Conditions préalables
- Créer un fichier de configuration de la synchronisation.
Procédure
Pour synchroniser les groupes OpenShift Container Platform avec le serveur LDAP :
$ oc adm groups sync --type=openshift --sync-config=config.yaml --confirmNotePar défaut, toutes les opérations de synchronisation de groupe sont effectuées à sec, vous devez donc activer l'option
--confirmsur la commandeoc adm groups syncpour apporter des modifications aux enregistrements de groupe d'OpenShift Container Platform.
18.2.3. Synchroniser les sous-groupes du serveur LDAP avec OpenShift Container Platform
Vous pouvez synchroniser un sous-ensemble de groupes LDAP avec OpenShift Container Platform en utilisant des fichiers de liste blanche, des fichiers de liste noire ou les deux.
Vous pouvez utiliser n'importe quelle combinaison de fichiers de liste noire, de fichiers de liste blanche ou d'éléments de liste blanche. Les fichiers de liste blanche et de liste noire doivent contenir un identifiant de groupe unique par ligne, et vous pouvez inclure des éléments de liste blanche directement dans la commande elle-même. Ces directives s'appliquent aux groupes trouvés sur les serveurs LDAP ainsi qu'aux groupes déjà présents dans OpenShift Container Platform.
Conditions préalables
- Créer un fichier de configuration de la synchronisation.
Procédure
Pour synchroniser un sous-ensemble de groupes LDAP avec OpenShift Container Platform, utilisez l'une des commandes suivantes :
$ oc adm groups sync --whitelist=<whitelist_file> \ --sync-config=config.yaml \ --confirm$ oc adm groups sync --blacklist=<blacklist_file> \ --sync-config=config.yaml \ --confirm$ oc adm groups sync <group_unique_identifier> \ --sync-config=config.yaml \ --confirm$ oc adm groups sync <group_unique_identifier> \ --whitelist=<whitelist_file> \ --blacklist=<blacklist_file> \ --sync-config=config.yaml \ --confirm$ oc adm groups sync --type=openshift \ --whitelist=<whitelist_file> \ --sync-config=config.yaml \ --confirmNotePar défaut, toutes les opérations de synchronisation de groupe sont effectuées à sec, vous devez donc activer l'option
--confirmsur la commandeoc adm groups syncpour apporter des modifications aux enregistrements de groupe d'OpenShift Container Platform.
18.3. Exécution d'un travail d'élagage de groupe
Un administrateur peut également choisir de supprimer les groupes des enregistrements d'OpenShift Container Platform si les enregistrements sur le serveur LDAP qui les a créés ne sont plus présents. La tâche d'élagage acceptera le même fichier de configuration de synchronisation et les mêmes listes blanches ou noires que ceux utilisés pour la tâche de synchronisation.
Par exemple :
$ oc adm prune groups --sync-config=/path/to/ldap-sync-config.yaml --confirm$ oc adm prune groups --whitelist=/path/to/whitelist.txt --sync-config=/path/to/ldap-sync-config.yaml --confirm$ oc adm prune groups --blacklist=/path/to/blacklist.txt --sync-config=/path/to/ldap-sync-config.yaml --confirm18.4. Synchronisation automatique des groupes LDAP
Vous pouvez synchroniser automatiquement les groupes LDAP sur une base périodique en configurant un travail cron.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. Vous avez configuré un fournisseur d'identité LDAP (IDP).
Cette procédure suppose que vous avez créé un secret LDAP nommé
ldap-secretet une carte de configuration nomméeca-config-map.
Procédure
Créez un projet dans lequel la tâche cron sera exécutée :
oc new-project ldap-sync1 - 1
- Cette procédure utilise un projet appelé
ldap-sync.
Localisez le secret et la carte de configuration que vous avez créés lors de la configuration du fournisseur d'identité LDAP et copiez-les dans ce nouveau projet.
Le secret et la carte de configuration existent dans le projet
openshift-configet doivent être copiés dans le nouveau projetldap-sync.Définir un compte de service :
Exemple
ldap-sync-service-account.yamlkind: ServiceAccount apiVersion: v1 metadata: name: ldap-group-syncer namespace: ldap-syncCréer le compte de service :
$ oc create -f ldap-sync-service-account.yamlDéfinir un rôle de cluster :
Exemple
ldap-sync-cluster-role.yamlapiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: ldap-group-syncer rules: - apiGroups: - '' - user.openshift.io resources: - groups verbs: - get - list - create - updateCréer le rôle de cluster :
$ oc create -f ldap-sync-cluster-role.yamlDéfinir une liaison de rôle de cluster pour lier le rôle de cluster au compte de service :
Exemple
ldap-sync-cluster-role-binding.yamlkind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: ldap-group-syncer subjects: - kind: ServiceAccount name: ldap-group-syncer1 namespace: ldap-sync roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: ldap-group-syncer2 Créez la liaison de rôle de cluster :
$ oc create -f ldap-sync-cluster-role-binding.yamlDéfinir une carte de configuration qui spécifie le fichier de configuration de la synchronisation :
Exemple
ldap-sync-config-map.yamlkind: ConfigMap apiVersion: v1 metadata: name: ldap-group-syncer namespace: ldap-sync data: sync.yaml: |1 kind: LDAPSyncConfig apiVersion: v1 url: ldaps://10.0.0.0:3892 insecure: false bindDN: cn=admin,dc=example,dc=com3 bindPassword: file: "/etc/secrets/bindPassword" ca: /etc/ldap-ca/ca.crt rfc2307:4 groupsQuery: baseDN: "ou=groups,dc=example,dc=com"5 scope: sub filter: "(objectClass=groupOfMembers)" derefAliases: never pageSize: 0 groupUIDAttribute: dn groupNameAttributes: [ cn ] groupMembershipAttributes: [ member ] usersQuery: baseDN: "ou=users,dc=example,dc=com"6 scope: sub derefAliases: never pageSize: 0 userUIDAttribute: dn userNameAttributes: [ uid ] tolerateMemberNotFoundErrors: false tolerateMemberOutOfScopeErrors: false- 1
- Définir le fichier de configuration de la synchronisation.
- 2
- Spécifiez l'URL.
- 3
- Spécifiez le site
bindDN. - 4
- Cet exemple utilise le schéma RFC2307 ; adaptez les valeurs si nécessaire. Vous pouvez également utiliser un schéma différent.
- 5
- Spécifiez le
baseDNpour legroupsQuery. - 6
- Spécifiez le
baseDNpour leusersQuery.
Créer la carte de configuration :
$ oc create -f ldap-sync-config-map.yamlDéfinir une tâche cron :
Exemple
ldap-sync-cron-job.yamlkind: CronJob apiVersion: batch/v1 metadata: name: ldap-group-syncer namespace: ldap-sync spec:1 schedule: "*/30 * * * *"2 concurrencyPolicy: Forbid jobTemplate: spec: backoffLimit: 0 ttlSecondsAfterFinished: 18003 template: spec: containers: - name: ldap-group-sync image: "registry.redhat.io/openshift4/ose-cli:latest" command: - "/bin/bash" - "-c" - "oc adm groups sync --sync-config=/etc/config/sync.yaml --confirm"4 volumeMounts: - mountPath: "/etc/config" name: "ldap-sync-volume" - mountPath: "/etc/secrets" name: "ldap-bind-password" - mountPath: "/etc/ldap-ca" name: "ldap-ca" volumes: - name: "ldap-sync-volume" configMap: name: "ldap-group-syncer" - name: "ldap-bind-password" secret: secretName: "ldap-secret"5 - name: "ldap-ca" configMap: name: "ca-config-map"6 restartPolicy: "Never" terminationGracePeriodSeconds: 30 activeDeadlineSeconds: 500 dnsPolicy: "ClusterFirst" serviceAccountName: "ldap-group-syncer"- 1
- Configurez les paramètres de la tâche cron. Voir "Création de tâches cron" pour plus d'informations sur les paramètres des tâches cron.
- 2
- L'horaire du travail spécifié au format cron. Dans cet exemple, la tâche cron s'exécute toutes les 30 minutes. Ajustez la fréquence si nécessaire, en veillant à prendre en compte le temps nécessaire à l'exécution de la synchronisation.
- 3
- Durée, en secondes, pendant laquelle les travaux terminés doivent être conservés. Cette durée doit correspondre à celle de la planification des tâches afin de nettoyer les anciennes tâches qui ont échoué et d'éviter les alertes inutiles. Pour plus d'informations, voir TTL-after-finished Controller dans la documentation Kubernetes.
- 4
- La commande de synchronisation LDAP pour le job cron à exécuter. Transmet le fichier de configuration de la synchronisation qui a été défini dans la carte de configuration.
- 5
- Ce secret a été créé lors de la configuration de l'IDP LDAP.
- 6
- Cette carte de configuration a été créée lors de la configuration de l'IDP LDAP.
Créez la tâche cron :
$ oc create -f ldap-sync-cron-job.yaml
18.5. Exemples de synchronisation de groupes LDAP
Cette section contient des exemples pour les schémas RFC 2307, Active Directory et Active Directory étendu.
Ces exemples supposent que tous les utilisateurs sont des membres directs de leurs groupes respectifs. Plus précisément, aucun groupe n'a d'autres groupes comme membres. Voir l'exemple de synchronisation des membres imbriqués pour plus d'informations sur la synchronisation des groupes imbriqués.
18.5.1. Synchronisation des groupes à l'aide du schéma RFC 2307
Pour le schéma RFC 2307, les exemples suivants synchronisent un groupe nommé admins qui a deux membres : Jane et Jim. Les exemples expliquent :
- Comment le groupe et les utilisateurs sont ajoutés au serveur LDAP.
- Ce que sera l'enregistrement de groupe résultant dans OpenShift Container Platform après la synchronisation.
Ces exemples supposent que tous les utilisateurs sont des membres directs de leurs groupes respectifs. Plus précisément, aucun groupe n'a d'autres groupes comme membres. Voir l'exemple de synchronisation des membres imbriqués pour plus d'informations sur la synchronisation des groupes imbriqués.
Dans le schéma RFC 2307, les utilisateurs (Jane et Jim) et les groupes existent sur le serveur LDAP en tant qu'entrées de première classe, et l'appartenance à un groupe est stockée dans les attributs du groupe. L'extrait suivant de ldif définit les utilisateurs et les groupes pour ce schéma :
Entrées LDAP qui utilisent le schéma RFC 2307 : rfc2307.ldif
dn: ou=users,dc=example,dc=com
objectClass: organizationalUnit
ou: users
dn: cn=Jane,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
cn: Jane
sn: Smith
displayName: Jane Smith
mail: jane.smith@example.com
dn: cn=Jim,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
cn: Jim
sn: Adams
displayName: Jim Adams
mail: jim.adams@example.com
dn: ou=groups,dc=example,dc=com
objectClass: organizationalUnit
ou: groups
dn: cn=admins,ou=groups,dc=example,dc=com
objectClass: groupOfNames
cn: admins
owner: cn=admin,dc=example,dc=com
description: System Administrators
member: cn=Jane,ou=users,dc=example,dc=com
member: cn=Jim,ou=users,dc=example,dc=comConditions préalables
- Créer le fichier de configuration.
Procédure
Exécutez la synchronisation avec le fichier
rfc2307_config.yaml:$ oc adm groups sync --sync-config=rfc2307_config.yaml --confirmOpenShift Container Platform crée l'enregistrement de groupe suivant suite à l'opération de synchronisation ci-dessus :
Groupe OpenShift Container Platform créé à l'aide du fichier
rfc2307_config.yamlapiVersion: user.openshift.io/v1 kind: Group metadata: annotations: openshift.io/ldap.sync-time: 2015-10-13T10:08:38-04001 openshift.io/ldap.uid: cn=admins,ou=groups,dc=example,dc=com2 openshift.io/ldap.url: LDAP_SERVER_IP:3893 creationTimestamp: name: admins4 users:5 - jane.smith@example.com - jim.adams@example.com- 1
- La dernière fois que ce groupe OpenShift Container Platform a été synchronisé avec le serveur LDAP, au format ISO 6801.
- 2
- L'identifiant unique du groupe sur le serveur LDAP.
- 3
- L'adresse IP et l'hôte du serveur LDAP où l'enregistrement de ce groupe est stocké.
- 4
- Le nom du groupe tel que spécifié par le fichier de synchronisation.
- 5
- Les utilisateurs membres du groupe, nommés comme spécifié dans le fichier de synchronisation.
18.5.2. Synchronisation des groupes à l'aide du schéma RFC2307 avec des correspondances de noms définies par l'utilisateur
Lors de la synchronisation de groupes avec des correspondances de noms définies par l'utilisateur, le fichier de configuration est modifié pour contenir ces correspondances, comme indiqué ci-dessous.
Configuration de synchronisation LDAP qui utilise le schéma RFC 2307 avec des correspondances de noms définies par l'utilisateur : rfc2307_config_user_defined.yaml
kind: LDAPSyncConfig
apiVersion: v1
groupUIDNameMapping:
"cn=admins,ou=groups,dc=example,dc=com": Administrators
rfc2307:
groupsQuery:
baseDN: "ou=groups,dc=example,dc=com"
scope: sub
derefAliases: never
pageSize: 0
groupUIDAttribute: dn
groupNameAttributes: [ cn ]
groupMembershipAttributes: [ member ]
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
pageSize: 0
userUIDAttribute: dn
userNameAttributes: [ mail ]
tolerateMemberNotFoundErrors: false
tolerateMemberOutOfScopeErrors: false- 1
- Le mappage du nom défini par l'utilisateur.
- 2
- L'attribut d'identifiant unique utilisé pour les clés dans le mappage de noms définis par l'utilisateur. Vous ne pouvez pas spécifier de filtres
groupsQuerylorsque vous utilisez DN pour groupUIDAttribute. Pour un filtrage plus fin, utilisez la méthode whitelist / blacklist. - 3
- L'attribut pour nommer les groupes OpenShift Container Platform avec si leur identifiant unique n'est pas dans le mappage de nom défini par l'utilisateur.
- 4
- L'attribut qui identifie de manière unique un utilisateur sur le serveur LDAP. Vous ne pouvez pas spécifier de filtres
usersQuerylorsque vous utilisez DN pour userUIDAttribute. Pour un filtrage plus fin, utilisez la méthode whitelist / blacklist.
Conditions préalables
- Créer le fichier de configuration.
Procédure
Exécutez la synchronisation avec le fichier
rfc2307_config_user_defined.yaml:$ oc adm groups sync --sync-config=rfc2307_config_user_defined.yaml --confirmOpenShift Container Platform crée l'enregistrement de groupe suivant suite à l'opération de synchronisation ci-dessus :
Groupe OpenShift Container Platform créé à l'aide du fichier
rfc2307_config_user_defined.yamlapiVersion: user.openshift.io/v1 kind: Group metadata: annotations: openshift.io/ldap.sync-time: 2015-10-13T10:08:38-0400 openshift.io/ldap.uid: cn=admins,ou=groups,dc=example,dc=com openshift.io/ldap.url: LDAP_SERVER_IP:389 creationTimestamp: name: Administrators1 users: - jane.smith@example.com - jim.adams@example.com- 1
- Le nom du groupe tel que spécifié par le mappage de nom défini par l'utilisateur.
18.5.3. Synchronisation de groupes à l'aide de la norme RFC 2307 avec des tolérances d'erreur définies par l'utilisateur
Par défaut, si les groupes en cours de synchronisation contiennent des membres dont les entrées sont en dehors de la portée définie dans la requête de membre, la synchronisation du groupe échoue avec une erreur :
Erreur dans la détermination de l'appartenance au groupe LDAP pour "<group>" : la recherche d'appartenance de l'utilisateur "<user>" au groupe "<group>" a échoué en raison de l'erreur suivante : "La recherche d'une entrée avec dn="<user-dn>" se ferait en dehors de la base dn spécifiée (dn="<base-dn>")\N".
Cela indique souvent une mauvaise configuration de baseDN dans le champ usersQuery. Cependant, dans les cas où le champ baseDN ne contient pas intentionnellement certains des membres du groupe, la configuration de tolerateMemberOutOfScopeErrors: true permet de poursuivre la synchronisation du groupe. Les membres hors périmètre seront ignorés.
De même, lorsque le processus de synchronisation des groupes ne parvient pas à localiser un membre pour un groupe, il échoue purement et simplement avec des erreurs :
Error determining LDAP group membership for "<group>": membership lookup for user "<user>" in group "<group>" failed because of "search for entry with base dn="<user-dn>" refers to a non-existent entry".
Error determining LDAP group membership for "<group>": membership lookup for user "<user>" in group "<group>" failed because of "search for entry with base dn="<user-dn>" and filter "<filter>" did not return any results".
Cela indique souvent que le champ usersQuery est mal configuré. Toutefois, dans les cas où le groupe contient des entrées de membres dont on sait qu'elles sont manquantes, le réglage de tolerateMemberNotFoundErrors: true permet de poursuivre la synchronisation du groupe. Les membres problématiques seront ignorés.
L'activation des tolérances d'erreur pour la synchronisation des groupes LDAP permet au processus de synchronisation d'ignorer les entrées de membres problématiques. Si la synchronisation des groupes LDAP n'est pas configurée correctement, les groupes OpenShift Container Platform synchronisés pourraient manquer de membres.
Entrées LDAP qui utilisent le schéma RFC 2307 et dont l'appartenance à un groupe pose problème : rfc2307_problematic_users.ldif
dn: ou=users,dc=example,dc=com
objectClass: organizationalUnit
ou: users
dn: cn=Jane,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
cn: Jane
sn: Smith
displayName: Jane Smith
mail: jane.smith@example.com
dn: cn=Jim,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
cn: Jim
sn: Adams
displayName: Jim Adams
mail: jim.adams@example.com
dn: ou=groups,dc=example,dc=com
objectClass: organizationalUnit
ou: groups
dn: cn=admins,ou=groups,dc=example,dc=com
objectClass: groupOfNames
cn: admins
owner: cn=admin,dc=example,dc=com
description: System Administrators
member: cn=Jane,ou=users,dc=example,dc=com
member: cn=Jim,ou=users,dc=example,dc=com
member: cn=INVALID,ou=users,dc=example,dc=com
member: cn=Jim,ou=OUTOFSCOPE,dc=example,dc=com Pour tolérer les erreurs de l'exemple ci-dessus, il faut ajouter les éléments suivants au fichier de configuration de la synchronisation :
Configuration de la synchronisation LDAP qui utilise le schéma RFC 2307 tolérant les erreurs : rfc2307_config_tolerating.yaml
kind: LDAPSyncConfig
apiVersion: v1
url: ldap://LDAP_SERVICE_IP:389
rfc2307:
groupsQuery:
baseDN: "ou=groups,dc=example,dc=com"
scope: sub
derefAliases: never
groupUIDAttribute: dn
groupNameAttributes: [ cn ]
groupMembershipAttributes: [ member ]
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
userUIDAttribute: dn
userNameAttributes: [ mail ]
tolerateMemberNotFoundErrors: true
tolerateMemberOutOfScopeErrors: true - 1
- L'attribut qui identifie de manière unique un utilisateur sur le serveur LDAP. Vous ne pouvez pas spécifier de filtres
usersQuerylorsque vous utilisez DN pour userUIDAttribute. Pour un filtrage plus fin, utilisez la méthode whitelist / blacklist. - 2
- Lorsque
true, le travail de synchronisation tolère les groupes pour lesquels certains membres n'ont pas été trouvés, et les membres dont les entrées LDAP ne sont pas trouvées sont ignorés. Le comportement par défaut du travail de synchronisation est d'échouer si un membre d'un groupe n'est pas trouvé. - 3
- Lorsque
true, le travail de synchronisation tolère les groupes dont certains membres sont en dehors du champ d'application de l'utilisateur indiqué dans le DN de baseusersQuery, et les membres en dehors du champ d'application de la requête du membre sont ignorés. Le comportement par défaut du travail de synchronisation est d'échouer si un membre d'un groupe est hors de la portée.
Conditions préalables
- Créer le fichier de configuration.
Procédure
Exécutez la synchronisation avec le fichier
rfc2307_config_tolerating.yaml:$ oc adm groups sync --sync-config=rfc2307_config_tolerating.yaml --confirmOpenShift Container Platform crée l'enregistrement de groupe suivant suite à l'opération de synchronisation ci-dessus :
Groupe OpenShift Container Platform créé à l'aide du fichier
rfc2307_config.yamlapiVersion: user.openshift.io/v1 kind: Group metadata: annotations: openshift.io/ldap.sync-time: 2015-10-13T10:08:38-0400 openshift.io/ldap.uid: cn=admins,ou=groups,dc=example,dc=com openshift.io/ldap.url: LDAP_SERVER_IP:389 creationTimestamp: name: admins users:1 - jane.smith@example.com - jim.adams@example.com- 1
- Les utilisateurs qui sont membres du groupe, comme spécifié par le fichier de synchronisation. Les membres pour lesquels la recherche a rencontré des erreurs tolérées sont absents.
18.5.4. Synchronisation des groupes à l'aide du schéma Active Directory
Dans le schéma Active Directory, les deux utilisateurs (Jane et Jim) existent dans le serveur LDAP en tant qu'entrées de première classe, et l'appartenance à un groupe est stockée dans les attributs de l'utilisateur. L'extrait suivant de ldif définit les utilisateurs et les groupes pour ce schéma :
Entrées LDAP qui utilisent le schéma Active Directory : active_directory.ldif
dn: ou=users,dc=example,dc=com
objectClass: organizationalUnit
ou: users
dn: cn=Jane,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jane
sn: Smith
displayName: Jane Smith
mail: jane.smith@example.com
memberOf: admins
dn: cn=Jim,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jim
sn: Adams
displayName: Jim Adams
mail: jim.adams@example.com
memberOf: admins- 1
- L'appartenance de l'utilisateur à un groupe est répertoriée en tant qu'attribut de l'utilisateur, et le groupe n'existe pas en tant qu'entrée sur le serveur. L'attribut
memberOfne doit pas nécessairement être un attribut littéral de l'utilisateur ; dans certains serveurs LDAP, il est créé lors de la recherche et renvoyé au client, mais n'est pas enregistré dans la base de données.
Conditions préalables
- Créer le fichier de configuration.
Procédure
Exécutez la synchronisation avec le fichier
active_directory_config.yaml:$ oc adm groups sync --sync-config=active_directory_config.yaml --confirmOpenShift Container Platform crée l'enregistrement de groupe suivant suite à l'opération de synchronisation ci-dessus :
Groupe OpenShift Container Platform créé à l'aide du fichier
active_directory_config.yamlapiVersion: user.openshift.io/v1 kind: Group metadata: annotations: openshift.io/ldap.sync-time: 2015-10-13T10:08:38-04001 openshift.io/ldap.uid: admins2 openshift.io/ldap.url: LDAP_SERVER_IP:3893 creationTimestamp: name: admins4 users:5 - jane.smith@example.com - jim.adams@example.com- 1
- La dernière fois que ce groupe OpenShift Container Platform a été synchronisé avec le serveur LDAP, au format ISO 6801.
- 2
- L'identifiant unique du groupe sur le serveur LDAP.
- 3
- L'adresse IP et l'hôte du serveur LDAP où l'enregistrement de ce groupe est stocké.
- 4
- Le nom du groupe tel qu'il est répertorié dans le serveur LDAP.
- 5
- Les utilisateurs membres du groupe, nommés comme spécifié dans le fichier de synchronisation.
18.5.5. Synchronisation des groupes à l'aide du schéma Active Directory augmenté
Dans le schéma Active Directory augmenté, les utilisateurs (Jane et Jim) et les groupes existent dans le serveur LDAP en tant qu'entrées de première classe, et l'appartenance à un groupe est stockée dans les attributs de l'utilisateur. L'extrait suivant de ldif définit les utilisateurs et les groupes pour ce schéma :
Entrées LDAP qui utilisent le schéma Active Directory augmenté : augmented_active_directory.ldif
dn: ou=users,dc=example,dc=com
objectClass: organizationalUnit
ou: users
dn: cn=Jane,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jane
sn: Smith
displayName: Jane Smith
mail: jane.smith@example.com
memberOf: cn=admins,ou=groups,dc=example,dc=com
dn: cn=Jim,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jim
sn: Adams
displayName: Jim Adams
mail: jim.adams@example.com
memberOf: cn=admins,ou=groups,dc=example,dc=com
dn: ou=groups,dc=example,dc=com
objectClass: organizationalUnit
ou: groups
dn: cn=admins,ou=groups,dc=example,dc=com
objectClass: groupOfNames
cn: admins
owner: cn=admin,dc=example,dc=com
description: System Administrators
member: cn=Jane,ou=users,dc=example,dc=com
member: cn=Jim,ou=users,dc=example,dc=comConditions préalables
- Créer le fichier de configuration.
Procédure
Exécutez la synchronisation avec le fichier
augmented_active_directory_config.yaml:$ oc adm groups sync --sync-config=augmented_active_directory_config.yaml --confirmOpenShift Container Platform crée l'enregistrement de groupe suivant suite à l'opération de synchronisation ci-dessus :
Groupe OpenShift Container Platform créé à l'aide du fichier
augmented_active_directory_config.yamlapiVersion: user.openshift.io/v1 kind: Group metadata: annotations: openshift.io/ldap.sync-time: 2015-10-13T10:08:38-04001 openshift.io/ldap.uid: cn=admins,ou=groups,dc=example,dc=com2 openshift.io/ldap.url: LDAP_SERVER_IP:3893 creationTimestamp: name: admins4 users:5 - jane.smith@example.com - jim.adams@example.com- 1
- La dernière fois que ce groupe OpenShift Container Platform a été synchronisé avec le serveur LDAP, au format ISO 6801.
- 2
- L'identifiant unique du groupe sur le serveur LDAP.
- 3
- L'adresse IP et l'hôte du serveur LDAP où l'enregistrement de ce groupe est stocké.
- 4
- Le nom du groupe tel que spécifié par le fichier de synchronisation.
- 5
- Les utilisateurs membres du groupe, nommés comme spécifié dans le fichier de synchronisation.
18.5.5.1. Exemple de synchronisation des membres imbriqués dans LDAP
Les groupes dans OpenShift Container Platform ne sont pas imbriqués. Le serveur LDAP doit aplatir l'appartenance à un groupe avant que les données puissent être consommées. Le serveur Active Directory de Microsoft prend en charge cette fonctionnalité via la règle LDAP_MATCHING_RULE_IN_CHAIN dont l'OID est 1.2.840.113556.1.4.1941. En outre, seuls les groupes explicitement inscrits sur la liste blanche peuvent être synchronisés lors de l'utilisation de cette règle de correspondance.
Cette section présente un exemple de schéma Active Directory augmenté, qui synchronise un groupe nommé admins dont les membres sont l'utilisateur Jane et le groupe otheradmins. Le groupe otheradmins a un utilisateur membre : Jim. Cet exemple explique :
- Comment le groupe et les utilisateurs sont ajoutés au serveur LDAP.
- A quoi ressemble le fichier de configuration de la synchronisation LDAP.
- Ce que sera l'enregistrement de groupe résultant dans OpenShift Container Platform après la synchronisation.
Dans le schéma Active Directory augmenté, les utilisateurs (Jane et Jim) et les groupes existent dans le serveur LDAP en tant qu'entrées de première classe, et l'appartenance à un groupe est stockée dans les attributs de l'utilisateur ou du groupe. L'extrait suivant de ldif définit les utilisateurs et les groupes pour ce schéma :
Entrées LDAP qui utilisent le schéma Active Directory augmenté avec des membres imbriqués : augmented_active_directory_nested.ldif
dn: ou=users,dc=example,dc=com
objectClass: organizationalUnit
ou: users
dn: cn=Jane,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jane
sn: Smith
displayName: Jane Smith
mail: jane.smith@example.com
memberOf: cn=admins,ou=groups,dc=example,dc=com
dn: cn=Jim,ou=users,dc=example,dc=com
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: testPerson
cn: Jim
sn: Adams
displayName: Jim Adams
mail: jim.adams@example.com
memberOf: cn=otheradmins,ou=groups,dc=example,dc=com
dn: ou=groups,dc=example,dc=com
objectClass: organizationalUnit
ou: groups
dn: cn=admins,ou=groups,dc=example,dc=com
objectClass: group
cn: admins
owner: cn=admin,dc=example,dc=com
description: System Administrators
member: cn=Jane,ou=users,dc=example,dc=com
member: cn=otheradmins,ou=groups,dc=example,dc=com
dn: cn=otheradmins,ou=groups,dc=example,dc=com
objectClass: group
cn: otheradmins
owner: cn=admin,dc=example,dc=com
description: Other System Administrators
memberOf: cn=admins,ou=groups,dc=example,dc=com
member: cn=Jim,ou=users,dc=example,dc=comLors de la synchronisation des groupes imbriqués avec Active Directory, vous devez fournir une définition de requête LDAP pour les entrées d'utilisateurs et de groupes, ainsi que les attributs avec lesquels les représenter dans les enregistrements de groupes internes d'OpenShift Container Platform. De plus, certaines modifications sont nécessaires dans cette configuration :
-
La commande
oc adm groups syncdoit explicitement établir une liste blanche des groupes. -
Le site
groupMembershipAttributesde l'utilisateur doit inclure le site"memberOf:1.2.840.113556.1.4.1941:"pour se conformer à la règleLDAP_MATCHING_RULE_IN_CHAINrègle. -
Le site
groupUIDAttributedoit être réglé surdn. Le site
groupsQuery:-
Ne doit pas définir
filter. -
Doit définir un
derefAliasesvalide. -
Ne pas définir
baseDNcar cette valeur est ignorée. -
Ne pas définir
scopecar cette valeur est ignorée.
-
Ne doit pas définir
Pour plus de clarté, le groupe que vous créez dans OpenShift Container Platform devrait utiliser des attributs autres que le nom distinctif dans la mesure du possible pour les champs orientés vers l'utilisateur ou l'administrateur. Par exemple, identifiez les utilisateurs d'un groupe OpenShift Container Platform par leur e-mail et utilisez le nom du groupe comme nom commun. Le fichier de configuration suivant crée ces relations :
Configuration de synchronisation LDAP qui utilise le schéma Active Directory augmenté avec des membres imbriqués : augmented_active_directory_config_nested.yaml
kind: LDAPSyncConfig
apiVersion: v1
url: ldap://LDAP_SERVICE_IP:389
augmentedActiveDirectory:
groupsQuery:
derefAliases: never
pageSize: 0
groupUIDAttribute: dn
groupNameAttributes: [ cn ]
usersQuery:
baseDN: "ou=users,dc=example,dc=com"
scope: sub
derefAliases: never
filter: (objectclass=person)
pageSize: 0
userNameAttributes: [ mail ]
groupMembershipAttributes: [ "memberOf:1.2.840.113556.1.4.1941:" ] - 1
groupsQueryne peuvent pas être spécifiés. Les valeurs du DN de base et du champ d'application degroupsQuerysont ignorées.groupsQuerydoit définir underefAliasesvalide.- 2
- L'attribut qui identifie de manière unique un groupe sur le serveur LDAP. Il doit être défini sur
dn. - 3
- L'attribut à utiliser comme nom du groupe.
- 4
- L'attribut à utiliser comme nom de l'utilisateur dans l'enregistrement du groupe OpenShift Container Platform.
mailousAMAccountNamesont les choix préférés dans la plupart des installations. - 5
- L'attribut de l'utilisateur qui stocke les informations relatives à l'adhésion. Notez l'utilisation de
LDAP_MATCHING_RULE_IN_CHAIN.
Conditions préalables
- Créer le fichier de configuration.
Procédure
Exécutez la synchronisation avec le fichier
augmented_active_directory_config_nested.yaml:$ oc adm groups sync \ 'cn=admins,ou=groups,dc=example,dc=com' \ --sync-config=augmented_active_directory_config_nested.yaml \ --confirmNoteVous devez explicitement mettre le groupe
cn=admins,ou=groups,dc=example,dc=comsur liste blanche.OpenShift Container Platform crée l'enregistrement de groupe suivant suite à l'opération de synchronisation ci-dessus :
Groupe OpenShift Container Platform créé à l'aide du fichier
augmented_active_directory_config_nested.yamlapiVersion: user.openshift.io/v1 kind: Group metadata: annotations: openshift.io/ldap.sync-time: 2015-10-13T10:08:38-04001 openshift.io/ldap.uid: cn=admins,ou=groups,dc=example,dc=com2 openshift.io/ldap.url: LDAP_SERVER_IP:3893 creationTimestamp: name: admins4 users:5 - jane.smith@example.com - jim.adams@example.com- 1
- La dernière fois que ce groupe OpenShift Container Platform a été synchronisé avec le serveur LDAP, au format ISO 6801.
- 2
- L'identifiant unique du groupe sur le serveur LDAP.
- 3
- L'adresse IP et l'hôte du serveur LDAP où l'enregistrement de ce groupe est stocké.
- 4
- Le nom du groupe tel que spécifié par le fichier de synchronisation.
- 5
- Les utilisateurs membres du groupe, nommés comme spécifié dans le fichier de synchronisation. Notez que les membres des groupes imbriqués sont inclus puisque l'appartenance au groupe a été aplatie par le serveur Microsoft Active Directory.
18.6. Spécification de la configuration de la synchronisation LDAP
La spécification de l'objet pour le fichier de configuration est présentée ci-dessous. Notez que les différents objets du schéma ont des champs différents. Par exemple, v1.ActiveDirectoryConfig n'a pas de champ groupsQuery alors que v1.RFC2307Config et v1.AugmentedActiveDirectoryConfig en ont un.
Les attributs binaires ne sont pas pris en charge. Toutes les données d'attributs provenant du serveur LDAP doivent être au format d'une chaîne codée en UTF-8. Par exemple, n'utilisez jamais un attribut binaire, tel que objectGUID, comme attribut d'identification. Vous devez plutôt utiliser des attributs de type chaîne, tels que sAMAccountName ou userPrincipalName.
18.6.1. v1.LDAPSyncConfig
LDAPSyncConfig contient les options de configuration nécessaires pour définir une synchronisation de groupe LDAP.
| Nom | Description | Schéma |
|---|---|---|
|
| Valeur de chaîne représentant la ressource REST que cet objet représente. Les serveurs peuvent déduire cette valeur du point d'accès auquel le client soumet ses demandes. Ne peut être mis à jour. En CamelCase. Plus d'informations : https://github.com/kubernetes/community/blob/master/contributors/devel/sig-architecture/api-conventions.md#types-kinds | chaîne de caractères |
|
| Définit le schéma versionné de cette représentation d'un objet. Les serveurs doivent convertir les schémas reconnus à la dernière valeur interne et peuvent rejeter les valeurs non reconnues. Plus d'informations : https://github.com/kubernetes/community/blob/master/contributors/devel/sig-architecture/api-conventions.md#resources | chaîne de caractères |
|
|
Host est le schéma, l'hôte et le port du serveur LDAP auquel se connecter : | chaîne de caractères |
|
| DN facultatif pour se lier au serveur LDAP. | chaîne de caractères |
|
| Mot de passe facultatif à utiliser lors de la phase de recherche. | v1.StringSource |
|
|
Si | booléen |
|
| Groupement facultatif d'autorités de certification de confiance à utiliser lors des demandes adressées au serveur. S'il est vide, les racines du système par défaut sont utilisées. | chaîne de caractères |
|
| Option de mappage direct des UID de groupes LDAP vers les noms de groupes de OpenShift Container Platform. | objet |
|
| Contient la configuration pour l'extraction de données d'un serveur LDAP configuré d'une manière similaire à la RFC2307 : entrées de groupe et d'utilisateur de première classe, l'appartenance à un groupe étant déterminée par un attribut à valeurs multiples sur l'entrée du groupe énumérant ses membres. | v1.RFC2307Config |
|
| Contient la configuration permettant d'extraire des données d'un serveur LDAP configuré d'une manière similaire à celle utilisée dans Active Directory : entrées d'utilisateurs de première classe, l'appartenance à un groupe étant déterminée par un attribut multivalué sur les membres énumérant les groupes dont ils sont membres. | v1.ActiveDirectoryConfig |
|
| Contient la configuration pour l'extraction de données d'un serveur LDAP configuré d'une manière similaire à celle utilisée dans Active Directory comme décrit ci-dessus, avec un ajout : des entrées de groupe de première classe existent et sont utilisées pour contenir des métadonnées mais pas l'appartenance à un groupe. | v1.AugmentedActiveDirectoryConfig |
18.6.2. v1.StringSource
StringSource permet de spécifier une chaîne en ligne, ou en externe via une variable d'environnement ou un fichier. Lorsqu'elle ne contient qu'une chaîne de caractères, elle est transformée en une simple chaîne JSON.
| Nom | Description | Schéma |
|---|---|---|
|
|
Spécifie la valeur en clair, ou une valeur cryptée si | chaîne de caractères |
|
|
Spécifie une variable d'environnement contenant la valeur en clair, ou une valeur cryptée si | chaîne de caractères |
|
|
Renvoie à un fichier contenant la valeur en clair, ou une valeur cryptée si | chaîne de caractères |
|
| Fait référence à un fichier contenant la clé à utiliser pour décrypter la valeur. | chaîne de caractères |
18.6.3. v1.LDAPQuery
LDAPQuery contient les options nécessaires à l'élaboration d'une requête LDAP.
| Nom | Description | Schéma |
|---|---|---|
|
| DN de la branche du répertoire à partir de laquelle toutes les recherches doivent être effectuées. | chaîne de caractères |
|
|
L'étendue facultative de la recherche. Peut être | chaîne de caractères |
|
|
Comportement facultatif de la recherche en ce qui concerne les alias. Peut être | chaîne de caractères |
|
|
Indique la limite de temps en secondes pendant laquelle une demande adressée au serveur peut rester en suspens avant que l'attente d'une réponse ne soit abandonnée. Si cette valeur est | entier |
|
| Un filtre de recherche LDAP valide qui récupère toutes les entrées pertinentes du serveur LDAP avec le DN de base. | chaîne de caractères |
|
|
Taille maximale de la page préférée, mesurée en entrées LDAP. Une taille de page de | entier |
18.6.4. v1.RFC2307Config
RFC2307Config contient les options de configuration nécessaires pour définir comment un sync de groupe LDAP interagit avec un serveur LDAP utilisant le schéma RFC2307.
| Nom | Description | Schéma |
|---|---|---|
|
| Contient le modèle d'une requête LDAP qui renvoie des entrées de groupe. | v1.LDAPQuery |
|
|
Définit l'attribut d'une entrée de groupe LDAP qui sera interprété comme son identifiant unique. ( | chaîne de caractères |
|
| Définit les attributs d'une entrée de groupe LDAP qui seront interprétés comme son nom à utiliser pour un groupe OpenShift Container Platform. | tableau de chaînes |
|
|
Définit les attributs d'une entrée de groupe LDAP qui seront interprétés comme ses membres. Les valeurs contenues dans ces attributs doivent pouvoir être interrogées par votre | tableau de chaînes |
|
| Contient le modèle d'une requête LDAP qui renvoie des entrées d'utilisateurs. | v1.LDAPQuery |
|
|
Définit l'attribut d'une entrée utilisateur LDAP qui sera interprété comme son identifiant unique. Il doit correspondre aux valeurs qui seront trouvées à partir de | chaîne de caractères |
|
|
Définit les attributs d'une entrée utilisateur LDAP qui seront utilisés, dans l'ordre, comme nom d'utilisateur OpenShift Container Platform. Le premier attribut ayant une valeur non vide est utilisé. Cela doit correspondre à votre paramètre | tableau de chaînes |
|
|
Détermine le comportement de la tâche de synchronisation LDAP lorsque des entrées d'utilisateurs manquantes sont rencontrées. Si | booléen |
|
|
Détermine le comportement du travail de synchronisation LDAP lorsque des entrées d'utilisateurs hors du champ d'application sont rencontrées. Si | booléen |
18.6.5. v1.ActiveDirectoryConfig
ActiveDirectoryConfig contient les options de configuration nécessaires pour définir comment une synchronisation de groupe LDAP interagit avec un serveur LDAP utilisant le schéma Active Directory.
| Nom | Description | Schéma |
|---|---|---|
|
| Contient le modèle d'une requête LDAP qui renvoie des entrées d'utilisateurs. | v1.LDAPQuery |
|
|
Définit les attributs d'une entrée utilisateur LDAP qui seront interprétés comme son nom d'utilisateur OpenShift Container Platform. L'attribut à utiliser comme nom de l'utilisateur dans l'enregistrement de groupe OpenShift Container Platform. | tableau de chaînes |
|
| Définit les attributs d'une entrée utilisateur LDAP qui seront interprétés comme les groupes dont il est membre. | tableau de chaînes |
18.6.6. v1.AugmentedActiveDirectoryConfig
AugmentedActiveDirectoryConfig contient les options de configuration nécessaires pour définir comment une synchronisation de groupe LDAP interagit avec un serveur LDAP utilisant le schéma Active Directory augmenté.
| Nom | Description | Schéma |
|---|---|---|
|
| Contient le modèle d'une requête LDAP qui renvoie des entrées d'utilisateurs. | v1.LDAPQuery |
|
|
Définit les attributs d'une entrée utilisateur LDAP qui seront interprétés comme son nom d'utilisateur OpenShift Container Platform. L'attribut à utiliser comme nom de l'utilisateur dans l'enregistrement de groupe OpenShift Container Platform. | tableau de chaînes |
|
| Définit les attributs d'une entrée utilisateur LDAP qui seront interprétés comme les groupes dont il est membre. | tableau de chaînes |
|
| Contient le modèle d'une requête LDAP qui renvoie des entrées de groupe. | v1.LDAPQuery |
|
|
Définit l'attribut d'une entrée de groupe LDAP qui sera interprété comme son identifiant unique. ( | chaîne de caractères |
|
| Définit les attributs d'une entrée de groupe LDAP qui seront interprétés comme son nom à utiliser pour un groupe OpenShift Container Platform. | tableau de chaînes |
Chapitre 19. Gestion des informations d'identification des fournisseurs de services en nuage
19.1. À propos du Cloud Credential Operator
Le Cloud Credential Operator (CCO) gère les informations d'identification des fournisseurs de cloud sous forme de définitions de ressources personnalisées (CRD). Le CCO se synchronise sur CredentialsRequest custom resources (CRs) pour permettre aux composants d'OpenShift Container Platform de demander des informations d'identification de fournisseur de cloud avec les autorisations spécifiques requises pour le fonctionnement du cluster.
En définissant différentes valeurs pour le paramètre credentialsMode dans le fichier install-config.yaml, le CCO peut être configuré pour fonctionner dans plusieurs modes différents. Si aucun mode n'est spécifié ou si le paramètre credentialsMode est défini comme une chaîne vide (""), l'OCC fonctionne dans son mode par défaut.
19.1.1. Modes
En définissant différentes valeurs pour le paramètre credentialsMode dans le fichier install-config.yaml, le CCO peut être configuré pour fonctionner en mode mint, passthrough ou manual. Ces options offrent transparence et flexibilité dans la manière dont le CCO utilise les informations d'identification du nuage pour traiter les CR CredentialsRequest dans le cluster, et permettent au CCO d'être configuré pour répondre aux exigences de sécurité de votre organisation. Tous les modes de CCO ne sont pas pris en charge par tous les fournisseurs de cloud.
- Mint: En mode menthe, le CCO utilise l'identifiant cloud de niveau administrateur fourni pour créer de nouveaux identifiants pour les composants du cluster avec uniquement les autorisations spécifiques requises.
- Passthrough: En mode passthrough, le CCO transmet les informations d'identification du nuage fournies aux composants qui demandent des informations d'identification du nuage.
Manual: En mode manuel, c'est un utilisateur qui gère les informations d'identification du nuage à la place du CCO.
- Manual with AWS Security Token Service: En mode manuel, vous pouvez configurer un cluster AWS pour qu'il utilise le service de jetons de sécurité d'Amazon Web Services (AWS STS). Avec cette configuration, le CCO utilise des informations d'identification temporaires pour différents composants.
- Manual with GCP Workload Identity: En mode manuel, vous pouvez configurer un cluster GCP pour utiliser GCP Workload Identity. Avec cette configuration, le CCO utilise des informations d'identification temporaires pour différents composants.
| Fournisseur d'informatique en nuage | Menthe | Passage | Manuel |
|---|---|---|---|
| Nuage d'Alibaba | X | ||
| Amazon Web Services (AWS) | X | X | X |
| Microsoft Azure | X [1] | X | |
| Google Cloud Platform (GCP) | X | X | X |
| IBM Cloud | X | ||
| Plate-forme Red Hat OpenStack (RHOSP) | X | ||
| Red Hat Virtualization (RHV) | X | ||
| VMware vSphere | X |
- Le mode manuel est la seule configuration CCO prise en charge pour Microsoft Azure Stack Hub.
19.1.2. Déterminer le mode de fonctionnement du Cloud Credential Operator
Pour les plates-formes qui prennent en charge l'utilisation du CCO dans plusieurs modes, vous pouvez déterminer le mode dans lequel le CCO est configuré à l'aide de la console Web ou de l'interface de ligne de commande (CLI).
19.1.2.1. Détermination du mode Cloud Credential Operator à l'aide de la console web
Vous pouvez déterminer le mode de fonctionnement du Cloud Credential Operator (CCO) à l'aide de la console web.
Seuls les clusters Amazon Web Services (AWS), Microsoft Azure et Google Cloud Platform (GCP) prennent en charge plusieurs modes de CCO.
Conditions préalables
- Vous avez accès à un compte OpenShift Container Platform avec des permissions d'administrateur de cluster.
Procédure
-
Connectez-vous à la console web de OpenShift Container Platform en tant qu'utilisateur ayant le rôle
cluster-admin. - Naviguez jusqu'à Administration → Cluster Settings.
- Sur la page Cluster Settings, sélectionnez l'onglet Configuration.
- Sous Configuration resource, sélectionnez CloudCredential.
- Sur la page CloudCredential details, sélectionnez l'onglet YAML.
Dans le bloc YAML, vérifiez la valeur de
spec.credentialsMode. Les valeurs suivantes sont possibles, bien qu'elles ne soient pas toutes prises en charge sur toutes les plateformes :-
'': Le CCO fonctionne dans le mode par défaut. Dans cette configuration, le CCO fonctionne en mode "menthe" ou "passthrough", en fonction des informations d'identification fournies lors de l'installation. -
Mint: Le CCO fonctionne en mode menthe. -
Passthrough: Le CCO fonctionne en mode "passthrough". -
Manual: Le CCO fonctionne en mode manuel.
ImportantPour déterminer la configuration spécifique d'un cluster AWS ou GCP dont l'adresse
spec.credentialsModeest'',Mint, ouManual, vous devez procéder à des recherches plus approfondies.Les clusters AWS et GCP prennent en charge l'utilisation du mode menthe avec le secret racine supprimé.
Un cluster AWS ou GCP qui utilise le mode manuel peut être configuré pour créer et gérer des informations d'identification cloud depuis l'extérieur du cluster à l'aide du service de jetons de sécurité AWS (STS) ou de l'identité de charge de travail GCP. Vous pouvez déterminer si votre cluster utilise cette stratégie en examinant l'objet cluster
Authentication.-
Les clusters AWS ou GCP qui utilisent la valeur par défaut (
'') uniquement : Pour déterminer si le cluster fonctionne en mode "mint" ou "passthrough", inspectez les annotations sur le secret racine du cluster :Naviguez jusqu'à Workloads → Secrets et recherchez le secret racine de votre fournisseur de cloud.
NoteAssurez-vous que la liste déroulante Project est réglée sur All Projects.
Expand Plate-forme Nom secret AWS
aws-credsPCG
gcp-credentialsPour afficher le mode CCO utilisé par le cluster, cliquez sur
1 annotationsous Annotations, et vérifiez le champ de valeur. Les valeurs suivantes sont possibles :-
Mint: Le CCO fonctionne en mode menthe. -
Passthrough: Le CCO fonctionne en mode "passthrough".
Si votre cluster utilise le mode "mint", vous pouvez également déterminer si le cluster fonctionne sans le secret racine.
-
Clusters AWS ou GCP qui utilisent uniquement le mode menthe : Pour déterminer si le cluster fonctionne sans le secret racine, accédez à Workloads → Secrets et recherchez le secret racine de votre fournisseur de cloud.
NoteAssurez-vous que la liste déroulante Project est réglée sur All Projects.
Expand Plate-forme Nom secret AWS
aws-credsPCG
gcp-credentials- Si vous voyez l'une de ces valeurs, votre cluster utilise le mode mint ou passthrough avec le secret root présent.
- Si vous ne voyez pas ces valeurs, c'est que votre cluster utilise l'OCC en mode menthe avec le secret racine supprimé.
Clusters AWS ou GCP qui utilisent uniquement le mode manuel : Pour déterminer si le cluster est configuré pour créer et gérer des informations d'identification cloud depuis l'extérieur du cluster, vous devez vérifier les valeurs YAML de l'objet cluster
Authentication.- Naviguez jusqu'à Administration → Cluster Settings.
- Sur la page Cluster Settings, sélectionnez l'onglet Configuration.
- Sous Configuration resource, sélectionnez Authentication.
- Sur la page Authentication details, sélectionnez l'onglet YAML.
Dans le bloc YAML, vérifiez la valeur du paramètre
.spec.serviceAccountIssuer.-
Une valeur qui contient une URL associée à votre fournisseur de cloud indique que le CCO utilise le mode manuel avec AWS STS ou GCP Workload Identity pour créer et gérer les informations d'identification du cloud depuis l'extérieur du cluster. Ces clusters sont configurés à l'aide de l'utilitaire
ccoctl. -
Une valeur vide (
'') indique que le cluster utilise le CCO en mode manuel mais qu'il n'a pas été configuré à l'aide de l'utilitaireccoctl.
-
Une valeur qui contient une URL associée à votre fournisseur de cloud indique que le CCO utilise le mode manuel avec AWS STS ou GCP Workload Identity pour créer et gérer les informations d'identification du cloud depuis l'extérieur du cluster. Ces clusters sont configurés à l'aide de l'utilitaire
19.1.2.2. Détermination du mode Cloud Credential Operator à l'aide de la CLI
Vous pouvez déterminer le mode de configuration du Cloud Credential Operator (CCO) à l'aide de la CLI.
Seuls les clusters Amazon Web Services (AWS), Microsoft Azure et Google Cloud Platform (GCP) prennent en charge plusieurs modes de CCO.
Conditions préalables
- Vous avez accès à un compte OpenShift Container Platform avec des permissions d'administrateur de cluster.
-
Vous avez installé l'OpenShift CLI (
oc).
Procédure
-
Connectez-vous à
ocsur le cluster en tant qu'utilisateur ayant le rôlecluster-admin. Pour déterminer le mode dans lequel le CCO est configuré, entrez la commande suivante :
$ oc get cloudcredentials cluster \ -o=jsonpath={.spec.credentialsMode}Les valeurs de sortie suivantes sont possibles, bien qu'elles ne soient pas toutes prises en charge sur toutes les plates-formes :
-
'': Le CCO fonctionne dans le mode par défaut. Dans cette configuration, le CCO fonctionne en mode "menthe" ou "passthrough", en fonction des informations d'identification fournies lors de l'installation. -
Mint: Le CCO fonctionne en mode menthe. -
Passthrough: Le CCO fonctionne en mode "passthrough". -
Manual: Le CCO fonctionne en mode manuel.
ImportantPour déterminer la configuration spécifique d'un cluster AWS ou GCP dont l'adresse
spec.credentialsModeest'',Mint, ouManual, vous devez procéder à des recherches plus approfondies.Les clusters AWS et GCP prennent en charge l'utilisation du mode menthe avec le secret racine supprimé.
Un cluster AWS ou GCP qui utilise le mode manuel peut être configuré pour créer et gérer des informations d'identification cloud depuis l'extérieur du cluster à l'aide du service de jetons de sécurité AWS (STS) ou de l'identité de charge de travail GCP. Vous pouvez déterminer si votre cluster utilise cette stratégie en examinant l'objet cluster
Authentication.-
Les clusters AWS ou GCP qui utilisent la valeur par défaut (
'') uniquement : Pour déterminer si le cluster fonctionne en mode "mint" ou "passthrough", exécutez la commande suivante :$ oc get secret <secret_name> \ -n kube-system \ -o jsonpath \ --template '{ .metadata.annotations }'où
<secret_name>estaws-credspour AWS ougcp-credentialspour GCP.Cette commande affiche la valeur du paramètre
.metadata.annotationsdans l'objet secret de la racine du cluster. Les valeurs suivantes sont possibles :-
Mint: Le CCO fonctionne en mode menthe. -
Passthrough: Le CCO fonctionne en mode "passthrough".
Si votre cluster utilise le mode "mint", vous pouvez également déterminer si le cluster fonctionne sans le secret racine.
-
Clusters AWS ou GCP qui utilisent uniquement le mode menthe : Pour déterminer si le cluster fonctionne sans le secret racine, exécutez la commande suivante :
$ oc get secret <secret_name> \ -n=kube-systemoù
<secret_name>estaws-credspour AWS ougcp-credentialspour GCP.Si le secret racine est présent, la sortie de cette commande renvoie des informations sur le secret. Une erreur indique que le secret racine n'est pas présent sur le cluster.
Clusters AWS ou GCP qui utilisent uniquement le mode manuel : Pour déterminer si le cluster est configuré pour créer et gérer des informations d'identification cloud depuis l'extérieur du cluster, exécutez la commande suivante :
$ oc get authentication cluster \ -o jsonpath \ --template='{ .spec.serviceAccountIssuer }'Cette commande affiche la valeur du paramètre
.spec.serviceAccountIssuerdans l'objet clusterAuthentication.-
Une sortie d'une URL associée à votre fournisseur de cloud indique que le CCO utilise le mode manuel avec AWS STS ou GCP Workload Identity pour créer et gérer les informations d'identification du cloud depuis l'extérieur du cluster. Ces clusters sont configurés à l'aide de l'utilitaire
ccoctl. -
Une sortie vide indique que le cluster utilise le CCO en mode manuel mais qu'il n'a pas été configuré à l'aide de l'utilitaire
ccoctl.
-
Une sortie d'une URL associée à votre fournisseur de cloud indique que le CCO utilise le mode manuel avec AWS STS ou GCP Workload Identity pour créer et gérer les informations d'identification du cloud depuis l'extérieur du cluster. Ces clusters sont configurés à l'aide de l'utilitaire
19.1.3. Comportement par défaut
Pour les plateformes sur lesquelles plusieurs modes sont pris en charge (AWS, Azure et GCP), lorsque l'OCC fonctionne dans son mode par défaut, il vérifie les informations d'identification fournies de manière dynamique afin de déterminer pour quel mode elles sont suffisantes pour traiter les CR CredentialsRequest.
Par défaut, l'OCC détermine si les informations d'identification sont suffisantes pour le mode menthe, qui est le mode de fonctionnement préféré, et utilise ces informations d'identification pour créer les informations d'identification appropriées pour les composants du cluster. Si les informations d'identification ne sont pas suffisantes pour le mode mint, il détermine si elles sont suffisantes pour le mode passthrough. Si les informations d'identification ne sont pas suffisantes pour le mode passthrough, le CCO ne peut pas traiter correctement les CR CredentialsRequest.
Si les informations d'identification fournies sont jugées insuffisantes lors de l'installation, celle-ci échoue. Pour AWS, le programme d'installation échoue au début du processus et indique les autorisations requises manquantes. D'autres fournisseurs peuvent ne pas fournir d'informations spécifiques sur la cause de l'erreur jusqu'à ce que des erreurs soient rencontrées.
Si les informations d'identification sont modifiées après une installation réussie et que le CCO détermine que les nouvelles informations d'identification sont insuffisantes, il pose des conditions à toute nouvelle CR CredentialsRequest pour indiquer qu'il ne peut pas les traiter en raison de l'insuffisance des informations d'identification.
Pour résoudre les problèmes liés à l'insuffisance des informations d'identification, fournissez une information d'identification avec des autorisations suffisantes. Si une erreur s'est produite lors de l'installation, essayez à nouveau de l'installer. Pour les problèmes liés aux nouvelles CR CredentialsRequest, attendez que le CCO essaie à nouveau de traiter la CR. Vous pouvez également créer manuellement un IAM pour AWS, Azure et GCP.
19.2. Utilisation du mode menthe
Le mode Mint est pris en charge pour Amazon Web Services (AWS) et Google Cloud Platform (GCP).
Le mode Mint est le mode par défaut sur les plateformes pour lesquelles il est pris en charge. Dans ce mode, le CCO (Cloud Credential Operator) utilise l'identifiant cloud de niveau administrateur fourni pour créer de nouveaux identifiants pour les composants du cluster avec uniquement les autorisations spécifiques requises.
Si l'identifiant n'est pas supprimé après l'installation, il est stocké et utilisé par le CCO pour traiter les CR CredentialsRequest pour les composants du cluster et créer de nouveaux identifiants pour chacun d'entre eux avec uniquement les autorisations spécifiques requises. Le rapprochement continu des informations d'identification du nuage en mode "mint" permet d'effectuer des actions qui nécessitent des informations d'identification ou des autorisations supplémentaires, telles que la mise à niveau.
Le mode Mint stocke les informations d'identification au niveau de l'administrateur dans l'espace de noms du cluster kube-system. Si cette approche ne répond pas aux exigences de sécurité de votre organisation, consultez Alternatives to storing administrator-level secrets in the kube-system project pour AWS ou GCP.
19.2.1. Exigences en matière de permissions pour le mode Mint
Lorsque vous utilisez l'OCC en mode menthe, assurez-vous que les informations d'identification que vous fournissez répondent aux exigences du nuage sur lequel vous exécutez ou installez OpenShift Container Platform. Si les informations d'identification fournies ne sont pas suffisantes pour le mode mint, le CCO ne peut pas créer d'utilisateur IAM.
19.2.1.1. Autorisations d'Amazon Web Services (AWS)
L'identifiant que vous fournissez pour le mode menthe dans AWS doit avoir les permissions suivantes :
-
iam:CreateAccessKey -
iam:CreateUser -
iam:DeleteAccessKey -
iam:DeleteUser -
iam:DeleteUserPolicy -
iam:GetUser -
iam:GetUserPolicy -
iam:ListAccessKeys -
iam:PutUserPolicy -
iam:TagUser -
iam:SimulatePrincipalPolicy
19.2.1.2. Autorisations pour Google Cloud Platform (GCP)
L'identifiant que vous fournissez pour le mode menthe dans GCP doit avoir les permissions suivantes :
-
resourcemanager.projects.get -
serviceusage.services.list -
iam.serviceAccountKeys.create -
iam.serviceAccountKeys.delete -
iam.serviceAccounts.create -
iam.serviceAccounts.delete -
iam.serviceAccounts.get -
iam.roles.get -
resourcemanager.projects.getIamPolicy -
resourcemanager.projects.setIamPolicy
19.2.2. Informations d'identification de l'administrateur Format du secret de la racine
Par convention, chaque fournisseur d'informatique en nuage utilise un secret racine d'identification dans l'espace de noms kube-system, qui est ensuite utilisé pour satisfaire toutes les demandes d'identification et créer leurs secrets respectifs. Cela se fait soit en créant de nouvelles informations d'identification avec mint mode, soit en copiant le secret racine des informations d'identification avec passthrough mode.
Le format du secret varie selon le nuage et est également utilisé pour chaque secret CredentialsRequest.
Format secret d'Amazon Web Services (AWS)
apiVersion: v1
kind: Secret
metadata:
namespace: kube-system
name: aws-creds
stringData:
aws_access_key_id: <base64-encoded_access_key_id>
aws_secret_access_key: <base64-encoded_secret_access_key>Format secret de Google Cloud Platform (GCP)
apiVersion: v1
kind: Secret
metadata:
namespace: kube-system
name: gcp-credentials
stringData:
service_account.json: <base64-encoded_service_account>19.2.3. Mode Mint avec suppression ou rotation des informations d'identification au niveau de l'administrateur
Actuellement, ce mode n'est pris en charge que sur AWS et GCP.
Dans ce mode, un utilisateur installe OpenShift Container Platform avec un credential de niveau administrateur comme dans le mode normal mint. Cependant, ce processus supprime le secret d'accès de niveau administrateur du cluster après l'installation.
L'administrateur peut demander au Cloud Credential Operator de faire sa propre demande d'autorisation en lecture seule, ce qui lui permet de vérifier si tous les objets CredentialsRequest ont les autorisations requises. L'autorisation au niveau de l'administrateur n'est donc pas nécessaire, à moins que quelque chose doive être modifié. Une fois que le justificatif d'identité associé est supprimé, il peut être supprimé ou désactivé sur le nuage sous-jacent, si on le souhaite.
Avant une mise à niveau sans z-stream, vous devez rétablir le secret d'authentification avec l'authentification de niveau administrateur. Si l'identifiant n'est pas présent, la mise à niveau risque d'être bloquée.
Les informations d'identification au niveau de l'administrateur ne sont pas stockées de manière permanente dans le cluster.
En suivant ces étapes, il est toujours nécessaire d'avoir des informations d'identification de niveau administrateur dans le cluster pendant de brèves périodes. Il faut également réinstaurer manuellement le secret avec les informations d'identification de niveau administrateur pour chaque mise à niveau.
19.2.3.1. Rotation manuelle des informations d'identification des fournisseurs de services en nuage
Si les informations d'identification de votre fournisseur de cloud sont modifiées pour une raison quelconque, vous devez mettre à jour manuellement le secret utilisé par le CCO (Cloud Credential Operator) pour gérer les informations d'identification du fournisseur de cloud.
Le processus de rotation des informations d'identification du nuage dépend du mode utilisé par l'OCC. Après avoir effectué la rotation des informations d'identification pour un cluster utilisant le mode menthe, vous devez supprimer manuellement les informations d'identification du composant qui ont été créées par l'information d'identification supprimée.
Conditions préalables
Votre cluster est installé sur une plateforme qui prend en charge la rotation manuelle des identifiants cloud avec le mode CCO que vous utilisez :
- Pour le mode menthe, Amazon Web Services (AWS) et Google Cloud Platform (GCP) sont pris en charge.
- Vous avez modifié les informations d'identification utilisées pour l'interface avec votre fournisseur de services en nuage.
- Les nouvelles informations d'identification ont des autorisations suffisantes pour le mode que CCO est configuré pour utiliser dans votre cluster.
Procédure
- Dans la perspective Administrator de la console web, naviguez vers Workloads → Secrets.
Dans le tableau de la page Secrets, recherchez le secret racine de votre fournisseur de cloud.
Expand Plate-forme Nom secret AWS
aws-credsPCG
gcp-credentials-
Cliquez sur le menu Options
 sur la même ligne que le secret et sélectionnez Edit Secret.
sur la même ligne que le secret et sélectionnez Edit Secret.
- Enregistrez le contenu du ou des champs Value. Vous pouvez utiliser ces informations pour vérifier que la valeur est différente après la mise à jour des informations d'identification.
- Mettez à jour le texte du ou des champs Value avec les nouvelles informations d'authentification de votre fournisseur de cloud, puis cliquez sur Save.
Supprimer chaque secret de composant référencé par les objets individuels
CredentialsRequest.-
Connectez-vous au CLI de OpenShift Container Platform en tant qu'utilisateur ayant le rôle
cluster-admin. Obtenir les noms et les espaces de noms de tous les secrets de composants référencés :
$ oc -n openshift-cloud-credential-operator get CredentialsRequest \ -o json | jq -r '.items[] | select (.spec.providerSpec.kind=="<provider_spec>") | .spec.secretRef'où
<provider_spec>est la valeur correspondante pour votre fournisseur de services en nuage :-
AWS :
AWSProviderSpec -
GCP :
GCPProviderSpec
Exemple partiel de sortie pour AWS
{ "name": "ebs-cloud-credentials", "namespace": "openshift-cluster-csi-drivers" } { "name": "cloud-credential-operator-iam-ro-creds", "namespace": "openshift-cloud-credential-operator" }-
AWS :
Supprimer chacun des secrets des composants référencés :
$ oc delete secret <secret_name> \1 -n <secret_namespace>2 Exemple de suppression d'un secret AWS
$ oc delete secret ebs-cloud-credentials -n openshift-cluster-csi-driversIl n'est pas nécessaire de supprimer manuellement les informations d'identification à partir de la console du fournisseur. En supprimant les secrets des composants référencés, le CCO supprimera les informations d'identification existantes de la plateforme et en créera de nouvelles.
-
Connectez-vous au CLI de OpenShift Container Platform en tant qu'utilisateur ayant le rôle
Vérification
Pour vérifier que les informations d'identification ont changé :
- Dans la perspective Administrator de la console web, naviguez vers Workloads → Secrets.
- Vérifiez que le contenu du ou des champs Value a été modifié.
19.2.3.2. Suppression des informations d'identification du fournisseur de services en nuage
Après avoir installé un cluster OpenShift Container Platform avec le Cloud Credential Operator (CCO) en mode mineur, vous pouvez supprimer le secret d'authentification de niveau administrateur de l'espace de noms kube-system dans le cluster. Le justificatif d'identité de niveau administrateur n'est requis que pour les modifications nécessitant des autorisations élevées, telles que les mises à niveau.
Avant une mise à niveau sans z-stream, vous devez rétablir le secret d'authentification avec l'authentification de niveau administrateur. Si l'identifiant n'est pas présent, la mise à niveau risque d'être bloquée.
Conditions préalables
- Votre cluster est installé sur une plateforme qui prend en charge la suppression des informations d'identification du nuage à partir du CCO. Les plateformes prises en charge sont AWS et GCP.
Procédure
- Dans la perspective Administrator de la console web, naviguez vers Workloads → Secrets.
Dans le tableau de la page Secrets, recherchez le secret racine de votre fournisseur de cloud.
Expand Plate-forme Nom secret AWS
aws-credsPCG
gcp-credentials-
Cliquez sur le menu Options
sur la même ligne que le secret et sélectionnez Delete Secret.
19.3. Utilisation du mode passthrough
Le mode Passthrough est pris en charge pour Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), Red Hat OpenStack Platform (RHOSP), Red Hat Virtualization (RHV) et VMware vSphere.
En mode passthrough, le Cloud Credential Operator (CCO) transmet le justificatif d'identité cloud fourni aux composants qui demandent des justificatifs d'identité cloud. L'identifiant doit être autorisé à effectuer l'installation et les opérations requises par les composants du cluster, mais il ne doit pas être en mesure de créer de nouveaux identifiants. Le CCO ne tente pas de créer d'autres informations d'identification à portée limitée en mode passthrough.
Le mode manuel est la seule configuration CCO prise en charge pour Microsoft Azure Stack Hub.
19.3.1. Exigences en matière de permissions pour le mode Passthrough
Lorsque vous utilisez le CCO en mode passthrough, assurez-vous que les informations d'identification que vous fournissez répondent aux exigences du nuage sur lequel vous exécutez ou installez OpenShift Container Platform. Si les informations d'identification fournies par le CCO à un composant qui crée un CR CredentialsRequest ne sont pas suffisantes, ce composant signalera une erreur lorsqu'il tentera d'appeler une API pour laquelle il ne dispose pas d'autorisations.
19.3.1.1. Autorisations d'Amazon Web Services (AWS)
L'identifiant que vous fournissez pour le mode passthrough dans AWS doit avoir toutes les autorisations requises pour tous les CR CredentialsRequest qui sont requis par la version d'OpenShift Container Platform que vous exécutez ou installez.
Pour trouver les CR CredentialsRequest nécessaires, voir Création manuelle d'IAM pour AWS.
19.3.1.2. Permissions Microsoft Azure
L'identifiant que vous fournissez pour le mode passthrough dans Azure doit avoir toutes les permissions requises pour tous les CR CredentialsRequest requis par la version d'OpenShift Container Platform que vous exécutez ou installez.
Pour trouver les CR CredentialsRequest nécessaires, voir Création manuelle d'IAM pour Azure.
19.3.1.3. Autorisations pour Google Cloud Platform (GCP)
L'identifiant que vous fournissez pour le mode passthrough dans GCP doit avoir toutes les autorisations requises pour tous les CR CredentialsRequest qui sont requis par la version d'OpenShift Container Platform que vous exécutez ou installez.
Pour trouver les CR CredentialsRequest nécessaires, voir Création manuelle d'IAM pour GCP.
19.3.1.4. Permissions de Red Hat OpenStack Platform (RHOSP)
Pour installer un cluster OpenShift Container Platform sur RHOSP, le CCO a besoin d'un identifiant avec les permissions d'un rôle d'utilisateur member.
19.3.1.5. Permissions de Red Hat Virtualization (RHV)
Pour installer un cluster OpenShift Container Platform sur RHV, le CCO a besoin d'un identifiant avec les privilèges suivants :
-
DiskOperator -
DiskCreator -
UserTemplateBasedVm -
TemplateOwner -
TemplateCreator -
ClusterAdminsur le cluster spécifique ciblé pour le déploiement d'OpenShift Container Platform
19.3.1.6. Permissions VMware vSphere
Pour installer un cluster OpenShift Container Platform sur VMware vSphere, le CCO a besoin d'un identifiant avec les privilèges vSphere suivants :
| Catégorie | Privilèges |
|---|---|
| Magasin de données | Allocate space |
| Dossier | Create folder, Delete folder |
| tagging vSphere | Tous les privilèges |
| Réseau | Assign network |
| Ressources | Assign virtual machine to resource pool |
| Stockage en fonction du profil | Tous les privilèges |
| vApp | Tous les privilèges |
| Machine virtuelle | Tous les privilèges |
19.3.2. Informations d'identification de l'administrateur Format du secret de la racine
Par convention, chaque fournisseur d'informatique en nuage utilise un secret racine d'identification dans l'espace de noms kube-system, qui est ensuite utilisé pour satisfaire toutes les demandes d'identification et créer leurs secrets respectifs. Cela se fait soit en créant de nouvelles informations d'identification avec mint mode, soit en copiant le secret racine des informations d'identification avec passthrough mode.
Le format du secret varie selon le nuage et est également utilisé pour chaque secret CredentialsRequest.
Format secret d'Amazon Web Services (AWS)
apiVersion: v1
kind: Secret
metadata:
namespace: kube-system
name: aws-creds
stringData:
aws_access_key_id: <base64-encoded_access_key_id>
aws_secret_access_key: <base64-encoded_secret_access_key>Format secret Microsoft Azure
apiVersion: v1
kind: Secret
metadata:
namespace: kube-system
name: azure-credentials
stringData:
azure_subscription_id: <base64-encoded_subscription_id>
azure_client_id: <base64-encoded_client_id>
azure_client_secret: <base64-encoded_client_secret>
azure_tenant_id: <base64-encoded_tenant_id>
azure_resource_prefix: <base64-encoded_resource_prefix>
azure_resourcegroup: <base64-encoded_resource_group>
azure_region: <base64-encoded_region>Sur Microsoft Azure, le format du secret d'identification comprend deux propriétés qui doivent contenir l'identifiant d'infrastructure du cluster, généré de manière aléatoire pour chaque installation de cluster. Cette valeur peut être trouvée après l'exécution de la création de manifestes :
$ cat .openshift_install_state.json | jq '."*installconfig.ClusterID".InfraID' -rExemple de sortie
mycluster-2mpcnCette valeur sera utilisée dans les données secrètes comme suit :
azure_resource_prefix: mycluster-2mpcn
azure_resourcegroup: mycluster-2mpcn-rgFormat secret de Google Cloud Platform (GCP)
apiVersion: v1
kind: Secret
metadata:
namespace: kube-system
name: gcp-credentials
stringData:
service_account.json: <base64-encoded_service_account>Format secret de la plateforme Red Hat OpenStack (RHOSP)
apiVersion: v1
kind: Secret
metadata:
namespace: kube-system
name: openstack-credentials
data:
clouds.yaml: <base64-encoded_cloud_creds>
clouds.conf: <base64-encoded_cloud_creds_init>Format secret de Red Hat Virtualization (RHV)
apiVersion: v1
kind: Secret
metadata:
namespace: kube-system
name: ovirt-credentials
data:
ovirt_url: <base64-encoded_url>
ovirt_username: <base64-encoded_username>
ovirt_password: <base64-encoded_password>
ovirt_insecure: <base64-encoded_insecure>
ovirt_ca_bundle: <base64-encoded_ca_bundle>Format secret VMware vSphere
apiVersion: v1
kind: Secret
metadata:
namespace: kube-system
name: vsphere-creds
data:
vsphere.openshift.example.com.username: <base64-encoded_username>
vsphere.openshift.example.com.password: <base64-encoded_password>19.3.3. Gestion des informations d'identification en mode "Passthrough
Si les CR de CredentialsRequest changent au fil du temps lors de la mise à niveau du cluster, vous devez mettre à jour manuellement les informations d'identification du mode passthrough pour répondre aux exigences. Pour éviter les problèmes d'informations d'identification lors d'une mise à niveau, vérifiez les CR CredentialsRequest dans l'image de la nouvelle version d'OpenShift Container Platform avant de procéder à la mise à niveau. Pour localiser les CR CredentialsRequest nécessaires pour votre fournisseur de cloud, voir Manually creating IAM pour AWS, Azure ou GCP.
19.3.3.1. Rotation manuelle des informations d'identification des fournisseurs de services en nuage
Si les informations d'identification de votre fournisseur de cloud sont modifiées pour une raison quelconque, vous devez mettre à jour manuellement le secret utilisé par le CCO (Cloud Credential Operator) pour gérer les informations d'identification du fournisseur de cloud.
Le processus de rotation des informations d'identification du nuage dépend du mode utilisé par l'OCC. Après avoir effectué la rotation des informations d'identification pour un cluster utilisant le mode menthe, vous devez supprimer manuellement les informations d'identification du composant qui ont été créées par l'information d'identification supprimée.
Conditions préalables
Votre cluster est installé sur une plateforme qui prend en charge la rotation manuelle des identifiants cloud avec le mode CCO que vous utilisez :
- Pour le mode passthrough, Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), Red Hat OpenStack Platform (RHOSP), Red Hat Virtualization (RHV) et VMware vSphere sont pris en charge.
- Vous avez modifié les informations d'identification utilisées pour l'interface avec votre fournisseur de services en nuage.
- Les nouvelles informations d'identification ont des autorisations suffisantes pour le mode que CCO est configuré pour utiliser dans votre cluster.
Procédure
- Dans la perspective Administrator de la console web, naviguez vers Workloads → Secrets.
Dans le tableau de la page Secrets, recherchez le secret racine de votre fournisseur de cloud.
Expand Plate-forme Nom secret AWS
aws-credsL'azur
azure-credentialsPCG
gcp-credentialsRHOSP
openstack-credentialsRHV
ovirt-credentialsVMware vSphere
vsphere-creds-
Cliquez sur le menu Options
sur la même ligne que le secret et sélectionnez Edit Secret.
- Enregistrez le contenu du ou des champs Value. Vous pouvez utiliser ces informations pour vérifier que la valeur est différente après la mise à jour des informations d'identification.
- Mettez à jour le texte du ou des champs Value avec les nouvelles informations d'authentification de votre fournisseur de cloud, puis cliquez sur Save.
Si vous mettez à jour les informations d'identification pour un cluster vSphere qui n'a pas activé vSphere CSI Driver Operator, vous devez forcer un déploiement du gestionnaire de contrôleur Kubernetes pour appliquer les informations d'identification mises à jour.
NoteSi le vSphere CSI Driver Operator est activé, cette étape n'est pas nécessaire.
Pour appliquer les informations d'identification vSphere mises à jour, connectez-vous au CLI de OpenShift Container Platform en tant qu'utilisateur ayant le rôle
cluster-adminet exécutez la commande suivante :$ oc patch kubecontrollermanager cluster \ -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date )"'"}}' \ --type=mergePendant que les informations d'identification sont diffusées, l'état de l'opérateur du contrôleur Kubernetes Controller Manager est indiqué à l'adresse
Progressing=true. Pour afficher l'état, exécutez la commande suivante :$ oc get co kube-controller-manager
Vérification
Pour vérifier que les informations d'identification ont changé :
- Dans la perspective Administrator de la console web, naviguez vers Workloads → Secrets.
- Vérifiez que le contenu du ou des champs Value a été modifié.
19.3.4. Réduire les autorisations après l'installation
Lorsque vous utilisez le mode "passthrough", chaque composant dispose des mêmes autorisations que celles utilisées par tous les autres composants. Si vous ne réduisez pas les autorisations après l'installation, tous les composants disposent des autorisations générales nécessaires à l'exécution du programme d'installation.
Après l'installation, vous pouvez réduire les autorisations sur votre justificatif d'identité à celles qui sont nécessaires pour exécuter le cluster, comme défini par les CR CredentialsRequest dans l'image de version pour la version d'OpenShift Container Platform que vous utilisez.
Pour trouver les CR CredentialsRequest nécessaires pour AWS, Azure ou GCP et savoir comment modifier les autorisations utilisées par le CCO, voir Manually creating IAM pour AWS, Azure ou GCP.
19.4. Utilisation du mode manuel
Le mode manuel est pris en charge pour Alibaba Cloud, Amazon Web Services (AWS), Microsoft Azure, IBM Cloud et Google Cloud Platform (GCP).
En mode manuel, un utilisateur gère les informations d'identification du nuage à la place de l'opérateur d'informations d'identification du nuage (CCO). Pour utiliser ce mode, vous devez examiner les CR CredentialsRequest dans l'image de la version d'OpenShift Container Platform que vous exécutez ou installez, créer les informations d'identification correspondantes dans le fournisseur de cloud sous-jacent et créer des Secrets Kubernetes dans les espaces de noms corrects pour satisfaire toutes les CR CredentialsRequest pour le fournisseur de cloud du cluster.
L'utilisation du mode manuel permet à chaque composant du cluster de ne disposer que des autorisations dont il a besoin, sans stocker d'informations d'identification de niveau administrateur dans le cluster. Ce mode ne nécessite pas non plus de connexion au point de terminaison IAM public d'AWS. Cependant, vous devez réconcilier manuellement les autorisations avec les nouvelles images de version pour chaque mise à niveau.
Pour plus d'informations sur la configuration de votre fournisseur de cloud pour utiliser le mode manuel, consultez les options de gestion manuelle des informations d'identification de votre fournisseur de cloud :
19.4.1. Mode manuel avec des informations d'identification créées et gérées en dehors du cluster
Un cluster AWS ou GCP qui utilise le mode manuel peut être configuré pour créer et gérer des informations d'identification cloud depuis l'extérieur du cluster à l'aide du service de jetons de sécurité AWS (STS) ou de l'identité de charge de travail GCP. Avec cette configuration, le CCO utilise des informations d'identification temporaires pour différents composants.
Pour plus d'informations, voir Utilisation du mode manuel avec Amazon Web Services Security Token Service ou Utilisation du mode manuel avec GCP Workload Identity.
19.4.2. Mise à jour des ressources des fournisseurs de services en nuage à l'aide d'informations d'identification gérées manuellement
Avant de mettre à niveau un cluster dont les informations d'identification sont gérées manuellement, vous devez créer de nouvelles informations d'identification pour l'image de version vers laquelle vous effectuez la mise à niveau. Vous devez également examiner les autorisations requises pour les informations d'identification existantes et prendre en compte les nouvelles exigences en matière d'autorisations dans la nouvelle version pour ces composants.
Procédure
Extraire et examiner la ressource personnalisée
CredentialsRequestpour la nouvelle version.La section "Création manuelle de IAM" du contenu d'installation de votre fournisseur de cloud explique comment obtenir et utiliser les informations d'identification requises pour votre cloud.
Mettez à jour les informations d'identification gérées manuellement sur votre cluster :
-
Créer de nouveaux secrets pour toutes les ressources personnalisées
CredentialsRequestqui sont ajoutées par la nouvelle image. -
Si les ressources personnalisées
CredentialsRequestpour les informations d'identification existantes qui sont stockées dans des secrets ont modifié les exigences en matière d'autorisations, mettez à jour les autorisations comme il se doit.
-
Créer de nouveaux secrets pour toutes les ressources personnalisées
Si votre cluster utilise les capacités du cluster pour désactiver un ou plusieurs composants optionnels, supprimez les ressources personnalisées
CredentialsRequestpour tous les composants désactivés.Exemple
credrequestscontenu du répertoire pour OpenShift Container Platform 4.12 sur AWS0000_30_machine-api-operator_00_credentials-request.yaml1 0000_50_cloud-credential-operator_05-iam-ro-credentialsrequest.yaml2 0000_50_cluster-image-registry-operator_01-registry-credentials-request.yaml3 0000_50_cluster-ingress-operator_00-ingress-credentials-request.yaml4 0000_50_cluster-network-operator_02-cncc-credentials.yaml5 0000_50_cluster-storage-operator_03_credentials_request_aws.yaml6 - 1
- Le certificat de conducteur de machine API est exigé.
- 2
- Le certificat d'opérateur de titres de créance en nuage est requis.
- 3
- Le certificat d'opérateur de registre d'images est requis.
- 4
- Le CR de l'opérateur d'entrée est requis.
- 5
- Le certificat d'opérateur de réseau est requis.
- 6
- Le Storage Operator CR est un composant optionnel et peut être désactivé dans votre cluster.
Exemple
credrequestscontenu du répertoire pour OpenShift Container Platform 4.12 sur GCP0000_26_cloud-controller-manager-operator_16_credentialsrequest-gcp.yaml1 0000_30_machine-api-operator_00_credentials-request.yaml2 0000_50_cloud-credential-operator_05-gcp-ro-credentialsrequest.yaml3 0000_50_cluster-image-registry-operator_01-registry-credentials-request-gcs.yaml4 0000_50_cluster-ingress-operator_00-ingress-credentials-request.yaml5 0000_50_cluster-network-operator_02-cncc-credentials.yaml6 0000_50_cluster-storage-operator_03_credentials_request_gcp.yaml7 - 1
- Le contrôleur de nuages Manager Operator CR est requis.
- 2
- Le certificat de conducteur de machine API est exigé.
- 3
- Le certificat d'opérateur de titres de créance en nuage est requis.
- 4
- Le certificat d'opérateur de registre d'images est requis.
- 5
- Le CR de l'opérateur d'entrée est requis.
- 6
- Le certificat d'opérateur de réseau est requis.
- 7
- Le Storage Operator CR est un composant optionnel et peut être désactivé dans votre cluster.
Prochaines étapes
-
Mettre à jour l'annotation
upgradeable-topour indiquer que le cluster est prêt à être mis à niveau.
19.4.2.1. Indique que la grappe est prête à être mise à niveau
L'état de Cloud Credential Operator (CCO) Upgradable pour un cluster dont les informations d'identification sont gérées manuellement est False par défaut.
Conditions préalables
-
Pour l'image de version vers laquelle vous effectuez la mise à niveau, vous avez traité toutes les nouvelles informations d'identification manuellement ou à l'aide de l'utilitaire Cloud Credential Operator (
ccoctl). -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
-
Connectez-vous à
ocsur le cluster en tant qu'utilisateur ayant le rôlecluster-admin. Modifiez la ressource
CloudCredentialpour ajouter une annotationupgradeable-todans le champmetadataen exécutant la commande suivante :$ oc edit cloudcredential clusterTexte à ajouter
... metadata: annotations: cloudcredential.openshift.io/upgradeable-to: <version_number> ...Où
<version_number>est la version vers laquelle vous effectuez la mise à niveau, au formatx.y.z. Par exemple, utilisez4.12.2pour OpenShift Container Platform 4.12.2.Plusieurs minutes peuvent s'écouler après l'ajout de l'annotation avant que l'état de mise à niveau ne change.
Vérification
- Dans la perspective Administrator de la console web, naviguez vers Administration → Cluster Settings.
Pour afficher les détails du statut du CCO, cliquez sur cloud-credential dans la liste Cluster Operators.
-
Si le statut Upgradeable de la section Conditions est False, vérifiez que l'annotation
upgradeable-toest exempte d'erreurs typographiques.
-
Si le statut Upgradeable de la section Conditions est False, vérifiez que l'annotation
- Lorsque l'état Upgradeable de la section Conditions est True, commencez la mise à niveau d'OpenShift Container Platform.
19.5. Utilisation du mode manuel avec le service de jetons de sécurité d'Amazon Web Services
Le mode manuel avec STS est pris en charge pour Amazon Web Services (AWS).
Cette stratégie d'informations d'identification n'est prise en charge que pour les nouveaux clusters OpenShift Container Platform et doit être configurée lors de l'installation. Vous ne pouvez pas reconfigurer un cluster existant qui utilise une stratégie d'informations d'identification différente pour utiliser cette fonctionnalité.
19.5.1. À propos du mode manuel avec AWS Security Token Service
En mode manuel avec STS, les composants individuels du cluster OpenShift Container Platform utilisent AWS Security Token Service (STS) pour attribuer aux composants des rôles IAM qui fournissent des informations d'identification de sécurité à court terme et à privilèges limités. Ces informations d'identification sont associées à des rôles IAM spécifiques à chaque composant qui effectue des appels d'API AWS.
Les demandes d'informations d'identification nouvelles et actualisées sont automatisées en utilisant un fournisseur d'identité AWS IAM OpenID Connect (OIDC) configuré de manière appropriée, associé à des rôles AWS IAM. OpenShift Container Platform signe des jetons de compte de service qui sont approuvés par AWS IAM, et peuvent être projetés dans un pod et utilisés pour l'authentification. Les jetons sont actualisés au bout d'une heure.
Figure 19.1. Flux d'authentification STS

L'utilisation du mode manuel avec STS modifie le contenu des informations d'identification AWS fournies aux composants individuels d'OpenShift Container Platform.
Format secret AWS utilisant des informations d'identification à long terme
apiVersion: v1
kind: Secret
metadata:
namespace: <target-namespace>
name: <target-secret-name>
data:
aws_access_key_id: <base64-encoded-access-key-id>
aws_secret_access_key: <base64-encoded-secret-access-key>Format secret AWS avec STS
apiVersion: v1
kind: Secret
metadata:
namespace: <target-namespace>
name: <target-secret-name>
stringData:
credentials: |-
[default]
sts_regional_endpoints = regional
role_name: <operator-role-name>
web_identity_token_file: <path-to-token> 19.5.2. Installation d'un cluster OpenShift Container Platform configuré en mode manuel avec STS
Pour installer un cluster configuré pour utiliser le Cloud Credential Operator (CCO) en mode manuel avec STS :
Comme le cluster fonctionne en mode manuel lorsqu'il utilise STS, il n'est pas en mesure de créer de nouvelles informations d'identification pour les composants avec les autorisations dont ils ont besoin. Lors de la mise à niveau vers une version mineure différente d'OpenShift Container Platform, il y a souvent de nouvelles exigences en matière d'autorisations AWS. Avant de mettre à niveau un cluster qui utilise STS, l'administrateur du cluster doit s'assurer manuellement que les autorisations AWS sont suffisantes pour les composants existants et disponibles pour tout nouveau composant.
19.5.2.1. Configuration de l'utilitaire Cloud Credential Operator
Pour créer et gérer des informations d'identification du nuage depuis l'extérieur du cluster lorsque le Cloud Credential Operator (CCO) fonctionne en mode manuel, extrayez et préparez le binaire de l'utilitaire CCO (ccoctl).
L'utilitaire ccoctl est un binaire Linux qui doit être exécuté dans un environnement Linux.
Conditions préalables
- Vous avez accès à un compte OpenShift Container Platform avec un accès administrateur de cluster.
-
Vous avez installé l'OpenShift CLI (
oc).
Vous avez créé un compte AWS pour l'utilitaire
ccoctlavec les autorisations suivantes :Expand Tableau 19.3. Autorisations AWS requises iamautorisationss3autorisations-
iam:CreateOpenIDConnectProvider -
iam:CreateRole -
iam:DeleteOpenIDConnectProvider -
iam:DeleteRole -
iam:DeleteRolePolicy -
iam:GetOpenIDConnectProvider -
iam:GetRole -
iam:GetUser -
iam:ListOpenIDConnectProviders -
iam:ListRolePolicies -
iam:ListRoles -
iam:PutRolePolicy -
iam:TagOpenIDConnectProvider -
iam:TagRole
-
s3:CreateBucket -
s3:DeleteBucket -
s3:DeleteObject -
s3:GetBucketAcl -
s3:GetBucketTagging -
s3:GetObject -
s3:GetObjectAcl -
s3:GetObjectTagging -
s3:ListBucket -
s3:PutBucketAcl -
s3:PutBucketTagging -
s3:PutObject -
s3:PutObjectAcl -
s3:PutObjectTagging
-
Procédure
Obtenez l'image de la version d'OpenShift Container Platform en exécutant la commande suivante :
$ RELEASE_IMAGE=$(./openshift-install version | awk '/release image/ {print $3}')Obtenez l'image du conteneur CCO à partir de l'image de la version d'OpenShift Container Platform en exécutant la commande suivante :
$ CCO_IMAGE=$(oc adm release info --image-for='cloud-credential-operator' $RELEASE_IMAGE -a ~/.pull-secret)NoteVeillez à ce que l'architecture de
$RELEASE_IMAGEcorresponde à l'architecture de l'environnement dans lequel vous utiliserez l'outilccoctl.Extrayez le binaire
ccoctlde l'image du conteneur CCO dans l'image de la version d'OpenShift Container Platform en exécutant la commande suivante :$ oc image extract $CCO_IMAGE --file="/usr/bin/ccoctl" -a ~/.pull-secretModifiez les autorisations pour rendre
ccoctlexécutable en exécutant la commande suivante :$ chmod 775 ccoctl
Vérification
Pour vérifier que
ccoctlest prêt à être utilisé, affichez le fichier d'aide en exécutant la commande suivante :$ ccoctl --helpSortie de
ccoctl --help:OpenShift credentials provisioning tool Usage: ccoctl [command] Available Commands: alibabacloud Manage credentials objects for alibaba cloud aws Manage credentials objects for AWS cloud gcp Manage credentials objects for Google cloud help Help about any command ibmcloud Manage credentials objects for IBM Cloud nutanix Manage credentials objects for Nutanix Flags: -h, --help help for ccoctl Use "ccoctl [command] --help" for more information about a command.
19.5.2.2. Création de ressources AWS avec l'utilitaire Cloud Credential Operator
Vous pouvez utiliser l'utilitaire CCO (ccoctl) pour créer les ressources AWS requises individuellement ou à l'aide d'une seule commande.
19.5.2.2.1. Créer des ressources AWS individuellement
Si vous devez examiner les fichiers JSON créés par l'outil ccoctl avant de modifier les ressources AWS, ou si le processus utilisé par l'outil ccoctl pour créer automatiquement des ressources AWS ne répond pas aux exigences de votre organisation, vous pouvez créer les ressources AWS individuellement. Par exemple, cette option peut être utile pour une organisation qui partage la responsabilité de la création de ces ressources entre différents utilisateurs ou départements.
Sinon, vous pouvez utiliser la commande ccoctl aws create-all pour créer automatiquement les ressources AWS.
Par défaut, ccoctl crée les objets dans le répertoire dans lequel les commandes sont exécutées. Pour créer les objets dans un autre répertoire, utilisez l'option --output-dir. Cette procédure utilise <path_to_ccoctl_output_dir> pour faire référence à ce répertoire.
Certaines commandes ccoctl font appel à l'API AWS pour créer ou modifier des ressources AWS. Vous pouvez utiliser l'option --dry-run pour éviter les appels d'API. Cette option permet de créer des fichiers JSON sur le système de fichiers local. Vous pouvez examiner et modifier les fichiers JSON, puis les appliquer à l'aide de l'outil CLI AWS en utilisant les paramètres --cli-input-json.
Conditions préalables
-
Extraire et préparer le binaire
ccoctl.
Procédure
Générer les fichiers de clés RSA publiques et privées qui sont utilisées pour configurer le fournisseur OpenID Connect pour le cluster :
$ ccoctl aws create-key-pairExemple de sortie :
2021/04/13 11:01:02 Generating RSA keypair 2021/04/13 11:01:03 Writing private key to /<path_to_ccoctl_output_dir>/serviceaccount-signer.private 2021/04/13 11:01:03 Writing public key to /<path_to_ccoctl_output_dir>/serviceaccount-signer.public 2021/04/13 11:01:03 Copying signing key for use by installeroù
serviceaccount-signer.privateetserviceaccount-signer.publicsont les fichiers clés générés.Cette commande crée également une clé privée dont le cluster a besoin lors de l'installation sur
/<path_to_ccoctl_output_dir>/tls/bound-service-account-signing-key.key.Créez un fournisseur d'identité OpenID Connect et un seau S3 sur AWS :
$ ccoctl aws create-identity-provider \ --name=<name> \ --region=<aws_region> \ --public-key-file=<path_to_ccoctl_output_dir>/serviceaccount-signer.publicoù :
-
<name>est le nom utilisé pour étiqueter toutes les ressources du nuage créées pour le suivi. -
<aws-region>est la région AWS dans laquelle les ressources en nuage seront créées. -
<path_to_ccoctl_output_dir>est le chemin d'accès au fichier de clé publique généré par la commandeccoctl aws create-key-pair.
Exemple de sortie :
2021/04/13 11:16:09 Bucket <name>-oidc created 2021/04/13 11:16:10 OpenID Connect discovery document in the S3 bucket <name>-oidc at .well-known/openid-configuration updated 2021/04/13 11:16:10 Reading public key 2021/04/13 11:16:10 JSON web key set (JWKS) in the S3 bucket <name>-oidc at keys.json updated 2021/04/13 11:16:18 Identity Provider created with ARN: arn:aws:iam::<aws_account_id>:oidc-provider/<name>-oidc.s3.<aws_region>.amazonaws.comoù
openid-configurationest un document de découverte etkeys.jsonun fichier d'ensemble de clés web JSON.Cette commande crée également un fichier de configuration YAML à l'adresse
/<path_to_ccoctl_output_dir>/manifests/cluster-authentication-02-config.yaml. Ce fichier définit le champ URL de l'émetteur pour les jetons de compte de service générés par le cluster, afin que le fournisseur d'identité AWS IAM fasse confiance aux jetons.-
Créer des rôles IAM pour chaque composant du cluster.
Extraire la liste des objets
CredentialsRequestde l'image de la version d'OpenShift Container Platform :$ oc adm release extract --credentials-requests \ --cloud=aws \ --to=<path_to_directory_with_list_of_credentials_requests>/credrequests1 --from=quay.io/<path_to>/ocp-release:<version>- 1
credrequestsest le répertoire dans lequel la liste des objetsCredentialsRequestest stockée. Cette commande crée le répertoire s'il n'existe pas.
Si votre cluster utilise les capacités du cluster pour désactiver un ou plusieurs composants optionnels, supprimez les ressources personnalisées
CredentialsRequestpour tous les composants désactivés.Exemple
credrequestscontenu du répertoire pour OpenShift Container Platform 4.12 sur AWS0000_30_machine-api-operator_00_credentials-request.yaml1 0000_50_cloud-credential-operator_05-iam-ro-credentialsrequest.yaml2 0000_50_cluster-image-registry-operator_01-registry-credentials-request.yaml3 0000_50_cluster-ingress-operator_00-ingress-credentials-request.yaml4 0000_50_cluster-network-operator_02-cncc-credentials.yaml5 0000_50_cluster-storage-operator_03_credentials_request_aws.yaml6 - 1
- Le certificat de conducteur de machine API est exigé.
- 2
- Le certificat d'opérateur de titres de créance en nuage est requis.
- 3
- Le certificat d'opérateur de registre d'images est requis.
- 4
- Le CR de l'opérateur d'entrée est requis.
- 5
- Le certificat d'opérateur de réseau est requis.
- 6
- Le Storage Operator CR est un composant optionnel et peut être désactivé dans votre cluster.
Utilisez l'outil
ccoctlpour traiter tous les objetsCredentialsRequestdans le répertoirecredrequests:$ ccoctl aws create-iam-roles \ --name=<name> \ --region=<aws_region> \ --credentials-requests-dir=<path_to_directory_with_list_of_credentials_requests>/credrequests \ --identity-provider-arn=arn:aws:iam::<aws_account_id>:oidc-provider/<name>-oidc.s3.<aws_region>.amazonaws.comNotePour les environnements AWS qui utilisent d'autres points d'accès à l'API IAM, tels que GovCloud, vous devez également spécifier votre région à l'aide du paramètre
--region.Si votre cluster utilise des fonctionnalités d'aperçu technologique activées par l'ensemble de fonctionnalités
TechPreviewNoUpgrade, vous devez inclure le paramètre--enable-tech-preview.Pour chaque objet
CredentialsRequest,ccoctlcrée un rôle IAM avec une politique de confiance liée au fournisseur d'identité OIDC spécifié et une politique de permissions telle que définie dans chaque objetCredentialsRequestde l'image de version d'OpenShift Container Platform.
Vérification
Pour vérifier que les secrets d'OpenShift Container Platform sont créés, listez les fichiers dans le répertoire
<path_to_ccoctl_output_dir>/manifests:$ ll <path_to_ccoctl_output_dir>/manifestsExemple de sortie :
total 24 -rw-------. 1 <user> <user> 161 Apr 13 11:42 cluster-authentication-02-config.yaml -rw-------. 1 <user> <user> 379 Apr 13 11:59 openshift-cloud-credential-operator-cloud-credential-operator-iam-ro-creds-credentials.yaml -rw-------. 1 <user> <user> 353 Apr 13 11:59 openshift-cluster-csi-drivers-ebs-cloud-credentials-credentials.yaml -rw-------. 1 <user> <user> 355 Apr 13 11:59 openshift-image-registry-installer-cloud-credentials-credentials.yaml -rw-------. 1 <user> <user> 339 Apr 13 11:59 openshift-ingress-operator-cloud-credentials-credentials.yaml -rw-------. 1 <user> <user> 337 Apr 13 11:59 openshift-machine-api-aws-cloud-credentials-credentials.yaml
Vous pouvez vérifier que les rôles IAM sont créés en interrogeant AWS. Pour plus d'informations, reportez-vous à la documentation AWS sur l'énumération des rôles IAM.
19.5.2.2.2. Créer des ressources AWS à l'aide d'une seule commande
Si vous n'avez pas besoin d'examiner les fichiers JSON créés par l'outil ccoctl avant de modifier les ressources AWS et si le processus utilisé par l'outil ccoctl pour créer des ressources AWS répond automatiquement aux exigences de votre organisation, vous pouvez utiliser la commande ccoctl aws create-all pour automatiser la création de ressources AWS.
Sinon, vous pouvez créer les ressources AWS individuellement.
Par défaut, ccoctl crée les objets dans le répertoire dans lequel les commandes sont exécutées. Pour créer les objets dans un autre répertoire, utilisez l'option --output-dir. Cette procédure utilise <path_to_ccoctl_output_dir> pour faire référence à ce répertoire.
Conditions préalables
Vous devez avoir :
-
Extraction et préparation du binaire
ccoctl.
Procédure
Extrayez la liste des objets
CredentialsRequestde l'image de la version d'OpenShift Container Platform en exécutant la commande suivante :$ oc adm release extract \ --credentials-requests \ --cloud=aws \ --to=<path_to_directory_with_list_of_credentials_requests>/credrequests \1 --from=quay.io/<path_to>/ocp-release:<version>- 1
credrequestsest le répertoire dans lequel la liste des objetsCredentialsRequestest stockée. Cette commande crée le répertoire s'il n'existe pas.
NoteL'exécution de cette commande peut prendre quelques instants.
Si votre cluster utilise les capacités du cluster pour désactiver un ou plusieurs composants optionnels, supprimez les ressources personnalisées
CredentialsRequestpour tous les composants désactivés.Exemple
credrequestscontenu du répertoire pour OpenShift Container Platform 4.12 sur AWS0000_30_machine-api-operator_00_credentials-request.yaml1 0000_50_cloud-credential-operator_05-iam-ro-credentialsrequest.yaml2 0000_50_cluster-image-registry-operator_01-registry-credentials-request.yaml3 0000_50_cluster-ingress-operator_00-ingress-credentials-request.yaml4 0000_50_cluster-network-operator_02-cncc-credentials.yaml5 0000_50_cluster-storage-operator_03_credentials_request_aws.yaml6 - 1
- Le certificat de conducteur de machine API est exigé.
- 2
- Le certificat d'opérateur de titres de créance en nuage est requis.
- 3
- Le certificat d'opérateur de registre d'images est requis.
- 4
- Le CR de l'opérateur d'entrée est requis.
- 5
- Le certificat d'opérateur de réseau est requis.
- 6
- Le Storage Operator CR est un composant optionnel et peut être désactivé dans votre cluster.
Utilisez l'outil
ccoctlpour traiter tous les objetsCredentialsRequestdans le répertoirecredrequests:$ ccoctl aws create-all \ --name=<name> \1 --region=<aws_region> \2 --credentials-requests-dir=<path_to_directory_with_list_of_credentials_requests>/credrequests \3 --output-dir=<path_to_ccoctl_output_dir> \4 --create-private-s3-bucket5 - 1
- Spécifiez le nom utilisé pour étiqueter toutes les ressources du nuage créées pour le suivi.
- 2
- Spécifiez la région AWS dans laquelle les ressources en nuage seront créées.
- 3
- Spécifiez le répertoire contenant les fichiers des objets du composant
CredentialsRequest. - 4
- Facultatif : Indiquez le répertoire dans lequel vous souhaitez que l'utilitaire
ccoctlcrée des objets. Par défaut, l'utilitaire crée les objets dans le répertoire dans lequel les commandes sont exécutées. - 5
- Facultatif : Par défaut, l'utilitaire
ccoctlstocke les fichiers de configuration OpenID Connect (OIDC) dans un seau S3 public et utilise l'URL S3 comme point de terminaison OIDC public. Pour stocker la configuration OIDC dans un seau S3 privé auquel le fournisseur d'identité IAM accède via une URL de distribution CloudFront publique, utilisez le paramètre--create-private-s3-bucket.
NoteSi votre cluster utilise des fonctionnalités d'aperçu technologique activées par l'ensemble de fonctionnalités
TechPreviewNoUpgrade, vous devez inclure le paramètre--enable-tech-preview.
Vérification
Pour vérifier que les secrets d'OpenShift Container Platform sont créés, listez les fichiers dans le répertoire
<path_to_ccoctl_output_dir>/manifests:$ ls <path_to_ccoctl_output_dir>/manifestsExemple de sortie :
cluster-authentication-02-config.yaml openshift-cloud-credential-operator-cloud-credential-operator-iam-ro-creds-credentials.yaml openshift-cluster-csi-drivers-ebs-cloud-credentials-credentials.yaml openshift-image-registry-installer-cloud-credentials-credentials.yaml openshift-ingress-operator-cloud-credentials-credentials.yaml openshift-machine-api-aws-cloud-credentials-credentials.yaml
Vous pouvez vérifier que les rôles IAM sont créés en interrogeant AWS. Pour plus d'informations, reportez-vous à la documentation AWS sur l'énumération des rôles IAM.
19.5.2.3. Exécution du programme d'installation
Conditions préalables
- Configurez un compte auprès de la plateforme cloud qui héberge votre cluster.
- Obtenir l'image de la version d'OpenShift Container Platform.
Procédure
Allez dans le répertoire qui contient le programme d'installation et créez le fichier
install-config.yaml:openshift-install create install-config --dir <installation_directory>où
<installation_directory>est le répertoire dans lequel le programme d'installation crée les fichiers.Modifiez le fichier de configuration
install-config.yamlde manière à ce qu'il contienne le paramètrecredentialsModefixé àManual.Exemple
install-config.yamlfichier de configurationapiVersion: v1 baseDomain: cluster1.example.com credentialsMode: Manual1 compute: - architecture: amd64 hyperthreading: Enabled- 1
- Cette ligne est ajoutée pour fixer le paramètre
credentialsModeàManual.
Créez les manifestes d'installation requis pour OpenShift Container Platform :
$ openshift-install create manifestsCopiez les manifestes générés par
ccoctldans le répertoire manifests créé par le programme d'installation :$ cp /<path_to_ccoctl_output_dir>/manifests/* ./manifests/Copiez la clé privée générée par
ccoctldans le répertoiretlsdans le répertoire d'installation :$ cp -a /<path_to_ccoctl_output_dir>/tls .Exécutez le programme d'installation d'OpenShift Container Platform :
$ ./openshift-install create cluster
19.5.2.4. Vérification de l'installation
- Connectez-vous au cluster OpenShift Container Platform.
Vérifiez que le cluster n'a pas d'identifiants
root:$ oc get secrets -n kube-system aws-credsLe résultat devrait ressembler à ce qui suit :
Error from server (NotFound): secrets "aws-creds" not foundVérifier que les composants assument les rôles IAM spécifiés dans les manifestes secrets, au lieu d'utiliser les informations d'identification créées par l'OCC :
Exemple de commande avec l'opérateur de registre d'images
$ oc get secrets -n openshift-image-registry installer-cloud-credentials -o json | jq -r .data.credentials | base64 --decodeLe résultat doit indiquer le rôle et le jeton d'identité Web utilisés par le composant et ressembler à ce qui suit :
Exemple de sortie avec l'opérateur de registre d'images
[default] role_arn = arn:aws:iam::123456789:role/openshift-image-registry-installer-cloud-credentials web_identity_token_file = /var/run/secrets/openshift/serviceaccount/token
19.6. Utilisation du mode manuel avec GCP Workload Identity
Le mode manuel avec l'identité de charge de travail GCP est pris en charge pour Google Cloud Platform (GCP).
Cette stratégie d'informations d'identification n'est prise en charge que pour les nouveaux clusters OpenShift Container Platform et doit être configurée lors de l'installation. Vous ne pouvez pas reconfigurer un cluster existant qui utilise une stratégie d'informations d'identification différente pour utiliser cette fonctionnalité.
En mode manuel avec GCP Workload Identity, les composants individuels du cluster OpenShift Container Platform peuvent se faire passer pour des comptes de service IAM à l'aide d'informations d'identification à court terme et à privilèges limités.
Les demandes d'informations d'identification nouvelles et actualisées sont automatisées en utilisant un fournisseur d'identité OpenID Connect (OIDC) configuré de manière appropriée, associé à des comptes de service IAM. OpenShift Container Platform signe des jetons de compte de service qui sont approuvés par GCP, et peuvent être projetés dans un pod et utilisés pour l'authentification. Par défaut, les jetons sont actualisés au bout d'une heure.
L'utilisation du mode manuel avec GCP Workload Identity modifie le contenu des informations d'identification GCP fournies aux composants individuels d'OpenShift Container Platform.
Format du secret des BPC
apiVersion: v1
kind: Secret
metadata:
namespace: <target_namespace>
name: <target_secret_name>
data:
service_account.json: <service_account> Contenu du fichier service_account.json encodé en Base64 à l'aide d'informations d'identification à long terme
{
"type": "service_account",
"project_id": "<project_id>",
"private_key_id": "<private_key_id>",
"private_key": "<private_key>",
"client_email": "<client_email_address>",
"client_id": "<client_id>",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/<client_email_address>"
}Contenu du fichier service_account.json encodé en Base64 à l'aide de l'identité de la charge de travail GCP
{
"type": "external_account",
"audience": "//iam.googleapis.com/projects/123456789/locations/global/workloadIdentityPools/test-pool/providers/test-provider",
"subject_token_type": "urn:ietf:params:oauth:token-type:jwt",
"token_url": "https://sts.googleapis.com/v1/token",
"service_account_impersonation_url": "https://iamcredentials.googleapis.com/v1/projects/-/serviceAccounts/<client_email_address>:generateAccessToken",
"credential_source": {
"file": "<path_to_token>",
"format": {
"type": "text"
}
}
}- 1
- Le type de certificat est
external_account. - 2
- Le public cible est le fournisseur d'identité de charge de travail GCP.
- 3
- L'URL de la ressource du compte de service qui peut être associé à ces informations d'identification.
- 4
- Le chemin d'accès au jeton du compte de service dans le pod. Par convention, il s'agit de
/var/run/secrets/openshift/serviceaccount/tokenpour les composants de OpenShift Container Platform.
19.6.1. Installation d'un cluster OpenShift Container Platform configuré en mode manuel avec GCP Workload Identity
Pour installer un cluster configuré pour utiliser le Cloud Credential Operator (CCO) en mode manuel avec GCP Workload Identity :
Comme le cluster fonctionne en mode manuel lors de l'utilisation de GCP Workload Identity, il n'est pas en mesure de créer de nouvelles informations d'identification pour les composants avec les autorisations dont ils ont besoin. Lors de la mise à niveau vers une version mineure différente d'OpenShift Container Platform, il y a souvent de nouvelles exigences en matière d'autorisations GCP. Avant de mettre à niveau un cluster qui utilise GCP Workload Identity, l'administrateur du cluster doit s'assurer manuellement que les autorisations GCP sont suffisantes pour les composants existants et disponibles pour tous les nouveaux composants.
19.6.1.1. Configuration de l'utilitaire Cloud Credential Operator
Pour créer et gérer des informations d'identification du nuage depuis l'extérieur du cluster lorsque le Cloud Credential Operator (CCO) fonctionne en mode manuel, extrayez et préparez le binaire de l'utilitaire CCO (ccoctl).
L'utilitaire ccoctl est un binaire Linux qui doit être exécuté dans un environnement Linux.
Conditions préalables
- Vous avez accès à un compte OpenShift Container Platform avec un accès administrateur de cluster.
-
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Obtenez l'image de la version d'OpenShift Container Platform en exécutant la commande suivante :
$ RELEASE_IMAGE=$(./openshift-install version | awk '/release image/ {print $3}')Obtenez l'image du conteneur CCO à partir de l'image de la version d'OpenShift Container Platform en exécutant la commande suivante :
$ CCO_IMAGE=$(oc adm release info --image-for='cloud-credential-operator' $RELEASE_IMAGE -a ~/.pull-secret)NoteVeillez à ce que l'architecture de
$RELEASE_IMAGEcorresponde à l'architecture de l'environnement dans lequel vous utiliserez l'outilccoctl.Extrayez le binaire
ccoctlde l'image du conteneur CCO dans l'image de la version d'OpenShift Container Platform en exécutant la commande suivante :$ oc image extract $CCO_IMAGE --file="/usr/bin/ccoctl" -a ~/.pull-secretModifiez les autorisations pour rendre
ccoctlexécutable en exécutant la commande suivante :$ chmod 775 ccoctl
Vérification
Pour vérifier que
ccoctlest prêt à être utilisé, affichez le fichier d'aide en exécutant la commande suivante :$ ccoctl --helpSortie de
ccoctl --help:OpenShift credentials provisioning tool Usage: ccoctl [command] Available Commands: alibabacloud Manage credentials objects for alibaba cloud aws Manage credentials objects for AWS cloud gcp Manage credentials objects for Google cloud help Help about any command ibmcloud Manage credentials objects for IBM Cloud nutanix Manage credentials objects for Nutanix Flags: -h, --help help for ccoctl Use "ccoctl [command] --help" for more information about a command.
19.6.1.2. Création de ressources GCP avec l'utilitaire Cloud Credential Operator
Vous pouvez utiliser la commande ccoctl gcp create-all pour automatiser la création de ressources GCP.
Par défaut, ccoctl crée les objets dans le répertoire dans lequel les commandes sont exécutées. Pour créer les objets dans un autre répertoire, utilisez l'option --output-dir. Cette procédure utilise <path_to_ccoctl_output_dir> pour faire référence à ce répertoire.
Conditions préalables
Vous devez avoir :
-
Extraction et préparation du binaire
ccoctl.
Procédure
Extrayez la liste des objets
CredentialsRequestde l'image de la version d'OpenShift Container Platform en exécutant la commande suivante :$ oc adm release extract \ --credentials-requests \ --cloud=gcp \ --to=<path_to_directory_with_list_of_credentials_requests>/credrequests \1 quay.io/<path_to>/ocp-release:<version>- 1
credrequestsest le répertoire dans lequel la liste des objetsCredentialsRequestest stockée. Cette commande crée le répertoire s'il n'existe pas.
NoteL'exécution de cette commande peut prendre quelques instants.
Si votre cluster utilise les capacités du cluster pour désactiver un ou plusieurs composants optionnels, supprimez les ressources personnalisées
CredentialsRequestpour tous les composants désactivés.Exemple
credrequestscontenu du répertoire pour OpenShift Container Platform 4.12 sur GCP0000_26_cloud-controller-manager-operator_16_credentialsrequest-gcp.yaml1 0000_30_machine-api-operator_00_credentials-request.yaml2 0000_50_cloud-credential-operator_05-gcp-ro-credentialsrequest.yaml3 0000_50_cluster-image-registry-operator_01-registry-credentials-request-gcs.yaml4 0000_50_cluster-ingress-operator_00-ingress-credentials-request.yaml5 0000_50_cluster-network-operator_02-cncc-credentials.yaml6 0000_50_cluster-storage-operator_03_credentials_request_gcp.yaml7 - 1
- Le contrôleur de nuages Manager Operator CR est requis.
- 2
- Le certificat de conducteur de machine API est exigé.
- 3
- Le certificat d'opérateur de titres de créance en nuage est requis.
- 4
- Le certificat d'opérateur de registre d'images est requis.
- 5
- Le CR de l'opérateur d'entrée est requis.
- 6
- Le certificat d'opérateur de réseau est requis.
- 7
- Le Storage Operator CR est un composant optionnel et peut être désactivé dans votre cluster.
Utilisez l'outil
ccoctlpour traiter tous les objetsCredentialsRequestdans le répertoirecredrequests:$ ccoctl gcp create-all \ --name=<name> \ --region=<gcp_region> \ --project=<gcp_project_id> \ --credentials-requests-dir=<path_to_directory_with_list_of_credentials_requests>/credrequestsoù :
-
<name>est le nom défini par l'utilisateur pour toutes les ressources GCP créées et utilisées pour le suivi. -
<gcp_region>est la région du GCP dans laquelle les ressources en nuage seront créées. -
<gcp_project_id>est l'identifiant du projet GCP dans lequel les ressources en nuage seront créées. -
<path_to_directory_with_list_of_credentials_requests>/credrequestsest le répertoire contenant les fichiers des manifestesCredentialsRequestpour créer les comptes de service GCP.
NoteSi votre cluster utilise des fonctionnalités d'aperçu technologique activées par l'ensemble de fonctionnalités
TechPreviewNoUpgrade, vous devez inclure le paramètre--enable-tech-preview.-
Vérification
Pour vérifier que les secrets d'OpenShift Container Platform sont créés, listez les fichiers dans le répertoire
<path_to_ccoctl_output_dir>/manifests:$ ls <path_to_ccoctl_output_dir>/manifests
Vous pouvez vérifier que les comptes de service IAM sont créés en interrogeant GCP. Pour plus d'informations, reportez-vous à la documentation GCP sur l'établissement de la liste des comptes de service IAM.
19.6.1.3. Exécution du programme d'installation
Conditions préalables
- Configurez un compte auprès de la plateforme cloud qui héberge votre cluster.
- Obtenir l'image de la version d'OpenShift Container Platform.
Procédure
Allez dans le répertoire qui contient le programme d'installation et créez le fichier
install-config.yaml:openshift-install create install-config --dir <installation_directory>où
<installation_directory>est le répertoire dans lequel le programme d'installation crée les fichiers.Modifiez le fichier de configuration
install-config.yamlde manière à ce qu'il contienne le paramètrecredentialsModefixé àManual.Exemple
install-config.yamlfichier de configurationapiVersion: v1 baseDomain: cluster1.example.com credentialsMode: Manual1 compute: - architecture: amd64 hyperthreading: Enabled- 1
- Cette ligne est ajoutée pour fixer le paramètre
credentialsModeàManual.
Créez les manifestes d'installation requis pour OpenShift Container Platform :
$ openshift-install create manifestsCopiez les manifestes générés par
ccoctldans le répertoire manifests créé par le programme d'installation :$ cp /<path_to_ccoctl_output_dir>/manifests/* ./manifests/Copiez la clé privée générée par
ccoctldans le répertoiretlsdans le répertoire d'installation :$ cp -a /<path_to_ccoctl_output_dir>/tls .Exécutez le programme d'installation d'OpenShift Container Platform :
$ ./openshift-install create cluster
19.6.1.4. Vérification de l'installation
- Connectez-vous au cluster OpenShift Container Platform.
Vérifiez que le cluster n'a pas d'identifiants
root:$ oc get secrets -n kube-system gcp-credentialsLe résultat devrait ressembler à ce qui suit :
Error from server (NotFound): secrets "gcp-credentials" not foundVérifiez que les composants utilisent les comptes de service spécifiés dans les manifestes secrets, au lieu d'utiliser les informations d'identification créées par l'OCC :
Exemple de commande avec l'opérateur de registre d'images
$ oc get secrets -n openshift-image-registry installer-cloud-credentials -o json | jq -r '.data."service_account.json"' | base64 -dLe résultat doit indiquer le rôle et le jeton d'identité Web utilisés par le composant et ressembler à ce qui suit :
Exemple de sortie avec l'opérateur de registre d'images
{ "type": "external_account",1 "audience": "//iam.googleapis.com/projects/123456789/locations/global/workloadIdentityPools/test-pool/providers/test-provider", "subject_token_type": "urn:ietf:params:oauth:token-type:jwt", "token_url": "https://sts.googleapis.com/v1/token", "service_account_impersonation_url": "https://iamcredentials.googleapis.com/v1/projects/-/serviceAccounts/<client-email-address>:generateAccessToken",2 "credential_source": { "file": "/var/run/secrets/openshift/serviceaccount/token", "format": { "type": "text" } } }
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.