Aperçu général de la Cluster Suite
Red Hat Cluster Suite de Red Hat Enterprise Linux 5
Édition 3
Résumé
Introduction
- Guide d'installation de Red Hat Enterprise Linux — Fournit des informations à propos de l'installation de Red Hat Enterprise Linux 5.
- Guide de déploiement de Red Hat Enterprise Linux — Fournit des informations à propos du déploiement, de la configuration et de l'administration de Red Hat Enterprise Linux 5.
- Configuration et gestion d'un cluster Red Hat — Fournit des informations à propos de l'installation, la configuration et la gestion des composants Red hat Cluster.
- LVM Administrator's Guide: Configuration and Administration — Provides a description of the Logical Volume Manager (LVM), including information on running LVM in a clustered environment.
- Système de fichiers GFS : configuration et administration — Fournit des informations à propos de l'installation, la configuration et la maintenance de Red Hat GFS (Red Hat Global File System).
- Système de fichiers GFS 2 : configuration et administration — Fournit des informations à propos de l'installation, la configuration et la maintenance de Red Hat GFS (Red Hat Global File System 2).
- Utilisation de "Device-Mapper Multipath" — Fournit des informations à propos de l'utilisation de la fonctionnalité "Device-Mapper Multipath" de Red Hat Enterprise Linux 5.
- Utilisation de GNBD avec le système de fichiers GFS — Fournit un aperçu de l'utilisation de GNBD (de l'anglais Global Network Block Device) avec Red Hat GFS.
- Administration du serveur virtuel Linux — Fournit des informations à propos de la configuration de systèmes et services à hautes performances avec le serveur virtuel Linux (LVS de l'anglais Linux Virtual Server).
- Notes de mise à jour de Red Hat Cluster Suite — Fournit des informations à propos de la version courante de Red Hat Cluster Suite.
1. Commentaire
Documentation-cluster.
Cluster_Suite_Overview(EN)-5 (2008-12-11T15:49)
Cluster_Suite_Overview(EN)-5 (2008-12-11T15:49)
Chapitre 1. Aperçu de Red Hat Cluster Suite
1.1. Les bases d'un cluster
- Stockage
- Haute disponibilité
- Répartition de charge
- Haute performance
Note
1.2. Red Hat Cluster Suite Introduction
- Infrastructure de cluster — Fournit des fonctions fondamentales pour que les noeuds puissent travailler ensemble afin de former un cluster : gestion des fichiers de configuration, gestion des adhésions, gestion du verrouillage et fencing.
- Gestion de services à haute disponibilité — Fournit un failover de services à partir du noeud d'un cluster vers un autre lorsqu'un noeud devient inopérant.
- Outils d'administration du cluster — Outils de configuration et de gestion pour le paramétrage, la configuration et la gestion d'un cluster Red Hat. Les outils sont utilisés avec les composants d'infrastructure de cluster, les composants à haute disponibilité et de gestion des services, et le stockage.
- Serveur virtuel Linux (LVS de l'anglais Linux Virtual Server) — Logiciel de routage qui fournit une adresse IP de répartition de charge. LVS s'exécute dans une paire de serveurs redondants qui distribuent les demandes des clients de façon égale vers des serveurs réels situés derrière les serveurs LVS.
- Red Hat GFS (de l'anglais Global File System) — Fournit un système de fichiers en cluster à utiliser avec Red Hat Cluster Suite. GFS permet à plusieurs noeuds de partager le stockage au niveau bloc comme si le stockage était connecté localement à chaque noeud du cluster.
- Gestionnaire de volumes logiques en cluster (CLVM de l'anglais Cluster Logical Volume Manager) — Fournit une gestion de volumes du stockage en cluster.
Note
When you create or modify a CLVM volume for a clustered environment, you must ensure that you are running theclvmddaemon. For further information, refer to Section 1.6, « Gestionnaire de volumes logiques du cluster ». - Périphérique bloc du réseau global (GNBD de l'anglais Global Network Block Device) — Un composant auxiliaire de GFS qui exporte le stockage de niveau bloc vers Ethernet. Ceci est un moyen économique permettant de rendre le stockage de niveau bloc disponible à Red Hat GFS.

Figure 1.1. Red Hat Cluster Suite Introduction
Note
1.3. Cluster Infrastructure
- Gestion du cluster
- Gestion du verrouillage
- Fencing
- Gestion de la configuration du cluster
1.3.1. Gestion du cluster
Note

Figure 1.2. CMAN/DLM Overview
1.3.2. Gestion du verrouillage
1.3.3. Fencing
fenced.
fenced est averti de l'échec, il déconnecte le noeud qui a échoué. D'autres composants d'infrastructure de cluster déterminent les actions à effectuer — autrement dit, ils effectuent les récupérations qui doivent être faites. Par exemple, DLM et GFS, lorsqu'ils sont informés d'un échec, suspendent toute activité jusqu'à ce que fenced ait terminé la déconnexion du noeud qui a échoué. Suite à la confirmation de la déconnexion du noeud, DLM et GFS effectuent la récupération. DLM libère les verrous du noeud ayant échoué et GFS récupère le fichier journal.
- Power fencing — Une méthode fencing qui utilise un contrôleur de courant pour éteindre un noeud inopérant.
- Fibre Channel switch fencing — Une méthode fencing qui désactive le port Fibre Channel connectant le stockage à un noeud inopérant.
- GNBD fencing — A fencing method that disables an inoperable node's access to a GNBD server.
- Other fencing — D'autres méthodes fencing qui désactivent les E/S ou le courant d'un noeud inopérant, y compris IBM Bladecenters, PAP, DRAC/MC, HP ILO, IPMI, IBM RSA II et autres.

Figure 1.3. Power Fencing Example

Figure 1.4. Fibre Channel Switch Fencing Example

Figure 1.5. Fencing a Node with Dual Power Supplies

Figure 1.6. Fencing a Node with Dual Fibre Channel Connections
1.3.4. Système de configuration du cluster

Figure 1.7. CCS Overview

Figure 1.8. Accessing Configuration Information
/etc/cluster/cluster.conf) est un fichier XML qui décrit les caractéristiques suivantes du cluster :
- Nom du cluster — Affiche le nom du cluster, le niveau de révision du fichier de configuration et des propriétés de base du minutage fence utilisées lorsqu'un noeud joint un cluster ou qu'il est déconnecté.
- Cluster — Affiche chaque noeud du cluster, en spécifiant le nom du noeud, l'ID du noeud, le nombre de votes du quorum et la méthode fencing pour ce noeud.
- Périphérique fence — Affiche les périphériques fence du cluster. Les paramètres varient en fonction du type de périphérique fence. Par exemple, pour un contrôleur de courant utilisé comme périphérique fence, la configuration du cluster définit le nom du contrôleur de courant, son adresse IP, son identifiant de connexion et son mot de passe.
- Ressources gérées — Affiche les ressources nécessaires afin de créer les services cluster. Les ressources gérées inclues la définition de domaines failover, les ressources (par exemple une adresse IP) et les services. Ensemble, les ressources gérées définissent les services cluster et le comportement failover des services cluster.
1.4. Gestion des services à haute disponibilité
rgmanager, implémente un failover "à froid" ("cold failover") pour les applications "off-the-shelf". Dans un cluster Red Hat, une application est configurée avec d'autres ressources de cluster pour former un service cluster à haute disponibilité. Un service cluster à haute disponibilité peut, en cas d'échec, passer d'un noeud du cluster à un autre sans interruption apparente pour les clients du cluster. Un failover de service cluster peut se produire si le noeud d'un cluster échoue ou si un administrateur système de clusters déplace le service d'un noeud à un autre (par exemple, en vue de l'arrêt d'un noeud du cluster).
Note

Figure 1.9. Les domaines failover
- Une ressource pour l'adresse IP — Adresse IP 10.10.10.201.
- An application resource named "httpd-content" — a web server application init script
/etc/init.d/httpd(specifyinghttpd). - A file system resource — Red Hat GFS named "gfs-content-webserver".

Figure 1.10. Web Server Cluster Service Example
1.5. Red Hat GFS
- Simplification de votre infrastructure de données.
- Installation et application de correctifs, une seule fois, pour l'ensemble du cluster.
- Élimine le besoin de copies redondantes des données de l'application (duplication).
- Active l'accès concurrent aux données en lecture/écriture par plusieurs clients.
- Simplifie la récupération des sauvegardes et de pertes de données (un seul système de fichiers à sauvegarder ou à restaurer).
- Maximise l'utilisation des ressources de stockage ; minimise les coûts d'administration du stockage.
- Permet de gérer le stockage dans sa globalité plutôt que par partition.
- Diminue dans l'ensemble le stockage en éliminant le besoin de réplication des données.
- Varie la dimension du cluster en ajoutant, à la volée, des serveurs ou du stockage.
- Plus de stockage du partitionnement via des techniques complexes.
- Ajoute, à la volée, des serveurs au cluster en les montant sur le système de fichiers commun.
Note
1.5.1. Performance et évolutivité supérieures

Figure 1.11. GFS with a SAN
1.5.2. Performance, évolutivité, prix modéré

Figure 1.12. GFS and GNBD with a SAN
1.5.3. Économie et performance

Figure 1.13. GFS et GNBD avec un stockage directement connecté
1.6. Gestionnaire de volumes logiques du cluster
clvmd. clvmd is a daemon that provides clustering extensions to the standard LVM2 tool set and allows LVM2 commands to manage shared storage. clvmd runs in each cluster node and distributes LVM metadata updates in a cluster, thereby presenting each cluster node with the same view of the logical volumes (refer to Figure 1.14, « CLVM Overview »). Logical volumes created with CLVM on shared storage are visible to all nodes that have access to the shared storage. CLVM allows a user to configure logical volumes on shared storage by locking access to physical storage while a logical volume is being configured. CLVM uses the lock-management service provided by the cluster infrastructure (refer to Section 1.3, « Cluster Infrastructure »).
Note
clvmd) or bien lesagents High Availability Logical Volume Management (HA-LVM). Si vous n'êtes pas en mesure d'utiliser le démon clvmd, ni HA-LVM pour des raisons opérationnelles, ou parce que vous ne possédez pas d'accès, vous ne pouvez pas utiliser un instance-simple LVM sur le disque partagé, car cela pourrait aboutir à une corruption des données. Si vous avez des questions, veuillez contacter votre représentant commercial Red Hat.
Note
/etc/lvm/lvm.conf afin de gérer le verrouillage à l'échelle du cluster.

Figure 1.14. CLVM Overview

Figure 1.15. LVM Graphical User Interface

Figure 1.16. Conga LVM Graphical User Interface

Figure 1.17. Creating Logical Volumes
1.7. Périphérique bloc du réseau global (GNBD)

Figure 1.18. Aperçu de GNBD
1.8. Serveur virtuel Linux
- Il répartit la charge à travers les serveurs réels.
- Il vérifie l'intégrité des services sur chaque serveur réel.
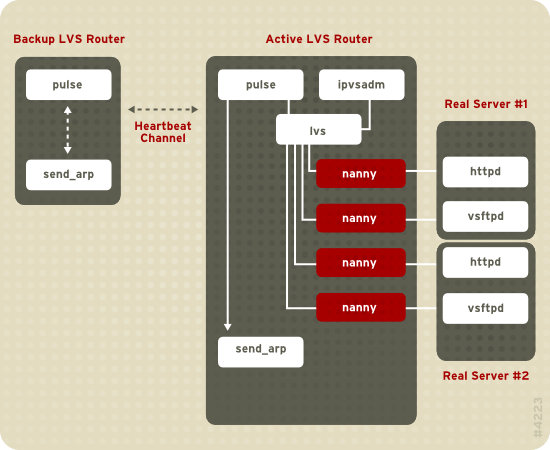
Figure 1.19. Components of a Running LVS Cluster
pulse est exécuté sur les deux routeurs LVS actifs et passifs. Sur le routeur LVS de sauvegarde, pulse envoie un signal heartbeat à l'interface publique du routeur actif afin de s'assurer que le routeur LVS actif fonctionne correctement. Sur le routeur LVS actif, pulse démarre le démon lvs et répond aux requêtes heartbeat du routeur LVS de sauvegarde.
lvs appelle l'utilitaire ipvsadm afin de configurer et maintenir la table de routage IPVS (de l'anglais IP Virtual Server) dans le noyau et démarre un processus nanny pour chaque serveur virtuel configuré sur chaque serveur réel. Chaque processus nanny vérifie l'état d'un service configuré sur un serveur réel et indique au démon lvs si le service sur ce serveur réel ne fonctionne pas correctement. Si un dysfonctionnement est détecté, le démon lvs demande à l'utilitaire ipvsadm de supprimer ce serveur réel de la table de routage IPVS.
send_arp afin de réassigner toutes les adresses IP virtuelles aux adresses matérielles NIC (adresse MAC) du routeur LVS de sauvegarde. Il envoie également une commande au routeur LVS actif via les interfaces réseau publiques et privées afin d'arrêter le démon lvs sur le routeur LVS actif et démarre le démon lvs sur le routeur LVS de sauvegarde afin d'accepter les requêtes pour les serveurs virtuels configurés.
- Synchroniser les données à travers les serveurs réels.
- Ajouter une troisième couche à la topologie pour l'accès aux données partagées.
rsync pour répliquer les données modifiées à travers tous les noeuds à un intervalle défini. Toutefois, dans les environnements où les utilisateurs téléchargent fréquemment des fichiers ou émettent des transactions avec la base de données, l'utilisation de scripts ou de la commande rsync pour la synchronisation des données ne fonctionne pas de façon optimale. Par conséquent, pour les serveurs réels avec un nombre élevé de téléchargements, transactions de base de données, ou autre trafic similaire, une topologie trois tiers est plus appropriée pour la synchronisation des données.
1.8.1. Two-Tier LVS Topology
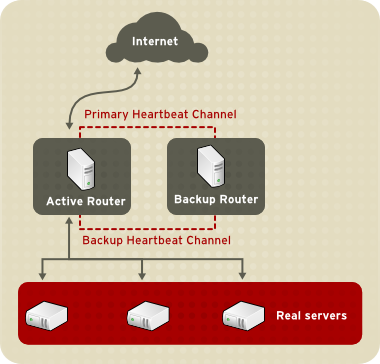
Figure 1.20. Two-Tier LVS Topology
eth0:1. De façon alternative, chaque serveur virtuel peut être associé à un périphérique différent par service. Par exemple, le trafic HTTP peut être traité sur eth0:1 et le trafic FTP peut être traité sur eth0:2.
- Programmation Round-Robin — Distribue chaque requête consécutivement autour d'un pool de serveurs réels. En utilisant cet algorithme, tous les serveurs réels sont traités de la même manière, sans prendre en compte la capacité ou la charge.
- Programmation Weighted Round-Robin — Distribue chaque requête consécutivement autour d'un pool de serveurs réels mais donne plus de travail aux serveurs ayant une plus grande capacité. La capacité est indiquée par un facteur de poids assigné par l'utilisateur, qui est ensuite ajusté en fonction des informations de charge dynamiques. Cette option est préférée s'il y a des différences sensibles entre la capacité des serveurs réels d'un pool de serveurs. Cependant, si la charge des requêtes varie considérablement, un serveur très alourdi pourrait répondre à plus de requêtes qu'il ne devrait.
- Least-Connection — Distribue davantage de requêtes aux serveurs réels ayant moins de connexions actives. Ceci est un genre d'algorithme de programmation dynamique. C'est une bonne option s'il y a un degré de variation important au niveau de la charge des requêtes. Il s'agit de l'algorithme qui correspond le mieux à un pool de serveurs où chaque noeud du serveur a approximativement la même capacité. Si les serveurs réels ont des capacités différentes, la programmation weighted least-connection constitue un meilleur choix.
- Weighted Least-Connections (par défaut) — Distribue davantage de requêtes aux serveurs ayant moins de connexions actives en fonction de leurs capacités. La capacité est indiquée par un facteur de poids assigné par l'utilisateur, qui est ensuite ajusté en fonction des informations de charge dynamiques. L'ajout de poids rend l'algorithme idéal lorsque le pool de serveurs réels contient du matériel avec différentes capacités.
- Programmation Locality-Based Least-Connection — Distribue davantage de requêtes aux serveurs ayant moins de connexions actives en fonction de leur adresse IP de destination. Cet algorithme est dédié à une utilisation au sein d'un cluster de serveurs proxy-cache. Il achemine les paquets d'une adresse IP vers le serveur de cette adresse à moins que ce serveur soit au-delà de ses capacités, auquel cas il assigne l'adresse IP au serveur réel le moins chargé.
- Programmation Locality-Based Least-Connection avec programmation répliquée — Distribue davantage de paquets aux serveurs ayant moins de connexions actives en fonction de leur adresse IP de destination. Cet algorithme est également dédié à une utilisation au sein d'un cluster de serveurs proxy-cache. Il diffère de la programmation Locality-Based Least-Connection car il mappe l'adresse IP cible à un sous-groupe de noeuds de serveurs réels. Les requêtes sont ensuite routées vers le serveur de ce sous-groupe ayant le moins de connexions. Si tous les noeuds pour l'adresse IP de destination sont en-dessus de leurs capacités, il réplique un nouveau serveur pour cette adresse IP de destination en ajoutant le serveur réel ayant le moins de connexions à partir du pool entier de serveurs réels vers le sous-groupe de serveurs réels. Le noeud le plus chargé est ensuite retiré du sous-groupe de serveurs réels pour éviter les excès de réplication.
- Programmation Source Hash — Distribue les requêtes vers le pool de serveurs réels en cherchant l'adresse IP source dans une table de hachage statique. Cet algorithme est dédié aux routeurs LVS avec plusieurs pare-feu.
1.8.2. Three-Tier LVS Topology
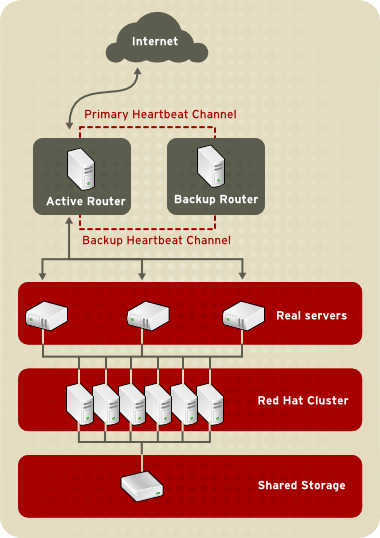
Figure 1.21. Three-Tier LVS Topology
1.8.3. Méthodes de routage
1.8.3.1. Routage NAT
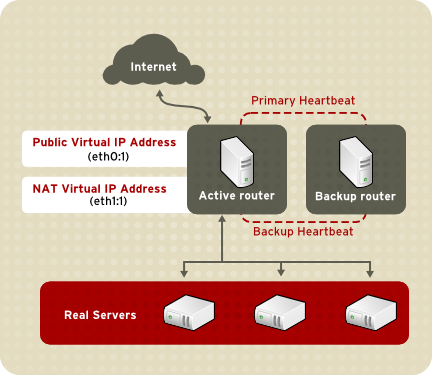
Figure 1.22. LVS Implemented with NAT Routing
1.8.3.2. Routage direct
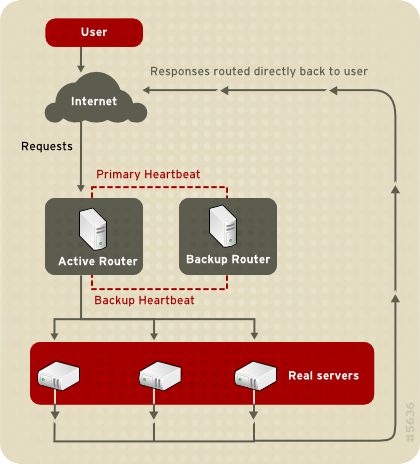
Figure 1.23. LVS Implemented with Direct Routing
arptables.
1.8.4. La persistance et les marques de pare-feu
1.8.4.1. Persistence
1.8.4.2. Marques de pare-feu
1.9. Outils d'administration du cluster
1.9.1. Conga
- Une interface Web pour la gestion du cluster et du stockage
- Un déploiement automatisé des données du cluster et des paquetages de support
- Une Intégration facile avec les clusters existants
- Il n'est pas nécessaire de s'authentifier à nouveau
- L'intégration du statut et des fichiers journaux du cluster
- Un contrôle minutieux des autorisations des utilisateurs
- — Fournit des outils pour l'ajout et la suppression d'ordinateurs et d'utilisateurs. Ces outils vous permettent également de configurer les privilèges des utilisateurs. Seul un administrateur système peut accéder à cet onglet.
- — Fournit des outils pour la création et la configuration des clusters. Chaque instance de luci liste les clusters qui ont été configurés avec ce serveur luci. Un administrateur système peut administrer tous les clusters listés sur cet onglet. Les autres utilisateurs peuvent seulement administrer les clusters pour lesquels ils ont des privilèges (accordés par un administrateur).
- — Fournit des outils pour l'administration à distance du stockage. Avec ces outils, vous pouvez gérer le stockage des ordinateurs qu'ils appartiennent à un cluster ou pas.

Figure 1.24. L'onglet de luci

Figure 1.25. L'onglet luci

Figure 1.26. L'onglet de luci
1.9.2. Interface graphique d'administration du cluster
system-config-cluster cluster administration graphical user interface (GUI) available with Red Hat Cluster Suite. The GUI is for use with the cluster infrastructure and the high-availability service management components (refer to Section 1.3, « Cluster Infrastructure » and Section 1.4, « Gestion des services à haute disponibilité »). The GUI consists of two major functions: the Cluster Configuration Tool and the Cluster Status Tool. The Cluster Configuration Tool provides the capability to create, edit, and propagate the cluster configuration file (/etc/cluster/cluster.conf). The Cluster Status Tool provides the capability to manage high-availability services. The following sections summarize those functions.
1.9.2.1. Cluster Configuration Tool

Figure 1.27. Cluster Configuration Tool
/etc/cluster/cluster.conf) avec un affichage graphique hiérarchique dans le panneau de gauche. Un icône en forme de triangle à gauche du nom d'un composant indique que le composant possède un ou plusieurs composants de second niveau. En cliquant sur cet icône vous pouvez agrandir et réduire la partie de l'arborescence située sous le composant. Les composants affichés dans l'interface utilisateur graphique sont structurés de la manière suivante :
- Cluster Nodes — Affiche les noeuds du cluster. Les neuds sont représentés par nom en tant qu'éléments de second niveau sous le composant Cluster Nodes.
- Fence Devices — Affiche les périphériques fence. Les périphériques fence sont représentés en tant qu'éléments de second niveau sous le composant Fence Devices. En utilisant les boutons de configuration situés en bas du cadre de droite (sous Properties), vous pouvez ajouter des périphériques fence, en supprimer et modifier leurs propriétés. Les périphériques fence doivent être définis avant que vous puissiez configurer le fencing (avec le bouton ) pour chaque noeud.
- Ressources gérées — Affiche les domaines failover, les ressources et les services.
- Failover Domains — Pour la configuration d'un ou plusieurs sous-groupes de noeuds du cluster utilisés pour exécuter un service à haute disponibilité en cas d'échec d'un noeud. Les domaines failover sont représentés en tant qu'éléments de second niveau sous sous le composant Failover Domains. En utilisant les boutons de configuration en bas du cadre de droite (sous Properties), vous pouvez créer des domaines failover (lorsque Failover Domains est sélectionné) ou modifier les propriétés d'un domaine failover (lorsqu'il est sélectionné).
- Resources — Pour la configuration de ressources partagées à utiliser avec les services à haute disponibilité. Les ressources partagées sont constituées de systèmes de fichiers, d'adresses IP, d'exports et de montages NFS et de scripts utilisateur disponibles pour un service à haute disponibilité au sein du cluster. Les ressources sont représentées en tant qu'éléments de second niveau sous sous le composant Resources. En utilisant les boutons de configuration en bas du cadre de droite (sous Properties), vous pouvez créer des ressources (lorsque Resources est sélectionné) ou modifier les propriétés d'une ressource (lorsqu'une ressource est sélectionnée).
Note
L'Cluster Configuration Tool offre également la possibilité de configurer des ressources privées. Une ressource privée est une ressource qui est configurée pour être utilisée avec un seul service. Vous pouvez configurer une ressource privée au sein d'un composant Service avec l'interface utilisateur graphique. - Services — Pour la création et la configuration de services à haute disponibilité. Un service est configuré en lui assignant des ressources (partagées ou privées), un domaine failover et une politique de récupération. Les services sont représentés en tant qu'éléments de niveau secondaire sous Services. En utilisant les boutons de configuration en bas du cadre de droite (sous Properties), vous pouvez créer des services (lorsque Services est sélectionné) ou modifier les propriétés d'un service (lorsqu'un service est sélectionné).
1.9.2.2. Cluster Status Tool

Figure 1.28. Cluster Status Tool
/etc/cluster/cluster.conf). Vous pouvez utiliser l'Cluster Status Tool pour activer, désactiver, redémarrer ou déplacer un service à haute disponibilité.
1.9.3. Outils d'administration en ligne de commande
system-config-cluster Cluster Administration GUI, command line tools are available for administering the cluster infrastructure and the high-availability service management components. The command line tools are used by the Cluster Administration GUI and init scripts supplied by Red Hat. Tableau 1.1, « Outils en ligne de commande » summarizes the command line tools.
| Outil en ligne de commande | Utilisé avec | Utilité |
|---|---|---|
ccs_tool — Outil système de configuration du cluster | Cluster Infrastructure | ccs_tool est un programme permettant d'effectuer des mises à jour en ligne du fichier de configuration du cluster. Il offre la possibilité de créer et modifier les composants d'infrastructure du cluster (par exemple, la création d'un cluster, l'ajout et la suppression d'un noeud). Pour davantage d'informations à propos de cet outil, reportez-vous à la page de manuel ccs_tool(8). |
cman_tool — Outil de gestion du cluster | Cluster Infrastructure | cman_tool est un programme qui contrôle le gestionnaire de cluster CMAN. Il offre la possibilité de joindre un cluster, quitter un cluster, supprimer un noeud ou changer les votes quorum attendus d'un noeud du cluster. Pour davantage d'informations à propos de cet outil, reportez-vous à la page de manuel cman_tool(8). |
fence_tool — Outil Fence | Cluster Infrastructure | fence_tool est un programme utilisé pour joindre ou quitté le domaine fence par défaut. Plus précisément, il démarre le démon fence (fenced) pour joindre le domaine et arrête fenced pour quitter le domaine. Pour davantage d'informations à propos de cet outil, reportez-vous à la page de manuel fence_tool(8). |
clustat — Utilitaire de statut du cluster | Composants de gestion des services à haute disponibilité | La commande clustat indique le statut du cluster. Elle affiche les informations d'appartenance, le mode du quorum et l'état de tous les services utilisateur configurés. Pour davantage d'informations à propos de cet outil, reportez-vous à la page de manuel clustat(8). |
clusvcadm — Utilitaire d'administration des services utilisateur du cluster | Composants de gestion des services à haute disponibilité | La commande clusvcadm vous permet d'activer, désactiver, déplacer et redémarrer les services à haute disponibilité au sein d'un cluster. Pour davantage d'informations à propos de cet outil, reportez-vous à la page de manuel clusvcadm(8). |
1.10. Interface utilisateur graphique d'administration du serveur virtuel Linux
/etc/sysconfig/ha/lvs.cf.
piranha-gui doit être en cours d'exécution sur le routeur LVS actif. Vous pouvez accéder à l'Piranha Configuration Tool localement ou à distance avec un navigateur Web. Localement, utilisez l'adresse suivante : http://localhost:3636. Pour accéder à l'Piranha Configuration Tool à distance, utilisez le nom de domaine ou l'adresse IP réelle suivi de :3636. Si vous accédez à l'Piranha Configuration Tool à distance, vous devez diposer d'une connexion ssh vers le routeur LVS actif en tant que super-utilisateur (root).
Figure 1.29. The Welcome Panel
1.10.1. CONTROL/MONITORING
pulse, de la table de routage LVS et des processus nanny créés par LVS.

Figure 1.30. The CONTROL/MONITORING Panel
- Auto update
- Permet à l'affichage des états d'être mis à jour automatiquement à un intervalle de temps configurable par l'utilisateur et défini dans la zone de texte Update frequency in seconds (la valeur par défaut est 10 secondes).Il n'est pas recommandé de paramétrer la mise à jour automatique à un intervalle inférieur à 10 secondes. Cela peut rendre la reconfiguration de l'intervalle Auto update difficile car la page sera mise à jour trop fréquemment. Si vous rencontrez ce problème, cliquez sur un autre panneau et retournez ensuite sur CONTROL/MONITORING.
- Permet de mettre à jour manuellement les informations d'état.
- En cliquant sur ce bouton vous affichez une page d'aide qui vous indique comment modifier le mot de passe administrateur de l'Piranha Configuration Tool.
1.10.2. GLOBAL SETTINGS

Figure 1.31. The GLOBAL SETTINGS Panel
- Primary server public IP
- L'adresse IP réelle routable publiquement pour le noeud LVS primaire.
- Primary server private IP
- L'adresse IP réelle pour une interface réseau alternative sur le noeud LVS primaire. Cette adresse est seulement utilisée en tant que canal "hearbeat" alternatif par le routeur de sauvegarde.
- Use network type
- Selection du routage NAT.
- NAT Router IP
- Il s'agit de l'adresse IP flottante privée. Cette adresse IP flottante devrait être utilisée comme la passerelle pour les serveurs réels.
- NAT Router netmask
- If the NAT router's floating IP needs a particular netmask, select it from drop-down list.
- NAT Router device
- Définit le nom du périphérique de l'interface réseau pour l'adresse IP flottante, par exemple
eth1:1.
1.10.3. REDUNDANCY
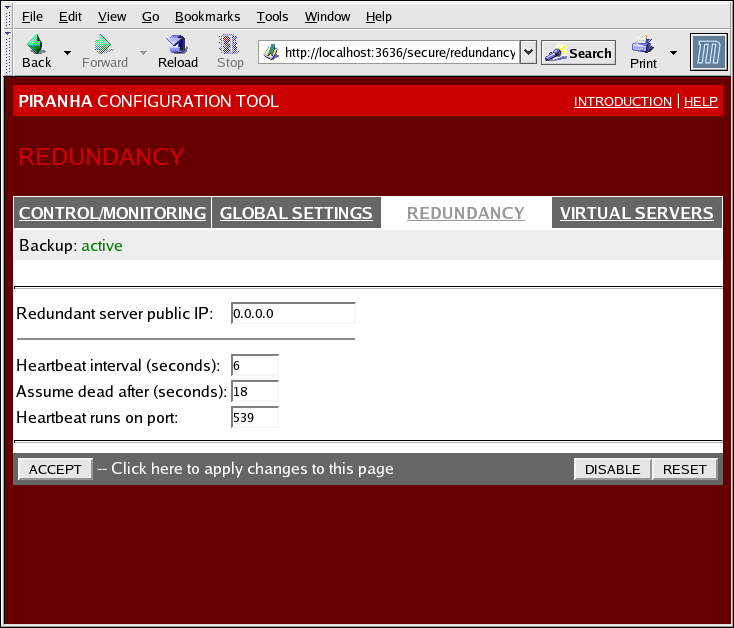
Figure 1.32. The REDUNDANCY Panel
- Redundant server public IP
- L'adresse IP réelle publique pour le routeur LVS de sauvegarde.
- Redundant server private IP
- The backup router's private real IP address.
- Heartbeat Interval (seconds)
- Définit le nombre de secondes entre les messages "hearbeat" — l'intervalle utilisé par le noeud de sauvegarde pour vérifier l'état fonctionnel du noeud LVS primaire.
- Assume dead after (seconds)
- Si le noeud LVS primaire ne répond pas après ce nombre de secondes, le noeud du routeur LVS de sauvegarde initiera un failover.
- Heartbeat runs on port
- Définit le port utilisé par le message "hearbeat" pour communiquer avec le noeud LVS primaire. Le port par défaut est 539 si cette zone de texte est vide.
1.10.4. VIRTUAL SERVERS
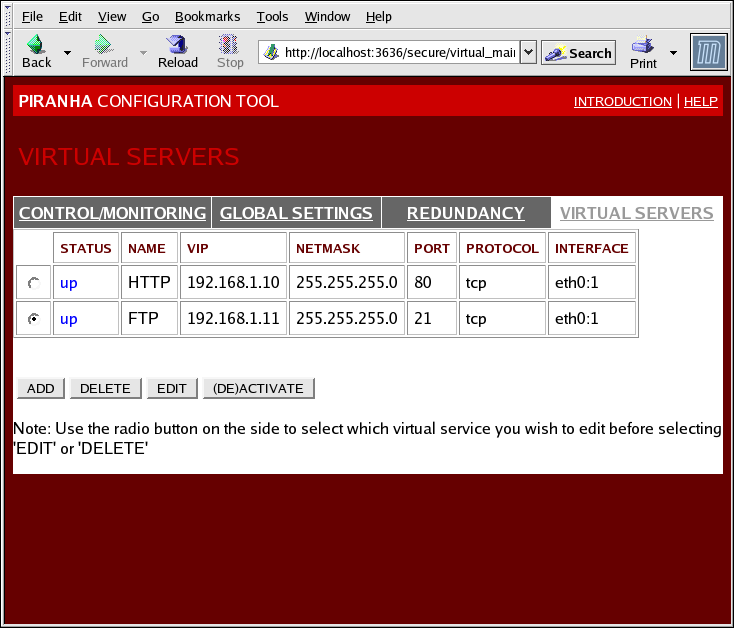
Figure 1.33. The VIRTUAL SERVERS Panel
1.10.4.1. La sous-section VIRTUAL SERVER

Figure 1.34. The VIRTUAL SERVERS Subsection
- Name
- Il s'agit d'un nom descriptif pour identifier le serveur virtuel. Ce nom ne correspond pas au nom d'hôte de la machine, saisissez donc un nom facile à identifier. Vous pouvez même référencer le protocole utilisé par le serveur virtuel, par exemple HTTP.
- Application port
- Le numéro de port à travers lequel l'application service écoutera.
- Donne le choix entre UDP et TCP, dans un menu déroulant.
- Virtual IP Address
- The virtual server's floating IP address.
- Le masque de réseau pour ce serveur virtuel, dans un menu déroulant.
- Firewall Mark
- Permet de saisir une valeur entière de marque de pare-feu lors du groupement de protocoles multiports ou de la création d'un serveur virtuel multiports pour des protocoles distincts mais liés.
- Device
- Le nom du périphérique réseau auquel vous voulez lier l'adresse IP flottante définie dans la zone de texte Virtual IP Address.Vous devriez créer un alias pour l'adresse IP flottante publique à l'interface Ethernet connectée au réseau public.
- Re-entry Time
- Une valeur entière qui définit le nombre de secondes avant que le routeur LVS actif essaie d'utiliser un serveur réel suite à l'échec du serveur réel.
- Service Timeout
- Une valeur entière qui définit le nombre de secondes avant qu'un serveur réel soit considéré comme étant inactif et indisponible.
- Quiesce server
- Lorsque le bouton radio Quiesce server est sélectionné, à chaque fois qu'un nouveau noeud de serveur réel est connecté, la table least-connections est remise à zéro pour que le routeur LVS actif dirige les requêtes comme si tous les serveurs réels venaient d'être ajoutés au cluster. Cette option empêche au nouveau serveur de s'enliser avec un nombre élevé de connexions suite à son arrivée au sein du cluster.
- Load monitoring tool
- Le routeur LVS peut surveiller la charge des différents serveurs réels en utilisant
rupouruptime. Si vous sélectionnezrupà partir du menu déroulant, chaque serveur réel doit exécuter le servicerstatd. Si vous sélectionnezruptime, chaque serveur réel doit exécuter le servicerwhod. - Scheduling
- Permet de sélectionner l'algorithme de programmation préféré à partir de ce menu déroulant. La valeur par défaut est
Weighted least-connection. - Persistence
- Peut être utilisé si vous avez besoin de connexions persistantes sur le serveur virtuel durant les transactions client. Spécifie, par l'intermédiaire de ce champ, le nombre de secondes d'inactivité autorisé avant qu'une connexion expire.
- Pour limiter la persistance à un sous-réseau particulier, sélectionnez le masque réseau approprié à partir du menu déroulant.
1.10.4.2. La sous-section REAL SERVER
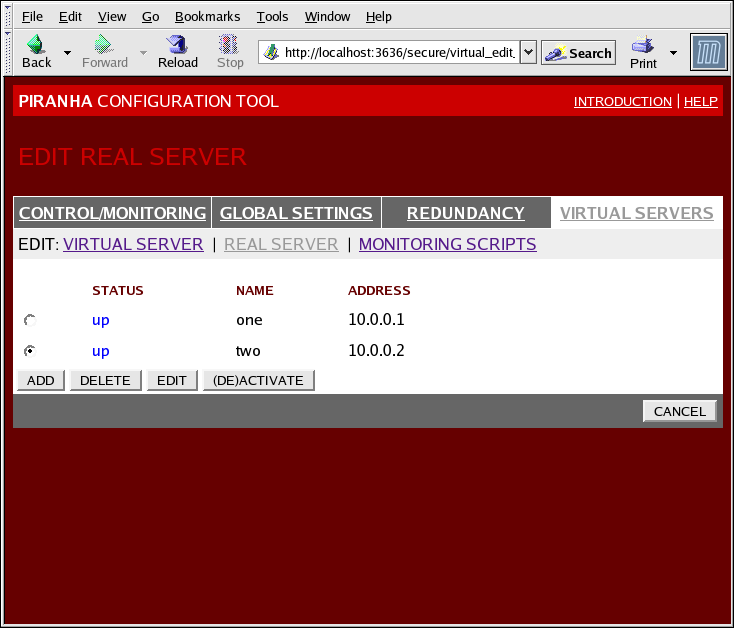
Figure 1.35. The REAL SERVER Subsection
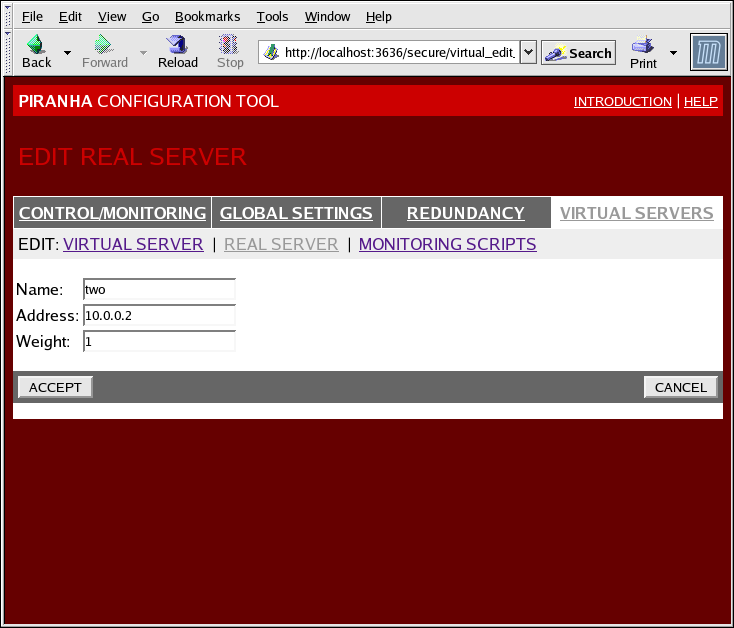
Figure 1.36. The REAL SERVER Configuration Panel
- Name
- Un nom descriptif pour le serveur réel.
Note
Ce nom ne correspond pas au nom d'hôte de la machine, saisissez donc un nom facile à identifier. - Address
- The real server's IP address. Since the listening port is already specified for the associated virtual server, do not add a port number.
- Weight
- An integer value indicating this host's capacity relative to that of other hosts in the pool. The value can be arbitrary, but treat it as a ratio in relation to other real servers.
1.10.4.3. EDIT MONITORING SCRIPTS Subsection
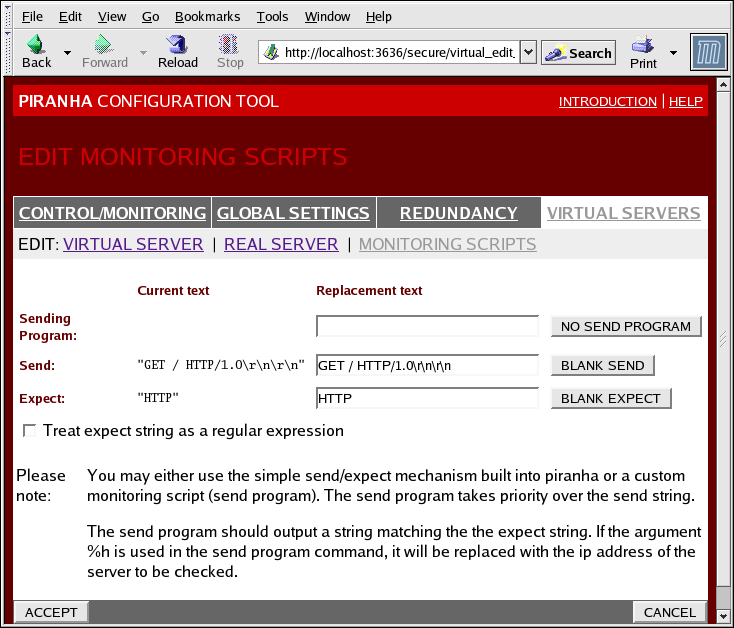
Figure 1.37. The EDIT MONITORING SCRIPTS Subsection
- Sending Program
- Pour une vérification de service plus avancée, vous pouvez utiliser ce champ afin de spécifier le chemin d'accès d'un script de vérification de service. Cette fonction est particulièrement utile pour les services qui requièrent que les données soient changées dynamiquement, par exemple HTTPS ou SSL.Pour utiliser cette fonctionnalité, vous devez écrire un script qui retourne une réponse textuelle. Paramétrez le script pour qu'il soit exécutable et saisissez son chemin d'accès dans le champ Sending Program.
Note
Si un programme externe est saisi dans le champ Sending Program, le champ Send est ignoré. - Send
- Saisissez dans ce champ une chaîne de caractères que le démon
nannyenverra à chaque serveur réel. Par défaut le champ d'envoi est configuré pour HTTP. Vous pouvez modifier cette valeur selon vos besoins. Si vous laissez ce champ vide, le démonnannyessaie d'ouvrir le port et, s'il réussit, suppose que le service est en cours d'exécution.Une seule séquence send est autorisée dans ce champ et elle ne peut contenir que des caractères imprimables, ASCII ainsi que les caractères d'échappement suivants :- \n pour une nouvelle ligne.
- \r pour un retour à la ligne.
- \t pour un onglet.
- \ pour échapper le caractère qui suit.
- Expect
- La réponse textuelle que le serveur devrait retourner s'il fonctionne correctement. Si vous avez écrit votre propre programme d'envoi, saisissez la réponse désirée.
Chapitre 2. Résumé des composants de Red Hat Cluster Suite
2.1. Composants de cluster
| Fonction | Composant | Description |
|---|---|---|
| Conga | luci | Système de gestion à distance - Station de gestion. |
ricci | Système de gestion à distance - Station gérée. | |
| Cluster Configuration Tool | system-config-cluster | Commande utilisée pour gérer la configuration du cluster dans un mode graphique. |
| Gestionnaire de volumes logiques en cluster (CLVM) | clvmd | Il s'agit du démon qui distribue les mises à jour de métadonnées LVM au sein du cluster. Il doit être exécuté sur tous les noeuds du cluster et renverra une erreur si un noeud du cluster n'exécute pas ce démon. |
lvm | Outils LVM2. Fournit les outils en ligne de commande pour LVM2. | |
system-config-lvm | Fournit une interface utilisateur graphique pour LVM2. | |
lvm.conf | Le fichier de configuration LVM. Le chemin d'accès complet est /etc/lvm/lvm.conf. | |
| Système de configuration du cluster (CCS) | ccs_tool | ccs_tool fait partie du système de configuration du cluster (CCS). Il est utilisé pour effectuer des mises à jour en ligne des fichiers de configuration CCS. De plus, il peut être utilisé pour mettre à niveau les fichiers de configuration du cluster à partir des archives CSS créées avec GFS 6.0 (et les versions précédentes) au format XML utilisé avec cette version de Red Hat Cluster Suite. |
ccs_test | Commande de diagnostique et de test utilisée pour récupérer des informations à partir des fichiers de configuration à travers le démon ccsd. | |
ccsd | Démon CCS exécuté sur tous les noeuds du cluster qui fournit des données du fichier de configuration au logiciel cluster. | |
cluster.conf | Il s'agit du fichier de configuration du cluster. Le chemin d'accès complet est /etc/cluster/cluster.conf. | |
| Gestionnaire de cluster (CMAN) | cman.ko | Le module noyau pour CMAN. |
cman_tool | Il s'agit de la partie frontale de l'administration de CMAN. Cet outil démarre et arrête CMAN et peut changer certains paramètres internes tels que les votes. | |
dlm_controld | Démon démarré par le script init de cman afin de gérer dlm dans le noyau ; il n'est pas encore utilisé par l'utilisateur. | |
gfs_controld | Démon démarré par le script init de cman afin de gérer gfs dans le noyau ; il n'est pas encore utilisé par l'utilisateur. | |
group_tool | Utilisé afin d'obtenir une liste des groupes liés au fencing, DLM, GFS, ainsi que des informations de débogage ; Cet outil inclut également ce que cman_tool services fournissait dans RHEL 4. | |
groupd | Démon démarré par le script init de cman afin de servir d'interface entre openais/cman et dlm_controld/gfs_controld/fenced; il n'est pas encore utilisé par l'utilisateur. | |
libcman.so.<version number> | Bibliothèque pour les programmes ayant besoin d'interagir avec cman.ko. | |
| Gestionnaire du groupe de ressources (rgmanager) | clusvcadm | Commande utilisée pour activer, désactiver, déplacer et redémarrer manuellement les services utilisateur dans un cluster. |
clustat | Commande utilisée pour afficher le statut du cluster, y compris l'adhésion aux noeuds et les services en cours d'exécution. | |
clurgmgrd | Démon utilisé pour traiter les requêtes des services utilisateur y compris le démarrage, la désactivation, le déplacement et le redémarrage d'un service. | |
clurmtabd | Démon utilisé pour traiter des tables de montage NFS clusterisées. | |
| Fence | fence_apc | Agent fence pour le commutateur de courant APC. |
fence_bladecenter | Agent fence pour IBM Bladecenters avec l'interface Telnet. | |
fence_bullpap | Agent fence pour l'interface du processeur d'administration de la plateforme (PAP de l'anglais Platform Administration Processor) Bull Novascale. | |
fence_drac | Agent fence pour la carte d'accès à distance Dell. | |
fence_ipmilan | Agent fence pour les machines contrôlées par l'interface de gestion intelligente de matériel (IPMI de l'anglais Intelligent Platform Management Interface) sur un LAN. | |
fence_wti | Agent fence pour le commutateur de courant WTI. | |
fence_brocade | Agent fence pour le commutateur Brocade Fibre Channel | |
fence_mcdata | Agent fence pour le commutateur McData Fibre Channel. | |
fence_vixel | Agent fence pour le commutateur Vixel Fibre Channel. | |
fence_sanbox2 | Agent fence pour le commutateur SANBox2 Fibre Channel. | |
fence_ilo | Agent fence pour les interfaces HP ILO (formerly fence_rib). | |
fence_rsa | Agent fence d'E/S pour IBM RSA II. | |
fence_gnbd | Agent fence utilisé avec le stockage GNBD. | |
fence_scsi | Agent fence d'E/S pour les réservations SCSI persistances. | |
fence_egenera | Agent fence utilisé avec le système Egenera BladeFrame. | |
fence_manual | Agent fence pour une interaction manuelle. REMARQUE : ce composant n'est pas supporté dans les environnements de production. | |
fence_ack_manual | Interface utilisateur pour l'agent fence_manual. | |
fence_node | Un programme qui effectue des E/S fence sur un seul noeud. | |
fence_xvm | Agent fence d'E/S pour les machines virtuelles Xen. | |
fence_xvmd | Agent hôte fence d'E/S pour les machines virtuelles Xen. | |
fence_tool | Un programme pour joindre et quitter le domaine fence. | |
fenced | Le démon fence d'E/S | |
| DLM | libdlm.so.<version number> | Bibliothèque pour la prise en charge du gestionnaire de verrouillage distribué (DLM de l'anglais Distributed Lock Manager). |
| GFS | gfs.ko | Module noyau qui implémente le système de fichiers GFS et qui est chargé sur les noeuds du cluster GFS. |
gfs_fsck | Commande qui répare un système de fichiers GFS qui n'est pas monté. | |
gfs_grow | Commande qui incrémente un système de fichiers GFS monté. | |
gfs_jadd | Commande qui ajoute des fichiers journaux dans un système de fichiers GFS. | |
gfs_mkfs | Commande qui crée un système de fichiers GFS sur un périphérique de stockage. | |
gfs_quota | Commande qui gère les quotas sur un système de fichiers GFS monté. | |
gfs_tool | Commande qui configure ou règle un système de fichiers monté. Cette commande peut également regrouper une variété d'informations à propos du système de fichiers. | |
mount.gfs | Assistant de montage appelé par mount(8); il n'est pas utilisé par l'utilisateur. | |
| GNBD | gnbd.ko | Module noyau qui implémente le pilote de périphérique GNBD sur les clients. |
gnbd_export | Commande permettant de créer, exporter et gérer les GNBD sur un serveur GNBD. | |
gnbd_import | Commande permettant d'importer et gérer les GNBD sur un client GNBD. | |
gnbd_serv | Un démon serveur qui permet à un noeud d'exporter le stockage local à travers le réseau. | |
| LVS | pulse | This is the controlling process which starts all other daemons related to LVS routers. At boot time, the daemon is started by the /etc/rc.d/init.d/pulse script. It then reads the configuration file /etc/sysconfig/ha/lvs.cf. On the active LVS router, pulse starts the LVS daemon. On the backup router, pulse determines the health of the active router by executing a simple heartbeat at a user-configurable interval. If the active LVS router fails to respond after a user-configurable interval, it initiates failover. During failover, pulse on the backup LVS router instructs the pulse daemon on the active LVS router to shut down all LVS services, starts the send_arp program to reassign the floating IP addresses to the backup LVS router's MAC address, and starts the lvs daemon. |
lvsd | Le démon lvs s'exécute sur le routeur LVS actif une fois qu'il est appelé par pulse. Il lit le fichier de configuration /etc/sysconfig/ha/lvs.cf, appelle l'utilitaire ipvsadm pour construire et maintenir la table de routage IPVS et assigne un processus nanny à chaque service LVS configuré. Si nanny reporte une panne sur un serveur réel, lvs indique à l'utilitaire ipvsadm de supprimer le serveur réel de la table de routage IPVS. | |
ipvsadm | Ce service met à jour la table de routage IPVS dans le noyau. Le démon lvs configure et administre LVS en appelant ipvsadm pour ajouter, changer ou supprimer les entrées dans la table de routage IPVS. | |
nanny | Le démon d'analyse nanny est démarré sur le routeur LVS actif. À travers ce démon, le routeur LVS actif détermine l'état de fonctionnement de chaque serveur réel et, éventuellement, analyse sa charge de travail. Un processus séparé est démarré pour chaque service défini sur chaque serveur réel. | |
lvs.cf | Il s'agit du fichier de configuration LVS. Le chemin d'accès complet pour le fichier est /etc/sysconfig/ha/lvs.cf. Directement ou indirectement, tous les démons obtiennent leurs informations de configuration à partir de ce fichier. | |
| Piranha Configuration Tool | Il s'agit de l'outil Web pour analyser, configurer et administrer LVS. Il s'agit de l'outil par défaut pour maintenir le fichier de configuration LVS /etc/sysconfig/ha/lvs.cf. | |
send_arp | Ce programme envoie les diffusions ARP lorsque l'adresse IP flottante change d'un nœud à un autre durant le failover. | |
| Disque quorum | qdisk | Un démon de quorum basé sur les disques pour CMAN / Linux-Cluster. |
mkqdisk | Utilitaire pour le disque quorum du cluster. | |
qdiskd | Démon pour le disque quorum du cluster. |
2.2. Pages de manuel
- Infrastructure de cluster
- ccs_tool (8) - L'outil utilisé pour effectuer des mises à jour en ligne de fichiers de configuration CSS
- ccs_test (8) - L'outil de diagnostique pour un système de configuration du cluster en cours d'exécution
- ccsd (8) - Le démon utilisé pour accéder aux fichiers de configuration du cluster CCS
- ccs (7) - Système de configuration du cluster
- cman_tool (8) - Outil de gestion du cluster
- cluster.conf [cluster] (5) - Le fichier de configuration pour les produits du cluster
- qdisk (5) - Un démon de quorum basé sur les disques pour CMAN / Linux-Cluster
- mkqdisk (8) - Utilitaire pour le disque quorum du cluster
- qdiskd (8) - Démon pour le disque quorum du cluster
- fence_ack_manual (8) - Programme exécuté par un opérateur dans le cadre d'un fence d'E/S manuel
- fence_apc (8) - Agent fence d'E/S pour APC MasterSwitch
- fence_bladecenter (8) - Agent fence d'E/S pour IBM Bladecenter
- fence_brocade (8) - Agent fence d'E/S pour les commutateurs Brocade FC
- fence_bullpap (8) - Agent fence d'E/S pour l'architecture Bull FAME contrôlée par une console de gestion PAP
- fence_drac (8) - Agent fence pour la carte d'accès à distance Dell
- fence_egenera (8) - Agent fence d'E/S pour le BladeFrame Egenera
- fence_gnbd (8) - Agent fence d'E/S pour les clusters GFS basés sur GNBD
- fence_ilo (8) - Agent fence d'E/S pour la carte HP Integrated Lights Out
- fence_ipmilan (8) - Agent fence d'E/S pour les machines contrôlées par IPMI à travers un LAN
- fence_manual (8) - programme exécuté par fenced dans le cadre du fence d'E/S manuel.
- fence_mcdata (8) - Agent fence d'E/S pour les commutateurs McData FC
- fence_node (8) - Un programme qui effectue des opérations fence d'E/S sur un seul noeud
- fence_rib (8) - I/O Agent fence pour la carte Compaq Remote Insight Lights Out
- fence_rsa (8) - I/O Agent fence d'E/S pour IBM RSA II
- fence_sanbox2 (8) - Agent fence d'E/S pour les commutateurs QLogic SANBox2 FC
- fence_scsi (8) - Agent fence d'E/S pour les réservations SCSI persistantes
- fence_tool (8) - Un programme pour joindre et quitter le domaine fence.
- fence_vixel (8) - Agent fence d'E/S pour les commutateurs Vixel FC
- fence_wti (8) - Agent fence d'E/S pour le commutateur WTI Network Power
- fence_xvm (8) - Agent fence d'E/S pour les machines virtuelles Xen
- fence_xvmd (8) - Agent hôte fence d'E/S pour les machines virtuelles Xen.
- fenced (8) - Le démon fence d'E/S
- Gestion des services à haute disponibilité
- clusvcadm (8) - Utilitaire d'administration des services utilisateur du cluster
- clustat (8) - Utilitaire de statut du cluster
- Clurgmgrd [clurgmgrd] (8) - Démon du gestionnaire de groupes de ressources (service cluster)
- clurmtabd (8) - Démon de la table de montage distante NFS du cluster
- GFS
- gfs_fsck (8) - Vérificateur de système de fichiers GFS hors ligne
- gfs_grow (8) - Agrandit un système de fichiers GFS
- gfs_jadd (8) - Ajoute des fichiers journaux à un système de fichiers.
- gfs_mount (8) - Options de montage GFS
- gfs_quota (8) - Manipule les quotas des disques GFS
- gfs_tool (8) - interface pour les appels gfs ioctl
- Gestionnaire de volumes logiques du cluster
- clvmd (8) - Démon LVM du cluster
- lvm (8) - Outils LVM2
- lvm.conf [lvm] (5) - Fichier de configuration pour LVM2
- lvmchange (8) - Change les attributs du gestionnaire de volumes logiques
- pvcreate (8) - Initialise un disque ou une partition pour utiliser avec LVM
- lvs (8) - Reporte des informations à propos de volumes logiques
- Périphérique bloc de réseau global
- gnbd_export (8) - L'interface pour exporter les GNBD
- gnbd_import (8) - Manipule les périphériques blocs GNBD sur un client
- gnbd_serv (8) - Démon serveur gnbd
- LVS
- pulse (8) - Démon émettant des signaux ("heartbeat") afin d'analyser le bon fonctionnement des noeuds du cluster.
- lvs.cf [lvs] (5) - fichier de configuration pour lvs
- lvscan (8) - Scanne (tous les disques) pour les volumes logiques
- lvsd (8) - Démon pour contrôler les services Red Hat de mise en cluster
- ipvsadm (8) - Administration du serveur virtuel Linux
- ipvsadm-restore (8) - Restaure le tableau IPVS à partir de stdin
- ipvsadm-save (8) - Enregistre le tableau IPVS vers stdout
- nanny (8) - Outil pour l'analyse du statut des services du cluster
- send_arp (8) - Outil pour informer le réseau d'une nouvelle correspondance adresse IP/adresse MAC
2.3. Matériel compatible
Annexe A. Historique de révision
| Historique des versions | |||
|---|---|---|---|
| Version 3-7.400 | 2013-10-31 | ||
| |||
| Version 3-7 | 2012-07-18 | ||
| |||
| Version 1.0-0 | Tue Jan 20 2008 | ||
| |||
Index
C
- cluster
- displaying status, Cluster Status Tool
- cluster administration
- displaying cluster and service status, Cluster Status Tool
- cluster component compatible hardware, Matériel compatible
- cluster component man pages, Pages de manuel
- cluster components table, Composants de cluster
- Cluster Configuration Tool
- accessing, Cluster Configuration Tool
- cluster service
- displaying status, Cluster Status Tool
- command line tools table, Outils d'administration en ligne de commande
- compatible hardware
- cluster components, Matériel compatible
- Conga
- overview, Conga
- Conga overview, Conga
F
- feedback, Commentaire
I
- introduction, Introduction
- other Red Hat Enterprise Linux documents, Introduction
L
- LVS
- direct routing
- requirements, hardware, Routage direct
- requirements, network, Routage direct
- requirements, software, Routage direct
- routing methods
- NAT, Méthodes de routage
- three tiered
- high-availability cluster, Three-Tier LVS Topology
M
- man pages
- cluster components, Pages de manuel
N
- NAT
- routing methods, LVS, Méthodes de routage
- network address translation (voir NAT)
O
- overview
- economy, Red Hat GFS
- performance, Red Hat GFS
- scalability, Red Hat GFS
P
- Piranha Configuration Tool
- CONTROL/MONITORING, CONTROL/MONITORING
- EDIT MONITORING SCRIPTS Subsection, EDIT MONITORING SCRIPTS Subsection
- GLOBAL SETTINGS, GLOBAL SETTINGS
- login panel, Interface utilisateur graphique d'administration du serveur virtuel Linux
- necessary software, Interface utilisateur graphique d'administration du serveur virtuel Linux
- REAL SERVER subsection, La sous-section REAL SERVER
- REDUNDANCY, REDUNDANCY
- VIRTUAL SERVER subsection, VIRTUAL SERVERS
- Firewall Mark , La sous-section VIRTUAL SERVER
- Persistence , La sous-section VIRTUAL SERVER
- Scheduling , La sous-section VIRTUAL SERVER
- Virtual IP Address , La sous-section VIRTUAL SERVER
- VIRTUAL SERVERS, VIRTUAL SERVERS
R
- Red Hat Cluster Suite
- components, Composants de cluster
T
- table
- cluster components, Composants de cluster
- command line tools, Outils d'administration en ligne de commande