ストレージ管理ガイド
Red Hat Enterprise Linux 6 における単一ノードストレージの導入と設定
概要
前書き
1. ドキュメント規則
1.1. 誤字規則
Mono-spaced Bold
現在の作業ディレクトリーのファイルmy_next_bestselling_novelの内容を表示するには、シェルプロンプトで cat my_next_bestselling_novel コマンドを入力し、Enter を押してコマンドを実行します。
Enter を押してコマンドを実行します。Ctrl+Alt+F2 を押して、仮想端末に切り替えます。
mono-spaced boldで示されます。以下に例を示します。
ファイル関連クラスには、ファイルシステムのfilesystem、ファイルのfile、ディレクトリーのdirが含まれます。各クラスには、独自の関連付けられたパーミッションセットがあります。
メインメニューバーから → → を選択して、Mouse Preferences を起動します。Buttons タブで、Left-handed mouse チェックボックスを選択し、 をクリックして、左から右に主要なマウスボタンを切り替えます (左側のマウスは適切なマウスになります)。特殊文字を gedit ファイルに挿入するには、メインメニューバーから → → を選択します。次に、Character Map メニューバーから → を選択し、Search フィールドに文字の名前を入力して をクリックします。目的の文字は Character Table に強調表示されます。この強調表示した文字をダブルクリックして、Text to copy フィールドに配置し、 ボタンをクリックします。次に、ドキュメントに戻り、gedit メニューバーから → を選択します。
ssh を使用してリモートマシンに接続するには、シェルプロンプトで ssh username@domain.name と入力します。リモートマシンがexample.comで、そのマシンのユーザー名が john の場合は、ssh john@example.com を入力します。mount -o remount file-system コマンドは、名前付きのファイルシステムを再マウントします。たとえば、/homeファイルシステムを再マウントする場合は、コマンドが mount -o remount /home になります。現在インストールされているパッケージのバージョンを表示するには、rpm -q package コマンドを使用します。結果は以下のようになります: package-version-release.
Publican は DocBook 公開システムです。
1.2. 引用規則
mono-spaced roman にセットされて表現されます。
books Desktop documentation drafts mss photos stuff svn books_tests Desktop1 downloads images notes scripts svgs
books Desktop documentation drafts mss photos stuff svn
books_tests Desktop1 downloads images notes scripts svgsmono-spaced roman にセットされますが、構文の強調表示が以下のように追加されます。
1.3. 注記および警告
2. ヘルプの利用とフィードバック提供
2.1. ヘルプが必要ですか?
- Red Hat 製品に関する技術サポート記事の知識ベースの検索または閲覧。
- Red Hat グローバルサポートサービス (GSS) へのサポートケースの送信。
- その他の製品ドキュメントへのアクセス。
2.2. ご意見をお寄せください
第1章 概要
1.1. Red Hat Enterprise Linux 6 の新機能
ファイルシステムの暗号化(テクノロジープレビュー)
ファイルシステムキャッシング(テクノロジープレビュー)
Btrfs (テクノロジープレビュー)
I/O 制限処理
ext4 サポート
ネットワークブロックストレージ
パート I. ファイルシステム
第2章 ファイルシステム構造とメンテナンス
- 共有可能ファイルと、共有できないファイル
- 変数と静的ファイル
2.1. ファイルシステム階層標準 (FHS) の概要
- 他の FHS 準拠システムとの互換性
/usr/パーティションを読み取り専用としてマウントする機能。これは、/usr/には共通の実行ファイルが含まれており、ユーザーが変更できないため、特に重要です。さらに、/usr/は読み取り専用としてマウントされているため、CD-ROM ドライブまたは他のマシンから、読み取り専用 NFS マウント経由でマウントできる必要があります。
2.1.1. FHS 組織
2.1.1.1. ファイルシステム情報の収集
例2.1 df コマンドの出力
例2.2 df -h コマンドの出力
/dev/shm はシステムの仮想メモリーファイルシステムを表します。
図2.1 GNOME システムモニターファイルシステムタブ
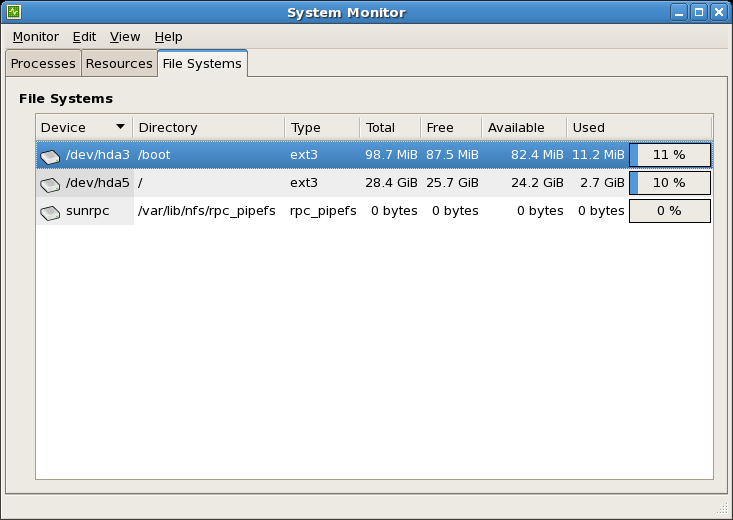
[D]
2.1.1.2. /boot/ ディレクトリー
/boot/ ディレクトリーには、Linux カーネルなど、システムの起動に必要な静的ファイルが含まれます。これらのファイルは、システムが正しく起動するためには不可欠です。
/boot/ ディレクトリーを削除しないでください。削除すると、システムが起動できなくなります。
2.1.1.3. /dev/ ディレクトリー
/dev/ ディレクトリーには、以下のデバイス種別を表すデバイスノードが含まれます。
- システムに接続されているデバイス
- カーネルが提供する仮想デバイス
/dev/ のデバイスノードを作成および削除します。
/dev/ ディレクトリーおよびサブディレクトリー内のデバイスは、文字 (マウスやキーボードなどの入力と出力のシリアルストリームのみを提供) またはブロック (ハードドライブやフロッピードライブなどのランダムにアクセス可能) のいずれかとして定義されます。GNOME または KDE がインストールされている場合は、一部のストレージデバイスは (USBなどで) 接続時または (CDまたはDVDドライブなどの) 挿入時に自動的に検出され、内容を表示するポップアップウィンドウが表示されます。
| ファイル | 詳細 |
|---|---|
| /dev/hda | プライマリー IDE チャネル上のマスターデバイス。 |
| /dev/hdb | プライマリー IDE チャンネル上のスレーブデバイス。 |
| /dev/tty0 | 最初の仮想コンソール。 |
| /dev/tty1 | 2 番目の仮想コンソール |
| /dev/sda | プライマリー SCSI または SATA チャネル上の最初のデバイス。 |
| /dev/lp0 | 最初の並列ポート。 |
| /dev/ttyS0 | シリアルポート。 |
2.1.1.4. /etc/ ディレクトリー
/etc/ ディレクトリーは、マシンのローカルとなる設定ファイル用に予約されています。バイナリーを含むことはできません。バイナリーは /bin/ または /sbin/ に移動する必要があります。
/etc/skel/ ディレクトリーには、「スケルトン」ユーザーファイルが格納されています。これは、ユーザーの初回作成時にホームディレクトリーを設定するために使用されます。また、アプリケーションはこのディレクトリーに設定ファイルを保存し、実行時にそれらを参照する可能性があります。/etc/exports ファイルは、どのファイルシステムをリモートホストにエクスポートするかを制御します。
2.1.1.5. /lib/ ディレクトリー
/lib/ ディレクトリーには、/ bin/ および /sbin/ でバイナリーの実行に必要なライブラリーのみが含まれている必要があります。これらの共有ライブラリーイメージは、システムを起動したり、root ファイルシステム内でコマンドを実行したりするために使用されます。
2.1.1.6. /media/ ディレクトリー
/media/ ディレクトリーには、USB ストレージメディア、DVD、CD-ROM などのリムーバブルメディアのマウントポイントとして使用されるサブディレクトリーが含まれます。
2.1.1.7. /mnt/ ディレクトリー
/mnt/ ディレクトリーは、NFS ファイルシステムのマウントなどの、一時的にマウントされたファイルシステム用に予約されています。すべてのリムーバブルストレージメディアには、/media/ ディレクトリーを使用します。リムーバブルメディアは自動的に /media ディレクトリーにマウントされます。
/mnt ディレクトリーは、インストールプログラムでは使用しないでください。
2.1.1.8. /opt/ ディレクトリー
/opt/ ディレクトリーは通常、デフォルトのインストールの一部ではないソフトウェアおよびアドオンパッケージ用に予約されています。/opt/ にインストールするパッケージは、その名前を持つディレクトリーを作成します (例: /opt/packagename/)多くの場合、このようなパッケージは、予測可能なサブディレクトリー構造に従います。ほとんどの場合、バイナリーは /opt/packagename/bin/ に保存され、man ページは /opt/packagename/man/ に保存されます。
2.1.1.9. /proc/ ディレクトリー
/proc/ ディレクトリーには、カーネルから情報を抽出するか、カーネルに情報を送信する特別なファイルが含まれています。このような情報の例には、システムメモリー、CPU 情報、およびハードウェア設定が含まれます。/proc/ の詳細は、「/proc 仮想ファイルシステム」 を参照してください。
2.1.1.10. /sbin/ Directory
/sbin/ ディレクトリーには、システムの起動、復元、復旧、または修復に不可欠なバイナリーが格納されています。/sbin/ のバイナリーを使用するには、root 権限が必要です。また、/sbin/ ディレクトリーがマウントされる 前に システムが使用するバイナリーが含まれています。/usr/ がマウントされた後に使用されるシステムユーティリティーが、通常は /usr/ sbin/ に配置されます。
/sbin/ に保存する必要があります。
- arp
- クロック
- halt
- init
- fsck.*
- grub
- ifconfig
- mingetty
- mkfs.*
- mkswap
- reboot
- route
- shutdown
- swapoff
- swapon
2.1.1.11. /srv/ ディレクトリー
/srv/ ディレクトリーには、Red Hat Enterprise Linux システムが提供するサイト固有のデータが含まれます。このディレクトリーは、FTP、WWW、または CVS などの特定サービスのデータファイルの場所をユーザーに提供します。特定のユーザーにのみ関連するデータは、/home/ ディレクトリー内になければなりません。
/var/www/html を使用します。
2.1.1.12. /sys/ ディレクトリー
/sys/ ディレクトリーは、2.6 カーネルに固有の新しい sysfs 仮想ファイルシステムを使用します。2.6 カーネルのホットプラグハードウェアデバイスのサポートが増えると、/sys/ ディレクトリーには、/proc/ が保持する情報と同様の情報が含まれますが、ホットプラグデバイスに固有のデバイス情報の階層ビューが表示されます。
2.1.1.13. /usr/ ディレクトリー
/usr/ ディレクトリーは、複数のマシンにまたがって共有できるファイル用です。多くの場合、/usr/ ディレクトリーは独自のパーティションにあり、読み取り専用でマウントされます。/usr/ ディレクトリーには、通常以下のサブディレクトリーが含まれます。
/usr/bin- このディレクトリーはバイナリーに使用されます。
/usr/etc- このディレクトリーは、システム全体の設定ファイルに使用されます。
/usr/games- このディレクトリにはゲームが保存されています。
/usr/include- このディレクトリーは C ヘッダーファイルに使用されます。
/usr/kerberos- このディレクトリーは、Kerberos 関連のバイナリーおよびファイルに使用されます。
/usr/lib- このディレクトリーは、シェルスクリプトまたはユーザーが直接使用するように設計されていないオブジェクトファイルやライブラリーに使用されます。このディレクトリーは 32 ビットシステム用です。
/usr/lib64- このディレクトリーは、シェルスクリプトまたはユーザーが直接使用するように設計されていないオブジェクトファイルやライブラリーに使用されます。このディレクトリーは、64 ビットシステム用です。
/usr/libexec- このディレクトリーには、他のプログラムによって呼び出される小さなヘルパープログラムが含まれます。
/usr/sbin- このディレクトリーには、
/sbin/ に属さないシステム管理バイナリーが格納されます。 /usr/share- このディレクトリーには、アーキテクチャー固有ではないファイルを保存します。
/usr/src- このディレクトリーには、ソースコードが保存されます。
/var/tmpにリンクされた/usr/tmp- このディレクトリーには、一時ファイルが保存されます。
/usr/ ディレクトリーには /local/ サブディレクトリーも含まれる必要があります。FHS によると、このサブディレクトリーは、ソフトウェアをローカルでインストールする際にシステム管理者によって使用されるので、システムの更新中に上書きされないようにする必要があります。/usr/local ディレクトリーの構造は /usr/ と似ており、以下のサブディレクトリーが含まれます。
/usr/local/bin/usr/local/etc/usr/local/games/usr/local/include/usr/local/lib/usr/local/libexec/usr/local/sbin/usr/local/share/usr/local/src
/usr/local/ の使用は、FHS と若干異なります。FHS は、/usr/local/ を使用して、システムソフトウェアをアップグレードする心配がないままのソフトウェアを保存するために使用する必要があることを記しています。RPM Package Manager はソフトウェアアップグレードを安全に実行できるため、ファイルを /usr/local/ に保存してファイルを保護する必要はありません。
/usr/local/ を使用します。たとえば、/usr/ ディレクトリーがリモートホストから読み取り専用の NFS 共有としてマウントされている場合でも、/usr/local/ ディレクトリーの下にパッケージまたはプログラムをインストールすることができます。
2.1.1.14. /var/ ディレクトリー
/usr/ を読み取り専用としてマウントする必要があるため、ログファイルを書き込むプログラムや、spool/ または lock/ ディレクトリーが必要なプログラムは、それらを /var/ ディレクトリーに書き込む必要があります。FHS によると、/var/ は、spool ディレクトリーおよびファイル、ロギングデータ、一時的ファイルを含む変数データ用となります。
/var/ ディレクトリー内にあるディレクトリーの一部です。
/var/account//var/arpwatch//var/cache//var/crash//var/db//var/empty//var/ftp//var/gdm//var/kerberos//var/lib//var/local//var/lock//var/log//var/spool/mail/にリンクされた/var/mail/var/mailman//var/named//var/nis//var/opt//var/preserve//var/run//var/spool//var/tmp//var/tux//var/www//var/yp/
messages および lastlog などのシステムログファイルは、/var/log/ ディレクトリーに移動します。/var/lib/rpm/ ディレクトリーには、RPM システムデータベースが含まれます。ロックファイルは、通常はファイルを使用するプログラムのディレクトリーにある /var/lock/ ディレクトリーに移動します。/var/spool/ ディレクトリーには、一部のプログラムのデータファイルを格納するサブディレクトリーがあります。これらのサブディレクトリーには以下が含まれます。
/var/spool/at//var/spool/clientmqueue//var/spool/cron//var/spool/cups//var/spool/exim//var/spool/lpd//var/spool/mail//var/spool/mailman//var/spool/mqueue//var/spool/news//var/spool/postfix//var/spool/repackage//var/spool/rwho//var/spool/samba//var/spool/squid//var/spool/squirrelmail//var/spool/up2date//var/spool/uucp//var/spool/uucppublic//var/spool/vbox/
2.2. 特別な Red Hat Enterprise Linux ファイルの場所
/var/lib/rpm/ ディレクトリーに保持されます。RPM の詳細は man rpm を参照してください。
/var/cache/yum/ ディレクトリーには、システムの RPM ヘッダー情報を含む Package Updater が使用するファイルが含まれます。この場所は、システムの更新中にダウンロードされた RPM を一時的に保存するためにも使用できます。Red Hat Network の詳細は、オンラインで https://rhn.redhat.com/ のドキュメントを参照してください。
/etc/sysconfig/ ディレクトリーです。このディレクトリーには、さまざまな設定情報が格納されています。システムの起動時に実行されるスクリプトの多くは、このディレクトリー内のファイルを使用します。
2.3. /proc 仮想ファイルシステム
/proc にはテキストファイルもバイナリーファイルも含まれていません。代わりに 仮想ファイルが含まれます。したがって、/proc は通常仮想ファイルシステムと呼ばれます。これらの仮想ファイルは、大量の情報が含まれている場合でも、サイズは通常 0 バイトになります。
/proc ファイルシステムはストレージには使用されません。この主な目的は、ハードウェア、メモリー、実行中のプロセス、および他のシステムコンポーネントにファイルベースのインターフェースを提供することです。リアルタイム情報は、対応する /proc ファイルを表示することで、多くのシステムコンポーネントで取得できます。/proc 内のファイルの一部は、カーネルを設定するために (ユーザーとアプリケーションの両方で) 操作することもできます。
/proc ファイルは、システムストレージの管理および監視に関連しています。
- /proc/devices
- 現在設定されているさまざまな文字およびブロックデバイスを表示します。
- /proc/filesystems
- カーネルで現在対応しているすべてのファイルシステムタイプを一覧表示します。
- /proc/mdstat
- システム上の複数ディスクまたは RAID 設定に関する現在の情報が含まれます (存在する場合)。
- /proc/mounts
- システムで現在使用しているマウントをすべて一覧表示します。
- /proc/partitions
- パーティションブロック割り当て情報が含まれます。
/proc ファイルシステムの詳細は、Red Hat Enterprise Linux 6 『デプロイメントガイド』 を参照してください。
2.4. 未使用ブロックの破棄
/sys/block/デバイス/queue/discard_max_bytes の値がゼロではない場合は、物理的な破棄操作に対応しています。
-o discard オプション( /etc/fstab または mount コマンドの一部として)指定され、ユーザーの介入なしでリアルタイムで実行します。オンライン破棄操作は、使用中から空きに移行しているブロックのみを破棄します。オンライン破棄操作は、Red Hat Enterprise Linux 6.2 以降である ext4 ファイルシステム、および Red Hat Enterprise Linux 6.4 以降である XFS ファイルシステムでサポートされます。
第3章 暗号化されたファイルシステム
ecryptfs-utils パッケージをインストールする必要があります。
3.1. ファイルシステムのマウント(暗号化済み)
mount -t ecryptfs /source /destination
# mount -t ecryptfs /source /destination/source )を暗号化すると、これが eCryptfs(上記の例では/destination )で暗号化されるマウントポイントにマウントします。/destination へのすべてのファイル操作は、基礎となる /source ファイルシステムに対して 暗号化されます。ただし、ファイル操作は eCryptfs レイヤーを通過せずに /source を直接変更する可能性があります。これにより、不整合になる可能性があります。
/source と / destination の両方の名前を同じようにすることを推奨します。以下に例を示します。
mount -t ecryptfs /home /home
# mount -t ecryptfs /home /home/home が eCryptfs レイヤーを通過するのに役立ちます。
- 暗号化キータイプ
openssl、tspi、またはpassphrase。passphraseを選択すると、マウント が要求されます。- 暗号
aes、blowfish、des3_ede、cast6、またはcast5。- キー bytesize
16、32、または24。plaintext passthrough- 有効または無効化。
filename encryption- 有効または無効化。
passphrase のキー タイプの aes 暗号、16 の鍵バイトサイズ plaintext passthrough を無効とすると、出力は以下のようになります。filename encryption
mount -t ecryptfs /home /home -o ecryptfs_unlink_sigs \ ecryptfs_key_bytes=16 ecryptfs_cipher=aes ecryptfs_sig=c7fed37c0a341e19[2]
# mount -t ecryptfs /home /home -o ecryptfs_unlink_sigs \
ecryptfs_key_bytes=16 ecryptfs_cipher=aes ecryptfs_sig=c7fed37c0a341e19[2]3.2. 追加情報
-utils パッケージで提供される)を参照してください。以下のカーネルドキュメント( kernel-doc パッケージで提供される )も、eCryptfs に関する追加情報も提供します。
/usr/share/doc/kernel-doc-version/Documentation/filesystems/ecryptfs.txt
第4章 Btrfs
Btrfs)は、パフォーマンスとスケーラビリティーを向上させるローカルシステムです。Btrfs は、Red Hat Enterprise Linux 6 でテクノロジープレビューとして、AMD64 および Intel 64 のアーキテクチャーに導入されました。Btrfs テクノロジープレビューは Red Hat Enterprise Linux 6.6 で終了し、今後更新されることはありません。Btrfs は Red Hat Enterprise Linux 6 の将来のリリースに含まれますが、いかなる方法でもサポートは提供されません。
Btrfs の機能
- 組み込みシステムのロールバック
- ファイルシステムのスナップショットを使用すると、問題が発生した場合にシステムを以前の状態にロールバックすることができます。
- 組み込み圧縮
- これにより、領域の節約が容易になります。
- チェックサム機能
- これにより、エラー検出が改善されます。
- 新規ストレージデバイスの動的、オンラインの追加、または削除
- コンポーネントデバイス全体での RAID の内部サポート
- メタデータまたはユーザーデータに異なる RAID レベルを使用できる機能
- すべてのメタデータおよびユーザーデータの完全なチェックサム機能。
第5章 Ext3 ファイルシステム。
- 可用性
- 予期しない停電やシステムクラッシュ (クリーンでないシステムシャットダウン とも言われる) が発生すると、マシンにマウントしている各 ext2 ファイルシステムは、e2fsck プログラムで整合性をチェックする必要があります。これは時間を浪費するプロセスであり、大量のファイルを含む大型ボリュームでは、システムの起動時間を著しく遅らせます。このプロセスの間、そのボリュームにあるデータは使用できません。ライブファイルシステムで fsck -n を実行できます。ただし、変更は加えられず、部分的に書き込まれたメタデータが発生した場合に、誤解を招く結果が表示される可能性があります。スタック内で LVM が使用されている場合は、ファイルシステムの LVM スナップショットを取り、スナップショットで fsck を実行する方法も考えられます。もしくは、ファイルシステムを読み込み専用で再マウントするオプションがあります。保留中のメタデータ更新 (および書き込み) は、すべて再マウントの前にディスクへ強制的に入れられます。これにより、以前の破損がないため、ファイルシステムが一貫した状態になります。fsck -n を実行できるようになりました。ext3 ファイルシステムで提供されるジャーナリングは、クリーンでないシステムシャットダウンが発生してもこの種のファイルシステムのチェックが不要であることを意味します。ext3 の使用していても整合性チェックが必要になる唯一の場面は、ハードドライブの障害が発生した場合など、ごく稀なハードウェア障害のケースのみです。クリーンでないシャットダウンの発生後に ext3 ファイルシステムを復元する時間は、ファイルシステムのサイズやファイルの数量ではなく、一貫性を維持するために使用される ジャーナル のサイズに依存します。デフォルトのジャーナルサイズは、ハードウェアの速度に応じて、復旧するのに約 1 秒かかります注記Red Hat で対応している ext3 の唯一のジャーナリングモードは data=ordered (デフォルト) です。
- データの整合性
- ext3 ファイルシステムは、クリーンでないシステムシャットダウンが発生した際にデータの整合性が失われることを防止します。ext3 ファイルシステムにより、データが受けることのできる保護のタイプとレベルを選択できるようになります。ファイルシステムの状態に関しては、ext3 のボリュームはデフォルトで高度なレベルのデータ整合性を維持するように設定されています。
- 速度
- 一部のデータを複数回書き込みますが、ext3 のジャーナリングにより、ハードドライブのヘッドモーションが最適化されるため、ほとんどの場合、ext3 のスループットは ext2 よりも高くなります。速度を最適化するために 3 つのジャーナリングモードから選択できますが、システムに障害が発生する可能性のある状況では、モードの選択はデータの整合性がトレードオフの関係になることがあります。
- 簡単なトランジション
- ext2 から ext3 に簡単に移行でき、再フォーマットをせずに、堅牢なジャーナリングファイルシステムの恩恵を受けることができます。このタスクの実行方法は、「Ext3 ファイルシステムへの変換」 を参照してください。
デフォルトの Inode サイズ変更
ディスク上の inode のデフォルトのサイズは、拡張属性(ACL、SELinux 属性など)のより効率的なストレージに増えました。この変更により、特定のサイズのファイルシステム上に作成されたデフォルトの inode の数が減少しました。inode サイズは、ske 2fs -I オプションで選択することも、/etc/mke2fs.conf で選択したりして、システム全体のデフォルト for mke2fs を設定できます。
新規のマウントオプション: data_err
新しいマウントオプションが追加されました: data_err=abortこのオプションは、data =ordered モードで(メタデータではなく)ファイルデータでエラーが発生した場合に、ジャーナルを中断するように ext3 に指示します。このオプションはデフォルトで無効にされています( data_err=ignoreに設定されています)。
より効率的なストレージの使用
ファイルシステム( mkfs)を作成すると、mke2fs は「discard」または「trim」ブロックを、ファイルシステムのメタデータで使用されていないブロックを試みます。これは、SSD またはシンプロビジョニングされたストレージを最適化するのに役立ちます。この動作を非表示にするには、withke 2fs -K オプションを使用します。
5.1. Ext3 ファイルシステムの作成
手順5.1 ext3 ファイルシステムを作成する
- mkfs で、ext3 ファイルシステムでパーティションをフォーマットします。
- e2label を使用してファイルシステムにラベルを付けます。
5.2. Ext3 ファイルシステムへの変換
ext2 ファイルシステムを ext3 に変換します。
ext2 ファイルシステムを ext3 に変換するには、root としてログインし、ターミナルに以下のコマンドを入力します。
tune2fs -j block_device
# tune2fs -j block_device- マップされたデバイス
- ボリュームグループの論理ボリューム (例: /dev/mapper/VolGroup00-LogVol02)。
- 静的デバイス
- たとえば、/dev/sdbX (sdb はストレージデバイス名で X はパーティション番号) などの従来のストレージボリューム。
5.3. Ext2 ファイルシステムへの復元
/dev/mapper/VolGroup00-LogVol02
手順5.2 ext3 から ext2 に戻す
- root としてログインし、パーティションをアンマウントして以下を入力します。
umount /dev/mapper/VolGroup00-LogVol02
# umount /dev/mapper/VolGroup00-LogVol02Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 以下のコマンドを入力して、ファイルシステムの種類を ext2 に変更します。
tune2fs -O ^has_journal /dev/mapper/VolGroup00-LogVol02
# tune2fs -O ^has_journal /dev/mapper/VolGroup00-LogVol02Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 以下のコマンドを入力して、パーティションでエラーの有無を確認します。
e2fsck -y /dev/mapper/VolGroup00-LogVol02
# e2fsck -y /dev/mapper/VolGroup00-LogVol02Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 次に、以下を入力して ext2 ファイルシステムとしてパーティションを再度マウントします。
mount -t ext2 /dev/mapper/VolGroup00-LogVol02 /mount/point
# mount -t ext2 /dev/mapper/VolGroup00-LogVol02 /mount/pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドでは、/mount/point を、パーティションのマウントポイントに置き換えます。注記.journalファイルがパーティションの root レベルに存在する場合は、これを削除します。
/etc/fstab ファイルを更新することを忘れないでください。そうしないと、起動後に元に戻されます。
第6章 Ext4 ファイルシステム
- 主な特長
- (ext2 および ext3 で使用された従来のブロックマッピングスキームと異なり) Ext4 はエクステントを使用し、サイズの大きいファイルを使用する場合のパフォーマンスが向上されているため、そのメタデータのオーバーヘッドが減少します。また、ext4 では、未使用のブロックグループと inode テーブルのセクションにそれぞれラベル付けが行なわれます。これにより、ファイルシステムのチェック時にこれらを省略することができます。また、ファイルシステムチェックの速度が上がるため、ファイルシステムが大きくなるほどその便宜性は顕著になります。
- 割り当て機能
- Ext4 ファイルシステムには、以下のような割り当てスキームが備わっています。
- 永続的な事前割り当て
- 遅延割り当て
- マルチブロック割り当て
- ストライプ認識割り当て
遅延割り当てや他のパフォーマンスが最適化されるため、ext4 のディスクへのファイル書き込み動作は ext3 の場合とは異なります。ext4 では、プログラムがファイルシステムへの書き込みを実行しても、fsync() 呼び出しを発行しない限り、その書き込みがオンディスクになる保証はありません。ext3 では、fsync() の呼び出しがなくても、ファイルが新たに作成されると、そのほぼ直後にデフォルトでディスクへの書き込みが強制されます。この動作により、書き込まれたデータがオンディスクにあることを、fsync() を使用して確認しないというプログラムのバグが表面化しませんでした。一方、ext4 ファイルシステムは、ディスクへの変更書き込みの前に数秒間待機することが多く、書き込みを結合して再度順序付けを行うことにより、ext3 を上回るディスクパフォーマンスを実現しています。警告ext3 とは異なり、ext4 ファイルシステムでは、トランザクションコミット時にディスクへのデータの書き込みを強制しません。このため、バッファーされた書き込みがディスクにフラッシュされるまでに時間がかかります。他のファイルシステムと同様、永続的なストレージにデータが書き込まれたことを確認するには、fsync() などのデータ整合性チェックの呼び出しを使用してください。 - Ext4 のその他の機能
- ext4 ファイルシステムでは次の機能にも対応しています。
- 拡張属性 (
xattr) - これにより、システムは、ファイルごとに、名前と値の組み合わせを追加で関連付けられるようになります。 - クォータジャーナリング - クラッシュ後に行なわれる時間がかかるクォータの整合性チェックが不要になります。注記ext4 で対応しているジャーナリングモードは data=ordered (デフォルト) のみです。
- サブセカンド (一秒未満) のタイムスタンプ - サブセカンドのタイムスタンプを指定します。
6.1. Ext4 ファイルシステムの作成
mkfs.ext4 /dev/device
# mkfs.ext4 /dev/device例6.1 mkfs.ext4 コマンドの出力
- stride=value
- RAID チャンクサイズを指定します。
- stripe-width=value
- RAID デバイス内のデータディスク数、または 1 ストライプ内のストライプユニット数を指定します。
mkfs.ext4 -E stride=16,stripe-width=64 /dev/device
# mkfs.ext4 -E stride=16,stripe-width=64 /dev/device6.2. Ext4 ファイルシステムのマウント
mount /dev/device /mount/point
# mount /dev/device /mount/pointmount -o acl,user_xattr /dev/device /mount/point
# mount -o acl,user_xattr /dev/device /mount/point書き込みバリア
mount -o nobarrier /dev/device /mount/point
# mount -o nobarrier /dev/device /mount/point6.3. Ext4 ファイルシステムのサイズ変更
resize2fs /mount/device node
# resize2fs /mount/device noderesize2fs /dev/device size
# resize2fs /dev/device size- s — 512 バイトのセクター
- K — キロバイト
- M — メガバイト
- G — ギガバイト
6.4. バックアップ ext2/3/4 ファイルシステム
手順6.1 バックアップ ext2/3/4 ファイルシステムの例
- 復元操作を行う前に、すべてのデータをバックアップする必要があります。データバックアップは定期的に行う必要があります。データの他に、
/etc/fstabや fdisk -l の出力など、保存すべき設定情報があります。sosreport/sysreport を実行すると、この情報を取得し、強く推奨されます。Copy to Clipboard Copied! Toggle word wrap Toggle overflow この例では、/dev/sda6パーティションを使用してバックアップファイルを保存します。また、/dev/sda6が/backup-files にマウントされていることを前提とします。 - バックアップされるパーティションがオペレーティングシステムのパーティションである場合は、システムを Single User モードに起動してください。通常のデータパーティションには、このステップは必要ありません。
- ダンプ を使用して、パーティションの内容をバックアップします。注記
- システムが長時間実行中の場合は、バックアップの前にパーティションで e2fsck を実行することが推奨されます。
- ダンプは、破損したバージョンのファイルをバックアップする可能性があるため、負荷の高いファイルシステムやマウントされたファイルシステムでは使用しないでください。この問題は以下に記載されています dump.sourceforge.net。重要オペレーティングシステムのパーティションをバックアップする場合は、パーティションをアンマウントする必要があります。通常のデータパーティションがマウントされている間に、通常のデータパーティションを作成することは可能ですが、可能な場合はこれをアンマウントすることが推奨されます。マウントされたデータパーティションをバックアップしようとすると予測できなくなる可能性があります。
dump -0uf /backup-files/sda1.dump /dev/sda1 dump -0uf /backup-files/sda2.dump /dev/sda2 dump -0uf /backup-files/sda3.dump /dev/sda3
# dump -0uf /backup-files/sda1.dump /dev/sda1 # dump -0uf /backup-files/sda2.dump /dev/sda2 # dump -0uf /backup-files/sda3.dump /dev/sda3Copy to Clipboard Copied! Toggle word wrap Toggle overflow リモートバックアップを実行する場合は、ssh の両方を使用するか、パスワード以外のログインを設定できます。注記標準のリダイレクトを使用する場合は、「-f」オプションを別々に渡す必要があります。dump -0u -f - /dev/sda1 | ssh root@remoteserver.example.com dd of=/tmp/sda1.dump
# dump -0u -f - /dev/sda1 | ssh root@remoteserver.example.com dd of=/tmp/sda1.dumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow
6.5. ext2/3/4 ファイルシステムの復元
手順6.2 ext2/3/4 ファイルシステムの例の復元
- オペレーティングシステムパーティションで復元を行っている場合は、レスキューモードにシステムを起動します。このステップは、通常のデータパーティションには不要です。
- fdisk コマンドを使用して、sda1/sda2/sda3/sda4/sda5 を再構築します。注記必要な場合は、復元されたファイルシステムを含むパーティションを作成します。新しいパーティションは、復元したデータを含めるのに十分な大きさである必要があります。開始番号と終了番号を常に取得することが重要になります。これらは、パーティションの開始点と終了セクター番号になります。
- 以下に示すように mkfs コマンドを使用して、宛先パーティションをフォーマットします。重要バックアップファイルを保存するため、上記の例では
/dev/sda6形式ではありません。mkfs.ext3 /dev/sda1 mkfs.ext3 /dev/sda2 mkfs.ext3 /dev/sda3
# mkfs.ext3 /dev/sda1 # mkfs.ext3 /dev/sda2 # mkfs.ext3 /dev/sda3Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 新しいパーティションを作成する場合は、すべてのパーティションに
fstabファイルに一致するようにラベルを付けます。パーティションが再作成されていない場合は、この手順は必要ありません。e2label /dev/sda1 /boot1 e2label /dev/sda2 / e2label /dev/sda3 /data mkswap -L SWAP-sda5 /dev/sda5
# e2label /dev/sda1 /boot1 # e2label /dev/sda2 / # e2label /dev/sda3 /data # mkswap -L SWAP-sda5 /dev/sda5Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 作業ディレクトリーを準備します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - データを復元します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow リモートホストから復元したり、リモートホストのバックアップファイルから復元する場合は、ssh または rsh のいずれかを使用できます。以下の例に、パスワードを使用しないログインを設定する必要があります。10.0.0.87 にログインし、ローカルの sda1.dump ファイルから sda1 を復元します。ssh 10.0.0.87 "cd /mnt/sda1 && cat /backup-files/sda1.dump | restore -rf -"
# ssh 10.0.0.87 "cd /mnt/sda1 && cat /backup-files/sda1.dump | restore -rf -"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 10.0.0.87 にログインし、リモートの 10.66.0.124 sda1.dump ファイルから sda1 を復元します。ssh 10.0.0.87 "cd /mnt/sda1 && RSH=/usr/bin/ssh restore -r -f 10.66.0.124:/tmp/sda1.dump"
# ssh 10.0.0.87 "cd /mnt/sda1 && RSH=/usr/bin/ssh restore -r -f 10.66.0.124:/tmp/sda1.dump"Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 再起動します。
6.6. Ext4 ファイルシステムのその他のユーティリティー
- e2fsck
- ext4 ファイルシステムの修復時に使用します。ext4 でディスク構造が変更されたため、ext3 ファイルシステムよりも効率的なチェックと修復が行えるようになりました。
- e2label
- ext4 ファイルシステムのラベル変更を行います。このツールは ext2 および ext3 のファイルシステムでも動作します。
- quota
- ext4 ファイルシステムで、ユーザーおよびグループごとのディスク領域 (ブロック) やファイル (inode) の使用量を制御し、それを報告します。quota の使用に関する詳細は、man quota および 「ディスククォータの設定」 を参照してください。
- debugfs
- ext2、ext3、ext4 の各ファイルシステムのデバッグを行います。
- e2image
- ext2、ext3、または ext4 の重要なファイルシステムメタデータをファイルに保存します。
第7章 Global File System 2
gfs2.ko カーネルモジュールは GFS2 ファイルシステムを実装しており、GFS2 クラスターノードにロードされます。
第8章 XFS ファイルシステム
- 主な特長
- XFS は、メタデータジャーナリング をサポートしているため、クラッシュリカバリーを迅速に行うことができます。XFS ファイルシステムは、マウントされ、アクティブな状態でデフラグし、拡張できます。また、Red Hat Enterprise Linux 6 は XFS 固有のバックアップおよび復元ユーティリティーをサポートしています。
- 割り当て機能
- XFS は、次の割り当てスキームを特長としています。
- エクステント (領域) ベースの割り当て
- ストライプを認識できる割り当てポリシー
- 遅延割り当て
- 領域の事前割り当て
遅延割り当てや他のパフォーマンスの最適化は、ext4 と同じように XFS に影響を与えます。つまり、XFS ファイルシステムへのプログラムの書き込みは、プログラムが後で fsync() 呼び出しを発行しない限り、ディスク上にあることが保証されません。ファイルシステムで遅延割り当ての影響についての詳細は、6章Ext4 ファイルシステム で 『割り当て機能』 を参照してください。XFS にディスクへの書き込みも適用できるようにする回避策です。 - その他の XFS 機能
- XFS ファイルシステムは、以下もサポートしています。
- 拡張属性 (
xattr) - これにより、システムが、ファイルごとに、名前と値の組み合わせを追加で関連付けられるようになります。
- クォータジャーナリング
- クラッシュ後に行なわれる、時間がかかるクォータの整合性チェックが不要になります。
- プロジェクト/ディレクトリークォータ
- ディレクトリーツリー全体にクォータ制限を適用できます。
- サブセカンド (一秒未満) のタイムスタンプ
- これにより、タイムスタンプはサブセカンド (一秒未満) になることができます。
- 拡張属性 (
8.1. XFS ファイルシステムの作成
例8.1 mkfs.xfs コマンドの出力
- su=value
- ストライプユニットまたは RAID チャンクサイズを指定します。value は、バイトで指定する必要があります。オプションで、
k、m、またはg接尾辞が付きます。 - sw=value
- RAID デバイス内のデータディスク数、または 1 ストライプ内のストライプユニット数を指定します。
mkfs.xfs -d su=64k,sw=4 /dev/device
# mkfs.xfs -d su=64k,sw=4 /dev/device8.2. XFS ファイルシステムのマウント
mount /dev/device /mount/point
# mount /dev/device /mount/pointmount -o inode64 /dev/device /mount/point
# mount -o inode64 /dev/device /mount/point書き込みバリア
mount -o nobarrier /dev/device /mount/point
# mount -o nobarrier /dev/device /mount/point8.3. XFS クォータ管理
- uquota/uqnoenforce: ユーザークォータ
- gquota/gqnoenforce: グループクォータ
- pquota/pqnoenforce: プロジェクトクォータ
- quota username/userID
- 指定の username または数値の userID の使用状況および制限を表示します。
- df
- ブロックおよび inode の空きおよび使用済みの数を表示します。
- report /path
- 特定のファイルシステムのクォータ情報を報告します。
- limit
- クォータの制限を変更します。
例8.2 サンプルクォータレポートの表示
/dev/blockdevice の) /home のクォータレポートのサンプルを表示するには、xfs_quota -x -c 'report -h' /home コマンドを使用します。これにより、以下のような出力が表示されます。
john (ホームディレクトリーが /home/john) に対して、inode 数のソフト制限およびハード制限をそれぞれ500 と 700 に設定するには、以下のコマンドを使用します。
xfs_quota -x -c 'limit isoft=500 ihard=700 /home/john'
# xfs_quota -x -c 'limit isoft=500 ihard=700 /home/john'例8.3 ソフトブロックおよびハードブロックの制限の設定
/target/path のファイルシステムで accounting をグループ化するために、ソフトおよびハードのブロック制限をそれぞれ 1000m と 1200m に設定するには、以下のコマンドを使用します。
xfs_quota -x -c 'limit -g bsoft=1000m bhard=1200m accounting' /target/path
# xfs_quota -x -c 'limit -g bsoft=1000m bhard=1200m accounting' /target/pathプロジェクト制限の設定
/etc/projects に追加します。プロジェクト名を /etc/projectid に追加して、プロジェクト ID をプロジェクト名にマップできます。プロジェクトを /etc/projects に追加したら、以下のコマンドを使用してプロジェクトディレクトリーを初期化します。
xfs_quota -c 'project -s projectname'
# xfs_quota -c 'project -s projectname'xfs_quota -x -c 'limit -p bsoft=1000m bhard=1200m projectname'
# xfs_quota -x -c 'limit -p bsoft=1000m bhard=1200m projectname'8.4. XFS ファイルシステムのサイズの拡大
xfs_growfs /mount/point -D size
# xfs_growfs /mount/point -D size8.5. XFS ファイルシステムの修復
xfs_repair /dev/device
# xfs_repair /dev/device8.6. XFS ファイルシステムの一時停止
xfsprogs パッケージで提供されます。これは x86_64 でのみ利用できます。
xfs_freeze -f /mount/point
# xfs_freeze -f /mount/pointxfs_freeze -u /mount/point
# xfs_freeze -u /mount/point8.7. XFS ファイルシステムのバックアップおよび復元
xfsdump -l 0 -f /dev/device /path/to/filesystem
# xfsdump -l 0 -f /dev/device /path/to/filesystem/dev/st0 宛先は通常テープドライブに使用されます。xfsdump 宛先は、テープドライブ、通常のファイル、またはリモートテープデバイスです。
xfsdump -l 1 -f /dev/st0 /path/to/filesystem
# xfsdump -l 1 -f /dev/st0 /path/to/filesystemxfsrestore -I
# xfsrestore -I例8.4 すべてのダンプのセッション ID およびラベル
xfsrestoreの単純なモード
xfsrestore -f /dev/st0 -S session-ID /path/to/destination
# xfsrestore -f /dev/st0 -S session-ID /path/to/destinationxfsrestoreの累積モード
xfsrestore -f /dev/st0 -S session-ID -r /path/to/destination
# xfsrestore -f /dev/st0 -S session-ID -r /path/to/destinationインタラクティブ操作
8.8. XFS ファイルシステムのその他のユーティリティー
- xfs_fsr
- マウントしている XFS ファイルシステムのデフラグを行う際に使用します。引数を指定せずに呼び出すと、xfs_fsr はマウントしているすべての XFS ファイルシステム内にあるすべての通常ファイルのデフラグを行います。このユーティリティーでは、ユーザーは指定された時間にデフラグを一時停止し、後で中断したところから再開することもできます。さらに、xfs_fsr /path/to/file のように指定すると、xfs_fsr で 1 つのファイルのみをデフラグできます。Red Hat は、通常保証されないため、ファイルシステム全体を定期的にデフラグすることをお勧めします。
- xfs_bmap
- XFS ファイルシステム内のファイル群で使用されているディスクブロックのマップを表示します。指定したファイルによって使用されているエクステントや、該当するブロックがないファイルの領域 (ホール) を一覧表示します。
- xfs_info
- XFS ファイルシステムの情報を表示します。
- xfs_admin
- XFS ファイルシステムのパラメーターを変更します。xfs_admin ユーティリティーで変更できるのは、アンマウントされているデバイスやファイルシステムのパラメーターのみです。
- xfs_copy
- XFS ファイルシステム全体のコンテンツを 1 つまたは複数のターゲットに同時にコピーします。
- xfs_metadump
- XFS ファイルシステムのメタデータをファイルにコピーします。xfs_metadump ユーティリティーは、アンマウントされたファイルシステム、読み取り専用、またはフリーズしたファイルシステムをコピーする場合にのみ使用する必要があります。それ以外の場合は、生成されたダンプが破損したり、一貫性のない可能性があります。
- xfs_mdrestore
- XFS メタダンプイメージ (xfs_metadump で生成されたイメージ) をファイルシステムのイメージに復元します。
- xfs_db
- XFS ファイルシステムをデバッグします。
第9章 Network File System (NFS)
9.1. NFS の仕組み
/etc/exports 設定ファイルを参照して、そのクライアントがエクスポート済みファイルシステムへのアクセスできるかどうかを確認します。アクセスが可能なことが確認されると、そのユーザーは、ファイルおよびディレクトリーへの全操作を行えるようになります。
9.1.1. 必要なサービス
- nfs
- service nfs start により NFS サーバーおよび該当の RPC プロセスが起動し、共有 NFS ファイルシステムの要求が処理されます。
- nfslock
- service nfslock は、NFS クライアントがサーバー上のファイルをロックできるように適切な RPC プロセスを開始する必須サービスをアクティブにします。
- rpcbind
- rpcbind は、ローカルの RPC サービスからのポート予約を受け入れます。その後、これらのポートは、対応するリモートの RPC サービスによりアクセス可能であることが公開されます。rpcbind は、RPC サービスの要求に応答し、要求された RPC サービスへの接続を設定します。このプロセスは NFSv4 では使用されません。
- rpc.nfsd
- rpc.nfsd は、サーバーが公開している明示的な NFS のバージョンとプロトコルを定義できます。NFS クライアントが接続するたびにサーバースレッドを提供するなど、NFS クライアントの動的な要求に対応するため、Linux カーネルと連携して動作します。このプロセスは、nfs サービスに対応します。注記Red Hat Enterprise Linux 6.3 では、NFSv4 サーバーのみが rpc.idmapd を使用します。NFSv4 クライアントは、キーリングベースの idmapper nfsidmap を使用します。nfsidmap は、ID マッピングを実行するためにオンデマンドでカーネルによって呼び出されるスタンドアロンプログラムです。nfsidmap に問題がある場合は、クライアントが rpc.idmapd の使用にフォールバックします。nfsidmap の詳細は、man ページの nfsidmap を参照してください。
- rpc.mountd
- NFS サーバーは、このプロセスを使用して NFSv2 クライアントおよび NFSv3 クライアントの MOUNT 要求を処理します。要求されている NFS 共有が現在 NFS サーバーによりエクスポートされているか、またその共有へのクライアントのアクセスが許可されているかを確認します。マウント要求が許可されると、rpc.mountd サーバーは
Successステータスで応答し、この NFS 共有のFile-Handleを NFS クライアントに戻します。 - lockd
- lockd は、クライアントとサーバーの両方で実行するカーネルスレッドです。Network Lock Manager (NLM) プロトコルを実装し、これにより、NFSv2 および NFSv3 クライアントがサーバー上のファイルをロックできるようになります。NFS サーバーが実行中で、NFS ファイルシステムがマウントされていれば、このプロセスは常に自動的に起動します。
- rpc.statd
- このプロセスは、Network Status Monitor (NSM) RPC プロトコルを実装します。NFS サーバーが正常にシャットダウンされずに再起動すると、NFS クライアントに通知します。rpc.statd は nfslock サービスが自動的に起動するため、ユーザー設定は必要ありません。このプロセスは NFSv4 では使用されません。
- rpc.rquotad
- このプロセスは、リモートユーザーのユーザークォーター情報を提供します。rpc.rquotad は nfs サービスにより自動的に起動するため、ユーザー設定は必要ありません。
- rpc.idmapd
- rpc.idmapd は、ネットワーク上の NFSv4 の名前 (
user@domain形式の文字列) とローカルの UID および GID とのマッピングを行う NFSv4 クライアントアップコールおよびサーバーアップコールを提供します。idmapd を NFSv4 で正常に動作させるには、/etc/idmapd.confファイルを設定する必要があります。少なくとも、NFSv4 マッピングドメインを定義する「Domain」パラメーターを指定する必要があります。NFSv4 マッピングドメインが DNS ドメイン名と同じ場合は、このパラメーターは必要ありません。クライアントとサーバーが ID マッピングの NFSv4 マッピングドメインに合意しないと、適切に動作しません。
9.2. pNFS
-o v4.1 マウントオプションを使用します。
nfs_layout_nfsv41_files カーネルが自動的に読み込まれます。モジュールが正常にロードされると、以下のメッセージが /var/log/messages ファイルに記録されます。
kernel: nfs4filelayout_init: NFSv4 File Layout Driver Registering...
kernel: nfs4filelayout_init: NFSv4 File Layout Driver Registering...mount | grep /proc/mounts
$ mount | grep /proc/mountsファイル、ブロック、オブジェクト、柔軟性ファイル、 および SCSI が含まれます。
9.3. NFS クライアント設定
mount -t nfs -o options server:/remote/export /local/directory
# mount -t nfs -o options server:/remote/export /local/directory- オプション
- マウントオプションのカンマ区切りリスト。有効な NFS マウントオプションの詳細については、「一般的な NFS マウントオプション」 を参照してください。
- server
- マウントするファイルシステムをエクスポートするサーバーのホスト名、IP アドレス、または完全修飾ドメイン名
- /remote/export
- サーバー からエクスポートされるファイルシステムまたはディレクトリー、つまり、マウントするディレクトリー
- /local/directory
- /remote/export がマウントされているクライアントの場所
/etc/fstab ファイルおよび autofs サービスの 2 つの方法を提供します。詳細は、「/etc/fstab を使用した NFS ファイルシステムのマウント」 および 「autofs」 を参照してください。
9.3.1. /etc/fstab を使用した NFS ファイルシステムのマウント
/etc/fstab ファイルに行を追加することです。その行には、NFS サーバーのホスト名、エクスポートされるサーバーディレクトリー、および NFS 共有がマウントされるローカルマシンディレクトリーを記述する必要があります。/etc/fstab ファイルを変更するには、root でなければなりません。
例9.1 構文の例
/etc/fstab の行の一般的な構文は以下の通りです。
server:/usr/local/pub /pub nfs defaults 0 0
server:/usr/local/pub /pub nfs defaults 0 0/pub がクライアントマシンに存在している必要があります。この行をクライアントシステムの /etc/fstab に追加した後に、コマンド mount /pub を使用すると、マウントポイント /pub がサーバーからマウントされます。
/etc/fstab ファイルは起動時に netfs サービスで参照されるため、NFS 共有を参照する行は、ブートプロセス中に手動で mount コマンドを入力するのと同じ効果があります。
/etc/fstab エントリーには、以下の情報が含まれている必要があります。
server:/remote/export /local/directory nfs options 0 0
server:/remote/export /local/directory nfs options 0 0/etc/fstab を読み取る前に、マウントポイント /local/directory はクライアントに存在している必要があります。そうしないと、マウントは失敗します。
/etc/fstab の詳細は、man fstab を参照してください。
9.4. autofs
/etc/fstab を使用する場合の欠点の 1 つは、NFS マウントされたファイルシステムにユーザーがアクセスする頻度に関わらず、マウントされたファイルシステムを所定の場所で維持するために、システムがリソースを割り当てる必要があることです。これは 1 つまたは 2 つのマウントでは問題になりませんが、システムが一度に多くのシステムへのマウントを維持している場合、システム全体のパフォーマンスに影響を与える可能性があります。/etc/fstab に代わるのは、カーネルベースの automount ユーティリティーを使用することです。自動マウント機能は以下の 2 つのコンポーネントで構成されます。
- ファイルシステムを実装するカーネルモジュール
- 他のすべての機能を実行するユーザー空間デーモン
/etc/auto.master (マスターマップ) を使用します。これは、ネームサービススイッチ (NSS) のメカニズムと autofs 設定 (/etc/sysconfig/autofs) を使用して別のネットワークソースと名前を使用するように変更できます。autofs バージョン 4 デーモンのインスタンスはマスターマップ内に設定された各マウントポイントに対して実行されるため、任意のマウントポイントに対してコマンドラインから手動で実行することが可能でした。しかし、autofs バージョン 5 では、設定されたすべてのマウントポイントは 1 つのデーモンを使用して管理されるため、これを実行することができなくなりました。これは、他の業界標準の自動マウント機能の通常の要件と一致しています。マウントポイント、ホスト名、エクスポートしたディレクトリー、および各種オプションは各ホストに対して手動で設定するのではなく、すべて 1 つのファイルセット (またはサポートされている別のネットワークソース) 内に指定することができます。
9.4.1. バージョン 4 と比較した autofs バージョン 5 の改善点
- ダイレクトマップのサポート
- autofs のダイレクトマップは、ファイルシステム階層の任意の時点でファイルシステムを自動的にマウントするメカニズムを提供します。ダイレクトマップは、マスターマップの
/-のマウントポイントによって示されます。ダイレクトマップのエントリーには、(間接マップで使用される相対パス名の代わりに) 絶対パス名がキーとして含まれています。 - レイジーマウントとアンマウントのサポート
- マルチマウントマップエントリーは、単一のキーの下にあるマウントポイントの階層を記述します。この良い例として、
-hostsマップがあります。これは通常、マルチマウントマップエントリーとして、/net/hostの下のホストからのすべてのエクスポートを自動マウントするために使用されます。-hostsマップを使用する場合は、/net/host の ls が、host からの各エクスポートの autofs トリガーマウントをマウントします。次に、これらはマウントされ、アクセスされると期限切れとなります。これにより、エクスポートが多数あるサーバーにアクセスする際に必要なアクティブなマウントの数を大幅に減らすことができます。 - 強化された LDAP サポート
- autofs 設定ファイル (
/etc/sysconfig/autofs) は、サイトが実装する autofs スキーマを指定するメカニズムを提供するため、アプリケーション自体で試行錯誤してこれを判断する必要がなくなります。さらに、共通の LDAP サーバー実装でサポートされるほとんどのメカニズムを使用して、LDAP サーバーへの認証済みバインドがサポートされるようになりました。このサポートには、新しい設定ファイル (/etc/autofs_ldap_auth.conf) が追加されました。デフォルトの設定ファイルは自己文書化されており、XML 形式を使用します。 - Name Service Switch (nsswitch) 設定の適切な使用
- Name Service Switch 設定ファイルは、特定の設定データがどこから来るのかを判別する手段を提供するために存在します。この設定の理由は、データにアクセスするための統一されたソフトウェアインターフェイスを維持しながら、管理者が最適なバックエンドデータベースを柔軟に使用できるようにするためです。バージョン 4 の自動マウント機能は、今まで以上に NSS 設定を処理できるようになっていますが、まだ完全ではありません。一方、autofs バージョン 5 は完全な実装です。このファイルで対応している構文の詳細は、man nsswitch.conf を参照してください。すべての NSS データベースが有効なマップソースである訳ではなく、パーサーは無効なデータベースを拒否します。有効なソースは、ファイル、yp、nis、nisplus、ldap および hesiod です。
- autofs マウントポイントごとの複数のマスターマップエントリー
- 頻繁に使用されますが、まだ記述されていないのは、直接マウントポイント
/-の複数のマスターマップエントリーの処理です。各エントリーのマップキーはマージされ、1 つのマップとして機能します。例9.2 autofs マウントポイントごとの複数のマスターマップエントリー
以下にダイレクトマウントの connectathon テストマップの例が表示されます。/- /tmp/auto_dcthon /- /tmp/auto_test3_direct /- /tmp/auto_test4_direct
/- /tmp/auto_dcthon /- /tmp/auto_test3_direct /- /tmp/auto_test4_directCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.4.2. autofs の設定
/etc/auto.master であり、マスターマップとも呼ばれます。マスターマップは、「バージョン 4 と比較した autofs バージョン 5 の改善点」 で説明されているとおり変更できます。マスターマップには、システム上の autofs 制御のマウントポイントと、それに対応する構成ファイルまたは自動マウントマップと呼ばれるネットワークソースが一覧表示されます。マスターマップの形式は次のとおりです。
mount-point map-name options
mount-point map-name options- mount-point
- autofs マウントポイント (例:
/home) - map-name
- マウントポイントの一覧とマウントポイントがマウントされるファイルシステムの場所が記載されているマップソース名です。マップエントリーの構文は以下で説明します。
- オプション
- 指定されている場合、それら自体にオプションが指定されていない場合に、指定されたマップ内のすべてのエントリーに適用されます。この動作は、オプションが累積されていた autofs バージョン 4 とは異なります。混合環境の互換性を実装させるため変更が加えられています。
例9.3 /etc/auto.master ファイル
/etc/auto.master ファイル内にある行の一例を示します (cat /etc/auto.master で表示)。
/home /etc/auto.misc
/home /etc/auto.miscmount-point [options] location
mount-point [options] location- mount-point
- これは autofs マウントポイントを参照します。これは 1 つのインダイレクトマウント用の 1 つのディレクトリー名にすることも、複数のダイレクトマウント用のマウントポイントの完全パスにすることもできます。ダイレクトマップとインダイレクトマップの各エントリキー (上記の mount-point) の後には、スペースで区切られたオフセットディレクトリー (それぞれ「/」で始まるサブディレクトリー名) のリストが続き、マルチマウントエントリーと呼ばれるものになります。
- オプション
- 指定した場合は、これらは、独自のオプションを指定しないマップエントリーのマウントオプションになります。
- location
- ローカルファイルシステムのパス (Sun マップ形式のエスケープ文字「:」が先頭に付き、マップ名が「/」で始まります)、NFS ファイルシステム、他の有効なファイルシステムの場所などのファイルシステムの場所を参照します。
/etc/auto.misc)。
payroll -fstype=nfs personnel:/exports/payroll sales -fstype=ext3 :/dev/hda4
payroll -fstype=nfs personnel:/exports/payroll
sales -fstype=ext3 :/dev/hda4personnel と呼ばれるサーバーの sales と payroll) を示します。2 番目のコラムは autofs マウントのオプションを示し、3 番目のコラムはマウントのソースを示しています。任意の設定に基づき、autofs マウントポイントは、/home/payroll と /home/sales になります。-fstype= オプションは省略されることが多く、通常は正しい操作には必要ありません。
- service autofs の起動 (自動マウントデーモンが停止した場合)
- service autofs restart
/home/payroll/2006/July.sxc などのアンマウントされている autofs ディレクトリーへのアクセスが要求されると、自動デーモンは、そのディレクトリーを自動的にマウントすることになります。タイムアウトを指定した場合は、タイムアウト期間中ディレクトリーにアクセスしないと、ディレクトリーが自動的にアンマウントされます。
service autofs status
# service autofs status9.4.3. サイト設定ファイルの上書きまたは拡張
- 自動マウント機能マップは NIS に保存され、
/etc/nsswitch.confファイルには以下のディレクティブがあります。automount: files nis
automount: files nisCopy to Clipboard Copied! Toggle word wrap Toggle overflow auto.masterファイルには、+auto.master
+auto.masterCopy to Clipboard Copied! Toggle word wrap Toggle overflow - NIS の
auto.masterマップファイルには、以下が含まれます。/home auto.home
/home auto.homeCopy to Clipboard Copied! Toggle word wrap Toggle overflow - NIS の
auto.homeマップには以下が含まれています。beth fileserver.example.com:/export/home/beth joe fileserver.example.com:/export/home/joe * fileserver.example.com:/export/home/&
beth fileserver.example.com:/export/home/beth joe fileserver.example.com:/export/home/joe * fileserver.example.com:/export/home/&Copy to Clipboard Copied! Toggle word wrap Toggle overflow - ファイルマップ
/etc/auto.homeは存在しません。
auto.home を無効にして、ホームのディレクトリーを別のサーバーからマウントする必要があると仮定します。この場合、クライアントは以下の /etc/auto.master マップを使用する必要があります。
/home /etc/auto.home +auto.master
/home /etc/auto.home
+auto.master/etc/auto.home マップにはエントリーが含まれます。
* labserver.example.com:/export/home/&
* labserver.example.com:/export/home/&/home には NIS auto.home マップではなく、/etc/auto.home のコンテンツが含まれます。
auto.home マップにいくつかのエントリーを加えて拡大させたい場合は、/etc/auto.home ファイルマップを作成して新しいエントリーを組み込みます。最後に、NIS の auto.home マップを含めます。次に、/etc/auto.home ファイルマップは以下のようになります。
mydir someserver:/export/mydir +auto.home
mydir someserver:/export/mydir
+auto.homeauto.home マップがリストされると、ls /home が出力されます。
beth joe mydir
beth joe mydir9.4.4. LDAP を使用した自動マウント機能マップの格納
openldap パッケージは automounter の依存パッケージとして自動的にインストールされるはずです。LDAP アクセスを設定する際は /etc/openldap/ldap.conf ファイルを編集します。BASE、URI、スキーマなどが使用するサイトに適した設定になっていることを確認してください。
rfc2307bis に記載されています。このスキーマを使用するには、スキーマ定義からコメント文字を削除して、autofs 設定 /etc/autofs.conf で設定する必要があります。
例9.4 autofs の設定
/etc/ systemconfig/autofs ファイルではなく、/etc/autofs.conf ファイルで設定されます。
rfc2307bis スキーマの cn 属性を置換します。設定例の LDIF の説明は次のとおりです。
例9.5 LDIF 設定
9.5. 一般的な NFS マウントオプション
/etc/fstab 設定、autofs と併用できます。
- intr
- サーバーがダウンした場合やサーバーにアクセスできない場合に、NFS 要求の割り込みを許可します。
- lookupcache=mode
- 任意のマウントポイントに対して、カーネルがディレクトリーエントリーのキャッシュを管理する方法を指定します。mode の有効な引数は、
all、none、またはpos/positiveです。 - nfsvers=version
- 使用する NFS プロトコルのバージョンを指定します。version は、2、3、または 4 になります。これは、複数の NFS サーバーを実行するホストに役立ちます。バージョンを指定しないと、NFS はカーネルおよび mount コマンドで対応している最近のバージョンを使用します。vers オプションは nfsvers と同じで、互換性のためにこのリリースに含まれています。
- noacl
- ACL の処理をすべてオフにします。古いバージョンの Red Hat Enterprise Linux、Red Hat Linux、Solaris と連動させる場合に必要となることがあります。こうした古いシステムには、最新の ACL テクノロジーに対する互換性がないためです。
- nolock
- ファイルのロック機能を無効にします。この設定は、古い NFS サーバーへの接続時に必要になることがあります。
- noexec
- マウントしたファイルシステムでバイナリーが実行されないようにします。互換性のないバイナリーを含む、Linux 以外のファイルシステムをマウントしている場合に便利です。
- nosuid
set-user-identifierまたはset-group-identifierビットを無効にします。これにより、リモートユーザーは、setuid プログラムを実行してより高い権限を取得できなくなります。- port=num
port=num- NFS サーバーポートの数値を指定します。num を 0 (デフォルト値) にすると、mount は、使用するポート番号に関するリモートホストの rpcbind サービスのクエリーを実行します。リモートホストの NFS デーモンがその rpcbind サービスに登録されていない場合は、標準の NFS ポート番号 TCP 2049 が代わりに使用されます。- rsize=num および wsize=num
- これらの設定は、大規模なデータブロックサイズ(数字、バイト単位
)を設定して、 読み取り(rsize)および書き込み(wsize)の NFS 通信を 1 度に転送します。これらの値を変更する場合には注意が必要です。古い Linux カーネルとネットワークカードは、大きなブロックサイズで適切に機能しません。注記rsize の値が指定されていない場合や、指定した値が、クライアントまたはサーバーがサポートできる最大値よりも大きい場合、クライアントとサーバーは両方のサポートが可能な最大サイズサイズをネゴシエートします。 - sec=mode
- NFS 接続の認証時に使用するセキュリティーのタイプを指定します。デフォルトの設定は
sec=sysで、NFS 操作を認証するAUTH_SYSを使用してローカルの UNIX UID および GID を使用します。sec=krb5は、ユーザー認証に、ローカルの UNIX の UID と GID ではなく、Kerberos V5 を使用します。sec=krb5iは、ユーザー認証に Kerberos V5 を使用し、データの改ざんを防ぐ安全なチェックサムを使用して、NFS 操作の整合性チェックを行います。sec=krb5pは、ユーザー認証に Kerberos V5 を使用し、整合性チェックを実行し、トラフィックの傍受を防ぐため NFS トラフィックの暗号化を行います。これが最も安全な設定になりますが、パフォーマンスのオーバーヘッドも最も高くなります。 - tcp
- NFS マウントが TCP プロトコルを使用するよう指示します。
- udp
- NFS マウントが UDP プロトコルを使用するよう指示します。
9.6. NFS の起動および停止
service rpcbind status
# service rpcbind statusservice nfs start
# service nfs startservice nfslock start
# service nfslock startservice nfs stop
# service nfs stoprestart オプションは、停止して NFS を起動する簡単な方法です。これは、NFS の設定ファイルを編集した後に設定変更を行う最も効率的な方法です。サーバータイプを再起動するには、以下を実行します。
service nfs restart
# service nfs restartcondrestart (条件付き再起動)オプションは、現在実行している場合にのみ nfs を起動します。このオプションは、デーモンが実行していない場合は起動しないため、スクリプトに役に立ちます。条件付きでサーバーを再起動するには、以下を入力します。
service nfs condrestart
# service nfs condrestartservice nfs reload
# service nfs reload9.7. NFS サーバーの設定
- NFS の設定ファイル (つまり
/etc/exports) を手動で編集する方法。 - コマンドラインで、コマンド exportfs を使用する方法。
9.7.1. /etc/exports 設定ファイル
/etc/exports ファイルは、リモートホストにどのファイルシステムをエクスポートするかを制御し、オプションを指定します。以下の構文ルールに従います。
- 空白行は無視する。
- コメント行は、ハッシュ記号 (#) で始める。
- 長い行は、バックスラッシュ (\) で改行できる。
- エクスポートするファイルシステムは、それぞれ 1 行で指定する。
- 許可するホストの一覧は、エクスポートするファイルシステムの後に空白文字を追加し、その後に追加する。
- 各ホストのオプションは、ホストの識別子の直後に括弧を追加し、その中に指定する。ホストと最初の括弧の間には空白を使用しない。
export host(options)
export host(options)- export
- エクスポートするディレクトリー
- host
- エクスポートを共有するホストまたはネットワーク
- オプション
- host に使用されるオプション
export host1(options1) host2(options2) host3(options3)
export host1(options1) host2(options2) host3(options3)/etc/exports ファイルに、エクスポートするディレクトリーと、そのディレクトリーへのアクセスを許可するホストを指定するだけです。以下の例のようになります。
例9.6 /etc/exports ファイル
/exported/directory bob.example.com
/exported/directory bob.example.combob.example.com は NFS サーバーから /exported/directory/ をマウントできます。この例ではオプションが指定されていないため、NFS はデフォルト設定 を使用します。
- ro
- エクスポートするファイルシステムは読み取り専用です。リモートホストは、このファイルシステムで共有されているデータを変更できません。このファイルシステムで変更 (つまり読み取り/書き込み) を可能にするには、
rwオプションを指定します。 - sync
- NFS サーバーは、以前の要求で発生した変更がディスクに書き込まれるまで、要求に応答しません。代わりに非同期書き込みを有効にするには、
asyncオプションを指定します。 - wdelay
- NFS サーバーは、別の書き込み要求が差し迫っていると判断すると、ディスクへの書き込みを遅らせます。これにより、複数の書き込みコマンドが同じディスクにアクセスする回数を減らすことができるため、書き込みのオーバーヘッドが低下し、パフォーマンスが向上します。これを無効にするには、
no_wdelayを指定します。no_wdelayは、デフォルトのsyncオプションが指定されている場合に限り使用できます。 - root_squash
- (ローカルからではなく) リモート から接続している root ユーザーが root 権限を持つことを阻止します。代わりに、そのユーザーには、NFS サーバーにより、ユーザー ID
nfsnobodyが割り当てられます。これにより、リモートの root ユーザーの権限を、最も低いローカルユーザーレベルにまで下げて (squash)、高い確率でリモートサーバーへの書き込む権限を与えないようにすることができます。root squashing を無効にするには、no_root_squashを指定します。
_squash を使用します。特定ホストのリモートユーザーに対して、NFS サーバーが割り当てるユーザー ID とグループ ID を指定するには、anonuid オプションと anongid オプションを以下のように使用します。
export host(anonuid=uid,anongid=gid)
export host(anonuid=uid,anongid=gid)anonuid オプションと anongid オプションにより、共有するリモート NFS ユーザー用に、特別なユーザーアカウントおよびグループアカウントを作成できます。
rw オプションを指定しないと、エクスポートするファイルシステムが読み取り専用として共有されます。以下は、/etc/exports の例になりますが、ここでは 2 つのデフォルトオプションを上書きします。
/another/exported/directory/ の読み書きをマウントでき、ディスクへの書き込みはすべて非同期になります。エクスポートオプションの詳細は、man exportfs を参照してください。
/etc/exports ファイルの形式では、特に空白文字の使用が非常に厳しく扱われます。ホストからエクスポートするファイルシステムの間、そしてホスト同士の間には、必ず空白文字を挿入してください。また、それ以外の場所 (コメント行を除く) には、空白文字を追加しないでください。
/home bob.example.com(rw) /home bob.example.com (rw)
/home bob.example.com(rw)
/home bob.example.com (rw)bob.example.com から /home ディレクトリーへの読み取り/書き込みアクセスのみを許可します。2 番目の行では、bob.example.com からのユーザーにディレクトリーを読み取り専用 (デフォルト) でマウントすることを許可し、その他のユーザーに読み取り/書き込みでマウントすることを許可します。
9.7.2. exportfs コマンド
/etc/exports ファイル内に一覧表示してあります。nfs サービスが開始すると、/usr/sbin/exportfs コマンドが起動してこのファイルを読み込み、実際のマウントプロセスのために制御を rpc.mountd (NFSv2 および NFSv3の場合) に渡してから、rpc.nfsd に渡します。この時点でリモートユーザーがファイルシステムを使用できるようになります。
/var/lib/nfs/etab に書き込みます。rpc.mountd はファイルシステムへのアクセス権限を決定する際に etab ファイルを参照するため、エクスポートしたファイルシステム一覧への変更はすぐに反映されます。
- -r
/etc/exportsに記載されるすべてのディレクトリーから、/etc/lib/nfs/etabに新しいエクスポート一覧を作成して、すべてのディレクトリーをエクスポートします。このオプションにより、/etc/exportsに変更が加えられると、エクスポート一覧が効果的に更新されます。- -a
- /usr/sbin/exportfs に渡される他のオプションに応じて、すべてのディレクトリーがエクスポートされるか、またはされないことになります。他のオプションが指定されない場合、/usr/sbin/exportfs は、
/etc/exports内に指定してあるすべてのファイルシステムをエクスポートします。 - -o file-systems
/etc/exports内に記載されていない、エクスポートされるディレクトリーを指定します。file-systems の部分を、エクスポートされる追加のファイルシステムに置き換えます。これらのファイルシステムは、/etc/exportsで指定されたものと同じフォーマットでなければなりません。このオプションは、エクスポートするファイルシステムのリストに永続的に追加する前に、エクスポートするファイルシステムをテストするためによく使用されます。/etc/exports構文の詳細は、「/etc/exports設定ファイル」 を参照してください。- -i
/etc/exportsを無視します。コマンドラインで指定されたオプションのみが、エクスポート用ファイルシステムの定義に使用されます。- -u
- すべての共有ディレクトリーをエクスポートしなくなります。コマンド /usr/sbin/exportfs -ua は、すべての NFS デーモンを稼働状態に維持しながら、NFS ファイル共有を保留します。NFS 共有を再度有効にするには、exportfs -r を使用します。
- -v
- 詳細な表示です。exportfs コマンドを実行するときに表示されるエクスポート、または非エクスポートのファイルシステムの情報が、より詳細に表示されます。
9.7.2.1. NFSv4 で exportfs の使用
/etc/sysconfig/nfs に RPCNFSDARGS= -N 4 を設定し、NFSv4 の使用を停止します。
9.7.3. ファイアウォール背後での NFS の実行
/etc/sysconfig/nfs 設定ファイルを編集して、必要な RPC サービスを実行するポートを制御します。
/etc/sysconfig/nfs が存在しない場合があります。存在しない場合は、これを作成し、以下の変数を追加して、port を未使用の ポート番号 で置き換えます(ファイルが存在する場合は、コメント解除して、デフォルトのエントリーを必要に応じて変更します)。
MOUNTD_PORT=port- rpc.mountd (rpc.mountd)が使用する TCP ポートおよび UDP ポートのマウント を制御します。
STATD_PORT=port- rpc.statd が使用する TCP および UDP ポートのステータス(rpc.statd)を制御します。
LOCKD_TCPPORT=port- どの TCP portnlock mgr (lockd)が使用するかを制御します。
LOCKD_UDPPORT=port- どの UDP ポートnlock mgr (lockd)が使用するかを制御します。
/var/log/messages を確認してください。通常、すでに使用中のポート番号を指定すると、NFS が起動しません。/etc/sysconfig/nfs を編集したら、service nfs restart を使用して NFS サービスを再起動します。rpcinfo -p コマンドを実行して変更を確認します。
手順9.1 NFS を許可するようにファイアウォールを設定
- NFS 用に TCP ポート 2049 および UDP ポート 2049 を許可します。
- TCP および UDP ポート 111(rpcbind/sunrpc)を許可します。
- で指定する TCP ポートおよび UDP ポートを許可します。
MOUNTD_PORT="port" - で指定する TCP ポートおよび UDP ポートを許可します。
STATD_PORT="port" - で指定する TCP ポートを許可します。
LOCKD_TCPPORT="port" - で指定する UDP ポートを許可します。
LOCKD_UDPPORT="port"
/proc/sys/fs/nfs/nfs_callback_tcpport を設定して、サーバーがクライアントのそのポートに接続できるようにします。
mountd、statd、および lockd のための他のポート群は純粋な NFSv4 環境では必要ありません。
9.7.3.1. NFS エクスポートの検出
showmount -e myserver Export list for mysever /exports/foo /exports/bar
$ showmount -e myserver
Export list for mysever
/exports/foo
/exports/bar/ を確認し、確認します。
9.7.4. ホスト名の形式
- 単独のマシン
- 完全修飾型ドメイン名 (サーバーで解決可能な形式)、ホスト名 (サーバーで解決可能な形式)、あるいは IP アドレス
- ワイルドカードで指定された一連のマシン
*文字または?文字を使用して文字列の一致を指定します。ワイルドカードは IP アドレスでは使用しないことになっていますが、逆引き DNS ルックアップが失敗した場合には誤って動作する可能性があります。完全修飾ドメイン名でワイルドカードを指定する場合、ドット (.) はワイルドカードに含まれません。たとえば、*.example.comにはone.example.comが含まれていますが、include one.two.example.comは含まれません。- IP ネットワーク
- a.b.c.d/z を使用します。ここで、a.b.c.d はネットワーク、z はネットマスクのビット数です (たとえば、192.168.0.0/24)。別の使用可能形式は a.b.c.d/netmask となり、ここで a.b.c.d がネットワークで、netmask がネットマスクです (たとえば、192.168.100.8/255.255.255.0)。
- Netgroups
- 形式 @group-name を使用します。ここで、group-name は NIS netgroup の名前です。
9.7.5. RDMA 経由の NFS
手順9.2 NFS サーバーでの RDMA トランスポートの有効化
- RDMA RPM がインストールされ、RDMA サービスが有効になっていることを確認します。
yum install rdma; chkconfig --level 2345 rdma on
# yum install rdma; chkconfig --level 2345 rdma onCopy to Clipboard Copied! Toggle word wrap Toggle overflow nfs-rdma サービスを提供するパッケージがインストールされ、サービスが有効であることを確認します。yum install rdma; chkconfig --level 345 nfs-rdma on
# yum install rdma; chkconfig --level 345 nfs-rdma onCopy to Clipboard Copied! Toggle word wrap Toggle overflow - RDMA ポートが推奨されるポートに設定されていることを確認します(Red Hat Enterprise Linux 6 のデフォルトは 2050):
/etc/rdma/rdma.confファイルを編集して、NFSoRDMA_LOAD=yesおよびNFSoRDMA_PORTを必要なポートに設定します。 - NFS マウントでは、エクスポートしたファイルシステムを通常通りセットアップします。
手順9.3 クライアントからの RDMA の有効化
- RDMA RPM がインストールされ、RDMA サービスが有効になっていることを確認します。
yum install rdma; chkconfig --level 2345 rdma on
# yum install rdma; chkconfig --level 2345 rdma onCopy to Clipboard Copied! Toggle word wrap Toggle overflow - マウント呼び出しで RDMA オプションを使用して、NFS でエクスポートされたパーティションをマウントします。port オプションは、任意で呼び出しに追加できます。
mount -t nfs -o rdma,port=port_number
# mount -t nfs -o rdma,port=port_numberCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.8. NFS のセキュア化
9.8.1. AUTH_SYS とエクスポート制御による NFS 保護
AUTH_SYS (AUTH_UNIX とも呼ぶ) を使って行われ、ユーザーの UID や GID の指定はクライアントに依存します。つまり、悪意のあるクライアントや誤って設定されたクライアントがこれを誤用し、ファイルへのアクセスを許可すべきではないユーザーに対して、ファイルへのアクセスを簡単に与えてしまうことができるため注意が必要です。
9.8.2. AUTH_GSSを使用した NFS セキュリティー
手順9.4 RPCSEC_GSS のセットアップ
nfs/client.mydomain@MYREALMおよびnfs/server.mydomain@MYREALMプリンシパルを作成します。- クライアントとサーバーのキータブに、対応する鍵を追加します。
- サーバーで、sec
=krb5,krb5i,krb5pをエクスポートに追加します。AUTH_SYS を引き続き許可するには、sec=sys、krb5、krb5i、krb5pを追加します。 - クライアントで、
sec=krb5(もしくは設定に応じてsec=krb5iまたはsec=krb5p) をマウントオプションに追加します。
RPCSEC_GSS フレームワークの詳細は、http://www.citi.umich.edu/projects/nfsv4/gssd/ を参照してください 。
9.8.2.1. NFSv4 による NFS の保護
9.8.3. ファイル権限
nobody に設定されます。root squashing は、デフォルトのオプション root_squash で制御されます。このオプションの詳細は、「/etc/exports 設定ファイル」 を参照してください。できる限りこの root squash 機能は無効にしないでください。
all_squash オプションの使用を検討してください。このオプションでは、エクスポートしたファイルシステムにアクセスするすべてのユーザーが、nfsnobody ユーザーのユーザー ID を取得します。
9.9. NFS および rpcbind
9.9.1. NFS と rpcbind のトラブルシューティング
rpcinfo -p
# rpcinfo -p例9.7 rpcinfo -p コマンドの出力
9.10. リファレンス
インストールされているドキュメント
- man mount — NFS のサーバー設定およびクライアント設定に使用するマウントオプションに関して総合的に説明しています。
- man fstab: 起動時にファイルシステムのマウントに使用される
/etc/fstabファイルのフォーマットの詳細を指定します。 - man nfs — NFS 固有のファイルシステムのエクスポートおよびマウントオプションについて詳細に説明しています。
- man exports — NFS ファイルシステムのエクスポート時に
/etc/exportsファイル内で使用する一般的なオプションを表示します。 - man 8 nfsidmap - nfsidmap cammand に従い、一般的なオプションを一覧表示します。
便利な Web サイト
- http://linux-nfs.org — プロジェクトの更新状況を確認できる開発者向けの最新サイトです。
- http://nfs.sourceforge.net/ — 開発者向けのホームページで、少し古いですが、役に立つ情報が多数掲載されています。
- http://www.citi.umich.edu/projects/nfsv4/linux/ — Linux 2.6 カーネル用 NFSv4 のリソースです。
- http://www.vanemery.com/Linux/NFSv4/NFSv4-no-rpcsec.html: Fedora Core 2 での NFSv4 の詳細を説明します。これには 2.6 カーネルが含まれます。
- http://citeseer.ist.psu.edu/viewdoc/summary?doi=10.1.1.111.4086 — NFS バージョン 4 プロトコルの機能および拡張機能について記載しているホワイトペーパーです。
第10章 FS-Cache
図10.1 FS-Cache の概要
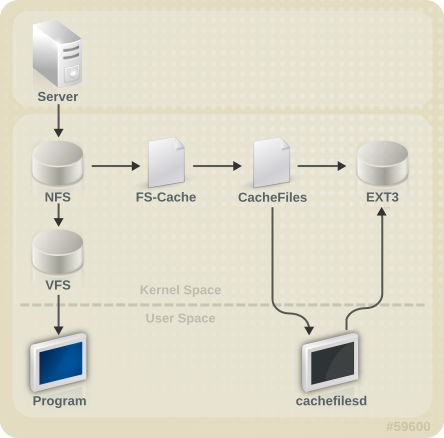
[D]
cachefilesd はデフォルトでインストールされず、手動でインストールする必要があります。
10.1. パフォーマンスに関する保証
10.2. キャッシュの設定
/etc/cachefilesd.conf ファイルは、cachefiles によるキャッシュサービスの提供方法を制御します。このタイプのキャッシュバックエンドを設定するには、cachefilesd パッケージがインストールされている必要があります。
dir /path/to/cache
$ dir /path/to/cache/etc/cachefilesd.conf 内に /var/cache/fscache として設定されます。
dir /var/cache/fscache
$ dir /var/cache/fscache/) をホストのファイルシステムとして使用することが推奨されますが、デスクトップマシンの場合は、キャッシュ専用のディスクパーティションをマウントするより慎重に行ってください。
- ext3 (拡張属性が有効)
- ext4
- BTRFS
- XFS
tune2fs -o user_xattr /dev/device
# tune2fs -o user_xattr /dev/devicemount /dev/device /path/to/cache -o user_xattr
# mount /dev/device /path/to/cache -o user_xattrservice cachefilesd start
# service cachefilesd startchkconfig cachefilesd on
# chkconfig cachefilesd on10.3. NFS でのキャッシュの使用
mount nfs-share:/ /mount/point -o fsc
# mount nfs-share:/ /mount/point -o fsc10.3.1. キャッシュの共有
- レベル 1: サーバーの詳細
- レベル 2: 一部のマウントオプション、セキュリティータイプ、FSID、識別子
- レベル 3: ファイルハンドル
- レベル 4: ファイル内のページ番号
例10.1 キャッシュの共有
/home/fred および /home/jim には同じオプションがあるため、スーパーブロックを共有する可能性が高くなります。特に NFS サーバー上の同じボリュームやパーティションから作成されている場合は共有する可能性が高くなります (home0)。ここで、2 つの後続のマウントコマンドを示します。
/home/fred と /home/jim は、レベル 2 キーの異なるネットワークアクセスパラメーターを持つため、スーパーブロックを共有しません。次のマウントシーケンスについても同じことが言えます。
/home/fred1 と /home/fred2) は 2 回 キャッシュされます。
home0:/disk0/fred および home0:/disk0/jim のレベル 2 キーを区別するものがないため、スーパーブロックの 1 つだけがキャッシュの使用を許可されます。これに対処するには、固有の識別子 を少なくともどちらか 1 つのマウントに追加します (fsc=unique-identifier)。以下に例を示します。
/home/jim のキャッシュで使用されるレベル 2 キーに固有識別子の jim が追加されます。
10.3.2. NFS でのキャッシュの制限
10.4. キャッシュカリング制限の設定
/etc/cachefilesd.conf の設定で管理されます。
- brun N% (ブロックのパーセンテージ) , frun N% (ファイルのパーセンテージ)
- キャッシュの空き領域と利用可能なファイルの数がこれらの制限を上回ると、カリングはオフになります。
- bcull N% (ブロックのパーセンテージ), fcull N% (ファイルのパーセンテージ)
- キャッシュの空き領域と利用可能なファイルの数がこれらの制限のいずれかを下回ると、カリング動作が開始します。
- bstop N% (ブロックのパーセンテージ), fstop N% (ファイルのパーセンテージ)
- キャッシュ内の使用可能な領域または使用可能なファイルの数がこの制限のいずれかを下回ると、カリングによってこれらの制限を超える状態になるまで、ディスク領域またはファイルのそれ以上の割り当ては許可されません。
N のデフォルト値は以下の通りです。
- brun/frun - 10%
- bcull/fcull - 7%
- bstop/fstop - 3%
10.5. 統計情報
/usr/share/doc/kernel-doc-version/Documentation/filesystems/caching/fscache.txt
10.6. リファレンス
/usr/share/doc/cachefilesd-version-number/README/usr/share/man/man5/cachefilesd.conf.5.gz/usr/share/man/man8/cachefilesd.8.gz
/usr/share/doc/kernel-doc-version/Documentation/filesystems/caching/fscache.txt
パート II. ストレージ管理
第11章 ストレージをインストールする際の注意点
11.1. インストール中のストレージ設定の更新
イーサネット上ファイバーチャネル (FCoE)
Anaconda で、インストール時に FCoE ストレージデバイスを設定できるようになりました。
ストレージデバイスのフィルタリングインターフェース
Anaconda で、インストール時に使用されるストレージデバイスの制御が改善されました。システムストレージに実際に使用されているデバイスや、インストーラーに利用可能なデバイス、または表示可能なデバイスを制御できるようになりました。デバイスのフィルタリングには、以下の 2 つのパスがあります。
- 基本パス
- ローカルで割り当てられたディスクおよびファームウェアの RAID アレイのみをストレージデバイスとして使用するシステムの場合は、
- 高度なパス
- SAN(マルチパス、iSCSI、FCoE)デバイスを使用するシステムの場合は、
自動パーティション設定および /home
自動パーティション設定では、LVM 物理ボリュームの割り当てに 50 GB 以上が利用可能な場合に、/home ファイルシステム用に別の論理ボリュームが作成されます。ルートファイルシステム(/)は、別の /home 論理ボリュームを作成する際に最大 50 GB に制限されますが、/home 論理ボリュームは、ボリュームグループの残りの領域をすべて占有します。
11.2. サポートされるファイルシステムの概要
| ファイルシステム | サポートされる最大サイズ | 最大ファイルオフセット | 最大サブディレクトリー(ディレクトリーごと) | Max Depth of Symbolic Links | ACL サポート | 詳細 |
|---|---|---|---|---|---|---|
| Ext2 | 8TB | 2TB | 32,000 | 8 | はい | 該当なし |
| Ext3 | 16TB | 2TB | 32,000 | 8 | はい | 5章Ext3 ファイルシステム。 |
| Ext4 | 16TB | 16TB[a] | 無制限[b] | 8 | はい | 6章Ext4 ファイルシステム |
| XFS | 100TB | 100TB[c] | 無制限 | 8 | はい | 8章XFS ファイルシステム |
[a]
この最大ファイルサイズは、64 ビットのマシンに基づいています。32 ビットマシンでは、最大ファイルサイズは 8TB です。
[b]
リンク数が 65,000 を超える場合は、リセットされ 1 にリセットされ、増加しなくなりました。
[c]
この最大ファイルサイズは、64 ビットのマシンのみになります。Red Hat Enterprise Linux は、32 ビットマシンで XFS に対応していません。
| ||||||
11.3. 特に注意を要する事項について
/home、/opt、/usr/local には別々のパーティションを用意する
/home、/opt、および /usr/local は別々のデバイスに配置します。これにより、ユーザーおよびアプリケーションデータを保存しながら、オペレーティングシステムを含むデバイス/ファイルシステムを再フォーマットできます。
IBM System Z における DASD デバイスと zFCP デバイス
DASD= パラメーターにデバイス番号 (またはデバイス番号の範囲) を記載することを意味します。
FCP_x= の行を使用して、インストーラーに対してこの情報を指定することができます。
LUKS を使用したブロックデバイスの暗号化
古い BIOS RAID メタデータ
iSCSI の検出および設定
FCoE の検出および設定
DASD
DIF/DIX を有効にしているブロックデバイス
第12章 ファイルシステムの確認
/etc/fstab に記載されている各ファイルシステムで実行されます。ジャーナリングファイルシステムの場合、通常これは非常に短い操作で実行できます。ファイルシステムのメタデータジャーナリングにより、クラッシュが発生した後でも整合性が確保されるためです。
/etc/fstab の 6 番目のフィールドを 0 に設定すると、システムの起動時にファイルシステムの確認を無効にできます。
12.1. fsck のベストプラクティス
- Dry run
- ほとんどのファイルシステムチェッカーは、ファイルシステムを修復しない操作モードを持ちます。このモードでは、チェッカーは、実際にファイルシステムを変更せずに、作成したアクションを見つけたエラーおよび操作を出力します。注記整合性の確認後のフェーズでは、修復モードで実行していた場合に前のフェーズで修正されていた不整合が検出される可能性があるため、追加のエラーが出力される場合があります。
- ファイルシステムイメージで最初に操作
- ほとんどのファイルシステムは、メタデータのみを含むスパースコピーである メタデータイメージ の作成に対応しています。ファイルシステムのチェッカーは、メタデータ上でのみ動作するため、このようなイメージを使用して、実際のファイルシステムの修復の Dry Run を実行し、実際に加えられた可能性のある変更を評価することができます。変更が受け入れ可能なものである場合、修復はファイルシステム自体で実行できます。注記ファイルシステムが大幅に損傷している場合は、メタデータイメージの作成に関連して問題が発生する可能性があります。
- サポート調査のためにファイルシステムイメージを保存します。
- 修復前のファイルシステムのメタデータイメージは、破損の原因がソフトウェアのバグの可能性がある場合のサポート調査を行う上で役に立つことがあります。修復前のイメージに見つかる破損のパターンは、根本原因の分析に役立つことがあります。
- アンマウントされたファイルシステムでのみ操作
- ファイルシステムの修復は、マウント解除されたファイルシステムでのみ実行する必要があります。ツールには、ファイルシステムへの単独アクセスが必要であり、それがないと追加の損傷が発生する可能性があります。一部のファイルシステムはマウントされているファイルシステムでチェックのみのモードのみをサポートしますが、ほとんどのファイルシステムツールは、修復モードでこの要件を実行します。チェックのみのモードがマウントされているファイルシステム上で実行されている場合は、アンマウントされていないファイルシステム上で実行される場合には見つからない正しくないエラーを見つける可能性があります。
- ディスクエラー
- ファイルシステムの確認ツールは、ハードウェアの問題を修復できません。修復を正常に動作させるには、ファイルシステムが完全に読み取り可能かつ書き込み可能である必要があります。ハードウェアエラーが原因でファイルシステムが破損した場合は、まず dd(8) ユーティリティーなどを使用して、ファイルシステムを適切なディスクに移動する必要があります。
12.2. fsck のファイルシステム固有の情報
12.2.1. ext2、ext3、および ext4
e2fsck バイナリーを使用して、ファイルシステムの確認と修復を実行します。ファイル名の fsck.ext2、fsck.ext3、および fsck.ext4 は、この同じバイナリーのハードリンクです。これらのバイナリーは、システムの起動時に自動的に実行し、その動作は確認されるファイルシステムと、そのファイルシステムの状態によって異なります。
- -n
- 非変更モード。チェックのみの操作。
- -b スーパーブロック
- プライマリースーパーブロックが損傷している場合は、別のスーパーブロックのブロック番号を指定します。
- -f
- スーパーブロックに記録されたエラーがなくても、フルチェックを強制実行します。
- -j ジャーナルデバイス
- 外部のジャーナルデバイス (ある場合) を指定します。
- -p
- ユーザー入力のないファイルシステムを自動的に修復または「preen (修復)」する
- -y
- すべての質問に「yes」の回答を想定する
- Inode、ブロック、およびサイズのチェック。
- ディレクトリー構造のチェック。
- ディレクトリー接続のチェック。
- 参照数のチェック。
- グループサマリー情報のチェック。
12.2.2. XFS
fsck.xfs バイナリーが存在しますが、これは、システムの起動時に fsck.filesystem バイナリーを検索する initscripts を満たすためにのみ存在します。fsck.xfs は、すぐに終了コード 0 で終了します。
- -n
- 非変更モードです。チェックのみの操作。
- -L
- ゼロメタデータログ。マウントによってログを再生できない場合にのみ使用します。
- -m maxmem
- 最大 MB の実行時に使用されるメモリーを制限します。必要な最小メモリーの概算を出すために 0 を指定できます。
- -l logdev
- 外部ログデバイス (ある場合) を指定します。
- Inode および inode ブロックマップ (アドレス指定) のチェック。
- Inode 割り当てマップのチェック。
- Inode サイズのチェック。
- ディレクトリーのチェック。
- パス名のチェック。
- リンク数のチェック。
- フリーマップのチェック。
- スーパーブロックチェック。
12.2.3. Btrfs
- エクステントのチェック。
- ファイルシステムの root チェック
- ルートの参照数のチェック。
第13章 Partitions
- 既存パーティションテーブルの表示
- 既存パーティションのサイズ変更
- 空き領域または他のハードドライブからの、パーティションの追加
parted パッケージが含まれています。parted を起動するには、root としてログインし、シェルプロンプトで parted /dev/sda コマンドを実行します( /dev/sda は設定するドライブのデバイス名です)。
| コマンド | 詳細 |
|---|---|
| check minor-num | ファイルシステムの簡単なチェックを実行する |
| cp from to | ファイルシステムをあるパーティションから別のパーティションにコピーします。from と to はパーティションのマイナー番号です。 |
| ヘルプ | 利用可能なコマンドの一覧を表示します |
| mklabel label | パーティションテーブル用のディスクラベルを作成します |
| mkfs minor-num file-system-type | タイプの file-system-typeのファイルシステムを作成します。 |
| mkpart part-type fs-type start-mb end-mb | 新しいファイルシステムを作成せずに、パーティションを作成します |
| mkpartfs part-type fs-type start-mb end-mb | パーティションを作成し、指定したファイルシステムを作成します。 |
| move minor-num start-mb end-mb | パーティションを移動します |
| name minor-num name | Mac と PC98 のディスクラベル用のみのパーティションに名前を付けます |
| パーティションテーブルを表示します | |
| quit | parted を終了します |
| rescue start-mb end-mb | start-mb から end-mb へ、消失したパーティションを復旧します。 |
| resize minor-num start-mb end-mb | パーティションを start-mb から end-mb に変更します。 |
| rm minor-num | パーティションを削除 |
| select device | 設定する別のデバイスを選択します |
| set minor-num flag state | パーティションにフラグを設定します。state はオンまたはオフのいずれかになります |
| toggle [NUMBER [FLAG] | パーティション NUMBER 上の FLAG の状態を切り替えます |
| unit UNIT | デフォルトのユニットを UNIT に設定します |
13.1. パーティションテーブルの表示
例13.1 パーティションテーブル
number です。たとえば、マイナー番号 1 のパーティションは、/dev/sda1 に対応します。Start および End の値はメガバイトです。有効な Type はメタデータ、フリー、プライマリー、拡張、または論理です。Filesystem はファイルシステムのタイプで、次のいずれかになります。
- ext2
- ext3
- fat16
- fat32
- hfs
- jfs
- linux-swap
- ntfs
- reiserfs
- hp-ufs
- sun-ufs
- xfs
Filesystem に値が表示されない場合は、そのファイルシステムタイプが不明であることを示します。
13.2. パーティションの作成
手順13.1 パーティションの作成
- パーティションを作成する前に、レスキューモードで起動します (または、デバイス上のパーティションをアンマウントして、デバイス上の swap 領域をすべてオフにします)。
- parted を起動します。
/dev/sdaは、パーティションを作成するデバイスに置き換えます。parted /dev/sda
# parted /dev/sdaCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 現在のパーティションテーブルを表示し、十分な空き領域があるかどうかを確認します。
print
# printCopy to Clipboard Copied! Toggle word wrap Toggle overflow
13.2.1. パーティションの作成
mkpart primary ext3 1024 2048
# mkpart primary ext3 1024 204813.2.2. パーティションのフォーマットとラベル付け
手順13.2 パーティションのフォーマットとラベル付け
- このパーティションには、引き続きファイルシステムがありません。以下のコマンドを実行してこれを作成します。# /sbin/mkfs -t ext3 /dev/sda6警告パーティションをフォーマットすると、そのパーティションに現存するすべてのデータが永久に抹消されます。
- 次に、パーティション上のファイルシステムにラベルを割り当てます。たとえば、新規パーティションのファイルシステムが
/dev/sda6であり、それに/workのラベルを付ける場合は、以下を使用します。e2label /dev/sda6 /work
# e2label /dev/sda6 /workCopy to Clipboard Copied! Toggle word wrap Toggle overflow
/work)を作成します。
13.2.3. /etc/fstab に追加
/etc/fstab ファイルを編集して、パーティションの UUID で新規パーティションを含めます。パーティションの UUID の完全なリストを表示するには、blkid -o list コマンドを使用し、個別のデバイス詳細を表示するには、blkid device コマンドを使用します。
UUID= の後にファイルシステムの UUID が含まれている必要があります。2 列には新しいパーティションのマウントポイントが含まれ、次の列はファイルシステムのタイプである必要があります(ext3 や swap など)。形式の詳細情報が必要な場合は、man コマンド man fstab で man ページを参照してください。
defaults という単語で、パーティションは起動時にマウントされます。再起動せずにパーティションをマウントするには、root で以下のコマンドを入力します。
13.3. パーティションの削除
手順13.3 パーティションの削除
- パーティションを削除する前に、レスキューモードで起動します (または、デバイス上のパーティションをアンマウントして、デバイス上の swap 領域をすべてオフにします)。
- parted を起動します。
/dev/sdaは、パーティションを削除するデバイスに置き換えます。parted /dev/sda
# parted /dev/sdaCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 現在のパーティションテーブルを表示して、削除するパーティションのマイナー番号を確認します。
print
# printCopy to Clipboard Copied! Toggle word wrap Toggle overflow - rm コマンドでパーティションを削除します。例えば、マイナー番号 3 のパーティションを削除するのは以下のコマンドです。
rm 3
# rm 3Copy to Clipboard Copied! Toggle word wrap Toggle overflow 変更は Enter を押すと変更が反映されるため、押す前にコマンドを再度確認してください。 - パーティションを削除したら、print コマンドを使用して、パーティションテーブルから削除されていることを確認します。また、パーティションが削除されるように、
/proc/partitionsの出力も表示する必要があります。cat /proc/partitions
# cat /proc/partitionsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 最後の手順では、
/etc/fstabファイルから削除します。削除したパーティションを宣言している行を見つけ、ファイルから削除します。
13.4. パーティションのサイズ変更
手順13.4 パーティションのサイズ
- パーティションのサイズを変更する前に、レスキューモードで起動します (または、デバイス上のパーティションをアンマウントして、デバイス上の swap 領域をすべてオフにします)。
- parted を起動します。
/dev/sdaは、パーティションのサイズを変更するデバイスです。parted /dev/sda
# parted /dev/sdaCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 現在のパーティションテーブルを表示して、サイズを変更するパーティションのマイナー番号と、パーティションの開始点と終了点を確認します。
print
# printCopy to Clipboard Copied! Toggle word wrap Toggle overflow - パーティションのサイズ変更には、サイズ変更 コマンドの後にパーティションのマイナー番号、メガバイトの開始場所、および終了場所(メガバイト単位)を使用します。
例13.2 パーティションのサイズ
以下に例を示します。resize 3 1024 2048警告パーティションをデバイスで利用可能な領域よりも大きくすることはできません。 - パーティションのサイズ変更後に、print コマンドを使用して、パーティションのサイズが正しく変更されており、正しいパーティションタイプで、ファイルシステムのタイプが正しいことを確認します。
- システムを通常モードに再起動したら、df コマンドを使用して、パーティションがマウントされ、新しいサイズで認識されるようにします。
第14章 LVM (論理ボリュームマネージャー)
/boot/ パーティションを除き、論理ボリューム に統合されます。ブートローダーが読み取れないため、/boot/ パーティションは論理ボリューム上に存在できません。root(/)パーティションが論理ボリュームにある場合は、ボリュームグループの一部ではない別の /boot/ パーティションを作成します。
図14.1 論理ボリューム
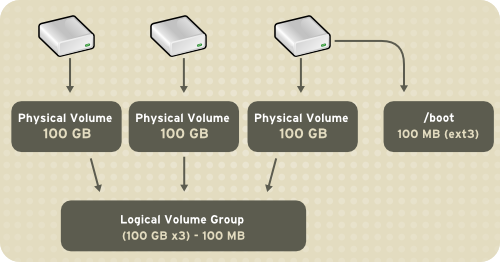
[D]
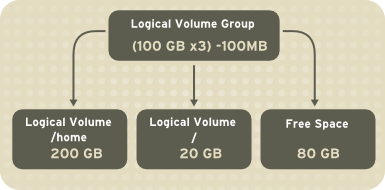
/home、/、ファイルシステムタイプ (ext2、ext3 など)などのマウントポイントが割り当てられます。「パーティション」がフル容量に達すると、ボリュームグループの空き領域を論理ボリュームに追加して、パーティションのサイズを大きくすることができます。新しいハードドライブがシステムに追加されると、そのドライブをボリュームグループに追加できます。また、論理ボリュームであるパーティションのサイズは増やすことができます。
図14.2 論理ボリューム
[D]
14.1. LVM2 とは
14.2. system-config-lvm の使用
yum install system-config-lvm
# yum install system-config-lvm例14.1 インストール時のボリュームグループの作成
/boot - (Ext3) file system. Displayed under 'Uninitialized Entities'. (DO NOT initialize this partition). LogVol00 - (LVM) contains the (/) directory (312 extents). LogVol02 - (LVM) contains the (/home) directory (128 extents). LogVol03 - (LVM) swap (28 extents).
/boot - (Ext3) file system. Displayed under 'Uninitialized Entities'. (DO NOT initialize this partition).
LogVol00 - (LVM) contains the (/) directory (312 extents).
LogVol02 - (LVM) contains the (/home) directory (128 extents).
LogVol03 - (LVM) swap (28 extents).
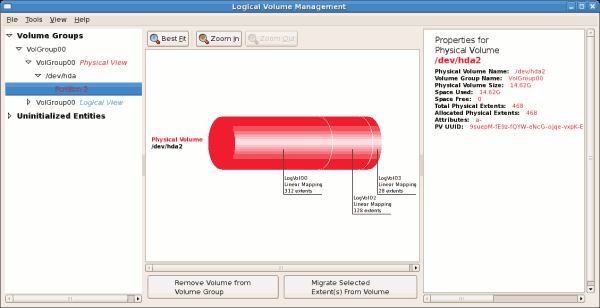
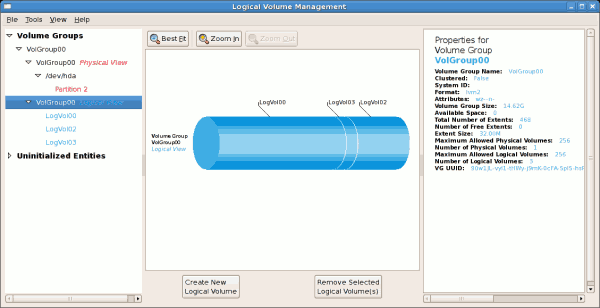
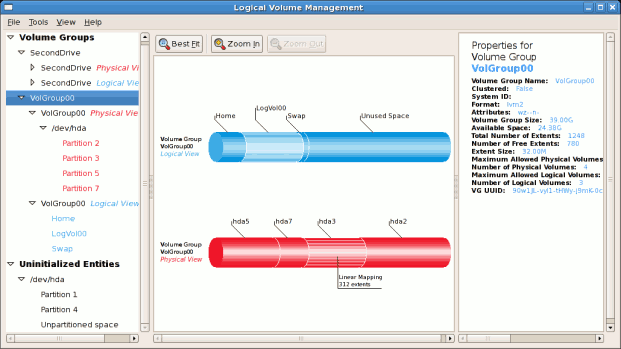
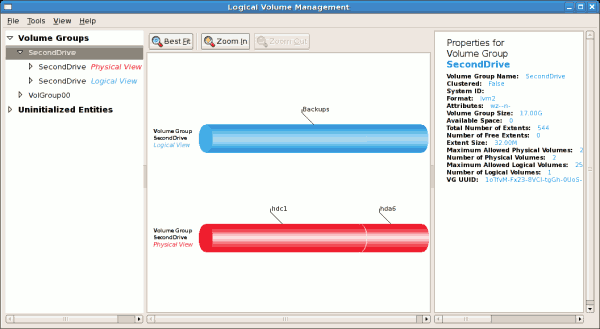
/dev/hda2 に作成されており、/ boot が / dev/hda1 に作成されました。システムは、例14.2「初期化されていないエントリー」 で説明されている「初期化のないエンティティー」で構成されています。以下の図は、LVM ユーティリティーの主なウィンドウを示しています。上記の設定の論理および物理ビューを以下に示します。3 つの論理ボリュームが同じ物理ボリューム(hda2)に存在します。
図14.3 メインの LVM ウインドウ
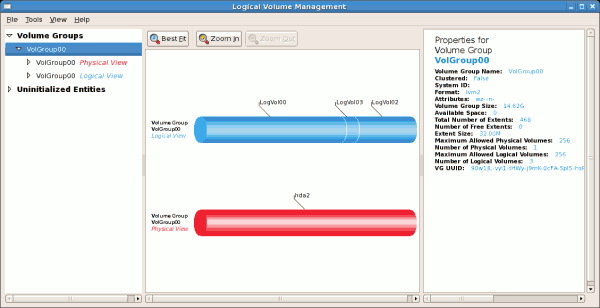
[D]
図14.4 物理ビューのウィンドウ
[D]
図14.5 論理表示ウィンドウ
[D]
図14.6 論理ボリュームの編集

[D]
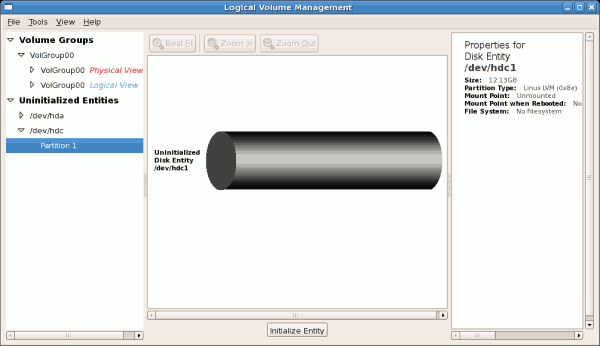
14.2.1. 初期化されていないエンタイトルメントの使用
/boot であるため初期化できません。初期化されていないエンティティーを以下に示します。
例14.2 初期化されていないエントリー
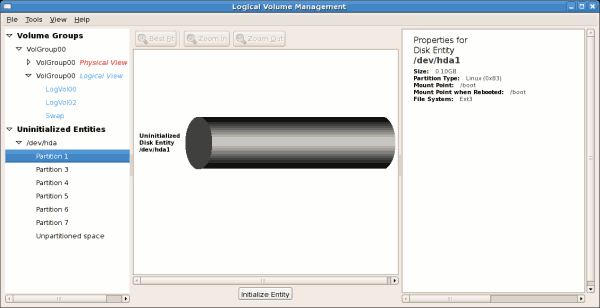
[D]
14.2.2. ボリュームグループへの未割り当てのボリュームの追加
- 新規ボリュームグループの作成
- 既存のボリュームグループに未割り当てのボリュームを追加します。
- LVM からボリュームを削除します。
図14.7 未割り当てのボリューム
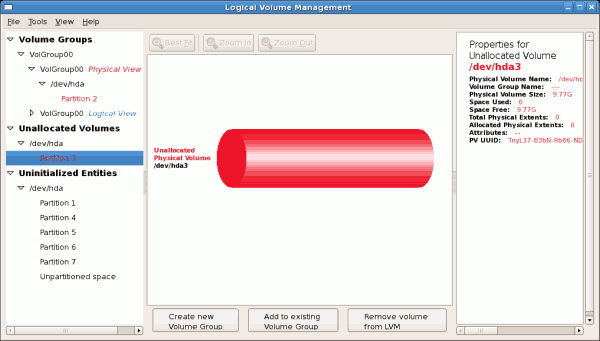
[D]
例14.3 ボリュームグループへの物理ボリュームの追加

[D]
- 新しい論理ボリュームを作成する(
- 既存の論理ボリュームのいずれかを選択し、エクステントを増やします( 「ボリュームグループの拡張」を参照)。
- この操作を実行するために未使用の領域を選択することはできません。
図14.8 ボリュームグループの論理ビュー
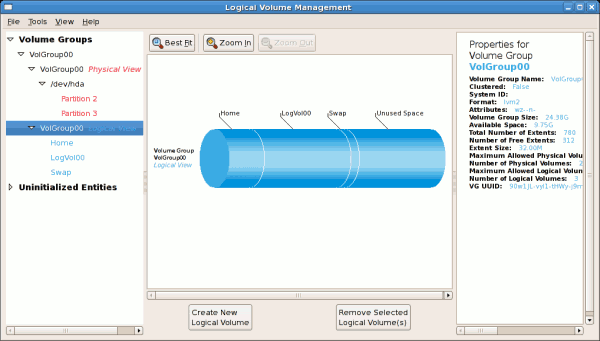
[D]
図14.9 ボリュームグループの論理ビュー
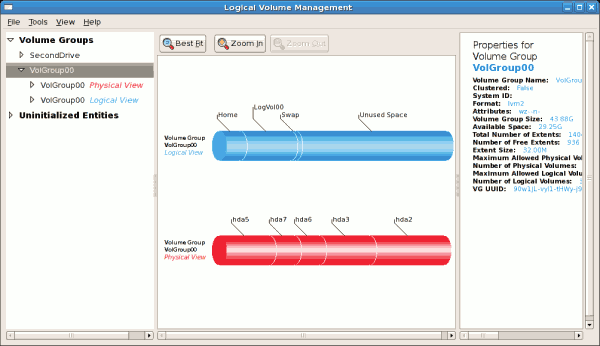
[D]
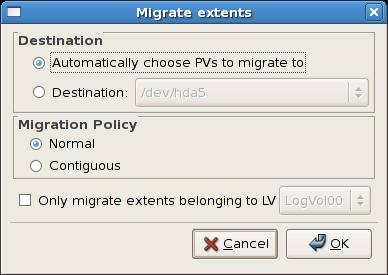
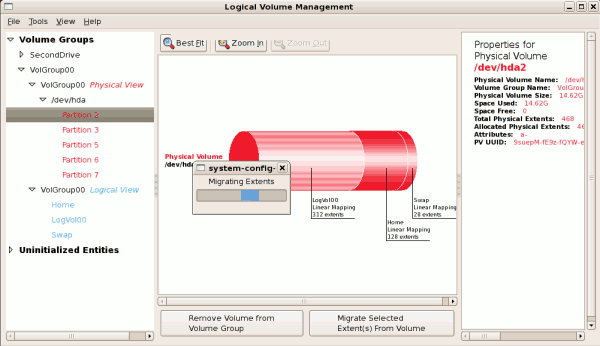
14.2.3. エクステントの移行
図14.10 エクステントの移行
[D]
図14.11 エクステントの移行中
[D]
図14.12 ボリュームグループの論理および物理ビュー
[D]
14.2.4. LVM を使用した新規ハードディスクの追加
図14.13 未初期化のハードディスク
[D]
14.2.5. 新規ボリュームグループの追加
例14.4 新規ボリュームグループの作成
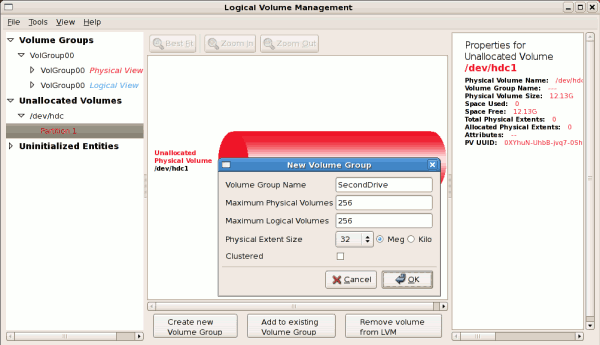
[D]
例14.5 エクステントの選択

[D]
図14.14 新規ボリュームグループの物理ビュー
[D]
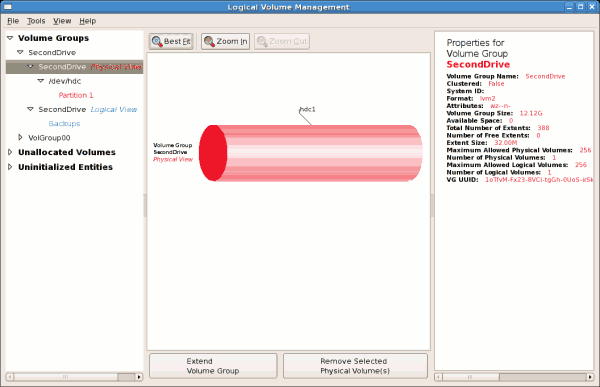
14.2.6. ボリュームグループの拡張
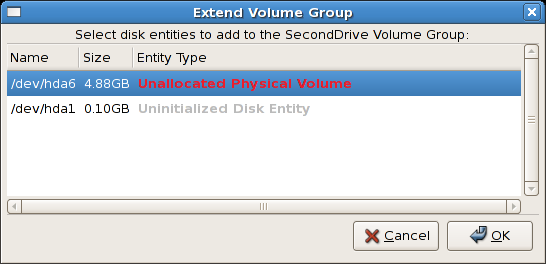
/dev/hda6 が選択されています。
図14.15 ディスクエンティティーの選択
[D]
図14.16 拡張ボリュームグループの論理および物理ビュー

[D]
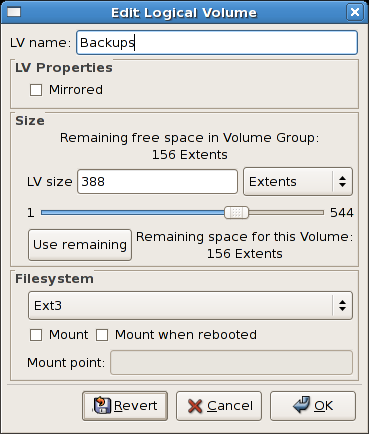
14.2.7. 論理ボリュームの編集
図14.17 論理ボリュームの編集
[D]
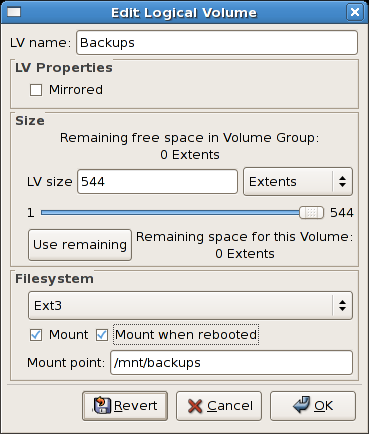
/mnt/backups にマウントされます。これは、以下の図を示しています。
図14.18 論理ボリュームの編集 - マウントオプションの指定
[D]
図14.19 論理ボリュームの編集
[D]
14.3. LVM リファレンス
インストールされているドキュメント
- rpm -qd lvm2 - このコマンドは、man ページなど、lvm パッケージで利用可能な すべてのドキュメントを表示します。
- LVM help - このコマンドは、利用可能な LVM コマンドをすべて表示します。
便利な Web サイト
- http://sources.redhat.com/lvm2: LVM2 Web ページ(概要、メーリングリストへのリンクなど)
- http://tldp.org/HOWTO/LVM-HOWTO/: Linux ドキュメントプロジェクトの LVM HOWTO。
第15章 swap 領域
| システム内の RAM の容量 | 推奨されるスワップ領域 | ハイバネートを許可する場合に推奨されるスワップ領域 |
|---|---|---|
| ⩽ 2 GB | RAM 容量の 2 倍 | RAM 容量の 3 倍 |
| > 2 GB ~ 8 GB | RAM 容量と同じ | RAM 容量の 2 倍 |
| > 8 GB ~ 64 GB | 最低 4GB | RAM 容量の 1.5 倍 |
| > 64 GB | 最低 4GB | ハイバネートは推奨されない |
rescue モードで起動している間に swap 領域を変更してください。『Red Hat Enterprise Linux 6 インストールガイド』 の レスキューモードでのコンピューターの起動 を参照してください。ファイルシステムをマウントするように指示されたら、 を選択します。
15.1. スワップ領域の追加
15.1.1. LVM2 論理ボリュームでのスワップ領域の拡張
/dev/VolGroup00/LogVol01 ボリュームのサイズを 2 GB 拡張するとします)。
手順15.1 LVM2 論理ボリュームでのスワップ領域の拡張
- 関連付けられている論理ボリュームのスワップ機能を無効にします。
swapoff -v /dev/VolGroup00/LogVol01
# swapoff -v /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow - LVM2 論理ボリュームのサイズを 2 GB 増やします。
lvresize /dev/VolGroup00/LogVol01 -L +2G
# lvresize /dev/VolGroup00/LogVol01 -L +2GCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 新しいスワップ領域をフォーマットします。
mkswap /dev/VolGroup00/LogVol01
# mkswap /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 拡張論理ボリュームを有効にします。
swapon -v /dev/VolGroup00/LogVol01
# swapon -v /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow
15.1.2. スワップの LVM2 論理ボリュームの作成
/dev/VolGroup00/LogVol02) を追加します。
- サイズが 2 GB の LVM2 論理ボリュームを作成します。
lvcreate VolGroup00 -n LogVol02 -L 2G
# lvcreate VolGroup00 -n LogVol02 -L 2GCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 新しいスワップ領域をフォーマットします。
mkswap /dev/VolGroup00/LogVol02
# mkswap /dev/VolGroup00/LogVol02Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 次のエントリーを
/etc/fstabファイルに追加します。/dev/VolGroup00/LogVol02 swap swap defaults 0 0
# /dev/VolGroup00/LogVol02 swap swap defaults 0 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 拡張論理ボリュームを有効にします。
swapon -v /dev/VolGroup00/LogVol02
# swapon -v /dev/VolGroup00/LogVol02Copy to Clipboard Copied! Toggle word wrap Toggle overflow
15.1.3. スワップファイルの作成
手順15.2 スワップファイルの追加
- 新しいスワップファイルのサイズをメガバイト単位で指定してから、そのサイズに 1024 をかけてブロック数を指定します。たとえばスワップファイルのサイズが 64 MB の場合は、ブロック数が 65536 になります。
- count を必要なブロックサイズと等しくなるには、以下のコマンドを入力します。
dd if=/dev/zero of=/swapfile bs=1024 count=65536
# dd if=/dev/zero of=/swapfile bs=1024 count=65536Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 次のコマンドでスワップファイルをセットアップします。
mkswap /swapfile
# mkswap /swapfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow - スワップが誰でも読み取り可能にならないようにパーミッションを変更することが推奨されます。
chmod 0600 /swapfile
# chmod 0600 /swapfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow - システムの起動時に自動的に swap ファイルは有効にしない場合は、次のコマンドを実行します。
swapon /swapfile
# swapon /swapfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow - システムの起動時に有効にするには、
/etc/fstabを編集して以下のエントリーを追加します。/swapfile swap swap defaults 0 0次にシステムを起動すると、新しいスワップファイルが有効になります。
15.2. スワップ領域の削除
15.2.1. LVM2 論理ボリュームでのスワップ領域の縮小
/dev/VolGroup00/LogVol01 が縮小するボリュームであるとします)。
手順15.3 LVM2 の swap 論理ボリュームの縮小
- 関連付けられている論理ボリュームのスワップ機能を無効にします。
swapoff -v /dev/VolGroup00/LogVol01
# swapoff -v /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow - LVM2 論理ボリュームのサイズを変更して 512 MB 削減します。
lvreduce /dev/VolGroup00/LogVol01 -L -512M
# lvreduce /dev/VolGroup00/LogVol01 -L -512MCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 新しいスワップ領域をフォーマットします。
mkswap /dev/VolGroup00/LogVol01
# mkswap /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 拡張論理ボリュームを有効にします。
swapon -v /dev/VolGroup00/LogVol01
# swapon -v /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow
15.2.2. スワップの LVM2 論理ボリュームの削除
/dev/VolGroup00/LogVol02 が削除するボリュームであるとします)。
手順15.4 swap ボリュームグループの削除
- 関連付けられている論理ボリュームのスワップ機能を無効にします。
swapoff -v /dev/VolGroup00/LogVol02
# swapoff -v /dev/VolGroup00/LogVol02Copy to Clipboard Copied! Toggle word wrap Toggle overflow - サイズが 512 MB の LVM2 論理ボリュームを削除します。
lvremove /dev/VolGroup00/LogVol02
# lvremove /dev/VolGroup00/LogVol02Copy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/fstabファイルから以下のエントリーを削除します。/dev/VolGroup00/LogVol02 swap swap defaults 0 0
15.2.3. スワップファイルの削除
手順15.5 swap ファイルの削除
- シェルプロンプトで次のコマンドを実行してスワップファイルを無効にします (スワップファイルの場所が
/swapfileであるとします)。swapoff -v /swapfile
# swapoff -v /swapfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/fstabファイルから該当するエントリーを削除します。- 実際のファイルを削除します。
rm /swapfile
# rm /swapfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
15.3. Swap 領域の移動
第16章 ディスククォータ
16.1. ディスククォータの設定
/etc/fstabを修正することで、ファイルシステムごとのクォータを有効にします。- ファイルシステムを再マウントします。
- クォータデータベースファイルを作成して、ディスク使用状況テーブルを生成します。
- クォータポリシーを割り当てます。
16.1.1. クォータの有効化
/etc/fstab ファイルを編集します。
例16.1 /etc/fstab の編集
vim を使用するには、以下を入力します。
vim /etc/fstab
# vim /etc/fstab例16.2 クォータの追加
/home ファイルシステムがユーザーとグループの両方のクォータを有効にしています。
/etc/fstab ファイル内でクォータポリシーを設定するために使用できます。
16.1.2. ファイルシステムの再マウント
エントリー が変更された各ファイルシステムを再マウントします。ファイルシステムが使用されていない場合は、以下のコマンドを使用します。
16.1.3. クォータデータベースファイルの作成
quota.user および aquota.group)を作成するには、quota check コマンドの -c オプションを使用します。
例16.3 クォータファイルの作成
/home ファイルシステムに対して有効になっている場合は、/home ディレクトリーにファイルを作成します。
quotacheck -cug /home
# quotacheck -cug /home-c オプションは、クォータが有効になっている各ファイルシステムにクォータファイルを作成する必要があることを指定し、- u オプションはユーザークォータの確認を指定し、- g オプションはグループクォータをチェックするように指定します。
-u オプションまたは -g オプションがいずれも指定されていないと、ユーザーのクォータファイルのみが作成されます。-g のみを指定すると、グループクォータファイルのみが作成されます。
quotacheck -avug
# quotacheck -avug- a
- クォータが有効にされた、ローカルマウントのファイルシステムをすべてチェック
- v
- クォータチェックの進行状態について詳細情報を表示
- u
- ユーザーディスククォータの情報をチェック
- g
- グループディスククォータの情報をチェック
home などのローカルにマウントされた各ファイルシステムのデータが設定されます。
16.1.4. ユーザーごとのクォータ割り当て
edquota username
# edquota username/home パーティションの /etc/fstab (以下の例では /dev/VolGroup00/LogVol02) に対して有効であり、コマンド edquota testuser を実行すると、システムでデフォルトとして設定されたエディターで以下のような出力が表示されます。
Disk quotas for user testuser (uid 501): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440436 0 0 37418 0 0
Disk quotas for user testuser (uid 501):
Filesystem blocks soft hard inodes soft hard
/dev/VolGroup00/LogVol02 440436 0 0 37418 0 0EDITOR 環境変数により定義されたテキストエディターは、edquota により使用されます。エディターを変更するには、~/.bash_profile ファイルの EDITOR 環境変数を、使用するエディターのフルパスに設定します。
inodes 列には、ユーザーが現在使用している inode の数が表示されます。最後の 2 列は、ファイルシステムのユーザーに対するソフトおよびハードの inode 制限を設定するのに使用されます。
例16.4 必要な制限の変更
Disk quotas for user testuser (uid 501): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440436 500000 550000 37418 0 0
Disk quotas for user testuser (uid 501):
Filesystem blocks soft hard inodes soft hard
/dev/VolGroup00/LogVol02 440436 500000 550000 37418 0 0quota username
Disk quotas for user username (uid 501):
Filesystem blocks quota limit grace files quota limit grace
/dev/sdb 1000* 1000 1000 0 0 0
# quota username
Disk quotas for user username (uid 501):
Filesystem blocks quota limit grace files quota limit grace
/dev/sdb 1000* 1000 1000 0 0 0
16.1.5. グループごとのクォータ割り当て
devel グループのグループクォータを設定するには (グループはグループクォータを設定する前に存在している必要があります)、次のコマンドを使用します。
edquota -g devel
# edquota -g develDisk quotas for group devel (gid 505): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440400 0 0 37418 0 0
Disk quotas for group devel (gid 505):
Filesystem blocks soft hard inodes soft hard
/dev/VolGroup00/LogVol02 440400 0 0 37418 0 0quota -g devel
# quota -g devel16.1.6. ソフト制限の猶予期間の設定
edquota -t
# edquota -t16.2. ディスククォータの管理
16.2.1. 有効化と無効化
quotaoff -vaug
# quotaoff -vaug-u オプションまたは -g オプションがいずれも指定されていないと、ユーザーのクォータのみが無効になります。-g のみを指定すると、グループのクォータのみが無効になります。-v スイッチにより、コマンドの実行時に詳細なステータス情報が表示されます。
quotaon -vaug
# quotaon -vaug/home などの特定のファイルシステムにクォータを有効にするには、以下のコマンドを使用します。
quotaon -vug /home
# quotaon -vug /home-u オプションまたは -g オプションがいずれも指定されていないと、ユーザーのクォータのみが有効になります。-g のみが指定されている場合は、グループのクォータのみが有効になります。
16.2.2. ディスククォータに関するレポート
例16.5 repquota コマンドの出力
-a) のディスク使用状況レポートを表示するには、次のコマンドを使用します。
repquota -a
# repquota -a-- はブロックまたは inode が超過しているかどうかを素早く判別するための手段です。どちらかのソフトリミットが超過していると、対応する - の位置に + が表示されます。最初の - はブロックの制限で、2 つ目が inode の制限を示します。
grace 列は通常空白です。ソフト制限が超過した場合、その列には猶予期間に残り時間量に相当する時間指定が含まれます。猶予期間の期間が過ぎると、none がその場所に表示されます。
16.2.3. クォータの精度維持
- 次回の再起動時に quotacheck を確実に実行する
- 注記この方法は、定期的に再起動する (ビジーな) 複数ユーザーシステムに最も適しています。root として、シェルスクリプトを
/etc/cron.daily/または/etc/cron.weekly/ディレクトリーに置くか、touch /forcequotacheck コマンドが含まれる crontab -e コマンドを使用してスケジュールします。このスクリプトは root ディレクトリーに空のforcequotacheckファイルを作成するため、起動時にシステムの init スクリプトがこれを検索します。このディレクトリーが検出されると、init スクリプトは quotacheck を実行します。その後、init スクリプトは/forcequotacheckファイルを削除します。このように、cronでこのファイルが定期的に作成されるようにスケジュールすることにより、次回の再起動時に quotacheck を確実に実行することができます。cron の詳細は、man cron を参照してください。 - シングルユーザーモードで quotacheck を実行
- quotacheck を安全に実行する別の方法として、クオータファイルのデータ破損の可能性を回避するためにシングルユーザーモードでシステムを起動して、以下のコマンドを実行する方法があります。
quotaoff -vaug /file_system
# quotaoff -vaug /file_systemCopy to Clipboard Copied! Toggle word wrap Toggle overflow quotacheck -vaug /file_system
# quotacheck -vaug /file_systemCopy to Clipboard Copied! Toggle word wrap Toggle overflow quotaon -vaug /file_system
# quotaon -vaug /file_systemCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 実行中のシステムで quotacheck を実行
- 必要な場合には、いずれのユーザーもログインしておらず、チェックされているファイルシステムに開いているファイルがない状態のマシン上で quotacheck を実行することができます。quotacheck -vaug file_system というコマンドを実行します。このコマンドは、quotacheck が指定された file_system を読み取り専用に再マウントできない場合に失敗します。チェックの後には、ファイルシステムは読み込み/書き込みとして再マウントされることに注意してください。警告読み込み/書き込みでマウントされているライブのファイルシステム上での quotacheck の実行は、quota ファイルが破損する可能性があるため、推奨されません。
16.3. ディスククオータのリファレンス
- quotacheck
- edquota
- repquota
- quota
- quotaon
- quotaoff
第17章 RAID (Redundant Array of Independent Disks)
- 速度を高める
- 1 台の仮想ディスクを使用してストレージ容量を増加する
- ディスク障害によるデータ損失を最小限に抑える
17.1. RAID のタイプ
ファームウェア RAID
ハードウェア RAID
ソフトウェア RAID
- マルチスレッド設計
- 再構築なしで Linux マシン間でのアレイの移植性
- アイドルシステムリソースを使用したバックグラウンドのアレイ再構築
- ホットスワップ可能なドライブのサポート
- CPU の自動検出でストリーミング SIMD サポートなどの特定 CPU の機能を活用
- アレイ内のディスク上にある不良セクターの自動修正
- RAID データの整合性を定期的にチェックしアレイの健全性を確保
- 重要なイベントで指定された電子メールアドレスに送信された電子メールアラートによるアレイのプロアクティブな監視
- 書き込みを集中としたビットマップ、アレイ全体を再同期させるのではなく再同期を必要とするディスク部分を正確にカーネルに認識させることで再同期イベントの速度を大幅に高速化
- チェックポイントを再同期して、再同期中にコンピューターを再起動すると、起動時に再同期が中断したところから再開し、最初からやり直さないようにします。
- インストール後のアレイのパラメーター変更が可能です。たとえば、新しいデバイスを追加しても、4 つのディスクの RAID5 アレイを 5 つのディスク RAID5 アレイに増大させることができます。この拡張操作はライブで行うため、新しいアレイで再インストールする必要はありません。
17.2. RAID レベルとリニアサポート
- レベル 0
- RAID レベル 0 は、多くの場合「ストライプ化」と呼ばれていますが、パフォーマンス指向のストライプ化データマッピング技術です。これは、アレイに書き込まれるデータがストライプに分割され、アレイのメンバーディスク全体に書き込まれることを意味します。これにより低い固有コストで高い I/O パフォーマンスを実現できますが、冗長性は提供されません。多くの RAID レベル 0 実装は、アレイ内の最小デバイスのサイズまで、メンバーデバイス全体にデータをストライプ化します。つまり、複数のデバイスのサイズが少し異なる場合、それぞれのデバイスは最小ドライブと同じサイズであるかのように処理されます。そのため、レベル 0 アレイの一般的なストレージ容量は、ハードウェア RAID 内の最小メンバーディスクの容量と同じか、アレイ内のディスク数またはパーティション数で乗算したソフトウェア RAID 内の最小メンバーパーティションの容量と同じになります。
- レベル 1
- RAID レベル 1 または「ミラーリング」は、他の RAID 形式よりも長く使用されています。レベル 1 は、アレイ内の各メンバーディスクに同一データを書き込むことで冗長性を提供し、各ディスクに対して「ミラーリング」コピーをそのまま残します。ミラーリングは、データの可用性の単純化と高レベルにより、いまでも人気があります。レベル 1 は 2 つ以上のディスクと連携して、非常に優れたデータ信頼性を提供し、読み取り集中型のアプリケーションに対してパフォーマンスが向上しますが、比較的コストが高くなります。[5]レベル 1 アレイのストレージ容量は、ハードウェア RAID 内でミラーリングされている最小サイズのハードディスクの容量と同じか、ソフトウェア RAID 内でミラーリングされている最小のパーティションと同じ容量になります。レベル 1 の冗長性は、すべての RAID タイプの中で最も高いレベルであり、アレイは 1 つのディスクのみで動作できます。
- レベル 4
- レベル 4 でパリティーを使用 [6] データを保護するため、1 つのディスクドライブで連結します。専用パリティーディスクは RAID アレイへのすべての書き込みトランザクションに固有のボトルネックを表すため、レベル 4 は、ライトバックキャッシュなどの付随技術なしで、またはシステム管理者がこれを使用してソフトウェア RAID デバイスを意図的に設計する特定の状況で使用されることはほとんどありません。ボトルネック (配列にデータが入力されると、書き込みトランザクションがほとんどまたはまったくない配列など) を念頭に置いてください。RAID レベル 4 にはほとんど使用されないため、Anaconda ではこのオプションとしては使用できません。ただし、実際には必要な場合は、ユーザーが手動で作成できます。ハードウェア RAID レベル 4 のストレージ容量は、最小メンバーパーティションの容量にパーティションの数を掛けて、-1 を引いたものになります。RAID レベル 4 アレイのパフォーマンスは常に非対称になります。つまり、読み込みは書き込みを上回ります。これは、パリティーを生成するときに書き込みが余分な CPU 帯域幅とメインメモリーの帯域幅を消費し、データだけでなくパリティーも書き込むため、実際のデータをディスクに書き込むときに余分なバス帯域幅も消費するためです。読み取りが必要なのは、アレイが劣化状態にない限り、パリティーではなくデータでを読み取るだけです。その結果、通常の動作条件下で同じ量のデータ転送を行う場合は、読み取りによってドライブへのトラフィック、またはコンピュータのバスを経由するトラフィックが少なくなります。
- レベル 5
- これは RAID の最も一般的なタイプです。RAID レベル 5 は、アレイのすべてのメンバーディスクドライブにパリティーを分散することにより、レベル 4 に固有の書き込みボトルネックを排除します。パリティー計算プロセス自体のみがパフォーマンスのボトルネックです。最新の CPU とソフトウェア RAID では、最近の CPU がパリティーが非常に高速になるため、通常はボトルネックではありません。ただし、ソフトウェア RAID5 アレイに多数のメンバーデバイスがあり、組み合わせたすべてのデバイス間のデータ転送速度が十分であれば、このボトルネックは再生できます。レベル 4 と同様に、レベル 5 のパフォーマンスは非対称であり、読み取りは書き込みを大幅に上回ります。RAID レベル 5 のストレージ容量は、レベル 4 と同じです。
- レベル 6
- パフォーマンスではなくデータの冗長性と保存が最重要事項であるが、レベル 1 の領域の非効率性が許容できない場合は、これが RAID の一般的なレベルです。レベル 6 では、複雑なパリティースキームを使用して、アレイ内の 2 つのドライブから失われたドライブから復旧できます。複雑なパリティースキームにより、ソフトウェア RAID デバイスで CPU 幅が大幅に高くなり、書き込みトランザクションの際に増大度が高まります。したがって、レベル 6 はレベル 4 や 5 よりもパフォーマンスにおいて、非常に非対称です。RAID レベル 6 アレイの合計容量は、RAID レベル 5 および 4 と同様に計算されますが、デバイス数から追加パリティーストレージ領域用に 2 つのデバイス (1 ではなく) を引きます。
- レベル 10
- この RAID レベルでは、レベル 0 のパフォーマンスとレベル 1 の冗長性を組み合わせます。また、2 を超えるデバイスを持つレベル 1 アレイで領域の一部を軽減するのに役立ちます。レベル 10 では、データごとに 2 つのコピーのみを格納するように設定された 3 ドライブアレイを作成することができます。これにより、全体用のアレイサイズを最小デバイスのみと同じサイズ (3 つのデバイス、レベル 1 アレイなど) ではなく、最小サイズのデバイスが 1.5 倍になります。レベル 10 アレイを作成する際の使用可能なオプションの数が多く、特定のユースケースに適切なオプションを選択することが簡単ではないため、インストール時に作成するのは実用的とは言えません。コマンドラインの mdadm ツールを使用して手動で作成できます。オプションの詳細と、それぞれのパフォーマンストレードオフに関する詳細は、man md を参照してください。
- リニア RAID
- リニア RAID は、より大きな仮想ドライブを作成するドライブの簡易グループ化です。リニア RAID では、あるメンバードライブからチャンクが順次割り当てられます。最初のドライブが完全に満杯になったときにのみ次のドライブに移動します。これにより、メンバードライブ間の I/O 操作が分割される可能性はないため、パフォーマンスの向上は見られません。リニア RAID には冗長性がなく、実際に、信頼性は低下します。いずれかのメンバードライブに障害が発生した場合は、アレイ全体を使用することができません。容量はすべてのメンバーディスクの合計になります。
17.3. Linux RAID サブシステム
Linux ハードウェア RAID のコントローラードライバー
mdraid
dmraid
17.4.
インストーラーにおける RAID サポート
17.5.
RAID セットの設定
mdadm
dmraid
17.6. RAID デバイスの詳細な作成
/boot または root ファイルシステムのアレイは複雑な RAID デバイスに設定されます。このような場合は、Anaconda インストーラーで対応していないアレイオプションの使用が必要になる場合があります。これを回避するには、以下の手順を行います。
手順17.1 RAID デバイスの詳細な作成
- 通常どおりにインストールディスクを挿入します。
- 初回起動時に、 または ではなく、 を選択します。システムが レスキューモード で完全に起動すると、コマンドラインターミナルが表示されます。
- このターミナルで parted を使用し、目的のハードドライブに RAID パーティションを作成します。次に mdadm を使用して、使用できるすべての設定およびオプションを使用して、このパーティションから RAID アレイを手動で作成します。詳細は、13章Partitions、man parted、および man mdadm を参照してください。
- アレイを作成したら、必要に応じてアレイにファイルシステムを作成することもできます。Red Hat Enterprise Linux 6 でサポートされるファイルシステムに関する基本的な技術情報は、「サポートされるファイルシステムの概要」 を参照してください。
- コンピューターを再起動して、今度は か を選択し通常通りにインストールを行います。Anaconda によってシステム内のディスクが検索され、すでに存在している RAID デバイスが検出されます。
- システムのディスクの使い方を求められたら、 を選択して をクリックします。デバイス一覧に、既存の MD RAID デバイスが表示されます。
- RAID デバイスを選択し、 をクリックしてそのマウントポイントと (必要に応じて) 使用するファイルシステムのタイプを設定し、 をクリックします。Anaconda は、この既存の RAID デバイスにインストールを実行し、レスキューモード で作成したときに選択したカスタムオプションを保持します。
第18章 mount コマンドの使い方
18.1. 現在マウントされているファイルシステムの一覧表示
mount
mountディレクトリー タイプ 上の デバイス (オプション)
findmnt
findmnt18.1.1. ファイルシステムタイプの指定
sysfs や tmpfs など各種の仮想ファイルシステムが含まれます。特定のファイルシステムタイプを持つデバイスのみを表示するには、コマンドラインで -t オプションを指定します。
mount -t type
mount -t typefindmnt -t type
findmnt -t typeext4 ファイルシステムの一覧表示」 を参照してください。
例18.1 現在マウントされている ext4 ファイルシステムの一覧表示
/ パーティションと /boot パーティションはいずれも ext4 を使用するようにフォーマットされます。このファイルシステムを使用するマウントポイントのみを表示するには、シェルプロンプトで以下を入力します。
mount -t ext4 /dev/sda2 on / type ext4 (rw) /dev/sda1 on /boot type ext4 (rw)
~]$ mount -t ext4
/dev/sda2 on / type ext4 (rw)
/dev/sda1 on /boot type ext4 (rw)
findmnt -t ext4 TARGET SOURCE FSTYPE OPTIONS / /dev/sda2 ext4 rw,realtime,seclabel,barrier=1,data=ordered /boot /dev/sda1 ext4 rw,realtime,seclabel,barrier=1,data=ordered
~]$ findmnt -t ext4
TARGET SOURCE FSTYPE OPTIONS
/ /dev/sda2 ext4 rw,realtime,seclabel,barrier=1,data=ordered
/boot /dev/sda1 ext4 rw,realtime,seclabel,barrier=1,data=ordered
18.2. ファイルシステムのマウント
mount [option]… device directory
mount [option]… device directoryfindmnt directory; echo $?
findmnt directory; echo $?1 を返します。
/etc/fstab 設定ファイルの内容を読み取り、指定したファイルシステムがリストされたかどうかを確認します。このファイルには、選択したファイルシステムがマウントされるデバイス名およびディレクトリーの一覧と、ファイルシステムのタイプおよびマウントオプションが含まれます。このため、このファイルで指定されたファイルシステムをマウントする場合は、以下のコマンドの以下のいずれかのバリアントを使用できます。
mount [option]… directory mount [option]… device
mount [option]… directory
mount [option]… deviceroot でコマンドを実行しない限り、ファイルシステムのマウントには権限が必要であることに注意してください (「マウントオプションの指定」 を参照)。
blkid device
blkid device/dev/sda3 に関する情報を表示するには、以下を入力します。
blkid /dev/sda3 /dev/sda3: LABEL="home" UUID="34795a28-ca6d-4fd8-a347-73671d0c19cb" TYPE="ext3"
~]# blkid /dev/sda3
/dev/sda3: LABEL="home" UUID="34795a28-ca6d-4fd8-a347-73671d0c19cb" TYPE="ext3"
18.2.1. ファイルシステムタイプの指定
NFS (Network File System) や CIFS (Common Internet File System) などの認識できないファイルシステムがあるため、こうしたファイルシステムの場合は手動で指定しなければなりません。ファイルシステムのタイプを指定するには、以下の形式で mount コマンドを使用します。
mount -t type device directory
mount -t type device directory| 型 | 詳細 |
|---|---|
ext2 | ext2 ファイルシステム。 |
ext3 | ext3 ファイルシステム。 |
ext4 | ext4 ファイルシステム。 |
iso9660 | ISO 9660 ファイルシステム。通常、これは光学メディア (通常は CD) で使用されます。 |
nfs | NFS ファイルシステム。通常、これはネットワーク経由でファイルにアクセスするために使用されます。 |
nfs4 | NFSv4 ファイルシステム。通常、これはネットワーク経由でファイルにアクセスするために使用されます。 |
udf | UDF ファイルシステム。通常、これは光学メディア (通常は DVD) で使用されます。 |
vfat | FAT ファイルシステム。通常、これは Windows オペレーティングシステムを実行しているマシンや、USB フラッシュドライブやフロッピーディスクなどの特定のデジタルメディアで使用されます。 |
例18.2 USB フラッシドライブのマウント
/dev/sdc1 デバイスを使用し、/media/flashdisk/ ディレクトリーが存在すると仮定して、root でシェルプロンプトに以下を入力し、このディレクトリーにマウントします。
mount -t vfat /dev/sdc1 /media/flashdisk
~]# mount -t vfat /dev/sdc1 /media/flashdisk18.2.2. マウントオプションの指定
mount -o options device directory
mount -o options device directory| オプション | 詳細 |
|---|---|
async | ファイルシステム上での非同期の入/出力を許可します。 |
auto | mount -a コマンドを使用したファイルシステムの自動マウントを許可します。 |
defaults | async,auto,dev,exec,nouser,rw,suid のエイリアスを指定します。 |
exec | 特定のファイルシステムでのバイナリーファイルの実行を許可します。 |
loop | イメージをループデバイスとしてマウントします。 |
noauto | mount -a コマンドを使用したファイルシステムの自動マウントをデフォルトの動作として拒否します。 |
noexec | 特定のファイルシステムでのバイナリーファイルの実行は許可しません。 |
nouser | 普通のユーザー (つまり root 以外のユーザー) によるファイルシステムのマウントおよびアンマウントは許可しません。 |
remount | ファイルシステムがすでにマウントされている場合は再度マウントを行います。 |
ro | 読み取り専用でファイルシステムをマウントします。 |
rw | ファイルシステムを読み取りと書き込み両方でマウントします。 |
user | 普通のユーザー (つまり root 以外のユーザー) によるファイルシステムのマウントおよびアンマウントを許可します。 |
例18.3 ISO イメージのマウント
/media/cdrom/ ディレクトリーが存在する場合は、root で以下のコマンドを実行してイメージをこのディレクトリーにマウントします。
mount -o ro,loop Fedora-14-x86_64-Live-Desktop.iso /media/cdrom
~]# mount -o ro,loop Fedora-14-x86_64-Live-Desktop.iso /media/cdrom18.2.3. マウントの共有
--bind オプションを実装します。以下のような使用法になります。
mount --bind old_directory new_directory
mount --bind old_directory new_directorymount --rbind old_directory new_directory
mount --rbind old_directory new_directory- 共有マウント
- 共有マウントにより、任意のマウントポイントと同一の複製マウントポイントを作成することができます。マウントポイントが共有マウントとしてマークされている場合は、元のマウントポイント内のすべてのマウントが複製マウントポイントに反映されます (その逆も同様です)。マウントポイントのタイプを共有マウントに変更するには、シェルプロンプトで以下を入力します。
mount --make-shared mount_point
mount --make-shared mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow または、選択したマウントポイントと、その下のすべてのマウントポイントのマウントタイプを変更する場合は、以下を入力します。mount --make-rshared mount_point
mount --make-rshared mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用例は、例18.4「共有マウントポイントの作成」 を参照してください。 - スレーブマウント
- スレーブマウントにより、所定のマウントポイントの複製を作成する際に制限を課すことができます。マウントポイントがスレーブマウントとしてマークされている場合は、元のマウントポイント内のすべてのマウントが複製マウントポイントに反映されますが、スレーブマウント内のマウントは元のポイントに反映されません。マウントポイントのタイプをスレーブマウントに変更するには、シェルプロンプトで次を入力します。
mount --make-slave mount_point
mount --make-slave mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow 選択したマウントポイントとその下にあるすべてのマウントポイントのマウントタイプを変更することも可能です。次のように入力します。mount --make-rslave mount_point
mount --make-rslave mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用例は、例18.5「スレーブマウントポイントの作成」 を参照してください。例18.5 スレーブマウントポイントの作成
この例は、/mediaディレクトリーのコンテンツが/mntにも表示され、/mntディレクトリーのマウントが/mediaに反映されないようにする方法を示しています。rootになり、まず/mediaディレクトリーに 「shared」 のマークを付けます。mount --bind /media /media mount --make-shared /media
~]# mount --bind /media /media ~]# mount --make-shared /mediaCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次に、/mntに複製を作成しますが、「スレーブ」 としてマークします。mount --bind /media /mnt mount --make-slave /mnt
~]# mount --bind /media /mnt ~]# mount --make-slave /mntCopy to Clipboard Copied! Toggle word wrap Toggle overflow /media内のマウントが/mntでも表示されるかを確認します。たとえば、CD-ROM ドライブに何らかのコンテンツを持つメディアがあり、/media/cdrom/ディレクトリーが存在する場合は次のコマンドを実行します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow また、/mntディレクトリー内にマウントされているファイルシステムが/mediaに反映されていないことを確認します。たとえば、/dev/sdc1デバイスを使用する空でないUSBフラッシュドライブが接続されていて、/mnt/flashdisk/ディレクトリーが存在する場合は、次のように入力します。mount /dev/sdc1 /mnt/flashdisk ls /media/flashdisk ls /mnt/flashdisk en-US publican.cfg
~]# mount /dev/sdc1 /mnt/flashdisk ~]# ls /media/flashdisk ~]# ls /mnt/flashdisk en-US publican.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow - プライベートマウント
- プライベートマウントはマウントのデフォルトタイプであり、共有マウントやスレーブマウントと異なり、伝播イベントの受信や転送は一切行いません。マウントポイントを明示的にプライベートマウントにするには、シェルプロンプトで以下を入力します。
mount --make-private mount_point
mount --make-private mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow または、選択したマウントポイントとその下にあるすべてのマウントポイントを変更することもできます。mount --make-rprivate mount_point
mount --make-rprivate mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用例は、例18.6「プライベートマウントポイントの作成」 を参照してください。例18.6 プライベートマウントポイントの作成
例18.4「共有マウントポイントの作成」 の状況を考慮に入れ、共有マウントポイントが次のコマンドを使用してrootで以前に作成されていると仮定します。mount --bind /media /media mount --make-shared /media mount --bind /media /mnt
~]# mount --bind /media /media ~]# mount --make-shared /media ~]# mount --bind /media /mntCopy to Clipboard Copied! Toggle word wrap Toggle overflow /mntディレクトリーに 「private」 のマークを付けるには、次のように入力します。mount --make-private /mnt
~]# mount --make-private /mntCopy to Clipboard Copied! Toggle word wrap Toggle overflow これで/media内のマウントはいずれも/mnt内では表示されないことを確認できるようになりました。たとえば、CD-ROM デバイスに何らかのコンテンツを含むメディアがあり、/media/cdrom/ディレクトリーが存在する場合に、次のコマンドを実行します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow また、/mntディレクトリーにマウントされているファイルシステムが/mediaに反映されていないことを確認することもできます。たとえば、/dev/sdc1デバイスを使用する空でないUSBフラッシュドライブが接続されていて、/mnt/flashdisk/ディレクトリーが存在する場合は、次のように入力します。mount /dev/sdc1 /mnt/flashdisk ls /media/flashdisk ls /mnt/flashdisk en-US publican.cfg
~]# mount /dev/sdc1 /mnt/flashdisk ~]# ls /media/flashdisk ~]# ls /mnt/flashdisk en-US publican.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow - バインド不可能なマウント
- 任意のマウントポイントに対して一切複製が行われないようにするには、バインド不能のマウントを使用します。マウントポイントのタイプをバインド不能のマウントに変更するには、次のようにシェルプロンプトに入力します。
mount --make-unbindable mount_point
mount --make-unbindable mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow または、選択したマウントポイントとその下にあるすべてのマウントポイントを変更することもできます。mount --make-runbindable mount_point
mount --make-runbindable mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用例は、例18.7「バインド不可能なマウントポイントの作成」 を参照してください。例18.7 バインド不可能なマウントポイントの作成
/mediaディレクトリーを共有しないようにするには、rootで次のコマンドを実行します。mount --bind /media /media mount --make-unbindable /media
~]# mount --bind /media /media ~]# mount --make-unbindable /mediaCopy to Clipboard Copied! Toggle word wrap Toggle overflow これにより、これ以降はこのマウントを複製しようとすると、エラーが発生して失敗します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.2.4. マウントポイントの移動
mount --move old_directory new_directory
mount --move old_directory new_directory例18.8 既存の NFS マウントポイントの移動
/mnt/userdirs/ にマウントされています。root として、次のコマンドを使用してこのマウントポイントを /home に移動します。
mount --move /mnt/userdirs /home
~]# mount --move /mnt/userdirs /homels /mnt/userdirs ls /home jill joe
~]# ls /mnt/userdirs
~]# ls /home
jill joe
18.3. ファイルシステムのアンマウント
umount directory umount device
umount directory
umount deviceroot でログインしている間に行わない場合は、アンマウントに適切な権限が必要です (「マウントオプションの指定」 を参照)。使用例は、例18.9「CD のアンマウント」 を参照してください。
fuser -m directory
fuser -m directory/media/cdrom/ ディレクトリーにマウントされたファイルシステムにアクセスするプロセスを一覧表示するには、以下を入力します。
fuser -m /media/cdrom /media/cdrom: 1793 2013 2022 2435 10532c 10672c
~]$ fuser -m /media/cdrom
/media/cdrom: 1793 2013 2022 2435 10532c 10672c
例18.9 CD のアンマウント
/media/cdrom/ ディレクトリーにマウントされた CD をアンマウントするには、シェルプロンプトで以下を入力します。
umount /media/cdrom
~]$ umount /media/cdrom18.4. mount コマンドのリファレンス
18.4.1. man ページドキュメント
- man 8 mount: mount コマンドの man ページです。使い方などに関する詳細が記載されています。
- man 8 umount: umount コマンドの man ページです。使い方などに関する詳細が記載されています。
- man 8 findmnt: findmnt コマンドの man ページです。使い方などに関する詳細が記載されています。
- man 5 fstab:
/etc/fstabファイル形式に関する詳細が記載されている man ページです。
18.4.2. 便利な Web サイト
- 『Shared subtrees』 — 共有サブツリーの概念について解説されている LWN の記事です。
第19章 volume_key 機能
19.1. コマンド
volume_key [OPTION]... OPERAND
volume_key [OPTION]... OPERAND- --save
- このコマンドは、オペランド ボリューム [packet] を想定します。packet を指定すると、volume_key は、そこからキーおよびパスフレーズを抽出します。packet が指定しないと、volume_key は volume からキーおよびパスフレーズを抽出し、必要に応じてユーザーに要求します。これらの鍵とパスフレーズは、1 つまたは複数の出力パケットに保存されます。
- --restore
- このコマンドは、オペランド ボリュームパケット を想定します。次に volume を開き、packet のキーとパスフレーズを使用して volume を再度アクセス可能にし、必要に応じてユーザー (たとえば、ユーザーが新しいパスフレーズの入力を許可するなど) を求めるプロンプトを出します。
- --setup-volume
- このコマンドは、オペランドの ボリュームパケット名 を想定します。次に volume を開き、packet のキーとパスフレーズを使用して、復号されたデータを name として使用するための volume を設定します。name は、dm-crypt ボリュームの名前です。この操作は、復号されたボリュームを
/dev/mapper/nameとして利用可能にします。この操作は、新しいパスフレーズを追加すると ボリュームを 永続的に変更しません(例: )。ユーザーは復号された volume にアクセスし、変更できます。 - --reencrypt、--secrets、および --dump
- これらの 3 つのコマンドは、さまざまな出力方法で同様の機能を実行します。それぞれオペランド パケット が必要で、それぞれが パケット を開き、必要に応じて復号化を行います。次に 、--reencrypt は情報を 1 つ以上の新規出力パケットに保存します。--secrets は、パケット に含まれるキーおよびパスフレーズを出力します。--dump は パケット の内容を出力しますが、キーおよびパスフレーズはデフォルトで出力されません。これは、コマンドに --with-secrets を追加することで変更できます。また、--unencrypted コマンドを使用すると、パケットの暗号化されていない部分のみをダンプできます。パスフレーズや秘密鍵のアクセスは必要ありません。
- -o, --output packet
- このコマンドは、デフォルトの鍵またはパスフレーズを パケット に書き込みます。デフォルトのキーまたはパスフレーズは、ボリュームの形式により異なります。有効期限が切れないものではなく、--restore によるボリュームへのアクセスを復元できるようにしてください。
- --output-format format
- このコマンドは、すべての出力パケットに指定された format 形式を使用します。現在、format は以下のいずれかになります。
- asymmetric: CMS を使用してパケット全体を暗号化し、証明書を必要とします。
- asymmetric_wrap_secret_only: シークレットまたはキーおよびパスフレーズのみをラップし、証明書を必要とします。
- パスフレーズ: GPG を使用してパケット全体を暗号化し、パスフレーズが必要です。
- --create-random-passphrase packet
- このコマンドは、ランダムの英数字のパスフレーズを生成し、ボリュームに追加して (他のパスフレーズに影響を与えずに)、このランダムパスフレーズを パケット に保存します。
19.2. volume_key を個別ユーザーとして使用する手順
/path/to/volume は LUKS デバイスであり、内に含まれる平文デバイスではありません。blkid -s type /path/to/volume should report type="crypto_LUKS".
手順19.1 volume_key スタンドアロンの使用
- 以下を実行します。次に、キーを保護するために、パケットパスフレーズの入力を求めるプロンプトが表示されます。
volume_key --save /path/to/volume -o escrow-packet
volume_key --save /path/to/volume -o escrow-packetCopy to Clipboard Copied! Toggle word wrap Toggle overflow - generatedescrow
-packetファイルを保存して、パスフレーズが記憶されないようにします。
手順19.2 エスクローパケットを使用したデータへのアクセスの復元
- volume_key を実行できる環境でシステムを起動し、エスクローパケットが利用できる(例: レスキューモード)
- 以下を実行します。エスクローパケットの作成時に使用された escrow パケットパスフレーズ、およびボリュームの新しいパスフレーズ用にプロンプトが表示されます。
volume_key --restore /path/to/volume escrow-packet
volume_key --restore /path/to/volume escrow-packetCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 選択したパスフレーズを使用してボリュームをマウントします。
19.3. 大規模な組織での volume_key の使用
19.3.1. 暗号化キーを保存するための準備
手順19.3 準備
- X509 証明書/プライベートのペアを作成します。
- 秘密鍵を侵害しないように信頼できるユーザーを指定します。これらのユーザーは escrow パケットを復号化できます。
- escrow パケットの復号に使用するシステムを選択します。このシステムでは、秘密鍵が含まれる NSS データベースを設定します。秘密鍵が NSS データベースに作成されていない場合は、以下の手順に従います。
- 証明書および秘密鍵を
PKCS#12ファイルに保存します。 - 以下を実行します。
certutil -d /the/nss/directory -N
certutil -d /the/nss/directory -NCopy to Clipboard Copied! Toggle word wrap Toggle overflow この時点で、NSS データベースパスワードを選択できます。各 NSS データベースは異なるパスワードを持つことができるため、指定したユーザーは各ユーザーが別の NSS データベースが使用される場合に、単一のパスワードを共有する必要はありません。 - 以下を実行します。
pk12util -d /the/nss/directory -i the-pkcs12-file
pk12util -d /the/nss/directory -i the-pkcs12-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
- システムのインストールや既存システムに鍵を保存したり、証明書を配布します。
- 保存された秘密鍵については、マシンおよびボリュームで検索できるストレージを準備します。たとえば、マシンごとに 1 つのサブディレクトリーを持つ簡単なディレクトリーや、他のシステム管理タスクに使用されるデータベースも指定できます。
19.3.2. 暗号化キーの保存
/path/to/volume は LUKS デバイスであり、これに含まれるプレーンテキストデバイスではありません。blkid -s type /path/to/volume は type="crypto_LUKS" を報告します。
手順19.4 暗号化キーの保存
- 以下を実行します。
volume_key --save /path/to/volume -c /path/to/cert escrow-packet
volume_key --save /path/to/volume -c /path/to/cert escrow-packetCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 準備済みストレージに generatedescrow
-packetファイルを保存して、システムとボリュームに関連付けます。
19.3.3. ボリュームへのアクセスの復元
手順19.5 ボリュームへのアクセスの復元
- パケットストレージからボリュームのエスクローパケットを取得し、これを復号化用に指定されたユーザーの 1 つに送信します。
- 指定されたユーザーは以下を実行します。
volume_key --reencrypt -d /the/nss/directory escrow-packet-in -o escrow-packet-out
volume_key --reencrypt -d /the/nss/directory escrow-packet-in -o escrow-packet-outCopy to Clipboard Copied! Toggle word wrap Toggle overflow NSS データベースのパスワードを指定したら、指定したユーザーは、暗号化用のパスフレーズを選択して、escrow -packet-out です。このパスフレーズは毎回異なる可能性があり、指定したユーザーからターゲットシステムに移動された間、暗号鍵を保護することができます。 - 指定したユーザーから、
escrow-packet-outファイルとパスフレーズを取得します。 - volume_key を実行し、レスキューモードなどでescrow
-packet-outファイルを利用できる環境でターゲットシステムを起動します。 - 以下を実行します。
volume_key --restore /path/to/volume escrow-packet-out
volume_key --restore /path/to/volume escrow-packet-outCopy to Clipboard Copied! Toggle word wrap Toggle overflow 指定されたユーザーが選択したパケットパスフレーズ、およびボリュームの新しいパスフレーズを求めるプロンプトが表示されます。 - 選択したボリュームパスフレーズを使用してボリュームをマウントします。
19.3.4. 緊急パスフレーズの設定
volume_key --save /path/to/volume -c /path/to/ert --create-random-passphrase passphrase-packet
volume_key --save /path/to/volume -c /path/to/ert --create-random-passphrase passphrase-packetpassphrase-packet に保存されます。--create-random-passphrase オプションおよび -o オプションを組み合わせて両方のパケットを同時に生成することもできます。
volume_key --secrets -d /your/nss/directory passphrase-packet
volume_key --secrets -d /your/nss/directory passphrase-packet19.4. volume_key 参照 s
/usr/share/doc/volume_key-*/READMEにある readme ファイル- volume_key で man volume_key を使用する manページ
第20章 アクセス制御リスト
acl パッケージが必要になります。このパッケージには、ACL 情報の追加、修正、削除および、取得のためのユーティリティーが同梱されています。
20.1. ファイルシステムのマウント
/etc/fstab ファイルにリストされている場合は、パーティションのエントリーに acl オプションを含むことができます。
LABEL=/work /work ext3 acl 1 2
LABEL=/work /work ext3 acl 1 2
--with-acl-support オプションでコンパイルされているためです。Samba 共有のアクセス時またはマウント時に特別なフラグは必要ありません。
20.1.1. NFS
20.2. アクセス ACL の設定
- 各ユーザー
- 各グループ
- 実効権マスクを使用して
- ファイルのユーザーグループに属さないユーザーに対して
-m オプションを使用すると、ファイルまたはディレクトリーの ACL を追加または修正できます。
setfacl -m rules files
# setfacl -m rules filesu:uid:perms- ユーザーにアクセス ACL を設定します。ユーザー名または UID を指定できます。システムで有効な任意のユーザーを指定できます。
g:gid:perms- グループにアクセス ACL を設定します。グループ名または GID を指定できます。システムで有効な任意のグループを指定できます。
m:perms- 実効権マスクを設定します。このマスクは、所有グループの全権限と、ユーザーおよびグループの全エントリーを結合したものです。
o:perms- ファイルのグループに属さないユーザーにアクセス ACL を設定します。
r、w、および x の文字の組み合わせで表示されます。
例20.1 読み取りと書き込みの権限付与
setfacl -m u:andrius:rw /project/somefile
# setfacl -m u:andrius:rw /project/somefile
-x オプションにいずれの権限も指定せずにコマンドを実行します。
setfacl -x rules files
# setfacl -x rules files例20.2 すべての権限の削除
setfacl -x u:500 /project/somefile
# setfacl -x u:500 /project/somefile
20.3. デフォルト ACL の設定
d: をルールの前に追加してから、ファイル名ではなくディレクトリー名を指定します。
例20.3 デフォルト ACL の設定
/share/ ディレクトリーにデフォルト ACL を設定し、ユーザーグループに属さないユーザーの読み取りと実行を設定するには、以下のコマンドを実行します (これにより、個別ファイルのアクセス ACL が上書きされます)。
setfacl -m d:o:rx /share
# setfacl -m d:o:rx /share
20.4. ACL の取り込み
例20.4 ACL の取り込み
getfacl home/john/picture.png
# getfacl home/john/picture.png
20.5. ACL が設定されているファイルシステムのアーカイブ作成
star パッケージが必要になります。
| オプション | 詳細 |
|---|---|
-c | アーカイブファイルを作成します。 |
-n | ファイルを抽出しません。-x と併用すると、ファイルが行う抽出を表示します。 |
-r | アーカイブ内のファイルを入れ替えます。パスとファイル名が同じファイルが置き換えられ、アーカイブファイルの末尾に書き込まれます。 |
-t | アーカイブファイルのコンテンツを表示します。 |
-u | アーカイブファイルを更新します。このファイルは、以下で指定されたアーカイブの最後に書き込まれます。
|
-x | アーカイブからファイルを抽出します。-U と併用すると、アーカイブ内のファイルがファイルシステムにあるファイルよりも古い場合、そのファイルは抽出されません。 |
-help | 最も重要なオプションを表示します。 |
-xhelp | 最も重要ではないオプションを表示します。 |
-/ | アーカイブからファイルを抽出する際に、ファイル名から先頭のスラッシュを削除します。デフォルトでは、ファイルの抽出時に先頭のスラッシュが削除されます。 |
-acl | 作成時または抽出時に、ファイルとディレクトリーに関連付けられているすべての ACL をアーカイブするか、または復元します。 |
20.6. 旧システムとの互換性
tune2fs -l filesystem-device
# tune2fs -l filesystem-devicee2fsprogs パッケージ (Red Hat Enterprise Linux 2.1 および 4 のバージョンも含む) に含まれている e2fsck ユーティリティーのバージョンは、ext_attr 属性を使用してファイルシステムを確認できます。古いバージョンではこの確認が拒否されます。
20.7. ACL 参照情報
- man acl: ACL の説明
- man getfacl: ファイルアクセス制御リストの取得方法
- man setfacl: ファイルアクセス制御リストの設定方法
- man star: star ユーティリティーとそのオプションの詳細説明
第21章 ソリッドステートディスクデプロイメントのガイドライン
/sys/block/sda/queue/discard_granularity を確認してください。
21.1. デプロイメントに関する考慮事項
が一致しない/inconsistent としてカウントされます。
/dev/sda2 を /mnt にマウントするには、次のコマンドを実行します。
mount -t ext4 -o discard /dev/sda2 /mnt
# mount -t ext4 -o discard /dev/sda2 /mnt
21.2. チューニングの留意事項
I/O スケジューラー
/usr/share/doc/kernel-version/Documentation/block/switching-sched.txt
仮想メモリー
vm_dirty_background_ratio および vm_dirty_ratio 設定をオフにする必要があります。ただし、これにより 全体的な I/O が生成されます。したがって、ワークロード固有のテストを使用せずに通常は推奨されません。
スワップ
第22章 書き込みバリア
22.1. Write Barriers の重要性
- まず、ファイルシステムはトランザクションのボディーをストレージデバイスに送信します。
- 次に、ファイルシステムはコミットブロックを送信します。
- トランザクションと対応するコミットブロックがディスクに書き込まれると、ファイルシステムは、トランザクションが power failure 後も存続することを想定します。
Write Barriers の仕組み
- ディスクにはすべてのデータが含まれます。
- 順序の並べ替えは発生していません。
22.2. Write Barriers の有効化/無効化
/var/log/messages に記録します( 表22.1「ファイルシステムごとの書き込みバリヤーエラーメッセージ」を参照)。
| ファイルシステム | エラーメッセージ |
|---|---|
| ext3/ext4 | JBD: barrier-based sync failed on device - disabling barriers |
| XFS | Filesystem device - Disabling barriers, trial barrier write failed |
| btrfs | btrfs: disabling barriers on dev device |
22.3. アバージーの作成に関する留意事項
書き込みキャッシュの無効化
hdparm -W0 /device/
# hdparm -W0 /device/
バッテリーバックグラウンド書き込みキャッシュ
MegaCli64 -LDGetProp -DskCache -LAll -aALL
# MegaCli64 -LDGetProp -DskCache -LAll -aALL
MegaCli64 -LDSetProp -DisDskCache -Lall -aALL
# MegaCli64 -LDSetProp -DisDskCache -Lall -aALL
high-End Arrays
NFS
第23章 ストレージ I/O アライメントとサイズ
23.1. ストレージアクセスのパラメーター
- physical_block_size
- デバイスが動作できる最小の内部ユニット
- logical_block_size
- デバイス上の場所指定に外部で使用される
- alignment_offset
- 基礎となる物理的なアライメントのオフセットとなる Linux ブロックデバイス (パーティション/MD/LVM デバイス) の先頭部分のバイト数
- minimum_io_size
- ランダムな I/O に対して推奨のデバイス最小ユニット
- optimal_io_size
- I/O ストリーミングにデバイスの優先単位
23.2. ユーザー空間アクセス
libblkid-devel パッケージで提供されます。
sysfs インターフェース
- /sys/block/
disk/alignment_offset - /sys/block/
disk/partition/alignment_offset - /sys/block/
disk/queue/physical_block_size - /sys/block/
disk/queue/logical_block_size - /sys/block/
disk/queue/minimum_io_size - /sys/block/
disk/queue/optimal_io_size
例23.1 sysfs インターフェース
alignment_offset: 0 physical_block_size: 512 logical_block_size: 512 minimum_io_size: 512 optimal_io_size: 0
alignment_offset: 0
physical_block_size: 512
logical_block_size: 512
minimum_io_size: 512
optimal_io_size: 0ブロックデバイス ioctls
- BLKALIGNOFF:
alignment_offset - BLKPBSZGET:
physical_block_size - BLKSSZGET:
logical_block_size - BLKIOMIN:
minimum_io_size - BLKIOOPT:
optimal_io_size
23.3. Standards(標準)
ATA
SCSI
BLOCK LIMITS VPD ページへのアクセスを取得する)および READ CAPACITY(16) コマンドのみを送信します。
LOGICAL BLOCK LENGTH IN BYTES/sys/block/disk/queue/physical_block_sizeを派生するのに使用されます。LOGICAL BLOCKS PER PHYSICAL BLOCK EXPONENT/sys/block/disk/queue/logical_block_sizeを派生するために使用されます。LOWEST ALIGNED LOGICAL BLOCK ADDRESS派生するのに使用されます。/sys/block/disk/alignment_offset/sys/block/disk/partition/alignment_offset
BLOCK LIMITS VPD ページ(0xb0)は、I/O ヒントを提供します。また、OPTIMAL TRANSFER LENGTH GRANULARITY および OPTIMAL TRANSFER LENGTH を使用して以下の派生します。
/sys/block/disk/queue/minimum_io_size/sys/block/disk/queue/optimal_io_size
sg3_utils パッケージは、sg_inq ユーティリティーを提供します。これは、BLOCK LIMITS VPD ページにアクセスできます。これを行うには、以下を実行します。
sg_inq -p 0xb0 disk
# sg_inq -p 0xb0 disk23.4. スタッキング I/O パラメーター
- I/O スタックにおける 1 つのレイヤーのみがゼロでない alignment_offset に対して調整する必要があります。レイヤーが調整されると、そのレイヤーがゼロの alignment_offset を持つデバイスをエクスポートします。
- LVM で作成したストライプ化デバイスマッパー(DM)デバイスは、ストライプ数(ディスクの数) とユーザーが指定するチャンクサイズとの対比で、minimum _io _size と optimal _io_size をエクスポートする必要があります。
23.5. 論理ボリュームマネージャー
/etc/lvm/lvm.conf の 0 に data_alignment_offset_detection を設定します。これを無効にすることは推奨していません。
etc/lvm/lvm.conf の data_alignment_detection を 0 に設定します。これを無効にすることは推奨していません。
23.6. パーティションおよびファイルシステムツール
util-linux-ng の libblkid および fdisk
util-linux-ng パッケージで提供される libblkid ライブラリーには、デバイスの I/O パラメーターにアクセスするためのプログラムによる API が含まれます。libblkid は、特に Direct I/O を使用するアプリケーションを使用して、I/O リクエストを適切にサイズできるようにします。util-linux-ng の fdisk ユーティリティーは、libblkid を使用して、すべてのパーティションの配置を最適なデバイスの I/O パラメーターを決定します。fdisk ユーティリティーは、すべてのパーティションを 1MB 境界に合わせます。
parted および libparted
libparted ライブラリーは、libblkid の I/O パラメーター API も使用します。Red Hat Enterprise Linux 6 インストーラー(Anaconda)は libparted を使用します。これは、インストーラーまたは parted によって作成されたすべてのパーティションが適切に調整されることを意味します。I/O パラメーターを提供していないデバイスで作成されたすべてのパーティションに対して、デフォルトの調整は 1MB になります。
- 常に、最初のプライマリーパーティションの開始のオフセットとして、報告された alignment_offset を使用します。
- optimal_io_size が定義されている場合(例: 0ではない)、すべてのパーティションを optimal_io_size 境界に合わせます。
- optimal_io_size が未定義である場合(例: 0)、recon se _offset は 0 で、min_io_size は 2 の累乗の場合は、1MB のデフォルトの調整を使用します。これは、I/O ヒントを提供するように見えない「レガシー」デバイスの catch-all です。そのため、デフォルトではすべてのパーティションが 1MB の境界に調整されます。注記Red Hat Enterprise Linux 6 は、I/O ヒントを提供していないデバイスと、reconse _offset=0 と optimal_io_size=0 を持つデバイスを区別することができません。このようなデバイスは、SAS 4K デバイスに 1 つある可能性があります。したがって、ディスクの起動時に最も悪い 1 MB の領域が失われます。
ファイルシステムツール
第24章 リモートディスクレスシステムの設定
tftp-serverxinetddhcpsyslinuxdracut-network
tftp-server が提供) および DHCP サービス (dhcp が提供) の両方が必要です。tftp サービスは、PXE ローダーを介してネットワーク経由でカーネルイメージと initrd を取得するために使用されます。
24.1. ディスクレスクライアントの tftp サービスの設定
/etc/xinetd.d/tftp の Disabled オプションを no に設定します。tftp を設定するには、以下の手順を実行します。
手順24.1 tftp を設定するには、以下を行います。
- tftp root ディレクトリー (chroot) は
/var/lib/tftpbootにあります。/usr/share/syslinux/pxelinux.0を、以下のように/var/lib/tftpboot/にコピーします。cp /usr/share/syslinux/pxelinux.0 /var/lib/tftpboot/ - tftp の root ディレクトリーに
pxelinux.cfgディレクトリーを作成します。mkdir -p /var/lib/tftpboot/pxelinux.cfg/
/etc/hosts.allow を使用して tftp へのホストアクセスを設定できます。TCP ラッパーおよび /etc/hosts.allow 設定ファイルの設定に関する詳細は、『Red Hat Enterprise Linux 6 『セキュリティーガイド』を参照してください』。また、man hosts_access は、/etc/hosts.allow に関する情報も提供します。
24.2. ディスクレスクライアントの DHCP の設定
/etc/dhcp/dhcp.conf に追加します。
server-ip を、tftp サービスおよび DHCP サービスが置かれているホストマシンの IP アドレスに置き換えます。tftp および DHCP が設定されているため、残りはすべて NFS およびエクスポートしたファイルシステムを設定します。手順については、「ディスクレスクライアントのエクスポートしたファイルシステムの設定」 を参照してください。
24.3. ディスクレスクライアントのエクスポートしたファイルシステムの設定
/etc/exports に root ディレクトリーを追加して、root ディレクトリーをエクスポートするように NFS サービスを設定します。その手順は、「/etc/exports 設定ファイル」 を参照してください。
rsync -a -e ssh --exclude='/proc/*' --exclude='/sys/*' hostname.com:/ /exported/root/directory
# rsync -a -e ssh --exclude='/proc/*' --exclude='/sys/*' hostname.com:/ /exported/root/directory/exported/root/directory を、エクスポートしたファイルシステムへのパスに置き換えます。
yum groupinstall Base --installroot=/exported/root/directory
yum groupinstall Base --installroot=/exported/root/directory手順24.2 ファイルシステムの設定
- エクスポートしたファイルシステムの
/etc/fstabを、以下の設定を含む(最低でも)設定します。none /tmp tmpfs defaults 0 0 tmpfs /dev/shm tmpfs defaults 0 0 sysfs /sys sysfs defaults 0 0 proc /proc proc defaults 0 0
none /tmp tmpfs defaults 0 0 tmpfs /dev/shm tmpfs defaults 0 0 sysfs /sys sysfs defaults 0 0 proc /proc proc defaults 0 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow - ディスクレスクライアントが使用するカーネル (
vmlinuz-kernel-version) を選択し、tftp の boot ディレクトリーにコピーします。cp /boot/vmlinuz-kernel-version /var/lib/tftpboot/
# cp /boot/vmlinuz-kernel-version /var/lib/tftpboot/Copy to Clipboard Copied! Toggle word wrap Toggle overflow - ネットワークサポートで
initrd(つまりinitramfs-kernel-version.img)を作成します。dracut initramfs-kernel-version.img kernel-version
# dracut initramfs-kernel-version.img kernel-versionCopy to Clipboard Copied! Toggle word wrap Toggle overflow 作成されたinitramfs-kernel-version.imgを tftp のブートディレクトリーにコピーします。 /var/lib/tftpboot内のinitrdおよびカーネルを使用するように、デフォルトのブート設定を編集します。この設定は、エクスポートしたファイルシステム (/exported/root/directory) を読み書きとしてマウントするよう、ディスクレスクライアントの root に指示を出します。これを行うには、/var/lib/tftpboot/pxelinux.cfg/defaultを以下のように設定します。default rhel6 label rhel6 kernel vmlinuz-kernel-version append initrd=initramfs-kernel-version.img root=nfs:server-ip:/exported/root/directory rw
default rhel6 label rhel6 kernel vmlinuz-kernel-version append initrd=initramfs-kernel-version.img root=nfs:server-ip:/exported/root/directory rwCopy to Clipboard Copied! Toggle word wrap Toggle overflow server-ipを、tftp サービスおよび DHCP サービスが置かれているホストマシンの IP アドレスに置き換えます。
第25章 デバイスマッパーマルチパスおよび仮想ストレージ
25.1. 仮想ストレージ
- ファイバーチャンネル
- iSCSI
- NFS
- GFS2
- ローカルストレージのプール
- ローカルストレージは、ホストに直接接続ストレージデバイス、ファイル、またはディレクトリーに対応します。ローカルストレージには、ローカルディレクトリー、直接割り当てられたディスク、および LVM ボリュームグループが含まれます。
- ネットワーク (共有) ストレージプール
- ネットワークストレージは、標準プロトコルを使用してネットワーク上で共有されるストレージデバイスに対応します。ファイバーチャネル、iSCSI、NFS、GFS2、および SCSI RDMA プロトコルを使用して共有ストレージデバイスが含まれ、ゲスト仮想化ゲストをホスト間で移行するための要件となります。
25.2. DM Multipath
- 冗長性
- DM-Multipath は、アクティブ/パッシブ構成でフェイルオーバーを提供できます。アクティブ/パッシブ構成では、パスは、I/O には常に半分しか使用されません。I/O パスの要素 (ケーブル、スイッチ、またはコントローラー) に障害が発生すると、DM-Multipath は代替パスに切り替えます。
- パフォーマンスの向上
- DM-Multipath を active/active モードに設定すると、I/O はラウンドロビン式でパス全体に分散されます。一部の設定では、DM Multipath は I/O パスの負荷を検出し、負荷を動的に再分散できます。
パート III. オンラインストレージ
第26章 ファイバーチャンネル
26.1. ファイバーチャネル API
/sys/class/ ディレクトリーのリストは次のとおりです。各項目では、ホスト番号が H、バス番号が B で指定され、ターゲットは T、論理ユニット番号 (LUN) は L で、リモートのポート番号は R になります。
- トランスポート -
/sys/class/fc_transport/targetH:B:T/ port_id- 24ビットポート ID/アドレスnode_name- 64ビットノード名port_name- 64ビットポート名
- リモートポート -
/sys/class/fc_remote_ports/rport-H:B-R/ port_idnode_nameport_namedev_loss_tmo- scsi デバイスがシステムから削除されるタイミングを制御します。dev_loss_tmoがトリガーされると、scsi デバイスが削除されます。multipath.confでは、dev_loss_tmoをinfinityに設定できます。これにより、その値を 2,147,483,647 秒または 68 年間 に設定し、dev_loss_tmoの最大値を設定できます。Red Hat Enterprise Linux 6 では、fast_io_fail_tmoはデフォルトで設定されないため、dev_loss_tmoの値は 600 秒に制限されます。fast_io_fail_tmo- リンクに「bad」のマークを付けるまでの待機秒数を指定します。リンクに「bad」のマークが付けられると、対応するパス上の既存の実行中の I/O または新しい I/O が失敗します。I/O がブロックされたキューに存在する場合は、dev_loss_tmoの期限が切れ、キューのブロックが解除されるまでエラーを起こしません。fast_io_fail_tmoをoff以外の値に設定すると、dev_loss_tmoは取得されません。fast_io_fail_tmoをoffに設定すると、システムからデバイスが削除されるまで I/O は失敗します。fast_io_fail_tmoを数字に設定すると、fast_io_fail_tmoがトリガーされると、I/O は即座に失敗します。
- ホスト -
/sys/class/fc_host/hostH/ port_idissue_lip- リモートポートを再検出するようにドライバーに指示します。
26.2. ネイティブファイバーチャネルドライバーおよび機能
lpfcqla2xxxzfcpmptfcbfa
| lpfc | qla2xxx | zfcp | mptfc | bfa | |
|---|---|---|---|---|---|
Transport port_id | X | X | X | X | X |
Transport node_name | X | X | X | X | X |
Transport port_name | X | X | X | X | X |
リモートポート dev_loss_tmo | X | X | X | X | X |
Remote Port fast_io_fail_tmo | X | X [a] | X [b] | X | |
Host port_id | X | X | X | X | X |
Host issue_lip | X | X | X | ||
[a]
Red Hat Enterprise Linux 5.4 でサポートされています。
[b]
Red Hat Enterprise Linux 6.0 でサポート
| |||||
第27章 iSCSI ターゲットおよびイニシエーターの設定
27.1. iSCSI ターゲットの作成
手順27.1 iSCSI ターゲットの作成
- scsi-target-utils をインストールします。
yum install scsi-target-utils
~]# yum install scsi-target-utilsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - ファイアウォールでポート 3260 を開きます。
iptables -I INPUT -p tcp -m tcp --dport 3260 -j ACCEPT service iptables save
~]# iptables -I INPUT -p tcp -m tcp --dport 3260 -j ACCEPT ~]# service iptables saveCopy to Clipboard Copied! Toggle word wrap Toggle overflow - ターゲットサービスを開始して有効にします。
service tgtd start chkconfig tgtd on
~]# service tgtd start ~]# chkconfig tgtd onCopy to Clipboard Copied! Toggle word wrap Toggle overflow - LUN にストレージを割り当てます。この例では、ブロックストレージ用に新しいパーティションが作成されます。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/tgt/targets.confファイルを編集し、ターゲットを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記の例では、1 つのバッキングストアと許可されたイニシエーター 1 つを含む簡単なターゲットが作成されます。YYYY-MM.reverse.domain.name : OptionalIdentifierの形式で、iqn の名前を指定して 名前を指定する必要があります。バッキングストアは、ストレージが置かれているデバイスです。initiator-address は、ストレージにアクセスするためのイニシエーターの IP アドレスです。- ターゲットサービスを再起動します。
service tgtd restart Stopping SCSI target daemon: [ OK ] Starting SCSI target daemon: [ OK ]
~]# service tgtd restart Stopping SCSI target daemon: [ OK ] Starting SCSI target daemon: [ OK ]Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 設定を確認します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
27.2. iSCSI イニシエーターの作成
手順27.2 iSCSI イニシエーターの作成
- iscsi-initiator-utils をインストールします。
yum install iscsi-initiator-utils
~]# yum install iscsi-initiator-utilsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - ターゲットを検出します。ターゲットの IP アドレスを使用します。以下に使用されている IP アドレスは、例としてのみ提供されます。
iscsiadm -m discovery -t sendtargets -p 192.168.1.1 Starting iscsid: [ OK ] 192.168.1.1:3260,1 iqn.2015-06.com.example.test:target1
~]# iscsiadm -m discovery -t sendtargets -p 192.168.1.1 Starting iscsid: [ OK ] 192.168.1.1:3260,1 iqn.2015-06.com.example.test:target1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記は、ターゲットの IP アドレスと IQN アドレスを示しています。これは、今後のステップに必要な IQN アドレスです。 - ターゲットに接続します。
iscsiadm -m node -T iqn.2015-06.com.example:target1 --login Logging in to [iface: default, target: iqn.2015-06.com.example:target1, portal: 192.168.1.1,3260] (multiple) Login in to [iface: default, target: iqn.2015-06.com.example:target1, portal: 192.168.1.1,3260] successful.
~]# iscsiadm -m node -T iqn.2015-06.com.example:target1 --login Logging in to [iface: default, target: iqn.2015-06.com.example:target1, portal: 192.168.1.1,3260] (multiple) Login in to [iface: default, target: iqn.2015-06.com.example:target1, portal: 192.168.1.1,3260] successful.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - iSCSI ディスク名を検索します。
grep "Attached SCSI" /var/log/messages Jun 19 01:30:26 test kernel: sd 7:0:0:1 [sdb] Attached SCSI disk
~]# grep "Attached SCSI" /var/log/messages Jun 19 01:30:26 test kernel: sd 7:0:0:1 [sdb] Attached SCSI diskCopy to Clipboard Copied! Toggle word wrap Toggle overflow - そのディスクにファイルシステムを作成します。
mkfs.ext4 /dev/sdb
~]# mkfs.ext4 /dev/sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow - ファイルシステムをマウントします。
mkdir /mnt/iscsiTest mount /dev/sdb /mnt/iscsiTest
~]# mkdir /mnt/iscsiTest ~]# mount /dev/sdb /mnt/iscsiTestCopy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/fstabファイルを編集して、再起動後も持続します。blkid /dev/sdb /dev/sdb: UUID="766a3bf4-beeb-4157-8a9a-9007be1b9e78" TYPE="ext4" vim /etc/fstab UUID=766a3bf4-beeb-4157-8a9a-9007be1b9e78 /mnt/iscsiTest ext4 _netdev 0 0
~]# blkid /dev/sdb /dev/sdb: UUID="766a3bf4-beeb-4157-8a9a-9007be1b9e78" TYPE="ext4" ~]# vim /etc/fstab UUID=766a3bf4-beeb-4157-8a9a-9007be1b9e78 /mnt/iscsiTest ext4 _netdev 0 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第28章 永続的な命名
- ホストバスアダプター(HBA)の PCI 識別子
- HBA 上のチャンネル番号
- リモート SCSI ターゲットアドレス
- 論理ユニット番号(LUN)
/dev/disk/by-path/ ディレクトリーにあるシンボリックリンクです。このシンボリックリンクは、パス識別子から現在の /dev/sd 名にマッピングします。たとえば、ファイバーチャネルデバイスの場合、PCI 情報 およびホスト:BusTarget:LUN info は以下のようになります。
pci-0000:02:0e.0-scsi-0:0:0:0 -> ../../sda
pci-0000:02:0e.0-scsi-0:0:0:0 -> ../../sda
28.1. WWID
0x83)または Unit Serial Number(ページ 0x80)を取得します。これらの WWID から現在の /dev/sd 名へのマッピングは、/ dev/disk/by-id/ ディレクトリーにあるシンボリックリンクで確認できます。
例28.1 WWID
0x83 の識別子を持つデバイスには、以下が含まれます。
scsi-3600508b400105e210000900000490000 -> ../../sda
scsi-3600508b400105e210000900000490000 -> ../../sda0x80 の識別子を持つデバイスには、以下が含まれます。
scsi-SSEAGATE_ST373453LW_3HW1RHM6 -> ../../sda
scsi-SSEAGATE_ST373453LW_3HW1RHM6 -> ../../sda/dev/disk/by-id/ 名を使用できます。
/dev/mapper/3600508b400105df70000e00000ac0000 など、/dev/mapper/wwid に単一の「pseudo-device」を表示します。
/dev/mapper/mpathn の形式の名前にマッピングされます。デフォルトでは、このマッピングは /etc/multipath/bindings ファイルに保持されています。これらの mpathn 名は、そのファイルが維持されている限り永続的です。
28.2. UUID およびその他の永続識別子
- UUID( Universally Unique Identifier )
- ファイルシステムのラベル
/dev/disk/by-label/ のオペレーティングシステムが管理するシンボリックリンクを使用してデバイスにアクセスすることもできます(例: Boot -> ../../sda1)および /dev/disk/by-uuid/ (例: f8bf09e3-4c16-4d91-bd5e-6f62da165c08 -> ../../sda1)ディレクトリー。
第29章 ストレージデバイスの削除
- 空きメモリーの合計は、100 あたり 10 個以上のサンプルで合計メモリーの 5% 未満です(コマンド free を使用すると合計メモリーの合計が表示されます)。
- swapping はアクティブです( vmstat 出力の
siおよびso列以外)。
手順29.1 デバイスの完全削除
- 必要に応じて、デバイスおよびバックアップデバイスデータのすべてのユーザーを閉じます。
- umount を使用して、デバイスをマウントしたファイルシステムのマウントを解除します。
- md ボリュームおよび LVM ボリュームを使用して、デバイスを削除します。デバイスが LVM ボリュームグループのメンバーである場合は、pvmove コマンドを使用してデバイスからデータを移動する必要がある場合は、vgreduce コマンドを使用して物理ボリュームを削除 (オプションで pvremove)、ディスクから LVM メタデータを削除する必要がある場合があります。
- デバイスがマルチパス機能を使用する場合は、multipath -l を実行して、デバイスへのパスをすべて書き留めておきます。その後、multipath -f デバイスを使用してマルチパスデバイスを削除します。
- blockdev --flushbufs デバイス を実行し、未処理の I/O をデバイスのすべてのパスにフラッシュします。これは特に、umount または vgreduce 操作がない raw デバイスに特に重要になります。これにより、I/O フラッシュが発生します。
- システムのアプリケーション、スクリプト、ユーティリティーの
/dev/sd、/dev/disk/by-path、major:minor 番号などのデバイスのパスベースの名前への参照を削除します。これは、今後追加される異なるデバイスが現在のデバイスには間違いにならないようにするために重要です。 - 最後に、SCSI サブシステムからデバイスへの各パスを削除します。これを実行するには、コマンド echo 1 > /sys/block/device-name/device/delete コマンドを使用します。たとえば
、device -name がde になります。この操作に関するもう 1 つのバリエーションは、1 > /sys/class/scsi_device/h:c:t:l/device/delete です。h は HBA 番号で、c は HBA のチャンネル、c は SCSI ターゲット ID、l が LUN です。注記このコマンドの古い形式である echo "scsi remove-single-device 0 0 0 0" > /proc/scsi/scsi は非推奨となりました。
第30章 ストレージデバイスへのパスの削除
手順30.1 ストレージデバイスへのパスの削除
- システムのアプリケーション、スクリプト、ユーティリティーの
/dev/sd またはまたは major:minor 番号などのデバイスのパスベースの名前への参照を削除します。これは、今後追加される異なるデバイスが現在のデバイスには間違いにならないようにするために重要です。/dev/disk/by-path - echo offline > /sys/block/sda/device/state を使用して、パスをオフラインにします。これにより、このパスのデバイスに送信された後続の I/O が即座に失敗します。device -mapper-multipath は、デバイスへの残りのパスを引き続き使用します。
- SCSI サブシステムからパスを削除します。そのためには、コマンド echo 1 > /sys/block/ device-name /device/delete コマンドを使用します(
例: 手順29.1「デバイスの完全削除」)。
第31章 ストレージデバイスまたはパスの追加
/dev/disk/by-path 名)は、システムが新しいデバイスに割り当てると、新しいデバイスに割り当てると、削除以降以降のデバイスにより使用されていた可能性があることに注意してください。そのため、パスベースのデバイス名への古い参照がすべて削除されていることを確認します。そうしないと、古いデバイスの新しいデバイスが間違っている可能性があります。
手順31.1 ストレージデバイスまたはパスの追加
- ストレージデバイスまたはパスを追加する最初の手順は、新しいストレージデバイスまたは既存のデバイスへの新規パスへのアクセスを物理的に有効にすることです。これは、ファイバーチャネルまたは iSCSI ストレージサーバーでベンダー固有のコマンドを使用します。これを実行する際には、ホストに表示される新規ストレージの LUN 値を書き留めておいてください。ストレージサーバーがファイバーチャネルである場合、ストレージサーバーの World Wide Node Name (WWNN)にも認識し、ストレージサーバーにあるすべてのポートに WWNN が 1 つあるかどうかを確認します。そうでない場合は、新しい LUN へのアクセスに使用される各ポートの World Wide Port Name (WWPN) をメモします。
- 次に、オペレーティングシステムが新しいストレージデバイスまたは既存デバイスへのパスを認識させます。使用が推奨されるコマンドは以下のとおりです。
echo "c t l" > /sys/class/scsi_host/hosth/scan
$ echo "c t l" > /sys/class/scsi_host/hosth/scanCopy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドでは、h が HBA 番号、c は HBA のチャンネル、t は SCSI ターゲット ID で、l が LUN になります。注記このコマンドの古い形式である echo "scsi add-single-device 0 0 0 0" > /proc/scsi/scsi は非推奨となりました。- 一部のファイバーチャネルハードウェアでは、LIP(Loop Initialization Protocol )操作を実行するまで、RAID アレイで新たに作成された LUN がオペレーティングシステムに表示されません。これを行う方法については、34章ストレージ Interconnect のスキャン を参照してください。重要LIP が必要な場合、この操作を実行する前に I/O を停止する必要があります。
- 新しい LUN が RAID アレイに追加され、オペレーティングシステムによって設定されていない場合には、sg3_utils パッケージの一部で、sg _luns コマンドを使用して、アレイでエクスポートされる LUN の一覧を確認します。これにより、SCSI REPORT LUNS コマンドを RAID アレイに発行し、存在する LUN の一覧を返します。
すべてのポートに単一の WWNN が実装されているファイバーチャネルストレージサーバーの場合は、sysfs で WWNN を検索することで、正しい h、c、および t の値 (すなわち、HBA 番号、HBA チャンネル、SCSI ターゲット ID) を決定することができます。例31.1 Determin correct h、c、および t の値
たとえば、ストレージサーバーの WWNN が0x5006016090203181の場合、以下を使用します。grep 5006016090203181 /sys/class/fc_transport/*/node_name
$ grep 5006016090203181 /sys/class/fc_transport/*/node_nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow これにより、以下のような出力が表示されるはずです。/sys/class/fc_transport/target5:0:2/node_name:0x5006016090203181 /sys/class/fc_transport/target5:0:3/node_name:0x5006016090203181 /sys/class/fc_transport/target6:0:2/node_name:0x5006016090203181 /sys/class/fc_transport/target6:0:3/node_name:0x5006016090203181
/sys/class/fc_transport/target5:0:2/node_name:0x5006016090203181 /sys/class/fc_transport/target5:0:3/node_name:0x5006016090203181 /sys/class/fc_transport/target6:0:2/node_name:0x5006016090203181 /sys/class/fc_transport/target6:0:3/node_name:0x5006016090203181Copy to Clipboard Copied! Toggle word wrap Toggle overflow これは、このターゲットに対する 4 つのファイバーチャネルルートがあることを示します(それぞれが 2 つのファイバーチャネル HBA。それぞれが 2 つのストレージポートになります)。LUN の値が56の場合、以下のコマンドは最初のパスを設定します。echo "0 2 56" > /sys/class/scsi_host/host5/scan
$ echo "0 2 56" > /sys/class/scsi_host/host5/scanCopy to Clipboard Copied! Toggle word wrap Toggle overflow これは、新規デバイスへのパスごとに行う必要があります。すべてのポートに単一の WWNN を実装しないファイバーチャネルストレージサーバーの場合、sysfs で各 WWPN を検索して、正しい HBA 番号、HBA チャネル、および SCSI ターゲット ID を確認できます。HBA 番号、HBA チャネル、および SCSI ターゲット ID を決定する別の方法は、新規デバイスと同じパスに設定されている別のデバイスを参照することです。これは、lsscsi、scsi _id、multipath -l、ls -l /dev/disk/by-* など、さまざまなコマンドで実行できます。この情報および新規デバイスの LUN 番号が上記のように使用して、新しいデバイスへのパスをプローブおよび設定できます。 - デバイスへの SCSI パスを追加したら、multipath コマンドを実行して、デバイスが正しく設定されていることを確認します。この時点で、デバイスは md、LVM、mkfs、または mount に追加できます。
第32章 イーサネットインターフェース上でのファイバーチャネルの設定
fcoe-utilslldpad
手順32.1 FCoE を使用するためにイーサネットインターフェースの設定
- 既存のネットワークスクリプト(例:
/etc/fcoe/cfg-eth0)を、FCoE に対応するイーサネットデバイスの名前にコピーして、新しい VLAN を設定します。これにより、設定するデフォルトファイルが提供されます。FCoE デバイスが ethX の場合は、次のコマンドを実行します。cp /etc/fcoe/cfg-eth0 /etc/fcoe/cfg-ethX
# cp /etc/fcoe/cfg-eth0 /etc/fcoe/cfg-ethXCopy to Clipboard Copied! Toggle word wrap Toggle overflow 必要に応じてcfg-ethXの内容を変更します。注記: ハードウェアのDCBX クライアントを実装するネットワークインターフェースには、DCB_REQUIREDをnoに設定する必要があります。 - システムの起動時にデバイスを自動的に読み込むように設定するには、対応する
/etc/sysconfig/network-scripts/ifcfg-ethXファイルにONBOOT=yesを設定します。たとえば、FCoE デバイスが eth2 の場合は、それに応じて/etc/sysconfig/network-scripts/ifcfg-eth2を編集します。 - 以下のコマンドを使用して、データセンターのブリッジデーモン(dcbd)を起動します。
/etc/init.d/lldpad start
# /etc/init.d/lldpad startCopy to Clipboard Copied! Toggle word wrap Toggle overflow - ハードウェアの DCBX クライアントを実装するネットワークインターフェースの場合は、この手順を省略して次の手順を実施します。ソフトウェア DCBX クライアントを必要とするインターフェースの場合は、次のコマンドを使用して、イーサネットインターフェースでデータセンターのブリッジングを有効にします。
dcbtool sc ethX dcb on
# dcbtool sc ethX dcb onCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次に、イーサネットインターフェースで FCoE を有効にするには、次のコマンドを実行します。dcbtool sc ethX app:fcoe e:1
# dcbtool sc ethX app:fcoe e:1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記これらのコマンドは、イーサネットインターフェースの dcbd 設定が変更されていない場合にのみ機能します。 - 以下を使用して FCoE デバイスを読み込みます。
ifconfig ethX up
# ifconfig ethX upCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 以下を使用して FCoE を起動します。
service fcoe start
# service fcoe startCopy to Clipboard Copied! Toggle word wrap Toggle overflow ファブリック上の他のすべての設定が正しいと仮定して、FCoE デバイスがすぐに表示されるはずです。設定した FCoE デバイスを表示するには、次のコマンドを実行します。fcoeadm -i
# fcoeadm -iCopy to Clipboard Copied! Toggle word wrap Toggle overflow
chkconfig lldpad on
# chkconfig lldpad on
chkconfig fcoe on
# chkconfig fcoe on
32.1. Fibre-Channel over Ethernet(FCoE)ターゲットのセットアップ
手順32.2 FCoE ターゲットの設定
- FCoE ターゲットを設定するには、
fcoe-target-utilsパッケージとその依存関係をインストールする必要があります。yum install fcoe-target-utils
# yum install fcoe-target-utilsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - FCoE のターゲットは LIO カーネルターゲットをベースとしており、ユーザー空間デーモンは必要ありません。ただし、fcoe-target サービスが必要なカーネルモジュールを読み込み、再起動後も設定を維持するには、引き続き設定する必要があります。
service fcoe-target start
# service fcoe-target startCopy to Clipboard Copied! Toggle word wrap Toggle overflow chkconfig fcoe-target on
# chkconfig fcoe-target onCopy to Clipboard Copied! Toggle word wrap Toggle overflow - FCoE ターゲットの設定は、期待通りに a
.confを編集するのではなく、targetcli ユーティリティーを使用して実行します。その後、設定が保存されるので、システムの再起動時に復元できます。targetcli
# targetcliCopy to Clipboard Copied! Toggle word wrap Toggle overflow targetcli は、階層設定シェルです。シェル内のノード間での移動は cd を使用して、ls は現在の設定ノードでコンテンツを表示します。その他のオプションを表示するには、コマンドのヘルプ も利用できます。 - バックストアとしてエクスポートするために、ファイル、ブロックデバイス、またはパススルー SCSI デバイスを定義します。
例32.1 デバイスを定義する例 1
/> backstores/block create example1 /dev/sda4
/> backstores/block create example1 /dev/sda4Copy to Clipboard Copied! Toggle word wrap Toggle overflow これにより、/dev/sda4ブロックデバイスにマップするバックストアexample1が作成されます。例32.2 デバイスを定義する 2 の例
/> backstores/fileio create example2 /srv/example2.img 100M
/> backstores/fileio create example2 /srv/example2.img 100MCopy to Clipboard Copied! Toggle word wrap Toggle overflow これにより、指定されたファイルへマップするexample2という名前のバックストアが作成されます。ファイルが存在しない場合は作成されます。ファイルサイズは K、M、または G の略語を使用でき、バッキングファイルが存在しない場合にのみ必要です。注記グローバルのauto_cd_after_createオプションがオンになっている場合(デフォルト)、create コマンドを実行すると、現在の設定ノードを新規作成されるオブジェクトに変更します。これは、グローバル auto_cd_after_create=false を設定して 無効にできます。cd / を使用すると、root ノードに戻ることができます。 - FCoE インターフェースで FCoE ターゲットインスタンスを作成します。
/> tcm_fc/ create 00:11:22:33:44:55:66:77
/> tcm_fc/ create 00:11:22:33:44:55:66:77Copy to Clipboard Copied! Toggle word wrap Toggle overflow FCoE インターフェースがシステムに存在する場合は、作成後のタブコンプリットブレッシングにより 、 利用可能なインターフェースの一覧が表示されます。そうでない場合は、fcoeadm -iにアクティブなインターフェースが表示されることを確認します。 - バックストアをターゲットインスタンスにマップします。
例32.3 バックストアのターゲットインスタンスへのマッピングの例
/> cd tcm_fc/00:11:22:33:44:55:66:77
/> cd tcm_fc/00:11:22:33:44:55:66:77Copy to Clipboard Copied! Toggle word wrap Toggle overflow /> luns/ create /backstores/fileio/example2
/> luns/ create /backstores/fileio/example2Copy to Clipboard Copied! Toggle word wrap Toggle overflow - FCoE イニシエーターから LUN へのアクセスを許可します。
/> acls/ create 00:99:88:77:66:55:44:33
/> acls/ create 00:99:88:77:66:55:44:33Copy to Clipboard Copied! Toggle word wrap Toggle overflow LUN がイニシエーターからアクセス可能になるはずです。 - exit または ctrl+D を入力して targetcli を終了します。
第33章 システムの起動時に FCoE インターフェースを自動マウントする設定
/usr/share/doc/fcoe-utils-version/README で参照できます。マイナーリリース間における変更については、該当するドキュメントを参照してください。
/etc/init.d/fcoe です。
例33.1 FCoE マウントコード
/etc/fstab のワイルドカードで指定されたファイルシステムをマウントする FCoE マウントコードの例です。
/etc/fstab の以下のパスで指定された FCoE ディスクがマウントされます。
/dev/disk/by-path/fc-0xXX:0xXX /mnt/fcoe-disk1 ext3 defaults,_netdev 0 0 /dev/disk/by-path/fc-0xYY:0xYY /mnt/fcoe-disk2 ext3 defaults,_netdev 0 0
/dev/disk/by-path/fc-0xXX:0xXX /mnt/fcoe-disk1 ext3 defaults,_netdev 0 0
/dev/disk/by-path/fc-0xYY:0xYY /mnt/fcoe-disk2 ext3 defaults,_netdev 0 0fc- および _netdev サブ文字列を含むエントリーは、mount_fcoe_disks_from_fstab 関数が FCoE ディスクマウントエントリーを識別できるようにします。/etc/fstab エントリーの詳細は、man 5 fstab を参照してください。
第34章 ストレージ Interconnect のスキャン
- 実施された相互接続上のすべての I/O は、手順を実行する前に一時停止してフラッシュする必要があります。また、I/O を再開する前にチェックされたスキャンの結果が必要になります。
- デバイスを削除するのと同様に、システムがメモリー不足の状態になると相互スキャンは推奨されません。メモリープレッシャーのレベルを確認するには、vmstat 1 100 コマンドを実行します。空きメモリーが合計メモリーの 5% 未満の場合、Interconnect スキャンは 100 あたり 10 を超える合計メモリーの 5% 未満の場合は推奨されません。また、スワップがアクティブな場合には相互スキャンは推奨されません( vmstat 出力のゼロ以外の
siおよびso列)。free コマンドは、合計メモリーも表示することができます。
- echo "1" > /sys/class/fc_host/hostN/issue_lip
- ( N はホスト番号に置き換えます。)この操作はLIP( Loop Initialization Protocol )を実行し、相互接続をスキャンし、SCSI レイヤーが更新され、バス上のデバイスを反映させます。LIP は、基本的にはバスリセットで、デバイスの追加と削除を生じさせます。この手順は、ファイバーチャネルの相互接続に新しい SCSI ターゲットを設定するために必要です。issue_lip は非同期操作であることに注意してください。このコマンドは、スキャン全体が完了する前に完了できます。issue_lip を終了するタイミングを決定するには、
/var/log/messagesを監視する必要があります。lpfcドライバー、qla2xxxドライバー、およびbnx2fcドライバーは issue_lip をサポートします。Red Hat Enterprise Linux の各ドライバーがサポートする API 機能に関する詳細は、表26.1「ファイバーチャネル API 機能」 を参照してください。 /usr/bin/rescan-scsi-bus.sh- Red Hat Enterprise Linux 5.4 に
/usr/bin/rescan-scsi-bus.shスクリプトが導入されました。デフォルトでは、このスクリプトはシステム上のすべての SCSI バスをスキャンし、SCSI レイヤーを更新して、バス上の新しいデバイスが反映されます。このスクリプトは、デバイスの削除と LIP の発行を可能にする追加のオプションを提供します。既知の問題など、このスクリプトの詳細は、38章論理ユニットの rescan-scsi-bus.sh の追加/削除 を参照してください。 - echo "- - -" > /sys/class/scsi_host/hosth/scan
- これは、31章ストレージデバイスまたはパスの追加 で説明されているコマンドと同じで、ストレージデバイスまたはパスを追加します。ただし、この場合は、チャンネル番号、SCSI ターゲット ID、および LUN の値はワイルドカードに置き換えられます。識別子とワイルドカードの組み合わせが許可されるため、必要に応じてコマンドを詳細または広範囲にすることができます。この手順では LUN を追加しますが、削除しません。
- modprobe --remove driver-name, modprobe driver-name
- modprobe --remove driver-name コマンドを実行して、modprobe driver-name コマンドにより、ドライバーが制御するすべての相互接続の状態を完全に再初期化します。極端な場合もありますが、上記のコマンドは特定の状況に適しています。別のモジュールパラメーター値を使用して、ドライバーを再起動する場合など、コマンドを使用できます。
第35章 iSCSI オフロードおよびインターフェースバインディングの設定
ping -I ethX target_IP
$ ping -I ethX target_IP35.1. 利用可能な iface 設定の表示
- ソフトウェア iSCSI ( scsi_tcp モジュールおよび ib_iser モジュールと同様)は、セッションごとに 1 つの接続とともに、セッションごとに iSCSI ホストインスタンス( scsi_hostなど)を割り当てます。これにより、
/sys/class_scsi_hostおよび/proc/scsiは、ログに記録した各接続/セッションの scsi_host を報告します。 - オフロード iSCSI (Chelsio cxgb3i、B roadx bnx2i および ServerEngines be2iscsi モジュールと同様)、このスタックは各 PCI デバイスに scsi_host を割り当てます。そのため、ホストバスアダプター上の各ポートは別の PCI デバイスとして表示され、HBA ポートごとに異なる scsi_host が表示されます。
/var/lib/iscsi/ifaces に iface 設定を入力する必要があります。
iface_name transport_name,hardware_address,ip_address,net_ifacename,initiator_name
iface_name transport_name,hardware_address,ip_address,net_ifacename,initiator_name| 設定 | 詳細 |
|---|---|
| iface_name | iface 設定名。 |
| transport_name | ドライバーの名前 |
| hardware_address | MAC アドレス |
| ip_address | このポートに使用する IP アドレス |
| net_iface_name | ソフトウェア iSCSI セッションの vlan またはエイリアスバインディングに使用される名前。iSCSI オフロードの場合には、この値は再起動後も維持されないため、net _iface_name は <empty> になります。 |
| initiator_name | この設定は、/etc/iscsi/initiatorname.iscsiで定義されているイニシエーターのデフォルト名をオーバーライドするために使用されます。 |
例35.1 iscsiadm -m iface コマンドの出力例
iface0 qla4xxx,00:c0:dd:08:63:e8,20.15.0.7,default,iqn.2005-06.com.redhat:madmax iface1 qla4xxx,00:c0:dd:08:63:ea,20.15.0.9,default,iqn.2005-06.com.redhat:madmax
iface0 qla4xxx,00:c0:dd:08:63:e8,20.15.0.7,default,iqn.2005-06.com.redhat:madmax
iface1 qla4xxx,00:c0:dd:08:63:ea,20.15.0.9,default,iqn.2005-06.com.redhat:madmax例35.2 iscsiadm -m iface output with a Chelsio network card
default tcp,<empty>,<empty>,<empty>,<empty> iser iser,<empty>,<empty>,<empty>,<empty> cxgb3i.00:07:43:05:97:07 cxgb3i,00:07:43:05:97:07,<empty>,<empty>,<empty>
default tcp,<empty>,<empty>,<empty>,<empty>
iser iser,<empty>,<empty>,<empty>,<empty>
cxgb3i.00:07:43:05:97:07 cxgb3i,00:07:43:05:97:07,<empty>,<empty>,<empty>iface.setting = value
iface.setting = value例35.3 Chelsio コンバージドモードでの iface 設定の使用
35.2. ソフトウェア iSCSI のペースの設定
iscsiadm -m iface -I iface_name --op=new
# iscsiadm -m iface -I iface_name --op=new
iscsiadm -m iface -I iface_name --op=update -n iface.setting -v hw_address
# iscsiadm -m iface -I iface_name --op=update -n iface.setting -v hw_address例35.4 Set MAC address of iface0
iface0 の MAC アドレス(hardware_address)を 00:0F:1F:92:6B:BF に設定するには、以下を実行します。
iscsiadm -m iface -I iface0 --op=update -n iface.hwaddress -v 00:0F:1F:92:6B:BF
# iscsiadm -m iface -I iface0 --op=update -n iface.hwaddress -v 00:0F:1F:92:6B:BF
default または iser は、iface 名として 使用しないでください。どちらの文字列も、後方互換性のために iscsiadm で使用される特殊な値です。default または iser という名前の 状態で手動で作成されると、後方互換性は無効になります。
35.3. iSCSI オフロードの該当設定
be2iscsi ドライバー(例: ServerEngines iSCSI HBA)を使用する ServerEngines デバイスの場合、IP アドレスは ServerEngines BIOS 設定画面に設定されます。
iscsiadm -m iface -I iface_name -o update -n iface.ipaddress -v target_IP
# iscsiadm -m iface -I iface_name -o update -n iface.ipaddress -v target_IP例35.5 Chelsio カードの iface IP アドレスの設定
cxgb3i.00:07:43:05:97:07に設定するには 、 以下を使用します。20.15.0.66
iscsiadm -m iface -I cxgb3i.00:07:43:05:97:07 -o update -n iface.ipaddress -v 20.15.0.66
# iscsiadm -m iface -I cxgb3i.00:07:43:05:97:07 -o update -n iface.ipaddress -v 20.15.0.66
35.4. ポータルへのペースのバインディング/選択解除
/var/lib/iscsi/ifaces の各 iface 設定の iface.transport 設定を確認します。次に、iscsiadm ユーティリティーは、検出されたポータルを iface .transport が tcp の任意の iface にバインドします。
iscsiadm -m discovery -t st -p target_IP:port -I iface_name -P 1
# iscsiadm -m discovery -t st -p target_IP:port -I iface_name -P 1
tcp に設定されないためです。そのため、Chelsio、Broadcom、および ServerEngines ポートの iface 設定は、検出されたポータルに手動でバインドする必要があります。
default を iface_name として使用します。
iscsiadm -m discovery -t st -p IP:port -I default -P 1
# iscsiadm -m discovery -t st -p IP:port -I default -P 1
iscsiadm -m node -targetname proper_target_name -I iface0 --op=delete[7]
# iscsiadm -m node -targetname proper_target_name -I iface0 --op=delete[7]iscsiadm -m node -I iface_name --op=delete
# iscsiadm -m node -I iface_name --op=delete
iscsiadm -m node -p IP:port -I iface_name --op=delete
# iscsiadm -m node -p IP:port -I iface_name --op=delete
/var/lib/iscsi/iface に iface 構成が定義されておらず、-I オプションが使用されていない場合、iscsiadm を使用すると、ネットワークサブシステムが特定のポータルで使用するデバイスを決定できます。
第36章 複数の LUN またはポータルを使用した iSCSI ターゲットのスキャン
iscsiadm -m session --rescan
# iscsiadm -m session --rescan
iscsiadm -m session -r SID --rescan[8]
# iscsiadm -m session -r SID --rescan[8]/var/lib/iscsi/nodes データベースの内容を上書きします。次に、/etc/iscsi/iscsid.conf の設定を使用して、このデータベースが再設定されます。ただし、セッションが現在ログインしており、使用中の場合にはこれは発生しません。
/var/lib/iscsi/nodes を上書きせずに新規ターゲット/ポータルを追加するには、以下のコマンドを使用します。
iscsiadm -m discovery -t st -p target_IP -o new
iscsiadm -m discovery -t st -p target_IP -o new
/var/lib/iscsi/nodes エントリーを削除するには、以下を使用します。
iscsiadm -m discovery -t st -p target_IP -o delete
iscsiadm -m discovery -t st -p target_IP -o delete
iscsiadm -m discovery -t st -p target_IP -o delete -o new
iscsiadm -m discovery -t st -p target_IP -o delete -o new
ip:port,target_portal_group_tag proper_target_name
ip:port,target_portal_group_tag proper_target_name例36.1 sendtargets コマンドの出力
10.16.41.155:3260,0 iqn.2001-05.com.equallogic:6-8a0900-ac3fe0101-63aff113e344a4a2-dl585-03-1
10.16.41.155:3260,0 iqn.2001-05.com.equallogic:6-8a0900-ac3fe0101-63aff113e344a4a2-dl585-03-1
iscsiadm --mode node --targetname proper_target_name --portal ip:port,target_portal_group_tag \ --login [9]
# iscsiadm --mode node --targetname proper_target_name --portal ip:port,target_portal_group_tag \ --login
[9]例36.2 完全な iscsiadm コマンド
iscsiadm --mode node --targetname \ iqn.2001-05.com.equallogic:6-8a0900-ac3fe0101-63aff113e344a4a2-dl585-03-1 \ --portal 10.16.41.155:3260,0 --login[9]
# iscsiadm --mode node --targetname \ iqn.2001-05.com.equallogic:6-8a0900-ac3fe0101-63aff113e344a4a2-dl585-03-1 \ --portal 10.16.41.155:3260,0 --login[9]第37章 オンライン論理ユニットのサイズ変更
37.1. ファイバーチャネル論理ユニットのサイズ変更
echo 1 > /sys/block/sdX/device/rescan
$ echo 1 > /sys/block/sdX/device/rescan
37.2. iSCSI 論理ユニットのサイズ変更
iscsiadm -m node --targetname target_name -R
# iscsiadm -m node --targetname target_name -R
iscsiadm -m node -R -I interface
# iscsiadm -m node -R -I interface- これは、コマンド echo "- - -" > /sys/class/scsi_host/host/scan と同じように新規デバイスをスキャンします( 36章複数の LUN またはポータルを使用した iSCSI ターゲットのスキャンを参照)。
- これは、new/modified 論理ユニットに再スキャンします。これは、コマンド echo 1 > /sys/block/sdX/device/rescan と同じように実行できます。このコマンドは、fibre-channel の論理ユニットの再スキャンに使用されるものと同じであることに注意してください。
37.3. マルチパスデバイスのサイズの更新
multipathd -k"resize map multipath_device"
# multipathd -k"resize map multipath_device"/dev/mapper 内のデバイスの対応するマルチパスエントリーです。マルチパスがシステムでどのように設定されているかに応じて、multipath_device は 2 つの形式のいずれかになります。
- mpathX。X は、デバイスの対応するエントリーです(例: mpath0)
- WWID(例: 3600508b400105e210000900000490000)
/etc/multipath.conf で) no_path_retry パラメーターを "queue" に設定し、デバイスへのアクティブなパスがない場合は、このコマンドを使用しないでください。
手順37.1 Corresponding Multipath デバイスのサイズ変更(Red Hat Enterprise Linux 5.0 - 5.2 で必須)
- 以下を使用して、マルチパスを設定したデバイスのデバイスマッパーテーブルをダンプします。dmsetup table multipath_device
- ダンプされたデバイスマッパーテーブルを table_name として保存し ます。このテーブルはリロードされ、後で編集されます。
- デバイスマッパーの表を確認します。各行の最初の 2 つの数字は、それぞれディスクの最初と終了セクターに対応します。
- デバイスマッパーのターゲットを一時停止します。dmsetup suspend multipath_device
- 先に保存したデバイスマッパーテーブル(例: table_name)を開きます。ディスク内で 512 バイトのセクター数を反映するために 2 番目の数(ディスク終了セクターなど)を変更します。たとえば、新規ディスクサイズが 2GB の場合は、2 番目の数を 4194304 に変更します。
- 変更したデバイスマッパー表を再読み込みします。dmsetup reload multipath_device table_name
- デバイスマッパーのターゲットを再開します。dmsetup resume multipath_device
37.4. オンライン論理ユニットの読み取りおよび書き込み状態の変更
blockdev --getro /dev/sdXYZ
# blockdev --getro /dev/sdXYZcat /sys/block/sdXYZ/ro 1 = read-only 0 = read-write
# cat /sys/block/sdXYZ/ro 1 = read-only 0 = read-write手順37.2 R/W 状態の変更
- デバイスを RO から R/W に移動するには、手順 2 を参照してください。デバイスを R/W から RO に移動するには、それ以上の書き込みが行われないようにします。これは、アプリケーションを停止するか、適切なアプリケーション固有のアクションを使用します。以下のコマンドを使用して、未処理の書き込み I/O がすべて完了していることを確認します。
blockdev --flushbufs /dev/device
# blockdev --flushbufs /dev/deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow device を希望のデザインレーターに置き換えます。デバイスマッパーマルチパスの場合、これはdev/mapperのデバイスのエントリーです。たとえば、/dev/mapper/mpath3 のようになります。 - ストレージデバイスの管理インターフェースを使用して、論理ユニットの状態を R/W から RO または RO から R/W に変更します。その手順は、アレイごとに異なります。詳細は、該当するストレージアレイベンダーのドキュメントを参照してください。
- デバイスの再スキャンを実行して、デバイスの R/W 状態のオペレーティングシステムのビューを更新します。デバイスマッパーのマルチパスを使用する場合には、そのデバイスマップを再読み込みするようにマルチパスを発行する前に、デバイスへの各パスに対してこの再スキャンを実行します。このプロセスについては、「論理ユニットの再スキャン」 で詳しく説明します。
37.4.1. 論理ユニットの再スキャン
echo 1 > /sys/block/sdX/device/rescan
# echo 1 > /sys/block/sdX/device/rescan例37.1 multipath -ll コマンドの使用
echo 1 > /sys/block/sdax/device/rescan echo 1 > /sys/block/sday/device/rescan echo 1 > /sys/block/sdaz/device/rescan echo 1 > /sys/block/sdba/device/rescan
# echo 1 > /sys/block/sdax/device/rescan
# echo 1 > /sys/block/sday/device/rescan
# echo 1 > /sys/block/sdaz/device/rescan
# echo 1 > /sys/block/sdba/device/rescan37.4.2. マルチパスデバイスの R/W 状態の更新
multipath -r
# multipath -r37.4.3. 資料
第38章 論理ユニットの rescan-scsi-bus.sh の追加/削除
sg3_utils パッケージは rescan-scsi-bus.sh スクリプトを提供し、必要に応じてホストの論理ユニット設定を自動的に更新できます(デバイスがシステムに追加された後)。rescan-scsi-bus.sh スクリプトでは、サポートされているデバイスで issue_lip も実行できます。このスクリプトの使用方法に関する詳細は、rescan-scsi-bus.sh --help を参照してください。
sg3_utils パッケージをインストールするには、yum install sg3_utils を実行します。
既知の問題(rescan-scsi-bus.sh)
rescan-scsi-bus.sh スクリプトを使用する場合は、以下の既知の問題に注意してください。
rescan-scsi-bus.shが適切に機能するには、LUN0 を最初にマッピングした論理ユニットである必要があります。rescan-scsi-bus.shは、LUN0 の場合、最初にマップされた論理ユニットのみを検出できます。--nooptscan オプションを使用する場合でも、最初にマップされた論理ユニットを検出する場合を除き、rescan-scsi-bus.shは、他の論理ユニットをスキャンできません。- 競合状態では、論理ユニットが初めてマッピングされている場合は、rescan
-scsi-bus.shを 2 回実行する必要があります。最初のスキャン中に、rescan-scsi-bus.shは LUN0 のみを追加します。その他の論理ユニットはすべて 2 つ目のスキャンに追加されます。 rescan-scsi-bus.shスクリプトのバグにより --remove オプションが使用される場合に、論理ユニットサイズの変更を認識するための機能が誤って実行されます。rescan-scsi-bus.shスクリプトは、ISCSI 論理ユニットの削除を認識しません。
第39章 リンクループ動作の変更
39.1. ファイバーチャンネル
dev_loss_tmo コールバックを実装している場合は、トランスポートの問題が検出されるとリンクを経由したデバイスへのアクセス試行がブロックされます。デバイスがブロックされているかどうかを確認するには、以下のコマンドを実行します。
cat /sys/block/device/device/state
$ cat /sys/block/device/device/stateblocked を返します。デバイスが正常に動作している場合、このコマンドは通常 running を返します。
手順39.1 リモートポートの状態の決定
- リモートポートの状態を確認するには、以下のコマンドを実行します。
cat /sys/class/fc_remote_port/rport-H:B:R/port_state
$ cat /sys/class/fc_remote_port/rport-H:B:R/port_stateCopy to Clipboard Copied! Toggle word wrap Toggle overflow - このコマンドは、リモートポート(そのポートからアクセスしたデバイスとともに)がブロックされると
Blockedを返します。リモートポートが正常に動作している場合、コマンドはOnlineを返します。 dev_loss_tmo秒以内に問題が解決されない場合、rport およびデバイスはブロックされず、そのデバイスで実行されているすべての I/O(そのデバイスに送信された新しい I/O とともに)は失敗します。
手順39.2 dev_loss_tmoの変更
dev_loss_tmoの値を変更するには、必要な値の echo をファイルに送信します。たとえば、dev_loss_tmoを 30 秒に設定するには、以下を実行します。echo 30 > /sys/class/fc_remote_port/rport-H:B:R/dev_loss_tmo
$ echo 30 > /sys/class/fc_remote_port/rport-H:B:R/dev_loss_tmoCopy to Clipboard Copied! Toggle word wrap Toggle overflow
dev_loss_tmo の詳細は、「ファイバーチャネル API」 を参照してください。
dev_loss_tmo を超えると、scsi_device デバイスおよび sdN デバイスが削除されます。ターゲットポートの SCSI ID バインディングが保存されます。ターゲットが返されると、SCSI アドレスおよび sdN割り当てが変更される可能性があります。LUN 設定がターゲットポートの背後で変更された場合は、SCSI アドレスが変更されます。sdN 名は、LUN 検出プロセスのタイミングのバリエーションや、ストレージ内で LUN 設定の変更により変化する可能性があります。これらの割り当ては、28章永続的な命名 に記載されているように永続されません。永続的なデバイスの命名方法は、28章永続的な命名 セクションを参照してください。
39.2. dm-multipathを使用した iSCSI 設定
/etc/multipath.conf の device { に以下の行をネストします。
features "1 queue_if_no_path"
features "1 queue_if_no_path"
39.2.1. NOP-Out Interval/Timeout
/etc/iscsi/iscsid.conf を開き、以下の行を編集します。
node.conn[0].timeo.noop_out_interval = [interval value]
node.conn[0].timeo.noop_out_interval = [interval value]/etc/iscsi/iscsid.conf を開き、以下の行を編集します。
node.conn[0].timeo.noop_out_timeout = [timeout value]
node.conn[0].timeo.noop_out_timeout = [timeout value]SCSI エラーハンドラー
iscsiadm -m session -P 3
# iscsiadm -m session -P 339.2.2. replacement_timeout
/etc/iscsi/iscsid.conf を開き、以下の行を編集します。
node.session.timeo.replacement_timeout = [replacement_timeout]
node.session.timeo.replacement_timeout = [replacement_timeout]/etc/multipath.conf の 1 つの queue_if_no_path オプションは、iSCSI タイマーを直ちにマルチパスレイヤーに遅延させるように設定します( 「dm-multipathを使用した iSCSI 設定」を参照)。この設定により、I/O エラーがアプリケーションに伝搬されないようにします。これにより replacement_timeout を 15-20 秒に設定することができます。
/etc/iscsi/iscsid.conf ではなく、/etc/multipath.conf の設定に基づいて内部 I/O をキューに入れます。
39.3. iSCSI ルート
/etc/iscsi/iscsid.conf を開き、以下のように編集します。
node.conn[0].timeo.noop_out_interval = 0 node.conn[0].timeo.noop_out_timeout = 0
node.conn[0].timeo.noop_out_interval = 0
node.conn[0].timeo.noop_out_timeout = 0
/etc/iscsi/iscsid.conf を開き、以下の行を編集します。
node.session.timeo.replacement_timeout = replacement_timeout
node.session.timeo.replacement_timeout = replacement_timeout/etc/iscsi/iscsid.conf の設定後に、影響を受けるストレージの再検索を実行する必要があります。これにより、システムが /etc/iscsi/iscsid.conf の新しい値を読み込み、使用できます。iSCSI デバイスの検出方法に関する詳細は、36章複数の LUN またはポータルを使用した iSCSI ターゲットのスキャン を参照してください。
特定のセッションのタイムアウトの設定
/etc/iscsi/iscsid.confを使用する代わりに)非永続的なものにすることもできます。それを行うには、以下のコマンドを実行します(それに応じて変数を置き換えます)。
iscsiadm -m node -T target_name -p target_IP:port -o update -n node.session.timeo.replacement_timeout -v $timeout_value
# iscsiadm -m node -T target_name -p target_IP:port -o update -n node.session.timeo.replacement_timeout -v $timeout_value第40章 SCSI コマンドタイマーおよびデバイスステータスの制御
- コマンドの中止
- デバイスのリセット
- バスのリセット
- ホストをリセットします。
デバイスの状態
cat /sys/block/device-name/device/state
$ cat /sys/block/device-name/device/stateecho running > /sys/block/device-name/device/state
$ echo running > /sys/block/device-name/device/stateコマンドタイマー
/sys/block/device-name/device/timeout に書き込むことができます。これを行うには、以下を実行します。
第41章 オンラインストレージ設定のトラブルシューティング
- 論理ユニットの削除ステータスは、ホストに反映されません。
- 設定されたファイルャーで論理ユニットが削除されると、その変更はホストに反映されません。このような場合は、論理ユニットが 古い 状態になっていたため、dm-multipath が使用されたときに lvm コマンドが無期限にハングします。これを回避するには、以下の手順を行います。
手順41.1 Around Stale 論理ユニット
/etc/lvm/cache/.cacheのどの mpath リンクエントリーが古い論理ユニットに固有のものであるかを判断します。これを実行するには、以下のコマンドを実行します。ls -l /dev/mpath | grep stale-logical-unit
$ ls -l /dev/mpath | grep stale-logical-unitCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例41.1 特定の mpath リンクエントリーの特定
たとえば、stale-logical-unit が 3600d0230003414f30000203a7bc41a00 の場合、以下のような結果が表示されます。lrwxrwxrwx 1 root root 7 Aug 2 10:33 /3600d0230003414f30000203a7bc41a00 -> ../dm-4 lrwxrwxrwx 1 root root 7 Aug 2 10:33 /3600d0230003414f30000203a7bc41a00p1 -> ../dm-5
lrwxrwxrwx 1 root root 7 Aug 2 10:33 /3600d0230003414f30000203a7bc41a00 -> ../dm-4 lrwxrwxrwx 1 root root 7 Aug 2 10:33 /3600d0230003414f30000203a7bc41a00p1 -> ../dm-5Copy to Clipboard Copied! Toggle word wrap Toggle overflow これは 3600d0230003414f30000203a7bc41a00 が dm-4 と dm -5 の 2 つの mpath リンクにマッピングされることを意味します。- 次に、
/etc/lvm/cache/.cacheを開きます。stale-logical-unit が含まれるすべての行と、stale-logical-unit がマップする mpath リンクをすべて削除します。例41.2 関連する行の削除
直前の手順で同じ例を使用して、削除する必要のある行は以下のとおりです。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
付録A 改訂履歴
| 改訂履歴 | ||||
|---|---|---|---|---|
| 改訂 2-82 | Mon Jun 4 2018 | |||
| ||||
| 改訂 2-81 | Wed Mar 21 2018 | |||
| ||||
| 改訂 2-70 | Mon Mar 13 2017 | |||
| ||||
| 改訂 2-64 | Thu May 10 2016 | |||
| ||||
| 改訂 2-63 | Thu Mar 31 2016 | |||
| ||||
| 改訂 2-52 | Wed Mar 25 2015 | |||
| ||||
| 改訂 2-51 | Thu Oct 9 2014 | |||
| ||||
| 改訂 2-38 | Mon Nov 18 2013 | |||
| ||||
| 改訂 2-35 | Thu Sep 05 2013 | |||
| ||||
| 改訂 2-11 | Mon Feb 18 2013 | |||
| ||||
| 改訂 2-1 | Fri Oct 19 2012 | |||
| ||||
| 改訂 1-45 | Mon Jun 18 2012 | |||
| ||||