RHEL での AMQ Streams の使用
AMQ Streams 1.6 on Red Hat Enterprise Linux 向け
概要
第1章 AMQ Streams の概要
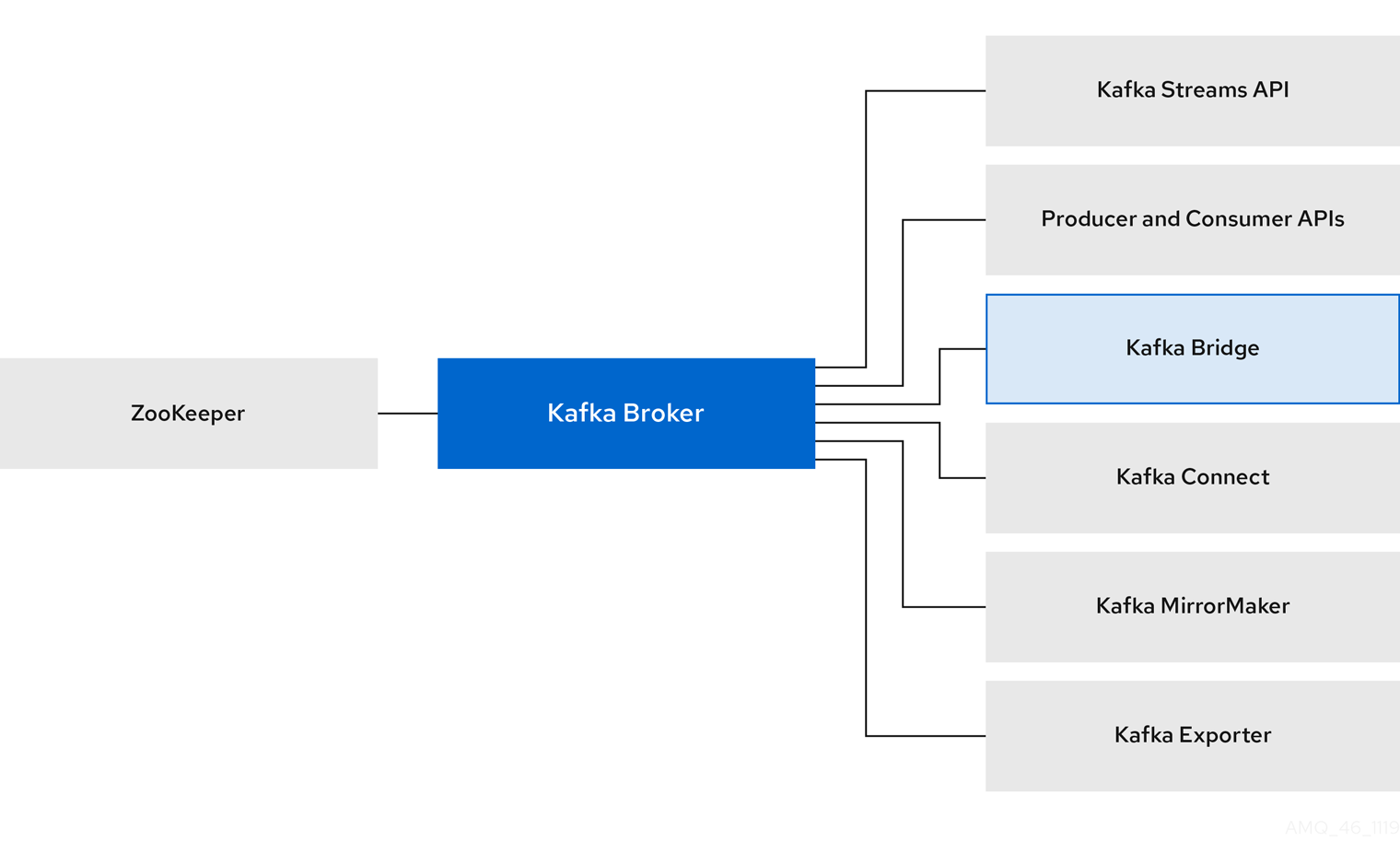
Red Hat AMQ Streams は、Apache ZooKeeper および Apache Kafka プロジェクトをベースとした、スケーラビリティーが高く、分散され、高パフォーマンスのデータストリーミングプラットフォームです。
主なコンポーネントは以下で構成されます。
- Kafka Broker
生成クライアントから消費側のクライアントにレコードを配信するメッセージングブローカー。
Apache ZooKeeper は Kafka のコア依存関係で、高信頼性の分散調整のためのクラスター調整サービスを提供します。
- Kafka Streams API
- ストリームプロセッサー アプリケーションを作成するための API。
- プロデューサーおよびコンシューマー API
- Kafka ブローカーとの間でメッセージを生成および消費するための Java ベースの API。
- Kafka Bridge
- AMQ Streams Kafka Bridge では、HTTP ベースのクライアントと Kafka クラスターとの対話を可能にする RESTful インターフェイスが提供されます。
- Kafka Connect
- Connector プラグインを使用して、Kafka ブローカーと他のシステム間でデータをストリーミングするツールキット。
- Kafka MirrorMaker
- データセンター内またはデータセンター全体の 2 つの Kafka クラスター間でデータをレプリケートします。
- Kafka Exporter
- 監視用に Kafka メトリクスデータの抽出に使用されるエクスポーター。
Kafka ブローカーのクラスターは、これらのすべてのコンポーネントを接続するハブです。ブローカーは、設定データの保存やクラスターの調整に Apache ZooKeeper を使用します。Apache Kafka の実行前に、Apache ZooKeeper クラスターを用意する必要があります。
図1.1 AMQ Streams のアーキテクチャー
1.1. Kafka の機能
Kafka の基盤のデータストリーム処理機能とコンポーネントアーキテクチャーによって以下が提供されます。
- スループットが非常に高く、レイテンシーが低い状態でデータを共有するマイクロサービスおよびその他のアプリケーション
- メッセージの順序の保証
- アプリケーションの状態を再構築するためにデータストレージからメッセージを巻き戻し/再生
- キーバリューログの使用時に古いレコードを削除するメッセージ圧縮
- クラスター設定での水平スケーラビリティー
- 耐障害性を制御するデータのレプリケーション
- 即時アクセス用の大量データの保持
1.2. Kafka のユースケース
Kafka の機能は、以下に適しています。
- イベント駆動型のアーキテクチャー
- アプリケーションの状態に加えられた変更をイベントのログとしてキャプチャーするイベントソーシング
- メッセージのブローカー
- Web サイトアクティビティーの追跡
- メトリクスによる運用上のモニタリング
- ログの収集および集計
- 分散システムのコミットログ
- アプリケーションがリアルタイムでデータに対応できるようにするストリーム処理
1.3. サポートされる構成
AMQ Streams をサポートされる構成で実行するには、以下の JVM バージョンの 1 つと、サポートされるオペレーティングシステムの 1 つで実行する必要があります。
| Java 仮想マシン | バージョン |
|---|---|
| OpenJDK | 1.8、11 |
| OracleJDK | 1.8 |
| IBM JDK | 1.8 |
| オペレーティングシステム | アーキテクチャー | バージョン |
|---|---|---|
| Red Hat Enterprise Linux | x86_64 | 7.x、8.x |
1.4. 本書の表記慣例
置き換え可能なテキスト
本書では、置き換え可能なテキストは、monospace フォントのイタリック体、大文字、およびハイフンで記載されています。
たとえば、以下のコードでは、BOOTSTRAP-ADDRESS および TOPIC-NAME を実際のアドレスおよびトピック名に置き換えます。
bin/kafka-console-consumer.sh --bootstrap-server BOOTSTRAP-ADDRESS --topic TOPIC-NAME --from-beginning
第2章 はじめに
2.1. AMQ Streams のディストリビューション
AMQ Streams は単一の ZIP ファイルとして配布されます。この ZIP ファイルには AMQ Streams コンポーネントが含まれます。
- Apache ZooKeeper
- Apache Kafka
- Apache Kafka Connect
- Apache Kafka MirrorMaker
- Kafka Bridge
- Kafka Exporter
2.2. AMQ Streams アーカイブのダウンロード
AMQ Streams のアーカイブディストリビューションは、Red Hat の Web サイトからダウンロードできます。以下の手順に従うと、ディストリビューションのコピーをダウンロードできます。
手順
- カスタマーポータル から、最新バージョンの Red Hat AMQ Streams アーカイブをダウンロードします。
2.3. AMQ Streams のインストール
以下の手順に従って、Red Hat Enterprise Linux に最新バージョンの AMQ Streams をインストールします。
既存のクラスターを AMQ Streams 1.6 にアップグレードする手順は、「 AMQ Streams および Kafka のアップグレード 」を参照してください。
前提条件
- インストールアーカイブ をダウンロードしている。
- レビュー: 「サポートされる構成」
手順
新しい
kafkaユーザーおよびグループを追加します。sudo groupadd kafka sudo useradd -g kafka kafka sudo passwd kafka
/opt/kafkaディレクトリーの作成sudo mkdir /opt/kafka
一時ディレクトリーを作成し、AMQ Streams ZIP ファイルの内容を展開します。
mkdir /tmp/kafka unzip amq-streams_y.y-x.x.x.zip -d /tmp/kafka展開した内容を
/opt/kafkaディレクトリーに移動して、一時ディレクトリーを削除します。sudo mv /tmp/kafka/kafka_y.y-x.x.x/* /opt/kafka/ rm -r /tmp/kafka/opt/kafkaディレクトリーの所有権をkafkaユーザーに変更します。sudo chown -R kafka:kafka /opt/kafka
ZooKeeper データを格納する
/var/lib/zookeeperディレクトリーを作成し、その所有権をkafkaユーザーに設定します。sudo mkdir /var/lib/zookeeper sudo chown -R kafka:kafka /var/lib/zookeeper
Kafka データを格納する
/var/lib/kafkaディレクトリーを作成し、その所有権をkafkaユーザーに設定します。sudo mkdir /var/lib/kafka sudo chown -R kafka:kafka /var/lib/kafka
2.4. データストレージに関する留意事項
効率的なデータストレージインフラストラクチャーは、AMQ Streams のパフォーマンスを最適化するために不可欠です。
AMQ Streams ではブロックストレージが必要で、Amazon Elastic Block Store (EBS) などのクラウドベースのブロックストレージソリューションとうまく機能します。ファイルストレージの使用は推奨されていません。
可能な場合はローカルストレージを選択します。ローカルストレージが利用できない場合は、ファイバーチャネルや iSCSI などのプロトコルがアクセスする SAN (Storage Area Network) を使用できます。
2.4.1. Apache Kafka および ZooKeeper ストレージのサポート
Apache Kafka と ZooKeeper には別々のディスクを使用します。
Kafka は、複数のディスクまたはボリュームのデータストレージ設定である JBOD(Just a Bunch of Disks)ストレージをサポートします。JBOD は、Kafka ブローカーのデータストレージを増やします。また、パフォーマンスを向上することもできます。
ソリッドステートドライブ (SSD) は必須ではありませんが、複数のトピックに対してデータが非同期的に送受信される大規模なクラスターで Kafka のパフォーマンスを向上させることができます。SSD は、高速で低レイテンシーのデータアクセスが必要な ZooKeeper で特に有効です。
Kafka と ZooKeeper の両方にデータレプリケーションが組み込まれているため、複製されたストレージのプロビジョニングは必要ありません。
2.4.2. ファイルシステム
XFS ファイルシステムを使用するようにストレージシステムを設定することが推奨されます。AMQ Streams は ext4 ファイルシステムとも互換性がありますが、最適な結果を得るには追加の設定が必要になることがあります。
関連情報
- XFS ファイルシステムの詳細は、「XFS ファイルシステム」 を参照してください。
2.5. 単一ノードの AMQ Streams クラスターの実行
この手順では、単一の Apache ZooKeeper ノードと単一の Apache Kafka ノード (両方とも同じホストで実行されている) で構成される基本的な AMQ Streams クラスターを実行する方法を説明します。デフォルトの設定ファイルは ZooKeeper および Kafka に使用されます。
単一ノードの AMQ Streams クラスターは、信頼性および高可用性を提供しないため、開発目的にのみ適しています。
前提条件
- AMQ Streams がホストにインストールされている。
クラスターの実行
ZooKeeper 設定ファイル
/opt/kafka/config/zookeeper.propertiesを編集します。dataDirオプションを/var/lib/zookeeper/に設定します。dataDir=/var/lib/zookeeper/
Kafka 設定ファイル
/opt/kafka/config/server.propertiesを編集します。log.dirsオプションを/var/lib/kafka/に設定します。log.dirs=/var/lib/kafka/
kafkaユーザーに切り替えます。su - kafka
ZooKeeper を起動します。
/opt/kafka/bin/zookeeper-server-start.sh -daemon /opt/kafka/config/zookeeper.properties
ZooKeeper が実行されていることを確認します。
jcmd | grep zookeeper
以下を返します。
number org.apache.zookeeper.server.quorum.QuorumPeerMain /opt/kafka/config/zookeeper.propertiesKafka を起動します。
/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
Kafka が稼働していることを確認します。
jcmd | grep kafka
以下を返します。
number kafka.Kafka /opt/kafka/config/server.properties
関連情報
- AMQ Streams のインストールに関する詳細は、「AMQ Streams のインストール」 を参照してください。
- AMQ Streams の設定に関する詳細は、「AMQ Streams の設定」 を参照してください。
2.6. クラスターの使用
この手順では、Kafka コンソールプロデューサーおよびコンシューマークライアントを起動し、それらを使用して複数のメッセージを送受信する方法を説明します。
新しいトピックは、ステップ 1 で自動的に作成されます。トピックの自動作成 は、auto.create.topics.enable 設定プロパティーを使用して制御されます (デフォルトでは true に設定されます)。または、クラスターを使用する前にトピックを設定および作成することもできます。詳細は、「トピック」 を参照してください。
手順
Kafka コンソールプロデューサーを起動し、メッセージを新しいトピックに送信するように設定します。
/opt/kafka/bin/kafka-console-producer.sh --broker-list <bootstrap-address> --topic <topic-name>
以下に例を示します。
/opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-topic
コンソールに複数のメッセージを入力します。Enter を押して、各メッセージを新しいトピックに送信します。
>message 1 >message 2 >message 3 >message 4
Kafka が新しいトピックを自動的に作成すると、トピックが存在しないという警告が表示される可能性があります。
WARN Error while fetching metadata with correlation id 39 : {4-3-16-topic1=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)この警告は、さらにメッセージを送信すると再度表示されなくなります。
新しいターミナルウィンドウで、Kafka コンソールコンシューマーを起動し、新しいトピックの最初からメッセージを読み取るように設定します。
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server <bootstrap-address> --topic <topic-name> --from-beginning
以下に例を示します。
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my-topic --from-beginning
受信メッセージがコンシューマーコンソールに表示されます。
- プロデューサーコンソールに切り替え、追加のメッセージを送信します。それらがコンシューマーコンソールに表示されていることを確認します。
- Ctrl+C を押して Kafka コンソールプロデューサーを停止し、コンシューマーを停止します。
2.7. AMQ Streams サービスの停止
スクリプトを実行して、Kafka および ZooKeeper サービスを停止できます。Kafka および ZooKeeper サービスへのすべての接続が終了します。
前提条件
- AMQ Streams がホストにインストールされている。
- ZooKeeper および Kafka が稼働している。
手順
Kafka ブローカーを停止します。
su - kafka /opt/kafka/bin/kafka-server-stop.sh
Kafka ブローカーが停止していることを確認します。
jcmd | grep kafka
ZooKeeper を停止します。
su - kafka /opt/kafka/bin/zookeeper-server-stop.sh
2.8. AMQ Streams の設定
前提条件
- AMQ Streams がホストにダウンロードされ、インストールされている。
手順
テキストエディターで ZooKeeper および Kafka ブローカー設定ファイルを開きます。設定ファイルは以下にあります。
- ZooKeeper
-
/opt/kafka/config/zookeeper.properties - Kafka
-
/opt/kafka/config/server.properties
設定オプションを編集します。設定ファイルは Java プロパティー形式です。すべての設定オプションは、以下の形式で別々の行に指定する必要があります。
<option> = <value>
#または!で始まる行はコメントとして処理され、AMQ Streams コンポーネントによって無視されます。# This is a comment
改行/キャリッジリターンの直前で
\を使用して、値を複数の行に分割することができます。sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \ username="bob" \ password="bobs-password";- 変更を保存します。
- ZooKeeper または Kafka ブローカーを再起動します。
- クラスターのすべてのノードでこの手順を繰り返します。
第3章 ZooKeeper の設定
Kafka は ZooKeeper を使用して設定データを保存し、クラスターの連携を行います。レプリケートされた ZooKeeper インスタンスのクラスターを実行することが強く推奨されます。
3.1. 基本設定
最も重要な ZooKeeper 設定オプションは次のとおりです。
tickTime- Zoo Keeper の基本時間単位 (ミリ秒)。ハートビートとセッションのタイムアウトに使用されます。たとえば、最小セッションタイムアウトは 2 ティックになります。
dataDir-
ZooKeeper がトランザクションログとインメモリーデータベースのスナップショットを保存するディレクトリー。これは、インストール時に作成された
/var/lib/zookeeper/ディレクトリーに設定する必要があります。 clientPort-
クライアントが接続できるポート番号。デフォルトは
2181です。
config/zookeeper.properties という名前の ZooKeeper 設定ファイルのサンプルは、AMQ Streams のインストールディレクトリーに置かれます。ZooKeeper でレイテンシーを最小限に抑えるために、別のディスクデバイスに dataDir ディレクトリーを配置することが推奨されます。
ZooKeeper 設定ファイルは /opt/kafka/config/zookeeper.properties に置く必要があります。設定ファイルの基本的な例は以下で確認できます。設定ファイルは kafka ユーザーが読み取りできる必要があります。
tickTime=2000 dataDir=/var/lib/zookeeper/ clientPort=2181
3.2. ZooKeeper クラスター設定
信頼できる ZooKeeper サービスでは、ZooKeeper をクラスターにデプロイする必要があります。そのため、実稼働のユースケースでは、レプリケートされた ZooKeeper インスタンスのクラスターを実行する必要があります。ZooKeeper クラスターは ensembles とも呼ばれます。
ZooKeeper クラスターは通常、奇数のノードで構成されます。ZooKeeper では、クラスター内のほとんどのノードが稼働している必要があります。以下に例を示します。
- 3 つのノードで構成されるクラスターでは、少なくとも 2 つのノードが稼働している必要があります。これは、1 つのノードが停止していることを許容できることを意味します。
- 5 つのノードで構成されるクラスターでは、最低でも 3 つのノードが利用可能である必要があります。これは、2 つのノードが停止していることを許容できることを意味します。
- 7 つのノードで構成されるクラスターでは、最低でも 4 つのノードが利用可能である必要があります。これは、3 つのノードが停止していることを許容できることを意味します。
ZooKeeper クラスターにより多くのノードがあると、クラスター全体の回復性と信頼性が向上します。
ZooKeeper は、偶数のノードを持つクラスターで実行できます。ただし、追加のノードは、クラスターの回復性は向上しません。4 つのノードで構成されるクラスターでは、少なくとも 3 つのノードが利用可能で、1 つのノードがダウンしているノードのみを許容する必要があります。そのため、3 つのノードのみを持つクラスターと全く同じ回復性があります。
理想的には、異なる ZooKeeper ノードを異なるデータセンターまたはネットワークセグメントに置く必要があります。ZooKeeper ノードの数を増やすと、クラスターの同期に費やされたワークロードが増えます。ほとんどの Kafka のユースケースでは、3、5、または 7 つのノードで構成される ZooKeeper クラスターでは十分です。
3 つのノードで構成される ZooKeeper クラスターは、利用できないノードを 1 つだけ許容できます。つまり、クラスターノードがクラッシュし、別のノードでメンテナンスを実施している場合、ZooKeeper クラスターが利用できなくなります。
レプリケートされた ZooKeeper 設定は、スタンドアロン設定でサポートされるすべての設定オプションをサポートします。クラスタリング設定にさらにオプションが追加されます。
initLimit-
フォロワーがクラスターリーダーに接続して同期できるようにする時間。時間はティック数として指定されます (詳細は
timeTickオプション を参照してください)。 syncLimit-
フォロワーがリーダーの背後にあることのできる時間。時間はティック数として指定されます (詳細は
timeTickオプション を参照してください)。 reconfigEnabled- 動的再設定 を有効または無効にします。サーバーを ZooKeeper クラスターに追加または削除するには、有効にする必要があります。
standaloneEnabled- ZooKeeper が 1 つのサーバーでのみ実行されるスタンドアロンモードを有効または無効にします。
上記のオプションの他に、すべての設定ファイルに ZooKeeper クラスターのメンバーである必要があるサーバーの一覧が含まれている必要があります。サーバーレコードは server.id=hostname:port1:port2 の形式で指定する必要があります。ここで、
id- ZooKeeper クラスターノードの ID。
hostname- ノードが接続をリッスンするホスト名または IP アドレス。
port1- クラスター内通信に使用されるポート番号。
port2- リーダーエレクションに使用されるポート番号。
以下は、3 つのノードで構成される ZooKeeper クラスターの設定ファイルの例になります。
timeTick=2000 dataDir=/var/lib/zookeeper/ initLimit=5 syncLimit=2 reconfigEnabled=true standaloneEnabled=false server.1=172.17.0.1:2888:3888:participant;172.17.0.1:2181 server.2=172.17.0.2:2888:3888:participant;172.17.0.2:2181 server.3=172.17.0.3:2888:3888:participant;172.17.0.3:2181
ZooKeeper 3.5.7 では、使用する前に、許可リストに 4 文字のコマンド を追加する必要があります。詳細は、Zoo Keeper のドキュメント を参照してください。
myid ファイル
ZooKeeper クラスターの各ノードには、一意の ID を割り当てる必要があります。各ノードの ID は myid ファイルで設定し、/var/lib/zookeeper/ のように dataDir フォルダーに保存する必要があります。myid ファイルには、テキストとして ID が記述された単一行のみが含まれている必要があります。ID には、1 から 255 までの任意の整数を指定することができます。このファイルは、各クラスターノードに手動で作成する必要があります。このファイルを使用すると、各 ZooKeeper インスタンスは設定ファイルの対応する server. 行の設定を使用して、そのリスナーを設定します。また、他の server. 行すべてを使用して、他のクラスターメンバーを特定します。
上記の例では、3 つのノードがあるので、各ノードは値がそれぞれ 1、2、および 3 の異なる myid を持ちます。
3.3. マルチノードの ZooKeeper クラスターの実行
この手順では、ZooKeeper をマルチノードクラスターとして設定し、実行する方法を説明します。
ZooKeeper 3.5.7 では、使用する前に、許可リストに 4 文字のコマンド を追加する必要があります。詳細は、Zoo Keeper のドキュメント を参照してください。
前提条件
- AMQ Streams が、ZooKeeper クラスターノードとして使用されるすべてのホストにインストールされている。
クラスターの実行
/var/lib/zookeeper/にmyidファイルを作成します。最初の ZooKeeper ノードに ID1を、2 番目の ZooKeeper ノードに2を、それぞれ入力します。su - kafka echo "<NodeID>" > /var/lib/zookeeper/myid以下に例を示します。
su - kafka echo "1" > /var/lib/zookeeper/myid
ZooKeeper 設定ファイル
/opt/kafka/config/zookeeper.propertiesを編集します。-
dataDirオプションを/var/lib/zookeeper/に設定します。 -
initLimitおよびsyncLimitオプションを設定します。 -
reconfigEnabledおよびstandaloneEnabledオプションを設定します。 すべての ZooKeeper ノードの一覧を追加します。この一覧には、現在のノードも含まれている必要があります。
5 つのメンバーを持つ ZooKeeper クラスターのノードの設定例
timeTick=2000 dataDir=/var/lib/zookeeper/ initLimit=5 syncLimit=2 reconfigEnabled=true standaloneEnabled=false server.1=172.17.0.1:2888:3888:participant;172.17.0.1:2181 server.2=172.17.0.2:2888:3888:participant;172.17.0.2:2181 server.3=172.17.0.3:2888:3888:participant;172.17.0.3:2181 server.4=172.17.0.4:2888:3888:participant;172.17.0.4:2181 server.5=172.17.0.5:2888:3888:participant;172.17.0.5:2181
-
デフォルトの設定ファイルで ZooKeeper を起動します。
su - kafka /opt/kafka/bin/zookeeper-server-start.sh -daemon /opt/kafka/config/zookeeper.properties
ZooKeeper が稼働していることを確認します。
jcmd | grep zookeeper
- クラスターのすべてのノードでこの手順を繰り返します。
クラスターのすべてのノードが稼働したら、
ncatユーティリティーを使用してstatコマンドを各ノードに送信して、すべてのノードがクラスターのメンバーであることを確認します。ncat stat を使用してノードのステータスを確認します。
echo stat | ncat localhost 2181
この出力に、ノードが
leaderまたはfollowerのいずれかである情報が表示されるはずです。ncatコマンドの出力例ZooKeeper version: 3.4.13-2d71af4dbe22557fda74f9a9b4309b15a7487f03, built on 06/29/2018 00:39 GMT Clients: /0:0:0:0:0:0:0:1:59726[0](queued=0,recved=1,sent=0) Latency min/avg/max: 0/0/0 Received: 2 Sent: 1 Connections: 1 Outstanding: 0 Zxid: 0x200000000 Mode: follower Node count: 4
関連情報
- AMQ Streams のインストールに関する詳細は、「AMQ Streams のインストール」 を参照してください。
- AMQ Streams の設定に関する詳細は、「AMQ Streams の設定」 を参照してください。
3.4. 認証
デフォルトでは、ZooKeeper はどのような認証も使用せず、匿名の接続を許可します。ただし、Simple Authentication and Security Layer(SASL)を使用した認証の設定に使用できる Java Authentication and Authorization Service (JAAS) をサポートします。ZooKeeper は、ローカルに保存されたクレデンシャルと DIGEST-MD5 SASL メカニズムを使用した認証をサポートします。
3.4.1. SASL を使用した認証
JAAS は個別の設定ファイルを使用して設定されます。JAAS 設定ファイルを ZooKeeper 設定と同じディレクトリー (/opt/kafka/config/) に置くことが推奨されます。推奨されるファイル名は zookeeper-jaas.conf です。複数のノードで ZooKeeper クラスターを使用する場合は、JAAS 設定ファイルをすべてのクラスターノードで作成する必要があります。
JAAS はコンテキストを使用して設定されます。サーバーとクライアントなどの個別の部分は、常に別の コンテキスト で設定されます。コンテキストは 設定 オプションで、以下の形式となっています。
ContextName {
param1
param2;
};SASL 認証は、サーバー間通信 (Zoo Keeper インスタンス間の通信) とクライアント間通信 (Kafka と Zoo Keeper 間の通信) に対して別々に構成されます。サーバー間の認証は、複数のノードを持つ ZooKeeper クラスターにのみ関連します。
サーバー間の認証
サーバー間の認証では、JAAS 設定ファイルには 2 つの部分が含まれます。
- サーバー設定
- クライアント設定
DIGEST-MD5 SASL メカニズムを使用する場合、認証サーバーの設定に QuorumServer コンテキストが使用されます。暗号化されていない形式で、接続できるすべてのユーザー名とパスワードが含まれている必要があります。2 つ目のコンテキスト QuorumLearner は、ZooKeeper に組み込まれるクライアント用に設定する必要があります。また、暗号化されていない形式のパスワードも含まれます。DIGEST-MD5 メカニズムの JAAS 設定ファイルの例は、以下を参照してください。
QuorumServer {
org.apache.zookeeper.server.auth.DigestLoginModule required
user_zookeeper="123456";
};
QuorumLearner {
org.apache.zookeeper.server.auth.DigestLoginModule required
username="zookeeper"
password="123456";
};JAAS 設定ファイルの他に、以下のオプションを指定して、通常の ZooKeeper 設定ファイルでサーバー間の認証を有効にする必要があります。
quorum.auth.enableSasl=true quorum.auth.learnerRequireSasl=true quorum.auth.serverRequireSasl=true quorum.auth.learner.loginContext=QuorumLearner quorum.auth.server.loginContext=QuorumServer quorum.cnxn.threads.size=20
KAFKA_OPTS 環境変数を使用して、JAAS 設定ファイルを Java プロパティーとして ZooKeeper サーバーに渡します。
su - kafka export KAFKA_OPTS="-Djava.security.auth.login.config=/opt/kafka/config/zookeeper-jaas.conf"; /opt/kafka/bin/zookeeper-server-start.sh -daemon /opt/kafka/config/zookeeper.properties
サーバー間の認証の詳細は、ZooKeeper Wiki を参照してください。
クライアント/サーバー間の認証
クライアント/サーバー間の認証は、サーバー間の認証と同じ JAAS ファイルで設定されます。ただし、サーバー間の認証とは異なり、サーバー設定のみが含まれます。設定のクライアント部分は、クライアントで実行する必要があります。認証を使用して ZooKeeper に接続するように Kafka ブローカーを設定する方法は、Kafka インストール セクションを参照してください。
JAAS 設定ファイルにサーバーコンテキストを追加して、クライアント/サーバー間の認証を設定します。DIGEST-MD5 メカニズムの場合は、すべてのユーザー名とパスワードを設定します。
Server {
org.apache.zookeeper.server.auth.DigestLoginModule required
user_super="123456"
user_kafka="123456"
user_someoneelse="123456";
};JAAS コンテキストの設定後、以下の行を追加して ZooKeeper 設定ファイルでクライアント/サーバー間の認証を有効にします。
requireClientAuthScheme=sasl authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider authProvider.2=org.apache.zookeeper.server.auth.SASLAuthenticationProvider authProvider.3=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
ZooKeeper クラスターの一部であるすべてのサーバーに authProvider.<ID> プロパティーを追加する必要があります。
KAFKA_OPTS 環境変数を使用して、JAAS 設定ファイルを Java プロパティーとして ZooKeeper サーバーに渡します。
su - kafka export KAFKA_OPTS="-Djava.security.auth.login.config=/opt/kafka/config/zookeeper-jaas.conf"; /opt/kafka/bin/zookeeper-server-start.sh -daemon /opt/kafka/config/zookeeper.properties
Kafka ブローカーでの ZooKeeper 認証の設定に関する詳細は、「ZooKeeper の認証」 を参照してください。
3.4.2. DIGEST-MD5 を使用したサーバー間の認証の有効化
この手順では、ZooKeeper クラスターのノード間で SASL DIGEST-MD5 メカニズムを使用した認証を有効にする方法を説明します。
前提条件
- AMQ Streams がホストにインストールされている。
- ZooKeeper クラスターが複数のノードで 設定 されている。
SASL DIGEST-MD5 認証の有効化
すべての ZooKeeper ノードで、
/opt/kafka/config/zookeeper-jaas.confJAAS 設定ファイルを作成または編集し、以下のコンテキストを追加します。QuorumServer { org.apache.zookeeper.server.auth.DigestLoginModule required user_<Username>="<Password>"; }; QuorumLearner { org.apache.zookeeper.server.auth.DigestLoginModule required username="<Username>" password="<Password>"; };ユーザー名とパスワードは両方の JAAS コンテキストで同一である必要があります。以下に例を示します。
QuorumServer { org.apache.zookeeper.server.auth.DigestLoginModule required user_zookeeper="123456"; }; QuorumLearner { org.apache.zookeeper.server.auth.DigestLoginModule required username="zookeeper" password="123456"; };すべての ZooKeeper ノードで、
/opt/kafka/config/zookeeper.propertiesZooKeeper 設定ファイルを編集し、以下のオプションを設定します。quorum.auth.enableSasl=true quorum.auth.learnerRequireSasl=true quorum.auth.serverRequireSasl=true quorum.auth.learner.loginContext=QuorumLearner quorum.auth.server.loginContext=QuorumServer quorum.cnxn.threads.size=20
すべての ZooKeeper ノードを 1 つずつ再起動します。JAAS 設定を ZooKeeper に渡すには、
KAFKA_OPTS環境変数を使用します。su - kafka export KAFKA_OPTS="-Djava.security.auth.login.config=/opt/kafka/config/zookeeper-jaas.conf"; /opt/kafka/bin/zookeeper-server-start.sh -daemon /opt/kafka/config/zookeeper.properties
関連情報
- AMQ Streams のインストールに関する詳細は、「AMQ Streams のインストール」 を参照してください。
- AMQ Streams の設定に関する詳細は、「AMQ Streams の設定」 を参照してください。
- ZooKeeper クラスターの実行に関する詳細は、「マルチノードの ZooKeeper クラスターの実行」 を参照してください。
3.4.3. DIGEST-MD5 を使用したクライアント/サーバー間の認証の有効化
この手順では、ZooKeeper クライアントと ZooKeeper との間で SASL DIGEST-MD5 メカニズムを使用した認証を有効にする方法を説明します。
前提条件
- AMQ Streams がホストにインストールされている。
- ZooKeeper クラスターが 設定され、稼働している。
SASL DIGEST-MD5 認証の有効化
すべての ZooKeeper ノードで、
/opt/kafka/config/zookeeper-jaas.confJAAS 設定ファイルを作成または編集し、以下のコンテキストを追加します。Server { org.apache.zookeeper.server.auth.DigestLoginModule required user_super="<SuperUserPassword>" user<Username1>_="<Password1>" user<USername2>_="<Password2>"; };superは自動的に管理者特権を持たせます。このファイルには複数のユーザーを含めることができますが、Kafka ブローカーが必要とする追加ユーザーは 1 つだけです。Kafka ユーザーに推奨される名前はkafkaです。以下の例は、クライアント/サーバー間の認証の
Serverコンテキストを示しています。Server { org.apache.zookeeper.server.auth.DigestLoginModule required user_super="123456" user_kafka="123456"; };すべての ZooKeeper ノードで、
/opt/kafka/config/zookeeper.propertiesZooKeeper 設定ファイルを編集し、以下のオプションを設定します。requireClientAuthScheme=sasl authProvider.<IdOfBroker1>=org.apache.zookeeper.server.auth.SASLAuthenticationProvider authProvider.<IdOfBroker2>=org.apache.zookeeper.server.auth.SASLAuthenticationProvider authProvider.<IdOfBroker3>=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
authProvider.<ID>プロパティーは、ZooKeeper クラスターの一部であるすべてのノードに追加する必要があります。3 ノードの ZooKeeper クラスターの設定例は以下のようになります。requireClientAuthScheme=sasl authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider authProvider.2=org.apache.zookeeper.server.auth.SASLAuthenticationProvider authProvider.3=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
すべての ZooKeeper ノードを 1 つずつ再起動します。JAAS 設定を ZooKeeper に渡すには、
KAFKA_OPTS環境変数を使用します。su - kafka export KAFKA_OPTS="-Djava.security.auth.login.config=/opt/kafka/config/zookeeper-jaas.conf"; /opt/kafka/bin/zookeeper-server-start.sh -daemon /opt/kafka/config/zookeeper.properties
関連情報
- AMQ Streams のインストールに関する詳細は、「AMQ Streams のインストール」 を参照してください。
- AMQ Streams の設定に関する詳細は、「AMQ Streams の設定」 を参照してください。
- ZooKeeper クラスターの実行に関する詳細は、「マルチノードの ZooKeeper クラスターの実行」 を参照してください。
3.5. 承認
ZooKeeper はアクセス制御リスト(ACL)をサポートし、内部に保存されているデータを保護します。Kafka ブローカーは、他の ZooKeeper ユーザーが変更できないように、作成するすべての ZooKeeper レコードに ACL 権限を自動的に設定できます。
Kafka ブローカーで ZooKeeper ACL を有効にする方法は、「ZooKeeper の承認」 を参照してください。
3.6. TLS
ZooKeeper は、暗号化または認証用に TLS をサポートします。
3.7. その他の設定オプション
ユースケースに基づいて、以下の追加の ZooKeeper 設定オプションを設定できます。
maxClientCnxns- ZooKeeper クラスターの単一のメンバーへの同時クライアント接続の最大数。
autopurge.snapRetainCount-
保持される ZooKeeper のインメモリーデータベースのスナップショットの数。デフォルト値は
3です。 autopurge.purgeInterval-
スナップショットをパージするための時間間隔 (時間単位)。デフォルト値は
0で、このオプションは無効になります。
利用可能なすべての設定オプションは、ZooKeeper のドキュメント を参照してください。
3.8. ロギング
ZooKeeper は、ロギングインフラストラクチャーとして log4j を使用しています。ロギング設定は、デフォルトでは /opt/kafka/config/ ディレクトリーまたはクラスパスのいずれかに配置される log4j.properties 設定ファイルから読み取られます。設定ファイルの場所と名前は、Java プロパティー log4j.configuration を使用して変更できます。これは、KAFKA_LOG4J_OPTS 環境変数を使用して ZooKeeper に渡すことができます。
su - kafka export KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:/my/path/to/log4j.properties"; /opt/kafka/bin/zookeeper-server-start.sh -daemon /opt/kafka/config/zookeeper.properties
Log4j の設定に関する詳細は、Log4j のドキュメント を参照してください。
第4章 Kafka の設定
Kafka はプロパティーファイルを使用して静的設定を保存します。推奨される設定ファイルの場所は /opt/kafka/config/server.properties です。設定ファイルは kafka ユーザーが読み取りできる必要があります。
AMQ Streams には、製品のさまざまな基本的な機能と高度な機能を強調する設定ファイルのサンプルが含まれています。AMQ Streams インストールディレクトリーの config/server.properties を参照してください。
本章では、最も重要な設定オプションについて説明します。サポートされる Kafka ブローカー設定オプションの完全リストは、「付録A ブローカー設定パラメーター」を参照してください。
4.1. ZooKeeper
Kafka ブローカーは、構成の一部を保存し、クラスターを調整するために (たとえば、どのノードがどのパーティションのリーダーであるかを決定するために) Zoo Keeper を必要とします。ZooKeeper クラスターの接続の詳細は、設定ファイルに保存されます。zookeeper.connect フィールドには、zookeeper クラスターのメンバーのホスト名およびポートのコンマ区切りリストが含まれます。
以下に例を示します。
zookeeper.connect=zoo1.my-domain.com:2181,zoo2.my-domain.com:2181,zoo3.my-domain.com:2181
Kafka はこれらのアドレスを使用して ZooKeeper クラスターに接続します。この設定により、すべての Kafka znodes が ZooKeeper データベースのルートに直接作成されます。そのため、このような ZooKeeper クラスターは単一の Kafka クラスターにのみ使用できます。単一の Zoo Keeper クラスターを使用するように複数の Kafka クラスターを構成するには、Kafka 構成ファイルの Zoo Keeper 接続文字列の最後にベース (プレフィックス) パスを指定します。
zookeeper.connect=zoo1.my-domain.com:2181,zoo2.my-domain.com:2181,zoo3.my-domain.com:2181/my-cluster-1
4.2. 「リスナー」
Kafka ブローカーは、複数のリスナーを使用するように設定できます。各リスナーは、異なるポートまたはネットワークインターフェースでリッスンするのに使用でき、異なる設定を指定できます。リスナーは、設定ファイルの listeners プロパティーで設定されます。listeners プロパティーには、< listenerName > :// <hostname > :_<port>_ として設定された各リスナーのリストが含まれます。ホスト名の値が空の場合、Kafka は java.net.InetAddress.getCanonicalHostName() をホスト名として使用します。以下の例は、複数のリスナーの設定方法を示しています。
listeners=INT1://:9092,INT2://:9093,REPLICATION://:9094
Kafka クライアントが Kafka クラスターに接続する場合、まず ブートストラップサーバー に接続します。ブートストラップサーバー はクラスターノードの 1 つです。クライアントに対し、クラスターの一部である他のすべてのブローカーのリストが提供され、クライアントはそれらを個別に接続します。デフォルトでは、ブートストラップサーバー は、listeners フィールドに基づいてノードの一覧をクライアントに提供します。
アドバタイズされたリスナー
listeners プロパティーで指定されたものとは異なるアドレスのセットをクライアントに付与することができます。これは、プロキシーなどの追加のネットワークインフラストラクチャーがクライアントとブローカー間にある場合、または IP アドレスの代わりに外部 DNS 名を使用する必要がある場合に役立ちます。ここで、ブローカーは advertised.listeners 設定プロパティーでリスナーのアドバタイズされたアドレスを定義できます。このプロパティーは listeners プロパティーと同じ形式です。以下の例は、アドバタイズされたリスナーの設定方法を示しています。
listeners=INT1://:9092,INT2://:9093 advertised.listeners=INT1://my-broker-1.my-domain.com:1234,INT2://my-broker-1.my-domain.com:1234:9093
リスナーの名前は、listeners プロパティーのリスナー名と一致する必要があります。
inter-broker リスナー
クラスターが複製されたトピックがある場合、これらのトピックでメッセージを複製するために、このようなトピックに対応するブローカーは相互に通信する必要があります。複数のリスナーが設定されている場合、設定フィールド inter.broker.listener.name を使用してブローカー間のレプリケーションに使用するリスナーの名前を指定します。以下に例を示します。
inter.broker.listener.name=REPLICATION
4.3. ログのコミット
Apache Kafka は、プロデューサーから受信するすべてのレコードをコミットログに保存します。コミットログには、Kafka が配信する必要がある実際のデータ (レコードの形式) が含まれます。これらは、ブローカーの動作を記録するアプリケーションログファイルではありません。
ログディレクトリー
log.dirs プロパティーファイルを使用してログディレクトリーを設定し、1 つまたは複数のログディレクトリーにコミットログを保存できます。これは、インストール時に作成された /var/lib/kafka ディレクトリーに設定する必要があります。
log.dirs=/var/lib/kafka
パフォーマンス上の理由から、log.dir を複数のディレクトリーに設定し、それぞれを別の物理デバイスに配置して、ディスク I/O のパフォーマンスを向上できます。以下に例を示します。
log.dirs=/var/lib/kafka1,/var/lib/kafka2,/var/lib/kafka3
4.4. ブローカー ID
ブローカー ID は、クラスター内の各ブローカーの一意の ID です。ブローカー ID として 0 以上の整数を割り当てることができます。ブローカー ID は、再起動またはクラッシュ後にブローカーを識別するために使用されます。そのため、ID が安定し、時間の経過とともに変更されないようにすることが重要です。ブローカー ID はブローカーのプロパティーファイルで設定されます。
broker.id=1
4.5. マルチノードの Kafka クラスターの実行
この手順では、Kafka をマルチノードクラスターとして設定および実行する方法を説明します。
前提条件
- Kafka ブローカーとして使用されるすべてのホストに AMQ Streams がインストールされている。
- ZooKeeper クラスターが 設定され、稼働している。
クラスターの実行
AMQ Streams クラスターの各 Kafka ブローカーに対して以下を行います。
以下のように、Kafka 設定ファイル
/opt/kafka/config/server.propertiesを編集します。-
最初のブローカーの
broker.idフィールドを0に、2 番目のブローカーを1に、それぞれ設定します。 -
zookeeper.connectオプションで ZooKeeper への接続の詳細を設定します。 - Kafka リスナーを設定します。
logs.dirのディレクトリーに、コミットログが保存されるディレクトリーを設定します。以下は、Kafka ブローカーの設定例です。
broker.id=0 zookeeper.connect=zoo1.my-domain.com:2181,zoo2.my-domain.com:2181,zoo3.my-domain.com:2181 listeners=REPLICATION://:9091,PLAINTEXT://:9092 inter.broker.listener.name=REPLICATION log.dirs=/var/lib/kafka
各 Kafka ブローカーが同じハードウェアで実行されている通常のインストールでは、
broker.id設定プロパティーのみがブローカー設定ごとに異なります。
-
最初のブローカーの
デフォルトの設定ファイルで Kafka ブローカーを起動します。
su - kafka /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
Kafka ブローカーが稼働していることを確認します。
jcmd | grep Kafka
ブローカーの検証
クラスターのすべてのノードが稼働したら、ncat ユーティリティーを使用して dump コマンドを ZooKeeper ノードのいずれかに送信して、すべてのノードが Kafka クラスターのメンバーであることを確認します。このコマンドは、ZooKeeper に登録されているすべての Kafka ブローカーを出力します。
ncat stat を使用してノードのステータスを確認します。
echo dump | ncat zoo1.my-domain.com 2181
出力には、設定および起動したすべての Kafka ブローカーが含まれるはずです。
3 つのノードで構成される Kafka クラスターの
ncatコマンドの出力例SessionTracker dump: org.apache.zookeeper.server.quorum.LearnerSessionTracker@28848ab9 ephemeral nodes dump: Sessions with Ephemerals (3): 0x20000015dd00000: /brokers/ids/1 0x10000015dc70000: /controller /brokers/ids/0 0x10000015dc70001: /brokers/ids/2
関連情報
- AMQ Streams のインストールに関する詳細は、「AMQ Streams のインストール」 を参照してください。
- AMQ Streams の設定に関する詳細は、「AMQ Streams の設定」 を参照してください。
- ZooKeeper クラスターの実行に関する詳細は、「マルチノードの ZooKeeper クラスターの実行」 を参照してください。
- サポートされる Kafka ブローカー設定オプションの完全リストは、「付録A ブローカー設定パラメーター」を参照してください。
4.6. ZooKeeper の認証
デフォルトでは、ZooKeeper と Kafka 間の接続は認証されません。ただし、Kafka および ZooKeeper は、SASL (Simple Authentication and Security Layer) を使用して認証を設定するのに使用できる Java Authentication and Authorization Service (JAAS) をサポートします。ZooKeeper は、ローカルに保存されたクレデンシャルと DIGEST-MD5 SASL メカニズムを使用した認証をサポートします。
4.6.1. JAAS 設定
ZooKeeper 接続の SASL 認証は JAAS 設定ファイルで設定する必要があります。デフォルトでは、Kafka は ZooKeeper への接続用に Client という名前の JAAS コンテキストを使用します。Clientコンテキストは /opt/kafka/config/jass.conf ファイルで設定する必要があります。以下の例のように、コンテキストでは PLAIN SASL 認証を有効にする必要があります。
Client {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="kafka"
password="123456";
};4.6.2. ZooKeeper 認証の有効化
この手順では、ZooKeeper に接続する際に SASL DIGEST-MD5 メカニズムを使用した認証を有効にする方法を説明します。
前提条件
- ZooKeeper でクライアント/サーバー間の認証が 有効である。
SASL DIGEST-MD5 認証の有効化
すべての Kafka ブローカーノードで、
/opt/kafka/config/jaas.confJAAS 設定ファイルを作成または編集し、以下のコンテキストを追加します。Client { org.apache.kafka.common.security.plain.PlainLoginModule required username="<Username>" password="<Password>"; };ユーザー名とパスワードは ZooKeeper で設定されているものと同じである必要があります。
Clientコンテキストの例を以下に示します。Client { org.apache.kafka.common.security.plain.PlainLoginModule required username="kafka" password="123456"; };すべての Kafka ブローカーノードを 1 つずつ再起動します。JAAS 設定を Kafka ブローカーに渡すには、
KAFKA_OPTS環境変数を使用します。su - kafka export KAFKA_OPTS="-Djava.security.auth.login.config=/opt/kafka/config/jaas.conf"; /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
関連情報
- ZooKeeper でのクライアント/サーバー間の認証の設定に関する詳細は、「認証」 を参照してください。
4.7. 承認
Kafka ブローカーの承認は、オーソライザープラグインを使用して実装されます。
本セクションでは、Kafka で提供される AclAuthorizer プラグインを使用する方法を説明します。
または、独自の承認プラグインを使用できます。たとえば、OAuth 2.0 トークンベースの認証 を使用している場合、OAuth 2.0 承認 を使用できます。
4.7.1. シンプルな ACL オーソライザー
AclAuthorizer を含む authorizer プラグインは authorizer.class.name プロパティーを使用して有効にします。
authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer
選択したオーソライザーには完全修飾名が必要です。AclAuthorizer の場合、完全修飾名は kafka.security.auth.SimpleAclAuthorizer です。
4.7.1.1. ACL ルール
AclAuthorizer は ACL ルールを使用して Kafka ブローカーへのアクセスを管理します。
ACL ルールは以下の形式で定義されます。
プリンシパル P は、ホスト H から Kafka リソース R で操作 O を許可または拒否されます。
たとえば、以下のようにルールを設定できます。
John は、ホスト 127.0.0.1 からトピック コメント を 表示 できます。
ホストは、John が接続しているマシンの IP アドレスです。
ほとんどの場合、ユーザーはプロデューサーまたはコンシューマーアプリケーションです。
Consumer01 は、ホスト 127.0.0.1 からコンシューマーグループ アカウント に 書き込み できます。
ACL ルールが存在しない場合
特定のリソースに ACL ルールが存在しない場合は、すべてのアクションが拒否されます。この動作は、Kafka 設定ファイル /opt/kafka/config/server.properties で allow.everyone.if.no.acl.found プロパティーを true に設定すると変更できます。
4.7.1.2. プリンシパル
プリンシパル はユーザーのアイデンティティーを表します。ID の形式は、クライアントが Kafka に接続するために使用される認証メカニズムによって異なります。
-
User:ANONYMOUS: 認証なしで接続する場合。 User:<username>: PLAIN や SCRAM などの単純な認証メカニズムを使用して接続する場合。例:
User:adminまたはUser:user1User:<DistinguishedName>: TLS クライアント認証を使用して接続する場合。例:
User:CN=user1,O=MyCompany,L=Prague,C=CZ-
User:<Kerberos username>: Kerberos を使用して接続する場合。
DistinguishedName はクライアント証明書からの識別名です。
Kerberos ユーザー名 は、Kerberos プリンシパルの主要部分で、Kerberos を使用して接続する場合のデフォルトで使用されます。sasl.kerberos.principal.to.local.rules プロパティーを使用して、Kerberos プリンシパルから Kafka プリンシパルを構築する方法を設定できます。
4.7.1.3. ユーザーの認証
承認を使用するには、認証を有効にし、クライアントにより使用される必要があります。そうでないと、すべての接続のプリンシパルは User:ANONYMOUS になります。
認証方法の詳細は、「暗号化および認証」 を参照してください。
4.7.1.4. スーパーユーザー
スーパーユーザーは、ACL ルールに関係なくすべてのアクションを実行できます。
スーパーユーザーは、super.users プロパティーを使用して Kafka 設定ファイルで定義されます。
以下に例を示します。
super.users=User:admin,User:operator
4.7.1.5. レプリカブローカーの認証
承認を有効にすると、これはすべてのリスナーおよびすべての接続に適用されます。これには、ブローカー間のデータのレプリケーションに使用される inter-broker の接続が含まれます。そのため、承認を有効にする場合は、inter-broker 接続に認証を使用し、ブローカーが使用するユーザーに十分な権限を付与してください。たとえば、ブローカー間の認証で kafka-broker ユーザーが使用される場合、スーパーユーザー設定にはユーザー名 super.users=User:kafka-broker が含まれている必要があります。
4.7.1.6. サポートされるリソース
Kafka ACL は、以下のタイプのリソースに適用できます。
- トピック
- コンシューマーグループ
- クラスター
- TransactionId
- DelegationToken
4.7.1.7. サポートされる操作
AclAuthorizer はリソースでの操作を承認します。
以下の表で X の付いたフィールドは、各リソースでサポートされる操作を表します。
| トピック | コンシューマーグループ | Cluster | |
|---|---|---|---|
| Read | X | X | |
| Write | X | ||
| Create | X | ||
| 削除 | X | ||
| Alter | X | ||
| Describe | X | X | X |
| ClusterAction | X | ||
| すべて | X | X | X |
4.7.1.8. ACL 管理オプション
ACL ルールは、Kafka ディストリビューションパッケージの一部として提供される bin/kafka-acls.sh ユーティリティーを使用して管理されます。
kafka-acls.sh パラメーターオプションを使用して、ACL ルールを追加、一覧表示、および削除したり、その他の機能を実行したりします。
パラメーターには、--add など、二重ハイフンの標記が必要です。
| オプション | タイプ | 説明 | デフォルト |
|---|---|---|---|
|
| アクション | ACL ルールを追加します。 | |
|
| アクション | ACL ルールを削除します。 | |
|
| アクション | ACL ルールを一覧表示します。 | |
|
| アクション | オーソライザーの完全修飾クラス名。 |
|
|
| 設定 | 初期化のためにオーソライザーに渡されるキー/値のペア。
| |
|
| リソース | Kafka クラスターに接続するためのホスト/ポートのペア。 |
このオプションまたは |
|
| リソース |
管理クライアントに渡す設定プロパティーファイル。これは | |
|
| リソース | クラスターを ACL リソースとして指定します。 | |
|
| リソース | トピック名を ACL リソースとして指定します。
ワイルドカードとして使用されるアスタリスク (
1 つのコマンドに複数の | |
|
| リソース | コンシューマーグループ名を ACL リソースとして指定します。
1 つのコマンドに複数の | |
|
| リソース | トランザクション ID を ACL リソースとして指定します。 トランザクション配信は、プロデューサーによって複数のパーティションに送信されたすべてのメッセージが正常に配信されるか、いずれも配信されない必要があることを意味します。
ワイルドカードとして使用されるアスタリスク ( | |
|
| リソース | 委任トークンを ACL リソースとして指定します。
ワイルドカードとして使用されるアスタリスク ( | |
|
| 設定 |
|
|
|
| プリンシパル | allow ACL ルールに追加されるプリンシパル。
1 つのコマンドに複数の | |
|
| プリンシパル | 拒否 ACL ルールに追加されるプリンシパル。
1 つのコマンドに複数の | |
|
| プリンシパル |
プリンシパルの ACL の一覧を返すために
1 つのコマンドに複数の | |
|
| Host |
ホスト名または CIDR 範囲はサポートされていません。 |
|
|
| Host |
ホスト名または CIDR 範囲はサポートされていません。 |
|
|
| 操作 | 操作を許可または拒否します。
1 つのコマンドに複数の | すべて |
|
| ショートカット | メッセージプロデューサーが必要とするすべての操作を許可または拒否するためのショートカット (トピックでは WRITE と DESCRIBE、クラスターでは CREATE)。 | |
|
| ショートカット | メッセージコンシューマーが必要とするすべての操作を許可または拒否するためのショートカット (トピックについては READ と DESCRIBE、コンシューマーグループについては READ)。 | |
|
| ショートカット |
プロデューサーが特定のトランザクション ID に基づいてメッセージを送信することを許可されている場合、Idepmotence は自動的に有効になります。 | |
|
| ショートカット | すべてのクエリーを受け入れ、プロンプトは表示されないショートカット。 |
4.7.2. 承認の有効化
この手順では、Kafka ブローカーでの承認用に AclAuthorizer プラグインを有効にする方法を説明します。
前提条件
- ブローカーとして使用されるすべてのホストに AMQ Streams がインストールされている。
手順
AclAuthorizerを使用するように、Kafka 設定ファイル/opt/kafka/config/server.propertiesを編集します。authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer
- Kafka ブローカーを (再) 起動します。
関連情報
- AMQ Streams の設定に関する詳細は、「AMQ Streams の設定」 を参照してください。
- Kafka クラスターの実行に関する詳細は、「マルチノードの Kafka クラスターの実行」 を参照してください。
4.7.3. ACL ルールの追加
AclAuthorizer は、ユーザーが実行できる/できない操作を記述するルールのセットを定義するアクセス制御リスト (ACL) を使用します。
この手順では、Kafka ブローカーで AclAuthorizer プラグインを使用する場合に、ACL ルールを追加する方法を説明します。
ルールは kafka-acls.sh ユーティリティーを使用して追加され、ZooKeeper に保存されます。
前提条件
- ブローカーとして使用されるすべてのホストに AMQ Streams がインストールされている。
- Kafka ブローカーで承認が 有効 である。
手順
--addオプションを指定してkafka-acls.shを実行します。例:
MyConsumerGroupコンシューマーグループを使用して、user1およびuser2のmyTopicからの読み取りを許可します。bin/kafka-acls.sh --authorizer-properties zookeeper.connect=zoo1.my-domain.com:2181 --add --operation Read --topic myTopic --allow-principal User:user1 --allow-principal User:user2 bin/kafka-acls.sh --authorizer-properties zookeeper.connect=zoo1.my-domain.com:2181 --add --operation Describe --topic myTopic --allow-principal User:user1 --allow-principal User:user2 bin/kafka-acls.sh --authorizer-properties zookeeper.connect=zoo1.my-domain.com:2181 --add --operation Read --operation Describe --group MyConsumerGroup --allow-principal User:user1 --allow-principal User:user2
user1が IP アドレスホスト127.0.0.1からmyTopicを読むためのアクセスを拒否します。bin/kafka-acls.sh --authorizer-properties zookeeper.connect=zoo1.my-domain.com:2181 --add --operation Describe --operation Read --topic myTopic --group MyConsumerGroup --deny-principal User:user1 --deny-host 127.0.0.1
MyConsumerGroupでmyTopicのコンシューマーとしてuser1を追加します。bin/kafka-acls.sh --authorizer-properties zookeeper.connect=zoo1.my-domain.com:2181 --add --consumer --topic myTopic --group MyConsumerGroup --allow-principal User:user1
関連情報
-
kafka-acls.shオプションの全一覧は、「シンプルな ACL オーソライザー」 を参照してください。
4.7.4. ACL ルールの一覧表示
この手順では、Kafka ブローカーで AclAuthorizer プラグインを使用する場合に、既存の ACL ルールを一覧表示する方法を説明します。
ルールは、kafka-acls.sh ユーティリティーを使用してリストされます。
前提条件
- ブローカーとして使用されるすべてのホストに AMQ Streams がインストールされている。
- Kafka ブローカーで承認が 有効 である。
- ACL が 追加されている。
手順
--listオプションを指定してkafka-acls.shを実行します。以下に例を示します。
$ bin/kafka-acls.sh --authorizer-properties zookeeper.connect=zoo1.my-domain.com:2181 --list --topic myTopic Current ACLs for resource `Topic:myTopic`: User:user1 has Allow permission for operations: Read from hosts: * User:user2 has Allow permission for operations: Read from hosts: * User:user2 has Deny permission for operations: Read from hosts: 127.0.0.1 User:user1 has Allow permission for operations: Describe from hosts: * User:user2 has Allow permission for operations: Describe from hosts: * User:user2 has Deny permission for operations: Describe from hosts: 127.0.0.1
関連情報
-
kafka-acls.shオプションの全一覧は、「シンプルな ACL オーソライザー」 を参照してください。
4.7.5. ACL ルールの削除
この手順では、Kafka ブローカーで AclAuthorizer プラグインを使用する場合に、ACL ルールを削除する方法を説明します。
ルールは kafka-acls.sh ユーティリティーを使用して削除されます。
前提条件
- ブローカーとして使用されるすべてのホストに AMQ Streams がインストールされている。
- Kafka ブローカーで承認が 有効 である。
- ACL が 追加されている。
手順
--removeオプションを指定してkafka-acls.shを実行します。例:
MyConsumerGroupコンシューマーグループを使用して、user1およびuser2のmyTopicからの読み取りを許可する ACL を削除します。bin/kafka-acls.sh --authorizer-properties zookeeper.connect=zoo1.my-domain.com:2181 --remove --operation Read --topic myTopic --allow-principal User:user1 --allow-principal User:user2 bin/kafka-acls.sh --authorizer-properties zookeeper.connect=zoo1.my-domain.com:2181 --remove --operation Describe --topic myTopic --allow-principal User:user1 --allow-principal User:user2 bin/kafka-acls.sh --authorizer-properties zookeeper.connect=zoo1.my-domain.com:2181 --remove --operation Read --operation Describe --group MyConsumerGroup --allow-principal User:user1 --allow-principal User:user2
MyConsumerGroupでmyTopicのコンシューマーとしてuser1を追加する ACL を削除します。bin/kafka-acls.sh --authorizer-properties zookeeper.connect=zoo1.my-domain.com:2181 --remove --consumer --topic myTopic --group MyConsumerGroup --allow-principal User:user1
user1が IP アドレスホスト127.0.0.1からmyTopicを読むためのアクセスを拒否する ACL を削除します。bin/kafka-acls.sh --authorizer-properties zookeeper.connect=zoo1.my-domain.com:2181 --remove --operation Describe --operation Read --topic myTopic --group MyConsumerGroup --deny-principal User:user1 --deny-host 127.0.0.1
関連情報
-
kafka-acls.shオプションの全一覧は、「シンプルな ACL オーソライザー」 を参照してください。 - 承認の有効化に関する詳細は、「承認の有効化」 を参照してください。
4.8. ZooKeeper の承認
Kafka と Zoo Keeper の間で認証が有効になっている場合、Zoo Keeper アクセス制御リスト (ACL) ルールを使用して、Zoo Keeper に格納されている Kafka のメタデータへのアクセスを自動的に制御できます。
4.8.1. ACL 設定
ZooKeeper ACL ルールの適用は、config/server.properties Kafka 設定ファイルの zookeeper.set.acl プロパティーによって制御されます。
プロパティーはデフォルトで無効になっていて、true に設定することにより有効になります。
zookeeper.set.acl=true
ACL ルールが有効になっている場合、ZooKeeper で znode が作成されると、作成した Kafka ユーザーのみが変更または削除できます。その他のすべてのユーザーには読み取り専用アクセスがあります。
Kafka は、新しく作成された ZooKeeper znodes に対してのみ ACL ルールを設定します。ACL がクラスターの最初の起動後にのみ有効である場合、zookeeper-security-migration.sh ツールは既存のすべての znodes に ACL を設定できます。
ZooKeeper のデータの機密性
ZooKeeper に保存されるデータには以下が含まれます。
- トピック名およびその設定
- SASL SCRAM 認証が使用される場合のソルトおよびハッシュ化されたユーザークレデンシャル
しかし、ZooKeeper は Kafka を使用して送受信されたレコードを保存しません。ZooKeeper に保存されるデータは機密ではないと想定されます。
データが機密として考慮される場合 (たとえば、トピック名にカスタマー ID が含まれるなど)、保護に使用できる唯一のオプションは、ネットワークレベルで ZooKeeper を分離し、Kafka ブローカーにのみアクセスを許可することです。
4.8.2. 新しい Kafka クラスターでの ZooKeeper ACL の有効化
この手順では、新しい Kafka クラスターの Kafka 設定で ZooKeeper ACL を有効にする方法を説明します。この手順は、Kafka クラスターの最初の起動前にのみ使用してください。すでに実行中のクラスターで ZooKeeper ACL を有効にする場合は、「既存の Kafka クラスターでの ZooKeeper ACL の有効化」 を参照してください。
前提条件
- Kafka ブローカーとして使用されるすべてのホストに AMQ Streams がインストールされている。
- ZooKeeper クラスターが 設定され、稼働している。
- ZooKeeper でクライアント/サーバー間の認証が 有効である。
- Kafka ブローカーで ZooKeeper の認証が 有効である。
- Kafka ブローカーがまだ起動していない。
手順
すべてのクラスターノードの
/opt/kafka/config/server.propertiesKafka 設定ファイルを編集し、zookeeper.set.aclフィールドをtrueに設定します。zookeeper.set.acl=true
- Kafka ブローカーを起動します。
4.8.3. 既存の Kafka クラスターでの ZooKeeper ACL の有効化
この手順では、稼働している Kafka クラスターの Kafka 設定で ZooKeeper ACL を有効にする方法を説明します。zookeeper-security-migration.sh ツールを使用して、既存のすべての znodes に ZooKeeper の ACL を設定します。zookeeper-security-migration.sh は AMQ Streams の一部として利用でき、bin ディレクトリーにあります。
前提条件
- Kafka クラスターが 設定され、稼働している。
ZooKeeper ACL の有効化
すべてのクラスターノードの
/opt/kafka/config/server.propertiesKafka 設定ファイルを編集し、zookeeper.set.aclフィールドをtrueに設定します。zookeeper.set.acl=true
- すべての Kafka ブローカーを 1 つずつ再起動します。
zookeeper-security-migration.shツールを使用して、既存のすべてのznodesノードに ACL を設定します。su - kafka cd /opt/kafka KAFKA_OPTS="-Djava.security.auth.login.config=./config/jaas.conf"; ./bin/zookeeper-security-migration.sh --zookeeper.acl=secure --zookeeper.connect=<ZooKeeperURL> exit以下に例を示します。
su - kafka cd /opt/kafka KAFKA_OPTS="-Djava.security.auth.login.config=./config/jaas.conf"; ./bin/zookeeper-security-migration.sh --zookeeper.acl=secure --zookeeper.connect=zoo1.my-domain.com:2181 exit
4.9. 暗号化と認証
AMQ Streams は、リスナー設定の一部として設定される暗号化および認証をサポートします。
4.9.1. リスナーの設定
Kafka ブローカーの暗号化および認証は、リスナーごとに設定されます。Kafka リスナーの設定に関する詳細は、「「リスナー」」 を参照してください。
Kafka ブローカーの各リスナーは、独自のセキュリティープロトコルで設定されます。設定プロパティー listener.security.protocol.map は、どのリスナーがどのセキュリティープロトコルを使用するかを定義します。各リスナー名がセキュリティープロトコルにマッピングされます。サポートされるセキュリティープロトコルは次のとおりです。
PLAINTEXT- 暗号化または認証を使用しないリスナー。
SSL- TLS 暗号化を使用し、オプションで TLS クライアント証明書を使用した認証を使用するリスナー。
SASL_PLAINTEXT- 暗号化なし、SASL ベースの認証を使用するリスナー。
SASL_SSL- TLS ベースの暗号化および SASL ベースの認証を使用するリスナー。
以下の listeners 設定の場合、
listeners=INT1://:9092,INT2://:9093,REPLICATION://:9094
listener.security.protocol.map は以下のようになります。
listener.security.protocol.map=INT1:SASL_PLAINTEXT,INT2:SASL_SSL,REPLICATION:SSL
これにより、リスナー INT1 は暗号化されていない接続および SASL 認証を使用し、リスナー INT2 は暗号化された接続および SASL 認証を使用し、REPLICATION インターフェイスは TLS による暗号化 (TLS クライアント認証が使用される可能性があり) を使用するように設定されます。同じセキュリティープロトコルを複数回使用できます。以下は、有効な設定の例です。
listener.security.protocol.map=INT1:SSL,INT2:SSL,REPLICATION:SSL
このような設定は、すべてのインターフェイスに TLS 暗号化および TLS 認証を使用します。以下の章では、TLS および SASL の設定方法について詳しく説明します。
4.9.2. TLS 暗号化
Kafka は、Kafka クライアントとの通信を暗号化するために TLS をサポートします。
TLS による暗号化およびサーバー認証を使用するには、秘密鍵と公開鍵が含まれるキーストアを提供する必要があります。これは通常、Java Keystore (JKS) 形式のファイルを使用して行われます。このファイルのパスは、ssl.keystore.location プロパティーに設定されます。ssl.keystore.password プロパティーを使用して、キーストアを保護するパスワードを設定する必要があります。以下に例を示します。
ssl.keystore.location=/path/to/keystore/server-1.jks ssl.keystore.password=123456
秘密鍵を保護するために、追加のパスワードが使用されることがあります。このようなパスワードは、ssl.key.password プロパティーを使用して設定できます。
Kafka は、認証局によって署名された鍵と自己署名の鍵を使用できます。認証局が署名する鍵を使用することが、常に推奨される方法です。クライアントが接続している Kafka ブローカーのアイデンティティーを検証できるようにするには、証明書に Common Name (CN) または Subject Alternative Names (SAN) としてアドバタイズされたホスト名が常に含まれる必要があります。
異なるリスナーに異なる SSL 設定を使用できます。ssl. で始まるすべてのオプションの前に listener.name.<NameOfTheListener>. を付けることができます。この場合、リスナーの名前は常に小文字である必要があります。これにより、その特定のリスナーのデフォルトの SSL 設定が上書きされます。以下の例は、異なるリスナーに異なる SSL 設定を使用する方法を示しています。
listeners=INT1://:9092,INT2://:9093,REPLICATION://:9094 listener.security.protocol.map=INT1:SSL,INT2:SSL,REPLICATION:SSL # Default configuration - will be used for listeners INT1 and INT2 ssl.keystore.location=/path/to/keystore/server-1.jks ssl.keystore.password=123456 # Different configuration for listener REPLICATION listener.name.replication.ssl.keystore.location=/path/to/keystore/server-1.jks listener.name.replication.ssl.keystore.password=123456
その他の TLS 設定オプション
上記のメインの TLS 設定オプションの他に、Kafka は TLS 設定を調整するための多くのオプションをサポートします。たとえば、TLS/ SSL プロトコルまたは暗号スイートを有効または無効にするには、次のコマンドを実行します。
ssl.cipher.suites- 有効な暗号スイートの一覧。各暗号スイートは、TLS 接続に使用される認証、暗号化、MAC、および鍵交換アルゴリズムの組み合わせです。デフォルトでは、利用可能なすべての暗号スイートが有効になっています。
ssl.enabled.protocols-
有効な TLS / SSL プロトコルのリスト。デフォルトは
TLSv1.2,TLSv1.1,TLSv1です。
サポートされる Kafka ブローカー設定オプションの完全リストは、「付録A ブローカー設定パラメーター」を参照してください。
4.9.3. TLS 暗号化の有効化
この手順では、Kafka ブローカーで暗号化を有効にする方法を説明します。
前提条件
- Kafka ブローカーとして使用されるすべてのホストに AMQ Streams がインストールされている。
手順
- クラスター内のすべての Kafka ブローカーの TLS 証明書を生成します。証明書には、Common Name または Subject Alternative Name にアドバタイズされたアドレスおよびブートストラップアドレスが必要です。
以下のように、すべてのクラスターノードの
/opt/kafka/config/server.propertiesKafka 設定ファイルを編集します。-
listener.security.protocol.mapフィールドを変更して、TLS 暗号化を使用するリスナーにSSLプロトコルを指定します。 -
ssl.keystore.locationオプションを、ブローカー証明書を持つ JKS キーストアへのパスに設定します。 ssl.keystore.passwordオプションを、キーストアの保護に使用したパスワードに設定します。以下に例を示します。
listeners=UNENCRYPTED://:9092,ENCRYPTED://:9093,REPLICATION://:9094 listener.security.protocol.map=UNENCRYPTED:PLAINTEXT,ENCRYPTED:SSL,REPLICATION:PLAINTEXT ssl.keystore.location=/path/to/keystore/server-1.jks ssl.keystore.password=123456
-
- Kafka ブローカーを (再) 起動します。
関連情報
- AMQ Streams の設定に関する詳細は、「AMQ Streams の設定」 を参照してください。
- Kafka クラスターの実行に関する詳細は、「マルチノードの Kafka クラスターの実行」 を参照してください。
クライアントでの TLS 暗号化の設定に関する詳細は、以下を参照してください。
4.9.4. 認証
認証には、以下を使用できます。
- 暗号化接続の X.509 証明書に基づく TLS クライアント認証
- サポートされる Kafka SASL (Simple Authentication and Security Layer) メカニズム
- OAuth 2.0 のトークンベースの認証
4.9.4.1. TLS クライアント認証
TLS クライアント認証は、TLS 暗号化を使用している接続でのみ使用できます。TLS クライアント認証を使用するには、公開鍵のあるトラストストアをブローカーに提供できます。これらのキーは、ブローカーに接続するクライアントを認証するために使用できます。トラストストアは Java Keystore (JKS) 形式で提供され、認証局の公開鍵が含まれている必要があります。トラストストアに含まれる認証局のいずれかによって署名された公開鍵および秘密鍵を持つクライアントはすべて認証されます。トラストストアの場所は、フィールド ssl.truststore.location を使用して設定されます。トラストストアがパスワードで保護される場合、ssl.truststore.password プロパティーでパスワードを設定する必要があります。以下に例を示します。
ssl.truststore.location=/path/to/keystore/server-1.jks ssl.truststore.password=123456
トラストストアが設定したら、ssl.client.auth プロパティーを使用して TLS クライアント認証を有効にする必要があります。このプロパティーは、3 つの異なる値のいずれかに設定できます。
none- TLS クライアント認証はオフになっています。(デフォルト値)
requested- TLS クライアント認証は任意です。クライアントは TLS クライアント証明書を使用した認証を要求されますが、選択することはできません。
required- クライアントは TLS クライアント証明書を使用して認証する必要があります。
クライアントが TLS クライアント認証を使用して認証する場合、認証されたプリンシパル名は認証済みクライアント証明書からの識別名になります。たとえば、CN=someuser という識別名の証明書を持つユーザーは、プリンシパル CN=someuser,OU=Unknown,O=Unknown,L=Unknown,ST=Unknown,C=Unknown で認証されます。TLS クライアント認証が使用されておらず、SASL が無効な場合、プリンシパル名は ANONYMOUS になります。
4.9.4.2. SASL 認証
SASL 認証は、Java Authentication and Authorization Service (JAAS) を使用して設定されます。JAAS は、Kafka と ZooKeeper 間の接続の認証にも使用されます。JAAS は独自の設定ファイルを使用します。このファイルに推奨される場所は /opt/kafka/config/jaas.conf です。ファイルは kafka ユーザーが読み取りできる必要があります。Kafka を実行中の場合、このファイルの場所は Java システムプロパティー java.security.auth.login.config を使用して指定されます。このプロパティーは、ブローカーノードの起動時に Kafka に渡す必要があります。
KAFKA_OPTS="-Djava.security.auth.login.config=/path/to/my/jaas.config"; bin/kafka-server-start.sh
SASL 認証は、暗号化されていないプレーンの接続と TLS 接続の両方を介してサポートされます。SASL はリスナーごとに個別に有効にできます。これを有効にするには、listener.security.protocol.map のセキュリティープロトコルを SASL_PLAINTEXT または SASL_SSL のいずれかにする必要があります。
Kafka の SASL 認証は、いくつかの異なるメカニズムをサポートします。
PLAIN- ユーザー名とパスワードに基づいて認証を実装します。ユーザー名とパスワードは Kafka 設定にローカルに保存されます。
SCRAM-SHA-256およびSCRAM-SHA-512- Salted Challenge Response Authentication Mechanism (SCRAM) を使用して認証を実装します。SCRAM 認証情報は、ZooKeeper に一元的に保存されます。SCRAM は、ZooKeeper クラスターノードがプライベートネットワークで分離された状態で実行されている場合に使用できます。
GSSAPI- Kerberos サーバーに対して認証を実装します。
PLAIN メカニズムは、ネットワークを通じてユーザー名とパスワードを暗号化されていない形式で送信します。そのため、TLS による暗号化と組み合わせる場合にのみ使用してください。
SASL メカニズムは JAAS 設定ファイルを使用して設定されます。Kafka は KafkaServer という名前の JAAS コンテキストを使用します。JAAS で設定された後、Kafka 設定で SASL メカニズムを有効にする必要があります。これは、sasl.enabled.mechanisms プロパティーを使用して実行されます。このプロパティーには、有効なメカニズムのコンマ区切りリストが含まれます。
sasl.enabled.mechanisms=PLAIN,SCRAM-SHA-256,SCRAM-SHA-512
inter-broker 通信に使用されるリスナーが SASL を使用している場合、sasl.mechanism.inter.broker.protocol プロパティーを使用して使用する SASL メカニズムを指定する必要があります。以下に例を示します。
sasl.mechanism.inter.broker.protocol=PLAIN
inter-broker 通信に使用されるユーザー名およびパスワードは、フィールド username および password を使用して KafkaServer JAAS コンテキストで指定する必要があります。
SASL プレーン
PLAIN メカニズムを使用するには、接続が許可されるユーザー名およびパスワードは JAAS コンテキストに直接指定されます。以下の例は、SASL PLAIN 認証に設定されたコンテキストを示しています。この例では、3 つの異なるユーザーを設定します。
-
admin -
user1 -
user2
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
user_admin="123456"
user_user1="123456"
user_user2="123456";
};ユーザーデータベースを持つ JAAS 設定ファイルは、すべての Kafka ブローカーで同期して維持する必要があります。
SASL PLAIN が inter-broker の認証にも使用される場合、username および password プロパティーを JAAS コンテキストに含める必要があります。
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="123456"
user_admin="123456"
user_user1="123456"
user_user2="123456";
};SASL SCRAM
Kafka の SCRAM 認証は、SCRAM-SHA-256 および SCRAM-SHA-512 の 2 つのメカニズムで構成されます。これらのメカニズムは、使用されるハッシュアルゴリズム (SHA-256 とより強力な SHA-512) のみが異なります。SCRAM 認証を有効にするには、JAAS 設定ファイルに以下の設定を含める必要があります。
KafkaServer {
org.apache.kafka.common.security.scram.ScramLoginModule required;
};Kafka 設定ファイルで SASL 認証を有効にすると、両方の SCRAM メカニズムが一覧表示されます。ただし、それらの 1 つのみを inter-broker 通信に選択できます。以下に例を示します。
sasl.enabled.mechanisms=SCRAM-SHA-256,SCRAM-SHA-512 sasl.mechanism.inter.broker.protocol=SCRAM-SHA-512
SCRAM メカニズムのユーザークレデンシャルは ZooKeeper に保存されます。kafka-configs.sh ツールを使用してそれらを管理できます。たとえば、以下のコマンドを実行して、パスワード 123456 で user1 を追加します。
bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --add-config 'SCRAM-SHA-256=[password=123456],SCRAM-SHA-512=[password=123456]' --entity-type users --entity-name user1
ユーザー認証情報を削除するには、以下を使用します。
bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --delete-config 'SCRAM-SHA-512' --entity-type users --entity-name user1
SASL GSSAPI
Kerberos を使用した認証に使用される SASL メカニズムは GSSAPI と呼ばれます。Kerberos SASL 認証を設定するには、以下の設定を JAAS 設定ファイルに追加する必要があります。
KafkaServer {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/etc/security/keytabs/kafka_server.keytab"
principal="kafka/kafka1.hostname.com@EXAMPLE.COM";
};Kerberos プリンシパルのドメイン名は常に大文字にする必要があります。
JAAS 設定の他に、Kerberos サービス名を Kafka 設定の sasl.kerberos.service.name プロパティーで指定する必要があります。
sasl.enabled.mechanisms=GSSAPI sasl.mechanism.inter.broker.protocol=GSSAPI sasl.kerberos.service.name=kafka
複数の SASL メカニズム
Kafka は複数の SASL メカニズムを同時に使用できます。異なる JAAS 設定はすべて同じコンテキストに追加できます。
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
user_admin="123456"
user_user1="123456"
user_user2="123456";
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/etc/security/keytabs/kafka_server.keytab"
principal="kafka/kafka1.hostname.com@EXAMPLE.COM";
org.apache.kafka.common.security.scram.ScramLoginModule required;
};複数のメカニズムを有効にすると、クライアントは使用するメカニズムを選択できます。
4.9.5. TLS クライアント認証の有効化
この手順では、Kafka ブローカーで TLS クライアント認証を有効にする方法を説明します。
前提条件
- Kafka ブローカーとして使用されるすべてのホストに AMQ Streams がインストールされている。
- TLS 暗号化が 有効になっている。
手順
- ユーザー証明書に署名するために使用される認証局の公開鍵が含まれる JKS トラストストアを準備します。
以下のように、すべてのクラスターノードの
/opt/kafka/config/server.propertiesKafka 設定ファイルを編集します。-
ssl.truststore.locationオプションを、ユーザー証明書の認証局が含まれる JKS トラストストアへのパスに設定します。 -
ssl.truststore.passwordオプションを、トラストストアの保護に使用したパスワードに設定します。 ssl.client.authオプションをrequiredに設定します。以下に例を示します。
ssl.truststore.location=/path/to/truststore.jks ssl.truststore.password=123456 ssl.client.auth=required
-
- Kafka ブローカーを (再) 起動します。
関連情報
- AMQ Streams の設定に関する詳細は、「AMQ Streams の設定」 を参照してください。
- Kafka クラスターの実行に関する詳細は、「マルチノードの Kafka クラスターの実行」 を参照してください。
クライアントでの TLS 暗号化の設定に関する詳細は、以下を参照してください。
4.9.6. SASL PLAIN 認証の有効化
この手順では、Kafka ブローカーで SASL PLAIN 認証を有効にする方法を説明します。
前提条件
- Kafka ブローカーとして使用されるすべてのホストに AMQ Streams がインストールされている。
手順
/opt/kafka/config/jaas.confJAAS 設定ファイルを編集するか、作成します。このファイルには、すべてのユーザーとそのパスワードが含まれている必要があります。このファイルがすべての Kafka ブローカーで同じであることを確認します。以下に例を示します。
KafkaServer { org.apache.kafka.common.security.plain.PlainLoginModule required user_admin="123456" user_user1="123456" user_user2="123456"; };以下のように、すべてのクラスターノードの
/opt/kafka/config/server.propertiesKafka 設定ファイルを編集します。-
listener.security.protocol.mapフィールドを変更して、SASL PLAIN 認証を使用するリスナーのSASL_PLAINTEXTまたはSASL_SSLプロトコルを指定します。 sasl.enabled.mechanismsオプションをPLAINに設定します。以下に例を示します。
listeners=INSECURE://:9092,AUTHENTICATED://:9093,REPLICATION://:9094 listener.security.protocol.map=INSECURE:PLAINTEXT,AUTHENTICATED:SASL_PLAINTEXT,REPLICATION:PLAINTEXT sasl.enabled.mechanisms=PLAIN
-
KAFKA_OPTS 環境変数を使用して Kafka ブローカーを (再) 起動し、JAAS 構成を Kafka ブローカーに渡します。
su - kafka export KAFKA_OPTS="-Djava.security.auth.login.config=/opt/kafka/config/jaas.conf"; /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
関連情報
- AMQ Streams の設定に関する詳細は、「AMQ Streams の設定」 を参照してください。
- Kafka クラスターの実行に関する詳細は、「マルチノードの Kafka クラスターの実行」 を参照してください。
クライアントでの SASL PLAIN 認証の設定に関する詳細は、以下を参照してください。
4.9.7. SASL SCRAM 認証の有効化
この手順では、Kafka ブローカーで SASL SCRAM 認証を有効にする方法を説明します。
前提条件
- Kafka ブローカーとして使用されるすべてのホストに AMQ Streams がインストールされている。
手順
/opt/kafka/config/jaas.confJAAS 設定ファイルを編集するか、作成します。KafkaServerコンテキストのScramLoginModuleを有効にします。このファイルがすべての Kafka ブローカーで同じであることを確認します。以下に例を示します。
KafkaServer { org.apache.kafka.common.security.scram.ScramLoginModule required; };以下のように、すべてのクラスターノードの
/opt/kafka/config/server.propertiesKafka 設定ファイルを編集します。-
listener.security.protocol.mapフィールドを変更して、SASL SCRAM 認証を使用するリスナーのSASL_PLAINTEXTまたはSASL_SSLプロトコルを指定します。 sasl.enabled.mechanismsオプションをSCRAM-SHA-256またはSCRAM-SHA-512に設定します。以下に例を示します。
listeners=INSECURE://:9092,AUTHENTICATED://:9093,REPLICATION://:9094 listener.security.protocol.map=INSECURE:PLAINTEXT,AUTHENTICATED:SASL_PLAINTEXT,REPLICATION:PLAINTEXT sasl.enabled.mechanisms=SCRAM-SHA-512
-
KAFKA_OPTS 環境変数を使用して Kafka ブローカーを (再) 起動し、JAAS 構成を Kafka ブローカーに渡します。
su - kafka export KAFKA_OPTS="-Djava.security.auth.login.config=/opt/kafka/config/jaas.conf"; /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
関連情報
- AMQ Streams の設定に関する詳細は、「AMQ Streams の設定」 を参照してください。
- Kafka クラスターの実行に関する詳細は、「マルチノードの Kafka クラスターの実行」 を参照してください。
- SASL SCRAM ユーザーの追加に関する詳細は、「SASL SCRAM ユーザーの追加」 を参照してください。
- SASL SCRAM ユーザーの削除に関する詳細は、「SASL SCRAM ユーザーの削除」 を参照してください。
クライアントでの SASL SCRAM 認証の設定に関する詳細は、以下を参照してください。
4.9.8. SASL SCRAM ユーザーの追加
この手順では、SASL SCRAM を使用した認証に新しいユーザーを追加する方法を説明します。
前提条件
- Kafka ブローカーとして使用されるすべてのホストに AMQ Streams がインストールされている。
- SASL SCRAM 認証が 有効になっている。
手順
kafka-configs.shツールを使用して、新しい SASL SCRAM ユーザーを追加します。bin/kafka-configs.sh --bootstrap-server <BrokerAddress> --alter --add-config 'SCRAM-SHA-512=[password=<Password>]' --entity-type users --entity-name <Username>
以下に例を示します。
bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --add-config 'SCRAM-SHA-512=[password=123456]' --entity-type users --entity-name user1
関連情報
クライアントでの SASL SCRAM 認証の設定に関する詳細は、以下を参照してください。
4.9.9. SASL SCRAM ユーザーの削除
この手順では、SASL SCRAM 認証を使用する場合にユーザーを削除する方法を説明します。
前提条件
- Kafka ブローカーとして使用されるすべてのホストに AMQ Streams がインストールされている。
- SASL SCRAM 認証が 有効になっている。
手順
kafka-configs.shツールを使用して SASL SCRAM ユーザーを削除します。bin/kafka-configs.sh --bootstrap-server <BrokerAddress> --alter --delete-config 'SCRAM-SHA-512' --entity-type users --entity-name <Username>
以下に例を示します。
bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --delete-config 'SCRAM-SHA-512' --entity-type users --entity-name user1
関連情報
クライアントでの SASL SCRAM 認証の設定に関する詳細は、以下を参照してください。
4.10. 「OAuth 2.0 トークンベース認証の使用」
AMQ Streams は、SASL OAUTHBEARER メカニズムを使用して OAuth 2.0 認証の使用をサポートします。
OAuth 2.0 は、アプリケーション間で標準的なトークンベースの認証および承認を有効にし、中央の承認サーバーを使用してリソースに制限されたアクセスを付与するトークンを発行します。
OAuth 2.0 認証を設定した後に OAuth 2.0 承認 を設定できます。OAuth 2.0 認証は、使用する承認サーバーに関係なく ACL ベースの Kafka 承認 と併用することもできます。OAuth 2.0 のトークンベースの認証を使用すると、アプリケーションクライアントはアカウントのクレデンシャルを公開せずにアプリケーションサーバー (リソースサーバー と呼ばれる) のリソースにアクセスできます。
アプリケーションクライアントは、アクセストークンを認証の手段として渡します。アプリケーションサーバーはこれを使用して、付与するアクセス権限のレベルを決定することもできます。承認サーバーは、アクセスの付与とアクセスに関する問い合わせを処理します。
AMQ Streams のコンテキストでは以下が行われます。
- Kafka ブローカーは OAuth 2.0 リソースサーバーとして動作します。
- Kafka クライアントは OAuth 2.0 アプリケーションクライアントとして動作します。
Kafka クライアントは Kafka ブローカーに対して認証を行います。ブローカーおよびクライアントは、必要に応じて OAuth 2.0 承認サーバーと通信し、アクセストークンを取得または検証します。
AMQ Streams のデプロイメントでは、OAuth 2.0 インテグレーションは以下を提供します。
- Kafka ブローカーのサーバー側の OAuth 2.0 サポート。
- Kafka MirrorMaker、Kafka Connect、および Kafka Bridge のクライアント側 OAuth 2.0 サポート。
その他のリソース
4.10.1. OAuth 2.0 認証メカニズム
Kafka SASL OAUTHBEARER メカニズムは、Kafka ブローカーで認証されたセッションを確立するために使用されます。
Kafka クライアントは、形式がアクセストークンであるクレデンシャルの交換に SASL OAUTHBEARER メカニズムを使用して Kafka ブローカーでセッションを開始します。
Kafka ブローカーおよびクライアントは、OAuth 2.0 を使用するように設定する必要があります。
4.10.1.1. プロパティーまたは変数を使用した OAuth 2.0 の設定
OAuth 2.0 設定は、Java Authentication and Authorization Service (JAAS) プロパティーまたは環境変数を使用して設定できます。
-
JAASのプロパティーは、
server.properties設定ファイルで設定され、listener.name.LISTENER-NAME.oauthbearer.sasl.jaas.configプロパティーのキーと値のペアとして渡されます。 環境変数を使用する場合は、
server.propertiesファイルにlistener.name.LISTENER-NAME.oauthbearer.sasl.jaas.configプロパティーが必要ですが、他の JAAS プロパティーを省略することができます。大文字の環境変数の命名規則または大文字の環境変数の命名規則を使用できます。
Kafka OAuth 2.0 ライブラリーは、oauth. で始まるプロパティーを使用して認証を設定し、strimzi で始まるプロパティーを使用して OAuth 2.0 承認を設定 します。
4.10.2. 「OAuth 2.0 Kafka ブローカーの設定」
OAuth 2.0 の Kafka ブローカー設定には、以下が関係します。
- 承認サーバーでの OAuth 2.0 クライアントの作成
- Kafka クラスターでの OAuth 2.0 認証の構成
承認サーバーに関連する Kafka ブローカーおよび Kafka クライアントはどちらも OAuth 2.0 クライアントと見なされます。
4.10.2.1. 承認サーバーの OAuth 2.0 クライアント設定
セッションの開始中に受信されたトークンを検証するように Kafka ブローカーを設定するには、承認サーバーで OAuth 2.0 クライアント 定義を作成し、以下のクライアントクレデンシャルを有効にして 機密 として設定することが推奨されます。
-
kafka-brokerのクライアント ID (例) - 認証メカニズムとしてのクライアント ID およびシークレット
承認サーバーのパブリックでないイントロスペクションエンドポイントを使用する場合のみ、クライアント ID およびシークレットを使用する必要があります。高速のローカル JWT トークンの検証と同様に、パブリック承認サーバーのエンドポイントを使用する場合は、通常クレデンシャルは必要ありません。
4.10.2.2. Kafka クラスターでの OAuth 2.0 認証設定
Kafka クラスターで OAuth 2.0 認証を使用するには、Kafka server.properties ファイルで Kafka クラスターのリスナー設定を有効にします。最小設定が必要です。また、TLS が inter-broker 通信に使用される TLS リスナーを設定することもできます。
以下を使用して、承認サーバーによるトークンの検証用にブローカーを設定できます。
- JWKS エンドポイントと署名済み JWT 形式のアクセストークンの組み合わせ
- イントロスペクション エンドポイント
ここで示される最低限の設定は、グローバル リスナー設定を適用します。つまり、ブローカー間の通信はアプリケーションクライアントと同じリスナーを通過します。
特定のリスナーの OAuth 2.0 設定を有効にするには、以下のリスナー設定の例に記載されている sasl.enabled.mechanisms の代わりに listener.name.LISTENER-NAME.sasl.enabled.mechanisms を指定します。LISTENER-NAME はリスナーの名前です(大文字小文字の区別なし)。以下の例では、リスナーに CLIENT という名前を付け、プロパティー名は listener.name.client.sasl.enabled.mechanisms になります。
JWKS エンドポイントを使用した OAuth 2.0 認証の最小リスナー設定
sasl.enabled.mechanisms=OAUTHBEARER 1 listeners=CLIENT://0.0.0.0:9092 2 listener.security.protocol.map=CLIENT:SASL_PLAINTEXT 3 listener.name.client.sasl.enabled.mechanisms=OAUTHBEARER 4 sasl.mechanism.inter.broker.protocol=OAUTHBEARER 5 inter.broker.listener.name=CLIENT 6 listener.name.client.oauthbearer.sasl.server.callback.handler.class=io.strimzi.kafka.oauth.server.JaasServerOauthValidatorCallbackHandler 7 listener.name.client.oauthbearer.sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \ 8 oauth.valid.issuer.uri="https://AUTH-SERVER-ADDRESS" \ 9 oauth.jwks.endpoint.uri="https://AUTH-SERVER-ADDRESS/jwks" \ 10 oauth.username.claim="preferred_username" \ 11 oauth.client.id="kafka-broker" \ 12 oauth.client.secret="kafka-secret" \ 13 oauth.token.endpoint.uri="https://AUTH-SERVER-ADDRESS/token" ; 14 listener.name.client.oauthbearer.sasl.login.callback.handler.class=io.strimzi.kafka.oauth.client.JaasClientOauthLoginCallbackHandler 15 listener.name.client.oauthbearer.connections.max.reauth.ms=3600000 16
- 1
- SASL でのクレデンシャル交換の SASL メカニズムとして OAUTHBEARER を有効にします。
- 2
- 接続するクライアントアプリケーションのリスナーを設定します。システム
hostnameはアドバタイズされたホスト名として使用されます。これは、再接続するためにクライアントが解決する必要があります。この例では、リスナーの名前はCLIENTです。 - 3
- リスナーのチャネルプロトコルを指定します。
SASL_SSLは TLS 用です。暗号化されていない接続 (TLS なし) にはSASL_PLAINTEXTが使用されますが、TCP 接続層での盗聴のリスクがあります。 - 4
- CLIENT リスナーの SASL として OAUTHBEARER を指定します。クライアント名(
CLIENT)は通常、listeners プロパティーでは大文字で、listeners.name プロパティー(listener.name.client)では小文字で、listener.nameプロパティーの一部として小文字で指定します。.クライアント.* - 5
- ブローカー間の通信に OAUTHBEARER を SASL として指定します。
- 6
- inter-broker 通信のリスナーを指定します。仕様は、有効な設定のために必要です。
- 7
- クライアントリスナーで OAuth 2.0 認証を設定します。
- 8
- クライアントおよび inter-broker 通信の認証設定を設定します。
oauth.client.id、oauth.client.secret、およびauth.token.endpoint.uriプロパティーは inter-broker 設定に関連するものです。 - 9
- 有効な発行者 URI。この発行者が発行するアクセストークンのみが受け入れられます。例: https://AUTH-SERVER-ADDRESS/auth/realms/REALM-NAME
- 10
- JWKS エンドポイント URL。例: https://AUTH-SERVER-ADDRESS/auth/realms/REALM-NAME/protocol/openid-connect/certs
- 11
- トークンの実際のユーザー名が含まれるトークン要求 (またはキー)。ユーザー名は、ユーザーの識別に使用される principal です。値は、使用される認証フローと承認サーバーによって異なります。
- 12
- すべてのブローカーで同じ Kafka ブローカーのクライアント ID。これは、
kafka-brokerとして承認サーバーに登録されたクライアントです。 - 13
- すべてのブローカーで同じ Kafka ブローカーのシークレット。
- 14
- 承認サーバーへの OAuth 2.0 トークンエンドポイント URL。実稼働環境では、常に HTTPS を使用してください 例: https://AUTH-SERVER-ADDRESS/auth/realms/REALM-NAME/protocol/openid-connect/token
- 15
- inter-broker 通信の OAuth2.0 認証を有効にします (これにのみ必要です)。
- 16
- (任意設定)トークンの有効期限が切れるとセッションの有効期限を強制し、Kafka の再認証メカニズム も有効にします。指定された値がアクセストークンの有効期限が切れるまでの残り時間未満の場合、クライアントは実際にトークンの有効期限が切れる前に再認証する必要があります。デフォルトでは、アクセストークンの期限が切れてもセッションは期限切れにならず、クライアントは再認証を試行しません。
OAuth 2.0 認証の TLS リスナー設定
sasl.enabled.mechanisms= listeners=REPLICATION://kafka:9091,CLIENT://kafka:9092 1 listener.security.protocol.map=REPLICATION:SSL,CLIENT:SASL_PLAINTEXT 2 listener.name.client.sasl.enabled.mechanisms=OAUTHBEARER inter.broker.listener.name=REPLICATION listener.name.replication.ssl.keystore.password=KEYSTORE-PASSWORD 3 listener.name.replication.ssl.truststore.password=TRUSTSTORE-PASSWORD listener.name.replication.ssl.keystore.type=JKS listener.name.replication.ssl.truststore.type=JKS listener.name.replication.ssl.endpoint.identification.algorithm=HTTPS 4 listener.name.replication.ssl.secure.random.implementation=SHA1PRNG 5 listener.name.replication.ssl.keystore.location=PATH-TO-KEYSTORE 6 listener.name.replication.ssl.truststore.location=PATH-TO-TRUSTSTORE 7 listener.name.replication.ssl.client.auth=required 8 listener.name.client.oauthbearer.sasl.server.callback.handler.class=io.strimzi.kafka.oauth.server.JaasServerOauthValidatorCallbackHandler listener.name.client.oauthbearer.sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \ oauth.valid.issuer.uri="https://AUTH-SERVER-ADDRESS" \ oauth.jwks.endpoint.uri="https://AUTH-SERVER-ADDRESS/jwks" \ oauth.username.claim="preferred_username" ; 9
- 1
- inter-broker 通信とクライアントアプリケーションには、個別の設定が必要です。
- 2
- REPLICATION リスナーが TLS を使用し、CLIENT リスナーが暗号化されていないチャネルで SASL を使用するように設定します。実稼働環境では、クライアントは暗号化されたチャンネル (
SASL_SSL) を使用できます。 - 3
ssl.プロパティーは TLS 設定を定義します。- 4
- 乱数ジェネレーターの実装。設定されていない場合は、Java プラットフォーム SDK デフォルトが使用されます。
- 5
- ホスト名の検証。空の文字列に設定すると、ホスト名の検証はオフになります。設定されていない場合、デフォルト値は HTTPS で、サーバー証明書のホスト名の検証を強制します。
- 6
- リスナーのキーストアへのパス。
- 7
- リスナーのトラストストアへのパス。
- 8
- (inter-broker 接続に使用される) TLS 接続の確立時に REPLICATION リスナーのクライアントがクライアント証明書で認証する必要があることを指定します。
- 9
- OAuth 2.0 の CLIENT リスナーを設定します。承認サーバーとの接続はセキュアな HTTPS 接続を使用する必要があります。
4.10.2.3. 高速なローカル JWT トークン検証の設定
高速なローカル JWT トークンの検証では、JWTトークンの署名がローカルでチェックされます。
ローカルチェックでは、トークンに対して以下が確認されます。
-
アクセストークンに
Bearerの (typ) 要求値が含まれ、トークンがタイプに準拠することを確認します。 - 有効であるか (期限切れでない) を確認します。
-
トークンに
validIssuerURIと一致する発行元があることを確認します。
承認サーバーによって発行されなかったすべてのトークンが拒否されるよう、リスナーの設定時に 有効な発行者 URI を指定します。
高速のローカル JWT トークン検証の実行中に、承認サーバーの通信は必要はありません。OAuth 2.0 承認サーバーによって公開される JWK エンドポイント URI を指定して、高速のローカル JWT トークン検証をアクティベートします。エンドポイントには、署名済み JWT トークンの検証に使用される公開鍵が含まれます。これらは、Kafka クライアントによってクレデンシャルとして送信されます。
承認サーバーとの通信はすべて HTTPS を使用して実行する必要があります。
TLS リスナーでは、証明書 トラストストア を設定し、トラストストアファイルをポイントできます。
高速なローカル JWT トークン検証のプロパティーの例
listener.name.client.oauthbearer.sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \ oauth.valid.issuer.uri="https://AUTH-SERVER-ADDRESS" \ 1 oauth.jwks.endpoint.uri="https://AUTH-SERVER-ADDRESS/jwks" \ 2 oauth.jwks.refresh.seconds="300" \ 3 oauth.jwks.refresh.min.pause.seconds="1" \ 4 oauth.jwks.expiry.seconds="360" \ 5 oauth.username.claim="preferred_username" \ 6 oauth.ssl.truststore.location="PATH-TO-TRUSTSTORE-P12-FILE" \ 7 oauth.ssl.truststore.password="TRUSTSTORE-PASSWORD" \ 8 oauth.ssl.truststore.type="PKCS12" ; 9
- 1
- 有効な発行者 URI。この発行者が発行するアクセストークンのみが受け入れられます。例: https://AUTH-SERVER-ADDRESS/auth/realms/REALM-NAME
- 2
- JWKS エンドポイント URL。例: https://AUTH-SERVER-ADDRESS/auth/realms/REALM-NAME/protocol/openid-connect/certs
- 3
- エンドポイントの更新間隔 (デフォルトは 300)。
- 4
- JWKS 公開鍵の更新が連続して試行される間隔の最小一時停止時間 (秒単位)。不明な署名キーが検出されると、JWKS キーの更新は、最後に更新を試みてから少なくとも指定された期間は一時停止し、通常の定期スケジュール以外でスケジュールされます。キーの更新は指数バックオフ (指数バックオフ) のルールに従い、
oauth.jwks.refresh.secondsに到達するまで、一時停止を増やして失敗した更新を再試行します。デフォルト値は 1 です。 - 5
- JWK 証明書が期限切れになる前に有効とみなされる期間。デフォルトは
360秒です。デフォルトよりも長い時間を指定する場合は、無効になった証明書へのアクセスが許可されるリスクを考慮してください。 - 6
- トークンの実際のユーザー名が含まれるトークン要求 (またはキー)。ユーザー名は、ユーザーの識別に使用される principal です。値は、使用される認証フローと承認サーバーによって異なります。
- 7
- TLS 設定で使用されるトラストストアの場所。
- 8
- トラストストアにアクセスするためのパスワード。
- 9
- PKCS #12 形式のトラストストアタイプ。
4.10.2.4. OAuth 2.0 イントロスペクションエンドポイントの設定
OAuth 2.0 のイントロスペクションエンドポイントを使用したトークンの検証では、受信したアクセストークンは不透明として対処されます。Kafka ブローカーは、アクセストークンをイントロスペクションエンドポイントに送信します。このエンドポイントは、検証に必要なトークン情報を応答として返します。ここで重要なのは、特定のアクセストークンが有効である場合は最新情報を返すことで、トークンの有効期限に関する情報も返します。
OAuth 2.0 イントロスペクションベースの検証を構成するには、高速ローカル JWT トークン検証用に指定された JWK エンドポイント URI ではなく、イントロスペクションエンドポイント URI を指定します。通常、イントロスペクションエンドポイントは保護されているため、承認サーバーに応じて client ID および client secret を指定する必要があります。
イントロスペクションエンドポイントのプロパティー例
listener.name.client.oauthbearer.sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \ oauth.introspection.endpoint.uri="https://AUTH-SERVER-ADDRESS/introspection" \ 1 oauth.client.id="kafka-broker" \ 2 oauth.client.secret="kafka-broker-secret" \ 3 oauth.ssl.truststore.location="PATH-TO-TRUSTSTORE-P12-FILE" \ 4 oauth.ssl.truststore.password="TRUSTSTORE-PASSWORD" \ 5 oauth.ssl.truststore.type="PKCS12" \ 6 oauth.username.claim="preferred_username" ; 7
- 1
- OAuth 2.0 イントロスペクションエンドポイント URI。例: https://AUTH-SERVER-ADDRESS/auth/realms/REALM-NAME/protocol/openid-connect/token/introspect
- 2
- Kafka ブローカーのクライアント ID。
- 3
- Kafka ブローカーのシークレット。
- 4
- TLS 設定で使用されるトラストストアの場所。
- 5
- トラストストアにアクセスするためのパスワード。
- 6
- PKCS #12 形式のトラストストアタイプ。
- 7
- トークンの実際のユーザー名が含まれるトークン要求 (またはキー)。ユーザー名は、ユーザーの識別に使用される principal です。
oauth.username.claimの値は、使用される承認サーバーによって異なります。
4.10.3. Kafka ブローカーの再認証の設定
AMQ Streams の OAuth 2.0 認証に使用される Kafka SASL OAUTHBEARER メカニズムは、再認証 メカニズムと呼ばれる Kafka 機能をサポートします。
リスナー設定で再認証メカニズムが有効になっている場合、アクセストークンの期限が切れるとブローカーの認証されたセッションが期限切れになります。その後、クライアントは接続を切断せずに新しい有効なアクセストークンをブローカーに送信し、既存のセッションを再認証する必要があります。
トークンの検証に成功すると、既存の接続を使用して新しいクライアントセッションが開始されます。クライアントが再認証に失敗した場合、さらにメッセージを送受信しようとすると、ブローカーは接続を閉じます。ブローカーで再認証メカニズムが有効になっていると、Kafka クライアントライブラリー 2.2 以降を使用する Java クライアントが自動的に再認証されます。
Kafka server.properties ファイルで Kafka ブローカーのセッションの再認証を有効にします。OAUTHBEARER を SASL メカニズムとして有効にした TLS リスナーに connections.max.reauth.ms プロパティーを設定します。
リスナーごとにセッションの再認証を指定できます。以下に例を示します。
listener.name.client.oauthbearer.connections.max.reauth.ms=3600000
セッションの再認証は、高速のローカル JWT とイントロスペクションエンドポイントの両タイプのトークン検証でサポートされます。設定例については、「Kafka ブローカーの OAuth 2.0 サポートの設定」 を参照してください。
Kafka バージョン 2.2 に追加された再認証メカニズムの詳細は、「KIP-368」を参照してください。
4.10.4. OAuth 2.0 Kafka クライアントの設定
Kafka クライアントは以下のいずれかで設定されます。
- 承認サーバーから有効なアクセストークンを取得するために必要な認証情報(クライアント ID およびシークレット)
- 承認サーバーから提供されたツールを使用して取得された、有効期限の長い有効なアクセストークンまたは更新トークン。
クレデンシャルは Kafka ブローカーに送信されることはありません。アクセストークンは、Kafka ブローカーに送信される唯一の情報です。クライアントによるアクセストークンの取得後、承認サーバーと通信する必要はありません。
クライアント ID とシークレットを使用した認証が最も簡単です。有効期間の長いアクセストークンまたは更新トークンを使用すると、承認サーバーツールに追加の依存関係があるため、より複雑になります。
有効期間が長いアクセストークンを使用している場合は、承認サーバーでクライアントを設定し、トークンの最大有効期間を長くする必要があります。
Kafka クライアントが直接アクセストークンで設定されていない場合、クライアントは承認サーバーと通信して Kafka セッションの開始中にアクセストークンのクレデンシャルを交換します。Kafka クライアントは以下のいずれかを交換します。
- クライアント ID およびシークレット
- クライアント ID、更新トークン、および (任意の) シークレット
4.10.5. OAuth 2.0 のクライアント認証フロー
ここでは、Kafka セッションの開始時における Kafka クライアント、Kafka ブローカー、および承認ブローカー間の通信フローを説明および可視化します。フローは、クライアントとサーバーの設定によって異なります。
Kafka クライアントがアクセストークンをクレデンシャルとして Kafka ブローカーに送信する場合、トークンを検証する必要があります。
使用する承認サーバーや利用可能な設定オプションによっては、以下の使用が適している場合があります。
- 承認サーバーと通信しない、JWT の署名確認およびローカルトークンのイントロスペクションをベースとした高速なローカルトークン検証。
- 承認サーバーによって提供される OAuth 2.0 のイントロスペクションエンドポイント。
高速のローカルトークン検証を使用するには、トークンでの署名検証に使用される公開証明書のある JWKS エンドポイントを提供する承認サーバーが必要になります。
この他に、承認サーバーで OAuth 2.0 のイントロスペクションエンドポイントを使用することもできます。新しい Kafka ブローカー接続が確立されるたびに、ブローカーはクライアントから受け取ったアクセストークンを承認サーバーに渡し、応答を確認してトークンが有効であるかどうかを確認します。
Kafka クライアントのクレデンシャルは以下に対して設定することもできます。
- 以前に生成された有効期間の長いアクセストークンを使用した直接ローカルアクセス。
- 新しいアクセストークンの発行についての承認サーバーとの通信。
承認サーバーは不透明なアクセストークンの使用のみを許可する可能性があり、この場合はローカルトークンの検証は不可能です。
4.10.5.1. クライアント認証フローの例
Kafka クライアントおよびブローカーが以下に設定されている場合の、Kafka セッション認証中のコミュニケーションフローを確認できます。
クライアントがクライアント ID とシークレットを使用し、ブローカーが検証を承認サーバーに委任する場合
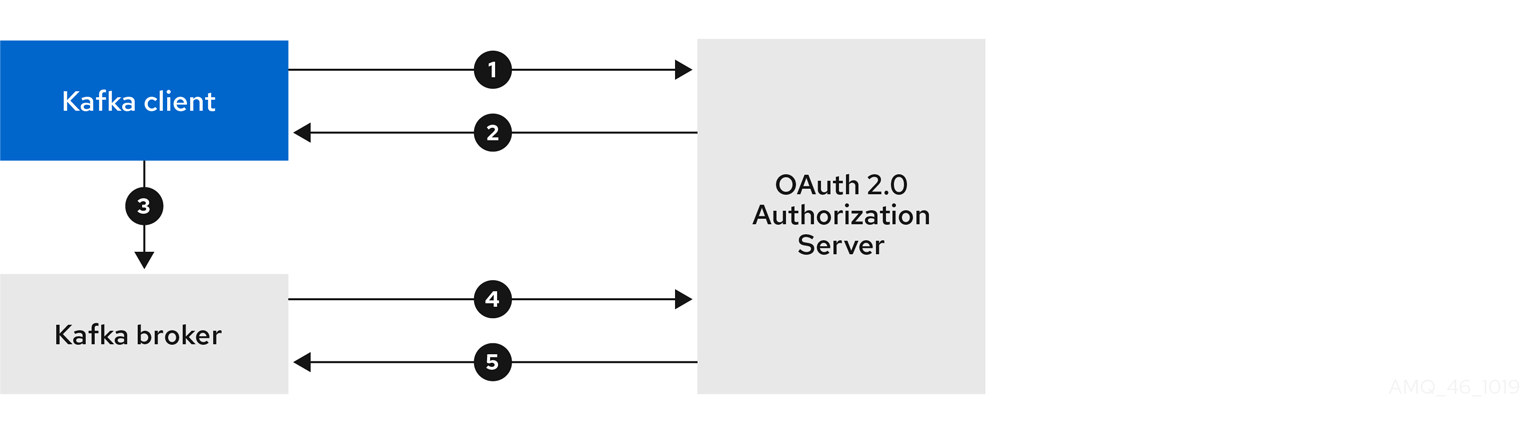
- Kafka クライアントは承認サーバーからアクセストークンを要求します。これにはクライアント ID とシークレットを使用し、任意で更新トークンも使用します。
- 承認サーバーによって新しいアクセストークンが生成されます。
- Kafka クライアントは SASL OAUTHBEARER メカニズムを使用してアクセストークンを渡し、Kafka ブローカーの認証を行います。
- Kafka ブローカーは、独自のクライアント ID およびシークレットを使用して、承認サーバーでトークンイントロスペクションエンドポイントを呼び出し、アクセストークンを検証します。
- トークンが有効な場合は、Kafka クライアントセッションが確立されます。
クライアントではクライアント ID およびシークレットが使用され、ブローカーによって高速のローカルトークン検証が実行される場合
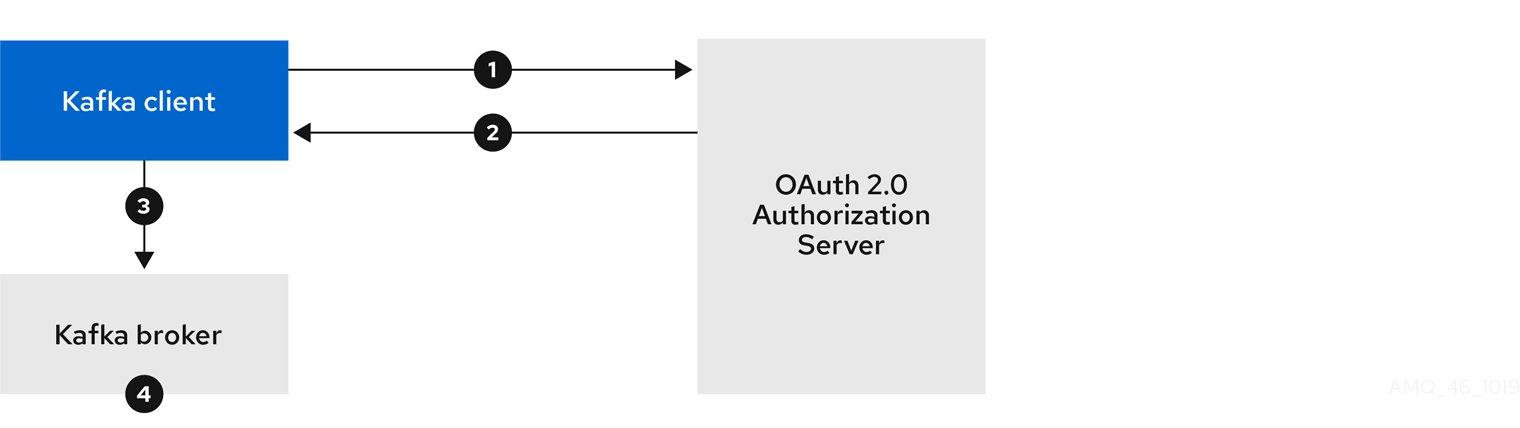
- Kafka クライアントは、トークンエンドポイントから承認サーバーの認証を行います。これにはクライアント ID とシークレットが使用され、任意で更新トークンも使用されます。
- 承認サーバーによって新しいアクセストークンが生成されます。
- Kafka クライアントは SASL OAUTHBEARER メカニズムを使用してアクセストークンを渡し、Kafka ブローカーの認証を行います。
- Kafka ブローカーは、JWT トークン署名チェックおよびローカルトークンイントロスペクションを使用して、ローカルでアクセストークンを検証します。
クライアントでは有効期限の長いアクセストークンが使用され、ブローカーによって検証が承認サーバーに委譲される場合
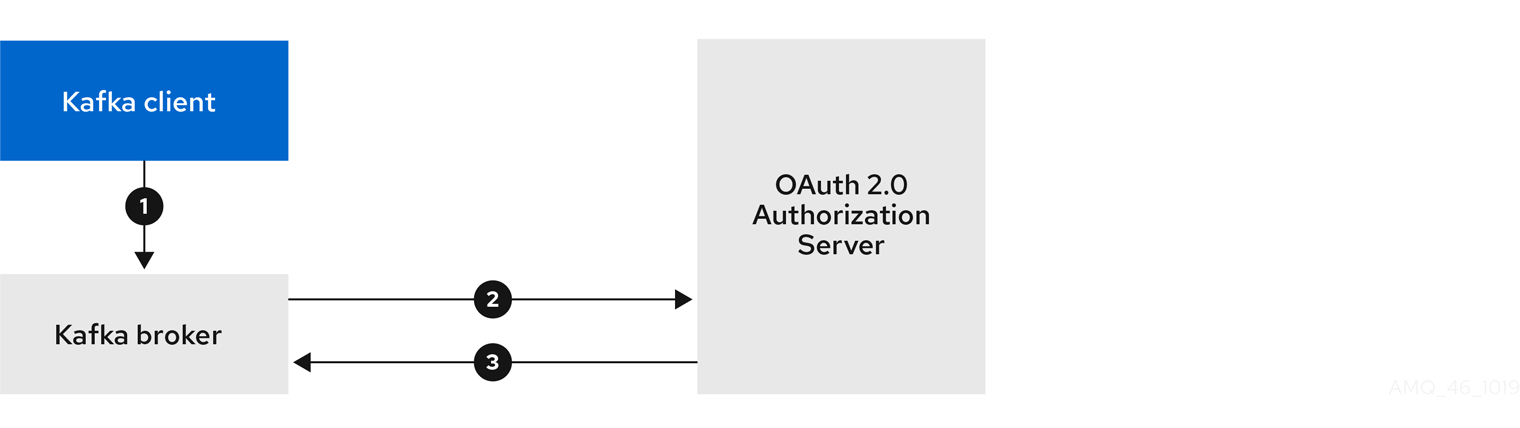
- Kafka クライアントは、SASL OAUTHBEARER メカニズムを使用して有効期限の長いアクセストークンを渡し、Kafka ブローカーの認証を行います。
- Kafka ブローカーは、独自のクライアント ID およびシークレットを使用して、承認サーバーでトークンイントロスペクションエンドポイントを呼び出し、アクセストークンを検証します。
- トークンが有効な場合は、Kafka クライアントセッションが確立されます。
クライアントでは有効期限の長いアクセストークンが使用され、ブローカーによって高速のローカル検証が実行される場合

- Kafka クライアントは、SASL OAUTHBEARER メカニズムを使用して有効期限の長いアクセストークンを渡し、Kafka ブローカーの認証を行います。
- Kafka ブローカーは、JWT トークン署名チェックおよびローカルトークンイントロスペクションを使用して、ローカルでアクセストークンを検証します。
トークンが取り消された場合に承認サーバーとのチェックが行われないため、高速のローカル JWT トークン署名の検証は有効期限の短いトークンにのみ適しています。トークンの有効期限はトークンに書き込まれますが、失効はいつでも発生する可能性があるため、承認サーバーと通信せずに対応することはできません。発行されたトークンはすべて期限切れになるまで有効とみなされます。
4.10.6. OAuth 2.0 認証の設定
OAuth 2.0 は、Kafka クライアントと AMQ Streams コンポーネントとの対話に使用されます。
AMQ Streams に OAuth 2.0 を使用するには、以下を行う必要があります。
4.10.6.1. OAuth 2.0 承認サーバーとしての Red Hat Single Sign-On の設定
この手順では、Red Hat Single Sign-On を承認サーバーとしてデプロイし、AMQ Streams と統合するための設定方法を説明します。
承認サーバーは、一元的な認証および承認の他、ユーザー、クライアント、およびパーミッションの一元管理を実現します。Red Hat Single Sign-On にはレルムの概念があります。レルム はユーザー、クライアント、パーミッション、およびその他の設定の個別のセットを表します。デフォルトの マスターレルム を使用できますが、新しいレルムを作成することもできます。各レルムは独自の OAuth 2.0 エンドポイントを公開します。そのため、アプリケーションクライアントとアプリケーションサーバーはすべて同じレルムを使用する必要があります。
AMQ Streams で OAuth 2.0 を使用するには、認証レルムを作成および管理できるように承認サーバーのデプロイメントが必要です。
Red Hat Single Sign-On がすでにデプロイされている場合は、デプロイメントの手順を省略して、現在のデプロイメントを使用できます。
作業を開始する前に
Red Hat Single Sign-On を使用するための知識が必要です。
インストールおよび管理の手順は、以下を参照してください。
前提条件
- AMQ Streams および Kafka が稼働している。
Red Hat Single Sign-On デプロイメントの場合:
- 「Red Hat Single Sign-On でサポートされる構成」 を確認している。
手順
Red Hat Single Sign-On をインストールします。
ZIP ファイルから、または RPM を使用してインストールできます。
Red Hat Single Sign-On の Admin Console にログインし、AMQ Streams の OAuth 2.0 ポリシーを作成します。
ログインの詳細は、Red Hat Single Sign-On のデプロイ時に提供されます。
レルムを作成し、有効にします。
既存のマスターレルムを使用できます。
- 必要に応じて、レルムのセッションおよびトークンのタイムアウトを調整します。
-
kafka-brokerというクライアントを作成します。 タブで以下を設定します。
-
Access Type を
Confidentialに設定します。 -
Standard Flow Enabled を
OFFに設定し、このクライアントからの Web ログインを無効にします。 -
Service Accounts Enabled を
ONに設定し、このクライアントが独自の名前で認証できるようにします。
-
Access Type を
- 続行する前に Save クリックします。
- タブにある、AMQ Streams の Kafka クラスター設定で使用するシークレットを書き留めておきます。
Kafka ブローカーに接続するすべてのアプリケーションクライアントに対して、このクライアント作成手順を繰り返し行います。
新しいクライアントごとに定義を作成します。
設定では、名前をクライアント ID として使用します。
次のステップ
承認サーバーのデプロイおよび設定後に、Kafka ブローカーが OAuth 2.0 を使用するように設定 します。
4.10.6.2. Kafka ブローカーの OAuth 2.0 サポートの設定
この手順では、ブローカーリスナーが承認サーバーを使用して OAuth 2.0 認証を使用するように、Kafka ブローカーを設定する方法について説明します。
TLS リスナーを設定して、暗号化されたインターフェイスで OAuth 2.0 を使用することが推奨されます。プレーンリスナーは推奨されません。
選択した承認サーバーをサポートするプロパティーと、実装している承認のタイプを使用して、Kafka ブローカーを設定します。
作業を開始する前の注意事項
Kafka ブローカーリスナーの設定および認証に関する詳細は、以下を参照してください。
リスナー設定で使用されるプロパティーの説明は、以下を参照してください。
前提条件
- AMQ Streams および Kafka が稼働している。
- OAuth 2.0 の承認サーバーがデプロイされている。
手順
server.propertiesファイルで Kafka ブローカーリスナー設定を設定します。以下に例を示します。
sasl.enabled.mechanisms=OAUTHBEARER listeners=CLIENT://0.0.0.0:9092 listener.security.protocol.map=CLIENT:SASL_PLAINTEXT listener.name.client.sasl.enabled.mechanisms=OAUTHBEARER sasl.mechanism.inter.broker.protocol=OAUTHBEARER inter.broker.listener.name=CLIENT listener.name.client.oauthbearer.sasl.server.callback.handler.class=io.strimzi.kafka.oauth.server.JaasServerOauthValidatorCallbackHandler listener.name.client.oauthbearer.sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required ; listener.name.client.oauthbearer.sasl.login.callback.handler.class=io.strimzi.kafka.oauth.client.JaasClientOauthLoginCallbackHandler
listener.name.client.oauthbearer.sasl.jaas.configの一部としてブローカーの接続設定を行います。この例では、接続設定オプションを示しています。
例 1: JWKS エンドポイント設定を使用したローカルトークンの検証
listener.name.client.oauthbearer.sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \ oauth.valid.issuer.uri="https://AUTH-SERVER-ADDRESS/auth/realms/REALM-NAME" \ oauth.jwks.endpoint.uri="https://AUTH-SERVER-ADDRESS/auth/realms/REALM-NAME/protocol/openid-connect/certs" \ oauth.jwks.refresh.seconds="300" \ oauth.jwks.refresh.min.pause.seconds="1" \ oauth.jwks.expiry.seconds="360" \ oauth.username.claim="preferred_username" \ oauth.ssl.truststore.location="PATH-TO-TRUSTSTORE-P12-FILE" \ oauth.ssl.truststore.password="TRUSTSTORE-PASSWORD" \ oauth.ssl.truststore.type="PKCS12" ; listener.name.client.oauthbearer.connections.max.reauth.ms=3600000
例 2: OAuth 2.0 イントロスペクションエンドポイントを使用した承認サーバーへのトークン検証の委譲
listener.name.client.oauthbearer.sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \ oauth.introspection.endpoint.uri="https://AUTH-SERVER-ADDRESS/auth/realms/REALM-NAME/protocol/openid-connect/introspection" \ # ...必要な場合は、承認サーバーへのアクセスを設定します。
この手順は通常、サービスメッシュ などの技術がコンテナーの外部でセキュアなチャネルを設定するために使用される場合を除き、実稼働環境で必要になります。
セキュアな承認サーバーに接続するためのカスタムトラストストアを指定します。承認サーバーへのアクセスには SSL が常に必要になります。
プロパティーを設定してトラストストアを設定します。
以下に例を示します。
listener.name.client.oauthbearer.sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \ # ... oauth.client.id="kafka-broker" \ oauth.client.secret="kafka-broker-secret" \ oauth.ssl.truststore.location="PATH-TO-TRUSTSTORE-P12-FILE" \ oauth.ssl.truststore.password="TRUSTSTORE-PASSWORD" \ oauth.ssl.truststore.type="PKCS12" ;
証明書のホスト名がアクセス URL ホスト名と一致しない場合は、証明書のホスト名の検証をオフにできます。
oauth.ssl.endpoint.identification.algorithm=""
このチェックは、承認サーバーへのクライアント接続が認証されるようにします。実稼働以外の環境で検証をオフにすることもできます。
選択した認証フローに応じて、追加のプロパティーを設定します。
listener.name.client.oauthbearer.sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \ # ... oauth.token.endpoint.uri="https://AUTH-SERVER-ADDRESS/auth/realms/REALM-NAME/protocol/openid-connect/token" \ 1 oauth.valid.issuer.uri="https://https://AUTH-SERVER-ADDRESS/auth/REALM-NAME" \ 2 oauth.client.id="kafka-broker" \ 3 oauth.client.secret="kafka-broker-secret" \ 4 oauth.refresh.token="REFRESH-TOKEN-FOR-KAFKA-BROKERS" \ 5 oauth.access.token="ACCESS-TOKEN-FOR-KAFKA-BROKERS" ; 6
- 1
- 承認サーバーへの OAuth 2.0 トークンエンドポイント URL。実稼働環境では、常に HTTPS を使用してください
KeycloakRBACAuthorizerを使用する場合、または inter-broker 通信に OAuth 2.0 が有効なリスナーが使用されている場合に必要です。 - 2
- 有効な発行者 URI。この発行者が発行するアクセストークンのみが受け入れられます。(常に必要です)
- 3
- すべてのブローカーで同一の、Kafka ブローカーの設定されたクライアント ID。これは、
kafka-brokerとして承認サーバーに登録されたクライアントです。イントロスペクションエンドポイントがトークンの検証に使用される場合、またはKeycloakRBACAuthorizerが使用される場合に必要です。 - 4
- すべてのブローカーで同じ Kafka ブローカーに設定されたシークレット。ブローカーが認証サーバーに対して認証する必要がある場合は、クライアントシークレット、アクセストークン、または更新トークンのいずれかを指定する必要があります。
- 5
- (オプション) Kafka ブローカー用の長期間有効な更新トークン。
- 6
- (オプション) Kafka ブローカー用の長期間有効なアクセストークン。
OAuth 2.0 認証の適用方法、および使用されている認証サーバーのタイプに応じて、構成設定を追加します。
listener.name.client.oauthbearer.sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \ # ... oauth.check.issuer=false \ 1 oauth.fallback.username.claim="CLIENT-ID" \ 2 oauth.fallback.username.prefix="CLIENT-ACCOUNT" \ 3 oauth.valid.token.type="bearer" \ 4 oauth.userinfo.endpoint.uri="https://AUTH-SERVER-ADDRESS/auth/realms/REALM-NAME/protocol/openid-connect/userinfo" ; 5
- 1
- 承認サーバーが
issクレームを提供しない場合は、発行者チェックを行うことができません。このような場合、oauth.check.issuerをfalseに設定し、oauth.valid.issuer.uriを指定しないようにします。デフォルトはtrueです。 - 2
- 承認サーバーは、通常ユーザーとクライアントの両方を識別する単一の属性を提供しない場合があります。クライアントが独自の名前で認証される場合、サーバーによって クライアント ID が提供されることがあります。更新トークンまたはアクセストークンを取得するために、ユーザー名およびパスワードを使用してユーザーが認証される場合、サーバーによってクライアント ID の他に ユーザー名 が提供されることがあります。プライマリーユーザー ID 属性が使用できない場合は、このフォールバックオプションで、使用するユーザー名クレーム (属性) を指定します。
- 3
oauth.fallback.username.claimが適用される場合、ユーザー名クレームの値とフォールバックユーザー名クレームの値が競合しないようにする必要もあることがあります。producerというクライアントが存在し、producerという通常ユーザーも存在する場合について考えてみましょう。この 2 つを区別するには、このプロパティーを使用してクライアントのユーザー ID に接頭辞を追加します。- 4
- (
oauth.introspection.endpoint.uriを使用する場合のみ該当): 使用している認証サーバーによっては、イントロスペクションエンドポイントによって トークンタイプ 属性が返されるかどうかは分からず、異なる値が含まれることがあります。イントロスペクションエンドポイントからの応答に含まれなければならない有効なトークンタイプ値を指定できます。 - 5
- (
oauth.introspection.endpoint.uriを使用する場合のみ該当): イントロスペクションエンドポイントの応答に識別可能な情報が含まれないように、承認サーバーが設定または実装されることがあります。ユーザー ID を取得するには、userinfoエンドポイントの URI をフォールバックとして設定します。oauth.fallback.username.claim、oauth.fallback.username.claim、およびoauth.fallback.username.prefix設定がuserinfoエンドポイントの応答に適用されます。
4.10.6.3. OAuth 2.0 を使用するための Kafka Java クライアントの設定
この手順では、Kafka ブローカーとの対話に OAuth 2.0 を使用するように Kafka プロデューサーおよびコンシューマー API を設定する方法を説明します。
クライアントコールバックプラグインを pom.xml ファイルに追加し、システムプロパティーを設定します。
前提条件
- AMQ Streams および Kafka が稼働している。
- OAuth 2.0 承認サーバーがデプロイされ、Kafka ブローカーへの OAuth のアクセスが設定されている。
- Kafka ブローカーが OAuth 2.0 に対して設定されている。
手順
OAuth 2.0 サポートのあるクライアントライブラリーを Kafka クライアントの
pom.xmlファイルに追加します。<dependency> <groupId>io.strimzi</groupId> <artifactId>kafka-oauth-client</artifactId> <version>0.6.1.redhat-00003</version> </dependency>
コールバックのシステムプロパティーを設定します。
以下はその例です。
System.setProperty(ClientConfig.OAUTH_TOKEN_ENDPOINT_URI, “https://AUTH-SERVER-ADDRESS/auth/realms/REALM-NAME/protocol/openid-connect/token”); 1 System.setProperty(ClientConfig.OAUTH_CLIENT_ID, "CLIENT-NAME"); 2 System.setProperty(ClientConfig.OAUTH_CLIENT_SECRET, "CLIENT_SECRET"); 3 System.setProperty(ClientConfig.OAUTH_SCOPE, "SCOPE-VALUE") 4
Kafka クライアント設定の TLS で暗号化された接続で SASL OAUTHBEARER メカニズムを有効にします。
以下は例になります。
props.put("sasl.jaas.config", "org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required;"); props.put("security.protocol", "SASL_SSL"); 1 props.put("sasl.mechanism", "OAUTHBEARER"); props.put("sasl.login.callback.handler.class", "io.strimzi.kafka.oauth.client.JaasClientOauthLoginCallbackHandler");- 1
- この例では、TLS 接続で
SASL_SSLを使用します。暗号化されていない接続ではSASL_PLAINTEXTを使用します。
- Kafka クライアントが Kafka ブローカーにアクセスできることを確認します。
4.11. OAuth 2.0 トークンベース承認の使用
AMQ Streams は、Red Hat Single Sign-On の 認証サービス による OAuth 2.0 トークンベースの承認をサポートします。これにより、セキュリティーポリシーとパーミッションの一元的な管理が可能になります。
Red Hat Single Sign-On で定義されたセキュリティーポリシーおよびパーミッションは、Kafka ブローカーのリソースへのアクセスを付与するために使用されます。ユーザーとクライアントは、Kafka ブローカーで特定のアクションを実行するためのアクセスを許可するポリシーに対して照合されます。
Kafka では、デフォルトですべてのユーザーがブローカーに完全アクセスできます。また、アクセス制御リスト(ACL)を基にして承認を設定するために AclAuthorizer プラグインが提供されます。
ZooKeeper には、ユーザー名 を基にしてリソースへのアクセスを付与または拒否する ACL ルールが保存されます。ただし、Red Hat Single Sign-On を使用した OAuth 2.0 トークンベースの承認では、より柔軟にアクセス制御を Kafka ブローカーに実装できます。さらに、Kafka ブローカーで OAuth 2.0 の承認および ACL が使用されるように設定することができます。
4.11.1. OAuth 2.0 の承認メカニズム
AMQ Streams の OAuth 2.0 での承認では、Red Hat Single Sign-On サーバーの Authorization Services REST エンドポイントを使用して、Red Hat Single Sign-On を使用するトークンベースの認証が拡張されます。これは、定義されたセキュリティーポリシーを特定のユーザーに適用し、そのユーザーの異なるリソースに付与されたパーミッションの一覧を提供します。ポリシーはロールとグループを使用して、パーミッションをユーザーと照合します。OAuth 2.0 の承認では、Red Hat Single Sign-On の Authorization Services から受信した、ユーザーに付与された権限のリストを基にして、権限がローカルで強制されます。
4.11.1.1. Kafka ブローカーのカスタムオーソライザー
AMQ Streams では、Red Hat Single Sign-On の オーソライザー (KeycloakRBACAuthorizer) が提供されます。Red Hat Single Sign-On によって提供される Authorization Services で Red Hat Single Sign-On REST エンドポイントを使用できるようにするには、Kafka ブローカーでカスタムオーソライザーを設定します。
オーソライザーは必要に応じて付与された権限のリストを承認サーバーから取得し、ローカルで Kafka ブローカーに承認を強制するため、クライアントの要求ごとに迅速な承認決定が行われます。
4.11.2. OAuth 2.0 承認サポートの設定
この手順では、Red Hat Single Sign-On の Authorization Services を使用して、OAuth 2.0 承認を使用するように Kafka ブローカーを設定する方法を説明します。
作業を開始する前に
特定のユーザーに必要なアクセス、または制限するアクセスについて検討してください。Red Hat Single Sign-On では、Red Hat Single Sign-On の グループ、ロール、クライアント、および ユーザー の組み合わせを使用して、アクセスを設定できます。
通常、グループは組織の部門または地理的な場所を基にしてユーザーを照合するために使用されます。また、ロールは職務を基にしてユーザーを照合するために使用されます。
Red Hat Single Sign-On を使用すると、ユーザーおよびグループを LDAP で保存できますが、クライアントおよびロールは LDAP で保存できません。ユーザーデータへのアクセスとストレージを考慮して、承認ポリシーの設定方法を選択する必要がある場合があります。
スーパーユーザー は、Kafka ブローカーに実装された承認にかかわらず、常に制限なく Kafka ブローカーにアクセスできます。
前提条件
- AMQ Streams は、トークンベースの認証 に Red Hat Single Sign-On と OAuth 2.0 を使用するように設定されている必要がある。承認を設定するときに、同じ Red Hat Single Sign-On サーバーエンドポイントを使用する必要があります。
- Red Hat Single Sign-On のドキュメント の説明にあるように、Red Hat Single Sign-On の Authorization Services のポリシーおよびパーミッションを管理する方法を理解している必要がある。
手順
- Red Hat Single Sign-On の Admin Console にアクセスするか、Red Hat Single Sign-On の Admin CLI を使用して、OAuth 2.0 認証の設定時に作成した Kafka ブローカークライアントの Authorization Services を有効にします。
- 承認サービスを使用して、クライアントのリソース、承認スコープ、ポリシー、およびパーミッションを定義します。
- ロールとグループをユーザーとクライアントに割り当てて、パーミッションをユーザーとクライアントにバインドします。
Red Hat Single Sign-On 承認を使用するように Kafka ブローカーを設定します。
以下を Kafka
server.properties設定ファイルに追加し、Kafka にオーソライザーをインストールします。authorizer.class.name=io.strimzi.kafka.oauth.server.authorizer.KeycloakRBACAuthorizer principal.builder.class=io.strimzi.kafka.oauth.server.authorizer.JwtKafkaPrincipalBuilder
Kafka ブローカーの設定を追加して、承認サーバーおよび Authorization Services にアクセスします。
ここでは、
server.propertiesへの追加プロパティーとして追加される設定例を示しますが、大文字で始める、または大文字の命名規則を使用して、環境変数として定義することもできます。strimzi.authorization.token.endpoint.uri="https://AUTH-SERVER-ADDRESS/auth/realms/REALM-NAME/protocol/openid-connect/token" 1 strimzi.authorization.client.id="kafka" 2
(オプション) 特定の Kafka クラスターの構成を追加します。
以下に例を示します。
strimzi.authorization.kafka.cluster.name="kafka-cluster" 1- 1
- 特定の Kafka クラスターの名前。名前はパーミッションをターゲットにするために使用され、同じ Red Hat シングルサインオンレルム内で複数のクラスターを管理できるようにします。デフォルト値は
kafka-clusterです。
(オプション) 単純許可に委任します。
以下に例を示します。
strimzi.authorization.delegate.to.kafka.acl="false" 1- 1
- Red Hat Single Sign-On Authorization Services ポリシーでアクセスが拒否された場合、Kafka
AclAuthorizerに権限を委任します。デフォルトはfalseです。
(オプション) TLS 接続の構成を許可サーバーに追加します。
以下に例を示します。
strimzi.authorization.ssl.truststore.location=<path-to-truststore> 1 strimzi.authorization.ssl.truststore.password=<my-truststore-password> 2 strimzi.authorization.ssl.truststore.type=JKS 3 strimzi.authorization.ssl.secure.random.implementation=SHA1PRNG 4 strimzi.authorization.ssl.endpoint.identification.algorithm=HTTPS 5
(オプション) 許可サーバーからの許可の更新を構成します。付与更新ジョブは、アクティブなトークンを列挙し、それぞれに最新の付与を要求することで機能します。
以下に例を示します。
strimzi.authorization.grants.refresh.period.seconds="120" 1 strimzi.authorization.grants.refresh.pool.size="10" 2
- クライアントまたは特定のロールを持つユーザーとして Kafka ブローカーにアクセスして、設定したパーミッションを検証し、必要なアクセス権限があり、付与されるべきでないアクセス権限がないことを確認します。
4.12. OPA ポリシーベースの承認の使用
Open Policy Agent (OPA) は、オープンソースのポリシーエンジンです。OPA と AMQ Streams を統合して、Kafka ブローカーでのクライアント操作を許可するポリシーベースの承認メカニズムとして機能します。
クライアントからリクエストが実行されると、OPA は Kafka アクセスに定義されたポリシーに対してリクエストを評価し、リクエストを許可または拒否します。
Red Hat は OPA サーバーをサポートしません。
4.12.1. OPA ポリシーの定義
OPA と AMQ Streams を統合する前に、粒度の細かいアクセス制御を提供するポリシーの定義方法を検討してください。
Kafka クラスター、コンシューマーグループ、およびトピックのアクセス制御を定義できます。たとえば、プロデューサークライアントから特定のブローカートピックへの書き込みアクセスを許可する承認ポリシーを定義できます。
このポリシーでは、以下の項目を指定することができます。
- プロデューサークライアントに関連付けられた ユーザープリンシパル および ホストアドレス
- クライアントに許可される 操作
-
ポリシーが適用される リソースタイプ (
topic) および リソース名
許可と拒否の決定がポリシーに書き込まれ、提供された要求とクライアント識別データに基づいて応答が提供されます。
この例では、プロデューサークライアントはトピックへの書き込みが許可されるポリシーを満たす必要があります。
4.12.2. OPA への接続
Kafka が OPA ポリシーエンジンにアクセスしてアクセス制御ポリシーをクエリーできるようにするには、Kafka server.properties ファイルでカスタム OPA オーソライザープラグイン (kafka-authorizer-opa-VERSION.jar) を設定します。
クライアントがリクエストを行うと、OPA ポリシーエンジンは、指定された URL アドレスと REST エンドポイントを使用してプラグインによってクエリーされます。これは、定義されたポリシーの名前でなければなりません。
プラグインは、ポリシーに対してチェックされる JSON 形式で、クライアント要求の詳細 (ユーザープリンシパル、操作、およびリソース) を提供します。詳細には、クライアントの一意のアイデンティティーが含まれます。たとえば、TLS 認証が使用される場合にクライアント証明書からの識別名を取ります。
OPA はデータを使用して、リクエストを許可または拒否するためにプラグインに true または false のいずれかの応答を提供します。
4.12.3. OPA 承認サポートの設定
この手順では、OPA 承認を使用するように Kafka ブローカーを設定する方法を説明します。
作業を開始する前に
特定のユーザーに必要なアクセス、または制限するアクセスについて検討してください。ユーザー リソースと Kafka リソース の組み合わせを使用して、OPA ポリシーを定義できます。
OPA を設定して、LDAP データソースからユーザー情報を読み込むことができます。
スーパーユーザー は、Kafka ブローカーに実装された承認にかかわらず、常に制限なく Kafka ブローカーにアクセスできます。
前提条件
- 接続には OPA サーバーを利用できる必要がある。
- Kafka の OPA オーソライザープラグイン。
手順
Kafka ブローカーで操作を実行するため、クライアントリクエストの承認に必要な OPA ポリシーを記述します。
「OPA ポリシーの定義」 を参照してください。
これで、Kafka ブローカーが OPA を使用するように設定します。
Kafka の OPA オーソライザープラグイン をインストールします。
「OPA への接続」 を参照してください。
プラグインファイルが Kafka クラスパスに含まれていることを確認してください。
以下を Kafka
server.properties設定ファイルに追加し、OPA プラグインを有効にします。authorizer.class.name: com.bisnode.kafka.authorization.OpaAuthorizer
Kafka ブローカーの
server.propertiesにさらに設定を追加して、OPA ポリシーエンジンおよびポリシーにアクセスします。以下に例を示します。
opa.authorizer.url=https://OPA-ADDRESS/allow 1 opa.authorizer.allow.on.error=false 2 opa.authorizer.cache.initial.capacity=50000 3 opa.authorizer.cache.maximum.size=50000 4 opa.authorizer.cache.expire.after.seconds=600000 5 super.users=User:alice;User:bob 6
- 1
- (必須) オーソライザープラグインがクエリーするポリシーの OAuth 2.0 トークンエンドポイント URL。この例では、ポリシーは
allowという名前です。 - 2
- オーソライザープラグインが OPA ポリシーエンジンとの接続に失敗した場合に、クライアントがデフォルトで許可または拒否されるかどうかを指定するフラグ。
- 3
- ローカルキャッシュの初期容量 (バイト単位)。すべてのリクエストについてプラグインに OPA ポリシーエンジンをクエリーする必要がないように、キャッシュが使用されます。
- 4
- ローカルキャッシュの最大容量 (バイト単位)。
- 5
- OPA ポリシーエンジンからのリロードによってローカルキャッシュが更新される時間 (ミリ秒単位)。
- 6
- スーパーユーザーとして扱われるユーザープリンシパルのリスト。これにより、Open Policy Agent ポリシーをクエリーしなくても常に許可されます。
認証および承認オプションの詳細は、Open Policy Agent の Web サイト を参照してください。
- 正しい承認を持つクライアントと持たないクライアントを使用して、Kafka ブローカーにアクセスして、設定したパーミッションを検証します。
4.13. ロギング
Kafka ブローカーは Log4j をロギングインフラストラクチャーとして使用します。デフォルトでは、ロギング設定は /opt/kafka/config/ ディレクトリーまたはクラスパスのいずれかに配置される log4j.properties 設定ファイルから読み取られます。設定ファイルの場所と名前は、Java プロパティー log4j.configuration を使用して変更できます。これは、KAFKA_LOG4J_OPTS 環境変数を使用して Kafka に渡すことができます。
su - kafka export KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:/my/path/to/log4j.config"; /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
Log4j の設定に関する詳細は、Log4j のマニュアル を参照してください。
4.13.1. Kafka ブローカーロガーのロギングレベルの動的な変更
Kafka ブローカーロギングは、複数の 各ブローカーのブローカーロガー によって提供されます。ブローカーを再起動することなく、ブローカーロガーのロギングレベルを動的に変更できます。ログで返される詳細度レベルを上げると (たとえば、INFO から DEBUG に変更)、Kafka クラスターでパフォーマンスの問題を調査するのに役立ちます。
ブローカーロガーは、デフォルトのロギングレベルに動的にリセットすることもできます。
手順
kafkaユーザーに切り替えます。su - kafka
kafka-configs.shツールを使用して、ブローカーのブローカーロガーの一覧を表示します。/opt/kafka/bin/kafka-configs.sh --bootstrap-server BOOTSTRAP-ADDRESS --describe --entity-type broker-loggers --entity-name BROKER-ID
たとえば、ブローカー
0の場合:/opt/kafka/bin/kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type broker-loggers --entity-name 0
これにより、
TRACE、DEBUG、INFO、WARN、ERROR、またはFATALの各ロガーのロギングレベルが返されます。以下に例を示します。#... kafka.controller.ControllerChannelManager=INFO sensitive=false synonyms={} kafka.log.TimeIndex=INFO sensitive=false synonyms={}1 つ以上のブローカーロガーのロギングレベルを変更します。
--alterおよび--add-configオプションを使用して、各ロガーとそのレベルを二重引用符のコンマ区切りリストとして指定します。/opt/kafka/bin/kafka-configs.sh --bootstrap-server BOOTSTRAP-ADDRESS --alter --add-config "LOGGER-ONE=NEW-LEVEL,LOGGER-TWO=NEW-LEVEL" --entity-type broker-loggers --entity-name BROKER-ID
たとえば、ブローカー
0の場合:/opt/kafka/bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --add-config "kafka.controller.ControllerChannelManager=WARN,kafka.log.TimeIndex=WARN" --entity-type broker-loggers --entity-name 0
成功すると、以下が返されます。
Completed updating config for broker: 0.
ブローカーロガーのリセット
kafka-configs.sh ツールを使用して、1 つ以上のブローカーロガーをデフォルトのロギングレベルにリセットできます。--alter および --delete-config オプションを使用して、各ブローカーロガーを二重引用符のコンマ区切りリストとして指定します。
/opt/kafka/bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --delete-config "LOGGER-ONE,LOGGER-TWO" --entity-type broker-loggers --entity-name BROKER-ID
関連情報
- Apache Kafka のドキュメントの Updating Broker Configs
第5章 トピック
Kafka のメッセージは、常にトピックとの間で送受信されます。本章では、Kafka トピックを設定および管理する方法を説明します。
5.1. パーティションおよびレプリカ
Kafka のメッセージは、常にトピックとの間で送受信されます。トピックは、常に 1 つ以上のパーティションに分割されます。パーティションはシャードとして機能します。つまり、プロデューサーによって送信されたすべてのメッセージは常に単一のパーティションにのみ書き込まれます。メッセージの異なるパーティションへのシャーディングにより、トピックを簡単に水平的にスケーリングできます。
各パーティションには 1 つ以上のレプリカを含めることができ、レプリカはクラスター内の異なるブローカーに保存されます。トピックの作成時に、レプリケーション係数 を使用してレプリカ数を設定できます。レプリケーション係数 は、クラスター内で保持するコピーの数を定義します。指定したパーティションのレプリカの 1 つがリーダーとして選択されます。リーダーレプリカは、プロデューサーが新しいメッセージを送信し、コンシューマーがメッセージを消費するために使用されます。他のレプリカはフォロワーレプリカです。フォロワーはリーダーを複製します。
リーダーが失敗すると、フォロワーの 1 つが新しいリーダーに自動的になります。各サーバーは、一部のパーティションのリーダーおよび他のパーティションのフォロワーとして機能し、クラスター内で負荷が均等に分散されます。
レプリケーション係数は、リーダーとフォロワーを含むレプリカ数を決定します。たとえば、レプリケーション係数を 3 に設定すると、1 つのリーダーと 2 つのフォロワーレプリカが設定されます。
5.2. メッセージの保持
メッセージの保持ポリシーは、Kafka ブローカーにメッセージを保存する期間を定義します。これは、時間、パーティションサイズ、またはその両方に基づいて定義できます。
たとえば、メッセージの保存に関して以下のように定義できます。
- 7 日間。
- 解析に 1 GB のメッセージが含まれるまで。制限に達すると、最も古いメッセージが削除されます。
- 7 日間、または 1 GB の制限に達するまで。最初に制限が使用されます。
Kafka ブローカーはメッセージをログセグメントに保存します。保持ポリシーを超えたメッセージは、新規ログセグメントが作成された場合にのみ削除されます。新しいログセグメントは、以前のログセグメントが設定されたログセグメントサイズを超えると作成されます。さらに、ユーザーは定期的に新しいセグメントの作成を要求できます。
さらに、Kafka ブローカーはコンパクト化ポリシーをサポートします。
圧縮ポリシーのあるトピックでは、ブローカーは常に各キーの最後のメッセージのみを保持します。同じキーを持つ古いメッセージは、パーティションから削除されます。圧縮は定期的に実行されるため、同じキーを持つ新しいメッセージがパーティションに送信されてもすぐには実行されません。代わりに、古いメッセージが削除されるまで時間がかかる場合があります。
メッセージの保持設定オプションの詳細は、「トピックの設定」 を参照してください。
5.3. トピックの自動作成
プロデューサーまたはコンシューマーが存在しないトピックとの間でメッセージを送受信しようとすると、Kafka はデフォルトでそのトピックを自動的に作成します。この動作は、デフォルトで true に設定された auto.create.topics.enable 設定プロパティーによって制御されます。
これを無効にするには、Kafka ブローカー設定ファイルで auto.create.topics.enable を false に設定します。
auto.create.topics.enable=false
5.4. トピックの削除
Kafka では、トピックの削除を無効にすることができます。これは、デフォルトで true (つまり、トピックの削除が可能) に設定されている delete.topic.enable プロパティーで設定されます。このプロパティーを false に設定すると、トピックの削除はできず、トピックの削除試行はすべて成功を返しますが、トピックは削除されません。
delete.topic.enable=false
5.5. トピックの設定
自動作成されたトピックは、ブローカーのプロパティーファイルで指定できるデフォルトのトピック設定を使用します。ただし、トピックを手動で作成する場合は、作成時に設定を指定できます。トピックの作成後に、トピックの設定を変更することもできます。手動で作成したトピックの主なトピック設定オプションは次のとおりです。
cleanup.policy-
deleteまたはcompactに保持ポリシーを設定します。deleteポリシーは古いレコードを削除します。compactポリシーはログの圧縮を有効にします。デフォルト値はdeleteです。ログコンパクションの詳細は、Kafka の Web サイト を参照してください。 compression.type-
保存されたメッセージに使用される圧縮を指定します。有効な値は、
gzip、snappy、lz4、uncompressed(圧縮なし)、およびproducer(プロデューサーによって使用される圧縮コーデックを保持) です。デフォルト値はproducerです。 max.message.bytes-
Kafka ブローカーによって許可されるメッセージのバッチの最大サイズ (バイト単位)。デフォルト値は
1000012です。 min.insync.replicas-
書き込みが成功したとみなされるために同期する必要があるレプリカの最小数。デフォルト値は
1です。 retention.ms-
ログセグメントが保持される最大ミリ秒数。この値より古いログセグメントは削除されます。デフォルト値は
604800000(7 日) です。 retention.bytes-
パーティションが保持する最大バイト数。パーティションサイズがこの制限を超えると、一番古いログセグメントが削除されます。
-1の値は無制限を意味します。デフォルト値は-1です。 segment.bytes-
単一のコミットログセグメントファイルの最大ファイルサイズ (バイト単位)。セグメントがそのサイズに達すると、新しいセグメントが起動します。デフォルト値は
1073741824バイト (1 ギガバイト) です。
サポートされるすべてのトピック設定オプションの一覧は、「付録B トピック設定パラメーター」を参照してください。
自動作成されたトピックのデフォルトは、同様のオプションを使用して Kafka ブローカー設定に指定できます。
log.cleanup.policy-
上記の
cleanup.policyを参照してください。 compression.type-
上記の
compression.typeを参照してください。 message.max.bytes-
上記の
max.message.bytesを参照してください。 min.insync.replicas-
上記の
min.insync.replicasを参照してください。 log.retention.ms-
上記の
retention.msを参照してください。 log.retention.bytes-
上記の
retention.bytesを参照してください。 log.segment.bytes-
上記の
segment.bytesを参照してください。 default.replication.factor-
自動的に作成されるトピックのデフォルトレプリケーション係数。デフォルト値は
1です。 num.partitions-
自動作成されるトピックのデフォルトパーティション数。デフォルト値は
1です。
サポートされるすべての Kafka ブローカー設定オプションの一覧は、「付録A ブローカー設定パラメーター」を参照してください。
5.6. 内部トピック
内部トピックは、Kafka ブローカーおよびクライアントによって内部で作成され、使用されます。Kafka には複数の内部トピックがあります。これらはコンシューマーオフセット (__consumer_offsets) またはトランザクションの状態 (__transaction_state) を格納するために使用されます。これらのトピックは、プレフィックス offsets.topic. および transaction.state.log. で始まる専用の Kafka ブローカー設定オプションを使用して設定できます。最も重要な設定オプションは以下のとおりです。
offsets.topic.replication.factor-
__consumer_offsetsトピックのレプリカの数です。デフォルト値は3です。 offsets.topic.num.partitions-
__consumer_offsetsトピックのパーティションの数です。デフォルト値は50です。 transaction.state.log.replication.factor-
__transaction_stateのトピックのレプリカ数デフォルト値は3です。 transaction.state.log.num.partitions-
__transaction_stateのトピックのパーティション数デフォルト値は50です。 transaction.state.log.min.isr-
__transaction_stateトピックへの書き込みが正常であると考えられるために、確認される必要のあるレプリカの最小数。この最小値が満たされない場合、プロデューサーは例外で失敗します。デフォルト値は2です。
5.7. トピックの作成
kafka-topics.sh ツールを使用してトピックを管理できます。kafka-topics.sh は AMQ Streams ディストリビューションの一部で、bin ディレクトリーにあります。
前提条件
- AMQ Streams クラスターがインストールされ、実行されている。
トピックの作成
kafka-topics.shユーティリティーを使用し以下の項目を指定して、トピックを作成します。-
--bootstrap-serverにおける Kafka ブローカーのホストおよびポート。 -
--createオプション: 作成される新しいトピック。 -
--topicオプション: トピック名。 -
--partitionsオプション: パーティション数。 --replication-factorオプション: トピックレプリケーション係数。また、
--configオプションを使用して、デフォルトのトピック設定オプションの一部を上書きすることもできます。このオプションは複数回使用して、異なるオプションを上書きできます。bin/kafka-topics.sh --bootstrap-server <BrokerAddress> --create --topic <TopicName> --partitions <NumberOfPartitions> --replication-factor <ReplicationFactor> --config <Option1>=<Value1> --config <Option2>=<Value2>
mytopicというトピックを作成するコマンドの例bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic mytopic --partitions 50 --replication-factor 3 --config cleanup.policy=compact --config min.insync.replicas=2
-
kafka-topics.shを使用して、トピックが存在することを確認します。bin/kafka-topics.sh --bootstrap-server <BrokerAddress> --describe --topic <TopicName>
mytopicというトピックを記述するコマンドの例bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic mytopic
関連情報
- トピック設定の詳細は、「トピックの設定」 を参照してください。
- サポートされるすべてのトピック設定オプションの一覧は、「付録B トピック設定パラメーター」を参照してください。
5.8. トピックの一覧表示および説明
kafka-topics.sh ツールは、トピックの一覧表示および説明に使用できます。kafka-topics.sh は AMQ Streams ディストリビューションの一部で、bin ディレクトリーにあります。
前提条件
- AMQ Streams クラスターがインストールされ、実行されている。
-
トピック
mytopicが存在する。
トピックの記述
kafka-topics.shユーティリティーを使用し以下の項目を指定して、トピックを説明します。-
--bootstrap-serverにおける Kafka ブローカーのホストおよびポート。 -
--describeオプション: トピックを記述することを指定するために使用します。 -
--topicオプション: このオプションでトピック名を指定する必要があります。 --topicオプションを省略すると、利用可能なすべてのトピックを記述します。bin/kafka-topics.sh --bootstrap-server <BrokerAddress> --describe --topic <TopicName>
mytopicというトピックを記述するコマンドの例bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic mytopic
describe コマンドは、このトピックに属するすべてのパーティションおよびレプリカを一覧表示します。また、すべてのトピック設定オプションも表示されます。
-
5.9. トピック設定の変更
kafka-configs.sh ツールを使用して、トピック設定を変更することができます。kafka-configs.sh は AMQ Streams ディストリビューションの一部で、bin ディレクトリーにあります。
前提条件
- AMQ Streams クラスターがインストールされ、実行されている。
-
トピック
mytopicが存在する。
トピック設定の変更
kafka-configs.shツールを使用して、現在の設定を取得します。-
--bootstrap-serverオプションで Kafka ブローカーのホストおよびポートを指定します。 -
--entity-typeをtopicとして、--entity-nameをトピックの名前に設定します。 --describeオプション: 現在の設定を取得するために使用します。bin/kafka-configs.sh --bootstrap-server <BrokerAddress> --entity-type topics --entity-name <TopicName> --describe
mytopicという名前のトピックの設定を取得するコマンドの例bin/kafka-configs.sh --bootstrap-server localhost:9092 --entity-type topics --entity-name mytopic --describe
-
kafka-configs.shツールを使用して、現在の設定を変更します。-
--bootstrap-serverオプションで Kafka ブローカーのホストおよびポートを指定します。 -
--entity-typeをtopicとして、--entity-nameをトピックの名前に設定します。 -
--alterオプション: 現在の設定を変更するのに使用します。 --add-configオプション: 追加または変更するオプションを指定します。bin/kafka-configs.sh --bootstrap-server <BrokerAddress> --entity-type topics --entity-name <TopicName> --alter --add-config <Option>=<Value>
mytopicという名前のトピックの設定を変更するコマンドの例bin/kafka-configs.sh --bootstrap-server localhost:9092 --entity-type topics --entity-name mytopic --alter --add-config min.insync.replicas=1
-
kafka-configs.shツールを使用して、既存の設定オプションを削除します。-
--bootstrap-serverオプションで Kafka ブローカーのホストおよびポートを指定します。 -
--entity-typeをtopicとして、--entity-nameをトピックの名前に設定します。 -
--delete-configオプション: 既存の設定オプションを削除するのに使用します。 --remove-configオプション: 削除するオプションを指定します。bin/kafka-configs.sh --bootstrap-server <BrokerAddress> --entity-type topics --entity-name <TopicName> --alter --delete-config <Option>
mytopicという名前のトピックの設定を変更するコマンドの例bin/kafka-configs.sh --bootstrap-server localhost:9092 --entity-type topics --entity-name mytopic --alter --delete-config min.insync.replicas
-
関連情報
- トピック設定の詳細は、「トピックの設定」 を参照してください。
- トピックの作成に関する詳細は、「トピックの作成」 を参照してください。
- サポートされるすべてのトピック設定オプションの一覧は、「付録B トピック設定パラメーター」を参照してください。
5.10. トピックの削除
kafka-topics.sh ツールを使用してトピックを管理できます。kafka-topics.sh は AMQ Streams ディストリビューションの一部で、bin ディレクトリーにあります。
前提条件
- AMQ Streams クラスターがインストールされ、実行されている。
-
トピック
mytopicが存在する。
トピックの削除
kafka-topics.shユーティリティーを使用してトピックを削除します。-
--bootstrap-serverにおける Kafka ブローカーのホストおよびポート。 -
--deleteオプション: 既存のトピックを削除することを指定するのに使用します。 --topicオプション: このオプションでトピック名を指定する必要があります。bin/kafka-topics.sh --bootstrap-server <BrokerAddress> --delete --topic <TopicName>
mytopicというトピックを作成するコマンドの例bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic mytopic
-
kafka-topics.shを使用して、トピックが削除されたことを確認します。bin/kafka-topics.sh --bootstrap-server <BrokerAddress> --listすべてのトピックを一覧表示するコマンドの例
bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
関連情報
- トピックの作成に関する詳細は、「トピックの作成」 を参照してください。
第6章 クライアント設定のチューニング
設定プロパティーを使用して、Kafka プロデューサーおよびコンシューマーのパフォーマンスを最適化します。
最小セットの設定プロパティーが必要ですが、プロパティーを追加または調整して、プロデューサーとコンシューマーが Kafka と対話する方法を変更できます。たとえば、プロデューサーの場合は、クライアントがリアルタイムでデータに応答できるように、メッセージのレイテンシーおよびスループットをチューニングできます。また、設定を変更して、より強力にメッセージの持続性を保証することもできます。
クライアントメトリックを分析して初期設定を行う場所を判断することから始め、必要な設定になるまで段階的に変更を加え、さらに比較を行うことができます。
6.1. Kafka プロデューサー設定のチューニング
特定のユースケースに合わせて調整されたオプションのプロパティーとともに、基本的なプロデューサー設定を使用します。
設定を調整してスループットを最大化すると、レイテンシーが増加する可能性があり、その逆も同様です。必要なバランスを取得するために、プロデューサー設定を実験して調整する必要があります。
6.1.1. 基本のプロデューサー設定
接続およびシリアライザープロパティーはすべてのプロデューサーに必要です。通常、追跡用のクライアント ID を追加し、プロデューサーで圧縮してリクエストのバッチサイズを減らすことが推奨されます。
基本的なプロデューサー設定は、以下のようになります。
- パーティション内のメッセージの順序は保証されません。
- ブローカーに到達するメッセージの完了通知は持続性を保証しません。
# ... bootstrap.servers=localhost:9092 1 key.serializer=org.apache.kafka.common.serialization.StringSerializer 2 value.serializer=org.apache.kafka.common.serialization.StringSerializer 3 client.id=my-client 4 compression.type=gzip 5 # ...
- 1
- (必須) Kafka ブローカーの host:port ブートストラップサーバーアドレスを使用して Kafka クラスターに接続するようプロデューサーを指示します。プロデューサーはアドレスを使用して、クラスター内のすべてのブローカーを検出し、接続します。サーバーがダウンした場合に備えて、コンマ区切りリストを使用して 2 つまたは 3 つのアドレスを指定しますが、クラスター内のすべてのブローカーのリストを提供する必要はありません。
- 2
- (必須) メッセージがブローカーに送信される前に、各メッセージの鍵をバイトに変換するシリアライザー。
- 3
- (必須) メッセージがブローカーに送信される前に、各メッセージの値をバイトに変換するシリアライザー。
- 4
- (オプション) クライアントの論理名。リクエストのソースを特定するためにログおよびメトリクスで使用されます。
- 5
- (オプション) メッセージを圧縮するコーデック。これは、送信され、圧縮された形式で格納された後、コンシューマーへの到達時に圧縮解除される可能性があります。圧縮はスループットを改善し、ストレージの負荷を減らすのに役立ちますが、圧縮や圧縮解除のコストが異常に高い低レイテンシーのアプリケーションには不適切である場合があります。
6.1.2. データの持続性
メッセージ配信の完了通知を使用して、データの持続性を適用し、メッセージが失われる可能性を最小限に抑えることができます。
# ...
acks=all 1
# ...- 1
acks=allを指定すると、パーティションリーダーは、メッセージリクエストが正常に受信されたことを確認する前に、一定数のフォロワーにメッセージを複製するように強制します。追加のチェックにより、acks=allはプロデューサーがメッセージを送信して確認応答を受信する間のレイテンシーを長くします。
完了通知がプロデューサーに送信される前にメッセージをログに追加する必要のあるブローカーの数は、トピックの min.insync.replicas 設定によって決定されます。最初に、トピックレプリケーション係数を 3 にし、他のブローカーの In-Sync レプリカを 2 にするのが一般的です。この設定では、単一のブローカーが利用できない場合でもプロデューサーは影響を受けません。2 番目のブローカーが利用できなくなると、プロデューサーは完了通知を受信せず、それ以上のメッセージを生成できなくなります。
acks=all をサポートするトピック設定
# ...
min.insync.replicas=2 1
# ...
- 1
- Sync レプリカでは
2を使用します。デフォルトは1です。
システムに障害が発生すると、バッファーの未送信データが失われる可能性があります。
6.1.3. 順序付き配信
メッセージは 1 度だけ配信されるため、べき等プロデューサーは重複を回避します。障害発生時でも配信の順序が維持されるように、ID とシーケンス番号がメッセージに割り当てられます。データの一貫性を保つために acks=all を使用している場合は、順序付けられた配信に冪等性を有効にすることが妥当です。
べき等を使った順序付き配信
# ... enable.idempotence=true 1 max.in.flight.requests.per.connection=5 2 acks=all 3 retries=2147483647 4 # ...
パフォーマンスコストが原因で acks=all と idempotency を使用していない場合には、インフライト (承認されていない) リクエストの数を 1 に設定して、順序を保持します。そうしないと、Message-A が失敗し、Message-B がブローカーに書き込まれた後にのみ成功する可能性があります。
べき等を使用しない順序付け配信
# ... enable.idempotence=false 1 max.in.flight.requests.per.connection=1 2 retries=2147483647 # ...
6.1.4. 信頼性の保証
べき等は、1 つのパーティションへの書き込みを 1 回だけ行う場合に便利です。トランザクションをべき等と使用すると、複数のパーティション全体で 1 度だけ書き込みを行うことができます。
トランザクションは、同じトランザクション ID を使用するメッセージが 1 度作成され、すべて がそれぞれのログに書き込まれるか、何も 書き込まれないかのどちらかになることを保証します。
# ... enable.idempotence=true max.in.flight.requests.per.connection=5 acks=all retries=2147483647 transactional.id=UNIQUE-ID 1 transaction.timeout.ms=900000 2 # ...
トランザクション保証を維持するには、transactional.id の選択が重要です。トランザクション ID は、一意なトピックパーティションセットに使用する必要があります。たとえば、トピックパーティション名からトランザクション ID への外部マッピングを使用したり、競合を回避する関数を使用してトピックパーティション名からトランザクション IDを算出したりすると、これを実現できます。
6.1.5. スループットおよびレイテンシーの最適化
通常、システムの要件は、指定のレイテンシー内であるメッセージの割合に対して、特定のスループットのターゲットを達成することです。たとえば、95 % のメッセージが 2 秒以内に完了確認される、1 秒あたり 500,000 個のメッセージをターゲットとします。
プロデューサーのメッセージングセマンティック (メッセージの順序付けと持続性) は、アプリケーションの要件によって定義される可能性があります。たとえば、アプリケーションが提供する重要なプロパティーや保証を壊さずに acks=0 または acks=1 を使用するオプションはありません。
ブローカーの再起動は、パーセンタイルの高いの統計に大きく影響します。たとえば、長期間では、99% のレイテンシーはブローカーの再起動に関する動作によるものです。これは、ベンチマークを設計したり、本番環境のパフォーマンスで得られた数字を使ってベンチマークを行い、そのパフォーマンスの数字を比較したりする場合に検討する価値があります。
目的に応じて、Kafka はスループットとレイテンシーのプロデューサーパフォーマンスを調整するために多くの設定パラメーターと設定方法を提供します。
- メッセージのバッチ処理 (
linger.msおよびbatch.size) -
メッセージのバッチ処理では、同じブローカー宛のメッセージをより多く送信するために、メッセージの送信を遅らせ、単一の生成リクエストでバッチ処理できるようにします。バッチ処理では、スループットを増やすためにレイテンシーを長くして妥協します。時間ベースのバッチ処理は
linger.msを使用して設定され、サイズベースのバッチ処理はbatch.sizeを使用して設定されます。 - 圧縮 (
compression.type) -
メッセージ圧縮処理により、プロデューサー (メッセージの圧縮に費やされた CPU 時間) のレイテンシーが追加されますが、リクエスト (および場合によってはディスクの書き込み) を小さくするため、スループットが増加します。圧縮に価値があるかどうか、および使用に最適な圧縮は、送信されるメッセージによって異なります。圧縮は
KafkaProducer.send()を呼び出すスレッドで発生するため、アプリケーションでこのメソッドのレイテンシーが重要となる場合は、より多くのスレッドの使用を検討する必要があります。 - パイプライン処理 (
max.in.flight.requests.per.connection) - パイプライン処理は、以前のリクエストへの応答を受け取る前により多くのリクエストを送信します。通常、パイプライン処理を増やすと、バッチ処理の悪化などの別の問題がスループットに悪影響を与え始めるしきい値まではスループットが増加します。
レイテンシーの短縮
アプリケーションが KafkaProducer.send() を呼び出す場合、メッセージは以下のようになります。
- インターセプターによる処理
- シリアライズ
- パーティションへの割り当て
- 圧縮処理
- パーティションごとのキュー内のメッセージのバッチに追加
ここで、send() メソッドが返されます。そのため、send() がブロックされる時間は、以下によって決定されます。
- インターセプター、シリアライザー、およびパーティションヤーで費やされた時間
- 使用される圧縮アルゴリズム
- 圧縮に使用するバッファーの待機に費やされた時間
バッチは、以下のいずれかが行われるまでキューに残ります。
-
バッチが満杯になる (
batch.sizeによる) -
linger.msによって導入された遅延が経過する - 送信者は他のパーティションのメッセージバッチを同じブローカーに送信しようとし、このバッチの追加も可能である
- プロデューサーがフラッシュまたは閉じられている
バッチ処理とバッファーの設定を参照して、レイテンシーをブロックする send() の影響を軽減します。
# ... linger.ms=100 1 batch.size=16384 2 buffer.memory=33554432 3 # ...
スループットの増加
メッセージの配信および送信リクエストの完了までの最大待機時間を調整して、メッセージリクエストのスループットを向上します。
また、カスタムパーティションを作成してデフォルトを置き換えることで、メッセージを指定のパーティションに転送することもできます。
# ... delivery.timeout.ms=120000 1 partitioner.class=my-custom-partitioner 2 # ...
6.2. Kafka コンシューマー設定の調整
特定のユースケースに合わせて調整されたオプションのプロパティーとともに、基本的なコンシューマー設定を使用します。
コンシューマーを調整する場合、最も重要なことは、取得するデータ量に効率的に対処できるようにすることです。プロデューサーのチューニングと同様に、コンシューマーが想定どおりに動作するまで、段階的に変更を加える必要があります。
6.2.1. 基本的なコンシューマー設定
接続およびデシリアライザープロパティーはすべてのコンシューマーに必要です。通常、追跡用にクライアント ID を追加することが推奨されます。
コンシューマー設定では、後続の設定に関係なく、以下を行います。
- メッセージをスキップまたは再読み取りするようオフセットを変更しない限り、コンシューマーはメッセージを指定のオフセットから取得し、順番に消費します。
- オフセットはクラスターの別のブローカーに送信される可能性があるため、オフセットを Kafka にコミットした場合でも、ブローカーはコンシューマーが応答を処理したかどうかを認識しません。
# ... bootstrap.servers=localhost:9092 1 key.deserializer=org.apache.kafka.common.serialization.StringDeserializer 2 value.deserializer=org.apache.kafka.common.serialization.StringDeserializer 3 client.id=my-client 4 group.id=my-group-id 5 # ...
- 1
- (必須) Kafka ブローカーの host:port ブートストラップサーバーアドレスを使用して、コンシューマーが Kafka クラスターに接続するよう指示しますコンシューマーはアドレスを使用して、クラスター内のすべてのブローカーを検出し、接続します。サーバーがダウンした場合に備えて、コンマ区切りリストを使用して 2 つまたは 3 つのアドレスを指定しますが、クラスター内のすべてのブローカーのリストを提供する必要はありません。ロードバランサーサービスを使用して Kafka クラスターを公開する場合、可用性はロードバランサーによって処理されるため、サービスのアドレスのみが必要になります。
- 2
- (必須) Kafka ブローカーから取得されたバイトをメッセージキーに変換するデシリアライザー。
- 3
- (必須) Kafka ブローカーから取得されたバイトをメッセージ値に変換するデシリアライザー。
- 4
- (オプション) クライアントの論理名。リクエストのソースを特定するためにログおよびメトリクスで使用されます。ID は、時間クォータの処理に基づいてコンシューマーにスロットリングを適用するために使用することもできます。
- 5
- (条件) コンシューマーがコンシューマーグループに参加するには、グループ ID が 必要 です。
コンシューマーグループは通常、特定のトピックから複数のプロデューサーで生成される大規模なデータストリームを共有するために使用されます。コンシューマーは group.id でグループ化され、メッセージをメンバー全体に分散できます。
6.2.2. コンシューマーグループを使用したデータ消費のスケーリング
コンシューマーグループは、特定のトピックから 1 つまたは複数のプロデューサーによって生成される、典型的な大量のデータストリームを共有します。group.id プロパティーが同じコンシューマーは同じグループにあります。グループ内のコンシューマーの 1 つがリーダーを選択し、パーティションをグループのコンシューマーにどのように割り当てるかを決定します。各パーティションは 1 つのコンシューマーにのみ割り当てることができます。
コンシューマーの数がパーティション数だけない場合には、同じ group.id を持つコンシューマーインスタンスを追加して、データ消費をスケーリングできます。コンシューマーをグループに追加して、パーティションの数より多くしても、スループットは改善されませんが、コンシューマーが機能しなくなったときに予備のコンシューマーを使用できます。より少ないコンシューマーでスループットの目標を達成できれば、リソースを節約できます。
同じコンシューマーグループのコンシューマーは、オフセットコミットとハートビートを同じブローカーに送信します。グループのコンシューマーの数が多いほど、ブローカーのリクエスト負荷が高くなります。
# ...
group.id=my-group-id 1
# ...- 1
- グループ ID を使用してコンシューマーグループにコンシューマーを追加します。
6.2.3. メッセージの順序の保証
Kafka ブローカーは、トピック、パーティション、およびオフセット位置のリストからメッセージを送信するようブローカーに要求するコンシューマーからフェッチリクエストを受け取ります。
コンシューマーは、ブローカーにコミットされたのと同じ順序でメッセージを単一のパーティションで監視します。つまり、Kafka は単一パーティションのメッセージ のみ 順序付けを保証します。逆に、コンシューマーが複数のパーティションからメッセージを消費している場合、コンシューマーによって監視される異なるパーティションのメッセージの順序は、必ずしも送信順序を反映しません。
1 つのトピックからメッセージを厳格に順序付ける場合は、コンシューマーごとに 1 つのパーティションを使用します。
6.2.4. スループットおよびレイテンシーの最適化
クライアントアプリケーションが KafkaConsumer.poll() を呼び出すときに返されるメッセージの数を制御します。
fetch.max.wait.ms および fetch.min.bytes プロパティーを使用して、Kafka ブローカーからコンシューマーによって取得される最小データ量を増やします。時間ベースのバッチ処理は fetch.max.wait.ms を使用して設定され、サイズベースのバッチ処理は fetch.min.bytes を使用して設定されます。
コンシューマーまたはブローカーの CPU 使用率が高い場合、コンシューマーからのリクエストが多すぎる可能性があります。fetch.max.wait.ms プロパティーおよび fetch.min.bytes プロパティーを調整して、より大きなバッチで要求とメッセージが配信されるようにすることができます。より高い値に調整することでスループットが改善されますが、レイテンシーのコストが発生します。生成されるデータ量が少ない場合、より高い値に調整することもできます。
たとえば、fetch.max.wait.ms を 500ms に設定し、fetch.min.bytes を 16384 バイトに設定した場合、Kafka がコンシューマーからフェッチリクエストを受信すると、いずれかのしきい値に最初に到達した時点で応答されます。
逆に、fetch.max.wait.ms プロパティーおよび fetch.min.bytes プロパティーを調整して、エンドツーエンドのレイテンシーを改善できます。
# ... fetch.max.wait.ms=500 1 fetch.min.bytes=16384 2 # ...
フェッチリクエストサイズの増加によるレイテンシーの短縮
fetch.max.bytes プロパティーおよび max.partition.fetch.bytes プロパティーを使用して、Kafka ブローカーからコンシューマーによって取得されるデータの最大量を増やします。
fetch.max.bytes プロパティーは、一度にブローカーから取得されるデータ量の上限をバイト単位で設定します。
max.partition.fetch.bytes は、各パーティションで返されるデータ量の上限をバイト単位で設定します。これは、max.message.bytes のブローカーまたはトピック設定に設定されたバイト数よりも大きくする必要があります。
クライアントが消費できるメモリーの最大量は、以下のように概算されます。
NUMBER-OF-BROKERS * fetch.max.bytes and NUMBER-OF-PARTITIONS * max.partition.fetch.bytes
メモリー使用量がこれに対応できる場合は、これら 2 つのプロパティーの値を増やすことができます。各リクエストでより多くのデータを許可すると、フェッチリクエストが少なくなるため、レイテンシーが向上されます。
# ... fetch.max.bytes=52428800 1 max.partition.fetch.bytes=1048576 2 # ...
6.2.5. オフセットをコミットする際のデータ損失または重複の回避
Kafka の 自動コミットメカニズム により、コンシューマーはメッセージのオフセットを自動的にコミットできます。有効にすると、コンシューマーはブローカーをポーリングして受信したオフセットを 5000ms 間隔でコミットします。
自動コミットのメカニズムは便利ですが、データ損失と重複のリスクが発生します。コンシューマーが多くのメッセージを取得および変換し、自動コミットの実行時にコンシューマーバッファーに処理されたメッセージがある状態でシステムがクラッシュすると、そのデータは失われます。メッセージの処理後、自動コミットの実行前にシステムがクラッシュした場合、リバランス後に別のコンシューマーインスタンスでデータが複製されます。
ブローカーへの次のポーリングの前またはコンシューマーが閉じられる前に、すべてのメッセージが処理された場合は、自動コミットによるデータの損失を回避できます。
データの損失や重複の可能性を最小限に抑えるには、enable.auto.commit を false に設定し、クライアントアプリケーションを開発して、オフセットのコミットをより詳細に制御できるようにします。または、auto.commit.interval.ms を使用してコミットの間隔を減らすことができます。
# ...
enable.auto.commit=false 1
# ...- 1
- 自動コミットを false に設定すると、オフセットのコミットの制御が強化されます。
enable.auto.commit を false に設定すると、すべての 処理が実行され、メッセージが消費された後にオフセットをコミットできます。たとえば、Kafka commitSync および commitAsync コミット API を呼び出すようにアプリケーションを設定できます。
commitSync API は、ポーリングから返されるメッセージバッチのオフセットをコミットします。バッチのメッセージすべての処理が完了したら API を呼び出します。commitSync API を使用する場合、アプリケーションはバッチの最後のオフセットがコミットされるまで新しいメッセージをポーリングしません。これがスループットに悪影響する場合は、コミットする頻度が低いか、commitAsync API を使用できます。commitAsync API はブローカーがコミットリクエストに応答するまで待機しませんが、リバランス時にさらに重複が発生するリスクがあります。一般的な方法として、両方のコミット API をアプリケーションで組み合わせ、コンシューマーをシャットダウンまたはリバランスの直前に commitSync API を使用し、最終コミットが正常に実行されるようにします。
6.2.5.1. トランザクションメッセージの制御
プロデューサー側でトランザクション ID を使用し、べき等性 (enable.idempotence=true) を有効にすることを検討してください。これにより、1 回限りの配信を保証します。コンシューマー側で、isolation.level プロパティーを使用して、コンシューマーによってトランザクションメッセージが読み取られる方法を制御できます。
isolation.level プロパティーには、有効な 2 つの値があります。
-
read_committed -
read_uncommitted(デフォルト)
read_committed を使用して、コミットされたトランザクションメッセージのみがコンシューマーによって読み取られるようにします。ただし、これによりトランザクションの結果を記録するトランザクションマーカー (committed または aborted) がブローカーによって書き込まれるまで、コンシューマーはメッセージを返すことができないため、エンドツーエンドのレイテンシーが長くなります。
# ...
enable.auto.commit=false
isolation.level=read_committed 1
# ...- 1
- コミットされたメッセージのみがコンシューマーによって読み取られるように、
read_committedに設定します。
6.2.6. データ損失を回避するための障害からの復旧
session.timeout.ms および heartbeat.interval.ms プロパティーを使用して、コンシューマーグループ内のコンシューマー障害をチェックし、復旧するのにかかった時間を設定します。
session.timeout.ms プロパティーは、コンシューマーグループ内のコンシューマーがブローカーとのコンタクトを絶った場合に、非アクティブとみなされ、グループ内のアクティブなコンシューマー間で リバランス が発生するまでの最大時間をミリ秒単位で指定します。グループのリバランス時に、パーティションはグループのメンバーに再割り当てされます。
heartbeat.interval.ms プロパティーは、コンシューマーがアクティブで接続されていることを示す、コンシューマーグループコーディネーターへの ハートビート チェックの間隔をミリ秒単位で指定します。通常、ハートビートの間隔はセッションタイムアウトの間隔の 3 分の 2 にする必要があります。
session.timeout.ms プロパティーを低く設定すると、失敗したコンシューマーが先に検出され、リバランスがより迅速に実行されます。ただし、タイムアウトの値を低くしすぎて、ブローカーがハートビートを時間内に受信できず、不必要なリバランスがトリガーされることがないように気を付けてください。
ハートビートの間隔が短くなると、誤ってリバランスを行う可能性が低くなりますが、ハートビートを頻繁に行うとブローカーリソースのオーバーヘッドが増えます。
6.2.7. オフセットポリシーの管理
auto.offset.reset プロパティーを使用して、オフセットがコミットされていない場合にコンシューマーの動作を制御するか、コミットされたオフセットが有効でなくなったりします。
コンシューマーアプリケーションを初めてデプロイし、既存のトピックからメッセージを読み取る場合について考えてみましょう。これは group.id が初めて使用されるため、__consumer_offsets トピックには、このアプリケーションのオフセット情報は含まれません。新しいアプリケーションは、ログの始めからすべての既存メッセージの処理を開始するか、新しいメッセージのみ処理を開始できます。デフォルトのリセット値は、パーティションの最後に開始する latest で、一部のメッセージは見逃されることを意味します。データの損失は避けたいが、処理量を増やしたい場合は、auto.offset.reset を earliest に設定して、パーティションの先頭から開始します。
また、ブローカーに設定されたオフセットの保持期間 (offsets.retention.minutes) が終了したときにメッセージが失われるのを防ぐために、earliest オプションの使用も検討してください。コンシューマーグループまたはスタンドアロンコンシューマーが非アクティブで、保持期間中にオフセットをコミットしない場合、以前にコミットされたオフセットは __consumer_offsets から削除されます。
# ... heartbeat.interval.ms=3000 1 session.timeout.ms=10000 2 auto.offset.reset=earliest 3 # ...
- 1
- 予想されるリバランスに応じて、ハートビートの間隔を短くして調整します。
- 2
- タイムアウトの期限が切れる前に Kafka ブローカーによってハートビートが受信されなかった場合、コンシューマーはコンシューマーグループから削除され、リバランスが開始されます。ブローカー設定に
group.min.session.timeout.msとgroup.max.session.timeout.msがある場合、セッションタイムアウト値はその範囲内である必要があります。 - 3
- パーティションの最初に戻り、オフセットがコミットされなかった場合にデータの損失を回避するために、
earliest値に設定します。
1 つのフェッチリクエストで返されるデータ量が大きい場合、コンシューマーが処理する前にタイムアウトが発生することがあります。この場合、max.partition.fetch.bytes を減らしたり、session.timeout.ms を増やすこともできます。
6.2.8. リバランスの影響の最小限化
グループのアクティブなコンシューマー間で行うパーティションのリバランスは、以下にかかる時間です。
- コンシューマーによるオフセットのコミット
- 作成される新しいコンシューマーグループ
- グループリーダーによるグループメンバーへのパーティションの割り当て
- 割り当てを受け取り、取得を開始するグループのコンシューマー
明らかに、このプロセスは特にコンシューマーグループクラスターのローリング再起動時に繰り返し発生するサービスのダウンタイムを増やします。
このような場合、静的メンバーシップ の概念を使用してリバランスの数を減らすことができます。リバランスによって、コンシューマーグループメンバー全体でトピックパーティションが割り当てられます。静的メンバーシップは永続性を使用し、セッションタイムアウト後の再起動時にコンシューマーインスタンスが認識されるようにします。
コンシューマーグループコーディネーターは、group.instance.id プロパティーを使用して指定される一意の ID を使用して新しいコンシューマーインスタンスを特定できます。再起動時には、コンシューマーには新しいメンバー ID が割り当てられますが、静的メンバーとして、同じインスタンス ID を使用し、同じトピックパーティションの割り当てが行われます。
コンシューマーアプリケーションが少なくとも max.poll.interval.ms ミリ秒毎にポーリングへの呼び出しを行わない場合、コンシューマーが失敗したと見なされ、リバランスが発生します。アプリケーションがポーリングから返されたすべてのレコードを時間内に処理できない場合は、max.poll.interval.ms プロパティーを使用してコンシューマーから新しいメッセージのポーリングの間隔をミリ秒単位で指定して、リバランスを回避することができます。または、max.poll.records プロパティーを使用して、コンシューマーバッファーから返されるレコードの数の上限を設定できます。これにより、アプリケーションは max.poll.interval.ms の制限内のより少ないレコードを処理できます。
# ... group.instance.id=UNIQUE-ID 1 max.poll.interval.ms=300000 2 max.poll.records=500 3 # ...
第7章 クラスターのスケーリング
7.1. Kafka クラスターのスケーリング
7.1.1. ブローカーのクラスターへの追加
トピックのスループットを向上させる主な方法は、そのトピックのパーティション数を増やすことです。これは、パーティションによってクラスター内のブローカー間でそのトピックの負荷が共有できるためです。ブローカーがすべて何らかのリソース (通常は I/O) によって制約されている場合、より多くのパーティションを使用してもスループットは向上しません。代わりに、クラスターにブローカーを追加する必要があります。
追加のブローカーをクラスターに追加する場合、AMQ Streams ではパーティションは自動的に割り当てられません。既存のブローカーから新しいブローカーに移動するパーティションを決定する必要があります。
すべてのブローカー間でパーティションが再分散されたら、各ブローカーのリソース使用率が低下するはずです。
7.1.2. クラスターからのブローカーの削除
クラスターからブローカーを削除する前に、そのブローカーにパーティションが割り当てられていないことを確認します。使用を停止するブローカーの各パーティションに対応する残りのブローカーを決定する必要があります。ブローカーに割り当てられたパーティションがない場合は、ブローカーを停止することができます。
7.2. パーティションの再割り当て
kafka-reassign-partitions.sh は、パーティションを別のブローカーに再割り当てする際に使用します。
これには、以下の 3 つのモードがあります。
--generate- トピックとブローカーのセットを取得し、再割り当て JSON ファイル を生成します。これにより、トピックのパーティションがブローカーに割り当てられます。再割り当て JSON ファイル を生成する簡単な方法です。ただし、トピック全体で機能するため、その使用が常に適切であるとは限りません。
--execute- 再割り当て JSON ファイル を取得し、クラスターのパーティションおよびブローカーに適用します。パーティションを取得するブローカーは、パーティションリーダーのフォロワーになります。特定のパーティションでは、新規ブローカーが ISR に参加できたら、古いブローカーはフォロワーではなくなり、そのレプリカが削除されます。
--verify-
--verifyは、-- executeステップと同じ 再割り当て JSON ファイル を使用して、ファイル内のすべてのパーティションが目的のブローカーに移動されたかどうかを確認します。再割り当てが完了すると、有効な スロットル も削除されます。スロットルを削除しないと、再割り当てが完了した後もクラスターは影響を受け続けます。
クラスターでは、1 度に 1 つの再割当てのみを実行でき、実行中の再割り当てをキャンセルすることはできません。再割り当てをキャンセルする必要がある場合は、割り当てが完了するのを待ってから別の再割り当てを実行し、最初の再割り当ての結果を元に戻します。kafka-reassign-partitions.sh によって、元に戻すための再割り当て JSON が出力の一部として生成されます。大規模な再割り当ては、進行中の再割り当てを停止する必要がある場合に備えて、複数の小さな再割り当てに分割するようにしてください。
7.2.1. 再割り当て JSON ファイル
再割り当て JSON ファイル には特定の構造があります。
{
"version": 1,
"partitions": [
<PartitionObjects>
]
}ここで <PartitionObjects> は、以下のようなコンマ区切りのオブジェクトリストになります。
{
"topic": <TopicName>,
"partition": <Partition>,
"replicas": [ <AssignedBrokerIds> ],
"log_dirs": [<LogDirs>]
}
"log_dirs" プロパティーはオプションで、パーティションを特定のログディレクトリーに移動するために使用されます。
以下は、トピック topic-a およびパーティション 4 をブローカー 2、4 および 7 に割り当て、トピック topic-b およびパーティション 2 をブローカー 1、5、および 7 に割り当てる、再割り当て JSON ファイルの例になります。
{
"version": 1,
"partitions": [
{
"topic": "topic-a",
"partition": 4,
"replicas": [2,4,7]
},
{
"topic": "topic-b",
"partition": 2,
"replicas": [1,5,7]
}
]
}JSON に含まれていないパーティションは変更されません。
7.2.2. 再割り当て JSON ファイルの生成
指定のトピックのセットのすべてのパーティションを、指定のブローカーのセットに割り当てる最も簡単な方法は、kafka-reassign-partitions.sh --generate コマンドを使用して再割り当て JSON ファイルを生成することです。
bin/kafka-reassign-partitions.sh --zookeeper <ZooKeeper> --topics-to-move-json-file <TopicsFile> --broker-list <BrokerList> --generate
<TopicsFile> は、移動するトピックをリストする JSON ファイルです。これには、以下の構造があります。
{
"version": 1,
"topics": [
<TopicObjects>
]
}ここで <TopicObjects> は、以下のようなコンマ区切りのオブジェクトリストになります。
{
"topic": <TopicName>
}
たとえば、topic-a および topic-b のすべてのパーティションをブローカー 4 および 7 に移動する場合は、以下を実行します。
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to-move-json-file topics-to-be-moved.json --broker-list 4,7 --generate
topics-to-be-moved.json のコンテンツがあります。
{
"version": 1,
"topics": [
{ "topic": "topic-a"},
{ "topic": "topic-b"}
]
}7.2.3. 手動による再割り当て JSON ファイルの作成
特定のパーティションを移動したい場合は、再割り当て JSON ファイルを手動で作成できます。
7.3. 再割り当てスロットル
パーティションの再割り当てには、多くのデータをブローカー間で移動させる必要があるため、処理が遅くなる可能性があります。クライアントへの悪影響を防ぐため、再割り当てに スロットル を使用できます。スロットルを使用すると、再割り当てに時間がかかる可能性があります。スロットルが低すぎると、新たに割り当てられたブローカーは公開されるレコードに遅れずに対応することはできず、再割り当ては永久に完了しません。スロットルが高すぎると、クライアントに影響します。たとえば、プロデューサーの場合は、承認待ちが通常のレイテンシーよりも大きくなる可能性があります。コンシューマーの場合は、ポーリング間のレイテンシーが大きいことが原因でスループットが低下する可能性があります。
7.4. Kafka クラスターのスケールアップ
この手順では、Kafka クラスターでブローカーの数を増やす方法を説明します。
前提条件
- 既存の Kafka クラスター。
- AMQ ブローカーが インストールされている 新しいマシン。
- 拡大されたクラスターで、パーティションをブローカーに再割り当てする方法を示す 再割り当て JSON ファイル。
手順
-
クラスター内の他のブローカーと同じ設定を使用して新しいブローカーの設定ファイルを作成します。ただし、
broker.idには他のブローカで使用されていない番号を指定してください。 前のステップで作成した設定ファイルを
kafka-server-start.shスクリプトの引数に渡して、新しい Kafka ブローカーを起動します。su - kafka /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
Kafka ブローカーが稼働していることを確認します。
jcmd | grep Kafka
- 新しいブローカーごとに上記の手順を繰り返します。
kafka-reassign-partitions.shコマンドラインツールを使用して、パーティションの再割り当てを実行します。kafka-reassign-partitions.sh --zookeeper <ZooKeeperHostAndPort> --reassignment-json-file <ReassignmentJsonFile> --execute
レプリケーションをスロットルで調整する場合、
--throttleと inter-broker のスロットル率 (バイト/秒単位) を渡すこともできます。以下に例を示します。kafka-reassign-partitions.sh --zookeeper zookeeper1:2181 --reassignment-json-file reassignment.json --throttle 5000000 --execute
このコマンドは、2 つの再割り当て JSON オブジェクトを出力します。最初の JSON オブジェクトには、移動されたパーティションの現在の割り当てが記録されます。後で再割り当てを元に戻す必要がある場合に備えて、これをファイルに保存する必要があります。2 つ目の JSON オブジェクトは、再割り当て JSON ファイルに渡したターゲットの再割り当てです。
再割り当ての最中にスロットルを変更する必要がある場合は、同じコマンドラインに別のスロットル率を指定して実行します。以下に例を示します。
kafka-reassign-partitions.sh --zookeeper zookeeper1:2181 --reassignment-json-file reassignment.json --throttle 10000000 --execute
kafka-reassign-partitions.shコマンドラインツールを使用して、再割り当てが完了したかどうかを定期的に確認します。これは先ほどの手順と同じコマンドですが、--executeオプションの代わりに--verifyオプションを使用します。kafka-reassign-partitions.sh --zookeeper <ZooKeeperHostAndPort> --reassignment-json-file <ReassignmentJsonFile> --verify
以下に例を示します。
kafka-reassign-partitions.sh --zookeeper zookeeper1:2181 --reassignment-json-file reassignment.json --verify
-
--verifyコマンドによって、移動した各パーティションが正常に完了したことが報告されると、再割り当ては終了します。この最終的な--verifyによって、結果的に再割り当てスロットルも削除されます。割り当てを元のブローカーに戻すために JSON ファイルを保存した場合は、ここでそのファイルを削除できます。
7.5. Kafka クラスターのスケールダウン
関連情報
この手順では、Kafka クラスターでブローカーの数を減らす方法を説明します。
前提条件
- 既存の Kafka クラスター。
- ブローカーが削除された後にクラスターのブローカーにパーティションを再割り当てする方法が記述されている 再割り当て JSON ファイル。
手順
kafka-reassign-partitions.shコマンドラインツールを使用して、パーティションの再割り当てを実行します。kafka-reassign-partitions.sh --zookeeper <ZooKeeperHostAndPort> --reassignment-json-file <ReassignmentJsonFile> --execute
レプリケーションをスロットルで調整する場合、
--throttleと inter-broker のスロットル率 (バイト/秒単位) を渡すこともできます。以下に例を示します。kafka-reassign-partitions.sh --zookeeper zookeeper1:2181 --reassignment-json-file reassignment.json --throttle 5000000 --execute
このコマンドは、2 つの再割り当て JSON オブジェクトを出力します。最初の JSON オブジェクトには、移動されたパーティションの現在の割り当てが記録されます。後で再割り当てを元に戻す必要がある場合に備えて、これをファイルに保存する必要があります。2 つ目の JSON オブジェクトは、再割り当て JSON ファイルに渡したターゲットの再割り当てです。
再割り当ての最中にスロットルを変更する必要がある場合は、同じコマンドラインに別のスロットル率を指定して実行します。以下に例を示します。
kafka-reassign-partitions.sh --zookeeper zookeeper1:2181 --reassignment-json-file reassignment.json --throttle 10000000 --execute
kafka-reassign-partitions.shコマンドラインツールを使用して、再割り当てが完了したかどうかを定期的に確認します。これは先ほどの手順と同じコマンドですが、--executeオプションの代わりに--verifyオプションを使用します。kafka-reassign-partitions.sh --zookeeper <ZooKeeperHostAndPort> --reassignment-json-file <ReassignmentJsonFile> --verify
以下に例を示します。
kafka-reassign-partitions.sh --zookeeper zookeeper1:2181 --reassignment-json-file reassignment.json --verify
-
--verifyコマンドによって、移動した各パーティションが正常に完了したことが報告されると、再割り当ては終了します。この最終的な--verifyによって、結果的に再割り当てスロットルも削除されます。割り当てを元のブローカーに戻すために JSON ファイルを保存した場合は、ここでそのファイルを削除できます。 すべてのパーティションの再割り当てが終了すると、削除されるブローカーはクラスター内のいずれのパーティションにも対応しないはずです。これを確認するには、ブローカーの
log.dirs設定パラメーターで指定された各ディレクトリーを確認します。ブローカーのログディレクトリーに、拡張正規表現[a-zA-Z0-9.-]+\.[a-z0-9]+-delete$と一致しないディレクトリーが含まれる場合、ブローカーにはライブパーティションがあるため、停止してはなりません。これを確認するには、以下のコマンドを実行します。
ls -l <LogDir> | grep -E '^d' | grep -vE '[a-zA-Z0-9.-]+\.[a-z0-9]+-delete$'上記のコマンドによって出力が生成される場合、ブローカーにはライブパーティションがあります。この場合、再割り当てが終了していないか、再割り当て JSON ファイルが適切ではありません。
ブローカーにライブパーティションがないことを確認したら、それを停止できます。
su - kafka /opt/kafka/bin/kafka-server-stop.sh
Kafka ブローカーが停止していることを確認します。
jcmd | grep kafka
7.6. ZooKeeper クラスターのスケールアップ
この手順では、Zoo Keeper クラスターにサーバー (ノード) を追加する方法について説明します。Zoo Keeper の 動的再設定 機能は、スケールアッププロセス中に安定した Zoo Keeper クラスターを維持します。
前提条件
-
動的再設定が ZooKeeper 設定ファイル (
reconfigEnabled=true) で有効になっている。 - ZooKeeper の認証が有効化され、認証メカニズムを使用して新しいサーバーにアクセスできる。
手順
各 ZooKeeper サーバーに対して、1 つずつ以下の手順を実行します。
- 「マルチノードの ZooKeeper クラスターの実行」 の説明に従ってサーバーを ZooKeeper クラスターに追加し、ZooKeeper を起動します。
- 新しいサーバーの IP アドレスと設定されたアクセスポートをメモします。
サーバーの
zookeeper-shellセッションを開始します。クラスターにアクセスできるマシンから次のコマンドを実行します (アクセスできる場合は、Zoo Keeper ノードまたはローカルマシンの 1 つである可能性があります)。su - kafka /opt/kafka/bin/zookeeper-shell.sh <ip-address>:<zk-port>
シェルセッションで、Zoo Keeper ノードが実行されている状態で、次の行を入力して、新しいサーバーを投票メンバーとしてクォーラムに追加します。
reconfig -add server.<positive-id> = <address1>:<port1>:<port2>[:role];[<client-port-address>:]<client-port>
以下に例を示します。
reconfig -add server.4=172.17.0.4:2888:3888:participant;172.17.0.4:2181
<positive-id>は、新しいサーバー ID4です。2 つのポートの
<port1>2888 は ZooKeeper サーバー間の通信用で、<port2>3888 はリーダーエレクション用です。新しい設定は ZooKeeper クラスターの他のサーバーに伝播されます。新しいサーバーはクォーラムの完全メンバーになります。
- 追加する他のサーバーについて、手順 1 から 4 を繰り返します。
7.7. ZooKeeper クラスターのスケールダウン
この手順では、ZooKeeper クラスターからサーバー (ノード) を削除する方法を説明します。Zoo Keeper の 動的再設定 機能は、スケールダウンプロセス中に安定した Zoo Keeper クラスターを維持します。
前提条件
-
動的再設定が ZooKeeper 設定ファイル (
reconfigEnabled=true) で有効になっている。 - ZooKeeper の認証が有効化され、認証メカニズムを使用して新しいサーバーにアクセスできる。
手順
各 ZooKeeper サーバーに対して、1 つずつ以下の手順を実行します。
スケールダウンの後も 維持される サーバーのいずれかで、
zookeeper-shellにログインします (例: サーバー1)。注記ZooKeeper クラスターに設定された認証メカニズムを使用してサーバーにアクセスします。
サーバー (サーバー 5 など) を削除します。
reconfig -remove 5
- 削除したサーバーを無効にします。
- ステップ 1 から 3 を繰り返し、クラスターサイズを縮小します。
関連情報
- 「ZooKeeper クラスターのスケールアップ」
- ZooKeeper ドキュメントのサーバーの削除
第8章 JMX を使用したクラスターの監視
Zoo Keeper、Kafka ブローカー、Kafka Connect、および Kafka クライアントはすべて、 Java Management Extensions (JMX) を使用して管理情報を公開します。管理情報の多くは、Kafka クラスターの状態やパフォーマンスを監視するのに役立つメトリクスの形式になっています。他の Java アプリケーションと同様に、Kafka は管理対象 Bean または MBean を介してこの管理情報を提供します。
JMX は、JVM (Java 仮想マシン) のレベルで動作します。管理情報を取得するために、外部ツールは ZooKeeper、Kafka ブローカーなどを実行している JVM に接続できます。デフォルトでは、同じマシン上で、JVM と同じユーザーとして実行しているツールのみが接続できます。
ZooKeeper の管理情報は、ここには記載されていません。JConsole で ZooKeeper メトリクスを表示できます。詳細は、「JConsole を使用した監視」 を参照してください。
8.1. JMX 設定オプション
JVM システムプロパティーを使用して JMX を設定します。AMQ Streams とともに提供されるスクリプト (bin/kafka-server-start.sh、bin/connect-distributed.sh など) では、環境変数 KAFKA_JMX_OPTS を使用してこれらのシステムプロパティーを設定しています。Kafka プロデューサー、コンシューマー、およびストリームアプリケーションは、通常、異なる方法で JVM を起動しますが、JMX を設定するためのシステムプロパティーは同じです。
8.2. JMX エージェントの無効化
AMQ Streams コンポーネントの JMX エージェントを無効にすることで、ローカルの JMX ツールが (たとえば、コンプライアンスの理由などで) JVM に接続しないようにすることができます。以下の手順では、Kafka ブローカーの JMX エージェントを無効にする方法を説明します。
手順
KAFKA_JMX_OPTS環境変数を使用してcom.sun.management.jmxremoteをfalseに設定します。export KAFKA_JMX_OPTS=-Dcom.sun.management.jmxremote=false bin/kafka-server-start.sh
- JVM を起動します。
8.3. 別のマシンからの JVM への接続
JMX エージェントがリッスンするポートを設定すると、別のマシンから JVM に接続できます。これは、JMX ツールがどこからでも認証なしで接続できるため、安全ではありません。
手順
KAFKA_JMX_OPTS環境変数を使用して-Dcom.sun.management.jmxremote.port=<port>を設定します。<port>には、Kafka ブローカーが JMX 接続をリッスンするポートの名前を入力します。export KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.port=<port> -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false" bin/kafka-server-start.sh- JVM を起動します。
リモート JMX 接続をセキュアにするには、認証と SSL を設定することが推奨されます。これを行うために必要なシステムプロパティーの詳細については、JMX のドキュメント を参照してください。
8.4. JConsole を使用した監視
JConsole ツールは Java Development Kit (JDK) とともに配布されます。JConsole を使用して、ローカルまたはリモート JVM に接続し、Java アプリケーションから管理情報を検出および表示できます。JConsole を使用してローカル JVM に接続する場合、AMQ Streams のさまざまなコンポーネントに対応する JVM プロセスの名前は以下のとおりです。
| AMQ Streams コンポーネント | JVM プロセス |
|---|---|
| ZooKeeper |
|
| Kafka ブローカー |
|
| Kafka Connect スタンドアロン |
|
| Kafka Connect distributed |
|
| Kafka producer、consumer、または Streams application |
アプリケーションの |
JConsole を使用してリモート JVM に接続する場合は、適切なホスト名と JMX ポートを使用します。
その他の多くのツールおよびモニタリング製品を使用して JMX を使用してメトリクスを取得し、そのメトリクスに基づいてモニタリングおよびアラートを提供できます。これらのツールについては、製品ドキュメントを参照してください。
8.5. 重要な Kafka ブローカーメトリクス
Kafka は、Kafka クラスターのブローカーのパフォーマンスを監視するための多くの MBean を提供します。これらは、クラスター全体ではなく、個別のブローカーに適用されます。
以下の表は、サーバー、ネットワーク、ロギング、およびコントローラーメトリクスに編成されるこれらのブローカーレベルの MBean の一部です。
8.5.1. Kafka サーバーメトリクス
以下の表は、Kafka サーバーに関する情報を報告するメトリクスの一部です。
| メトリクス | MBean | 説明 | 想定される値 |
|---|---|---|---|
| 1 秒あたりのメッセージ数 |
| 個々のメッセージがブローカーによって消費されるレート。 | クラスターの他のブローカーとほぼ同じです。 |
| 1 秒あたりのバイト数 |
| プロデューサーから送信されたデータがブローカーによって消費されるレート。 | クラスターの他のブローカーとほぼ同じです。 |
| 1 秒あたりのレプリケーションバイト数 |
| 他のブローカーから送信されたデータがフォロワーブローカーによって消費されるレート。 | 該当なし |
| 1 秒あたりのバイト数 |
| コンシューマーによってブローカーからデータを取得および読み取るレート。 | 該当なし |
| 1 秒あたりのレプリケーションバイト数 |
| ブローカーから他のブローカーにデータを送信するレート。このメトリクスは、ブローカーがパーティションのグループのリーダーであるかどうかを監視するのに役立ちます。 | 該当なし |
| 複製の数が最低数未満パーティション |
| フォロワーレプリカに完全にレプリケートされていないパーティションの数。 | ゼロ |
| 最小 ISR パーティション数 |
| 最小の In-Sync Replica (ISR) カウント下のパーティションの数。ISR 数は、リーダーと最新の状態にあるレプリカのセットを示します。 | ゼロ |
| パーティションの数 |
| ブローカーのパーティション数。 | 他のブローカーと比較してほぼ同じです。 |
| リーダー数 |
| このブローカーがリーダーであるレプリカの数。 | クラスターの他のブローカーとほぼ同じです。 |
| ISR は 1 秒あたりに縮小します |
| ブローカー内の ISR の数が減少する割合 | ゼロ |
| 1 秒あたりの ISR 拡張 |
| ブローカー内の ISR の数が増大する割合 | ゼロ |
| 最大ラグ |
| メッセージがリーダーレプリカとフォロワーレプリカによって受信される時間の間の最大ラグ。 | 生成リクエストの最大バッチサイズに比例します。 |
| producer purgatory での要求 |
| producer purgatory の送信リクエストの数。 | 該当なし |
| fetch purgatory での要求 |
| fetch purgatory のフェッチリクエストの数。 | 該当なし |
| リクエストハンドラーの平均アイドル率 |
| リクエストハンドラー (IO) スレッドが使用されていない時間の割合を示します。 | 値が小さいほど、ブローカーのワークロードが高いことを示します。 |
| リクエスト (スロットルを除外されるリクエスト) |
| スロットリングから除外される要求の数。 | 該当なし |
| Zoo Keeper リクエストのレイテンシー (ミリ秒) |
| ブローカーからの Zoo Keeper リクエストのレイテンシー (ミリ秒単位)。 | 該当なし |
| ZooKeeper セッションの状態 |
| ブローカーの ZooKeeper への接続状態。 | 接続済み |
8.5.2. Kafka ネットワークメトリクス
以下の表は、リクエストに関する情報を報告するメトリクスの一部です。
| メトリクス | MBean | 説明 | 想定される値 |
|---|---|---|---|
| 1 秒あたりのリクエスト数 |
|
1 秒あたりの要求タイプに対して行われるリクエストの合計数。 | 該当なし |
| リクエストバイト (バイト単位のリクエストサイズ) |
|
MBean 名の | 該当なし |
| バイト単位の一時メモリーサイズ |
| メッセージ形式の変換およびメッセージの展開に使用される一時メモリーの量。 | 該当なし |
| メッセージ変換時間 |
| メッセージ形式の変換に費やされた時間 (ミリ秒単位)。 | 該当なし |
| ミリ秒単位の合計リクエスト時間 |
| リクエストの処理に費やされた合計時間 (ミリ秒単位)。 | 該当なし |
| ミリ秒単位の要求キュー時間 |
|
| 該当なし |
| ミリ秒単位の現地時間 (リーダーの現地処理時間) |
| リーダーがリクエストを処理するのにかかる時間 (ミリ秒単位)。 | 該当なし |
| ミリ秒単位のリモート時間 (リーダーのリモート処理時間) |
|
要求がフォロワーを待機する時間の長さ (ミリ秒単位)。すべての利用可能な要求タイプの個別の MBean が | 該当なし |
| ミリ秒単位の応答キュー時間 |
| 要求が応答キューで待機する時間の長さ (ミリ秒単位)。 | 該当なし |
| ミリ秒単位の応答送信時間 |
| 応答の送信にかかった時間 (ミリ秒単位)。 | 該当なし |
| ネットワークプロセッサーの平均アイドル率 |
| ネットワークプロセッサーがアイドル状態である時間の平均パーセンテージ。 | 0 から 1 の間。 |
8.5.3. Kafka ログメトリクス
次の表は、ロギングに関する情報を報告するメトリクスの選択を示しています。
| メトリクス | MBean | 説明 | 想定される値 |
|---|---|---|---|
| ログのフラッシュ速度と時間 (ミリ秒) |
| ログデータがディスクに書き込まれる速度 (ミリ秒単位)。 | 該当なし |
| オフラインのログディレクトリー数 |
| オフラインログディレクトリーの数 (たとえば、ハードウェア障害後)。 | ゼロ |
8.5.4. Kafka コントローラーメトリクス
次の表は、クラスターのコントローラーに関する情報を報告するメトリクスの選択を示しています。
| メトリクス | MBean | 説明 | 想定される値 |
|---|---|---|---|
| アクティブなコントローラーの数 |
| コントローラーとして指定されるブローカーの数。 | 1 つは、ブローカーがクラスターのコントローラーであることを示します。 |
| リーダーエレクション率と時間 (ミリ秒) |
| 新しいリーダーレプリカが選出されるレート。 | ゼロ |
8.5.5. Yammer メトリクス
レートまたは時間の単位を表すメトリクスは、Yammer メトリクスとして提供されます。Yammer メトリクスを使用する MBean のクラス名には、com.yammer.metrics というプレフィックスがつきます。
Yammer レートメトリクスには、要求を監視する以下の属性があります。
- Count
- EventType (バイト)
- FifteenMinuteRate
- RateUnit (秒)
- MeanRate
- OneMinuteRate
- FiveMinuteRate
Yammer 時間メトリクスには、要求を監視するための以下の属性があります。
- Max
- Min
- Mean
- StdDev
- 75/95/98/99/99.9 パーセンタイル
8.6. プロデューサー MBean
以下の MBean は、Kafka Streams アプリケーションやソースコネクターのある Kafka Connect など、Kafka プロデューサーアプリケーションに存在します。
8.6.1. kafka.producer:type=producer-metrics,client-id=* と一致する MBean
これらはプロデューサーレベルでのメトリクスです。
| 属性 | 説明 |
|---|---|
| batch-size-avg | 要求ごとにパーティションごとに送信されるバイトの平均数。 |
| batch-size-max | リクエストごとおよびパーティションごとに送信されるバイトの最大数。 |
| batch-split-rate | 1 秒あたりのバッチスプリットの平均数。 |
| batch-split-total | バッチスプリットの合計数。 |
| buffer-available-bytes | 使用されていない (未割り当てまたは空きリストにある) バッファメモリーの合計量。 |
| buffer-total-bytes | クライアントが使用できるバッファメモリーの最大量 (現在使用されているかどうかに関係なく)。 |
| bufferpool-wait-time | アペンダーがスペースの割り当てを待つ時間の割合。 |
| compression-rate-avg | レコードバッチの平均圧縮率。 |
| connection-close-rate | ウィンドウで 1 秒間に閉じられる接続。 |
| connection-count | アクティブな接続の現在の数。 |
| connection-creation-rate | ウィンドウで 1 秒間に確立される新しい接続。 |
| failed-authentication-rate | 認証に失敗した接続数。 |
| incoming-byte-rate | すべてのソケットから読み取られたバイト/秒。 |
| io-ratio | I/O スレッドが I/O の実行に費やした時間の割合。 |
| io-time-ns-avg | 選択した呼び出しごとの I/O の平均時間 (ナノ秒単位)。 |
| io-wait-ratio | I/O スレッドが待機に費やした時間の割合。 |
| io-wait-time-ns-avg | 読み取りまたは書き込みの準備ができたソケットの待機に費やされた I/O スレッドの平均時間 (ナノ秒単位)。 |
| metadata-age | 使用されている現在のプロデューサーメタデータの秒単位の経過時間。 |
| network-io-rate | 1 秒あたりのすべての接続でのネットワーク操作 (読み取りまたは書き込み) の平均数。 |
| outgoing-byte-rate | すべてのサーバーに 1 秒間に送信する送信バイトの平均数。 |
| produce-throttle-time-avg | リクエストがブローカーによって抑制された平均時間 (ミリ秒)。 |
| produce-throttle-time-max | ブローカーによってリクエストがスロットルされた最大時間 (ミリ秒単位)。 |
| record-error-rate | エラーとなったレコード送信の 1 秒あたりの平均数。 |
| record-error-total | エラーとなったレコード送信の合計数。 |
| record-queue-time-avg | 送信バッファーで費やされたレコードバッチの平均時間 (ミリ秒)。 |
| record-queue-time-max | 送信バッファーで費やされたレコードバッチの最長時間 (ミリ秒)。 |
| record-retry-rate | 再試行されたレコード送信の 1 秒あたりの平均数。 |
| record-retry-total | 再試行されたレコード送信の合計数。 |
| record-send-rate | 1 秒間に送信するレコードの平均数。 |
| record-send-total | 送信されたレコードの総数。 |
| record-size-avg | 平均レコードサイズ。 |
| record-size-max | 最大レコードサイズ。 |
| records-per-request-avg | リクエストごとの平均レコード数。 |
| request-latency-avg | ミリ秒単位の平均リクエストレイテンシー。 |
| request-latency-max | ミリ秒単位の最大リクエストレイテンシー。 |
| request-rate | 1 秒間に送信するリクエストの平均数。 |
| request-size-avg | ウィンドウのすべてのリクエストの平均サイズ。 |
| request-size-max | ウィンドウの送信リクエストの最大サイズ。 |
| requests-in-flight | 応答を待機するインフライトリクエストの現在の数。 |
| response-rate | 1 秒間に送信される受信レスポンス。 |
| select-rate | I/O レイヤーが実行する新しい I/O をチェックする 1 秒あたりの回数。 |
| successful-authentication-rate | SASL または SSL を使用して正常に認証された接続。 |
| waiting-threads | バッファーメモリーがレコードをキューに入れるのを待機するブロックされたユーザースレッドの数。 |
8.6.2. kafka.producer:type=producer-metrics,client-id=*,node-id=* と一致する MBean
これらは、各ブローカーへの接続に関するプロデューサーレベルのメトリクスです。
| 属性 | 説明 |
|---|---|
| incoming-byte-rate | ノードが 1 秒間に受信したレスポンスの平均数。 |
| outgoing-byte-rate | ノードが 1 秒間に送信する送信バイトの平均数。 |
| request-latency-avg | ノードの平均リクエストレイテンシー (ミリ秒単位)。 |
| request-latency-max | ノードの最大リクエストレイテンシー (ミリ秒単位)。 |
| request-rate | ノードが 1 秒間に送信するリクエストの平均数。 |
| request-size-avg | ノードのウィンドウにあるすべてのリクエストの平均サイズ。 |
| request-size-max | ノードのウィンドウに送信されるリクエストの最大サイズ。 |
| response-rate | ノードに対して 1 秒間に送信される受信応答。 |
8.6.3. kafka.producer:type=producer-topic-metrics,client-id=*,topic=* と一致する MBean
これらは、プロデューサーがメッセージを送信しているトピックに関するトピックレベルのメトリクスです。
| 属性 | 説明 |
|---|---|
| byte-rate | トピックに対して 1 秒間に送信するバイトの平均数。 |
| byte-total | トピックに対して送信するバイトの合計数。 |
| compression-rate | トピックに対するレコードバッチの平均圧縮率。 |
| record-error-rate | トピックに対してエラーとなったレコード送信の 1 秒あたりの平均数。 |
| record-error-total | トピックに対してエラーとなったレコード送信の合計数。 |
| record-retry-rate | トピックに対して再試行されたレコード送信の 1 秒あたりの平均数。 |
| record-retry-total | トピックに対して再試行されたレコード送信の合計数。 |
| record-send-rate | トピックに対して 1 秒間に送信するレコードの平均数。 |
| record-send-total | トピックに対して送信するレコードの合計数。 |
8.7. コンシューマー MBean
以下の MBean は、Kafka Streams アプリケーションやシンクコネクターのある Kafka Connect など、Kafka コンシューマーアプリケーションに存在します。
8.7.1. kafka.consumer:type=consumer-metrics,client-id=* と一致する MBean
これらは、コンシューマーレベルのメトリクスです。
| 属性 | 説明 |
|---|---|
| connection-close-rate | ウィンドウで 1 秒間に閉じられる接続。 |
| connection-count | アクティブな接続の現在の数。 |
| connection-creation-rate | ウィンドウで 1 秒間に確立される新しい接続。 |
| failed-authentication-rate | 認証に失敗した接続数。 |
| incoming-byte-rate | すべてのソケットから読み取られたバイト/秒。 |
| io-ratio | I/O スレッドが I/O の実行に費やした時間の割合。 |
| io-time-ns-avg | 選択した呼び出しごとの I/O の平均時間 (ナノ秒単位)。 |
| io-wait-ratio | I/O スレッドが待機に費やした時間の割合。 |
| io-wait-time-ns-avg | 読み取りまたは書き込みの準備ができたソケットの待機に費やされた I/O スレッドの平均時間 (ナノ秒単位)。 |
| network-io-rate | 1 秒あたりのすべての接続でのネットワーク操作 (読み取りまたは書き込み) の平均数。 |
| outgoing-byte-rate | すべてのサーバーに 1 秒間に送信する送信バイトの平均数。 |
| request-rate | 1 秒間に送信するリクエストの平均数。 |
| request-size-avg | ウィンドウのすべてのリクエストの平均サイズ。 |
| request-size-max | ウィンドウの送信リクエストの最大サイズ。 |
| response-rate | 1 秒間に送信される受信レスポンス。 |
| select-rate | I/O レイヤーが実行する新しい I/O をチェックする 1 秒あたりの回数。 |
| successful-authentication-rate | SASL または SSL を使用して正常に認証された接続。 |
8.7.2. kafka.consumer:type=consumer-metrics,client-id=*,node-id=* と一致する MBean
これらは、各ブローカーへの接続に関するコンシューマーレベルのメトリクスです。
| 属性 | 説明 |
|---|---|
| incoming-byte-rate | ノードが 1 秒間に受信したレスポンスの平均数。 |
| outgoing-byte-rate | ノードが 1 秒間に送信する送信バイトの平均数。 |
| request-latency-avg | ノードの平均リクエストレイテンシー (ミリ秒単位)。 |
| request-latency-max | ノードの最大リクエストレイテンシー (ミリ秒単位)。 |
| request-rate | ノードが 1 秒間に送信するリクエストの平均数。 |
| request-size-avg | ノードのウィンドウにあるすべてのリクエストの平均サイズ。 |
| request-size-max | ノードのウィンドウに送信されるリクエストの最大サイズ。 |
| response-rate | ノードに対して 1 秒間に送信される受信応答。 |
8.7.3. kafka.consumer:type=consumer-coordinator-metrics,client-id=* と一致する MBean
これらは、コンシューマーグループに関するコンシューマーレベルのメトリクスです。
| 属性 | 説明 |
|---|---|
| assigned-partitions | このコンシューマーに現在割り当てられているパーティションの数。 |
| commit-latency-avg | コミットリクエストにかかる平均時間。 |
| commit-latency-max | コミットリクエストにかかる最大時間。 |
| commit-rate | 1 秒あたりのコミットコールの数。 |
| heartbeat-rate | 1 秒あたりのハートビートの平均数。 |
| heartbeat-response-time-max | ハートビート要求への応答を受信するのにかかる最大時間。 |
| join-rate | 1 秒あたりのグループ参加数。 |
| join-time-avg | グループの再参加にかかる平均時間。 |
| join-time-max | グループの再参加にかかる最大時間。 |
| last-heartbeat-seconds-ago | 最後のコントローラーハートビートからの秒数。 |
| sync-rate | 1 秒あたりのグループ同期数。 |
| sync-time-avg | グループ同期にかかる平均時間。 |
| sync-time-max | グループ同期にかかる最大時間。 |
8.7.4. kafka.consumer:type=consumer-fetch-manager-metrics,client-id=* と一致する MBean
これらは、コンシューマーのフェッチャーに関するコンシューマーレベルのメトリクスです。
| 属性 | 説明 |
|---|---|
| bytes-consumed-rate | 1 秒あたり消費される平均のバイト数。 |
| bytes-consumed-total | 消費された総バイト数。 |
| fetch-latency-avg | フェッチリクエストにかかる平均時間。 |
| fetch-latency-max | 任意のフェッチリクエストにかかる最大時間。 |
| fetch-rate | 1 秒あたりのフェッチリクエストの数。 |
| fetch-size-avg | リクエストごとにフェッチされたバイトの平均数。 |
| fetch-size-max | リクエストごとにフェッチされたバイトの最大数。 |
| fetch-throttle-time-avg | ミリ秒単位の平均スロットル時間。 |
| fetch-throttle-time-max | ミリ秒単位の最大スロットル時間。 |
| fetch-total | フェッチリクエストの総数。 |
| records-consumed-rate | 1 秒あたり消費される平均のレコード数。 |
| records-consumed-total | 消費されるレコードの総数。 |
| records-lag-max | このウィンドウの任意のパーティションのレコード数に関する最大ラグ。 |
| records-lead-min | このウィンドウの任意のパーティションのレコード数に関する最小のリード。 |
| records-per-request-avg | 各リクエストの平均レコード数。 |
8.7.5. kafka.consumer:type=consumer-fetch-manager-metrics,client-id=*,topic=* と一致する MBean
これらは、コンシューマーのフェッチャーに関するトピックレベルのメトリクスです。
| 属性 | 説明 |
|---|---|
| bytes-consumed-rate | トピックに対して 1 秒あたり消費される平均のバイト数。 |
| bytes-consumed-total | トピックで消費された総バイト数。 |
| fetch-size-avg | トピックに対してリクエストごとにフェッチされたバイトの平均数。 |
| fetch-size-max | トピックに対してリクエストごとにフェッチされたバイトの最大数。 |
| records-consumed-rate | トピックに対して 1 秒あたり消費される平均のレコード数。 |
| records-consumed-total | トピックで消費されたレコードの合計数。 |
| records-per-request-avg | トピックの各リクエストの平均レコード数。 |
8.7.6. kafka.consumer:type=consumer-fetch-manager-metrics,client-id=*,topic=*,partition=* と一致する MBean
これらは、コンシューマーのフェッチャーに関するパーティションレベルのメトリクスです。
| 属性 | 説明 |
|---|---|
| preferred-read-replica | パーティションの現在の読み取りレプリカ。リーダーから読み取る場合は -1。 |
| records-lag | パーティションの最新のラグ。 |
| records-lag-avg | パーティションの平均ラグ。 |
| records-lag-max | パーティションの最大ラグ数。 |
| records-lead | パーティションの最新のリード。 |
| records-lead-avg | パーティションの平均リード。 |
| records-lead-min | パーティションの最小リード。 |
8.8. Kafka Connect MBean
8.8.1. kafka.connect:type=connect-metrics,client-id=* と一致する MBean
これらは接続レベルのメトリクスです。
| 属性 | 説明 |
|---|---|
| connection-close-rate | ウィンドウで 1 秒間に閉じられる接続。 |
| connection-count | アクティブな接続の現在の数。 |
| connection-creation-rate | ウィンドウで 1 秒間に確立される新しい接続。 |
| failed-authentication-rate | 認証に失敗した接続数。 |
| incoming-byte-rate | すべてのソケットから読み取られたバイト/秒。 |
| io-ratio | I/O スレッドが I/O の実行に費やした時間の割合。 |
| io-time-ns-avg | 選択した呼び出しごとの I/O の平均時間 (ナノ秒単位)。 |
| io-wait-ratio | I/O スレッドが待機に費やした時間の割合。 |
| io-wait-time-ns-avg | 読み取りまたは書き込みの準備ができたソケットの待機に費やされた I/O スレッドの平均時間 (ナノ秒単位)。 |
| network-io-rate | 1 秒あたりのすべての接続でのネットワーク操作 (読み取りまたは書き込み) の平均数。 |
| outgoing-byte-rate | すべてのサーバーに 1 秒間に送信する送信バイトの平均数。 |
| request-rate | 1 秒間に送信するリクエストの平均数。 |
| request-size-avg | ウィンドウのすべてのリクエストの平均サイズ。 |
| request-size-max | ウィンドウの送信リクエストの最大サイズ。 |
| response-rate | 1 秒間に送信される受信レスポンス。 |
| select-rate | I/O レイヤーが実行する新しい I/O をチェックする 1 秒あたりの回数。 |
| successful-authentication-rate | SASL または SSL を使用して正常に認証された接続。 |
8.8.2. kafka.connect:type=connect-metrics,client-id=*,node-id=* と一致する MBean
これらは、各ブローカーへの接続に関する接続レベルのメトリクスです。
| 属性 | 説明 |
|---|---|
| incoming-byte-rate | ノードが 1 秒間に受信したレスポンスの平均数。 |
| outgoing-byte-rate | ノードが 1 秒間に送信する送信バイトの平均数。 |
| request-latency-avg | ノードの平均リクエストレイテンシー (ミリ秒単位)。 |
| request-latency-max | ノードの最大リクエストレイテンシー (ミリ秒単位)。 |
| request-rate | ノードが 1 秒間に送信するリクエストの平均数。 |
| request-size-avg | ノードのウィンドウにあるすべてのリクエストの平均サイズ。 |
| request-size-max | ノードのウィンドウに送信されるリクエストの最大サイズ。 |
| response-rate | ノードに対して 1 秒間に送信される受信応答。 |
8.8.3. kafka.connect:type=connect-worker-metrics と一致する MBean
これらは接続レベルのメトリクスです。
| 属性 | 説明 |
|---|---|
| connector-count | このワーカーで実行されるコネクターの数。 |
| connector-startup-attempts-total | このワーカーが試みたコネクター起動の合計数。 |
| connector-startup-failure-percentage | このワーカーのコネクター起動のうち、失敗したものの平均割合。 |
| connector-startup-failure-total | 失敗したコネクター起動の総数。 |
| connector-startup-success-percentage | このワーカーのコネクター起動のうち、成功したものの平均割合。 |
| connector-startup-success-total | 成功したコネクター起動の総数。 |
| task-count | このワーカーで実行されるタスクの数。 |
| task-startup-attempts-total | このワーカーが試みたタスク起動の合計数。 |
| task-startup-failure-percentage | このワーカーのタスク起動のうち、失敗したものの平均割合。 |
| task-startup-failure-total | 失敗したタスク開始の合計数。 |
| task-startup-success-percentage | このワーカーのタスク起動のうち、成功したものの平均割合。 |
| task-startup-success-total | 成功したタスク開始の合計数。 |
8.8.4. kafka.connect:type=connect-worker-rebalance-metrics と一致する MBean
| 属性 | 説明 |
|---|---|
| completed-rebalances-total | このワーカーが完了したリバランスの合計数。 |
| connect-protocol | このクラスターによって使用される Connect プロトコル。 |
| epoch | このワーカーのエポックまたは生成番号。 |
| leader-name | グループリーダーの名前。 |
| rebalance-avg-time-ms | このワーカーがリバランスに費やした平均時間 (ミリ秒単位)。 |
| rebalance-max-time-ms | このワーカーがリバランスするために費やした最大時間 (ミリ秒単位)。 |
| rebalancing | このワーカーが現在リバランス中であるかどうか。 |
| time-since-last-rebalance-ms | このワーカーが最新のリバランスを完了してからのミリ秒単位の時間。 |
8.8.5. kafka.connect:type=connector-metrics,connector=* と一致する MBean
| 属性 | 説明 |
|---|---|
| connector-class | コネクタークラスの名前。 |
| connector-type | コネクターのタイプ。「ソース」または「シンク」のいずれか。 |
| connector-version | コネクターによって報告されるコネクタークラスのバージョン。 |
| status | コネクターのステータス。「unassigned」、「running」、「paused」、「failed」、「destroyed」のいずれか。 |
8.8.6. kafka.connect:type=connector-task-metrics,connector=*,task=* と一致する MBean
| 属性 | 説明 |
|---|---|
| batch-size-avg | コネクターによって処理されるバッチの平均サイズ。 |
| batch-size-max | コネクターによって処理されるバッチの最大サイズ。 |
| offset-commit-avg-time-ms | このタスクがオフセットをコミットするのに要した平均時間 (ミリ秒単位)。 |
| offset-commit-failure-percentage | このタスクのオフセットコミット試行のうち、失敗したものの平均割合。 |
| offset-commit-max-time-ms | このタスクがオフセットをコミットするのにかかる最大時間 (ミリ秒単位)。 |
| offset-commit-success-percentage | このタスクのオフセットコミット試行のうち、成功したものの平均割合。 |
| pause-ratio | このタスクが pause 状態で費やした時間の割合。 |
| running-ratio | このタスクが running 状態で費やした時間の割合。 |
| status | コネクタータスクのステータス。「unassigned」、「running」、「paused」、「failed」、「destroyed」のいずれか。 |
8.8.7. kafka.connect:type=sink-task-metrics,connector=*,task=* と一致する MBean
| 属性 | 説明 |
|---|---|
| offset-commit-completion-rate | 正常に完了したオフセットコミット完了の 1 秒あたりの平均数。 |
| offset-commit-completion-total | 正常に完了したオフセットコミット完了の合計数。 |
| offset-commit-seq-no | オフセットコミットの現在のシーケンス番号。 |
| offset-commit-skip-rate | 受信が遅すぎてスキップ/無視されたオフセットコミット完了の 1 秒あたりの平均数。 |
| offset-commit-skip-total | 受信が遅すぎてスキップ/無視されたオフセットコミット完了の合計数。 |
| partition-count | このワーカーの名前付きシンクコネクターに属するこのタスクに割り当てられたトピックパーティションの数。 |
| put-batch-avg-time-ms | このタスクがシンクの記録を一括して行うためにかかった平均時間。 |
| put-batch-max-time-ms | このタスクがシンクの記録を一括して行うためにかかった最大時間。 |
| sink-record-active-count | Kafka から読み込まれたものの、シンクタスクがまだ完全にコミット、フラッシュ、確認していないレコードの数。 |
| sink-record-active-count-avg | Kafka から読み込まれたものの、シンクタスクが完全にコミット、フラッシュ、確認していないレコードの平均数。 |
| sink-record-active-count-max | Kafka から読み込まれたものの、シンクタスクが完全にコミット、フラッシュ、確認していないレコードの最大数。 |
| sink-record-lag-max | 任意のトピックパーティションで、シンクタスクがコンシューマーの位置の背後であるレコード数に関する最大ラグ。 |
| sink-record-read-rate | このワーカーの名前付きシンクコネクターに属するこのタスクで、Kafka から読み取られるレコードの 1 秒あたりの平均数。これは、変換が適用される前に行われます。 |
| sink-record-read-total | タスクが最後に再起動されてから、このワーカーの名前付きシンクコネクターに属するこのタスクによって Kafka から読み取られたレコードの合計数。 |
| sink-record-send-rate | 変換から出力されたレコードの 1 秒あたりの平均数。このワーカーの名前付きシンクコネクターに属するこのタスクに送信または配置します。これは、変換の適用後で、変換によってフィルタリングされたレコードをすべて除外します。 |
| sink-record-send-total | タスクが最後に再起動されてから、このワーカーの名前付きシンクコネクターに属するこのタスクに送信または配置する、変換から出力されたレコードの合計数。 |
8.8.8. kafka.connect:type=source-task-metrics,connector=*,task=* と一致する MBean
| 属性 | 説明 |
|---|---|
| poll-batch-avg-time-ms | このタスクがソースレコードのバッチをポーリングするためにかかった平均時間 (ミリ秒単位)。 |
| poll-batch-max-time-ms | このタスクがソースレコードのバッチをポーリングするためにかかった最大時間 (ミリ秒単位)。 |
| source-record-active-count | このタスクによって生成され、まだ完全に Kafka に書き込まれていないレコードの数。 |
| source-record-active-count-avg | このタスクによって生成され、まだ完全に Kafka に書き込まれていないレコードの平均数。 |
| source-record-active-count-max | このタスクによって生成され、まだ完全に Kafka に書き込まれていないレコードの最大数。 |
| source-record-poll-rate | このワーカーの名前付きソースコネクターに属するこのタスクによって生成/ポーリングされた (変換前) レコードの 1 秒あたりの平均数。 |
| source-record-poll-total | このワーカーの名前付きソースコネクターに属するこのタスクによって生成/ポーリングされた (変換前) レコードの合計数。 |
| source-record-write-rate | 変換から出力され、このワーカーの名前付きソースコネクターに属するこのタスクの Kafka に書き込まれたレコードの 1 秒あたりの平均数。これは、変換の適用後で、変換によってフィルタリングされたレコードをすべて除外します。 |
| source-record-write-total | タスクが最後に再起動されてから、変換から出力され、このワーカーの名前付きソースコネクターに属するこのタスクの Kafka に書き込まれたレコードの数。 |
8.8.9. kafka.connect:type=task-error-metrics,connector=*,task=* と一致する MBean
| 属性 | 説明 |
|---|---|
| deadletterqueue-produce-failures | デッドレターキューへの書き込み失敗数。 |
| deadletterqueue-produce-requests | デッドレターキューへの書き込み試行の数。 |
| last-error-timestamp | このタスクで最後にエラーが発生したときのエポックタイムスタンプ。 |
| total-errors-logged | ログに記録されたエラーの数。 |
| total-record-errors | このタスクでのレコード処理エラーの数。 |
| total-record-failures | このタスクでのレコード処理の失敗数。 |
| total-records-skipped | エラーによりスキップされたレコードの数。 |
| total-retries | 再試行された操作の数。 |
8.9. Kafka Streams MBean
8.9.1. kafka.streams:type=stream-metrics,client-id=* と一致する MBean
これらのメトリクスは、metrics.recording.level 設定パラメーターが info または debug の場合に収集されます。
| 属性 | 説明 |
|---|---|
| commit-latency-avg | このスレッドのすべての実行中のタスクにおけるコミットの平均実行時間 (ミリ秒単位)。 |
| commit-latency-max | このスレッドのすべての実行中のタスクにおけるコミットの最大実行時間 (ミリ秒単位)。 |
| commit-rate | 1 秒あたりの平均コミット数。 |
| commit-total | すべてのタスクにまたがるコミット呼び出しの合計数。 |
| poll-latency-avg | このスレッドのすべての実行中のタスクにおけるポーリングの平均実行時間 (ミリ秒単位)。 |
| poll-latency-max | このスレッドのすべての実行中のタスクにおけるポーリングの最大実行時間 (ミリ秒単位)。 |
| poll-rate | 1 秒あたりの平均ポーリング数。 |
| poll-total | すべてのタスクのポーリングコールの合計数。 |
| process-latency-avg | このスレッドのすべての実行中のタスクにおける処理の平均実行時間 (ミリ秒単位)。 |
| process-latency-max | このスレッドのすべての実行中のタスクにおける処理の最大実行時間 (ミリ秒単位)。 |
| process-rate | 1 秒あたりのプロセスコールの平均数。 |
| process-total | すべてのタスクにまたがるプロセスコールの合計数。 |
| punctuate-latency-avg | このスレッドのすべての実行中のタスクにおける punctuate の平均実行時間 (ミリ秒単位)。 |
| punctuate-latency-max | このスレッドのすべての実行中のタスクにおける punctuate の最大実行時間 (ミリ秒単位)。 |
| punctuate-rate | 1 秒あたりの punctuate の平均数。 |
| punctuate-total | すべてのタスクの punctuate コールの合計数。 |
| skipped-records-rate | 1 秒あたりのスキップされたレコードの平均数。 |
| skipped-records-total | スキップされたレコードの合計数。 |
| task-closed-rate | 1 秒間に閉じられたタスクの平均数。 |
| task-closed-total | 閉じられたタスクの合計数。 |
| task-created-rate | 1 秒あたりの新規作成タスクの平均数。 |
| task-created-total | 作成されたタスクの合計数。 |
8.9.2. kafka.streams:type=stream-task-metrics,client-id=*,task-id=* と一致する MBean
タスクメトリクス
これらのメトリクスは、metrics.recording.level 設定パラメーターが debug のときに収集されます。
| 属性 | 説明 |
|---|---|
| commit-latency-avg | このタスクの平均コミット時間 (ナノ秒単位)。 |
| commit-latency-max | このタスクの最大コミット時間 (ナノ秒単位)。 |
| commit-rate | 1 秒あたりのコミットコールの平均数。 |
| commit-total | コミットコールの合計数。 |
8.9.3. kafka.streams:type=stream-processor-node-metrics,client-id=*,task-id=*,processor-node-id=* と一致する MBean
プロセッサーノードメトリクス
これらのメトリクスは、metrics.recording.level 設定パラメーターが debug のときに収集されます。
| 属性 | 説明 |
|---|---|
| create-latency-avg | 平均作成実行時間 (ナノ秒単位)。 |
| create-latency-max | 最大作成実行時間 (ナノ秒単位)。 |
| create-rate | 1 秒あたりの作成操作の平均数。 |
| create-total | 呼び出された作成操作の合計数。 |
| destroy-latency-avg | 平均破棄実行時間 (ナノ秒単位)。 |
| destroy-latency-max | 最大破棄実行時間 (ナノ秒単位)。 |
| destroy-rate | 1 秒あたりの破棄操作の平均数。 |
| destroy-total | 呼び出された破棄操作の合計数。 |
| forward-rate | ソースノードのみからダウンストリームに転送されるレコードの 1 秒あたりの平均レート。 |
| forward-total | ソースノードのみからダウンストリームに転送されるレコードの合計数。 |
| process-latency-avg | 平均プロセス実行時間 (ナノ秒単位)。 |
| process-latency-max | 最大プロセス実行時間 (ナノ秒単位)。 |
| process-rate | 1 秒あたりのプロセス操作の平均数。 |
| process-total | 呼び出されたプロセス操作の合計数。 |
| punctuate-latency-avg | 平均 punctuate 実行時間 (ナノ秒単位)。 |
| punctuate-latency-max | 最大 punctuate 実行時間 (ナノ秒単位)。 |
| punctuate-rate | 1 秒あたりの punctuate 操作の平均数。 |
| punctuate-total | 呼び出された punctuate 操作の合計数。 |
8.9.4. kafka.streams:type=stream-[store-scope]-metrics,client-id=*,task-id=*,[store-scope]-id=* と一致する MBean
ステートストアメトリクス
これらのメトリクスは、metrics.recording.level 設定パラメーターが debug のときに収集されます。
| 属性 | 説明 |
|---|---|
| all-latency-avg | すべての操作の平均実行時間 (ns)。 |
| all-latency-max | すべての操作の最大実行時間 (ns)。 |
| all-rate | このストアのすべての操作レートの平均。 |
| all-total | このストアのすべての操作コールの合計数。 |
| delete-latency-avg | 平均削除実行時間 (ナノ秒単位)。 |
| delete-latency-max | 最大削除実行時間 (ナノ秒単位)。 |
| delete-rate | このストアの平均削除レート。 |
| delete-total | このストアの削除コールの合計数。 |
| flush-latency-avg | フラッシュの平均実行時間 (ナノ秒単位)。 |
| flush-latency-max | フラッシュの最大実行時間 (ナノ秒単位)。 |
| flush-rate | このストアの平均フラッシュレート。 |
| flush-total | このストアのフラッシュコールの合計数。 |
| get-latency-avg | get の平均実行時間 (ナノ秒単位)。 |
| get-latency-max | get の最大実行時間 (ナノ秒単位)。 |
| get-rate | このストアの平均 get レート。 |
| get-total | このストアの get コールの総数。 |
| put-all-latency-avg | put-all の平均実行時間 (ナノ秒単位)。 |
| put-all-latency-max | put-all の最大実行時間 (ナノ秒単位)。 |
| put-all-rate | このストアの平均 put-all レート。 |
| put-all-total | このストアの put-all コールの合計数。 |
| put-if-absent-latency-avg | put-if-absent の平均実行時間 (ナノ秒単位)。 |
| put-if-absent-latency-max | put-if-absent の最大実行時間 (ナノ秒単位)。 |
| put-if-absent-rate | このストアの平均 put-if-absent レート。 |
| put-if-absent-total | このストアの put-if-absent コールの合計数。 |
| put-latency-avg | put の平均実行時間 (ナノ秒単位)。 |
| put-latency-max | put の最大実行時間 (ナノ秒単位)。 |
| put-rate | このストアの平均 put レート。 |
| put-total | このストアの put コールの合計数。 |
| range-latency-avg | 平均範囲実行時間 (ナノ秒単位)。 |
| range-latency-max | 最大範囲実行時間 (ナノ秒単位)。 |
| range-rate | このストアの平均範囲のレート。 |
| range-total | このストアの範囲コールの合計数。 |
| restore-latency-avg | 復元の平均実行時間 (ナノ秒単位)。 |
| restore-latency-max | 復元の最大実行時間 (ナノ秒単位)。 |
| restore-rate | このストアの平均復元レート。 |
| restore-total | このストアの復元コールの合計数。 |
8.9.5. kafka.streams:type=stream-record-cache-metrics,client-id=*,task-id=*,record-cache-id=* と一致する MBean
レコードキャッシュメトリクス
これらのメトリクスは、metrics.recording.level 設定パラメーターが debug のときに収集されます。
| 属性 | 説明 |
|---|---|
| hitRatio-avg | キャッシュ読み取り要求の合計に対するキャッシュ読み取りヒット率として定義される平均キャッシュヒット率。 |
| hitRatio-max | 最大キャッシュヒット率。 |
| hitRatio-min | 最小キャッシュヒット率。 |
第9章 Kafka Connect
Kafka Connect は、Apache Kafka と外部システムとの間でデータをストリーミングするためのツールです。スケーラビリティーと信頼性を維持しながら大量のデータを移動するためのフレームワークが提供されます。Kafka Connect は通常、Kafka を Kafka クラスター外のデータベース、ストレージシステム、およびメッセージングシステムと統合するために使用されます。
Kafka Connect は、さまざまな種類の外部システムへの接続を実装するコネクタープラグインを使用します。コネクタープラグインには、シンクとソースの 2 つのタイプがあります。シンクコネクターは、Kafka から外部システムにデータをストリーミングします。ソースコネクターは、外部システムから Kafka にデータをストリーミングします。
Kafka Connect はスタンドアロンまたは分散モードで実行できます。
- スタンドアロンモード
- スタンドアロンモードでは、Kafka Connect はプロパティーファイルから読み込んだユーザー定義の設定を持つ単一ノードで実行されます。
- 分散モード
- 分散モードでは、Kafka Connect は 1 つまたは複数のワーカーノードで実行され、ワークロードはワーカーノード間で分散されます。コネクターとその設定は、HTTP REST インターフェイスを使用して管理します。
9.1. スタンドアロンモードでの Kafka Connect
スタンドアロンモードでは、Kafka Connect は単一ノードで単一のプロセスとして実行されます。スタンドアロンモードの設定は、プロパティーファイルを使用して管理します。
9.1.1. スタンドアロンモードでの Kafka Connect の設定
Kafka Connect をスタンドアロンモードで設定するには、config/connect-standalone.properties 設定ファイルを編集します。以下のオプションが最も重要です。
bootstrap.servers-
Kafka へのブートストラップ接続として使用される Kafka ブローカーアドレスのリスト。たとえば、
kafka0.my-domain.com:9092,kafka1.my-domain.com:9092,kafka2.my-domain.com:9092です。 key.converter-
メッセージキーを Kafka 形式との間で変換するために使用されるクラス。たとえば、
org.apache.kafka.connect.json.JsonConverterです。 value.converter-
メッセージペイロードを Kafka 形式との間で変換するために使用されるクラス。たとえば、
org.apache.kafka.connect.json.JsonConverterです。 offset.storage.file.filename- オフセットデータが保存されるファイルを指定します。
設定ファイルの例は、config/connect-standalone.properties のインストールディレクトリーにあります。サポートされるすべての Kafka Connect 設定オプションの完全リストは、[kafka-connect-configuration-parameters-str] を参照してください。
コネクタープラグインは、ブートストラップアドレスを使用して Kafka ブローカーへのクライアント接続を開きます。これらの接続を設定するには、標準的な Kafka のプロデューサーとコンシューマーの設定オプションを使用し、producer. または consumer. プレフィックスを付けます。
Kafka プロデューサーおよびコンシューマーの設定に関する詳細は、以下を参照してください。
9.1.2. スタンドアロンモードでの Kafka Connect でのコネクターの設定
プロパティーファイルを使用すると、スタンドアロンモードで Kafka Connect のコネクタープラグインを設定できます。ほとんどの設定オプションは、各コネクターに固有のものです。以下のオプションはすべてのコネクターに適用されます。
name- 現在の Kafka Connect インスタンス内で一意である必要があるコネクターの名前。
connector.class-
コネクタープラグインのクラス。たとえば、
org.apache.kafka.connect.file.FileStreamSinkConnectorです。 tasks.max- 指定のコネクターが使用できるタスクの最大数。タスクにより、コネクターは並行して作業を実行できます。コネクターは、指定された数よりも少ないタスクを作成する可能性があります。
key.converter-
メッセージキーを Kafka 形式との間で変換するために使用されるクラス。これにより、Kafka Connect 設定によって設定されたデフォルト値がオーバーライドされます。たとえば、
org.apache.kafka.connect.json.JsonConverterです。 value.converter-
メッセージペイロードを Kafka 形式との間で変換するために使用されるクラス。これにより、Kafka Connect 設定によって設定されたデフォルト値がオーバーライドされます。たとえば、
org.apache.kafka.connect.json.JsonConverterです。
さらに、シンクコネクターには以下のオプションの 1 つ以上を設定する必要があります。
topics- 入力として使用されるトピックのカンマ区切りリスト。
topics.regex- 入力として使用されるトピックの Java 正規表現。
その他のオプションについては、利用可能なコネクターのドキュメントを参照してください。
AMQ Streamsには、コネクタ構成ファイルの例が含まれています。AMQ Streamsのインストール・ディレクトリーにある config/connect-file-sink.properties および config/connect-file-source.properties を参照してください。
9.1.3. スタンドアロンモードでの Kafka Connect の実行
この手順では、スタンドアロンモードで Kafka Connect を設定し、実行する方法を説明します。
前提条件
- インストールされ、実行されている AMQ Streams クラスター。
手順
/opt/kafka/config/connect-standalone.propertiesKafka Connect 設定ファイルを編集し、bootstrap.serverが Kafka ブローカーを指すように設定します。以下に例を示します。bootstrap.servers=kafka0.my-domain.com:9092,kafka1.my-domain.com:9092,kafka2.my-domain.com:9092
設定ファイルで Kafka Connect を起動し、1 つ以上のコネクター設定を指定します。
su - kafka /opt/kafka/bin/connect-standalone.sh /opt/kafka/config/connect-standalone.properties connector1.properties [connector2.properties ...]
KafkaConnect が実行されていることを確認します。
jcmd | grep ConnectStandalone
関連情報
- AMQ Streams のインストールに関する詳細は、「AMQ Streams のインストール」 を参照してください。
- AMQ Streams の設定に関する詳細は、「AMQ Streams の設定」 を参照してください。
- サポートされる Kafka Connect 設定オプションの完全なリストは、「付録F Kafka Connect 設定パラメーター」を参照してください。
9.2. 分散モードでの Kafka Connect
分散モードでは、Kafka Connect は 1 つまたは複数のワーカーノードで実行され、ワークロードはワーカーノード間で分散されます。コネクタープラグインとその設定は、HTTP REST インターフェイスを使用して管理します。
9.2.1. 分散モードでの Kafka Connect の設定
Kafka Connect をスタンドアロンモードで設定するには、config/connect-distributed.properties 設定ファイルを編集します。以下のオプションが最も重要です。
bootstrap.servers-
Kafka へのブートストラップ接続として使用される Kafka ブローカーアドレスのリスト。たとえば、
kafka0.my-domain.com:9092,kafka1.my-domain.com:9092,kafka2.my-domain.com:9092です。 key.converter-
メッセージキーを Kafka 形式との間で変換するために使用されるクラス。たとえば、
org.apache.kafka.connect.json.JsonConverterです。 value.converter-
メッセージペイロードを Kafka 形式との間で変換するために使用されるクラス。たとえば、
org.apache.kafka.connect.json.JsonConverterです。 group.id-
分散された Kafka Connect クラスターの名前。これは一意でなければならず、他のコンシューマーグループ ID と競合することはできません。デフォルト値は
connect-clusterです。 config.storage.topic-
コネクター設定の保存に使用される Kafka トピック。デフォルト値は
connect-configsです。 offset.storage.topic-
オフセットを保存するために使用される Kafka トピック。デフォルト値は
connect-offsetです。 status.storage.topic-
ワーカーノードのステータスに使用される Kafka トピック。デフォルト値は
connect-statusです。
AMQ Streams には、分散モードの Kafka Connect の設定ファイル例が含まれています。AMQ Streams のインストールディレクトリーにある config/connect-distributed.properties を参照してください。
サポートされるすべての Kafka Connect 設定オプションの完全リストは、付録F Kafka Connect 設定パラメーター を参照してください。
コネクタープラグインは、ブートストラップアドレスを使用して Kafka ブローカーへのクライアント接続を開きます。これらの接続を設定するには、標準的な Kafka のプロデューサーとコンシューマーの設定オプションを使用し、producer. または consumer. プレフィックスを付けます。
Kafka プロデューサーおよびコンシューマーの設定に関する詳細は、以下を参照してください。
9.2.2. 分散 Kafka Connect でのコネクターの設定
HTTP REST インターフェイス
分散 Kafka Connect のコネクターは、HTTP REST インターフェイスを使用して設定されます。REST インターフェイスはデフォルトで 8083 番ポートをリッスンします。以下のエンドポイントをサポートします。
GET /connectors- 既存のコネクターのリストを返します。
POST /connectors- コネクターを作成します。リクエストボディーは、コネクター設定が含まれる JSON オブジェクトである必要があります。
GET /connectors/<name>- 特定のコネクターの情報を取得します。
GET /connectors/<name>/config- 特定のコネクターの設定を取得します。
PUT /connectors/<name>/config- 特定のコネクターの設定を更新します。
GET /connectors/<name>/status- 特定のコネクターのステータスを取得します。
PUT /connectors/<name>/pause- コネクターとそのすべてのタスクを一時停止します。コネクターはメッセージの処理を停止します。
PUT /connectors/<name>/resume- 一時停止されたコネクターを再開します。
POST /connectors/<name>/restart- コネクターに障害が発生した場合に、コネクターを再起動します。
DELETE /connectors/<name>- コネクターを削除します。
GET /connector-plugins- サポートされるすべてのコネクタープラグインのリストを取得します。
コネクター設定
ほとんどの設定オプションはコネクター固有で、コネクターのドキュメントに含まれています。以下のフィールドは、すべてのコネクターで共通しています。
name- コネクターの名前。特定の Kafka Connect インスタンス内で一意である必要があります。
connector.class-
コネクタープラグインのクラス。たとえば、
org.apache.kafka.connect.file.FileStreamSinkConnectorです。 tasks.max- このコネクターによって使用されるタスクの最大数。タスクは、コネクターが作業を並列処理するために使用します。コネクターは、指定された数よりも少ないタスクを作成する場合があります。
key.converter-
メッセージキーを Kafka 形式との間で変換するために使用されるクラス。これにより、Kafka Connect 設定によって設定されたデフォルト値がオーバーライドされます。たとえば、
org.apache.kafka.connect.json.JsonConverterです。 value.converter-
メッセージペイロードを Kafka 形式との間で変換するために使用されるクラス。これにより、Kafka Connect 設定によって設定されたデフォルト値がオーバーライドされます。たとえば、
org.apache.kafka.connect.json.JsonConverterです。
さらに、シンクコネクターには、以下のオプションの 1 つを設定する必要があります。
topics- 入力として使用されるトピックのカンマ区切りリスト。
topics.regex- 入力として使用されるトピックの Java 正規表現。
その他のオプションについては、特定のコネクターのドキュメントを参照してください。
AMQ Streams には、コネクター設定ファイルのサンプルが含まれています。AMQ Streams インストールディレクトリーの config/connect-file-sink.properties および config/connect-file-source.properties にあります。
9.2.3. 分散 Kafka Connect の実行
この手順では、Kafka Connect を分散モードで設定および実行する方法を説明します。
前提条件
- インストールされ、実行されている AMQ Streams クラスター。
クラスターの実行
すべての Kafka Connect ワーカーノードで
/opt/kafka/config/connect-distributed.propertiesKafka Connect 設定ファイルを編集します。-
bootstrap.serverオプションを設定して、Kafka ブローカーを示すようにします。 -
group.idオプションを設定します。 -
config.storage.topicオプションを設定します。 -
offset.storage.topicオプションを設定します。 status.storage.topicオプションを設定します。以下に例を示します。
bootstrap.servers=kafka0.my-domain.com:9092,kafka1.my-domain.com:9092,kafka2.my-domain.com:9092 group.id=my-group-id config.storage.topic=my-group-id-configs offset.storage.topic=my-group-id-offsets status.storage.topic=my-group-id-status
-
すべての Kafka Connect ワーカーノードで
/opt/kafka/config/connect-distributed.propertiesKafka Connect ワーカーを起動します。su - kafka /opt/kafka/bin/connect-distributed.sh /opt/kafka/config/connect-distributed.properties
KafkaConnect が実行されていることを確認します。
jcmd | grep ConnectDistributed
関連情報
- AMQ Streams のインストールに関する詳細は、「AMQ Streams のインストール」 を参照してください。
- AMQ Streams の設定に関する詳細は、「AMQ Streams の設定」 を参照してください。
- サポートされる Kafka Connect 設定オプションの完全なリストは、「付録F Kafka Connect 設定パラメーター」を参照してください。
9.2.4. コネクターの作成
この手順では、Kafka Connect REST API を使用して分散モードで Kafka Connect で使用するコネクタープラグインを作成する方法を説明します。
前提条件
- 分散モードで実行する Kafka Connect インストール。
手順
コネクター設定で JSON ペイロードを準備します。以下に例を示します。
{ "name": "my-connector", "config": { "connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector", "tasks.max": "1", "topics": "my-topic-1,my-topic-2", "file": "/tmp/output-file.txt" } }POST リクエストを
<KafkaConnectAddress>:8083/connectorsに送信してコネクターを作成します。以下の例では、curlを使用します。curl -X POST -H "Content-Type: application/json" --data @sink-connector.json http://connect0.my-domain.com:8083/connectors
<KafkaConnectAddress>:8083/connectorsに GET リクエストを送信して、コネクターがデプロイされたことを確認します。以下の例では、curlを使用します。curl http://connect0.my-domain.com:8083/connectors
9.2.5. コネクターの削除
この手順では、Kafka Connect REST API を使用して分散モードの Kafka Connect からコネクタープラグインを削除する方法を説明します。
前提条件
- 分散モードで実行する Kafka Connect インストール。
コネクターの削除
<KafkaConnectAddress>:8083/connectors/<ConnectorName>にGETリクエストを送信して、コネクターが存在することを確認します。以下の例では、curlを使用します。curl http://connect0.my-domain.com:8083/connectors
コネクターを削除するには、
DELETEリクエストを<KafkaConnectAddress>:8083/connectorsに送信します。以下の例では、curlを使用します。curl -X DELETE http://connect0.my-domain.com:8083/connectors/my-connector
<KafkaConnectAddress>:8083/connectorsに GET リクエストを送信して、コネクターがデプロイされたことを確認します。以下の例では、curlを使用します。curl http://connect0.my-domain.com:8083/connectors
9.3. コネクタープラグイン
AMQ Streams には以下のコネクタープラグインが含まれています。
FileStreamSink: Kafka トピックからデータを読み取り、ファイルに書き込みます。
FileStreamSource: ファイルからデータを読み取り、データを Kafka トピックに送信します。
必要に応じて、さらにコネクタープラグインを追加できます。Kafka Connect は起動時に、追加のコネクタープラグインを検索し、実行します。Kafka Connect がプラグインを検索するパスを定義するには、plugin.path configuration オプションを設定します。
plugin.path=/opt/kafka/connector-plugins,/opt/connectors
plugin.path 設定オプションには、コンマ区切りのパスのリストを含めることができます。
Kafka Connect を分散モードで実行する場合、プラグインはすべてのワーカーノードで利用可能でなければなりません。
9.4. コネクタープラグインの追加
この手順では、コネクタープラグインを追加する方法を説明します。
前提条件
- インストールされ、実行されている AMQ Streams クラスター。
手順
/opt/kafka/connector-pluginsディレクトリーを作成します。su - kafka mkdir /opt/kafka/connector-plugins
/opt/kafka/config/connect-standalone.propertiesまたは/opt/kafka/config/connect-distributed.propertiesKafka Connect 設定ファイルを編集し、plugin.pathオプションを/opt/kafka/connector-pluginsに設定します。以下に例を示します。plugin.path=/opt/kafka/connector-plugins
-
コネクタープラグインを
/opt/kafka/connector-pluginsにコピーします。 - Kafka Connect ワーカーを起動または再起動します。
関連情報
- AMQ Streams のインストールに関する詳細は、「AMQ Streams のインストール」 を参照してください。
- AMQ Streams の設定に関する詳細は、「AMQ Streams の設定」 を参照してください。
- Kafka Connect をスタンドアロンモードで実行するための詳細は、「スタンドアロンモードでの Kafka Connect の実行」 を参照してください。
- Kafka Connect を分散モードで実行するための詳細は、「分散 Kafka Connect の実行」 を参照してください。
- サポートされる Kafka Connect 設定オプションの完全なリストは、「付録F Kafka Connect 設定パラメーター」を参照してください。
第10章 AMQ Streams の MirrorMaker 2.0 との使用
MirrorMaker 2.0 は、データセンター内またはデータセンター全体の 2 台以上の Kafka クラスター間でデータを複製するために使用されます。
クラスター全体のデータレプリケーションでは、以下が必要な状況がサポートされます。
- システム障害時のデータの復旧
- 分析用のデータの集計
- 特定のクラスターへのデータアクセスの制限
- レイテンシーを改善するための特定場所でのデータのプロビジョニング
MirrorMaker 2.0 には、以前のバージョンの MirrorMaker ではサポートされない機能があります。ただし、MirrorMaker 2.0 をレガシーモードで使用されるように設定 できます。
10.1. MirrorMaker 2.0 のデータレプリケーション
MirrorMaker 2.0 はソースの Kafka クラスターからメッセージを消費して、ターゲットの Kafka クラスターに書き込みます。
MirrorMaker 2.0 は以下を使用します。
- ソースクラスターからデータを消費するソースクラスターの設定
- データをターゲットクラスターに出力するターゲットクラスターの設定
MirrorMaker 2.0 は Kafka Connect フレームワークをベースとし、コネクター によってクラスター間のデータ転送が管理されます。MirrorMaker 2.0 の MirrorSourceConnector は、ソースクラスターからターゲットクラスターにトピックを複製します。
あるクラスターから別のクラスターにデータを ミラーリング するプロセスは非同期です。推奨されるパターンは、ソース Kafka クラスターとともにローカルでメッセージが作成され、ターゲットの Kafka クラスターの近くでリモートで消費されることです。
MirrorMaker 2.0 は、複数のソースクラスターで使用できます。
図10.1 2 つのクラスターにおけるレプリケーション
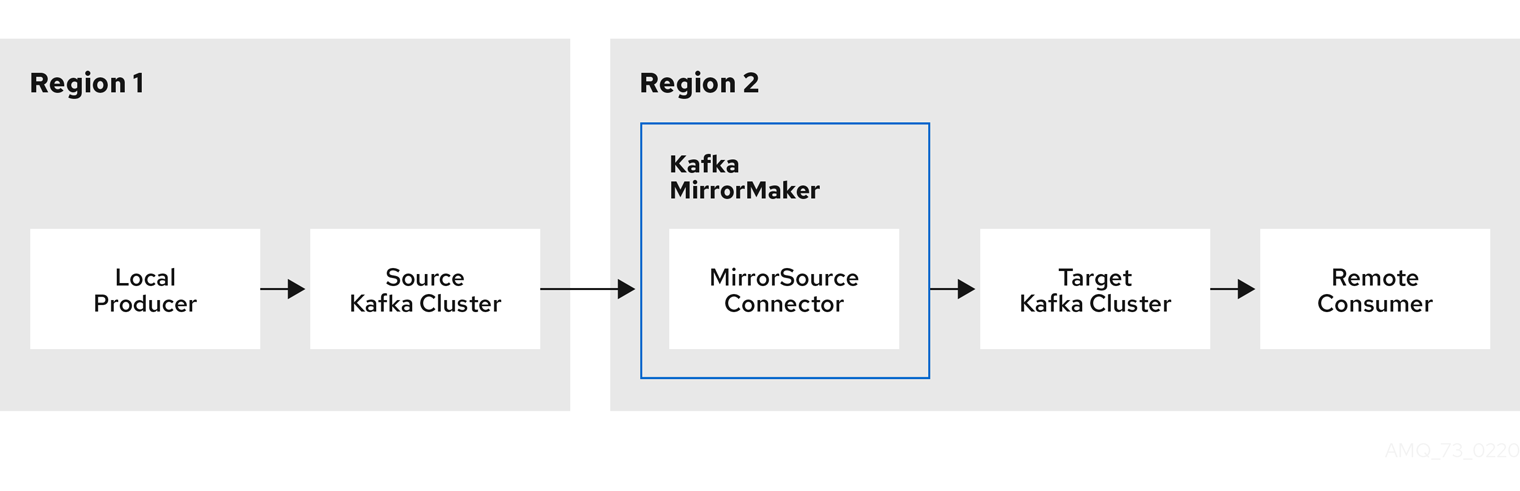
10.2. クラスターの設定
active/passive または active/active クラスター設定で MirrorMaker 2.0 を使用できます。
- active/active 設定では、両方のクラスターがアクティブで、同じデータを同時に提供します。これは、地理的に異なる場所で同じデータをローカルで利用可能にする場合に便利です。
- active/passive 設定では、アクティブなクラスターからのデータはパッシブなクラスターで複製され、たとえば、システム障害時のデータ復旧などでスタンバイ状態を維持します。
プロデューサーとコンシューマーがアクティブなクラスターのみに接続することを前提とします。
MirrorMaker 2.0 クラスターは、ターゲットの宛先ごとに必要です。
10.2.1. 双方向レプリケーション (active/active)
MirrorMaker 2.0 アーキテクチャーでは、active/active クラスター設定で双方向レプリケーションがサポートされます。
各クラスターは、source および remote トピックの概念を使用して、別のクラスターのデータを複製します。同じトピックが各クラスターに保存されるため、リモートトピックの名前がソースクラスターを表すように自動的に MirrorMaker 2.0 によって変更されます。元のクラスターの名前の先頭には、トピックの名前が追加されます。
図10.2 トピック名の変更
ソースクラスターにフラグを付けると、トピックはそのクラスターに複製されません。
remote トピックを介したレプリケーションの概念は、データの集約が必要なアーキテクチャーの設定に役立ちます。コンシューマーは、同じクラスター内でソースおよびリモートトピックにサブスクライブできます。これに個別の集約クラスターは必要ありません。
10.2.2. 一方向レプリケーション (active/passive)
MirrorMaker 2.0 アーキテクチャーでは、active/passive クラスター設定でー方向レプリケーションがサポートされます。
active/passive のクラスター設定を使用してバックアップを作成したり、データを別のクラスターに移行したりできます。この場合、リモートトピックの名前を自動的に変更したくないことがあります。
IdentityReplicationPolicy を KafkaMirrorMaker2 リソースのソースコネクター設定に追加することで、名前の自動変更をオーバーライドできます。この設定が適用されると、トピックには元の名前が保持されます。
10.2.3. トピック設定の同期
トピック設定は、ソースクラスターとターゲットクラスター間で自動的に同期化されます。設定プロパティーを同期化することで、リバランスの必要性が軽減されます。
10.2.4. データの整合性
MirrorMaker 2.0 は、ソーストピックを監視し、設定変更をリモートトピックに伝播して、不足しているパーティションを確認および作成します。MirrorMaker 2.0 のみがリモートトピックに書き込みできます。
10.2.5. オフセットの追跡
MirrorMaker 2.0 では、内部トピックを使用してコンシューマーグループのオフセットを追跡します。
- オフセット同期 トピックは、複製されたトピックパーティションのソースおよびターゲットオフセットをレコードメタデータからマッピングします。
- チェックポイント トピックは、各コンシューマーグループの複製されたトピックパーティションのソースおよびターゲットクラスターで最後にコミットされたオフセットをマッピングします。
チェックポイント トピックのオフセットは、設定によって事前定義された間隔で追跡されます。両方のトピックは、フェイルオーバー時に正しいオフセットの位置からレプリケーションの完全復元を可能にします。
MirrorMaker 2.0 は、MirrorCheckpointConnector を使用して、オフセット追跡の チェックポイントを生成します。
10.2.6. 接続性チェック
ハートビート 内部トピックによって、クラスター間の接続性が確認されます。
ハートビート トピックは、ソースクラスターから複製されます。
ターゲットクラスターは、トピックを使用して以下を確認します。
- クラスター間の接続を管理するコネクターが稼働しているかどうか
- ソースクラスターが利用可能かどうか
MirrorMaker 2.0 は MirrorHeartbeatConnector を使用して、これらのチェックを実行する ハートビート を生成します。
10.3. ACL ルールの同期
AclAuthorizer が使用されている場合、ブローカーへのアクセスを管理する ACL ルールはリモートトピックにも適用されます。ソーストピックを読み取りできるユーザーは、そのリモートトピックを読み取りできます。
OAuth 2.0 での承認は、このようなリモートトピックへのアクセスをサポートしません。
10.4. MirrorMaker 2.0 を使用した Kafka クラスター間でのデータの同期
MirrorMaker 2.0 を使用して、設定を介して Kafka クラスター間のデータを同期します。
以前のバージョンの MirrorMaker は、レガシーモードで MirrorMaker 2.0 を実行 することにより、引き続きサポートされます。
設定では以下を指定する必要があります。
- 各 Kafka クラスター
- TLS 認証を含む各クラスターの接続情報
レプリケーションのフローおよび方向
- クラスター対クラスター
- トピック対トピック
- レプリケーションルール
- コミットされたオフセット追跡間隔
この手順では、プロパティーファイルで設定を作成し、MirrorMaker スクリプトファイルを使用して接続を設定する際にプロパティーを渡し、MirrorMaker 2.0 を実装する方法を説明します。
MirrorMaker 2.0 は Kafka Connect を使用して接続を確立し、クラスター間でデータを転送します。Kafka は、データの複製に MirrorMaker シンクおよびソースコネクターを提供します。MirrorMaker スクリプトの代わりにコネクターを使用する場合は、Kafka Connect クラスターでコネクターを設定する必要があります。詳細は、Apache Kafka のドキュメント を参照してください。
作業を開始する前に
設定プロパティーファイルの例は ./config/connect-mirror-maker.properties にあります。
前提条件
- 複製している各 Kafka クラスターノードのホストに AMQ Streams がインストールされている必要がある。
手順
テキストエディターでサンプルプロパティーファイルを開くか、新しいプロパティーファイルを作成し、ファイルを編集して接続情報と各 Kafka クラスターのレプリケーションフローを追加します。
以下の例は、cluster-1 および cluster-2 の 2 つのクラスターを双方向に接続する設定を示しています。クラスター名は、
clustersプロパティーで設定できます。clusters=cluster-1,cluster-2 1 cluster-1.bootstrap.servers=<my-cluster>-kafka-bootstrap-<my-project>:443 2 cluster-1.security.protocol=SSL 3 cluster-1.ssl.truststore.password=<my-truststore-password> cluster-1.ssl.truststore.location=<path-to-truststore>/truststore.cluster-1.jks cluster-1.ssl.keystore.password=<my-keystore-password> cluster-1.ssl.keystore.location=<path-to-keystore>/user.cluster-1.p12 cluster-2.bootstrap.servers=<my-cluster>-kafka-bootstrap-<my-project>:443 4 cluster-2.security.protocol=SSL 5 cluster-2.ssl.truststore.password=<my-truststore-password> cluster-2.ssl.truststore.location=<path-to-truststore>/truststore.cluster-2.jks cluster-2.ssl.keystore.password=<my-keystore-password> cluster-2.ssl.keystore.location=<path-to-keystore>/user.cluster-2.p12 cluster-1->cluster-2.enabled=true 6 cluster-1->cluster-2.topics=.* 7 cluster-2->cluster-1.enabled=true 8 cluster-2->cluster-1B->C.topics=.* 9 replication.policy.separator=- 10 sync.topic.acls.enabled=false 11 refresh.topics.interval.seconds=60 12 refresh.groups.interval.seconds=60 13
- 1
- 各 Kafka クラスターは、そのエイリアスで識別されます。
- 2
- ブートストラップアドレス およびポート 443 を使用した、cluster-1 の接続情報。両方のクラスターはポート 443 を使用し、OpenShift Routes を使用して Kafka に接続します。
- 3
ssl.プロパティーは、cluster-1 の TLS 設定を定義します。- 4
- cluster-2 の接続情報。
- 5
ssl.プロパティーは、cluster-2 の TLS 設定を定義します。- 6
- cluster-1 クラスターから cluster-2 クラスターへのレプリケーションフローが有効になりました。
- 7
- すべてのトピックを cluster-1 クラスターから cluster-2 クラスターに複製します。
- 8
- cluster-2 クラスターから cluster-1 クラスターへのレプリケーションフローが有効になりました。
- 9
- すべてのトピックを cluster-2 クラスターから cluster-1 クラスターに複製します。
- 10
- リモートトピック名の変更に使用する区切り文字を定義します。
- 11
- 有効にすると、同期されたトピックに ACL が適用されます。デフォルトは
falseです。 - 12
- 新しいトピックの同期をチェックする間隔。
- 13
- 新しいコンシューマーグループの同期をチェックする間隔。
(オプション)必要に応じて、リモートトピックの名前の自動変更を上書きするポリシーを追加します。その名前の前にソースクラスターの名前を追加するのではなく、トピックが元の名前を保持します。
このオプションの設定は、active/passive バックアップおよびデータ移行に使用されます。
replication.policy.class=io.strimzi.kafka.connect.mirror.IdentityReplicationPolicy
ターゲットクラスターで ZooKeeper および Kafka を起動します。
su - kafka /opt/kafka/bin/zookeeper-server-start.sh -daemon /opt/kafka/config/zookeeper.properties
/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
プロパティーファイルで定義したクラスター接続設定およびレプリケーションポリシーで MirrorMaker を起動します。
/opt/kafka/bin/connect-mirror-maker.sh /config/connect-mirror-maker.properties
MirrorMaker はクラスター間の接続を設定します。
ターゲットクラスターごとに、トピックが複製されていることを確認します。
/bin/kafka-topics.sh --bootstrap-server <BrokerAddress> --list
10.5. レガシーモードでの MirrorMaker 2.0 の使用
この手順では、MirrorMaker 2.0 をレガシーモードで使用する設定方法を説明します。レガシーモードは、以前のバージョンの MirrorMaker をサポートします。
MirrorMaker スクリプト /opt/kafka/bin/kafka-mirror-maker.sh は、レガシーモードで MirrorMaker 2.0 を実行できます。
前提条件
現時点でレガシーバージョンの MirrorMaker と使用しているプロパティーファイルが必要。
-
/opt/kafka/config/consumer.properties -
/opt/kafka/config/producer.properties
手順
MirrorMakerの
consumer.propertiesとproducer.propertiesファイルを編集して、MirrorMaker 2.0 の機能をオフにします。以下に例を示します。
replication.policy.class=org.apache.kafka.mirror.LegacyReplicationPolicy 1 refresh.topics.enabled=false 2 refresh.groups.enabled=false emit.checkpoints.enabled=false emit.heartbeats.enabled=false sync.topic.configs.enabled=false sync.topic.acls.enabled=false
変更を保存し、以前のバージョンの MirrorMaker で使用していたプロパティーファイルで MirrorMaker を再起動します。
su - kafka /opt/kafka/bin/kafka-mirror-maker.sh \ --consumer.config /opt/kafka/config/consumer.properties \ --producer.config /opt/kafka/config/producer.properties \ --num.streams=2
consumerプロパティーはソースクラスターの設定を提供し、producerプロパティーはターゲットクラスターの設定を提供します。MirrorMaker はクラスター間の接続を設定します。
ターゲットクラスターで ZooKeeper および Kafka を起動します。
su - kafka /opt/kafka/bin/zookeeper-server-start.sh -daemon /opt/kafka/config/zookeeper.properties
su - kafka /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
ターゲットクラスターごとに、トピックが複製されていることを確認します。
/bin/kafka-topics.sh --bootstrap-server <BrokerAddress> --list
第11章 Kafka クライアント
kafka-clients JAR ファイルには、Kafka Producer および Consumer API と、Kafka AdminClient API が含まれています。
- Producer API は、アプリケーションが Kafka ブローカーにデータを送信できるようにします。
- Consumer API は、アプリケーションが Kafka ブローカーからデータを消費できるようにします。
- AdminClient API は、トピック、ブローカー、およびその他のコンポーネントなどの Kafka クラスターを管理するための機能を提供します。
11.1. Maven プロジェクトへの依存関係としての Kafka クライアントの追加
この手順では、AMQ Streams Java クライアントを Maven プロジェクトに依存関係として追加する方法を説明します。
前提条件
-
既存の
pom.xmlを持つ Maven プロジェクト。
手順
Red Hat Maven リポジトリーを
pom.xmlファイルの<repositories>セクションに追加します。<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <!-- ... --> <repositories> <repository> <id>redhat-maven</id> <url>https://maven.repository.redhat.com/ga/</url> </repository> </repositories> <!-- ... --> </project>クライアントを
pom.xmlファイルの<dependencies>セクションに追加します。<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <!-- ... --> <dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.6.0.redhat-00004</version> </dependency> </dependencies> <!-- ... --> </project>- Maven プロジェクトをビルドします。
第12章 Kafka Streams API の概要
Kafka Streams API を使用すると、アプリケーションは 1 つ以上の入力ストリームからデータを受け取り、マッピング、フィルタリング、または結合などの複雑な操作を実行し、結果を 1 つ以上の出力ストリームに書き込むことができます。これは、Red Hat Maven リポジトリーで利用可能な kafka-streams JAR パッケージの一部です。
12.1. Maven プロジェクトへの依存関係としての Kafka Streams API の追加
この手順では、AMQ Streams Java クライアントを Maven プロジェクトに依存関係として追加する方法を説明します。
前提条件
-
既存の
pom.xmlを持つ Maven プロジェクト。
手順
Red Hat Maven リポジトリーを
pom.xmlファイルの<repositories>セクションに追加します。<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <!-- ... --> <repositories> <repository> <id>redhat-maven</id> <url>https://maven.repository.redhat.com/ga/</url> </repository> </repositories> <!-- ... --> </project>pom.xmlファイルの<dependencies>セクションにkafka-streamsを追加します。<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <!-- ... --> <dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-streams</artifactId> <version>2.6.0.redhat-00004</version> </dependency> </dependencies> <!-- ... --> </project>- Maven プロジェクトをビルドします。
第13章 Kafka Bridge
本章では、AMQ Streams Kafka Bridge on Red Hat Enterprise Linux について概説し、その REST API を使用して AMQ Streams と対話するためのサポートをします。ローカル環境で Kafka Bridge を試すには、本章で後述する 「Kafka Bridge クイックスタート」 を参照してください。
関連情報
- リクエストおよび応答の例など、API ドキュメントを確認するには、『Strimzi Kafka Bridge Documentation 』を参照してください。
- 分散トレーシング用に Kafka Bridge を設定するには、「Kafka Bridge のトレースの有効化」 を参照してください。
13.1. Kafka Bridge の概要
Kafka Bridge では、HTTP ベースのクライアントと Kafka クラスターとの対話を可能にする RESTful インターフェイスが提供されます。また、クライアントアプリケーションが Kafka プロトコルを変換する必要なく、AMQ Streams で Web API コネクションの利点を活用できます。
API には consumers と topics の 2 つの主なリソースがあります。これらのリソースは、Kafka クラスターでコンシューマーおよびプロデューサーと対話するためにエンドポイント経由で公開され、アクセスが可能になります。リソースと関係があるのは Kafka ブリッジのみで、Kafka に直接接続されたコンシューマーやプロデューサーとは関係はありません。
HTTP 要求
Kafka Bridge は、以下の方法で Kafka クラスターへの HTTP 要求をサポートします。
- トピックにメッセージを送信する。
- トピックからメッセージを取得する。
- トピックのパーティションリストを取得する。
- コンシューマーを作成および削除する。
- コンシューマーをトピックにサブスクライブし、このようなトピックからメッセージを受信できるようにする。
- コンシューマーがサブスクライブしているトピックの一覧を取得する。
- トピックからコンシューマーのサブスクライブを解除する。
- パーティションをコンシューマーに割り当てる。
- コンシューマーオフセットの一覧をコミットする。
- パーティションで検索して、コンシューマーが最初または最後のオフセットの位置、または指定のオフセットの位置からメッセージを受信できるようにする。
上記の方法で、JSON 応答と HTTP 応答コードのエラー処理を行います。メッセージは JSON またはバイナリー形式で送信できます。
クライアントは、ネイティブの Kafka プロトコルを使用する必要なくメッセージを生成して使用できます。
AMQ Streams のインストールと同様に、Red Hat Enterprise Linux にインストールするために Kafka Bridge ファイルをダウンロードできます。「Kafka Bridge アーカイブのダウンロード」 を参照してください。
KafkaBridge リソースのホストおよびポートの設定に関する詳細は、「Kafka Bridge プロパティーの設定」 を参照してください。
13.1.1. 認証および暗号化
HTTP クライアントと Kafka Bridge 間の認証および暗号化はまだサポートされていません。そのため、クライアントから Kafka Bridge に送信されるリクエストは以下のようになります。
- 暗号化されず、HTTPS ではなく HTTP を使用する必要がある。
- 認証なしで送信される。
Kafka Bridge と Kafka クラスターとの間で、TLS または SASL ベースの認証 を設定できます。
プロパティーファイル を使用して、認証用に Kafka Bridge を設定します。
13.1.2. Kafka Bridge への要求
データ形式と HTTP ヘッダーを指定し、有効な要求が Kafka Bridge に送信されるようにします。
API 要求および応答本文は、常に JSON としてエンコードされます。
13.1.2.1. コンテンツタイプヘッダー
すべてのリクエストに対して、Content-Type のヘッダーを提出する必要があります。唯一の例外は、POST リクエストボディが空の場合で、Content-Type ヘッダーを追加するとリクエストが失敗します。
コンシューマー操作 (/consumers エンドポイント) とプロデューサー操作 (/topics エンドポイント) では、異なる Content-Type ヘッダーが必要です。
コンシューマー操作の Content-Type ヘッダー
埋め込まれたデータ形式にかかわらず、コンシューマー操作の POST リクエストは、リクエストボディーにデータが含まれている場合に、以下の Content-Type ヘッダーを提供する必要があります。
Content-Type: application/vnd.kafka.v2+json
プロデューサー操作の Content-Type ヘッダー
プロデューサー操作を行う場合に、POST 要求には、生成されるメッセージの 埋め込みデータ形式 を示す Content-Type ヘッダーを指定する必要があります。これは json または binary のいずれかになります。
| 埋め込みデータ形式 | Content-Type ヘッダー |
|---|---|
| JSON |
|
| バイナリー |
|
次のセクションで説明されているように、埋め込みデータ形式はコンシューマーごとに設定されます。
POST 要求の本文が空の場合は、Content-Typeを設定しないでください。空の本文を使用して、デフォルト値のコンシューマーを作成できます。
13.1.2.2. 埋め込みデータ形式
埋め込みデータ形式は、Kafka メッセージが Kafka Bridge によりプロデューサーからコンシューマーに HTTP で送信される際の形式です。サポートされる埋め込みデータ形式には、JSON またはバイナリーの 2 つがサポートされます。
/consumers/groupid エンドポイントを使用してコンシューマーを作成する場合、POST リクエスト本文で JSON またはバイナリーいずれかの埋め込みデータ形式を指定する必要があります。これは、以下の例のようにリクエストボディーの format フィールドで指定します。
{
"name": "my-consumer",
"format": "binary", 1
...
}- 1
- バイナリー埋め込みデータ形式。
コンシューマーの埋め込みデータ形式が指定されていない場合は、バイナリー形式が設定されます。
コンシューマーの作成時に指定する埋め込みデータ形式は、コンシューマーが消費する Kafka メッセージのデータ形式と一致する必要があります。
バイナリー埋め込みデータ形式を指定する場合は、以降のプロデューサー要求で、要求本文にバイナリーデータが Base64 でエンコードされた文字列として含まれる必要があります。たとえば、POST リクエストを /topics/topicname エンドポイントに対して作成してメッセージを送信する場合、value は Base64 でエンコードする必要があります。
{
"records": [
{
"key": "my-key",
"value": "ZWR3YXJkdGhldGhyZWVsZWdnZWRjYXQ="
},
]
}
プロデューサー要求には、埋め込みデータ形式に対応する Content-Type ヘッダーも含まれる必要があります (例: Content-Type: application/vnd.kafka.binary.v2+json)。
13.1.2.3. メッセージの形式
/topics エンドポイントを使用してメッセージを送信する場合は、records パラメーターの要求本文にメッセージペイロードを入力します。
records パラメーターには、以下のオプションフィールドを含めることができます。
-
Message
key -
Message
value -
Destination
partition -
Message
headers
/topicsへのPOST 要求の例
curl -X POST \
http://localhost:8080/topics/my-topic \
-H 'content-type: application/vnd.kafka.json.v2+json' \
-d '{
"records": [
{
"key": "my-key",
"value": "sales-lead-0001"
"partition": 2
"headers": [
{
"key": "key1",
"value": "QXBhY2hlIEthZmthIGlzIHRoZSBib21iIQ==" 1
}
]
},
]
}'
- 1
- バイナリー形式のヘッダー値。Base64 としてエンコードされます。
13.1.2.4. Accept ヘッダー
コンシューマーを作成したら、以降のすべての GET 要求には Accept ヘッダーが以下のような形式で含まれる必要があります。
Accept: application/vnd.kafka.embedded-data-format.v2+json
embedded-data-format は json または binary です。
たとえば、サブスクライブされたコンシューマーのレコードを JSON 埋め込みデータ形式で取得する場合、この Accept ヘッダーが含まれるようにします。
Accept: application/vnd.kafka.json.v2+json
13.1.3. Kafka Bridge のロガーの設定
AMQ Streams Kafka ブリッジを使用すると、関連する OpenAPI 仕様で定義される操作ごとに異なるログレベルを設定できます。
操作にはそれぞれ、対応の API エンドポイントがあり、このエンドポイントを通して、ブリッジが HTTP クライアントから要求を受信します。各エンドポイントのログレベルを変更すると、受信および送信 HTTP 要求に関する詳細なログ情報を作成できます。
ロガーは log4j.properties ファイルで定義されます。このファイルには healthy および ready エンドポイントの以下のデフォルト設定が含まれています。
log4j.logger.http.openapi.operation.healthy=WARN, out log4j.additivity.http.openapi.operation.healthy=false log4j.logger.http.openapi.operation.ready=WARN, out log4j.additivity.http.openapi.operation.ready=false
その他すべての操作のログレベルは、デフォルトで INFO に設定されます。ロガーは以下のようにフォーマットされます。
log4j.logger.http.openapi.operation.<operation-id>
<operation-id> は、特定の操作の識別子です。以下は、OpenAPI 仕様によって定義される操作の一覧です。
-
createConsumer -
deleteConsumer -
subscribe -
unsubscribe -
poll -
assign -
commit -
send -
sendToPartition -
seekToBeginning -
seekToEnd -
seek -
healthy -
ready -
openapi
13.1.4. Kafka Bridge API リソース
リクエストやレスポンスの例などを含む REST API エンドポイントおよび説明の完全リストは、「Kafka Bridge API reference」を参照してください。
13.1.5. Kafka Bridge アーカイブのダウンロード
AMQ Streams Kafka Bridge の zip 形式のディストリビューションは、Red Hat の Web サイトからダウンロードできます。
手順
- カスタマーポータル から、最新バージョンの Red Hat AMQ Streams Kafka Bridge アーカイブをダウンロードします。
13.1.6. Kafka Bridge プロパティーの設定
この手順では、AMQ Streams Kafka Bridge によって使用される Kafka および HTTP 接続プロパティーの設定方法を説明します。
Kafka 関連のプロパティーに適切な接頭辞を使用して、他の Kafka クライアントと同様に Kafka Bridge を設定します。
-
kafka.は、サーバー接続やセキュリティーなど、プロデューサーとコンシューマーに適用される一般的な設定用です。 -
kafka.consumer.は、コンシューマーにのみ渡されるコンシューマー固有の設定用です。 -
kafka.producer.は、プロデューサーにのみ渡されるプロデューサー固有の設定用です。
HTTP プロパティーは、Kafka クラスターへの HTTP アクセスを有効にする他に、CPRS (Cross-Origin Resource Sharing) により Kafka Bridge のアクセス制御を有効化または定義する機能を提供します。CORS は、複数のオリジンから指定のリソースにブラウザーでアクセスできるようにする HTTP メカニズムです。CORS を設定するには、許可されるリソースオリジンのリストと、それらにアクセスする HTTP メソッドを定義します。リクエストの追加の HTTP ヘッダーには Kafka クラスターへのアクセスが許可されるオリジンが記述 されています。
手順
AMQ Streams Kafka Bridge のインストールアーカイブにある
application.propertiesファイルを編集します。プロパティーファイルを使用して、Kafka および HTTP 関連のプロパティーを指定し、分散トレースを有効にします。
Kafka コンシューマーおよびプロデューサーに固有のプロパティーなど、標準の Kafka 関連のプロパティーを設定します。
以下を使用します。
-
kafka.bootstrap.servers: Kafkaクラスターへのホスト/ポート接続を定義する。 -
kafka.producer.acks: HTTP クライアントに確認を提供する。 kafka.consumer.auto.offset.reset: Kafka のオフセットのリセットを管理する方法を決定する。Kafka プロパティーの設定に関する詳細は、Apache Kafka の Web サイトを参照してください。
-
Kafka クラスターへの HTTP アクセスを有効にするために HTTP 関連のプロパティーを設定します。
以下に例を示します。
http.enabled=true http.host=0.0.0.0 http.port=8080 1 http.cors.enabled=true 2 http.cors.allowedOrigins=https://strimzi.io 3 http.cors.allowedMethods=GET,POST,PUT,DELETE,OPTIONS,PATCH 4
分散トレースを有効または無効にします。
bridge.tracing=jaeger
分散トレースを有効にするため、プロパティーからコードコメントを削除します。
13.1.7. Kafka Bridge のインストール
以下の手順に従って、AMQ Streams Kafka Bridge on Red Hat Enterprise Linux をインストールします。
前提条件
手順
- AMQ Streams KafkaBridge インストールアーカイブを任意のディレクトリーに解凍します (まだ解答していない場合)。
設定プロパティーをパラメーターとして使用して、Kafka Bridge スクリプトを実行します。
以下に例を示します。
./bin/kafka_bridge_run.sh --config-file=_path_/configfile.properties
インストールが成功したことをログで確認します。
HTTP-Kafka Bridge started and listening on port 8080 HTTP-Kafka Bridge bootstrap servers localhost:9092
13.2. Kafka Bridge クイックスタート
このクイックスタートを使用して、AMQ Streams Kafka Bridge on Red Hat Enterprise Linux を試行します。以下の方法について説明します。
- Kafka Bridge のインストール
- Kafka クラスターのトピックおよびパーティションへのメッセージを生成する。
- Kafka Bridge コンシューマーを作成する。
- 基本的なコンシューマー操作を実行する (たとえば、コンシューマーをトピックにサブスクライブする、生成したメッセージを取得するなど)。
このクイックスタートでは、HTTP 要求はターミナルにコピーアンドペーストできる curl コマンドを使用します。
前提条件を確認し、本章に指定されている順序でタスクを行うようにしてください。
データ形式について
このクイックスタートでは、バイナリーではなく JSON 形式でメッセージを生成および消費します。リクエスト例で使用されるデータ形式および HTTP ヘッダーの詳細は、「認証および暗号化」 を参照してください。
クイックスタートの前提条件
13.2.1. Kafka Bridge のローカルデプロイメント
AMQ Streams Kafka Bridge のインスタンスをホストにデプロイします。インストールアーカイブで提供される application.properties ファイルを使用して、デフォルトの設定を適用します。
手順
application.propertiesファイルを開き、デフォルトのHTTP related settingsが定義されていることを確認します。http.enabled=true http.host=0.0.0.0 http.port=8080
これにより、Kafka Bridge がポート 8080 でリクエストをリッスンするように設定されます。
設定プロパティーをパラメーターとして使用して、Kafka Bridge スクリプトを実行します。
./bin/kafka_bridge_run.sh --config-file=<path>/application.properties
次のステップ
13.2.2. トピックおよびパーティションへのメッセージの作成
トピック エンドポイントを使用して、トピックへのメッセージを JSON 形式で生成します。
以下のように、メッセージの宛先パーティションをリクエストボディーに指定できます。partitions エンドポイントは、全メッセージの単一の宛先パーティションをパスパラメーターとして指定する代替方法を提供します。
手順
kafka-topics.shユーティリティーを使用してトピックを作成します。bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic bridge-quickstart-topic --partitions 3 --replication-factor 1 --config retention.ms=7200000 --config segment.bytes=1073741824
3 つのパーティションを指定します。
トピックが作成されたことを確認します。
bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic bridge-quickstart-topic
Kafka Bridge を使用して、作成したトピックに 3 つのメッセージを生成します。
curl -X POST \ http://localhost:8080/topics/bridge-quickstart-topic \ -H 'content-type: application/vnd.kafka.json.v2+json' \ -d '{ "records": [ { "key": "my-key", "value": "sales-lead-0001" }, { "value": "sales-lead-0002", "partition": 2 }, { "value": "sales-lead-0003" } ] }'-
sales-lead-0001は、キーのハッシュに基づいてパーティションに送信されます。 -
sales-lead-0002は、パーティション 2 に直接送信されます。 -
sales-lead-0003は、ラウンドロビン方式を使用してbridge-quickstart-topicトピックのパーティションに送信されます。
-
リクエストが正常に行われると、Kafka Bridge は
offsetsアレイを200(OK) コードとapplication/vnd.kafka.v2+jsonのcontent-typeヘッダーとともに返します。各メッセージで、offsets配列は以下を記述します。- メッセージが送信されたパーティション。
パーティションの現在のメッセージオフセット。
応答の例
#... { "offsets":[ { "partition":0, "offset":0 }, { "partition":2, "offset":0 }, { "partition":0, "offset":1 } ] }
次のステップ
トピックおよびパーティションへのメッセージを作成したら、Kafka Bridge コンシューマーを作成します。
関連情報
- API リファレンスドキュメントの「POST /topics/{topicname}」
- API リファレンスドキュメントの「POST /topics/{topicname}/partitions/{partitionid}」
13.2.3. Kafka Bridge コンシューマーの作成
Kafka クラスターで何らかのコンシューマー操作を実行する前に、consumers エンドポイントを使用して最初にコンシューマーを作成する必要があります。コンシューマーは Kafka Bridge コンシューマー と呼ばれます。
手順
bridge-quickstart-consumer-groupという名前の新しいコンシューマーグループに Kafka Bridge コンシューマーを作成します。curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group \ -H 'content-type: application/vnd.kafka.v2+json' \ -d '{ "name": "bridge-quickstart-consumer", "auto.offset.reset": "earliest", "format": "json", "enable.auto.commit": false, "fetch.min.bytes": 512, "consumer.request.timeout.ms": 30000 }'-
コンシューマーには
bridge-quickstart-consumerという名前を付け、埋め込みデータ形式はjsonとして設定します。 コンシューマーはログへのオフセットに自動でコミットしません。これは、
enable.auto.commitがfalseに設定されているからです。このクイックスタートでは、オフセットを後で手作業でコミットします。注記リクエストボディーにコンシューマー名を指定しない場合、Kafka Bridge はランダムなコンシューマー名を生成します。
リクエストが正常に行われると、Kafka Bridge はレスポンス本文でコンシューマー ID (
instance_id) とベース URL (base_uri) を200(OK) コードとともに返します。応答例
#... { "instance_id": "bridge-quickstart-consumer", "base_uri":"http://<bridge-name>-bridge-service:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer" }
-
コンシューマーには
-
ベース URL (
base_uri) をコピーし、このクイックスタートの他のコンシューマー操作で使用します。
次のステップ
上記で作成した Kafka Bridge コンシューマーをトピックにサブスクライブできます。
関連情報
- API リファレンスドキュメントの「POST /consumers/{groupid}」
13.2.4. Kafka Bridge コンシューマーのトピックへのサブスクライブ
subscription エンドポイントを使用して、Kafka Bridge コンシューマーを 1 つ以上のトピックにサブスクライブします。サブスクライブすると、コンシューマーはトピックに生成されたすべてのメッセージの受信を開始します。
手順
前述の「トピックおよびパーティションへのメッセージの作成」の手順ですでに作成した
bridge-quickstart-topicトピックに、コンシューマーをサブスクライブします。curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/subscription \ -H 'content-type: application/vnd.kafka.v2+json' \ -d '{ "topics": [ "bridge-quickstart-topic" ] }'topicsアレイには、上述のような単一のトピック、または複数のトピックを含めることができます。正規表現に一致する複数のトピックにコンシューマーをサブスクライブする場合は、topics配列の代わりにtopic_pattern文字列を使用できます。リクエストが正常に行われると、Kafka Bridge によって
204 No Contentコードのみが返されます。
次のステップ
Kafka Bridge コンシューマーをトピックにサブスクライブしたら、コンシューマーからメッセージを取得できます。
関連情報
- API リファレンスドキュメントの「POST /consumers/{groupid}/instances/{name}/subscription」
13.2.5. Kafka Bridge コンシューマーからの最新メッセージの取得
records エンドポイントからデータを要求して、Kafka Bridge コンシューマーから最新のメッセージを取得します。実稼働環境では、HTTP クライアントはこのエンドポイントを繰り返し (ループで) 呼び出すことができます。
手順
- 「トピックおよびパーティションへのメッセージの生成」の説明に従い、Kafka Bridge コンシューマーに新たなメッセージを生成します。
GET要求をrecordsエンドポイントに送信します。curl -X GET http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/records \ -H 'accept: application/vnd.kafka.json.v2+json'
Kafka Bridge コンシューマーを作成し、サブスクライブした後に、最初の GET リクエストによって空のレスポンスが返されます。これは、ポーリング操作がリバランスプロセスをトリガーしてパーティションを割り当てるためです。
手順 2 を繰り返し、Kafka Bridge コンシューマーからメッセージを取得します。
Kafka Bridge は、レスポンス本文でメッセージのアレイ (トピック名、キー、値、パーティション、オフセットの記述) を
200(OK) コードとともに返します。メッセージはデフォルトで最新のオフセットから取得されます。HTTP/1.1 200 OK content-type: application/vnd.kafka.json.v2+json #... [ { "topic":"bridge-quickstart-topic", "key":"my-key", "value":"sales-lead-0001", "partition":0, "offset":0 }, { "topic":"bridge-quickstart-topic", "key":null, "value":"sales-lead-0003", "partition":0, "offset":1 }, #...注記空のレスポンスが返される場合は、「トピックおよびパーティションへのメッセージの生成」の説明に従い、コンシューマーに対して追加のレコードを生成し、メッセージの取得を再試行します。
次のステップ
Kafka Bridge コンシューマーからメッセージを取得したら、ログへのオフセットをコミットします。
関連情報
- API リファレンスドキュメントの「GET /consumers/{groupid}/instances/{name}/records」
13.2.6. ログへのオフセットのコミット
offsets エンドポイントを使用して、Kafka Bridge コンシューマーによって受信されるすべてのメッセージに対して、手動でオフセットをログにコミットします。この操作が必要なのは、前述の「Kafka Bridge コンシューマーの作成」で作成した Kafka Bridge コンシューマー が enable.auto.commit の設定で false に指定されているからです。
手順
bridge-quickstart-consumerのオフセットをログにコミットします。curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/offsets
要求本文は送信されないので、オフセットはコンシューマーによって受信されたすべてのレコードに対してコミットされます。この代わりに、リクエスト本文に、オフセットをコミットするトピックおよびパーティションを指定するアレイ (OffsetCommitSeekList) を含めることができます。
リクエストが正常に行われると、Kafka Bridge によって
204 No Contentコードのみが返されます。
次のステップ
オフセットをログにコミットしたら、オフセットをシークのエンドポイントを試行します。
関連情報
- API リファレンスドキュメントの「POST /consumers/{groupid}/instances/{name}/offsets」
13.2.7. パーティションのオフセットのシーク
positions エンドポイントを使用して、Kafka Bridge コンシューマーを設定し、パーティションのメッセージを特定のオフセットから取得し、さらに最新のオフセットから取得します。これは Apache Kafka では、シーク操作と呼ばれます。
手順
quickstart-bridge-topicトピックで、パーティション 0 の特定のオフセットをシークします。curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/positions \ -H 'content-type: application/vnd.kafka.v2+json' \ -d '{ "offsets": [ { "topic": "bridge-quickstart-topic", "partition": 0, "offset": 2 } ] }'リクエストが正常に行われると、Kafka Bridge によって
204 No Contentコードのみが返されます。GET要求をrecordsエンドポイントに送信します。curl -X GET http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/records \ -H 'accept: application/vnd.kafka.json.v2+json'
Kafka Bridge は、シークしたオフセットからのメッセージを返します。
同じパーティションの最後のオフセットをシークし、デフォルトのメッセージ取得動作を復元します。この時点で、positions/end エンドポイントを使用します。
curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/positions/end \ -H 'content-type: application/vnd.kafka.v2+json' \ -d '{ "partitions": [ { "topic": "bridge-quickstart-topic", "partition": 0 } ] }'リクエストが正常に行われると、Kafka Bridge によって別の
204 No Contentコードが返されます。
また、positions/beginning エンドポイントを使用して、1 つ以上のパーティションの最初のオフセットをシークすることもできます。
次のステップ
このクイックスタートでは、AMQ Streams Kafka Bridge を使用して Kafka クラスターの一般的な操作をいくつか実行しました。これで、すでに作成した Kafka Bridge コンシューマーを削除 できます。
関連情報
- API リファレンスドキュメントの「POST /consumers/{groupid}/instances/{name}/positions」
- API リファレンスドキュメントの「POST /consumers/{groupid}/instances/{name}/positions/beginning」
- API リファレンスドキュメントの「POST /consumers/{groupid}/instances/{name}/positions/end」
13.2.8. Kafka Bridge コンシューマーの削除
最後に、このクイックスタートを通して使用した Kafa Bridge コンシューマーを削除します。
手順
DELETEリクエストを instances エンドポイントに送信し、Kafka Bridge コンシューマーを削除します。curl -X DELETE http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer
リクエストが正常に行われると、Kafka Bridge によって
204 No Contentコードのみが返されます。
関連情報
- API リファレンスドキュメントの「DELETE /consumers/{groupid}/instances/{name}」
第14章 Kerberos(GSSAPI)認証の使用
AMQ Streams は、Kafka クラスターへの安全なシングルサインオンアクセスのために、Kerberos (GSSAPI) 認証プロトコルの使用をサポートします。GSSAPI は、Kerberos 機能の API ラッパーで、基盤の実装の変更からアプリケーションを保護します。
Kerberos は、対称暗号化と信頼できるサードパーティーの Kerberos Key Distribution Centre(KDC)を使用して、クライアントとサーバーが相互に認証できるようにするネットワーク認証システムです。
14.1. Kerberos (GSSAPI) 認証を使用するための AMQ Streams の設定
この手順では、Kafka クライアントが Kerberos (GSSAPI) 認証を使用して Kafka および ZooKeeper にアクセスできるように AMQ Streams を設定する方法を説明します。
この手順では、Kerberos krb5 リソースサーバーが Red Hat Enterprise Linux ホストに設定されていることを前提としています。
この手順では、例を用いて以下の設定方法を説明します。
- サービスプリンシパル
- Kerberos ログインを使用する Kafka ブローカー
- Kerberos ログインを使用するための ZooKeeper
- Kerberos 認証を使用して Kafka にアクセスするためのプロデューサーおよびコンシューマークライアント
この手順では、単一のホストでの単一の ZooKeeper および Kafka インストールの Kerberos 設定について説明し、プロデューサーおよびコンシューマークライアントの追加設定についても説明します。
前提条件
Kafka および ZooKeeper が Kerberos クレデンシャルを認証および承認するように設定できるようにするには、以下が必要です。
- Kerberos サーバーへのアクセス
- 各 Kafka ブローカーホストの Kerberos クライアント
Kerberos サーバー、およびブローカーホストのクライアントを設定する手順の詳細は、example Kerberos on RHEL set up configuration を参照してください。
Kerberos のデプロイ方法は、お使いのオペレーティングシステムによって異なります。Red Hat は、Red Hat Enterprise Linux で Kerberos を設定する際に Identity Management(IdM)を使用することを推奨します。Oracle または IBM JDK のユーザーは、Java Cryptography Extension(JCE)をインストールする必要があります。
認証用のサービスプリンシパルの追加
Kerberos サーバーから、ZooKeeper、Kafka ブローカー、Kafka プロデューサーおよびコンシューマークライアントのサービスプリンシパル (ユーザー) を作成します。
サービスプリンシパルは SERVICE-NAME/FULLY-QUALIFIED-HOST-NAME@DOMAIN-REALM の形式にする必要があります。
Kerberos KDC を使用してサービスプリンシパルと、プリンシパルキーを保存するキータブを作成します。
以下に例を示します。
-
zookeeper/node1.example.redhat.com@EXAMPLE.REDHAT.COM -
kafka/node1.example.redhat.com@EXAMPLE.REDHAT.COM -
producer1/node1.example.redhat.com@EXAMPLE.REDHAT.COM consumer1/node1.example.redhat.com@EXAMPLE.REDHAT.COMZooKeeper サービスプリンシパルは、Kafka
config/server.propertiesファイルのzookeeper.connect設定と同じホスト名である必要があります。zookeeper.connect=node1.example.redhat.com:2181ホスト名が同じでない場合、localhost が使用され、認証に失敗します。
-
ホストにディレクトリーを作成し、キータブファイルを追加します。
以下に例を示します。
/opt/kafka/krb5/zookeeper-node1.keytab /opt/kafka/krb5/kafka-node1.keytab /opt/kafka/krb5/kafka-producer1.keytab /opt/kafka/krb5/kafka-consumer1.keytab
kafkaユーザーがディレクトリーにアクセスできることを確認します。chown kafka:kafka -R /opt/kafka/krb5
Kerberos ログインを使用するための ZooKeeper の設定
認証に Kerberos Key Distribution Center (KDC) を使用するように zookeeper のために作成したユーザープリンシパルとキータブを使用して ZooKeeper を設定します。
opt/kafka/config/jaas.confファイルを作成または変更して、ZooKeeper クライアントおよびサーバー操作をサポートします。Client { com.sun.security.auth.module.Krb5LoginModule required debug=true useKeyTab=true 1 storeKey=true 2 useTicketCache=false 3 keyTab="/opt/kafka/krb5/zookeeper-node1.keytab" 4 principal="zookeeper/node1.example.redhat.com@EXAMPLE.REDHAT.COM"; 5 }; Server { com.sun.security.auth.module.Krb5LoginModule required debug=true useKeyTab=true storeKey=true useTicketCache=false keyTab="/opt/kafka/krb5/zookeeper-node1.keytab" principal="zookeeper/node1.example.redhat.com@EXAMPLE.REDHAT.COM"; }; QuorumServer { com.sun.security.auth.module.Krb5LoginModule required debug=true useKeyTab=true storeKey=true keyTab="/opt/kafka/krb5/zookeeper-node1.keytab" principal="zookeeper/node1.example.redhat.com@EXAMPLE.REDHAT.COM"; }; QuorumLearner { com.sun.security.auth.module.Krb5LoginModule required debug=true useKeyTab=true storeKey=true keyTab="/opt/kafka/krb5/zookeeper-node1.keytab" principal="zookeeper/node1.example.redhat.com@EXAMPLE.REDHAT.COM"; };- 1
trueに設定し、キータブからプリンシパルキーを取得します。- 2
trueに設定し、プリンシパルキーを保存します。- 3
trueに設定し、チケットキャッシュから Ticket Granting Ticket (TGT) を取得します。- 4
keyTabプロパティーは、Kerberos KDC からコピーされた keytab ファイルの場所を示します。その場所とファイルは、kafkaユーザーが読み取りできるものでなければなりません。- 5
principalプロパティーは、KDC ホストで作成された完全修飾プリンシパル名と一致するように設定され、その形式はSERVICE-NAME/FULLY-QUALIFIED-HOST-NAME@DOMAIN-NAMEに従います。
opt/kafka/config/zookeeper.propertiesを編集して、更新された JAAS 設定を使用します。# ... requireClientAuthScheme=sasl jaasLoginRenew=3600000 1 kerberos.removeHostFromPrincipal=false 2 kerberos.removeRealmFromPrincipal=false 3 quorum.auth.enableSasl=true 4 quorum.auth.learnerRequireSasl=true 5 quorum.auth.serverRequireSasl=true quorum.auth.learner.loginContext=QuorumLearner 6 quorum.auth.server.loginContext=QuorumServer quorum.auth.kerberos.servicePrincipal=zookeeper/_HOST 7 quorum.cnxn.threads.size=20
- 1
- ログイン更新の頻度をミリ秒単位で制御します。これは、チケットの更新間隔に合わせて調整できます。デフォルトは 1 時間です。
- 2
- ホスト名がログインプリンシパル名の一部として使用されるかどうかを指定します。クラスターのすべてのノードで単一の keytab を使用する場合、これは
trueに設定されます。ただし、トラブルシューティングのために、各ブローカーホストに個別のキータブと完全修飾プリンシパルを生成することが推奨されます。 - 3
- Kerberos ネゴシエーションのプリンシパル名からレルム名を削除するかどうかを制御します。この設定は、
falseにすることをお勧めします。 - 4
- ZooKeeper サーバーおよびクライアントの SASL 認証メカニズムを有効にします。
- 5
RequireSaslプロパティーは、マスター選出などのクォーラムイベントに SASL 認証を必要とするかどうかを制御します。- 6
loginContextプロパティーは、指定されたコンポーネントの認証設定に使用される JAAS 設定のログインコンテキストの名前を識別します。loginContext 名は、opt/kafka/config/jaas.confファイルの関連セクションの名前に対応します。- 7
- 識別に使用されるプリンシパル名を形成するために使用される命名規則を制御します。プレースホルダー
_HOSTは、実行時にserver.1プロパティーによって定義されたホスト名に自動的に解決されます。
JVM パラメーターで ZooKeeper を起動し、Kerberos ログイン設定を指定します。
su - kafka export EXTRA_ARGS="-Djava.security.krb5.conf=/etc/krb5.conf -Djava.security.auth.login.config=/opt/kafka/config/jaas.conf"; /opt/kafka/bin/zookeeper-server-start.sh -daemon /opt/kafka/config/zookeeper.properties
デフォルトのサービス名 (
zookeeper) を使用していない場合は、-Dzookeeper.sasl.client.username=NAMEパラメーターを使用して名前を追加します。注記/etc/krb5.confを場所として使用している場合は、ZooKeeper、Kafka、Kafka プロデューサーおよびコンシューマーの起動時に-Djava.security.krb5.conf=/etc/krb5.confを指定する必要はありません。
Kerberos ログインを使用するための Kafka ブローカーサーバーの設定
認証に Kerberos Key Distribution Center (KDC) を使用するように kafka のために作成したユーザープリンシパルとキータブを使用して Kafka を設定します。
opt/kafka/config/jaas.confファイルを以下の要素で修正します。KafkaServer { com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true storeKey=true keyTab="/opt/kafka/krb5/kafka-node1.keytab" principal="kafka/node1.example.redhat.com@EXAMPLE.REDHAT.COM"; }; KafkaClient { com.sun.security.auth.module.Krb5LoginModule required debug=true useKeyTab=true storeKey=true useTicketCache=false keyTab="/opt/kafka/krb5/kafka-node1.keytab" principal="kafka/node1.example.redhat.com@EXAMPLE.REDHAT.COM"; };Kafka クラスターの各ブローカーを設定するには、
config/server.propertiesファイルのリスナー設定を変更して、リスナーが SASL/GSSAPI ログインを使用するようにします。リスナーのセキュリティープロトコルのマップに SASL プロトコルを追加し、不要なプロトコルを削除します。
以下に例を示します。
# ... broker.id=0 # ... listeners=SECURE://:9092,REPLICATION://:9094 1 inter.broker.listener.name=REPLICATION # ... listener.security.protocol.map=SECURE:SASL_PLAINTEXT,REPLICATION:SASL_PLAINTEXT 2 # .. sasl.enabled.mechanisms=GSSAPI 3 sasl.mechanism.inter.broker.protocol=GSSAPI 4 sasl.kerberos.service.name=kafka 5 ...
- 1
- クライアントとの汎用通信 (通信用の TLS をサポート) と inter-broker 通信用のレプリケーションリスナーの 2 つのリスナーが設定されます。
- 2
- TLS 対応のリスナーの場合、プロトコル名は SASL_PLAINTEXT です。TLS に対応していないコネクターの場合、プロトコル名は SASL_PLAINTEXT です。SSL が必要ない場合は、
ssl.*プロパティーを削除できます。 - 3
- Kerberos 認証のための SASL メカニズムは
GSSAPIです。 - 4
- inter-broker 通信の Kerberos 認証。
- 5
- 認証要求に使用するサービスの名前は、同じ Kerberos 設定を使用している他のサービスと区別するために指定されます。
Kafka ブローカーを起動し、JVM パラメーターを使用して Kerberos ログイン設定を指定します。
su - kafka export KAFKA_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf -Djava.security.auth.login.config=/opt/kafka/config/jaas.conf"; /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
ブローカーおよび ZooKeeper クラスターが以前に設定されていて、Kerberos ベース以外の認証システムで動作している場合は、ZooKeeper およびブローカークラスターを起動し、ログで設定エラーを確認することができます。
ブローカーおよび Zookeeper インスタンスを起動すると、Kerberos 認証用にクラスターが設定されました。
Kerberos 認証を使用ための Kafka プロデューサーおよびコンシューマークライアントの設定
認証に Kerberos Key Distribution Center (KDC) を使用するように producer1 および consumer1 のために作成したユーザープリンシパルとキータブを使用して Kafka プロデューサーおよびコンシューマークライアントを設定します。
プロデューサーまたはコンシューマー設定ファイルに Kerberos 設定を追加します。
以下に例を示します。
/opt/kafka/config/producer.properties
# ... sasl.mechanism=GSSAPI 1 security.protocol=SASL_PLAINTEXT 2 sasl.kerberos.service.name=kafka 3 sasl.jaas.config=com.sun.security.auth.module.Krb5LoginModule required \ 4 useKeyTab=true \ useTicketCache=false \ storeKey=true \ keyTab="/opt/kafka/krb5/producer1.keytab" \ principal="producer1/node1.example.redhat.com@EXAMPLE.REDHAT.COM"; # ...
/opt/kafka/config/consumer.properties
# ... sasl.mechanism=GSSAPI security.protocol=SASL_PLAINTEXT sasl.kerberos.service.name=kafka sasl.jaas.config=com.sun.security.auth.module.Krb5LoginModule required \ useKeyTab=true \ useTicketCache=false \ storeKey=true \ keyTab="/opt/kafka/krb5/consumer1.keytab" \ principal="consumer1/node1.example.redhat.com@EXAMPLE.REDHAT.COM"; # ...クライアントを実行して、Kafka ブローカーからメッセージを送受信できることを確認します。
プロデューサークライアント:
export KAFKA_HEAP_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf -Dsun.security.krb5.debug=true"; /opt/kafka/bin/kafka-console-producer.sh --producer.config /opt/kafka/config/producer.properties --topic topic1 --bootstrap-server node1.example.redhat.com:9094
コンシューマークライアント:
export KAFKA_HEAP_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf -Dsun.security.krb5.debug=true"; /opt/kafka/bin/kafka-console-consumer.sh --consumer.config /opt/kafka/config/consumer.properties --topic topic1 --bootstrap-server node1.example.redhat.com:9094
関連情報
- Kerberos の man ページ: krb5.conf(5)、kinit(1)、klist(1)、および kdestroy(1)
- 「AMQ Streams on RHEL - Example Kerberos set up configuration」
- 「AMQ Streams on RHEL - Example Kafka client with Kerberos authentication」
第15章 Cruise Control によるクラスターのリバランス
Cruise Control によるクラスターのリバランスはテクノロジープレビューの機能です。テクノロジープレビュー機能は、Red Hat の実稼働サービスレベルアグリーメント (SLA) でサポートされておらず、機能的に完全でない可能性があります。Red Hat は、本番環境でのテクノロジープレビュー機能の実装は推奨しません。テクノロジープレビューの機能は、最新の技術をいち早く提供して、開発段階で機能のテストやフィードバックの収集を可能にするために提供されます。Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、「テクノロジプレビュー機能のサポート範囲」 を参照してください。
Cruise Control を AMQ Streams クラスターにデプロイし、これを使用して Kafka ブローカー全体で負荷のリバランスを実行できます。
Cruise Control は、クラスターワークロードの監視、事前定義の制約を基にしたクラスターの再分散、異常の検出および修正などの Kafka の操作を自動化するオープンソースのシステムです。これは、4 つのコンポーネント (Load Monitor、Analyzer、Anomaly Detector、Executor) および REST API で構成されます。
AMQ Streams と Cruise Control の両方が Red Hat Enterprise Linux にデプロイされている場合、Cruise Control REST API から Cruise Control 機能にアクセスできます。以下の機能がサポートされます。
- 最適化の目標 と 容量制限 の設定
/rebalanceエンドポイントを使用した以下の実行- 設定された最適化ゴールまたはリクエストパラメーターとして提供される ユーザー提供ゴール を基にして、最適化プロポーザル をドライランとして生成する
- 最適化プロポーザルを開始し、Kafka クラスターをリバランスする
-
/user_tasksエンドポイントを使用した、アクティブなリバランス操作の進捗の確認 -
/stop_proposal_executionエンドポイントを使用した、アクティブなリバランス操作の停止
異常検出、通知、独自のゴールの作成、トピックレプリケーションファクターの変更など、その他すべての Cruise Control 機能は現在サポートされていません。Web UI コンポーネント (Cruise Control Frontend) はサポートされていません。
Red Hat Enterprise Linux 上の AMQ Streams の Cruise Control は、個別の zip 形式のディストリビューションとして提供されます。詳細は、「Cruise Control アーカイブのダウンロード」 を参照してください。
15.1. Cruise Control とは
Cruise Control は、Kafka クラスターの効率的な実行に必要な時間および労力を削減し、ブローカー全体でワークロードをより均等に分散します。
通常、クラスターの負荷は時間とともに不均等になります。大量のメッセージトラフィックを処理するパーティションは、使用可能なブローカー全体で不均等に分散される可能性があります。クラスターを再分散するには、管理者はブローカーの負荷を監視し、トラフィックの多いパーティションを容量に余裕のあるブローカーに手作業で再割り当てします。
Cruise Control は、このクラスターのリバランス処理を自動化します。CPU、ディスク、およびネットワークの負荷に基づいて、リソース使用率の ワークロードモデル を構築します。設定可能な最適化ゴールのセットを使用すると、Cruise Control に、よりバランスの取れたパーティション割り当てのためのドライラン最適化プロポーザルを生成するよう指示できます。
ドライランの最適化プロポーザルを確認したら、Cruise Control に対してそのプロポーザルに基づいてクラスターのリバランスを開始するように指示したり、新しいプロポーザルを生成したりすることができます。
クラスターのリバランス操作が完了すると、ブローカーがより効果的に使用され、Kafka クラスターの負荷がより均等に分散されます。
15.2. Cruise Control アーカイブのダウンロード
Red Hat Enterprise Linux 上の AMQ Streams の Cruise Control は zip ディストリビューションとして、Red Hat カスタマーポータル からダウンロードできます。
手順
- Red Hat カスタマーポータル から、最新バージョンの Red Hat AMQ Streams Cruise Control アーカイブをダウンロードします。
/opt/cruise-controlディレクトリーを作成します。sudo mkdir /opt/cruise-control
Cruise Control ZIP ファイルの内容を新しいディレクトリーに展開します。
unzip amq-streams-y.y.y-cruise-control-bin.zip -d /opt/cruise-control/opt/cruise-controlディレクトリーの所有権をkafkaユーザーに変更します。sudo chown -R kafka:kafka /opt/cruise-control
15.3. Cruise Control Metrics Reporter のデプロイ
Cruise Control を起動する前に、提供される Cruise Control Metrics Reporter を使用するように Kafka ブローカーを設定する必要があります。
実行時にロードされると、Metrics Reporter は 自動作成された 3 つのトピックの 1 つである __CruiseControlMetrics トピックにメトリクスを送信します。Cruise Control はこれらのメトリクスを使用して、ワークロードモデルを作成および更新し、最適化プロポーザルを計算します。
前提条件
-
Red Hat Enterprise Linux に
kafkaユーザーとしてログインしている。 - Kafka と ZooKeeper が実行されている。
- 「Cruise Control アーカイブのダウンロード」
手順
Kafka クラスターの各ブローカーに対して、以下を 1 つずつ実行します。
Kafka ブローカーを停止します。
/opt/kafka/bin/kafka-server-stop.sh
Cruise Control Metrics Reporter
.jarファイルを Kafka libraries ディレクトリーにコピーします。cp /opt/cruise-control/libs/cruise-control-metrics-reporter-y.y.yyy.redhat-0000x.jar /opt/kafka/libsKafka 設定ファイル (
/opt/kafka/config/server.properties) で、Cruise Control Metrics Reporter を設定します。CruiseControlMetricsReporterクラスをmetric.reporters設定オプションに追加します。既存の Metrics Reporters を削除しないでください。metric.reporters=com.linkedin.kafka.cruisecontrol.metricsreporter.CruiseControlMetricsReporter
以下の設定オプションおよび値を Kafka 設定ファイルに追加します。
cruise.control.metrics.topic.auto.create=true cruise.control.metrics.topic.num.partitions=1 cruise.control.metrics.topic.replication.factor=1
これらのオプションにより、Cruise Control Metrics Reporter は、
__CruiseControlMetricsトピックをログクリーンアップポリシーDELETEで作成します。詳細は、「自動作成されたトピック」 および 「Cruise Control Metrics トピックのログクリーンアップポリシー」 を参照してください。
必要に応じて SSL を設定します。
Kafka 設定ファイル (
/opt/kafka/config/server.properties) では、関連するクライアント設定プロパティーを設定することで、Cruise Control Metrics Reporter と Kafka ブローカー間の SSL を設定します。Metrics Reporter は、
cruise.control.metrics.reporterという接頭辞を持つ、すべての標準のプロデューサー固有の設定プロパティーを受け入れます。たとえば、cruise.control.metrics.reporter.ssl.truststore.passwordです。Cruise Control 設定ファイル (
/opt/cruise-control/config/cruisecontrol.properties) では、関連するクライアント設定プロパティーを設定することで、Kafka ブローカーと Cruise Control サーバーとの間の SSL を設定します。Cruise Control は、Kafka から SSL クライアントプロパティーオプションを継承し、すべての Cruise Control サーバークライアントにこれらのプロパティーを使用します。
Kafka ブローカーを再起動します。
/opt/kafka/bin/kafka-server-start.sh
- 残りのブローカーで手順 1-5 を繰り返します。
15.4. Cruise Control の設定および起動
Cruise Control が使用するプロパティーを設定し、cruise-control-start.sh スクリプトを使用して Cruise Control サーバーを起動します。サーバーは、Kafka クラスター全体の単一のマシンでホストされます。
Cruise Control の起動時に 3 つのトピックが自動作成されます。詳細は、「自動作成されたトピック」 を参照してください。
前提条件
-
Red Hat Enterprise Linux に
kafkaユーザーとしてログインしている。 - Cruise Control アーカイブをダウンロードしている。
- Cruise Control Metrics Reporter をデプロイしている。
手順
-
Cruise Control プロパティーファイル (
/opt/cruise-control/config/cruisecontrol.properties) を編集します。 以下の設定例のように、プロパティーを設定します。
# The Kafka cluster to control. bootstrap.servers=localhost:9092 1 # The replication factor of Kafka metric sample store topic sample.store.topic.replication.factor=2 2 # The configuration for the BrokerCapacityConfigFileResolver (supports JBOD, non-JBOD, and heterogeneous CPU core capacities) #capacity.config.file=config/capacity.json #capacity.config.file=config/capacityCores.json capacity.config.file=config/capacityJBOD.json 3 # The list of goals to optimize the Kafka cluster for with pre-computed proposals default.goals={List of default optimization goals} 4 # The list of supported goals goals={list of master optimization goals} 5 # The list of supported hard goals hard.goals={List of hard goals} 6 # How often should the cached proposal be expired and recalculated if necessary proposal.expiration.ms=60000 7 # The zookeeper connect of the Kafka cluster zookeeper.connect=localhost:2181 8
- 1
- Kafka ブローカーのホストおよびポート番号 (常にポート 9092)。
- 2
- Kafka メトリクスサンプルストアトピックのレプリケーション係数。単一ノードの Kafka および ZooKeeper クラスターで Cruise Control を評価する場合は、このプロパティーを 1 に設定します。実稼働環境で使用する場合は、このプロパティーを 2 以上に設定します。
- 3
- ブローカーリソースの最大容量制限を設定する設定ファイル。Kafka デプロイメント設定に適用されるファイルを使用します。詳細は、「容量の設定」 を参照してください。
- 4
- 完全修飾ドメイン名(FQDN)を使用したデフォルトの最適化ゴールのコンマ区切りリスト。マスター最適化ゴール(5 を参照)がデフォルトの最適化ゴールとしてすでに設定されています。必要に応じてゴールを追加または削除できます。詳細は、「「最適化ゴールの概要」」を参照してください。
- 5
- FQDN を使用したマスター最適化ゴールのコンマ区切りリスト。最適化プロポーザルの生成にゴールが使用されないように完全に除外するには、それらをリストから削除します。詳細は、「「最適化ゴールの概要」」を参照してください。
- 6
- FQDN を使用したハードゴールのコンマ区切りリスト。マスター最適化ゴールの 6 個は、すでにハードゴールとして設定されています。必要に応じてゴールを追加または削除できます。詳細は、「「最適化ゴールの概要」」を参照してください。
- 7
- デフォルトの最適化ゴールから生成される、キャッシュされた最適化プロポーザルを更新する間隔 (ミリ秒単位)。詳細は、「最適化プロポーザルの概要」 を参照してください。
- 8
- ZooKeeper 接続のホストおよびポート番号 (常にポート 2181)。
Cruise Control サーバーを起動します。デフォルトでは、サーバーはポート 9092 で起動します。オプションで別のポートを指定します。
cd /opt/cruise-control/ ./bin/cruise-control-start.sh config/cruisecontrol.properties PORTCruise Control が実行されていることを確認するには、Cruise Control サーバーの
/stateエンドポイントに GET リクエストを送信します。curl 'http://HOST:PORT/kafkacruisecontrol/state'
自動作成されたトピック
以下の表は、Cruise Control の起動時に自動的に作成される 3 つのトピックを表しています。これらのトピックは、Cruise Control が適切に動作するために必要であるため、削除または変更しないでください。
| 自動作成されたトピック | 作成元 | 機能 |
|---|---|---|
|
| Cruise Control Metrics Reporter | Metrics Reporter からの raw メトリクスを各 Kafka ブローカーに格納します。 |
|
| Cruise Control | 各パーティションの派生されたメトリクスを格納します。これらは Metric Sample Aggregator によって作成されます。 |
|
| Cruise Control | クラスターワークロードモデル の作成に使用されるメトリクスサンプルを格納します。 |
自動作成されたトピックでログコンパクションが 無効 になっていることを確認するには、「Cruise Control Metrics Reporter のデプロイ」 の説明に従って Cruise Control Metrics Reporter を設定するようにしてください。ログコンパクションは、Cruise Control が必要とするレコードを削除し、適切に動作しないようにすることができます。
15.5. 最適化ゴールの概要
Cruise Control は Kafka クラスターをリバランスするために、最適化ゴールを使用して 最適化プロポーザル を生成します。最適化ゴールは、Kafka クラスター全体のワークロード再分散およびリソース使用の制約です。
Red Hat Enterprise Linux 上の AMQ Streams は、Cruise Control プロジェクトで開発された最適化の目標をすべてサポートします。以下に、サポートされるゴールをデフォルトの優先度順に示します。
- ラックアウェアネス (Rack Awareness)
- レプリカの容量
- 容量: ディスク容量、ネットワークインバウンド容量、ネットワークアウトバウンド容量
- CPU 容量
- レプリカの分散
- 潜在的なネットワーク出力
- リソース分布: ディスク使用率の分布、ネットワークインバウンド使用率の分布、ネットワークアウトバウンド使用率の分布。
- リーダーへの単位時間あたりバイト流入量の分布
- トピックレプリカの分散
- CPU 使用率の分散
- リーダーレプリカの分散
- 優先リーダーエレクション
- Kafka Assigner のディスク使用率の分散
- ブローカー内のディスク容量
- ブローカー内のディスク使用率
各最適化ゴールの詳細は、Cruise Control Wiki の Goals を参照してください。
Cruise Control プロパティーファイルのゴール設定
最適化目標の設定は、cruise-control/config/ ディレクトリー内の cruisecontrol.properties ファイルで行います。必ず満たさなければならない ハード 最適化ゴールの設定と、マスター 最適化ゴールおよび デフォルト 最適化ゴールの設定があります。
オプションで、ユーザー提供 の最適化ゴールは、実行時に /rebalance エンドポイントへのリクエストのパラメーターとして設定されます。
最適化ゴールは、ブローカーリソースのあらゆる 容量制限 の対象となります。
以下のセクションでは、各ゴール設定の詳細を説明します。
マスター最適化ゴール
マスター最適化ゴールは、すべてのユーザーが使用できます。マスター最適化ゴールにリストされていないゴールは、Cruise Control 操作で使用できません。
以下のマスター最適化ゴールは cruisecontrol.properties ファイルにあり、goals プロパティーに、優先順位の高い順に事前設定されています。
RackAwareGoal; ReplicaCapacityGoal; DiskCapacityGoal; NetworkInboundCapacityGoal; NetworkOutboundCapacityGoal; ReplicaDistributionGoal; PotentialNwOutGoal; DiskUsageDistributionGoal; NetworkInboundUsageDistributionGoal; NetworkOutboundUsageDistributionGoal; CpuUsageDistributionGoal; TopicReplicaDistributionGoal; LeaderReplicaDistributionGoal; LeaderBytesInDistributionGoal; PreferredLeaderElectionGoal
1 つ以上のゴールが最適化プロポーザルの生成に使用されることを完全に除外する必要がない限り、便宜上、事前設定されたマスター最適化ゴールを変更しないことをお勧めします。必要な場合、マスター最適化ゴールの優先順位は、デフォルトの最適化ゴールの設定で変更できます。
事前設定されたマスター最適化ゴールを変更する必要がある場合は、goals プロパティーにゴールのリストを優先度が高いものから順に指定します。cruisecontrol.properties ファイルに記載されているように、完全修飾ドメイン名を使用します。
マスターゴールを 1 つ以上指定する必要があります。そうしないと、Cruise Control がクラッシュします。
事前設定のマスター最適化ゴールを変更する場合、必ず設定した hard.goals が設定したマスター最適化ゴールのサブセットになるようにしてください。そうでないと、最適化プロポーザルの生成時にエラーが発生します。
ハードゴールおよびソフトゴール
ハードゴールは最適化プロポーザルで 必ず 満たさなければならないゴールです。ハードゴールとして設定されていないゴールは ソフトゴール と呼ばれます。ソフトゴールは ベストエフォート ゴールと解釈できます。これらは、最適化プロポーザルで満たす必要はありませんが、最適化の計算に含まれます。
Cruise Control は、すべてのハードゴールを満たし、優先度順にできるだけ多くのソフトゴールを満たす最適化プロポーザルを算出します。すべてのハードゴールを 満たさない 最適化プロポーザルは Analyzer によって拒否され、ユーザーには送信されません。
たとえば、クラスター全体でトピックのレプリカを均等に分散するソフトゴールがあるとします (トピックレプリカ分散のゴール)。このソフトゴールを無視すると、設定されたハードゴールがすべて有効になる場合、Cruise Control はこのソフトゴールを無視します。
以下のマスター最適化ゴールは、cruisecontrol.properties ファイルの hard.goals プロパティーにハードゴールとして事前設定されています。
RackAwareGoal; ReplicaCapacityGoal; DiskCapacityGoal; NetworkInboundCapacityGoal; NetworkOutboundCapacityGoal; CpuCapacityGoal
ハードゴールを変更するには、hard.goals プロパティーを編集し、完全修飾ドメイン名を使用して、希望のゴールを指定します。
ハードゴールの数を増やすと、Cruise Control が有効な最適化プロポーザルを計算して生成する可能性が低くなります。
デフォルトの最適化ゴール
Cruise Control は デフォルトの最適化ゴール リストを使用して、キャッシュされた最適化プロポーザル を生成します。詳細は、「最適化プロポーザルの概要」 を参照してください。
ユーザー提供の最適化ゴール を設定すると、デフォルトの最適化ゴールを実行時に上書きできます。
以下のデフォルトの最適化ゴールは cruisecontrol.properties ファイルにあり、default.goals プロパティーに、優先順位の高い順に事前設定されています。
RackAwareGoal; ReplicaCapacityGoal; DiskCapacityGoal; NetworkInboundCapacityGoal; NetworkOutboundCapacityGoal; CpuCapacityGoal; ReplicaDistributionGoal; PotentialNwOutGoal; DiskUsageDistributionGoal; NetworkInboundUsageDistributionGoal; NetworkOutboundUsageDistributionGoal; CpuUsageDistributionGoal; TopicReplicaDistributionGoal; LeaderReplicaDistributionGoal; LeaderBytesInDistributionGoal
デフォルトのゴールを 1 つ以上指定する必要があります。そうしないと、Cruise Control がクラッシュします。
デフォルトの最適化ゴールを変更するには、default.goals プロパティーにゴールのリストを優先度が高いものから順に指定します。デフォルトのゴールはマスター最適化ゴールのサブセットである必要があります。完全修飾ドメイン名を使用します。
ユーザー提供の最適化ゴール
ユーザー提供の最適化ゴール は、特定の最適化プロポーザルの設定済みのデフォルトゴールを絞り込みます。必要に応じて、/rebalance エンドポイントへの HTTP リクエストのパラメーターとして設定することができます。詳細は、「最適化プロポーザルの生成」 を参照してください。
ユーザー提供の最適化ゴールは、さまざまな状況の最適化プロポーザルを生成できます。たとえば、ディスクの容量やディスクの使用率を考慮せずに、Kafka クラスター全体でリーダーレプリカの分布を最適化したい場合があります。そのため、/rebalance エンドポイントに、リーダーレプリカディストリビューションの単一のゴールが含まれるリクエストを送信します。
ユーザー提供の最適化ゴールには、以下が必要です。
- 設定済みの ハードゴール がすべて含まれるようにする必要があります。そうしないと、エラーが発生します。
- マスター最適化ゴール のサブセットである必要があります。
最適化プロポーザルの設定済みのハードゴールを無視するには、skip_hard_goals_check=true パラメーターをリクエストに追加します。
関連情報
- 「Cruise Control の設定」
- Cruise Control Wiki の 「Configurations」
15.6. 最適化プロポーザルの概要
最適化プロポーザル は、提案された変更の要約であり、適用された場合、よりバランスの取れた Kafka クラスターを生成し、パーティションのワークロードがブローカー間でより均等に分散されます。各最適化プロポーザルは、それを生成するために使用された 最適化ゴール のセットに基づいており、ブローカーリソースに設定された 容量制限 が適用されます。
/rebalance エンドポイントに POST リクエストを要求すると、最適化プロポーザルが応答として返されます。プロポーザルの情報を使用して、プロポーザルに基づいてクラスターのリバランスを開始するかどうかを決定します。または、最適化ゴールを変更してから、別のプロポーザルを生成することもできます。
デフォルトでは、最適化プロポーザルは ドライラン として生成され、個別に開始する必要があります。生成できる最適化プロポーザルの数に制限はありません。
キャッシュされた最適化プロポーザル
Cruise Control は、設定済みの デフォルトの最適化ゴール を基にした キャッシュされた最適化プロポーザル を維持します。キャッシュされた最適化プロポーザルはワークロードモデルから生成され、Kafka クラスターの現在の状況を反映するために 15 分ごとに更新されます。
以下のゴール設定が使用される場合に、キャッシュされた最新の最適化プロポーザルが返されます。
- デフォルトの最適化ゴール
- 現在キャッシュされているプロポーザルで達成できるユーザー提供の最適化ゴール
キャッシュされた最適化プロポーザルの更新間隔を変更するには、Cruise Control デプロイメント設定の cruisecontrol.properties ファイルの proposal.expiration.ms 設定を編集します。更新間隔を短くすると、Cruise Control サーバーの負荷が増えますが、変更が頻繁に行われるクラスターでは、更新間隔を短くするよう考慮してください。
最適化プロポーザルの内容
以下の表は、最適化プロポーザルに含まれるプロパティーを表しています。
| プロパティー | 説明 |
|---|---|
|
|
リバランス操作中のパフォーマンスへの影響度: 比較的高い。
リバランス操作中のパフォーマンスへの影響度: 場合による。MB の数が大きいほど、クラスターのリバランスの完了にかかる時間が長くなります。 |
|
|
リバランス操作中のパフォーマンスへの影響度: 比較的高いが、
リバランス操作中のパフォーマンスへの影響度: 場合による。値が大きいほど、クラスターのリバランスの完了にかかる時間が長くなります。大量のデータを移動する場合、同じブローカーのディスク間で移動する方が個別のブローカー間で移動するよりも影響度が低くなります ( |
|
| 最適化プロポーザルのパーティションレプリカ/リーダーの移動の計算から除外されたトピックの数。 以下のいずれかの方法で、トピックを除外することができます。
正規表現と一致するトピックが応答に一覧表示され、クラスターのリバランスから除外されます。 |
|
|
リバランス操作中のパフォーマンスへの影響度: 比較的低い。 |
|
|
|
|
|
|
|
| Kafka クラスターの全体的なバランスの測定。
Cruise Control は、複数の要因を基にして
|
15.7. リバランスパフォーマンスチューニングの概要
クラスターリバランスのパフォーマンスチューニングオプションを調整できます。これらのオプションは、リバランスのパーティションレプリカおよびリーダーシップの移動が実行される方法を制御し、また、リバランス操作に割り当てられた帯域幅も制御します。
パーティション再割り当てコマンド
最適化プロポーザル は、個別のパーティション再割り当てコマンドで構成されています。プロポーザルを開始すると、Cruise Control サーバーはこれらのコマンドを Kafka クラスターに適用します。
パーティション再割り当てコマンドは、以下のいずれかの操作で構成されます。
パーティションの移動: パーティションレプリカとそのデータを新しい場所に転送します。パーティションの移動は、以下の 2 つの形式のいずれかになります。
- ブローカー間の移動: パーティションレプリカを、別のブローカーのログディレクトリーに移動します。
- ブローカー内の移動: パーティションレプリカを、同じブローカーの異なるログディレクトリーに移動します。
- リーダーシップの移動: パーティションのレプリカのリーダーを切り替えます。
Cruise Control によって、パーティション再割り当てコマンドがバッチで Kafka クラスターに発行されます。リバランス中のクラスターのパフォーマンスは、各バッチに含まれる各タイプの移動数に影響されます。
パーティション再割り当てコマンドを設定するには、「リバランスチューニングオプション」 を参照してください。
レプリカの移動ストラテジー
クラスターリバランスのパフォーマンスは、パーティション再割り当てコマンドのバッチに適用される レプリカ移動ストラテジー の影響も受けます。デフォルトでは、Cruise Control は BaseReplicaMovementStrategy を使用します。これは、生成された順序でコマンドを適用します。ただし、プロポーザルの初期に非常に大きなパーティションの再割り当てがある場合、このストラテジーによって他の再割り当ての適用が遅くなる可能性があります。
Cruise Control は、最適化プロポーザルに適用できる 3 つの代替レプリカ移動ストラテジーを提供します。
-
PrioritizeSmallReplicaMovementStrategy: サイズの昇順で再割り当てを並べ替えます。 -
PrioritizeLargeReplicaMovementStrategy: サイズの降順で再割り当ての順序です。 -
PostponeUrpReplicaMovementStrategy: 非同期レプリカがないパーティションのレプリカの再割り当てを優先します。
これらのストラテジーをシーケンスとして設定できます。最初のストラテジーは、内部ロジックを使用して 2 つのパーティション再割り当ての比較を試みます。再割り当てが同等である場合は、順番を決定するために再割り当てをシーケンスの次のストラテジーに渡します。
レプリカの移動ストラテジーを設定するには、「リバランスチューニングオプション」 を参照してください。
リバランスチューニングオプション
Cruise Control には、リバランスパラメーターを調整する設定オプションが複数あります。これらのオプションは、以下の方法で設定されます。
-
プロパティーとして、Cruise Control のデフォルト設定および
cruisecontrol.propertiesファイルに設定 -
パラメーターとして、
/rebalanceエンドポイントへの POST リクエストに設定
両方の方法に関連する設定を以下の表にまとめています。
| プロパティーおよび要求パラメーターの設定 | 説明 | デフォルト値 |
|---|---|---|
|
| 各パーティション再割り当てバッチでのブローカー間パーティション移動の最大数。 | 5 |
|
| ||
|
| 各パーティション再割り当てバッチでのブローカー内パーティション移動の最大数。 | 2 |
|
| ||
|
| 各パーティション再割り当てバッチにおけるパーティションリーダー変更の最大数。 | 1000 |
|
| ||
|
| パーティションの再割り当てに割り当てる帯域幅(バイト/秒単位)。 | Null(制限なし) |
|
| ||
|
|
パーティション再割り当てコマンドが、生成されたプロポーザルに対して実行される順番を決定するために使用されるストラテジー (優先順位順) の一覧。3つのストラテジー
プロパティーには、ストラテジークラスの完全修飾名のコンマ区切りリストを使用します(各クラス名の先頭に パラメーターには、レプリカ移動ストラテジーのクラス名のコンマ区切りリストを使用します。 |
|
|
|
デフォルト設定を変更すると、リバランスの完了までにかかる時間と、リバランス中の Kafka クラスターの負荷に影響します。値を小さくすると負荷は減りますが、かかる時間は長くなり、その逆も同様です。
関連情報
- Cruise Control Wiki の 「Configurations」
- Cruise Control Wiki の 「REST API」
15.8. Cruise Control の設定
config/cruisecontrol.properties ファイルには Cruise Control の設定が含まれます。このファイルは、以下のいずれかのタイプのプロパティーで構成されます。
- 文字列
- 数値
- Boolean
Cruise Control Wiki の 「Configurations」 セクションに記載されているすべてのプロパティーを指定および設定できます。
容量の設定
Cruise Control は 容量制限 を使用して、特定のリソースベースの最適化ゴールが破損しているか判断します。1 つ以上のリソースベースのゴールがハードゴールとして設定され、破損すると、最適化の試みは失敗します。これにより、最適化を使用して最適化プロポーザルを生成できなくなります。
Kafka ブローカーリソースの容量制限は、cruise-control/config の以下の 3 つの .json ファイルのいずれかに指定します。
-
capacityJBOD.json: JBOD Kafka デプロイメントでの使用(デフォルトのファイル)。 -
capacity.json: 各ブローカーに同じ数の CPU コアがある、JBOD 以外の Kafka デプロイメントでの使用。 -
capacityCores.json: 各ブローカーによって CPU コアの数が異なる、JBOD 以外の Kafka デプロイメントでの使用。
cruisecontrol.properties の capacity.config.file プロパティーにファイルを設定します。選択したファイルは、ブローカーの容量解決に使用されます。以下に例を示します。
capacity.config.file=config/capacityJBOD.json
容量制限は、記述された単位で以下のブローカーリソースに設定できます。
-
DISK: ディスクストレージ(MB 単位) -
CPU: パーセント (0-100) またはコアの数としての CPU 使用率 -
NW_IN: KB 毎秒単位のインバウンドネットワークスループット -
NW_OUT: KB 毎秒単位のアウトバウンドネットワークスループット
Cruise Control によって監視される各ブローカーに同じ容量制限を適用するには、ブローカー ID -1 の容量制限を設定します。個々のブローカーに異なる容量制限を設定するには、各ブローカー ID とその容量設定を指定します。
容量制限の設定例
{
"brokerCapacities":[
{
"brokerId": "-1",
"capacity": {
"DISK": "100000",
"CPU": "100",
"NW_IN": "10000",
"NW_OUT": "10000"
},
"doc": "This is the default capacity. Capacity unit used for disk is in MB, cpu is in percentage, network throughput is in KB."
},
{
"brokerId": "0",
"capacity": {
"DISK": "500000",
"CPU": "100",
"NW_IN": "50000",
"NW_OUT": "50000"
},
"doc": "This overrides the capacity for broker 0."
}
]
}
詳細は、Cruise Control Wiki の 「Populating the Capacity Configuration File」 を参照してください。
Cruise Control Metrics トピックのログクリーンアップポリシー
自動作成された __CruiseControlMetrics トピック (「自動作成されたトピック」 を参照) には、COMPACT ではなく DELETE のログクリーンアップポリシーを設定することが重要です。設定されていない場合は、Cruise Control が必要とするレコードが削除される可能性があります。
「Cruise Control Metrics Reporter のデプロイ」 で説明されているように、Kafka 設定ファイルに以下のオプションを設定すると、COMPACT ログクリーンアップポリシーが正しく設定されます。
-
cruise.control.metrics.topic.auto.create=true -
cruise.control.metrics.topic.num.partitions=1 -
cruise.control.metrics.topic.replication.factor=1
Cruise Control Metrics Reporter (cruise.control.metrics.topic.auto.create=false) でトピックの自動作成が 無効 で、Kafka クラスターで 有効 になっている場合、__CruiseControlMetrics トピックはブローカーによって自動的に作成されます。この場合は、kafka-configs.sh ツールを使用して、__CruiseControlMetrics トピックのログクリーンアップポリシーを DELETE に変更する必要があります。
__CruiseControlMetricsトピックの現在の設定を取得します。bin/kafka-configs.sh --bootstrap-server <BrokerAddress> --entity-type topics --entity-name __CruiseControlMetrics --describeトピック設定でログクリーンアップポリシーを変更します。
bin/kafka-configs.sh --bootstrap-server <BrokerAddress> --entity-type topics --entity-name __CruiseControlMetrics --alter --add-config cleanup.policy=delete
Cruise Control Metrics Reporter および Kafka クラスターの両方でトピックの自動作成が 無効 になっている場合は、__CruiseControlMetrics トピックを手動で作成してから、kafka-configs.sh ツールを使用して DELETE ログクリーンアップポリシーを使用するように設定する必要があります。
詳細は、「トピック設定の変更」 を参照してください。
ロギングの設定
Cruise Control はすべてのサーバーロギングに log4j1 を使用します。デフォルト設定を変更するには、/opt/cruise-control/config/log4j.properties の log4j.properties ファイルを編集します。
変更を反映するには、Cruise Control サーバーを再起動する必要があります。
15.9. 最適化プロポーザルの生成
/rebalance エンドポイントに POST リクエストを行うと、Cruise Control は提供された最適化ゴールを基にして、Kafka クラスターをリバランスするために最適化プロポーザルを生成します。
dryrun パラメーターが指定され、false に設定されない限り、最適化プロポーザルは ドライラン として生成されます。
その後、ドライランの最適化プロポーザルの情報を分析し、開始するかどうかを決定します。
以下は、/rebalance エンドポイントへの要求に追加できるキーパラメーターです。利用可能なすべてのパラメーターの詳細は、Cruise Control Wiki の 「REST APIs」 を参照してください。
dryrun
type: boolean、デフォルト: true
最適化プロポーザルのみを生成するか (true)、最適化プロポーザルを生成してクラスターのリバランスを実行するか (false) を Cruise Control に通知します。
excluded_topics
type: regex
最適化プロポーザルの計算から除外するトピックと一致する正規表現。
goals
type: 文字列のリスト。default: 設定済み default.goals リスト
最適化プロポーザルを準備するために使用するユーザー提供の最適化ゴールのリスト。goalsが指定されていない場合は、cruisecontrol.properties ファイルに設定されている default.goals リストが使用されます。
skip_hard_goals_check
type: boolean、デフォルト: false
デフォルトでは、Cruise Control はユーザー提供の最適化ゴール (goals パラメーター) に設定済みのハードゴール (hard.goals) がすべて含まれていることを確認します。設定された hard.goals のサブセットではないゴールを指定すると、リクエストは失敗します。
設定されたすべての hard.goals を含まない、ユーザー提供の最適化ゴールで最適化プロポーザルを生成する場合は、skip_hard_goals_check を true に設定します。
json
type: boolean、デフォルト: false
Cruise Control サーバーによって返される応答のタイプを制御します。指定のない場合、または false に設定された場合、Cruise Control はコマンドラインで表示するためにフォーマットされたテキストを返します。返された情報の要素をプログラムで抽出する場合は、json=true を設定します。これにより、jq などのツールにパイプ処理できる JSON 形式のテキストを返したり、スクリプトやプログラムで解析することができます。
verbose
type: boolean、デフォルト: false
Cruise Control サーバーが返す応答の詳細レベルを制御します。
前提条件
- Kafka と ZooKeeper が実行されている。
- Cruise Control が実行されている。
手順
コンソール用にフォーマットされた最適化プロポーザルを生成するには、POST リクエストを
/rebalanceエンドポイントに送信します。設定された
default.goalsを使用するには、以下を実行します。curl -v -X POST 'cruise-control-server:9090/kafkacruisecontrol/rebalance'
キャッシュされた最適化プロポーザルは即座に返されます。
注記NotEnoughValidWindowsが返されると、Cruise Control は最適化プロポーザルを生成するために十分なメトリクスデータを記録していません。数分待ってからリクエストを再送信します。設定された
default.goalsではなく、ユーザー提供の最適化ゴールを指定するには、goalsパラメーターに 1 つ以上のゴールを指定します。curl -v -X POST 'cruise-control-server:9090/kafkacruisecontrol/rebalance?goals=RackAwareGoal,ReplicaCapacityGoal'
指定されたゴールを満たしている場合、キャッシュされた最適化プロポーザルは即座に返されます。それ以外の場合は、提供されたゴールを使用して新しい最適化プロポーザルが生成されます。計算には時間がかかります。この動作を強制するには、リクエストに
ignore_proposal_cache=trueパラメーターを追加します。設定済みのハードゴールすべてが含まれないユーザー提供の最適化ゴールを指定するには、
skip_hard_goal_check=trueパラメーターをリクエストに追加します。curl -v -X POST 'cruise-control-server:9090/kafkacruisecontrol/rebalance?goals=RackAwareGoal,ReplicaCapacityGoal,ReplicaDistributionGoal&skip_hard_goal_check=true'
応答に含まれる最適化プロポーザルを確認します。プロパティーは、保留中のクラスターリバランス操作を記述します。
プロポーザルには、提案された最適化の概要、各デフォルトの最適化ゴールの概要、およびプロポーザルの実行後に予想されるクラスター状態が含まれます。
以下の情報に特に注意してください。
-
Cluster load after rebalanceの概要。要件を満たす場合には、概要を使用して、提案された変更の影響を評価する必要があります。 -
n inter-broker replica (y MB) movesはブローカー間でネットワークを介して移動されるデータ量を示します。値が高いほど、リバランス中の Kafka クラスターへの潜在的なパフォーマンスの影響が大きくなります。 -
n intra-broker replica (y MB) movesは、ブローカー内部で(ディスク間) でどれだけのデータを移動させるかを示します。値が大きいほど、個々のブローカーに対する潜在的なパフォーマンスの影響は大きくなります (ただしn inter-broker replica (y MB) movesの影響よりも小さい)。 - リーダーシップ移動の数。これは、リバランス中のクラスターのパフォーマンスにほとんど影響しません。
-
非同期応答
Cruise Control REST API エンドポイントは、デフォルトでは 10 秒後にタイムアウトしますが、プロポーザルの生成はサーバー上で継続されます。最近キャッシュされた最適化プロポーザルが準備状態にない場合や、ユーザー提供の最適化ゴールが ignore_proposal_cache=true で指定された場合は、タイムアウトが発生することがあります。
後で最適化プロポーザルを取得できるようにするには、/rebalance エンドポイントからの応答のヘッダーにあるリクエストの一意識別子を書き留めておきます。
curl を使用して応答を取得するには、詳細 (-v) オプションを指定します。
curl -v -X POST 'cruise-control-server:9090/kafkacruisecontrol/rebalance'
ヘッダーの例を以下に示します。
* Connected to cruise-control-server (::1) port 9090 (#0)
> POST /kafkacruisecontrol/rebalance HTTP/1.1
> Host: cc-host:9090
> User-Agent: curl/7.70.0
> Accept: /
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Date: Mon, 01 Jun 2020 15:19:26 GMT
< Set-Cookie: JSESSIONID=node01wk6vjzjj12go13m81o7no5p7h9.node0; Path=/
< Expires: Thu, 01 Jan 1970 00:00:00 GMT
< User-Task-ID: 274b8095-d739-4840-85b9-f4cfaaf5c201
< Content-Type: text/plain;charset=utf-8
< Cruise-Control-Version: 2.0.103.redhat-00002
< Cruise-Control-Commit_Id: 58975c9d5d0a78dd33cd67d4bcb497c9fd42ae7c
< Content-Length: 12368
< Server: Jetty(9.4.26.v20200117-redhat-00001)
タイムアウト時間内に最適化プロポーザルが準備ができなかった場合、POST リクエストを再送信できます。これには、ヘッダーにある元リクエストの User-Task-ID が含まれます。
curl -v -X POST -H 'User-Task-ID: 274b8095-d739-4840-85b9-f4cfaaf5c201' 'cruise-control-server:9090/kafkacruisecontrol/rebalance'
次のステップ
15.10. クラスターリバランスの開始
最適化プロポーザルに満足している場合、Cruise Control にクラスターのリバランスを開始するように指示し、プロポーザルで要約されているようにパーティションの再割り当てを開始できます。
最適化プロポーザルを生成し、クラスターリバランスを開始するまでの時間をできるだけ短くします。元の最適化プロポーザルの生成後に時間が経過した場合、クラスターの状態が変更されている可能性があります。そのため、開始されたクラスターのリバランスは、確認したものとは異なる場合があります。不明な場合は、最初に新しい最適化プロポーザルを生成します。
ステータスが "Active" の進行中のクラスターリバランスは、一度に 1 つだけになります。
前提条件
- Cruise Control から 最適化プロポーザルを生成済み である。
手順
最近生成された最適化プロポーザルを実行するには、
dryrun=falseパラメーターで POST リクエストを/rebalanceエンドポイントに送信します。curl -X POST 'cruise-control-server:9090/kafkacruisecontrol/rebalance?dryrun=false'
Cruise Control はクラスターリバランスを開始し、最適化プロポーザルを返します。
- 最適化プロポーザルで要約された変更を確認します。変更が予想される内容ではない場合は、リバランスを停止 できます。
/user_tasksエンドポイントを使用して、クラスターリバランスの進捗を確認します。進行中のクラスターリバランスのステータスは "Active" です。Cruise Control サーバーで実行されるすべてのクラスターリバランスタスクを表示するには、以下を実行します。
curl 'cruise-control-server:9090/kafkacruisecontrol/user_tasks' USER TASK ID CLIENT ADDRESS START TIME STATUS REQUEST URL c459316f-9eb5-482f-9d2d-97b5a4cd294d 0:0:0:0:0:0:0:1 2020-06-01_16:10:29 UTC Active POST /kafkacruisecontrol/rebalance?dryrun=false 445e2fc3-6531-4243-b0a6-36ef7c5059b4 0:0:0:0:0:0:0:1 2020-06-01_14:21:26 UTC Completed GET /kafkacruisecontrol/state?json=true 05c37737-16d1-4e33-8e2b-800dee9f1b01 0:0:0:0:0:0:0:1 2020-06-01_14:36:11 UTC Completed GET /kafkacruisecontrol/state?json=true aebae987-985d-4871-8cfb-6134ecd504ab 0:0:0:0:0:0:0:1 2020-06-01_16:10:04 UTC
特定のクラスターリバランスタスクの状態を表示するには、
user-task-idsパラメーターおよびタスク ID を指定します。curl 'cruise-control-server:9090/kafkacruisecontrol/user_tasks?user_task_ids=c459316f-9eb5-482f-9d2d-97b5a4cd294d'
15.11. アクティブなクラスターリバランスの停止
現在進行中のクラスターリバランスを停止できます。
これにより、現在のパーティション再割り当てのバッチ処理を完了し、リバランスを停止するよう Cruise Control が指示されます。リバランスの停止時に、完了したパーティションの再割り当てはすでに適用されています。そのため、Kafka クラスターの状態は、リバランス操作の開始前とは異なります。さらなるリバランスが必要な場合は、新しい最適化プロポーザルを生成してください。
中間 (停止) 状態の Kafka クラスターのパフォーマンスは、初期状態の場合よりも悪くなる可能性があります。
前提条件
- クラスターリバランスが進行中である (ステータスは "Active")。
手順
POST リクエストを
/stop_proposal_executionエンドポイントに送信します。curl -X POST 'cruise-control-server:9090/kafkacruisecontrol/stop_proposal_execution'
関連情報
第16章 分散トレース
分散トレーシングを使用すると、分散システムのアプリケーション間で実行されるトランザクションの進捗を追跡できます。マイクロサービスのアーキテクチャーでは、トレーシングはサービス間のトランザクションの進捗を追跡します。トレースデータは、アプリケーションのパフォーマンスを監視し、ターゲットシステムおよびエンドユーザーアプリケーションの問題を調べるのに役立ちます。
Red Hat Enterprise Linux での AMQ Streams は、トレーシングにより、ソースシステムから Kafka へ、さらに Kafka からターゲットシステムおよびアプリケーションへのメッセージのエンドツーエンドの追跡が容易になります。トレースは、利用可能な JMX メトリクス を補完します。
AMQ Streams によるトレーシングのサポート方法
以下のクライアントおよびコンポーネントに対して、トレースのサポートが提供されます。
Kafka クライアント:
- Kafka プロデューサーおよびコンシューマー
- Kafka Streams API アプリケーション
Kafka コンポーネント:
- Kafka Connect
- Kafka Bridge
- MirrorMaker
- MirrorMaker 2.0
トレースを有効にするには、ハイレベルタスクを 4 つ実行します。
- Jaeger トレーサーを有効にします。
インターセプターを有効にします。
- Kafka クライアントの場合、OpenTracing Apache Kafka Client Instrumentation ライブラリー (AMQ Streams に含まれる) を使用してアプリケーションコードを インストルメント化 します。
- Kafka コンポーネントでは、各コンポーネントに設定プロパティーを設定します。
- トレーシングの環境変数 を設定します。
- クライアントまたはコンポーネントをデプロイします。
インストルメント化されると、クライアントはトレースデータを生成します。たとえば、メッセージの作成時やログへのオフセットの書き込み時などです。
トレースは、サンプリングストラテジーに従いサンプル化され、Jaeger ユーザーインターフェイスで可視化されます。
トレーシングは Kafka ブローカーではサポートされません。
AMQ Streams 以外のアプリケーションおよびシステムにトレーシングを設定する方法については、本章の対象外となります。この件についての詳細は、OpenTracing のドキュメント を参照し、「inject and extrac」を検索してください。
手順の概要
AMQ Streams のトレーシングを設定するには、以下の手順を順番に行います。
クライアントのトレーシングを設定します。
MirrorMaker、MirrorMaker 2.0、および Kafka Connect のトレースを設定します。
- Kafka Bridge のトレースを有効化します。
前提条件
- Jaeger バックエンドコンポーネントがホストオペレーティングシステムにデプロイされている。デプロイメント手順の詳細は、Jaeger デプロイメントのドキュメントを参照してください。
16.1. OpenTracing および Jaeger の概要
AMQ Streams では OpenTracing および Jaeger プロジェクトが使用されます。
OpenTracing は、トレーシングまたは監視システムに依存しない API 仕様です。
- OpenTracing API は、アプリケーションコードを インストルメント化 するために使用されます。
- インストルメント化されたアプリケーションは、分散システム全体で個別のトランザクションの トレース を生成します。
- トレースは、特定の作業単位を定義する スパン で構成されます。
Jaeger はマイクロサービスベースの分散システムのトレーシングシステムです。
- Jaeger は OpenTracing API を実装し、インストルメント化のクライアントライブラリーを提供します。
- Jaeger ユーザーインターフェイスを使用すると、トレースデータをクエリー、フィルター、および分析できます。

関連情報
16.2. Kafka クライアントのトレーシング設定
Jaeger トレーサーを初期化し、分散トレーシング用にクライアントアプリケーションをインストルメント化します。
16.2.1. Kafka クライアント用の Jaeger トレーサーの初期化
一連の トレーシング環境変数 を使用して、Jaeger トレーサーを設定および初期化します。
手順
各クライアントアプリケーションで以下を行います。
Jaeger の Maven 依存関係をクライアントアプリケーションの
pom.xmlファイルに追加します。<dependency> <groupId>io.jaegertracing</groupId> <artifactId>jaeger-client</artifactId> <version>1.1.0.redhat-00002</version> </dependency>- トレーシング環境変数 を使用して Jaeger トレーサーの設定を定義します。
2. で定義した環境変数から、Jaeger トレーサーを作成します。
Tracer tracer = Configuration.fromEnv().getTracer();
注記別の Jaeger トレーサーの初期化方法については、Java OpenTracing ライブラリー のドキュメントを参照してください。
Jaeger トレーサーをグローバルトレーサーとして登録します。
GlobalTracer.register(tracer);
これで、Jaeger トレーサーはクライアントアプリケーションが使用できるように初期化されました。
16.2.2. Kafka プロデューサーおよびコンシューマーをトレース用にインストルメント化
Decorator パターンまたは Interceptor を使用して、Java プロデューサーおよびコンシューマーアプリケーションコードをトレーシング用にインストルメント化します。
手順
各プロデューサーおよびコンシューマーアプリケーションのアプリケーションコードで以下を行います。
OpenTracing の Maven 依存関係を、プロデューサーまたはコンシューマーの
pom.xmlファイルに追加します。<dependency> <groupId>io.opentracing.contrib</groupId> <artifactId>opentracing-kafka-client</artifactId> <version>0.1.12.redhat-00001</version> </dependency>Decorator パターンまたは Interceptor のいずれかを使用して、クライアントアプリケーションコードをインストルメント化します。
Decorator パターンを使用する場合は以下を行います。
// Create an instance of the KafkaProducer: KafkaProducer<Integer, String> producer = new KafkaProducer<>(senderProps); // Create an instance of the TracingKafkaProducer: TracingKafkaProducer<Integer, String> tracingProducer = new TracingKafkaProducer<>(producer, tracer); // Send: tracingProducer.send(...); // Create an instance of the KafkaConsumer: KafkaConsumer<Integer, String> consumer = new KafkaConsumer<>(consumerProps); // Create an instance of the TracingKafkaConsumer: TracingKafkaConsumer<Integer, String> tracingConsumer = new TracingKafkaConsumer<>(consumer, tracer); // Subscribe: tracingConsumer.subscribe(Collections.singletonList("messages")); // Get messages: ConsumerRecords<Integer, String> records = tracingConsumer.poll(1000); // Retrieve SpanContext from polled record (consumer side): ConsumerRecord<Integer, String> record = ... SpanContext spanContext = TracingKafkaUtils.extractSpanContext(record.headers(), tracer);Interceptor を使用する場合は以下を使用します。
// Register the tracer with GlobalTracer: GlobalTracer.register(tracer); // Add the TracingProducerInterceptor to the sender properties: senderProps.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, TracingProducerInterceptor.class.getName()); // Create an instance of the KafkaProducer: KafkaProducer<Integer, String> producer = new KafkaProducer<>(senderProps); // Send: producer.send(...); // Add the TracingConsumerInterceptor to the consumer properties: consumerProps.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, TracingConsumerInterceptor.class.getName()); // Create an instance of the KafkaConsumer: KafkaConsumer<Integer, String> consumer = new KafkaConsumer<>(consumerProps); // Subscribe: consumer.subscribe(Collections.singletonList("messages")); // Get messages: ConsumerRecords<Integer, String> records = consumer.poll(1000); // Retrieve the SpanContext from a polled message (consumer side): ConsumerRecord<Integer, String> record = ... SpanContext spanContext = TracingKafkaUtils.extractSpanContext(record.headers(), tracer);
Decorator パターンのカスタムスパン名
スパン は Jaeger の論理作業単位で、操作名、開始時間、および期間が含まれます。
プロデューサーとコンシューマーのアプリケーションをインストルメントするために Decorator パターンを使用するには、TracingKafkaProducer および TracingKafkaConsumer オブジェクトを作成する際に、追加の引数として BiFunction オブジェクトを渡して、カスタムスパン名を定義します。OpenTracing の Apache Kafka Client Instrumentation ライブラリーには、複数の組み込みスパン名が含まれています。
例: カスタムスパン名を使用した Decorator パターンでのクライアントアプリケーションコードのインストルメント化
// Create a BiFunction for the KafkaProducer that operates on (String operationName, ProducerRecord consumerRecord) and returns a String to be used as the name:
BiFunction<String, ProducerRecord, String> producerSpanNameProvider =
(operationName, producerRecord) -> "CUSTOM_PRODUCER_NAME";
// Create an instance of the KafkaProducer:
KafkaProducer<Integer, String> producer = new KafkaProducer<>(senderProps);
// Create an instance of the TracingKafkaProducer
TracingKafkaProducer<Integer, String> tracingProducer = new TracingKafkaProducer<>(producer,
tracer,
producerSpanNameProvider);
// Spans created by the tracingProducer will now have "CUSTOM_PRODUCER_NAME" as the span name.
// Create a BiFunction for the KafkaConsumer that operates on (String operationName, ConsumerRecord consumerRecord) and returns a String to be used as the name:
BiFunction<String, ConsumerRecord, String> consumerSpanNameProvider =
(operationName, consumerRecord) -> operationName.toUpperCase();
// Create an instance of the KafkaConsumer:
KafkaConsumer<Integer, String> consumer = new KafkaConsumer<>(consumerProps);
// Create an instance of the TracingKafkaConsumer, passing in the consumerSpanNameProvider BiFunction:
TracingKafkaConsumer<Integer, String> tracingConsumer = new TracingKafkaConsumer<>(consumer,
tracer,
consumerSpanNameProvider);
// Spans created by the tracingConsumer will have the operation name as the span name, in upper-case.
// "receive" -> "RECEIVE"
ビルトインスパン名
カスタムスパン名を定義するとき、ClientSpanNameProvider クラスで以下の BiFunctions を使用できます。spanNameProvider を指定しないと、CONSUMER_OPERATION_NAME および PRODUCER_OPERATION_NAME が使用されます。
| BiFunction | 説明 |
|---|---|
|
|
|
|
|
|
|
|
メッセージの送信先または送信元となったトピックの名前を |
|
|
|
|
|
操作名およびトピック名を |
|
|
|
16.2.3. Kafka Streams アプリケーションのトレース用のインストルメント化
サプライヤーインターフェイスを使用して、分散トレーシングのために Kafka Streams アプリケーションをインストルメント化します。これにより、アプリケーションのインターセプターが有効になります。
手順
各 Kafka Streams アプリケーションで以下を行います。
opentracing-kafka-streams依存関係を、Kafka Streams API アプリケーションのpom.xmlファイルに追加します。<dependency> <groupId>io.opentracing.contrib</groupId> <artifactId>opentracing-kafka-streams</artifactId> <version>0.1.12.redhat-00001</version> </dependency>TracingKafkaClientSupplierサプライヤーインターフェイスのインスタンスを作成します。KafkaClientSupplier supplier = new TracingKafkaClientSupplier(tracer);
サプライヤーインターフェイスを
KafkaStreamsに提供します。KafkaStreams streams = new KafkaStreams(builder.build(), new StreamsConfig(config), supplier); streams.start();
16.3. MirrorMaker および Kafka Connect のトレース設定
本セクションでは、分散トレーシング用に MirrorMaker、MirrorMaker 2.0、および Kafka Connect を設定する方法を説明します。
コンポーネントごとに Jaeger トレーサーを有効にする必要があります。
16.3.1. MirrorMaker のトレースの有効化
Interceptor プロパティーをコンシューマーおよびプロデューサー設定パラメーターとして渡すことで、MirrorMaker の分散トレーシングを有効にします。
メッセージはソースクラスターからターゲットクラスターにトレースされます。トレースデータは、MirrorMaker コンポーネントに出入りするメッセージを記録します。
手順
- Jaeger トレーサーを設定し、有効にします。
/opt/kafka/config/consumer.propertiesファイルを編集します。以下のインターセプタープロパティーを追加します。
consumer.interceptor.classes=io.opentracing.contrib.kafka.TracingConsumerInterceptor
/opt/kafka/config/producer.propertiesファイルを編集します。以下のインターセプタープロパティーを追加します。
producer.interceptor.classes=io.opentracing.contrib.kafka.TracingProducerInterceptor
コンシューマーおよびプロデューサー設定ファイルをパラメーターとして MirrorMaker を起動します。
su - kafka /opt/kafka/bin/kafka-mirror-maker.sh --consumer.config /opt/kafka/config/consumer.properties --producer.config /opt/kafka/config/producer.properties --num.streams=2
16.3.2. MirrorMaker 2.0 のトレースの有効化
MirrorMaker 2.0 プロパティーファイルに Interceptor プロパティーを定義して、MirrorMaker 2.0 の分散トレーシングを有効にします。
メッセージは Kafka クラスター間でトレースされます。トレースデータは、MirrorMaker 2.0 コンポーネントに出入りするメッセージを記録します。
手順
- Jaeger トレーサーを設定し、有効にします。
MirrorMaker 2.0 設定プロパティーファイル
./config/connect-mirror-maker.propertiesを編集し、以下のプロパティーを追加します。header.converter=org.apache.kafka.connect.converters.ByteArrayConverter 1 consumer.interceptor.classes=io.opentracing.contrib.kafka.TracingConsumerInterceptor 2 producer.interceptor.classes=io.opentracing.contrib.kafka.TracingProducerInterceptor
- 「MirrorMaker 2.0 を使用した Kafka クラスター間でのデータの同期」 の手順を使用して、MirrorMaker 2.0 を起動します。
16.3.3. Kafka Connect のトレースの有効化
設定プロパティーを使用して Kafka Connect の分散トレーシングを有効にします。
Kafka Connect により生成および消費されるメッセージのみがトレーシングされます。Kafka Connect と外部システム間で送信されるメッセージをトレーシングするには、これらのシステムのコネクターでトレーシングを設定する必要があります。
手順
- Jaeger トレーサーを設定し、有効にします。
関連する Kafka Connect 設定ファイルを編集します。
-
スタンドアロンモードで Kafka Connect を実行している場合は、
/opt/kafka/config/connect-standalone.propertiesファイルを編集します。 -
分散モードで Kafka Connect を実行している場合は、
/opt/kafka/config/connect-distributed.propertiesファイルを編集します。
-
スタンドアロンモードで Kafka Connect を実行している場合は、
以下のプロパティーを設定ファイルに追加します。
producer.interceptor.classes=io.opentracing.contrib.kafka.TracingProducerInterceptor consumer.interceptor.classes=io.opentracing.contrib.kafka.TracingConsumerInterceptor
- 設定を保存します。
- トレーシング環境変数を設定してから、スタンドアロンまたは分散モードで Kafka Connect を実行します。
Kafka Connect の内部コンシューマーおよびプロデューサーのインターセプターが有効になりました。
16.4. Kafka Bridge のトレースの有効化
Kafka Bridge 設定ファイルを編集して、Kafka Bridge の分散トレーシングを有効にします。その後、分散トレース用に設定された Kafka Bridge インスタンスをホストオペレーティングシステムにデプロイできます。
トレースは、以下の場合に生成されます。
- Kafka Bridge が HTTP クライアントにメッセージを送信し、HTTP クライアントからメッセージを消費する場合
- HTTP クライアントが HTTP リクエストを送信し、Kafka Bridge 経由でメッセージを送受信する場合
エンドツーエンドのトレーシングを設定するために、HTTP クライアントでトレーシングを設定する必要があります。
手順
Kafka Bridge インストールディレクトリーの
config/application.propertiesファイルを編集します。以下の行からコードのコメントを削除します。
bridge.tracing=jaeger
- 設定を保存します。
設定プロパティーをパラメーターとして使用し、
bin/kafka_bridge_run.shスクリプトを実行します。cd kafka-bridge-0.xy.x.redhat-0000x ./bin/kafka_bridge_run.sh --config-file=config/application.properties
Kafka Bridge の内部コンシューマーおよびプロデューサーのインターセプターが有効になりました。
16.5. トレーシングの環境変数
Kafka クライアントおよびコンポーネントに Jaeger トレーサーを設定する場合は、これらの環境変数を使用します。
トレーシング環境変数は Jaeger プロジェクトの一部で、変更される場合があります。最新の環境変数については、Jaeger のドキュメント を参照してください。
| プロパティー | 必要性 | 説明 |
|---|---|---|
|
| 必要 | Jaeger トレーサーサービスの名前。 |
|
| 不要 |
UDP (User Datagram Protocol) を介した |
|
| 不要 |
UDP を介した |
|
| 不要 |
|
|
| 不要 | エンドポイントに bearer トークンとして送信する認証トークン。 |
|
| 不要 | Basic 認証を使用する場合にエンドポイントに送信するユーザー名。 |
|
| 不要 | Basic 認証を使用する場合にエンドポイントに送信するパスワード。 |
|
| 不要 |
トレースコンテキストの伝播に使用するカンマ区切りの形式リスト。デフォルトは標準の Jaeger 形式です。有効な値は |
|
| 不要 | レポーターがスパンも記録する必要があるかどうかを示します。 |
|
| 不要 | レポーターの最大キューサイズ。 |
|
| 不要 | レポーターのフラッシュ間隔 (ミリ秒単位)。Jaeger レポーターがスパンバッチをフラッシュする頻度を定義します。 |
|
| 不要 | クライアントトレースに使用するサンプリングストラテジー。
すべてのトレースをサンプリングするには、Constant サンプリングストラテジーを使用し、パラメーターを 1 にします。 詳細は、Jaeger ドキュメントを参照してください。 |
|
| 不要 | サンプラーのパラメーター (数値)。 |
|
| 不要 | リモートサンプリングストラテジーを選択する場合に使用するホスト名およびポート。 |
|
| 不要 | 報告されたすべてのスパンに追加されるトレーサーレベルのタグのカンマ区切りリスト。
また、 |
第17章 Kafka Exporter
Kafka Exporter は、Apache Kafka ブローカーおよびクライアントの監視を強化するオープンソースプロジェクトです。
Kafka Exporter は、Kafka クラスターとのデプロイメントを実現するために AMQ Streams で提供され、オフセット、コンシューマーグループ、コンシューマーラグ、およびトピックに関連する Kafka ブローカーから追加のメトリクスデータを抽出します。
一例として、メトリクスデータを使用すると、低速なコンシューマーの識別に役立ちます。
ラグデータは Prometheus メトリクスとして公開され、解析のために Grafana で使用できます。
ビルトイン Kafka メトリクスを監視するために Prometheus および Grafana をすでに使用している場合、Kafka Exporter Prometheus エンドポイントをスクレープするように Prometheus を設定することもできます。
関連情報
Kafka は JMX 経由でメトリクスを公開し、続いて Prometheus メトリクスとしてエクスポートできます。
17.1. コンシューマーラグ
コンシューマーラグは、メッセージの生成と消費の差を示しています。具体的には、指定のコンシューマーグループのコンシューマーラグは、パーティションの最後のメッセージと、そのコンシューマーが現在ピックアップしているメッセージとの時間差を示しています。ラグには、パーティションログの最後を基準とする、コンシューマーオフセットの相対的な位置が反映されます。
この差は、Kafka ブローカートピックパーティションの読み取りと書き込みの場所である、プロデューサーオフセットとコンシューマーオフセットの間の デルタ とも呼ばれます。
あるトピックで毎秒 100 個のメッセージがストリーミングされる場合を考えてみましょう。プロデューサーオフセット (トピックパーティションの先頭) と、コンシューマーが読み取った最後のオフセットとの間のラグが 1000 個のメッセージであれば、10 秒の遅延があることを意味します。
コンシューマーラグ監視の重要性
可能な限りリアルタイムのデータの処理に依存するアプリケーションでは、コンシューマーラグを監視して、ラグが過度に大きくならないようにチェックする必要があります。ラグが大きくなるほど、リアルタイム処理の達成から遠ざかります。
たとえば、パージされていない古いデータの大量消費や、予定外のシャットダウンが、コンシューマーラグの原因となることがあります。
コンシューマーラグの削減
通常、ラグを削減するには以下を行います。
- 新規コンシューマーを追加してコンシューマーグループをスケールアップします。
- メッセージがトピックに留まる保持時間を延長します。
- ディスク容量を追加してメッセージバッファーを増強します。
コンシューマーラグを減らす方法は、基礎となるインフラストラクチャーや、AMQ Streams によりサポートされるユースケースによって異なります。たとえば、ラグが生じているコンシューマーの場合、ディスクキャッシュからフェッチリクエストに対応できるブローカーを活用できる可能性は低いでしょう。場合によっては、コンシューマーの状態が改善されるまで、自動的にメッセージをドロップすることが許容されることがあります。
17.2. Kafka Exporter アラートルールの例
Kafka Exporter に固有のサンプルのアラート通知ルールには以下があります。
UnderReplicatedPartition- トピックで複製の数が最低数未満であり、ブローカーがパーティションで十分な複製を作成していないことを警告するアラートです。デフォルトの設定では、トピックに複製の数が最低数未満のパーティションが 1 つ以上ある場合のアラートになります。このアラートは、Kafka インスタンスがダウンしているか Kafka クラスターがオーバーロードの状態であることを示す場合があります。レプリケーションプロセスを再起動するには、Kafka ブローカーの計画的な再起動が必要な場合があります。
TooLargeConsumerGroupLag- 特定のトピックパーティションでコンシューマーグループのラグが大きすぎることを警告するアラートです。デフォルト設定は 1000 レコードです。ラグが大きい場合、コンシューマーが遅すぎてプロデューサーの処理に追い付いてない可能性があります。
NoMessageForTooLong- トピックが一定期間にわたりメッセージを受信していないことを警告するアラートです。この期間のデフォルト設定は 10 分です。この遅れは、設定の問題により、プロデューサーがトピックにメッセージを公開できないことが原因である可能性があります。
アラートルールは、特定のニーズに合わせて調整できます。
関連情報
アラートルールの設定についての詳細は、Prometheus のドキュメントの 「Configuration」 を参照してください。
17.3. Kafka Exporter メトリクス
ラグ情報は、Grafana で示す Prometheus メトリクスとして Kafka Exporter によって公開されます。
Kafka Exporter は、ブローカー、トピック、およびコンシューマーグループのメトリクスデータを公開します。
| 名前 | 詳細 |
|---|---|
|
| Kafka クラスターに含まれるブローカーの数 |
| 名前 | 詳細 |
|---|---|
|
| トピックのパーティション数 |
|
| ブローカーの現在のトピックパーティションオフセット |
|
| ブローカーの最も古いトピックパーティションオフセット |
|
| トピックパーティションの In-Sync レプリカ数 |
|
| トピックパーティションのリーダーブローカー ID |
|
|
トピックパーティションが優先ブローカーを使用している場合は、 |
|
| このトピックパーティションのレプリカ数 |
|
|
トピックパーティションの複製の数が最低数未満である場合に |
| 名前 | 詳細 |
|---|---|
|
| コンシューマーグループの現在のトピックパーティションオフセット |
|
| トピックパーティションのコンシューマーグループの現在のラグ (概算値) |
17.4. Kafka Exporter の実行
Kafka Exporter は、AMQ Streams のインストール に使用されるダウンロードアーカイブで提供されます。
これを実行して、Grafana ダッシュボードに表示するための Prometheus メトリクスを公開できます。
この手順は、Grafana ユーザーインターフェイスへのアクセス権がすでにあり、Prometheus がデプロイされてデータソースとして追加されていることを前提としています。
手順
適切な設定パラメーター値を使用して Kafka Exporter スクリプトを実行します。
./bin/kafka_exporter --kafka.server=<kafka-bootstrap-address>:9092 --kafka.version=2.6.0 --<my-other-parameters>
パラメーターには、
--kafka.serverなど、二重ハイフンの標記が必要です。表17.4 Kafka Exporter 設定パラメーター オプション 説明 デフォルト kafka.serverKafka サーバーのホスト/ポストアドレス。
kafka:9092kafka.versionKafka ブローカーのバージョン。
1.0.0group.filterメトリクスに含まれるコンシューマーグループを指定する正規表現。
.*(すべて)topic.filterメトリクスに含まれるトピックを指定する正規表現。
.*(すべて)sasl.<parameter>ユーザー名とパスワードで SASL/PLAIN 認証を使用して Kafka クラスターを有効にし、接続するパラメーター。
falsetls.<parameter>任意の証明書およびキーで TLS 認証を使用して Kafka クラスターへの接続を有効にするパラメーター。
falseweb.listen-addressメトリクスを公開するポートアドレス。
:9308web.telemetry-path公開されるメトリクスのパス。
/metricslog.level指定の重大度 (debug、info、warn、error、fatal) 以上でメッセージをログに記録するためのログ設定。
infolog.enable-saramaSarama ロギングを有効にするブール値 (Kafka Exporter によって使用される Go クライアントライブラリー)。
falseプロパティーの詳細は、
kafka_exporter --helpを使用できます。Kafka Exporter メトリクスを監視するように Prometheus を設定します。
Prometheus の設定に関する詳細は、Prometheus のドキュメント を参照してください。
Grafana を有効にして、Prometheus によって公開される Kafka Exporter メトリクスデータを表示します。
詳細は、「Grafana での Kafka Exporter メトリクスの表示」 を参照してください。
17.5. Grafana での Kafka Exporter メトリクスの表示
Kafka Exporter Prometheus メトリクスをデータソースとして使用すると、Grafana チャートのダッシュボードを作成できます。
たとえば、メトリクスから、以下の Grafana チャートを作成できます。
- 毎秒のメッセージ (トピックから)
- 毎分のメッセージ (トピックから)
- コンシューマーグループごとのラグ
- 毎分のメッセージ消費 (コンシューマーグループごと)
メトリクスデータが収集されると、Kafka Exporter のチャートにデータが反映されます。
Grafana のチャートを使用して、ラグを分析し、ラグ削減の方法が対象のコンシューマーグループに影響しているかどうかを確認します。たとえば、ラグを減らすように Kafka ブローカーを調整すると、ダッシュボードには コンシューマーグループごとのラグ のチャートが下降し 毎分のメッセージ消費 のチャートが上昇する状況が示されます。
第18章 AMQ Streams および Kafka のアップグレード
AMQ Streams は、クラスターのダウンタイムを発生せずにアップグレードできます。AMQ Streams の各バージョンは、Apache Kafka の 1 つ以上のバージョンをサポートします。使用する AMQ Streams バージョンでサポートされれば、より高いバージョンの Kafka にアップグレードできます。より新しいバージョンの AMQ Streams はより新しいバージョンの Kafka をサポートしますが、AMQ Streams を アップグレードしてから、サポートされる上位バージョンの Kafka にアップグレードする必要があります。
18.1. アップグレードの前提条件
アップグレードプロセスを開始する前に、以下を確認します。
- AMQ Streams がインストールされている。手順は、「2章はじめに」を参照してください。
- 『 AMQ Streams 1.6 on Red Hat Enterprise Linux Release Notes』 で説明されているアップグレードの変更を理解している。
18.2. アップグレードプロセス
AMQ Streams のアップグレードは 2 段階のプロセスで行います。ダウンタイムなしでブローカーとクライアントをアップグレードするには、以下の順序でアップグレード手順を 必ず 完了してください。
最新の AMQ Streams バージョンにアップグレードします。
すべての Kafka ブローカーとクライアントアプリケーションを、最新の Kafka バージョンにアップグレードします。
18.3. Kafka バージョン
Kafka のログメッセージ形式バージョンおよびブローカー間のプロトコルバージョンは、メッセージに追加されるログ形式バージョンとクラスターで使用されるプロトコルのバージョンを指定します。そのためアップグレードプロセスでは、既存の Kafka ブローカーの設定変更およびクライアントアプリケーション (コンシューマーおよびプロデューサー) のコード変更により、必ず正しいバージョンを使用されるようにする必要になります。
以下の表は、Kafka バージョンの違いを示しています。
| Kafka バージョン | Interbroker プロトコルバージョン | ログメッセージ形式バージョン | ZooKeeper のバージョン |
|---|---|---|---|
| 2.5.0 | 2.5 | 2.5 | 3.5.8 |
| 2.6.0 | 2.6 | 2.6 | 3.5.8 |
メッセージ形式バージョン
プロデューサーが Kafka ブローカーにメッセージを送信すると、特定の形式を使用してメッセージがエンコードされます。この形式は Kafka のリリースによって変わるため、メッセージにはエンコードに使用された形式のバージョンが含まれます。ブローカーがメッセージをログに追加する前に、メッセージを新しい形式バージョンから特定の旧形式バージョンに変換するように、Kafka ブローカーを設定できます。
Kafka には、メッセージ形式のバージョンを設定する 2 通りの方法があります。
-
message.format.versionプロパティーをトピックに設定します。 -
log.message.format.versionプロパティーを Kafka ブローカーに設定します。
トピックの message.format.version のデフォルト値は、Kafka ブローカーに設定される log.message.format.version によって定義されます。トピックの message.format.version は、トピック設定を編集すると手動で設定できます。
本セクションのアップグレード作業では、メッセージ形式のバージョンが log.message.format.version によって定義されることを前提としています。
18.4. AMQ Streams 1.6 へのアップグレード
このセクションでは、AMQ Streams 1.6 を使用するようにデプロイメントをアップグレードする手順について説明します。
AMQ Streams によって管理される Kafka クラスターの可用性は、アップグレード操作の影響を受けません。
特定バージョンの AMQ Streams へのアップグレード方法については、そのバージョンをサポートするドキュメントを参照してください。
18.4.1. Kafka ブローカーおよび ZooKeeper のアップグレード
この手順では、最新バージョンの AMQ Streams を使用するように、ホストマシンで Kafka ブローカーおよび ZooKeeper をアップグレードする方法を説明します。
前提条件
-
Red Hat Enterprise Linux に
kafkaユーザーとしてログインしている。
手順
AMQ Streams クラスターの各 Kafka ブローカーに対して、以下を 1 つずつ行います。
カスタマーポータル から AMQ Streams アーカイブをダウンロードします。
注記プロンプトが表示されたら、Red Hat アカウントにログインします。
コマンドラインで一時ディレクトリーを作成し、
amq-streams-x.y.z-bin.zipファイルの内容を展開します。mkdir /tmp/kafka unzip amq-streams-x.y.z-bin.zip -d /tmp/kafka
実行中の場合は、ホストで実行している ZooKeeper および Kafka ブローカーを停止します。
/opt/kafka/bin/zookeeper-server-stop.sh /opt/kafka/bin/kafka-server-stop.sh jcmd | grep zookeeper jcmd | grep kafka
既存のインストールから
libs、bin、およびdocsディレクトリーを削除します。rm -rf /opt/kafka/libs /opt/kafka/bin /opt/kafka/docs
一時ディレクトリーから、
libs、bin、およびdocsディレクトリーをコピーします。cp -r /tmp/kafka/kafka_y.y-x.x.x/libs /opt/kafka/ cp -r /tmp/kafka/kafka_y.y-x.x.x/bin /opt/kafka/ cp -r /tmp/kafka/kafka_y.y-x.x.x/docs /opt/kafka/
一時ディレクトリーを削除します。
rm -r /tmp/kafka
-
テキストエディターで、一般的に
/opt/kafka/config/ディレクトリーに保存されているブローカープロパティーファイルを開きます。 inter.broker.protocol.versionおよびlog.message.format.versionプロパティーが 現行 バージョンに設定されていることを確認します。inter.broker.protocol.version=2.5 log.message.format.version=2.5
Inter.broker.protocol.versionを変更しないと、ブローカーはアップグレード中も相互に通信を継続できます。プロパティーが設定されていない場合は、現在のバージョンでプロパティーを追加します。
更新された ZooKeeper および Kafka ブローカーを再起動します。
/opt/kafka/bin/zookeeper-server-start.sh -daemon /opt/kafka/config/zookeeper.properties /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
Kafka ブローカーおよび Zookeeper は、最新の Kafka バージョンのバイナリーの使用を開始します。
-
再起動したKafkaブローカーが、フォローしているパーティションレプリカに追いついたことを確認します。
kafka-topics.shツールを使用して、ブローカーに含まれるすべてのレプリカが同期していることを確認します。手順は、トピックの一覧表示および説明 を参照してください。 - 「Kafka のアップグレード」 の説明に従って、Kafka をアップグレードする手順を実行します。
18.4.2. Kafka Connect のアップグレード
この手順では、ホストマシンで Kafka Connect クラスターをアップグレードする方法を説明します。
Kafka Connect はクライアントアプリケーションで、クライアントをアップグレードするために選択したストラテジーに追加する必要があります。詳細は、「 クライアントをアップグレードするストラテジー」を 参照してください。
前提条件
-
Red Hat Enterprise Linux に
kafkaユーザーとしてログインしている。 - Kafka Connect が起動していない。
手順
AMQ Streams クラスターの各 Kafka ブローカーに対して、以下を 1 つずつ行います。
カスタマーポータル から AMQ Streams アーカイブをダウンロードします。
注記プロンプトが表示されたら、Red Hat アカウントにログインします。
コマンドラインで一時ディレクトリーを作成し、
amq-streams-x.y.z-bin.zipファイルの内容を展開します。mkdir /tmp/kafka unzip amq-streams-x.y.z-bin.zip -d /tmp/kafka
実行中の場合は、ホストで実行している Kafka ブローカーおよび ZooKeeper を停止します。
/opt/kafka/bin/kafka-server-stop.sh /opt/kafka/bin/zookeeper-server-stop.sh
既存のインストールから
libs、bin、およびdocsディレクトリーを削除します。rm -rf /opt/kafka/libs /opt/kafka/bin /opt/kafka/docs
一時ディレクトリーから、
libs、bin、およびdocsディレクトリーをコピーします。cp -r /tmp/kafka/kafka_y.y-x.x.x/libs /opt/kafka/ cp -r /tmp/kafka/kafka_y.y-x.x.x/bin /opt/kafka/ cp -r /tmp/kafka/kafka_y.y-x.x.x/docs /opt/kafka/
一時ディレクトリーを削除します。
rm -r /tmp/kafka
スタンドアロンまたは分散モードのいずれかで Kafka Connect を起動します。
スタンドアロンモードで起動するには、
connect-standalone.shスクリプトを実行します。Kafka Connect スタンドアロン設定ファイルおよびご使用中の Kafka Connect コネクターの設定ファイルを指定します。su - kafka /opt/kafka/bin/connect-standalone.sh /opt/kafka/config/connect-standalone.properties connector1.properties [connector2.properties ...]
分散モードで起動するには、すべての Kafka Connect ノードで
/opt/kafka/config/connect-distributed.properties設定ファイルで Kafka Connect ワーカーを起動します。su - kafka /opt/kafka/bin/connect-distributed.sh /opt/kafka/config/connect-distributed.properties
KafkaConnect が実行されていることを確認します。
スタンドアロンモードの場合:
jcmd | grep ConnectStandalone
分散モードの場合:
jcmd | grep ConnectDistributed
- Kafka Connect が想定どおりにデータを生成および消費していることを確認します。
18.5. Kafka のアップグレード
バイナリーをアップグレードして最新バージョンの AMQ Streams を使用 する 後、ブローカーおよびクライアントをアップグレードして、サポートされる上位バージョンの Kafka を使用できます。
正しい順序で手順を実行してください。
Kafka のアップグレードの後、必要な場合は Kafka コンシューマーをアップグレードして Incremental Cooperative Rebalance プロトコルを使用できます。
18.5.1. 新しいブローカー間プロトコルバージョンを使用するための Kafka ブローカーのアップグレード
新しいブローカー間プロトコルバージョンを使用するように、すべての Kafka ブローカーを手動で設定および再起動します。これらの手順の実行後に、新しい inter-broker プロトコルバージョンを使用して Kafka ブローカー間でデータが送信されます。
受信したメッセージは、以前のメッセージ形式のバージョンでメッセージログに追加されます。
この手順の完了後に AMQ Streams をダウングレードすることはできません。
前提条件
- ZooKeeper バイナリーを更新し、すべての Kafka ブローカーを AMQ Streams 1.6 にアップグレードしている。
-
Red Hat Enterprise Linux に
kafkaユーザーとしてログインしている。
手順
AMQ Streams クラスターの各 Kafka ブローカーに対して、以下を 1 つずつ行います。
-
テキストエディターで、更新する Kafka ブローカーのブローカープロパティーファイルを開きます。ブローカープロパティーファイルは、一般的に
/opt/kafka/config/ディレクトリーに保存されます。 inter.broker.protocol.versionを2.6 に設定します。inter.broker.protocol.version=2.6
コマンドラインで、変更した Kafka ブローカーを停止します。
/opt/kafka/bin/kafka-server-stop.sh jcmd | grep kafka
変更した Kafka ブローカーを再起動します。
/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
-
再起動したKafkaブローカーが、フォローしているパーティションレプリカに追いついたことを確認します。
kafka-topics.shツールを使用して、ブローカーに含まれるすべてのレプリカが同期していることを確認します。手順は、「トピックの一覧表示および説明」 を参照してください。
18.5.2. クライアントをアップグレードするストラテジー
クライアントアプリケーション (Kafka Connect コネクターを含む) をアップグレードする最善の方法は、特定の状況によって異なります。
消費するアプリケーションは、そのアプリケーションが理解するメッセージ形式のメッセージを受信する必要があります。その状態であることを、以下のいずれかの方法で確認できます。
- プロデューサーをアップグレードする 前に、トピックのすべてのコンシューマーをアップグレードする。
- ブローカーでメッセージをダウンコンバートする。
ブローカーのダウンコンバートを使用すると、ブローカーに余分な負荷が加わるので、すべてのトピックで長期にわたりダウンコンバートに頼るのは最適な方法ではありません。ブローカーの実行を最適化するには、ブローカーがメッセージを一切ダウンコンバートしないようにしてください。
ブローカーのダウンコンバートは 2 通りの方法で設定できます。
-
トピックレベルの
message.format.version。単一のトピックが設定されます。 -
ブローカーレベルの
log.message.format.version。トップレベルのmessage.format.versionが設定されていないトピックのデフォルトです。
新バージョンの形式でトピックにパブリッシュされるメッセージは、コンシューマーによって認識されます。これは、メッセージがコンシューマーに送信されるときでなく、ブローカーがプロデューサーからメッセージを受信するときに、ブローカーがダウンコンバートを実行するからです。
クライアントのアップグレードに使用できるストラテジーは複数あります。
- コンシューマーを最初にアップグレード
- コンシューマーとして機能するアプリケーションをすべてアップグレードします。
-
ブローカーレベル
log.message.format.versionを新バージョンに変更します。 プロデューサーとして機能するアプリケーションをアップグレードします。
このストラテジーは分かりやすく、ブローカーのダウンコンバートの発生をすべて防ぎます。ただし、所属組織内のすべてのコンシューマーを整然とアップグレードできることが前提になります。また、コンシューマーとプロデューサーの両方に該当するアプリケーションには通用しません。さらにリスクとして、アップグレード済みのクライアントに問題がある場合は、新しい形式のメッセージがメッセージログに追加され、以前のコンシューマーバージョンに戻せなくなる場合があります。
- トピック単位でコンシューマーを最初にアップグレード
トピックごとに以下を実行します。
- コンシューマーとして機能するアプリケーションをすべてアップグレードします。
-
トピックレベルの
message.format.versionを新バージョンに変更します。 プロデューサーとして機能するアプリケーションをアップグレードします。
このストラテジーではブローカーのダウンコンバートがすべて回避され、トピックごとにアップグレードできます。この方法は、同じトピックのコンシューマーとプロデューサーの両方に該当するアプリケーションには通用しません。ここでもリスクとして、アップグレード済みのクライアントに問題がある場合は、新しい形式のメッセージがメッセージログに追加される可能性があります。
- トピック単位でコンシューマーを最初にアップグレード、ダウンコンバートあり
トピックごとに以下を実行します。
-
トピックレベルの
message.format.versionを、旧バージョンに変更します (または、デフォルトがブローカーレベルのlog.message.format.versionのトピックを利用します)。 - コンシューマーおよびプロデューサーとして機能するアプリケーションをすべてアップグレードします。
- アップグレードしたアプリケーションが正しく機能することを確認します。
トピックレベルの
message.format.versionを新バージョンに変更します。このストラテジーにはブローカーのダウンコンバートが必要ですが、ダウンコンバートは一度に 1 つのトピック (またはトピックの小さなグループ) のみに必要になるので、ブローカーへの負荷は最小限に抑えられます。この方法は、同じトピックのコンシューマーとプロデューサーの両方に該当するアプリケーションにも通用します。この方法により、新しいメッセージ形式バージョンを使用する前に、アップグレードされたプロデューサーとコンシューマーが正しく機能することが保証されます。
この方法の主な欠点は、多くのトピックやアプリケーションが含まれるクラスターでの管理が複雑になる場合があることです。
-
トピックレベルの
クライアントアプリケーションをアップグレードするストラテジーは他にもあります。
複数のストラテジーを適用することもできます。たとえば、最初のいくつかのアプリケーションとトピックに、「トピック単位でコンシューマーを最初にアップグレード、ダウンコンバートあり」のストラテジーを適用します。これが問題なく適用されたら、より効率的な別のストラテジーの使用を検討できます。
18.5.3. クライアントアプリケーションの新しい Kafka バージョンへのアップグレード
この手順では、クライアントアプリケーションを AMQ Streams 1.6 に使用される Kafka バージョンにアップグレードする方法の 1 つを説明します。
この手順は、「 クライアントをアップグレードするストラテジー」で説明されている「トピック単位でコンシューマーを最初にアップグレードする」アプローチに 基づいています。
クライアントアプリケーションには、プロデューサー、コンシューマー、Kafka Connect、Kafka Streams アプリケーション、および MirrorMaker が含まれます。
前提条件
- ZooKeeper バイナリーを更新し、すべての Kafka ブローカーを AMQ Streams 1.6 にアップグレードしている。
- 新しいブローカー間プロトコルバージョンを使用するように Kafka ブローカーを設定している。
-
Red Hat Enterprise Linux に
kafkaユーザーとしてログインしている。
手順
トピックごとに以下を実行します。
コマンドラインで、
message.format.version設定オプションを 2.5 に設定します。bin/kafka-configs.sh --bootstrap-server <BrokerAddress> --entity-type topics --entity-name <TopicName> --alter --add-config message.format.version=2.5
- トピックに対してすべてのコンシューマーおよびプロデューサーをアップグレードします。
- 任意で、Kafka 2.4.0 で追加された Incremental Cooperative Rebalance プロトコルを使用するようにコンシューマーおよび Kafka Streams アプリケーションをアップグレードする場合は、「コンシューマーおよび Kafka Streams アプリケーションの Cooperative Rebalancing へのアップグレード」 を参照してください。
- アップグレードしたアプリケーションが正しく機能することを確認します。
トピックの
message.format.version設定オプションを2.6 に変更します。bin/kafka-configs.sh --bootstrap-server <BrokerAddress> --entity-type topics --entity-name <TopicName> --alter --add-config message.format.version=2.6
18.5.4. 新しいメッセージ形式バージョンを使用するための Kafka ブローカーのアップグレード
クライアントアプリケーションがアップグレードされたら、Kafka ブローカーを更新して、新しいメッセージ形式バージョンを使用できます。
AMQ Streams 1.6 に必要な Kafka バージョンを使用するようにクライアントアプリケーションをアップグレードしたときにトピック設定を変更し なかっ た場合、Kafka ブローカーはメッセージを以前のメッセージ形式のバージョンに変換されるため、パフォーマンスが低下する可能性があります。そのため、すべての Kafka ブローカーを更新して、できるだけ早く新しいメッセージ形式バージョンを使用することが重要になります。
Kafka ブローカーを 1 つずつ更新および再起動します。変更したブローカーを再起動する前に、以前に設定および再起動したブローカーを停止します。
前提条件
手順
AMQ Streams クラスターの各 Kafka ブローカーに対して、以下を 1 つずつ行います。
-
テキストエディターで、更新する Kafka ブローカーのブローカープロパティーファイルを開きます。ブローカープロパティーファイルは、一般的に
/opt/kafka/config/ディレクトリーに保存されます。 log.message.format.versionを2.6 に設定します。log.message.format.version=2.6
コマンドラインで、この手順の一部として変更および再起動した Kafka ブローカーを停止します。この手順で最初の Kafka ブローカーを変更する場合は、ステップ 4 に進みます。
/opt/kafka/bin/kafka-server-stop.sh jcmd | grep kafka
ステップ 2 で設定を変更した Kafka ブローカーを再起動します。
/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
-
再起動したKafkaブローカーが、フォローしているパーティションレプリカに追いついたことを確認します。
kafka-topics.shツールを使用して、ブローカーに含まれるすべてのレプリカが同期していることを確認します。手順は、トピックの一覧表示および説明 を参照してください。
18.5.5. コンシューマーおよび Kafka Streams アプリケーションの Cooperative Rebalancing へのアップグレード
Kafka コンシューマーおよび Kafka Streams アプリケーションをアップグレードすることで、パーティションの再分散にデフォルトの Eager Rebalance プロトコルではなく Incremental Cooperative Rebalance プロトコルを使用できます。この新しいプロトコルが Kafka 2.4.0 に追加されました。
コンシューマーは、パーティションの割り当てを Cooperative Rebalance で保持し、クラスターの分散が必要な場合にプロセスの最後でのみ割り当てを取り消します。これにより、コンシューマーグループまたは Kafka Streams アプリケーションが使用不可能になる状態が削減されます。
Incremental Cooperative Rebalance プロトコルへのアップグレードは任意です。Eager Rebalance プロトコルは引き続きサポートされます。
前提条件
- 「AMQ Streams 1.6 へのアップグレード」
- 「新しいブローカー間プロトコルバージョンを使用するための Kafka ブローカーのアップグレード」
- Cruise Control Metrics Reporter をデプロイしている。
手順
Incremental Cooperative Rebalance プロトコルを使用するように Kafka コンシューマーをアップグレードする方法:
-
Kafka クライアント
.jarファイルを新バージョンに置き換えます。 -
コンシューマー設定で、
partition.assignment.strategyにcooperative-stickyを追加します。たとえば、rangeストラテジーが設定されている場合は、設定をrange, cooperative-stickyに変更します。 - グループ内の各コンシューマーを順次再起動し、再起動後に各コンシューマーがグループに再度参加するまで待ちます。
-
コンシューマー設定から前述の
partition.assignment.strategyを削除して、グループの各コンシューマーを再設定し、cooperative-stickyストラテジーのみを残します。 - グループ内の各コンシューマーを順次再起動し、再起動後に各コンシューマーがグループに再度参加するまで待ちます。
Incremental Cooperative Rebalance プロトコルを使用するように Kafka Streams アプリケーションをアップグレードするには以下を行います。
-
Kafka Streams の
.jarファイルを新バージョンに置き換えます。 -
Kafka Streams の設定で、
upgrade.from設定パラメーターをアップグレード前の Kafka バージョンに設定します (例: 2.3)。 - 各ストリームプロセッサー (ノード) を順次再起動します。
-
upgrade.from設定パラメーターを Kafka Streams 設定から削除します。 - グループ内の各コンシューマーを順次再起動します。
関連情報
- Apache Kafka ドキュメントの「Notable changes in 2.4.0」。
付録A ブローカー設定パラメーター
zookeeper.connectタイプ: string
重大度: 高
動的更新: read-only
ZooKeeper 接続文字列を
hostname:portの形式で指定します。ここで、ホストとポートは ZooKeeper サーバーのホストおよびポートになります。ZooKeeper マシンが停止しているときに他の ZooKeeper ノード経由で接続できるようにするには、hostname1:port1,hostname2:port2,hostname3:port3の形式で複数のホストを指定することもできます。また、サーバーには ZooKeeper 接続文字列の一部として ZooKeeper の chroot パスを含めることもできます。この文字列は、データをグローバル ZooKeeper namespace の一部のパスに配置します。たとえば、/chroot/pathの chroot パスを指定するには、接続文字列にhostname1:port1,hostname2:port2,hostname3:port3/chroot/pathを指定します。advertised.host.nameタイプ: string
デフォルト: null
重要度: 高
動的更新: 読み取り専用
非推奨:
advertised.またはリスナーが設定されていない場合にのみ使用されます。代わりにlistenersadvertised.listenersを使用してください。使用するクライアントの ZooKeeper にパブリッシュするホスト名。IaaS 環境では、ブローカーをバインドするインターフェイスとは異ならなくてはならない場合があります。これが設定されていない場合には、host.nameの値を使用します(設定されている場合)。それ以外の場合は、java.net.InetAddress.getCanonicalHostName()から返された値を使用します。advertised.listenersタイプ: string
デフォルト: null
重要度: 高
動的更新: ブローカーごと
クライアントが使用する ZooKeeper にパブリッシュするリスナー (
listeners設定プロパティーとは異なる場合)。IaaS 環境では、ブローカーをバインドするインターフェイスとは異ならなくてはならない場合があります。これが設定されていない場合、listenersの値が使用されます。リスナーとは異なり、0.0.0.0 メタアドレスをアドバタイズすることはできません。advertised.portタイプ: int
デフォルト: null
重要度: 高
動的更新: 読み取り専用
非推奨:
advertised.またはリスナーが設定されていない場合にのみ使用されます。代わりにlistenersadvertised.listenersを使用してください。クライアントが使用する ZooKeeper に公開するポート。IaaS 環境では、これはブローカーがバインドするポートとは異なる必要がある場合があります。これが設定されていない場合、ブローカーがバインドするポートと同じポートを公開します。auto.create.topics.enableタイプ: boolean
デフォルト: true
重要度: 高
動的更新: 読み取り専用
サーバーでトピックの自動作成を有効にします。
auto.leader.rebalance.enableタイプ: boolean
デフォルト: true
重要度: 高
動的更新: 読み取り専用
自動リーダーバランシングを有効にします。バックグラウンドスレッドは、
leader.imbalance.check.interval.secondsによって設定可能な一定間隔でパーティションリーダーの分散をチェックします。リーダーインバランスがleader.imbalance.per.broker.percentageを超える場合、パーティションの優先リーダーへのリーダーのリバランスがトリガーされます。background.threadsType: int
Default: 10
Valid Values: [1,…]
Importance: high
Dynamic update: cluster-wide
さまざまなバックグラウンド処理タスクに使用するスレッドの数。
broker.idタイプ: int
デフォルト: -1
重要度: 高
動的更新: 読み取り専用
このサーバーのブローカー ID。未設定の場合は、一意のブローカー ID が生成されます。zookeeper が生成するブローカー ID とユーザーが設定したブローカー ID の間の競合を避けるために、生成されたブローカー ID は reserved.broker.max.id + 1 から開始します。
compression.typeタイプ: string
デフォルト: プロデューサー
重要度: 高
動的更新: クラスター全体
特定のトピックの最終的な圧縮タイプを指定します。この設定は、標準の圧縮コーデック ('gzip'、'snappy'、'lz4'、'zstd') を受け入れます。さらに、圧縮なしに相当する 'uncompressed' と、プロデューサーによって設定された元の圧縮コーデックを維持する 'producer' も使用できます。
control.plane.listener.nameタイプ: string
デフォルト: null
重要度: 高
動的更新: 読み取り専用
コントローラーとブローカー間の通信に使用されるリスナーの名前。ブローカーは control.plane.listener.name を使用して、リスナーリスト内のエンドポイントを特定し、コントローラーからの接続をリッスンします。たとえば、ブローカーの設定が : listeners = INTERNAL://192.1.1.8:9092, EXTERNAL://10.1.1.5:9093, CONTROLLER://192.1.1.8:9094 listener.security.protocol.map = INTERNAL:PLAINTEXT, EXTERNAL:SSL, CONTROLLER:SSL control.plane.listener.name = CONTROLLER On startup の場合、ブローカーはセキュリティープロトコル "SSL" を使用して "192.1.1.8:9094" でリッスンを開始します。コントローラー側で、zookeeper を介してブローカーの公開済みエンドポイントを検出すると、control.plane.listener.name を使用してブローカーへの接続を確立するために使用するエンドポイントを見つけます。たとえば、zookeeper 上のブローカーの公開済みのエンドポイントが : "endpoints" : ["INTERNAL://broker1.example.com:9092","EXTERNAL://broker1.example.com:9093","CONTROLLER://broker1.example.com:9094"] で、コントローラーの設定が : listener.security.protocol.map = INTERNAL:PLAINTEXT, EXTERNAL:SSL, CONTROLLER:SSL control.plane.listener.name = CONTROLLER の場合、コントローラーはセキュリティープロトコル "SSL" で "broker1.example.com:9094" を使用してブローカーに接続します。明示的に設定されていない場合、デフォルト値は null で、コントローラー接続専用のエンドポイントはありません。
delete.topic.enableタイプ: boolean
デフォルト: true
重要度: 高
動的更新: 読み取り専用
トピックの削除を有効にします。この設定をオフの場合、管理ツールを介してトピックを削除しても効果はありません。
host.nameタイプ: string
デフォルト: ""
重大度: 高
動的更新: read-only
非推奨:
リスナーが設定されていない場合にのみ使用されます。ブローカーのホスト名の代わりにリスナーを使用します。これが設定されている場合、このアドレスにのみバインドされます。これが設定されていない場合には、すべてのインターフェースにバインドされます。leader.imbalance.check.interval.seconds型: long
デフォルト: 300
重要度: 高
動的更新: 読み取り専用
パーティションリバランスチェックがコントローラーによってトリガーされる頻度。
leader.imbalance.per.broker.percentage型: int
デフォルト: 10
重要度: 高
動的更新: 読み取り専用
ブローカーごとに許可されるリーダーのインバランスの比率。コントローラーは、ブローカーごとにこの値を超えると、リーダーのバランスをトリガーします。この値はパーセンテージで指定されます。
listenersタイプ: string
デフォルト: null
重要度: 高
動的更新: ブローカーごと
リスナーリスト - リッスンする URI とリスナー名のコンマ区切りリストリスナー名がセキュリティープロトコルでない場合は、listeners.security.protocol.map も設定する必要があります。ホスト名を 0.0.0.0 として指定し、すべてのインターフェイスにバインドします。ホスト名を空白のままにして、デフォルトのインターフェイスにバインドします。正当なリスナーリストの例: PLAINTEXT://myhost:9092,SSL://:9091 CLIENT://0.0.0.0:9092,REPLICATION://localhost:9093.
log.dirタイプ: string
デフォルト: /tmp/kafka-logs
重要度: 高
動的更新: 読み取り専用
ログデータが保持されるディレクトリー (log.dirs プロパティーで補足)。
log.dirsタイプ: string
デフォルト: null
重要度: 高
動的更新: 読み取り専用
ログデータが保持されるディレクトリー。設定されていない場合は、log.dir の値が使用されます。
log.flush.interval.messagesType: long
Default: 9223372036854775807
Valid Values: [1,…]
Importance: high
Dynamic update: cluster-wide
メッセージがディスクにフラッシュされる前に、ログパーティションで累積されるメッセージの数。
log.flush.interval.msタイプ: long
デフォルト: null
重要度: 高
動的更新: クラスター全体
ディスクにフラッシュされる前に、トピックのメッセージがメモリーに保持される最大時間 (ミリ秒単位)。設定されていない場合は、log.flush.scheduler.interval.ms の値が使用されます。
log.flush.offset.checkpoint.interval.msType: int
Default: 60000 (1 minute)
Valid Values: [0,…]
Importance: high
Dynamic update: read-only
ログリカバリーポイントとして動作する最後のフラッシュの永続レコードを更新する頻度。
log.flush.scheduler.interval.ms型: long
デフォルト: 9223372036854775807
重要度: 高
動的更新: 読み取り専用
ログフラッシャーが、ログをディスクにフラッシュする必要があるかどうかをチェックする頻度(ミリ秒単位)。
log.flush.start.offset.checkpoint.interval.msType: int
Default: 60000 (1 minute)
Valid Values: [0,…]
Importance: high
Dynamic update: read-only
ログ開始オフセットの永続レコードを更新する頻度。
log.retention.bytesタイプ: long
デフォルト: -1
重要度: 高
動的更新: クラスター全体
ログを削除する前のログの最大サイズ。
log.retention.hours型: int
デフォルト: 168
重要度: 高
動的更新: 読み取り専用
ログファイルを削除する前にログファイルを保持する時間 (時間単位) (log.retention.ms プロパティーに対してターシャリー)。
log.retention.minutesタイプ: int
デフォルト: null
重要度: 高
動的更新: 読み取り専用
ログファイルを削除する前にログファイルを保持する分数 (分単位) (log.retention.ms プロパティーに対してセカンダリー)。設定されていない場合は、log.retention.hours の値が使用されます。
log.retention.msタイプ: long
デフォルト: null
重要度: 高
動的更新: クラスター全体
ログファイルを削除する前にログファイルを保持する秒数 (ミリ秒単位)。設定されていない場合は、log.retention.minutes の値が使用されます。-1 に設定すると、時間制限は適用されません。
log.roll.hours型: int
デフォルト: 168
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
新しいログセグメントがロールアウトされるまでの最大時間 (時間単位) (log.roll.ms プロパティーに対してセカンダリー)
log.roll.jitter.hours型: int
デフォルト: 0
有効な値: [0,…]
重要度: 高
動的更新: 読み取り専用
logRollTimeMillis から差し引く最大ジッター (時間単位) (log.roll.jitter.ms プロパティーに対してセカンダリー)
log.roll.jitter.msタイプ: long
デフォルト: null
重要度: 高
動的更新: クラスター全体
logRollTimeMillis から減算する最大ジッター (ミリ秒単位)。設定されていない場合は、log.roll.jitter.hours の値が使用されます。
log.roll.msタイプ: long
デフォルト: null
重要度: 高
動的更新: クラスター全体
新しいログセグメントがロールアウトされるまでの最大時間 (ミリ秒単位)。設定されていない場合は、log.roll.hours の値が使用されます。
log.segment.bytes型: int
デフォルト: 1073741824 (1 ギビバイト)
有効な値: [14,…]
重要度: 高
動的更新: クラスター全体
1 つのログファイルの最大サイズ。
log.segment.delete.delay.ms型: long
デフォルト: 60000 (1 分)
有効な値: [0,…]
重要度: 高
動的更新: クラスター全体
ファイルシステムからファイルを削除するまでの待機時間。
message.max.bytes型: int
デフォルト: 1048588
有効な値: [0,…]
重要度: 高
動的更新: クラスター全体
Kafka によって許可される最大のレコードバッチサイズ (圧縮が有効な場合は圧縮後)。これが増加し、0.10.2 より古いコンシューマーが存在する場合、コンシューマーのフェッチサイズも増加して、このような大きなレコードバッチをフェッチできるようにする必要があります。最新のメッセージ形式バージョンでは、効率化のためにレコードは常にバッチにグループ化されます。以前のメッセージ形式のバージョンでは、圧縮されていないレコードはバッチにグループ化されず、この制限はその場合は 1 つのレコードにのみ適用されます。これは、トピックレベルの
max.message.bytes設定でトピックごとに設定できます。min.insync.replicas型: int
デフォルト: 1
有効な値: [1,…]
重要度: 高
動的更新: クラスター全体
プロデューサーが acks を "all" (または "-1"),に設定すると、min.insync.replicas は、書き込みが正常に実行されるように書き込みを承認しなければならないレプリカの最小数を指定します。この最小値が満たされない場合、プロデューサーは例外 (NotEnoughReplicas または NotEnoughReplicasAfterAppend のいずれか) を発生させます。min.insync.replicas と acks を併用することで、より高い持続性が保証されます。一般的なシナリオでは、レプリケーション係数 3 のトピックを作成し、min.insync.replicas を 2 に設定し、acks を all にして生成します。これにより、レプリカの大部分が書き込みを受信しない場合に、プロデューサーは確実に例外を発生させます。
num.io.threads型: int
デフォルト: 8
有効な値: [1,…]
重要度: 高
動的更新: クラスター全体
サーバーが要求の処理に使用するスレッドの数。これにはディスク I/O が含まれる場合があります。
num.network.threads型: int
デフォルト: 3
有効な値: [1,…]
重要度: 高
動的更新: クラスター全体
サーバーがネットワークから要求を受信し、応答をネットワークに送信するために使用するスレッドの数。
num.recovery.threads.per.data.dir型: int
デフォルト: 1
有効な値: [1,…]
重要度: 高
動的更新: クラスター全体
起動時のログリカバリーおよびシャットダウン時にフラッシュするために使用されるデータディレクトリーごとのスレッド数。
num.replica.alter.log.dirs.threadsタイプ: int
デフォルト: null
重要度: 高
動的更新: 読み取り専用
ログディレクトリー間でレプリカを移動できるスレッドの数。これにはディスク I/O が含まれる場合があります。
num.replica.fetchers型: int
デフォルト: 1
重要度: 高
動的更新: クラスターワイド
ソースブローカーからメッセージを複製するために使用されるフェッチャースレッドの数。この値を増やすと、フォロワーブローカーの I/O 並列処理のレベルを増やすことができます。
offset.metadata.max.bytes型: int
デフォルト: 4096 (4 ギビバイト)
重要度: 高
動的更新: 読み取り専用
オフセットコミットに関連付けられたメタデータエントリーの最大サイズ。
offsets.commit.required.acksタイプ: short
デフォルト: -1
重要度: 高
動的更新: 読み取り専用
コミットを許可する前に必要な acks。通常、デフォルトの(-1)は上書きできません。
offsets.commit.timeout.ms型: int
デフォルト: 5000 (5 秒)
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
オフセットコミットは、オフセットトピックのすべてのレプリカがコミットを受信するか、またはこのタイムアウトに達するまで遅延します。これは、プロデューサーリクエストのタイムアウトと似ています。
offsets.load.buffer.size型: int
デフォルト: 5242880
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
オフセットをキャッシュに読み込むときにオフセットセグメントから読み取るバッチサイズ (ソフトリミット。レコードが大きすぎるとオーバーライドされます)。
offsets.retention.check.interval.ms型: long
デフォルト: 600000 (10 分)
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
古いオフセットをチェックする頻度。
offsets.retention.minutes型: int
デフォルト: 10080
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
コンシューマーグループがすべてのコンシューマーを失った後 (つまり空になった場合)、そのオフセットは破棄される前にこの保持期間は保持されます。(手動割り当てを使用する) スタンドアロンコンシューマーの場合、オフセットは最後のコミットの期間と、この保持期間後に期限切れになります。
offsets.topic.compression.codec型: int
デフォルト: 0
重要度: 高
動的更新: 読み取り専用
オフセットトピックの圧縮コーデック - 圧縮は "atomic" コミットの達成に使用できます。
offsets.topic.num.partitions型: int
デフォルト: 50
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
オフセットコミットトピックのパーティション数 (デプロイメント後には変更しないでください)。
offsets.topic.replication.factor型: short
デフォルト: 3
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
オフセットトピックのレプリケーション係数 (可用性を確保するために高く設定します)。内部トピックの作成は、クラスターのサイズがこのレプリケーション係数の要件を満たすまで失敗します。
offsets.topic.segment.bytes型: int
デフォルト: 104857600 (100 メビバイト)
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
ログコンパクションとキャッシュの負荷をより高速にするために、オフセットトピックセグメントバイトは比較的小さく維持する必要があります。
portタイプ: int
デフォルト: 9092
重大度: 高
動的更新: read-only
非推奨:
リスナーが設定されていない場合にのみ使用されます。代わりにリスナーを使用します。ポートを使用して接続をリッスンおよび許可します。queued.max.requests型: int
デフォルト: 500
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
ネットワークスレッドをブロックする前に、データプレーンで許可されるキューに置かれた要求の数。
quota.consumer.defaultタイプ: long
デフォルト: 9223372036854775807
有効な値: [1,…]
重大度: 高
動的更新: read-only
非推奨: Zookeeper の <user, <client-id> または <user, client-id> に動的デフォルトクォータが設定されていない場合に限り使用します。clientId/consumer グループによるコンシューマーの区別は、この値を 1 秒以上フェッチするとスロットリングされます。
quota.producer.defaultタイプ: long
デフォルト: 9223372036854775807
有効な値: [1,…]
重大度: 高
動的更新: read-only
非推奨: 動的デフォルトクォータが Zookeeper の <user>、<client-id> または <user、client-id> に対して設定されていない場合にのみ使用されます。clientId によるプロデューサーの区別は、1 秒あたりこの値を超えるバイトを生成するとスロットリングされます。
replica.fetch.min.bytes型: int
デフォルト: 1
重要度: 高
動的更新: 読み取り専用
各フェッチ応答で想定される最小バイト数。十分なバイトがない場合は、replicasMaxWaitTimeMs まで待機します。
replica.fetch.wait.max.ms型: int
デフォルト: 500
重要度: 高
動的更新: 読み取り専用
フォロワーレプリカが発行する各フェッチャーリクエストの最大待機時間。低スループットトピックの ISR が頻繁に縮小するのを防ぐために、この値は常に replica.lag.time.max.ms よりも小さくする必要があります。
replica.high.watermark.checkpoint.interval.ms型: long
デフォルト: 5000 (5 秒)
重要度: 高
動的更新: 読み取り専用
最高レベルのウォーターマークがディスクに保存される頻度。
replica.lag.time.max.ms型: long
デフォルト: 30000 (30 秒)
重要度: 高
動的更新: 読み取り専用
フォロワーがフェッチリクエストを送信していない場合や、リーダーのログ終了オフセットまで少なくともこの時間消費していない場合、リーダーはフォロワーを isr から削除します。
replica.socket.receive.buffer.bytes型: int
デフォルト: 65536 (64 キビバイト)
重要度: 高
動的更新: 読み取り専用
ネットワーク要求のソケット受信バッファー。
replica.socket.timeout.ms型: int
デフォルト: 30000 (30 秒)
重要度: 高
動的更新: 読み取り専用
ネットワーク要求のソケットタイムアウト。その値は、少なくとも replica.fetch.wait.max.ms である必要があります。
request.timeout.ms型: int
デフォルト: 30000 (30 秒)
重要度: 高
動的更新: 読み取り専用
この設定は、クライアントの要求の応答を待つ最大時間を制御します。タイムアウトが経過する前に応答が受信されない場合、クライアントは必要に応じてリクエストを再送信します。または、再試行が使い切られるとリクエストが失敗します。
socket.receive.buffer.bytes型: int
デフォルト: 102400 (100 キビバイト)
重要度: 高
動的更新: 読み取り専用
ソケットサーバーソケットの SO_RCVBUF バッファー。値が -1 の場合、OS のデフォルトが使用されます。
socket.request.max.bytes型: int
デフォルト: 104857600 (100 メビバイト)
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
ソケットリクエストの最大バイト数。
socket.send.buffer.bytes型: int
デフォルト: 102400 (100 キビバイト)
重要度: 高
動的更新: 読み取り専用
ソケットサーバーソケットの SO_SNDBUF バッファー。値が -1 の場合、OS のデフォルトが使用されます。
transaction.max.timeout.ms型: int
デフォルト: 900000 (15 分)
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
トランザクションの最大許容タイムアウト。クライアントの要求されたトランザクション時間がこの値を超えると、ブローカーは InitProducerIdRequest でエラーを返します。これにより、クライアントがタイムアウトを大きくしすぎて、トランザクションに含まれるトピックからの読み取りを消費者が停止する可能性がなくなります。
transaction.state.log.load.buffer.size型: int
デフォルト: 5242880
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
プロデューサー ID とトランザクションをキャッシュにロードするときにトランザクションログセグメントから読み取るバッチサイズ (ソフトリミット。レコードが大きすぎると上書きされます)。
transaction.state.log.min.isr型: int
デフォルト: 2
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
トランザクショントピックの上書きされた min.insync.replicas 設定。
transaction.state.log.num.partitions型: int
デフォルト: 50
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
トランザクショントピックのパーティション数 (デプロイメント後には変更しないでください)。
transaction.state.log.replication.factor型: short
デフォルト: 3
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
トランザクショントピックのレプリケーション係数 (可用性を確保するために高く設定します)。内部トピックの作成は、クラスターのサイズがこのレプリケーション係数の要件を満たすまで失敗します。
transaction.state.log.segment.bytes型: int
デフォルト: 104857600 (100 メビバイト)
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
ログコンパクションとキャッシュの負荷をより高速にするために、トランザクショントピックセグメントバイトは比較的小さく維持する必要があります。
transactional.id.expiration.ms型: int
デフォルト: 604800000 (7 日)
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
トランザクションコーディネーターが、トランザクション ID の有効期限が切れる前に、現在のトランザクションのトランザクションステータスの更新を受信せずに待機する時間 (ミリ秒単位)。この設定は、プロデューサー ID の有効期限にも影響します。プロデューサー ID は、指定されたプロデューサー ID で最後に書き込んだ後、この時間が経過すると期限切れになります。トピックの保持設定が原因で、プロデューサー ID からの最後の書き込みが削除された場合、プロデューサー ID の有効期限が早くなる可能性があることに注意してください。
unclean.leader.election.enableタイプ: boolean
デフォルト: false
重要度: 高
動的更新: クラスター全体
データが失われる可能性がある場合でも、ISRセットにないレプリカを最後の手段としてリーダーとして選出できるようにするかどうかを示します。
zookeeper.connection.timeout.msタイプ: int
デフォルト: null
重要度: 高
動的更新: 読み取り専用
クライアントが zookeeper への接続を確立するまで待機する最大時間。設定されていない場合は、zookeeper.session.timeout.ms の値が使用されます。
zookeeper.max.in.flight.requests型: int
デフォルト: 10
有効な値: [1,…]
重要度: 高
動的更新: 読み取り専用
ブロックする前にクライアントが Zookeeper に送信する確認されていないリクエストの最大数。
zookeeper.session.timeout.ms型: int
デフォルト: 18000 (18 秒)
重要度: 高
動的更新: 読み取り専用
ZooKeeper セッションのタイムアウト。
zookeeper.set.aclタイプ: boolean
デフォルト: false
重要度: 高
動的更新: 読み取り専用
セキュアな ACL を使用するようにクライアントを設定します。
broker.id.generation.enableタイプ: boolean
デフォルト: true
重要度: 中
動的更新: 読み取り専用
サーバーでブローカー ID の自動生成を有効にします。これを有効にすると、reserved.broker.max.id に設定された値を確認する必要があります。
broker.rackタイプ: string
デフォルト: null
重要度: 中
動的更新: 読み取り専用
ブローカーのラック。これは、フォールトトレランスのためのラック対応レプリケーション割り当てで使用されます。たとえば、
RACK1、us-east-1dです。connections.max.idle.ms型: long
デフォルト: 600000 (10 分)
重要度: 中
動的更新: 読み取り専用
アイドル接続のタイムアウト: サーバーソケットプロセッサースレッドは、これ以上にアイドル状態にある接続を閉じます。
connections.max.reauth.ms型: long
デフォルト: 0
重要度: 高
動的更新: 読み取り専用
正数 (デフォルトは正数ではなく 0) に明示的に設定されている場合、設定された値を超えないセッションライフタイムは、認証時に v2.2.0 以降のクライアントに通知されます。ブローカーは、セッションの有効期間内に再認証されなかったあらゆる接続を切断し、その後、これは再認証以外の目的で使用されます。設定名には、任意でリスナー接頭辞と SASL メカニズム名を小文字でプレフィックスできます。たとえば、listener.name.sasl_ssl.oauthbearer.connections.max.reauth.ms=3600000 などです。
controlled.shutdown.enableタイプ: boolean
デフォルト: true
重要度: 中
動的更新: 読み取り専用
サーバーの制御されたシャットダウンを有効にします。
controlled.shutdown.max.retries型: int
デフォルト: 3
重要度: 中
動的更新: 読み取り専用
制御されたシャットダウンは、複数の理由で失敗する可能性があります。これにより、このような障害が発生した場合の再試行回数が決まります。
controlled.shutdown.retry.backoff.ms型: long
デフォルト: 5000 (5 秒)
重要度: 中
動的更新: 読み取り専用
それぞれの再試行の前に、システムは以前の障害を引き起こした状態 (コントローラーのフェイルオーバー、レプリカの遅延など) から回復する時間が必要です。この設定は、再試行までの待機時間を決定します。
controller.socket.timeout.ms型: int
デフォルト: 30000 (30 秒)
重要度: 中
動的更新: 読み取り専用
controller-to-broker チャネルのソケットタイムアウト。
default.replication.factor型: int
デフォルト: 1
重要度: 中
動的更新: 読み取り専用
自動的に作成されるトピックのデフォルトレプリケーション係数。
delegation.token.expiry.time.ms型: long
デフォルト: 86400000 (1 日)
有効な値: [1,…]
重要度: 中
動的更新: 読み取り専用
トークンの更新が必要となるまでのトークンの有効時間 (ミリ秒単位)。デフォルト値は 1 日です。
delegation.token.master.keyタイプ: password
デフォルト: null
重要度: 中
動的更新: 読み取り専用
マスター/シークレットキー。委譲トークンを生成して確認します。同じキーをすべてのブローカーで設定する必要があります。キーが設定されていないか、空の文字列に設定されていると、ブローカーは委任トークンのサポートを無効にします。
delegation.token.max.lifetime.ms型: long
デフォルト: 604800000 (7 日)
有効な値: [1,…]
重要度: 中
動的更新: 読み取り専用
トークンの最大有効期間は、それを超えると更新できなくなります。デフォルト値は 7 日です。
delete.records.purgatory.purge.interval.requests型: int
デフォルト: 1
重要度: 中
動的更新: 読み取り専用
delete records request purgatory のパージ間隔 (リクエストの回数)。
fetch.max.bytes型: int
デフォルト: 57671680 (55 メビバイト)
有効な値: [1024,…]
重要度: 中
動的更新: 読み取り専用
フェッチリクエストに対して返す最大バイト数。1024 以上でなければなりません。
fetch.purgatory.purge.interval.requests型: int
デフォルト: 1000
重要度: 中
動的更新: 読み取り専用
fetch request purgatory のパージ間隔 (リクエストの回数)。
group.initial.rebalance.delay.ms型: int
デフォルト: 3000 (3 秒)
重要度: 中
動的更新: 読み取り専用
グループコーディネーターが最初のリバランスを実行する前に、より多くのコンシューマーが新しいグループに参加するのを待つ時間。遅延が長くなると、リバランスが少なくなる可能性がありますが、処理が開始されるまでの時間が長くなります。
group.max.session.timeout.ms型: int
デフォルト: 1800000 (30 分)
重要度: 中
動的更新: 読み取り専用
登録されたコンシューマーに許可される最大セッションタイムアウト。タイムアウトが長くなると、コンシューマーはハートビートの間にメッセージを処理する時間が長くなりますが、障害の検出に時間がかかります。
group.max.size型: int
デフォルト: 2147483647
有効な値: [1,…]
重要度: 中
動的更新: 読み取り専用
1 つのコンシューマーグループが対応できるコンシューマーの最大数。
group.min.session.timeout.ms型: int
デフォルト: 6000 (6 秒)
重要度: 中
動的更新: 読み取り専用
登録されたコンシューマーに許可される最小セッションタイムアウト。タイムアウトを短くすると、障害の検出が速くなりますが、コンシューマーのハートビートが頻繁に発生し、ブローカーのリソースが対応できなくなる可能性があります。
inter.broker.listener.nameタイプ: string
デフォルト: null
重要度: 中
動的更新: 読み取り専用
ブローカー間の通信に使用されるリスナーの名前。これが設定されていない場合、リスナー名は security.inter.broker.protocol によって定義されます。これと security.inter.broker.protocol プロパティーを同時に設定するとエラーになります。
inter.broker.protocol.versionタイプ: string
デフォルト: 2.6-IV0
有効な値: [0.8.0, 0.8.1, 0.8.2, 0.9.0, 0.10.0-IV0, 0.10.0-IV1, 0.10.1-IV0, 0.10.1-IV1, 0.10.1-IV2, 0.10.2-IV0, 0.11.0-IV0, 0.11.0-IV1, 0.11.0-IV2, 1.0-IV0, 1.1-IV0, 2.0-IV0, 2.0-IV1, 2.1-IV0, 2.1-IV1, 2.1-IV2, 2.2-IV0, 2.2-IV1, 2.3-IV0, 2.3-IV1, 2.4-IV0, 2.4-IV1, 2.5-IV0, 2.6-IV0]
重大度: 中
Dynamic update: read-only
使用する inter-broker プロトコルのバージョンを指定します。通常、これはすべてのブローカーが新しいバージョンにアップグレードされた後に表示されます。いくつかの有効な値の例は。0.8.0、0.8.1、0.8.1.1、0.8.2、0.8.2.0、0.8.2.1、0.9.0.0、0.9.0.1 です。完全なリストについては ApiVersion を確認してください。
log.cleaner.backoff.ms型: long
デフォルト: 15000 (15 秒)
有効な値: [0,…]
重要度: 中
動的更新: クラスター全体
クリーニングするログがない場合のスリープ時間。
log.cleaner.dedupe.buffer.size型: long
デフォルト: 134217728
重要度: 中
動的更新: クラスター全体
すべてのクリーナースレッドにおけるログの重複排除に使用されるメモリーの合計。
log.cleaner.delete.retention.ms型: long
デフォルト: 86400000 (1 日)
重要度: 中
動的更新: クラスター全体
削除レコードが保持される期間。
log.cleaner.enableタイプ: boolean
デフォルト: true
重要度: 中
動的更新: 読み取り専用
ログクリーナープロセスを有効にして、サーバー上で実行できるようにします。内部オフセットトピックを含む cleanup.policy=compact でトピックを使用する場合は、有効にする必要があります。無効にすると、これらのトピックは圧縮されず、サイズが継続的に大きくなります。
log.cleaner.io.buffer.load.factor型: double
デフォルト: 0.9
重要度: 中
動的更新: クラスター全体
ログクリーナー重複排除バッファーの負荷率。重複排除バッファーの最大パーセンテージ。値を大きくすると、一度により多くのログをクリーンアップできますが、ハッシュ衝突が多くなります。
log.cleaner.io.buffer.size型: int
デフォルト: 524288
有効な値: [0,…]
重要度: 中
動的更新: クラスター全体
すべてのクリーナースレッドにまたがってログクリーナー I/O バッファーに使用されるメモリーの合計。
log.cleaner.io.max.bytes.per.second型: double
デフォルト: 1.7976931348623157E308
重要度: 中
動的更新: クラスター全体
ログクリーナーは、読み取りと書き込みの I/O の合計が平均してこの値よりも小さくなるようにスロットリングされます。
log.cleaner.max.compaction.lag.ms型: long
デフォルト: 9223372036854775807
重要度: 中
動的更新: クラスター全体
メッセージがログのコンパクションの対象外のままになる最大時間。圧縮されるログにのみ適用されます。
log.cleaner.min.cleanable.ratio型: double
デフォルト: 0.5
重要度: 中
動的更新: クラスター全体
クリーニングの対象となるログの、合計ログに対するダーティーログの最小比率。log.cleaner.max.compaction.lag.ms または log.cleaner.min.compaction.lag.ms 設定も指定されている場合、ログコンパクターは次のいずれかの場合にすぐにログをコンパクションの対象と見なします。(i) ダーティー比率のしきい値に達し、ログに少なくとも log.cleaner.min.compaction.lag.ms 期間のダーティー (圧縮されていない) レコードがある場合、または (ii) ログに最大で log.cleaner.max.compaction.lag.ms 期間のダーティー (圧縮されていない) レコードがある場合。
log.cleaner.min.compaction.lag.ms型: long
デフォルト: 0
重要度: 中
動的更新: クラスター全体
メッセージがログで圧縮されないままになる最小時間。圧縮されるログにのみ適用されます。
log.cleaner.threads型: int
デフォルト: 1
有効な値: [0,…]
重要度: 中
動的更新: クラスター全体
ログのクリーニングに使用するバックグラウンドスレッドの数。
log.cleanup.policyタイプ: list
デフォルト: delete
有効な値: [compact, delete]
重要度: 中
動的更新: クラスター全体
保持期間を超えたセグメントのデフォルトのクリーンアップポリシー。有効なポリシーのコンマ区切りリスト。有効なポリシーは "delete" と "compact" です。
log.index.interval.bytes型: int
デフォルト: 4096 (4 キビバイト)
有効な値: [0,…]
重要度: 中
動的更新: クラスター全体
オフセットインデックスにエントリーを追加する間隔。
log.index.size.max.bytes型: int
デフォルト: 10485760 (10 メビバイト)
有効な値: [4,…]
重要度: 中
動的更新: クラスター全体
オフセットインデックスの最大サイズ (バイト単位)。
log.message.format.versionタイプ: string
デフォルト: 2.6-IV0
有効な値: [0.8.0, 0.8.1, 0.8.2, 0.9.0, 0.10.0-IV0, 0.10.0-IV1, 0.10.1-IV0, 0.10.1-IV1, 0.10.1-IV2, 0.10.2-IV0, 0.11.0-IV0, 0.11.0-IV1, 0.11.0-IV2, 1.0-IV0, 1.1-IV0, 2.0-IV0, 2.0-IV1, 2.1-IV0, 2.1-IV1, 2.1-IV2, 2.2-IV0, 2.2-IV1, 2.3-IV0, 2.3-IV1, 2.4-IV0, 2.4-IV1, 2.5-IV0, 2.6-IV0]
重大度: 中
Dynamic update: read-only
ブローカーがログにメッセージを追加するために使用するメッセージ形式バージョンを指定します。この値は有効な ApiVersion である必要があります。たとえば、0.8.2、0.9.0.0、0.10.0 です。詳細は ApiVersion を確認してください。特定のメッセージ形式のバージョンを設定することで、ユーザーは、ディスク上の既存のメッセージすべてが指定したバージョンよりも小さいか、または等しいことを認定します。この値を誤って設定すると、以前のバージョンを持つコンシューマーが、認識されない形式でメッセージを受信するため、破損します。
log.message.timestamp.difference.max.ms型: long
デフォルト: 9223372036854775807
重要度: 中
動的更新: クラスター全体
ブローカーがメッセージを受信したときのタイムスタンプと、メッセージに指定されたタイムスタンプとの間の最大差。log.message.timestamp.type=CreateTime の場合、タイムスタンプの差がこのしきい値を超えると、メッセージが拒否されます。この設定は、log.message.timestamp.type=LogAppendTime の場合に無視されます。不必要に頻繁なログのローリングを回避するために、許可される最大タイムスタンプの差はlog.retention.ms 以下にする必要があります。
log.message.timestamp.type型: string
デフォルト: CreateTime
有効な値: [CreateTime, LogAppendTime]
重要度: 中
動的更新: クラスター全体
メッセージのタイムスタンプが、メッセージ作成時間かログの追加時間であるかを定義します。値は
CreateTimeまたはLogAppendTimeである必要があります。log.preallocateタイプ: boolean
デフォルト: false
重要度: 中
動的更新: クラスター全体
新規セグメントの作成時にファイルを事前に割り当てる必要がありますか?Windows で Kafka を使用している場合は、true に設定する必要があります。
log.retention.check.interval.ms型: long
デフォルト: 300000 (5 分)
有効な値: [1,…]
重要度: 中
動的更新: 読み取り専用
ログクリーナーが、削除の対象となるログがあるかどうかを確認する頻度 (ミリ秒単位)。
max.connections型: int
デフォルト: 2147483647
有効な値: [0,…]
重要度: 中
動的更新: クラスター全体
ブローカーでいつでも許可する最大接続数。この制限は、max.connections.per.ip を使用して設定された各 IP の制限に加えて適用されます。リスナーレベルの制限は、設定名の前にリスナー接頭辞を付けて設定することもできます (例:
listener.name.internal.max.connections)。ブローカー全体の制限はブローカー容量に基づいて設定する必要がありますが、リスナー制限はアプリケーション要件に基づいて設定する必要があります。リスナーまたはブローカーの制限のいずれかに達すると、新しい接続はブロックされます。inter-broker リスナーの接続は、ブローカー全体の制限に到達しても許可されます。この場合、別のリスナーで一番最近使用されていない接続が閉じられます。max.connections.per.ip型: int
デフォルト: 2147483647
有効な値: [0,…]
重要度: 中
動的更新: クラスター全体
各 IP アドレスから許容される接続の最大数。これは、max.connections.per.ip.overrides プロパティーを使用して上書きが設定されている場合は 0 に設定できます。制限に達すると、IP アドレスからの新規接続はドロップされます。
max.connections.per.ip.overridesタイプ: string
デフォルト: ""
重要度: 中
動的更新: クラスター全体
ip ごとまたはホスト名のコンマ区切りリストは、デフォルトの最大接続数よりも優先されます。値の例は "hostName:100,127.0.0.1:200" です。
max.incremental.fetch.session.cache.slots型: int
デフォルト: 1000
有効な値: [0,…]
重要度: 中
動的更新: 読み取り専用
維持する増分フェッチセッションの最大数。
num.partitions型: int
デフォルト: 1
有効な値: [1,…]
重要度: 中
動的更新: 読み取り専用
トピックごとのログパーティションのデフォルト数。
password.encoder.old.secretタイプ: password
デフォルト: null
重要度: 中
動的更新: 読み取り専用
動的に設定されたパスワードをエンコードするために使用されていた古いシークレット。これは、シークレットが更新される場合にのみ必要です。指定されている場合、動的にエンコードされたパスワードはすべて、この古いシークレットを使用してデコードされ、ブローカーの起動時に password.encoder.secret を使用して再エンコードされます。
password.encoder.secretタイプ: password
デフォルト: null
重要度: 中
動的更新: 読み取り専用
このブローカーに動的に設定されたパスワードをエンコードするために使用されるシークレット。
principal.builder.classタイプ: class
デフォルト: null
重大度: 中
動的更新: ブローカーごとに
承認中に使用される KafkaPrincipal オブジェクトを構築するために使用される KafkaPrincipalBuilder インターフェイスを実装するクラスの完全修飾名。この設定は、これまで SSL によるクライアント認証に使用されていた非推奨の PrincipalBuilder インターフェースもサポートします。プリンシパルビルダーが定義されていない場合、デフォルトの動作は使用中のセキュリティープロトコルによって異なります。SSL 認証の場合、プリンシパルは、クライアント証明書 (提供されている場合) からの識別名に適用される
ssl.principal.mapping.rulesによって定義されたルールを使用して派生されます。それ以外の場合は、クライアント認証が不要な場合はプリンシパル名は ANONYMOUS になります。SASL 認証の場合、プリンシパルは、GSSAPI が使用されている場合はsasl.kerberos.principal.to.local.rulesで定義されるルールを使用して、他のメカニズムを使用している場合は SASL 認証 ID を使用して派生されます。PLAINTEXT の場合、プリンシパルは ANONYMOUS になります。producer.purgatory.purge.interval.requests型: int
デフォルト: 1000
重要度: 中
動的更新: 読み取り専用
producer request purgatory のパージ間隔 (リクエストの回数)。
queued.max.request.bytesタイプ: long
デフォルト: -1
重要度: 中
動的更新: 読み取り専用
これ以上要求が読み取られなくなるまでに許可されるキューに入れられたバイト数。
replica.fetch.backoff.ms型: int
デフォルト: 1000 (1 秒)
有効な値: [0,…]
重要度: 中
動的更新: 読み取り専用
パーティションのフェッチエラーが発生したときにスリープする時間。
replica.fetch.max.bytes型: int
デフォルト: 1048576 (1 メビバイト)
有効な値: [0,…]
重要度: 中
動的更新: 読み取り専用
パーティションごとにフェッチを試みるメッセージのバイト数。これは絶対的な最大値ではありません。フェッチの最初の空ではないパーティションの最初のレコードバッチがこの値よりも大きい場合でも、確実に前進することができるようにレコードバッチが返されます。ブローカーによって許可される最大レコードバッチサイズは、
message.max.bytes(ブローカー設定) またはmax.message.bytes(トピック設定) で定義されます。replica.fetch.response.max.bytes型: int
デフォルト: 10485760 (10 メビバイト)
有効な値: [0,…]
重要度: 中
動的更新: 読み取り専用
フェッチ応答全体に対して想定される最大バイト数。レコードはバッチで取得され、フェッチの最初の空ではないパーティションの最初のレコードバッチがこの値よりも大きい場合でも、確実に前進することができるようにレコードバッチが返されます。そのため、これは絶対的な最大値ではありません。ブローカーによって許可される最大レコードバッチサイズは、
message.max.bytes(ブローカー設定) またはmax.message.bytes(トピック設定) で定義されます。replica.selector.classタイプ: string
デフォルト: null
重要度: 中
動的更新: 読み取り専用
ReplicaSelector を実装する完全修飾クラス名。これは、推奨される読み取りレプリカを見つけるためにブローカーによって使用されます。デフォルトでは、リーダーを返す実装を使用します。
reserved.broker.max.id型: int
デフォルト: 1000
有効な値: [0,…]
重要度: 中
動的更新: 読み取り専用
broker.id に使用できる最大数。
sasl.client.callback.handler.classタイプ: class
デフォルト: null
重要度: 中
動的更新: 読み取り専用
AuthenticateCallbackHandler インターフェイスを実装する SASL クライアントコールバックハンドラークラスの完全修飾名。
sasl.enabled.mechanisms型: list
デフォルト: GSSAPI
重要度: 中
動的更新: per-broker
Kafka サーバーで有効になっている SASL メカニズムの一覧。このリストには、セキュリティープロバイダーを利用できるメカニズムが含まれている場合があります。GSSAPI のみがデフォルトで有効になっています。
sasl.jaas.configタイプ: password
デフォルト: null
重要度: 中
動的更新: ブローカーごと
JAAS 設定ファイルで使用される形式の SASL 接続の JAAS ログインコンテキストパラメーター。JAAS 設定ファイルの形式は、こちら で説明されています。値の形式は 「loginModuleClass controlFlag(optionName=optionValue)*;」 です。ブローカーの場合、設定の前にリスナー接頭辞と SASL メカニズム名を小文字で指定する必要があります。たとえば、listener.name.sasl_ssl.scram-sha-256.sasl.jaas.config=com.example.ScramLoginModule required; などです。
sasl.kerberos.kinit.cmdタイプ: string
デフォルト: /usr/bin/kinit
重要度: 中
動的更新: ブローカーごと
Kerberos kinit コマンドパス。
sasl.kerberos.min.time.before.relogin型: long
デフォルト: 60000
重要度: 中
動的更新: per-broker
更新試行間のログインスレッドのスリープ時間。
sasl.kerberos.principal.to.local.rules型: list
デフォルト: DEFAULT
重要度: 中
動的更新: ブローカーごと
プリンシパル名から短縮名 (通常はオペレーティングシステムのユーザー名) にマッピングするためのルールの一覧です。ルールは順番に評価され、プリンシパル名と一致する最初のルールは、これを短縮名にマップするために使用されます。一覧の後続のルールは無視されます。デフォルトでは、{username}/{hostname}@{REALM} 形式のプリンシパル名は {username} にマッピングされます。形式の詳細は、 security authorization and acls を参照してください。この設定は、
principal.builder.class設定によって KafkaPrincipalBuilder のエクステンションが提供される場合は無視されます。sasl.kerberos.service.nameタイプ: string
デフォルト: null
重要度: 中
動的更新: ブローカーごと
Kafka が実行される Kerberos プリンシパル名。これは、Kafka の JAAS 設定または Kafka の設定で定義できます。
sasl.kerberos.ticket.renew.jitter型: double
デフォルト: 0.05
重要度: 中
動的更新: per-broker
更新時間に追加されたランダムなジッターの割合。
sasl.kerberos.ticket.renew.window.factor型: double
デフォルト: 0.8
重要度: 中
動的更新: per-broker
ログインスレッドは、最後の更新からチケットの有効期限までの指定された時間のウィンドウファクターに達するまでスリープし、その時点でチケットの更新を試みます。
sasl.login.callback.handler.classタイプ: class
デフォルト: null
重要度: 中
動的更新: 読み取り専用
AuthenticateCallbackHandler インターフェイスを実装する SASL ログインコールバックハンドラークラスの完全修飾名。ブローカーの場合、ログインコールバックハンドラー設定の前には、リスナー接頭辞 と SASL メカニズム名を小文字で指定する必要があります。たとえば、listener.name.sasl_ssl.scram-sha-256.sasl.login.callback.handler.class=com.example.CustomScramLoginCallbackHandler などです。
sasl.login.classタイプ: class
デフォルト: null
重要度: 中
動的更新: 読み取り専用
Login インターフェイスを実装するクラスの完全修飾名。ブローカーの場合、ログイン設定の前にリスナー接頭辞 と SASL メカニズム名を小文字で指定する必要があります。たとえば、listener.name.sasl_ssl.scram-sha-256.sasl.login.class=com.example.CustomScramLogin です。
sasl.login.refresh.buffer.seconds型: short
デフォルト: 300
重要度: 中
動的更新: per-broker
クレデンシャルを更新するときに維持するクレデンシャルの有効期限が切れるまでのバッファー時間 (秒単位)。更新が、バッファ秒数よりも有効期限に近いときに発生する場合、更新は、可能な限り多くのバッファー時間を維持するために上に移動されます。設定可能な値は 0 から 3600 (1 時間) です。値を指定しない場合は、デフォルト値の 300 (5 分) が使用されます。この値および sasl.login.refresh.min.period.seconds は、その合計がクレデンシャルの残りの有効期間を超える場合にどちらも無視されます。現在、OAUTHBEARER にのみ適用されます。
sasl.login.refresh.min.period.seconds型: short
デフォルト: 60
重要度: 中
動的更新: per-broker
ログイン更新スレッドがクレデンシャルを更新する前に待機する最小時間 (秒単位)。設定可能な値は 0 から 900 (15 分) です。値を指定しない場合は、デフォルト値の 60 (1 分) が使用されます。この値および sasl.login.refresh.buffer.seconds は、その合計がクレデンシャルの残りの有効期間を超える場合に両方とも無視されます。現在、OAUTHBEARER にのみ適用されます。
sasl.login.refresh.window.factor型: double
デフォルト: 0.8
重要度: 中
動的更新: per-broker
ログイン更新スレッドは、クレデンシャルの有効期間との関連で指定の期間ファクターに達するまでスリープ状態になり、達成した時点でクレデンシャルの更新を試みます。設定可能な値は 0.5(50%)から 1.0(100%)までです。値が指定されていない場合、デフォルト値の 0.8(80%)が使用されます。現在、OAUTHBEARER にのみ適用されます。
sasl.login.refresh.window.jitter型: double
デフォルト: 0.05
重要度: 中
動的更新: per-broker
ログイン更新スレッドのスリープ時間に追加されるクレデンシャルの存続期間に関連するランダムジッターの最大量。設定可能な値は 0 から 0.25(25%)です。値が指定されていない場合は、デフォルト値の 0.05(5%)が使用されます。現在、OAUTHBEARER にのみ適用されます。
sasl.mechanism.inter.broker.protocol型: string
デフォルト: GSSAPI
重要度: 中
動的更新: per-broker
inter-broker 通信に使用される SASL メカニズム。デフォルトは GSSAPI です。
sasl.server.callback.handler.classタイプ: class
デフォルト: null
重要度: 中
動的更新: 読み取り専用
AuthenticateCallbackHandler インターフェイスを実装する SASL サーバーコールバックハンドラークラスの完全修飾名。サーバーコールバックハンドラーの前には、リスナー接頭辞 と SASL メカニズム名を小文字で指定する必要があります。たとえば、listener.name.sasl_ssl.plain.sasl.server.callback.handler.class=com.example.CustomPlainCallbackHandler などです。
security.inter.broker.protocol型: string
デフォルト: PLAINTEXT
重要度: 中
動的更新: 読み取り専用
inter-broker 通信に使用されるセキュリティープロトコル。有効な値は、PLAINTEXT、SSL、SASL_PLAINTEXT、SASL_SSL です。これと inter.broker.listener.name プロパティーを同時に設定するとエラーになります。
ssl.cipher.suitesタイプ: list
デフォルト: ""
重要度: 中
動的更新: ブローカーごと
暗号化スイートの一覧。これは、TLS または SSL ネットワークプロトコルを使用してネットワーク接続のセキュリティー設定をネゴシエートするために使用される認証、暗号化、MAC、および鍵交換アルゴリズムの名前付きの組み合わせです。デフォルトでは、利用可能なすべての暗号スイートがサポートされます。
ssl.client.authタイプ: string
デフォルト: none
有効な値: [required, requested, none]
重要度: 中
動的更新: ブローカーごと
クライアント認証を要求する kafka ブローカーを設定します。以下の設定は一般的な設定です。
-
ssl.client.auth=required: 必要なクライアント認証が必要な場合 -
ssl.client.auth=requestedこれは、クライアント認証は任意となります。要求されたとは異なり、このオプションを設定するとクライアント自体の認証情報を提供しないよう選択できることを意味します。 -
ssl.client.auth=none: これは、クライアント認証が不要であることを意味します。
-
ssl.enabled.protocols型: list
デフォルト: TLSv1.2、TLSv1.3
重要度: 中
動的更新: per-broker
SSL 接続で有効なプロトコルの一覧。Java 11 以降で実行する場合、デフォルトは 'TLSv1.2,TLSv1.3' で、それ以外の場合は 'TLSv1.2' になります。Java 11 のデフォルト値では、クライアントとサーバーの両方が TLSv1.3 をサポートする場合は TLSv1.3 を優先し、そうでない場合は TLSv1.2 にフォールバックします (両方が少なくとも TLSv1.2 をサポートすることを前提とします)。ほとんどの場合、このデフォルトは問題ありません。
ssl.protocolの設定ドキュメントも参照してください。ssl.key.passwordタイプ: password
デフォルト: null
重要度: 中
動的更新: ブローカーごと
キーストアファイルの秘密鍵のパスワード。これはクライアントにとってオプションになります。
ssl.keymanager.algorithm型: string
デフォルト: SunX509
重要度: 中
動的更新: per-broker
SSL 接続のキーマネージャーファクトリーによって使用されるアルゴリズム。デフォルト値は、Java 仮想マシンに設定されたキーマネージャーファクトリーアルゴリズムです。
ssl.keystore.locationタイプ: string
デフォルト: null
重要度: 中
動的更新: ブローカーごと
キーストアファイルの場所。これはクライアントではオプションで、クライアントの双方向認証に使用できます。
ssl.keystore.passwordタイプ: password
デフォルト: null
重要度: 中
動的更新: ブローカーごと
キーストアファイルのストアパスワード。これはクライアントのオプションで、ssl.keystore.location が設定されている場合のみ必要です。
ssl.keystore.type型: string
デフォルト: JKS
重要度: 中
動的更新: ブローカーごと
キーストアファイルのファイル形式。これはクライアントにとってオプションになります。
ssl.protocol型: string
デフォルト: TLSv1.3
重要度: 中
動的更新: per-broker
SSLContext の生成に使用される SSL プロトコル。Java 11 以降で実行する場合、デフォルトは 'TLSv1.3' になります。それ以外の場合は 'TLSv1.2' になります。この値は、ほとんどのユースケースで問題ありません。最近の JVM で許可される値は 'TLSv1.2' および 'TLSv1.3' です。'TLS'、'TLSv1.1'、'SSL'、'SSLv2'、および 'SSLv3' は古い JVM でサポートされる可能性がありますが、既知のセキュリティー脆弱性のために使用は推奨されません。この設定のデフォルト値および 'ssl.enabled.protocols' では、サーバーが 'TLSv1.3' に対応していない場合は、クライアントは 'TLSv1.2' にダウングレードされます。この設定が 'TLSv1.2' に設定されている場合、'TLSv1.3' が ssl.enabled.protocols の値の 1 つで、サーバーが 'TLSv1.3' のみをサポートする場合でも、クライアントは 'TLSv1.3' を使用しません。
ssl.providerタイプ: string
デフォルト: null
重要度: 中
動的更新: ブローカーごと
SSL 接続に使用されるセキュリティープロバイダーの名前。デフォルト値は JVM のデフォルトのセキュリティープロバイダーです。
ssl.trustmanager.algorithm型: string
デフォルト: PKIX
重要度: 中
動的更新: ブローカーごと
SSL 接続のトラストマネージャーファクトリーによって使用されるアルゴリズム。デフォルト値は、Java 仮想マシンに設定されたトラストマネージャーファクトリーアルゴリズムです。
ssl.truststore.locationタイプ: string
デフォルト: null
重要度: 中
動的更新: ブローカーごと
トラストストアファイルの場所。
ssl.truststore.passwordタイプ: password
デフォルト: null
重要度: 中
動的更新: ブローカーごと
トラストストアファイルのパスワード。パスワードがトラストストアへのアクセスを設定しなくても、整合性チェックは無効になります。
ssl.truststore.type型: string
デフォルト: JKS
重要度: 中
動的更新: ブローカーごと
トラストストアファイルのファイル形式。
zookeeper.clientCnxnSocketタイプ: string
デフォルト: null
重要度: 中
動的更新: 読み取り専用
通常、ZooKeeper への TLS 接続を使用する場合は
org.apache.zookeeper.ClientCnxnSocketNettyに設定されます。同じ名前が付けられたzookeeper.clientCnxnSocketシステムプロパティーを介して設定された明示的な値を上書きします。zookeeper.ssl.client.enableタイプ: boolean
デフォルト: false
重要度: 中
動的更新: 読み取り専用
ZooKeeper への接続時に TLS を使用するようにクライアントを設定します。明示的な値は、
zookeeper.client.secureシステムプロパティーを介して設定された値を上書きします (別の名前に注意してください)。どちらも設定されていない場合は false に設定されます。true の場合はzookeeper.clientCnxnSocketを設定する必要があります (通常はorg.apache.zookeeper.ClientCnxnSocketNettyに設定)。設定するその他の値には、zookeeper.ssl.cipher.suites、zookeeper.ssl.crl.enable、zookeeper.ssl.enabled.protocols、zookeeper.ssl.endpoint.identification.algorithm、zookeeper.ssl.keystore.location、zookeeper.ssl.keystore.password、zookeeper.ssl.keystore.type、zookeeper.ssl.ocsp.enable、zookeeper.ssl.protocol、zookeeper.ssl.truststore.location、zookeeper.ssl.truststore.password、zookeeper.ssl.truststore.typeなどがあります。zookeeper.ssl.keystore.locationタイプ: string
デフォルト: null
重要度: 中
動的更新: 読み取り専用
ZooKeeper への TLS 接続でクライアント側の証明書を使用する場合のキーストアの場所。
zookeeper.ssl.keyStore.locationシステムプロパティーを介して設定された明示的な値を上書きします (camelCase に注意)。zookeeper.ssl.keystore.passwordタイプ: password
デフォルト: null
重要度: 中
動的更新: 読み取り専用
ZooKeeper への TLS 接続でクライアント側の証明書を使用する場合のキーストアパスワード。
zookeeper.ssl.keyStore.passwordシステムプロパティーを介して設定された明示的な値を上書きします (camelCase に注意)。ZooKeeper はキーストアパスワードとは異なるキーパスワードをサポートしないため、キーストアのキーパスワードをキーストアのパスワードと同じ値に設定してください。そうしないと、Zookeeper への接続は失敗します。zookeeper.ssl.keystore.typeタイプ: string
デフォルト: null
重要度: 中
動的更新: 読み取り専用
ZooKeeper への TLS 接続でクライアント側の証明書を使用する場合のキーストアタイプ。
zookeeper.ssl.keyStore.typeシステムプロパティーを介して設定された明示的な値を上書きします (camelCase に注意)。nullのデフォルト値は、キーストアのファイル名のエクステンションに基づいて、タイプが自動検出されることを意味します。zookeeper.ssl.truststore.locationタイプ: string
デフォルト: null
重要度: 中
動的更新: 読み取り専用
ZooKeeper への TLS 接続を使用する場合のトラストストアの場所。
zookeeper.ssl.trustStore.locationシステムプロパティーを介して設定された明示的な値を上書きします (camelCase に注意)。zookeeper.ssl.truststore.passwordタイプ: password
デフォルト: null
重要度: 中
動的更新: 読み取り専用
ZooKeeper への TLS 接続を使用する場合のトラストストアパスワード。
zookeeper.ssl.trustStore.passwordシステムプロパティーを介して設定された明示的な値を上書きします (camelCase に注意)。zookeeper.ssl.truststore.typeタイプ: string
デフォルト: null
重要度: 中
動的更新: 読み取り専用
ZooKeeper への TLS 接続を使用する場合のトラストストアタイプ。
zookeeper.ssl.trustStore.typeシステムプロパティーを介して設定された明示的な値を上書きします (camelCase に注意)。デフォルト値のnullは、タイプがトラストストアのファイル名のエクステンションに基づいて自動検出されることを意味します。alter.config.policy.class.nameタイプ: class
デフォルト: null
重要度: 低
動的更新: 読み取り専用
検証に使用する必要のある alter configs ポリシークラス。クラスは
org.apache.kafka.server.policy.AlterConfigPolicyインターフェイスを実装する必要があります。alter.log.dirs.replication.quota.window.num型: int
デフォルト: 11
有効な値: [1,…]
重要度: 低
動的更新: 読み取り専用
ログディレクトリーレプリケーションクォータを変更するためにメモリー内に保持するサンプル数。
alter.log.dirs.replication.quota.window.size.seconds型: int
デフォルト: 1
有効な値: [1,…]
重要度: 低
動的更新: 読み取り専用
ログディレクトリーレプリケーションクォータを変更する各サンプルの期間。
authorizer.class.name型: string
デフォルト: ""
重要度 低
動的更新: 読み取り専用
承認のためにブローカーによって使用される、sorg.apache.kafka.server.authorizer.Authorizer インターフェースを実装するクラスの完全修飾名。この設定は、以前は承認に使用されていた非推奨の kafka.security.auth.Authorizer トレイトを実装するオーソライザーもサポートします。
client.quota.callback.classタイプ: class
デフォルト: null
重要度: 低
動的更新: 読み取り専用
ClientQuotaCallback インターフェースを実装するクラスの完全修飾名。これは、クライアント要求に適用されるクォータ制限を決定するために使用されます。デフォルトでは、ZooKeeper に保存されている <user, client-id>、<user> または <client-id> クォータが適用されます。指定されたリクエストでは、セッションのユーザープリンシパルと、リクエストのクライアントIDに一致する最も具体的なクォータが適用されます。
connection.failed.authentication.delay.ms型: int
デフォルト: 100
有効な値: [0,…]
重要度: 低
動的更新: 読み取り専用
認証に失敗した場合の connection close 遅延:これは、認証に失敗した場合に connection close が遅延する時間(ミリ秒単位)です。これは、接続のタイムアウトを防ぐために、 connections.max.idle.ms 未満になるように設定する必要があります。
create.topic.policy.class.nameタイプ: class
デフォルト: null
重要度: 低
動的更新: 読み取り専用
検証に使用する必要があるトピックポリシークラスを作成します。クラスは
org.apache.kafka.server.policy.CreateTopicPolicyインターフェイスを実装する必要があります。delegation.token.expiry.check.interval.ms型: long
デフォルト: 3600000 (1 時間)
有効な値: [1,…]
重要度: 低
動的更新: 読み取り専用
期限切れの委任トークンを削除する間隔をスキャンします。
kafka.metrics.polling.interval.secs型: int
デフォルト: 10
有効な値: [1,…]
重要度: 低
動的更新: 読み取り専用
kafka.metrics.reporters 実装で使用できるメトリクスポーリング間隔 (秒単位)。
kafka.metrics.reportersタイプ: list
デフォルト: ""
重要度: 低
動的更新: 読み取り専用
Yammer メトリクスカスタムレポーターとして使用するクラスの一覧。レポーターは
kafka.metrics.KafkaMetricsReporterトレイトを実装する必要があります。クライアントがカスタムレポーターで JMX 操作を公開する必要がある場合、カスタムレポーターはkafka.metrics.KafkaMetricsReporterMBeanトレイトを拡張する MBean トレイトを追加で実装し、登録された MBean が標準の MBean 規則に準拠するようにする必要があります。listener.security.protocol.map型: string
デフォルト: PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
重要度: low
動的更新: per-broker
リスナー名とセキュリティープロトコル間のマッピング。これは、複数のポートまたは IP で同じセキュリティープロトコルを使用できるように定義する必要があります。たとえば、SSL が両方に必要であっても、内部トラフィックと外部トラフィックは分離することができます。具体的には、ユーザーは INTERNAL および EXTERNAL という名前のリスナーを定義し、このプロパティーを
INTERNAL:SSL,EXTERNAL:SSLのように定義できます。表示されているように、キーと値はコロンで区切られ、マップエントリーはコンマで区切ります。各リスナー名はマップで一度だけ表示されます。設定名に正規化された接頭辞 (リスナー名は小文字) を追加して、各リスナーに異なるセキュリティー (SSL および SASL) 設定を設定できます。たとえば、INTERNAL リスナーに異なるキーストアを設定するには、listener.name.internal.ssl.keystore.locationという名前の設定が設定されます。リスナー名の設定が設定されていない場合、設定は汎用設定(ssl.keystore.locationなど)にフォールバックします。log.message.downconversion.enableタイプ: boolean
デフォルト: true
重要度: 低
動的更新: クラスター全体
この設定は、消費リクエストを満たすためにメッセージ形式のダウンコンバートを有効にするかどうかを制御します。
falseに設定すると、ブローカーは古いメッセージ形式を想定しているコンシューマーに対してダウンコンバートを実行しません。ブローカーは、そのような古いクライアントからの消費リクエストに対して、UNSUPPORTED_VERSIONエラーを返します。この設定は、フォロワーへのレプリケーションに必要なメッセージ形式の変換には適用されません。metric.reportersタイプ: list
デフォルト: ""
重要度: 低
動的更新: クラスター全体
メトリクスレポーターとして使用するクラスの一覧。
org.apache.kafka.common.metrics.MetricsReporterインターフェイスを実装すると、新しいメトリクスの作成が通知されるクラスのプラグが可能になります。JmxReporter は、JMX 統計を登録するために常に含まれます。metrics.num.samples型: int
デフォルト: 2
有効な値: [1,…]
重要度: 低
動的更新: 読み取り専用
メトリクスを計算するために保持されるサンプルの数。
metrics.recording.level型: string
デフォルト: INFO
重要度 低
動的更新: 読み取り専用
メトリクスの最も高い記録レベル。
metrics.sample.window.ms型: long
デフォルト: 30000 (30 秒)
有効な値: [1,…]
重要度: 低
動的更新: 読み取り専用
メトリクスサンプルが計算される時間枠。
password.encoder.cipher.algorithm型: string
デフォルト: AES/CBC/PKCS5Padding
重要度: 低
動的更新: 読み取り専用
動的に設定されたパスワードをエンコードする際に使用する暗号アルゴリズム。
password.encoder.iterations型: int
デフォルト: 4096
有効な値: [1024,…]
重要度: 低
動的更新: 読み取り専用
動的に設定されたパスワードのエンコードに使用される反復カウント。
password.encoder.key.length型: int
デフォルト: 128
有効な値: [8,…]
重要度: 低
動的更新: 読み取り専用
動的に設定されたパスワードをエンコードするために使用されるキーの長さ。
password.encoder.keyfactory.algorithmタイプ: string
デフォルト: null
重要度: 低
動的更新: 読み取り専用
動的に設定されたパスワードをエンコードするのに使用される SecretKeyFactory アルゴリズム。それ以外の場合は、デフォルトで PBKDF2WithHmacSHA512 および PBKDF2WithHmacSHA1 になります。
quota.window.num型: int
デフォルト: 11
有効な値: [1,…]
重要度: 低
動的更新: 読み取り専用
クライアントクォータのメモリー内に保持するサンプル数。
quota.window.size.seconds型: int
デフォルト: 1
有効な値: [1,…]
重要度: 低
動的更新: 読み取り専用
クライアントクォータの各サンプルの時間の長さ。
replication.quota.window.num型: int
デフォルト: 11
有効な値: [1,…]
重要度: 低
動的更新: 読み取り専用
レプリケーションクォータのメモリーに保持するサンプル数。
replication.quota.window.size.seconds型: int
デフォルト: 1
有効な値: [1,…]
重要度: 低
動的更新: 読み取り専用
レプリケーションクォータの各サンプルの期間。
security.providersタイプ: string
デフォルト: null
重要度: 低
動的更新: 読み取り専用
設定可能なクリエータークラスのリストで、それぞれがセキュリティーアルゴリズムを実装するプロバイダーを返します。これらのクラスは
org.apache.kafka.common.security.auth.SecurityProviderCreatorインターフェイスを実装する必要があります。ssl.endpoint.identification.algorithmタイプ: string
デフォルト: https
重要度: 低
動的更新: ブローカーごと
サーバー証明書を使用してサーバーのホスト名を検証するエンドポイント識別アルゴリズム。
ssl.engine.factory.classタイプ: class
デフォルト: null
重要度: 低
動的更新: ブローカーごと
SSLEngine オブジェクトを提供する org.apache.kafka.common.security.auth.SslEngineFactory タイプのクラス。デフォルト値はorg.apache.kafka.common.security.ssl.DefaultSslEngineFactory です。
ssl.principal.mapping.rules型: string
デフォルト: DEFAULT
重要度 低
動的更新: 読み取り専用
クライアント証明書の識別名から短縮名にマッピングするためのルールのリスト。ルールは順番に評価され、プリンシパル名と一致する最初のルールは、これを短縮名にマップするために使用されます。一覧の後続のルールは無視されます。デフォルトでは、X.500 証明書の識別名はプリンシパルになります。形式の詳細は、 security authorization and acls を参照してください。この設定は、
principal.builder.class設定によって KafkaPrincipalBuilder のエクステンションが提供される場合は無視されます。ssl.secure.random.implementationタイプ: string
デフォルト: null
重要度: 低
動的更新: ブローカーごと
SSL 暗号操作に使用する SecureRandom PRNG 実装。
transaction.abort.timed.out.transaction.cleanup.interval.ms型: int
デフォルト: 10000 (10 秒)
有効な値: [1,…]
重要度: 低
動的更新: 読み取り専用
タイムアウトしたトランザクションをロールバックする間隔。
transaction.remove.expired.transaction.cleanup.interval.ms型: int
デフォルト: 3600000 (1 時間)
有効な値: [1,…]
重要度: 低
動的更新: 読み取り専用
transactional.id.expiration.msを渡すために期限切れとなったトランザクションを削除する間隔。zookeeper.ssl.cipher.suitesタイプ: list
デフォルト: null
重要度: 低
動的更新: 読み取り専用
ZooKeeper TLS negotiation(csv)で使用される有効な暗号スイートを指定します。
zookeeper.ssl.ciphersuitesシステムプロパティーを介して設定された明示的な値を上書きします ("ciphersuites" という単語に注意)。デフォルト値のnullは、有効な暗号スイートのリストが、使用される Java ランタイムによって決定されることを意味します。zookeeper.ssl.crl.enableタイプ: boolean
デフォルト: false
重要度: 低
動的更新: 読み取り専用
ZooKeeper TLS プロトコルで、証明書失効リストを有効にするかどうかを指定します。
zookeeper.ssl.crlシステムプロパティーを介して設定された明示的な値を上書きします (短い名前に注意)。zookeeper.ssl.enabled.protocolsタイプ: list
デフォルト: null
重要度: 低
動的更新: 読み取り専用
ZooKeeper TLS negotiation(csv)で有効なプロトコルを指定します。
zookeeper.ssl.enabledProtocolsシステムプロパティーを介して設定された明示的な値を上書きします (camelCase に注意)。デフォルト値のnullは、有効化されたプロトコルがzookeeper.ssl.protocol設定プロパティーの値になることを意味します。zookeeper.ssl.endpoint.identification.algorithm型: string
デフォルト: HTTPS
重要度: 低
動的更新: 読み取り専用
ZooKeeper TLS ネゴシエーションプロセスのホスト名検証を有効にするかどうかを指定します。この場合 (大文字小文字を区別しない) "https" は ZooKeeper ホスト名の検証が有効で、明示的な空白値は無効であることを意味します (無効にすることはテスト目的でのみ推奨されます)。明示的な値は、
zookeeper.ssl.hostnameVerificationシステムプロパティーを介して設定される "true" または "false" の値を上書きします (異なる名前と値に注意してください。true は https を意味し、false は空白を意味します)。zookeeper.ssl.ocsp.enableタイプ: boolean
デフォルト: false
重要度: 低
動的更新: 読み取り専用
ZooKeeper TLS プロトコルで Online Certificate Status Protocol を有効にするかどうかを指定します。
zookeeper.ssl.ocspシステムプロパティーを介して設定した明示的な値を上書きします (短い名前に注意)。zookeeper.ssl.protocol型: string
デフォルト: TLSv1.2
重要度: 低
動的更新: 読み取り専用
ZooKeeper TLS ネゴシエーションで使用されるプロトコルを指定します。明示的な値は、同じ名前が付けられた
zookeeper.ssl.protocolシステムプロパティーで設定された値を上書きします。zookeeper.sync.time.ms型: int
デフォルト: 2000 (2 秒)
重要度: 低
動的更新: 読み取り専用
ZK フォロワーが ZK リーダーの後ろにどれだけ遅れることができるか
付録B トピック設定パラメーター
cleanup.policyタイプ: list
デフォルト: delete
有効な値: [compact, delete]
サーバーデフォルトプロパティー: log.cleanup.policy
重要度: 中
"delete" または "compact" のいずれか、または両方である文字列。この文字列は、古いログセグメントで使用する保持ポリシーを指定します。デフォルトのポリシー ("delete") は、保持期間またはサイズ制限に達すると古いセグメントを破棄します。"compact" 設定は、トピックで ログコンパクション を有効にします。
compression.typeタイプ: string
デフォルト: producer
有効な値: [uncompressed, zstd, lz4, snappy, gzip, producer]
サーバーデフォルトプロパティー: compression.type
重要度: 中
特定のトピックの最終的な圧縮タイプを指定します。この設定は、標準の圧縮コーデック ('gzip'、'snappy'、'lz4'、'zstd') を受け入れます。さらに、圧縮なしに相当する 'uncompressed' と、プロデューサーによって設定された元の圧縮コーデックを維持する 'producer' も使用できます。
delete.retention.ms型: long
デフォルト: 86400000 (1 日)
有効な値: [0,…]
サーバーのデフォルトプロパティー: log.cleaner.delete.retention.ms
重要度: 中
ログ圧縮 トピックの tombstone 削除マーカーを保持する期間。また、この設定は、最終ステージの有効なスナップショットを確実に取得するために、コンシューマーがオフセット 0 から開始する場合に読み取りを完了しなければならない時間にも制限を与えます(そうでない場合、スキャンを完了する前に、削除 tombstone が収集される可能性があります)。
file.delete.delay.ms型: long
デフォルト: 60000 (1 分)
有効な値: [0,…]
サーバーのデフォルトプロパティー: log.segment.delete.delay.ms
重要度: 中
ファイルシステムからファイルを削除するまでの待機時間。
flush.messages型: long
デフォルト: 9223372036854775807
有効な値: [0,…]
サーバーのデフォルトプロパティー: log.flush.interval.messages
重要度: 中
この設定により、ログに書き込まれたデータの fsync を強制する間隔を指定できます。たとえば、これが 1 に設定されている場合、すべてのメッセージの後に fsync を実行します。5 に設定されている場合は、5 つのメッセージごとに fsync します。一般的には、これを設定せず、永続性のためにレプリケーションを使用し、より効率的であるため、オペレーティングシステムのバックグラウンドフラッシュ機能を使用することが推奨されます。この設定は、トピックごとに上書きできます (トピックごとの設定セクション を参照)。
flush.ms型: long
デフォルト: 9223372036854775807
有効な値: [0,…]
サーバーのデフォルトプロパティー: log.flush.interval.ms
重要度: 中
この設定により、ログに書き込まれるデータのfsyncを強制する時間間隔を指定できます。たとえば、これが 1000 に設定されていた場合は、1000 ミリ秒が経過した後に fsync を実行します。一般的には、これを設定せず、永続性のためにレプリケーションを使用し、より効率的であるため、オペレーティングシステムのバックグラウンドフラッシュ機能を使用することが推奨されます。
follower.replication.throttled.replicas型: list
デフォルト: ""
有効な値: [partitionId]:[brokerId],[partitionId]:[brokerId],…
サーバーのデフォルトプロパティー: follower.replication.throttled.replicas
重要度: 中
ログレプリケーションをフォロワー側でスロットリングする必要があるレプリカの一覧。リストには、レプリカのセットを [PartitionId]:[BrokerId],[PartitionId]:[BrokerId]:…の形式で記述する必要があります。または、ワイルドカード * を使用して、このトピックのすべてのレプリカを調整できます。
index.interval.bytes型: int
デフォルト: 4096 (4 キビバイト)
有効な値: [0,…]
サーバーのデフォルトプロパティー: log.index.interval.bytes
重要度: 中
この設定は、Kafka がインデックスエントリーをオフセットインデックスに追加する頻度を制御します。デフォルト設定では、およそ 4096 バイトごとにメッセージを確実にインデックス化します。インデックス化を増やすことで、読み取りをログ内の正確な位置に近づけることができますが、インデックスは大きくなりますおそらくこれを変更する必要はありません。
leader.replication.throttled.replicas型: list
デフォルト: ""
有効な値: [partitionId]:[brokerId],[partitionId]:[brokerId],…
サーバーのデフォルトプロパティー: leader.replication.throttled.replicas
重要度: 中
ログレプリケーションをリーダー側でスロットリングする必要があるレプリカの一覧。リストには、レプリカのセットを [PartitionId]:[BrokerId],[PartitionId]:[BrokerId]:…の形式で記述する必要があります。または、ワイルドカード * を使用して、このトピックのすべてのレプリカを調整できます。
max.compaction.lag.ms型: long
デフォルト: 9223372036854775807
有効な値: [1,…]
サーバーのデフォルトプロパティー: log.cleaner.max.compaction.lag.ms
重要度: 中
メッセージがログのコンパクションの対象外のままになる最大時間。圧縮されるログにのみ適用されます。
max.message.bytes型: int
デフォルト: 1048588
有効な値: [0,…]
サーバーのデフォルトプロパティー: message.max.bytes
重要度: 中
Kafka によって許可される最大のレコードバッチサイズ (圧縮が有効な場合は圧縮後)。これが増加し、0.10.2 より古いコンシューマーが存在する場合、コンシューマーのフェッチサイズも増加して、このような大きなレコードバッチをフェッチできるようにする必要があります。最新のメッセージ形式バージョンでは、効率化のためにレコードは常にバッチにグループ化されます。以前のメッセージ形式のバージョンでは、圧縮されていないレコードはバッチにグループ化されず、この制限はその場合の単一レコードにのみ適用されます
message.format.versionタイプ: string
デフォルト: 2.6-IV0
有効な値: [0.8.0, 0.8.1, 0.8.2, 0.9.0, 0.10.0-IV0, 0.10.0-IV1, 0.10.1-IV0, 0.10.1-IV1, 0.10.1-IV2, 0.10.2-IV0, 0.11.0-IV0, 0.11.0-IV1, 0.11.0-IV2, 1.0-IV0, 1.1-IV0, 2.0-IV0, 2.0-IV1, 2.1-IV0, 2.1-IV1, 2.1-IV2, 2.2-IV0, 2.2-IV1, 2.3-IV0, 2.3-IV1, 2.4-IV0, 2.4-IV1, 2.5-IV0, 2.6-IV0]
サーバーの デフォルトプロパティー: log.message.format.version
重大度: 中
ブローカーがログにメッセージを追加するために使用するメッセージ形式バージョンを指定します。この値は有効な ApiVersion である必要があります。たとえば、0.8.2、0.9.0.0、0.10.0 です。詳細は ApiVersion を確認してください。特定のメッセージ形式のバージョンを設定することで、ユーザーは、ディスク上の既存のメッセージすべてが指定したバージョンよりも小さいか、または等しいことを認定します。この値を誤って設定すると、以前のバージョンを持つコンシューマーが、認識されない形式でメッセージを受信するため、破損します。
message.timestamp.difference.max.ms型: long
デフォルト: 9223372036854775807
有効な値: [0,…]
サーバーのデフォルトプロパティー: log.message.timestamp.difference.max.ms
重要度: 中
ブローカーがメッセージを受信したときのタイムスタンプと、メッセージに指定されたタイムスタンプとの間の最大差。message.timestamp.type=CreateTime の場合、タイムスタンプの相違点がこのしきい値を超えるとメッセージが拒否されます。この設定は、message.timestamp.type=LogAppendTime の場合は無視されます。
message.timestamp.type型: string
デフォルト: CreateTime
有効な値: [CreateTime, LogAppendTime]
サーバーのデフォルトプロパティー: log.message.timestamp.type
重要度: medium
メッセージのタイムスタンプが、メッセージ作成時間かログの追加時間であるかを定義します。値は
CreateTimeまたはLogAppendTimeである必要があります。min.cleanable.dirty.ratio型: double
デフォルト: 0.5
有効な値: [0,…,1]
サーバーのデフォルトプロパティー: log.cleaner.min.cleanable.ratio
重要度: 中
この設定は、ログコンパクターがログのクリーンアップを試行する頻度を制御します (ログコンパクション が有効になっている場合).。デフォルトでは、50% を超えるログが圧縮されているログのクリーニングは回避されます。この比率は、重複によって無駄になるログの最大スペースを制限します (50%の場合、最大でログの50%が重複している可能性があります)。比率が高いほど、より少ない、より効率的なクリーニングを意味しますが、ログ内の無駄なスペースが多くなることを意味します。max.compaction.lag.ms または min.compaction.lag.ms 設定も指定されている場合、ログコンパクターは、次のいずれかの場合にすぐにログをコンパクションの対象と見なします。(i) ダーティー比率のしきい値に達し、ログに少なくとも min.compaction.lag.ms duration 期間のダーティー (圧縮されていない) レコードがある場合、または (ii) ログに最大で max.compaction.lag.ms 期間のダーティー (圧縮されていない) レコードがある場合。
min.compaction.lag.ms型: long
デフォルト: 0
有効な値: [0,…]
サーバーのデフォルトプロパティー: log.cleaner.min.compaction.lag.ms
重要度: 中
メッセージがログで圧縮されないままになる最小時間。圧縮されるログにのみ適用されます。
min.insync.replicas型: int
デフォルト: 1
有効な値: [1,…]
サーバーのデフォルトプロパティー: min.insync.replicas
重要度: 中
プロデューサーが acks を "all" (または "-1") に設定すると、この設定は、書き込みが成功したとみなされるために書き込みを確認する必要のあるレプリカの最小数を指定します。この最小値が満たされない場合、プロデューサーは例外 (NotEnoughReplicas または NotEnoughReplicasAfterAppend のいずれか) を発生させます。
min.insync.replicasとacksを併用することで、より高い持続性が保証されます。一般的なシナリオでは、レプリケーション係数 3 のトピックを作成し、min.insync.replicasを 2 に設定し、acksを all にして生成します。これにより、レプリカの大部分が書き込みを受信しない場合に、プロデューサーは確実に例外を発生させます。preallocateタイプ: boolean
デフォルト: false
サーバーデフォルトプロパティー: log.preallocate
重要度: 中
新規ログセグメントの作成時にファイルをディスクに事前割り当てする場合は True。
retention.bytesタイプ: long
デフォルト: -1
サーバーデフォルトプロパティー: log.retention.bytes
重要度: 中
この設定は、"delete" 保持ポリシーを使用している場合に、領域を解放するために古いログセグメントを破棄する前に、パーティション (ログセグメントで構成される) が成長できる最大サイズを制御します。デフォルトでは、サイズ制限はなく、時間制限のみがあります。この制限はパーティションレベルで適用されるため、これにパーティションの数を掛けて、トピックの保持をバイト単位で計算します。
retention.ms型: long
デフォルト: 604800000 (7 日)
有効な値: [-1,…]
サーバーのデフォルトプロパティー: log.retention.ms
重要度: 中
この設定は、"delete" 保持ポリシーを使用している場合に、古いログセグメントを破棄して領域を解放する前にログを保持する最大時間を制御します。これは、消費者がどれだけ早くデータを読み込まなければならないかという SLA を意味します。-1 に設定すると、時間制限は適用されません。
segment.bytes型: int
デフォルト: 1073741824 (1 ギビバイト)
有効な値: [14,…]
サーバーのデフォルトプロパティー: log.segment.bytes
重要度: 中
この設定は、ログのセグメントファイルサイズを制御します。保持とクリーニングは常に 1 ファイルずつ行われるため、セグメントサイズが大きくなると、ファイルは少なくなりますが、保持の制御が細かくできなくなります。
segment.index.bytes型: int
デフォルト: 10485760 (10 mebibytes)
有効な値: [0,…]
サーバーのデフォルトプロパティー: log.index.size.max.bytes
重要度: 中
この設定では、オフセットをファイルの位置にマップするインデックスのサイズを制御します。このインデックスファイルを事前割り当てし、ログロールの後にのみ縮小します。通常、この設定を変更する必要はありません。
segment.jitter.ms型: long
デフォルト: 0
有効な値: [0,…]
サーバーのデフォルトプロパティー: log.roll.jitter.ms
重要度: 中
セグメントローリングの大規模な集約を避けるために、スケジュールされたセグメントロール時間から差し引いたランダムなジッターの最大値。
segment.ms型: long
デフォルト: 604800000 (7 日)
有効な値: [1,…]
サーバーのデフォルトプロパティー: log.roll.ms
重要度: 中
この設定は、セグメントファイルがいっぱいでない場合でも、Kafka がログを強制的にロールして、古いデータを削除または圧縮できるようにする期間を制御します。
unclean.leader.election.enableタイプ: boolean
デフォルト: false
サーバーデフォルトプロパティー: unclean.leader.election.enable
重要度: 中
データが失われる可能性がある場合でも、ISRセットにないレプリカを最後の手段としてリーダーとして選出できるようにするかどうかを示します。
message.downconversion.enableタイプ: boolean
デフォルト: true
サーバーデフォルトプロパティー: log.message.downconversion.enable
重要度: 低
この設定は、消費リクエストを満たすためにメッセージ形式のダウンコンバートを有効にするかどうかを制御します。
falseに設定すると、ブローカーは古いメッセージ形式を想定しているコンシューマーに対してダウンコンバートを実行しません。ブローカーは、そのような古いクライアントからの消費リクエストに対して、UNSUPPORTED_VERSIONエラーを返します。この設定は、フォロワーへのレプリケーションに必要なメッセージ形式の変換には適用されません。
付録C コンシューマー設定パラメーター
key.deserializerタイプ: class
重要度: 高
org.apache.kafka.common.serialization.Deserializerインターフェイスを実装するキーのデシリアライザークラス。value.deserializerタイプ: class
重要度: 高
org.apache.kafka.common.serialization.Deserializerインターフェイスを実装する値のデシリアライザークラス。bootstrap.serversタイプ: list
デフォルト: ""
有効な値: non-null string
重要度: 高
Kafka クラスターへの最初の接続を確立するために使用されるホストとポートのペアの一覧。クライアントは、ブートストラップ用にここで指定されたサーバーに関係なく、すべてのサーバーを利用します。この一覧は、サーバーのフルセットを検出するために使用される最初のホストにのみ影響します。この一覧は、
host1:port1,host2:port2,…の形式にする必要があります。これらのサーバーは、(動的に変更される可能性がある) 完全なクラスターメンバーシップを検出するための最初の接続にだけ使用されるため、このリストにはサーバーの完全なセットを含める必要はありません (ただし、サーバーがダウンした場合に備えて、複数のサーバーが必要になる場合があります)。fetch.min.bytes型: int
デフォルト: 1
有効な値: [0,…]
重要度: 高
サーバーがフェッチ要求に対して返す必要のあるデータの最小量。利用可能なデータが不十分な場合、リクエストは、リクエストに応答する前に、十分なデータが蓄積されるのを待ちます。デフォルト設定の 1 バイトは、1 バイトのデータが使用可能になるか、データの到着を待機してフェッチ要求がタイムアウトするとすぐに、フェッチ要求に応答することを意味します。これを 1 を超える値に設定すると、サーバーは大量のデータが蓄積されるのを待機することになり、追加の遅延を犠牲にしてサーバーのスループットを少し向上させることができます。
group.idタイプ: string
デフォルト: null
重要度: 高
このコンシューマーが属するコンシューマーグループを識別する一意の文字列。このプロパティーは、コンシューマーが
subscribe(topic)を使用したグループ管理機能または Kafka ベースのオフセット管理ストラテジーのいずれかを使用する場合に必要です。heartbeat.interval.ms型: int
デフォルト: 3000 (3 秒)
重要度: 高
Kafka のグループ管理機能を使用する場合の、ハートビートからコンシューマーコーディネーター間の想定される時間。ハートビートは、コンシューマーのセッションがアクティブな状態を維持し、新しいコンシューマーがグループに参加したり離脱したりする際のリバランスを促進するために使用されます。この値は
session.timeout.msよりも低く設定する必要がありますが、通常はその値の 1/3 以下に設定する必要があります。さらに低く調整することで、通常のリバランスの予想時間を制御することもできます。max.partition.fetch.bytes型: int
デフォルト: 1048576 (1 メビバイト)
有効な値: [0,…]
重要度: 高
サーバーが返すパーティションごとのデータの最大量。レコードはコンシューマーによってバッチでフェッチされます。フェッチの最初の空でないパーティションの最初のレコードバッチがこの制限よりも大きい場合でも、コンシューマーが確実に前進することができるようにバッチが返されます。ブローカーによって許可される最大レコードバッチサイズは、
message.max.bytes(ブローカー設定) またはmax.message.bytes(トピック設定) で定義されます。コンシューマーのリクエストサイズを制限する場合は、fetch.max.bytes を参照してください。session.timeout.ms型: int
デフォルト: 10000 (10 秒)
重要度: 高
Kafka のグループ管理機能の使用時にクライアント障害を検出するために使用されるタイムアウト。クライアントは定期的にハートビートを送信し、liveness をブローカーに示します。このセッションタイムアウトの期限切れ前にブローカーによってハートビートが受信されない場合、ブローカーはグループからこのクライアントを削除し、リバランスを開始します。この値は、
group.min.session.timeout.msおよびgroup.max.session.timeout.msによってブローカー設定で設定される許容範囲内である必要があることに注意してください。ssl.key.passwordタイプ: password
デフォルト: null
重要度: 高
キーストアファイルの秘密鍵のパスワード。これはクライアントにとってオプションになります。
ssl.keystore.locationタイプ: string
デフォルト: null
重要度: 高
キーストアファイルの場所。これはクライアントではオプションで、クライアントの双方向認証に使用できます。
ssl.keystore.passwordタイプ: password
デフォルト: null
重要度: 高
キーストアファイルのストアパスワード。これはクライアントのオプションで、ssl.keystore.location が設定されている場合のみ必要です。
ssl.truststore.locationタイプ: string
デフォルト: null
重要度: 高
トラストストアファイルの場所。
ssl.truststore.passwordタイプ: password
デフォルト: null
重要度: 高
トラストストアファイルのパスワード。パスワードがトラストストアへのアクセスを設定しなくても、整合性チェックは無効になります。
allow.auto.create.topicsタイプ: boolean
デフォルト: true
重要度: 中
トピックをサブスクライブまたは割り当てるときに、ブローカーでのトピックの自動作成を許可します。サブスクライブするトピックは、ブローカーが
auto.create.topics.enableブローカー設定を使用して許可されている場合にのみ自動的に作成されます。この設定は、0.11.0 より古いブローカーを使用する場合は、falseに設定する必要があります。auto.offset.resetタイプ: string
デフォルト: latest
有効な値: [latest, earliest, none]
重要度: 中
Kafka に初期オフセットがない場合や、現在のオフセットがサーバー上に存在しない場合 (例: データが削除された場合など) の対処方法。
- earliest: 自動的にオフセットを最も古いオフセットにリセットする
- latest: 自動的にオフセットを最新のオフセットにリセットする
- none: コンシューマーのグループに以前のオフセットが見つからない場合は、コンシューマーに例外をスローする
- anything else: コンシューマーに例外をスローする
client.dns.lookupタイプ: string
デフォルト : use_all_dns_ips
有効な値: [default, use_all_dns_ips, resolve_canonical_bootstrap_servers_only]
重大度: 中
クライアントが DNS ルックアップを使用する方法を制御します。
use_all_dns_ipsに設定すると、正常な接続が確立されるまで、返された各 IP アドレスに順番に接続します。切断後に、次の IP が使用されます。すべての IP が一度使用されると、クライアントはホスト名から IP を再度解決します (ただし、JVM と OS の両方は DNS 名の検索をキャッシュします)。resolve_canonical_bootstrap_servers_onlyに設定すると、各ブートストラップアドレスを正規名の一覧に解決します。ブートストラップフェーズ後、これはuse_all_dns_ipsと同じように動作します。default(非推奨)に設定すると、ルックアップで複数の IP アドレスが返された場合でも、ルックアップで返された最初の IP アドレスへの接続を試みます。connections.max.idle.ms型: long
デフォルト: 540000 (9 分)
重要度: 中
この設定で指定された期間 (ミリ秒単位) の後にアイドル状態の接続を閉じます。
default.api.timeout.ms型: int
デフォルト: 60000 (1 分)
有効な値: [0,…]
重要度: 中
クライアント API のタイムアウト (ミリ秒単位) を指定します。この設定は、
timeoutパラメーターを指定しないすべてのクライアント操作のデフォルトタイムアウトとして使用されます。enable.auto.commitタイプ: boolean
デフォルト: true
重要度: 中
true の場合、コンシューマーのオフセットは定期的にバックグラウンドでコミットされます。
exclude.internal.topicsタイプ: boolean
デフォルト: true
重要度: 中
サブスクライブされたパターンと一致する内部トピックをサブスクリプションから除外するべきかどうか。常に内部トピックに明示的にサブスクライブできます。
fetch.max.bytes型: int
デフォルト: 52428800 (50 メビバイトs)
有効な値: [0,…]
重要度: 中
サーバーがフェッチリクエストに対して返す必要のあるデータの最大量。レコードはコンシューマーによってバッチで取得され、フェッチの最初の空ではないパーティションの最初のレコードバッチがこの値よりも大きい場合でも、コンシューマーが確実に前進することができるようにレコードバッチが返されます。そのため、絶対的な最大値ではありません。ブローカーによって許可される最大レコードバッチサイズは、
message.max.bytes(ブローカー設定) またはmax.message.bytes(トピック設定) で定義されます。コンシューマーは複数のフェッチを並行して実行することに注意してください。group.instance.idタイプ: string
デフォルト: null
重要度: 中
エンドユーザーが提供するコンシューマーインスタンスの一意の識別子。non-empty strings のみが許可されます。設定されている場合、コンシューマーは静的メンバーとして扱われます。つまり、常に、この ID を持つ 1 つのインスタンスのみがコンシューマーグループで許可されます。これは、より大きなセッションタイムアウトと組み合わせて使用して、一時的な利用不可 (プロセス再起動など) によるグループのリバランスを回避します。設定しないと、コンシューマーは従来の動作である動的メンバーとしてグループに参加します。
isolation.levelタイプ: string
デフォルト: read_uncommitted
有効な値: [read_committed, read_uncommitted]
重要度: 中
トランザクションで書き込まれたメッセージを読み取る方法を制御します。
read_committedに設定すると、consumer.poll() はコミットされたトランザクションメッセージのみを返します。'read_uncommitted'(デフォルト)に設定された場合、consumer.poll()は中断されたトランザクションメッセージであっても、すべてのメッセージを返します。非トランザクションメッセージは、どちらのモードでも無条件に返されます。メッセージは常にオフセットの順序で返されます。そのため、
read_committedモードでは、consumer.poll() は最初のオープントランザクションのオフセットよりも 1 つ小さい最後の安定したオフセット (LSO) までのメッセージのみを返します。特に、継続中のトランザクションに属するメッセージの後に表示されるメッセージは、関連するトランザクションが完了するまで保留されます。その結果、read_committedコンシューマーはフライトトランザクションがある場合に高基準値を読み取ることができません。Further, when in `read_committed` the seekToEnd method will return the LSO.
max.poll.interval.ms型: int
デフォルト: 300000 (5 分)
有効な値: [1,…]
重要度: 中
コンシューマーグループ管理を使用する場合の poll() の呼び出し間の最大遅延。これにより、コンシューマーがさらにレコードをフェッチする前にアイドル状態になることができる時間に上限が設定されます。このタイムアウトの期限が切れる前に poll() が呼び出されない場合、コンシューマーは失敗とみなされ、グループはパーティションを別のメンバーに再割り当てするためにリバランスします。null 以外の
group.instance.idを使用しているコンシューマーがこのタイムアウトに達した場合、パーティションは即座に再割り当てされません。代わりに、コンシューマーはハートビートの送信を停止し、session.timeout.msの期限が切れるとパーティションが再割り当てされます。これは、シャットダウンした静的コンシューマーの動作を反映します。max.poll.records型: int
デフォルト: 500
有効な値: [1,…]
重要度: 中
poll() への単一の呼び出しで返される最大レコード数。
partition.assignment.strategyタイプ: list
デフォルト: class org.apache.kafka.clients.consumer.RangeAssignor
有効な値: null でない文字列
重大度: 中
グループ管理が使用されている場合に、クライアントがコンシューマーインスタンス間でパーティションの所有権を分散するために使用する、サポートされているパーティション割り当て戦略のクラス名またはクラスタイプのリスト (優先度順)。
以下に示すデフォルトクラスの他に、コンシューマーへのパーティションのラウンドロビンの割り当てに 'org.apache.kafka.clients.consumer.RoundRobinAssignor'class を使用できます。
org.apache.kafka.clients.consumer.ConsumerPartitionAssignorインターフェースを実装すると、カスタム assignmentstrategy でプラグインできます。receive.buffer.bytes型: int
デフォルト: 65536 (64 キビバイト)
有効な値: [-1,…]
重要度: 中
データの読み取り時に使用する TCP 受信バッファー(SO_RCVBUF)のサイズ。値が -1 の場合、OS のデフォルトが使用されます。
request.timeout.ms型: int
デフォルト: 30000 (30 秒)
有効な値: [0,…]
重要度: 中
この設定は、クライアントの要求の応答を待つ最大時間を制御します。タイムアウトが経過する前に応答が受信されない場合、クライアントは必要に応じてリクエストを再送信します。または、再試行が使い切られるとリクエストが失敗します。
sasl.client.callback.handler.classタイプ: class
デフォルト: null
重要度: 中
AuthenticateCallbackHandler インターフェイスを実装する SASL クライアントコールバックハンドラークラスの完全修飾名。
sasl.jaas.configタイプ: password
デフォルト: null
重要度: 中
JAAS 設定ファイルで使用される形式の SASL 接続の JAAS ログインコンテキストパラメーター。JAAS 設定ファイルの形式は、こちら で説明されています。値の形式は 「loginModuleClass controlFlag(optionName=optionValue)*;」 です。ブローカーの場合、設定の前にリスナー接頭辞と SASL メカニズム名を小文字で指定する必要があります。たとえば、listener.name.sasl_ssl.scram-sha-256.sasl.jaas.config=com.example.ScramLoginModule required; などです。
sasl.kerberos.service.nameタイプ: string
デフォルト: null
重要度: 中
Kafka が実行される Kerberos プリンシパル名。これは、Kafka の JAAS 設定または Kafka の設定で定義できます。
sasl.login.callback.handler.classタイプ: class
デフォルト: null
重要度: 中
AuthenticateCallbackHandler インターフェイスを実装する SASL ログインコールバックハンドラークラスの完全修飾名。ブローカーの場合、ログインコールバックハンドラー設定の前には、リスナー接頭辞 と SASL メカニズム名を小文字で指定する必要があります。たとえば、listener.name.sasl_ssl.scram-sha-256.sasl.login.callback.handler.class=com.example.CustomScramLoginCallbackHandler などです。
sasl.login.classタイプ: class
デフォルト: null
重要度: 中
Login インターフェイスを実装するクラスの完全修飾名。ブローカーの場合、ログイン設定の前にリスナー接頭辞 と SASL メカニズム名を小文字で指定する必要があります。たとえば、listener.name.sasl_ssl.scram-sha-256.sasl.login.class=com.example.CustomScramLogin です。
sasl.mechanism型: string
デフォルト: GSSAPI
重要度: 中
クライアント接続に使用される SASL メカニズム。これは、セキュリティープロバイダーが利用可能な任意のメカニズムである可能性がありますGSSAPI はデフォルトのメカニズムです。
security.protocol型: string
デフォルト: PLAINTEXT
重要度: 中
ブローカーとの通信に使用されるプロトコル。有効な値は、PLAINTEXT、SSL、SASL_PLAINTEXT、SASL_SSL です。
send.buffer.bytes型: int
デフォルト: 131072 (128 キビバイト)
有効な値: [-1,…]
重要度: 中
データの送信時に使用する TCP 送信バッファー (SO_SNDBUF) のサイズ。値が -1 の場合、OS のデフォルトが使用されます。
ssl.enabled.protocols型: list
デフォルト: TLSv1.2、TLSv1.3
重要度: 中
SSL 接続で有効なプロトコルの一覧。Java 11 以降で実行する場合、デフォルトは 'TLSv1.2,TLSv1.3' で、それ以外の場合は 'TLSv1.2' になります。Java 11 のデフォルト値では、クライアントとサーバーの両方が TLSv1.3 をサポートする場合は TLSv1.3 を優先し、そうでない場合は TLSv1.2 にフォールバックします (両方が少なくとも TLSv1.2 をサポートすることを前提とします)。ほとんどの場合、このデフォルトは問題ありません。
ssl.protocolの設定ドキュメントも参照してください。ssl.keystore.type型: string
デフォルト: JKS
重要度: 中
キーストアファイルのファイル形式。これはクライアントにとってオプションになります。
ssl.protocol型: string
デフォルト: TLSv1.3
重要度: 中
SSLContext の生成に使用される SSL プロトコル。Java 11 以降で実行する場合、デフォルトは 'TLSv1.3' になります。それ以外の場合は 'TLSv1.2' になります。この値は、ほとんどのユースケースで問題ありません。最近の JVM で許可される値は 'TLSv1.2' および 'TLSv1.3' です。'TLS'、'TLSv1.1'、'SSL'、'SSLv2'、および 'SSLv3' は古い JVM でサポートされる可能性がありますが、既知のセキュリティー脆弱性のために使用は推奨されません。この設定のデフォルト値および 'ssl.enabled.protocols' では、サーバーが 'TLSv1.3' に対応していない場合は、クライアントは 'TLSv1.2' にダウングレードされます。この設定が 'TLSv1.2' に設定されている場合、'TLSv1.3' が ssl.enabled.protocols の値の 1 つで、サーバーが 'TLSv1.3' のみをサポートする場合でも、クライアントは 'TLSv1.3' を使用しません。
ssl.providerタイプ: string
デフォルト: null
重要度: 中
SSL 接続に使用されるセキュリティープロバイダーの名前。デフォルト値は JVM のデフォルトのセキュリティープロバイダーです。
ssl.truststore.type型: string
デフォルト: JKS
重要度: 中
トラストストアファイルのファイル形式。
auto.commit.interval.ms型: int
デフォルト: 5000 (5 秒)
有効な値: [0,…]
重要度: 低
enable.auto.commitがtrueに設定されている場合にコンシューマーオフセットが Kafka に自動コミットされる頻度 (ミリ秒単位)。check.crcsタイプ: boolean
デフォルト: true
重要度: 低
消費されたレコードの CRC32 を自動的に確認します。これにより、メッセージのネットワーク上またはディスク上の破損が発生しなくなります。このチェックはオーバーヘッドを追加するため、極端なパフォーマンスを求める場合は無効になる可能性があります。
client.idタイプ: string
デフォルト: ""
重要度: 低
要求の実行時にサーバーに渡す ID 文字列。この目的は、サーバー側の要求ロギングに論理アプリケーション名を含めることを許可することにより、ip/port の他にもリクエストのソースを追跡できるようにすることです。
client.rackタイプ: string
デフォルト: ""
重要度: 低
このクライアントのラック識別子。これには、このクライアントが物理的に存在する場所を示す任意の文字列値を指定できます。ブローカー設定 'broker.rack' に対応します。
fetch.max.wait.ms型: int
デフォルト: 500
有効な値: [0,…]
重要度: 低
fetch.min.bytes で指定された要件をすぐに満たすために十分なデータがない場合に、サーバーがフェッチリクエストに応答するまでにブロックする最大時間。
interceptor.classesタイプ: list
デフォルト: ""
有効な値: non-null string
重要度: 低
インターセプターとして使用するクラスの一覧。
org.apache.kafka.clients.consumer.ConsumerInterceptorインターフェイスを実装すると、コンシューマーによって受信される (場合によっては変更) レコードを傍受できます。デフォルトでは、インターセプターはありません。metadata.max.age.ms型: long
デフォルト: 300000 (5 分)
有効な値: [0,…]
重要度: low
新しいブローカーまたはパーティションをプロアクティブに検出するためのパーティションリーダーシップの変更がない場合でも、メタデータの更新を強制するまでの期間 (ミリ秒単位)。
metric.reportersタイプ: list
デフォルト: ""
有効な値: non-null string
重要度: 低
メトリクスレポーターとして使用するクラスの一覧。
org.apache.kafka.common.metrics.MetricsReporterインターフェイスを実装すると、新しいメトリクスの作成が通知されるクラスのプラグが可能になります。JmxReporter は、JMX 統計を登録するために常に含まれます。metrics.num.samples型: int
デフォルト: 2
有効な値: [1,…]
重要度: 低
メトリクスを計算するために保持されるサンプルの数。
metrics.recording.level型: string
デフォルト: INFO
有効な値: [INFO, DEBUG]
重要度: 低
メトリクスの最も高い記録レベル。
metrics.sample.window.ms型: long
デフォルト: 30000 (30 秒)
有効な値: [0,…]
重要度: 低
メトリクスサンプルが計算される時間枠。
reconnect.backoff.max.ms型: long
デフォルト: 1000 (1 秒)
有効な値: [0,…]
重要度: 低
接続に繰り返し失敗したブローカーへの再接続時に待機する最大時間 (ミリ秒単位)。これが指定されている場合、ホストごとのバックオフは、連続して接続に失敗するたびに、この最大値まで指数関数的に増加します。バックオフの増加を計算した後、コネクションストームを回避するために 20% のランダムなジッターが追加されます。
reconnect.backoff.ms型: long
デフォルト: 50
有効な値: [0,…]
重要度: 低
特定のホストへの再接続を試みる前に待機するベース時間。これにより、タイトなループでホストに繰り返し接続することを回避します。このバックオフは、クライアントによるブローカーへのすべての接続試行に適用されます。
retry.backoff.ms型: long
デフォルト: 100
有効な値: [0,…]
重要度: 低
特定のトピックパーティションに対して失敗したリクエストを再試行するまでの待機時間。これにより、一部の障害シナリオでタイトループでリクエストを繰り返し送信することを回避できます。
sasl.kerberos.kinit.cmdタイプ: string
デフォルト: /usr/bin/kinit
重要度: 低
Kerberos kinit コマンドパス。
sasl.kerberos.min.time.before.relogin型: long
デフォルト: 60000
重要度: 低
更新試行間のログインスレッドのスリープ時間。
sasl.kerberos.ticket.renew.jitter型: double
デフォルト: 0.05
重要度: 低
更新時間に追加されたランダムなジッターの割合。
sasl.kerberos.ticket.renew.window.factor型: double
デフォルト: 0.8
重要度: 低
ログインスレッドは、最後の更新からチケットの有効期限までの指定された時間のウィンドウファクターに達するまでスリープし、その時点でチケットの更新を試みます。
sasl.login.refresh.buffer.seconds型: short
デフォルト: 300
有効な値: [0,…,3600]
重要度: 低
クレデンシャルを更新するときに維持するクレデンシャルの有効期限が切れるまでのバッファー時間 (秒単位)。更新が、バッファ秒数よりも有効期限に近いときに発生する場合、更新は、可能な限り多くのバッファー時間を維持するために上に移動されます。設定可能な値は 0 から 3600 (1 時間) です。値を指定しない場合は、デフォルト値の 300 (5 分) が使用されます。この値および sasl.login.refresh.min.period.seconds は、その合計がクレデンシャルの残りの有効期間を超える場合にどちらも無視されます。現在、OAUTHBEARER にのみ適用されます。
sasl.login.refresh.min.period.seconds型: short
デフォルト: 60
有効な値: [0,…,900]
重要度: 低
ログイン更新スレッドがクレデンシャルを更新する前に待機する最小時間 (秒単位)。設定可能な値は 0 から 900 (15 分) です。値を指定しない場合は、デフォルト値の 60 (1 分) が使用されます。この値および sasl.login.refresh.buffer.seconds は、その合計がクレデンシャルの残りの有効期間を超える場合に両方とも無視されます。現在、OAUTHBEARER にのみ適用されます。
sasl.login.refresh.window.factor型: double
デフォルト: 0.8
有効な値: [0.5,…,1.0]
重要度: 低
ログイン更新スレッドは、クレデンシャルの有効期間との関連で指定の期間ファクターに達するまでスリープ状態になり、達成した時点でクレデンシャルの更新を試みます。設定可能な値は 0.5(50%)から 1.0(100%)までです。値が指定されていない場合、デフォルト値の 0.8(80%)が使用されます。現在、OAUTHBEARER にのみ適用されます。
sasl.login.refresh.window.jitter型: double
デフォルト: 0.05
有効な値: [0.0,…,0.25]
重要度: 低
ログイン更新スレッドのスリープ時間に追加されるクレデンシャルの存続期間に関連するランダムジッターの最大量。設定可能な値は 0 から 0.25(25%)です。値が指定されていない場合は、デフォルト値の 0.05(5%)が使用されます。現在、OAUTHBEARER にのみ適用されます。
security.providersタイプ: string
デフォルト: null
重要度: 低
設定可能なクリエータークラスのリストで、それぞれがセキュリティーアルゴリズムを実装するプロバイダーを返します。これらのクラスは
org.apache.kafka.common.security.auth.SecurityProviderCreatorインターフェイスを実装する必要があります。ssl.cipher.suitesタイプ: list
デフォルト: null
重要度: 低
暗号化スイートの一覧。これは、TLS または SSL ネットワークプロトコルを使用してネットワーク接続のセキュリティー設定をネゴシエートするために使用される認証、暗号化、MAC、および鍵交換アルゴリズムの名前付きの組み合わせです。デフォルトでは、利用可能なすべての暗号スイートがサポートされます。
ssl.endpoint.identification.algorithmタイプ: string
デフォルト: https
重要度: 低
サーバー証明書を使用してサーバーのホスト名を検証するエンドポイント識別アルゴリズム。
ssl.engine.factory.classタイプ: class
デフォルト: null
重要度: 低
SSLEngine オブジェクトを提供する org.apache.kafka.common.security.auth.SslEngineFactory タイプのクラス。デフォルト値はorg.apache.kafka.common.security.ssl.DefaultSslEngineFactory です。
ssl.keymanager.algorithm型: string
デフォルト: SunX509
重要度: 低
SSL 接続のキーマネージャーファクトリーによって使用されるアルゴリズム。デフォルト値は、Java 仮想マシンに設定されたキーマネージャーファクトリーアルゴリズムです。
ssl.secure.random.implementationタイプ: string
デフォルト: null
重要度: 低
SSL 暗号操作に使用する SecureRandom PRNG 実装。
ssl.trustmanager.algorithm型: string
デフォルト: PKIX
重要度: 低
SSL 接続のトラストマネージャーファクトリーによって使用されるアルゴリズム。デフォルト値は、Java 仮想マシンに設定されたトラストマネージャーファクトリーアルゴリズムです。
付録D プロデューサー設定パラメーター
key.serializerタイプ: class
重要度: 高
org.apache.kafka.common.serialization.Serializerインターフェイスを実装するキーのシリアライザークラス。value.serializerタイプ: class
重要度: 高
org.apache.kafka.common.serialization.Serializerインターフェイスを実装する値のシリアライザークラス。acksタイプ: string
デフォルト: 1
有効な値: [all, -1, 0, 1]
重大度: 高
リクエストが完了したと見なす前に、プロデューサーがリーダーに受け取ったことを要求する確認の数。これは、送信されるレコードの耐久性を制御します。以下の設定が許可されます。
-
acks=0ゼロに設定すると、プロデューサーはサーバーからの確認応答を一切待ちません。レコードは直ちにソケットバッファーに追加され、送信済みと見なされます。この場合、サーバーがレコードを受信したかどうかは保証されず、retriesの設定は有効になりません (クライアントは通常、失敗を知ることができないからです)。各レコードで返されるオフセットは、常に-1に設定されます。 -
acks=1これは、リーダーはその記録をローカルログに書き込みますが、全フォロワーからの完全な承認を待たずに応答します。この場合、リーダーがレコードを確認した直後に失敗し、これがフォロワーがレコードを複製する前であった場合は、レコードは失われます。 -
acks=allリーダーは同期しているレプリカの完全セットがレコードを確認するのを待ちます。これにより、少なくとも 1 つの In-Sync レプリカが動作している限り、レコードが失われないことが保証されます。これは利用可能な最強の保証になります。これは acks=-1 設定に相当します。
-
bootstrap.serversタイプ: list
デフォルト: ""
有効な値: non-null string
重要度: 高
Kafka クラスターへの最初の接続を確立するために使用されるホストとポートのペアの一覧。クライアントは、ブートストラップ用にここで指定されたサーバーに関係なく、すべてのサーバーを利用します。この一覧は、サーバーのフルセットを検出するために使用される最初のホストにのみ影響します。この一覧は、
host1:port1,host2:port2,…の形式にする必要があります。これらのサーバーは、(動的に変更される可能性がある) 完全なクラスターメンバーシップを検出するための最初の接続にだけ使用されるため、このリストにはサーバーの完全なセットを含める必要はありません (ただし、サーバーがダウンした場合に備えて、複数のサーバーが必要になる場合があります)。buffer.memory型: long
デフォルト: 33554432
有効な値: [0,…]
重要度: 高
プロデューサーが、サーバーへの送信を待機しているレコードをバッファリングするために使用できるメモリーの合計バイト数。レコードの送信がサーバーへの配信よりも速い場合、プロデューサーは
max.block.msの間ブロックし、その後例外をスローします。この設定は、プロデューサーが使用する合計メモリーにおおまかに対応する必要がありますが、プロデューサーが使用するすべてのメモリーがバッファリングに使用されるわけではないため、ハードバウンドではありません。一部の追加メモリーは、圧縮 (圧縮が有効な場合) やインフライトリクエストの維持に使用されます。
compression.typeタイプ: string
デフォルト: none
重要度: 高
プロデューサーによって生成されたすべてのデータの圧縮タイプ。デフォルトは none (圧縮なし) です。有効な値は、
none、gzip、snappy、lz4、またはzstdです。圧縮はデータの完全なバッチであるため、バッチ処理の有効性は圧縮率にも影響します (バッチ処理が多いほど圧縮率が高くなります)。retries型: int
デフォルト: 2147483647
有効な値: [0,…,2147483647]
重要度: 高
ゼロより大きい値を設定すると、クライアントは、一時的なエラーの可能性により送信に失敗したレコードを再送信します。この再試行は、クライアントがエラーを受信したときにレコードを再送した場合と同じであることに注意してください。
max.in.flight.requests.per.connectionに 1 を設定せずに再試行を許可すると、レコードの順序が変わる可能性があります。なぜなら、2 つのバッチが 1 つのパーティションに送信され、最初のバッチが失敗して再試行され、2番目のバッチが成功した場合、2 番目のバッチのレコードが最初に表示される可能性があるからです。さらに、確認が正常に実行される前にdelivery.timeout.msによって設定されたタイムアウトが期限切れになると、再試行の回数が指定数に達する前に行る前に生成の要求に失敗することに注意してください。通常は、この設定は未設定のままにし、代わりにdelivery.timeout.msを使用して再試行動作を制御します。ssl.key.passwordタイプ: password
デフォルト: null
重要度: 高
キーストアファイルの秘密鍵のパスワード。これはクライアントにとってオプションになります。
ssl.keystore.locationタイプ: string
デフォルト: null
重要度: 高
キーストアファイルの場所。これはクライアントではオプションで、クライアントの双方向認証に使用できます。
ssl.keystore.passwordタイプ: password
デフォルト: null
重要度: 高
キーストアファイルのストアパスワード。これはクライアントのオプションで、ssl.keystore.location が設定されている場合のみ必要です。
ssl.truststore.locationタイプ: string
デフォルト: null
重要度: 高
トラストストアファイルの場所。
ssl.truststore.passwordタイプ: password
デフォルト: null
重要度: 高
トラストストアファイルのパスワード。パスワードがトラストストアへのアクセスを設定しなくても、整合性チェックは無効になります。
batch.size型: int
デフォルト: 16384
有効な値: [0,…]
重要度: 中
複数のレコードが同じパーティションに送信されるときは常に、プロデューサーはレコードをまとめてより少ない要求にバッチ処理しようとします。これにより、クライアントとサーバーの両方でパフォーマンスが向上します。この設定では、デフォルトのバッチサイズをバイト単位で制御します。
このサイズより大きいレコードをバッチ処理することはありません。
ブローカーに送信されるリクエストには、複数のバッチが含まれます (送信可能なデータがあるパーティションごとに 1 つ)。
バッチサイズを小さくすると、バッチ処理が少なくなり、スループットが低下する可能性があります (バッチサイズがゼロの場合、バッチ処理は完全に無効になります)。バッチサイズが非常に大きい場合は、追加のレコードを想定して、常に指定のバッチサイズのバッファーを割り当てるため、メモリーを多少無駄に使用する可能性があります。
client.dns.lookupタイプ: string
デフォルト : use_all_dns_ips
有効な値: [default, use_all_dns_ips, resolve_canonical_bootstrap_servers_only]
重大度: 中
クライアントが DNS ルックアップを使用する方法を制御します。
use_all_dns_ipsに設定すると、正常な接続が確立されるまで、返された各 IP アドレスに順番に接続します。切断後に、次の IP が使用されます。すべての IP が一度使用されると、クライアントはホスト名から IP を再度解決します (ただし、JVM と OS の両方は DNS 名の検索をキャッシュします)。resolve_canonical_bootstrap_servers_onlyに設定すると、各ブートストラップアドレスを正規名の一覧に解決します。ブートストラップフェーズ後、これはuse_all_dns_ipsと同じように動作します。default(非推奨)に設定すると、ルックアップで複数の IP アドレスが返された場合でも、ルックアップで返された最初の IP アドレスへの接続を試みます。client.idタイプ: string
デフォルト: ""
重要度: 中
要求の実行時にサーバーに渡す ID 文字列。この目的は、サーバー側の要求ロギングに論理アプリケーション名を含めることを許可することにより、ip/port の他にもリクエストのソースを追跡できるようにすることです。
connections.max.idle.ms型: long
デフォルト: 540000 (9 分)
重要度: 中
この設定で指定された期間 (ミリ秒単位) の後にアイドル状態の接続を閉じます。
delivery.timeout.ms型: int
デフォルト: 120000 (2 分)
有効な値: [0,…]
重要度: 中
send()の呼び出しが返された後、成功または失敗を報告する時間の上限。これにより、送信前にレコードが遅延する合計時間、ブローカーから確認応答を待つ時間 (予想される場合)、および再試行可能な送信の失敗に許容される時間が制限されます。プロデューサーは、回復不可能なエラーが発生した場合や再試行し尽くした場合、またはレコードが早い配信有効期限に達したバッチに追加された場合に、この設定よりも前にレコードの送信の失敗を報告する可能性があります。この設定の値は、request.timeout.msおよびlinger.msの合計値以上である必要があります。linger.ms型: long
デフォルト: 0
有効な値: [0,…]
重要度: 中
プロデューサーは、リクエストの送信の間に到着したレコードを 1 つのバッチリクエストにグループ化します。通常、これは、レコードが送信できるよりも早く到着した場合に、負荷がかかった状態でのみ発生します。ただし、状況によっては、中程度の負荷がかかっている場合でも、クライアントがリクエストの数を減らしたい場合があります。この設定は、少量の人為的な遅延を追加することでこれを実現します。つまり、レコードをすぐに送信するのではなく、プロデューサーは指定された遅延まで待機して他のレコードを送信できるようにし、送信をまとめてバッチ処理できるようにします。これは、TCP の Nagle アルゴリズムに類似するものと考えることができます。この設定は、バッチ処理の遅延の上限を提供します。あるパーティションで
batch.size相当のレコードを取得すると、この設定に関係なくすぐに送信されますが、このパーティションで蓄積されたバイト数がこれより少ない場合は、指定された時間の間、さらにレコードが取得されるのを「待つ」ことになります。デフォルトは 0 (つまり遅延なし) に設定されます。たとえば、linger.ms=5を設定すると、送信されるリクエストの数が減りますが、負荷がない状態で送信されるレコードに最大 5 ミリ秒のレイテンシーが追加されます。max.block.ms型: long
デフォルト: 60000 (1 分)
有効な値: [0,…]
重要度: 中
この設定は、
KafkaProducer.send()およびKafkaProducer.partitionsFor()がブロックする期間を制御します。バッファーが満杯またはメタデータが利用できないため、これらのメソッドはブロックできます。ユーザーが提供するシリアライザーやパーティションャーはこのタイムアウトに対してカウントされません。max.request.size型: int
デフォルト: 1048576
有効な値: [0,…]
重要度: 中
リクエストの最大サイズ (バイト単位)。この設定により、プロデューサーが 1 回のリクエストで送信するレコードバッチの数が制限され、大量のリクエストが送信されないようになります。これは事実上、圧縮されていないレコードの最大バッチサイズの上限でもあります。サーバーには、レコードバッチサイズ (圧縮が有効な場合は圧縮後) に独自の上限があり、これとは異なる可能性があることに注意してください。
partitioner.class型: class
デフォルト: org.apache.kafka.clients.producer.internals.DefaultPartitioner
重要度: 中
org.apache.kafka.clients.producer.Partitionerインターフェースを実装するパーティションクラス。receive.buffer.bytes型: int
デフォルト: 32768 (32 キビバイト)
有効な値: [-1,…]
重要度: 中
データの読み取り時に使用する TCP 受信バッファー(SO_RCVBUF)のサイズ。値が -1 の場合、OS のデフォルトが使用されます。
request.timeout.ms型: int
デフォルト: 30000 (30 秒)
有効な値: [0,…]
重要度: 中
この設定は、クライアントの要求の応答を待つ最大時間を制御します。タイムアウトが経過する前に応答が受信されない場合、クライアントは必要に応じてリクエストを再送信します。または、再試行が使い切られるとリクエストが失敗します。これは、不必要なプロデューサーの再試行によるメッセージの重複の可能性を減らすために、
replica.lag.time.max.ms(ブローカーの設定) よりも大きくする必要があります。sasl.client.callback.handler.classタイプ: class
デフォルト: null
重要度: 中
AuthenticateCallbackHandler インターフェイスを実装する SASL クライアントコールバックハンドラークラスの完全修飾名。
sasl.jaas.configタイプ: password
デフォルト: null
重要度: 中
JAAS 設定ファイルで使用される形式の SASL 接続の JAAS ログインコンテキストパラメーター。JAAS 設定ファイルの形式は、こちら で説明されています。値の形式は 「loginModuleClass controlFlag(optionName=optionValue)*;」 です。ブローカーの場合、設定の前にリスナー接頭辞と SASL メカニズム名を小文字で指定する必要があります。たとえば、listener.name.sasl_ssl.scram-sha-256.sasl.jaas.config=com.example.ScramLoginModule required; などです。
sasl.kerberos.service.nameタイプ: string
デフォルト: null
重要度: 中
Kafka が実行される Kerberos プリンシパル名。これは、Kafka の JAAS 設定または Kafka の設定で定義できます。
sasl.login.callback.handler.classタイプ: class
デフォルト: null
重要度: 中
AuthenticateCallbackHandler インターフェイスを実装する SASL ログインコールバックハンドラークラスの完全修飾名。ブローカーの場合、ログインコールバックハンドラー設定の前には、リスナー接頭辞 と SASL メカニズム名を小文字で指定する必要があります。たとえば、listener.name.sasl_ssl.scram-sha-256.sasl.login.callback.handler.class=com.example.CustomScramLoginCallbackHandler などです。
sasl.login.classタイプ: class
デフォルト: null
重要度: 中
Login インターフェイスを実装するクラスの完全修飾名。ブローカーの場合、ログイン設定の前にリスナー接頭辞 と SASL メカニズム名を小文字で指定する必要があります。たとえば、listener.name.sasl_ssl.scram-sha-256.sasl.login.class=com.example.CustomScramLogin です。
sasl.mechanism型: string
デフォルト: GSSAPI
重要度: 中
クライアント接続に使用される SASL メカニズム。これは、セキュリティープロバイダーが利用可能な任意のメカニズムである可能性がありますGSSAPI はデフォルトのメカニズムです。
security.protocol型: string
デフォルト: PLAINTEXT
重要度: 中
ブローカーとの通信に使用されるプロトコル。有効な値は、PLAINTEXT、SSL、SASL_PLAINTEXT、SASL_SSL です。
send.buffer.bytes型: int
デフォルト: 131072 (128 キビバイト)
有効な値: [-1,…]
重要度: 中
データの送信時に使用する TCP 送信バッファー (SO_SNDBUF) のサイズ。値が -1 の場合、OS のデフォルトが使用されます。
ssl.enabled.protocols型: list
デフォルト: TLSv1.2、TLSv1.3
重要度: 中
SSL 接続で有効なプロトコルの一覧。Java 11 以降で実行する場合、デフォルトは 'TLSv1.2,TLSv1.3' で、それ以外の場合は 'TLSv1.2' になります。Java 11 のデフォルト値では、クライアントとサーバーの両方が TLSv1.3 をサポートする場合は TLSv1.3 を優先し、そうでない場合は TLSv1.2 にフォールバックします (両方が少なくとも TLSv1.2 をサポートすることを前提とします)。ほとんどの場合、このデフォルトは問題ありません。
ssl.protocolの設定ドキュメントも参照してください。ssl.keystore.type型: string
デフォルト: JKS
重要度: 中
キーストアファイルのファイル形式。これはクライアントにとってオプションになります。
ssl.protocol型: string
デフォルト: TLSv1.3
重要度: 中
SSLContext の生成に使用される SSL プロトコル。Java 11 以降で実行する場合、デフォルトは 'TLSv1.3' になります。それ以外の場合は 'TLSv1.2' になります。この値は、ほとんどのユースケースで問題ありません。最近の JVM で許可される値は 'TLSv1.2' および 'TLSv1.3' です。'TLS'、'TLSv1.1'、'SSL'、'SSLv2'、および 'SSLv3' は古い JVM でサポートされる可能性がありますが、既知のセキュリティー脆弱性のために使用は推奨されません。この設定のデフォルト値および 'ssl.enabled.protocols' では、サーバーが 'TLSv1.3' に対応していない場合は、クライアントは 'TLSv1.2' にダウングレードされます。この設定が 'TLSv1.2' に設定されている場合、'TLSv1.3' が ssl.enabled.protocols の値の 1 つで、サーバーが 'TLSv1.3' のみをサポートする場合でも、クライアントは 'TLSv1.3' を使用しません。
ssl.providerタイプ: string
デフォルト: null
重要度: 中
SSL 接続に使用されるセキュリティープロバイダーの名前。デフォルト値は JVM のデフォルトのセキュリティープロバイダーです。
ssl.truststore.type型: string
デフォルト: JKS
重要度: 中
トラストストアファイルのファイル形式。
enable.idempotenceタイプ: boolean
デフォルト: false
重大度: 低
'true' に設定すると、プロデューサーは、プロデューサーは各メッセージのコピーが 1 つだけストリームに書き込まれるようにします。'false' の場合、ブローカーの失敗などによるプロデューサーの再試行により、再試行されたメッセージの重複がストリームに書き込まれる可能性があります。べき等を有効にするには、
max.in.flight.requests.per.connectionは 5 以下、retriesは 0 よりも大きい必要があり、acksは all でなければなりません。これらの値がユーザーによって明示的に設定されていない場合は、適切な値が選択されます。互換性のない値が設定された場合は、ConfigExceptionがスローされます。interceptor.classesタイプ: list
デフォルト: ""
有効な値: non-null string
重要度: 低
インターセプターとして使用するクラスの一覧。
org.apache.kafka.clients.producer.ProducerInterceptorインターフェイスを実装すると、プロデューサーが受信したレコードが Kafka クラスターに公開される前に、そのレコードをインターセプト (場合によってはミューテーションも可能) できます。デフォルトでは、インターセプターはありません。max.in.flight.requests.per.connection型: int
デフォルト: 5
有効な値: [1,…]
重要度: 低
ブロックする前にクライアントが 1 つの接続で送信する確認されていないリクエストの最大数。この設定が 1 を超える値に設定され、送信に失敗した場合は、再試行によりメッセージの順序が及ぶ可能性があります(再試行が有効な場合など)。
metadata.max.age.ms型: long
デフォルト: 300000 (5 分)
有効な値: [0,…]
重要度: low
新しいブローカーまたはパーティションをプロアクティブに検出するためのパーティションリーダーシップの変更がない場合でも、メタデータの更新を強制するまでの期間 (ミリ秒単位)。
metadata.max.idle.ms型: long
デフォルト: 300000 (5 分)
有効な値: [5000,…]
重要度: low
アイドル状態のトピックのメタデータをプロデューサーがキャッシュする時間を制御します。トピックが最後に作成されてからの経過時間がメタデータのアイドル期間を超えた場合、トピックのメタデータは忘れられ、次にアクセスするとメタデータフェッチ要求が強制されます。
metric.reportersタイプ: list
デフォルト: ""
有効な値: non-null string
重要度: 低
メトリクスレポーターとして使用するクラスの一覧。
org.apache.kafka.common.metrics.MetricsReporterインターフェイスを実装すると、新しいメトリクスの作成が通知されるクラスのプラグが可能になります。JmxReporter は、JMX 統計を登録するために常に含まれます。metrics.num.samples型: int
デフォルト: 2
有効な値: [1,…]
重要度: 低
メトリクスを計算するために保持されるサンプルの数。
metrics.recording.level型: string
デフォルト: INFO
有効な値: [INFO, DEBUG]
重要度: 低
メトリクスの最も高い記録レベル。
metrics.sample.window.ms型: long
デフォルト: 30000 (30 秒)
有効な値: [0,…]
重要度: 低
メトリクスサンプルが計算される時間枠。
reconnect.backoff.max.ms型: long
デフォルト: 1000 (1 秒)
有効な値: [0,…]
重要度: 低
接続に繰り返し失敗したブローカーへの再接続時に待機する最大時間 (ミリ秒単位)。これが指定されている場合、ホストごとのバックオフは、連続して接続に失敗するたびに、この最大値まで指数関数的に増加します。バックオフの増加を計算した後、コネクションストームを回避するために 20% のランダムなジッターが追加されます。
reconnect.backoff.ms型: long
デフォルト: 50
有効な値: [0,…]
重要度: 低
特定のホストへの再接続を試みる前に待機するベース時間。これにより、タイトなループでホストに繰り返し接続することを回避します。このバックオフは、クライアントによるブローカーへのすべての接続試行に適用されます。
retry.backoff.ms型: long
デフォルト: 100
有効な値: [0,…]
重要度: 低
特定のトピックパーティションに対して失敗したリクエストを再試行するまでの待機時間。これにより、一部の障害シナリオでタイトループでリクエストを繰り返し送信することを回避できます。
sasl.kerberos.kinit.cmdタイプ: string
デフォルト: /usr/bin/kinit
重要度: 低
Kerberos kinit コマンドパス。
sasl.kerberos.min.time.before.relogin型: long
デフォルト: 60000
重要度: 低
更新試行間のログインスレッドのスリープ時間。
sasl.kerberos.ticket.renew.jitter型: double
デフォルト: 0.05
重要度: 低
更新時間に追加されたランダムなジッターの割合。
sasl.kerberos.ticket.renew.window.factor型: double
デフォルト: 0.8
重要度: 低
ログインスレッドは、最後の更新からチケットの有効期限までの指定された時間のウィンドウファクターに達するまでスリープし、その時点でチケットの更新を試みます。
sasl.login.refresh.buffer.seconds型: short
デフォルト: 300
有効な値: [0,…,3600]
重要度: 低
クレデンシャルを更新するときに維持するクレデンシャルの有効期限が切れるまでのバッファー時間 (秒単位)。更新が、バッファ秒数よりも有効期限に近いときに発生する場合、更新は、可能な限り多くのバッファー時間を維持するために上に移動されます。設定可能な値は 0 から 3600 (1 時間) です。値を指定しない場合は、デフォルト値の 300 (5 分) が使用されます。この値および sasl.login.refresh.min.period.seconds は、その合計がクレデンシャルの残りの有効期間を超える場合にどちらも無視されます。現在、OAUTHBEARER にのみ適用されます。
sasl.login.refresh.min.period.seconds型: short
デフォルト: 60
有効な値: [0,…,900]
重要度: 低
ログイン更新スレッドがクレデンシャルを更新する前に待機する最小時間 (秒単位)。設定可能な値は 0 から 900 (15 分) です。値を指定しない場合は、デフォルト値の 60 (1 分) が使用されます。この値および sasl.login.refresh.buffer.seconds は、その合計がクレデンシャルの残りの有効期間を超える場合に両方とも無視されます。現在、OAUTHBEARER にのみ適用されます。
sasl.login.refresh.window.factor型: double
デフォルト: 0.8
有効な値: [0.5,…,1.0]
重要度: 低
ログイン更新スレッドは、クレデンシャルの有効期間との関連で指定の期間ファクターに達するまでスリープ状態になり、達成した時点でクレデンシャルの更新を試みます。設定可能な値は 0.5(50%)から 1.0(100%)までです。値が指定されていない場合、デフォルト値の 0.8(80%)が使用されます。現在、OAUTHBEARER にのみ適用されます。
sasl.login.refresh.window.jitter型: double
デフォルト: 0.05
有効な値: [0.0,…,0.25]
重要度: 低
ログイン更新スレッドのスリープ時間に追加されるクレデンシャルの存続期間に関連するランダムジッターの最大量。設定可能な値は 0 から 0.25(25%)です。値が指定されていない場合は、デフォルト値の 0.05(5%)が使用されます。現在、OAUTHBEARER にのみ適用されます。
security.providersタイプ: string
デフォルト: null
重要度: 低
設定可能なクリエータークラスのリストで、それぞれがセキュリティーアルゴリズムを実装するプロバイダーを返します。これらのクラスは
org.apache.kafka.common.security.auth.SecurityProviderCreatorインターフェイスを実装する必要があります。ssl.cipher.suitesタイプ: list
デフォルト: null
重要度: 低
暗号化スイートの一覧。これは、TLS または SSL ネットワークプロトコルを使用してネットワーク接続のセキュリティー設定をネゴシエートするために使用される認証、暗号化、MAC、および鍵交換アルゴリズムの名前付きの組み合わせです。デフォルトでは、利用可能なすべての暗号スイートがサポートされます。
ssl.endpoint.identification.algorithmタイプ: string
デフォルト: https
重要度: 低
サーバー証明書を使用してサーバーのホスト名を検証するエンドポイント識別アルゴリズム。
ssl.engine.factory.classタイプ: class
デフォルト: null
重要度: 低
SSLEngine オブジェクトを提供する org.apache.kafka.common.security.auth.SslEngineFactory タイプのクラス。デフォルト値はorg.apache.kafka.common.security.ssl.DefaultSslEngineFactory です。
ssl.keymanager.algorithm型: string
デフォルト: SunX509
重要度: 低
SSL 接続のキーマネージャーファクトリーによって使用されるアルゴリズム。デフォルト値は、Java 仮想マシンに設定されたキーマネージャーファクトリーアルゴリズムです。
ssl.secure.random.implementationタイプ: string
デフォルト: null
重要度: 低
SSL 暗号操作に使用する SecureRandom PRNG 実装。
ssl.trustmanager.algorithm型: string
デフォルト: PKIX
重要度: 低
SSL 接続のトラストマネージャーファクトリーによって使用されるアルゴリズム。デフォルト値は、Java 仮想マシンに設定されたトラストマネージャーファクトリーアルゴリズムです。
transaction.timeout.ms型: int
デフォルト: 60000 (1 分)
重要度: 低
進行中のトランザクションを積極的に中止する前に、トランザクションコーディネーターがプロデューサーからのトランザクションステータスの更新を待機する最大時間(ミリ秒単位)。この値がブローカーの transaction.max.timeout.ms 設定よりも大きい場合、リクエストは
InvalidTransactionTimeoutエラーで失敗します。transactional.idタイプ: string
デフォルト: null
有効な値: non-empty string
重要度: 低
トランザクション配信に使用する TransactionalId。これにより、クライアントは、新しいトランザクションを開始する前に同じ TransactionalId を使用するトランザクションが完了したことを保証できるため、複数のプロデューサーセッションにまたがる信頼性セマンティクスが可能になります。TransactionalId が指定されていない場合、プロデューサーはべき等配信に制限されます。TransactionalId が設定されている場合は、暗黙的に
enable.idempotenceになります。デフォルトでは、TransactionId は設定されていません。つまり、トランザクションは使用できません。なお、デフォルトでは、トランザクションには少なくとも 3 つのブローカーのクラスターが必要で、これは本番環境では推奨される設定です。開発環境ではtransaction.state.log.replication.factor設定を調整して変更できます。
付録E 管理クライアント設定パラメーター
bootstrap.serversタイプ: list
重要度: 高
Kafka クラスターへの最初の接続を確立するために使用されるホストとポートのペアの一覧。クライアントは、ブートストラップ用にここで指定されたサーバーに関係なく、すべてのサーバーを利用します。この一覧は、サーバーのフルセットを検出するために使用される最初のホストにのみ影響します。この一覧は、
host1:port1,host2:port2,…の形式にする必要があります。これらのサーバーは、(動的に変更される可能性がある) 完全なクラスターメンバーシップを検出するための最初の接続にだけ使用されるため、このリストにはサーバーの完全なセットを含める必要はありません (ただし、サーバーがダウンした場合に備えて、複数のサーバーが必要になる場合があります)。ssl.key.passwordタイプ: password
デフォルト: null
重要度: 高
キーストアファイルの秘密鍵のパスワード。これはクライアントにとってオプションになります。
ssl.keystore.locationタイプ: string
デフォルト: null
重要度: 高
キーストアファイルの場所。これはクライアントではオプションで、クライアントの双方向認証に使用できます。
ssl.keystore.passwordタイプ: password
デフォルト: null
重要度: 高
キーストアファイルのストアパスワード。これはクライアントのオプションで、ssl.keystore.location が設定されている場合のみ必要です。
ssl.truststore.locationタイプ: string
デフォルト: null
重要度: 高
トラストストアファイルの場所。
ssl.truststore.passwordタイプ: password
デフォルト: null
重要度: 高
トラストストアファイルのパスワード。パスワードがトラストストアへのアクセスを設定しなくても、整合性チェックは無効になります。
client.dns.lookupタイプ: string
デフォルト : use_all_dns_ips
有効な値: [default, use_all_dns_ips, resolve_canonical_bootstrap_servers_only]
重大度: 中
クライアントが DNS ルックアップを使用する方法を制御します。
use_all_dns_ipsに設定すると、正常な接続が確立されるまで、返された各 IP アドレスに順番に接続します。切断後に、次の IP が使用されます。すべての IP が一度使用されると、クライアントはホスト名から IP を再度解決します (ただし、JVM と OS の両方は DNS 名の検索をキャッシュします)。resolve_canonical_bootstrap_servers_onlyに設定すると、各ブートストラップアドレスを正規名の一覧に解決します。ブートストラップフェーズ後、これはuse_all_dns_ipsと同じように動作します。default(非推奨)に設定すると、ルックアップで複数の IP アドレスが返された場合でも、ルックアップで返された最初の IP アドレスへの接続を試みます。client.idタイプ: string
デフォルト: ""
重要度: 中
要求の実行時にサーバーに渡す ID 文字列。この目的は、サーバー側の要求ロギングに論理アプリケーション名を含めることを許可することにより、ip/port の他にもリクエストのソースを追跡できるようにすることです。
connections.max.idle.ms型: long
デフォルト: 300000 (5 分)
重要度: 中
この設定で指定された期間 (ミリ秒単位) の後にアイドル状態の接続を閉じます。
default.api.timeout.ms型: int
デフォルト: 60000 (1 分)
有効な値: [0,…]
重要度: 中
クライアント API のタイムアウト (ミリ秒単位) を指定します。この設定は、
timeoutパラメーターを指定しないすべてのクライアント操作のデフォルトタイムアウトとして使用されます。receive.buffer.bytes型: int
デフォルト: 65536 (64 キビバイト)
有効な値: [-1,…]
重要度: 中
データの読み取り時に使用する TCP 受信バッファー(SO_RCVBUF)のサイズ。値が -1 の場合、OS のデフォルトが使用されます。
request.timeout.ms型: int
デフォルト: 30000 (30 秒)
有効な値: [0,…]
重要度: 中
この設定は、クライアントの要求の応答を待つ最大時間を制御します。タイムアウトが経過する前に応答が受信されない場合、クライアントは必要に応じてリクエストを再送信します。または、再試行が使い切られるとリクエストが失敗します。
sasl.client.callback.handler.classタイプ: class
デフォルト: null
重要度: 中
AuthenticateCallbackHandler インターフェイスを実装する SASL クライアントコールバックハンドラークラスの完全修飾名。
sasl.jaas.configタイプ: password
デフォルト: null
重要度: 中
JAAS 設定ファイルで使用される形式の SASL 接続の JAAS ログインコンテキストパラメーター。JAAS 設定ファイルの形式は、こちら で説明されています。値の形式は 「loginModuleClass controlFlag(optionName=optionValue)*;」 です。ブローカーの場合、設定の前にリスナー接頭辞と SASL メカニズム名を小文字で指定する必要があります。たとえば、listener.name.sasl_ssl.scram-sha-256.sasl.jaas.config=com.example.ScramLoginModule required; などです。
sasl.kerberos.service.nameタイプ: string
デフォルト: null
重要度: 中
Kafka が実行される Kerberos プリンシパル名。これは、Kafka の JAAS 設定または Kafka の設定で定義できます。
sasl.login.callback.handler.classタイプ: class
デフォルト: null
重要度: 中
AuthenticateCallbackHandler インターフェイスを実装する SASL ログインコールバックハンドラークラスの完全修飾名。ブローカーの場合、ログインコールバックハンドラー設定の前には、リスナー接頭辞 と SASL メカニズム名を小文字で指定する必要があります。たとえば、listener.name.sasl_ssl.scram-sha-256.sasl.login.callback.handler.class=com.example.CustomScramLoginCallbackHandler などです。
sasl.login.classタイプ: class
デフォルト: null
重要度: 中
Login インターフェイスを実装するクラスの完全修飾名。ブローカーの場合、ログイン設定の前にリスナー接頭辞 と SASL メカニズム名を小文字で指定する必要があります。たとえば、listener.name.sasl_ssl.scram-sha-256.sasl.login.class=com.example.CustomScramLogin です。
sasl.mechanism型: string
デフォルト: GSSAPI
重要度: 中
クライアント接続に使用される SASL メカニズム。これは、セキュリティープロバイダーが利用可能な任意のメカニズムである可能性がありますGSSAPI はデフォルトのメカニズムです。
security.protocol型: string
デフォルト: PLAINTEXT
重要度: 中
ブローカーとの通信に使用されるプロトコル。有効な値は、PLAINTEXT、SSL、SASL_PLAINTEXT、SASL_SSL です。
send.buffer.bytes型: int
デフォルト: 131072 (128 キビバイト)
有効な値: [-1,…]
重要度: 中
データの送信時に使用する TCP 送信バッファー (SO_SNDBUF) のサイズ。値が -1 の場合、OS のデフォルトが使用されます。
ssl.enabled.protocols型: list
デフォルト: TLSv1.2、TLSv1.3
重要度: 中
SSL 接続で有効なプロトコルの一覧。Java 11 以降で実行する場合、デフォルトは 'TLSv1.2,TLSv1.3' で、それ以外の場合は 'TLSv1.2' になります。Java 11 のデフォルト値では、クライアントとサーバーの両方が TLSv1.3 をサポートする場合は TLSv1.3 を優先し、そうでない場合は TLSv1.2 にフォールバックします (両方が少なくとも TLSv1.2 をサポートすることを前提とします)。ほとんどの場合、このデフォルトは問題ありません。
ssl.protocolの設定ドキュメントも参照してください。ssl.keystore.type型: string
デフォルト: JKS
重要度: 中
キーストアファイルのファイル形式。これはクライアントにとってオプションになります。
ssl.protocol型: string
デフォルト: TLSv1.3
重要度: 中
SSLContext の生成に使用される SSL プロトコル。Java 11 以降で実行する場合、デフォルトは 'TLSv1.3' になります。それ以外の場合は 'TLSv1.2' になります。この値は、ほとんどのユースケースで問題ありません。最近の JVM で許可される値は 'TLSv1.2' および 'TLSv1.3' です。'TLS'、'TLSv1.1'、'SSL'、'SSLv2'、および 'SSLv3' は古い JVM でサポートされる可能性がありますが、既知のセキュリティー脆弱性のために使用は推奨されません。この設定のデフォルト値および 'ssl.enabled.protocols' では、サーバーが 'TLSv1.3' に対応していない場合は、クライアントは 'TLSv1.2' にダウングレードされます。この設定が 'TLSv1.2' に設定されている場合、'TLSv1.3' が ssl.enabled.protocols の値の 1 つで、サーバーが 'TLSv1.3' のみをサポートする場合でも、クライアントは 'TLSv1.3' を使用しません。
ssl.providerタイプ: string
デフォルト: null
重要度: 中
SSL 接続に使用されるセキュリティープロバイダーの名前。デフォルト値は JVM のデフォルトのセキュリティープロバイダーです。
ssl.truststore.type型: string
デフォルト: JKS
重要度: 中
トラストストアファイルのファイル形式。
metadata.max.age.ms型: long
デフォルト: 300000 (5 分)
有効な値: [0,…]
重要度: low
新しいブローカーまたはパーティションをプロアクティブに検出するためのパーティションリーダーシップの変更がない場合でも、メタデータの更新を強制するまでの期間 (ミリ秒単位)。
metric.reportersタイプ: list
デフォルト: ""
重要度: 低
メトリクスレポーターとして使用するクラスの一覧。
org.apache.kafka.common.metrics.MetricsReporterインターフェイスを実装すると、新しいメトリクスの作成が通知されるクラスのプラグが可能になります。JmxReporter は、JMX 統計を登録するために常に含まれます。metrics.num.samples型: int
デフォルト: 2
有効な値: [1,…]
重要度: 低
メトリクスを計算するために保持されるサンプルの数。
metrics.recording.level型: string
デフォルト: INFO
有効な値: [INFO, DEBUG]
重要度: 低
メトリクスの最も高い記録レベル。
metrics.sample.window.ms型: long
デフォルト: 30000 (30 秒)
有効な値: [0,…]
重要度: 低
メトリクスサンプルが計算される時間枠。
reconnect.backoff.max.ms型: long
デフォルト: 1000 (1 秒)
有効な値: [0,…]
重要度: 低
接続に繰り返し失敗したブローカーへの再接続時に待機する最大時間 (ミリ秒単位)。これが指定されている場合、ホストごとのバックオフは、連続して接続に失敗するたびに、この最大値まで指数関数的に増加します。バックオフの増加を計算した後、コネクションストームを回避するために 20% のランダムなジッターが追加されます。
reconnect.backoff.ms型: long
デフォルト: 50
有効な値: [0,…]
重要度: 低
特定のホストへの再接続を試みる前に待機するベース時間。これにより、タイトなループでホストに繰り返し接続することを回避します。このバックオフは、クライアントによるブローカーへのすべての接続試行に適用されます。
retries型: int
デフォルト: 2147483647
有効な値: [0,…,2147483647]
重要度: 低
ゼロより大きい値を設定すると、クライアントは、一時的なエラーの可能性がある失敗した要求を再送信します。
retry.backoff.ms型: long
デフォルト: 100
有効な値: [0,…]
重要度: 低
失敗した要求を再試行するまでの待機時間。これにより、一部の障害シナリオでタイトループでリクエストを繰り返し送信することを回避できます。
sasl.kerberos.kinit.cmdタイプ: string
デフォルト: /usr/bin/kinit
重要度: 低
Kerberos kinit コマンドパス。
sasl.kerberos.min.time.before.relogin型: long
デフォルト: 60000
重要度: 低
更新試行間のログインスレッドのスリープ時間。
sasl.kerberos.ticket.renew.jitter型: double
デフォルト: 0.05
重要度: 低
更新時間に追加されたランダムなジッターの割合。
sasl.kerberos.ticket.renew.window.factor型: double
デフォルト: 0.8
重要度: 低
ログインスレッドは、最後の更新からチケットの有効期限までの指定された時間のウィンドウファクターに達するまでスリープし、その時点でチケットの更新を試みます。
sasl.login.refresh.buffer.seconds型: short
デフォルト: 300
有効な値: [0,…,3600]
重要度: 低
クレデンシャルを更新するときに維持するクレデンシャルの有効期限が切れるまでのバッファー時間 (秒単位)。更新が、バッファ秒数よりも有効期限に近いときに発生する場合、更新は、可能な限り多くのバッファー時間を維持するために上に移動されます。設定可能な値は 0 から 3600 (1 時間) です。値を指定しない場合は、デフォルト値の 300 (5 分) が使用されます。この値および sasl.login.refresh.min.period.seconds は、その合計がクレデンシャルの残りの有効期間を超える場合にどちらも無視されます。現在、OAUTHBEARER にのみ適用されます。
sasl.login.refresh.min.period.seconds型: short
デフォルト: 60
有効な値: [0,…,900]
重要度: 低
ログイン更新スレッドがクレデンシャルを更新する前に待機する最小時間 (秒単位)。設定可能な値は 0 から 900 (15 分) です。値を指定しない場合は、デフォルト値の 60 (1 分) が使用されます。この値および sasl.login.refresh.buffer.seconds は、その合計がクレデンシャルの残りの有効期間を超える場合に両方とも無視されます。現在、OAUTHBEARER にのみ適用されます。
sasl.login.refresh.window.factor型: double
デフォルト: 0.8
有効な値: [0.5,…,1.0]
重要度: 低
ログイン更新スレッドは、クレデンシャルの有効期間との関連で指定の期間ファクターに達するまでスリープ状態になり、達成した時点でクレデンシャルの更新を試みます。設定可能な値は 0.5(50%)から 1.0(100%)までです。値が指定されていない場合、デフォルト値の 0.8(80%)が使用されます。現在、OAUTHBEARER にのみ適用されます。
sasl.login.refresh.window.jitter型: double
デフォルト: 0.05
有効な値: [0.0,…,0.25]
重要度: 低
ログイン更新スレッドのスリープ時間に追加されるクレデンシャルの存続期間に関連するランダムジッターの最大量。設定可能な値は 0 から 0.25(25%)です。値が指定されていない場合は、デフォルト値の 0.05(5%)が使用されます。現在、OAUTHBEARER にのみ適用されます。
security.providersタイプ: string
デフォルト: null
重要度: 低
設定可能なクリエータークラスのリストで、それぞれがセキュリティーアルゴリズムを実装するプロバイダーを返します。これらのクラスは
org.apache.kafka.common.security.auth.SecurityProviderCreatorインターフェイスを実装する必要があります。ssl.cipher.suitesタイプ: list
デフォルト: null
重要度: 低
暗号化スイートの一覧。これは、TLS または SSL ネットワークプロトコルを使用してネットワーク接続のセキュリティー設定をネゴシエートするために使用される認証、暗号化、MAC、および鍵交換アルゴリズムの名前付きの組み合わせです。デフォルトでは、利用可能なすべての暗号スイートがサポートされます。
ssl.endpoint.identification.algorithmタイプ: string
デフォルト: https
重要度: 低
サーバー証明書を使用してサーバーのホスト名を検証するエンドポイント識別アルゴリズム。
ssl.engine.factory.classタイプ: class
デフォルト: null
重要度: 低
SSLEngine オブジェクトを提供する org.apache.kafka.common.security.auth.SslEngineFactory タイプのクラス。デフォルト値はorg.apache.kafka.common.security.ssl.DefaultSslEngineFactory です。
ssl.keymanager.algorithm型: string
デフォルト: SunX509
重要度: 低
SSL 接続のキーマネージャーファクトリーによって使用されるアルゴリズム。デフォルト値は、Java 仮想マシンに設定されたキーマネージャーファクトリーアルゴリズムです。
ssl.secure.random.implementationタイプ: string
デフォルト: null
重要度: 低
SSL 暗号操作に使用する SecureRandom PRNG 実装。
ssl.trustmanager.algorithm型: string
デフォルト: PKIX
重要度: 低
SSL 接続のトラストマネージャーファクトリーによって使用されるアルゴリズム。デフォルト値は、Java 仮想マシンに設定されたトラストマネージャーファクトリーアルゴリズムです。
付録F Kafka Connect 設定パラメーター
config.storage.topicタイプ: string
重要度: 高
コネクター設定が保存される Kafka トピックの名前。
group.idタイプ: string
重要度: 高
このワーカーが属する Connect クラスターグループを識別する一意の文字列。
key.converterタイプ: class
重要度: 高
Kafka Connect 形式と Kafka に書き込まれるシリアライズされた形式の間の変換に使用されるコンバータークラス。これは、Kafka に対して書き込みまたは読み取りされたメッセージのキーの形式を制御します。これはコネクターとは独立しているため、任意のコネクターが任意のシリアル化形式で動作することができます。一般的なフォーマットの例には、JSON や Avro などがあります。
offset.storage.topicタイプ: string
重要度: 高
コネクターオフセットが保存される Kafka トピックの名前。
status.storage.topicタイプ: string
重要度: 高
コネクターおよびタスクのステータスが保存される Kafka トピックの名前。
value.converterタイプ: class
重要度: 高
Kafka Connect 形式と Kafka に書き込まれるシリアライズされた形式の間の変換に使用されるコンバータークラス。これは、Kafka に対して書き込みまたは読み取りされたメッセージの値の形式を制御します。これはコネクターとは独立しているため、任意のコネクターが任意のシリアル化形式で動作することができます。一般的なフォーマットの例には、JSON や Avro などがあります。
bootstrap.serversタイプ: list
デフォルト: localhost:9092
重要度: 高
Kafka クラスターへの最初の接続を確立するために使用されるホストとポートのペアの一覧。クライアントは、ブートストラップ用にここで指定されたサーバーに関係なく、すべてのサーバーを利用します。この一覧は、サーバーのフルセットを検出するために使用される最初のホストにのみ影響します。この一覧は、
host1:port1,host2:port2,…の形式にする必要があります。これらのサーバーは、(動的に変更される可能性がある) 完全なクラスターメンバーシップを検出するための最初の接続にだけ使用されるため、このリストにはサーバーの完全なセットを含める必要はありません (ただし、サーバーがダウンした場合に備えて、複数のサーバーが必要になる場合があります)。heartbeat.interval.ms型: int
デフォルト: 3000 (3 秒)
重要度: 高
Kafka のグループ管理機能を使用する場合の、グループコーディネーターへのハートビート間の予想時間。ハートビートは、ワーカーのセッションがアクティブな状態を維持し、新しいメンバーがグループに参加したり離脱したりする際のリバランスを促進するために使用されます。この値は
session.timeout.msよりも低く設定する必要がありますが、通常はその値の 1/3 以下に設定する必要があります。さらに低く調整することで、通常のリバランスの予想時間を制御することもできます。rebalance.timeout.ms型: int
デフォルト: 60000 (1 分)
重要度: 高
リバランスが開始された後、各ワーカーがグループに参加するための最大許容時間。これは基本的に、すべてのタスクが保留中のデータをフラッシュしてオフセットをコミットするために必要な時間の制限です。タイムアウトを超えると、ワーカーはグループから削除され、オフセットコミットの失敗が発生します。
session.timeout.ms型: int
デフォルト: 10000 (10 秒)
重要度: 高
ワーカーの障害検出に使用されるタイムアウト。ワーカーは定期的にハートビートを送信し、liveness をブローカーに示します。このセッションタイムアウトの期限切れ前にブローカーによってハートビートが受信されない場合、ブローカーはグループからワーカーを削除し、リバランスを開始します。この値は、
group.min.session.timeout.msおよびgroup.max.session.timeout.msによってブローカー設定で設定される許容範囲内である必要があることに注意してください。ssl.key.passwordタイプ: password
デフォルト: null
重要度: 高
キーストアファイルの秘密鍵のパスワード。これはクライアントにとってオプションになります。
ssl.keystore.locationタイプ: string
デフォルト: null
重要度: 高
キーストアファイルの場所。これはクライアントではオプションで、クライアントの双方向認証に使用できます。
ssl.keystore.passwordタイプ: password
デフォルト: null
重要度: 高
キーストアファイルのストアパスワード。これはクライアントのオプションで、ssl.keystore.location が設定されている場合のみ必要です。
ssl.truststore.locationタイプ: string
デフォルト: null
重要度: 高
トラストストアファイルの場所。
ssl.truststore.passwordタイプ: password
デフォルト: null
重要度: 高
トラストストアファイルのパスワード。パスワードがトラストストアへのアクセスを設定しなくても、整合性チェックは無効になります。
client.dns.lookupタイプ: string
デフォルト : use_all_dns_ips
有効な値: [default, use_all_dns_ips, resolve_canonical_bootstrap_servers_only]
重大度: 中
クライアントが DNS ルックアップを使用する方法を制御します。
use_all_dns_ipsに設定すると、正常な接続が確立されるまで、返された各 IP アドレスに順番に接続します。切断後に、次の IP が使用されます。すべての IP が一度使用されると、クライアントはホスト名から IP を再度解決します (ただし、JVM と OS の両方は DNS 名の検索をキャッシュします)。resolve_canonical_bootstrap_servers_onlyに設定すると、各ブートストラップアドレスを正規名の一覧に解決します。ブートストラップフェーズ後、これはuse_all_dns_ipsと同じように動作します。default(非推奨)に設定すると、ルックアップで複数の IP アドレスが返された場合でも、ルックアップで返された最初の IP アドレスへの接続を試みます。connections.max.idle.ms型: long
デフォルト: 540000 (9 分)
重要度: 中
この設定で指定された期間 (ミリ秒単位) の後にアイドル状態の接続を閉じます。
connector.client.config.override.policyタイプ: string
デフォルト: None
重大度: 中
ConnectorClientConfigOverridePolicyの実装のクラス名またはエイリアス。コネクターによってオーバーライドできるクライアント設定を定義します。デフォルトの実装はNoneです。このフレームワークでは、他にもAllやPrincipalといったポリシーが考えられます。receive.buffer.bytes型: int
デフォルト: 32768 (32 キビバイト)
有効な値: [0,…]
重要度: 中
データの読み取り時に使用する TCP 受信バッファー(SO_RCVBUF)のサイズ。値が -1 の場合、OS のデフォルトが使用されます。
request.timeout.ms型: int
デフォルト: 40000 (40 秒)
有効な値: [0,…]
重要度: 中
この設定は、クライアントの要求の応答を待つ最大時間を制御します。タイムアウトが経過する前に応答が受信されない場合、クライアントは必要に応じてリクエストを再送信します。または、再試行が使い切られるとリクエストが失敗します。
sasl.client.callback.handler.classタイプ: class
デフォルト: null
重要度: 中
AuthenticateCallbackHandler インターフェイスを実装する SASL クライアントコールバックハンドラークラスの完全修飾名。
sasl.jaas.configタイプ: password
デフォルト: null
重要度: 中
JAAS 設定ファイルで使用される形式の SASL 接続の JAAS ログインコンテキストパラメーター。JAAS 設定ファイルの形式は、こちら で説明されています。値の形式は 「loginModuleClass controlFlag(optionName=optionValue)*;」 です。ブローカーの場合、設定の前にリスナー接頭辞と SASL メカニズム名を小文字で指定する必要があります。たとえば、listener.name.sasl_ssl.scram-sha-256.sasl.jaas.config=com.example.ScramLoginModule required; などです。
sasl.kerberos.service.nameタイプ: string
デフォルト: null
重要度: 中
Kafka が実行される Kerberos プリンシパル名。これは、Kafka の JAAS 設定または Kafka の設定で定義できます。
sasl.login.callback.handler.classタイプ: class
デフォルト: null
重要度: 中
AuthenticateCallbackHandler インターフェイスを実装する SASL ログインコールバックハンドラークラスの完全修飾名。ブローカーの場合、ログインコールバックハンドラー設定の前には、リスナー接頭辞 と SASL メカニズム名を小文字で指定する必要があります。たとえば、listener.name.sasl_ssl.scram-sha-256.sasl.login.callback.handler.class=com.example.CustomScramLoginCallbackHandler などです。
sasl.login.classタイプ: class
デフォルト: null
重要度: 中
Login インターフェイスを実装するクラスの完全修飾名。ブローカーの場合、ログイン設定の前にリスナー接頭辞 と SASL メカニズム名を小文字で指定する必要があります。たとえば、listener.name.sasl_ssl.scram-sha-256.sasl.login.class=com.example.CustomScramLogin です。
sasl.mechanism型: string
デフォルト: GSSAPI
重要度: 中
クライアント接続に使用される SASL メカニズム。これは、セキュリティープロバイダーが利用可能な任意のメカニズムである可能性がありますGSSAPI はデフォルトのメカニズムです。
security.protocol型: string
デフォルト: PLAINTEXT
重要度: 中
ブローカーとの通信に使用されるプロトコル。有効な値は、PLAINTEXT、SSL、SASL_PLAINTEXT、SASL_SSL です。
send.buffer.bytes型: int
デフォルト: 131072 (128 キビバイト)
有効な値: [0,…]
重要度: 中
データの送信時に使用する TCP 送信バッファー (SO_SNDBUF) のサイズ。値が -1 の場合、OS のデフォルトが使用されます。
ssl.enabled.protocols型: list
デフォルト: TLSv1.2、TLSv1.3
重要度: 中
SSL 接続で有効なプロトコルの一覧。Java 11 以降で実行する場合、デフォルトは 'TLSv1.2,TLSv1.3' で、それ以外の場合は 'TLSv1.2' になります。Java 11 のデフォルト値では、クライアントとサーバーの両方が TLSv1.3 をサポートする場合は TLSv1.3 を優先し、そうでない場合は TLSv1.2 にフォールバックします (両方が少なくとも TLSv1.2 をサポートすることを前提とします)。ほとんどの場合、このデフォルトは問題ありません。
ssl.protocolの設定ドキュメントも参照してください。ssl.keystore.type型: string
デフォルト: JKS
重要度: 中
キーストアファイルのファイル形式。これはクライアントにとってオプションになります。
ssl.protocol型: string
デフォルト: TLSv1.3
重要度: 中
SSLContext の生成に使用される SSL プロトコル。Java 11 以降で実行する場合、デフォルトは 'TLSv1.3' になります。それ以外の場合は 'TLSv1.2' になります。この値は、ほとんどのユースケースで問題ありません。最近の JVM で許可される値は 'TLSv1.2' および 'TLSv1.3' です。'TLS'、'TLSv1.1'、'SSL'、'SSLv2'、および 'SSLv3' は古い JVM でサポートされる可能性がありますが、既知のセキュリティー脆弱性のために使用は推奨されません。この設定のデフォルト値および 'ssl.enabled.protocols' では、サーバーが 'TLSv1.3' に対応していない場合は、クライアントは 'TLSv1.2' にダウングレードされます。この設定が 'TLSv1.2' に設定されている場合、'TLSv1.3' が ssl.enabled.protocols の値の 1 つで、サーバーが 'TLSv1.3' のみをサポートする場合でも、クライアントは 'TLSv1.3' を使用しません。
ssl.providerタイプ: string
デフォルト: null
重要度: 中
SSL 接続に使用されるセキュリティープロバイダーの名前。デフォルト値は JVM のデフォルトのセキュリティープロバイダーです。
ssl.truststore.type型: string
デフォルト: JKS
重要度: 中
トラストストアファイルのファイル形式。
worker.sync.timeout.ms型: int
デフォルト: 3000 (3 秒)
重要度: 中
ワーカーが他のワーカーと同期されず、設定を再同期する必要がある場合は、この時間まで待機してから、ギブアップし、グループから離脱し、バックオフ期間を待ってから再度参加します。
worker.unsync.backoff.ms型: int
デフォルト: 300000 (5 分)
重要度: 中
ワーカーが他のワーカーと同期されず、worker.sync.timeout.ms 内で追いつくことができない場合は、再度参加する前に、この期間は Connect クラスターを離れます。
access.control.allow.methodsタイプ: string
デフォルト: ""
重要度: 低
Access-Control-Allow-Methods ヘッダーを設定することにより、クロスオリジン要求でサポートされるメソッドを設定します。Access-Control-Allow-Methods ヘッダーのデフォルト値は、GET、POST、および HEAD のクロスオリジン要求を許可します。
access.control.allow.originタイプ: string
デフォルト: ""
重要度: 低
REST API リクエスト用に Access-Control-Allow-Origin ヘッダーを設定する値。クロスオリジンアクセスを有効にするには、これを API へのアクセスを許可する必要があるアプリケーションのドメインに設定するか、'*' を設定して任意のドメインからのアクセスを許可します。デフォルト値は、REST API のドメインからのみアクセスを許可します。
admin.listenersタイプ: list
デフォルト: null
有効な値: org.apache.kafka.connect.runtime.WorkerConfig$AdminListenersValidator@6fffcba5
重大度: 低
管理 REST API がリッスンするコンマ区切りの URI の一覧。サポートされるプロトコルは HTTP および HTTPS です。空または空白の文字列は、この機能を無効にします。デフォルトの動作では、通常のリスナーを使用します ('listeners' プロパティーで指定)。
client.idタイプ: string
デフォルト: ""
重要度: 低
要求の実行時にサーバーに渡す ID 文字列。この目的は、サーバー側の要求ロギングに論理アプリケーション名を含めることを許可することにより、ip/port の他にもリクエストのソースを追跡できるようにすることです。
config.providersタイプ: list
デフォルト: ""
重要度: 低
指定された順序でロードされ、使用される
ConfigProviderクラスのコンマ区切りリスト。インターフェイスConfigProviderを実装すると、外部化されたシークレットなどのコネクター設定の変数参照を置き換えることができます。config.storage.replication.factor型: short
デフォルト: 3
有効な値: Kafka クラスター内のブローカーの数以下の正の数。ブローカーのデフォルトを使用する場合は -1
重要度: 低
設定ストレージトピックの作成時に使用されるレプリケーション係数。
connect.protocolタイプ: string
デフォルト: sessioned
有効な値: [eager, compatible, sessioned]
重要度: 低
Kafka Connect プロトコルの互換性モード。
header.converterタイプ: class
デフォルト: org.apache.kafka.connect.storage.SimpleHeaderConverter
重要度: 低
Kafka Connect 形式と Kafka に書き込まれるシリアライズされた形式の間の変換に使用される HeaderConverter クラス。これは、Kafka に対して書き込みまたは読み取りされたメッセージのヘッダー値の形式を制御します。これはコネクターから独立しているため、任意のコネクターが任意のシリアル化形式で動作することができます。一般的なフォーマットの例には、JSON や Avro などがあります。デフォルトでは、SimpleHeaderConverter はヘッダー値を文字列にシリアライズし、スキーマを推測してデシリアライズするために使用されます。
inter.worker.key.generation.algorithm型: string
デフォルト: HmacSHA256
有効な値: ワーカー JVM によってサポートされる KeyGenerator アルゴリズム
重要度: 低
内部要求キーの生成に使用するアルゴリズム。
inter.worker.key.sizeタイプ: int
デフォルト: null
重要度: 低
内部要求の署名に使用するキーのサイズ (ビット単位)。null の場合、キー生成アルゴリズムのデフォルトキーサイズが使用されます。
inter.worker.key.ttl.ms型: int
デフォルト: 3600000 (1 時間)
有効な値: [0,…,2147483647]
重要度: 低
内部リクエスト検証に使用される生成されたセッションキーの TTL (ミリ秒単位)。
inter.worker.signature.algorithm型: string
デフォルト: HmacSHA256
有効な値: ワーカー JVM によってサポートされる MAC アルゴリズム
重要度: 低
内部リクエストの署名に使用されるアルゴリズム。
inter.worker.verification.algorithms型: list
デフォルト: HmacSHA256
有効な値: 1 つ以上の MAC アルゴリズムの一覧 (各アルゴリズムはワーカー JVM でサポートされる)
重要度: 低
内部要求を検証するために許可されたアルゴリズムのリスト。
internal.key.converterタイプ: class
デフォルト: org.apache.kafka.connect.json.JsonConverter
重大度: 低
Kafka Connect 形式と Kafka に書き込まれるシリアライズされた形式の間の変換に使用されるコンバータークラス。これは、Kafka に対して書き込みまたは読み取りされたメッセージのキーの形式を制御します。これはコネクターとは独立しているため、任意のコネクターが任意のシリアル化形式で動作することができます。一般的なフォーマットの例には、JSON や Avro などがあります。この設定は、設定やオフセットなどのフレームワークで使用される内部予約データに使用される形式を制御します。そのため、ユーザーは通常機能するコンバーターの実装を使用できます。非推奨。今後のバージョンでは削除されます。
internal.value.converterタイプ: class
デフォルト: org.apache.kafka.connect.json.JsonConverter
重大度: 低
Kafka Connect 形式と Kafka に書き込まれるシリアライズされた形式の間の変換に使用されるコンバータークラス。これは、Kafka に対して書き込みまたは読み取りされたメッセージの値の形式を制御します。これはコネクターとは独立しているため、任意のコネクターが任意のシリアル化形式で動作することができます。一般的なフォーマットの例には、JSON や Avro などがあります。この設定は、設定やオフセットなどのフレームワークで使用される内部予約データに使用される形式を制御します。そのため、ユーザーは通常機能するコンバーターの実装を使用できます。非推奨。今後のバージョンでは削除されます。
listenersタイプ: list
デフォルト: null
重要度: 低
REST API がリッスンするコンマ区切りの URI の一覧。サポートされるプロトコルは HTTP および HTTPS です。ホスト名を 0.0.0.0 として指定し、すべてのインターフェイスにバインドします。ホスト名を空白のままにして、デフォルトのインターフェイスにバインドします。正当なリスナーリストの例は、HTTP://myhost:8083、HTTPS://myhost:8084 です。
metadata.max.age.ms型: long
デフォルト: 300000 (5 分)
有効な値: [0,…]
重要度: low
新しいブローカーまたはパーティションをプロアクティブに検出するためのパーティションリーダーシップの変更がない場合でも、メタデータの更新を強制するまでの期間 (ミリ秒単位)。
metric.reportersタイプ: list
デフォルト: ""
重要度: 低
メトリクスレポーターとして使用するクラスの一覧。
org.apache.kafka.common.metrics.MetricsReporterインターフェイスを実装すると、新しいメトリクスの作成が通知されるクラスのプラグが可能になります。JmxReporter は、JMX 統計を登録するために常に含まれます。metrics.num.samples型: int
デフォルト: 2
有効な値: [1,…]
重要度: 低
メトリクスを計算するために保持されるサンプルの数。
metrics.recording.level型: string
デフォルト: INFO
有効な値: [INFO, DEBUG]
重要度: 低
メトリクスの最も高い記録レベル。
metrics.sample.window.ms型: long
デフォルト: 30000 (30 秒)
有効な値: [0,…]
重要度: 低
メトリクスサンプルが計算される時間枠。
offset.flush.interval.ms型: long
デフォルト: 60000 (1 分)
重要度: 低
タスクのオフセットのコミットを試行する間隔。
offset.flush.timeout.ms型: long
デフォルト: 5000 (5 秒)
重要度: 低
プロセスをキャンセルし、今後の試行でコミットするオフセットデータを復元する前に、レコードをフラッシュして、パーティションオフセットデータがオフセットストレージにコミットするまでの最大待機時間 (ミリ秒単位)。
offset.storage.partitions型: int
デフォルト: 25
有効な値: 正の数。ブローカーのデフォルトを使用する場合は -1
重要度: 低
オフセットストレージトピックの作成時に使用されるパーティションの数。
offset.storage.replication.factor型: short
デフォルト: 3
有効な値: Kafka クラスター内のブローカーの数以下の正の数。ブローカーのデフォルトを使用する場合は -1
重要度: 低
オフセットストレージトピックの作成時に使用されるレプリケーション係数。
plugin.pathタイプ: list
デフォルト: null
重要度: 低
プラグイン (コネクター、コンバーター、変換) が含まれるコンマ (,) で区切られたパスのリスト。リストは、次の任意の組み合わせを含むトップレベルのディレクトリーで構成される必要があります。a) プラグインとその依存関係を含む jars を直接含むディレクトリー b) プラグインとその依存関係を含む uber-jars c) プラグインのクラスとその依存関係のパッケージディレクトリー構造を直接含むディレクトリー。注記: 依存関係またはプラグインを検出するために、シンボリックリンクが続きます。例: : plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors。設定プロバイダーが初期化され、変数の置き換えとして使用される前にワーカーのスキャナーによって raw パスが使用されるため、このプロパティーで設定プロバイダーの変数を使用しないでください。
reconnect.backoff.max.ms型: long
デフォルト: 1000 (1 秒)
有効な値: [0,…]
重要度: 低
接続に繰り返し失敗したブローカーへの再接続時に待機する最大時間 (ミリ秒単位)。これが指定されている場合、ホストごとのバックオフは、連続して接続に失敗するたびに、この最大値まで指数関数的に増加します。バックオフの増加を計算した後、コネクションストームを回避するために 20% のランダムなジッターが追加されます。
reconnect.backoff.ms型: long
デフォルト: 50
有効な値: [0,…]
重要度: 低
特定のホストへの再接続を試みる前に待機するベース時間。これにより、タイトなループでホストに繰り返し接続することを回避します。このバックオフは、クライアントによるブローカーへのすべての接続試行に適用されます。
response.http.headers.config型: string
デフォルト: ""
有効な値: コンマ区切りのヘッダールール。各ヘッダールールの形式は '[action] [header name]:[header value]' で、ヘッダールールの一部にコンマが含まれている場合は二重引用符で囲むことができます。
重要度: 低
REST API HTTP レスポンスヘッダーのルール。
rest.advertised.host.nameタイプ: string
デフォルト: null
重要度: 低
これが設定されている場合、これは、他のワーカーの接続用に提供されるホスト名です。
rest.advertised.listenerタイプ: string
デフォルト: null
重要度: 低
他のワーカーが使用するために提供されるアドバタイズされたリスナー (HTTP または HTTPS) を設定します。
rest.advertised.portタイプ: int
デフォルト: null
重要度: 低
これが設定されている場合、これは、他のワーカーの接続用に提供されるポートになります。
rest.extension.classesタイプ: list
デフォルト: ""
重要度: 低
指定された順序でロードされ、呼び出される
ConnectRestExtensionクラスのコンマ区切りリスト。インターフェイスConnectRestExtensionを実装すると、フィルターなどの Connect の REST API ユーザー定義リソースを注入できます。通常、ロギング、セキュリティーなどのカスタム機能の追加に使用されます。rest.host.nameタイプ: string
デフォルト: null
重要度: 低
REST API のホスト名。これが設定されると、このインターフェースにのみバインドされます。
rest.portタイプ: int
デフォルト: 8083
重大度: 低
リッスンする REST API のポート。
retry.backoff.ms型: long
デフォルト: 100
有効な値: [0,…]
重要度: 低
特定のトピックパーティションに対して失敗したリクエストを再試行するまでの待機時間。これにより、一部の障害シナリオでタイトループでリクエストを繰り返し送信することを回避できます。
sasl.kerberos.kinit.cmdタイプ: string
デフォルト: /usr/bin/kinit
重要度: 低
Kerberos kinit コマンドパス。
sasl.kerberos.min.time.before.relogin型: long
デフォルト: 60000
重要度: 低
更新試行間のログインスレッドのスリープ時間。
sasl.kerberos.ticket.renew.jitter型: double
デフォルト: 0.05
重要度: 低
更新時間に追加されたランダムなジッターの割合。
sasl.kerberos.ticket.renew.window.factor型: double
デフォルト: 0.8
重要度: 低
ログインスレッドは、最後の更新からチケットの有効期限までの指定された時間のウィンドウファクターに達するまでスリープし、その時点でチケットの更新を試みます。
sasl.login.refresh.buffer.seconds型: short
デフォルト: 300
有効な値: [0,…,3600]
重要度: 低
クレデンシャルを更新するときに維持するクレデンシャルの有効期限が切れるまでのバッファー時間 (秒単位)。更新が、バッファ秒数よりも有効期限に近いときに発生する場合、更新は、可能な限り多くのバッファー時間を維持するために上に移動されます。設定可能な値は 0 から 3600 (1 時間) です。値を指定しない場合は、デフォルト値の 300 (5 分) が使用されます。この値および sasl.login.refresh.min.period.seconds は、その合計がクレデンシャルの残りの有効期間を超える場合にどちらも無視されます。現在、OAUTHBEARER にのみ適用されます。
sasl.login.refresh.min.period.seconds型: short
デフォルト: 60
有効な値: [0,…,900]
重要度: 低
ログイン更新スレッドがクレデンシャルを更新する前に待機する最小時間 (秒単位)。設定可能な値は 0 から 900 (15 分) です。値を指定しない場合は、デフォルト値の 60 (1 分) が使用されます。この値および sasl.login.refresh.buffer.seconds は、その合計がクレデンシャルの残りの有効期間を超える場合に両方とも無視されます。現在、OAUTHBEARER にのみ適用されます。
sasl.login.refresh.window.factor型: double
デフォルト: 0.8
有効な値: [0.5,…,1.0]
重要度: 低
ログイン更新スレッドは、クレデンシャルの有効期間との関連で指定の期間ファクターに達するまでスリープ状態になり、達成した時点でクレデンシャルの更新を試みます。設定可能な値は 0.5(50%)から 1.0(100%)までです。値が指定されていない場合、デフォルト値の 0.8(80%)が使用されます。現在、OAUTHBEARER にのみ適用されます。
sasl.login.refresh.window.jitter型: double
デフォルト: 0.05
有効な値: [0.0,…,0.25]
重要度: 低
ログイン更新スレッドのスリープ時間に追加されるクレデンシャルの存続期間に関連するランダムジッターの最大量。設定可能な値は 0 から 0.25(25%)です。値が指定されていない場合は、デフォルト値の 0.05(5%)が使用されます。現在、OAUTHBEARER にのみ適用されます。
scheduled.rebalance.max.delay.ms型: int
デフォルト: 300000 (5 分)
有効な値: [0,…,2147483647]
重要度: low
1人または複数の離脱したワーカーが戻ってくるのを待ってから、コネクタやタスクをリバランスしてグループに再割り当てするために予定されている最大の遅延時間。この期間は、離脱したワーカーのコネクタやタスクが割り当てられないままです。
ssl.cipher.suitesタイプ: list
デフォルト: null
重要度: 低
暗号化スイートの一覧。これは、TLS または SSL ネットワークプロトコルを使用してネットワーク接続のセキュリティー設定をネゴシエートするために使用される認証、暗号化、MAC、および鍵交換アルゴリズムの名前付きの組み合わせです。デフォルトでは、利用可能なすべての暗号スイートがサポートされます。
ssl.client.authタイプ: string
デフォルト: none
重要度: 低
クライアント認証を要求する kafka ブローカーを設定します。以下の設定は一般的な設定です。
-
ssl.client.auth=required: 必要なクライアント認証が必要な場合 -
ssl.client.auth=requestedこれは、クライアント認証は任意となります。要求されたとは異なり、このオプションを設定するとクライアント自体の認証情報を提供しないよう選択できることを意味します。 -
ssl.client.auth=none: これは、クライアント認証が不要であることを意味します。
-
ssl.endpoint.identification.algorithmタイプ: string
デフォルト: https
重要度: 低
サーバー証明書を使用してサーバーのホスト名を検証するエンドポイント識別アルゴリズム。
ssl.engine.factory.classタイプ: class
デフォルト: null
重要度: 低
SSLEngine オブジェクトを提供する org.apache.kafka.common.security.auth.SslEngineFactory タイプのクラス。デフォルト値はorg.apache.kafka.common.security.ssl.DefaultSslEngineFactory です。
ssl.keymanager.algorithm型: string
デフォルト: SunX509
重要度: 低
SSL 接続のキーマネージャーファクトリーによって使用されるアルゴリズム。デフォルト値は、Java 仮想マシンに設定されたキーマネージャーファクトリーアルゴリズムです。
ssl.secure.random.implementationタイプ: string
デフォルト: null
重要度: 低
SSL 暗号操作に使用する SecureRandom PRNG 実装。
ssl.trustmanager.algorithm型: string
デフォルト: PKIX
重要度: 低
SSL 接続のトラストマネージャーファクトリーによって使用されるアルゴリズム。デフォルト値は、Java 仮想マシンに設定されたトラストマネージャーファクトリーアルゴリズムです。
status.storage.partitions型: int
デフォルト: 5
有効な値: 正の数。ブローカーのデフォルトを使用する場合は -1
重要度: 低
ステータスストレージトピックの作成時に使用されるパーティションの数。
status.storage.replication.factor型: short
デフォルト: 3
有効な値: Kafka クラスター内のブローカーの数以下の正の数。ブローカーのデフォルトを使用する場合は -1
重要度: 低
ステータスストレージトピックの作成時に使用されるレプリケーション係数。
task.shutdown.graceful.timeout.ms型: long
デフォルト: 5000 (5 秒)
重要度: 低
タスクを正常にシャットダウンするまで待機する時間。これは、タスクごとにではなく、合計時間です。タスクはすべてシャットダウンされ、順番に待機します。
topic.creation.enableタイプ: boolean
デフォルト: true
重要度: 低
ソースコネクターが
topic.creation.プロパティーで設定されている場合、ソースコネクターによって使用されるトピックの自動作成を許可するかどうか。各タスクは管理クライアントを使用してトピックを作成し、トピックを自動的に作成する Kafka ブローカーに依存しません。topic.tracking.allow.resetタイプ: boolean
デフォルト: true
重要度: 低
true に設定すると、ユーザーリクエストはコネクターごとにアクティブなトピックのセットをリセットできます。
topic.tracking.enableタイプ: boolean
デフォルト: true
重要度: 低
ランタイム時におけるコネクターごとにアクティブなトピックのセットの追跡を有効にします。
付録G Kafka Streams 設定パラメーター
application.idタイプ: string
重要度: 高
ストリーム処理アプリケーションの識別子。Kafka クラスター内で一意である必要があります。これは、1) デフォルトのクライアントIDのプレフィックス、2) メンバーシップ管理のためのグループID、3) Changelog のトピックのプレフィックスとして使用されます。
bootstrap.serversタイプ: list
重要度: 高
Kafka クラスターへの最初の接続を確立するために使用されるホストとポートのペアの一覧。クライアントは、ブートストラップ用にここで指定されたサーバーに関係なく、すべてのサーバーを利用します。この一覧は、サーバーのフルセットを検出するために使用される最初のホストにのみ影響します。この一覧は、
host1:port1,host2:port2,…の形式にする必要があります。これらのサーバーは、(動的に変更される可能性がある) 完全なクラスターメンバーシップを検出するための最初の接続にだけ使用されるため、このリストにはサーバーの完全なセットを含める必要はありません (ただし、サーバーがダウンした場合に備えて、複数のサーバーが必要になる場合があります)。replication.factorタイプ: int
デフォルト: 1
重大度: 高
ストリーム処理アプリケーションによって作成されたログトピックおよびパーティショントピックを変更するためのレプリケーション係数。
state.dirタイプ: string
デフォルト: /tmp/kafka-streams
重要度: 高
状態ストアのディレクトリーの場所。このパスは、同じ基礎となるファイルシステムを共有するストリームインスタンスごとに一意である必要があります。
acceptable.recovery.lag型: long
デフォルト: 10000
有効な値: [0,…]
重要度: 中
クライアントがアクティブなタスクに対して取り戻したと見なされる最大許容遅延 (補うためのオフセット数) です。特定のワークロードに対して、1 分間でリカバリー時間に十分に対応できるはずです。0 以上である必要があります。
cache.max.bytes.buffering型: long
デフォルト: 10485760
有効な値: [0,…]
重要度: 中
すべてのスレッドでバッファーするのに使用されるメモリーバイトの最大数。
client.idタイプ: string
デフォルト: ""
重要度: 中
内部コンシューマー、プロデューサー、および復元コンシューマーのクライアントIDに使用される ID プレフィックス。パターンは、'<client.id>-StreamThread-<threadSequenceNumber>-<consumer|producer|restore-consumer>' です。
default.deserialization.exception.handlerタイプ: class
デフォルト: org.apache.kafka.streams.errors.LogAndFailExceptionHandler
重要度: 中
org.apache.kafka.streams.errors.DeserializationExceptionHandlerインターフェイスを実装する例外処理クラス。default.key.serdeタイプ: class
デフォルト: org.apache.kafka.common.serialization.Serdes$ByteArraySerde
重大度: 中
org.apache.kafka.common.serialization.Serdeインターフェイスを実装するキーのデフォルトのシリアライザー/デシリアライザークラス。windowed serde クラスを使用する場合は、org.apache.kafka.common.serialization.Serdeインターフェースを実装した inner serde クラスを 'default.windowed.key.serde.inner' または 'default.windowed.value.serde.inner' で設定する必要があることに注意してください。default.production.exception.handlerタイプ: class
デフォルト: org.apache.kafka.streams.errors.DefaultProductionExceptionHandler
重要度: 中
org.apache.kafka.streams.errors.ProductionExceptionHandlerインターフェイスを実装する例外処理クラス。default.timestamp.extractorタイプ: class
デフォルト: org.apache.kafka.streams.processor.FailOnInvalidTimestamp
重要度: 中
org.apache.kafka.streams.processor.TimestampExtractorインターフェイスを実装した、デフォルトのタイムスタンプ抽出クラスです。default.value.serdeタイプ: class
デフォルト: org.apache.kafka.common.serialization.Serdes$ByteArraySerde
重大度: 中
org.apache.kafka.common.serialization.Serdeインターフェイスを実装する値のデフォルトのシリアライザー/デシリアライザークラス。windowed serde クラスを使用する場合は、org.apache.kafka.common.serialization.Serdeインターフェイスを実装した inner serde クラスを 'default.windowed.key.serde.inner' または 'default.windowed.value.serde.inner' で設定する必要があることに注意してください。max.task.idle.ms型: long
デフォルト: 0
重要度: 中
複数の入力ストリームで順不同のレコード処理を防ぐために、すべてのパーティションバッファーにレコードが含まれない場合に、ストリームタスクがアイドル状態になる最大時間。
max.warmup.replicas型: int
デフォルト: 2
有効な値: [1,…]
重要度: 中
タスクが再割り当てされたあるインスタンスでウォームアップしている間に、別のインスタンスでタスクを利用できるようにするために、一度に割り当てることができるウォームアップレプリカ (設定されたnum.standbysを超える追加のスタンドバイ) の最大数です。高可用性を確保するために追加のブローカートラフィックとクラスターの状態を調整するのに使用されます。1 以上でなければなりません。
num.standby.replicasタイプ: int
デフォルト: 0
重大度: 中
各タスクのスタンバイレプリカ数。
num.stream.threads型: int
デフォルト: 1
重要度: 中
ストリーム処理を実行するスレッドの数。
processing.guaranteeタイプ: string
デフォルト: at_least_once
有効な値: [at_least_once, exactly_once, exactly_once_beta]
重大度: 中
使用されるべき処理保証です。使用可能な値は、
at_least_once(デフォルト)、exactly_once(ブローカーバージョン 0.11.0 以降が必要)、およびexactly_once_beta(ブローカーバージョン 2.5 以降が必要)です。正確に1回の処理には、デフォルトで少なくとも3つのブローカーのクラスターが必要であることに注意してください。これは、実稼働環境に推奨される設定です。開発の場合、ブローカー設定transaction.state.log.replication.factorおよびtransaction.state.log.min.isrを調整することにより、これを変更できます。security.protocol型: string
デフォルト: PLAINTEXT
重要度: 中
ブローカーとの通信に使用されるプロトコル。有効な値は、PLAINTEXT、SSL、SASL_PLAINTEXT、SASL_SSL です。
topology.optimizationタイプ: string
デフォルト: none
有効な値: [none, all]
重要度: 中
デフォルトでは、トポロジーを最適化する必要がある場合に Kafka Streams に指示する設定。
application.serverタイプ: string
デフォルト: ""
重要度: 低
この KafkaStreams インスタンスでの状態ストア検出とインタラクティブなクエリーに使用できるユーザー定義のエンドポイントを参照する host:port ペア。
buffered.records.per.partition型: int
デフォルト: 1000
重要度: 低
パーティションごとにバッファーを行う最大レコード数。
built.in.metrics.versionタイプ: string
デフォルト: latest
有効な値: [0.10.0-2.4, latest]
重大度: 低
使用する組み込みメトリクスのバージョン。
commit.interval.ms型: long
デフォルト: 30000 (30 秒)
有効な値: [0,…]
重要度: 低
プロセッサーの位置を保存する頻度。(なお、
processing.guaranteeがexactly_onceに設定されている場合はデフォルトで100、そうでない場合はデフォルトで30000となっています。connections.max.idle.ms型: long
デフォルト: 540000 (9 分)
重要度: low
この設定で指定された期間 (ミリ秒単位) の後にアイドル状態の接続を閉じます。
metadata.max.age.ms型: long
デフォルト: 300000 (5 分)
有効な値: [0,…]
重要度: low
新しいブローカーまたはパーティションをプロアクティブに検出するためのパーティションリーダーシップの変更がない場合でも、メタデータの更新を強制するまでの期間 (ミリ秒単位)。
metric.reportersタイプ: list
デフォルト: ""
重要度: 低
メトリクスレポーターとして使用するクラスの一覧。
org.apache.kafka.common.metrics.MetricsReporterインターフェイスを実装すると、新しいメトリクスの作成が通知されるクラスのプラグが可能になります。JmxReporter は、JMX 統計を登録するために常に含まれます。metrics.num.samples型: int
デフォルト: 2
有効な値: [1,…]
重要度: 低
メトリクスを計算するために保持されるサンプルの数。
metrics.recording.level型: string
デフォルト: INFO
有効な値: [INFO, DEBUG]
重要度: 低
メトリクスの最も高い記録レベル。
metrics.sample.window.ms型: long
デフォルト: 30000 (30 秒)
有効な値: [0,…]
重要度: 低
メトリクスサンプルが計算される時間枠。
partition.grouperタイプ: class
デフォルト: org.apache.kafka.streams.processor.DefaultPartitionGrouper
重大度: 低
org.apache.kafka.streams.processor.PartitionGrouperインターフェースを実装するパーティショングループクラス。警告: この設定は非推奨になり、3.0.0 リリースで削除されます。poll.ms型: long
デフォルト: 100
重要度: 低
入力を待つためにブロックする時間をミリ秒単位で指定します。
probing.rebalance.interval.ms型: long
デフォルト: 600000 (10 分)
有効な値: [60000,…]
重要度: low
準備が完了し、アクティブになる準備が整っているウォームアップレプリカのリバランスをトリガーする前に待機する最大時間。プローブリバランスは、割り当てが分散されるまで引き続きトリガーされます。1 分以上でなければなりません。
receive.buffer.bytes型: int
デフォルト: 32768 (32 キビバイト)
有効な値: [-1,…]
重要度: low
データの読み取り時に使用する TCP 受信バッファー(SO_RCVBUF)のサイズ。値が -1 の場合、OS のデフォルトが使用されます。
reconnect.backoff.max.ms型: long
デフォルト: 1000 (1 秒)
有効な値: [0,…]
重要度: 低
接続に繰り返し失敗したブローカーへの再接続時に待機する最大時間 (ミリ秒単位)。これが指定されている場合、ホストごとのバックオフは、連続して接続に失敗するたびに、この最大値まで指数関数的に増加します。バックオフの増加を計算した後、コネクションストームを回避するために 20% のランダムなジッターが追加されます。
reconnect.backoff.ms型: long
デフォルト: 50
有効な値: [0,…]
重要度: 低
特定のホストへの再接続を試みる前に待機するベース時間。これにより、タイトなループでホストに繰り返し接続することを回避します。このバックオフは、クライアントによるブローカーへのすべての接続試行に適用されます。
request.timeout.ms型: int
デフォルト: 40000 (40 秒)
有効な値: [0,…]
重要度: 低
この設定は、クライアントの要求の応答を待つ最大時間を制御します。タイムアウトが経過する前に応答が受信されない場合、クライアントは必要に応じてリクエストを再送信します。または、再試行が使い切られるとリクエストが失敗します。
retries型: int
デフォルト: 0
有効な値: [0,…,2147483647]
重要度: 低
ゼロより大きい値を設定すると、クライアントは、一時的なエラーの可能性がある失敗した要求を再送信します。
retry.backoff.ms型: long
デフォルト: 100
有効な値: [0,…]
重要度: 低
特定のトピックパーティションに対して失敗したリクエストを再試行するまでの待機時間。これにより、一部の障害シナリオでタイトループでリクエストを繰り返し送信することを回避できます。
rocksdb.config.setterタイプ: class
デフォルト: null
重要度: 低
org.apache.kafka.streams.state.RocksDBConfigSetterインターフェイスを実装する Rocks DB 設定セッタークラスまたはクラス名。send.buffer.bytes型: int
デフォルト: 131072 (128 キビバイト)
有効な値: [-1,…]
重要度: low
データの送信時に使用する TCP 送信バッファー (SO_SNDBUF) のサイズ。値が -1 の場合、OS のデフォルトが使用されます。
state.cleanup.delay.ms型: long
デフォルト: 600000 (10 分)
重要度: low
パーティションが移行されたときに状態を削除するまで待機する時間 (ミリ秒単位)。少なくとも
state.cleanup.delay.msの間変更されていない state ディレクトリーのみが削除されます。upgrade.fromタイプ: string
デフォルト: null
有効な値: [null, 0.10.0, 0.10.1, 0.10.2, 0.11.0, 1.0, 1.1, 2.0, 2.1, 2.2, 2.3]
重要度: 低
後方互換性のある方法でのアップグレードを許可します。これは、[0.10.0, 1.1] から 2.0+ にアップグレード、または [2.0, 2.3] から 2.4+ にアップグレードする際に必要です。2.4 から新しいバージョンにアップグレードする場合は、この設定を指定する必要はありません。デフォルトは
nullです。許可される値は 0.10.0、0.10.1、0.10.2、0.11.0、1.0、1.1、2.0、2.1、2.2、2.3 (対応する旧バージョンからのアップグレード用) です。windowstore.changelog.additional.retention.ms型: long
デフォルト: 86400000 (1 日)
重要度: 低
windows maintainMs に追加され、データがログから早期に削除されないようにします。クロックドリフトを許可します。デフォルトは 1 日です。
付録H サブスクリプションの使用
AMQ Streams は、ソフトウェアサブスクリプションから提供されます。サブスクリプションを管理するには、Red Hat カスタマーポータルでアカウントにアクセスします。
アカウントへのアクセス
- access.redhat.com に移動します。
- アカウントがない場合は、作成します。
- アカウントにログインします。
サブスクリプションのアクティベート
- access.redhat.com に移動します。
- サブスクリプション に移動します。
- Activate a subscription に移動し、16 桁のアクティベーション番号を入力します。
Zip および Tar ファイルのダウンロード
zip または tar ファイルにアクセスするには、カスタマーポータルを使用して、ダウンロードする関連ファイルを検索します。RPM パッケージを使用している場合は、この手順は必要ありません。
- ブラウザーを開き、access.redhat.com/downloads で Red Hat カスタマーポータルの Product Downloads ページにログインします。
- JBOSS INTEGRATION AND AUTOMATION カテゴリーの Red Hat AMQ Streams エントリーを見つけます。
- 必要な AMQ Streams 製品を選択します。Software Downloads ページが開きます。
- コンポーネントの ダウンロード リンクをクリックします。
パッケージ用システムの登録
RPM パッケージを Red Hat Enterprise Linux にインストールするには、システムが登録されている必要があります。zip または tar ファイルを使用している場合、この手順は必要ありません。
- access.redhat.com に移動します。
- Registration Assistant に移動します。
- ご使用の OS バージョンを選択し、次のページに進みます。
- システムターミナルで listed コマンドを使用して、登録を完了します。
詳細は、How to Register and Subscribe a System to the Red Hat Customer Portalを参照してください。
改訂日時: 2022-09-09 07:35:04 +1000