Guide de vidage de mémoire sur incident noyau
Configuration et Analyse du vidage de mémoire sur incident noyau
Résumé
kdump dans Red Hat Enterprise Linux 7, et fournit un aperçu succinct sur la façon d'analyser les résultats du vidage de mémoire par l'utilitaire de déboggage crash. Il s'adresse aux administrateurs de systèmes possédant des connaissances de base du système Red Hat Enterprise Linux.
Chapitre 1. Introduction à kdump
1.1. kdump et kexec
1.2. Besoins en mémoire
x86_64 ) et l'imprimer dans la sortie standard, saisir la commande suivante à l'invite de commandes shell :
uname -mImportant
Chapitre 2. Installer et configurer kdump
2.1. Installer kdump
kdump est installé et activé par défaut sur les nouvelles Red Hat Enterprise Linux 7 Le programme d'installation Anaconda fournit un écran de configuration kdump pendant l'installation interactice par l'interface graphique ou texte. L'écran du programme d'installation s'intitule Kdump et on y accède à partir de l'écran Sommaire d'installation, qui permet une configuration limitée uniquement - vous ne pouvez sélectionner que si kdump sera activé ou non et la quantité de mémoire réservée. Vous trouverez des renseignements sur les besoins en mémoire pour kdump dans Section B.1, « Besoins en mémoire pour kdump ». L'écran de configuration de kdump du programme d'installation est documenté dans le Red Hat Enterprise Linux 7 Guide d'installation.
Note
root à l'invite du shell :
# yum install kexec-toolsNote
rpm pour vérifier :
$ rpm -q kexec-toolsroot :
# yum install system-config-kdumpImportant
Intel IOMMU empêche le service kdump de récupérer l'image de vidage de mémoire. Pour pouvoir utiliser kdump dans des architectures Intel de manière fiable, désactiver le support IOMMU.
2.2. Configuration de kdump à partir de la ligne de commande
2.2.1. Configuration l'utilisation de la mémoire
Procédure 2.1. Modifier les options de mémoire dans GRUB2
- Ouvrez le fichier de configuration
/etc/default/gruben tant qu'utilisateurrootà l'aide d'un éditeur de texte brut tel que vim ou Gedit. - Dans ce fichier, trouvez la ligne commençant par
GRUB_CMDLINE_LINUX. Elle ressemblera à ceci :GRUB_CMDLINE_LINUX="rd.lvm.lv=rhel/swap crashkernel=auto rd.lvm.lv=rhel/root rhgb quiet"Notez l'optioncrashkernel=surlignée, qui correspond à la mémoire réservée. - Modifiez la valeur de l'option
crashkernel=pour qu'elle corresponde au montant de mémoire que vous souhaitez réserver. Ainsi, pour réserver 128 Mo de mémoire, utilisez la commande suivante :crashkernel=128MNote
Il y a plusieurs façons de configurer la mémoire réservée - par exemple, vous pouvez définir une valeur de décallage ou plusieurs montants de mémoires multiples basés sur le montant de mémoire RAM disponible dans le système au démarrage. C'est décrit plus loin dans cette section.Puis, enregistrez le fichier et sortez de l'éditeur de texte. - Enfin, générer la configuration GRUB2 en utilisant le fichier
defaultédité. Si votre système utilise un firmware BIOS, exécutez la commande suivante :# grub2-mkconfig -o /boot/grub2/grub.cfgSur un système équipé d'un firmware UEFI, exécutez la commande suivante à la place :# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
Procédure 2.2. Modifier les options de mémoire dans zipl
- Ouvrez le fichier de configuration
/etc/zipl.confen tant qu'utilisateurrootà l'aide d'un éditeur de texte brut tel que vim ou Gedit. - Dans ce fichier, cherchez la section
parameters=, et modifiez le paramètrecrashkernel=(ou ajoutez-le s'il n'est pas présent). Ainsi, pour réserver 128 Mo de mémoire, utilisez la commande suivante :crashkernel=128MNote
Il y a plusieurs façons de configurer la mémoire réservée - par exemple, vous pouvez définir une valeur de décallage ou plusieurs montants de mémoires multiples basés sur le montant de mémoire RAM disponible dans le système au démarrage. C'est décrit plus loin dans cette section.Puis, enregistrez le fichier et sortez de l'éditeur de texte. - Finalement, regénérez la configuration de zipl :
# ziplNote
Exécuter la commandezipluniquement, sans option supplémentaire, utilisera les valeurs par défaut. Consulter la page man dezipl(8)pour obtenir des informations sur les options disponibles.
crashkernel= peut être définie de plusieurs manières. La valeur auto active la configuration automatique de mémoire réservée, basée sur le montant total de mémoire présente sur le système, en suivant les lignes directrices décrites dans Section B.1, « Besoins en mémoire pour kdump ». Remplacer la valeur d' auto par un montant de mémoire spécifique pour changer ce comportement. Par exemple, pour réserver 128 Mo de mémoire, exécutez :
crashkernel=128Mcrashkernel=<range1>:<size1>,<range2>:<size2>. Exemple :
crashkernel=512M-2G:64M,2G-:128Mcrashkernel=128M@16Mcrashkernel=512M-2G:64M,2G-:128M@16M).
2.2.2. Configuration du type de kdump
NFS (Network File System) ou SSH. Pour l'instant, on ne peut définir qu'une option, et l'option par défaut est de stocker le fichier vmcore dans le répertoire /var/crash/ du système de fichiers local. Pour modifier ceci, en tant qu'utilisateur root, ouvrir le fichier de configuration /etc/kdump.conf dans l'éditeur, et éditer les options décrites ci-dessous.
#path /var/crash et le remplacer par la valeur du chemin d'accès du répertoire souhaité.
path /usr/local/coresImportant
path doit exister lorsque le service kdump systemd est démarré - sinon le service échouera. Ce comportement est différent des versions antérieures de Red Hat Enterprise Linux, où le répertoire était créé automatiquement s'il n'existait pas lors du démarrage du service.
#ext4. Vous pourrez alors utiliser un nom de périphérique #ext4 /dev/vg/lv_kdump line), un nom de système de fichier (#ext4 LABEL=/boot line) ou un UUID (la ligne #ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937). Changer le type de système de fichier, ainsi que le nom du périphérique, le libellé ou l'UUID aux valeurs désirées. Par exemple :
ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937Important
LABEL= ou un UUID= pour spécifier les périphériques de stockage. Les noms de disques comme /dev/sda3 ne sont pas forcément consistents à travers les démarrages. Voir le Red Hat Enterprise Linux 7 Guide d'administration de stockage pour plus d'informations sur le nommage des disques persistent.
Important
/etc/dasd.conf avant de procéder.
#raw /dev/vg/lv_kdump et le remplacer par le nom du périphérique souhiaté. Exemple :
raw /dev/sdb1NFS, supprimer le signe de hachage (« # ») qui se trouve devant #nfs my.server.com:/export/tmp, et remplacez sa valeur par un nom d'hôte et un chemin d'accès valides. Exemple :
nfs penguin.example.com:/export/coresSSH, supprimer le signe de hachage (« # ») qui se trouve devant #ssh user@my.server.com, et remplacez sa valeur par un nom d'hôte et un nom d'utilisateur valides. Pour inclure votre clé SSH dans la configuration également, supprimer le signe de hachage (« # ») qui se trouve au début de la ligne suivante #sshkey /root/.ssh/kdump_id_rsa et changer la valeur de l'emplacement d'une clé valide sur le serveur sur lequel vous essayez de vider la mémoire. Exemple :
ssh john@penguin.example.com
sshkey /root/.ssh/mykey2.2.3. Configuration d'un client DHCP
vmcore, kdump vous permet de spécifier une application externe (un core collector) pour compresser les données, et si on le souhaite, éviter toutes les informations non pertinentes. Actuellement, le seul core collector qui soit pris en charge totalement est makedumpfile.
root, ouvrir le fichier de configuration /etc/kdump.conf dans un éditeur, et supprimer le signe de hachage (« # ») du début de la ligne #core_collector makedumpfile -l --message-level 1 -d 31, et éditer les options de ligne de commande comme décrit ci-dessous.
-c. Exemple :
core_collector makedumpfile -c-d value, avec value représentant une somme de valeurs de pages que vous souhaitez omettre comme décrit dans Tableau B.4, « Niveaux de filtrage pris en charge ». Ainsi, pour supprimer les pages zéro ou libres, exécutez la commande suivante :
core_collector makedumpfile -d 17 -cmakedumpfile(8) pour obtenir une liste complète des options disponibles.
2.2.4. Configurer une action par défaut
kdump ne parvient pas à créer de mémoire de vidage dans l'emplacement cible spécifié dans Section 2.2.2, « Configuration du type de kdump », le système de fichiers root est monté et kdump essaie de sauvegarder le coeur localement. Afin de modifier ce comportement, en tant qu'utilisateur root, ouvrir le fichier de configuration /etc/kdump.conf dans un éditeur de texte, supprimer le signe de hachage (« # ») en début de ligne #default shell, et remplacer sa valeur par celle d'une action souhaitée comme indiqué dans Tableau B.5, « Actions par défaut prises en charge ».
default reboot2.2.5. Activer le service
kdump au démarrage, saisir ce qui suit à l'invite du shell, en tant qu'utisateur root:
systemctl enable kdump.servicemulti-user.target. De même, si vous saisissez systemctl stop kdump, vous le désactiverez. Pour démarrer le service dans une session en cours, exécuter la commande suivante en tant qu'utilisateur root :
systemctl start kdump.serviceImportant
kdump démarre - sinon le service échouera. Ce comportement est différent par rapport aux autres versions de Red Hat Enterprise Linux, quand le répertoire était créé automatiquement s'il n'existait pas déjà quand on démarrait le service.
2.3. Configurer kdump par l'interface graphique
system-config-kdump à l'invite du shell. Vous aurez accès à une fenêtre, comme expliqué dans Figure 2.1, « Paramètres de base ».
kdump ainsi que d'activer ou désactiver le démarrage du service à l'amorçage (boot). Une fois que c'est fait, cliquer sur pour enregistrer les changements. À moins d'être déjà authentifié, on vous demandera de saisir le mot de passe du superutilisateur. L'utilisateur vous rapellera également que vous devez redémarrer le système pour pouvoir appliquer les changements que vous avez fait à la configuration.
Important
SELinux en mode Enforcing, le booléen kdumpgui_run_bootloader Boolean doit être activé avant de lancer l'utilitaire Kernel Dump Configuration. Ce booléen permet à system-config-kdump d'exécuter le chargeur de démarrage dans le domaine bootloader_t SELinux. Pour activer le booléen de manière permanente, exécuter la commande suivante en tant qu'utilisateur root;
# setsebool -P kdumpgui_run_bootloader 1Important
/etc/dasd.conf avant de procéder.
2.3.1. Configuration l'utilisation de la mémoire
kdump. Pour cela, sélectionner le bouton radio Manual settings et cliquer les flèches vers le haut ou vers le bas, à côté du champ New kdump Memory pour augmenter ou diminuer le montant de mémoire à réserver. Notez que le champ Usable Memory change proportionnellement, montrant le montant de mémoire restante dans le système. Consulter Section 1.2, « Besoins en mémoire » pour obtenir plus d'informations sur les besoins en mémoire de kdump.
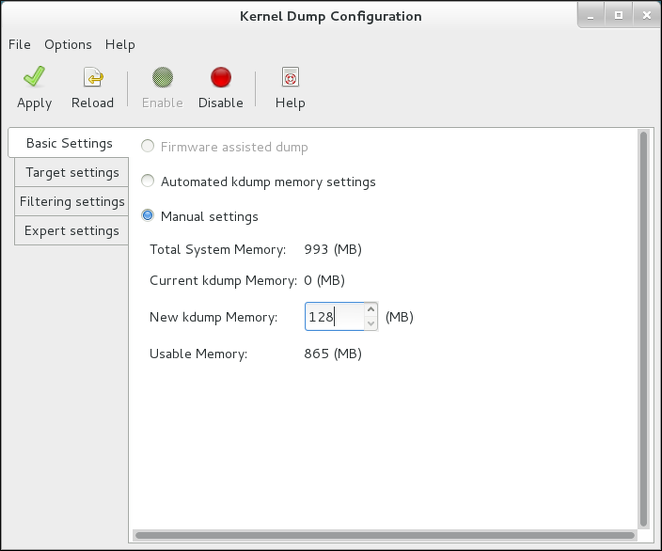
Figure 2.1. Paramètres de base
2.3.2. Configuration du type de kdump
vmcore. La mémoire de vidage peut être stockée en tant que fichier dans un système de fichiers local, ou bien figurer directement sur un périphérique, ou encore, elle peut être envoyée via réseau par l'intermédiaire des protocoles NFS (Network File System) ou SSH (Secure Shell).

Figure 2.2. Configurations de la cible
Important
kdump démarre - sinon le service échouera. Ce comportement est différent par rapport aux autres versions de Red Hat Enterprise Linux, quand le répertoire était créé automatiquement s'il n'existait pas déjà quand on démarrait le service.
NFS, sélectionner le bouton radio NFS, et remplir les champs Server name et Path to directory. Pour utiliser le protocole SSH, sélectionner le bouton radio SSH, et indiquer dans les champs Server name, Path to directory, et User name l'adresse du serveur, le répertoire cible et un nom d'utilisateur valides respectivement.
2.3.3. Configuration d'un client DHCP
vmcore.

Figure 2.3. Configuration du filtrage
2.3.4. Configurer une action par défaut
kdump ne parvient pas à créer de mémoire de vidage, sélectionner une option à partir du menu déroulant Default action. Les options possibles sont (l'action par défaut qui tente de sauvegarder le coeur localement et reboot le système), (reboot système), (invite shell interactive), (pour arrêter le système), et (pour éteindre le système).

Figure 2.4. Configuration du filtrage
makedumpfile, modifier les champs de texte du Core collector; consulter Section 2.2.3, « Configuration d'un client DHCP » pour obtenir plus d'informations.
2.3.5. Activer le service
kdump dès l'amorçage, cliquer sur le bouton qui se trouve sur la barre d'outils, puis cliquer sur . Cela permettra l'activation du service pour multi-user.target. Cliquer sur le bouton et confirmer en cliquant sur qui désactivera le service immédiatement.
Important
kdump démarre - sinon le service échouera. Ce comportement est différent par rapport aux autres versions de Red Hat Enterprise Linux, quand le répertoire était créé automatiquement s'il n'existait pas déjà quand on démarrait le service.
2.4. Tester la configuration kdump
Avertissement
kdump activé, et veillez à ce que le système soit en cours d'exécution :
~]# systemctl is-active kdump
activeecho 1 > /proc/sys/kernel/sysrq
echo c > /proc/sysrq-triggeraddress-YYYY-MM-DD-HH:MM:SS/vmcore sera copié à l'emplacement que vous aurez sélectionné dans la configuration (c-a-d dans /var/crash/ par défaut).
Note
2.5. Ressources supplémentaires
2.5.1. Documentation installée
- kdump.conf(5) — page man pour le fichier de configuration
/etc/kdump.confqui contient la documentation complète des options disponibles. - zipl.conf(5) — page man du fichier de configuration
/etc/zipl.conf. - zipl(8) — page man de l'utilitaire du chargeur de démarrage
zipldes IBM System z. - makedumpfile(8) — page man du core collector
makedumpfile. - kexec(8) — page man de kexec.
- crash(8) — page man de l'utilitaire crash.
/usr/share/doc/kexec-tools-version/kexec-kdump-howto.txt— aperçu général dekdump, installation et utilisation de kexec.
2.5.2. Documentation en ligne
- https://access.redhat.com/site/solutions/6038
- L'article de la base de connaissance de Red Hat sur la configuration
kexecetkdump. - https://access.redhat.com/site/solutions/223773
- L'article de base de connaissance de Red Hat sur les cibles
kdumpprises en charge. - http://people.redhat.com/anderson/
- system-config-users
- https://www.gnu.org/software/grub/
- La page d'accueil et la documentation du chargeur de démarrage GRUB2.
Chapitre 3. Analyse d'un vidage de mémoire
netdump, diskdump, xendump, ou kdump.
3.1. Installer l'utilitaire crash
root :
yum install crashdebuginfo-install en tant qu'utilisateur root:
debuginfo-install kernel3.2. Exécuter l'utilitaire crash
crash /var/crash/<timestamp>/vmcore /usr/lib/debug/lib/modules/<kernel>/vmlinuxkdump. Pour savoir quel noyau vous exécutez actuellement, saisir la commande uname -r.
Exemple 3.1. Exécuter l'utilitaire crash
~]# crash /usr/lib/debug/lib/modules/2.6.32-69.el6.i686/vmlinux \
/var/crash/127.0.0.1-2010-08-25-08:45:02/vmcore
crash 5.0.0-23.el6
Copyright (C) 2002-2010 Red Hat, Inc.
Copyright (C) 2004, 2005, 2006 IBM Corporation
Copyright (C) 1999-2006 Hewlett-Packard Co
Copyright (C) 2005, 2006 Fujitsu Limited
Copyright (C) 2006, 2007 VA Linux Systems Japan K.K.
Copyright (C) 2005 NEC Corporation
Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc.
Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc.
This program is free software, covered by the GNU General Public License,
and you are welcome to change it and/or distribute copies of it under
certain conditions. Enter "help copying" to see the conditions.
This program has absolutely no warranty. Enter "help warranty" for details.
GNU gdb (GDB) 7.0
Copyright (C) 2009 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "i686-pc-linux-gnu"...
KERNEL: /usr/lib/debug/lib/modules/2.6.32-69.el6.i686/vmlinux
DUMPFILE: /var/crash/127.0.0.1-2010-08-25-08:45:02/vmcore [PARTIAL DUMP]
CPUS: 4
DATE: Wed Aug 25 08:44:47 2010
UPTIME: 00:09:02
LOAD AVERAGE: 0.00, 0.01, 0.00
TASKS: 140
NODENAME: hp-dl320g5-02.lab.bos.redhat.com
RELEASE: 2.6.32-69.el6.i686
VERSION: #1 SMP Tue Aug 24 10:31:45 EDT 2010
MACHINE: i686 (2394 Mhz)
MEMORY: 8 GB
PANIC: "Oops: 0002 [#1] SMP " (check log for details)
PID: 5591
COMMAND: "bash"
TASK: f196d560 [THREAD_INFO: ef4da000]
CPU: 2
STATE: TASK_RUNNING (PANIC)
crash>3.3. Afficher la mémoire tampon des messages
log lorsque vous y serez invités.
Exemple 3.2. Afficher la mémoire tampon des messages du noyau
crash> log
... several lines omitted ...
EIP: 0060:[<c068124f>] EFLAGS: 00010096 CPU: 2
EIP is at sysrq_handle_crash+0xf/0x20
EAX: 00000063 EBX: 00000063 ECX: c09e1c8c EDX: 00000000
ESI: c0a09ca0 EDI: 00000286 EBP: 00000000 ESP: ef4dbf24
DS: 007b ES: 007b FS: 00d8 GS: 00e0 SS: 0068
Process bash (pid: 5591, ti=ef4da000 task=f196d560 task.ti=ef4da000)
Stack:
c068146b c0960891 c0968653 00000003 00000000 00000002 efade5c0 c06814d0
<0> fffffffb c068150f b7776000 f2600c40 c0569ec4 ef4dbf9c 00000002 b7776000
<0> efade5c0 00000002 b7776000 c0569e60 c051de50 ef4dbf9c f196d560 ef4dbfb4
Call Trace:
[<c068146b>] ? __handle_sysrq+0xfb/0x160
[<c06814d0>] ? write_sysrq_trigger+0x0/0x50
[<c068150f>] ? write_sysrq_trigger+0x3f/0x50
[<c0569ec4>] ? proc_reg_write+0x64/0xa0
[<c0569e60>] ? proc_reg_write+0x0/0xa0
[<c051de50>] ? vfs_write+0xa0/0x190
[<c051e8d1>] ? sys_write+0x41/0x70
[<c0409adc>] ? syscall_call+0x7/0xb
Code: a0 c0 01 0f b6 41 03 19 d2 f7 d2 83 e2 03 83 e0 cf c1 e2 04 09 d0 88 41 03 f3 c3 90 c7 05 c8 1b 9e c0 01 00 00 00 0f ae f8 89 f6 <c6> 05 00 00 00 00 01 c3 89 f6 8d bc 27 00 00 00 00 8d 50 d0 83
EIP: [<c068124f>] sysrq_handle_crash+0xf/0x20 SS:ESP 0068:ef4dbf24
CR2: 0000000000000000help log pour plus d'informations sur l'utilisation de la commande.
Note
vmcore-dmesg.txt. Cela est bien utile quand on n'a pas pu obtenir le fichier vmcore complet, par exemple, en cas de manque d'espace dans l'emplacement cible. Le fichier par défaut utilisé est vmcore-dmesg.txt qui se trouve dans le répertoire /var/crash/.
3.4. Afficher un backtrace
bt dans l'invite shell. Vous pouvez saisir bt <pid> pour afficher l'historique d'appels d'un seul processus.
Exemple 3.3. Ne pas afficher l'interface utilisateur
crash> bt
PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash"
#0 [ef4dbdcc] crash_kexec at c0494922
#1 [ef4dbe20] oops_end at c080e402
#2 [ef4dbe34] no_context at c043089d
#3 [ef4dbe58] bad_area at c0430b26
#4 [ef4dbe6c] do_page_fault at c080fb9b
#5 [ef4dbee4] error_code (via page_fault) at c080d809
EAX: 00000063 EBX: 00000063 ECX: c09e1c8c EDX: 00000000 EBP: 00000000
DS: 007b ESI: c0a09ca0 ES: 007b EDI: 00000286 GS: 00e0
CS: 0060 EIP: c068124f ERR: ffffffff EFLAGS: 00010096
#6 [ef4dbf18] sysrq_handle_crash at c068124f
#7 [ef4dbf24] __handle_sysrq at c0681469
#8 [ef4dbf48] write_sysrq_trigger at c068150a
#9 [ef4dbf54] proc_reg_write at c0569ec2
#10 [ef4dbf74] vfs_write at c051de4e
#11 [ef4dbf94] sys_write at c051e8cc
#12 [ef4dbfb0] system_call at c0409ad5
EAX: ffffffda EBX: 00000001 ECX: b7776000 EDX: 00000002
DS: 007b ESI: 00000002 ES: 007b EDI: b7776000
SS: 007b ESP: bfcb2088 EBP: bfcb20b4 GS: 0033
CS: 0073 EIP: 00edc416 ERR: 00000004 EFLAGS: 00000246help bt pour plus d'informations sur l'utilisation de la commande.
3.5. Explication du processus
ps dans l'invite shell. Vous pouvez saisir ps<pid> pour afficher le statut d'un seul processus.
Exemple 3.4. Afficher le statut des processus dans le système
crash> ps
PID PPID CPU TASK ST %MEM VSZ RSS COMM
> 0 0 0 c09dc560 RU 0.0 0 0 [swapper]
> 0 0 1 f7072030 RU 0.0 0 0 [swapper]
0 0 2 f70a3a90 RU 0.0 0 0 [swapper]
> 0 0 3 f70ac560 RU 0.0 0 0 [swapper]
1 0 1 f705ba90 IN 0.0 2828 1424 init
... several lines omitted ...
5566 1 1 f2592560 IN 0.0 12876 784 auditd
5567 1 2 ef427560 IN 0.0 12876 784 auditd
5587 5132 0 f196d030 IN 0.0 11064 3184 sshd
> 5591 5587 2 f196d560 RU 0.0 5084 1648 bashhelp ps pour plus d'informations sur l'utilisation de la commande.
3.6. Afficher des informations de mémoire virtuelle
vm à l'invite de commande. Vous pouvez utiliser vm <pid> pour afficher des informations sur un processus unique.
Exemple 3.5. Afficher des informations de mémoire virtuelle sur le contexte en cours
crash> vm
PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash"
MM PGD RSS TOTAL_VM
f19b5900 ef9c6000 1648k 5084k
VMA START END FLAGS FILE
f1bb0310 242000 260000 8000875 /lib/ld-2.12.so
f26af0b8 260000 261000 8100871 /lib/ld-2.12.so
efbc275c 261000 262000 8100873 /lib/ld-2.12.so
efbc2a18 268000 3ed000 8000075 /lib/libc-2.12.so
efbc23d8 3ed000 3ee000 8000070 /lib/libc-2.12.so
efbc2888 3ee000 3f0000 8100071 /lib/libc-2.12.so
efbc2cd4 3f0000 3f1000 8100073 /lib/libc-2.12.so
efbc243c 3f1000 3f4000 100073
efbc28ec 3f6000 3f9000 8000075 /lib/libdl-2.12.so
efbc2568 3f9000 3fa000 8100071 /lib/libdl-2.12.so
efbc2f2c 3fa000 3fb000 8100073 /lib/libdl-2.12.so
f26af888 7e6000 7fc000 8000075 /lib/libtinfo.so.5.7
f26aff2c 7fc000 7ff000 8100073 /lib/libtinfo.so.5.7
efbc211c d83000 d8f000 8000075 /lib/libnss_files-2.12.so
efbc2504 d8f000 d90000 8100071 /lib/libnss_files-2.12.so
efbc2950 d90000 d91000 8100073 /lib/libnss_files-2.12.so
f26afe00 edc000 edd000 4040075
f1bb0a18 8047000 8118000 8001875 /bin/bash
f1bb01e4 8118000 811d000 8101873 /bin/bash
f1bb0c70 811d000 8122000 100073
f26afae0 9fd9000 9ffa000 100073
... several lines omitted ...help vm pour plus d'informations sur l'utilisation de la commande.
3.7. Afficher les fichiers ouverts
files dans l'invite shell. Vous pouvez exécuter la commande files <pid> pour afficher les fichiers ouverts par un processus unique sélectionné.
Exemple 3.6. Afficher des informations sur les fichiers ouverts dans le contexte actuel
crash> files
PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash"
ROOT: / CWD: /root
FD FILE DENTRY INODE TYPE PATH
0 f734f640 eedc2c6c eecd6048 CHR /pts/0
1 efade5c0 eee14090 f00431d4 REG /proc/sysrq-trigger
2 f734f640 eedc2c6c eecd6048 CHR /pts/0
10 f734f640 eedc2c6c eecd6048 CHR /pts/0
255 f734f640 eedc2c6c eecd6048 CHR /pts/0help files pour plus d'informations sur l'utilisation de la commande.
3.8. Sortir de l'utilitaire
exit ou q.
Exemple 3.7. Sortir de l'utilitaire crash
crash> exit
~]#Annexe A. Foire Aux Questions
- Q : Quelles méthodes de vidage sont-t-elles disponibles pour les machines virtuelles ?
- Q : Comment télécharger un fichier de vidage volumineux dans Red Hat Support Services ?
- Q : Combien de temps faut-il pour compléter un vidage de mémoire suite à un incident ?
kdump est suffisante pour obtenir un vidage de mémoire d'une machine après un crash ou en cas de panique. Cela peut être mis en place de la même manière que les installations en bare metal.
libvirt pour cela : pvpanic et virsh dump. Ces deux méthodes sont décrites dans le guide Virtualization Deployment and Administration Guide.
pvpanic est décrit dans le guide Virtualization Deployment and Administration Guide - Setting a Panic Device.
virsh dump est expliquée dans le guide Virtualization Deployment and Administration Guide - Creating a Dump File of a Domain's Core.
dropbox.redhat.com et les fichiers doivent être téléchargés dans le répertoire /incoming/. Votre client FTP doit être défini en mode passif ; si votre parefeu n'autorise pas ce mode, vous pourrez utiliser le serveur origin-dropbox.redhat.com en mode actif.
ssh, par exemple, peut prendre plus de temps qu'un disque SATA connecté localement.
Annexe B. Cibles et configurations kdump prises en charge
B.1. Besoins en mémoire pour kdump
| Architecture | Mémoire disponible | Mémoire réservée minimum |
|---|---|---|
AMD64 et Intel 64 (x86_64) | 2 Go et plus | 160 Mo + 2 bits pour chaque 4 KB de RAM. Pour un système de 1 To de mémoire, 224 Mo est le minimum (160 + 64 Mo). |
IBM POWER (ppc64) | 2 Go à 4 Go | 256 Mo de RAM. |
| 4 Go à 32 Go | 512 Mo de RAM. | |
| 32 Go à 64 Go | 1 Go de RAM. | |
| 64 Go à 128 Go | 2 Go ou RAM. | |
| 128 Go et plus | 4 Go de RAM. | |
IBM System z (s390x) | 2 Go et plus | 160 Mo + 2 bits pour chaque 4 KB de RAM. Pour un système de 1 To de mémoire, 224 Mo est le minimum (160 + 64 Mo). |
B.2. Limite minimum pour la réservation de mémoire automatique
crashkernel=auto dans le fichier de configuration du bootloader, soit en activant cette option dans l'utilitaire de configuration graphique. Pour que cette réservation automatique fonctionne, cependant, une certaine quantité de mémoire totale doit être disponible dans le système. Ce montant diffère selon l'architecture du système.
| Architecture | Mémoire requise |
|---|---|
AMD64 et Intel 64 (x86_64) | 2 Go |
IBM POWER (ppc64) | 2 Go |
IBM System z (s390x) | 4 Go |
B.3. Cibles kdump prises en charge
| Type | Cibles prises en charge | Cibles non prises en charge |
|---|---|---|
| Périphérique brut | Toutes les partitions et tous les disques bruts attachés localement. | — |
| Systèmes de fichiers locaux | Les systèmes de fichiers ext2, ext3, ext4, btrfs et xfs sur disques durs attachés directement, sur lecteurs logiques RAID hardware, périphériques LVM, et disques mdraid. | Tout système de fichiers local non listé explicitement, supporté dans ce tableau, y compris le type auto (détection de système de fichiers automatique) |
| Répertoire personnel | Répertoires à distance accédés via protocoles NFS ou SSH sur IPv4. | Répertoires à distance sur le système de fichiers rootfs auxquels on a accédé en utilisant le protocole NFS. |
Répertoires à distance auxquels on a accédé via le protocole iSCSI par l'intermédiaire d'initiateurs logiciels et matériels à la fois. | Répertoires à distance auxquels on a accédé via le protocole iSCSI sur matériel be2iscsi. | |
| Stockages basés multipath | — | |
| — | Répertoires à distance auxquels on a accédé via le protocole IPv6. | |
Répertoires à distance auxquels on a accédé via protocoles SMB/CIFS. | ||
Répertoires à distance auxquels on a accédé via le protocole FCoE (Fibre Channel over Ethernet). | ||
| Répertoires à distance auquels on a accédé par des interfaces de réseau wireless. |
B.4. Niveaux de filtrage kdump pris en charge
makedumpfile pour compresser les données et parfois délaisse des informations importantes. Le tableau ci-dessous contient une liste complète des niveaux de filtrage actuellement pris en charge par l'utilitaire makedumpfile.
| Option | Description |
|---|---|
1 | Pages zéro |
2 | Pages de cache |
4 | Cache privé |
8 | Pages utilisateur |
16 | Pages libres |
Note
makedumpfile supporte la suppression de pages huges et hugetlbfs transparentes dans Red Hat Enterprise Linux 7.3 et versions supérieures. Ces deux types de pages huge sont considérées comme des pages utilisateur et seront supprimées par le niveau -8.
B.5. Actions par défaut prises en charge
| Option | Description |
|---|---|
dump_to_rootfs | Essaie d'enregistrer la mémoire de vidage dans le système de fichiers racine. Cette option est particulièrement utile en combinaison avec une cible réseau : si la cible réseau est inaccessible, cette option configure kdump pour enregistrer le vidage de la mémoire du noyau localement. Le système est redémarré par la suite. |
reboot | Redémarre les systèmes, en perdant la mémoire de vidage au cours du processus. |
halt | Arrête le système, en perdant la mémoire de vidage au cours du processus. |
poweroff | Éteint le système, en perdant la mémoire de vidage au cours du processus. |
shell | Exécute une sesssion shell dans initramfs, autorisant l'utilisateur à enregistrer la mémoire de vidage manuellement. |
B.6. Estimation de la taille de Kdump
kdump , il est nécessaire de savoir combien d'espace est nécessaire pour le fichier de mémoire de vidage avant qu'on l'ait produite. La commande makedumpfile peut vous y aider.
--mem-usage fournit un rapport utile sur les pages qui peuvent être excluses, et qui peut être utilisé pour déterminer le niveau de mémoire de vidage que vous souhaitez affecter. Cette commande doit être exécutée lorsque le système est sous charge représentative, sinon makedumpfile renverra une valeur inférieure à celle qui est attendue dans votre environnement de production.
[root@hostname ~]# makedumpfile --mem-usage /proc/kcore
TYPE PAGES EXCLUDABLE DESCRIPTION
----------------------------------------------------------------------
ZERO 501635 yes Pages filled with zero
CACHE 51657 yes Cache pages
CACHE_PRIVATE 5442 yes Cache pages + private
USER 16301 yes User process pages
FREE 77738211 yes Free pages
KERN_DATA 1333192 no Dumpable kernel dataImportant
makedumpfile produit un rapport en pages. Cela signifie que vous devez calculer la taille de la mémoire utilisée par rapport à la taille de la page du noyau, ce qui, dans Red Hat Enterprise Linux kernel, correspond à 4 kilooctets (4096 octets).
Annexe C. Historique des versions
| Historique des versions | |||
|---|---|---|---|
| Version 1.3-2.1 | Mon Jul 3 2017 | ||
| |||
| Version 1.3-2 | Fri Nov 4 2016 | ||
| |||
| Version 1.2-9 | Thu 18 Aug 2016 | ||
| |||
| Version 1.2-0 | Fri 06 Mar 2015 | ||
| |||
| Version 1.1-3 | Wed 18 Feb 2015 | ||
| |||
| Version 1.1-0 | Fri 05 Dec 2014 | ||
| |||
| Version 1.0-0 | Mon 02 Jun 2014 | ||
| |||
| Version 0.0-8 | Thu Jan 17 2013 | ||
| |||