Guide de l'administrateur systèmes
Déploiement, configuration, et administration de Red Hat Enterprise Linux 7
Résumé
Note
Partie I. Configuration de base du système
Chapitre 1. Paramètres régionaux et configuration du clavier
/etc/locale.conf ou en utilisant l'utilitaire localectl. Ainsi, vous pouvez utiliser l'interface utilisateur graphique pour effectuer la tâche. Pour obtenir une description de la méthode, veuillez consulter le Guide d'installation Red Hat Enterprise Linux 7.
1.1. Définir les paramètres régionaux
/etc/locale.conf, qui est lu au début du démarrage par le démon systemd. Les paramètres régionaux configurés dans /etc/locale.conf sont hérités par chaque service ou utilisateur, à moins qu'un programme ou utilisateur individuel ne l'outrepasse.
/etc/locale.conf est une liste séparée par des lignes d'affectation de variables. Voici des paramètres allemands avec des messages en anglais dans /etc/locale.conf :
LANG=de_DE.UTF-8 LC_MESSAGES=C
LANG=de_DE.UTF-8
LC_MESSAGES=C
/etc/locale.conf, vous pouvez utiliser plusieurs autres options. Les plus courantes sont résumées dans Tableau 1.1, « Options configurables dans /etc/locale.conf ». Veuillez consulter la page du manuel locale(7) pour obtenir des informations détaillées sur ces options. Veuillez remarquer que l'option LC_ALL, qui représente toutes les options possibles, ne doit pas être configurée dans /etc/locale.conf.
| Option | Description |
|---|---|
| LANG | Fournit une valeur par défaut pour les paramètres régionaux. |
| LC_COLLATE | Modifie le comportement des fonctions qui comparent les chaînes dans l'alphabet local. |
| LC_CTYPE | Modifie le comportement des fonctions de gestion et de classification des caractères et les fonctions des caractères multioctets. |
| LC_NUMERIC | Décrit la manière par laquelle les chiffres sont habituellement imprimés, avec des détails tels que le point décimal versus la virgule décimale. |
| LC_TIME | Modifie l'affichage de l'heure actuelle, 24 heures versus 12 heures. |
| LC_MESSAGES | Détermine les paramètres régionaux utilisés pour les messages de diagnostique écrits dans la sortie d'erreur standard. |
1.1.1. Afficher le statut actuel
localectl peut être utilisée pour effectuer des requêtes et modifier les paramètres régionaux et les paramètres d'agencement du clavier. Pour afficher les paramètres actuels, veuilles utiliser l'option status :
localectl status
localectl statusExemple 1.1. Afficher le statut actuel
localectl status
System Locale: LANG=en_US.UTF-8
VC Keymap: us
X11 Layout: n/a
~]$ localectl status
System Locale: LANG=en_US.UTF-8
VC Keymap: us
X11 Layout: n/a
1.1.2. Répertorier les paramètres régionaux disponibles
localectl list-locales
localectl list-localesExemple 1.2. Répertorier les paramètres régionaux
1.1.3. Définir les paramètres régionaux
root :
localectl set-locale LANG=locale
localectl set-locale LANG=localelocalectl list-locales. La syntaxe ci-dessus peut également être utilisée pour configurer les paramètres de Tableau 1.1, « Options configurables dans /etc/locale.conf ».
Exemple 1.3. Modifier les paramètres régionaux par défaut
list-locales. Puis, en tant qu'utilisateur root, saisir une commande du modèle suivant :
localectl set-locale LANG=en_GB.utf8
~]# localectl set-locale LANG=en_GB.utf81.2. Modifier l'agencement du clavier
1.2.1. Afficher les paramètres actuels
localectl status
localectl statusExemple 1.4. Afficher les paramètres du clavier
localectl status
System Locale: LANG=en_US.utf8
VC Keymap: us
X11 Layout: us
~]$ localectl status
System Locale: LANG=en_US.utf8
VC Keymap: us
X11 Layout: us
1.2.2. Répertorier les agencements de clavier disponibles
localectl list-keymaps
localectl list-keymapsExemple 1.5. Rechercher un agencement de clavier particulier
grep peut être utilisée pour rechercher un nom d'agencement de clavier particulier dans la sortie de la commande précédente. De multiples agencements de clavier sont souvent compatibles avec vos paramètres régionaux actuels. Par exemple, pour trouver des agencements de clavier tchèques, veuillez saisir :
1.2.3. Définir l'agencement du clavier
root :
localectl set-keymap map
localectl set-keymap maplocalectl list-keymaps. À moins que l'option --no-convert ne soit passée, le paramètre sélectionné est également appliqué au mappage du clavier par défaut du système de fenêtres X11, après l'avoir converti au mappage de clavier X11 correspondant le mieux. Ceci s'applique à l'inverse, vous pouvez spécifier les deux agencements de clavier avec la commande suivante en tant qu'utilisateur root :
localectl set-x11-keymap map
localectl set-x11-keymap map--no-convert.
localectl --no-convert set-x11-keymap map
localectl --no-convert set-x11-keymap mapExemple 1.6. Définir l'agencement du clavier X11 séparément
root, veuillez saisir :
localectl --no-convert set-x11-keymap de
~]# localectl --no-convert set-x11-keymap delocalectl status
System Locale: LANG=de_DE.UTF-8
VC Keymap: us
X11 Layout: de
~]$ localectl status
System Locale: LANG=de_DE.UTF-8
VC Keymap: us
X11 Layout: de
localectl set-x11-keymap map model variant options
localectl set-x11-keymap map model variant optionskbd(4).
1.3. Ressources supplémentaires
Documentation installée
localectl(1) — la page du manuel de l'utilitaire de ligne de commandelocalectldocumente comment utiliser cet outil pour configurer les paramètres régionaux du système et la structure du clavier.loadkeys(1) — la page du manuel de la commandeloadkeysfournit des informations supplémentaires sur la manière d'utiliser cet outil pour modifier la structure du clavier dans une console virtuelle.
Voir aussi
- Le Chapitre 5, Obtention de privilèges documente comment obtenir des privilèges administratifs en utilisant les commandes
suetsudo. - Le Chapitre 9, Gérer les services avec systemd fournit des informations supplémentaires sur
systemdet documente comment utiliser la commandesystemctlpour gérer des services de système.
Chapitre 2. Configurer l'heure et la date
- Une horloge temps réel (« Real-Time Clock », ou RTC), communément appelée horloge matérielle, (habituellement un circuit intégré sur la carte système) est complètement indépendante de l'état actuel du système d'exploitation et fonctionne même lorsque l'ordinateur est éteint.
- Une horloge système, également appelée horloge logicielle, est habituellement maintenue par le noyau et sa valeur initiale est basée sur l'horloge temps réel. Une fois le système démarré et l'horloge système initialisée, celle-ci est entièrement indépendante de l'horloge temps réel.
timedatectl, qui est nouveau sur Red Hat Enterprise Linux 7 et fait partie de systemd ; la commande traditionnelle date ; et l'utilitaire hwclock pour accéder à l'horloge matérielle.
2.1. Utilisation de la commande timedatectl
systemd et permet de réviser et modifier la configuration de l'horloge système. Vous pouvez utiliser cet outil pour modifier l'heure et la date actuelle, pour définir le fuseau horaire, ou pour activer la synchronisation automatique de l'horloge système avec un serveur distant.
2.1.1. Afficher l'heure et la date actuelle
timedatectl sans aucune autre option de ligne de commande :
timedatectl
timedatectlNTP (« Network Time Protocol »), ainsi que des informations supplémentaires liées à DST.
Exemple 2.1. Afficher l'heure et la date actuelle
timedatectl sur un système qui n'utilise pas NTP pour synchroniser l'horloge système avec un serveur distant :
Important
chrony ou à ntpd ne seront pas notés immédiatement par timedatectl. S'il y a eu des changements de configuration ou de statut à ces outils, saisir la commande suivante :
systemctl restart systemd-timedated.services
~]# systemctl restart systemd-timedated.services2.1.2. Modifier l'heure actuelle
root:
timedatectl set-time HH:MM:SS
timedatectl set-time HH:MM:SSdate --set et hwclock --systohc.
NTP est activé. Voir Section 2.1.5, « Synchroniser l'horloge système avec un serveur à distance » pour désactiver le service de façon temporaire.
Exemple 2.2. Modifier l'heure actuelle
root :
timedatectl set-time 23:26:00
~]# timedatectl set-time 23:26:00timedatectl avec l'option set-local-rtc en tant qu'utilisateur root :
timedatectl set-local-rtc boolean
timedatectl set-local-rtc booleanyes (ou bien par y, true, t, ou 1). Pour configurer le système de manière à utiliser UTC, veuillez remplacer boolean par no (ou bien par, n, false, f, ou 0). L'option par défaut est no.
2.1.3. Modifier la date actuelle
root:
timedatectl set-time YYYY-MM-DD
timedatectl set-time YYYY-MM-DDExemple 2.3. Modifier la date actuelle
root :
timedatectl set-time '2013-06-02 23:26:00'
~]# timedatectl set-time '2013-06-02 23:26:00'2.1.4. Modifier le fuseau horaire
timedatectl list-timezones
timedatectl list-timezonesroot :
timedatectl set-timezone time_zone
timedatectl set-timezone time_zonetimedatectl list-timezones.
Exemple 2.4. Modifier le fuseau horaire
timedatectl avec l'option de ligne de commande list-timezones. Par exemple, pour répertorier tous les fuseaux horaires en Europe, veuillez saisir :
Europe/Prague, veuillez saisir ce qui suit en tant qu'utilisateur root :
timedatectl set-timezone Europe/Prague
~]# timedatectl set-timezone Europe/Prague2.1.5. Synchroniser l'horloge système avec un serveur à distance
timedatectl vous permet également d'activer la synchronisation automatique de votre horloge système avec un groupe de serveurs à distance en utilisant le protocole NTP. L'activation de NTP active chronyd ou ntpd, selon le service installé.
NTP peut être activé et désactivé par une commande sur le modèle suivant :
timedatectl set-ntp boolean
timedatectl set-ntp booleanNTP à distance, veuillez remplacer boolean par yes (option par défaut). Pour désactiver cette fonctionnalité, veuillez remplacer boolean par no.
Exemple 2.5. Synchroniser l'horloge système avec un serveur à distance
timedatectl set-ntp yes
~]# timedatectl set-ntp yesNTP n'est pas installé. Voir Section 15.3.1, « Installer Chrony » pour plus d'informations.
2.2. Utiliser la commande date
date est disponible sur tous les systèmes Linux et vous permet d'afficher et de configurer l'heure et la date actuelle. Celle-ci est fréquemment utilisée dans les scripts pour afficher des informations détaillées sur l'horloge système sous un format personnalisé.
timedatectl ».
2.2.1. Afficher l'heure et la date actuelle
date sans aucune autre option de ligne de commande :
date
datedate affiche l'heure local. Pour afficher l'heure UTC, veuillez exécuter la commande avec l'option de ligne de commande --utc ou -u :
date --utc
date --utc+"format" sur la ligne de commande :
date +"format"
date +"format"date(1) pour une liste complète de ces options.
| Séquence de contrôle | Description |
|---|---|
%H | Heures sous le format HH (par exemple, 17). |
%M | Minutes sous le format MM (par exemple, 30). |
%S | Secondes sous le format SS (par exemple, 24). |
%d | Jour du mois sous le format DD (par exemple, 16). |
%m | Mois sous le format MM (par exemple, 09). |
%Y | Année sous le format YYYY (par exemple, 2013). |
%Z | Abbréviation du fuseau horaire (par exemple, CEST). |
%F | Date complète sous le format YYYY-MM-DD (par exemple, 2013-09-16). Cette option correspond à %Y-%m-%d. |
%T | Heure complète sous le format HH:MM:SS (par exemple, 17:30:24). Cette option correspond à %H:%M:%S |
Exemple 2.6. Afficher l'heure et la date actuelle
date Mon Sep 16 17:30:24 CEST 2013
~]$ date
Mon Sep 16 17:30:24 CEST 2013date --utc Mon Sep 16 15:30:34 UTC 2013
~]$ date --utc
Mon Sep 16 15:30:34 UTC 2013date, veuillez saisir :
date +"%Y-%m-%d %H:%M" 2013-09-16 17:30
~]$ date +"%Y-%m-%d %H:%M"
2013-09-16 17:302.2.2. Modifier l'heure actuelle
date avec l'option --set ou -s en tant qu'utilisateur root :
date --set HH:MM:SS
date --set HH:MM:SSdate définit l'horloge système sur l'heure locale. Pour définir l'horloge système sur UTC, exécutez la commande avec l'option de ligne de commande --utc ou -u :
date --set HH:MM:SS --utc
date --set HH:MM:SS --utcExemple 2.7. Modifier l'heure actuelle
root :
date --set 23:26:00
~]# date --set 23:26:002.2.3. Modifier la date actuelle
date avec l'option --set ou -s en tant qu'utilisateur root :
date --set YYYY-MM-DD
date --set YYYY-MM-DDExemple 2.8. Modifier la date actuelle
root :
date --set 2013-06-02 23:26:00
~]# date --set 2013-06-02 23:26:002.3. Utilisation de la commande hwclock
hwclock est un utilitaire pour accéder à l'horloge matérielle, également appelée horloge RTC (« Real Time Clock »). L'horloge matérielle est indépendante du système d'exploitation utilisé et fonctionne même lorsque l'ordinateur est éteint. Cet utilitaire est utilisé pour afficher l'heure de l'horloge matérielle. hwclock offre aussi la possibilité de compenser pour la dérive systématique de l'horloge matérielle.
hwclock enregistre ses paramètres dans le fichier /etc/adjtime, qui est créé lors du premier changement effectué. Par exemple, lorsque l'heure est définie manuellement ou lorsque l'horloge matérielle est synchronisée avec l'heure système.
Note
hwclock était exécutée automatiquement à chaque fermeture ou redémarrage du système, mais ceci n'est pas le cas sur Red Hat Enterprise Linux 7. Lorsque l'horloge système est synchronisée par le protocole NTP (« Network Time Protocol ») ou PTP (« Precision Time Protocol »), le noyau synchronise automatiquement l'horloge matérielle avec l'horloge système toutes les 11 minutes.
2.3.1. Afficher l'heure et la date actuelle
hwclock sans aucun option de ligne de commande en tant qu'utilisateur root retourne l'heure et la date locale sur la sortie standard.
hwclock
hwclock--utc ou --localtime avec la commande hwclock ne signifie pas que vous tentiez d'afficher l'heure de l'horloge matérielle en temps UTC ou en temps local. Ces options sont utilisées pour définir l'horloge matérielle de manière à conserver l'heure. L'heure est toujours affichée en heure locale. En outre, l'utilisation des commandes hwclock --utc ou hwclock --local ne modifie pas l'enregistrement dans le fichier /etc/adjtime. Cette commande peut être utile lorsque vous savez que le paramètre enregistré dans /etc/adjtime est incorrect mais que vous ne souhaitez pas modifier ce paramètre. D'autre part, vous pourriez recevoir des informations risquant de vous induire en erreur si vous utilisez une commande de la mauvaise manière. Veuillez consulter la page man de hwclock(8) pour obtenir davantage de détails.
Exemple 2.9. Afficher l'heure et la date actuelle
root :
hwclock Tue 15 Apr 2014 04:23:46 PM CEST -0.329272 seconds
~]# hwclock
Tue 15 Apr 2014 04:23:46 PM CEST -0.329272 seconds2.3.2. Paramétrer l'heure et la date
--set et --date dans vos spécifications :
hwclock --set --date "dd mmm yyyy HH:MM"
hwclock --set --date "dd mmm yyyy HH:MM"--utc ou --localtime, respectivement. Dans ce cas, UTC ou LOCAL est enregistré dans le fichier /etc/adjtime.
Exemple 2.10. Paramétrer l'horloge matérielle à une heure et date en particulier
root sous le format suivant :
hwclock --set --date "21 Oct 2014 21:17" --utc
~]# hwclock --set --date "21 Oct 2014 21:17" --utc2.3.3. Synchroniser l'heure et la date
- Vous pouvez définir l'horloge matérielle sur l'heure système actuelle à l'aide de cette commande :
hwclock --systohc
hwclock --systohcCopy to Clipboard Copied! Toggle word wrap Toggle overflow Remarquez que si vous utilisez NTP, l'horloge matérielle est automatiquement synchronisée à l'horloge système toutes les 11 minutes, et cette commande n'est utile que pendant le démarrage pour obtenir une heure système initiale raisonnable. - Vous pouvez également définir l'heure système à partir de l'horloge matérielle en utilisant la commande suivante :
hwclock --hctosys
hwclock --hctosysCopy to Clipboard Copied! Toggle word wrap Toggle overflow
--utc ou --localtime. De même qu'avec --set, UTC ou LOCAL est enregistré dans le fichier /etc/adjtime.
hwclock --systohc --utc est fonctionnellement similaire à timedatectl set-local-rtc false et la commande hwclock --systohc --local est une alternative à timedatectl set-local-rtc true.
Exemple 2.11. Synchroniser l'horloge matérielle avec l'heure système
root :
hwclock --systohc --localtime
~]# hwclock --systohc --localtime2.4. Ressources supplémentaires
Documentation installée
timedatectl(1) — la page du ma de l'utilitaire de ligne de commandetimedatectldocumente comment utiliser cet outil pour effectuer des requêtes et modifier l'horloge système et ses paramètres.date(1) — la page du man de la commandedatefournit une liste complète des options de ligne de commande prises en charge.hwclock(8) — la page du man de la commandehwclockfournit une liste complète des options de ligne de commande.
Voir aussi
- Chapitre 1, Paramètres régionaux et configuration du clavier documente comment configurer l'agencement du clavier.
- Chapitre 5, Obtention de privilèges documente comment obtenir des privilèges administratifs en utilisant les commandes
suetsudo. - Chapitre 9, Gérer les services avec systemd fournit davantage d'informations sur systemd et documente comment utiliser la commande
systemctlpour gérer les services du système.
Chapitre 3. Gérer les utilisateurs et les groupes
3.1. Introduction aux utilisateurs et aux groupes
root, et les permissions d'accès quant à elles peuvent être modifiées aussi bien par l'utilisateur root, que par le propriétaire du fichier.
ID d'utilisateurs et de groupes réservés
cat /usr/share/doc/setup*/uidgid
cat /usr/share/doc/setup*/uidgidUID_MIN et GID_MIN dans le fichier /etc/login.defs :
[file contents truncated] UID_MIN 5000[file contents truncated] GID_MIN 5000[file contents truncated]
[file contents truncated]
UID_MIN 5000[file contents truncated]
GID_MIN 5000[file contents truncated]Note
UID_MIN et GID_MIN, les UID démarreront toujours par la valeur par défaut de 1000.
3.1.1. Groupes privés d'utilisateurs
/etc/bashrc. Habituellement sur les système basés UNIX, l'umask a pour valeur 022, ce qui permet uniquement à l'utilisateur ayant créé le fichier ou le répertoire d'effectuer des modifications. Sous ce schéma, tous les autres utilisateurs, y compris les membres du groupe du créateur, ne sont pas autorisés à effectuer des modifications. Cependant, sous le schéma UPG, cette « protection de groupe » n'est pas nécessaire puisque chaque utilisateur possède son propre groupe privé.
/etc/group.
3.1.2. Mots de passe cachés (« Shadow Passwords »)
- Les mots de passe cachés améliorent la sécurité du système en déplaçant les hachages de mots de passe chiffrés depuis le fichier lisible
/etc/passwdsur le fichier/etc/shadow, qui est uniquement lisible par l'utilisateurroot. - Les mots de passe cachés stockent des informations sur l'ancienneté du mot de passe.
- Les mots de passe cachés permettent d'appliquer les politiques de sécurité définies dans le fichier
/etc/login.defs.
/etc/shadow, certains utilitaires et certaines commandes ne fonctionneront pas si les mots de passe cachés ne sont pas activés :
- Utilitaire
chagepour définir les paramètres d'ancienneté de mot de passe. Pour obtenir des détails, veuillez consulter la section Sécurité du mot de passe dans le Guide de sécurité Red Hat Enterprise Linux 7. - Utilitaire
gpasswdpour administrer le fichier/etc/group. - Commande
usermodavec l'option-e, --expiredateou-f, --inactive. - La commande
useraddavec l'option-e, --expiredateou-f, --inactive.
3.2. Gestion des utilisateurs dans un environnement graphique
3.2.1. Utiliser l'outil des paramètres d'utilisateurs « Users Settings Tool »
Users puis appuyez sur Entrée. L'outil des paramètres Users s'affiche. La touche Super apparaît sous une variété de formes, selon le clavier et matériel, mais le plus souvent, il s'agit de la touche Windows ou Commande, et elle se trouve habituellement à gauche de la barre d'espace. Alternativement, vous pouvez ouvrir l'utilitaire Users à partir du menu après avoir cliqué sur votre nom d'utilisateur dans le coin supérieur droit de l'écran.
root. Pour ajouter et supprimer des utilisateurs, veuillez sélectionner les boutons et respectivement. Pour ajouter un utilisateur au groupe administratif wheel, veuillez changer le de Standard à Administrateur. Pour modifier le paramètre de langue d'un utilisateur, veuillez sélectionner la langue et un menu déroulant apparaîtra.
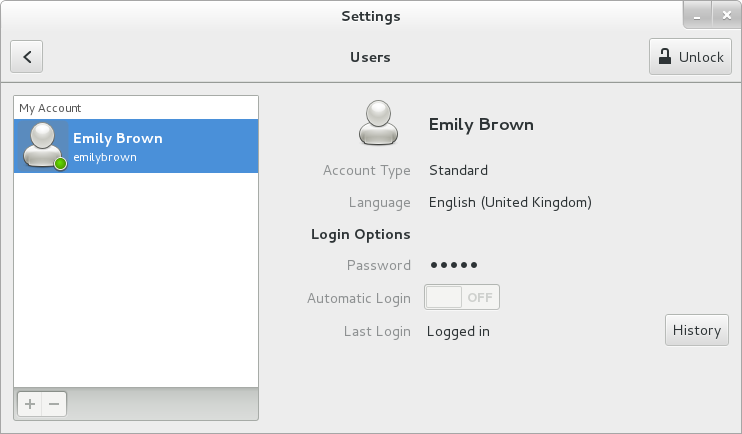
Figure 3.1. Outil des paramètres d'utilisateurs « Users Settings Tool »
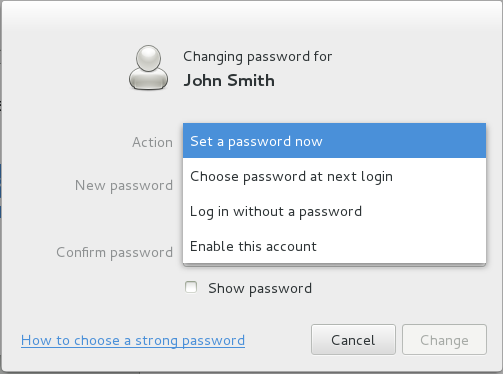
Figure 3.2. Menu Password
3.3. Utiliser des outils de ligne de commande
| Utilitaires | Description |
|---|---|
id | Affiche les ID d'utilisateur et de groupe. |
useradd, usermod, userdel | Utilitaires standard pour ajouter, modifier, et supprimer des comptes utilisateur. |
groupadd, groupmod, groupdel | Utilitaires standard pour ajouter, modifier, et supprimer des groupes. |
gpasswd | Utilitaire utilisé surtout pour modifier le mot de passe du groupe dans le fichier /etc/gshadow utilisé par la commande newgrp. |
pwck, grpck | Utilitaires pouvant être utilisés pour la vérification du mot de passe, du groupe et des fichiers cachés associés. |
pwconv, pwunconv | Utilitaires pouvant être utilisés pour la conversion de mots de passe en mots de passe cachés, ou au contraire de mots de passe cachés en mots de passe standard. |
grpconv, grpunconv | De manière similaire à ce qui précède, ces utilitaires peuvent être utilisés pour la conversion d'informations cachées pour les comptes de groupe. |
3.3.1. Ajout d'un nouvel utilisateur
root :
useradd [options] username
useradd [options] usernameuseradd crée un compte utilisateur verrouillé. Pour déverrouiller le compte, veuillez exécuter la commande suivante en tant qu'utilisateur root pour assigner un mot de passe :
passwd username
passwd username| Option | Description |
|---|---|
-c 'comment' | comment peut être remplacé par n'importe quelle chaîne. Cette option est généralement utilisée pour spécifier le nom complet d'un utilisateur. |
-d home_directory | Répertoire personnel à utiliser à la place de /home/username/. |
-e date | Date à laquelle le compte sera désactivé sous le format YYYY-MM-DD. |
-f days | Nombre de jours après l'expiration du mot de passe avant que le compte soit désactivé. Si 0 est spécifié, le compte est désactivé immédiatement après l'expiration du mot de passe. Si -1 est spécifié, le compte n'est pas désactivé après l'expiration du mot de passe. |
-g group_name | Nom de groupe ou numéro de groupe du groupe (principal) par défaut de l'utilisateur. Le groupe doit exister avant d'être spécifié ici. |
-G group_list | Liste des noms ou numéros de groupes supplémentaires (autres que ceux par défaut), séparés par des virgules, dont l'utilisateur est membre. Les groupes doivent exister avant d'être spécifiés ici. |
-m | Créer le répertoire personnel s'il n'existe pas. |
-M | Ne pas créer de répertoire personnel. |
-f | Ne pas créer de groupe privé d'utilisateurs pour l'utilisateur. |
-p password | Mot de passe chiffré avec crypt. |
-r | Entraîne la création d'un compte système avec un ID utilisateur (UID) inférieur à 1000 et sans répertoire personnel. |
-s | Shell de connexion de l'utilisateur, qui est par défaut /bin/bash. |
-u uid | ID utilisateur de l'utilisateur, qui doit être unique et supérieur à 999. |
usermod sont essentiellement les mêmes. Remarquez que si vous souhaitez ajouter un utilisateur à un autre groupe supplémentaire, vous devrez utiliser l'option -a, --append avec l'option -G. Sinon, la liste des groupes supplémentaires de l'utilisateur sera remplacée par ceux spécifiés par la commande usermod -G.
Important
/etc/login.defs.
Explication du processus
useradd juan est exécutée sur un système sur lequel les mots de passe cachés sont activés :
- Une nouvelle ligne pour
juanest créée dans/etc/passwd:juan:x:1001:1001::/home/juan:/bin/bash
juan:x:1001:1001::/home/juan:/bin/bashCopy to Clipboard Copied! Toggle word wrap Toggle overflow La ligne possède les caractéristiques suivantes :- Celle-ci commence par le nom d'utilisateur
juan. - Un
xse trouve dans le champ du mot de passe, indiquant que le système utilise des mots de passe cachés. - Un UID supérieur à 999 est créé. Dans Red Hat Enterprise Linux 7, les UID inférieurs à 1000 sont réservés à l'utilisation système et ne doivent pas être assignés aux utilisateurs.
- Un GID supérieur à 999 est créé. Dans Red Hat Enterprise Linux 7, les GID inférieurs à 1000 sont réservés à l'utilisation système et ne doivent pas être assignés aux utilisateurs.
- Les informations optionnelles GECOS sont laissées vides. Le champ GECOS peut être utilisé pour fournir des informations supplémentaires sur l'utilisateur, comme son nom complet ou son numéro de téléphone.
- Le répertoire personnel de
juanest défini sur/home/juan/. - Le shell par défaut est défini sur
/bin/bash.
- Une nouvelle ligne pour
juanest créée dans/etc/shadow:juan:!!:14798:0:99999:7:::
juan:!!:14798:0:99999:7:::Copy to Clipboard Copied! Toggle word wrap Toggle overflow La ligne possède les caractéristiques suivantes :- Celle-ci commence par le nom d'utilisateur
juan. - Deux points d'exclamation (
!!) apparaissent dans le champ du mot de passe du fichier/etc/shadow, qui verrouille le compte.Note
Si un mot de passe chiffré est saisi en utilisant l'indicateur-p, il sera placé dans le fichier/etc/shadowsur la nouvelle ligne pour l'utilisateur. - Le mot de passe est paramétré de manière à ne jamais expirer.
- Une nouvelle ligne pour un groupe nommé
juanest créée dans/etc/group:juan:x:1001:
juan:x:1001:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Un groupe avec le même nom qu'un utilisateur est appelé un groupe privé d'utilisateurs. Pour obtenir davantage d'informations sur les groupes privés d'utilisateurs, veuillez consulter la section Section 3.1.1, « Groupes privés d'utilisateurs ».La ligne créée dans/etc/grouppossède les caractéristiques suivantes :- Celle-ci commence par le nom de groupe
juan. - Un
xapparaît dans le champ du mot de passe, indiquant que le système utilise des mots de passe de groupe cachés. - Le GID correspond à celui qui est répertorié pour le groupe principal de
juandans/etc/passwd.
- Une nouvelle ligne pour un groupe nommé
juanest créée dans/etc/gshadow:juan:!::
juan:!::Copy to Clipboard Copied! Toggle word wrap Toggle overflow La ligne possède les caractéristiques suivantes :- Celle-ci commence par le nom de groupe
juan. - Un point d'exclamation (
!) apparaît dans le champ du mot de passe du fichier/etc/gshadow, qui verrouille le groupe. - Tous les autres champs sont vierges.
- Un répertoire pour l'utilisateur
juanest créé dans le répertoire/home:ls -ld /home/juan drwx------. 4 juan juan 4096 Mar 3 18:23 /home/juan
~]# ls -ld /home/juan drwx------. 4 juan juan 4096 Mar 3 18:23 /home/juanCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ce répertoire appartient à l'utilisateurjuanet au groupejuan. Il possède les privilèges read (lecture), write (écriture), et execute (exécution) uniquement pour l'utilisateurjuan. Toutes les autres permissions sont refusées. - Les fichiers dans le répertoire
/etc/skel/(qui contient les paramètres par défaut de l'utilisateur) sont copiés dans le nouveau répertoire/home/juan/:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
juan existe sur le système. Pour l'activer, l'administrateur doit assigner un mot de passe au compte en utilisant la commande passwd et optionnellement, paramétrer des directives concernant l'ancienneté du mot de passe (veuillez consulter la section Sécurité du mot de passe dans le Guide de sécurité Red Hat Enterprise Linux 7 pour obtenir des détails supplémentaires).
3.3.2. Ajout d'un nouveau groupe
root :
groupadd [options] group_name
groupadd [options] group_name| Option | Description |
|---|---|
-f, --force | Lorsqu'utilisé avec -g gid et que gid existe déjà, groupadd choisira un nouveau gid unique pour le groupe. |
-g gid | ID de groupe du groupe, qui doit être unique et supérieur à 999. |
-K, --key key=value | Remplace les valeurs par défaut de /etc/login.defs. |
-o, --non-unique | Permet la création de groupes avec un GID dupliqué. |
-p, --password password | Utilise ce mot de passe chiffré pour le nouveau groupe. |
-r | Entraîne la création d'un groupe système avec un GID inférieur à 1000. |
3.3.3. Création de répertoire de groupes
/opt/myproject/. Il est fait confiance à certaines personnes pour modifier le contenu de ce répertoire, mais pas à tout le monde.
- En tant qu'utilisateur
root, veuillez créer le répertoire/opt/myproject/en saisissant ce qui suit dans l'invite de shell :mkdir /opt/myproject
mkdir /opt/myprojectCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Ajoutez le groupe
myprojectau système :groupadd myproject
groupadd myprojectCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Associez le contenu du répertoire
/opt/myproject/au groupemyproject:chown root:myproject /opt/myproject
chown root:myproject /opt/myprojectCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Autorisez les utilisateurs du groupe à créer des fichiers dans le répertoire et paramétrez le setgid :
chmod 2775 /opt/myproject
chmod 2775 /opt/myprojectCopy to Clipboard Copied! Toggle word wrap Toggle overflow À ce moment, tous les membres du groupemyprojectpeuvent créer et modifier des fichiers dans le répertoire/opt/myproject/sans que l'administrateur ne soit obligé de modifier les permissions de fichier à chaque fois qu'un utilisateur écrit un nouveau fichier. Pour vérifier si les permissions ont été paramétrées correctement, veuillez exécuter la commande suivante :ls -ld /opt/myproject drwxrwsr-x. 3 root myproject 4096 Mar 3 18:31 /opt/myproject
~]# ls -ld /opt/myproject drwxrwsr-x. 3 root myproject 4096 Mar 3 18:31 /opt/myprojectCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Ajoutez les utilisateurs au groupe
myproject:usermod -aG myproject username
usermod -aG myproject usernameCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.4. Ressources supplémentaires
Documentation installée
useradd(8) — la page du manuel de la commandeuseradddocumente comment l'utiliser pour créer de nouveaux utilisateurs.userdel(8) — la page du manuel de la commandeuserdeldocumente comment l'utiliser pour supprimer des utilisateurs.usermod(8) — la page du manuel de la commandeusermoddocumente comment l'utiliser pour modifier les utilisateurs.groupadd(8) — la page du manuel de la commandegroupadddocumente comment l'utiliser pour créer de nouveaux groupes.groupdel(8) — la page du manuel de la commandegroupdeldocumente comment l'utiliser pour supprimer des groupes.groupmod(8) — la page du manuel de la commandegroupmoddocumente comment l'utiliser pour modifier les appartenances aux groupes.gpasswd(1) — la page du manuel de la commandegpasswddocumente comment gérer le fichier/etc/group.grpck(8) — la page du manuel de la commandegrpckdocumente comment l'utiliser pour vérifier l'intégrité du fichier/etc/group.pwck(8) — la page du manuel de la commandepwckdocumente comment l'utiliser pour vérifier l'intégrité des fichiers/etc/passwdet/etc/shadow.pwconv(8) — la page du manuel des commandespwconv,pwunconv,grpconv, etgrpunconvdocumentent comment convertir des informations cachées pour des mots de passe et des groupes.id(1) — la page du manuel de la commandeiddocumente comment afficher les ID d'utilisateur et de groupe.
group(5) — la page du manuel du fichier/etc/groupdocumente comment utiliser ce fichier pour définir les groupes de système.passwd(5) — la page du manuel du fichier/etc/passwddocumente comment utiliser ce fichier pour définir les informations d'utilisateur.shadow(5) — la page du manuel du fichier/etc/shadowdocumente comment utiliser ce fichier pour définir les informations d'expiration des mots de passe et des comptes sur ce système.
Documentation en ligne
- Guide de sécurité Red Hat Enterprise Linux 7 — Le Guide de sécurité de Red Hat Enterprise Linux 7 fournit des informations supplémentaires sur la manière d'assurer le sécurité du mot de passe et de sécuriser la station de travail en activant l'ancienneté des mots de passe et le verrouillage des comptes utilisateur.
Voir aussi
- Le Chapitre 5, Obtention de privilèges documente comment obtenir des privilèges administratifs en utilisant les commandes
suetsudo.
Chapitre 4. Listes des contrôle d'accès (ACL)
acl et la prise en charge dans le noyau sont requis pour implémenter les ACL. Ce paquet contient les utilitaires nécessaires pour l'ajout, la modification, la suppression et la récupération d'informations sur les ACL.
cp et mv copient ou déplacent toutes les ACL associées à des fichiers et répertoires.
4.1. Monter des systèmes de fichiers
mount -t ext3 -o acl device-name partition
mount -t ext3 -o acl /dev/VolGroup00/LogVol02 /work
/etc/fstab, l'entrée de la partition peut inclure l'option acl :
LABEL=/work /work ext3 acl 1 2
LABEL=/work /work ext3 acl 1 2--with-acl-support. Aucun indicateur particulier n'est requis lors de l'accession ou du montage d'un partage Samba.
4.1.1. NFS
no_acl dans le fichier /etc/exports. Pour désactiver les ACL d'un partage NFS quand vous la montez sur un client, montez-la avec l'option no_acl via la ligne de commandes ou par le fichier /etc/fstab
4.2. Définir les ACL d'accès
- Par utilisateur
- Par groupe
- Via le masque des droits en vigueur
- Pour les utilisateur ne se trouvant pas dans le groupe d'utilisateurs du fichier
setfacl définit les ACL pour les fichiers et répertoires. Veuillez utiliser l'option -m pour ajouter ou modifier l'ACL d'un fichier ou répertoire :
setfacl -m rules files
# setfacl -m rules filesu:uid:perms- Définit l'ACL d'accès d'un utilisateur. Le nom d'utilisateur, ou UID, peut être spécifié. L'utilisateur peut être tout utilisateur valide sur le système.
g:gid:perms- Définit l'ACL d'accès d'un groupe. Le nom du groupe, ou GID, peut être spécifié. Le groupe peut être tout groupe valide sur le système.
m:perms- Définit le masque des permissions. Le masque est l'union de toutes les permissions du groupe propriétaire et des toutes les entrées d'utilisateur et de groupe.
o:perms- Définit l'ACL d'accès du fichier pour les utilisateurs ne faisant pas partie du groupe.
r, w et x pour lecture, écriture, et exécution.
setfacl est utilisée, les règles supplémentaires sont ajoutées à l'ACL existante ou la règle existante sera modifiée.
Exemple 4.1. Donner des permissions de lecture et écriture
setfacl -m u:andrius:rw /project/somefile
# setfacl -m u:andrius:rw /project/somefile-x et ne spécifier aucune permission :
setfacl -x rules files
# setfacl -x rules filesExemple 4.2. Supprimer toutes les permissions
setfacl -x u:500 /project/somefile
# setfacl -x u:500 /project/somefile4.3. Définit les ACL par défaut
d: avant la règle et spécifiez un répertoire à la place d'un nom de fichier.
Exemple 4.3. Définir les ACL par défaut
/share/ afin de pouvoir effectuer des lectures et exécutions pour les utilisateurs ne se trouvant pas dans le groupe d'utilisateurs (une ACL d'accès pour un fichier individuel peut la remplacer) :
setfacl -m d:o:rx /share
# setfacl -m d:o:rx /share4.4. Récupérer des ACL
getfacl. Dans l'exemple ci-dessous, getfacl est utilisé pour déterminer les ACL existantes pour un fichier.
Exemple 4.4. Récupérer des ACL
getfacl home/john/picture.png
# getfacl home/john/picture.pnggetfacl home/sales/ affichera une sortie similaire à la suivante :
4.5. Archiver des systèmes de fichiers avec des ACL
dump préserve désormais les ACL pendant les opérations de sauvegarde. Lors de l'archivage d'un fichier ou d'un système de fichiers avec tar, utilisez l'option --acls pour préserver les ACL. De manière similaire, lors de l'utilisation de cp pour copier des fichiers avec des ACL, veuillez inclure l'option --preserve=mode afin de vous assurer que les ACL soient également copiées. En outre, l'option -a (équivalente à -dR --preserve=all) de cp préserve également les ACL lors des opérations de sauvegarde ainsi que d'autres informations, commes les horodatages, les contextes SELinux, etc. Pour obtenir davantage d'informations sur dump, tar, ou cp, veuillez consulter les pages man respectives.
star est similaire à l'utilitaire tar car il peut être utilisé pour générer des archives de fichiers ; cependant, certaines de ses options sont différentes. Veuillez consulter le Tableau 4.1, « Options de ligne de commande pour star » pour obtenir une liste des options communément utilisées. Pour toutes les options disponibles, veuillez consulter man star. Le paquet star est requis pour faire usage de cet utilitaire.
| Option | Description |
|---|---|
-c | Crée un fichier archive. |
-n | Ne pas extraire les fichiers. À utiliser en conjonction avec -x pour afficher le résultat provoqué par l'extraction de fichiers. |
-r | Remplace les fichiers dans l'archive. Les fichiers sont écrits à la fin du fichier archive, remplaçant tout fichier ayant le même chemin et le même nom de fichier. |
-t | Affiche le contenu du fichier archive. |
-u | Met à jour le fichier archive. Les fichiers sont écrits à la fin de l'archive si ceux-ci n'existent pas dans l'archive, ou si les fichiers sont plus récents que les fichiers de même nom dans l'archive. Cette option fonctionne uniquement si l'archive est un fichier ou une bande non-bloquée pouvant être inversé. |
-x | Extrait les fichiers de l'archive. Si utilisé avec -U et qu'un fichier dans l'archive est plus ancien que le fichier correspondant sur le système de fichers, le fichier ne sera pas extrait. |
-help | Affiche les options les plus importantes. |
-xhelp | Affiche les options les moins importantes. |
-/ | Ne pas supprimer les barres obliques des noms de fichiers lors de l'extraction de fichiers d'une archive. Par défaut, celles-ci sont supprimées lorsque les fichiers sont extraits. |
-acl | Pendant la création ou l'extraction, archive ou restaure toute ACL associée aux fichiers et répertoires. |
4.6. Compatibilité avec d'anciens systèmes
ext_attr. Cet attribut peut être affiché à l'aide de la commande suivante :
tune2fs -l filesystem-device
# tune2fs -l filesystem-deviceext_attr peut être monté avec d'anciens noyaux, mais ces noyaux n'appliqueront aucune ACL définie.
e2fsck incluses dans la version 1.22 et dans les versions supérieures du paquet e2fsprogs (y compris les versions dans Red Hat Enterprise Linux 2.1 et 4) peuvent vérifier un système de fichiers avec l'attribut ext_attr. Les versions plus anciennes refuseront de le vérifier.
4.7. Références des ACL
man acl— Description des ACLman getfacl— Traite de la manière d'obtenir des listes de contrôle d'accèsman setfacl— Explique comment définir des listes de contrôle d'accès aux fichiersman star— Explique l'utilitairestaret ses nombreuses options
Chapitre 5. Obtention de privilèges
root est potentiellement dangereux et peut causer des dommages qui se répandent sur le système et sur les données. Ce chapitre couvre les manières d'obtenir des privilèges administratifs en utilisant des programmes setuid tels que su et sudo. Ces programmes autorisent des utilisateurs spécifiques à effectuer des tâches qui seraient normalement uniquement disponibles à l'utilisateur root tout en conservant un niveau de contrôle et de sécurité du système élevés.
5.1. La commande su
su, il lui est demandé le mot de passe de l'utilisateur root. Une invite de shell root s'ouvrira après l'authentification.
su, l'utilisateur devient l'utilisateur root et possède un accès administratif absolu sur le système. Veuillez remarquer que cet accès reste sujet aux restrictions imposées par SELinux, si activé. En outre, une fois qu'un utilisateur est connecté en tant qu'utilisateur root, il est lui est possible d'utiliser la commande su pour modifier tout autre utilisateur sur le système sans avoir à saisir de mot de passe.
root :
usermod -a -G wheel username
~]# usermod -a -G wheel usernamewheel.
- Veuillez appuyer sur la touche Super pour accéder à « Vue d'ensembles des activités », saisissez
Utilisateurspuis appuyez sur Entrée. L'outil des paramètres Utilisateurs s'affiche. La touche Super apparaît sous une variété de formes, selon le clavier et autre matériel, mais le plus souvent, il s'agit de la touche Windows ou Commande, et elle se trouve habituellement à gauche de la Barre d'espace. - Pour autoriser les modifications, veuillez cliquer sur le bouton , puis saisissez un mot de passe d'administrateur valide.
- Veuillez cliquer sur l'icône dans la colonne de gauche pour afficher les propriétés de l'utilisateur dans le volet du côté droit.
- Modifiez le de
StandardàAdministrateur. Cela aura pour effet d'ajouter l'utilisateur au groupewheel.
wheel, il est recommandé d'autoriser ces utilisateurs spécifiques uniquement à utiliser la commande su. Pour faire cela, veuillez modifier le fichier de configuration Pluggable Authentication Module (PAM) de su, /etc/pam.d/su. Ouvrez ce fichier dans un éditeur de texte et enlevez la ligne suivante du commentaire en supprimant le caractère # :
#auth required pam_wheel.so use_uid
#auth required pam_wheel.so use_uidwheel peuvent basculer sur un autre utilisateur en utilisant la commande su.
Note
root fait partie du groupe wheel par défaut.
5.2. La commande sudo
sudo offre une autre approche pour donner un accès administratif aux utilisateurs. Lorsque des utilisateurs de confiance ajoutent sudo avant une commande administrative, il leur est demandé leur propre mot de passe. Puis, lorsqu'ils ont été authentifié et en supposant que la commande soit autorisée, la commande administrative est exécutée comme s'ils étaient un utilisateur root.
sudo est comme suit :
sudo command
sudo commandroot, telle que mount.
sudo offre un haut niveau de flexibilité. Par exemple, seuls les utilisateurs répertoriés dans le fichier de configuration /etc/sudoers sont autorisés à utiliser la commande sudo et la commande est exécutée dans le shell de l'utilisateur, et non dans un shell root. Cela signifie que le shell root peut être complètement désactivé, comme indiqué dans le Guide de sécurité Red Hat Enterprise Linux 7.
sudo est journalisée sur le fichier /var/log/messages et la commande passée avec le nom d'utilisateur de son émetteur est journalisée sur le fichier /var/log/secure. Si davantage de détails sont requis, veuillez utiliser le module pam_tty_audit pour activer les audits TTY pour des utilisateurs spécifiques en ajoutant la ligne suivante à votre fichier /etc/pam.d/system-auth :
session required pam_tty_audit.so disable=pattern enable=pattern
session required pam_tty_audit.so disable=pattern enable=patternroot et les désactivera pour tous les autres utilisateurs :
session required pam_tty_audit.so disable=* enable=root
session required pam_tty_audit.so disable=* enable=rootImportant
pam_tty_audit pour les audits TTY n'enregistre que les entrées TTY. Cela signifie que, lorsque l'utilisateur audité se connecte, pam_tty_audit enregistre les saisies de touches précises de l'utilisateur dans le fichier /var/log/audit/audit.log. Pour plus d'informations, voir la page man pam_tty_audit(8).
sudo est qu'un administrateur peut autoriser différents utilisateurs à accéder à des commandes spécifiques en fonction de leurs besoins.
sudo, /etc/sudoers, doivent utiliser la commande visudo.
visudo et ajoutez une ligne similaire à la suivante dans la section de spécification des privilèges utilisateur :
juan ALL=(ALL) ALL
juan ALL=(ALL) ALLjuan peut utiliser sudo à partir de n'importe quel hôte et peut exécuter n'importe quelle commande.
sudo :
%users localhost=/usr/sbin/shutdown -h now
%users localhost=/usr/sbin/shutdown -h nowusers peut exécuter la commande /sbin/shutdown -h now tant que c'est à partir de la console.
sudoers offre une liste détaillée des options pour ce fichier.
Important
sudo. Vous pouvez les éviter en modifier le fichier de configuration /etc/sudoers en utilisant visudo, comme indiqué ci-dessus. Laisser le ficher /etc/sudoers dans son état par défaut donnera à tout utilisateur du groupe wheel un accès root illimité.
- Par défaut,
sudostocke le mot de passe de l'utilisateur sudo pour une période de cinq minutes. Toute utilisation de la commande pendant cette période ne demandera pas à l'utilisateur de saisir à nouveau le mot de passe. Ceci peut être exploité par une personne malveillante si l'utilisateur laisse son poste de travail connecté, sans surveillance et déverrouillé. Ce comportement peut être modifié en ajoutant la ligne suivante au fichier/etc/sudoers:Defaults timestamp_timeout=value
Defaults timestamp_timeout=valueCopy to Clipboard Copied! Toggle word wrap Toggle overflow où value est la longueur souhaitée du délai en minutes. Définir value sur 0 amènesudoà réclamer un mot de passe à chaque fois. - Si le compte sudo d'utilisateur est compromis, une personne malveillante peut utiliser
sudopour ouvrir un nouveau shell avec des privilèges administratifs :sudo /bin/bash
sudo /bin/bashCopy to Clipboard Copied! Toggle word wrap Toggle overflow L'ouverture d'un nouveau shell en tant qu'utilisateurrootde cette manière, ou d'une manière similaire, peut offrir un accès administratif à une personne malveillante sur une durée théoriquement illimitée, outrepassant ainsi la limite de la durée du délai spécifiée dans le fichier/etc/sudoerset il ne sera pas demandé à cette personne malveillante de ressaisir le mot de passesudotant que la session ouverte n'est pas fermée.
5.3. Ressources supplémentaires
Documentation installée
su(1) — la page man desuoffre des informations concernant les options dispionibles avec cette commande.sudo(8) — la page man desudoinclut une description détaillée de la commande et répertorie les options disponibles pour personnaliser son comportement.pam(8) — page du manuel décrivant l'utilisation des modules PAM manual (« Pluggable Authentication Modules ») pour Linux.
Documentation en ligne
- Guide de sécurité Red Hat Enterprise Linux 7 — le Guide de sécurité de Red Hat Enterprise Linux 7 traite de manière plus approfondie des problèmes de sécurité pertinents aux programmes setuid, ainsi que des techniques utilisées pour réduire ces risques.
Voir aussi
- Le Chapitre 3, Gérer les utilisateurs et les groupes documente comment gérer les groupes et utilisateurs système dans l'interface utilisateur graphique et sur la ligne de commande.
Partie II. Abonnement et support
Chapitre 6. Enregistrer le système et Gérer les abonnements
Note
6.1. Enregistrer le système et y ajouter des abonnnements
subscription-manager sont censées être exécutées en tant qu'utilisateur root.
- Exécutez la commande suivante pour enregistrer votre système. Votre nom d'utilisateur et votre mot de passe vous seront demandés. Remarquez que le nom d'utilisateur et le mot de passe sont les mêmes que vos identifiants de connexion pour le Portail Client Red Hat.
subscription-manager register
subscription-manager registerCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Déterminer l'ID du pool d'un abonnement dont vous avez besoin. Pour ce faire, tapez ce qui suit à une invite du shell pour afficher une liste de tous les abonnements qui sont disponibles pour votre système :
subscription-manager list --available
subscription-manager list --availableCopy to Clipboard Copied! Toggle word wrap Toggle overflow Pour chaque abonnement disponible, cette commande affiche son nom, son identifiant unique, sa date d'expiration et autres détails liés à votre abonnement. Pour répertorier les abonnements de toutes les architectures, ajouter l'option--all. L'ID du pool est répertorié sur une ligne commençant parPool ID. - Attachez un abonnement qui convient au système en saisissant la commande suivante :
subscription-manager attach --pool=pool_id
subscription-manager attach --pool=pool_idCopy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacez pool_id par l'ID de pool déterminé dans l'étape précédente.Pour vérifier la liste des abonnements actuellement attachés à votre système, exécutez, à tout moment :subscription-manager list --consumed
subscription-manager list --consumedCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.2. Gérer des référentiels de logiciels
/etc/yum.repos.d/. Pour vérifier cela, veuillez utiliser yum pour répertorier les référentiels activés :
yum repolist
yum repolistsubscription-manager repos --list
subscription-manager repos --listrhel-variant-rhscl-version-rpms rhel-variant-rhscl-version-debug-rpms rhel-variant-rhscl-version-source-rpms
rhel-variant-rhscl-version-rpms
rhel-variant-rhscl-version-debug-rpms
rhel-variant-rhscl-version-source-rpmsserver ou workstation), et version est la version du système Red Hat Enterprise Linux (6 ou 7), par exemple :
rhel-server-rhscl-7-eus-rpms rhel-server-rhscl-7-eus-source-rpms rhel-server-rhscl-7-eus-debug-rpms
rhel-server-rhscl-7-eus-rpms
rhel-server-rhscl-7-eus-source-rpms
rhel-server-rhscl-7-eus-debug-rpmssubscription-manager repos --enable repository
subscription-manager repos --enable repositorysubscription-manager repos --disable repository
subscription-manager repos --disable repository6.3. Supprimer des abonnements
- Déterminez le numéro de série de l'abonnement que vous souhaitez supprimer en répertoriant les informations sur les abonnements déjà attachés :
subscription-manager list --consumed
subscription-manager list --consumedCopy to Clipboard Copied! Toggle word wrap Toggle overflow Le numér de série est le numéro répertorié en tant que sériel («serial»). Par exemple,744993814251016831ci-dessous :Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Saisissez une commande comme suit pour supprimer l'abonnement sélectionné :
subscription-manager remove --serial=serial_number
subscription-manager remove --serial=serial_numberCopy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacez serial_number par le numéro de série déterminé dans l'étape précédente.
subscription-manager remove --all
subscription-manager remove --all6.4. Ressources supplémentaires
Documentation installée
subscription-manager(8) — la page du manuel de Red Hat Subscription Management fournit une liste complète des options et commandes prises en charge.
Livres apparentés
- Collection de guides Red Hat Subscription Management — Ces guides contiennent des informations détaillées sur la manière d'utiliser Red Hat Subscription Management.
- Guide d'installation — veuillez consulter le chapitre Installation initiale pour obtenir des informations détaillées sur la manière de s'enregistrer pendant le processus d'installation initiale.
Voir également
- Le Chapitre 5, Obtention de privilèges documente la façon d'obtenir des privilèges administratifs en utilisant les commandes
suetsudo. - Le Chapitre 8, Yum fournit des informations sur l'utilisation du gestionnaire de paquets yum pour installer et mettre à jour des logiciels.
Chapitre 7. Accéder au support en utilisant l'outil « Red Hat Support Tool »
SSH ou à partir de n'importe quel terminal. Par exemple, il permet d'effectuer des recherches dans la base de connaissances Red Hat (« Red Hat Knowledgebase ») à partir de la ligne de commande, de copier les solutions directement sur la ligne de commande, de créer et de mettre à jour des dossiers de support, et d'envoyer des fichier à Red Hat pour les analyser.
7.1. Installer l'outil Red Hat Support Tool
root :
yum install redhat-support-tool
~]# yum install redhat-support-tool7.2. Enregistrer l'outil Red Hat Support Tool en utilisant la ligne de commande
- Quand nom d'utilisateur correspond au nom d'utilisateur du compte sur le Portail Client Red Hat.
redhat-support-tool config user nom d'utilisateur
~]# redhat-support-tool config user nom d'utilisateurCopy to Clipboard Copied! Toggle word wrap Toggle overflow redhat-support-tool config password Please enter the password for username:
~]# redhat-support-tool config password Please enter the password for username:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.3. Utiliser Red Hat Support Tool en mode shell interactif
redhat-support-tool Welcome to the Red Hat Support Tool. Command (? for help):
~]$ redhat-support-tool
Welcome to the Red Hat Support Tool.
Command (? for help):root.
?. Le programme ou la sélection du menu peuvent être « quittés » en saisissant le caractère q ou e. Votre nom d'utilisateur et votre mot de passe du Portail Client Red Hat vous seront demandés lors de votre première recherche sur la base de connaissances ou des dossiers de support. Alternativement, définissez le nom d'utilisateur et le mot de passe de votre compte Portail Client Red Hat en utilisant le mode interactif, et optionnellement, enregistrez-le sur le fichier de configuration.
7.4. Configurer l'outil Red Hat Support Tool
config --help :
Procédure 7.1. Enregistrer l'outil Red Hat Support Tool en utilisant le mode interactif
- Lancez l'outil en saisissant la commande suivante :
redhat-support-tool
~]# redhat-support-toolCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Saisissez votre nom d'utilisateur du Portail Client Red Hat :Pour enregistrer votre nom d'utilisateur dans le fichier de configuration globale , veuillez ajouter l'option
Command (? for help): config user nom d'utilisateur
Command (? for help): config user nom d'utilisateurCopy to Clipboard Copied! Toggle word wrap Toggle overflow -g. - Saisissez votre mot de passe du Portail Client Red Hat :
Command (? for help): config password Please enter the password for username:
Command (? for help): config password Please enter the password for username:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.4.1. Enregistrer les paramètres dans les fichiers de configuration
~/.redhat-support-tool/redhat-support-tool.conf. Si requis, il est recommandé d'enregistrer les mots de passe dans ce fichier car il est uniquement lisible par cet utilisateur particulier. Lorsque l'outil est lancé, il lira les valeurs du fichier de configuration globale /etc/redhat-support-tool.conf ainsi que celles du fichier de configuration local. Les valeurs et options stockées localement ont priorité sur les paramètres stockés globalement.
Avertissement
/etc/redhat-support-tool.conf car le mot de passe est uniquement chiffré base64 et peut facilement être déchiffré. En outre, le fichier est lisible par tous.
-g, --global comme suit :
Command (? for help): config setting -g value
Command (? for help): config setting -g valueNote
-g, --global, l'outil Red Hat Support Tool doit être exécuté en tant qu'utilisateur root car les utilisateurs normaux n'ont pas les permissions requises pour écrire sur /etc/redhat-support-tool.conf.
-u, --unset comme suit :
Command (? for help): config setting -u value
Command (? for help): config setting -u valueNote
-u, --unset, mais elles peuvent être effacées, et annulées de la définition, à partir de l'instance actuellement en cours d'utilisation de l'outil en utilisant l'option -g, --global simultanément avec l'option -u, --unset. Si exécuté en tant qu'utilisateur root, les valeurs et options peuvent être supprimées du fichier de configuration globale en utilisant -g, --global simultanément avec l'option -u, --unset.
7.5. Créer et mettre à jour des dossiers de support en utilisant le mode interactif
Procédure 7.2. Créer un nouveau dossier de support en utilisant le mode interactif
- Lancez l'outil en saisissant la commande suivante :
redhat-support-tool
~]# redhat-support-toolCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Saisissez la commande
opencase:Command (? for help): opencase
Command (? for help): opencaseCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Suivez les invites affichées sur l'écran pour sélectionner un produit, puis une version.
- Saisissez un récapitulatif du dossier.
- Saisissez une description du dossier, puis appuyez sur Ctrl+D sur une ligne vide lorsque vous aurez terminé.
- Sélectionnez une sévérité pour le dossier.
- Optionnellement, vous pouvez choisir si une solution au problème existe avant de créer un dossier de support.
- Confirmez que vous souhaitez tout de même créer le dossier de support.
Le dossier de support 0123456789 a été créé
Le dossier de support 0123456789 a été crééCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Optionnellement, vous pouvez choisir d'attacher un rapport SOS.
- Optionnellement, vous pouvez choisir d'attacher un fichier.
Procédure 7.3. Afficher et mettre à jour un dossier de support existant en utilisant le mode interactif
- Lancez l'outil en saisissant la commande suivante :
redhat-support-tool
~]# redhat-support-toolCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Saisissez la commande
getcase:Quand numéro de cas correspond au numéro du dossier que vous souhaitez afficher et mettre à jour.Command (? for help): getcase case-number
Command (? for help): getcase case-numberCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Suivez les invites à l'écran pour afficher le dossier, modifier ou ajouter des commentaires, et pour obtenir ou ajouter des pièces jointes.
Procédure 7.4. Modifier un dossier de support existant en utilisant le mode interactif
- Lancez l'outil en saisissant la commande suivante :
redhat-support-tool
~]# redhat-support-toolCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Saisissez la commande
modifycase:Quand numéro de cas correspond au numéro du dossier que vous souhaitez afficher et mettre à jour.Command (? for help): modifycase numéro de cas
Command (? for help): modifycase numéro de casCopy to Clipboard Copied! Toggle word wrap Toggle overflow - La liste de modification de sélection s'affiche :Suivez les invites affichées sur l'écran pour modifier une ou plusieurs des options.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Par exemple, pour modifier le statut, veuillez saisir
3:Selection: 3 1 Waiting on Customer 2 Waiting on Red Hat 3 Closed Please select a status (or 'q' to exit):
Selection: 3 1 Waiting on Customer 2 Waiting on Red Hat 3 Closed Please select a status (or 'q' to exit):Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.6. Afficher des dossiers de support sur la ligne de commande
redhat-support-tool getcase case-number
~]# redhat-support-tool getcase case-number7.7. Ressources supplémentaires
Partie III. Installer et gérer un logiciel
Chapitre 8. Yum
Important
Note
su ou sudo.
8.1. Recherche et Mise à jour des paquets
8.1.1. Vérifier les mises à jour
yum check-update
yum check-updateExemple 8.1. Exemple de sortie de la commande yum check-update :
yum check-update peut être similaire à la suivante :
dracut— nom du paquetx86_64— architecture du CPU pour laquelle le paquet a été créé,0.5.8— version du paquet mis à jour à installer,360.el7— version du paquet mis à jour,_2— version ajoutée dans le cadre de la mise à jour z-stream,rhel-7-server-rpms— référentiel dans lequel le paquet mis à jour se trouve.
yum.
8.1.2. Mise à jour de paquets
Mise à jour d'un paquet unique
root :
yum update package_name
yum update package_nameExemple 8.2. Mise à jour du paquet rpm
Loaded plugins: langpacks, product-id, subscription-manager— Yum vous informe toujours quels greffons yum sont installés et activés. Veuillez consulter la Section 8.6, « Greffons Yum » pour des informations générales sur les greffons yum, ou la Section 8.6.3, « Utiliser des greffons Yum » pour des descriptions de greffons particuliers.rpm.x86_64— il est possible de télécharger et d'installer un nouveau paquet rpm ainsi que ses dépendances. Une vérification de transaction est effectuée pour chacun de ces paquets.- Yum présente les informations de mise à jour et vous demande de confirmer la mise à jour ; yum est exécuté interactivement par défaut. Si vous savez déjà quelles transactions la commande
yumplanifie d'effectuer, vous pouvez utiliser l'option-ypour répondre automatiquement oui («yes») à toute question posée par yum (dans ce cas, l'exécution n'est pas interactive). Cependant, vous devriez toujours examiner les changements que yum planifie d'effectuer sur le système afin de pouvoir facilement résoudre tout problème qui se pose. Il est également possible de télécharger le paquet sans l'installer. Pour faire cela, veuillez sélectionner l'optionddans l'invite du téléchargement. Cela lance le téléchargement en arrière-plan du paquet sélectionné.Si une transaction échoue, vous pouvez afficher l'historique des transactions yum en utilisant la commandeyum historycomme décrit dans la Section 8.4, « Utiliser l'historique des transactions ».
Important
yum update ou yum install.
rpm -i kernel qui installe un nouveau noyau, au lieu de rpm -u kernel qui remplace le noyau actuel. Veuillez consulter la Section A.2.1, « Installation et mise à niveau des paquets » pour obtenir davantage d'informations sur l'installation et la mise à niveau de noyaux avec RPM.
root :
yum group update group_name
yum group update group_nameupgrade qui est égale à update avec une option de configuration obsoletes (veuillez consulter la Section 8.5.1, « Définir les options [main] »). Par défaut, obsoletes est activé dans /etc/yum.conf, ce qui rend ces deux commandes équivalentes.
Mettre à jour tous les paquets et leurs dépendances
yum update sans aucun argument :
yum update
yum updateMettre à jour des paquets liés à la sécurité
root :
yum update --security
yum update --securityroot :
yum update-minimal --security
yum update-minimal --security- le paquet kernel-3.10.0-1 est installé sur votre système ;
- le paquet kernel-3.10.0-2 est une mise à jour de sécurité ;
- la paquet kernel-3.10.0-3 est une mise à jour de correctif,
yum update-minimal --security mettra à jour le paquet à kernel-3.10.0-2, et yum update --security mettra à jour le paquet à kernel-3.10.0-3.
8.1.3. Préserver les changements au fichier de configuration
8.1.4. Mise à jour du système hors ligne avec ISO et Yum
yum update avec l'image ISO d'installation de Red Hat Enterprise Linux est un façon simple et rapide de mettre à niveau les systèmes à la dernière version mineure. Les étapes suivantes nous montrent le processus de mise à niveau :
- Créer un répertoire cible dans lequel monter votre image ISO. Le répertoire n'est pas créé automatiquement lors du montage, donc, il vous faudra le créer avant de procéder à l'étape suivante. En tant qu'utilisateur
root, saisissez :mkdir mount_dir
mkdir mount_dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacer mount_dir par un chemin menant au répertoire de montage. Normalement, les utilisateurs le créent en tant que sous-répertoire du répertoire/media. - Monter l'image ISO d'installation de Red Hat Enterprise Linux 7 dans le répertoire cible préalablement créé. En tant qu'utilisateur
root, saisir :mount -o loop iso_name mount_dir
mount -o loop iso_name mount_dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacez iso_name par le nom du chemin de votre image ISO et mount_dir par le nom du chemin du répertoire cible. Là, l'option-oloopest exigée pour pouvoir monter le fichier en tant que périphérique bloc. - Copier le fichier
media.repodu répertoire de montage/etc/yum.repos.d/. Notez que les fichiers de configuration de ce répertoire doivent posséder l'extension .repo pour pouvoir fonctionner correctement.cp mount_dir/media.repo /etc/yum.repos.d/new.repo
cp mount_dir/media.repo /etc/yum.repos.d/new.repoCopy to Clipboard Copied! Toggle word wrap Toggle overflow Cela créera un fichier de configuration pour le référentiel yum. Remplacer new.repo par le nom du fichier, comme par exemple rhel7.repo. - Modifiez le nouveau fichier de configuration de façon à ce qu'il puisse pointer vers l'ISO d'installation de Red Hat Enterprise Linux. Ajouter la ligne suivante au fichier
/etc/yum.repos.d/new.repo:baseurl=file:///mount_dir
baseurl=file:///mount_dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacez mount_dir par un chemin qui mène au point de montage. - Mettez à jour tous les référentiels yum, y compris
/etc/yum.repos.d/new.repocréé dans les étapes précédentes. En tant qu'utilisateurroot, saisissez :yum update
yum updateCopy to Clipboard Copied! Toggle word wrap Toggle overflow Cela mettra à jour votre système à la version fournie par l'image ISO montée. - Après la mise à niveau, vous pourrez dé-monter l'image ISO. En tant qu'utilisateur
root, saisissez :umount mount_dir
umount mount_dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow avec mount_dir comme chemin qui mène à votre répertoire de montage. Aussi, vous pourrez supprimer le répertoire de montage créé dans la première étape. En tant qu'utilisateurroot, saisissez :rmdir mount_dir
rmdir mount_dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Si vous ne souhaitez pas utiliser le fichier de configuration déjà créé pour une autre installation ou mise à jour, vous pouvez le supprimer. En tant qu'utilisateur
root, saisissez :rm /etc/yum.repos.d/new.repo
rm /etc/yum.repos.d/new.repoCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Exemple 8.3. Mise à niveau de Red Hat Enterprise Linux 7.0 à 7.1
rhel-server-7.1-x86_64-dvd.iso, créer un répertoire cible de montage, comme /media/rhel7/. En tant qu'utilisateur root, allez dans le répertoire avec votre image ISO et saisissez :
mount -o loop rhel-server-7.1-x86_64-dvd.iso /media/rhel7/
~]# mount -o loop rhel-server-7.1-x86_64-dvd.iso /media/rhel7/media.repo à partir du répertoire de montage :
cp /media/rhel7/media.repo /etc/yum.repos.d/rhel7.repo
~]# cp /media/rhel7/media.repo /etc/yum.repos.d/rhel7.repo/etc/yum.repos.d/rhel7.repo copié dans l'étape précédente :
baseurl=file:///media/rhel7/
baseurl=file:///media/rhel7/rhel-server-7.1-x86_64-dvd.iso. En tant qu'utilisateur root, exécutez :
yum update
~]# yum updateumount /media/rhel7/
~]# umount /media/rhel7/rmdir /media/rhel7/
~]# rmdir /media/rhel7/rm /etc/yum.repos.d/rhel7.repo
~]# rm /etc/yum.repos.d/rhel7.repo8.2. Utiliser des paquets
8.2.1. Rechercher des paquets
yum search term…
yum search term…Exemple 8.4. Rechercher les paquets correspondants à une chaîne spécifique
yum search est utile pour rechercher des paquets dont vous ne connaissez pas le nom, mais dont vous connaissez un terme connexe. Remarquez que par défaut, yum search retourne les correspondances par nom de paquet et résumé, ce qui rend les recherches plus rapides. Veuillez utiliser la commande yum search all pour effectuer une recherche plus exhaustive mais également plus lente.
Filtrer les résultats
* (qui s'étend pour correspondre à tout sous-ensemble de caractères) et ? (qui s'étend pour correspondre à tout caractère unique).
yum, sinon le shell Bash les interprétera comme des expansions de nom de fichier, et pourrait potentiellement faire passer tous les fichiers du répertoire actuel correspondant aux expressions globales sur yum. Pour vous assurer que les expressions glob soient passées sur yum comme souhaité, veuillez utiliser l'une des méthodes suivantes :
- échappez les caractères génériques en les faisant précéder du caractère de la barre oblique inversée
- mettez l'expression glob entre guillemets simples ou entre guillemets doubles.
8.2.2. Répertorier les paquets
yum list all
yum list allyum list glob_expression…
yum list glob_expression…Exemple 8.5. Répertorier les paquets liés à ABRT
installed. La colonne la plus à droite dans la sortie répertorie le référentiel à partir duquel le paquet a été récupéré.
yum list installed glob_expression…
yum list installed glob_expression…Exemple 8.6. Répertorier tous les versions installées du paquet krb
yum list installed "krb?-*" Loaded plugins: langpacks, product-id, search-disabled-repos, subscription-manager Installed Packages krb5-libs.x86_64 1.13.2-10.el7 @rhel-7-server-rpms
~]$ yum list installed "krb?-*"
Loaded plugins: langpacks, product-id, search-disabled-repos, subscription-manager
Installed Packages
krb5-libs.x86_64 1.13.2-10.el7 @rhel-7-server-rpmsyum list available glob_expression…
yum list available glob_expression…Exemple 8.7. Répertorier les greffons gstreamer disponibles
Répertorier les référentiels
yum repolist
yum repolist-v. Avec cette option activée, les informations comprenant le nom du fichier, la taille générale, la date de la dernière mise à jour, et l'URL de base sont affichées pour chaque référentiel répertorié. Alternativement, vous pouvez utiliser la commande repoinfo qui produira la même sortie.
yum repolist -v
yum repolist -vyum repoinfo
yum repoinfo yum repolist all
yum repolist alldisabled en tant que premier argument, vous pouvez limiter la sortie de la commande aux référentiels désactivés. Pour des spécifications plus précises, vous pouvez passer l'ID ou le nom des référentiels ou des glob_expressions comme arguments. Remarquez que s'il y a une correspondance exacte entre l'ID ou le nom du référentiel et l'argument inséré, ce référentiel est répertorié, même s'il ne passe pas le filtre enabled ou disabled.
8.2.3. Afficher des informations sur le paquet
yum info package_name…
yum info package_name…Exemple 8.8. Afficher des informations sur le paquet abrt
yum info package_name est similaire à la commande rpm -q --info package_name, mais elle fournit des informations supplémentaires, comme le nom du référentiel yum dans lequel le paquet RPM était installé (consultez la ligne From repo: dans la sortie).
Utiliser yumdb
yumdb info package_name
yumdb info package_nameuser indique une installation par l'utilisateur, et dep indique une installation pour raison de dépendance).
Exemple 8.9. Exécuter une requête yumdb pour trouver des informations sur le paquet yum
yumdb, veuillez consulter la page man de yumdb(8).
8.2.4. Installation de paquets
root :
yum install package_name
yum install package_nameroot :
yum install package_name package_name…
yum install package_name package_name…yum install package_name.arch
yum install package_name.archExemple 8.10. Installer des paquets sur un système multilib
i686, veuillez saisir :
yum install sqlite.i686
~]# yum install sqlite.i686root, veuillez exécuter :
yum install glob_expression…
yum install glob_expression…Exemple 8.11. Installer tous les greffons audacieux
yum install audacious-plugins-\*
~]# yum install audacious-plugins-\*yum install. Si vous connaissez le nom du binaire que vous souhaitez installer, mais pas son nom de paquet, vous pouvez donner le nom du chemin à yum install. En tant qu'utilisateur root, veuillez saisir :
yum install /usr/sbin/named
yum install /usr/sbin/named/usr/sbin/named, s'il existe, et vous demande si vous souhaitez l'installer.
yum install ne requiert pas d'arguments strictement définis. Il peut traiter divers formats de noms de paquets et d'expressions glob, ce qui rend l'installation plus facile pour les utilisateurs. D'autre part, yum peut prendre longtemps à analyser l'entrée correctement, particulièrement si vous spécifiez un grand nombre de paquets. Pour optimiser la recherche de paquets, vous pouvez utiliser les commandes suivantes pour définir de manière explicite comment analyser les arguments :
yum install-n name
yum install-n nameyum install-na name.architecture
yum install-na name.architectureyum install-nevra name-epoch:version-release.architecture
yum install-nevra name-epoch:version-release.architectureinstall-n, yum interprète name comme étant le nom exact du paquet. La commande install-na indique à yum que l'argument suivant contient le nom du paquet et l'architecture divisés par le caractère « point ». Avec install-nevra, yum s'attendra à un argument sous la forme name-epoch:version-release.architecture. Similairement, vous pouvez utiliser yum remove-n, yum remove-na, et yum remove-nevra lorsque vous cherchez des paquets à supprimer.
Note
named, mais que vous ne savez pas dans quel répertoire bin/ ou sbin/ le fichier est installé, veuillez utiliser la commande yum provides avec une expression glob :
yum provides "*/file_name" est une astuce utile pour trouver le paquet ou les paquets qui contiennent le file_name.
Exemple 8.12. Processus d'installation
root :
y (oui) et N (non), vous pouvez également choisir d (télécharger uniquement) pour télécharger les paquets sans les installer directement. Si vous choisissez y, l'installation continuera avec les messages suivants jusqu'à ce qu'elle se termine.
yum localinstall path
yum localinstall path8.2.5. Télécharger des paquets
... Total size: 1.2 M Is this ok [y/d/N]: ...
...
Total size: 1.2 M
Is this ok [y/d/N]:
...
d option, yum downloads the packages without installing them immediately. You can install these packages later offline with the yum localinstall command or you can share them with a different device. Downloaded packages are saved in one of the subdirectories of the cache directory, by default /var/cache/yum/$basearch/$releasever/packages/. The downloading proceeds in background mode so that you can use yum for other operations in parallel.
8.2.6. Supprimer des paquets
root :
yum remove package_name…
yum remove package_name…Exemple 8.13. Supprimer plusieurs paquets
yum remove totem
~]# yum remove toteminstall, remove peut prendre ces arguments :
- noms de paquet
- expressions glob
- listes de fichiers
- ce que le paquet fournit
Avertissement
8.3. Utiliser des groupes de paquets
yum groups est une commande de haut niveau qui couvre toutes les opérations agissant sur les groupes de paquets dans yum.
8.3.1. Répertorier les groupes de paquets
summary (résumé) est utilisée pour afficher le nombre de groupes installés, les groupes disponibles, les groupes d'environnement disponibles, ainsi que les deux groupes de langues disponibles et installés :
yum groups summary
yum groups summaryExemple 8.14. Exemple de sortie de résumé des groupes yum
list. Vous pouvez également filtrer la sortie de la commande par nom de groupe.
yum group list glob_expression…
yum group list glob_expression…hidden pour répertorier les groupes qui ne sont pas marqués comme étant visibles par les utilisateurs, et ids pour répertorier les ID de groupe. Vous pouvez ajouter les options language, environment, installed, ou available pour réduire la sortie de la commande à un type de groupe spécifique.
yum group info glob_expression…
yum group info glob_expression…Exemple 8.15. Afficher des informations sur le groupe de paquets LibreOffice
- «
-» — le paquet n'est pas installé et ne sera pas installé comme s'il faisait partie du groupe de paquets. - «
+» — le paquet n'est pas installé mais sera installé lors de la prochaine mise à niveauyum upgradeouyum group upgrade. - «
=» — le paquet est installé et a été installé en faisant partie du groupe de paquets. - « no symbol » — le paquet est installé mais il a été installé hors du groupe de paquets. Cela signifie que
yum group removene supprimera pas ce paquet.
group_command est défini sur objects, qui est le paramètre par défaut. Définissez ce paramètre sur une autre valeur si vous ne souhaitez pas que yum vérifie si un paquet a été installé en tant que faisant partie d'un groupe ou séparément, ce qui rendra les paquets « no symbol » équivalents aux paquets « = ».
yum group mark. Par exemple, yum group mark packages marque les paquets installés donnés en tant que membre d'un groupe spécifié. Pour éviter l'installation de nouveaux paquets sur une mise à jour de groupe, veuillez utiliser yum group mark blacklist. Consultez la page man de yum(8) pour obtenir davantage d'informations sur les capacités de yum group mark.
Note
yum group list, info, install, ou remove, veuillez inclure @group_name pour spécifier un groupe de paquets, @^group_name pour spécifier un groupe environnemental, ou group_name pour inclure les deux.
8.3.2. Installer un groupe de paquets
yum group list ids
yum group list ids Exemple 8.16. Trouver le nom et l'ID de groupe d'un groupe de paquets
yum group list ids kde\* Available environment groups: KDE Plasma Workspaces (kde-desktop-environment) Done
~]$ yum group list ids kde\*
Available environment groups:
KDE Plasma Workspaces (kde-desktop-environment)
Donehidden pour répertorier les groupes cachés également :
yum group list hidden ids kde\* Loaded plugins: product-id, subscription-manager Available Groups: KDE (kde-desktop) Done
~]$ yum group list hidden ids kde\*
Loaded plugins: product-id, subscription-manager
Available Groups:
KDE (kde-desktop)
Donegroup install. En tant qu'utilisateur root, veuillez saisir :
yum group install "group name"
yum group install "group name"root, veuillez exécuter la commande suivante :
yum group install groupid
yum group install groupidinstall si vous ajoutez également le symbole @ comme préfixe, ce qui indique à yum que vous souhaitez effectuer une installation de type group install. En tant qu'utilisateur root, veuillez saisir :
yum install @group
yum install @groupyum install @^group
yum install @^groupExemple 8.17. Quatre manières équivalentes d'installer le groupe KDE Desktop
yum group install "KDE Desktop" yum group install kde-desktop yum install @"KDE Desktop" yum install @kde-desktop
~]# yum group install "KDE Desktop"
~]# yum group install kde-desktop
~]# yum install @"KDE Desktop"
~]# yum install @kde-desktop8.3.3. Supprimer un groupe de paquets
install, en utilisant le nom du groupe de paquets ou son ID. En tant qu'utilisateur root, veuillez saisir :
yum group remove group_name
yum group remove group_nameyum group remove groupid
yum group remove groupidremove si vous ajoutez également le symbole @ comme préfixe, ce qui indique à yum que vous souhaitez effectuer une suppression de type group remove. En tant qu'utilisateur root, veuillez saisir :
yum remove @group
yum remove @groupyum remove @^group
yum remove @^groupExemple 8.18. Quatre manières équivalentes de supprimer le groupe KDE Desktop.
yum group remove "KDE Desktop" yum group remove kde-desktop yum remove @"KDE Desktop" yum remove @kde-desktop
~]# yum group remove "KDE Desktop"
~]# yum group remove kde-desktop
~]# yum remove @"KDE Desktop"
~]# yum remove @kde-desktop8.4. Utiliser l'historique des transactions
yum history permet aux utilisateurs d'examiner des informations sur la chronologie des transactions yum, les dates et heures auxquelles elles se sont produites, le nombre de paquets affectés, si ces transactions ont réussi ou échoué, et si la base de données RPM a été modifiées entre les transactions. En outre, cette commande peut être utilisée pour annuler ou refaire certaines transactions. Tout l'historique des données est stocké dans la base de données de l'historique (history DB) dans le répertoire /var/lib/yum/history/.
8.4.1. Répertorier les transactions
root, veuillez exécuter yum history sans argument supplémentaire, ou saisissez ce qui suit dans une invite shell :
yum history list
yum history listall :
yum history list all
yum history list allyum history list start_id..end_id
yum history list start_id..end_idyum history list glob_expression…
yum history list glob_expression…Exemple 8.19. Répertorier les cinq transactions les plus anciennes
yum history list, la transaction la plus récente est affichée en haut de la liste. Pour afficher des informations sur les cinq plus anciennes transactions stockées dans la base de données de l'historique, veuillez saisir :
yum history list produisent une sortie tabulaire dont chaque ligne comporte les colonnes suivantes :
ID— valeur d'entier identifiant une transaction particulière.Login user— nom de l'utilisateur dont la session de connexion a été utilisée pour initier une transaction. Cette information est typiquement présentée sous la formeFull Name <username>. Pour les transactions qui n'ont pas été effectuées par un utilisateur (comme les mises à jour automatiques du système),System <unset>est utilisé à la place.Date and time— la date et l'heure à laquelle une transaction a été effectuée.Action(s)— liste d'actions effectuées au cours d'une transaction, comme décrit dans Tableau 8.1, « Valeurs possibles du champ « Action(s) » ».Altered— nombre de paquets qui ont été affectés par une transaction, probablement suivis d'informations supplémentaires comme décrit dans Tableau 8.2, « Les valeurs possibles du champ « Altered » ».
| Action | Abbréviation | Description |
|---|---|---|
Downgrade | D | Un paquet au moins a été mis à niveau à une version antérieure. |
Erase | E | Un paquet au moins a été supprimé. |
Install | I | Un nouveau paquet au moins a été installé. |
Obsoleting | O | Un paquet au mons a été marqué comme obsolète. |
Reinstall | R | Un paquet au moins a été réinstallé. |
Update | U | Un paquet au moins a été mis à jour à une version plus récente. |
| Symbole | Description |
|---|---|
< | Avant que la transaction se termine, la base de données rpmdb a été modifiée hors de yum. |
> | Une fois la transaction terminée, la base de données rpmdb a été modifiée hors de yum. |
* | La transaction ne s'est pas terminée correctement. |
# | La transaction s'est terminée correctement, mais yum a retourné un code de sortie différent de zéro. |
E | La transaction s'est terminée correctement, mais une erreur ou un avertissement s'est affiché. |
P | La transaction s'est terminée correctement, mais des problèmes existaient déjà dans la base de données rpmdb. |
s | La transaction s'est terminée correctement, mais l'option de ligne de commande --skip-broken a été utilisée et certains paquets ont été ignorés. |
rpmdb ou yumdb pour tout paquet installé avec la base de données rpmdb ou yumdb actuellement utilisée, veuillez saisir ce qui suit :
yum history sync
yum history syncyum history stats
yum history statsExemple 8.20. Exemple de sortie de yum history stats
root :
yum history summary
yum history summaryyum history summary start_id..end_id
yum history summary start_id..end_idyum history list, vous pouvez également afficher un résumé des transactions concernant un ou plusieurs paquets particuliers en fournissant un nom de paquet ou une expression glob :
yum history summary glob_expression…
yum history summary glob_expression…Exemple 8.21. Résumé des cinq transactions les plus récentes
yum history summary produisent une sortie tabulaire simplifiée similaire à la sortie de yum history list.
yum history list et yum history summary sont orientées vers les transactions, et même si elles permettent d'uniquement afficher les transactions concernant un ou plusieurs paquets en particulier, des détails cruciaux seront manquants, comme la version des paquets. Pour répertorier les transactions depuis la perspective du paquet, veuillez exécuter la commande suivante en tant qu'utilisateur root :
yum history package-list glob_expression…
yum history package-list glob_expression…Exemple 8.22. Traçage de l'historique d'un paquet
8.4.2. Examiner les transactions
root, utilisez la commande yum history summary sous la forme suivante :
yum history summary id
yum history summary idroot :
yum history info id…
yum history info id…yum history info start_id..end_id
yum history info start_id..end_idExemple 8.23. Exemple de sortie de yum history info
root :
yum history addon-info id
yum history addon-info idyum history info, lorsqu'aucun id n'est fourni, yum utilise automatiquement la dernière transaction. Une autre manière de faire référence à la traduction la plus récente consiste à utiliser le mot-clé last :
yum history addon-info last
yum history addon-info lastExemple 8.24. Exemple de sortie de yum history addon-info
yum history addon-info fournit la sortie suivante :
yum history addon-info, trois types d'informations sont disponibles :
config-main— options yum globales qui étaient utilisées pendant la transaction. Veuillez consulter la Section 8.5.1, « Définir les options [main] » pour obtenir des informations sur la manière de modifier les options globales.config-repos— options des référentiels yum individuels. Veuillez consulter la Section 8.5.2, « Définir les options [repository] » pour obtenir des informations sur la manière de modifier les options de référentiels individuels.saved_tx— les données pouvant être utilisées par la commandeyum load-transactionafin de répéter la transaction sur une autre machine (voir ci-dessous).
root :
yum history addon-info id information
yum history addon-info id information8.4.3. Restaurer et répéter des transactions
yum history fournit un moyen de restaurer ou de répéter une transaction sélectionnée. Pour restaurer une transaction, veuillez saisir ce qui suit dans l'invite shell en tant qu'utilisateur root :
yum history undo id
yum history undo idroot :
yum history redo id
yum history redo idlast pour annuler ou répéter la dernière transaction.
yum history undo et yum history redo restaurent ou répètent uniquement les étapes qui ont été effectuées pendant une transaction. Si la transaction a installé un nouveau paquet, la commande yum history undo le désinstallera, et si la transaction a désinstallé un paquet, la commande l'installera à nouveau. Cette commande tente également de faire une mise à niveau inférieur de tous les paquets mis à jour vers leur version précédente si ces paquets plus anciens sont toujours disponibles.
root :
yum -q history addon-info id saved_tx > file_name
yum -q history addon-info id saved_tx > file_nameroot :
yum load-transaction file_name
yum load-transaction file_nameload-transaction de manière à ignorer les paquets manquants ou la version rpmdb. Pour obtenir davantage d'informations sur ces options de configuration, veuillez consulter la page man yum.conf(5).
8.4.4. Lancer un nouvel historique des transactions
root :
yum history new
yum history new/var/lib/yum/history/. L'ancien historique des transactions sera conservé, mais il ne sera pas accessible tant qu'un fichier de base de données plus récent sera présent dans le répertoire.
8.5. Configurer Yum et les référentiels Yum
Note
/etc/yum.conf. Ce fichier contient une section [main] obligatoire, qui vous permet de définir les options yum qui ont un effet global, et peut également contenir une ou plusieurs section(s) [repository], ce qui vous permet de définir des options spécifiques au référentiel. Cependant, il est recommandé de définir des référentiels individuels dans les fichiers .repo existants ou nouveaux, qui se trouvent dans le répertoire /etc/yum.repos.d/. Les valeurs que vous définissez dans les sections [repository] du fichier /etc/yum.conf remplacent les valeurs définies dans la section [main].
- définir des options yum globales en modifiant la section
[main]du fichier de configuration/etc/yum.conf; - définir des options de référentiels individuels en modifiant les sections
[repository]des fichiers/etc/yum.confet.repodans le répertoire/etc/yum.repos.d/; - utiliser des variables yum dans
/etc/yum.confet des fichiers dans le répertoire/etc/yum.repos.d/afin que la version dynamique et les valeurs de l'architecture soient gérées correctement ; - ajouter, activer, et désactiver des référentiels yum sur la ligne de commande ;
- définir votre propre référentiel yum personnalisé.
8.5.1. Définir les options [main]
/etc/yum.conf contient une seule section [main] précisément, et même si certaines des paires clés-valeurs dans cette section affectent la manière dont yum opère, d'autres affectent la manière dont yum traite les référentiels. Vous pouvez ajouter de nombreuses options sous l'en-tête de la section [main] dans /etc/yum.conf.
/etc/yum.conf ressemble à ceci :
[main] les plus couramment utilisées :
assumeyes=value- L'option
assumeyespermet de déterminer si yum demande de confirmer les actions critiques ou non. Remplacez value par l'une des valeurs suivantes :0(par défaut) — yum demande de confirmer les actions critiques effectuées.1— ne demande pas de confirmer les actions critiques deyum. Siassumeyes=1est défini, yum se comportera de la même manière qu'avec les options de ligne de commande-yet--assumeyes. cachedir=directory- Veuillez utiliser cette option pour définir le répertoire dans lequel yum stockera son cache et ses fichiers de base de données. Remplacez directory par un chemin complet vers le répertoire. Par défaut, le répertoire du cache de yum est le suivant :
/var/cache/yum/$basearch/$releasever/.Veuillez consulter la Section 8.5.3, « Utiliser des variables Yum » pour les descriptions des variables yum$basearchet$releasever. debuglevel=value- Cette option indique le niveau de détails de la sortie de débogage produite par yum. Ici, value est un entier entre
1et10. Définir une valeurdebuglevelplus élevée amènera yum à afficher une sortie de débogage plus détaillée.debuglevel=2est la valeur par défaut, tandis quedebuglevel=0désactive la sortie de débogage. exactarch=value- Avec cette option, vous pouvez définir yum pour que l'architecture exacte soit prise en considération lors de la mise à jour de paquets installés au préalable. Veuillez remplacer value par :
0— ne pas prendre en compte l'architecture exacte pendant la mise à jour des paquets.1(par défaut) — prendre en considération l'architecture exacte pendant la mise à jour des paquets. Avec ce paramètre, yum n'installera pas de paquets pour une architecture 32 bits pour mettre à jour un paquet déjà installé sur un système avec une architecture 64 bits. exclude=package_name [more_package_names]- L'option
excludevous permet d'exclure des paquets par mot-clé pendant une installation ou une mise à jour du système. Il est possible de sélectionner plusieurs paquets les exclure en indiquant une liste de paquets délimités par des espaces. Les expression glob du shell utilisant des caractères génériques (par exemple,*et?) sont autorisées. gpgcheck=value- Veuillez utiliser l'option
gpgcheckpour spécifier si yum doit effectuer une vérification des signatures GPG sur les paquets. Remplacez value par :0— désactive la vérification des signatures GPG sur les paquets de tous les référentiels, y compris l'installation de paquets locaux.1(par défaut) — active la vérification de signatures GPG sur tous les paquets dans tous les référentiels, y compris l'installation de paquets locaux. Lorsquegpgcheckest activé, les signatures de tous les paquets sont vérifiées.Si cette option est définie dans la section[main]du fichier/etc/yum.conf, elle définit une règle de vérification GPG pour tous les référentiels. Cependant, vous pouvez également définirgpgcheck=valuepour les référentiels individuels à la place ; c'est-à-dire que vous pouvez activer la vérification GPG sur un référentiel tout en le désactivant sur un autre. Définirgpgcheck=valuepour un référentiel individuel dans son fichier.repocorrespondant remplace la valeur par défaut si elle est présente dans/etc/yum.conf.Pour obtenir davantage d'informations sur la vérification de signatures GPG, veuillez consulter la Section A.3.2, « Vérification des signatures de paquets ». group_command=value- Utilisez l'option
group_commandpour spécifier de quelle manière les commandesyum group install,yum group upgrade, etyum group removegèrent un groupe de paquets. Remplacez value par l'une des valeurs suivantes :simple— installe tous les membres d'un groupe de paquets. Met à niveau les paquets installés antérieurement uniquement, mais n'installe pas de paquets qui ont été ajoutés au groupe entretemps.compat— est similaire àsimplemaisyum upgradeinstalle également des paquets qui ont été ajoutés au groupe depuis la mise à niveau précédente.objects— (par défaut.) Avec cette option, yum garde sous surveillance les groupes installés antérieurement et fait une distinction entre les paquets installés faisant partie du groupe et les paquets installés séparément. Veuillez consulter l'Exemple 8.15, « Afficher des informations sur le groupe de paquets LibreOffice » group_package_types=package_type [more_package_types]- Vous pouvez spécifier ici quel type de paquet (optionnel, par défaut ou obligatoire) est installé lorsque la commande
yumgroupinstallest appelé. Les types de paquets par défaut et obligatoire sont choisis par défaut. history_record=value- Avec cette option, vous pouvez définir yum pour enregistrer l'historique des transactions. Remplacez value par l'une des valeurs suivantes :
0— yum ne doit pas enregistrer d'entrées de l'historique pour les transactions.1(par défaut) — yum devrait enregistrer les entrées de l'historique des transactions. Cette opération prend une certaine quantité d'espace disque et un certain temps supplémentaire avec les transactions, mais elle fournit également de nombreuses informations concernant les anciennes opérations, qui peuvent être affichées par la commandeyumhistory.history_record=1est la valeur par défaut.Pour obtenir davantage d'informations sur la commandeyumhistory, veuillez consulter la Section 8.4, « Utiliser l'historique des transactions ».Note
Yum utilise des enregistrements de l'historique pour détecter les modifications apportées à la base de donnéesrpmdbqui ont été effectuées hors de yum. Dans de tels cas, yum affiche un avertissement et recherche automatiquement les problèmes possibles causés par l'altération derpmdb. Lorsquehistory_recordest éteint, yum n'est pas en mesure de détecter ces changements et aucune vérifications automatique n'est effectuée. installonlypkgs=space separated list of packages- Ici vous pouvez fournir une liste de paquets séparés par des virgules que yum peut installer, mais ne mettra jamais à jour. Veuillez consulter la page man
yum.conf(5) pour obtenir la liste des paquets qui sont par défaut « install-only » (uniquement pour installation).Si vous ajoutez la directiveinstallonlypkgsà/etc/yum.conf, vous devriez vous assurer de répertorier tous les paquets install-only, y compris ceux répertoriés sous la sectioninstallonlypkgsdeyum.conf(5). Particulièrement, les paquets du noyau doivent toujours être répertoriés dansinstallonlypkgs(comme ils le sont par défaut), etinstallonly_limitdevrait toujours être défini sur une valeur supérieure à2afin qu'un noyau de secours soit toujours disponible en cas d'échec du démarrage du noyau par défaut. installonly_limit=value- Cette option définit combien de paquets répertoriés dans la directive
installonlypkgspeuvent être installés au même moment. Remplacez value par un entier représentant le nombre maximal de versions pouvant être installées simultanément pour tout paquet unique répertorié dansinstallonlypkgs.Les valeurs par défaut de la directiveinstallonlypkgsincluent plusieurs paquets de noyaux différents. Ainsi, veuillez ne pas oublier que modifier la valeur deinstallonly_limitaffecte également le nombre maximal de versions installées pour un paquet de noyau unique. La valeur par défaut répertoriée dans/etc/yum.confestinstallonly_limit=3, et il n'est pas recommandé de réduire cette valeur, et plus particulièrement à une valeur inférieure à2. keepcache=value- L'option
keepcachedétermine si yum garde le cache des en-têtes et des paquets après une installation réussie. Ici, value correspond à l'une des valeurs suivantes :0(par défaut) — ne pas retenir le cache des en-têtes et des paquets après une installation réussie.1— retenir le cache après une installation réussie. logfile=file_name- Pour spécifier l'emplacement de journalisation de la sortie, veuillez remplacer file_name par un chemin complet vers le fichier dans lequel yum écrira la sortie journalisée. Par défaut, yum enregistre les journaux dans
/var/log/yum.log. max_connenctions=number- value correspond au nombre maximal de connexions simultanées, la valeur par défaut est 5.
multilib_policy=value- L'option
multilib_policydéfinit le comportement de l'installation si plusieurs versions de l'architecture sont disponibles pour une installation de paquet. Ici, value correspond à :best— installe le meilleur choix d'architecture pour ce système. Par exemple, paramétrermultilib_policy=bestsur un système AMD64 amène yum à installer les versions 64 bits de tous les paquets.all— installe à chaque fois toutes les architectures possibles pour chaque paquet. Par exemple, avecmultilib_policydéfini surallsur un système AMD64, yum installerait les versions i686 et AMD64 d'un paquet, si ces deux versions étaient disponibles. obsoletes=valeur- L'option
obsoletesactive la logique de traitement obsolète pendant les mises à jour. Lorsqu'un paquet déclare dans son fichier de spécifications qu'il rend un autre paquet obsolète, ce dernier est remplacé par l'ancien paquet lorsque le premier est installé. Les fichiers obsolètes sont déclarés, par exemple, lorsqu'un paquet est renommé. Remplacez valeur par soit :0— désactive la logique de traitement obsolète de yum lorsque des mises à jour sont effectuées.1(par défaut) — active la logique de traitement obsolète de yum lorsque des mises à jour sont effectuées. plugins=value- Interrupteur global pour activer ou désactiver les greffons yum, value est l'une des valeurs suivantes :
0— désactive tous les greffons yum globalement.Important
La désactivation de tous les greffons n'est pas recommandée car certains greffons fournissent des services yum importants. En particulier, les greffons product-id et subscription-manager fournissent la prise en charge duContent Delivery Network(CDN) basé certificats. La désactivation globale des greffons est offerte en tant qu'option pratique, et n'est généralement recommandée que lors du diagnostique d'un problème potentiel avec yum.1(par défaut) — active tous les greffons yum globalement. Avecplugins=1, vous pouvez toujours désactiver un greffon yum spécifique en paramétrantenabled=0dans le fichier de configuration de ce greffon.Pour obtenir davantage d'informations sur les divers greffons yum, veuillez consulter la Section 8.6, « Greffons Yum ». Pour obtenir des informations supplémentaires sur le contrôle des greffons, veuillez consulter la Section 8.6.1, « Activer, configurer, et désactiver des greffons Yum ». reposdir=directory- Ici, directory est un chemin complet vers le répertoire où se trouvent les fichiers
.repo. Tous les fichiers.repocontiennent des informations de référentiel (similairement aux sections[référentiel]de/etc/yum.conf). Yum collecte toutes les informations des référentiels des fichiers.repoet la section[référentiel]du fichier/etc/yum.confpour créer une liste maître des référentiels à utiliser pour des transactions. Sireposdirn'est pas défini, yum utilisera le répertoire par défaut/etc/yum.repos.d/. retries=valeur- Cette option définit le nombre de fois que yum doit tenter de récupérer un fichier avant de retourner une erreur. value est un entier
0ou supérieur. Définir la valeur sur0fait que yum effectuera des tentatives indéfiniement. La valeur par défaut est10.
[main] disponibles, veuillez consulter la section [main] OPTIONS de la page man de yum.conf(5).
8.5.2. Définir les options [repository]
[repository], où repository est un ID de référentiel unique, tel que my_personal_repo (les espaces ne sont pas autorisés), vous permet de définir des référentiels yum individuels. Afin d'éviter tout conflit, les référentiels personnalisés ne doivent pas utiliser des noms utilisés dans les référentiels Red Hat.
[repository] :
[repository] name=repository_name baseurl=repository_url
[repository]
name=repository_name
baseurl=repository_url[référentiel] doit contenir les directives suivantes :
name=nom référentiel- Ici, nom référentiel est une chaîne lisible par l'utilitsateur décrivant le référentiel.
baseurl=url référentiel- Remplacez url référentiel par un URL vers le répertoire où se trouve le référentiel repodata d'un référentiel :
- Si le référentiel est disponible sur HTTP, veuillez utiliser :
http://path/to/repo - Si le référentiel est disponible sur FTP, veuillez utiliser :
ftp://path/to/repo - Si le référentiel est local à la machine, veuillez utiliser :
file:///path/to/local/repo - Si un référentiel en ligne spécifique requiert une authentification HTTP de base, vous pouvez spécifier votre nom d'utilisateur et mot de passe en les ajoutant au début de l'URL comme ceci :
nom d'utilisateur:mot de âsse@lien. Par exemple, si un référentiel sur http://www.example.com/repo/ requiert un nom d'utilisateur « user » et un mot de passe « password », alors le lienbaseurllink pourra être spécifié comme suit :http://.user:password@www.example.com/repo/
Habituellement, cet URL est un lien HTTP, tel que :baseurl=http://path/to/repo/releases/$releasever/server/$basearch/os/
baseurl=http://path/to/repo/releases/$releasever/server/$basearch/os/Copy to Clipboard Copied! Toggle word wrap Toggle overflow Remarquez que yum étend toujours les variables$releasever,$arch, et$basearchdans les URL. Pour obtenir davantage d'informations sur les variables yum, veuillez consulter la Section 8.5.3, « Utiliser des variables Yum ».
[référentiel] utiles incluent :
enabled=valeur- Ceci est une manière simple de dire à yum d'utiliser ou d'ignorer un référentiel en particulier, la value correspond à l'une des valeurs suivantes :
0— ne pas inclure ce référentiel en tant que source de paquet lorsque vous effectuez des mises à jour et des installations. Ceci est une manière simple d'activer et de désactiver des référentiels, ce qui est utile lorsque vous souhaitez un certain paquet d'un référentiel que vous ne souhaitez pas activer pour les mises à jour ou les installations.1— inclure ce référentiel en tant que source de paquets.Activer et désactiver des référentiels peut également être effectué en passant l'option--enablerepo=repo_nameou--disablerepo=repo_namesuryum, ou par la fenêtre Ajouter/Supprimer un logiciel de l'utilitaire PackageKit. async=valeur- Contrôle le téléchargement parallèle de paquets de référentiels. La valeur correspond à :
auto(par défaut) — un téléchargement parallèle est utilisé si possible, ce qui signifie que yum le désactive automatiquement pour les référentiels créés par les greffons afin d'éviter des échecs.on— téléchargement parallèle activé pour le référentiel.off— téléchargement parallèle désactivé pour le référentiel.
[référentiel] existent. Quelques-unes d'entre elles ont la même forme et fonction que certaines options [main]. Pour une liste complète, veuillez consulter la section [repository] OPTIONS de la page man deyum.conf(5).
Exemple 8.25. Exemple de fichier /etc/yum.repos.d/redhat.repo
/etc/yum.repos.d/redhat.repo :
8.5.3. Utiliser des variables Yum
yum et dans tous les fichiers de configuration yum (c'est-à-dire /etc/yum.conf et tous les fichiers .repo dans le répertoire /etc/yum.repos.d/) :
$releasever- Vous pouvez utiliser cette variable pour faire référence à la version Red Hat Enterprise Linux. Yum obtient la valeur de
$releaseverà partir de la lignedistroverpkg=valuedans le fichier de configuration/etc/yum.conf. Si cette ligne n'existe pas dans/etc/yum.conf, alors yum déduira la valeur correcte en dérivant la numéro de version à partir du paquetredhat-releaseproduitqui fournit le fichierredhat-release. $arch- Vous pouvez utiliser cette variable pour faire référence à l'architecture du CPU du système comme retourné lors d'un appel à la fonction
os.uname()de Python. Les valeurs valides de$archincluent :i586,i686etx86_64. $basearch- Vous pouvez utiliser
$basearchpour faire référence à l'architecture de base du système. Par exemple, les machines i686 et i586 ont toutes deux une architecture de basei386, et les machines AMD64 et Intel64 ont une architecture de basex86_64. $YUM0-9- Ces dix variables sont chacunes remplacées par la valeur d'une variable d'environnement shell du même nom. Si l'une de ces variables est référencée (par exemple dans
/etc/yum.conf) et qu'une variable d'environnement shell du même nom n'existe pas, alors la variable du fichier de configuration ne sera pas remplacée.
$ ») dans le répertoire /etc/yum/vars/, et ajoutez la valeur souhaitée sur la première ligne.
$osname, créez un nouveau fichier avec « Red Hat Enterprise Linux » sur la première ligne et enregistrez-le sous /etc/yum/vars/osname :
echo "Red Hat Enterprise Linux 7" > /etc/yum/vars/osname
~]# echo "Red Hat Enterprise Linux 7" > /etc/yum/vars/osname.repo :
name=$osname $releasever
name=$osname $releasever8.5.4. Afficher la configuration actuelle
[main] du fichier /etc/yum.conf), veuillez exécuter la commande yum-config-manager sans aucune option de ligne de commande :
yum-config-manager
yum-config-manageryum-config-manager section…
yum-config-manager section…yum-config-manager glob_expression…
yum-config-manager glob_expression…Exemple 8.26. Afficher la configuration de la section principale
8.5.5. Ajouter, activer, et désactiver un référentielr Yum
Note
yum-config-manager.
Important
Content Delivery Network (CDN) basé sur certificats, les outils Red Hat Subscription Manager sont utilisés pour gérer des référentiels dans le fichier /etc/yum.repos.d/redhat.repo.
Ajouter un référentiel Yum
[référentiel] dans le fichier /etc/yum.conf, ou au fichier .repo du répertoire /etc/yum.repos.d/. Tous les fichiers avec l'extension de fichier .repo présents dans ce répertoire sont lus par yum, et il est recommandé de définir vos référentiels ici plutôt que dans /etc/yum.conf.
Avertissement
Content Delivery Network (CDN) basé sur certificats de Red Hat constitue un risque de sécurité potentiel, et pourrait provoquer des problèmes de sécurité, de stabilité, de compatibilité, et de maintenance.
.repo. Pour ajouter un tel référentiel à votre système et pour l'activer, veuillez exécuter la commande suivante en tant qu'utilisateur root :
yum-config-manager --add-repo repository_url
yum-config-manager --add-repo repository_url.repo.
Exemple 8.27. Ajouter example.repo
Activer un référentiel Yum
root :
yum-config-manager --enable repository…
yum-config-manager --enable repository…yum repolist all pour répertorier les ID des référentiels disponibles). Alternativement, vous pouvez utiliser une expression glob pour activer tous les référentiels correspondants :
yum-config-manager --enable glob_expression…
yum-config-manager --enable glob_expression…Exemple 8.28. Activer les référentiels définis dans des sections personnalisées de /etc/yum.conf.
[example], [example-debuginfo], et [example-source], veuillez saisir :
Exemple 8.29. Activer tous les référentiels
/etc/yum.conf et dans le répertoire /etc/yum.repos.d/, saisissez :
yum-config-manager --enable affiche la configuration du référentiel actuel.
Désactiver un référentiel Yum
root :
yum-config-manager --disable repository…
yum-config-manager --disable repository…yum repolist all pour répertorier les ID des référentiels disponibles). De même qu'avec yum-config-manager --enable, vous pouvez utiliser une expression glob pour désactiver tous les référentiels correspondants en même temps :
yum-config-manager --disable glob_expression…
yum-config-manager --disable glob_expression…Exemple 8.30. Désactiver tous les référentiels
/etc/yum.conf et dans le répertoire /etc/yum.repos.d/, saisissez :
yum-config-manager --disable affiche la configuration actuelle.
8.5.6. Création d'un référentiel Yum
- Installez le paquet createrepo. Pour faire cela, veuillez saisir ce qui suit dans l'invite shell en tant qu'utilisateur
root:yum install createrepo
yum install createrepoCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Copiez tous les paquets que vous souhaitez avoir dans votre référentiel dans un seul répertoire, comme
/mnt/local_repo/. - Déplacez-vous sur ce répertoire et exécutez la commande suivante :
createrepo --database /mnt/local_repo
createrepo --database /mnt/local_repoCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceci crée les métadonnées nécessaires pour votre référentiel yum, ainsi que la base de données sqlite pour accélérer les opérations yum.
8.5.7. Ajouter les référentiels « Optional » (Optionnel) et « Supplementary » (Supplémentaire)
8.6. Greffons Yum
yum. Exemple :
yum info yum Loaded plugins: langpacks, product-id, subscription-manager[sortie tronquée]
~]# yum info yum
Loaded plugins: langpacks, product-id, subscription-manager[sortie tronquée]Loaded plugins sont les noms que vous pouvez fournir à l'option --disableplugin=plugin_name.
8.6.1. Activer, configurer, et désactiver des greffons Yum
plugins= soit effectivement présente dans la section [main] du fichier /etc/yum.conf, et que sa valeur soit égale à 1 :
plugins=1
plugins=1plugins=0.
Important
Content Delivery Network (CDN) basé sur certificats. La désactivation globale des greffons est offerte en tant qu'option pratique, et est généralement uniquement recommandée lors du diagnostique d'un problème potentiel avec yum.
/etc/yum/pluginconf.d/. Vous pouvez définir des options spécifiques aux greffons dans ces fichiers. Par exemple, ci-dessous figure le fichier de configuration du greffon aliases nommé aliases.conf :
[main] enabled=1
[main]
enabled=1/etc/yum.conf, les fichiers de configuration des greffons contiennent toujours une section [main] où l'option enabled= contrôle si le greffon est activé lorsque vous exécutez des commandes yum. Si cette option est manquante, vous pouvez l'ajouter manuellement au fichier.
enabled=0 dans /etc/yum.conf, alors tous les greffons seront désactivés, peu importe s'ils étaient activés dans leurs fichiers de configuration individuels.
yum unique, veuillez utiliser l'option --noplugins.
yum, ajoutez l'option --disableplugin=plugin_name à la commande. Par exemple, pour désactiver le greffon aliases pendant une mise à jour du système, veuillez saisir :
yum update --disableplugin=aliases
~]# yum update --disableplugin=aliases--disableplugin= sont les mêmes que ceux répertoriés après la ligne Loaded plugins dans la sortie de toute commande yum. Vous pouvez désactiver de multiples greffons en séparant leurs noms par des virgules. En outre, vous pouvez faire correspondre plusieurs noms de greffons ou raccourcir les plus longs en utilisant des expressions glob :
yum update --disableplugin=aliases,lang*
~]# yum update --disableplugin=aliases,lang*8.6.2. Installer des greffons Yum supplémentaires
yum-plugin-plugin_name, ,mais pas toujours : par exemple, le paquet qui fournit le greffon kabi est nommé kabi-yum-plugins. Vous pouvez installer un greffon yum de la même manière que si vous installiez d'autres paquets. Par exemple, pour installer le greffon yum-aliases, veuillez saisir ce qui suit dans l'invite shell :
yum install yum-plugin-aliases
~]# yum install yum-plugin-aliases8.6.3. Utiliser des greffons Yum
- search-disabled-repos (subscription-manager)
- Le greffon search-disabled-repos permet d'activer temporairement ou de façon permanente des référentiels désactivés afin de vous aider à résoudre des problèmes de dépendances. Avec ce greffon activé, quand Yum échoue à l'installation d'un paquet à cause d'une erreur de résolution de dépendance, il propose d'activer temporairement les référentiels désactivés pour essayer à nouveau. Si l'installation réussit, Yum propose également d'activer les référentiels utilisés de façon permanente. Notez que le greffon ne fonctionne qu'avec les référentiels qui sont gérés par le subscription-manager et ne fonctionne pas avec les référentiels personnalisés.
Important
Quandyumexécute avec l'option--assumeyesou-y, ou si la directiveassumeyesest activée dans/etc/yum.conf, le greffon active les référentiels désactivés, à la fois temporairement et de façon permanente, sans invitation de confirmation. Cela peut mener à des problèmes, comme par exemple, d'activer des référentiels que vous ne souhaitez pas activer.Pour configurer le greffon search-disabled-repos, modifiez le fichier de configuration situé dans/etc/yum/pluginconf.d/search-disabled-repos.conf. Une liste de directives pouvant être utilisées dans la section[main]est affichée dans le tableau suivant.Expand Tableau 8.3. Directives search-disabled-repos.conf prises en charge Directive Description enabled=valeurVous permet d'activer ou de désactiver le greffon. La valeur doit être 1(activé), ou0(désactivé). Le greffon est activé par défaut.notify_only=valeurVous permet de limiter le comportement du greffon aux notifications uniquement. La valeur doit correspondre à 1(notifie sans modifier le comportement de Yum), ou0(modifie le comportement de Yum). Par défaut, le greffon ne notifie que l'utilisateur.ignored_repos=référentielsVous permet de spécifier les référentiels qui ne seront pas activés par le greffon. - kabi (kabi-yum-plugins)
- Le greffon kabi vérifie si un paquet de mise à jour de pilote est conforme à l'interface binaire d'application du noyau officielle de Red Hat (« kernel Application Binary Interface », ou kABI). Avec l'activation de ce greffon, lorsqu'un utilisateur tente d'installer un paquet qui utilise des symboles du noyau ne se trouvant pas sur une liste blanche, un message d'avertissement est écrit sur le journal système. En outre, configurer le greffon pour qu'il soit exécuté en mode « enforcing » empêche de tels paquets d'être installés.Pour configurer le greffon kabi, modifiez le fichier de configuration situé dans
/etc/yum/pluginconf.d/kabi.conf. Une liste de directives pouvant être utilisées dans la section[main]est affichée dans le tableau ci-dessous.Expand Tableau 8.4. Directives kabi.conf prises en charge Directive Description enabled=valeurVous permet d'activer ou de désactiver le greffon. La valeur valeur doit être 1(activé), ou0(désactivé). Une fois installé, le greffon est activé par défaut.whitelists=répertoirePermet de spécifier le répertoire dans lequel les fichiers avec les symboles du noyau pris en charge se trouvent. Par défaut, le greffon kabi utilise des fichiers fournis par le paquet kernel-abi-whitelists (c'est-à-dire le répertoire /usr/lib/modules/kabi-rhel70/).enforce=valeurVous permet d'activer ou de désactiver le mode « enforcing ». La valeur doit être égale à 1(activé), ou à0(désactivé). Par défaut, cette option est mise en commentaire et le greffon kabi n'affiche qu'un message d'avertissement. - product-id (subscription-manager)
- Le greffon product-id gère les certificats d'identité des produits installés à partir du CDN. Le greffon product-id est installé par défaut.
- langpacks (yum-langpacks)
- Le greffon langpacks est utilisé pour rechercher les paquets des paramètres régionaux d'une langue sélectionnée pour chaque paquet ayant été installé. Le greffon langpacks est installé par défaut.
- aliases (yum-plugin-aliases)
- Le greffon aliases offre l'option de ligne de commande
aliasqui autorise la configuration et l'utilisation d'alias pour les commandesyum. - yum-changelog (yum-plugin-changelog)
- Le greffon yum-changelog offre l'option de ligne de commande
--changelogqui permet d'afficher les journaux des changements d'un paquet avant et après une mise à jour. - yum-tmprepo (yum-plugin-tmprepo)
- Le greffon yum-tmprepo offre l'option de ligne de commande
--tmprepoqui prend l'URL d'un fichier référentiel, le télécharge et l'active pour une seule transaction. Ce greffon essaie d'assurer une utilisation temporaire sécurisée de ses référentiels. Par défaut, il ne permet pas de désactiver la vérification GPG. - yum-verify (yum-plugin-verify)
- Le greffon yum-verify offre les options de ligne de commande
verify,verify-rpm, etverify-allpour afficher les données de vérification sur le système. - yum-versionlock (yum-plugin-versionlock)
- Le greffon yum-versionlock exclut les autres versions des paquets sélectionnés, ce qui permet de protéger des paquets de mise à jour vers de nouvelles versions. Avec l'option de ligne de commande
versionlock, vous pouvez afficher et modifier la liste des paquets verrouillés.
8.7. Ressources supplémentaires
Documentation installée
yum(8) — la page du man de l'utilitaire de ligne de commande yum fournit une liste complète des options et des commandes prises en charge.yumdb(8) — la page du man de l'utilitaire de ligne de commandeyumdbdocumente comment utiliser cet outil pour effectuer des requêtes, et altérer la base de données yum si nécessaire.yum.conf(5) — la page du man deyum.confdocumente les options de configuration yum disponibles.yum-utils(1) — la page du man deyum-utilsrépertorie et décrit brièvement les utilitaires supplémentaires pour gérer des configurations yum, manipuler des référentiels, et utiliser une base de données yum.
Ressources en ligne
- Yum Guides — la page des Guides Yum sur la page d'accueil du projet fournit des liens vers une documentation supplémentaire.
- Red Hat Access Labs — les Red Hat Access Labs incluent un « Yum Repository Configuration Helper ».
Voir aussi
- Chapitre 5, Obtention de privilèges documente comment obtenir des privilèges administratifs en utilisant les commandes
suetsudo. - Annexe A, RPM décrit le gestionnaire de paquets RPM (« RPM Package Manager », ou RPM), qui est le système de mise en paquet utilisé par Red Hat Enterprise Linux.
Partie IV. Services d'infrastructure
Chapitre 9. Gérer les services avec systemd
9.1. Introduction à systemd
| Type d'unité | Extension de fichier | Description |
|---|---|---|
| Unité du service | .service | Service système. |
| Unité cible | .target | Un groupe d'unités systemd. |
| Unité Automount | .automount | Un point Automount du système de fichiers. |
| Unité du périphérique | .device | Fichier du périphérique reconnu par le noyau. |
| Unité de montage | .mount | Point de montage du système de fichiers. |
| Unité de chemin | .path | Un fichier ou répertoire dans un système de fichiers. |
| Unité scope | .scope | Un processus créé de manière externe. |
| Unité de tranche | .slice | Un groupe d'unités organisées de manière hiérarchique qui gèrent des processus système. |
| Unité d'instantané | .snapshot | Un état enregistré du gestionnaire systemd. |
| Unité de socket | .socket | Un socket de communication inter-processus. |
| Unité swap | .swap | Un périphérique ou fichier swap. |
| Unité minuteur | .timer | Un minuteur systemd. |
| Répertoire | Description |
|---|---|
/usr/lib/systemd/system/ | Fichiers d'unités systemd distribuées avec des paquets RPM installés. |
/run/systemd/system/ | Les fichiers d'unités systemd créées pendant l'exécution. Ce répertoire a priorité sur le répertoire de fichiers d'unités de service installées. |
/etc/systemd/system/ | Les fichiers d'unités systemd créées par systemctl enable ainsi que les fichiers d'unités ajoutés pour étendre un service. Ce répertoire a priorité sur le répertoire de fichiers d'unités de service installées. |
9.1.1. Fonctionnalités principales
- Activation basée socket — pendant l'initialisation, systemd crée des sockets d'écoute pour tous les services système qui prennent en charge ce type d'activation, et passe les sockets à ces services dès qu'ils sont lancés. Ceci permet à systemd de lancer les services en parallèle, mais rend également possible le redémarrage d'un service sans perdre de message qui lui aurait été envoyé pendant son indisponibilité : le socket correspondant reste accessible et tous les messages sont mis en file d'attente.Systemd utilise des unités de socket « socket units » pour une activation basée socket.
- Activation basée sur Bus — les services système qui utilisent D-Bus pour les communications inter-processus peuvent être lancés à la demande la première fois qu'une application cliente tente de communiquer avec eux. Systemd utilise des fichiers de service « D-Bus service files » pour une activation basée bus.
- Activation basée périphérique — les services système qui prennent en charge l'activation basée périphérique peuvent être lancés à la demande lorsqu'un type particulier de matériel physique est branché ou devient disponible. Systemd utilise des unités de périphérique « device units » pour l'activation basée périphérique.
- Activation basée chemin — les services système qui prennent en charge l'activation basée chemin peuvent être lancés à la demande lorsqu'un fichier ou répertoire particulier change d'état. Systemd utilise les unités de chemin « path units » pour l'activation basée chemin.
- Instantanés d'état système — Systemd peut temporairement enregistrer l'état actuel de toutes les unités ou restaurer un état précédent du système à partir d'un instantané créé dynamiquement. Pour stocker l'état actuel du système, systemd utilise des unités d'instantané « snapshot units » créées dynamiquement.
- Gestion des points de montage et des points Automount — Systemd surveille et gère tous les points de montage et d'Automount. Systemd utilise « mount units » pour les points de montage et « automount units » pour les points d'Automount.
- Parallélisation aggressive — à cause de l'activation basée socket, systemd peut lancer des services système en parallèle une fois que tous les sockets d'écoute sont en place. Lorsque combinés aux services système qui prennent en charge l'activation à la demande, l'activation en parallèle réduit largement le temps qu'il faut pour démarrer le système.
- Logique d'activation d'unité transactionnelle — avant d'activer ou de désactiver une unité, systemd calcule ses dépendances, crée une transaction temporaire, et vérifie que celle-ci soit bien cohérente. Si une transaction est incohérente, systemd tente automatiquement de la corriger et d'en supprimer les tâches non essentielles avant de rapporter une erreur.
- Rétro-compatibilité avec SysV init — Systemd prend en charge les scripts SysV init comme décrit dans la spécification « Linux Standard Base Core Specification », ce qui facilite le chemin de mise à niveau des unités de service Systemd.
9.1.2. Changements de compatibilité
- Systemd n'offre qu'une prise en charge limitée des niveaux d'exécution. Il fournit un certain nombre d'unités cibles pouvant être directement mappées à ces niveaux d'exécution et est également distribué avec l'ancienne commande
runlevelpour des raisons de compatibilité. Les cibles Systemd ne peuvent pas toutes être directement mappées aux niveaux d'exécution. Par conséquent, cette commande peut retournerN, pour indiquer un niveau d'exécution inconnu. Il est recommandé d'éviter d'utiliser la commanderunlevelsi possible.Pour obtenir davantage d'informations sur les cibles Systemd et leurs comparaisons aux niveaux d'exécution, veuillez consulter la Section 9.3, « Travailler avec des cibles Systemd ». - L'utilitaire
systemctlne prend pas en charge les commandes personnalisées. En plus des commandes standards, commestart,stop, etstatus, les auteurs de scripts SysV init peuvent implémenter un nombre de commandes arbitraires afin de fournir des fonctionnalités supplémentaires. Par exemple, le script init d'iptablessur Red Hat Enterprise Linux 6 peut être exécuté avec la commandepanic, qui active immédiatement le mode de panique et reconfigure le système pour ne plus recevoir de paquets entrants et ne plus pouvoir envoyer de paquets sortants. Ceci n'est pas pris en charge sur Systemd etsystemctln'accepte que les commandes documentées.Pour obtenir davantage d'informations sur l'utilitairesystemctlet sa comparaison avec l'ancien utilitaireservice, veuillez consulter la Section 9.2, « Gérer les services système ». - L'utilitaire
systemctlne communique pas avec les services qui n'ont pas été lancés par Systemd. Lorsque Systemd lance un service système, il stocket l'ID de son processus principal afin d'en garder la trace. L'utilitairesystemctlutilise ensuite ce PID pour effectuer des requêtes et pour gérer le service. Par conséquent, si un utilisateur lance un démon particulier directement sur la ligne de commande,systemctlsera incapable de déterminer son statut actuel ou de l'arrêter. - Systemd arrête uniquement les services en cours d'exécution. Précédemment, lorsque la séquence de fermeture était initiée, Red Hat Enterprise Linux 6 et les versions plus anciennes du système utilisaient des liens symboliques situés dans le répertoire
/etc/rc0.d/pour arrêter tous les services systèmes, quel que soit leur statut. Avec Systemd, seuls les services en cours d'exécution sont arrêtés pendant la fermeture. - Les services système sont incapables de lire le flux d'entrées standard. Lorsque Systemd lance un service, il connecte son entrée standard sur
/dev/nullpour empêcher toute interaction avec l'utilisateur. - Les services système n'héritent d'aucun contexte (comme les variables d'environnement
HOMEetPATH) provenant de l'utilisateur les invoquant et de sa session. Chaque service est exécuté dans un contexte d'exécution épuré. - Lors du chargement d'un script SysV init, systemd lit les informations de dépendance codées dans l'en-tête LSB (« Linux Standard Base ») et les interprète pendant l'exécution.
- Toutes les opérations sur les unités de service sont sujettes à un délai par défaut de 5 minutes pour empêcher à tout service malfonctionnant de geler le système. Cette valeur est codée en dur pour les services générés à partir d’initscripts et ne peut pas être modifiée. Toutefois, des fichiers de configuration individuels peuvent servir à spécifier une valeur de délai d’attente plus longue pour chaque service individuel, voir Exemple 9.21, « Modifier la limite du délai d'attente »
9.2. Gérer les services système
Note
/etc/rc.d/init.d/. Ces scripts init étaient habituellement écrits en Bash, et autorisaient l'administrateur systèmes à contrôler l'état des services et des démons dans leurs systèmes. Sur Red Hat Enterprise Linux 7, ces scripts init ont été remplacés par des unités de service (« service units »).
.service et ont un but similaire à celui des scripts init. Pour afficher, lancer, arrêter, redémarrer, activer ou désactiver des services système, veuillez utiliser la commande systemctl décrite dans Tableau 9.3, « Comparaison du service Utility avec systemctl », Tableau 9.4, « Comparaison de l'utilitaire chkconfig avec systemctl », et un peu plus bas dans cette section. Les commandes service et chkconfig sont toujours disponibles dans le système et fonctionnent comme prévu, mais sont uniquement incluses pour des raisons de compatibilité et doivent être évitées.
| service | systemctl | Description |
|---|---|---|
service nom start
| systemctl start nom.service
| Lance un service. |
service nom stop
| systemctl stop nom.service
| Arrête un service. |
service nom restart
| systemctl restart nom.service
| Redémarre un service. |
service nom condrestart
| systemctl try-restart nom.service
| Redémarre un service uniquement s'il est en cours d'exécution. |
service nom reload
| systemctl reload nom.service
| Recharge la configuration. |
service nomstatus
| systemctl status nom.service
systemctl is-active nom.service
| Vérifie si un service est en cours d'exécution. |
service --status-all
| systemctl list-units --type service --all
| Affiche le statut de tous les services. |
| chkconfig | systemctl | Description |
|---|---|---|
chkconfig nom on
| systemctl enable nom.service
| Active un service. |
chkconfig nom off
| systemctl disable nom.service
| Désactive un service. |
chkconfig --list nom
| systemctl status nom.service
systemctl is-enabled nom.service
| Vérifie si un service est activé. |
chkconfig --list
| systemctl list-unit-files --type service
| Répertorie tous les services et vérifie s'ils sont activés. |
chkconfig --list
| systemctl list-dependencies --after
| Répertorie les services qui doivent démarrer avant l'unité spécifiée. |
chkconfig --list
| systemctl list-dependencies --before
| Répertorie les services qui doivent démarrer aprés l'unité spécifiée. |
Spécifier les unités de service
.service. Exemple :
systemctl stop nfs-server.service
~]# systemctl stop nfs-server.servicesystemctl assume que l'argument suppose qu'il s'agit d'une unité de service. La commande suivante équivaut à celle se trouvant ci-dessus :
systemctl stop nfs-server
~]# systemctl stop nfs-serversystemctl show nfs-server.service -p Names
~]# systemctl show nfs-server.service -p Names9.2.1. Répertorier les services
systemctl list-units --type service
systemctl list-units --type serviceUNIT) suivi d'une note indiquant si le ficiers d'unités a été chargée (LOAD), son état d'activation de haut niveau (ACTIVE) et de bas niveau (SUB), ainsi qu'une courte description (DESCRIPTION).
systemctl list-units affiche uniquement les unités actives. Si vous souhaitez afficher toutes les unités chargées, quel que soit leur état, veuillez exécuter cette commande avec l'option de ligne de commande --all ou -a :
systemctl list-units --type service --all
systemctl list-units --type service --allsystemctl list-unit-files --type service
systemctl list-unit-files --type serviceUNIT FILE) suivi d'informations indiquant si l'unité de service est activée ou non (STATE). Pour obtenir des informations sur la manière de déterminer le statut des unités de service individuelles, veuillez consulter la Section 9.2.2, « Afficher le statut du service ».
Exemple 9.1. Répertorier les services
9.2.2. Afficher le statut du service
systemctl status name.service
systemctl status name.servicegdm). Cette commande affiche le nom de l'unité de service sélectionnée suivi d'une courte description, un ou plusieurs champs décrit dans la Tableau 9.5, « Informations sur les unités de service disponibles », et si elle est exécutée par l'utilisateur root, les entrées de journal les plus récentes seront également incluses.
| Champ | Description |
|---|---|
Loaded | Informations indiquant si l'unité de service est chargée, le chemin absolu vers le fichier de l'unité, et une note indiquant si l'unité est activée. |
Active | Informations indiquant si l'unité de service exécutée est suivie d'un horodatage. |
Main PID | Le PID du service système correspondant est suivi par son nom. |
Status | Informations supplémentaires sur le service système correspondant. |
Process | Informations supplémentaires sur les processus connexes. |
CGroup | Informations supplémentaires sur les Groupes de contrôle connexes (cgroups). |
systemctl is-active name.service
systemctl is-active name.servicesystemctl is-enabled name.service
systemctl is-enabled name.servicesystemctl is-active et systemctl is-enabled retournent un statut de sortie (« exit status ») de 0 si l'unité de service spécifiée est en cours d'exécution ou si elle est activée. Pour obtenir des informations sur la manière de répertorier toutes les unités de service actuellement chargées, veuillez consulter la Section 9.2.1, « Répertorier les services ».
Exemple 9.2. Afficher le statut du service
gdm.service. Pour déterminer le statut actuel de cette unité de service, veuillez saisir ce qui suit dans une invite de shell :
Exemple 9.3. Pour afficher les services qui doivent démarrer avant un service.
Exemple 9.4. Pour afficher les services qui doivent démarrer après un service.
9.2.3. Lancer un service
root :
systemctl start name.service
systemctl start name.servicegdm). Cette commande lance l'unité de service sélectionnée dans la session actuelle. Pour obtenir des informations sur la manière d'activer une unité de service pour qu'elle soit lancée pendant l'initialisation, veuillez consulter la Section 9.2.6, « Activer un service ». Pour obtenir des informations sur la façon de déterminer le statut d'une unité de service particulière, veuillez consulter la Section 9.2.2, « Afficher le statut du service ».
Exemple 9.5. Lancer un service
httpd.service. Pour activer cette unité de service et lancer le démon httpd dans la session actuelle, veuillez exécuter la commande suivante en tant qu'utilisateur root :
systemctl start httpd.service
~]# systemctl start httpd.service9.2.4. Arrêter un service
root :
systemctl stop name.service
systemctl stop name.servicebluetooth). Cette commande arrête l'unité de service sélectionnée dans la session actuelle. Pour obtenir des informations sur la manière de désactiver une unité de service pour l'empêcher d'être lancée pendant l'initialisation, veuillez consulter la Section 9.2.7, « Désactiver un service ». Pour obtenir des informations sur comment déterminer le statut d'une unité de service particulière, veuillez consulter la Section 9.2.2, « Afficher le statut du service ».
Exemple 9.6. Arrêter un service
bluetoothd est nommée bluetooth.service. Pour désactiver cette unité de service et arrêter le démon bluetoothd dans la session actuelle, veuillez exécuter la commande suivante en tant qu'utilisateur root :
systemctl stop bluetooth.service
~]# systemctl stop bluetooth.service9.2.5. Redémarrer un service
root :
systemctl restart name.service
systemctl restart name.servicehttpd). Cette commande arrête l'unité de service sélectionnée dans la session actuelle et la redémarre immédiatement. De manière plus importante, si l'unité de service n'est pas en cours d'exécution, cette commande la lancera également. Pour ordonner à Systemd de redémarrer une unité de service uniquement si le service correspondant est déjà en cours d'exécution, veuillez exécuter la commande suivante en tant qu'utilisateur root :
systemctl try-restart name.service
systemctl try-restart name.serviceroot, veuillez saisir :
systemctl reload name.service
systemctl reload name.servicesystemctl prend également en charge les commandes reload-or-restart et reload-or-try-restart qui redémarrent de tels services. Pour obtenir des informations sur la manière de déterminer le statut d'une certaine unité de service, veuillez consulter la Section 9.2.2, « Afficher le statut du service ».
Exemple 9.7. Redémarrer un service
root :
systemctl reload httpd.service
~]# systemctl reload httpd.service9.2.6. Activer un service
root :
systemctl enable name.service
systemctl enable name.servicehttpd). Cette commande lit la section [Install] de l'unité de service sélectionnée et crée les liens symboliques appropriés vers le fichier /usr/lib/systemd/system/name.service dans le répertoire /etc/systemd/system/ et ses sous-répertoires. Cependant, cette commande ne réécrit pas les liens qui existent déjà. Si vous souhaitez vous assurer que les liens symboliques soient créés à nouveau, veuillez exécuter la commande suivante en tant qu'utilisateur root :
systemctl reenable name.service
systemctl reenable name.serviceExemple 9.8. Activer un service
root :
systemctl enable httpd.service Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
~]# systemctl enable httpd.service
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.9.2.7. Désactiver un service
root :
systemctl disable name.service
systemctl disable name.servicebluetooth). Cette commande lit la section [Install] de l'unité de service sélectionnée et supprime les liens symboliques appropriés pointant vers le fichier /usr/lib/systemd/system/name.service du répertoire /etc/systemd/system/ et de ses sous-répertoires. En outre, vous pouvez masquer toute unité de service pour l'empêcher d'être lancée manuellement ou par un autre service. Pour faire cela, veuillez exécuter la commande suivante en tant qu'utilisateur root :
systemctl mask name.service
systemctl mask name.service/etc/systemd/system/name.service par un lien symbolique pointant vers /dev/null, ce qui rend le fichier de l'unité inaccessible à Systemd. Pour inverser cette action et démasquer une unité de service, veuillez saisir en tant qu'utilisateur root :
systemctl unmask name.service
systemctl unmask name.serviceExemple 9.9. Désactiver un service
bluetooth.service dans la session actuelle. Pour empêcher cette unité de service d'être lancée pendant l'initialisation, veuillez saisir ce qui suit dans une invite de shell en tant qu'utilisateur root :
systemctl disable bluetooth.service Removed symlink /etc/systemd/system/bluetooth.target.wants/bluetooth.service. Removed symlink /etc/systemd/system/dbus-org.bluez.service.
~]# systemctl disable bluetooth.service
Removed symlink /etc/systemd/system/bluetooth.target.wants/bluetooth.service.
Removed symlink /etc/systemd/system/dbus-org.bluez.service.9.3. Travailler avec des cibles Systemd
.target et leur unique but consiste à regrouper d'autres unités Systemd dans une chaîne de dépendances. Par exemple, l'unité graphical.target, qui est utilisée pour lancer une session graphique, lance des services système comme le gestionnaire d'affichage GNOME (gdm.service) ou le services des comptes (accounts-daemon.service) et active également l'unité multi-user.target. De manière similaire, l'unité multi-user.target lance d'autres services système essentiels, tels que NetworkManager (NetworkManager.service) ou D-Bus (dbus.service) et active une autre unité cible nommée basic.target.
| Niveau d'exécution | Unités de cible | Description |
|---|---|---|
0 | runlevel0.target, poweroff.target | Quitter et éteindre le système. |
1 | runlevel1.target, rescue.target | Installer un shell de secours. |
2 | runlevel2.target, multi-user.target | Installer un système multi-utilisateurs non graphique. |
3 | runlevel3.target, multi-user.target | Installer un système multi-utilisateurs non graphique. |
4 | runlevel4.target, multi-user.target | Installer un système multi-utilisateurs non graphique. |
5 | runlevel5.target, graphical.target | Installer un système graphique multi-utilisateurs. |
6 | runlevel6.target, reboot.target | Quitter et redémarrer le système. |
systemctl comme décrit dans la Tableau 9.7, « Comparaison des commandes SysV init avec systemctl » ainsi que dans les sections ci-dessous. Les commandes runlevel et telinit sont toujours disponibles dans le système et fonctionnent comme prévu, mais ne sont incluses que pour des raisons de compatibilité et doivent être évitées.
| Ancienne commande | Nouvelle commande | Description |
|---|---|---|
runlevel | systemctl list-units --type target | Répertorie les unités de cible actuellement chargées. |
telinit runlevel | systemctl isolate name.target | Modifie la cible actuelle. |
9.3.1. Afficher la cible par défaut
systemctl get-default
systemctl get-default/etc/systemd/system/default.target et affiche le résultat. Pour obtenir des informations sur comment modifier la cible par défaut, veuillez consulter la Section 9.3.3, « Modifier la cible par défaut ». Pour obtenir des informations sur comment répertorier toutes les unités de cible actuellement chargées, veuillez consulter la Section 9.3.2, « Afficher la cible actuelle ».
Exemple 9.10. Afficher la cible par défaut
systemctl get-default graphical.target
~]$ systemctl get-default
graphical.target9.3.2. Afficher la cible actuelle
systemctl list-units --type target
systemctl list-units --type targetUNIT) suivi d'une note indiquant si l'unité a été chargée (LOAD), son état d'activation de haut niveau (ACTIVE) et de bas niveau (SUB), ainsi qu'une courte description (DESCRIPTION).
systemctl list-units affiche uniquement les unités actives. Si vous souhaitez afficher toutes les unités chargées, quel que soit leur état, veuillez exécuter cette commande avec l'option de ligne de commande --all ou -a :
systemctl list-units --type target --all
systemctl list-units --type target --allExemple 9.11. Afficher la cible actuelle
9.3.3. Modifier la cible par défaut
root :
systemctl set-default name.target
systemctl set-default name.targetmulti-user). Cette commande remplace le fichier /etc/systemd/system/default.target par un lien symbolique pointant vers /usr/lib/systemd/system/name.target, où name est le nom de l'unité cible que vous souhaitez utiliser. Pour obtenir davantage d'informations sur la manière de modifier la cible actuelle, veuillez consulter la Section 9.3.4, « Modifier la cible actuelle ». Pour obtenir des informations sur la manière de répertorier toutes les unités de cible actuellement chargées, veuillez consulter la Section 9.3.2, « Afficher la cible actuelle ».
Exemple 9.12. Modifier la cible par défaut
multi-user.target par défaut, veuillez saisir la commande suivante dans une invite de shell en tant qu'utilisateur root :
systemctl set-default multi-user.target rm '/etc/systemd/system/default.target' ln -s '/usr/lib/systemd/system/multi-user.target' '/etc/systemd/system/default.target'
~]# systemctl set-default multi-user.target
rm '/etc/systemd/system/default.target'
ln -s '/usr/lib/systemd/system/multi-user.target' '/etc/systemd/system/default.target'9.3.4. Modifier la cible actuelle
root :
systemctl isolate name.target
systemctl isolate name.targetmulti-user). Cette commande remplace l'unité de cible nommée name et toutes ses unités dépendantes, et arrête immédiatement toutes les autres. Pour obtenir des informations sur la manière de modifier la cible par défaut, veuillez consulter la Section 9.3.3, « Modifier la cible par défaut ». Pour obtenir des informations sur la manière de répertorier toutes les unités de cible actuellement chargées, veuillez consulter la Section 9.3.2, « Afficher la cible actuelle ».
Exemple 9.13. Modifier la cible actuelle
multi-user.target dans la session actuelle, veuillez saisir la commande suivante en tant qu'utilisateur root :
systemctl isolate multi-user.target
~]# systemctl isolate multi-user.target9.3.5. Passer en mode de secours
root :
systemctl rescue
systemctl rescuesystemctl isolate rescue.target, mais elle envoie également un message informatif à tous les utilisateurs actuellement connectés au système. Pour empêcher Systemd d'envoyer ce message, veuillez exécuter cette commande avec l'option de ligne de commande --no-wall :
systemctl --no-wall rescue
systemctl --no-wall rescueExemple 9.14. Passer en mode de secours
root :
systemctl rescue Broadcast message from root@localhost on pts/0 (Fri 2013-10-25 18:23:15 CEST): The system is going down to rescue mode NOW!
~]# systemctl rescue
Broadcast message from root@localhost on pts/0 (Fri 2013-10-25 18:23:15 CEST):
The system is going down to rescue mode NOW!9.3.6. Passer en mode d'urgence
root :
systemctl emergency
systemctl emergencysystemctl isolate emergency.target, mais elle envoie également un message informatif à tous les utilisateurs actuellement connectés au système. Pour empêcher Systemd d'envoyer ce message, veuillez exécuter cette commande avec l'option de ligne de commande --no-wall :
systemctl --no-wall emergency
systemctl --no-wall emergencyExemple 9.15. Passer en mode d'urgence
root :
systemctl --no-wall emergency
~]# systemctl --no-wall emergency9.4. Arrêter, suspendre, et mettre le système en hibernation
systemctl remplace un certain nombre de commandes de gestion de l'alimentation utilisées dans des versions précédentes du système Red Hat Enterprise Linux. Les commandes répertoriées dans la Tableau 9.8, « Comparaison des commandes de gestion de l'alimentation avec systemctl » sont toujours disponibles sur le système pour des raisons de compatibilité, mais il est conseillé d'utiliser systemctl lorsque possible.
| Ancienne commande | Nouvelle commande | Description |
|---|---|---|
halt | systemctl halt | Arrête le système. |
poweroff | systemctl poweroff | Met le système hors-tension. |
reboot | systemctl reboot | Redémarre le système. |
pm-suspend | systemctl suspend | Suspend le système. |
pm-hibernate | systemctl hibernate | Met le système en hibernation. |
pm-suspend-hybrid | systemctl hybrid-sleep | Met en hibernation et suspend le système. |
9.4.1. Arrêter le système
systemctl fournit des commandes de fermeture du système, mais la commande traditionnelle shutdown est également prise en charge. Bien que la commande shutdown fasse appel à l’utilitaire systemctl pour la fermeture, elle présente l'avantage d'intégrer un argument de temps. C'est particulièrement utile pour la maintenance et pour laisser plus de temps aux utilisateurs pour réagir à une notification de fermeture du système. La possibilité de pouvoir annuler le fermeture peut également être un plus.
Utilisation de la commande systemctl
root :
systemctl poweroff
systemctl poweroffroot :
systemctl halt
systemctl halt--no-wall. Exemple :
systemctl --no-wall poweroff
systemctl --no-wall poweroffUtilisation de la commande Shutdown
root : shutdown --poweroff hh:mm
shutdown --poweroff hh:mm/run/nologin est créé 5 minutes avant la fermeture du système pour éviter les nouvelles connexions. Quand un argument de temps est utilisé, un message en option, le wall message, pourra être ajouté à la commande.
root : shutdown --halt +m
shutdown --halt +mnow est un alias de +0.
root comme suit : shutdown -c
shutdown -cshutdown(8) pour obtenir des options de commandes supplémentaires.
9.4.2. Redémarrer le système
root :
systemctl reboot
systemctl reboot--no-wall :
systemctl --no-wall reboot
systemctl --no-wall reboot9.4.3. Suspendre le système
root :
systemctl suspend
systemctl suspend9.4.4. Hiberner le système
root :
systemctl hibernate
systemctl hibernateroot :
systemctl hybrid-sleep
systemctl hybrid-sleep9.5. Contrôler systemd sur une machine distante
systemctl permet également d'interagir avec systemd pendant une exécution sur une machine distante à traver le protocole SSH. Si le service sshd est en cours d'exécution sur la machine distante, vous pourrez vous connecter à cette machine en exécutant la commande systemctl avec l'option de ligne de commande --host ou -H :
systemctl --host user_name@host_name command
systemctl --host user_name@host_name commandcommand par n'importe quelle commande systemctl décrite ci-dessus. Remarquez que la machine distante doit être configurée afin d'autoriser l'accès distant à l'utilisateur sélectionné par le protocole SSH. Pour obtenir davantage d'informations sur la manière de configurer un serveur SSH, veuillez consulter le Chapitre 10, OpenSSH.
Exemple 9.16. Gestion à distance
server-01.example.com en tant qu'utilisateur root et déterminer le statut actuel de l'unité httpd.service, veuillez saisir ce qui suit dans une invite de shell :
9.6. Créer et modifier des fichiers d'unité systemd
systemctl fonctionnent avec des fichiers d'unité dans l'arrière-plan. Pour faire des ajustements plus précis, l'administrateur systèmes doit modifier ou créer des fichiers d'unité manuellement. La Tableau 9.2, « Emplacements des fichiers d'unités systemd » répertorie trois répertoires principaux sur lesquels les fichiers d'unités sont stockés sur le système, le répertoire /etc/systemd/system/ est réservé aux fichiers d'unité créés ou personnalisés par l'administrateur systèmes.
unit_name.type_extension
unit_name.type_extensionsshd.service et une unité sshd.socket sont habituellement présentes sur votre système.
sshd.service, veuillez créer le fichier sshd.service.d/custom.conf et insérez-y les directives supplémentaires. Pour obtenir davantage d'informations sur les répertoires de configuration, veuillez consulter la Section 9.6.4, « Modifier les fichiers d'unité existants ».
sshd.service.wants/ et sshd.service.requires/ peuvent également être créés. Ces répertoires contiennent des liens symboliques vers les fichiers d'unités qui sont des dépendances du service sshd. Les liens symboliques sont automatiquement créés pendant l'installation selon les options du fichiers de l'unité [Install] (veuillez consulter la Tableau 9.11, « Options importantes de la section [Install] ») ou pendant le temps d'exécution basé sur les options [Unit] (veuillez consulter la Tableau 9.9, « Options importantes de la section [Unit] »). Il est également possible de créer ces répertoires et les liens symboliques manuellement.
9.6.1. Comprendre la structure des fichiers d'unité
- [Unit] — contient des options génériques qui ne sont pas dépendantes du type de l'unité. Ces options fournissent une description de l'unité, spécifient le comportement de l'unité, et définissent les dépendances avec d'autres unités. Pour une liste des options [Unit] les plus fréquemment utilisées, veuillez consulter la Tableau 9.9, « Options importantes de la section [Unit] ».
- [unit type] — si une unité possède des directives spécifiques au type, celles-ci seront regroupées dans une section nommée par le type d'unité. Par exemple, les fichiers de l'unité de service contiennent la section [Service], veuillez consulter la Tableau 9.10, « Options importantes de la section [Service] » pour voir les options [Service] les plus fréquemment utilisées.
- [Install] — contient des informations sur l'installation de l'unité utilisée par les commandes
systemctl enableetdisable, veuillez consulter la Tableau 9.11, « Options importantes de la section [Install] » pour voir une liste des options [Install].
| Option[a] | Description |
|---|---|
Description | Description significative de l'unité. En tant qu'exemple, le texte est affiché dans la sortie de la commande systemctl status. |
Documentation | Fournit une liste des URI référençant la documentation de l'unité. |
After[b] | Définit l'ordre dans lequel les unités sont lancées. L'unité est lancée uniquement après l'activation des unités spécifiées dans After. Contrairement à Requires, After n'active pas explicitement les unités spécifiées. L'option Before offre une fonctionnalité contraire à After. |
Requires | Configure les dépendances sur d'autres unités. Les unités répertoriées dans Requires sont activées ensembles avec l'unité. Si le lancement de l'une des unités requises échoue, l'unité n'est pas activée. |
Wants | Configure les dépendances plus faibles que Requires. Si l'une des unités répertoriées ne démarre pas, cela n'aura pas d'impact sur l'activation de l'unité. C'est la méthode recommandée pour établir des dépendances d'unité personnalisées. |
Conflicts | Configure des dépendances négatives, à l'opposé de Requires. |
[a]
Pour une liste complète des options configurables dans la section [Unit], veuillez consulter la page man de systemd.unit(5).
[b]
Dans la plupart des cas, il est suffisant de ne déterminer que les dépendances d'ordonnancement qu'avec les options de fichier After et Before. Si vous définissez aussi une dépendance avec Wants (conseillé) ou Requires, la dépendance d'ordonnancement devra toujours être spécifiée. C'est parce que l'ordonnancement et les exigences de dépendances fonctionnent indépendamment.
| |
| Option[a] | Description |
|---|---|
Type | Configure le type de démarrage de processus d'unité qui affecte la fonctionnalité d'ExecStart et des options connexes. L'une des options suivantes :
|
ExecStart | Spécifie les commandes ou scripts à exécuter lorsque l'unité est lancée. ExecStartPre et ExecStartPost spécifient des commandes personnalisées à exécuter avant et après ExecStart. Type=oneshot permet de spécifier des commandes multiples personnalisées exécutées de manière séquentielle par la suite. |
ExecStop | Spécifie les commandes ou scripts à exécuter lorsque l'unité est arrêtée. |
ExecReload | Spécifie les commandes ou scripts à exécuter lorsque l'unité est rechargée. |
Restart | Avec cette option activée, le service est redémarré après que son processus se soit arrêté, à l'exception d'un arrêt gracieux avec la commande systemctl. |
RemainAfterExit | Si défini sur True, le service est considéré comme actif, même lorsque tous ses processus sont arrêtés. La valeur par défaut est False. Cette option est particulièrement utile si Type=oneshot est configuré. |
[a]
Pour une liste complète des options configurables dans la section [Service], veuillez consulter la page man de systemd.service(5).
| |
| Option[a] | Description |
|---|---|
Alias | Fournit une liste de noms supplémentaires de l'unité séparés par des espaces. La plupart des commandes systemctl, sauf systemctl enable, peuvent utiliser des alias à la place du nom de l'unité. |
RequiredBy | Une liste des unités qui dépendent de l'unité. Lorsque cette unité est activée, les unités répertoriées dans RequiredBy obtiennent une dépendance Require de l'unité. |
WantedBy | Une liste des unités qui dépendent faiblement de l'unité. Lorsque cette unité est activée, les unités répertoriées dans WantedBy obtiennent une dépendance Want de l'unité. |
Also | Indique une liste des unités à installer ou désinstaller avec l'unité. |
DefaultInstance | Limitée aux unités instanciées, cette option indique l'instance par défaut pour laquelle l'unité est activée. Veuillez consulter la Section 9.6.5, « Travailler avec des unités instanciées » |
[a]
Pour voir une liste complète des options configurables dans la section [Install], veuillez consulter la page man de systemd.unit(5).
| |
Exemple 9.17. Fichier d'unité postfix.service
/usr/lib/systemd/system/postifix.service tel qu'il est fourni par le paquet postfix :
EnvironmentFile désigne l'emplacement où les variables d'environnement du service sont définies, PIDFile spécifie un PID stable pour le processus principale du service. Finalement, la section [Install] répertorie les unités qui dépendent de ce service.
9.6.2. Créer des fichiers d'unité personnalisés
- Préparez le fichier exécutable avec le service personnalisé. Il peut s'agir d'un script créé et personnalisé, ou d'un exécutable remis par un fournisseur de logiciels. Si requis, veuillez préparer un fichier PID pour contenir un PID constant pour le processus principal du service personnalisé. Il est également possible d'inclure des fichiers d'environnement pour stocker des variables shell pour le service. Assurez-vous que le script source soit exécutable (en exécutant
chmod a+x) et qu'il ne soit pas interactif. - Créez un fichier d'unité dans le répertoire
/etc/systemd/system/et assurez-vous qu'il possède les permissions de fichier correctes. Veuillez exécuter en tant qu'utilisateurroot:touch /etc/systemd/system/name.service chmod 664 /etc/systemd/system/name.service
touch /etc/systemd/system/name.service chmod 664 /etc/systemd/system/name.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacez name par le nom du service à créer. Remarquez que le fichier n'a pas besoin d'être exécutable. - Ouvrez le fichier
name.servicecréé dans l'étape précédente, et ajoutez les options de configuration du service. Une variété d'options peut être utilisée selon le type de service que vous souhaitez créer, consulter Section 9.6.1, « Comprendre la structure des fichiers d'unité ». Voici un exemple de configuration d'unité pour un service concernant le réseau :Copy to Clipboard Copied! Toggle word wrap Toggle overflow Quand :- service_description est une description informative affichée dans les fichiers journaux et dans la sortie de la commande
systemctl status. - le paramètre
Afterpermet de s'assurer que le service est démarré uniquement après l'exécution du réseau. Ajoutez une liste séparée par des espaces d'autres services ou cibles connexes. - path_to_executable correspond au chemin vers l'exécutable du service.
Type=forkingest utilisé pour les démons effectuant l'appel système « fork ». Le processus principal du service est créé avec le PID spécifié dans path_to_pidfile. D'autres types de démarrage se trouvent dans la Tableau 9.10, « Options importantes de la section [Service] ».WantedByfait état de la cible ou des cibles sous laquelle ou sous lesquelles le service devrait être lancé. Ces cibles peuvent être vues comme remplaçant l'ancien concept des niveaux d'exécution, veuillez consulter la Section 9.3, « Travailler avec des cibles Systemd » pour obtenir des détails supplémentaires.
- Notifier systemd qu'un nouveau fichier
name.serviceexiste en exécutant la commande suivante en tant qu'utilisateurroot:systemctl daemon-reload systemctl start name.service
systemctl daemon-reload systemctl start name.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow Avertissement
Exécutez la commandesystemctl daemon-reloadà chaque fois que vous créez des nouveaux fichiers d'unités ou lorsque vous modifiez des fichiers d'unités existants. Sinon, les commandessystemctl startousystemctl enablepeuvent échouer à cause d'une mauvaise correspondance entre les états de systemd et les fichiers d'unités de service qui se trouvent sur le disque.L'unité name.service peut désormais être gérée comme tout autre service système par des commandes décrites dans la Section 9.2, « Gérer les services système ».
Exemple 9.18. Créer le fichier emacs.service
- Créez un fichier d'unité dans le répertoire
/etc/systemd/system/et assurez-vous qu'il possède les permissions de fichier correctes. Veuillez exécuter en tant qu'utilisateurroot:touch /etc/systemd/system/emacs.service chmod 664 /etc/systemd/system/emacs.service
~]# touch /etc/systemd/system/emacs.service ~]# chmod 664 /etc/systemd/system/emacs.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Ajouter le contenu suivant au fichier de configuration :
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Avec la configuration ci-dessus, l'exécutable/usr/bin/emacsest lancé en mode démon pendant le démarrage du service. La variable d'environnement SSH_AUTH_SOCK est paramétrée en utilisant le spécificateur d'unité « %t » qui correspond au répertoire du runtime. Le service redémarre également le processus Emacs s'il s'arrête de manière inattendue. - Veuillez exécuter les commandes suivantes pour recharger la configuration et lancer le service personnalisé :
systemctl daemon-reload systemctl start emacs.service
~]# systemctl daemon-reload ~]# systemctl start emacs.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
systemctl standard. Ainsi, exécutez systemctl status emacs pour afficher le statut de l'éditeur ou systemctl enable emacs pour le lancer automatiquement pendant le démarrage système.
Exemple 9.19. Création d'une seconde instance du service sshd
sshd :
- Veuillez créer une copie du fichier
sshd_configqui sera utilisée par le second démon :cp /etc/ssh/sshd{,-second}_config~]# cp /etc/ssh/sshd{,-second}_configCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Veuillez modifier le fichier
sshd-second_configcréé dans l'étape précédente pour assigner un numéro de port différent et un fichier PID au second démon :Port 22220 PidFile /var/run/sshd-second.pid
Port 22220 PidFile /var/run/sshd-second.pidCopy to Clipboard Copied! Toggle word wrap Toggle overflow Veuillez consulter la page man desshd_config(5) pour obtenir plus d'informations sur les optionsPortetPidFile. Assurez-vous que le port choisi n'est pas en cours d'utilisation par un autre service. Le fichier PID ne doit pas forcément exister avant l'exécution du service, il est généré automatiquement lors du démarrage du service. - Veuillez créer une copie du fichier d'unité systemd pour le service
sshd.cp /usr/lib/systemd/system/sshd.service /etc/systemd/system/sshd-second.service
~]# cp /usr/lib/systemd/system/sshd.service /etc/systemd/system/sshd-second.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Veuillez altérer le fichier
sshd-second.servicecréé pendant l'étape précédente comme suit:- Modifiez l'option
Description:Description=OpenSSH server second instance daemon
Description=OpenSSH server second instance daemonCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Veuillez ajouter sshd.service aux services spécifiés dans l'option
After, afin que la seconde instance soit lancée uniquement après le lancement de la première :After=syslog.target network.target auditd.service sshd.service
After=syslog.target network.target auditd.service sshd.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow - La première instance de sshd inclut la génération de clés, veuillez donc supprimer la ligne ExecStartPre=/usr/sbin/sshd-keygen.
- Ajoutez le paramètre
-f /etc/ssh/sshd-second_configà la commandesshdafin que le fichier de configuration alternatif soit utilisé :ExecStart=/usr/sbin/sshd -D -f /etc/ssh/sshd-second_config $OPTIONS
ExecStart=/usr/sbin/sshd -D -f /etc/ssh/sshd-second_config $OPTIONSCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Après les modifications indiquées ci-dessus, le fichier sshd-second.service devrait ressembler à ce qui suit :
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- Si vous utilisez SELinux, veuillez ajouter le port pour la seconde instance de sshd sur les ports SSH, sinon la seconde instance de sshd sera rejetée pour lier le port :
semanage port -a -t ssh_port_t -p tcp 22220
~]# semanage port -a -t ssh_port_t -p tcp 22220Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Veuillez activer sshd-second.service, afin qu'il soit lancé automatiquement pendant le démarrage :
systemctl enable sshd-second.service
~]# systemctl enable sshd-second.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow Vérifiez si sshd-second.service est en cours d'utilisation par la commandesystemctl status. Veuillez également vérifier si le port est activé correctement en effectuant une connexion au service :ssh -p 22220 user@server
~]$ ssh -p 22220 user@serverCopy to Clipboard Copied! Toggle word wrap Toggle overflow Si le pare-feu est en cours d'utilisation, veuillez vous assurer qu'il soit correctement configuré de manière à permettre des connexions à la seconde instance de sshd.
9.6.3. Convertir des scripts init SysV en fichiers d'unité
postfix sur Red Hat Enterprise Linux 6 :
Trouver la description du service
Description de la section [Unit] du fichier d'unité. L'en-tête LSB peut contenir des données similaires sur les lignes #Short-Description et #Description.
Trouver les dépendances de service
| Option LSB | Description | Équivalent de fichier d'unité |
|---|---|---|
Provides | Spécifie le nom de l'installation de démarrage du service, à qui il peut être fait référence dans d'autres scripts init (avec le préfixe « $ »). Ceci n'est plus nécessaire car les fichiers d'unité font référence aux autres unités par leur nom de fichier. | – |
Required-Start | Contient les noms des installations de démarrage des services requis. Ceci se traduit par une dépendance d'ordre, les noms d'installations de démarrage sont remplacés par les noms des fichiers d'unité des services correspondants ou les cibles auxquelles ils appartiennent. Par exemple, dans le cas de postfix, la dépendance « Required-Start » sur « $network » a été traduite sur la dépendance « After » sur « network.target ». | After, Before |
Should-Start | Constitue des dépendances plus faibles que Required-Start. Les dépendances Should-Start échouées n'affecteront pas le démarrage du service. | After, Before |
Required-Stop, Should-Stop | Constitue des dépendances négatives. | Conflicts |
Trouver les cibles par défaut du service
WantedBy de la section [Install] du fichier d'unité. Par exemple, postfix avait auparavant été lancé dans les niveaux d'exécution 2, 3, 4, et 5, qui se traduisent par multi-user.target et graphical.target dans Red Hat Enterprise Linux 7. Veuillez remarquer que graphical.target dépend de multiuser.target, donc il n'est pas nécessaire de spécifier les deux, comme dans l'Exemple 9.17, « Fichier d'unité postfix.service ». Vous trouverez également des informations sur les niveaux d'exécution par défaut et interdits dans les lignes #Default-Start et #Default-Stop de l'en-tête LSB.
Trouver les fichiers utilisés par le service
EnvironmentFile. Le fichier PID spécifié sur la ligne du script init #pidfile est importé sur le fichier d'unité avec l'option PIDFile.
postfix affiche le bloc de code à exécuter lors du lancement du service.
conf_check() et make_aliasesdb(), qui sont appelées à partir du bloc de la fonction start(). En examinant cela de plus près, plusieurs fichiers externes et plusieurs répertoires sont mentionnés dans le code ci-dessus : l'exécutable du service principal, /usr/sbin/postfix, les répertoires de configuration/etc/postfix/ et /var/spool/postfix/, ainsi que le répertoire /usr/sbin/postconf/.
ExecStart, ExecStartPre, ExecStartPost, ExecStop, et ExecReload. Dans le cas de postfix dans Red Hat Enterprise Linux 7, /usr/sbin/postfix accompagné de scripts pris en charge sont exécutés pendant le lancement du service. Veuillez consulter le fichier d'unité postfix dans l'Exemple 9.17, « Fichier d'unité postfix.service ».
9.6.4. Modifier les fichiers d'unité existants
/usr/lib/systemd/system/. Les administrateurs systèmes ne doivent pas modifier ces fichiers directement, ainsi toute personnalisation doit être confinée aux fichiers de configuration dans le répertoire /etc/systemd/system/. Veuillez choisir l'une des approches suivantes, en fonction de l'étendue des changements requis :
- Veuillez créer un répertoire pour les fichiers de configuration supplémentaires dans
/etc/systemd/system/unit.d/. Cette méthode est recommandée pour la plupart des cas d'utilisation. Elle permet d'étendre la configuration par défaut avec des fonctionnalités supplémentaires, tout en continuant à faire référence au fichier d'unité d'origine. Les changements apportés à l'unité par défaut qui ont eu lieu lors d'une mise à niveau de paquet(s) sont ainsi appliqués automatiquement. Veuillez consulter la section intitulée « Étendre la configuration de l'unité par défaut » pour obtenir davantage d'informations. - Veuillez créer une copie du fichier d'unité d'origine
/usr/lib/systemd/system/dans/etc/systemd/system/et effectuez-y les changements souhaités. La copie remplace le fichier d'origine, donc les changement introduits par la mise à jour du paquet ne sont pas appliqués. Cette méthode est utile pour effectuer des changements significatifs qui devront être persistants, quelles que soient les mises à jour de paquets se produisant. Veuillez consulter la section intitulée « Remplacer la configuration de l'unité par défaut » pour obtenir des détails.
/etc/systemd/system/. Pour appliquer les changements aux fichiers d'unité sans redémarrer le système, veuillez exécuter :
systemctl daemon-reload
systemctl daemon-reloaddaemon-reload recharge tous les fichiers d'unité et recrée la totalité de l'arbre de dépendances, ce qui est nécessaire pour appliquer immédiatement tout changement sur un fichier d'unité. Alternativement, le même résultat peut être atteint à l'aide de la commande suivante :
init q
init qsystemctl restart name.service
systemctl restart name.serviceÉtendre la configuration de l'unité par défaut
/etc/systemd/system/. Si vous étendez une unité de service, veuillez exécuter la commande suivante en tant qu'utilisateur root :
mkdir /etc/systemd/system/name.service.d/
mkdir /etc/systemd/system/name.service.d/touch /etc/systemd/system/name.service.d/config_name.conf
touch /etc/systemd/system/name.service.d/config_name.conf[Unit] Requires=new_dependency After=new_dependency
[Unit]
Requires=new_dependency
After=new_dependency[Service] Restart=always RestartSec=30
[Service]
Restart=always
RestartSec=30root :
systemctl daemon-reload systemctl restart name.service
systemctl daemon-reload
systemctl restart name.serviceExemple 9.20. Étendre la configuration httpd.service
mkdir /etc/systemd/system/httpd.service.d/ touch /etc/systemd/system/httpd.service.d/custom_script.conf
~]# mkdir /etc/systemd/system/httpd.service.d/
~]# touch /etc/systemd/system/httpd.service.d/custom_script.conf/usr/local/bin/custom.sh, veuillez insérer le texte suivant dans le fichier custom_script.conf :
[Service] ExecStartPost=/usr/local/bin/custom.sh
[Service]
ExecStartPost=/usr/local/bin/custom.sh
systemctl daemon-reload systemctl restart httpd.service
~]# systemctl daemon-reload
~]# systemctl restart httpd.serviceNote
/etc/systemd/system/ ont priorité sur les fichiers d'unité dans /usr/lib/systemd/system/. Ainsi, si les fichiers de configuration contiennent une option qui peut être spécifiée une seule fois, comme Description ou ExecStart, la valeur par défaut de cette option sera remplacée. Remarquez que dans la sortie de la commande systemd-delta décrite dans la section intitulée « Surveiller les unités remplacées », de telles unités sont toujours marquées comme [EXTENDED], même si au total, certaines options sont remplacées.
Remplacer la configuration de l'unité par défaut
/etc/systemd/system/. Pour cela, veuillez exécuter la commande suivante en tant qu'utilisateur root :
cp /usr/lib/systemd/system/name.service /etc/systemd/system/name.service
cp /usr/lib/systemd/system/name.service /etc/systemd/system/name.serviceroot :
systemctl daemon-reload systemctl restart name.service
systemctl daemon-reload
systemctl restart name.serviceExemple 9.21. Modifier la limite du délai d'attente
/etc/systemd/system/network.service.d/timeout.conf et ajouter une ligne à la nouvelle configuration à ce endroit. La commande systemctl show network -p TimeoutStartUSec affichera le délai d’attente actuel maximum. Après avoir changé la limite à 10 secondes, comme dans l’exemple ci-dessous, pensez à redémarrer systemd avec systemctl daemon-reload pour que les modifications puissent entrer en vigueur :
Surveiller les unités remplacées
systemd-delta
systemd-deltasystemd-delta. Remarquez que si un fichier est remplacé, systemd-delta affiche par défaut un sommaire des changements similaires à la sortie de la commande diff.
| Type | Description |
|---|---|
|
[MASKED]
|
Fichiers d'unités masqués, veuillez consulter la Section 9.2.7, « Désactiver un service » pour une description du masquage d'unité.
|
|
[EQUIVALENT]
|
Copies non modifiées qui remplacent les fichiers d'origine mais dont le contenu, typiquement les liens symboliques, ne diffère pas.
|
|
[REDIRECTED]
|
Fichiers redirigés vers d'autres fichiers.
|
|
[OVERRIDEN]
|
Fichiers remplacés et modifiés.
|
|
[EXTENDED]
|
Fichiers étendus avec les fichiers .conf dans le répertoire
/etc/systemd/system/unit.d/.
|
|
[UNCHANGED]
|
Fichiers non modifiés, uniquement affichés lorsque l'option
--type=unchanged est utilisée.
|
systemd-delta après une mise à jour système pour vérifier si des mises à jour d'unités par défaut sont actuellement remplacées par une configuration personnalisée. Il est également possible de limiter la sortie à un certain type de différence uniquement. Par exemple, pour uniquement afficher les unités remplacées, veuillez exécuter :
systemd-delta --type=overridden
systemd-delta --type=overridden9.6.5. Travailler avec des unités instanciées
Requires ou Wants), ou par la commande systemctl start. Les unités de service instanciées sont nommées comme suit.
template_name@instance_name.service
template_name@instance_name.serviceunit_name@.service
unit_name@.serviceWants suivant dans un fichier d'unité :
Wants=getty@ttyA.service,getty@ttyB.service
Wants=getty@ttyA.service,getty@ttyB.servicegetty@.service, lira la configuration à partir de celui-ci, et lancera les services.
| Spécificateur d'unité | Signification | Description |
|---|---|---|
%n | Nom d'unité complet | Correspond au nom d'unité complet, y compris le suffixe du type. %N possède la même signification mais remplace également les caractères interdits avec les codes ASCII. |
%p | Nom du préfixe | Correspond à un nom d'unité avec le suffixe de type supprimé. Pour les unités instanciées, %p correspond à la partie du nom de l'unité avant le caractère « @ ». |
%i | Nom d'instance | Il s'agit de la partie du nom d'unité instanciée entre le caractère « @ » et le suffixe du type. %I possède la même signification mais remplace également les caractères interdits par des codes ASCII. |
%H | Nom d'hôte | Correspond au nom d'hôte du système en cours d'exécution au moment où la configuration de l'unité est chargée. |
%t | Répertoire du runtime | Représente le répertoire du runtime, qui est /run pour l'utilisateur root, ou la valeur de la variable XDG_RUNTIME_DIR pour les utilisateur non-privilégiés. |
systemd.unit(5).
getty@.service contient les directives suivante :
Description= est résolu en tant que Getty on ttyA et Getty on ttyB.
9.7. Ressources supplémentaires
Documentation installée
systemctl(1) — la page du manuel de l'utilitaire de ligne de commandesystemctlfournit une liste complète des options et des commandes prises en charge.systemd(1) — la page du manuel du gestionnaire de systèmes et servicessystemdfournit davantage d'informations sur ses concepts et documente les options de ligne de commande et les variables d'environnement disponibles, les fichiers de configuration et répertoires pris en charge, les signaux reconnus, ainsi que les options de noyau disponibles.systemd-delta(1) — la page du manuel de l'utilitairesystemd-deltaqui permet de trouver des fichiers de configuration étendus et remplacés.systemd.unit(5) — la page du manuel nomméesystemd.unitfournit des informations détaillées sur les fichiers d'unité systemd et documente toutes les options de configuration disponibles.systemd.service(5) — la page du manuel nomméesystemd.servicedocumente le format des fichiers d'unité de service.systemd.target(5) — la page du manuel nomméesystemd.targetdocumente le format des fichiers d'unité cibles.systemd.kill(5) — la page du manuel nomméesystemd.killdocumente la configuration de la procédure de fermeture de processus (« process killing »).
Documentation en ligne
- Guide de mise en réseau Red Hat Enterprise Linux 7 — le Guide de mise en réseau de Red Hat Enterprise Linux 7 documente les informations pertinentes à la configuration et à l'administration des interfaces réseau et des services réseau sur ce système. Il fournit une introduction à l'utilitaire
hostnamectlet explique comment l'utiliser pour afficher et définir des noms d'hôtes sur la ligne de commande localement et à distance, et fournit des informations importantes sur la sélection des noms d'hôte et des noms de domaines - Guide de migration et d'administration de bureau Red Hat Enterprise Linux 7 — le Guide de migration et d'administration de bureau de Red Hat Enterprise Linux 7 documente la planification de la migration, le déploiement, la configuration, et l'administration du bureau GNOME 3 sur ce système. Le service
logindy est également présenté, ses fonctionnalités les plus importantes sont énumérées, et la manière d'utiliser l'utilitaireloginctlpour répertorier les sessions actives et activer la prise en charge « multi-seat » est expliquée. - Guide de l'utilisateur et de l'administrateur SELinux Red Hat Enterprise Linux 7 — le Guide de l'utilisateur et de l'administrateur SELinux Red Hat Enterprise Linux 7 décrit les principes de base de SELinux et documente en détails comment configurer et utiliser SELinux avec divers services, tels que Apache HTTP Server, Postfix, PostgreSQL, ou OpenShift. Celui-ci explique comment configurer les permissions d'accès SELinux pour les services système gérés par systemd.
- Guide d'installation Red Hat Enterprise Linux 7 — le Guide d'installation de Red Hat Enterprise Linux 7 documente comment installer le système d'exploitation sur des systèmes AMD64 et Intel 64, sur des serveurs IBM Power Systems 64 bits, ainsi que sur IBM System z. Il couvre également des méthodes d'installation avancées telles que les installations Kickstart, PXE, et les installations au moyen du protocole VNC. En outre, ce manuel décrit les tâches post-installation communes et explique comment résoudre les problèmes d'installation, il comprend également des instructions détaillées sur la manière de démarrer en mode de secours ou de récupérer le mot de passe root.
- Guide de sécurité Red Hat Enterprise Linux 7 — le Guide de sécurité Red Hat Enterprise Linux 7 assiste les utilisateurs et les administrateurs dans leur apprentissage des processus et pratiques de sécurisation de leurs stations de travail et serveurs envers des intrusions locales et distantes, des exploitations, et autres activités malicieuses. Celui-ci explique également comment sécuriser des services de système critiques.
- Page d'accueil systemd — la page d'accueil du projet fournit davantage d'informations sur systemd.
Voir aussi
- Le Chapitre 1, Paramètres régionaux et configuration du clavier documente comment gérer les paramètres régionaux du système et les structures du clavier. Il explique également comment utiliser l'utilitaire
localectlpour afficher les paramètres régionaux actuels sur la ligne de commande, pour répertorier les paramètres régionaux disponibles, et les définir sur la ligne de commande, ainsi que pour afficher la structure actuelle du clavier, répertorier les dispositions claviers, et activer une disposition clavier particulière sur la ligne de commande. - Le Chapitre 2, Configurer l'heure et la date documente comment gérer la date et l'heure du système. Il explique les différences entre une horloge temps réel et une horloge système, et décrit comment utiliser l'utilitaire
timedatectlpour afficher les paramètres actuels de l'hologe système, configurer l'heure et la date, changer de fuseau horaires, et pour synchroniser l'horloge système avec un serveur distant. - Le Chapitre 5, Obtention de privilèges documente comment obtenir des privilèges administratifs en utilisant les commandes
suetsudo. - Le Chapitre 10, OpenSSH décrit comment configurer un serveur SSH et comment utiliser les utilitaires client
ssh,scp, etsftppour y accéder. - Le Chapitre 20, Afficher et gérer des fichiers journaux fournit une introduction à journald. Il décrit le journal, introduit le service
journald, et documente comment utiliser l'utilitairejournalctlpour afficher les entrées de journal, entrer en mode d'affichage en direct, et filtrer les entrées du journal. En outre, ce chapitre décrit comment autoriser les utilisateurs non root d'accéder aux journaux du système et comment activer le stockage persistant des fichiers journaux.
Chapitre 10. OpenSSH
SSH (Secure Shell) est un protocole qui facilite les communications sécurisées entre deux systèmes en utilisant une architecture client-serveur, et qui permet aux utilisateurs de se connecter à des systèmes hôtes de serveur à distance. À la différence d'autres protocoles de communication à distance tels que FTP ou Telnet, SSH codifie la session de connexion, ce qui la rend difficile d'accès aux intrus qui souhaiteraient récupérer les mots de passe.
telnet ou rsh. Un programme connexe appelé scp remplace les anciens programmes conçus pour copier des fichiers entre les ordinateurs hôtes, comme rcp. Comme ces applications plus anciennes ne cryptent pas les mots de passe qui sont transmis entre le client et le serveur, évitez-les autant que possible. En utilisant des méthodes sûres pour vous connecter à des systèmes distants, vous diminuez les risques pour le système client et l'hôte distant à la fois.
10.1. Le protocole SSH
10.1.1. Pourquoi utiliser SSH ?
- Interception de communication entre deux systèmes
- L'attaquant peut être quelque part sur le réseau entre les parties communicantes, copiant des informations passées entre elles. Il peut intercepter et maintenir l'information, ou la modifier et l'envoyer à des destinataires designés.Cette attaque est généralement réalisée à l'aide d'un renifleur de paquets (packet sniffer), un utilitaire de réseau plutôt commun, qui capte chaque paquet qui passe à travers le réseau et qui en analyse le contenu.
- Emprunt d’identité d'un hôte particulier
- Le système de l'attaquant est configuré pour se poser en tant que destinataire d'une transmission. Si cette stratégie fonctionne, le système de l'utilisateur ne sait pas qu'il communique avec le mauvais hôte.Cette attaque peut être effectuée par une technique appelée un empoisonnement DNS, ou via ce que l'on appelle une usurpation d'adresse IP. Dans le premier cas, l'intrus utilise un serveur DNS qui aura failli dans le but de pointer les systèmes client à un hôte qui aura été malicieusement dupliqué. Dans le second cas, l'intrus envoie des paquets réseau falsifiés qui semblent provenir d'un hôte de confiance.
10.1.2. Fonctionnalités principales
- Personne ne peut se faire passer pour un serveur intentionnel
- Après avoir effectué une connexion initiale, le client peut s'assurer que sa connexion est établie avec le même serveur que lors de sa session précédente.
- Personne ne peut récupérer les données d'authentification
- Le client transmet ses données d'authentification au serveur au moyen d'un chiffrement solide de 128 bits.
- Personne ne peut intercepter la communication
- Toutes les données envoyées et reçues lors d'une session sont transférées au moyen d'un chiffrement 128 bits, rendant ainsi le déchiffrement et la lecture de toute transmission interceptée extrêmement difficile.
- Il fournit des moyens sûrs d'utiliser les applications graphiques par l'intermédiaire d'un réseau.
- En utilisant une technique appelée X11 forwarding, le client peut envoyer des applications X11 (X Window System) en partance du serveur.
- Cela fournit un moyen de sécuriser des protocoles non sécurisés normalement
- Le protocole SSH crypte tout ce qu'il envoie et reçoit. En utilisant une technique appelée port forwarding, un serveur SSH peut devenir un moyen de sécuriser des protocoles normalement non protégés, comme POP, tout en augementant la sécurité des données et du système en général.
- Il peut être utilisé pour créer un canal sécurisé
- Le serveur OpenSSH et le client peuvent être configurés afin de créer un tunnel semblable à un réseau virtuel privé pour permettre le trafic entre le serveur et les machines clientes.
- Il prend en charge l'authentification Kerberos
- Les clients et serveurs OpenSSH peuvent être configurés pour authentifier par l'interface GSSAPI (Generic Security Services Application Program Interface) du protocole d'authentification du réseau Kerberos.
10.1.3. Versions de protocole
Important
10.1.4. Séquence d'événements d'une connexion SSH
- Une liaison cryptographique est établie afin de permettre au client de vérifier qu'il est bien en communication avec le serveur souhaité.
- La couche de transport de la connexion entre le client et tout hôte distant est chiffrée au moyen d'un moyen de chiffrement symétrique.
- Le client s'authentifie auprès du serveur.
- Le client peut interagir avec l'hôte distant au moyen d'une connexion chiffrée.
10.1.4.1. Couche de transport
- Des clés sont échangées.
- L'algorithme de chiffrement de clés publiques est déterminé
- L'algorithme de chiffrement symétrique est déterminé
- L'algorithme d'authentification de message est déterminé
- L'algorithme de hachage est déterminé
Avertissement
10.1.4.2. Authentification
10.1.4.3. Canaux
10.2. Configuration d'OpenSSH
10.2.1. Fichiers de configuration
ssh, scp, et sftp), et pour les serveurs (le démon sshd).
/etc/ssh/ comme décrit dans Tableau 10.1, « Fichiers de configuration du système dans son ensemble ». Les informations de configuration spécifiques à l'utilisateur SSH sont stockées dans ~/.ssh/ dans le répertoire d'accueil de l'utilisateur, comme décrit dans Tableau 10.2, « Fichiers de configuration spécifiques à l'utilisateur ».
| Fichier | Description |
|---|---|
/etc/ssh/moduli | Contient les groupes Diffie-Hellman utilisés pour l'échange de clés Diffie-Hellman, ce qui est essentiel pour la création d'une couche de transport sécurisé. Lorsque les clés sont échangées au début d'une session SSH, une valeur partagée, secrète est alors créée ne pouvant être déterminée par l'une des parties seule. Cette valeur est ensuite utilisée pour fournir une authentification de l'hôte. |
/etc/ssh/ssh_config | Le fichier de configuration du client SSH par défaut. Notez qu'il sera remplacé par ~/.ssh/config si ce fichier existe. |
/etc/ssh/sshd_config | Le fichier de configuration du démon sshd. |
/etc/ssh/ssh_host_ecdsa_key | La clé ECDSA privée utilisée par le démon sshd. |
/etc/ssh/ssh_host_ecdsa_key.pub | La clé ECDSA publique utilisée par le démon sshd. |
/etc/ssh/ssh_host_key | La clé privée RSA utilisée par le démon sshd pour la version 1 du protocole SSH. |
/etc/ssh/ssh_host_key.pub | La clé publique RSA utilisée par le démon sshd pour la version 1 du protocole SSH. |
/etc/ssh/ssh_host_rsa_key | La clé privée RSA utilisée par le démon sshd pour la version 2 du protocole SSH. |
/etc/ssh/ssh_host_rsa_key.pub | La clé publique RSA utilisée par le démon sshd pour la version 2 du protocole SSH. |
/etc/pam.d/sshd | Le fichier de configuration AM du démon sshd. |
/etc/sysconfig/sshd | Fichier de configuration du service sshd. |
| Fichier | Description |
|---|---|
~/.ssh/authorized_keys | Contient une liste des clés publiques autorisées pour les serveurs. Quand le client se connecte à un serveur, le serveur authentifie le client en vérifiant sa clé publique stockée dans ce fichier. |
~/.ssh/id_ecdsa | Contient la clé privée ECDSA de l'utilisateur |
~/.ssh/id_ecdsa.pub | Le clé publique de l'utilisateur. |
~/.ssh/id_rsa | La clé privée RSA utilisée par ssh pour la version 2 du protocole SSH. |
~/.ssh/id_rsa.pub | La clé publique RSA utilisée par ssh pour la version 2 du protocole SSH. |
~/.ssh/identity | La clé privée RSA utilisée par ssh pour la version 1 du protocole SSH. |
~/.ssh/identity.pub | La clé publique RSA utilisée par ssh pour la version 1 du protocole SSH. |
~/.ssh/known_hosts | Contient les clés hôtes des serveurs SSH auquels l'utilisateur a accès. Ce fichier est important pour s'assurer que le client SSH est connecté au bon serveur SSH. |
ssh_config(5) et sshd_config(5).
10.2.2. Démarrage d'un serveur OpenSSH
sshd dans la session actuelle, veuillez saisir ce qui suit dans l'invite de shell en tant qu'utilisateur root :
systemctl start sshd.service
~]# systemctl start sshd.servicesshd dans la session actuelle, veuillez saisir ce qui suit dans l'invite de shell en tant qu'utilisateur root :
systemctl stop sshd.service
~]# systemctl stop sshd.serviceroot:
systemctl enable sshd.service Created symlink from /etc/systemd/system/multi-user.target.wants/sshd.service to /usr/lib/systemd/system/sshd.service.
~]# systemctl enable sshd.service
Created symlink from /etc/systemd/system/multi-user.target.wants/sshd.service to /usr/lib/systemd/system/sshd.service.sshd dépend de l’unité cible network.target, ce qui suffit pour les interfaces réseau configuré statique et pour les options par défaut ListenAddress 0.0.0.0. Pour spécifier des adresses différentes dans la directive ListenAddress et utiliser une configuration de réseau dynamique plus lente, ajouter la dépendance sur l’unité cible de network-online.target dans le fichier d'unité de sshd.service. Pour ce faire, créez le fichier /etc/systemd/system/sshd.service.d/local.conf avec les options suivantes :
[Unit] Wants=network-online.target After=network-online.target
[Unit]
Wants=network-online.target
After=network-online.targetsystemd par la commande suivante :
systemctl daemon-reload
~]# systemctl daemon-reload/etc/ssh/. Voir Tableau 10.1, « Fichiers de configuration du système dans son ensemble » pour une liste complète, et restaurez les fichiers à chaque fois que vous réinstallez le système.
10.2.3. Utilisation nécessaire de SSH pour les connexions à distance
telnet, rsh, rlogin et vsftpd.
vsftpd, voir Section 14.2, « FTP ». Pour savoir comment gérer les services système, consulter Chapitre 9, Gérer les services avec systemd.
10.2.4. Authentification basée clés
/etc/ssh/sshd_config dans un éditeur de texte comme vi ou nano et modifiez l'option PasswordAuthentication comme suit :
PasswordAuthentication no
PasswordAuthentication noPubkeyAuthentication no n'ait pas été défini. Si connecté à distance, ne pas utiliser l'accès console ou out-of-band, il est conseillé de tester le processus de journalisation basé clé avant de désactiver l'authentification de mot de passe.
ssh, scp, ou sftp pour se connecter au serveur à partir d'une machine client, créer une paire de clé d'autorisation en suivant les étapes suivantes. Notez que les clés doivent être créées séparemment pour chaque utilisateur.
Important
root, seul root pourra utiliser les clés.
Note
~/.ssh/. Après avoir réinstallé, recopiez-le sur votre répertoire personnel. Ce processus peut être fait pour tous les utilisateurs sur votre système, y compris l'utilisateur root.
10.2.4.1. Création de paires de clés
- La mise à jour d'un paquet est semblable à son installation. Saisir la commande suivante à l'invite du shell :
ssh-keygen -t rsa Création de la paire de clés publique/privée. Saisir le fichier dans lequel sauvegarder la clé (/home/USER/.ssh/id_rsa):
~]$ ssh-keygen -t rsa Création de la paire de clés publique/privée. Saisir le fichier dans lequel sauvegarder la clé (/home/USER/.ssh/id_rsa):Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Appuyer sur la touche Entrée pour confirmer le chemin d'accès par défaut ,
~/.ssh/id_rsa, pour la clé nouvellement créée. - Saisissez une phrase de passe, et confirmez-là en la saisissant à nouveau quand on vous le demande. Pour des raisons de sécurité, évitez d'utiliser le même mot de passe que celui que vous aurez utilisé quand vous vous êtes connecté à votre compte.Après cela, vous verrez un message semblable à celui-ci :
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Par défaut, les permissions du répertoire
~/.ssh/sont définies àrwx------ou700exprimées en notation octale. Ceci est pour s'assurer que l'utilisateur USER puisse voir les contenus. Si cela est nécessaire, on peut le confirmer par la commande suivante :ls -ld ~/.ssh drwx------. 2 USER USER 54 Nov 25 16:56 /home/USER/.ssh/
~]$ ls -ld ~/.ssh drwx------. 2 USER USER 54 Nov 25 16:56 /home/USER/.ssh/Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour copier une clé publique dans une machine distante, lancer la commande dans le format suivant :Cela aura pour effet de copier la clé publique
ssh-copy-id user@hostname
ssh-copy-id user@hostnameCopy to Clipboard Copied! Toggle word wrap Toggle overflow ~/.ssh/id*.pubqui a été modifiée le plus récemment si elle n'a pas encore été installée. Sinon, indiquer le nom du fichier de clés publiques comme suit :Cela aura pour effet de copier le contenu dessh-copy-id -i ~/.ssh/id_rsa.pub user@hostname
ssh-copy-id -i ~/.ssh/id_rsa.pub user@hostnameCopy to Clipboard Copied! Toggle word wrap Toggle overflow ~/.ssh/id_rsa.pubdans le fichier~/.ssh/authorized_keysde la machine sur laquelle vous souhaitez vous connecter. Si le fichier existe déjà, les clés y seront ajoutées.
- Pour créer une paire de clés ECDSA, saisir la commande suivante à l'invite du shell :
ssh-keygen -t ecdsa Créer une paire de clés publique/privée ecdsa. Saisir le fichier dans lequel vous souhaitez sauvegarder la clé (/home/USER/.ssh/id_ecdsa):
~]$ ssh-keygen -t ecdsa Créer une paire de clés publique/privée ecdsa. Saisir le fichier dans lequel vous souhaitez sauvegarder la clé (/home/USER/.ssh/id_ecdsa):Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Appuyer sur la touche Entrée pour confirmer le chemin d'accès par défaut ,
~/.ssh/id_ecdsa, pour la clé nouvellement créée. - Saisissez une phrase de passe, et confirmez-là en la saisissant à nouveau quand on vous le demande. Pour des raisons de sécurité, évitez d'utiliser le même mot de passe que celui que vous aurez utilisé quand vous vous êtes connecté à votre compte.Après cela, vous verrez un message semblable à celui-ci :
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Par défaut, les permissions du répertoire
~/.ssh/sont définies àrwx------ou700exprimées en notation octale. Ceci est pour s'assurer que l'utilisateur USER puisse voir les contenus. Si cela est nécessaire, on peut le confirmer par la commande suivante :ls -ld ~/.ssh ~]$ ls -ld ~/.ssh/ drwx------. 2 USER USER 54 Nov 25 16:56 /home/USER/.ssh/~]$ ls -ld ~/.ssh ~]$ ls -ld ~/.ssh/ drwx------. 2 USER USER 54 Nov 25 16:56 /home/USER/.ssh/Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour copier une clé publique dans une machine distante, lancer la commande sous le format suivant :Cela aura pour effet de copier la clé publique
ssh-copy-id USER@hostname
ssh-copy-id USER@hostnameCopy to Clipboard Copied! Toggle word wrap Toggle overflow ~/.ssh/id*.pubqui a été modifiée le plus récemment si elle n'a pas encore été installée. Sinon, indiquer le nom du fichier de clés publiques comme suit :Cela aura pour effet de copier le contenu dessh-copy-id -i ~/.ssh/id_ecdsa.pub USER@hostname
ssh-copy-id -i ~/.ssh/id_ecdsa.pub USER@hostnameCopy to Clipboard Copied! Toggle word wrap Toggle overflow ~/.ssh/id_ecdsa.pubdans le fichier~/.ssh/authorized_keysde la machine sur laquelle vous souhaitez vous connecter. Si le fichier existe déjà, les clés y seront ajoutées.
Important
10.2.4.2. Configurer les partages Samba
ssh-agent. Si vous utilisez GNOME, vous pouvez la configurer pour qu'elle vous demande votre mot de passe chaque fois que vous ouvrez une session et pour qu'elle s'en souvienne tout au cours de la session. Sinon, vous pouvez stocker la phrase de passe pour une invite du shell en particulier.
- Assurez-vous de bien avoir le paquet openssh-askpass installé. Sinon, voir Section 8.2.4, « Installation de paquets » pour obtenir plus d'informations sur la façon d'installer de nouveaux paquets dans Red Hat Enterprise Linux.
- Appuyez sur la touche Super pour entrer dans la vue d'ensemble des activités, tapez
Startup Applicationset appuyez sur Entrée. L'outil Startup Applications Preferences s'affiche. L'onglet contenant une liste de programmes de démarrage disponibles s'affichera par défaut. La touche Super apparait dans une variété de formes, selon le clavier et autre matériel, mais souvent en tant que touche Commande ou Windows, généralement à gauche de la barre d'espace.
Figure 10.1. Préférences des applications au démarrage
- Cliquer sur le bouton à droite, et saisir
/usr/bin/ssh-adddans le champ Command.
Figure 10.2. Ajouter une nouvelle application
- Cliquer sur et vérifiez que la case qui se trouve à côté de l'élément qui vient d'être ajouté est sélectionnée.

Figure 10.3. Activer l'application
- Déconnecter et reconnecter. Une boîte de dialogue apparaîtra pour vous demander de mettre votre phrase de passe. À partir de ce moment, vous ne devriez pas être sollicité de donner un mot de passe par les commandes
ssh,scp, ousftp.
Figure 10.4. Saisir une phrase de passe
ssh-add Saisir la phrase de passe pour /home/USER/.ssh/id_rsa :
~]$ ssh-add
Saisir la phrase de passe pour /home/USER/.ssh/id_rsa :10.3. Clients OpenSSH
10.3.1. Comment se servir de l'utilitaire ssh
ssh vous permet de vous connecter à une machine distante et à y exécuter des commandes à cet endroit. Cela remplace les programmes rlogin, rsh, et telnet.
telnet, connectez-vous à une machine distante par la commande suivante :
ssh hostname
ssh hostnamepenguin.example.com, saisir ce qui suit quand on vous y invite :
ssh penguin.example.com
~]$ ssh penguin.example.comssh username@hostname
ssh username@hostnamepenguin.example.com en tant que USER, saisir :
ssh USER@penguin.example.com
~]$ ssh USER@penguin.example.comThe authenticity of host 'penguin.example.com' can't be established. ECDSA key fingerprint is 256 da:24:43:0b:2e:c1:3f:a1:84:13:92:01:52:b4:84:ff. Are you sure you want to continue connecting (yes/no)?
The authenticity of host 'penguin.example.com' can't be established.
ECDSA key fingerprint is 256 da:24:43:0b:2e:c1:3f:a1:84:13:92:01:52:b4:84:ff.
Are you sure you want to continue connecting (yes/no)?ssh-keygen, comme suit :
ssh-keygen -l -f /etc/ssh/ssh_host_ecdsa_key.pub 256 da:24:43:0b:2e:c1:3f:a1:84:13:92:01:52:b4:84:ff (ECDSA)
~]# ssh-keygen -l -f /etc/ssh/ssh_host_ecdsa_key.pub
256 da:24:43:0b:2e:c1:3f:a1:84:13:92:01:52:b4:84:ff (ECDSA)yes pour accepter la clé et confirmer la connexion. Vous verrez une notice apparaître vous indiquant que le serveur a été ajouté à la liste des hôtes connus et une invite vous demandant votre mot de passe :
Warning: Permanently added 'penguin.example.com' (ECDSA) to the list of known hosts. USER@penguin.example.com's password:
Warning: Permanently added 'penguin.example.com' (ECDSA) to the list of known hosts.
USER@penguin.example.com's password:Important
~/.ssh/known_hosts. Avant de procéder, cependant, contactez l'administrateur systèmes du serveur SSH pour vérifier que le serveur n'est pas compromis.
~/.ssh/known_hosts, lancez la commande suivante :
ssh-keygen -R penguin.example.com # Host penguin.example.com found: line 15 type ECDSA /home/USER/.ssh/known_hosts updated. Original contents retained as /home/USER/.ssh/known_hosts.old
~]# ssh-keygen -R penguin.example.com
# Host penguin.example.com found: line 15 type ECDSA
/home/USER/.ssh/known_hosts updated.
Original contents retained as /home/USER/.ssh/known_hosts.oldssh peut être utilisé pour exécuter une commande sur la machine distante sans qu'il soit nécessaire de vous connecter à une invite de shell :
ssh [username@]hostname command
ssh [username@]hostname command/etc/redhat-release vous donne des informations sur la version Red Hat Enterprise Linux. Pour voir le contenu de ce fichier dans penguin.example.com, saisissez :
~]$ ssh USER@penguin.example.com cat /etc/redhat-release USER@penguin.example.com's password: Red Hat Enterprise Linux Server release 7.0 (Maipo)
~]$ ssh USER@penguin.example.com cat /etc/redhat-release
USER@penguin.example.com's password:
Red Hat Enterprise Linux Server release 7.0 (Maipo)10.3.2. rsh
scp peut être utilisée pour transférer des fichers entre des machines à travers une connexion cryptée sécurisée. Le concept ressemble à celui de rcp.
scp localfile username@hostname:remotefile
scp localfile username@hostname:remotefiletaglist.vim vers une machine distante nommée penguin.example.com, saisissez ce qui suit dans l'invite de commande :
scp taglist.vim USER@penguin.example.com:.vim/plugin/taglist.vim USER@penguin.example.com's password: taglist.vim 100% 144KB 144.5KB/s 00:00
~]$ scp taglist.vim USER@penguin.example.com:.vim/plugin/taglist.vim
USER@penguin.example.com's password:
taglist.vim 100% 144KB 144.5KB/s 00:00.vim/plugin/ dans le même répertoire d'une machine distante penguin.example.com, saisissez la commande suivante :
scp .vim/plugin/* USER@penguin.example.com:.vim/plugin/ USER@penguin.example.com's password: closetag.vim 100% 13KB 12.6KB/s 00:00 snippetsEmu.vim 100% 33KB 33.1KB/s 00:00 taglist.vim 100% 144KB 144.5KB/s 00:00
~]$ scp .vim/plugin/* USER@penguin.example.com:.vim/plugin/
USER@penguin.example.com's password:
closetag.vim 100% 13KB 12.6KB/s 00:00
snippetsEmu.vim 100% 33KB 33.1KB/s 00:00
taglist.vim 100% 144KB 144.5KB/s 00:00scp username@hostname:remotefile localfile
scp username@hostname:remotefile localfile.vimrc d'une machine distante, saisissez :
scp USER@penguin.example.com:.vimrc .vimrc USER@penguin.example.com's password: .vimrc 100% 2233 2.2KB/s 00:00
~]$ scp USER@penguin.example.com:.vimrc .vimrc
USER@penguin.example.com's password:
.vimrc 100% 2233 2.2KB/s 00:0010.3.3. rsh
sftp peut être utilisé pour ouvrir une session FTP interactive, sécurisée. Dans le concept, c'est similaire à ftp sauf qu'on utilise une connexion sécurisée, cryptée.
sftp username@hostname
sftp username@hostnamepenguin.example.com, avec USER comme nom d'utilisateur, saisissez ce qui suit :
sftp USER@penguin.example.com USER@penguin.example.com's password: Connected to penguin.example.com. sftp>
~]$ sftp USER@penguin.example.com
USER@penguin.example.com's password:
Connected to penguin.example.com.
sftp>sftp accepte un ensemble de commandes qui ressemble à celles utilisées avec ftp (voir Tableau 10.3, « Une sélection de commandes sftp disponibles »).
| Commande | Description |
|---|---|
ls [directory] | Lister le contenu du directory (répertoire) distant. S'il n'y en aucun, on utilisera le répertoire de travail en cours par défaut. |
cd directory | Changer le répertoire de travail distant à répertoire. |
mkdir répertoire | --smbservers=<server> |
rmdir chemin | Supprimer un répertoire distant. |
put fichier local [fichier distant] | Transférer le fichier local à une machine distante. |
get fichier distant [fichier local] | Transférer le fichier distant à partir d'une machine distante. |
sftp(1).
10.4. Beaucoup plus qu'un shell sécurisé
10.4.1. Transfert X11
ssh -Y nom d'utilisateur@nom d'hôte
ssh -Y nom d'utilisateur@nom d'hôtepenguin.example.com, avec USER comme nom d'utilisateur, saisissez ce qui suit :
ssh -Y USER@penguin.example.com mot de passe de USER@penguin.example.com :
~]$ ssh -Y USER@penguin.example.com
mot de passe de USER@penguin.example.com :root pour installer le groupe de packages X11 :
yum group install "X Window System"
~]# yum group install "X Window System"system-config-printer &
~]$ system-config-printer &10.4.2. Réacheminement de port
TCP/IP normalement non sécurisés par le réacheminement de port. Quand vous utilisez cette technique, le serveur SSH fait figure de conduit crypté vers le client SSH.
Note
root.
localhost, utiliser une commande de la forme suivante :
ssh -L port-local:nom d'hôte distant:port-distant nom d'utilisateur@nom d'hôte
ssh -L port-local:nom d'hôte distant:port-distant nom d'utilisateur@nom d'hôtemail.example.com qui utilise POP3 par l'intermédiaire d'une connexion cryptée, utiliser la commande suivante :
ssh -L 1100:mail.example.com:110 mail.example.com
~]$ ssh -L 1100:mail.example.com:110 mail.example.com1100 sur le localhost pour vérifier s'il y a de nouveaux messages. Toutes les requêtes envoyées au port 1100 sur le système client seront redirigées en toute sécurité vers le serveur mail.example.com.
mail.example.com n'exécute pas sur un serveur SSH, mais qu'une autre machine le fasse sur le même réseau, SSH peut toujours être utilisé pour sécuriser une partie de la connexion. Cependant, il vous faudra une commande légèrement différente :
ssh -L 1100:mail.example.com:110 other.example.com
~]$ ssh -L 1100:mail.example.com:110 other.example.com1100 de la machine cliente sont transmises via la connexion SSH sur le port 22 au serveur SSH, other.example.com. Ensuite, other.example.com se connectera au port 110 sur mail.exemple.com pour vérifier les nouveaux messages. Notez que lorsque vous utilisez cette technique, seule la connexion entre le système client et le serveur SSH other.example.com est sûre.
Important
No sur la ligne AllowTcpForwarding dans /etc/ssh/sshd_config et redémarrer le service sshd.
10.5. Ressources supplémentaires
Documentation installée
sshd(8) — la page man des options de ligne de commande de documents de démonsshddisponibles et la liste complète des fichiers et répertoires de configuration pris en charge.ssh(1) — la page man pour l'application clientsshfournit une liste complète des options de ligne de commande disponibles et des fichiers et répertoires de configuration.scp(1) — la page man de l'utilitairescpfournit une description plus détaillée de cet utilitaire et de son utilisation.sftp(1) — la page man de l'utilitairesftp.ssh-keygen(1) — la page man de l'utilitairessh-keygendocumente en détails comment l'utiliser pour générer, gérer, et convertir les clés d'authentification utilisées parssh.ssh_config(5) — la page man nomméessh_configdocumente les options de configuration de client SSH disponibles.sshd_config(5) — la page man nomméesshd_configfournit une description compléte des options de configuration de démon SSH disponibles.
Documentation en ligne
- OpenSSH Home Page — la page d'accueil d'OpenSSH contient encore davantage de documentations, une foire aux questions, des liens aux listes d'email, des rapports de bogues, et autres informations utiles.
- OpenSSL Home Page — page d'accueil d'OpenSSL contenant davantage de documentation, une foire aux questions, des liens de listes de diffusion, ainsi que d'autres ressources utiles.
Voir aussi
- Chapitre 5, Obtention de privilèges documente la façon d'obtenir des privilèges administratifs en utilisant les commandes
suetsudo. - Chapitre 9, Gérer les services avec systemd fournit davantage d'informations sur systemd et documente comment utiliser la commande
systemctlpour gérer les services système.
Chapitre 11. TigerVNC
TigerVNC (de l'anglais, « Tiger Virtual Network Computing ») est un système pour le partage de bureau graphique vous permettant de contrôler d'autres ordinateurs à distance.
TigerVNC fonctionne sur le principe client-serveur : un serveur partage sa sortie (vncserver) et un client (vncviewer) se connecte au serveur.
Note
TigerVNC utilise le démon de gestion de systèmes systemd pour sa configuration. Le fichier de configuration /etc/sysconfig/vncserver a été remplacé par /etc/systemd/system/vncserver@.service.
11.1. Serveur VNC
vncserver est un utilitaire qui lance un bureau VNC (Virtual Network Computing). Il exécute Xvnc avec les options appropriées et lance un gestionnaire de fenêtre sur le bureau VNC. vncserver autorise les utilisateurs à exécuter des sessions séparées en parallèle sur une machine qui peut ensuite être accédée par un nombre illimité de clients, quelle que soit leur origine.
11.1.1. Installer un serveur VNC
root :
yum install tigervnc-server
~]# yum install tigervnc-server11.1.2. Configurer un serveur VNC
Procédure 11.1. Configurer un affichage VNC pour un utilisateur unique
- Un fichier de configuration nommé
/etc/systemd/system/vncserver@.serviceest requis. Pour créer ce fichier, copiez le fichier/usr/lib/systemd/system/vncserver@.serviceen tant qu'utilisateurroot:cp /usr/lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@.service
~]# cp /usr/lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow Il n'est pas nécessaire d'inclure le numéro d'affichage dans le nom du fichier carsystemdcrée automatiquement l'instance nommée de manière appropriée en mémoire à la demande, en remplaçant'%i'dans le fichier du service par le numéro d'affichage. Pour un utilisateur unique, il n'est pas nécessaire de renommer le fichier. Pour de multiples utilisateurs, un fichier de service nommé de manière unique est requis pour chaque utilisateur, par exemple, en ajoutant le nom d'utilisateur au nom du fichier. Veuillez consulter Section 11.1.2.1, « Configurer un serveur VNC pour deux utilisateurs » pour obtenir plus de détails. - Modifiez
/etc/systemd/system/vncserver@.service, en remplaçant USER par le nom de l'utilisateur. Veuillez laisser les lignes restantes du fichier intactes. L'argument-geometryspécifie la taille du bureau VNC à créer. Par défaut, celle-ci est définie sur1024x768.ExecStart=/usr/sbin/runuser -l USER -c "/usr/bin/vncserver %i -geometry 1280x1024" PIDFile=/home/USER/.vnc/%H%i.pid
ExecStart=/usr/sbin/runuser -l USER -c "/usr/bin/vncserver %i -geometry 1280x1024" PIDFile=/home/USER/.vnc/%H%i.pidCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Enregistrez les changements.
- Pour que les changements entrent en vigueur immédiatement, veuillez exécuter la commande suivante :
systemctl daemon-reload
~]# systemctl daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Paramétrez le mot de passe de l'utilisateur (ou des utilisateurs) défini(s) dans le fichier de configuration. Remarquez que vous devrez d'abord passer de l'utilisateur
rootà utilisateur USER.su - USER vncpasswd Password: Verify:
~]# su - USER ~]$ vncpasswd Password: Verify:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Important
Le mot de passe stocké n'est pas chiffré, toute personne ayant accès au fichier de mot de passe peut trouver le mot de passe en texte clair.
11.1.2.1. Configurer un serveur VNC pour deux utilisateurs
- Créez deux fichiers de service, par exemple
vncserver-USER_1@.serviceetvncserver-USER_2@.service. Veuillez substituer USER dans ces deux fichiers par le nom d'utilisateur correct. - Définissez les mots de passe pour les deux utilisateurs :
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
11.1.3. Lancer le serveur VNC
%i est remplacé par le numéro d'affichage par systemd. Avec un numéro d'affichage valide, exécutez la commande suivante :
systemctl start vncserver@:display_number.service
~]# systemctl start vncserver@:display_number.servicevncserver est automatiquement lancé. En tant qu'utilisateur root, veuillez exécuter une commande comme suit :
systemctl enable vncserver@:display_number.service
~]# systemctl enable vncserver@:display_number.service11.1.3.1. Configurer un serveur VNC pour deux utilisateurs et deux affichages différents
systemctl start vncserver-USER_1@:3.service systemctl start vncserver-USER_2@:5.service
~]# systemctl start vncserver-USER_1@:3.service
~]# systemctl start vncserver-USER_2@:5.service11.1.4. Fermer une session VNC
vncserver, il est possible de désactiver le lancement automatique du service pendant le démarrage système :
systemctl disable vncserver@:display_number.service
~]# systemctl disable vncserver@:display_number.serviceroot :
systemctl stop vncserver@:display_number.service
~]# systemctl stop vncserver@:display_number.service11.2. Partager un Bureau existant
0 affiché. Un utilisateur peut partager son ordinateur de bureau par l'intermédiaire du serveur TigerVNC x0vncserver.
Procédure 11.2. Partager un ordinateur de bureau X
x0vncserver, procédez ainsi :
- Saisir la commande suivante en tant qu'utilisateur
rootyum install tigervnc-server
~]# yum install tigervnc-serverCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Voir le mot de passe VNC de l'utilisateur :
vncpasswd Password: Verify:
~]$ vncpasswd Password: Verify:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Exécutez la commande suivante en tant qu'utilisateur :
x0vncserver -PasswordFile=.vnc/passwd -AlwaysShared=1
~]$ x0vncserver -PasswordFile=.vnc/passwd -AlwaysShared=1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5900, le visionneur distant peut maintenant se connecter pour afficher 0, et voir le bureau utilisateur connecté. Voir Section 11.3.2.1, « Configurer le pare-feu pour VNC » pour obtenir des informations sur la façon de configurer le parefeu.
11.3. Visionneur VNC
vncviewer est un programme qui affiche les interfaces utilisateur graphique et contrôle vncserver à distance.
vncviewer, il existe un menu contextuel qui contient des entrées permettant d'effectuer diverses actions, comme basculer en et hors du mode plein écran, ou quitter le visionneur. Alternativement, il est possible d'opérer vncviewer via le terminal. Saisissez vncviewer -h sur la ligne de commande pour répertorier les paramètres de vncviewer.
11.3.1. Installer le visionneur VNC Viewer
vncviewer, veuillez exécuter la commande suivante en tant qu'utilisateur root : yum install tigervnc
~]# yum install tigervnc11.3.2. Connexion au serveur VNC
Procédure 11.3. Connexion à un serveur VNC à l'aide d'une interface utilisateur graphique
- Saisissez la commande
vncviewersans le moindre argument, et l'utilitaire VNC Viewer: Connection Details s'affichera. Il demandera alors sur quel serveur VNC la connexion doit être établie. - Si nécessaire, pour empêcher de déconnecter toute connexion VNC sur le même affichage, sélectionnez l'option permettant de partager le bureau, comme suit :
- Sélectionnez le bouton .
- Sélectionnez l'onglet Divers.
- Sélectionnez le bouton .
- Appuyez sur Valider pour retourner au menu principal.
- Veuillez saisir une adresse et un numéro d'affichage auquel vous connecter :
address:display_number
address:display_numberCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Veuillez appuyer sur Connecter pour vous connecter à l'affichage du serveur VNC.
- Il vous sera demandé de saisir le mot de passe VNC. Ce sera le mot de passe VNC pour l'utilisateur correspondant au numéro d'affichage, à moins qu'un mot de passe VNC global par défaut n'ait été paramétré.Une fenêtre apparaît affichant le bureau du serveur VNC. Remarquez qu'il ne s'agit pas du bureau qu'un utilisateur normal peut voir, il s'agit d'un bureau Xvnc.
Procédure 11.4. Connexion à un serveur VNC à l'aide de l'interface de ligne de commande
- Veuillez saisir la commande
vieweravec l'adresse et le numéro d'affichage comme arguments :, où address est une adressevncviewer address:display_number
vncviewer address:display_numberCopy to Clipboard Copied! Toggle word wrap Toggle overflow IPou un nom d'hôte. - Authentifiez-vous en saisissant le mot de passe VNC. Ce sera le mot de passe VNC de l'utilisateur correspondant au numéro d'affichage, à moins qu'un mot de passe VNC global par défaut n'ait été paramétré.
- Une fenêtre apparaît affichant le bureau du serveur VNC. Remarquez qu'il ne s'agit pas du bureau qu'un utilisateur normal peut voir, il s'agit du bureau Xvnc.
11.3.2.1. Configurer le pare-feu pour VNC
firewalld peut bloquer la connexion. Pour autoriser firewalld à transférer les paquets VNC, vous pouvez ouvrir des ports spécifiques au trafic TCP. Lors de l'utilisation de l'option -via, le trafic est redirigé sur SSH, qui est activé par défaut dans firewalld.
Note
0 à 3, utilisez la prise en charge firewalld du service VNC par l'option service comme décrit ci-dessous. Remarquez que pour les numéros d'affichage supérieurs à 3, les ports correspondants devront être spécifiquement ouverts, comme expliqué dans Procédure 11.6, « Ouvrir des ports sur firewalld ».
Procédure 11.5. Activer le service VNC sur firewalld
- Veuillez exécuter la commande suivante pour afficher les informations concernant les paramètres
firewalld:firewall-cmd --list-all
~]$ firewall-cmd --list-allCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour autoriser toutes les connexions VNC en provenance d'une adresse particulière, veuillez utiliser une commande comme suit :Veuillez noter que ces changements ne persisteront pas lors d'un nouveau démarrage. Pour rendre les changements au parefeu permanents, répétez la commande an ajoutant l'option
firewall-cmd --add-rich-rule='rule family="ipv4" source address="192.168.122.116" service name=vnc-server accept' success
~]# firewall-cmd --add-rich-rule='rule family="ipv4" source address="192.168.122.116" service name=vnc-server accept' successCopy to Clipboard Copied! Toggle word wrap Toggle overflow --permanent. Veuillez consulter le Guide de sécurité Red Hat Enterprise Linux 7 pour obtenir davantage d'informations sur l'utilisation de commandes en langage riche pour pare-feux. - Pour vérifier les paramètres ci-dessus, veuillez utiliser une commande comme suit :
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
--add-port sur l'outil de ligne de commande firewall-cmd. Par exemple, l'affichage VNC 4 requiert que le port 5904 soit ouvert au trafic TCP.
Procédure 11.6. Ouvrir des ports sur firewalld
- Pour ouvrir un port au trafic
TCPdans la zone publique, veuillez exécuter la commande suivante en tant qu'utilisateurroot:firewall-cmd --zone=public --add-port=5904/tcp success
~]# firewall-cmd --zone=public --add-port=5904/tcp successCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour afficher les ports actuellement ouverts à la zone publique, veuillez exécuter une commande comme suit :
firewall-cmd --zone=public --list-ports 5904/tcp
~]# firewall-cmd --zone=public --list-ports 5904/tcpCopy to Clipboard Copied! Toggle word wrap Toggle overflow
firewall-cmd --zone=zone --remove-port=number/protocol.
--permanent. Pour obtenir davantage d'informations sur l'ouverture et la fermeture des ports de firewalld, veuillez consulter le Guide de sécurité Red Hat Enterprise Linux 7 .
11.3.3. Connexion à un serveur VNC à l'aide de SSH
-via. Cela créera un tunnel SSH entre le serveur VNC et le client.
vncviewer -via user@host:display_number
vncviewer -via user@host:display_numberExemple 11.1. En utilisant l'option -via
- Pour se connecter à un serveur VNC en utilisant
SSH, veuillez saisir une commande comme suit :vncviewer -via USER_2@192.168.2.101:3
~]$ vncviewer -via USER_2@192.168.2.101:3Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Lorsque cela vous est demandé, saisissez le mot de passe, et confirmez en appuyant sur Entrée.
- Une fenêtre avec un bureau distant s'affichera sur votre écran.
Restreindre l'accès VNC
-localhost dans le fichier systemd.service, la ligne ExecStart :
ExecStart=/usr/sbin/runuser -l user -c "/usr/bin/vncserver -localhost %i"
ExecStart=/usr/sbin/runuser -l user -c "/usr/bin/vncserver -localhost %i"vncserver d'accepter toute connexion, sauf les connexions de l'hôte local et les connexions transférées par port ayant été envoyées à l'aide de SSH, conséquemment à l'utilisation de l'option -via.
SSH, veuillez consulter le Chapitre 10, OpenSSH.
11.4. Ressources supplémentaires
Documentation installée
vncserver(1)— la page du manuel de l'utilitaire du serveur VNC.vncviewer(1)— la page du manuel du visionneur VNC.vncpasswd(1)— la page du manuel de la commande du mot de passe VNC.Xvnc(1)— la page du manuel des options de configuration du serveur Xvnc.x0vncserver(1)— la page du manuel du serveurTigerVNCpour le partage de serveurs X existants.
Partie V. Serveurs
Chapitre 12. Serveurs web
12.1. Serveur Apache HTTP
httpd, un serveur web open source développé par la Fondation Apache Software.
httpd. Cette section traite de certaines nouvelles fonctionnalités ajoutées, souligne les changements importants entre les versions 2.2 et 2.4 du serveur Apache HTTP, et vous guide à travers la mise à jour des anciens fichiers de configuration.
12.1.1. Changements notables
- Contrôle du service httpd
- Avec la migration vers l'extérieur des scripts init SysV, les administrateurs de serveur devront se mettre à utiliser les commandes
apachectletsystemctlpour contrôler le service, à la place de la commandeservice. Les exemples suivants sont spécifiques au servicehttpd.La commande :est remplacée parservice httpd graceful
service httpd gracefulCopy to Clipboard Copied! Toggle word wrap Toggle overflow . Le fichier unitéapachectl graceful
apachectl gracefulCopy to Clipboard Copied! Toggle word wrap Toggle overflow systemddehttpda un comportement différent du script init, comme suit :La commande :- Un redémarrage correct est utilisé par défaut lorsque le service est rechargé.
- Un arrêt correct est utilisé par défaut lorsque le service est arrêté.
est remplacée parservice httpd configtest
service httpd configtestCopy to Clipboard Copied! Toggle word wrap Toggle overflow apachectl configtest
apachectl configtestCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Répertoire /tmp privé
- Pour améliorer la sécurité du système, le fichier unité
systemdexécute le démonhttpden utilisant un répertoire privé/tmp, séparé du répertoire/tmpdu système. - Structure de la configuration
- Les fichiers de configuration qui chargent les modules sont désormais placés dans le répertoire
/etc/httpd/conf.modules.d/. Les paquets fournissant des modules supplémentaires qui peuvent être chargés pourhttpd, comme php, placeront un fichier dans ce répertoire. Une directiveIncludeavant la section principale du fichier/etc/httpd/conf/httpd.confest utilisée pour inclure les fichiers dans le répertoire/etc/httpd/conf.modules.d/. Cela signifie que tous les fichiers de configuration deconf.modules.d/sont traités avant le corps principal dehttpd.conf. Une directiveIncludeOptionalpour les fichiers dans le répertoire/etc/httpd/conf.d/est placée à la fin du fichierhttpd.conf. Cela signifie que les fichiers qui se trouvent dans/etc/httpd/conf.d/sont désormais traités après le corps principal dehttpd.conf.Certains fichiers de configuration supplémentaires sont fournis par le paquet httpd :/etc/httpd/conf.d/autoindex.conf— Permet de configurer l'indexation du répertoire mod_autoindex./etc/httpd/conf.d/userdir.conf— Permet de configurer l'accès aux répertoires utilisateurs. Par exemple,http://example.com/~username/; ce type d'accès est désactivé par défaut pour des raisons de sécurité./etc/httpd/conf.d/welcome.conf— Tout comme dans les versions précédentes, cela permet de configurer la page d'accueil affichée pourhttp://localhost/lorsqu'aucun contenu n'est présent.
- Configuration par défaut
- Un fichier
httpd.confminimal est désormais fourni par défaut. De nombreux paramètres de configuration courants, commeTimeoutouKeepAlive, ne sont plus explicitement configurés dans la configuration par défaut ; au lieu de ceux-ci, les paramètres codés de manière irréversibles seront utilisés par défaut. Les paramètres codés de manière irréversible par défaut pour toutes les directives de configuration sont spécifiés dans le manuel. Veuillez consulter la section intitulée « Documentation installable » pour obtenir davantage d'informations. - Modifications incompatibles de la syntaxe
- Lors de la migration d'une configuration existante de httpd 2.2 à httpd 2.4, un certain nombre de modifications incompatibles en arrière apportées à la syntaxe de la configuration
httpdnécessiteront des changements. Veuillez consulter le document Apache suivant pour obtenir davantage d'informations concernant la mise à niveau de http://httpd.apache.org/docs/2.4/upgrading.html - Modèle de traitement
- Dans les versions précédentes de Red Hat Enterprise Linux, différents modèles de multiples traitements (« multi-processing models », ou MPM) étaient disponibles aux différents binaires
httpd: le modèle fourchu, « prefork »,/usr/sbin/httpd; et le modèle basé sur thread « worker »,/usr/sbin/httpd.worker.Sur Red Hat Enterprise Linux 7, seul un binairehttpdest utilisé, et trois MPM sont disponibles en tant que modules chargeables : « worker », « prefork » (par défaut), et « event ». Veuillez modifier le fichier de configuration/etc/httpd/conf.modules.d/00-mpm.confcomme requis, en ajoutant et supprimant le caractère dièse (#), afin qu'un seul des trois modules MPM soit chargé. - Modifications de paquets
- Les modules d'authentification et d'autorisation LDAP sont désormais fournis dans un sous-paquet séparé, mod_ldap. Le nouveau module mod_session et les modules d'aide associés sont fournis dans un nouveau sous-paquet, mod_session. Les nouveaux modules mod_proxy_html et mod_xml2enc sont fournis dans un nouveau sous-paquet, mod_proxy_html. Ces paquets se trouvent tous dans le canal « Optional ».
Note
Avant de vous abonner aux canaux « Optional » et « Supplementary », veuillez consulter les Détails de l'étendue de la couverture. Si vous décidez d'installer des paquets à partir de ces canaux, veuillez suivre les étapes documentées dans l'article nommé Comment accéder aux canaux « Optional » et « Supplementary » et aux paquets -devel en utilisant Red Hat Subscription Manager (RHSM) ? sur le Portail Client Red Hat. - Empaquetage des structures de systèmes de fichiers
- Le répertoire
/var/cache/mod_proxy/n'est plus fourni ; à la place, le répertoire/var/cache/httpd/est empaqueté avec un sous-répertoireproxyetssl.Le contenu empaqueté avechttpda été déplacé de/var/www/à/usr/share/httpd/:/usr/share/httpd/icons/— Le répertoire contenant un ensemble d'icônes avec des indices de répertoire, auparavant contenus dans/var/www/icons/, a été déplacé sur/usr/share/httpd/icons/. Disponible surhttp://localhost/icons/dans la configuration par défaut ; l'emplacement et la disponibilité des icônes est configurable dans le fichier/etc/httpd/conf.d/autoindex.conf./usr/share/httpd/manual/—/var/www/manual/a été déplacé sur/usr/share/httpd/manual/. Ce répertoire, qui fait partie du paquet httpd-manual, contient la version HTML du manuel dehttpd. Disponible surhttp://localhost/manual/si le paquet est installé, l'emplacement et la disponibilité du manuel sont configurables dans le fichier/etc/httpd/conf.d/manual.conf./usr/share/httpd/error/—/var/www/error/a été déplacé sur/usr/share/httpd/error/. Pages d'erreurs HTTP de langues multiples personnalisées. Non configuré par défaut, le fichier de configuration exemple est fourni sur/usr/share/doc/httpd-VERSION/httpd-multilang-errordoc.conf.
- Authentifications, autorisations et contrôle des accès
- Les directives de configuration utilisées pour contrôler l'authentification, les autorisations et le contrôle des accès ont changé de manière significative. Les fichiers de configuration existants qui utilisent les directives
Order,DenyetAllowdoivent être adaptés afin de pouvoir utiliser la nouvelle syntaxeRequire. Veuillez consulter le document Apache suivant pour obtenir davantage d'informations : http://httpd.apache.org/docs/2.4/howto/auth.html - suexec
- Pour améliorer la sécurité du système, le binaire suexec n'est plus installé par l'équivalent de l'utilisateur
root; au lieu de cela, il possède une fonctionnalité «bit Set» dans le système de fichiers, qui limite les restrictions. En conjonction avec ce changement, le binaire suexec n'utilise plus le fichier journal/var/log/httpd/suexec.log. Au lieu de cela, des messages de journalisation sont envoyés sur syslog. Par défaut, ceux-ci apparaîtront dans le fichier journal/var/log/secure. - Interface du module
- Des modules binaires de tierce-partie créés avec httpd 2.2 ne sont pas compatibles avec httpd 2.4 à cause de changements apportés à l'interface du module
httpd. De tels modules devront être ajustés comme nécessaire pour l'interface du module httpd 2.4, puis recréés. Une liste détaillée des changements d'API dans la version2.4sont disponibles ici : http://httpd.apache.org/docs/2.4/developer/new_api_2_4.html.Le binaire apxs utilisé pour créer des modules source a été déplacé de/usr/sbin/apxsà/usr/bin/apxs. - Modules supprimés
- Liste des modules
httpdsupprimés de Red Hat Enterprise Linux 7 :- mod_auth_mysql, mod_auth_pgsql
- httpd 2.4 fournit la prise en charge de l'authentification de bases de données SQL de manière interne dans le module mod_authn_dbd.
- mod_perl
- mod_perl n'est pas officiellement pris en charge avec httpd 2.4 en amont.
- mod_authz_ldap
- httpd 2.4 offre la prise en charge LDAP dans le sous-paquet mod_ldap en utilisant mod_authnz_ldap.
12.1.2. Mettre à jour la configuration
- Comme ils peuvent avoir été modifiés, assurez-vous que tous les noms de modules soient corrects. Ajustez la directive
LoadModulepour chaque module dont le nom a changé. - Compilez à nouveau tous les modules de tierce-partie avant de tenter de les charger. Typiquement, cela signifie des modules d'authentification et d'autorisation.
- Si vous utilisez Apache HTTP Secure Server, veuillez consulter la Section 12.1.8, « Activer le module mod_ssl » pour obtenir des informations importantes sur l'activation du protocole SSL (« Secure Sockets Layer »).
apachectl configtest Syntax OK
~]# apachectl configtest
Syntax OK12.1.3. Exécuter le service httpd
httpd, assurez-vous que httpd soit effectivement installé. Cela peut être effectué en utilisant la commande suivante :
yum install httpd
~]# yum install httpd12.1.3.1. Lancer le service
httpd, veuillez saisir ce qui suit à l'invite de shell en tant qu'utilisateur root :
systemctl start httpd.service
~]# systemctl start httpd.servicesystemctl enable httpd.service Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
~]# systemctl enable httpd.service
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.Note
12.1.3.2. Arrêter le service
httpd, veuillez saisir ce qui suit dans une invite de shell en tant qu'utilisateur root :
systemctl stop httpd.service
~]# systemctl stop httpd.servicesystemctl disable httpd.service Removed symlink /etc/systemd/system/multi-user.target.wants/httpd.service.
~]# systemctl disable httpd.service
Removed symlink /etc/systemd/system/multi-user.target.wants/httpd.service.12.1.3.3. Redémarrer le service
httpd :
- Pour redémarrer le système entièrement, exécutez la commande suivante en tant qu'utilisateur
root:systemctl restart httpd.service
~]# systemctl restart httpd.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceci arrête le service en cours d'exécutionhttpdet le lance immédiatement après. Veuillez utiliser cette commande après avoir installé ou supprimé un module chargé dynamiquement, comme le module PHP. - Pour uniquement recharger la configuration, veuillez saisir en tant qu'utilisateur
root:systemctl reload httpd.service
~]# systemctl reload httpd.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceci cause au service en cours d'exécutionhttpdde recharger son fichier de configuration. Toute requête actuellement en cours de traitement sera interrompue, ce qui pourrait causer à un navigateur client d'afficher un message d'erreur ou d'effectuer un rendu partiel de page. - Pour recharger sa configuration sans affecter de requête active, veuillez saisir la commande suivante en tant qu'utilisateur
root:apachectl graceful
~]# apachectl gracefulCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceci cause au service en cours d'exécutionhttpdde recharger son fichier de configuration. Toute requête actuellement en cours de traitement continuera d'utiliser l'ancienne configuration.
12.1.3.4. Vérifier le statut du service
httpdest effectivement en cours d'exécution, veuillez saisir ce qui suit dans l'invite du shell :
systemctl is-active httpd.service active
~]# systemctl is-active httpd.service
active12.1.4. Modifier les fichiers de configuration
httpd est lancé, par défaut, il lit la configuration à partir d'emplacements répertoriés dans la Tableau 12.1, « Fichiers de configuration du service httpd ».
httpd.
apachectl configtest Syntax OK
~]# apachectl configtest
Syntax OK12.1.5. Utiliser des modules
httpd est distribué avec un certain nombre d'objets partagés dynamiques (« Dynamic Shared Objects », ou DSO), qui peuvent être chargés ou déchargés dynamiquement pendant le runtime, selon les besoins. Dans Red Hat Enterprise Linux 7, ces modules se trouvent dans /usr/lib64/httpd/modules/.
12.1.5.1. Charger un module
LoadModule. Remarquez que les modules fournis par un paquet séparé possèdent souvent leur propre fichier de configuration dans le répertoire /etc/httpd/conf.d/.
Exemple 12.1. Charger mod_ssl DSO
LoadModule ssl_module modules/mod_ssl.so
LoadModule ssl_module modules/mod_ssl.sohttpd.
12.1.5.2. Écrire un module
root :
yum install httpd-devel
~]# yum install httpd-develapxs) requis pour compiler un module.
apxs -i -a -c module_name.c
~]# apxs -i -a -c module_name.c12.1.6. Paramétrer des hôtes virtuels
/usr/share/doc/httpd-VERSION/httpd-vhosts.conf dans le répertoire /etc/httpd/conf.d/, et remplacez les valeurs d'espaces réservés @@Port@@ et @@ServerRoot@@. Personnalisez les options selon vos besoins, comme affiché dans l'Exemple 12.2, « Exemple de configuration d'hôte virtuel ».
Exemple 12.2. Exemple de configuration d'hôte virtuel
ServerName doit être un nom DNS valide assigné à la machine. Le conteneur <VirtualHost> est hautement personnalisable, et accepte la plupart des directives disponibles dans la configuration du serveur principal. Les directives qui ne sont pas prises en charge dans ce conteneur incluent User et Group, remplacées par SuexecUserGroup.
Note
Listen dans la section des paramètres globaux du fichier /etc/httpd/conf/httpd.conf en conséquence.
httpd.
12.1.7. Paramétrer un serveur SSL
mod_ssl, un module qui utilise le kit de ressources OpenSSL pour fournir la prise en charge SSL/TLS, est couramment appelé un serveur SSL. Red Hat Enterprise Linux prend également en charge l'utilisation de Mozilla NSS comme implémentation TLS. La prise en charge de Mozilla NSS est fournie par le module mod_nss.
12.1.7.1. Vue d'ensemble des certificats et de la sécurité
| Navigateur Web | Lien |
|---|---|
| Mozilla Firefox | Liste d'AC root Mozilla. |
| Opera | Informations sur les certificats root utilisés par Opera. |
| Internet Explorer | Informations sur les certificats root utilisés par Microsoft Windows. |
| Chromium | Informations sur les certificats root utilisés par le projet Chromium. |
12.1.8. Activer le module mod_ssl
mod_ssl, il n'est pas possible qu'une autre application ou qu'un autre module, comme mod_nss, soit configuré pour utiliser le même port. Le port 443 est le port par défaut pour HTTPS.
mod_ssl et le kit de ressources OpenSSL toolkit, veuillez installer les paquets mod_ssl et openssl. Saisissez la commande suivante en tant qu'utilisateur root :
yum install mod_ssl openssl
~]# yum install mod_ssl opensslmod_ssl sur /etc/httpd/conf.d/ssl.conf, qui est inclus dans le fichier de configuration principal du serveur Apache HTTP Server par défaut. Pour que le module soit chargé, veuillez redémarrer le service httpd comme décrit dans la Section 12.1.3.3, « Redémarrer le service ».
Important
SSL et d'utiliser TLSv1.1 ou TLSv1.2 uniquement. Une rétrocompatibilité peut être effectuée en utilisant TLSv1.0. De nombreux produits pris en charge par Red Hat ont la capacité d'utiliser le protocole SSLv2 ou SSLv3, ou de les activer par défaut. Cependant, l'utilisation de SSLv2 ou de SSLv3 est désormais fortement déconseillée.
12.1.8.1. Activer et désactiver SSL et TLS sur mod_ssl
SSLProtocol dans la section « ## SSL Global Context » du fichier de configuration et en la supprimant partout ailleurs, ou modifiez l'entrée par défaut sous « # SSL Protocol support » dans toutes les sections « VirtualHost ». Si vous ne le spécifiez pas dans la section VirtualHost par domaine, les paramètres hérités proviendront de la section globale. Pour vous assurer qu'une version du protocole est en cours de désactivation, l'administrateur doit uniquement spécifier SSLProtocol dans la section « SSL Global Context », ou bien, le spécifier dans toutes les sections VirtualHost par domaine.
Procédure 12.1. Désactiver SSLv2 et SSLv3
- En tant qu'utilisateur
root, ouvrez le fichier/etc/httpd/conf.d/ssl.confet recherchez toutes les instances de la directiveSSLProtocol. Par défaut, le fichier de configuration contient une section qui ressemble à cela :Cette section se trouve dans la section VirtualHost.vi /etc/httpd/conf.d/ssl.conf # SSL Protocol support: # List the enable protocol levels with which clients will be able to # connect. Disable SSLv2 access by default: SSLProtocol all -SSLv2
~]# vi /etc/httpd/conf.d/ssl.conf # SSL Protocol support: # List the enable protocol levels with which clients will be able to # connect. Disable SSLv2 access by default: SSLProtocol all -SSLv2Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Modifiez la ligne
SSLProtocolcomme suit :Répétez cette action pour toutes les sections VirtualHost. Enregistrez et fermez le fichier.# SSL Protocol support: # List the enable protocol levels with which clients will be able to connect. Disable SSLv2 access by default: SSLProtocol all -SSLv2 -SSLv3
# SSL Protocol support: # List the enable protocol levels with which clients will be able to # connect. Disable SSLv2 access by default: SSLProtocol all -SSLv2 -SSLv3Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Vérifiez que toutes les occurrences de la directive
SSLProtocolont été modifiées comme suit :Cette étape est particulièrement importante si vous avez plus d'une section VirtualHost par défaut.grep SSLProtocol /etc/httpd/conf.d/ssl.conf SSLProtocol all -SSLv2 -SSLv3
~]# grep SSLProtocol /etc/httpd/conf.d/ssl.conf SSLProtocol all -SSLv2 -SSLv3Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Redémarrez le démon Apache comme suit :Remarquez que toutes les sessions seront interrompues.
systemctl restart httpd
~]# systemctl restart httpdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Procédure 12.2. Désactiver tous les protocoles SSL et TLS sauf TLS 1 et ses versions supérieures
- En tant qu'utilisateur
root, ouvrez le fichier/etc/httpd/conf.d/ssl.confet recherchez toutes les instances de la directiveSSLProtocol. Par défaut, le fichier contient une section qui ressemble à cela :vi /etc/httpd/conf.d/ssl.conf # SSL Protocol support: # List the enable protocol levels with which clients will be able to # connect. Disable SSLv2 access by default: SSLProtocol all -SSLv2
~]# vi /etc/httpd/conf.d/ssl.conf # SSL Protocol support: # List the enable protocol levels with which clients will be able to # connect. Disable SSLv2 access by default: SSLProtocol all -SSLv2Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Modifiez la ligne
SSLProtocolcomme suit :Enregistrer et fermer le fichier.# SSL Protocol support: # List the enable protocol levels with which clients will be able to connect. Disable SSLv2 access by default: SSLProtocol -all +TLSv1 +TLSv1.1 +TLSv1.2
# SSL Protocol support: # List the enable protocol levels with which clients will be able to # connect. Disable SSLv2 access by default: SSLProtocol -all +TLSv1 +TLSv1.1 +TLSv1.2Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Vérifiez le changement comme suit :
grep SSLProtocol /etc/httpd/conf.d/ssl.conf SSLProtocol -all +TLSv1 +TLSv1.1 +TLSv1.2
~]# grep SSLProtocol /etc/httpd/conf.d/ssl.conf SSLProtocol -all +TLSv1 +TLSv1.1 +TLSv1.2Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Redémarrez le démon Apache comme suit :Remarquez que toutes les sessions seront interrompues.
systemctl restart httpd
~]# systemctl restart httpdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Procédure 12.3. Tester le statut des protocoles SSL et TLS
openssl s_client -connect. La commande se trouve sous le format suivant : openssl s_client -connect hostname:port -protocol
openssl s_client -connect hostname:port -protocollocalhost comme nom d'hôte. Par exemple, pour tester le port par défaut pour des connexion HTTPS sécurisées, pour voir si SSLv3 est activé sur le port 443, exécutez la commande suivante :
- La sortie ci-dessus indique que la tentative de connexion a échoué et qu'aucun chiffrement n'a été négocié.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - La sortie ci-dessus indique qu'aucun échec de tentative de connexion n'a eu lieu et qu'un ensemble de chiffrements a été négocié.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
openssl s_client sont documentées dans la page man de s_client(1).
12.1.9. Activer le module mod_nss
mod_nss, vous ne pourrez pas avoir le paquet mod_ssl installé avec ses paramètres par défaut car mod_ssl utilisera le port 443 par défaut, cependant ceci est le port HTTPS par défaut. Si possible, veuillez supprimer le paquet.
root :
yum remove mod_ssl
~]# yum remove mod_sslNote
mod_ssl est requis à d'autres fins, veuillez modifier le fichier /etc/httpd/conf.d/ssl.conf afin qu'il utilise un autre port que le port 443 pour empêcher que mod_ssl entre en conflit avec mod_nss lorsque son port d'écoute est changé sur le port 443.
mod_nss et mod_ssl peuvent uniquement coexister au même moment s'ils utilisent des ports uniques. Pour cette raison, mod_nss utilise par défaut le port 8443, mais le port HTTPS par défaut est le port 443. Le port est spécifié par la directive Listen ainsi que dans le nom ou l'adresse VirtualHost.
Procédure 12.4. Configurer mod_nss
- Installez mod_nss en tant qu'utilisateur
root:yum install mod_nss
~]# yum install mod_nssCopy to Clipboard Copied! Toggle word wrap Toggle overflow Cela créera le fichier de configurationmod_nssdans/etc/httpd/conf.d/nss.conf. Le répertoire/etc/httpd/conf.d/est inclus dans le fichier de configuration principal du serveur Apache HTTP Server par défaut. Pour que le module soit chargé, veuillez redémarrer le servicehttpdcomme décrit dans la Section 12.1.3.3, « Redémarrer le service ». - En tant qu'utilisateur
root, ouvrez le fichier/etc/httpd/conf.d/nss.confet recherchez toutes les instances de la directiveListen.Modifiez la ligneListen 8443comme suit :Le portListen 443
Listen 443Copy to Clipboard Copied! Toggle word wrap Toggle overflow 443est le port par défaut pourHTTPS. - Modifiez la ligne
VirtualHost _default_:8443par défaut comme suit :Veuillez modifier toute autre section d'hôte virtuel qui n'est pas par défaut s'il en existe. Puis enregistrez et fermez le fichier.VirtualHost _default_:443
VirtualHost _default_:443Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Mozilla NSS stocke les certificats dans une base de données de certificats de serveur indiquée par la directive
NSSCertificateDatabasedans le fichier/etc/httpd/conf.d/nss.conf. Par défaut, le chemin est défini sur/etc/httpd/alias, la base de données NSS créée pendant l'installation.Pour afficher la base de données NSS par défaut, veuillez exécuter la commande suivante :Dans la sortie de commande ci-dessus,Copy to Clipboard Copied! Toggle word wrap Toggle overflow Server-Certest leNSSNicknamepar défaut. L'option-Lrépertorie tous les certificats, ou affiche des informations sur un certificat nommé, dans une base de données de certificats. L'option-dspécifie le répertoire de la base de données contenant le certificat et les fichiers-clés de la base de données. Veuillez consulter la page mancertutil(1)pour davantage d'options de ligne de commande. - Pour configurer mod_nss de manière à utiliser une autre base de données, veuillez modifier la ligne
NSSCertificateDatabasedans le fichier/etc/httpd/conf.d/nss.conf. Le fichier par défaut possède les lignes suivantes dans la section VirtualHost.Dans la sortie la commande ci-dessus,# Server Certificate Database: # The NSS security database directory that holds the certificates and # keys. The database consists of 3 files: cert8.db, key3.db and secmod.db. # Provide the directory that these files exist. NSSCertificateDatabase /etc/httpd/alias
# Server Certificate Database: # The NSS security database directory that holds the certificates and # keys. The database consists of 3 files: cert8.db, key3.db and secmod.db. # Provide the directory that these files exist. NSSCertificateDatabase /etc/httpd/aliasCopy to Clipboard Copied! Toggle word wrap Toggle overflow aliasest le répertoire de la base de données NSS par défaut,/etc/httpd/alias/. - Pour appliquer un mot de passe à la base de données des certificats NSS par défaut, veuillez utiliser la commande suivante en tant qu'utilisateur
root:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Avant de déployer le serveur HTTPS, veuillez créer une nouvelle base de données de certificats en utilisant un certificat signé par une autorité de certification (AC).
Exemple 12.3. Ajouter un certificat à la base de données Mozilla NSS
La commandecertutilest utilisée pour ajouter un certificat AC aux fichiers de la base de données NSS :certutil -d /etc/httpd/nss-db-directory/ -A -n "CA_certificate" -t CT,, -a -i certificate.pem
certutil -d /etc/httpd/nss-db-directory/ -A -n "CA_certificate" -t CT,, -a -i certificate.pemCopy to Clipboard Copied! Toggle word wrap Toggle overflow La commande ci-dessus ajoute un certificat AC stocké dans un fichier au format PEM nommé certificate.pem. L'option-dspécifie le répertoire de la base de données NSS contenant le certificat et les fichiers-clés de la base de données, l'option-ndéfinit un nom pour le certificat,-tCT,signifie que le certificat est approuvé pour être utilisé dans les serveurs et clients TLS. L'option-Aajoute un certificat existant dans une base de données de certificats. Si la base de données n'existe pas, elle sera créée. L'option-apermet l'utilisation du format ASCII pour les entrées ou les sorties et l'option-itransmet le fichier d'entréecertificate.pemà la commande.Veuillez consulter la page man decertutil(1)pour obtenir davantage d'options de ligne de commande. - La base de données NSS doit être protégée par un mot de passe afin de garantir la sécurité de la clé privée.
Exemple 12.4. Définir un mot de passe pour la base de données Mozilla NSS
L'outilcertutilpeut être utilisé pour définir un mot de passe pour une base de données NSS comme suit :certutil -W -d /etc/httpd/nss-db-directory/
certutil -W -d /etc/httpd/nss-db-directory/Copy to Clipboard Copied! Toggle word wrap Toggle overflow Par exemple, pour la base de données par défaut, veuillez exécuter une commande en tant qu'utilisateurroot, comme suit :Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Configurez
mod_nssde manière à utiliser le jeton logiciel NSS interne en modifiant la ligne avec la directiveNSSPassPhraseDialog, comme suit :Ceci sert à éviter la saisie manuelle de mots de passe pendant le démarrage système. Le jeton logiciel existe dans la base de données NSS, mais vous pouvez également posséder une clé physique contenant les certificats.vi /etc/httpd/conf.d/nss.conf NSSPassPhraseDialog file:/etc/httpd/password.conf
~]# vi /etc/httpd/conf.d/nss.conf NSSPassPhraseDialog file:/etc/httpd/password.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Si le certificat du serveur SSL situé dans la base de données NSS est un certificat RSA, assurez-vous que le paramètre
NSSNicknamene soit pas mis en commentaire et qu'il corresponde bien au nom affiché dans l'étape 4 ci-dessus :vi /etc/httpd/conf.d/nss.conf NSSNickname Server-Cert
~]# vi /etc/httpd/conf.d/nss.conf NSSNickname Server-CertCopy to Clipboard Copied! Toggle word wrap Toggle overflow Si le certificat du serveur SSL situé dans la base de données NSS est un certificat ECC, assurez-vous que le paramètreNSSECCNicknamene soit pas mis en commentaire et qu'il corresponde bien au surnom affiché dans l'étape 4 ci-dessus :vi /etc/httpd/conf.d/nss.conf NSSECCNickname Server-Cert
~]# vi /etc/httpd/conf.d/nss.conf NSSECCNickname Server-CertCopy to Clipboard Copied! Toggle word wrap Toggle overflow Assurez-vous que le paramètreNSSCertificateDatabasene soit pas mis en commentaire et qu'il pointe vers le répertoire de la base de données NSS affiché dans l'étape 4 ou configuré dans l'étape 5 ci-dessus :Remplacezvi /etc/httpd/conf.d/nss.conf NSSCertificateDatabase /etc/httpd/alias
~]# vi /etc/httpd/conf.d/nss.conf NSSCertificateDatabase /etc/httpd/aliasCopy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/httpd/aliaspar le chemin vers la base de données de certificats à utiliser. - Créez le fichier
/etc/httpd/password.confen tant qu'utilisateurroot:Ajoutez une ligne sous le format suivant :vi /etc/httpd/password.conf
~]# vi /etc/httpd/password.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow en remplaçant password par le mot de passe appliqué aux bases de données de sécurité NSS dans l'étape 6 ci-dessus.internal:password
internal:passwordCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Veuillez appliquer l'appartenance et les permissions appopriées au fichier
/etc/httpd/password.conf:chgrp apache /etc/httpd/password.conf chmod 640 /etc/httpd/password.conf ls -l /etc/httpd/password.conf -rw-r-----. 1 root apache 10 Dec 4 17:13 /etc/httpd/password.conf
~]# chgrp apache /etc/httpd/password.conf ~]# chmod 640 /etc/httpd/password.conf ~]# ls -l /etc/httpd/password.conf -rw-r-----. 1 root apache 10 Dec 4 17:13 /etc/httpd/password.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour configurer
mod_nssde manière à utiliser le jeton logiciel NSS dans/etc/httpd/password.conf, veuillez modifier/etc/httpd/conf.d/nss.confcomme suit :vi /etc/httpd/conf.d/nss.conf
~]# vi /etc/httpd/conf.d/nss.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Redémarrez le serveur Apache pour que les changements entrent en vigueur, comme décrit dans la Section 12.1.3.3, « Redémarrer le service »
Important
SSL et d'utiliser TLSv1.1 ou TLSv1.2 uniquement. Une rétrocompatibilité peut être effectuée en utilisant TLSv1.0. De nombreux produits pris en charge par Red Hat ont la capacité d'utiliser le protocole SSLv2 ou SSLv3, ou de les activer par défaut. Cependant, l'utilisation de SSLv2 ou de SSLv3 est désormais fortement déconseillée.
12.1.9.1. Activer et désactiver SSL et TLS sur mod_nss
NSSProtocol dans la section « ## SSL Global Context » du fichier de configuration et en la supprimant partout ailleurs, ou modifiez l'entrée par défaut sous « # SSL Protocol » dans toutes les sections « VirtualHost ». Si vous ne le spécifiez pas dans la section VirtualHost par domaine, les paramètres hérités proviendront de la section globale. Pour vous assurer qu'une version du protocole est en cours de désactivation, l'administrateur doit uniquement spécifier NSSProtocol dans la section « SSL Global Context », ou bien dans toutes les sections VirtualHost par domaine.
Procédure 12.5. Désactiver tous les protocoles SSL et TLS sauf TLS 1 et ses versions supérieures dans mod_nss
- En tant qu'utilisateur
root, ouvrez le fichier/etc/httpd/conf.d/nss.confet recherchez toutes les instances de la directiveNSSProtocol. Par défaut, le fichier de configuration contient une section qui ressemble à cela :Cette section se trouve dans la section VirtualHost.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Modifiez la ligne
NSSProtocolcomme suit :Répétez cette action pour toutes les sections VirtualHost.# SSL Protocol: NSSProtocol TLSv1.0,TLSv1.1
# SSL Protocol: NSSProtocol TLSv1.0,TLSv1.1Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Modifiez la ligne
Listen 8443comme suit :Listen 443
Listen 443Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Modifiez la ligne
VirtualHost _default_:8443par défaut comme suit :Veuillez modifier toute autre section d'hôte virtuel qui n'est pas par défaut s'il en existe. Puis enregistrez et fermez le fichier.VirtualHost _default_:443
VirtualHost _default_:443Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Vérifiez que toutes les occurrences de la directive
NSSProtocolont été modifiées comme suit :Cette étape est particulièrement importante si vous possédez plus d'une section VirtualHost.grep NSSProtocol /etc/httpd/conf.d/nss.conf # middle of a range may be excluded, the entry "NSSProtocol SSLv3,TLSv1.1" # is identical to the entry "NSSProtocol SSLv3,TLSv1.0,TLSv1.1". NSSProtocol TLSv1.0,TLSv1.1
~]# grep NSSProtocol /etc/httpd/conf.d/nss.conf # middle of a range may be excluded, the entry "NSSProtocol SSLv3,TLSv1.1" # is identical to the entry "NSSProtocol SSLv3,TLSv1.0,TLSv1.1". NSSProtocol TLSv1.0,TLSv1.1Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Redémarrez le démon Apache comme suit :Remarquez que toutes les sessions seront interrompues.
service httpd restart
~]# service httpd restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Procédure 12.6. Tester le statut des protocoles SSL et TLS dans mod_nss
openssl s_client -connect. Installez le paquet openssl en tant qu'utilisateur root :
yum install openssl
~]# yum install opensslopenssl s_client -connect se trouve sous le format suivant : openssl s_client -connect hostname:port -protocol
openssl s_client -connect hostname:port -protocollocalhost comme nom d'hôte. Par exemple, pour tester le port par défaut pour des connexions HTTPS sécurisées, pour voir si SSLv3 est activé sur le port 443, exécutez la commande suivante :
- La sortie ci-dessus indique que la tentative de connexion a échoué et qu'aucun chiffrement n'a été négocié.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - La sortie ci-dessus indique qu'aucun échec de tentative de connexion n'a eu lieu et qu'un ensemble de chiffrements a été négocié.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
openssl s_client sont documentées dans la page man de s_client(1).
12.1.10. Utiliser une clé existante et un certificat
- Vous modifiez l'adresse IP ou le nom du domaine.Des certificats sont créés pour une paire adresse IP et nom de domaine particuliers. Si l'une de ces valeurs change, le certificat est invalide.
- Vous avez un certificat de VeriSign, et vous changez le logiciel du serveur.VeriSign, une autorité de certification largement utilisée, octroit des certificats pour un produit logiciel, une adresse IP, et un nom de domaine particulier. Modifier le produit logiciel rend le certificat invalide.
/etc/pki/tls/private/ et /etc/pki/tls/certs/, respectivement. Vous pouvez faire cela exécutant les commandes suivantes en tant qu'utilisateur root :
mv key_file.key /etc/pki/tls/private/hostname.key mv certificate.crt /etc/pki/tls/certs/hostname.crt
~]# mv key_file.key /etc/pki/tls/private/hostname.key
~]# mv certificate.crt /etc/pki/tls/certs/hostname.crt/etc/httpd/conf.d/ssl.conf :
SSLCertificateFile /etc/pki/tls/certs/hostname.crt SSLCertificateKeyFile /etc/pki/tls/private/hostname.key
SSLCertificateFile /etc/pki/tls/certs/hostname.crt
SSLCertificateKeyFile /etc/pki/tls/private/hostname.keyhttpd comme décrit dans la Section 12.1.3.3, « Redémarrer le service ».
Exemple 12.5. Utiliser une clé et un certificat du serveur web sécurisé « Red Hat Secure Web Server »
mv /etc/httpd/conf/httpsd.key /etc/pki/tls/private/penguin.example.com.key mv /etc/httpd/conf/httpsd.crt /etc/pki/tls/certs/penguin.example.com.crt
~]# mv /etc/httpd/conf/httpsd.key /etc/pki/tls/private/penguin.example.com.key
~]# mv /etc/httpd/conf/httpsd.crt /etc/pki/tls/certs/penguin.example.com.crt12.1.11. Générer une nouvelle clé et un nouveau certificat
root :
yum install crypto-utils
~]# yum install crypto-utilsImportant
root, veuillez utiliser la commande suivante au lieu de genkey :
openssl req -x509 -new -set_serial number -key hostname.key -out hostname.crt
~]# openssl req -x509 -new -set_serial number -key hostname.key -out hostname.crtNote
root :
rm /etc/pki/tls/private/hostname.key
~]# rm /etc/pki/tls/private/hostname.keygenkey en tant qu'utilisateur root, suivie du nom d'hôte approprié (par exemple, penguin.example.com) :
genkey hostname
~]# genkey hostname- Examinez les emplacements cibles dans lesquels la clé et le certificat seront stockés.
Figure 12.1. Exécuter l'utilitaire genkey
Veuillez utiliser la touche Tab pour sélectionner le bouton , et appuyez sur Entrée pour passer à l'écran suivant. - En utilisant les touches de flèches haut et bas, sélectionnez une taille de clé convenable. Remarquez que malgré qu'une clé de plus grande taille améliore la sécurité, celle-ci augmentera également le temps de réponse de votre serveur. L'organisme NIST recommande d'utiliser
2048 bits. Veuillez consulter le document NIST Special Publication 800-131A.
Figure 12.2. Sélectionner la taille de la clé
Une fois terminé, veuillez utiliser la touche Tab pour sélectionner le bouton , et appuyez sur Entrée pour initier le processus de génération de bits aléatoire. Selon la taille de clé sélectionnée, ceci peut prendre longtemps. - Décidez si vous souhaitez envoyer une requête de certificat à une autorité de certification.
Figure 12.3. Générer une requête de certificat
Utilisez la touche Tab pour sélectionner afin de composer une requête de certificat, ou pour générer un certificat auto-signé. Puis appuyez sur Entrée pour confirmer votre choix. - À l'aide de la barre d'espace, activez (
[*]) ou désactivez ([ ]) le chiffrement de la clé privée.
Figure 12.4. Chiffrer la clé privée
Veuillez utiliser la touche Tab pour sélectionner le bouton , et appuyez sur Entrée pour passer à l'écran suivant. - Si vous avez activé le chiffrement de clé privée, veuillez saisir une phrase de passe convenable. Remarquez que pour des raisons de sécurité, celle-ci n'est pas affichée lorsque vous la saisissez, et doit faire 5 caractères au minimum.

Figure 12.5. Saisir une phrase de passe
Veuillez utiliser la touche Tab pour sélectionner le bouton , et appuyez sur Entrée pour passer à l'écran suivant.Important
Saisir la phrase de passe correctement est requis pour que le serveur démarre. Si vous la perdez, vous devrez générer une nouvelle clé et un nouveau certificat. - Personnaliser les détails du certificat.
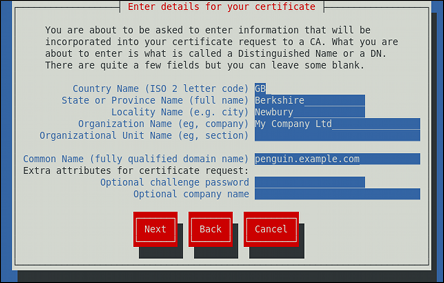
Figure 12.6. Spécifier les informations du certificat
Veuillez utiliser la touche Tab pour sélectionner le bouton , et appuyez sur Entrée pour terminer avec la génération de clé. - Si vous avez activé la génération de requête de certificat, il vous sera demandé de l'envoyer à une autorité de certification.
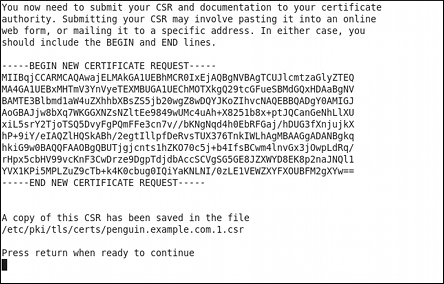
Figure 12.7. Instructions sur la manière d'envoyer une requête de certificat
Appuyez sur Entrée pour retourner dans une invite shell.
/etc/httpd/conf.d/ssl.conf :
SSLCertificateFile /etc/pki/tls/certs/hostname.crt SSLCertificateKeyFile /etc/pki/tls/private/hostname.key
SSLCertificateFile /etc/pki/tls/certs/hostname.crt
SSLCertificateKeyFile /etc/pki/tls/private/hostname.keyhttpd comme décrit dans la Section 12.1.3.3, « Redémarrer le service » afin que la configuration mise à jour soit chargée.
12.1.12. Configurez le pare-feu pour HTTP et HTTPS en utilisant la ligne de commande
HTTP et HTTPS. Pour autoriser le système à agir en tant que serveur web, veuillez utiliser les services firewalld pris en charge pour que le trafic HTTP et que le trafic HTTPS soient autorisés à passer à travers le pare-feu comme requis.
HTTP en utilisant la ligne de commande, veuillez exécuter la commande suivante en tant qu'utilisateur root :
firewall-cmd --add-service http success
~]# firewall-cmd --add-service http
successHTTPS en utilisant la ligne de commande, veuillez exécuter la commande suivante en tant qu'utilisateur root :
firewall-cmd --add-service https success
~]# firewall-cmd --add-service https
success--permanent.
12.1.12.1. Vérifier l'accès réseau de HTTPS et de HTTPS entrant en utilisant la ligne de commande
root :
firewall-cmd --list-all public (default, active) interfaces: em1 sources: services: dhcpv6-client sshsortie tronquée
~]# firewall-cmd --list-all
public (default, active)
interfaces: em1
sources:
services: dhcpv6-client sshsortie tronquéeHTTP et HTTPS n'ont pas été autorisés à passer à travers.
HTTP et HTTP activés, la ligne services apparaîtra et sera similaire à ceci :
services: dhcpv6-client http https ssh
services: dhcpv6-client http https sshfirewalld, veuillez consulter le Guide de sécurité Red Hat Enterprise Linux 7 .
12.1.13. Ressources supplémentaires
Documentation installée
httpd(8)— la page du manuel du servicehttpdcontenant la liste complète de ses options de ligne de commande.genkey(1)— la page du manuel de l'utilitairegenkey, fournie par le paquet crypto-utils.apachectl(8)— la page du manuel de l'interface de contrôle du serveur HTTP Apache.
Documentation installable
- http://localhost/manual/ — documentation officielle du serveur HTTP Apache avec la description complète de ses directives et modules disponibles. Remarquez que pour accéder à cette documentation, le paquet httpd-manual doit être installé, et le serveur web doit être en cours d'exécution.Avant d'accéder à la documentation, veuillez exécuter la commande suivante en tant qu'utilisateur
root:yum install httpd-manual apachectl graceful
~]# yum install httpd-manual ~]# apachectl gracefulCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Documentation en ligne
- http://httpd.apache.org/ — site web officiel du serveur HTTP Apache avec la documentation sur toutes les directives et tous les modules par défaut.
- http://www.openssl.org/ — page d'accueil d'OpenSSL contenant davantage de documentation, une foire aux questions, des liens de listes de diffusion, ainsi que d'autres ressources utiles.
Chapitre 13. Serveurs de courrier
13.1. Protocoles de courrier électronique
13.1.1. Protocoles de transport de courrier
13.1.1.1. SMTP
13.1.2. Protocoles d'accès au courrier
13.1.2.1. POP
Note
root :
yum install dovecot
~]# yum install dovecotPOP, les messages électroniques sont téléchargés par les applications clientes de courrier. Par défaut, la plupart des clients de courrier POP sont automatiquement configurés pour supprimer le message sur le serveur de courrier une fois son tranfert réussi. Ce paramètre peut toutefois être modifié.
POP est totalement compatible avec les standards de messagerie Internet importants, tels que MIME (Multipurpose Internet Mail Extensions), qui permet d'ajouter des pièces jointes aux courriers électroniques.
POP fonctionne mieux pour les utilisateurs qui possèdent un système sur lequel lire les courriers électroniques. Celui-ci fonctionne également mieux pour les utilisateurs qui ne possèdent pas de connexion persistante sur Internet ou sur le réseau contenant le serveur de courrier. Malheureusement, pour les personnes dont les connexions réseau sont lentes, POP exige que les programmes clients téléchargent la totalité du contenu de chaque message une fois l'authentification effectuée. Ceci peut prendre un long moment si un courrier contient une pièce jointe de grande taille.
POP standard est POP3.
POP :
- APOP —
POP3avec une authentificationMD5. Un hachage chiffré du mot de passe utilisateur est envoyé à partir du client de messagerie vers le serveur, plutôt que d'envoyer un mot de passe non chiffré. - KPOP —
POP3avec authentification Kerberos. - RPOP —
POP3avec authentificationRPOP. Ceci utilise un ID par utilisateur, similairement à un mot de passe, mais pour authentifier les requêtes POP. Cependant, cet ID n'est pas chiffré, etRPOPn'est ainsi pas plus sécurisé que le protocolePOPstandard.
pop3s, ou en utilisant l'application stunnel. Pour obtenir davantage d'informations sur la sécurisation des communications par courrier électronique, veuillez consulter la Section 13.5.1, « Sécuriser les communications ».
13.1.2.2. IMAP
IMAP par défaut sous Red Hat Enterprise Linux se nomme Dovecot et est fourni par le paquet dovecot. Veuillez consulter la Section 13.1.2.1, « POP » pour obtenir des informations sur la manière d'installer Dovecot.
IMAP, les messages électroniques restent sur le serveur, les utilisateurs peuvent donc les lire ou les supprimer. IMAP autorise également les applications clientes à créer, renommer, ou supprimer des répertoires de courrier sur le serveur pour organiser et stocker les courriers électroniques.
IMAP est particulièrement utile pour les utilisateurs accédant à leur courrier électronique à partir de plusieurs machines. Le protocole est également utile pour les utiisateurs se connectant au serveur de courrier via une connexion lente, car jusqu'à ce que le courrier soit ouvert, seules les informations de l'en-tête des courriers électroniques sont téléchargées, économisant ainsi de la bande passante. L'utilisateur a également la possibilité de supprimer des messages sans les voir ou sans les télécharger.
IMAP sont capables de mettre en cache des copies de messages localement, permettant ainsi à l'utilisateur de parcourir des messages précédemment lus sans pour autant être directement connecté au serveur IMAP.
IMAP, tout comme POP, est complètement compatible avec les standards de messagerie Internet importants, tels que MIME, qui autorise l'ajout de pièces jointes.
SSL pour l'authentification de client et les sessions de transfert de données. Ceci peut être activé en utilisant le service imaps, ou en utilisant le programme stunnel. Pour obtenir davantage d'informations sur la sécurisation des communications par courrier électronique, veuillez consulter la Section 13.5.1, « Sécuriser les communications ».
13.1.2.3. dovecot
imap-login et pop3-login qui implémentent les protocoles IMAP et POP3 sont engendrés par le démon dovecot maître inclus dans le paquet dovecot. L'utilisation d'IMAP et de POP est configurée via le fichier de configuration /etc/dovecot/dovecot.conf ; par défaut dovecot exécute IMAP et POP3 avec leur version sécurisée en utilisant SSL. Pour configurer dovecot de manière à utiliser POP, veuillez appliquer les étapes suivantes :
- Modifiez le fichier de configuration
/etc/dovecot/dovecot.confde manière à vous assurer que la variableprotocolsne se trouve pas dans un commentaire (supprimez le caractère dièse (#) au début de la ligne) et qu'elle contienne bien l'argumentpop3. Exemple :protocols = imap pop3 lmtp
protocols = imap pop3 lmtpCopy to Clipboard Copied! Toggle word wrap Toggle overflow Lorsque la variableprotocolsne se trouve plus dans un commentaire,dovecotutilisera les valeurs par défaut comme décrit ci-dessus. - Rendre le changement opérationnel pour la session actuelle en exécutant la commande suivante en tant qu'utilisateur
root:systemctl restart dovecot
~]# systemctl restart dovecotCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Rendre le changement opérationnel après le prochain redémarrage en exécutant la commande :
systemctl enable dovecot Created symlink from /etc/systemd/system/multi-user.target.wants/dovecot.service to /usr/lib/systemd/system/dovecot.service.
~]# systemctl enable dovecot Created symlink from /etc/systemd/system/multi-user.target.wants/dovecot.service to /usr/lib/systemd/system/dovecot.service.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Note
Veuillez remarquer quedovecotrapporte uniquement qu'il a démarré le serveurIMAP, mais il lance également le serveurPOP3.
SMTP, IMAP et POP3 nécessitent de connecter les clients pour s'authentifier en utilisant un nom d'utilisateur et un mot de passe.. Par défaut, les mots de passe de ces deux protocoles sont passés à travers le réseau de manière non-chiffrée.
SSL sur dovecot :
- Modifiez le fichier de configuration
/etc/dovecot/conf.d/10-ssl.confpour vous assurer que la variablessl_protocolsest bien décommentée et contient les arguments!SSLv2 !SSLv3:ssl_protocols = !SSLv2 !SSLv3
ssl_protocols = !SSLv2 !SSLv3Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ces valeurs permettent de s'assurer quedovecotévite SSL versions 2 et 3, qui sont toutes deux connues pour ne pas être sécurisées. Ceci est dû à la vulnérabilité décrite dans POODLE: SSLv3 vulnerability (CVE-2014-3566). Veuillez consulter la Résolution de la vulnérabilité SSL 3.0 POODLE (CVE-2014-3566) dans Postfix et Dovecot pour obtenir davantage de détails. - Modifiez le fichier de configuration
/etc/pki/dovecot/dovecot-openssl.cnfselon vos préférences. Cependant, dans une installation typique, ce fichier ne requiert pas de modification. - Renommez, déplacez ou supprimez les fichiers
/etc/pki/dovecot/certs/dovecot.pemet/etc/pki/dovecot/private/dovecot.pem. - Exécutez le script
/usr/libexec/dovecot/mkcert.shqui crée les certificats auto-signésdovecot. Ces certificats sont copiés dans les répertoires/etc/pki/dovecot/certset/etc/pki/dovecot/private. Pour implémenter les changements, redémarrezdovecoten exécutant la commande suivante en tant qu'utilisateurroot:systemctl restart dovecot
~]# systemctl restart dovecotCopy to Clipboard Copied! Toggle word wrap Toggle overflow
dovecot peuvent être trouvés en ligne sur http://www.dovecot.org.
13.2. Classifications des programmes de courrier électronique
13.2.1. Agent de transport de courrier
SMTP. Un message peut impliquer plusieurs MTA pendant son déplacement vers la destination prévue.
13.2.2. Agent distributeur de courrier
mail ou Procmail.
13.2.3. Agent d'utilisateur de messagerie
POP ou IMAP, paramétrant des boîtes à lettres pour stocker des messages, et envoyant des messages sortant vers un MTA.
13.3. Agents de transport de courrier
root pour basculer sur Sendmail :
alternatives --config mta
~]# alternatives --config mtasystemctl enable service
~]# systemctl enable servicesystemctl disable service
~]# systemctl disable service13.3.1. Postfix
13.3.1.1. Installation Postfix par défaut
postfix. Ce démon lance tous les processus nécessaires à la gestion de la remise du courrier.
/etc/postfix/. Voici une liste de fichiers les plus couramment utilisés :
access— utilisé pour le contrôle des accès, ce fichier spécifie les hôtes autorisés à se connecter à Postfix.main.cf— fichier de configuration global de Postfix. La majorité des options de configuration sont spécifiées dans ce fichier.master.cf— spécifie la manière par laquelle Postfix interagit avec les divers processus pour effectuer la remise du courrier.transport— fait correspondre les adresses électroniques avec les hôtes de relais.
aliases se trouve dans le répertoire /etc. Ce fichier est partagé entre Postfix et Sendmail. Il s'agit d'une liste configurable requise par le protocole de messagerie qui décrit les alias des ID utilisateurs.
Important
/etc/postfix/main.cf par défaut n'autorise pas Postfix à accepter de connexions réseau d'un hôte autre que l'ordinateur local. Pour obtenir des instructions sur la configuration de Postfix en tant que serveur pour d'autres clients, veuillez consulter la Section 13.3.1.3, « Configuration de base Postfix ».
postfix après avoir modifié toute option des fichiers de configuration sous le répertoire /etc/postfix/ afin que les changements entrent en vigueur. Pour faire cela, veuillez exécuter la commande suivante en tant qu'utilisateur root :
systemctl restart postfix
~]# systemctl restart postfix13.3.1.2. Mettre à niveau à partir d'une version précédente
disable_vrfy_command = no— ce paramètre est désactivé par défaut, ce qui est différent des valeurs par défaut de Sendmail. Si modifié suryes, il peut empêcher certaines méthodes de récolte d'adresses électroniques.allow_percent_hack = yes— ce paramètre est activé par défaut. Il permet la suppression des caractères%dans les adresses électroniques. Le bricolage du pourcentage est une ancienne solution de contournement qui permettait le routage contrôlé par l'envoyeur des messages électroniques.DNSet le routage de courrier sont désormais bien plus fiables, mais Postfix continue de prendre en charge ce bricolage. Pour désactiver la réécriture du pourcentage, veuillez définirallow_percent_hacksurno.smtpd_helo_required = no— ce paramètre est désactivé par défaut, tout comme sur Sendmail, car il empêche certaines applications d'envoyer des courriers électroniques. Il peut être modifié suryespour requérir des clients qu'ils envoient des commandes HELO ou EHLO avant de tenter d'envoyer les commandes MAIL, FROM, ou ETRN.
13.3.1.3. Configuration de base Postfix
root pour activer la remise de courrier pour d'autres hôtes sur le réseau :
- Modifiez le fichier
/etc/postfix/main.cfavec un editeur de texte, tel quevi. - Décommentez la ligne
mydomainen supprimant le caractère dièse (#), et remplacez domain.tld par le domaine entretenu par le serveur de courrier, tel queexample.com. - Décommentez la ligne
myorigin = $mydomain. - Décommentez la ligne
myhostname, et remplacez host.domain.tld par le nom d'hôte de la machine. - Décommentez la ligne
mydestination = $myhostname, localhost.$mydomain. - Décommentez la ligne
mynetworks, et remplacez 168.100.189.0/28 par un paramètre réseau valide pour les hôtes qui peuvent se connecter au serveur. - Décommentez la ligne
inet_interfaces = all. - Mettez la ligne
inet_interfaces = localhosten commentaire. - Redémarrez le service
postfix.
/etc/postfix/main.cf. Des ressources supplémentaires, y compris des informations sur la configuration de Postfix, l'intégration de SpamAssassin, ou des descriptions détaillées des paramètres /etc/postfix/main.cf sont disponibles en ligne sur http://www.postfix.org/.
Important
SSL et d'utiliser TLSv1.1 ou TLSv1.2 uniquement. Voir Résolution de la vulnérabilité POODLE SSL 3.0 (CVE-2014-3566) dans Postfix et Dovecot pour obtenir plus de détails.
13.3.1.4. Utiliser Postfix avec LDAP
LDAP en tant que source pour diverses tables de recherche (par exemple : aliases, virtual, canonical, etc.). Ceci permet à LDAP de stocker des informations utilisateur hiérarchiques et à Postfix de recevoir le résultat des requêtes LDAP uniquement lorsque nécessaire. En ne stockant pas ces informations localement, les administrateurs peuvent les maintenir plus facilement.
13.3.1.4.1. L'exemple de recherche /etc/aliases
LDAP pour rechercher le fichier /etc/aliases. Assurez-vous que le fichier /etc/postfix/main.cf contienne bien :
alias_maps = hash:/etc/aliases, ldap:/etc/postfix/ldap-aliases.cf
alias_maps = hash:/etc/aliases, ldap:/etc/postfix/ldap-aliases.cf/etc/postfix/ldap-aliases.cf, si vous n'en possédez pas déjà un, et assurez-vous qu'il contiennent effectivement ce qui suit :
server_host = ldap.example.com search_base = dc=example, dc=com
server_host = ldap.example.com
search_base = dc=example, dc=comldap.example.com, example, et com sont des paramètres qui doivent être remplacés avec la spécification d'un serveur LDAP existant et disponible.
Note
/etc/postfix/ldap-aliases.cf peut spécifier divers paramètres, y compris des paramètres activant LDAP SSL et STARTTLS. Pour obtenir davantage d'informations, veuillez consulter la page man de ldap_table(5).
LDAP, voir OpenLDAP dans le guide System-Level Authentication Guide.
13.3.2. Sendmail
SMTP. Veuillez remarquer que l'utilisation de Sendmail est déconseillée et ses utilisateurs sont encouragés à utiliser Postfix lorsque possible. Veuillez consulter la Section 13.3.1, « Postfix » pour obtenir davantage d'informations.
13.3.2.1. Objectif et limites
POP ou IMAP pour télécharger les messages sur la machine locale. Ces utilisateurs peuvent également préférer d'utiliser une interface Web pour obtenir accès à leur boîte de réception. Les autres applications peuvent fonctionner en conjonction avec Sendmail, mais elles existent pour différentes raisons et peuvent opérer séparément les unes des autres.
13.3.2.2. Installation Sendmail par défaut
root :
yum install sendmail
~]# yum install sendmailroot :
yum install sendmail-cf
~]# yum install sendmail-cfsendmail.
/etc/mail/sendmail.cf. Veuillez éviter de modifier le fichier sendmail.cf directement. Pour effectuer des changements de configuration sur Sendmail, veuillez modifier le fichier /etc/mail/sendmail.mc, effectuer une copie de sauvegarde du fichier /etc/mail/sendmail.cf d'origine, puis utiliser les alternatives suivantes pour générer un nouveau fichier de configuration :
- Veuillez utiliser le fichier makefile inclus dans le fichier de configuration
/etc/mail/pour créer un nouveau fichier de configuration/etc/mail/sendmail.cf:make all -C /etc/mail/
~]# make all -C /etc/mail/Copy to Clipboard Copied! Toggle word wrap Toggle overflow Tous les autres fichiers générés dans/etc/mail(fichiers db) seront générés à nouveau si nécessaire. Les anciennes commandes makemap sont toujours utilisables. La commande make est automatiquement utilisée lorsque vous démarrez ou redémarrez le servicesendmail.
/etc/mail/, y compris :
access— indique quels systèmes peuvent utiliser Sendmail pour les courriers électroniques sortants.domaintable— spécifie le mappage du nom de domaine.local-host-names— spécifie les alias de l'hôte.mailertable— spécifie les instructions qui outrepassent le routage de certains domaines particuliers.virtusertable— spécifie une forme de crénelage spécifique aux domaines, permettant à de multiples domaines virtuels d'être hébergés sur une machine.
/etc/mail/, comme access, domaintable, mailertable et virtusertable, doivent stocker leurs informations dans des fichiers de base de données avant que Sendmail puisse utiliser un changement de configuration. Pour inclure tout changement apporté à ces configurations dans leurs fichiers de base de données, veuillez exécuter les commandes suivantes en tant qu'utilisateur root :
cd /etc/mail/ make all
~]# cd /etc/mail/
~]# make allvirtusertable.db, access.db, domaintable.db, mailertable.db, sendmail.cf, et submit.cf.
make name.db all
make name.db allmake name.db
make name.dbsendmail pour que les changements entrent en vigueur en exécutant :
systemctl restart sendmail
~]# systemctl restart sendmailexample.com soient remis à bob@other-example.com, veuillez ajouter la ligne suivante au fichier virtusertable :
@example.com bob@other-example.com
@example.com bob@other-example.comvirtusertable.db doit être mis à jour :
make virtusertable.db all
~]# make virtusertable.db allall provoquera la mise à jour simultanée de virtusertable.db et access.db.
13.3.2.3. Changements communs de la configuration Sendmail
/etc/mail/sendmail.cf complètement nouveau.
Avertissement
sendmail.cf, veuillez créer une copie de sauvegarde.
/etc/mail/sendmail.mc en tant qu'utilisateur root. Après avoir terminé, veuillez redémarrer le service sendmail, si le paquet m4 est installé, le processeur macro m4 générera automatiquement un nouveau fichier de configuration sendmail.cf :
systemctl restart sendmail
~]# systemctl restart sendmailImportant
sendmail.cf par défaut interdit à Sendmail d'accepter des connexions réseau en provenance de tout autre hôte que l'ordinateur local. Pour configurer Sendmail en tant que serveur pour d'autres clients, veuillez modifier le fichier /etc/mail/sendmail.mc, et modifiez l'adresse spécifiée dans l'option Addr= de la directive DAEMON_OPTIONS en provenance de 127.0.0.1 par l'adresse IP d'un périphérique réseau actif ou mettez en commentaire la directive DAEMON_OPTIONS toute entière en plaçant dnl au début de la ligne. Une fois cela terminé, veuillez générer un nouveau fichier /etc/mail/sendmail.cf en redémarrant le service :
systemctl restart sendmail
~]# systemctl restart sendmailSMTP. Cependant, cela ne fonctionne pas pour les sites UUCP (« UNIX-to-UNIX Copy Protocol »). Si vous utilisez le transfert de courrier UUCP, le fichier /etc/mail/sendmail.mc doit être reconfiguré et un nouveau fichier /etc/mail/sendmail.cf doit être généré.
/usr/share/sendmail-cf/README avant de mettre à jour tout fichier dans les répertoires situés sous le répertoire /usr/share/sendmail-cf/, car ils peuvent affecter la future configuration du fichier /etc/mail/sendmail.cf.
13.3.2.4. Camouflage
mail.example.com qui gère tout le courrier électronique et assigne une adresse de retour cohérente à tout courrier sortant.
user@example.com au lieu de user@host.example.com.
/etc/mail/sendmail.mc :
sendmail.cf en utilisant le processeur macro m4, cette configuration fait apparaître tout le courrier intérieur au réseau comme s'il avait été envoyé par example.com.
DNS et DHCP, ainsi que toute application de provisioning, doivent s'accorder sur le format des noms d'hôtes utilisé dans une organisation. Veuillez consulter le Guide de mise en réseau Red Hat Enterprise Linux 7 pour obtenir davantage d'informations sur les pratiques de dénomination recommandées.
13.3.2.5. Arrêter le courrier indésirable
SMTP, aussi appelé relais, a été désactivé par défaut depuis la version 8.9 de Sendmail. Avant ce changement, Sendmail ordonnait à l'hôte du courrier (x.edu) d'accepter les messages d'une partie (y.com) et de les envoyer à une autre partie (z.net). Cependant, Sendmail doit désormais être configuré pour autoriser à tout domaine de relayer le courrier à travers le serveur. Pour configurer les domaines de relais, veuillez modifier le fichier /etc/mail/relay-domains et redémarrer Sendmail
systemctl restart sendmail
~]# systemctl restart sendmail/etc/mail/access peuvent être utilisées pour empêcher des connexions d'hôtes indésirables. L'exemple suivant illustre comment utiliser ce fichier pour bloquer et spécifiquement autoriser l'accès au serveur Sendmail :
badspammer.com ERROR:550 "Go away and do not spam us anymore" tux.badspammer.com OK 10.0 RELAY
badspammer.com ERROR:550 "Go away and do not spam us anymore" tux.badspammer.com OK 10.0 RELAYbadspammer.com est bloqué avec un code d'erreur de conformité 550 RFC-821, avec un message renvoyé. Le courrier électronique envoyé à partir du sous-domaine tux.badspammer.com est accepté. La dernière ligne affiche que tout courrier électronique envoyé depuis le réseau 10.0.*.* peut être relayé à travers le serveur de courrier.
/etc/mail/access.db est une base de données, veuillez utiliser la commande makemap pour mettre à jour tout changement. Pour effectuer cela, veuillez utiliser la commande suivante en tant qu'utilisateur root :
makemap hash /etc/mail/access < /etc/mail/access
~]# makemap hash /etc/mail/access < /etc/mail/accessSMTP stockent des informations sur le parcours d'un courrier électronique dans l'en-tête du message. Tandis que le messages se déplacent d'un MTA à un autre, chacun ajoute un en-tête Received (« Reçu ») au-dessus des autres en-têtes Received. Il est important de noter que ces informations peuvent être altérées par les expéditeurs du courrier indésirable.
/usr/share/sendmail-cf/README pour obtenir davantage d'informations et d'exemples.
13.3.2.6. Utiliser Sendmail avec LDAP
LDAP est une manière rapide et puissante de trouver des informations spécifiques sur un utilisateur particulier dans un groupe de grande taille. Par exemple, un serveur LDAP peut être utilisé pour rechercher une adresse électronique particulière dans un annuaire d'entreprise commun en utilisant le nom de famille de l'utilisateur. Dans ce type d'implémentation, LDAP est relativement différent de Sendmail, avec LDAP stockant les informations hiérarchiques des utilisateurs et Sendmail ne reçevant que le résultat des requêtes LDAP dans des messages électroniques pré-adressés.
LDAP, avec laquelle LDAP est utilisé pour remplacer des fichiers maintenus séparément, comme /etc/aliases et /etc/mail/virtusertables, sur différents serveurs de courrier fonctionnant ensemble pour prendre en charge une organisation de niveau moyen à niveau entreprise. Autrement dit, LDAP fait une abtraction du niveau de routage du courrier de Sendmail et de ses fichiers de configuration séparés sur un cluster LDAP puissant dont de nombreuses différentes applications peuvent tirer profit.
LDAP. Pour étendre le serveur Sendmail utilisant LDAP, commencez par exécuter un serveur LDAP correctement configuré, tel que OpenLDAP. Puis modifiez /etc/mail/sendmail.mc de manière à inclure ceci :
LDAPROUTE_DOMAIN('yourdomain.com')dnl
FEATURE('ldap_routing')dnl
LDAPROUTE_DOMAIN('yourdomain.com')dnl
FEATURE('ldap_routing')dnlNote
LDAP. La configuration peut être largement différente en fonction de l'implémentation de LDAP, particulièrement lors de la configuration de plusieurs machines Sendmail pour utiliser un serveur LDAP commun.
/usr/share/sendmail-cf/README pour des instructions et exemples de configuration du routage LDAP.
/etc/mail/sendmail.cf en exécutant le macro processeur m4 et redémarrez Sendmail. Veuillez consulter la Section 13.3.2.3, « Changements communs de la configuration Sendmail » pour obtenir des instructions.
LDAP, voir OpenLDAP dans le guide System-Level Authentication Guide.
13.3.3. Fetchmail
POP3 et IMAP. Il peut également transférer les messages électroniques sur un serveur SMTP si nécessaire.
Note
root :
yum install fetchmail
~]# yum install fetchmail.fetchmailrc dams le répertoire personnel de l'utilisateur. S'il n'existe pas déjà, veuillez créer le fichier .fetchmailrc dans votre répertoire personnel
.fetchmailrc, Fetchmail vérifie le courrier sur un serveur distant et le télécharge. Il le livre ensuite sur le port 25 de la machine locale, en utilisant le MTA local pour placer le courrier dans le fichier spool du bon utilisateur. Si Procmail est disponible, il est lancé pour filtrer le courrier électronique et le placer dans une boîte aux lettres afin qu'il soit lu par un MUA.
13.3.3.1. Options de Configuration Fetchmail
.fetchmailrc est bien plus facile. Placez toutes les options de configuration souhaitées dans le fichier .fetchmailrc afin qu'elles soient utilisées chaque fois que la commande fetchmail est exécutée. Il est possible d'outrepasser ces commandes pendant l'exécution de Fetchmail en spécifiant cette option sur la ligne de commande.
.fetchmailrc d'un utilisateur contient trois classes d'option de configuration :
- options globales — celles-ci donnent à Fetchmail des instructions contrôlant l'opération du programme ou fournissent des paramètres pour chaque connexion vérifiant le courrrier électronique.
- options du serveur — elles spécifient les informations nécessaires sur le serveur en cours d'interrogation, comme le nom d'hôte, ainsi que les préférences de serveurs de courrier électronique particuliers, comme le port à vérifier ou le nombre de secondes à attendre avant expiration. Ces options affectent tous les utilisateurs utilisant ce serveur.
- options d'utilisateur — contient des informations nécessaires à l'authentification et à la vérification du courrier électronique, telles que le nom d'utilisateur et le mot de passe, en utilisant un serveur de courrier électronique spécifié.
.fetchmailrc, suivies par une ou plusieurs options de serveur, qui désigne chacune un différent serveur de courrier électronique que Fetchmail devrait vérifier. Les options d'utilisateur suivent les options de serveur pour chaque compte utilisateur vérifiant ce serveur de courrier électronique. Tout comme les options de serveur, des options de multiples utilisateurs peuvent être spécifiées pour une utilisation avec un serveur particulier, ainsi que pour vérifier de multiples comptes utilisateur sur le même serveur.
.fetchmailrc par l'utilisation d'un verbe spéciale option, poll (interroger) ou skip (ignorer), qui précède les informations serveur. L'action poll (interroger) ordonne à Fetchmail d'utiliser cette option de serveur lors de son exécution. Elle vérifie le courrier électronique en utilisant les options spécifiées par l'utilisateur. Cependant, toute option de serveur située après une action skip (ignorer), ne sera pas vérifiée, à moins que le nom d'hôte de ce serveur soit spécifié lorsque Fetchmail est invoqué. L'option skip est utile pendant des tests de configuration dans le fichier .fetchmailrc car elle ne vérifie que les serveurs ignorés si invoquée, et n'affecte aucune configuration fonctionnant actuellement.
.fetchmailrc :
postmaster) et toutes les erreurs de courrier électronique sont envoyées au «postmaster » au lieu de l'envoyeur (option bouncemail). L'action set transmet à Fetchmail que cette ligne contient une option globale. Puis, deux serveurs de courrier sont spécifiés, l'un est paramétré pour vérifier en utilisant POP3, et l'autre pour tenter divers protocoles dans le but d'en trouver un qui fonctionne. Deux utilisateurs sont vérifés en utilisant la seconde option du serveur, mais tous le courrier trouvé pour un utilisateur quelconque est envoyé dans le spool du courrier de l'utilisateur user1. Ceci permet à de multiples boîtes aux lettres d'être vérifiées sur de multiples serveurs, tout en apparaissant comme n'étant qu'une seule boîte aux lettres MUA. Les informations spécifiques de chaque utilisateur commencent par l'action user.
Note
.fetchmailrc. L'omission de la section with password 'password' cause à Fetchmail de demander un mot de passe lorsqu'il est lancé.
fetchmail explique chaque option en détail, mais les plus communes sont répertoriées dans les trois sections suivantes.
13.3.3.2. Options globales
set.
daemon seconds— spécifie le mode du démon, où Fetchmail reste en arrière-plan. Veuillez remplacer seconds par le nombre de secondes pendant lesquelles Fetchmail doit patienter avant d'interroger le serveur.postmaster— Spécifie un utilisateur local à qui envoyer le courrier en cas de problème de remise du courrier électronique.syslog— Spécifie le fichier journal pour les messages d'erreur et de statut. Par défaut, ce fichier est/var/log/maillog.
13.3.3.3. Options de serveur
.fetchmailrc, après une action poll ou skip.
auth auth-type— remplace auth-type par le type d'authentification à utiliser. Par défaut, l'authentificationpasswordest utilisée, mais certains protocoles prennent en charge d'autres types d'authentification, y compriskerberos_v5,kerberos_v4, etssh. Si le type d'authentificationanyest utilisé, Fetchmail tentera d'abord des méthodes qui ne requièrent pas de mot de passe, puis des méthodes qui masquent le mot de passe, et tentera finalement d'envoyer le mot de passe non chiffré pour s'authentifier sur le serveur.interval number— interroge le serveur spécifié toutes lesnumberfois qu'il vérifie le courrier électronique sur tous les serveurs configurés. Cette option est généralement utilisée pour les serveurs de courrier sur lesquels l'utilisateur reçoit rarement de messages.port port-number— remplace port-number par le numéro du port. Cette valeur remplace le numéro de port par défaut pour le protocole spécifié.proto protocol— remplace protocol par le protocole à utiliser, commepop3ouimap, pendant les vérifications de messages sur le serveurtimeout seconds— remplace seconds par le nombre de secondes d'inactivité du serveur après lesquelles Fetchmail abandonnera une tentative de connexion. Si cette valeur n'est pas définie, la valeur par défaut de300sera utilisée.
13.3.3.4. Options d'utilisateur
user (définie ci-dessous).
fetchall— ordonne à Fetchmail de télécharger tous les messages de la file, y compris les messages qui ont déjà été lus. Par défaut, Fetchmail ne télécharge que les nouveaux messages.fetchlimit number— remplace number par le nombre de messages à récupérer avant d'arrêter.flush— supprime tous les messages déjà vus qui se trouvent dans la file avant de récupérer les nouveaux messages.limit max-number-bytes— remplace max-number-bytes par la taille de message maximale autorisée en octets lorsque les messages sont récupérés par Fetchmail. Cette option est utile avec les liens réseau lents, lorsqu'un message de grande taille prend trop de temps à télécharger.password 'password'— remplace password par le mot de passe de l'utilisateur.preconnect "command"— remplace command par la commande à exécuter avant de récupérer les messages pour l'utilisateur.postconnect "command"— remplace command par la commande à exécuter après avoir récupéré les messages pour l'utilisateur.ssl— active l'encodage. Au moment de la rédaction de cet ouvrage, l'action par défaut est d'utiliser soitSSL2,SSL3,SSL23,TLS1,TLS1.1ouTLS1.2suivant ce qu'il y a de mieux de disponible. Notez queSSL2est considéré comme étant obsolète à cause de POODLE: Vulnérabilité SSLv3 (CVE-2014-3566),SSLv3ne doit pas être utilisé. Cependant, il n'est pas utile de forcer l'utilisation de TLS1 ou version plus récente, donc, veillez bien à ce que le serveur de messagerie connecté soit configuré de façon à ne pas utiliserSSLv2ouSSLv3. Utiliserstunnelquand le serveur ne peut pas être configuré à ne pas utiliserSSLv2ouSSLv3.sslproto— définit les protocoles SSL ou TLS autorisés. Les valeurs possibles sontSSL2,SSL3,SSL23etTLS1. La valeur par défaut, sisslprotoest omis, désactivé ou défini à une valeur non valide, estSSL23. L’action par défaut consiste à utiliser soitSSLv2,SSLv3,TLSv1,TLS1.1ouTLS1.2. Notez que la définition de toute autre valeur pour SSL ou TLS désactive tous les autres protocoles. À cause de POODLE:ulnérabilité SSLv3 (CVE-2014-3566), il est recommandé d’omettre cette option, ou de la définir àSSLv23, et de configurer le serveur de messagerie correspondant à ne pas utiliserSSLv2etSSLv3. Utilisezstunneloù le serveur ne peut pas être configuré à ne pas utiliserSSLv2etSSLv3.user "username"— Veuillez remplacer username par le nom d'utilisateur utilisé par Fetchmail pour récupérer les messages. Cette option doit précéder toutes les autres options d'utilisateur.
13.3.3.5. Options de commande Fetchmail
fetchmail reflètent les options de configuration .fetchmailrc. Ainsi, Fetchmail peut être utilisé avec ou sans fichier de configuration. Ces options ne sont pas utilisées sur la ligne de commande par la plupart des utilisateurs car il est plus facile de les laisser dans le fichier .fetchmailrc.
fetchmail avec d'autres options dans un but particulier. Il est possible d'exécuter des options de commande pour outrepasser de manière temporaire un paramètre .fetchmailrc qui causerait une erreur, comme toute option spécifiée sur la ligne de commande outrepasse les options du fichier de configuration.
13.3.3.6. Options de débogage ou à caractère informatif
fetchmail peuvent fournir d'importantes informations.
--configdump— affiche toutes les options possibles en se basant sur les informations de.fetchmailrcet sur les valeurs par défaut de Fetchmail. Aucun courrier n'est récupéré pour un utilisateur lorsque cette option est utilisée.-s— exécute Fetchmail en mode silence, empêchant tout message autre que des messages d'erreur d'apparaître après la commandefetchmail.-v— exécute Fetchmail en mode détaillé, affichant toutes les communications entre Fetchmail et les serveurs de courrier distants.-V— affiche des informations détaillées sur la version, répertorie ses options globales, et affiche les paramètres à utiliser avec chaque utilisateur, y compris le protocole du courrier et la méthode d'authentification. Aucun courrier n'est récupéré pour un utilisateur lorsque cette option est utilisée.
13.3.3.7. Options spéciales
.fetchmailrc.
-a— Fetchmail télécharge tous les messages du serveur de courrier distant, qu'ils soient nouveaux ou qu'ils aient déjà été vus. Par défaut, Fetchmail télécharge uniquement les nouveaux messages.-k— Fetchmail laisse les messages sur le serveur de courrier distant après les avoir téléchargés. Cette option outrepasse le comportement par défaut qui consiste à supprimer les messages après les avoir téléchargés.-l max-number-bytes— Fetchmail ne télécharge aucun message au-delà d'une taille particulière et les laisse sur le serveur de courrier distant.--quit— quitte le processus du démon Fetchmail.
.fetchmailrc se trouvent sur la page man de fetchmail.
13.3.4. Configuration de l'agent de transport de courrier (« Mail Transport Agent », ou MTA)
mail pour envoyer du courrier contenant des messages de journalisation à l'utilisateur root du système local.
13.4. Agents de remise de courrier (« Mail Delivery Agents »)
mail. Ces deux applications sont considérées comme des LDA et déplacent le courrier depuis le fichier spool du MTA dans la boîte aux lettre de l'utilisateur. Cependant, Procmail offre un système de filtrage robuste.
mail, veuillez consulter sa page man (man mail).
/etc/procmailrc ou ~/.procmailrc (également appelé un fichier rc) dans le répertoire personnel de l'utilisateur invoque Procmail chaque fois qu'un MTA reçoit un nouveau message.
rc global n'existe dans le répertoire /etc et aucun fichier .procmailrc n'existe dans les répertoires de base d'aucun utilisateur. Ainsi, pour utiliser Procmail, chaque utilisateur doit construire un fichier .procmailrc avec des variables et des règles d'environnement spécifiques.
rc. Si un message correspond à une recette, alors le courrier est placé dans un fichier spécifié, supprimé, ou traité autrement.
/etc/procmailrc et les fichiers rc du répertoire /etc/procmailrcs/. Procmail recherche ensuite un fichier .procmailrc dans le répertoire personnel de l'utilisateur. De nombreux utilisateurs créent également des fichiers rc supplémentaires pour Procmail auxquels il est fait référence dans le fichier .procmailrc de leur répertoire personnel.
13.4.1. Configuration Procmail
~/.procmailrc sous le format suivant :
env-variable="value"
env-variable="value"env-variable est le nom de la variable et value définit la variable.
DEFAULT— définit la boîte aux lettres par défaut où sont placés les messages ne correspondant à aucune recette.La valeur par défautDEFAULTest la même que la valeur$ORGMAIL.INCLUDERC— spécifie des fichiersrcsupplémentaires contenant davantage de recettes avec lesquelles vérifier les messages. Ceci divise les listes des recettes Procmail en fichiers individuels qui remplissent différents rôles, comme bloquer le courrier indésirable et gérer les listes de courrier électronique, qui peuvent également être activés ou désactivés en utilisant les caractères de mise en commentaire dans le fichier de l'utilisateur~/.procmailrc.Par exemple, les lignes du fichier~/.procmailrcd'un utilisateur pourraient ressembler à celles-ci :MAILDIR=$HOME/Msgs INCLUDERC=$MAILDIR/lists.rc INCLUDERC=$MAILDIR/spam.rc
MAILDIR=$HOME/Msgs INCLUDERC=$MAILDIR/lists.rc INCLUDERC=$MAILDIR/spam.rcCopy to Clipboard Copied! Toggle word wrap Toggle overflow Pour désactiver le filtrage Procmail des listes de courrier électronique tout en laissant le contrôle du courrier indésirable en place, veuillez mettre en commentaire la première ligneINCLUDERCavec le caractère dièse (#). Remarquez que des chemins relatifs au répertoire actuel sont utilisés.LOCKSLEEP— définit la durée, en secondes, qui doit s'écouler entre chaque tentative d'utilisation d'un fichier lockfile particulier par Procmail. La valeur par défaut s'élève à8secondes.LOCKTIMEOUT— définit la durée, en secondes, qui doit s'écouler après la modification d'un fichier lockfile avant que Procmail considère que ce fichier lockfileest trop ancien et doit être supprimé. La valeur par défaut s'élève à1024secondes.LOGFILE— fichier sur lequel toutes les informations et tous les messages d'erreur Procmail sont écrits.MAILDIR— définit le répertoire de travail actuel de Procmail. Si défini, tous les autres chemins Procmail seront relatifs à ce répertoire.ORGMAIL— spécifie la boîte aux lettres d'origine, ou un autre endroit où placer les messages s'ils ne peuvent pas être mis dans l'emplacement par défaut ou l'emplacement requis par la recette.Par défaut, une valeur de/var/spool/mail/$LOGNAMEest utilisée.SUSPEND— définit la durée, en secondes, pendant laquelle Procmail fait une pause si une ressource importante, telle que l'espace swap, n'est pas disponible.SWITCHRC— permet à un utilisateur de spécifier un fichier externe contenant des recettes Procmail supplémentaires similaires à l'optionINCLUDERC, sauf que la vérification de recette s'arrête sur le fichier de configuration reférant et seules les recettes se trouvant sur le fichier spécifié parSWITCHRCsont utilisées.VERBOSE— amène Procmail à journaliser davantage d'information. Cette option est utile pour le débogage.
LOGNAME, le nom de connexion ; HOME, l'emplacement du répertoire personnel ; et SHELL, le shell par défaut.
procmailrc.
13.4.2. Recettes Procmail
flags indiquent qu'un fichier lockfile est créé pour ce message. Si un ficier lockfile est créé, le nom peut être spécifié en remplaçant lockfile-name.
*).
action-to-perform spécifie l'action effectuée lorsque le message correspond à l'une des conditions. Il ne peut y avoir qu'une seule action par recette. Dans de nombreux cas, le nom d'une boîte aux lettres est utilisé pour diriger les messages correspondants vers ce fichier, triant ainsi le courrier électronique. Les caractères d'action spéciaux peuvent également être utilisés avant que l'action ne soit spécifiée. Veuillez consulter la Section 13.4.2.4, « Conditions et actions spéciales » pour obtenir davantage d'informations.
13.4.2.1. Recettes de remise vs. Recettes de non-remise
{ }, qui sont effectuées sur les messages correspondants aux conditions de la recette. Les blocs imbriqués peuvent être imbriqués à l'intérieur les uns des autres, offrant ainsi un meilleur contrôle pour identifier et effectuer des actions sur les messages.
13.4.2.2. Marqueurs
A— spécifie que cette recette est uniquement utilisée si la recette précédente sans marqueurAouacorrespondait également à ce message.a— spécifie que cette recette est uniquement utilisée si la recette précédente avec un marqueurAouacorrespondait également à ce message et a été appliquée.B— analyse le corps du message et recherche des conditions correpondantes.b— utilise le corps dans toute action résultante, comme l'écriture du message sur un fichier ou son transfert. Il s'agit du comportement par défaut.c— génère une copie carbone du courrier électronique. Ceci est utile avec les recettes de remise, car l'action requise peut être effectuée sur le message et une copie du message peut toujours être en cours de traitement dans les fichiersrc.D— fait respecter la casse à la comparaisonegrep. Par défaut, le processus de comparaison ne respecte pas la casse.E— malgré des similarités avec le marqueurA, les conditions de la recette sont uniquement comparées au message si la recette la précédant immédiatement sans marqeurEne correspondait pas. Ceci est comparable à une action else.e— la recette est comparée au message uniquement si l'action spécifiée dans la recette la précédant immédiatement échoue.f— utilise le tube (« pipe ») en tant que filtre.H— analyse l'en-tête du message et recherche des conditions correspondantes. Ceci est le comportement par défaut.h— utilise l'en-tête dans une action résultante. Ceci est le comportement par défaut.w— ordonne à Procmail d'attendre que le filtre ou programme spécifié se termine, et rapporte si celui-ci a réussi ou non avant de considérer le message comme filtré.W— est identique àw, sauf que les messages « Échec du programme » sont supprimés.
procmailrc.
13.4.2.3. Spécifier un fichier lockfile local
:) après tout marqueur se trouvant sur la première ligne d'une recette. Ceci crée un fichier lockfile local basé sur le nom du fichier destinataire plus ce qui a été défini dans la variable globale d'environnement LOCKEXT.
13.4.2.4. Conditions et actions spéciales
*) au début de la ligne de condition d'une recette :
!— dans la ligne de condition, ce caractère inverse la condition. Ainsi, une correspondance ne se produira que si la condition ne correspond pas au message.<— vérifie si le message fait moins qu'un nombre d'octets spécifié.>— vérifie si le message fait plus qu'un nombre d'octets spécifié.
!— dans la ligne de l'action, ce caractère ordonne à Procmail de transférer le message vers les adresses électroniques spécifiées.$— fait référence à une variable précédemment définie dans le fichierrc. Souvent utilisé pour définir une boîte aux lettres commune à laquelle diverses recettes font référence.|— lance un programme spécifié pour traiter le message.{and}— permet de construire un bloc imbriqué, utilisé pour contenir des recettes supplémentaires pour appliquer des messages correspondants.
13.4.2.5. Exemples de recettes
grep(1).
:0: new-mail.spool
:0:
new-mail.spoolLOCKEXT. Aucune condition n'est spécifiée, donc chaque message correspond à cette recette et est placé dans l'unique fichier spool nommé new-mail.spool, qui est situé dans un répertoire spécifié par la variable d'environnement MAILDIR. Un MUA peut ensuite afficher les messages dans ce fichier.
rc pour diriger les messages vers un emplacement par défaut.
:0 * ^From: spammer@domain.com /dev/null
:0
* ^From: spammer@domain.com
/dev/nullspammer@domain.com est envoyé sur le périphérique /dev/null, qui les supprime.
Avertissement
/dev/null pour une suppression permanente. Si une recette obtient des messages de manière non-intentionnelle et que ces messages disparaissent, il sera difficile de résoudre le problème de la règle.
/dev/null.
:0: * ^(From|Cc|To).*tux-lug tuxlug
:0:
* ^(From|Cc|To).*tux-lug
tuxlugtux-lug@domain.com est automatiquement placé dans la boîte aux lettres tuxlug pour le MUA. Veuillez remarquer que la condition dans cet exemple correspond au message si l'adresse de la liste de diffusion se trouve sur la ligne De (« From »), Cc, ou À (« To »).
13.4.2.6. Filtres du courrier indésirable
Note
root :
yum install spamassassin
~]# yum install spamassassin~/.procmailrc :
INCLUDERC=/etc/mail/spamassassin/spamassassin-default.rc
INCLUDERC=/etc/mail/spamassassin/spamassassin-default.rc/etc/mail/spamassassin/spamassassin-default.rc contient une règle Procmail simple qui active SpamAssassin pour le courrier entrant. Si un courrier électronique est déterminé comme étant un courrier indésirable, son en-tête est balisé comme tel et le modèle suivant est ajouté au début de son titre :
*****SPAM*****
*****SPAM*****:0 Hw * ^X-Spam-Status: Yes spam
:0 Hw * ^X-Spam-Status: Yes spamspam.
spamd) et l'application cliente (spamc) sur des serveurs occupés. Cependant, la configuration de SpamAssassin de cette manière, requiert un accès root à l'hôte.
spamd, veuillez saisir la commande suivante :
systemctl start spamassassin
~]# systemctl start spamassassinsystemctl enable spamassassin.service
systemctl enable spamassassin.service~/.procmailrc. Pour une configuration globale, veuillez la placer dans /etc/procmailrc :
INCLUDERC=/etc/mail/spamassassin/spamassassin-spamc.rc
INCLUDERC=/etc/mail/spamassassin/spamassassin-spamc.rc13.5. Mail User Agents (MUA)
mutt.
13.5.1. Sécuriser les communications
POP et IMAP passent des informations d'authentification non chiffrées, il est possible qu'une personne malveillante obtienne accès aux comptes des utilisateurs en récupérant les noms d'utilisateurs et mots de passe quand ils sont passés sur le réseau.
13.5.1.1. Clients de messagerie sécurisés
IMAP et POP ont des numéros de port (993 et 995, respectivement) utilisés par le MUA pour authentifier et télécharger des messages.
13.5.1.2. Sécurisation des communications des clients de messagerie
IMAP et POP sur le serveur de messagerie est une simple question.
Avertissement
IMAP ou POP, rendez-vous dans le répertoire /etc/pki/dovecot/, modifiez les paramètres du certificat dans le fichier de configuration /etc/pki/dovecot/dovecot-openssl.cnf selon vos préférences, puis saisissez les commandes suivantes en tant qu'utilisateur root :
dovecot]# rm -f certs/dovecot.pem private/dovecot.pem dovecot]# /usr/libexec/dovecot/mkcert.sh
dovecot]# rm -f certs/dovecot.pem private/dovecot.pem
dovecot]# /usr/libexec/dovecot/mkcert.sh/etc/dovecot/conf.d/10-ssl.conf :
ssl_cert = </etc/pki/dovecot/certs/dovecot.pem ssl_key = </etc/pki/dovecot/private/dovecot.pem
ssl_cert = </etc/pki/dovecot/certs/dovecot.pem
ssl_key = </etc/pki/dovecot/private/dovecot.pemdovecot :
systemctl restart dovecot
~]# systemctl restart dovecotstunnel peut être utilisée comme emballage de chiffrement autour des connexions standards non-sécurisées aux services IMAP ou POP.
stunnel utilise des bibliothèques OpenSSL externes incluses avec Red Hat Enterprise Linux pour fournir un chiffrement fort et pour protéger les connexions réseau. Il est recommandé d'appliquer sur un CA pour obtenir un certificat SSL, mais il est également possible de créer un certificat autosigné.
stunnel et pour créer sa configuration de base. Pour configurer stunnel comme emballage pour IMAPS et POP3S, veuillez ajouter les lignes suivantes au fichier de configuration /etc/stunnel/stunnel.conf :
stunnel. Une fois lancé, il est possible d'utiliser un client de messagerie IMAP ou POP et de se connecter au serveur de messagerie en utilisant le chiffrement SSL.
13.6. Ressources supplémentaires
13.6.1. Documentation installée
- Des informations sur la configuration de Sendmail sont incluses avec les paquets sendmail et sendmail-cf.
/usr/share/sendmail-cf/README— contient des informations sur le processeur macrom4, les emplacements des fichiers pour Sendmail, les logiciels de messagerie pris en charge, sur les manières d'accéder aux fonctionnalités améliorées, et bien plus.
En outre, les pages man desendmailetaliasescontiennent des informations utiles traitant des diverses options Sendmail et de la configuration correcte du fichier Sendmail/etc/mail/aliases. /usr/share/doc/postfix-version-number/— contient une grande quantité d'informations sur comment configurer Postfix. Remplacez version-number par le numéro de version de Postfix./usr/share/doc/fetchmail-version-number/— contient une liste complète des fonctionnalités de Fetchmail dans le fichierFEATURESainsi qu'uneFAQd'introduction. Remplacez version-number par le numéro de version de Fetchmail./usr/share/doc/procmail-version-number/— contient un fichierREADMEqui fournit une vue d'ensemble de Procmail, un fichierFEATURESqui explore toutes les fonctionnalités du programme, et un fichierFAQavec les réponses à de nombreuses questions communes sur la configuration. Remplacez version-number par le numéro de version de Procmail.Lors de l'apprentissage de Procmail et de la création de nouvelles recettes, les pages man Procmail suivantes seront indispensables :procmail— fournit une vue d'ensemble du fonctionnement de Procmail et des étapes impliquées dans le filtrage du courrier.procmailrc— explique le format du fichierrcutilisé pour créer des recettes.procmailex— donne un certain nombre d'exemples utiles et réels de recettes Procmail.procmailsc— explique la technique de notation pondérée utilisée par Procmail pour faire correspondre une recette particulière à un message./usr/share/doc/spamassassin-version-number/— contient une grande quantité d'informations pertinentes à SpamAssassin. Remplacez version-number par le numéro de version du paquet spamassassin.
13.6.2. Documentation en ligne
- Comment configurer postfix avec TLS ? — un article de Red Hat Knowledgebase qui décrit comment configurer postfix pour utiliser TLS.
- http://www.sendmail.org/ — offre une décomposition minutieuse des fonctionnalités, de la documentation, et des exemples de configuration de Sendmail.
- http://www.sendmail.com/ — contient des informations, entretiens, et articles concernant Sendmail, y compris une vue étendue des nombreuses options disponibles.
- http://www.postfix.org/ — la page d'accueil du projet Postfix contient une mine d'informations sur Postfix. La liste de diffusion est particulièrement utile pour rechercher des informations.
- http://www.fetchmail.info/fetchmail-FAQ.html — FAQ détaillée sur Fetchmail.
- http://www.procmail.org/ — page d'accueil de Procmail avec des liens vers les listes de diffusion dédiées à Procmail ainsi que divers documents FAQ.
- http://www.uwasa.fi/~ts/info/proctips.html — contient une douzaine de conseils qui permettent une utilisation bien plus facile de Procmail. Y compris des instructions sur la manière de tester les fichiers
.procmailrcet d'utiliser la notation Procmail pour décider si une action particulière doit être prise. - http://www.spamassassin.org/ — site officiel du projet SpamAssassin.
Chapitre 14. Serveurs de fichiers et d'impression
CIFS), et vsftpd, le principal serveur FTP fourni avec Red Hat Enterprise Linux. En outre, il explique comment utiliser l'outil Imprimer les paramètres pour configurer les imprimantes.
14.1. Samba
SMB). SMB permet à Microsoft Windows®, Linux, UNIX, et à d'autres systèmes d'exploitation d'accéder à des fichiers et à des imprimantes partagés à partir de serveurs qui prennent en charge ce protocole. L'utilisation de SMB par Samba leur permet d'apparaître comme serveur Windows pour les clients Windows.
Note
root :
yum install samba
~]# yum install samba14.1.1. Introduction à Samba
Ce que Samba peut faire :
- Servir des structures de répertoires et des imprimantes à des clients Linux, UNIX, et Windows
- Assister lors de la navigation réseau (avec NetBIOS)
- Authentifier les connexions aux domaines Windows
- Fournir des résolutions de serveur de noms Windows Internet Name Service (
WINS) - Agir en tant que contrôleur de domaine de sauvegarde (PDC) NT®-style Primary Domain Controller
- Agir en tant que contrôleur de domaine de sauvegarde (BDC) Backup Domain Controller pour un PDC basé Samba
- Agir en tant que serveur membre d'un domaine Active Directory
- Joindre un serveur Windows NT/2000/2003/2008 PDC/Windows Server 2012
Ce que Samba ne peut pas faire :
- Agir en tant que BDC pour un PDC Windows (et vice-versa)
- Agir en tant que contrôleur de domaine Active Directory
14.1.2. Démons Samba et services connexes
smbd, nmbd, et winbindd). Trois services (smb, nmb, et winbind) contrôlent la manière par laquelle les démons sont lancés, arrêtés, ainsi que d'autres fonctionnalités liées aux services. Ces services agissent comme scripts init différents. Chaque démon est répertorié de manière détaillée ci-dessous, ainsi que les services spécifiques qui en possèdent le contrôle.
smbd
smbd fournit des services d'impression et de partage de fichiers aux clients Windows. De plus, il est responsable pour l'authentification utilisateur, le verrouillage de ressources, et le partage de données via le protocole SMB. Les ports par défaut sur lesquels le serveur écoute le trafic SMB sont les ports TCP 139 et 445.
smbd est contrôlé par le service smb.
nmbd
nmbd comprend et répond aux requêtes de service de noms NetBIOS comme celles produites par SMB/CIFS sur des systèmes basés Windows. Ces systèmes incluent des clients Windows 95/98/ME, Windows NT, Windows 2000, Windows XP, et LanManager. Il participte également aux protocoles de navigation qui composent l'affichage du Voisinage réseau Windows. Le port par défaut sur lequel le serveur écoute le trafic NMB et le port UDP 137.
nmbd est contrôlé par le service nmb.
winbindd
windbind résout les informations des utilisateurs et des groupes reçues d'un serveur exécutant Windows NT, 2000, 2003, Windows Server 2008, ou Windows Server 2012. Ceci rend les informations des utilisateurs et des groupes Windows compréhensibles par les plateformes UNIX. Cela est effectué en utilisant des appels Microsoft RPC, PAM (« Pluggable Authentication Modules »), et NSS (« Name Service Switch »). Cela permet aux utilisateurs de domaines Windows NT et d'AD (Active Directory) d'apparaître et d'opérer comme s'ils étaient des utilisateurs UNIX sur une machine UNIX. Malgré qu'il soit combiné à la distribution Samba, le service winbind est contrôlé séparément à partir du service smb.
winbind est contrôlé par le service winbind et ne requiert pas que le service smb soit lancé pour opérer. winbind est également utilisé lorsque Samba est un membre d'Active Directory, et peut aussi être utilisé sur un contrôleur de domaines Samba (pour implémenter des groupes imbriqués et une confiance interdomaines). Comme winbind est un service côté client utilisé pour connecter des serveurs Windows basés NT, une discussion approfondie sur winbind est au-delà de l'étendue de ce chapitre.
Note
14.1.3. Se connecter à un partage Samba
Procédure 14.1. Se connecter à un partage Samba via Nautilus
- Pour afficher une liste des groupes de travail Samba et des domaines sur votre réseau, veuillez sélectionner → dans le panneau GNOME, puis sélectionner le réseau souhaité. Vous pouvez également saisir
smb:dans la barre → de Nautilus.Comme indiqué dans la Figure 14.1, « Groupes de travail SMB dans Nautilus », une icône s'affiche pour chaque groupe de travail ou domaineSMBsur le réseau.
Figure 14.1. Groupes de travail SMB dans Nautilus
- Faites un double clic sur l'icône de groupe de travail ou de domaine pour afficher la liste des ordinateurs dans ce groupe de travail ou dans ce domaine.
Figure 14.2. Machines SMB dans Nautilus
- Comme indiqué dans la Figure 14.2, « Machines SMB dans Nautilus », une icône existe pour chaque machine dans le groupe de travail. Faites un double clic sur une icône pour afficher les partages Samba sur la machine. Si une combinaison nom d'utilisateur et mot de passe est requise, celle-ci vous sera demandée.Alternativement, vous pouvez également spécifier le serveur Samba et le nom du partage dans la barre Location: de Nautilus en utilisant la syntaxe suivante (remplacez servername et sharename par les valeurs appropriées) :
smb://servername/sharename
smb://servername/sharenameCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Procédure 14.2. Se connecter à un partage Samba par l'interface en ligne de commande
- Pour se connecter à un partage Samba à partir d'une invite de shell, veuillez saisir la commande suivante :
smbclient //hostname/sharename -U username
~]$ smbclient //hostname/sharename -U usernameCopy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacez hostname par le nom d'hôte ou par l'adresseIPdu serveur Samba auquel vous souhaitez vous connecter, sharename par le nom du répertoire partagé que vous souhaitez parcourir, et username par le nom d'utilisateur Samba du système. Saisissez le mot de passe correct ou appuyez sur Entrée si aucun mot de passe n'est requis pour l'utilisateur.Si vous voyez l'invitesmb:\>, cela signifie que vous vous êtes connecté. Une fois connecté, veuillez saisirhelppour obtenir la liste des commandes. Si vous souhaitez parcourir le contenu de votre répertoire personnel, remplacez sharename par votre nom d'utilisateur. Si le commutateur-Un'est pas utilisé, le nom d'utilisateur de l'utilisateur actuel sera transmis au serveur Samba. - Pour quitter
smbclient, saisissezexità l'invitesmb:\>.
14.1.5. Configurer un serveur Samba
/etc/samba/smb.conf) permet aux utilisateurs de voir leur répertoire personnel en tant que partage Samba. Il partage également toutes les imprimantes configurées pour le système en tant qu'imprimantes partagées Samba. Vous pouvez attacher une imprimante au système et l'utiliser à partir de machines Windows sur votre réseau.
14.1.5.1. Configuration graphique
14.1.5.2. Configuration en ligne de commande
/etc/samba/smb.conf comme fichier de configuration. Si vous modifiez cela, les changements n'entreront en vigueur que lorsque vous redémarrez le démon Samba avec la commande suivante, en tant qu'utilisateur root :
systemctl restart smb.service
~]# systemctl restart smb.service/etc/samba/smb.conf :
workgroup = WORKGROUPNAME server string = BRIEF COMMENT ABOUT SERVER
workgroup = WORKGROUPNAME
server string = BRIEF COMMENT ABOUT SERVER/etc/samba/smb.conf (après l'avoir modifiée pour refléter vos besoins et ceux de votre système) :
Exemple 14.1. Exemple de configuration de serveur Samba
tfox et carole de lire et d'écrire sur le répertoire /home/share/, situé sur le serveur Samba, à partir d'un client Samba.
14.1.5.3. Mots de passe chiffrés
smbpasswd :
smbpasswd -a username
smbpasswd -a username14.1.6. Lancer et arrêter Samba
root :
systemctl start smb.service
~]# systemctl start smb.serviceImportant
net join avant de lancer le service smb. Il est également recommandé d'exécuter winbind avant smbd.
root :
systemctl stop smb.service
~]# systemctl stop smb.servicerestart est une façon rapide d'arrêter, puis de redémarrer Samba. Cette manière est la plus efficace pour que les changements de configuration puissent entrer en vigueur après avoir modifié le fichier de configuration de Samba. Remarquez que l'option de redémarrage lance le démon même s'il n'était pas exécuté à l'origine.
root :
systemctl restart smb.service
~]# systemctl restart smb.servicecondrestart (redémarrage conditionnel, « conditional restart ») lance smb à condition d'être actuellement en cours d'exécution. Cette option est utile pour les scripts, car elle ne lance pas le démon s'il n'est pas en cours d'exécution.
Note
/etc/samba/smb.conf est modifié, Samba le recharge automatiquement après quelques minutes. Exécuter un redémarrage manuel (« restart ») ou un rechargement manuel (« reload ») est tout autant efficace.
root :
systemctl try-restart smb.service
~]# systemctl try-restart smb.service/etc/samba/smb.conf peut être utile en cas d'échec du rechargement automatique effectué par le service smb. Pour vous assurer que le fichier de configuration du serveur Samba soit rechargé sans redémarrer le service, veuillez saisir la commande suivante en tant qu'utilisateur root :
systemctl reload smb.service
~]# systemctl reload smb.servicesmb n'est pas lancé automatiquement pendant l'initialisation. Pour configurer Samba pour qu'il soit lancé pendant l'initialisation, veuillez saisir ce qui suit dans une invite de shell en tant qu'utilisateur root :
systemctl enable smb.service
~]# systemctl enable smb.service14.1.7. Mode de sécurité de Samba
14.1.7.1. Sécurité Niveau utilisateur
security = user n’est pas répertoriée dans le fichier /etc/samba/smb.conf, elle sera utilisée par Samba. Si le serveur accepte le nom d'utilisateur et mot de passe du client, le client peut alors monter plusieurs partages sans spécifier un mot de passe pour chaque instance. Samba peut également accepter des demandes de noms et mots de passe basés sur une session utilisateur. Le client maintient plusieurs contextes d’authentification en utilisant un UID unique pour chaque ouverture de session.
/etc/samba/smb.conf, la directive security = user qui détermine la sécurité niveau utilisateur correspond à :
[GLOBAL] ... security = user ...
[GLOBAL]
...
security = user
...Partages d'invités Samba
security = share, suivre la procédure ci-dessous :
Procédure 14.3. Configuration des partages d'invités Samba
- Créer un fichier de mise en correspondance des noms d'utilisateur, dans cet exemple,
/etc/samba/smbusers, et y ajouter la ligne suivante :nobody = guest
nobody = guestCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Ajouter la directive suivante à la section principale du fichier
/etc/samba/smb.conf. Ne pas utiliser la directivevalid users.Copy to Clipboard Copied! Toggle word wrap Toggle overflow La directiveusername mapvous donne un chemin vers le fichier de mappage des noms utilisateurs dans l'étape précédente. - Ajouter la directive suivante à la section partages dans le fichier
/ect/samba/smb.conf. Ne pas utiliser la directivevalid users.[SHARE] ... guest ok = yes ...
[SHARE] ... guest ok = yes ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Mode de sécurité domaine (sécurité niveau utilisateur)
/etc/samba/smb.conf :
[GLOBAL] ... security = domain workgroup = MARKETING ...
[GLOBAL]
...
security = domain
workgroup = MARKETING
...Mode de sécurité Active Directory (sécurité niveau utilisateur)
/etc/samba/smb.conf, les directives suivantes font de Samba un membre d'Active Directory.
14.1.8. Navigation réseau Samba
TCP/IP. La mise en réseau basée NetBIOS utilise une messagerie de diffusion (UDP) pour accomplir la gestion de liste de parcours. Sans NetBIOS et WINS comme méthode principale de résolution de nom d'hôte TCP/IP, d'autres méthodes comme les fichiers statiques (/etc/hosts) ou DNS devront être utilisées.
14.1.8.1. Exploration de domaines
/etc/samba/smb.conf pour un explorateur principal local (ou sans aucune exploration) dans un environnement de contrôleur de domaine est la même chose qu'une configuration de groupe de travail (veuillez consulter Section 14.1.5, « Configurer un serveur Samba »).
14.1.8.2. WINS (« Windows Internet Name Server »)
/etc/samba/smb.conf, dans lequel le serveur Samba sert de serveur WINS :
Exemple 14.2. Exemple de configuration de serveur WINS
[global] wins support = yes
[global]
wins support = yesNote
14.1.9. Programmes de distribution Samba
net
net <protocol> <function> <misc_options> <target_options>
net <protocol> <function> <misc_options> <target_options>net est similaire à l'utilitaire net utilisé pour Windows et MS-DOS. Le premier argument est utilisé pour spécifier le protocole à utiliser lors de l'exécution d'une commande. L'option protocol peut être ads, rap, ou rpc pour spécifier le type de connexion serveur. Active Directory utilise ads, Win9x/NT3 utilise rap et Windows NT4/2000/2003/2008 utilise rpc. Si le protocole est omis, net tente de le déterminer automatiquement.
wakko :
wakko :
nmblookup
nmblookup <options> <netbios_name>
nmblookup <options> <netbios_name>nmblookup résout les noms NetBIOS en adresses IP. Le programme diffuse sa requête sur le sous-réseau local jusqu'à ce que la machine cible réponde.
IP du nom NetBIOS trek :
nmblookup trek querying trek on 10.1.59.255 10.1.56.45 trek<00>
~]$ nmblookup trek
querying trek on 10.1.59.255
10.1.56.45 trek<00>pdbedit
pdbedit <options>
pdbedit <options>pdbedit gère les comptes situés dans la base de données SAM. Tous les serveurs principaux sont pris en charge, y compris smbpasswd, LDAP, et la bibliothèque de base de données tdb.
rpcclient
rpcclient <server> <options>
rpcclient <server> <options>rpcclient exécute des commandes administratives en utilisant des RPC Microsoft, qui fournissent accès aux interfaces utilisateur graphique (GUI) d'administration Windows pour la gestion des systèmes. Ce programme est souvent utilisé par des utilisateurs de niveau avancé, qui comprennent parfaitement la complexité des RPC Microsoft.
smbcacls
smbcacls <//server/share> <filename> <options>
smbcacls <//server/share> <filename> <options>smbcacls modifie les ACL Windows sur les fichiers et répertoires partagés par un serveur Samba ou un serveur Windows.
smbclient
smbclient <//server/share> <password> <options>
smbclient <//server/share> <password> <options>smbclient est un client UNIX polyvalent offrant une fonctionnalité similaire à ftp.
smbcontrol
smbcontrol -i <options>
smbcontrol -i <options>smbcontrol <options> <destination> <messagetype> <parameters>
smbcontrol <options> <destination> <messagetype> <parameters>smbcontrol envoie des messages de contrôle aux démons en cours d'exécution smbd, nmbd, ou winbindd. L'exécution de smbcontrol -i exécute des commandes de manière interactive jusqu'à ce qu'une ligne blanche ou que le caractère 'q' soit saisi(e).
smbpasswd
smbpasswd <options> <username> <password>
smbpasswd <options> <username> <password>smbpasswd gère des mots de passe chiffrés. Ce programme peut être utilisé par un super-utilisateur pour modifier le mot de passe de tout autre utilisateur, ainsi que par un utilisateur ordinaire pour qu'il puisse modifier son propre mot de passe Samba.
smbspool
smbspool <job> <user> <title> <copies> <options> <filename>
smbspool <job> <user> <title> <copies> <options> <filename>smbspool est une interface d'impression compatible avec CUPS sur Samba. Malgré sa conception destinée à une utilisation avec des imprimantes CUPS, smbspool peut également fonctionner avec des imprimantes n'utilisant pas CUPS.
smbstatus
smbstatus <options>
smbstatus <options>smbstatus affiche le statut des connexions actuelles à un serveur Samba.
smbtar
smbtar <options>
smbtar <options>smbcacls effectue des copies de sauvegarde et des restaurations de fichiers et répertoires de partage basés Windows sur une bande d'archive locale. Malgré des similarités avec la commande tar, les deux ne sont pas compatibles.
testparm
testparm <options> <filename> <hostname IP_address>
testparm <options> <filename> <hostname IP_address>testparm vérifie la syntaxe du fichier /etc/samba/smb.conf. Si votre fichier smb.conf ne se trouve pas dans l'emplacement par défaut (/etc/samba/smb.conf), vous n'aurez pas besoin de spécifier l'emplacement. La spécification du nom d'hôte et de l'adresse IP sur le programme testparm vérifie si les fichiers hosts.allow et host.deny sont correctement configurés. Le programme testparm affiche également un résumé du fichier smb.conf et le rôle du serveur (stand-alone, domain, etc.), après avoir effectué des tests. Ceci est utile lors du débogage car les commentaires sont exclus et les informations sont présentées de façon concise pour permettre leur lecture à des administrateurs expérimentés. Exemple :
wbinfo
wbinfo <options>
wbinfo <options>wbinfo affiche des informations du démon winbindd. Le démon winbindd doit être en cours d'exécution pour que wbinfo fonctionne.
14.1.10. Ressources supplémentaires
Documentation installée
/usr/share/doc/samba-<version-number->/— comprend tous les fichiers supplémentaires inclus avec la distribution de Samba. Ceux-ci incluent tous les scripts d'aide, tous les exemples de fichiers de configuration, et toute la documentation.- Veuillez consulter les pages de manuel suivantes pour obtenir des informations détaillées sur les fonctionnalités de Samba :
- smb.conf(5)
- samba(7)
- smbd(8)
- nmbd(8)
- winbindd(8)
Sites Web utiles
- http://www.samba.org/ — page d'accueil de la distribution de Samba ainsi que de toute la documentation créée par l'équipe de développement Samba. De nombreuses ressources sont disponibles sous les formats HTML et PDF, tandis que d'autres sont uniquement disponibles à l'achat. Même si un grand nombre de ces liens ne sont pas spécifiques à Red Hat Enterprise Linux, certains concepts peuvent s'appliquer.
- https://wiki.samba.org/index.php/User_Documentation — documentation officielle de Samba 4.x
- http://samba.org/samba/archives.html — listes actives de courriers électroniques de la communauté Samba. L'activation du mode de synthèse (« digest mode ») est recommandé à cause du niveau élevé d'activité de la liste.
- Samba newsgroups — des groupes d'informations en threads de Samba, par exemple www.gmane.org, qui utilisent le protocole
NNTPsont également disponibles. Cela est une alternative à la réception de courriers électroniques de la liste de diffusion.
14.2. FTP
FTP) est l'un des protocoles les plus anciens et des plus couramment utilisés sur Internet de nos jours. Son but est de permettre un transfert fiable entre ordinateurs hôtes sur un réseau sans que l'utilisateur ait besoin de se connecter directement à l'hôte distant ou ne possède de connaissances sur l'utilisation d'un système distant. Il permet aux utilisateurs d'accéder à des fichiers sur des systèmes distants en utilisant un ensemble standard de commandes simples.
FTP et présente vsftpd, qui est le serveur FTP préféré sur Red Hat Enterprise Linux.
14.2.1. Le protocole de transfert de fichiers
TCP. Comme FTP est une protocole relativement ancien, l'authentification du nom d'utilisateur et du mot de passe n'est pas chiffrée. Pour cela, FTP est considéré comme un protocole non sécurisé et ne doit pas être utilisé sauf si absolument nécessaire. Cepedant, FTP est si répandu sur Internet qu'il est souvent requis pour partager des fichiers avec le public. Ainsi, les administrateurs doivent avoir connaissanece des caractéristiques uniques de FTP.
TLS et comment sécuriser un serveur FTP à l'aide de SELinux. Un bon protocole de substitution de FTP est sftp, de la suite d'outils OpenSSH. Pour obtenir des informations sur la configuration d'OpenSSH et sur le protocole SSH en général, veuillez consulter le Chapitre 10, OpenSSH.
FTP requiert de multiples ports réseau pour fonctionner correctement. Lorsqu'une application cliente FTP initie une connexion vers un serveur FTP, celle-ci ouvre le port 21 sur le serveur — qui est également appelé port des commandes. Ce port est utilisé pour exécuter toutes les commandes sur le serveur. Toutes les données requises du serveur sont retournées vers le client via un port de données. Le numéro de port pour les connexions de données et la manière par laquelle celles-ci sont initialisées dépendent de si le client requiert les données en mode actif ou passif.
- mode actif
- Le mode actif est la méthode d'origine utilisée par le protocole
FTPpour transférer des données vers l'application cliente. Lorsqu'un transfert de données en mode actif est initié par le clientFTP, le serveur ouvre une connexion sur le port20du serveur pour l'adresseIPainsi qu'un port aléatoire, non privilégié (supérieur à1024), spécifié par le client. Cet arrangement signifie que la machine cliente doit être autorisée à accepter des connexions sur tout port supérieur à1024. Avec l'augmentation des réseaux non sécurisés, comme internet, l'utilisation de pare-feux pour protéger les machines clientes s'est répandue. Comme les pare-feux du côté client refusent souvent des connexions entrantes en provenance de serveursFTPen mode actif, un mode passif a été conçu. - mode passif
- Le mode passif, tout comme le mode actif, est initié par l'application cliente
FTP. Lorsque des données sont requises du serveur, le clientFTPindique qu'il souhaite accéder aux données en mode passif et le serveur fournit l'adresseIPainsi qu'un port aléatoire, non-privilégié (supérieur à1024) sur le serveur. Le client se connecte ensuite à ce port sur le serveur pour télécharger les informations requises.Même si le mode passif résout des problèmes d'interférences du pare-feu côté client avec les connexions de données, il peut également compliquer l'administration du pare-feu côté serveur. Vous pouvez réduire le nombre de ports ouverts sur un serveur en limitant la plage de ports non-privilégiés sur le serveurFTP. Cela simplifie également le processus de configuration des règles du pare-feu pour le serveur.
14.2.2. Serveur vsftpd
vsftpd (Very Secure FTP Daemon) a été conçu dès le début pour être rapide, stable, et surtout sécurisé. vsftpd est le seul serveur FTP autonome distribué avec Red Hat Enterprise Linux, grâce à sa capacité de gestion efficace et sécurisée de grands nombres de connexion.
vsftpd offre trois aspects principaux :
- Une importante séparation entre les processus privilégiés et non-privilégiés — les processus séparés gèrent différentes tâches, et chacun de ces processus est exécuté avec les privilèges minimaux requis pour la tâche.
- Les tâches qui requièrent des privilèges élevés sont gérées par des processus avec le minimum des privilèges nécessaires — en tirant profit des compatibilités trouvées dans la bibliothèque
libcap, les tâches qui requièrent normalement la totalité des privilèges root peuvent être exécutées de manière plus sécurisée à partir d'un processus moins privilégié. - La plupart des processus sont exécutés dans une prison
chroot— lorsque c'est possible, les processus sont « change-rooted » sur le répertoire en cours de partage ; ce répertoire est ensuite considéré comme une prisonchroot. Par exemple, si le répertoire/var/ftp/est le répertoire principal partagé,vsftpdréassigne/var/ftp/au nouveau répertoire root, nommé/. Ceci prévient toute activité pirate potentielle d'une personne malveillante sur tous les répertoires qui ne sont pas contenus dans le nouveau répertoire root.
vsftpd traite les requêtes :
- Le processus parent est exécuté avec le minimum de privilèges requis — le processus parent calcule dynamiquement le niveau de privilèges requis pour minimiser le niveau de risques. Les processus enfants gèrent les interactions directes avec les clients
FTPet sont exécutés avec aussi peu de privilèges que possible. - Toutes les opérations nécessitant une élévation de privilèges sont gérées par un petit processus parent — tout comme avec le serveur
HTTPApache,vsftpdlance des processus enfants non privilégiés pour gérer les connexions entrantes. Ceci permet au processsus parent privilégié d'être aussi petit que possible et de gérer un nombre de tâches relativement faible. - Le processus parent se méfie de toutes les requêtes des processus enfants non privilégiés — Les communications avec les processus enfants sont reçues via un socket, et la validité des information en provenance d'un processus enfant est vérifiée avant qu'une action ne soit déclenchée.
- La plupart des interactions avec des clients
FTPsont gérées par des processus enfants non privilégiés dans une prisonchroot— comme ces processus enfants ne sont pas privilégiés et ont uniquement accès au répertoire partagé, tout processus ayant échoué n'autorisera une personne malveillante à n'accéder qu'aux fichiers partagés.
14.2.2.1. Démarrage et arrêt de vsftpd
vsftpd dans la session actuelle, veuillez saisir ce qui suit dans l'invite de shell en tant qu'utilisateur root :
systemctl start vsftpd.service
~]# systemctl start vsftpd.serviceroot :
systemctl stop vsftpd.service
~]# systemctl stop vsftpd.servicevsftpd, veuillez exécuter la commande suivante en tant qu'utilisateur root :
systemctl restart vsftpd.service
~]# systemctl restart vsftpd.servicevsftpd, ce qui est la manière la plus efficace de faire en sorte que les changements entrent en vigueur après avoir modifié le fichier de configuration de ce serveur FTP. De manière alternative, vous pouvez utiliser la commande suivante pour redémarrer le service vsftpd, uniquement s'il est déjà en cours d'exécution :
systemctl try-restart vsftpd.service
~]# systemctl try-restart vsftpd.servicevsftpd n'est pas lancé automatiquement pendant l'initialisation. Pour configurer le service vsftpd pour qu'il soit lancé pendant le démarrage, veuillez saisir ce qui suit dans une invite de shell en tant qu'utilisateur root :
systemctl enable vsftpd.service Created symlink from /etc/systemd/system/multi-user.target.wants/vsftpd.service to /usr/lib/systemd/system/vsftpd.service.
~]# systemctl enable vsftpd.service
Created symlink from /etc/systemd/system/multi-user.target.wants/vsftpd.service to /usr/lib/systemd/system/vsftpd.service.14.2.2.2. Lancer de multiples copies de vsftpd
FTP. Cette technique est nommée multihoming (multiréseaux). Une manière d'effectuer un multihome en utilisant vsftpd consiste à exécuter de multiples copies du démon, chacune avec son propre fichier de configuration.
IP à des périphériques réseau ou à des alias de périphériques réseau sur le système. Pour obtenir davantage d'informations sur la configuration des périphériques réseau, des alias de périphériques, ainsi que des informations sur les scripts de configuration réseau, veuillez consulter le Guide de mise en réseau Red Hat Enterprise Linux 7.
FTP devra être configuré pour faire référence à la machine qui convient. Pour obtenir des informations sur BIND, le protocole d'implémentation DNS utilisé sur Red Hat Enterprise Linux, ainsi que sur ses fichiers de configuration, veuillez consulter le Guide de mise en réseau Red Hat Enterprise Linux 7.
vsftpd réponde à des requêtes sur différentes adresses IP, de multiples copies du démon doivent être en cours d'exécution. Pour faciliter le lancement de multiples instances du démon vsftpd, une unité spéciale du service systemd (vsftpd@.service) pour lancer vsftpd en tant que service instancié est fournie dans le paquet vsftpd.
vsftpd séparé pour chaque instance du serveur FTP requise devra être créé et placé dans le répertoire /etc/vsftpd/. Remarquez que chacun de ces fichiers de configuration doit posséder un nom unique (tel que /etc/vsftpd/vsftpd-site-2.conf) et doit uniquement être accessible en lecture et écriture par l'utilisateur root.
FTP écoutant sur un réseau IPv4, la directive suivante doit être unique :
listen_address=N.N.N.N
listen_address=N.N.N.NIP unique pour le site FTP servi. Si le site utilise IPv6, veuillez utiliser la directive listen_address6 à la place.
/etc/vsftpd/, des instances individuelles du démon vsftpd peuvent être lancées par la commande suivante en tant qu'utilisateur root :
systemctl start vsftpd@configuration-file-name.service
~]# systemctl start vsftpd@configuration-file-name.servicevsftpd-site-2. Remarquez que l'extension .conf du fichier de configuration ne doit pas être incluse dans la commande.
vsftpd à la fois, vous pouvez utiliser un fichier d'unité cible systemd (vsftpd.target), qui est fourni dans le paquet vsftpd. Cette cible systemd entraîne le lancement d'un démon indépendant vsftpd pour chaque fichier de configuration vsftpd qui se trouve dans le répertoire /etc/vsftpd/. Veuillez exécuter la commande suivante en tant qu'utilisateur root pour activer la cible :
systemctl enable vsftpd.target Created symlink from /etc/systemd/system/multi-user.target.wants/vsftpd.target to /usr/lib/systemd/system/vsftpd.target.
~]# systemctl enable vsftpd.target
Created symlink from /etc/systemd/system/multi-user.target.wants/vsftpd.target to /usr/lib/systemd/system/vsftpd.target.vsftpd (avec les instances configurées du serveur vsftpd) pendant l'initialisation. Pour lancer le service immédiatement, sans redémarrer le système, veuillez exécuter la commande suivante en tant qu'utilisateur root :
systemctl start vsftpd.target
~]# systemctl start vsftpd.targetanon_rootlocal_rootvsftpd_log_filexferlog_file
14.2.2.3. Chiffrer des connexions vsftpd en utilisant TLS
FTP, qui transmet les noms d'utilisateur, mots de passe, et données sans chiffrement par défaut, le démon vsftpd peut être configuré pour utiliser le protocole TLS afin d'authentifier les connexions et de chiffrer tous les transferts. Remarquez qu'un client FTP prenant en charge TLS est nécessaire pour communiquer avec vsftpd avec TLS activé.
Note
SSL (« Secure Sockets Layer ») est le nom d'une ancienne implémentation du protocole de sécurité. Les nouvelles versions sont appelées TLS (« Transport Layer Security »). Seules les nouvelles versions (TLS) doivent être utilisées car SSL connaît de graves défaillances de sécurité. La documentation incluse avec le serveur vsftpd, ainsi que les directives de configuration utilisées dans le fichier vsftpd.conf, utilisent le nom SSL lorsqu'elles font référence à des sujets liés à la sécurité, mais TLS est pris en charge et est utilisé par défaut lorsque la directive ssl_enable est paramétrée sur YES.
ssl_enable du fichier vsftpd.conf sur YES pour activer la prise en charge TLS. Les paramètres par défaut des autres directives liées à TLS qui sont automatiquement activés lorsque l'option ssl_enable est activée elle-même, fournissent une installation TLS relativement bien configurée. Ceci exige, entre autre, d'utiliser le protocole TLS v1 pour toutes les connexions (l'utilisation des versions non sécurisées du protocole SSL est désactivée par défaut) ou de forcer toutes les connexions non anonymes à utiliser TLS pour envoyer des mots de passe et des transferts de données.
Exemple 14.3. Configurer vsftpd pour utiliser TLS
SSL dans le fichier vsftpd.conf :
ssl_enable=YES ssl_tlsv1=YES ssl_sslv2=NO ssl_sslv3=NO
ssl_enable=YES
ssl_tlsv1=YES
ssl_sslv2=NO
ssl_sslv3=NOvsftpd après avoir modifié sa configuration :
systemctl restart vsftpd.service
~]# systemctl restart vsftpd.serviceTLS-related configuration directives for fine-tuning the use of TLS by vsftpd.
14.2.2.4. Politique SELinux pour vsftpd
vsftpd (ainsi que d'autres processus ftpd) définit un contrôle d'accès obligatoire qui est, par défaut, basé sur le moins d'accès requis. Dans le but d'autoriser le démon FTP à accéder à des fichiers ou répertoires spécifiques, des étiquettes appropriées devront leur être assignés.
public_content_t doit être assignée aux fichiers et répertoires à partager. Vous pouvez effectuer ceci en utilisant la commande chcon en tant qu'utilisateur root :
chcon -R -t public_content_t /path/to/directory
~]# chcon -R -t public_content_t /path/to/directorypublic_content_rw_t à ce répertoire en particulier. En outre, l'option du booléen SELinux allow_ftpd_anon_write doit être paramétrée sur 1. Veuillez utiliser la commande setsebool en tant qu'utilisateur root pour cela :
setsebool -P allow_ftpd_anon_write=1
~]# setsebool -P allow_ftpd_anon_write=1FTP, ce qui est le paramètre par défaut sur Red Hat Enterprise Linux 7, l'option du booléen ftp_home_dir doit être définie sur 1. Si vsftpd est autorisé à être exécuté en mode autonome, ce qui est également le cas par défaut sur Red Hat Enterprise Linux 7, l'option ftpd_is_daemon devra également être définie sur 1.
FTP. Also, see the Red Hat Enterprise Linux 7 SELinux User's and Administrator's Guide for more detailed information about SELinux in general.
14.2.3. Ressources supplémentaires
vsftpd, veuillez consulter les ressources suivantes.
14.2.3.1. Documentation installée
/usr/share/doc/vsftpd-version-number/directory — Remplacez version-number par la version installée du paquet vsftpd. Ce répertoire contient un fichierREADMEavec des informations de base sur le logiciel. Le fichierTUNINGcontient des conseils de réglage de base des performances et le répertoireSECURITY/contient des informations sur le modèle de sécurité employé parvsftpd.- Pages de manuel liées à
vsftpd— il existe des pages de manuel pour le démon et les fichiers de configuration. Ci-dessous figure une liste des pages de manuel les plus importantes.- Applications du serveur
- vsftpd(8) — Describes available command-line options for
vsftpd.
- Fichiers de configuration
- vsftpd.conf(5) — Contains a detailed list of options available within the configuration file for
vsftpd. - hosts_access(5) — Describes the format and options available within the
TCPwrappers configuration files:hosts.allowandhosts.deny.
- Interaction avec SELinux
- ftpd_selinux(8) — Contains a description of the SELinux policy governing
ftpdprocesses as well as an explanation of the way SELinux labels need to be assigned and Booleans set.
14.2.3.2. Documentation en ligne
- À propos de vsftpd et de FTP en général
- http://vsftpd.beasts.org/ — la page du projet
vsftpdest un bon emplacement pour trouver la documentation la plus récente et contacter l'auteur du logiciel. - http://slacksite.com/other/ftp.html — Ce site web fournit une explication détaillée des différences entre les modes
FTPactifs et passifs.
- Documentation Red Hat Enterprise Linux
- Guide de mise en réseau Red Hat Enterprise Linux 7 — Le Guide de mise en réseau de Red Hat Enterprise Linux 7 documente les informations pertinentes à la configuration et à l'administration des interfaces réseau et des services réseau sur ce système. Il fournit une introduction à l'utilitaire
hostnamectlet explique comment l'utiliser pour afficher et définir des noms d'hôtes sur la ligne de commande localement et à distance. - Guide de l'utilisateur et de l'administrateur SELinux Red Hat Enterprise Linux 7 — le Guide de l'utilisateur et de l'administrateur SELinux Red Hat Enterprise Linux 7 décrit les principes de base de SELinux et documente en détails comment configurer et utiliser SELinux avec divers services, tels que Apache HTTP Server, Postfix, PostgreSQL, ou OpenShift. Celui-ci explique comment configurer les permissions d'accès SELinux pour les services système gérés par
systemd. - Guide de sécurité Red Hat Enterprise Linux 7 — le Guide de sécurité Red Hat Enterprise Linux 7 assiste les utilisateurs et administrateurs dans leur apprentissage des processus et pratiques de sécurisation de leurs stations de travail et serveurs contre des intrusions locales et distantes, les exploitations, et autres activités malicieuses. Celui-ci explique également comment sécuriser des services de système critiques.
- Documents RFC pertinents
- RFC 0959 — Demande de commentaires (RFC de l'anglais Request For Comments) d'origine du protocole
FTPformulée par IETF. - RFC 1123 — la petite section concernant
FTPétend et clarifie la demande RFC 0959. - RFC 2228 — extensions de sécurité
FTP. vsftpd implémente le mini sous-ensemble qu'il faut pour prendre en charge les connexions TLS et SSL. - RFC 2428 — prise en charge
IPv6.
14.3. L'outil « Print Settings »
Important
cupsd.conf documente la configuration d'un serveur CUPS. Elle inclut des directives pour activer la prise en charge SSL. Cependant, CUPS ne permet pas le contrôle des versions de protocole utilisées. À cause de la vulnérabilité décrite dans la Résolution sur la vulnérabilité POODLE SSLv3.0 (CVE-2014-3566) pour les composants ne permettant pas à SSLv3 d'être désactivé via des paramètres de configuration, Red Hat recommande de ne pas se fier à cela pour la sécurité. Il est recommandé d'utiliser stunnel pour fournir un tunnel sécurisé et désactiver SSLv3. Pour obtenir davantage d'informations sur l'utilisation de stunnel, veuillez consulter le Guide de sécurité Red Hat Enterprise Linux 7.
SSH comme décrit dans la Section 10.4.1, « Transfert X11 ».
Note
14.3.1. Lancer l'outil de configuration « Print Settings »
system-config-printer à l'invite de shell. L'outil Print Settings apparaît. Alternativement, si le bureau GNOME est utilisé, appuyez sur la touche Super pour aller sur la « Vue d'ensemble des activités », saisissez Print Settings puis appuyez sur Entrée. L'outil Print Settings apparaît. La touche Super peut se trouver sous diverses formes, selon le clavier ou le matériel, mais le plus souvent, il s'agit de la touche Windows ou de la touche de Commande, habituellement à gauche de la Barre d'espace.
Figure 14.3. Fenêtre « Print Settings »
14.3.2. Lancer l'installation d'une imprimante
root. Les imprimantes locales connectées avec d'autres types de port et les imprimantes réseau doivent être installées manuellement.
- Lancez l'outil « Print Settings » (veuillez consulter la Section 14.3.1, « Lancer l'outil de configuration « Print Settings » »).
- Rendez-vous sur → → .
- Dans la boîte de dialogue Authentification, veuillez saisir un mot de passe d'administrateur ou d'utilisateur
root. S'il s'agit de la première fois que vous configurez une imprimante distante, il vous sera demandé d'autoriser un ajustement du pare-feu. - Veuillez sélectionner le type de connexion de l'imprimante et fournir ses détails dans la zone se trouvant sur la droite.
14.3.3. Ajouter une imprimante locale
- Ouvrez la boîte de dialogue Ajouter (veuillez consulter la Section 14.3.2, « Lancer l'installation d'une imprimante »).
- Si le périphérique n'apparaît pas automatiquement, veuillez sélectionner le port sur lequel l'imprimante est connectée dans la liste sur la gauche (tel que Serial Port #1 ou LPT #1).
- Sur la droite, veuillez saisir les propriétés de connexion :
- pour Other
- URI (par exemple file:/dev/lp0)
- pour Serial Port
- Débit en baudsParitéMorceaux de donnéesContrôle du flux
Figure 14.4. Ajouter une imprimante locale
- Cliquez sur .
- Sélectionnez le modèle de l'imprimante. Veuillez consulter la Section 14.3.8, « Sélectionner le modèle de l'imprimante et terminer » pour obtenir des détails.
14.3.4. Ajouter une imprimante AppSocket/HP JetDirect
- Ouvrez la boîte de dialogue
Nouvelle imprimante(veuillez consulter la Section 14.3.1, « Lancer l'outil de configuration « Print Settings » »). - Dans la liste sur la gauche, sélectionnez → .
- Sur la droite, veuillez saisir les paramètres de connexion :
- Nom d'hôte
- Le nom d'hôte de l'imprimante ou l'adresse
IP. - Numéro de port
- Écoute du port de l'imprimante pour les tâches d'impression (Par défaut,
9100).

Figure 14.5. Ajouter une imprimante JetDirect
- Cliquez sur .
- Sélectionnez le modèle de l'imprimante. Veuillez consulter la Section 14.3.8, « Sélectionner le modèle de l'imprimante et terminer » pour obtenir des détails.
14.3.5. Ajouter une imprimante IPP
IPP est une imprimante attachée à un système différent sur le même réseau TCP/IP. Le système auquel cette imprimante est attachée pourrait également exécuter CUPS ou être simplement configuré pour utiliser IPP.
TCP entrantes sur le port 631. Remarquez que le protocole de navigation CUPS autorise les machines clientes à découvrir les files d'attentes CUPS partagées automatiquement. Pour activer cela, le pare-feu sur la machine cliente doit être configuré pour autoriser les paquets UDP entrants sur le port 631.
IPP :
- Ouvrez la boîte de dialogue
Nouvelle imprimante(veuillez consulter la Section 14.3.2, « Lancer l'installation d'une imprimante »). - Dans la liste des périphériques se trouvant sur la gauche, veuillez sélectionner et ou .
- Sur la droite, veuillez saisir les paramètres de connexion :
- Hôte
- Nom d'hôte de l'imprimante
IPP. - File d'attente
- Nom de la file d'attente à donner à la nouvelle file d'attente (si la boîte reste vide, un nom basé sur le nœud du périphérique sera utilisé).

Figure 14.6. Ajouter une imprimante IPP
- Cliquez sur pour continuer.
- Sélectionnez le modèle de l'imprimante. Veuillez consulter la Section 14.3.8, « Sélectionner le modèle de l'imprimante et terminer » pour obtenir des détails.
14.3.6. Ajouter un hôte ou une imprimante LPD/LPR
- Ouvrez la boîte de dialogue
Nouvelle imprimante(veuillez consulter la Section 14.3.2, « Lancer l'installation d'une imprimante »). - Dans la liste des périphériques sur la gauche, sélectionnez → .
- Sur la droite, veuillez saisir les paramètres de connexion :
- Hôte
- Nom d'hôte de l'imprimante ou de l'hôte LPD/LPR.Optionnellement, cliquez sur pour trouver les files d'attente situées sur l'hôte LPD.
- File d'attente
- Nom de la file d'attente à donner à la nouvelle file d'attente (si la boîte reste vide, un nom basé sur le nœud du périphérique sera utilisé).
Figure 14.7. Ajouter une imprimante LPD/LPR
- Cliquez sur pour continuer.
- Sélectionnez le modèle de l'imprimante. Veuillez consulter la Section 14.3.8, « Sélectionner le modèle de l'imprimante et terminer » pour obtenir des détails.
14.3.7. Ajouter une imprimante Samba (SMB)
Note
root :
yum install samba-client
yum install samba-client- Ouvrez la boîte de dialogue
Nouvelle imprimante(veuillez consulter la Section 14.3.2, « Lancer l'installation d'une imprimante »). - Dans la liste sur la gauche, veuillez sélectionner → .
- Veuillez saisir l'adresse SMB dans le champ smb://. Utilisez le format nom d'ordinateur/partage d'imprimante. Dans la Figure 14.8, « Ajouter une imprimante SMB », le nom d'ordinateur est
dellboxet le partage d'imprimante estr2.
Figure 14.8. Ajouter une imprimante SMB
- Veuillez cliquer sur pour afficher les groupes de travail ou domaines disponibles. Pour uniquement afficher les files d'attente d'un hôte particulier, veuillez saisir le nom d'hôte (nom NetBios) et cliquez sur .
- Veuillez sélectionner l'une des options :
- Demander à l'utilisateur si l'authentification est requise : le nom d'utilisateur et le mot de passe sont exigés de l'utilisateur lors de l'impression d'un document.
- Définir les infos d'authentification maintenant : permet de fournir les informations d'authentification immédiatment afin qu'elles ne soient pas requises ultérieurement. Dans le champ Nom d'utilisateur, veuillez saisir le nom d'utilisateur pour accéder à l'imprimante. Cet utilisateur doit exister sur le système SMB, et l'utilisateur doit avoir la permission d'accéder à l'imprimante. Le nom d'utilisateur par défaut est habituellement «
guest» (invité) pout les serveurs Windows, ou «nobody» pour les serveurs Samba.
- Saisissez le Mot de passe (si requis) de l'utilisateur spécifié dans le champ Nom d'utilisateur.
Avertissement
Les noms d'utilisateurs et mots de passe Samba sont stockés dans le serveur de l'imprimante en tant que fichiers non chiffrés lisibles par l'utilisateurrootet le démon d'impression Linux (« Linux Printing Daemon »),lpd. Ainsi, les autres utilisateurs ayant un accèsrootau serveur de l'imprimante peuvent afficher le nom d'utilisateur et le mot de passe à utiliser pour accéder à l'imprimante Samba.Ainsi, lorsque vous choisissez un nom d'utilisateur et un mot de passe pour accéder à une imprimante Samba, il est recommandé de choisir un mot de passe différent de celui utilisé pour accéder à votre système Red Hat Enterprise Linux local.Si des fichiers sont partagés sur le serveur de l'imprimante Samba, il est également recommandé de choisir un mot de passe différent de celui qui est utilisé par la file d'attente d'impression. - Cliquez sur pour tester la connexion. Lorsque la vérification est réussie, une boîte de dialogue apparaît confirmant l'accessibilité du partage de l'imprimante.
- Cliquez sur .
- Sélectionnez le modèle de l'imprimante. Veuillez consulter la Section 14.3.8, « Sélectionner le modèle de l'imprimante et terminer » pour obtenir des détails.
14.3.8. Sélectionner le modèle de l'imprimante et terminer
- Dans la fenêtre affichée après l'échec de la détection automatique du pilote, veuillez sélectionner l'une des options suivantes :
- Sélectionner une imprimante dans la base de données — le système choisit un pilote en se basant sur la marque de l'imprimante sélectionnée dans la liste des Marques. Si votre imprimante n'est pas répertoriée, veuillez choisir Générique.
- Fournir le fichier PPD — le système utilise le fichier « PostScript Printer Description » (ou PPD) pour l'installation. Un fichier PPD peut également être remis avec votre imprimante comme s'il était normalement fourni par le constructeur. Si le fichier PPD est disponible, vous pourrez choisir cette option et utiliser la barre de navigation sous la description de l'option pour sélectionner le fichier PPD.
- Rechercher un pilote d'imprimante à télécharger — saisissez la marque et le modèle de l'imprimante dans le champ Marque et modèle pour rechercher les paquets appropriés sur OpenPrinting.org.

Figure 14.9. Sélectionner une marque d'imprimante
- Selon votre choix précédent, veuillez fournir des détails dans la zone affichée ci-dessous :
- Marque de l'imprimante pour l'option Sélectionner l'imprimante dans la base de données.
- Emplacement du fichier PPD pour l'option Fournir le fichier PPD.
- Marque et modèle de l'imprimante pour l'option Rechercher un pilote d'imprimante à télécharger.
- Cliquez sur pour continuer.
- Si cela est applicable pour votre option, la fenêtre affichée dans la Figure 14.10, « Sélectionner un modèle d'imprimante » apparaît. Choisissez le modèle correspondant dans la colonne Modèles sur la gauche.
Note
Sur la droite, le pilote de l'imprimante recommandé est automatiquement sélectionné, cependant il est possible de sélectionner un autre pilote disponible. Le pilote de l'imprimante traite les données que vous souhaitez imprimer sous un format que l'imprimante peut comprendre. Comme une imprimante est attachée directement à l'ordinateur, il est nécessaire d'avoit un pilote d'imprimante pour traiter les données envoyées sur l'imprimante.
Figure 14.10. Sélectionner un modèle d'imprimante
- Cliquez sur .
- Sous
Décrire l'imprimante, saisissez un nom unique pour l'imprimante dans le champ Nom de l'imprimante. Le nom de l'imprimante peut contenir des lettres, des chiffres, des tirets (-), et des traits de soulignement (_) ; il ne doit pas contenir d'espaces. Vous pouvez également utiliser les champs Description et Emplacement pour ajouter des informations supplémentaires sur l'imprimante. Ces champs sont optionnels et peuvent contenir des espaces.
Figure 14.11. Installation de l'imprimante
- Veuillez cliquer sur pour confirmer la configuration de l'imprimante et ajouter la file d'attente de l'imprimante si les paramètres sont corrects. Veuillez cliquer sur pour modifier la configuration de l'imprimante.
- Une fois les changements appliqués, une boîte de dialogue apparaît, vous permettant d'imprimer une page test. Cliquez sur pour imprimer la page test maintenant. Alternativement, il est possible d'imprimer une page test ultérieurement, comme décrit dans la Section 14.3.9, « Imprimer une page test ».
14.3.9. Imprimer une page test
- Faites un clic droit dans la fenêtre Impression et cliquez sur .
- Dans la fenêtre Propriétés, cliquez sur Paramètres sur la gauche.
- Sur l'onglet Paramètres affiché, cliquez sur le bouton .
14.3.10. Modifier les imprimantes existantes
14.3.10.1. Page des paramètres
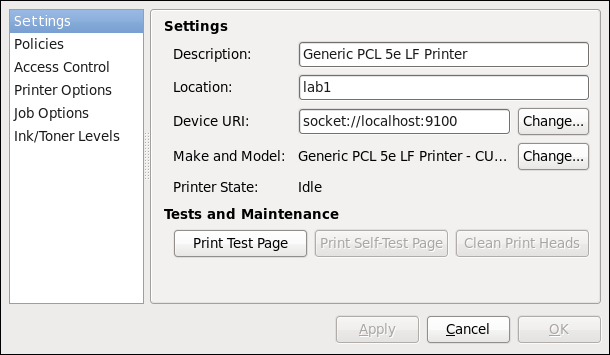
Figure 14.12. Page des paramètres
14.3.10.2. Page des politiques
14.3.10.2.1. Partager des imprimantes
Figure 14.13. Page des comportements
TCP entrantes sur le port 631, le port du protocole IPP (« Network Printing Server »). Pour autoriser le trafic IPP à travers le pare-feu sur Red Hat Enterprise Linux 7, utilisez le service firewalld IPP. Pour cela, veuillez procéder comme suit :
Procédure 14.4. Activer le service IPP dans firewalld
- Pour lancer l'outil graphique firewall-config, veuillez appuyer sur la touche Super pour entrer dans la « Vue d'ensemble des activités », saisissez
firewall, puis appuyez sur la touche Entrée. La fenêtre Configuration du pare-feu s'ouvrira. Il vous sera alors demandé un mot de passe d'administrateur ou d'utilisateurroot.Alternativement, pour lancer l'outil de configuration du pare-feu graphique en utilisant la ligne de commande, veuillez saisir la commande suivante en tant qu'utilisateurroot:La fenêtre Configuration du pare-feu s'ouvrira.firewall-config
~]# firewall-configCopy to Clipboard Copied! Toggle word wrap Toggle overflow Recherchez le mot « Connecté » (« Connected ») dans le coin en bas à gauche. Ceci indique que l'outil firewall-config est connecté au démon de l'espace utilisateurfirewalld.Pour immédiatement changer les paramètres actuels du pare-feu, assurez-vous que le menu de sélection déroulant étiquetté Configuration est défini sur . Alternativement, pour modifier les paramètres à appliquer lors du prochain démarrage système, ou du prochain rechargement du pare-feu, sélectionnez dans la liste déroulante. - Sélectionnez l'onglet Zones et sélectionnez la zone du pare-feu à faire correspondre avec l'interface réseau à utiliser. La zone par défaut est la zone « » (publique). L'onglet affiche quelles interfaces ont été assignées à une zone.
- Veuillez sélectionner l'onglet Services puis sélectionnez le service pour activer le partage. Le service est requis pour accéder aux imprimantes réseau.
- Fermez l'outil firewall-config.
firewalld, veuillez consulter le Guide de sécurité Red Hat Enterprise Linux 7.
14.3.10.2.2. Page de contrôle des accès
Figure 14.14. Page de contrôle des accès
14.3.10.2.3. Page des options d'imprimante
Figure 14.15. Page des options d'imprimante
14.3.10.2.4. Page des options de tâches
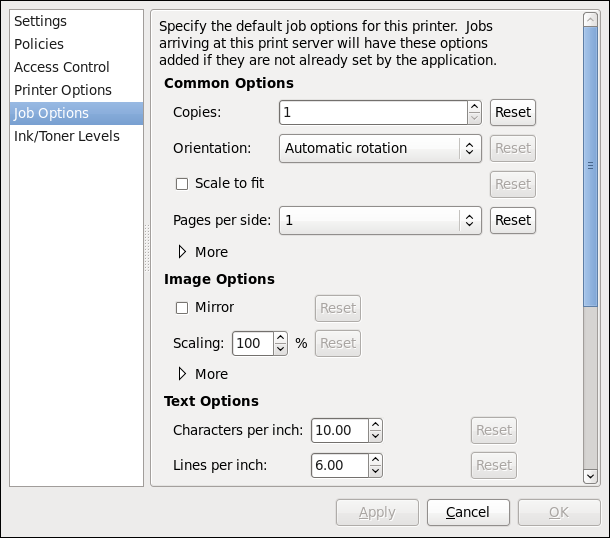
Figure 14.16. Page des options de tâches
14.3.10.2.5. Page des niveaux d'encre / du toner
Figure 14.17. Page des niveaux d'encre / du toner
14.3.10.3. Gérer les tâches d'impression
Figure 14.18. Statut de l'impression GNOME
lpstat -o. Les quelques dernières lignes seront similaires à ce qui suit :
Exemple 14.4. Exemple de sortie de lpstat -o
lpstat -o Charlie-60 twaugh 1024 Tue 08 Feb 2011 16:42:11 GMT Aaron-61 twaugh 1024 Tue 08 Feb 2011 16:42:44 GMT Ben-62 root 1024 Tue 08 Feb 2011 16:45:42 GMT
$ lpstat -o
Charlie-60 twaugh 1024 Tue 08 Feb 2011 16:42:11 GMT
Aaron-61 twaugh 1024 Tue 08 Feb 2011 16:42:44 GMT
Ben-62 root 1024 Tue 08 Feb 2011 16:45:42 GMTlpstat -o, puis utilisez la commande cancel numéro de tâche. Par exemple, cancel 60 annulera la tâche d'impression dans Exemple 14.4, « Exemple de sortie de lpstat -o ». Il n'est pas possible d'annuler des tâches d'impression lancées par d'autres utilisateurs avec la commande cancel. Cependant, il est possible de supprimer ces tâches en utilisant la commande cancel -U root numéro_de_tâche. Pour empêcher ce type d'annulation, modifiez la politique d'opération de l'imprimante sur Authenticated (« Authentifié ») pour forcer l'authentification root.
lp sample.txt imprimera le fichier texte sample.txt. Le filtre d'impression détermine le type de fichier dont il s'agit et le convertit sous un format compréhensible par l'imprimante.
14.3.11. Ressources supplémentaires
Documentation installée
lp(1)— page du manuel de la commandelp, qui permet d'imprimer des fichiers à partir de la ligne de commande.lpr(1)— page du manuel de la commandelpr, qui permet d'imprimer des fichiers à partir de la ligne de commande.cancel(1)— page du manuel de l'utilitaire de ligne de commande pour supprimer des tâches de la file d'attente d'impression.mpage(1)— page du manuel de l'utilitaire de ligne de commande pour imprimer plsieurs pages sur une seule feuille.cupsd(8)— page du manuel du démon d'imprimante CUPS.cupsd.conf(5)— page du manuel du fichier de configuration du démon d'imprimante CUPS.classes.conf(5)— page du manuel pour le fichier de configuration de classe de CUPS.lpstat(1)— page du manuel de la commandelpstat, qui affiche des informations sur le statut des classes, tâches, et imprimantes.
Documentation en ligne
- http://www.linuxprinting.org/ — Le groupe OpenPrinting sur le site web Linux Foundation contient une grande quantité d'informations sur les impressions sur Linux.
- http://www.cups.org/ — Le site web CUPS fournit la documentation, des FAQ, et des groupes d'informations sur CUPS.
Chapitre 15. Configurer NTP en utilisant Chrony Suite
NTP est implémenté par un démon exécuté dans l'espace utilisateur.
ntpd et chronyd, qui se trouvent dans les référentiels des paquets ntp et chrony respectivement. Cette section décrit l'utilisation de la suite d'utilitaires chrony pour mettre à jour l'horloge système sur les systèmes n'entrant pas dans la catégorie conventionnelle des serveurs dédiés, toujours en cours de fonctionnement et sur le réseau de manière permanente.
15.1. Introduction à Chrony Suite
chronyd, un démon exécuté dans l'espace utilisateur, et de chronyc, un programme de ligne de commande pour effectuer des ajustements sur chronyd. Les systèmes qui ne sont pas connectés de manière permanente, ou qui ne sont pas alimentés de manière permanente, prennent un temps relativement long à ajuster leurs horloges système avec ntpd. Ceci est dû au fait que de nombreuses petites corrections sont effectuées sur la base des observations de dérive et de décalage des horloges. Les changements de température, qui peuvent être significatives lors du démarrage d'un système, affectent la stabilité des horloges matérielles. Même si les ajustements commencent dès les premières millisecondes du démarrage d'un système, la précision acceptable peut prendre entre zéro et dix secondes pour un redémarrage de type « warm » à plusieurs heures, selon les besoins, l'environnement d'exploitation, et le matériel. chrony est une implémentation du protocole NTP différente de ntpd, et peut ajuster l'horloge système plus rapidement.
15.1.1. Différences entre ntpd et chronyd
ntpd et chronyd réside dans les algorithmes utilisés pour contrôler l'horloge de l'ordinateur. Ce que chronyd peut faire mieux que ntpd inclut :
chronydpeut bien fonctionner lorsque les références horaires externes sont accessibles de manière intermittente, tandis quentpda besoin d'interroger les références horaires régulièrement pour bien fonctionner.chronydpeut bien fonctionner même lorsque le réseau est encombré pendant de longues périodes.chronydpeut habituellement synchroniser l'horloge plus rapidement et avec une meilleure précision.chronyds'adapte rapidement aux changements soudains de vitesse de l'horloge, par exemple lorsque ceux-ci sont dus à des changements de température de l'oscillateur à cristal, tandis quentpdpourrait nécessiter plus de temps pour se réajuster.- Dans la configuration par défaut,
chronydn'arrête jamais l'heure après la synchronisation de l'horloge pendant le démarrage système, afin de ne pas perturber les autres programmes en cours d'exécution.ntpdpeut également être configuré de manière à ne jamais arrêter le temps, mais doit utiliser différents moyens pour ajuster l'horloge, ce qui entraîne un certain nombre d'inconvénients. chronydpeut ajuster la vitesse de l'horloge sur un système Linux dans une plage plus importante, ce qui lui permet d'opérer même sur des machines ayant une horloge endommagée ou instable. Par exemple, sur certaines machines virtuelles.
chronyd peut faire, que ntpd ne peut pas faire :
chronydfournit la prise en charge des réseaux isolés, où l'unique méthode de correction du temps possible est manuelle, comme lorsque l'administrateur regarde l'horloge.chronydpeut examiner les erreurs corrigées lors de différentes mises à jour pour estimer la vitesse à laquelle l'ordinateur gagne ou perd du temps, et utilise ces estimations pour ajuster l'horloge système conséquemment.chronydfournit la prise en charge pour calculer la quantité de gains ou pertes de temps de l'horloge temps réel, l'horloge matérielle, et maintient l'heure lorsque l'ordinateur est éteint. Ces données peuvent être utilisées lorsque le système démarre pour définir l'heure système à l'aide d'une valeur ajustée de l'heure prise de l'horloge temps réel. Cette fonctionnalité, au moment de la rédaction de ce guide, est uniquement disponible sur Linux.
ntpd peut faire, que chronyd ne peut pas faire :
ntpdprend totalement en chargeNTPversion 4 (RFC 5905), y compris la diffusion, multidiffusion, et le Manycast des clients et serveurs, ainsi que le mode Orphelin. Il prend également en charge des schémas d'authentification supplémentaires basés sur chiffrement de clé publique (RFC 5906).chronydutiliseNTPversion 3 (RFC 1305), qui est compatible avec la version 4.ntpdinclut des pilotes pour de nombreuses horloges de référence, tandis quechronydrepose sur d'autres programmes, comme par exemple gpsd pour accéder aux données des horloges de référence.
15.1.2. Choisir les démons NTP
- Chrony devrait être pris en considération pour tous les systèmes qui sont fréquemment suspendus ou déconnectés de manière intermittente puis reconnectés à un réseau, comme des systèmes virtuels et mobiles.
- Le démon
NTP(ntpd) doit être considéré pour les systèmes habituellement en cours d'exécution de manière permanente. Les systèmes qui requièrent l'utilisation d'une adresseIPde diffusion ou de multidiffusion, ou qui effectuent l'authentification de paquets avec le protocoleAutokeydevraient envisager d'utiliserntpd. Chrony prend uniquement en charge l'authentification de clés symétriques à l'aide d'un code d'authentification de message (MAC) avec MD5, SHA1 ou avec des fonctions de hachage plus robustes, tandis quentpdprend également en charge le protocole d'authentificationAutokey, qui peut utiliser le système PKI.Autokeyest décrit dans RFC 5906.
15.2. Comprendre Chrony et sa configuration
15.2.1. Comprendre Chronyd
chronyd, exécuté dans l'espace utilisateur, ajuste l'horloge système exécutée dans le noyau. Ces ajustements sont effectués en consultant des sources de temps externes, en utilisant le protocole NTP, chaque fois que l'accès réseau le permet. Lorsqu'aucune référence externe n'est disponible, chronyd utilisera la dernière dérive stockée dans le fichier de dérive. On peut également lui demander de faire des corrections manuelles, via chronyc.
15.2.2. Comprendre Chronyc
chronyd, peut être contrôlé par un utilitaire de ligne de commande, chronyc. Cet utilitaire fournit une invite de commande qui permet de saisir un nombre de commandes pour effectuer des changements sur chronyd. La configuration par défaut fait que chronyd accepte les commandes d'une instance locale de chronyc, mais chronyc peut être utilisé pour altérer la configuration, ainsi chronyd autorisera un contrôle externe. chronyc peut être exécuté à distance après avoir configuré chronyd pour accepter les connexions à distance. Les adresses IP autorisées à se connecter à chronyd doivent être minutieusement contrôlées.
15.2.3. Comprendre les commandes de configuration Chrony
chronyd est /etc/chrony.conf. L'option -f peut être utilisée pour spécifier un autre chemin de fichier de configuration. Veuillez consulter la page man chronyd pour obtenir des options supplémentaires. Pour obtenir une liste complète des directives pouvant être utilisées, veuillez consulter http://chrony.tuxfamily.org/manual.html#Configuration-file. Voici une sélection des options de configuration :
- Commentaires
- Les commentaires doivent être précédés de #, %, ; ou de !
- autoriser
- Optionnellement, spécifiez un hôte, un sous-réseau, ou un réseau à partir duquel autoriser les connexions
NTPà une machine qui puisse agir en tant que serveurNTP. Par défaut, les connexions ne sont pas autorisées.Exemples :
allow server1.example.com
allow server1.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow Veuillez utiliser ce format pour spécifier un hôte particulier, par son nom d'hôte, afin d'être autorisé à y accéder.allow 192.0.2.0/24
allow 192.0.2.0/24Copy to Clipboard Copied! Toggle word wrap Toggle overflow Veuillez utiliser ce format pour spécifier un réseau particulier afin d'être autorisé à y accéder.allow 2001:db8::/32
allow 2001:db8::/32Copy to Clipboard Copied! Toggle word wrap Toggle overflow Veuillez utiliser ce format pour spécifier une adresseIPv6afin d'être autorisé à y accéder.
- cmdallow
- Similaire à la directive
allow(veuillez consulter la sectionallow), sauf que l'accès de contrôle est autorisé (plutôt que l'accès clientNTP) sur un sous-réseau ou un hôte particulier. (« accès de contrôle » signifie que chronyc peut être exécuté sur ces hôtes et connecté avec succès àchronydsur cet ordinateur.) La syntaxe est identique. Il existe également une directivecmddeny allavec un comportement similaire à la directivecmdallow all. - dumpdir
- Chemin vers le répertoire pour enregistrer l'historique des mesures à travers les redémarrages de
chronyd(en supposant qu'aucun changement n'ait été appliqué au comportement de l'horloge système pendant qu'elle n'était pas en cours d'exécution). Si cette capacité doit être utilisée (via la commandedumponexitdans le fichier de configuration, ou la commandedumpdans chronyc), la commandedumpdirdoit être utilisée pour définir le répertoire dans lequel les historiques des mesures sont enregistrés. - dumponexit
- Si cette commande est présente, elle infique que
chronyddevrait enregistrer l'historique des mesure de chacune de ses sources horaire lorsque le programme se ferme. (Veuillez consulter la commandedumpdirci-dessus). - local
- Le mot-clé
localest utilisé pour quechronydpuisse apparaître synchronisé avec le temps réel du point de vue des interrogations des clients, même s'il ne possède pas de source de synchronisation actuellement. Cette option est normalement utilisée sur l'ordinateur « maître » dans un réseau isolé, où il est requis que plusieurs ordinateurs soient synchronisés les uns aux autres, et où le « maître » est aligné au temps réel par saisie manuelle.Voici un exemple de la commande :Une valeur élevée de 10 indique que l'horloge se trouve si loin de l'horloge de référence que son heure n'est pas fiable. Si l'ordinateur a accès à un autre ordinateur qui lui est synchronisé à une horloge de référence, celui-ci se trouvera à un stratum de moins de 10. Ainsi, le choix d'une valeur élevée, comme 10 pour la commandelocal stratum 10
local stratum 10Copy to Clipboard Copied! Toggle word wrap Toggle overflow local, empêche à l'heure de la machine d'être confondue avec le temps réel, si celle-ci devait un jour se propager aux clients qui peuvent voir des serveurs réels. - log
- La commande
logindique que certaines informations doivent être journalisées. La commande accepte les options suivantes :Les fichiers journaux sont écrits sur le répertoire spécifié par la commande- measurements
- Cette option journalise les mesures
NTPbrutes et les informations les concernants dans un fichier nommémeasurements.log. - statistics
- Cette option journalise les informations concernant le traitement de régression sur un fichier nommé
statistics.log. - tracking
- Cette option journalise les changements apportés à l'estimation des taux de gains ou pertes du système, sur un fichier nommé
tracking.log. - rtc
- Cette option journalise les informations sur l'horloge temps réel du système.
- refclocks
- Cette option journalise les mesures brutes et filtrées des horloges de référence sur un fichier nommé
refclocks.log. - tempcomp
- Cette option journalise les mesures de température et les compensations de vitesse du système sur un fichier nommé
tempcomp.log.
logdir. Ci-dessous figure un exemple de la commande :log measurements statistics tracking
log measurements statistics trackingCopy to Clipboard Copied! Toggle word wrap Toggle overflow - logdir
- Cette directive permet de spécifier le répertoire où les fichiers journaux sont écrits. Ci-dessous figure un exemple d'utilisation de cette directive :
logdir /var/log/chrony
logdir /var/log/chronyCopy to Clipboard Copied! Toggle word wrap Toggle overflow - makestep
- Normalement,
chronydfera que le système corrigera peu à peu tout décalage horaire, en ralentissant ou en accélérant l'horloge selon les besoins. Dans certaines situations, l'horloge système peut avoir dérivé au point où le processus de correction risque de prendre un long moment avant de corriger l'horloge système. Cette directive forcechronydà modifier l'horloge système si cet ajustement est supérieur à la valeur maximale, mais seulement s'il n'y a pas eu de mise à jour de l'horloge depuis quechronyda été lancé dans la limite spécifiée (une valeur négative peut être utilisée pour désactiver la limite). Ceci est particulièrement utile lors de l'utilisation d'horloges de référence, car la directiveinitstepslewfonctionne uniquement avec des sourcesNTP.Ci-dessous figure un exemple d'utilisation de la directive :Cette directive modifierait l'horloge système si l'ajustement était plus important que 1000 secondes, mais seulement lors des dix premières mises à jour horaires.makestep 1000 10
makestep 1000 10Copy to Clipboard Copied! Toggle word wrap Toggle overflow - maxchange
- Cette directive paramètre le décalage maximal autorisé corrigé sur une mise à jour de l'horloge. La vérification est effectuée uniquement après le nombre indiqué de mises à jour afin de permettre un ajustement initial important de l'horloge système. Lorsqu'un décalage supérieur au maximum spécifié se produit, il sera ignoré pour le nombre de fois indiqué, puis
chronydabandonnera et quittera (une valeur négative peut être utilisée afin de ne jamais quitter). Dans les deux cas, un message sera envoyé à syslog.Ci-dessous figure un exemple d'utilisation de la directive :Après la première mise à jour de l'horloge,maxchange 1000 1 2
maxchange 1000 1 2Copy to Clipboard Copied! Toggle word wrap Toggle overflow chronydvérifiera le décalage sur chaque mise à jour de l'horloge, ignorera deux ajustements de plus de 1000 secondes et quittera lors d'un ajustement ultérieur. - maxupdateskew
- L'une des tâches de
chronydconsiste à trouver à quelle vitesse l'horloge de l'ordinateur fonctionne comparé à ses sources de référence. En outre, une estimation des limites de l'erreur est calculée autour de l'estimation. Si la marge d'erreurs est trop importante, cela indique que les mesures n'ont pas encore été paramétrées et que la vitesse estimée de gain ou de perte n'est pas très fiable. Le paramètremaxupdateskewcorrespond à la limite pour déterminer si une estimation n'est pas assez fiable pour être utilisée. Par défaut, la limite est de 1000 ppm. Le format de la syntaxe est comme suit :Des valeurs typiques de skew-in-ppm peuvent s'élever à 100 pour une connexion téléphonique de serveurs à travers une ligne téléphonique, et à 5 ou 10 pour un ordinateur sur un réseau LAN. Remarquez qu'il ne s'agit pas de l'unique moyen de protection contre l'utilisation d'estimations non fiables. À tout moment,maxupdateskew skew-in-ppm
maxupdateskew skew-in-ppmCopy to Clipboard Copied! Toggle word wrap Toggle overflow chronydconserve la trace des vitesses estimées de gain ou de perte, et de la limite d'erreur de l'estimation. Lorsqu'une nouvelle estimation est générée suivant une autre mesure de l'une des sources, un algorithme de combinaison pondéré est utilisé pour mettre à jour l'estimation maître. Ainsi. sichronydpossède une estimation maître très fiable et qu'une nouvelle estimation est générée avec une marge d'erreurs supérieure, l'esimation maître existante prévaudra sur la nouvelle estimation maître. - noclientlog
- Cette directive, qui ne reçoit aucun argument, indique que les accès client ne doivent pas être journalisés. Ceux-ci sont normalement journalisés, permettant ainsi aux statistiques d'être rapportées en utilisant la commande client dans chronyc.
- reselectdist
- Lorsque
chronydsélectionne une source de synchronisation parmi les sources disponibles, une source avec une distance de synchronisation minimale est préférable. Cependant, pour éviter une resélection fréquente lorsqu'il se trouve plusieurs sources à une distance similaire, une distance fixe est ajoutée à la distance des sources qui ne sont pas sélectionnées. Cette distance peut être définie avec l'optionreselectdist. Par défaut, la distance s'élève à 100 microsecondes.Le format de la syntaxe est comme suit :reselectdist dist-in-seconds
reselectdist dist-in-secondsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - stratumweight
- La directive
stratumweightdéfinit la distance devant être ajoutée par stratum à la distance de synchronisation lorsquechronydsélectionne la source de synchronisation parmi les sources disponibles.Le format de la syntaxe est comme suit :Par défaut, la valeur de dist-in-seconds s'élève à 1 seconde. Cela signifie que les sources possédant un stratum plus bas sont normalement préférées aux sources avec un stratum plus élevé, même lorsque leur distance est significativement plus élevée. Définirstratumweight dist-in-seconds
stratumweight dist-in-secondsCopy to Clipboard Copied! Toggle word wrap Toggle overflow stratumweightsur 0 cause àchronydd'ignorer le stratum lors de la sélection de la source. - rtcfile
- La directive
rtcfiledéfinit le nom du fichier dans lequelchronydpeut enregistrer les paramètres associés au suivi de la précision de l'horloge temps réel (RTC) du système. Le format de la syntaxe est comme suit :rtcfile /var/lib/chrony/rtc
rtcfile /var/lib/chrony/rtcCopy to Clipboard Copied! Toggle word wrap Toggle overflow chronydenregistre les informations dans ce fichier lorsqu'il se ferme et quand la commandewritertcest exécutée dans chronyc. Les informations enregistrées contiennent l'erreur de l'horloge RTC à une certaine époque, cette époque (en secondes depuis le 1er janvier 1970), et la vitesse à laquelle l'horloge RTC gagne ou perd du temps. Toutes les horloges RTC ne sont pas prises en charge car leur code est spécifique au système. Remarquez que si cette directive est utilisée, alors l'horloge RTC ne devrait pas être ajustée manuellement car cela interfère avec le besoin de chrony de mesurer la vitesse à laquelle l'horloge dérive si elle est ajustée à des intervalles aléatoires. - rtcsync
- La directive
rtcsyncest présente dans le fichier/etc/chrony.confpar défaut. Cela informera le noyau que l'horloge système est synchronisée et que le noyau mettra à jour l'horloge RTC toutes les 11 minutes.
15.2.4. Sécurité avec Chronyc
chronyd de la même manière qu'on puisse le faire par une modifcation des fichiers de configuration, l'accès à chronyc doit être limité. Des mots de passe écrits en ASCII ou HEX peuvent être spécifiés dans le fichier clé pour restreindre l'utilisation de chronyc. L'une des entrées est utilisée pour restreindre l'utilisation de commandes opérationnelles et est désignée comme étant la commande clé. Dans la configuration par défaut, une clé de commande aléatoire est générée automatiquement lors du démarrage. Il ne devrait pas être nécessaire de la spécifier ou de l'altérer manuellement.
NTP pour authentifier les paquets reçus de serveurs ou de pairs NTP distants. Les deux côtés doivent partager une clé avec un ID, un type de hachage et un mot de passe identiques dans leurs fichier clé. Cela nécessite la création manuelle des clés, ainsi que de les copier au moyen d'un support sécurisé, tel que SSH. Ainsi, si l'ID clé était de 10, alors les systèmes agissant en tant que clients doivent avoir une ligne dans leurs fichiers de configuration sous le format suivant :
server w.x.y.z key 10 peer w.x.y.z key 10
server w.x.y.z key 10
peer w.x.y.z key 10
/etc/chrony.conf. L'entrée par défaut dans le fichier de configuration est comme suit :
keyfile /etc/chrony.keys
keyfile /etc/chrony.keys/etc/chrony.conf à l'aide de la directive commandkey, il s'agit de la clé que chronyd utilisera pour l'authentification des commandes utilisateurs. La directive du fichier de configuration prend le format suivant :
commandkey 1
commandkey 1/etc/chrony.keys, pour la clé de commande est comme suit :
1 SHA1 HEX:A6CFC50C9C93AB6E5A19754C246242FC5471BCDF
1 SHA1 HEX:A6CFC50C9C93AB6E5A19754C246242FC5471BCDF1 est l'ID clé, SHA1 est la fonction de hachage à utiliser, HEX est le format de la clé, et A6CFC50C9C93AB6E5A19754C246242FC5471BCDF est la clé générée de manière aléatoire lorsque chronyd a été lancé pour la première fois. La clé peut être donnée sous un format hexadécimal ou ASCII (par défaut).
NTP, peut être aussi simple que ce qui suit :
20 foobar
20 foobar20 est l'ID clé et foobar est la clé d'authentification secrète, le hachage par défaut est MD5, et ASCII est le format par défaut de la clé.
chronyd est configuré pour écouter uniquement les commandes en provenance de localhost (127.0.0.1 et ::1) sur le port 323. Pour accéder à chronyd à distance avec chronyc, toutes les directives bindcmdaddress devront être supprimées du fichier /etc/chrony.conf afin de permettre l'écoute sur toutes les interfaces et la directive cmdallow devra être utilisée pour autoriser les commandes en provenance de l'adresse IP distante, ou du réseau ou sous-réseau distant. En outre, le port 323 doit être ouvert dans le pare-feu pour se connecter à partir un système distant. Remarquez que la directive allow est utilisée pour l'accès NTP tandis que la directive cmdallow sert à activer la réception de commandes distantes. Il est possible d'effectuer ces changements de manière temporaire en utilisant chronyc localement. Pour rendre les changements persistants, veuillez modifier le fichier de configuration.
UDP, qui doit donc être autorisé avant de pouvoir exécuter des commandes opérationnelles. Pour autoriser son utilisation, veuillez exécuter les commandes authhash et password comme suit :
chronyc> authhash SHA1 chronyc> password HEX:A6CFC50C9C93AB6E5A19754C246242FC5471BCDF 200 OK
chronyc> authhash SHA1
chronyc> password HEX:A6CFC50C9C93AB6E5A19754C246242FC5471BCDF
200 OK-a exécutera les commandes authhash et password automatiquement.
activity, authhash, dns, exit, help, password, quit, rtcdata, sources, sourcestats, tracking, waitsync
.
15.3. Utiliser Chrony
15.3.1. Installer Chrony
root pour vous assurer qu'elle soit effectivement installée :
yum install chrony
~]# yum install chrony/usr/sbin/chronyd. L'utilitaire de ligne de commande sera installé sur /usr/bin/chronyc.
15.3.2. Vérifier le statut de Chronyd
chronyd, veuillez exécuter la commande suivante :
systemctl status chronyd chronyd.service - NTP client/server Loaded: loaded (/usr/lib/systemd/system/chronyd.service; enabled) Active: active (running) since Wed 2013-06-12 22:23:16 CEST; 11h ago
~]$ systemctl status chronyd
chronyd.service - NTP client/server
Loaded: loaded (/usr/lib/systemd/system/chronyd.service; enabled)
Active: active (running) since Wed 2013-06-12 22:23:16 CEST; 11h ago15.3.3. Lancer Chronyd
chronyd, veuillez exécuter la commande suivante en tant qu'utilisateur root :
systemctl start chronyd
~]# systemctl start chronydchronyd soit lancé automatiquement lors du démarrage système, veuillez exécuter la commande suivante en tant qu'utilisateur root :
systemctl enable chronyd
~]# systemctl enable chronyd15.3.4. Arrêter Chronyd
chronyd, veuillez exécuter la commande suivante en tant qu'utilisateur root :
systemctl stop chronyd
~]# systemctl stop chronydchronyd pendant le démarrage système, veuillez exécuter la commande suivante en tant qu'utilisateur root :
systemctl disable chronyd
~]# systemctl disable chronyd15.3.5. Vérifier si Chrony est synchronisé
tracking, sources, et sourcestats.
15.3.5.1. Vérifier le suivi Chrony
- Reference ID
- Il s'agit de l'ID de référence et du nom (ou de l'adresse
IP), si disponible, du serveur avec lequel l'ordinateur est actuellement synchronisé. S'il s'agit de127.127.1.1, cela signifie que l'ordinateur n'est synchronisé à aucune source externe et que le mode « local » est en cours d'exécution (via la commande locale dans chronyc, ou la directivelocaldans le fichier/etc/chrony.conf(veuillez consulter la sectionlocal)). - Stratum
- Le stratum indique à combien de sauts d'un ordinateur avec une horloge de référence attachée nous nous trouvons. Ce type d'ordinateur est un ordinateur stratum-1, ainsi l'ordinateur de l'exemple se trouve à deux sauts (c'est-à-dire, a.b.c est un stratum-2 et est synchronisé à partir d'un stratum-1).
- Ref time
- Il s'agit de l'heure (UTC) à laquelle la dernière mesure en provenance de la source de référence a été traitée.
- System time
- Lors d'une opération normale,
chronydne réajuste jamais l'horloge système, car tout saut dans le calendrier peut avoir des conséquences adverses pour certains programmes d'application. Au lieu de cela, toute erreur dans l'horloge système est corrigée en l'accélérant ou en la ralentissant légèrement jusqu'à ce que l'erreur soit résolue, puis celle-ci retourne à la vitesse normale. Une conséquence de cela est qu'il y aura une période pendant laquelle l'horloge système (comme lue par d'autres programmes utilisant l'appel systèmegettimeofday(), ou par la commande de date dans le shell) sera différente de l'estimation de l'heure actuelle réelle dechronyd(qui est rapportée sur les clientsNTPlors de son exécution en mode serveur). La valeur rapportée sur cette ligne est la différence causée par cet effet. - Last offset
- Décalage local estimé lors de la dernière mise à jour de l'horloge.
- RMS offset
- Moyenne à long terme de la valeur de décalage.
- Frequency
- La valeur « frequency » est la vitesse à laquelle l'horloge système serait erronée si
chronydne la corrigeait pas. Celle-ci est exprimée en ppm (parties par million). Par exemple, une valeur de 1ppm signifie que lorsque l'horloge système est une seconde en avance, celle-ci a réellement avancé de 1,000001 secondes, de manière relative à l'heure réelle. - Residual freq
- Ceci affiche la « fréquence résiduelle » de la source de référence actuellement sélectionnée. Celle-ci reflète la différence entre ce que la fréquence devrait être selon les indications des mesures de la source de référence et la fréquence réellement utilisée. Le résultat ne correspond pas toujours zéro car une procédure d'ajustement est appliquée à la fréquence. Chaque fois qu'une mesure de la source de référence est obtenue et qu'une nouvelle fréquence résiduelle est calculée, la précision estimée de ce résidu est comparée à la précision estimée (consultez
skew) de la valeur de la fréquence. Une moyenne pondérée est calculée pour la nouvelle fréquence, et les coefficients dépendent de la précision. Si les mesures de la source de référence suivent une tendance cohérente, le résidu se rapprochera de zéro petit à petit. - Skew
- Estimation de la limite de l'erreur sur la fréquence.
- Root delay
- Total des délais de chemins réseau vers l'ordinateur stratum-1 à partir duquel l'ordinateur est finalement synchronisé. Dans certaines situations extrêmes, cette valeur peut être négative. (Cela peut se produire dans un arrangement de pairs symétriques dans lequel les fréquences des ordinateurs n'effectuent pas de suivi les unes des autres et où le délai réseau est très court relativement à la durée du délai d'exécution de chaque ordinateur.)
- Root dispersion
- Dispersion totale accumulée à travers tous les ordinateurs en retournant à l'ordinateur stratum-1 à partir duquel l'ordinateur est finalement synchronisé. La dispersion est dûe à la résolution de l'horloge système, aux variations des mesures des statistiques, etc.
- Leap status
- Statut de l'intercalaire, qui peut être « Normal », « Insert second » (insérer une seconde), « Delete second » (supprimer une seconde)¸ou « Not synchronized » (non synchronisé).
15.3.5.2. Vérifier les sources Chrony
chronyd. L'argument optionnel -v, qui signifie verbosité, peut être spécifié. Dans ce cas, des lignes de légende supplémentaires sont affichées comme rappel de la signification des colonnes.
- M
- Ceci indique le mode la source.
^signifie un serveur,=signifie un pair, et#indique une horloge de référence connectée localement. - S
- Cette colonne indique l'état des sources. « * » indique la source avec laquelle
chronydest actuellement synchronisé. « + » indique les sources acceptables qui sont combinées avec la source sélectionnée. « - » indique les sources acceptables qui sont exclues de l'algorithme de combinaison. « ? » indique les sources dont la connectivité a été perdue ou dont les paquets n'ont pas passé tous les tests. « x » indique une horloge quechronydcroit être de type falseticker (son heure est incohérente avec la majorité des autres sources). « ~ » indique une source dont la variabilité de l'heure semble trop importante. La condition « ? » est également affichée lors du démarrage, jusqu'à ce qu'au moins 3 échantillons en soient prélevés. - Name/IP address
- Affiche le nom ou l'adresse
IPde la source, ou l'ID de référence pour les horloges de référence. - Stratum
- Affiche le stratum de la source ainais noté dans l'échantillon reçu le plus récemment. Stratum 1 indique un ordinateur avec une horloge de référence attachée localement. Un ordinateur synchronisé avec un ordinateur stratum 1 se trouve au stratum 2. Un ordinateur synchronisé avec un ordinateur stratum 2 se trouve au stratum 3, et ainsi de suite.
- Poll
- Affiche la vitesse à laquelle la source est sondée, en tant que logarithme de base 2 de l'intervalle en secondes. Ainsi, une valeur de 6 indiquerait qu'une mesure est prise toutes les 64 secondes.
chronydfait varier automatiquement la vitesse de sondage en réponse aux conditions actuelles. - Reach
- Affiche l'enregistrement de la portée de la source imprimé en tant que nombre octal. L'enregistrement compte 8 bits et est mis à jour chaque fois qu'un paquet est reçu ou n'a pas été reçu de la source. Une valeur de 377 indique qu'une réponse valide a été reçue pour chacune des huit dernières transmissions.
- LastRx
- Cette colonne affiche le temps écoulé depuis que le dernier échantillon a été reçu de la source. Cette valeur est généralement exprimée en secondes. Les lettres
m,h,douyindiquent les minutes, heures, jours ou années. Une valeur de 10 ans indique qu'aucun échantillon n'a encore été reçu de cette source. - Last sample
- Cette colonne affiche le décalage entre l'horloge locale et la source lors de la dernière mesure. Le chiffre entre les crochets montre le décalage mesuré réel. Celui-ci peut être suivi du suffixe
ns(indiquant des nanosecondes),us(indiquant des microsecondes),ms(indiquant des millisecondes), ous(indiquant des secondes). Le nombre à gauche des crochets affiche la mesure d'origine ajustée pour permettre tout changement appliqué à l'horloge locale. Le nombre suivant qui se trouve après le marqueur+/-affiche la marge d'erreur de la mesure. Des décalages positifs indiquent que l'horloge locale est en avance comparé à la source.
15.3.5.3. Vérifier les statistiques des sources Chrony
sourcestats affiche des informations sur le taux de dérive et sur le processus d'estimation de décalage de chacune des sources actuellement examinées par chronyd. On peut spécifier l'argument optionnel -v qui indique une sortie verbeuse. Dans ce cas, des lignes de légende supplémentaires sont affichées pour rappeler ce que les colonnes signifient.
chronyc sourcestats 210 Number of sources = 1 Name/IP Address NP NR Span Frequency Freq Skew Offset Std Dev =============================================================================== abc.def.ghi 11 5 46m -0.001 0.045 1us 25us
~]$ chronyc sourcestats
210 Number of sources = 1
Name/IP Address NP NR Span Frequency Freq Skew Offset Std Dev
===============================================================================
abc.def.ghi 11 5 46m -0.001 0.045 1us 25us- Name/IP address
- Nom ou adresse
IPdu serveur (ou pair)NTPou de l'ID de référence de l'horloge de référence à laquelle le reste de la ligne se réfère. - NP
- Nombre de points des échantillons actuellement conservés pour le serveur. Le taux de dérive et décalage actuel sont estimés en effectuant une régression linéaire à travers ces points.
- NR
- Nombre de courses des résidus possédant le même signe suivant la dernière régression. Si ce nombre devient trop bas par rapport au nombre d'échantillons, cela indique qu'une ligne droite ne conviendra plus aux données. Si le nombre de courses est trop bas,
chronydabandonnera les échantillons plus anciens et ré-exécutera la régression jusqu'à ce que le nombre de courses redevienne acceptable. - Span
- Intervalle entre les échantillons les plus anciens et les plus récents. Si aucune unité n'est affichée, la valeur est en secondes. Dans l'exemple, l'intervalle est égale à 46 minutes.
- Frequency
- Fréquence résiduelle estimée du serveur, en parties par million. Dans ce cas, il est estimé que l'horloge de l'ordinateur exécute 1 partie sur 109 plus lentement que le serveur.
- Freq Skew
- Limites des erreurs estimées sur Freq (en partie par millon).
- Offset
- Estimation du décalage de la source.
- Std Dev
- Estimation de la déviation standard de l'échantillon
15.3.6. Ajuster l'horloge système manuellement
root :
chronyc chrony> password commandkey-password 200 OK chrony> makestep 200 OK
~]# chronyc
chrony> password commandkey-password
200 OK
chrony> makestep
200 OKrtcfile est utilisée, l'horloge temps réel ne devrait pas être ajustée manuellement. Des ajustements aléatoires interféreront avec le besoin de chrony de mesurer le taux auquel l'horloge temps réel dérive.
-a exécutera les commandes authhash et password automatiquement. Cela signifie que la session interactive illustrée ci-dessus peut être remplacée par : chronyc -a makestep
chronyc -a makestep15.4. Paramétrer Chrony pour différents environnements
15.4.1. Paramétrer Chrony pour un système rarement connecté
/etc/chrony.conf sont similaires à :
driftfile /var/lib/chrony/drift commandkey 1 keyfile /etc/chrony.keys
driftfile /var/lib/chrony/drift
commandkey 1
keyfile /etc/chrony.keyscommandkey dans le fichier des clés, /etc/chrony.keys.
root, veuillez ajouter les adresses de quatre serveurs NTP comme suit :
server 0.pool.ntp.org offline server 1.pool.ntp.org offline server 2.pool.ntp.org offline server 3.pool.ntp.org offline
server 0.pool.ntp.org offline
server 1.pool.ntp.org offline
server 2.pool.ntp.org offline
server 3.pool.ntp.org offlineoffline peut être utile pour empêcher les systèmes de tenter d'activer des connexions. Le démon chrony attendra que chronyc l'informe si le système est connecté au réseau ou à Internet.
15.4.2. Paramétrer Chrony pour un système dans un réseau isolé
settime est utilisée.
root, veuillez modifier le fichier /etc/chrony.conf comme suit :
192.0.2.0 est l'adresse du réseau ou du sous-réseau à partir de laquelle les clients sont autorisés à se connecter.
root, veuillez modifier le fichier /etc/chrony.conf comme suit :
192.0.2.123 est l'adresse du maître, et master est le nom d'hôte du maître. Les clients avec cette configuration resynchroniseront le maître s'il redémarre.
/etc/chrony.conf devrait être le même, sauf que les directives local et allow doivent être omises.
15.5. Utiliser Chronyc
15.5.1. Utiliser Chronyc pour contrôler Chronyd
chronyd en utilisant l'utilitaire de ligne de commande chronyc en mode interactif, veuillez saisir la commande suivante en tant qu'utilisateur root :
chronyc -a
~]# chronyc -aroot. L'option -a est utilisée pour l'authentification automatique à l'aide de clés locales lors de la configuration de chronyd sur le système local. Veuillez consulter la Section 15.2.4, « Sécurité avec Chronyc » pour obtenir davantage d'informations.
chronyc>
chronyc>help pour répertorier toutes les commandes.
chronyc command
chronyc commandNote
chronyd. Pour appliquer des changements de manière permanente, veuillez modifier le fichier /etc/chrony.conf.
15.5.2. Utiliser Chronyc pour administrer à distance
chronyd, veuillez exécuter une commande sous le format suivant :
chronyc -h hostname
~]$ chronyc -h hostnamechronyd sur un port qui n'est pas celui par défaut, veuillez exécuter une commande sous le format suivant :
chronyc -h hostname -p port
~]$ chronyc -h hostname -p portchronyd.
password sur l'invite de commande chronyc comme suit :
chronyc> password password 200 OK
chronyc> password password
200 OKauthhash comme suit :
chronyc> authhash SHA1 chronyc> password HEX:A6CFC50C9C93AB6E5A19754C246242FC5471BCDF 200 OK
chronyc> authhash SHA1
chronyc> password HEX:A6CFC50C9C93AB6E5A19754C246242FC5471BCDF
200 OKSSH. Une connexion SSH devrait être établie sur la machine distante et les ID de la clé de commande du fichier /etc/chrony.conf et de la clé de commande dans le fichier /etc/chrony.keys seront mémorisés ou stockés pendant la durée de la session.
15.6. Ressources supplémentaires
15.6.1. Documentation installée
- Page man
chrony(1)— présente le démon chrony et l'outil de l'interface de ligne de commande.
- Page man
chronyc(1)— décrit l'outil de ligne de commande chronyc y compris les commandes et options de commandes.
- Page man
chronyd(1)— décrit le démon chronyd y compris les commandes et options de commandes.
- Page man
chrony.conf(5)— décrit le fichier de configuration chrony. /usr/share/doc/chrony*/chrony.txt— Guide de l'utilisateur de la suite chrony.
15.6.2. Documentation en ligne
- http://chrony.tuxfamily.org/manual.html
- Guide de l'utilisateur chrony en ligne.
Chapitre 16. Configurer NTP à l'aide de ntpd
16.1. Introduction à NTP
NTP fournissent le temps universel coordonné « Coordinated Universal Time » (UTC). Des informations sur ces serveurs de temps se trouvent sur www.pool.ntp.org.
NTP est implémenté par un démon exécuté dans l'espace utilisateur. Le démon de l'espace utilisateur NTP par défaut dans Red Hat Enterprise Linux 7 est nommé chronyd. Il doit être désactivé si vous souhaitez utiliser le démon ntpd. Veuillez consulter le Chapitre 15, Configurer NTP en utilisant Chrony Suite pour obtenir davantage d'informations sur chrony.
rtc(4) et hwclock(8) pour obtenir des informations sur les horloges matériel. L'horloge système peut rester à l'heure en utilisant diverses sources horaires. Habituellement, le Time Stamp Counter (TSC) est utilisé. Le TSC est un enregistrement du processeur qui compte le nombre de cycles depuis la dernière réinitialisation. Celui-ci est très rapide, possède une haute résolution, et aucune interruption ne se produit. Lors du démarrage système, l'horloge système lit l'heure et la date à partir de l'heure RTC. L'horloge RTC peut se décaler de l'heure réelle jusqu'à 5 minutes par mois à cause des variations de température. D'où le besoin pour l'horloge système d'être constamment synchronisée avec des références horaires externes. Lorsque l'horloge système est synchronisée par ntpd, le noyau met automatiquement à jour l'heure RTC toutes les 11 minutes.
16.2. Stratum NTP
NTP sont classés en fonction de leur distance de synchronisation avec les horloges atomiques qui sont la source des signaux horaires. Les serveurs sont arrangés en couches, ou stratums, du stratum 1 en haut, jusqu'au stratum 15 en bas. Ainsi le mot stratum est utilisé pour faire référence à une couche particulière. Les horloges atomiques sont appelées Stratum 0 car elles sont la source, mais aucun paquet Stratum 0 n'est envoyé sur l'Internet, toutes les horloges atomiques stratum 0 sont attachées à un serveur appelé stratum 1. Ces serveurs envoient des paquets marqués Stratum 1. Un serveur synchronisé au moyen de paquets marqués stratum n appartient au stratum suivant, plus bas, et marquera ses paquets en tant que stratum n+1. Les serveurs du même stratum peuvent échanger des paquets mais sont toujours désignés comme appartenant à un seul stratum, le stratum se trouvant sous la meilleure référence de synchronisation. L'appellation Stratum 16 est utilisée pour indiquer que le serveur n'est pas actuellement synchronisé à une source horaire fiable.
NTP agissent en tant que serveurs dans le stratum se trouvant en-dessous.
NTP :
- Stratum 0 :
- Les horloges atomiques et leurs signaux sont diffusés via Radio et GPS
- GPS (« Global Positioning System »)
- Systèmes de téléphonie mobile
- Transmissions Radio à basses fréquences WWVB (Colorado, USA.), JJY-40 et JJY-60 (Japon), DCF77 (Allemagne), et MSF (Royaume-Uni)
Ces signaux peuvent être reçus par des périphériques dédiés et sont habituellement connectés par RS-232 à un système utilisé comme serveur d'heure organisationnel ou pour l'ensemble du site. - Stratum 1 :
- Ordinateur avec une horloge radio, une horloge GPS, ou une horloge atomique attachée
- Stratum 2 :
- Lit le contenu du stratum 1, et le sert au stratum en-dessous
- Stratum 3 :
- Lit le contenu du stratum 2, et le sert au stratum en-dessous
- Stratum n+1 :
- Lit le contenu du stratum n, et le sert au stratum en-dessous
- Stratum 15 :
- Lit le contenu du stratum 14, il s'agit du stratum le plus bas.
16.3. Comprendre NTP
NTP utilisée par Red Hat Enterprise Linux est comme celle qui est décrite dans la RFC 1305 Network Time Protocol (Version 3) Specification, Implementation and Analysis et RFC 5905 Network Time Protocol Version 4: Protocol and Algorithms Specification
NTP permet d'atteindre une précision à la fraction de seconde. Sur Internet, une précision au dixième de seconde est normale. Sur un réseau LAN, une précision au millième de seconde est possible dans des conditions idéales. Ceci est dû au fait que la dérive horaire est désormais prise en charge et corrigée, ce qui n'était pas le cas sur les systèmes de protocoles de temps plus anciens, qui étaient plus simples. Une résolution de 233 picosecondes est offerte avec l'utilisation d'horodatages de 64 bits. Les premiers 32 bits de l'horodatage sont utilisés pour les secondes, et les derniers 32 bits sont utilisés pour les fractions de seconde.
NTP représente l'heure en tant que total du nombre de secondes depuis 00:00 (minuit) le 1er janvier, 1900 GMT. Comme 32 bits sont utilisés pour compter les secondes, cela signifie que l'heure devra être « basculée » en 2036. Cependant, NTP fonctionne avec les différences entre horodatages, ceci ne présente donc pas le même niveau de problème que les autres implémentations de protocole de temps ont pu offrir. Si une horloge matérielle se trouvant à 68 ans de l'heure correcte est disponible au moment du démarrage, alors NTP interprétera correctement la date actuelle. La spécification NTP4 fournit un numéro d'ère (« « Era Number » ») et un décalage d'ère (« « Era Offset » ») qui peuvent être utilisés pour rendre le logiciel plus robuste lorsqu'il doit gérer des durées de plus de 68 ans. Remarque : veuillez ne pas confondre ceci avec le problème Unix de l'an 2038.
NTP fournit des informations supplémentaires pour améliorere la précision. Quatre horodatages sont utilisés pour permettre le calcul du temps d'un aller-retour et du temps de réponse du serveur. Dans son rôle de client NTP, pour qu'un système puisse se synchroniser avec un serveur de temps référence, un paquet est envoyé avec un « horodatage d'origine ». Lorsque le paquet arrive, le serveur de temps ajoute un « horodatage de réception ». Après avoir traité la requête d'informations sur l'heure et la date et juste avant de retourner le paquet, un « horodatage de transmission » est ajouté. Lorsque le paquet retourné arrive sur le client NTP, un « horodatage de réception » est généré. Le client peut désormais calculer le temps d'aller-retour total et dériver le temps de transfert réel en soustrayant le temps de traitement. En supposant que les temps de transfert aller et retour soient égaux, le délai d'un seul transfert lors de la réception des données NTP est calculé. L'algorithme NTP est bien plus complexe que ce qui est présenté ici.
ntpd a déterminé. L'horloge système est ajustée lentement, au maximum à une vitesse de 0,5 ms par seconde, afin de réduire ce décalage en changeant la fréquence du compteur utilisé. Ainsi, un minimum de 2000 secondes est nécessaire pour ajuster l'horloge d'une seconde en utilisant cette méthode. Ce lent changement est appelé « Slewing » (changement d'angle d'orientation) et ne peut pas être inversé. Si le décalage de l'horloge est supérieur à 128 ms (paramètre par défaut), ntpd peut « incrémenter » l'horloge plus haut ou plus bas. Si le décalage est supérieur à 1000 seconde, alors l'utilisateur ou un script d'installation devra effectuer un ajustement manuel. Veuillez consulter le Chapitre 2, Configurer l'heure et la date. Avec l'option -g ajoutée à commande ntpd (utilisée par défaut), tout décalage lors du démarrage système sera corrigé, mais pendant une opération normale, seuls les décalages de plus de 1000 secondes seront corrigés.
-x (qui n'est pas liée à l'option -g). L'utilisation de l'option -x pour augmenter la limite de réajustement 0,128 s. à 600 s. présente un inconvénient car une méthode différente de contrôle de l'horloge doit être utilisée. Celle-ci désactive la discipline de l'horloge du noyau et peut avoir un impact négatif sur la précision de l'horloge. L'option -x peut être ajoutée au fichier de configuration /etc/sysconfig/ntpd.
16.4. Comprendre le fichier de dérive
ntpd. Le fichier de dérive est remplacé plutôt que simplement mis à jour, et pour cette raison, le fichier de dérive se trouve dans un répertoire sur lequel ntpd possède des permissions d'écriture.
16.5. UTC, Fuseaux horaires, et Heure d'été
NTP est entièrement en temps universel coordonné (UTC), les fuseaux horaires et l'heure d'été sont appliqués localement par le système. Le fichier /etc/localtime est une copie, ou un lien symbolique du fichier d'informations sur le fuseau /usr/share/zoneinfo. L'horloge temps réel (ou RTC) peut se trouver en heure locale ou en UTC, comme spécifié par la troisième ligne de /etc/adjtime, qui sera LOCAL ou UTC pour indiquer comment l'horloge RTC a été paramétrée. Les utilisateurs peuvent facilement modifier ce paramètre en cochant la case L'horloge système utilise UTC dans l'outil de configuration graphique Date et heure. Veuillez consulter le Chapitre 2, Configurer l'heure et la date pour obtenir des informations sur la manière d'utiliser cet outil. Il est recommandé d'exécutier l'horloge RTC avec le temps UTC pour éviter divers problèmes lorsque l'heure d'été change.
ntpd est expliquée en détails sur la page man de ntpd(8). La section des ressources répertorie des sources d'informations utiles. Veuillez consulter la Section 16.20, « Ressources supplémentaires ».
16.6. Options d'authentification NTP
NTPv4 ajoute la prise en charge de l'architecture de sécurité Autokey (« Autokey Security Architecture »), qui est basée sur un chiffrement asymétrique public tout en conservant la prise en charge du chiffrement de clés symétriques. L'architecture de sécurité Autokey est décrite dans la page RFC 5906 Network Time Protocol Version 4: Autokey Specification. La page man de ntp_auth(5) décrit les options et commandes d'authentification de ntpd.
NTP avec des informations horaires incorrectes. Sur les systèmes utilisant le pool public des serveurs NTP, ce risque peut être réduit en ayant plus de trois serveurs NTP dans la liste des serveurs NTP publics située dans /etc/ntp.conf. Si une seule source horaire est compromise ou usurpée, ntpd ignorera cette source. Vous devriez effectuer une évaluation des risques et prendre en considération l'impact de l'heure incorrecte sur vos applications et votre organisation. Si vous possédez des sources horaires internes, vous devriez envisager de prendre des mesures pour protéger le réseau sur lequel les paquets NTP sont distribués. Si vous effectuez une évaluation des risques et concluez que le risque est acceptable, et que l'impact sur vos applications est minime, alors vous pouvez choisir de ne pas utiliser l'authentification.
disable auth dans le fichier ntp.conf. Alternativement, l'authentification doit être configurée en utilisant des clés symétriques SHA1 ou MD5, ou avec un chiffrement à clés (asymétriques) publiques, en utilisant le schéma Autokey. Le schéma Autokey pour un chiffrement asymétrique est expliqué sur la page man ntp_auth(8) et la génération des clés est expliquée sur ntp-keygen(8). Pour implémenter le chiffrement de clés symétriques, veuillez consulter la Section 16.17.12, « Configurer l'authentification symétrique en utilisant une clé » pour une explication de l'option key.
16.7. Gérer le temps sur des machines virtuelles
kvm-clock. Veuillez consulter le chapitre Gestion du temps des invités KVM du Guide d'administration et de déploiement de la virtualisation Red Hat Enterprise Linux 7.
16.8. Comprendre les secondes intercalaires
NTP transmet des informations sur les secondes intercalaires en attente et les applique automatiquement.
16.9. Comprendre le fichier de configuration ntpd
ntpd lit le fichier de configuration au démarrage système ou lorsque le service est redémarré. L'emplacement par défaut du fichier est /etc/ntp.conf et le fichier peut être affiché en saisissant la commande suivante :
less /etc/ntp.conf
~]$ less /etc/ntp.confntp.conf(5) pour davantage de détails.
- L'entrée driftfile
- Un chemin vers le fichier de dérive (« drift file ») est spécifié, l'entrée par défaut de Red Hat Enterprise Linux est :Si vous changez ceci, assurez-vous que le répertoire soit accessible en écriture par
driftfile /var/lib/ntp/drift
driftfile /var/lib/ntp/driftCopy to Clipboard Copied! Toggle word wrap Toggle overflow ntpd. Le fichier contient une valeur utilisée pour ajuster la fréquence de l'horloge système après chaque démarrage du système ou du service. Veuillez consulter Comprendre le fichier de dérive pour obtenir davantage d'informations. - Entrées de contrôle d'accès
- La ligne suivante définit les restrictions de contrôle d'accès par défaut :
restrict default nomodify notrap nopeer noquery
restrict default nomodify notrap nopeer noqueryCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Les options
nomodifyempêchent tout changement de configuration. - L'option
notrapempêche les interruptions de protocole de messages de contrôlentpdc. - L'option
nopeerempêche la formation d'association de pairs. - L'option
noqueryempêche de répondre aux requêtesntpqetntpdc, mais n'empêche pas de répondre aux requêtes de temps.
Important
Les requêtesntpqetntpdcpeuvent être utilisées dans les attaques d'amplification, veuillez donc ne pas supprimer l'optionnoqueryde la commanderestrict defaultsur des systèmes accessibles publiquement.Veuillez consulter CVE-2013-5211 pour obtenir davantage de détails.Les adresses situées dans la plage127.0.0.0/8sont parfois requises par divers processus ou applications. Comme la ligne « restrict default » (restreindre par défaut) ci-dessus prévient l'accès à tout ce qui n'est pas explicitement autorisé, l'accès à l'adresse de bouclageIPv4etIPv6est autorisé au moyen des lignes suivantes :Les adresses peuvent être ajoutées ci-dessous si elles sont spécifiquement requises par une autre application.# the administrative functions. restrict 127.0.0.1 restrict ::1
# the administrative functions. restrict 127.0.0.1 restrict ::1Copy to Clipboard Copied! Toggle word wrap Toggle overflow Les hôtes sur le réseau local ne sont pas autorisés à cause de la ligne ci-dessus « restrict default » (restreindre par défaut). Pour changer cela, par exemple pour autoriser les hôtes du réseau192.0.2.0/24à demander l'heure et les statistiques et rien de plus, une ligne au format suivant est requise :Pour autoriser un accès non limité à partir d'un hôte spécifique, par exemple à partir derestrict 192.0.2.0 mask 255.255.255.0 nomodify notrap nopeer
restrict 192.0.2.0 mask 255.255.255.0 nomodify notrap nopeerCopy to Clipboard Copied! Toggle word wrap Toggle overflow 192.0.2.250/32, une ligne au format suivant est requise :Un masque derestrict 192.0.2.250
restrict 192.0.2.250Copy to Clipboard Copied! Toggle word wrap Toggle overflow 255.255.255.255est appliqué si aucun masque n'est spécifié.Les commandes de restriction sont expliquées dans la page man dentp_acc(5). - Entrées de serveurs publics
- Par défaut, le fichier
ntp.confcontient quatre entrées de serveurs publics :server 0.rhel.pool.ntp.org iburst server 1.rhel.pool.ntp.org iburst server 2.rhel.pool.ntp.org iburst server 3.rhel.pool.ntp.org iburst
server 0.rhel.pool.ntp.org iburst server 1.rhel.pool.ntp.org iburst server 2.rhel.pool.ntp.org iburst server 3.rhel.pool.ntp.org iburstCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Entrées de serveurs de diffusion et de multidiffusion
- Par défaut, le fichier
ntp.confcontient quelques exemples mis en commentaire. Ces exemples sont principalement explicites. Veuillez consulter la Section 16.17, « Configurer NTP » pour une explication des commandes spécifiques. Si requis, ajoutez vos commandes sous les exemples.
Note
DHCP, dhclient reçoit une liste de serveurs NTP du serveur DHCP, il les ajoute à ntp.conf et redémarre le service. Pour désactiver cette fonctionnalité, veuillez ajouter PEERNTP=no à /etc/sysconfig/network.
16.10. Comprendre le fichier Sysconfig ntpd
ntpd au démarrage du service. Le contenu par défaut est comme suit :
# Command line options for ntpd OPTIONS="-g"
# Command line options for ntpd
OPTIONS="-g"-g active ntpd pour ignorer la limite de décalage de 1000s et tente de synchroniser l'heure même si le décalage est plus important que 1000s, mais uniquement lors du démarrage système. Sans cette option, ntpd se fermera si le décalage dépasse 1000s. Il se fermera également après un démarrage système si le service est redémarré et que le décalage fait plus de 1000s même avec l'option -g.
16.11. Désactiver chrony
ntpd, le démon de l'espace utilisateur par défaut, chronyd doit être arrêté et désactivé. Veuillez exécuter la commande suivante en tant qu'utilisateur root :
systemctl stop chronyd
~]# systemctl stop chronydroot :
systemctl disable chronyd
~]# systemctl disable chronydchronyd, veuillez exécuter la commande suivante :
systemctl status chronyd
~]$ systemctl status chronyd16.12. Vérifier si le démon NTP est installé
ntpd est installé, veuillez saisir la commande suivante en tant qu'utilisateur root :
yum install ntp
~]# yum install ntpNTP est implémenté par le démon ou le service ntpd, qui se trouve dans le paquet ntp.
16.13. Installer le démon NTP (ntpd)
ntpd, veuillez saisir la commande suivante en tant qu'utilisateur root :
yum install ntp
~]# yum install ntpntpd lors du démarrage système, veuillez saisir la commande suivante en tant qu'utilisateur root :
systemctl enable ntpd
~]# systemctl enable ntpd16.14. Vérifier le statut de NTP
ntpd est en cours d'exécution et configuré pour être exécuté lors du démarrage système, veuillez exécuter la commande suivante :
systemctl status ntpd
~]$ systemctl status ntpdntpd, veuillez exécuter la commande suivante :
ntpstat unsynchronised time server re-starting polling server every 64 s
~]$ ntpstat
unsynchronised
time server re-starting
polling server every 64 sntpstat synchronised to NTP server (10.5.26.10) at stratum 2 time correct to within 52 ms polling server every 1024 s
~]$ ntpstat
synchronised to NTP server (10.5.26.10) at stratum 2
time correct to within 52 ms
polling server every 1024 s16.15. Configurer le pare-feu pour autoriser les paquets NTP entrants
NTP consiste en paquets UDP sur le port 123 et doit être autorisé sur le réseau et sur les pare-feux basés hôte pour que NTP puisse fonctionner.
NTP entrant pour les clients utilisant l'outil de configuration du pare-feu graphique Firewall Configuration.
firewall puis appuyez sur Entrée. La fenêtre « Configuration du pare-feu » s'ouvre. Le mot de passe de l'utilisateur vous sera demandé.
root :
firewall-config
~]# firewall-configroot vous sera quand même demandé de temps à autre.
firewalld.
16.15.1. Modifier les paramètres du pare-feu
Note
16.15.2. Ouvrir des ports du pare-feu pour les paquets NTP
123 et sélectionnez dans la liste déroulante.
16.16. Configurer les serveurs ntpdate
ntpdate est de régler l'horloge pendant le démarrage système. C'était utilisé pour veiller à ce que les services lancés après ntpdate aient l'heure correcte sans « sauts » d'horloge. L'utilisation de ntpdate et de la liste des « step-tickers » sont déconseillés et Red Hat Enterprise Linux 7 utilise désormais l'option -g sur la commande ntpd et non plus ntpdate par défaut.
ntpdate de Red Hat Enterprise Linux 7 est plus utile en autonome, sans ntpd. Avec systemd, qui lance des services en parallèle, l'activation du service ntpdate ne garantit pas que d'autres services lancés par la suite auront l'heure correcte, à moins qu'ils ne spécifient une dépendance de classement sur time-sync.target, qui est fournie par le service ntpdate. Pour vous assurer qu'un service soit lancé avec l'heure correcte, ajoutez After=time-sync.target au service et activez l'un des services qui fournit la cible (ntpdate ou sntp). Cette dépendance est incluse par défaut sur certains services Red Hat Enterprise Linux 7 ( par exemple, dhcpd, dhcpd6, et crond).
ntpdate est activé pour s'exécuter pendant le démarrage système, veuillez exécuter la commande suivante :
systemctl status ntpdate
~]$ systemctl status ntpdateroot :
systemctl enable ntpdate
~]# systemctl enable ntpdate/etc/ntp/step-tickers par défaut contient 0.rhel.pool.ntp.org. Pour configurer des serveurs ntpdate supplémentaires, veuillez utiliser un éditeur de texte en tant qu'utilisateur root et modifiez /etc/ntp/step-tickers. Le nombre de serveurs répertoriés n'est pas très important car ntpdate utilisera uniquement ceci pour obtenir des informations sur la date une fois que le système aura démarré. Si vous possédez un serveur de temps interne, alors utilisez ce nom d'hôte pour la première ligne. Un hôte supplémentaire sur la seconde ligne en tant que copie de sauvegarde est une bonne idée. La sélection des serveurs de sauvegarde et le choix d'un second hôte interne ou externe dépend de votre évaluation des risques. Par exemple, quelles sont les chances qu'un problème affectant le premier serveur puissent également affecter le second serveur ? Est-ce que la connectivité d'un serveur externe sera plus facilement disponible que la connectivité aux serveurs internes en cas de panne réseau perturbant l'accès au premier serveur ?
16.17. Configurer NTP
NTP, veuillez utiliser un éditeur de texte exécuté en tant qu'utilisateur root pour modifier le fichier /etc/ntp.conf. Ce fichier est installé avec ntpd et est configuré pour utiliser des serveurs de temps du pool Red Hat par défaut. La page man ntp.conf(5) décrit les options de commande pouvant être utilisées dans le fichier de configuration, mises à part les commandes d'accès et de limitation du taux, qui sont expliquées dans la page man de ntp_acc(5).
16.17.1. Configurer le contrôle d'accès à un service NTP
NTP exécuté sur un système, veuillez utiliser la commande restrict dans le fichier ntp.conf. Voir l'exemple en commentaire :
# Hosts on local network are less restricted. #restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
# Hosts on local network are less restricted.
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notraprestrict prend la forme suivante :
restrict option
restrict optionignore— Tous les paquets seront ignorés, y compris les requêtesntpqountpdcou une combinaison de ces options.kod— un paquet « Kiss-o'-death » » (KoD) sera envoyé pour réduire les requêtes indésirables.limited— ne pas répondre aux requêtes de service de temps si le paquet transgresse les valeurs par défaut de la limite de taux ou les valeurs spécifiées par la commandediscard. Les requêtesntpqetntpdcne sont pas affectées. Pour obtenir davantage d'informations sur la commandediscardet sur les valeurs par défaut, veuillez consulter la Section 16.17.2, « Configurer le taux limite d'accès à un service NTP ».lowpriotrap— interruptions définies comme étant de basse priorité par les hôtes correspondants.nomodify— empêche tout changement de configuration.noquery— empêche de répondre aux requêtesntpqetntpdc, mais n'empêche pas de répondre aux requêtes de temps.nopeer— empêche la formation d'association de pairs.noserve— refuse tous les paquets, sauf les requêtesntpqetntpdc.notrap— empêche les interruptions de protocole de messages de contrôlentpdc.notrust— refuse les paquets dont le chiffrement n'est pas authentifié.ntpport— modifie l'algorithme de correspondance pour appliquer la restriction uniquement si le port source est le port standardNTPUDP123.version— refuse les paquets qui ne correspondent pas à la versionNTPactuelle.
restrict respective doit inclure l'option limited. Si ntpd doit répondre avec un paquet KoD, la commande restrict devra inclure les options limited et kod.
ntpq et ntpdc peuvent être utilisées dans les attaques d'amplification (consultez CVE-2013-5211 pour plus de détails), veuillez donc ne pas supprimer l'option noquery de la commande restrict default sur des systèmes accessibles publiquement.
16.17.2. Configurer le taux limite d'accès à un service NTP
NTP exécuté sur un système, veuillez ajouter l'option limited à la commande restrict comme expliqué dans Section 16.17.1, « Configurer le contrôle d'accès à un service NTP ». Si vous ne souhaitez pas utiliser les paramètres d'abandon par défaut, alors veuillez également utiliser la commande discard, comme décrit ici.
discard prend la forme suivante :
discard [average value] [minimum value] [monitor value]
discard [average value] [minimum value] [monitor value]average— spécifie l'espacement de paquets moyen minimum autorisé, un argument est également accepté en log2 secondes. La valeur par défaut est de 3 (23 équivaut à 8 secondes).minimum— spécifie l'espacement de paquets minimum autorisé, un argument est accepté en log2 secondes. La valeur par défaut est de 1 (21 équivaut à 2 secondes).monitor— spécifie la probabilité d'abandon de paquet une fois que les limites de taux autorisées ont été dépassées. La valeur par défaut est de 3000 secondes. Cette option est conçue pour les serveurs recevant 1000 requêtes ou plus par seconde.
discard command are as follows: discard average 4
discard average 4discard average 4 minimum 2
discard average 4 minimum 216.17.3. Ajouter l'adresse d'un pair
NTP du même stratum, veuillez utiliser la commande peer dans le fichier ntp.conf.
peer prend la forme suivante :
peer address
peer addressIP ou un nom DNS résolvable. L'adresse doit uniquement être celle d'un système connu comme étant membre du même stratum. Les homologues (peer) doivent avoir au moins une source de temps différente l'un par rapport à l'autre. Habituellement, les homologues sont des systèmes sous le même contrôle administratif.
16.17.4. Ajouter une adresse de serveur
NTP d'un stratum plus élevé, veuillez utiliser la commande server dans le fichier ntp.conf.
server prend la forme suivante :
server address
server addressIP ou un nom DNS résolvable. Adresse d'un serveur de référence distant ou d'une horloge de référence locale à partir de laquelle les paquets seront reçus.
16.17.5. Ajouter une adresse de serveur de diffusion ou de multidiffusion
NTP de diffusion ou de multidiffusion, utilisez la commande broadcast dans le fichier ntp.conf.
broadcast prend la forme suivante :
broadcast address
broadcast addressIP sur laquelle les paquets sont envoyés.
NTP. L'adresse utilisée doit être une adresse de diffusion ou de multidiffusion. Une adresse de diffusion implique l'adresse IPv4 255.255.255.255. Par défaut, les routeurs ne transmettent pas de messages de diffusion. L'adresse de multidiffusion peut être une adresse IPv4 de class D, ou une adresse IPv6. L'IANA a assigné l'adresse de multidiffusion IPv4 224.0.1.1 et l'adresse IPv6 FF05::101 (locale au site) à NTP. Les adresses de multidiffusion IPv4 dans un cadre administratif peuvent également être utilisées, comme décrit dans la page RFC 2365 Administratively Scoped IP Multicast.
16.17.6. Ajouter une adresse de client Manycast
NTP, utiliser la commande manycastclient dans le fichier ntp.conf.
manycastclient prend la forme suivante :
manycastclient address
manycastclient addressIP à partir de laquelle les paquets seront reçus. Le client enverra une requête à l'adresse et sélectionnera les meilleurs serveurs à partir des réponses et ignorera les autres serveurs. La communication NTP utilise ensuite des associations de monodiffusion, comme si les serveurs NTP découverts étaient répertoriés dans ntp.conf.
NTP. Les systèmes peuvent être client et serveur à la fois.
16.17.7. Ajouter une adresse de client de diffusion
NTP y soient vérifiés, assurez-vous de bien utiliser la commande broadcastclient dans le fichier ntp.conf.
broadcastclient prend la forme suivante :
broadcastclient
broadcastclientNTP. Les systèmes peuvent être client et serveur à la fois.
16.17.8. Ajouter une adresse de serveur Manycast
NTP, utiliser la commande manycastserver dans le fichier ntp.conf.
manycastserver prend la forme suivante :
manycastserver address
manycastserver addressNTP. Les systèmes peuvent être client et serveur à la fois.
16.17.9. Ajouter une adresse de client de multidiffusion
NTP y soient vérifiés, assurez-vous de bien utiliser la commande multicastclient dans le fichier ntp.conf.
multicastclient prend la forme suivante :
multicastclient address
multicastclient addressNTP. Les systèmes peuvent être client et serveur à la fois.
16.17.10. Configurer l'option Burst
burst sur un serveur public est considéré comme un abus. N'utilisez pas cette option sur des serveurs NTP publics. Ne l'utilisez que pour les applications qui appartiennent à votre organisation.
burst
burstserver pour améliorer la qualité moyenne des calculs de décalage horaire.
16.17.11. Configurer l'option iburst
iburst
iburstcalldelay pour permettre un temps supplémentaire pour l'appel ISDN ou modem. À utiliser avec la commande server pour réduire le temps pris pour une synchronisation initiale. Celle-ci est désormais une option par défaut dans le fichier de configuration.
16.17.12. Configurer l'authentification symétrique en utilisant une clé
key number
key number1 à 65534 inclus. Cette option autorise l'utilisation d'un code d'authentification de message (message authentication code, ou MAC) dans les paquets. Cette option est conçue pour une utilisation avec les commandes peer, server, broadcast, et manycastclient.
/etc/ntp.conf comme suit :
server 192.168.1.1 key 10 broadcast 192.168.1.255 key 20 manycastclient 239.255.254.254 key 30
server 192.168.1.1 key 10
broadcast 192.168.1.255 key 20
manycastclient 239.255.254.254 key 3016.17.13. Configurer l'intervalle d'interrogation
minpoll value and maxpoll value
minpoll value and maxpoll valueminpoll par défaut est 6, 26 équivaut à 64s. La valeur par défaut de maxpoll est de 10, ce qui équivaut à 1024s. Les valeurs autorisées se trouvent entre 3 et 17 inclus, ce qui signifie entre 8s et 36.4h respectivement. Ces options sont pour une utilisation avec la commande peer ou server. Définir une valeur maxpoll plus basse peut améliorer la précision de l'horloge.
16.17.14. Configurer les préférences du serveur
prefer
preferpeer ou server.
16.17.15. Configurer la valeur de durée de vie (« Time-to-Live ») des paquets NTP
ttl value
ttl valueNTP. Spécifiez la valeur TTL maximale à utiliser pour la recherche « « expanding ring search » » par un client Manycast. La valeur par défaut est de 127.
16.17.16. Configurer la version NTP à utiliser
NTP à utiliser à la place de celle par défaut, veuillez ajouter l'option suivante à la fin d'une commande serveur ou pair :
version value
version valueNTP définie dans les paquets NTP créés. La valeur peut se trouver dans une gamme allant de 1 à 4. La valeur par défaut est 4.
16.18. Configurer la mise à jour de l'horloge matérielle
- Mise à jour ponctuelle instantanée
- Pour effectuer une mise à jour ponctuelle instantanée de l'horloge matérielle, exécutez cette commande en tant qu'utilisateur root :
hwclock --systohc
~]# hwclock --systohcCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Mise à jour à chaque démarrage
- Pour effectuer la mise à jour de l'horloge matérielle à chaque démarrage, après avoir exécuté l'utilitaire de synchronisation suivant ntpdate, procédez ainsi :
- Ajouter la ligne suivante au fichier
/etc/sysconfig/ntpdate:SYNC_HWCLOCK=yes
SYNC_HWCLOCK=yesCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Activee le service
ntpdateen tant qu'utilisateur root :systemctl enable ntpdate.service
~]# systemctl enable ntpdate.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Notez que le servicentpdateutilise les serveurs NTP définis dans le fichier/etc/ntp/step-tickers.Note
Dans les machines virtuelles, l'horloge matérielle sera mise à jour lors du prochain démarrage de la machine hôte, et non pas de la machine virtuelle. - Mettre à jour via NTP
- Pour effectuer la mise à jour de l'horloge matérielle à chaque fois que l'horloge système est mise à jour par le service
ntpdouchronyd, démarrez le servicentpdateen tant qu'utilisateur root :systemctl start ntpdate.service
~]# systemctl start ntpdate.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow Pour que le comportement soit consistant à travers les démarrages, rendez le service automatique au démarage :systemctl enable ntpdate.service
~]# systemctl enable ntpdate.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow Après avoir activé le servicentpdate, à chaque fois que l'horloge système sera synchronisée parntpdouchronyd, le noyau mettra à jour l'horloge matérielle automatiquement toutes les 11 minutes.Avertissement
Cette approche risque de ne pas toujours fonctionner car ce mode 11-minutes n'est pas toujours activé, donc la mise à jour de l'horloge matérielle n'a pas forcément lieu au même moment que la mise à jour de l'horloge système.
16.19. Configurer les sources des horloges
cd /sys/devices/system/clocksource/clocksource0/ clocksource0]$ cat available_clocksource kvm-clock tsc hpet acpi_pm clocksource0]$ cat current_clocksource kvm-clock
~]$ cd /sys/devices/system/clocksource/clocksource0/
clocksource0]$ cat available_clocksource
kvm-clock tsc hpet acpi_pm
clocksource0]$ cat current_clocksource
kvm-clockclocksource à la ligne GRUB du noyau. Utiliser l'outil grubby pour effectuer ce changement. Ainsi, pour forcer le noyau par défaut sur un système pour qu'il utilise le source d'horloge tsc, saisir la commande suivante :
grubby --args=clocksource=tsc --update-kernel=DEFAULT
~]# grubby --args=clocksource=tsc --update-kernel=DEFAULT--update-kernel accepte également le mot clé ALL, ou une liste de numéros d'indexes de noyaux séparée par des virgules.
16.20. Ressources supplémentaires
NTP et ntpd.
16.20.1. Documentation installée
- Page man
ntpd(8)— décritntpden détails, y compris les options de ligne de commandes. - Page man
ntp.conf(5)— contient des informations sur la manière de configurer des associations avec des serveurs et des pairs. - Page man
ntpq(8)— décrit l'utilitaire de requêtesNTPpour surveiller et effectuer des requêtes sur un serveurNTP. - Page man
ntpdc(8)— décrit l'utilitairentpdpour effectuer des requêtes et changer l'état dentpd. - Page man
ntp_auth(5)— décrit les options d'authentification, commandes, et la gestion des clés dentpd. - Page man
ntp_keygen(8)— décrit la génération de clés publiques et privées pourntpd. - Page man
ntp_acc(5)— décrit les options de contrôle d'accès en utilisant la commanderestrict. - Page man
ntp_mon(5)— décrit les options de surveillance pour la collecte de statistiques. - Page man
ntp_clock(5)— décrit les commandes pour configurer les horloges de référence. - Page man
ntp_misc(5)— décrit les options diverses. - Page man
ntp_decode(5)— répertorie le mots de statut, messages d'événements et codes d'erreur utilisés pour les rapports et la surveillancentpd. - Page man
ntpstat(8)— décrit un utilitaire pour rapporter l'état de synchronisation du démonNTPexécuté sur la machine locale. - Page man
ntptime(8)— décrit un utilitaire pour lire et paramétrer les variables de temps du noyau. - Page man
tickadj(8)— décrit un utilitaire pour lire, et optionnellement paramétrer la longueur du tic.
16.20.2. Sites Web utiles
- http://doc.ntp.org/
- Archive de la documentation NTP
- http://www.eecis.udel.edu/~mills/ntp.html
- Projet de recherche sur la synchronisation du temps réseau
- http://www.eecis.udel.edu/~mills/ntp/html/manyopt.html
- Informations sur le découverte automatique de serveurs sur
NTPv4.
Chapitre 17. Configurer PTP en utilisant ptp4l
17.1. Introduction à PTP
PTP est capable d'atteindre une précision inférieure à la microseconde, ce qui est bien mieux que les résultats normalement obtenus avec NTP. La prise en charge de PTP est divisée entre le noyau et l'espace utilisateur. Le noyau dans Red Hat Enterprise Linux inclut la prise en charge des horloges PTP, qui sont fournies par les pilotes réseaux. L'implémentation du protocole est connue sous le nom linuxptp, une implémentation PTPv2 selon le standard IEEE 1588 pour Linux.
PTP et l'« Ordinary Clock ». Avec l'horodatage matériel, ce paquet est utilisé pour synchroniser l'horloge matérielle PTP à l'horloge maître, et avec l'horodatage logiciel, il permet de synchroniser l'horloge système à l'horloge maître. Le programme phc2sys n'est utilie que pour l'horodatage matériel, pour synchroniser l'horloge système à l'horloge matérielle PTP sur la carte réseau (NIC).
17.1.1. Comprendre PTP
PTP sont organisées sous une hiérarchie de type maître-esclave. Les esclaves sont synchronisés à leurs maîtres qui peuvent eux-mêmes être esclaves d'autres maîtres. La hiérarchie est créée et mise à jour automatiquement par l'algorithme « best master clock » (BMC), qui est exécuté sur chaque horloge. Lorsqu'une horloge ne possède qu'un seul port, celle-ci peut être maître (« master ») ou esclave (« slave »), ce type d'horloge est appelé une Ordinary Clock (OC). Une horloge avec de multiples ports peut être maître sur un port et esclave sur un autre, ce type d'horloge est appelé une Boundary Clock (BC). L'horloge maître se trouvant tout en haut est appelée Grandmaster Clock, et peut être synchronisée en utilisant une source de temps GPS (Global Positioning System). En utilisant une source de temps basée GPS, des réseaux disparates peuvent être synchronisés avec un haut degré de précision.
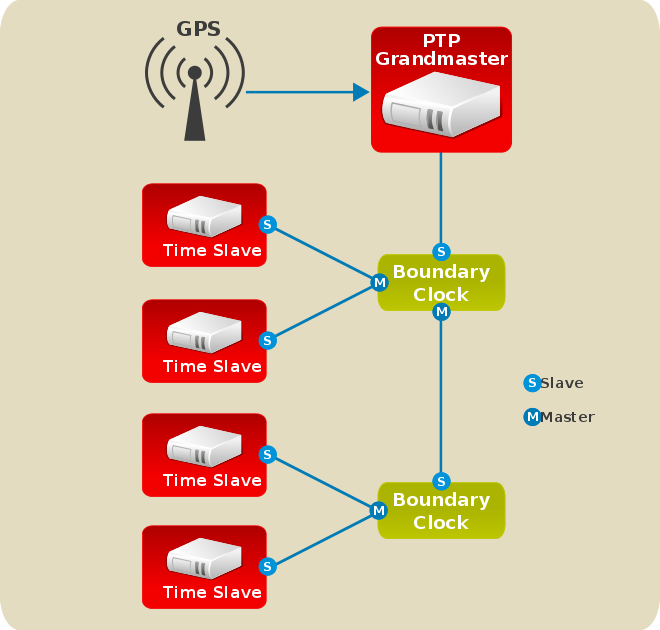
Figure 17.1. Horloges PTP grandmaster, horloges boundary, et horloges esclaves
17.1.2. Avantages de PTP
PTP comparé au protocole Network Time Protocol (ou NTP) est la prise en charge matérielle présente dans divers NIC (Network Interface Controllers) et interrupteurs réseau. Ce matériel spécialisé permet à PTP de tenir compte des délais de transfert de messages, et de largement augmenter la précision de la synchronisation du temps. Même s'il est possible d'utiliser des composants matériel dans le réseau sur lesquels PTP n'est pas activé, cela causera souvent une instabilité ou introduira une asymétrie dans le délai, résultant en inexactitudes de synchronisation, et en une multitude de composants ne reconnaissant pas PTP, utilisés tout au long du chemin de communication. Pour atteindre la meilleure précision possible, il est recommandé que le matériel autorise PTP sur tous les composants réseau entre horloges PTP . La synchronisation du temps dans les réseaux de plus grandes taille où tout le matériel réseau ne prend pas forcément en charge PTP pourrait être plus adéquat pour NTP.
PTP, le NIC possède sa propre horloge intégrée, qui est utilisée pour horodater les messages PTP reçus et transmis. Cette horloge intégrée est effectivement synchronisée avec l'horloge maître PTP, et l'horloge système de l'ordinateur est synchronisée avec l'horloge matérielle PTP sur le NIC. Avec la prise en charge PTP, l'horloge système est utilisée pour horodater les messages PTP et est synchronisée avec l'horloge maître PTP directement. La prise en charge matérielle PTP offre une meilleure précision puisque le NIC peut horodater les paquets PTP au moment exact où ils sont envoyés et reçus, tandis que la prise en charge PTP logicielle requiert le traitement supplémentaire des paquets PTP par le système d'exploitation.
17.2. Utiliser PTP
PTP, le pilote réseau du noyau de l'interface doit offrir des capacités de prise en charge d'horodatage logiciel ou matériel.
17.2.1. Vérifier la prise en charge des pilotes et du matériel
SOF_TIMESTAMPING_SOFTWARE
SOF_TIMESTAMPING_TX_SOFTWARE
SOF_TIMESTAMPING_RX_SOFTWARE
SOF_TIMESTAMPING_RAW_HARDWARE
SOF_TIMESTAMPING_TX_HARDWARE
SOF_TIMESTAMPING_RX_HARDWARE
17.2.2. Installer PTP
PTP. La prise en charge de l'espace utilisateur est fournie par les outils du paquet linuxptp. Pour installer linuxptp, veuillez exécuter la commande suivante en tant qu'utilisateur root :
yum install linuxptp
~]# yum install linuxptpPTP en utilisant NTP, veuillez consulter la Section 17.8, « Servir le temps PTP avec NTP ».
17.2.3. Lancer ptp4l
/etc/sysconfig/ptp4l. Les options requises pour une utilisation par le service et sur la ligne de commande doivent être spécifiées dans le fichier /etc/ptp4l.conf. Le fichier /etc/sysconfig/ptp4l inclut l'option de ligne de commande -f /etc/ptp4l.conf, qui cause au programme ptp4l de lire le fichier /etc/ptp4l.conf et de traiter les options contenues. L'utilisation du fichier /etc/ptp4l.conf est expliquée dans la Section 17.4, « Spécifier un fichier de configuration ». Des informations supplémentaires sur les différentes options ptp4l et sur les paramètres du fichier de configuration se trouvent sur la page man ptp4l(8).
Lancer ptp4l en tant que service
root :
systemctl start ptp4l
~]# systemctl start ptp4lUtiliser ptp4l dans la ligne de commande
-i. Veuillez saisir la commande suivante en tant qu'utilisateur root :
ptp4l -i eth3 -m
~]# ptp4l -i eth3 -mPTP du NIC est synchronisée avec une horloge maître :
s0, s1, s2 indiquent différents états de l'horloge servo : s0 est déverrouillé, s1 est un step (ou décalage) d'horloge et s2 est verrouillé. Une fois le servo dans un état verrouillé (s2), l'horloge ne sera pas décalée (mais uniquement légèrement ajustée), à moins que l'option pi_offset_const ne soit définie sur une valeur positive dans le fichier de configuration (décrit sur la page man ptp4l(8)). La valeur adj est l'ajustement de la fréquence de l'horloge en ppb (« parts per billion », ou parties par milliard). La valeur du délai du chemin correspond au délai estimé des messages de synchronisation envoyés depuis l'horloge maître en nanosecondes. Le port 0 est un socket de domaines Unix utilisé pour la gestion PTP locale. Le port 1 est l'interface eth3 (basé sur l'exemple ci-dessus.) Les états du port possibles incluent INITIALIZING, LISTENING, UNCALIBRATED et SLAVE, ceux-ci peuvent changer lors des événements INITIALIZE, RS_SLAVE, MASTER_CLOCK_SELECTED. Dans le dernier message de changement d'état, l'état du port est passé de UNCALIBRATED à SLAVE, ce qui indique une synchronisation réussie avec une horloge PTP maître.
Journaliser des messages à partir de ptp4l
/var/log/messages. Cependant, spécifier l'option -m active la journalisation sur la sortie standard, ce qui peut être utile pour des raisons de débogage.
-S doit être utilisée comme suit :
ptp4l -i eth3 -m -S
~]# ptp4l -i eth3 -m -S17.2.3.1. Sélectionner un mécanisme de mesure du délai
ptp4l :
-P- L'option
-Ppermet de sélectionner le mécanisme de mesure de délai pair à pair ( peer-to-peer, ou P2P).Le mécanisme P2P est préféré car il réagit aux changements de la topologie réseau plus rapidement, et peut être plus précis dans la mesure du délai que les autres mécanismes. Le mécanisme P2P peut uniquement être utilisé sur les topologies où chaque port échanges des messages PTP avec au moins un autre port P2P. Il doit être pris en charge et utilisé par tout le matériel sur le chemin de communication, y compris les horloges transparentes. -E- L'option
-Esélectionne le mécanisme de mesure de délai end-to-end (E2E). Ce mécanisme est utilisé par défaut.Le mécanisme E2E est également appelé mécanisme « request-response » (requête-réponse) du délai. -A- L'option
-Aactive la sélection automatique du mécanisme de mesure du délai.L'option automatique lance ptp4l en mode E2E. Celle-ci passera en mode P2P si une requête de délai est reçue.
Note
PTP doivent utiliser le même mécanisme de mesure de délai. Des avertissements seront imprimés dans les circonstances suivantes :
- Lorsqu'une requête de délai est reçue sur un port utilisant le mécanisme E2E.
- Lorsqu'une requête de délai E2E est reçue sur un port utilisant le mécanisme P2P.
17.3. Utiliser PTP en interfaces multiples
sysctl a l'habitude de lire et d'écrire des valeurs dans le noyau. Vous pouvez effectuer des modifications à un système en cours d'exécution par les commandes sysctl directement en ligne de commandes, et des changements permanents en ajoutant des lignes au fichier /etc/sysctl.conf.
- Pour passer au mode loose (non strict) de filtrage global, saisir les commandes suivantes en tant qu'utilisateur
root:sysctl -w net.ipv4.conf.default.rp_filter=2 sysctl -w net.ipv4.conf.all.rp_filter=2
~]# sysctl -w net.ipv4.conf.default.rp_filter=2 sysctl -w net.ipv4.conf.all.rp_filter=2Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour changer le mode « Reverse path filtering » (filtrage chemin inversé) pour chaque interface de réseau, exécuter la commande
net.ipv4.interface.rp_filtersur toutes les interfaces PTP. Ainsi, pour une interface ayant comme nom de périphériqueem1:sysctl -w net.ipv4.conf.em1.rp_filter=2
~]# sysctl -w net.ipv4.conf.em1.rp_filter=2Copy to Clipboard Copied! Toggle word wrap Toggle overflow
/etc/sysctl.conf. Ainsi, pour changer le mode sur toutes les interfaces, ouvrir le fichier /etc/sysctl.conf à l'aide d'un éditeur en tant qu'utilisateur root et ajouter la ligne suivante : net.ipv4.conf.all.rp_filter=2
net.ipv4.conf.all.rp_filter=2net.ipv4.conf.interface.rp_filter=2
net.ipv4.conf.interface.rp_filter=217.4. Spécifier un fichier de configuration
-f. Par exemple :
ptp4l -f /etc/ptp4l.conf
~]# ptp4l -f /etc/ptp4l.conf-i eth3 -m -S affichées ci-dessus peut ressembler à ceci :
~]# cat /etc/ptp4l.conf [global] verbose 1 time_stamping software [eth3]
~]# cat /etc/ptp4l.conf
[global]
verbose 1
time_stamping software
[eth3]17.5. Utiliser le client de gestion PTP
PTP, pmc, peut être utilisé pour obtenir des informations supplémentaires de ptp4l comme suit :
-b sur zéro limite la valeur « Boundary » à l'instance ptp4l exécutée localement. Une valeur « Boundary » plus importante récupérera également les informations des nœuds PTP plus éloignés de l'horloge locale. Les informations récupérables incluent :
stepsRemovedest le nombre de chemins de communication vers le « Grandmaster Clock ».offsetFromMasteret master_offset est le dernier décalage mesuré de l'horloge depuis l'horloge maître en nanosecondes.meanPathDelayest le délai estimé des messages de synchronisation envoyés depuis l'horloge maître en nanosecondes.- Si
gmPresentest « true », l'horlogePTPest synchronisée sur une horloge maitre, l'horloge locale ne sera plus le « Grandmaster Clock ». gmIdentityest l'identité du « Grandmaster ».
root :
pmc help
~]# pmc helppmc(8).
17.6. Synchroniser les horloges
PTP (PHC) sur le NIC. Le service phc2sys est configuré dans le fichier de configuration /etc/sysconfig/phc2sys. Le paramètre par défaut du fichier /etc/sysconfig/phc2sys est comme suit : OPTIONS="-a -r"
OPTIONS="-a -r"-a amène phc2sys à lire les horloges devant être synchronisées à partir de l'application ptp4l. Il suivra les changements des états des ports PTP, ajustant la synchronisation entre horloges matérielles NIC en conséquence. L'horloge système n'est pas synchronsée, à moins que l'option -r soit également spécifiée. Si vous souhaitez que l'horloge système soit une source de temps éligible, veuillez spécifier l'option -r deux fois.
/etc/sysconfig/phc2sys, redémarrez le service phc2sys à partir de la ligne de commande en exécutant une commande en tant qu'utilisateur root :
systemctl restart phc2sys
~]# systemctl restart phc2syssystemctl pour lancer, arrêter, et redémarrer le service phc2sys.
root :
phc2sys -a -r
~]# phc2sys -a -r-a amène phc2sys à lire les horloges devant être synchronisées à partir de l'application ptp4l. Si vous souhaitez que l'horloge système puisse être une source de temps éligible, veuillez spécifier l'option -r deux fois.
-s pour synchroniser l'horloge système avec l'horloge matérielle PTP d'une l'interface spécifique. Par exemple :
phc2sys -s eth3 -w
~]# phc2sys -s eth3 -w-w attend que l'application ptp4l synchronise l'horloge PTP et récupère le décalage TAI de l'horloge UTC de ptp4l.
PTP opère sous l'échelle horaire du temps atomique international (International Atomic Time, ou TAI), tandis que l'horloge système reste dans le temps universel coordonné (Coordinated Universal Time, ou UTC). Le décalage actuel entre les heures TAI et UTC est de 36 secondes. Le décalage change lorsque des secondes intercalaires sont insérées ou supprimées, ce qui se produit habituellement au bout de quelques années régulièrement. L'option -O doit être utilisée pour paramétrer ce décalage manuellement lorsque l'option -w n'est pas utilisée, comme suit :
phc2sys -s eth3 -O -36
~]# phc2sys -s eth3 -O -36-S ne soit utilisée. Cela signifie que le programme phc2sys devrait être lancé après que le programme ptp4l ait synchronisé l'horloge matérielle PTP. Cependant avec -w, il n'est pas utile de lancer phc2sys après ptp4l comme celui-ci attendra que l'horloge soit synchronisée.
systemctl start phc2sys
~]# systemctl start phc2sys/etc/sysconfig/phc2sys. On peut trouver davantage d'informations sur les différentes options phc2sys dans la page man phc2sys(8).
17.7. Vérifier la synchronisation du temps
PTP fonctionne correctement, de nouveaux messages avec des décalages et des ajustements de fréquence seront imprimés de manière périodique sur les sorties ptp4l et phc2sys (si l'horodatage matériel est utilisé). Ces valeurs convergeront éventuellement après une courte période. On peut voir ces messages dans le fichier /var/log/messages. En voici un exemple :
summary_interval, permettant de réduire les sorties et de n'imprimer que les statistiques, car normalement un message sera imprimé à peu près à chaque seconde. Ainsi, pour réduire les sorties à une toutes les 1024 secondes, veuillez ajouter la ligne suivante au fichier /etc/ptp4l.conf :
summary_interval 10
summary_interval 10summary_interval 6 :
-u comme suit :
phc2sys -u summary-updates
~]# phc2sys -u summary-updates17.8. Servir le temps PTP avec NTP
ntpd peut être configuré pour distribuer le temps à partir de l'horloge système synchronisée par ptp4l ou phc2sys en utilisant le pilote de l'horloge de référence LOCAL. Pour empêcher ntpd d'ajuster l'horloge système, le fichier ntp.conf ne doit pas spécifier de serveur NTP. Voici un petit exemple de ntp.conf :
~]# cat /etc/ntp.conf server 127.127.1.0 fudge 127.127.1.0 stratum 0
~]# cat /etc/ntp.conf
server 127.127.1.0
fudge 127.127.1.0 stratum 0Note
DHCP, dhclient, reçoit une liste de serveurs NTP du serveur DHCP, il les ajoute au fichier ntp.conf et redémarre le service. Pour désactiver cette fonctionnalité, veuillez ajouter PEERNTP=no à /etc/sysconfig/network.
17.9. Servir le temps NTP avec PTP
NTP avec PTP est également possible dans le sens contraire. Lorsque ntpd est utilisé pour synchroniser l'horloge système, ptp4l peut être configuré avec l'option priority1 (ou avec d'autres options d'horloge incluses dans le meilleur algorithme d'horloge maître) pour être l'horloge « Grandmaster » et distribuer le temps depuis l'horloge système via PTP :
~]# cat /etc/ptp4l.conf [global] priority1 127 [eth3] ptp4l -f /etc/ptp4l.conf
~]# cat /etc/ptp4l.conf
[global]
priority1 127
[eth3]
# ptp4l -f /etc/ptp4l.confPTP avec l'horloge système. Si phc2sys est exécuté en tant que service, modifiez le fichier de configuration /etc/sysconfig/phc2sys. Le paramètre par défaut dans le fichier /etc/sysconfig/phc2sys est comme suit : OPTIONS="-a -r"
OPTIONS="-a -r"root, modifiez cette ligne comme suit :
vi /etc/sysconfig/phc2sys OPTIONS="-a -r -r"
~]# vi /etc/sysconfig/phc2sys
OPTIONS="-a -r -r"-r est utilisée deux fois pour permettre la synchronisation de l'horloge matérielle PTP sur le NIC à partir de l'horloge système. Veuillez redémarrer le service phc2sys pour que les changements puissent entrer en vigueur :
systemctl restart phc2sys
~]# systemctl restart phc2sysPTP, la synchronisation de l'horloge système peut être relâchée en utilisant des constantes P (proportionelle) et I (intégrale) plus basses pour le servo PI :
phc2sys -a -r -r -P 0.01 -I 0.0001
~]# phc2sys -a -r -r -P 0.01 -I 0.000117.10. Synchroniser avec le temps PTP ou NTP en utilisant Timemaster
PTP sont disponibles sur le réseau, ou lorsqu'un basculement sur NTP est nécessaire, le programme timemaster peut être utilisé pour synchroniser l'horloge système sur toutes les sources de temps disponibles. Le temps PTP est fourni par phc2sys et ptp4l via des horloges de référence de pilotes de mémoire partagée shared memory driver (SHM ) sur chronyd ou ntpd (selon le démon NTP qui a été configuré sur le système). Le démon NTP peut ensuite comparer toutes les sources de temps, PTP et NTP, et utiliser les meilleures sources pour synchroniser l'horloge système.
NTP et PTP, vérifie quelles interfaces réseau possèdent la leur ou partagent une horloge matérielle PTP (PHC), génère des fichiers de configuration pour ptp4l et chronyd ou pour ntpd, et lance les processus ptp4l, phc2sys, et chronyd ou ntpd selon les besoins. Il supprimera également les fichiers de configuration générés lors de la fermeture. Il écrit des fichiers de configuration pour chronyd, ntpd, et ptp4l sur /var/run/timemaster/.
17.10.1. Lancer timemaster en tant que service
root :
systemctl start timemaster
~]# systemctl start timemaster /etc/timemaster.conf. Pour obtenir des informations supplémentaires sur la gestion des services système sur Red Hat Enterprise Linux 7, veuillez consulter le Chapitre 9, Gérer les services avec systemd.
17.10.2. Comprendre le fichier de configuration timemaster
/etc/timemaster.conf par défaut avec un certain nombre de sections contenant les options par défaut. Les en-têtes de section sont entre crochets.
[ntp_server address]
[ntp_server address]NTP, « ntp-server.local » est un exemple de nom d'hôte pour un serveur NTP sur le réseau LAN local. Ajoutez davantage de sections selon les besoins en utilisant un nom d'hôte ou une adresse IP faisant partie du nom de la section. Remarquez que les valeurs d'interrogation courtes dans cet exemple de section ne sont pas convenables pour un serveur public, veuillez consulter le Chapitre 16, Configurer NTP à l'aide de ntpd pour une explication sur des valeurs minpoll et maxpoll qui conviennent.
[ptp_domain number]
[ptp_domain number]PTP synchronisées. Elles peuvent être ou ne pas être synchronisées avec des horloges dans un autre domaine. Les horloges configurées avec le même numéro de domaine compose celui-ci. Cela inclut une horloge PTP « Grandmaster » . Le numéro de domaine dans chaque section « PTP domain » doit correspondre à l'un des domaines PTP configuré sur le réseau.
PTP et l'horodatage matériel est activé automatiquement. Les interfaces qui prennent en charge l'horodatage matériel possèdent une horloge PTP (PHC) attachée, cependant il est possible pour un groupe d'interfaces sur un NIC de partager une horloge PHC. Une instance ptp4l séparée sera lancée pour chaque groupe d'interfaces partageant le même PHC et pour chaque interface qui prend en charge l'horodatage logiciel uniquement. Toutes les instances ptp4l sont configurées pour être exécutées en tant qu'esclaves. Si une interface avec horodatage matériel est spécifiée dans plus d'un domaine PTP, alors seule l'instance ptp4l créée aura l'horodatage matériel activé.
[timemaster]
[timemaster]ntpd du système et la configuration chrony (/etc/ntp.conf ou /etc/chronyd.conf) afin d'inclure la configuration des restrictions d'accès les clés d'authentification. Cela signifie que tout serveur NTP spécifié sera également utilisé avec timemaster.
[ntp_server ntp-server.local]— spécifie les intervalles d'interrogation de ce serveur. Crée des sections supplémentaires selon les besoins. Inclut le nom d'hôte ou l'adresseIPdans l'en-tête de section.[ptp_domain 0]— spécifier les interfaces sur lesquelle les horlogesPTPsont configurées pour ce domaine. Crée des sections supplémentaires avec le numéro de domaine approprié, selon les besoins.[timemaster]— spécifie le démonNTPà utiliser. Les valeurs possibles sontchronydetntpd.[chrony.conf]— spécifie tout paramètre supplémentaire à copier dans le fichier de configuration généré pourchronyd.[ntp.conf]— spécifie tout paramètre supplémentaire à copier dans le fichier de configuration généré pourntpd.[ptp4l.conf]— spécifie les options à copier dans le fichier de configuration généré pour ptp4l.[chronyd]— spécifie tout paramètre supplémentaire à passer sur la ligne de commande pourchronyd.[ntpd]— spécifie tout paramètre supplémentaire à passer sur la ligne de commande pourntpd.[phc2sys]— spécifie tout paramètre supplémentaire à passer sur la ligne de commande pour phc2sys.[ptp4l]— spécifie tout paramètre supplémentaire à passer sur la ligne de commande pour toutes les instances de ptp4l.
timemaster(8).
17.10.3. Configurer les options timemaster
Procédure 17.1. Modifier le fichier de configuration timemaster
- Pour modifier la configuration par défaut, veuillez ouvrir le fichier
/etc/timemaster.confpour effectuer des modifications en tant qu'utilisateurroot:vi /etc/timemaster.conf
~]# vi /etc/timemaster.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour chaque serveur
NTPque vous souhaitez contrôler en utilisant timemaster, veuillez créer des sections[ntp_server address]. Remarquez que les valeurs d'interrogation courtes dans la section exemple ne conviennent pas à un serveur public, veuillez consulter le Chapitre 16, Configurer NTP à l'aide de ntpd pour une explication sur des valeursminpolletmaxpollqui conviennent. - Pour ajouter des interfaces qui doivent être utilisées dans un domaine, veuillez modifier la section
#[ptp_domain 0]et ajouter les interfaces. Créer des domaines supplémentaires selon les besoins. Par exemple :[ptp_domain 0] interfaces eth0 [ptp_domain 1] interfaces eth1[ptp_domain 0] interfaces eth0 [ptp_domain 1] interfaces eth1Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Si vous devez d'utiliser
ntpdcomme démonNTPsur ce système, veuillez modifier l'entrée par défaut dans la section[timemaster]dechronydàntpd. Veuillez consulter le Chapitre 15, Configurer NTP en utilisant Chrony Suite pour obtenir des informations sur les différences entre ntpd et chronyd. - Si vous utilisez
chronydcomme serveurNTPsur ce système, ajoutez toute option supplémentaire sous l'entrée par défautinclude /etc/chrony.confdans la section[chrony.conf]. Modifiez l'entrée par défautincludesi le chemin vers/etc/chrony.confa changé. - Si vous utilisez
ntpdcomme serveurNTPsur ce système, ajoutez toute option supplémentaire sous l'entrée par défautinclude /etc/ntp.confdans la section[ntp.conf]. Modifiez l'entréer par défautincludesi le chemin vers/etc/ntp.confa changé. - Dans la section
[ptp4l.conf], ajoutez les options à copier au fichier de configuration généré pour ptp4l. Ce chapitre documente les options communes et davantage d'informations sont disponibles sur la page man deptp4l(8). - Dans la section
[chronyd], veuillez ajouter les options de ligne de commande à passer surchronydlorsque appelé par timemaster. Veuillez consulter le Chapitre 15, Configurer NTP en utilisant Chrony Suite pour obtenir des informations sur l'utilisation dechronyd. - Dans la section
[ntpd], veuillez ajouter les options de ligne de commande à passer surntpdlorsque appelé par timemaster. Veuillez consulter le Chapitre 16, Configurer NTP à l'aide de ntpd pour obtenir des informations sur l'utilisation dentpd. - Dans la section
[phc2sys], ajoutez les options de ligne de commande à passer sur phc2sys lorsque appelé par timemaster. Ce chapitre documente les options communes et davantage d'informations sont disponibles sur la page man dephy2sys(8). - Dans la section
[ptp4l], ajoutez les options de ligne de commande à passer sur ptp4l lorsque appelé par timemaster. Ce chapitre documente les options communes et davantage d'informations sont disponibles sur la page man deptp4l(8). - Enregistrez le fichier de configuration et redémarrez timemaster en saisissant la commande suivante en tant qu'utilisateur
root:systemctl restart timemaster
~]# systemctl restart timemasterCopy to Clipboard Copied! Toggle word wrap Toggle overflow
17.11. Améliorer la précision
PTP par la même occasion (en contrepartie d'une augmentation de la consommation de l'alimentation). Le mode sans tic du noyau peut être désactivé en ajoutant nohz=off aux paramètres d'option de démarrage du noyau. Cependant, de récentes améliorations appliquées à kernel-3.10.0-197.el7 ont fortement amélioré la stabilité de l'horloge système et la différence de stabilité de l'horloge avec et sans nohz=off devrait désormais être bien moindre pour la plupart des utilisateurs.
/etc/ptp4l.conf : clock_servo linreg
clock_servo linreg/etc/ptp4l.conf, redémarrez le service ptp4l à partir de la ligne de commande en exécutant la commande suivante en tant qu'utilisateur root :
systemctl restart ptp4l
~]# systemctl restart ptp4l/etc/sysconfig/phc2sys : -E linreg
-E linreg/etc/sysconfig/phc2sys, redémarrez le service phc2sys à partir de la ligne de commande en passant la commande suivante en tant qu'utilisateur root :
systemctl restart phc2sys
~]# systemctl restart phc2sys17.12. Ressources supplémentaires
PTP et les outils ptp4l.
17.12.1. Documentation installée
- Page man
ptp4l(8)— décrit les options ptp4l, y compris le format du fichier de configuration. - Page man
pmc(8)— décrit le client de gestionPTPet ses options de commande. - Page man
phc2sys(8)— décrit un outil pour synchroniser l'horloge système avec une horloge matériellePTP(PHC). - Page man
timemaster(8)— décrit un programme qui utilise ptp4l et phc2sys pour synchroniser l'horloge système à l'aide dechronydountpd.
17.12.2. Sites Web utiles
- http://www.nist.gov/el/isd/ieee/ieee1588.cfm
- Standard IEEE 1588.
Partie VI. Surveillance et automatisation
Chapitre 18. Outils de surveillance du système
18.1. Afficher les processus système
18.1.1. Utiliser la commande ps
ps permet d'afficher des informations sur l'exécution de processus. Elle produit une liste statique, ou instantané, de ce qui est cours d'exécution au moment où la commande est exécutée. Si vous souhaitez afficher une liste des processus en cours d'exécution constamment mise à jour, veuillez utiliser la commande top ou l'application de surveillance système « System Monitor » à la place.
ps ax
ps axps ax affiche l'ID du processus (PID), le terminal qui y est associé (TTY), le statut actuel (STAT), le temps CPU accumulé (TIME), et le nom du fichier exécutable (COMMAND). Exemple :
ps aux
ps auxps ax, ps aux affiche le nom d'utilisateur du propriétaire du processus (USER), le pourcentage d'utilisation du CPU (%CPU) et de la mémoire (%MEM), la taille de la mémoire virtuelle en kilo-octets (VSZ), la taille de la mémoire physique non swap en kilo-octets (RSS), et l'heure ou la date à laquelle le processus a été lancé. Exemple :
ps en conjonction avec grep pour voir si un processus particulier est en cours d'utilisation. Par exemple, pour déterminer si Emacs est en cours d'utilisation, veuillez saisir :
ps ax | grep emacs 12056 pts/3 S+ 0:00 emacs 12060 pts/2 S+ 0:00 grep --color=auto emacs
~]$ ps ax | grep emacs
12056 pts/3 S+ 0:00 emacs
12060 pts/2 S+ 0:00 grep --color=auto emacs18.1.2. Utiliser la commande top
top affiche une liste en temps réel des processus exécutés sur le système. Elle affiche également des informations supplémentaires sur le temps d'activité du système, l'utilisation actuelle du CPU et de la mémoire, ou le nombre total de processus en cours d'exécution, et vous permet d'effectuer des actions comme le tri de la liste ou l'arrêt d'un processus.
top, veuillez saisir ce qui suit dans une invite de shell :
top
toptop affiche l'ID du processus (PID), le nom du propriétaire du processus (USER), la priorité (PR), la valeur nice (NI), la quantité de mémoire virtuelle utilisée par le processus (VIRT), la quantité de mémoire physique non swap qu'il utilise (RES), la quantité de mémoire partagée qu'il utilise (SHR), le champ de statut du processus S), le pourcentage d'utilisation du CPU (%CPU) et de la mémoire (%MEM), le temps CPU cummulé (TIME+), et le nom du fichier exécutable (COMMAND). Exemple :
top. Pour obtenir des informations supplémentaires, veuillez consulter la page man de top(1).
| Commande | Description |
|---|---|
| Entrée, Espace | Réactualise immédiatement l'affichage. |
| h | Affiche un écran d'aide pour les commandes interactives. |
| h, ? | Affiche un écran d'aide pour les fenêtres et les groupes de champs. |
| k | Arrête un processus. Il vous sera demandé l'ID du processus et le signal à envoyer. |
| n | Modifie le nombre de processus affichés. Ce nombre vous sera demandé. |
| u | Trie la liste par utilisateur. |
| M | Trie la liste selon l'utilisation mémoire. |
| P | Trie la liste selon l'utilisation du CPU. |
| q | Termine l'utilitaire et retourne à l'invite du shell. |
18.1.3. Utiliser l'outil de surveillance du système « System Monitor »
gnome-system-monitor à l'invite de shell. L'outil System Monitor apparaît. Alternativement, si le bureau GNOME est utilisé, appuyez sur la touche Super pour aller sur la « Vue d'ensemble des activités », saisissez System Monitor puis appuyez sur Entrée. L'outil System Monitor apparaît. La touche Super peut se trouver sous diverses formes selon le clavier ou du matériel, mais le plus souvent, il s'agit de la touche Windows ou de la touche de Commande, habituellement à gauche de la Barre d'espace.
Figure 18.1. System Monitor — Processus
- d'afficher les processus actifs uniquement,
- d'afficher tous les processus,
- d'afficher vos processus,
- d'afficher les dépendances des processus,
- Réactualiser la liste des processus,
- terminer un processus en le sélectionnant dans la liste et en cliquant sur le bouton .
18.2. Afficher l'utilisation de la mémoire
18.2.1. Utiliser la commande free
free permet d'afficher la quantité de mémoire libre et utilisée sur le système. Pour faire cela, veuillez saisir ce qui suit dans une invite de shell :
free
freefree fournit à la fois des informations sur la mémoire physique (Mem) et sur l'espace swap (Swap). Elle affiche le montant de mémoire total (total), ainsi que le montant de mémoire utilisée (used), la mémoire libre (free), la mémoire partagée (shared), les mémoires tampon et cache ajoutées ensemble (buff/cache), et ce qui reste de disponible (available). Exemple :
free
total used free shared buff/cache available
Mem: 1016800 727300 84684 3500 204816 124068
Swap: 839676 66920 772756
~]$ free
total used free shared buff/cache available
Mem: 1016800 727300 84684 3500 204816 124068
Swap: 839676 66920 772756free affiche les valeurs en kilo-octets. Pour afficher les valeurs en méga-octets, veuillez ajouter l'option de ligne de commande -m :
free -m
free -mfree -m
total used free shared buff/cache available
Mem: 992 711 81 3 200 120
Swap: 819 65 754
~]$ free -m
total used free shared buff/cache available
Mem: 992 711 81 3 200 120
Swap: 819 65 75418.2.2. Utiliser l'outil de surveillance du système « System Monitor »
gnome-system-monitor à l'invite de shell. L'outil System Monitor apparaît. Alternativement, si le bureau GNOME est utilisé, appuyez sur la touche Super pour aller sur la « Vue d'ensemble des activités », saisissez System Monitor puis appuyez sur Entrée. L'outil System Monitor apparaît. La touche Super peut se trouver sous diverses formes selon le clavier ou du matériel, mais le plus souvent, il s'agit de la touche Windows ou de la touche de Commande, habituellement à gauche de la Barre d'espace.
Figure 18.2. System Monitor — Ressources
18.3. Afficher l'utilisation du CPU
18.3.1. Utiliser l'outil de surveillance du système « System Monitor »
gnome-system-monitor à l'invite de shell. L'outil System Monitor apparaît. Alternativement, si le bureau GNOME est utilisé, appuyez sur la touche Super pour aller sur la « Vue d'ensemble des activités », saisissez System Monitor puis appuyez sur Entrée. L'outil System Monitor apparaît. La touche Super peut se trouver sous diverses formes selon le clavier ou du matériel, mais le plus souvent, il s'agit de la touche Windows ou de la touche de Commande, habituellement à gauche de la Barre d'espace.
18.4. Afficher les périphériques bloc et les systèmes de fichiers
18.4.1. Utiliser la commande lsblk
lsblk permet d'afficher une liste des périphériques bloc disponibles. Elle fournit des informations et un meilleur contrôle sur le formatage des sortie que la commande blkid. Elle lit les informations d'udev, et est donc utilisable par les utilisateurs non root. Pour afficher une liste des périphériques bloc, veuillez saisir ce qui suit dans une invite de shell :
lsblk
lsblklsblk affiche le nom du périphérique (NAME), le numéro majeur et mineur du périphérique (MAJ:MIN), si le périphérique peut être déplacé (RM), sa taille (SIZE), si le périphérique est accessible en lecture seule (RO), son type (TYPE), et sur quel emplacement il est monté (MOUNTPOINT). Exemple :
lsblk répertorie les périphériques bloc sous un format qui ressemble à une arborescence. Pour afficher les informations dans une liste ordinaire, veuillez ajouter l'option de ligne de commande -l :
lsblk -l
lsblk -l18.4.2. Utiliser la commande blkid
blkid permet d'afficher des informations de bas niveau sur les périphériques bloc. Elle exige des privilèges root, donc des utilisateurs non root doivent utiliser la commande lsblk. Pour cela, veuillez saisir ce qui suit à l'invite de shell en tant qu'utilisateur root :
blkid
blkidblkid affiche les attributs disponibles, comme son identifiant unique universel (UUID), le type de système de fichiers (TYPE), ou l'étiquette de volume (LABEL). Exemple :
blkid /dev/vda1: UUID="7fa9c421-0054-4555-b0ca-b470a97a3d84" TYPE="ext4" /dev/vda2: UUID="7IvYzk-TnnK-oPjf-ipdD-cofz-DXaJ-gPdgBW" TYPE="LVM2_member" /dev/mapper/vg_kvm-lv_root: UUID="a07b967c-71a0-4925-ab02-aebcad2ae824" TYPE="ext4" /dev/mapper/vg_kvm-lv_swap: UUID="d7ef54ca-9c41-4de4-ac1b-4193b0c1ddb6" TYPE="swap"
~]# blkid
/dev/vda1: UUID="7fa9c421-0054-4555-b0ca-b470a97a3d84" TYPE="ext4"
/dev/vda2: UUID="7IvYzk-TnnK-oPjf-ipdD-cofz-DXaJ-gPdgBW" TYPE="LVM2_member"
/dev/mapper/vg_kvm-lv_root: UUID="a07b967c-71a0-4925-ab02-aebcad2ae824" TYPE="ext4"
/dev/mapper/vg_kvm-lv_swap: UUID="d7ef54ca-9c41-4de4-ac1b-4193b0c1ddb6" TYPE="swap"blkid répertorie tous les périphériques bloc disponibles. Pour n'afficher des informations que sur un périphérique en particulier, veuillez spécifier le nom du périphérique sur la ligne de commande :
blkid device_name
blkid device_name/dev/vda1, veuillez saisir en tant qu'utilisateur root :
blkid /dev/vda1 /dev/vda1: UUID="7fa9c421-0054-4555-b0ca-b470a97a3d84" TYPE="ext4"
~]# blkid /dev/vda1
/dev/vda1: UUID="7fa9c421-0054-4555-b0ca-b470a97a3d84" TYPE="ext4"-p et -o udev pour obtenir des informations plus détaillées. Remarquez que des privilèges root sont requis pour exécuter cette commande :
blkid -po udev device_name
blkid -po udev device_name18.4.3. Utiliser la commande findmnt
findmnt permet d'afficher une liste de systèmes de fichiers actuellement montés. Pour faire cela, veuillez saisir ce qui suit dans une invite de shell :
findmnt
findmntfindmnt affiche le point de montage cible (TARGET), le périphérique source (SOURCE), le type de système de fichiers (FSTYPE), et les options de montage connexes (OPTIONS). Exemple :
findmnt répertorie les systèmes de fichiers sous un format qui ressemble à une arborescence. Pour afficher les informations dans une liste ordinaire, veuillez ajouter l'option de ligne de commande -l :
findmnt -l
findmnt -l-t suivie d'un type de système de fichiers :
findmnt -t type
findmnt -t typexfs, veuillez saisir :
findmnt -t xfs TARGET SOURCE FSTYPE OPTIONS / /dev/mapper/rhel-root xfs rw,relatime,seclabel,attr2,inode64,noquota └─/boot /dev/vda1 xfs rw,relatime,seclabel,attr2,inode64,noquota
~]$ findmnt -t xfs
TARGET SOURCE FSTYPE OPTIONS
/ /dev/mapper/rhel-root xfs rw,relatime,seclabel,attr2,inode64,noquota
└─/boot /dev/vda1 xfs rw,relatime,seclabel,attr2,inode64,noquota18.4.4. Utiliser la commande df
df permet d'afficher un rapport détaillé sur l'utilisation de l'espace disque du système. Pour faire cela, veuillez saisir ce qui suit dans une invite de shell :
df
dfdf affiche son nom (Filesystem), sa taille (1K-blocks ou Size), combien d'espace est utilisé (Used), combien d'espace reste disponible (Available), le pourcentage d'utilisation de l'espace (Use%), et l'endroit où le système de fichiers est monté (Mounted on). Exemple :
df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/vg_kvm-lv_root 18618236 4357360 13315112 25% / tmpfs 380376 288 380088 1% /dev/shm /dev/vda1 495844 77029 393215 17% /boot
~]$ df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/vg_kvm-lv_root 18618236 4357360 13315112 25% /
tmpfs 380376 288 380088 1% /dev/shm
/dev/vda1 495844 77029 393215 17% /bootdf affiche la taille de la partition en bloc de 1 kilo-octet et la quantité d'espace disque utilisé et disponible en kilo-octets. Pour afficher ces informations en méga-octets et giga-octets, veuillez ajouter l'option de ligne de commande -h, ce qui amène df à afficher les valeurs sous un format lisible :
df -h
df -hdf -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/vg_kvm-lv_root 18G 4.2G 13G 25% / tmpfs 372M 288K 372M 1% /dev/shm /dev/vda1 485M 76M 384M 17% /boot
~]$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg_kvm-lv_root 18G 4.2G 13G 25% /
tmpfs 372M 288K 372M 1% /dev/shm
/dev/vda1 485M 76M 384M 17% /boot18.4.5. Utiliser la commande du
du permet d'afficher la quantité d'espace utilisée par des fichiers dans un répertoire. Pour afficher l'utilisation du disque de chaque sous-répertoire dans le répertoire de travail actuel, veuillez exécuter la commande sans aucune option de ligne de commande supplémentaire :
du
dudu affiche l'usage du disque kilo-octets. Pour afficher ces informations en méga-octets et giga-octets, veuillez ajouter l'option de ligne de commande -h, ce qui mène l'utilitaire à afficher les valeurs sous un format lisible :
du -h
du -hdu affiche toujours le total du répertoire actuel. Pour afficher cette information uniquement, veuillez ajouter l'option de ligne de commande -s :
du -sh
du -shdu -sh 15M .
~]$ du -sh
15M .18.4.6. Utiliser l'outil de surveillance du système « System Monitor »
gnome-system-monitor à l'invite de shell. L'outil System Monitor apparaît. Alternativement, si le bureau GNOME est utilisé, appuyez sur la touche Super pour aller sur la « Vue d'ensemble des activités », saisissez System Monitor puis appuyez sur Entrée. L'outil System Monitor apparaît. La touche Super peut se trouver sous diverses formes selon le clavier ou du matériel, mais le plus souvent, il s'agit de la touche Windows ou de la touche de Commande, habituellement à gauche de la Barre d'espace.
Figure 18.3. System Monitor — Systèmes de fichiers
18.5. Afficher les informations matériel
18.5.1. Utiliser la commande lspci
free permet d'afficher des informations sur les bus PCI et les périphériques qui y sont attachés. Pour faire répertorier tous les périphériques PCI sur le système, veuillez saisir ce qui suit dans une invite de shell :
lspci
lspci-v pour afficher une sortie plus détaillée, ou -vv pour une sortie très détaillée :
lspci -v|-vv
lspci -v|-vv18.5.2. Utiliser la commande lsusb
lsusb permet d'afficher des informations sur les bus USB et les périphériques qui y sont attachés. Pour répertorier tous les périphériques USB du système, veuillez saisir ce qui suit dans une invite de shell :
lsusb
lsusb-v pour afficher une sortie plus détaillée :
lsusb -v
lsusb -v18.5.3. Utiliser la commande lscpu
lscpu permet de répertorier des informations sur les CPU présents sur le système, y compris le nombre de CPU, leur architecture, fournisseur, famille, modèle, cache de CPU, etc. Pour cela, veuillez saisir ce qui suit dans une invite de shell :
lscpu
lscpu18.6. Vérification des erreurs matériel
rasdaemon, collecte et gère tous les événements d'erreurs en matière de fiabilité, disponibilité et facilité de gestion qui arrivent dans le mécanisme de suivi du noyau (RAS en anglais pour Reliability, Availability, and Serviceability). Les fonctions qui étaient fournies par edac-utils auparavant sont maintenant remplacées par rasdaemon.
rasdaemon, veuillez saisir la commande suivante en tant qu'utilisateur root :
yum install rasdaemon
~]# yum install rasdaemonsystemctl start rasdaemon
~]# systemctl start rasdaemonrasdaemon(8).
ras-mc-ctl nous donne un moyen de travailler avec les pilotes EDAC . Saisir la commande suivante pour afficher une liste des options de commande :
ras-mc-ctl --help Usage: ras-mc-ctl [OPTIONS...] --quiet Quiet operation. --mainboard Print mainboard vendor and model for this hardware. --status Print status of EDAC drivers.sortie tronquée
~]$ ras-mc-ctl --help
Usage: ras-mc-ctl [OPTIONS...]
--quiet Quiet operation.
--mainboard Print mainboard vendor and model for this hardware.
--status Print status of EDAC drivers.sortie tronquéeras-mc-ctl(8).
18.7. Surveiller les performances avec Net-SNMP
SNMP.
18.7.1. Installer Net-SNMP
| Paquet | Fournit |
|---|---|
| net-snmp | Le démon de l'agent SNMP et la documentation. Ce paquet est requis pour exporter des données de performance. |
| net-snmp-libs | La bibliothèque netsnmp et les management information bases (MIB) groupése. Ce paquet est requis pour exporter des données de performance. |
| net-snmp-utils | Les clients SNMP tels que snmpget et snmpwalk. Ce paquet est requis pour effectuer des requêtes de données de performance d'un système sur SNMP. |
| net-snmp-perl | L'utilitaire mib2c et le module Perl NetSNMP. Remarquez que ce paquet est fournit par le canal optionnel « Optional ». Veuillez consulter la Section 8.5.7, « Ajouter les référentiels « Optional » (Optionnel) et « Supplementary » (Supplémentaire) » pour obtenir davantage d'informations sur les canaux supplémentaires de Red Hat. |
| net-snmp-python | La bibliothèque cliente SNMP de Python. Remarquez que ce paquet est fourni par le canal « Optional ». Veuillez consulter la Section 8.5.7, « Ajouter les référentiels « Optional » (Optionnel) et « Supplementary » (Supplémentaire) » pour obtenir davantage d'informations sur les canaux supplémentaires Red Hat. |
yum sous la forme suivante :
yum install package…
yum install package…root :
yum install net-snmp net-snmp-libs net-snmp-utils
~]# yum install net-snmp net-snmp-libs net-snmp-utils18.7.2. Exécuter le démon Net-SNMP
snmpd, le démon de l'agent SNMP. Cette section fournit des informations sur la manière de lancer, arrêter, et redémarrer le service snmpd. Pour obtenir davantage d'informations sur la gestion des services systèmes dans Red Hat Enterprise Linux 7, veuillez consulter le Chapitre 9, Gérer les services avec systemd.
18.7.2.1. Lancer le service
snmpd dans la session actuelle, veuillez saisir ce qui suit dans l'invite de shell en tant qu'utilisateur root :
systemctl start snmpd.service
systemctl start snmpd.servicesystemctl enable snmpd.service
systemctl enable snmpd.service18.7.2.2. Arrêter le service
snmpd, veuillez saisir ce qui suit dans une invite de shell en tant qu'utilisateur root :
systemctl stop snmpd.service
systemctl stop snmpd.servicesystemctl disable snmpd.service
systemctl disable snmpd.service18.7.2.3. Redémarrer le service
snmpd, saisissez ce qui suit dans l'invite du shell :
systemctl restart snmpd.service
systemctl restart snmpd.servicesystemctl reload snmpd.service
systemctl reload snmpd.servicesnmpd à recharger sa configuration.
18.7.3. Configurer Net-SNMP
/etc/snmp/snmpd.conf. Le fichier par défaut snmpd.conf inclus avec Red Hat Enterprise Linux 7 contient beaucoup de commentaires et peut servir de bon point de départ pour la configuration de l'agent.
snmpd.conf(5). En outre, il existe un utilitaire dans le paquet net-snmp nommé snmpconf, qui peut être utilisé de manière interactive pour générer une configuration d'agent valide.
snmpwalk décrit dans cette section.
Note
snmpd à relire la configuration en exécutant la commande suivante en tant qu'utilisateur root :
systemctl reload snmpd.service
systemctl reload snmpd.service18.7.3.1. Définir les informations système
system. Par exemple, la commande snmpwalk suivante montre l'arborescence system avec une configuration d'agent par défaut.
snmpwalk -v2c -c public localhost system SNMPv2-MIB::sysDescr.0 = STRING: Linux localhost.localdomain 3.10.0-123.el7.x86_64 #1 SMP Mon May 5 11:16:57 EDT 2014 x86_64 SNMPv2-MIB::sysObjectID.0 = OID: NET-SNMP-MIB::netSnmpAgentOIDs.10 DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (464) 0:00:04.64 SNMPv2-MIB::sysContact.0 = STRING: Root <root@localhost> (configure /etc/snmp/snmp.local.conf)[sortie tronquée]
~]# snmpwalk -v2c -c public localhost system
SNMPv2-MIB::sysDescr.0 = STRING: Linux localhost.localdomain 3.10.0-123.el7.x86_64 #1 SMP Mon May 5 11:16:57 EDT 2014 x86_64
SNMPv2-MIB::sysObjectID.0 = OID: NET-SNMP-MIB::netSnmpAgentOIDs.10
DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (464) 0:00:04.64
SNMPv2-MIB::sysContact.0 = STRING: Root <root@localhost> (configure /etc/snmp/snmp.local.conf)[sortie tronquée]sysName est défini sur le nom d'hôte. Les objets sysLocation et sysContact peuvent être configurés dans le fichier /etc/snmp/snmpd.conf en modifiant la valeur des directives syslocation et syscontact. Exemple :
syslocation Datacenter, Row 4, Rack 3 syscontact UNIX Admin <admin@example.com>
syslocation Datacenter, Row 4, Rack 3
syscontact UNIX Admin <admin@example.com>snmpwalk à nouveau :
18.7.3.2. Configurer l'authentification
Configurer une communauté SNMP Version 2c
rocommunity ou rwcommunity dans le fichier de configuration /etc/snmp/snmpd.conf. Le format des directives est comme suit :
directive community [source [OID]]
directive community [source [OID]]system à un client utilisant la chaîne de communité « redhat » sur la machine locale :
rocommunity redhat 127.0.0.1 .1.3.6.1.2.1.1
rocommunity redhat 127.0.0.1 .1.3.6.1.2.1.1snmpwalk avec les options -v et -c.
Configurer un utilisateur SNMP Version 3
net-snmp-create-v3-user. Cette command ajoute des entrées aux fichiers /var/lib/net-snmp/snmpd.conf et /etc/snmp/snmpd.conf qui créent l'utilisateur et offrent accès à l'utilisateur. Remarque que la commande net-snmp-create-v3-user peut uniquement être exécutée lorsque l'agent n'est pas en cours d'exécution. L'exemple suivant crée l'utilisateur « admin » avec le mot de passe « redhatsnmp » :
rwuser (ou rouser lorsque l'option de ligne de commande -ro est fournie) ajoutée par net-snmp-create-v3-user à /etc/snmp/snmpd.conf possède un format similaire aux directives rwcommunity et rocommunity :
directive user [noauth|auth|priv] [OID]
directive user [noauth|auth|priv] [OID]auth). L'option noauth vous permet d'autoriser des requêtes non authentifiées, et l'option priv applique l'utilisation du chiffrement. L'option authpriv spécifie que les requêtes doivent être authentifiées et que les réponses doivent être chiffrées.
rwuser admin authpriv .1
rwuser admin authpriv .1.snmp/ dans le répertoire personnel de l'utilisateur, ainsi qu'un fichier de configuration nommé snmp.conf dans ce répertoire (~/.snmp/snmp.conf) avec les lignes suivantes :
defVersion 3 defSecurityLevel authPriv defSecurityName admin defPassphrase redhatsnmp
defVersion 3
defSecurityLevel authPriv
defSecurityName admin
defPassphrase redhatsnmpsnmpwalk utilisera ces paramètres d'authentification lorsque des requêtes sont effectuées sur l'agent :
snmpwalk -v3 localhost system SNMPv2-MIB::sysDescr.0 = STRING: Linux localhost.localdomain 3.10.0-123.el7.x86_64 #1 SMP Mon May 5 11:16:57 EDT 2014 x86_64[sortie tronquée]
~]$ snmpwalk -v3 localhost system
SNMPv2-MIB::sysDescr.0 = STRING: Linux localhost.localdomain 3.10.0-123.el7.x86_64 #1 SMP Mon May 5 11:16:57 EDT 2014 x86_64[sortie tronquée]18.7.4. Récupérer des données de performance sur SNMP
18.7.4.1. Configuration du matériel
Host Resources MIB », inclus avec Net-SNMP présente des informations sur la configuration du matériel et des logiciels d'un hôte à un utilitaire client. Tableau 18.3, « OID disponibles » résume les différents OID disponibles sous ce MIB.
| OID | Description |
|---|---|
HOST-RESOURCES-MIB::hrSystem | Contient des informations système générales telles que le temps d'activité, le nombre d'utilisateurs, et le nombre de processus en cours d'utilisation. |
HOST-RESOURCES-MIB::hrStorage | Contient des données sur l'utilisation de la mémoire et des systèmes de fichiers. |
HOST-RESOURCES-MIB::hrDevices | Contient une liste des processeurs, périphériques réseau, et systèmes de fichiers. |
HOST-RESOURCES-MIB::hrSWRun | Contient une liste de tous les processus en cours d'utilisation. |
HOST-RESOURCES-MIB::hrSWRunPerf | Contient des statistiques sur la mémoire et le CPU sur la table de processus de HOST-RESOURCES-MIB::hrSWRun. |
HOST-RESOURCES-MIB::hrSWInstalled | Contient une liste de la base de données RPM. |
HOST-RESOURCES-MIB::hrFSTable :
HOST-RESOURCES-MIB, veuillez consulter le fichier /usr/share/snmp/mibs/HOST-RESOURCES-MIB.txt.
18.7.4.2. Informations mémoire et CPU
UCD SNMP MIB ». L'OID systemStats fournit un certain nombre de compteurs autour de l'utilisation du processeur :
ssCpuRawUser, ssCpuRawSystem, ssCpuRawWait, et ssCpuRawIdle fournissent des compteurs qui sont utiles pour déterminer si un système passe la plupart de son temps de traitement dans l'espace du noyau, l'espace utilisateur, ou les E/S. ssRawSwapIn et ssRawSwapOut peuvent être utiles pour déterminer si un système souffre d'épuisement de mémoire.
UCD-SNMP-MIB::memory, qui fournit des données similaires à la commande free :
UCD SNMP MIB ». La table SNMP UCD-SNMP-MIB::laTable possède une liste des moyennes de charges de 1, 5, et 15 minutes :
18.7.4.3. Informations sur les systèmes de fichiers et les disques
Host Resources MIB » fournit des informations sur la taille et l'utilisation du système de fichiers. Chaque système de fichiers (ainsi que chaque pool de mémoire) possède une entrée dans la table HOST-RESOURCES-MIB::hrStorageTable :
HOST-RESOURCES-MIB::hrStorageSize et HOST-RESOURCES-MIB::hrStorageUsed peuvent être utilisés pour calculer la capacité restante de chaque système de fichiers monté.
UCD-SNMP-MIB::systemStats (ssIORawSent.0 et ssIORawRecieved.0) et sur UCD-DISKIO-MIB::diskIOTable. Ce dernier fournit des données plus granulaires. Sous cette table, se trouvent des OID pour diskIONReadX et diskIONWrittenX, qui fournissent des compteurs pour le nombre d'octets lus et écrits sur le périphérique bloc en question depuis le démarrage système :
18.7.4.4. Informations réseau
Interfaces MIB », fournit des informations sur les périphériques réseau. IF-MIB::ifTable fournit une table SNMP avec une entrée pour chaque interface sur le système, la configuration de l'interface, et divers compteurs de paquets pour l'interface. L'exemple suivant affiche les premières colonnes d'ifTable sur un système avec deux interfaces réseau physiques :
IF-MIB::ifOutOctets et IF-MIB::ifInOctets. Les requêtes SNMP suivantes récupéreront le trafic réseau pour chacune des interfaces sur ce système :
18.7.5. Étendre Net-SNMP
18.7.5.1. Étendre Net-SNMP avec des scripts Shell
NET-SNMP-EXTEND-MIB) qui peut être utilisée pour effectuer des requêtes de scripts shell arbitraires. Pour indiquer quel script shell exécuter, veuillez utiliser la directive extend dans le fichier /etc/snmp/snmpd.conf. Une fois défini, l'agent fournira le code de sortie et toute sortie de la commande sur SNMP. L'exemple ci-dessous fait une démonstration de ce mécanisme avec un script qui détermine le nombre de processus httpd dans la table des processus.
Note
proc. Veuillez consulter la page man de snmpd.conf(5) pour obtenir davantage d'informations.
httpd exécutés sur le système à un moment donné :
#!/bin/sh NUMPIDS=`pgrep httpd | wc -l` exit $NUMPIDS
#!/bin/sh
NUMPIDS=`pgrep httpd | wc -l`
exit $NUMPIDSextend au fichier /etc/snmp/snmpd.conf. Le format de la directive extend est comme suit :
extend name prog args
extend name prog args/usr/local/bin/check_apache.sh, la directive suivante ajoutera le script à l'arborescence SNMP :
extend httpd_pids /bin/sh /usr/local/bin/check_apache.sh
extend httpd_pids /bin/sh /usr/local/bin/check_apache.shNET-SNMP-EXTEND-MIB::nsExtendObjects :
extend. Par exemple, le script shell suivant peut être utilisé pour déterminer le nombre de processus correspondants à une chaîne arbitraire, et fera également sortir une chaîne de texte donnant le nombre de processus :
/etc/snmp/snmpd.conf donneront le nombre de PID httpd ainsi que le nombre de PID snmpd lorsque le script ci-dessus est copié sur /usr/local/bin/check_proc.sh :
extend httpd_pids /bin/sh /usr/local/bin/check_proc.sh httpd extend snmpd_pids /bin/sh /usr/local/bin/check_proc.sh snmpd
extend httpd_pids /bin/sh /usr/local/bin/check_proc.sh httpd
extend snmpd_pids /bin/sh /usr/local/bin/check_proc.sh snmpdsnmpwalk de l'OID nsExtendObjects :
Avertissement
httpd. Cette requête pourrait être utilisée pendant un test de performance pour déterminer l'impact du nombre de processus sur la pression mémoire :
snmpget localhost \
'NET-SNMP-EXTEND-MIB::nsExtendResult."httpd_pids"' \
UCD-SNMP-MIB::memAvailReal.0
NET-SNMP-EXTEND-MIB::nsExtendResult."httpd_pids" = INTEGER: 8
UCD-SNMP-MIB::memAvailReal.0 = INTEGER: 799664 kB
~]$ snmpget localhost \
'NET-SNMP-EXTEND-MIB::nsExtendResult."httpd_pids"' \
UCD-SNMP-MIB::memAvailReal.0
NET-SNMP-EXTEND-MIB::nsExtendResult."httpd_pids" = INTEGER: 8
UCD-SNMP-MIB::memAvailReal.0 = INTEGER: 799664 kB18.7.5.2. Extension de Net-SNMP avec Perl
extend est une méthode assez limitée pour exposer des indicateurs d'application personnalisée sur SNMP. L'agent Net-SNMP fournit également une interface Perl intégrée pour exposer des objets personnalisés. Le paquet net-snmp-perl dans le canal « Optional » fournit le module Perl NetSNMP::agent, qui est utilisé pour écrire des greffons Perl intégrés dans Red Hat Enterprise Linux.
Note
NetSNMP::agent fournit un objet agent utilisé pour gérer les requêtes d'une partie de l'arborescence OID de l'agent. Le constructeur de l'objet agent offre des options pour exécuter l'agent en tant que sous-agent de snmpd ou en tant qu'agent autonome. Aucun argument n'est nécessaire pour créer un agent intégré :
use NetSNMP::agent (':all');
my $agent = new NetSNMP::agent();
use NetSNMP::agent (':all');
my $agent = new NetSNMP::agent();agent offre une méthode register utilisée pour enregistrer une fonction de rappel avec un OID particulier. La fonction register prend un nom, un OID, et un pointeur sur la fonction de rappel. L'exemple suivant enregistrera une fonction de rappel nommée hello_handler avec l'agent SNM, qui gérera les requêtes sous l'OID .1.3.6.1.4.1.8072.9999.9999 :
$agent->register("hello_world", ".1.3.6.1.4.1.8072.9999.9999",
\&hello_handler);
$agent->register("hello_world", ".1.3.6.1.4.1.8072.9999.9999",
\&hello_handler);Note
.1.3.6.1.4.1.8072.9999.9999 (NET-SNMP-MIB::netSnmpPlaypen) est utilisé pour effectuer des démonstrations uniquement. Si votre organisation ne possède pas déjà un OID root, vous pouvez en obtenir un en contactant une autorité d'enregistrement de nom ISO (appelé ANSI aux États-Unis).
HANDLER, REGISTRATION_INFO, REQUEST_INFO, et REQUESTS. Le paramètre REQUESTS contient une liste de requêtes dans l'appel actuel et devrait être itéré et rempli avec des données. Les objets request dans la liste possèdent des méthodes get et set qui permettent de manipuler l' OID et la valeur value de la requête. Par exemple, l'appel suivant définira la valeur d'un objet de requête sur la chaîne « hello world » :
$request->setValue(ASN_OCTET_STR, "hello world");
$request->setValue(ASN_OCTET_STR, "hello world");getMode sur l'objet request_info passé en tant que troisième paramètre à la fonction de gestionnaire. Si la requête est une requête GET, l'appelant s'attendra à ce que le gestionnaire définisse la valeur value de l'objet request, selon l'OID de la requête. Si la requête est une requête GETNEXT request, l'appelant devra également s'attendre à ce que le gestionnaire définisse l'OID de la requête sur le prochain OID disponible dans l'arborescence. Ceci est illustré dans l'exemple de code suivant :
getMode retourne MODE_GET, le gestionnaire analyse la valeur de l'appel getOID sur l'objet request. La valeur value de request est définie sur string_value si l'OID se termine par « .1.0 », ou sur integer_value si l'OID se termine par « .1.1 ». Si getMode retourne MODE_GETNEXT, le gestionnaire détermine si l'OID de la requête est « .1.0 », puis définit l'OID et la valeur pour « .1.1 ». Si la requête est plus élevée que « .1.0 » sur l'arborescence, l'OID et la valeur de « .1.0 » est définie. Ceci retourne la valeur « next » dans l'arborescence afin qu'un programme comme snmpwalk puisse traverser l'arborescence sans connaître la structure au préalable.
NetSNMP::ASN. Veuillez consulter le perldoc de NetSNMP::ASN pour une liste complète des constantes disponibles.
/usr/share/snmp/hello_world.pl et ajoutez la ligne suivante au fichier de configuration /etc/snmp/snmpd.conf :
perl do "/usr/share/snmp/hello_world.pl"
perl do "/usr/share/snmp/hello_world.pl"snmpwalk devrait retourner les nouvelles données :
snmpwalk localhost NET-SNMP-MIB::netSnmpPlaypen NET-SNMP-MIB::netSnmpPlaypen.1.0 = STRING: "hello world" NET-SNMP-MIB::netSnmpPlaypen.1.1 = INTEGER: 8675309
~]$ snmpwalk localhost NET-SNMP-MIB::netSnmpPlaypen
NET-SNMP-MIB::netSnmpPlaypen.1.0 = STRING: "hello world"
NET-SNMP-MIB::netSnmpPlaypen.1.1 = INTEGER: 8675309snmpget doit également être utilisé pour exercer l'autre mode du gestionnaire :
snmpget localhost \
NET-SNMP-MIB::netSnmpPlaypen.1.0 \
NET-SNMP-MIB::netSnmpPlaypen.1.1
NET-SNMP-MIB::netSnmpPlaypen.1.0 = STRING: "hello world"
NET-SNMP-MIB::netSnmpPlaypen.1.1 = INTEGER: 8675309
~]$ snmpget localhost \
NET-SNMP-MIB::netSnmpPlaypen.1.0 \
NET-SNMP-MIB::netSnmpPlaypen.1.1
NET-SNMP-MIB::netSnmpPlaypen.1.0 = STRING: "hello world"
NET-SNMP-MIB::netSnmpPlaypen.1.1 = INTEGER: 867530918.8. Ressources supplémentaires
18.8.1. Documentation installée
- lscpu(1) — page du manuel pour la commande
lscpu. - lsusb(8) — page du manuel pour la commande
lsusb. - findmnt(8) — page du manuel pour la commande
findmnt. - blkid(8) — page du manuel pour la commande
blkid. - lsblk(8) — page du manuel pour la commande
lsblk. - ps(1) — page du manuel pour la commande
ps. - top(1) — page du manuel pour la commande
top. - free(1) — page du manuel pour la commande
free. - df(1) — page du manuel pour la commande
df. - du(1) — page du manuel pour la commande
du. - lspci(8) — page du manuel pour la commande
lspci. - snmpd(8) — page du manuel du service
snmpd. - snmpd.conf(5) — page du manuel du fichier
/etc/snmp/snmpd.confcontenant la documentation complète des directives de configuration disponibles.
Chapitre 19. OpenLMI
19.1. OpenLMI
- Agents de gestion de système — ces agents sont installés sur un système géré et implémentent un modèle d'objet qui est présenté à un courtier entre objets standard. Les agents initiaux implémentés dans OpenLMI incluent la configuration du stockage et la configuration du réseau ; un travail ultérieur offrira des éléments supplémentaires pour la gestion de systèmes. Les agents de gestion de systèmes sont couramment appelés des fournisseurs CIM (Common Information Model).
- Courtier d'objets standard — le courtier d'objets gère les agents de gestion et leur fournit une interface. Le courtier d'objets standard est aussi appelé un CIMOM (de l'anglais, CIM Object Monitor).
- Applications et scripts clients — les applications et scripts clients appellent les agents de gestion du système via le courtier d'objets standard.
19.1.1. Fonctionnalités principales
- OpenLMI fournit une interface standard pour la configuration, la gestion, et la surveillance de vos systèmes locaux et distants.
- OpenLMI vous permet de configurer, gérer, et surveiller des serveurs de production exécutés sur des machines physiques et virtuelles.
- OpenLMI est distribué avec un ensemble de fournisseurs CIM qui vous permettent de configurer, gérer, et surveiller des périphériques de stockage et des réseaux complexes.
- OpenLMI vous permet d'appeler des fonctions de gestion de systèmes à partir de programmes C, C++, Python, et Java, et inclut LMIShell, qui fournit une interface en ligne de commande.
- OpenLMI est un logiciel gratuit basé sur les standards du secteur du logiciel libre.
19.1.2. Capacités de gestion
| Nom du paquet | Description |
|---|---|
| openlmi-account | Un fournisseur CIM pour la gestion des comptes utilisateurs. |
| openlmi-logicalfile | Un fournisseur CIM pour la lecture des fichiers et répertoires. |
| openlmi-networking | Un fournisseur CIM pour la gestion des réseaux. |
| openlmi-powermanagement | Un fournisseur CIM pour la gestion de l'alimentation. |
| openlmi-service | Un fournisseur CIM pour la gestion des systèmes service. |
| openlmi-storage | Un fournisseur CIM pour la gestion du stockage. |
| openlmi-fan | Un fournisseur CIM pour contrôler les ventilateurs de l'ordinateur. |
| openlmi-hardware | Un fournisseur CIM pour récupérer les informations du matériel. |
| openlmi-realmd | Un fournisseur CIM pour configurer realmd. |
| openlmi-software[a] | Un fournisseur CIM pour la gestion de logiciels. |
[a]
In Red Hat Enterprise Linux 7, the OpenLMI Software provider is included as a Technology Preview. This provider is fully functional, but has a known performance scaling issue where listing large numbers of software packages may consume excessive amount of memory and time. To work around this issue, adjust package searches to return as few packages as possible.
| |
19.2. Installer OpenLMI
19.2.1. Installer OpenLMI sur un système géré
- Veuillez installer le paquet tog-pegasus en saisissant ce qui suit dans l'invite de shell en tant qu'utilisateur
root:yum install tog-pegasus
yum install tog-pegasusCopy to Clipboard Copied! Toggle word wrap Toggle overflow Cette commande installe le CIMOM OpenPegasus et toutes ses dépendances sur le système et crée un compte utilisateur pour l'utilisateurpegasus. - Veuillez installer les fournisseurs CIM requis en exécutant la commande suivante en tant qu'utilisateur
root:yum install openlmi-{storage,networking,service,account,powermanagement}yum install openlmi-{storage,networking,service,account,powermanagement}Copy to Clipboard Copied! Toggle word wrap Toggle overflow Cette commande installe les fournisseurs CIM pour le stockage, le réseau, le service, le compte et la gestion de l'alimentation. Pour une liste complète des fournisseurs CIM distribués avec Red Hat Enterprise Linux 7, veuillez consulter la Tableau 19.1, « Fournisseurs CIM disponibles ». - Modifiez le fichier de configuration
/etc/Pegasus/access.confpour personnaliser la liste des utilisateurs autorisés à se connecter au CIMOM OpenPegasus. Par défaut, seul l'utilisateurpegasusest autorisé à accéder au CIMOM à distance et localement. Pour activer ce compte utilisateur, veuillez exécuter la commande suivante en tant qu'utilisateurrootpour définir le mot de passe de l'utilisateur :passwd pegasus
passwd pegasusCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Lancez le CIMOM OpenPegasus en activant l'unité
tog-pegasus.service. Pour activer l'unitétog-pegasus.servicedans la session actuelle, veuillez saisir ce qui suit dans l'invite de shell en tant qu'utilisateurroot:systemctl start tog-pegasus.service
systemctl start tog-pegasus.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow Pour configurer l'unitétog-pegasus.servicepour qu'elle soit lancée automatiquement pendant le démarrage, veuillez saisir ceci en tant qu'utilisateurroot:systemctl enable tog-pegasus.service
systemctl enable tog-pegasus.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Si vous souhaitez interagir avec le système géré à partir d'une machine distante, veuillez activer les communications TCP sur le port
5989(wbem-https). Pour ouvrir ce port dans la session actuelle, veuillez exécuter la commande suivante en tant qu'utilisateurroot:firewall-cmd --add-port 5989/tcp
firewall-cmd --add-port 5989/tcpCopy to Clipboard Copied! Toggle word wrap Toggle overflow Pour ouvrir le port5989pour les communications TCP de manière permanente, veuillez saisir ceci en tant qu'utilisateurroot:firewall-cmd --permanent --add-port 5989/tcp
firewall-cmd --permanent --add-port 5989/tcpCopy to Clipboard Copied! Toggle word wrap Toggle overflow
19.2.2. Installer OpenLMI sur un système client
- Veuillez installer le paquet openlmi-tools en saisissant ce qui suit à l'invite de shell en tant qu'utilisateur
root:yum install openlmi-tools
yum install openlmi-toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Cette commande installe LMIShell, un client et interprète interactif pour accéder aux objets CIM fournis par OpenPegasus, et toutes ses dépendances au système. - Veuillez configurer les certificats SSL pour OpenPegasus comme décrit dans la Section 19.3, « Configurer des certificats SSL pour OpenPegasus ».
19.3. Configurer des certificats SSL pour OpenPegasus
- Les certificats auto-signés requièrent une moindre utilisation de l'infrastructure, mais sont plus difficiles à déployer sur des clients et à gérer de manière sécurisée.
- Les certificats signés par une autorité sont plus faciles à déployer sur des clients une fois qu'ils sont paramétrés, mais ils nécessitent un investissement initial plus élevé.
| Option de configuration | Emplacement | Description |
|---|---|---|
sslCertificateFilePath | /etc/Pegasus/server.pem | Certificat public du CIMOM. |
sslKeyFilePath | /etc/Pegasus/file.pem | Clé privée uniquement connue par le CIMOM. |
sslTrustStore | /etc/Pegasus/client.pem | Fichier ou répertoire fournissant la liste des autorités de certificats de confiance. |
Important
tog-pegasus pour vous assurer qu'il reconnaisse les nouveaux certificats. Pour redémarrer le service, veuillez saisir ce qui suit à l'invite de shell en tant qu'utilisateur root :
systemctl restart tog-pegasus.service
systemctl restart tog-pegasus.service19.3.1. Gérer les certificats auto-signés
tog-pegasus ait été lancé une première fois, un ensemble de certificats auto-signés seront automatiquement générés en utilisant le nom d'hôte principal du système comme sujet du certificat.
Important
- Veuillez copier le certificat
/etc/Pegasus/server.pemdu système géré au répertoire/etc/pki/ca-trust/source/anchors/sur le système client. Pour cela, veuillez saisir ce qui suit dans une invite de shell en tant qu'utilisateurroot:scp root@hostname:/etc/Pegasus/server.pem /etc/pki/ca-trust/source/anchors/pegasus-hostname.pem
scp root@hostname:/etc/Pegasus/server.pem /etc/pki/ca-trust/source/anchors/pegasus-hostname.pemCopy to Clipboard Copied! Toggle word wrap Toggle overflow Veuillez remplacer hostname par le nom d'hôte du système géré. Remarquez que cette commande fonctionne uniquement si le servicesshdest en cours d'exécution sur le système géré et est configuré pour autoriser l'utilisateurrootà se connecter au système via le protocole SSH. Pour obtenir des informations supplémentaires sur la manière d'installer et de configurer le servicesshd, ainsi que sur la commandescppour transférer des fichiers sur le protocole SSH, veuillez consulter le Chapitre 10, OpenSSH. - Veuillez vérifier l'intégrité du certificat sur le système client en comparant son checksum avec celui du fichier d'origine. Pour calculer le checksum du fichier
/etc/Pegasus/server.pemsur le système géré, veuillez exécuter la commande suivante en tant qu'utilisateurrootsur ce système :sha1sum /etc/Pegasus/server.pem
sha1sum /etc/Pegasus/server.pemCopy to Clipboard Copied! Toggle word wrap Toggle overflow Pour calculer le checksum du fichier/etc/pki/ca-trust/source/anchors/pegasus-hostname.pemsur le système client, veuillez exécuter la commande suivante sur ce système :sha1sum /etc/pki/ca-trust/source/anchors/pegasus-hostname.pem
sha1sum /etc/pki/ca-trust/source/anchors/pegasus-hostname.pemCopy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacez hostname par le nom d'hôte du système géré. - Mettez à jour le trust store sur le système client en exécutant la commande suivante en tant qu'utilisateur
root:update-ca-trust extract
update-ca-trust extractCopy to Clipboard Copied! Toggle word wrap Toggle overflow
19.3.2. Gestion de certificats signés par des autorités avec Identity Management (recommandé)
- Veuillez installer le paquet ipa-client et enregistrer le système sur Identity Management, comme décrit dans le Guide des politiques, de l'authentification et des identités de domaines Linux Red Hat Enterprise Linux 7.
- Veuillez copier le certificat de signature Identity Management dans le trust store en saisissant la commande suivante en tant qu'utilisateur
root:cp /etc/ipa/ca.crt /etc/pki/ca-trust/source/anchors/ipa.crt
cp /etc/ipa/ca.crt /etc/pki/ca-trust/source/anchors/ipa.crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Mettre à jour le trust store en exécutant la commande suivante en tant qu'utilisateur
root:update-ca-trust extract
update-ca-trust extractCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Enregistrer Pegasus en tant que service dans le domaine Identity Management en exécutant la commande suivante en tant qu'utilisateur de domaine privilégié :
ipa service-add CIMOM/hostname
ipa service-add CIMOM/hostnameCopy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacez hostname par le nom d'hôte du système géré.Cette commande peut être exécutée à partir de n'importe quel système dans le domaine Identity Management sur lequel le paquet ipa-admintools a été installé. Une entrée de service est créée dans Identity Management, celle-ci peut être utilisée pour générer des certificats SSL. - Effectuez une copie de sauvegarde des fichiers PEM situés dans le répertoire
/etc/Pegasus/(recommandé). - Récupérer le certificat signé en exécutant la commande suivante en tant qu'utilisateur
root:ipa-getcert request -f /etc/Pegasus/server.pem -k /etc/Pegasus/file.pem -N CN=hostname -K CIMOM/hostname
ipa-getcert request -f /etc/Pegasus/server.pem -k /etc/Pegasus/file.pem -N CN=hostname -K CIMOM/hostnameCopy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacez hostname par le nom d'hôte du système géré.Le certificat et les fichiers clé sont désormais conservés dans des emplacements corrects. Le démoncertmonger, installé sur le système géré par le scriptipa-client-installgarantit que le certificat soit à jour et renouvellé comme nécessaire.Pour obtenir davantage d'informations, veuillez consulter le Guide des politiques, de l'authentification et des identités de domaines Linux Red Hat Enterprise Linux 7.
- Veuillez installer le paquet ipa-client et enregistrer le système sur Identity Management, comme décrit dans le Guide des politiques, de l'authentification et des identités de domaines Linux Red Hat Enterprise Linux 7.
- Veuillez copier le certificat de signature Identity Management dans le trust store en saisissant la commande suivante en tant qu'utilisateur
root:cp /etc/ipa/ca.crt /etc/pki/ca-trust/source/anchors/ipa.crt
cp /etc/ipa/ca.crt /etc/pki/ca-trust/source/anchors/ipa.crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Mettre à jour le trust store en exécutant la commande suivante en tant qu'utilisateur
root:update-ca-trust extract
update-ca-trust extractCopy to Clipboard Copied! Toggle word wrap Toggle overflow
- Veuillez copier le fichier
/etc/ipa/ca.crtde manière sécurisée depuis tout autre système joint au même domaine Identity Management sur le répertoire du magasin des confiances/etc/pki/ca-trust/source/anchors/en tant qu'utilisateurroot. - Mettre à jour le trust store en exécutant la commande suivante en tant qu'utilisateur
root:update-ca-trust extract
update-ca-trust extractCopy to Clipboard Copied! Toggle word wrap Toggle overflow
19.3.3. Gérer manuellement les certificats signés par des autorités
- Si une autorité de certificats est de confiance par défaut, il n'est pas nécessaire d'effectuer des étapes particulières pour accomplir ceci.
- Si l'autorité du certificat n'est pas de confiance par défaut, le certificat devra être importé sur le client et sur les systèmes gérés.
- Copiez le certificat sur le magasin des confiances en saisissant la commande suivante en tant qu'utilisateur
root:cp /path/to/ca.crt /etc/pki/ca-trust/source/anchors/ca.crt
cp /path/to/ca.crt /etc/pki/ca-trust/source/anchors/ca.crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Mettre à jour le trust store en exécutant la commande suivante en tant qu'utilisateur
root:update-ca-trust extract
update-ca-trust extractCopy to Clipboard Copied! Toggle word wrap Toggle overflow
- Créer le fichier de configuration SSL
/etc/Pegasus/ssl.cnfpour stocker des informations sur le certificat. Le contentu de ce fichier doit être similaire à l'exemple suivante :Copy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacez hostname avec le nom de domaine complet du système géré. - Générez une clé privée sur le système géré en utilisant la commande suivante en tant qu'utilisateur
root:openssl genrsa -out /etc/Pegasus/file.pem 1024
openssl genrsa -out /etc/Pegasus/file.pem 1024Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Veuillez générer une requête de signature de certificat (CSR) en exécutant la commande suivante en tant qu'utilisateur
root:openssl req -config /etc/Pegasus/ssl.cnf -new -key /etc/Pegasus/file.pem -out /etc/Pegasus/server.csr
openssl req -config /etc/Pegasus/ssl.cnf -new -key /etc/Pegasus/file.pem -out /etc/Pegasus/server.csrCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Veuillez envoyer le fichier
/etc/Pegasus/server.csrsur l'autorité du certificat pour la signature. La procédure détaillée de soumission du fichier dépend de l'autorité du certificat en question. - Lorsque le certificat signé est reçu de l'autorité du certificat, enregistrez-le sous
/etc/Pegasus/server.pem. - Veuillez copier le certificat de l'autorité de confiance sur le magasin des confiances Pegasus afin de vous assurer que Pegasus est capable de croire en son propre certificat en exécutant la commande suivante en tant qu'utilisateur
root:cp /path/to/ca.crt /etc/Pegasus/client.pem
cp /path/to/ca.crt /etc/Pegasus/client.pemCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Important
19.4. Utiliser LMIShell
19.4.1. Lancer, utiliser, et quitter LMIShell
Lancer le LMIShell en mode interactif
lmishell sans argument supplémentaire :
lmishell
lmishelllmishell avec l'option de ligne de commande --noverify ou -n :
lmishell --noverify
lmishell --noverifyUtiliser la saisie semi-automatique avec la touche « Tab »
Historique de navigation
~/.lmishell_history. Cela vous permet de parcourir l'historique des commandes et de réutiliser les lignes déjà saisies en mode interactif sans avoir à les réécrire dans l'invite. Pour reculer dans l'historique, veuillez appuyer sur la Flèche vers le haut ou sur la combinaison de touches Ctrl+p. Pour avancer dans l'historique des commandes, veuillez appuyer sur la touche Flèche vers le bas ou sur la combinaison de touches Ctrl+n.
> (reverse-i-search)`connect': c = connect("server.example.com", "pegasus")
> (reverse-i-search)`connect': c = connect("server.example.com", "pegasus")clear_history() comme suit :
clear_history()
clear_history()history_length dans le fichier de configuration ~/.lmishellrc. En outre, vous pouvez modifier l'emplacement du fichier de l'historique en changeant la valeur de l'option history_file dans ce fichier de configuration. Par exemple, pour paramétrer l'emplacement du fichier de l'historique sur ~/.lmishell_history et pour configurer LMIShell pour qu'un maximum de 1000 lignes y soient stockées, veuillez ajouter les lignes suivantes au fichier ~/.lmishellrc :
history_file = "~/.lmishell_history" history_length = 1000
history_file = "~/.lmishell_history"
history_length = 1000Gestion des exceptions
use_exceptions() comme suit :
use_exceptions()
use_exceptions()use_exception(False)
use_exception(False)use_exceptions dans le fichier de configuration ~/.lmishellrc sur True :
use_exceptions = True
use_exceptions = TrueConfigurer un cache temporaire
clear_cache() comme suit :
object_name.clear_cache()
object_name.clear_cache()use_cache() comme suit :
object_name.use_cache(False)
object_name.use_cache(False)object_name.use_cache(True)
object_name.use_cache(True)use_cache dans le fichier de configuration ~/.lmishellrc sur False :
use_cache = False
use_cache = FalseQuitter LMIShell
quit() comme suit :
> quit() ~]$
> quit()
~]$Exécuter un script LMIShell
lmishell comme suit :
lmishell file_name
lmishell file_name--interact ou -i :
lmishell --interact file_name
lmishell --interact file_name.lmi.
19.4.2. Connexion à un CIMOM
Connexion à un CIMOM distant
connect() comme suit :
connect(host_name, user_name[, password])
connect(host_name, user_name[, password])LMIConnection.
Exemple 19.1. Connexion à un CIMOM distant
server.example.com en tant qu'utilisateur pegasus, veuillez saisir ce qui suit dans l'invite interactive :
> c = connect("server.example.com", "pegasus")
password:
>
> c = connect("server.example.com", "pegasus")
password:
>Connexion à un CIMOM local
root et le socket /var/run/tog-pegasus/cimxml.socket doit exister.
connect() comme suit :
connect(host_name)
connect(host_name)localhost, 127.0.0.1, ou ::1. la fonction retourne un objet LMIConnection ou None.
Exemple 19.2. Connexion à un CIMOM local
localhost en tant qu'utilisateur root, veuillez saisir ce qui suit dans l'invite interactive :
> c = connect("localhost")
>
> c = connect("localhost")
>Vérifier une connexion sur un CIMOM
connect() retourne soit un objet LMIConnection, ou None si la connexion n'a pas pu être établie. En outre, lorsque la fonction connect() ne parvient pas à établir une connexion, un message d'erreur est imprimé sur la sortie d'erreur standard.
isinstance() comme suit :
isinstance(object_name, LMIConnection)
isinstance(object_name, LMIConnection)True si object_name est un objet LMIConnection, sinon elle retournera False.
Exemple 19.3. Vérifier une connexion sur un CIMOM
c, créée dans l'Exemple 19.1, « Connexion à un CIMOM distant », contient un objet LMIConnection, veuillez saisir ce qui suit dans l'invite interactive :
> isinstance(c, LMIConnection) True >
> isinstance(c, LMIConnection)
True
>c n'est pas égal à None :
> c is None False >
> c is None
False
>19.4.3. Utiliser des espaces de noms
root est le premier point d'entrée d'un objet de connexion.
Répertorier les espaces de noms disponibles
print_namespaces(), comme suit :
object_name.print_namespaces()
object_name.print_namespaces()namespaces :
object_name.namespaces
object_name.namespacesExemple 19.4. Répertorier les espaces de noms disponibles
root de l'objet de connexion c créé dans l'Exemple 19.1, « Connexion à un CIMOM distant » et pour répertorier les espaces de noms disponibles, veuillez saisir ce qui suit dans l'invite interactive :
root_namespaces, veuillez saisir :
> root_namespaces = c.root.namespaces >
> root_namespaces = c.root.namespaces
>Accéder aux objets d'espaces de noms
object_name.namespace_name
object_name.namespace_nameLMINamespace sera retourné.
Exemple 19.5. Accéder aux objets d'espaces de noms
cimv2 de l'objet de connexion c créé dans l'Exemple 19.1, « Connexion à un CIMOM distant » et l'assigner à une variable nommée ns, veuillez saisir ce qui suit dans l'invite interactive :
> ns = c.root.cimv2 >
> ns = c.root.cimv2
> 19.4.4. Utiliser des classes
Répertorier les classes disponibles
print_classes() comme suit :
namespace_object.print_classes()
namespace_object.print_classes()classes() :
namespace_object.classes()
namespace_object.classes()Exemple 19.6. Répertorier les classes disponibles
ns de l'objet de connexion créé dans l'Exemple 19.5, « Accéder aux objets d'espaces de noms » et pour répertorier les classes disponibles, veuillez saisir ce qui suit dans l'invite interactive :
cimv2_classes, veuillez saisir :
> cimv2_classes = ns.classes() >
> cimv2_classes = ns.classes()
>Accéder aux objets de classe
namespace_object.class_name
namespace_object.class_nameExemple 19.7. Accéder aux objets de classe
LMI_IPNetworkConnection de l'objet de l'espace de noms ns créé dans l'Exemple 19.5, « Accéder aux objets d'espaces de noms » et l'assigner à une variable nommée cls, veuillez saisir ce qui suit dans l'invite interactive :
> cls = ns.LMI_IPNetworkConnection >
> cls = ns.LMI_IPNetworkConnection
>Examiner les objets de classe
class_object.classname
class_object.classnameclass_object.namespace
class_object.namespacedoc() comme suit :
class_object.doc()
class_object.doc()Exemple 19.8. Examiner les objets de classe
cls créé dans l'Exemple 19.7, « Accéder aux objets de classe » et pour afficher son nom et son espace de noms correspondant, veuillez saisir ce qui suit dans l'invite interactive :
> cls.classname 'LMI_IPNetworkConnection' > cls.namespace 'root/cimv2' >
> cls.classname
'LMI_IPNetworkConnection'
> cls.namespace
'root/cimv2'
>Répertorier les méthodes disponibles
print_methods(), comme suit :
class_object.print_methods()
class_object.print_methods()methods() :
class_object.methods()
class_object.methods()Exemple 19.9. Répertorier les méthodes disponibles
cls créé dans l'Exemple 19.7, « Accéder aux objets de classe » et pour répertorier toutes les méthodes disponibles, veuillez saisir ce qui suit dans l'invite interactive :
> cls.print_methods() RequestStateChange >
> cls.print_methods()
RequestStateChange
>service_methods, veuillez saisir :
> service_methods = cls.methods() >
> service_methods = cls.methods()
>Répertorier les propriétés disponibles
print_properties() comme suit :
class_object.print_properties()
class_object.print_properties()properties() :
class_object.properties()
class_object.properties()Exemple 19.10. Répertorier les propriétés disponibles
cls créé dans l'Exemple 19.7, « Accéder aux objets de classe » et pour répertorier toutes les propriétés disponibles, veuillez saisir ce qui suit dans l'invite interactive :
service_properties, veuillez saisir :
> service_properties = cls.properties() >
> service_properties = cls.properties()
>Répertorier et afficher les propriétés ValueMap
print_valuemap_properties(), comme suit :
class_object.print_valuemap_properties()
class_object.print_valuemap_properties()valuemap_properties() :
class_object.valuemap_properties()
class_object.valuemap_properties()Exemple 19.11. Répertorier les propriétés ValueMap
cls créé dans l'Exemple 19.7, « Accéder aux objets de classe » et pour répertorier toutes les propriétés ValueMap disponibles, veuillez saisir ce qui suit dans l'invite interactive :
service_valuemap_properties, veuillez saisir :
> service_valuemap_properties = cls.valuemap_properties() >
> service_valuemap_properties = cls.valuemap_properties()
>class_object.valuemap_propertyValues
class_object.valuemap_propertyValuesprint_values(), comme suit :
class_object.valuemap_propertyValues.print_values()
class_object.valuemap_propertyValues.print_values()values() :
class_object.valuemap_propertyValues.values()
class_object.valuemap_propertyValues.values()Exemple 19.12. Accéder aux propriétés ValueMap
RequestedState. Pour inspecter cette propriété et répertorier les valeurs constantes disponibles, veuillez saisir ce qui suit dans l'invite interactive :
requested_state_values, veuillez saisir :
> requested_state_values = cls.RequestedStateValues.values() >
> requested_state_values = cls.RequestedStateValues.values()
>class_object.valuemap_propertyValues.constant_value_name
class_object.valuemap_propertyValues.constant_value_namevalue() comme suit :
class_object.valuemap_propertyValues.value("constant_value_name")
class_object.valuemap_propertyValues.value("constant_value_name")value_name() :
class_object.valuemap_propertyValues.value_name("constant_value")
class_object.valuemap_propertyValues.value_name("constant_value")Exemple 19.13. Accéder à des valeurs constantes
RequestedState fournit une valeur constante nommée Reset. Pour accéder à cette valeur constante nommée, veuillez saisir ce qui suit dans l'invite interactive :
> cls.RequestedStateValues.Reset
11
> cls.RequestedStateValues.value("Reset")
11
>
> cls.RequestedStateValues.Reset
11
> cls.RequestedStateValues.value("Reset")
11
>> cls.RequestedStateValues.value_name(11) u'Reset' >
> cls.RequestedStateValues.value_name(11)
u'Reset'
>Rechercher un objet CIMClass
CIMClass, ce qui explique pourquoi LMIShell recherche uniquement cet objet dans le CIMOM lorsqu'une méthode appelée en a besoin. Pour rechercher l'objet CIMClass manuellement, veuillez utiliser la méthode fetch(), comme suit :
class_object.fetch()
class_object.fetch()CIMClass le recherchent automatiquement.
19.4.5. Utiliser des instances
Accéder à des instances
instances() comme suit :
class_object.instances()
class_object.instances()LMIInstance.
first_instance() :
class_object.first_instance()
class_object.first_instance()LMIInstance.
instances() et first_instance() prennent en charge un argument optionnel vous permettant de filtrer les résultats :
class_object.instances(criteria)
class_object.instances(criteria)class_object.first_instance(criteria)
class_object.first_instance(criteria)Exemple 19.14. Accéder à des instances
cls créé dans l'Exemple 19.7, « Accéder aux objets de classe » dont la propriété ElementName est égale à eth0 et pour l'assigner à une variable nommée device, veuillez saisir ce qui suit dans l'invite interactive :
> device = cls.first_instance({"ElementName": "eth0"})
>
> device = cls.first_instance({"ElementName": "eth0"})
>Examiner des instances
instance_object.classname
instance_object.classnameinstance_object.namespace
instance_object.namespaceinstance_object.path
instance_object.pathLMIInstanceName.
doc() comme suit :
instance_object.doc()
instance_object.doc()Exemple 19.15. Examiner des instances
device créé dans l'Exemple 19.14, « Accéder à des instances » et pour afficher son nom de classe et son espace de nom correspondant, veuillez saisir ce qui suit dans l'invite interactive :
> device.classname u'LMI_IPNetworkConnection' > device.namespace 'root/cimv2' >
> device.classname
u'LMI_IPNetworkConnection'
> device.namespace
'root/cimv2'
>Créer de nouvelles instances
create_instance() comme suit :
class_object.create_instance(properties)
class_object.create_instance(properties)LMIInstance.
Exemple 19.16. Créer de nouvelles instances
LMI_Group représente les groupes de système et la classe LMI_Account représente les comptes utilisateurs sur le système géré. Pour utiliser l'objet d'espace de noms ns créé dans l'Exemple 19.5, « Accéder aux objets d'espaces de noms », veuillez créer des instances de ces deux classes pour le groupe de systèmes nommé pegasus et l'utilisateur nommé lmishell-user, et assignez-les aux variables nommées group et user, puis saisissez ce qui suit dans l'invite interactive :
> group = ns.LMI_Group.first_instance({"Name" : "pegasus"})
> user = ns.LMI_Account.first_instance({"Name" : "lmishell-user"})
>
> group = ns.LMI_Group.first_instance({"Name" : "pegasus"})
> user = ns.LMI_Account.first_instance({"Name" : "lmishell-user"})
>LMI_Identity pour l'utilisateur lmishell-user, veuillez utiliser :
> identity = user.first_associator(ResultClass="LMI_Identity") >
> identity = user.first_associator(ResultClass="LMI_Identity")
>LMI_MemberOfGroup représente l'adhésion au groupe de systèmes. Pour utiliser la classe LMI_MemberOfGroup pour ajouter lmishell-user au groupe pegasus, veuillez créer une nouvelle instance de cette classe comme suit :
> ns.LMI_MemberOfGroup.create_instance({
... "Member" : identity.path,
... "Collection" : group.path})
LMIInstance(classname="LMI_MemberOfGroup", ...)
>
> ns.LMI_MemberOfGroup.create_instance({
... "Member" : identity.path,
... "Collection" : group.path})
LMIInstance(classname="LMI_MemberOfGroup", ...)
>Supprimer des instances individuelles
delete(), comme suit :
instance_object.delete()
instance_object.delete()Exemple 19.17. Supprimer des instances individuelles
LMI_Account représente les comptes utilisateurs sur le système géré. Pour utiliser l'objet d'espace de noms ns créé dans l'Exemple 19.5, « Accéder aux objets d'espaces de noms », veuillez créer une instance de la classe LMI_Account pour l'utilisateur nommé lmishell-user, et assignez-la à une variable nommée user, puis saisissez ce qui suit dans l'invite interactive :
> user = ns.LMI_Account.first_instance({"Name" : "lmishell-user"})
>
> user = ns.LMI_Account.first_instance({"Name" : "lmishell-user"})
>lmishell-user du système, veuillez saisir :
> user.delete() True >
> user.delete()
True
>Répertorier et accéder aux propriétés disponibles
print_properties(), comme suit :
instance_object.print_properties()
instance_object.print_properties()properties() :
instance_object.properties()
instance_object.properties()Exemple 19.18. Répertorier les propriétés disponibles
device créé dans l'Exemple 19.14, « Accéder à des instances » et pour répertorier toutes les propriétés disponibles, veuillez saisir ce qui suit dans l'invite interactive :
device_properties, veuillez saisir :
> device_properties = device.properties() >
> device_properties = device.properties()
>instance_object.property_name
instance_object.property_nameinstance_object.property_name = value
instance_object.property_name = valuepush() :
instance_object.push()
instance_object.push()Exemple 19.19. Accéder aux propriétés individuelles
device créé dans l'Exemple 19.14, « Accéder à des instances » et pour afficher la valeur de la propriété nommée SystemName, veuillez saisir ce qui suit dans l'invite interactive :
> device.SystemName u'server.example.com' >
> device.SystemName
u'server.example.com'
>Répertorier et utiliser les méthodes disponibles
print_methods(), comme suit :
instance_object.print_methods()
instance_object.print_methods()methods() :
instance_object.methods()
instance_object.methods()Exemple 19.20. Répertorier les méthodes disponibles
device créé dans l'Exemple 19.14, « Accéder à des instances » et pour répertorier toutes les méthodes disponibles, veuillez saisir ce qui suit dans l'invite interactive :
> device.print_methods() RequestStateChange >
> device.print_methods()
RequestStateChange
>network_device_methods, veuillez saisir :
> network_device_methods = device.methods() >
> network_device_methods = device.methods()
>instance_object.method_name(
parameter=value,
...)
instance_object.method_name(
parameter=value,
...)Important
LMIInstance ne réactualisent pas automatiquement leur contenu (propriétés, méthodes, qualificateurs, et ainsi de suite). Pour cela, veuillez utiliser la méthode refresh() comme décrit ci-dessous.
Exemple 19.21. Utiliser des méthodes
PG_ComputerSystem représente le système. Pour créer une instance de cette classe en utilisant l'objet d'espace de noms ns créé dans l'Exemple 19.5, « Accéder aux objets d'espaces de noms » et pour l'assigner à une variable nommée sys, veuillez saisir ce qui suit dans l'invite interactive :
> sys = ns.PG_ComputerSystem.first_instance() >
> sys = ns.PG_ComputerSystem.first_instance()
>LMI_AccountManagementService implémente les méthodes qui vous permettent de gérer des utilisateurs et des groupes dans le système. Pour créer une instance de cette classe et l'assigner à une variable nommée acc, veuillez saisir :
> acc = ns.LMI_AccountManagementService.first_instance() >
> acc = ns.LMI_AccountManagementService.first_instance()
>lmishell-user dans le système, veuillez utiliser la méthode CreateAccount(), comme suit :
> acc.CreateAccount(Name="lmishell-user", System=sys)
LMIReturnValue(rval=0, rparams=NocaseDict({u'Account': LMIInstanceName(classname="LMI_Account"...), u'Identities': [LMIInstanceName(classname="LMI_Identity"...), LMIInstanceName(classname="LMI_Identity"...)]}), errorstr='')
> acc.CreateAccount(Name="lmishell-user", System=sys)
LMIReturnValue(rval=0, rparams=NocaseDict({u'Account': LMIInstanceName(classname="LMI_Account"...), u'Identities': [LMIInstanceName(classname="LMI_Identity"...), LMIInstanceName(classname="LMI_Identity"...)]}), errorstr='')LMI_StorageJobLMI_SoftwareInstallationJobLMI_NetworkJob
instance_object.Syncmethod_name(
parameter=value,
...)
instance_object.Syncmethod_name(
parameter=value,
...)Sync dans leur nom et retournent un tuple à trois éléments consistant de la valeur de retour de la tâche, des paramètres de retour de la tâche, et de la chaîne d'erreur de celle-ci.
PreferPolling, comme suit :
instance_object.Syncmethod_name(
PreferPolling=True
parameter=value,
...)
instance_object.Syncmethod_name(
PreferPolling=True
parameter=value,
...)Répertorier et afficher les paramètres ValueMap
print_valuemap_parameters(), comme suit :
instance_object.method_name.print_valuemap_parameters()
instance_object.method_name.print_valuemap_parameters()valuemap_parameters() :
instance_object.method_name.valuemap_parameters()
instance_object.method_name.valuemap_parameters()Exemple 19.22. Répertorier les paramètres ValueMap
acc créé dans l'Exemple 19.21, « Utiliser des méthodes » et pour répertorier tous les paramètres ValueMap disponibles de la méthode CreateAccount(), veuillez saisir ce qui suit dans l'invite interactive :
> acc.CreateAccount.print_valuemap_parameters() CreateAccount >
> acc.CreateAccount.print_valuemap_parameters()
CreateAccount
>create_account_parameters, veuillez saisir :
> create_account_parameters = acc.CreateAccount.valuemap_parameters() >
> create_account_parameters = acc.CreateAccount.valuemap_parameters()
>instance_object.method_name.valuemap_parameterValues
instance_object.method_name.valuemap_parameterValuesprint_values(), comme suit :
instance_object.method_name.valuemap_parameterValues.print_values()
instance_object.method_name.valuemap_parameterValues.print_values()values() :
instance_object.method_name.valuemap_parameterValues.values()
instance_object.method_name.valuemap_parameterValues.values()Exemple 19.23. Accéder aux paramètres ValueMap
CreateAccount. Pour inspecter ce paramètre et répertorier les valeurs constantes disponibles, veuillez saisir ce qui suit dans l'invite interactive :
create_account_values, veuillez saisir :
> create_account_values = acc.CreateAccount.CreateAccountValues.values() >
> create_account_values = acc.CreateAccount.CreateAccountValues.values()
>instance_object.method_name.valuemap_parameterValues.constant_value_name
instance_object.method_name.valuemap_parameterValues.constant_value_namevalue() comme suit :
instance_object.method_name.valuemap_parameterValues.value("constant_value_name")
instance_object.method_name.valuemap_parameterValues.value("constant_value_name")value_name() :
instance_object.method_name.valuemap_parameterValues.value_name("constant_value")
instance_object.method_name.valuemap_parameterValues.value_name("constant_value")Exemple 19.24. Accéder à des valeurs constantes
CreateAccount fournit une valeur constante nommée Failed. Pour accéder à cette valeur constante nommée, veuillez saisir ce qui suit dans l'invite interactive :
> acc.CreateAccount.CreateAccountValues.Failed
2
> acc.CreateAccount.CreateAccountValues.value("Failed")
2
>
> acc.CreateAccount.CreateAccountValues.Failed
2
> acc.CreateAccount.CreateAccountValues.value("Failed")
2
>> acc.CreateAccount.CreateAccountValues.value_name(2) u'Failed' >
> acc.CreateAccount.CreateAccountValues.value_name(2)
u'Failed'
>Actualiser les objets d'instances
refresh(), comme suit :
instance_object.refresh()
instance_object.refresh()Exemple 19.25. Actualiser les objets d'instances
device créé dans l'Exemple 19.14, « Accéder à des instances », veuillez saisir ce qui suit dans l'invite interactive :
> device.refresh()
LMIReturnValue(rval=True, rparams=NocaseDict({}), errorstr='')
>
> device.refresh()
LMIReturnValue(rval=True, rparams=NocaseDict({}), errorstr='')
>Afficher la représentation MOF
tomof() comme suit :
instance_object.tomof()
instance_object.tomof()Exemple 19.26. Afficher la représentation MOF
device créé dans l'Exemple 19.14, « Accéder à des instances », veuillez saisir ce qui suit dans l'invite interactive :
19.4.6. Utiliser des noms d'instance
Accéder aux noms d'instances
CIMInstance sont identifiés par des objets CIMInstanceName. Pour obtenir une liste de tous les objets des noms d'instances disponibles, veuillez utiliser la méthode instance_names(), comme suit :
class_object.instance_names()
class_object.instance_names()LMIInstanceName.
first_instance_name() :
class_object.first_instance_name()
class_object.first_instance_name()LMIInstanceName.
instances_names() et first_instance_name() prennent en charge un argument optionnel vous permettant de filtrer les résultats :
class_object.instance_names(criteria)
class_object.instance_names(criteria)class_object.first_instance_name(criteria)
class_object.first_instance_name(criteria)Exemple 19.27. Accéder aux noms d'instances
cls créé dans l'Exemple 19.7, « Accéder aux objets de classe » dont la propriété clé Name est égale à eth0 et pour l'assigner à une variable nommée device_name, veuillez saisir ce qui suit dans l'invite interactive :
> device_name = cls.first_instance_name({"Name": "eth0"})
>
> device_name = cls.first_instance_name({"Name": "eth0"})
>Examiner des noms d'instance
instance_name_object.classname
instance_name_object.classnameinstance_name_object.namespace
instance_name_object.namespaceExemple 19.28. Examiner des noms d'instance
device_name créé dans l'Exemple 19.27, « Accéder aux noms d'instances » et pour afficher son nom de classe et son espace de nom correspondant, veuillez saisir ce qui suit dans l'invite interactive :
> device_name.classname u'LMI_IPNetworkConnection' > device_name.namespace 'root/cimv2' >
> device_name.classname
u'LMI_IPNetworkConnection'
> device_name.namespace
'root/cimv2'
>Créer de nouveaux noms d'instance
CIMInstanceName encapsulé (« wrapped ») si vous connaissez toutes les clés principales d'un objet distant. Cet objet de nom d'instance peut ensuite être utilisé pour récupérer l'objet d'instance entier.
new_instance_name(), comme suit :
class_object.new_instance_name(key_properties)
class_object.new_instance_name(key_properties)LMIInstanceName.
Exemple 19.29. Créer de nouveaux noms d'instance
LMI_Account représente les comptes utilisateurs sur le système géré. Pour utiliser l'objet d'espace de noms ns créé dans l'Exemple 19.5, « Accéder aux objets d'espaces de noms », et pour créer une nouvelle instance de la classe LMI_Account représentant l'utilisateur lmishell-user sur le système géré, veuillez saisir ce qui suit dans l'invite interactive :
Répertorier et accéder aux propriétés clés
print_key_properties(), comme suit :
instance_name_object.print_key_properties()
instance_name_object.print_key_properties()key_properties() :
instance_name_object.key_properties()
instance_name_object.key_properties()Exemple 19.30. Répertorier les propriétés clés disponibles
device_name créé dans l'Exemple 19.27, « Accéder aux noms d'instances » et pour répertorier toutes les propriétés clés disponibles, veuillez saisir ce qui suit dans l'invite interactive :
device_name_properties, veuillez saisir :
> device_name_properties = device_name.key_properties() >
> device_name_properties = device_name.key_properties()
>instance_name_object.key_property_name
instance_name_object.key_property_nameExemple 19.31. Accéder aux propriétés clés individuelles
device_name créé dans l'Exemple 19.27, « Accéder aux noms d'instances » et pour afficher la valeur de la propriété clé nommée SystemName, veuillez saisir ce qui suit dans l'invite interactive :
> device_name.SystemName u'server.example.com' >
> device_name.SystemName
u'server.example.com'
>Convertir des noms d'instances en instances
to_instance() comme suit :
instance_name_object.to_instance()
instance_name_object.to_instance()LMIInstance.
Exemple 19.32. Convertir des noms d'instances en instances
device_name créé dans l'Exemple 19.27, « Accéder aux noms d'instances » en objet d'instance et pour l'assigner à une variable nommée device, veuillez saisir ce qui suit dans l'invite interactive :
> device = device_name.to_instance() >
> device = device_name.to_instance()
>19.4.7. Utiliser des objets associés
Accéder à des instances associées
associators() comme suit :
first_associator() :
AssocClass— chaque objet retourné doit être associé à l'objet source à travers une instance de cette classe ou de l'une de ses sous-classes. La valeur par défaut estNone.ResultClass— chaque objet retourné doit être une instance de cette classe ou de l'une de ses sous-classes, ou doit être cette classe ou l'une de ses sous-classes. La valeur par défaut estNone.Role— chaque objet retourné doit être associé à l'objet source à travers une association dans laquelle l'objet source joue le rôle spécifié. Le nom de la propriété dans la classe d'association faisant référence à l'objet source doit correspondre à la valeur de ce paramètre. La valeur par défaut estNone.ResultRole— chaque objet retourné doit être associé à l'objet source à travers une association pour laquelle l'objet retourné joue le rôle spécifié. Le nom de la propriété dans la classe d'association faisant référence à l'objet retourné doit correspondre à la valeur de ce paramètre. La valeur par défaut estNone.
IncludeQualifiers— un booléen indiquant si les qualificateurs de chaque objet (y compris les qualificateurs de l'objet et de toute propriété retournée) doivent être inclus en tant qu'éléments « QUALIFIER » dans la réponse. La valeur par défaut estFalse.IncludeClassOrigin— un booléen indiquant si l'attribut CLASSORIGIN doit être présent sur tous les éléments correspondants de chaque objet retourné. La valeur par défaut estFalse.PropertyList— les membres de cette liste définissent un ou plusieurs noms de propriétés. Les objets retournés n'inclueront pas d'éléments pour toute propriété manquante à cette liste. SiPropertyListest une liste vide, aucune propriété ne sera incluse dans les objets retournés. SiNone, aucun filtre supplémentaire ne sera défini. La valeur par défaut estNone.
Exemple 19.33. Accéder à des instances associées
LMI_StorageExtent représente les périphériques blocs disponibles sur le système. Pour utiliser l'objet d'espace de nom ns créé dans l'Exemple 19.5, « Accéder aux objets d'espaces de noms », veuillez créer une instance de la classe LMI_StorageExtent pour le périphérique bloc nommé /dev/vda, et assignez-la à une variable nommée vda, puis saisissez ce qui suit dans l'invite interactive :
> vda = ns.LMI_StorageExtent.first_instance({
... "DeviceID" : "/dev/vda"})
>
> vda = ns.LMI_StorageExtent.first_instance({
... "DeviceID" : "/dev/vda"})
>vda_partitions, veuillez utiliser la méthode associators() comme suit :
> vda_partitions = vda.associators(ResultClass="LMI_DiskPartition") >
> vda_partitions = vda.associators(ResultClass="LMI_DiskPartition")
> Accéder aux noms d'instances associés
associator_names() comme suit :
instance_object.associator_names(
AssocClass=class_name,
ResultClass=class_name,
Role=role,
ResultRole=role)
instance_object.associator_names(
AssocClass=class_name,
ResultClass=class_name,
Role=role,
ResultRole=role)first_associator_name() :
instance_object.first_associator_name(
AssocClass=class_object,
ResultClass=class_object,
Role=role,
ResultRole=role)
instance_object.first_associator_name(
AssocClass=class_object,
ResultClass=class_object,
Role=role,
ResultRole=role)AssocClass— chaque nom retourné identifie un objet devant être associé à l'objet source à travers une instance de cette classe ou de l'une de ses sous-classes. La valeur par défaut estNone.ResultClass— chaque nom retourné identifie un objet qui est une instance de cette classe ou l'une de ses sous-classes, ou qui doit être cette classe ou l'une de ses sous-classes. La valeur par défaut estNone.Role— chaque nom retourné identifie un objet devant être associé à l'objet source à travers une association dans laquelle l'objet source joue le rôle spécifié. Le nom de la propriété dans la classe d'association faisant référence à l'objet source doit correspondre à la valeur de ce paramètre. La valeur par défaut estNone.ResultRole— chaque nom retourné identifie un objet devant être associé à l'objet source à travers une association dans laquelle l'objet nommé retourné joue le rôle spécifié. Le nom de la propriété dans la classe d'association faisant référence à l'objet retourné doit correspondre à la valeur de ce paramètre. La valeur par défaut estNone.
Exemple 19.34. Accéder aux noms d'instances associés
vda créé dans l'Exemple 19.33, « Accéder à des instances associées », veuillez obtenir une liste de ses noms d'instances associés, puis assignez-la à une variable nommée vda_partitions, saisissez :
> vda_partitions = vda.associator_names(ResultClass="LMI_DiskPartition") >
> vda_partitions = vda.associator_names(ResultClass="LMI_DiskPartition")
>19.4.8. Utiliser des objets d'association
Accéder à des instances d'association
references(), comme suit :
first_reference() :
ResultClass— chaque objet retourné doit être une instance de cette classe ou de l'une de ses sous-classes, ou doit être cette classe ou l'une de ses sous-classes. La valeur par défaut estNone.Role— chaque objet retourné doit faire référence à l'objet cible à travers une propriété avec un nom correspondant à la valeur de ce paramètre. La valeur par défaut estNone.
IncludeQualifiers— un booléen indiquant si chaque objet (y compris les qualificateurs de l'objet et de toute propriété retournée) doit être inclus en tant qu'élément « QUALIFIER » dans la réponse. La valeur par défaut estFalse.IncludeClassOrigin— un booléen indiquant si l'attribut CLASSORIGIN doit être présent sur tous les éléments correspondants de chaque objet retourné. La valeur par défaut estFalse.PropertyList— les membres de cette liste définissent un ou plusieurs noms de propriété. Les objets retournés n'inclueront pas d'éléments pour toute propriété manquante de cette liste. SiPropertyListest une liste vide, aucune propriété ne sera incluse dans les objets retournés. SiNone, aucun filtre supplémentaire ne sera défini. La valeur par défaut estNone.
Exemple 19.35. Accéder à des instances d'association
LMI_LANEndpoint représente un point de terminaison de communication associé à un certain périphérique d'interface réseau. Pour utiliser l'objet d'espace de noms ns créé dans l'Exemple 19.5, « Accéder aux objets d'espaces de noms », veuillez créer une instance de la classe LMI_LANEndpoint pour le périphérique d'interface réseau nommé eth0, et assignez-la à une variable nommée lan_endpoint, puis saisissez ce qui suit dans l'invite interactive :
> lan_endpoint = ns.LMI_LANEndpoint.first_instance({
... "Name" : "eth0"})
>
> lan_endpoint = ns.LMI_LANEndpoint.first_instance({
... "Name" : "eth0"})
>LMI_BindsToLANEndpoint et pour l'assigner à une variable nommée bind, veuillez saisir :
> bind = lan_endpoint.first_reference( ... ResultClass="LMI_BindsToLANEndpoint") >
> bind = lan_endpoint.first_reference(
... ResultClass="LMI_BindsToLANEndpoint")
>Dependent pour accéder à la classe dépendante LMI_IPProtocolEndpoint qui représente l'adresse IP du périphérique de l'interface réseau correspondant :
> ip = bind.Dependent.to_instance() > print ip.IPv4Address 192.168.122.1 >
> ip = bind.Dependent.to_instance()
> print ip.IPv4Address
192.168.122.1
>Accéder aux noms d'instances d'associations
reference_names() comme suit :
instance_object.reference_names(
ResultClass=class_name,
Role=role)
instance_object.reference_names(
ResultClass=class_name,
Role=role)first_reference_name() :
instance_object.first_reference_name(
ResultClass=class_name,
Role=role)
instance_object.first_reference_name(
ResultClass=class_name,
Role=role)ResultClass— chaque objet retourné doit identifier une instance de cette classe ou de l'une de ses sous-classes, ou cette classe ou l'une de ses sous-classes. La valeur par défaut estNone.Role— chaque objet retourné doit identifier un objet ui se réfère à une instance cible à travers une propriété avec un nom correspondant à la valeur de ce paramètre. La valeur par défaut estNone.
Exemple 19.36. Accéder aux noms d'instances d'associations
Ian_endpoint créé dans l'Exemple 19.35, « Accéder à des instances d'association », accéder au premier nom d'instance d'association faisant référence à un objet LMI_BindsToLANEndpoint, et l'assigner à une variable nommée bind, veuillez saisir :
> bind = lan_endpoint.first_reference_name( ... ResultClass="LMI_BindsToLANEndpoint")
> bind = lan_endpoint.first_reference_name(
... ResultClass="LMI_BindsToLANEndpoint")Dependent pour accéder à la classe dépendante LMI_IPProtocolEndpoint qui représente l'adresse IP du périphérique de l'interface réseau correspondant :
> ip = bind.Dependent.to_instance() > print ip.IPv4Address 192.168.122.1 >
> ip = bind.Dependent.to_instance()
> print ip.IPv4Address
192.168.122.1
>19.4.9. Travailler avec des indications
S'abonner à des indications
subscribe_indication(), comme suit :
connection_object.subscribe_indication(
Query='SELECT * FROM CIM_InstModification',
Name="cpu",
Destination="http://host_name:5988")
connection_object.subscribe_indication(
Query='SELECT * FROM CIM_InstModification',
Name="cpu",
Destination="http://host_name:5988")permanente = True à l'appel de méthode subscribe_indication(). Cela empêchera LMIShell de supprimer l'abonnement.
Exemple 19.37. S'abonner à des indications
c créé dans Exemple 19.1, « Connexion à un CIMOM distant » et pour vous abonner à une indication nommée cpu, veuillez saisir ce qui suit dans l'invite interactive :
Répertorier les indications abonnées
print_subscribed_indications(), comme suit :
connection_object.print_subscribed_indications()
connection_object.print_subscribed_indications()subscribed_indications() comme suit :
connection_object.subscribed_indications()
connection_object.subscribed_indications()Exemple 19.38. Répertorier les indications abonnées
c créé dans l'Exemple 19.1, « Connexion à un CIMOM distant » et pour répertorier les indications abonnées, veuillez saisir ce qui suit dans l'invite interactive :
> c.print_subscribed_indications() >
> c.print_subscribed_indications()
>indications, veuillez saisir :
> indications = c.subscribed_indications() >
> indications = c.subscribed_indications()
>Se désabonner des indications
unsubscribe_indication() comme suit :
connection_object.unsubscribe_indication(indication_name)
connection_object.unsubscribe_indication(indication_name)unsubscribe_all_indications() :
connection_object.unsubscribe_all_indications()
connection_object.unsubscribe_all_indications()Exemple 19.39. Se désabonner des indications
c créé dans Exemple 19.1, « Connexion à un CIMOM distant » et pour vous désabonner de l'indication créée dans l' Exemple 19.37, « S'abonner à des indications », veuillez saisir ce qui suit dans l'invite interactive :
> c.unsubscribe_indication('cpu')
LMIReturnValue(rval=True, rparams=NocaseDict({}), errorstr='')
>
> c.unsubscribe_indication('cpu')
LMIReturnValue(rval=True, rparams=NocaseDict({}), errorstr='')
>Implémenter un gestionnaire d'indications (« Indication Handler »)
subscribe_indication() vous permet de spécifier le nom d'hôte du système sur lequel vous souhaitez remettre les indications. L'exemple ci-dessous montre comment implémenter un gestionnaire d'indications :
LmiIndication, qui contient une liste de méthodes et d'objets exportés par l'indication. D'autres paramètres sont spécifiques à l'utilisateur : ces arguments devront être spécifiés lors de l'ajout d'un gestionnaire au listener.
add_handler() utilise une chaîne spéciale avec huit caractères « X ». Ces caractères sont remplacés par une chaîne aléatoire générée par des listeners afin d'éviter une collision possible de noms de gestionnaire. Pour utiliser la chaîne aléatoire, commencez par lancer le listener d'indications, puis abonnez-vous à une indication afin que la propriété Destination de l'objet du gestionnaire contienne la valeur suivante : schema://host_name/random_string.
Exemple 19.40. Implémenter un gestionnaire d'indications (« Indication Handler »)
192.168.122.1 et qui appelle la fonction indication_callback() lorsqu'un nouveau compte utilisateur est créé :
19.4.10. Exemple d'utilisation
c = connect("host_name", "user_name", "password")
ns = c.root.cimv2
c = connect("host_name", "user_name", "password")
ns = c.root.cimv2Utiliser le fournisseur du service OpenLMI
Exemple 19.41. Répertorier les services disponibles
TRUE) ou est arrêté (FALSE), et la chaîne de statut, veuillez utiliser l'extrait de code suivant :
for service in ns.LMI_Service.instances():
print "%s:\t%s" % (service.Name, service.Status)
for service in ns.LMI_Service.instances():
print "%s:\t%s" % (service.Name, service.Status)cls = ns.LMI_Service
for service in cls.instances():
if service.EnabledDefault == cls.EnabledDefaultValues.Enabled:
print service.Name
cls = ns.LMI_Service
for service in cls.instances():
if service.EnabledDefault == cls.EnabledDefaultValues.Enabled:
print service.NameEnabledDefault est égale à 2 pour les services activés et à 3 pour les services désactivés.
cups, veuillez utiliser :
cups = ns.LMI_Service.first_instance({"Name": "cups.service"})
cups.doc()
cups = ns.LMI_Service.first_instance({"Name": "cups.service"})
cups.doc()Exemple 19.42. Lancer et arrêter des services
cups et pour afficher son statut actuel, veuillez utiliser l'extrait de code suivant :
cups = ns.LMI_Service.first_instance({"Name": "cups.service"})
cups.StartService()
print cups.Status
cups.StopService()
print cups.Status
cups = ns.LMI_Service.first_instance({"Name": "cups.service"})
cups.StartService()
print cups.Status
cups.StopService()
print cups.StatusExemple 19.43. Activer et désactiver des services
cups et pour afficher sa propriété EnabledDefault, veuillez utiliser l'extrait de code suivant :
cups = ns.LMI_Service.first_instance({"Name": "cups.service"})
cups.TurnServiceOff()
print cups.EnabledDefault
cups.TurnServiceOn()
print cups.EnabledDefault
cups = ns.LMI_Service.first_instance({"Name": "cups.service"})
cups.TurnServiceOff()
print cups.EnabledDefault
cups.TurnServiceOn()
print cups.EnabledDefaultUtiliser le fournisseur réseau OpenLMI
Exemple 19.44. Répertorier les adresses IP associées à un numéro de port donné
LMI_IPProtocolEndpoint associée à une classe LMI_IPNetworkConnection donnée.
for rsap in device.associators(AssocClass="LMI_NetworkRemoteAccessAvailableToElement", ResultClass="LMI_NetworkRemoteServiceAccessPoint"):
if rsap.AccessContext == ns.LMI_NetworkRemoteServiceAccessPoint.AccessContextValues.DefaultGateway:
print "Default Gateway: %s" % rsap.AccessInfo
for rsap in device.associators(AssocClass="LMI_NetworkRemoteAccessAvailableToElement", ResultClass="LMI_NetworkRemoteServiceAccessPoint"):
if rsap.AccessContext == ns.LMI_NetworkRemoteServiceAccessPoint.AccessContextValues.DefaultGateway:
print "Default Gateway: %s" % rsap.AccessInfoLMI_NetworkRemoteServiceAccessPoint dont la propriété AccessContext est égale à DefaultGateway.
- Obtenez les instances
LMI_IPProtocolEndpointassociées avecLMI_IPNetworkConnectionen utilisantLMI_NetworkSAPSAPDependency. - Utilisez la même association pour les instances
LMI_DNSProtocolEndpoint.
LMI_NetworkRemoteServiceAccessPoint dont la propriété AccessContext est égale au serveur DNS associé à travers LMI_NetworkRemoteAccessAvailableToElement possèdent l'adresse du serveur DNS dans la propriété AccessInfo.
RemoteServiceAccessPath et les entrées peuvent être dupliquées. L'extrait de code suivant utilise la fonction set() pour supprimer les entrées dupliquées de la liste des serveurs DNS :
Exemple 19.45. Créer une nouvelle connexion et configurer une adresse IP statique
LMI_CreateIPSetting() sur l'instance de LMI_IPNetworkConnectionCapabilities, qui est associée avec LMI_IPNetworkConnection à travers LMI_IPNetworkConnectionElementCapabilities. Il utilise également la méthode push() pour modifier le paramètre.
Exemple 19.46. Activer une connexion
ApplySettingToIPNetworkConnection() de la classe LMI_IPConfigurationService. Cette méthode est asynchrone et retourne une tâche. Les extraits de code suivants illustrent comment appeler cette méthode de manière synchrone :
setting = ns.LMI_IPAssignmentSettingData.first_instance({ "Caption": "eth0 Static" })
port = ns.LMI_IPNetworkConnection.first_instance({ 'ElementName': 'ens8' })
service = ns.LMI_IPConfigurationService.first_instance()
service.SyncApplySettingToIPNetworkConnection(SettingData=setting, IPNetworkConnection=port, Mode=32768)
setting = ns.LMI_IPAssignmentSettingData.first_instance({ "Caption": "eth0 Static" })
port = ns.LMI_IPNetworkConnection.first_instance({ 'ElementName': 'ens8' })
service = ns.LMI_IPConfigurationService.first_instance()
service.SyncApplySettingToIPNetworkConnection(SettingData=setting, IPNetworkConnection=port, Mode=32768)Mode affecte la manière dont le paramètre est appliqué. Les valeurs les plus couramment utilisées de ce paramètre sont comme suit :
1— applique le paramètre immédiatement et le rend automatiquement actif.2— rend le paramètre automatiquement actif mais ne l'applique pas immédiatement.4— déconnecte et désactive l'activation automatique.5— ne modifie pas l'état du paramètre, désactive uniquement l'activation automatique.32768— applique le paramètre.32769— déconnexion.
Utiliser le fournisseur de stockage OpenLMI
c et ns, ces exemples utilisent les définitions de variables suivantes :
MEGABYTE = 1024*1024 storage_service = ns.LMI_StorageConfigurationService.first_instance() filesystem_service = ns.LMI_FileSystemConfigurationService.first_instance()
MEGABYTE = 1024*1024
storage_service = ns.LMI_StorageConfigurationService.first_instance()
filesystem_service = ns.LMI_FileSystemConfigurationService.first_instance()Exemple 19.47. Créer un groupe de volumes
/dev/myGroup/ qui possède trois membres et une taille d'extension par défaut de 4 Mo, veuillez utiliser l'extrait de code suivant :
Exemple 19.48. Créer un volume logique
Exemple 19.49. Créer un système de fichiers
ext3 sur un volume logique lv selon l'Exemple 19.48, « Créer un volume logique », veuillez utiliser l'extrait de code suivant :
(ret, outparams, err) = filesystem_service.SyncLMI_CreateFileSystem(
FileSystemType=filesystem_service.LMI_CreateFileSystem.FileSystemTypeValues.EXT3,
InExtents=[lv])
(ret, outparams, err) = filesystem_service.SyncLMI_CreateFileSystem(
FileSystemType=filesystem_service.LMI_CreateFileSystem.FileSystemTypeValues.EXT3,
InExtents=[lv])Exemple 19.50. Monter un système de fichiers
Exemple 19.51. Répertorier les périphériques blocs
Utiliser le fournisseur de matériel OpenLMI
Exemple 19.52. Afficher les informations du CPU
cpu = ns.LMI_Processor.first_instance() cpu_cap = cpu.associators(ResultClass="LMI_ProcessorCapabilities")[0] print cpu.Name print cpu_cap.NumberOfProcessorCores print cpu_cap.NumberOfHardwareThreads
cpu = ns.LMI_Processor.first_instance()
cpu_cap = cpu.associators(ResultClass="LMI_ProcessorCapabilities")[0]
print cpu.Name
print cpu_cap.NumberOfProcessorCores
print cpu_cap.NumberOfHardwareThreadsExemple 19.53. Afficher les informations de mémoire
mem = ns.LMI_Memory.first_instance()
for i in mem.associators(ResultClass="LMI_PhysicalMemory"):
print i.Name
mem = ns.LMI_Memory.first_instance()
for i in mem.associators(ResultClass="LMI_PhysicalMemory"):
print i.NameExemple 19.54. Afficher les informations du châssis
chassis = ns.LMI_Chassis.first_instance() print chassis.Manufacturer print chassis.Model
chassis = ns.LMI_Chassis.first_instance()
print chassis.Manufacturer
print chassis.ModelExemple 19.55. Répertorier les périphériques PCI
for pci in ns.LMI_PCIDevice.instances():
print pci.Name
for pci in ns.LMI_PCIDevice.instances():
print pci.Name19.5. Utiliser OpenLMI Scripts
lmi, un utilitaire extensible pouvant être utilisé pour interagir avec ces bibliothèques à partir de la ligne de commande.
easy_install --user openlmi-scripts
easy_install --user openlmi-scriptslmi dans le répertoire ~/.local/. Pour étendre la fonctionnalité de l'utilitaire lmi, veuillez installer des modules OpenLMI supplémentaires en utilisant la commande suivante :
easy_install --user package_name
easy_install --user package_name19.6. Ressources supplémentaires
Documentation installée
- lmishell(1) — The manual page for the
lmishellclient and interpreter provides detailed information about its execution and usage.
Documentation en ligne
- Guide de mise en réseau Red Hat Enterprise Linux 7 — Le Guide de mise en réseau de Red Hat Enterprise Linux 7 documente les informations pertinentes à la configuration et à l'administration des interfaces réseau et des services réseau sur le système.
- Guide d'administration du stockage Red Hat Enterprise Linux 7 — Le Guide d'administration du stockage de Red Hat Enterprise Linux 7 fournit des instructions sur la manière de gérer les périphériques de stockage et les systèmes de fichiers sur le système.
- Guide de gestion de l'alimentation Red Hat Enterprise Linux 7 — Le Guide de gestion de l'alimentation de Red Hat Enterprise Linux 7 explique comment gérer la consommation électrique du système de manière efficace. Il traite de différentes techniques permettant de réduire la consommation électrique des serveurs et des ordinateurs portables, et explique comment chaque technique affecte les performances générales du système.
- Guide de la politique, de l'authentification, et de l'identité de domaines Linux Red Hat Enterprise Linux 7 — Le Guide de la politique, de l'authentification, et de l'identité de domaines Linux de Red Hat Enterprise Linux 7 couvre tous les aspects de l'installation, de la configuration et de la gestion des domaines IPA, y compris les serveurs et les clients. Ce guide est conçu pour les administrateurs systèmes et administrateurs informatique.
- Documentation FreeIPA — La Documentation FreeIPA sert de documentation utilisateur principale pour l'utilisation du projet de gestion des identités FreeIPA (« FreeIPA Identity Management »).
- Page d'accueil OpenSSL — La page d'accueil d'OpenSSL fournit une vue d'ensemble du projet OpenSSL.
- Documentation Mozilla NSS — La Documentation Mozilla NSS sert de documentation utilisateur principale pour utiliser le projet Mozilla NSS.
Voir aussi
- Le Chapitre 3, Gérer les utilisateurs et les groupes documente comment gérer les groupes et utilisateurs système dans l'interface utilisateur graphique et sur la ligne de commande.
- Le Chapitre 8, Yum décrit comment utiliser le gestionnaire de paquets Yum pour rechercher, installer, mettre à jour, et désinstaller des paquets sur la ligne de commande.
- Le Chapitre 9, Gérer les services avec systemd offre une introduction à
systemdet documente comment utiliser la commandesystemctlpour gérer des services système, configurer des cibles systemd, et exécuter des commandes de gestion de l'alimentation. - Le Chapitre 10, OpenSSH décrit comment configurer un serveur SSH et comment utiliser les utilitaires client
ssh,scp, etsftppour y accéder.
Chapitre 20. Afficher et gérer des fichiers journaux
rsyslogd. Le démon rsyslogd est un remplacement amélioré de sysklogd, et fournit un filtrage étendu, une redirection de messages protégée par un cryptage, diverses options de configuration, des modules d'entrée et de sortie, et la prise en charge du transport via les protocoles TCP ou UDP. Notez que rsyslog est compatible avec sysklogd.
journald – un composant de systemd. Le démon journald capture les messages Syslog, les messages du journal du noyau, les messages du disque RAM initial et du début du démarrage, ainsi que les messages inscrits sur la sortie standard et la sortie d'erreur standard de tous les services, puis il les indexe et rend ceci disponibles à l'utilisateur. Le format du fichier journal natif, qui est un fichier binaire structuré et indexé, améliore les recherches et permet une opération plus rapide, celui-ci stocke également des informations de métadonnées, comme l'horodatage ou les ID d'utilisateurs. Les fichiers journaux produits par journald sont par défaut non persistants, les fichiers journaux sont uniquement stockés en mémoire ou dans une petite mémoire tampon en anneau dans le répertoire /run/log/journal/. La quantité de données journalisées dépend de la mémoire libre, lorsque la capacité limite est atteinte, les entrées les plus anciennes sont supprimées. Cependant, ce paramètre peut être altéré – veuillez consulter la Section 20.10.5, « Activer le stockage persistant ». Pour obtenir davantage d' informations sur le Journal, veuillez consulter la Section 20.10, « Utiliser le Journal ».
journald est l'outil principal de résolution de problèmes. Il fournit également les données supplémentaires nécessaires à la création de messages journaux structurés. Les données acquises par journald sont transférées sur le socket /run/systemd/journal/syslog pouvant être utilisé par rsyslogd pour traiter davantage les données. Cependant, rsyslog effectue l'intégration par défaut via le module d'entrée imjournal, évitant ainsi le socket susmentionné. Il est également possible de transférer les données dans la direction opposée, depuis rsyslogd vers journald par le module omjournal. Veuillez consulter la Section 20.7, « Interaction de Rsyslog et de Journal » pour obtenir des informations supplémentaires. L'intégration permet de maintenir des journaux basés texte sous un format cohérent afin d'assurer la compatibilité avec de possibles applications ou configurations dépendants de rsyslogd. Vous pouvez également maintenir les messages rsyslog sous un format structuré (veuillez consulter la Section 20.8, « Journalisation structurée avec Rsyslog »).
20.1. Localiser les fichiers journaux
rsyslogd dans le fichier de configuration /etc/rsyslog.conf. La plupart des fichiers journaux se trouvent dans le répertoire /var/log/. Certaines applications, comme httpd et samba, peuvent avoir un répertoire dans /var/log/ pour leurs fichiers journaux.
/var/log/ suivis par des chiffres (par exemple, cron-20100906). Ces chiffres représentent un horodatage ajouté à un fichier journal rotatif. Les fichiers journaux sont en rotation afin que leur taille ne devienne pas trop importante. Le paquet logrotate contient une tâche faisant pivoter les fichiers journaux automatiquement, en fonction du fichier de configuration /etc/logrotate.conf et des fichiers de configuration situés dans le répertoire /etc/logrotate.d/.
20.2. Configuration de base de Rsyslog
/etc/rsyslog.conf. Vous pouvez y spécifier des directives globales, des modules, et des règles consistant en une partie « filter » (filtre) et une partie « action ». Vous pouvez également ajouter des commentaires sous la forme d'un texte suivant un caractère dièse (#).
20.2.1. Filtres
/etc/rsyslog.conf, définissez un filtre et une action, un par ligne, et séparez-les par un ou plusieurs espaces ou par une ou plusieurs tabulations.
- Filtres basés Facility/Priorité
- La manière la plus utilisée et la plus connue de filtrer des messages syslog consiste à utiliser les filtres basés facility/priorité (type/priorité), qui filtrent les messages syslog en se basant sur deux conditions : facility (ou type) et priorité séparés par un point. Pour créer un sélecteur, veuillez utiliser la syntaxe suivante :
FACILITY.PRIORITY
FACILITY.PRIORITYCopy to Clipboard Copied! Toggle word wrap Toggle overflow où :- FACILITY spécifie le sous-système produisant un message syslog particulier. Par exemple, le sous-système
mailgère tous les messages syslog concernant le courrier. FACILITY peut être représenté par l'un des mots-clés suivants (ou par un code numérique) :kern(0),user(1),mail(2),daemon(3),auth(4),syslog(5),lpr(6),news(7),uucp(8),cron(9),authpriv(10),ftp(11), etlocal0vialocal7(16 - 23). - PRIORITY spécifie la priorité d'un message syslog. PRIORITY peut être représenté par l'un des mots-clés suivants (ou par un numéro) :
debug(7),info(6),notice(5),warning(4),err(3),crit(2),alert(1), etemerg(0).La syntaxe susmentionnée sélectionne les messages syslog avec la priorité définie ou avec une priorité supérieure. En faisant précéder tout mot-clé de priorité par le caractère égal (=), vous spécifiez que seuls les messages syslog avec la priorité spécifiée seront sélectionnés. Toutes les autres priorités seront ignorées. De même, faire précéder un mot-clé de priorité par un point d'exclamation (!) sélectionne tous les messages syslog sauf ceux dont la priorité est définie.
En plus des mots-clés spécifiés ci-dessus, vous pouvez également utiliser un astérisque (*) pour définir tous les types (« Facilities ») ou priorités (selon l'endroit où vous placez l'astérisque, avant ou après la virgule). Spécifier le mot-clé de prioriténone(aucun) sert aux types sans priorité donnée. Les conditions du type et de la priorité ne respectent pas la casse.Pour définir de multiples types et priorités, veuillez les séparer par une virgule (,). Pour définir de multiples sélecteurs sur une seule ligne, séparez-les avec un point-virgule (;). Remarquez que chaque sélecteur dans le champ des sélecteurs est capable d'outrepasser les précédents, ce qui peut exclure certaines priorités du modèle.Exemple 20.1. Filtres basés Facility/Priorité
Ci-dessous figurent quelques exemples de filtres basés facility/priorité simples pouvant être spécifiés dans/etc/rsyslog.conf. Pour sélectionner tous les messages syslog du noyau avec n'importe quelle priorité, ajoutez le texte suivant dans le fichier de configuration.kern.*
kern.*Copy to Clipboard Copied! Toggle word wrap Toggle overflow Pour sélectionner tous les messages syslog de courrier avec une prioritécritou supérieure, veuillez utiliser le format ci-dessous :mail.crit
mail.critCopy to Clipboard Copied! Toggle word wrap Toggle overflow Pour sélectionner tous les messages syslog cron sauf ceux avec la prioritéinfooudebug, paramétrez la configuration sous le format suivant :cron.!info,!debug
cron.!info,!debugCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Filtres basés Propriété
- Les filtres basés propriété vous permettent de filtrer les messages syslog par toute propriété, comme
timegeneratedousyslogtag. Pour obtenir davantage d'informations sur les propriétés, veuillez consulter la section intitulée « Propriétés ». Vous pouvez comparer chacune des propriétés spécifiées avec une valeur particulière en utilisant l'une des opérations de comparaison répertoriées dans la Tableau 20.1, « Opération de comparaison basée propriété ». Les noms des propriétés et les opérations de comparaison respectent la casse.Un filtre basé propriété doit commencer par un caractère des deux-points (:). Pour définir le filtre, veuillez utiliser la syntaxe suivante ::PROPERTY, [!]COMPARE_OPERATION, "STRING"
:PROPERTY, [!]COMPARE_OPERATION, "STRING"Copy to Clipboard Copied! Toggle word wrap Toggle overflow où :- L'attribut PROPERTY spécifie la propriété souhaitée.
- Le point d'exclamation optionnel (
!) ignore la sortie de l'opération de comparaison. D'autres opérateurs booléens ne sont pas actuellement pris en charge par les filtres basés propriété. - L'attribut COMPARE_OPERATION spécifie l'une des opérations de comparaison répertoriée dans la Tableau 20.1, « Opération de comparaison basée propriété ».
- L'attribut STRING spécifie la valeur à laquelle est comparé le texte fourni par la propriété. Cette valeur doit se trouver entre guillemets. Pour échapper certains caractères se trouvant dans la chaîne (par exemple un guillemet (
")), veuillez utiliser le caractère de la barre oblique inversée (\).
Expand Tableau 20.1. Opération de comparaison basée propriété Opération de comparaison Description containsVérifie si la chaîne fournie correspond à toute partie du texte fourni par la propriété. Pour effectuer des comparaisons ne respectant pas la casse, veuillez utiliser contains_i.isequalCompare la chaîne fournie avec tout le texte de la propriété. Ces deux valeurs doivent être exactement pareilles pour correspondre. startswithVérifie si la chaîne fournie est trouvée précisément au début du texte fourni par la propriété. Pour effectuer des comparaisons ne respectant pas la casse, veuillez utiliser startswith_i.regexCompare l'expression BRE (« Basic Regular Expression ») POSIX fournie avec le texte fourni par la propriété. ereregexCompare l'expression régulière ERE (« Extended Regular Expression ») POSIX fournie avec le texte fourni par la propriété. isemptyVérifie si la propriété est vide. La valeur est abandonnée. Ceci est particulièrement utile lors de l'utilisation de données normalisées, avec lesquelles certains champs peuvent être remplis en se basant sur le résultat de la normalisation. Exemple 20.2. Filtres basés Propriété
Ci-dessous figurent quelques exemples de filtres basés propriété pouvant être spécifiés dans/etc/rsyslog.conf. Pour sélectionner les messages syslog qui contiennent la chaîneerrordans leur texte, veuillez utiliser ::msg, contains, "error"
:msg, contains, "error"Copy to Clipboard Copied! Toggle word wrap Toggle overflow Le filtre suivant sélectionne les messages syslog reçus du nom d'hôtehost1::hostname, isequal, "host1"
:hostname, isequal, "host1"Copy to Clipboard Copied! Toggle word wrap Toggle overflow Pour sélectionner les messages syslog qui ne mentionnent pas les motsfataleterroravec ou sans texte entre ces mots (par exemple,fatal lib error), veuillez saisir ::msg, !regex, "fatal .* error"
:msg, !regex, "fatal .* error"Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Filtres basés Expression
- Les filtres basés Expression sélectionnent des messages syslog en fonction de l'arithmétique définie, ou des opérations des booléens et des chaînes. Les filtres basés Expression utilisent un langage propre à rsyslog, nommé RainerScript, pour créer des filtres complexes.La syntaxe de base des filtres basés expression ressemble à ceci :
if EXPRESSION then ACTION else ACTION
if EXPRESSION then ACTION else ACTIONCopy to Clipboard Copied! Toggle word wrap Toggle overflow où :- L'attribut EXPRESSION représente une expression à évaluer, par exemple :
$msg startswith 'DEVNAME'ou$syslogfacility-text == 'local0'. Il est possible de spécifier plus d'une expression dans un seul filtre en utilisant les opérateursandetor. - L'attribut ACTION représente une action à effectuer si l'expression retourne la valeur
true. Ceci peut être une action unique, ou un script complexe arbitraire se trouvant entre des accolades. - Les filtres basés Expression sont indiqués par le mot-clé if au début d'une nouvelle ligne. Le mot-clé then sépare l'EXPRESSION de l'ACTION. Optionnellement, il est possible d'utiliser le mot-clé else pour spécifier l'action à effectuer au cas où la condition n'est pas remplie.
Avec les filtres basés expression, il est possible d'imbriquer les conditions en utilisant un script se trouvant entre des accolades, comme dans l'Exemple 20.3, « Filtres basés Expression ». Le script vous permet d'utiliser des filtres basés facility/priorité dans l'expression. D'autre part, les filtres basés propriété ne sont pas recommandés ici. RainerScript prend en charge les expressions régulières avec les fonctions spécialiséesre_match()etre_extract().Exemple 20.3. Filtres basés Expression
L'expression suivante contient deux conditions imbriquées. Les fichiers journaux créés par un programme nommé prog1 sont divisés en deux fichiers basés sur la présence de la chaîne « test » dans le message.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
20.2.2. Actions
- Enregistrer des messages syslog dans les fichiers journaux
- La majorité des actions spécifient le fichier journal sur lequel un message syslog est enregistré. Ceci peut être effectué en spécifiant un chemin de fichier après le sélecteur défini au préalable :
FILTER PATH
FILTER PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow où FILTER correspond au sélecteur spécifié par l'utilisateur et PATH est le chemin d'un fichier cible.Par exemple, la règle suivante comprend un sélecteur, qui sélectionne tous les messages syslog cron et une action qui les enregistre sans le fichier journal/var/log/cron.log:cron.* /var/log/cron.log
cron.* /var/log/cron.logCopy to Clipboard Copied! Toggle word wrap Toggle overflow Par défaut, le fichier journal est synchronisé chaque fois qu'un message syslog est généré. Utilisez un tiret (-) comme préfixe du chemin du fichier que vous spécifiez pour omettre la synchronisation :FILTER -PATH
FILTER -PATHCopy to Clipboard Copied! Toggle word wrap Toggle overflow Remarquez que vous pourriez perdre des informations si le système quitte juste après une tentative d'écriture. Cependant ce paramètre peut améliorer les performances, particulièrement si vous exécutez des programmes produisant des messages de journaux très détaillés.Le chemin du fichier spécifié peut être statique ou dynamique. Les fichiers statiques sont représentés par un chemin de fichier fixe, comme décrit dans l'exemple ci-dessus. Des chemins de fichier dynamiques peuvent être différents en fonction du message reçu. Les chemins de fichiers dynamiques sont représentés par un modèle et un point d'interrogation (?) comme préfixe :FILTER ?DynamicFile
FILTER ?DynamicFileCopy to Clipboard Copied! Toggle word wrap Toggle overflow où DynamicFile est le nom d'un modèle prédéfini qui modifie les chemins de sortie. Il est possible d'utiliser un tiret (-) comme préfixe pour désactiver la synchronisation. Il est également possible d'utiliser de multiples modèles séparés par un point-virgule (;). Pour obtenir davantage d'informations sur les modèles, veuillez consulter la section intitulée « Générer des noms de fichiers dynamiques ».Pendant l'utilisation du système X Window, si le fichier spécifié est un terminal ou un périphérique/dev/console, des messages syslog seront envoyés respectivement dans la sortie standard (à l'aide d'une gestion spéciale du terminal), ou dans la console (à l'aide d'une gestion spéciale de/dev/console). - Envoyer des messages syslog sur le réseau
- rsyslog permet d'envoyer et de recevoir des messages syslog sur le réseau. Cette fonctionnalité permet d'administrer des messages syslog d'hôtes multiples sur une seule machine. Pour transférer des messages syslog sur une machine distante, veuillez utiliser la syntaxe suivante :
@[(zNUMBER)]HOST:[PORT]
@[(zNUMBER)]HOST:[PORT]Copy to Clipboard Copied! Toggle word wrap Toggle overflow où :- Le caractère arobase (
@) indique que les messages syslog sont transférés sur un hôte utilisant le protocoleUDP. Pour utiliser le protocoleTCP, utilisez deux caractères arobase sans les espacer (@@). - Le paramètre optionnel
zNUMBERactive la compression zlib des messages syslog. L'attribut NUMBER spécifie le niveau de compression (de 1 – le plus bas à 9 – maximum). Le gain de compression est automatiquement vérifié parrsyslogd, les messages sont uniquement compressés s'il y a un gain de compression et les messages faisant moins de 60 octets ne sont jamais compressés. - L'attribut HOST spécifie l'hôte qui reçoit les messages syslog sélectionnés.
- L'attribut PORT spécifie le port de la machine hôte.
Lors de la spécification d'une adresseIPv6en tant qu'hôte, veuillez ajouter l'adresse entre crochets ([,]).Exemple 20.4. Envoyer des messages syslog sur le réseau
Ci-dessous figurent quelques exemples d'actions qui transfèrent des messages syslog sur le réseau (remarquez que toutes les actions sont précédées d'un sélecteur qui sélectionne tous les messages prioritaires). Pour transférer des messages sur192.168.0.1via le protocoleUDP, veuillez saisir :*.* @192.168.0.1
*.* @192.168.0.1Copy to Clipboard Copied! Toggle word wrap Toggle overflow Pour transférer des messages sur « example.com » en utilisant le port 6514 et le protocoleTCP, veuillez utiliser :*.* @@example.com:6514
*.* @@example.com:6514Copy to Clipboard Copied! Toggle word wrap Toggle overflow La commande ci-dessous compresse les messages avec zlib (compression de niveau 9) et les transfère vers2001:db8::1en utilisant le protocoleUDP*.* @(z9)[2001:db8::1]
*.* @(z9)[2001:db8::1]Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Canaux de sortie
- Les canaux de sortie sont principalement utilisés pour spécifier la taille maximum qu'un fichier journal peut faire. Ceci est particulièrement utile lors des rotations de fichiers journaux (pour obtenir davantage d'informations, veuillez consulter la Section 20.2.5, « Rotation de journaux »). Un canal de sortie est une collection d'informations sur l'action de sortie. Les canaux de sortie sont définis par la directive
$outchannel. Pour définir un canal de sortie dans/etc/rsyslog.conf, veuillez utiliser la syntaxe suivante :$outchannel NAME, FILE_NAME, MAX_SIZE, ACTION
$outchannel NAME, FILE_NAME, MAX_SIZE, ACTIONCopy to Clipboard Copied! Toggle word wrap Toggle overflow où :- L'attribut NAME spécifie le nom du canal de sortie.
- L'attribut FILE_NAME spécifie le nom du fichier de sortie. Les canaux de sortie peuvent uniquement écrire dans des fichiers, et non dans les tubes, dans un terminal ou dans tout autre type de sortie.
- L'attribut MAX_SIZE représente la taille maximale que le fichier spécifié (dans FILE_NAME) peut faire. Cette valeur est spécifiée en octets.
- L'attribut ACTION spécifie l'action qui est prise lorsque la taille maximale, définie dans MAX_SIZE, est atteinte.
Pour utiliser la canal de sortie défini comme action à l'intérieur d'une règle, veuillez saisir :FILTER :omfile:$NAME
FILTER :omfile:$NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow Exemple 20.5. Rotation du journal d'un canal de sortie
La sortie suivante affiche une simple rotation de journal à travers l'utilisation d'un canal de sortie. Avant tout, le canal est défini via la directive$outchannel:$outchannel log_rotation, /var/log/test_log.log, 104857600, /home/joe/log_rotation_script
$outchannel log_rotation, /var/log/test_log.log, 104857600, /home/joe/log_rotation_scriptCopy to Clipboard Copied! Toggle word wrap Toggle overflow puis, il est utilisé dans une règle qui sélectionne chaque message syslog avec une priorité, et exécute le canal de sortie défini au préalable sur les messages syslog acquis :*.* :omfile:$log_rotation
*.* :omfile:$log_rotationCopy to Clipboard Copied! Toggle word wrap Toggle overflow Une fois la limite atteinte (dans l'exemple100 Mo),/home/joe/log_rotation_scriptest exécuté. Ce script peut contenir une instruction souhaitée, que ce soit de déplacer le fichier dans un autre répertoire, modifier un contenu particulier, ou simplement le supprimer. - Envoyer des messages syslog à des utilisateurs particuliers
- rsyslog peut envoyer des messages syslog à des utilisateurs particuliers en spécifiant le nom d'utilisateur de l'utilisateur auquel vous souhaitez envoyer les messages (comme décrit dans l'Exemple 20.7, « Spécifier de multiples actions »). Pour spécifier plus d'un utilisateur, séparez chaque nom d'utilisateur par une virgule (
,). Pour envoyer des messages à chaque utilisateur actuellement connecté, veuillez ajouter un astérisque (*). - Exécuter un programme
- rsyslog permet d'exécuter un programme pour les messages syslog sélectionnés et utilise l'appel
system()pour exécuter le programme dans un shell. Pour spécifier l'exécution d'un programme, ajoutez un préfixe avec le caractère caret (^). Par conséquent, spécifiez un modèle qui formate le message reçu et le passe à l'exécutable spécifié en tant que paramètre sur une seule ligne (pour obtenir davantage d'informations sur les modèles, veuillez consulter la Section 20.2.3, « Modèles »).FILTER ^EXECUTABLE; TEMPLATE
FILTER ^EXECUTABLE; TEMPLATECopy to Clipboard Copied! Toggle word wrap Toggle overflow Ici, une sortie de la condition FILTER est traitée par un programme représenté par EXECUTABLE. Ce programme peut être n'importe quel exécutable valide. Remplacez TEMPLATE par le nom du modèle de formatage.Exemple 20.6. Exécuter un programme
Dans l'exemple suivante, tout message syslog avec une priorité est sélectionné, formaté avec le modèletemplateet passé en tant que paramètre sur le programme test-program, qui est ensuite exécuté avec le paramètre fourni :*.* ^test-program;template
*.* ^test-program;templateCopy to Clipboard Copied! Toggle word wrap Toggle overflow Avertissement
Lorsque vous acceptez des messages d'un hôte, et que vous utilisez l'action « shell execute », vous pouvez être vulnérable à une injection de commande. Un attaquant peut tenter d'injecter et d'exécuter des commandes dans le programme dont vous avez spécifié l'exécution dans votre action. Pour éviter toute menace de sécurité possible, considérez bien l'utilisation de l'action « shell execute ». - Stocker les messages syslog dans une base de données
- Les messages syslog sélectionnés peuvent être écrits directement dans une table de base de données en utilisant l'action d'écriture sur base de données « database writer ». L'écriture sur base de données utilise la syntaxe suivante :
:PLUGIN:DB_HOST,DB_NAME,DB_USER,DB_PASSWORD;[TEMPLATE]
:PLUGIN:DB_HOST,DB_NAME,DB_USER,DB_PASSWORD;[TEMPLATE]Copy to Clipboard Copied! Toggle word wrap Toggle overflow où :- PLUGIN appelle le greffon spécifié qui gère l'écriture sur la base de données (par exemple, le greffon
ommysql). - L'attribut DB_HOST spécifie le nom d'hôte de la base de données.
- L'attribut DB_NAME spécifie le nom de la base de données.
- L'attribut DB_USER spécifie l'utilisateur de la base de données.
- L'attribut DB_PASSWORD spécifie le mot de passe utilisé avec l'utilisateur de la base de données susmentionné.
- L'attribut TEMPLATE spécifie une utilisation optionnelle d'un modèle qui modifie le message syslog. Pour obtenir davantage d'informations sur les modèles, veuillez consulter la Section 20.2.3, « Modèles ».
Important
Actuellement, rsyslog fournit uniquement la prise en charge des bases de donnéesMySQLetPostgreSQL. Pour utiliser les fonctionnalités d'écriture sur base de données deMySQLetPostgreSQL, veuillez installer les paquets rsyslog-mysql et rsyslog-pgsql, respectivement. Veuillez également vous assurez de charger les modules appropriés dans votre fichier de configuration/etc/rsyslog.conf:$ModLoad ommysql # Output module for MySQL support $ModLoad ompgsql # Output module for PostgreSQL support
$ModLoad ommysql # Output module for MySQL support $ModLoad ompgsql # Output module for PostgreSQL supportCopy to Clipboard Copied! Toggle word wrap Toggle overflow Pour obtenir davantage d'informations sur les modules rsyslog, veuillez consulter la Section 20.6, « Utiliser des modules Rsyslog ».Alternativement, vous pouvez utiliser une interface de base de données générique fournie par le moduleomlibdb(prise en charge : Firebird/Interbase, MS SQL, Sybase, SQLLite, Ingres, Oracle, mSQL). - Abandonner des messages syslog
- Pour abandonner les messages sélectionnés, veuillez utiliser le caractère tilde (
~).FILTER ~
FILTER ~Copy to Clipboard Copied! Toggle word wrap Toggle overflow L'action « discard » est principalement utilisée pour filtrer les messages avant de continuer à les traiter. Celle-ci peut être efficace si vous souhaitez omettre certains message répétitifs qui auraient rempli les fichiers journaux. Les résultats de l'action discard dépendent de l'endroit où elle se trouve dans le fichier de configuration. Pour de meilleurs résultats, veuillez placer ces actions tout en haut de la liste des actions. Veuillez remarquer qu'une fois qu'un message a été abandonné, il est impossible de le récupérer dans les lignes suivantes du fichier de configuration.Par exemple, la règle suivante abandonne tout message syslog cron :cron.* ~
cron.* ~Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Spécifier de multiples actions
FILTER ACTION & ACTION & ACTION
FILTER ACTION
& ACTION
& ACTIONExemple 20.7. Spécifier de multiples actions
crit) sont envoyés à l'utilisateur user1, traités par le modèle temp et passés sur l'exécutable test-program, puis transférés sur 192.168.0.1 via le protocole UDP.
kern.=crit user1 & ^test-program;temp & @192.168.0.1
kern.=crit user1
& ^test-program;temp
& @192.168.0.1
;) et spécifiez le nom du modèle. Pour obtenir davantage d'informations sur les modèles, veuillez consulter la Section 20.2.3, « Modèles ».
Avertissement
/etc/rsyslog.conf.
20.2.3. Modèles
/etc/rsyslog.conf :
$template TEMPLATE_NAME,"text %PROPERTY% more text", [OPTION]
$template TEMPLATE_NAME,"text %PROPERTY% more text", [OPTION]$templateest la directive du modèle indiquant que le texte la suivant définit un modèle.TEMPLATE_NAMEest le nom du modèle. Utilisez ce nom pour faire référence au modèle.- Tout ce qui se trouve entre deux guillemets (
"…") fait partie du texte du modèle. Avec ce texte, des caractères spéciaux, tels que\npour une nouvelle ligne, ou\rpour un retour chariot, peuvent être utilisés. d'autres caractères, tels que%ou", doivent être échappés si vous souhaitez utiliser ces caractères de manière litérale. - Tout texte se trouvant entre deux caractères de pourcentage (
%) indique une propriété vous permettant d'accéder au contenu particulier d'un message syslog. Pour obtenir davantage d'informations sur les propriétés, veuillez consulter la section intitulée « Propriétés ». - L'attribut
OPTIONspécifie une option qui modifie la fonctionnalité du modèle. Les options de modèle actuellement prises en charge incluentsqletstdsql, qui sont utilisées pour formater le texte en tant que requête SQL.Note
Remarquez que le programme d'écriture sur base de données vérifie si les optionssqloustdsqlsont spécifiées dans le modèle. Si ce n'est pas le cas, le programme d'écriture sur base de données n'effectuera aucune action. Cela permet d'empêcher toute menace de sécurité, comme les injections SQL.Veuillez consulter la section Stocker des messages syslog dans une base de donneés dans Section 20.2.2, « Actions » pour obtenir davantage d'informations.
Générer des noms de fichiers dynamiques
timegenerated, qui extrait un horodatage du message pour générer un nom de fichier unique pour chaque message syslog :
$template DynamicFile,"/var/log/test_logs/%timegenerated%-test.log"
$template DynamicFile,"/var/log/test_logs/%timegenerated%-test.log"$template indique uniquement le modèle. Vous devez l'utiliser dans une règle pour qu'elle puisse entrer en vigueur. Dans le fichier /etc/rsyslog.conf, utilisez le point d'interrogation (?) dans une définition d'action pour marquer le modèle du nom de fichier dynamique :
*.* ?DynamicFile
*.* ?DynamicFilePropriétés
%) permettent l'accès à divers contenus d'un message syslog par l'utilisation d'un remplaçant de propriété (property replacer). Pour définir une propriété située dans un modèle (entre les deux guillemets ("…"), veuillez utiliser la syntaxe suivante :
%PROPERTY_NAME[:FROM_CHAR:TO_CHAR:OPTION]%
%PROPERTY_NAME[:FROM_CHAR:TO_CHAR:OPTION]%- L'attribut PROPERTY_NAME spécifie le nom de la propriété. Une liste de toutes les propriétés disponibles et leur description détaillée peut être trouvée dans la page man de
rsyslog.conf(5)sous la section Propriétés disponibles. - Les attributs FROM_CHAR et TO_CHAR dénotent une gamme de caractères qui déclencheront une réaction de la part de la propriété spécifiée. Alternativement, des expressions régulières peuvent être utilisées pour spécifier une gamme de caractères. Pour effectuer cela, paramétrez la lettre
Rcomme attribut FROM_CHAR et spécifiez l'expression régulière souhaitée comme attribut TO_CHAR. - L'attribut OPTION spécifie toute option de propriété, comme l'option
lowercase, qui permet de convertir l'entrée en minuscules. Une liste de toutes les options des propriétés disponibles et leur description détaillée se trouve dans la page manrsyslog.conf(5), sous la section Options des propriétés.
- La propriété ci-dessous obtient le texte du message complet d'un message syslog :
%msg%
%msg%Copy to Clipboard Copied! Toggle word wrap Toggle overflow - La propriété ci-dessous obtient les deux premiers caractères du texte d'un message syslog :
%msg:1:2%
%msg:1:2%Copy to Clipboard Copied! Toggle word wrap Toggle overflow - La propriété ci-dessous obtient le texte du message complet d'un message syslog et abandonne le dernier caractère de saut de ligne :
%msg:::drop-last-lf%
%msg:::drop-last-lf%Copy to Clipboard Copied! Toggle word wrap Toggle overflow - La propriété suivante obtient les 10 premiers caractères de l'horodatage généré lorsque le message syslog est reçu et le formate en fonction du standard de date RFC 3999.
%timegenerated:1:10:date-rfc3339%
%timegenerated:1:10:date-rfc3339%Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Exemples de modèles
Exemple 20.8. Un modèle de message syslog détaillé
$template verbose, "%syslogseverity%, %syslogfacility%, %timegenerated%, %HOSTNAME%, %syslogtag%, %msg%\n"
$template verbose, "%syslogseverity%, %syslogfacility%, %timegenerated%, %HOSTNAME%, %syslogtag%, %msg%\n"mesg(1) est paramétrée sur yes). Ce modèle inclut le texte du message dans sa sortie, ainsi qu'un nom d'hôte, une balise de message et un horodatage sur une nouvelle ligne (en utilisant \r et \n, et émet un son (en utilisant \7).
Exemple 20.9. Modèle de message « wall »
$template wallmsg,"\r\n\7Message from syslogd@%HOSTNAME% at %timegenerated% ...\r\n %syslogtag% %msg%\n\r"
$template wallmsg,"\r\n\7Message from syslogd@%HOSTNAME% at %timegenerated% ...\r\n %syslogtag% %msg%\n\r"sql à la fin du modèle spécifié en tant qu'option de modèle. Elle indique au programme d'écriture sur base de données de formater le message en tant que requête SQL MySQL.
Exemple 20.10. Modèle de message formaté base de données
$template dbFormat,"insert into SystemEvents (Message, Facility, FromHost, Priority, DeviceReportedTime, ReceivedAt, InfoUnitID, SysLogTag) values ('%msg%', %syslogfacility%, '%HOSTNAME%', %syslogpriority%, '%timereported:::date-mysql%', '%timegenerated:::date-mysql%', %iut%, '%syslogtag%')", sql
$template dbFormat,"insert into SystemEvents (Message, Facility, FromHost, Priority, DeviceReportedTime, ReceivedAt, InfoUnitID, SysLogTag) values ('%msg%', %syslogfacility%, '%HOSTNAME%', %syslogpriority%, '%timereported:::date-mysql%', '%timegenerated:::date-mysql%', %iut%, '%syslogtag%')", sqlRSYSLOG_. Ceux-ci sont réservés à l'utilisation de syslog et il est recommandé de ne pas créer de modèle en utilisant ce préfixe afin d'éviter les conflits. Ci-dessous figure une liste de ces modèles prédéfinis ainsi que leurs définitions.
RSYSLOG_DebugFormat- Format spécial utilisé pour résoudre les problèmes de propriétés.
"Debug line with all properties:\nFROMHOST: '%FROMHOST%', fromhost-ip: '%fromhost-ip%', HOSTNAME: '%HOSTNAME%', PRI: %PRI%,\nsyslogtag '%syslogtag%', programname: '%programname%', APP-NAME: '%APP-NAME%', PROCID: '%PROCID%', MSGID: '%MSGID%',\nTIMESTAMP: '%TIMESTAMP%', STRUCTURED-DATA: '%STRUCTURED-DATA%',\nmsg: '%msg%'\nescaped msg: '%msg:::drop-cc%'\nrawmsg: '%rawmsg%'\n\n\"
"Debug line with all properties:\nFROMHOST: '%FROMHOST%', fromhost-ip: '%fromhost-ip%', HOSTNAME: '%HOSTNAME%', PRI: %PRI%,\nsyslogtag '%syslogtag%', programname: '%programname%', APP-NAME: '%APP-NAME%', PROCID: '%PROCID%', MSGID: '%MSGID%',\nTIMESTAMP: '%TIMESTAMP%', STRUCTURED-DATA: '%STRUCTURED-DATA%',\nmsg: '%msg%'\nescaped msg: '%msg:::drop-cc%'\nrawmsg: '%rawmsg%'\n\n\"Copy to Clipboard Copied! Toggle word wrap Toggle overflow RSYSLOG_SyslogProtocol23Format- Format spécifié sur IETF internet-draft ietf-syslog-protocol-23, qui est supposé devenir le nouveau standard RFC de syslog.
"%PRI%1 %TIMESTAMP:::date-rfc3339% %HOSTNAME% %APP-NAME% %PROCID% %MSGID% %STRUCTURED-DATA% %msg%\n\"
"%PRI%1 %TIMESTAMP:::date-rfc3339% %HOSTNAME% %APP-NAME% %PROCID% %MSGID% %STRUCTURED-DATA% %msg%\n\"Copy to Clipboard Copied! Toggle word wrap Toggle overflow RSYSLOG_FileFormat- Format logfile moderne similaire à TraditionalFileFormat, mais avec un horodatage de haute précision et des informations sur les fuseaux horaires.
"%TIMESTAMP:::date-rfc3339% %HOSTNAME% %syslogtag%%msg:::sp-if-no-1st-sp%%msg:::drop-last-lf%\n\"
"%TIMESTAMP:::date-rfc3339% %HOSTNAME% %syslogtag%%msg:::sp-if-no-1st-sp%%msg:::drop-last-lf%\n\"Copy to Clipboard Copied! Toggle word wrap Toggle overflow RSYSLOG_TraditionalFileFormat- Ancien format de fichier journal par défaut avec un horodatage peu précis.
"%TIMESTAMP% %HOSTNAME% %syslogtag%%msg:::sp-if-no-1st-sp%%msg:::drop-last-lf%\n\"
"%TIMESTAMP% %HOSTNAME% %syslogtag%%msg:::sp-if-no-1st-sp%%msg:::drop-last-lf%\n\"Copy to Clipboard Copied! Toggle word wrap Toggle overflow RSYSLOG_ForwardFormat- Format de transfert avec horodatage de haute précision et informations sur les fuseaux horaires.
"%PRI%%TIMESTAMP:::date-rfc3339% %HOSTNAME% %syslogtag:1:32%%msg:::sp-if-no-1st-sp%%msg%\"
"%PRI%%TIMESTAMP:::date-rfc3339% %HOSTNAME% %syslogtag:1:32%%msg:::sp-if-no-1st-sp%%msg%\"Copy to Clipboard Copied! Toggle word wrap Toggle overflow RSYSLOG_TraditionalForwardFormat- Format de transfert traditionnel avec un horodatage peu précis.
"%PRI%%TIMESTAMP% %HOSTNAME% %syslogtag:1:32%%msg:::sp-if-no-1st-sp%%msg%\"
"%PRI%%TIMESTAMP% %HOSTNAME% %syslogtag:1:32%%msg:::sp-if-no-1st-sp%%msg%\"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
20.2.4. Directives globales
rsyslogd. Elles indiquent habituellement la valeur d'une variable prédéfinie qui affecte le comportement du démon rsyslogd ou une règle qui suit. Toutes les directives globales doivent commencer par le caractère du dollar ($). Une seule directive peut être spécifiée sur chaque ligne. Ci-dessous figure un exemple de directive globale qui spécifie la taille maximale de la file d'attente des messages syslog :
$MainMsgQueueSize 50000
$MainMsgQueueSize 50000
10,000 messages) peut être outrepassée en spécifiant une valeur différente (comme montré dans l'exemple ci-dessus).
/etc/rsyslog.conf. Une directive affecte le comportement de toutes les options de configuration jusqu'à ce qu'une autre occurrence de cette même directive soit détectée. Les directives globales peuvent être utilisées pour configurer des actions, des files d'attente, et pour le débogage. Une liste complète des toutes les directives de configuration disponibles se trouve dans la section intitulée « Documentation en ligne ». Actuellement, un nouveau format de configuration a été développé pour remplacer la syntaxe basée $ (veuillez consulter la Section 20.3, « Utiliser le nouveau format de configuration »). Cependant, les directives globales classiques sont toujours prises en charge comme format hérité.
20.2.5. Rotation de journaux
/etc/logrotate.conf :
.gz. Toute ligne commençant par le caractère dièse (#) est un commentaire et ne sera donc pas traité.
/etc/logrotate.d/ et d'y définir les options de configuration souhaitées.
/etc/logrotate.d/ :
/var/log/messages. Les paramètres spécifiés ici outrepassent les paramètres globaux lorsque possible. Ainsi, le fichier journal rotatif /var/log/messages sera conservé pendant cinq semaines au lieu des quatre semaines définies dans les options globales.
weekly— spécifie la rotation hebdomadaire des fichiers journaux à effectuer. Les directives similaires incluent :dailymonthlyyearly
compress— active la compression des fichiers journaux dont la rotation a été effectuée. Les directives similaires incluent :nocompresscompresscmd— spécifie la commande à utiliser pour la compression.uncompresscmdcompressext— spécifie quelle extension doit être utilisée pour la compression.compressoptions— permet de spécifier toute option pouvant être passée au programme de compression utilisé.delaycompress— reporte la compression des fichiers journaux jusqu'à la prochaine rotation des fichiers journaux.
rotate INTEGER— spécifie le nombre de rotations qu'un fichier journal effectue avant d'être supprimé ou envoyé à une adresse spécifique. Si la valeur0est spécifiée, les anciens fichiers journaux sont supprimés au lieu d'être mis en rotation.mail ADDRESS— cette option active l'envoi vers une adresse spécifiée pour les fichiers journaux qui ont été mis en rotation le nombre de fois défini par la directiverotate. Directives similaires :nomailmailfirst— indique que seuls les fichiers journaux qui viennent d'effectuer une rotation doivent être envoyés, au lieu d'envoyer les fichiers journaux sur le point d'expirer.maillast— spécifie que les fichiers journaux sur le point d'expirer doivent être envoyés, au lieu d'envoyer les fichiers journaux qui viennent d'effectuer une rotation. Cette option est utilisée par défaut lorsquemailest activé.
logrotate(5).
20.3. Utiliser le nouveau format de configuration
/etc/rsyslog.conf.
input() et ruleset(), qui permettent au fichier de configuration /etc/rsyslog.conf d'être écrit sous le nouveau style uniquement. La différence avec la nouvelle syntaxe, c'est qu'elle est plus structurée ; les paramètres sont passés sous forme d'arguments aux déclarations, telles que les entrées, les actions, les modèles et les chargements de modules. L'étendue des options est réduite en blocs. Cela améliore la lisibilité et diminue le nombre de bogues causés par les problèmes de configuration. Il y a également une amélioration de performance importante. Certaines fonctionnalités sont dans les deux syntaxes, certaines dans une seule.
$InputFileName /tmp/inputfile $InputFileTag tag1: $InputFileStateFile inputfile-state $InputRunFileMonitor
$InputFileName /tmp/inputfile
$InputFileTag tag1:
$InputFileStateFile inputfile-state
$InputRunFileMonitor
input(type="imfile" file="/tmp/inputfile" tag="tag1:" statefile="inputfile-state")
input(type="imfile" file="/tmp/inputfile" tag="tag1:" statefile="inputfile-state")
20.3.1. Rulesets
/etc/rsyslog.conf écrit de manière traditionnelle, toutes les règles sont évaluées dans leur ordre d'apparition pour chaque message d'entrée. Ce processus est lancé avec la première règle et continue jusqu'à ce que toutes les règles soient traitées ou jusqu'à ce que le message soit rejeté par l'une des règles.
/etc/rsyslog.conf ressemblera à ceci :
$RuleSet rulesetname rule rule2
$RuleSet rulesetname
rule
rule2$RuleSet RSYSLOG_DefaultRuleset
$RuleSet RSYSLOG_DefaultRulesetinput() et ruleset() sont réservées à cette opération. Le nouveau format de la définition du ruleset de /etc/rsyslog.conf ressemble à ceci :
RSYSLOG_ car l'utilisation de cet espace nom est réservé à rsyslog. RSYSLOG_DefaultRuleset définit ensuite un ensemble de règles à effectuer si aucun autre ruleset n'est assigné au message. Avec rule et rule2, vous pouvez définir les règles sous le format de filtrage d'actions mentionné ci-dessus. Avec le paramètre call, vous pouvez imbriquer des rulesets en les appelant à partir d'autres blocs de rulesets.
input(type="input_type" port="port_num" ruleset="rulesetname");
input(type="input_type" port="port_num" ruleset="rulesetname");input(). Remplacez rulesetname par le nom du ruleset devant être évalué avec le message. Au cas où un message d'entrée n'est pas explicitement limité à un ruleset, le ruleset par défaut est déclenché.
Exemple 20.11. Utiliser des rulesets
/etc/rsyslog.conf :
601, les messages sont triés selon la fonctionnalité. Puis, l'entrée TCP est activée et elle est limitée aux rulesets. Remarquez que vous devez charger les modules requis (imtcp) pour que cette configuration fonctionne.
20.3.2. Compatibilité avec sysklogd
-c existe en rsyslog version 5, mais pas en version 7. Les options de ligne de commande de style sysklogd sont dépréciées et la configuration de rsyslog à l'aide de ces options de ligne de commande doit être évitée. Cependant, vous pouvez utiliser plusieurs modèles et directives pour configurer rsyslogd afin d'émuler un comportement similaire à sysklogd.
rsyslogd, veuillez consulter la page man de rsyslogd(8).
20.4. Utiliser des files d'attente dans Rsyslog
Figure 20.1. Flux de messages dans Rsyslog
/etc/rsyslog.conf sont appliquées. Basé sur ces règles, le processeur de règles évalue quelles sont les actions devant être effectuées. Chaque action possède sa propre file d'attente d'actions. Les messages sont transférés à travers cette file vers le processeur d'action respectif, qui créera la sortie finale. Remarquez qu'à ce moment, plusieurs actions peuvent être exécutées simultanément sur un seul message. Dans ce but précis, un message est dupliqué et transféré vers de multiples processeurs d'actions.
- elles servent de tampon, découplant les producteurs et consommateurs dans la structure de rsyslog
- elles permettent la parallélisation des actions effectués sur des messages
Avertissement
SSH, ce qui peut ensuite interdire l'accès SSH. Il est donc recommandé d'utiliser des files d'actions dédiées pour les sorties transférées à travers un réseau ou une base de données.
20.4.1. Définir des files d'attente
/etc/rsyslog.conf :
$objectQueueType queue_type
$objectQueueType queue_typeMainMsg) ou pour une file d'actions (remplacez object par Action). Remplacez queue_type par direct, linkedlist ou fixedarray (qui sont des files en mémoire), ou par disk.
Files « Direct »
$objectQueueType Direct
$objectQueueType DirectMainMsg ou par Action pour utiliser cette option sur la file de messages principale ou pour une file d'actions, respectivement. Avec une file « Direct », les messages sont immédiatement et directement transférés du producteur au consommateur.
Files « Disk »
/etc/rsyslog.conf :
$objectQueueType Disk
$objectQueueType DiskMainMsg ou par Action pour utiliser cette option pour la file de messages principale ou pour une file d'actions, respectivement. Les files « Disk » sont écrites sur différentes parties, avec une taille par défaut de 10 Mo. Cette taille par défaut peut être modifiée avec la directive de configuration suivante :
$objectQueueMaxFileSize size
$objectQueueMaxFileSize size$objectQueueFilename name
$objectQueueFilename nameFiles « In-memory »
$ActionQueueSaveOnShutdown pour enregistrer les données avant la fermeture. Il existe deux types de files en mémoire :
- La file FixedArray — mode par défaut de la file de messages principale, avec une limite de 10,000 éléments. Ce type de file utilise une matrice fixée, pré-allouée qui contient des pointeurs vers des éléments de files d'attente. À cause de ces pointeurs, même si la file est vide, une bonne quantité de mémoire est utilisée. Cependant, FixedArray offre des meilleures performances de temps d'activité et est optimal lorsque vous vous attendez à un nombre relativement faible de messages en file d'attente et à des performances élevées.
- File LinkedList — ici, toutes les structures sont allouées dynamiquement dans une liste liée. Ainsi, la mémoire est uniquement allouée lorsque nécessaire. Les files LinkedList gèrent également très bien les rafales occasionnelles de messages.
$objectQueueType LinkedList
$objectQueueType LinkedList$objectQueueType FixedArray
$objectQueueType FixedArrayMainMsg ou par Action pour utiliser cette option sur la file de messages principale ou la file d'actions, respectivement.
Files « Disk-Assisted In-memory »
$objectQueueFileName pour définir un nom de fichier pour l'assistance disque. Cette file deviendra ainsi une file assistée par disque, ce qui signifie qu'une file en mémoire est combinée à une file de disque et celles-ci fonctionneront en tandem.
$objectQueueHighWatermark number
$objectQueueHighWatermark number$objectQueueLowWatermark number
$objectQueueLowWatermark numberMainMsg ou par Action pour utiliser cette option pour la file de messages principale ou pour une file d'actions, respectivement. Remplacez number par le nombre de messages mis en file d'attente. Lorsqu'une file en mémoire atteint le nombre défini par le filigrane du haut, les messages commencent à être écrits sur le disque et cela continue jusqu'à ce que la taille de la file en mémoire passe sous le nombre défini par le filigrane du bas. La définition correcte des filigranes minimise les écritures sur disque non nécessaires, mais cela laisse également de l'espace mémoire pour les rafales de messages, puisque l'écriture sur fichiers de disque est relativement longue. Ainsi, le filigrane du haut doit être plus bas que la totalité de la capacité de la file définie avec $objectQueueSize. La différence entre le filigrane du haut et la taille de la file en général est un tampon de mémoire supplémentaire réservé aux rafales de message. D'autre part, définir le filigrane du haut trop bas activera l'assistance par disque trop souvent.
Exemple 20.12. Transférer des messages journaux sur un serveur de manière fiable
UDP.
Procédure 20.1. Effectuer un transfert sur un seul serveur
- Veuillez utiliser la configuration suivante dans
/etc/rsyslog.confou créez un fichier avec le contenu suivant dans le répertoire/etc/rsyslog.d/:$ActionQueueType LinkedList $ActionQueueFileName example_fwd $ActionResumeRetryCount -1 $ActionQueueSaveOnShutdown on *.* @@example.com:6514
$ActionQueueType LinkedList $ActionQueueFileName example_fwd $ActionResumeRetryCount -1 $ActionQueueSaveOnShutdown on *.* @@example.com:6514Copy to Clipboard Copied! Toggle word wrap Toggle overflow Où :$ActionQueueTypeactive une file en mémoire LinkedList,$ActionFileNamedéfinit un stockage sur disque. Dans ce cas, les fichiers de sauvegarde sont créés dans le répertoire/var/lib/rsyslog/avec le préfixe example_fwd,- le paramètre
$ActionResumeRetryCount -1empêche rsyslog d'abandonner des messages lorsqu'il essaie de se connecter à nouveau si le serveur ne répond pas, $ActionQueueSaveOnShutdownactivé enregistre les données en mémoire si rsyslog s'éteint,- la dernière ligne transfère tous les messages reçus au serveur d'enregistrement, la spécification de port est optionnelle.
Avec la configuration ci-dessus, rsyslog conserve les messages en mémoire si le serveur distant n'est pas joignable. Un fichier sur disque est uniquement créé si rsyslog ne possède plus d'espace configuré de file d'attente en mémoire ou s'il doit s'éteindre, ce qui profite aux performances système.
Procédure 20.2. Effectuer un transfert vers plusieurs serveurs
- Chaque serveur destinataire requiert une règle de transfert séparée, une spécification de file d'actions séparée, et un fichier de sauvegarde sur disque séparé. Par exemple, veuillez utiliser la configuration suivante dans
/etc/rsyslog.confou créez un fichier avec le contenu suivant dans le répertoire/etc/rsyslog.d/:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
20.4.2. Créez un nouveau répertoire pour les fichiers de journalisation rsyslog
syslogd et est géré par SELinux. De ce fait, tous les fichiers dans lesquels rsyslog écrit doivent posséder le contexte de fichier SELinux qui convient.
Procédure 20.3. Création d'un nouveau répertoire de travail
- Si vous avez besoin d'un répertoire différent pour stocker les fichiers de travail, créer un répertoire comme suit :
mkdir /rsyslog
~]# mkdir /rsyslogCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Installer les utilitaires requis pour la Stratégie SELinux :
yum install policycoreutils-python
~]# yum install policycoreutils-pythonCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Définir le contexte de répertoire SELinux pour qu'il corresponde à celui du répertoire
/var/lib/rsyslog/:semanage fcontext -a -t syslogd_var_lib_t /rsyslog
~]# semanage fcontext -a -t syslogd_var_lib_t /rsyslogCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Appliquer le contexte SELinux :
restorecon -R -v /rsyslog restorecon reset /rsyslog context unconfined_u:object_r:default_t:s0->unconfined_u:object_r:syslogd_var_lib_t:s0
~]# restorecon -R -v /rsyslog restorecon reset /rsyslog context unconfined_u:object_r:default_t:s0->unconfined_u:object_r:syslogd_var_lib_t:s0Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Si nécessaire, vérifiez le contexte SELinux comme suit :
ls -Zd /rsyslog drwxr-xr-x. root root system_u:object_r:syslogd_var_lib_t:s0 /rsyslog
~]# ls -Zd /rsyslog drwxr-xr-x. root root system_u:object_r:syslogd_var_lib_t:s0 /rsyslogCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Créer des sous-répertoires selon les besoins. Exemple :Les sous-répertoires seront créés avec le même contexte SELinux que le répertoire parent.
mkdir /rsyslog/work/
~]# mkdir /rsyslog/work/Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Ajouter la ligne suivante dans
/etc/rsyslog.confjuste avant qu'elle puisse entrer en vigueur :Ce paramétre demeurera valide jusqu'à ce que l'on rencontre une nouvelle directive de$WorkDirectory /rsyslog/work
$WorkDirectory /rsyslog/workCopy to Clipboard Copied! Toggle word wrap Toggle overflow WorkDirectorylors de l'analyse des fichiers de configuration.
20.4.3. Gestion des files
Limiter la taille de file d'attente
$objectQueueHighWatermark number
$objectQueueHighWatermark numberMainMsg ou par Action pour utiliser cette option pour la file de messages principale ou pour une file d'actions, respectivement. Remplacez nombre par le nombre de messages mis en file d'attente. Vous pouvez uniquement définir la taille de la file en tant que nombre de messages, et non en tant que taille de mémoire. La taille de la file par défaut s'élève à 10,000 messages pour la file de messages principale et les files ruleset, et à 1000 pour les files d'actions.
$objectQueueMaxDiscSpace number
$objectQueueMaxDiscSpace numberMainMsg ou par Action. Lorsque la limite de la taille spécifiée par le nombre est atteinte, les messages sont abandonnés jusqu'à ce que suffisamment d'espace soit libéré par les messages sortis de la file.
Abandonner des messages
$objectQueueDiscardMark number
$objectQueueDiscardMark numberMainMsg ou par Action pour utiliser cette option sur la file de messages principale ou sur une file d'actions, respectivement. Le nombre correspond au nombre de messages qui doit se trouver dans la file pour lancer le processus d'abandon. Pour définir quels messages abandonner, veuillez utiliser :
$objectQueueDiscardSeverity priority
$objectQueueDiscardSeverity prioritydebug (7), info (6), notice (5), warning (4), err (3), crit (2), alert (1), et emerg (0). Avec ce paramètre, les messages entrants et les messages se trouvant déjà en file d'attente avec une priorité plus basse que celle qui est définie, sont effacés de la file dès que la marque d'abandon aura été atteinte.
Utiliser des délais
$objectQueueDequeueTimeBegin hour
$objectQueueDequeueTimeBegin hour$objectQueueDequeueTimeEnd hour
$objectQueueDequeueTimeEnd hourConfigurer les threads de travail
$objectQueueWorkerThreadMinimumMessages number
$objectQueueWorkerThreadMinimumMessages number$objectQueueWorkerThreads number
$objectQueueWorkerThreads number$objectQueueWorkerTimeoutThreadShutdown time
$objectQueueWorkerTimeoutThreadShutdown time-1, aucun thread ne sera fermé.
Retirer un lot de la file
$objectQueueDequeueBatchSize number
$objectQueueDequeueBatchSize numberTerminer des files d'attente
$objectQueueTimeoutShutdown time
$objectQueueTimeoutShutdown time$objectQueueTimeoutActionCompletion time
$objectQueueTimeoutActionCompletion time$objectQueueTimeoutSaveOnShutdown time
$objectQueueTimeoutSaveOnShutdown time20.4.4. Utilisation d'une nouvelle syntaxe pour les files d'attente rsyslog
action() qui peut être utilisé à la fois séparemment ou à l'intérieur d'un ruleset dans /etc/rsyslog.conf. Le format d'une file d'attente d'action ressemble à ce qui suit :
action(type="action_type" queue.size="queue_size" queue.type="queue_type" queue.filename="file_name")
action(type="action_type" queue.size="queue_size" queue.type="queue_type" queue.filename="file_name")disk ou bien, parmi l'une des files d'attente en mémoire : direct, linkedlist ou fixedarray. Pour file_name ne spécifier qu'un nom de fichier, et non pas un chemin. Notez que si vous créez une nouveau répertoire contenant les fichiers de journalisation, le context SELinux devra être défini. Voir un exemple dans Section 20.4.2, « Créez un nouveau répertoire pour les fichiers de journalisation rsyslog ».
Exemple 20.13. Définir une File d'attente d'action
action(type="omfile" queue.size="10000" queue.type="linkedlist" queue.filename="logfile")
action(type="omfile" queue.size="10000" queue.type="linkedlist" queue.filename="logfile")*.* action(type="omfile" file="/var/lib/rsyslog/log_file
)
*.* action(type="omfile" file="/var/lib/rsyslog/log_file
)*.* action(type="omfile"
queue.filename="log_file"
queue.type="linkedlist"
queue.size="10000"
)
*.* action(type="omfile"
queue.filename="log_file"
queue.type="linkedlist"
queue.size="10000"
)global(workDirectory="/directory")
global(workDirectory="/directory")Exemple 20.14. Redirection vers un Serveur unique avec la nouvelle Syntaxe
omfwd est utilisé pour le transfert via UDP ou TCP. La valeur par défaut est UDP. Comme le greffon est intégré, il n'a pas besoin d'être téléchargé.
/etc/rsyslog.conf ou créez un fichier avec le contenu suivant dans le répertoire /etc/rsyslog.d/ :
queue.type="linkedlist"permet d'avoir une file d'attente LinkedList en mémoire,queue.filenamedéfinit un stockage sur disque. Les fichiers de sauvegarde sont créés avec le préfixe example_fwd, dans le répertoire de travail spécifié par la directiveworkDirectoryglobale qui précède,- le paramètre
action.resumeRetryCount -1empêche rsyslog d'abandonner des messages lorsqu'il essaie de se connecter à nouveau si le serveur ne répond pas, queue.saveOnShutdown="on"activé enregistre les données en mémoire si rsyslog s'éteint,- la dernière ligne transfère tous les messages reçus au serveur d'enregistrement, la spécification de port est optionnelle.
20.5. Configurer rsyslog sur un serveur d'enregistrement
rsyslog fournit une installation pour exécuter un serveur d'enregistrement et pour configurer des systèmes individuels pour qu'ils envoient leurs fichiers journaux sur le serveur d'enregistrement. Veuillez consulter Exemple 20.12, « Transférer des messages journaux sur un serveur de manière fiable » pour obtenir des informations sur la configuration rsyslog du client.
rsyslog doit être installé sur le système que vous comptiez utiliser en tant que serveur d'enregistrement et sur tous les systèmes qui seront configurés pour y envoyer leurs journaux. Rsyslog est installé par défaut sur Red Hat Enterprise Linux 7. Si requis, pour vous assurer que c'est bien le cas, veuillez saisir la commande suivante en tant qu'utilisateur root :
yum install rsyslog
~]# yum install rsyslogUDP et 514, comme indiqué dans le fichier /etc/services. Cependant, rsyslog utilise par défaut TCP sur le port 514. Dans le fichier de configuration, /etc/rsyslog.conf, TCP est indiqué par @@.
semanage port -l | grep syslog syslogd_port_t tcp 6514, 601 syslogd_port_t udp 514, 6514, 601
~]# semanage port -l | grep syslog
syslogd_port_t tcp 6514, 601
syslogd_port_t udp 514, 6514, 601semanage est fourni dans le cadre du paquet policycoreutils-python. Si nécessaire, installez le package comme suit :
yum install policycoreutils-python
~]# yum install policycoreutils-pythonrsyslog, rsyslogd_t par défaut est configuré de façon à permettre d'envoyer et de recevoir dans le port de shell distant (rsh) ayant comme type de SELinux rsh_port_t, avec par défaut TCP sur le port 514. De ce fait, vous n'avez pas besoin d'utiliser semanage pour permettre explicitement TCP sur le port 514. Ainsi, pour vérifier ce sur quoi SELinux est défini pour autoriser l'accès au port 514, saisir la commande suivante :
semanage port -l | grep 514sortie omise rsh_port_t tcp 514 syslogd_port_t tcp 6514, 601 syslogd_port_t udp 514, 6514, 601
~]# semanage port -l | grep 514sortie omise
rsh_port_t tcp 514
syslogd_port_t tcp 6514, 601
syslogd_port_t udp 514, 6514, 601root :
Procédure 20.4. Configurez SELinux pour autoriser le trafic rsyslog sur un port
rsyslog, suivez cette procédure sur le serveur de journalisation et sur les clients. Ainsi, pour recevoir et envoyer le trafic TCP sur le port 10514, procédez ainsi :
semanage port -a -t syslogd_port_t -p tcp 10514
~]# semanage port -a -t syslogd_port_t -p tcp 10514Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Vérifiez les ports SELinux en saisissant la commande suivante :
semanage port -l | grep syslog
~]# semanage port -l | grep syslogCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Si le nouveau port était déjà configuré dans
/etc/rsyslog.conf, redémarrezrsyslogmaintenant pour que le changement puisse avoir lieu :service rsyslog restart
~]# service rsyslog restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Vérifiez sur quels ports
rsyslogécoute :netstat -tnlp | grep rsyslog tcp 0 0 0.0.0.0:10514 0.0.0.0:* LISTEN 2528/rsyslogd tcp 0 0 :::10514 :::* LISTEN 2528/rsyslogd
~]# netstat -tnlp | grep rsyslog tcp 0 0 0.0.0.0:10514 0.0.0.0:* LISTEN 2528/rsyslogd tcp 0 0 :::10514 :::* LISTEN 2528/rsyslogdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
semanage-port(8) pour obtenir plus d'informations sur la commande semanage port.
Procédure 20.5. Configurer firewalld
firewalld pour autoriser le trafic rsyslog. Ainsi, pour autoriser le trafic TCP sur le port 10514, procédez ainsi :
firewall-cmd --zone=zone --add-port=10514/tcp success
~]# firewall-cmd --zone=zone --add-port=10514/tcp successCopy to Clipboard Copied! Toggle word wrap Toggle overflow Quand zone correspond à la zone d'interface à utiliser. Veuillez noter que ces changements ne persisteront pas lors d'un nouveau démarrage. Pour rendre les changements au parefeu permanents, répétez la commande an ajoutant l'option--permanent. Pour obtenir davantage d'informations sur l'ouverture et la fermeture des ports defirewalld, veuillez consulter le Guide de sécurité Red Hat Enterprise Linux 7 .- Pour vérifier les paramètres ci-dessus, veuillez utiliser une commande comme suit :
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Procédure 20.6. Configurer rsyslog pour Recevoir et Trier les Messages de journalisation distants
- Ouvrez le fichier
/etc/rsyslog.confdans un éditeur de texte puis procédez comme suit :- Ajoutez ces lignes sous la section des modules mais au-dessus de la section «
Provides UDP syslog reception» (Fournit la réception syslog UDP) :# Define templates before the rules that use them ### Per-Host Templates for Remote Systems ### $template TmplAuthpriv, "/var/log/remote/auth/%HOSTNAME%/%PROGRAMNAME:::secpath-replace%.log" $template TmplMsg, "/var/log/remote/msg/%HOSTNAME%/%PROGRAMNAME:::secpath-replace%.log"
# Define templates before the rules that use them ### Per-Host Templates for Remote Systems ### $template TmplAuthpriv, "/var/log/remote/auth/%HOSTNAME%/%PROGRAMNAME:::secpath-replace%.log" $template TmplMsg, "/var/log/remote/msg/%HOSTNAME%/%PROGRAMNAME:::secpath-replace%.log"Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Remplacez la section par défaut «
Provides TCP syslog reception» par ce qui suit :Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Enregistrez les changements sur le fichier/etc/rsyslog.conf. - Le service
rsyslogdoit être en cours d'exécution sur le serveur d'enregistrement et sur les systèmes tentant de s'y connecter.- Veuillez utiliser la commande
systemctlpour lancer le servicersyslog.systemctl start rsyslog
~]# systemctl start rsyslogCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour vous assurer que le service
rsyslogdémarre automatiquement dans le futur, veuillez saisir la commande suivante en tant qu'utilisateur root :systemctl enable rsyslog
~]# systemctl enable rsyslogCopy to Clipboard Copied! Toggle word wrap Toggle overflow
20.5.1. Utilisation d'une nouvelle Syntaxe pour les Files d'attente rsyslog
20.6. Utiliser des modules Rsyslog
$ModLoad MODULE
$ModLoad MODULE$ModLoad est la directive globale qui charge le module spécifié et MODULE représente le module souhaité. Par exemple, si vous souhaitez charger le module « Text File Input » (imfile) qui permet à rsyslog de convertir tout fichier texte standard en message syslog, spécifiez la ligne suivante dans le fichier de configuration /etc/rsyslog.conf :
$ModLoad imfile
$ModLoad imfile
- Modules d'entrée — les modules d'entrée collectent des messages provenant de différentes sources. Le nom d'un module d'entrée commence toujours par le préfixe
im, commeimfileetimjournal. - Modules de sortie — les modules de sortie offrent la possibilité de remettre un message à différentes cibles, par exemple en l'envoyant à travers un réseau, en le stockant dans une base de données, ou le chiffrant. Le nom d'un module de sortie commence toujours par le préfixe
om, commeomsnmp,omrelp, etc. - Modules d'analyse — ces modules sont utiles à la création de règles d'analyse personnalisées ou pour analyser des messages mal formés. Avec des connaissances modérées du langage de programmation C, il est possible de créer votre propre analyseur de messages. Le nom d'un module d'analyse commence toujours par le préfixe
pm, commepmrfc5424,pmrfc3164, et ainsi de suite. - Modules de modification de messages — les modules de modification de messages changent le contenu des messages syslog. Les noms de ces modules commencent par le préfixe
mm. Les modules de modification de messages commemmanon,mmnormalize, oummjsonparsesont utilisée pour l'anonymisation ou la normalisation des messages. - Modules générateurs de chaînes — les modules générateurs de chaînes génèrent des chaînes basées sur le contenu du message et coopèrent bien avec la fonctionnalité de modèle fournie par rsyslog. Pour obtenir davantage d'informations sur les modèles, veuillez consulter la Section 20.2.3, « Modèles ». Le nom d'un module générateur de chaînes commence toujours par le préfixe
sm, commesmfileousmtradfile. - Modules de bibliothèques — les modules de bibliothèques fournissent des fonctionnalités pour d'autres modules chargeables. Ces modules sont chargés automatiquement par rsyslog lorsque nécessaire et ne peuvent pas être configurés par l'utilisateur.
Avertissement
20.6.1. Importer des fichiers texte
imfile, permet à rsyslog de convertir tout fichier texte en flux de messages syslog. Vous pouvez utiliser imfile pour importer des messages journaux d'applications qui créent leurs propres journaux de fichiers texte. Pour charger imfile, ajoutez ce qui suit au fichier /etc/rsyslog.conf :
$ModLoad imfile $InputFilePollInterval int
$ModLoad imfile
$InputFilePollInterval intimfile une seule fois est suffisant, même pendant l'importation de multiples fichiers. La directive globale $InputFilePollInterval spécifie à quelle fréquence rsyslog recherche des changements dans les fichiers texte connectés. L'intervalle par défaut s'élève à 10 secondes, et pour le modifier, remplacez int par un intervalle spécifié en secondes.
/etc/rsyslog.conf :
- remplacez path_to_file par un chemin vers le fichier texte.
- remplacez tag: par un nom de balise pour ce message.
- remplacez state_file_name par un nom unique pour le fichier d'état. Les fichiers d'état, qui sont stockés dans le répertoire de travail de rsyslog, conservent les curseurs des fichiers surveillés et marquent less partitions déjà traitées. Si vous les supprimer, les fichiers entiers seront lus à nouveau. Assurez-vous de spécifier un nom qui n'existe pas déjà.
- ajoutez la directive $InputRunFileMonitor qui active la surveillance de fichiers. Sans ce paramètre, le fichier texte sera ignoré.
Exemple 20.15. Importer des fichiers texte
imfile pour importer les messages. Ajoutez ce qui suit au fichier /etc/rsyslog.conf :
20.6.2. Exporter des messages sur une base de données
ommysql, ompgsql, omoracle, ou ommongodb. Alternativement, utilisez le module de sortie générique omlibdbi qui repose sur la bibliothèque libdbi. Le module omlibdbi prend en charge les systèmes des bases de données Firebird/Interbase, MS SQL, Sybase, SQLite, Ingres, Oracle, mSQL, MySQL, et PostgreSQL.
Exemple 20.16. Exporter des messages Rsyslog sur une base de données
/etc/rsyslog.conf :
$ModLoad ommysql $ActionOmmysqlServerPort 1234 *.* :ommysql:database-server,database-name,database-userid,database-password
$ModLoad ommysql
$ActionOmmysqlServerPort 1234
*.* :ommysql:database-server,database-name,database-userid,database-password
20.6.3. Enabling Encrypted Transport
TLS
- Définir le pilote gtls netstream comme pilote par défaut :
$DefaultNetstreamDriver gtls
$DefaultNetstreamDriver gtlsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Fournissez les chemins menant aux fichiers de certificat :
$DefaultNetstreamDriverCAFile path_ca.pem $DefaultNetstreamDriverCertFile path_cert.pem $DefaultNetstreamDriverKeyFile path_key.pem
$DefaultNetstreamDriverCAFile path_ca.pem $DefaultNetstreamDriverCertFile path_cert.pem $DefaultNetstreamDriverKeyFile path_key.pemCopy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacer path_ca.pem par le chemin qui mène à votre clé publique, path_cert.pem par le chemin qui mène au fichier de certificat, et path_key.pem par le chemin qui mène à la clé privée. - Charger le module imtcp :
$ModLoad imtcp
$ModLoad imtcpCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Démarrer le serveur et définir les options de pilote :
$InputTCPServerStreamDriverMode number $InputTCPServerStreamDriverAuthMode anon $InputTCPServerRun port
$InputTCPServerStreamDriverMode number $InputTCPServerStreamDriverAuthMode anon $InputTCPServerRun portCopy to Clipboard Copied! Toggle word wrap Toggle overflow Vous pourrez, ici, définir le mode du pilote en remplaçant le nombre, inscrire1pour activer le mode TCP-only. Le paramètre anon signifie que le client n'est pas authentifié. Remplacer port pour démarrer un listener sur le port requis.
- Télécharger la clé publique :
$DefaultNetstreamDriverCAFile path_ca.pem
$DefaultNetstreamDriverCAFile path_ca.pemCopy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacer path_ca.pem par le chemin qui mène à la clé publique : - Définir le pilote gtls netstream comme pilote par défaut :
$DefaultNetstreamDriver gtls
$DefaultNetstreamDriver gtlsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Configurez le pilote et spécifier l'action à effectuer :
$InputTCPServerStreamDriverMode number $InputTCPServerStreamDriverAuthMode anon *.* @@server.net:10514
$InputTCPServerStreamDriverMode number $InputTCPServerStreamDriverAuthMode anon *.* @@server.net:10514Copy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacer nombre et anon selon les configurations correspondantes du serveur. Sur la dernière ligne, un exemple d'action transfert les messages du serveur vers un port TCP indiqué.
Utiliser GSSAPI
/etc/rsyslog.conf :
$ModLoad imgssapi
$ModLoad imgssapi
$InputGSSServerServiceName name $InputGSSServerPermitPlainTCP on/off $InputGSSServerMaxSessions number $InputGSSServerRun port
$InputGSSServerServiceName name
$InputGSSServerPermitPlainTCP on/off
$InputGSSServerMaxSessions number
$InputGSSServerRun portNote
imgssapi sera initié aussitôt que le lecteur de fichier de configuration rencontrera la directive $InputGSSServerRun dans le fichier de configuration /etc/rsyslog.conf. Les options supplémentaires configurées après $InputGSSServerRun sont donc ignorées. Pour que la configuration puisse avoir lieu, toutes les options de configuration d'imgssapi doivent être mises avant $InputGSSServerRun.
Exemple 20.17. Utiliser GSSAPI
$ModLoad imgssapi $InputGSSServerPermitPlainTCP on $InputGSSServerRun 1514
$ModLoad imgssapi
$InputGSSServerPermitPlainTCP on
$InputGSSServerRun 1514
20.6.4. Utiliser RELP
- Commencer par créer une clé publique, une clé privée et un fichier de certificat, voir Section 12.1.11, « Générer une nouvelle clé et un nouveau certificat »
- Pour configurer le client, télécharger les modules suivants :
module(load="imuxsock") module(load="omrelp") module(load="imtcp")
module(load="imuxsock") module(load="omrelp") module(load="imtcp")Copy to Clipboard Copied! Toggle word wrap Toggle overflow Configurer l'entrée TCP ainsi :input(type="imtcp" port="port″)
input(type="imtcp" port="port″)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacer port pour démarrer un listener sur le port demandé.Avec le nouveau format de configuration, toutes les configurations de transport sont définies comme paramètres d'une action :Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ici, target_IP et target_port sont utilisés pour identifier le serveur cible, le paramètre tls="on" active le protocole TLS. Passez les chemins de fichiers de certification par path_ca.pem, path_cert.pem, et path_key.pem. Pour définir le mode d'authentification de la transaction, remplacer le mode par "name" ou "fingerprint". Avec tls.permittedpeer, vous pourrez limiter la connexion à un groupe de pairs sélectionnés. Remplacer peer_name par une empreinte de certificat de pair autorisé. - La configuration de serveur démarre par le chargement de module :
module(load="imuxsock") module(load="imrelp" ruleset="relp")
module(load="imuxsock") module(load="imrelp" ruleset="relp")Copy to Clipboard Copied! Toggle word wrap Toggle overflow Configurer l'entrée TCP sur le modèle de la configuration client :Copy to Clipboard Copied! Toggle word wrap Toggle overflow Ces paramètres d'entrée ont la même signification que les options de configuration du client qui sont expliquées dans la deuxième étape. Dans la dernière étape, configurez les règles et sélectionnez une action. Dans l'exemple suivant, les messages se trouvent à l'emplacement suivant :ruleset (name="relp") { action(type="omfile" file="log_path") }ruleset (name="relp") { action(type="omfile" file="log_path") }Copy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacer ici log_path par un chemin menant à un répertoire où vous souhaitez stocker vos fichiers de journalisation.
20.7. Interaction de Rsyslog et de Journal
rsyslogd utilise le module imjournal comme mode d'entrée par défaut pour les fichiers journaux. Avec ce module, vous importez non seulement les messages, mais également les données structurées fournies par journald. Aussi, des données plus anciennes peuvent être importées de journald (sauf si interdit avec la directive $ImjournalIgnorePreviousMessages). Veuillez consulter la Section 20.8.1, « Importer des données de Journal » pour voir une configuration de base de imjournal.
rsyslogd pour effectuer la lecture à partir du socket fourni par journal en tant que sortie pour des applications basées syslog. Le chemin vers le socket est le suivant : /run/systemd/journal/syslog. Veuillez utiliser cette option lorsque vous souhaitez maintenir des messages syslog simples. Comparé à imjournal, l'entrée du socket offre actuellement davantage de fonctionnalités, comme la liaison ou le filtrage de rulesets. Pour importer des données Journal à travers le socket, veuillez utiliser la configuration suivante dans le fichier /etc/rsyslog.conf :
$ModLoad imuxsock $OmitLocalLogging off
$ModLoad imuxsock
$OmitLocalLogging off
imuxsock et éteint la directive $OmitLocalLogging, qui permet l'importation à travers le socket du système. Le chemin vers ce socket est spécifié séparément, dans le fichier /etc/rsyslog.d/listen.conf comme suit :
$SystemLogSocketName /run/systemd/journal/syslog
$SystemLogSocketName /run/systemd/journal/syslog
omjournal. Configurez la sortie dans le fichier /etc/rsyslog.conf comme suit :
$ModLoad omjournal *.* :omjournal:
$ModLoad omjournal
*.* :omjournal:
20.8. Journalisation structurée avec Rsyslog
Oct 25 10:20:37 localhost anacron[1395]: Jobs will be executed sequentially
Oct 25 10:20:37 localhost anacron[1395]: Jobs will be executed sequentially{"timestamp":"2013-10-25T10:20:37", "host":"localhost", "program":"anacron", "pid":"1395", "msg":"Jobs will be executed sequentially"}
{"timestamp":"2013-10-25T10:20:37", "host":"localhost", "program":"anacron", "pid":"1395", "msg":"Jobs will be executed sequentially"}imjournal. Avec le module mmjsonparse, vous pouvez analyser des données importées de Journal et d'autres sources, puis les traiter davantage, par exemple en tant que sortie de base de données. Pour que l'analyse réussisse, mmjsonparse requiert que les messages d'entrée soient structurés d'une manière définie par le projet Lumberjack.
@cee: {"pid":17055, "uid":1000, "gid":1000, "appname":"logger", "msg":"Message text."}
@cee: {"pid":17055, "uid":1000, "gid":1000, "appname":"logger", "msg":"Message text."} libumberlog pour générer des messages sous un format compatible avec lumberjack. Pour obtenir davantage d'informations sur libumberlog, veuillez consulter la section intitulée « Documentation en ligne ».
20.8.1. Importer des données de Journal
imjournal est le module d'entrée de Rsyslog permettant de lire les fichiers journaux de manière native (consultez la Section 20.7, « Interaction de Rsyslog et de Journal »). Les messages Journal sont ensuite journalisés en format texte comme les autres messages rsyslog. Cependant, avec un traitement supplémentaire, il est possible de traduire les métadonnées fournies par Journal en message structuré.
/etc/rsyslog.conf :
- Avec number_of_messages, il est possible de spécifier la fréquence à laquelle les données Journal doivent être enregistrées. Ceci se produit chaque fois que le nombre spécifié de messages est atteint.
- Remplacez path par un chemin vers le fichier d'état. Ce fichier surveille la dernière entrée de journal traitée.
- Avec seconds, il est possible de définir la longueur de l'intervalle de limite du taux. Le nombre de messages traités pendant cet intervalle ne peut pas dépasser la valeur spécifiée dans burst_number. Le paramètre par défaut s'élève à 20,000 messages pour 600 secondes. Rsyslog abandonne les messages arrivant après la rafale maximale dans le délai spécifié.
- Avec
$ImjournalIgnorePreviousMessages, vous pouvez ignorer les messages se trouvant actuellement dans le Journal et importer les nouveaux messages uniquement, ce qui est utilisé lors qu’aucun fichier d'état n'est spécifié. Le paramètre par défaut est «off». Veuillez remarquer que si ce paramètre est inactif et qu'il n'y a pas de fichier d'état, tous les messages dans le Journal sont traités, même s'ils ont déjà été traités dans une session rsyslog précédente.
Note
imjournal simultanément avec le module imuxsock qui est l'entrée de journal système traditionnelle. Cependant, pour éviter la duplication de messages, vous devez empêcher imuxsock de lire le socket du système du Journal. Pour cela, veuillez utiliser la directive $OmitLocalLogging :
systemd.journal-fields(7). Par exemple, il est possible de se concentrer sur les champs de journal du noyau, qui sont utilisés par des messages provenant du noyau.
20.8.2. Filtrer des messages structurés
template(name="CEETemplate" type="string" string="%TIMESTAMP% %HOSTNAME% %syslogtag% @cee: %$!all-json%\n")
template(name="CEETemplate" type="string" string="%TIMESTAMP% %HOSTNAME% %syslogtag% @cee: %$!all-json%\n")
@cee: au début de la chaîne JSON et peut être appliqué, par exemple, pendant la création d'un fichier de sortie avec le module omfile. Pour accéder aux noms de champ JSON, veuillez utiliser le préfixe $!. Ainsi, la condition de filtre suivante recherche des messages avec un nom d'hôte et un UID spécifique :
($!hostname == "hostname" && $!UID== "UID")
($!hostname == "hostname" && $!UID== "UID")
20.8.3. Analyser JSON
mmjsonparse est utilisé pour analyser les messages structurés. Ces messages peuvent provenir de Journal ou d'autres sources d'entrées, et doivent être formatés d'une manière définie par le projet Lumberjack. Ces messages sont identifiés par la présence de la chaîne @cee:. mmjsonparse vérifie si la structure JSON est valide, puis le message est analysé.
mmjsonparse, veuillez utiliser la configuration suivante dans le fichier /etc/rsyslog.conf :
$ModLoad mmjsonparse *.* :mmjsonparse:
$ModLoad mmjsonparse
*.* :mmjsonparse:
mmjsonparse est chargé sur la première ligne, puis tous les messages y sont transférés. Aucun paramètre de configuration n'est actuellement disponible pour mmjsonparse.
20.8.4. Stocker des messages dans MongoDB
/etc/rsyslog.conf (les paramètres de configuration de ommongodb sont uniquement disponibles sous le nouveau format de configuration ; veuillez consulter la Section 20.3, « Utiliser le nouveau format de configuration ») :
$ModLoad ommongodb *.* action(type="ommongodb" server="DB_server" serverport="port" db="DB_name" collection="collection_name" uid="UID" pwd="password")
$ModLoad ommongodb
*.* action(type="ommongodb" server="DB_server" serverport="port" db="DB_name" collection="collection_name" uid="UID" pwd="password")
- Remplacez DB_server par le nom ou l'adresse du serveur MongoDB. Spécifiez port pour sélectionner un port non standard du serveur MongoDB. La valeur port par défaut est
0, et il n'est pas habituellement nécessaire de modifier ce paramètre. - Avec DB_name, il est possible d'identifier la base de données sur le serveur MongoDB sur laquelle vous souhaitez diriger la sortie. Remplacez collection_name par le nom d'une collection dans cette base de données. Dans MongoDB, une collection est un groupe de documents, l'équivalent d'une table RDBMS.
- Vous pouvez définir vos détails de connexion en remplaçant l'UID et le mot de passe.
20.9. Déboguer Rsyslog
rsyslogd en mode de débogage, veuillez utiliser la commande suivante :
rsyslogd -dn
rsyslogd -dnrsyslogd produit des informations de débogage et les imprime sur la sortie standard. L'option-n correspond à « no fork ». Vous pouvez modifier le débogage avec des variables d'environnement. Par exemple, vous pouvez stocker la sortie du débogage dans un fichier journal. Avant de lancer rsyslogd, veuillez saisir ce qui suit sur la ligne de commande :
export RSYSLOG_DEBUGLOG="path" export RSYSLOG_DEBUG="Debug"
export RSYSLOG_DEBUGLOG="path"
export RSYSLOG_DEBUG="Debug"
rsyslogd(8).
/etc/rsyslog.conf est valide, veuillez utiliser :
rsyslogd -N 1
rsyslogd -N 11 représente le niveau de détails du message de sortie. Ceci est une option de compatibilité de transfert car un seul niveau est actuellement fourni. Cependant, vous devez ajouter cet argument pour exécuter la validation.
20.10. Utiliser le Journal
rsyslogd. Journal a été développé pour répondre aux problèmes liés aux connexions traditionnelles. Il est étroitement intégré avec le reste du système, prend en charge diverses technologies de connexion et la gestion des accès pour les fichiers journaux.
journald de Journal. Il crée et maintient des fichiers binaires nommés des journaux basés sur des informations de journalisation reçues du noyau, des processus utilisateur, de la sortie standard, et de la sortie d'erreurs standard des services système ou via son API native. Ces journaux sont structurés et indexés, ce qui fournit un temps de recherche relativement rapide. Les entrées de journaux peuvent comporter un identifiant unique. Le service journald collecte de nombreux champs de métadonnées pour chaque message de journal. Les fichiers journaux sont sécurisés et ne peuvent donc pas être modifiés manuellement.
20.10.1. Afficher les fichiers journaux
root :
journalctl
journalctl/var/log/messages/ mais elle offre quelques améliorations :
- la priorité des entrées est marquée visuellement. Des lignes de priorités d'erreurs et des priorités plus élevées sont surlignées en rouge et des caractère en gras sont utilisés pour les lignes avec une notification et une priorité d'avertissement
- les horodatages sont convertis au fuseau horaire local de votre système
- toutes les données journalisées sont affichées, y compris les journaux rotatifs
- le début d'un démarrage est marqué d'une ligne spéciale
Exemple 20.18. Exemple de sortie journalctl
journalctl consiste à utiliser l'option -n qui répertorie uniquement le nombre spécifié des entrées les plus récentes du journal :
journalctl -n Number
journalctl -n Numberjournalctl affiche les dix entrées les plus récentes.
journalctl permet de contrôler le format de la sortie avec la syntaxe suivante :
journalctl -o form
journalctl -o formverbose, qui retourne des éléments d'entrée complètement structurés avec tous les champs, export, qui crée un courant binaire convenable aux sauvegardes et transferts réseau, et json, qui formate les entrées en tant que structures de données JSON. Pour obtenir la liste complète des mots-clés, veuillez consulter la page man de journalctl(1).
Exemple 20.19. Sortie détaillée de journalctl
systemd.journal-fields(7).
20.10.2. Contrôle des accès
root peuvent uniquement voir les fichiers journaux qu'ils ont générés. L'administrateur systèmes peut ajouter les utilisateurs sélectionnés au groupe adm, qui leur offre accès aux fichiers journaux complets. Pour effectuer ceci, veuillez saisir en tant qu'utilisateur root :
usermod -a -G adm username
usermod -a -G adm usernamejournalctl que l'utilisateur root. Remarquez que le contrôle des accès fonctionne uniquement lorsque le stockage persistant est activé pour Journal.
20.10.3. Utiliser l'affichage Live
journalctl affiche la liste complète des entrées, en commençant par l'entrée collectée la plus ancienne. Avec l'affichage Live, vous pouvez superviser les messages journaux en temps réel pendant l'impression continuelle des nouvelles entrées au fur et à mesure qu'elles apparaissent. Pour lancer journalctl en mode d'affichage Live, veuillez saisir :
journalctl -f
journalctl -f20.10.4. Filtrer les messages
journalctl exécutée sans paramètre est souvent extensive. Ainsi, vous pouvez utiliser différentes méthodes de filtrage pour extraire des informations qui correspondent à vos besoins.
Filtrer par priorité
journalctl -p priority
journalctl -p prioritydebug (7), info (6), notice (5), warning (4), err (3), crit (2), alert (1), et emerg (0).
Exemple 20.20. Filtrer par priorité
journalctl -p err
journalctl -p errFiltrer par heure
journalctl -b
journalctl -b-b ne réduira pas significativement la sortie de journalctl. Dans de tels cas, le filtrage basé heure sera plus utile :
journalctl --since=value --until=value
journalctl --since=value --until=value--since et --until, vous pouvez uniquement afficher les messages journaux créés dans un intervalle spécifié. Vous pouvez attribuer des valeurs à ces options sous la forme de date ou d'heure, ou les deux, comme indiqué dans l'exemple ci-dessous.
Exemple 20.21. Filtrer par heure et par priorité
journalctl -p warning --since="2013-3-16 23:59:59"
journalctl -p warning --since="2013-3-16 23:59:59"Filtrage avancé
systemd, veuillez consulter la page man de systemd.journal-fields(7). Ces métadonnées sont collectées pour chaque message journal, sans intervention de la part de l'utilisateur. Les valeurs sont habituellement basées texte, mais elles peuvent également prendre des valeurs de binaire et de grande taille. Les champs peuvent se voir assigner des multiples valeurs, même si cela n'est pas très commun.
journalctl -F fieldname
journalctl -F fieldnamejournalctl fieldname=value
journalctl fieldname=valueNote
systemd est assez important, il est facile d'oublier le nom exact du champ d'intérêt. En cas d'incertitude, veuillez saisir :
journalctl
journalctljournalctl fieldname=
journalctl fieldname=journalctl -F fieldname.
journalctl fieldname=value1 fieldname=value2 ...
journalctl fieldname=value1 fieldname=value2 ...OR des deux correspondances. Les entrées qui correspondent à value1 ou value2 sont affichées.
journalctl fieldname1=value fieldname2=value ...
journalctl fieldname1=value fieldname2=value ...AND logique. Les entrées doivent correspondre aux deux conditions pour être affichées.
OR logique des correspondances pour plusieurs champs :
journalctl fieldname1=value + fieldname2=value ...
journalctl fieldname1=value + fieldname2=value ...Exemple 20.22. Filtrage avancé
avahi-daemon.service ou crond.service sous un utilisateur avec l'UID 70, veuillez utiliser la commande suivante :
journalctl _UID=70 _SYSTEMD_UNIT=avahi-daemon.service _SYSTEMD_UNIT=crond.service
journalctl _UID=70 _SYSTEMD_UNIT=avahi-daemon.service _SYSTEMD_UNIT=crond.service_SYSTEMD_UNIT, les deux résultats seront affichés, mais uniquement lorsqu'ils correspondent à la condition _UID=70. Ceci peut être exprimé simplement comme suit : (UID=70 and (avahi or cron)).
journalctl -f fieldname=value ...
journalctl -f fieldname=value ...20.10.5. Activer le stockage persistant
/run/log/journal/. Cela est suffisant pour afficher l'historique récent des journaux avec journalctl. Ce répertoire est volatile, les données de journal ne sont pas enregistrées de manière permanente. Avec la configuration par défaut, syslog lit les enregistrements de journal et les stocke dans le répertoire /var/log/. Avec la journalisation persistante activée, les fichiers journaux sont stockés dans /var/log/journal, ce qui signifie qu'ils persisteront après un redémarrage. Journal peut ensuite remplacer rsyslog pour certains utilisateurs (veuillez consulter l'introduction du chapitre).
- Des données enrichies sont enregistrées pour la résolution de problèmes pendant une longue période
- Pour une résolution de problème immédiate, des données enrichies seront disponibles après un redémarrage
- Actuellement, la console du serveur lit les données à partir du journal, et non à partir des fichiers journaux
- Même avec un stockage persistant, la quantité de données stockée dépend de la mémoire disponible, il n'y a pas de garantie de couverture d'une période spécifique
- Davantage d'espace disque est nécessaire pour les journaux
root, veuillez saisir :
mkdir -p /var/log/journal/
mkdir -p /var/log/journal/journald pour appliquer le changement :
systemctl restart systemd-journald
systemctl restart systemd-journald20.11. Gérer des fichiers journaux dans un environnement graphique
20.11.1. Afficher les fichiers journaux
Vi ou Emacs. Certains fichiers journaux sont lisibles par tous les utilisateurs sur le système. Cependant, des privilèges root sont requis pour lire la plupart des fichiers journaux.
Note
root :
yum install gnome-system-log
~]# yum install gnome-system-loggnome-system-log
~]$ gnome-system-log
Figure 20.2. System Log
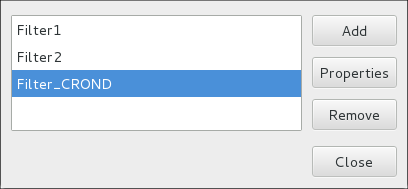
Figure 20.3. System Log - Filtres

Figure 20.4. System Log - définir un filtre
- Name — nom du filtre.
- Regular Expression — expression régulière qui sera appliquée au fichier journal et qui tentera de correspondre à toutes les chaînes possibles de celui-ci.
- Effect
- Highlight — si sélectionné, les résultats trouvés seront surlignés avec la couleur choisie. Vous pouvez également sélectionner si vous souhaitez surligner l'arrière-plan ou l'avant-plan du texte.
- Hide — si sélectionné, les résultats trouvés seront cachés du fichier journal affiché.
Figure 20.5. System Log - activer un filtre
20.11.2. Ajouter un fichier journal
Figure 20.6. System Log - ajouter un fichier journal
Note
.gz.
20.11.3. Surveiller des fichiers journaux

Figure 20.7. System Log - nouvelle alerte de journal
20.12. Ressources supplémentaires
rsyslog et sur la manière de localiser, d'afficher, et de contrôler les fichiers journaux, veuillez consulter les ressources répertoriées ci-dessous.
Documentation installée
rsyslogd(8) — la page du manuel du démonrsyslogddocumente son utilisation.rsyslog.conf(5) — la page du manuel nomméersyslog.confdocumente ses options de configuration disponibles.logrotate(8) — la page du manuel de l'utilitaire logrotate explique des manière très détaillée comment le configurer et l'utiliser.journalctl(1) — la page du manuel du démonjournalctldocumente son utilisation.journald.conf(5) — cette page du manuel documente les options de configuration disponibles.systemd.journal-fields(7) — cette page du manuel répertorie les champs spéciaux de Journal.
Documentation installable
/usr/share/doc/rsyslogversion/html/index.html — ce fichier, fourni par le paquet rsyslog-doc en provenance du canal « Optional », contient des informations sur rsyslog. Voir Section 8.5.7, « Ajouter les référentiels « Optional » (Optionnel) et « Supplementary » (Supplémentaire) » pour obtenir des informations sur les canaux supplémentaires Red Hat. Avant d'accéder à la documentation, vous devez exécuter la commande suivante en tant qu'utilisateur root :
yum install rsyslog-doc
~]# yum install rsyslog-docDocumentation en ligne
- Documentation RainerScript de la page d'accueil rsyslog — résumé commenté des types de données, des expressions, et des fonctions disponibles dans RainerScript.
- Documentation rsyslog version 7 sur la page d'accueil rsyslog — la version 7 de rsyslog est disponible pour Red Hat Enterprise Linux 7 dans le paquet rsyslog.
- Description of files d'attente sur la Page d'accueil rsyslog — informations générales sur les divers types de files d'attente de messages et sur leur utilisation.
Voir aussi
- Le Chapitre 5, Obtention de privilèges documente la façon d'obtenir des privilèges administratifs en utilisant les commandes
suetsudo. - Le Chapitre 9, Gérer les services avec systemd fournit des informations supplémentaires sur systemd et documente comment utiliser la commande
systemctlpour gérer les services système.
Chapitre 21. Automatiser les tâches système
locate est mise à jour quotidiennement. Un administrateur systèmes peut utiliser des tâches automatisées pour effectuer des copies de sauvegarde périodiques, surveiller le système, exécuter des scripts personnalisés, et ainsi de suite.
cron, anacron, at, et batch.
systemd.timer pour exécuter une tâche à un moment spécifique. Veuillez consulter la page man systemd.timer(5) pour obtenir davantage d'informations.
21.1. Cron et Anacron
21.1.1. Installer Cron et Anacron
rpm -q cronie cronie-anacron
rpm -q cronie cronie-anacronyum sous le format suivant en tant qu'utilisateur root :
yum install package
yum install packageyum install cronie cronie-anacron
~]# yum install cronie cronie-anacron21.1.2. Exécuter le service Crond
crond. Cette section fournit des informations sur la manière de démarrer, arrêter, et de redémarrer le service crond, et montre comment le configurer afin qu'il soit lancé automatiquement lors du démarrage. Pour obtenir davantage d'informations sur la manière de gérer des services système sur Red Hat Enterprise Linux 7 en général, veuillez consulter le Chapitre 9, Gérer les services avec systemd.
21.1.2.1. Démarrer et arrêter le service Cron
systemctl status crond.service
systemctl status crond.servicecrond dans la session actuelle, veuillez saisir ce qui suit dans l'invite de shell en tant qu'utilisateur root :
systemctl start crond.service
systemctl start crond.serviceroot :
systemctl enable crond.service
systemctl enable crond.service21.1.2.2. Arrêter le service Cron
crond dans sa session actuelle, veuillez saisir ce qui suit dans l'invite de shell en tant qu'utilisateur root :
systemctl stop crond.service
systemctl stop crond.serviceroot :
systemctl disable crond.service
systemctl disable crond.service21.1.2.3. Redémarrer le service Cron
crond, veuillez saisir ce qui suit dans une invite de shell en tant qu'utilisateur root :
systemctl restart crond.service
systemctl restart crond.service21.1.3. Configurer les tâches Anacron
/etc/anacrontab, auquel seul l'utilisateur root peut accéder. Le fichier contient ce qui suit :
SHELL— environnement shell utilisé pour exécuter des tâches (dans l'exemple, le shell Bash)PATH— chemins d'accès des programmes exécutablesMAILTO— nom d'utilisateur de l'utilisateur destinataire de la sortie des tâches anacron par courrier électroniqueSi la variableMAILTOn'est pas définie (MAILTO=), alors le courrier électronique n'est pas envoyé.
RANDOM_DELAY— nombre de minutes maximum pouvant être ajoutées à la variabledelay in minutes(« délai en minutes »), qui est spécifiée pour chaque tâcheLa valeur de délai minimum est définie par défaut sur 6 minutes.Par exemple, siRANDOM_DELAYest défini sur12, alors 6 à 12 minutes sont ajoutées à la variabledelay in minutespour chaque tâche dans cet anacrontab particulier.RANDOM_DELAYpeut également être défini avec une valeur plus basse que6, y compris0. Si défini sur0, aucun délai aléatoire n'est ajouté. Ceci se révèle utile lorsque, par exemple, davantage d'ordinateurs qui partagent une connexion réseau doivent téléverser les mêmes données chaque jour.START_HOURS_RANGE— intervalle en heures définissant à quel moment les tâches planifiées peuvent être exécutéesDans le cas où l'intervalle est manqué, à cause d'une panne de l'alimentation par exemple, les tâches planifiées ne seront pas exécutées ce jour.
/etc/anacrontab représentent les tâches planifiées et suivent ce format :
period in days delay in minutes job-identifier command
period in days delay in minutes job-identifier commandperiod in days— fréquence d'exécution des tâches, en joursLa valeur de la propriété peut être définie en tant qu'entier ou macro (@daily,@weekly,@monthly), où@dailypossède la même valeur qu'un entier de 1,@weeklypossède la même que 7, et@monthlyspécifie que la tâche est exécutée une fois par mois, quelle que soit la longueur du mois.delay in minutes— nombre de minutes qu'Anacron attend avant d'exécuter la tâcheLa valeur de la propriété est définie en tant qu'entier. Si la valeur est définie sur0, aucun délai ne s'appliquera.job-identifier— nom unique faisant référence à une tâche particulière utilisée dans les fichiers journauxcommand— commande devant être exécutéeLa commande peut être une commande telle quels /proc >> /tmp/procou une commande qui exécute un script personnalisé.
21.1.3.1. Exemples de tâches Anacron
/etc/anacrontab simple :
anacrontab sont retardées de 6 à 30 minutes et peuvent être exécutées entre 16h00 et 20h00.
/etc/cron.daily/ à l'aide du script run-parts (les scripts run-parts acceptent un répertoire en tant qu'argument de ligne de commande et exécutent séquentiellement tous les programmes dans le répertoire). Veuillez consulter la page man run-parts pour obtenir davantage d'informations sur le script run-parts.
weeklyjob.bash dans le répertoire /etc une fois par semaine.
/proc sur le fichier /tmp/proc (ls /proc >> /tmp/proc) une fois par mois.
21.1.4. Configuration des tâches Cron
/etc/crontab, et peut uniquement être modifié par l'utilitasteur root. Le fichier contient ce qui suit :
anacrontab : SHELL, PATH, et MAILTO. Pour obtenit davantage d'informations sur ces variables, veuillez consulter la Section 21.1.3, « Configurer les tâches Anacron ».
HOME. La variable HOME définit le répertoire, qui sera utilisé comme répertoire personnel lorsque des commandes ou scripts seront exécutés par la tâche.
/etc/crontab représentent les tâches planifiées et se trouvent sous le format suivant :
minute hour day month day of week username command
minute hour day month day of week username commandminute— un entier de 0 à 59hour— un entier de 0 à 23day— un entier de 1 à 31 (doit être un jour valide si le mois est spécifié)month— un entier de 1 à 12 (ou l'abbrévation du nom en anglais, par exemple « jan » ou « feb »)day of week— un entier de 0 à 7, où soit 0, soit 7, correspond au dimanche (ou l'abbréviation du nom en anglais du jour de la semaine, par exemple « sun » ou « mon »)
username— indique l'utilisateur sous lequel les tâches doivent être exécutées.command— la commande devant être exécutée.La commande peut être une commande telle quels /proc /tmp/proc, ou une commande qui exécute un script personnalisé.
1-4 signifie les entiers 1, 2, 3, et 4.
3,4,6,8 indique exactement ces quatre entiers.
/entier. Par exemple, la valeur minute définie par 0-59/2 indique chaque seconde minute du champ minute. Des valeurs étapes peuvent également être utilisées avec un astérisque. Par exemple, si la valeur du mois est définie par */3, la tâche sera exécutée tous les trois mois.
root peuvent configurer les tâches Cron avec l'utilitaire crontab. Les crontabs définis utilisateur sont stockés dans le répertoire /var/spool/cron/ et exécutés comme s'ils étaient exécutés par les utilisateurs qui les ont créés.
crontab -e pour modifier le crontab de l'utilisateur avec l'éditeur spécifié dans la variable d'environnement VISUAL ou EDITOR. Le fichier utilise le même format que /etc/crontab. Lorsque les changements crontab sont enregistrés, le crontab est stocké selon le nom d'utilisateur, puis écrit sur le fichier /var/spool/cron/username. Pour répertorier le contenu du fichier crontab de l'utilisateur, veuillez utiliser la commande crontab -l.
/etc/cron.d/ contient des fichiers qui possèdent la même syntaxe que le fichier /etc/crontab. Seul l'utilisateur root est autorisé à créer et à modifier des fichiers dans ce répertoire.
Note
/etc/anacrontab, le fichier /etc/crontab, le répertoire /etc/cron.d/, et le répertoire /var/spool/cron/ chaque minute et tout changement détecté est chargé en mémoire. Ainsi, il n'est pas utile de redémarrer le démon après le changement d'un fichier anacrontab ou crontab.
21.1.5. Contrôle de l'accès à cron
/etc/cron.allow et /etc/cron.deny. Ces fichiers de contrôle d'accès utilisent le même format avec un nom d'utilisateur sur chaque ligne. N'oubliez pas que les caractères d'espace ne sont pas autorisés dans ces fichiers.
cron.allow existe, seuls les utilisateurs répertoriés dans celui-ci seront autorisés à utiliser cron, et le fichier cron.deny sera ignoré.
cron.allow n'existe pas, les utilisateurs répertoriés dans le fichier cron.deny ne seront pas autorisés à utiliser Cron.
crond) n'a pas besoin d'être redémarré si les fichiers de contrôle d'accès sont modifiés. Les fichiers de contrôle d'accès sont vérifiés chaque fois qu'un utilisateur tente d'ajouter ou de supprimer une tâche Cron.
root peut toujours utiliser Cron, peu importe les noms d'utilisateurs répertoriés dans les fichiers de contrôle d'accès.
/etc/security/access.conf. Par exemple, après avoir ajouté la ligne suivante au fichier, aucun utilisateur autre que l'utilisateur root ne pourra créer de Crontabs :
-:ALL EXCEPT root :cron
-:ALL EXCEPT root :croncrontab -e est utilisée, retournées vers la sortie standard. Pour obtenir davantage d'informations, veuillez consulter la page du manuel access.conf.5.
21.1.6. Mettre des tâches Cron sur liste noire et sur liste blanche
/etc/cron.daily/ : si l'utilisateur ajoute des programmes se trouvant dans le répertoire à la liste noire des tâches, le script run-parts n'exécutera pas ces programmes.
jobs.deny dans le répertoire à partir duquel les scripts run-parts sont exécutés. Par exemple, si vous devez éviter un programme particulier dans /etc/cron.daily/, veuillez créer le fichier /etc/cron.daily/jobs.deny. Dans ce fichier, spécifiez les noms des programmes à supprimer de l'exécution (seuls les programmes se trouvant dans le même répertoire peuvent être inscrits). Si une tâche exécute une commande qui exécute les programmes du répertoire /etc/cron.daily/, comme run-parts /etc/cron.daily, les programmes définis dans le fichier jobs.deny ne seront pas exécutés.
jobs.allow.
jobs.deny et jobs.allow sont les mêmes que ceux de cron.deny et cron.allow, ils sont décrits dans la section Section 21.1.5, « Contrôle de l'accès à cron ».
21.2. « At » et « Batch »
21.2.1. Installer « At » et « Batch »
rpm -q at
rpm -q atyum sous le format suivant en tant qu'utilisateur root :
yum install package
yum install packageyum install at
~]# yum install at21.2.2. Exécuter le service « At »
atd. Cette section fournit des informations sur la manière de démarrer, arrêter, et de redémarrer le service atd, et montre comment le configurer afin qu'il soit lancé automatiquement lors du démarrage. Pour obtenir davantage d'informations sur la manière de gérer des services système sur Red Hat Enterprise Linux 7 en général, veuillez consulter le Chapitre 9, Gérer les services avec systemd.
21.2.2.1. Démarrer et arrêter le service « At »
systemctl status atd.service
systemctl status atd.serviceatd dans la session actuelle, veuillez saisir ce qui suit dans l'invite de shell en tant qu'utilisateur root :
systemctl start atd.service
systemctl start atd.serviceroot :
systemctl enable atd.service
systemctl enable atd.serviceNote
atd lors du démarrage.
21.2.2.2. Arrêter le service « At »
atd, veuillez saisir ce qui suit dans une invite de shell en tant qu'utilisateur root :
systemctl stop atd.service
systemctl stop atd.serviceroot :
systemctl disable atd.service
systemctl disable atd.service21.2.2.3. Redémarrer le service « At »
atd, veuillez saisir ce qui suit dans une invite de shell en tant qu'utilisateur root :
systemctl restart atd.service
systemctl restart atd.service21.2.3. Configurer une tâche « At »
- Sur la ligne de commande, veuillez saisir la commande
at TIME, oùTIMEreprésente l'heure à laquelle la commande doit être exécutée.L'argument TIME peut être défini à l'aide de l'un des formats suivants :HH:MMindique l'heure et la minute exacte ; par exemple,04:00signifie 04h00.midnightsignifie 00h00.noonsignifie 12h00.teatimesignifie 16h00.- Format
MONTHDAYYEAR; par exemple,January 15 2012signifie le 15ème jour du mois de janvier de l'année 2012. La valeur de l'année est optionnelle. - Formats
MMDDYY,MM/DD/YY, ouMM.DD.YY; par exemple,011512pour le 15ème jour du mois de janvier de l'année 2012. now + TIMEoù TIME est défini en tant que nombre entier et le type de valeur : minutes (« minutes »), heures (« hours »), jour (« days »), ou semaines (« weeks »). Par exemple,now + 5 daysindique que la commande sera exécutée à la même heure dans cinq jours.L'heure doit être spécifiée en premier, suivie de la date optionnelle. Pour obtenir davantage d'informations sur le format de l'heure, veuillez consulter le fichier texte/usr/share/doc/at-<version>/timespec.
Si l'heure spécifiée est déjà passée, la tâche sera exécutée au même moment le jour suivant. - Définissez les commandes de la tâche dans l'invite
at>affichée :- Veuillez saisir la commande que la tâche devra exécuter et appuyez sur Entrée. Optionnellement, répétez l'étape pour fournir des commandes multiples.
- Saisissez un script shell à l'invite et appuyez sur Entrée après chaque ligne du script.La tâche utilisera l'ensemble du shell dans l'environnement
SHELLde l'utilisateur, le shell de connexion de l'utilisateur, ou/bin/sh(en fonction de ce qui est trouvé en premier).
- Une fois terminé, veuillez appuyer sur Ctrl+D sur une ligne vide pour sortir de l'invite de commande.
atq. Veuillez consulter la Section 21.2.5, « Afficher les tâches en attente » pour obtenir davantage d'informations.
at. Pour obtenir davantage d'informations, veuillez consulter la Section 21.2.7, « Contrôle de l'accès à « At » et « Batch » ».
21.2.4. Configurer une tâche « Batch »
- Sur la ligne de commande, saisir la commande
batch. - Définissez les commandes de la tâche dans l'invite
at>affichée :- Veuillez saisir la commande que la tâche devra exécuter et appuyez sur Entrée. Optionnellement, répétez l'étape pour fournir des commandes multiples.
- Saisissez un script shell à l'invite et appuyez sur Entrée après chaque ligne du script.Si un script est saisi, la tâche utilise l'ensemble du shell dans l'environnement
SHELLde l'utilisateur, le shell de connexion de l'utilisateur, ou/bin/sh(en fonction de ce qui est trouvé en premier).
- Une fois terminé, veuillez appuyer sur Ctrl+D sur une ligne vide pour sortir de l'invite de commande.
atq. Veuillez consulter la Section 21.2.5, « Afficher les tâches en attente » pour obtenir davantage d'informations.
batch. Pour obtenir davantage d'informations, veuillez consulter la Section 21.2.7, « Contrôle de l'accès à « At » et « Batch » ».
21.2.5. Afficher les tâches en attente
At et Batch en attente, exécutez la commande atq. La commande atq affiche une liste des tâches en attente, avec chaque tâche sur une ligne séparée. Chaque ligne suit le numéro de la tâche, la date, l'heure, la classe de la tâche, et le format du nom d'utilisateur. Les utilisateur peuvent uniquement afficher leurs propres tâches. Si l'utilisateur root exécute la commande atq, toutes les tâches de tous les utilisateurs seront affichées.
21.2.6. Options de ligne de commande supplémentaires
at et batch incluent :
| Option | Description |
|---|---|
-f | Lit les commandes ou le script shell depuis un fichier au lieu de les spécifier à l'invite de commande. |
-m | Envoie un courrier électronique à l'utilisateur une fois la tâche accomplie. |
-v | Affiche l'heure à laquelle la tâche sera exécutée. |
21.2.7. Contrôle de l'accès à « At » et « Batch »
at et batch à l'aide des fichiers /etc/at.allow et /etc/at.deny. Ces fichiers de contrôle d'accès utilisent le même format en définissant un nom d'utilisateur sur chaque ligne. N'oubliez pas que les espaces ne sont pas autorisés dans ces fichiers.
at.allow existe, seuls les utilisateurs répertoriés dans celui-ci seront autorisés à utiliser at ou batch, et le fichier at.deny sera ignoré.
at.allow n'existe pas, les utilisateurs répertoriés dans le fichier at.deny ne seront pas autorisés à utiliser at ou batch.
at (atd) n'a pas besoin d'être redémarré si les fichiers de contrôle d'accès sont modifiés. Les fichiers de contrôle d'accès sont lus chaque fois qu'un utilisateur tente d'exécuter les commandes at ou batch.
root peut toujours exécuter les commandes at et batch, indépendamment du contenu des fichiers de contrôle d'accès.
21.3. Ressources supplémentaires
- La page man de
cron(8)offre une vue d'ensemble de Cron. - Les pages man de
crontabdans les sections 1 et 5 :- La page du manuel dans la section 1 contient une vue d'ensemble du fichier
crontab. - La page man dans la section 5 contient le format du fichier et quelques exemples d'entrées.
- La page man de
anacron(8)contient une vue d'ensemble d'Anacron. - La page man de
anacrontab(5)contient une vue d'ensemble du fichieranacrontab. - La page man de
run-parts(4)contient une vue d'ensemble du scriptrun-parts. /usr/share/doc/at-version/timespeccontient des informations détaillées sur les valeurs de temps pouvant être utilisées dans les définitions de tâches Cron.- La page man de
atcontient des descriptions des commandesatetbatchet de leurs options de ligne de commande.
Chapitre 22. ABRT (Automatic Bug Reporting Tool)
22.1. Introduction à ABRT
abrtd et d'un nombre de services et utilitaires système pour le traitement, l'analyse et le rapport des problèmes détectés. Le démon est exécuté silencieusement en arrière-plan la plupart du temps et entre en action lorsqu'un incident d'application survient ou lorsqu'un oops de noyau se produit. Le démon collecte ensuite les données problématiques correspondantes, telles que le fichier cœur s'il en existe un, les paramètres de ligne de commande de l'application tombée en panne, ainsi que d'autres données utiles.
FTP ou de SCP, les envoyer en tant que courrier électronique, ou les écrire sur un fichier.
22.2. Installer ABRT et lancer ses services
Avertissement
/proc/sys/kernel/core_pattern, qui contient un modèle utilisé pour nommer les fichiers core-dump. Le contenu de ce fichier sera remplacé sur :
|/usr/libexec/abrt-hook-ccpp %s %c %p %u %g %t e
|/usr/libexec/abrt-hook-ccpp %s %c %p %u %g %t e22.2.1. Installer l'interface utilisateur graphique ABRT
root :
yum install abrt-desktop
~]# yum install abrt-desktopps -el | grep abrt-applet 0 S 500 2036 1824 0 80 0 - 61604 poll_s ? 00:00:00 abrt-applet
~]$ ps -el | grep abrt-applet
0 S 500 2036 1824 0 80 0 - 61604 poll_s ? 00:00:00 abrt-appletabrt-applet :
abrt-applet & [1] 2261
~]$ abrt-applet &
[1] 226122.2.2. Installer ABRT pour l'interface en ligne de commande
root :
yum install abrt-cli
~]# yum install abrt-cli22.2.3. Installer les outils ABRT supplémentaires
root :
yum install libreport-plugin-mailx
~]# yum install libreport-plugin-mailxroot de la machine locale. La destination du courrier électronique peut être configurée dans le fichier /etc/libreport/plugins/mailx.conf.
root :
yum install abrt-java-connector
~]# yum install abrt-java-connector22.2.4. Lancer les services ABRT
abrtd est configuré pour être lancé lors du démarrage. Vous pouvez utiliser la commande suivante pour vérifier son statut actuel :
systemctl is-active abrtd.service active
~]$ systemctl is-active abrtd.service
activesystemctl retourne inactive (inactif) ou unknown (inconnu), alors le démon n'est pas en cours d'exécution. Vous pouvez le démarrer pour la session en cours en saisissant la commande suivante en tant qu'utilisateur root :
systemctl start abrtd.service
~]# systemctl start abrtd.serviceabrt-ccpp est en cours d'exécution si vous souhaitez qu'ABRT détecte les incidents C ou C++. Veuillez consulter la Section 22.4, « Détection de problèmes logiciels » pour obtenir une liste de tous les services de détection ABRT disponibles et de leurs paquets respectifs.
abrt-vmcore et abrt-pstoreoops, qui sont uniquement lancés lorsqu'une panique ou un oops de noyau se produit, tous les services ABRT sont automatiquement activés et lancés au moment du démarrage lorsque leurs paquets respectifs sont installés. Vous pouvez activer ou désactiver un service ABRT en utilisant l'utilitaire systemctl comme décrit dans le Chapitre 9, Gérer les services avec systemd.
22.2.5. Tester la détection d'incidents ABRT
kill pour envoyer le signal SEGV pour arrêter un processus. Par exemple, lancez un processus sleep et arrêtez-le avec la commande kill de la manière suivante :
sleep 100 & [1] 2823 kill -s SIGSEGV 2823
~]$ sleep 100 &
[1] 2823
~]$ kill -s SIGSEGV 2823kill, et si une session graphique est en cours d'exécution, l'utilisateur sera notifié du problème détecté par la mini-application de notification de la GUI. Dans l'environnement de ligne de commande, vous pouvez vérifier si l'incident a été détecté en exécutant la commande abrt-cli list ou en examinant le vidage du noyau créé dans le répertoire /var/tmp/abrt/. Veuillez consulter la Section 22.5, « Gestion des problèmes détectés » pour obtenir davantage d'informations sur les manières de travailler avec les incidents détectés.
22.3. Configurer ABRT
- Événement #1 — un répertoire de données des problèmes (« Problem-data directory ») est créé.
- Événement #2 — les données des problèmes sont analysées.
- Événement #3 — le problème est rapporté sur Bugzilla.
analyzer, architecture, coredump, cmdline, executable, kernel, os_release, reason, time, et uid.
backtrace, peuvent être créés pendant l'analyse du problème, selon la méthode de l'analyseur utilisée et ses paramètres de configuration. Chacun de ces fichiers contient des informations spécifiques sur le système et le problème. Par exemple, le fichier kernel enregistre la version du noyau tombé en panne.
22.3.1. Configurer des événements
report_Bugzilla.conf, dans les répertoires /etc/libreport/events/ ou $HOME/.cache/abrt/events/gnome-abrt et abrt-cli lisent les données de configuration de ces fichiers et les passent aux événements qu'ils exécutent.
event_name.xml du répertoire /usr/share/libreport/events/. Ces fichiers sont utilisés par gnome-abrt et abrt-cli pour rendre l'interface utilisateur plus conviviale. Ne modifiez pas ces fichiers à moins de souhaiter modifier l'installation standard. Si vous comptez modifier celle-ci, veuillez copier le fichier à modifier sur le répertoire /etc/libreport/events/ et modifiez le nouveau fichier. Ces fichiers peuvent contenir les informations suivantes :
- un nom d'événement convivial et une description (Bugzilla, rapport au suivi de bogues Bugzilla),
- une liste d'éléments d'un répertoire de données de problèmes dont on a besoin pour que l'événement réussisse,
- une sélection par défaut et une sélection obligatoire d'éléments à envoyer ou à ne pas envoyer,
- si la GUI doit demander de vérifier les données,
- quelles options de configuration existent, leurs types (chaîne, booléen, etc.), valeur par défaut, chaîne d'invite, etc. ; ceci permet à la GUI de créer les boîtes de dialogue appropriées.
report_Logger accepte un nom de fichier de sortie en tant que paramètre. En utilisant le fichier event_name.xml respectif, l'interface utilisateur graphique ABRT détermine quels paramètres peuvent être spécifiés pour un événement sélectionné et permet à l'utilisateur de définir les valeurs de ces paramètres. Les valeurs sont enregistrées par l'interface utilisateur graphique ABRT et réutilisées lors des invocations ultérieures de ces événements. Remarquez que l'interface utilisateur graphique ABRT enregistre les options de configuration en utilisant l'outil GNOME Keyring, et en les passant aux événements, remplace les données provenant des fichiers de configuration en texte.

Figure 22.1. Configurer des événements ABRT
Important
/etc/libreport/ sont lisibles globalement et sont conçus pour être utilisés en tant que paramètres globaux. Ainsi, il n'est pas recommandé de stocker les noms d'utilisateurs, mots de passe, ou toutes autres données sensibles dedans. Les paramètres propres à l'utilisateur (paramétrés dans l'application de la GUI et uniquement lisible par le propriétaire de $HOME) sont stockés de manière sécurisée dans GNOME Keyring ; il peuvent également être stockés dans un fichier de configuration texte dans $HOME/.abrt/abrt-cli.
/etc/libreport/events.d/, ainsi qu'une brève description. Remarquez qu'alors que les fichiers de configuration utilisent des identificateurs d'événements, l'interface utilisateur graphique ABRT fait référence aux événements individuels en utilisant leurs noms. Remarquez également que tous les événements ne peuvent pas être paramétrés à l'aide de la GUI. Pour obtenir des informations sur la manière de définit un événement personnalisé, veuillez consulter la Section 22.3.2, « Créer des événements personnalisés ».
| Nom | Identificateur et fichier de configuration | Description |
|---|---|---|
| uReport |
report_uReport
| Téléverse un μReport sur un serveur FAF. |
| Mailx |
report_Mailx
mailx_event.conf
| Envoie le rapport problématique via l'utilitaire Mailx vers une adresse électronique spécifiée. |
| Bugzilla |
report_Bugzilla
bugzilla_event.conf
| Rapporte le problème à l'installation spécifiée de l'outil de suivi de bogues Bugzilla. |
| Red Hat Customer Support |
report_RHTSupport
rhtsupport_event.conf
| Rapporte le problème au système de Support technique de Red Hat. |
| Analyse d'un incident C ou C++ |
analyze_CCpp
ccpp_event.conf
| Envoie le vidage du noyau dans un serveur retrace distant pour analyses, ou effectue une analyse locale si celle à distance échoue. |
| Téléverseur de rapports |
report_Uploader
uploader_event.conf
| Téléverse une archive tarball (.tar.gz) avec des données problématiques sur la destination choisie, en utilisant le protocole FTP ou SCP. |
| Analyser le vidage mémoire |
analyze_VMcore
vmcore_event.conf
| Exécute GDB (le débogueur GNU) sur les données problématiques d'un oops de noyau et génère un backtrace du noyau. |
| Débogueur GNU local |
analyze_LocalGDB
ccpp_event.conf
| Exécute GDB (le débogueur GNU) sur les données problématiques d'une application et génère un backtrace du programme. |
| Collect .xsession-errors |
analyze_xsession_errors
ccpp_event.conf
| Enregistre les lignes utiles du fichier ~/.xsession-errors sur le rapport de problème. |
| Logger |
report_Logger
print_event.conf
| Crée un rapport sur le problème et l'enregistre sur un fichier local spécifié. |
| Kerneloops.org |
report_Kerneloops
koops_event.conf
| Envoie un problème de noyau sur l'outil de suivi des oops sur kerneloops.org. |
22.3.2. Créer des événements personnalisés
/etc/libreport/events.d/. Ces fichiers de configuration sont chargés par le fichier de configuration principal, /etc/libreport/report_event.conf. Vous n'avez nul besoin de modifier les fichiers de configuration par défaut car abr exécutera des scripts qui se trouvent dans /etc/libreport/events.d/. Ce fichier accepte les métacaractères shell (*, $, ?, etc. ) et interprète les chemins relatifs en fonction de son emplacement.
espace ou par le caractère de Tabulation est considérée comme faisant partie de cette règle. Chaque règle consiste de deux parties, la partie condition et la partie programme. La partie condition contient des conditions sous l'une des formes suivantes :
- VAR=VAL
- VAR!=VAL
- VAL~=REGEX
- VAR est soit le mot clé
EVENT(événement) ou le nom d'un élément de répertoire de données problématiques (tel qu'executable,package,hostname, etc. ), - VAL est soit le nom d'un événement ou d'un élément de données problématiques, et
- REGEX est une expression rationnelle.
EVENT=post-create date > /tmp/dt
echo $HOSTNAME `uname -r`
EVENT=post-create date > /tmp/dt
echo $HOSTNAME `uname -r`/tmp/dt par l'heure et la date actuelles et imprimera le nom d'hôte de la machine et sa version de noyau dans la sortie standard.
~/.xsession-errors sur le rapport de problème d'un problème pour lequel le service abrt-ccpp a été utilisé, à condition que des bibliothèques X11 aient été chargées au moment où l'application a échoué :
/etc/libreport/events.d/.
post-create- Cet événement est exécuté par
abrtdpour traiter les nouveaux répertoires de données problématiques créés. Lorsque l'événementpost-createest exécuté,abrtdvérifie si les nouvelles données problématiques correspondent à celles des répertoires de problèmes déjà existants. Si un tel répertoire de problèmes existe, les nouvelles données problématiques seront supprimées. Notez que si le script qui se trouve dans la définition de l'événementpost-createexiste avec une valeur non nulle,abrtdinterrompera le processus et abandonnera les données du problème. notify,notify-dup- L'événement
notifyest exécuté une fois quepost-createest terminé. Lorsque l'événement est exécuté, l'utilisateur sait que le problème requiert son attention.notify-dupest similaire, sauf qu'il est utilisé pour des instances dupliquées d'un même problème. analyze_name_suffix- où name_suffix est la partie remplaçable du nom de l'événement. Cet événement est utilisé pour traiter les données collectées. Par exemple, l'événement
analyze_LocalGDButilise GNU Debugger (GDB) pour traiter l'image mémoire d'une application et produire un backtrace de l'incident. collect_name_suffix- …où name_suffix est la partie ajustable du nom de l'événement. Cet événement est utilisé pour collecter des informations supplémentaires sur les problèmes.
report_name_suffix- …où name_suffix est la partie ajustable du nom de l'événement. Cet événement est utilisé pour rapporter un problème.
22.3.3. Paramétrer les rapports automatiques
root :
abrt-auto-reporting enabled
~]# abrt-auto-reporting enabledAutoreportingEnabled (rapports automatiques activés) du fichier de configuration /etc/abrt/abrt.conf sur « yes ». Ce paramètre global s'applique à tous les utilisateurs du système. Remarquez qu'en activant cette option, les rapports automatiques seront également activés dans l'environnement de bureau graphique. Pour activer les rapport automatiques dans l'interface utilisateur graphique ABRT uniquement, veuillez faire basculer l'option Envoyer des uReport automatiquement sur YES dans la fenêtre Configuration des rapports de problèmes. Pour ouvrir cette fenêtre, veuillez choisir → à partir d'une instance de l'application gnome-abrt en cours d'exécution. Pour lancer l'application, veuillez vous rendre sur → → .

Figure 22.2. Configuration des rapports de problèmes ABRT
Note
AutoreportingEvent du fichier de configuration /etc/abrt/abrt.conf de manière à pointer vers un événement ABRT différent. Veuillez consulter le Tableau 22.1, « Événements ABRT standard » pour un aperçu des événements standard.
22.4. Détection de problèmes logiciels
| Langage/projet | Paquet |
|---|---|
| C ou C++ | abrt-addon-ccpp |
| Python | abrt-addon-python |
| Ruby | rubygem-abrt |
| Java | abrt-java-connector |
| X.Org | abrt-addon-xorg |
| Linux (oops de noyau) | abrt-addon-kerneloops |
| Linux (panique de noyau) | abrt-addon-vmcore |
| Linux (stockage persistant) | abrt-addon-pstoreoops |
22.4.1. Détection d'incidents C et C++
abrt-ccpp installe son propre gestionnaire core-dump, qui, lorsque démarré, remplace la valeur par défaut de la variable core_pattern du noyau, afin que les incidents C et C++ soient gérés par abrtd. Si vous arrêtez le service abrt-ccpp, l'ancienne valeur de core_pattern sera réintégrée.
/proc/sys/kernel/core_pattern contient la chaîne core, ce qui signifie que le noyau produit des fichiers avec le préfixe core. dans le répertoire actuel du processus en panne. Le service abrt-ccpp remplace le fichier core_pattern afin qu'il contienne la commande suivante :
|/usr/libexec/abrt-hook-ccpp %s %c %p %u %g %t e
|/usr/libexec/abrt-hook-ccpp %s %c %p %u %g %t eabrt-hook-ccpp program, which stores it in ABRT's dump location and notifies the abrtd daemon of the new crash. It also stores the following files from the /proc/PID/ directory (where PID is the ID of the crashed process) for debugging purposes: maps, limits, cgroup, status. See proc(5) for a description of the format and the meaning of these files.
22.4.2. Détection des exceptions Python
abrt.pth installé dans /usr/lib64/python2.7/site-packages/, qui importera à son tour le fichier abrt_exception_handler.py. Ceci remplace le fichier Python par défaut sys.excepthook par un gestionnaire personnalisé, qui transfère les exceptions non gérées au démon abrtd via son API Socket.
-S à l'interprète Python :
python -S file.py
~]$ python -S file.py22.4.3. Détection des exceptions Ruby
at_exit, qui est exécutée lorsqu'un programme se termine. Ceci permet de vérifier les exceptions non gérées possibles. Chaque fois qu'une exception non gérée est capturée, le gestionnaire ABRT prépare un rapport de bogue, qui pourra être soumis à Red Hat Bugzilla à l'aide des outils ABRT standard.
22.4.4. Détection des exceptions Java
abrtd. L'agent enregistre plusieurs rappels d'événement JVMTI et doit être chargé dans JVM à l'aide du paramètre de ligne de commande -agentlib. Remarquez que le traitement des rappels enregistrés affecte négativement les performances de l'application. Pour intercepter les exceptions ABRT d'une classe Java, veuillez utiliser la commande suivante :
java -agentlib:abrt-java-connector[=abrt=on] $MyClass -platform.jvmtiSupported true
~]$ java -agentlib:abrt-java-connector[=abrt=on] $MyClass -platform.jvmtiSupported trueabrt=on au connecteur, vous vous assurez que les exceptions sont gérées par abrtd. Dans le cas où vous souhaiteriez faire en sorte que le connecteur fasse sortir les exceptions sur la sortie standard, ne pas utiliser cette option.
22.4.5. Détection d'incidents X.Org
abrt-xorg collecte et traite les informations sur les incidents du serveur X.Org server qui proviennent du fichier /var/log/Xorg.0.log. Remarquez qu'aucun rapport n'est généré si un module X.org sur liste noire est chargé. À la place, un fichier not-reportable est créé dans le répertoire de données problématiques avec une explication appropriée. Vous trouverez la liste des modules fautifs dans le fichier /etc/abrt/plugins/xorg.conf. Seuls les modules de pilotes graphiques propriétaires sont mis sur liste noire par défaut.
22.4.6. Détection d'oops et de paniques de noyau
abrt-oops.
abrt-vmcore. Le service démarre uniquement lorsqu'un fichier vmcore (un fichier d'image mémoire noyau) apparaît dans le répertoire /var/crash/. Lorsqu'un fichier d'image mémoire est trouvé, abrt-vmcore crée un nouveau répertoire de données problématiques dans le répertoire /var/tmp/abrt/ et déplace le fichier de l'image mémoire sur le nouveau répertoire de données problématiques créé. Une fois la recherche du répertoire /var/crash/ est terminée, le service est arrêté.
kdump doit être activé sur le système. La quantité de mémoire réservée au noyau kdump doit être définie correctement. Cela peut être effectué en utilisant l'outil graphique system-config-kdump ou en spécifiant le paramètre crashkernel dans la liste des options de noyau dans le menu GRUB. Pour obtenir des détails sur la manière d'activer et de configurer kdump, veuillez consulter le Guide de vidage sur incident noyau Red Hat Enterprise Linux 7. Pour obtenir des informations sur la façon d'apporter des modifications au menu GRUB, voir Chapitre 24, Utiliser le chargeur de démarrage GRUB 2.
abrt-pstoreoops, ABRT est capable de collecter et de traiter des informations sur les paniques de noyau, qui, sur les systèmes prenant en charge pstore, sont stockées dans le répertoire monté automatiquement /sys/fs/pstore/. L'interface pstore (stockage persistant) dépendante de la plateforme, fournit un mécanisme de stockage de données à travers les redémarrages système, permettant ainsi de préserver les informations sur les paniques de noyau. Le service démarre automatiquement lorsque les fichiers de vidage sur incident du noyau apparaissent dans le répertoire /sys/fs/pstore/.
22.5. Gestion des problèmes détectés
abrtd peuvent être affichées, rapportées, et supprimées en utilisant l'outil de ligne de commande abrt-cli, ou l'outil graphique gnome-abrt.
Note
22.5.1. Utiliser l'outil de ligne de commande
ABRT has detected 1 problem(s). For more info run: abrt-cli list --since 1398783164
ABRT has detected 1 problem(s). For more info run: abrt-cli list --since 1398783164abrt-cli list :
abrt-cli list possède un identifiant unique et un répertoire qui peut être utilisé pour des manipulations supplémentaires en utilisant abrt-cli.
abrt-cli info :
abrt-cli info [-d] directory_or_id
abrt-cli info [-d] directory_or_id list et info, veuillez leur passer l'option -d (--detailed), qui affiche toutes les informations stockées sur les problèmes répertoriés, y compris les fichiers backtrace respectifs si ceux-ci ont déjà été générés.
abrt-cli report :
abrt-cli report directory_or_id
abrt-cli report directory_or_id abrt-cli ouvre un éditeur de texte avec le contenu du rapport. Vous pouvez voir ce qui est rapporté et vous pouvez inclure des instructions sur la manière de reproduire l'incident, ainsi qu'ajouter d'autres commentaires. Vous pouvez également vérifier le backtrace car celui-ci peut être envoyé sur un serveur public et vu par tout le monde, selon les paramètres de l'événement rapport-problème.
Note
abrt-cli utilise l'éditeur défini dans la variable d'environnement ABRT_EDITOR. Si la variable n'est pas définie, les variables VISUAL et EDITOR seront vérifiées. Si aucune de ces variables n'est définie, alors l'éditeur vi sera utilisé. Vour pouvez définir l'éditeur préféré dans votre fichier de configuration .bashrc. Par exemple, si vous préférez GNU Emacs, veuillez ajouter la ligne suivante au fichier :
export VISUAL=emacs
export VISUAL=emacsabrt-cli rm directory_or_id
abrt-cli rm directory_or_id abrt-cli en particulier, veuillez utiliser l'option --help :
abrt-cli command --help
abrt-cli command --help 22.5.2. Utilisation de la GUI
D-Bus chaque fois qu'un rapport de problème est créé. Si la miniapplication ABRT est en cours d'exécution dans un environnement de bureau graphique, elle recevra ce message et affichera une boîte de dialogue de notification sur le bureau. Vous pouvez ouvrir la GUI ABRT en utilisant cette boîte de dialogue en cliquant sur le bouton . Vous pouvez également ouvrir la GUI ABRT en sélectionnant l'élément de menu → → .
gnome-abrt &
~]$ gnome-abrt &
Figure 22.3. GUI ABRT
22.6. Ressources supplémentaires
Documentation installée
- abrtd(8) — The manual page for the
abrtddaemon provides information about options that can be used with the daemon. - abrt_event.conf(5) — The manual page for the
abrt_event.confconfiguration file describes the format of its directives and rules and provides reference information about event meta-data configuration in XML files.
Documentation en ligne
- Guide de mise en réseau Red Hat Enterprise Linux 7 — Le Guide de mise en réseau de Red Hat Enterprise Linux 7 documente les informations pertinentes à la configuration et à l'administration des interfaces réseau et des services réseau sur ce système.
- Guide de vidage sur incident noyau Red Hat Enterprise Linux 7 Kernel Crash Dump Guide — Le Guide de vidage sur incident noyau de Red Hat Enterprise Linux 7 documente comment configurer, tester, et utiliser le service de récupération sur incident
kdumpet fournit un bref aperçu sur la manière d'analyser l'image mémoire à l'aide de l'utilitaire de débogage crash.
Voir aussi
- Chapitre 20, Afficher et gérer des fichiers journaux décrit la configuration du démon
rsysloget du journal systemd et explique comment localiser, afficher et surveiller les journaux système. - Chapitre 8, Yum décrit comment utiliser le gestionnaire de paquets Yum pour rechercher, installer, mettre à jour, et désinstaller des paquets sur la ligne de commande.
- Chapitre 9, Gérer les services avec systemd offre une introduction à
systemdet documente comment utiliser la commandesystemctlpour gérer des services système, configurer des cibles systemd, et exécuter des commandes de gestion de l'alimentation.
Chapitre 23. OProfile
oprofile doit être installé pour utiliser cet outil.
- Utilisation des bibliothèques partagées — les échantillons de code dans les bibliothèques partagées ne sont pas attribués à l'application en particulier, à moins que l'option
--separate=librarysoit utilisée. - Les échantillons de surveillance des performances sont inexacts — lorsque la surveillance des performances déclenche un échantillon, la gestion de l'interruption n'est pas précise comme une division par une exception zéro. À cause de l'exécution désordonnée des instructions par le processeur, l'échantillon peut être enregistré sur une instruction aux alentours.
opreportn'associe pas les échantillons pour les fonctions « inline » correctement —opreportutilise un simple mécanisme de gamme d'adresse pour déterminer dans quelle fonction se trouve une adresse. Les échantillons de fonctions « Inline » ne sont pas attribués à la fonction « inline » mais plutôt à la fonction dans laquelle la fonction « inline » a été insérée.- OProfile accumule les données de multiples exécutions — OProfile est un profileur global et s'attend à ce que les processus démarrent et s'arrêtent à plusieurs reprises. Ainsi, les échantillons des multiples exécutions s'accumulent. Veuillez utiliser la commande
opcontrol --resetpour supprimer les échantillons des exécutions précédentes. - Les compteurs de performance du matériel ne fonctionnent pas sur les machines virtuelles invitées — comme les compteurs de performance du matériel ne sont pas disponibles sur les systèmes virtuels, vous devrez utiliser le mode
timer. Saisissez la commandeopcontrol --deinit, puis exécutezmodprobe oprofile timer=1pour activer le modetimer. - Problèmes de performances non limités au CPU — OProfile est conçu pour trouver des problèmes liés aux processus limités par les CPU. OProfile n'identifie pas les processus endormis car ils attendent qu'un verrouillage ou qu'un autre type d'événement se produise (par exemple qu'un périphérique d'E/S termine une opération).
23.1. Aperçu des outils
oprofile.
| Commande | Description |
|---|---|
ophelp |
Affiche les événements disponibles pour le processeur du système avec une brève description de chacun d'entre eux.
|
opimport |
Convertit les fichiers de la base de données d'un format binaire étranger au format natif du système. Utilisez cette option uniquement lors de l'analyse d'un échantillon de base de données provenant d'une architecture différente.
|
opannotate | Crée une source annotée pour un exécutable si l'application a été compilée avec des symboles de débogage. Veuillez consulter la Section 23.6.4, « Utiliser opannotate » pour voir des détails. |
opcontrol |
Configure les données à collecter. Veuillez consulter la Section 23.3, « Configurer OProfile en utilisant le mode hérité » pour voir des détails.
|
operf |
Outil recommandé à la place de
Pour voir les différences entre opcontrol pour le profilage. Veuillez consulter la Section 23.2, « Utiliser operf » pour voir des détails.
operf et opcontrol, veuillez consulter la Section 23.1.1, « operf vs. opcontrol ». |
opreport |
Récupère les données du profil. Veuillez consulter la Section 23.6.1, « Utiliser
opreport » pour voir des détails.
|
oprofiled |
S'exécute en tant que démon pour écrire des données échantillon sur le disque de manière périodique.
|
23.1.1. operf vs. opcontrol
operf, ou l'outil opcontrol.
operf
operf utilise le sous-système « Linux Performance Events Subsystem », et ne requiert ainsi pas le pilote du noyau oprofile. L'outil operf vous permet de cibler votre profilage de manière plus précise, en tant que processus unique ou global, il permet également à OProfile de mieux co-exister avec les autres outils utilisant le matériel de surveillance des performances sur votre système. Contrairement à opcontrol, celui-ci peut être utilisé sans les privilèges d'utilisateur root. Cependant, operf est également capable d'effectuer des opérations globales en utilisant l'option --system-wide, lorsque les privilèges root sont requis.
operf, aucun paramétrage initial n'est nécessaire. Vous pouvez invoquer operf avec des options de ligne de commande pour spécifier vos paramètres de profilage. Après cela, vous pourrez exécuter les outils OProfile post-traitement comme décrit dans la Section 23.6, « Analyser les données ». Veuillez consulter la Section 23.2, « Utiliser operf » pour obtenir davantage d'informations.
opcontrol
opcontrol, le démon oprofiled, et plusieurs outils post-traitement. La commande opcontrol est utilisée pour configurer, lancer et arrêter une session de profilage. Un pilote de noyau OProfile, habituellement créé en tant que module de noyau, est utilisé pour collecter les échantillons, qui sont ensuite enregistrés dans des fichiers d'échantillon par oprofiled. Vous pouvez utiliser le mode hérité uniquement si vous possédez les privilèges root. Dans certains cas, comme lorsque vous devez échantillonner des zones sur lesquelles IRQ (« Interrupt Request ») est désactivé, cette alternative est la meilleure.
23.2. Utiliser operf
operf est le mode de profilage recommandé et ne requiert pas de paramétrage initial avant d'être lancé. Tous les paramètres sont spécifiés comme options de ligne de commande et il n'y a pas de commande séparée pour lancer le processus de profilage. Pour arrêter operf, appuyez sur Ctrl+C. La syntaxe de la commande operf habituelle est comme suit :
operf options range command args
operf options range command argsoperf(1). Remplacez range par l'une des options suivantes :
--system-wide - ce paramètre permet d'effectuer un profilage global, veuillez consulter Note
--pid=PID - sert à profiler une application en cours d'exécution, où PID est l'ID du processus que vous souhaitez profiler.
--pid ou --system-wide est requis, mais ces options ne peuvent pas être utilisées simultanément.
operf sur la ligne de commande sans paramétrer l'option range, des données seront collectées pour les processus enfants.
Note
operf --system-wide, vous devrez être connecté avec les privilèges root. À la fin du profilage, vous pourrez arrêter operf avec Ctrl+C.
operf --system-wide en tant que processus d'arrière-plan (avec &), arrêtez-le de manière contrôlée pour traiter les données de profil collectées. Pour cela, veuillez utiliser :
kill -SIGINT operf-PID
kill -SIGINT operf-PID operf --system-wide, il est recommandé d'utiliser le répertoire /root ou un sous-répertoire de /root comme répertoire de travail actuel afin que les fichiers de données échantillons ne soient pas stockés dans des emplacements accessibles aux utilisateurs normaux.
23.2.1. Spécifier le noyau
operf --vmlinux=vmlinux_path
operf --vmlinux=vmlinux_path23.2.2. Paramétrer les événements à surveiller
Note
operf. Si vous recevez ce message :
Your kernel's Performance Events Subsystem does not support your processor type
Your kernel's Performance Events Subsystem does not support your processor type
operf, essayez d'effectuer un profilage avec opcontrol pour voir si votre type de processeur pourrait être pris en charge par le mode hérité d'OProfile.
Note
root :
opcontrol --deinit
opcontrol --deinitmodprobe oprofile timer=1
modprobe oprofile timer=1operf --events=event1,event2…
operf --events=event1,event2…event-name:sample-rate:unit-mask:kernel:user
event-name:sample-rate:unit-mask:kernel:user| Spécification | Description |
|---|---|
| event-name | Nom de l'événement symbolique exact pris de ophelp |
| sample-rate | Nombre d'événements à attendre avant d'échantillonner à nouveau. Plus le compte est faible, plus les échantillons sont fréquents. Pour les événements qui ne se produisent pas fréquemment, un compte plus faible peut être nécessaire pour capturer un nombre statistiquement significatif d'instances d'événements. D'un autre côté, un échantillonnage trop fréquent peut surcharger le système. Par défaut, OProfile utilise un ensemble d'événements basé temps, ce qui crée un échantillon tous les 100,000 cycles d'horloge par processeur. |
| unit-mask | Les masques d'unité, qui définissent encore plus l'événement, sont répertoriés dans ophelp. Vous pouvez insérer une valeur hexadécimale, commençant par « 0x », ou une chaîne qui correspond au premier mot de la description du masque d'unité dans ophelp. La définition par nom est valide pour les masques d'unité comprenant des paramètres « extra: », comme indiqué par la sortie de ophelp. Ce type de masque d'unité ne peut pas être défini avec une valeur hexadécimale. Remarquez que sur certaines architectures, il peut y avoir de multiples masques d'unité avec la même valeur hexadécimale. Dans ce cas, ils devront être spécifiés par leurs nom uniquement. |
| kernel | Indique s'il faut profiler le code du noyau (insérez 0 ou 1 (par défaut)) |
| user | Indique s'il faut profiler le code de l'espace utilisateur (insérez 0 ou 1 (par défaut)) |
ophelp.
ophelp
ophelp23.2.3. Catégorisation des échantillons
--separate-thread catégorise les échantillons par ID de groupe de thread (tgid) et par ID de thread (tid). Ceci est utile pour voir les échantillons par thread dans les applications à threads multiples. Lorsqu'utilisé en conjonction avec l'option --system-wide, --separate-thread est également utile pour voir les échantillons par processus (par groupe de threads) dans le cas où de multiples processus seraient exécutés par le même programme pendant l'exécution d'un profilage.
--separate-cpu catégorises les échantillons par CPU.
23.3. Configurer OProfile en utilisant le mode hérité
opcontrol pour configurer OProfile. Tandis que les commandes opcontrol sont exécutées, les options de l'installation sont enregistrées sur le fichier /root/.oprofile/daemonrc.
23.3.1. Spécifier le noyau
root :
opcontrol --setup --vmlinux=/usr/lib/debug/lib/modules/`uname -r`/vmlinux
opcontrol --setup --vmlinux=/usr/lib/debug/lib/modules/`uname -r`/vmlinuxImportant
root :
opcontrol --setup --no-vmlinux
opcontrol --setup --no-vmlinuxoprofile du noyau si celui-ci n'est pas déjà chargé, et crée le répertoire /dev/oprofile/ s'il n'existe pas déjà. Veuillez consulter la Section 23.7, « Comprendre le répertoire /dev/oprofile/ » pour obtenir des détails sur ce répertoire.
23.3.2. Paramétrer les événements à surveiller
| Processeur | cpu_type | Nombre de compteurs |
|---|---|---|
| AMD64 | x86-64/hammer | 4 |
| AMD Family 10h | x86-64/family10 | 4 |
| AMD Family 11h | x86-64/family11 | 4 |
| AMD Family 12h | x86-64/family12 | 4 |
| AMD Family 14h | x86-64/family14 | 4 |
| AMD Family 15h | x86-64/family15 | 6 |
| Applied Micro X-Gene | arm/armv8-xgene | 4 |
| ARM Cortex A53 | arm/armv8-ca53 | 6 |
| ARM Cortex A57 | arm/armv8-ca57 | 6 |
| IBM eServer System i et IBM eServer System p | timer | 1 |
| IBM POWER4 | ppc64/power4 | 8 |
| IBM POWER5 | ppc64/power5 | 6 |
| IBM PowerPC 970 | ppc64/970 | 8 |
| IBM PowerPC 970MP | ppc64/970MP | 8 |
| IBM POWER5+ | ppc64/power5+ | 6 |
| IBM POWER5++ | ppc64/power5++ | 6 |
| IBM POWER56 | ppc64/power6 | 6 |
| IBM POWER7 | ppc64/power7 | 6 |
| IBM POWER8 | ppc64/power7 | 8 |
| IBM S/390 et IBM System z | timer | 1 |
| Intel Core i7 | i386/core_i7 | 4 |
| Intel Nehalem microarchitecture | i386/nehalem | 4 |
| Intel Westmere microarchitecture | i386/westmere | 4 |
| Intel Haswell microarchitecture (non-hyper-threaded) | i386/haswell | 8 |
| Intel Haswell microarchitecture (hyper-threaded) | i386/haswell-ht | 4 |
| Intel Ivy Bridge microarchitecture (non-hyper-threaded) | i386/ivybridge | 8 |
| Intel Ivy Bridge microarchitecture (hyper-threaded) | i386/ivybridge-ht | 4 |
| Intel Sandy Bridge microarchitecture (non-hyper-threaded) | i386/sandybridge | 8 |
| Intel Sandy Bridge microarchitecture | i386/sandybridge-ht | 4 |
| Intel Broadwell microarchitecture (non-hyper-threaded) | i386/broadwell | 8 |
| Intel Broadwell microarchitecture (hyper-threaded) | i386/broadwell-ht | 4 |
| Intel Silvermont microarchitecture | i386/silvermont | 2 |
| TIMER_INT | timer | 1 |
timer sera utilisé en tant que type de processeur.
timer est utilisé, les événements ne pourront être paramétrés pour aucun processeur car il n'offre pas la prise en charge des compteurs de performances du matériel. Au contraire, l'interruption « timer » est utilisée pour le profilage.
timer n'est pas utilisé comme type de processeur, les événements surveillés pourront être modifiés, et le compteur 0 du processeur est défini sur un événement basé temps par défaut. S'il existe plus d'un compteur sur le processeur, les compteurs autres que 0 ne seront pas définis sur un événement par défaut. Les événements par défaut surveillés sont affichés dans la Tableau 23.4, « Événements par défaut ».
| Processeur | Événement par défaut du compteur | Description |
|---|---|---|
| AMD Athlon et AMD64 | CPU_CLK_UNHALTED | L'horloge du processeur n'est pas à l'arrêt |
| AMD Family 10h, AMD Family 11h, AMD Family 12h | CPU_CLK_UNHALTED | L'horloge du processeur n'est pas à l'arrêt |
| AMD Family 14h, AMD Family 15h | CPU_CLK_UNHALTED | L'horloge du processeur n'est pas à l'arrêt |
| Applied Micro X-Gene | CPU_CYCLES | Cycles de processeur |
| ARM Cortex A53 | CPU_CYCLES | Cycles de processeur |
| ARM Cortex A57 | CPU_CYCLES | Cycles de processeur |
| IBM POWER4 | CYCLES | Cycles de processeur |
| IBM POWER5 | CYCLES | Cycles de processeur |
| IBM POWER8 | CYCLES | Cycles de processeur |
| IBM PowerPC 970 | CYCLES | Cycles de processeur |
| Intel Core i7 | CPU_CLK_UNHALTED | L'horloge du processeur n'est pas à l'arrêt |
| Intel Nehalem microarchitecture | CPU_CLK_UNHALTED | L'horloge du processeur n'est pas à l'arrêt |
| Intel Pentium 4 (hyper-threaded et non-hyper-threaded) | GLOBAL_POWER_EVENTS | Période pendant laquelle le processeur n'est pas arrêté |
| Intel Westmere microarchitecture | CPU_CLK_UNHALTED | L'horloge du processeur n'est pas à l'arrêt |
| Intel Broadwell microarchitecture | CPU_CLK_UNHALTED | L'horloge du processeur n'est pas à l'arrêt |
| Intel Silvermont microarchitecture | CPU_CLK_UNHALTED | L'horloge du processeur n'est pas à l'arrêt |
| TIMER_INT | (aucun) | Échantillon pour chaque interruption du timer |
ls -d /dev/oprofile/[0-9]*
ls -d /dev/oprofile/[0-9]*ophelp pour déterminer les événements disponibles pour le profilage. La liste est spécifique au type de processeur du système.
ophelp
ophelpNote
ophelp échoue avec le message d'erreur suivant :
Unable to open cpu_type file for reading Make sure you have done opcontrol --init cpu_type 'unset' is not valid you should upgrade oprofile or force the use of timer mode
Unable to open cpu_type file for reading
Make sure you have done opcontrol --init
cpu_type 'unset' is not valid
you should upgrade oprofile or force the use of timer modeopcontrol :
opcontrol --event=event-name:sample-rate
opcontrol --event=event-name:sample-rateophelp, et remplacez sample-rate par le nombre d'événements entre échantillons.
23.3.2.1. Taux d'échantillonnage
cpu_type n'est pas égal à timer, chaque événement aura un taux d'échantillonnage paramétré. Le taux d'échantillonnage correspond au nombre d'événements entre chaque capture d'échantillon.
opcontrol --event=event-name:sample-rate
opcontrol --event=event-name:sample-rateAvertissement
23.3.2.2. Masques d'unités
ophelp. Les valeurs de chaque masque d'unité sont répertoriées sous un format hexadécimal. Pour spécifier plus d'un masque d'unité, les valeurs hexadécimales doivent être combinées en utilisant une opération bitwise or.
opcontrol --event=event-name:sample-rate:unit-mask
opcontrol --event=event-name:sample-rate:unit-mask23.3.3. Séparer les profils du noyau et de l'espace utilisateur
opcontrol --event=event-name:sample-rate:unit-mask:0
opcontrol --event=event-name:sample-rate:unit-mask:0opcontrol --event=event-name:sample-rate:unit-mask:1
opcontrol --event=event-name:sample-rate:unit-mask:1opcontrol --event=event-name:sample-rate:unit-mask:1:0
opcontrol --event=event-name:sample-rate:unit-mask:1:0opcontrol --event=event-name:sample-rate:unit-mask:1:1
opcontrol --event=event-name:sample-rate:unit-mask:1:1opcontrol --separate=choice
opcontrol --separate=choicenone— ne pas séparer les profils (valeur par défaut).library— générer des profils par application pour les bibliothèques.kernel— générer des profils par application pour le noyau et les modules du noyau.all— générer des profils par application pour les bibliothèques et des profils par application pour le noyau et les modules du noyau.
--separate=library est utilisé, le nom du fichier échantillon inclura également le nom de l'exécutable, ainsi que le nom de la bibliothèque.
Note
23.4. Lancer et arrêter OProfile en utilisant le mode hérité
opcontrol --start
opcontrol --startUsing log file /var/lib/oprofile/oprofiled.log Daemon started. Profiler running.
Using log file /var/lib/oprofile/oprofiled.log Daemon started. Profiler running./root/.oprofile/daemonrc sont utilisés.
oprofiled, est lancé. Il écrit de manière périodique les données échantillons sur le répertoire /var/lib/oprofile/samples/. Le fichier journal du démon se trouve dans /var/lib/oprofile/oprofiled.log.
Important
nmi_watchdog est enregistré avec un sous-système perf. Pour cette raison, le sous-système perf prend contrôle des enregistrements du compteur des performance pendant le démarrage, ce qui empêche à OProfile de fonctionner.
nmi_watchdog=0 défini, ou exécutez la commande suivante en tant qu'utilisateur root pour désactiver nmi_watchdog pendant le démarrage :
echo 0 > /proc/sys/kernel/nmi_watchdog
echo 0 > /proc/sys/kernel/nmi_watchdognmi_watchdog, veuillez utiliser la commande suivante en tant qu'utilisateur root :
echo 1 > /proc/sys/kernel/nmi_watchdog
echo 1 > /proc/sys/kernel/nmi_watchdogopcontrol --shutdown
opcontrol --shutdown23.5. Enregistrer des données en mode hérité
opcontrol --save=name
opcontrol --save=name/var/lib/oprofile/samples/name/ et les fichiers d'échantillons actuels y sont copiés.
--session-dir. Si non spécifiées, les données sont enregistrées dans le répertoire oprofile_data/ se trouvant sur le chemin actuel.
23.6. Analyser les données
operf ou opcontrol en mode hérité.
operf stocke les données de profilage dans le répertoire current_dir/oprofile_data/. Vous pouvez modifier l'emplacement avec l'option --session-dir. Les outil d'analyse post-profilage, tels qu'opreport et opannotate, peuvent être utilisés pour générer des rapports de profil. Ces outils recherchent des échantillons dans le répertoire current_dir/oprofile_data/ en premier. Si ce répertoire n'existe pas, les outils d'analyse utilisent le répertoire de la session standard de /var/lib/oprofile/. Des statistiques, comme le total des échantillons reçus et le total des échantillons perdus, sont écrites sur le fichier session_dir/samples/operf.log.
oprofiled collecte périodiquement les échantillons et les écrits dans le répertoire /var/lib/oprofile/samples/. Avant de lire les données, assurez-vous que toutes les données ont bien été écrites sur ce répertoire, en exécutant la commande suivante en tant qu'utilisateur root :
opcontrol --dump
opcontrol --dump/bin/bash devient :
\{root\}/bin/bash/\{dep\}/\{root\}/bin/bash/CPU_CLK_UNHALTED.100000
\{root\}/bin/bash/\{dep\}/\{root\}/bin/bash/CPU_CLK_UNHALTED.100000opreportopannotate
Avertissement
oparchive peut être utilisé pour répondre à ce problème.
23.6.1. Utiliser opreport
opreport offre une vue d'ensemble sur tous les exécutables en cours de profilage. Voici un extrait d'échantillon de la commande opreport :
opreport(1) pour afficher une liste des options de ligne de commande disponibles, comme l'option -r utilisée pour trier la sortie de l'exécutable avec le plus petit nombre d'échantillons vers celui en ayant le plus grand nombre. Vous pouvez également utiliser l'option -t ou --threshold pour réduire la sortie de opcontrol.
23.6.2. Utiliser opreport sur un seul exécutable
opreport mode executable
opreport mode executable-l- Cette option est utilisée pour répertorier les données d'échantillon par symbole. Par exemple, l'exécution de cette commande :
opreport -l /usr/lib/tls/libc-version.so
~]# opreport -l /usr/lib/tls/libc-version.soCopy to Clipboard Copied! Toggle word wrap Toggle overflow produit la sortie suivante :Copy to Clipboard Copied! Toggle word wrap Toggle overflow La première colonne correspond au nombre d'échantillons pour le symbole, la seconde colonne est le pourcentage d'échantillons de ce symbole relatif au nombre total d'échantillons de l'exécutable, et la troisième colonne est le nom du symbole.Pour trier la sortie depuis le plus grand nombre d'échantillons au plus petit (l'ordre contraire), veuillez utiliser-ren conjonction à l'option-l. -isymbol-name- Lister les données d'échantillons spécifiques à un nom de symbole. Par exemple, en exécutant :
opreport -l -i __gconv_transform_utf8_internal /usr/lib/tls/libc-version.so
~]# opreport -l -i __gconv_transform_utf8_internal /usr/lib/tls/libc-version.soCopy to Clipboard Copied! Toggle word wrap Toggle overflow retournera la sortie suivante :samples % symbol name 12 100.000 __gconv_transform_utf8_internal
samples % symbol name 12 100.000 __gconv_transform_utf8_internalCopy to Clipboard Copied! Toggle word wrap Toggle overflow La première ligne est un résumé de la combinaison symbole/exécutable.La première colonne correspond au nombre d'échantillons pour le symbole de mémoire, la seconde colonne est le pourcentage d'échantillons de l'adresse mémoire relatif au nombre total d'échantillons du symbole, et la troisième colonne est le nom du symbole. -d- Cette option répertorie les données d'échantillons par symboles avec plus de détails que l'option
-l. Par exemple, avec la commande suivante :opreport -d -i __gconv_transform_utf8_internal /usr/lib/tls/libc-version.so
~]# opreport -d -i __gconv_transform_utf8_internal /usr/lib/tls/libc-version.soCopy to Clipboard Copied! Toggle word wrap Toggle overflow la sortie suivante est retournée :Copy to Clipboard Copied! Toggle word wrap Toggle overflow Les données sont les mêmes qu'avec l'option-lsauf que pour chaque symbole, chaque adresse de mémoire virtuelle est affichée. Pour chaque adresse de mémoire virtuelle, le nombre d'échantillons et le pourcentage d'échantillons relatif au nombre d'échantillons du symbole est affiché. -esymbol-name…- Avec cette option, vous pouvez exclure certains symboles de la sortie. Remplacez symbol-name par une liste des symboles que vous souhaitez exclure, séparés par des virgules.
session:name- Ici, vous pouvez spécifier le chemin complet de la session, un répertoire relatif au répertoire
/var/lib/oprofile/samples/, ou si vous utilisezoperf, un répertoire relatif à./oprofile_data/samples/.
23.6.3. Obtenir une sortie plus détaillée sur les modules
initrd pendant le démarrage système, du répertoire avec les divers modules de noyau, ou d'un module de noyau créé localement. Par conséquent, lorsqu'OProfile enregistre des échantillons pour un module, il répertorie les échantillons des modules d'un exécutable dans le répertoire root, mais il est improbable que ce soit l'emplacement où se trouve le code du module. Vous devrez prendre certaines précautions pour vous assurer que les outils d'analyse puissent obtenir le bon exécutable.
uname -a, obtenez le paquet debuginfo approprié et installez-le sur la machine.
opcontrol --reset
opcontrol --resetopcontrol --setup --vmlinux=/usr/lib/debug/lib/modules/`uname -r`/vmlinux --event=CPU_CLK_UNHALTED:500000
~]# opcontrol --setup --vmlinux=/usr/lib/debug/lib/modules/`uname -r`/vmlinux --event=CPU_CLK_UNHALTED:50000023.6.4. Utiliser opannotate
opannotate tente de faire correspondre les échantillons de certaines instructions avec les lignes correspondantes du code source. Les fichiers générés en résultant devraient avoir les échantillons des lignes sur le côté gauche. Cet outil met également un commentaire au début de chaque fonction qui répertorie la totalité des échantillons de cette fonction.
opannotate est comme suit :
opannotate --search-dirs src-dir --source executable
opannotate --search-dirs src-dir --source executableopannotate(1) pour voir une liste des options de ligne de commande supplémentaires.
23.7. Comprendre le répertoire /dev/oprofile/
/dev/oprofile/ est utilisé pour stocker le système de fichiers pour OProfile. D'un autre côté, operf ne requiert pas /dev/oprofile/. Veuillez utiliser la commande cat pour afficher les valeurs des fichiers virtuels dans ce système de fichiers. Par exemple, la commande suivante affiche le type de processeur détecté par OProfile :
cat /dev/oprofile/cpu_type
cat /dev/oprofile/cpu_type/dev/oprofile/ pour chaque compteur. Par exemple, s'il y a 2 compteurs, vous verrez les répertoires /dev/oprofile/0/ et /dev/oprofile/1/.
count— l'intervalle entre échantillons.enabled— si égal à 0, le compteur est éteint et aucun échantillon n'est collecté. Si égal à 1, le compteur est allumé et les échantillonssont collectés.event— l'événement à surveiller.extra— utilisé sur les machines avec des processeurs Nehalem pour mieux spécifier l'événement à surveiller.kernel— si égal à 0, les échantillons ne sont pas collectés pour ce compteur même si le processeur se trouve dans l'espace du noyau. Si égal à 1, les échantillons sont collectés même si le processeur se trouve dans l'espace du noyau.unit_mask— définit quels masques d'unité sont activés pour le compteur.user— si égal à 0, les échantillons ne sont pas collectés pour le compteur même si le processeur se trouve dans l'espace utilisateur. Si égal à 1, les échantillons sont collectés même si le processeur se trouve dans l'espace utilisateur.
cat. Exemple :
cat /dev/oprofile/0/count
cat /dev/oprofile/0/count23.8. Exemple d'utilisation
- Déterminer les applications et services les plus utilisés sur un système —
opreportpeut être utilisé pour déterminer combien de temps processeur est utilisé par une application ou un service. Si le système est utilisé pour de multiples services mais qu'il est sous-performant, les services consommant le plus de temps processeur pourront être déplacés sur des systèmes dédiés. - Déterminer l'utilisation du processeur — l'événemement
CPU_CLK_UNHALTEDpeut être surveillé pour déterminer la charge du processeur pendant une période donnée. Ces données peuvent ensuite être utilisées pour déterminer si des processeurs supplémentaires ou si un processeur plus rapide pourrait améliorer les performances système.
23.9. Prise en charge Java d'OProfile
23.9.1. Profiler le code Java
-agentlib:jvmti_oprofile
-agentlib:jvmti_oprofile-agentlib:/usr/lib64/oprofile/libjvmti_oprofile.so
-agentlib:/usr/lib64/oprofile/libjvmti_oprofile.so--debug, ce qui active le mode de débogage.
Note
23.10. Interface graphique
oprofile-gui, qui fournit l'interface utilisateur graphique OProfile, soit bien installé sur votre système. Pour lancer l'interface, veuillez exécuter la commande oprof_start en tant qu'utilisateur root dans l'invite de shell.
/root/.oprofile/daemonrc, et l'application se ferme.
Note
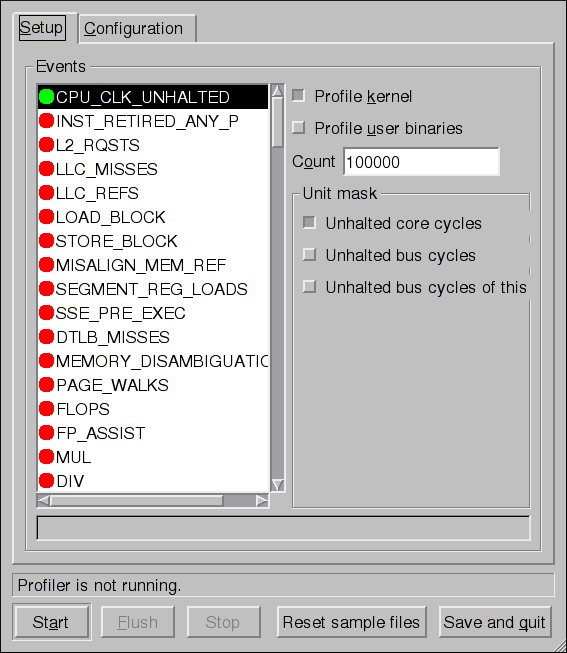
Figure 23.1. Paramétrage d'OProfile
vmlinux que le noyau devra surveiller dans le champs de texte Fichier image du noyau. Pour configurer OProfile de manière à ne pas surveiller le noyau, veuillez sélectionner Aucune image de noyau.
Figure 23.2. Configuration OProfile
oprofiled inclura davantage d'informations détaillées.
opcontrol --separate=library. Si Profils par application, y compris le noyau est sélectionné, OProfile générera des profils par application pour le noyau et les modules du noyau comme expliqué dans la Section 23.3.3, « Séparer les profils du noyau et de l'espace utilisateur ». Il n'existe pas d'équivalent à la commande opcontrol --separate=kernel.
opcontrol --dump.
23.11. OProfile et SystemTap
netstat, ps, top, et iostat ; cependant SystemTap est conçu pour offrir davantage d'options d'analyse et de filtrage pour les informations rassemblées.
23.12. Ressources supplémentaires
Documentation installée
/usr/share/doc/oprofile-version/oprofile.html— OProfile Manual- Page du manuel
oprofile(1)— expliqueopcontrol,opreport,opannotate, etophelp - Page du manuel
operf(1)
Documentation en ligne
- http://oprofile.sourceforge.net/ — documentation en amont contenant des documents, des listes de diffusion, des canaux IRC et d'autres informations sur le projet OProfile. Sur Red Hat Enterprise Linux 7, la version 0.9.9. d'OProfile est fournie.
Voir aussi
- Le Guide du débutant SystemTap — fournit des instructions de base sur la manière d'utiliser SystemTap afin de contrôler les différents sous-systèmes de Red Hat Enterprise Linux avec plus de détails.
Partie VII. Configuration du noyau, de modules et de pilotes
Chapitre 24. Utiliser le chargeur de démarrage GRUB 2
24.1. Introduction à GRUB 2
/boot/grub2/grub.cfg pour les machines traditionnelles basées BIOS et dans le fichier /boot/efi/EFI/redhat/grub.cfg pour les machines UEFI. Ce fichier contient des informations de menu.
grub.cfg, est généré en cours d'installation, ou bien, en invoquant l'utilitaire /usr/sbin/grub2-mkconfig, et est mis à jour par grubby automatiquement à chaque fois qu'un nouveau noyau est installé. Quand il est regénéré manuellement par grub2-mkconfig, le fichier est regénéré selon les fichiers de modèle qui se trouvent dans /etc/grub.d/, et les paramètres de configuration personnalisés du fichier /etc/default/grub. Les changements apportées à grub.cfg seront perdues à chaque fois que grub2-mkconfig est utilisé pour regénérer le fichier, donc il faut faire refléter les changements manuels dans le fichier /etc/default/grub également.
grub.cfg, comme la suppression ou le rajout de nouveaux noyaux, doivent être effectuées par l'outil grubby et pour les scripts, par l'outil new-kernel-pkg. Si vous utilisez grubby pour changer le noyau par défaut, les changements seront hérités quand vous installerez des nouveaux noyaux. Pour plus d'informations sur grubby, voir Section 24.4, « Effectuer des Changements persistnats à un menu GRUB 2 par l'outil grubby ».
/etc/default/grub est utilisé par l'outil grub2-mkconfig, utilisé lui-même par anaconda quand on crée grub.cfg au cours du processus d'installation, et il peut être utilisé en cas d'échec du système, comme par exemple, au cas où les configurations du chargeur de démarrage ont besoin d'être créées à nouveau. En général, il n'est pas conseillé de remplacer le fichier grub.cfg en exécutant grub2-mkconfig manuellement, sauf en cas de dernier recours. Notez que tout changement manuel à /etc/default/grub entraîne la création à nouveau du fichier grub.cfg.
Entrées de menu dans grub.cfg
grub.cfg contient un ou plusieurs bloc(s) menuentry, qui représentent chacun une entrée unique du menu de démarrage GRUB 2. Ces blocs commencent toujours par le mot-clé menuentry suivi d'un titre, d'une liste d'options, et d'une accolade d'ouverture, et se terminant avec une accolade de fermeture. Tout ce qui se trouve entre l'accolade d'ouverture et l'accolade de fermeture doit être indenté. Par exemple, ci-dessous figure un exemple de bloc menuentry pour Red Hat Enterprise Linux 7 avec le noyau Linux 3.8.0-0.40.el7.x86_64 :
menuentry qui représente un noyau Linux installé contient linux sur 64 bits IBM POWER Series, linux16 sur systèmes basés BIOS x86_64, et linuxefi sur systèmes basés UEFI. Puis les directives initrd suivies par le chemin vers le noyau et l'image initramfs, respectivement. Si une autre partition /boot a été créée, les chemins vers le noyau et l'image initramfs sont relatifs à /boot. Dans l'exemple ci-dessus, la ligne initrd /initramfs-3.8.0-0.40.el7.x86_64.img signifie que l'image initramfs est en fait située sur /boot/initramfs-3.8.0-0.40.el7.x86_64.img lorsque le système de fichiers root est monté, et de même pour le chemin du noyau.
linux16 /vmlinuz-kernel_version doit correspondre au numéro de version de l'image initramfs donnée sur la ligne initrd /initramfs-kernel_version.img de chaque bloc menuentry. Pour obtenir des informations supplémentaires sur la manière de vérifier l'image du disque RAM initial, veuillez consulter la Section 25.5, « Vérifier l'image de disque RAM initial ».
Note
menuentry, la directive initrd doit indiquer l'emplacement (relatif au répertoire /boot s'il se trouve sur une autre partition) du fichier initramfs correspondant à la même version du noyau. Cette directive est appellée initrd car l'outil précédant, qui avait créé les images de disque RAM initial, mkinitrd, créait des fichiers nommés des fichiers initrd. La directive grub.cfg reste initrd afin de rester compatible avec d'autres outils. La convention de dénomination de fichiers des systèmes utilisant l'utilitaire dracut pour créer l'image du disque RAM initial est comme suit : initramfs-kernel_version.img.
24.2. Configurer le chargeur de démarrage GRUB 2
- Pour effectuer des changements non persistants au menu GRUB 2, voir Section 24.3, « Effectuer des Changements temporaires à un menu GRUB 2 ».
- Pour effectuer des changements persistants à un système en cours d'exécution, voir Section 24.4, « Effectuer des Changements persistnats à un menu GRUB 2 par l'outil grubby ».
- Pour obtenir des informations sur la façon de créer ou de personnaliser un fichier de configuration GRUB 2, voir Section 24.5, « Personnalisation du fichier de configuration GRUB 2 ».
24.3. Effectuer des Changements temporaires à un menu GRUB 2
Procédure 24.1. Effectuer des Changements temporaires à une Saisie de menu de noyau
- Lancez le système, et, sur l'écran de démarrage GRUB 2, déplacez le curseur sur l'entrée de menu que vous souhaitez modifier, et appuyez sur la touche e pour effectuer des modifications.
- Déplacez le curseur sur la ligne de commande de noyau que vous souhaitez. La ligne de commande de noyau commence par
linuxsur IBM Power Series 64 bits,linux16sur les systèmes basés BIOS x86-64, oulinuxefisur les systèmes UEFI. - Placez le curseur en fin de ligne.Appuyez sur Ctrl+a et Ctrl+e pour directement passer au début ou à la fin d'une ligne, respectivement. Sur certains systèmes, les touches Début et Fin peuvent également fonctionner.
- Modifiez les paramètres de noyau selon les besoins. Par exemple, pour exécuter le système en mode d'urgence, veuilez ajouter le paramètre emergency à la fin de la ligne
linux16:Les paramètreslinux16 /vmlinuz-3.10.0-0.rc4.59.el7.x86_64 root=/dev/mapper/rhel-root ro rd.md=0 rd.dm=0 rd.lvm.lv=rhel/swap crashkernel=auto rd.luks=0 vconsole.keymap=us rd.lvm.lv=rhel/root rhgb quiet emergency
linux16 /vmlinuz-3.10.0-0.rc4.59.el7.x86_64 root=/dev/mapper/rhel-root ro rd.md=0 rd.dm=0 rd.lvm.lv=rhel/swap crashkernel=auto rd.luks=0 vconsole.keymap=us rd.lvm.lv=rhel/root rhgb quiet emergencyCopy to Clipboard Copied! Toggle word wrap Toggle overflow rhgbetquietpeuvent être supprimés afin d'activer les messages système.Ces paramètres de configuration ne sont pas persistants et s'appliquent à un seul démarrage (boot). Pour rendre les modifications à une saisie de menu persistantes, utiliser l'outil suivantgrubby. Voir la section intitulée « Ajouter ou Supprimer des Arguments d'une entrée de Menu GRUB » pour obtenir plus d'informations sur la façon d'utilisergrubby.
24.4. Effectuer des Changements persistnats à un menu GRUB 2 par l'outil grubby
grubby peut être utilisé pour lire des informations, et effectuer des modifications permanentes au fichier grub.cfg. Il nous permet, par exemple, de modifier les entrées de menu GRUB pour préciser les arguments à faire passer au noyau au démarrage du système, ou changer le noyau par défaut.
grubby est invoqué manuellement, sans indiquer de fichier de configuration GRUB, il recherchera /etc/grub2.cfg par défaut, qui est un lien symbolic du fichier grub.cfg, dont l'emplacement est dépendant de l'architecture. S'il ne trouve pas ce fichier, il cherchera une valeur par défaut dépendant de l'architecture.
Recherche du Noyau par défaut
grubby --default-kernel /boot/vmlinuz-3.10.0-229.4.2.el7.x86_64
~]# grubby --default-kernel
/boot/vmlinuz-3.10.0-229.4.2.el7.x86_64grubby --default-index 0
~]# grubby --default-index
0Changer l'entrée de démarrage par défaut
grubby sur le modèle suivant :
grubby --set-default /boot/vmlinuz-3.10.0-229.4.2.el7.x86_64
~]# grubby --set-default /boot/vmlinuz-3.10.0-229.4.2.el7.x86_64Visualiser l'entrée de menu GRUB d'un noyau
grubby --info=ALL
~]$ grubby --info=ALLgrubby doivent être saisies en tant qu'utilisateur root.
/boot.
Ajouter ou Supprimer des Arguments d'une entrée de Menu GRUB
--update-kernel peut être utilisée pour mettre à jour une entrée de menu si utilisé en conjonction à--args pour ajouter de nouveaux arguments et --remove-arguments pour supprimer des arguments existants. Ces options acceptent une liste séparée par des espaces avec des guillemets : grubby --remove-args="argX argY" --args="argA argB" --update-kernel /boot/kernel
grubby --remove-args="argX argY" --args="argA argB" --update-kernel /boot/kernelgrubby --remove-args="rhgb quiet" --args=console=ttyS0,115200 --update-kernel /boot/vmlinuz-3.10.0-229.4.2.el7.x86_64
~]# grubby --remove-args="rhgb quiet" --args=console=ttyS0,115200 --update-kernel /boot/vmlinuz-3.10.0-229.4.2.el7.x86_64--info comme suit :
Mise à jour de tous les Menus de noyau par les mêmes Arguments
grubby --update-kernel=ALL --args=console=ttyS0,115200
~]# grubby --update-kernel=ALL --args=console=ttyS0,115200--update-kernel accepte également DEFAULT, ou une liste de numéros d'indexes de noyaux séparés par des virgules.
Changer un argument de noyau
grubby(8) pour obtenir d'autres options de commande.
24.5. Personnalisation du fichier de configuration GRUB 2
/etc/grub.d/. Les fichiers suivants sont inclus :
00_header, qui charge les paramètres GRUB 2 du fichier/etc/default/grub.01_users, qui lit le mot de passe du superutilisateur dans le fichieruser.cfg. Dans Red Hat Enterprise Linux 7.0 et 7.1, ce fichier n'a été créé que lorsque le mot de passe boot a été défini dans le fichier kickstart au moment de l'installation, et il inclut le mot de passe défini en texte brut.10_linux, qui localise les noyaux dans la partition par défaut de Red Hat Enterprise Linux.30_os-prober, qui génère des entrées pour les systèmes d'exploitations trouvés sur d'autres partitions.40_custom, un modèle pouvant être utilisé pour créer des entrées de menu supplémentaires.
/etc/grub.d/ sont lus en ordre alphabétique et peuvent ainsi être renommés pour modifier l'ordre de démarrage d'entrées spécifiques du menu.
Important
GRUB_TIMEOUT définie sur 0 dans le fichier /etc/default/grub, GRUB 2 n'affiche pas la liste des noyaux démarrables lorsque le système est démarré. Pour afficher cette liste pendant le démarrage, appuyez continuellement sur n'importe quelle touche alphanumérique lorsque les informations BIOS sont affichées, GRUB 2 vous présentera le menu GRUB.
24.5.1. Changer l'entrée de démarrage par défaut
GRUB_DEFAULT dans le fichier /etc/default/grub est le mot « saved ». Cela ordonne à GRUB 2 de charger le noyau spécifié par la directive « saved_entry » dans le fichier d'environnement GRUB 2, qui se trouve dans /boot/grub2/grubenv. Vous pouvez également définir un autre enregistrement GRUB par défaut en utilisant la commande grub2-set-default, qui met à jour le fichier d'environnement GRUB 2.
saved_entry est définie avec le nom du noyau installé le plus récent du type de paquet kernel. Ceci est défini dans /etc/sysconfig/kernel par les directives UPDATEDEFAULT et DEFAULTKERNEL. Le fichier peut être affiché par l'utilisateur root comme suit :
DEFAULTKERNEL spécifie quel type de paquet sera utilisé par défaut. Installer un paquet de type kernel-debug ne changera pas le noyau par défaut tant que DEFAULTKERNEL est défini sur les paquets de type kernel.
saved_entry change l'ordre par défaut dans lequel les systèmes d'exploitation sont chargés. Pour spécifier quel système d'exploitation doit être chargé en premier, veuillez inclure son numéro dans la commande grub2-set-default. Exemple :
grub2-set-default 2
~]# grub2-set-default 2GRUB_DEFAULT dans le fichier /etc/default/grub. Pour répertorier les entrées du menu disponibles, veuillez exécuter la commande suivante en tant qu'utilisateur root :
awk -F\' '$1=="menuentry " {print $2}' /etc/grub2.cfg
~]# awk -F\' '$1=="menuentry " {print $2}' /etc/grub2.cfg/etc/grub2.cfg est un lien symbolic qui mène au fichier grub.cfg, dont l'emplacement dépendra de l'architecture. Pour des raisons de fiabilité, le lien symbolic n'est pas utilisé dans d'autres exemples dans ce chapitre. Il vaut mieux utiliser des chemins absolus quand on écrit dans un fichier, surtout quand on le répare.
/etc/default/grub requièrent de régénérer le fichier grub.cfg comme suit :
- Sur les machines basées BIOS, exécutez la commande suivante en tant qu'utilisateur
root:grub2-mkconfig -o /boot/grub2/grub.cfg
~]# grub2-mkconfig -o /boot/grub2/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Sur les machines basées UEFI, veuillez exécuter la commande suivante en tant qu'utilisateur
root:grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
~]# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
24.5.2. Modifier une entrée de menu
GRUB_CMDLINE_LINUX dans le fichier /etc/default/grub. Remarquez que vous pouvez spécifier plusieurs paramètres pour la clé GRUB_CMDLINE_LINUX, similairement à l'ajout de paramètres dans le menu de démarrage GRUB 2. Exemple : GRUB_CMDLINE_LINUX="console=tty0 console=ttyS0,9600n8"
GRUB_CMDLINE_LINUX="console=tty0 console=ttyS0,9600n8"console=tty0 est le premier terminal virtuel et console=ttyS0 est le terminal série à utiliser.
/etc/default/grub requièrent de régénérer le fichier grub.cfg comme suit :
- Sur les machines basées BIOS, exécutez la commande suivante en tant qu'utilisateur
root:grub2-mkconfig -o /boot/grub2/grub.cfg
~]# grub2-mkconfig -o /boot/grub2/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Sur les machines basées UEFI, veuillez exécuter la commande suivante en tant qu'utilisateur
root:grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
~]# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
24.5.3. Ajouter une nouvelle entrée
grub2-mkconfig, GRUB 2 recherche des noyaux Linux et d'autres systèmes d'exploitation basés sur les fichiers situés dans le répertoire /etc/grub.d/. Le script /etc/grub.d/10_linux recherche les noyaux Linux installés sur la même partition. Le script /etc/grub.d/30_os-prober recherche d'autres systèmes d'exploitation. Des entrées du menu sont également automatiquement ajoutées au menu de démarrage lors de la mise à jour du noyau.
40_custom situé dans le répertoire /etc/grub.d/ est un modèle pour les entrées personnalisées et ressemble à ce qui suit :
#!/bin/sh exec tail -n +3 $0 # This file provides an easy way to add custom menu entries. Simply type the menu entries you want to add after this comment. Be careful not to change # the 'exec tail' line above.
#!/bin/sh
exec tail -n +3 $0
# This file provides an easy way to add custom menu entries. Simply type the
# menu entries you want to add after this comment. Be careful not to change
# the 'exec tail' line above.menuentry "<Title>"{
<Data>
}
menuentry "<Title>"{
<Data>
}24.5.4. Créer un menu personnalisé
Important
/etc/grub.d/ au cas où vous devriez annuler les changement ultérieurement.
Note
/etc/default/grub n'a aucun effet sur la création de menus personnalisés.
- Sur les machines basées BIOS, copiez le contenu de
/boot/grub2/grub.cfg, ou le contenu de/boot/efi/EFI/redhat/grub.cfgsur les machines UEFI. Ajoutez le contenu degrub.cfgdans le fichier/etc/grub.d/40_customsous les lignes d'en-tête. La partie exécutable du script40_customdoit être préservée. - Dans le contenu intégré au fichier
/etc/grub.d/40_custom, seuls les blocsmenuentrysont nécessaires à la création d'un menu personnalisé. Les fichiers/boot/grub2/grub.cfget/boot/efi/EFI/redhat/grub.cfgpeuvent contenir des spécifications de fonctions ainsi que d'autres contenus au-dessus et au-dessous des blocsmenuentry. Si vous avez inclus ces lignes non nécessaires dans le fichier40_customdans l'étape précédente, veuillez les supprimer.Voici un exemple de script40_custompersonnalisé :Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Supprimez tous les fichier du répertoire
/etc/grub.d/sauf les fichiers suivants :00_header,40_custom,01_users(s'il existe),- et
README.
Alternativement, si vous souhaitez conserver les fichiers dans le répertoire/etc/grub2.d/, rendez-les non exécutables par la commandechmod.a-x<file_name> - Modifiez, ajoutez, ou supprimez des entrées de menu dans le fichier
40_customcomme vous le souhaitez. - Créez à nouveau le fichier
grub.cfgen exécutant la commandegrub2-mkconfig:-o- Sur les machines basées BIOS, exécutez la commande suivante en tant qu'utilisateur
root:grub2-mkconfig -o /boot/grub2/grub.cfg
~]# grub2-mkconfig -o /boot/grub2/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Sur les machines basées UEFI, veuillez exécuter la commande suivante en tant qu'utilisateur
root:grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
~]# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
24.6. Protection de GRUB 2 par un mot de passe
- Un mot de passe est exigé pour pouvoir modifier les entreés de menu mais pas pour les entrées de menu boot existantes.
- Un mot de passe est requis pour pouvoir modifier les entrées de menu et pour pouvoir démarrer un, plusieurs ou toutes les entrées de menu.
Configurer GRUB2 pour qu'un mot de passe ne soit exigé que pour les saisie de modification.
- Exécutez la commande
grub2-setpassworden tant qu'utilisateur root :grub2-setpassword
~]# grub2-setpasswordCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Saisir et confirmer le mot de passe :
Enter password: Confirm password:
Enter password: Confirm password:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
/boot/grub2/user.cfg qui contient le hachage du mot de passe. L'utilisateur de ce mot de passe, root, est défini dans le fichier /boot/grub2/grub.cfg. Avec ce changement, pour modifier une entrée boot au moment de l'amorçage nécessite que vous spécifiez le nom d'utilisateur root et votre mot de passe.
Configurer GRUB 2 pour qu'un mot de passe soit exigé pour les saisies de modification et de booting.
grub2-setpassword protègent les entrées de menu de modifications non autorisées, mais pas de booting non autorisé. Pour demander un mot de passe de booting d'entrée, suivre ces étapes après avoir défini le mot de passe avec grub2-setpassword :
Avertissement
- Ouvrir un fichier
/boot/grub2/grub.cfg. - Cherchez l'entrée boot que vous souhaitez protéger avec le mot de passe en cherchant des lignes commençant par
menuentry. - Supprimer le paramètre
--unrestricteddu bloc d'entrée de menu comme dans l'exemple :[file contents truncated] menuentry 'Red Hat Enterprise Linux Server (3.10.0-327.18.2.rt56.223.el7_2.x86_64) 7.2 (Maipo)' --class red --class gnu-linux --class gnu --class os --unrestricted $menuentry_id_option 'gnulinux-3.10.0-327.el7.x86_64-advanced-c109825c-de2f-4340-a0ef-4f47d19fe4bf' { load_video set gfxpayload=keep [file contents truncated][file contents truncated] menuentry 'Red Hat Enterprise Linux Server (3.10.0-327.18.2.rt56.223.el7_2.x86_64) 7.2 (Maipo)' --class red --class gnu-linux --class gnu --class os --unrestricted $menuentry_id_option 'gnulinux-3.10.0-327.el7.x86_64-advanced-c109825c-de2f-4340-a0ef-4f47d19fe4bf' { load_video set gfxpayload=keep [file contents truncated]Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Enregistrer et fermer le fichier.
root pour le booting.
Note
/boot/grub2/grub.cfg persistent quand de nouvelles versions de noyau sont installées, mais sont perdues quand on génère à nouveau grub.cfg par la commande grub2-mkconfig. Ainsi, pour conserver la protection du mot de passe, il vous faudra utiliser la procédure ci-dessus à chaque fois que vous utiliserez grub2-mkconfig.
Note
--unrestricted de chaque entrée de menu dans le fichier /boot/grub2/grub.cfg, alors tous les noyaux nouvellement installés auront une entrée de menu créée sans --unrestricted et donc, héritera automatiquement la protection du mot de passe.
Mots de passe définis avant la mise à jour à Red Hat Enterprise Linux 7.2
grub2-setpassword a été ajouté dans Red Hat Enterprise Linux 7.2 et représente maintenant la méthode de choix pour définir les mots de passe GRUB 2. Ceci est en contraste avec les anciennes versions de Red Hat Enterprise Linux, où les entrées boot avaient besoin d'être spécifiées manuellement dans le fichier /etc/grub.d/40_custom, et les superutilisateurs dans le fichier /etc/grub.d/01_users.
Utilisateurs GRUB 2 supplémentaires
--unrestricted nécessitent le mot de passe root. Cependant, GRUB 2 permet également de créer des utilisateurs non-root supplémentaires qui peuvent initialiser ces entrés sans mot de passe. Vous aurez quand même besoin d'un mot de passe pour modifier ces entrées. Pour obtenir des informations sur la façon de créer ces utilisateurs, voir le manuel GRUB 2.
24.7. Réinstaller GRUB 2
- Mise à niveau d'une version précédente de GRUB.
- L'utilisateur requiert que le chargeur de démarrage GRUB 2 contrôle les systèmes d'exploitation installés. Cependant, certains systèmes d'exploitation sont installés avec leur propre chargeur de démarrage. Réinstaller GRUB 2 redonne contrôle sur le système d'exploitation souhaité.
- Ajouter les informations de démarrage sur un autre disque.
24.7.1. Réinstaller GRUB 2 sur des machines basées BIOS
grub2-install, les informations de démarrage sont mises à jour et les fichiers manquants sont restaurés. Remarquez que les fichiers sont uniquement restaurés s'ils ne sont pas corrompus.
grub2-install device pour réinstaller GRUB 2 si le système fonctionne normalement. Par exemple, si sda correspond à votre périphérique :
grub2-install /dev/sda
~]# grub2-install /dev/sda24.7.2. Réinstaller GRUB 2 sur des machines basées UEFI
yum reinstall grub2-efi shim, les informations de démarrage sont mises à jour et les fichiers manquants sont restaurés. Notez que les fichiers sont uniquement restaurés s'ils ne sont pas corrompus.
yum reinstall grub2-efi shim pour réinstaller GRUB 2 si le système fonctionne normalement. Exemple :
yum reinstall grub2-efi shim
~]# yum reinstall grub2-efi shim24.7.3. Reparamétrer et réinstaller GRUB 2
root :
- Exécutez la commande
rm /etc/grub.d/*; - Exécutez la commande
rm /etc/sysconfig/grub; - Pour les systèmes EFI uniquement, veuillez exécuter la commande suivante :
yum reinstall grub2-efi shim grub2-tools
~]# yum reinstall grub2-efi shim grub2-toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour les systèmes BIOS et EFI, exécuter cette commande :
yum reinstall grub2-tools
~]# yum reinstall grub2-toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Créez à nouveau le fichier
grub.cfgen exécutant la commandegrub2-mkconfig:-o- Sur les machines basées BIOS, exécutez la commande suivante en tant qu'utilisateur
root:grub2-mkconfig -o /boot/grub2/grub.cfg
~]# grub2-mkconfig -o /boot/grub2/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Sur les machines basées UEFI, veuillez exécuter la commande suivante en tant qu'utilisateur
root:grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
~]# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
- Puis suivez la procédure indiquée dans Section 24.7, « Réinstaller GRUB 2 » pour restaurer GRUB2 sur la partition
/boot/.
24.8. GRUB 2 sur une Console série
24.8.1. Configurer le menu GRUB 2
rhgb et quit, et ajouter les paramètres de console en fin de ligne linux16 comme suit :
linux16 /vmlinuz-3.10.0-0.rc4.59.el7.x86_64 root=/dev/mapper/rhel-root ro rd.md=0 rd.dm=0 rd.lvm.lv=rhel/swap crashkernel=auto rd.luks=0 vconsole.keymap=us rd.lvm.lv=rhel/root console=ttyS0,115200
linux16 /vmlinuz-3.10.0-0.rc4.59.el7.x86_64 root=/dev/mapper/rhel-root ro rd.md=0 rd.dm=0 rd.lvm.lv=rhel/swap crashkernel=auto rd.luks=0 vconsole.keymap=us rd.lvm.lv=rhel/root console=ttyS0,115200grubby. Ainsi, pour mettre à jour l'entrée du noyau par défaut, saisir la commande suivante :
grubby --remove-args="rhgb quiet" --args=console=ttyS0,115200 --update-kernel=DEFAULT
~]# grubby --remove-args="rhgb quiet" --args=console=ttyS0,115200 --update-kernel=DEFAULT--update-kernel accepte également le mot clé ALL, ou une liste de numéros d'indexes de noyaux séparée par des virgules. Voir la section intitulée « Ajouter ou Supprimer des Arguments d'une entrée de Menu GRUB » pour plus d'informations sur la façon d'utiliser grubby.
/etc/default/grub :
GRUB_TERMINAL="serial" GRUB_SERIAL_COMMAND="serial --speed=9600 --unit=0 --word=8 --parity=no --stop=1"
GRUB_TERMINAL="serial"
GRUB_SERIAL_COMMAND="serial --speed=9600 --unit=0 --word=8 --parity=no --stop=1"GRUB_TERMINAL fait qu'elle prend précédent sur les valeurs GRUB_TERMINAL_INPUT et GRUB_TERMINAL_OUTPUT. Sur la seconde ligne, ajustez le débit en bauds, la parité, et les autres valeurs pour qu'elles correspondre à votre environnement et matériel. Un débit en bauds beaucoup plus élevé, par exemple 115200, est préférable pour les tâches comme le suivi de fichiers journaux. Une fois les changements effectués dans le fichier /etc/default/grub, il sera nécessaire de mettre à jour le fichier de configuration GRUB 2.
grub.cfg en exécutant la commande grub2-mkconfig -o :
- Sur les machines basées BIOS, exécutez la commande suivante en tant qu'utilisateur
root:grub2-mkconfig -o /boot/grub2/grub.cfg
~]# grub2-mkconfig -o /boot/grub2/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Sur les machines basées UEFI, veuillez exécuter la commande suivante en tant qu'utilisateur
root:grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
~]# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Note
console=ttyS0,9600n8
console=ttyS0,9600n8console=ttyS0 est le terminal série à utiliser, 9600 est le débit en bauds, n signifie pas de parité, et 8 est la longueur de mot en bits. Un débit en bauds beaucoup plus élevé, par exemple 115200, est préérable pour les tâches comme le suivi de fichiers journaux.
24.8.2. Utiliser « screen » pour se connecter à la console série
root :
yum install screen
~]# yum install screenscreen /dev/console_port baud_rate
screen /dev/console_port baud_ratescreen /dev/console_port 115200
~]$ screen /dev/console_port 115200ttyS0, ou ttyUSB0, etc.
:quit et appuyez sur Entrée.
screen(1) pour des options supplémentaires et des informations détaillées.
24.9. Modification du menu du terminal pendant le démarrage
24.9.1. Démarrer en mode de secours
root.
- Pour entrer en mode de secours pendant le démarrage, sur l'écran de démarrage GRUB 2, appuyez sur la touche e pour effectuer des modifications.
- Ajoutez le paramètre suivant à la fin de la ligne
linuxsur IBM Power Series 64 bits, sur la lignelinux16sur systèmes basés BIOS x86-64, ou sur la lignelinuxefipour les systèmes UEFI :systemd.unit=rescue.target
systemd.unit=rescue.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow Appuyez sur Ctrl+a et Ctrl+e pour directement passer au début ou à la fin d'une ligne, respectivement. Sur certains systèmes, les touches Début et Fin peuvent également fonctionner.Remarquez que des paramètres équivalents,1,s, etsingle, peuvent également être passés au noyau. - Appuyez sur Ctrl+x pour démarrer le système avec le paramètre.
24.9.2. Démarrer en mode d'urgence
root uniquement en lecture, il ne tentera pas de monter d'autres systèmes de fichiers locaux, n'activera pas d'interface réseau, et lancera uniquement quelques services essentiels. Dans Red Hat Enterprise Linux 7, le mode d'urgence requiert le mot de passe root.
- Pour entrer en mode d'urgence, sur l'écran de démarrage GRUB 2, appuyez sur la touche e pour effectuer des modifications.
- Ajoutez le paramètre suivant à la fin de la ligne
linuxsur IBM Power Series 64 bits, sur la lignelinux16sur systèmes basés BIOS x86-64, ou sur la lignelinuxefipour les systèmes UEFI :systemd.unit=emergency.target
systemd.unit=emergency.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow Appuyez sur Ctrl+a et Ctrl+e pour directement passer au début ou à la fin d'une ligne, respectivement. Sur certains systèmes, les touches Début et Fin peuvent également fonctionner.Remarquez que des paramètres équivalents,emergencyetbpeuvent également être passés sur le noyau. - Appuyez sur Ctrl+x pour démarrer le système avec le paramètre.
24.9.3. Démarrer le shell de débogage
systemd fournit un shell tout au début du processus de démarrage, qui peut être utilisé pour faire le diagnostic de problèmes de démarrage liés à systemd. Une fois dans le shell de débogage, les commandes de systemctl telles que systemctl list-jobs, et systemctl list-units peuvent être utilisées pour rechercher la cause des problèmes de démarrage. De plus, l'option debug peut être ajoutée à la ligne de commande du noyau pour augmenter le nombre de messages de journalisation. Pour systemd, l'option de ligne de commande du noyau debug est mainteant un raccourci de systemd.log_level=debug.
Procédure 24.2. Ajouter une commande de shell de débogage
- Sur l'écran de démarrage GRUB 2, déplacez le curseur sur l'entrée de menu que vous souhaitez modifier, et appuyez sur la touche e pour effectuer des modifications.
- Ajoutez le paramètre suivant à la fin de la ligne
linuxsur IBM Power Series 64 bits, sur la lignelinux16sur systèmes basés BIOS x86-64, ou sur la lignelinuxefipour les systèmes UEFI :Vous pouvez ajouter l'optionsystemd.debug-shell
systemd.debug-shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow debug.Appuyez sur Ctrl+a et Ctrl+e pour directement passer au début ou à la fin d'une ligne, respectivement. Sur certains systèmes, les touches Début et Fin peuvent également fonctionner. - Appuyez sur Ctrl+x pour démarrer le système avec le paramètre.
systemctl enable debug-shell. Sinon, l'outil grubby peut être utilisé pour faire des changements persistants à la ligne de commande du noyau dans le menu GRUB 2. Voir Section 24.4, « Effectuer des Changements persistnats à un menu GRUB 2 par l'outil grubby » pour obtenir plus d'informations sur la façon d'utiliser grubby.
Avertissement
Procédure 24.3. Se connecter à un shell de débogage
systemd-debug-generator configurera le shell de débogage TTY9.
- Appuyer sur Ctrl+Alt+F9 pour vous connecter au shell de débogage. Si vous êtes dans une machine virtuelle, cette combinaison de touches devra être prise en charge par l'application de virtualisation. Ainsi, si vous utilisez Virtual Machine Manager, sélectionnez → dans le menu.
- Le shell de débogage ne requiert aucune authentification, donc vous verrez sans doute une invite similaire à ce qui suit dans TTY9 :
[root@localhost /]# - Si nécessaire, pour vérifier que vous êtes bien dans le shell de débogage, saisir une commande comme suit :
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour retourner au shell par défaut, si l'amorçage a réussi, appuyez sur Ctrl+Alt+F1.
systemd peuvent être masquées en ajoutant systemd.mask=unit_name une ou plusieurs fois à la ligne de commande du noyau. Pour démarrer des processus supplémentaires lors du processus d'amorçage, ajouter systemd.wants=unit_name à la ligne de commande du noyau. La page man systemd-debug-generator(8) décrit ces options.
24.9.4. Changer et reconfigurer le mot de passe root
root est obligatoire lors de l'installation de Red Hat Enterprise Linux 7. Si vous oubliez ou perdez le mot de passe root, il est possible de le réinitialiser. Cependant, les utilisateurs membre du groupe « wheel » peuvent changer le mot de passe root comme suit :
sudo passwd root
~]$ sudo passwd rootroot est désormais requis pour opérer en mode mono-utilisateur (« single-user »), ainsi qu'en mode d'urgence (« emergency »).
root sont affichées ici :
- La Procédure 24.4, « Réinitialiser le mot de passe root en utilisant un disque d'installation » vous conduit à utiliser une invite shell sans avoir à modifier le menu GRUB. Cette procédure recommandée est la plus courte des deux. Vous pouvez utiliser un disque de démarrage ou un disque d'installation Red Hat Enterprise Linux 7 normal.
- La Procédure 24.5, « Réinitialiser le mot de passe root en utilisant rd.break » utilise
rd.breakpour interrompre le processus de démarrage avant que le contrôle ne passe d'initramfsàsystemd. L'inconvénient de cette méthode est qu'elle requiert davantage d'étapes, y compris la modification du menu GRUB, et implique de devoir choisir entre un ré-étiquetage du fichier SELinux, ou la modification du mode « Enforcing » de SELinux, puis la restauration du contexte de sécurité SELinux pour/etc/shadow/lorsque le démarrage est terminé.
Procédure 24.4. Réinitialiser le mot de passe root en utilisant un disque d'installation
- Démarrez le système et lorsque les informations BIOS sont affichées, sélectionnez l'option pour un menu de démarrage et sélectionnez de démarrer à partir du disque d'installation.
- Choisissez « » (Résolution de problèmes).
- Choisissez « » (Secourir un système Red Hat Enterprise Linux).
- Choisissez , qui est l'option par défaut. À ce moment, vous pourrez passer et l'étape suivante, et on vous demandera une phrase de passe si un système de fichiers chiffré est trouvé.
- Appuyez sur Valider pour accepter les informations affichées jusqu'à ce que l'invite shell apparaisse.
- Modifiez le système de fichiers
rootcomme suit :chroot /mnt/sysimage
sh-4.2# chroot /mnt/sysimageCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Saisir la commande
passwdet suivez les instructions affichées sur la ligne de commande pour modifier le mot de passeroot. - Supprimez le fichier
autorelablepour empêcher le long ré-étiquetage SELinux du disque :rm -f /.autorelabel
sh-4.2# rm -f /.autorelabelCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Saisissez la commande
exitpour quitter l'environnementchroot. - Saisissez la commande
exità nouveau pour reprendre l'initialisation et terminer le démarrage système.
Procédure 24.5. Réinitialiser le mot de passe root en utilisant rd.break
- Lancez le système, sur l'écran de démarrage GRUB 2, appuyez sur la touche e pour effectuer des modifications.
- Supprimez les paramètres
rhgbetquietsitués à la fin, ou près de la fin de la lignelinux16, ou la lignelinuxefisur les systèmes UEFI.Appuyez sur Ctrl+a et Ctrl+e pour directement passer au début ou à la fin d'une ligne, respectivement. Sur certains systèmes, les touches Début et Fin peuvent également fonctionner.Important
Les paramètresrhgbetquietdoivent être supprimés afin d'activer les messages système. - Ajoutez les paramètres suivants à la fin de la ligne
linuxsur IBM Power Series 64 bits, de la lignelinux16sur systèmes basés BIOS x86-64, ou de la lignelinuxefisur les systèmes UEFI :Ajouter l'optionrd.break enforcing=0
rd.break enforcing=0Copy to Clipboard Copied! Toggle word wrap Toggle overflow enforcing=0permet d'omettre le long processus de ré-étiquetage SELinux.initramfss'arrêtera avant de donner le contrôle au noyau Linux (Linux kernel), vous permettant de travailler en utilisant le système de fichiersroot.Remarquez que l'inviteinitramfsapparaîtra sur la dernière console spécifiée sur la ligne Linux. - Appuyez sur Ctrl+x pour démarrer le système avec les paramètres modifiés.Avec un système de fichiers chiffré, un mot de passe est requis. Cependant, l'invite du mot de passe peut ne pas apparaître et être obscurcie par les messages de journalisation. Vous pouvez appuyer sur la touche Retour Arrière (« Backspace ») pour afficher l'invite. Relâchez la touche et saisissez le mot de passe du système de fichiers chiffré tout en ignorant les messages de journalisation.L'invite
initramfsswitch_roots'affiche. - Le système de fichiers est monté en lecture seule sur
/sysroot/. Vous n'aurez pas le droit de modifier le mot de passe si le système de fichiers n'est pas accessible en écriture.Remontez le système de fichier comme étant accessible en écriture :switch_root:/# mount -o remount,rw /sysroot
switch_root:/# mount -o remount,rw /sysrootCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Le système de fichiers est remonté et est accessible en écriture.Modifiez le
rootdu système de fichiers comme suit :L'invite est modifée surswitch_root:/# chroot /sysroot
switch_root:/# chroot /sysrootCopy to Clipboard Copied! Toggle word wrap Toggle overflow sh-4.2#. - Saisir la commande
passwdet suivez les instructions affichées sur la ligne de commande pour modifier le mot de passeroot.Remarquez que si le système n'est pas accessible en écriture, l'outil passwd échouera avec l'erreur suivante :Erreur de manipulation du jeton d'authentification
Erreur de manipulation du jeton d'authentificationCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Mise à jour des résultats du fichier du mot de passe avec un contexte de sécurité SELinux incorrect. Pour ré-étiqueter tous les fichiers lors du prochain démarrage, veuillez saisir la commande suivante :Alternativement, pour économiser le temps pris pour ré-étiqueter un disque de grande taille, vous pouvez omettre cette étape, à condition d'avoir inclus l'option
touch /.autorelabel
sh-4.2# touch /.autorelabelCopy to Clipboard Copied! Toggle word wrap Toggle overflow enforcing=0dans l'étape 3. - Remontez le système de fichier en lecture seule :
mount -o remount,ro /
sh-4.2# mount -o remount,ro /Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Saisissez la commande
exitpour quitter l'environnementchroot. - Saisissez la commande
exità nouveau pour reprendre l'initialisation et terminer le démarrage système.Avec un système de fichiers chiffré, un mot de passe ou une phrase de passe est requis(e). Cependant, l'invite du mot de passe peut ne pas apparaître et être obscurcie par les messages de journalisation. Vous pouvez appuyer de façon prolongée sur la touche Retour Arrière (« Backspace ») pour afficher l'invite. Relâchez la touche et saisissez le mot de passe du système de fichiers chiffré tout en ignorant les messages de journalisation.Note
Remarquez que le processus de ré-étiquetage SELinux peut prendre longtemps. Un redémarrage système se produira automatiquement lorsque le processus sera terminé. - Si vous avez ajouté l'option
enforcing=0dans l'étape 3 et omis la commandetouch /.autorelabeldans l'étape 8, veuillez saisir la commande suivante pour restaurer le contexte de sécurité SELinux du fichier/etc/shadow:Saisissez les commandes suivante pour réactiver l'application de la politique SELinux et vérifier qu'elle soit bien en cours d'exécution :restorecon /etc/shadow
~]# restorecon /etc/shadowCopy to Clipboard Copied! Toggle word wrap Toggle overflow setenforce 1 getenforce Enforcing
~]# setenforce 1 ~]# getenforce EnforcingCopy to Clipboard Copied! Toggle word wrap Toggle overflow
24.10. Démarrage sécurisé UEFI Secure Boot (« Unified Extensible Firmware Interface »)
shim.efi, est signé par une clé privée UEFI et authentifié par une clé publique, signé par une autorité de certification (CA), stockée dans la base de données. shim.efi contient la clé publique de Red Hat, « Red Hat Secure Boot (CA key 1) », qui est utilisée pour authentifier le chargeur de démarrage GRUB 2, grubx64.efi, et le noyau Red Hat. Le noyau contient des clés publiques pour authentifier les pilotes et modules.
- une interface de programmation pour les variables UEFI protégées par chiffrement dans un stockage non volatile,
- la manière dont les certificats root X.509 sont stockés dans des variables UEFI,
- la validation d'applications UEFI comme les chargeurs de démarrage et les pilotes,
- les procédures de révocation des mauvais certificats et hachages d'applications connus.
24.10.1. Prise en charge du démarrage sécurisé UEFI Secure Boot sur Red Hat Enterprise Linux 7
Restrictions imposées par UEFI Secure Boot
24.11. Ressources supplémentaires
Documentation installée
/usr/share/doc/grub2-tools-version-number/— Ce répertoire contient des informations sur l'utilisation et la configuration de GRUB 2. version-number correspond à la version du paquet GRUB 2 installé.info grub2— La page d'information de GRUB 2 contient des leçons, ainsi qu'un manuel de référence pour les utilisateurs et les programmeurs et une Foire Aux Questions (FAQ) sur GRUB 2 et son utilisation.grubby(8)— la page man de l'outil en ligne de commande qui sert à configurer GRUB et GRUB 2.new-kernel-pkg(8)— la page man de l'outil de script d'intallation du noyau.
Documentation installable et externe
/usr/share/doc/kernel-doc-kernel_version/Documentation/serial-console.txt— Ce fichier, fourni par le paquet kernel-doc, contient des informations sur la console série. Avant d'accéder à la documentation du noyau, vous devez exécuter la commande suivante en tant qu'utilisateurroot:yum install kernel-doc
~]# yum install kernel-docCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Guide d'installation Red Hat — Le guide d'installation fournit des informations de base sur GRUB 2, par exemple, l'installation, la terminologie, les interfaces, et les commandes.
Chapitre 25. Mettre à niveau le noyau manuellement
rpm au lieu de yum.
Avertissement
Avertissement
25.1. Vue d'ensemble des paquets du noyau
- kernel — contient le noyau pour des systèmes unique, multi-cœurs, et multiprocesseurs.
- kernel-debug — contient un noyau avec de nombreuses options de débogage activées pour le diagnostique du noyau, ce qui entraîne une réduction des performances.
- kernel-devel — contient les en-têtes et makefiles suffisants pour créer des modules avec le paquet kernel.
- kernel-debug-devel — contient la version de développement du noyau avec de nombreuses options de débogage activées pour le diagnostique du noyau, ce qui entraîne une réduction des performances.
- kernel-doc — fichiers de documentation de la source du noyau. Diverses portions du noyau Linux et des pilotes de périphériques envoyés avec sont documenté dans ces fichiers. L'installation de ce paquet fournit une référence sur les options pouvant être passées sur les modules du noyau Linux pendant le chargement.Par défaut, ces fichiers sont placés dans le répertoire
/usr/share/doc/kernel-doc-kernel_version/. - kernel-headers — inclut les fichiers d'en-tête C qui spécifient l'interface entre le noyau Linux, les bibliothèques et programmes de l'espace utilisateur. Les fichiers d'en-tête définissent les structures et les constantes qui servent à la création de la plupart des programmes standard.
- linux-firmware — contient tous les fichiers de microprogramme requis par les différents périphériques pour opérer.
- perf — ce paquet contient l'outil perf qui permet la surveillance des performances du noyau Linux.
- kernel-abi-whitelists — contient des informations pertinentes à l'ABI du noyau de Red Hat Enterprise Linux, y compris une liste des symboles de noyau nécessaires aux modules de noyau Linux externes et un greffon yum permettant son application.
- kernel-tools — contient des outils pour manipuler le noyau Linux et la documentation de prise en charge.
25.2. Préparer pour une mise à niveau
VFAT. Vous pouvez créer un support de démarrage USB formatté ext2, ext3, ext4, ou VFAT.
4 Go pour une image de DVD de distribution, environ 700 Mo pour une image de CD de distribution, et 10 Mo pour une image de support de démarrage minimal.
boot.iso provenant d'un DVD d'installation Red Hat Enterprise Linux, ou du CD-ROM #1 d'installation, il vous faudra également un périphérique de stockage USB formaté avec le système de fichiers VFAT, ainsi que 16 Mo d'espace libre. La procédure suivante n'affectera pas les fichiers existants sur le périphérique de stockage USB à moins qu'ils aient les mêmes noms de chemin que les fichiers copiés dans celui-ci. Pour créer le support de démarrage USB, veuillez exécuter les commandes suivantes en tant qu'utilisateur root :
- Veuillez installer le paquet syslinux s'il n'est pas déjà installé sur votre système. Pour cela, veuillez exécuter la commande
yum install syslinuxen tant qu'utilisateur root. - Veuillez installer le chargeur de démarrage SYSLINUX sur le périphérique de stockage USB :
syslinux /dev/sdX1
~]# syslinux /dev/sdX1Copy to Clipboard Copied! Toggle word wrap Toggle overflow ... avec sdX comme nom de périphérique. - Veuillez créer des points de montage pour
boot.isoet le périphérique de stockage USB :mkdir /mnt/isoboot /mnt/diskboot
~]# mkdir /mnt/isoboot /mnt/diskbootCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Montez
boot.iso:mount -o loop boot.iso /mnt/isoboot
~]# mount -o loop boot.iso /mnt/isobootCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Montez le périphérique de stockage USB :
mount /dev/sdX1 /mnt/diskboot
~]# mount /dev/sdX1 /mnt/diskbootCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Copiez les fichiers ISOLINUX depuis
boot.isosur le périphérique de stockage USB :cp /mnt/isoboot/isolinux/* /mnt/diskboot
~]# cp /mnt/isoboot/isolinux/* /mnt/diskbootCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Veuillez utiliser le fichier
isolinux.cfgdeboot.isocomme fichiersyslinux.cfgpour le périphérique USB :grep -v local /mnt/isoboot/isolinux/isolinux.cfg > /mnt/diskboot/syslinux.cfg
~]# grep -v local /mnt/isoboot/isolinux/isolinux.cfg > /mnt/diskboot/syslinux.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Démontez
boot.isoet le périphérique de stockage USB :umount /mnt/isoboot /mnt/diskboot
~]# umount /mnt/isoboot /mnt/diskbootCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Vous devez redémarrer la machine avec le support de démarrage et vérifier que vous êtes en mesure de démarrer avec avant de continuer.
mkbootdisk en tant qu'utilisateur root. Veuillez consulter la page man man mkbootdisk après avoir installé le paquet pour les informations d'utilisation.
yum list installed "kernel-*" à l'invite du shell. La sortie comprendra certains ou tous les paquets suivants, selon l'architecture du système, et les numéros de version peuvent différer :
yum list installed "kernel-*" kernel.x86_64 3.10.0-54.0.1.el7 @rhel7/7.0 kernel-devel.x86_64 3.10.0-54.0.1.el7 @rhel7 kernel-headers.x86_64 3.10.0-54.0.1.el7 @rhel7/7.0
~]# yum list installed "kernel-*"
kernel.x86_64 3.10.0-54.0.1.el7 @rhel7/7.0
kernel-devel.x86_64 3.10.0-54.0.1.el7 @rhel7
kernel-headers.x86_64 3.10.0-54.0.1.el7 @rhel7/7.025.3. Télécharger le noyau mis à niveau
- Errata de sécurité — veuillez consulter https://access.redhat.com/site/security/updates/active/ pour obtenir des informations sur les errata de sécurité, y compris les mises à niveau de noyau qui corrigent les problèmes de sécurité.
- The Red Hat Content Delivery Network — pour un système abonné au Red Hat Content Delivery Network, le gestionnaire de paquets yum peut télécharger le dernier noyau et mettre à jour le noyau sur le système. L'utilitaire Dracut va créer une image de disque RAM initial si nécessaire, et configurer le chargeur de démarrage pour démarrer le nouveau noyau. Pour obtenir davantage d'informations sur la façon d'installer des packages sur le Red Hat Content Delivery Network, consulter Chapitre 8, Yum. Pour obtenir plus d'informations sur la façon d'abonner un système au Red Hat Content Delivery Network, voir Chapitre 6, Enregistrer le système et Gérer les abonnements.
25.4. Effectuer la mise à niveau
Important
-i avec la commande rpm pour garder l'ancien noyau. N'utilisez pas l'option -U, car elle remplacera le noyau actuellement installé, ce qui créera des problèmes avec le chargeur de démarrage. Par exemple :
rpm -ivh kernel-kernel_version.arch.rpm
~]# rpm -ivh kernel-kernel_version.arch.rpm 25.5. Vérifier l'image de disque RAM initial
initramfs en exécutant la commande dracut. Cependant, il n'est habituellement pas nécessaire de créer une image initramfs manuellement : cette étape est automatiquement effectuée si le noyau et ses paquets associés sont installés ou mis à niveau à partir des paquets RPM distribués par Red Hat.
initramfs correspondant à votre version du noyau actuel existe et qu'elle est correctement spécifiée dans le fichier de configuration grub.cfg en suivant la procédure ci-dessous :
Procédure 25.1. Vérifier l'image de disque RAM initial
- En tant qu'utilisateur
root, répertoriez le contenu du répertoire/bootet trouvez le noyau (vmlinuz-kernel_version) etinitramfs-kernel_versionavec le numéro de version le plus récent :Exemple 25.1. Assurez-vous que les versions du noyau et d'initramfs correspondent bien
Copy to Clipboard Copied! Toggle word wrap Toggle overflow L'Exemple 25.1, « Assurez-vous que les versions du noyau et d'initramfs correspondent bien » montre que :- trois noyaux sont installés (ou plutôt, trois fichiers noyau sont présents dans le répertoire
/boot/), - le dernier noyau est nommé
vmlinuz-3.10.0-78.el7.x86_64, et - un fichier
initramfscorrespondant à la version du noyauinitramfs-3.10.0-78.el7.x86_64kdump.imgexiste également.
Important
Dans le répertoire/boot, vous trouverez plusieurs fichiersinitramfs-kernel_versionkdump.img. Ces fichiers sont des fichiers spéciaux créés par le mécanisme Kdump à des fins de débogage de noyau, ils ne sont pas utilisés pour démarrer le système, et peuvent être ignorés en toute sécurité. Pour obtenir davantage d'informations surkdump, veuillez consulter le Guide de vidage sur incident de noyau Red Hat Enterprise Linux 7. - Si le fichier
initramfs-kernel_versionne correspond pas à la version du noyau le plus récent du fichier/boot, ou dans d'autres situations, si vous deviez générer un fichierinitramfsavec l'utilitaire Dracut, veuillez simplement invoquerdracuten tant qu'utilisateurrootsans lui faire générer de fichierinitramfsdans le répertoire/boot/pour obtenir le noyau le plus récent présent dans ce répertoire :dracut
~]# dracutCopy to Clipboard Copied! Toggle word wrap Toggle overflow Vous devez utiliser l'option-f,--forcesi vous souhaitez quedracutremplace le fichierinitramfsexistant (par exemple, siinitramfsa été corrompu). Sinon,dracutrefusera de remplacer le fichierinitramfsexistant :dracut Ne remplacera pas le fichier initramfs existant (/boot/initramfs-3.10.0-78.el7.x86_64.img) sans --force
~]# dracut Ne remplacera pas le fichier initramfs existant (/boot/initramfs-3.10.0-78.el7.x86_64.img) sans --forceCopy to Clipboard Copied! Toggle word wrap Toggle overflow You can create an initramfs in the current directory by callingdracut initramfs_name kernel_version:dracut "initramfs-$(uname -r).img" $(uname -r)
~]# dracut "initramfs-$(uname -r).img" $(uname -r)Copy to Clipboard Copied! Toggle word wrap Toggle overflow If you need to specify specific kernel modules to be preloaded, add the names of those modules (minus any file name suffixes such as.ko) inside the parentheses of theadd_dracutmodules+="module [more_modules]"directive of the/etc/dracut.confconfiguration file. You can list the file contents of aninitramfsimage file created by dracut by using thelsinitrd initramfs_filecommand:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Veuillez consulterman dracutetman dracut.confpour obtenir davantage d'informations sur les options et l'utilisation. - Examinez le fichier de configuration
/boot/grub2/grub.cfgpour vous assurer qu'un fichierinitramfs-kernel_version.imggrep initramfs /boot/grub2/grub.cfg initrd16 /initramfs-3.10.0-123.el7.x86_64.img initrd16 /initramfs-0-rescue-6d547dbfd01c46f6a4c1baa8c4743f57.img
~]# grep initramfs /boot/grub2/grub.cfg initrd16 /initramfs-3.10.0-123.el7.x86_64.img initrd16 /initramfs-0-rescue-6d547dbfd01c46f6a4c1baa8c4743f57.imgCopy to Clipboard Copied! Toggle word wrap Toggle overflow Veuillez consulter Section 25.6, « Vérifier le chargeur de démarrage » pour obtenir davantage d'informations.
Vérifier l'image de disque RAM initial et le noyau sur IBM eServer System i
addRamDisk. Cela est effectué automatiquement si le noyau et ses paquets associés sont installés ou mis à niveau à partir des paquets RPM distribués par Red Hat ; ainsi, il n'est pas nécessaire de l'exécuter manuellement. Pour vérifier qu'il a bien été créé, veuillez exécuter la commande suivante en tant qu'utilisateur root pour vous assurer que le fichier /boot/vmlinitrd-kernel_version existe au préalable :
ls -l /boot/
ls -l /boot/Annuler les changements faits à l'image de disque RAM initial
Procédure 25.2. Annuler des changements faits à l'image de disque RAM initial
- Redémarrez le système en sélectionnant le noyau de secours dans le menu GRUB.
- Changez le paramètre de configuration qui a amené
initramfsà mal-fonctionner. - Recréer
initramfsavec les paramètres qui conviennent en exécutant la commande suivante en tant qu'utilisateur root :dracut --kver kernel_version --force
~]# dracut --kver kernel_version --forceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
vm.nr_hugepages dans le fichier sysctl.conf. Comme le fichier sysctl.conf est inclus dans initramfs, la nouvelle configuration de vm.nr_hugepages sera appliquée à initramfs et initramfs sera reconstruit. Cependant, comme la configuration est erronée, le nouvel initramfs est endommagé et le nouveau noyau ne démarre pas, ce qui nécessite une correction par la procédure ci-dessus.
Répertorier le contenu de l'image de disque RAM initial
initramfs, exécutez la commande suivante en tant qu'utilisateur root :
lsinitrd
~]# lsinitrd/etc, utilisez la commande suivante :
lsinitrd | grep etc/
~]# lsinitrd | grep etc/initramfs pour le noyau actuel, utiliser l'option -f :
lsinitrd -f filename
~]# lsinitrd -f filenamesysctl.conf, utilisez la commande suivante :
lsinitrd -f /etc/sysctl.conf
~]# lsinitrd -f /etc/sysctl.conf--kver :
lsinitrd --kver kernel_version -f /etc/sysctl.conf
~]# lsinitrd --kver kernel_version -f /etc/sysctl.conflsinitrd --kver 3.10.0-327.10.1.el7.x86_64 -f /etc/sysctl.conf
~]# lsinitrd --kver 3.10.0-327.10.1.el7.x86_64 -f /etc/sysctl.conf25.6. Vérifier le chargeur de démarrage
rpm, le paquet du noyau crée une entrée dans le fichier de configuration du chargeur de démarrage de ce nouveau noyau. Cependant, rpm ne configure pas le nouveau noyau pour démarrer en tant que noyau par défaut. Cela doit être effectué manuellement pendant l'installation d'un nouveau noyau avec rpm.
rpm afin de vous assurer que la configuration soit correcte. Autrement, le système pourrait ne pas être en mesure de démarrer dans Red Hat Enterprise Linux correctement. Si cela se produit, veuillez démarrer le système avec le support de démarrage créé précédemment et configurez à nouveau le chargeur de démarrage.
Chapitre 26. Utiliser des modules de noyau
- un pilote de périphérique qui ajoute la prise en charge de nouveau matériel ; ou,
- la prise en charge d'un système de fichiers tel que
btrfsouNFS.
- utiliser les utilitaires kmod d'espace utilisateur pour afficher, effectuer des requêtes, charger et décharger des modules de noyau et leurs dépendances ;
- définir des paramètres de modules sur la ligne de commande de manière dynamique et permanente afin de pouvoir personnaliser le comportement de vos modules de noyau ; et,
- charger les modules pendant le démarrage.
Note
yum install kmod
~]# yum install kmod26.1. Répertorier les modules actuellement chargés
lsmod, exemple :
lsmod spécifie :
- le nom d'un module de noyau actuellement chargé en mémoire ;
- la quantité de mémoire utilisée ;
- la somme totale des processus utilisant le module et des autres modules qui en dépendent, suivie d'une liste des noms de ces modules, s'ils existent. À l'aide de cette liste, vous pouvez décharger tous les modules selon le module que vous souhaitez décharger. Pour obtenir davantage d'informations, veuillez consulter la Section 26.4, « Décharger un module ».
lsmod est moins verbeuse et considérablement plus facile à lire que le contenu du pseudo-fichier /proc/modules.
26.2. Afficher des informations sur un module
modinfo module_name.
Note
.ko à la fin du nom. Les noms de module de noyau n'ont pas d'extensions. mais leurs fichiers correspondants en ont.
Exemple 26.1. Répertorier des informations sur un module de noyau avec lsmod
e1000e, qui est le pilote réseau Intel PRO/1000, veuillez saisir la commande suivante en tant qu'utilisateur root :
modinfo :
- filename
- Chemin absolu vers le fichier objet du noyau
.ko. Vous pouvez utilisermodinfo -nen tant que raccourci de commande pour imprimer le nom de fichierfilenameuniquement. - description
- Courte description du module. Vous pouvez utiliser
modinfo -dcomme raccourci de commande pour imprimer le champ de la description uniquement. - alias
- Le champ
aliasapparaît autant de fois qu'il existe d'alias pour un module, ou il est entièrment omis s'il n'y en a pas. - depends
- Ce champ contient une liste de tous les modules séparés par des virgules dont ce module dépend.
Note
Si un module ne possède aucune dépendance, le champdependspeut être omis de la sortie. - parm
- Chaque champ
parmprésente un paramètre de module sous le formatparameter_name:description, où :- parameter_name est la syntaxe exacte à utiliser lors d'une utilisation comme paramètre de module sur la ligne de commande, ou dans une ligne d'option dans un fichier
.confdans le répertoire/etc/modprobe.d/; - description est une brève explication de ce que le paramètre fait, ainsi qu'une attente quant au type de valeur acceptée entre parenthèses (comme int, unit ou array of int).
Exemple 26.2. Répertorier les paramètres de modules
Vous pouvez répertorier tous les paramètres pris en charge par le module en utilisant l'option-p. Cependant, comme des informations utiles concernant le type de valeur sont omises de la sortiemodinfo -p, il est plus utile d'exécuter :Copy to Clipboard Copied! Toggle word wrap Toggle overflow
26.3. Charger un module
modprobe module_name en tant qu'utilisateur root. Par exemple, pour charger le module wacom, veuillez exécuter :
modprobe wacom
~]# modprobe wacommodprobe tente de charger le module de /lib/modules/kernel_version/kernel/drivers/. Dans ce répertoire, chaque type de module possède son propre sous-répertoire, comme net/ et scsi/, pour les pilotes des interfaces réseau et SCSI, respectivement.
modprobe prend toujours les dépendances en compte lorsqu'elle effectue des opérations. Lorsque vous demandez à modprobe de charger un module de noyau spécifique, il examine avant tout les dépendances de ce module, s'il y en a, et les charge si elles ne sont pas déjà chargées dans le noyau. modprobe résoud les dépendances de manière récursive : les dépendances des dépendances seront chargées, et ainsi de suite si nécessaire, assurant ainsi que toutes les dépendances soient bien résolues.
-v (ou --verbose) pour faire en sorte que modprobe affiche des informations détaillées sur ce qui est fait, ce qui peut inclure le chargement de dépendances de modules.
Exemple 26.3. modprobe -v affiche les dépendances de module au fur et à mesure de leur chargement
Fibre Channel over Ethernet de manière détaillée en saisissant ce qui suit dans l'invite shell :
modprobe a chargé les modules scsi_tgt, scsi_transport_fc, libfc et libfcoe en tant que dépendances avant de finalement charger fcoe. Remarquez également que modprobe a utilisé une commande plus primitive, insmod, pour insérer les modules dans le noyau en cours d'exécution.
Important
insmod peut également être utilisée pour charger des modules de noyau, elle ne résoud pas de dépendances. Par conséquent, vous devriez toujours charger les modules à l'aide de modprobe.
26.4. Décharger un module
modprobe -r module_name en tant qu'utilisateur root. Par exemple, si le module wacom est déjà chargé dans le noyau, vous pouvez le décharger en exécutant :
modprobe -r wacom
~]# modprobe -r wacom- le module
wacom; - un module dont
wacomdépend directement ; ou - tout module dont
wacomdépend indirectement à travers l'arborescence des dépendances.
lsmod pour obtenir les noms des modules qui vous empêchent de décharger un certain module.
Exemple 26.4. Décharger un module de noyau
firewire_ohci, votre session de terminal pourrait ressembler à ceci :
modinfo -F depends firewire_ohci firewire-core modinfo -F depends firewire_core crc-itu-t modinfo -F depends crc-itu-t
~]# modinfo -F depends firewire_ohci
firewire-core
~]# modinfo -F depends firewire_core
crc-itu-t
~]# modinfo -F depends crc-itu-tfirewire_ohci dépend de firewire_core, qui dépend de crc-itu-t.
firewire_ohci en utilisant la commande modprobe -v -r module_name , où -r est un raccourci pour --remove et -v pour --verbose :
modprobe -r -v firewire_ohci rmmod firewire_ohci rmmod firewire_core rmmod crc_itu_t
~]# modprobe -r -v firewire_ohci
rmmod firewire_ohci
rmmod firewire_core
rmmod crc_itu_tImportant
rmmod peut être utilisée pour décharger des modules de noyau, il est recommandé d'utiliser modprobe -r à la place.
26.5. Définir les paramètres de module
- Vous pouvez décharger toutes les dépendances du module dont vous souhaitez définir les paramètres, déchargez le module en utilisant
modprobe -r, puis chargez-le avecmodprobe, ainsi qu'avec une liste de paramètres personnalisés. Cette méthode, couverte dans cette section, est souvent utilisée lorsque le module ne possède que peu de dépendances, ou pour tester différentes combinaisons de paramètres sans les rendre persistants. - Alternativement, vous pouvez répertorier les nouveaux paramètres dans un fichier nouveau ou existant dans le répertoire
/etc/modprobe.d/. Cette méthode rend les paramètres du module persistants en assurant qu'ils soient définis chaque fois que le module est chargé, comme après chaque redémarrage, ou après la commandemodprobe. Même si les informations suivantes sont des conditions préalables, cette méthode est couverte dans la Section 26.6, « Chargement de modules persistants ».
Exemple 26.5. Fournir des paramètres optionnels lors du chargement d'un module de noyau
modprobe pour charger un module de noyau avec des paramètres personnalisés en utilisant le format de ligne de commande suivant :
modprobe module_name [parameter=value]
~]# modprobe module_name [parameter=value] - Vous pouvez saisir plusieurs paramètres et valeurs en les séparant par des espaces.
- Certains paramètres de module s'attendent à une liste de valeurs séparées par des virgules comme arguments. Lorsque la liste des valeurs est saisie, n'insérez pas d'espace après les virgules, ou
modproben'interprétera pas correctement les valeurs qui suivent les espaces en tant que paramètres supplémentaires. - La commande
modprobefonctionne silencieusement avec un statut de sortie de0si :- le module est bien chargé, ou
- le module est déjà chargé dans le noyau.
Ainsi, vous devez vous assurer que le module n'est pas déjà chargé avant de tenter de le charger avec des paramètres personnalisés. La commandemodprobene recharge pas automatiquement le module, ou ne vous alerte pas automatiquement qu'il est déjà chargé.
e1000e, qui est le pilote réseau des adaptateurs réseau Intel PRO/1000 :
Procédure 26.1. Charger un module de noyau avec des paramètres personnalisés
- Veuillez commencer par vous assurer que le module n'est pas chargé dans le noyau :
lsmod |grep e1000e ~]#
~]# lsmod |grep e1000e ~]#Copy to Clipboard Copied! Toggle word wrap Toggle overflow La sortie indiquera que le module est déjà chargé dans le noyau, dans lequel cas vous devrez tout d'abord le décharger avant de continuer. Veuillez consulter la Section 26.4, « Décharger un module » pour obtenir des instructions sur la manière de le décharger en toute sécurité. - Chargez le module et répertoriez tous les paramètres personnalisés après le nom du module. Par exemple, si vous souhaitez charger le pilote réseau Intel PRO/1000 avec un taux d'accélération d'interruptions défini sur 3000 interruptions par seconde pour la première, seconde et troisième instance du pilote, et activer le débogage, vous devrez exécuter en tant qu'utilisateur
root:modprobe e1000e InterruptThrottleRate=3000,3000,3000 debug=1
~]# modprobe e1000e InterruptThrottleRate=3000,3000,3000 debug=1Copy to Clipboard Copied! Toggle word wrap Toggle overflow Cet exemple illustre le transfert de plusieurs valeurs sur un paramètre unique en les séparant avec des virgules et en omettant tout espace les séparant.
26.6. Chargement de modules persistants
systemd-modules-load.service en créant le fichier program.conf dans le répertoire /etc/modules-load.d/, où program est un nom descriptif de votre choix. Les fichiers dans /etc/modules-load.d/ sont des fichiers texte qui répertorient les modules à charger, un par ligne.
Exemple 26.6. Un fichier texte pour charger un module
virtio-net.ko, créez un fichier /etc/modules-load.d/virtio-net.conf avec le contenu suivant :
# Load virtio-net.ko at boot virtio-net
# Load virtio-net.ko at boot
virtio-netmodules-load.d(5) et systemd-modules-load.service(8) pour obtenir davantage d'informations.
26.7. Installation de modules à partir d'un disque de mise à jour de pilote
5.
Procédure 26.2. Installation de nouveaux modules à partir d'un disque de mise à jour de pilote
- Installer le disque de mise à jour de pilote.
- Créer un point de montage et monter le DUD. Ainsi, en tant qu'utilisateur
root:mkdir /run/OEMDRV mount -r -t iso9660 /dev/sr0 /run/OEMDRV
~]# mkdir /run/OEMDRV ~]# mount -r -t iso9660 /dev/sr0 /run/OEMDRVCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Afficher les contenus de DUD. Exemple :
ls /run/OEMDRV/ rhdd3 rpms src
~]# ls /run/OEMDRV/ rhdd3 rpms srcCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Rendez vous dans le répertoire qui correspond à l'architecture de votre système, qui se trouve dans
rpms/, et listez-en le contenu. Exemple :Dans la sortie ci-dessus, la version du package estcd /run/OEMDRV/rpms/x86_64/ ls kmod-bnx2x-1.710.51-3.el7_0.x86_64.rpm kmod-bnx2x-firmware-1.710.51-3.el7_0.x86_64.rpm repodata
~]# cd /run/OEMDRV/rpms/x86_64/ ~]# ls kmod-bnx2x-1.710.51-3.el7_0.x86_64.rpm kmod-bnx2x-firmware-1.710.51-3.el7_0.x86_64.rpm repodataCopy to Clipboard Copied! Toggle word wrap Toggle overflow 1.710.51et la version est3.el7_0. - Installer les fichiers RPM simultanément. Exemple :
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Saisir la commande suivante pour que
depmodpuisse interroger tous les modules et mettre à jour la liste des dépendances :depmod -a
~]# depmod -aCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Faire une copie de sauvegarde du système de fichiers RAM initial, en saisissant la commande suivante :
cp /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.$(date +%m-%d-%H%M%S).bak
~]# cp /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.$(date +%m-%d-%H%M%S).bakCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Construire à nouveau le système de fichiers RAM initial :
dracut -f -v
~]# dracut -f -vCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour faire la liste de contenu du fichier sur une image de système de fichiers RAM initial créé par dracut, saisir la commande suivante :La sortie de commande est très longue, filtrer par la barre verticale cette sortie avec
lsinitrd /boot/initramfs-3.10.0-229.el7.x86_64.img
~]# lsinitrd /boot/initramfs-3.10.0-229.el7.x86_64.imgCopy to Clipboard Copied! Toggle word wrap Toggle overflow lessougreppour trouver le module que vous êtes en train de mettre à jour. Exemple :Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Le système doit être redémarré pour que les changements entrent en vigueur.
modinfo driver_name comme suit :
26.8. Signer des modules de noyau pour le démarrage sécurisé « Secure Boot »
26.8.1. Conditions préalables
| Outil | Fourni par le paquet | Utilisé sur | But |
|---|---|---|---|
openssl | openssl | Système de génération | Génère une paire de clés X.509 publique et privée |
sign-file | kernel-devel | Système de génération | Script Perl utilisé pour signer les modules de noyau |
perl | perl | Système de génération | Interprète Perl utilisé pour exécuter le script de signature |
mokutil | mokutil | Système cible | Outil optionnel utilisé pour inscrire la clé publique manuellement |
keyctl | keyutils | Système cible | Outil optionnel utilisé pour afficher des clés publiques dans l'anneau de clés du système |
Note
26.8.2. Authentification du module de noyau
26.8.2.1. Sources de clés publiques utilisées pour authentifier des modules de noyau
| Source des clés X.509 | Capacité de l'utilisateur à ajouter des clés | État UEFI Secure Boot | Clés chargées pendant le démarrage |
|---|---|---|---|
| Intégré au noyau | Non | - | .system_keyring |
| UEFI Secure Boot "db" | Limité | Non activé | Non |
| Activé | .system_keyring | ||
| UEFI Secure Boot "dbx" | Limité | Non activé | Non |
| Activé | .system_keyring | ||
Intégré au chargeur de démarrage shim.efi | Non | Non activé | Non |
| Activé | .system_keyring | ||
| Liste MOK (« Machine Owner Key ») | Oui | Non activé | Non |
| Activé | .system_keyring |
keyctl. Ci-dessous figure un exemple abbrévié d'un système Red Hat Enterprise Linux 7 sur lequel UEFI Secure Boot n'est pas activé.
keyctl list %:.system_keyring 3 keys in keyring: ...asymmetric: Red Hat Enterprise Linux Driver Update Program (key 3): bf57f3e87... ...asymmetric: Red Hat Enterprise Linux kernel signing key: 4249689eefc77e95880b... ...asymmetric: Red Hat Enterprise Linux kpatch signing key: 4d38fd864ebe18c5f0b7...
~]# keyctl list %:.system_keyring
3 keys in keyring:
...asymmetric: Red Hat Enterprise Linux Driver Update Program (key 3): bf57f3e87...
...asymmetric: Red Hat Enterprise Linux kernel signing key: 4249689eefc77e95880b...
...asymmetric: Red Hat Enterprise Linux kpatch signing key: 4d38fd864ebe18c5f0b7...Red Hat Secure Boot (CA key 1), qui est intégrée au chargeur de démarrage shim.efi. Vous pouvez également chercher les messages de la console du noyau qui identifient les clés avec une source liée à UEFI Secure Boot, c'est-à-dire UEFI Secure Boot db, un shim intégré, et une liste MOK.
dmesg | grep 'EFI: Loaded cert' [5.160660] EFI: Loaded cert 'Microsoft Windows Production PCA 2011: a9290239... [5.160674] EFI: Loaded cert 'Microsoft Corporation UEFI CA 2011: 13adbf4309b... [5.165794] EFI: Loaded cert 'Red Hat Secure Boot (CA key 1): 4016841644ce3a8...
~]# dmesg | grep 'EFI: Loaded cert'
[5.160660] EFI: Loaded cert 'Microsoft Windows Production PCA 2011: a9290239...
[5.160674] EFI: Loaded cert 'Microsoft Corporation UEFI CA 2011: 13adbf4309b...
[5.165794] EFI: Loaded cert 'Red Hat Secure Boot (CA key 1): 4016841644ce3a8...26.8.2.2. Conditions préalables à l'authentification de modules de noyau
module.sig_enforce a été spécifié, alors seuls les modules de noyau signés qui sont authentifiés à l'aide d'une clé sur l'anneau des clés du système pourront être chargés, à condition que la clé publique ne se trouve pas sur l'anneau des clés sur liste noire du système. Si UEFI Secure Boot est désactivé et si le paramètre de noyau module.sig_enforce n'a pas été spécifié, alors les modules de noyau non-signés et les modules de noyau signés sans clé publique pourront être chargés. Ceci est résumé dans la Tableau 26.3, « Conditions préalables à l'authentification de modules de noyau pour effectuer un chargement ».
| Module signé | Clé publique trouvée et signature valide | État UEFI Secure Boot | module.sig_enforce | Charge du module | Noyau avarié |
|---|---|---|---|---|---|
| Non signé | - | Non activé | Non activé | Réussi | Oui |
| Non activé | Activé | Échoué | |||
| Activé | - | Échoué | - | ||
| Signé | Non | Non activé | Non activé | Réussi | Oui |
| Non activé | Activé | Échoué | - | ||
| Activé | - | Échoué | - | ||
| Signé | Oui | Non activé | Non activé | Réussi | Non |
| Non activé | Activé | Réussi | Non | ||
| Activé | - | Réussi | Non |
26.8.3. Générer une paire de clés X.509 publique et privée
- L'outil
opensslpeut être utilisé pour générer une paire de clés qui satisfait les conditions préalables à la signature d'un module de noyau sur Red Hat Enterprise Linux 7. Certains des paramètres de cette requêtre de génération de clé sont mieux spécifiés à l'aide d'un fichier de configuration ; veuillez suivre l'exemple ci-dessous pour créer votre propre fichier de configuration.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Après avoir créé le fichier de configuration, vous pouvez créer une paire de clés X.509 publique et privée. La clé publique sera écrite sur le fichier
public_key.deret la clé privée sera écrite sur le fichierprivate_key.priv.openssl req -x509 -new -nodes -utf8 -sha256 -days 36500 \ -batch -config configuration_file.config -outform DER \ -out public_key.der \ -keyout private_key.priv
~]# openssl req -x509 -new -nodes -utf8 -sha256 -days 36500 \ -batch -config configuration_file.config -outform DER \ -out public_key.der \ -keyout private_key.privCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Veuillez inscrire votre clé publique sur tous les systèmes sur lesquels vous souhaitez authentifier et charger votre module de noyau.
Avertissement
26.8.4. Inscrire une clé publique sur un système cible
26.8.4.1. Image du microprogramme d'usine, y compris la clé publique
26.8.4.2. Image d'inscription de clé exécutable ajoutant une clé publique
26.8.4.3. Administrateur systèmes ajoutant manuellement la clé publique à la liste MOK
mokutil.
- Demandez l'ajout de votre clé publique à la liste MOK en utilisant un utilitaire d'espace utilisateur Red Hat Enterprise Linux 7 :
mokutil --import my_signing_key_pub.der
~]# mokutil --import my_signing_key_pub.derCopy to Clipboard Copied! Toggle word wrap Toggle overflow Il vous sera demandé de saisir et de confirmer un mot de passe pour cette requête d'inscription MOK. - Redémarrez la machine.
- La requête d'inscription de clé MOK en attente sera remarquée par
shim.efiet lanceraMokManager.efiafin de vous permettre de terminer l'inscription à partir de la console UEFI. Vous devrez saisir le mot de passe précédemment associé à cette requête et confirmer l'inscription. Votre clé publique est ajoutée à la liste MOK, qui est persistante.
26.8.5. Signer un module de noyau avec la clé privée
- Générez votre module
my_module.kode manière standard :make -C /usr/src/kernels/$(uname -r) M=$PWD modules
~]# make -C /usr/src/kernels/$(uname -r) M=$PWD modulesCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Signez votre module de noyau avec votre clé privée. Ceci peut être fait avec un script Perl. Remarquez que le script requiert que les fichiers contenant la clé privée et la clé publique soient fournis, ainsi que le fichier du module de noyau que vous souhaitez signer.
perl /usr/src/kernels/$(uname -r)/scripts/sign-file \ sha256 \ my_signing_key.priv \ my_signing_key_pub.der \ my_module.ko
~]# perl /usr/src/kernels/$(uname -r)/scripts/sign-file \ sha256 \ my_signing_key.priv \ my_signing_key_pub.der \ my_module.koCopy to Clipboard Copied! Toggle word wrap Toggle overflow
my_module.ko. L'utilitaire modinfo peut être utilisé pour afficher des informations sur la signature du module du noyau, si elle est présente. Pour obtenir des informations sur l'utilisation de l'utilitaire, veuillez consulter la Section 26.2, « Afficher des informations sur un module ».
readelf ne seront pas en mesure d'afficher la signature sur votre module de noyau.
26.8.6. Charger un module de noyau signé
mokutil pour ajouter votre clé publique à la liste MOK et vous chargerez votre module de noyau manuellement avec modprobe.
- Optionnellement, vous pouvez vérifier que votre module de noyau ne se charge pas avant d'avoir inscrit la clé publique. Premièrement, veuillez vérifier quelles clés ont été ajoutées à l'anneau des clés du système lors du démarrage actuel en exécutant la commande
keyctl list %:.system_keyringen tant qu'utilisateur root. Comme votre clé publique n'a pas encore été inscrite, elle ne sera pas affichée dans la sortie de la commande. - Demander l'inscription de votre clé publique.
mokutil --import my_signing_key_pub.der
~]# mokutil --import my_signing_key_pub.derCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Redémarrez et terminez l'inscription sur la console UEFI.
reboot
~]# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Après les redémarrages système, veuillez vérifier à nouveau les clés sur l'anneau des clés du système.
keyctl list %:.system_keyring
~]# keyctl list %:.system_keyringCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Vous devriez désormais être en mesure de charger votre module de noyau.
modprobe -v my_module insmod /lib/modules/3.10.0-123.el7.x86_64/extra/my_module.ko lsmod | grep my_module my_module 12425 0
~]# modprobe -v my_module insmod /lib/modules/3.10.0-123.el7.x86_64/extra/my_module.ko ~]# lsmod | grep my_module my_module 12425 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
26.9. Ressources supplémentaires
Documentation de la page du manuel
lsmod(8)— page man de la commandelsmod.modinfo(8)— page man de la commandemodinfo.modprobe(8)— page man de la commandemodprobe.rmmod(8)— page man de la commandermmod.ethtool(8)— page man de la commandeethtool.mii-tool(8)— page man de la commandemii-tool.
Documentation installable et externe
/usr/share/doc/kernel-doc-kernel_version/Documentation/— Ce répertoire, fourni par le paquet kernel-doc, contient des informations sur le noyau sur les modules de noyau, et sur leurs paramètres respectifs. Avant d'accéder à la documentation du noyau, vous devez exécuter la commande suivante en tant qu'utilisateurroot:yum install kernel-doc
~]# yum install kernel-docCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Linux Loadable Kernel Module HOWTO — « Linux Loadable Kernel Module HOWTO », du projet « Linux Documentation Project » contient davantage d'informations sur l'utilisation des modules de noyau.
Partie VIII. Sauvegarde et Restauration du système
Chapitre 27. Relax-and-Recover (ReaR)
- démarrer l'ordinateur en « Mode de Secours » (Rescue Mode)
- reproduire la configuration de stockage d'origine
- restaurer les fichiers d'utilisateur et de système
rear recovery, qui démarre le processus de récupération. Au cours de ce processus, ReaR reproduit le schéma de partition et les systèmes de fichiers, et lance des invites pour restaurer les fichiers système et utilisateur de la sauvegarde créée par le logiciel de sauvegarde, et enfin, installe le boot loader. Par défaut, le système de sauvetage créé par ReaR restaure uniquement le schéma de stockage et le chargeur de démarrage, mais pas l’utilisateur réel et les fichiers système.
27.1. Basic ReaR Usage
27.1.1. Installer ReaR
yum install rear genisoimage syslinux
~]# yum install rear genisoimage syslinux27.1.2. Configurer ReaR
/etc/rear/local.conf. Spécifier la configuration du système de secours en ajoutant les lignes suivantes :
OUTPUT=output format OUTPUT_URL=output location
OUTPUT=output format
OUTPUT_URL=output locationISO pour un disque ou une image ISO, et USB pour une clé USB enfichable.
file:///mnt/rescue_system/ par un répertoire de système de fichiers local ou sftp://backup:password@192.168.0.0/ pour un répertoire SFTP.
Exemple 27.1. Configurer l'emplacement et le format du système de secours système
/mnt/rescue_system/, ajouter les lignes suivantes au fichier /etc/rear/local.conf :
OUTPUT=ISO OUTPUT_URL=file:///mnt/rescue_system/
OUTPUT=ISO
OUTPUT_URL=file:///mnt/rescue_system/27.1.3. Créer un système de secours
/mnt/rescue_system/. Comme le nom d'hôte du sysème est rhel7, l'emplacement de sauvegarde contient maintenant le répertoire rhel7/ avec le système de secours et les fichiers auxiliaires :
27.1.4. Programmer ReaR
/etc/crontab :
minute hour day_of_month month day_of_week root /usr/sbin/rear mkrescue
minute hour day_of_month month day_of_week root /usr/sbin/rear mkrescueExemple 27.2. Programmer ReaR
/etc/crontab :
0 22 * * 1-5 root /usr/sbin/rear mkrescue
0 22 * * 1-5 root /usr/sbin/rear mkrescue27.1.5. Dépanner un système
- Démarrer le système de secours sur le nouveau matériel. Par exemple, graver l'image ISO sur un DVD et démarrez à partir du DVD.
- Dans l'interface de la console, sélectionner l'option « Recover » :

Figure 27.1. Rescue system: menu
- Invite :
Figure 27.2. Rescue system: invite
Avertissement
Une fois que vous aurez démarré le processus de restauration, vous ne pourrez sans doute pas revenir en arrière, et vous risquez de perdre ce que vous avez stocké dans les disques physiques du système. - Exécuter la commande
rear recoverpour effectuer la restauration ou la migration. Le système de migration pourra alors créer les partitions et les systèmes de fichiers :
Figure 27.3. Rescue system: exécuter « rear recover »
- Restaurer les fichiers utilisateur et système à partir de la sauvegarde dans le répertoire
/mnt/local/.Exemple 27.3. Restaurer les fichiers d'utilisateur et de système
Dans cet exemple, le fichier de sauvegarde est une archive tar créée selon les instructions qui se trouvent dans Section 27.2.1.1, « Configurer la méthode de sauvegarde interne ». Veuillez, tout d'abord, copier l'archive de son stockage, puis dépaqueter les fichiers dans/mnt/local/, et finalement, supprimer l'archive :scp root@192.168.122.7:/srv/backup/rhel7/backup.tar.gz /mnt/local/ tar xf /mnt/local/backup.tar.gz -C /mnt/local/ rm -f /mnt/local/backup.tar.gz
~]# scp root@192.168.122.7:/srv/backup/rhel7/backup.tar.gz /mnt/local/ ~]# tar xf /mnt/local/backup.tar.gz -C /mnt/local/ ~]# rm -f /mnt/local/backup.tar.gzCopy to Clipboard Copied! Toggle word wrap Toggle overflow Le nouveau stockage doit avoir sufisamment d'espace pour l'archive et les fichiers extraits à la fois. - Vérifiez bien que les fichiers ont bien été restaurés :
ls /mnt/local/
~]# ls /mnt/local/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 
Figure 27.4. Rescue system: restaurer les fichiers d'utilisateur et de système à partir de la copie de sauvegarde
- Veuillez à ce que SELinux renomme les fichiers lors du nouveau démarrage :
touch /mnt/local/.autorelabel
~]# touch /mnt/local/.autorelabelCopy to Clipboard Copied! Toggle word wrap Toggle overflow Sinon, vous risquez de ne pas pouvoir vous connecter au système, car le fichier/etc/passwdpourrait avoir un contexte SELinux incorrect. - Terminer le processus de recouvrement en saisissant la commande
exit. ReaR installera alors le boot loader. Ensuite, redémarrez le système :
Figure 27.5. Rescue system: terminer la restauration
Lors du second démarrage, SELinux renomme le système de fichiers dans son ensemble. Vous pourrez, ensuite, vous connecter au système restauré.
27.2. Intégrer ReaR au logiciel de sauvegarde
27.2.1. La méthode de sauvegarde intégrée
- un système de secours et une sauvegarde de système totale peuvent être créés en un coup par la commande
rear mkbackup - le système de secours restaure les fichiers de la sauvegarde automatiquement
27.2.1.1. Configurer la méthode de sauvegarde interne
/etc/rear/local.conf :
BACKUP=NETFS BACKUP_URL=backup location
BACKUP=NETFS
BACKUP_URL=backup locationtar". Remplacez l'emplacement de sauvegarde par l’une des options de la section « Backup Software Integration » de la page man de rear(8). Assurez-vous que l’emplacement de sauvegarde possède assez d’espace.
Exemple 27.4. Ajouter des Sauvegardes tar
/srv/backup/ :
OUTPUT=ISO OUTPUT_URL=file:///mnt/rescue_system/ BACKUP=NETFS BACKUP_URL=file:///srv/backup/
OUTPUT=ISO
OUTPUT_URL=file:///mnt/rescue_system/
BACKUP=NETFS
BACKUP_URL=file:///srv/backup/- Pour conserver d'anciennes archives de sauvegarde quand vous en créez de nouvelles, ajouter la ligne suivante :
NETFS_KEEP_OLD_BACKUP_COPY=y
NETFS_KEEP_OLD_BACKUP_COPY=yCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Par défaut, ReaR crée une sauvegarde totale pour chaque exécution. Pour rendre les sauvegardes incrémentales, c'est à dire, pour que les fichiers modifiés soient sauvegardés à chaque exécution, ajouter la ligne suivante :
BACKUP_TYPE=incremental
BACKUP_TYPE=incrementalCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ceci définitNETFS_KEEP_OLD_BACKUP_COPYautomatiquement ày. - Pour qu'une sauvegarde complète soit faîte régulièrement, en plus des sauvegardes incrémentielles, ajouter la ligne suivante :
FULLBACKUPDAY="Day"
FULLBACKUPDAY="Day"Copy to Clipboard Copied! Toggle word wrap Toggle overflow Remplacer "Jour" par un parmi "Lun", "Mar", "Mer", "Jeu". "Ven", "Sam", "Dim". - ReaR peut également inclure le système de secours et la sauvegarde de l'image ISO à la fois. Pour cela, définir
BACKUP_URLàiso:///backup/:BACKUP_URL=iso:///backup/
BACKUP_URL=iso:///backup/Copy to Clipboard Copied! Toggle word wrap Toggle overflow C'est la manière la plus simple d'effectuer une sauvegarde complète d'un système, car le système de secours n'a pas besoin que l'utilisateur aille chercher la sauvegarde lors du processus de recouvrement. Cependant, cela nécessite plus de stockage. Aussi, les sauvegardes d'ISO simples ne peuvent pas être incrémentales.Note
ReaR crée actuellement deux copies de l'image ISO, et utilise donc deux fois plus de stockage. Pour plus d'informations, voir le chapitre ReaR crée deux images ISO au lieu d'une qui se trouve dans les Notes de sortie de Red Hat Enterprise Linux 6.Exemple 27.5. Configurer un Système de secours ISO-Single et les Sauvegardes
Cette configuration crée un système de secours et un fichier de sauvegarde sous forme d'une image ISO et la met dans le répertoire/srv/backup/:OUTPUT=ISO OUTPUT_URL=file:///srv/backup/ BACKUP=NETFS BACKUP_URL=iso:///backup/
OUTPUT=ISO OUTPUT_URL=file:///srv/backup/ BACKUP=NETFS BACKUP_URL=iso:///backup/Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour utiliser
rsyncà la place detar, ajouter la ligne suivante :BACKUP_PROG=rsync
BACKUP_PROG=rsyncCopy to Clipboard Copied! Toggle word wrap Toggle overflow Notes que les sauvegardes incrémentielles ne sont pas prisses en charge quand on utilise la commandetar.
27.2.1.2. Créer une sauvegarde par la Méthode de sauvegarde interne
BACKUP=NETFS défini, ReaR peut soit créer un système de secours, soit un fichier de sauvegarde, ou les deux.
- Pour créer un système de secours uniquement, exécutez :
rear mkrescue
rear mkrescueCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour créer une sauvegarde uniquement, exécutez :
rear mkbackuponly
rear mkbackuponlyCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour créer un système de secours et une sauvegarde, exécutez :
rear mkbackup
rear mkbackupCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Note
BACKUP=NETFS s'attend à ce que la sauvegarde existe avant d'exécuter rear recover. Ainsi, une fois que le système de secours démarre, copier le fichier de sauvegarde dans le répertoire de sauvegarde indiqué dans BACKUP_URL, à moins que vous utilisiez une seule image ISO. Seulement après cela, exécutez rear recover.
rear checklayout echo $?
~]# rear checklayout
~]# echo $?Important
rear checklayout ne vérifie pas si le système de secours est actuellement présent dans la sortie, et peut retourner 0 même s'il n'est pas présent. Il n'y a donc aucune garantie que le système de secours soit disponible, cela indique uniquement un changement de disposition depuis la dernière création de système de secours.
Exemple 27.6. La commande rear checklayout
rear checklayout || rear mkrescue
~]# rear checklayout || rear mkrescue27.2.2. Méthodes de sauvegarde prises en charge
27.2.3. Méthodes de sauvegarde non prises en charge
- Le système de secours invite l'utilisateur à restaurer les fichiers manuellement. Ce sécnario est décrit dans "Utilisation de ReaR de base", sauf pour le format de fichier de sauvegarde, qui peut prendre un forme différente que sous forme de tar.
- ReaR exécute les commandes personnalisées fournies par l'utilisateur. Pour configurer cela, définir la directive
BACKUPàEXTERNAL. Puis, spécifier les commandes à exécuter lors de la sauvegarde et la restauration, en utilisant les directivesEXTERNAL_BACKUPetEXTERNAL_RESTORE. Spécifiez, en option, les directivesEXTERNAL_IGNORE_ERRORSetEXTERNAL_CHECKégalement. Voir/usr/share/rear/conf/default.confpour obtenir un exemple de configuration.
Annexe A. RPM
Avertissement
.tar.gz habituels.
Note
root dans la plupart des cas.
A.1. Objectifs de la conception RPM
- Upgradability
- Avec RPM, vous pouvez mettre à jour différents composants de votre système sans besoin de réinstallation complète. Quand vous obtenez une nouvelle version du système d'exploitation basé sur RPM, tels que Red Hat Enterprise Linux, vous n'avez pas besoin de réinstaller une nouvelle copie du système d'exploitation sur votre machine (ce que vous devrez peut-être effectuer avec des systèmes d'exploitation basés sur d'autres systèmes de packaging). RPM permet des mises à jour intelligentes, entièrement automatisées, sur place, dans votre système. De plus, les paquets, les fichiers de configuration des paquets sont conservés à travers les mises à jour, ce qui vous permet de conserver vos personnalisations. Il n'y a aucun fichier de mise à niveau spécial nécessaire pour mettre à jour un paquet parce qu'un même fichier RPM est utilisé à la fois pour installer et mettre à niveau le paquet sur votre système.
- Powerful Querying
- RPM est conçu pour fournir des options de recherche puissantes. Vous pouvez effectuer des recherches de paquets ou même simplement des fichiers sur votre copie de la base de données. Vous pouvez également facilement trouver à quel paquet appartient un fichier et d'où le paquet vient. Les fichiers contenus par un paquet RPM sont dans une archive compressée, avec un en-tête binaire personnalisé contenant des informations utiles sur l'emballage et son contenu, vous permettant de chercher des paquets un par un, rapidement et facilement.
- System Verification
- Une autre fonctionnalité puissante de RPM est sa capacité de vérifier les paquets. RPM vous permet de vérifier que les fichiers installés sur le système sont les mêmes que ceux qui sont fournis par un paquet donné. Si une incohérence est détectée, RPM vous informe, et vous pouvez réinstaller le paquet si nécessaire. Les fichiers de configuration que vous avez modifiés sont préservés lors de la réinstallation.
- Pristine Sources
- Un objectif de conception crucial consistait à permettre l'utilisation de sources intactes de logiciels, distribuées par les auteurs d'origine du logiciel. Avec RPM, vous avez les sources intactes, ainsi que tous les correctifs qui ont été utilisés, en plus des instructions de build. Il s'agit d'un avantage important pour plusieurs raisons. Par exemple, si une nouvelle version de programme est lancée, vous n'avez pas forcément besoin de tout recommencer du début pour le compiler. Vous pouvez regarder le correctif pour voir ce que vous pourriez faire. Tous les défauts compilés et toutes les modifications qui ont été faites pour que le logiciel puisse compiler correctement sont bien visibles avec cette technique.Le but de conserver les sources pristines ne peut sembler important qu'aux développeurs, mais cela amène à de meilleurs résultats de qualité de logiciels pour les utilisateurs finaux.
A.2. Utilisation de RPM
rpm --help or see rpm(8). Also, see Section A.5, « Ressources supplémentaires » for more information on RPM.
A.2.1. Installation et mise à niveau des paquets
package_name-version-release-operating_system-CPU_architecture.rpm
package_name-version-release-operating_system-CPU_architecture.rpmtree-1.6.0-10.el7.x86_64.rpm inclut le nom de paquet (tree), la version (1.6.0), la distribution (10), la version majeure de système d'exploitation (el7) et l'architecture de CPU (x86_64).
Important
x86_64.rpm.
-U (ou --upgrade) possède deux fonctions, elle peut être utilisée pour :
- mettre un programme existant à jour sur le sytème d'une nouvelle version, ou
- installer un paquet si une ancienne version n'est pas encore installée.
rpm -U package.rpm est soit capable, soit de mettre à niveau ou d'installer, selon la présence d'une ancienne version de package.rpm sur le système.
tree-1.6.0-10.el7.x86_64.rpm soit dans le répertoire actif, connectez-vous en tant qu'utilisateur root et tapez la commande suivante à l'invite du shell pour mettre à niveau ou installer le paquet tree :
rpm -Uvh tree-1.6.0-10.el7.x86_64.rpm
~]# rpm -Uvh tree-1.6.0-10.el7.x86_64.rpm-v et -h (qui sont combinées à -U) amènent le rpm à afficher des sorties plus détaillées et une jauge de progression utilisant des signes de hachage. Si la mise à niveau ou l'installation réussissent, la sortie suivante s'affichera :
Preparing... ################################# [100%] Updating / installing... 1:tree-1.6.0-10.el7 ################################# [100%]
Preparing... ################################# [100%]
Updating / installing...
1:tree-1.6.0-10.el7 ################################# [100%]Avertissement
rpmfournit deux options différentes pour installer les paquets : l'option -U, qui est historiquement utilisée pour les mise à niveau (de l'anglais upgrade), et l'option -i, qui est historiquement utilisée pour les installations (de l'anglais install). Comme l'option -U inclut à la fois les fonctions d'installation et de mise à niveau, l'utilisation de la commande rpm -Uvh pour tous les paquets, exceptés les paquets de noyau, est conseillée.
-i pour installer un nouveau paquet de noyau au lieu de le mettre à niveau. C'est parce que l'option -U de mise à jour d'un paquet de noyau supprime le paquet de noyau précédent (plus ancien), ce qui pourrait rendre le système incapable de démarrer s'il y a un problème avec le nouveau noyau. Par conséquent, utiliser la commande rpm -i kernel_package pour installer un nouveau noyau sans avoir à remplacer tous les paquets de noyau plus anciens. Pour plus d'informations sur l'installation des paquets de noyau, voir Chapitre 25, Mettre à niveau le noyau manuellement.
NOKEY:
warning: tree-1.6.0-10.el7.x86_64.rpm: Header V3 RSA/SHA256 Signature, key ID 431d51: NOKEY
warning: tree-1.6.0-10.el7.x86_64.rpm: Header V3 RSA/SHA256 Signature, key ID 431d51: NOKEYA.2.1.1. Remplacer les paquets déjà installés
Preparing... ########################################### [100%]
package tree-1.6.0-10.el7.x86_64 is already installed
Preparing... ########################################### [100%]
package tree-1.6.0-10.el7.x86_64 is already installed--replacepkgs, qui indique au RPM d'ignorer l'erreur :
rpm -Uvh --replacepkgs tree-1.6.0-10.el7.x86_64.rpm
~]# rpm -Uvh --replacepkgs tree-1.6.0-10.el7.x86_64.rpm--oldpackage :
rpm -Uvh --oldpackage older_package.rpm
rpm -Uvh --oldpackage older_package.rpmA.2.1.2. Résolution des conflits de fichiers
--replacefiles :
rpm -Uvh --replacefiles package.rpm
rpm -Uvh --replacefiles package.rpmA.2.1.3. Résoudre les dépendances manquantes
--whatprovides :
rpm -q --whatprovides "required_file"
rpm -q --whatprovides "required_file"Avertissement
RPM à installer un paquet ayant une dépendance non résolue (à l'aide de l'option --nodeps), ce n'est pas recommandé et cela entraînera généralement la suspension du logiciel installé. L'installation de paquets avec l'option --nodeps peut provoquer des troubles de comportements d'applications et des interruptions inattendues. Cela peut également provoquer des problèmes graves de gestion de paquets ou de défaillance du système. Pour ces raisons, tenez compte des avertissements à propos des dépendances manquantes. Le gestionnaire de paquets Yum effectue la résolution de dépendance automatique et récupère les dépendances de référentiels en ligne.
A.2.1.4. Préservation des changements dans les fichiers de configuration
sauvegarder /etc/configuration_file.conf en tant que /etc/configuration_file.conf.rpmsave
sauvegarder /etc/configuration_file.conf en tant que /etc/configuration_file.conf.rpmsaveconfiguration_file.conf.rpmnew et laisser le fichier de configuration que vous venez de modifier intact. Il vous reste à résoudre tous les conflits entre votre fichier de configuration modifié et le nouveau, en procédant normalement à la fusion des modifications de l'ancien dans le nouveau, à l'aide du programme diff, par exemple.
A.2.2. Désinstaller les paquets
root à l'invite du shell :
rpm -e package
rpm -e packageNote
rpm-e et que vous fournissez le nom complet du fichier d'origine, vous recevez une erreur de nom de paquet.
Avertissement
rpm à désinstaller un package dont les dépendances ne sont pas résolues (à l'aide de l'option --nodeps), ce n'est pas recommandé. La suppression de paquets avec l'option --nodeps peut provoquer des problèmes de comportement ou des interruptions inattendues de la part des paquets dont les dépendances sont retirées. Il peut également provoquer des problèmes graves de gestion de paquets, voire de défaillance du système. Pour ces raisons, tenez compte des avertissements de dépendances ayant échoué.
A.2.3. Rafraîchissement de paquets
root :
rpm -Fvh package.rpm
rpm -Fvh package.rpm-F (ou --freshen) compare les versions des paquets nommés sur la ligne de commande par rapport aux versions des paquets qui sont déjà installés sur le système. Lorsqu'une nouvelle version d'un paquet déjà installé est traitée par l'option --freshen, elle est mis à niveau à une version plus récente. Cependant, l'option --freshen n'installe pas un paquet si aucun paquet précédemment installée du même nom existe déjà. Cela diffère de la mise à niveau régulière, car une mise à jour installe tous les paquets spécifiés indépendamment de savoir si oui ou non les anciennes versions des paquets sont déjà installées.
*.rpm :
rpm -Fvh *.rpm
~]# rpm -Fvh *.rpmA.2.4. Recherche de paquets
/var/lib/rpm/ et est utilisé pour beaucoup de choses, y compris pour savoir quels paquets sont installés, quelle est la version de chaque paquet, et pour le calcul des modifications apportées aux fichiers en paquets depuis leur installation. Pour interroger cette base de données, utilisez la commande rpm avec l'option -q (ou --query) :
rpm -q package_name
rpm -q package_namerpm -q tree tree-1.6.0-10.el7.x86_64
~]$ rpm -q tree
tree-1.6.0-10.el7.x86_64Package Selection Options subheading in the rpm(8) manual page for a list of options that can be used to further refine or qualify your query. Use options listed below the Package Query Options subheading to specify what information to display about the queried packages.
A.2.5. Vérification des paquets
rpm avec l'option -V (or --verify) pour vérifier les paquets. Par exemple :
rpm -V tree
~]$ rpm -V treePackage Selection Options subheading in the rpm(8) manual page for a list of options that can be used to further refine or qualify your query. Use options listed below the Verify Options subheading to specify what characteristics to verify in the queried packages.
rpm -V abrt S.5....T. c /etc/abrt/abrt.conf .M....... /var/spool/abrt-upload
~]# rpm -V abrt
S.5....T. c /etc/abrt/abrt.conf
.M....... /var/spool/abrt-upload.) signifie que le test a pu être passé, et le caractère point d'interrogation (?) signifie que le test ne peut pas être effectué. Le tableau suivant répertorie les symboles qui indiquent certaines incohérences :
| Symbole | Description |
|---|---|
S | la taille des fichiers diffère |
M | le mode diffère (inclut les permissions et le type de fichier) |
5 | digest (anciennement MD5 sum) diffère |
D | non correspondance du numéro de version mineur/majeur de la machine |
L | readLink(2) path mismatch |
U | appartenance utilisateur diffère |
G | appartenance groupe diffère |
T | mtime diffère |
P | les capacités diffèrent |
| Marqueurs | Description |
|---|---|
c | fichier de configuration |
d | fichier de documentation |
l | fichier de licence |
r | fichier readme |
A.3. Recherche et Vérification de paquets RPM
A.3.1. Recherche de paquets RPM
- Official RPM repositories provided with the Yum package manager. See Chapitre 8, Yum for details on how to use the official Red Hat Enterprise Linux package repositories.
- La page Red Hat Errata se trouve sur le Portail Client à l'adresse suivante https://rhn.redhat.com/rhn/errata/RelevantErrata.do.
- Extra Packages for Enterprise Linux (EPEL) is a community effort to provide a repository with high-quality add-on packages for Red Hat Enterprise Linux. See http://fedoraproject.org/wiki/EPEL for details on EPEL RPM packages.
- De façon non officielle, les référentiels de tierce partie non affiliés à Red Hat fournissent également des paquets RPM.
Important
Quand on examine les référentiels de tierce partie qui puissent être utilisés avec votre système Red Hat Enterprise Linux, observer attentivement le site web du référentiel en ce qui concerne la compatibilité de paquet avant d'ajouter le référentiel comme paquet source. D'autres référentiels de paquets peuvent offrir des versions différentes et incompatibles du même logiciel, y compris des paquets déjà inclus dans les référentiels Red Hat Enterprise Linux.
A.3.2. Vérification des signatures de paquets
rpmkeys avec l'option -K (ou --checksig) :
rpmkeys -K package.rpm
rpmkeys -K package.rpmA.3.2.1. Import de clés GPG
rpm -qa gpg-pubkey*
~]$ rpm -qa gpg-pubkey*rpm -qi suivie de la sortie de la commande précédente. Par exemple :
rpm -qi gpg-pubkey-fd431d51-4ae0493b
~]$ rpm -qi gpg-pubkey-fd431d51-4ae0493brpmkeys avec l'option --import pour installer une nouvelle clé à utiliser avec RPM. L'emplacement par défaut pour stocker les clés GPG RPM est le répertoire /etc/pki/rpm-gpg /. Pour importer de nouvelles clés, utiliser une commande semblable à celle-ci en tant qu'utilisateur root :
rpmkeys --import /etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
~]# rpmkeys --import /etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-releaseA.4. Exemples communs de l'utilisation de RPM
- Pour vérifier dans tout votre système quels sont les fichiers manquants, lancez la commande suivante en tant qu'utilisateur
root:rpm -Va
rpm -VaCopy to Clipboard Copied! Toggle word wrap Toggle overflow Si certains fichiers ont disparu ou semblent avoir été corrompus, il vaut mieux réinstaller les paquets qui conviennent. - Pour savoir à quel paquet un fichier appartient, saisir :
rpm -qf file
rpm -qf fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour vérifier l'appartenance d'un fichier particulier à un paquet, saisir la commande suivante en tant qu'utilisateur
root:rpm -Vf file
rpm -Vf fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour trouver l'emplacement de fichiers de documentation qui font partie d'un paquet auquel un fichier appartient, saisir :
rpm -qdf file
rpm -qdf fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour trouver des informations sur un fichier de paquet (non installé), utiliser la commande suivante :
rpm -qip package.rpm
rpm -qip package.rpmCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Pour afficher des fichiers contenus dans un paquet, utiliser :
rpm -qlp package.rpm
rpm -qlp package.rpmCopy to Clipboard Copied! Toggle word wrap Toggle overflow
A.5. Ressources supplémentaires
Documentation installée
rpm --help— cette commande afficher une référence rapide de paramètres RPM.- rpm(8) — The RPM manual page offers an overview of all available RPM parameters.
Documentation en ligne
- Red Hat Enterprise Linux 7 Security Guide — Le guide de sécurité Security Guide de Red Hat Enterprise Linux 7 documente la façon de conserver votre système à jour grâce au gestionnaire de paquets Yum et comment vérifier et installer les paquets téléchargés.
- Le site web RPM — http://www.rpm.org/
- La liste de diffusion RPM — http://lists.rpm.org/mailman/listinfo/rpm-list
Voir aussi
- Chapitre 8, Yum décrit comment utiliser le gestionnaire de paquets Yum pour chercher, installer, mettre à jour et installer des paquets par la ligne de commande.
Annexe B. Historique des versions
| Historique des versions | |||
|---|---|---|---|
| Version 0.14-8.4 | Thu May 31 2018 | ||
| |||
| Version 0.14-8.3 | Tue Jul 4 2017 | ||
| |||
| Version 0.14-8.2 | Mon Apr 3 2017 | ||
| |||
| Version 0.14-8.1 | Mon Feb 6 2017 | ||
| |||
| Version 0.14-8 | Mon Nov 3 2016 | ||
| |||
| Version 0.14-7 | Mon Jun 20 2016 | ||
| |||
| Version 0.14-6 | Thu Mar 10 2016 | ||
| |||
| Version 0.14-5 | Thu Jan 21 2016 | ||
| |||
| Version 0.14-3 | Wed Nov 11 2015 | ||
| |||
| Version 0.14-1 | Mon Nov 9 2015 | ||
| |||
| Version 0.14-0.3 | Fri Apr 3 2015 | ||
| |||
| Version 0.13-2 | Tue Feb 24 2015 | ||
| |||
| Version 0.12-0.6 | Tue Nov 18 2014 | ||
| |||
| Version 0.12-0.4 | Mon Nov 10 2014 | ||
| |||
| Version 0.12-0 | Tue 19 Aug 2014 | ||
| |||
Index
Symboles
- .fetchmailrc, Options de Configuration Fetchmail
- options d'utilisateur, Options d'utilisateur
- options de serveur, Options de serveur
- .procmailrc, Configuration Procmail
- /dev/oprofile/, Comprendre le répertoire /dev/oprofile/
- /var/spool/anacron , Configurer les tâches Anacron
- /var/spool/cron , Configuration des tâches Cron
- (voir OProfile)
A
- abonnements, Enregistrer le système et Gérer les abonnements
- ABRT, Introduction à ABRT
- (voir aussi abrtd)
- (voir aussi Bugzilla)
- (voir aussi Support technique Red Hat)
- CLI, Utiliser l'outil de ligne de commande
- configurer, Configurer ABRT
- configurer des événements, Configurer des événements
- créer des événements, Créer des événements personnalisés
- démarrer, Installer ABRT et lancer ses services, Lancer les services ABRT
- détection d'incident, Introduction à ABRT
- événements standard, Configurer des événements
- GUI, Utilisation de la GUI
- installer, Installer ABRT et lancer ses services
- introduction, Introduction à ABRT
- problèmes
- détection, Détection de problèmes logiciels
- gestion, Gestion des problèmes détectés
- pris en charge, Détection de problèmes logiciels
- rapports automatiques, Paramétrer les rapports automatiques
- ressources supplémentaires, Ressources supplémentaires
- tester, Tester la détection d'incidents ABRT
- ABRT CLI
- installation, Installer ABRT pour l'interface en ligne de commande
- abrtd
- démarrer, Installer ABRT et lancer ses services, Lancer les services ABRT
- redémarrer, Lancer les services ABRT
- ressources supplémentaires, Ressources supplémentaires
- statut, Lancer les services ABRT
- tester, Tester la détection d'incidents ABRT
- ACL
- ACL d'accès, Définir les ACL d'accès
- ACL par défaut, Définit les ACL par défaut
- archiver avec, Archiver des systèmes de fichiers avec des ACL
- avec Samba, Listes des contrôle d'accès (ACL)
- définir
- ACL d'accès, Définir les ACL d'accès
- monter des partages NFS avec des, NFS
- monter des systèmes de fichiers avec des, Monter des systèmes de fichiers
- récupération, Récupérer des ACL
- ressources supplémentaires, Références des ACL
- sur systèmes de fichiers ext3, Listes des contrôle d'accès (ACL)
- ACLs
- getfacl , Récupérer des ACL
- setfacl , Définir les ACL d'accès
- agent d'utilisateur de messagerie (voir courrier électronique)
- Agent de Transport de Courrier (voir courrier électronique)
- agent distributeur de courrier (voir courrier électronique)
- ajouter
- groupe, Ajout d'un nouveau groupe
- utilisateur, Ajout d'un nouvel utilisateur
- anacron, Cron et Anacron
- fichier de configuration anacron, Configurer les tâches Anacron
- tâches définies par l'utilisateur, Configurer les tâches Anacron
- anacrontab , Configurer les tâches Anacron
- analyse système
- OProfile (voir OProfile)
- Apache HTTP Server
- arrêter, Arrêter le service
- directories
- /etc/httpd/conf.d/ , Modifier les fichiers de configuration
- fichiers
- /etc/httpd/conf.d/nss.conf , Activer le module mod_nss
- /etc/httpd/conf.d/ssl.conf , Activer le module mod_ssl
- files
- /etc/httpd/conf/httpd.conf , Modifier les fichiers de configuration
- hôte virtuel, Paramétrer des hôtes virtuels
- lancement, Lancer le service
- modules
- charger, Charger un module
- développer, Écrire un module
- mod_ssl , Paramétrer un serveur SSL
- mod_userdir, Mettre à jour la configuration
- redémarrer, Redémarrer le service
- répertoires
- /usr/lib64/httpd/modules/ , Utiliser des modules
- ressources supplémentaires
- documentation installable, Ressources supplémentaires
- documentation installée, Ressources supplémentaires
- sites web utiles, Ressources supplémentaires
- serveur SSL
- autorité de certification, Vue d'ensemble des certificats et de la sécurité
- certificat, Vue d'ensemble des certificats et de la sécurité, Utiliser une clé existante et un certificat, Générer une nouvelle clé et un nouveau certificat
- clé privée, Vue d'ensemble des certificats et de la sécurité, Utiliser une clé existante et un certificat, Générer une nouvelle clé et un nouveau certificat
- clé publique, Vue d'ensemble des certificats et de la sécurité
- vérifier la configuration, Modifier les fichiers de configuration
- vérifier le statut, Vérifier le statut du service
- version 2.4
- mettre à jour à partir de la version 2.2, Mettre à jour la configuration
- at , « At » et « Batch »
- ressources supplémentaires, Ressources supplémentaires
B
- batch , « At » et « Batch »
- ressources supplémentaires, Ressources supplémentaires
- blkid, Utiliser la commande blkid
C
- ch-email .fetchmailrc
- options globales, Options globales
- Changements au fichier de configuration, Préserver les changements au fichier de configuration
- chargeur de démarrage
- chargeur de démarrage GRUB 2, Utiliser le chargeur de démarrage GRUB 2
- vérifier, Vérifier le chargeur de démarrage
- clés ECDSA
- gérérer les clés, Création de paires de clés
- clés RSA
- générer les clés, Création de paires de clés
- commande useradd
- création de compte utilisateur à l'aide de, Ajout d'un nouvel utilisateur
- configuration de l'utilisateur
- afficher la liste des utilisateurs, Gestion des utilisateurs dans un environnement graphique
- configuration du clavier, Paramètres régionaux et configuration du clavier
- structure, Modifier l'agencement du clavier
- configuration du groupe
- afficher la liste des groupes, Gestion des utilisateurs dans un environnement graphique
- groupadd, Ajout d'un nouveau groupe
- configuration utilisateur
- configuration de ligne de commande
- passwd, Ajout d'un nouvel utilisateur
- useradd, Ajout d'un nouvel utilisateur
- courrier électronique
- classifications des programmes, Classifications des programmes de courrier électronique
- courrier indésirable
- filtrage, Filtres du courrier indésirable
- Fetchmail, Fetchmail
- Postfix, Postfix
- Procmail, Agents de remise de courrier (« Mail Delivery Agents »)
- protocoles, Protocoles de courrier électronique
- ressources supplémentaires, Ressources supplémentaires
- documentation en ligne, Documentation en ligne
- documentation installée, Documentation installée
- livres apparentés, Livres apparentés
- sécurité, Sécuriser les communications
- Sendmail, Sendmail
- serveur de courrier
- Dovecot, dovecot
- types
- agent d'utilisateur de messagerie, Agent d'utilisateur de messagerie
- Agent de Transport de Courrier, Agent de transport de courrier
- Agent Distributeur de Courrier, Agent distributeur de courrier
- createrepo, Création d'un référentiel Yum
- cron, Cron et Anacron
- fichier de configuration cron, Configuration des tâches Cron
- ressources supplémentaires, Ressources supplémentaires
- tâches définies par l'utilisateur, Configuration des tâches Cron
- crontab , Configuration des tâches Cron
- CUPS (voir Print Settings)
D
- df, Utiliser la commande df
- documentation
- chercher installés, Exemples communs de l'utilisation de RPM
- du, Utiliser la commande du
E
- extra packages for Enterprise Linux (EPEL)
- installable packages, Recherche de paquets RPM
F
- Fetchmail, Fetchmail
- options de commande, Options de commande Fetchmail
- à caractère informatif, Options de débogage ou à caractère informatif
- spéciales, Options spéciales
- options de configuration, Options de Configuration Fetchmail
- options d'utilisateur, Options d'utilisateur
- options de serveur, Options de serveur
- options globales, Options globales
- ressources supplémentaires, Ressources supplémentaires
- fichiers journaux, Afficher et gérer des fichiers journaux
- (voir aussi Journal système)
- afficher, Afficher les fichiers journaux
- contrôler, Surveiller des fichiers journaux
- description, Afficher et gérer des fichiers journaux
- localiser, Localiser les fichiers journaux
- rotatifs, Localiser les fichiers journaux
- rsyslogd daemon, Afficher et gérer des fichiers journaux
- findmnt, Utiliser la commande findmnt
- free, Utiliser la commande free
- FTP, FTP
- (voir aussi vsftpd)
- définition, FTP
- introduction, Le protocole de transfert de fichiers
- mode actif, Le protocole de transfert de fichiers
- mode passif, Le protocole de transfert de fichiers
- port des commandes, Le protocole de transfert de fichiers
- port des données, Le protocole de transfert de fichiers
G
- Gestionnaire de paquets RPM (voir RPM)
- getfacl , Récupérer des ACL
- gnome-system-log (voir System Log)
- gnome-system-monitor, Utiliser l'outil de surveillance du système « System Monitor », Utiliser l'outil de surveillance du système « System Monitor », Utiliser l'outil de surveillance du système « System Monitor », Utiliser l'outil de surveillance du système « System Monitor »
- GnuPG
- vérification des signatures des paquets de RPM, Vérification des signatures de paquets
- Greffon security (voir Sécurité)
- groupes (voir configuration du groupe)
- GID, Gérer les utilisateurs et les groupes
- introduction, Gérer les utilisateurs et les groupes
- outils pour la gestion de
- privés d'utilisateurs, Groupes privés d'utilisateurs
- répertoires partagés, Création de répertoire de groupes
- ressources supplémentaires, Ressources supplémentaires
- documentation installée, Ressources supplémentaires
- groupes de paquets
- répertorier des groupes de paquets avec yum
- groupes yum, Répertorier les groupes de paquets
- groupes privés d'utilisateurs (voir groupes)
- et répertoires partagés, Création de répertoire de groupes
- GRUB 2
- configurer GRUB 2, Utiliser le chargeur de démarrage GRUB 2
- personnaliser GRUB 2, Utiliser le chargeur de démarrage GRUB 2
- réinstaller GRUB 2, Utiliser le chargeur de démarrage GRUB 2
H
- hôte virtuel (voir Apache HTTP Server )
- httpd (voir Serveur Apache HTTP )
I
- image de disque RAM initial
- vérifier
- IBM eServer System i, Vérifier l'image de disque RAM initial
- image de disque RAM initiale
- recréer, Vérifier l'image de disque RAM initial
- vérifier, Vérifier l'image de disque RAM initial
- imprimantes (voir Print Settings)
- informations
- sur votre système, Outils de surveillance du système
- informations système
- collecte, Outils de surveillance du système
- matériel, Afficher les informations matériel
- processus, Afficher les processus système
- actuellement en cours d'utilisation, Utiliser la commande top
- systèmes de fichiers, Afficher les périphériques bloc et les systèmes de fichiers
- utilisation de la mémoire, Afficher l'utilisation de la mémoire
- utilisation du CPU, Afficher l'utilisation du CPU
- initial RPM repositories
- installable packages, Recherche de paquets RPM
- insmod, Charger un module
- (voir aussi module de noyau)
- installer le noyau, Mettre à niveau le noyau manuellement
- Interface utilisateur graphique ABRT
- installation, Installer l'interface utilisateur graphique ABRT
L
- Liste de contrôle d'accès (voir ACL)
- localectl (voir configuration du clavier)
- logrotate, Localiser les fichiers journaux
- lsblk, Utiliser la commande lsblk
- lscpu, Utiliser la commande lscpu
- lsmod, Répertorier les modules actuellement chargés
- (voir aussi module de noyau)
- lspci, Utiliser la commande lspci
- lsusb, Utiliser la commande lsusb
M
- Mail Transport Agent (voir MTA)
- Mail Transport Agent Switcher, Configuration de l'agent de transport de courrier (« Mail Transport Agent », ou MTA)
- Mail User Agent, Configuration de l'agent de transport de courrier (« Mail Transport Agent », ou MTA)
- matériel
- afficher, Afficher les informations matériel
- MDA (voir agent distributeur de courrier)
- mise à niveau du noyau
- préparation, Préparer pour une mise à niveau
- Mises à jour Yum
- mettre à jour des paquets liés à la sécurité, Mise à jour de paquets
- mettre à jour tous les paquets et leurs dépendances, Mise à jour de paquets
- mise à jour d'un paquet unique, Mise à jour de paquets
- mise à jour des paquets, Mise à jour de paquets
- modinfo, Afficher des informations sur un module
- (voir aussi module de noyau)
- modprobe, Charger un module, Décharger un module
- (voir aussi module de noyau)
- module (voir module de noyau)
- module de noyau
- chargement
- au moment du démarrage, Chargement de modules persistants
- pour la session actuelle, Charger un module
- décharger, Décharger un module
- définition, Utiliser des modules de noyau
- fichiers
- /proc/modules, Répertorier les modules actuellement chargés
- paramètres de module
- fournir, Définir les paramètres de module
- répertoires
- /etc/modules-load.d/, Chargement de modules persistants
- /usr/lib/modules/kernel_version/kernel/drivers/, Charger un module
- répertorier
- information sur un module, Afficher des informations sur un module
- modules actuellement chargés, Répertorier les modules actuellement chargés
- utilitaires
- insmod, Charger un module
- lsmod, Répertorier les modules actuellement chargés
- modinfo, Afficher des informations sur un module
- modprobe, Charger un module, Décharger un module
- rmmod, Décharger un module
- mots de passe
- mots de passe cachés
- vue d'ensemble des, Mots de passe cachés (« Shadow Passwords »)
- MTA (voir Agent de Transport de Courrier)
- changement à l'aide deMail Transport Agent Switcher, Configuration de l'agent de transport de courrier (« Mail Transport Agent », ou MTA)
- paramétres par défaut, Configuration de l'agent de transport de courrier (« Mail Transport Agent », ou MTA)
- MUA, Configuration de l'agent de transport de courrier (« Mail Transport Agent », ou MTA) (voir agent d'utilisateur de messagerie)
N
- net program, Programmes de distribution Samba
- nmblookup programme, Programmes de distribution Samba
- noyau
- effectuer la mise à niveau, Effectuer la mise à niveau
- installer les paquets du noyau, Mettre à niveau le noyau manuellement
- mettre à jour le noyau, Mettre à niveau le noyau manuellement
- mise à niveau
- préparation, Préparer pour une mise à niveau
- support de démarrage fonctionnant, Préparer pour une mise à niveau
- noyau de mise à niveau disponible, Télécharger le noyau mis à niveau
- Errata de sécurité, Télécharger le noyau mis à niveau
- Red Hat Content Delivery Network, Télécharger le noyau mis à niveau
- paquet, Mettre à niveau le noyau manuellement
- paquet RPM, Mettre à niveau le noyau manuellement
- paquets du noyau, Vue d'ensemble des paquets du noyau
- télécharger, Télécharger le noyau mis à niveau
O
- opannotate (voir OProfile)
- opcontrol (voir OProfile)
- OpenSSH, OpenSSH, Fonctionnalités principales
- (voir aussi SSH)
- authentification basée clés, Authentification basée clés
- clés ECDSA
- générer les clés, Création de paires de clés
- clés RSA
- générer les clés, Création de paires de clés
- client, Clients OpenSSH
- scp, rsh
- sftp, rsh
- ssh, Comment se servir de l'utilitaire ssh
- ressources supplémentaires, Ressources supplémentaires
- serveur, Démarrage d'un serveur OpenSSH
- arrêt, Démarrage d'un serveur OpenSSH
- démarrage, Démarrage d'un serveur OpenSSH
- ssh-add, Configurer les partages Samba
- ssh-agent, Configurer les partages Samba
- ssh-keygen
- OpenSSL
- ressources supplémentaires, Ressources supplémentaires
- SSL (voir SSL )
- TLS (voir TLS )
- ophelp, Paramétrer les événements à surveiller
- opreport (voir OProfile)
- OProfile, OProfile
- /dev/oprofile/, Comprendre le répertoire /dev/oprofile/
- aperçu des outils, Aperçu des outils
- configurer, Configurer OProfile en utilisant le mode hérité
- séparer les profils, Séparer les profils du noyau et de l'espace utilisateur
- enregistrer des données, Enregistrer des données en mode hérité
- événements
- paramétrer, Paramétrer les événements à surveiller
- taux d'échantillonnage, Taux d'échantillonnage
- Java, Prise en charge Java d'OProfile
- lancer, Lancer et arrêter OProfile en utilisant le mode hérité
- lire les données, Analyser les données
- masque d'unité, Masques d'unités
- opannotate, Utiliser opannotate
- opcontrol, Configurer OProfile en utilisant le mode hérité
- --no-vmlinux, Spécifier le noyau
- --start, Lancer et arrêter OProfile en utilisant le mode hérité
- --vmlinux=, Spécifier le noyau
- ophelp, Paramétrer les événements à surveiller
- opreport, Utiliser opreport, Obtenir une sortie plus détaillée sur les modules
- sur un seul exécutable, Utiliser opreport sur un seul exécutable
- oprofiled, Lancer et arrêter OProfile en utilisant le mode hérité
- fichier journal, Lancer et arrêter OProfile en utilisant le mode hérité
- ressources supplémentaires, Ressources supplémentaires
- surveiller le noyau, Spécifier le noyau
- SystemTap, OProfile et SystemTap
- oprofiled (voir OProfile)
- oprof_start, Interface graphique
- Outils ABRT
- installation, Installer les outils ABRT supplémentaires
P
- packages
- extra packages for Enterprise Linux (EPEL), Recherche de paquets RPM
- initial RPM repositories, Recherche de paquets RPM
- Red Hat Enterprise Linux installation media, Recherche de paquets RPM
- RPM
- pristine sources, Objectifs de la conception RPM
- paquet
- perf
- fichiers du microprogramme, Vue d'ensemble des paquets du noyau
- RPM du noyau, Mettre à niveau le noyau manuellement
- paquet de noyau
- perf
- fichiers du microprogramme, Vue d'ensemble des paquets du noyau
- paquet du noyau
- kernel-devel
- en-têtes de noyau et makefiles, Vue d'ensemble des paquets du noyau
- kernel-doc
- fichiers de documentation, Vue d'ensemble des paquets du noyau
- kernel-headers
- C header files files, Vue d'ensemble des paquets du noyau
- linux-firmware
- fichiers du microprogramme, Vue d'ensemble des paquets du noyau
- noyau
- pour systèmes uniques, multi-cœurs, et multiprocesseurs, Vue d'ensemble des paquets du noyau
- paquets, Utiliser des paquets
- afficher des paquets
- yum info, Afficher des informations sur le paquet
- afficher des paquets avec yum
- yum info, Afficher des informations sur le paquet
- dépendances, Résoudre les dépendances manquantes
- désinstaller des paquets avec yum, Supprimer des paquets
- déterminer l'appartenance d'un fichier, Exemples communs de l'utilisation de RPM
- installation avec yum, Installation de paquets
- installation RPM, Installation et mise à niveau des paquets
- installer un groupe de paquets avec yum, Installer un groupe de paquets
- kernel-devel
- en-têtes de noyau et makefiles, Vue d'ensemble des paquets du noyau
- kernel-doc
- fichiers de documentation, Vue d'ensemble des paquets du noyau
- kernel-headers
- C header files files, Vue d'ensemble des paquets du noyau
- linux-firmware
- fichiers du microprogramme, Vue d'ensemble des paquets du noyau
- mise à niveau RPM, Installation et mise à niveau des paquets
- noyau
- pour systèmes uniques, multi-cœurs, et multiprocesseurs, Vue d'ensemble des paquets du noyau
- obtenir une liste de fichiers, Exemples communs de l'utilisation de RPM
- recherche de paquets RPM de Red Hat, Recherche de paquets RPM
- recherche des fichiers supprimés de, Exemples communs de l'utilisation de RPM
- rechercher des paquets avec yum
- recherche yum, Rechercher des paquets
- répertorier des paquets avec yum
- expressions glob, Rechercher des paquets
- liste yum disponible, Répertorier les paquets
- liste yum installée, Répertorier les paquets
- recherche yum, Répertorier les paquets
- yum repolist, Répertorier les paquets
- RPM, RPM
- astuces, Exemples communs de l'utilisation de RPM
- changements de fichiers de configuration, Préservation des changements dans les fichiers de configuration
- conflit, Résolution des conflits de fichiers
- déjà installés, Remplacer les paquets déjà installés
- dépendances ayant échoué, Résoudre les dépendances manquantes
- désinstallation, Désinstaller les paquets
- paquets source et binaires, RPM
- rafraîchissement, Rafraîchissement de paquets
- recherche, Recherche de paquets
- suppression, Désinstaller les paquets
- vérification, Vérification des paquets
- suppression, Désinstaller les paquets
- télécharger des paquets avec yum, Télécharger des paquets
- trouver l'emplacement de documentation pour, Exemples communs de l'utilisation de RPM
- vérification non installés, Exemples communs de l'utilisation de RPM
- Yum à la place de RPM, RPM
- Paquets liés à la sécurité
- mettre à jour des paquets liés à la sécurité, Mise à jour de paquets
- paramètres de module (voir module de noyau)
- pdbedit programme, Programmes de distribution Samba
- pilotes (voir module de noyau)
- Postfix, Postfix
- installation par défaut, Installation Postfix par défaut
- postfix, Configuration de l'agent de transport de courrier (« Mail Transport Agent », ou MTA)
- Print Settings
- CUPS, L'outil « Print Settings »
- Imprimantes IPP, Ajouter une imprimante IPP
- Imprimantes LDP/LPR, Ajouter un hôte ou une imprimante LPD/LPR
- Imprimantes locales, Ajouter une imprimante locale
- Imprimantes Samba, Ajouter une imprimante Samba (SMB)
- Nouvelle imprimante, Lancer l'installation d'une imprimante
- Paramètres, Page des paramètres
- Partager des imprimantes, Partager des imprimantes
- Tâches d'impression, Gérer les tâches d'impression
- processus, Afficher les processus système
- Procmail, Agents de remise de courrier (« Mail Delivery Agents »)
- configuration, Configuration Procmail
- recettes, Recettes Procmail
- actions spéciales, Conditions et actions spéciales
- conditions spéciales, Conditions et actions spéciales
- de non-remise, Recettes de remise vs. Recettes de non-remise
- exemples, Exemples de recettes
- lockfiles locaux, Spécifier un fichier lockfile local
- marqueurs, Marqueurs
- remises, Recettes de remise vs. Recettes de non-remise
- SpamAssassin, Filtres du courrier indésirable
- ressources supplémentaires, Ressources supplémentaires
- protocole SSH
- authentification, Authentification
- couches
- canaux, Canaux
- couche de transport, Couche de transport
- fichiers de configuration, Fichiers de configuration
- fichiers de configuration pour tout le système, Fichiers de configuration
- fichiers de configuration spécifiques utilisateur, Fichiers de configuration
- fonctionnalités, Fonctionnalités principales
- pré-requis pour une connexion à distance, Utilisation nécessaire de SSH pour les connexions à distance
- protocoles non sécurisés, Utilisation nécessaire de SSH pour les connexions à distance
- risques de sécurité, Pourquoi utiliser SSH ?
- séquence de connexion, Séquence d'événements d'une connexion SSH
- version 1, Versions de protocole
- version 2, Versions de protocole
- Protocole SSH
- réacheminement de port, Réacheminement de port
- ps, Utiliser la commande ps
R
- RAM, Afficher l'utilisation de la mémoire
- rcp, rsh
- ReaR
- utilisation de base, Basic ReaR Usage
- Red Hat Support Tool
- obtenir du support sur la ligne de commande, Accéder au support en utilisant l'outil « Red Hat Support Tool »
- Red Hat Enterprise Linux installation media
- installable packages, Recherche de paquets RPM
- Red Hat Subscription Management
- rmmod, Décharger un module
- (voir aussi module de noyau)
- rpcclientprogramme, Programmes de distribution Samba
- RPM, RPM
- astuces, Exemples communs de l'utilisation de RPM
- changements de fichiers de configuration, Préservation des changements dans les fichiers de configuration
- conflits, Résolution des conflits de fichiers
- conflits de fichiers
- résoudre, Résolution des conflits de fichiers
- déjà installés, Remplacer les paquets déjà installés
- dépendances, Résoudre les dépendances manquantes
- dépendances ayant échoué, Résoudre les dépendances manquantes
- design goals
- powerful querying, Objectifs de la conception RPM
- system verification, Objectifs de la conception RPM
- upgradability, Objectifs de la conception RPM
- désinstallation, Désinstaller les paquets
- déterminer l'appartenance d'un fichier, Exemples communs de l'utilisation de RPM
- documentation avec, Exemples communs de l'utilisation de RPM
- documentation en ligne, Ressources supplémentaires
- GnuPG, Vérification des signatures de paquets
- installation, Installation et mise à niveau des paquets
- interroger une liste de fichiers, Exemples communs de l'utilisation de RPM
- mise à niveau, Installation et mise à niveau des paquets
- modes de base, Utilisation de RPM
- nom de fichier, Installation et mise à niveau des paquets
- objectifs de conception, Objectifs de la conception RPM
- rafraîchissement, Rafraîchissement de paquets
- recherche, Recherche de paquets
- recherche de paquets RPM de Red Hat, Recherche de paquets RPM
- recherche des fichiers supprimés avec, Exemples communs de l'utilisation de RPM
- recherche et vérification de paquets RPM, Recherche et Vérification de paquets RPM
- ressources supplémentaires, Ressources supplémentaires
- site web, Ressources supplémentaires
- vérification, Vérification des paquets
- vérification des paquets non installés, Exemples communs de l'utilisation de RPM
- vérification des signatures de paquets, Vérification des signatures de paquets
- voir aussi, Ressources supplémentaires
- rsyslog, Afficher et gérer des fichiers journaux
- actions, Actions
- configuration, Configuration de base de Rsyslog
- déboguer, Déboguer Rsyslog
- directives globales, Directives globales
- files d'attente, Utiliser des files d'attente dans Rsyslog
- filtres, Filtres
- modèles, Modèles
- modules, Utiliser des modules Rsyslog
- nouveau format de configuration, Utiliser le nouveau format de configuration
- rotation de journaux, Rotation de journaux
- rulesets, Rulesets
S
- Samba (voir Samba)
- avec Windows NT 4.0, 2000, ME, et XP, Mots de passe chiffrés
- Capacités, Introduction à Samba
- configuration, Configurer un serveur Samba, Configuration en ligne de commande
- par défaut, Configurer un serveur Samba
- configuration graphique, Configuration graphique
- démon
- nmbd, Démons Samba et services connexes
- smbd, Démons Samba et services connexes
- vue d'ensemble, Démons Samba et services connexes
- winbindd, Démons Samba et services connexes
- Imprimantes Samba, Ajouter une imprimante Samba (SMB)
- Introduction, Introduction à Samba
- Modes de sécurité, Mode de sécurité de Samba, Sécurité Niveau utilisateur
- Mode de sécurité Active Directory, Sécurité Niveau utilisateur
- Mode de sécurité domaine, Sécurité Niveau utilisateur
- Sécurité Niveau partage, Sécurité Niveau partage
- Sécurité Niveau utilisateur, Sécurité Niveau utilisateur
- mots de passe chiffrés, Mots de passe chiffrés
- Navigation, Navigation réseau Samba
- Navigation réseau, Navigation réseau Samba
- Exploration de domaines, Exploration de domaines
- WINS, WINS (« Windows Internet Name Server »)
- partage
- connexion via la ligne de commande, Se connecter à un partage Samba
- monter, Monter le partage
- se connecter avec Nautilus, Se connecter à un partage Samba
- Programmes, Programmes de distribution Samba
- net, Programmes de distribution Samba
- nmblookup, Programmes de distribution Samba
- pdbedit, Programmes de distribution Samba
- rpcclient, Programmes de distribution Samba
- smbcacls, Programmes de distribution Samba
- smbclient, Programmes de distribution Samba
- smbcontrol, Programmes de distribution Samba
- smbpasswd, Programmes de distribution Samba
- smbspool, Programmes de distribution Samba
- smbstatus, Programmes de distribution Samba
- smbtar, Programmes de distribution Samba
- testparm, Programmes de distribution Samba
- wbinfo, Programmes de distribution Samba
- Référence, Samba
- Ressources supplémentaires, Ressources supplémentaires
- documentation installée, Ressources supplémentaires
- sites web utiles, Ressources supplémentaires
- service
- arrêter, Lancer et arrêter Samba
- lancer, Lancer et arrêter Samba
- recharger, Lancer et arrêter Samba
- redémarrage conditionnel, Lancer et arrêter Samba
- redémarrer, Lancer et arrêter Samba
- smbclient, Se connecter à un partage Samba
- WINS, WINS (« Windows Internet Name Server »)
- scp (voir OpenSSH)
- Sendmail, Sendmail
- alias, Camouflage
- avec UUCP, Changements communs de la configuration Sendmail
- camouflage, Camouflage
- changements communs de configuration, Changements communs de la configuration Sendmail
- courrier indésirable, Arrêter le courrier indésirable
- installation par défaut, Installation Sendmail par défaut
- LDAP, Utiliser Sendmail avec LDAP
- limitations, Objectif et limites
- objectif, Objectif et limites
- ressources supplémentaires, Ressources supplémentaires
- sendmail, Configuration de l'agent de transport de courrier (« Mail Transport Agent », ou MTA)
- Server web (voir Apache HTTP Server)
- Serveur HTTP (voir Apache HTTP Server)
- Serveur HTTP Apache
- version 2.4
- changements, Changements notables
- serveur SSL (voir Apache HTTP Server )
- setfacl , Définir les ACL d'accès
- sftp (voir OpenSSH)
- smbcacls programme, Programmes de distribution Samba
- smbclient, Se connecter à un partage Samba
- smbclient programme, Programmes de distribution Samba
- smbcontrol programme, Programmes de distribution Samba
- smbpasswd programme, Programmes de distribution Samba
- smbspoolprogramme, Programmes de distribution Samba
- smbstatusprogramme, Programmes de distribution Samba
- smbtar programme, Programmes de distribution Samba
- SpamAssassin
- utilisation avec Procmail, Filtres du courrier indésirable
- ssh (voir OpenSSH)
- SSH protocol
- transfert X11, Transfert X11
- ssh-add, Configurer les partages Samba
- ssh-agent, Configurer les partages Samba
- SSL , Paramétrer un serveur SSL
- (voir aussi Apache HTTP Server )
- star , Archiver des systèmes de fichiers avec des ACL
- stunnel, Sécurisation des communications des clients de messagerie
- support de démarrage, Préparer pour une mise à niveau
- System Log
- contrôler, Surveiller des fichiers journaux
- filtrer, Afficher les fichiers journaux
- fréquence d'actualisation, Afficher les fichiers journaux
- rechercher, Afficher les fichiers journaux
- System Monitor, Utiliser l'outil de surveillance du système « System Monitor », Utiliser l'outil de surveillance du système « System Monitor », Utiliser l'outil de surveillance du système « System Monitor », Utiliser l'outil de surveillance du système « System Monitor »
- systèmes
- enregistrement, Enregistrer le système et Gérer les abonnements
- gestion des abonnements, Enregistrer le système et Gérer les abonnements
- systèmes de fichiers, Afficher les périphériques bloc et les systèmes de fichiers
T
- Tâches automatisées, Automatiser les tâches système
- testparm programme, Programmes de distribution Samba
- TLS , Paramétrer un serveur SSL
- (voir aussi Apache HTTP Server )
- top, Utiliser la commande top
U
- Users settings tool (voir configuration de l'utilisateur)
- utilisateurs (voir configuration de l'utilisateur)
- introduction, Gérer les utilisateurs et les groupes
- outils pour la gestion de
- useradd, Utiliser des outils de ligne de commande
- Users setting tool, Utiliser des outils de ligne de commande
- ressources supplémentaires, Ressources supplémentaires
- documentation installée, Ressources supplémentaires
- UID, Gérer les utilisateurs et les groupes
- utilisation de la mémoire, Afficher l'utilisation de la mémoire
- utilisation du CPU, Afficher l'utilisation du CPU
V
- vsftpd
- arrêt, Démarrage et arrêt de vsftpd
- chiffrer, Chiffrer des connexions vsftpd en utilisant TLS
- configuration multihome, Lancer de multiples copies de vsftpd
- démarrage, Démarrage et arrêt de vsftpd
- lancer de multiples copies, Lancer de multiples copies de vsftpd
- redémarrage, Démarrage et arrêt de vsftpd
- ressources supplémentaires, Ressources supplémentaires
- documentation en ligne, Documentation en ligne
- documentation installée, Documentation installée
- sécuriser, Chiffrer des connexions vsftpd en utilisant TLS, Politique SELinux pour vsftpd
- SELinux, Politique SELinux pour vsftpd
- statut, Démarrage et arrêt de vsftpd
- TLS, Chiffrer des connexions vsftpd en utilisant TLS
W
- wbinfoprogramme, Programmes de distribution Samba
- Windows 2000
- connexion aux partages en utilisant Samba, Mots de passe chiffrés
- Windows 98
- connexion aux partages en utilisant Samba, Mots de passe chiffrés
- Windows ME
- connexion aux partages en utilisant Samba, Mots de passe chiffrés
- Windows NT 4.0
- connexion aux partages en utilisant Samba, Mots de passe chiffrés
- Windows XP
- connexion aux partages en utilisant Samba, Mots de passe chiffrés
Y
- Yum
- activer des greffons, Activer, configurer, et désactiver des greffons Yum
- afficher des paquets
- yum info, Afficher des informations sur le paquet
- afficher des paquets avec yum
- yum info, Afficher des informations sur le paquet
- configurer des greffons, Activer, configurer, et désactiver des greffons Yum
- configurer yum et les référentiels yum, Configurer Yum et les référentiels Yum
- définir les options [main], Définir les options [main]
- définir les options [repository], Définir les options [repository]
- désactiver des greffons, Activer, configurer, et désactiver des greffons Yum
- désinstaller des paquets avec yum, Supprimer des paquets
- greffons Yum, Greffons Yum
- installation avec yum, Installation de paquets
- installer un groupe de paquets avec yum, Installer un groupe de paquets
- paquets, Utiliser des paquets
- plug-ins
- aliases, Utiliser des greffons Yum
- kabi, Utiliser des greffons Yum
- langpacks, Utiliser des greffons Yum
- product-id, Utiliser des greffons Yum
- search-disabled-repos, Utiliser des greffons Yum
- yum-changelog, Utiliser des greffons Yum
- yum-tmprepo, Utiliser des greffons Yum
- yum-verify, Utiliser des greffons Yum
- yum-versionlock, Utiliser des greffons Yum
- rechercher des paquets avec yum
- recherche yum, Rechercher des paquets
- référentiel, Ajouter, activer, et désactiver un référentielr Yum, Création d'un référentiel Yum
- référentiels Yum
- configurer yum et les référentiels yum, Configurer Yum et les référentiels Yum
- répertorier des groupes de paquets avec yum
- liste des groupes yum, Répertorier les groupes de paquets
- répertorier des paquets avec yum
- expressions glob, Rechercher des paquets
- liste yum, Répertorier les paquets
- liste yum disponible, Répertorier les paquets
- liste yum installée, Répertorier les paquets
- yum repolist, Répertorier les paquets
- télécharger des paquets avec yum, Télécharger des paquets
- variables, Utiliser des variables Yum
- yum update, Mise à jour du système hors ligne avec ISO et Yum
- Yum Updates
- vérifier les besoins de mise à jour, Vérifier les mises à jour