可観測性
詳細は、可観測性サービスを有効にしてカスタマイズし、マネージドクラスターを最適化する方法を参照してください。
概要
第1章 環境の監視の紹介
可観測性サービスを有効にすると、Red Hat Advanced Cluster Management for Kubernetes を使用して、マネージドクラスターに関する理解を深め、最適化することができます。この情報は、コストを節約し、不要なイベントを防ぐことができます。
1.1. 環境の監視
Red Hat Advanced Cluster Management for Kubernetes を使用して、マネージドクラスターに関する理解を深め、最適化することができます。可観測性サービス Operator (multicluster-observability-operator) を有効化して、マネージドクラスターの状態を監視します。以下のセクションでは、マルチクラスター可観測性サービスのアーキテクチャーについて説明します。
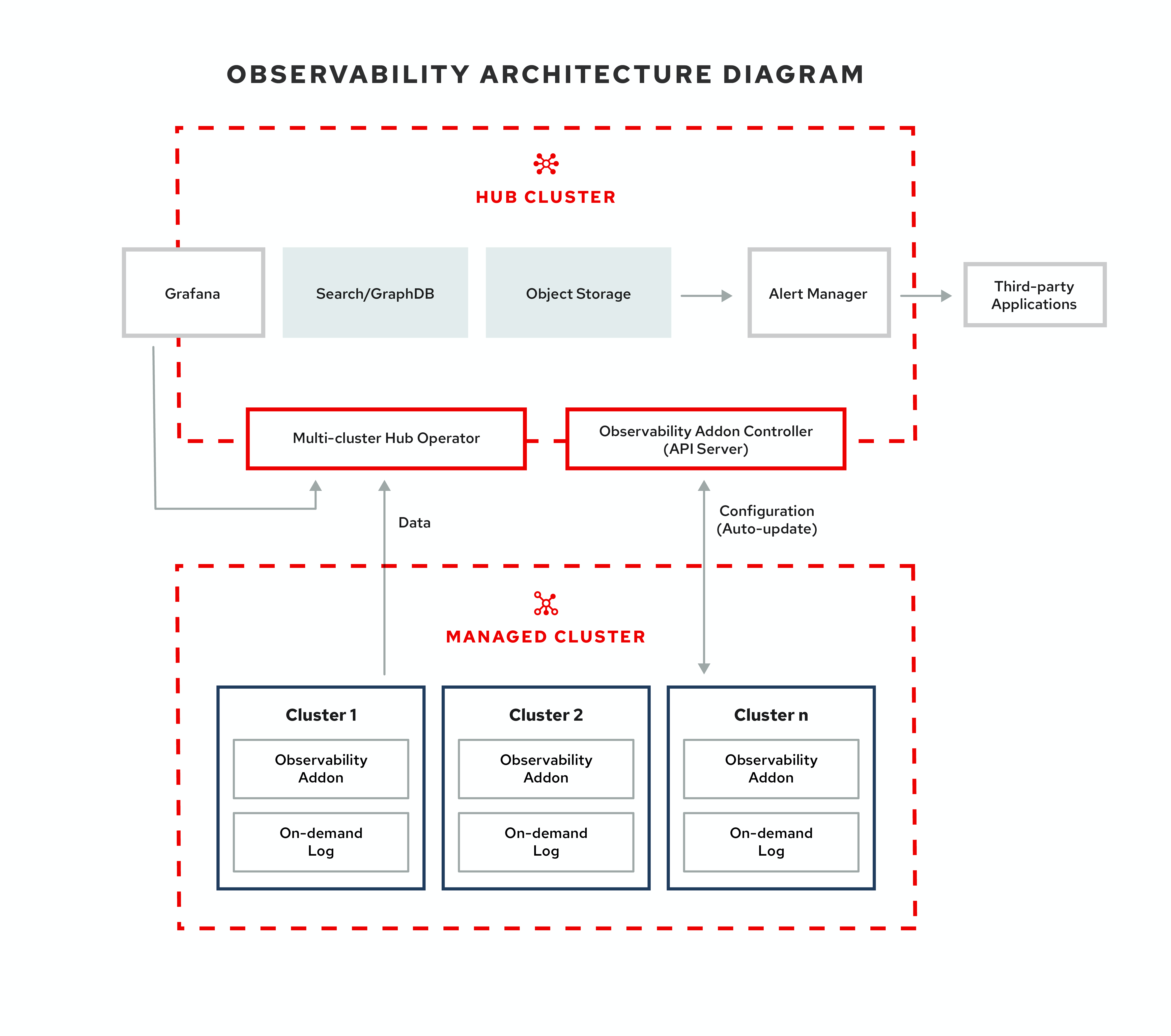
注記: オンデマンドログ は、特定 の Pod のログをリアルタイムで取得するエンジニア用のアクセスを提供します。ハブクラスターからのログは集約されません。これらのログは、検索サービスとコンソールの他の部分を使用してアクセスできます。
1.1.1. 可観測性サービス
デフォルトでは可観測性は、製品のインストール時に追加されますが、有効化されません。永続ストレージの要件で、可観測性サービスはデフォルトで有効化されていません。Red Hat Advanced Cluster Management は、以下の S3 互換のある、安定したオブジェクトストアをサポートします。
Amazon S3
注記: Thanos のオブジェクトストアインターフェースは、AWS S3 RESTFUL API 互換の API、または Minio や Ceph などのその他の S3 と互換のあるオブジェクトストアをサポートします。
- Google Cloud Storage
- Azure ストレージ
Red Hat OpenShift Container Storage
重要: オブジェクトストアを設定する場合は、機密データを永続化する時に必要な暗号化要件を満たすようにしてください。サポートされるオブジェクトストアの全一覧は、Thanos のドキュメント を参照してください。
サービスを有効にすると、observability-endpoint-operator はインポートまたは作成された各クラスターに自動的にデプロイされます。このコントローラーは、Red Hat OpenShift Container Platform Prometheus からデータを収集してから、Red Hat Advanced Cluster Management ハブクラスターに送信します。
ハブクラスターが local-cluster として自己インポートする場合は、可観測性もそのクラスターで有効になり、メトリクスがハブクラスターから収集されます。
注記: Red Hat Advanced Cluster Management では、metrics-collector は Red Hat OpenShift Container Platform 4.x クラスターでのみサポートされます。
可観測性サービスは、Prometheus AlertManager のインスタンスをデプロイすることで、サードパーティーのアプリケーションでのアラートの転送が可能になります。また、ダッシュボード (静的) またはデータ検索を使用してデータの可視化を有効にする Grafana のインスタンスも含まれます。Red Hat Advanced Cluster Management は、Grafana のバージョン 7.4.2 をサポートします。Grafana ダッシュボードを設計することもできます。詳細は、Grafana ダッシュボードの設計を参照してください。
カスタムの レコーディングルール または アラートルール を作成して、可観測性サービスをカスタマイズできます。
可観測性有効化の詳細は、「可観測性サービスの有効化」を参照してください。
1.1.2. メトリクスのタイプ
デフォルトで、OpenShift Container Platform は Telemetry サービスを使用してメトリクスを Red Hat に送信します。以下のメトリクスが Red Hat Advanced Cluster Management に追加され、テレメトリーに同梱されていますが、Red Hat Advanced Cluster Management Observe 環境の概要 ダッシュボードには表示されません。
-
visual_web_terminal_sessions_totalはハブクラスターで収集されます。 -
acm_managed_cluster_infoは、各マネージドクラスターで収集され、ハブクラスターに送信されます。
OpenShift Container Platform ドキュメントで、Telemetry を使用して収集されて送信されるメトリクスのタイプについて確認します。詳細は、Telemetry で収集される情報 を参照してください。
1.1.3. 可観測性 Pod の容量要求
可観測性サービスをインストールするには、可観測性コンポーネントで 2701mCPU および 11972Mi のメモリーが必要です。以下の表は、observability-addons が有効なマネージドクラスター 5 台の Pod 容量要求の一覧です。
| デプロイメントまたは StatefulSet | コンテナー名 | CPU (mCPU) | メモリー (Mi) | レプリカ | Pod の合計 CPU | Pod の合計メモリー |
|---|---|---|---|---|---|---|
| observability-alertmanager | Alertmanager | 4 | 200 | 3 | 12 | 600 |
| config-reloader | 4 | 25 | 3 | 12 | 75 | |
| alertmanager-proxy | 1 | 20 | 3 | 3 | 60 | |
| observability-grafana | grafana | 4 | 100 | 2 | 8 | 200 |
| grafana-dashboard-loader | 4 | 50 | 2 | 8 | 100 | |
| observability-observatorium-api | observatorium-api | 20 | 128 | 2 | 40 | 256 |
| observability-observatorium-operator | observatorium-operator | 100 | 100 | 1 | 10 | 50 |
| observability-rbac-query-proxy | rbac-query-proxy | 20 | 100 | 2 | 40 | 200 |
| oauth-proxy | 1 | 20 | 2 | 2 | 40 | |
| observability-thanos-compact | thanos-compact | 100 | 512 | 1 | 100 | 512 |
| observability-thanos-query | thanos-query | 300 | 1024 | 2 | 600 | 2048 |
| observability-thanos-query-frontend | thanos-query-frontend | 100 | 256 | 2 | 200 | 512 |
| observability-thanos-query-frontend-memcached | Memcached CRD | 45 | 128 | 3 | 135 | 384 |
| exporter | 5 | 50 | 3 | 15 | 150 | |
| observability-thanos-receive-controller | thanos-receive-controller | 4 | 32 | 1 | 4 | 32 |
| observability-thanos-receive-default | thanos-receive | 300 | 512 | 3 | 900 | 1536 |
| observability-thanos-rule | thanos-rule | 50 | 512 | 3 | 150 | 1536 |
| configmap-reloader | 4 | 25 | 3 | 12 | 75 | |
| observability-thanos-store-memcached | Memcached CRD | 45 | 128 | 3 | 135 | 384 |
| exporter | 5 | 50 | 3 | 15 | 150 | |
| observability-thanos-store-shard | thanos-store | 100 | 1024 | 3 | 300 | 3072 |
1.1.4. 可観測性サービスで使用される永続ストア
Red Hat Advanced Cluster Management をインストールするときは、次の永続ボリューム (PV) を作成して、Persistent Volume Claims (PVC) を自動的にアタッチできるようにする必要があります。デフォルトのストレージクラスが指定されていない場合、またはデフォルト以外のストレージクラスを使用して PV をホストする場合は、MultiClusterObservability でストレージクラスを定義する必要があります。Prometheus が使用するものと同様に、ブロックストレージを使用することをお勧めします。また、alertmanager、thanos-compactor、thanos-ruler、thanos-receive-default、および thanos-store-shard の各レプリカには、独自の PV が必要です。次の表を参照します。
| 永続ボリューム名 | 目的 |
| Alertmanager |
Alertmanager は |
| thanos-compact | コンパクターは、処理の中間データとバケット状態キャッシュの保存にローカルのディスク領域が必要です。必要な領域は、下層にあるブロックサイズにより異なります。コンパクターには、すべてのソースブロックをダウンロードして、ディスクで圧縮ブロックを構築するために十分な領域が必要です。ディスク上のデータは、次回の再起動までに安全に削除でき、最初の試行でクラッシュループコンパクターの停止が解決されるはずです。ただし、次の再起動までにバケットの状態キャッシュを効果的に使用するためには、コンパクターの永続ディスクを用意することが推奨されます。 |
| thanos-rule |
thanos ruler は、固定の間隔でクエリーを発行して、選択したクエリー API に対して Prometheus 記録およびアラートルールを評価します。ルールの結果は、Prometheus 2.0 ストレージ形式でディスクに書き込まれます。このステートフルセットで保持されるデータの期間 (時間または日) は、API バージョンの |
| thanos-receive-default |
Thanos receiver は、受信データ (Prometheus リモート書き込みリクエスト) を受け入れて Prometheus TSDB のローカルインスタンスに書き込みます。TSDB ブロックは定期的に (2 時間)、長期的に保存および圧縮するためにオブジェクトストレージにアップロードされます。ローカルキャッシュを実行するこのステートフルセットで保持される期間 (時間または日) は、API バージョン |
| thanos-store-shard | これは、主に API ゲートウェイとして機能するため、大量のローカルディスク容量は必要ありません。これは、起動時に Thanos クラスターに参加して、アクセスできるデータを広告します。ローカルディスク上のすべてのリモートブロックに関する情報のサイズを小さく保ち、バケットと同期させます。このデータは通常、起動時間が長くなると、再起動時に安全に削除できます。 |
注記: 時系列の履歴データはオブジェクトストアに保存されます。Thanos は、オブジェクトストレージをメトリクスおよび関連するメタデータのプライマリーストレージとして使用します。オブジェクトストレージおよび downsampling 機能の詳細は、「可観測性サービスの有効化」を参照してください。
1.1.5. サポート
Red Hat Advanced Cluster Management は、Red Hat OpenShift Container Storage でテストされ、完全にサポートされます。
Red Hat Advanced Cluster Management は、S3 API と互換性のあるユーザー提供のオブジェクトストレージにおけるマルチクラスター可観測性 Operator の機能をサポートします。
Red Hat Advanced Cluster Management はビジネス的に妥当な範囲内で、根本原因の特定を支援します。
サポートチケットが発行され、根本的な原因がお客様が提供したS3互換オブジェクトストレージの結果であると判断された場合は、カスタマーサポートチャネルを使用して問題を解決する必要があります。
Red Hat Advanced Cluster Management は、お客様が起票したサポートチケットの根本的な原因が S3 互換性のあるオブジェクトストレージプロバイダーである場合に、問題修正サポートの確約はありません。
1.2. 可観測性サービスの有効化
可観測性サービス (multicluster-observability-operator) でマネージドクラスターの状態を監視します。
必要なアクセス権限: クラスターの管理者または open-cluster-management:cluster-manager-admin ロール。
1.2.1. 前提条件
- Red Hat Advanced Cluster Management for Kubernetes がインストールされている。詳細は、「ネットワーク接続時のオンラインインストール」を参照してください。
ストレージソリューションを作成するようにオブジェクトストアが設定されている。Red Hat Advanced Cluster Management は、安定したオブジェクトストアで以下のクラウドプロバイダーをサポートします。
- Amazon Web Services S3 (AWS S3)
- Red Hat Ceph(S3 互換 API)
- Google Cloud Storage
- Azure ストレージ
- Red Hat OpenShift Container Storage
Red Hat OpenShift on IBM(ROKS)
重要: オブジェクトストアを設定する場合は、機密データを永続化する時に必要な暗号化要件を満たすようにしてください。Thanos がサポートするオブジェクトストアの詳細は、Thanos のドキュメント を参照してください。
1.2.2. 可観測性の有効化
MultiClusterObservability カスタムリソース (CR) を作成して可観測性サービスを有効にします。可観測性を有効にする前に、「可観測性 Pod の容量要求」を参照してください。可観測性サービスを有効にするには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ハブクラスターにログインします。
以下のコンマを使用して可観測性サービスの namespace を作成します。
oc create namespace open-cluster-management-observability
oc create namespace open-cluster-management-observabilityCopy to Clipboard Copied! Toggle word wrap Toggle overflow プルシークレットを生成します。Red Hat Advanced Cluster Management が
open-cluster-managementnamespace に インストールされている場合は、以下のコマンドを実行します。DOCKER_CONFIG_JSON=`oc extract secret/multiclusterhub-operator-pull-secret -n open-cluster-management --to=-`
DOCKER_CONFIG_JSON=`oc extract secret/multiclusterhub-operator-pull-secret -n open-cluster-management --to=-`Copy to Clipboard Copied! Toggle word wrap Toggle overflow multiclusterhub-operator-pull-secretが namespace に定義されていない場合には、pull-secretをopenshift-confignamespace からopen-cluster-management-observabilitynamespace にコピーします。以下のコマンドを実行します。DOCKER_CONFIG_JSON=`oc extract secret/pull-secret -n openshift-config --to=-`
DOCKER_CONFIG_JSON=`oc extract secret/pull-secret -n openshift-config --to=-`Copy to Clipboard Copied! Toggle word wrap Toggle overflow 次に
open-cluster-management-observabilitynamespace でプルリクエストを作成して、以下のコマンドを実行します。oc create secret generic multiclusterhub-operator-pull-secret \ -n open-cluster-management-observability \ --from-literal=.dockerconfigjson="$DOCKER_CONFIG_JSON" \ --type=kubernetes.io/dockerconfigjsonoc create secret generic multiclusterhub-operator-pull-secret \ -n open-cluster-management-observability \ --from-literal=.dockerconfigjson="$DOCKER_CONFIG_JSON" \ --type=kubernetes.io/dockerconfigjsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow お使いのクラウドプロバイダーのオブジェクトストレージのシークレットを作成します。シークレットには、ストレージソリューションへの認証情報を追加する必要があります。たとえば、以下のコマンドを実行します。
oc create -f thanos-object-storage.yaml -n open-cluster-management-observability
oc create -f thanos-object-storage.yaml -n open-cluster-management-observabilityCopy to Clipboard Copied! Toggle word wrap Toggle overflow サポートされるオブジェクトストアのシークレットの例を以下に示します。
Red Hat Advanced Cluster Management では、以下のファイルのようになります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Amazon S3 または S3 と互換性のある場合には、シークレットは以下のファイルのようになります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 詳細は、『Amazon Simple Storage Service ユーザーガイド』を参照してください。
Google の場合は、以下のファイルのようになります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 詳細は、「Google Cloud Storage とは」を参照してください。
Azure の場合は、以下のファイルのようになります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 詳細は、Azure Storage のドキュメント を参照してください。
注記: Azure を Red Hat OpenShift Container Platform クラスターのオブジェクトストレージとして使用する場合、クラスターに関連付けられたストレージアカウントはサポートされません。新規のストレージアカウントを作成する必要があります。
Red Hat OpenShift Container Storage では、以下のファイルのようになります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 詳細は、「 Red Hat OpenShift Container Storage 」を参照してください。
Red Hat OpenShift on IBM (ROKS) では、シークレットは以下のファイルのようになります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 詳細は、IBM Cloud のドキュメント「Cloud Object Storage」を参照してください。サービスの認証情報を使用してオブジェクトストレージに接続するようにしてください。詳細は、IBM Cloud のドキュメント、Cloud Object Store および Service Credentials を参照してください。
以下のコマンドを使用して、クラウドプロバイダーの S3 アクセスキーおよびシークレットキーを取得できます。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
シークレットの base64 文字列のデコード、編集、エンコードが必要です。
1.2.2.1. MultiClusterObservability CR の作成
以下の手順を実行して、マネージドクラスターの MultiClusterObservability カスタムリソース (CR) を作成します。
multiclusterobservability_cr.yamlという名前のMultiClusterObservabilityカスタムリソースの YAML ファイルを作成します。可観測性については、以下のデフォルト YAML ファイルを確認してください。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow advancedセクションでretentionConfigパラメーターの値を変更する必要がある場合があります。詳細は、Thanos Downsampling resolution and retention を参照してください。マネージドクラスターの数によっては、ステートフルセットのストレージ容量を更新する必要がある場合があります。詳細は、「Observability API」を参照してください。インフラストラクチャーマシンセットにデプロイするには、
MultiClusterObservabilityYAML のnodeSelectorを更新して、セットのラベルを設定する必要があります。YAML の内容は以下のようになります。nodeSelector: node-role.kubernetes.io/infra:nodeSelector: node-role.kubernetes.io/infra:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 詳細は、「インフラストラクチャーマシンセットの作成」を参照してください。
以下のコマンドを実行して可観測性 YAML をクラスターに適用します。
oc apply -f multiclusterobservability_cr.yaml
oc apply -f multiclusterobservability_cr.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Thanos、Grafana および AlertManager の
open-cluster-management-observabilitynamespace に全 Pod を作成します。Red Hat Advanced Cluster Management ハブクラスターに接続されたマネージドクラスターはすべて、メトリクスを Red Hat Advanced Cluster Management の可観測性サービスに送信できます。可観測性サービスが有効になっていることを確認するには、Grafana ダッシュボードを起動して、データが追加されていることを確認します。以下の手順を実行します。
- Red Hat Advanced Cluster Management コンソールにログインします。
- ナビゲーションメニューから Home > Overview の順に選択します。
コンソールヘッダーの近くにある Grafana リンクをクリックして、マネージドクラスターからメトリクスを表示します。
注記: 可観測性データを収集しないように特定のマネージドクラスターを除外するには、クラスターに
observability: disabledのクラスターラベルを追加します。
可観測性サービスを有効化します。可観測性サービスを有効にしたら、以下の機能が開始されます。
- マネージドクラスターからのアラートマネージャーはすべて、Red Hat Advanced Cluster Management ハブクラスターに転送されます。
Red Hat Advanced Cluster Management ハブクラスターに接続されたマネージドクラスターはすべて、アラートを Red Hat Advanced Cluster Management の可観測性サービスに送信できます。Red Hat Advanced Cluster Management Alertmanager を設定して、重複を排除してグループ化し、アラートをメール、PagerDuty、または OpsGenie などの適切なレシーバー統合にルーティングすることができます。アラートの通知解除や抑制にも対応できます。
注記: Red Hat Advanced Cluster Management ハブクラスター機能へのアラート転送は、Red Hat OpenShift Container Platform バージョン 4.8 以降のマネージドクラスターでのみサポートされます。可観測性を有効にして Red Hat Advanced Cluster Management をインストールすると、OpenShift Container Platform v4.8 以降のアラートは自動的にハブクラスターに転送されます。
詳細は、「送信アラート」を参照してください。
1.2.3. Red Hat OpenShift Container Platform コンソールからの可観測性の有効化
- Red Hat OpenShift Container Platform クラスターにログインします。
- ナビゲーションメニューから Home > Projects の順に選択します。
- Create Project ボタンをクリックします。プロジェクトの名前には、open-cluster-management-observability と入力する必要があります。
- Create をクリックします。
イメージのプルシークレットを作成します。
-
open-cluster-management-observabilityプロジェクトで、multiclusterhub-operator-pull-secretという名前のイメージプルシークレットを作成します。OpenShift Container Platform コンソールナビゲーションメニューで、Workloads > Secrets を選択します。 - Create button > Image Pull Secret の順に選択します。
- Create Image Pul Secret フォームに入力し、Create をクリックします。
-
open-cluster-management-observabilityプロジェクトにthanos-object-storageという名前のオブジェクトストレージシークレットを作成します。以下の例では、可観測性サービスの Amazon S3 オブジェクトストレージシークレットを作成します。- OpenShift Container Platform ナビゲーションメニューで、Workloads > Secrets を選択します。
- Create button > From YAML の順にクリックします。
オブジェクトストレージシークレットの詳細を入力し、Create をクリックします。
注記: 可観測性の有効化 セクションの手順 4 を参照して、シークレットの例を確認してください。
MultiClusterObservabilityCR を作成します。- OpenShift Container Platform ナビゲーションメニューから Home > Explore を選択します。
-
MultiClusterObservability にクエリーを行い、
MultiClusterObservabilityAPI リソースを検索します。 -
バージョン
v1beta2のMultiClusterObservabilityを選択して、リソースの詳細を表示します。 - Instances タブを選択し、Create MultiClusterObservability ボタンをクリックします。
-
MultiClusterObservabilityインスタンスの詳細を入力してから Createをクリックします。 -
Conditions セクションを表示して
MultiClusterObservabilityインスタンスのステータスを確認します。Observability components are deployed and runningのメッセージが表示されたら、obseravbility サービスが正常に有効化されています。
OpenShift Container Platform コンソールから可観測性を有効にしました。
1.2.3.1. 外部メトリクスクエリーの使用
可観測性には、外部 API があり、OpenShift ルート (rbac-query-proxy) を使用してメトリクスをクエリーできます。以下のタスクを確認して、rbac-query-proxy ルートを使用します。
以下のコマンドを使用して、ルートの詳細を取得できます。
oc get route rbac-query-proxy -n open-cluster-management-observability
oc get route rbac-query-proxy -n open-cluster-management-observabilityCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
rbac-query-proxyルートにアクセスするには、OpenShift OAuth アクセストークンが必要です。トークンは、namespace 取得のパーミッションがあるユーザーまたはサービスアカウントと関連付ける必要があります。詳細は、ユーザーが所有する OAuth アクセストークンの管理 について参照してください。 デフォルトの CA 証明書を取得し、キー
tls.crtの内容をローカルファイルに保存します。以下のコマンドを実行します。oc -n openshift-ingress get secret router-certs-default -o jsonpath="{.data.tls\.crt}" | base64 -d > ca.crtoc -n openshift-ingress get secret router-certs-default -o jsonpath="{.data.tls\.crt}" | base64 -d > ca.crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下のコマンドを実行してメトリクスのクエリーを実行します。
curl --cacert ./ca.crt -H "Authorization: Bearer {TOKEN}" https://{PROXY_ROUTE_URL}/api/v1/query?query={QUERY_EXPRESSION}curl --cacert ./ca.crt -H "Authorization: Bearer {TOKEN}" https://{PROXY_ROUTE_URL}/api/v1/query?query={QUERY_EXPRESSION}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記:
TheQUERY_EXPRESSIONは標準の Prometheus クエリー式です。たとえば、cluster_infrastructure_providerメトリクスのクエリーには、前述したコマンドの URL をhttps://{PROXY_ROUTE_URL}/api/v1/query?query=cluster_infrastructure_providerの URL に置き換えます。詳細は、「prometheus のクエリー」を参照してください。rbac-query-proxyルートの証明書を置き換えることもできます。-
「証明書を生成するための OpenSSL コマンド」を参照して、証明書を作成します。
csr.cnfをカスタマイズする時に、DNS.1をrbac-query-proxyルートのホスト名に更新します。 以下のコマンドを実行して、生成された証明書を使用して
proxy-byo-caおよびproxy-byo-certシークレットを作成します。oc -n open-cluster-management-observability create secret tls proxy-byo-ca --cert ./ca.crt --key ./ca.key oc -n open-cluster-management-observability create secret tls proxy-byo-cert --cert ./ingress.crt --key ./ingress.key
oc -n open-cluster-management-observability create secret tls proxy-byo-ca --cert ./ca.crt --key ./ca.key oc -n open-cluster-management-observability create secret tls proxy-byo-cert --cert ./ingress.crt --key ./ingress.keyCopy to Clipboard Copied! Toggle word wrap Toggle overflow
-
「証明書を生成するための OpenSSL コマンド」を参照して、証明書を作成します。
1.2.4. 可観測性の無効化
可観測性 リソースをアンインストールして、可観測性サービスを無効にします。手順については、「コマンドを使用した MultiClusterHub インスタンスの削除」のステップ 1 を参照してください。
可観測性サービスのカスタマイズ方法の詳細は、「可観測性のカスタマイズ」を参照してください。
1.3. 可観測性のカスタマイズ
可観測性サービスが収集するデータのカスタマイズ、管理、および表示については、以下のセクションを参照してください。
must-gather コマンドで可観測性リソース用に作成される新規情報についてのログを収集します。詳細は、『トラブルシューティング』ドキュメントの「Must-gather」のセクションを参照してください。
1.3.1. カスタムルールの作成
Prometheus レコードルール および アラートルール を可観測性リソースに追加して、可観測性のインストール時のカスタムルールを作成できます。詳細は、Prometheus configuration を参照してください。
- レコードルールでは、必要に応じてコストの掛かる式を事前に計算するか、コンピュートできます。結果は新たな時系列のセットとして保存されます。
- アラートルールでは、アラートを外部サービスに送信する方法に基づいてアラート条件を指定する機能を提供します。
Prometheus でカスタムルールを定義してアラート条件を作成し、通知を外部メッセージングサービスに送信します。注記: カスタムルールを更新すると、observability-thanos-rule Pod は自動的に再起動されます。
カスタムルールを作成するには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ハブクラスターにログインします。
open-cluster-management-observabilitynamespace にthanos-ruler-custom-rulesという名前の ConfigMap を作成します。以下の例のように、キーはcustom_rules.yamlという名前を指定する必要があります。設定には、複数のルールを作成できます。デフォルトでは、同梱のアラートルールは
open-cluster-management-observabilitynamespace のthanos-ruler-default-rulesConfigMap に定義されます。たとえば、CPU の使用状況が定義値を超えた場合に通知するカスタムのアラートルールを作成できます。YAML の内容は以下のようになります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow thanos-ruler-custom-rulesConfigMap 内にカスタムの録画ルールを作成することもできます。たとえば、Pod のコンテナーメモリーキャッシュの合計を取得できるようにする記録ルールを作成することができます。YAML の内容は以下のようになります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記: これが最初の新規カスタムルールである場合には、すぐに作成されます。ConfigMap に変更が加えられると、設定は自動的に再読み込みされます。この設定は、
observability-thanos-rulerサイドカー内のconfig-reloadにより再読み込みされます。
アラートルールが適切に機能していることを確認するには、以下の手順を実行します。
- Grafana ダッシュボードにアクセスし、Explore アイコンをクリックします。
-
メトリクス の検索バーで、「
ALERTS」と入力してクエリーを実行します。システムにある現在保留中または実行状態にあるALERTSがすべて表示されます。 - アラートが表示されない場合は、ルールを再度表示して、式が正しいかどうかを確認します。
カスタムルールが作成されました。
1.3.2. AlertManager の設定
メール、Slack、PagerDuty などの外部メッセージングツールを統合し、AlertManager から通知を受信します。open-cluster-management-observability namespace で alertmanager-config シークレットを上書きして、統合を追加し、AlertManager のルートを設定します。以下の手順を実行して、カスタムのレシーバールールを更新します。
alertmanager-configシークレットからデータを抽出します。以下のコマンドを実行します。oc -n open-cluster-management-observability get secret alertmanager-config --template='{{ index .data "alertmanager.yaml" }}' |base64 -d > alertmanager.yamloc -n open-cluster-management-observability get secret alertmanager-config --template='{{ index .data "alertmanager.yaml" }}' |base64 -d > alertmanager.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下のコマンドを実行し、
alertmanager.yamlファイル設定を編集して保存します。oc -n open-cluster-management-observability create secret generic alertmanager-config --from-file=alertmanager.yaml --dry-run -o=yaml | oc -n open-cluster-management-observability replace secret --filename=-
oc -n open-cluster-management-observability create secret generic alertmanager-config --from-file=alertmanager.yaml --dry-run -o=yaml | oc -n open-cluster-management-observability replace secret --filename=-Copy to Clipboard Copied! Toggle word wrap Toggle overflow 更新したシークレットは以下の内容のようになります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
変更内容は、変更後すぐに適用されます。AlertManager の例については、prometheus/alertmanager を参照してください。
1.3.3. カスタムメトリクスの追加
metrics_list.yaml ファイルにメトリクスを追加して、マネージドクラスターから収集されるようにします。
カスタムメトリクスを追加するには、以下の手順を実行します。
- クラスターにログインします。
mco observabilityが有効化されていることを確認します。status.conditions.messageの メッセージがObservability components are deployed and runningとなっていることを確認します。以下のコマンドを実行します。oc get mco observability -o yaml
oc get mco observability -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下の内容で、
observability-metrics-custom-allowlist.yamlという名前のファイルを作成します。metrics_list.yamlパラメーターにカスタムメトリクスの記録ルールと名前を追加します。たとえば、マネージドクラスターからnode_memory_MemTotal_bytesおよびapiserver_request_duration_seconds:histogram_quantile_90を収集します。ConfigMap の YAML は、以下の内容のようになります。Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
namesセクションで、マネージドクラスターから収集されるカスタムメトリクスの名前を追加します。 -
rulesセクションで、exprおよびrecordパラメーターペアに値を 1 つだけ入力し、クエリー式を定義します。メトリクスは、マネージドクラスターのrecordパラメーターで定義される名前で収集されます。クエリー式の実行後の結果が、メトリクスの値として返されます。 -
namesとrulesセクションはオプションです。セクションのいずれかまたは両方を使用できます。
-
以下のコマンドを実行して、
open-cluster-management-observabilitynamespace にobservability-metrics-custom-allowlistConfigMap を作成します。oc apply -n open-cluster-management-observability -f observability-metrics-custom-allowlist.yaml
oc apply -n open-cluster-management-observability -f observability-metrics-custom-allowlist.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Grafana ダッシュボードでメトリクスを表示して、カスタムメトリクスがマネージドクラスターから収集されていることを確認します。ハブクラスターから、Grafana ダッシュボード のリンクを選択します。
- Grafana 検索バーから、表示するメトリクスを入力します。カスタムメトリクスからデータを収集します。
- 更新したメトリクスを Grafana ダッシュボードで使用する場合は、「Grafana ダッシュボードの設計」を参照してダッシュボードを更新します。
1.3.4. デフォルトメトリクスの削除
特定のメトリクス用にデータを収集しない場合は、observability-metrics-custom-allowlist.yaml ファイルからメトリクスを削除できます。メトリクスを削除すると、メトリクスも削除されます。メトリクス名の先頭にハイフン - を指定して、デフォルトのメトリクスの名前を metrics_list.yaml パラメーターに追加できます。
デフォルトのメトリクスを削除するには、以下の手順を実行します。
- クラスターにログインします。
mco observabilityが有効化されていることを確認します。status.conditions.messageの メッセージがObservability components are deployed and runningとなっていることを確認します。以下のコマンドを実行します。oc get mco observability -o yaml
oc get mco observability -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow observability-metrics-custom-allowlist.yamlファイルで、メトリクス名の先頭にハイフン-を指定してmetrics_list.yamlパラメーターにデフォルトメトリクスの名前を追加します。たとえば、-cluster_infrastructure_providerをメトリクス一覧に追加します。ConfigMap の YAML は、以下の内容のようになります。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下のコマンドを実行して、
open-cluster-management-observabilitynamespace にobservability-metrics-custom-allowlistConfigMap を作成します。oc apply -n open-cluster-management-observability -f observability-metrics-custom-allowlist.yaml
oc apply -n open-cluster-management-observability -f observability-metrics-custom-allowlist.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Grafana ダッシュボードでメトリクスを表示して、デフォルトメトリクスがマネージドクラスターから収集されていないことを確認します。ハブクラスターから、Grafana ダッシュボード のリンクを選択します。
- Grafana 検索バーから、確認するメトリクスを入力します。デフォルトのメトリクスからデータが収集されなくなります。
- 更新されたメトリクスが Grafana ダッシュボードで使用されている場合には、ConfigMap からメトリクスを削除できます。ConfigMap での Grafana ダッシュボードの設計 を参照して、ダッシュボードを更新します。
1.3.5. 詳細 設定の追加
詳細 設定セクションを追加して、可観測性コンポーネントごとの保持内容を更新できます。以下の手順を実行します。
- クラスターにログインします。
mco observabilityを編集します。以下のコマンドを実行します。oc edit mco observability -o yaml
oc edit mco observability -o yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 詳細設定をthemco observabilityYAML に追加します。YAML ファイルは以下の内容のようになります。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
詳細 設定に追加できるすべてのパラメーターの説明は、「Observability API」を参照してください。
1.3.6. コンソールからの multiclusterobservability CR レプリカの更新
ワークロードが増加する場合は、可観測性 Pod のレプリカ数を増やします。以下の手順を実行してレプリカを更新します。
- Red Hat Advanced Cluster Management クラスターにログインします。
- コンソールヘッダーから、Applications ボタン > OpenShift Container Platform をクリックします。
- OpenShift Container Platform ナビゲーションメニューから Administration > CustomerResourceDefinitions を選択します。
-
multiclusterobservabilityを検索します。 -
Instances タブで、
可観測性インスタンスを選択します。 YAML タブで YAML ファイルを編集します。更新した YAML は以下の内容のようになります。
spec: advanced: receive: replicas: 6spec: advanced: receive: replicas: 6Copy to Clipboard Copied! Toggle word wrap Toggle overflow これは、環境に 6 つのレシーバーがあることを意味します。
observability CR 内のパラメーターの詳細は、「Observability API」を参照してください。
1.3.7. アラートの転送
可観測性を有効にした後には、OpenShift Container Platform マネージドクラスターからのアラートは自動的にハブクラスターに送信されます。alertmanager-config YAML ファイルを使用して、外部通知システムでアラートを設定できます。alertmanager-config YAML ファイルにアクセスするには、以下の手順を実行します。
- 管理者として Red Hat Advanced Cluster Management ハブクラスターにログインします。
- ナビゲーションメニューから Infrastructure > Clusters の順に選択してマネージドクラスターを表示します。
- 表示するマネージドクラスターを選択します。
- Details タブで、OpenShift Container Platform Console URL のリンクを選択します。
OpenShift Container Platform ナビゲーションメニューで、Secrets を選択します。
alertmanager-configシークレットを選択し、YAML ファイルを表示します。注記:
alertmanager-configシークレットを変更する場合には、評価の間隔は約 1 分です。alertmanager-configYAML ファイルの例を以下に示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow アラート転送のプロキシーを設定する必要がある場合は、以下の
グローバルエントリーをalertmanager-configYAML ファイルに追加します。global: slack_api_url: '<slack_webhook_url>' http_config: proxy_url: http://****global: slack_api_url: '<slack_webhook_url>' http_config: proxy_url: http://****Copy to Clipboard Copied! Toggle word wrap Toggle overflow
詳細は、Prometheus Alertmanager のドキュメント を参照してください。
1.3.8. データの表示および展開
Grafana にアクセスして、マネージドクラスターからデータを表示します。コンソールから Grafana ダッシュボードを表示するには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ハブクラスターにログインします。
- ナビゲーションメニューから infrastructure > Clusters をクリックします。
- Grafana リンクをクリックして、Grafana ダッシュボードにアクセスします。
- Grafana ナビゲーションメニューから Explore アイコンを選択して、Prometheus メトリクスエクスプローラーにアクセスします。
単一ノードクラスターから提供されるメトリクスをクエリーするには、クエリー式
{clusterType="SNO"}にラベルを追加します。たとえば、単一ノードクラスターから cluster_infrastructure_provider をクエリーするには、以下のクエリー式cluster_infrastructure_provider{clusterType="SNO"}を使用します。注記: 単一ノードのマネージドクラスターで可観測性が有効になっている場合は、
ObservabilitySpec.resources.CPU.limitsパラメーターを設定しないでください。CPU 制限を設定すると、可観測性 Pod がマネージドクラスターの容量にカウントされます。詳細は、「管理ワークロードのパーティショニング」を参照してください。
1.3.8.1. etcd テーブルの表示
以下の手順を実行して、Grafana のハブクラスターダッシュボードから etcd テーブルを表示できます。
- Red Hat Advanced Cluster Management ハブクラスターにログインします。
- ナビゲーションメニューから Overview を選択します。Grafana のリンクをクリックします。
- ハブクラスターダッシュボードから etcd テーブルを表示し、マネージドクラスター全体の Leader election changes を確認します。
- 詳細を表示する個別のクラスターを選択します。
1.3.9. 可観測性の無効化
可観測性を無効にして、Red Hat Advanced Cluster Management ハブクラスターでデータ収集を停止します。
1.3.9.1. すべてのクラスターでの可観測性の無効化
すべてのマネージドクラスターで可観測性コンポーネントを削除して、可観測性を無効にします。
enableMetrics を false に設定して、multicluster-observability-operator リソースを更新します。更新されたリソースは、以下のような変更内容になります。
spec:
imagePullPolicy: Always
imagePullSecret: multiclusterhub-operator-pull-secret
observabilityAddonSpec: # The ObservabilityAddonSpec defines the global settings for all managed clusters which have observability add-on enabled
enableMetrics: false #indicates the observability addon push metrics to hub server
spec:
imagePullPolicy: Always
imagePullSecret: multiclusterhub-operator-pull-secret
observabilityAddonSpec: # The ObservabilityAddonSpec defines the global settings for all managed clusters which have observability add-on enabled
enableMetrics: false #indicates the observability addon push metrics to hub server1.3.9.2. 単一クラスターでの可観測性の無効化
以下のいずれかの手順を実行して、特定のマネージドクラスターの可観測性を無効にします。
-
managedclusters.cluster.open-cluster-management.ioのカスタムリソースにobservability: disabledラベルを追加します。 Red Hat Advanced Cluster Management コンソールの Clusters ページから、以下の手順を実行し、
observability: disabledラベルを追加します。- Red Hat Advanced Cluster Management コンソールで、infrastructure > Clusters を選択します。
- 可観測性に送信されるデータ収集を無効にするクラスターの名前を選択します。
- Labels を選択します。
以下のラベルを追加して、可観測性コレクションを無効にするラベルを作成します。
observability=disabled
observability=disabledCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Add を選択してラベルを追加します。
- Done を選択してラベルの一覧を閉じます。
注記: 可観測性コンポーネントが含まれるマネージドクラスターをデタッチすると、metrics-collector デプロイメントが削除されます。
可観測性サービスを使用したコンソールでのデータの監視に関する詳細は、「環境の監視の紹介」を参照してください。
1.4. Grafana ダッシュボードの設計
grafana-dev インスタンスを作成して、Grafana ダッシュボードを設計できます。
1.4.1. Grafana 開発者インスタンスの設定
まず、stolostron/multicluster-observability-operator/ リポジトリーのクローンを作成し、tools フォルダーにあるスクリプトを実行できるようにします。Grafana 開発者インスタンスを設定するには、以下の手順を実行します。
setup-grafana-dev.shを実行して、Grafana インスタンスを設定します。スクリプトを実行すると、secret/grafana-dev-config、deployment.apps/grafana-dev、service/grafana-dev、ingress.extensions/grafana-dev、persistentvolumeclaim/grafana-devのリソースが作成されます。Copy to Clipboard Copied! Toggle word wrap Toggle overflow switch-to-grafana-admin.shスクリプトを使用して、ユーザーロールを Grafana 管理者に切り替えます。-
Grafana の URL
https://$ACM_URL/grafana-dev/を選択して、ログインします。 次に、以下のコマンドを実行して、切り替えユーザーを Grafana 管理者として追加します。たとえば、
kubeadminを使用してログインしたら、以下のコマンドを実行します。./switch-to-grafana-admin.sh kube:admin User <kube:admin> switched to be grafana admin
./switch-to-grafana-admin.sh kube:admin User <kube:admin> switched to be grafana adminCopy to Clipboard Copied! Toggle word wrap Toggle overflow
-
Grafana の URL
Grafana 開発者インスタンを設定します。
1.4.2. Grafana ダッシュボードの設計
Grafana インスタンスを設定したら、ダッシュボードを設計できます。Grafana コンソールを更新し、ダッシュボードを設計するには、以下の手順を実行します。
- Grafana コンソールのナビゲーションパネルから Create アイコンを選択してダッシュボードを作成します。Dashboard を選択し、Add new panel をクリックします。
- New Dashboard/Edit Panel ビューで、Query タブを選択します。
-
データソースセレクターから
Observatoriumを選択し、PromQL クエリーを入力してクエリーを設定します。 - Grafana ダッシュボードヘッダーから、ダッシュボードヘッダーにある Save アイコンをクリックします。
- 説明的な名前を追加し、Save をクリックします。
1.4.2.1. ConfigMap での Grafana ダッシュボードの設計
ConfigMap で Grafana ダッシュボードを設計するには、以下の手順を実行します。
generate-dashboard-configmap-yaml.shスクリプトを使用してダッシュボードの ConfigMap を生成し、ローカルで ConfigMap を保存できます。./generate-dashboard-configmap-yaml.sh "Your Dashboard Name" Save dashboard <your-dashboard-name> to ./your-dashboard-name.yaml
./generate-dashboard-configmap-yaml.sh "Your Dashboard Name" Save dashboard <your-dashboard-name> to ./your-dashboard-name.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 前述のスクリプトを実行するパーミッションがない場合は、以下の手順を実行します。
- ダッシュボードを選択し、Dashboard 設定 アイコンをクリックします。
- ナビゲーションパネルから JSON Model アイコンをクリックします。
-
ダッシュボード JSON データをコピーし、
dataセクションに貼り付けます。 nameを、$your-dashboard-nameに置き換えます。ConfigMap は、以下のファイルのようになります。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記: ダッシュボードが General フォルダーにない場合は、この ConfigMap の
annotationsセクションにフォルダー名を指定できます。annotations: observability.open-cluster-management.io/dashboard-folder: Custom
annotations: observability.open-cluster-management.io/dashboard-folder: CustomCopy to Clipboard Copied! Toggle word wrap Toggle overflow ConfigMap の更新が完了したら、インストールしてダッシュボードを Grafana インスタンスにインポートできます。
1.4.3. Grafana 開発者インスタンスのアンインストール
インスタンスをアンインストールすると、関連するリソースも削除されます。以下のコマンドを実行します。
1.5. Red Hat Insights の可観測性
Red Hat Insights は、Red Hat Advanced Cluster Management 可観測性と統合されており、クラスター内の既存の問題や発生しうる問題を特定できるように有効化されています。Red Hat Insights は、安定性、パフォーマンス、ネットワーク、およびセキュリティーリスクの特定、優先順位付け、および解決に役立ちます。Red Hat OpenShift Container Platform は、OpenShift Cluster Manager を使用してクラスターのヘルスモニタリングを提供します。OpenShift Cluster Manager は、クラスターのヘルス、使用状況、サイズの情報を匿名で累積して収集します。詳細は、Red Hat Insights の製品ドキュメント を参照してください。
OpenShift クラスターを作成またはインポートすると、マネージドクラスターからの匿名データは自動的に Red Hat に送信されます。この情報を使用してクラスターのヘルス情報を提供する insights を作成します。Red Hat Advanced Cluster Management 管理者は、このヘルス情報を使用して重大度に基づいてアラートを作成できます。
必要なアクセス権限:: クラスターの管理者
1.5.1. 前提条件
- Red Hat Insights が有効になっていることを確認する。詳細は、グローバルクラスタープルシークレットの変更によるリモートヘルスレポートの無効化 を参照してください。
- OpenShift Container Platform バージョン 4.0 以降をインストールしておく。
- OpenShift Cluster Manager に登録されているハブクラスターユーザーが OpenShift Cluster Manager の全 Red Hat Advanced Cluster Management マネージドクラスターを管理できる。
1.5.2. Red Hat Advanced Cluster Management コンソールからの Red Hat Insights
以下で、統合に関する機能の説明を確認します。
- Clusters ページからクラスターを選択すると、Status カードから 特定された問題の数 を選択できます。Status カードには、ノード、アプリケーション、ポリシー違反 および 特定された問題 に関する情報が表示されます。Identified issues カードは、Red Hat Insights からの情報を表します。Identified issues のステータスには、重大度による問題数が表示されます。問題の対応レベルは、Critical、Major、Low および Warning の重大度に分類されます。
- 数字をクリックすると、Potential issue のサイドパネルが表示されます。パネルにすべての問題の概要およびチャートが表示されます。検索機能を使用して、推奨される修復を検索することもできます。修復オプションは、脆弱性の 説明、脆弱性に関連する カテゴリー、および 全体的なリスクを表示します。
- 説明 セクションから、脆弱性へのリンクを選択できます。How to remediate タブを選択して脆弱性を解決するための手順を表示します。Reason タブをクリックすると、脆弱性が発生した理由を確認することもできます。
詳細は、「Insight PolicyReportsの管理」を参照してください。
1.6. Insights PolicyReports の管理
Insight PolicyReports の管理および表示方法については、以下のセクションを参照してください。
1.6.1. Insight ポリシーレポートの検索
マネージドクラスター全体で、違反した特定の insight PolicyReport を検索できます。インストールポリシーレポートを検索するには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ハブクラスターにログインします。
- コンソールヘッダーの Search アイコンをクリックして Search ページに移動します。
-
Search ページから、
kind:policyreportというクエリーを入力します。 Enter を押すと、insight ポリシーレポートの表一覧が Policyreport セクションに表示されます。
注記:
PolicyReport名はクラスターの名前と同じになります。- また、クエリーは、insight ポリシー違反およびカテゴリー別にさらに指定することもできます。
-
PolicyReport名を選択すると、関連付けられたクラスターの Details ページにリダイレクトされます。Insights サイドバーが自動的に表示されます。 検索サービスが無効になり、insight を検索する必要がある場合は、ハブクラスターから以下のコマンドを実行します。
oc get policyreport --all-namespaces
oc get policyreport --all-namespacesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
1.6.2. コンソールから特定された問題の表示
以下の手順を実行して、特定のクラスターで脆弱性を表示できます。
- Red Hat Advanced Cluster Management クラスターにログインします。
- ナビゲーションメニューから Overview を選択します。クラスターの問題 の概要カードから、クラスターの問題と重要性の詳細を表示できます。
-
重大度を選択して、対象の重大度に関連付けられた
PolicyReportsを表示します。PolicyReportの詳細が表示される Search ページに移動します。 -
PolicyReport名を選択して、Clusters ページから insights に移動します。 - または、ナビゲーションメニューから Clusters を選択できます。
- テーブルからマネージドクラスターを選択して、詳細情報を表示します。
- Status カードから、特定された問題の数を表示します。
- 発生する可能性のある問題数を選択して、重大度チャートと、その問題に対して推奨される修復を表示します。
- 脆弱性へのリンクをクリックすると、「修復する方法」と脆弱性の「理由」の手順を表示します。
表示する脆弱性が他にある場合は、Back をクリックし発生する可能性のある問題の一覧を表示します。
注記: 問題の解決後には、Red Hat Advanced Cluster Management で Red Hat Insights の情報を30 分ごとに受信し、Red Hat Insights は 2 時間ごとに更新されます。
詳細は、AlertManager のルールの設定 について参照してください。