Ce contenu n'est pas disponible dans la langue sélectionnée.
Development Guide Volume 3: Reference Material
This guide is intended for developers
Abstract
Chapter 1. Architecture
1.1. Terminology
- VM or Process - a JBoss EAP instance running JBoss Data Virtualization.
- Host - a machine that is "hosting" one or more VMs.
- Service - a subsystem running in a VM (often in many VMs) and providing a related set of functionality
- Session - the Session service manages active session information.
- Buffer Manager - the Buffer Manager service provides access to data management for intermediate results. See Section 1.2.2, “Buffer Management”.
- Transaction - the Transaction service manages global, local, and request scoped transactions. See Section 5.1, “Transaction Support” for more information.
1.2. Data Management
1.2.1. Cursoring and Batching
1.2.2. Buffer Management
- Memory Management
- The buffer manager has two storage managers, these being a memory manager and a disk manager. The buffer manager maintains the state of all the batches and determines when batches must be moved from memory to disk.
- Disk Management
- Each tuple source has a dedicated file (named by the ID) on disk. This file will be created only if at least one batch for the tuple source had to be swapped to disk. This is a random access file. The connector batch size and processor batch size properties define how many rows can exist in a batch and thus define how granular the batches are when stored into the storage manager. Batches are always read and written from the storage manager together at once.The disk storage manager has a cap on the maximum number of open files to prevent running out of file handles. In cases with heavy buffering, this can cause wait times while waiting for a file handle to become available (the default max open files is 64).
1.2.3. Cleanup
1.3. Query Termination
1.3.1. Canceling Queries
1.3.2. User Query Timeouts
java.sql.Statement.setQueryTimeout method. You can also set a default statement timeout via the connection property QUERYTIMEOUT. ODBC clients may also use QUERYTIMEOUT as an execution property via a set statement to control the default timeout setting. See Red Hat JBoss Development Guide: Client Development for more on connection/execution properties and set statements.
1.4. Processing
1.4.1. Join Algorithms
1.4.2. Sort-Based Algorithms
1.5. Load Balancing
1.5.1. Configure Load Balancing
Chapter 2. SQL Support
2.1. SQL Support
2.2. Identifiers
2.2.1. Identifiers
- TABLE: <schema_name>.<table_spec>
- COLUMN: <schema_name>.<table_spec>.<column_name>
- Identifiers can consist of alphanumeric characters, or the underscore (_) character, and must begin with an alphabetic character. Any Unicode character may be used in an identifier.
- Identifiers in double quotes can have any contents. The double quote character can be used if it is escaped with an additional double quote; for example,
"some "" id". - Because different data sources organize tables in different ways (some prepending catalog or schema or user information) JBoss Data Virtualization allows table specification to be a dot delimited construct.
Note
When a table specification contains a dot, resolving will allow for the match of a partial name against any number of the end segments in the name. For example, a table with the fully qualified namevdbname."sourceschema.sourcetable"would match the partial namesourcetable. - Columns, schemas, alias identifiers cannot contain a dot.
- Identifiers, even when quoted, are not case sensitive in JBoss Data Virtualization.
- MySchema.Portfolios
- "MySchema.Portfolios"
- MySchema.MyCatalog.dbo.Authors
- MySchema.Portfolios.portfolioID
- "MySchema.Portfolios"."portfolioID"
- MySchema.MyCatalog.dbo.Authors.lastName
2.2.2. Reserved Words
2.3. Expressions
2.3.1. Expressions
- Column identifiers
- Refer to Section 2.3.2, “Column Identifiers”.
- Literals
- Refer to Section 2.3.3, “Literals”.
- Aggregate functions
- Refer to Section 2.3.4, “Aggregate Functions”.
- Window functions
- Refer to Section 2.3.5, “Window Functions”.
- Case and searched case
- Refer to Section 2.3.8, “Case and Searched Case”.
- Scalar subqueries
- Refer to Section 2.3.9, “Scalar Subqueries”.
- Parameter references
- Refer to Section 2.3.10, “Parameter References”.
- Criteria
- Refer to Section 2.3.11, “Criteria”.
2.3.2. Column Identifiers
2.3.3. Literals
- Integer values will be assigned an integral data type big enough to hold the value (integer, long, or biginteger).
- Floating point values will always be parsed as a double.
- The keyword 'null' is used to represent an absent or unknown value and is inherently untyped. In many cases, a null literal value will be assigned an implied type based on context. For example, in the function '5 + null', the null value will be assigned the type 'integer' to match the type of the value '5'. A null literal used in the SELECT clause of a query with no implied context will be assigned to type 'string'.
'abc''isn''t true'- use an extra single tick to escape a tick in a string with single ticks5-37.75e01- scientific notation100.0- parsed as BigDecimaltruefalse'\u0027'- unicode character
2.3.4. Aggregate Functions
COUNT(*)- count the number of values (including nulls and duplicates) in a groupCOUNT(x)- count the number of values (excluding nulls) in a groupSUM(x)- sum of the values (excluding nulls) in a groupAVG(x)- average of the values (excluding nulls) in a groupMIN(x)- minimum value in a group (excluding null)MAX(x)- maximum value in a group (excluding null)ANY(x)/SOME(x)- returns TRUE if any value in the group is TRUE (excluding null)EVERY(x)- returns TRUE if every value in the group is TRUE (excluding null)VAR_POP(x)- biased variance (excluding null) logically equals (sum(x^2) - sum(x)^2/count(x))/count(x); returns a double; null if count = 0VAR_SAMP(x)- sample variance (excluding null) logically equals (sum(x^2) - sum(x)^2/count(x))/(count(x) - 1); returns a double; null if count < 2STDDEV_POP(x)- standard deviation (excluding null) logically equals SQRT(VAR_POP(x))STDDEV_SAMP(x)- sample standard deviation (excluding null) logically equals SQRT(VAR_SAMP(x))TEXTAGG(FOR (expression [as name], ... [DELIMITER char] [QUOTE char] [HEADER] [ENCODING id] [ORDER BY ...])- CSV text aggregation of all expressions in each row of a group. When DELIMITER is not specified, by default comma (,) is used as delimiter. Double quotes(") is the default quote character. Use QUOTE to specify a different value. All non-null values will be quoted. If HEADER is specified, the result contains the header row as the first line. The header line will be present even if there are no rows in a group. This aggregation returns a BLOB. See Section 2.6.15, “ORDER BY Clause”. Example:TEXTAGG(col1, col2 as name DELIMITER '|' HEADER ORDER BY col1)
TEXTAGG(col1, col2 as name DELIMITER '|' HEADER ORDER BY col1)Copy to Clipboard Copied! Toggle word wrap Toggle overflow XMLAGG(xml_expr [ORDER BY ...])- XML concatenation of all XML expressions in a group (excluding null). The ORDER BY clause cannot reference alias names or use positional ordering. See Section 2.6.15, “ORDER BY Clause”.JSONARRAY_AGG(x [ORDER BY ...])- creates a JSON array result as a CLOB including null value. The ORDER BY clause cannot reference alias names or use positional ordering. Also see Section 2.4.15, “JSON Functions”. Integer value example:jsonArray_Agg(col1 order by col1 nulls first)
jsonArray_Agg(col1 order by col1 nulls first)Copy to Clipboard Copied! Toggle word wrap Toggle overflow could return[null,null,1,2,3]
[null,null,1,2,3]Copy to Clipboard Copied! Toggle word wrap Toggle overflow STRING_AGG(x, delim)- creates a lob results from the concatenation of x using the delimiter delim. If either argument is null, no value is concatenated. Both arguments are expected to be character (string/clob) or binary (varbinary, blob) and the result will be clob or blob respectively. DISTINCT and ORDER BY are allowed in STRING_AGG. Example:string_agg(col1, ',' ORDER BY col1 ASC)
string_agg(col1, ',' ORDER BY col1 ASC)Copy to Clipboard Copied! Toggle word wrap Toggle overflow could return'a,b,c'
'a,b,c'Copy to Clipboard Copied! Toggle word wrap Toggle overflow agg([DISTINCT|ALL] arg ... [ORDER BY ...])- this is a user-defined aggregate function.ARRAY_AGG(x [ORDER BY …])- This creates an array with a base type matching the expression x. TheORDER BYclause cannot reference alias names or use positional ordering.
- Some aggregate functions may contain the keyword 'DISTINCT' before the expression, indicating that duplicate expression values should be ignored. DISTINCT is not allowed in COUNT(*) and is not meaningful in MIN or MAX (result would be unchanged), so it can be used in COUNT, SUM, and AVG.
- Aggregate functions cannot be used in FROM, GROUP BY, or WHERE clauses without an intervening query expression.
- Aggregate functions cannot be nested within another aggregate function without an intervening query expression.
- Aggregate functions may be nested inside other functions.
- Any aggregate function may take an optional FILTER clause of the following form:The condition may be any boolean value expression that does not contain a subquery or a correlated variable. The filter will logically be evaluated for each row prior to the grouping operation. If false, the aggregate function will not accumulate a value for the given row.
FILTER ( WHERE condition )
FILTER ( WHERE condition )Copy to Clipboard Copied! Toggle word wrap Toggle overflow - User defined aggregate functions need ALL specified if no other aggregate specific constructs are used to distinguish the function as an aggregate rather than normal function.
2.3.5. Window Functions
aggregate|ranking OVER ([PARTITION BY expression [, expression]*] [ORDER BY ...])
aggregate|ranking OVER ([PARTITION BY expression [, expression]*] [ORDER BY ...])aggregate can be any of those in Section 2.3.4, “Aggregate Functions”. Ranking can be one of ROW_NUMBER(), RANK(), DENSE_RANK().
- Window functions can only appear in the SELECT and ORDER BY clauses of a query expression.
- Window functions cannot be nested in one another.
- Partitioning and ORDER BY expressions cannot contain subqueries or outer references.
- The ranking (ROW_NUMBER, RANK, DENSE_RANK) functions require the use of the window specification ORDER BY clause.
- An XMLAGG ORDER BY clause cannot be used when windowed.
- The window specification ORDER BY clause cannot reference alias names or use positional ordering.
- Windowed aggregates may not use DISTINCT if the window specification is ordered.
2.3.6. Window Functions: Analytical Function Definitions
- ROW_NUMBER() - functionally the same as COUNT(*) with the same window specification. Assigns a number to each row in a partition starting at 1.
- RANK() - Assigns a number to each unique ordering value within each partition starting at 1, such that the next rank is equal to the count of prior rows.
- DENSE_RANK() - Assigns a number to each unique ordering value within each partition starting at 1, such that the next rank is sequential.
2.3.7. Window Functions: Processing
SELECT name, salary, max(salary) over (partition by name) as max_sal,
rank() over (order by salary) as rank, dense_rank() over (order by salary) as dense_rank,
row_number() over (order by salary) as row_num FROM employees
SELECT name, salary, max(salary) over (partition by name) as max_sal,
rank() over (order by salary) as rank, dense_rank() over (order by salary) as dense_rank,
row_number() over (order by salary) as row_num FROM employees|
name
|
salary
|
max_sal
|
rank
|
dense_rank
|
row_num
|
|---|---|---|---|---|---|
|
John
|
100000
|
100000
|
2
|
2
|
2
|
|
Henry
|
50000
|
100000
|
5
|
4
|
5
|
|
John
|
60000
|
60000
|
3
|
3
|
3
|
|
Suzie
|
60000
|
150000
|
3
|
3
|
4
|
|
Suzie
|
150000
|
150000
|
1
|
1
|
1
|
2.3.8. Case and Searched Case
- CASE <expr> ( WHEN <expr> THEN <expr>)+ [ELSE expr] END
- CASE ( WHEN <criteria> THEN <expr>)+ [ELSE expr] END
2.3.9. Scalar Subqueries
2.3.10. Parameter References
2.3.11. Criteria
- Predicates that evaluate to true or false
- Logical criteria that combines criteria (AND, OR, NOT)
- A value expression with type boolean
criteria AND|OR criteria
criteria AND|OR criteriaCopy to Clipboard Copied! Toggle word wrap Toggle overflow NOT criteria
NOT criteriaCopy to Clipboard Copied! Toggle word wrap Toggle overflow (criteria)
(criteria)Copy to Clipboard Copied! Toggle word wrap Toggle overflow expression (=|<>|!=|<|>|<=|>=) (expression|((ANY|ALL|SOME) subquery|(array_expression)))
expression (=|<>|!=|<|>|<=|>=) (expression|((ANY|ALL|SOME) subquery|(array_expression)))Copy to Clipboard Copied! Toggle word wrap Toggle overflow expression [NOT] IS NULL
expression [NOT] IS NULLCopy to Clipboard Copied! Toggle word wrap Toggle overflow expression [NOT] IN (expression[,expression]*)|subquery
expression [NOT] IN (expression[,expression]*)|subqueryCopy to Clipboard Copied! Toggle word wrap Toggle overflow expression [NOT] LIKE pattern [ESCAPE char]
expression [NOT] LIKE pattern [ESCAPE char]Copy to Clipboard Copied! Toggle word wrap Toggle overflow LIKE matches the string expression against the given string pattern. The pattern may contain % to match any number of characters and _ to match any single character. The escape character can be used to escape the match characters % and _.expression [NOT] SIMILAR TO pattern [ESCAPE char]
expression [NOT] SIMILAR TO pattern [ESCAPE char]Copy to Clipboard Copied! Toggle word wrap Toggle overflow SIMILAR TO is a cross between LIKE and standard regular expression syntax. % and _ are still used, rather than .* and . respectively.Note
JBoss Data Virtualization does not exhaustively validate SIMILAR TO pattern values. Rather, the pattern is converted to an equivalent regular expression. Care should be taken not to rely on general regular expression features when using SIMILAR TO. If additional features are needed, then LIKE_REGEX should be used. Usage of a non-literal pattern is discouraged as pushdown support is limited.expression [NOT] LIKE_REGEX pattern
expression [NOT] LIKE_REGEX patternCopy to Clipboard Copied! Toggle word wrap Toggle overflow LIKE_REGEX allows for standard regular expression syntax to be used for matching. This differs from SIMILAR TO and LIKE in that the escape character is no longer used (\ is already the standard escape mechansim in regular expressions and % and _ have no special meaning. The runtime engine uses the JRE implementation of regular expressions - see the java.util.regex.Pattern class for details.Important
JBoss Data Virtualization does not exhaustively validate LIKE_REGEX pattern values. It is possible to use JRE only regular expression features that are not specified by the SQL specification. Additionally, not all sources support the same regular expression syntax or extensions. Care should be taken in pushdown situations to ensure that the pattern used will have the same meaning in JBoss Data Virtualization and across all applicable sources.EXISTS(subquery)
EXISTS(subquery)Copy to Clipboard Copied! Toggle word wrap Toggle overflow expression [NOT] BETWEEN minExpression AND maxExpression
expression [NOT] BETWEEN minExpression AND maxExpressionCopy to Clipboard Copied! Toggle word wrap Toggle overflow JBoss Data Virtualization converts BETWEEN into the equivalent form expression >= minExpression AND expression <= maxExpression.expression
expressionCopy to Clipboard Copied! Toggle word wrap Toggle overflow Where expression has type boolean.
- The precedence ordering from lowest to highest is: comparison, NOT, AND, OR.
- Criteria nested by parenthesis will be logically evaluated prior to evaluating the parent criteria.
- (balance > 2500.0)
- 100*(50 - x)/(25 - y) > z
- concat(areaCode,concat('-',phone)) LIKE '314%1'
Note
2.3.12. Operator Precedence
|
Operator
|
Description
|
|---|---|
|
+,-
|
positive/negative value expression
|
|
*,/
|
multiplication/division
|
|
+,-
|
addition/subtraction
|
|
||
|
concat
|
|
criteria
|
2.3.13. Criteria Precedence
|
Condition
|
Description
|
|---|---|
|
SQL operators
| |
|
EXISTS, LIKE, SIMILAR TO, LIKE_REGEX, BETWEEN, IN, IS NULL, <, <=, >, >=, =, <>
|
comparison
|
|
NOT
|
negation
|
|
AND
|
conjunction
|
|
OR
|
disjunction
|
2.4. Scalar Functions
2.4.1. Scalar Functions
2.4.2. Numeric Functions
|
Function
|
Definition
|
Data Type Constraint
|
|---|---|---|
|
+ - * /
|
Standard numeric operators
|
x in {integer, long, float, double, biginteger, bigdecimal}, return type is same as x
Note
The precision and scale of non-bigdecimal arithmetic function functions results matches that of Java. The results of bigdecimal operations match Java, except for division, which uses a preferred scale of max(16, dividend.scale + divisor.precision + 1), which then has trailing zeros removed by setting the scale to max(dividend.scale, normalized scale).
|
|
ABS(x)
|
Absolute value of x
|
See standard numeric operators above
|
|
ACOS(x)
|
Arc cosine of x
|
x in {double, bigdecimal}, return type is double
|
|
ASIN(x)
|
Arc sine of x
|
x in {double, bigdecimal}, return type is double
|
|
ATAN(x)
|
Arc tangent of x
|
x in {double, bigdecimal}, return type is double
|
|
ATAN2(x,y)
|
Arc tangent of x and y
|
x, y in {double, bigdecimal}, return type is double
|
|
CEILING(x)
|
Ceiling of x
|
x in {double, float}, return type is double
|
|
COS(x)
|
Cosine of x
|
x in {double, bigdecimal}, return type is double
|
|
COT(x)
|
Cotangent of x
|
x in {double, bigdecimal}, return type is double
|
|
DEGREES(x)
|
Convert x degrees to radians
|
x in {double, bigdecimal}, return type is double
|
|
EXP(x)
|
e^x
|
x in {double, float}, return type is double
|
|
FLOOR(x)
|
Floor of x
|
x in {double, float}, return type is double
|
|
FORMATBIGDECIMAL(x, y)
|
Formats x using format y
|
x is bigdecimal, y is string, returns string
|
|
FORMATBIGINTEGER(x, y)
|
Formats x using format y
|
x is biginteger, y is string, returns string
|
|
FORMATDOUBLE(x, y)
|
Formats x using format y
|
x is double, y is string, returns string
|
|
FORMATFLOAT(x, y)
|
Formats x using format y
|
x is float, y is string, returns string
|
|
FORMATINTEGER(x, y)
|
Formats x using format y
|
x is integer, y is string, returns string
|
|
FORMATLONG(x, y)
|
Formats x using format y
|
x is long, y is string, returns string
|
|
LOG(x)
|
Natural log of x (base e)
|
x in {double, float}, return type is double
|
|
LOG10(x)
|
Log of x (base 10)
|
x in {double, float}, return type is double
|
|
MOD(x, y)
|
Modulus (remainder of x / y)
|
x in {integer, long, float, double, biginteger, bigdecimal}, return type is same as x
|
|
PARSEBIGDECIMAL(x, y)
|
Parses x using format y
|
x, y are strings, returns bigdecimal
|
|
PARSEBIGINTEGER(x, y)
|
Parses x using format y
|
x, y are strings, returns biginteger
|
|
PARSEDOUBLE(x, y)
|
Parses x using format y
|
x, y are strings, returns double
|
|
PARSEFLOAT(x, y)
|
Parses x using format y
|
x, y are strings, returns float
|
|
PARSEINTEGER(x, y)
|
Parses x using format y
|
x, y are strings, returns integer
|
|
PARSELONG(x, y)
|
Parses x using format y
|
x, y are strings, returns long
|
|
PI()
|
Value of Pi
|
return is double
|
|
POWER(x,y)
|
x to the y power
|
x in {double, bigdecimal, biginteger}, return is the same type as x
|
|
RADIANS(x)
|
Convert x radians to degrees
|
x in {double, bigdecimal}, return type is double
|
|
RAND()
|
Returns a random number, using generator established so far in the query or initializing with system clock if necessary.
|
Returns double.
|
|
RAND(x)
|
Returns a random number, using new generator seeded with x.
|
x is integer, returns double.
|
|
ROUND(x,y)
|
Round x to y places; negative values of y indicate places to the left of the decimal point
|
x in {integer, float, double, bigdecimal} y is integer, return is same type as x
|
|
SIGN(x)
|
1 if x > 0, 0 if x = 0, -1 if x < 0
|
x in {integer, long, float, double, biginteger, bigdecimal}, return type is integer
|
|
SIN(x)
|
Sine value of x
|
x in {double, bigdecimal}, return type is double
|
|
SQRT(x)
|
Square root of x
|
x in {long, double, bigdecimal}, return type is double
|
|
TAN(x)
|
Tangent of x
|
x in {double, bigdecimal}, return type is double
|
|
BITAND(x, y)
|
Bitwise AND of x and y
|
x, y in {integer}, return type is integer
|
|
BITOR(x, y)
|
Bitwise OR of x and y
|
x, y in {integer}, return type is integer
|
|
BITXOR(x, y)
|
Bitwise XOR of x and y
|
x, y in {integer}, return type is integer
|
|
BITNOT(x)
|
Bitwise NOT of x
|
x in {integer}, return type is integer
|
2.4.3. Parsing Numeric Data Types from Strings
parseDouble- parses a string as a doubleparseFloat- parses a string as a floatparseLong- parses a string as a longparseInteger- parses a string as an integer
java.text.DecimalFormat class. See examples below.
|
Input String
|
Function Call to Format String
|
Output Value
|
Output Data Type
|
|---|---|---|---|
|
'$25.30'
|
parseDouble(cost, '$#,##0.00;($#,##0.00)')
|
25.3
|
double
|
|
'25%'
|
parseFloat(percent, '#,##0%')
|
25
|
float
|
|
'2,534.1'
|
parseFloat(total, '#,##0.###;-#,##0.###')
|
2534.1
|
float
|
|
'1.234E3'
|
parseLong(amt, '0.###E0')
|
1234
|
long
|
|
'1,234,567'
|
parseInteger(total, '#,##0;-#,##0')
|
1234567
|
integer
|
Note
2.4.4. Formatting Numeric Data Types as Strings
formatDouble- formats a double as a stringformatFloat- formats a float as a stringformatLong- formats a long as a stringformatInteger- formats an integer as a string
java.text.DecimalFormat class. See examples below.
|
Input Value
|
Input Data Type
|
Function Call to Format String
|
Output String
|
|---|---|---|---|
|
25.3
|
double
|
formatDouble(cost, '$#,##0.00;($#,##0.00)')
|
'$25.30'
|
|
25
|
float
|
formatFloat(percent, '#,##0%')
|
'25%'
|
|
2534.1
|
float
|
formatFloat(total, '#,##0.###;-#,##0.###')
|
'2,534.1'
|
|
1234
|
long
|
formatLong(amt, '0.###E0')
|
'1.234E3'
|
|
1234567
|
integer
|
formatInteger(total, '#,##0;-#,##0')
|
'1,234,567'
|
Note
2.4.5. String Functions
Important
ASCII(x), CHR(x), and CHAR(x) may produce different results or exceptions depending on where the function is evaluated (JBoss Data Virtualization vs. source). JBoss Data Virtualization uses Java default int to char and char to int conversions, which operates over UTF16 values.
|
Function
|
Definition
|
DataType Constraint
|
|---|---|---|
|
x || y
|
Concatenation operator
|
x,y in {string}, return type is string
|
|
ASCII(x)
|
Provide ASCII value of the left most character in x. The empty string will return null.
|
return type is integer
|
|
CHR(x) CHAR(x)
|
Provide the character for ASCII value x
|
x in {integer}
|
|
CONCAT(x, y)
|
Concatenates x and y with ANSI semantics. If x and/or y is null, returns null.
|
x, y in {string}
|
|
CONCAT2(x, y)
|
Concatenates x and y with non-ANSI null semantics. If x and y is null, returns null. If only x or y is null, returns the other value.
|
x, y in {string}
|
|
ENDSWITH(x, y)
|
Checks if y ends with x. If only x or y is null, returns null.
|
x, y in {string}, returns boolean
|
|
INITCAP(x)
|
Make first letter of each word in string x capital and all others lowercase
|
x in {string}
|
|
INSERT(str1, start, length, str2)
|
Insert string2 into string1
|
str1 in {string}, start in {integer}, length in {integer}, str2 in {string}
|
|
LCASE(x)
|
Lowercase of x
|
x in {string}
|
|
LEFT(x, y)
|
Get left y characters of x
|
x in {string}, y in {integer}, return string
|
|
LENGTH(x)
|
Length of x
|
return type is integer
|
|
LOCATE(x, y)
|
Find position of x in y starting at beginning of y
|
x in {string}, y in {string}, return integer
|
|
LOCATE(x, y, z)
|
Find position of x in y starting at z
|
x in {string}, y in {string}, z in {integer}, return integer
|
|
LPAD(x, y)
|
Pad input string x with spaces on the left to the length of y
|
x in {string}, y in {integer}, return string
|
|
LPAD(x, y, z)
|
Pad input string x on the left to the length of y using character z
|
x in {string}, y in {string}, z in {character}, return string
|
|
LTRIM(x)
|
Left trim x of blank characters
|
x in {string}, return string
|
|
QUERYSTRING(path [, expr [AS name] ...])
|
Returns a properly encoded query string appended to the given path. Null valued expressions are omitted, and a null path is treated as ''.
Names are optional for column reference expressions.
e.g. QUERYSTRING('path', 'value' as "&x", ' & ' as y, null as z) returns 'path?%26x=value&y=%20%26%20'
|
path, expr in {string}. name is an identifier
|
|
REPEAT(str1,instances)
|
Repeat string1 a specified number of times
|
str1 in {string}, instances in {integer} return string
|
|
RIGHT(x, y)
|
Get right y characters of x
|
x in {string}, y in {integer}, return string
|
|
RPAD(input string x, pad length y)
|
Pad input string x with spaces on the right to the length of y
|
x in {string}, y in {integer}, return string
|
|
RPAD(x, y, z)
|
Pad input string x on the right to the length of y using character z
|
x in {string}, y in {string}, z in {character}, return string
|
|
RTRIM(x)
|
Right trim x of blank characters
|
x is string, return string
|
|
SPACE(x)
|
Repeats space x times
|
x in {integer}
|
|
SUBSTRING(x, y)
SUBSTRING(x FROM y)
|
Get substring from x, from position y to the end of x
|
y in {integer}
|
|
SUBSTRING(x, y, z)
SUBSTRING(x FROM y FOR z)
|
Get substring from x from position y with length z
|
y, z in {integer}
|
|
TO_CHARS(x, encoding)
|
Return a CLOB from the BLOB with the given encoding. BASE64, HEX, and the built-in Java Charset names are valid values for the encoding.
Note
For charsets, unmappable chars will be replaced with the charset default character. Binary formats, such as BASE64, will error in their conversion to bytes if an unrecognizable character is encountered.
|
x is a BLOB, encoding is a string, and returns a CLOB
|
|
TO_BYTES(x, encoding)
|
Return a BLOB from the CLOB with the given encoding. BASE64, HEX, and the builtin Java Charset names are valid values for the encoding.
|
x in a CLOB, encoding is a string, and returns a BLOB
|
|
TRANSLATE(x, y, z)
|
Translate string x by replacing each character in y with the character in z at the same position.
Note that the second arg (y) and the third arg (z) must be the same length. If they are not equal, Red Hat JBoss data Virtualization throws this exception: 'TEIID30404 Source and destination character lists must be the same length.'
|
x in {string}
|
|
TRIM([[LEADING|TRAILING|BOTH] [x] FROM] y)
|
Trim character x from the leading, trailing, or both ends of string y. If LEADING/TRAILING/BOTH is not specified, BOTH is used by default. If no trim character x is specified, a blank space ' ' is used for x by default.
|
x in {character}, y in {string}
|
|
UCASE(x)
|
Uppercase of x
|
x in {string}
|
|
UNESCAPE(x)
|
Unescaped version of x. Possible escape sequences are \b - backspace, \t - tab, \n - line feed, \f - form feed, \r - carriage return. \uXXXX, where X is a hex value, can be used to specify any unicode character. \XXX, where X is an octal digit, can be used to specify an octal byte value. If any other character appears after an escape character, that character will appear in the output and the escape character will be ignored.
|
x in {string}
|
2.4.5.1. Replacement Functions
REPLACE to replace all occurrences of a given string with another:
REPLACE(x, y, z)
REPLACE(x, y, z)REGEXP_REPLACE(str, pattern, sub [, flags])
REGEXP_REPLACE(str, pattern, sub [, flags])|
Flag
|
Name
|
Meaning
|
|---|---|---|
|
g
|
global
|
Replace all occurrences, not just the first.
|
|
m
|
multiline
|
Match over multiple lines.
|
|
i
|
case insensitive
|
Match without case sensitivity.
|
xxbye Wxx using the global and case insensitive options:
regexp_replace('Goodbye World', '[g-o].', 'x', 'gi')
regexp_replace('Goodbye World', '[g-o].', 'x', 'gi')
2.4.6. Date/Time Functions
|
Function
|
Definition
|
Datatype Constraint
|
|---|---|---|
|
CURDATE()
|
Return current date
|
returns date
|
|
CURTIME()
|
Return current time
|
returns time
|
|
NOW()
|
Return current timestamp (date and time)
|
returns timestamp
|
|
DAYNAME(x)
|
Return name of day in the default locale
|
x in {date, timestamp}, returns string
|
|
DAYOFMONTH(x)
|
Return day of month
|
x in {date, timestamp}, returns integer
|
|
DAYOFWEEK(x)
|
Return day of week (Sunday=1, Saturday=7)
|
x in {date, timestamp}, returns integer
|
|
DAYOFYEAR(x)
|
Return day number
|
x in {date, timestamp}, returns integer
|
|
EXTRACT(YEAR|MONTH|DAY|HOUR|MINUTE|SECOND FROM x)
|
Return the given field value from the date value x. Produces the same result as the associated YEAR, MONTH, DAYOFMONTH, HOUR, MINUTE, SECOND functions.
The SQL specification also allows for TIMEZONE_HOUR and TIMEZONE_MINUTE as extraction targets. In JBoss Data Virtualization, all date values are in the timezone of the server.
|
x in {date, time, timestamp}, returns integer
|
|
FORMATDATE(x, y)
|
Format date x using format y
|
x is date, y is string, returns string
|
|
FORMATTIME(x, y)
|
Format time x using format y
|
x is time, y is string, returns string
|
|
FORMATTIMESTAMP(x, y)
|
Format timestamp x using format y
|
x is timestamp, y is string, returns string
|
|
FROM_UNIXTIME (unix_timestamp)
|
Return the Unix timestamp (in seconds) as a Timestamp value
|
Unix timestamp (in seconds)
|
|
HOUR(x)
|
Return hour (in military 24-hour format)
|
x in {time, timestamp}, returns integer
|
|
MINUTE(x)
|
Return minute
|
x in {time, timestamp}, returns integer
|
|
MODIFYTIMEZONE (timestamp, startTimeZone, endTimeZone)
|
Returns a timestamp based upon the incoming timestamp adjusted for the differential between the start and end time zones. i.e. if the server is in GMT-6, then modifytimezone({ts '2006-01-10 04:00:00.0'},'GMT-7', 'GMT-8') will return the timestamp {ts '2006-01-10 05:00:00.0'} as read in GMT-6. The value has been adjusted 1 hour ahead to compensate for the difference between GMT-7 and GMT-8.
|
startTimeZone and endTimeZone are strings, returns a timestamp
|
|
MODIFYTIMEZONE (timestamp, endTimeZone)
|
Return a timestamp in the same manner as modifytimezone(timestamp, startTimeZone, endTimeZone), but will assume that the startTimeZone is the same as the server process.
|
Timestamp is a timestamp; endTimeZone is a string, returns a timestamp
|
|
MONTH(x)
|
Return month
|
x in {date, timestamp}, returns integer
|
|
MONTHNAME(x)
|
Return name of month in the default locale
|
x in {date, timestamp}, returns string
|
|
PARSEDATE(x, y)
|
Parse date from x using format y
|
x, y in {string}, returns date
|
|
PARSETIME(x, y)
|
Parse time from x using format y
|
x, y in {string}, returns time
|
|
PARSETIMESTAMP(x,y)
|
Parse timestamp from x using format y
|
x, y in {string}, returns timestamp
|
|
QUARTER(x)
|
Return quarter
|
x in {date, timestamp}, returns integer
|
|
SECOND(x)
|
Return seconds
|
x in {time, timestamp}, returns integer
|
|
TIMESTAMPCREATE(date, time)
|
Create a timestamp from a date and time
|
date in {date}, time in {time}, returns timestamp
|
|
TIMESTAMPADD(interval, count, timestamp)
|
Add a specified interval (hour, day of week, month) to the timestamp, where intervals can be:
Note
The full interval amount based upon calendar fields will be added. For example adding 1 QUARTER will move the timestamp up by three full months and not just to the start of the next calendar quarter.
|
The interval constant may be specified either as a string literal or a constant value. Interval in {string}, count in {integer}, timestamp in {date, time, timestamp}
|
|
TIMESTAMPDIFF(interval, startTime, endTime)
|
Calculates the date part intervals crossed between the two timestamps. interval is one of the same keywords as those used for TIMESTAMPADD.
If (endTime > startTime), a positive number will be returned. If (endTime < startTime), a negative number will be returned. The date part difference is counted regardless of how close the timestamps are. For example, '2000-01-02 00:00:00.0' is still considered 1 hour ahead of '2000-01-01 23:59:59.999999'.
Note
TIMESTAMPDIFF typically returns an integer, however JBoss Data Virtualization returns a long. You will encounter an exception if you expect a value out of the integer range from a pushed down TIMESTAMPDIFF.
Note
The implementation of TIMESTAMPDIFF in previous versions returned values based upon the number of whole canonical interval approximations (365 days in a year, 91 days in a quarter, 30 days in a month, etc.) crossed. For example the difference in months between 2013-03-24 and 2013-04-01 was 0, but based upon the date parts crossed is 1. See the System Properties section in Red Hat JBoss Data Virtualization Administration and Configuration Guide for backwards compatibility.
|
Interval in {string}; startTime, endTime in {timestamp}, returns a long.
|
|
WEEK(x)
|
Return week in year (1-53). see also System Properties for customization.
|
x in {date, timestamp}, returns integer
|
|
YEAR(x)
|
Returns four-digit year.
|
x in {date, timestamp}, returns integer
|
|
UNIX_TIMESTAMP (unix_timestamp)
|
Returns the long Unix timestamp (in seconds).
|
unix_timestamp String in the default format of yyyy/mm/dd hh:mm:ss
|
2.4.7. Parsing Date Data Types from Strings
parseDateparseTimeparseTimestamp
java.text.SimpleDateFormat class. See examples below.
|
String
|
Function Call To Parse String
|
|---|---|
|
'19970101'
|
parseDate(myDateString, 'yyyyMMdd')
|
|
'31/1/1996'
|
parseDate(myDateString, 'dd''/''MM''/''yyyy')
|
|
'22:08:56 CST'
|
parseTime (myTime, 'HH:mm:ss z')
|
|
'03.24.2003 at 06:14:32'
|
parseTimestamp(myTimestamp, 'MM.dd.yyyy ''at'' hh:mm:ss')
|
Note
2.4.8. Specifying Time Zones
2.4.9. Type Conversion Functions
|
Function
|
Definition
|
|---|---|
|
CONVERT(x, type)
|
Convert x to type, where type is a JBoss Data Virtualization Base Type
|
|
CAST(x AS type)
|
Convert x to type, where type is a JBoss Data Virtualization Base Type
|
2.4.10. Choice Functions
|
Function
|
Definition
|
Data Type Constraint
|
|---|---|---|
|
COALESCE(x,y+)
|
Returns the first non-null parameter
|
x and all y's can be any compatible types
|
|
IFNULL(x,y)
|
If x is null, return y; else return x
|
x, y, and the return type must be the same type but can be any type
|
|
NVL(x,y)
|
If x is null, return y; else return x
|
x, y, and the return type must be the same type but can be any type
|
|
NULLIF(param1, param2)
|
Equivalent to case when (param1 = param2) then null else param1
|
param1 and param2 must be compatible comparable types
|
Note
2.4.11. Decode Functions
|
Function
|
Definition
|
Data Type Constraint
|
|---|---|---|
|
DECODESTRING(x, y [, z])
|
Decode column x using value pairs in y (with optional delimiter, z) and return the decoded column as a set of strings.
Warning
Deprecated. Use a CASE expression instead.
|
All string
|
|
DECODEINTEGER(x, y [, z])
|
Decode column x using value pairs in y (with optional delimiter z) and return the decoded column as a set of integers.
Warning
Deprecated. Use a CASE expression instead.
|
All string parameters, return integer
|
- x is the input value for the decode operation. This will generally be a column name.
- y is the literal string that contains a delimited set of input values and output values.
- z is an optional parameter on these methods that allows you to specify what delimiter the string specified in y uses.
SELECT DECODEINTEGER(IS_IN_STOCK, 'false, 0, true, 1') FROM PartsSupplier.PARTS;
SELECT DECODEINTEGER(IS_IN_STOCK, 'false, 0, true, 1') FROM PartsSupplier.PARTS;SELECT DECODESTRING(IS_IN_STOCK, 'false, no, true, yes, null') FROM PartsSupplier.PARTS;
SELECT DECODESTRING(IS_IN_STOCK, 'false, no, true, yes, null') FROM PartsSupplier.PARTS;SELECT DECODESTRING(IS_IN_STOCK, 'false:no:true:yes:null',':') FROM PartsSupplier.PARTS;
SELECT DECODESTRING(IS_IN_STOCK, 'false:no:true:yes:null',':') FROM PartsSupplier.PARTS;SELECT DECODESTRING( IS_IN_STOCK, 'null,no,"null",no,nil,no,false,no,true,yes' ) FROM PartsSupplier.PARTS;
SELECT DECODESTRING( IS_IN_STOCK, 'null,no,"null",no,nil,no,false,no,true,yes' ) FROM PartsSupplier.PARTS;2.4.12. Lookup Function
codeTable, the following function will find the row where keyColumn has the value, keyValue, and return the associated returnColumn value (or null if no matching key is found).
LOOKUP(codeTable, returnColumn, keyColumn, keyValue)
LOOKUP(codeTable, returnColumn, keyColumn, keyValue)codeTable must be a string literal that is the fully qualified name of the target table. returnColumn and keyColumn must also be string literals and match corresponding column names in codeTable. keyValue can be any expression that must match the datatype of the keyColumn. The return data type matches that of returnColumn.
ISOCountryCodes table is used to translate country names to ISO codes:
lookup('ISOCountryCodes', 'CountryCode', 'CountryName', 'UnitedStates')
lookup('ISOCountryCodes', 'CountryCode', 'CountryName', 'UnitedStates')CountryName represents a key column and CountryCode represents the ISO code of the country. A query to this lookup table would provide a CountryName, in this case 'UnitedStates', and expect a CountryCode in response.
Note
Important
- The key column must contain unique values. If the column contains duplicate values, an exception will be thrown.
2.4.13. System Functions
|
Function
|
Definition
|
Data Type Constraint
|
|---|---|---|
COMMANDPAYLOAD([key])
|
If the key parameter is provided, the command payload object is cast to a java.util.Properties object and the corresponding property value for the key is returned. If the key is not specified, the return value is the command payload toString value.
The command payload is set by the
TeiidStatement.setPayload method on the Data Virtualization JDBC API extensions on a per-query basis.
|
key in {string}, return value is string
|
ENV(key)
|
Retrieve a system environment property.
Note
The only key specific to the current session is 'sessionid'. The preferred mechanism for getting the session id is with the session_id() function.
Note
To prevent untrusted access to system properties, this function is not enabled by default. The ENV function may be enabled via the allowEnvFunction property.
|
key in {string}, return value is string
|
SESSION_ID()
|
Retrieve the string form of the current session id.
|
return value is string
|
USER()
|
Retrieve the name of the user executing the query.
|
return value is string
|
CURRENT_DATABASE()
|
Retrieve the catalog name of the database which, for the VDB, is the VDB name.
|
return value is string
|
TEIID_SESSION_GET(name)
|
Retrieve the session variable.
A null name will return a null value. Typically you will use the a get wrapped in a CAST to convert to the desired type.
|
name in {string}, return value is object
|
TEIID_SESSION_SET(name, value)
|
Set the session variable.
The previous value for the key or null will be returned. A set has no effect on the current transaction and is not affected by commit/rollback.
|
name in {string}, value in {object}, return value is object.
|
NODE_ID()
|
This retrieves the node id. This is typically the system property value for
jboss.node.name which is not set for Red Hat JDV embedded.
|
The returned value is a string.
|
2.4.14. XML Functions
| CustomerID | CustomerName | ContactName | Address | City | PostalCode | Country |
|---|---|---|---|---|---|---|
| 87 | Wartian Herkku | Pirkko Koskitalo | Torikatu 38 | Oulu | 90110 | Finland |
| 88 | Wellington Importadora | Paula Parente | Rua do Mercado, 12 | Resende | 08737-363 | Brazil |
| 89 | White Clover Markets | Karl Jablonski | 305 - 14th Ave. S. Suite 3B | Seattle | 98128 | USA |
- XMLCAST
- Cast to or from XML:
XMLCAST(expression AS type)
XMLCAST(expression AS type)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The expression or type must be XML. The returned value will be a type. This is the same functionality as XMLTABLE uses to convert values to the desired runtime type, with the exception that array type targets are not supported with XMLCAST. - XMLCOMMENT
XMLCOMMENT(comment)
XMLCOMMENT(comment)Copy to Clipboard Copied! Toggle word wrap Toggle overflow This returns an XML comment.Thecommentis a string. The returned value is XML.- XMLCONCAT
XMLCONCAT(content [, content]*)
XMLCONCAT(content [, content]*)Copy to Clipboard Copied! Toggle word wrap Toggle overflow This returns XML with the concatenation of the given XML types. If a value is null, it will be ignored. If all values are null, null is returned. This is how you concatenate two or more XML fragments:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Thecontentis XML. The returned value is XML.- XMLELEMENT
XMLELEMENT([NAME] name [, <NSP>] [, <ATTR>][, content]*) ATTR:=XMLATTRIBUTES(exp [AS name] [, exp [AS name]]*) NSP:=XMLNAMESPACES((uri AS prefix | DEFAULT uri | NO DEFAULT))+
XMLELEMENT([NAME] name [, <NSP>] [, <ATTR>][, content]*) ATTR:=XMLATTRIBUTES(exp [AS name] [, exp [AS name]]*) NSP:=XMLNAMESPACES((uri AS prefix | DEFAULT uri | NO DEFAULT))+Copy to Clipboard Copied! Toggle word wrap Toggle overflow Returns an XML element with the given name and content. If the content value is of a type other than XML, it will be escaped when added to the parent element. Null content values are ignored. Whitespace in XML or the string values of the content is preserved, but no whitespace is added between content values.XMLNAMESPACES is used to provide namespace information. NO DEFAULT is equivalent to defining the default namespace to the null URI -xmlns="". Only one DEFAULT or NO DEFAULT namespace item may be specified. The namespace prefixesxmlnsandxmlare reserved.If an attribute name is not supplied, the expression must be a column reference, in which case the attribute name will be the column name. Null attribute values are ignored.For example, with an xml_value of <doc/>,XMLELEMENT(NAME "elem", 1, '<2/>', xml_value)
XMLELEMENT(NAME "elem", 1, '<2/>', xml_value)Copy to Clipboard Copied! Toggle word wrap Toggle overflow returns<elem>1<2/><doc/><elem/>
<elem>1<2/><doc/><elem/>Copy to Clipboard Copied! Toggle word wrap Toggle overflow nameandprefixare identifiers.uriis a string literal.contentcan be any type. Return value is XML. The return value is valid for use in places where a document is expected.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - XMLFOREST
XMLFOREST(content [AS name] [, <NSP>] [, content [AS name]]*)
XMLFOREST(content [AS name] [, <NSP>] [, content [AS name]]*)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Returns an concatenation of XML elements for each content item. See XMLELEMENT for the definition of NSP. If a name is not supplied for a content item, the expression must be a column reference, in which case the element name will be a partially escaped version of the column name.nameis an identifier.contentcan be any type. Return value is XML.You can use XMLFORREST to simplify the declaration of multiple XMLELEMENTS, XMLFOREST function allows you to process multiple columns at once:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - XMLAGG
- XMLAGG is an aggregate function, that takes a collection of XML elements and returns an aggregated XML document.
XMLAGG(xml)
XMLAGG(xml)Copy to Clipboard Copied! Toggle word wrap Toggle overflow In the XMLElement example, each row in the Customer table generates a row of XML if there are multiple rows matching the criteria. This will be valid XML, but it will not be well formed, because it lacks the root element. Use XMLAGG to correct that:Copy to Clipboard Copied! Toggle word wrap Toggle overflow - XMLPARSE
XMLPARSE((DOCUMENT|CONTENT) expr [WELLFORMED])
XMLPARSE((DOCUMENT|CONTENT) expr [WELLFORMED])Copy to Clipboard Copied! Toggle word wrap Toggle overflow Returns an XML type representation of the string value expression. If DOCUMENT is specified, then the expression must have a single root element and may or may not contain an XML declaration. If WELLFORMED is specified then validation is skipped; this is especially useful for CLOB and BLOB known to already be valid.exprin {string, clob, blob and varbinary}. Return value is XML.If DOCUMENT is specified then the expression must have a single root element and may or may not contain an XML declaration. If WELLFORMED is specified then validation is skipped; this is especially useful for CLOB and BLOB known to already be valid.SELECT XMLPARSE(CONTENT '<customer><name>Wartian Herkku</name><contact>Pirkko Koskitalo</contact></customer>' WELLFORMED);
SELECT XMLPARSE(CONTENT '<customer><name>Wartian Herkku</name><contact>Pirkko Koskitalo</contact></customer>' WELLFORMED);Copy to Clipboard Copied! Toggle word wrap Toggle overflow Will return a SQLXML with contents:<customer><name>Wartian Herkku</name><contact>Pirkko Koskitalo</contact></customer>
<customer><name>Wartian Herkku</name><contact>Pirkko Koskitalo</contact></customer>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - XMLPI
XMLPI([NAME] name [, content])
XMLPI([NAME] name [, content])Copy to Clipboard Copied! Toggle word wrap Toggle overflow Returns an XML processing instruction.nameis an identifier.contentis a string. Return value is XML.- XMLQUERY
XMLQUERY([<NSP>] xquery [<PASSING>] [(NULL|EMPTY) ON EMPTY]] PASSING:=PASSING exp [AS name] [, exp [AS name]]*
XMLQUERY([<NSP>] xquery [<PASSING>] [(NULL|EMPTY) ON EMPTY]] PASSING:=PASSING exp [AS name] [, exp [AS name]]*Copy to Clipboard Copied! Toggle word wrap Toggle overflow Returns the XML result from evaluating the givenxquery. See XMLELEMENT for the definition of NSP. Namespaces may also be directly declared in the XQuery prolog.The optional PASSING clause is used to provide the context item, which does not have a name, and named global variable values. If the XQuery uses a context item and none is provided, then an exception will be raised. Only one context item may be specified and should be an XML type. All non-context non-XML passing values will be converted to an appropriate XML type.The ON EMPTY clause is used to specify the result when the evaluated sequence is empty. EMPTY ON EMPTY, the default, returns an empty XML result. NULL ON EMPTY returns a null result.xqueryin string. Return value is XML.Note
XMLQUERY is part of the SQL/XML 2006 specification.See also XMLTABLE.- XMLEXISTS
- Returns true if a non-empty sequence would be returned by evaluating the given xquery.
XMLEXISTS([<NSP>] xquery [<PASSING>]] PASSING:=PASSING exp [AS name] [, exp [AS name]]*
XMLEXISTS([<NSP>] xquery [<PASSING>]] PASSING:=PASSING exp [AS name] [, exp [AS name]]*Copy to Clipboard Copied! Toggle word wrap Toggle overflow Namespaces may also be directly declared in the xquery prolog.The optional PASSING clause is used to provide the context item, which does not have a name, and named global variable values. If the xquery uses a context item and none is provided, then an exception will be raised. Only one context item may be specified and should be an XML type. All non-context non-XML passing values will be converted to an appropriate XML type. Null/Unknown will be returned if the context item evaluates to null.xquery in string. Return value is boolean.XMLEXISTS is part of the SQL/XML 2006 specification. - XMLSERIALIZE
XMLSERIALIZE([(DOCUMENT|CONTENT)] xml [AS datatype] [ENCODING enc] [VERSION ver] [(INCLUDING|EXCLUDING) XMLDECLARATION])
XMLSERIALIZE([(DOCUMENT|CONTENT)] xml [AS datatype] [ENCODING enc] [VERSION ver] [(INCLUDING|EXCLUDING) XMLDECLARATION])Copy to Clipboard Copied! Toggle word wrap Toggle overflow Returns a character type representation of the XML expression.datatypemay be character (string, varchar, clob) or binary (blob, varbinary). CONTENT is the default. If DOCUMENT is specified and the XML is not a valid document or fragment, then an exception is raised.Return value matches data type. If no data type is specified, then CLOB will be assumed.The encodingencis specified as an identifier. A character serialization may not specify an encoding. The versionveris specified as a string literal. If a particular XMLDECLARATION is not specified, then the result will have a declaration only if performing a non UTF-8/UTF-16 or non version 1.0 document serialization or the underlying XML has an declaration. If CONTENT is being serialized, then the declaration will be omitted if the value is not a document or element.The following example produces a BLOB of XML in UTF-16 including the appropriate byte order mark of FE FF and XML declaration:XMLSERIALIZE(DOCUMENT value AS BLOB ENCODING "UTF-16" INCLUDING XMLDECLARATION)
XMLSERIALIZE(DOCUMENT value AS BLOB ENCODING "UTF-16" INCLUDING XMLDECLARATION)Copy to Clipboard Copied! Toggle word wrap Toggle overflow - XMLTEXT
- This returns XML text.
XMLTEXT(text)
XMLTEXT(text)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The text is a string and the returned value is XML. - XSLTRANSFORM
XSLTRANSFORM(doc, xsl)
XSLTRANSFORM(doc, xsl)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Applies an XSL stylesheet to the given document.docandxslin {string, clob, xml}. Return value is a CLOB. If either argument is null, the result is null.- XPATHVALUE
XPATHVALUE(doc, xpath)
XPATHVALUE(doc, xpath)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Applies the XPATH expression to the document and returns a string value for the first matching result. For more control over the results and XQuery, use the XMLQUERY function.Matching a non-text node will still produce a string result, which includes all descendant text nodes.docandxpathin {string, clob, xml}. Return value is a string.When the input document utilizes namespaces, it is sometimes necessary to specify XPATH that ignores namespaces. For example, given the following XML,<?xml version="1.0" ?> <ns1:return xmlns:ns1="http://com.test.ws/exampleWebService">Hello<x> World</x></return>
<?xml version="1.0" ?> <ns1:return xmlns:ns1="http://com.test.ws/exampleWebService">Hello<x> World</x></return>Copy to Clipboard Copied! Toggle word wrap Toggle overflow the following function results in 'Hello World'.xpathValue(value, '/*[local-name()="return"])
xpathValue(value, '/*[local-name()="return"])Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.4.15. JSON Functions
- JSONTOXML
JSONTOXML(rootElementName, json)
JSONTOXML(rootElementName, json)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Returns an XML document from JSON. The appropriate UTF encoding (8, 16LE. 16BE, 32LE, 32BE) will be detected for JSON BLOBS. If another encoding is used, see the TO_CHARS function (see Section 2.4.5, “String Functions”).rootElementNameis a string,jsonis in {clob, blob}. Return value is XML. The result is always a well-formed XML document.The mapping to XML uses the following rules:- The current element name is initially the
rootElementName, and becomes the object value name as the JSON structure is traversed. - All element names must be valid XML 1.1 names. Invalid names are fully escaped according to the SQLXML specification.
- Each object or primitive value will be enclosed in an element with the current name.
- Unless an array value is the root, it will not be enclosed in an additional element.
- Null values will be represented by an empty element with the attribute
xsi:nil="true" - Boolean and numerical value elements will have the attribute
xsi:typeset tobooleananddecimalrespectively.
Example 2.1. Sample JSON to XML for jsonToXml('person', x)
JSON:{ "firstName" : "John" , "children" : [ "Randy", "Judy" ] }{ "firstName" : "John" , "children" : [ "Randy", "Judy" ] }Copy to Clipboard Copied! Toggle word wrap Toggle overflow XML:<?xml version="1.0" ?><person><firstName>John</firstName><children>Randy</children><children>Judy</children></person>
<?xml version="1.0" ?><person><firstName>John</firstName><children>Randy</children><children>Judy</children></person>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example 2.2. Sample JSON to XML for jsonToXml('person', x) with a root array.
JSON:[{ "firstName" : "George" }, { "firstName" : "Jerry" }][{ "firstName" : "George" }, { "firstName" : "Jerry" }]Copy to Clipboard Copied! Toggle word wrap Toggle overflow XML (Notice there is an extra "person" wrapping element to keep the XML well-formed):<?xml version="1.0" ?><person><person><firstName>George</firstName></person><person><firstName>Jerry</firstName></person></person>
<?xml version="1.0" ?><person><person><firstName>George</firstName></person><person><firstName>Jerry</firstName></person></person>Copy to Clipboard Copied! Toggle word wrap Toggle overflow JSON:Example 2.3. Sample JSON to XML for jsonToXml('root', x) with an invalid name.
{"/invalid" : "abc" }{"/invalid" : "abc" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow XML:Example 2.4. Sample JSON to XML for jsonToXml('root', x) with an invalid name.
<?xml version="1.0" ?> <root> <_u002F_invalid>abc</_u002F_invalid> </root>
<?xml version="1.0" ?> <root> <_u002F_invalid>abc</_u002F_invalid> </root>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - JSONARRAY
JSONARRAY(value...)
JSONARRAY(value...)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Returns a JSON array.valueis any object convertable to a JSON value (see Section 2.4.16, “Conversion to JSON”). Return value is a CLOB marked as being valid JSON. Null values will be included in the result as null literals.For example:jsonArray('a"b', 1, null, false, {d'2010-11-21'})jsonArray('a"b', 1, null, false, {d'2010-11-21'})Copy to Clipboard Copied! Toggle word wrap Toggle overflow returns["a\"b",1,null,false,"2010-11-21"]
["a\"b",1,null,false,"2010-11-21"]Copy to Clipboard Copied! Toggle word wrap Toggle overflow - JSONOBJECT
JSONARRAY(value [as name] ...)
JSONARRAY(value [as name] ...)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Returns a JSON object.valueis any object convertable to a JSON value (see Section 2.4.16, “Conversion to JSON”). Return value is a clob marked as being valid JSON.Null values will be included in the result as null literals.If a name is not supplied and the expression is a column reference, the column name will be used otherwise exprN will be used where N is the 1-based index of the value in the JSONARRAY expression.For example:jsonObject('a"b' as val, 1, null as "null")jsonObject('a"b' as val, 1, null as "null")Copy to Clipboard Copied! Toggle word wrap Toggle overflow returns{"val":"a\"b","expr2":1,"null":null}{"val":"a\"b","expr2":1,"null":null}Copy to Clipboard Copied! Toggle word wrap Toggle overflow - JSONPARSE
JSONPARSE(value, wellformed)
JSONPARSE(value, wellformed)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Validates and returns a JSON result.valueis blob with an appropriate JSON binary encoding (UTF-8, UTF-16, or UTF-32) or clob.wellformedis a boolean indicating that validation should be skipped. Return value is a CLOB marked as being valid JSON.A null for either input will return null.jsonParse('"a"')jsonParse('"a"')Copy to Clipboard Copied! Toggle word wrap Toggle overflow - JSONARRAY_AGG
- This creates a JSON array result as a Clob, including a null value. This is similar to JSONARRAY but aggregates its contents into single object.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow You can also wrap the array:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.4.16. Conversion to JSON
- null values are included as the null literal.
- values parsed as JSON or returned from a JSON construction function (JSONPARSE, JSONARRAY, JSONARRAY_AGG) will be directly appended into a JSON result.
- boolean values are included as true/false literals
- numeric values are included as their default string conversion - in some circumstances if not a number or +-infinity results are allowed, invalid JSON may be obtained.
- string values are included in their escaped/quoted form.
- binary values are not implicitly convertible to JSON values and require a specific prior to inclusion in JSON.
- all other values will be included as their string conversion in the appropriate escaped/quoted form.
2.4.17. Spatial Functions
Important
Conversion Functions
- ST_GeomFromText
- Returns a geometry from a Clob in WKT format.
ST_GeomFromText(text [, srid])
ST_GeomFromText(text [, srid])Copy to Clipboard Copied! Toggle word wrap Toggle overflow text is a clob, srid is an optional integer. Return value is a geometry. - ST_GeomFromWKB/ST_GeomFromBinary
- Returns a geometry from a blob in WKB format.
ST_GeomFromWKB(bin [, srid])
ST_GeomFromWKB(bin [, srid])Copy to Clipboard Copied! Toggle word wrap Toggle overflow bin is a blob, srid is an optional integer. Return value is a geometry. - ST_GeomFromGeoJSON
- Returns a geometry from a Clob in GeoJSON format.
ST_GeomFromGeoJson(text [, srid])
ST_GeomFromGeoJson(text [, srid])Copy to Clipboard Copied! Toggle word wrap Toggle overflow text is a clob, srid is an optional integer. Return value is a geometry. - ST_GeomFromGML
- Returns a geometry from a Clob in GML2 format.
ST_GeomFromGML(text [, srid])
ST_GeomFromGML(text [, srid])Copy to Clipboard Copied! Toggle word wrap Toggle overflow text is a clob, srid is an optional integer. Return value is a geometry. - ST_AsText
ST_GeomAsText(geom)
ST_GeomAsText(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. Return value is clob in WKT format.- ST_AsBinary
ST_GeomAsBinary(geom)
ST_GeomAsBinary(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. Return value is a blob in WKB format.- ST_GeomFromEWKB
- Returns a geometry from a blob in EWKB format.
ST_GeomFromEWKB(bin)
ST_GeomFromEWKB(bin)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The bin is a blob. Return value is a geometry. Only two dimensions are supported. - ST_AsGeoJSON
ST_GeomAsGeoJSON(geom)
ST_GeomAsGeoJSON(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. Return value is a clob with the GeoJSON value.- ST_AsGML
ST_GeomAsGML(geom)
ST_GeomAsGML(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. Return value is a clob with the GML2 value.- ST_AsEWKT
ST_AsEWKT(geom)
ST_AsEWKT(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. Return value is a clob with the EWKT value. The EWKT value is the WKT value with the SRID prefix.- ST_AsKML
ST_AsKML(geom)
ST_AsKML(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. Return value is a clob with the KML value. The KML value is effectively a simplified GML value and projected into SRID 4326.
Operators
- &&
- Returns true if the bounding boxes of geom1 and geom2 intersect.
geom1 && geom2
geom1 && geom2Copy to Clipboard Copied! Toggle word wrap Toggle overflow geom1 and geom2 are geometries. The returned value is a boolean.
Relationship Functions
- ST_CONTAINS
- Returns true if geom1 contains geom2 contains another.
ST_CONTAINS(geom1, geom2)
ST_CONTAINS(geom1, geom2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow geom1, geom2 are geometries. Return value is a boolean. - ST_CROSSES
- Returns true if the geometries cross.
ST_CROSSES(geom1, geom2)
ST_CROSSES(geom1, geom2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom1 and geom2 are geometries. Return value is a boolean. - ST_DISJOINT
- Returns true if the geometries are disjoint.
ST_DISJOINT(geom1, geom2)
ST_DISJOINT(geom1, geom2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom1 and geom2 are geometries. Return value is a boolean. - ST_DISTANCE
- Returns the distance between two geometries.
ST_DISTANCE(geom1, geom2)
ST_DISTANCE(geom1, geom2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom1 and geom2 are geometries. Return value is a double. - ST_EQUALS
- Returns true if the two geometries are spatially equal - the points and order may differ, but neither geometry lies outside of the other.
ST_EQUALS(geom1, geom2)
ST_EQUALS(geom1, geom2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom1 and geom2 are geometries. Return value is a boolean. - ST_INTERSECTS
- Returns true if the geometries intersect.
ST_INTERSECT(geom1, geom2)
ST_INTERSECT(geom1, geom2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom1 and geom2 are geometries. Return value is a boolean. - ST_OVERLAPS
- Returns true if the geometries overlap.
ST_OVERLAPS(geom1, geom2)
ST_OVERLAPS(geom1, geom2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom1 and geom2 are geometries. Return value is a boolean. - ST_TOUCHES
- Returns true if the geometries touch.
ST_TOUCHES(geom1, geom2)
ST_TOUCHES(geom1, geom2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom1 and geom2 are geometries. Return value is a boolean. - ST_DWithin
- Returns true if the geometries are within a given distance of one another.
ST_DWithin(geom1, geom2, dist)
ST_DWithin(geom1, geom2, dist)Copy to Clipboard Copied! Toggle word wrap Toggle overflow geom1 and geom2 are geometries. dist is a double. The returned value is a boolean. - ST_OrderingEquals
- Returns true if geom1 and geom2 have the same structure and the same ordering of points.
ST_OrderingEquals(geom1, geom2)
ST_OrderingEquals(geom1, geom2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow geom1 and geom2 are geometries. The returned value is a boolean. - ST_Relate
- Test or return the intersection of geom1 and geom2.
ST_Relate(geom1, geom2, pattern)
ST_Relate(geom1, geom2, pattern)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom1 and geom2 are geometries. Pattern is a nine character DE-9IM pattern string. The returned value is a boolean. - ST_Within
- Returns true if geom1 is completely inside geom2.
ST_Within(geom1, geom2)
ST_Within(geom1, geom2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom1 and geom2 are geometries. The returned value is a boolean.
Attributes and Tests
- ST_Area
- Returns the area of geom.
ST_Area(geom)
ST_Area(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. Return value is a double. - ST_CoordDim
- Returns the coordinate dimensions of geom.
ST_CoordDim(geom)
ST_CoordDim(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is an integer between 0 and 3. - ST_Dimension
- This returns the dimension of geom.
ST_Dimension(geom)
ST_Dimension(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is an integer between 0 and 3. - ST_EndPoint
- This returns the endpoint of the LineString geom. Returns null if geom is not a LineString.
ST_EndPoint(geom)
ST_EndPoint(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a geometry. - ST_ExteriorRing
- Returns the exterior ring or shell LineString of the Polygon geom. Returns null if geom is not a Polygon.
ST_ExteriorRing(geom)
ST_ExteriorRing(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a geometry. - ST_GeometryN
- Returns the nth geometry at the given 1-based index in geom. Returns null if a geometry at the given index does not exist. Non collection types return themselves at the first index.
ST_GeometryN(geom, index)
ST_GeometryN(geom, index)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The index is an integer. The returned value is a geometry. - ST_GeometryType
- Returns the type name of geom as ST_name, where the name will be LineString, Polygon, Point and so forth.
ST_GeometryType(geom)
ST_GeometryType(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a string. - ST_HasArc
- Tests if the geometry has a circular string. Will currently only report false as curved geometry types are not supported.
ST_HasArc(geom)
ST_HasArc(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a geometry. - ST_InteriorRingN
- Returns the nth interior ring LinearString geometry at the given 1-based index in geom. Returns null if a geometry at the given index does not exist or if geom is not a Polygon.
ST_InteriorRingN(geom, index)
ST_InteriorRingN(geom, index)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The index is an integer. The returned value is a geometry. - ST_IsClosed
- Returns true if LineString geom is closed. Returns false if geom is not a LineString
ST_IsClosed(geom)
ST_IsClosed(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The index is an integer. The returned value is a boolean. - ST_IsEmpty
- Returns true if the set of points is empty.
ST_IsEmpty(geom)
ST_IsEmpty(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a boolean. - ST_IsRing
- Returns true if the LineString geom is a ring. Returns false if geom is not a LineString.
ST_IsRing(geom)
ST_IsRing(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a boolean. - ST_IsSimple
- Returns true if the geom is simple.
ST_IsSimple(geom)
ST_IsSimple(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a boolean. - ST_IsValid
- Returns true if the geom is valid.
ST_IsValid(geom)
ST_IsValid(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a boolean. - ST_Length
- Returns the length of a (Multi)LineString otherwise 0.
ST_Length(geom)
ST_Length(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a double. - ST_NumGeometries
- Returns the number of geometries in the geom. Will return 1 if it is not a geometry collection.
ST_NumGeometries(geom)
ST_NumGeometries(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is an integer. - ST_NumInteriorRings
- Returns the number of interior rings in the Polygon geom. Returns null if geom is not a Polygon.
ST_NumInteriorRings(geom)
ST_NumInteriorRings(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is an integer. - ST_NunPoints
- Returns the number of points in a geom.
ST_NunPoints(geom)
ST_NunPoints(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is an integer. - ST_PointOnSurface
- Returns a point that is guaranteed to be on the surface of the geom.
ST_PointOnSurface(geom)
ST_PointOnSurface(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a point geometry. - ST_Perimeter
- Returns the perimeter of the (Multi)Polygon geom. It ill return 0 if the geom is not a (multi)polygon.
ST_Perimeter(geom)
ST_Perimeter(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a double. - ST_PointN
- Returns the nth Point at the given 1-based index in geom. Returns null if a point at the given index does not exist or if the geom is not a LineString.
ST_PointN(geom, index)
ST_PointN(geom, index)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The index is an integer. The returned value is a geometry. - ST_SRID
- Returns the SRID for the geometry.
ST_SRID(geom)
ST_SRID(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. Return value is an integer. A 0 value rather than null will be returned for an unknown SRID on a non-null geometry. - ST_SetSRID
- Set the SRID for the given geometry.
ST_SetSRID(geom, srid)
ST_SetSRID(geom, srid)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The srid is an integer. The returned value is a geometry. Only the SRID metadata for the geometry is modified. - ST_StartPoint
- Returns the start Point of the LineString geom. Returns null if geom is not a LineString.
ST_StartPoint(geom)
ST_StartPoint(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a geometry. - ST_X
- Returns the X ordinate value, or null if the point is empty. It throws an exception if the geometry is not a point.
ST_X(geom)
ST_X(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a double. - ST_Y
- Returns the Y ordinate value, or null if the point is empty. It throws an exception if the geometry is not a point.
ST_Y(geom)
ST_Y(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a double. - ST_Z
- Returns the Z ordinate value, or null if the point is empty. It throws an exception if the geometry is not a point. It will typically return null as three dimensions are not fully supported.
ST_Z(geom)
ST_Z(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a double.
Miscellaneous Functions
- ST_Boundary
- Computes the boundary of the given geometry.
ST_Boundary(geom)
ST_Boundary(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a geometry. - ST_Buffer
- Computes the geometry that has points within the given distance of a geom.
ST_Buffer(geom, distance)
ST_Buffer(geom, distance)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The distance is a double. The returned value is a geometry. - ST_Centroid
- Computes the geometric center point of a geom.
ST_Centroid(geom)
ST_Centroid(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a geometry. - ST_ConvexHull
- Return the smallest convex polygon that contains all of the points in a geom.
ST_ConvexHull(geom)
ST_ConvexHull(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a geometry. - ST_Difference
- Computes the closure of the set of the points contained in geom1 that are not in geom2.
ST_Difference(geom1, geom2)
ST_Difference(geom1, geom2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom1 and geom2 are the geometry. The returned value is a geometry. - ST_Envelope
- Computes the 2D bounding box of the given geometry.
ST_Envelope(geom)
ST_Envelope(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a geometry. - ST_Force_2D
- Removes the z coordinate value if it is present.
ST_Force_2D(geom)
ST_Force_2D(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a geometry. - ST_Intersection
- Computes the point set intersection of the points contained in geom1 and geom2.
ST_Intersection(geom1, geom2)
ST_Intersection(geom1, geom2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom1 and geom2 are the geometry. The returned value is a geometry. - ST_Simplify
- Simplifies a geometry using the Douglas-Peucker algorithm, but may oversimplify to an invalid or empty geometry.
ST_Simplify(geom, distanceTolerance)
ST_Simplify(geom, distanceTolerance)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. distanceTolerance is a double. The returned value is a geometry. - ST_SimplifyPreserveTopology
- Simplifies a Geometry using the Douglas-Peucker algorithm. This always returns a valid geometry.
ST_SimplifyPreserveTopology(geom, distanceTolerance)
ST_SimplifyPreserveTopology(geom, distanceTolerance)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. distanceTolerance is a double. The returned value is a geometry. - ST_SnapToGrid
- Snaps all of the points in the geometry to a grid of a given size.
ST_SnapToGrid(geom, size)
ST_SnapToGrid(geom, size)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. Size is a double. The returned value is a geometry. - ST_SymDifference
- Return the part of geom1 that does not intersect with geom2 and vice versa.
ST_SymDifference(geom1, geom2)
ST_SymDifference(geom1, geom2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom1 and geom2 are the geometry. The returned value is a geometry. - ST_Transform
- Transforms the geometry value from one coordinate system to another.
ST_Tranform(geom, srid)
ST_Tranform(geom, srid)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. srid is an integer. Return value is a geometry. The srid value and the srid of the geometry value must exist in the SPATIAL_REF_SYS view. - ST_Union
- Returns a geometry that represents the point set containing all of geom1 and geom2.
ST_Union(geom1, geom2)
ST_Union(geom1, geom2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom1 and geom2 are the geometry. The returned value is a geometry.
Aggregate Functions
- ST_Extent
- Computes the 2D bounding box around all of the geometric values. All values should have the same srid.
ST_Extent(geom)
ST_Extent(geom)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a geometry. The returned value is a geometry.
Construction Functions
- ST_Point
- Returns the point for the given coordinates.
ST_Point(x, y)
ST_Point(x, y)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The x and y are doubles. The returned value is a point geometry. - ST_Polygon
- Returns the polygon for the given shell and srid.
ST_Polygon(geom, srid)
ST_Polygon(geom, srid)Copy to Clipboard Copied! Toggle word wrap Toggle overflow The geom is a linear ring geometry and the srid is an integer. The returned value is a polygon geometry.
2.4.18. Security Functions
- HASROLE
hasRole([roleType,] roleName)
hasRole([roleType,] roleName)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Whether the current caller has the JBoss Data Virtualization data roleroleName.roleNamemust be a string, the return type is boolean.The two argument form is provided for backwards compatibility.roleTypeis a string and must be 'data'.Role names are case-sensitive and only match JBoss Data Virtualization data roles (see Section 7.1, “Data Roles”). JAAS roles/groups names are not valid for this function, unless there is corresponding data role with the same name.
2.4.19. Miscellaneous Functions
- array_get
array_get(array, index)
array_get(array, index)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Returns the object value at a given array index.arrayis the object type,indexmust be an integer, and the return type is object.One-based indexing is used. The actual array value must be ajava.sql.Arrayor Java array type. An exception will be thrown if the array value is the wrong type of the index is out of bounds.- array_length
array_length(array)
array_length(array)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Returns the length for a given array.arrayis the object type, and the return type is integer.The actual array value must be ajava.sql.Arrayor Java array type. An exception will be thrown if the array value is the wrong type.- uuid
uuid()
uuid()Copy to Clipboard Copied! Toggle word wrap Toggle overflow Returns a universally unique identifier.The return type is string.Generates a type 4 (pseudo randomly generated) UUID using a cryptographically strong random number generator. The format is XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX where each X is a hex digit.
2.4.20. Nondeterministic Function Handling
- Deterministic - the function will always return the same result for the given inputs. Deterministic functions are evaluated by the engine as soon as all input values are known, which may occur as soon as the rewrite phase. Some functions, such as the
lookupfunction, are not truly deterministic, but is treated as such for performance. All functions not categorized below are considered deterministic. - User Deterministic - the function will return the same result for the given inputs for the same user. This includes the
hasRoleand user functions. User deterministic functions are evaluated by the engine as soon as all input values are known, which may occur as soon as the rewrite phase. If a user deterministic function is evaluated during the creation of a prepared processing plan, then the resulting plan will be cached only for the user. - Session Deterministic - the function will return the same result for the given inputs under the same user session. This category includes the
envfunction. Session deterministic functions are evaluated by the engine as soon as all input values are known, which may occur as soon as the rewrite phase. If a session deterministic function is evaluated during the creation of a prepared processing plan, then the resulting plan will be cached only for the user's session. - Command Deterministic - the result of function evaluation is only deterministic within the scope of the user command. This category include the
curdate,curtime,now, andcommandpayloadfunctions. Command deterministic functions are delayed in evaluation until processing to ensure that even prepared plans utilizing these functions will be executed with relevant values. Command deterministic function evaluation will occur prior to pushdown; however, multiple occurrences of the same command deterministic time function are not guaranteed to evaluate to the same value. - Nondeterministic - the result of function evaluation is fully nondeterministic. This category includes the
randfunction and UDFs marked as nondeterministic. Nondeterministic functions are delayed in evaluation until processing with a preference for pushdown. If the function is not pushed down, then it may be evaluated for every row in its execution context (for example, if the function is used in the select clause).
2.5. DML Commands
2.5.1. DML Commands
2.5.2. SELECT Command
[WITH ...]SELECT ...[FROM ...][WHERE ...][GROUP BY ...][HAVING ...][ORDER BY ...][(LIMIT ...) | ([OFFSET ...] [FETCH ...])][OPTION ...]
- WITH stage - gathers all rows from all WITH items in the order listed. Subsequent WITH items and the main query can reference a WITH item as if it is a table.
- FROM stage - gathers all rows from all tables involved in the query and logically joins them with a Cartesian product, producing a single large table with all columns from all tables. Joins and join criteria are then applied to filter rows that do not match the join structure.
- WHERE stage - applies a criteria to every output row from the FROM stage, further reducing the number of rows.
- GROUP BY stage - groups sets of rows with matching values in the GROUP BY columns.
- HAVING stage - applies criteria to each group of rows. Criteria can only be applied to columns that will have constant values within a group (those in the grouping columns or aggregate functions applied across the group).
- SELECT stage - specifies the column expressions that should be returned from the query. Expressions are evaluated, including aggregate functions based on the groups of rows, which will no longer exist after this point. The output columns are named using either column aliases or an implicit name determined by the engine. If SELECT DISTINCT is specified, duplicate removal will be performed on the rows being returned from the SELECT stage.
- ORDER BY stage - sorts the rows returned from the SELECT stage as desired. Supports sorting on multiple columns in specified order, ascending or descending. The output columns will be identical to those columns returned from the SELECT stage and will have the same name.
- LIMIT stage - returns only the specified rows (with skip and limit values).
Note
TABLE x may be used as a shortcut for SELECT * FROM x.
2.5.3. INSERT Command
- INSERT INTO table (column,...) VALUES (value,...)
- INSERT INTO table (column,...) query
2.5.4. UPDATE Command
- UPDATE table SET (column=value,...) [WHERE criteria]
2.5.5. DELETE Command
- DELETE FROM table [WHERE criteria]
2.5.6. MERGE Command
MERGE INTO table (column,...) VALUES (value,...)
MERGE INTO table (column,...) VALUES (value,...)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
MERGE INTO table (column,...) query
MERGE INTO table (column,...) queryCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Note
2.5.7. EXECUTE Command
- EXECUTE proc()
- CALL proc(value, ...)
- EXECUTE proc(name1=>value1,name4=>param4, ...) - named parameter syntax
- The default order of parameter specification is the same as how they are defined in the procedure definition.
- You can specify the parameters in any order by name. Parameters that have default values and/or are nullable in the metadata, can be omitted from the named parameter call and will have the appropriate value passed at runtime.
- Positional parameters that are have default values and/or are nullable in the metadata, can be omitted from the end of the parameter list and will have the appropriate value passed at runtime.
- If the procedure does not return a result set, the values from the RETURN, OUT, and IN_OUT parameters will be returned as a single row when used as an inline view query.
- A VARIADIC parameter may be repeated 0 or more times as the last positional argument.
2.5.8. Procedural Relational Command
- SELECT * FROM proc
- SELECT output_param1, output_param2 FROM proc WHERE input_param1 = 'x'
- SELECT output_param1, output_param2 FROM proc, table WHERE input_param1 = table.col1 AND input_param2 = table.col2
- The procedure as a table projects the same columns as an exec with the addition of the input parameters. For procedures that do not return a result set, IN_OUT columns will be projected as two columns, one that represents the output value and one named {column name}_IN that represents the input of the parameter.
- Input values are passed via criteria. Values can be passed by '=','is null', or 'in' predicates. Disjuncts are not allowed. It is also not possible to pass the value of a non-comparable column through an equality predicate.
- The procedure view automatically has an access pattern on its IN and IN_OUT parameters which allows it to be planned correctly as a dependent join when necessary or fail when sufficient criteria cannot be found.
- Procedures containing duplicate names between the parameters (IN, IN_OUT, OUT, RETURN) and result set columns cannot be used in a procedural relational command.
- Default values for IN, IN_OUT parameters are not used if there is no criteria present for a given input. Default values are only valid for named procedure syntax. See Section 2.5.7, “EXECUTE Command”.
Note
Note
2.5.9. Set Operations
queryExpression (UNION|INTERSECT|EXCEPT) [ALL] queryExpression [ORDER BY...]
queryExpression (UNION|INTERSECT|EXCEPT) [ALL] queryExpression [ORDER BY...]- The output columns will be named by the output columns of the first set operation branch.
- Each SELECT must have the same number of output columns and compatible data types for each relative column. Data type conversion will be performed if data types are inconsistent and implicit conversions exist.
- If UNION, INTERSECT, or EXCEPT is specified without all, then the output columns must be comparable types.
- INTERSECT ALL, and EXCEPT ALL are currently not supported.
2.5.10. Subqueries
- Scalar subquery - a subquery that returns only a single column with a single value. Scalar subqueries are a type of expression and can be used where single valued expressions are expected.
- Correlated subquery - a subquery that contains a column reference to form the outer query.
- Uncorrelated subquery - a subquery that contains no references to the outer subquery.
2.5.11. Inline Views
SELECT a FROM (SELECT Y.b, Y.c FROM Y WHERE Y.d = 3) AS X WHERE a = X.c AND b = X.b
SELECT a FROM (SELECT Y.b, Y.c FROM Y WHERE Y.d = 3) AS X WHERE a = X.c AND b = X.bSee Also:
2.5.12. Alternative Subquery Usage
Example 2.5. Example Subquery in WHERE Using EXISTS
SELECT a FROM X WHERE EXISTS (SELECT 1 FROM Y WHERE c=X.a)
SELECT a FROM X WHERE EXISTS (SELECT 1 FROM Y WHERE c=X.a)Example 2.6. Example Quantified Comparison Subqueries
SELECT a FROM X WHERE a >= ANY (SELECT b FROM Y WHERE c=3) SELECT a FROM X WHERE a < SOME (SELECT b FROM Y WHERE c=4) SELECT a FROM X WHERE a = ALL (SELECT b FROM Y WHERE c=2)
SELECT a FROM X WHERE a >= ANY (SELECT b FROM Y WHERE c=3)
SELECT a FROM X WHERE a < SOME (SELECT b FROM Y WHERE c=4)
SELECT a FROM X WHERE a = ALL (SELECT b FROM Y WHERE c=2)Example 2.7. Example IN Subquery
SELECT a FROM X WHERE a IN (SELECT b FROM Y WHERE c=3)
SELECT a FROM X WHERE a IN (SELECT b FROM Y WHERE c=3)2.6. DML Clauses
2.6.1. DML Clauses
2.6.2. WITH Clause
WITH name [(column, ...)] AS (query expression) ...
WITH name [(column, ...)] AS (query expression) ...- All of the projected column names must be unique. If they are not unique, then the column name list must be provided.
- If the columns of the WITH clause item are declared, then they must match the number of columns projected by the query expression.
- Each WITH clause item must have a unique name.
Note
2.6.3. Recursive Common Table Expressions
WITH name [(column, ...)] AS (anchor query expression UNION [ALL] recursive query expression) ...
WITH name [(column, ...)] AS (anchor query expression UNION [ALL] recursive query expression) ...
Important
teiid.maxRecusion to a larger integer value. Once the maximum has been exceeded, an exception is thrown.
SELECT teiid_session_set('teiid.maxRecursion', 25);
WITH n (x) AS (values('a') UNION select chr(ascii(x)+1) from n where x < 'z') select * from n
SELECT teiid_session_set('teiid.maxRecursion', 25);
WITH n (x) AS (values('a') UNION select chr(ascii(x)+1) from n where x < 'z') select * from n
2.6.4. SELECT Clause
SELECT [DISTINCT|ALL] ((expression [[AS] name])|(group identifier.STAR))*|STAR ...
SELECT [DISTINCT|ALL] ((expression [[AS] name])|(group identifier.STAR))*|STAR ...- Aliased expressions are only used as the output column names and in the ORDER BY clause. They cannot be used in other clauses of the query.
- DISTINCT may only be specified if the SELECT symbols are comparable.
2.6.5. FROM Clause
- FROM table [[AS] alias]
- FROM table1 [INNER|LEFT OUTER|RIGHT OUTER|FULL OUTER] JOIN table2 ON join-criteria
- FROM table1 CROSS JOIN table2
- FROM (subquery) [AS] alias
- FROM TABLE(subquery) [AS] alias
Note
- FROM table1 JOIN /*+ MAKEDEP */ table2 ON join-criteria
- FROM table1 JOIN /*+ MAKENOTDEP */ table2 ON join-criteria
- FROM /*+ MAKEIND */ table1 JOIN table2 ON join-criteria
- FROM /*+ NO_UNNEST */ vw1 JOIN table2 ON join-criteria
- FROM table1 left outer join /*+ optional */ table2 ON join-criteria
Note
- FROM TEXTTABLE...
- FROM XMLTABLE...
Note
- FROM ARRAYTABLE...
- FROM OBJECTTABLE...
- FROM (SELECT ...)
Note
2.6.6. FROM Clause Hints
FROM /*+ MAKEDEP PRESERVE */ (tbl1 inner join tbl2 inner join tbl3 on tbl2.col1 = tbl3.col1 on tbl1.col1 = tbl2.col1), tbl3 WHERE tbl1.col1 = tbl2.col1
FROM /*+ MAKEDEP PRESERVE */ (tbl1 inner join tbl2 inner join tbl3 on tbl2.col1 = tbl3.col1 on tbl1.col1 = tbl2.col1), tbl3 WHERE tbl1.col1 = tbl2.col1
- Dependent Joins Hints
- MAKEIND, MAKEDEP, and MAKENOTDEP are hints used to control dependent join behavior (see Section 13.7.3, “Dependent Joins”). They should only be used in situations where the optimizer does not choose the most optimal plan based upon query structure, metadata, and costing information. The hints may appear in a comment following the FROM keyword. The hints can be specified against any FROM clause, not just a named table.
- NO_UNNEST
- NO_UNNEST can be specified against a FROM clause or view to instruct the planner not to merge the nested SQL in the surrounding query - also known as view flattening. This hint only applies to JBoss Data Virtualization planning and is not passed to source queries. NO_UNNEST may appear in a comment following the FROM keyword.
- PRESERVE
- The PRESERVE hint can be used against an ANSI join tree to preserve the structure of the join rather than allowing the JBoss Data Virtualization optimizer to reorder the join. This is similar in function to the Oracle ORDERED or MySQL STRAIGHT_JOIN hints.
FROM /*+ PRESERVE */ (tbl1 inner join tbl2 inner join tbl3 on tbl2.col1 = tbl3.col1 on tbl1.col1 = tbl2.col1)
FROM /*+ PRESERVE */ (tbl1 inner join tbl2 inner join tbl3 on tbl2.col1 = tbl3.col1 on tbl1.col1 = tbl2.col1)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.6.7. Nested Tables
select * from t1, TABLE(call proc(t1.x)) t2
select * from t1, TABLE(call proc(t1.x)) t2select * from TABLE(call proc(t1.x)) t2, t1
select * from TABLE(call proc(t1.x)) t2, t1Note
2.6.8. Nested Tables: TEXTTABLE
TEXTTABLE(expression [SELECTOR string] COLUMNS <COLUMN>, ... [NO ROW DELIMITER] [DELIMITER char] [(QUOTE|ESCAPE) char] [HEADER [integer]] [SKIP integer]) AS name
TEXTTABLE(expression [SELECTOR string] COLUMNS <COLUMN>, ... [NO ROW DELIMITER] [DELIMITER char] [(QUOTE|ESCAPE) char] [HEADER [integer]] [SKIP integer]) AS nameCOLUMN := name (FOR ORDINALITY | ([HEADER string] datatype [WIDTH integer [NO TRIM]] [SELECTOR string integer]))
COLUMN := name (FOR ORDINALITY | ([HEADER string] datatype [WIDTH integer [NO TRIM]] [SELECTOR string integer]))Parameters
- expression is the text content to process, which should be convertible to CLOB.
- SELECTOR specifies that delimited lines should only match if the line begins with the selector string followed by a delimiter. The selector value is a valid column value. If a TEXTTABLE SELECTOR is specified, a SELECTOR may also be specified for column values. A column SELECTOR argument will select the nearest preceding text line with the given SELECTOR prefix and select the value at the given 1-based integer position (which includes the selector itself). If no such text line or position with a given line exists, a null value will be produced.
- NO ROW DELIMITER indicates that fixed parsing should not assume the presence of newline row delimiters.
- DELIMITER sets the field delimiter character to use. Defaults to ','.
- QUOTE sets the quote, or qualifier, character used to wrap field values. Defaults to '"'.
- ESCAPE sets the escape character to use if no quoting character is in use. This is used in situations where the delimiter or new line characters are escaped with a preceding character, e.g. \,
- HEADER specifies the text line number (counting every new line) on which the column names occur. All lines prior to the header will be skipped. If HEADER is specified, then the header line will be used to determine the TEXTTABLE column position by case-insensitive name matching. This is especially useful in situations where only a subset of the columns are needed. If the HEADER value is not specified, it defaults to 1. If HEADER is not specified, then columns are expected to match positionally with the text contents.
- SKIP specifies the number of text lines (counting every new line) to skip before parsing the contents. You can still specify a HEADER with SKIP.
- A FOR ORDINALITY column is typed as integer and will return the 1-based item number as its value.
- WIDTH indicates the fixed-width length of a column in characters - not bytes. The CR NL newline value counts as a single character.
- NO TRIM specifies that the text value should not be trimmed of all leading and trailing white space.
Syntax Rules:
- If width is specified for one column it must be specified for all columns and be a non-negative integer.
- If width is specified, then fixed width parsing is used and ESCAPE, QUOTE, and HEADER should not be specified.
- If width is not specified, then NO ROW DELIMITER cannot be used.
- The column names must not contain duplicates.
Examples
- Use of the HEADER parameter, returns 1 row ['b']:
SELECT * FROM TEXTTABLE(UNESCAPE('col1,col2,col3\na,b,c') COLUMNS col2 string HEADER) xSELECT * FROM TEXTTABLE(UNESCAPE('col1,col2,col3\na,b,c') COLUMNS col2 string HEADER) xCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Use of fixed width, returns 2 rows ['a', 'b', 'c'], ['d', 'e', 'f']:
SELECT * FROM TEXTTABLE(UNESCAPE('abc\ndef') COLUMNS col1 string width 1, col2 string width 1, col3 string width 1) xSELECT * FROM TEXTTABLE(UNESCAPE('abc\ndef') COLUMNS col1 string width 1, col2 string width 1, col3 string width 1) xCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Use of fixed width without a row delimiter, returns 3 rows ['a'], ['b'], ['c']:
SELECT * FROM TEXTTABLE('abc' COLUMNS col1 string width 1 NO ROW DELIMITER) xSELECT * FROM TEXTTABLE('abc' COLUMNS col1 string width 1 NO ROW DELIMITER) xCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Use of ESCAPE parameter, returns 1 row ['a,', 'b']:
SELECT * FROM TEXTTABLE('a:,,b' COLUMNS col1 string, col2 string ESCAPE ':') xSELECT * FROM TEXTTABLE('a:,,b' COLUMNS col1 string, col2 string ESCAPE ':') xCopy to Clipboard Copied! Toggle word wrap Toggle overflow - As a nested table:
SELECT x.* FROM t, TEXTTABLE(t.clobcolumn COLUMNS first string, second date SKIP 1) x
SELECT x.* FROM t, TEXTTABLE(t.clobcolumn COLUMNS first string, second date SKIP 1) xCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Use of SELECTOR, returns 2 rows ['c', 'd', 'b'], ['c', 'f', 'b']:
SELECT * FROM TEXTTABLE('a,b\nc,d\nc,f' SELECTOR 'c' COLUMNS col1 string, col2 string col3 string SELECTOR 'a' 2) xSELECT * FROM TEXTTABLE('a,b\nc,d\nc,f' SELECTOR 'c' COLUMNS col1 string, col2 string col3 string SELECTOR 'a' 2) xCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.6.9. Nested Tables: XMLTABLE
XMLTABLE([<NSP>,] xquery-expression [<PASSING>] [COLUMNS <COLUMN>, ... )] AS name
XMLTABLE([<NSP>,] xquery-expression [<PASSING>] [COLUMNS <COLUMN>, ... )] AS nameCOLUMN := name (FOR ORDINALITY | (datatype [DEFAULT expression] [PATH string]))
COLUMN := name (FOR ORDINALITY | (datatype [DEFAULT expression] [PATH string]))Note
Parameters
- The optional XMLNAMESPACES clause specifies the namespaces for use in the XQuery and COLUMN path expressions.
- The xquery-expression must be a valid XQuery. Each sequence item returned by the xquery will be used to create a row of values as defined by the COLUMNS clause.
- If COLUMNS is not specified, then that is the same as having the COLUMNS clause: "COLUMNS OBJECT_VALUE XML PATH '.'", which returns the entire item as an XML value.
- A FOR ORDINALITY column is typed as integer and will return the one-based item number as its value.
- Each non-ordinality column specifies a type and optionally a PATH and a DEFAULT expression.
- If PATH is not specified, then the path will be the same as the column name.
Syntax Rules:
- Only 1 FOR ORDINALITY column may be specified.
- The columns names must not contain duplicates.
- The blob data type is supported, but there is only built-in support for xs:hexBinary values. For xs:base64Binary, use a workaround of a PATH that uses the explicit value constructor "xs:base64Binary(<path>)".
Examples
- Use of passing, returns 1 row [1]:
select * from xmltable('/a' PASSING xmlparse(document '<a id="1"/>') COLUMNS id integer PATH '@id') xselect * from xmltable('/a' PASSING xmlparse(document '<a id="1"/>') COLUMNS id integer PATH '@id') xCopy to Clipboard Copied! Toggle word wrap Toggle overflow - As a nested table:
select x.* from t, xmltable('/x/y' PASSING t.doc COLUMNS first string, second FOR ORDINALITY) xselect x.* from t, xmltable('/x/y' PASSING t.doc COLUMNS first string, second FOR ORDINALITY) xCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.6.10. Nested Tables: ARRAYTABLE
ARRAYTABLE(expression COLUMNS <COLUMN>, ...) AS name
ARRAYTABLE(expression COLUMNS <COLUMN>, ...) AS nameCOLUMN := name datatype
COLUMN := name datatypeParameters
- expression - the array to process, which should be a java.sql.Array or java array value.
Syntax Rules:
- The columns names must not contain duplicates.
- As a nested table:
select x.* from (call source.invokeMDX('some query')) r, arraytable(r.tuple COLUMNS first string, second bigdecimal) xselect x.* from (call source.invokeMDX('some query')) r, arraytable(r.tuple COLUMNS first string, second bigdecimal) xCopy to Clipboard Copied! Toggle word wrap Toggle overflow
ARRAYTABLE(val COLUMNS col1 string, col2 integer) AS X
ARRAYTABLE(val COLUMNS col1 string, col2 integer) AS XTABLE(SELECT cast(array_get(val, 1) AS string) AS col1, cast(array_get(val, 2) AS integer) AS col2) AS X
TABLE(SELECT cast(array_get(val, 1) AS string) AS col1, cast(array_get(val, 2) AS integer) AS col2) AS X2.6.11. Nested Tables: OBJECTTABLE
OBJECTTABLE([LANGUAGE lang] rowScript [PASSING val AS name ...] COLUMNS colName colType colScript [DEFAULT defaultExpr] ...) AS id
OBJECTTABLE([LANGUAGE lang] rowScript [PASSING val AS name ...] COLUMNS colName colType colScript [DEFAULT defaultExpr] ...) AS idParameters
- lang - an optional string literal that is the case sensitive language name of the scripts to be processed. The script engine must be available via a JSR-223 ScriptEngineManager lookup. In some instances this may mean making additional modules available to your VDB, which can be done via the same process as adding modules/libraries for UDFs (see Non-Pushdown Support for User-Defined Functions in the Development Guide: Server Development). If a LANGUAGE is not specified, the default of 'teiid_script' (see below) will be used.
- name - an identifier that will bind the val expression value into the script context.
- rowScript is a string literal specifying the script to create the row values. For each non-null item the Iterator produces the columns will be evaluated.
- colName/colType are the id/data type of the column, which can optionally be defaulted with the DEFAULT clause expression defaultExpr.
- colScript is a string literal specifying the script that evaluates to the column value.
Syntax Rules:
- The column names must be not contain duplicates.
- JBoss Data Virtualization will place several special variables in the script execution context. The CommandContext is available as teiid_context. Additionally the colScripts may access teiid_row and teiid_row_number. teiid_row is the current row object produced by the row script. teiid_row_number is the current 1-based row number.
- rowScript is evaluated to an Iterator. If the results is already an Iterator, it is used directly. If the evaluation result is an Iteratable, then an Iterator will be obtained. Any other Object will be treated as an Iterator of a single item). In all cases null row values will be skipped.
Note
Examples
- Accessing special variables:
SELECT x.* FROM OBJECTTABLE('teiid_context' COLUMNS "user" string 'teiid_row.userName', row_number integer 'teiid_row_number') AS xSELECT x.* FROM OBJECTTABLE('teiid_context' COLUMNS "user" string 'teiid_row.userName', row_number integer 'teiid_row_number') AS xCopy to Clipboard Copied! Toggle word wrap Toggle overflow The result would be a row with two columns containing the user name and 1 respectively.
Note
getFoo() and foo() method, then the accessor foo references foo() and getFoo should be used to call the getter.
Examples
- To get the VDB description string:
teiid_context.session.vdb.description
teiid_context.session.vdb.descriptionCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.6.12. WHERE Clause
WHERE criteria
WHERE criteriaSee Also:
2.6.13. GROUP BY Clause
GROUP BY expression (,expression)*
GROUP BY expression (,expression)*Syntax Rules:
- Column references in the GROUP BY clause must be unaliased output columns.
- Expressions used in the GROUP BY clause must appear in the SELECT clause.
- Column references and expressions in the SELECT clause that are not used in the GROUP BY clause must appear in aggregate functions.
- If an aggregate function is used in the SELECT clause and no GROUP BY is specified, an implicit GROUP BY will be performed with the entire result set as a single group. In this case, every column in the SELECT must be an aggregate function as no other column value will be fixed across the entire group.
- The group by columns must be of a comparable type.
HAVING clause is processed. A ROLLUP of expressions will produce the same output as a regular grouping with the addition of aggregate values computed at higher aggregation levels. For N expressions in the ROLLUP, aggregates will be provided over (), (expr1), (expr1, expr2) and so on, up to (expr1, … exprN-1) with the other grouping expressions in the output as null values. Here is an example using the normal aggregation query:
SELECT country, city, sum(amount) from sales group by country, city
SELECT country, city, sum(amount) from sales group by country, city
| Country | City | Amount |
|---|---|---|
| US | St Louis | 10000 |
| US | Raleigh | 150000 |
| US | Denver | 20000 |
| UK | Birmingham | 50000 |
| UK | London | 75000 |
SELECT country, city, sum(amount) from sales group by rollup(country, city)
SELECT country, city, sum(amount) from sales group by rollup(country, city)
| Country | City | Amount |
|---|---|---|
| US | St Louis | 10000 |
| US | Raleigh | 150000 |
| US | Denver | 20000 |
| US | Null | 180000 |
| UK | Birmingham | 50000 |
| UK | London | 75000 |
| UK | Null | 125000 |
Note
Note
2.6.14. HAVING Clause
Syntax Rules:
- Expressions used in the GROUP BY clause must either contain an aggregate function: COUNT, AVG, SUM, MIN, MAX. or be one of the grouping expressions.
2.6.15. ORDER BY Clause
ORDER BY expression [ASC|DESC] [NULLS (FIRST|LAST)], ...
ORDER BY expression [ASC|DESC] [NULLS (FIRST|LAST)], ...Syntax Rules:
- Sort columns may be specified positionally by a 1-based positional integer, by SELECT clause alias name, by SELECT clause expression, or by an unrelated expression.
- Column references may appear in the SELECT clause as the expression for an aliased column or may reference columns from tables in the FROM clause. If the column reference is not in the SELECT clause the query must not be a set operation, specify SELECT DISTINCT, or contain a GROUP BY clause.
- Unrelated expressions, expressions not appearing as an aliased expression in the SELECT clause, are allowed in the ORDER BY clause of a non-set QUERY. The columns referenced in the expression must come from the FROM clause table references. The column references cannot be to alias names or positional.
- The ORDER BY columns must be of a comparable type.
- If an ORDER BY is used in an inline view or view definition without a LIMIT clause, it will be removed by the JBoss Data Virtualization optimizer.
- If NULLS FIRST/LAST is specified, then nulls are guaranteed to be sorted either first or last. If the null ordering is not specified, then results will typically be sorted with nulls as low values, which is the JBoss Data Virtualization internal default sorting behavior. However not all sources return results with nulls sorted as low values by default, and JBoss Data Virtualization may return results with different null orderings.
Warning
2.6.16. LIMIT Clause
LIMIT [offset,] limit
LIMIT [offset,] limit[OFFSET offset ROW|ROWS] [FETCH FIRST|NEXT [limit] ROW|ROWS ONLY
[OFFSET offset ROW|ROWS] [FETCH FIRST|NEXT [limit] ROW|ROWS ONLYSyntax Rules:
- The limit/offset expressions must be a non-negative integer or a parameter reference (?). An offset of 0 is ignored. A limit of 0 will return no rows.
- The terms FIRST/NEXT are interchangeable as well as ROW/ROWS.
- The LIMIT clause may take an optional preceding NON_STRICT hint to indicate that push operations should not be inhibited even if the results will not be consistent with the logical application of the limit. The hint is only needed on unordered limits, e.g. "SELECT * FROM VW /*+ NON_STRICT */ LIMIT 2".
Examples:
- LIMIT 100 - returns the first 100 records (rows 1-100)
- LIMIT 500, 100 - skips 500 records and returns the next 100 records (rows 501-600)
- OFFSET 500 ROWS - skips 500 records
- OFFSET 500 ROWS FETCH NEXT 100 ROWS ONLY - skips 500 records and returns the next 100 records (rows 501-600)
- FETCH FIRST ROW ONLY - returns only the first record
2.6.17. INTO Clause
Warning
2.6.18. OPTION Clause
OPTION option, (option)*
OPTION option, (option)*Supported options:
- MAKEDEP table [(,table)*] - specifies source tables that will be made dependent in the join
- MAKENOTDEP table [(,table)*] - prevents a dependent join from being used
- NOCACHE [table (,table)*] - prevents cache from being used for all tables or for the given tables
Examples:
- OPTION MAKEDEP table1
- OPTION NOCACHE
Note
2.7. DDL Commands
2.7.1. DDL Commands
Note
MetadataRepository must be configured to make a non-temporary metadata update persistent. See Runtime Metadata Updates in Red Hat JBoss Data Virtualization Development Guide: Server Development for more information.
2.7.2. Local and Global Temporary Tables
2.7.2.1. Local Temporary Tables
INSERT statement or explicitly with a CREATE TABLE statement. Implicitly created temporary tables must have a name that starts with '#'.
Creation syntax:
- Local temporary tables can be defined explicitly with a CREATE TABLE statement:
CREATE LOCAL TEMPORARY TABLE name (column type [NOT NULL], ... [PRIMARY KEY (column, ...)])
CREATE LOCAL TEMPORARY TABLE name (column type [NOT NULL], ... [PRIMARY KEY (column, ...)])Copy to Clipboard Copied! Toggle word wrap Toggle overflow Use the SERIAL data type to specify a NOT NULL and auto-incrementing INTEGER column. The starting value of a SERIAL column is 1. - Local temporary tables can be defined implicitly by referencing them in an INSERT statement.
INSERT INTO #name (column, ...) VALUES (value, ...)
INSERT INTO #name (column, ...) VALUES (value, ...)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Note
If #name does not exist, it will be defined using the given column names and types from the value expressions.INSERT INTO #name [(column, ...)] select c1, c2 from t
INSERT INTO #name [(column, ...)] select c1, c2 from tCopy to Clipboard Copied! Toggle word wrap Toggle overflow Note
If #name does not exist, it will be defined using the target column names and the types from the query derived columns. If target columns are not supplied, the column names will match the derived column names from the query.
Drop syntax:
- DROP TABLE name
2.7.2.2. Global Temporary Tables
CREATE GLOBAL TEMPORARY TABLE name (column type [NOT NULL], ... [PRIMARY KEY (column, ...)]) OPTIONS (UPDATABLE 'true')
CREATE GLOBAL TEMPORARY TABLE name (column type [NOT NULL], ... [PRIMARY KEY (column, ...)]) OPTIONS (UPDATABLE 'true')
SERIAL data type, then each session’s instance of the global temporary table will have its own sequence.
UPDATABLE if you want to update the temporary table.
2.7.2.3. Common Features
Primary Key Support
- All key columns must be comparable.
- If you use a primary key, it will create a clustered index that supports search improvements for
comparison,in,like, andorder by. - You can use
Nullas a primary key value, but there must only be one row that has an all-null key.
Transaction Support
- THere is a
READ_UNCOMMITEDtransaction isolation level. There are no locking mechanisms available to support higher isolation levels and the result of a rollback may be inconsistent across multiple transactions. If concurrent transactions are not associated with the same local temporary table or session, then the transaction isolation level is effectively serializable. If you want full consistency with local temporary tables, then only use a connection with 1 transaction at a time. This mode of operation is ensured by connection pooling that tracks connections by transaction.
Limitations
- With the CREATE TABLE syntax only basic table definition (column name and type information) and an optional primary key are supported. For global temporary tables additional metadata in the create statement is effectively ignored when creating the temporary table instance - but may still be utilized by planning similar to any other table entry.
- You can use
ON COMMIT PRESERVE ROWS. No otherON COMMITclause is supported. - You cannot use the "drop behavior" option in the drop statement.
- Temporary tables are not fail-over safe.
- Non-inlined LOB values (XML, CLOB, BLOB) are tracked by reference rather than by value in a temporary table. If you insert LOB values from external sources in your temporary table, they may become unreadable when the associated statement or connection is closed.
2.7.3. Foreign Temporary Tables
CREATE FOREIGN TEMPORARY TABLE name ... ON schema
CREATE FOREIGN TEMPORARY TABLE name ... ON schema- the source on commit behavior (most likely DELETE ROWS or DROP) will ensure clean-up. Keep in mind that a JBoss Data Virtualization DROP does not issue a source command and is not guaranteed to occur (in some exception cases, loss of DB connectivity, hard shutdown, etc.).
- the source pool when using track connections by transaction will ensure that multiple uses of that source by JBoss Data Virtualization will use the same connection/session and thus the same temporary table and data.
Note
2.7.4. Alter View
ALTER VIEW name AS queryExpression
ALTER VIEW name AS queryExpressionSyntax Rules:
- The alter query expression may be prefixed with a cache hint for materialized view definitions. The hint will take effect the next time the materialized view table is loaded.
2.7.5. Alter Procedure
ALTER PROCEDURE name AS block
ALTER PROCEDURE name AS blockSyntax Rules:
- The alter block should not include 'CREATE VIRTUAL PROCEDURE'
- The alter block may be prefixed with a cache hint for cached procedures.
2.7.6. Create Trigger
CREATE TRIGGER ON name INSTEAD OF INSERT|UPDATE|DELETE AS FOR EACH ROW block
CREATE TRIGGER ON name INSTEAD OF INSERT|UPDATE|DELETE AS FOR EACH ROW blockSyntax Rules:
- The target, name, must be an updatable view.
- An INSTEAD OF TRIGGER must not yet exist for the given event.
- Triggers are not yet true schema objects. They are scoped only to their view and have no name.
Limitations:
- There is no corresponding DROP operation. See Section 2.7.7, “Alter Trigger” for enabling/disabling an existing trigger.
2.7.7. Alter Trigger
ALTER TRIGGER ON name INSTEAD OF INSERT|UPDATE|DELETE (AS FOR EACH ROW block) | (ENABLED|DISABLED)
ALTER TRIGGER ON name INSTEAD OF INSERT|UPDATE|DELETE (AS FOR EACH ROW block) | (ENABLED|DISABLED)Syntax Rules:
- The target, name, must be an updatable view.
- Triggers are not yet true schema objects. They are scoped only to their view and have no name.
- Update Procedures must already exist for the given trigger event. See Section 2.10.6, “Update Procedures”.
Note
2.8. XML Document Generation
Important
2.8.1. XML Document Generation
Note
2.8.2. XML SELECT Command
SELECT ... FROM ... [WHERE ...] [ORDER BY ...]
SELECT ... FROM ... [WHERE ...] [ORDER BY ...]"model"."document name".[path to element]."element name"
"model"."document name".[path to element]."element name""model"."document name".[path to element]."element name".[@]"attribute name"
"model"."document name".[path to element]."element name".[@]"attribute name"2.8.3. XML SELECT: FROM Clause
"model"."document name".
Syntax Rules:
- The FROM clause must contain only one unary clause specifying the desired document.
2.8.4. XML SELECT: SELECT Clause
Example Syntax:
- select * from model.doc
- select model.doc.root.parent.element.* from model.doc
- select element, element1.@attribute from model.doc
Syntax Rules:
- SELECT * and SELECT "xml" are equivalent and specify that every element and attribute of the document should be output.
- The SELECT clause of an XML Query may only contain *, "xml", or element and attribute references from the specified document. Any other expressions are not allowed.
- If the SELECT clause contains an element or attribute reference (other than * or "xml") then only the specified elements, attributes, and their ancestor elements will be in the generated document.
- element.* specifies that the element, its attribute, and all child content should be output.
2.8.5. XML SELECT: WHERE Clause
Example Syntax:
- select element, element1.@attribute from model.doc where element1.@attribute = 1
- select element, element1.@attribute from model.doc where context(element1, element1.@attribute) = 1
Syntax Rules:
- Each criteria conjunct must refer to a single context and can be criteria that applies to a mapping class, contain a
rowlimitfunction, or containrowlimitexceptionfunction. Refer to Section 2.8.9, “ROWLIMIT Function” and Section 2.8.10, “ROWLIMITEXCEPTION Function”. - Criteria that applies to a mapping class is associated to that mapping class using the
contextfunction. The absence of a context function implies the criteria applies to the root context. Refer to Section 2.8.8, “CONTEXT Function”. - At a given context the criteria can span multiple mapping classes provided that all mapping classes involved are either parents of the context, the context itself, or a descendant of the context.
Note
2.8.6. XML SELECT: ORDER BY Clause
Syntax Rules:
- Each ORDER BY item must be an element or attribute reference tied a output value from a mapping class.
- The order of the ORDER BY items is the relative order applied to their respective mapping classes.
2.8.7. XML SELECT Command Specific Functions
- CONTEXT Function
- ROWLIMIT Function
- ROWLIMITEXCEPTION Function
2.8.8. CONTEXT Function
CONTEXT(arg1, arg2)
Syntax Rules:
- Context functions apply to the whole conjunct.
- The first argument must be an element or attribute reference from the mapping class whose context the criteria conjunct will apply to.
- The second parameter is the return value for the function.
2.8.9. ROWLIMIT Function
ROWLIMIT(arg)
Syntax Rules:
- The first argument must be an element or attribute reference from the mapping class whose context the row limit applies.
- The ROWLIMIT function must be used in equality comparison criteria with the right hand expression equal to an positive integer number or rows to limit.
- Only one row limit or row limit exception may apply to a given context.
2.8.10. ROWLIMITEXCEPTION Function
ROWLIMITEXCEPTION(arg)
Syntax Rules:
- The first argument must be an element or attribute reference from the mapping class whose context the row limit exception applies.
- The ROWLIMITEXCEPTION function must be used in equality comparison criteria with the right hand expression equal to an positive integer number or rows to limit.
- Only one row limit or row limit exception may apply to a given context.
2.8.11. Document Generation
Note
2.8.12. Document Validation
XMLValidation is set to 'true' generated documents will be checked for correctness. However, correctness checking will not prevent invalid documents from being generated, since correctness is checked after generation.
2.9. Procedural Language
2.9.1. Procedural Language
2.9.2. Command Statement
command [(WITH|WITHOUT) RETURN];
command [(WITH|WITHOUT) RETURN];
Example 2.8. Example Command Statements
SELECT * FROM MySchema.MyTable WHERE ColA > 100 WITHOUT RETURN; INSERT INTO MySchema.MyTable (ColA,ColB) VALUES (50, 'hi');
SELECT * FROM MySchema.MyTable WHERE ColA > 100 WITHOUT RETURN;
INSERT INTO MySchema.MyTable (ColA,ColB) VALUES (50, 'hi');var = EXEC proc.... To access OUT or IN/OUT values named parameter syntax must be used. For example, EXEC proc(in_param=>'1', out_param=>var) will assign the value of the out parameter to the variable var. It is expected that the data type of parameter will be implicitly convertible to the data type of the variable.
2.9.3. Dynamic SQL
EXECUTE IMMEDIATE <expression> [AS <variable> <type> [, <variable> <type>]* [INTO <variable>]] [USING <variable>=<expression> [,<variable>=<expression>]*] [UPDATE <literal>]
EXECUTE IMMEDIATE <expression> [AS <variable> <type> [, <variable> <type>]* [INTO <variable>]] [USING <variable>=<expression> [,<variable>=<expression>]*] [UPDATE <literal>] Syntax Rules:
- The "AS" clause is used to define the projected symbols names and types returned by the executed SQL string. The "AS" clause symbols will be matched positionally with the symbols returned by the executed SQL string. Non-convertible types or too few columns returned by the executed SQL string will result in an error.
- The "INTO" clause will project the dynamic SQL into the specified temp table. With the "INTO" clause specified, the dynamic command will actually execute a statement that behaves like an INSERT with a QUERY EXPRESSION. If the dynamic SQL command creates a temporary table with the "INTO" clause, then the "AS" clause is required to define the table's metadata.
- The "USING" clause allows the dynamic SQL string to contain variable references that are bound at runtime to specified values. This allows for some independence of the SQL string from the surrounding procedure variable names and input names. In the dynamic command "USING" clause, each variable is specified by short name only. However in the dynamic SQL the "USING" variable must be fully qualified to "DVAR.". The "USING" clause is only for values that will be used in the dynamic SQL as legal expressions. It is not possible to use the "USING" clause to replace table names, keywords, etc. This makes using symbols equivalent in power to normal bind (?) expressions in prepared statements. The "USING" clause helps reduce the amount of string manipulation needed. If a reference is made to a USING symbol in the SQL string that is not bound to a value in the "USING" clause, an exception will occur.
- The "UPDATE" clause is used to specify the updating model count. Accepted values are (0,1,*). 0 is the default value if the clause is not specified. See Section 5.3, “Updating Model Count”.
Example 2.9. Example Dynamic SQL
Example 2.10. Example Dynamic SQL with USING clause and dynamically built criteria string
2.9.4. Dynamic SQL Limitations
- The use of dynamic SQL command results in an assignment statement requires the use of a temp table.
Example 2.11. Example Assignment
EXECUTE IMMEDIATE <expression> AS x string INTO #temp; DECLARE string VARIABLES.RESULT = (SELECT x FROM #temp);
EXECUTE IMMEDIATE <expression> AS x string INTO #temp; DECLARE string VARIABLES.RESULT = (SELECT x FROM #temp);Copy to Clipboard Copied! Toggle word wrap Toggle overflow - The construction of appropriate criteria will be cumbersome if parts of the criteria are not present. For example if "criteria" were already NULL, then the following example results in "criteria" remaining NULL.
Example 2.12. Example Dangerous NULL handling
... criteria = '(' || criteria || ' and (Customer.Accounts.Birthdate = DVARS.BirthDay))';... criteria = '(' || criteria || ' and (Customer.Accounts.Birthdate = DVARS.BirthDay))';Copy to Clipboard Copied! Toggle word wrap Toggle overflow The preferred approach is for the user to ensure the criteria is not NULL prior its usage. If this is not possible, a good approach is to specify a default as shown in the following example.Example 2.13. Example NULL handling
... criteria = '(' || nvl(criteria, '(1 = 1)') || ' and (Customer.Accounts.Birthdate = DVARS.BirthDay))';... criteria = '(' || nvl(criteria, '(1 = 1)') || ' and (Customer.Accounts.Birthdate = DVARS.BirthDay))';Copy to Clipboard Copied! Toggle word wrap Toggle overflow - If the dynamic SQL is an UPDATE, DELETE, or INSERT command, and the user needs to specify the "AS" clause (which would be the case if the number of rows effected needs to be retrieved). The user will still need to provide a name and type for the return column if the into clause is specified.
Example 2.14. Example with AS and INTO clauses
/* This name does not need to match the expected update command symbol "count". */ EXECUTE IMMEDIATE <expression> AS x integer INTO #temp;
/* This name does not need to match the expected update command symbol "count". */ EXECUTE IMMEDIATE <expression> AS x integer INTO #temp;Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Unless used in other parts of the procedure, tables in the dynamic command will not be seen as sources in Teiid Designer.
- When using the "AS" clause only the type information will be available to Teiid Designer. Result set columns generated from the "AS" clause then will have a default set of properties for length, precision, etc.
2.9.5. Declaration Statement
DECLARE <type> [VARIABLES.]<name> [= <expression>];
DECLARE <type> [VARIABLES.]<name> [= <expression>];Example Syntax
declare integer x; declare string VARIABLES.myvar = 'value';
declare integer x; declare string VARIABLES.myvar = 'value';Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Syntax Rules:
- You cannot redeclare a variable with a duplicate name in a sub-block
- The VARIABLES group is always implied even if it is not specified.
- The assignment value follows the same rules as for an Assignment Statement.
- In addition to the standard types, you may specify EXCEPTION if declaring an exception variable.
2.9.6. Assignment Statement
<variable reference> = <expression>;
<variable reference> = <expression>;Example Syntax
myString = 'Thank you'; VARIABLES.x = (SELECT Column1 FROM MySchema.MyTable);
myString = 'Thank you'; VARIABLES.x = (SELECT Column1 FROM MySchema.MyTable);Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.9.7. Special Variables
VARIABLES.ROWCOUNT integer variable will contain the numbers of rows affected by the last INSERT/UPDATE/DELETE statement executed. Inserts that are processed by dynamic SQL with an INTO clause also update the ROWCOUNT.
... UPDATE FOO SET X = 1 WHERE Y = 2; DECLARE INTEGER UPDATED = VARIABLES.ROWCOUNT; ...
...
UPDATE FOO SET X = 1 WHERE Y = 2;
DECLARE INTEGER UPDATED = VARIABLES.ROWCOUNT;
...
2.9.8. Compound Statement
Note
Syntax Rules
- If NOT ATOMIC or no ATOMIC clause is specified, the block will be executed non-atomically.
- If the ATOMIC clause is specified, the block must execute atomically. If a transaction is already associated with the thread, no additional action will be taken - savepoints and/or sub-transactions are not currently used. Otherwise a transaction will be associated with the execution of the block.
- The label must not be the same as any other label used in statements containing this one.
2.9.9. Exception Handling
Note
RuntimeException will not be caught.
|
Variable
|
Type
|
Description
|
|---|---|---|
|
STATE
|
string
|
The SQL State
|
|
ERRORCODE
|
integer
|
The error or vendor code. In the case of an internal exception, this will be the integer suffix of the TEIIDxxxx code
|
|
TEIIDCODE
|
string
|
The full event code. Typically TEIIDxxxx.
|
|
EXCEPTION
|
object
|
The exception being caught, will be an instance of
TeiidSQLException
|
|
CHAIN
|
object
|
The chained exception or cause of the current exception
|
Note
Example 2.15. Example Exception Group Handling
2.9.10. If Statement
IF (criteria) block [ELSE block] END
IF (criteria)
block
[ELSE
block]
ENDExample 2.16. Example If Statement
IS DISTINCT FROM predicate referencing row values:
rowVal IS [NOT] DISTINCT FROM rowValOther
rowVal IS [NOT] DISTINCT FROM rowValOther
rowVal and rowValOther are references to row value group. Use this instead of update triggers on views to quickly determine if the row values are changing:
IF ( "new" IS DISTINCT FROM "old") BEGIN ...statement... END
IF ( "new" IS DISTINCT FROM "old")
BEGIN
...statement...
END
IS DISTINCT FROM considers null values equivalent and never produces an UNKNOWN value.
Note
2.9.11. Loop Statement
[label :] LOOP ON <select statement> AS <cursorname> block
[label :] LOOP ON <select statement> AS <cursorname>
blockSyntax Rules
- The label must not be the same as any other label used in statements containing this one.
2.9.12. While Statement
[label :] WHILE <criteria> block
[label :] WHILE <criteria>
blockSyntax Rules
- The label must not be the same as any other label used in statements containing this one.
2.9.13. Continue Statement
CONTINUE [label];
CONTINUE [label];Syntax Rules
- If the label is specified, it must exist on a containing LOOP or WHILE statement.
- If no label is specified, the statement will affect the closest containing LOOP or WHILE statement.
2.9.14. Break Statement
BREAK [label];
BREAK [label];Syntax Rules
- If the label is specified, it must exist on a containing LOOP or WHILE statement.
- If no label is specified, the statement will affect the closest containing LOOP or WHILE statement.
2.9.15. Leave Statement
LEAVE label;
LEAVE label;Syntax Rules
- The label must exist on a containing compound statement, LOOP, or WHILE statement.
2.9.16. Return Statement
RETURN [expression];
RETURN [expression];Syntax Rules
- If an expression is specified, the procedure must have a return parameter and the value must be implicitly convertible to the expected type.
- Even if the procedure has a return value, it is not required to specify a return value in a RETURN statement.
2.9.17. Error Statement
ERROR message;
ERROR message;Example 2.17. Example Error Statement
ERROR 'Invalid input value: ' || nvl(Acct.GetBalance.AcctID, 'null');
ERROR 'Invalid input value: ' || nvl(Acct.GetBalance.AcctID, 'null');RAISE SQLEXCEPTION message;
RAISE SQLEXCEPTION message;2.9.18. Raise Statement
RAISE [SQLWARNING] exception;
RAISE [SQLWARNING] exception;Syntax Rules
- If SQLWARNING is specified, the exception will be sent to the client as a warning and the procedure will continue to execute.
- A null warning will be ignored. A null non-warning exception will still cause an exception to be raised.
Example 2.18. Example Raise Statement
RAISE SQLWARNING SQLEXCEPTION 'invalid' SQLSTATE '05000';
RAISE SQLWARNING SQLEXCEPTION 'invalid' SQLSTATE '05000';
2.9.19. Exception Expression
SQLEXCEPTION message [SQLSTATE state [, code]] CHAIN exception
SQLEXCEPTION message [SQLSTATE state [, code]] CHAIN exceptionSyntax Rules
- Any of the values may be null;
- message and state are string expressions specifying the exception message and SQL state respectively. JBoss Data Virtualization does not yet fully comply with the ANSI SQL specification on SQL state usage, but you are allowed to set any SQL state you choose.
- code is an integer expression specifying the vendor code
- exception must be a variable reference to an exception or an exception expression and will be chained to the resulting exception as its parent.
2.10. Procedures
2.10.1. Virtual Procedures
CREATE VIRTUAL PROCEDURE block
CREATE VIRTUAL PROCEDURE
block2.10.2. Virtual Procedure Parameters
- Name - The name of the input parameter.
- Datatype - The design-time type of the input parameter.
- Default value - The default value if the input parameter is not specified.
- Nullable - NO_NULLS, NULLABLE, NULLABLE_UNKNOWN; parameter is optional if nullable, and is not required to be listed when using named parameter syntax
Example 2.19. Example of Referencing an Input Parameter and Assigning an Out Parameter for 'GetBalance' Procedure
CREATE VIRTUAL PROCEDURE BEGIN MySchema.GetBalance.RetVal = UPPER(MySchema.GetBalance.AcctID); SELECT Balance FROM MySchema.Accts WHERE MySchema.Accts.AccountID = MySchema.GetBalance.AcctID; END
CREATE VIRTUAL PROCEDURE
BEGIN
MySchema.GetBalance.RetVal = UPPER(MySchema.GetBalance.AcctID);
SELECT Balance FROM MySchema.Accts WHERE MySchema.Accts.AccountID = MySchema.GetBalance.AcctID;
END2.10.3. Example Virtual Procedures
Example 2.20. Virtual Procedure Using LOOP, CONTINUE, BREAK
Example 2.21. Virtual Procedure with Conditional SELECT
2.10.4. Executing Virtual Procedures
SELECT * FROM (EXEC ...) AS x
SELECT * FROM (EXEC ...) AS x2.10.5. Virtual Procedure Limitations
2.10.6. Update Procedures
INSTEAD OF triggers on views in a similar way to how they would be used in traditional databases. You can only have one FOR EACH ROW procedure for each INSERT, UPDATE, or DELETE operation against a view.
CREATE TRIGGER ON view_name INSTEAD OF INSERT|UPDATE|DELETE AS FOR EACH ROW ...
CREATE TRIGGER ON view_name INSTEAD OF INSERT|UPDATE|DELETE AS
FOR EACH ROW
...
2.10.7. Update Procedure Processing
- The user application submits the SQL command through one of SOAP, JDBC, or ODBC.
- The view this SQL command is executed against is detected.
- The correct procedure is chosen depending upon whether the command is an INSERT, UPDATE, or DELETE.
- The procedure is executed. The procedure itself can contain SQL commands of its own which can be of different types than the command submitted by the user application that invoked the procedure.
- Commands, as described in the procedure, are issued to the individual physical data sources or other views.
- A value representing the number of rows changed is returned to the calling application.
2.10.8. The FOR EACH ROW Procedure
FOR EACH ROW
BEGIN ATOMIC
...
END
FOR EACH ROW
BEGIN ATOMIC
...
ENDNote
2.10.9. Special Variables for Update Procedures
- NEW
- Every attribute in the view whose UPDATE and INSERT transformations you are defining has an equivalent variable named NEW.<column_name>When an INSERT or an UPDATE command is executed against the view, these variables are initialized to the values in the INSERT VALUES clause or the UPDATE SET clause respectively.In an UPDATE procedure, the default value of these variables, if they are not set by the command, is the old value. In an INSERT procedure, the default value of these variables is the default value of the virtual table attributes. See CHANGING variables for distinguishing defaults from passed values.
- OLD
- Every attribute in the view whose UPDATE and DELETE transformations you are defining has an equivalent variable named OLD.<column_name>When a DELETE or UPDATE command is executed against the view, these variables are initialized to the current values of the row being deleted or updated respectively.
- CHANGING
- Every attribute in the view whose UPDATE and INSERT transformations you are defining has an equivalent variable named CHANGING.<column_name>When an INSERT or an UPDATE command is executed against the view, these variables are initialized to
trueorfalsedepending on whether the INPUT variable was set by the command. A CHANGING variable is commonly used to differentiate between a default insert value and one specified in the user query.For example, for a view with columns A, B, C:Expand If User Executes... Then... INSERT INTO VT (A, B) VALUES (0, 1)CHANGING.A = true, CHANGING.B = true, CHANGING.C = false UPDATE VT SET C = 2CHANGING.A = false, CHANGING.B = false, CHANGING.C = true
2.10.10. Example Update Procedures
Example 2.22. Sample DELETE Procedure
FOR EACH ROW
BEGIN
DELETE FROM X WHERE Y = OLD.A;
DELETE FROM Z WHERE Y = OLD.A; // cascade the delete
END
FOR EACH ROW
BEGIN
DELETE FROM X WHERE Y = OLD.A;
DELETE FROM Z WHERE Y = OLD.A; // cascade the delete
ENDExample 2.23. Sample UPDATE Procedure
2.10.11. Comments
/* */:
/* comment comment comment... */
/* comment
comment
comment... */
SELECT ... -- comment
SELECT ... -- comment
Chapter 3. Data Types
3.1. Supported Types
Note
| Type | Description | Java Runtime Class | JDBC Type | ODBC Type |
|---|---|---|---|---|
| string or varchar | variable length character string with a maximum length of 4000. Note that the length cannot be explicitly set with the type declaration, e.g. varchar(100) is invalid. | java.lang.String | VARCHAR | VARCHAR |
| varbinary | variable length binary string with a maximum length of 8192. Note that the length cannot be explicitly set with the type declaration, e.g. varbinary(100) is invalid. | byte[] [a] | VARBINARY | VARBINARY |
| char | a single Unicode character | java.lang.Character | CHAR | CHAR |
| boolean | a single bit, or Boolean, that can be true, false, or null (unknown) | java.lang.Boolean | BIT | SMALLINT |
| byte or tinyint | numeric, integral type, signed 8-bit | java.lang.Byte | TINYINT | SMALLINT |
| short or smallint | numeric, integral type, signed 16-bit | java.lang.Short | SMALLINT | SMALLINT |
| integer or serial | numeric, integral type, signed 32-bit. The serial type also implies not null and has an auto-incrementing value that starts at 1. Serial types are not automatically UNIQUE. | java.lang.Integer | INTEGER | INTEGER |
| long or bigint | numeric, integral type, signed 64-bit | java.lang.Long | BIGINT | NUMERIC |
| biginteger | numeric, integral type, arbitrary precision of up to 1000 digits | java.math.BigInteger | NUMERIC | NUMERIC |
| float or real | numeric, floating point type, 32-bit IEEE 754 floating-point numbers | java.lang.Float | REAL | FLOAT |
| double | numeric, floating point type, 64-bit IEEE 754 floating-point numbers | java.lang.Double | DOUBLE | DOUBLE |
| bigdecimal or decimal | numeric, floating point type, arbitrary precision of up to 1000 digits. Note that the precision and scale cannot be explicitly set with the type literal, e.g. decimal(38, 2). | java.math.BigDecimal | NUMERIC | NUMERIC |
| date | datetime, representing a single day (year, month, day) | java.sql.Date | DATE | DATE |
| time | datetime, representing a single time (hours, minutes, seconds, milliseconds) | java.sql.Time | TIME | TIME |
| timestamp | datetime, representing a single date and time (year, month, day, hours, minutes, seconds, milliseconds, nanoseconds) | java.sql.Timestamp | TIMESTAMP | TIMESTAMP |
| object | any arbitrary Java object, must implement java.lang.Serializable | Any | JAVA_OBJECT | VARCHAR |
| blob | binary large object, representing a stream of bytes | java.sql.Blob [b] | BLOB | VARCHAR |
| clob | character large object, representing a stream of characters | java.sql.Clob [c] | CLOB | VARCHAR |
| xml | XML document | java.sql.SQLXML [d] | JAVA_OBJECT | VARCHAR |
| geometry | Geospatial Object | java.sql.Blob [e] | BLOB | BLOB |
[a]
The runtime type is org.teiid.core.types.BinaryType. Translators will need to explicitly handle BinaryType values. UDFs will instead have a byte[] value passed.
[b]
The concrete type is expected to be org.teiid.core.types.BlobType
[c]
The concrete type is expected to be org.teiid.core.types.ClobType
[d]
The concrete type is expected to be org.teiid.core.types.XMLType
[e]
The concrete type is expected to be org.teiid.core.types.GeometryType
| ||||
[] to the type declaration for each array dimension.
string[] integer[][]
string[]
integer[][]
Note
Important
3.2. Type Conversions
CONVERT function or CAST keyword.
Note
integer[] to long[].
- Any type may be implicitly converted to the OBJECT type.
- The OBJECT type may be explicitly converted to any other type.
- The
NULLvalue may be converted to any type. - Any valid implicit conversion is also a valid explicit conversion.
- Situations involving literal values that would normally require explicit conversions may have the explicit conversion applied implicitly if no loss of information occurs.
- If
widenComparisonToStringis false (the default), when Red Hat JBoss Data Virtualization detects that an explicit conversion that can not be applied implicitly in criteria, it will throw an exception.If widenComparisonToStringis true, then depending upon the comparison, a widening conversion is applied or the criteria are treated as false.SELECT * FROM my.table WHERE created_by = 'not a date'
SELECT * FROM my.table WHERE created_by = 'not a date'Copy to Clipboard Copied! Toggle word wrap Toggle overflow WithwidenComparisonToStringis false andcreated_byis a date, rather than convertingnot a dateto a date value, Red Hat JBoss Data Virtualization throws an exception. - When Red Hat JBoss Data Virtualization detects that an explicit conversion can not be applied implicitly in criteria, the criteria will be treated as false. For example:
SELECT * FROM my.table WHERE created_by = 'not a date'
SELECT * FROM my.table WHERE created_by = 'not a date'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Given that created_by is typed as date, rather than converting'not a date'to a date value, the criteria will remain as a string comparison and therefore be false. - Explicit conversions that are not allowed between two types will result in an exception before execution. Allowed explicit conversions may still fail during processing if the runtime values are not actually convertible.
Warning
The JBoss Data Virtualization conversions of float/double/bigdecimal/timestamp to string rely on the JDBC/Java defined output formats. Pushdown behavior attempts to mimic these results, but may vary depending upon the actual source type and conversion logic. Care must be taken to not assume the string form in criteria or other places where a variation may cause different results.
| Source Type | Valid Implicit Target Types | Valid Explicit Target Types |
|---|---|---|
| string | clob | char, boolean, byte, short, integer, long, biginteger, float, double, bigdecimal, xml [a] |
| char | string | |
| boolean | string, byte, short, integer, long, biginteger, float, double, bigdecimal | |
| byte | string, short, integer, long, biginteger, float, double, bigdecimal | boolean |
| short | string, integer, long, biginteger, float, double, bigdecimal | boolean, byte |
| integer | string, long, biginteger, double, bigdecimal | boolean, byte, short, float |
| long | string, biginteger, bigdecimal | boolean, byte, short, integer, float, double |
| biginteger | string, bigdecimal | boolean, byte, short, integer, long, float, double |
| bigdecimal | string | boolean, byte, short, integer, long, biginteger, float, double |
| date | string, timestamp | |
| time | string, timestamp | |
| timestamp | string | date, time |
| clob | string | |
| xml | string [b] | |
[a]
string to xml is equivalent to XMLPARSE(DOCUMENT exp).
[b]
xml to string is equivalent to XMLSERIALIZE(exp AS STRING).
| ||
3.3. Conversion of String Literals
SELECT * FROM my.table WHERE created_by = '2003-01-02'
SELECT * FROM my.table WHERE created_by = '2003-01-02'3.4. Converting to Boolean
| Type | Literal Value | Boolean Value |
|---|---|---|
| String | 'false' | false |
| 'unknown' | null | |
| other | true | |
| Numeric | 0 | false |
| other | true |
3.5. Date and Time Conversions
| String Literal Format | Possible Implicit Conversion Type |
|---|---|
| yyyy-mm-dd | DATE |
| hh:mm:ss | TIME |
| yyyy-mm-dd hh:mm:ss.[fff...] | TIMESTAMP |
PARSEDATE , PARSETIME , PARSETIMESTAMP .
3.6. Escaped Literal Syntax
| Data type | Escaped Syntax | Standard Literal |
|---|---|---|
| BOOLEAN | {b 'true'} | TRUE |
| DATE | {d 'yyyy-mm-dd'} | DATE 'yyyy-mm-dd' |
| TIME | {t 'hh-mm-ss'} | TIME 'hh-mm-ss' |
| TIMESTAMP | {ts 'yyyy-mm-dd hh:mm:ss.[fff...]'} | TIMESTAMP 'yyyy-mm-dd[ hh:mm:ss.[fff…]]' |
Chapter 4. Updatable Views
4.1. Updatable Views
- A set operation (INTERSECT, EXCEPT, UNION).
- SELECT DISTINCT
- Aggregation (aggregate functions, GROUP BY, HAVING)
- A LIMIT clause
- An INSERT/UPDATE can only modify a single key-preserved table.
- To allow DELETE operations there must be only a single key-preserved table.
4.2. Key-Preserved Table
Chapter 5. Transaction Support
5.1. Transaction Support
| Scope | Description |
|---|---|
| Command | Treats the user command as if all source commands are executed within the scope of the same transaction. The AutoCommitTxn execution property controls the behavior of command level transactions. |
| Local | The transaction boundary is local defined by a single client session. |
| Global | JBoss Data Virtualization participates in a global transaction as an XA Resource. |
5.2. AutoCommitTxn Execution Property
| Setting | Description |
|---|---|
| OFF | Do not wrap each command in a transaction. Individual source commands may commit or rollback regardless of the success or failure of the overall command. |
| ON | Wrap each command in a transaction. This mode is the safest, but may introduce performance overhead. |
| DETECT | This is the default setting. Will automatically wrap commands in a transaction, but only if the command seems to be transactionally unsafe. |
- A user command is fully pushed to the source.
- The user command is a SELECT (including XML) and the transaction isolation is not REPEATABLE_READ nor SERIALIZABLE.
- The user command is a stored procedure and the transaction isolation is not REPEATABLE_READ nor SERIALIZABLE and the updating model count is zero.
5.3. Updating Model Count
| Count | Description |
|---|---|
| 0 | No updates are performed by this command. |
| 1 | Indicates that only one model is updated by this command (and its subcommands). Also the success or failure of that update corresponds to the success or failure of the command. It should not be possible for the update to succeed while the command fails. Execution is not considered transactionally unsafe. |
| * | Any number greater than 1 indicates that execution is transactionally unsafe and an XA transaction will be required. |
5.4. JDBC API Functionality
- Command
- Connection autoCommit property set to true.
- Local
- Connection autoCommit property set to false. The transaction is committed by setting autoCommit to true or calling
java.sql.Connection.commit. The transaction can be rolled back by a call tojava.sql.Connection.rollback. - Global
- The XAResource interface provided by an XAConnection is used to control the transaction. Note that XAConnections are available only if JBoss Data Virtualization is consumed through its XADataSource,
org.teiid.jdbc.TeiidDataSource. JEE containers or data access APIs typically control XA transactions on behalf of application code.
5.5. J2EE Usage Models
- Client-Controlled
- The client of a bean begins and ends a transaction explicitly.
- Bean-Managed
- The bean itself begins and ends a transaction explicitly.
- Container-Managed
- The application server container begins and ends a transaction automatically.
5.6. Transactional Behavior with JBoss Data Source Types
- xa-datasource: Capable of participating in the distributed transaction using XA. This is the recommended type be used with any JBoss Data Virtualization sources.
- local-datasource: Does not participate in XA, unless this is the only local-datasource participating among other xa-datasources in the current distributed transaction. This technique is called last commit optimization. However, if you have more than one local datasource participating in a transaction, the transaction manager will throw an exception: "Could not enlist in transaction on entering meta-aware object!".
- no-tx-datasource: Does not participate in distributed transaction at all. In the scope of a JBoss Data Virtualization command over multiple sources, you can include this type of datasource in the same distributed transaction context, however this source will not be subject to any transactional participation. Any changes done on this source as part of the transaction scope, cannot be rolled back.
- A-xa B-xa, C-xa : Can participate in all transactional scopes. No restrictions.
- A-xa, B-xa, c-local: Can participate in all transactional scopes. Note that there is only one single source, "local". It is assumed that, in the Global scope, any third party datasource other than JBoss Data Virtualization datasource is also XA.
- A-xa, B-xa, C-no-tx : Can participate in all transactional scopes. Note "C" is not bound by any transactional contract. A and B are the only participants in the XA transaction.
- A-xa, B-local, C-no-tx : Can participate in all transactional scopes. Note "C" is not bound by any transactional contract, and there is only a single "local" source.
- If any two or more sources are "local" : They can only participate in Command mode with "autoCommitTxn=OFF". Otherwise they will end with an exception and the message "Could not enlist in transaction on entering meta-aware object!;" because it is not possible to do a XA transaction with "local" datasources.
- A-no-tx, B-no-tx, C-no-tx : Can participate in all transaction scopes, but none of the sources will be bound by transactional terms. This is equivalent to not using transactions or setting Command mode with "autoCommitTxn=OFF".
Important
EAP_HOME/docs/teiid/datasources directory.
- Use XA datasource if possible
- Use no-tx datasource if applicable
- Use autoCommitTxn = OFF, and let go distributed transactions, though not recommended
- Write a compensating XA based implementation.
| Teiid-Tx-Scope | XA source | Local Source | No-Tx Source |
|---|---|---|---|
| Local | always | Only If Single Source | never |
| Global | always | Only If Single Source | never |
| Auto-commit=true, AutoCommitTxn=ON | always | Only If Single Source | never |
| Auto-commit=true, AutoCommitTxn=OFF | never | never | never |
| Auto-commit=true, AutoCommitTxn=DETECT | always | Only If Single Source | never |
5.7. Limitations
- The client setting of transaction isolation level is not propagated to the connectors. The transaction isolation level can be set on each XA connector, however this isolation level is fixed and cannot be changed at runtime for specific connections/commands.
Chapter 6. Virtual Databases
6.1. VDB Definition
EAP_HOME/docs/teiid/schema directory.
Example 6.1. Example VDB XML
6.2. VDB Definition: The VDB Element
Attributes
- nameThe name of the VDB. The VDB name referenced through the driver or datasource during the connection time.
- versionThe version of the VDB (should be an positive integer). This determines the deployed directory location (see Name), and provides an explicit versioning mechanism to the VDB name.
Property Elements
- cache-metadataCan be "true" or "false". If "false", JBoss Data Virtualization will obtain metadata once for every launch of the VDB. "true" will save a file containing the metadata into the
EAP_HOME/MODE/datadirectory. Defaults to "false" for-vdb.xmldeployments otherwise "true". - query-timeoutSets the default query timeout in milliseconds for queries executed against this VDB. 0 indicates that the server default query timeout should be used. Defaults to 0. Will have no effect if the server default query timeout is set to a lesser value. Note that clients can still set their own timeouts that will be managed on the client side.
- libSet to a list of modules for the VDB classpath for user defined function loading. See also Support for Non-Pushdown User Defined Functions in Red Hat JBoss Data Virtualization Development Guide: Server Development.
- security-domainSet to the security domain to use if a specific security domain is applicable to the VDB. Otherwise the security domain list from the transport will be used.
<property name="security-domain" value="custom-security" />
<property name="security-domain" value="custom-security" />Copy to Clipboard Copied! Toggle word wrap Toggle overflow Important
An administrator needs to configure a matching "custom-security" login module in the standalone.xml configuration file before the VDB is deployed. - connection.XXXThis is for use by the ODBC transport and OData. They use it to set the default connection/execution properties. Note that the properties are set on the connection after it has been established.
<property name="connection.partialResultsMode" value="true" />
<property name="connection.partialResultsMode" value="true" />Copy to Clipboard Copied! Toggle word wrap Toggle overflow - authentication-typeAuthentication type of configured security domain. Allowed values currently are (GSS, USERPASSWORD). The default is set on the transport (typically USERPASSWORD).
- password-patternRegular expression matched against the connecting user's name that determines if USERPASSWORD authentication is used. password-pattern Takes precedence of over authentication-type. The default is authentication-type.
- gss-patternRegular expression matched against the connecting user's name that determines if GSS authentication is used. gss-pattern Takes precedence of over password-pattern. The default is password-pattern.
- model.visibleUsed to override the visibility of imported vdb models, where model is the name of the imported model..
- include-pg-metadataBy default, PG metadata is always added to VDB unless System Properties set property org.teiid.addPGMetadata to false. This property enables adding PG metadata per VDB. Please note that if you are using ODBC to access your VDB, the VDB must include PG metadata.
- lazy-invalidateBy default TTL expiration will be invalidating. Setting lazy-invalidate to true makes ttl refreshes non-invalidating.
6.3. VDB Definition: The import-vdb Element
Attributes
- name The name of the VDB to be imported.
- version The version of the VDB to be imported (should be an positive integer).
- import-data-policies Optional attribute to indicate whether the data policies should be imported as well. Defaults to TRUE.
6.4. VDB Definition: The model Element
Attributes
- nameThis is the name of the model is used as a top level schema name for all of the metadata imported from the connector. The name must be unique among all Models in the VDB and must not contain the '.' character.
- versionThis is the version of the VDB (it should be an positive integer). This determines the deployed directory location (see Name), and provides an explicit versioning mechanism for the VDB name.
- visibilityBy default this value is set to "true". When the value is set to "false", this model will not be visible to JDBC metadata queries. Usually it is used to hide a model from client applications that must not directly issue queries against it. However, this does not prohibit either client applications or other view models from using it, if they know its schema.
Source Element
- nameThe name of the source to use for this model. This can be any name you like, but will typically be the same as the model name. Having a name different from the model name is only useful in multi-source scenarios. In multi-source, the source names under a given model must be unique. If you have the same source bound to multiple models it may have the same name for each. An exception will be raised if the same source name is used for different sources.
- translator-nameThe name or type of the JBoss Data Virtualization Translator to use. Possible values include the built-in types (ws, file, ldap, oracle, sqlserver, db2, derby, etc.) and translators defined in the translators section.
- connection-jndi-nameThe JNDI name of this source's connection factory. Check out the deploying VDB dependencies section for info. You also need to deploy these connection factories before you can deploy the VDB.
Property Elements
- importer.<propertyname>Property to be used by the connector importer for the model for purposes importing metadata. See possible property name/values in the Translator specific section. Note that using these properties you can narrow or widen the data elements available for integration.
Metadata Element
- The optional metadata element defines the metadata repository type and optional raw metadata to be consumed by the metadata repository.
- typeThe metadata repository type. Defaults to INDEX for Designer VDBs and NATIVE for non-Designer VDB source models. For all other deployments/models a value must be specified. Built-in types include DDL, NATIVE, INDEX, and DDL-FILE. The usage of the raw text varies with the by type. The raw text is not used with NATIVE and INDEX (only for Designer VDBs) metadata repositories. The raw text for DDL is expected to be a series of DDL statements that define the schema. DDL-FILE (used only with zip deployments) is similar to DDL, except that the raw text specifies an absolute path relative to the vdb root of the location of a file containing the DDL. See also about a Custom Metadata Repository in Red Hat JBoss Development Guide: Server Development.
6.5. VDB Definition: The translator Element
Attributes
- nameThe name of the Translator. Referenced by the source element.
- typeThe base type of the Translator. Can be one of the built-in types (ws, file, ldap, oracle, sqlserver, db2, derby, etc.).
Property Elements
- Set a value that overrides a translator default property. See possible property name/values in the Translator specific section.
6.6. Dynamic VDBs
6.7. Dynamic VDB XML Deployment
NAME-vdb.xml file. The XML file captures information about the VDB, the sources it integrates, and preferences for importing metadata.
Note
EAP_HOME/docs/teiid/schema/vdb-deployer.xsd.
6.8. Dynamic VDB ZIP Deployment
- The deployment must end with the extension
.vdb. - The VDB XML file must be named
vdb.xmland placed in the ZIP under theMETA-INFdirectory. - If a
libfolder exists, any JARs found underneath will automatically be added to the VDB classpath. - For backwards compatibility with Teiid Designer VDBs, if any
.INDEXfile exists, the default metadata repository will be assumed to be INDEX. - Files within the VDB ZIP are accessible by a Custom Metadata Repository using the
MetadataFactory.getVDBResources()method, which returns a map of allVDBResourcesin the VDB keyed by absolute path relative to the VDB root. See Red Hat JBoss Data Virtualization Development Guide: Server Development for more information about custom metadata repositories. - The built-in
DDL-FILEmetadata repository type may be used to define DDL-based metadata in files outside of thevdb.xml. This improves the memory footprint of the VDB metadata and the maintainability ofvdb.xml.
Example 6.2. Example VDB Zip Structure
vdb.xml could use a DDL-FILE metadata type for schema1:
<model name="schema1" ... <metadata type="DDL-FILE">/ddl/schema1.ddl<metadata> </model>
<model name="schema1" ...
<metadata type="DDL-FILE">/ddl/schema1.ddl<metadata>
</model>
6.9. VDB Reuse
Example 6.3. Example reuse VDB XML
6.10. Metadata Repositories
Chapter 7. Data Roles
7.1. Data Roles
teiid subsystem policy-decider-module. Data roles also have built-in system functions (see Section 2.4.18, “Security Functions”) that can be used for row-based and other authorization checks.
hasRole system function will return true if the current user has the given data role. The hasRole function can be used in procedure or view definitions to allow for a more dynamic application of security - which allows for things such as value masking or row level security.
Note
Warning
7.2. Role Mapping
Note
security-domain property to the relevant domain.
7.3. Permissions
7.3.1. User Query Permissions
Warning
7.3.2. Assigning Permissions
- READ - on the Table(s) being accessed or the procedure being called.
- READ - on every column referenced.
- CREATE - on the Table being inserted into.
- CREATE - on every column being inserted on that Table.
- UPDATE - on the Table being updated.
- UPDATE - on every column being updated on that Table.
- READ - on every column referenced in the criteria.
- DELETE - on the Table being deleted.
- READ - on every column referenced in the criteria.
- EXECUTE (or READ) - on the Procedure being executed.
- EXECUTE (or READ) - on the Function being called.
- ALTER - on the view or procedure that is effected. INSTEAD OF Triggers (update procedures) are not yet treated as full schema objects and are instead treated as attributes of the view.
- LANGUAGE - specifying the language name that is allowed.
- allow-create-temporary-tables attribute on any applicable role
- CREATE - against the target source/schema if defining a FOREIGN temporary table.
7.3.3. Row and Column-Based Security Conditions
7.3.4. Row-Based Security Conditions
7.3.5. Applying Row-Based Security Conditions
7.3.6. Considerations When Using Conditions
OR statement to not be pushed down. If you need to insert permission conditions, be careful when adding an inline view as this can cause performance problems if your sources do not support them.
hasRole, user, or other security functions. The advantage of this latter approach is that it provides you with a static row-based policy. As a result, all of your query plans can be shared between your users.
ISNULL checks to ensure that null values are allowed when a column is "nullable".
7.3.7. Limitations to Using Conditions
- Conditions on source tables that act as check constraints must currently not contain correlated subqueries.
- Conditions may not contain aggregate or windowed functions.
- Tables and procedures referenced via subqueries will still have row-based filters and column masking applied to them.
Note
Row-based filter conditions are enforced even for materialized view loads.You should ensure that tables consumed to produce materialized views do not have row-based filter conditions on them that could affect the materialized view results.
7.3.8. Column Masking
7.3.9. Applying Column Masking
7.3.10. Column Masking Considerations
hasRole , user , and other such security functions. The advantage of the latter approach is that there is effectively a static masking policy in effect such that all query plans can still be shared between users.
7.3.11. Column Masking Limitations
- In the event that two masks have the same order value, it is not well defined what order they are applied in.
- Masks or their conditions may not contain aggregate or windowed functions.
- Tables and procedures referenced via subqueries will still have row-based filters and column masking applied to them.
Note
Masking is enforced even for materialized view loads.You should ensure that tables consumed to produce materialized views do not have masking on them that could affect the materialized view results.
7.4. Data Role Definition
7.4.1. Data Role Definition
vdb.xml file. (You will find this inside the .vdb zip archive under META-INF/vdb.xml if you used Teiid Designer). The vdb.xml file is checked against the vdb-deployer.xsd schema file found in the EAP_HOME/docs/teiid/schema directory.
7.4.2. Data Role Definition Example
- RoleA has permissions to read, write access to TableA, but can not delete.
- RoleB has no permissions that allow access to TableA
- RoleC has permissions that only allow read access to TableA.column1
Example 7.1. vdb.xml defining RoleA, RoleB, and RoleC
7.4.3. Data Role Definition Example: Additional Attributes
Example 7.2. Temp Table Role for Any Authenticated
7.4.4. Data Role Definition Example: Language Access
Example 7.3. vdb.xml allowing JavaScript access
7.4.5. Data Role Definition Example: Row-Based Security
Example 7.4. vdb.xml allowing conditional access
7.4.6. Data Role Definition Example: Column Masking
Example 7.5. vdb.xml with column masking
Chapter 8. System Schemas and Procedures
8.1. System Schemas
8.2. VDB Metadata
- SYSADMIN.Usage
- This table supplies information about how views and procedures are defined:
Expand Column NameTypeDescriptionVDBNamestringVDB name.UIDstringObject UID.object_typestringType of object (StoredProcedure, View, and so forth).NamestringObject Name or parent name.ElementNamestringName of column or parameter (may be null to indicate a table or procedure).Uses_UIDstringUsed object UID.Uses_object_typestringUsed object type.Uses_SchemaNamestringUsed object schema.Uses_NamestringUsed object name or parent name.Uses_ElementNamestringUsed column or parameter name (may be null to indicate a table/procedure level dependency).Schema_NamestringSchema name.Every column, parameter, table, or procedure referenced in a procedure or view definition will be shown as used. Likewise every column, parameter, table, or procedure referenced in the expression that defines a view column will be shown as used by that column. Here is an example of how it is used:SELECT * FROM SYSADMIN.Usage
SELECT * FROM SYSADMIN.UsageCopy to Clipboard Copied! Toggle word wrap Toggle overflow Recursive common table queries can be used to determine transitive relationships:Copy to Clipboard Copied! Toggle word wrap Toggle overflow This example finds all outgoing usage:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- SYSADMIN.MatViews
- This table supplies information about all the materialized views in the virtual database:
|
Column Name
|
Type
|
Description
|
|---|---|---|
|
VDBName
|
string
|
VDB name.
|
|
SchemaName
|
string
|
Schema name.
|
|
Name
|
string
|
Short group name.
|
|
TargetSchemaName
|
string
|
Name of the materialized table schema. Will be null for internal materialization.
|
|
TargetName
|
string
|
Name of the materialized table.
|
|
Valid
|
boolean
|
True if materialized table is currently valid. Will be null for external materialization.
|
|
LoadState
|
boolean
|
The load state, can be one of NEEDS_LOADING, LOADING, LOADED, FAILED_LOAD. Will be null for external materialization.
|
|
Updated
|
timestamp
|
The timestamp of the last full refresh. Will be null for external materialization.
|
|
Cardinality
|
integer
|
The number of rows in the materialized view table. Will be null for external materialization.
|
SELECT * FROM SYSADMIN.MatViews
SELECT * FROM SYSADMIN.MatViews
- SYSADMIN.Triggers
- This table provides the triggers in the virtual database.
|
Column Name
|
Type
|
Description
|
|---|---|---|
|
VDBName
|
string
|
VDB name.
|
|
SchemaName
|
string
|
Schema name.
|
|
TableName
|
string
|
Table name.
|
|
Name
|
string
|
Trigger name.
|
|
TriggerType
|
string
|
Trigger type.
|
|
TriggerEvent
|
string
|
Triggering event.
|
|
Status
|
string
|
Is Enabled.
|
|
Body
|
clob
|
Trigger action (for each row).
|
|
TableUID
|
string
|
Table unique Id.
|
SELECT * FROM SYSADMIN.Triggers
SELECT * FROM SYSADMIN.Triggers
- SYSADMIN.Views
- This table provides the views in the virtual database.
|
Column Name
|
Type
|
Description
|
|---|---|---|
|
VDBName
|
string
|
VDB name.
|
|
SchemaName
|
string
|
Schema name.
|
|
Name
|
string
|
View name.
|
|
Body
|
clob
|
View Definition Body (SELECT …)
|
|
UID
|
string
|
Table unique Id.
|
SELECT * FROM SYSADMIN.Views
SELECT * FROM SYSADMIN.Views
- SYSADMIN.StoredProcedures
- This table provides the stored procedures in the virtual database.
|
Column Name
|
Type
|
Description
|
|---|---|---|
|
VDBName
|
string
|
VDB name.
|
|
SchemaName
|
string
|
Schema name.
|
|
Name
|
string
|
Procedure name.
|
|
Body
|
clob
|
Procedure Definition Body (BEGIN …)
|
|
UID
|
string
|
Unique ID.
|
SELECT * FROM SYSADMIN.StoredProcedures
SELECT * FROM SYSADMIN.StoredProcedures
- SYSADMIN.VDBResources
- This table provides the current VDB contents.
Expand Column NameTypeDescriptionresourcePathstringThe path to the contents.contentsblobThe contents as a blob. - SYS.VirtualDatabases
- This table supplies information about the currently connected virtual database, of which there is always exactly one (in the context of a connection).
Expand Column NameTypeDescriptionNamestringThe name of the VDBVersionstringThe version of the VDB - SYS.Schemas
- This table supplies information about all the schemas in the virtual database, including the system schema itself (System).
Expand Column NameTypeDescriptionVDBNamestringVDB nameNamestringSchema nameIsPhysicalbooleanTrue if this represents a sourceUIDstringUnique IDOIDintegerUnique IDDescriptionstringDescriptionPrimaryMetamodelURIstringURI for the primary metamodel describing the model used for this schema - SYS.Properties
- This table supplies user-defined properties on all objects based on metamodel extensions. Normally, this table is empty if no metamodel extensions are being used.
Expand Column NameTypeDescriptionNamestringExtension property nameValuestringExtension property valueUIDstringKey unique IDOIDintegerUnique IDClobValueclobClob Value
Warning
8.3. Reference Key Columns
|
Column Name
|
Type
|
Description
|
|---|---|---|
|
PKTABLE_CAT
|
string
|
VDB name
|
|
PKTABLE_SCHEM
|
string
|
Schema Name
|
|
PKTABLE_NAME
|
string
|
Table/View Name
|
|
PKCOLUMN_NAME
|
string
|
Column Name
|
|
FKTABLE_CAT
|
string
|
VDB Name
|
|
FKTABLE_SCHEM
|
string
|
Schema Name
|
|
FKTABLE_NAME
|
string
|
Table/View Name
|
|
FKCOLUMN_NAME
|
string
|
Column Name
|
|
KEY_SEQ
|
short
|
Key Sequence
|
|
UPDATE_RULE
|
integer
|
Update Rule
|
|
DELETE_RULE
|
integer
|
Delete Rule
|
|
FK_NAME
|
string
|
FK Name
|
|
PK_NAME
|
string
|
PK Name
|
|
DEFERRABILITY
|
integer
|
-
|
8.4. Table Metadata
- SYS.Tables
- This table supplies information about all the groups (tables, views and documents) in the virtual database.
Expand Column NameTypeDescriptionVDBNamestringVDB nameSchemaNamestringSchema NameNamestringShort group nameTypestringTable type (Table, View, Document, ...)NameInSourcestringName of this group in the sourceIsPhysicalbooleanTrue if this is a source tableSupportsUpdatesbooleanTrue if group can be updatedUIDstringGroup unique IDOIDintegerUnique IDCardinalityintegerApproximate number of rows in the groupDescriptionstringDescriptionIsSystembooleanTrue if in system tableIsMaterializedbooleanTrue if materialized. - SYS.Columns
- This table supplies information about all the elements (columns, tags, attributes, etc) in the virtual database.
Expand Column NameTypeDescriptionVDBNamestringVDB nameSchemaNamestringSchema NameTableNamestringTable nameNamestringElement name (not qualified)PositionintegerPosition in group (1-based)NameInSourcestringName of element in sourceDataTypestringData Virtualization runtime data type nameScaleintegerNumber of digits after the decimal pointElementLengthintegerElement length (mostly used for strings)sLengthFixedbooleanWhether the length is fixed or variableSupportsSelectbooleanElement can be used in SELECTSupportsUpdatesbooleanValues can be inserted or updated in the elementIsCaseSensitivebooleanElement is case-sensitiveIsSignedbooleanElement is signed numeric valueIsCurrencybooleanElement represents monetary valueIsAutoIncrementedbooleanElement is auto-incremented in the sourceNullTypestringNullability: "Nullable", "No Nulls", "Unknown"MinRangestringMinimum valueMaxRangestringMaximum valueDistinctCountintegerDistinct value count, -1 can indicate unknownNullCountintegerNull value count, -1 can indicate unknownSearchTypestringSearchability: "Searchable", "All Except Like", "Like Only", "Unsearchable"FormatstringFormat of string valueDefaultValuestringDefault valueJavaClassstringJava class that will be returnedPrecisionintegerNumber of digits in numeric valueCharOctetLengthintegerMeasure of return value sizeRadixintegerRadix for numeric valuesGroupUpperNamestringUpper-case full group nameUpperNamestringUpper-case element nameUIDstringElement unique IDOIDintegerUnique IDDescriptionstringDescription - SYS.Keys
- This table supplies information about primary, foreign, and unique keys.
Expand Column NameTypeDescriptionVDBNamestringVDB nameSchemaNamestringSchema NameTable NamestringTable nameNamestringKey nameDescriptionstringDescriptionNameInSourcestringName of key in source systemTypestringType of key: "Primary", "Foreign", "Unique", etcIsIndexedbooleanTrue if key is indexedRefKeyUIDstringReferenced key UID (if foreign key)UIDstringKey unique IDOIDintegerUnique IDTableUIDstring-RefTableUIDstring-ColPositionsshort[]- - SYS.KeyColumns
- This table supplies information about the columns referenced by a key.
Expand Column NameTypeDescriptionVDBNamestringVDB nameSchemaNamestringSchema NameTableNamestringTable nameNamestringElement nameKeyNamestringKey nameKeyTypestringKey type: "Primary", "Foreign", "Unique", etcRefKeyUIDstringReferenced key UIDUIDstringKey UIDOIDintegerUnique IDPositionintegerPosition in key
Warning
- SYS.Spatial_Sys_Ref
- Here are the attributes for this table:
Expand Column NameTypeDescriptionsridintegerSpatial Reference Identifierauth_namestringName of the standard or standards body.auth_sridintegerSRID for the auth_name authority.srtextstringWell-Known Text representationproj4textstringFor use with the Proj4 library. - SYS.Geometry_Columns
- Here are the attributes for this table:
Expand Column NameTypeDescriptionF_TABLE_CATALOGstringcatalog nameF_TABLE_SCHEMAstringschema nameF_TABLE_NAMEstringtable nameF_GEOMETRY_COLUMNstringcolumn nameCOORD_DIMENSIONintegerNumber of coordinate dimensionsSRIDintegerSpatial Reference IdentifierTYPEstringGeometry type name
Note
8.5. Procedure Metadata
- SYS.Procedures
- This table supplies information about the procedures in the virtual database.
Expand Column NameTypeDescriptionVDBNamestringVDB nameSchemaNamestringSchema NameNamestringProcedure nameNameInSourcestringProcedure name in source systemReturnsResultsbooleanReturns a result setUIDstringProcedure UIDOIDintegerUnique IDDescriptionstringDescription - SYS.ProcedureParams
- This supplies information on procedure parameters.
Expand Column NameTypeDescriptionVDBNamestringVDB nameSchemaNamestringSchema NameProcedureNamestringProcedure nameNamestringParameter nameDataTypestringData Virtualization runtime data type namePositionintegerPosition in procedure argsTypestringParameter direction: "In", "Out", "InOut", "ResultSet", "ReturnValue"OptionalbooleanParameter is optionalPrecisionintegerPrecision of parameterTypeLengthintegerLength of parameter valueScaleintegerScale of parameterRadixintegerRadix of parameterNullTypestringNullability: "Nullable", "No Nulls", "Unknown"UIDstringProcedure UIDDescriptionstringDescriptionOIDintegerUnique ID
Warning
8.6. Function Metadata
- SYS.Functions
- This table supplies information about the functions in the virtual database.
Expand Column NameTypeDescriptionVDBNamestringVDB nameSchemaNamestringSchema NameNamestringFunction nameNameInSourcestringFunction name in source systemUIDstringFunction UIDDescriptionstringDescriptionIsVarArgsbooleanDoes the function accept variable arguments? - SYS.FunctionParams
- This supplies information on functionparameters.
Expand Column NameTypeDescriptionVDBNamestringVDB nameSchemaNamestringSchema NameFunctionNamestringFunction nameFunctionUIDstringFunction UIDNamestringParameter nameDataTypestringData Virtualization runtime data type namePositionintegerPosition in function argsTypestringParameter direction: "In", "Out", "InOut", "ResultSet", "ReturnValue"PrecisionintegerPrecision of parameterTypeLengthintegerLength of parameter valueScaleintegerScale of parameterRadixintegerRadix of parameterNullTypestringNullability: "Nullable", "No Nulls", "Unknown"UIDstringFunction Parameter UIDDescriptionstringDescriptionOIDintegerUnique ID
Warning
8.7. Data Type Metadata
- SYS.DataTypes
- This table supplies information on data types. See Section 3.1, “Supported Types”.
Expand Column NameTypeDescriptionNamestringJBoss Data Virtualization design-time type nameIsStandardbooleanAlways falseIsPhysicalbooleanAlways falseTypeNamestringDesign-time type name (same as Name)JavaClassstringJava class returned for this typeScaleintegerMax scale of this typeTypeLengthintegerMax length of this typeNullTypestringNullability: "Nullable", "No Nulls", "Unknown"IsSignedbooleanIs signed numeric?IsAutoIncrementedbooleanIs auto-incremented?IsCaseSensitivebooleanIs case-sensitive?PrecisionintegerMax precision of this typeRadixintegerRadix of this typeSearchTypestringSearchability: "Searchable", "All Except Like", "Like Only", "Unsearchable"UIDstringData type unique IDOIDintegerUnique IDRuntimeTypestringJBoss Data Virtualization runtime data type nameBaseTypestringBase typeDescriptionstringDescription of type
Warning
8.8. System Procedures
- SYS.getXMLSchemas
- Returns a result set with a single column, schema, containing the schemas as clobs.
SYS.getXMLSchemas(document in string) returns schema string
SYS.getXMLSchemas(document in string) returns schema stringCopy to Clipboard Copied! Toggle word wrap Toggle overflow - SYSADMIN.logMsg
- Log a message to the underlying logging system.
SYSADMIN.logMsg(logged RETURN boolean, level IN string, context IN string, msg IN object)
SYSADMIN.logMsg(logged RETURN boolean, level IN string, context IN string, msg IN object)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Returns true if the message was logged. level can be one of the log4j levels: OFF, FATAL, ERROR, WARN, INFO, DEBUG, TRACE. level defaults to 'DEBUG' and context defaults to 'org.teiid.PROCESSOR' - SYSADMIN.isLoggable
- Tests if logging is enabled at the given level and context.
SYSADMIN.isLoggable(loggable RETURN boolean, level IN string, context IN string)
SYSADMIN.isLoggable(loggable RETURN boolean, level IN string, context IN string)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Returns true if logging is enabled. level can be one of the log4j levels: OFF, FATAL, ERROR, WARN, INFO, DEBUG, TRACE. level defaults to 'DEBUG' and context defaults to 'org.teiid.PROCESSOR' - SYSADMIN.refreshMatView
- Returns integer RowsUpdated. -1 indicates a load is in progress, otherwise the cardinality of the table is returned.
SYSADMIN.refreshMatView(RowsUpdated return integer, ViewName in string, Invalidate in boolean)
SYSADMIN.refreshMatView(RowsUpdated return integer, ViewName in string, Invalidate in boolean)Copy to Clipboard Copied! Toggle word wrap Toggle overflow - SYSADMIN.refreshMatViewRow
- Returns integer RowsUpdated. -1 indicates the materialized table is currently invalid. 0 indicates that the specified row did not exist in the live data query or in the materialized table.
SYSADMIN.refreshMatViewRow(RowsUpdated return integer, ViewName in string, Key in object)
SYSADMIN.refreshMatViewRow(RowsUpdated return integer, ViewName in string, Key in object)Copy to Clipboard Copied! Toggle word wrap Toggle overflow - SYSADMIN.refreshMatViewRows
- Refreshes rows in an internal materialized view.Returns integer RowsUpdated. -1 indicates the materialized table is currently invalid. Any row that does not exist in the live data query or in the materialized table will not count toward the RowsUpdated.
SYSADMIN.refreshMatViewRows(OUT RowsUpdated integer NOT NULL RESULT, IN ViewName string NOT NULL, VARIADIC Key object[] NOT NULL)
SYSADMIN.refreshMatViewRows(OUT RowsUpdated integer NOT NULL RESULT, IN ViewName string NOT NULL, VARIADIC Key object[] NOT NULL)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Using SAMPLEMATVIEW as an example and assuming the primary key only contains one column, id, here is how you update all rows:EXEC SYSADMIN.refreshMatViewRows('TestMat.SAMPLEMATVIEW', ('100',), ('101',), ('102',))EXEC SYSADMIN.refreshMatViewRows('TestMat.SAMPLEMATVIEW', ('100',), ('101',), ('102',))Copy to Clipboard Copied! Toggle word wrap Toggle overflow Assuming the primary key contains more columns, id, a and b compose of the primary key, here is how you update all rows:EXEC SYSADMIN.refreshMatViewRows('TestMat.SAMPLEMATVIEW', ('100', 'a0', 'b0'), ('101', 'a1', 'b1'), ('102', 'a2', 'b2'))EXEC SYSADMIN.refreshMatViewRows('TestMat.SAMPLEMATVIEW', ('100', 'a0', 'b0'), ('101', 'a1', 'b1'), ('102', 'a2', 'b2'))Copy to Clipboard Copied! Toggle word wrap Toggle overflow - SYSADMIN.updateMatView
- Use the
updateMatViewprocedure to update a subset of an internal or external materialized table based on the refresh criteria.The refresh criteria may reference the view columns by qualified name, but all instances of'.'in the view name are replaced by'_'as an alias is actually being used.This returns the integerRowsUpdated. -1 indicates that the materialized table is currently invalid. -3 indicates there was an exception when performing the update.SYSADMIN.updateMatView(IN schemaName string NOT NULL, IN viewName string NOT NULL, IN refreshCriteria string) RETURNS integer
SYSADMIN.updateMatView(IN schemaName string NOT NULL, IN viewName string NOT NULL, IN refreshCriteria string) RETURNS integerCopy to Clipboard Copied! Toggle word wrap Toggle overflow - SYS.ArrayIterate
- Returns a resultset with a single column with a row for each value in the array.
SYS.ArrayIterate(IN val object[]) RETURNS TABLE (col object)
SYS.ArrayIterate(IN val object[]) RETURNS TABLE (col object)Copy to Clipboard Copied! Toggle word wrap Toggle overflow This produces two rows, 'b', and 'd':select array_get(cast(x.col as string[]), 2) from (exec arrayiterate((('a', 'b'),('c','d')))) xselect array_get(cast(x.col as string[]), 2) from (exec arrayiterate((('a', 'b'),('c','d')))) xCopy to Clipboard Copied! Toggle word wrap Toggle overflow
8.9. Metadata Procedures
- SYSADMIN.setTableStats
- Set statistics for the given table.
SYSADMIN.setTableStats(TableName in string, Cardinality in integer)
SYSADMIN.setTableStats(TableName in string, Cardinality in integer)Copy to Clipboard Copied! Toggle word wrap Toggle overflow - SYSADMIN.setColumnStats
- Set statistics for the given column.
SYSADMIN.setColumnStats(TableName in string, ColumnName in string, DistinctCount in integer, NullCount in integer, Max in string, Min in string)
SYSADMIN.setColumnStats(TableName in string, ColumnName in string, DistinctCount in integer, NullCount in integer, Max in string, Min in string)Copy to Clipboard Copied! Toggle word wrap Toggle overflow All stat values are nullable. Passing a null stat value will leave corresponding metadata value unchanged. - SYSADMIN.setProperty
- Set an extension metadata property for the given record. Extension metadata is typically used by translators.
SYSADMIN.setProperty(OldValue return clob, Uid in string, Name in string, Value in clob)
SYSADMIN.setProperty(OldValue return clob, Uid in string, Name in string, Value in clob)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Setting a value to null will remove the property.The use of this procedure will not trigger replanning of associated prepared plans.
Chapter 9. Generated REST Services
9.1. Generated REST Services
9.2. REST Properties
|
Property Name
|
Description
|
Is Required
|
Allowed Values
|
|---|---|---|---|
|
METHOD
|
HTTP Method to use
|
Yes
|
GET | POST| PUT | DELETE
|
|
URI
|
URI of procedure
|
Yes
|
ex:/procedure
|
|
PRODUCES
|
Type of content produced by the service
|
no
|
xml | json | plain | any text
|
|
CHARSET
|
When procedure returns Blob, and content type text based, this character set to used to convert the data
|
no
|
US-ASCII | UTF-8
|
9.3. Example VDB with REST Properties
http://{host}:8080/sample_1/view/g1/123
http://{host}:8080/sample_1/view/g1/123
Note
http://{host}:8080/sample_1/view/g1?p1=123
http://{host}:8080/sample_1/view/g1/123?p2=foo
http://{host}:8080/sample_1/view/g1?p1=123
http://{host}:8080/sample_1/view/g1/123?p2=foo
9.4. Considerations for Generated REST Services
Warning
9.5. Security for Generated REST Services
Example 9.1. Example vdb.xml file security specification
- security-type - defines the security type. allowed values are "HttpBasic" or "none". If omitted will default to "HttpBasic"
- security-domain - defines JAAS security domain to be used with HttpBasic. If omitted will default to "teiid-security"
- security-role - security role that HttpBasic will use to authorize the users. If omitted the value will default to "rest"
- passthough-auth - when defined the pass-through-authentication is used to login in to JBoss Data Virtualization. When this is set to "true", make sure that the "embedded" transport configuration in
standalone.xmlhas defined a security-domain that can be authenticated against. Failure to add the configuration change will result in authentication error. Defaults to false.
Important
9.6. Ad-Hoc REST Services
http://localhost:8080/sample_1/view/query
sql=SELECT XMLELEMENT(NAME "rows",XMLAGG(XMLELEMENT(NAME "row", XMLFOREST(e1, e2)))) AS xml_out FROM PM1.G1
http://localhost:8080/sample_1/view/query
sql=SELECT XMLELEMENT(NAME "rows",XMLAGG(XMLELEMENT(NAME "row", XMLFOREST(e1, e2)))) AS xml_out FROM PM1.G1
Chapter 10. Multi-Source Models
10.1. Multi-Source Models
10.2. Multi-Source Model Configuration
true and then more than one source can be listed for the model in the vdb.xml file. The following example shows a single model dynamic VDB with multiple sources defined.
Note
vdb.xml file in the VDB archive using a Text editor to add the additional sources as defined above. You must deploy a separate data source for each source defined in the XML file.
Customers, that has multiple sources (chicago, newyork, and la) that define different instances of data.
10.3. The Multi-Source Column
chicago , la , newyork for each of the respective sources. The name of the column defaults to SOURCE_NAME, but is configurable by setting the model property multisource.columnName . If a column already exists on the table (or an IN procedure parameter) with the same name, the engine will assume that it should represent the multi-source column and it will not be used to retrieve physical data. If the multi-source column is not present, the generated column will be treated as a pseudo column which is not selectable via wildcards (* nor tbl.*).
select * from table where SOURCE_NAME = 'newyork'
update table column=value where SOURCE_NAME='chicago'
delete from table where column = x and SOURCE_NAME='la'
insert into table (column, SOURCE_NAME) VALUES ('value', 'newyork')
select * from table where SOURCE_NAME = 'newyork'
update table column=value where SOURCE_NAME='chicago'
delete from table where column = x and SOURCE_NAME='la'
insert into table (column, SOURCE_NAME) VALUES ('value', 'newyork')
10.4. The Multi-Source Column in System Metadata
- With either VDB type to make the multi-source column present in the system metadata, you can set the model property multisource.addColumn to true on a multi-source model. Care must be taken though when using this property in Teiid Designer as any transformation logic (views/procedures) that you have defined will not have been aware of the multi-source column and may fail validation upon server deployment.
- If using Teiid Designer, you can manually add the multi-source column.
- If using Dynamic VDBs, the pseudo-column will already be available to transformations, but will not be present in your System metadata by default. If you are using DDL and you would like to be selective (rather than using the multisource.addColumn property), you can manually add the column via DDL.
10.5. Multi-Source Models: Planning and Execution
10.6. Multi-Source Models: SELECT, UPDATE and DELETE
- A multi-source query against a SELECT/UPDATE/DELETE may affect any subset of the sources based upon the evaluation of the WHERE clause.
- The multi-source column may not be targeted in an update change set.
- The sum of the update counts for UPDATEs/DELETEs will be returned as the resultant update count.
- When running under a transaction in a mode that detects the need for a transaction and multiple updates may performed or a transactional read is required and multiple sources may be read from, a transaction will be started to enlist each source.
10.7. Multi-Source Models: INSERT
- A multi-source INSERT must use the source_name column as an insert column to specify which source will be targeted by the INSERT. Only an INSERT using the VALUES clause is supported.
10.8. Multi-Source Models: Stored Procedures
Example 10.1. Example DDL
CREATE FOREIGN PROCEDURE PROC (arg1 IN STRING NOT NULL, arg2 IN STRING, SOURCE_NAME IN STRING)
CREATE FOREIGN PROCEDURE PROC (arg1 IN STRING NOT NULL, arg2 IN STRING, SOURCE_NAME IN STRING)
Example 10.2. Example Calls Against A Single Source
CALL PROC(arg1=>'x', SOURCE_NAME=>'sourceA')
EXEC PROC('x', 'y', 'sourceB')
CALL PROC(arg1=>'x', SOURCE_NAME=>'sourceA')
EXEC PROC('x', 'y', 'sourceB')
Example 10.3. Example Calls Against All Sources
CALL PROC(arg1=>'x')
EXEC PROC('x', 'y')
CALL PROC(arg1=>'x')
EXEC PROC('x', 'y')
Chapter 11. DDL Metadata
11.1. DDL Metadata
-vdb.xml file. See the <metadata> element under <model>.
Example 11.1. Example to show view definition
Note
NATIVE or DDL-FILE is supported out of the box, however the MetadataRepository interface allows users to plug-in their own metadata facilities. For example, you can write a Hibernate based store that can feed the necessary metadata. You can find out more about custom metadata repositories in Red Hat JBoss Data Virtualization Development Guide: Server Development.
Note
Note
11.2. Foreign Table
Example 11.2. Example:Create Foreign Table(Created on PHYSICAL model)
CREATE FOREIGN TABLE Customer (id integer PRIMARY KEY, firstname varchar(25), lastname varchar(25), dob timestamp); CREATE FOREIGN TABLE Order (id integer PRIMARY KEY, customerid integer, saledate date, amount decimal(25,4), CONSTRAINT fk FOREGIN KEY(customerid) REFERENCES Customer(id));
CREATE FOREIGN TABLE Customer (id integer PRIMARY KEY, firstname varchar(25), lastname varchar(25), dob timestamp);
CREATE FOREIGN TABLE Order (id integer PRIMARY KEY, customerid integer, saledate date, amount decimal(25,4), CONSTRAINT fk FOREGIN KEY(customerid) REFERENCES Customer(id));
Note
11.3. View
CREATE VIEW CustomerOrders (name varchar(50), saledate date, amount decimal) OPTIONS (CARDINALITY 100, ANNOTATION 'Example') AS SELECT concat(c.firstname, c.lastname) as name, o.saledate as saledate, o.amount as amount FROM Customer C JOIN Order o ON c.id = o.customerid;
CREATE VIEW CustomerOrders (name varchar(50), saledate date, amount decimal) OPTIONS (CARDINALITY 100, ANNOTATION 'Example')
AS
SELECT concat(c.firstname, c.lastname) as name, o.saledate as saledate, o.amount as amount FROM Customer C JOIN Order o ON c.id = o.customerid;
11.4. Table Options
|
Property
|
Data Type or Allowed Values
|
Description
|
|---|---|---|
|
UUID
|
string
|
This is the unique identifier for a view.
|
|
MATERIALIZED
|
'TRUE'|'FALSE'
|
This is applicable to views only. It defines if a table is materialized.
|
|
MATERIALIZED_TABLE
|
'table.name'
|
This is applicable to views only. If this view is being materialized to a external database, this defines the name of the table that is being materialized.
|
|
CARDINALITY
|
int
|
Costing information. Number of rows in the table. Used for planning purposes
|
|
UPDATABLE
|
'TRUE'|'FALSE'
|
Defines if the view is allowed to update or not
|
|
ANNOTATION
|
string
|
Description of the view
|
11.5. Column Options
|
Property
|
Data Type or Allowed Values
|
Description
|
|---|---|---|
|
UUID
|
string
|
A unique identifier for the column
|
|
NAMEINSOURCE
|
string
|
If this is a column name on the FOREIGN table, this value represents name of the column in source database, if omitted the column name is used when querying for data against the source
|
|
CASE_SENSITIVE
|
'TRUE'|'FALSE'
| |
|
SELECTABLE
|
'TRUE'|'FALSE'
|
TRUE when this column is available for selection from the user query
|
|
UPDATABLE
|
'TRUE'|'FALSE'
|
Defines if the column is updatable. Defaults to true if the view/table is updatable.
|
|
SIGNED
|
'TRUE'|'FALSE'
| |
|
CURRENCY
|
'TRUE'|'FALSE'
| |
|
FIXED_LENGTH
|
'TRUE'|'FALSE'
| |
|
SEARCHABLE
|
'SEARCHABLE'|'UNSEARCHABLE'|'LIKE_ONLY'|'ALL_EXCEPT_LIKE'
|
column searchability, usually dictated by the data type
|
|
MIN_VALUE
| | |
|
MAX_VALUE
| | |
|
CHAR_OCTET_LENGTH
|
integer
| |
|
ANNOTATION
|
string
| |
|
NATIVE_TYPE
|
string
| |
|
RADIX
|
integer
| |
|
NULL_VALUE_COUNT
|
long
|
costing information. Number of NULLS in this column
|
|
DISTINCT_VALUES
|
long
|
costing information. Number of distinct values in this column
|
11.6. Table Constraints
Example 11.3. Example of CONSTRAINTs
CREATE VIEW CustomerOrders (name varchar(50), saledate date, amount decimal, CONSTRAINT EXAMPLE_INDEX INDEX (name, amount) ACCESSPATTERN (name) PRIMARY KEY ...
CREATE VIEW CustomerOrders (name varchar(50), saledate date, amount decimal,
CONSTRAINT EXAMPLE_INDEX INDEX (name, amount)
ACCESSPATTERN (name)
PRIMARY KEY ...
11.7. INSTEAD OF Triggers
Example 11.4. Example:Define instead of trigger on View
11.8. Procedures and Functions
- Source Procedure ("CREATE FOREIGN PROCEDURE") - a stored procedure in source
- Source Function ("CREATE FOREIGN FUNCTION") - A function that is supported by the source, where JBoss Data Virtualization will pushdown to source instead of evaluating in the JBoss Data Virtualization engine.
- Virtual Procedure ("CREATE VIRTUAL PROCEDURE") - Similar to stored procedure, however this is defined using the JBoss Data Virtualization Procedure language and evaluated in the JBoss Data Virtualization engine.
- Function/UDF ("CREATE VIRTUAL FUNCTION") - A user defined function, that can be defined using the Teiid procedure language or can have the implementation defined using a JAVA Class.
CREATE VIRTUAL PROCEDURE CustomerActivity(customerid integer) RETURNS (name varchar(25), activitydate date, amount decimal) AS
BEGIN
...
END
CREATE VIRTUAL PROCEDURE CustomerActivity(customerid integer) RETURNS (name varchar(25), activitydate date, amount decimal) AS
BEGIN
...
ENDCREATE VIRTUAL FUNCTION CustomerRank(customerid integer) RETURNS integer AS BEGIN ... END
CREATE VIRTUAL FUNCTION CustomerRank(customerid integer) RETURNS integer AS
BEGIN
...
END
11.9. Variable Argument Support
Example 11.5. Example:Vararg procedure
CREATE FOREIGN PROCEDURE proc (x integer, VARIADIC z integer) returns (x string);
CREATE FOREIGN PROCEDURE proc (x integer, VARIADIC z integer) returns (x string);11.10. Function Options
|
Property
|
Data Type or Allowed Values
|
Description
|
|---|---|---|
|
UUID
|
string
|
unique Identifier
|
|
NAMEINSOURCE
|
If this is source function/procedure the name in the physical source, if different from the logical name given above
| |
|
ANNOTATION
|
string
|
Description of the function/procedure
|
|
CATEGORY
|
string
|
Function Category
|
|
DETERMINISM
|
| |
|
NULL-ON-NULL
|
'TRUE'|'FALSE'
| |
|
JAVA_CLASS
|
string
|
Java Class that defines the method in case of UDF
|
|
JAVA_METHOD
|
string
|
The Java method name on the above defined java class for the UDF implementation
|
|
VARARGS
|
'TRUE'|'FALSE'
|
Indicates that the last argument of the function can be repeated 0 to any number of times. default false. It is more proper to use a VARIADIC parameter.
|
|
AGGREGATE
|
'TRUE'|'FALSE'
|
Indicates the function is a user defined aggregate function. Properties specific to aggregates are listed below:
|
11.11. Aggregate Function Options
|
Property
|
Data Type or Allowed Values
|
Description
|
|---|---|---|
|
ANALYTIC
|
'TRUE'|'FALSE'
|
indicates the aggregate function must be windowed. default false.
|
|
ALLOWS-ORDERBY
|
'TRUE'|'FALSE'
|
indicates the aggregate function supports an ORDER BY clause. default false
|
|
ALLOWS-DISTINCT
|
'TRUE'|'FALSE'
|
indicates the aggregate function supports the DISTINCT keyword. default false
|
|
DECOMPOSABLE
|
'TRUE'|'FALSE'
|
indicates the single argument aggregate function can be decomposed as agg(agg(x) ) over subsets of data. default false
|
|
USES-DISTINCT-ROWS
|
'TRUE'|'FALSE'
|
indicates the aggregate function effectively uses distinct rows rather than all rows. default false
|
Note
11.12. Procedure Options
|
Property
|
Data Type or Allowed Values
|
Description
|
|---|---|---|
|
UUID
|
string
|
Unique Identifier
|
|
NAMEINSOURCE
|
string
|
In the case of source
|
|
ANNOTATION
|
string
|
Description of the procedure
|
|
UPDATECOUNT
|
int
|
if this procedure updates the underlying sources, what is the update count, when update count is >1 the XA protocol for execution is enforced
|
11.13. Options
Note
11.14. Alter Statement
Example 11.6. Example ALTER
ALTER FOREIGN TABLE "customer" OPTIONS (ADD CARDINALITY 10000); ALTER FOREIGN TABLE "customer" ALTER COLUMN "name" OPTIONS(SET UPDATABLE FALSE)
ALTER FOREIGN TABLE "customer" OPTIONS (ADD CARDINALITY 10000);
ALTER FOREIGN TABLE "customer" ALTER COLUMN "name" OPTIONS(SET UPDATABLE FALSE)
Example 11.7. Example VDB
11.15. Namespaces for Extension Metadata
Example 11.8. Example of Namespace
SET NAMESPACE 'http://custom.uri' AS foo
CREATE VIEW MyView (...) OPTIONS ("foo:mycustom-prop" 'anyvalue')
SET NAMESPACE 'http://custom.uri' AS foo
CREATE VIEW MyView (...) OPTIONS ("foo:mycustom-prop" 'anyvalue')
|
Prefix
|
URI
|
Description
|
|---|---|---|
|
teiid_rel
|
Relational extensions. Uses include function and native query metadata
| |
|
teiid_sf
|
Salesforce extensions.
|
11.16. Example DDL Metadata
Chapter 12. Translators
12.1. JBoss Data Virtualization Connector Architecture
- a translator (mandatory) and
- a resource adapter (optional), also known as a connector. Most of the time, this will be a Java EE Connector Architecture (JCA) Adapter.
- translate JBoss Data Virtualization commands into commands understood by the datasource for which the translator is being used,
- execute those commands,
- return batches of results from the datasource, translated into the formats that JBoss Data Virtualization is expecting.
- handles all communications with individual enterprise information systems, (which can include databases, data feeds, flat files and so forth),
- can be a JCA Adapter or any other custom connection provider (the JCA specification ensures the writing, packaging and configuration are undertaken in a consistent manner),
Note
Many software vendors provide JCA Adapters to access different systems. Red Hat recommends using vendor-supplied JCA Adapters when using JMS with JCA. See http://docs.oracle.com/cd/E21764_01/integration.1111/e10231/adptr_jms.htm - removes concerns such as connection information, resource pooling, and authentication for translators.
12.2. Translators
Note
EAP_HOME/docs/teiid/datasources for more information about configuring resource adapters.
12.3. Translator Properties
- Execution Properties - these properties determine aspects of how data is retrieved. A list of properties common to all translators are provided in Section 12.5, “Base Execution Properties”.
Note
The execution properties for a translator typically have reasonable defaults. For specific translator types, base execution properties are already tuned to match the source. In most cases the user will not need to adjust their values. - Importer Properties - these properties determine what metadata is read for import. There are no common importer properties.
Note
12.4. Translators in Red Hat JBoss Data Virtualization
- accumulo
- amazon-s3
- cassandra
- couchbase
- excel
- file
- google-spreadsheet
- infinispan-cache
- infinispan-cache-dsl
- infinispan-cache-hotrod
- jpa2
- ldap
- loopback
- map-cache
- mongodb
- odata
- odata4
- olap
- salesforce
- salesforce-34
- sap-gateway
- sap-nw-gateway
- simpledb
- solr
- ws
- jdbc-ansi
- jdbc-simple
- access
- actian-vector
- db2
- derby
- hbase
- excel-odbc
- greenplum
- h2
- hana
- hive
- hsql
- impala
- ingres
- ingres93
- intersystems-cache
- informix
- metamatrix
- modeshape
- mysql5
- netezza
- oracle
- osisoft-pi
- postgresql
- prestodb
- redshift
- sqlserver
- sybase
- teiid
- teradata
- vertica
12.5. Base Execution Properties
| Name | Description | Default |
|---|---|---|
| Immutable | Set to true to indicate that the source never changes. | false |
| RequiresCriteria | Set to true to indicate that source SELECT/UPDATE/DELETE queries require a WHERE clause. | false |
| SupportsOrderBy | Set to true to indicate that the ORDER BY clause is supported. | false |
| SupportsOuterJoins | Set to true to indicate that OUTER JOINs are supported. | false |
| SupportsFullOuterJoins | If outer joins are supported, true indicates that FULL OUTER JOINs are supported. | false |
| SupportsInnerJoins | Set to true to indicate that INNER JOINs are supported. | false |
| SupportedJoinCriteria | If joins are supported, defines what criteria may be used as the join criteria. May be one of (ANY, THETA, EQUI, or KEY). | ANY |
| MaxInCriteriaSize | If in criteria are supported, defines what the maximum number of in entries are per predicate. -1 indicates no limit. | -1 |
| MaxDependentInPredicates | If IN criteria are supported, defines what the maximum number of predicates that can be used for a dependent join. Values less than 1 indicate to use only one IN predicate per dependent value pushed. | -1 |
|
DirectQueryProcedureName
|
f the direct query procedure is supported on the translator, this property indicates the name of the procedure.
|
native
|
|
SupportsDirectQueryProcedure
|
Set to true to indicate the translator supports the direct execution of commands
|
false
|
|
ThreadBound
|
Set to true to indicate the translator's Executions should be processed by only a single thread
|
false
|
|
CopyLobs
|
If true, then returned LOBs (clob, blob, sql/xml) will be copied by the engine in a memory-safe manner. Use this option if the source does not support memory-safe LOBs or you want to disconnect LOBs from the source connection.
|
false
|
Note
12.6. Override Execution Properties
vdb.xml file:
<translator type="oracle-override" name="oracle">
<property name="RequiresCriteria" value="true"/>
</translator>
<translator type="oracle-override" name="oracle">
<property name="RequiresCriteria" value="true"/>
</translator>
12.7. Parameterizable Native Queries
12.8. Delegating Translators
org.teiid.translator.BaseDelegatingExecutionFactory class.
|
Name
|
Description
|
Default
|
|---|---|---|
|
delegateName
|
Translator instance name to delegate to.
| |
- You first write a custom delegating translator:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Then you deploy this translator.
- Then modify your
-vdb.xmlor.vdbfile:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12.9. Amazon S3 Translator
amazon-s3, allows you to use Amazon S3 object resources. The Web Service Data Source resource-adapter is used to access it. Use it together with TEXTTABLE or XMLTABLE table functions to access CSV and XML formatted data. This translator supports access to Amazon S3 using access-key and secret-key.
e1,e2,e3 5,'five',5.0 6,'six',6.0 7,'seven',7.0
e1,e2,e3
5,'five',5.0
6,'six',6.0
7,'seven',7.0
| Name | Description | Default |
|---|---|---|
| Encoding | The encoding that should be used for CLOBs returned by the getTextFiles procedure. The value should match an encoding known to the JRE. | The system default encoding. |
| Accesskey | Amazon Security Access Key. Log in to Amazon console to find your security access key. When provided, this becomes the default access key | n/a |
| Secretkey | Amazon Security secret Key. Log in to Amazon console to find your security secret key. When provided, this becomes the default secret key. | n/a |
| Region | Amazon Region to be used with the request. When provided this will be default region used. | n/a |
| Bucket | Amazon S3 bucket name, if provided this will serve as default bucket to be used for all the requests | n/a |
| Encryption | When SSE-C type encryption used, where customer supplies the encryption key, this key will be used for defining the "type" of encryption algorithm used. Supported are AES-256, AWS-KMS. If provided this will be used as default algorithm for all "get" based calls | n/a |
| Encryptionkey | When SSE-C type encryption used, where customer supplies the encryption key, this key will be used for defining the "encryption key". If provided this will be used as default key for all "get" based calls | n/a |
Note
getTextFile(string name NOT NULL, string bucket, string region, string endpoint, string accesskey, string secretkey,string encryption, string encryptionkey, boolean stream default false) returns TABLE(file blob, endpoint string, lastModified string, etag string, size long);
getTextFile(string name NOT NULL, string bucket, string region,
string endpoint, string accesskey, string secretkey,string encryption, string encryptionkey, boolean stream default false)
returns TABLE(file blob, endpoint string, lastModified string, etag string, size long);
Note
getFile(string name NOT NULL, string bucket, string region, string endpoint, string accesskey, string secretkey, string encryption, string encryptionkey, boolean stream default false) returns TABLE(file blob, endpoint string, lastModified string, etag string, size long)
getFile(string name NOT NULL, string bucket, string region,
string endpoint, string accesskey, string secretkey, string encryption, string encryptionkey, boolean stream default false)
returns TABLE(file blob, endpoint string, lastModified string, etag string, size long)
exec getFile(name=>'myfile.xml', bucket=>'mybucket', region=>'us-east-1', accesskey=>'xxxx', secretkey=>'xxxx');
select b.* from (exec getFile(name=>'myfile.xml', bucket=>'mybucket', region=>'us-east-1', accesskey=>'xxxx', secretkey=>'xxxx')) as a,
XMLTABLE('/contents' PASSING XMLPARSE(CONTENT a.result WELLFORMED) COLUMNS e1 integer, e2 string, e3 double) as b;
exec getFile(name=>'myfile.xml', bucket=>'mybucket', region=>'us-east-1', accesskey=>'xxxx', secretkey=>'xxxx');
select b.* from (exec getFile(name=>'myfile.xml', bucket=>'mybucket', region=>'us-east-1', accesskey=>'xxxx', secretkey=>'xxxx')) as a,
XMLTABLE('/contents' PASSING XMLPARSE(CONTENT a.result WELLFORMED) COLUMNS e1 integer, e2 string, e3 double) as b;
call saveFile(string name NOT NULL, string bucket, string region, string endpoint, string accesskey, string secretkey, contents object)
call saveFile(string name NOT NULL, string bucket, string region, string endpoint,
string accesskey, string secretkey, contents object)
Note
exec saveFile(name=>'g4.txt', contents=>'e1,e2,e3\n1,one,1.0\n2,two,2.0');
exec saveFile(name=>'g4.txt', contents=>'e1,e2,e3\n1,one,1.0\n2,two,2.0');
call deleteFile(string name NOT NULL, string bucket, string region, string endpoint, string accesskey, string secretkey)
call deleteFile(string name NOT NULL, string bucket, string region, string endpoint, string accesskey, string secretkey)
exec deleteFile(name=>'myfile.txt');
exec deleteFile(name=>'myfile.txt');
call list(string bucket, string region, string accesskey, string secretkey, nexttoken string)
returns Table(result clob)
call list(string bucket, string region, string accesskey, string secretkey, nexttoken string)
returns Table(result clob)
select b.* from (exec list(bucket=>'mybucket', region=>'us-east-1')) as a, XMLTABLE(XMLNAMESPACES(DEFAULT 'http://s3.amazonaws.com/doc/2006-03-01/'), '/ListBucketResult/Contents' PASSING XMLPARSE(CONTENT a.result WELLFORMED) COLUMNS Key string, LastModified string, ETag string, Size string, StorageClass string, NextContinuationToken string PATH '../NextContinuationToken') as b;
select b.* from (exec list(bucket=>'mybucket', region=>'us-east-1')) as a,
XMLTABLE(XMLNAMESPACES(DEFAULT 'http://s3.amazonaws.com/doc/2006-03-01/'), '/ListBucketResult/Contents'
PASSING XMLPARSE(CONTENT a.result WELLFORMED) COLUMNS Key string, LastModified string, ETag string, Size string,
StorageClass string, NextContinuationToken string PATH '../NextContinuationToken') as b;
SELECT * FROM Bucket
SELECT * FROM Bucket
Note
Web Service Data Source.
12.10. Amazon SimpleDB Translator
| Simple DB Name | SQL (Teiid) |
|---|---|
| Domain |
Table
|
| Item Name |
Column (ItemName) Primary Key
|
| attribute - single value |
Column - String Datatype
|
| attribute - multi value |
Column - String Array Datatype
|
Important
Note
jboss-as/docs/teiid/datasources/simpledb file.
| SimpleDB Query | Teiid Query |
|---|---|
| select * from mydomain where Rating = '4 stars' or Rating = '****' |
select * from mydomain where Rating = ('4 stars','****')
|
| select * from mydomain where Keyword = 'Book' and Keyword = 'Hardcover' |
select * from mydomain where intersection(Keyword,'Book','Hardcover')
|
| select * from mydomain where every(Rating) = '****' |
select * from mydomain where every(Rating) = '****'
|
INSERT INTO mydomain (ItemName, title, author, year, pages, keyword, rating) values ('0385333498', 'The Sirens of Titan', 'Kurt Vonnegut', ('1959'), ('Book', Paperback'), ('*****','5 stars','Excellent'))
INSERT INTO mydomain (ItemName, title, author, year, pages, keyword, rating) values ('0385333498', 'The Sirens of Titan', 'Kurt Vonnegut', ('1959'), ('Book', Paperback'), ('*****','5 stars','Excellent'))
Warning
Note
SELECT X.*
FROM simpledb_source.native('SELECT firstname, lastname FROM users') n, ARRAYTABLE(n.tuple COLUMNS firstname string, lastname string) AS X
SELECT X.*
FROM simpledb_source.native('SELECT firstname, lastname FROM users') n, ARRAYTABLE(n.tuple COLUMNS firstname string, lastname string) AS X
12.11. Apache Accumulo Translator
- The Accumulo source can be used in JDV, to continually add/update the documents in the Accumulo system from other sources automatically.
- Access Accumulo through the SQL interface.
- Make use of cell-level security through enterprise roles.
- The Accumulo translator can be used as an indexing system to gather data from other enterprise sources such as RDBMS, Web Services, SalesForce and so forth, all in a single-client call transparently with out any coding.
Important
| Property Name | Description | Required? | Default |
|---|---|---|---|
| ColumnNamePattern |
How the column name is to be formed
|
false
|
{CF}_{CQ}
|
| ValueIn |
Where the value for column is defined CQ or VALUE
|
false
|
{VALUE}
|
Note
| Property Name | Description | Required? | Default |
|---|---|---|---|
| CF |
Column Family
|
true
|
none
|
| CQ |
Column Qualifier
|
false
|
empty
|
| VALUE-IN |
Value of column defined in. Possible values (VALUE, CQ)
|
false
|
VALUE
|
12.12. Apache SOLR Translator
- Solr source can be used in Teiid, to continually add/update the documents in the search system from other sources automatically.
- If the search fields are stored in Solr system, this can be used as very low latency data retrieval for serving high traffic applications.
- The Solr translator can be used as a fast full-text search system. The Solr document might only contain index information. If so, then the results will be an inverted index. You can use this to gather target documents from the other enterprise sources such as RDBMS, Web Services, SalesForce and so on, and consolidate them all in a single client call without any coding.
jboss-as/docs/teiid/datasources/solr
12.13. Cassandra Translator
Warning
SELECT X.*
FROM cassandra_source.native('SELECT firstname, lastname FROM users WHERE birth_year = $1 AND country = $2 ALLOW FILTERING', 1981, 'US') n,
ARRAYTABLE(n.tuple COLUMNS firstname string, lastname string) AS X
SELECT X.*
FROM cassandra_source.native('SELECT firstname, lastname FROM users WHERE birth_year = $1 AND country = $2 ALLOW FILTERING', 1981, 'US') n,
ARRAYTABLE(n.tuple COLUMNS firstname string, lastname string) AS X
12.14. Couchbase Translator
couchbase, exposes querying functionality for Couchbase data sources. The Couchbase Translator provides a solution for integrating Couchbase JSON documents with the relational model. This allows applications to use normal SQL queries against a Couchbase server. The translator converts Red Hat JBoss Data Virtualization push-down commands into Couchbase N1QL.
Note
- Regular Tables: these map to keyspaces.
- Array Tables: these map to arrays in documents.
| Name | Description | Default |
|---|---|---|
| sampleSize | Set the SampleSize property to the number of documents that you want the connector to sample. | 100 |
| sampleKeyspaces | This is a comma-separated list of the keyspace names, used to control which keyspaces will be mapped. The smaller the scope of the keyspaces, the larger the sampleSize. Use this if you want to focus on a specific keyspace and want more precise metadata. | All |
| typeNameList | This is a comma-separated list of key/value pairs that the keyspaces use to specify document types. Each list item must be a keyspace name surrounded by back quotes, a colon, and an attribute name enclosed in back quotes: `KEYSPACE`:`ATTRIBUTE`,`KEYSPACE`:`ATTRIBUTE`,`KEYSPACE`:`ATTRIBUTE`. The keyspaces must be under the same namespace. The attribute must be a non-object or array, resident on the root of keyspace, and its type should be the equivalent String. If a typeNameList that is set on a specific keyspace has multiple types, and a document has all these types, the first one will be chosen. For example, the TypeNameList below indicates that the keyspaces test and default use the type attribute to specify the type of each document. During schema generation, all type referenced values are treated as though they are table names: TypeNameList=`test`:`type`,`default`:`type`:`type` The TypeNameList indicates that the keyspace test use type, name and category attribute to specify the type of each document, during schema generation, the teiid connector scan the documents under test, if a document has attribute as any of type, name and category, its referenced value will be treated as table name: TypeNameList=`test`:`type`,`test`:`name`,`test`:`category` | 100 |
| Name | Description |
|---|---|
| teiid_couchbase:NAMEDTYPEPAIR | A NAMEDTYPEPAIR OPTION in table declare the name of typed key/value pair. This option is used once the typeNameList importer property is used and the table is typeName referenced table. |
| teiid_couchbase:ISARRAYTABLE | A ISARRAYTABLE OPTION in table used to differentiate the array table from the regular table:
|
- Click ->
- Create a new JBoss data source connection profile, by specifying as the JNDI name for the resource adapter. Select as the translator type.
- Click .
- Create a VDB and deploy into Teiid Server and use either jdbc, odbc or odata to query.
Couchbase Resource Adapter with this translator.
teiid_rel:native-query extension. The procedure will invoke the native query similar to a direct procedure call with the benefits that the query is predetermined and that the result column types are known:
EXEC CouchbaseVDB.native('DELETE FROM test USE KEYS ["customer-3", "order-3"]')
EXEC CouchbaseVDB.native('DELETE FROM test USE KEYS ["customer-3", "order-3"]')getDocuments to return JSON documents that match the given document id or id pattern as BLOBs:
getDocuments(id, keyspace)
getDocuments(id, keyspace)id: This is the document id or SQL like pattern of what documents to return, for example, the '%' sign is used to define wildcards (missing letters) both before and after the pattern.keyspace: This is the keyspace name used to retrieve the documents.
call getDocuments('customer%', 'test')
call getDocuments('customer%', 'test')Important
Note
- Generate the schema using the translator.
- Use the Web Management Console or the Adminshell to review the schema and make your edits.
- Add the resulting schema to the VDB.
12.14.1. Couchbase Data Model
- a key pair with no typed value.
- nested arrays.
- arrays of differently-typed elements.
- nested documents which contain the above three items.
- the keyspace/bucket is mapped as the top table which contains all of the key/value pairs not including the nested arrays/documents. The key is mapped to the column name and the value type is mapped to column type.
- The nested arrays/documents are mapped to different tables with names in this format: parenttable_nestarray(ordocument)key.
- each table has a primary key column mapped to the document id.
- if a nested array has a nested array item, the array item is treated as an object.
12.15. File Translator
12.15.1. File Translator
org.teiid.translator.file.FileExecutionFactory class and known by the translator type name file.
Note
file data source in the JBoss EAP instance. See the Red Hat JBoss Data Virtualization Administration and Configuration Guide for more configuration information.
12.15.2. File Translator: Execution Properties
| Name | Description | Default |
|---|---|---|
| Encoding | The encoding that must be used for CLOBs returned by the getTextFiles procedure. | The system default encoding |
| ExceptionIfFileNotFound | Throw an exception in getFiles or getTextFiles if the specified file/directory does not exist. | true (false in previous releases) |
12.15.3. File Translator: Usage
call getFiles('path/*.ext')
call getFiles('path/*.ext')ExceptionIfFileNotFound is false, otherwise an exception will be raised.
call getTextFiles('path/*.ext')
call getTextFiles('path/*.ext')getTextFiles will retrieve the same files as getFiles, only the results will be CLOB values using the encoding execution property as the character set.
call saveFile('path', value)
call saveFile('path', value)Note
12.16. Google Spreadsheet Translator
12.16.1. Google Spreadsheet Translator
org.teiid.translator.google.SpreadsheetExecutionFactory class and known by the translator type name google-spreadsheet.
- Any column that has data can be queried.
- All datatypes (including strings) featuring empty cells are returned as NULL.
- If the first row is present and contains string values, then it will be assumed to represent the column labels.
Note
google data source in the JBoss EAP instance. See the Red Hat JBoss Data Virtualization Administration and Configuration Guide for more configuration information.
12.16.2. Google Spreadsheet Translator: Native Queries
12.16.3. Google Spreadsheet Translator: Native Procedure
Warning
Example 12.1. Select Example
SELECT x.* FROM (call pm1.native('worksheet=People;query=SELECT A, B, C')) w,
ARRAYTABLE(w.tuple COLUMNS "id" string , "type" string, "name" String) AS x
SELECT x.* FROM (call pm1.native('worksheet=People;query=SELECT A, B, C')) w,
ARRAYTABLE(w.tuple COLUMNS "id" string , "type" string, "name" String) AS x
|
Property
|
Description
|
Required
|
|---|---|---|
|
worksheet
|
Google spreadsheet name
|
yes
|
|
query
|
spreadsheet query
|
yes
|
|
limit
|
number rows to fetch
|
no
|
|
offset
|
offset of rows to fetch from limit or beginning
|
no
|
Note
vdb.xml file to change it to any other procedure name.
12.17. Red Hat JBoss Data Grid Translator
probuf file then this translator works with the definition objects found in that file. The resource adapter for this translator is the Infinispan Data Source.
.proto file with the translator configuration, which is read and converted to the model’s schema. This file is then registered in Red Hat JBoss Data Grid.
Note
.proto file. This is due to a limitation in the way that the protobuf is defined. Because Red Hat JBoss Data Grid uses Java, the package name must follow the Java package naming standards. Dashes, for instance, are not allowed.
| JBoss Data Grid | Mapped to Relational Entity | Example |
|---|---|---|
| Message | Table. | Person. |
| enum | Integer attribute in table. | NA. |
| repeated | Use as an array for simple types or as a separate table with one-to-many relationship to parent message. | PhoneNumber. |
- All required fields are modeled as non-null columns.
- All indexed columns are marked as searchable.
- The default values are captured.
- To enable updates, the top level message object must define the @id annotation on one of its columns.
Note
.proto file has more than one single top level "message" object to be stored as the root object in the cache, each of the objects must be stored in a different cache to avoid key conflicts in a single cache store. Since each of the messages will be in a different cache store, you can define the cache store name for the "message" object. For this, define an extension property called teiid_ispn:cache on the corresponding Red Hat JBoss Data Virtualization table:
| Name | Description | Default |
|---|---|---|
| ProtoFilePath | The file path to a Protobuf .proto file accessible to the server to be read and convert into metadata. | NA. |
| ProtobufName | The name of the Protobuf .protofile that has been registered with the JDG node, that Red Hat JBoss Data Virtualization will read and convert into metadata. The property value must exactly match the registered name. | NA. |
- Bulk update support is not available.
- Transactions are not supported. The last edit stands.
- Aggregate functions like SUM, AVG etc are not supported on inner objects.
- UPSERT support on complex objects is always results in INSERT.
- LOBS are not streamed, use caution as this can lead to OOM errors.
- There is no function library in JDG.
- Array objects can not be projected but they do show up in the metadata.
- When using DATE/TIMESTAMP/TIME types in Teiid metadata, they are by default marshaled into a LONG type in JDG.
- SSL and identity support is not currently available.
- Native or direct query execution is not supported.
Important
12.18. JDBC Translator
12.18.1. JDBC Translator
org.teiid.translator.jdbc.JDBCExecutionFactory class.
Note
12.18.2. JDBC Translator: Execution Properties
| Name | Description | Default |
|---|---|---|
| DatabaseTimeZone | The time zone of the database. Used when fetching date, time, or timestamp values. | The system default time zone |
| DatabaseVersion | The specific database version. Used to further tune pushdown support. | The base supported version or derived from the DatabaseMetadata.getProduceVersion string. Automatic detection requires a Connection. If there are circumstances where you are getting an exception from capabilities being unavailable (most likely due to an issue obtaining a Connection), then set the DatabaseVersion property. Use the JDBCExecutionFactory.usesDatabaseVersion() method to control whether your translator requires a connection to determine capabilities. |
| TrimStrings | Set to true to trim trailing whitespace from fixed length character strings. Note that JBoss Data Virtualization only has a string, or varchar, type that treats trailing whitespace as meaningful. | false |
| UseBindVariables | Set to true to indicate that PreparedStatements will be used and that literal values in the source query will be replaced with bind variables. If false, only LOB values will trigger the use of PreparedStatements. | true |
| UseCommentsInSourceQuery | This will embed a leading comment with session/request id in source SQL query for informational purposes | false |
| CommentFormat | MessageFormat string to be used if UseCommentsInSourceQuery is enabled. Available properties:
| /*teiid sessionid:{0}, requestid:{1}.{2}*/ |
| MaxPreparedInsertBatchSize | The max size of a prepared insert batch. | 2048 |
| StructRetrieval | Struct retrieval mode can be one of OBJECT - getObject value returned, COPY - returned as a SerialStruct, ARRAY - returned as an Array) | OBJECT |
| EnableDependentJoins | For sources that support temporary tables (DB2, Derby, H2, HSQL 2.0+, MySQL 5.0+, Oracle, PostgreSQL, SQLServer, Sybase) allow dependent join pushdown | false |
12.18.3. JDBC Translator: Importer Properties
| Name | Description | Default |
|---|---|---|
| catalog | See DatabaseMetaData.getTables at http://download.oracle.com/javase/6/docs/api/java/sql/DatabaseMetaData.html for more information. | null |
| importRowIdAsBinary | 'true' will import RowId columns as varbinary values. | false |
| schemaPattern | See DatabaseMetaData.getTables at http://download.oracle.com/javase/6/docs/api/java/sql/DatabaseMetaData.html for more information. | null |
| tableNamePattern | See DatabaseMetaData.getTables at http://download.oracle.com/javase/6/docs/api/java/sql/DatabaseMetaData.html for more information. | null |
| procedureNamePattern | See DatabaseMetaData.getProcedures at http://download.oracle.com/javase/6/docs/api/java/sql/DatabaseMetaData.html for more information. | null |
| tableTypes | Comma separated list - without spaces - of imported table types. See DatabaseMetaData.getTables at http://download.oracle.com/javase/6/docs/api/java/sql/DatabaseMetaData.html for more information. | null |
| excludeTables | A case-insensitive regular expression that when matched against a fully qualified JBoss Data Virtualization table name will exclude it from import. Applied after table names are retrieved. Use a negative look-ahead (?!<inclusion pattern>).* to act as an inclusion filter. | null |
| excludeProcedures | A case-insensitive regular expression that when matched against a fully qualified JBoss Data Virtualization procedure name will exclude it from import. Applied after procedure names are retrieved. Use a negative look-ahead (?!<inclusion pattern>).* to act as an inclusion filter. | null |
| autoCreateUniqueConstraints | True to create a unique constraint if one is not found for a foreign keys | true |
| useFullSchemaName | When false, directs the importer to drop the source catalog/schema from the JBoss Data Virtualization object name, so that the JBoss Data Virtualization fully qualified name will be in the form of <model name>.<table name>. Note that when this is false, it may lead to objects with duplicate names when importing from multiple schemas, which results in an exception. This option does not affect the name in source property. | true |
| importKeys | Set to true to import primary and foreign keys. | true |
| importIndexes | Set to true to import index/unique key/cardinality information. | false |
| importApproximateIndexes | Set to true to import approximate index information. See DatabaseMetaData.getIndexInfo at http://download.oracle.com/javase/6/docs/api/java/sql/DatabaseMetaData.html for more information. | true |
| importProcedures | Set to true to import procedures and procedure columns. Note that it is not always possible to import procedure result set columns due to database limitations. It is also not currently possible to import overloaded procedures. | true |
| widenUnsignedTypes | Set to true to convert unsigned types to the next widest type. For example SQL Server reports tinyint as an unsigned type. With this option enabled, tinyint would be imported as a short instead of a byte. | true |
| quoteNameInSource | Set to false to override the default and direct JBoss Data Virtualization to create source queries using unquoted identifiers. | true |
| useProcedureSpecificName | Set to true to allow the import of overloaded procedures (which will normally result in a duplicate procedure error) by using the unique procedure-specific name as the JBoss Data Virtualization name. This option will only work with JDBC 4.0 compatible drivers that report specific names. | false |
| useCatalogName | Set to true to use any non-null/non-empty catalog name as part of the name in source, e.g. "catalog"."table"."column", and in the JBoss Data Virtualization runtime name if useFullSchemaName is true. Set to false to not use the catalog name in either the name in source or the JBoss Data Virtualization runtime name. Must be set to false for sources that do not fully support a catalog concept, but return a non-null catalog name in their metadata, such as HSQL. | true |
| useQualifiedName | True will use name qualification for both the Teiid name and name in source as dictated by the useCatalogName and useFullSchemaName properties. Set to false to disable all qualification for both the Teiid name and the name in source, which effectively ignores the useCatalogName and useFullSchemaName properties. Note: when false this may lead to objects with duplicate names when importing from multiple schemas, which results in an exception. | true |
| useAnyIndexCardinality | True will use the maximum cardinality returned from DatabaseMetaData.getIndexInfo. importKeys or importIndexes needs to be enabled for this setting to have an effect. This allows for better stats gathering from sources that do not support returning a statistical index. | false |
| importStatistics | This uses database-dependent logic to determine the cardinality if none is determined. (This is currently only supported on Oracle and MySQL.) | false |
Warning
12.18.4. JDBC Translator: Translator Types
Note
schemaPattern = {targetSchema}
tableTypes = TABLE
schemaPattern = {targetSchema}
tableTypes = TABLE
- jdbc-ansi
- This translator provides support for most SQL constructs supported by JBoss Data Virtualization, except for row limit/offset and EXCEPT/INTERSECT. It translates source SQL into ANSI compliant syntax.This translator can be used when another more specific type is not available.
- jdbc-simple
- This translator is the same as jdbc-ansi, except that it disables support for function, UNION and aggregate pushdown.
- access
- This translator is for use with Microsoft Access 2003 or later.
- actian-vector
- This translator is for use Actian Vector in Hadoop.
Note
Download the JDBC driver from http://esd.actian.com/platform. Note that the port number in the connection URL is "AH7" which maps to 16967. - db2
- This translator is for use with DB2 8 or later (and DB2 for i 5.4 or later).Execution properties specific to DB2:
- DB2ForI indicates that the DB2 instance is DB2 for i. The default is "false".
- hbase
- The Apache HBase Translator exposes querying functionality to HBase Tables. Apache Phoenix is an SQL interface for HBase. With the Phoenix Data Sources, the translator translates Teiid push-down commands into Phoenix SQL.The HBase Translator does not support Join commands, because Phoenix has more simple constraints. The only supported is that for the Primary Key, which maps to the HBase Table Row ID. This translator is developed with Phoenix 4.x for HBase 0.98.1+.
Warning
The translator implements INSERT/UPDATE through the Phoenix UPSERT operation. This means you can see different behavior than with standard INSERT/UPDATE, such as repeated inserts will not throw a duplicate key exception, but will instead update the row in question.Warning
Due to Phoenix driver limitations, the importer will not look for unique constraints and does not import foreign keys by default.Warning
The Phoenix driver does not have robust handling of time values. If your time values are normalized to use a date component of 1970-01-01, then the default handling will work correctly. If not, then the time column should be modeled as timestamp instead.If you use the translator for Apache HBase, be aware that insert statements can rewrite data. To illustrate, here is a standard set of SQL queries:CREATE TABLE TableA (id integer PRIMARY KEY, name varchar(10)); INSERT INTO TableA (id, name) VALUES (1, 'name1'); INSERT INTO TableA (id, name) VALUES (1, 'name2');
CREATE TABLE TableA (id integer PRIMARY KEY, name varchar(10)); INSERT INTO TableA (id, name) VALUES (1, 'name1'); INSERT INTO TableA (id, name) VALUES (1, 'name2');Copy to Clipboard Copied! Toggle word wrap Toggle overflow Normally, the second INSERT command would fail as the uniqueness of the primary key would be corrupted. However, with the HBase translator, the command will not fail. Rather, it will rewrite the data in the table, (so "name1" would become "name2"). This is because the translator converts the INSERT command into an UPSERT command. - Derby
- derby - for use with Derby 10.1 or later.
- excel-odbc
Important
This translator is now deprecated as the JDBC-ODBC bridge has been removed from Java 1.8.This translator is for use with Excel 2003 or later via a JDBC-ODBC bridge.- greenplum
- This translator is for use with the Greenplum database.
- h2
- This translator is for use with h2 version 1.1 or later.
- hana
- This translator is for use with SAP Hana.
- hive
- This translator is for use with Hive v.10 and Apache SparkSQL v1.0 and later.Spark is configured to use the Hive Metastore and its configured target to store data. Apache Spark introduces a new computational model alternative to MapReduce. To access data stored in Apache Spark, use the hive jdbc driver while connecting to a hive-specific JDBC URL.Hive has limited support for data types as it does not support time-based types, XML or LOBs. A view table can use these types but you would need to configure the translator to specify the necessary transformations. In these situations, the evaluations will be done in the JBoss Data Virtualization engine.
Important
The Hive translator does not use the DatabaseTimeZone property.Important
The Hive importer does not have concept of catalog or source schema, nor does it import keys, procedures and indexes.Another limitation of Hive is that it only supports EQUI joins. If you try to use any other kind of join on the source tables, you will have inefficient queries. To write criteria based on partitioned columns, model them on source tables, but do not include them in selection columns.These importer qualities are specific to the Hive translator:- trimColumnNames: For Hive 0.11.0 and later the DESCRIBE command metadata is returned with padding. Set to true to strip white space from column names. By default it is set to false.useDatabaseMetaData: For Hive 0.13.0 and later the normal JDBC DatabaseMetaData facilities are sufficient to perform an import. Set to true to use the normal import logic with the option to import index information disabled. Defaults to false. When true, trimColumnNames has no effect. If it is set to false, the typical JDBC DatabaseMetaData calls are not used so not all of the common JDBC importer properties are applicable to Hive. You can still use excludeTables anyway.
Important
When the database name used in the Hive is differs from "default", the metadata retrieval and execution of queries does not work as expected in Teiid, as Hive JDBC driver seems to be implicitly connecting (tested with versions lower than 0.12) to "default" database, thus ignoring the database name mentioned on connection URL. You can work around this in Red Hat JBoss Data Virtualization in the JBoss EAP environment by setting the following in data source configuration:<new-connection-sql>use {database-name}</new-connection-sql><new-connection-sql>use {database-name}</new-connection-sql>Copy to Clipboard Copied! Toggle word wrap Toggle overflow This is fixed in version 0.13 and later of the Hive driver.
- hsql
- This translator is for use with HSQLDB 1.7 or later.
- impala
- This translator is for use with Cloudera Impala 1.2.1 or later.Impala has limited support for data types. It does not have native support for time/date/xml or LOBs. These limitations are reflected in the translator capabilities. A Teiid view can use these types, however the transformation would need to specify the necessary conversions. Note that in those situations, the evaluations will be done in Teiid engine.Impala only supports EQUI join, so using any other joins types on its source tables will result in inefficient queries.To write criteria based on partitioned columns, model them on the source table, but do not include them in selection columns.
Important
The Impala importer does not currently use typical JDBC DatabaseMetaData calls, nor does it have the concept of catalog or source schema, nor does it import keys, procedures, indexes, etc. Thus not all of the common JDBC importer properties are applicable to Impala. You may still use excludeTables.Impala specific importer properties:useDatabaseMetaData - Set to true to use the normal import logic with the option to import index information disabled. Defaults to false.If false the typical JDBC DatabaseMetaData calls are not used so not all of the common JDBC importer properties are applicable to Impala. (You can still use excludeTables regardless.)Important
Some versions of Impala require the use of a LIMIT when performing an ORDER BY. If no default is configured in Impala, an exception can occur when a Teiid query with an ORDER BY but no LIMIT is issued. You must set an Impala wide default, or configure the connection pool to use a new connection SQL string to issue a SET DEFAULT_ORDER_BY_LIMIT statement. See the Cloudera documentation for more on limit options, such as controlling what happens when the limit is exceeded. - ingres
- This translator is for use with Ingres 2006 or later.
- ingres93
- This translator is for use with Ingres 9.3 or later.
- intersystems-cache
- For use with Intersystems Cache Object database (only relational aspect of it)
- informix
- For use with any Informix version.
- metamatrix
- This translator is for use with MetaMatrix 5.5.0 or later.
- modeshape
- This translator is for use with Modeshape 2.2.1 or later.The PATH, NAME, LOCALNODENAME, DEPTH, and SCORE functions are accessed as pseudo-columns, e.g. "nt:base"."jcr:path".JBoss Data Virtualization user defined functions (prefixed by JCR_) are available for CONTAINS, ISCHILDNODE, ISDESCENDENT, ISSAMENODE, REFERENCE. See the
JCRFunctions.xmifile.If a selector name is needed in a JCR function, you can use the pseudo-column "jcr:path". For example, JCR_ISCHILDNODE(foo.jcr_path, 'x/y') would become ISCHILDNODE(foo, 'x/y') in the ModeShape query.An additional pseudo-column "mode:properties" can be imported by setting the ModeShape JDBC connection property teiidsupport=true. The "mode:properties" column should be used by the JCR_REFERENCE and other functions that expect a .* selector name. For example, JCR_REFERENCE(nt_base.jcr_properties) would become REFERENCE("nt:base".*) in the ModeShape query. - mysql5
- This translator is for use with MySQL version 5 or later. It also works with backwards-compatible MySQL derivatives, including MariaDB.The MySQL Translator expects the database or session to be using ANSI mode. If the database is not using ANSI mode, an initialization query must be used on the pool to set ANSI mode:
set SESSION sql_mode = 'ANSI'
set SESSION sql_mode = 'ANSI'Copy to Clipboard Copied! Toggle word wrap Toggle overflow If you deal with null timestamp values, then set the connection property zeroDateTimeBehavior=convertToNull. Otherwise you'll get conversion errors in Teiid that '0000-00-00 00:00:00' cannot be converted to a timestamp. - netezza
- This translator is for use with any Netezza version.
Important
The current Netezza vendor supplied JDBC driver performs poorly with single transactional updates. As is generally the case, use batched updates when possible.Netezza-specific execution properties:SqlExtensionsInstalled- indicates that SQL Extensions including support fo REGEXP_LIKE are installed. Defaults to false. - oracle
- This translator is for use with Oracle 9i or later.Sequences may be used with the Oracle translator. A sequence may be modeled as a table with a name in source of DUAL and columns with the name in source set to this:
<sequence name>.[nextval|currval].
<sequence name>.[nextval|currval].Copy to Clipboard Copied! Toggle word wrap Toggle overflow Teiid 8.4 and Prior Oracle Sequence DDLCREATE FOREIGN TABLE seq (nextval integer OPTIONS (NAMEINSOURCE 'seq.nextval'), currval integer options (NAMEINSOURCE 'seq.currval') ) OPTIONS (NAMEINSOURCE 'DUAL')
CREATE FOREIGN TABLE seq (nextval integer OPTIONS (NAMEINSOURCE 'seq.nextval'), currval integer options (NAMEINSOURCE 'seq.currval') ) OPTIONS (NAMEINSOURCE 'DUAL')Copy to Clipboard Copied! Toggle word wrap Toggle overflow With Teiid 8.5 it is no longer necessary to rely on a table representation and Oracle specific handling for sequences. See DDL Metadata for representing currval and nextval as source functions.You can also use a sequence as the default value for insert columns by setting the column to autoincrement and the name in source to this:<element name>:SEQUENCE=<sequence name>.<sequence value>
<element name>:SEQUENCE=<sequence name>.<sequence value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow A rownum column can be added to any Oracle physical table to support the rownum pseudo-column. The name of the column has to berownum.These rownum columns do not have the same semantics as the Oracle rownum construct so care must be taken in their usage.Oracle specific importer properties:useGeometryType- Use the Teiid Geomety type when importing columns with a source type of SDO_GEOMETRY. Defaults to false.useIntegralTypes- Use integral types rather than decimal when the scale is 0. Defaults to false.Execution properties specific to Oracle:- OracleSuppliedDriver - indicates that the Oracle supplied driver (typically prefixed by ojdbc) is being used. Defaults to true. Set to false when using DataDirect or other Oracle JDBC drivers.Oracle translator supports geo spatial functions. The supported functions are:
- Relate = sdo_relate
CREATE FOREIGN FUNCTION sdo_relate (arg1 string, arg2 string, arg3 string) RETURNS string; CREATE FOREIGN FUNCTION sdo_relate (arg1 Object, arg2 Object, arg3 string) RETURNS string; CREATE FOREIGN FUNCTION sdo_relate (arg1 string, arg2 Object, arg3 string) RETURNS string; CREATE FOREIGN FUNCTION sdo_relate (arg1 Object, arg2 string, arg3 string) RETURNS string;
CREATE FOREIGN FUNCTION sdo_relate (arg1 string, arg2 string, arg3 string) RETURNS string; CREATE FOREIGN FUNCTION sdo_relate (arg1 Object, arg2 Object, arg3 string) RETURNS string; CREATE FOREIGN FUNCTION sdo_relate (arg1 string, arg2 Object, arg3 string) RETURNS string; CREATE FOREIGN FUNCTION sdo_relate (arg1 Object, arg2 string, arg3 string) RETURNS string;Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Nearest_Neighbor = dso_nn
CREATE FOREIGN FUNCTION sdo_nn (arg1 string, arg2 Object, arg3 string, arg4 integer) RETURNS string; CREATE FOREIGN FUNCTION sdo_nn (arg1 Object, arg2 Object, arg3 string, arg4 integer) RETURNS string; CREATE FOREIGN FUNCTION sdo_nn (arg1 Object, arg2 string, arg3 string, arg4 integer) RETURNS string;
CREATE FOREIGN FUNCTION sdo_nn (arg1 string, arg2 Object, arg3 string, arg4 integer) RETURNS string; CREATE FOREIGN FUNCTION sdo_nn (arg1 Object, arg2 Object, arg3 string, arg4 integer) RETURNS string; CREATE FOREIGN FUNCTION sdo_nn (arg1 Object, arg2 string, arg3 string, arg4 integer) RETURNS string;Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Within_Distance = sdo_within_distance
CREATE FOREIGN FUNCTION sdo_within_distance (arg1 Object, arg2 Object, arg3 string) RETURNS string; CREATE FOREIGN FUNCTION sdo_within_distance (arg1 string, arg2 Object, arg3 string) RETURNS string; CREATE FOREIGN FUNCTION sdo_within_distance (arg1 Object, arg2 string, arg3 string) RETURNS string;
CREATE FOREIGN FUNCTION sdo_within_distance (arg1 Object, arg2 Object, arg3 string) RETURNS string; CREATE FOREIGN FUNCTION sdo_within_distance (arg1 string, arg2 Object, arg3 string) RETURNS string; CREATE FOREIGN FUNCTION sdo_within_distance (arg1 Object, arg2 string, arg3 string) RETURNS string;Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Nearest_Neighbour_Distance = sdo_nn_distance
CREATE FOREIGN FUNCTION sdo_nn_distance (arg integer) RETURNS integer;
CREATE FOREIGN FUNCTION sdo_nn_distance (arg integer) RETURNS integer;Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Filter = sdo_filter
CREATE FOREIGN FUNCTION sdo_filter (arg1 Object, arg2 string, arg3 string) RETURNS string; CREATE FOREIGN FUNCTION sdo_filter (arg1 Object, arg2 Object, arg3 string) RETURNS string; CREATE FOREIGN FUNCTION sdo_filter (arg1 string, arg2 object, arg3 string) RETURNS string;
CREATE FOREIGN FUNCTION sdo_filter (arg1 Object, arg2 string, arg3 string) RETURNS string; CREATE FOREIGN FUNCTION sdo_filter (arg1 Object, arg2 Object, arg3 string) RETURNS string; CREATE FOREIGN FUNCTION sdo_filter (arg1 string, arg2 object, arg3 string) RETURNS string;Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- osisoft-pi
- The OSISoft Translator, known by the type name osisoft-pi, is for use with OSIsoft PI OLEDB Enterprise. This translator uses the JDBC driver provided by the OSISoft.When you are installing on Linux, make sure you have the OpenSSL libraries installed, and you have these export statements added correctly to your shell environment variables. Otherwise you can also add it to the
[EAP_HOME]/bin/standalone.shfile or to the[EAP_HOME]/bin/domain.shfile.export PI_RDSA_LIB=/path/pipc/jdbc/lib/libRdsaWrapper-1.5b.so export PI_RDSA_LIB64=/path/pipc/jdbc/lib/libRdsaWrapper64-1.5b.so
export PI_RDSA_LIB=/path/pipc/jdbc/lib/libRdsaWrapper-1.5b.so export PI_RDSA_LIB64=/path/pipc/jdbc/lib/libRdsaWrapper64-1.5b.soCopy to Clipboard Copied! Toggle word wrap Toggle overflow To execute from Linux, you also need the gSoap library, as the PI JDBC driver uses SOAP over HTTPS to communicate with the PI server.To install on Microsoft Windows, follow the installation program provided by OSISoft for installing the JDBC drivers. Make sure you have these environment variables configured (the JDBC Driver installer sets them automatically):PI_RDSA_LIB C:\Program Files (x86)\PIPC\JDBC\RDSAWrapper.dll PI_RDSA_LIB64 C:\Program Files\PIPC\JDBC\RDSAWrapper64.dll
PI_RDSA_LIB C:\Program Files (x86)\PIPC\JDBC\RDSAWrapper.dll PI_RDSA_LIB64 C:\Program Files\PIPC\JDBC\RDSAWrapper64.dllCopy to Clipboard Copied! Toggle word wrap Toggle overflow The PI translator is an extension of jdbc-ansi translator, so all standard SQL ANSI queries are supported. The PI translator also you to performLATERALjoins with Table Valued Functions (TVF). Here is an example query:SELECT EH.Name, BT."Time", BT."Number of Computers", BT."Temperature" FROM Sample.Asset.ElementHierarchy EH LEFT JOIN LATERAL (exec "TransposeArchive_Building Template"(EH.ElementID, TIMESTAMPADD(SQL_TSI_HOUR, -1, now()), now())) BT on 1=1 WHERE EH.ElementID IN (SELECT ElementID FROM Sample.Asset.ElementHierarchy WHERE Path='\Data Center\')
SELECT EH.Name, BT."Time", BT."Number of Computers", BT."Temperature" FROM Sample.Asset.ElementHierarchy EH LEFT JOIN LATERAL (exec "TransposeArchive_Building Template"(EH.ElementID, TIMESTAMPADD(SQL_TSI_HOUR, -1, now()), now())) BT on 1=1 WHERE EH.ElementID IN (SELECT ElementID FROM Sample.Asset.ElementHierarchy WHERE Path='\Data Center\')Copy to Clipboard Copied! Toggle word wrap Toggle overflow Note
ANSI SQL semantics require aONclause, butCROSS APPLYorOUTER APPLYdo not use theONclause. For this reason you must pass in a dummyONclause likeON (1 = 1), which will be ignored when converted to theAPPLYclause which will be pushed down.By default this translator sets theimporter.ImportKeysto false.Note
You must model the PI data type,GUID,Stringand define theNATIVE_TYPEon the column asguid, then the translator will appropriately convert the data back and forth with the PI datasource’s native GUID type with appropriate type casting from the string. - postgresql
- This translator is for use with 8.0 or later clients and 7.1 or later server.PostgreSQL specific execution properties:PostGisVersion - indicate the PostGIS version in use. Defaults to 0 meaning PostGIS is not installed. Will be set automatically if the database version is not set.ProjSupported - boolean indicating if Proj is support for PostGis. Will be set automatically if the database version is not set.
- prestodb
- The PrestoDB translator, known by the type name prestodb, exposes querying functionality to PrestoDB Data Sources. In data integration respect, PrestoDB has very similar capabilities of Teiid, however it goes beyond in terms of distributed query execution with multiple worker nodes. Teiid's execution model is limited to single execution node and focuses more on pushing the query down to sources. Currently Teiid has much more complete query support and many enterprise features.The PrestoDB translator supports only SELECT statements with a restrictive set of capabilities. This translator is developed with 0.85 version of PrestoDB and capabilities are designed for this version. With new versions of PrestoDB Teiid will adjust the capabilities of this translator. Since PrestoDB exposes a relational model, the usage of this is no different than any RDBMS source like Oracle, DB2 etc. For configuring the PrestoDB consult the PrestoDB documentation.
Note
PrestoDB does not support multiple columns in theORDER BYinJOINsituations. The translator propertysupportsOrderBycan be used to disableOrder byin some specific situations.Note
Some versions of PrestoDB do not support nulls as valid values in subqueries.Note
PrestoDB does not support transactions. To overcome issues caused by this limitation, define the datasource as non-transactional.Note
Every catalog in PrestoDB has aninformation_schemaby default. If you have to configure multiple catalogs, use import options to filter the schemas, to avoid a duplicate table error that causes the VDB deploy to fail. For instance, setcatalogto a specific catalog name to match the catalog name as it is stored in the PrestoDB, setschemaPatternto a regular expression to filter schemas by matching result and setexcludeTablesto a regular expression to filter tables by matching results.Note
The PrestoDB JDBC driver uses the Joda-Time library to work with time/date/timestamps. If you need to customize your server’s time zone (using the setting-Duser.timezone via JAVA_OPTS), you cannot use theGMT/…ID as Joda-Time does not recognize it. However, you can use equivalentETC/...ID. - redshift
- The Redshift Translator, known by the type name redshift, is for use with the Redshift database. This translator is an extension of the PostgreSQL Translator and inherits its options.
- sqlserver
- This translator is for use with SQL Server 2000 or later. A SQL Server JDBC driver version 2.0 or later (or compatible e.g. JTDS 1.2 or later) must be used. The SQL Server
DatabaseVersionproperty may be set to 2000, 2005, 2008, or 2012, but otherwise expects a standard version number, for example, 10.0.Execution properties specific to SQL Server:- JtdsDriver - indicates that the open source JTDS driver is being used. Defaults to false.
- sybase
- This translator is for use with Sybase version 12.5 or later. If used in a dynamic vdb and no import properties are specified (not recommended, see import properties below), then exceptions can be thrown retrieving system table information. Specify a schemaPattern or use excludeTables to exclude system tables if this occurs.If the name in source metadata contains quoted identifiers (such as reserved words or words containing characters that would not otherwise be allowed) and you are using a jconnect Sybase driver, you must first configure the connection pool to enable
quoted_identifier.Example 12.2. Driver URL with SQLINITSTRING
jdbc:sybase:Tds:host.at.some.domain:5000/db_name?SQLINITSTRING=set quoted_identifier on
jdbc:sybase:Tds:host.at.some.domain:5000/db_name?SQLINITSTRING=set quoted_identifier onCopy to Clipboard Copied! Toggle word wrap Toggle overflow Execution properties specific to Sybase:- JtdsDriver - indicates that the open source JTDS driver is being used. Defaults to false.
Important
You must set the connection parameter JCONNECT_VERSION to 6 or later when using the Sybase data source. If you do not do so, you will encounter an exception.
- sybaseiq
- This translator is for use with Sybase IQ version 15.1 or later.
- teiid
- This translator is for use with Teiid 6.0 or later.
- teradata
- This translator is for use with Teradata V2R5.1 or later.
- vertica
- This translator is for use with Vertica 6 or later.
12.18.5. JDBC Translator: Usage
12.18.6. JDBC Translator: Native Queries
12.18.7. JDBC Translator: Native Procedure
Warning
Example 12.3. Select Example
SELECT x.* FROM (call pm1.native('select * from g1')) w,
ARRAYTABLE(w.tuple COLUMNS "e1" integer , "e2" string) AS x
SELECT x.* FROM (call pm1.native('select * from g1')) w,
ARRAYTABLE(w.tuple COLUMNS "e1" integer , "e2" string) AS x
Example 12.4. Insert Example
SELECT x.* FROM (call pm1.native('insert into g1 (e1,e2) values (?, ?)', 112, 'foo')) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
SELECT x.* FROM (call pm1.native('insert into g1 (e1,e2) values (?, ?)', 112, 'foo')) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
Example 12.5. Update Example
SELECT x.* FROM (call pm1.native('update g1 set e2=? where e1 = ?','blah', 112)) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
SELECT x.* FROM (call pm1.native('update g1 set e2=? where e1 = ?','blah', 112)) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
Example 12.6. Delete Example
SELECT x.* FROM (call pm1.native('delete from g1 where e1 = ?', 112)) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
SELECT x.* FROM (call pm1.native('delete from g1 where e1 = ?', 112)) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
Important
vdb.xml file to change it to any other procedure name. See Section 12.6, “Override Execution Properties”.
12.19. JPA Translator
Warning
Note
SELECT x.* FROM (call jpa_source.native('search;FROM Account')) w,
ARRAYTABLE(w.tuple COLUMNS "id" string , "type" string, "name" String) AS x
SELECT x.* FROM (call jpa_source.native('search;FROM Account')) w,
ARRAYTABLE(w.tuple COLUMNS "id" string , "type" string, "name" String) AS x
SELECT x.* FROM (call jpa_source.native('delete;<jpa-ql>')) w,
ARRAYTABLE(w.tuple COLUMNS "updatecount" integer) AS x
SELECT x.* FROM (call jpa_source.native('delete;<jpa-ql>')) w,
ARRAYTABLE(w.tuple COLUMNS "updatecount" integer) AS x
SELECT x.* FROM
(call jpa_source.native('update;<jpa-ql>')) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
SELECT x.* FROM
(call jpa_source.native('update;<jpa-ql>')) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
SELECT x.* FROM
(call jpa_source.native('create;', <entity>)) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
SELECT x.* FROM
(call jpa_source.native('create;', <entity>)) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
12.20. LDAP Translator
12.20.1. LDAP Translator
org.teiid.translator.ldap.LDAPExecutionFactory class and known by the translator type name ldap.
Note
ldap data source in the JBoss EAP instance. See the Red Hat JBoss Data Virtualization Administration and Configuration Guide for more configuration information.
12.20.2. LDAP Translator: Execution Properties
| Name | Description | Default |
|---|---|---|
| SearchDefaultBaseDN | Default Base DN for LDAP Searches | null |
| SearchDefaultScope | Default Scope for LDAP Searches. Can be one of SUBTREE_SCOPE, OBJECT_SCOPE, ONELEVEL_SCOPE. | ONELEVEL_SCOPE |
| RestrictToObjectClass | Restrict Searches to objectClass named in the Name field for a table | false |
| UsePagination | Use a PagedResultsControl to page through large results. This is not supported by all directory servers. | false |
| ExceptionOnSizeLimitExceeded | Set to true to throw an exception when a SizeLimitExceededException is received and a LIMIT is not properly enforced. | false |
Note
create foreign table ldap_groups (objectClass string[], DN string, name string options (nameinsource 'cn'), uniqueMember string[]) options (nameinsource 'ou=groups,dc=teiid,dc=org', updatable true)
create foreign table ldap_groups (objectClass string[], DN string, name string options (nameinsource 'cn'), uniqueMember string[]) options (nameinsource 'ou=groups,dc=teiid,dc=org', updatable true)
insert into ldap_groups (objectClass, DN, name, uniqueMember) values (('top', 'groupOfUniqueNames'), 'cn=a,ou=groups,dc=teiid,dc=org', 'a', ('cn=Sam Smith,ou=people,dc=teiid,dc=org',))
insert into ldap_groups (objectClass, DN, name, uniqueMember) values (('top', 'groupOfUniqueNames'), 'cn=a,ou=groups,dc=teiid,dc=org', 'a', ('cn=Sam Smith,ou=people,dc=teiid,dc=org',))
12.20.3. LDAP Translator: Native Queries
CREATE FOREIGN PROCEDURE proc (arg1 integer, arg2 string) OPTIONS ("teiid_rel:native-query" 'search;context-name=corporate;filter=(&(objectCategory=person)(objectClass=user)(!cn=$2));count-limit=5;timeout=$1;search-scope=ONELEVEL_SCOPE;attributes=uid,cn') returns (col1 string, col2 string);
CREATE FOREIGN PROCEDURE proc (arg1 integer, arg2 string) OPTIONS ("teiid_rel:native-query" 'search;context-name=corporate;filter=(&(objectCategory=person)(objectClass=user)(!cn=$2));count-limit=5;timeout=$1;search-scope=ONELEVEL_SCOPE;attributes=uid,cn') returns (col1 string, col2 string);
Note
12.20.4. LDAP Translator: Native Procedure
Warning
12.20.5. LDAP Translator Example: Search
Example 12.7. Search Example
SELECT x.* FROM (call pm1.native('search;context-name=corporate;filter=(objectClass=*);count-limit=5;timeout=6;search-scope=ONELEVEL_SCOPE;attributes=uid,cn')) w,
ARRAYTABLE(w.tuple COLUMNS "uid" string , "cn" string) AS x
SELECT x.* FROM (call pm1.native('search;context-name=corporate;filter=(objectClass=*);count-limit=5;timeout=6;search-scope=ONELEVEL_SCOPE;attributes=uid,cn')) w,
ARRAYTABLE(w.tuple COLUMNS "uid" string , "cn" string) AS x
|
Name
|
Description
|
Required
|
|---|---|---|
|
context-name
|
LDAP Context name
|
Yes
|
|
filter
|
query to filter the records in the context
|
No
|
|
count-limit
|
limit the number of results. same as using LIMIT
|
No
|
|
timeout
|
Time out the query if not finished in given milliseconds
|
No
|
|
search-scope
|
LDAP search scope, one of SUBTREE_SCOPE, OBJECT_SCOPE, ONELEVEL_SCOPE
|
No
|
|
attributes
|
attributes to retrieve
|
Yes
|
12.20.6. LDAP Translator Example: Delete
Example 12.8. Delete Example
SELECT x.* FROM (call pm1.native('delete;uid=doe,ou=people,o=teiid.org')) w,
ARRAYTABLE(w.tuple COLUMNS "updatecount" integer) AS x
SELECT x.* FROM (call pm1.native('delete;uid=doe,ou=people,o=teiid.org')) w,
ARRAYTABLE(w.tuple COLUMNS "updatecount" integer) AS x
12.20.7. LDAP Translator Example: Create and Update
Example 12.9. Create Example
SELECT x.* FROM
(call pm1.native('create;uid=doe,ou=people,o=teiid.org;attributes=one,two,three', 'one', 2, 3.0)) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
SELECT x.* FROM
(call pm1.native('create;uid=doe,ou=people,o=teiid.org;attributes=one,two,three', 'one', 2, 3.0)) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
Example 12.10. Update Example
SELECT x.* FROM
(call pm1.native('update;uid=doe,ou=people,o=teiid.org;attributes=one,two,three', 'one', 2, 3.0)) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
SELECT x.* FROM
(call pm1.native('update;uid=doe,ou=people,o=teiid.org;attributes=one,two,three', 'one', 2, 3.0)) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
Important
vdb.xml file. See Section 12.6, “Override Execution Properties”.
12.20.8. LDAP Connector Capabilities Support
SELECTclause support- select individual element support (firstname, lastname, guid)
FROMsupportWHEREclause criteria support- nested criteria support
- AND, OR support
- Compare criteria (Greater-than) support
INsupport
12.20.9. LDAP Connector Capabilities Support List
SELECTqueriesSELECTelement pushdown (for example, individual attribute selection)ANDcriteria- Compare criteria (e.g. <, <=, >, >=, =, !=)
INcriteriaLIKEcriteria.ORcriteriaINSERT,UPDATE,DELETEstatements (must meet Modeling requirements)
SELECTqueries
- Functions
- Aggregates
BETWEENCriteria- Case Expressions
- Aliased Groups
- Correlated Subqueries
EXISTSCriteria- Joins
- Inline views
IS NULLcriteriaNOTcriteriaORDER BY- Quantified compare criteria
- Row Offset
- Searched Case Expressions
- Select Distinct
- Select Literals
UNION- XA Transactions
ldap translator in the vdb.xml file.
standalone-teiid.xml file. See a example in JBOSS-HOME/docs/teiid/datasources/ldap.
SELECT * FROM HR_Group
SELECT * FROM HR_Group
12.20.10. LDAP Attribute Datatype Support
java.lang.String and byte[], and do not support the ability to return any other attribute value type. The LDAP Connector currently supports attribute value types of java.lang.String only. Therefore, all attributes are modeled using the String datatype in Teiid Designer.
CONVERT functions.
CONVERT functions are not supported by the underlying LDAP system, they will be evaluated in JBoss Data Virtualization. Therefore, if any criteria is evaluated against a converted datatype, that evaluation cannot be pushed to the data source, since the native type is String.
Note
12.20.11. LDAP: Testing Your Connector
12.20.12. LDAP: Console Deployment Issues
If you receive an exception when you synchronize the server and your LDAP Connector is the only service that does not start, it means that there was a problem starting the connector. Verify whether you have correctly typed in your connector properties to resolve this issue.
12.21. Loopback Translator
| Name | Description | Default |
|---|---|---|
ThrowError |
True to always throw an error
|
false
|
RowCount |
Rows returned for non-update queries.
|
1
|
WaitTime |
True to always throw an error
|
false
|
PollIntervalInMilli |
if positive results will be "asynchronously" returned - that is a DataNotAvailableException will be thrown initially and the engine will wait the poll interval before polling for the results.
|
-1
|
DelegateName |
Set to the name of the translator which is to be mimicked.
|
-
|
12.22. Microsoft Excel Translator
Note
| Excel Term | Relational Term |
|---|---|
| Workbook |
schema
|
| Sheet |
Table
|
| Row |
Row of data
|
| Cell |
Column Definition or Data of a column
|
jboss-as/docs/teiid/datasources/file. Once you configure both of the above, you can deploy them to Teiid Server and access the Excel Document using either the JDB, ODBC or OData protocol.
Note
| Property | Description | Default |
|---|---|---|
| importer.excelFileName |
Defines the name of the Excel Document
|
required
|
| importer.headerRowNumber |
optional, default is first data row of sheet
|
required
|
| importer.dataRowNumber |
optional, default is first data row of sheet
|
required
|
Note
Note
| Property | Schema Item | Description | Mandatory? |
|---|---|---|---|
| FILE |
Table
|
Defines Excel Document name or name pattern
|
yes
|
| FIRST_DATA_ROW_NUMBER |
Table
|
Defines the row number where records start
|
Optional
|
| CELL_NUMBER |
Column of Table
|
Defines cell number to use for reading data of particular column
|
Yes
|
Note
Note
12.23. MongoDB Translator
12.23.1. MongoDB
12.23.2. MongoDB Translator
- Users that are using relational databases and would like to move/migrate their data to MongoDB to take advantage of scaling and performance, without modifying end user applications that are currently running.
- Users that are starting out with MongoDB and do not have experience with MongoDB, but are seasoned SQL developers. This provides a low barrier of entry compared to using MongoDB directly as an application developer.
- Integrating other enterprise data sources with MongoDB based data.
Note
Note
EAP_HOME/docs/teiid/datasources/mongodb.
12.23.3. MongoDB Translator: Example DDL
INSERT INTO Customer(customer_id, FirstName, LastName) VALUES (1, 'John', 'Doe');
INSERT INTO Customer(customer_id, FirstName, LastName) VALUES (1, 'John', 'Doe');
Note
Note
12.23.4. MongoDB Translator: Metadata Extensions
- teiid_mongo:EMBEDDABLE - Means that data defined in this table is allowed to be included as an "embeddable" document in any parent document. The parent document is referenced by the foreign key relationships. In this scenario, Teiid maintains more than one copy of the data in MongoDB store, one in its own collection and also a copy in each of the parent tables that have relationship to this table. You can even nest embeddable table inside another embeddable table with some limitations. Use this property on table, where table can exist, encompass all its relations on its own. For example, a "Category" table that defines a "Product"'s category is independent of Product, which can be embeddable in "Products" table.
- teiid_mongo:MERGE - Means that data of this table is merged with the defined parent table. There is only a single copy of the data that is embedded in the parent document. Parent document is defined using the foreign key relationships.
Important
- EMBEDDABLE - Means that data defined in this table is allowed to be included as an "embeddable" document in a parent document. The parent document is defined by the foreign key relationships. In this situation, JBoss Data Services maintains more than one copy of the data in a MongoDB store: one in its own collection and also a copy in each of the parent tables that have relationship to this table.
- EMBEDIN - Means that data of this table is embedded in the defined parent table. There is only a single copy of the data that is embedded in the parent document.
- ONE-2-ONE: Here is the DDL structure representing the ONE-2-ONE relationship:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow By default, this will produce two different collections in MongoDB, like with sample data it will look like this:Copy to Clipboard Copied! Toggle word wrap Toggle overflow You can enhance the storage in MongoDB to a single collection by using "teiid_mongo:MERGE' extension property on the table's OPTIONS clause:Copy to Clipboard Copied! Toggle word wrap Toggle overflow This will produce a single collection in the MongoDB:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Both tables are merged into a single collection that can be queried together using the JOIN clause in the SQL command. Since the existence of child/additional record has no meaning with out parent table using the "teiid_mongo:MERGE" extension property is right choice in this situation.Note
Note that the Foreign Key defined on child table, must refer to Primary Keys on both parent and child tables to form a One-2-One relationship. - ONE-2-MANY: Typically there are only two tables involved in this relationship. If MANY side is only associated one table, then use "EMBEDIN" property on MANY side of table and define the parent. If associated with more than single table, then use "EMBEDDABLE". When MANY side is stored in ONE side, they are stored as array of embedded document. If associated with more than single table then use "teiid_mongo:EMBEDDABLE".Here is a sample DDL:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow In this sample, a single Customer can have many orders. There are two options to define the how we store the MongoDB document. If in your schema, the Customer table's CustomerId is only referenced in Order table (i.e. Customer information used for only Order purposes), you can useCopy to Clipboard Copied! Toggle word wrap Toggle overflow This will produce a single document for the customer table:Copy to Clipboard Copied! Toggle word wrap Toggle overflow If the customer table is referenced in more tables other than Order table, then use the "teiid_mongo:EMBEDDABLE" property:Copy to Clipboard Copied! Toggle word wrap Toggle overflow This creates three different collections in MongoDB:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Here the Customer table contents are embedded along with other table's data where they were referenced. This creates duplicated data where multiple of these embedded documents are managed automatically in the MongoDB translator.Warning
All the SELECT, INSERT, DELETE operations that are generated against the tables with "teiid_mongo:EMBEDDABLE" property are atomic, except for UPDATES, as there can be multiple operations involved to update all the copies. - MANY-2-ONE: This is the same as ONE-2-MANY. Apply them in reverse.
Note
A parent table can have multiple "embedded" and as well as "merge" documents inside it, it not limited so either one or other. However, please note that MongoDB imposes document size is limited can not exceed 16MB. - Many-to-Many: This can also mapped with combination of "teiid_mongo:MERGE" and "teiid_mongo:EMBEDDABLE" properties (partially). Here is a sample DDL:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Modify the DDL so that it looks like this:Copy to Clipboard Copied! Toggle word wrap Toggle overflow A document that looks like this is produced:Copy to Clipboard Copied! Toggle word wrap Toggle overflow Warning
- Currently nested embedding of documents has limited support due to capabilities of handling nested arrays is limited in the MongoDB. Nesting of "EMBEDDABLE" property with multiple levels is allowed but more than one level with MERGE is not. Also, be careful not to exceed the document size of 16 MB for a single row, (hence deep nesting is not recommended).
- JOINS between related tables, must use either the "EMBEDDABLE" or "MERGE" property, otherwise the query will result in error. In order for Teiid to correctly plan and support the JOINS, in the case that any two tables are NOT embedded in each other, use allow-joins=false property on the Foreign Key that represents the relation. Here is an example:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow In this case, Teiid will create two collections. However when a user issues query such as this, instead of resulting in error, the JOIN processing will happen in the Teiid engine, without the above property it will result in an error:SELECT OrderID, LastName FROM Order JOIN Customer ON Order.CustomerId = Customer.CustomerId;
SELECT OrderID, LastName FROM Order JOIN Customer ON Order.CustomerId = Customer.CustomerId;Copy to Clipboard Copied! Toggle word wrap Toggle overflow
SELECT loc FROM maps where mongo.geoWithin(loc, 'LineString', ((cast(1.0 as double), cast(2.0 as double)), (cast(1.0 as double), cast(2.0 as double))))
SELECT loc FROM maps where mongo.geoWithin(loc, 'LineString', ((cast(1.0 as double), cast(2.0 as double)), (cast(1.0 as double), cast(2.0 as double))))
Important
Warning
Note
select x.* from TABLE(call native('city;{$match:{"city":"FREEDOM"}}')) t,
xmltable('/city' PASSING JSONTOXML('city', cast(array_get(t.tuple, 1) as BLOB)) COLUMNS city string, state string) x
select x.* from TABLE(call native('city;{$match:{"city":"FREEDOM"}}')) t,
xmltable('/city' PASSING JSONTOXML('city', cast(array_get(t.tuple, 1) as BLOB)) COLUMNS city string, state string) x
Important
"collectionName;{$pipeline instr}+"
"collectionName;{$pipeline instr}+"
"$ShellCmd;collectionName;operationName;{$instr}+"
"$ShellCmd;collectionName;operationName;{$instr}+"
"$ShellCmd;MyTable;remove;{ qty: { $gt: 20 }}"
"$ShellCmd;MyTable;remove;{ qty: { $gt: 20 }}"12.24. Object Translator
12.24.1. Object Translator
map-cache- supports a local cache that is of type Map and using Key searching. This translator is implemented by theorg.teiid.translator.object.ObjectExecutionFactoryclass.
Note
12.24.2. Object Translator: Execution Properties
|
Name
|
Description
|
Required
|
Default
|
|---|---|---|---|
|
SupportsLuceneSearching
|
Setting to true assumes your objects are annotated and Hibernate/Lucene will be used to search the cache
|
N
|
false
|
12.24.3. Object Translator: Supported Capabilities
- SELECT command
- CompareCriteria - only EQ
- InCriteria
- SELECT command
- CompareCriteria - EQ, NE, LT, GT, etc.
- InCriteria
- OrCriteria
- And/Or Criteria
- Like Criteria
- INSERT, UPDATE, DELETE
12.24.4. Object Translator: Usage
- The primary object returned by the cache should have a name in source of 'this'. All other columns will have their name in source (which defaults to the column name) interpreted as the path to the column value from the primary object.
- All columns that are not the primary key nor covered by a lucene index should be marked as SEARCHABLE 'Unsearchable'.
12.25. OData Translator
12.25.1. OData Translator
org.teiid.translator.odata.ODataExecutionFactory class and known by the translator type name odata.
Note
|
OData
|
Mapped to Relational Entity
|
|---|---|
|
EntitySet
|
Table
|
|
FunctionImport
|
Procedure
|
|
AssociationSet
|
Foreign Keys on the Table*
|
|
ComplexType
|
ignored**
|
Note
webservice data source in the JBoss EAP instance. See the Red Hat JBoss Data Virtualization Administration and Configuration Guide for more configuration information.
12.25.2. OData Translator: Execution Properties
|
Name
|
Description
|
Default
|
|---|---|---|
|
DatabaseTimeZone
|
The time zone of the database. Used when fetching date, time, or timestamp values
|
The system default time zone
|
12.25.3. OData Translator: Importer Properties
|
Name
|
Description
|
Default
|
|---|---|---|
|
schemaNamespace
|
Namespace of the schema to import
|
null
|
|
entityContainer
|
Entity Container Name to import
|
default container
|
<property name="importer.schemaNamespace" value="System.Data.Objects"/> <property name="importer.schemaPattern" value="NetflixCatalog"/>
<property name="importer.schemaNamespace" value="System.Data.Objects"/>
<property name="importer.schemaPattern" value="NetflixCatalog"/>
12.25.4. OData Translator: Usage
| Property | Description | Default |
|---|---|---|
| DatabaseTimeZone |
The time zone of the database. Used when fetchings date, time, or timestamp values
|
The system default time zone
|
| SupportsOdataCount |
Supports $count
|
True
|
| SupportsOdataFilter |
Supports $filter
|
True
|
| SupportsOdataOrderBy |
Supports $orderby
|
true
|
| SupportsOdataSkip |
Supports $skip
|
True
|
| SupportsOdataTop |
Supports $top
|
True
|
| Property | Description | Default |
|---|---|---|
| schemaNamespace |
Namespace of the schema to import
|
Null
|
| entityContainer |
Entity Container Name to import
|
Default container
|
<property name="importer.schemaNamespace" value="System.Data.Objects"/> <property name="importer.schemaPattern" value="NetflixCatalog"/>
<property name="importer.schemaNamespace" value="System.Data.Objects"/>
<property name="importer.schemaPattern" value="NetflixCatalog"/>
Note
<translator name="odata-override" type="odata"> <property name="SupportsOdataFilter" value="false"/> </translator>
<translator name="odata-override" type="odata">
<property name="SupportsOdataFilter" value="false"/>
</translator>
Note
Note
12.26. OData Version 4 Translator
12.26.1. OData Version 4 Translator
| OData | Relational Entity |
|---|---|
| EntitySet | Table |
| EntityType | Table. (This is only mapped if the EntityType is exposed as the EntitySet in the Entity Container.) |
| ComplexType | Table. (This is mapped only if the complex type is used as a property in the exposed EntitySet. This table will be either a child table with a foreign key [one to one] or [one to many] relationship with its parent.) |
| FunctionImport | Procedure. (If the return type is EntityType or ComplexType, the procedure will return a table.) |
| ActionImport | Procedure. (If the return type is EntityType or ComplexType, the procedure will return a table.) |
| NavigationProperties | Table. (Navigation properties are exposed as tables. These tables are created with foreign key relationships to the parent.) |
- Configure your resource adapter to look like this:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Deployed the virtual database.
- Connect to it using the JDBC driver.
- You can then issue SQL queries like these:
SELECT * FROM trippin.People; SELECT * FROM trippin.People WHERE UserName = 'russelwhyte'; SELECT * FROM trippin.People p INNER JOIN trippin.People_Friends pf ON p.UserName = pf.People_UserName; EXEC GetNearestAirport(lat, lon) ;
SELECT * FROM trippin.People; SELECT * FROM trippin.People WHERE UserName = 'russelwhyte'; SELECT * FROM trippin.People p INNER JOIN trippin.People_Friends pf ON p.UserName = pf.People_UserName; EXEC GetNearestAirport(lat, lon) ;Copy to Clipboard Copied! Toggle word wrap Toggle overflow Note
People_UserName is implicitly added by the metadata.
12.26.1.1. Translator Configuration Options
12.26.1.1.1. Execution Options
| Name | Description | Default |
|---|---|---|
| SupportsOdataCount | Supports $count | true |
| SupportsOdataFilter | Supports $filter | true |
| SupportsOdataOrderBy | Supports $orderby | true |
| SupportsOdataSkip | Supports $skip | true |
| SupportsOdataTop | Supports $top | true |
| SupportsUpdates | Supports INSERT/UPDATE/DELETE | true |
- To turn off $filter, add the following configuration to your vdb.xml file:
<translator name="odata-override" type="odata"> <property name="SupportsOdataFilter" value="false"/> </translator><translator name="odata-override" type="odata"> <property name="SupportsOdataFilter" value="false"/> </translator>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Use "odata-override" as the source model's translator name.
12.26.1.1.2. Importer Properties
| Name | Description | Default |
|---|---|---|
| schemaNamespace | This is the namespace of the schema to import. | null |
<property name="importer.schemaNamespace" value="Microsoft.OData.SampleService.Models.TripPin"/>
<property name="importer.schemaNamespace" value="Microsoft.OData.SampleService.Models.TripPin"/>
Note
12.26.1.1.3. JCA Resource Adapter
Important
12.27. OLAP Translator
12.27.1. OLAP Translator
org.teiid.translator.olap.OlapExecutionFactory class and known by the translator type name olap.
Note
mondrian.xml). To access any other OLAP servers using XMLA interface, the data source for them can be created using the example template in olap-xmla.xml. These example files can be found in the EAP_HOME/docs/teiid/datasources/ directory. See the Red Hat JBoss Data Virtualization Administration and Configuration Guide for more configuration information.
12.27.2. OLAP Translator: Usage
invokeMDX.
invokeMdx returns a result set of the tuples as array values.
Procedure invokeMdx(mdx in STRING, params VARIADIC OBJECT) returns table (tuple object)
Procedure invokeMdx(mdx in STRING, params VARIADIC OBJECT) returns table (tuple object)Note
12.27.3. OLAP Translator: Native Queries
Note
12.27.4. OLAP Translator: Native Procedure
12.28. Salesforce Translator
12.28.1. Properties
SELECT, DELETE, INSERT and UPDATE operations against a Salesforce.com account.
Important
salesforce, provides Salesforce API 22.0 support. The translator must be used with the corresponding Salesforce resource adapter of the same API version.
Note
salesforce data source in the Red Hat JBoss EAP instance.
salesforce-34, provides Salesforce API 34.0 support. The translator must be used with the corresponding Salesforce resource adapter of the same API version.
- Create a self-signed certificate in Salesforce by clicking ->->->.
- Download the certificate and the keystore.
- Create a connected application and select and click all the .
- Save the custom domain.
- Create a profile and a permission set assigned to the connected application.
- Add the certificate by clicking .
- Add the security domain to the settings file:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
12.28.2. Salesforce Translator: Execution Properties
| Name | Description | Default |
|---|---|---|
| ModelAuditFields | Audit Model Fields | false |
| MaxBulkInsertBatchSize | Batch size to use when inserting in bulk | 2048 |
| Name | Description | Required | Default |
|---|---|---|---|
| NormalizeNames | If the importer should attempt to modify the object/field names so that they can be used unquoted. | false | true |
| excludeTables | A case-insensitive regular expression that when matched against a table name will exclude it from import. Applied after table names are retrieved. Use a negative look-ahead inclusion pattern to act as an inclusion filter. | false | n/a |
| includeTables | A case-insensitive regular expression that when matched against a table name will be included during import. Applied after table names are retrieved from source. | false | n/a |
| importStatstics | Retrieves cardinalities during import using the REST API explain plan feature. | false | false |
12.28.3. Salesforce Translator: SQL Processing
SELECT sum(Reports) FROM Supervisor where Division = 'customer support';
SELECT sum(Reports) FROM Supervisor where Division = 'customer support';SELECT Reports FROM Supervisor where Division = 'customer support';
SELECT Reports FROM Supervisor where Division = 'customer support';DELETE From Case WHERE Status = 'Closed';
DELETE From Case WHERE Status = 'Closed';SELECT ID From Case WHERE Status = 'Closed'; DELETE From Case where ID IN (<result of query>);
SELECT ID From Case WHERE Status = 'Closed';
DELETE From Case where ID IN (<result of query>);12.28.4. Salesforce Translator: Multi-Select Picklists
boolean includes(Column column, String param) boolean excludes(Column column, String param)
boolean includes(Column column, String param)
boolean excludes(Column column, String param)- current
- working
- critical
SELECT * FROM Issue WHERE true = includes (Status, 'current, working' ); SELECT * FROM Issue WHERE true = excludes (Status, 'current, working' ); SELECT * FROM Issue WHERE true = includes (Status, 'current;working, critical' );
SELECT * FROM Issue WHERE true = includes (Status, 'current, working' );
SELECT * FROM Issue WHERE true = excludes (Status, 'current, working' );
SELECT * FROM Issue WHERE true = includes (Status, 'current;working, critical' );SELECT * FROM Issue WHERE Status = 'current'; SELECT * FROM Issue WHERE Status = 'current;critical'; SELECT * FROM Issue WHERE Status != 'current;working';
SELECT * FROM Issue WHERE Status = 'current';
SELECT * FROM Issue WHERE Status = 'current;critical';
SELECT * FROM Issue WHERE Status != 'current;working';12.28.5. Salesforce Translator: Selecting All Objects
select * from Contact where isDeleted = true;
select * from Contact where isDeleted = true;select * from Contact where isDeleted = false;
select * from Contact where isDeleted = false;12.28.6. Salesforce Translator: Selecting Updated Objects
12.28.7. Salesforce Translator: Selecting Deleted Objects
12.28.8. Salesforce Translator: Relationship Queries
SELECT Account.name, Contact.Name from Contact LEFT OUTER JOIN Account on Contact.Accountid = Account.id
SELECT Account.name, Contact.Name from Contact LEFT OUTER JOIN Account
on Contact.Accountid = Account.idSELECT Contact.Account.Name, Contact.Name FROM Contact
SELECT Contact.Account.Name, Contact.Name FROM Contactselect Contact.Name, Account.Name from Account Left outer Join Contact on Contact.Accountid = Account.id
select Contact.Name, Account.Name from Account Left outer Join Contact
on Contact.Accountid = Account.idSELECT Account.Name, (SELECT Contact.Name FROM Account.Contacts) FROM Account
SELECT Account.Name, (SELECT Contact.Name FROM
Account.Contacts) FROM Account12.28.9. Salesforce Translator: Bulk Insert Queries
vdb.xml file. The default value of the batch is 2048. The bulk insert feature uses the async REST based API exposed by Salesforce for execution for better performance.
12.28.10. Salesforce Translator: Supported Capabilities
- SELECT command
- INSERT Command
- UPDATE Command
- DELETE Command
- CompareCriteriaEquals
- InCriteria
- LikeCriteria - Supported for String fields only.
- RowLimit
- AggregatesCountStar
- NotCriteria
- OrCriteria
- CompareCriteriaOrdered
- OuterJoins with join criteria KEY
12.28.11. Salesforce Translator: Native Queries
Example 12.11. Example DDL for a SF native procedure
CREATE FOREIGN PROCEDURE proc (arg1 integer, arg2 string) OPTIONS ("teiid_rel:native-query" 'search;SELECT ... complex SOQL ... WHERE col1 = $1 and col2 = $2') returns (col1 string, col2 string, col3 timestamp);
CREATE FOREIGN PROCEDURE proc (arg1 integer, arg2 string) OPTIONS ("teiid_rel:native-query" 'search;SELECT ... complex SOQL ... WHERE col1 = $1 and col2 = $2') returns (col1 string, col2 string, col3 timestamp);
12.28.12. Salesforce Translator: Native Procedure
Warning
12.28.13. Salesforce Translator Example: Select
Example 12.12. Select Example
SELECT x.* FROM (call pm1.native('search;SELECT Account.Id, Account.Type, Account.Name FROM Account')) w,
ARRAYTABLE(w.tuple COLUMNS "id" string , "type" string, "name" String) AS x
SELECT x.* FROM (call pm1.native('search;SELECT Account.Id, Account.Type, Account.Name FROM Account')) w,
ARRAYTABLE(w.tuple COLUMNS "id" string , "type" string, "name" String) AS x
Note
12.28.14. Salesforce Translator Example: Delete
Example 12.13. Delete Example
SELECT x.* FROM (call pm1.native('delete;', 'id1', 'id2')) w,
ARRAYTABLE(w.tuple COLUMNS "updatecount" integer) AS x
SELECT x.* FROM (call pm1.native('delete;', 'id1', 'id2')) w,
ARRAYTABLE(w.tuple COLUMNS "updatecount" integer) AS x
12.28.15. Salesforce Translator Example: Create and Update
Example 12.14. Create Example
SELECT x.* FROM
(call pm1.native('create;type=table;attributes=one,two,three', 'one', 2, 3.0)) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
SELECT x.* FROM
(call pm1.native('create;type=table;attributes=one,two,three', 'one', 2, 3.0)) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
|
Property Name
|
Description
|
Required
|
|---|---|---|
|
type
|
Table Name
|
Yes
|
|
attributes
|
comma separated list of names of the columns
| |
Example 12.15. Update Example
SELECT x.* FROM
(call pm1.native('update;id=pk;type=table;attributes=one,two,three', 'one', 2, 3.0)) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
SELECT x.* FROM
(call pm1.native('update;id=pk;type=table;attributes=one,two,three', 'one', 2, 3.0)) w,
ARRAYTABLE(w.tuple COLUMNS "update_count" integer) AS x
Important
vdb.xml file to change it.
12.29. SAP Gateway Translator
| Property | Description | Default |
|---|---|---|
| DatabaseTimeZone |
The time zone of the database. Used when fetchings date, time, or timestamp values
|
The system default time zone
|
| SupportsOdataCount |
Supports $count
|
True
|
| SupportsOdataFilter |
Supports $filter
|
True
|
| SupportsOdataOrderBy |
Supports $orderby
|
True
|
| SupportsOdataSkip |
Supports $skip
|
True
|
| SupportsOdataTop |
Supports $top
|
True
|
Warning
Warning
12.30. Web Services Translator
12.30.1. Web Services Translator
org.teiid.translator.ws.WSExecutionFactory class and known by the translator type name ws.
Note
webservices data source in the JBoss EAP instance. See the Red Hat JBoss Data Virtualization Administration and Configuration Guide for more configuration information.
Important
12.30.2. Web Services Translator: Execution Properties
| Name | Description | When Used | Default |
|---|---|---|---|
| DefaultBinding | The binding that should be used if one is not specified. Can be one of HTTP, SOAP11, or SOAP12 | invoke* | SOAP12 |
| DefaultServiceMode | The default service mode. For SOAP, MESSAGE mode indicates that the request will contain the entire SOAP envelope and not just the contents of the SOAP body. Can be one of MESSAGE or PAYLOAD. | invoke* or WSDL call | PAYLOAD |
| XMLParamName | Used with the HTTP binding (typically with the GET method) to indicate that the request document should be part of the query string. | invoke* | null - unused |
Important
<validate-on-match>true</validate-on-match>
<validate-on-match>true</validate-on-match> 12.30.3. Web Services Translator: Usage
12.30.4. Web Services Translator: Invoke Procedure
Procedure invoke(binding in STRING, action in STRING, request in XML, endpoint in STRING) returns XML
Procedure invoke(binding in STRING, action in STRING, request in XML, endpoint in STRING) returns XMLcall invoke(binding=>'HTTP', action=>'GET')
call invoke(binding=>'HTTP', action=>'GET')12.30.5. Web Services Translator: InvokeHTTP Procedure
invokeHttp can return the byte contents of an HTTP or HTTPS call.
Procedure invokeHttp(action in STRING, request in OBJECT, endpoint in STRING, contentType out STRING) returns BLOB
Procedure invokeHttp(action in STRING, request in OBJECT, endpoint in STRING, contentType out STRING) returns BLOBcall invokeHttp(action=>'GET')
call invokeHttp(action=>'GET')TO_BYTES function to control the byte encoding.
call invokeHttp(... headers=>jsonObject('application/json' as ContentType, jsonArray('gzip', 'deflate') as "Accept-Encoding"))
call invokeHttp(... headers=>jsonObject('application/json' as ContentType, jsonArray('gzip', 'deflate') as "Accept-Encoding"))
Note
Important
Chapter 13. Federated Planning
13.1. Federated Planning
13.2. Planning Overview
- Parsing - syntax is validated and converted to internal form.
- Resolving - all identifiers are linked to metadata, and functions are linked to the function library.
- Validating - SQL semantics are validated based on metadata references and type signatures.
- Rewriting - SQL is rewritten to simplify expressions and criteria.
- Logical plan optimization - the rewritten canonical SQL is converted into a logical plan for in-depth optimization. The JBoss Data Virtualization optimizer is predominantly rule-based. Based upon the query structure and hints, a certain rule set will be applied. These rules may in turn trigger the execution of more rules. Within several rules, JBoss Data Virtualization also takes advantage of costing information. The logical plan optimization steps can be seen by using the SHOWPLAN DEBUG clause and are described in Section 13.9.1, “Query Planner”.
- Processing plan conversion - the logic plan is converted into an executable form where the nodes are representative of basic processing operations. The final processing plan is displayed as the query plan. See Section 13.8.1, “Query Plans”.
- select - select or filter rows based on a criteria,
- project - project or compute column values,
- join,
- source - retrieve data from a table,
- sort - ORDER BY,
- duplicate removal - SELECT DISTINCT,
- group - GROUP BY, and
- union - UNION.
13.3. Example Query
Example 13.1. Example query
SELECT e.title, e.lastname FROM Employees AS e JOIN Departments AS d ON e.dept_id = d.dept_id WHERE year(e.birthday) >= 1970 AND d.dept_name = 'Engineering'
SELECT e.title, e.lastname FROM Employees AS e JOIN
Departments AS d ON e.dept_id = d.dept_id WHERE year(e.birthday) >= 1970 AND d.dept_name = 'Engineering'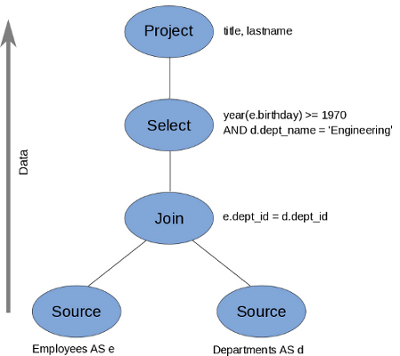
Figure 13.1. Canonical Query Plan
13.4. Subquery Optimization
- EXISTS subqueries are typically rewrite to "SELECT 1 FROM ..." to prevent unnecessary evaluation of SELECT expressions.
- Quantified compare SOME subqueries are always turned into an equivalent IN predicate or comparison against an aggregate value. e.g. col > SOME (select col1 from table) would become col > (select min(col1) from table)
- Uncorrelated EXISTs and scalar subquery that are not pushed to the source can be evaluated prior to source command formation.
- Correlated subqueries used in DELETEs or UPDATEs that are not pushed as part of the corresponding DELETE/UPDATE will cause JBoss Data Virtualization to perform row-by-row compensating processing. This will only happen if the affected table has a primary key. If it does not, then an exception will be thrown.
- WHERE or HAVING clause IN, Quantified Comparison, Scalar Subquery Compare, and EXISTs predicates can take the MJ (merge join), DJ (dependent join), or NO_UNNEST (no unnest) hints appearing just before the subquery. The MJ hint directs the optimizer to use a traditional, semijoin, or antisemijoin merge join if possible. The DJ is the same as the MJ hint, but additionally directs the optimizer to use the subquery as the independent side of a dependent join if possible. The NO_UNNEST hint, which supercedes the other hints, will direct the optimizer to leave the subquery in place.
Example 13.2. Merge Join Hint Usage
SELECT col1 from tbl where col2 IN /*+ MJ */ (SELECT col1 FROM tbl2)
SELECT col1 from tbl where col2 IN /*+ MJ */ (SELECT col1 FROM tbl2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example 13.3. Dependent Join Hint Usage
SELECT col1 from tbl where col2 IN /*+ DJ */ (SELECT col1 FROM tbl2)
SELECT col1 from tbl where col2 IN /*+ DJ */ (SELECT col1 FROM tbl2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow Example 13.4. No Unnest Hint Usage
SELECT col1 from tbl where col2 IN /*+ NO_UNNEST */ (SELECT col1 FROM tbl2)
SELECT col1 from tbl where col2 IN /*+ NO_UNNEST */ (SELECT col1 FROM tbl2)Copy to Clipboard Copied! Toggle word wrap Toggle overflow - The system property org.teiid.subqueryUnnestDefault controls whether the optimizer will by default unnest subqueries. If true, then most non-negated WHERE or HAVING clause non-negated EXISTS or IN subquery predicates can be converted to a traditional join.
- The planner will always convert to anitjoin or semijoin vartiants is costing is favorable. Use a hint to override this behavior if needed.
- EXISTs and scalar subqueries that are not pushed down, and not converted to merge joins, are implicitly limited to 1 and 2 result rows respectively.
- Conversion of subquery predicates to nested loop joins is not yet available.
13.5. XQuery Optimization
Example 13.5. Streaming Eligible XMLQUERY
XMLQUERY('/*:root/*:child' PASSING doc)
XMLQUERY('/*:root/*:child' PASSING doc)Example 13.6. Streaming Ineligible XMLQUERY
XMLQUERY('//child' PASSING doc)
XMLQUERY('//child' PASSING doc)Example 13.7. Streaming Eligible XMLTABLE
XMLTABLE('/*:root/*:child' PASSING doc COLUMNS fullchild XML PATH '.', parent_attr string PATH '../@attr', child_val integer)
XMLTABLE('/*:root/*:child' PASSING doc COLUMNS fullchild XML PATH '.', parent_attr string PATH '../@attr', child_val integer)Example 13.8. Streaming Ineligible XMLTABLE
XMLTABLE('/*:root/*:child' PASSING doc COLUMNS sibling_attr string PATH '../other_child/@attr')
XMLTABLE('/*:root/*:child' PASSING doc COLUMNS sibling_attr string PATH '../other_child/@attr')13.6. Partial Results
13.7. Federated Optimizations
13.7.1. Access Patterns
13.7.2. Pushdown
13.7.3. Dependent Joins
- Join based on in/equality support: where the engine will determine how to break of the queries
- Key Pushdown: where the translator has access to the full set of key values and determines what queries to send
- Full Pushdown - where translator ships the all data from the independent side to the translator. Can be used automatically by costing or can be specified as an option in the hint.
- MAKEIND - indicates that the clause should be the independent side of a dependent join.
- MAKEDEP - indicates that the clause should be the dependent side of a join. MAKEDEP as a non-comment hint supports optional max and join arguments - MAKEDEP(JOIN) meaning that the entire join should be pushed, and MAKEDEP(MAX:5000) meaning that the dependent join should only be performed if there are less than the max number of values from the independent side.
- MAKENOTDEP - prevents the clause from being the dependent side of a join.
Note
Note
13.7.4. Copy Criteria
13.7.5. Projection Minimization
13.7.6. Partial Aggregate Pushdown
13.7.7. Optional Join
Example 13.9. Example Optional Join Hint
select a.column1, b.column2 from a, /*+ optional */ b WHERE a.key = b.key
select a.column1, b.column2 from a, /*+ optional */ b WHERE a.key = b.keyselect a.column1 from a
select a.column1 from aExample 13.10. Example ANSI Optional Join Hint
select a.column1, b.column2, c.column3 from /*+ optional */ (a inner join b ON a.key = b.key) INNER JOIN c ON a.key = c.key
select a.column1, b.column2, c.column3 from /*+ optional */ (a inner join b ON a.key = b.key) INNER JOIN c ON a.key = c.keyExample 13.11. Example Bridging Table
select a.column1, b.column2, c.column3 from /*+ optional */ a, b, c WHERE ON a.key = b.key AND a.key = c.key
select a.column1, b.column2, c.column3 from /*+ optional */ a, b, c WHERE ON a.key = b.key AND a.key = c.keyNote
Example 13.12. Example Unnecessary Optional Join Hint
select a.column1, b.column2 from a LEFT OUTER JOIN /*+optional*/ b ON a.key = b.key
select a.column1, b.column2 from a LEFT OUTER JOIN /*+optional*/ b ON a.key = b.keyWarning
/*+ sh[[ KEEP ALIASES]:'arg'] source-name[ KEEP ALIASES]:'arg1' ... */
/*+ sh[[ KEEP ALIASES]:'arg'] source-name[ KEEP ALIASES]:'arg1' ... */
SELECT /*+ sh:'general hint' */ ...
SELECT /*+ sh:'general hint' */ ...
SELECT /*+ sh KEEP ALIASES:'general hint' my-oracle:'oracle hint' */ ...
SELECT /*+ sh KEEP ALIASES:'general hint' my-oracle:'oracle hint' */ ...
13.7.8. Partitioned Union
Note
13.7.9. Standard Relational Techniques
- Rewrite analysis for function simplification and evaluation.
- Boolean optimizations for basic criteria simplification.
- Removal of unnecessary view layers.
- Removal of unnecessary sort operations.
- Advanced search techniques through the left-linear space of join trees.
- Parallelizing of source access during execution.
- Subquery optimization ( Section 13.4, “Subquery Optimization”)
13.8. Query Plans
13.8.1. Query Plans
13.8.2. Getting a Query Plan
- SET SHOWPLAN [ON|DEBUG]- Returns the processing plan or the plan and the full planner debug log.
org.teiid.jdbc.TeiidStatement interface or by using the "SHOW PLAN" statement.
Example 13.13. Retrieving a Query Plan
statement.execute("set showplan on");
ResultSet rs = statement.executeQuery("select ...");
TeiidStatement tstatement = statement.unwrap(TeiidStatement.class);
PlanNode queryPlan = tstatement.getPlanDescription();
System.out.println(queryPlan);
statement.execute("set showplan on");
ResultSet rs = statement.executeQuery("select ...");
TeiidStatement tstatement = statement.unwrap(TeiidStatement.class);
PlanNode queryPlan = tstatement.getPlanDescription();
System.out.println(queryPlan);13.8.3. Analyzing a Query Plan
- Source pushdown - what parts of the query were pushed to each source? Ensure that any predicates, especially against, indexes are pushed.
- Join ordering - as federated joins can be quite expensive. They are typically influenced by costing.
- Join criteria type mismatches.
- Join algorithm used - merge, enhanced merge, nested loop and so forth.
- Presence of federated optimizations, such as dependent joins.
- Join criteria type mismatches.
13.8.4. Relational Plans
- Access
- Access a source. A source query is sent to the connection factory associated with the source. [For a dependent join, this node is called Dependent Access.]
- Dependent Procedure Access
- Access a stored procedure on a source using multiple sets of input values.
- Batched Update
- Processes a set of updates as a batch.
- Project
- Defines the columns returned from the node. This does not alter the number of records returned.
- Project Into
- Like a normal project, but outputs rows into a target table.
- Select
- Select is a criteria evaluation filter node (WHERE / HAVING). When there is a subquery in the criteria, this node is called Dependent Select.
- Insert Plan Execution
- Similar to a project into, but executes a plan rather than a source query. Typically created when executing an insert into view with a query expression.
- Window Function Project
- Like a normal project, but includes window functions.
- Join
- Defines the join type, join criteria, and join strategy (merge or nested loop).
- Union All
- There are no properties for this node; it just passes rows through from its children. Depending upon other factors, such as if there is a transaction or the source query concurrency allowed, not all of the union children will execute in parallel.
- Sort
- Defines the columns to sort on, the sort direction for each column, and whether to remove duplicates or not.
- Dup Remove
- Removes duplicate rows. The processing uses a tree structure to detect duplicates so that results will effectively stream at the cost of IO operations.
- Grouping
- Groups sets of rows into groups and evaluates aggregate functions.
- Null
- A node that produces no rows. Usually replaces a Select node where the criteria is always false (and whatever tree is underneath). There are no properties for this node.
- Plan Execution
- Executes another sub plan. Typically the sub plan will be a non-relational plan.
- Dependent Procedure Execution
- Executes a sub plan using multiple sets of input values.
- Limit
- Returns a specified number of rows, then stops processing. Also processes an offset if present.
- XML Table
- Evaluates XMLTABLE. The debug plan will contain more information about the XQuery/XPath with regards to their optimization - see the XQuery section below or XQuery Optimization.
- Text Table
- Evaluates TEXTTABLE
- Array Table
- Evaluates ARRAYTABLE
- Object Table
- Evaluates OBJECTTABLE
13.8.5. Relational Plans: Node Statistics
|
Statistic
|
Description
|
Units
|
|---|---|---|
|
Node Output Rows
|
Number of records output from the node
|
count
|
|
Node Next Batch Process Time
|
Time processing in this node only
|
millisec
|
|
Node Cumulative Process Time
|
Elapsed time from beginning of processing to end
|
millisec
|
|
Node Cumulative Next Batch Process Time
|
Time processing in this node + child nodes
|
millisec
|
|
Node Next Batch Calls
|
Number of times a node was called for processing
|
count
|
|
Node Blocks
|
Number of times a blocked exception was thrown by this node or a child
|
count
|
|
Cost Estimates
|
Description
|
Units
|
|---|---|---|
|
Estimated Node Cardinality
|
Estimated number of records that will be output from the node; -1 if unknown
|
count
|
13.8.6. Source Hints
| Top level Statistics | Description | Units |
|---|---|---|
| Data Bytes Sent | The size of the serialized data result (row and lob values) sent to the client | bytes |
- Output Columns - what columns make up the tuples returned by this node
- Data Bytes Sent - how many data byte, not including messaging overhead, were sent by this query
- Planning Time - the amount of time in milliseconds spent planning the query
- Relational Node ID - matches the node ids seen in the debug log Node(id)
- Criteria - the boolean expression used for filtering
- Select Columns - the columns that define the projection
- Grouping Columns - the columns used for grouping
- Query - the source query
- Model Name - the model name
- Sharing ID - nodes sharing the same source results will have the same sharing id
- Dependent Join - if a dependent join is being used
- Join Strategy - the join strategy (Nested Loop, Sort Merge, Enhanced Sort, etc.)
- Join Type - the join type (Left Outer Join, Inner Join, Cross Join)
- Join Criteria - the join predicates
- Execution Plan - the nested execution plan
- Into Target - the insertion target
- Sort Columns - the columns for sorting
- Sort Mode - if the sort performs another function as well, such as distinct removal
- Rollup - if the group by has the rollup option
- Statistics - the processing statistics
- Cost Estimates - the cost/cardinality estimates including dependent join cost estimates
- Row Offset - the row offset expression
- Row Limit - the row limit expression
- With - the with clause
- Window Functions - the window functions being computed
- Table Function - the table function (XMLTABLE, OBJECTTABLE, TEXTTABLE, etc.)
- Message
- Tag
- Namespace
- Data Column
- Namespace Declarations
- Optional Flag
- Default Value
- Recursion Direction
- Bindings
- Is Staging Flag
- Source In Memory Flag
- Condition
- Default Program
- Encoding
- Formatted Flag
- Expression
- Result Set
- Program
- Variable
- Then
- Else
13.8.7. Statistics Gathering and Single Partitions
SYSADMIN.setTableStats(IN tableName string NOT NULL, IN cardinality long NOT NULL)
SYSADMIN.setTableStats(IN tableName string NOT NULL, IN cardinality long NOT NULL)
13.9. Query Planner
13.9.1. Query Planner
- Relational Planner
- Procedure Planner
- XML Planner
- Generate canonical plan
- Optimization
- Plan to process converter - converts plan data structure into a processing form
13.9.2. Relational Planner
- WITH (create common table expressions) - handled by a specialized PROJECT NODE
- FROM (read and join all data from tables) - SOURCE node for each from clause item, Join node (if >1 table)
- WHERE (filter rows) - SELECT node
- GROUP BY (group rows into collapsed rows) - GROUP node
- HAVING (filter grouped rows) - SELECT node
- SELECT (evaluate expressions and return only requested rows) - PROJECT node and DUP_REMOVE node (for SELECT DISTINCT)
- INTO - specialized PROJECT with a SOURCE child
- ORDER BY (sort rows) - SORT node
- LIMIT (limit result set to a certain range of results) - LIMIT node
Project(groups=[anon_grp0], props={PROJECT_COLS=[anon_grp0.agg0 AS expr1]})
Group(groups=[anon_grp0], props={SYMBOL_MAP={anon_grp0.agg0=MAX(pm1.g1.e1)}})
Select(groups=[pm1.g1], props={SELECT_CRITERIA=e2 = 1})
Source(groups=[pm1.g1])
Project(groups=[anon_grp0], props={PROJECT_COLS=[anon_grp0.agg0 AS expr1]})
Group(groups=[anon_grp0], props={SYMBOL_MAP={anon_grp0.agg0=MAX(pm1.g1.e1)}})
Select(groups=[pm1.g1], props={SELECT_CRITERIA=e2 = 1})
Source(groups=[pm1.g1])
- ACCESS - a source access or plan execution.
- DUP_REMOVE - removes duplicate rows
- JOIN - a join (LEFT OUTER, FULL OUTER, INNER, CROSS, SEMI, etc.)
- PROJECT - a projection of tuple values
- SELECT - a filtering of tuples
- SORT - an ordering operation, which may be inserted to process other operations such as joins
- SOURCE - any logical source of tuples including an inline view, a source access, XMLTABLE, etc.
- GROUP - a grouping operation
- SET_OP - a set operation (UNION/INTERSECT/EXCEPT)
- NULL - a source of no tuples
- TUPLE_LIMIT - row offset / limit
- ATOMIC_REQUEST - The final form of a source request
- MODEL_ID - The metadata object for the target model/schema
- PROCEDURE_CRITERIA/PROCEDURE_INPUTS/PROCEDURE_DEFAULTS - Used in planning procedureal relational queries
- IS_MULTI_SOURCE - set to true when the node represents a multi-source access
- SOURCE_NAME - used to track the multi-source source name
- CONFORMED_SOURCES - tracks the set of conformed sources when the conformed extension metadata is used
- SUB_PLAN/SUB_PLANS - used in multi-source planning
- SET_OPERATION/USE_ALL - defines the set operation (UNION/INTERSECT/EXCEPT) and if all rows or distinct rows are used.
- JOIN_CRITERIA - all join predicates
- JOIN_TYPE - type of join (INNER, LEFT OUTER, etc.)
- JOIN_STRATEGY - the algorithm to use (nested loop, merge, etc.)
- LEFT_EXPRESSIONS - the expressions in equi-join predicates that originate from the left side of the join
- RIGHT_EXPRESSIONS - the expressions in equi-join predicates that originate from the right side of the join
- DEPENDENT_VALUE_SOURCE - set if a dependent join is used
- NON_EQUI_JOIN_CRITERIA - non-equi join predicates
- SORT_LEFT - if the left side needs sorted for join processing
- SORT_RIGHT - if the right side needs sorted for join processing
- IS_OPTIONAL - if the join is optional
- IS_LEFT_DISTINCT - if the left side is distinct with respect to the equi join predicates
- IS_RIGHT_DISTINCT - if the right side is distinct with respect to the equi join predicates
- IS_SEMI_DEP - if the dependent join represents a semi-join
- PRESERVE - if the preserve hint is preserving the join order
- PROJECT_COLS - the expressions projected
- INTO_GROUP - the group targeted if this is a select into or insert with a query expression
- HAS_WINDOW_FUNCTIONS - true if window functions are used
- CONSTRAINT - the constraint that must be met if the values are being projected into a group
- SELECT_CRITERIA - the filter
- IS_HAVING - if the filter is applied after grouping
- IS_PHANTOM - true if the node is marked for removal, but temporarily left in the plan.
- IS_TEMPORARY - inferred criteria that may not be used in the final plan
- IS_COPIED - if the criteria has already been processed by rule copy criteria
- IS_PUSHED - if the criteria is pushed as far as possible
- IS_DEPENDENT_SET - if the criteria is the filter of a dependent join
- SORT_ORDER - the order by that defines the sort
- UNRELATED_SORT - if the ordering includes a value that is not being projected
- IS_DUP_REMOVAL - if the sort should also perform duplicate removal over the entire projection
- Source Properties - many source properties also become present on associated access nodes
- SYMBOL_MAP - the mapping from the columns above the source to the projected expressions. Also present on Group nodes
- PARTITION_INFO - the partitioning of the union branches
- VIRTUAL_COMMAND - if the source represents an view or inline view, the query that defined the view
- MAKE_DEP - hint information
- PROCESSOR_PLAN - the processor plan of a non-relational source (typically from the NESTED_COMMAND)
- NESTED_COMMAND - the non-relational command
- TABLE_FUNCTION - the table function (XMLTABLE, OBJECTTABLE, etc.) defining the source
- CORRELATED_REFERENCES - the correlated references for the nodes below the source
- MAKE_NOT_DEP - if make not dep is set
- INLINE_VIEW - If the source node represents an inline view
- NO_UNNEST - if the no_unnest hint is set
- MAKE_IND - if the make ind hint is set
- SOURCE_HINT - the source hint. See Federated Optimizations.
- ACCESS_PATTERNS - access patterns yet to be satisfied
- ACCESS_PATTERN_USED - satisfied access patterns
- REQUIRED_ACCESS_PATTERN_GROUPS - groups needed to satisfy the access patterns. Used in join planning.
- GROUP_COLS - the grouping columns
- ROLLUP - if the grouping includes a rollup
- MAX_TUPLE_LIMIT - expression that evaluates to the max number of tuples generated
- OFFSET_TUPLE_COUNT - Expression that evaluates to the tuple offset of the starting tuple
- IS_IMPLICIT_LIMIT - if the limit is created by the rewriter as part of a subquery
- IS_NON_STRICT - if the unordered limit should not be enforced strictly optimization
- OUTPUT_COLS - the output columns for the node. Is typically set after rule assign output elements.
- EST_SET_SIZE - represents the estimated set size this node would produce for a sibling node as the independent node in a dependent join scenario
- EST_DEP_CARDINALITY - value that represents the estimated cardinality (amount of rows) produced by this node as the dependent node in a dependent join scenario
- EST_DEP_JOIN_COST - value that represents the estimated cost of a dependent join (the join strategy for this could be Nested Loop or Merge)
- EST_JOIN_COST - value that represents the estimated cost of a merge join (the join strategy for this could be Nested Loop or Merge)
- EST_CARDINALITY - represents the estimated cardinality (amount of rows) produced by this node
- EST_COL_STATS - column statistics including number of null values, distinct value count,
- EST_SELECTIVITY - represents the selectivity of a criteria node
- Access Pattern Validation - ensures that all access patterns have been satisfied
- Apply Security - applies row and column level security
- Assign Output Symbol - this rule walks top down through every node and calculates the output columns for each node. Columns that are not needed are dropped at every node, which is known as projection minimization. This is done by keeping track of both the columns needed to feed the parent node and also keeping track of columns that are “created” at a certain node.
- Calculate Cost - adds costing information to the plan
- Choose Dependent - this rule looks at each join node and determines whether the join should be made dependent and in which direction. Cardinality, the number of distinct values, and primary key information are used in several formulas to determine whether a dependent join is likely to be worthwhile. The dependent join differs in performance ideally because a fewer number of values will be returned from the dependent side. Also, we must consider the number of values passed from independent to dependent side. If that set is larger than the max number of values in an IN criteria on the dependent side, then we must break the query into a set of queries and combine their results. Executing each query in the connector has some overhead and that is taken into account. Without costing information a lot of common cases where the only criteria specified is on a non-unique (but strongly limiting) field are missed. A join is eligible to be dependent if:there is at least one equi-join criterion, i.e. tablea.col = tableb.colthe join is not a full outer join and the dependent side of the join is on the inner side of the joinThe join will be made dependent if one of the following conditions, listed in precedence order, holds:There is an unsatisfied access pattern that can be satisfied with the dependent join criteriaThe potential dependent side of the join is marked with an option makedep if costing was enabled, the estimated cost for the dependent join (possibly in each direction in the case of inner joins) is computed and compared to not performing the dependent join. If the costs were all determined (which requires all relevant table cardinality, column ndv, and possibly nnv values to be populated) the lowest is chosen.If key metadata information indicates that the potential dependent side is not “small” and the other side is “not small” or the potential dependent side is the inner side of a left outer join.Dependent join is the key optimization we use to efficiently process multi-source joins.Instead of reading all of source A and all of source B and joining them on A.x = B.x, we read all of A then build a set of A.x that are passed as a criteria when querying B. In cases where A is small and B is large, this can drastically reduce the data retrieved from B, thus greatly speeding the overall query.
- Choose Join Strategy - choose the join strategy based upon the cost and attributes of the join.
- Clean Criteria - removes phantom criteria
- Collapse Source - takes all of the nodes below an access node and creates a SQL query representation
- Copy Criteria - this rule copies criteria over an equality criteria that is present in the criteria of a join. Since the equality defines an equivalence, this is a valid way to create a new criteria that may limit results on the other side of the join (especially in the case of a multi-source join).
- Decompose Join - this rule performs a partition-wise join optimization on joins of Federated Optimizations Partitioned Union. The decision to decompose is based upon detecting that each side of the join is a partitioned union (note that non-ansi joins of more than 2 tables may cause the optimization to not detect the appropriate join). The rule currently only looks for situations where at most 1 partition matches from each side.
- Implement Join Strategy - adds necessary sort and other nodes to process the chosen join strategy
- Merge Criteria - combines select nodes and can convert subqueries to semi-joins
- Merge Virtual - removes view and inline view layers
- Place Access - places access nodes under source nodes. An access node represents the point at which everything below the access node gets pushed to the source or is a plan invocation. Later rules focus on either pushing under the access or pulling the access node up the tree to move more work down to the sources. This rule is also responsible for placing Federated Optimizations Access Patterns.
- Plan Joins - this rule attempts to find an optimal ordering of the joins performed in the plan, while ensuring that Federated Optimizations Access Patterns dependencies are met. This rule has three main steps. First it must determine an ordering of joins that satisfy the access patterns present. Second it will heuristically create joins that can be pushed to the source (if a set of joins are pushed to the source, we will not attempt to create an optimal ordering within that set. More than likely it will be sent to the source in the non-ANSI multi-join syntax and will be optimized by the database). Third it will use costing information to determine the best left-linear ordering of joins performed in the processing engine. This third step will do an exhaustive search for 6 or less join sources and is heuristically driven by join selectivity for 7 or more sources.
- Plan Procedures - plans procedures that appear in procedural relational queries
- Plan Sorts - optimizations around sorting, such as combining sort operations or moving projection
- Plan Unions - reorders union children for more pushdown
- Plan Aggregates - performs aggregate decomposition over a join or union
- Push Limit - pushes the effect of a limit node further into the plan
- Push Non-Join Criteria - this rule will push predicates from the On Clause if it is not necessary for the correctness of the join.
- Push Select Criteria - pushed select nodes as far as possible through unions, joins, and views layers toward the access nodes. In most cases movement down the tree is good as this will filter rows earlier in the plan. We currently do not undo the decisions made by Push Select Criteria. However in situations where criteria cannot be evaluated by the source, this can lead to sub optimal plans.
- Raise Access - this rule attempts to raise the Access nodes as far up the plan as possible. This is mostly done by looking at the source’s capabilities and determining whether the operations can be achieved in the source or not.
- Raise Null - raises null nodes. Raising a null node removes the need to consider any part of the old plan that was below the null node.
- Remove Optional Joins - removes joins that are marked as or determined to be optional
- Substitute Expressions - used only when a function based index is present
- Validate Where All - ensures criteria is used when required by the source
OPTIMIZATION COMPLETE: PROCESSOR PLAN: AccessNode(0) output=[e1] SELECT g_0.e1 FROM pm1.g1 AS g_0
OPTIMIZATION COMPLETE:
PROCESSOR PLAN:
AccessNode(0) output=[e1] SELECT g_0.e1 FROM pm1.g1 AS g_0The procedure planner is fairly simple. It converts the statements in the procedure into instructions in a program that will be run during processing. This is mostly a 1-to-1 mapping and very little optimization is performed.
- Document selection - determine which tags of the virtual document should be excluded from the output document. This is done based on a combination of the model (which marks parts of the document excluded) and the query (which may specify a subset of columns to include in the SELECT clause).
- Criteria evaluation - breaks apart the user’s criteria, determine which result set the criteria should be applied to, and add that criteria to that result set query.
- Result set ordering - the query’s ORDER BY clause is broken up and the ORDER BY is applied to each result set as necessary
- Result set planning - ultimately, each result set is planned using the relational planner and taking into account all the impacts from the user's query. The planner will also look to automatically create staging tables and dependent joins based upon the mapping class hierarchy.
- Program generation - a set of instructions to produce the desired output document is produced, taking into account the final result set queries and the excluded parts of the document. Generally, this involves walking through the virtual document in document order, executing queries as necessary and emitting elements and attributes.
Appendix A. BNF for SQL Grammar
A.1. Main Entry Points
- callable statement
- ddl statement
- procedure body definition
- directly executable statement
A.2. Reserved Keywords
|
Keyword
|
Usage
|
|---|---|
|
ADD
|
add set option
|
|
ALL
|
standard aggregate function , function , query expression body , query term select clause , quantified comparison predicate
|
|
ALTER
|
alter , alter column options , alter options
|
|
AND
|
between predicate , boolean term
|
|
ANY
|
standard aggregate function , quantified comparison predicate
|
|
ARRAY_AGG
|
ordered aggregate function
|
|
AS
|
alter , array table , create procedure , option namespace , create table , create trigger , derived column , dynamic data statement , function , loop statement , xml namespace element , object table , select derived column , table subquery , text table , table name , with list element , xml serialize , xml table
|
|
ASC
|
sort specification
|
|
ATOMIC
|
compound statement , for each row trigger action
|
|
BEGIN
|
compound statement , for each row trigger action
|
|
BETWEEN
|
between predicate
|
|
BIGDECIMAL
|
data type
|
|
BIGINT
|
data type
|
|
BIGINTEGER
|
data type
|
|
BLOB
|
data type , xml serialize
|
|
BOOLEAN
|
data type
|
|
BOTH
|
function
|
|
BREAK
|
branching statement
|
|
BY
|
group by clause , order by clause , window specification
|
|
BYTE
|
data type
|
|
CALL
|
callable statement , call statement
|
|
CASE
|
case expression , searched case expression
|
|
CAST
|
function
|
|
CHAR
|
function , data type
|
|
CLOB
|
data type , xml serialize
|
|
COLUMN
|
alter column options
|
|
CONSTRAINT
|
create table body
|
|
CONTINUE
|
branching statement
|
|
CONVERT
|
function
|
|
CREATE
|
create procedure , create foreign temp table , create table , create temporary table , create trigger , procedure body definition
|
|
CROSS
|
cross join
|
|
DATE
|
data type
|
|
DAY
|
function
|
|
DECIMAL
|
data type
|
|
DECLARE
|
declare statement
|
|
DEFAULT
|
table element , xml namespace element , object table column , procedure parameter , xml table column
|
|
DELETE
|
alter , create trigger , delete statement
|
|
DESC
|
sort specification
|
|
DISTINCT
|
standard aggregate function , function , query expression body , query term , select clause
|
|
DOUBLE
|
data type
|
|
DROP
|
drop option , drop table
|
|
EACH
|
for each row trigger action
|
|
ELSE
|
case expression , if statement , searched case expression
|
|
END
|
case expression , compound statement , for each row trigger action , searched case expression
|
|
ERROR
|
raise error statement
|
|
ESCAPE
|
match predicate , text table
|
|
EXCEPT
|
query expression body
|
|
EXEC
|
dynamic data statement , call statement
|
|
EXECUTE
|
dynamic data statement , call statement
|
|
EXISTS
|
exists predicate
|
|
FALSE
|
non numeric literal
|
|
FETCH
|
fetch clause
|
|
FILTER
|
filter clause
|
|
FLOAT
|
data type
|
|
FOR
|
for each row trigger action , function , text aggregate function , xml table column
|
|
FOREIGN
|
alter options , create procedure , create foreign temp table , create table , foreign key
|
|
FROM
|
delete statement , from clause , function
|
|
FULL
|
qualified table
|
|
FUNCTION
|
create procedure
|
|
GROUP
|
group by clause
|
|
HAVING
|
having clause
|
|
HOUR
|
function
|
|
IF
|
if statement
|
|
IMMEDIATE
|
dynamic data statement
|
|
IN
|
procedure parameter , in predicate
|
|
INNER
|
qualified table
|
|
INOUT
|
procedure parameter
|
|
INSERT
|
alter , create trigger , function , insert statement
|
|
INTEGER
|
data type
|
|
INTERSECT
|
query term
|
|
INTO
|
dynamic data statement , insert statement , into clause
|
|
IS
|
is null predicate
|
|
JOIN
|
cross join , qualified table
|
|
LANGUAGE
|
object table
|
|
LATERAL
|
table subquery
|
|
LEADING
|
function
|
|
LEAVE
|
branching statement
|
|
LEFT
|
function , qualified table
|
|
LIKE
|
match predicate
|
|
LIKE_REGEX
|
like regex predicate
|
|
LIMIT
|
limit clause
|
|
LOCAL
|
create temporary table
|
|
LONG
|
data type
|
|
LOOP
|
loop statement
|
|
MAKEDEP
|
option clause , table primary
|
|
MAKENOTDEP
|
option clause , table primary
|
|
MERGE
|
insert statement
|
|
MINUTE
|
function
|
|
MONTH
|
function
|
|
NO
|
xml namespace element , text table column , text table
|
|
NOCACHE
|
option clause
|
|
NOT
|
between predicate , compound statement , table element , is null predicate , match predicate , boolean factor , procedure parameter , procedure result column , like regex predicate , in predicate , temporary table element
|
|
NULL
|
table element , is null predicate , non numeric literal , procedure parameter , procedure result column , temporary table element , xml query
|
|
OBJECT
|
data type
|
|
OF
|
alter , create trigger
|
|
OFFSET
|
limit clause
|
|
ON
|
alter , create foreign temp table , create trigger , loop statement , qualified table , xml query
|
|
ONLY
|
fetch clause
|
|
OPTION
|
option clause
|
|
OPTIONS
|
alter options list , options clause
|
|
OR
|
boolean value expression
|
|
ORDER
|
order by clause
|
|
OUT
|
procedure parameter
|
|
OUTER
|
qualified table
|
|
OVER
|
window specification
|
|
PARAMETER
|
alter column options
|
|
PARTITION
|
window specification
|
|
PRIMARY
|
table element , create temporary table , primary key
|
|
PROCEDURE
|
alter , alter options , create procedure , procedure body definition
|
|
REAL
|
data type
|
|
REFERENCES
|
foreign key
|
|
RETURN
|
assignment statement , return statement , data statement
|
|
RETURNS
|
create procedure
|
|
RIGHT
|
function , qualified table
|
|
ROW
|
fetch clause , for each row trigger action , limit clause , text table
|
|
ROWS
|
fetch clause , limit clause
|
|
SECOND
|
function
|
|
SELECT
|
select clause
|
|
SET
|
add set option , option namespace , update statement
|
|
SHORT
|
data type
|
|
SIMILAR
|
match predicate
|
|
SMALLINT
|
data type
|
|
SOME
|
standard aggregate function , quantified comparison predicate
|
|
SQLEXCEPTION
|
sql exception
|
|
SQLSTATE
|
sql exception
|
|
SQLWARNING
|
raise statement
|
|
STRING
|
dynamic data statement , data type , xml serialize
|
|
TABLE
|
alter options , create procedure , create foreign temp table , create table , create temporary table , drop table , query primary , table subquery
|
|
TEMPORARY
|
create foreign temp table , create temporary table
|
|
THEN
|
case expression , searched case expression
|
|
TIME
|
data type
|
|
TIMESTAMP
|
data type
|
|
TINYINT
|
data type
|
|
TO
|
match predicate
|
|
TRAILING
|
function
|
|
TRANSLATE
|
function
|
|
TRIGGER
|
alter , create trigger
|
|
TRUE
|
non numeric literal
|
|
UNION
|
cross join , query expression body
|
|
UNIQUE
|
other constraints , table element
|
|
UNKNOWN
|
non numeric literal
|
|
UPDATE
|
alter , create trigger , dynamic data statement , update statement
|
|
USER
|
function
|
|
USING
|
dynamic data statement
|
|
VALUES
|
insert statement
|
|
VARBINARY
|
data type , xml serialize
|
|
VARCHAR
|
data type , xml serialize
|
|
VIRTUAL
|
alter options , create procedure , create table , procedure body definition
|
|
WHEN
|
case expression , searched case expression
|
|
WHERE
|
filter clause , where clause
|
|
WHILE
|
while statement
|
|
WITH
|
assignment statement , query expression , data statement
|
|
WITHOUT
|
assignment statement , data statement
|
|
XML
|
data type
|
|
XMLAGG
|
ordered aggregate function
|
|
XMLATTRIBUTES
|
xml attributes
|
|
XMLCOMMENT
|
function
|
|
XMLCONCAT
|
function
|
|
XMLELEMENT
|
xml element
|
|
XMLFOREST
|
xml forest
|
|
XMLNAMESPACES
|
xml namespaces
|
|
XMLPARSE
|
xml parse
|
|
XMLPI
|
function
|
|
XMLQUERY
|
xml query
|
|
XMLSERIALIZE
|
xml serialize
|
|
XMLTABLE
|
xml table
|
|
YEAR
|
function
|
A.3. Non-Reserved Keywords
|
Keyword
|
Usage
|
|---|---|
|
ACCESSPATTERN
|
other constraints , non-reserved identifier
|
|
ARRAYTABLE
|
array table , non-reserved identifier
|
|
AUTO_INCREMENT
|
table element , non-reserved identifier
|
|
AVG
|
standard aggregate function , non-reserved identifier
|
|
CHAIN
|
sql exception , non-reserved identifier
|
|
COLUMNS
|
array table , non-reserved identifier , object table , text table , xml table
|
|
CONTENT
|
non-reserved identifier , xml parse , xml serialize
|
|
COUNT
|
standard aggregate function , non-reserved identifier
|
|
DELIMITER
|
non-reserved identifier , text aggregate function , text table
|
|
DENSE_RANK
|
analytic aggregate function , non-reserved identifier
|
|
DISABLED
|
alter , non-reserved identifier
|
|
DOCUMENT
|
non-reserved identifier , xml parse , xml serialize
|
|
EMPTY
|
non-reserved identifier , xml query
|
|
ENABLED
|
alter , non-reserved identifier
|
|
ENCODING
|
non-reserved identifier , text aggregate function , xml serialize
|
|
EVERY
|
standard aggregate function , non-reserved identifier
|
|
EXCEPTION
|
compound statement , declare statement , non-reserved identifier
|
|
EXCLUDING
|
non-reserved identifier , xml serialize
|
|
EXTRACT
|
function , non-reserved identifier
|
|
FIRST
|
fetch clause , non-reserved identifier , sort specification
|
|
HEADER
|
non-reserved identifier , text aggregate function , text table
|
|
INCLUDING
|
non-reserved identifier , xml serialize
|
|
INDEX
|
other constraints , table element , non-reserved identifier
|
|
INSTEAD
|
alter , create trigger , non-reserved identifier
|
|
JSONARRAY_AGG
|
non-reserved identifier , ordered aggregate function
|
|
JSONOBJECT
|
json object , non-reserved identifier
|
|
KEY
|
table element , create temporary table , foreign key , non-reserved identifier , primary key
|
|
LAST
|
non-reserved identifier , sort specification
|
|
MAX
|
standard aggregate function , non-reserved identifier
|
|
MIN
|
standard aggregate function , non-reserved identifier
|
|
NAME
|
function , non-reserved identifier , xml element
|
|
NAMESPACE
|
option namespace , non-reserved identifier
|
|
NEXT
|
fetch clause , non-reserved identifier
|
|
NULLS
|
non-reserved identifier , sort specification
|
|
OBJECTTABLE
|
non-reserved identifier , object table
|
|
ORDINALITY
|
non-reserved identifier , xml table column
|
|
PASSING
|
non-reserved identifier , object table , xml query , xml table
|
|
PATH
|
non-reserved identifier , xml table column
|
|
QUERYSTRING
|
non-reserved identifier , querystring function
|
|
QUOTE
|
non-reserved identifier , text aggregate function , text table
|
|
RAISE
|
non-reserved identifier , raise statement
|
|
RANK
|
analytic aggregate function , non-reserved identifier
|
|
RESULT
|
non-reserved identifier , procedure parameter
|
|
ROW_NUMBER
|
analytic aggregate function , non-reserved identifier
|
|
SELECTOR
|
non-reserved identifier , text table column , text table
|
|
SERIAL
|
non-reserved identifier , temporary table element
|
|
SKIP
|
non-reserved identifier , text table
|
|
SQL_TSI_DAY
|
time interval , non-reserved identifier
|
|
SQL_TSI_FRAC_SECOND
|
time interval , non-reserved identifier
|
|
SQL_TSI_HOUR
|
time interval , non-reserved identifier
|
|
SQL_TSI_MINUTE
|
time interval , non-reserved identifier
|
|
SQL_TSI_MONTH
|
time interval , non-reserved identifier
|
|
SQL_TSI_QUARTER
|
time interval , non-reserved identifier
|
|
SQL_TSI_SECOND
|
time interval , non-reserved identifier
|
|
SQL_TSI_WEEK
|
time interval , non-reserved identifier
|
|
SQL_TSI_YEAR
|
time interval , non-reserved identifier
|
|
STDDEV_POP
|
standard aggregate function , non-reserved identifier
|
|
STDDEV_SAMP
|
standard aggregate function , non-reserved identifier
|
|
SUBSTRING
|
function , non-reserved identifier
|
|
SUM
|
standard aggregate function , non-reserved identifier
|
|
TEXTAGG
|
non-reserved identifier , text aggregate function
|
|
TEXTTABLE
|
non-reserved identifier , text table
|
|
TIMESTAMPADD
|
function , non-reserved identifier
|
|
TIMESTAMPDIFF
|
function , non-reserved identifier
|
|
TO_BYTES
|
function , non-reserved identifier
|
|
TO_CHARS
|
function , non-reserved identifier
|
|
TRIM
|
function , non-reserved identifier , text table column
|
|
VARIADIC
|
non-reserved identifier , procedure parameter
|
|
VAR_POP
|
standard aggregate function , non-reserved identifier
|
|
VAR_SAMP
|
standard aggregate function , non-reserved identifier
|
|
VERSION
|
non-reserved identifier , xml serialize
|
|
VIEW
|
alter , alter options , create table , non-reserved identifier
|
|
WELLFORMED
|
non-reserved identifier , xml parse
|
|
WIDTH
|
non-reserved identifier , text table column
|
|
XMLDECLARATION
|
non-reserved identifier , xml serialize
|
A.4. Reserved Keywords For Future Use
|
ALLOCATE
|
ARE
|
ARRAY
|
ASENSITIVE
|
ASYMETRIC
|
AUTHORIZATION
|
BINARY
|
CALLED
|
|
CASCADED
|
CHARACTER
|
CHECK
|
CLOSE
|
COLLATE
|
COMMIT
|
CONNECT
|
CORRESPONDING
|
|
CRITERIA
|
CURRENT_DATE
|
CURRENT_TIME
|
CURRENT_TIMESTAMP
|
CURRENT_USER
|
CURSOR
|
CYCLE
|
DATALINK
|
|
DEALLOCATE
|
DEC
|
DEREF
|
DESCRIBE
|
DETERMINISTIC
|
DISCONNECT
|
DLNEWCOPY
|
DLPREVIOUSCOPY
|
|
DLURLCOMPLETE
|
DLURLCOMPLETEONLY
|
DLURLCOMPLETEWRITE
|
DLURLPATH
|
DLURLPATHONLY
|
DLURLPATHWRITE
|
DLURLSCHEME
|
DLURLSERVER
|
|
DLVALUE
|
DYNAMIC
|
ELEMENT
|
EXTERNAL
|
FREE
|
GET
|
GLOBAL
|
GRANT
|
|
HAS
|
HOLD
|
IDENTITY
|
IMPORT
|
INDICATOR
|
INPUT
|
INSENSITIVE
|
INT
|
|
INTERVAL
|
ISOLATION
|
LARGE
|
LOCALTIME
|
LOCALTIMESTAMP
|
MATCH
|
MEMBER
|
METHOD
|
|
MODIFIES
|
MODULE
|
MULTISET
|
NATIONAL
|
NATURAL
|
NCHAR
|
NCLOB
|
NEW
|
|
NONE
|
NUMERIC
|
OLD
|
OPEN
|
OUTPUT
|
OVERLAPS
|
PRECISION
|
PREPARE
|
|
RANGE
|
READS
|
RECURSIVE
|
REFERENCING
|
RELEASE
|
REVOKE
|
ROLLBACK
|
ROLLUP
|
|
SAVEPOINT
|
SCROLL
|
SEARCH
|
SENSITIVE
|
SESSION_USER
|
SPECIFIC
|
SPECIFICTYPE
|
SQL
|
|
START
|
STATIC
|
SUBMULTILIST
|
SYMETRIC
|
SYSTEM
|
SYSTEM_USER
|
TIMEZONE_HOUR
|
TIMEZONE_MINUTE
|
|
TRANSLATION
|
TREAT
|
VALUE
|
VARYING
|
WHENEVER
|
WINDOW
|
WITHIN
|
XMLBINARY
|
|
XMLCAST
|
XMLDOCUMENT
|
XMLEXISTS
|
XMLITERATE
|
XMLTEXT
|
XMLVALIDATE
| | |
A.5. Tokens
|
Name
|
Definition
|
Usage
|
|---|---|---|
|
all in group identifier
|
< identifier > < period > < star >
|
all in group
|
|
binary string literal
|
"X" | "x" "\'" (< hexit > < hexit >)+ "\'"
|
non numeric literal
|
|
colon
|
":"
|
statement
|
|
comma
|
","
|
alter options list , column list , create procedure , typed element list , create table body , create temporary table , derived column list , sql exception named parameter list , expression list , from clause , function limit clause , object table , option clause , options clause , order by clause , data type , query expression , querystring function select clause , set clause list , in predicate , text aggreate function , text table , xml attributes , xml element , xml forest , xml namespaces , xml query , xml table
|
|
concat_op
|
"||"
|
common value expression
|
|
decimal numeric literal
|
(< digit >)* < period > < unsigned integer literal >
|
unsigned numeric literal
|
|
digit
|
["0"-"9"]
| |
|
dollar
|
"$"
|
unsigned value expression primary
|
|
eq
|
"="
|
assignment statement , callable statement , declare statement , named parameter list , comparison operator , set clause list
|
|
escaped function
|
"{" "fn"
|
unsigned value expression primary
|
|
escaped join
|
"{" "oj"
|
table reference
|
|
escaped type
|
"{" ("d" | "t" | "ts" | "b")
|
non numeric literal
|
|
approximate numeric literal
|
< digit > < period > < unsigned integer literal > ["e","E"] (< plus > | < minus >)? < unsigned integer literal >
|
unsigned numeric literal
|
|
ge
|
">="
|
comparison operator
|
|
gt
|
">"
|
named parameter list , comparison operator
|
|
hexit
|
["a"-"f","A"-"F"] | < digit >
| |
|
identifier
|
< quoted_id > (< period > < quoted_id >)*
|
identifier , unsigned value expression primary
|
|
id_part
|
("@" | "#" | < letter >) (< letter > | "_" | < digit >)*
| |
|
lbrace
|
"{"
|
callable statement , match predicate
|
|
le
|
"<="
|
comparison operator
|
|
letter
|
["a"-"z","A"-"Z"] | ["\u0153"-"\ufffd"]
| |
|
lparen
|
"("
|
standard aggregate function , alter options list , analytic aggregate function , array table , callable statement , column list , other constraints , create procedure , create table body , create temporary table , filter clause , function , if statement , insert statement , json object , loop statement , object table , options clause , ordered aggreate function , data type , query primary , querystring function , in predicate , call statement , subquery , table subquery , table primary , text aggregate function , text table , unsigned value expression primary , while statement , window specification , with list element , xml attributes , xml element , xml forest , xml namespaces , xml parse , xml query , xml serialize , xml table
|
|
lsbrace
|
"["
|
unsigned value expression primary
|
|
lt
|
"<"
|
comparison operator
|
|
minus
|
"-"
|
plus or minus
|
|
ne
|
"<>"
|
comparison operator
|
|
ne2
|
"!="
|
comparison operator
|
|
period
|
"."
| |
|
plus
|
"+"
|
plus or minus
|
|
qmark
|
"?"
|
callable statement , integer parameter , unsigned value expression primary
|
|
quoted_id
|
< id_part > | "\"" ("\"\"" | ~["\""])+ "\""
| |
|
rbrace
|
"}"
|
callable statement , match predicate , non numeric literal , table reference , unsigned value expression primary
|
|
rparen
|
")"
|
standard aggregate function , alter options list , analytic aggregate function , array table , callable statement , column list , other constraints , create procedure , create table body , create temporary table , filter clause , function , if statement , insert statement , json object , loop statement , object table , options clause , ordered aggregate function , data type , query primary , querystring function , in predicate , call statement , subquery , table subquery , table primary , text aggregate function , text table , unsigned value expression primary , while statement , window specification , with list element , xml attributes , xml element , xml forest , xml namespaces , xml parse , xml query , xml serialize , xml table
|
|
rsbrace
|
"]"
|
unsigned value expression primary
|
|
semicolon
|
";"
|
ddl statement , delimited statement
|
|
slash
|
"/"
|
star or slash
|
|
star
|
"*"
|
standard aggregate function , dynamic data statement , select clause , star or slash
|
|
string literal
|
("N" | "E")? "\'" ("\'\'" | ~["\'"])* "\'"
|
string
|
|
unsigned integer literal
|
(< digit >)+
|
unsigned integer , unsigned numeric literal
|
A.6. Production Cross-Reference
|
Name
|
Usage
|
|---|---|
|
add set option
|
alter options list
|
|
standard aggregate function
|
unsigned value expression primary
|
|
all in group
|
select sublist
|
|
alter
|
directly executable statement
|
|
alter column options
|
alter options
|
|
alter options list
|
alter column options , alter options
|
|
alter options
|
ddl statement
|
|
analytic aggregate function
|
unsigned value expression primary
|
|
array table
|
table primary
|
|
assignment statement
|
delimited statement
|
|
assignment statement operand
|
assignment statement , declare statement
|
|
between predicate
|
boolean primary
|
|
boolean primary
|
filter clause , boolean factor
|
|
branching statement
|
delimited statement
|
|
case expression
|
unsigned value expression primary
|
|
character
|
match predicate , text aggregate function , text table
|
|
column list
|
other constraints , create temporary table , foreign key , insert statement primary key , with list element
|
|
common value expression
|
between predicate , boolean primary , comparison predicate , sql exception , match predicate , like regex predicate , in predicate , text table , unsigned value expression primary
|
|
comparison predicate
|
boolean primary
|
|
boolean term
|
boolean value expression
|
|
boolean value expression
|
condition
|
|
compound statement
|
statement
|
|
other constraints
|
create table body
|
|
table element
|
create table body
|
|
create procedure
|
ddl statement
|
|
typed element list
|
array table , dynamic data statement
|
|
create foreign temp table
|
directly executable statement
|
|
option namespace
|
ddl statement
|
|
create table
|
ddl statement
|
|
create table body
|
create foreign temp table , create table
|
|
create temporary table
|
directly executable statement
|
|
create trigger
|
ddl statement , directly executable statement
|
|
condition
|
expression , having clause , if statement , qualified table , searched case expression , where clause , while statement
|
|
cross join
|
joined table
|
|
declare statement
|
delimited statement
|
|
delete statement
|
assignment statement operand , directly executable statement
|
|
delimited statement
|
statement
|
|
derived column
|
derived column list , object table , querystring function , text aggregate function , xml attributes , xml query , xml table
|
|
derived column list
|
json object , xml forest
|
|
drop option
|
alter options list
|
|
drop table
|
directly executable statement
|
|
dynamic data statement
|
data statement
|
|
raise error statement
|
delimited statement
|
|
sql exception
|
assignment statement operand , exception reference
|
|
exception reference
|
sql exception , raise statement
|
|
named parameter list
|
call statement
|
|
exists predicate
|
boolean primary
|
|
expression
|
standard aggregate function , assignment statement operand , case expression , derived column , dynamic data statement , raise error statement , named parameter list , expression list , function , object table column , ordered aggregate function , querystring function , return statement , searched case expression , select derived column , set clause list , sort key , unsigned value expression primary , xml table column , xml element , xml parse , xml serialize
|
|
expression list
|
callable statement , other constraints , function , group by clause , insert statement , call statement , window specification
|
|
fetch clause
|
limit clause
|
|
filter clause
|
function , unsigned value expression primary
|
|
for each row trigger action
|
alter , create trigger
|
|
foreign key
|
create table body
|
|
from clause
|
query
|
|
function
|
unsigned value expression primary
|
|
group by clause
|
query
|
|
having clause
|
query
|
|
identifier
|
alter , alter column options , alter options , array table , assignment statement , branching statement , callable statement , column list , compound statement , table element , create procedure , typed element list , create foreign temp table , option namespace , create table , create table body , create temporary table , create trigger , declare statement , delete statement , derived column , drop option , drop table , dynamic data statement , exception reference , named parameter list , foreign key , function , insert statement , into clause , loop statement , xml namespace element , object table column , object table , option clause , option pair , procedure parameter , procedure result column , query primary , select derived column , set clause list , statement , call statement , table subquery , temporary table element , text aggregate function , text table column , text table , table name , update statement , with list element , xml table column , xml element , xml serialize , xml table
|
|
if statement
|
statement
|
|
insert statement
|
assignment statement operand , directly executable statement
|
|
integer parameter
|
fetch clause , limit clause
|
|
unsigned integer
|
dynamic data statement , integer parameter , data type , text table column , text table , unsigned value expression primary
|
|
time interval
|
function
|
|
into clause
|
query
|
|
is null predicate
|
boolean primary
|
|
joined table
|
table primary , table reference
|
|
json object
|
function
|
|
limit clause
|
query expression body
|
|
loop statement
|
statement
|
|
match predicate
|
boolean primary
|
|
xml namespace element
|
xml namespaces
|
|
non numeric literal
|
option pair , value expression primary
|
|
non-reserved identifier
|
identifier , unsigned value expression primary
|
|
boolean factor
|
boolean term
|
|
object table column
|
object table
|
|
object table
|
table primary
|
|
comparison operator
|
comparison predicate , quantified comparison predicate
|
|
option clause
|
callable statement , delete statement , insert statement , query expression body , call statement , update statement
|
|
option pair
|
add set option , options clause
|
|
options clause
|
table element , create procedure , create table , create table body , procedure parameter , procedure result column
|
|
order by clause
|
function , ordered aggregate function , query expression body , text aggregate function , window specification
|
|
ordered aggregate function
|
unsigned value expression primary
|
|
data type
|
table element , create procedure , typed element list , declare statement , function , object table column , procedure parameter , procedure result column , temporary table element , text table column , xml table column
|
|
numeric value expression
|
common value expression
|
|
plus or minus
|
option pair , numeric value expression , value expression primary
|
|
primary key
|
create table body
|
|
procedure parameter
|
create procedure
|
|
procedure result column
|
create procedure
|
|
qualified table
|
joined table
|
|
query
|
query primary
|
|
query expression
|
alter , assignment statement operand , create table , insert statement , loop statement , subquery , table subquery , directly executable statement , with list element
|
|
query expression body
|
query expression , query primary
|
|
query primary
|
query term
|
|
querystring function
|
function
|
|
query term
|
query expression body
|
|
raise statement
|
delimited statement
|
|
like regex predicate
|
boolean primary
|
|
return statement
|
delimited statement
|
|
searched case expression
|
unsigned value expression primary
|
|
select clause
|
query
|
|
select derived column
|
select sublist
|
|
select sublist
|
select clause
|
|
set clause list
|
dynamic data statement , update statement
|
|
in predicate
|
boolean primary
|
|
sort key
|
sort specification
|
|
sort specification
|
order by clause
|
|
data statement
|
delimited statement
|
|
statement
|
alter , compound statement , create procedure , for each row trigger action , if statement , loop statement , procedure body definition , while statement
|
|
call statement
|
assignment statement , subquery , table subquery , directly executable statement
|
|
string
|
character , table element , option namespace , function , xml namespace element , non numeric literal , object table column , object table , procedure parameter , text table column , text table , xml table column , xml query , xml serialize , xml table
|
|
subquery
|
exists predicate , in predicate , quantified comparison predicate , unsigned value expression primary
|
|
quantified comparison predicate
|
boolean primary
|
|
table subquery
|
table primary
|
|
temporary table element
|
create temporary table
|
|
table primary
|
cross join , joined table
|
|
table reference
|
from clause , qualified table
|
|
text aggregate function
|
unsigned value expression primary
|
|
text table column
|
text table
|
|
text table
|
table primary
|
|
term
|
numeric value expression
|
|
star or slash
|
term
|
|
table name
|
table primary
|
|
unsigned numeric literal
|
option pair , value expression primary
|
|
unsigned value expression primary
|
value expression primary
|
|
update statement
|
assignment statement operand , directly executable statement
|
|
directly executable statement
|
data statement
|
|
value expression primary
|
array table , term
|
|
where clause
|
delete statement , query , update statement
|
|
while statement
|
statement
|
|
window specification
|
unsigned value expression primary
|
|
with list element
|
query expression
|
|
xml attributes
|
xml element
|
|
xml table column
|
xml table
|
|
xml element
|
function
|
|
xml forest
|
function
|
|
xml namespaces
|
xml element , xml forest , xml query , xml table
|
|
xml parse
|
function
|
|
xml query
|
function
|
|
xml serialize
|
function
|
|
xml table
|
table primary
|
A.7. Productions
string ::=
Expand < string literal >
'a string'
'a string''it''s a string'
'it''s a string'reserved identifier ::=
Expand INSTEADExpand VIEWExpand ENABLEDExpand DISABLEDExpand KEYExpand SERIALExpand TEXTAGGExpand COUNTExpand ROW_NUMBERExpand RANKExpand DENSE_RANKExpand SUMExpand AVGExpand MINExpand MAXExpand EVERYExpand STDDEV_POPExpand STDDEV_SAMPExpand VAR_SAMPExpand VAR_POPExpand DOCUMENTExpand CONTENTExpand TRIMExpand EMPTYExpand ORDINALITYExpand PATHExpand FIRSTExpand LASTExpand NEXTExpand SUBSTRINGExpand EXTRACTExpand TO_CHARSExpand TO_BYTESExpand TIMESTAMPADDExpand TIMESTAMPDIFFExpand QUERYSTRINGExpand NAMESPACEExpand RESULTExpand INDEXExpand ACCESSPATTERNExpand AUTO_INCREMENTExpand WELLFORMEDExpand SQL_TSI_FRAC_SECONDExpand SQL_TSI_SECONDExpand SQL_TSI_MINUTEExpand SQL_TSI_HOURExpand SQL_TSI_DAYExpand SQL_TSI_WEEKExpand SQL_TSI_MONTHExpand SQL_TSI_QUARTERExpand SQL_TSI_YEARExpand TEXTTABLEExpand ARRAYTABLEExpand SELECTORExpand SKIPExpand WIDTHExpand PASSINGExpand NAMEExpand ENCODINGExpand COLUMNSExpand DELIMITERExpand QUOTEExpand HEADERExpand NULLSExpand OBJECTTABLEExpand VERSIONExpand INCLUDINGExpand EXCLUDINGExpand XMLDECLARATIONExpand VARIADICExpand RAISEExpand EXCEPTIONExpand CHAINExpand JSONARRAY_AGGExpand JSONOBJECT
identifier ::=
Expand < identifier >Expand < non-reserved identifier >
tbl.col
tbl.col"tbl"."col"
"tbl"."col"create trigger ::=
Expand CREATE TRIGGER ON < identifier > INSTEAD OF ( INSERT | UPDATE | DELETE ) AS < for each row trigger action >
CREATE TRIGGER ON vw INSTEAD OF INSERT AS FOR EACH ROW BEGIN ATOMIC ... END
CREATE TRIGGER ON vw INSTEAD OF INSERT AS FOR EACH ROW BEGIN ATOMIC ... ENDalter ::=
Expand ALTER ( ( VIEW < identifier > AS < query expression > ) | ( PROCEDURE < identifier > AS < statement > ) | ( TRIGGER ON < identifier > INSTEAD OF ( INSERT | UPDATE | DELETE ) ( ( AS < for each row trigger action > ) | ENABLED | DISABLED ) ) )
ALTER VIEW vw AS SELECT col FROM tbl
ALTER VIEW vw AS SELECT col FROM tblfor each row trigger action ::=
Expand FOR EACH ROW ( ( BEGIN ( ATOMIC )? ( < statement > )* END ) | < statement > )
FOR EACH ROW BEGIN ATOMIC ... END
FOR EACH ROW BEGIN ATOMIC ... ENDdirectly executable statement ::=
Expand < query expression >Expand < call statement >Expand < insert statement >Expand < update statement >Expand < delete statement >Expand < drop table >Expand < create temporary table >Expand < create foreign temp table >Expand < alter >Expand < create trigger >
SELECT * FROM tbl
SELECT * FROM tbldrop table ::=
Expand DROP TABLE < identifier >
CREATE TRIGGER ON vw INSTEAD OF INSERT AS FOR EACH ROW BEGIN ATOMIC ... END
CREATE TRIGGER ON vw INSTEAD OF INSERT AS FOR EACH ROW BEGIN ATOMIC ... ENDcreate temporary table ::=
Expand CREATE LOCAL TEMPORARY TABLE < identifier > < lparen > < temporary table element > ( < comma > < temporary table element > )* ( < comma > PRIMARY KEY < column list > )? < rparen >
CREATE LOCAL TEMPORARY TABLE tmp (col integer)
CREATE LOCAL TEMPORARY TABLE tmp (col integer)temporary table element ::=
Expand < identifier > ( < data type > | SERIAL ) ( NOT NULL )?
col string NOT NULL
col string NOT NULLraise error statement ::=
Expand ERROR < expression >
ERROR 'something went wrong'
ERROR 'something went wrong'raise statement ::=
Expand RAISE ( SQLWARNING )? < exception reference >
RAISE SQLEXCEPTION 'something went wrong'
RAISE SQLEXCEPTION 'something went wrong'exception reference ::=
Expand < identifier >Expand < sql exception >
SQLEXCEPTION 'something went wrong' SQLSTATE '00X', 2
SQLEXCEPTION 'something went wrong' SQLSTATE '00X', 2sql exception ::=
Expand SQLEXCEPTION < common value expression > ( SQLSTATE < common value expression > ( < comma > < common value expression > )? )? ( CHAIN < exception reference > )?
SQLEXCEPTION 'something went wrong' SQLSTATE '00X', 2
SQLEXCEPTION 'something went wrong' SQLSTATE '00X', 2statement ::=
Expand ( ( < identifier > < colon > )? ( < loop statement > | < while statement > | < compound statement > ) )Expand < if statement > | < delimited statement >
IF (x = 5) BEGIN ... END
IF (x = 5) BEGIN ... ENDdelimited statement ::=
Expand ( < assignment statement > | < data statement > | < raise error statement > | < raise statement > | < declare statement > | < branching statement > | < return statement > ) < semicolon >
SELECT * FROM tbl;
SELECT * FROM tbl;compound statement ::=
Expand BEGIN ( ( NOT )? ATOMIC )? ( < statement > )* ( EXCEPTION < identifier > ( < statement > )* )? END
BEGIN NOT ATOMIC ... END
BEGIN NOT ATOMIC ... ENDbranching statement ::=
Expand ( ( BREAK | CONTINUE ) ( < identifier > )? )Expand ( LEAVE < identifier > )
BREAK x
BREAK xreturn statement ::=
Expand RETURN ( < expression > )?
RETURN 1
RETURN 1while statement ::=
Expand WHILE < lparen > < condition > < rparen > < statement >
WHILE (var) BEGIN ... END
WHILE (var) BEGIN ... ENDloop statement ::=
Expand LOOP ON < lparen > < query expression > < rparen > AS < identifier > < statement >
IF (boolVal) BEGIN variables.x = 1 END ELSE BEGIN variables.x = 2 END
IF (boolVal) BEGIN variables.x = 1 END ELSE BEGIN variables.x = 2 ENDif statement ::=
Expand IF < lparen > < condition > < rparen > < statement > ( ELSE < statement > )?
LOOP ON (SELECT * FROM tbl) AS x BEGIN ... END
LOOP ON (SELECT * FROM tbl) AS x BEGIN ... ENDdeclare statement ::=
Expand DECLARE ( < data type > | EXCEPTION ) < identifier > ( < eq > < assignment statement operand > )?
DECLARE STRING x = 'a'
DECLARE STRING x = 'a'assignment statement ::=
Expand < identifier > < eq > ( < assignment statement operand > | ( < call statement > ( ( WITH | WITHOUT ) RETURN )? ) )
x = 'b'
x = 'b'assignment statement operand ::=
Expand < insert statement >Expand < update statement >Expand < delete statement >Expand < expression >Expand < query expression >Expand < sql exception >
Note
data statement ::=
Expand ( < directly executable statement > | < dynamic data statement > ) ( ( WITH | WITHOUT ) RETURN )?
procedure body definition ::=
Expand ( CREATE ( VIRTUAL )? PROCEDURE )? < statement >
CREATE VIRTUAL PROCEDURE BEGIN ... END
CREATE VIRTUAL PROCEDURE BEGIN ... ENDdynamic data statement ::=
Expand ( EXECUTE | EXEC ) ( STRING | IMMEDIATE )? < expression > ( AS < typed element list > ( INTO < identifier > )? )? ( USING < set clause list > )? ( UPDATE ( < unsigned integer > | < star > ) )?
EXECUTE IMMEDIATE 'SELECT * FROM tbl' AS x STRING INTO #temp
EXECUTE IMMEDIATE 'SELECT * FROM tbl' AS x STRING INTO #tempset clause list ::=
Expand < identifier > < eq > < expression > ( < comma > < identifier > < eq > < expression > )*
col1 = 'x', col2 = 'y' ...
col1 = 'x', col2 = 'y' ...typed element list ::=
Expand < identifier > < data type > ( < comma > < identifier > < data type > )*
col1 string, col2 integer ...
col1 string, col2 integer ...callable statement ::=
Expand < lbrace > ( < qmark > < eq > )? CALL < identifier > ( < lparen > ( < expression list > )? < rparen > )? < rbrace > ( < option clause > )?
{? = CALL proc}
{? = CALL proc}call statement ::=
Expand ( ( EXEC | EXECUTE | CALL ) < identifier > < lparen > ( < named parameter list > | ( < expression list > )? ) < rparen > ) ( < option clause > )?
CALL proc('a', 1)
CALL proc('a', 1)named parameter list ::=
Expand ( < identifier > < eq > ( < gt > )? < expression > ( < comma > < identifier > < eq > ( < gt > )? < expression > )* )
param1 => 'x', param2 => 1
param1 => 'x', param2 => 1insert statement ::=
Expand ( INSERT | MERGE ) INTO < identifier > ( < column list > )? ( ( VALUES < lparen > < expression list > < rparen > ) | < query expression > ) ( < option clause > )?
INSERT INTO tbl (col1, col2) VALUES ('a', 1)
INSERT INTO tbl (col1, col2) VALUES ('a', 1)expression list ::=
Expand < expression > ( < comma > < expression > )*
col1, 'a', ...
col1, 'a', ...update statement ::=
Expand UPDATE < identifier > SET < set clause list > ( < where clause > )? ( < option clause > )?
UPDATE tbl SET (col1 = 'a') WHERE col2 = 1
UPDATE tbl SET (col1 = 'a') WHERE col2 = 1delete statement ::=
Expand DELETE FROM < identifier > ( < where clause > )? ( < option clause > )?
DELETE FROM tbl WHERE col2 = 1
DELETE FROM tbl WHERE col2 = 1query expression ::=
Expand ( WITH < with list element > ( < comma > < with list element > )* )? < query expression body >
SELECT * FROM tbl WHERE col2 = 1
SELECT * FROM tbl WHERE col2 = 1with list element ::=
Expand < identifier > ( < column list > )? AS < lparen > < query expression > < rparen >
X (Y, Z) AS (SELECT 1, 2)
X (Y, Z) AS (SELECT 1, 2)query expression body ::=
Expand < query term > ( ( UNION | EXCEPT ) ( ALL | DISTINCT )? < query term > )* ( < order by clause > )? ( < limit clause > )? ( < option clause > )?
SELECT * FROM tbl ORDER BY col1 LIMIT 1
SELECT * FROM tbl ORDER BY col1 LIMIT 1query term ::=
Expand < query primary > ( INTERSECT ( ALL | DISTINCT )? < query primary > )*
SELECT * FROM tbl
SELECT * FROM tblSELECT * FROM tbl1 INTERSECT SELECT * FROM tbl2
SELECT * FROM tbl1 INTERSECT SELECT * FROM tbl2query primary ::=
Expand < query >Expand ( TABLE < identifier > )Expand ( < lparen > < query expression body > < rparen > )
TABLE tbl
TABLE tblSELECT * FROM tbl1
SELECT * FROM tbl1query ::=
Expand < select clause > ( < into clause > )? ( < from clause > ( < where clause > )? ( < group by clause > )? ( < having clause > )? )?
SELECT col1, max(col2) FROM tbl GROUP BY col1
SELECT col1, max(col2) FROM tbl GROUP BY col1into clause ::=
Expand INTO < identifier >
Note
INTO tbl
INTO tblselect clause ::=
Expand SELECT ( ALL | DISTINCT )? ( < star > | ( < select sublist > ( < comma > < select sublist > )* ) )
SELECT *
SELECT *SELECT DISTINCT a, b, c
SELECT DISTINCT a, b, cselect sublist ::=
Expand < select derived column >Expand < all in group >
tbl.*
tbl.*tbl.col AS x
tbl.col AS xselect derived column ::=
Expand ( < expression > ( ( AS )? < identifier > )? )
Note
tbl.col AS x
tbl.col AS xderived column ::=
Expand ( < expression > ( AS < identifier > )? )
tbl.col AS x
tbl.col AS xall in group ::=
Expand < all in group identifier >
tbl.*
tbl.*ordered aggreate function ::=
Expand ( XMLAGG | ARRAY_AGG | JSONARRAY_AGG ) < lparen > < expression > ( < order by clause > )? < rparen >
XMLAGG(col1) ORDER BY col2
XMLAGG(col1) ORDER BY col2ARRAY_AGG(col1)
ARRAY_AGG(col1)text aggreate function ::=
Expand TEXTAGG < lparen > ( FOR )? < derived column > ( < comma > < derived column > )* ( DELIMITER < character > )? ( QUOTE < character > )? ( HEADER )? ( ENCODING < identifier > )? ( < order by clause > )? < rparen >
TEXTAGG (col1 as t1, col2 as t2 DELIMITER ',' HEADER)
TEXTAGG (col1 as t1, col2 as t2 DELIMITER ',' HEADER)standard aggregate function ::=
Expand ( COUNT < lparen > < star > < rparen > )Expand ( ( COUNT | SUM | AVG | MIN | MAX | EVERY | STDDEV_POP | STDDEV_SAMP | VAR_SAMP | VAR_POP | SOME | ANY ) < lparen > ( DISTINCT | ALL )? < expression > < rparen > )
COUNT(*)
COUNT(*)analytic aggregate function ::=
Expand ( ROW_NUMBER | RANK | DENSE_RANK ) < lparen > < rparen >
ROW_NUMBER()
ROW_NUMBER()filter clause ::=
Expand FILTER < lparen > WHERE < boolean primary > < rparen >
FILTER (WHERE col1='a')
FILTER (WHERE col1='a')from clause ::=
Expand FROM ( < table reference > ( < comma > < table reference > )* )
FROM a, b
FROM a, bFROM a right outer join b, c, d join e".</p>
FROM a right outer join b, c, d join e".</p>table reference ::=
Expand ( < escaped join > < joined table > < rbrace > )Expand < joined table >
a
aa inner join b
a inner join bjoined table ::=
Expand < table primary > ( < cross join > | < qualified table > )*
a
aa inner join b
a inner join bcross join ::=
Expand ( ( CROSS | UNION ) JOIN < table primary > )
a CROSS JOIN b
a CROSS JOIN bqualified table ::=
Expand ( ( ( RIGHT ( OUTER )? ) | ( LEFT ( OUTER )? ) | ( FULL ( OUTER )? ) | INNER )? JOIN < table reference > ON < condition > )
a inner join b
a inner join btable primary ::=
Expand ( < text table > | < array table > | < xml table > | < object table > | < table name > | < table subquery > | ( < lparen > < joined table > < rparen > ) ) ( MAKEDEP | MAKENOTDEP )?
a
axml serialize ::=
Expand XMLSERIALIZE < lparen > ( DOCUMENT | CONTENT )? < expression > ( AS ( STRING | VARCHAR | CLOB | VARBINARY | BLOB ) )? ( ENCODING < identifier > )? ( VERSION < string > )? ( ( INCLUDING | EXCLUDING ) XMLDECLARATION )? < rparen >
XMLSERIALIZE(col1 AS CLOB)
XMLSERIALIZE(col1 AS CLOB)array table ::=
Expand ARRAYTABLE < lparen > < value expression primary > COLUMNS < typed element list > < rparen > ( AS )? < identifier >
ARRAYTABLE (col1 COLUMNS x STRING) AS y
ARRAYTABLE (col1 COLUMNS x STRING) AS ytext table ::=
Expand TEXTTABLE < lparen > < common value expression > ( SELECTOR < string > )? COLUMNS < text table column > ( < comma > < text table column > )* ( NO ROW DELIMITER )? ( DELIMITER < character > )? ( ( ESCAPE < character > ) | ( QUOTE < character > ) )? ( HEADER ( < unsigned integer > )? )? ( SKIP < unsigned integer > )? < rparen > ( AS )? < identifier >
TEXTTABLE (file COLUMNS x STRING) AS y
TEXTTABLE (file COLUMNS x STRING) AS ytext table column ::=
Expand < identifier > < data type > ( WIDTH < unsigned integer > ( NO TRIM )? )? ( SELECTOR < string > < unsigned integer > )?
x INTEGER WIDTH 6
x INTEGER WIDTH 6xml query ::=
Expand XMLQUERY < lparen > ( < xml namespaces > < comma > )? < string > ( PASSING < derived column > ( < comma > < derived column > )* )? ( ( NULL | EMPTY ) ON EMPTY )? < rparen >
XMLQUERY('<a>...</a>' PASSING doc)
XMLQUERY('<a>...</a>' PASSING doc)object table ::=
Expand OBJECTTABLE < lparen > ( LANGUAGE < string > )? < string > ( PASSING < derived column > ( < comma > < derived column > )* )? COLUMNS < object table column > ( < comma > < object table column > )* < rparen > ( AS )? < identifier >
OBJECTTABLE('z' PASSING val AS z COLUMNS col OBJECT 'teiid_row') AS X
OBJECTTABLE('z' PASSING val AS z COLUMNS col OBJECT 'teiid_row') AS Xobject table column ::=
Expand < identifier > < data type > < string > ( DEFAULT < expression > )?
y integer 'teiid_row_number'
y integer 'teiid_row_number'xml table ::=
Expand XMLTABLE < lparen > ( < xml namespaces > < comma > )? < string > ( PASSING < derived column > ( < comma > < derived column > )* )? ( COLUMNS < xml table column > ( < comma > < xml table column > )* )? < rparen > ( AS )? < identifier >
XMLTABLE('/a/b' PASSING doc COLUMNS col XML PATH '.') AS X
XMLTABLE('/a/b' PASSING doc COLUMNS col XML PATH '.') AS Xxml table column ::=
Expand < identifier > ( ( FOR ORDINALITY ) | ( < data type > ( DEFAULT < expression > )? ( PATH < string > )? ) )
y FOR ORDINALITY
y FOR ORDINALITYunsigned integer ::=
Expand < unsigned integer literal >
12345
12345table subquery ::=
Expand ( TABLE | LATERAL )? < lparen > ( < query expression > | < call statement > ) < rparen > ( AS )? < identifier >
(SELECT * FROM tbl) AS x
(SELECT * FROM tbl) AS xtable name ::=
Expand ( < identifier > ( ( AS )? < identifier > )? )
tbl AS x
tbl AS xwhere clause ::=
Expand WHERE < condition >
WHERE x = 'a'
WHERE x = 'a'condition ::=
Expand < boolean value expression >
boolean value expression ::=
Expand < boolean term > ( OR < boolean term > )*
boolean term ::=
Expand < boolean factor > ( AND < boolean factor > )*
boolean factor ::=
Expand ( NOT )? < boolean primary >
NOT x = 'a'
NOT x = 'a'boolean primary ::=
Expand ( < common value expression > ( < between predicate > | < match predicate > | < like regex predicate > | < in predicate > | < is null predicate > | < quantified comparison predicate > | < comparison predicate > )? )Expand < exists predicate >
col LIKE 'a%'
col LIKE 'a%'comparison operator ::=
Expand < eq >Expand < ne >Expand < ne2 >Expand < lt >Expand < le >Expand < gt >Expand < ge >
=
=comparison predicate ::=
Expand < comparison operator > < common value expression >
= 'a'
= 'a'subquery ::=
Expand < lparen > ( < query expression > | < call statement > ) < rparen >
(SELECT * FROM tbl)
(SELECT * FROM tbl)quantified comparison predicate ::=
Expand < comparison operator > ( ANY | SOME | ALL ) < subquery >
= ANY (SELECT col FROM tbl)
= ANY (SELECT col FROM tbl)match predicate ::=
Expand ( NOT )? ( LIKE | ( SIMILAR TO ) ) < common value expression > ( ESCAPE < character > | ( < lbrace > ESCAPE < character > < rbrace > ) )?
LIKE 'a_'
LIKE 'a_'like regex predicate ::=
Expand ( NOT )? LIKE_REGEX < common value expression >
LIKE_REGEX 'a.*b'
LIKE_REGEX 'a.*b'character ::=
Expand < string >
'a'
'a'between predicate ::=
Expand ( NOT )? BETWEEN < common value expression > AND < common value expression >
BETWEEN 1 AND 5
BETWEEN 1 AND 5is null predicate ::=
Expand IS ( NOT )? NULL
IS NOT NULL
IS NOT NULLin predicate ::=
Expand ( NOT )? IN ( < subquery > | ( < lparen > < common value expression > ( < comma > < common value expression > )* < rparen > ) )
IN (1, 5)
IN (1, 5)exists predicate ::=
Expand EXISTS < subquery >
EXISTS (SELECT col FROM tbl)
EXISTS (SELECT col FROM tbl)group by clause ::=
Expand GROUP BY < expression list >
GROUP BY col1, col2
GROUP BY col1, col2having clause ::=
Expand HAVING < condition >
HAVING max(col1) = 5
HAVING max(col1) = 5order by clause ::=
Expand ORDER BY < sort specification > ( < comma > < sort specification > )*
ORDER BY x, y DESC
ORDER BY x, y DESCsort specification ::=
Expand < sort key > ( ASC | DESC )? ( NULLS ( FIRST | LAST ) )?
col1 NULLS FIRST
col1 NULLS FIRSTsort key ::=
Expand < expression >
col1
col1integer parameter ::=
Expand < unsigned integer >Expand < qmark >
?
?limit clause ::=
Expand ( LIMIT < integer parameter > ( < comma > < integer parameter > )? )Expand ( OFFSET < integer parameter > ( ROW | ROWS ) ( < fetch clause > )? )Expand < fetch clause >
LIMIT 2
LIMIT 2fetch clause ::=
Expand FETCH ( FIRST | NEXT ) ( < integer parameter > )? ( ROW | ROWS ) ONLY
FETCH FIRST 1 ROWS ONLY
FETCH FIRST 1 ROWS ONLYoption clause ::=
Expand OPTION ( MAKEDEP < identifier > ( < comma > < identifier > )* | MAKENOTDEP < identifier > ( < comma > < identifier > )* | NOCACHE ( < identifier > ( < comma > < identifier > )* )? )*
OPTION MAKEDEP tbl
OPTION MAKEDEP tblexpression ::=
Expand < condition >
col1
col1common value expression ::=
Expand ( < numeric value expression > ( < concat_op > < numeric value expression > )* )
'a' || 'b'
'a' || 'b'numeric value expression ::=
Expand ( < term > ( < plus or minus > < term > )* )
1 + 2
1 + 2plus or minus ::=
Expand < plus >Expand < minus >
+
+term ::=
Expand ( < value expression primary > ( < star or slash > < value expression primary > )* )
1 * 2
1 * 2star or slash ::=
Expand < star >Expand < slash >
/
/value expression primary ::=
Expand < non numeric literal >Expand ( < plus or minus > )? ( < unsigned numeric literal > | < unsigned value expression primary > )
+col1
+col1unsigned value expression primary ::=
Expand < qmark >Expand ( < dollar > < unsigned integer > )Expand ( < escaped function > < function > < rbrace > )Expand ( ( < text aggreate function > | < standard aggregate function > | < ordered aggreate function > ) ( < filter clause > )? ( < window specification > )? )Expand ( < analytic aggregate function > ( < filter clause > )? < window specification > )Expand ( < function > ( < window specification > )? )Expand ( ( < identifier > | < non-reserved identifier > ) ( < lsbrace > < common value expression > < rsbrace > )? )Expand < subquery >Expand ( < lparen > < expression > < rparen > ( < lsbrace > < common value expression > < rsbrace > )? )Expand < searched case expression >Expand < case expression >
col1
col1window specification ::=
Expand OVER < lparen > ( PARTITION BY < expression list > )? ( < order by clause > )? < rparen >
OVER (PARTION BY col1)
OVER (PARTION BY col1)case expression ::=
Expand CASE < expression > ( WHEN < expression > THEN < expression > )+ ( ELSE < expression > )? END
CASE col1 WHEN 'a' THEN 1 ELSE 2
CASE col1 WHEN 'a' THEN 1 ELSE 2searched case expression ::=
Expand CASE ( WHEN < condition > THEN < expression > )+ ( ELSE < expression > )? END
CASE WHEN x = 'a' THEN 1 WHEN y = 'b' THEN 2
CASE WHEN x = 'a' THEN 1 WHEN y = 'b' THEN 2function ::=
Expand ( CONVERT < lparen > < expression > < comma > < data type > < rparen > )Expand ( CAST < lparen > < expression > AS < data type > < rparen > )Expand ( SUBSTRING < lparen > < expression > ( ( FROM < expression > ( FOR < expression > )? ) | ( < comma > < expression list > ) ) < rparen > )Expand ( EXTRACT < lparen > ( YEAR | MONTH | DAY | HOUR | MINUTE | SECOND ) FROM < expression > < rparen > )Expand ( TRIM < lparen > ( ( ( ( LEADING | TRAILING | BOTH ) ( < expression > )? ) | < expression > ) FROM )? < expression > < rparen > )Expand ( ( TO_CHARS | TO_BYTES ) < lparen > < expression > < comma > < string > < rparen > )Expand ( ( TIMESTAMPADD | TIMESTAMPDIFF ) < lparen > < time interval > < comma > < expression > < comma > < expression > < rparen > )Expand < querystring function >Expand ( ( LEFT | RIGHT | CHAR | USER | YEAR | MONTH | HOUR | MINUTE | SECOND | XMLCONCAT | XMLCOMMENT ) < lparen > ( < expression list > )? < rparen > )Expand ( ( TRANSLATE | INSERT ) < lparen > ( < expression list > )? < rparen > )Expand < xml parse >Expand < xml element >Expand ( XMLPI < lparen > ( ( NAME )? < identifier > ) ( < comma > < expression > )? < rparen > )Expand < xml forest >Expand < json object >Expand < xml serialize >Expand < xml query >Expand ( < identifier > < lparen > ( ALL | DISTINCT )? ( < expression list > )? ( < order by clause > )? < rparen > ( < filter clause > )? )
func('1', col1)
func('1', col1)xml parse ::=
Expand XMLPARSE < lparen > ( DOCUMENT | CONTENT ) < expression > ( WELLFORMED )? < rparen >
XMLPARSE(DOCUMENT doc WELLFORMED)
XMLPARSE(DOCUMENT doc WELLFORMED)querystring function ::=
Expand QUERYSTRING < lparen > < expression > ( < comma > < derived column > )* < rparen >
QUERYSTRING(col1 AS opt, col2 AS val)
QUERYSTRING(col1 AS opt, col2 AS val)xml element ::=
Expand XMLELEMENT < lparen > ( ( NAME )? < identifier > ) ( < comma > < xml namespaces > )? ( < comma > < xml attributes > )? ( < comma > < expression > )* < rparen >
XMLELEMENT(NAME "root", child)
XMLELEMENT(NAME "root", child)xml attributes ::=
Expand XMLATTRIBUTES < lparen > < derived column > ( < comma > < derived column > )* < rparen >
XMLATTRIBUTES(col1 AS attr1, col2 AS attr2)
XMLATTRIBUTES(col1 AS attr1, col2 AS attr2)json object ::=
Expand JSONOBJECT < lparen > < derived column list > < rparen >
JSONOBJECT(col1 AS val1, col2 AS val2)
JSONOBJECT(col1 AS val1, col2 AS val2)derived column list ::=
Expand < derived column > ( < comma > < derived column > )*
col1 AS val1, col2 AS val2
col1 AS val1, col2 AS val2xml forest ::=
Expand XMLFOREST < lparen > ( < xml namespaces > < comma > )? < derived column list > < rparen >
XMLFOREST(col1 AS ELEM1, col2 AS ELEM2)
XMLFOREST(col1 AS ELEM1, col2 AS ELEM2)xml namespaces ::=
Expand XMLNAMESPACES < lparen > < xml namespace element > ( < comma > < xml namespace element > )* < rparen >
XMLNAMESPACES('http://foo' AS foo)
XMLNAMESPACES('http://foo' AS foo)xml namespace element ::=
Expand ( < string > AS < identifier > )Expand ( NO DEFAULT )Expand ( DEFAULT < string > )
NO DEFAULT
NO DEFAULTdata type ::=
Expand ( STRING ( < lparen > < unsigned integer > < rparen > )? )Expand ( VARCHAR ( < lparen > < unsigned integer > < rparen > )? )Expand BOOLEANExpand BYTEExpand TINYINTExpand SHORTExpand SMALLINTExpand ( CHAR ( < lparen > < unsigned integer > < rparen > )? )Expand INTEGERExpand LONGExpand BIGINTExpand ( BIGINTEGER ( < lparen > < unsigned integer > < rparen > )? )Expand FLOATExpand REALExpand DOUBLEExpand ( BIGDECIMAL ( < lparen > < unsigned integer > ( < comma > < unsigned integer > )? < rparen > )? )Expand ( DECIMAL ( < lparen > < unsigned integer > ( < comma > < unsigned integer > )? < rparen > )? )Expand DATEExpand TIMEExpand TIMESTAMPExpand OBJECTExpand ( BLOB ( < lparen > < unsigned integer > < rparen > )? )Expand ( CLOB ( < lparen > < unsigned integer > < rparen > )? )Expand ( VARBINARY ( < lparen > < unsigned integer > < rparen > )? )Expand XML
STRING
STRINGtime interval ::=
Expand SQL_TSI_FRAC_SECONDExpand SQL_TSI_SECONDExpand SQL_TSI_MINUTEExpand SQL_TSI_HOURExpand SQL_TSI_DAYExpand SQL_TSI_WEEKExpand SQL_TSI_MONTHExpand SQL_TSI_QUARTERExpand SQL_TSI_YEAR
SQL_TSI_HOUR
SQL_TSI_HOURnon numeric literal ::=
Expand < string >Expand < binary string literal >Expand FALSEExpand TRUEExpand UNKNOWNExpand NULLExpand ( < escaped type > < string > < rbrace > )
'a'
'a'unsigned numeric literal ::=
Expand < unsigned integer literal >Expand < approximate numeric literal >Expand < decimal numeric literal >
1.234
1.234ddl statement ::=
Expand ( < create table > | < create procedure > | < option namespace > | < alter options > | < create trigger > ) ( < semicolon > )?
CREATE FOREIGN TABLE X (Y STRING)
CREATE FOREIGN TABLE X (Y STRING)option namespace ::=
Expand SET NAMESPACE < string > AS < identifier >
SET NAMESPACE 'http://foo' AS foo
SET NAMESPACE 'http://foo' AS foocreate procedure ::=
Expand CREATE ( VIRTUAL | FOREIGN )? ( PROCEDURE | FUNCTION ) ( < identifier > < lparen > ( < procedure parameter > ( < comma > < procedure parameter > )* )? < rparen > ( RETURNS ( ( ( TABLE )? < lparen > < procedure result column > ( < comma > < procedure result column > )* < rparen > ) | < data type > ) )? ( < options clause > )? ( AS < statement > )? )
CREATE FOREIGN PROCEDURE proc (param STRING) RETURNS STRING
CREATE FOREIGN PROCEDURE proc (param STRING) RETURNS STRINGprocedure parameter ::=
Expand ( IN | OUT | INOUT | VARIADIC )? < identifier > < data type > ( NOT NULL )? ( RESULT )? ( DEFAULT < string > )? ( < options clause > )?
OUT x INTEGER
OUT x INTEGERprocedure result column ::=
Expand < identifier > < data type > ( NOT NULL )? ( < options clause > )?
x INTEGER
x INTEGERcreate table ::=
Expand CREATE ( FOREIGN TABLE | ( VIRTUAL )? VIEW ) < identifier > ( < create table body > | ( < options clause > )? ) ( AS < query expression > )?
CREATE VIEW vw AS SELECT 1
CREATE VIEW vw AS SELECT 1create foreign temp table ::=
Expand CREATE FOREIGN TEMPORARY TABLE < identifier > < create table body > ON < identifier >
CREATE FOREIGN TEMPORARY TABLE t (x string) ON z
CREATE FOREIGN TEMPORARY TABLE t (x string) ON zcreate table body ::=
Expand ( < lparen > < table element > ( < comma > < table element > )* ( < comma > ( CONSTRAINT < identifier > )? ( < primary key > | < other constraints > | < foreign key > ) ( < options clause > )? )* < rparen > )? ( < options clause > )?
(x string) OPTIONS (CARDINALITY 100)
(x string) OPTIONS (CARDINALITY 100)foreign key ::=
Expand FOREIGN KEY < column list > REFERENCES < identifier > ( < column list > )?
FOREIGN KEY (a, b) REFERENCES tbl (x, y)
FOREIGN KEY (a, b) REFERENCES tbl (x, y)primary key ::=
Expand PRIMARY KEY < column list >
PRIMARY KEY (a, b)
PRIMARY KEY (a, b)other constraints ::=
Expand ( ( UNIQUE | ACCESSPATTERN ) < column list > )Expand ( INDEX < lparen > < expression list > < rparen > )
UNIQUE (a)
UNIQUE (a)column list ::=
Expand < lparen > < identifier > ( < comma > < identifier > )* < rparen >
(a, b)
(a, b)table element ::=
Expand < identifier > < data type > ( NOT NULL )? ( AUTO_INCREMENT )? ( ( PRIMARY KEY ) | ( ( UNIQUE )? ( INDEX )? ) ) ( DEFAULT < string > )? ( < options clause > )?
x INTEGER NOT NULL
x INTEGER NOT NULLoptions clause ::=
Expand OPTIONS < lparen > < option pair > ( < comma > < option pair > )* < rparen >
OPTIONS ('x' 'y', 'a' 'b')
OPTIONS ('x' 'y', 'a' 'b')option pair ::=
Expand < identifier > ( < non numeric literal > | ( < plus or minus > )? < unsigned numeric literal > )
'key' 'value'
'key' 'value'alter options ::=
Expand ALTER ( VIRTUAL | FOREIGN )? ( TABLE | VIEW | PROCEDURE ) < identifier > ( < alter options list > | < alter column options > )
ALTER FOREIGN TABLE foo OPTIONS (ADD cardinality 100)
ALTER FOREIGN TABLE foo OPTIONS (ADD cardinality 100)alter options list ::=
Expand OPTIONS < lparen > ( < add set option > | < drop option > ) ( < comma > ( < add set option > | < drop option > ) )* < rparen >
OPTIONS (ADD updatable true)
OPTIONS (ADD updatable true)drop option ::=
Expand DROP < identifier >
DROP updatable
DROP updatableadd set option ::=
Expand ( ADD | SET ) < option pair >
ADD updatable true
ADD updatable truealter column options ::=
Expand ALTER ( COLUMN | PARAMETER )? < identifier > < alter options list >
ALTER COLUMN bar OPTIONS (ADD updatable true)
ALTER COLUMN bar OPTIONS (ADD updatable true)Appendix B. Dashboard Builder
B.1. JBoss Dashboard Builder
- Visual configuration and personalization of dashboards.
- Graphical representation of KPIs (Key Performance Indicators).
- Definition of interactive report tables.
- Filtering and search, both in-memory or database based.
- Process execution metrics dashboards.
- Data extraction from external systems, through different protocols.
- Access control for different user profiles to different levels of information.
B.2. Log in to JBoss Dashboard Builder
Prerequisites
- Red Hat JBoss Data Virtualization must be installed and running.
- You must have a JBoss Dashboard Builder user account.
Procedure B.1. Log in to the JBoss Dashboard Builder
Navigate to JBoss Dashboard Builder
Navigate to JBoss Dashboard Builder in your web browser. The default location is http://localhost:8080/dashboard.Log in to JBoss Dashboard Builder
Enter the Username and Password of a valid JBoss Dashboard Builder user.
B.3. Adding a JBoss Dashboard Builder User
user- a user has permission to view the dashboardadmin- a user has permission to modify the dashboard
Important
true on the URL; otherwise, the default username and password defined for the datasource are used.
Example B.1. The PassthroughAuthentication property set on the connection URL
jdbc:teiid:VDBName;PassthroughAuthentication="true"
jdbc:teiid:VDBName;PassthroughAuthentication="true"
Appendix C. Supported Data Sources and Translators
C.1. Recommended Translators for Data Sources
Note
Note
Appendix D. Revision History
| Revision History | |||
|---|---|---|---|
| Revision 6.4.0-59 | Fri 25 May 2018 | ||
| |||