AMQ Streams on OpenShift の使用
OpenShift Container Platform 上で AMQ Streams 1.4 を使用
概要
第1章 AMQ Streams の概要
AMQ Streams は、OpenShift クラスターで Apache Kafka を実行するプロセスを簡素化します。
1.1. Kafka の機能
Kafka の基盤のデータストリーム処理機能とコンポーネントアーキテクチャーによって以下が提供されます。
- スループットが非常に高く、レイテンシーが低い状態でデータを共有するマイクロサービスおよびその他のアプリケーション。
- メッセージの順序の保証。
- アプリケーションの状態を再構築するためにデータストレージからメッセージを巻き戻し/再生。
- キーバリューログの使用時に古いレコードを削除するメッセージ圧縮。
- クラスター設定での水平スケーラビリティー。
- 耐障害性を制御するデータのレプリケーション。
- 即座にアクセスするために大容量のデータを保持。
1.2. Kafka のユースケース
Kafka の機能は、以下に適しています。
- イベント駆動型のアーキテクチャー。
- アプリケーションの状態変更をイベントのログとしてキャプチャーするイベントソーシング。
- メッセージのブローカー。
- Web サイトアクティビティーの追跡。
- メトリクスによるオペレーションの監視。
- ログの収集および集計。
- 分散システムのログのコミット。
- アプリケーションがリアルタイムでデータに対応できるようにするストリーム処理。
1.3. AMQ Streams による Kafka のサポート
AMQ Streams は、Kafka を OpenShift で実行するためのコンテナーイメージおよび Operator を提供します。AMQ Streams Operator は、AMQ Streams の実行に必要です。AMQ Streams で提供される Operator は、Kafka を効果的に管理するために、専門的なオペレーション情報で目的に合うよう構築されています。
Operator は以下のプロセスを単純化します。
- Kafka クラスターのデプロイおよび実行。
- Kafka コンポーネントのデプロイおよび実行。
- Kafka へアクセスするための設定。
- Kafka へのアクセスをセキュア化。
- Kafka のアップグレード。
- ブローカーの管理。
- トピックの作成および管理。
- ユーザーの作成および管理。
1.4. Operator
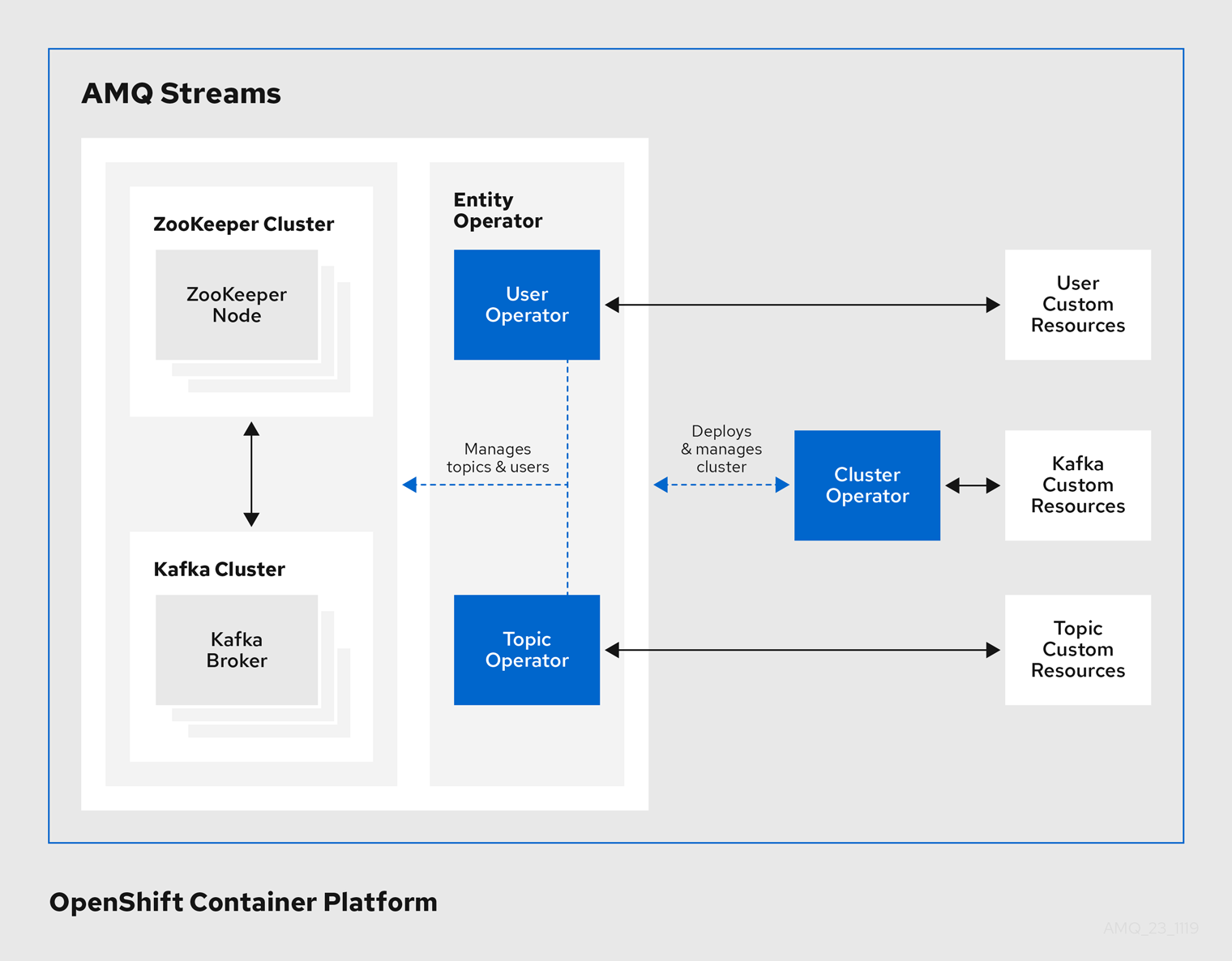
AMQ Streams は、OpenShift クラスター内で実行中の Kafka クラスターを管理するための Operator を提供します。
- Cluster Operator
- Apache Kafka クラスター、Kafka Connect、Kafka MirrorMaker、Kafka Bridge、Kafka Exporter、および Entity Operator をデプロイおよび管理します。
- Entitiy Operator
- Topic Operator および User Operator を構成します。
- Topic Operator
- Kafka トピックを管理します。
- User Operator
- Kafka ユーザーを管理します。
Cluster Operator は、Kafka クラスターと同時に、Topic Operator および User Operator を Entity Operator 設定の一部としてデプロイできます。
AMQ Streams アーキテクチャー内の Operator
1.5. AMQ Streams のインストール方法
AMQ Streams を OpenShift にインストールする方法は 2 つあります。
| インストール方法 | 説明 | サポート対象バージョン |
|---|---|---|
| インストールアーティファクト (YAML ファイル) |
AMQ Streams のダウンロードサイト から | OpenShift 3.11 以上 |
| OperatorHub | OperatorHub で AMQ Streams Operator を使用し、Cluster Operator を単一またはすべての namespace にデプロイします。 | OpenShift 4.x のみ |
柔軟性が重要な場合は、インストールアーティファクトによる方法を選択します。OpenShift 4 Web コンソールを使用して標準設定で AMQ Streams を OpenShift 4 にインストールする場合は、OperatorHub による方法を選択します。OperatorHub を使用すると、自動更新も利用できます。
どちらの方法でも、Cluster Operator は OpenShift クラスターにデプロイされ、提供される YAML サンプルファイルを使用して、Kafka クラスターから順に AMQ Streams の他のコンポーネントをデプロイする準備が整います。
AMQ Streams インストールアーティファクト
AMQ Streams インストールアーティファクトには、OpenShift にデプロイできるさまざまな YAML ファイルが含まれ、oc 使用して以下を含むカスタムリソースが作成されます。
- デプロイメント
- Custom Resource Definition (CRD)
- ロールおよびロールバインディング
- サービスアカウント
YAML インストールファイルは、Cluster Operator、Topic Operator、User Operator、および Strimzi Admin ロールに提供されます。
OperatorHub
OpenShift 4 では、Operator Lifecycle Manager (OLM) を使用することにより、クラスター管理者はクラスター全体で実行されるすべての Operator やそれらの関連サービスをインストール、更新、および管理できます。OLM は、Kubernetes のネイティブアプリケーション (Operator) を効率的に自動化された拡張可能な方法で管理するために設計されたオープンソースツールキットの Operator Framework の一部です。
OperatorHub は OpenShift 4 Web コンソールの一部です。クラスター管理者はこれを使用して Operator を検出、インストール、およびアップグレードできます。Operator は OperatorHub からプルでき、単一の (プロジェクト) namespace またはすべての (プロジェクト) namespace への OpenShift クラスターにインストールできます。Operator は OLM で管理できます。エンジニアリングチームは OLM を使用して、独自に開発、テスト、および本番環境でソフトウェアを管理できます。
OperatorHub は、バージョン 4 未満の OpenShift では使用できません。
AMQ Streams Operator
AMQ Streams Operator は OperatorHub からインストールできます。AMQ Streams Operator のインストール後、必要な CRD およびロールベースアクセス制御 (RBAC) リソースと共に Cluster Operator が OpenShift クラスターにデプロイされます。
その他のリソース
インストールアーティファクトを使用した AMQ Streams のインストール:
OperatorHub からの AMQ Streams のインストール:
- 「OperatorHub からの Cluster Operator のデプロイ」
- OpenShift ドキュメントの『Operator』
1.6. 本書の表記慣例
置き換え可能なテキスト
本書では、置き換え可能なテキストは等幅フォントおよびイタリック体で記載されています。
たとえば、以下のコードでは my-namespace を namespace の名前に置き換えます。
sed -i 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yaml
sed -i 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yaml第2章 AMQ Streams の使用
AMQ Streams は、パブリックおよびプライベートクラウドからデプロイメントを目的とするローカルデプロイメントまで、ディストリビューションに関係なくすべてのタイプの OpenShift クラスターで動作するよう設計されています。AMQ Streams は、OpenShift 固有の一部機能をサポートします。そのようなインテグレーションは OpenShift ユーザーに有用で、標準の OpenShift を使用して同様に実装することはできません。
本ガイドでは、OpenShift クラスターが使用できることを仮定し、さらに oc コマンドラインツールがインストールされ、稼働中のクラスターに接続するように設定されていることを仮定しています。
AMQ Streams は Strimzi 0.17.x をベースとしています。本章では、OpenShift 3.11 以降に AMQ Streams をデプロイする方法を説明します。
本ガイドのコマンドを実行するには、クラスターユーザーに RBAC (ロールベースアクセス制御) および CRD を管理する権限を付与する必要があります。
2.1. AMQ Streams のインストールおよびコンポーネントのデプロイ
AMQ Streams をインストールするには、AMQ Streams のダウンロードページ から amq-streams-x.y.z-ocp-install-examples.zip ファイルをダウンロードし、展開します。
フォルダーには、複数の YAML ファイルが含まれています。これらのファイルは、AMQ Streams のコンポーネントを OpenShift にデプロイするのに役立ち、共通の操作を実行し、Kafka クラスターを設定します。YAML ファイルは本書を通して参照されます。
本章の後半では、提供される YAML ファイルを使用してコンポーネントを OpenShift にデプロイするための各コンポーネントおよび手順の概要を取り上げます。
AMQ Streams のコンテナーイメージは Red Hat Container Catalog で使用できますが、この代わりに提供される YAML ファイルを使用することが推奨されます。
2.2. カスタムリソース
カスタムリソースを使用すると、デフォルトの AMQ Streams デプロイメントを設定し、変更を追加することができます。カスタムリソースを使用するには、最初にカスタムリソース定義を指定する必要があります。
カスタムリソース定義 (CRD) は Kubernetes API を拡張し、カスタムリソースを OpenShift クラスターに追加する定義を提供します。カスタムリソースは、CRD によって追加される API のインスタンスとして作成されます。
AMQ Streams では、Kafka、Kafka Connect、Kafka MirrorMaker 、ユーザーおよびトピックカスタムリソースなどの AMQ Streams に固有のカスタムリソースが CRD によって OpenShift クラスターに導入されます。CRD によって設定手順が提供され、AMQ Streams 固有のリソースをインスタンス化および管理するために使用されるスキーマが定義されます。また、CRD によって、CLI へのアクセスや設定検証などのネイティブ OpenShift 機能を AMQ Streams リソースで活用することもできます。
CRD はクラスターで 1 度インストールする必要があります。クラスターの設定によりますが、インストールには通常、クラスター管理者権限が必要です。
カスタムリソースの管理は、 AMQ Streams 管理者 のみが行えます。
CRD およびカスタムリソースは YAML ファイルとして定義されます。
kind:Kafka などの新しい kind リソースは、OpenShift クラスター内で CRD によって定義されます。
Kubernetes API サーバーを使用すると、kind を基にしたカスタムリソースの作成が可能になり、カスタムリソースが OpenShift クラスターに追加されたときにカスタムリソースの検証および格納方法を CRD から判断します。
CRD が削除されると、そのタイプのカスタムタイプも削除されます。さらに、Pod や Statefulset などのカスタムリソースによって作成されたリソースも削除されます。
2.2.1. AMQ Streams カスタムリソースの例
AMQ Streams 固有の各カスタムリソースは、リソースの kind の CRD によって定義されるスキーマに準拠します。
CRD とカスタムリソースの関係を理解するため、Kafka トピックの CRD の例を見てみましょう。
Kafka トピックの CRD
- 1
- CRD を識別するためのトピック CRD、その名前および名前のメタデータ。
- 2
- この CRD に指定された項目には、トピックの API にアクセスするため URL に使用されるグルShortNameープ (ドメイン) 名、複数名、およびサポートされるスキーマバージョンが含まれます。他の名前は、CLI のインスタンスリソースを識別するために使用されます。例:
oc get kafkatopic my-topicまたはoc get kafkatopics - 3
- ShortName は CLI コマンドで使用できます。たとえば、
oc get kafkatopicの代わりにoc get ktを略名として使用できます。 - 4
- カスタムリソースで
getコマンドを使用する場合に示される情報。 - 5
- リソースの スキーマ参照 に記載されている CRD の現在のステータス。
- 6
- openAPIV3Schema 検証によって、トピックカスタムリソースの作成が検証されます。たとえば、トピックには 1 つ以上のパーティションと 1 つのレプリカが必要です。
ファイル名に、インデックス番号とそれに続く「Crd」が含まれるため、AMQ Streams インストールファイルと提供される CRD YAML ファイルを識別できます。
KafkaTopic カスタムリソースに該当する例は次のとおりです。
Kafka トピックカスタムリソース
- 1
kindおよびapiVersionによって、インスタンスであるカスタムリソースの CRD が特定されます。- 2
- トピックまたはユーザーが属する Kafka クラスターの名前 (
Kafkaリソースの名前と同じ) を定義する、KafkaTopicおよびKafkaUserリソースのみに適用可能なラベル。この名前は、トピックまたはユーザーの作成時に Kafka クラスターを識別するために Topic Operator および User Operator によって使用されます。
- 3
- 指定内容には、トピックのパーティション数およびレプリカ数や、トピック自体の設定パラメーターが示されています。この例では、メッセージがトピックに保持される期間や、ログのセグメントファイルサイズが指定されています。
- 4
KafkaTopicリソースのステータス条件。lastTransitionTimeでtype条件がReadyに変更されています。
プラットフォーム CLI からカスタムリソースをクラスターに適用できます。カスタムリソースが作成されると、Kubernetes API の組み込みリソースと同じ検証が使用されます。
KafkaTopic の作成後、Topic Operator は通知を受け取り、該当する Kafka トピックが AMQ Streams で作成されます。
2.2.2. AMQ Streams カスタムリソースのステータス
AMQ Streams カスタムリソースの status プロパティーは、リソースに関する情報を必要とするユーザーおよびツールにその情報をパブリッシュします。
下記の表のとおり、複数のリソースに status プロパティーがあります。
| AMQ Streams リソース | スキーマ参照 | ステータス情報がパブリッシュされる場所 |
|---|---|---|
|
| Kafka クラスター | |
|
| デプロイされている場合は Kafka Connect クラスター。 | |
|
| デプロイされている場合は Source-to-Image (S2I) サポートのある Kafka Connect クラスター。 | |
|
|
デプロイされている場合は | |
|
| デプロイされている場合は Kafka MirrorMakerツール。 | |
|
| Kafka クラスターの Kafka トピック | |
|
| Kafka クラスターの Kafka ユーザー。 | |
|
| デプロイされている場合は AMQ Streams の Kafka Bridge。 |
リソースの status プロパティーによって、リソースの下記項目の情報が提供されます。
-
status.conditionsプロパティーの Current state (現在の状態)。 -
status.observedGenerationプロパティーの Last observed generation (最後に確認された生成)。
status プロパティーによって、リソース固有の情報も提供されます。以下に例を示します。
-
KafkaConnectStatusによって、Kafka Connect コネクターの REST API エンドポイントが提供されます。 -
KafkaUserStatusによって、Kafka ユーザーの名前と、ユーザーのクレデンシャルが保存されるSecretが提供されます。 -
KafkaBridgeStatusによって、外部クライアントアプリケーションが Bridge サービスにアクセスできる HTTP アドレスが提供されます。
リソースの Current state (現在の状態) は、spec プロパティーによって定義される Desired state (望ましい状態) を実現するリソースに関する進捗を追跡するのに便利です。ステータス条件によって、リソースの状態が変更された時間および理由が提供され、Operator によるリソースの望ましい状態の実現を妨げたり遅らせたりしたイベントの詳細が提供されます。
Last observed generation (最後に確認された生成) は、Cluster Operator によって最後に照合されたリソースの生成です。observedGeneration の値が metadata.generation の値と異なる場合、リソースの最新の更新が Operator によって処理されていません。これらの値が同じである場合、リソースの最新の変更がステータス情報に反映されます。
AMQ Streams によってカスタムリソースのステータスが作成および維持されます。定期的にカスタムリソースの現在の状態が評価され、その結果に応じてステータスが更新されます。くださいーたとえば、oc edit を使用してカスタムリソースで更新を行う場合、その status は編集不可能です。さらに、status の変更は Kafka クラスターステータスの設定に影響しません。
以下では、Kafka カスタムリソースに status プロパティーが指定されています。
Kafka カスタムリソースとステータス
- 1
- status の
conditionsは、既存のリソース情報から推測できないステータスに関連する基準や、リソースのインスタンスに固有する基準を記述します。 - 2
Ready条件は、Cluster Operator が現在 Kafka クラスターでトラフィックの処理が可能であると判断するかどうかを示しています。- 3
observedGenerationは、最後に Cluster Operator によって照合されたKafkaカスタムリソースの生成を示しています。- 4
listenersは、現在の Kafka ブートストラップアドレスをタイプ別に示しています。重要タイプが
nodeportの外部リスナーのカスタムリソースステータスにおけるアドレスは、現在サポートされていません。
Kafka ブートストラップアドレスがステータスに一覧表示されても、それらのエンドポイントまたは Kafka クラスターが準備状態であるとは限りません。
ステータス情報のアクセス
リソースのステータス情報はコマンドラインから取得できます。詳細は 「カスタムリソースのステータスの確認」 を参照してください。
2.3. Cluster Operator
Cluster Operator は、OpenShift クラスター内で Apache Kafka クラスターのデプロイおよび管理を行います。
2.3.1. Cluster Operator
AMQ Streams では、Cluster Operator を使用して以下のクラスターをデプロイおよび管理します。
- Kafka (ZooKeeper、Entity Operator、および Kafka Exporter を含む)
- Kafka Connect
- Kafka MirrorMaker
- Kafka Bridge
クラスターのデプロイメントにはカスタムリソースが使用されます。
たとえば、以下のように Kafka クラスターをデプロイします。
-
クラスター設定のある
Kafkaリソースが OpenShift クラスター内で作成されます。 -
Kafkaリソースに宣言された内容を基にして、該当する Kafka クラスターが Cluster Operator によってデプロイされます。
Cluster Operator で以下もデプロイできます (Kafka リソースの設定より)。
-
KafkaTopicカスタムリソースより Operator スタイルのトピック管理を提供する Topic Operator -
KafkaUserカスタムリソースより Operator スタイルのユーザー管理を提供する User Operator
デプロイメントの Entity Operator 内の Topic Operator および User Operator 関数。
Cluster Operator のアーキテクチャー例

2.3.2. Cluster Operator デプロイメントの監視オプション
Cluster Operator の稼働中に、Kafka リソースの更新に対する監視が開始されます。
Cluster Operator はデプロイメントに応じて、以下から Kafka リソースを監視できます。
AMQ Streams では、デプロイメントの処理を簡単にするため、サンプル YAML ファイルが提供されます。
Cluster Operator では、以下のリソースの変更が監視されます。
-
Kafka クラスターの
Kafka。 -
KafkaConnectの Kafka Connect クラスター。 -
Source2Image がサポートされる Kafka Connect クラスターの
KafkaConnectS2I。 -
Kafka Connect クラスターでコネクターを作成および管理するための
KafkaConnector。 -
Kafka MirrorMaker インスタンスの
KafkaMirrorMaker。 -
Kafka Bridge インスタンスの
KafkaBridge。
OpenShift クラスターでこれらのリソースの 1 つが作成されると、Operator によってクラスターの詳細がリソースより取得されます。さらに、StatefulSet、Service、および ConfigMap などの必要な OpenShift リソースが作成され、リソースの新しいクラスターの作成が開始されます。
Kafka リソースが更新されるたびに、リソースのクラスターを構成する OpenShift リソースで該当する更新が Operator によって実行されます。
クラスターの望ましい状態がリソースのクラスターに反映されるようにするため、リソースへのパッチ適用後またはリソースの削除後にリソースが再作成されます。この操作は、サービスの中断を引き起こすローリングアップデートの原因となる可能性があります。
リソースが削除されると、Operator によってクラスターがアンデプロイされ、関連する OpenShift リソースがすべて削除されます。
2.3.3. 単一の namespace を監視対象とする Cluster Operator のデプロイメント
前提条件
-
この手順では、
CustomResourceDefinitions、ClusterRoles、およびClusterRoleBindingsを作成できる OpenShift ユーザーアカウントを使用する必要があります。通常、OpenShift クラスターでロールベースアクセス制御 (RBAC) を使用する場合、これらのリソースを作成、編集、および削除する権限を持つユーザーはsystem:adminなどの OpenShift クラスター管理者に限定されます。 Cluster Operator がインストールされる namespace に従い、インストールファイルを編集します。
Linux の場合は、以下を使用します。
sed -i 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yaml
sed -i 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow MacOS の場合は、以下を使用します。
sed -i '' 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yaml
sed -i '' 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
手順
Cluster Operator をデプロイします。
oc apply -f install/cluster-operator -n my-namespace
oc apply -f install/cluster-operator -n my-namespaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.3.4. 複数の namespace を監視対象とする Cluster Operator のデプロイメント
前提条件
-
この手順では、
CustomResourceDefinitions、ClusterRoles、およびClusterRoleBindingsを作成できる OpenShift ユーザーアカウントを使用する必要があります。通常、OpenShift クラスターでロールベースアクセス制御 (RBAC) を使用する場合、これらのリソースを作成、編集、および削除する権限を持つユーザーはsystem:adminなどの OpenShift クラスター管理者に限定されます。 Cluster Operator がインストールされる namespace にしたがって、インストールファイルを編集します。
Linux の場合は、以下を使用します。
sed -i 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yaml
sed -i 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow MacOS の場合は、以下を使用します。
sed -i '' 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yaml
sed -i '' 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
手順
install/cluster-operator/050-Deployment-strimzi-cluster-operator.yamlファイルを編集し、環境変数STRIMZI_NAMESPACEで、Cluster Operator がリソースを監視するすべての namespace を一覧表示します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow Cluster Operator によって監視されるすべての namespace (上記の例では
watched-namespace-1、watched-namespace-2、およびwatched-namespace-3) に対して、RoleBindingsをインストールします。watched-namespaceは、直前のステップで使用した namespace に置き換えます。oc applyを使用してこれを行うことができます。oc apply -f install/cluster-operator/020-RoleBinding-strimzi-cluster-operator.yaml -n watched-namespace oc apply -f install/cluster-operator/031-RoleBinding-strimzi-cluster-operator-entity-operator-delegation.yaml -n watched-namespace oc apply -f install/cluster-operator/032-RoleBinding-strimzi-cluster-operator-topic-operator-delegation.yaml -n watched-namespace
oc apply -f install/cluster-operator/020-RoleBinding-strimzi-cluster-operator.yaml -n watched-namespace oc apply -f install/cluster-operator/031-RoleBinding-strimzi-cluster-operator-entity-operator-delegation.yaml -n watched-namespace oc apply -f install/cluster-operator/032-RoleBinding-strimzi-cluster-operator-topic-operator-delegation.yaml -n watched-namespaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow Cluster Operator をデプロイします。
oc applyを使用してこれを行うことができます。oc apply -f install/cluster-operator -n my-namespace
oc apply -f install/cluster-operator -n my-namespaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.3.5. すべての namespace を対象とする Cluster Operator のデプロイメント
OpenShift クラスターのすべての namespace で AMQ Streams リソースを監視するように Cluster Operator を設定できます。このモードで実行している場合、Cluster Operator によって、新規作成された namespace でクラスターが自動的に管理されます。
前提条件
-
この手順では、
CustomResourceDefinitions、ClusterRoles、およびClusterRoleBindingsを作成できる OpenShift ユーザーアカウントを使用する必要があります。通常、OpenShift クラスターでロールベースアクセス制御 (RBAC) を使用する場合、これらのリソースを作成、編集、および削除する権限を持つユーザーはsystem:adminなどの OpenShift クラスター管理者に限定されます。 - OpenShift クラスターが稼働している必要があります。
手順
すべての namespace を監視するように Cluster Operator を設定します。
-
050-Deployment-strimzi-cluster-operator.yamlファイルを編集します。 STRIMZI_NAMESPACE環境変数の値を*に設定します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
クラスター全体ですべての namespace にアクセスできる権限を Cluster Operator に付与する
ClusterRoleBindingsを作成します。oc create clusterrolebindingコマンドを使用します。oc create clusterrolebinding strimzi-cluster-operator-namespaced --clusterrole=strimzi-cluster-operator-namespaced --serviceaccount my-namespace:strimzi-cluster-operator oc create clusterrolebinding strimzi-cluster-operator-entity-operator-delegation --clusterrole=strimzi-entity-operator --serviceaccount my-namespace:strimzi-cluster-operator oc create clusterrolebinding strimzi-cluster-operator-topic-operator-delegation --clusterrole=strimzi-topic-operator --serviceaccount my-namespace:strimzi-cluster-operator
oc create clusterrolebinding strimzi-cluster-operator-namespaced --clusterrole=strimzi-cluster-operator-namespaced --serviceaccount my-namespace:strimzi-cluster-operator oc create clusterrolebinding strimzi-cluster-operator-entity-operator-delegation --clusterrole=strimzi-entity-operator --serviceaccount my-namespace:strimzi-cluster-operator oc create clusterrolebinding strimzi-cluster-operator-topic-operator-delegation --clusterrole=strimzi-topic-operator --serviceaccount my-namespace:strimzi-cluster-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow my-namespaceは、Cluster Operator をインストールする namespace に置き換えます。Cluster Operator を OpenShift クラスターにデプロイします。
oc applyコマンドを使用します。oc apply -f install/cluster-operator -n my-namespace
oc apply -f install/cluster-operator -n my-namespaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.3.6. OperatorHub からの Cluster Operator のデプロイ
OperatorHub から AMQ Streams Operator をインストールして、Cluster Operator を OpenShift クラスターにデプロイできます。OperatorHub は OpenShift 4 のみで使用できます
前提条件
-
Red Hat Operator の
OperatorSourceが OpenShift クラスターで有効になっている必要があります。適切なOperatorSourceが有効になっていれば OperatorHub に Red Hat Operator が表示されます。詳細は、『Operator』を参照してください。 - インストールには、Operator を OperatorHub からインストールするための権限を持つユーザーが必要です
手順
- OpenShift 4 Web コンソールで、Operators > OperatorHub をクリックします。
Streaming & Messaging カテゴリーの AMQ Streams Operator を検索または閲覧します。
- AMQ Streams タイルをクリックし、右側のサイドバーで Install をクリックします。
Create Operator Subscription 画面で、以下のインストールおよび更新オプションから選択します。
- Installation Mode: AMQ Streams Operator をクラスターのすべての (プロジェクト) namespace にインストール (デフォルト) するか、特定の (プロジェクト) namespace インストールするかを選択します。namespace を使用して関数を分離することが推奨されます。Kafka クラスターおよび他の AMQ Streams コンポーネントが含まれる namespace とは別に、独自の namespace に Operator をインストールすることが推奨されます。
- Approval Strategy: デフォルトでは、OLM (Operator Lifecycle Manager) によって、AMQ Streams Operator が自動的に最新の AMQ Streams バージョンにアップグレードされます。今後のアップグレードを手動で承認する場合は、Manual を選択します。詳細は、OpenShift ドキュメントの『Operator』を参照してください。
Subscribe をクリックすると、AMQ Streams Operator が OpenShift クラスターにインストールされます。
AMQ Streams Operator によって、Cluster Operator、CRD、およびロールベースアクセス制御 (RBAC) リソースは選択された namespace またはすべての namespace にデプロイされます。
Installed Operators 画面で、インストールの進捗を確認します。AMQ Streams Operator は、ステータスが InstallSucceeded に変更されると使用できます。

次に、YAML サンプルファイルを使用して、Kafka クラスターから順に AMQ Streams の他のコンポーネントをデプロイできます。
2.4. Kafka クラスター
AMQ Streams を使用して、一時または永続 Kafka クラスターを OpenShift にデプロイできます。Kafka をインストールする場合、AMQ Streams によって ZooKeeper クラスターもインストールされ、Kafka と ZooKeeper との接続に必要な設定が追加されます。
AMQ Streams を使用して、Kafka Exporter をデプロイすることもできます。
- 一時クラスター
-
通常、Kafka の一時クラスターは開発およびテスト環境での使用に適していますが、本番環境での使用には適していません。このデプロイメントでは、ブローカー情報 (ZooKeeper) と、トピックまたはパーティション (Kafka) を格納するための
emptyDirボリュームが使用されます。emptyDirボリュームを使用すると、その内容は厳密に Pod のライフサイクルと関連し、Pod がダウンすると削除されます。 - 永続クラスター
-
Kafka の永続クラスターでは、
PersistentVolumesを使用して ZooKeeper および Kafka データを格納します。PersistentVolumeClaimを使用してPersistentVolumeが取得され、PersistentVolumeの実際のタイプには依存しません。たとえば、YAML ファイルを変更しなくても Amazon AWS デプロイメントで Amazon EBS ボリュームを使用できます。PersistentVolumeClaimでStorageClassを使用し、自動ボリュームプロビジョニングをトリガーすることができます。
AMQ Streams には、Kafka クラスターをデプロイするサンプルが複数含まれています。
-
kafka-persistent.yamlは、3 つの Zookeeper ノードと 3 つの Kafka ノードを使用して永続クラスターをデプロイします。 -
kafka-jbod.yamlは、それぞれが複数の永続ボリューを使用する、3 つの ZooKeeper ノードと 3 つの Kafka ノードを使用して、永続クラスターをデプロイします。 -
kafka-persistent-single.yamlは、1 つの ZooKeeper ノードと 1 つの Kafka ノードを使用して、永続クラスターをデプロイします。 -
kafka-ephemeral.yamlは、3 つの ZooKeeper ノードと 3 つの Kafka ノードを使用して、一時クラスターをデプロイします。 -
kafka-ephemeral-single.yamlは、3 つの ZooKeeper ノードと 1 つの Kafka ノードを使用して、一時クラスターをデプロイします。
サンプルクラスターの名前はデフォルトで my-cluster になります。クラスター名はリソースの名前によって定義され、クラスターがデプロイされた後に変更できません。クラスターをデプロイする前にクラスター名を変更するには、関連する YAML ファイルのリソースの Kafka.metadata.name プロパティーを編集します。
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster # ...
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
# ...2.4.1. Kafka クラスターのデプロイメント
コマンドラインで、Kafka の一時または永続クラスターを OpenShift にデプロイできます。
前提条件
- Cluster Operator がデプロイされている必要があります。
手順
クラスターを開発またはテストの目的で使用する予定である場合は、
oc applyを使用して一時クラスターを作成およびデプロイできます。oc apply -f examples/kafka/kafka-ephemeral.yaml
oc apply -f examples/kafka/kafka-ephemeral.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターを実稼働で使用する予定である場合は、
oc applyを使用して永続クラスターを作成およびデプロイします。oc apply -f examples/kafka/kafka-persistent.yaml
oc apply -f examples/kafka/kafka-persistent.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
-
Kafkaリソースによってサポートされる異なる設定オプションの詳細は、「Kafka クラスターの設定」 を参照してください。
2.5. Kafka Connect
Kafka Connect は、Apache Kafka と外部システムとの間でデータをストリーミングするためのツールです。Kafka Connect では、スケーラビリティーと信頼性を維持しながら Kafka クラスターで大量のデータを出し入れするためのフレームワークが提供されます。Kafka Connect は通常、Kafka を外部データベース、ストレージシステム、およびメッセージングシステムと統合するために使用されます。
Kafka Connect では、ソースコネクター は外部システムからデータを取得し、それをメッセージとして Kafka に提供するランタイムエンティティーです。シンクコネクター は、Kafka トピックからメッセージを取得し、外部システムに提供するランタイムエンティティーです。コネクターのワークロードは タスク に分割されます。タスクは、Connect クラスター を構成するノード (ワーカー とも呼ばれる) の間で分散されます。これにより、メッセージのフローが非常にスケーラブルになり、信頼性が高くなります。
各コネクターは特定の コネクタークラス のインスタンスで、メッセージに関して関連する外部システムとの通信方法を認識しています。コネクターは多くの外部システムで使用でき、独自のコネクターを開発することもできます。
コネクター という用語は、Kafka Connect クラスター内で実行されているコネクターインスタンスや、コネクタークラスと同じ意味で使用されます。本ガイドでは、本文の内容で意味が明確である場合に コネクター という用語を使用します。
AMQ Stremas では以下を行うことが可能です。
- 必要なコネクターが含まれる Kafka Connect イメージの作成。
-
KafkaConnectリソースを使用した OpenShift 内での Kafka Connect クラスターのデプロイおよび管理。 -
任意で
KafkaConnectorリソースを使用して管理された Kafka Connect クラスター内でのコネクターの実行。
Kafka Connect には、ファイルベースのデータを Kafka クラスターで出し入れするために以下の組み込みコネクターが含まれています。
| ファイルコネクター | 説明 |
|---|---|
|
| ファイル (ソース) から Kafka クラスターにデータを転送します。 |
|
| Kafka クラスターからファイル (シンク) にデータを転送します。 |
その他のコネクタークラスを使用するには、以下の手順の 1 つにしたがってコネクターイメージを準備する必要があります。
Cluster Operator では、Kafka Connect クラスターを OpenShift クラスターにデプロイするために作成するイメージを使用できます。
Kafka Connect クラスターは、設定可能な数量のワーカーで Deployment として実装されます。
コネクターを作成および管理 するには、KafkaConnector リソースを使用するか、8083 番ポートで <connect-cluster-name>-connect-api サービスとして使用できる Kafka Connect REST API を手作業で使用します。REST API でサポートされる操作は、Apache Kafka のドキュメント を参照してください。
2.5.1. Kafka Connect のクラスターへのデプロイメント
Cluster Operator を使用して、Kafka Connect クラスターを OpenShift クラスターにデプロイできます。
前提条件
- Cluster Operator をデプロイ する必要があります。
手順
oc applyコマンドを使用して、kafka-connect.yamlファイルに基づいてKafkaConnectリソースを作成します。oc apply -f examples/kafka-connect/kafka-connect.yaml
oc apply -f examples/kafka-connect/kafka-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.5.2. コネクタープラグインでの Kafka Connect の拡張
Kafka Connect の AMQ Streams コンテナーイメージには、FileStreamSourceConnector と FileStreamSinkConnector の 2 つの組み込みファイルコネクターが含まれています。以下を行うと、独自のコネクターを追加できます。
- Kafka Connect ベースイメージからコンテナーイメージを作成します (たとえば、手作業による作成または CI (継続インテグレーション) を使用した作成)。
- OpenShift ビルドおよび S2I (Source-to-Image) を使用してコンテナーイメージを作成します (OpenShift の場合のみ)。
2.5.2.1. Kafka Connect ベースイメージからの Docker イメージの作成
Red Hat Container Catalog の Kafka コンテナーイメージを、追加のコネクタープラグインで独自のカスタムイメージを作成するためのベースイメージとして使用できます。
以下の手順では、カスタムイメージを作成し、/opt/kafka/plugins ディレクトリーに追加する方法を説明します。AMQ Stream バージョンの Kafka Connect は起動時に、/opt/kafka/plugins ディレクトリーに含まれるサードパーティーのコネクタープラグインをロードします。
前提条件
- Cluster Operator をデプロイ する必要があります。
手順
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0をベースイメージとして使用して、新しいDockerfileを作成します。FROM registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0 USER root:root COPY ./my-plugins/ /opt/kafka/plugins/ USER 1001
FROM registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0 USER root:root COPY ./my-plugins/ /opt/kafka/plugins/ USER 1001Copy to Clipboard Copied! Toggle word wrap Toggle overflow - コンテナーイメージをビルドします。
- カスタムイメージをコンテナーレジストリーにプッシュします。
新しいコンテナーイメージを示します。
以下のいずれかを行います。
KafkaConnectカスタムリソースのKafkaConnect.spec.imageプロパティーを編集します。設定された場合、このプロパティーによって Cluster Operator の
STRIMZI_KAFKA_CONNECT_IMAGES変数がオーバーライドされます。Copy to Clipboard Copied! Toggle word wrap Toggle overflow または、以下を実行します。
-
install/cluster-operator/050-Deployment-strimzi-cluster-operator.yamlファイルのSTRIMZI_KAFKA_CONNECT_IMAGES変数を編集して新しいコンテナーイメージを示すようにした後、Cluster Operator を再インストールします。
その他のリソース
-
KafkaConnect.spec.image propertyの詳細は 「コンテナーイメージ」 を参照してください。 -
STRIMZI_KAFKA_CONNECT_IMAGES変数の詳細は 「Cluster Operator の設定」 を参照してください。
2.5.2.2. OpenShift ビルドおよび S2I (Source-to-Image) を使用したコンテナーイメージの作成
OpenShift ビルド と S2I (Source-to-Image) フレームワークを使用して、新しいコンテナーイメージを作成できます。OpenShift ビルドは、S2I がサポートされるビルダーイメージとともに、ユーザー提供のソースコードおよびバイナリーを取得し、これらを使用して新しいコンテナーイメージを構築します。構築後、コンテナーイメージは OpenShfit のローカルコンテナーイメージリポジトリーに格納され、デプロイメントで使用可能になります。
S2I がサポートされる Kafka Connect ビルダーイメージは、registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0 イメージの一部として、Red Hat Container Catalog で提供されます。このS2I イメージは、バイナリー (プラグインおよびコネクターとともに) を取得し、/tmp/kafka-plugins/s2i ディレクトリーに格納されます。このディレクトリーから、Kafka Connect デプロイメントとともに使用できる新しい Kafka Connect イメージを作成します。改良されたイメージの使用を開始すると、Kafka Connect は /tmp/kafka-plugins/s2i ディレクトリーからサードパーティープラグインをロードします。
手順
コマンドラインで
oc applyコマンドを使用し、Kafka Connect の S2I クラスターを作成およびデプロイします。oc apply -f examples/kafka-connect/kafka-connect-s2i.yaml
oc apply -f examples/kafka-connect/kafka-connect-s2i.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka Connect プラグインでディレクトリーを作成します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc start-buildコマンドで、準備したディレクトリーを使用してイメージの新しいビルドを開始します。oc start-build my-connect-cluster-connect --from-dir ./my-plugins/
oc start-build my-connect-cluster-connect --from-dir ./my-plugins/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記ビルドの名前は、デプロイされた Kafka Connect クラスターと同じになります。
- ビルドが完了したら、Kafka Connect のデプロイメントによって新しいイメージが自動的に使用されます。
2.5.3. コネクターの作成および管理
コネクタープラグインのコンテナーイメージを作成したら、Kafka Connect クラスターにコネクターインスタンスを作成する必要があります。その後、稼働中のコネクターインスタンスを設定、監視、および管理できます。
AMQ Streams では、コネクターの作成および管理に 2 つの API が提供されます。
-
KafkaConnectorリソース (KafkaConnectorsと呼ばれます) - Kafka Connect REST API
API を使用すると、以下を行うことができます。
- コネクターインスタンスのステータスの確認。
- 稼働中のコネクターの再設定。
- コネクターインスタンスのタスク数の増減。
-
失敗したタスクの再起動 (
KafkaConnectorリソースによってサポートされません)。 - コネクターインスタンスの一時停止。
- 一時停止したコネクターインスタンスの再開。
- コネクターインスタンスの削除。
2.5.3.1. KafkaConnector リソース
KafkaConnectors を使用すると、Kafka Connect のコネクターインスタンスを OpenShift ネイティブに作成および管理できるため、cURL などの HTTP クライアントが必要ありません。その他の Kafka リソースと同様に、コネクターの望ましい状態を OpenShift クラスターにデプロイされた KafkaConnector YAML ファイルに宣言し、コネクターインスタンスを作成します。
該当する KafkaConnector を更新して稼働中のコネクターインスタンスを管理した後、更新を適用します。該当する KafkaConnector を削除して、コネクターを削除します。
これまでのバージョンの AMQ Streams との互換性を維持するため、KafkaConnectors はデフォルトで無効になっています。Kafka Connect クラスターのために有効にするには、KafkaConnect リソースでアノテーションを使用する必要があります。手順は、「KafkaConnector リソースの有効化」 を参照してください。
KafkaConnectors が有効になると、Cluster Operator によって監視が開始されます。KafkaConnectors に定義された設定と一致するよう、稼働中のコネクターインスタンスの設定を更新します。
AMQ Streams には、examples/connector/source-connector.yaml という名前のサンプル KafkaConnector が含まれています。このサンプルを使用して、FileStreamSourceConnector を作成および管理できます。
2.5.3.2. Kafka Connect REST API の可用性
Kafka Connect REST API は、<connect-cluster-name>-connect-api サービスとして 8083 番ポートで使用できます。
KafkaConnectors が有効になっている場合、Kafka Connect REST API に直接手作業で追加された変更は Cluster Operator によって元に戻されます。
2.5.4. KafkaConnector リソースの Kafka Connect へのデプロイ
サンプル KafkaConnector を Kafka Connect クラスターにデプロイします。YAML の例によって FileStreamSourceConnector が作成され、ライセンスファイルの各行が my-topic という名前のトピックでメッセージとして Kafka に送信されます。
前提条件
-
KafkaConnectorsが有効になっている Kafka Connect デプロイメントが必要です。 - 稼働中の Cluster Operator が必要です。
手順
examples/connector/source-connector.yamlファイルを編集します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow OpenShift クラスターに
KafkaConnectorを作成します。oc apply -f examples/connector/source-connector.yaml
oc apply -f examples/connector/source-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow リソースが作成されたことを確認します。
oc get kctr --selector strimzi.io/cluster=my-connect-cluster -o name
oc get kctr --selector strimzi.io/cluster=my-connect-cluster -o nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.6. Kafka MirrorMaker
Cluster Operator によって、1 つ以上の Kafka MirrorMaker のレプリカがデプロイされ、Kafka クラスターの間でデータが複製されます。このプロセスはミラーリングと言われ、Kafka パーティションのレプリケーションの概念と混同しないようにします。MirrorMaker は、ソースクラスターからメッセージを消費し、これらのメッセージをターゲットクラスターにパブリッシュします。
リソースの例や Kafka MirrorMaker のデプロイ形式に関する詳細は、「Kafka MirrorMaker の設定」を参照してください。
2.6.1. Kafka MirrorMaker のデプロイ
前提条件
- Kafka MirrorMaker をデプロイする前に、Cluster Operator をデプロイする必要があります。
手順
コマンドラインから Kafka MirrorMaker クラスターを作成します。
oc apply -f examples/kafka-mirror-maker/kafka-mirror-maker.yaml
oc apply -f examples/kafka-mirror-maker/kafka-mirror-maker.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
2.7. Kafka Bridge
Cluster Operator によって、1 つ以上の Kafka Bridge のレプリカがデプロイされ、HTTP API 経由で Kafka クラスターとクライアントの間でデータが送信されます。
リソースの例や Kafka Bridge のデプロイ形式に関する詳細は、「Kafka Bridge の設定」を参照してください。
2.7.1. Kafka Bridge を OpenShift クラスターへデプロイ
Cluster Operator を使用して、Kafka Bridge クラスターを OpenShift クラスターにデプロイできます。
前提条件
- Cluster Operator を OpenShift にデプロイする必要があります。
手順
oc applyコマンドを使用して、kafka-bridge.yamlファイルに基づいてKafkaBridgeリソースを作成します。oc apply -f examples/kafka-bridge/kafka-bridge.yaml
oc apply -f examples/kafka-bridge/kafka-bridge.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
2.8. サンプルクライアントのデプロイ
前提条件
- クライアントが接続する既存の Kafka クラスターが必要です。
手順
プロデューサーをデプロイします。
oc runを使用します。oc run kafka-producer -ti --image=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0 --rm=true --restart=Never -- bin/kafka-console-producer.sh --broker-list cluster-name-kafka-bootstrap:9092 --topic my-topic
oc run kafka-producer -ti --image=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0 --rm=true --restart=Never -- bin/kafka-console-producer.sh --broker-list cluster-name-kafka-bootstrap:9092 --topic my-topicCopy to Clipboard Copied! Toggle word wrap Toggle overflow - プロデューサーが実行しているコンソールにメッセージを入力します。
- Enter を押してメッセージを送信します。
コンシューマーをデプロイします。
oc runを使用します。oc run kafka-consumer -ti --image=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0 --rm=true --restart=Never -- bin/kafka-console-consumer.sh --bootstrap-server cluster-name-kafka-bootstrap:9092 --topic my-topic --from-beginning
oc run kafka-consumer -ti --image=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0 --rm=true --restart=Never -- bin/kafka-console-consumer.sh --bootstrap-server cluster-name-kafka-bootstrap:9092 --topic my-topic --from-beginningCopy to Clipboard Copied! Toggle word wrap Toggle overflow - コンシューマーコンソールに受信メッセージが表示されることを確認します。
2.9. Topic Operator
Topic Operator は、OpenShift クラスター内で稼働している Kafka クラスター内の Kafka トピックを管理します。
2.9.1. Topic Operator
Topic Operator は、OpenShift リソースより Kafka クラスターのトピックを管理する方法を提供します。
Topic Operator のアーキテクチャー例
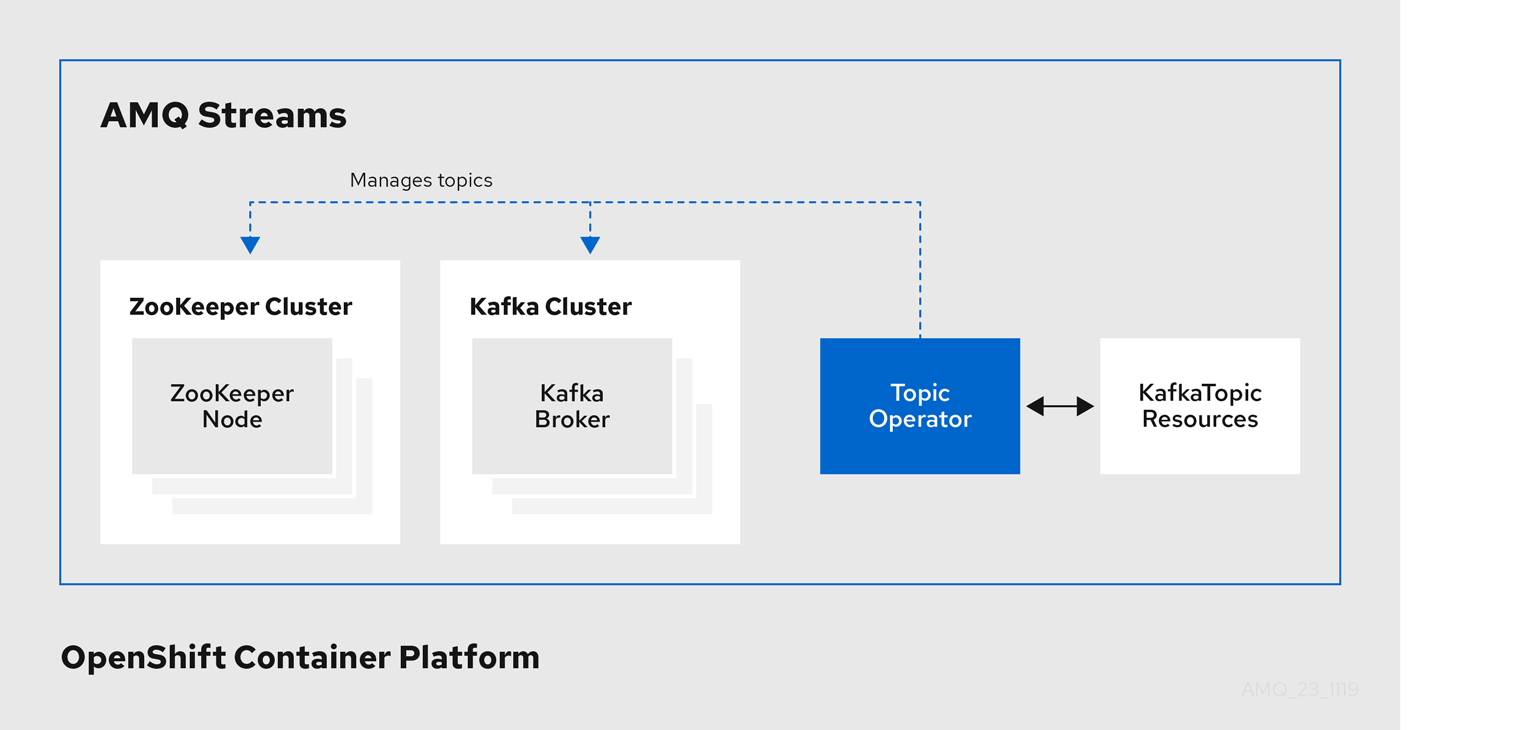
Topic Operator の役割は、対応する Kafka トピックと同期して Kafka トピックを記述する KafkaTopic OpenShift リソースのセットを保持することです。
KafkaTopic とトピックの関係は次のとおりです。
-
KafkaTopicが作成されると、Topic Operator によってトピックが作成されます。 -
KafkaTopicが削除されると、Topic Operator によってトピックが削除されます。 -
KafkaTopicが変更されると、Topick Operator によってトピックが更新されます。
上記と逆になるトピックと KafkaTopic の関係は次のとおりです。
-
トピックが Kafka クラスター内で作成されると、Operator によって
KafkaTopicが作成されます。 -
トピックが Kafka クラスターから削除されると、Operator によって
KafkaTopicが削除されます。 -
トピックが Kafka クラスターで変更されると、Operator によって
KafkaTopicが更新されます。
このため、KafkaTopic をアプリケーションのデプロイメントの一部として宣言でき、トピックの作成は Topic Operator によって行われます。アプリケーションは、必要なトピックからの作成または消費のみに対処する必要があります。
トピックが再設定された場合や、別の Kafka ノードに再割り当てされた場合、KafkaTopic は常に最新の状態になります。
2.9.2. Cluster Operator を使用した Topic Operator のデプロイ
この手順では、Cluster Operator を使用して Topic Operator をデプロイする方法を説明します。AMQ Streams によって管理されない Kafka クラスターを Topic Operator と使用する場合は、Topic Operator をスタンドアロンコンポーネントとしてデプロイする必要があります。詳細は「スタンドアロン Topic Operator のデプロイ」を参照してください。
前提条件
- 稼働中の Cluster Operator が必要です。
-
作成または更新する
Kafkaリソースが必要です。
手順
Kafka.spec.entityOperatorオブジェクトがKafkaリソースに存在することを確認します。このオブジェクトによって Entity Operator が設定されます。Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
「
EntityTopicOperatorSpecスキーマ参照」 で説明されたプロパティーを使用して、Topic Operator を設定します。 OpenShift で Kafka リソースを作成または更新します。
oc applyを使用します。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
- Entity Operator のデプロイメントに関する詳細は、「Entitiy Operator」 を参照してください。
-
Cluster Operator によってデプロイされた場合に Topic Operator の設定に使用される
Kafka.spec.entityOperatorオブジェクトに関する詳細は、「EntityOperatorSpecスキーマ参照」 を参照してください。
2.10. User Operator
User Operator は、OpenShift クラスター内で稼働している Kafka クラスター内の Kafka ユーザーを管理します。
2.10.1. User Operator
User Operator は、Kafka ユーザーが記述される KafkaUser リソースを監視して Kafka クラスターの Kafka ユーザーを管理し、Kafka ユーザーが Kafka クラスターで適切に設定されるようにします。
たとえば、KafkaUser とユーザーの関係は次のようになります。
-
KafkaUserが作成されると、User Operator によって記述されるユーザーが作成されます。 -
KafkaUserが削除されると、User Operator によって記述されるユーザーが削除されます。 -
KafkaUserが変更されると、User Operator によって記述されるユーザーが更新されます。
User Operator は Topic Operator とは異なり、Kafka クラスターからの変更は OpenShift リソースと同期されません。アプリケーションで直接 Kafka トピックを Kafka で作成することは可能ですが、ユーザーが User Operator と同時に直接 Kafka クラスターで管理されることは想定されません。
User Operator では、アプリケーションのデプロイメントの一部として KafkaUser リソースを宣言できます。ユーザーの認証および承認メカニズムを指定できます。たとえば、ユーザーがブローカーへのアクセスを独占しないようにするため、Kafka リソースの使用を制御する ユーザークォータ を設定することもできます。
ユーザーが作成されると、ユーザークレデンシャルが Secret に作成されます。アプリケーションはユーザーとそのクレデンシャルを使用して、認証やメッセージの生成または消費を行う必要があります。
User Operator は 認証のクレデンシャルを管理する他に、KafkaUser 宣言にユーザーのアクセス権限の記述を含めることで承認も管理します。
2.10.2. Cluster Operator を使用した User Operator のデプロイ
前提条件
- 稼働中の Cluster Operator が必要です。
-
作成または更新する
Kafkaリソースが必要です。
手順
-
Kafkaリソースを編集し、希望どおりに User Operator を設定するKafka.spec.entityOperator.userOperatorオブジェクトが含まれるようにします。 OpenShift で Kafka リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
-
Cluster Operator によってデプロイされた場合に Topic Operator の設定に使用される
Kafka.spec.entityOperatorオブジェクトに関する詳細は「EntityOperatorSpecスキーマ参照」を参照してください。
2.11. Strimzi 管理者
AMQ Streams には複数のカスタムリソースが含まれています。デフォルトでは、これらのリソースを作成、編集、および削除する権限は OpenShift クラスター管理者に制限されます。クラスター管理者以外に AMQ Streams リソースを管理する権限を与える場合は、Strimzi 管理者ロールを割り当てる必要があります。
2.11.1. Strimzi 管理者の指名
前提条件
-
AMQ Streams の
CustomResourceDefinitionsがインストールされている必要があります。
手順
OpenShift で
strimzi-adminクラスターロールを作成します。oc applyを使用します。oc apply -f install/strimzi-admin
oc apply -f install/strimzi-adminCopy to Clipboard Copied! Toggle word wrap Toggle overflow strimzi-adminClusterRoleを OpenShift クラスターの 1 人以上の既存ユーザーに割り当てます。oc createを使用します。oc create clusterrolebinding strimzi-admin --clusterrole=strimzi-admin --user=user1 --user=user2
oc create clusterrolebinding strimzi-admin --clusterrole=strimzi-admin --user=user1 --user=user2Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.12. コンテナーイメージ
AMQ Streams のコンテナーイメージは Red Hat Container Catalog にあります。AMQ Streams によって提供されるインストール YAML ファイルは、直接 Red Hat Container Catalog からイメージをプルします。
Red Hat Container Catalog にアクセスできない場合や独自のコンテナーリポジトリーを使用する場合は以下を行います。
- リストにある すべての コンテナーイメージをプルします。
- 独自のレジストリーにプッシュします。
- インストール YAML ファイルのイメージ名を更新します。
リリースに対してサポートされる各 Kafka バージョンには別のイメージがあります。
| コンテナーイメージ | namespace/リポジトリー | 説明 |
|---|---|---|
| Kafka |
| 次を含む、Kafka を実行するための AMQ Streams イメージ。
|
| Operator |
| Operator を実行するための AMQ Streams イメージ。
|
| Kafka Bridge |
| AMQ Streams Kafka Bridge を稼働するための AMQ Streams イメージ |
第3章 デプロイメント設定
本章では、サポートされるデプロイメントの異なる側面を設定する方法について説明します。
- Kafka クラスター
- Kafka Connect クラスター
- Source2Image がサポートされる Kafka Connect クラスター
- Kafka Mirror Maker
- Kafka Bridge
- OAuth 2.0 のトークンベースの認証
- OAuth 2.0 のトークンベースの承認
3.1. Kafka クラスターの設定
Kafka リソースの完全なスキーマは 「Kafka スキーマ参照」 に記載されています。指定の Kafka リソースに適用されたすべてのラベルは、Kafka クラスターを構成する OpenShift リソースにも適用されます。そのため、必要に応じてリソースにラベルが適用されるため便利です。
3.1.1. Kafka YAML の設定例
Kafka デプロイメントで利用可能な設定オプションを理解するには、ここに提供されるサンプル YAML ファイルを参照してください。
例では、可能な設定オプションの一部のみを取り上げますが、特に重要なオプションは次のとおりです。
- リソース要求 (CPU/メモリー)
- 最大および最小メモリー割り当ての JVM オプション
- リスナー (および認証)
- 認証
- ストレージ
- ラックアウェアネス (Rack Awareness)
- メトリクス
- 1
- レプリカは、ブローカーノードの数を指定します。
- 2
- アップグレード手順にしたがうと変更できる Kafka バージョン。
- 3
- リソース要求は、指定のコンテナーに対して予約するリソースを指定します。
- 4
- リソースの制限は、コンテナーによって消費可能な最大リソースを指定します。
- 5
- JVM オプションは、JVM の最小 (
-Xms) および最大 (-Xmx) メモリー割り当てを指定 できます。 - 6
- リスナーは、ブートストラップアドレスでクライアントが Kafka クラスターに接続する方法を設定します。リスナーは、
plain(暗号化なし)、tls、またはexternalとして設定 されます。 - 7
- リスナーの認証メカニズムは各リスナーに対して設定でき、相互 TLS または SCRAM-SHA として指定 できます。
- 8
- 外部リスナー設定は、
route、loadbalancer、またはnodeportからなど、Kafka クラスターが外部の OpenShift に公開される方法 を指定します。 - 9
- 外部の認証局によって管理される Kafka リスナー証明書 の任意設定。
brokerCertChainAndKeyプロパティーは、サーバー証明書および秘密鍵を保持するSecretを指定します。Kafka リスナー証明書も TLS リスナーに対して設定できます。 - 10
- 11
- 設定によって、ブローカー設定が指定されます。標準の Apache Kafka 設定が提供されることがあり、AMQ Streams によって直接管理されないプロパティーに限定されます。
- 12
- ストレージは、
ephemeral、persistent-claim、またはjbodとして設定されます。 - 13
- 14
- 15
- ラックアウェアネスは、異なるラック全体でレプリカを分散 ために設定されます。
topologyキーはクラスターノードのラベルと一致する必要があります。 - 16
- 17
- JMX Exporter でメトリクスを Grafana ダッシュボードにエクスポートする Kafka ルール。AMQ Streams によって提供されるルールのセットは Kafka リソース設定にコピーされることがあります。
- 18
- Kafka 設定と似たプロパティーが含まれる、ZooKeeper 固有の設定。
- 19
- Topic Operator および User Operator の設定を指定する、Entity Operator 設定。
- 20
- データを Prometheus メトリクスとして公開するために使用される Kafka Exporter 設定。
3.1.2. データストレージに関する留意事項
効率的なデータストレージインフラストラクチャーは、AMQ Streams のパフォーマンスを最適化するために不可欠です。
ブロックストレージが必要です。NFS などのファイルストレージは、Kafka では機能しません。
ブロックストレージには、以下などを選択できます。
- Amazon Elastic Block Store (EBS)などのクラウドベースのブロックストレージソリューション。
- ローカルの永続ボリューム。
- ファイバーチャネル や iSCSI などのプロトコルがアクセスする SAN (ストレージネットワークエリア) ボリューム。
Strimzi には OpenShift の raw ブロックボリュームは必要ありません。
3.1.2.1. ファイルシステム
XFS ファイルシステムを使用するようにストレージシステムを設定することが推奨されます。AMQ Streams は ext4 ファイルシステムとも互換性がありますが、最適化するには追加の設定が必要になることがあります。
3.1.2.2. Apache Kafka および ZooKeeper ストレージ
Apache Kafka と ZooKeeper には別々のディスクを使用します。
3 つのタイプのデータストレージがサポートされます。
- 一時データストレージ (開発用のみで推奨されます)
- 永続データストレージ
- JBOD (Just a Bunch of Disks、Kafka のみに適しています)
詳細は「Kafka および ZooKeeper ストレージ」を参照してください。
ソリッドステートドライブ (SSD) は必須ではありませんが、複数のトピックに対してデータが非同期的に送受信される大規模なクラスターで Kafka のパフォーマンスを向上させることができます。SSD は、高速で低レイテンシーのデータアクセスが必要な ZooKeeper で特に有効です。
Kafka と ZooKeeper の両方にデータレプリケーションが組み込まれているため、複製されたストレージのプロビジョニングは必要ありません。
3.1.3. Kafka および ZooKeeper のストレージタイプ
Kafka および ZooKeeper はステートフルなアプリケーションであるため、データをディスクに格納する必要があります。AMQ Streams では、3 つのタイプのストレージがサポートされます。
- 一時ストレージ
- 永続ストレージ
- JBOD ストレージ
JBOD ストレージは Kafka でサポートされ、ZooKeeper ではサポートされていません。
Kafka リソースを設定する場合、Kafka ブローカーおよび対応する ZooKeeper ノードによって使用されるストレージのタイプを指定できます。以下のリソースの storage プロパティーを使用して、ストレージタイプを設定します。
-
Kafka.spec.kafka -
Kafka.spec.zookeeper
ストレージタイプは type フィールドで設定されます。
Kafka クラスターをデプロイした後に、ストレージタイプを変更することはできません。
その他のリソース
- 一時ストレージの詳細は、「一時ストレージのスキーマ参照」を参照してください。
- 永続ストレージの詳細は、「永続ストレージのスキーマ参照」を参照してください。
- JBOD ストレージの詳細は、「JBOD スキーマ参照」を参照してください。
-
Kafkaのスキーマに関する詳細は、「Kafkaスキーマ参照」を参照してください。
3.1.3.1. 一時ストレージ
一時ストレージは `emptyDir` volumes ボリュームを使用してデータを保存します。一時ストレージを使用するには、type フィールドを ephemeral に設定する必要があります。
emptyDir ボリュームは永続的ではなく、保存されたデータは Pod の再起動時に失われます。新規 Pod の起動後に、クラスターの他のノードからすべてのデータを復元する必要があります。一時ストレージは、単一ノードの ZooKeeper クラスターやレプリケーション係数が 1 の Kafka トピックでの使用には適していません。これはデータが損失する原因となるからです。
一時ストレージの例
3.1.3.1.1. ログディレクトリー
一時ボリュームは、以下のパスにマウントされるログディレクトリーとして Kafka ブローカーによって使用されます。
/var/lib/kafka/data/kafka-log_idx_-
idxは、Kafka ブローカー Pod インデックスです。例:/var/lib/kafka/data/kafka-log0
3.1.3.2. 永続ストレージ
永続ストレージは Persistent Volume Claim (永続ボリューム要求、PVC) を使用して、データを保存するための永続ボリュームをプロビジョニングします。永続ボリューム要求を使用すると、ボリュームのプロビジョニングを行う ストレージクラス に応じて、さまざまなタイプのボリュームをプロビジョニングできます。永続ボリューム要求と使用できるデータタイプには、多くのタイプの SAN ストレージやローカル永続ボリューム などがあります。
永続ストレージを使用するには、type を persistent-claim に設定する必要があります。永続ストレージでは、追加の設定オプションがサポートされます。
id(任意)-
ストレージ ID 番号。このオプションは、JBOD ストレージ宣言で定義されるストレージボリュームには必須です。デフォルトは
0です。 size(必須)- 永続ボリューム要求のサイズを定義します (例: 1000Gi)。
class(任意)- 動的ボリュームプロビジョニングに使用する OpenShift の ストレージクラス。
selector(任意)- 使用する特定の永続ボリュームを選択できます。このようなボリュームを選択するラベルを表す key:value ペアが含まれます。
deleteClaim(任意)-
クラスターのアンデプロイ時に永続ボリューム要求を削除する必要があるかどうかを指定するブール値。デフォルトは
falseです。
既存の AMQ Streams クラスターで永続ボリュームのサイズを増やすことは、永続ボリュームのサイズ変更をサポートする OpenShift バージョンでのみサポートされます。サイズを変更する永続ボリュームには、ボリューム拡張をサポートするストレージクラスを使用する必要があります。ボリューム拡張をサポートしないその他のバージョンの OpenShift およびストレージクラスでは、クラスターをデプロイする前に必要なストレージサイズを決定する必要があります。既存の永続ボリュームのサイズを縮小することはできません。
size が 1000Gi の永続ストレージ設定の例 (抜粋)
# ... storage: type: persistent-claim size: 1000Gi # ...
# ...
storage:
type: persistent-claim
size: 1000Gi
# ...以下の例は、ストレージクラスの使用例を示しています。
特定のストレージクラスを指定する永続ストレージ設定の例 (抜粋)
最後に、selector を使用して特定のラベルが付いた永続ボリュームを選択し、SSD などの必要な機能を提供できます。
セレクターを指定する永続ストレージ設定の例 (抜粋)
3.1.3.2.1. ストレージクラスのオーバーライド
デフォルトのストレージクラスを使用する代わりに、1 つ以上の Kafka ブローカーに異なるストレージクラスを指定できます。これは、ストレージクラスが、異なるアベイラビリティーゾーンやデータセンターに制限されている場合などに便利です。この場合、overrides フィールドを使用できます。
以下の例では、デフォルトのストレージクラスの名前は my-storage-class になります。
ストレージクラスのオーバーライドを使用した AMQ Streams クラスターの例
overrides プロパティーが設定され、ブローカーボリュームによって以下のストレージクラスが使用されます。
-
broker 0 の永続ボリュームでは
my-storage-class-zone-1aが使用されます。 -
broker 1 の永続ボリュームでは
my-storage-class-zone-1bが使用されます。 -
broker 2 の永続ボリュームでは
my-storage-class-zone-1cが使用されます。
現在、overrides プロパティーは、ストレージクラスの設定をオーバーライドするためのみに使用されます。他のストレージ設定フィールドのオーバーライドは現在サポートされていません。ストレージ設定の他のフィールドは現在サポートされていません。
3.1.3.2.2. Persistent Volume Claim (永続ボリューム要求、PVC) の命名
永続ストレージが使用されると、以下の名前で Persistent Volume Claim (永続ボリューム要求、PVC) が作成されます。
data-cluster-name-kafka-idx-
Kafka ブローカー Pod
idxのデータを保存するために使用されるボリュームの永続ボリューム要求です。 data-cluster-name-zookeeper-idx-
ZooKeeper ノード Pod
idxのデータを保存するために使用されるボリュームの永続ボリューム要求です。
3.1.3.2.3. ログディレクトリー
永続ボリュームは、以下のパスにマウントされるログディレクトリーとして Kafka ブローカーによって使用されます。
/var/lib/kafka/data/kafka-log_idx_-
idxは、Kafka ブローカー Pod インデックスです。例:/var/lib/kafka/data/kafka-log0
3.1.3.3. 永続ボリュームのサイズ変更
既存の AMQ Streams クラスターによって使用される永続ボリュームのサイズを増やすことで、ストレージ容量を増やすことができます。永続ボリュームのサイズ変更は、JBOD ストレージ設定で 1 つまたは複数の永続ボリュームが使用されるクラスターでサポートされます。
永続ボリュームのサイズを拡張することはできますが、縮小することはできません。永続ボリュームのサイズ縮小は、現在 OpenShift ではサポートされていません。
前提条件
- ボリュームのサイズ変更をサポートする OpenShift クラスター。
- Cluster Operator が稼働している必要があります。
- ボリューム拡張をサポートするストレージクラスを使用して作成された永続ボリュームを使用する Kafka クラスター。
手順
Kafkaリソースで、Kafka クラスター、ZooKeeper クラスター、またはその両方に割り当てられた永続ボリュームのサイズを増やします。-
Kafka クラスターに割り当てられたボリュームサイズを増やすには、
spec.kafka.storageプロパティーを編集します。 ZooKeeper クラスターに割り当てたボリュームサイズを増やすには、
spec.zookeeper.storageプロパティーを編集します。たとえば、ボリュームサイズを
1000Giから2000Giに増やすには、以下のように編集します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
Kafka クラスターに割り当てられたボリュームサイズを増やすには、
リソースを作成または更新します。
oc applyを使用します。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow OpenShift では、Cluster Operator からの要求に応じて、選択された永続ボリュームの容量が増やされます。サイズ変更が完了すると、サイズ変更された永続ボリュームを使用するすべての Pod が Cluster Operator によって再起動されます。これは自動的に行われます。
その他のリソース
OpenShift での永続ボリュームのサイズ変更に関する詳細は、「Resizing Persistent Volumes using Kubernetes」を参照してください。
3.1.3.4. JBOD ストレージの概要
AMQ Streams で、複数のディスクやボリュームのデータストレージ設定である JBOD を使用するように設定できます。JBOD は、Kafka ブローカーのデータストレージを増やす方法の 1 つです。また、パフォーマンスを向上することもできます。
JBOD 設定は 1 つまたは複数のボリュームによって記述され、各ボリュームは 一時 または 永続 ボリュームのいずれかになります。JBOD ボリューム宣言のルールおよび制約は、一時および永続ストレージのルールおよび制約と同じです。たとえば、永続ストレージのボリュームをプロビジョニング後に変更することはできません。
3.1.3.4.1. JBOD の設定
AMQ Streams で JBOD を使用するには、ストレージ type を jbod に設定する必要があります。volumes プロパティーを使用すると、JBOD ストレージアレイまたは設定を構成するディスクを記述できます。以下は、JBOD 設定例の抜粋になります。
id は、JBOD ボリュームの作成後に変更することはできません。
ユーザーは JBOD 設定に対してボリュームを追加または削除できます。
3.1.3.4.2. JBOD および 永続ボリューム要求 (PVC)
永続ストレージを使用して JBOD ボリュームを宣言する場合、永続ボリューム要求 (Persistent Volume Claim、PVC) の命名スキームは以下のようになります。
data-id-cluster-name-kafka-idx-
idは、Kafka ブローカー Podidxのデータを保存するために使用されるボリュームの ID に置き換えます。
3.1.3.4.3. ログディレクトリー
JBOD ボリュームは、以下のパスにマウントされるログディレクトリーとして Kafka ブローカーによって使用されます。
/var/lib/kafka/data-id/kafka-log_idx_-
idは、Kafka ブローカー Podidxのデータを保存するために使用されるボリュームの ID に置き換えます。例:/var/lib/kafka/data-0/kafka-log0
3.1.3.5. JBOD ストレージへのボリュームの追加
この手順では、JBOD ストレージを使用するように設定されている Kafka クラスターにボリュームを追加する方法を説明します。この手順は、他のストレージタイプを使用するように設定されている Kafka クラスターには適用できません。
以前使用され、削除された id の下に新規ボリュームを追加する場合、以前使用された PersistentVolumeClaims が必ず削除されているよう確認する必要があります。
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
- JBOD ストレージのある Kafka クラスター。
手順
Kafkaリソースのspec.kafka.storage.volumesプロパティーを編集します。新しいボリュームをvolumesアレイに追加します。たとえば、id が2の新しいボリュームを追加します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 新しいトピックを作成するか、既存のパーティションを新しいディスクに再度割り当てします。
その他のリソース
トピックの再割り当てに関する詳細は 「パーティションの再割り当て」 を参照してください。
3.1.3.6. JBOD ストレージからのボリュームの削除
この手順では、JBOD ストレージを使用するように設定されている Kafka クラスターからボリュームを削除する方法を説明します。この手順は、他のストレージタイプを使用するように設定されている Kafka クラスターには適用できません。JBOD ストレージには、常に 1 つのボリュームが含まれている必要があります。
データの損失を避けるには、ボリュームを削除する前にすべてのパーティションを移動する必要があります。
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
- 複数のボリュームがある JBOD ストレージのある Kafka クラスター。
手順
- 削除するディスクからすべてのパーティションを再度割り当てます。削除するディスクに割り当てられたままになっているパーティションのデータは削除される可能性があります。
Kafkaリソースのspec.kafka.storage.volumesプロパティーを編集します。volumesアレイから 1 つまたは複数のボリュームを削除します。たとえば、ID が1と2のボリュームを削除します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
トピックの再割り当てに関する詳細は 「パーティションの再割り当て」 を参照してください。
3.1.4. Kafka ブローカーレプリカ
Kafka クラスターは多くのブローカーを使って実行できます。Kafka.spec.kafka.replicas の Kafka クラスターに使用されるブローカーの数を設定できます。クラスターに最適なブローカー数は、特定のユースケースに基づいて決定する必要があります。
3.1.4.1. ブローカーノード数の設定
この手順では、新規クラスターの Kafka ブローカーノードの数を設定する方法を説明します。これは、パーティションのない新しいクラスターのみに適用できます。クラスターにトピックがすでに定義されている場合は、「クラスターのスケーリング」を参照してください。
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
- トピックが定義されていない Kafka クラスター。
手順
Kafkaリソースのreplicasプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
クラスターにトピックがすでに定義されている場合は、「クラスターのスケーリング」を参照してください。
3.1.5. Kafka ブローカーの設定
AMQ Streams では、Kafka クラスターの Kafka ブローカーの設定をカスタマイズできます。Apache Kafka ドキュメント の「Broker Configs」セクションに記載されているほとんどのオプションを指定および設定できます。以下に関係する設定オプションは設定できません。
- セキュリティー (暗号化、認証、および承認)
- リスナーの設定
- Broker ID の設定
- ログデータディレクトリーの設定
- ブローカー間の通信
- ZooKeeper の接続
これらのオプションは AMQ Streams によって自動的に設定されます。
3.1.5.1. Kafka ブローカーの設定
Kafka.spec.kafka の config プロパティーには Kafka ブローカー設定オプションがキーとして含まれ、それらの値は以下の JSON タイプの 1 つになります。
- 文字列
- Number
- ブール値
AMQ Streams によって直接管理されるオプション以外は、Apache Kafka ドキュメント の「Broker Configs」セクションにあるすべてのオプションを指定および設定できます。以下の文字列の 1 つと同じキーまたは以下の文字列の 1 つで始まるキーを持つ設定オプションはすべて変更できません。
-
listeners -
advertised. -
broker. -
listener. -
host.name -
port -
inter.broker.listener.name -
sasl. -
ssl. -
security. -
password. -
principal.builder.class -
log.dir -
zookeeper.connect -
zookeeper.set.acl -
authorizer. -
super.user
制限されたオプションが config プロパティーに指定された場合、そのオプションは無視され、Cluster Operator のログファイルに警告メッセージが出力されます。サポートされるその他すべてのオプションは Kafka に渡されます。
Kafka ブローカー設定の例
3.1.5.2. Kafka ブローカーの設定
既存の Kafka ブローカーを設定するか、指定した設定で新しい Kafka ブローカーを作成します。
前提条件
- OpenShift クラスターが利用できる必要があります。
- Cluster Operator が稼働している必要があります。
手順
-
クラスターデプロイメントを指定する
Kafkaリソースが含まれる YAML 設定ファイルを開きます。 Kafkaリソースのspec.kafka.configプロパティーで、Kafka 設定を 1 つまたは複数入力します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 新しい設定を適用してリソースを作成または更新します。
oc applyを使用します。oc apply -f kafka.yaml
oc apply -f kafka.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow kafka.yamlは、設定するリソースの YAML 設定ファイルに置き換えます (例:kafka-persistent.yaml)。
3.1.6. Kafka ブローカーリスナー
Kafka ブローカーで有効なリスナーを設定できます。以下のタイプのリスナーがサポートされます。
- ポート 9092 のプレーンリスナー (TLS による暗号化なし)
- ポート 9093 の TLS リスナー (TLS による暗号化を使用)
- OpenShift の外部からアクセスするためのポート 9094 の外部リスナー
OAuth 2.0
OAuth 2.0 トークンベースの認証を使用している場合、承認サーバーに接続するようにリスナーを設定できます。詳細は、「OAuth 2.0 トークンベース認証の使用」を参照してください。
リスナー証明書
TLS による暗号化が有効になっている TLS または外部リスナーの Kafka リスナー証明書 と呼ばれる独自のサーバー証明書を提供できます。詳細は 「Kafka リスナー証明書」 を参照してください。
3.1.6.1. Kafka リスナー
Kafka.spec.kafka リソースの listeners プロパティーを使用して Kafka ブローカーリスナーを設定できます。listeners プロパティーには 3 つのサブプロパティーが含まれます。
-
plain -
tls -
external
各リスナーは、listeners オブジェクトに指定のプロパティーがある場合にのみ定義されます。
すべてのリスナーが有効な listeners プロパティーの例
プレーンリスナーのみが有効な listeners プロパティーの例
# ...
listeners:
plain: {}
# ...
# ...
listeners:
plain: {}
# ...3.1.6.2. Kafka リスナーの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
Kafka.spec.kafkaリソースのlistenersプロパティーを編集します。認証のないプレーン (暗号化されていない) リスナーの設定例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
-
スキーマの詳細は、「
KafkaListenersスキーマ参照」を参照してください。
3.1.6.3. リスナー認証
リスナーの authentication プロパティーは、そのリスナーに固有の認証メカニズムを指定するために使用されます。
- 相互 TLS 認証 (TLS による暗号化のリスナーのみ)
- SCRAM-SHA 認証
authentication プロパティーが指定されていない場合、リスナーはそのリスナー経由で接続するクライアントを認証しません。
認証は、User Operator を使用して KafkaUsers を管理する場合に設定する必要があります。
3.1.6.3.1. リスナーの認証設定
以下の例で指定されるものは次のとおりです。
-
SCRAM-SHA 認証に設定された
plainリスナー -
相互 TLS 認証を使用する
tlsリスナー -
相互 TLS 認証を使用する
externalリスナー
リスナー認証設定の例
3.1.6.3.2. 相互 TLS 認証
相互 TLS 認証は、Kafka ブローカーと ZooKeeper Pod 間の通信で常に使用されます。
相互認証または双方向認証は、サーバーとクライアントの両方が証明書を提示するときに使用されます。AMQ Streams では、Kafka が TLS (Transport Layer Security) を使用して、相互認証の有無を問わず、Kafka ブローカーとクライアントとの間で暗号化された通信が行われるよう設定できます。相互認証を設定する場合、ブローカーによってクライアントが認証され、クライアントによってブローカーが認証されます。
TLS 認証は一般的には一方向で、一方が他方のアイデンティティーを認証します。たとえば、Web ブラウザーと Web サーバーの間で HTTPS が使用される場合、サーバーはブラウザーのアイデンティティーの証明を取得します。
3.1.6.3.2.1. クライアントに相互 TLS 認証を使用する場合
以下の場合、Kafka クライアントの認証に相互 TLS 認証が推奨されます。
- 相互 TLS 認証を使用した認証がクライアントでサポートされる場合。
- パスワードの代わりに TLS 証明書を使用する必要がある場合。
- 期限切れの証明書を使用しないように、クライアントアプリケーションを定期的に再設定および再起動できる場合。
3.1.6.3.3. SCRAM-SHA 認証
SCRAM (Salted Challenge Response Authentication Mechanism) は、パスワードを使用して相互認証を確立できる認証プロトコルです。AMQ Streams では、Kafka が SASL (Simple Authentication and Security Layer) SCRAM-SHA-512 を使用するよう設定し、暗号化されていないクライアントの接続と TLS で暗号化されたクライアントの接続の両方で認証を提供できます。TLS 認証は、Kafka ブローカーと ZooKeeper ノードの間で常に内部で使用されます。TLS クライアント接続で TLS プロトコルを使用すると、接続が暗号化されますが、認証には使用されません。
SCRAM の以下のプロパティーは、暗号化されていない接続でも SCRAM-SHA を安全に使用できるようにします。
- 通信チャネル上では、パスワードはクリアテキストで送信されません。代わりに、クライアントとサーバーはお互いにチャレンジを生成し、認証するユーザーのパスワードを認識していることを証明します。
- サーバーとクライアントは、認証を交換するたびに新しいチャレンジを生成します。よって、交換はリレー攻撃に対して回復性を備えています。
3.1.6.3.3.1. サポートされる SCRAM クレデンシャル
AMQ Streams では SCRAM-SHA-512 のみがサポートされます。KafkaUser.spec.authentication.type を scram-sha-512 に設定すると、User Operator によって、大文字と小文字の ASCII 文字と数字で構成された無作為の 12 文字のパスワードが生成されます。
3.1.6.3.3.2. クライアントに SCRAM-SHA 認証を使用する場合
以下の場合、Kafka クライアントの認証に SCRAM-SHA が推奨されます。
- SCRAM-SHA-512 を使用した認証がクライアントでサポートされる場合。
- TLS 証明書の代わりにパスワードを使用する必要がある場合。
- 暗号化されていない通信に認証が必要な場合。
3.1.6.4. 外部リスナー
外部リスナーを使用して AMQ Streams の Kafka クラスターを OpenShift 環境外のクライアントに公開します。
その他のリソース
3.1.6.4.1. 外部リスナーでアドバタイズされたアドレスのカスタマイズ
デフォルトでは、AMQ Streams は Kafka クラスターがそのクライアントにアドバタイズするホスト名とポートを自動的に決定しようとします。AMQ Streams が稼働しているインフラストラクチャーでは Kafka にアクセスできる正しいホスト名やポートを提供しない可能性があるため、デフォルトの動作はすべての状況に適しているわけではありません。外部リスナーの overrides プロパティーで、アドバタイズされたホスト名およびポートをカスタマイズできます。その後、TLS ホスト名の検証で使用できるようにするため、AMQ Streams では Kafka ブローカーでアドバタイズされたアドレスが自動的に設定され、ブローカー証明書に追加されます。アドバタイズされたホストおよびポートのオーバーライドは、すべてのタイプの外部リスナーで利用できます。
アドバタイズされたアドレスのオーバーライドが設定された外部リスナーの例
さらに、ブートストラップサービスの名前を指定することもできます。この名前はブローカー証明書に追加され、TLS ホスト名の検証に使用できます。すべてのタイプの外部リスナーで、ブートストラップアドレスを追加できます。
追加のブートストラップアドレスが設定された外部リスナーの例
3.1.6.4.2. ルート外部リスナー
タイプ route の外部リスナーは、OpenShift のRoutes および HAProxy ルーターを使用して Kafka を公開します。
route は OpenShift でのみサポートされます。
3.1.6.4.2.1. OpenShift Routes を使用した Kafka の公開
OpenShift Routes および HAProxy ルーターを使用して Kafka を公開する場合、各 Kafka ブローカー Pod に専用の Route が作成されます。追加の Route が作成され、Kafka ブートストラップアドレスとして提供されます。これらの Routes を使用すると、Kafka クライアントを 443 番ポートで Kafka に接続することができます。
TLS による暗号化は常に Routes と使用されます。
デフォルトでは、ルートホストは OpenShift によって自動的に割り当てられます。ただし、 overrides プロパティーに要求されたホストを指定すると、割り当てられたルートをオーバーライドすることができます。AMQ Streams では、要求されたホストが利用可能であるか検証されません。そのため、ホストが利用可能であることをユーザーが確認する必要があります。
OpenShift ルートホストのオーバーライドが設定されたタイプ routes の外部リスナーの例
Routes を使用した Kafka へのアクセスに関する詳細は 「OpenShift ルートを使用した Kafka へのアクセス」 を参照してください。
3.1.6.4.2.2. OpenShift ルートを使用した Kafka へのアクセス
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
外部リスナーが有効で、タイプ
routeに設定されている Kafka クラスターをデプロイします。Routesを使用するよう設定された外部リスナーがある設定の例Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow ブートストラップ
Routeのアドレスを見つけます。oc get routes _cluster-name_-kafka-bootstrap -o=jsonpath='{.status.ingress[0].host}{"\n"}'oc get routes _cluster-name_-kafka-bootstrap -o=jsonpath='{.status.ingress[0].host}{"\n"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow このアドレスと Kafkaクライアントの 443 番ポートをブートストラップアドレスとして使用します。
ブローカーの認証局の公開証明書を取得します。
oc get secret _<cluster-name>_-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crtoc get secret _<cluster-name>_-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka クライアントで取得した証明書を使用して TLS 接続を設定します。認証が有効になっている場合は、SASL または TLS 認証を設定する必要もあります。
その他のリソース
-
スキーマの詳細は、「
KafkaListenersスキーマ参照」を参照してください。
3.1.6.4.3. ロードバランサー外部リスナー
タイプが loadbalancer の外部リスナーは、Loadbalancer タイプの Services を使用して、Kafka を公開します。
3.1.6.4.3.1. ロードバランサーを使用した Kafka の公開
Loadbalancer タイプの Services を使用して Kafka を公開すると、Kafka ブローカー Pod ごとに新しいロードバランサーサービスが作成されます。追加のロードバランサーが作成され、Kafkaの ブートストラップ アドレスとして提供されます。ロードバランサーは 9094 番ポートで接続をリッスンします。
デフォルトでは、TLS による暗号化は有効になっています。これを無効にするには、tls フィールドを false に設定します。
タイプが loadbalancer の外部リスナーの例
ロードバランサーを使用した Kafka へのアクセスに関する詳細は 「ロードバランサーを使用した Kafka へのアクセス」 を参照してください。
3.1.6.4.3.2. 外部ロードバランサーリスナーの DNS 名のカスタマイズ
loadbalancer リスナーでは、dnsAnnotations プロパティーを使用して追加のアノテーションをロードバランサーサービスに追加できます。これらのアノテーションを使用すると、自動的に DNS 名をロードバランサーサービスに割り当てる ExternalDNS などの DNS ツールをインストルメント化できます。
dnsAnnotations を使用するタイプ loadbalancer の外部リスナーの例
3.1.6.4.3.3. ロードバランサー IP アドレスのカスタマイズ
loadbalancer リスナーで、ロードバランサーの作成時に loadBalancerIP プロパティーを使用すると、特定の IP アドレスをリクエストできます。特定の IP アドレスでロードバランサーを使用する必要がある場合は、このプロパティーを使用します。クラウドプロバイダーがこの機能に対応していない場合、loadBalancerIP フィールドは無視されます。
特定のロードバランサー IP アドレスリクエストのある loadbalancer タイプの外部リスナーの例
3.1.6.4.3.4. ロードバランサーを使用した Kafka へのアクセス
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
外部リスナーが有効で、タイプ
loadbalancerに設定されている Kafka クラスターをデプロイします。ロードバランサーを使用するよう設定された外部リスナーがある設定の例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow ブートストラップロードバランサーのホスト名を見つけます。
oc getを使用してこれを行うことができます。oc get service cluster-name-kafka-external-bootstrap -o=jsonpath='{.status.loadBalancer.ingress[0].hostname}{"\n"}'oc get service cluster-name-kafka-external-bootstrap -o=jsonpath='{.status.loadBalancer.ingress[0].hostname}{"\n"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト名が見つからない場合 (コマンドによって返されなかった場合)、ロードバランサーの IP アドレスを使用します。
oc getを使用してこれを行うことができます。oc get service cluster-name-kafka-external-bootstrap -o=jsonpath='{.status.loadBalancer.ingress[0].ip}{"\n"}'oc get service cluster-name-kafka-external-bootstrap -o=jsonpath='{.status.loadBalancer.ingress[0].ip}{"\n"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow ホスト名または IP アドレスと Kafkaクライアントの 9094 番ポートをブートストラップアドレスとして使用します。
TLS による暗号化が無効になっている場合を除き、ブローカーの認証局の公開証明書を取得します。
oc getを使用してこれを行うことができます。oc get secret cluster-name-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crtoc get secret cluster-name-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka クライアントで取得した証明書を使用して TLS 接続を設定します。認証が有効になっている場合は、SASL または TLS 認証を設定する必要もあります。
その他のリソース
-
スキーマの詳細は、「
KafkaListenersスキーマ参照」を参照してください。
3.1.6.4.4. ノードポートの外部リスナー
タイプが nodeport の外部リスナーは、NodePort タイプの Services を使用して、Kafka を公開します。
3.1.6.4.4.1. ノードポートを使用した Kafka の公開
NodePort タイプの Services を使用して Kafka を公開する場合、Kafka クライアントは OpenShift のノードに直接接続されます。各クライアントの OpenShift ノード上のポートへのアクセスを有効にする必要があります (ファイアウォール、セキュリティーグループなど)。各 Kafka ブローカー Pod が別々のポートでアクセス可能になります。追加の NodePort 型 Service が作成され、Kafka ブートストラップアドレスとして提供されます。
Kafka ブローカー Pod にアドバタイズされたアドレスを設定する場合、AMQ Stremas では該当の Pod が稼働しているノードのアドレスが使用されます。ノードアドレスを選択する場合、以下の優先順位で異なるアドレスタイプが使用されます。
- ExternalDNS
- ExternalIP
- Hostname
- InternalDNS
- InternalIP
デフォルトでは、TLS による暗号化は有効になっています。これを無効にするには、tls フィールドを false に設定します。
ノードポートを使用して Kafka クラスターを公開する場合、現在 TLS ホスト名の検証はサポートされません。
デフォルトでは、ブートストラップおよびブローカーサービスに使用されるポート番号は OpenShift によって自動的に割り当てられます。ただし、overrides プロパティーに要求されたポート番号を指定すると、割り当てられたノードポートをオーバーライドすることができます。AMQ Streams では、要求されたポートで検証を実行しません。そのため、ポートが使用可能であることをユーザーが確認する必要があります。
ノードポートのオーバーライドが設定された外部リスナーの例
ノードポートを使用した Kafka へのアクセスに関する詳細は 「ノードポートを使用した Kafka へのアクセス」 を参照してください。
3.1.6.4.4.2. 外部ノードポートリスナーの DNS 名のカスタマイズ
nodeport リスナーでは、dnsAnnotations プロパティーを使用して追加のアノテーションをノードポートサービスに追加できます。これらのアノテーションを使用すると、自動的に DNS 名をクラスターノードに割り当てる ExternalDNS などの DNS ツールをインストルメント化できます。
dnsAnnotations を使用するタイプ nodeport の外部リスナーの例
3.1.6.4.4.3. ノードポートを使用した Kafka へのアクセス
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
外部リスナーが有効で、タイプ
nodeportに設定されている Kafka クラスターをデプロイします。ノードポートを使用するよう設定された外部リスナーがある設定の例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow ブートストラップサービスのポート番号を見つけます。
oc getを使用してこれを行うことができます。oc get service cluster-name-kafka-external-bootstrap -o=jsonpath='{.spec.ports[0].nodePort}{"\n"}'oc get service cluster-name-kafka-external-bootstrap -o=jsonpath='{.spec.ports[0].nodePort}{"\n"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka ブートストラップアドレスでポートを使用する必要があります。
OpenShift ノードのアドレスを見つけます。
oc getを使用してこれを行うことができます。oc get node node-name -o=jsonpath='{range .status.addresses[*]}{.type}{"\t"}{.address}{"\n"}'oc get node node-name -o=jsonpath='{range .status.addresses[*]}{.type}{"\t"}{.address}{"\n"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 異なるアドレスが返される場合は、以下の順序を基にしてアドレスタイプを選択します。
- ExternalDNS
- ExternalIP
- Hostname
- InternalDNS
InternalIP
アドレスと前述のステップで見つけたポートを、Kafka ブートストラップアドレスで使用します。
TLS による暗号化が無効になっている場合を除き、ブローカーの認証局の公開証明書を取得します。
oc getを使用してこれを行うことができます。oc get secret cluster-name-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crtoc get secret cluster-name-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka クライアントで取得した証明書を使用して TLS 接続を設定します。認証が有効になっている場合は、SASL または TLS 認証を設定する必要もあります。
その他のリソース
-
スキーマの詳細は、「
KafkaListenersスキーマ参照」を参照してください。
3.1.6.4.5. OpenShift Ingress 外部リスナー
タイプが ingress の外部リスナーは、Kubernetes Ingress と NGINX Ingress Controller for Kubernetes を使用して Kafka を公開します。
3.1.6.4.5.1. Kubernetes Ingress を使用した Kafka の公開
Kubernetes Ingress と NGINX Ingress Controller for Kubernetes を使用して Kafka が公開されると、Kafka ブローカー Pod ごとに専用の Ingress リソースが作成されます。追加の Ingress リソースが作成され、Kafka ブートストラップアドレスとして提供されます。これらの Ingress リソースを使用すると、Kafka クライアントを 443 番ポートで Kafka に接続することができます。
Ingress を使用する外部リスナーは、現在 NGINX Ingress Controller for Kubernetes でのみテストされています。
AMQ Streams では、NGINX Ingress Controller for Kubernetes の TLS パススルー機能が使用されます。TLS パススルーが NGINX Ingress Controller for Kubernetes デプロイメントで有効になっていることを確認してください。TLS パススルーの有効化に関する詳細は、TLS パススルーのドキュメント を参照してください。Ingress を使用して Kafka を公開する場合、TLS パススルー機能を使用するため、TLS による暗号化を無効にできません。
Ingress コントローラーはホスト名を自動的に割り当てません。spec.kafka.listeners.external.configuration セクションに、ブートストラップおよびブローカーごとのサービスによって使用されるホスト名を指定する必要があります。また、確実にホスト名が Ingress エンドポイントに解決することを確認する必要があります。AMQ Streams では、要求されたホストが利用可能で、適切に Ingress エンドポイントにルーティングされることを検証しません。
タイプが ingress の外部リスナーの例
Ingress を使用した Kafka へのアクセスに関する詳細は 「ingress を使用した Kafka へのアクセス」 を参照してください。
3.1.6.4.5.2. Ingress クラスの設定
デフォルトでは、Ingress クラスは nginx に設定されます。class プロパティーを使用して Ingress クラスを変更できます。
Ingress クラス nginx-internal を使用するタイプ ingress の外部リスナーの例
3.1.6.4.5.3. 外部 ingress リスナーの DNS 名のカスタマイズ
ingress リスナーでは、dnsAnnotations プロパティーを使用して追加のアノテーションを ingress リソースに追加できます。これらのアノテーションを使用すると、自動的に DNS 名を ingress リソースに割り当てる ExternalDNS などの DNS ツールをインストルメント化できます。
dnsAnnotations を使用するタイプ ingress の外部リスナーの例
3.1.6.4.5.4. ingress を使用した Kafka へのアクセス
以下の手順では、Ingress を使用して OpenShift の外部から AMQ Streams Kafka クラスターにアクセスする方法を説明します。
前提条件
- OpenShift クラスター。
- TLS パススルーが有効になっている、デプロイ済みの NGINX Ingress Controller for Kubernetes。
- 稼働中の Cluster Operator が必要です。
手順
外部リスナーが有効で、タイプ
ingressに設定されている Kafka クラスターをデプロイします。Ingressを使用するよう設定された外部リスナーがある設定の例Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
configurationセクションのホストが適切に Ingress エンドポイントに解決することを確認してください。 リソースを作成または更新します。
oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow ブローカーの認証局の公開証明書を取得します。
oc get secret cluster-name-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crtoc get secret cluster-name-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Kafka クライアントで取得した証明書を使用して TLS 接続を設定します。認証が有効になっている場合は、SASL または TLS 認証を設定する必要もあります。443 番ポートで、クライアントを設定で指定したホストに接続します。
その他のリソース
-
スキーマの詳細は、「
KafkaListenersスキーマ参照」を参照してください。
3.1.6.5. ネットワークポリシー
AMQ Streams では、Kafka ブローカーで有効になっているリスナーごとに NetworkPolicy リソースが自動的に作成されます。デフォルトでは、すべてのアプリケーションと namespace にアクセスする権限が NetworkPolicy によってリスナーに付与されます。
ネットワークレベルでのリスナーへのアクセスを指定のアプリケーションまたは namespace のみに制限するには、networkPolicyPeers フィールドを使用します。
認証および承認と合わせてネットワークポリシーを使用します。
リスナーごとに、異なる networkPolicyPeers 設定を指定できます。
3.1.6.5.1. リスナーのネットワークポリシー設定
以下に、plain および tls リスナーの networkPolicyPeers 設定の例を示します。
この例では以下が設定されています。
-
ラベル
app: kafka-sasl-consumerおよびapp: kafka-sasl-producerと一致するアプリケーション Pod のみがplainリスナーに接続できます。アプリケーション Pod は Kafka ブローカーと同じ namespace で実行されている必要があります。 -
ラベル
project: myprojectおよびproject: myproject2と一致する namespace で稼働するアプリケーション Pod のみがtlsリスナーに接続できます。
networkPolicyPeers フィールドの構文は、NetworkPolicy リソースの from フィールドと同じです。スキーマの詳細は、「NetworkPolicyPeer API reference」および「KafkaListeners スキーマ参照」を参照してください。
AMQ Streams でネットワークポリシーを使用するには、ingress NetworkPolicies が OpenShift の設定でサポートされる必要があります。
3.1.6.5.2. networkPolicyPeers を使用した Kafka リスナーへのアクセス制限
networkPolicyPeers フィールドを使用すると、リスナーへのアクセスを指定のアプリケーションのみに制限できます。
前提条件
- Ingress NetworkPolicies をサポートする OpenShift クラスター。
- Cluster Operator が稼働している必要があります。
手順
-
Kafkaリソースを開きます。 networkPolicyPeersフィールドで、Kafka クラスターへのアクセスが許可されるアプリケーション Pod または namespace を定義します。以下は、ラベル
appがkafka-clientに設定されているアプリケーションからの接続のみを許可するようtlsリスナーを設定する例になります。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用します。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
-
スキーマの詳細は、「NetworkPolicyPeer API reference」および「
KafkaListenersスキーマ参照」を参照してください。
3.1.7. 認証および承認
AMQ Streams では認証および承認がサポートされます。認証は、リスナーごとに独立して設定できます。承認は、常に Kafka クラスター全体に対して設定されます。
3.1.7.1. 認証
認証は、authentication プロパティーの リスナー設定 の一部として設定されます。認証メカニズムは type フィールドで定義されます。
authentication プロパティーがない場合、指定のリスナーで認証が有効になりません。認証がないと、リスナーではすべての接続が許可されます。
サポートされる認証メカニズム
- TLS クライアント認証
- SASL SCRAM-SHA-512
- OAuth 2.0 のトークンベースの認証
3.1.7.1.1. TLS クライアント認証
TLS クライアント認証は、type を tls に指定して有効にします。TLS クライアント認証は tls リスナーでのみサポートされます。
タイプ tls の authentication の例
# ... authentication: type: tls # ...
# ...
authentication:
type: tls
# ...3.1.7.2. Kafka ブローカーでの認証の設定
前提条件
- OpenShift クラスターが利用できる必要があります。
- Cluster Operator が稼働している必要があります。
手順
-
クラスターデプロイメントを指定する
Kafkaリソースが含まれる YAML 設定ファイルを開きます。 Kafkaリソースのspec.kafka.listenersプロパティーで、認証を有効にするリスナーにauthenticationフィールドを追加します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 新しい設定を適用してリソースを作成または更新します。
oc applyを使用します。oc apply -f kafka.yaml
oc apply -f kafka.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow kafka.yamlは、設定するリソースの YAML 設定ファイルに置き換えます (例:kafka-persistent.yaml)。
その他のリソース
- サポートされる認証メカニズムの詳細は、「認証」を参照してください。
-
Kafkaのスキーマに関する詳細は、「Kafkaスキーマ参照」を参照してください。
3.1.7.3. 承認
Kafka.spec.kafka リソースの authorization プロパティーを使用して Kafka ブローカーの承認を設定できます。authorization プロパティーがないと、承認が有効になりません。承認を有効にすると、承認は有効なすべての リスナー に適用されます。承認方法は type フィールドで定義されます。
以下を設定できます。
- 簡易承認
- OAuth 2.0 での承認 (OAuth 2.0 トークンベースの認証を使用している場合)
3.1.7.3.1. 簡易承認
AMQ Streams の簡易承認では、SimpleAclAuthorizer が使用されます。これは、Apache Kafka で提供されるデフォルトのアクセス制御リスト (ACL) 承認プラグインです。ACL を使用すると、ユーザーがアクセスできるリソースを細かく定義できます。簡易承認を有効にするには、type フィールドを simple に設定します。
簡易承認の例
# ... authorization: type: simple # ...
# ...
authorization:
type: simple
# ...
ユーザーのアクセスルールは、アクセス制御リスト (ACL) を使用して定義されます。必要に応じて、superUsers フィールドにスーパーユーザーのリストを指定できます。
3.1.7.3.2. スーパーユーザー
スーパーユーザーは、ACL で定義されたアクセス制限に関係なく、Kafka クラスターのすべてのリソースにアクセスできます。Kafka クラスターのスーパーユーザーを指定するには、superUsers フィールドにユーザープリンシパルのリストを入力します。ユーザーが TLS クライアント認証を使用する場合、ユーザー名は CN= で始まる証明書のサブジェクトの共通名になります。
スーパーユーザーの指定例
Kafka.spec.kafka の config プロパティーにある super.user 設定オプションは無視されます。この代わりに、authorization プロパティーでスーパーユーザーを指定します。詳細は「Kafka ブローカーの設定」を参照してください。
3.1.7.4. Kafka ブローカーでの承認の設定
承認を設定し、特定の Kafka ブローカーのスーパーユーザーを指定します。
前提条件
- OpenShift クラスター。
- Cluster Operator が稼働している必要があります。
手順
Kafka.spec.kafkaリソースでauthorizationプロパティーを追加または編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
- サポートされる承認方法の詳細は、「承認」を参照してください。
-
Kafkaのスキーマに関する詳細は、「Kafkaスキーマ参照」を参照してください。 - ユーザー認証の設定に関する詳細は、「Kafka User リソース」を参照してください。
3.1.8. ZooKeeper レプリカ
通常、ZooKeeper クラスターまたはアンサンブルは、一般的に 3、5、7 個の奇数個のノードで実行されます。
効果的なクォーラムを維持するには、過半数のノードが利用可能である必要があります。ZooKeeper クラスターでクォーラムを損失すると、クライアントへの応答が停止し、Kafka ブローカーが機能しなくなります。AMQ Streams では、 ZooKeeper クラスターの安定性および高可用性が重要になります。
- 3 ノードクラスター
- 3 ノードの ZooKeeper クラスターでは、クォーラムを維持するために、少なくとも 2 つのノードが稼働している必要があります。このクラスターは、利用できないノードが 1 つのみであれば対応できます。
- 5 ノードクラスター
- 5 ノードの ZooKeeper クラスターでは、クォーラムを維持するために、少なくとも 3 つのノードが稼働している必要があります。このクラスターは、利用できないノードが 2 つの場合まで対応できます。
- 7 ノードクラスター
- 7 ノードの ZooKeeper クラスターでは、クォーラムを維持するために、少なくとも 4 つのノードが稼働している必要があります。このクラスターは、利用できないノードが 3 つの場合まで対応できます。
開発の目的で、単一ノードの ZooKeeper を実行することも可能です。
クラスターのノードの数が多いほどクォーラムを維持するコストも高くなるため、ノードの数が多いほどパフォーマンスが向上するとは限りません。可用性の要件に応じて、使用するノードの数を決定します。
3.1.8.1. ZooKeeper ノードの数
ZooKeeper ノードの数は、Kafka.spec.zookeeper の replicas プロパティーを使用して設定できます。
レプリカの設定を示す例
3.1.8.2. ZooKeeper レプリカの数の変更
前提条件
- OpenShift クラスターが利用できる必要があります。
- Cluster Operator が稼働している必要があります。
手順
-
クラスターデプロイメントを指定する
Kafkaリソースが含まれる YAML 設定ファイルを開きます。 Kafkaリソースのspec.zookeeper.replicasプロパティーで、複製された ZooKeeper サーバーの数を入力します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 新しい設定を適用してリソースを作成または更新します。
oc applyを使用します。oc apply -f kafka.yaml
oc apply -f kafka.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow kafka.yamlは、設定するリソースの YAML 設定ファイルに置き換えます (例:kafka-persistent.yaml)。
3.1.9. ZooKeeper の設定
AMQ Streams では、Apache ZooKeeper ノードの設定をカスタマイズできます。ZooKeeper のドキュメントに記載されているほとんどのオプションを指定および設定できます。
以下に関連するオプションは設定できません。
- セキュリティー (暗号化、認証、および承認)
- リスナーの設定
- データディレクトリーの設定
- ZooKeeper クラスターの構成
これらのオプションは AMQ Streams によって自動的に設定されます。
3.1.9.1. ZooKeeper の設定
ZooKeeper ノードは、Kafka.spec.zookeeper の config プロパティーを使用して設定されます。このプロパティーには、ZooKeeper 設定オプションがキーとして含まれます。値は、以下の JSON タイプの 1 つを使用して記述できます。
- 文字列
- Number
- ブール値
ユーザーは、AMQ Streams で直接管理されるオプションを除き、ZooKeeper ドキュメント に記載されているオプションを指定および設定できます。以下の文字列の 1 つと同じキーまたは以下の文字列の 1 つで始まるキーを持つ設定オプションはすべて禁止されています。
-
server. -
dataDir -
dataLogDir -
clientPort -
authProvider -
quorum.auth -
requireClientAuthScheme
禁止されているオプションの 1 つが config プロパティーにある場合、そのオプションは無視され、警告メッセージが Cluster Operator ログファイルに出力されます。その他のオプションは、すべて ZooKeeper に渡されます。
Cluster Operator では、提供された config オブジェクトのキーまたは値は検証されません。無効な設定を指定すると、ZooKeeper クラスターが起動しなかったり、不安定になる可能性があります。このような場合、Kafka.spec.zookeeper.config オブジェクトの設定を修正し、Cluster Operator によって新しい設定がすべての ZooKeeper ノードにロールアウトされるようにします。
選択したオプションのデフォルト値は次のとおりです。
-
timeTick、デフォルト値2000 -
initLimit、デフォルト値5 -
syncLimit、デフォルト値2 -
autopurge.purgeInterval、デフォルト値1
これらのオプションは、Kafka.spec.zookeeper.config プロパティーにない場合に自動的に設定されます。
ZooKeeper 設定を示す例
3.1.9.2. ZooKeeper の設定
前提条件
- OpenShift クラスターが利用できる必要があります。
- Cluster Operator が稼働している必要があります。
手順
-
クラスターデプロイメントを指定する
Kafkaリソースが含まれる YAML 設定ファイルを開きます。 Kafkaリソースのspec.zookeeper.configプロパティーで、ZooKeeper 設定を 1 つまたは複数入力します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 新しい設定を適用してリソースを作成または更新します。
oc applyを使用します。oc apply -f kafka.yaml
oc apply -f kafka.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow kafka.yamlは、設定するリソースの YAML 設定ファイルに置き換えます (例:kafka-persistent.yaml)。
3.1.10. ZooKeeper の接続
ZooKeeper サービスは暗号化および認証でセキュア化され、AMQ Streams の一部でない外部アプリケーションでの使用は想定されていません。
しかし、kafka-topics ツールなどの ZooKeeper への接続を必要とする Kafka CLI ツールを使用する場合は、Kafka コンテナー内でターミナルを使用し、localhost:2181 を ZooKeeper アドレスとして使用して、TLS トンネルのローカル側を ZooKeeper に接続できます。
3.1.10.1. ターミナルからの ZooKeeper への接続
Kafka コンテナー内でターミナルを開き、ZooKeeper の接続を必要とする Kafka CLI ツールを使用します。
前提条件
- OpenShift クラスターが利用できる必要があります。
- Kafka クラスターが稼働している必要があります。
- Cluster Operator が稼働している必要があります。
手順
OpenShift コンソールを使用してターミナルを開くか、CLI から
execコマンドを実行します。以下に例を示します。
oc exec -it my-cluster-kafka-0 -- bin/kafka-topics.sh --list --zookeeper localhost:2181
oc exec -it my-cluster-kafka-0 -- bin/kafka-topics.sh --list --zookeeper localhost:2181Copy to Clipboard Copied! Toggle word wrap Toggle overflow 必ず
localhost:2181を使用してください。ZooKeeper に対して Kafka コマンドを実行できるようになりました。
3.1.11. Entitiy Operator
Entity Operator は、実行中の Kafka クラスターで Kafka 関連のエンティティーを管理します。
Entity Operator は以下と構成されます。
- Kafka トピックを管理する Topic Operator
- Kafka ユーザーを管理する User Operator
Cluster Operator は Kafka リソース設定を介して、Kafka クラスターのデプロイ時に、上記の Operator の 1 つまたは両方を含む Entity Operator をデプロイできます。
デプロイされると、デプロイメント設定に応じて、Entity Operator にオペレーターが含まれます。
これらのオペレーターは、Kafka クラスターのトピックおよびユーザーを管理するために自動的に設定されます。
3.1.11.1. Entity Operator の設定プロパティー
Entity Operator は Kafka.spec の entityOperator を使用して設定できます。
entityOperator プロパティーでは複数のサブプロパティーがサポートされます。
-
tlsSidecar -
topicOperator -
userOperator -
template
tlsSidecar プロパティーは、ZooKeeper との通信に使用される TLS サイドカーコンテナーの設定に使用できます。TLS サイドカーコンテナーの設定に関する詳細は、「TLS サイドカー」 を参照してください。
template プロパティーを使用すると、ラベル、アノテーション、アフィニティー、容認 (Toleration) などの Entity Operator Pod の詳細を設定できます。
topicOperator プロパティーには、Topic Operator の設定が含まれます。このオプションがないと、Entity Operator は Topic Operator なしでデプロイされます。
userOperator プロパティーには、User Operator の設定が含まれます。このオプションがないと、Entity Operator は User Operator なしでデプロイされます。
両方の Operator を有効にする基本設定の例
topicOperator および userOperator プロパティーの両方がない場合、Entity Operator はデプロイされません。
3.1.11.2. Topic Operator 設定プロパティー
Topic Operator デプロイメントは、topicOperator オブジェクト内で追加オプションを使用すると設定できます。以下のプロパティーがサポートされます。
watchedNamespace-
User Operator によって
KafkaTopicsが監視される OpenShift namespace。デフォルトは、Kafka クラスターがデプロイされた namespace です。 reconciliationIntervalSeconds-
定期的な調整 (reconciliation) の間隔 (秒単位)。デフォルトは
90です。 zookeeperSessionTimeoutSeconds-
ZooKeeper セッションのタイムアウト (秒単位)。デフォルトは
20です。 topicMetadataMaxAttempts-
Kafka からトピックメタデータの取得を試行する回数。各試行の間隔は、指数バックオフとして定義されます。パーティションまたはレプリカの数によって、トピックの作成に時間がかかる可能性がある場合は、この値を増やすことを検討してください。デフォルトは
6です。 image-
imageプロパティーを使用すると、使用されるコンテナーイメージを設定できます。カスタムコンテナーイメージの設定に関する詳細は、「コンテナーイメージ」を参照してください。 resources-
resourcesプロパティーを使用すると、Topic Operator に割り当てられるリソースの量を設定できます。リソースの要求と制限の設定に関する詳細は、「CPU およびメモリーリソース」を参照してください。 logging-
loggingプロパティーは、Topic Operator のロギングを設定します。詳細は「Operator ロガー」を参照してください。
Topic Operator 設定の例
3.1.11.3. User Operator 設定プロパティー
User Operator デプロイメントは、userOperator オブジェクト内で追加オプションを使用すると設定できます。以下のプロパティーがサポートされます。
watchedNamespace-
User Operator によって
KafkaUsersが監視される OpenShift namespace。デフォルトは、Kafka クラスターがデプロイされた namespace です。 reconciliationIntervalSeconds-
定期的な調整 (reconciliation) の間隔 (秒単位)。デフォルトは
120です。 zookeeperSessionTimeoutSeconds-
ZooKeeper セッションのタイムアウト (秒単位)。デフォルトは
6です。 image-
imageプロパティーを使用すると、使用されるコンテナーイメージを設定できます。カスタムコンテナーイメージの設定に関する詳細は、「コンテナーイメージ」を参照してください。 resources-
resourcesプロパティーを使用すると、User Operator に割り当てられるリソースの量を設定できます。リソースの要求と制限の設定に関する詳細は、「CPU およびメモリーリソース」を参照してください。 logging-
loggingプロパティーは、User Operator のロギングを設定します。詳細は「Operator ロガー」を参照してください。
User Operator 設定の例
3.1.11.4. Operator ロガー
Topic Operator および User Operator には設定可能なロガーがあります。
-
rootLogger.level
これらの Operator では Apache log4j2 ロガー実装が使用されます。
logging リソースの Kafka プロパティーを使用して、ロガーおよびロガーレベルを設定します。
ログレベルを設定するには、ロガーとレベルを直接指定 (インライン) するか、またはカスタム (外部) ConfigMap を使用します。ConfigMap を使用する場合、logging.name プロパティーを外部ロギング設定が含まれる ConfigMap の名前に設定します。ConfigMap 内では、ロギング設定は log4j2.properties を使用して記述されます。
inline および external ロギングの例は次のとおりです。
inline ロギング
外部ロギング
その他のリソース
- ガベッジコレクター (GC) ロギングを有効 (または無効) にすることもできます。GC ロギングの詳細は「JVM 設定」を参照してください。
- ログレベルの詳細は、「Apache logging services」を参照してください。
3.1.11.5. Entity Operator の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
KafkaリソースのentityOperatorプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.1.12. CPU およびメモリーリソース
AMQ Streams では、デプロイされたコンテナーごとに特定のリソースを要求し、これらのリソースの最大消費を定義できます。
AMQ Streams では、以下の 2 つのタイプのリソースがサポートされます。
- CPU
- メモリー
AMQ Streams では、CPU およびメモリーリソースの指定に OpenShift 構文が使用されます。
3.1.12.1. リソースの制限および要求
リソースの制限と要求は、以下のリソースで resources プロパティーを使用して設定されます。
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.KafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
その他のリソース
- OpenShift におけるコンピュートリソースの管理に関する詳細は、「Managing Compute Resources for Containers」を参照してください。
3.1.12.1.1. リソース要求
要求によって、指定のコンテナーに対して予約するリソースが指定されます。リソースを予約すると、リソースが常に利用できるようになります。
リソース要求が OpenShift クラスターで利用可能な空きリソースを超える場合、Pod はスケジュールされません。
リソース要求は requests プロパティーで指定されます。AMQ Streams では、現在以下のリソース要求がサポートされます。
-
cpu -
memory
1 つまたは複数のサポートされるリソースに対してリクエストを設定できます。
すべてのリソースを対象とするリソース要求の設定例
3.1.12.1.2. リソース制限
制限によって、指定のコンテナーが消費可能な最大リソースが指定されます。制限は予約されず、常に利用できるとは限りません。コンテナーは、リソースが利用できる場合のみ、制限以下のリソースを使用できます。リソース制限は、常にリソース要求よりも高くする必要があります。
リソース制限は limits プロパティーで指定されます。AMQ Streams では、現在以下のリソース制限がサポートされます。
-
cpu -
memory
1 つまたは複数のサポートされる制限に対してリソースを設定できます。
リソース制限の設定例
3.1.12.1.3. サポートされる CPU 形式
CPU の要求および制限は以下の形式でサポートされます。
-
整数値 (
5CPU コア) または少数 (2.5CPU コア) の CPU コアの数。 -
数値または ミリ CPU / ミリコア (
100m)。1000 ミリコア は1CPU コアと同じです。
CPU ユニットの例
1 つの CPU コアのコンピューティング能力は、OpenShift がデプロイされたプラットフォームによって異なることがあります。
その他のリソース
- CPU 仕様の詳細は、「Meaning of CPU」を参照してください。
3.1.12.1.4. サポートされるメモリー形式
メモリー要求および制限は、メガバイト、ギガバイト、メビバイト、およびギビバイトで指定されます。
-
メモリーをメガバイトで指定するには、
M接尾辞を使用します。例:1000M -
メモリーをギガバイトで指定するには、
G接尾辞を使用します。例:1G -
メモリーをメビバイトで指定するには、
Mi接尾辞を使用します。例:1000Mi -
メモリーをギビバイトで指定するには、
Gi接尾辞を使用します。例:1Gi
異なるメモリー単位の使用例
その他のリソース
- メモリーの指定およびサポートされるその他の単位に関する詳細は、「Meaning of memory」を参照してください。
3.1.12.2. リソース要求および制限の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
クラスターデプロイメントを指定するリソースの
resourcesプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
-
スキーマの詳細は、「
Resourcesスキーマ参照」を参照してください。
3.1.13. Kafka ロガー
Kafka には独自の設定可能なロガーがあります。
-
kafka.root.logger.level -
log4j.logger.org.I0Itec.zkclient.ZkClient -
log4j.logger.org.apache.zookeeper -
log4j.logger.kafka -
log4j.logger.org.apache.kafka -
log4j.logger.kafka.request.logger -
log4j.logger.kafka.network.Processor -
log4j.logger.kafka.server.KafkaApis -
log4j.logger.kafka.network.RequestChannel$ -
log4j.logger.kafka.controller -
log4j.logger.kafka.log.LogCleaner -
log4j.logger.state.change.logger -
log4j.logger.kafka.authorizer.logger
ZooKeeper にも設定可能なロガーもあります。
-
zookeeper.root.logger
Kafka と ZooKeeper では Apache log4j ロガー実装が使用されます。
logging プロパティーを使用してロガーおよびロガーレベルを設定します。
ログレベルを設定するには、ロガーとレベルを直接指定 (インライン) するか、またはカスタム (外部) ConfigMap を使用します。ConfigMap を使用する場合、logging.name プロパティーを外部ロギング設定が含まれる ConfigMap の名前に設定します。ConfigMap 内では、ロギング設定は log4j.properties を使用して記述されます。
inline および external ロギングの例は次のとおりです。
inline ロギング
外部ロギング
log4j2.properties を使用して ConfigMap 内にロギング設定を記述するため、Operator によって Apache log4j2 ロガー実装が使用されます。詳細は 「Operator ロガー」 を参照してください。
その他のリソース
- ガベッジコレクター (GC) ロギングを有効 (または無効) にすることもできます。ガべージコレクションの詳細は、「JVM 設定」 を参照してください。
- ログレベルの詳細は、「Apache logging services」を参照してください。
3.1.14. Kafka のラックアウェアネス (Rack awareness)
AMQ Streams のラックアウェアネス (Rack awareness) 機能は、Kafka ブローカー Pod および Kafka トピックレプリカを異なるラック全体に分散できるようにします。ラック認識を有効にすることで、Kafka ブローカーや Kafka ブローカーがホストしているトピックの可用性を向上できるようにします。
「ラック」(Rack) は、可用性ゾーン、データセンター、またはデータセンターの実際のラックを表す可能性があります。
3.1.14.1. Kafka ブローカーでのラック認識 (Rack awareness) の設定
Kafka のラック認識 (Rack awareness) は、Kafka.spec.kafka の rack プロパティーで設定できます。rack オブジェクトには、topologyKeyという名前の必須フィールドが 1 つあります。このキーは、OpenShift クラスターノードに割り当てられたラベルの 1 つと一致する必要があります。このラベルは、Kafka ブローカー Pod をノードにスケジュールする際に OpenShift によって使用されます。OpenShift クラスターがクラウドプロバイダープラットフォームで稼働している場合、そのラベルはノードが稼働している可用性ゾーンを表す必要があります。通常、ノードには、topologyKey の値として簡単に使用できる failure-domain.beta.kubernetes.io/zone のラベルが付けられます。これにより、ブローカー Pod がゾーン全体に分散され、Kafka ブローカー内にブローカーの broker.rack 設定パラメーターも設定されます。
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
- ノードがデプロイされたゾーンやラックを表すノードラベルについては、OpenShift 管理者に相談します。
ラベルをトポロジーキーとして使用し、
Kafkaリソースのrackプロパティーを編集します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
- Kafka ラック認識に init コンテナーイメージを設定するための詳細は 「コンテナーイメージ」 を参照してください。
3.1.15. ヘルスチェック
ヘルスチェックは、アプリケーションの健全性を検証する定期的なテストです。ヘルスチェックプローブが失敗すると、OpenShift によってアプリケーションが正常でないと見なされ、その修正が試行されます。
OpenShift では、以下の 2 つのタイプのおよび ヘルスチェックプローブがサポートされます。
- Liveness プローブ
- Readiness プローブ
プローブの詳細は、「Configure Liveness and Readiness Probes」を参照してください。AMQ Streams コンポーネントでは、両タイプのプローブが使用されます。
ユーザーは、Liveness および Readiness プローブに選択されたオプションを設定できます。
3.1.15.1. ヘルスチェックの設定
Liveness および Readiness プローブは、以下のリソースの livenessProbe および readinessProbe プロパティーを使用して設定できます。
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.KafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
livenessProbe および readinessProbe の両方によって以下のオプションがサポートされます。
-
initialDelaySeconds -
timeoutSeconds -
periodSeconds -
successThreshold -
failureThreshold
livenessProbe および readinessProbe オプションの詳細については、「Probe スキーマ参照」 を参照してください。
Liveness および Readiness プローブの設定例
3.1.15.2. ヘルスチェックの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
Kafka、KafkaConnect、またはKafkaConnectS2IリソースのlivenessProbeまたはreadinessProbeプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.1.16. Prometheus メトリクス
AMQ Streams では、Apache Kafka および ZooKeeper によってサポートされる JMX メトリクスを Prometheus メトリクスに変換するために、Prometheus JMX エクスポーター を使用した Prometheus メトリクスがサポートされます。有効になったメトリクスは、9404 番ポートで公開されます。
Prometheus および Grafana の設定に関する詳細は「メトリクス」を参照してください。
3.1.16.1. メトリクスの設定
Prometheus メトリクスは、以下のリソースに metrics プロパティーを設定して有効化されます。
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
KafkaConnect.spec -
KafkaConnectS2I.spec
metrics プロパティーがリソースに定義されていない場合、Prometheus メトリクスは無効になります。追加設定なしで Prometheus メトリクスのエクスポートを有効にするには、空のオブジェクト ({}) を設定します。
追加設定なしでメトリクスを有効にする例
metrics プロパティーには、Prometheus JMX エスクポーター の追加設定が含まれることがあります。
追加の Prometheus JMX Exporter 設定を使用したメトリクスを有効化する例
3.1.16.2. Prometheus メトリクスの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
Kafka、KafkaConnect、またはKafkaConnectS2Iリソースのmetricsプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.1.17. JMX オプション
AMQ Streams では、JMX ポートを 9999 番で開放することで、Kafka ブローカーから JMX メトリクスを取得することがサポートされます。各 Kafka ブローカーに関するさまざまなメトリクスを取得できます。たとえば、BytesPerSecond の値やブローカーのネットワークの要求レートなどの、使用データを取得できます。AMQ Streams では、パスワードとユーザー名で保護された JMX ポートの開放や、保護されていない JMX ポートの開放がサポートされます。
3.1.17.1. JMX オプションの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
以下のリソースで jmxOptions プロパティーを使用すると JMX オプションを設定できます。
-
Kafka.spec.kafka
Kafka ブローカーで開放された JMX ポートの、ユーザー名とパスワードの保護を設定できます。
JMX ポートのセキュリティー保護
JMX ポートをセキュアにすると、非承認の Pod によるポートへのアクセスを防ぐことができます。現在、JMX ポートをセキュアにする唯一の方法がユーザー名とパスワードを使用することです。JMX ポートのセキュリティーを有効にするには、authentication フィールドの type パラメーターを password に設定します。
これにより、ヘッドレスサービスを使用し、対応するブローカーを指定して Pod をクラスター内部にデプロイし、JMX メトリクスを取得することができます。ブローカー 0 から JMX メトリクスを取得するには、指定するヘッドレスサービスの前にブローカー 0 を追加します。
"<cluster-name>-kafka-0-<cluster-name>-<headless-service-name>"
"<cluster-name>-kafka-0-<cluster-name>-<headless-service-name>"JMX ポートがセキュアである場合、Pod のデプロイメントで JMX シークレットからユーザー名とパスワードを参照すると、そのユーザー名とパスワードを取得できます。
開放された JMX ポートの使用
JMX ポートのセキュリティーを無効にする場合は、authentication フィールドに何も入力しません。
これにより、ヘッドレスサービスで JMX ポートを開放し、上記と似た方法で Pod をクラスター内にデプロイすることができます。唯一の違いは、すべての Pod が JMX ポートから読み取りできることです。
3.1.18. JVM オプション
AMQ Streams の以下のコンポーネントは、仮想マシン (VM) 内で実行されます。
- Apache Kafka
- Apache ZooKeeper
- Apache Kafka Connect
- Apache Kafka MirrorMaker
- AMQ Streams Kafka Bridge
JVM 設定オプションによって、さまざまなプラットフォームおよびアーキテクチャーのパフォーマンスが最適化されます。AMQ Streams では、これらのオプションの一部を設定できます。
3.1.18.1. JVM 設定
JVM オプションは、以下のリソースの jvmOptions プロパティーを使用して設定できます。
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
使用可能な JVM オプションの選択されたサブセットのみを設定できます。以下のオプションがサポートされます。
-Xms および -Xmx
-Xms は、JVM の起動時に最初に割り当てられる最小ヒープサイズを設定します。-Xmx は、最大ヒープサイズを設定します。
-Xmx や -Xms などの JVM 設定で使用できる単位は、対応するイメージの JDK java バイナリーによって許可される単位です。そのため、1g または 1G は 1,073,741,824 バイトを意味し、Gi は接尾辞として有効な単位ではありません。これは、1G は 1,000,000,000 バイト、1Gi は 1,073,741,824 バイトを意味する OpenShift の慣例に準拠している メモリー要求および制限 に使用される単位とは対照的です。
-Xms および -Xmx に使用されるデフォルト値は、コンテナーに メモリー要求 の制限が設定されているかどうかによって異なります。
- メモリーの制限がある場合は、JVM の最小および最大メモリーは制限に対応する値に設定されます。
-
メモリーの制限がない場合、JVM の最小メモリーは
128Mに設定され、JVM の最大メモリーは定義されません。これにより、JVM のメモリーを必要に応じて拡張できます。これは、テストおよび開発での単一ノード環境に適しています。
-Xmx を明示的に設定するには、以下の点に注意する必要があります。
-
JVM のメモリー使用量の合計は、
-Xmxによって設定された最大ヒープの約 4 倍になります。 -
適切な OpenShift メモリー制限を設定せずに
-Xmxが設定された場合、OpenShift ノードで、実行されている他の Pod からメモリー不足が発生するとコンテナーが強制終了される可能性があります。 -
適切な OpenShift メモリー要求を設定せずに
-Xmxが設定された場合、コンテナーはメモリー不足のノードにスケジュールされる可能性があります。この場合、コンテナーは起動せずにクラッシュします (-Xmsが-Xmxに設定されている場合は即座にクラッシュし、そうでない場合はその後にクラッシュします)。
-Xmx を明示的に設定する場合は、以下を行うことが推奨されます。
- メモリー要求とメモリー制限を同じ値に設定します。
-
-Xmxの 4.5 倍以上のメモリー要求を使用します。 -
-Xmsを-Xmxと同じ値に設定することを検討してください。
大量のディスク I/O を実行するコンテナー (Kafka ブローカーコンテナーなど) は、オペレーティングシステムのページキャッシュとして使用できるメモリーを確保しておく必要があります。このようなコンテナーでは、要求されるメモリーは JVM によって使用されるメモリーよりもはるかに多くなります。
-Xmx および -Xms の設定例 (抜粋)
# ... jvmOptions: "-Xmx": "2g" "-Xms": "2g" # ...
# ...
jvmOptions:
"-Xmx": "2g"
"-Xms": "2g"
# ...上記の例では、JVM のヒープに 2 GiB (2,147,483,648 バイト) が使用されます。メモリー使用量の合計は約 8GiB になります。
最初のヒープサイズ (-Xms) および最大ヒープサイズ (-Xmx) に同じ値を設定すると、JVM が必要以上のヒープを割り当てて起動後にメモリーを割り当てないようにすることができます。Kafka および ZooKeeper Pod では、このような割り当てによって不要なレイテンシーが発生する可能性があります。Kafka Connect では、割り当ての過剰を防ぐことが最も重要になります。これは、コンシューマーの数が増えるごとに割り当て過剰の影響がより深刻になる分散モードで特に重要です。
-server
-server はサーバー JVM を有効にします。このオプションは true または false に設定できます。
-server の設定例 (抜粋)
# ... jvmOptions: "-server": true # ...
# ...
jvmOptions:
"-server": true
# ...
いずれのオプション (-server および -XX) も指定されないと、Apache Kafka の KAFKA_JVM_PERFORMANCE_OPTS のデフォルト設定が使用されます。
-XX
-XX オブジェクトは、JVM の高度なランタイムオプションの設定に使用できます。-server および -XX オプションは、Apache Kafka の KAFKA_JVM_PERFORMANCE_OPTS オプションの設定に使用されます。
-XX オブジェクトの使用例
上記の設定例の場合、JVM オプションは以下のようになります。
-XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:-UseParNewGC
-XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:-UseParNewGC
いずれのオプション (-server および -XX) も指定されないと、Apache Kafka の KAFKA_JVM_PERFORMANCE_OPTS のデフォルト設定が使用されます。
3.1.18.1.1. ガベッジコレクターのロギング
jvmOptions セクションでは、ガベージコレクター (GC) のロギングを有効または無効にすることもできます。GC ロギングはデフォルトで無効になっています。これを有効にするには、以下のように gcLoggingEnabled プロパティーを設定します。
GC ロギングを有効にする例
# ... jvmOptions: gcLoggingEnabled: true # ...
# ...
jvmOptions:
gcLoggingEnabled: true
# ...3.1.18.2. JVM オプションの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
Kafka、KafkaConnect、KafkaConnectS2I、KafkaMirrorMaker、またはKafkaBridgeリソースのjvmOptionsプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.1.19. コンテナーイメージ
AMQ Streams では、コンポーネントに使用されるコンテナーイメージを設定できます。コンテナーイメージのオーバーライドは、別のコンテナーレジストリーを使用する必要がある特別な状況でのみ推奨されます。たとえば、AMQ Streams によって使用されるコンテナーリポジトリーにネットワークがアクセスできない場合などがこれに該当します。そのような場合は、AMQ Streams イメージをコピーするか、ソースからビルドする必要があります。設定したイメージが AMQ Streams イメージと互換性のない場合は、適切に機能しない可能性があります。
3.1.19.1. コンテナーイメージの設定
以下のリソースの image プロパティーを使用すると、各コンポーネントに使用するコンテナーイメージを指定できます。
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
3.1.19.1.1. Kafka、Kafka Connect、および Kafka MirrorMaker の image プロパティーの設定
Kafka、Kafka Connect (S2I サポートのある Kafka Connect を含む)、および Kafka MirrorMaker では、複数のバージョンの Kafka がサポートされます。各コンポーネントには独自のイメージが必要です。異なる Kafka バージョンのデフォルトイメージは、以下の環境変数で設定されます。
-
STRIMZI_KAFKA_IMAGES -
STRIMZI_KAFKA_CONNECT_IMAGES -
STRIMZI_KAFKA_CONNECT_S2I_IMAGES -
STRIMZI_KAFKA_MIRROR_MAKER_IMAGES
これらの環境変数には、Kafka バージョンと対応するイメージ間のマッピングが含まれます。マッピングは、image および version プロパティーとともに使用されます。
-
imageとversionのどちらもカスタムリソースに指定されていない場合、versionは Cluster Operator のデフォルトの Kafka バージョンに設定され、環境変数のこのバージョンに対応するイメージが指定されます。 -
imageが指定されていてもversionが指定されていない場合、指定されたイメージが使用され、Cluster Operator のデフォルトの Kafka バージョンがversionであると想定されます。 -
versionが指定されていてもimageが指定されていない場合、環境変数の指定されたバージョンに対応するイメージが使用されます。 -
versionとimageの両方を指定すると、指定されたイメージが使用されます。このイメージには、指定のバージョンの Kafka イメージが含まれると想定されます。
異なるコンポーネントの image および version は、以下のプロパティーで設定できます。
-
Kafka の場合は
spec.kafka.imageおよびspec.kafka.version。 -
Kafka Connect、Kafka Connect S2I、および Kafka MirrorMaker の場合は
spec.imageおよびspec.version。
version のみを提供し、image プロパティーを未指定のままにしておくことが推奨されます。これにより、カスタムリソースの設定時に間違いが発生する可能性が低減されます。異なるバージョンの Kafka に使用されるイメージを変更する必要がある場合は、Cluster Operator の環境変数を設定することが推奨されます。
3.1.19.1.2. 他のリソースでの image プロパティーの設定
他のカスタムリソースの image プロパティーでは、デプロイメント中に指定の値が使用されます。image プロパティーがない場合、Cluster Operator 設定に指定された image が使用されます。image 名が Cluster Operator 設定に定義されていない場合、デフォルト値が使用されます。
Kafka ブローカー TLS サイドカーの場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_TLS_SIDECAR_KAFKA_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
- ZooKeeper ノードの場合:
ZooKeeper ノードの TLS サイドカーの場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_TLS_SIDECAR_ZOOKEEPER_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Topic Operator の場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_TOPIC_OPERATOR_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
User Operator の場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_USER_OPERATOR_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Entity Operator TLS サイドカーの場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_TLS_SIDECAR_ENTITY_OPERATOR_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Kafka Exporter の場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_KAFKA_EXPORTER_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Kafka Bridge の場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_KAFKA_BRIDGE_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-bridge-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Kafka ブローカーイニシャライザーの場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_KAFKA_INIT_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
コンテナーイメージのオーバーライドは、別のコンテナーレジストリーを使用する必要がある特別な状況でのみ推奨されます。たとえば、AMQ Streams によって使用されるコンテナーリポジトリーにネットワークがアクセスできない場合などがこれに該当します。そのような場合は、AMQ Streams イメージをコピーするか、ソースからビルドする必要があります。設定したイメージが AMQ Streams イメージと互換性のない場合は、適切に機能しない可能性があります。
コンテナーイメージ設定の例
3.1.19.2. コンテナーイメージの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
Kafka、KafkaConnect、またはKafkaConnectS2Iリソースのimageプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.1.20. TLS サイドカー
サイドカーは、Pod で実行されるコンテナーですが、サポートの目的で提供されます。AMQ Streams では、TLS サイドカーは TLS を使用して、各種のコンポーネントと ZooKeeper との間のすべての通信を暗号化および復号化します。ZooKeeper にはネイティブの TLS サポートがありません。
TLS サイドカーは以下で使用されます。
- Kafka ブローカー
- ZooKeeper ノード
- Entitiy Operator
3.1.20.1. TLS サイドカー設定
TLS サイドカーは、以下で tlsSidecar プロパティーを使用して設定できます。
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
Kafka.spec.entityOperator
TLS サイドカーは、以下の追加オプションをサポートします。
-
image -
resources -
logLevel -
readinessProbe -
livenessProbe
resources プロパティーを使用すると、TLS サイドカーに割り当てられる メモリーおよび CPU リソース を指定できます。
image プロパティーを使用すると、使用されるコンテナーイメージを設定できます。カスタムコンテナーイメージの設定に関する詳細は、「コンテナーイメージ」を参照してください。
logLevel プロパティーは、ログレベルを指定するために使用されます。以下のログレベルがサポートされます。
- emerg
- alert
- crit
- err
- warning
- notice
- info
- debug
デフォルト値は notice です。
readinessProbe および livenessProbe プロパティーの設定に関する詳細は 「ヘルスチェックの設定」 を参照してください。
TLS サイドカーの設定例
3.1.20.2. TLS サイドカーの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
KafkaリソースのtlsSidecarプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.1.21. Pod スケジューリングの設定
2 つのアプリケーションが同じ OpenShift ノードにスケジュールされた場合、両方のアプリケーションがディスク I/O のように同じリソースを使用し、パフォーマンスに影響する可能性があります。これにより、パフォーマンスが低下する可能性があります。ノードを他の重要なワークロードと共有しないように Kafka Pod をスケジュールする場合、適切なノードを使用したり、Kafka 専用のノードのセットを使用すると、このような問題を適切に回避できます。
3.1.21.1. 他のアプリケーションに基づく Pod のスケジューリング
3.1.21.1.1. 重要なアプリケーションがノードを共有しないようにする
Pod の非アフィニティーを使用すると、重要なアプリケーションが同じディスクにスケジュールされないようにすることができます。Kafka クラスターの実行時に、Pod の非アフィニティーを使用して、Kafka ブローカーがデータベースなどの他のワークロードとノードを共有しないようにすることが推奨されます。
3.1.21.1.2. アフィニティー
アフィニティーは、以下のリソースの affinity プロパティーを使用して設定できます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
アフィニティー設定には、さまざまなタイプのアフィニティーを含めることができます。
- Pod のアフィニティーおよび非アフィニティー
- ノードのアフィニティー
affinity プロパティーの形式は、OpenShift の仕様に準拠します。詳細は、Kubernetes のノードおよび Pod のアフィニティーに関するドキュメント を参照してください。
3.1.21.1.3. Kafka コンポーネントでの Pod の非アフィニティーの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
クラスターデプロイメントを指定するリソースの
affinityプロパティーを編集します。ラベルを使用して、同じノードでスケジュールすべきでない Pod を指定します。topologyKeyをkubernetes.io/hostnameに設定し、選択した Pod が同じホスト名のノードでスケジュールされてはならないことを指定する必要があります。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.1.21.2. 特定のノードへの Pod のスケジューリング
3.1.21.2.1. ノードのスケジューリング
OpenShift クラスターは、通常多くの異なるタイプのワーカーノードで構成されます。ワークロードが非常に大きい環境の CPU に対して最適化されたものもあれば、メモリー、ストレージ (高速のローカル SSD)、または ネットワークに対して最適化されたものもあります。異なるノードを使用すると、コストとパフォーマンスの両面で最適化しやすくなります。最適なパフォーマンスを実現するには、AMQ Streams コンポーネントのスケジューリングで適切なノードを使用できるようにすることが重要です。
OpenShift は、ノードのアフィニティーを使用してワークロードを特定のノードにスケジュールします。ノードのアフィニティーにより、Pod がスケジュールされるノードにスケジューリングの制約を作成できます。制約はラベルセレクターとして指定されます。beta.kubernetes.io/instance-type などの組み込みノードラベルまたはカスタムラベルのいずれかを使用してラベルを指定すると、適切なノードを選択できます。
3.1.21.2.2. アフィニティー
アフィニティーは、以下のリソースの affinity プロパティーを使用して設定できます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
アフィニティー設定には、さまざまなタイプのアフィニティーを含めることができます。
- Pod のアフィニティーおよび非アフィニティー
- ノードのアフィニティー
affinity プロパティーの形式は、OpenShift の仕様に準拠します。詳細は、Kubernetes のノードおよび Pod のアフィニティーに関するドキュメント を参照してください。
3.1.21.2.3. Kafka コンポーネントでのノードのアフィニティーの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
AMQ Streams コンポーネントをスケジュールする必要のあるノードにラベルを付けます。
oc labelを使用してこれを行うことができます。oc label node your-node node-type=fast-network
oc label node your-node node-type=fast-networkCopy to Clipboard Copied! Toggle word wrap Toggle overflow または、既存のラベルによっては再利用が可能です。
クラスターデプロイメントを指定するリソースの
affinityプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.1.21.3. 専用ノードの使用
3.1.21.3.1. 専用ノード
クラスター管理者は、選択した OpenShift ノードをテイントとしてマーク付けできます。テイントのあるノードは、通常のスケジューリングから除外され、通常の Pod はそれらのノードでの実行はスケジュールされません。ノードに設定されたテイントを許容できるサービスのみをスケジュールできます。このようなノードで実行されるその他のサービスは、ログコレクターやソフトウェア定義のネットワークなどのシステムサービスのみです。
テイントは専用ノードの作成に使用できます。専用のノードで Kafka とそのコンポーネントを実行する利点は多くあります。障害の原因になったり、Kafka に必要なリソースを消費するその他のアプリケーションが同じノードで実行されません。これにより、パフォーマンスと安定性が向上します。
専用ノードで Kafka Pod をスケジュールするには、ノードのアフィニティー と 許容 (toleration) を設定します。
3.1.21.3.2. アフィニティー
アフィニティーは、以下のリソースの affinity プロパティーを使用して設定できます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
アフィニティー設定には、さまざまなタイプのアフィニティーを含めることができます。
- Pod のアフィニティーおよび非アフィニティー
- ノードのアフィニティー
affinity プロパティーの形式は、OpenShift の仕様に準拠します。詳細は、Kubernetes のノードおよび Pod のアフィニティーに関するドキュメント を参照してください。
3.1.21.3.3. 許容 (Toleration)
許容 (Toleration) は、以下のリソースの tolerations プロパティーを使用して設定できます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
tolerations プロパティーの形式は、OpenShift の仕様に準拠します。詳細は、Kubernetes の「Taints and Tolerations」を参照してください。
3.1.21.3.4. 専用ノードの設定と Pod のスケジューリング
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
- 専用ノードとして使用するノードを選択します。
- これらのノードにスケジュールされているワークロードがないことを確認します。
選択したノードにテイントを設定します。
oc adm taintを使用してこれを行うことができます。oc adm taint node your-node dedicated=Kafka:NoSchedule
oc adm taint node your-node dedicated=Kafka:NoScheduleCopy to Clipboard Copied! Toggle word wrap Toggle overflow さらに、選択したノードにラベルも追加します。
oc labelを使用してこれを行うことができます。oc label node your-node dedicated=Kafka
oc label node your-node dedicated=KafkaCopy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターデプロイメントを指定するリソースの
affinityおよびtolerationsプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.1.22. Kafka Exporter
Kafka リソースを設定すると、クラスターに Kafka Exporter を自動的にデプロイできます。
Kafka Exporter は、主にオフセット、コンシューマーグループ、コンシューマーラグ、およびトピックに関連するデータである分析用のデータを Prometheus メトリクスとして抽出します。
Kafka Exporter の詳細と、パフォーマンスのためにコンシューマーラグを監視する重要性の理由については、「Kafka Exporter」を参照してください。
3.1.22.1. Kafka Exporter の設定
KafkaExporter プロパティーを使用して、Kafka リソースの Kafka Exporter を設定します。
Kafka リソースとそのプロパティーの概要は、「Kafka YAML の設定例」を参照してください。
この手順では、Kafka Exporter 設定に関連するプロパティーを取り上げます。
これらのプロパティーは、Kafka クラスターのデプロイメントまたは再デプロイメントの一部として設定できます。
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
KafkaリソースのKafkaExporterプロパティーを編集します。設定可能なプロパティーは以下の例のとおりです。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc apply -f kafka.yaml
oc apply -f kafka.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
次のステップ
Kafka Exporter の設定およびデプロイ後に、Grafana を有効にして Kafka Exporter ダッシュボードを表示できます。
その他のリソース
3.1.23. Kafka クラスターのローリングアップデートの実行
この手順では、OpenShift アノテーションを使用して、既存の Kafka クラスターのローリングアップデートを手動でトリガーする方法を説明します。
前提条件
- 稼働中の Kafka クラスター。
- 稼働中の Cluster Operator。
手順
手動で更新する Kafka Pod を制御する
StatefulSetの名前を見つけます。たとえば、Kafka クラスターの名前が my-cluster の場合、対応する
StatefulSetの名前は my-cluster-kafka になります。OpenShift で
StatefulSetリソースにアノテーションを付けます。以下はoc annotateを使用した例になります。oc annotate statefulset cluster-name-kafka strimzi.io/manual-rolling-update=true
oc annotate statefulset cluster-name-kafka strimzi.io/manual-rolling-update=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
次の調整が発生するまで待ちます (デフォルトでは 2 分ごとです)。アノテーションが調整プロセスで検出されれば、アノテーションが付いた
StatefulSet内のすべての Pod でローリングアップデートがトリガーされます。すべての Pod のローリングアップデートが完了すると、アノテーションはStatefulSetから削除されます。
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
- Kafka クラスターのデプロイメントに関する詳細は、「Kafka クラスターのデプロイメント」 を参照してください。
3.1.24. ZooKeeper クラスターのローリングアップデートの実行
この手順では、OpenShift アノテーションを使用して、既存の ZooKeeper クラスターのローリングアップデートを手動でトリガーする方法を説明します。
前提条件
- 稼働中の ZooKeeper クラスター。
- 稼働中の Cluster Operator。
手順
手動で更新する ZooKeeper Pod を制御する
StatefulSetの名前を見つけます。たとえば、Kafka クラスターの名前が my-cluster の場合、対応する
StatefulSetの名前は my-cluster-zookeeper になります。OpenShift で
StatefulSetリソースにアノテーションを付けます。以下はoc annotateを使用した例になります。oc annotate statefulset cluster-name-zookeeper strimzi.io/manual-rolling-update=true
oc annotate statefulset cluster-name-zookeeper strimzi.io/manual-rolling-update=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
次の調整が発生するまで待ちます (デフォルトでは 2 分ごとです)。アノテーションが調整プロセスで検出されれば、アノテーションが付いた
StatefulSet内のすべての Pod でローリングアップデートがトリガーされます。すべての Pod のローリングアップデートが完了すると、アノテーションはStatefulSetから削除されます。
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
- ZooKeeper クラスターのデプロイメントに関する詳細は、「Kafka クラスターのデプロイメント」 を参照してください。
3.1.25. クラスターのスケーリング
3.1.25.1. Kafka クラスターのスケーリング
3.1.25.1.1. ブローカーのクラスターへの追加
トピックのスループットを向上させる主な方法は、そのトピックのパーティション数を増やすことです。これにより、追加のパーティションによってクラスター内の異なるブローカー間でトピックの負荷が共有されます。ただし、各ブローカーが特定のリソース (通常は I/O) によって制約される場合、パーティションを増やしてもスループットは向上しません。代わりに、ブローカーをクラスターに追加する必要があります。
追加のブローカーをクラスターに追加する場合、Kafka ではパーティションは自動的に割り当てられません。既存のブローカーから新規のブローカーに移動するパーティションを決定する必要があります。
すべてのブローカー間でパーティションが再分散されたら、各ブローカーのリソース使用率が低下するはずです。
3.1.25.1.2. クラスターからのブローカーの削除
AMQ Streams では StatefulSets を使用してブローカー Pod を管理されるため、あらゆる Pod を削除できるわけではありません。クラスターから削除できるのは、番号が最も大きい 1 つまたは複数の Pod のみです。たとえば、12 個のブローカーがあるクラスターでは、Pod の名前は cluster-name-kafka-0 から cluster-name-kafka-11 になります。1 つのブローカー分をスケールダウンする場合、cluster-name-kafka-11 が削除されます。
クラスターからブローカーを削除する前に、そのブローカーにパーティションが割り当てられていないことを確認します。また、使用が停止されたブローカーの各パーティションを引き継ぐ、残りのブローカーを決める必要もあります。ブローカーに割り当てられたパーティションがなければ、クラスターを安全にスケールダウンできます。
3.1.25.2. パーティションの再割り当て
現在、Topic Operator はレプリカを別のブローカーに再割当てすることをサポートしないため、ブローカー Pod に直接接続してレプリカをブローカーに再割り当てする必要があります。
ブローカー Pod 内では、kafka-reassign-partitions.sh ユーティリティーを使用してパーティションを別のブローカーに再割り当てできます。
これには、以下の 3 つのモードがあります。
--generate- トピックとブローカーのセットを取り、再割り当て JSON ファイル を生成します。これにより、トピックのパーティションがブローカーに割り当てられます。これはトピック全体で動作するため、一部のトピックのパーティションを再割り当てする必要がある場合は使用できません。
--execute- 再割り当て JSON ファイル を取り、クラスターのパーティションおよびブローカーに適用します。その結果、パーティションを取得したブローカーは、パーティションリーダーのフォロワーになります。新規ブローカーが ISR (In-Sync Replica、同期レプリカ) に参加できたら、古いブローカーはフォロワーではなくなり、そのレプリカが削除されます。
--verify-
--verifyは、--executeステップと同じ 再割り当て JSON ファイル を使用して、ファイル内のすべてのパーティションが目的のブローカーに移動されたかどうかを確認します。再割り当てが完了すると、--verify は有効な スロットル も削除します。スロットルを削除しないと、再割り当てが完了した後もクラスターは影響を受け続けます。
クラスターでは、1 度に 1 つの再割当てのみを実行でき、実行中の再割当てをキャンセルすることはできません。再割り当てをキャンセルする必要がある場合は、割り当てが完了するのを待ってから別の再割り当てを実行し、最初の再割り当ての結果を元に戻します。kafka-reassign-partitions.sh によって、元に戻すための再割り当て JSON が出力の一部として生成されます。大規模な再割り当ては、進行中の再割り当てを停止する必要がある場合に備えて、複数の小さな再割り当てに分割するようにしてください。
3.1.25.2.1. 再割り当て JSON ファイル
再割り当て JSON ファイル には特定の構造があります。
ここで <PartitionObjects> は、以下のようなコンマ区切りのオブジェクトリストになります。
{
"topic": <TopicName>,
"partition": <Partition>,
"replicas": [ <AssignedBrokerIds> ]
}
{
"topic": <TopicName>,
"partition": <Partition>,
"replicas": [ <AssignedBrokerIds> ]
}
Kafka は "log_dirs" プロパティーもサポートしますが、Red Hat AMQ Streams では使用しないでください。
以下は、トピック topic-a およびパーティション 4 をブローカー 2、4、および 7 に割り当て、トピック topic-b およびパーティション 2 をブローカー 1、5、および 7 に割り当てる、再割り当て JSON ファイルの例になります。
JSON に含まれていないパーティションは変更されません。
3.1.25.2.2. JBOD ボリューム間でのパーティションの再割り当て
Kafka クラスターで JBOD ストレージを使用する場合は、特定のボリュームとログディレクトリー (各ボリュームに単一のログディレクトリーがある) との間でパーティションを再割り当てを選択することができます。パーティションを特定のボリュームに再割り当てするには、再割り当て JSON ファイルで log_dirs オプションを <PartitionObjects> に追加します。
log_dirs オブジェクトに含まれるログディレクトリーの数は、replicas オブジェクトで指定されるレプリカ数と同じである必要があります。値は、ログディレクトリーへの絶対パスか、any キーワードである必要があります。
以下に例を示します。
3.1.25.3. 再割り当て JSON ファイルの生成
この手順では、kafka-reassign-partitions.sh ツールを使用して、指定のトピックセットすべてのパーティションを再割り当てする再割り当て JSON ファイルを生成する方法を説明します。
前提条件
- 稼働中の Cluster Operator が必要です。
-
Kafkaリソース - パーティションを再割り当てするトピックセット。
手順
移動するトピックを一覧表示する
topics.jsonという名前の JSON ファイルを準備します。これには、以下の構造が必要です。Copy to Clipboard Copied! Toggle word wrap Toggle overflow ここで <TopicObjects> は、以下のようなコンマ区切りのオブジェクトリストになります。
{ "topic": <TopicName> }{ "topic": <TopicName> }Copy to Clipboard Copied! Toggle word wrap Toggle overflow たとえば、
topic-aとtopic-bのすべてのパーティションを再割り当てするには、以下のようなtopics.jsonファイルを準備する必要があります。Copy to Clipboard Copied! Toggle word wrap Toggle overflow topics.jsonファイルをブローカー Pod の 1 つにコピーします。cat topics.json | oc exec -c kafka <BrokerPod> -i -- \ /bin/bash -c \ 'cat > /tmp/topics.json'
cat topics.json | oc exec -c kafka <BrokerPod> -i -- \ /bin/bash -c \ 'cat > /tmp/topics.json'Copy to Clipboard Copied! Toggle word wrap Toggle overflow kafka-reassign-partitions.shコマンドを使用して、再割り当て JSON を生成します。oc exec <BrokerPod> -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --topics-to-move-json-file /tmp/topics.json \ --broker-list <BrokerList> \ --generate
oc exec <BrokerPod> -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --topics-to-move-json-file /tmp/topics.json \ --broker-list <BrokerList> \ --generateCopy to Clipboard Copied! Toggle word wrap Toggle overflow たとえば、
topic-aおよびtopic-bのすべてのパーティションをブローカー4および7に移動する場合は、以下を実行します。oc exec <BrokerPod> -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --topics-to-move-json-file /tmp/topics.json \ --broker-list 4,7 \ --generate
oc exec <BrokerPod> -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --topics-to-move-json-file /tmp/topics.json \ --broker-list 4,7 \ --generateCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.1.25.4. 手動による再割り当て JSON ファイルの作成
特定のパーティションを移動したい場合は、再割り当て JSON ファイルを手動で作成できます。
3.1.25.5. 再割り当てスロットル
パーティションの再割り当てには、ブローカーの間で大量のデータを転送する必要があるため、処理が遅くなる可能性があります。クライアントへの悪影響を防ぐため、再割り当て処理をスロットルで調整することができます。これにより、再割り当ての完了に時間がかかる可能性があります。
- スロットルが低すぎると、新たに割り当てられたブローカーは公開されるレコードに遅れずに対応することはできず、再割り当ては永久に完了しません。
- スロットルが高すぎると、クライアントに影響します。
たとえば、プロデューサーの場合は、承認待ちが通常のレイテンシーよりも大きくなる可能性があります。コンシューマーの場合は、ポーリング間のレイテンシーが大きいことが原因でスループットが低下する可能性があります。
3.1.25.6. Kafka クラスターのスケールアップ
この手順では、Kafka クラスターでブローカーの数を増やす方法を説明します。
前提条件
- 既存の Kafka クラスター。
-
拡大されたクラスターでパーティションをブローカーに再割り当てする方法が記述される
reassignment.jsonというファイル名の 再割り当て JSON ファイル。
手順
-
Kafka.spec.kafka.replicas設定オプションを増やして、新しいブローカーを必要なだけ追加します。 - 新しいブローカー Pod が起動したことを確認します。
後でコマンドを実行するブローカー Pod に
reassignment.jsonファイルをコピーします。cat reassignment.json | \ oc exec broker-pod -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'
cat reassignment.json | \ oc exec broker-pod -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
cat reassignment.json | \ oc exec my-cluster-kafka-0 -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'
cat reassignment.json | \ oc exec my-cluster-kafka-0 -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 同じブローカー Pod から
kafka-reassign-partitions.shコマンドラインツールを使用して、パーティションの再割り当てを実行します。oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --execute
oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --executeCopy to Clipboard Copied! Toggle word wrap Toggle overflow レプリケーションをスロットルで調整する場合、
--throttleとブローカー間のスロットル率 (バイト/秒単位) を渡すこともできます。以下に例を示します。oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 5000000 \ --execute
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 5000000 \ --executeCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、2 つの再割り当て JSON オブジェクトを出力します。最初の JSON オブジェクトには、移動されたパーティションの現在の割り当てが記録されます。後で再割り当てを元に戻す必要がある場合に備え、この値をローカルファイル (Pod のファイル以外) に保存します。2 つ目の JSON オブジェクトは、再割り当て JSON ファイルに渡した目的の再割り当てです。
再割り当ての最中にスロットルを変更する必要がある場合は、同じコマンドラインに別のスロットル率を指定して実行します。以下に例を示します。
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 10000000 \ --execute
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 10000000 \ --executeCopy to Clipboard Copied! Toggle word wrap Toggle overflow ブローカー Pod のいずれかから
kafka-reassign-partitions.shコマンドラインツールを使用して、再割り当てが完了したかどうかを定期的に確認します。これは先ほどの手順と同じコマンドですが、--executeオプションの代わりに--verifyオプションを使用します。oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --verify
oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --verifyCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例:
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --verify
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --verifyCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
--verifyコマンドによって、移動した各パーティションが正常に完了したことが報告されると、再割り当ては終了します。この最終的な--verifyによって、結果的に再割り当てスロットルも削除されます。割り当てを元のブローカーに戻すために JSON ファイルを保存した場合は、ここでそのファイルを削除できます。
3.1.25.7. Kafka クラスターのスケールダウン
その他のリソース
この手順では、Kafka クラスターでブローカーの数を減らす方法を説明します。
前提条件
- 既存の Kafka クラスター。
-
最も番号の大きい
Pod(s)のブローカーが削除された後にクラスターのブローカーにパーティションを再割り当てする方法が記述されている、reassignment.jsonという名前の 再割り当て JSON ファイル。
手順
後でコマンドを実行するブローカー Pod に
reassignment.jsonファイルをコピーします。cat reassignment.json | \ oc exec broker-pod -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'
cat reassignment.json | \ oc exec broker-pod -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
cat reassignment.json | \ oc exec my-cluster-kafka-0 -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'
cat reassignment.json | \ oc exec my-cluster-kafka-0 -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 同じブローカー Pod から
kafka-reassign-partitions.shコマンドラインツールを使用して、パーティションの再割り当てを実行します。oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --execute
oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --executeCopy to Clipboard Copied! Toggle word wrap Toggle overflow レプリケーションをスロットルで調整する場合、
--throttleとブローカー間のスロットル率 (バイト/秒単位) を渡すこともできます。以下に例を示します。oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 5000000 \ --execute
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 5000000 \ --executeCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、2 つの再割り当て JSON オブジェクトを出力します。最初の JSON オブジェクトには、移動されたパーティションの現在の割り当てが記録されます。後で再割り当てを元に戻す必要がある場合に備え、この値をローカルファイル (Pod のファイル以外) に保存します。2 つ目の JSON オブジェクトは、再割り当て JSON ファイルに渡した目的の再割り当てです。
再割り当ての最中にスロットルを変更する必要がある場合は、同じコマンドラインに別のスロットル率を指定して実行します。以下に例を示します。
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 10000000 \ --execute
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 10000000 \ --executeCopy to Clipboard Copied! Toggle word wrap Toggle overflow ブローカー Pod のいずれかから
kafka-reassign-partitions.shコマンドラインツールを使用して、再割り当てが完了したかどうかを定期的に確認します。これは先ほどの手順と同じコマンドですが、--executeオプションの代わりに--verifyオプションを使用します。oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --verify
oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --verifyCopy to Clipboard Copied! Toggle word wrap Toggle overflow 例:
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --verify
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 \ --reassignment-json-file /tmp/reassignment.json \ --verifyCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
--verifyコマンドによって、移動した各パーティションが正常に完了したことが報告されると、再割り当ては終了します。この最終的な--verifyによって、結果的に再割り当てスロットルも削除されます。割り当てを元のブローカーに戻すために JSON ファイルを保存した場合は、ここでそのファイルを削除できます。 すべてのパーティションの再割り当てが終了すると、削除されるブローカーはクラスター内のいずれのパーティションにも対応しないはずです。これは、ブローカーのデータログディレクトリーにライブパーティションのログが含まれていないことを確認すると検証できます。ブローカーのログディレクトリーに、拡張正規表現
\.[a-z0-9]-delete$と一致しないディレクトリーが含まれる場合、ブローカーにライブパーティションがあるため、停止してはなりません。これを確認するには、以下のコマンドを実行します。
oc exec my-cluster-kafka-0 -c kafka -it -- \ /bin/bash -c \ "ls -l /var/lib/kafka/kafka-log_<N>_ | grep -E '^d' | grep -vE '[a-zA-Z0-9.-]+\.[a-z0-9]+-delete$'"
oc exec my-cluster-kafka-0 -c kafka -it -- \ /bin/bash -c \ "ls -l /var/lib/kafka/kafka-log_<N>_ | grep -E '^d' | grep -vE '[a-zA-Z0-9.-]+\.[a-z0-9]+-delete$'"Copy to Clipboard Copied! Toggle word wrap Toggle overflow N は削除された
Pod(s)の数に置き換えます。上記のコマンドによって出力が生成される場合、ブローカーにはライブパーティションがあります。この場合、再割り当てが終了していないか、再割り当て JSON ファイルが適切ではありません。
-
ブローカーにライブパーティションがないことが確認できたら、
KafkaリソースのKafka.spec.kafka.replicasを編集できます。これにより、StatefulSetがスケールダウンされ、番号が最も大きいブローカーPod(s)が削除されます。
3.1.26. Kafka ノードの手動による削除
その他のリソース
この手順では、OpenShift アノテーションを使用して既存の Kafka ノードを削除する方法を説明します。Kafka ノードの削除するには、Kafka ブローカーが稼働している Pod と、関連する PersistentVolumeClaim の両方を削除します (クラスターが永続ストレージでデプロイされた場合)。削除後、Pod と関連する PersistentVolumeClaim は自動的に再作成されます。
PersistentVolumeClaim を削除すると、データが永久に失われる可能性があります。以下の手順は、ストレージで問題が発生した場合にのみ実行してください。
前提条件
- 稼働中の Kafka クラスター。
- 稼働中の Cluster Operator。
手順
削除する
Podの名前を見つけます。たとえば、クラスターの名前が cluster-name の場合、Pod の名前は cluster-name-kafka-index になります。index はゼロで始まり、レプリカーの合計数で終わる値です。
OpenShift で
Podリソースにアノテーションを付けます。oc annotateを使用します。oc annotate pod cluster-name-kafka-index strimzi.io/delete-pod-and-pvc=true
oc annotate pod cluster-name-kafka-index strimzi.io/delete-pod-and-pvc=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 基盤となる永続ボリューム要求 (Persistent Volume Claim) でアノテーションが付けられた Pod が削除され、再作成されるときに次の調整の実行を待ちます。
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
- Kafka クラスターのデプロイメントに関する詳細は、「Kafka クラスターのデプロイメント」 を参照してください。
3.1.27. ZooKeeper ノードの手動による削除
この手順では、OpenShift アノテーションを使用して既存の ZooKeeper ノードを削除する方法を説明します。ZooKeeper ノードの削除するには、ZooKeeper が稼働している Pod と、関連する PersistentVolumeClaim の両方を削除します (クラスターが永続ストレージでデプロイされた場合)。削除後、Pod と関連する PersistentVolumeClaim は自動的に再作成されます。
PersistentVolumeClaim を削除すると、データが永久に失われる可能性があります。以下の手順は、ストレージで問題が発生した場合にのみ実行してください。
前提条件
- 稼働中の ZooKeeper クラスター。
- 稼働中の Cluster Operator。
手順
削除する
Podの名前を見つけます。たとえば、クラスターの名前が cluster-name の場合、Pod の名前は cluster-name-zookeeper-index になります。index はゼロで始まり、レプリカーの合計数で終わる値です。
OpenShift で
Podリソースにアノテーションを付けます。oc annotateを使用します。oc annotate pod cluster-name-zookeeper-index strimzi.io/delete-pod-and-pvc=true
oc annotate pod cluster-name-zookeeper-index strimzi.io/delete-pod-and-pvc=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 基盤となる永続ボリューム要求 (Persistent Volume Claim) でアノテーションが付けられた Pod が削除され、再作成されるときに次の調整の実行を待ちます。
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
- ZooKeeper クラスターのデプロイメントに関する詳細は、「Kafka クラスターのデプロイメント」 を参照してください。
3.1.28. ローリングアップデートのメンテナンス時間枠
メンテナンス時間枠によって、Kafka および ZooKeeper クラスターの特定のローリングアップデートが便利な時間に開始されるようにスケジュールできます。
3.1.28.1. メンテナンス時間枠の概要
ほとんどの場合、Cluster Operator は対応する Kafka リソースの変更に対応するために Kafka または ZooKeeper クラスターのみを更新します。これにより、Kafka リソースの変更を適用するタイミングを計画し、Kafka クライアントアプリケーションへの影響を最小限に抑えることができます。
ただし、Kafka リソースの変更がなくても Kafka および ZooKeeper クラスターの更新が発生することがあります。たとえば、Cluster Operator によって管理される CA (認証局) 証明書が期限切れ直前である場合にローリング再起動の実行が必要になります。
サービスの 可用性 は Pod のローリング再起動による影響を受けないはずですが (ブローカーおよびトピックの設定が適切である場合)、Kafka クライアントアプリケーションの パフォーマンス は影響を受ける可能性があります。メンテナンス時間枠によって、Kafka および ZooKeeper クラスターのこのような自発的なアップデートが便利な時間に開始されるようにスケジュールできます。メンテナンス時間枠がクラスターに設定されていない場合は、予測できない高負荷が発生する期間など、不便な時間にこのような自発的なローリングアップデートが行われる可能性があります。
3.1.28.2. メンテナンス時間枠の定義
Kafka.spec.maintenanceTimeWindows プロパティーに文字列の配列を入力して、メンテナンス時間枠を設定します。各文字列は、UTC (協定世界時、Coordinated Universal Time) であると解釈される cron 式 です。UTC は実用的にはグリニッジ標準時と同じです。
以下の例では、日、月、火、水、および木曜日の午前 0 時に開始し、午前 1 時 59 分 (UTC) に終わる、単一のメンテナンス時間枠が設定されます。
# ... maintenanceTimeWindows: - "* * 0-1 ? * SUN,MON,TUE,WED,THU *" # ...
# ...
maintenanceTimeWindows:
- "* * 0-1 ? * SUN,MON,TUE,WED,THU *"
# ...
実際には、必要な CA 証明書の更新が設定されたメンテナンス時間枠内で完了できるように、Kafka リソースの Kafka.spec.clusterCa.renewalDays および Kafka.spec.clientsCa.renewalDays プロパティーとともにメンテナンス期間を設定する必要があります。
AMQ Streams では、指定の期間にしたがってメンテナンス操作を正確にスケジュールしません。その代わりに、調整ごとにメンテナンス期間が現在「オープン」であるかどうかを確認します。これは、特定の時間枠内でのメンテナンス操作の開始が、最大で Cluster Operator の調整が行われる間隔の長さ分、遅れる可能性があることを意味します。したがって、メンテナンス時間枠は最低でもその間隔の長さにする必要があります。
その他のリソース
- Cluster Operator 設定についての詳細は、「Cluster Operator の設定」 を参照してください。
3.1.28.3. メンテナンス時間枠の設定
サポートされるプロセスによってトリガーされるローリングアップデートのメンテナンス時間枠を設定できます。
前提条件
- OpenShift クラスターが必要です。
- Cluster Operator が稼働している必要があります。
手順
KafkaリソースでmaintenanceTimeWindowsプロパティーを追加または編集します。たとえば、0800 から 1059 までと、1400 から 1559 までのメンテナンスを可能にするには、以下のようにmaintenanceTimeWindowsを設定します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
- Kafka クラスターのローリングアップデートの実行については、「Kafka クラスターのローリングアップデートの実行」 を参照してください。
- ZooKeeper クラスターのローリングアップデートの実行については、「ZooKeeper クラスターのローリングアップデートの実行」 を参考してください。
3.1.29. CA 証明書の手動更新
Kafka.spec.clusterCa.generateCertificateAuthority および Kafka.spec.clientsCa.generateCertificateAuthority オブジェクトが false に設定されていない限り、クラスターおよびクライアント CA 証明書は、それぞれの証明書の更新期間の開始時に自動で更新されます。セキュリティー上の理由で必要であれば、証明書の更新期間が始まる前に、これらの証明書のいずれかまたは両方を手動で更新できます。更新された証明書は、古い証明書と同じ秘密鍵を使用します。
前提条件
- Cluster Operator が稼働している必要があります。
- CA 証明書と秘密鍵がインストールされている Kafka クラスターが必要です。
手順
strimzi.io/force-renewアノテーションを、更新対象の CA 証明書が含まれるSecretに適用します。Expand 証明書 Secret annotate コマンド クラスター CA
<cluster-name>-cluster-ca-cert
oc annotate secret <cluster-name>-cluster-ca-cert strimzi.io/force-renew=trueクライアント CA
<cluster-name>-clients-ca-cert
oc annotate secret <cluster-name>-clients-ca-cert strimzi.io/force-renew=true
次回の調整で、アノテーションを付けた Secret の新規 CA 証明書が Cluster Operator によって生成されます。メンテナンス時間枠が設定されている場合、Cluster Operator によって、最初の調整時に次のメンテナンス時間枠内で新規 CA 証明書が生成されます。
Cluster Operator によって更新されたクラスターおよびクライアント CA 証明書をクライアントアプリケーションがリロードする必要があります。
3.1.30. 秘密鍵の置換
クラスター CA およびクライアント CA 証明書によって使用される秘密鍵を交換できます。秘密鍵を交換すると、Cluster Operator は新しい秘密鍵の新規 CA 証明書を生成します。
前提条件
- Cluster Operator が稼働している必要があります。
- CA 証明書と秘密鍵がインストールされている Kafka クラスターが必要です。
手順
strimzi.io/force-replaceアノテーションを、更新対象の秘密鍵が含まれるSecretに適用します。Expand 秘密鍵 Secret annotate コマンド クラスター CA
<cluster-name>-cluster-ca
oc annotate secret <cluster-name>-cluster-ca strimzi.io/force-replace=trueクライアント CA
<cluster-name>-clients-ca
oc annotate secret <cluster-name>-clients-ca strimzi.io/force-replace=true
次回の調整時に、Cluster Operator は以下を生成します。
-
アノテーションを付けた
Secretの新しい秘密鍵 - 新規 CA 証明書
メンテナンス時間枠が設定されている場合、Cluster Operator によって、最初の調整時に次のメンテナンス時間枠内で新しい秘密鍵と CA 証明書が生成されます。
Cluster Operator によって更新されたクラスターおよびクライアント CA 証明書をクライアントアプリケーションがリロードする必要があります。
その他のリソース
3.1.31. Kafka クラスターの一部として作成されたリソースの一覧
以下のリソースは、OpenShift クラスターの Cluster Operator によって作成されます。
cluster-name-kafka- Kafka ブローカー Pod の管理を担当する StatefulSet。
cluster-name-kafka-brokers- DNS が Kafka ブローカー Pod の IP アドレスを直接解決するのに必要なサービス。
cluster-name-kafka-bootstrap- サービスは、Kafka クライアントのブートストラップサーバーとして使用できます。
cluster-name-kafka-external-bootstrap- OpenShift クラスター外部から接続するクライアントのブートストラップサービス。このリソースは、外部リスナーが有効な場合にのみ作成されます。
cluster-name-kafka-pod-id- トラフィックを OpenShift クラスターの外部から個別の Pod にルーティングするために使用されるサービス。このリソースは、外部リスナーが有効な場合にのみ作成されます。
cluster-name-kafka-external-bootstrap-
OpenShift クラスターの外部から接続するクライアントのブートストラップルート。このリソースは、外部リスナーが有効になっていて、タイプ
routeに設定されている場合にのみ作成されます。 cluster-name-kafka-pod-id-
OpenShift クラスターの外部から個別の Pod へのトラフィックに対するルート。このリソースは、外部リスナーが有効になっていて、タイプ
routeに設定されている場合にのみ作成されます。 cluster-name-kafka-config- Kafka 補助設定が含まれ、Kafka ブローカー Pod によってボリュームとしてマウントされる ConfigMap。
cluster-name-kafka-brokers- Kafka ブローカーキーのあるシークレット。
cluster-name-kafka- Kafka ブローカーによって使用されるサービスアカウント。
cluster-name-kafka- Kafka ブローカーに設定された Pod の Disruption Budget。
strimzi-namespace-name-cluster-name-kafka-init- Kafka ブローカーによって使用されるクラスターロールバインディング。
cluster-name-zookeeper- ZooKeeper ノード Pod の管理を担当する StatefulSet。
cluster-name-zookeeper-nodes- DNS が ZooKeeper Pod の IP アドレスを直接解決するのに必要なサービス。
cluster-name-zookeeper-client- Kafka ブローカーがクライアントとして ZooKeeper ノードに接続するために使用するサービス。
cluster-name-zookeeper-config- ZooKeeper 補助設定が含まれ、ZooKeeper ノード Pod によってボリュームとしてマウントされる ConfigMap。
cluster-name-zookeeper-nodes- ZooKeeper ノードキーがあるシークレット。
cluster-name-zookeeper- ZooKeeper ノードに設定された Pod の Disruption Budget。
cluster-name-entity-operator- Topic および User Operator とのデプロイメント。このリソースは、Cluster Operator によって Entity Operator がデプロイされた場合のみ作成されます。
cluster-name-entity-topic-operator-config- Topic Operator の補助設定のある ConfigMap。このリソースは、Cluster Operator によって Entity Operator がデプロイされた場合のみ作成されます。
cluster-name-entity-user-operator-config- User Operator の補助設定のある ConfigMap。このリソースは、Cluster Operator によって Entity Operator がデプロイされた場合のみ作成されます。
cluster-name-entity-operator-certs- Kafka および ZooKeeper と通信するための Entity Operator キーのあるシークレット。このリソースは、Cluster Operator によって Entity Operator がデプロイされた場合のみ作成されます。
cluster-name-entity-operator- Entity Operator によって使用されるサービスアカウント。
strimzi-cluster-name-topic-operator- Entity Operator によって使用されるロールバインディング。
strimzi-cluster-name-user-operator- Entity Operator によって使用されるロールバインディング。
cluster-name-cluster-ca- クラスター通信の暗号化に使用されるクラスター CA のあるシークレット。
cluster-name-cluster-ca-cert- クラスター CA 公開鍵のあるシークレット。このキーは、Kafka ブローカーのアイデンティティーの検証に使用できます。
cluster-name-clients-ca- Kafka ブローカーと Kafka クライアントとの間の通信を暗号化するために使用されるクライアント CA のあるシークレット。
cluster-name-clients-ca-cert- クライアント CA 公開鍵のあるシークレット。このキーは、Kafka ブローカーのアイデンティティーの検証に使用できます。
cluster-name-cluster-operator-certs- Kafka および ZooKeeper と通信するための Cluster Operator キーのあるシークレット。
data-cluster-name-kafka-idx-
Kafka ブローカー Pod
idxのデータを保存するために使用されるボリュームの永続ボリューム要求です。このリソースは、データを保存するために永続ボリュームのプロビジョニングに永続ストレージが選択された場合のみ作成されます。 data-id-cluster-name-kafka-idx-
Kafka ブローカー Pod
idxのデータを保存するために使用されるボリュームidの永続ボリューム要求です。このリソースは、永続ボリュームをプロビジョニングしてデータを保存する場合に、JBOD ボリュームに永続ストレージが選択された場合のみ作成されます。 data-cluster-name-zookeeper-idx-
ZooKeeper ノード Pod
idxのデータを保存するために使用されるボリュームの永続ボリューム要求です。このリソースは、データを保存するために永続ボリュームのプロビジョニングに永続ストレージが選択された場合のみ作成されます。 cluster-name-jmx- Kafka ブローカーポートのセキュア化に使用される JMX ユーザー名およびパスワードのあるシークレット。
3.2. Kafka Connect クラスターの設定
KafkaConnect リソースの完全なスキーマは 「KafkaConnect スキーマ参照」 に記載されています。指定の KafkaConnect リソースに適用されたすべてのラベルは、Kafka Connect クラスターを構成する OpenShift リソースにも適用されます。そのため、必要に応じてリソースにラベルが適用されるため便利です。
3.2.1. レプリカ
Kafka Connect クラスターは、1 つ以上のノードで構成されます。ノードの数は KafkaConnect および KafkaConnectS2I リソースで定義されます。Kafka Connect クラスターを複数のノードで実行すると、可用性とスケーラビリティーが向上します。ただし、OpenShift で Kafka Connect を実行する場合は、高可用性のために Kafka Connect で複数のノードを実行する必要はありません。Kafka Connect がデプロイされたノードがクラッシュした場合、OpenShift によって Kafka Connect Pod が別のノードに自動的に再スケジュールされます。ただし、他のノードがすでに稼働しているため、Kafka Connect を複数のノードで実行すると、より高速なフェイルオーバーを実現できます。
3.2.1.1. ノード数の設定
Kafka Connect ノードの数は、KafkaConnect.spec および KafkaConnectS2I.spec の replicas プロパティーを使用して設定されます。
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
KafkaConnectまたはKafkaConnectS2Iリソースのreplicasプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.2. ブートストラップサーバー
Kafka Connect クラスターは、常に Kafka クラスターと組み合わせて動作します。Kafka クラスターはブートストラップサーバーのリストとして指定されます。OpenShift では、そのリストに cluster-name-kafka-bootstrap という名前の Kafka クラスターブートストラップサービスが含まれ、さらに平文トラフィックの場合はポート 9092、暗号化されたトラフィックの場合はポート 9093 が含まれることが理想的です。
ブートストラップサーバーのリストは、KafkaConnect.spec および KafkaConnectS2I.spec の bootstrapServers プロパティーで設定されます。サーバーは、1 つ以上の Kafka ブローカーを指定するコンマ区切りリスト、または hostname:_port_ ペアとして指定される Kafka ブローカーを示すサービスとして定義される必要があります。
AMQ Streams によって管理されない Kafka クラスターで Kafka Connect を使用する場合は、クラスターの設定に応じてブートストラップサーバーのリストを指定できます。
3.2.2.1. ブートストラップサーバーの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
KafkaConnectまたはKafkaConnectS2IリソースのbootstrapServersプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.3. TLS を使用した Kafka ブローカーへの接続
デフォルトでは、Kafka Connect はプレーンテキスト接続を使用して Kafka ブローカーへの接続を試みます。TLS を使用する場合は、追加の設定が必要です。
3.2.3.1. Kafka Connect での TLS サポート
TLS サポートは、KafkaConnect.spec および KafkaConnectS2I.spec の tls プロパティーで設定されます。tls プロパティーには、保存される証明書のキー名があるシークレットのリストが含まれます。証明書は X509 形式で保存する必要があります。
複数の証明書がある TLS 設定の例
複数の証明書が同じシークレットに保存されている場合は、複数回リストできます。
同じシークレットに複数の証明書がある TLS 設定の例
3.2.3.2. Kafka Connect での TLS の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
-
TLS サーバー認証に使用される証明書の
Secretの名前と、Secretに保存された証明書のキー (存在する場合)。
手順
(任意手順): 認証で使用される TLS 証明書が存在しない場合はファイルで準備し、
Secretを作成します。注記Kafka クラスターの Cluster Operator によって作成されるシークレットは直接使用されることがあります。
oc createを使用してこれを行うことができます。oc create secret generic my-secret --from-file=my-file.crt
oc create secret generic my-secret --from-file=my-file.crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow KafkaConnectまたはKafkaConnectS2Iリソースのtlsプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.4. 認証での Kafka ブローカーへの接続
デフォルトでは、Kafka Connect は認証なしで Kafka ブローカーへの接続を試みます。認証は KafkaConnect および KafkaConnectS2I リソースにより有効になります。
3.2.4.1. Kafka Connect での認証サポート
認証は、KafkaConnect.spec および KafkaConnectS2I.spec の authentication プロパティーで設定されます。authentication プロパティーによって、使用する認証メカニズムのタイプと、メカニズムに応じた追加設定の詳細が指定されます。サポートされる認証タイプは次のとおりです。
- TLS クライアント認証
- SCRAM-SHA-512 メカニズムを使用した SASL ベースの認証
- PLAIN メカニズムを使用した SASL ベースの認証
- OAuth 2.0 のトークンベースの認証
3.2.4.1.1. TLS クライアント認証
TLS クライアント認証を使用するには、type プロパティーを tls の値に設定します。TLS クライアント認証は TLS 証明書を使用して認証します。証明書は certificateAndKey プロパティーで指定され、常に OpenShift シークレットからロードされます。シークレットでは、公開鍵と秘密鍵の 2 つの鍵を使用して証明書を X509 形式で保存する必要があります。
TLS クライアント認証は TLS 接続でのみ使用できます。Kafka Connect の TLS 設定の詳細は 「TLS を使用した Kafka ブローカーへの接続」 を参照してください。
TLS クライアント認証の設定例
3.2.4.1.2. SASL ベースの SCRAM-SHA-512 認証
Kafka Connect で SASL ベースの SCRAM-SHA-512 認証が使用されるようにするには、type プロパティーを scram-sha-512 に設定します。この認証メカニズムには、ユーザー名とパスワードが必要です。
-
usernameプロパティーでユーザー名を指定します。 -
passwordSecretプロパティーで、パスワードを含むSecretへのリンクを指定します。secretNameプロパティーにはSecretの名前が含まれ、passwordプロパティーにはSecret内にパスワードが格納されるキーの名前が含まれます。
password フィールドには、実際のパスワードを指定しないでください。
SASL ベースの SCRAM-SHA-512 クライアント認証の設定例
3.2.4.1.3. SASL ベースの PLAIN 認証
Kafka Connect で SASL ベースの PLAIN 認証が使用されるようにするには、type プロパティーを plain に設定します。この認証メカニズムには、ユーザー名とパスワードが必要です。
SASL PLAIN メカニズムでは、ネットワーク全体でユーザー名とパスワードがプレーンテキストで転送されます。TLS 暗号化が有効になっている場合にのみ SASL PLAIN 認証を使用します。
-
usernameプロパティーでユーザー名を指定します。 -
passwordSecretプロパティーで、パスワードを含むSecretへのリンクを指定します。secretNameプロパティーにはそのようなSecretの名前が含まれ、passwordプロパティーにはSecret内にパスワードが格納されるキーの名前が含まれます。
password フィールドには、実際のパスワードを指定しないでください。
SASL ベースの PLAIN クライアント認証の設定例
3.2.4.2. Kafka Connect での TLS クライアント認証の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
-
TLS クライアント認証に使用される公開鍵と秘密鍵がある
Secret、およびSecretに保存される公開鍵と秘密鍵のキー (存在する場合)。
手順
(任意手順): 認証に使用される鍵が存在しない場合はファイルで準備し、
Secretを作成します。注記User Operator によって作成されたシークレットを使用できます。
oc createを使用してこれを行うことができます。oc create secret generic my-secret --from-file=my-public.crt --from-file=my-private.key
oc create secret generic my-secret --from-file=my-public.crt --from-file=my-private.keyCopy to Clipboard Copied! Toggle word wrap Toggle overflow KafkaConnectまたはKafkaConnectS2Iリソースのauthenticationプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.4.3. Kafka Connect での SCRAM-SHA-512 認証の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
- 認証に使用するユーザーのユーザー名。
-
認証に使用されるパスワードがある
Secretの名前と、Secretに保存されたパスワードのキー (存在する場合)。
手順
(任意手順): 認証で使用されるパスワードがない場合はファイルで準備し、
Secretを作成します。注記User Operator によって作成されたシークレットを使用できます。
oc createを使用してこれを行うことができます。echo -n '<password>' > <my-password.txt> oc create secret generic <my-secret> --from-file=<my-password.txt>
echo -n '<password>' > <my-password.txt> oc create secret generic <my-secret> --from-file=<my-password.txt>Copy to Clipboard Copied! Toggle word wrap Toggle overflow KafkaConnectまたはKafkaConnectS2Iリソースのauthenticationプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
OpenShift では
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.5. Kafka Connect の設定
AMQ Streams では、Apache Kafka ドキュメント に記載されている特定のオプションを編集して、Apache Kafka Connect ノードの設定をカスタマイズできます。
以下に関連する設定オプションは設定できません。
- Kafka クラスターブートストラップアドレス
- セキュリティー (暗号化、認証、および承認)
- リスナー / REST インターフェースの設定
- プラグインパスの設定
これらのオプションは AMQ Streams によって自動的に設定されます。
3.2.5.1. Kafka Connect の設定
Kafka Connect は、KafkaConnect.spec および KafkaConnectS2I.spec の config プロパティーを使用して設定されます。このプロパティーには、Kafka Connect 設定オプションがキーとして含まれます。値は以下の JSON タイプのいずれかになります。
- String
- Number
- ブール値
AMQ Streams で直接管理されるオプションを除き、Apache Kafka ドキュメント に記載されているオプションを指定および設定できます。以下の文字列の 1 つと同じキーまたは以下の文字列の 1 つで始まるキーを持つ設定オプションは禁止されています。
-
ssl. -
sasl. -
security. -
listeners -
plugin.path -
rest. -
bootstrap.servers
禁止されているオプションが config プロパティーにある場合、そのオプションは無視され、警告メッセージが Cluster Operator ログファイルに出力されます。その他のオプションはすべて Kafka Connect に渡されます。
提供された config オブジェクトのキーまたは値は Cluster Operator によって検証されません。無効な設定を指定すると、Kafka Connect クラスターが起動しなかったり、不安定になる可能性があります。この状況で、KafkaConnect.spec.config または KafkaConnectS2I.spec.config オブジェクトの設定を修正すると、Cluster Operator は新しい設定をすべての Kafka Connect ノードにロールアウトできます。
以下のオプションにはデフォルト値があります。
-
group.id、デフォルト値connect-cluster -
offset.storage.topic、デフォルト値connect-cluster-offsets -
config.storage.topic、デフォルト値connect-cluster-configs -
status.storage.topic、デフォルト値connect-cluster-status -
key.converter、デフォルト値org.apache.kafka.connect.json.JsonConverter -
value.converter、デフォルト値org.apache.kafka.connect.json.JsonConverter
これらのオプションは、KafkaConnect.spec.config または KafkaConnectS2I.spec.config プロパティーになかった場合に自動的に設定されます。
Kafka Connect の設定例
3.2.5.2. 複数インスタンスの Kafka Connect 設定
Kafka Connect のインスタンスを複数実行している場合は、以下のプロパティーのデフォルト設定に注意してください。
これら 3 つのトピックの値は、同じ group.id を持つすべての Kafka Connect インスタンスで同じする必要があります。
デフォルト設定を変更しないと、同じ Kafka クラスターに接続する各 Kafka Connect インスタンスは同じ値でデプロイされます。その結果、事実上はすべてのインスタンスが結合されてクラスターで実行され、同じトピックが使用されます。
複数の Kafka Connect クラスターが同じトピックの使用を試みると、Kafka Connect は想定どおりに動作せず、エラーが生成されます。
複数の Kafka Connect インスタンスを実行する場合は、インスタンスごとにこれらのプロパティーの値を変更してください。
3.2.5.3. Kafka Connect の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
KafkaConnectまたはKafkaConnectS2Iリソースのconfigプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.6. CPU およびメモリーリソース
AMQ Streams では、デプロイされたコンテナーごとに特定のリソースを要求し、これらのリソースの最大消費を定義できます。
AMQ Streams では、以下の 2 つのタイプのリソースがサポートされます。
- CPU
- メモリー
AMQ Streams では、CPU およびメモリーリソースの指定に OpenShift 構文が使用されます。
3.2.6.1. リソースの制限および要求
リソースの制限と要求は、以下のリソースで resources プロパティーを使用して設定されます。
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.KafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
その他のリソース
- OpenShift におけるコンピュートリソースの管理に関する詳細は、「Managing Compute Resources for Containers」を参照してください。
3.2.6.1.1. リソース要求
要求によって、指定のコンテナーに対して予約するリソースが指定されます。リソースを予約すると、リソースが常に利用できるようになります。
リソース要求が OpenShift クラスターで利用可能な空きリソースを超える場合、Pod はスケジュールされません。
リソース要求は requests プロパティーで指定されます。AMQ Streams では、現在以下のリソース要求がサポートされます。
-
cpu -
memory
1 つまたは複数のサポートされるリソースに対してリクエストを設定できます。
すべてのリソースを対象とするリソース要求の設定例
3.2.6.1.2. リソース制限
制限によって、指定のコンテナーが消費可能な最大リソースが指定されます。制限は予約されず、常に利用できるとは限りません。コンテナーは、リソースが利用できる場合のみ、制限以下のリソースを使用できます。リソース制限は、常にリソース要求よりも高くする必要があります。
リソース制限は limits プロパティーで指定されます。AMQ Streams では、現在以下のリソース制限がサポートされます。
-
cpu -
memory
1 つまたは複数のサポートされる制限に対してリソースを設定できます。
リソース制限の設定例
3.2.6.1.3. サポートされる CPU 形式
CPU の要求および制限は以下の形式でサポートされます。
-
整数値 (
5CPU コア) または少数 (2.5CPU コア) の CPU コアの数。 -
数値または ミリ CPU / ミリコア (
100m)。1000 ミリコア は1CPU コアと同じです。
CPU ユニットの例
1 つの CPU コアのコンピューティング能力は、OpenShift がデプロイされたプラットフォームによって異なることがあります。
その他のリソース
- CPU 仕様の詳細は、「Meaning of CPU」を参照してください。
3.2.6.1.4. サポートされるメモリー形式
メモリー要求および制限は、メガバイト、ギガバイト、メビバイト、およびギビバイトで指定されます。
-
メモリーをメガバイトで指定するには、
M接尾辞を使用します。例:1000M -
メモリーをギガバイトで指定するには、
G接尾辞を使用します。例:1G -
メモリーをメビバイトで指定するには、
Mi接尾辞を使用します。例:1000Mi -
メモリーをギビバイトで指定するには、
Gi接尾辞を使用します。例:1Gi
異なるメモリー単位の使用例
その他のリソース
- メモリーの指定およびサポートされるその他の単位に関する詳細は、「Meaning of memory」を参照してください。
3.2.6.2. リソース要求および制限の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
クラスターデプロイメントを指定するリソースの
resourcesプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
-
スキーマの詳細は、「
Resourcesスキーマ参照」を参照してください。
3.2.7. Kafka Connect ロガー
Kafka Connect には独自の設定可能なロガーがあります。
-
connect.root.logger.level -
log4j.logger.org.reflections
Kafka Connect では Apache log4j ロガー実装が使用されます。
logging プロパティーを使用してロガーおよびロガーレベルを設定します。
ログレベルを設定するには、ロガーとレベルを直接指定 (インライン) するか、またはカスタム (外部) ConfigMap を使用します。ConfigMap を使用する場合、logging.name プロパティーを外部ロギング設定が含まれる ConfigMap の名前に設定します。ConfigMap 内では、ロギング設定は log4j.properties を使用して記述されます。
inline および external ロギングの例は次のとおりです。
inline ロギング
外部ロギング
その他のリソース
- ガベッジコレクター (GC) ロギングを有効 (または無効) にすることもできます。GC ロギングの詳細は「JVM 設定」を参照してください。
- ログレベルの詳細は、「Apache logging services」を参照してください。
3.2.8. Healthcheck
ヘルスチェックは、アプリケーションの健全性を検証する定期的なテストです。ヘルスチェックプローブが失敗すると、OpenShift によってアプリケーションが正常でないと見なされ、その修正が試行されます。
OpenShift では、以下の 2 つのタイプのおよび ヘルスチェックプローブがサポートされます。
- Liveness プローブ
- Readiness プローブ
プローブの詳細は、「Configure Liveness and Readiness Probes」を参照してください。AMQ Streams コンポーネントでは、両タイプのプローブが使用されます。
ユーザーは、Liveness および Readiness プローブに選択されたオプションを設定できます。
3.2.8.1. ヘルスチェックの設定
Liveness および Readiness プローブは、以下のリソースの livenessProbe および readinessProbe プロパティーを使用して設定できます。
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.KafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
livenessProbe および readinessProbe の両方によって以下のオプションがサポートされます。
-
initialDelaySeconds -
timeoutSeconds -
periodSeconds -
successThreshold -
failureThreshold
livenessProbe および readinessProbe オプションの詳細については、「Probe スキーマ参照」 を参照してください。
Liveness および Readiness プローブの設定例
3.2.8.2. ヘルスチェックの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
Kafka、KafkaConnect、またはKafkaConnectS2IリソースのlivenessProbeまたはreadinessProbeプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.9. Prometheus メトリクス
AMQ Streams では、Apache Kafka および ZooKeeper によってサポートされる JMX メトリクスを Prometheus メトリクスに変換するために、Prometheus JMX エクスポーター を使用した Prometheus メトリクスがサポートされます。有効になったメトリクスは、9404 番ポートで公開されます。
Prometheus および Grafana の設定に関する詳細は「メトリクス」を参照してください。
3.2.9.1. メトリクスの設定
Prometheus メトリクスは、以下のリソースに metrics プロパティーを設定して有効化されます。
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
KafkaConnect.spec -
KafkaConnectS2I.spec
metrics プロパティーがリソースに定義されていない場合、Prometheus メトリクスは無効になります。追加設定なしで Prometheus メトリクスのエクスポートを有効にするには、空のオブジェクト ({}) を設定します。
追加設定なしでメトリクスを有効にする例
metrics プロパティーには、Prometheus JMX エスクポーター の追加設定が含まれることがあります。
追加の Prometheus JMX Exporter 設定を使用したメトリクスを有効化する例
3.2.9.2. Prometheus メトリクスの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
Kafka、KafkaConnect、またはKafkaConnectS2Iリソースのmetricsプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.10. JVM オプション
AMQ Streams の以下のコンポーネントは、仮想マシン (VM) 内で実行されます。
- Apache Kafka
- Apache ZooKeeper
- Apache Kafka Connect
- Apache Kafka MirrorMaker
- AMQ Streams Kafka Bridge
JVM 設定オプションによって、さまざまなプラットフォームおよびアーキテクチャーのパフォーマンスが最適化されます。AMQ Streams では、これらのオプションの一部を設定できます。
3.2.10.1. JVM 設定
JVM オプションは、以下のリソースの jvmOptions プロパティーを使用して設定できます。
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
使用可能な JVM オプションの選択されたサブセットのみを設定できます。以下のオプションがサポートされます。
-Xms および -Xmx
-Xms は、JVM の起動時に最初に割り当てられる最小ヒープサイズを設定します。-Xmx は、最大ヒープサイズを設定します。
-Xmx や -Xms などの JVM 設定で使用できる単位は、対応するイメージの JDK java バイナリーによって許可される単位です。そのため、1g または 1G は 1,073,741,824 バイトを意味し、Gi は接尾辞として有効な単位ではありません。これは、1G は 1,000,000,000 バイト、1Gi は 1,073,741,824 バイトを意味する OpenShift の慣例に準拠している メモリー要求および制限 に使用される単位とは対照的です。
-Xms および -Xmx に使用されるデフォルト値は、コンテナーに メモリー要求 の制限が設定されているかどうかによって異なります。
- メモリーの制限がある場合は、JVM の最小および最大メモリーは制限に対応する値に設定されます。
-
メモリーの制限がない場合、JVM の最小メモリーは
128Mに設定され、JVM の最大メモリーは定義されません。これにより、JVM のメモリーを必要に応じて拡張できます。これは、テストおよび開発での単一ノード環境に適しています。
-Xmx を明示的に設定するには、以下の点に注意する必要があります。
-
JVM のメモリー使用量の合計は、
-Xmxによって設定された最大ヒープの約 4 倍になります。 -
適切な OpenShift メモリー制限を設定せずに
-Xmxが設定された場合、OpenShift ノードで、実行されている他の Pod からメモリー不足が発生するとコンテナーが強制終了される可能性があります。 -
適切な OpenShift メモリー要求を設定せずに
-Xmxが設定された場合、コンテナーはメモリー不足のノードにスケジュールされる可能性があります。この場合、コンテナーは起動せずにクラッシュします (-Xmsが-Xmxに設定されている場合は即座にクラッシュし、そうでない場合はその後にクラッシュします)。
-Xmx を明示的に設定する場合は、以下を行うことが推奨されます。
- メモリー要求とメモリー制限を同じ値に設定します。
-
-Xmxの 4.5 倍以上のメモリー要求を使用します。 -
-Xmsを-Xmxと同じ値に設定することを検討してください。
大量のディスク I/O を実行するコンテナー (Kafka ブローカーコンテナーなど) は、オペレーティングシステムのページキャッシュとして使用できるメモリーを確保しておく必要があります。このようなコンテナーでは、要求されるメモリーは JVM によって使用されるメモリーよりもはるかに多くなります。
-Xmx および -Xms の設定例 (抜粋)
# ... jvmOptions: "-Xmx": "2g" "-Xms": "2g" # ...
# ...
jvmOptions:
"-Xmx": "2g"
"-Xms": "2g"
# ...上記の例では、JVM のヒープに 2 GiB (2,147,483,648 バイト) が使用されます。メモリー使用量の合計は約 8GiB になります。
最初のヒープサイズ (-Xms) および最大ヒープサイズ (-Xmx) に同じ値を設定すると、JVM が必要以上のヒープを割り当てて起動後にメモリーを割り当てないようにすることができます。Kafka および ZooKeeper Pod では、このような割り当てによって不要なレイテンシーが発生する可能性があります。Kafka Connect では、割り当ての過剰を防ぐことが最も重要になります。これは、コンシューマーの数が増えるごとに割り当て過剰の影響がより深刻になる分散モードで特に重要です。
-server
-server はサーバー JVM を有効にします。このオプションは true または false に設定できます。
-server の設定例 (抜粋)
# ... jvmOptions: "-server": true # ...
# ...
jvmOptions:
"-server": true
# ...
いずれのオプション (-server および -XX) も指定されないと、Apache Kafka の KAFKA_JVM_PERFORMANCE_OPTS のデフォルト設定が使用されます。
-XX
-XX オブジェクトは、JVM の高度なランタイムオプションの設定に使用できます。-server および -XX オプションは、Apache Kafka の KAFKA_JVM_PERFORMANCE_OPTS オプションの設定に使用されます。
-XX オブジェクトの使用例
上記の設定例の場合、JVM オプションは以下のようになります。
-XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:-UseParNewGC
-XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:-UseParNewGC
いずれのオプション (-server および -XX) も指定されないと、Apache Kafka の KAFKA_JVM_PERFORMANCE_OPTS のデフォルト設定が使用されます。
3.2.10.1.1. ガベッジコレクターのロギング
jvmOptions セクションでは、ガベージコレクター (GC) のロギングを有効または無効にすることもできます。GC ロギングはデフォルトで無効になっています。これを有効にするには、以下のように gcLoggingEnabled プロパティーを設定します。
GC ロギングを有効にする例
# ... jvmOptions: gcLoggingEnabled: true # ...
# ...
jvmOptions:
gcLoggingEnabled: true
# ...3.2.10.2. JVM オプションの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
Kafka、KafkaConnect、KafkaConnectS2I、KafkaMirrorMaker、またはKafkaBridgeリソースのjvmOptionsプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.11. コンテナーイメージ
AMQ Streams では、コンポーネントに使用されるコンテナーイメージを設定できます。コンテナーイメージのオーバーライドは、別のコンテナーレジストリーを使用する必要がある特別な状況でのみ推奨されます。たとえば、AMQ Streams によって使用されるコンテナーリポジトリーにネットワークがアクセスできない場合などがこれに該当します。そのような場合は、AMQ Streams イメージをコピーするか、ソースからビルドする必要があります。設定したイメージが AMQ Streams イメージと互換性のない場合は、適切に機能しない可能性があります。
3.2.11.1. コンテナーイメージの設定
以下のリソースの image プロパティーを使用すると、各コンポーネントに使用するコンテナーイメージを指定できます。
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
3.2.11.1.1. Kafka、Kafka Connect、および Kafka MirrorMaker の image プロパティーの設定
Kafka、Kafka Connect (S2I サポートのある Kafka Connect を含む)、および Kafka MirrorMaker では、複数のバージョンの Kafka がサポートされます。各コンポーネントには独自のイメージが必要です。異なる Kafka バージョンのデフォルトイメージは、以下の環境変数で設定されます。
-
STRIMZI_KAFKA_IMAGES -
STRIMZI_KAFKA_CONNECT_IMAGES -
STRIMZI_KAFKA_CONNECT_S2I_IMAGES -
STRIMZI_KAFKA_MIRROR_MAKER_IMAGES
これらの環境変数には、Kafka バージョンと対応するイメージ間のマッピングが含まれます。マッピングは、image および version プロパティーとともに使用されます。
-
imageとversionのどちらもカスタムリソースに指定されていない場合、versionは Cluster Operator のデフォルトの Kafka バージョンに設定され、環境変数のこのバージョンに対応するイメージが指定されます。 -
imageが指定されていてもversionが指定されていない場合、指定されたイメージが使用され、Cluster Operator のデフォルトの Kafka バージョンがversionであると想定されます。 -
versionが指定されていてもimageが指定されていない場合、環境変数の指定されたバージョンに対応するイメージが使用されます。 -
versionとimageの両方を指定すると、指定されたイメージが使用されます。このイメージには、指定のバージョンの Kafka イメージが含まれると想定されます。
異なるコンポーネントの image および version は、以下のプロパティーで設定できます。
-
Kafka の場合は
spec.kafka.imageおよびspec.kafka.version。 -
Kafka Connect、Kafka Connect S2I、および Kafka MirrorMaker の場合は
spec.imageおよびspec.version。
version のみを提供し、image プロパティーを未指定のままにしておくことが推奨されます。これにより、カスタムリソースの設定時に間違いが発生する可能性が低減されます。異なるバージョンの Kafka に使用されるイメージを変更する必要がある場合は、Cluster Operator の環境変数を設定することが推奨されます。
3.2.11.1.2. 他のリソースでの image プロパティーの設定
他のカスタムリソースの image プロパティーでは、デプロイメント中に指定の値が使用されます。image プロパティーがない場合、Cluster Operator 設定に指定された image が使用されます。image 名が Cluster Operator 設定に定義されていない場合、デフォルト値が使用されます。
Kafka ブローカー TLS サイドカーの場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_TLS_SIDECAR_KAFKA_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
- ZooKeeper ノードの場合:
ZooKeeper ノードの TLS サイドカーの場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_TLS_SIDECAR_ZOOKEEPER_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Topic Operator の場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_TOPIC_OPERATOR_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
User Operator の場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_USER_OPERATOR_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Entity Operator TLS サイドカーの場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_TLS_SIDECAR_ENTITY_OPERATOR_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Kafka Exporter の場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_KAFKA_EXPORTER_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Kafka Bridge の場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_KAFKA_BRIDGE_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-bridge-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Kafka ブローカーイニシャライザーの場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_KAFKA_INIT_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
コンテナーイメージのオーバーライドは、別のコンテナーレジストリーを使用する必要がある特別な状況でのみ推奨されます。たとえば、AMQ Streams によって使用されるコンテナーリポジトリーにネットワークがアクセスできない場合などがこれに該当します。そのような場合は、AMQ Streams イメージをコピーするか、ソースからビルドする必要があります。設定したイメージが AMQ Streams イメージと互換性のない場合は、適切に機能しない可能性があります。
コンテナーイメージ設定の例
3.2.11.2. コンテナーイメージの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
Kafka、KafkaConnect、またはKafkaConnectS2Iリソースのimageプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.12. Pod スケジューリングの設定
2 つのアプリケーションが同じ OpenShift ノードにスケジュールされた場合、両方のアプリケーションがディスク I/O のように同じリソースを使用し、パフォーマンスに影響する可能性があります。これにより、パフォーマンスが低下する可能性があります。ノードを他の重要なワークロードと共有しないように Kafka Pod をスケジュールする場合、適切なノードを使用したり、Kafka 専用のノードのセットを使用すると、このような問題を適切に回避できます。
3.2.12.1. 他のアプリケーションに基づく Pod のスケジューリング
3.2.12.1.1. 重要なアプリケーションがノードを共有しないようにする
Pod の非アフィニティーを使用すると、重要なアプリケーションが同じディスクにスケジュールされないようにすることができます。Kafka クラスターの実行時に、Pod の非アフィニティーを使用して、Kafka ブローカーがデータベースなどの他のワークロードとノードを共有しないようにすることが推奨されます。
3.2.12.1.2. アフィニティー
アフィニティーは、以下のリソースの affinity プロパティーを使用して設定できます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
アフィニティー設定には、さまざまなタイプのアフィニティーを含めることができます。
- Pod のアフィニティーおよび非アフィニティー
- ノードのアフィニティー
affinity プロパティーの形式は、OpenShift の仕様に準拠します。詳細は、Kubernetes のノードおよび Pod のアフィニティーに関するドキュメント を参照してください。
3.2.12.1.3. Kafka コンポーネントでの Pod の非アフィニティーの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
クラスターデプロイメントを指定するリソースの
affinityプロパティーを編集します。ラベルを使用して、同じノードでスケジュールすべきでない Pod を指定します。topologyKeyをkubernetes.io/hostnameに設定し、選択した Pod が同じホスト名のノードでスケジュールされてはならないことを指定する必要があります。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.12.2. 特定のノードへの Pod のスケジューリング
3.2.12.2.1. ノードのスケジューリング
OpenShift クラスターは、通常多くの異なるタイプのワーカーノードで構成されます。ワークロードが非常に大きい環境の CPU に対して最適化されたものもあれば、メモリー、ストレージ (高速のローカル SSD)、または ネットワークに対して最適化されたものもあります。異なるノードを使用すると、コストとパフォーマンスの両面で最適化しやすくなります。最適なパフォーマンスを実現するには、AMQ Streams コンポーネントのスケジューリングで適切なノードを使用できるようにすることが重要です。
OpenShift は、ノードのアフィニティーを使用してワークロードを特定のノードにスケジュールします。ノードのアフィニティーにより、Pod がスケジュールされるノードにスケジューリングの制約を作成できます。制約はラベルセレクターとして指定されます。beta.kubernetes.io/instance-type などの組み込みノードラベルまたはカスタムラベルのいずれかを使用してラベルを指定すると、適切なノードを選択できます。
3.2.12.2.2. アフィニティー
アフィニティーは、以下のリソースの affinity プロパティーを使用して設定できます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
アフィニティー設定には、さまざまなタイプのアフィニティーを含めることができます。
- Pod のアフィニティーおよび非アフィニティー
- ノードのアフィニティー
affinity プロパティーの形式は、OpenShift の仕様に準拠します。詳細は、Kubernetes のノードおよび Pod のアフィニティーに関するドキュメント を参照してください。
3.2.12.2.3. Kafka コンポーネントでのノードのアフィニティーの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
AMQ Streams コンポーネントをスケジュールする必要のあるノードにラベルを付けます。
oc labelを使用してこれを行うことができます。oc label node your-node node-type=fast-network
oc label node your-node node-type=fast-networkCopy to Clipboard Copied! Toggle word wrap Toggle overflow または、既存のラベルによっては再利用が可能です。
クラスターデプロイメントを指定するリソースの
affinityプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.12.3. 専用ノードの使用
3.2.12.3.1. 専用ノード
クラスター管理者は、選択した OpenShift ノードをテイントとしてマーク付けできます。テイントのあるノードは、通常のスケジューリングから除外され、通常の Pod はそれらのノードでの実行はスケジュールされません。ノードに設定されたテイントを許容できるサービスのみをスケジュールできます。このようなノードで実行されるその他のサービスは、ログコレクターやソフトウェア定義のネットワークなどのシステムサービスのみです。
テイントは専用ノードの作成に使用できます。専用のノードで Kafka とそのコンポーネントを実行する利点は多くあります。障害の原因になったり、Kafka に必要なリソースを消費するその他のアプリケーションが同じノードで実行されません。これにより、パフォーマンスと安定性が向上します。
専用ノードで Kafka Pod をスケジュールするには、ノードのアフィニティー と 許容 (toleration) を設定します。
3.2.12.3.2. アフィニティー
アフィニティーは、以下のリソースの affinity プロパティーを使用して設定できます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
アフィニティー設定には、さまざまなタイプのアフィニティーを含めることができます。
- Pod のアフィニティーおよび非アフィニティー
- ノードのアフィニティー
affinity プロパティーの形式は、OpenShift の仕様に準拠します。詳細は、Kubernetes のノードおよび Pod のアフィニティーに関するドキュメント を参照してください。
3.2.12.3.3. 許容 (Toleration)
許容 (Toleration) は、以下のリソースの tolerations プロパティーを使用して設定できます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
tolerations プロパティーの形式は、OpenShift の仕様に準拠します。詳細は、Kubernetes の「Taints and Tolerations」を参照してください。
3.2.12.3.4. 専用ノードの設定と Pod のスケジューリング
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
- 専用ノードとして使用するノードを選択します。
- これらのノードにスケジュールされているワークロードがないことを確認します。
選択したノードにテイントを設定します。
oc adm taintを使用してこれを行うことができます。oc adm taint node your-node dedicated=Kafka:NoSchedule
oc adm taint node your-node dedicated=Kafka:NoScheduleCopy to Clipboard Copied! Toggle word wrap Toggle overflow さらに、選択したノードにラベルも追加します。
oc labelを使用してこれを行うことができます。oc label node your-node dedicated=Kafka
oc label node your-node dedicated=KafkaCopy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターデプロイメントを指定するリソースの
affinityおよびtolerationsプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.13. 外部設定およびシークレットの使用
コネクターは、Kafka Connect の HTTP REST インターフェースまたは KafkaConnectors を使用して作成、再設定、および削除されます。これらの方法の詳細は、「コネクターの作成および管理」 を参照してください。コネクター設定は、HTTP リクエストの一部として Kafka Connect に渡され、Kafka 自体に保存されます。
ConfigMap およびシークレットは、設定やデータの保存に使用される標準的な OpenShift リソースです。コネクターの管理に使用するいずれの方法でも、ConfigMap およびシークレットを使用してコネクターの特定の要素を設定できます。その後、HTTP REST コマンドで設定値を参照できます (これにより、必要な場合は設定が分離され、よりセキュアになります)。この方法は、ユーザー名、パスワード、証明書などの機密性の高いデータに適用されます。
3.2.13.1. コネクター設定の外部への保存
ConfigMap またはシークレットをボリュームまたは環境変数として Kafka Connect Pod にマウントできます。ボリュームおよび環境変数は、KafkaConnect.spec および KafkaConnectS2I.spec の externalConfiguration プロパティーで設定されます。
3.2.13.1.1. 環境変数としての外部設定
env プロパティーは、1 つ以上の環境変数を指定するために使用されます。これらの変数には ConfigMap または Secret からの値を含めることができます。
ユーザー定義の環境変数に、KAFKA_ または STRIMZI_ で始まる名前を付けることはできません。
シークレットから環境変数に値をマウントするには、以下の例のように valueFrom プロパティーおよび secretKeyRef を使用します。
シークレットからの値に設定された環境変数の例
シークレットを環境変数にマウントする一般的なユースケースとして、コネクターが Amazon AWS と通信する必要があり、クレデンシャルで AWS_ACCESS_KEY_ID および AWS_SECRET_ACCESS_KEY 環境変数を読み取る必要がある場合が挙げられます。
ConfigMap から環境変数に値をマウントするには、以下の例のように valueFromプロパティーで configMapKeyRef を使用します。
ConfigMap からの値に設定された環境変数の例
3.2.13.1.2. ボリュームとしての外部設定
ConfigMap またはシークレットをボリュームとして Kafka Connect Pod にマウントすることもできます。以下の場合、環境変数の代わりにボリュームを使用すると便利です。
- TLS 証明書でのトラストストアまたはキーストアのマウント
- Kafka Connect コネクターの設定に使用されるプロパティーファイルのマウント
externalConfiguration リソースの volumes プロパティーで、ボリュームとしてマウントされる ConfigMap またはシークレットをリストします。各ボリュームは name プロパティーに名前を指定し、ConfigMap またはシークレットを参照する必要があります。
外部設定のあるボリュームの例
ボリュームは、パス /opt/kafka/external-configuration/<volume-name> の Kafka Connect コンテナー内にマウントされます。たとえば、connector1 という名前のボリュームのファイルは /opt/kafka/external-configuration/connector1 ディレクトリーにあります。
コネクター設定でマウントされたプロパティーファイルから値を読み取るには、FileConfigProvider を使用する必要があります。
3.2.13.2. 環境変数としてのシークレットのマウント
OpenShift シークレットを作成し、これを環境変数として Kafka Connect にマウントできます。
前提条件
- 稼働中の Cluster Operator。
手順
環境変数としてマウントされる情報が含まれるシークレットを作成します。以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka Connect リソースを作成または編集します。シークレットを参照するように、
KafkaConnectまたはKafkaConnectS2IカスタムリソースのexternalConfigurationセクションを設定します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 変更を Kafka Connect デプロイメントに適用します。
oc applyを使用します。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
コネクターの開発時に、環境変数が使用できるようになりました。
その他のリソース
-
Kafka Connect の外部設定の詳細は、「
ExternalConfigurationスキーマ参照」 を参照してください。
3.2.13.3. シークレットのボリュームとしてのマウント
OpenShift シークレットを作成してボリュームとして Kafka Connect にマウントし、これを使用して Kafka Connect コネクターを設定します。
前提条件
- 稼働中の Cluster Operator。
手順
コネクター設定の設定オプションを定義するプロパティーファイルが含まれるシークレットを作成します。以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka Connect リソースを作成または編集します。シークレットを参照するように、
configセクションのFileConfigProviderと、KafkaConnectまたはKafkaConnectS2IカスタムリソースのexternalConfigurationセクションを設定します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 変更を Kafka Connect デプロイメントに適用します。
oc applyを使用します。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow コネクター設定のある JSON ペイロードのマウントされたプロパティーファイルから値を使用します。以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
-
Kafka Connect の外部設定の詳細は、「
ExternalConfigurationスキーマ参照」 を参照してください。
3.2.14. KafkaConnector リソースの有効化
Kafka Connect クラスターの KafkaConnectors を有効にするには、strimzi.io/use-connector-resources アノテーションを KafkaConnect または KafkaConnectS2I カスタムリソースに追加します。
前提条件
- 稼働中の Cluster Operator が必要です。
手順
KafkaConnectまたはKafkaConnectS2Iリソースを編集します。strimzi.io/use-connector-resourcesアノテーションを追加します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc applyを使用してリソースを作成または更新します。oc apply -f kafka-connect.yaml
oc apply -f kafka-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.2.15. Kafka Connect クラスターの一部として作成されたリソースの一覧
以下のリソースは、OpenShift クラスターの Cluster Operator によって作成されます。
- connect-cluster-name-connect
- Kafka Connect ワーカーノード Pod の作成を担当するデプロイメント。
- connect-cluster-name-connect-api
- Kafka Connect クラスターを管理するために REST インターフェースを公開するサービス。
- connect-cluster-name-config
- Kafka Connect 補助設定が含まれ、Kafka ブローカー Pod によってボリュームとしてマウントされる ConfigMap。
- connect-cluster-name-connect
- Kafka Connect ワーカーノードに設定された Pod の Disruption Budget。
3.3. Source2Image がサポートされる Kafka Connect クラスター
KafkaConnectS2I リソースの完全なスキーマは 「KafkaConnectS2I スキーマ参照」 に記載されています。指定の KafkaConnectS2I リソースに適用されたすべてのラベルは、Source2Image がサポートされる Kafka Connect クラスターを構成する OpenShift リソースにも適用されます。そのため、必要に応じてリソースにラベルが適用されるため便利です。
3.3.1. レプリカ
Kafka Connect クラスターは、1 つ以上のノードで構成されます。ノードの数は KafkaConnect および KafkaConnectS2I リソースで定義されます。Kafka Connect クラスターを複数のノードで実行すると、可用性とスケーラビリティーが向上します。ただし、OpenShift で Kafka Connect を実行する場合は、高可用性のために Kafka Connect で複数のノードを実行する必要はありません。Kafka Connect がデプロイされたノードがクラッシュした場合、OpenShift によって Kafka Connect Pod が別のノードに自動的に再スケジュールされます。ただし、他のノードがすでに稼働しているため、Kafka Connect を複数のノードで実行すると、より高速なフェイルオーバーを実現できます。
3.3.1.1. ノード数の設定
Kafka Connect ノードの数は、KafkaConnect.spec および KafkaConnectS2I.spec の replicas プロパティーを使用して設定されます。
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
KafkaConnectまたはKafkaConnectS2Iリソースのreplicasプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.2. ブートストラップサーバー
Kafka Connect クラスターは、常に Kafka クラスターと組み合わせて動作します。Kafka クラスターはブートストラップサーバーのリストとして指定されます。OpenShift では、そのリストに cluster-name-kafka-bootstrap という名前の Kafka クラスターブートストラップサービスが含まれ、さらに平文トラフィックの場合はポート 9092、暗号化されたトラフィックの場合はポート 9093 が含まれることが理想的です。
ブートストラップサーバーのリストは、KafkaConnect.spec および KafkaConnectS2I.spec の bootstrapServers プロパティーで設定されます。サーバーは、1 つ以上の Kafka ブローカーを指定するコンマ区切りリスト、または hostname:_port_ ペアとして指定される Kafka ブローカーを示すサービスとして定義される必要があります。
AMQ Streams によって管理されない Kafka クラスターで Kafka Connect を使用する場合は、クラスターの設定に応じてブートストラップサーバーのリストを指定できます。
3.3.2.1. ブートストラップサーバーの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
KafkaConnectまたはKafkaConnectS2IリソースのbootstrapServersプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.3. TLS を使用した Kafka ブローカーへの接続
デフォルトでは、Kafka Connect はプレーンテキスト接続を使用して Kafka ブローカーへの接続を試みます。TLS を使用する場合は、追加の設定が必要です。
3.3.3.1. Kafka Connect での TLS サポート
TLS サポートは、KafkaConnect.spec および KafkaConnectS2I.spec の tls プロパティーで設定されます。tls プロパティーには、保存される証明書のキー名があるシークレットのリストが含まれます。証明書は X509 形式で保存する必要があります。
複数の証明書がある TLS 設定の例
複数の証明書が同じシークレットに保存されている場合は、複数回リストできます。
同じシークレットに複数の証明書がある TLS 設定の例
3.3.3.2. Kafka Connect での TLS の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
-
TLS サーバー認証に使用される証明書の
Secretの名前と、Secretに保存された証明書のキー (存在する場合)。
手順
(任意手順): 認証で使用される TLS 証明書が存在しない場合はファイルで準備し、
Secretを作成します。注記Kafka クラスターの Cluster Operator によって作成されるシークレットは直接使用されることがあります。
oc createを使用してこれを行うことができます。oc create secret generic my-secret --from-file=my-file.crt
oc create secret generic my-secret --from-file=my-file.crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow KafkaConnectまたはKafkaConnectS2Iリソースのtlsプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.4. 認証での Kafka ブローカーへの接続
デフォルトでは、Kafka Connect は認証なしで Kafka ブローカーへの接続を試みます。認証は KafkaConnect および KafkaConnectS2I リソースにより有効になります。
3.3.4.1. Kafka Connect での認証サポート
認証は、KafkaConnect.spec および KafkaConnectS2I.spec の authentication プロパティーで設定されます。authentication プロパティーによって、使用する認証メカニズムのタイプと、メカニズムに応じた追加設定の詳細が指定されます。サポートされる認証タイプは次のとおりです。
- TLS クライアント認証
- SCRAM-SHA-512 メカニズムを使用した SASL ベースの認証
- PLAIN メカニズムを使用した SASL ベースの認証
- OAuth 2.0 のトークンベースの認証
3.3.4.1.1. TLS クライアント認証
TLS クライアント認証を使用するには、type プロパティーを tls の値に設定します。TLS クライアント認証は TLS 証明書を使用して認証します。証明書は certificateAndKey プロパティーで指定され、常に OpenShift シークレットからロードされます。シークレットでは、公開鍵と秘密鍵の 2 つの鍵を使用して証明書を X509 形式で保存する必要があります。
TLS クライアント認証は TLS 接続でのみ使用できます。Kafka Connect の TLS 設定の詳細は、「TLS を使用した Kafka ブローカーへの接続」 を参照してください。
TLS クライアント認証の設定例
3.3.4.1.2. SASL ベースの SCRAM-SHA-512 認証
Kafka Connect で SASL ベースの SCRAM-SHA-512 認証が使用されるようにするには、type プロパティーを scram-sha-512 に設定します。この認証メカニズムには、ユーザー名とパスワードが必要です。
-
usernameプロパティーでユーザー名を指定します。 -
passwordSecretプロパティーで、パスワードを含むSecretへのリンクを指定します。secretNameプロパティーにはSecretの名前が含まれ、passwordプロパティーにはSecret内にパスワードが格納されるキーの名前が含まれます。
password フィールドには、実際のパスワードを指定しないでください。
SASL ベースの SCRAM-SHA-512 クライアント認証の設定例
3.3.4.1.3. SASL ベースの PLAIN 認証
Kafka Connect で SASL ベースの PLAIN 認証が使用されるようにするには、type プロパティーを plain に設定します。この認証メカニズムには、ユーザー名とパスワードが必要です。
SASL PLAIN メカニズムでは、ネットワーク全体でユーザー名とパスワードがプレーンテキストで転送されます。TLS 暗号化が有効になっている場合にのみ SASL PLAIN 認証を使用します。
-
usernameプロパティーでユーザー名を指定します。 -
passwordSecretプロパティーで、パスワードを含むSecretへのリンクを指定します。secretNameプロパティーにはそのようなSecretの名前が含まれ、passwordプロパティーにはSecret内にパスワードが格納されるキーの名前が含まれます。
password フィールドには、実際のパスワードを指定しないでください。
SASL ベースの PLAIN クライアント認証の設定例
3.3.4.2. Kafka Connect での TLS クライアント認証の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
-
TLS クライアント認証に使用される公開鍵と秘密鍵がある
Secret、およびSecretに保存される公開鍵と秘密鍵のキー (存在する場合)。
手順
(任意手順): 認証に使用される鍵が存在しない場合はファイルで準備し、
Secretを作成します。注記User Operator によって作成されたシークレットを使用できます。
oc createを使用してこれを行うことができます。oc create secret generic my-secret --from-file=my-public.crt --from-file=my-private.key
oc create secret generic my-secret --from-file=my-public.crt --from-file=my-private.keyCopy to Clipboard Copied! Toggle word wrap Toggle overflow KafkaConnectまたはKafkaConnectS2Iリソースのauthenticationプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.4.3. Kafka Connect での SCRAM-SHA-512 認証の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
- 認証に使用するユーザーのユーザー名。
-
認証に使用されるパスワードがある
Secretの名前と、Secretに保存されたパスワードのキー (存在する場合)。
手順
(任意手順): 認証で使用されるパスワードがない場合はファイルで準備し、
Secretを作成します。注記User Operator によって作成されたシークレットを使用できます。
oc createを使用してこれを行うことができます。echo -n '<password>' > <my-password.txt> oc create secret generic <my-secret> --from-file=<my-password.txt>
echo -n '<password>' > <my-password.txt> oc create secret generic <my-secret> --from-file=<my-password.txt>Copy to Clipboard Copied! Toggle word wrap Toggle overflow KafkaConnectまたはKafkaConnectS2Iリソースのauthenticationプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
OpenShift では
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.5. Kafka Connect の設定
AMQ Streams では、Apache Kafka ドキュメント に記載されている特定のオプションを編集して、Apache Kafka Connect ノードの設定をカスタマイズできます。
以下に関連する設定オプションは設定できません。
- Kafka クラスターブートストラップアドレス
- セキュリティー (暗号化、認証、および承認)
- リスナー / REST インターフェースの設定
- プラグインパスの設定
これらのオプションは AMQ Streams によって自動的に設定されます。
3.3.5.1. Kafka Connect の設定
Kafka Connect は、KafkaConnect.spec および KafkaConnectS2I.spec の config プロパティーを使用して設定されます。このプロパティーには、Kafka Connect 設定オプションがキーとして含まれます。値は以下の JSON タイプのいずれかになります。
- String
- Number
- ブール値
AMQ Streams で直接管理されるオプションを除き、Apache Kafka ドキュメント に記載されているオプションを指定および設定できます。以下の文字列の 1 つと同じキーまたは以下の文字列の 1 つで始まるキーを持つ設定オプションは禁止されています。
-
ssl. -
sasl. -
security. -
listeners -
plugin.path -
rest. -
bootstrap.servers
禁止されているオプションが config プロパティーにある場合、そのオプションは無視され、警告メッセージが Cluster Operator ログファイルに出力されます。その他のオプションはすべて Kafka Connect に渡されます。
提供された config オブジェクトのキーまたは値は Cluster Operator によって検証されません。無効な設定を指定すると、Kafka Connect クラスターが起動しなかったり、不安定になる可能性があります。この状況で、KafkaConnect.spec.config または KafkaConnectS2I.spec.config オブジェクトの設定を修正すると、Cluster Operator は新しい設定をすべての Kafka Connect ノードにロールアウトできます。
以下のオプションにはデフォルト値があります。
-
group.id、デフォルト値connect-cluster -
offset.storage.topic、デフォルト値connect-cluster-offsets -
config.storage.topic、デフォルト値connect-cluster-configs -
status.storage.topic、デフォルト値connect-cluster-status -
key.converter、デフォルト値org.apache.kafka.connect.json.JsonConverter -
value.converter、デフォルト値org.apache.kafka.connect.json.JsonConverter
これらのオプションは、KafkaConnect.spec.config または KafkaConnectS2I.spec.config プロパティーになかった場合に自動的に設定されます。
Kafka Connect の設定例
3.3.5.2. 複数インスタンスの Kafka Connect 設定
Kafka Connect のインスタンスを複数実行している場合は、以下のプロパティーのデフォルト設定に注意してください。
これら 3 つのトピックの値は、同じ group.id を持つすべての Kafka Connect インスタンスで同じする必要があります。
デフォルト設定を変更しないと、同じ Kafka クラスターに接続する各 Kafka Connect インスタンスは同じ値でデプロイされます。その結果、事実上はすべてのインスタンスが結合されてクラスターで実行され、同じトピックが使用されます。
複数の Kafka Connect クラスターが同じトピックの使用を試みると、Kafka Connect は想定どおりに動作せず、エラーが生成されます。
複数の Kafka Connect インスタンスを実行する場合は、インスタンスごとにこれらのプロパティーの値を変更してください。
3.3.5.3. Kafka Connect の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
KafkaConnectまたはKafkaConnectS2Iリソースのconfigプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.6. CPU およびメモリーリソース
AMQ Streams では、デプロイされたコンテナーごとに特定のリソースを要求し、これらのリソースの最大消費を定義できます。
AMQ Streams では、以下の 2 つのタイプのリソースがサポートされます。
- CPU
- メモリー
AMQ Streams では、CPU およびメモリーリソースの指定に OpenShift 構文が使用されます。
3.3.6.1. リソースの制限および要求
リソースの制限と要求は、以下のリソースで resources プロパティーを使用して設定されます。
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.KafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
その他のリソース
- OpenShift におけるコンピュートリソースの管理に関する詳細は、「Managing Compute Resources for Containers」を参照してください。
3.3.6.1.1. リソース要求
要求によって、指定のコンテナーに対して予約するリソースが指定されます。リソースを予約すると、リソースが常に利用できるようになります。
リソース要求が OpenShift クラスターで利用可能な空きリソースを超える場合、Pod はスケジュールされません。
リソース要求は requests プロパティーで指定されます。AMQ Streams では、現在以下のリソース要求がサポートされます。
-
cpu -
memory
1 つまたは複数のサポートされるリソースに対してリクエストを設定できます。
すべてのリソースを対象とするリソース要求の設定例
3.3.6.1.2. リソース制限
制限によって、指定のコンテナーが消費可能な最大リソースが指定されます。制限は予約されず、常に利用できるとは限りません。コンテナーは、リソースが利用できる場合のみ、制限以下のリソースを使用できます。リソース制限は、常にリソース要求よりも高くする必要があります。
リソース制限は limits プロパティーで指定されます。AMQ Streams では、現在以下のリソース制限がサポートされます。
-
cpu -
memory
1 つまたは複数のサポートされる制限に対してリソースを設定できます。
リソース制限の設定例
3.3.6.1.3. サポートされる CPU 形式
CPU の要求および制限は以下の形式でサポートされます。
-
整数値 (
5CPU コア) または少数 (2.5CPU コア) の CPU コアの数。 -
数値または ミリ CPU / ミリコア (
100m)。1000 ミリコア は1CPU コアと同じです。
CPU ユニットの例
1 つの CPU コアのコンピューティング能力は、OpenShift がデプロイされたプラットフォームによって異なることがあります。
その他のリソース
- CPU 仕様の詳細は、「Meaning of CPU」を参照してください。
3.3.6.1.4. サポートされるメモリー形式
メモリー要求および制限は、メガバイト、ギガバイト、メビバイト、およびギビバイトで指定されます。
-
メモリーをメガバイトで指定するには、
M接尾辞を使用します。例:1000M -
メモリーをギガバイトで指定するには、
G接尾辞を使用します。例:1G -
メモリーをメビバイトで指定するには、
Mi接尾辞を使用します。例:1000Mi -
メモリーをギビバイトで指定するには、
Gi接尾辞を使用します。例:1Gi
異なるメモリー単位の使用例
その他のリソース
- メモリーの指定およびサポートされるその他の単位に関する詳細は、「Meaning of memory」を参照してください。
3.3.6.2. リソース要求および制限の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
クラスターデプロイメントを指定するリソースの
resourcesプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
-
スキーマの詳細は、「
Resourcesスキーマ参照」を参照してください。
3.3.7. S2I ロガーのある Kafka Connect
Source2Image がサポートされる Kafka Connect には独自の設定可能なロガーがあります。
-
connect.root.logger.level -
log4j.logger.org.reflections
Kafka Connect では Apache log4j ロガー実装が使用されます。
logging プロパティーを使用してロガーおよびロガーレベルを設定します。
ログレベルを設定するには、ロガーとレベルを直接指定 (インライン) するか、またはカスタム (外部) ConfigMap を使用します。ConfigMap を使用する場合、logging.name プロパティーを外部ロギング設定が含まれる ConfigMap の名前に設定します。ConfigMap 内では、ロギング設定は log4j.properties を使用して記述されます。
inline および external ロギングの例は次のとおりです。
inline ロギング
外部ロギング
その他のリソース
- ガベッジコレクター (GC) ロギングを有効 (または無効) にすることもできます。GC ロギングの詳細は「JVM 設定」を参照してください。
- ログレベルの詳細は、「Apache logging services」を参照してください。
3.3.8. Healthcheck
ヘルスチェックは、アプリケーションの健全性を検証する定期的なテストです。ヘルスチェックプローブが失敗すると、OpenShift によってアプリケーションが正常でないと見なされ、その修正が試行されます。
OpenShift では、以下の 2 つのタイプのおよび ヘルスチェックプローブがサポートされます。
- Liveness プローブ
- Readiness プローブ
プローブの詳細は、「Configure Liveness and Readiness Probes」を参照してください。AMQ Streams コンポーネントでは、両タイプのプローブが使用されます。
ユーザーは、Liveness および Readiness プローブに選択されたオプションを設定できます。
3.3.8.1. ヘルスチェックの設定
Liveness および Readiness プローブは、以下のリソースの livenessProbe および readinessProbe プロパティーを使用して設定できます。
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.KafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
livenessProbe および readinessProbe の両方によって以下のオプションがサポートされます。
-
initialDelaySeconds -
timeoutSeconds -
periodSeconds -
successThreshold -
failureThreshold
livenessProbe および readinessProbe オプションの詳細については、「Probe スキーマ参照」 を参照してください。
Liveness および Readiness プローブの設定例
3.3.8.2. ヘルスチェックの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
Kafka、KafkaConnect、またはKafkaConnectS2IリソースのlivenessProbeまたはreadinessProbeプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.9. Prometheus メトリクス
AMQ Streams では、Apache Kafka および ZooKeeper によってサポートされる JMX メトリクスを Prometheus メトリクスに変換するために、Prometheus JMX エクスポーター を使用した Prometheus メトリクスがサポートされます。有効になったメトリクスは、9404 番ポートで公開されます。
Prometheus および Grafana の設定に関する詳細は「メトリクス」を参照してください。
3.3.9.1. メトリクスの設定
Prometheus メトリクスは、以下のリソースに metrics プロパティーを設定して有効化されます。
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
KafkaConnect.spec -
KafkaConnectS2I.spec
metrics プロパティーがリソースに定義されていない場合、Prometheus メトリクスは無効になります。追加設定なしで Prometheus メトリクスのエクスポートを有効にするには、空のオブジェクト ({}) を設定します。
追加設定なしでメトリクスを有効にする例
metrics プロパティーには、Prometheus JMX エスクポーター の追加設定が含まれることがあります。
追加の Prometheus JMX Exporter 設定を使用したメトリクスを有効化する例
3.3.9.2. Prometheus メトリクスの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
Kafka、KafkaConnect、またはKafkaConnectS2Iリソースのmetricsプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.10. JVM オプション
AMQ Streams の以下のコンポーネントは、仮想マシン (VM) 内で実行されます。
- Apache Kafka
- Apache ZooKeeper
- Apache Kafka Connect
- Apache Kafka MirrorMaker
- AMQ Streams Kafka Bridge
JVM 設定オプションによって、さまざまなプラットフォームおよびアーキテクチャーのパフォーマンスが最適化されます。AMQ Streams では、これらのオプションの一部を設定できます。
3.3.10.1. JVM 設定
JVM オプションは、以下のリソースの jvmOptions プロパティーを使用して設定できます。
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
使用可能な JVM オプションの選択されたサブセットのみを設定できます。以下のオプションがサポートされます。
-Xms および -Xmx
-Xms は、JVM の起動時に最初に割り当てられる最小ヒープサイズを設定します。-Xmx は、最大ヒープサイズを設定します。
-Xmx や -Xms などの JVM 設定で使用できる単位は、対応するイメージの JDK java バイナリーによって許可される単位です。そのため、1g または 1G は 1,073,741,824 バイトを意味し、Gi は接尾辞として有効な単位ではありません。これは、1G は 1,000,000,000 バイト、1Gi は 1,073,741,824 バイトを意味する OpenShift の慣例に準拠している メモリー要求および制限 に使用される単位とは対照的です。
-Xms および -Xmx に使用されるデフォルト値は、コンテナーに メモリー要求 の制限が設定されているかどうかによって異なります。
- メモリーの制限がある場合は、JVM の最小および最大メモリーは制限に対応する値に設定されます。
-
メモリーの制限がない場合、JVM の最小メモリーは
128Mに設定され、JVM の最大メモリーは定義されません。これにより、JVM のメモリーを必要に応じて拡張できます。これは、テストおよび開発での単一ノード環境に適しています。
-Xmx を明示的に設定するには、以下の点に注意する必要があります。
-
JVM のメモリー使用量の合計は、
-Xmxによって設定された最大ヒープの約 4 倍になります。 -
適切な OpenShift メモリー制限を設定せずに
-Xmxが設定された場合、OpenShift ノードで、実行されている他の Pod からメモリー不足が発生するとコンテナーが強制終了される可能性があります。 -
適切な OpenShift メモリー要求を設定せずに
-Xmxが設定された場合、コンテナーはメモリー不足のノードにスケジュールされる可能性があります。この場合、コンテナーは起動せずにクラッシュします (-Xmsが-Xmxに設定されている場合は即座にクラッシュし、そうでない場合はその後にクラッシュします)。
-Xmx を明示的に設定する場合は、以下を行うことが推奨されます。
- メモリー要求とメモリー制限を同じ値に設定します。
-
-Xmxの 4.5 倍以上のメモリー要求を使用します。 -
-Xmsを-Xmxと同じ値に設定することを検討してください。
大量のディスク I/O を実行するコンテナー (Kafka ブローカーコンテナーなど) は、オペレーティングシステムのページキャッシュとして使用できるメモリーを確保しておく必要があります。このようなコンテナーでは、要求されるメモリーは JVM によって使用されるメモリーよりもはるかに多くなります。
-Xmx および -Xms の設定例 (抜粋)
# ... jvmOptions: "-Xmx": "2g" "-Xms": "2g" # ...
# ...
jvmOptions:
"-Xmx": "2g"
"-Xms": "2g"
# ...上記の例では、JVM のヒープに 2 GiB (2,147,483,648 バイト) が使用されます。メモリー使用量の合計は約 8GiB になります。
最初のヒープサイズ (-Xms) および最大ヒープサイズ (-Xmx) に同じ値を設定すると、JVM が必要以上のヒープを割り当てて起動後にメモリーを割り当てないようにすることができます。Kafka および ZooKeeper Pod では、このような割り当てによって不要なレイテンシーが発生する可能性があります。Kafka Connect では、割り当ての過剰を防ぐことが最も重要になります。これは、コンシューマーの数が増えるごとに割り当て過剰の影響がより深刻になる分散モードで特に重要です。
-server
-server はサーバー JVM を有効にします。このオプションは true または false に設定できます。
-server の設定例 (抜粋)
# ... jvmOptions: "-server": true # ...
# ...
jvmOptions:
"-server": true
# ...
いずれのオプション (-server および -XX) も指定されないと、Apache Kafka の KAFKA_JVM_PERFORMANCE_OPTS のデフォルト設定が使用されます。
-XX
-XX オブジェクトは、JVM の高度なランタイムオプションの設定に使用できます。-server および -XX オプションは、Apache Kafka の KAFKA_JVM_PERFORMANCE_OPTS オプションの設定に使用されます。
-XX オブジェクトの使用例
上記の設定例の場合、JVM オプションは以下のようになります。
-XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:-UseParNewGC
-XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:-UseParNewGC
いずれのオプション (-server および -XX) も指定されないと、Apache Kafka の KAFKA_JVM_PERFORMANCE_OPTS のデフォルト設定が使用されます。
3.3.10.1.1. ガベッジコレクターのロギング
jvmOptions セクションでは、ガベージコレクター (GC) のロギングを有効または無効にすることもできます。GC ロギングはデフォルトで無効になっています。これを有効にするには、以下のように gcLoggingEnabled プロパティーを設定します。
GC ロギングを有効にする例
# ... jvmOptions: gcLoggingEnabled: true # ...
# ...
jvmOptions:
gcLoggingEnabled: true
# ...3.3.10.2. JVM オプションの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
Kafka、KafkaConnect、KafkaConnectS2I、KafkaMirrorMaker、またはKafkaBridgeリソースのjvmOptionsプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.11. コンテナーイメージ
AMQ Streams では、コンポーネントに使用されるコンテナーイメージを設定できます。コンテナーイメージのオーバーライドは、別のコンテナーレジストリーを使用する必要がある特別な状況でのみ推奨されます。たとえば、AMQ Streams によって使用されるコンテナーリポジトリーにネットワークがアクセスできない場合などがこれに該当します。そのような場合は、AMQ Streams イメージをコピーするか、ソースからビルドする必要があります。設定したイメージが AMQ Streams イメージと互換性のない場合は、適切に機能しない可能性があります。
3.3.11.1. コンテナーイメージの設定
以下のリソースの image プロパティーを使用すると、各コンポーネントに使用するコンテナーイメージを指定できます。
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
3.3.11.1.1. Kafka、Kafka Connect、および Kafka MirrorMaker の image プロパティーの設定
Kafka、Kafka Connect (S2I サポートのある Kafka Connect を含む)、および Kafka MirrorMaker では、複数のバージョンの Kafka がサポートされます。各コンポーネントには独自のイメージが必要です。異なる Kafka バージョンのデフォルトイメージは、以下の環境変数で設定されます。
-
STRIMZI_KAFKA_IMAGES -
STRIMZI_KAFKA_CONNECT_IMAGES -
STRIMZI_KAFKA_CONNECT_S2I_IMAGES -
STRIMZI_KAFKA_MIRROR_MAKER_IMAGES
これらの環境変数には、Kafka バージョンと対応するイメージ間のマッピングが含まれます。マッピングは、image および version プロパティーとともに使用されます。
-
imageとversionのどちらもカスタムリソースに指定されていない場合、versionは Cluster Operator のデフォルトの Kafka バージョンに設定され、環境変数のこのバージョンに対応するイメージが指定されます。 -
imageが指定されていてもversionが指定されていない場合、指定されたイメージが使用され、Cluster Operator のデフォルトの Kafka バージョンがversionであると想定されます。 -
versionが指定されていてもimageが指定されていない場合、環境変数の指定されたバージョンに対応するイメージが使用されます。 -
versionとimageの両方を指定すると、指定されたイメージが使用されます。このイメージには、指定のバージョンの Kafka イメージが含まれると想定されます。
異なるコンポーネントの image および version は、以下のプロパティーで設定できます。
-
Kafka の場合は
spec.kafka.imageおよびspec.kafka.version。 -
Kafka Connect、Kafka Connect S2I、および Kafka MirrorMaker の場合は
spec.imageおよびspec.version。
version のみを提供し、image プロパティーを未指定のままにしておくことが推奨されます。これにより、カスタムリソースの設定時に間違いが発生する可能性が低減されます。異なるバージョンの Kafka に使用されるイメージを変更する必要がある場合は、Cluster Operator の環境変数を設定することが推奨されます。
3.3.11.1.2. 他のリソースでの image プロパティーの設定
他のカスタムリソースの image プロパティーでは、デプロイメント中に指定の値が使用されます。image プロパティーがない場合、Cluster Operator 設定に指定された image が使用されます。image 名が Cluster Operator 設定に定義されていない場合、デフォルト値が使用されます。
Kafka ブローカー TLS サイドカーの場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_TLS_SIDECAR_KAFKA_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
- ZooKeeper ノードの場合:
ZooKeeper ノードの TLS サイドカーの場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_TLS_SIDECAR_ZOOKEEPER_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Topic Operator の場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_TOPIC_OPERATOR_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
User Operator の場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_USER_OPERATOR_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Entity Operator TLS サイドカーの場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_TLS_SIDECAR_ENTITY_OPERATOR_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Kafka Exporter の場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_KAFKA_EXPORTER_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Kafka Bridge の場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_KAFKA_BRIDGE_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-bridge-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Kafka ブローカーイニシャライザーの場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_KAFKA_INIT_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
コンテナーイメージのオーバーライドは、別のコンテナーレジストリーを使用する必要がある特別な状況でのみ推奨されます。たとえば、AMQ Streams によって使用されるコンテナーリポジトリーにネットワークがアクセスできない場合などがこれに該当します。そのような場合は、AMQ Streams イメージをコピーするか、ソースからビルドする必要があります。設定したイメージが AMQ Streams イメージと互換性のない場合は、適切に機能しない可能性があります。
コンテナーイメージ設定の例
3.3.11.2. コンテナーイメージの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
Kafka、KafkaConnect、またはKafkaConnectS2Iリソースのimageプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.12. Pod スケジューリングの設定
2 つのアプリケーションが同じ OpenShift ノードにスケジュールされた場合、両方のアプリケーションがディスク I/O のように同じリソースを使用し、パフォーマンスに影響する可能性があります。これにより、パフォーマンスが低下する可能性があります。ノードを他の重要なワークロードと共有しないように Kafka Pod をスケジュールする場合、適切なノードを使用したり、Kafka 専用のノードのセットを使用すると、このような問題を適切に回避できます。
3.3.12.1. 他のアプリケーションに基づく Pod のスケジューリング
3.3.12.1.1. 重要なアプリケーションがノードを共有しないようにする
Pod の非アフィニティーを使用すると、重要なアプリケーションが同じディスクにスケジュールされないようにすることができます。Kafka クラスターの実行時に、Pod の非アフィニティーを使用して、Kafka ブローカーがデータベースなどの他のワークロードとノードを共有しないようにすることが推奨されます。
3.3.12.1.2. アフィニティー
アフィニティーは、以下のリソースの affinity プロパティーを使用して設定できます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
アフィニティー設定には、さまざまなタイプのアフィニティーを含めることができます。
- Pod のアフィニティーおよび非アフィニティー
- ノードのアフィニティー
affinity プロパティーの形式は、OpenShift の仕様に準拠します。詳細は、Kubernetes のノードおよび Pod のアフィニティーに関するドキュメント を参照してください。
3.3.12.1.3. Kafka コンポーネントでの Pod の非アフィニティーの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
クラスターデプロイメントを指定するリソースの
affinityプロパティーを編集します。ラベルを使用して、同じノードでスケジュールすべきでない Pod を指定します。topologyKeyをkubernetes.io/hostnameに設定し、選択した Pod が同じホスト名のノードでスケジュールされてはならないことを指定する必要があります。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.12.2. 特定のノードへの Pod のスケジューリング
3.3.12.2.1. ノードのスケジューリング
OpenShift クラスターは、通常多くの異なるタイプのワーカーノードで構成されます。ワークロードが非常に大きい環境の CPU に対して最適化されたものもあれば、メモリー、ストレージ (高速のローカル SSD)、または ネットワークに対して最適化されたものもあります。異なるノードを使用すると、コストとパフォーマンスの両面で最適化しやすくなります。最適なパフォーマンスを実現するには、AMQ Streams コンポーネントのスケジューリングで適切なノードを使用できるようにすることが重要です。
OpenShift は、ノードのアフィニティーを使用してワークロードを特定のノードにスケジュールします。ノードのアフィニティーにより、Pod がスケジュールされるノードにスケジューリングの制約を作成できます。制約はラベルセレクターとして指定されます。beta.kubernetes.io/instance-type などの組み込みノードラベルまたはカスタムラベルのいずれかを使用してラベルを指定すると、適切なノードを選択できます。
3.3.12.2.2. アフィニティー
アフィニティーは、以下のリソースの affinity プロパティーを使用して設定できます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
アフィニティー設定には、さまざまなタイプのアフィニティーを含めることができます。
- Pod のアフィニティーおよび非アフィニティー
- ノードのアフィニティー
affinity プロパティーの形式は、OpenShift の仕様に準拠します。詳細は、Kubernetes のノードおよび Pod のアフィニティーに関するドキュメント を参照してください。
3.3.12.2.3. Kafka コンポーネントでのノードのアフィニティーの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
AMQ Streams コンポーネントをスケジュールする必要のあるノードにラベルを付けます。
oc labelを使用してこれを行うことができます。oc label node your-node node-type=fast-network
oc label node your-node node-type=fast-networkCopy to Clipboard Copied! Toggle word wrap Toggle overflow または、既存のラベルによっては再利用が可能です。
クラスターデプロイメントを指定するリソースの
affinityプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.12.3. 専用ノードの使用
3.3.12.3.1. 専用ノード
クラスター管理者は、選択した OpenShift ノードをテイントとしてマーク付けできます。テイントのあるノードは、通常のスケジューリングから除外され、通常の Pod はそれらのノードでの実行はスケジュールされません。ノードに設定されたテイントを許容できるサービスのみをスケジュールできます。このようなノードで実行されるその他のサービスは、ログコレクターやソフトウェア定義のネットワークなどのシステムサービスのみです。
テイントは専用ノードの作成に使用できます。専用のノードで Kafka とそのコンポーネントを実行する利点は多くあります。障害の原因になったり、Kafka に必要なリソースを消費するその他のアプリケーションが同じノードで実行されません。これにより、パフォーマンスと安定性が向上します。
専用ノードで Kafka Pod をスケジュールするには、ノードのアフィニティー と 許容 (toleration) を設定します。
3.3.12.3.2. アフィニティー
アフィニティーは、以下のリソースの affinity プロパティーを使用して設定できます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
アフィニティー設定には、さまざまなタイプのアフィニティーを含めることができます。
- Pod のアフィニティーおよび非アフィニティー
- ノードのアフィニティー
affinity プロパティーの形式は、OpenShift の仕様に準拠します。詳細は、Kubernetes のノードおよび Pod のアフィニティーに関するドキュメント を参照してください。
3.3.12.3.3. 許容 (Toleration)
許容 (Toleration) は、以下のリソースの tolerations プロパティーを使用して設定できます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
tolerations プロパティーの形式は、OpenShift の仕様に準拠します。詳細は、Kubernetes の「Taints and Tolerations」を参照してください。
3.3.12.3.4. 専用ノードの設定と Pod のスケジューリング
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
- 専用ノードとして使用するノードを選択します。
- これらのノードにスケジュールされているワークロードがないことを確認します。
選択したノードにテイントを設定します。
oc adm taintを使用してこれを行うことができます。oc adm taint node your-node dedicated=Kafka:NoSchedule
oc adm taint node your-node dedicated=Kafka:NoScheduleCopy to Clipboard Copied! Toggle word wrap Toggle overflow さらに、選択したノードにラベルも追加します。
oc labelを使用してこれを行うことができます。oc label node your-node dedicated=Kafka
oc label node your-node dedicated=KafkaCopy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターデプロイメントを指定するリソースの
affinityおよびtolerationsプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.13. 外部設定およびシークレットの使用
コネクターは、Kafka Connect の HTTP REST インターフェースまたは KafkaConnectors を使用して作成、再設定、および削除されます。これらの方法の詳細は、「コネクターの作成および管理」 を参照してください。コネクター設定は、HTTP リクエストの一部として Kafka Connect に渡され、Kafka 自体に保存されます。
ConfigMap およびシークレットは、設定やデータの保存に使用される標準的な OpenShift リソースです。コネクターの管理に使用するいずれの方法でも、ConfigMap およびシークレットを使用してコネクターの特定の要素を設定できます。その後、HTTP REST コマンドで設定値を参照できます (これにより、必要な場合は設定が分離され、よりセキュアになります)。この方法は、ユーザー名、パスワード、証明書などの機密性の高いデータに適用されます。
3.3.13.1. コネクター設定の外部への保存
ConfigMap またはシークレットをボリュームまたは環境変数として Kafka Connect Pod にマウントできます。ボリュームおよび環境変数は、KafkaConnect.spec および KafkaConnectS2I.spec の externalConfiguration プロパティーで設定されます。
3.3.13.1.1. 環境変数としての外部設定
env プロパティーは、1 つ以上の環境変数を指定するために使用されます。これらの変数には ConfigMap または Secret からの値を含めることができます。
ユーザー定義の環境変数に、KAFKA_ または STRIMZI_ で始まる名前を付けることはできません。
シークレットから環境変数に値をマウントするには、以下の例のように valueFrom プロパティーおよび secretKeyRef を使用します。
シークレットからの値に設定された環境変数の例
シークレットを環境変数にマウントする一般的なユースケースとして、コネクターが Amazon AWS と通信する必要があり、クレデンシャルで AWS_ACCESS_KEY_ID および AWS_SECRET_ACCESS_KEY 環境変数を読み取る必要がある場合が挙げられます。
ConfigMap から環境変数に値をマウントするには、以下の例のように valueFromプロパティーで configMapKeyRef を使用します。
ConfigMap からの値に設定された環境変数の例
3.3.13.1.2. ボリュームとしての外部設定
ConfigMap またはシークレットをボリュームとして Kafka Connect Pod にマウントすることもできます。以下の場合、環境変数の代わりにボリュームを使用すると便利です。
- TLS 証明書でのトラストストアまたはキーストアのマウント
- Kafka Connect コネクターの設定に使用されるプロパティーファイルのマウント
externalConfiguration リソースの volumes プロパティーで、ボリュームとしてマウントされる ConfigMap またはシークレットをリストします。各ボリュームは name プロパティーに名前を指定し、ConfigMap またはシークレットを参照する必要があります。
外部設定のあるボリュームの例
ボリュームは、パス /opt/kafka/external-configuration/<volume-name> の Kafka Connect コンテナー内にマウントされます。たとえば、connector1 という名前のボリュームのファイルは /opt/kafka/external-configuration/connector1 ディレクトリーにあります。
コネクター設定でマウントされたプロパティーファイルから値を読み取るには、FileConfigProvider を使用する必要があります。
3.3.13.2. 環境変数としてのシークレットのマウント
OpenShift シークレットを作成し、これを環境変数として Kafka Connect にマウントできます。
前提条件
- 稼働中の Cluster Operator。
手順
環境変数としてマウントされる情報が含まれるシークレットを作成します。以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka Connect リソースを作成または編集します。シークレットを参照するように、
KafkaConnectまたはKafkaConnectS2IカスタムリソースのexternalConfigurationセクションを設定します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 変更を Kafka Connect デプロイメントに適用します。
oc applyを使用します。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
コネクターの開発時に、環境変数が使用できるようになりました。
その他のリソース
-
Kafka Connect の外部設定の詳細は、「
ExternalConfigurationスキーマ参照」 を参照してください。
3.3.13.3. シークレットのボリュームとしてのマウント
OpenShift シークレットを作成してボリュームとして Kafka Connect にマウントし、これを使用して Kafka Connect コネクターを設定します。
前提条件
- 稼働中の Cluster Operator。
手順
コネクター設定の設定オプションを定義するプロパティーファイルが含まれるシークレットを作成します。以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka Connect リソースを作成または編集します。シークレットを参照するように、
configセクションのFileConfigProviderと、KafkaConnectまたはKafkaConnectS2IカスタムリソースのexternalConfigurationセクションを設定します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 変更を Kafka Connect デプロイメントに適用します。
oc applyを使用します。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow コネクター設定のある JSON ペイロードのマウントされたプロパティーファイルから値を使用します。以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
-
Kafka Connect の外部設定の詳細は、「
ExternalConfigurationスキーマ参照」 を参照してください。
3.3.14. KafkaConnector リソースの有効化
Kafka Connect クラスターの KafkaConnectors を有効にするには、strimzi.io/use-connector-resources アノテーションを KafkaConnect または KafkaConnectS2I カスタムリソースに追加します。
前提条件
- 稼働中の Cluster Operator が必要です。
手順
KafkaConnectまたはKafkaConnectS2Iリソースを編集します。strimzi.io/use-connector-resourcesアノテーションを追加します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc applyを使用してリソースを作成または更新します。oc apply -f kafka-connect.yaml
oc apply -f kafka-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.3.15. Source2Image がサポートされる Kafka Connect クラスターの一部として作成されたリソースの一覧
以下のリソースは、OpenShift クラスターの Cluster Operator によって作成されます。
- connect-cluster-name-connect-source
- 新たにビルドされた Docker イメージのベースイメージとして使用される ImageStream。
- connect-cluster-name-connect
- あたらしい Kafka Connect Docker イメージのビルドを担当する BuildConfig。
- connect-cluster-name-connect
- 新たにビルドされた Docker イメージがプッシュされる ImageStream。
- connect-cluster-name-connect
- Kafka Connect ワーカーノード Pod の作成を担当する DeploymentConfig。
- connect-cluster-name-connect-api
- Kafka Connect クラスターを管理するために REST インターフェースを公開するサービス。
- connect-cluster-name-config
- Kafka Connect 補助設定が含まれ、Kafka ブローカー Pod によってボリュームとしてマウントされる ConfigMap。
- connect-cluster-name-connect
- Kafka Connect ワーカーノードに設定された Pod の Disruption Budget。
3.3.16. OpenShift ビルドおよび S2I (Source-to-Image) を使用したコンテナーイメージの作成
OpenShift ビルド と S2I (Source-to-Image) フレームワークを使用して、新しいコンテナーイメージを作成できます。OpenShift ビルドは、S2I がサポートされるビルダーイメージとともに、ユーザー提供のソースコードおよびバイナリーを取得し、これらを使用して新しいコンテナーイメージを構築します。構築後、コンテナーイメージは OpenShfit のローカルコンテナーイメージリポジトリーに格納され、デプロイメントで使用可能になります。
S2I がサポートされる Kafka Connect ビルダーイメージは、registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0 イメージの一部として、Red Hat Container Catalog で提供されます。このS2I イメージは、バイナリー (プラグインおよびコネクターとともに) を取得し、/tmp/kafka-plugins/s2i ディレクトリーに格納されます。このディレクトリーから、Kafka Connect デプロイメントとともに使用できる新しい Kafka Connect イメージを作成します。改良されたイメージの使用を開始すると、Kafka Connect は /tmp/kafka-plugins/s2i ディレクトリーからサードパーティープラグインをロードします。
手順
コマンドラインで
oc applyコマンドを使用し、Kafka Connect の S2I クラスターを作成およびデプロイします。oc apply -f examples/kafka-connect/kafka-connect-s2i.yaml
oc apply -f examples/kafka-connect/kafka-connect-s2i.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka Connect プラグインでディレクトリーを作成します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc start-buildコマンドで、準備したディレクトリーを使用してイメージの新しいビルドを開始します。oc start-build my-connect-cluster-connect --from-dir ./my-plugins/
oc start-build my-connect-cluster-connect --from-dir ./my-plugins/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記ビルドの名前は、デプロイされた Kafka Connect クラスターと同じになります。
- ビルドが完了したら、Kafka Connect のデプロイメントによって新しいイメージが自動的に使用されます。
3.4. Kafka MirrorMaker の設定
本章では、Kafka クラスター間でデータを複製するために AMQ Streams クラスターで Kafka MirrorMaker デプロイメントを設定する方法を説明します。
AMQ Streams では、MirrorMaker または MirrorMaker 2.0 を使用できます。MirrorMaker 2.0 は最新バージョンで、Kafka クラスター間でより効率的にデータをミラーリングする方法を提供します。
MirrorMaker 2.0 はテクノロジープレビュー機能です。テクノロジープレビューの機能は、Red Hat の本番環境のサービスレベルアグリーメント (SLA) ではサポートされず、機能的に完全ではないことがあります。Red Hat は、本番環境でのテクノロジープレビュー機能の実装は推奨しません。テクノロジープレビューの機能は、最新の技術をいち早く提供して、開発段階で機能のテストやフィードバックの収集を可能にするために提供されます。Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳しい情報は、「テクノロジプレビュー機能の サポート範囲」を参照してください。
MirrorMaker
MirrorMaker を使用している場合は、KafkaMirrorMaker リソースを設定します。
以下の手順は、リソースの設定方法を示しています。
サポート対象のプロパティーも以下で詳細に説明されています。
KafkaMirrorMaker リソースの完全なスキーマは、「KafkaMirrorMaker スキーマ参照」に記載されています。
KafkaMirrorMaker リソースに適用されるラベルは、Kafka MirrorMaker を構成する OpenShift リソースにも適用されます。そのため、必要に応じてリソースにラベルが適用されるため便利です。
MirrorMaker 2.0
MirrorMaker 2.0 を使用している場合は、KafkaMirrorMaker2 リソースを設定します。
MirrorMaker 2.0 では、クラスターの間でデータを複製する全く新しい方法が導入されました。
その結果、リソースの設定は MirrorMaker の以前のバージョンとは異なります。MirrorMaker 2.0 の使用を選択した場合、現在、レガシーサポートがないため、リソースを手作業で新しい形式に変換する必要があります。
MirrorMaker 2.0 によってデータが複製される方法は、以下に説明されています。
以下の手順では、MirrorMaker 2.0 に対してリソースが設定される方法について取り上げます。
KafkaMirrorMaker2 リソースの完全なスキーマは、「KafkaMirrorMaker2 スキーマ参照」に記載されています。
3.4.1. Kafka MirrorMaker の設定
KafkaMirrorMaker リソースのプロパティーを使用して、Kafka MirrorMaker デプロイメントを設定します。
TLS または SASL 認証を使用して、プロデューサーおよびコンシューマーのアクセス制御を設定できます。この手順では、コンシューマーおよびプロデューサー側で TLS による暗号化および認証を使用する設定を説明します。
前提条件
- AMQ Streams および Kafka がデプロイされている必要があります。
- ソースおよびターゲットの Kafka クラスターが使用できる必要があります。
手順
KafkaMirrorMakerリソースのspecプロパティーを編集します。設定可能なプロパティーは以下の例のとおりです。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- レプリカノードの数。
- 2
- コンシューマーおよびプロデューサーのブートストラップサーバー。
- 3
- コンシューマーのグループ ID。
- 4
- コンシューマーストリームの数。
- 5
- オフセットの自動コミット間隔 (ミリ秒単位)。
- 6
- コンシューマーまたはプロデューサーの TLS 証明書が X.509 形式で保存されるキー名のある TLS による暗号化。詳細は、「
KafkaMirrorMakerTlsスキーマ参照」を参照してください。 - 7
- OAuth ベアラートークン、SASL ベースの SCRAM-SHA-512 または PLAIN メカニズムを使用し、ここで示された TLS メカニズム を使用する、コンシューマーおよびプロデューサーの認証。
- 8
- コンシューマーおよびプロデューサーの Kafka 設定オプション。
- 9
trueに設定された場合、Kafka MirrorMaker が終了し、メッセージの送信失敗後にコンテナーが再起動します。- 10
- ソースからターゲット Kafka クラスターにミラーリングされたトピック。
- 11
- 現在
cpuおよびmemoryである、サポートされるリソースの予約を要求し、消費可能な最大リソースを指定を制限します。 - 12
- ConfigMap より直接的 (
inline) または間接的 (external) に追加されたロガーおよびログレベルを指定します。カスタム ConfigMap は、log4j.propertiesまたはlog4j2.propertiesキー下に配置する必要があります。MirrorMaker にはmirrormaker.root.loggerと呼ばれる単一のロガーがあります。ログレベルは INFO、ERROR、WARN、TRACE、DEBUG、FATAL、または OFF に設定できます。 - 13
- コンテナーを再起動するタイミング (liveness) およびコンテナーがトラフィックを許可できるタイミング (readiness) を把握するためのヘルスチェック。
- 14
- Prometheus メトリクス。この例では、Prometheus JMX エクスポーターの設定で有効になっています。
metrics: {}を使用すると追加設定なしでメトリクスを有効にすることができます。 - 15
- Kafka MirrorMaker を実行している仮想マシン (VM) のパフォーマンスを最適化するための JVM 設定オプション。
- 16
- 高度な任意手順: 特別な場合のみ推奨される コンテナーイメージの設定。
- 17
- テンプレートのカスタマイズ。ここでは、Pod は非アフィニティーでスケジュールされるため、Pod は同じホスト名のノードではスケジュールされません。
警告abortOnSendFailureプロパティーがfalseに設定されると、プロデューサーはトピックの次のメッセージを送信しようとします。失敗したメッセージは再送されないため、元のメッセージが失われる可能性があります。リソースを作成または更新します。
oc apply -f <your-file>
oc apply -f <your-file>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.4.2. Kafka MirrorMaker 設定プロパティー
KafkaMirrorMaker リソースの spec 設定プロパティーを使用して、MirrorMaker デプロイメントを設定します。
サポートされるプロパティーの詳細は以下を参照してください。
3.4.2.1. レプリカ
replicas プロパティーを使用してレプリカを設定します。
複数の MirrorMaker レプリカを実行して、可用性とスケーラビリティーを向上できます。OpenShift で Kafka MirrorMaker を実行する場合、高可用性を実現するために Kafka MirrorMaker の複数のレプリカを実行する必要はありません。Kafka MirrorMaker がデプロイされたノードがクラッシュした場合、OpenShift では 自動的に Kafka MirrorMaker Pod が別のノードに再スケジュールされます。ただし、複数のレプリカで Kafka MirrorMaker を実行すると、他のノードが稼働しているため、フェイルオーバー時間が短縮されます。
3.4.2.2. ブートストラップサーバー
consumer.bootstrapServers および producer.bootstrapServers プロパティーを使用して、コンシューマーおよびプロデューサーのブートストラップサーバーのリストを設定します。
Kafka MirrorMaker は常に 2 つの Kafka クラスター (ソースおよびターゲット) と連携します。ソースおよびターゲット Kafka クラスターは、<hostname>:<port> ペアのコンマ区切りリストを 2 つ形式として用いて指定されます。それぞれのコンマ区切りリストには、<hostname>:<port> ペアとして指定された 1 つ以上の Kafka ブローカーまたは Kafka ブローカーを示す 1 つの Service が含まれます。
ブートストラップサーバーリストは、同じ OpenShift クラスターにデプロイする必要がない Kafka クラスターを参照できます。AMQ Streams によってデプロイされたまたはされていない Kafka クラスターを参照することもできますが、外部でアクセス可能な別の OpenShift クラスターである必要があります。
同じ OpenShift クラスターである場合、各リストに <cluster-name>-kafka-bootstrap という名前の Kafka クラスターブートストラップサービスが含まれ、さらに平文トラフィックの場合はポート 9092、暗号化されたトラフィックの場合はポート 9093 が含まれることが理想的です。AMQ Streams によって異なる OpenShift クラスターにデプロイされた場合、リストの内容はクラスターを公開するために使用された方法によって異なります (ルート、ノードポート、またはロードバランサー)。
AMQ Streams によって管理されない Kafka クラスターで Kafka MirrorMaker を使用する場合は、指定のクラスターの設定に応じてブートストラップサーバーのリストを指定できます。
3.4.2.3. ホワイトリスト
whitelist プロパティーを使用して、Kafka MirrorMaker がソースからターゲット Kafka クラスターにミラーリングするトピックのリストを設定します。
このプロパティーでは、簡単な単一のトピック名から複雑なパターンまですべての正規表現が許可されます。たとえば、「A|B」を使用してトピック A と B をミラーリングでき、「*」を使用してすべてのトピックをミラーリングできます。また、複数の正規表現をコンマで区切って Kafka MirrorMaker に渡すこともできます。
3.4.2.4. コンシューマーグループ ID
consumer.groupId プロパティーを使用して、コンシューマーにコンシューマーグループ ID を設定します。
Kafka MirrorMaker は Kafka コンシューマーを使用してメッセージを消費し、他の Kafka コンシューマークライアントと同様に動作します。ソース Kafka クラスターから消費されるメッセージは、ターゲット Kafka クラスターにミラーリングされます。パーティションの割り当てには、コンシューマーがコンシューマーグループの一部である必要があるため、グループ ID が必要です。
3.4.2.5. コンシューマーストリーム
consumer.numStreams プロパティーを使用して、コンシューマーのストリームの数を設定します。
コンシューマースレッドの数を増やすと、ミラーリングトピックのスループットを増やすことができます。コンシューマースレッドは、Kafka MirrorMaker に指定されたコンシューマーグループに属します。トピックパーティションはコンシューマースレッド全体に割り当てられ、メッセージが並行して消費されます。
3.4.2.6. オフセットの自動コミット間隔
consumer.offsetCommitInterval プロパティーを使用して、コンシューマーのオフセット自動コミット間隔を設定します。
Kafka MirrorMaker によってソース Kafka クラスターのデータが消費された後に、オフセットがコミットされる通常の間隔を指定できます。間隔はミリ秒単位で設定され、デフォルト値は 60,000 です。
3.4.2.7. メッセージ送信の失敗での中止
producer.abortOnSendFailure プロパティーを使用して、プロデューサーからメッセージ送信の失敗を処理する方法を設定します。
デフォルトでは、メッセージを Kafka MirrorMaker から Kafka クラスターに送信する際にエラーが発生した場合、以下が行われます。
- Kafka MirrorMaker コンテナーが OpenShift で終了します。
- その後、コンテナーが再作成されます。
abortOnSendFailure オプションを false に設定した場合、メッセージ送信エラーは無視されます。
3.4.2.8. Kafka プロデューサーおよびコンシューマー
consumer.config および producer.config プロパティーを使用して、コンシューマーおよびプロデューサーの Kafka オプションを設定します。
config プロパティーには、Kafka MirrorMaker コンシューマーとプロデューサーの設定オプションがキーとして含まれ、値は以下の JSON タイプの 1 つに設定されます。
- 文字列
- Number
- ブール値
例外
標準の Kafka コンシューマーおよびプロデューサーオプションを指定および設定できます。
しかし、以下に関連する AMQ Streams によって自動的に設定され直接管理されるオプションには例外があります。
- Kafka クラスターブートストラップアドレス
- セキュリティー (暗号化、認証、および承認)
- コンシューマーグループ ID
以下の文字列の 1 つと同じキーまたは以下の文字列の 1 つで始まるキーを持つ設定オプションはすべて禁止されています。
-
ssl. -
sasl. -
security. -
bootstrap.servers -
group.id
禁止されているオプションが config プロパティーにある場合、そのオプションは無視され、警告メッセージが Cluster Operator ログファイルに出力されます。その他のオプションはすべて Kafka MirrorMaker に渡されます。
Cluster Operator では、提供された config オブジェクトのキーまたは値は検証されません。無効な設定が指定されると、Kafka MirrorMaker が起動しなかったり、不安定になったりする場合があります。このような場合、KafkaMirrorMaker.spec.consumer.config または KafkaMirrorMaker.spec.producer.config オブジェクトの設定を修正し、Cluster Operator によって Kafka MirrorMaker の新しい設定がロールアウトされるようにします。
3.4.2.9. CPU およびメモリーリソース
reources.requests および resources.limits プロパティーを使用して、リソース要求および制限を設定します。
AMQ Streams では、デプロイされたコンテナーごとに特定のリソースを要求し、これらのリソースの最大消費を定義できます。
AMQ Streams では、以下のリソースタイプの要求および制限がサポートされます。
-
cpu -
memory
AMQ Streams では、このようなリソースの指定に OpenShift の構文が使用されます。
OpenShift におけるコンピュートリソースの管理に関する詳細は、「Managing Compute Resources for Containers」を参照してください。
リソース要求
要求によって、指定のコンテナーに対して予約するリソースが指定されます。リソースを予約すると、リソースが常に利用できるようになります。
リソース要求が OpenShift クラスターで利用可能な空きリソースを超える場合、Pod はスケジュールされません。
1 つまたは複数のサポートされるリソースに対してリクエストを設定できます。
リソース制限
制限によって、指定のコンテナーが消費可能な最大リソースが指定されます。制限は予約されず、常に利用できるとは限りません。コンテナーは、リソースが利用できる場合のみ、制限以下のリソースを使用できます。リソース制限は、常にリソース要求よりも高くする必要があります。
1 つまたは複数のサポートされる制限に対してリソースを設定できます。
サポートされる CPU 形式
CPU の要求および制限は以下の形式でサポートされます。
-
整数値 (
5CPU コア) または少数 (2.5CPU コア) の CPU コアの数。 -
数値または ミリ CPU / ミリコア (
100m)。1000 ミリコア は1CPU コアと同じです。
1 つの CPU コアのコンピューティング能力は、OpenShift がデプロイされたプラットフォームによって異なることがあります。
CPU 仕様の詳細は、「Meaning of CPU」を参照してください。
サポートされるメモリー形式
メモリー要求および制限は、メガバイト、ギガバイト、メビバイト、およびギビバイトで指定されます。
-
メモリーをメガバイトで指定するには、
M接尾辞を使用します。例:1000M -
メモリーをギガバイトで指定するには、
G接尾辞を使用します。例:1G -
メモリーをメビバイトで指定するには、
Mi接尾辞を使用します。例:1000Mi -
メモリーをギビバイトで指定するには、
Gi接尾辞を使用します。例:1Gi
メモリーの指定およびサポートされるその他の単位に関する詳細は、「Meaning of memory」を参照してください。
3.4.2.10. Kafka MirrorMaker ロガー
Kafka MirrorMaker には、独自の設定可能なロガーがあります。
-
mirrormaker.root.logger
MirrorMaker では Apache log4j ロガー実装が使用されます。
logging プロパティーを使用してロガーおよびロガーレベルを設定します。
ログレベルを設定するには、ロガーとレベルを直接指定 (インライン) するか、またはカスタム (外部) ConfigMap を使用します。ConfigMap を使用する場合、logging.name プロパティーを外部ロギング設定が含まれる ConfigMap の名前に設定します。ConfigMap 内では、ロギング設定は log4j.properties を使用して記述されます。
inline および external ロギングの例は次のとおりです。
その他のリソース
- ガベッジコレクター (GC) ロギングを有効 (または無効) にすることもできます。GC ロギングの詳細は「JVM 設定」を参照してください。
- ログレベルの詳細は、「Apache logging services」を参照してください。
3.4.2.11. Healthcheck
livenessProbe および readinessProbe プロパティーを使用して、AMQ Streams でサポートされる healthcheck プローブを設定します。
ヘルスチェックは、アプリケーションの健全性を検証する定期的なテストです。ヘルスチェックプローブが失敗すると、OpenShift によってアプリケーションが正常でないと見なされ、その修正が試行されます。
プローブの詳細は、「Configure Liveness and Readiness Probes」を参照してください。
livenessProbe および readinessProbe の両方によって以下のオプションがサポートされます。
-
initialDelaySeconds -
timeoutSeconds -
periodSeconds -
successThreshold -
failureThreshold
Liveness および Readiness プローブの設定例
livenessProbe および readinessProbe オプションの詳細については、「Probe スキーマ参照」を参照してください。
3.4.2.12. Prometheus メトリクス
metrics プロパティーを使用して、Prometheus メトリクスを有効化および設定します。
metrics プロパティーに、Prometheus JMX エスクポーター の追加設定を含めることもできます。AMQ Streams では、Apache Kafka および ZooKeeper によってサポートされる JMX メトリクスを Prometheus メトリクスに変換するために、Prometheus JMX エクスポーターを使用した Prometheus メトリクスがサポートされます。
追加設定なしで Prometheus メトリクスのエクスポートを有効にするには、空のオブジェクト ({}) を設定します。
有効になったメトリクスは、9404 番ポートで公開されます。
metrics プロパティーがリソースに定義されていない場合、Prometheus メトリクスは無効になります。
Prometheus および Grafana の設定に関する詳細は「メトリクス」を参照してください。
3.4.2.13. JVM オプション
jvmOptions プロパティーを使用して、コンポーネントが稼働している JVM のサポートされるオプションを設定します。
サポートされる JVM オプションは、さまざまなプラットフォームやアーキテクチャーのパフォーマンスを最適化するのに便利です。
サポートされるオプションの詳細は、「JVM 設定」を参照してください。
3.4.2.14. コンテナーイメージ
image プロパティーを使用して、コンポーネントによって使用されるコンテナーイメージを設定します。
コンテナーイメージのオーバーライドは、別のコンテナーレジストリーやカスタマイズされたイメージを使用する必要がある特別な状況でのみ推奨されます。
たとえば、ネットワークで AMQ Streams によって使用されるコンテナーリポジトリーへのアクセスが許可されない場合、AMQ Streams イメージのコピーまたはソースからのビルドを行うことができます。しかし、設定したイメージが AMQ Streams イメージと互換性のない場合は、適切に機能しない可能性があります。
コンテナーイメージのコピーはカスタマイズでき、デバッグに使用されることもあります。
詳細は、「コンテナーイメージの設定」を参照してください。
3.4.3. Kafka MirrorMaker の一部として作成されたリソースの一覧
以下のリソースは、OpenShift クラスターの Cluster Operator によって作成されます。
- <mirror-maker-name>-mirror-maker
- Kafka MirrorMaker Pod の作成を担当するデプロイメント。
- <mirror-maker-name>-config
- Kafka MirrorMaker の補助設定が含まれ、Kafka ブローカー Pod によってボリュームとしてマウントされる ConfigMap。
- <mirror-maker-name>-mirror-maker
- Kafka MirrorMaker ワーカーノードに設定された Pod の Disruption Budget。
3.4.4. AMQ Streams の MirrorMaker 2.0 との使用
このセクションでは、AMQ Streams の MirrorMaker 2.0 との使用について説明します。
MirrorMaker 2.0 は、データセンター内またはデータセンター全体の 2 台以上の Kafka クラスター間でデータを複製するために使用されます。
クラスター全体のデータレプリケーションでは、以下が必要な状況がサポートされます。
- システム障害時のデータの復旧
- 分析用のデータの集計
- 特定のクラスターへのデータアクセスの制限
- レイテンシーを改善するための特定場所でのデータのプロビジョニング
MirrorMaker 2.0 には、以前のバージョンの MirrorMaker ではサポートされない機能があります。
3.4.4.1. MirrorMaker 2.0 のデータレプリケーション
MirrorMaker 2.0 はソースの Kafka クラスターからメッセージを消費して、ターゲットの Kafka クラスターに書き込みます。
MirrorMaker 2.0 は以下を使用します。
- ソースクラスターからデータを消費するソースクラスターの設定。
- データをターゲットクラスターに出力するターゲットクラスターの設定。
MirrorMaker 2.0 は Kafka Connect フレームワークをベースとし、コネクターによってクラスター間のデータ転送が管理されます。MirrorMaker 2.0 の MirrorSourceConnector は、ソースクラスターからターゲットクラスターにトピックを複製します。
あるクラスターから別のクラスターにデータを ミラーリング するプロセスは非同期です。推奨されるパターンは、ソース Kafka クラスターとともにローカルでメッセージが作成され、ターゲットの Kafka クラスターの近くでリモートで消費されることです。
MirrorMaker 2.0 は、複数のソースクラスターで使用できます。
図3.1 2 つのクラスターにおけるレプリケーション
3.4.4.2. クラスターの設定
active/passive または active/active クラスター設定で MirrorMaker 2.0 を使用できます。
- active/passive 設定では、アクティブなクラスターからのデータはパッシブなクラスターで複製され、たとえば、システム障害時のデータ復旧などでスタンバイ状態を維持します。
- active/active 設定では、両方のクラスターがアクティブで、同じデータを同時に提供します。これは、地理的に異なる場所で同じデータをローカルで利用可能にする場合に便利です。
プロデューサーとコンシューマーがアクティブなクラスターのみに接続することを前提とします。
3.4.4.2.1. 双方向レプリケーション
MirrorMaker 2.0 アーキテクチャーでは、active/active クラスター設定で双方向レプリケーションがサポートされます。MirrorMaker 2.0 クラスターは、ターゲット宛先ごとに必要です。
各クラスターは、 source および remote トピックの概念を使用して、別のクラスターのデータを複製します。同じトピックが各クラスターに保存されるため、リモートトピックの名前がソースクラスターを表すように自動的に MirrorMaker 2.0 によって変更されます。
図3.2 トピックの名前変更
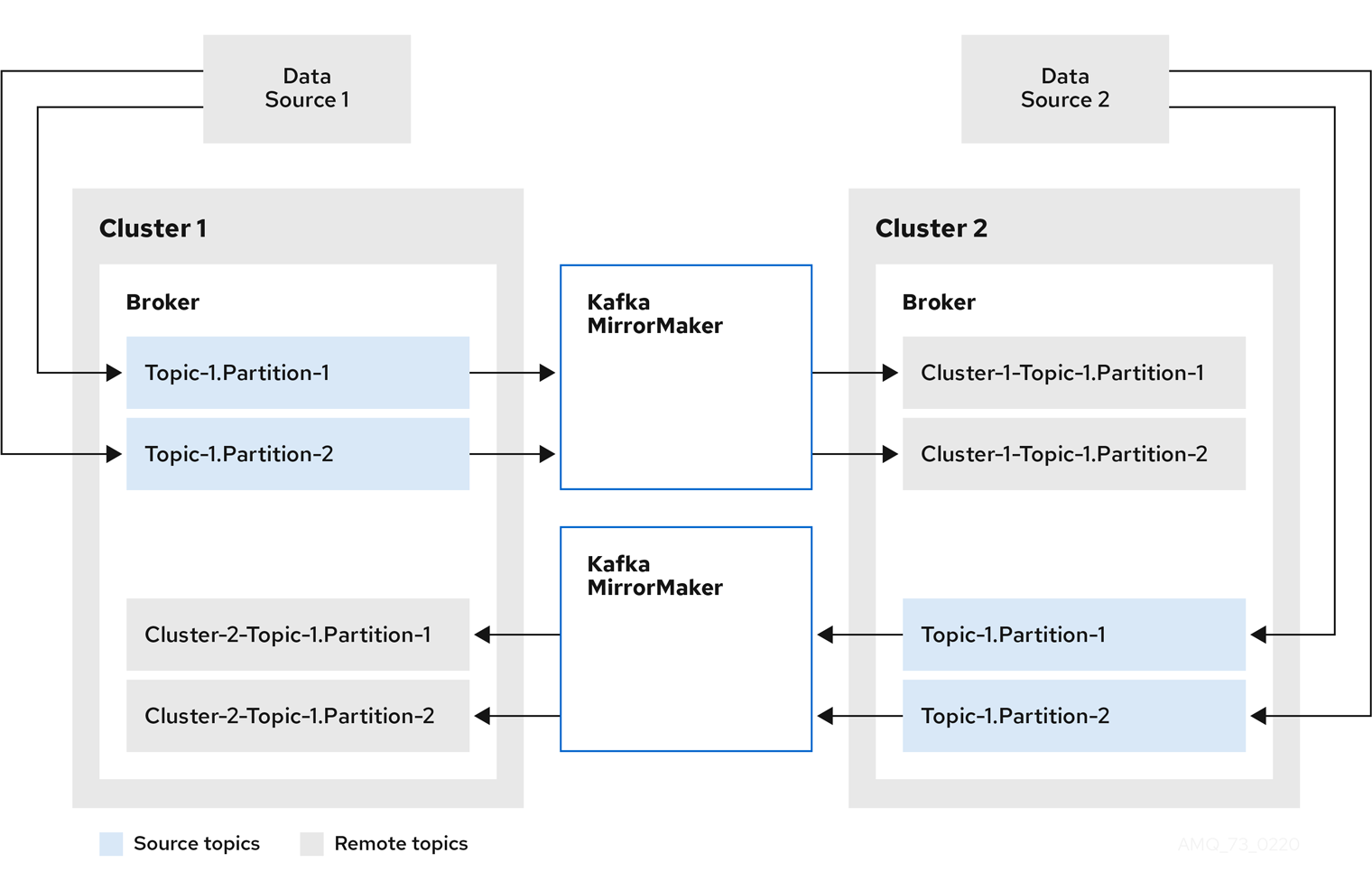
ソースクラスターにフラグを付けると、トピックはそのクラスターに複製されません。
remote トピックを介したレプリケーションの概念は、データの集約が必要なアーキテクチャーの設定に役立ちます。コンシューマーは、同じクラスター内でソースおよびリモートトピックにサブスクライブできます。これに個別の集約クラスターは必要ありません。
3.4.4.2.2. トピック設定の同期
トピック設定は、ソースクラスターとターゲットクラスター間で自動的に同期化されます。設定プロパティーを同期化することで、リバランスの必要性が軽減されます。
3.4.4.2.3. データの整合性
MirrorMaker 2.0 は、ソーストピックを監視し、設定変更をリモートトピックに伝播して、不足しているパーティションを確認および作成します。MirrorMaker 2.0 のみがリモートトピックに書き込みできます。
3.4.4.2.4. オフセットの追跡
MirrorMaker 2.0 では、内部トピックを使用してコンシューマーグループのオフセットを追跡します。
- オフセット同期 トピックは、複製されたトピックパーティションのソースおよびターゲットオフセットをレコードメタデータからマッピングします。
- チェックポイント トピックは、各コンシューマーグループの複製されたトピックパーティションのソースおよびターゲットクラスターで最後にコミットされたオフセットをマッピングします。
チェックポイント トピックのオフセットは、設定によって事前定義された間隔で追跡されます。両方のトピックは、フェイルオーバー時に正しいオフセットの位置からレプリケーションの完全復元を可能にします。
MirrorMaker 2.0 は、MirrorCheckpointConnector を使用して、オフセット追跡の チェックポイントを生成します。
3.4.4.2.5. 接続性チェック
ハートビート 内部トピックによって、クラスター間の接続性が確認されます。
ハートビート トピックは、ソースクラスターから複製されます。
ターゲットクラスターは、トピックを使用して以下を確認します。
- クラスター間の接続を管理するコネクターが稼働している。
- ソースクラスターが利用可能である。
MirrorMaker 2.0 は MirrorHeartbeatConnector を使用して、これらのチェックを実行する ハートビート を生成します。
3.4.4.3. ACL ルールの同期
User Operator を使用して いない 場合は、ACL でリモートトピックにアクセスできます。
User Operator なしで SimpleAclAuthorizer が使用されている場合、ブローカーへのアクセスを管理する ACL ルールはリモートトピックにも適用されます。ソーストピックを読み取りできるユーザーは、そのリモートトピックを読み取りできます。
OAuth 2.0 での承認は、このようなリモートトピックへのアクセスをサポートしません。
3.4.4.4. MirrorMaker 2.0 を使用した Kafka クラスター間でのデータの同期
MirrorMaker 2.0 を使用して、設定を介して Kafka クラスター間のデータを同期します。
以前のバージョンの MirrorMaker は継続してサポートされます。以前のバージョンに設定したリソースを使用する場合は、MirrorMaker 2.0 でサポートされる形式に更新する必要があります。
設定では以下を指定する必要があります。
- 各 Kafka クラスター
- TLS 認証を含む各クラスターの接続情報
レプリケーションのフローおよび方向
- クラスター対クラスター
- トピック対トピック
KafkaMirrorMaker2 リソースのプロパティーを使用して、Kafka MirrorMaker 2.0 デプロイメントを設定します。
MirrorMaker 2.0 によって、レプリケーション係数などのプロパティーのデフォルト設定値が提供されます。デフォルトに変更がない最小設定の例は以下のようになります。
TLS または SASL 認証を使用して、ソースおよびターゲットクラスターのアクセス制御を設定できます。この手順では、ソースおよびターゲットクラスターに対して TLS による暗号化および認証を使用する設定を説明します。
前提条件
- AMQ Streams および Kafka がデプロイされている必要があります。
- ソースおよびターゲットの Kafka クラスターが使用できる必要があります。
手順
KafkaMirrorMaker2リソースのspecプロパティーを編集します。設定可能なプロパティーは以下の例のとおりです。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- Kafka Connect のバージョン。
- 2
- レプリカノードの数。
- 3
- Kafka Connect のクラスターエイリアス。
- 4
- 同期される Kafka クラスターの指定。
- 5
- ソースの Kafka クラスターのクラスターエイリアス。
- 6
- 7
- ソース Kafka クラスターに接続するためのブートストラップサーバー。
- 8
- ソース Kafka クラスターの TLS 証明書が X.509 形式で保存されるキー名のある TLS による暗号化。詳細は、「
KafkaMirrorMaker2Tlsスキーマ参照」を参照してください。 - 9
- ターゲット Kafka クラスターのクラスターエイリアス。
- 10
- ターゲット Kafka クラスターの認証は、ソース Kafka クラスターと同様に設定されます。
- 11
- ターゲット Kafka クラスターに接続するためのブートストラップサーバー。
- 12
- Kafka Connect の設定。標準の Apache Kafka 設定が提供されることがあり、AMQ Streams によって直接管理されないプロパティーに限定されます。
- 13
- ターゲット Kafka クラスターの TLS による暗号化は、ソース Kafka クラスターと同様に設定されます。
- 14
- MirrorMaker 2.0 コネクター。
- 15
- MirrorMaker 2.0 コネクターによって使用されるソースクラスターのエイリアス。
- 16
- MirrorMaker 2.0 コネクターによって使用されるターゲットクラスターのエイリアス。
- 17
- リモートトピックを作成する
MirrorSourceConnectorの設定。デフォルトの設定オプションはconfigによって上書きされます。 - 18
- ターゲットクラスターで作成されるミラーリングされたトピックのレプリケーション係数。
- 19
- ソースおよびターゲットクラスターのオフセットをマップする
MirrorSourceConnectoroffset-syncs内部トピックのレプリケーション係数。 - 20
- 有効にすると、同期されたトピックに ACL が適用されます。デフォルトは
trueです。 - 21
- 接続性チェックを実行する
MirrorHeartbeatConnectorの設定。デフォルトの設定オプションはconfigによって上書きされます。 - 22
- ターゲットクラスターで作成されたハートビートトピックのレプリケーション係数。
- 23
- オフセットを追跡する
MirrorCheckpointConnectorの設定。デフォルトの設定オプションはconfigによって上書きされます。 - 24
- ターゲットクラスターで作成されたチェックポイントトピックのレプリケーション係数。
- 25
- 正規表現パターンとして定義されたソースクラスターからのトピックレプリケーション。ここで、すべてのトピックを要求します。
- 26
- 正規表現パターンとして定義されたソースクラスターからのコンシューマーグループレプリケーション。ここで、3 つのコンシューマーグループを名前で要求します。コンマ区切りリストを使用できます。
リソースを作成または更新します。
oc apply -f <your-file>
oc apply -f <your-file>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.5. Kafka Bridge の設定
KafkaBridge リソースの完全なスキーマは 「KafkaBridge スキーマ参照」 に記載されています。指定の KafkaBridge リソースに適用されたすべてのラベルは、Kafka Bridge クラスターを構成する OpenShift リソースにも適用されます。そのため、必要に応じてリソースにラベルが適用されるため便利です。
3.5.1. レプリカ
Kafka Bridge では複数のノードを実行できます。ノードの数は KafkaBridge リソースで定義されます。複数のノードで Kafka Bridge を実行すると、可用性とスケーラビリティーが向上します。ただし、OpenShift で Kafka Bridge を実行する場合は、高可用性のために Kafka Bridge で複数のノードを実行する必要は全くありません。
Kafka Bridge がデプロイされたノードがクラッシュした場合、OpenShift によって Kafka Bridge Pod が別のノードに自動的に再スケジュールされます。クライアントのコンシューマーリクエストが異なる Kafka Bridge インスタンスによって処理された場合に発生する問題を防ぐには、アドレスベースのルーティングを利用して、要求が適切な Kafka Bridge インスタンスにルーティングされるようにする必要があります。また、独立した各 Kafka Bridge インスタンスにレプリカが必要です。Kafka Bridge インスタンスには、別のインスタンスと共有されない独自の状態があります。
3.5.1.1. ノード数の設定
Kafka Bridge ノードの数は、KafkaBridge.spec の replicas プロパティーを使用して設定されます。
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
KafkaBridgeリソースのreplicasプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.5.2. ブートストラップサーバー
Kafka Bridge は、常に Kafka クラスターと組み合わせて動作します。Kafka クラスターはブートストラップサーバーのリストとして指定されます。OpenShift では、そのリストに cluster-name-kafka-bootstrap という名前の Kafka クラスターブートストラップサービスが含まれ、さらに平文トラフィックの場合はポート 9092、暗号化されたトラフィックの場合はポート 9093 が含まれることが理想的です。
ブートストラップサーバーのリストは、KafkaBridge.kafka.spec の bootstrapServers プロパティーで設定されます。サーバーは、1 つ以上の Kafka ブローカーを指定するコンマ区切りリスト、または hostname:_port_ ペアとして指定される Kafka ブローカーを示すサービスとして定義される必要があります。
AMQ Streams によって管理されない Kafka クラスターで Kafka Bridge を使用する場合は、クラスターの設定に応じてブートストラップサーバーのリストを指定できます。
3.5.2.1. ブートストラップサーバーの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
KafkaBridgeリソースのbootstrapServersプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.5.3. TLS を使用した Kafka ブローカーへの接続
デフォルトでは、Kafka Bridge はプレーンテキスト接続を使用して Kafka ブローカーへの接続を試みます。TLS を使用する場合は、追加の設定が必要です。
3.5.3.1. Kafka ブリッジへの Kafka 接続の TLS サポート
Kafka 接続の TLS サポートは、KafkaBridge.spec の tls プロパティーに設定されます。tls プロパティーには、保存される証明書のキー名があるシークレットのリストが含まれます。証明書は X509 形式で保存する必要があります。
複数の証明書がある TLS 設定の例
複数の証明書が同じシークレットに保存されている場合は、複数回リストできます。
同じシークレットに複数の証明書がある TLS 設定の例
3.5.3.2. Kafka Bridge での TLS の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
-
TLS サーバー認証に使用される証明書の
Secretの名前と、Secretに保存された証明書のキー (存在する場合)。
手順
(任意手順): 認証で使用される TLS 証明書が存在しない場合はファイルで準備し、
Secretを作成します。注記Kafka クラスターの Cluster Operator によって作成されるシークレットは直接使用されることがあります。
oc create secret generic my-secret --from-file=my-file.crt
oc create secret generic my-secret --from-file=my-file.crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow KafkaBridgeリソースのtlsプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.5.4. 認証での Kafka ブローカーへの接続
デフォルトでは、Kafka Bridge は認証なしで Kafka ブローカーへの接続を試みます。認証は KafkaBridge リソースを使用して有効化されます。
3.5.4.1. Kafka Bridge での認証サポート
認証は、KafkaBridge.spec の authentication プロパティーで設定されます。authentication プロパティーによって、使用する認証メカニズムのタイプと、メカニズムに応じた追加設定の詳細が指定されます。現在サポートされている認証タイプは次のとおりです。
- TLS クライアント認証
- SCRAM-SHA-512 メカニズムを使用した SASL ベースの認証
- PLAIN メカニズムを使用した SASL ベースの認証
- OAuth 2.0 のトークンベースの認証
3.5.4.1.1. TLS クライアント認証
TLS クライアント認証を使用するには、type プロパティーを tls の値に設定します。TLS クライアント認証は TLS 証明書を使用して認証します。証明書は certificateAndKey プロパティーで指定され、常に OpenShift シークレットからロードされます。シークレットでは、公開鍵と秘密鍵の 2 つの鍵を使用して証明書を X509 形式で保存する必要があります。
TLS クライアント認証は TLS 接続でのみ使用できます。Kafka Bridge の TLS 設定の詳細は、「TLS を使用した Kafka ブローカーへの接続」 を参照してください。
TLS クライアント認証の設定例
3.5.4.1.2. SCRAM-SHA-512 認証
Kafka Bridge で SASL ベースの SCRAM-SHA-512 認証が使用されるようにするには、type プロパティーを scram-sha-512 に設定します。この認証メカニズムには、ユーザー名とパスワードが必要です。
-
usernameプロパティーでユーザー名を指定します。 -
passwordSecretプロパティーで、パスワードを含むSecretへのリンクを指定します。secretNameプロパティーにはSecretの名前が含まれ、passwordプロパティーにはSecret内にパスワードが格納されるキーの名前が含まれます。
password フィールドには、実際のパスワードを指定しないでください。
SASL ベースの SCRAM-SHA-512 クライアント認証の設定例
3.5.4.1.3. SASL ベースの PLAIN 認証
Kafka Bridge で SASL ベースの PLAIN 認証が使用されるようにするには、type プロパティーを plain に設定します。この認証メカニズムには、ユーザー名とパスワードが必要です。
SASL PLAIN メカニズムでは、ネットワーク全体でユーザー名とパスワードがプレーンテキストで転送されます。TLS 暗号化が有効になっている場合にのみ SASL PLAIN 認証を使用します。
-
usernameプロパティーでユーザー名を指定します。 -
passwordSecretプロパティーで、パスワードを含むSecretへのリンクを指定します。secretNameプロパティーにはSecretの名前が含まれ、passwordプロパティーにはSecret内にパスワードが格納されるキーの名前が含まれます。
password フィールドには、実際のパスワードを指定しないでください。
SASL ベースの PLAIN クライアント認証の設定例
3.5.4.2. Kafka Bridge での TLS クライアント認証の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
-
TLS クライアント認証に使用される公開鍵と秘密鍵がある
Secret、およびSecretに保存される公開鍵と秘密鍵のキー (存在する場合)。
手順
(任意手順): 認証に使用される鍵が存在しない場合はファイルで準備し、
Secretを作成します。注記User Operator によって作成されたシークレットを使用できます。
oc create secret generic my-secret --from-file=my-public.crt --from-file=my-private.key
oc create secret generic my-secret --from-file=my-public.crt --from-file=my-private.keyCopy to Clipboard Copied! Toggle word wrap Toggle overflow KafkaBridgeリソースのauthenticationプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.5.4.3. Kafka Bridge での SCRAM-SHA-512 認証の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
- 認証に使用するユーザーのユーザー名。
-
認証に使用されるパスワードがある
Secretの名前と、Secretに保存されたパスワードのキー (存在する場合)。
手順
(任意手順): 認証で使用されるパスワードがない場合はファイルで準備し、
Secretを作成します。注記User Operator によって作成されたシークレットを使用できます。
echo -n '<password>' > <my-password.txt> oc create secret generic <my-secret> --from-file=<my-password.txt>
echo -n '<password>' > <my-password.txt> oc create secret generic <my-secret> --from-file=<my-password.txt>Copy to Clipboard Copied! Toggle word wrap Toggle overflow KafkaBridgeリソースのauthenticationプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.5.5. Kafka Bridge の設定
AMQ Streams では、コンシューマー向けの Apache Kafka 設定ドキュメント および プロデューサー向けの Apache Kafka 設定ドキュメント に記載されている特定のオプションを編集して、Apache Kafka Bridge ノードの設定をカスタマイズできます。
以下に関連している設定オプションを設定できます。
- Kafka クラスターブートストラップアドレス
- セキュリティー (暗号化、認証、および承認)
- コンシューマー設定
- プロデューサーの設定
- HTTP の設定
3.5.5.1. Kafka Bridge コンシューマーの設定
Kafka Bridge コンシューマーは、KafkaBridge.spec.consumer でプロパティーを使用して設定されます。このプロパティーには、Kafka Bridge コンシューマーの設定オプションがキーとして含まれます。値は以下の JSON タイプのいずれかになります。
- String
- Number
- ブール値
AMQ Streams で直接管理されるオプションを除き、コンシューマー向けの Apache Kafka 設定ドキュメント に記載されているオプションを指定および設定できます。以下の文字列の 1 つと同じキーまたは以下の文字列の 1 つで始まるキーを持つ設定オプションはすべて禁止されています。
-
ssl. -
sasl. -
security. -
bootstrap.servers -
group.id
禁止されているオプションの 1 つが config プロパティーにある場合、そのオプションは無視され、警告メッセージが Cluster Operator ログファイルに出力されます。その他のオプションはすべて Kafka に渡されます。
提供された config オブジェクトのキーまたは値は Cluster Operator によって検証されません。無効な設定を指定すると、Kafka Bridge クラスターが起動しなかったり、不安定になる可能性があります。この状況で、KafkaBridge.spec.consumer.config オブジェクトの設定を修正すると、Cluster Operator は新しい設定をすべての Kafka Bridge ノードにロールアウトできます。
Kafka Bridge コンシューマーの設定例
3.5.5.2. Kafka Bridge プロデューサーの設定
Kafka Bridge プロデューサーは、KafkaBridge.spec.producer でプロパティーを使用して設定されます。このプロパティーには、Kafka Bridge プロデューサーの設定オプションがキーとして含まれます。値は以下の JSON タイプのいずれかになります。
- String
- Number
- ブール値
AMQ Streams で直接管理されるオプションを除き、プロデューサー向けの Apache Kafka 設定ドキュメント に記載されているオプションを指定および設定できます。以下の文字列の 1 つと同じキーまたは以下の文字列の 1 つで始まるキーを持つ設定オプションはすべて禁止されています。
-
ssl. -
sasl. -
security. -
bootstrap.servers
提供された config オブジェクトのキーまたは値は Cluster Operator によって検証されません。無効な設定を指定すると、Kafka Bridge クラスターが起動しなかったり、不安定になる可能性があります。この状況で、KafkaBridge.spec.producer.config オブジェクトの設定を修正すると、Cluster Operator は新しい設定をすべての Kafka Bridge ノードにロールアウトできます。
Kafka Bridge プロデューサーの設定例
3.5.5.3. Kafka Bridge HTTP の設定
Kafka Bridge HTTP の設定は、KafkaBridge.spec.http でプロパティーを使用して設定されます。このプロパティーには、Kafka Bridge HTTP の設定オプションが含まれます。
-
port
Kafka Bridge HTTP の設定例
3.5.5.4. Kafka Bridge の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
KafkaBridgeリソースのkafka、http、consumer、またはproducerプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.5.6. CPU およびメモリーリソース
AMQ Streams では、デプロイされたコンテナーごとに特定のリソースを要求し、これらのリソースの最大消費を定義できます。
AMQ Streams では、以下の 2 つのタイプのリソースがサポートされます。
- CPU
- メモリー
AMQ Streams では、CPU およびメモリーリソースの指定に OpenShift 構文が使用されます。
3.5.6.1. リソースの制限および要求
リソースの制限と要求は、以下のリソースで resources プロパティーを使用して設定されます。
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.KafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
その他のリソース
- OpenShift におけるコンピュートリソースの管理に関する詳細は、「Managing Compute Resources for Containers」を参照してください。
3.5.6.1.1. リソース要求
要求によって、指定のコンテナーに対して予約するリソースが指定されます。リソースを予約すると、リソースが常に利用できるようになります。
リソース要求が OpenShift クラスターで利用可能な空きリソースを超える場合、Pod はスケジュールされません。
リソース要求は requests プロパティーで指定されます。AMQ Streams では、現在以下のリソース要求がサポートされます。
-
cpu -
memory
1 つまたは複数のサポートされるリソースに対してリクエストを設定できます。
すべてのリソースを対象とするリソース要求の設定例
3.5.6.1.2. リソース制限
制限によって、指定のコンテナーが消費可能な最大リソースが指定されます。制限は予約されず、常に利用できるとは限りません。コンテナーは、リソースが利用できる場合のみ、制限以下のリソースを使用できます。リソース制限は、常にリソース要求よりも高くする必要があります。
リソース制限は limits プロパティーで指定されます。AMQ Streams では、現在以下のリソース制限がサポートされます。
-
cpu -
memory
1 つまたは複数のサポートされる制限に対してリソースを設定できます。
リソース制限の設定例
3.5.6.1.3. サポートされる CPU 形式
CPU の要求および制限は以下の形式でサポートされます。
-
整数値 (
5CPU コア) または少数 (2.5CPU コア) の CPU コアの数。 -
数値または ミリ CPU / ミリコア (
100m)。1000 ミリコア は1CPU コアと同じです。
CPU ユニットの例
1 つの CPU コアのコンピューティング能力は、OpenShift がデプロイされたプラットフォームによって異なることがあります。
その他のリソース
- CPU 仕様の詳細は、「Meaning of CPU」を参照してください。
3.5.6.1.4. サポートされるメモリー形式
メモリー要求および制限は、メガバイト、ギガバイト、メビバイト、およびギビバイトで指定されます。
-
メモリーをメガバイトで指定するには、
M接尾辞を使用します。例:1000M -
メモリーをギガバイトで指定するには、
G接尾辞を使用します。例:1G -
メモリーをメビバイトで指定するには、
Mi接尾辞を使用します。例:1000Mi -
メモリーをギビバイトで指定するには、
Gi接尾辞を使用します。例:1Gi
異なるメモリー単位の使用例
その他のリソース
- メモリーの指定およびサポートされるその他の単位に関する詳細は、「Meaning of memory」を参照してください。
3.5.6.2. リソース要求および制限の設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
クラスターデプロイメントを指定するリソースの
resourcesプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
-
スキーマの詳細は、「
Resourcesスキーマ参照」を参照してください。
3.5.7. Kafka Bridge ロガー
Kafka Bridge には独自の設定可能なロガーがあります。
-
log4j.logger.io.strimzi.kafka.bridge -
log4j.logger.http.openapi.operation.<operation-id>
log4j.logger.http.openapi.operation.<operation-id> ロガーの <operation-id> 置き換えると、特定の操作のログレベルを設定できます。
-
createConsumer -
deleteConsumer -
subscribe -
unsubscribe -
poll -
assign -
commit -
send -
sendToPartition -
seekToBeginning -
seekToEnd -
seek -
healthy -
ready -
openapi
各操作は OpenAPI 仕様にしたがって定義されます。各操作にはブリッジが HTTP クライアントから要求を受信する対象の API エンドポイントがあります。各エンドポイントのログレベルを変更すると、送信および受信 HTTP 要求に関する詳細なログ情報を作成できます。
Kafka Bridge では Apache log4j ロガー実装が使用されます。ロガーは log4j.properties ファイルで定義されます。このファイルには healthy および ready エンドポイントの以下のデフォルト設定が含まれています。
log4j.logger.http.openapi.operation.healthy=WARN, out log4j.additivity.http.openapi.operation.healthy=false log4j.logger.http.openapi.operation.ready=WARN, out log4j.additivity.http.openapi.operation.ready=false
log4j.logger.http.openapi.operation.healthy=WARN, out
log4j.additivity.http.openapi.operation.healthy=false
log4j.logger.http.openapi.operation.ready=WARN, out
log4j.additivity.http.openapi.operation.ready=false
その他すべての操作のログレベルは、デフォルトで INFO に設定されます。
logging プロパティーを使用してロガーおよびロガーレベルを設定します。
ログレベルを設定するには、ロガーとレベルを直接指定 (インライン) するか、またはカスタム (外部) ConfigMap を使用します。ConfigMap を使用する場合、logging.name プロパティーを外部ロギング設定が含まれる ConfigMap の名前に設定します。ConfigMap 内では、ロギング設定は log4j.properties を使用して記述されます。
inline および external ロギングの例は次のとおりです。
inline ロギング
外部ロギング
その他のリソース
- ガベッジコレクター (GC) ロギングを有効 (または無効) にすることもできます。GC ロギングの詳細は「JVM 設定」を参照してください。
- ログレベルの詳細は、「Apache logging services」を参照してください。
3.5.8. JVM オプション
AMQ Streams の以下のコンポーネントは、仮想マシン (VM) 内で実行されます。
- Apache Kafka
- Apache ZooKeeper
- Apache Kafka Connect
- Apache Kafka MirrorMaker
- AMQ Streams Kafka Bridge
JVM 設定オプションによって、さまざまなプラットフォームおよびアーキテクチャーのパフォーマンスが最適化されます。AMQ Streams では、これらのオプションの一部を設定できます。
3.5.8.1. JVM 設定
JVM オプションは、以下のリソースの jvmOptions プロパティーを使用して設定できます。
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
使用可能な JVM オプションの選択されたサブセットのみを設定できます。以下のオプションがサポートされます。
-Xms および -Xmx
-Xms は、JVM の起動時に最初に割り当てられる最小ヒープサイズを設定します。-Xmx は、最大ヒープサイズを設定します。
-Xmx や -Xms などの JVM 設定で使用できる単位は、対応するイメージの JDK java バイナリーによって許可される単位です。そのため、1g または 1G は 1,073,741,824 バイトを意味し、Gi は接尾辞として有効な単位ではありません。これは、1G は 1,000,000,000 バイト、1Gi は 1,073,741,824 バイトを意味する OpenShift の慣例に準拠している メモリー要求および制限 に使用される単位とは対照的です。
-Xms および -Xmx に使用されるデフォルト値は、コンテナーに メモリー要求 の制限が設定されているかどうかによって異なります。
- メモリーの制限がある場合は、JVM の最小および最大メモリーは制限に対応する値に設定されます。
-
メモリーの制限がない場合、JVM の最小メモリーは
128Mに設定され、JVM の最大メモリーは定義されません。これにより、JVM のメモリーを必要に応じて拡張できます。これは、テストおよび開発での単一ノード環境に適しています。
-Xmx を明示的に設定するには、以下の点に注意する必要があります。
-
JVM のメモリー使用量の合計は、
-Xmxによって設定された最大ヒープの約 4 倍になります。 -
適切な OpenShift メモリー制限を設定せずに
-Xmxが設定された場合、OpenShift ノードで、実行されている他の Pod からメモリー不足が発生するとコンテナーが強制終了される可能性があります。 -
適切な OpenShift メモリー要求を設定せずに
-Xmxが設定された場合、コンテナーはメモリー不足のノードにスケジュールされる可能性があります。この場合、コンテナーは起動せずにクラッシュします (-Xmsが-Xmxに設定されている場合は即座にクラッシュし、そうでない場合はその後にクラッシュします)。
-Xmx を明示的に設定する場合は、以下を行うことが推奨されます。
- メモリー要求とメモリー制限を同じ値に設定します。
-
-Xmxの 4.5 倍以上のメモリー要求を使用します。 -
-Xmsを-Xmxと同じ値に設定することを検討してください。
大量のディスク I/O を実行するコンテナー (Kafka ブローカーコンテナーなど) は、オペレーティングシステムのページキャッシュとして使用できるメモリーを確保しておく必要があります。このようなコンテナーでは、要求されるメモリーは JVM によって使用されるメモリーよりもはるかに多くなります。
-Xmx および -Xms の設定例 (抜粋)
# ... jvmOptions: "-Xmx": "2g" "-Xms": "2g" # ...
# ...
jvmOptions:
"-Xmx": "2g"
"-Xms": "2g"
# ...上記の例では、JVM のヒープに 2 GiB (2,147,483,648 バイト) が使用されます。メモリー使用量の合計は約 8GiB になります。
最初のヒープサイズ (-Xms) および最大ヒープサイズ (-Xmx) に同じ値を設定すると、JVM が必要以上のヒープを割り当てて起動後にメモリーを割り当てないようにすることができます。Kafka および ZooKeeper Pod では、このような割り当てによって不要なレイテンシーが発生する可能性があります。Kafka Connect では、割り当ての過剰を防ぐことが最も重要になります。これは、コンシューマーの数が増えるごとに割り当て過剰の影響がより深刻になる分散モードで特に重要です。
-server
-server はサーバー JVM を有効にします。このオプションは true または false に設定できます。
-server の設定例 (抜粋)
# ... jvmOptions: "-server": true # ...
# ...
jvmOptions:
"-server": true
# ...
いずれのオプション (-server および -XX) も指定されないと、Apache Kafka の KAFKA_JVM_PERFORMANCE_OPTS のデフォルト設定が使用されます。
-XX
-XX オブジェクトは、JVM の高度なランタイムオプションの設定に使用できます。-server および -XX オプションは、Apache Kafka の KAFKA_JVM_PERFORMANCE_OPTS オプションの設定に使用されます。
-XX オブジェクトの使用例
上記の設定例の場合、JVM オプションは以下のようになります。
-XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:-UseParNewGC
-XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:-UseParNewGC
いずれのオプション (-server および -XX) も指定されないと、Apache Kafka の KAFKA_JVM_PERFORMANCE_OPTS のデフォルト設定が使用されます。
3.5.8.1.1. ガベッジコレクターのロギング
jvmOptions セクションでは、ガベージコレクター (GC) のロギングを有効または無効にすることもできます。GC ロギングはデフォルトで無効になっています。これを有効にするには、以下のように gcLoggingEnabled プロパティーを設定します。
GC ロギングを有効にする例
# ... jvmOptions: gcLoggingEnabled: true # ...
# ...
jvmOptions:
gcLoggingEnabled: true
# ...3.5.8.2. JVM オプションの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
Kafka、KafkaConnect、KafkaConnectS2I、KafkaMirrorMaker、またはKafkaBridgeリソースのjvmOptionsプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.5.9. Healthcheck
ヘルスチェックは、アプリケーションの健全性を検証する定期的なテストです。ヘルスチェックプローブが失敗すると、OpenShift によってアプリケーションが正常でないと見なされ、その修正が試行されます。
OpenShift では、以下の 2 つのタイプのおよび ヘルスチェックプローブがサポートされます。
- Liveness プローブ
- Readiness プローブ
プローブの詳細は、「Configure Liveness and Readiness Probes」を参照してください。AMQ Streams コンポーネントでは、両タイプのプローブが使用されます。
ユーザーは、Liveness および Readiness プローブに選択されたオプションを設定できます。
3.5.9.1. ヘルスチェックの設定
Liveness および Readiness プローブは、以下のリソースの livenessProbe および readinessProbe プロパティーを使用して設定できます。
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.KafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
livenessProbe および readinessProbe の両方によって以下のオプションがサポートされます。
-
initialDelaySeconds -
timeoutSeconds -
periodSeconds -
successThreshold -
failureThreshold
livenessProbe および readinessProbe オプションの詳細については、「Probe スキーマ参照」 を参照してください。
Liveness および Readiness プローブの設定例
3.5.9.2. ヘルスチェックの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
Kafka、KafkaConnect、またはKafkaConnectS2IリソースのlivenessProbeまたはreadinessProbeプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.5.10. コンテナーイメージ
AMQ Streams では、コンポーネントに使用されるコンテナーイメージを設定できます。コンテナーイメージのオーバーライドは、別のコンテナーレジストリーを使用する必要がある特別な状況でのみ推奨されます。たとえば、AMQ Streams によって使用されるコンテナーリポジトリーにネットワークがアクセスできない場合などがこれに該当します。そのような場合は、AMQ Streams イメージをコピーするか、ソースからビルドする必要があります。設定したイメージが AMQ Streams イメージと互換性のない場合は、適切に機能しない可能性があります。
3.5.10.1. コンテナーイメージの設定
以下のリソースの image プロパティーを使用すると、各コンポーネントに使用するコンテナーイメージを指定できます。
-
Kafka.spec.kafka -
Kafka.spec.kafka.tlsSidecar -
Kafka.spec.zookeeper -
Kafka.spec.zookeeper.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
3.5.10.1.1. Kafka、Kafka Connect、および Kafka MirrorMaker の image プロパティーの設定
Kafka、Kafka Connect (S2I サポートのある Kafka Connect を含む)、および Kafka MirrorMaker では、複数のバージョンの Kafka がサポートされます。各コンポーネントには独自のイメージが必要です。異なる Kafka バージョンのデフォルトイメージは、以下の環境変数で設定されます。
-
STRIMZI_KAFKA_IMAGES -
STRIMZI_KAFKA_CONNECT_IMAGES -
STRIMZI_KAFKA_CONNECT_S2I_IMAGES -
STRIMZI_KAFKA_MIRROR_MAKER_IMAGES
これらの環境変数には、Kafka バージョンと対応するイメージ間のマッピングが含まれます。マッピングは、image および version プロパティーとともに使用されます。
-
imageとversionのどちらもカスタムリソースに指定されていない場合、versionは Cluster Operator のデフォルトの Kafka バージョンに設定され、環境変数のこのバージョンに対応するイメージが指定されます。 -
imageが指定されていてもversionが指定されていない場合、指定されたイメージが使用され、Cluster Operator のデフォルトの Kafka バージョンがversionであると想定されます。 -
versionが指定されていてもimageが指定されていない場合、環境変数の指定されたバージョンに対応するイメージが使用されます。 -
versionとimageの両方を指定すると、指定されたイメージが使用されます。このイメージには、指定のバージョンの Kafka イメージが含まれると想定されます。
異なるコンポーネントの image および version は、以下のプロパティーで設定できます。
-
Kafka の場合は
spec.kafka.imageおよびspec.kafka.version。 -
Kafka Connect、Kafka Connect S2I、および Kafka MirrorMaker の場合は
spec.imageおよびspec.version。
version のみを提供し、image プロパティーを未指定のままにしておくことが推奨されます。これにより、カスタムリソースの設定時に間違いが発生する可能性が低減されます。異なるバージョンの Kafka に使用されるイメージを変更する必要がある場合は、Cluster Operator の環境変数を設定することが推奨されます。
3.5.10.1.2. 他のリソースでの image プロパティーの設定
他のカスタムリソースの image プロパティーでは、デプロイメント中に指定の値が使用されます。image プロパティーがない場合、Cluster Operator 設定に指定された image が使用されます。image 名が Cluster Operator 設定に定義されていない場合、デフォルト値が使用されます。
Kafka ブローカー TLS サイドカーの場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_TLS_SIDECAR_KAFKA_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
- ZooKeeper ノードの場合:
ZooKeeper ノードの TLS サイドカーの場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_TLS_SIDECAR_ZOOKEEPER_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Topic Operator の場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_TOPIC_OPERATOR_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
User Operator の場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_USER_OPERATOR_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Entity Operator TLS サイドカーの場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_TLS_SIDECAR_ENTITY_OPERATOR_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Kafka Exporter の場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_KAFKA_EXPORTER_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Kafka Bridge の場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_KAFKA_BRIDGE_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-bridge-rhel7:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
Kafka ブローカーイニシャライザーの場合:
-
Cluster Operator 設定から
STRIMZI_DEFAULT_KAFKA_INIT_IMAGE環境変数に指定されたコンテナーイメージ。 -
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0コンテナーイメージ。
-
Cluster Operator 設定から
コンテナーイメージのオーバーライドは、別のコンテナーレジストリーを使用する必要がある特別な状況でのみ推奨されます。たとえば、AMQ Streams によって使用されるコンテナーリポジトリーにネットワークがアクセスできない場合などがこれに該当します。そのような場合は、AMQ Streams イメージをコピーするか、ソースからビルドする必要があります。設定したイメージが AMQ Streams イメージと互換性のない場合は、適切に機能しない可能性があります。
コンテナーイメージ設定の例
3.5.10.2. コンテナーイメージの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
Kafka、KafkaConnect、またはKafkaConnectS2Iリソースのimageプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.5.11. Pod スケジューリングの設定
2 つのアプリケーションが同じ OpenShift ノードにスケジュールされた場合、両方のアプリケーションがディスク I/O のように同じリソースを使用し、パフォーマンスに影響する可能性があります。これにより、パフォーマンスが低下する可能性があります。ノードを他の重要なワークロードと共有しないように Kafka Pod をスケジュールする場合、適切なノードを使用したり、Kafka 専用のノードのセットを使用すると、このような問題を適切に回避できます。
3.5.11.1. 他のアプリケーションに基づく Pod のスケジューリング
3.5.11.1.1. 重要なアプリケーションがノードを共有しないようにする
Pod の非アフィニティーを使用すると、重要なアプリケーションが同じディスクにスケジュールされないようにすることができます。Kafka クラスターの実行時に、Pod の非アフィニティーを使用して、Kafka ブローカーがデータベースなどの他のワークロードとノードを共有しないようにすることが推奨されます。
3.5.11.1.2. アフィニティー
アフィニティーは、以下のリソースの affinity プロパティーを使用して設定できます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
アフィニティー設定には、さまざまなタイプのアフィニティーを含めることができます。
- Pod のアフィニティーおよび非アフィニティー
- ノードのアフィニティー
affinity プロパティーの形式は、OpenShift の仕様に準拠します。詳細は、Kubernetes のノードおよび Pod のアフィニティーに関するドキュメント を参照してください。
3.5.11.1.3. Kafka コンポーネントでの Pod の非アフィニティーの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
クラスターデプロイメントを指定するリソースの
affinityプロパティーを編集します。ラベルを使用して、同じノードでスケジュールすべきでない Pod を指定します。topologyKeyをkubernetes.io/hostnameに設定し、選択した Pod が同じホスト名のノードでスケジュールされてはならないことを指定する必要があります。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.5.11.2. 特定のノードへの Pod のスケジューリング
3.5.11.2.1. ノードのスケジューリング
OpenShift クラスターは、通常多くの異なるタイプのワーカーノードで構成されます。ワークロードが非常に大きい環境の CPU に対して最適化されたものもあれば、メモリー、ストレージ (高速のローカル SSD)、または ネットワークに対して最適化されたものもあります。異なるノードを使用すると、コストとパフォーマンスの両面で最適化しやすくなります。最適なパフォーマンスを実現するには、AMQ Streams コンポーネントのスケジューリングで適切なノードを使用できるようにすることが重要です。
OpenShift は、ノードのアフィニティーを使用してワークロードを特定のノードにスケジュールします。ノードのアフィニティーにより、Pod がスケジュールされるノードにスケジューリングの制約を作成できます。制約はラベルセレクターとして指定されます。beta.kubernetes.io/instance-type などの組み込みノードラベルまたはカスタムラベルのいずれかを使用してラベルを指定すると、適切なノードを選択できます。
3.5.11.2.2. アフィニティー
アフィニティーは、以下のリソースの affinity プロパティーを使用して設定できます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
アフィニティー設定には、さまざまなタイプのアフィニティーを含めることができます。
- Pod のアフィニティーおよび非アフィニティー
- ノードのアフィニティー
affinity プロパティーの形式は、OpenShift の仕様に準拠します。詳細は、Kubernetes のノードおよび Pod のアフィニティーに関するドキュメント を参照してください。
3.5.11.2.3. Kafka コンポーネントでのノードのアフィニティーの設定
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
AMQ Streams コンポーネントをスケジュールする必要のあるノードにラベルを付けます。
oc labelを使用してこれを行うことができます。oc label node your-node node-type=fast-network
oc label node your-node node-type=fast-networkCopy to Clipboard Copied! Toggle word wrap Toggle overflow または、既存のラベルによっては再利用が可能です。
クラスターデプロイメントを指定するリソースの
affinityプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.5.11.3. 専用ノードの使用
3.5.11.3.1. 専用ノード
クラスター管理者は、選択した OpenShift ノードをテイントとしてマーク付けできます。テイントのあるノードは、通常のスケジューリングから除外され、通常の Pod はそれらのノードでの実行はスケジュールされません。ノードに設定されたテイントを許容できるサービスのみをスケジュールできます。このようなノードで実行されるその他のサービスは、ログコレクターやソフトウェア定義のネットワークなどのシステムサービスのみです。
テイントは専用ノードの作成に使用できます。専用のノードで Kafka とそのコンポーネントを実行する利点は多くあります。障害の原因になったり、Kafka に必要なリソースを消費するその他のアプリケーションが同じノードで実行されません。これにより、パフォーマンスと安定性が向上します。
専用ノードで Kafka Pod をスケジュールするには、ノードのアフィニティー と 許容 (toleration) を設定します。
3.5.11.3.2. アフィニティー
アフィニティーは、以下のリソースの affinity プロパティーを使用して設定できます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
アフィニティー設定には、さまざまなタイプのアフィニティーを含めることができます。
- Pod のアフィニティーおよび非アフィニティー
- ノードのアフィニティー
affinity プロパティーの形式は、OpenShift の仕様に準拠します。詳細は、Kubernetes のノードおよび Pod のアフィニティーに関するドキュメント を参照してください。
3.5.11.3.3. 許容 (Toleration)
許容 (Toleration) は、以下のリソースの tolerations プロパティーを使用して設定できます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
tolerations プロパティーの形式は、OpenShift の仕様に準拠します。詳細は、Kubernetes の「Taints and Tolerations」を参照してください。
3.5.11.3.4. 専用ノードの設定と Pod のスケジューリング
前提条件
- OpenShift クラスターが必要です。
- 稼働中の Cluster Operator が必要です。
手順
- 専用ノードとして使用するノードを選択します。
- これらのノードにスケジュールされているワークロードがないことを確認します。
選択したノードにテイントを設定します。
oc adm taintを使用してこれを行うことができます。oc adm taint node your-node dedicated=Kafka:NoSchedule
oc adm taint node your-node dedicated=Kafka:NoScheduleCopy to Clipboard Copied! Toggle word wrap Toggle overflow さらに、選択したノードにラベルも追加します。
oc labelを使用してこれを行うことができます。oc label node your-node dedicated=Kafka
oc label node your-node dedicated=KafkaCopy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターデプロイメントを指定するリソースの
affinityおよびtolerationsプロパティーを編集します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.5.12. Kafka Bridge クラスターの一部として作成されたリソースの一覧
以下のリソースは、OpenShift クラスターの Cluster Operator によって作成されます。
- bridge-cluster-name-bridge
- Kafka Bridge ワーカーノード Pod の作成を担当するデプロイメント。
- bridge-cluster-name-bridge-service
- Kafka Bridge クラスターの REST インターフェースを公開するサービス。
- bridge-cluster-name-bridge-config
- Kafka Bridge の補助設定が含まれ、Kafka ブローカー Pod によってボリュームとしてマウントされる ConfigMap。
- bridge-cluster-name-bridge
- Kafka Bridge ワーカーノードに設定された Pod の Disruption Budget。
3.6. OAuth 2.0 トークンベース認証の使用
AMQ Streams は、SASL OAUTHBEARER メカニズムを使用して OAuth 2.0 認証の使用をサポートします。
OAuth 2.0 は、アプリケーション間で標準的なトークンベースの認証および承認を有効にし、中央の承認サーバーを使用してリソースに制限されたアクセス権限を付与するトークンを発行します。
AMQ Streams では、OAuth 2.0 準拠の承認サーバーの認証で OAuth 2.0 がサポートされます。また、Keycloak を承認サーバーとして使用する場合にも OAuth 2.0 のトークンベースの承認がサポートされ、この承認サービスの機能を利用して、Kafka リソースに対するユーザーの権限が一元管理されます。ただし、OAuth 2.0 認証は、使用する承認サーバーに関係なく ACL ベースの Kafka 承認 と併用できます。
OAuth 2.0 のトークンベースの認証を使用すると、アプリケーションクライアントはアカウントのクレデンシャルを公開せずにアプリケーションサーバー (リソースサーバー と呼ばれる) のリソースにアクセスできます。
アプリケーションクライアントは、アクセストークンを認証の手段として渡します。アプリケーションサーバーはこれを使用して、付与するアクセス権限のレベルを決定することもできます。承認サーバーは、アクセスの付与とアクセスに関する問い合わせを処理します。
AMQ Streams のコンテキストでは以下が行われます。
- Kafka ブローカーは OAuth 2.0 リソースサーバーとして動作します。
- Kafka クライアントは OAuth 2.0 アプリケーションクライアントとして動作します。
Kafka クライアントは Kafka ブローカーに対して認証を行います。ブローカーおよびクライアントは、必要に応じて OAuth 2.0 承認サーバーと通信し、アクセストークンを取得または検証します。
AMQ Streams のデプロイメントでは、OAuth 2.0 インテグレーションは以下を提供します。
- Kafka ブローカーのサーバー側の OAuth 2.0 サポート。
- Kafka MirrorMaker、Kafka Connect、および Kafka Bridge のクライアント側 OAuth 2.0 サポート。
その他のリソース
3.6.1. OAuth 2.0 認証メカニズム
Kafka SASL OAUTHBEARER メカニズムは、Kafka ブローカーで認証されたセッションを確立するために使用されます。
Kafka クライアントは、形式がアクセストークンであるクレデンシャルの交換に SASL OAUTHBEARER メカニズムを使用して Kafka ブローカーでセッションを開始します。
Kafka ブローカーおよびクライアントは、OAuth 2.0 を使用するように設定する必要があります。
3.6.2. OAuth 2.0 Kafka ブローカーの設定
OAuth 2.0 の Kafka ブローカー設定には、以下が関係します。
- 承認サーバーでの OAuth 2.0 クライアントの作成
- Kafka カスタムリソースでの OAuth 2.0 認証の設定
承認サーバーに関連する Kafka ブローカーおよび Kafka クライアントはどちらも OAuth 2.0 クライアントと見なされます。
3.6.2.1. 承認サーバーの OAuth 2.0 クライアント設定
セッションの開始中に受信されたトークンを検証するように Kafka ブローカーを設定するには、承認サーバーで OAuth 2.0 の クライアント 定義を作成し、以下のクライアントクレデンシャルが有効な状態で 機密情報 として設定することが推奨されます。
-
kafkaのクライアント ID (例) - 認証メカニズムとしてのクライアント ID およびシークレット
承認サーバーのパブリックでないイントロスペクションエンドポイントを使用する場合のみ、クライアント ID およびシークレットを使用する必要があります。高速のローカル JWT トークンの検証と同様に、パブリック承認サーバーのエンドポイントを使用する場合は、通常クレデンシャルは必要ありません。
3.6.2.2. Kafka クラスターでの OAuth 2.0 認証設定
Kafka クラスターで OAuth 2.0 認証を使用するには、たとえば、認証方法が oauth の Kafka クラスターカスタムリソースの TLS リスナー設定を指定します。
OAuth 2.0 の認証方法タイプの割り当て
「Kafka ブローカーリスナー」で説明されているように、plain、tls、および external リスナーを設定できますが、OAuth 2.0 では TLS による暗号化が無効になっている plain リスナーまたは external リスナーを使用しないことが推奨されます。これは、ネットワークでのデータ漏えいの脆弱性や、トークンの盗難による不正アクセスへの脆弱性が発生するためです。
external リスナーを type: oauth で設定し、セキュアなトランスポート層がクライアントと通信するようにします。
OAuth 2.0 の外部リスナーとの使用
tls プロパティーはデフォルトで true に設定されているため、省略することができます。
認証のタイプを OAuth 2.0 として定義した場合、検証のタイプに基づいて、 高速のローカル JWT 検証 または イントロスペクションエンドポイントを使用したトークンの検証 のいずれかとして、設定を追加します。
説明や例を用いてリスナー向けに OAuth 2.0 を設定する手順は、「Kafka ブローカーの OAuth 2.0 サポートの設定」を参照してください。
3.6.2.3. 高速なローカル JWT トークン検証の設定
高速なローカル JWT トークンの検証では、JWTトークンの署名がローカルでチェックされます。
ローカルチェックでは、トークンに対して以下が確認されます。
-
アクセストークンに
Bearerの (typ) 要求値が含まれ、トークンがタイプに準拠することを確認します。 - 有効であるか (期限切れでない) を確認します。
-
トークンに
validIssuerURIと一致する発行元があることを確認します。
承認サーバーによって発行されなかったすべてのトークンが拒否されるよう、リスナーの設定時に validIssuerUrI 属性を指定します。
高速のローカル JWT トークン検証の実行中に、承認サーバーの通信は必要はありません。OAuth 2.0 の承認サーバーによって公開されるエンドポイントの jwksEndpointUri 属性を指定して、高速のローカル JWT トークン検証をアクティベートします。エンドポイントには、署名済み JWT トークンの検証に使用される公開鍵が含まれます。これらは、Kafka クライアントによってクレデンシャルとして送信されます。
承認サーバーとの通信はすべて TLS による暗号化を使用して実行する必要があります。
証明書トラストストアを AMQ Streams プロジェクト namespace の OpenShift シークレットとして設定し、tlsTrustedCertificates 属性を使用してトラストストアファイルが含まれる OpenShift シークレットを示すことができます。
JWT トークンからユーザー名を適切に取得するため、userNameClaim の設定を検討してください。Kafka ACL 承認を使用する場合は、認証中にユーザー名でユーザーを特定する必要があります。JWT トークンの sub 要求は、通常は一意な ID でユーザー名ではありません。
高速なローカル JWT トークン検証の設定例
3.6.2.4. OAuth 2.0 イントロスペクションエンドポイントの設定
OAuth 2.0 のイントロスペクションエンドポイントを使用したトークンの検証では、受信したアクセストークンは不透明として対処されます。Kafka ブローカーは、アクセストークンをイントロスペクションエンドポイントに送信します。このエンドポイントは、検証に必要なトークン情報を応答として返します。ここで重要なのは、特定のアクセストークンが有効である場合は最新情報を返すことで、トークンの有効期限に関する情報も返します。
OAuth 2.0 のイントロスペクションベースの検証を設定するには、高速のローカル JWT トークン検証に指定された jwksEndpointUri 属性ではなく、introspectionEndpointUri 属性を指定します。通常、イントロスペクションエンドポイントは保護されているため、承認サーバーに応じて clientId および clientSecret を指定する必要があります。
イントロスペクションエンドポイントの設定例
3.6.3. OAuth 2.0 Kafka クライアントの設定
Kafka クライアントは以下のいずれかで設定されます。
- 承認サーバーから有効なアクセストークンを取得するために必要なクレデンシャル (クライアント ID およびシークレット)。
- 承認サーバーから提供されたツールを使用して取得された、有効期限の長い有効なアクセストークンまたは更新トークン。
アクセストークンは、Kafka ブローカーに送信される唯一の情報です。アクセストークンを取得するために承認サーバーでの認証に使用されるクレデンシャルは、ブローカーに送信されません。
クライアントによるアクセストークンの取得後、承認サーバーと通信する必要はありません。
クライアント ID とシークレットを使用した認証が最も簡単です。有効期間の長いアクセストークンまたは更新トークンを使用すると、承認サーバーツールに追加の依存関係があるため、より複雑になります。
有効期間が長いアクセストークンを使用している場合は、承認サーバーでクライアントを設定し、トークンの最大有効期間を長くする必要があります。
Kafka クライアントが直接アクセストークンで設定されていない場合、クライアントは承認サーバーと通信して Kafka セッションの開始中にアクセストークンのクレデンシャルを交換します。Kafka クライアントは以下のいずれかを交換します。
- クライアント ID およびシークレット
- クライアント ID、更新トークン、および (任意の) シークレット
3.6.4. OAuth 2.0 のクライアント認証フロー
ここでは、Kafka セッションの開始時における Kafka クライアント、Kafka ブローカー、および承認ブローカー間の通信フローを説明および可視化します。フローは、クライアントとサーバーの設定によって異なります。
Kafka クライアントがアクセストークンをクレデンシャルとして Kafka ブローカーに送信する場合、トークンを検証する必要があります。
使用する承認サーバーや利用可能な設定オプションによっては、以下の使用が適している場合があります。
- 承認サーバーと通信しない、JWT の署名確認およびローカルトークンのイントロスペクションをベースとした高速なローカルトークン検証。
- 承認サーバーによって提供される OAuth 2.0 のイントロスペクションエンドポイント。
高速のローカルトークン検証を使用するには、トークンでの署名検証に使用される公開証明書のある JWKS エンドポイントを提供する承認サーバーが必要になります。
この他に、承認サーバーで OAuth 2.0 のイントロスペクションエンドポイントを使用することもできます。新しい Kafka ブローカー接続が確立されるたびに、ブローカーはクライアントから受け取ったアクセストークンを承認サーバーに渡し、応答を確認してトークンが有効であるかどうかを確認します。
Kafka クライアントのクレデンシャルは以下に対して設定することもできます。
- 以前に生成された有効期間の長いアクセストークンを使用した直接ローカルアクセス。
- 新しいアクセストークンの発行についての承認サーバーとの通信。
承認サーバーは不透明なアクセストークンの使用のみを許可する可能性があり、この場合はローカルトークンの検証は不可能です。
3.6.4.1. クライアント認証フローの例
Kafka クライアントおよびブローカーが以下に設定されている場合の、Kafka セッション認証中のコミュニケーションフローを確認できます。
クライアントではクライアント ID とシークレットが使用され、ブローカーによって検証が承認サーバーに委譲される場合
- Kafka クライアントは承認サーバーからアクセストークンを要求します。これにはクライアント ID とシークレットを使用し、任意で更新トークンも使用します。
- 承認サーバーによって新しいアクセストークンが生成されます。
- Kafka クライアントは SASL OAUTHBEARER メカニズムを使用してアクセストークンを渡し、Kafka ブローカーの認証を行います。
- Kafka ブローカーは、独自のクライアント ID およびシークレットを使用して、承認サーバーでトークンイントロスペクションエンドポイントを呼び出し、アクセストークンを検証します。
- トークンが有効な場合は、Kafka クライアントセッションが確立されます。
クライアントではクライアント ID およびシークレットが使用され、ブローカーによって高速のローカルトークン検証が実行される場合
- Kafka クライアントは、トークンエンドポイントから承認サーバーの認証を行います。これにはクライアント ID とシークレットが使用され、任意で更新トークンも使用されます。
- 承認サーバーによって新しいアクセストークンが生成されます。
- Kafka クライアントは SASL OAUTHBEARER メカニズムを使用してアクセストークンを渡し、Kafka ブローカーの認証を行います。
- Kafka ブローカーは、JWT トークン署名チェックおよびローカルトークンイントロスペクションを使用して、ローカルでアクセストークンを検証します。
クライアントでは有効期限の長いアクセストークンが使用され、ブローカーによって検証が承認サーバーに委譲される場合
- Kafka クライアントは、SASL OAUTHBEARER メカニズムを使用して有効期限の長いアクセストークンを渡し、Kafka ブローカーの認証を行います。
- Kafka ブローカーは、独自のクライアント ID およびシークレットを使用して、承認サーバーでトークンイントロスペクションエンドポイントを呼び出し、アクセストークンを検証します。
- トークンが有効な場合は、Kafka クライアントセッションが確立されます。
クライアントでは有効期限の長いアクセストークンが使用され、ブローカーによって高速のローカル検証が実行される場合

- Kafka クライアントは、SASL OAUTHBEARER メカニズムを使用して有効期限の長いアクセストークンを渡し、Kafka ブローカーの認証を行います。
- Kafka ブローカーは、JWT トークン署名チェックおよびローカルトークンイントロスペクションを使用して、ローカルでアクセストークンを検証します。
トークンが取り消された場合に承認サーバーとのチェックが行われないため、高速のローカル JWT トークン署名の検証は有効期限の短いトークンにのみ適しています。トークンの有効期限はトークンに書き込まれますが、失効はいつでも発生する可能性があるため、承認サーバーと通信せずに対応することはできません。発行されたトークンはすべて期限切れになるまで有効とみなされます。
3.6.5. OAuth 2.0 認証の設定
OAuth 2.0 は、Kafka クライアントと AMQ Streams コンポーネントとの対話に使用されます。
AMQ Streams に OAuth 2.0 を使用するには、以下を行う必要があります。
3.6.5.1. OAuth 2.0 承認サーバーとしての Red Hat Single Sign-On の設定
この手順では、Red Hat Single Sign-On を承認サーバーとしてデプロイし、AMQ Streams と統合するための設定方法を説明します。
承認サーバーは、一元的な認証および承認の他、ユーザー、クライアント、およびパーミッションの一元管理を実現します。Red Hat Single Sign-On にはレルムの概念があります。レルム はユーザー、クライアント、パーミッション、およびその他の設定の個別のセットを表します。デフォルトの マスターレルム を使用できますが、新しいレルムを作成することもできます。各レルムは独自の OAuth 2.0 エンドポイントを公開します。そのため、アプリケーションクライアントとアプリケーションサーバーはすべて同じレルムを使用する必要があります。
AMQ Streams で OAuth 2.0 を使用するには、Red Hat Single Sign-On のデプロイメントを使用して認証レルムを作成および管理します。
Red Hat Single Sign-On がすでにデプロイされている場合は、デプロイメントの手順を省略して、現在のデプロイメントを使用できます。
作業を開始する前の注意事項
Red Hat Single Sign-On を使用するための知識が必要です。
デプロイメントおよび管理の手順は、以下を参照してください。
前提条件
- AMQ Streams および Kafka が稼働している必要があります。
Red Hat Single Sign-On デプロイメントに関する条件:
- 「Red Hat Single Sign-On でサポートされる構成」を確認しておく必要があります。
- インストールには、system:admin などの cluster-admin ロールを持つユーザーが必要です。
手順
Red Hat Single Sign-On を OpenShift クラスターにデプロイします。
OpenShift Web コンソールでデプロイメントの進捗を確認します。
Red Hat Single Sign-On の Admin Console にログインし、AMQ Streams の OAuth 2.0 ポリシーを作成します。
ログインの詳細は、Red Hat Single Sign-On のデプロイ時に提供されます。
レルムを作成し、有効にします。
既存のマスターレルムを使用できます。
- 必要に応じて、レルムのセッションおよびトークンのタイムアウトを調整します。
-
kafka-brokerというクライアントを作成します。 タブで以下を設定します。
-
Access Type を
Confidentialに設定します。 -
Standard Flow Enabled を
OFFに設定し、このクライアントからの Web ログインを無効にします。 -
Service Accounts Enabled を
ONに設定し、このクライアントが独自の名前で認証できるようにします。
-
Access Type を
- 続行する前に Save クリックします。
- タブにある、AMQ Streams の Kafka クラスター設定で使用するシークレットを書き留めておきます。
Kafka ブローカーに接続するすべてのアプリケーションクライアントに対して、このクライアント作成手順を繰り返し行います。
新しいクライアントごとに定義を作成します。
設定では、名前をクライアント ID として使用します。
次のステップ
承認サーバーのデプロイおよび設定後に、Kafka ブローカーが OAuth 2.0 を使用するように設定 します。
3.6.5.2. Kafka ブローカーの OAuth 2.0 サポートの設定
この手順では、ブローカーリスナーが承認サーバーを使用して OAuth 2.0 認証を使用するように、Kafka ブローカーを設定する方法について説明します。
TLS リスナーを設定して、暗号化されたインターフェースで OAuth 2.0 を使用することが推奨されます。プレーンリスナーは推奨されません。
承認サーバーが信頼できる CA によって署名された証明書を使用し、OAuth 2.0 サーバーのホスト名と一致する場合、TLS 接続はデフォルト設定を使用して動作します。その他の場合は、トークンの検証を承認サーバーに委譲するときに 2 つの設定オプションをリスナー設定に使用できます。
作業を開始する前の注意事項
Kafka ブローカーリスナーの OAuth 2.0 認証の設定に関する詳細は、以下を参照してください。
前提条件
- AMQ Streams および Kafka が稼働している必要があります。
- OAuth 2.0 の承認サーバーがデプロイされている必要があります。
手順
エディターで、
Kafkaリソースの Kafka ブローカー設定 (Kafka.spec.kafka) を更新します。oc edit kafka my-cluster
oc edit kafka my-clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka ブローカーの
listeners設定を行います。各タイプのリスナーは独立しているため、同じ設定にする必要はありません。
以下は、外部リスナーに設定された設定オプションの例になります。
例 1: 高速なローカル JWT トークン検証の設定
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
oauthに設定されたリスナータイプ。- 2
- 認証に使用されるトークン発行者の URI。
- 3
- ローカルの JWT 検証に使用される JWKS 証明書エンドポイントの URI。
- 4
- トークンの実際のユーザー名が含まれるトークン要求 (またはキー)。ユーザー名は、ユーザーの識別に使用される principal です。
userNameClaimの値は、使用される認証フローと承認サーバーによって異なります。 - 5
- (任意設定): 承認サーバーへの TLS 接続用の信用できる証明書。
- 6
- (任意設定): TLS ホスト名の検証を無効にします。デフォルトは
falseです。 - 7
- JWK 証明書が期限切れになる前に有効とみなされる期間。デフォルトは
360秒 です。デフォルトよりも長い時間を指定する場合は、取り消された証明書へのアクセスが許可されるリスクを考慮してください。 - 8
- JWK 証明書を更新する間隔。この間隔は、有効期間よりも 60 秒以上短くする必要があります。デフォルトは
300秒 です。 - 9
- (任意設定): ECDSA を使用して承認サーバーで JWT トークンを署名する場合は、これを有効にする必要があります。BouncyCastle 暗号ライブラリーを使用して追加の暗号プロバイダーがインストールされます。デフォルトは
falseです。
例 2: イントロスペクションエンドポイントを使用したトークンの検証の設定
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - エディターを保存および終了してから、ローリングアップデートが完了するまで待ちます。
ログで更新を確認するか、Pod の状態遷移を監視して確認します。
oc logs -f ${POD_NAME} -c ${CONTAINER_NAME} oc get po -woc logs -f ${POD_NAME} -c ${CONTAINER_NAME} oc get po -wCopy to Clipboard Copied! Toggle word wrap Toggle overflow ローリングアップデートによって、ブローカーが OAuth 2.0 認証を使用するように設定されます。
次のステップ
3.6.5.3. OAuth 2.0 を使用するよう Kafka Java クライアントを設定
この手順では、Kafka ブローカーとの対話に OAuth 2.0 を使用するように Kafka プロデューサーおよびコンシューマー API を設定する方法を説明します。
クライアントコールバックプラグインを pom.xml ファイルに追加し、システムプロパティーを設定します。
前提条件
- AMQ Streams および Kafka が稼働している必要があります。
- OAuth 2.0 承認サーバーがデプロイされ、Kafka ブローカーへの OAuth のアクセスが設定されている必要があります。
- Kafka ブローカーが OAuth 2.0 に対して設定されている必要があります。
手順
OAuth 2.0 サポートのあるクライアントライブラリーを Kafka クライアントの
pom.xmlファイルに追加します。<dependency> <groupId>io.strimzi</groupId> <artifactId>kafka-oauth-client</artifactId> <version>0.3.0.redhat-00001</version> </dependency>
<dependency> <groupId>io.strimzi</groupId> <artifactId>kafka-oauth-client</artifactId> <version>0.3.0.redhat-00001</version> </dependency>Copy to Clipboard Copied! Toggle word wrap Toggle overflow コールバックのシステムプロパティーを設定します。
以下に例を示します。
System.setProperty(ClientConfig.OAUTH_TOKEN_ENDPOINT_URI, “https://<auth-server-address>/auth/realms/master/protocol/openid-connect/token”); System.setProperty(ClientConfig.OAUTH_CLIENT_ID, "<client-name>"); System.setProperty(ClientConfig.OAUTH_CLIENT_SECRET, "<client-secret>");
System.setProperty(ClientConfig.OAUTH_TOKEN_ENDPOINT_URI, “https://<auth-server-address>/auth/realms/master/protocol/openid-connect/token”);1 System.setProperty(ClientConfig.OAUTH_CLIENT_ID, "<client-name>");2 System.setProperty(ClientConfig.OAUTH_CLIENT_SECRET, "<client-secret>");3 Copy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka クライアント設定の TLS で暗号化された接続で SASL OAUTHBEARER メカニズムを有効にします。
以下に例を示します。
props.put("sasl.jaas.config", "org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required;"); props.put("security.protocol", "SASL_SSL"); props.put("sasl.mechanism", "OAUTHBEARER"); props.put("sasl.login.callback.handler.class", "io.strimzi.kafka.oauth.client.JaasClientOauthLoginCallbackHandler");props.put("sasl.jaas.config", "org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required;"); props.put("security.protocol", "SASL_SSL");1 props.put("sasl.mechanism", "OAUTHBEARER"); props.put("sasl.login.callback.handler.class", "io.strimzi.kafka.oauth.client.JaasClientOauthLoginCallbackHandler");Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- この例では、TLS 接続で
SASL_SSLを使用します。暗号化されていない接続ではSASL_PLAINTEXTを使用します。
- Kafka クライアントが Kafka ブローカーにアクセスできることを確認します。
次のステップ
3.6.5.4. Kafka コンポーネントの OAuth 2.0 の設定
この手順では、承認サーバーを使用して OAuth 2.0 認証を使用するように Kafka コンポーネントを設定する方法を説明します。
以下の認証を設定できます。
- Kafka Connect
- Kafka MirrorMaker
- Kafka Bridge
この手順では、Kafka コンポーネントと承認サーバーは同じサーバーで稼働しています。
作業を開始する前の注意事項
Kafka コンポーネントの OAuth 2.0 認証の設定に関する詳細は、以下を参照してください。
前提条件
- AMQ Streams および Kafka が稼働している必要があります。
- OAuth 2.0 承認サーバーがデプロイされ、Kafka ブローカーへの OAuth のアクセスが設定されている必要があります。
- Kafka ブローカーが OAuth 2.0 に対して設定されている必要があります。
手順
クライアントシークレットを作成し、これを環境変数としてコンポーネントにマウントします。
以下は、Kafka Bridge の
Secretを作成する例になります。Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
clientSecretキーは base64 形式である必要があります。
Kafka コンポーネントのリソースを作成または編集し、OAuth 2.0 認証が認証プロパティーに設定されるようにします。
OAuth 2.0 認証では、以下を使用できます。
- クライアント ID およびシークレット
- クライアント ID および更新トークン
- アクセストークン
- TLS
KafkaClientAuthenticationOAuth スキーマ参照は、それぞれの例を提供します。
以下は、クライアント ID、シークレット、および TLS を使用して OAuth 2.0 が Kafka Bridge クライアントに割り当てられる例になります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow OAuth 2.0 認証の適用方法や、承認サーバーのタイプによって、使用できる追加の設定オプションがあります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka リソースのデプロイメントに変更を適用します。
oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow ログで更新を確認するか、Pod の状態遷移を監視して確認します。
oc logs -f ${POD_NAME} -c ${CONTAINER_NAME} oc get pod -woc logs -f ${POD_NAME} -c ${CONTAINER_NAME} oc get pod -wCopy to Clipboard Copied! Toggle word wrap Toggle overflow ローリングアップデートでは、OAuth 2.0 認証を使用して Kafka ブローカーと対話するコンポーネントが設定されます。
3.7. OAuth 2.0 トークンベース承認の使用
OAuth 2.0 での承認はテクノロジープレビュー機能です。テクノロジープレビューの機能は、Red Hat の本番環境のサービスレベルアグリーメント (SLA) ではサポートされず、機能的に完全ではないことがあります。Red Hat は、本番環境でのテクノロジープレビュー機能の実装は推奨しません。テクノロジープレビューの機能は、最新の技術をいち早く提供して、開発段階で機能のテストやフィードバックの収集を可能にするために提供されます。Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳しい情報は、「テクノロジプレビュー機能の サポート範囲」を参照してください。
この機能について
OAuth 2.0 トークンベースの承認はテクノロジープレビューであるため、Red Hat Single Sign-On 7.3 ではサポートされません。この機能を試す場合は、Keycloak 8.0.2 を承認サーバーとする開発環境での使用はテストされています。
Kafka ブローカーへのアクセスの承認
AMQ Streams は、Keycloak Authorization Services による OAuth 2.0 トークンベースの承認をサポートします。これにより、セキュリティーポリシーとパーミッションの一元的な管理が可能になります。
Keycloak で定義されたセキュリティーポリシーおよびパーミッションは、Kafka ブローカーのリソースへのアクセスを付与するために使用されます。ユーザーとクライアントは、Kafka ブローカーで特定のアクションを実行するためのアクセスを許可するポリシーに対して照合されます。
Kafka では、デフォルトですべてのユーザーがブローカーに完全アクセスできます。また、アクセス制御リスト (ACL) を基にして承認を設定するために SimpleACLAuthorizer プラグインが提供されます。ZooKeeper には、 ユーザー名 を基にしてリソースへのアクセスを付与または拒否する ACL ルールが保存されます。ただし、Keycloak を使用した OAuth 2.0 トークンベースの承認では、より柔軟にアクセス制御を Kafka ブローカーに実装できます。さらに、Kafka ブローカーで OAuth 2.0 での承認および ACL が使用されるように設定することができます。
3.7.1. OAuth 2.0 の承認メカニズム
AMQ Streams の OAuth 2.0 の承認では、Keycloak サーバーの Authorization Services REST エンドポイントを使用して、Keycloak を使用するトークンベースの認証が拡張されます。これは、定義されたセキュリティーポリシーを特定のユーザーに適用し、そのユーザーの異なるリソースに付与されたパーミッションの一覧を提供します。ポリシーはロールとグループを使用して、パーミッションをユーザーと照合します。OAuth 2.0 の承認では、Keycloak Authorization Services から受信した、ユーザーに付与された権限のリストを基にして、権限がローカルで強制されます。
3.7.1.1. Kafka ブローカーのカスタムオーソライザー
AMQ Streams では、Keycloak オーソライザー (KeycloakRBACAuthorizer) が提供されます。Keycloak によって提供される Authorization Services で Keycloak REST エンドポイントを使用できるようにするには、Kafka ブローカーでカスタムオーソライザーを設定します。
オーソライザーは必要に応じて付与された権限のリストを承認サーバーから取得し、ローカルで Kafka ブローカーに承認を強制するため、クライアントの要求ごとに迅速な承認決定が行われます。
3.7.2. OAuth 2.0 承認サポートの設定
この手順では、Keycloak Authorization Services を使用して、OAuth 2.0 の承認を使用するように Kafka ブローカーを設定する方法を説明します。
作業を開始する前の注意事項
特定のユーザーに必要なアクセス、または制限するアクセスについて検討してください。Keycloak では、Keycloak グループ、ロール、クライアント、および ユーザー の組み合わせを使用して、アクセスを設定できます。
通常、グループは組織の部門または地理的な場所を基にしてユーザーを照合するために使用されます。また、ロールは職務を基にしてユーザーを照合するために使用されます。
Keycloak を使用すると、ユーザーおよびグループを LDAP で保存できますが、クライアントおよびロールは LDAP で保存できません。ユーザーデータへのアクセスとストレージを考慮して、承認ポリシーの設定方法を選択する必要がある場合があります。
スーパーユーザー は、Kafka ブローカーに実装された承認にかかわらず、常に制限なく Kafka ブローカーにアクセスできます。
前提条件
- AMQ Streams は、トークンベースの認証 に Keycloak と OAuth 2.0 を使用するように設定されている必要があります。承認を設定するときに、同じ Keycloak サーバーエンドポイントを使用する必要があります。
- Keycloak ドキュメント の説明にあるように、Keycloak Authorization Services のポリシーおよびパーミッションを管理する方法を理解する必要があります。
手順
- Keycloak Admin Console にアクセスするか、Keycloak Admin CLI を使用して、OAuth 2.0 認証の設定時に作成した Kafka ブローカークライアントの Authorization Services を有効にします。
- 承認サービスを使用して、クライアントのリソース、承認スコープ、ポリシー、およびパーミッションを定義します。
- ロールとグループをユーザーとクライアントに割り当てて、パーミッションをユーザーとクライアントにバインドします。
エディターで
Kafkaリソースの Kafka ブローカー設定 (Kafka.spec.kafka) を更新して、Kafka ブローカーで Keycloak による承認が使用されるように設定します。oc edit kafka my-cluster
oc edit kafka my-clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka ブローカーの
kafka設定を指定して、keycloakによる承認を使用し、承認サーバーと Red Hat Single Sign-On の Authorization Services にアクセスできるようにします。以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- タイプ
keycloakは、Keycloak による承認を有効にします。 - 2
- Keycloak トークンエンドポイントの URI。本番環境では常に HTTP を使用してください。
- 3
- 承認サービスが有効になっている Keycloak の OAuth 2.0 クライアント定義のクライアント ID。通常、
kafkaが ID として使用されます。 - 4
- (任意設定): Keycloak Authorization Services のポリシーによってアクセスが拒否されている場合は、Kafka
SimpleACLAuthorizerに承認を委譲します。デフォルトはfalseです。 - 5
- (任意設定): TLS ホスト名の検証を無効にします。デフォルトは
falseです。 - 6
- (任意設定): 指定の スーパーユーザー。
- 7
- (任意設定): 承認サーバーへの TLS 接続用の信用できる証明書。
- エディターを保存して終了し、ローリングアップデートの完了を待ちます。
ログで更新を確認するか、Pod の状態遷移を監視して確認します。
oc logs -f ${POD_NAME} -c kafka oc get po -woc logs -f ${POD_NAME} -c kafka oc get po -wCopy to Clipboard Copied! Toggle word wrap Toggle overflow ローリングアップデートによって、ブローカーが OAuth 2.0 承認を使用するように設定されます。
- クライアントまたは特定のロールを持つユーザーとして Kafka ブローカーにアクセスして、設定したパーミッションを検証し、必要なアクセス権限があり、付与されるべきでないアクセス権限がないことを確認します。
3.8. デプロイメントのカスタマイズ
AMQ Streams では、OpenShift の operator によって管理される Deployments、StatefulSets、Pods、および Services などの複数の OpenShift リソースが作成されます。特定の OpenShift リソースの管理を担当する operator のみがそのリソースを変更できます。operator によって管理される OpenShift リソースを手動で変更しようとすると、operator はその変更を元に戻します。
しかし、オペレーターが管理する OpenShift リソースの変更は、以下のような特定のタスクを実行する場合に役立ちます。
-
Podsが Istio またはその他のサービスによって処理される方法を制御するカスタムラベルまたはアノテーションを追加する場合。 -
Loadbalancerタイプのサービスがクラスターによって作成される方法を管理する場合。
このような変更は、AMQ Streams カスタムリソースの template プロパティーを使用して追加します。
3.8.1. テンプレートプロパティー
template プロパティーを使用すると、リソース作成プロセスの内容を設定できます。以下のリソースおよびプロパティーに追加できます。
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
Kafka.spec.entityOperator -
Kafka.spec.kafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMakerSpec -
KafkaBridge.spec
以下の例では、template プロパティーを使用して Kafka ブローカーの StatefulSet のラベルを変更します。
3.8.1.1. Kafka クラスターでサポートされるテンプレートプロパティー
statefulset-
Kafka ブローカーによって使用される
StatefulSetを設定します。 pod-
StatefulSetによって作成される Kafka ブローカーPodsを設定します。 bootstrapService- OpenShift 内で実行中のクライアントによって使用されるブートストラップサービスを設定し、Kafka ブローカーに接続します。
brokersService- ヘッドレスサービスを設定します。
externalBootstrapService- OpenShift の外部から Kafka ブローカーに接続するクライアントによって使用されるブートストラップサービスを設定します。
perPodService- OpenShift の外部から Kafka ブローカーに接続しているクライアントによって使用される Pod ごとのサービスを設定し、個別のブローカーにアクセスします。
externalBootstrapRoute-
OpenShift
Routesを使用して OpenShift の外部から Kafka ブローカーに接続するクライアントによって使用されるブートストラップルートを設定します。 perPodRoute-
OpenShift の外部から Kafka ブローカーに接続するクライアントによって使用される Pod ごとのルートを設定し、OpenShift
Routesを使用して個別のブローカーにアクセスします。 podDisruptionBudget-
Kafka ブローカー
StatefulSetの Pod の Disruption Budget を設定します。 kafkaContainer- カスタム環境変数を含む、Kafka ブローカーの実行に使用されるコンテナーを設定します。
tlsSidecarContainer- カスタム環境変数を含む、TLS サイドカーコンテナーを設定します。
initContainer- ブローカーの初期化に使用されるコンテナーを設定します。
persistentVolumeClaim-
Kafka
PersistentVolumeClaimsのメタデータを設定します。
その他のリソース
3.8.1.2. ZooKeeper クラスターでサポートされるテンプレートプロパティー
statefulset-
ZooKeeper の
StatefulSetを設定します。 pod-
StatefulSetによって作成される ZooKeeperPodsを設定します。 clientsService- ZooKeeper にアクセスするためにクライアントによって使用されるサービスを設定します。
nodesService- ヘッドレスサービスを設定します。
podDisruptionBudget-
ZooKeeper
StatefulSetの Pod の Disruption Budget を設定します。 zookeeperContainer- カスタム環境変数を含む、ZooKeeper ノードの実行に使用されるコンテナーを設定します。
tlsSidecarContainer- カスタム環境変数を含む、TLS サイドカーコンテナーを設定します。
persistentVolumeClaim-
ZooKeeper
PersistentVolumeClaimsのメタデータを設定します。
その他のリソース
3.8.1.3. Entity Operator でサポートされるテンプレートプロパティー
deployment- Entity Operator によって使用されるデプロイメントを設定します。
pod-
Deploymentによって作成された Entity OperatorPodを設定します。 topicOperatorContainer- カスタム環境変数を含む、Topic Operator の実行に使用されるコンテナーを設定します。
userOperatorContainer- カスタム環境変数を含む、User Operator の実行に使用されるコンテナーを設定します。
tlsSidecarContainer- カスタム環境変数を含む、TLS サイドカーコンテナーを設定します。
その他のリソース
3.8.1.4. Kafka Exporter でサポートされるテンプレートプロパティー
deployment- Kafka Exporter によって使用されるデプロイメントを設定します。
pod-
Deploymentによって作成される Kafka ExporterPodを設定します。 services- Kafka Exporter サービスを設定します。
container- カスタム環境変数を含む、Kafka Exporter の実行に使用されるコンテナーを設定します。
その他のリソース
3.8.1.5. Kafka Connect および Source2Image がサポートされる Kafka Connect でサポートされるテンプレート。
deployment-
Kafka Connect の
Deploymentを設定します。 pod-
Deploymentによって作成される Kafka ConnectPodsを設定します。 apiService- Kafka Connect REST API で使用されるサービスを設定します。
podDisruptionBudget-
Kafka Connect
Deploymentの Pod の Disruption Budget を設定します。 connectContainer- カスタム環境変数を含む、Kafka Connect の実行に使用されるコンテナーを設定します。
その他のリソース
3.8.1.6. Kafka MirrorMaker でサポートされるテンプレートプロパティー
deployment-
Kafka MirrorMaker の
Deploymentを設定します。 pod-
Deploymentによって作成される Kafka MirrorMakerPodsを設定します。 podDisruptionBudget-
Kafka MirrorMaker
Deploymentの Pod の Disruption Budget を設定します。 mirrorMakerContainer- カスタム環境変数を含む、Kafka MirrorMaker の実行に使用されるコンテナーを設定します。
その他のリソース
3.8.2. ラベルおよびアノテーション
各リソースに、追加の Labels および Annotations を設定できます。Labels および Annotations は、リソースの識別および整理に使用され、metadata プロパティーで設定されます。
以下に例を示します。
labels および annotations フィールドには、予約された文字列 strimzi.io が含まれないすべてのラベルやアノテーションを含めることができます。strimzi.io が含まれるラベルやアノテーションは、内部で AMQ Streams によって使用され、設定することはできません。
Kafka Connect では、KafkaConnect リソースのアノテーションは KafkaConnector リソースを使用したコネクターの作成および管理を有効にするために使用されます。詳細は、「KafkaConnector リソースの有効化」 を参照してください。
metadata プロパティーは、kafkaContainer などのコンテナーテンプレートには適用できません。
3.8.3. Pod のカスタマイズ
ラベルやアノテーションの他に、Pod の他のフィールドもカスタマイズできます。これらのフィールドの説明は以下の表を参照してください。これらのフィールドは Pod の作成方法に影響します。
| フィールド | 説明 |
|---|---|
|
|
Pod が正常終了されるはずの期間 (秒単位) を定義します。正常終了の期間後、Pod とそのコンテナーは強制的に終了 (kill) されます。デフォルト値は 注記: 非常に大型な Kafka クラスターの場合は、正常終了期間を延長し、Kafka ブローカーの終了前に作業を別のブローカーに転送する時間を十分確保する必要があることがあります。 |
|
| プライベートリポジトリーからコンテナーイメージをプルするために使用できる OpenShift シークレットへの参照のリストを定義します。クレデンシャルを使用してシークレットを作成する方法の詳細は「Pull an Image from a Private Registry」を参照してください。
注記: Cluster Operator の |
|
| 特定の Pod の一部として実行されているコンテナーの Pod レベルのセキュリティー属性を設定します。SecurityContext の設定に関する詳細は、「Configure a Security Context for a Pod or Container」を参照してください。 |
|
| 指定の Pod に使用される Priority Class (優先順位クラス) の名前を設定します。Priority Class (優先順位クラス) の詳細は、「Pod Priority and Preemption」を参照してください。 |
|
|
この |
これらのフィールドは、各タイプのクラスター (Kafka および ZooKeeper、Kafka Connect および S2I サポートのある Kafka Connect、Kafka MirrorMaker) で有効です。
以下は、template プロパティーのカスタマイズされたフィールドの例になります。
その他のリソース
-
詳細は 「
PodTemplateスキーマ参照」 を参照してください。
3.8.4. 環境変数でのコンテナーのカスタマイズ
関連する template コンテナープロパティーを使用すると、コンテナーのカスタム環境変数を設定できます。以下の表は、各カスタムリソースの AMQ Streams コンテナーと、関連するテンプレート設定プロパティー (spec で定義) を示しています。
| AMQ Streams 要素 | コンテナー | 設定プロパティー |
|---|---|---|
| Kafka | Kafka Broker |
|
| Kafka | Kafka Broker TLS Sidecar |
|
| Kafka | Kafka Initialization |
|
| Kafka | ZooKeeper Node |
|
| Kafka | ZooKeeper TLS Sidecar |
|
| Kafka | Topic Operator |
|
| Kafka | User Operator |
|
| Kafka | Entity Operator TLS Sidecar |
|
| KafkaConnect | Connect and ConnectS2I |
|
| KafkaMirrorMaker | MirrorMaker |
|
| KafkaBridge | Bridge |
|
環境変数は、env プロパティーで name および value フィールドのあるオブジェクトのリストとして定義されます。以下は、Kafka ブローカーコンテナーに設定された 2 つのカスタム環境変数の例になります。
KAFKA_ で始まる環境変数は AMQ Streams 内部となるため、使用しないようにしてください。AMQ Streams によってすでに使用されているカスタム環境変数を設定すると、その環境変数は無視され、警告がログに記録されます。
その他のリソース
-
詳細は 「
ContainerTemplateスキーマ参照」 を参照してください。
3.8.5. 外部サービスのカスタマイズ
ロードバランサーまたはノードポートを使用して OpenShift 外部で Kafka を公開する場合、ラベルとアノテーションの他に追加のカスタマイズプロパティーを使用できます。外部サービスのプロパティーの説明は以下の表を参照してください。外部サービスのプロパティーはサービスの作成方法に影響します。
| フィールド | 説明 |
|---|---|
|
|
サービスによって外部トラフィックがローカルノードのエンドポイントまたはクラスター全体のエンドポイントにルーティングされるかどうかを指定します。 |
|
|
クライアントがロードバランサータイプのリスナーに接続できる CIDR 形式による範囲 (例: 詳細は「https://kubernetes.io/docs/tasks/access-application-cluster/configure-cloud-provider-firewall/」を参照してください。 |
これらのプロパティーは、externalBootstrapService および perPodService で使用できます。以下は、template のカスタマイズされたプロパティーの例になります。
その他のリソース
-
詳細は 「
ExternalServiceTemplateスキーマ参照」 を参照してください。
3.8.6. イメージプルポリシーのカスタマイズ
AMQ Streams では、Cluster Operator によってデプロイされたすべての Pod のコンテナーのイメージプルポリシーをカスタマイズできます。イメージプルポリシーは、Cluster Operator デプロイメントの環境変数 STRIMZI_IMAGE_PULL_POLICY を使用して設定されます。STRIMZI_IMAGE_PULL_POLICY 環境変数に設定できる値は 3 つあります。
Always- Pod が起動または再起動されるたびにコンテナーイメージがレジストリーからプルされます。
IfNotPresent- 以前プルされたことのないコンテナーイメージのみがレジストリーからプルされます。
Never- コンテナーイメージはレジストリーからプルされることはありません。
現在、イメージプルポリシーはすべての Kafka、Kafka Connect、および Kafka MirrorMaker クラスターに対してのみ 1 度にカスタマイズできます。ポリシーを変更すると、すべての Kafka、Kafka Connect、および Kafka MirrorMaker クラスターのローリングアップデートが実行されます。
その他のリソース
- Cluster Operator の設定に関する詳細は、「Cluster Operator」 を参照してください。
- イメージプルポリシーに関する詳細は、「Disruptions」を参照してください。
3.8.7. Pod の Disruption Budget (停止状態の予算) のカスタマイズ
AMQ Streams では、新しい StatefulSet または Deployment ごとに Pod の Disruption Budget が作成されます。デフォルトでは、PodDisruptionBudget.spec リソースの maxUnavailable の値が 1 に設定され、Pod の Disruption Budget で単一の Pod を利用不可能にすることができます。Pod の Disruption Budget のテンプレートで maxUnavailable のデフォルト値を変更すると、許容される利用不可能な Pod の数を変更できます。このテンプレートは、各タイプのクラスター (Kafka および ZooKeeper、Kafka Connect および S2I サポートのある Kafka Connect、および Kafka MirrorMaker) に適用されます。
以下は、template プロパティーのカスタマイズされた podDisruptionBudget フィールドの例になります。
その他のリソース
-
詳細は 「
PodDisruptionBudgetTemplateスキーマ参照」 を参照してください。 - Kubernetes ドキュメントの「Disruptions」の章を参照してください。
3.8.8. デプロイメントのカスタマイズ
この手順では、Kafka クラスターの Labels をカスタマイズする方法を説明します。
前提条件
- OpenShift クラスター。
- 稼働中の Cluster Operator。
手順
Kafka、KafkaConnect、KafkaConnectS2I、またはKafkaMirrorMakerリソースのtemplateプロパティーを編集します。たとえば、Kafka ブローカーStatefulSetのラベルを変更する場合は、以下を使用します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc applyを使用します。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow あるいは、
oc editを使用します。oc edit Resource ClusterName
oc edit Resource ClusterNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.9. 外部ロギング
リソースのロギングレベルを設定する場合、リソース YAML の spec.logging プロパティーで直接 インライン で指定できます。
または external ロギングを指定することもできます。
spec:
# ...
logging:
type: external
name: customConfigMap
spec:
# ...
logging:
type: external
name: customConfigMap
外部ロギングでは、ロギングプロパティーは ConfigMap に定義されます。ConfigMap の名前は spec.logging.name プロパティーで参照されます。
ConfigMap を使用する利点は、ロギングプロパティーが 1 カ所で維持され、複数のリソースにアクセスできることです。
3.9.1. ロギングの ConfigMap の作成
ConfigMap を使用してロギングプロパティーを定義するには、ConfigMap を作成してから、リソースの spec にあるロギング定義の一部としてそれを参照します。
ConfigMap には適切なロギング設定が含まれる必要があります。
-
Kafka コンポーネント、ZooKeeper、および Kafka Bridge の
log4j.properties。 -
Topic Operator および User Operator の
log4j2.properties。
設定はこれらのプロパティーの配下に配置する必要があります。
ここでは、ConfigMap によって Kafka リソースのルートロガーが定義される方法を実証します。
手順
ConfigMap を作成します。
ConfigMap を YAML ファイルとして作成するか、コマンドラインで
ocを使用してプロパティーファイルから Config Map を作成します。Kafka のルートロガー定義が含まれる ConfigMap の例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow プロパティーファイルを使用してコマンドラインから作成します。
oc create configmap logging-configmap --from-file=log4j.properties
oc create configmap logging-configmap --from-file=log4j.propertiesCopy to Clipboard Copied! Toggle word wrap Toggle overflow プロパティーファイルではロギング設定が定義されます。
# Define the root logger kafka.root.logger.level="INFO" # ...
# Define the root logger kafka.root.logger.level="INFO" # ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow logging.nameを ConfigMap の名前に設定し、リソースのspecの external ロギングを定義します。spec: # ... logging: type: external name: logging-configmapspec: # ... logging: type: external name: logging-configmapCopy to Clipboard Copied! Toggle word wrap Toggle overflow リソースを作成または更新します。
oc apply -f kafka.yaml
oc apply -f kafka.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第4章 Operator
4.1. Cluster Operator
Cluster Operator を使用して Kafka クラスターや他の Kafka コンポーネントをデプロイします。
Kafka で利用可能なデプロイメントオプションの詳細は、「Kafka クラスターの設定」を参照してください。
OpenShift では、Kafka Connect デプロイメントに Source2Image 機能を組み込み、追加のコネクターを加えるための便利な方法として利用できます。
4.1.1. Cluster Operator
AMQ Streams では、Cluster Operator を使用して以下のクラスターをデプロイおよび管理します。
- Kafka (ZooKeeper、Entity Operator、および Kafka Exporter を含む)
- Kafka Connect
- Kafka MirrorMaker
- Kafka Bridge
クラスターのデプロイメントにはカスタムリソースが使用されます。
たとえば、以下のように Kafka クラスターをデプロイします。
-
クラスター設定のある
Kafkaリソースが OpenShift クラスター内で作成されます。 -
Kafkaリソースに宣言された内容を基にして、該当する Kafka クラスターが Cluster Operator によってデプロイされます。
Cluster Operator で以下もデプロイできます (Kafka リソースの設定より)。
-
KafkaTopicカスタムリソースより Operator スタイルのトピック管理を提供する Topic Operator -
KafkaUserカスタムリソースより Operator スタイルのユーザー管理を提供する User Operator
デプロイメントの Entity Operator 内の Topic Operator および User Operator 関数。
Cluster Operator のアーキテクチャー例
4.1.2. Cluster Operator デプロイメントの監視オプション
Cluster Operator の稼働中に、Kafka リソースの更新に対する監視が開始されます。
Cluster Operator はデプロイメントに応じて、以下から Kafka リソースを監視できます。
AMQ Streams では、デプロイメントの処理を簡単にするため、サンプル YAML ファイルが提供されます。
Cluster Operator では、以下のリソースの変更が監視されます。
-
Kafka クラスターの
Kafka。 -
KafkaConnectの Kafka Connect クラスター。 -
Source2Image がサポートされる Kafka Connect クラスターの
KafkaConnectS2I。 -
Kafka Connect クラスターでコネクターを作成および管理するための
KafkaConnector。 -
Kafka MirrorMaker インスタンスの
KafkaMirrorMaker。 -
Kafka Bridge インスタンスの
KafkaBridge。
OpenShift クラスターでこれらのリソースの 1 つが作成されると、Operator によってクラスターの詳細がリソースより取得されます。さらに、StatefulSet、Service、および ConfigMap などの必要な OpenShift リソースが作成され、リソースの新しいクラスターの作成が開始されます。
Kafka リソースが更新されるたびに、リソースのクラスターを構成する OpenShift リソースで該当する更新が Operator によって実行されます。
クラスターの望ましい状態がリソースのクラスターに反映されるようにするため、リソースへのパッチ適用後またはリソースの削除後にリソースが再作成されます。この操作は、サービスの中断を引き起こすローリングアップデートの原因となる可能性があります。
リソースが削除されると、Operator によってクラスターがアンデプロイされ、関連する OpenShift リソースがすべて削除されます。
4.1.3. 単一の namespace を監視対象とする Cluster Operator のデプロイメント
前提条件
-
この手順では、
CustomResourceDefinitions、ClusterRoles、およびClusterRoleBindingsを作成できる OpenShift ユーザーアカウントを使用する必要があります。通常、OpenShift クラスターでロールベースアクセス制御 (RBAC) を使用する場合、これらのリソースを作成、編集、および削除する権限を持つユーザーはsystem:adminなどの OpenShift クラスター管理者に限定されます。 Cluster Operator がインストールされる namespace に従い、インストールファイルを編集します。
Linux の場合は、以下を使用します。
sed -i 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yaml
sed -i 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow MacOS の場合は、以下を使用します。
sed -i '' 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yaml
sed -i '' 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
手順
Cluster Operator をデプロイします。
oc apply -f install/cluster-operator -n my-namespace
oc apply -f install/cluster-operator -n my-namespaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.1.4. 複数の namespace を監視対象とする Cluster Operator のデプロイメント
前提条件
-
この手順では、
CustomResourceDefinitions、ClusterRoles、およびClusterRoleBindingsを作成できる OpenShift ユーザーアカウントを使用する必要があります。通常、OpenShift クラスターでロールベースアクセス制御 (RBAC) を使用する場合、これらのリソースを作成、編集、および削除する権限を持つユーザーはsystem:adminなどの OpenShift クラスター管理者に限定されます。 Cluster Operator がインストールされる namespace にしたがって、インストールファイルを編集します。
Linux の場合は、以下を使用します。
sed -i 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yaml
sed -i 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow MacOS の場合は、以下を使用します。
sed -i '' 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yaml
sed -i '' 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
手順
install/cluster-operator/050-Deployment-strimzi-cluster-operator.yamlファイルを編集し、環境変数STRIMZI_NAMESPACEで、Cluster Operator がリソースを監視するすべての namespace を一覧表示します。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow Cluster Operator によって監視されるすべての namespace (上記の例では
watched-namespace-1、watched-namespace-2、およびwatched-namespace-3) に対して、RoleBindingsをインストールします。watched-namespaceは、直前のステップで使用した namespace に置き換えます。oc applyを使用してこれを行うことができます。oc apply -f install/cluster-operator/020-RoleBinding-strimzi-cluster-operator.yaml -n watched-namespace oc apply -f install/cluster-operator/031-RoleBinding-strimzi-cluster-operator-entity-operator-delegation.yaml -n watched-namespace oc apply -f install/cluster-operator/032-RoleBinding-strimzi-cluster-operator-topic-operator-delegation.yaml -n watched-namespace
oc apply -f install/cluster-operator/020-RoleBinding-strimzi-cluster-operator.yaml -n watched-namespace oc apply -f install/cluster-operator/031-RoleBinding-strimzi-cluster-operator-entity-operator-delegation.yaml -n watched-namespace oc apply -f install/cluster-operator/032-RoleBinding-strimzi-cluster-operator-topic-operator-delegation.yaml -n watched-namespaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow Cluster Operator をデプロイします。
oc applyを使用してこれを行うことができます。oc apply -f install/cluster-operator -n my-namespace
oc apply -f install/cluster-operator -n my-namespaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.1.5. すべての namespace を対象とする Cluster Operator のデプロイメント
OpenShift クラスターのすべての namespace で AMQ Streams リソースを監視するように Cluster Operator を設定できます。このモードで実行している場合、Cluster Operator によって、新規作成された namespace でクラスターが自動的に管理されます。
前提条件
-
この手順では、
CustomResourceDefinitions、ClusterRoles、およびClusterRoleBindingsを作成できる OpenShift ユーザーアカウントを使用する必要があります。通常、OpenShift クラスターでロールベースアクセス制御 (RBAC) を使用する場合、これらのリソースを作成、編集、および削除する権限を持つユーザーはsystem:adminなどの OpenShift クラスター管理者に限定されます。 - OpenShift クラスターが稼働している必要があります。
手順
すべての namespace を監視するように Cluster Operator を設定します。
-
050-Deployment-strimzi-cluster-operator.yamlファイルを編集します。 STRIMZI_NAMESPACE環境変数の値を*に設定します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
クラスター全体ですべての namespace にアクセスできる権限を Cluster Operator に付与する
ClusterRoleBindingsを作成します。oc create clusterrolebindingコマンドを使用します。oc create clusterrolebinding strimzi-cluster-operator-namespaced --clusterrole=strimzi-cluster-operator-namespaced --serviceaccount my-namespace:strimzi-cluster-operator oc create clusterrolebinding strimzi-cluster-operator-entity-operator-delegation --clusterrole=strimzi-entity-operator --serviceaccount my-namespace:strimzi-cluster-operator oc create clusterrolebinding strimzi-cluster-operator-topic-operator-delegation --clusterrole=strimzi-topic-operator --serviceaccount my-namespace:strimzi-cluster-operator
oc create clusterrolebinding strimzi-cluster-operator-namespaced --clusterrole=strimzi-cluster-operator-namespaced --serviceaccount my-namespace:strimzi-cluster-operator oc create clusterrolebinding strimzi-cluster-operator-entity-operator-delegation --clusterrole=strimzi-entity-operator --serviceaccount my-namespace:strimzi-cluster-operator oc create clusterrolebinding strimzi-cluster-operator-topic-operator-delegation --clusterrole=strimzi-topic-operator --serviceaccount my-namespace:strimzi-cluster-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow my-namespaceは、Cluster Operator をインストールする namespace に置き換えます。Cluster Operator を OpenShift クラスターにデプロイします。
oc applyコマンドを使用します。oc apply -f install/cluster-operator -n my-namespace
oc apply -f install/cluster-operator -n my-namespaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
4.1.6. 調整
Operator は OpenShift クラスターから受信する必要なクラスターリソースに関するすべての通知に対応しますが、Operator が実行されていない場合や、何らかの理由で通知が受信されない場合、必要なリソースは実行中の OpenShift クラスターの状態と同期しなくなります。
フェイルオーバーを適切に処理するために、Cluster Operator によって定期的な調整プロセスが実行され、必要なリソースすべてで一貫した状態になるように、必要なリソースの状態を現在のクラスターデプロイメントと比較できます。[STRIMZI_FULL_RECONCILIATION_INTERVAL_MS] 変数を使用して、定期的な調整の期間を設定できます。
4.1.7. Cluster Operator の設定
Cluster Operator は、以下のサポートされる環境変数を使用して設定できます。
STRIMZI_NAMESPACEOperator が操作する namespace のカンマ区切りのリスト。設定されていない場合や、空の文字列や
*に設定された場合は、Cluster Operator はすべての namespace で操作します。Cluster Operator デプロイメントでは OpenShift Downward API を使用して、これを Cluster Operator がデプロイされる namespace に自動設定することがあります。以下に例を示します。env: - name: STRIMZI_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespaceenv: - name: STRIMZI_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
STRIMZI_FULL_RECONCILIATION_INTERVAL_MS - 任意設定、デフォルトは 120000 ミリ秒です。定期的な調整の間隔 (秒単位)。
STRIMZI_LOG_LEVEL-
任意設定、デフォルトは
INFOです。ロギングメッセージの出力レベル。設定可能な値:ERROR、WARNING、INFO、DEBUG、およびTRACE STRIMZI_OPERATION_TIMEOUT_MS- 任意設定、デフォルトは 300000 ミリ秒です。内部操作のタイムアウト (ミリ秒単位)。この値は、標準の OpenShift 操作の時間が通常よりも長いクラスターで (Docker イメージのダウンロードが遅い場合など) AMQ Streams を使用する場合に増やす必要があります。
STRIMZI_KAFKA_IMAGES-
必須。Kafka バージョンから、そのバージョンの Kafka ブローカーが含まれる該当の Docker イメージへのマッピングが提供されます。必要な構文は、空白またはカンマ区切りの
<version>=<image>ペアです。例:2.3.0=registry.redhat.io/amq7/amq-streams-kafka-23-rhel7:1.4.0, 2.4.0=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0これは、「コンテナーイメージ」に説明されているように、Kafka.spec.kafka.versionプロパティーは指定されていてもKafka.spec.kafka.imageプロパティーは指定されていない場合に使用されます。 STRIMZI_DEFAULT_KAFKA_INIT_IMAGE-
任意設定で、デフォルトは
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0です。「コンテナーイメージ」 でkafka-init-imageとして指定されたイメージがない場合に、初期設定作業 (ラックサポート) のブローカーの前に開始される init コンテナーのデフォルトとして使用するイメージ名。 STRIMZI_DEFAULT_TLS_SIDECAR_KAFKA_IMAGE-
任意設定で、デフォルトは
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0です。「コンテナーイメージ」 でKafka.spec.kafka.tlsSidecar.imageとして指定されたイメージがない場合に、Kafka の TLS サポートを提供するサイドカーコンテナーをデプロイする際にデフォルトとして使用するイメージ名。 STRIMZI_DEFAULT_TLS_SIDECAR_ZOOKEEPER_IMAGE-
任意設定で、デフォルトは
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0です。「コンテナーイメージ」 でKafka.spec.zookeeper.tlsSidecar.imageとして指定されたイメージがない場合に、ZooKeeper の TLS サポートを提供するサイドカーコンテナーをデプロイする際にデフォルトとして使用するイメージ名。 STRIMZI_KAFKA_CONNECT_IMAGES-
必須。Kafka バージョンから、そのバージョンの Kafka Connect が含まれる該当の Docker イメージへのマッピングが提供されます。必要な構文は、空白またはカンマ区切りの
<version>=<image>ペアです。例:2.3.0=registry.redhat.io/amq7/amq-streams-kafka-23-rhel7:1.4.0, 2.4.0=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0これは、「コンテナーイメージ」に説明されているように、KafkaConnect.spec.versionプロパティーは指定されていてもKafkaConnect.spec.imageプロパティーは指定されていない場合に使用されます。 STRIMZI_KAFKA_CONNECT_S2I_IMAGES-
必須。Kafka バージョンから、そのバージョンの Kafka Connect が含まれる該当の Docker イメージへのマッピングが提供されます。必要な構文は、空白またはカンマ区切りの
<version>=<image>ペアです。例:2.3.0=registry.redhat.io/amq7/amq-streams-kafka-23-rhel7:1.4.0, 2.4.0=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0これは、「コンテナーイメージ」に説明されているように、KafkaConnectS2I.spec.versionプロパティーは指定されていてもKafkaConnectS2I.spec.imageプロパティーは指定されていない場合に使用されます。 STRIMZI_KAFKA_MIRROR_MAKER_IMAGES-
必須。Kafka バージョンから、そのバージョンの Kafka Mirror Maker が含まれる該当の Docker イメージへのマッピングが提供されます。必要な構文は、空白またはカンマ区切りの
<version>=<image>ペアです。例:2.3.0=registry.redhat.io/amq7/amq-streams-kafka-23-rhel7:1.4.0, 2.4.0=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0これは、「コンテナーイメージ」に説明されているように、KafkaMirrorMaker.spec.versionプロパティーは指定されていてもKafkaMirrorMaker.spec.imageプロパティーは指定されていない場合に使用されます。 STRIMZI_DEFAULT_TOPIC_OPERATOR_IMAGE-
任意設定で、デフォルトは
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0です。Kafkaリソースの 「コンテナーイメージ」 にKafka.spec.entityOperator.topicOperator.imageとして指定されたイメージがない場合に、Topic Operator のデプロイ時にデフォルトとして使用するイメージ名。 STRIMZI_DEFAULT_USER_OPERATOR_IMAGE-
任意設定で、デフォルトは
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0です。Kafkaリソースの 「コンテナーイメージ」 にKafka.spec.entityOperator.userOperator.imageとして指定されたイメージがない場合に、User Operator のデプロイ時にデフォルトとして使用するイメージ名。 STRIMZI_DEFAULT_TLS_SIDECAR_ENTITY_OPERATOR_IMAGE-
任意設定で、デフォルトは
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0です。「コンテナーイメージ」 でKafka.spec.entityOperator.tlsSidecar.imageとして指定されたイメージがない場合に、Entity Operator の TLS サポートを提供するサイドカーコンテナーをデプロイする際にデフォルトとして使用するイメージ名。 STRIMZI_IMAGE_PULL_POLICY-
任意設定。AMQ Streams の Cluster Operator によって管理されるすべての Pod のコンテナーに適用される
ImagePullPolicy。有効な値は、Always、IfNotPresent、およびNeverです。指定のない場合、OpenShift のデフォルトが使用されます。ポリシーを変更すると、すべての Kafka、Kafka Connect、および Kafka MirrorMaker クラスターのローリングアップデートが実行されます。 STRIMZI_IMAGE_PULL_SECRETS-
任意設定。
Secret名のカンマ区切りのリスト。ここで参照されるシークレットには、コンテナーイメージがプルされるコンテナーレジストリーへのクレデンシャルが含まれます。シークレットは、Cluster Operator によって作成されるすべてのPodsのimagePullSecretsフィールドで使用されます。このリストを変更すると、Kafka、Kafka Connect、および Kafka MirrorMaker のすべてのクラスターのローリングアップデートが実行されます。 STRIMZI_KUBERNETES_VERSION任意設定。API サーバーから検出された OpenShift バージョン情報をオーバーライドします。以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
4.1.8. ロールベースアクセス制御 (RBAC)
4.1.8.1. Cluster Operator のロールベースアクセス制御 (RBAC) のプロビジョニング
Cluster Operator が機能するには、Kafka、KafkaConnect などのリソースや ConfigMaps、Pods、Deployments、StatefulSets、Services などの管理リソースと対話するために OpenShift クラスター内でパーミッションが必要になり ます。このようなパーミッションは、OpenShift のロールベースアクセス制御 (RBAC) リソースに記述されます。
-
ServiceAccount -
RoleおよびClusterRole -
RoleBindingおよびClusterRoleBinding
Cluster Operator は、ClusterRoleBinding を使用して独自の ServiceAccount で実行される他に、OpenShift リソースへのアクセスを必要とするコンポーネントの RBAC リソースを管理します。
また OpenShift には、ServiceAccount で動作するコンポーネントが、その ServiceAccount にはない他の ServiceAccounts の権限を付与しないようにするための特権昇格の保護機能も含まれています。Cluster Operator は、ClusterRoleBindings と、それが管理するリソースで必要な RoleBindings を作成できる必要があるため、Cluster Operator にも同じ権限が必要です。
4.1.8.2. 委譲された権限
Cluster Operator が必要な Kafka リソースのリソースをデプロイする場合、以下のように ServiceAccounts、RoleBindings、および ClusterRoleBindings も作成します。
Kafka ブローカー Pod は
cluster-name-kafkaというServiceAccountを使用します。-
ラック機能が使用されると、
strimzi-cluster-name-kafka-initClusterRoleBindingは、strimzi-kafka-brokerと呼ばれるClusterRole経由で、クラスター内のノードへのServiceAccountアクセスを付与するために使用されます。 - ラック機能が使用されていない場合は、バインディングは作成されません。
-
ラック機能が使用されると、
-
ZooKeeper Pod は
cluster-name-zookeeperというServiceAccountを使用します。 Entity Operator は、
cluster-name-entity-operatorというServiceAccountを使用します。-
Topic Operator はステータス情報のある OpenShift イベントを生成し、
ServiceAccountがstrimzi-entity-operatorというClusterRoleにバインドされるようにします。strimzi-entity-operatorはこのアクセス権限をstrimzi-entity-operatorRoleBinding経由で付与します。
-
Topic Operator はステータス情報のある OpenShift イベントを生成し、
-
KafkaConnectおよびKafkaConnectS2Iリソースの Pod はcluster-name-cluster-connectというServiceAccountを使用します。 -
KafkaMirrorMakerの Pod はcluster-name-mirror-makerというServiceAccountを使用します。 -
KafkaBridgeの Pod はcluster-name-bridgeというServiceAccountを使用します。
4.1.8.3. ServiceAccount
Cluster Operator は ServiceAccount を使用して最適に実行されます。
Cluster Operator の ServiceAccount の例
その後、Cluster Operator の Deployment で、これを spec.template.spec.serviceAccountName に指定する必要があります。
Cluster Operator の Deployment の部分的な例
strimzi-cluster-operator ServiceAccount が serviceAccountName として指定されている 12 行目に注目してください。
4.1.8.4. ClusterRoles
Cluster Operator は、必要なリソースへのアクセス権限を付与する ClusterRoles を使用して操作する必要があります。OpenShift クラスターの設定によっては、クラスター管理者が ClusterRoles を作成する必要があることがあります。
クラスター管理者の権限は ClusterRoles の作成にのみ必要です。Cluster Operator はクラスター管理者アカウントで実行されません。
ClusterRoles は、 最小権限の原則に従い、Kafka、Kafka Connect、および ZooKeeper クラスターを操作するために Cluster Operator が必要とする権限のみが含まれます。最初に割り当てられた一連の権限により、Cluster Operator で StatefulSets、Deployments、Pods、および ConfigMaps などの OpenShift リソースを管理できます。
Cluster Operator は ClusterRoles を使用して、namespace スコープリソースのレベルおよびクラスタースコープリソースのレベルで権限を付与します。
Cluster Operator の namespaced リソースのある ClusterRole
2 番目の一連の権限には、クラスタースコープリソースに必要な権限が含まれます。
Cluster Operator のクラスタースコープリソースのある ClusterRole
strimzi-kafka-broker ClusterRole は、ラック機能に使用される Kafka Pod の init コンテナーが必要とするアクセス権限を表します。「委譲された権限」で説明したように、このアクセスを委譲できるようにするには、このロールも Cluster Operator に必要です。
Cluster Operator の ClusterRole により、OpenShift ノードへのアクセスを Kafka ブローカー Pod に委譲できます。
strimzi-topic-operator の ClusterRole は、Topic Operator が必要とするアクセスを表します。「委譲された権限」で説明したように、このアクセスを委譲できるようにするには、このロールも Cluster Operator に必要です。
Cluster Operator の ClusterRole により、イベントへのアクセスを Topic Operator に委譲できます。
4.1.8.5. ClusterRoleBindings
Operator には ClusterRoleBindings と、ClusterRole をServiceAccount に関連付ける RoleBindings が必要です。ClusterRoleBindings は、クラスタースコープリロースが含まれる ClusterRoles に必要です。
Cluster Operator の ClusterRoleBinding の例
ClusterRoleBindings は、委譲に必要な ClusterRoles にも必要です。
Cluster Operator の RoleBinding の例
namespaced リソースのみが含まれる ClusterRoles は、RoleBindings のみを使用してバインドされます。
4.2. Topic Operator
4.2.1. Topic Operator
Topic Operator は、OpenShift リソースより Kafka クラスターのトピックを管理する方法を提供します。
Topic Operator のアーキテクチャー例
Topic Operator の役割は、対応する Kafka トピックと同期して Kafka トピックを記述する KafkaTopic OpenShift リソースのセットを保持することです。
KafkaTopic とトピックの関係は次のとおりです。
-
KafkaTopicが作成されると、Topic Operator によってトピックが作成されます。 -
KafkaTopicが削除されると、Topic Operator によってトピックが削除されます。 -
KafkaTopicが変更されると、Topick Operator によってトピックが更新されます。
上記と逆になるトピックと KafkaTopic の関係は次のとおりです。
-
トピックが Kafka クラスター内で作成されると、Operator によって
KafkaTopicが作成されます。 -
トピックが Kafka クラスターから削除されると、Operator によって
KafkaTopicが削除されます。 -
トピックが Kafka クラスターで変更されると、Operator によって
KafkaTopicが更新されます。
このため、KafkaTopic をアプリケーションのデプロイメントの一部として宣言でき、トピックの作成は Topic Operator によって行われます。アプリケーションは、必要なトピックからの作成または消費のみに対処する必要があります。
トピックが再設定された場合や、別の Kafka ノードに再割り当てされた場合、KafkaTopic は常に最新の状態になります。
4.2.2. トピック処理用の Kafka クラスターの特定
KafkaTopic リソースには、このリソースが属する Kafka クラスターに適した名前 (Kafka リソースの名前から派生) を定義するラベルが含まれています。
ラベルは、KafkaTopic リソースを特定し、新しいトピックを作成するために、Topic Operator によって使用されます。また、以降のトピックの処理でも使用されます。
ラベルが Kafka クラスターと一致しない場合、Topic Operator は KafkaTopic を識別できず、トピックは作成されません。
4.2.3. Topic Operator について
Operator にとって解決しなければならない基本的な問題として、信頼できる唯一の情報源 (SSOT: single source of truth) がないことがあります。KafkaTopic リソースと Kafka 内のトピックの両方とも、Operator に関係なく変更される可能性があります面倒なことに、Topic Operator は KafkaTopic リソースと Kafka トピックで変更を常にリアルタイムで監視できるとは限りません (たとえば Operator が停止している場合もあります)。
これを解決するために、Operator は各トピックに関する情報の独自のプライベートコピーを維持します。Kafka クラスターまたは OpenShift で変更が生じると、他のシステムの状態とプライベートコピーの両方を確認し、すべての同期が保たれるように何を変更する必要があるかを判断します。同じことが Operator の起動時に必ず実行され、また Operator の稼働中にも定期的に行われます。
たとえば、Topic Operator が実行されていないときに KafkaTopic の my-topic が作成された場合を考えてみましょう。Operator は、起動時に「my-topic」のプライベートコピーを持たないので、Operator が前回稼働状態であった後に KafkaTopic が作成されたと推測できます。Operator によって「my-topic」に対応するトピックが作成され、さらに「my-topic」のメタデータのプライベートコピーが保存されます。
このプライベートコピーによって、Operator は、Kafka と OpenShift の両方でトピック設定が変更される場合に対処できますが、それができるのは変更に矛盾 (たとえば両方で同じトピックの config キーが異なる値に変更される場合など) がない場合に限ります。変更に矛盾がある場合、Kafka の設定が優先され、KafkaTopic はそれを反映する形で更新されます。
プライベートコピーは、Kafka が使用するのと同じ ZooKeeper アンサンブルに保持されます。これにより可用性の懸念が軽減されます。これは、ZooKeeper が実行中でなければ Kafka 自体を実行できないため、Operator がステートレスであっても可用性は下がらないからです。
4.2.4. Cluster Operator を使用した Topic Operator のデプロイ
この手順では、Cluster Operator を使用して Topic Operator をデプロイする方法を説明します。AMQ Streams によって管理されない Kafka クラスターを Topic Operator と使用する場合は、Topic Operator をスタンドアロンコンポーネントとしてデプロイする必要があります。詳細は「スタンドアロン Topic Operator のデプロイ」を参照してください。
前提条件
- 稼働中の Cluster Operator が必要です。
-
作成または更新する
Kafkaリソースが必要です。
手順
Kafka.spec.entityOperatorオブジェクトがKafkaリソースに存在することを確認します。このオブジェクトによって Entity Operator が設定されます。Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
「
EntityTopicOperatorSpecスキーマ参照」 で説明されたプロパティーを使用して、Topic Operator を設定します。 OpenShift で Kafka リソースを作成または更新します。
oc applyを使用します。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
- Entity Operator のデプロイメントに関する詳細は、「Entitiy Operator」 を参照してください。
-
Cluster Operator によってデプロイされた場合に Topic Operator の設定に使用される
Kafka.spec.entityOperatorオブジェクトに関する詳細は、「EntityOperatorSpecスキーマ参照」 を参照してください。
4.2.5. リソース要求および制限のある Topic Operator の設定
CPU やメモリーなどのリソースを Topic Operator に割り当て、Topic Operator が消費できるリソースの量に制限を設定できます。
前提条件
- Cluster Operator が稼働している必要があります。
手順
必要に応じてエディターで Kafka クラスター設定を更新します。
oc editを使用します。oc edit kafka my-cluster
oc edit kafka my-clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafkaリソースのspec.entityOperator.topicOperator.resourcesプロパティーで、Topic Operator のリソース要求および制限を設定します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 新しい設定を適用してリソースを作成または更新します。
oc applyを使用します。oc apply -f kafka.yaml
oc apply -f kafka.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
-
resourcesオブジェクトのスキーマの詳細は、「ResourceRequirementsスキーマ参照」 を参照してください。
4.2.6. スタンドアロン Topic Operator のデプロイ
Topic Operator をスタンドアロンコンポーネントとしてデプロイすることは、Cluster Operator を使用してインストールする場合よりも複雑ですが、柔軟性があります。たとえば、Cluster Operator によってデプロイされた Kafka クラスターに限らず、どの Kafka クラスターでも動作します。
前提条件
- Topic Operator が接続する既存の Kafka クラスターが必要です。
手順
install/topic-operator/05-Deployment-strimzi-topic-operator.yamlリソースを編集します。以下を変更する必要があります。-
Deployment.spec.template.spec.containers[0].envのSTRIMZI_KAFKA_BOOTSTRAP_SERVERS環境変数は、hostname:portペアのカンマ区切りのリストとして、Kafka クラスターのブートストラップブローカーのリストに設定する必要があります。 -
Deployment.spec.template.spec.containers[0].envのSTRIMZI_ZOOKEEPER_CONNECT環境変数は、hostname:portペアのカンマ区切りのリストとして、ZooKeeper ノードのリストに設定する必要があります。これは、Kafka クラスターが使用する ZooKeeper クラスターと同じである必要があります。 -
Deployment.spec.template.spec.containers[0].envのSTRIMZI_NAMESPACE環境変数は、Operator によってKafkaTopicリソースが監視される OpenShift namespace に設定する必要があります。
-
Topic Operator をデプロイします。
oc applyを使用してこれを行うことができます。oc apply -f install/topic-operator
oc apply -f install/topic-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow Topic Operator が正常にデプロイされていることを確認します。
oc describeを使用してこれを行うことができます。oc describe deployment strimzi-topic-operator
oc describe deployment strimzi-topic-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow Replicas:エントリーに1 availableが表示されれば、Topic Operator はデプロイされています。注記OpenShift への接続が低速な場合やイメージが事前にダウンロードされていない場合は、表示に時間がかかることがあります。
その他のリソース
- Topic Operator の設定に使用される環境変数の詳細は、「Topic Operator 環境」 を参照してください。
- Cluster Operator を使用して Topic Operator をデプロイする方法についての詳細は、「Cluster Operator を使用した Topic Operator のデプロイ」 を参照してください。
4.2.7. Topic Operator 環境
スタンドアロンでデプロイする場合、Topic Operator は環境変数を使用して設定できます。
Cluster Operator によってデプロイされる場合、Topic Operator は Kafka.spec.entityOperator.topicOperator プロパティーを使用して設定する必要があります。
STRIMZI_RESOURCE_LABELS-
ラベルセレクター。Operator によって管理される
KafkaTopicsの識別に使用します。 STRIMZI_ZOOKEEPER_SESSION_TIMEOUT_MS-
ZooKeeper セッションのタイムアウト (秒単位)。例:
10000デフォルトは20000(20 秒) です。 STRIMZI_KAFKA_BOOTSTRAP_SERVERS- Kafka ブートストラップサーバーのリスト。この変数は必須です。
STRIMZI_ZOOKEEPER_CONNECT- ZooKeeper 接続情報。この変数は必須です。
STRIMZI_FULL_RECONCILIATION_INTERVAL_MS- 定期的な調整の間隔 (秒単位)。
STRIMZI_TOPIC_METADATA_MAX_ATTEMPTS-
Kafka からトピックメタデータの取得を試行する回数。各試行の間隔は、指数バックオフとして定義されます。パーティションまたはレプリカの数によって、トピックの作成に時間がかかる可能性がある場合は、この値を増やすことを検討してください。デフォルトは
6です。 STRIMZI_TOPICS_PATH-
Zookeeper ノードパス。ここに Topic Operator がそのメタデータを保存します。デフォルトは
/strimzi/topicsです。 STRIMZI_LOG_LEVEL-
ロギングメッセージの出力レベル。設定可能な値:
ERROR、WARNING、INFO、DEBUG、およびTRACEデフォルトはINFOです。 STRIMZI_TLS_ENABLED-
Kafka ブローカーとの通信を暗号化するために、TLS サポートを有効にします。デフォルトは
trueです。 STRIMZI_TRUSTSTORE_LOCATION-
TLS ベースの通信を有効にするための証明書が含まれるトラストストアへのパス。この変数は、TLS が
STRIMZI_TLS_ENABLEDによって有効になっている場合のみ必須です。 STRIMZI_TRUSTSTORE_PASSWORD-
STRIMZI_TRUSTSTORE_LOCATIONで定義される、トラストストアにアクセスするためのパスワード。この変数は、TLS がSTRIMZI_TLS_ENABLEDによって有効になっている場合のみ必須です。 STRIMZI_KEYSTORE_LOCATION-
TLS ベースの通信を有効にするための秘密鍵が含まれるキーストアへのパス。この変数は、TLS が
STRIMZI_TLS_ENABLEDによって有効になっている場合のみ必須です。 STRIMZI_KEYSTORE_PASSWORD-
STRIMZI_KEYSTORE_LOCATIONで定義される、キーストアにアクセスするためのパスワード。この変数は、TLS がSTRIMZI_TLS_ENABLEDによって有効になっている場合のみ必須です。
4.3. User Operator
User Operator はカスタムリソースを使用して Kafka ユーザーを管理します。
4.3.1. User Operator
User Operator は、Kafka ユーザーが記述される KafkaUser リソースを監視して Kafka クラスターの Kafka ユーザーを管理し、Kafka ユーザーが Kafka クラスターで適切に設定されるようにします。
たとえば、KafkaUser とユーザーの関係は次のようになります。
-
KafkaUserが作成されると、User Operator によって記述されるユーザーが作成されます。 -
KafkaUserが削除されると、User Operator によって記述されるユーザーが削除されます。 -
KafkaUserが変更されると、User Operator によって記述されるユーザーが更新されます。
User Operator は Topic Operator とは異なり、Kafka クラスターからの変更は OpenShift リソースと同期されません。アプリケーションで直接 Kafka トピックを Kafka で作成することは可能ですが、ユーザーが User Operator と同時に直接 Kafka クラスターで管理されることは想定されません。
User Operator では、アプリケーションのデプロイメントの一部として KafkaUser リソースを宣言できます。ユーザーの認証および承認メカニズムを指定できます。たとえば、ユーザーがブローカーへのアクセスを独占しないようにするため、Kafka リソースの使用を制御する ユーザークォータ を設定することもできます。
ユーザーが作成されると、ユーザークレデンシャルが Secret に作成されます。アプリケーションはユーザーとそのクレデンシャルを使用して、認証やメッセージの生成または消費を行う必要があります。
User Operator は 認証のクレデンシャルを管理する他に、KafkaUser 宣言にユーザーのアクセス権限の記述を含めることで承認も管理します。
4.3.2. ユーザー処理用の Kafka クラスターの特定
KafkaUser リソースには、このリソースが属する Kafka クラスターに適した名前 (Kafka リソースの名前から派生) を定義するラベルが含まれています。
このラベルは、KafkaUser リソースを特定し、新しいユーザーを作成するために、User Operator によって使用されます。また、以降のユーザーの処理でも使用されます。
ラベルが Kafka クラスターと一致しない場合、User Operator は kafkaUser を識別できず、ユーザーは作成されません。
4.3.3. Cluster Operator を使用した User Operator のデプロイ
前提条件
- 稼働中の Cluster Operator が必要です。
-
作成または更新する
Kafkaリソースが必要です。
手順
-
Kafkaリソースを編集し、希望どおりに User Operator を設定するKafka.spec.entityOperator.userOperatorオブジェクトが含まれるようにします。 OpenShift で Kafka リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
-
Cluster Operator によってデプロイされた場合に Topic Operator の設定に使用される
Kafka.spec.entityOperatorオブジェクトに関する詳細は「EntityOperatorSpecスキーマ参照」を参照してください。
4.3.4. リソース要求および制限のある User Operator の設定
CPU やメモリーなどのリソースを User Operator に割り当て、User Operator が消費できるリソースの量に制限を設定できます。
前提条件
- Cluster Operator が稼働している必要があります。
手順
必要に応じてエディターで Kafka クラスター設定を更新します。
oc edit kafka my-cluster
oc edit kafka my-clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafkaリソースのspec.entityOperator.userOperator.resourcesプロパティーで、User Operator のリソース要求および制限を設定します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow ファイルを保存し、エディターを終了します。Cluster Operator によって変更が自動的に適用されます。
その他のリソース
-
resourcesオブジェクトのスキーマの詳細は、「ResourceRequirementsスキーマ参照」 を参照してください。
4.3.5. スタンドアロン User Operator のデプロイ
User Operator をスタンドアロンコンポーネントとしてデプロイすることは、Cluster Operator を使用してインストールする場合よりも複雑ですが、柔軟性があります。たとえば、Cluster Operator によってデプロイされた Kafka クラスターのみに限らず、どの Kafka クラスターでも動作します。
前提条件
- User Operator が接続する既存の Kafka クラスターが必要です。
手順
install/user-operator/05-Deployment-strimzi-user-operator.yamlリソースを編集します。以下を変更する必要があります。-
Deployment.spec.template.spec.containers[0].envのSTRIMZI_CA_CERT_NAME環境変数は、TLS クライアント認証に対して新しいユーザー証明書を署名するための認証局の公開鍵が含まれる OpenShiftSecretを参照するように設定する必要があります。Secretのca.crtキーには、認証局の公開鍵が含まれている必要があります。 -
Deployment.spec.template.spec.containers[0].envのSTRIMZI_CA_KEY_NAME環境変数は、TLS クライアント認証に対して新しいユーザー証明書を署名するための認証局の秘密鍵が含まれる OpenShiftSecretを参照するように設定する必要があります。Secretのca.keyキーに、認証局の秘密鍵が含まれている必要があります。 -
Deployment.spec.template.spec.containers[0].envのSTRIMZI_ZOOKEEPER_CONNECT環境変数は、hostname:portペアのカンマ区切りのリストとして、ZooKeeper ノードのリストに設定する必要があります。これは、Kafka クラスターが使用する ZooKeeper クラスターと同じである必要があります。 -
Deployment.spec.template.spec.containers[0].envのSTRIMZI_NAMESPACE環境変数は、Operator によってKafkaUserリソースが監視される OpenShift namespace に設定する必要があります。
-
User Operator をデプロイします。
oc applyを使用してこれを行うことができます。oc apply -f install/user-operator
oc apply -f install/user-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow User Operator が正常にデプロイされていることを確認します。
oc describeを使用してこれを行うことができます。oc describe deployment strimzi-user-operator
oc describe deployment strimzi-user-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow Replicas:エントリーに1 availableが表示されれば、User Operator はデプロイされています。注記OpenShift への接続が低速な場合やイメージが事前にダウンロードされていない場合は、表示に時間がかかることがあります。
その他のリソース
- Cluster Operator を使用して User Operator をデプロイする方法についての詳細は、「Cluster Operator を使用した User Operator のデプロイ」 を参照してください。
第5章 Topic Operator の使用
5.1. Topic Operator の使用に関する推奨事項
トピックを使用する場合は、一貫した方法で使用し、常に KafkaTopic リソースで操作するか、またはトピックで直接操作します。特定のトピックで、両方の方法を頻繁に切り替えないでください。
トピックの性質を反映するトピック名を使用し、後で名前を変更できないことに注意してください。
Kafka でトピックを作成する場合は、有効な OpenShift リソース名である名前を使用します。それ以外の場合は、Topic Operator は対応する KafkaTopic を OpenShift ルールに準じた名前で作成する必要があります。
OpenShift の識別子および名前の推奨事項については、OpenShift コミュニティーの記事「Identifiers and Names」を参照してください。
Kafka トピックの命名規則
Kafka と OpenShift では、Kafka と KafkaTopic.metadata.name でのトピックの命名にそれぞれ独自の検証ルールを適用します。トピックごとに有効な名前があり、他のトピックには無効です。
spec.topicName プロパティーを使用すると、OpenShift の Kafka トピックでは無効な名前を使用して、Kafka で有効なトピックを作成できます。
spec.topicName プロパティーは Kafka の命名検証ルールを継承します。
- 249 文字を超える名前は使用できません。
-
Kafka トピックの有効な文字は ASCII 英数字、
.、_、および-です。 -
名前を
.または..にすることはできませんが、.はexampleTopic.や.exampleTopicのように名前で使用できます。
spec.topicName は変更しないでください。
以下に例を示します。
上記は下記のように変更できません
Kafka Streams など一部の Kafka クライアントアプリケーションは、プログラムを使用して Kafka でトピックを作成できます。これらのトピックに、OpenShift リソース名としては無効な名前が付いている場合、Topic Operator はそれらのトピックに Kafka 名に基づく有効な名前を付けます。無効な文字が置き換えられ、ハッシュが名前に追加されます。
5.2. トピックの作成
この手順では、KafkaTopic OpenShift リソースを使用して Kafka トピックを作成する方法を説明します。
前提条件
- 稼働中の Kafka クラスターが必要です。
- 稼働中の Topic Operator が必要です (通常は Entity Operator を使用してデプロイされます) 。
手順
作成する
KafkaTopicが含まれるファイルを準備します。KafkaTopicの例Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記KafkaTopic.spec.topicNameプロパティーの設定が必要ないため、トピック名を有効な OpenShift リソース名にすることが推奨されます。KafkaTopic.spec.topicNameは作成後に変更することはできません。注記KafkaTopic.spec.partitionsを減らすことはできません。OpenShift で
KafkaTopicリソースを作成します。oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
-
KafkaTopicsのスキーマに関する詳細は、「KafkaTopicスキーマ参照」を参照してください。 - Cluster Operator を使用した Kafka クラスターのデプロイメントに関する詳細は、「Cluster Operator」を参照してください。
- Cluster Operator を使用した Topic Operator のデプロイメントに関する詳細は、「Cluster Operator を使用した Topic Operator のデプロイ」を参照してください。
- スタンドアロン Topic Operator のデプロイメントに関する詳細は、「スタンドアロン Topic Operator のデプロイ」を参照してください。
5.3. トピックの変更
この手順は、KafkaTopic OpenShift リソースを使用して、既存の Kafka トピックの設定を変更する方法を説明します。
前提条件
- 稼働中の Kafka クラスターが必要です。
- 稼働中の Topic Operator が必要です (通常は Entity Operator でデプロイされます)。
-
変更する既存の
KafkaTopic。
手順
必要な
KafkaTopicが含まれるファイルを準備します。KafkaTopicの例Copy to Clipboard Copied! Toggle word wrap Toggle overflow ヒントoc get kafkatopic orders -o yamlを使用すると、現行バージョンのリソースを取得できます。注記KafkaTopic.spec.topicName変数を使用したトピック名の変更、およびKafkaTopic.spec.partitions変数を使用したパーティションサイズの縮小は、Kafka ではサポートされていません。Importantキーのあるトピックの
spec.partitionsを増やすと、レコードをパーティション化する方法が変更されます。これは、トピックがセマンティックパーティションを使用するとき、特に問題になる場合があります。OpenShift で
KafkaTopicリソースを更新します。oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
-
KafkaTopicsのスキーマに関する詳細は、「KafkaTopicスキーマ参照」を参照してください。 - Kafka クラスターのデプロイメントに関する詳細は、「Cluster Operator」を参照してください。
- Cluster Operator を使用した Topic Operator のデプロイメントに関する詳細は、「Cluster Operator を使用した Topic Operator のデプロイ」を参照してください。
- Topic Operator を使用したトピックの作成に関する詳細は、「トピックの作成」を参照してください。
5.4. トピックの削除
この手順では、KafkaTopic OpenShift リソースを使用して Kafka トピックを削除する方法を説明します。
前提条件
- 稼働中の Kafka クラスターが必要です。
- 稼働中の Topic Operator が必要です (通常は Entity Operator でデプロイされます)。
-
削除する既存の
KafkaTopic。 -
delete.topic.enable=true(デフォルト)
delete.topic.enable プロパティーは、Kafka.spec.kafka.config で true に設定する必要があります。それ以外の場合は、ここで説明した手順によって KafkaTopic リソースが削除されますが、Kafka トピックとそのデータは保持されます。Topic Operator による調整後、カスタムリソースが再作成されます。
手順
OpenShift で
KafkaTopicリソースを削除します。oc deleteを使用してこれを行うことができます。oc delete kafkatopic your-topic-name
oc delete kafkatopic your-topic-nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
- Cluster Operator を使用した Kafka クラスターのデプロイメントに関する詳細は、「Cluster Operator」を参照してください。
- Cluster Operator を使用した Topic Operator のデプロイメントに関する詳細は、「Cluster Operator を使用した Topic Operator のデプロイ」を参照してください。
- Topic Operator を使用したトピックの作成に関する詳細は、「トピックの作成」を参照してください。
第6章 User Operator の使用
User Operator は、OpenShift リソースより Kafka ユーザーを管理する方法を提供します。
6.1. User Operator
User Operator は、Kafka ユーザーが記述される KafkaUser リソースを監視して Kafka クラスターの Kafka ユーザーを管理し、Kafka ユーザーが Kafka クラスターで適切に設定されるようにします。
たとえば、KafkaUser とユーザーの関係は次のようになります。
-
KafkaUserが作成されると、User Operator によって記述されるユーザーが作成されます。 -
KafkaUserが削除されると、User Operator によって記述されるユーザーが削除されます。 -
KafkaUserが変更されると、User Operator によって記述されるユーザーが更新されます。
User Operator は Topic Operator とは異なり、Kafka クラスターからの変更は OpenShift リソースと同期されません。アプリケーションで直接 Kafka トピックを Kafka で作成することは可能ですが、ユーザーが User Operator と同時に直接 Kafka クラスターで管理されることは想定されません。
User Operator では、アプリケーションのデプロイメントの一部として KafkaUser リソースを宣言できます。ユーザーの認証および承認メカニズムを指定できます。たとえば、ユーザーがブローカーへのアクセスを独占しないようにするため、Kafka リソースの使用を制御する ユーザークォータ を設定することもできます。
ユーザーが作成されると、ユーザークレデンシャルが Secret に作成されます。アプリケーションはユーザーとそのクレデンシャルを使用して、認証やメッセージの生成または消費を行う必要があります。
User Operator は 認証のクレデンシャルを管理する他に、KafkaUser 宣言にユーザーのアクセス権限の記述を含めることで承認も管理します。
6.2. 相互 TLS 認証
相互 TLS 認証は、Kafka ブローカーと ZooKeeper Pod 間の通信で常に使用されます。
相互認証または双方向認証は、サーバーとクライアントの両方が証明書を提示するときに使用されます。AMQ Streams では、Kafka が TLS (Transport Layer Security) を使用して、相互認証の有無を問わず、Kafka ブローカーとクライアントとの間で暗号化された通信が行われるよう設定できます。相互認証を設定する場合、ブローカーによってクライアントが認証され、クライアントによってブローカーが認証されます。
TLS 認証は一般的には一方向で、一方が他方のアイデンティティーを認証します。たとえば、Web ブラウザーと Web サーバーの間で HTTPS が使用される場合、サーバーはブラウザーのアイデンティティーの証明を取得します。
6.2.1. クライアントに相互 TLS 認証を使用する場合
以下の場合、Kafka クライアントの認証に相互 TLS 認証が推奨されます。
- 相互 TLS 認証を使用した認証がクライアントでサポートされる場合。
- パスワードの代わりに TLS 証明書を使用する必要がある場合。
- 期限切れの証明書を使用しないように、クライアントアプリケーションを定期的に再設定および再起動できる場合。
6.3. 相互 TLS 認証を使用した Kafka ユーザーの作成
前提条件
- TLS 認証を使用してリスナーで設定された稼働中の Kafka クラスターが必要です。
- 稼働中の User Operator (通常は Entity Operator でデプロイされる) が必要です。
手順
作成する
KafkaUserが含まれる YAML ファイルを準備します。KafkaUserの例Copy to Clipboard Copied! Toggle word wrap Toggle overflow OpenShift で
KafkaUserリソースを作成します。oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
アプリケーションで、
my-userシークレットからのクレデンシャルを使用します。
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
- TLS を使用して認証するリスナーの設定に関する詳細は、「Kafka ブローカーリスナー」を参照してください。
- Entity Operator のデプロイメントに関する詳細は、「Entitiy Operator」 を参照してください。
-
KafkaUserオブジェクトの詳細は、「KafkaUserスキーマ参照」を参照してください。
6.4. SCRAM-SHA 認証
SCRAM (Salted Challenge Response Authentication Mechanism) は、パスワードを使用して相互認証を確立できる認証プロトコルです。AMQ Streams では、Kafka が SASL (Simple Authentication and Security Layer) SCRAM-SHA-512 を使用するよう設定し、暗号化されていないクライアントの接続と TLS で暗号化されたクライアントの接続の両方で認証を提供できます。TLS 認証は、Kafka ブローカーと ZooKeeper ノードの間で常に内部で使用されます。TLS クライアント接続で TLS プロトコルを使用すると、接続が暗号化されますが、認証には使用されません。
SCRAM の以下のプロパティーは、暗号化されていない接続でも SCRAM-SHA を安全に使用できるようにします。
- 通信チャネル上では、パスワードはクリアテキストで送信されません。代わりに、クライアントとサーバーはお互いにチャレンジを生成し、認証するユーザーのパスワードを認識していることを証明します。
- サーバーとクライアントは、認証を交換するたびに新しいチャレンジを生成します。よって、交換はリレー攻撃に対して回復性を備えています。
6.4.1. サポートされる SCRAM クレデンシャル
AMQ Streams では SCRAM-SHA-512 のみがサポートされます。KafkaUser.spec.authentication.type を scram-sha-512 に設定すると、User Operator によって、大文字と小文字の ASCII 文字と数字で構成された無作為の 12 文字のパスワードが生成されます。
6.4.2. クライアントに SCRAM-SHA 認証を使用する場合
以下の場合、Kafka クライアントの認証に SCRAM-SHA が推奨されます。
- SCRAM-SHA-512 を使用した認証がクライアントでサポートされる場合。
- TLS 証明書の代わりにパスワードを使用する必要がある場合。
- 暗号化されていない通信に認証が必要な場合。
6.5. SCRAM SHA 認証を使用した Kafka ユーザーの作成
前提条件
- SCRAM SHA 認証を使用してリスナーで設定された稼働中の Kafka クラスターが必要です。
- 稼働中の User Operator (通常は Entity Operator でデプロイされる) が必要です。
手順
作成する
KafkaUserが含まれる YAML ファイルを準備します。KafkaUserの例Copy to Clipboard Copied! Toggle word wrap Toggle overflow OpenShift で
KafkaUserリソースを作成します。oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
アプリケーションで、
my-userシークレットからのクレデンシャルを使用します。
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
- SCRAM SHA を使用して認証するリスナーの設定に関する詳細は、「Kafka ブローカーリスナー」を参照してください。
- Entity Operator のデプロイメントに関する詳細は、「Entitiy Operator」 を参照してください。
-
KafkaUserオブジェクトの詳細は、「KafkaUserスキーマ参照」を参照してください。
6.6. Kafka ユーザーの編集
この手順では、KafkaUser OpenShift リソースを使用して既存の Kafka ユーザーの設定を変更する方法を説明します。
前提条件
- 稼働中の Kafka クラスターが必要です。
- 稼働中の User Operator (通常は Entity Operator でデプロイされる) が必要です。
-
変更する既存の
KafkaUser。
手順
必要な
KafkaUserが含まれる YAML ファイルを準備します。KafkaUserの例Copy to Clipboard Copied! Toggle word wrap Toggle overflow OpenShift で
KafkaUserリソースを更新します。oc applyを使用してこれを行うことができます。oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
my-userシークレットからの更新済みのクレデンシャルをアプリケーションで使用します。
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
- Entity Operator のデプロイメントに関する詳細は、「Entitiy Operator」 を参照してください。
-
KafkaUserオブジェクトの詳細は、「KafkaUserスキーマ参照」を参照してください。
6.7. Kafka ユーザーの削除
この手順では、KafkaUser OpenShift リソースで作成した Kafka ユーザーを削除する方法を説明します。
前提条件
- 稼働中の Kafka クラスターが必要です。
- 稼働中の User Operator (通常は Entity Operator でデプロイされる) が必要です。
-
削除する既存の
KafkaUser。
手順
OpenShift で
KafkaUserリソースを削除します。oc deleteを使用してこれを行うことができます。oc delete kafkauser your-user-name
oc delete kafkauser your-user-nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
-
KafkaUserオブジェクトの詳細は、「KafkaUserスキーマ参照」を参照してください。
6.8. Kafka User リソース
KafkaUser リソースを使用して、ユーザーの認証メカニズム、承認メカニズム、およびアクセス権限を設定します。
KafkaUser の完全なスキーマは、「KafkaUser スキーマ参照」で確認できます。
6.8.1. 認証
認証は、KafkaUser.spec の authentication プロパティーを使用して設定されます。ユーザーに有効な認証メカニズムは、type フィールドを使用して指定されます。現在、サポートされる唯一の認証メカニズムは、TLS クライアント認証メカニズムと SCRAM-SHA-512 メカニズムです。
認証メカニズムを指定しないと、User Operator によってユーザーまたはそのクレデンシャルが作成されません。
その他のリソース
6.8.1.1. TLS クライアント認証
TLS クライアント認証を使用するには、type フィールドを tls に設定します。
TLS クライアント認証が有効になっている KafkaUser の例
ユーザーが User Operator によって作成されると、User Operator は KafkaUser リソースと同じ名前で新規シークレットを作成します。シークレットには、TLS クライアント認証に使用する必要のある公開鍵および秘密鍵が含まれます。ユーザー証明書の署名に使用されたクライアント認証局の公開キーがバンドルされます。すべてのキーは X509 形式になります。
ユーザークレデンシャルのある Secret の例
6.8.1.2. SCRAM-SHA-512 認証
SCRAM-SHA-512 認証メカニズムを使用するには、type フィールドを scram-sha-512 に設定します。
SCRAM-SHA-512 認証が有効になっている KafkaUser の例
ユーザーが User Operator によって作成されると、User Operator は KafkaUser リソースと同じ名前で新規シークレットを作成します。シークレットの password キーには、生成されたパスワードが含まれ、base64 でエンコードされます。パスワードを使用するにはデコードする必要があります。
ユーザークレデンシャルのある Secret の例
生成されたパスワードは次のようにデコードします。
echo "Z2VuZXJhdGVkcGFzc3dvcmQ=" | base64 --decode
echo "Z2VuZXJhdGVkcGFzc3dvcmQ=" | base64 --decode6.8.2. 承認
簡易承認は、KafkaUser.spec の authorization プロパティーを使用して設定されます。ユーザーに有効な承認タイプは、type フィールドを使用して指定します。
承認が指定されていない場合は、User Operator によるユーザーのアクセス権限のプロビジョニングは行われません。
さらに、OAuth 2.0 トークンベースの認証を使用している場合、OAuth 2.0 承認を設定する こともできます。
6.8.2.1. 簡易承認
簡易承認では、デフォルトの Kafka 承認プラグインである SimpleAclAuthorizer が使用されます。
簡易承認を使用するには、KafkaUser.spec で type プロパティーを simple に設定します。
ACL ルール
SimpleAclAuthorizer は、ACL ルールを使用して Kafka ブローカーへのアクセスを管理します。
ACL ルールによって、acls プロパティーで指定したユーザーにアクセス権限が付与されます。
AclRule はプロパティーのセットとして指定されます。
resourceresourceプロパティーで、ルールが適用されるリソースを指定します。簡易承認は、
typeプロパティーに指定される、以下の 4 つのリソースタイプをサポートします。-
トピック (
topic) -
コンシューマーグループ (
group) -
クラスター (
cluster) -
トランザクション ID (
transactionalId)
Topic、Group、および Transactional ID リソースでは、
nameプロパティーでルールが適用されるリソースの名前を指定できます。クラスタータイプのリソースには名前がありません。
名前は、
patternTypeプロパティーを使用してliteralまたはprefixとして指定されます。-
リテラル (literal) 名には、
nameフィールドに指定された名前がそのまま使われます。 -
接頭辞 (prefix) 名には、
nameからの値が接頭辞として使用され、その値で始まる名前を持つすべてのリソースにルールが適用されます。
-
トピック (
typetypeプロパティーは ACL ルールのタイプであるallowまたはdenyを指定します。typeフィールドの設定は任意です。typeの指定がない場合、ACL ルールはallowルールとして処理されます。operationoperationは、許可または拒否する操作を指定します。以下の操作がサポートされます。
- Read
- Write
- Delete
- Alter
- Describe
- All
- IdempotentWrite
- ClusterAction
- Create
- AlterConfigs
- DescribeConfigs
特定の操作のみが各リソースで機能します。
SimpleAclAuthorizer、ACL、およびサポートされるリソースと操作の組み合わせの詳細は、「Authorization and ACL」 を参照してください。hosthostプロパティーは、ルールを許可または拒否するリモートホストを指定します。アスタリスク (
*) を使用して、すべてのホストからの操作を許可または拒否します。hostフィールドの設定は任意です。hostを指定しないと、値*がデフォルトで使用されます。
AclRule オブジェクトの詳細は、「AclRule スキーマ参照」を参照してください。
承認をともなう KafkaUser の例
6.8.2.2. Kafka ブローカーへのスーパーユーザーアクセス
ユーザーを Kafka ブローカー設定のスーパーユーザーのリストに追加すると、ACL で定義された承認制約に関係なく、そのユーザーにはクラスターへのアクセスが無制限に許可されます。
スーパーユーザーの設定に関する詳細は、Kafka ブローカーの「認証および承認」を参照してください。
6.8.3. ユーザークォータ
KafkaUser リソースの spec を設定してクォータを強制し、バイトしきい値または CPU 使用の時間制限に基づいてユーザーが Kafka ブローカーへのアクセスを超過しないようにすることができます。
ユーザークォータをともなう KafkaUser の例
これらのプロパティーの詳細は、「KafkaUserQuotas スキーマ参照」を参照してください。
第7章 Kafka Bridge
本章では、AMQ Streams Kafka Bridge について概説し、その REST API を使用して AMQ Streams と対話するために役立つ情報を提供します。ローカル環境で Kafka Bridge を試すには、本章で後述する「Kafka Bridge クイックスタート」を参照してください。
7.1. Kafka Bridge の概要
Kafka Bridge をインターフェースとして使用し、Kafka クラスターに対して特定タイプのリクエストを行うことができます。
7.1.1. Kafka Bridge インターフェース
AMQ Streams Kafka Bridge では、HTTP ベースのクライアントと Kafka クラスターとの対話を可能にする RESTful インターフェースが提供されます。 Kafka Bridge では、クライアントアプリケーションによる Kafka プロトコルの変換は必要なく、Web API コネクションの利点が AMQ Streams に提供されます。
API には consumers と topics の 2 つの主なリソースがあります。これらのリソースは、Kafka クラスターでコンシューマーおよびプロデューサーと対話するためにエンドポイント経由で公開され、アクセスが可能になります。リソースと関係があるのは Kafka ブリッジのみで、Kafka に直接接続されたコンシューマーやプロデューサーとは関係はありません。
7.1.1.1. HTTP リクエスト
Kafka Bridge は、以下の方法で Kafka クラスターへの HTTP リクエストをサポートします。
- トピックにメッセージを送信する。
- トピックからメッセージを取得する。
- コンシューマーを作成および削除する。
- コンシューマーをトピックにサブスクライブし、このようなトピックからメッセージを受信できるようにする。
- コンシューマーがサブスクライブしているトピックの一覧を取得する。
- トピックからコンシューマーのサブスクライブを解除する。
- パーティションをコンシューマーに割り当てる。
- コンシューマーオフセットの一覧をコミットする。
- パーティションで検索して、コンシューマーが最初または最後のオフセットの位置、または指定のオフセットの位置からメッセージを受信できるようにする。
上記の方法で、JSON 応答と HTTP 応答コードのエラー処理を行います。メッセージは JSON またはバイナリー形式で送信できます。
クライアントは、ネイティブの Kafka プロトコルを使用する必要なくメッセージを生成して使用できます。
その他のリソース
- リクエストおよび応答の例など、API ドキュメントを確認するには、Strimzi Web サイトの「https://strimzi.io/docs/bridge/latest/」を参照してください。
7.1.2. Kafka Bridge でサポートされるクライアント
Kafka Bridge を使用して、内部および外部の HTTP クライアントアプリケーションの両方を Kafka クラスターに統合できます。
- 内部クライアント
-
内部クライアントとは、Kafka Bridge 自体と同じ OpenShift クラスターで実行されるコンテナーベースの HTTP クライアントのことです。内部クライアントは、ホストの Kafka Bridge および
KafkaBridgeのカスタムリソースで定義されたポートにアクセスできます。 - 外部クライアント
- 外部クライアントとは、Kafka Bridge がデプロイおよび実行される OpenShift クラスター外部で実行される HTTP クライアントのことです。外部クライアントは、OpenShift Route、ロードバランサーサービス、または Ingress を使用して Kafka Bridge にアクセスできます。
HTTP 内部および外部クライアントの統合
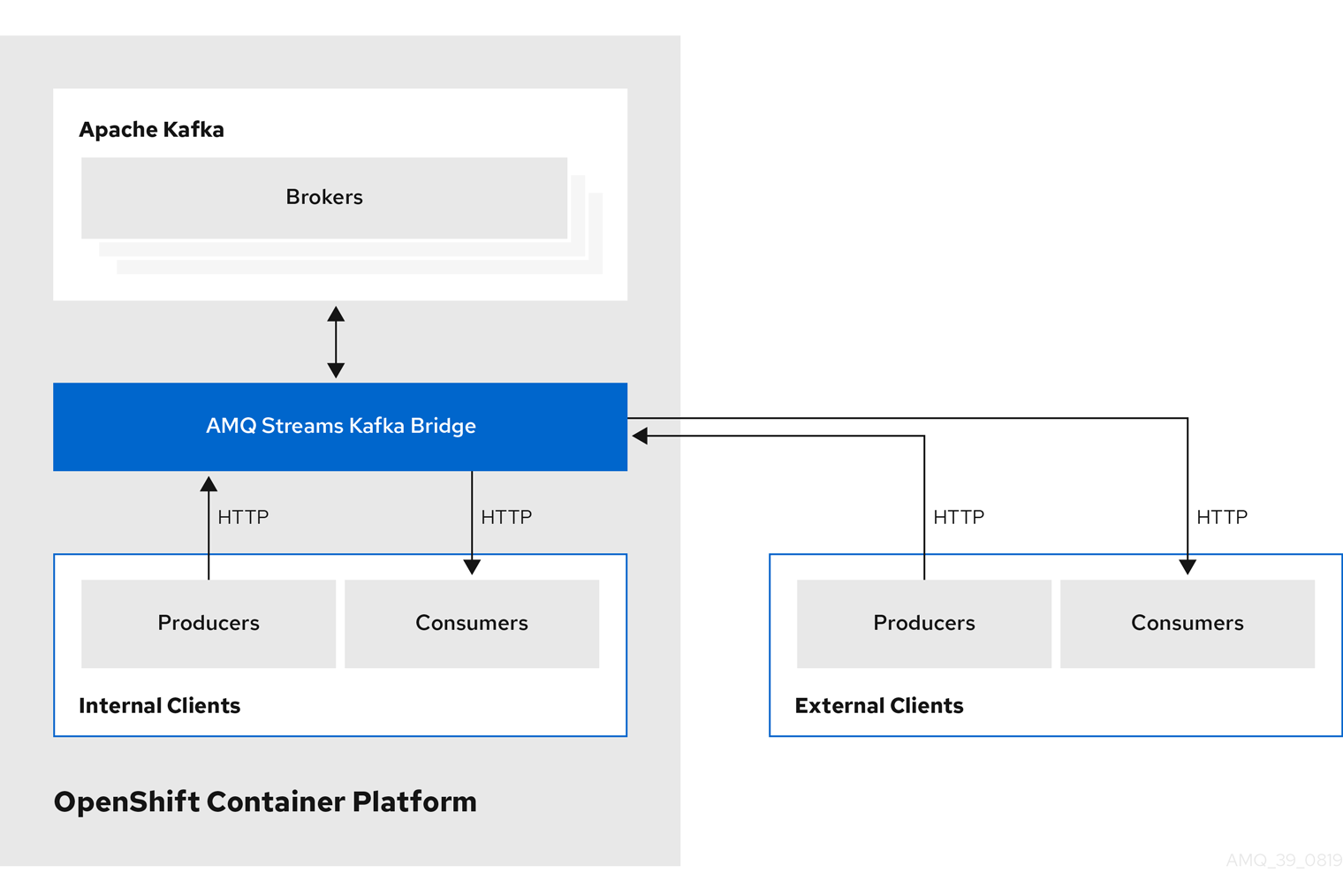
7.1.3. Kafka Bridge のセキュリティー保護
AMQ Streams には、現在 Kafka Bridge の暗号化、認証、または承認は含まれていません。そのため、外部クライアントから Kafka Bridge に送信されるリクエストは以下のようになります。
- 暗号化されず、HTTPS ではなく HTTP を使用する必要がある。
- 認証なしで送信される。
ただし、以下のような他の方法で Kafka Bridge をセキュアにできます。
- Kafka Bridge にアクセスできる Pod を定義する OpenShift ネットワークポリシー。
- 認証または承認によるリバースプロキシー (例: OAuth2 プロキシー)。
- API ゲートウェイ。
- TLS 終端をともなう Ingress または OpenShift ルート。
Kafka Bridge では、Kafka Broker への接続時に TLS 暗号化と、TLS および SASL 認証がサポートされます。OpenShift クラスター内で以下を設定できます。
- Kafka Bridge と Kafka クラスター間の TLS または SASL ベースの認証。
- Kafka Bridge と Kafka クラスター間の TLS 暗号化接続。
詳細は 「Kafka Bridge での認証サポート」 を参照してください。
Kafka ブローカーで ACL を使用することで、Kafka Bridge を使用して消費および生成できるトピックを制限することができます。
7.1.4. OpenShift 外部の Kafka Bridge へのアクセス
デプロイメント後、AMQ Streams Kafka Bridge には同じ OpenShift クラスターで実行しているアプリケーションのみがアクセスできます。これらのアプリケーションは、kafka-bridge-name-bridge-service サービスを使用して API にアクセスします。
OpenShift クラスター外部で実行しているアプリケーションに Kafka Bridge がアクセスできるようにする場合は、以下の機能のいずれかを使用して Kafka Bridge を手動で公開できます。
- LoadBalancer または NodePort タイプのサービス
- Ingress リソース
- OpenShift ルート
サービスを作成する場合には、selector で以下のラベルを使用して、サービスがトラフィックをルーティングする Pod を設定します。
# ...
selector:
strimzi.io/cluster: kafka-bridge-name
strimzi.io/kind: KafkaBridge
#...
# ...
selector:
strimzi.io/cluster: kafka-bridge-name
strimzi.io/kind: KafkaBridge
#...- 1
- OpenShift クラスターでの Kafka Bridge カスタムリソースの名前。
7.1.5. Kafka Bridge へのリクエスト
データ形式と HTTP ヘッダーを指定し、有効なリクエストが Kafka Bridge に送信されるようにします。
7.1.5.1. コンテンツタイプヘッダー
API リクエストおよびレスポンス本文は、常に JSON としてエンコードされます。
コンシューマー操作の実行時に、
POSTリクエストの本文が空でない場合は、以下のContent-Typeヘッダーが含まれている必要があります。Content-Type: application/vnd.kafka.v2+json
Content-Type: application/vnd.kafka.v2+jsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow プロデューサー操作の実行時に、
POSTリクエストは、以下の表のように、jsonまたはbinaryのいずれかの 埋め込みデータ形式 を指定するContent-Typeヘッダーが含まれている必要があります。Expand 埋め込みデータ形式 Content-Type ヘッダー JSON
Content-Type: application/vnd.kafka.json.v2+jsonバイナリー
Content-Type: application/vnd.kafka.binary.v2+json
consumers/groupid エンドポイントを使用してコンシューマーを作成するときに、埋め込みデータ形式を設定します。詳細は、次のセクションを参照してください。
POST リクエストに空の本文がある場合は、Content-Type を設定しないでください。空の本文を使用して、デフォルト値のコンシューマーを作成できます。
7.1.5.2. 埋め込みデータ形式
埋め込みデータ形式は、Kafka メッセージが Kafka Bridge によりプロデューサーからコンシューマーに HTTP で送信される際の形式です。サポートされる埋め込みデータ形式には、JSON とバイナリーの 2 種類があります。
/consumers/groupid エンドポイントを使用してコンシューマーを作成する場合、POST リクエスト本文で JSON またはバイナリーいずれかの埋め込みデータ形式を指定する必要があります。これは、以下の例のように format フィールドで指定します。
{
"name": "my-consumer",
"format": "binary",
...
}
{
"name": "my-consumer",
"format": "binary",
...
}- 1
- バイナリー埋め込みデータ形式。
コンシューマーの作成時に指定する埋め込みデータ形式は、コンシューマーが消費する Kafka メッセージのデータ形式と一致する必要があります。
バイナリー埋め込みデータ形式を指定する場合は、以降のプロデューサーリクエストで、リクエスト本文にバイナリーデータが Base64 でエンコードされた文字列として含まれる必要があります。たとえば、/topics/topicname エンドポイントを使用してメッセージを送信する場合は、records.value を Base64 でエンコードする必要があります。
プロデューサーリクエストには、埋め込みデータ形式に対応する Content-Type ヘッダーも含まれる必要があります (例: Content-Type: application/vnd.kafka.binary.v2+json)。
7.1.5.3. Accept ヘッダー
コンシューマーを作成したら、以降のすべての GET リクエストには Accept ヘッダーが以下のような形式で含まれる必要があります。
Accept: application/vnd.kafka.embedded-data-format.v2+json
Accept: application/vnd.kafka.embedded-data-format.v2+json
embedded-data-format は、json または binary のどちらかです。
たとえば、サブスクライブされたコンシューマーのレコードを JSON 埋め込みデータ形式で取得する場合、この Accept ヘッダーが含まれるようにします。
Accept: application/vnd.kafka.json.v2+json
Accept: application/vnd.kafka.json.v2+json7.1.6. Kafka Bridge API リソース
リクエストやレスポンスの例などを含む REST API エンドポイントおよび説明の完全リストは、Strimzi の Web サイト https://strimzi.io/docs/bridge/latest/ を参照してください。
7.1.7. Kafka Bridge デプロイメント
Cluster Operator を使用して、Kafka Bridge を OpenShift クラスターにデプロイします。
Kafka Bridge をデプロイすると、Cluster Operator により OpenShift クラスターに Kafka Bridge オブジェクトが作成されます。オブジェクトには、デプロイメント、サービス、および Pod が含まれ、それぞれ Kafka Bridge のカスタムリソースに付与された名前が付けられます。
その他のリソース
- デプロイメントの手順は、「Kafka Bridge を OpenShift クラスターへデプロイ」を参照してください。
- Kafka Bridge の設定に関する詳細は、「Kafka Bridge の設定」を参照してください。
-
KafkaBridgeリソースのホストおよびポートの設定に関する詳細は、「Kafka Bridge HTTP の設定」を参照してください。 - 外部クライアントの統合に関する詳細は、「OpenShift 外部の Kafka Bridge へのアクセス」を参照してください。
7.2. Kafka Bridge クイックスタート
このクイックスタートを使用して、ローカルの開発環境で AMQ Streams の Kafka Bridge を試すことができます。以下の方法について説明します。
- OpenShift クラスターに Kafka Bridge をデプロイする。
- ポート転送を使用して Kafka Bridge サービスをローカルマシンに公開する。
- Kafka クラスターのトピックおよびパーティションへのメッセージを生成する。
- Kafka Bridge コンシューマーを作成する。
- 基本的なコンシューマー操作を実行する (たとえば、コンシューマーをトピックにサブスクライブする、生成したメッセージを取得するなど)。
このクイックスタートでは、HTTP リクエストはターミナルにコピーおよび貼り付けできる curl コマンドを使用します。OpenShift クラスターへのアクセスが必要になります。ローカルの OpenShift クラスターを実行および管理するには、Minikube、CodeReady Containers、または MiniShift などのツールを使用します。
前提条件を確認し、本章に指定されている順序でタスクを行うようにしてください。
データ形式について
このクイックスタートでは、バイナリーではなく JSON 形式でメッセージを生成および消費します。リクエスト例で使用されるデータ形式および HTTP ヘッダーの詳細は、「Kafka Bridge へのリクエスト」を参照してください。
クイックスタートの前提条件
- ローカルまたはリモート OpenShift クラスターにアクセスできるクラスター管理者権限が必要です。
- AMQ Streams がインストールされている必要があります。
- Cluster Operator によってデプロイされた稼働中の Kafka クラスターが OpenShift namespace に必要です。
- Entity Operator がデプロイされ、Kafka クラスターの一部として稼働している必要があります。
7.2.1. OpenShift クラスターへの Kafka Bridge のデプロイメント
AMQ Streams には、AMQ Streams Kafka Bridge の設定を指定する YAML サンプルが含まれています。このファイルに最小限の変更を加え、Kafka Bridge のインスタンスを OpenShift クラスターにデプロイします。
手順
examples/kafka-bridge/kafka-bridge.yamlファイルを編集します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka Bridge を OpenShift クラスターにデプロイします。
oc apply -f examples/kafka-bridge/kafka-bridge.yaml
oc apply -f examples/kafka-bridge/kafka-bridge.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow quickstart-bridgeデプロイメント、サービス、および他の関連リソースが OpenShift クラスターに作成されます。Kafka Bridge が正常にデプロイされたことを確認します。
oc get deployments
oc get deploymentsCopy to Clipboard Copied! Toggle word wrap Toggle overflow NAME READY UP-TO-DATE AVAILABLE AGE quickstart-bridge 1/1 1 1 34m my-cluster-connect 1/1 1 1 24h my-cluster-entity-operator 1/1 1 1 24h #...
NAME READY UP-TO-DATE AVAILABLE AGE quickstart-bridge 1/1 1 1 34m my-cluster-connect 1/1 1 1 24h my-cluster-entity-operator 1/1 1 1 24h #...Copy to Clipboard Copied! Toggle word wrap Toggle overflow
次のステップ
Kafka Bridge を OpenShift クラスターにデプロイしたら、Kafka Bridge サービスをローカルマシンに公開します。
その他のリソース
- Kafka Bridge の設定に関する詳細は、「Kafka Bridge の設定」を参照してください。
7.2.2. Kafka Bridge サービスのローカルマシンへの公開
次に、ポート転送を使用して AMQ Streams の Kafka Bridge サービスを http://localhost:8080 上でローカルマシンに公開します。
ポート転送は、開発およびテストの目的でのみ適切です。
手順
OpenShift クラスターの Pod の名前をリストします。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow ポート
8080でquickstart-bridgePod に接続します。oc port-forward pod/quickstart-bridge-589d78784d-9jcnr 8080:8080 &
oc port-forward pod/quickstart-bridge-589d78784d-9jcnr 8080:8080 &Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記ローカルマシンのポート 8080 がすでに使用中の場合は、代わりの HTTP ポート (
8008など) を使用します。
これで、API リクエストがローカルマシンのポート 8080 から Kafka Bridge Pod のポート 8080 に転送されるようになります。
7.2.3. トピックおよびパーティションへのメッセージの作成
次に、topics エンドポイントを使用して、トピックへのメッセージを JSON 形式で生成します。以下に示すように、メッセージの宛先パーティションをリクエスト本文に指定できます。partitions エンドポイントは、全メッセージの単一の宛先パーティションをパスパラメーターとして指定する代替方法を提供します。
手順
テキストエディターを使用して、3 つのパーティションがある Kafka トピックの YAML 定義を作成します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
ファイルを
bridge-quickstart-topic.yamlとしてexamples/topicディレクトリーに保存します。 OpenShift クラスターにトピックを作成します。
oc apply -f examples/topic/bridge-quickstart-topic.yaml
oc apply -f examples/topic/bridge-quickstart-topic.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka Bridge を使用して、作成したトピックに 3 つのメッセージを生成します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
sales-lead-0001は、キーのハッシュに基づいてパーティションに送信されます。 -
sales-lead-0002は、パーティション 2 に直接送信されます。 -
sales-lead-0003は、ラウンドロビン方式を使用してbridge-quickstart-topicトピックのパーティションに送信されます。
-
リクエストが正常に行われると、Kafka Bridge は
offsetsアレイを200コードとapplication/vnd.kafka.v2+jsonのcontent-typeヘッダーとともに返します。各メッセージで、offsetsアレイは以下を記述します。- メッセージが送信されたパーティション。
パーティションの現在のメッセージオフセット。
応答の例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
次のステップ
トピックおよびパーティションへのメッセージを作成したら、Kafka Bridge コンシューマーを作成します。
その他のリソース
- API リファレンスドキュメントの「POST /topics/{topicname}」
- API リファレンスドキュメントの「POST /topics/{topicname}/partitions/{partitionid}」
7.2.4. Kafka Bridge コンシューマーの作成
Kafka クラスターで何らかのコンシューマー操作を実行するには、まず consumers エンドポイントを使用してコンシューマーを作成する必要があります。コンシューマーは Kafka Bridge コンシューマー と呼ばれます。
手順
bridge-quickstart-consumer-groupという名前の新しいコンシューマーグループに Kafka Bridge コンシューマーを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
コンシューマーには
bridge-quickstart-consumerという名前を付け、埋め込みデータ形式はjsonとして設定します。 - 一部の基本的な設定が定義されます。
コンシューマーはログへのオフセットに自動でコミットしません。これは、
enable.auto.commitがfalseに設定されているからです。このクイックスタートでは、オフセットを跡で手作業でコミットします。リクエストが正常に行われると、Kafka Bridge はレスポンス本文でコンシューマー ID (
instance_id) とベース URL (base_uri) を200コードとともに返します。応答の例
#... { "instance_id": "bridge-quickstart-consumer", "base_uri":"http://<bridge-name>-bridge-service:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer" }#... { "instance_id": "bridge-quickstart-consumer", "base_uri":"http://<bridge-name>-bridge-service:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
コンシューマーには
-
ベース URL (
base_uri) をコピーし、このクイックスタートの他のコンシューマー操作で使用します。
次のステップ
上記で作成した Kafka Bridge コンシューマーをトピックにサブスクライブできます。
その他のリソース
- API リファレンスドキュメントの「POST /consumers/{groupid}」
7.2.5. Kafka Bridge コンシューマーのトピックへのサブスクライブ
Kafka Bridge コンシューマーを作成したら、subscription エンドポイントを使用して、1 つ以上のトピックにサブスクライブします。サブスクライブすると、コンシューマーはトピックに生成されたすべてのメッセージの受信を開始します。
手順
前述の「トピックおよびパーティションへのメッセージの作成」の手順ですでに作成した
bridge-quickstart-topicトピックに、コンシューマーをサブスクライブします。Copy to Clipboard Copied! Toggle word wrap Toggle overflow topicsアレイには、例のような単一のトピック、または複数のトピックを含めることができます。正規表現に一致する複数のトピックにコンシューマーをサブスクライブする場合は、topicsアレイの代わりにtopic_pattern文字列を使用できます。リクエストが正常に行われると、Kafka Bridge によって
204(No Content) コードのみが返されます。
次のステップ
Kafka Bridge コンシューマーをトピックにサブスクライブしたら、コンシューマーからメッセージを取得できます。
その他のリソース
- API リファレンスドキュメントの「POST /consumers/{groupid}/instances/{name}/subscription」
7.2.6. Kafka Bridge コンシューマーからの最新メッセージの取得
次に、records エンドポイントからデータをリクエストすることで、Kafka Bridge コンシューマーから最新メッセージを取得します。実稼働環境では、HTTP クライアントはこのエンドポイントを繰り返し (ループで) 呼び出すことができます。
手順
- 「トピックおよびパーティションへのメッセージの生成」の説明に従い、Kafka Bridge コンシューマーに新たなメッセージを生成します。
GETリクエストをrecordsエンドポイントに送信します。curl -X GET http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/records \ -H 'accept: application/vnd.kafka.json.v2+json'
curl -X GET http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/records \ -H 'accept: application/vnd.kafka.json.v2+json'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka Bridge コンシューマーを作成し、サブスクライブすると、最初の GET リクエストによって空のレスポンスが返されます。これは、ポーリング操作がリバランスプロセスを開始してパーティションを割り当てるからです。
手順 2 を繰り返し、Kafka Bridge コンシューマーからメッセージを取得します。
Kafka Bridge は、レスポンス本文でメッセージのアレイ (トピック名、キー、値、パーティション、オフセットの記述) を
200コードとともに返します。メッセージはデフォルトで最新のオフセットから取得されます。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記空のレスポンスが返される場合は、「トピックおよびパーティションへのメッセージの生成」の説明に従い、コンシューマーに対して追加のレコードを生成し、メッセージの取得を再試行します。
次のステップ
Kafka Bridge コンシューマーからメッセージを取得したら、ログへのオフセットをコミットします。
その他のリソース
- API リファレンスドキュメントの「GET /consumers/{groupid}/instances/{name}/records」
7.2.7. ログへのオフセットのコミット
次に、offsets エンドポイントを使用して、Kafka Bridge コンシューマーによって受信されるすべてのメッセージに対して、手動でオフセットをログにコミットします。この操作が必要なのは、前述の「Kafka Bridge コンシューマーの作成」で作成した Kafka Bridge コンシューマー が enable.auto.commit の設定で false に指定されているからです。
手順
bridge-quickstart-consumerのオフセットをログにコミットします。curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/offsets
curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/offsetsCopy to Clipboard Copied! Toggle word wrap Toggle overflow リクエスト本文は送信されないので、オフセットはコンシューマーによって受信されたすべてのレコードに対してコミットされます。この代わりに、リクエスト本文に、オフセットをコミットするトピックおよびパーティションを指定するアレイ (OffsetCommitSeekList) を含めることができます。
リクエストが正常に行われると、Kafka Bridge は
204コードのみを返します。
次のステップ
オフセットをログにコミットしたら、オフセットをシークのエンドポイントを試行します。
その他のリソース
- API リファレンスドキュメントの「POST /consumers/{groupid}/instances/{name}/offsets」
7.2.8. パーティションのオフセットのシーク
次に、positions エンドポイントを使用して、Kafka Bridge コンシューマーを設定することで、パーティションのメッセージを特定のオフセットから取得し、さらに最新のオフセットから取得します。これは Apache Kafka では、シーク操作と呼ばれます。
手順
quickstart-bridge-topicトピックで、パーティション 0 の特定のオフセットをシークします。Copy to Clipboard Copied! Toggle word wrap Toggle overflow リクエストが正常に行われると、Kafka Bridge は
204コードのみを返します。GETリクエストをrecordsエンドポイントに送信します。curl -X GET http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/records \ -H 'accept: application/vnd.kafka.json.v2+json'
curl -X GET http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/records \ -H 'accept: application/vnd.kafka.json.v2+json'Copy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka Bridge は、シークしたオフセットからのメッセージを返します。
同じパーティションの最後のオフセットをシークし、デフォルトのメッセージ取得動作を復元します。この時点で、positions/end エンドポイントを使用します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow リクエストが正常に行われると、Kafka Bridge は別の
204コードを返します。
また、positions/beginning エンドポイントを使用して、1 つ以上のパーティションの最初のオフセットをシークすることもできます。
次のステップ
このクイックスタートでは、AMQ Streams Kafka Bridge を使用して Kafka クラスターの一般的な操作をいくつか実行しました。これで、すでに作成した Kafka Bridge コンシューマーを削除 できます。
その他のリソース
- API リファレンスドキュメントの「POST /consumers/{groupid}/instances/{name}/positions」
- API リファレンスドキュメントの「POST /consumers/{groupid}/instances/{name}/positions/beginning」
- API リファレンスドキュメントの「POST /consumers/{groupid}/instances/{name}/positions/end」
7.2.9. Kafka Bridge コンシューマーの削除
最後に、このクイックスタートを通して使用した Kafa Bridge コンシューマーを削除します。
手順
DELETEリクエストを instances エンドポイントに送信し、Kafka Bridge コンシューマーを削除します。curl -X DELETE http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer
curl -X DELETE http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumerCopy to Clipboard Copied! Toggle word wrap Toggle overflow リクエストが正常に行われると、Kafka Bridge は
204コードのみを返します。
その他のリソース
- API リファレンスドキュメントの「DELETE /consumers/{groupid}/instances/{name}」
第8章 3scale での Kafka Bridge の使用
Red Hat 3scale API Management をデプロイし、AMQ Streams の Kafka Bridge と統合できます。
8.1. 3scale での Kafka Bridge の使用
Kafka Bridge のプレーンデプロイメントでは、認証または承認のプロビジョニングがなく、TLS 暗号化による外部クライアントへの接続はサポートされません。
3scale を使用すると、TLS によって Kafka Bridge のセキュリティーが保護され、認証および承認も提供されます。また、3scale との統合により、メトリクス、流量制御、請求などの追加機能も利用できるようになります。
3scale では、AMQ Streams へのアクセスを希望する外部クライアントからのリクエストに対して、各種タイプの認証を使用できます。3scale では、以下のタイプの認証がサポートされます。
- 標準 API キー
- 識別子およびシークレットトークンとして機能する、ランダムな単一文字列またはハッシュ。
- アプリケーション ID とキーのペア
- イミュータブルな識別子およびミュータブルなシークレットキー文字列。
- OpenID Connect
- 委譲された認証のプロトコル。
既存の 3scale デプロイメントを使用する場合
3scale がすでに OpenShift にデプロイされており、Kafka Bridge と併用する場合は、正しく設定されていることを確認してください。
設定については、「Kafka Bridge を使用するための 3scale のデプロイメント」を参照してください。
8.1.1. Kafka Bridge のサービス検出
3scale は、サービス検出を使用して統合されますが、これには 3scale が AMQ Streams および Kafka Bridge と同じ OpenShift クラスターにデプロイされている必要があります。
AMQ Streams Cluster Operator デプロイメントには、以下の環境変数が設定されている必要があります。
- STRIMZI_CUSTOM_KAFKA_BRIDGE_SERVICE_LABELS
- STRIMZI_CUSTOM_KAFKA_BRIDGE_SERVICE_ANNOTATIONS
Kafka Bridge をデプロイすると、Kafka Bridge の REST インターフェースを公開するサービスは、3scale による検出にアノテーションとラベルを使用します。
-
3scale によって
discovery.3scale.net=trueラベルが使用され、サービスが検出されます。 - アノテーションによってサービスに関する情報が提供されます。
OpenShift コンソールで設定を確認するには、Kafka Bridge インスタンスの Services に移動します。Annotations に、Kafka Bridge の OpenAPI 仕様へのエンドポイントが表示されます。
8.1.2. 3scale APIcast ゲートウェイポリシー
3scale は 3scale APIcast と併用されます。3scale APIcast は、Kafka Bridge の単一エントリーポイントを提供する 3scale とデプロイされる API ゲートウェイです。
APIcast ポリシーは、ゲートウェイの動作をカスタマイズするメカニズムを提供します。3scale には、ゲートウェイ設定のための標準ポリシーのセットが含まれています。また、独自のポリシーを作成することもできます。
APIcast ポリシーの詳細は、3scale ドキュメントの「API ゲートウェイの管理」を参照してください。
Kafka Bridge の APIcast ポリシー
3scale と Kafka Bridge との統合のポリシー設定例は policies_config.json ファイルに含まれており、このファイルでは以下を定義します。
- Anonymous Access (匿名アクセス)
- Header Modification (ヘッダー変更)
- Routing (ルーティング)
- URL Rewriting (URL の書き換え)
ゲートウェイポリシーは、このファイルを使用して有効または無効に設定します。
この例をひな形として使用し、独自のポリシーを定義できます。
- Anonymous Access (匿名アクセス)
- Anonymous Access ポリシーでは、認証をせずにサービスが公開され、HTTP クライアントがデフォルトのクレデンシャル (匿名アクセス用) を提供しない場合に、このポリシーによって提供されます。このポリシーは必須ではなく、認証が常に必要であれば無効または削除できます。
- Header Modification (ヘッダー変更)
Header Modification ポリシーを使用すると、既存の HTTP ヘッダーを変更したり、ゲートウェイを通過するリクエストまたはレスポンスへ新規ヘッダーを追加したりすることができます。3scale の統合では、このポリシーによって、HTTP クライアントから Kafka Bridge までゲートウェイを通過するすべてのリクエストにヘッダーが追加されます。
Kafka Bridge は、新規コンシューマー作成のリクエストを受信すると、URI のある
base_uriフィールドが含まれる JSON ペイロードを返します。コンシューマーは後続のすべてのリクエストにこの URI を使用する必要があります。以下に例を示します。{ "instance_id": "consumer-1", "base_uri":"http://my-bridge:8080/consumers/my-group/instances/consumer1" }{ "instance_id": "consumer-1", "base_uri":"http://my-bridge:8080/consumers/my-group/instances/consumer1" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow APIcast を使用する場合、クライアントは以降のリクエストをすべてゲートウェイに送信し、Kafka Bridge には直接送信しません。そのため URI には、ゲートウェイの背後にある Kafka Bridge のアドレスではなく、ゲートウェイのホスト名が必要です。
Header Modification ポリシーを使用すると、ヘッダーが HTTP クライアントからリクエストに追加されるので、Kafka Bridge はゲートウェイホスト名を使用します。
たとえば、
Forwarded: host=my-gateway:80;proto=httpヘッダーを適用すると、Kafka Bridge は以下をコンシューマーに提供します。{ "instance_id": "consumer-1", "base_uri":"http://my-gateway:80/consumers/my-group/instances/consumer1" }{ "instance_id": "consumer-1", "base_uri":"http://my-gateway:80/consumers/my-group/instances/consumer1" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow X-Forwarded-Pathヘッダーには、クライアントからゲートウェイへのリクエストに含まれる元のパスが含まれています。このヘッダーは、ゲートウェイが複数の Kafka Bridge インスタンスをサポートする場合に適用される Routing ポリシーに密接に関連します。- Routing (ルーティング)
Routing ポリシーは、複数の Kafka Bridge インスタンスがある場合に適用されます。コンシューマーが最初に作成された Kafka Bridge インスタンスにリクエストを送信する必要があるため、適切な Kafka Bridge インスタンスにリクエストを転送するようゲートウェイのルートをリクエストに指定する必要があります。
Routing ポリシーは各ブリッジインスタンスに名前を付け、ルーティングはその名前を使用して実行されます。Kafka Bridge のデプロイ時に、
KafkaBridgeカスタムリソースで名前を指定します。たとえば、コンシューマーから以下への各リクエスト (
X-Forwarded-Pathを使用) について考えてみましょう。http://my-gateway:80/my-bridge-1/consumers/my-group/instances/consumer1この場合、各リクエストは以下に転送されます。
http://my-bridge-1-bridge-service:8080/consumers/my-group/instances/consumer1URL Rewriting ポリシーはブリッジ名を削除しますが、これは、リクエストをゲートウェイから Kafka Bridge に転送するときにこのポリシーが使用されないからです。
- URL Rewriting (URL の書き換え)
URL Rewiring ポリシーは、ゲートウェイから Kafka Bridge にリクエストが転送されるとき、クライアントから特定の Kafka Bridge インスタンスへのリクエストにブリッジ名が含まれないようにします。
ブリッジ名は、ブリッジが公開するエンドポイントで使用されません。
8.1.3. TLS の検証
TLS の検証用に APIcast を設定できます。これにはテンプレートを使用した APIcast の自己管理によるデプロイメントが必要になります。apicast サービスがルートとして公開されます。
TLS ポリシーを Kafka Bridge API に適用することもできます。
TLS 設定の詳細は、3scale ドキュメントの「API ゲートウェイの管理」を参照してください。
8.1.4. 3scale ドキュメント
3scale を Kafka Bridge と使用するためにデプロイする手順は、3scale をある程度理解していることを前提としています。
詳細は、3scale の製品ドキュメントを参照してください。
8.2. Kafka Bridge を使用するための 3scale のデプロイメント
3scale を Kafka Bridge で使用するには、まず 3scale をデプロイし、次に Kafka Bridge API の検出を設定します。
また、3scale APIcast および 3scale toolbox も使用します。
- APIcast は、HTTP クライアントが Kafka Bridge API サービスに接続するための NGINX ベースの API ゲートウェイとして、3scale により提供されます。
- 3scale toolbox は設定ツールで、Kafka Bridge サービスの OpenAPI 仕様を 3scale にインポートするために使用されます。
このシナリオでは、AMQ Streams、Kafka、Kafka Bridge、および 3scale/APIcast を、同じ OpenShift クラスターで実行します。
3scale がすでに Kafka Bridge と同じクラスターにデプロイされている場合は、デプロイメントの手順を省略して、現在のデプロイメントを使用できます。
3scale デプロイメントの場合:
- 「Red Hat 3scale API Management Supported Configurations」を確認します。
-
インストールには、
cluster-adminロール (system:adminなど) を持つユーザーが必要です。 以下が記述されている JSON ファイルにアクセスできる必要があります。
-
Kafka Bridge OpenAPI 仕様 (
openapiv2.json) Kafka Bridge のヘッダー変更および Routing ポリシー (
policies_config.json)GitHub で JSON ファイルを探します。
-
Kafka Bridge OpenAPI 仕様 (
手順
3scale API Management を OpenShift クラスターにデプロイします。
新規プロジェクトを作成するか、または既存プロジェクトを使用します。
oc new-project my-project \ --description="description" --display-name="display_name"oc new-project my-project \ --description="description" --display-name="display_name"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 3scale をデプロイします。
「3scale のインストール」 ガイドに記載の情報に従い、テンプレートまたは Operator を使用して OpenShift に 3scale をデプロイします。
どの方法を使用する場合も、WILDCARD_DOMAIN パラメーターが OpenShift クラスターのドメインに設定されていることを確認してください。
3scale 管理ポータルにアクセスするために表示される URL およびクレデンシャルを書き留めておきます。
3scale が Kafka Bridge サービスを検出するように承認を付与します。
oc adm policy add-cluster-role-to-user view system:serviceaccount:my-project:amp
oc adm policy add-cluster-role-to-user view system:serviceaccount:my-project:ampCopy to Clipboard Copied! Toggle word wrap Toggle overflow 3scale が OpenShift コンソールまたは CLI から Openshift クラスターに正常にデプロイされたことを確認します。
以下に例を示します。
oc get deployment 3scale-operator
oc get deployment 3scale-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow 3scale toolbox を設定します。
- 『Operating 3scale』 に記載の情報を使用して、3scale toolbox をインストールします。
3scale と対話できるように環境変数を設定します。
export REMOTE_NAME=strimzi-kafka-bridge export SYSTEM_NAME=strimzi_http_bridge_for_apache_kafka export TENANT=strimzi-kafka-bridge-admin export PORTAL_ENDPOINT=$TENANT.3scale.net export TOKEN=3scale access token
export REMOTE_NAME=strimzi-kafka-bridge1 export SYSTEM_NAME=strimzi_http_bridge_for_apache_kafka2 export TENANT=strimzi-kafka-bridge-admin3 export PORTAL_ENDPOINT=$TENANT.3scale.net4 export TOKEN=3scale access token5 Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
REMOTE_NAMEは、3scale 管理ポータルのリモートアドレスに割り当てられた名前です。- 2
SYSTEM_NAMEは、3scale toolbox で OpenAPI 仕様をインポートして作成される 3scale サービス/API の名前です。- 3
TENANTは、3scale 管理ポータルのテナント名です (https://$TENANT.3scale.net)。- 4
PORTAL_ENDPOINTは、3scale 管理ポータルを実行するエンドポイントです。- 5
TOKENは、3scale toolbox または HTTP リクエストを介して対話するために 3scale 管理ポータルによって提供されるアクセストークンです。
3scale toolbox のリモート Web アドレスを設定します。
3scale remote add $REMOTE_NAME https://$TOKEN@$PORTAL_ENDPOINT/
3scale remote add $REMOTE_NAME https://$TOKEN@$PORTAL_ENDPOINT/Copy to Clipboard Copied! Toggle word wrap Toggle overflow これで、toolbox を実行するたびに、3scale 管理ポータルのエンドポイントアドレスを指定する必要がなくなりました。
Cluster Operator デプロイメントに、3scale が Kafka Bridge サービスを検出するために必要なラベルプロパティーおよびアノテーションプロパティーがあることを確認します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow これらのプロパティーがない場合は、OpenShift コンソールからプロパティーを追加するか、Cluster Operator および Kafka Bridge を再デプロイします。
3scale で Kafka Bridge API サービスを検出します。
- 3scale をデプロイしたときに提供されたクレデンシャルを使用して、3scale 管理ポータルにログインします。
- 3scale 管理ポータルから、 → に移動します。ここで、Kafka Bridge サービスが表示されます。
をクリックします。
ページを更新して Kafka Bridge サービスを表示することが必要な場合もあります。
ここで、サービスの設定をインポートする必要があります。エディターからインポートしますが、ポータルを開いたまま正常にインポートされたことを確認します。
OpenAPI 仕様 (JSON ファイル) の Host フィールドを編集して、Kafka Bridge サービスのベース URL を使用します。
以下に例を示します。
"host": "my-bridge-bridge-service.my-project.svc.cluster.local:8080"
"host": "my-bridge-bridge-service.my-project.svc.cluster.local:8080"Copy to Clipboard Copied! Toggle word wrap Toggle overflow hostURL に以下が正しく含まれることを確認します。- Kafka Bridge 名 (my-bridge)
- プロジェクト名 (my-project)
- Kafka Bridge のポート (8080)
3scale toolbox を使用して、更新された OpenAPI 仕様をインポートします。
3scale import openapi -k -d $REMOTE_NAME openapiv2.json -t myproject-my-bridge-bridge-service
3scale import openapi -k -d $REMOTE_NAME openapiv2.json -t myproject-my-bridge-bridge-serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow サービスの Header Modification および Routing ポリシー (JSON ファイル) をインポートします。
3scale で作成したサービスの ID を特定します。
ここでは、`jq` ユーティリティー を使用します。
export SERVICE_ID=$(curl -k -s -X GET "https://$PORTAL_ENDPOINT/admin/api/services.json?access_token=$TOKEN" | jq ".services[] | select(.service.system_name | contains(\"$SYSTEM_NAME\")) | .service.id")
export SERVICE_ID=$(curl -k -s -X GET "https://$PORTAL_ENDPOINT/admin/api/services.json?access_token=$TOKEN" | jq ".services[] | select(.service.system_name | contains(\"$SYSTEM_NAME\")) | .service.id")Copy to Clipboard Copied! Toggle word wrap Toggle overflow ポリシーをインポートするときにこの ID が必要です。
ポリシーをインポートします。
curl -k -X PUT "https://$PORTAL_ENDPOINT/admin/api/services/$SERVICE_ID/proxy/policies.json" --data "access_token=$TOKEN" --data-urlencode policies_config@policies_config.json
curl -k -X PUT "https://$PORTAL_ENDPOINT/admin/api/services/$SERVICE_ID/proxy/policies.json" --data "access_token=$TOKEN" --data-urlencode policies_config@policies_config.jsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow
- 3scale 管理ポータルから、 → に移動し、Kafka Bridge サービスのエンドポイントとポリシーが読み込まれていることを確認します。
- アプリケーションプランを作成するために、 → に移動します。
アプリケーションを作成するために、 → → → に移動します。
認証のユーザーキーを取得するためにアプリケーションが必要になります。
実稼働環境用の手順: 実稼働環境のゲートウェイで API を利用可能にするには、設定をプロモートします。
3scale proxy-config promote $REMOTE_NAME $SERVICE_ID
3scale proxy-config promote $REMOTE_NAME $SERVICE_IDCopy to Clipboard Copied! Toggle word wrap Toggle overflow API テストツールを使用して、コンシューマーの作成に呼び出しを使用する APIcast ゲートウェイと、アプリケーションに作成されたユーザーキーで、Kafka Bridge にアクセスできることを検証します。
以下に例を示します。
https//my-project-my-bridge-bridge-service-3scale-apicast-staging.example.com:443/consumers/my-group?user_key=3dfc188650101010ecd7fdc56098ce95
https//my-project-my-bridge-bridge-service-3scale-apicast-staging.example.com:443/consumers/my-group?user_key=3dfc188650101010ecd7fdc56098ce95Copy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka Bridge からペイロードが返されれば、コンシューマーが正常に作成されています。
{ "instance_id": "consumer1", "base uri": "https//my-project-my-bridge-bridge-service-3scale-apicast-staging.example.com:443/consumers/my-group/instances/consumer1" }{ "instance_id": "consumer1", "base uri": "https//my-project-my-bridge-bridge-service-3scale-apicast-staging.example.com:443/consumers/my-group/instances/consumer1" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow ベース URI は、クライアントが以降のリクエストで使用するアドレスです。
第9章 Service Registry を使用したスキーマの管理
本章では、AMQ Streams をデプロイし Red Hat Service Registry と統合する方法について解説します。Service Registry は、データストリーミングのサービススキーマの集中型ストアとして使用できます。Kafka では、Service Registry を使用して Apache Avro または JSON スキーマを格納できます。
Service Registry は、REST API および Java REST クライアントを提供し、サーバー側のエンドポイントを介してクライアントアプリケーションからスキーマを登録およびクエリーします。プロデューサークライアントおよびコンシューマークライアントが Service Registry を使用するように設定できます。
Maven プラグインも提供されるので、ビルドの一部としてスキーマをアップロードおよびダウンロードできます。スキーマの更新がクライアントアプリケーションと互換性があることを確認する場合、Maven プラグインはテストおよび検証に役立ちます。
Service Registry はテクノロジープレビューとしてのみ提供されます。テクノロジープレビューの機能は、Red Hat の本番環境のサービスレベルアグリーメント (SLA) ではサポートされず、機能的に完全ではないことがあります。Red Hat は、本番環境でのテクノロジープレビュー機能の実装は推奨しません。テクノロジープレビューの機能は、最新の技術をいち早く提供して、開発段階で機能のテストやフィードバックの収集を可能にするために提供されます。Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、「テクノロジプレビュー機能のサポート範囲」を参照してください。
その他のリソース
- Service Registry のドキュメント
- Service Registry は、GitHub の Apicurio/Apicurio-registry で利用可能な Apicurio Registry オープンソースコミュニティープロジェクトで構築されます。
- また Service Registry のデモは、GitHub の Apicurio/Apicurio-registry-demo から利用できます。
- Apache Avro
9.1. Service Registry を使用する理由
Service Registry を使用すると、クライアントアプリケーションの設定からスキーマ管理のプロセスが分離されます。クライアントコードに URL を指定して、アプリケーションがレジストリーからスキーマを使用できるようにします。
たとえば、メッセージをシリアライズおよびデシリアライズするスキーマをレジストリーに保存できます。保存後、スキーマを使用するアプリケーションから参照され、アプリケーションが送受信するメッセージがこれらのスキーマと互換性を維持するようにします。
Kafka クライアントアプリケーションは実行時にスキーマを Service Registry からプッシュまたはプルできます。
スキーマは進化するので、Service Registry でルールを定義できます。たとえば、スキーマへの変更が有効で、アプリケーションによって使用される以前のバージョンとの互換性を維持するようにします。Service Registry は、変更済みのスキーマと前バージョンのスキーマを比較することで、互換性をチェックします。
Service Registry は Avro スキーマのスキーマレジストリーを完全にサポートします。Avro スキーマは、Service Registry で提供される Kafka クライアントのシリアライザー/デシリアライザー (SerDe) サービスを通じてクライアントアプリケーションによって使用されます。
9.2. プロデューサースキーマの設定
プロデューサークライアントアプリケーションは、シリアライザーを使用して、特定のブローカートピックに送信するメッセージを正しいデータ形式にします。
プロデューサーが Service Registry を使用してシリアライズできるようにするには、以下を行います。
- スキーマを Service Registry に定義、登録します。
- Service Registry の URL
- メッセージで使用する Service Registry シリアライザーサービス
- Service Registry でのシリアライズに使用するスキーマを検索する ストラテジー
スキーマを登録したら、Kafka および Service Registry を開始するときに、スキーマにアクセスして、プロデューサーにより Kafka ブローカートピックに送信されるメッセージをフォーマットできます。
スキーマがすでに存在する場合、Service Registry に定義される互換性ルールに基づいて、REST API により新バージョンのスキーマを作成できます。バージョンは、スキーマの進化にともなう互換性チェックに使用します。アーティファクト ID およびスキーマバージョンは、スキーマを識別する一意のタプルを表します。
9.3. コンシューマースキーマの設定
コンシューマークライアントアプリケーションは、デシリアライザーを使用することで、そのアプリケーションが消費するメッセージを特定のブローカートピックから正しいデータ形式にします。
コンシューマーがデシリアライズに Service Registry を使用できるようにするには、以下を実行します。
- スキーマを Service Registry に定義、登録します。
以下を使用して コンシューマークライアントコードを設定します。
- Service Registry の URL
- メッセージで使用する Service Registry デシリアライザーサービス
- デシリアライズの入力データストリーム
次に、消費されるメッセージに書き込まれたグローバル ID を使用して、デシリアライザーによってスキーマが取得されます。このため、受信されるメッセージにはグローバル ID およびメッセージデータが含まれる必要があります。
以下に例を示します。
# ... [MAGIC_BYTE] [GLOBAL_ID] [MESSAGE DATA]
# ...
[MAGIC_BYTE]
[GLOBAL_ID]
[MESSAGE DATA]これで、Kafka および Service Registry を開始するとき、スキーマにアクセスして、Kafka ブローカートピックから受信するメッセージをフォーマットできます。
9.4. スキーマ検索のストラテジー
Service Registry ストラテジー は、Service Registry でメッセージスキーマが登録されるアーティファクト ID またはグローバル ID を判断するために、Kafka クライアントシリアライザー/デシリアライザーによって使用されます。
特定のトピックおよびメッセージで、以下の Java クラスの実装を使用できます。
-
ArtifactIdStrategy、アーティファクト ID を返します。 -
GlobalIdStrategy、グローバル ID を返します。
返されるアーティファクト ID は、メッセージの キー または 値 のどちらがシリアライズされるかによって異なります。
各 ストラテジー のクラスは、io.apicurio.registry.utils.serde.strategy パッケージにまとめられています。
デフォルトのストラテジー、TopicIdStrategy は、メッセージを受信する Kafka トピックと同じ名前の Service Registry アーティファクトを検索します。
以下に例を示します。
public String artifactId(String topic, boolean isKey, T schema) {
return String.format("%s-%s", topic, isKey ? "key" : "value");
}
public String artifactId(String topic, boolean isKey, T schema) {
return String.format("%s-%s", topic, isKey ? "key" : "value");
}-
topicパラメーターは、メッセージを受信する Kafka トピックの名前です。 -
isKeyパラメーター は、メッセージキーがシリアライズされる場合は true、メッセージ値がシリアライズされる場合は false です。 -
schemaパラメーターは、シリアライズ/デシリアライズされるメッセージのスキーマです。 -
返される
artifactIDは、スキーマが Service Registry に登録される ID です。
使用する検索アップストラテジーは、スキーマを保存する方法と場所によって異なります。たとえば、同じ Avro メッセージタイプを持つ Kafka トピックが複数ある場合、レコード ID を使用するストラテジーを使用することがあります。
アーティファクト ID を返すストラテジー
これらのストラテジーは、ArtifactIdStrategy の実装に基づいてアーティファクト ID を返します。
RecordIdStrategy- スキーマのフルネームを使用する Avro 固有のストラテジー。
TopicRecordIdStrategy- トピック名およびスキーマのフルネームを使用する Avro 固有のストラテジー。
TopicIdStrategy-
(デフォルト) トピック名と、
keyまたはvalue接尾辞を使用するストラテジー。 SimpleTopicIdStrategy- トピック名のみを使用する単純なストラテジー。
グローバル ID を返すストラテジー
これらのストラテジーは、GlobalIdStrategy の実装に基づいてグローバル ID を返します。
FindLatestIdStrategy- アーティファクト ID に基づいて最新のスキーマバージョンのグローバル ID を返すストラテジー。
FindBySchemaIdStrategy- アーティファクト ID に基づいてスキーマコンテンツと一致する、グローバル ID を返すストラテジー。
GetOrCreateIdStrategy- アーティファクト ID に基づいて最新スキーマの取得を試み、スキーマが存在しなければ新規スキーマを作成するストラテジー。
AutoRegisterIdStrategy- スキーマを更新し、更新されたスキーマのグローバル ID を使用するストラテジー。
9.5. Service Registry の定数
このセクションで概説する定数を使用して、特定のクライアントの SerDe サービスおよびスキーマ検索ストラテジーを直接クライアントに設定できます。
または、プロパティーファイルまたはプロパティーインスタンスで定数を指定することもできます。
シリアライザー/デシリアライザー (SerDe) サービスの定数
- 1
- (必須) Service Registry の URL。
- 2
- クライアントがリクエストを実行し、以前の結果のキャッシュから情報を検索して処理時間を短縮できるようにします。キャッシュが空の場合、検索は Service Registry から実行されます。
- 3
- ID 処理を拡張することで、他の ID 形式をサポートし、その形式に Service Registry SerDe サービスとの互換性を持たせます。たとえば、ID 形式を
LongからIntegerに変更すると Confluent ID 形式がサポートされます。 - 4
- Confluent ID の処理を簡素化するフラグ。
trueに設定すると、Integerがグローバル ID の検索に使用されます。
検索ストラテジーの定数
public abstract class AbstractKafkaStrategyAwareSerDe<T, S extends AbstractKafkaStrategyAwareSerDe<T, S>> extends AbstractKafkaSerDe<S> {
public static final String REGISTRY_ARTIFACT_ID_STRATEGY_CONFIG_PARAM = "apicurio.registry.artifact-id";
public static final String REGISTRY_GLOBAL_ID_STRATEGY_CONFIG_PARAM = "apicurio.registry.global-id";
public abstract class AbstractKafkaStrategyAwareSerDe<T, S extends AbstractKafkaStrategyAwareSerDe<T, S>> extends AbstractKafkaSerDe<S> {
public static final String REGISTRY_ARTIFACT_ID_STRATEGY_CONFIG_PARAM = "apicurio.registry.artifact-id";
public static final String REGISTRY_GLOBAL_ID_STRATEGY_CONFIG_PARAM = "apicurio.registry.global-id"; コンバーターの定数
public class SchemalessConverter<T> extends AbstractKafkaSerDe<SchemalessConverter<T>> implements Converter {
public static final String REGISTRY_CONVERTER_SERIALIZER_PARAM = "apicurio.registry.converter.serializer";
public static final String REGISTRY_CONVERTER_DESERIALIZER_PARAM = "apicurio.registry.converter.deserializer";
public class SchemalessConverter<T> extends AbstractKafkaSerDe<SchemalessConverter<T>> implements Converter {
public static final String REGISTRY_CONVERTER_SERIALIZER_PARAM = "apicurio.registry.converter.serializer";
public static final String REGISTRY_CONVERTER_DESERIALIZER_PARAM = "apicurio.registry.converter.deserializer"; Avro データプロバイダーの定数
public interface AvroDatumProvider<T> {
String REGISTRY_AVRO_DATUM_PROVIDER_CONFIG_PARAM = "apicurio.registry.avro-datum-provider";
String REGISTRY_USE_SPECIFIC_AVRO_READER_CONFIG_PARAM = "apicurio.registry.use-specific-avro-reader";
public interface AvroDatumProvider<T> {
String REGISTRY_AVRO_DATUM_PROVIDER_CONFIG_PARAM = "apicurio.registry.avro-datum-provider";
String REGISTRY_USE_SPECIFIC_AVRO_READER_CONFIG_PARAM = "apicurio.registry.use-specific-avro-reader"; DefaultAvroDatumProvider (io.apicurio.registry.utils.serde.avro) ReflectAvroDatumProvider (io.apicurio.registry.utils.serde.avro)
DefaultAvroDatumProvider (io.apicurio.registry.utils.serde.avro)
ReflectAvroDatumProvider (io.apicurio.registry.utils.serde.avro) 9.6. Service Registry のインストール
AMQ Streams ストレージで Service Registry をインストールする手順は、Service Registry のドキュメントを参照してください。
クラスターの設定に応じて、複数の Service Registry インスタンスをインストールできます。インスタンス数は、使用するストレージタイプと、処理する必要のあるスキーマの数によって異なります。
9.7. スキーマの Service Registry への登録
スキーマを Apache Avro などの適切な形式で定義したら、スキーマを Service Registry に追加できます。
スキーマは以下を使用して追加できます。
- Service Registry API を使用する curl コマンド
- Service Registry に付属する Maven プラグイン
- クライアントコードに加えられたスキーマ設定
スキーマを登録するまでは、クライアントアプリケーションは Service Registry を使用できません。
curl の例
プラグインの例
(プロデューサー) クライアントによる設定例
9.8. プロデューサークライアントからの Service Registry スキーマの使用
この手順では、Service Registry からのスキーマを使用するように Java プロデューサークライアントを設定する方法について説明します。
手順
Service Registry の URL でクライアントを設定します。
以下に例を示します。
String registryUrl_node1 = PropertiesUtil.property(clientProperties, "registry.url.node1", "https//my-cluster-service-registry-myproject.example.com"); RegistryService service = RegistryClient.cached(registryUrl);String registryUrl_node1 = PropertiesUtil.property(clientProperties, "registry.url.node1", "https//my-cluster-service-registry-myproject.example.com"); RegistryService service = RegistryClient.cached(registryUrl);Copy to Clipboard Copied! Toggle word wrap Toggle overflow クライアントをシリアライザーサービスで設定し、Service Registry でスキーマを検索するようにストラテジーを設定します。
以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.9. コンシューマークライアントからの Service Registry スキーマの使用
この手順では、Service Registry からのスキーマを使用するように Java コンシューマークライアントを設定する方法について説明します。
手順
Service Registry の URL でクライアントを設定します。
以下に例を示します。
String registryUrl_node1 = PropertiesUtil.property(clientProperties, "registry.url.node1", "https//my-cluster-service-registry-myproject.example.com"); RegistryService service = RegistryClient.cached(registryUrl);String registryUrl_node1 = PropertiesUtil.property(clientProperties, "registry.url.node1", "https//my-cluster-service-registry-myproject.example.com"); RegistryService service = RegistryClient.cached(registryUrl);Copy to Clipboard Copied! Toggle word wrap Toggle overflow Service Registry デシリアライザーサービスでクライアントを設定します。
以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第10章 メトリクスの概要
このセクションでは、Prometheus を使用して AMQ Streams Kafka、Zookeeper、および Kafka Connect クラスターを監視し、Grafana ダッシュボードなどのモニタリングデータを提供する方法について説明します。
Prometheus サーバーは、AMQ Streams ディストリビューションの一部としてサポートされません。しかし、メトリクスを公開するために使用される Prometheus エンドポイントと JMX エクスポーターはサポートされます。監視のために Prometheus を AMQ Streams で使用する場合、手順とメトリクス設定ファイルのサンプルが提供されます。
Grafana ダッシュボードのサンプルを実行するには、以下を行う必要があります。
このセクションで参照されるリソースは、まず監視を設定することを目的としており、これらはサンプルとしてのみ提供されます。実稼働環境で Prometheus または Grafana を設定、実行するためにサポートがさらに必要な場合は、それぞれのコミュニティーに連絡してください。
その他のリソース
- Prometheus の詳細は、Prometheus のドキュメントを参照してください。
- Grafana の詳細は、Grafana のドキュメントを参照してください。
- Apache Kafka Monitoring では、Apache Kafka により公開される JMX メトリクスについて解説しています。
- ZooKeeper JMX では、Apache Zookeeper により公開される JMX メトリックについて解説しています。
10.1. メトリクスファイルの例
メトリクス設定のサンプルファイルは、examples/metrics ディレクトリーにあります。
- 1
- Grafana イメージのインストールファイル。
- 2
- Grafana ダッシュボードの設定。
- 3
- Kafka Exporter に固有の Grafana ダッシュボード設定。
- 4
- Kafka Connect に対する Prometheus JMX Exporter の再ラベル付けルールを定義するメトリクス設定。
- 5
- Kafka および ZooKeeper に対する Prometheus JMX Exporter の再ラベル付けルールを定義するメトリクス設定。
- 6
- サービス監視のロールを追加する設定。
- 7
- Alertmanager による通知送信のためのフック定義。
- 8
- Alertmanager をデプロイおよび設定するためのリソース。
- 9
- Prometheus Alertmanager と使用するアラートルールの例 (Prometheus とデプロイ)。
- 10
- Prometheus イメージのインストールファイル。
- 11
- メトリクスデータをスクレープする Prometheus ジョブ定義。
10.2. Prometheus メトリクス
AMQ Streams は、Prometheus JMX Exporter を使用して、HTTP エンドポイントを使用する Kafka および ZooKeeper から JMX メトリクスを公開し、さらにメトリクスは Prometheus サーバーによってスクレープされます。
10.2.1. Prometheus メトリクスの設定
AMQ Streams には、Grafana の設定ファイルのサンプルが含まれています。
Grafana ダッシュボードは、以下に対して定義される Prometheus JMX Exporter の再ラベル付けルールに依存します。
-
kafka-metrics.yamlサンプルファイルで、Kafkaリソース設定とする Kafka および ZooKeeper。 -
サンプル
kafka-connect-metrics.yamlファイルで、KafkaConnectおよびKafkaConnectS2Iリソースとする Kafka Connect。
ラベルは名前と値のペアです。再ラベル付けは、ラベルを動的に書き込むプロセスです。たとえば、ラベルの値は Kafka サーバーおよびクライアント ID の名前から派生されます。
このセクションでは、kafka-metrics.yaml を使用してメトリクス設定を説明しますが、このプロセスは kafka-connect-metrics.yaml ファイルを使用して Kafka Connect を設定する場合と同じです。
その他のリソース
再ラベル付けの使用方法の詳細は、Prometheus ドキュメントの「Configuration」を参照してください。
10.2.2. Prometheus メトリクスのデプロイメントオプション
再ラベル付けルールのメトリクス設定例を Kafka クラスターに適用するには、以下のいずれかを行います。
10.2.3. Prometheus メトリクス設定の Kafka リソースへのコピー
Grafana ダッシュボードを監視に使用するには、メトリクス設定サンプルを Kafka リソースにコピーします。
手順
デプロイメントの Kafka リソースごとに以下の手順を実行します。
エディターで
Kafkaリソースを更新します。oc edit kafka my-cluster
oc edit kafka my-clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
kafka-metrics.yamlの設定例を、ユーザーのKafkaリソース定義にコピーします。 - ファイルを保存し、エディターを終了して更新したリソースが調整されるのを待ちます。
10.2.4. Prometheus メトリクス設定での Kafka クラスターのデプロイメント
Grafana ダッシュボードを監視に使用するには、メトリクス設定でサンプル Kafka クラスターをデプロイできます。
手順
メトリクス設定で Kafka クラスターをデプロイします。
oc apply -f kafka-metrics.yaml
oc apply -f kafka-metrics.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.3. Prometheus
Prometheus では、システム監視とアラート通知のオープンソースのコンポーネントセットが提供されます。
ここでは、CoreOS Prometheus Operator を使用して、実稼働環境での使用に適している Prometheus サーバーを実行および管理する方法を説明します。正しい設定を使用すれば、すべての Prometheus サーバーを実行できます。
Prometheus サーバーの設定では、サービス検出を使用して、メトリクス取得元のクラスター内にある Pod を検出します。この機能が正しく機能するには、Prometheus サービス Pod の稼働に使用されるサービスアカウントで API サーバーにアクセスし、Pod リストを取得できる必要があります。
詳細は、「Discovering services」を参照してください。
10.3.1. Prometheus の設定
AMQ Streams では、Prometheus サーバーの設定ファイルのサンプル が提供されます。
デプロイメント用に Prometheus イメージが提供されます。
-
prometheus.yaml
Prometheus 関連の追加設定も、以下のファイルに含まれています。
-
prometheus-additional.yaml -
prometheus-rules.yaml -
strimzi-service-monitor.yaml
Prometheus で監視データを取得するには以下を行います。
次に、設定ファイルを使用して以下を行います。
アラートルール
prometheus-rules.yaml ファイルには、Alertmanager で使用するアラートルールのサンプルが含まれています。
10.3.2. Prometheus リソース
Prometheus 設定を適用すると、以下のリソースが OpenShift クラスターに作成され、Prometheus Operator によって管理されます。
-
ClusterRole。コンテナーメトリクスのために Kafka と ZooKeeper の Pod、cAdvisor および kubelet によって公開される health エンドポイントを読み取る権限を Prometheus に付与します。 -
ServiceAccount。これで Prometheus Pod が実行されます。 -
ClusterRoleBinding。ClusterRoleをServiceAccountにバインドします。 -
Deployment。Prometheus Operator Pod を管理します。 -
ServiceMonitor。Prometheus Pod の設定を管理します。 -
Prometheus。Prometheus Pod の設定を管理します。 -
PrometheusRule。Prometheus Pod のアラートルールを管理します。 -
Secret。Prometheus の追加設定を管理します。 -
Service。クラスターで稼働するアプリケーションが Prometheus に接続できるようにします (例: Prometheus をデータソースとして使用する Grafana)。
10.3.3. Prometheus Operator のデプロイメント
Prometheus Operator を Kafka クラスターにデプロイするには、Prometheus CoreOS リポジトリー から YAML リソースファイルを適用します。
手順
リポジトリーからリソースファイルをダウンロードし、サンプルの
namespaceを独自の namespace に置き換えます。Linux の場合は、以下を使用します。
curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-deployment.yaml | sed -e 's/namespace: .\*/namespace: my-namespace/' > prometheus-operator-deployment.yaml
curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-deployment.yaml | sed -e 's/namespace: .\*/namespace: my-namespace/' > prometheus-operator-deployment.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-cluster-role.yaml > prometheus-operator-cluster-role.yaml
curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-cluster-role.yaml > prometheus-operator-cluster-role.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-cluster-role-binding.yaml | sed -e 's/namespace: .*/namespace: my-namespace/' > prometheus-operator-cluster-role-binding.yaml
curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-cluster-role-binding.yaml | sed -e 's/namespace: .*/namespace: my-namespace/' > prometheus-operator-cluster-role-binding.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-service-account.yaml | sed -e 's/namespace: .*/namespace: my-namespace/' > prometheus-operator-service-account.yaml
curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-service-account.yaml | sed -e 's/namespace: .*/namespace: my-namespace/' > prometheus-operator-service-account.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow MacOS の場合は、以下を使用します。
curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-deployment.yaml | sed -e '' 's/namespace: .\*/namespace: my-namespace/' > prometheus-operator-deployment.yaml
curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-deployment.yaml | sed -e '' 's/namespace: .\*/namespace: my-namespace/' > prometheus-operator-deployment.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-cluster-role.yaml > prometheus-operator-cluster-role.yaml
curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-cluster-role.yaml > prometheus-operator-cluster-role.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-cluster-role-binding.yaml | sed -e '' 's/namespace: .*/namespace: my-namespace/' > prometheus-operator-cluster-role-binding.yaml
curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-cluster-role-binding.yaml | sed -e '' 's/namespace: .*/namespace: my-namespace/' > prometheus-operator-cluster-role-binding.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-service-account.yaml | sed -e '' 's/namespace: .*/namespace: my-namespace/' > prometheus-operator-service-account.yaml
curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-service-account.yaml | sed -e '' 's/namespace: .*/namespace: my-namespace/' > prometheus-operator-service-account.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注記これが必要ない場合は、
spec.template.spec.securityContextプロパティーをprometheus-operator-deployment.yamlファイルから手動で削除できます。Prometheus Operator をデプロイします。
oc apply -f prometheus-operator-deployment.yaml oc apply -f prometheus-operator-cluster-role.yaml oc apply -f prometheus-operator-cluster-role-binding.yaml oc apply -f prometheus-operator-service-account.yaml
oc apply -f prometheus-operator-deployment.yaml oc apply -f prometheus-operator-cluster-role.yaml oc apply -f prometheus-operator-cluster-role-binding.yaml oc apply -f prometheus-operator-service-account.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.3.4. Prometheus のデプロイメント
Prometheus を Kafka クラスターにデプロイして監視データを取得するには、Prometheus Docker イメージのリソースサンプルファイルと Prometheus 関連リソースの YAML ファイルを適用します。
デプロイメントプロセスでは、ClusterRoleBinding が作成され、デプロイメントのために指定された namespace で Alertmanager インスタンスが検出されます。
Prometheus Operator はデフォルトでは、endpoints ロールが含まれるジョブのみをサービス検出でサポートします。ターゲットは、エンドポイントのポートアドレスごとに検出およびスクレープされます。エンドポイントの検出では、ポートアドレスはサービス (role: service) または Pod (role: pod) の検出から派生する可能性があります。
前提条件
- 提供されるアラートルールのサンプルを確認します。
手順
Prometheus のインストール先となる namespace に従い、Prometheus インストールファイル (
prometheus.yaml) を変更します。Linux の場合は、以下を使用します。
sed -i 's/namespace: .*/namespace: my-namespace/' prometheus.yaml
sed -i 's/namespace: .*/namespace: my-namespace/' prometheus.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow MacOS の場合は、以下を使用します。
sed -i '' 's/namespace: .*/namespace: my-namespace/' prometheus.yaml
sed -i '' 's/namespace: .*/namespace: my-namespace/' prometheus.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
ServiceMonitorリソースをstrimzi-service-monitor.yamlで編集し、メトリクスデータをスクレープする Prometheus ジョブを定義します。 別のロールを使用するには、以下を実行します。
Secretリソースを作成します。oc create secret generic additional-scrape-configs --from-file=prometheus-additional.yaml
oc create secret generic additional-scrape-configs --from-file=prometheus-additional.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
prometheus.yamlファイルでadditionalScrapeConfigsプロパティーを編集し、Secretの名前と、追加の設定が含まれる YAML ファイル (prometheus-additional.yaml) を追加します。
Prometheus リソースをデプロイします。
oc apply -f strimzi-service-monitor.yaml oc apply -f prometheus-rules.yaml oc apply -f prometheus.yaml
oc apply -f strimzi-service-monitor.yaml oc apply -f prometheus-rules.yaml oc apply -f prometheus.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.4. Prometheus Alertmanager
Prometheus Alertmanager は、アラートを処理して通知サービスにルーティングするためのプラグインです。Alertmanager は、アラートルールを基にして潜在的な問題と見られる状態を通知し、監視で必要な条件に対応します。
10.4.1. Alertmanager の設定
AMQ Streams には、Prometheus Alertmanager の設定ファイルのサンプルが含まれます。
設定ファイルは、Alertmanager をデプロイするためのリソースを定義します。
-
alert-manager.yaml
追加の設定ファイルには、Kafka クラスターから通知を送信するためのフック定義が含まれます。
-
alert-manager-config.yaml
Alertmanger で Prometheus アラートの処理を可能にするには、設定ファイルを使用して以下を行います。
10.4.2. アラートルール
アラートルールによって、メトリクスで監視される特定条件についての通知が提供されます。ルールは Prometheus サーバーで宣言されますが、アラート通知は Prometheus Alertmanager で対応します。
Prometheus アラートルールでは、継続的に評価される PromQL 表現を使用して条件が記述されます。
アラート表現が true になると、条件が満たされ、Prometheus サーバーからアラートデータが Alertmanager に送信されます。次に Alertmanager は、そのデプロイメントに設定された通信方法を使用して通知を送信します。
Alertmanager は、電子メール、チャットメッセージなどの通知方法を使用するように設定できます。
その他のリソース
アラートルールの設定についての詳細は、Prometheus ドキュメントの「Configuration」を参照してください。
10.4.3. アラートルールの例
Kafka および ZooKeeper メトリクスのアラートルールのサンプルは AMQ Streams に含まれており、Prometheus デプロイメントで使用できます。
アラートルールの定義に関する一般的な留意点:
-
forプロパティーはルールと併用され、アラートがトリガーされる前に条件が維持されなければならない期間を決定します。 -
ティック (tick) は ZooKeeper の基本的な時間単位です。ミリ秒単位で測定され、
Kafka.spec.zookeeper.configのtickTimeパラメーターを使用して設定されます。たとえば、ZooKeeper でtickTime=3000の場合、3 ティック (3 x 3000) は 9000 ミリ秒と等しくなります。 -
ZookeeperRunningOutOfSpaceメトリクスおよびアラートを利用できるかどうかは、使用される OpenShift 設定およびストレージ実装によります。特定のプラットフォームのストレージ実装では、メトリクスによるアラートの提供に必要な利用可能な領域について情報が提供されない場合があります。
Kafka アラートルール
UnderReplicatedPartitions-
現在のブローカーがリードレプリカでありながら、パーティションのトピックに設定された
min.insync.replicasよりも複製数が少ないパーティションの数が示されます。このメトリクスにより、フォロワーレプリカをホストするブローカーの詳細が提供されます。リーダーからこれらのフォロワーへの複製が追い付いていません。その理由として、現在または過去にオフライン状態になっていたり、過剰なスロットリングが適用されたブローカー間の複製であることが考えられます。この値がゼロより大きい場合にアラートが発生し、複製の数が最低数未満であるパーティションの情報がブローカー別に通知されます。 AbnormalControllerState- 現在のブローカーがクラスターのコントローラーであるかどうかを示します。メトリクスは 0 または 1 です。クラスターのライフサイクルでは、1 つのブローカーのみかコントローラーとなるはずで、クラスターには常にアクティブなコントローラーが存在する必要があります。複数のブローカーがコントローラーであることが示される場合は問題になります。そのような状態が続くと、すべてのブローカーのこのメトリクスの合計値が 1 でない場合にアラートが発生します。合計値が 0 であればアクティブなコントローラーがなく、合計値が 1 を超えればコントローラーが複数あることを意味します。
UnderMinIsrPartitionCount-
書き込み操作の完了を通知しなければならないリード Kafka ブローカーの ISR (In-Sync レプリカ) が最小数 (
min.insync.replicasを使用して指定) に達していないことを示します。このメトリクスでは、ブローカーがリードし、In-Sync レプリカの数が最小数に達していない、パーティションの数が定義されます。この値がゼロより大きい場合にアラートが発生し、完了通知 (ack) が最少数未満であった各ブローカーのパーティション数に関する情報が提供されます。 OfflineLogDirectoryCount- ハードウェア障害などの理由によりオフライン状態であるログディレクトリーの数を示します。そのため、ブローカーは受信メッセージを保存できません。この値がゼロより大きい場合にアラートが発生し、各ブローカーのオフライン状態であるログディレクトリーの数に関する情報が提供されます。
KafkaRunningOutOfSpace-
データの書き込みに使用できる残りのディスク容量を示します。この値が 5GiB 未満になるとアラートが発生し、永続ボリューム要求 (Persistent Volume Claim、PVC) ごとに容量不足のディスクに関する情報が提供されます。しきい値は
prometheus-rules.yamlで変更できます。
ZooKeeper アラートルール
AvgRequestLatency- サーバーがクライアントリクエストに応答するまでの時間を示します。この値が 10 (tick) を超えるとアラートが発生し、各サーバーの平均リクエストレイテンシーの実際の値が通知されます。
OutstandingRequests- サーバーでキューに置かれたリクエストの数を示します。この値は、サーバーが処理能力を超えるリクエストを受信すると上昇します。この値が 10 よりも大きい場合にアラートが発生し、各サーバーの未処理のリクエスト数が通知されます。
ZookeeperRunningOutOfSpace- このメトリクスは、ZooKeeper へのデータ書き込みに使用できる残りのディスク容量を示します。この値が 5GiB 未満になるとアラートが発生し、永続ボリューム要求 (Persistent Volume Claim、PVC) ごとに容量不足のディスクに関する情報が提供されます。
10.4.4. Alertmanager のデプロイメント
Alertmanager をデプロイするには、設定ファイルのサンプルを適用します。
AMQ Streams に含まれる設定サンプルでは、Slack チャネルに通知を送信するように Alertmanager を設定します。
デプロイメントで以下のリソースが定義されます。
-
Alertmanager。Alertmanager Pod を管理します。 -
Secret。Alertmanager の設定を管理します。 -
Service。参照しやすいホスト名を提供し、他のサービスが Alertmanager に接続できるようにします (Prometheus など)。
手順
Alertmanager 設定ファイル (
alert-manager-config.yaml) からSecretリソースを作成します。oc create secret generic alertmanager-alertmanager --from-file=alertmanager.yaml=alert-manager-config.yaml
oc create secret generic alertmanager-alertmanager --from-file=alertmanager.yaml=alert-manager-config.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow alert-manager-config.yamlファイルを更新し、以下を行います。-
slack_api_urlプロパティーを、Slack ワークスペースのアプリケーションに関連する Slack API URL の実際の値に置き換えます。 -
channelプロパティーを、通知が送信される実際の Slack チャネルに置き換えます。
-
Alertmanager をデプロイします。
oc apply -f alert-manager.yaml
oc apply -f alert-manager.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.5. Grafana
Grafana では、Prometheus メトリクスを視覚化できます。
AMQ Streams で提供される Grafana ダッシュボードサンプルをデプロイして有効化できます。
10.5.1. Grafana の設定
AMQ Streams には、Grafana のダッシュボード設定ファイルのサンプル が含まれています。
Grafana Docker イメージがデプロイメント用に提供されます。
-
grafana.yaml
ダッシュボードのサンプルも JSON ファイルで提供されます。
-
strimzi-kafka.json -
strimzi-kafka-connect.json -
strimzi-zookeeper.json
ダッシュボードのサンプルは、主なメトリクスの監視を開始するための雛形として使用できますが、使用できるすべてのメトリックスを対象としていません。使用するインフラストラクチャーに応じて、ダッシュボードのサンプルの編集や、他のメトリクスの追加が必要な場合もあります。
Grafana でダッシュボードを表示するには、設定ファイルを使用して以下を行います。
10.5.2. Grafana のデプロイメント
Grafana をデプロイして Prometheus メトリクスを視覚化するには、設定ファイルのサンプルを適用します。
前提条件
手順
Grafana をデプロイします。
oc apply -f grafana.yaml
oc apply -f grafana.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Grafana ダッシュボードを有効にします。
10.5.3. Grafana ダッシュボードサンプルの有効化
Prometheus データソースおよびダッシュボードのサンプルを設定し、監視用に Grafana を有効にします。
アラート通知ルールは定義されていません。
ダッシュボードにアクセスする場合、port-forward コマンドを使用して Grafana Pod からホストにトラフィックを転送できます。
たとえば、以下のように Grafana ユーザーインターフェースにアクセスできます。
-
oc port-forward svc/grafana 3000:3000を実行します。 -
ブラウザーで
http://localhost:3000を指定します。
Grafana Pod の名前はユーザーごとに異なります。
手順
admin/adminクレデンシャルを使用して、Grafana ユーザーインターフェースにアクセスします。最初のビューで、パスワードのリセットを選択します。

Add data source ボタンをクリックします。
Prometheus をデータソースとして追加します。
- 名前を指定します。
- Prometheus をタイプとして追加します。
- URL フィールドに、Prometheus サーバーへ接続する URL (http://prometheus-operated:9090) を指定します。
Add をクリックしてデータソースへの接続をテストします。
Dashboards、Import の順にクリックして、Import Dashboard ウィンドウを開き、ダッシュボードのサンプルをインポートします (または JSON を貼り付けます)。
ダッシュボードをインポートしたら、Grafana ダッシュボードのホームページに Kafka および ZooKeeper ダッシュボードが表示されます。
Prometheus サーバーが AMQ Streams クラスターのメトリクスを収集すると、それがダッシュボードに反映されます。
図10.1 Kafka ダッシュボード
図10.2 ZooKeeper ダッシュボード
第11章 分散トレーシング
本章では、Jaeger を使用した AMQ Streams での分散トレーシングのサポートについて説明します。
分散トレーシングの設定方法は、AMQ Streams クライアントとコンポーネントによって異なります。
- OpenTracing クライアントライブラリーを使用して、Kafka Producer、Consumer、および Streams API の各アプリケーションを分散トレーシング向けに インストルメント化 します。これには、インストルメント化コードをこれらのクライアントに追加することが含まれ、レースデータを生成するために個々のトランザクションの実行が監視されます。
- 分散トレーシングのサポートは、AMQ Streams の Kafka Connect、MirrorMaker、および Kafka Bridge コンポーネントに組み込まれています。これらのコンポーネントを分散トレーシング向けに設定するには、関連するカスタムリソースを設定および更新します。
AMQ Streams クライアントおよびコンポーネントで分散トレーシングを設定する前に、「Kafka クライアント用の Jaeger トレーサーの初期化」の手順に従い、最初に Kafka クラスターで Jaeger トレーサーを初期化して設定する必要があります。
分散トレーシングは Kafka ブローカーではサポートされません。
11.1. AMQ Streams での分散トレーシングの概要
分散トレーシングを使用すると、開発者およびシステム管理者は、分散システム内のアプリケーション (およびマイクロサービスアーキテクチャー内のサービス) 間のトランザクションの進捗を追跡できます。この情報は、アプリケーションのパフォーマンスを監視し、ターゲットシステムおよびエンドユーザーアプリケーションの問題を調べるのに役立ちます。
AMQ Streams およびデータストリーミングのプラットフォームでは、通常、分散トレーシングによって、メッセージのエンドツーエンドでの追跡 (ソースシステムから Kafka クラスターへ、さらにターゲットシステムおよびアプリケーションへ) が容易になります。
分散トレーシングは、システムの可観測性の要素として、Grafana ダッシュボードで表示可能なメトリクスと各コンポーネントで利用可能なロガーを補完します。
OpenTracing の概要
AMQ Streams の分散トレーシングは、オープンソースの OpenTracing および Jaeger プロジェクトを使用して実装されます。
OpenTracing 仕様では、分散トレーシングのアプリケーションをインストルメント化するために開発者が使用する API が定義されます。これは、トレーシングシステムに依存しません。
アプリケーションがインストルメント化されると、個々のトランザクションの トレース が生成されます。トレースは、特定の作業単位を定義する スパン で構成されます。
Kafka Bridge と、Kafka Producer、Consumer、および Streams API アプリケーションのインストルメンテーションを簡素化するために、AMQ Streams には OpenTracing Apache Kafka Client Instrumentation ライブラリーが含まれています。
OpenTracing プロジェクトは OpenCensus プロジェクトと統合されました。新たに統合されたプロジェクトの名前は OpenTelemetry です。OpenTelemetry は、OpenTracing API を使用してインストルメント化されたアプリケーションの互換性を維持します。
Jaeger の概要
Jaeger はトレーシングシステムで、マイクロサービスベースの分散システムの監視およびトラブルシューティングに使用される OpenTracing API の実装です。4 つの主要コンポーネントで構成され、アプリケーションのインストルメント化するためのクライアントライブラリーが提供されます。Jaeger ユーザーインターフェースを使用すると、トレースデータを視覚化、クエリー、フィルタリング、および分析できます。
Jaeger ユーザーインターフェースのクエリー例

11.1.1. AMQ Streams での分散トレーシングのサポート
AMQ Streams では、分散トレーシングは以下でサポートされます。
- Kafka Connect (Source2Image がサポートされる Kafka Connect を含む)
- MirrorMaker
- AMQ Streams Kafka Bridge
これらのコンポーネントの分散トレーシングを有効化および設定するには、関連するカスタムリソース (例: KafkaConnect、KafkaBridge) でテンプレート設定プロパティーを設定します。
Kafka Producer、Consumer、および Streams API の各アプリケーションで分散トレーシングを有効にするには、OpenTracing Apache Kafka Client Instrumentation ライブラリーを使用してアプリケーションコードをインストルメント化します。インストルメント化されると、クライアントはメッセージのトレースを生成します (メッセージの作成時やログへのオフセットの書き込み時など)。
トレースは、サンプリングストラテジーに従いサンプル化され、Jaeger ユーザーインターフェースで可視化されます。このトレースデータは、Kafka クラスターのパフォーマンスの監視や、ターゲットシステムおよびアプリケーションの問題のデバッグに便利です。
手順の概要
AMQ Streams の分散トレーシングを設定するには、以下の手順に従います。
本章では、AMQ Streams クライアントおよびコンポーネントの分散トレーシングの設定についてのみ説明します。AMQ Streams 以外のアプリケーションおよびシステムに分散トレーシングを設定する方法については、本章の対象外となります。この件についての詳細は、OpenTracing ドキュメントを参照し、「inject and extrac」を検索してください。
作業を開始する前の注意事項
AMQ Streams の分散トレーシングを設定する前に、以下を理解しておくと便利です。
- OpenTracing の基本として、トレース、スパン、トレーサーなどの主な概念。OpenTracing ドキュメントを参照してください。
- Jaeger アーキテクチャーのコンポーネント。
前提条件
- Jaeger バックエンドコンポーネントが OpenShift クラスターにデプロイされている必要があります。デプロイメント手順の詳細は、Jaeger デプロイメントのドキュメントを参照してください。
11.2. Kafka クライアントのトレース設定
本セクションでは、分散トレーシング用にクライアントアプリケーションをインストルメント化できるように、Jaeger トレーサーを初期化する方法について説明します。
11.2.1. Kafka クライアント用の Jaeger トレーサーの初期化
一連のトレーシング環境変数を使用して、Jaeger トレーサーを設定および初期化します。
手順
クライアントアプリケーションごとに以下の手順を実行します。
Jaeger の Maven 依存関係をクライアントアプリケーションの
pom.xmlファイルに追加します。<dependency> <groupId>io.jaegertracing</groupId> <artifactId>jaeger-client</artifactId> <version>1.1.0.redhat-00002</version> </dependency><dependency> <groupId>io.jaegertracing</groupId> <artifactId>jaeger-client</artifactId> <version>1.1.0.redhat-00002</version> </dependency>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - トレーシング環境変数を使用して Jaeger トレーサーの設定を定義します。
2. で定義した環境変数から、Jaeger トレーサーを作成します。
Tracer tracer = Configuration.fromEnv().getTracer();
Tracer tracer = Configuration.fromEnv().getTracer();Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記別の Jaeger トレーサーの初期化方法については、Java OpenTracing ライブラリーのドキュメントを参照してください。
Jaeger トレーサーをグローバルトレーサーとして登録します。
GlobalTracer.register(tracer);
GlobalTracer.register(tracer);Copy to Clipboard Copied! Toggle word wrap Toggle overflow
これで、Jaeger トレーサーはクライアントアプリケーションが使用できるように初期化されました。
11.2.2. トレーシング環境変数
ここに示す環境変数は、Kafka クライアントに Jaeger トレーサーを設定するときに使用します。
トレーシング環境変数は Jaeger プロジェクトの一部で、変更される場合があります。最新の環境変数については、Jaeger ドキュメントを参照してください。
| プロパティー | 必要性 | 説明 |
|---|---|---|
|
| 必要 | Jaeger トレーサーサービスの名前。 |
|
| 不要 |
UDP (User Datagram Protocol) を介した |
|
| 不要 |
UDP を介した |
|
| 不要 |
traces エンドポイント。クライアントアプリケーションが |
|
| 不要 | エンドポイントに bearer トークンとして送信する認証トークン。 |
|
| 不要 | Basic 認証を使用する場合にエンドポイントに送信するユーザー名。 |
|
| 不要 | Basic 認証を使用する場合にエンドポイントに送信するパスワード。 |
|
| 不要 |
トレースコンテキストの伝播に使用するカンマ区切りの形式リスト。デフォルトは標準の Jaeger 形式です。有効な値は |
|
| 不要 | レポーターがスパンも記録する必要があるかどうかを示します。 |
|
| 不要 | レポーターの最大キューサイズ。 |
|
| 不要 | レポーターのフラッシュ間隔 (ミリ秒単位)。Jaeger レポーターがスパンバッチをフラッシュする頻度を定義します。 |
|
| 不要 | クライアントトレースに使用するサンプリングストラテジー: Constant、Probabilistic、Rate Limiting、または Remote (デフォルトタイプ) 全トレースをサンプリングするには、パラメーターに 1 を指定して Constant サンプリングストラテジーを使用します。 詳細は、Jaeger ドキュメントを参照してください。 |
|
| 不要 | サンプラーのパラメーター (数値)。 |
|
| 不要 | リモートサンプリングストラテジーを選択する場合に使用するホスト名およびポート。 |
|
| 不要 | 報告されたすべてのスパンに追加されるトレーサーレベルのタグのカンマ区切りリスト。
この値に |
その他のリソース
11.3. トレーサーでの Kafka クライアントのインストルメント化
本セクションでは、分散トレーシングのために Kafka Producer、Consumer、および Streams API アプリケーションをインストルメント化する方法を説明します。
11.3.1. トレーシングのための Kafka Producer および Consumer のインストルメント化
Decorator パターンまたは Interceptor を使用して、Java Producer および Consumer アプリケーションコードを分散トレーシング用にインストルメント化します。
手順
Kafka Producer および Consumer アプリケーションのアプリケーションコードで以下の手順を実行します。
OpenTracing の Maven 依存関係を、Producer または Consumer の
pom.xmlファイルに追加します。<dependency> <groupId>io.opentracing.contrib</groupId> <artifactId>opentracing-kafka-client</artifactId> <version>0.1.11.redhat-00001</version> </dependency><dependency> <groupId>io.opentracing.contrib</groupId> <artifactId>opentracing-kafka-client</artifactId> <version>0.1.11.redhat-00001</version> </dependency>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Decorator パターンまたは Interceptor のいずれかを使用して、クライアントアプリケーションコードをインストルメント化します。
デコレーターパターンを使用する場合は、以下の例を使用します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow インターセプターを使用する場合は、以下の例を使用します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
11.3.1.1. Decorator パターンのカスタムスパン名
スパン は Jaeger の論理作業単位で、操作名、開始時間、および期間が含まれます。
Decorator パターンを使用して Kafka Producer および Consumer の各アプリケーションをインストルメント化する場合、TracingKafkaProducer および TracingKafkaConsumer オブジェクトの作成時に BiFunction オブジェクトを追加の引数として渡すと、カスタムスパン名を定義できます。OpenTracing の Apache Kafka Client Instrumentation ライブラリーには、以下のようなビルトインスパン名がいくつか含まれています。
例: カスタムスパン名を使用した Decorator パターンでのクライアントアプリケーションコードのインストルメント化
11.3.1.2. ビルトインスパン名
カスタムスパン名を定義するとき、ClientSpanNameProvider クラスで以下の BiFunctions を使用できます。spanNameProvider の指定がない場合は、CONSUMER_OPERATION_NAME および PRODUCER_OPERATION_NAME が使用されます。
| BiFunction | 説明 |
|---|---|
|
|
|
|
|
|
|
|
メッセージの送信先または送信元となったトピックの名前を |
|
|
|
|
|
操作名およびトピック名を |
|
|
|
11.3.2. Kafka Streams アプリケーションのトレーシングのインストルメント化
本セクションでは、分散トレーシングのために Kafka Streams API アプリケーションをインストルメント化する方法を説明します。
手順
Kafka Streams API アプリケーションごとに以下の手順を実行します。
opentracing-kafka-streams依存関係を、Kafka Streams API アプリケーションの pom.xml ファイルに追加します。<dependency> <groupId>io.opentracing.contrib</groupId> <artifactId>opentracing-kafka-streams</artifactId> <version>0.1.11.redhat-00001</version> </dependency><dependency> <groupId>io.opentracing.contrib</groupId> <artifactId>opentracing-kafka-streams</artifactId> <version>0.1.11.redhat-00001</version> </dependency>Copy to Clipboard Copied! Toggle word wrap Toggle overflow TracingKafkaClientSupplierサプライヤーインターフェースのインスタンスを作成します。KafkaClientSupplier supplier = new TracingKafkaClientSupplier(tracer);
KafkaClientSupplier supplier = new TracingKafkaClientSupplier(tracer);Copy to Clipboard Copied! Toggle word wrap Toggle overflow サプライヤーインターフェースを
KafkaStreamsに提供します。KafkaStreams streams = new KafkaStreams(builder.build(), new StreamsConfig(config), supplier); streams.start();
KafkaStreams streams = new KafkaStreams(builder.build(), new StreamsConfig(config), supplier); streams.start();Copy to Clipboard Copied! Toggle word wrap Toggle overflow
11.4. MirrorMaker、Kafka Connect、および Kafka Bridge のトレース設定
分散トレーシングは、MirrorMaker、Kafka Connect (Source2Image がサポートされる Kafka Connect を含む)、および AMQ Streams Kafka Bridge でサポートされます。
MirrorMaker でのトレース
MirrorMaker では、メッセージはソースクラスターからターゲットクラスターにトレースされます。トレースデータは、MirrorMaker コンポーネントに出入りするメッセージを記録します。
Kafka Connect でのトレース
Kafka Connect により生成および消費されるメッセージのみがトレーシングされます。Kafka Connect と外部システム間で送信されるメッセージをトレーシングするには、これらのシステムのコネクターでトレーシングを設定する必要があります。詳細は「Kafka Connect クラスターの設定」を参照してください。
Kafka Bridge でのトレーシング
Kafka Bridge によって生成および消費されるメッセージがトレーシングされます。Kafka Bridge を介してメッセージを送受信するクライアントアプリケーションから受信する HTTP リクエストもトレースされます。エンドツーエンドのトレースを設定するために、HTTP クライアントでトレースを設定する必要があります。
11.4.1. MirrorMaker、Kafka Connect、および Kafka Bridge リソースでのトレースの有効化
KafkaMirrorMaker、KafkaConnect、KafkaConnectS2I、およびKafkaBridge カスタムリソースの設定を更新して、リソースごとに Jaeger トレーサーサービスを指定および設定します。OpenShift クラスターでトレースが有効になっているリソースを更新すると、2 つのイベントがトリガーされます。
- インターセプタークラスは、MirrorMaker、Kafka Connect、または AMQ Streams Kafka Bridge の統合されたコンシューマーおよびプロデューサーで更新されます。
- MirrorMaker および Kafka Connect では、リソースに定義されたトレース設定に基づいて、Jaeger トレーサーがトレーシングエージェントによって初期化されます。
- Kafka Bridge では、リソースに定義されたトレース設定に基づいて、Jaeger トレーサーが Kafka Bridge によって初期化されます。
手順
各 KafkaMirrorMaker、KafkaConnect、KafkaConnectS2I、および KafkaBridge リソースにこれらのステップを実行します。
spec.templateプロパティーで、Jaeger トレーサーサービスを設定します。以下に例を示します。Kafka Connect の Jaeger トレーサー設定
Copy to Clipboard Copied! Toggle word wrap Toggle overflow MirrorMaker の Jaeger トレーサー設定
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka Bridge の Jaeger トレーサー設定
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
- トレーシング環境変数をテンプレートの設定プロパティーとして使用します。
- 2
spec.tracing.typeプロパティーをjaegerに設定します。
リソースを作成または更新します。
oc apply -f your-file
oc apply -f your-fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
第12章 Kafka Exporter
Kafka Exporter は、Apache Kafka ブローカーおよびクライアントの監視を強化するオープンソースプロジェクトです。Kafka Exporter は、Kafka クラスターとのデプロイメントを実現するために AMQ Streams で提供され、オフセット、コンシューマーグループ、コンシューマーラグ、およびトピックに関連する Kafka ブローカーから追加のメトリクスデータを抽出します。
一例として、メトリクスデータを使用すると、低速なコンシューマーの識別に役立ちます。
ラグデータは Prometheus メトリクスとして公開され、解析のために Grafana で使用できます。
ビルトイン Kafka メトリクスを監視するために Prometheus および Grafana をすでに使用している場合、Kafka Exporter Prometheus エンドポイントをスクレープするように Prometheus を設定することもできます。
その他のリソース
12.1. コンシューマーラグ
コンシューマーラグは、メッセージの生成と消費の差を示しています。具体的には、指定のコンシューマーグループのコンシューマーラグは、パーティションの最後のメッセージと、そのコンシューマーが現在ピックアップしているメッセージとの時間差を示しています。ラグには、パーティションログの最後を基準とする、コンシューマーオフセットの相対的な位置が反映されます。
この差は、Kafka ブローカートピックパーティションの読み取りと書き込みの場所である、プロデューサーオフセットとコンシューマーオフセットの間の デルタ とも呼ばれます。
あるトピックで毎秒 100 個のメッセージがストリーミングされる場合を考えてみましょう。プロデューサーオフセット (トピックパーティションの先頭) と、コンシューマーが読み取った最後のオフセットとの間のラグが 1000 個のメッセージであれば、10 秒の遅延があることを意味します。
コンシューマーラグ監視の重要性
可能な限りリアルタイムのデータの処理に依存するアプリケーションでは、コンシューマーラグを監視して、ラグが過度に大きくならないようにチェックする必要があります。ラグが大きくなるほど、リアルタイム処理の達成から遠ざかります。
たとえば、パージされていない古いデータの大量消費や、予定外のシャットダウンが、コンシューマーラグの原因となることがあります。
コンシューマーラグの削減
通常、ラグを削減するには以下を行います。
- 新規コンシューマーを追加してコンシューマーグループをスケールアップします。
- メッセージがトピックに留まる保持時間を延長します。
- ディスク容量を追加してメッセージバッファーを増強します。
コンシューマーラグを減らす方法は、基礎となるインフラストラクチャーや、AMQ Streams によりサポートされるユースケースによって異なります。たとえば、ラグが生じているコンシューマーの場合、ディスクキャッシュからフェッチリクエストに対応できるブローカーを活用できる可能性は低いでしょう。場合によっては、コンシューマーの状態が改善されるまで、自動的にメッセージをドロップすることが許容されることがあります。
12.2. Kafka Exporter アラートルールの例
メトリクスをデプロイメントに導入するステップが実行済みである場合、Kafka Exporter をサポートするアラート通知ルールを使用するよう Kafka クラスターがすでに設定された状態になっています。
Kafka Exporter のルールは prometheus-rules.yaml に定義されており、Prometheus でデプロイされます。詳細は、「Prometheus」を参照してください。
Kafka Exporter に固有のサンプルのアラート通知ルールには以下があります。
UnderReplicatedPartition- トピックで複製の数が最低数未満であり、ブローカーがパーティションで十分な複製を作成していないことを警告するアラートです。デフォルトの設定では、トピックに複製の数が最低数未満のパーティションが 1 つ以上ある場合のアラートになります。このアラートは、Kafka インスタンスがダウンしているか Kafka クラスターがオーバーロードの状態であることを示す場合があります。レプリケーションプロセスを再起動するには、Kafka ブローカーの計画的な再起動が必要な場合があります。
TooLargeConsumerGroupLag- 特定のトピックパーティションでコンシューマーグループのラグが大きすぎることを警告するアラートです。デフォルト設定は 1000 レコードです。ラグが大きい場合、コンシューマーが遅すぎてプロデューサーの処理に追い付いてない可能性があります。
NoMessageForTooLong- トピックが一定期間にわたりメッセージを受信していないことを警告するアラートです。この期間のデフォルト設定は 10 分です。この遅れは、設定の問題により、プロデューサーがトピックにメッセージを公開できないことが原因である可能性があります。
これらのルールのデフォルト設定は、特定のニーズに合わせて調整してください。
その他のリソース
12.3. Kafka Exporter メトリクス
ラグ情報は、Grafana で示す Prometheus メトリクスとして Kafka Exporter によって公開されます。
Kafka Exporter は、ブローカー、トピック、およびコンシューマーグループのメトリクスデータを公開します。
抽出されるデータを以下に示します。
| 名前 | 詳細 |
|---|---|
|
| Kafka クラスターに含まれるブローカーの数 |
| 名前 | 詳細 |
|---|---|
|
| トピックのパーティション数 |
|
| ブローカーの現在のトピックパーティションオフセット |
|
| ブローカーの最も古いトピックパーティションオフセット |
|
| トピックパーティションの In-Sync レプリカ数 |
|
| トピックパーティションのリーダーブローカー ID |
|
|
トピックパーティションが優先ブローカーを使用している場合は、 |
|
| このトピックパーティションのレプリカ数 |
|
|
トピックパーティションの複製の数が最低数未満である場合に |
| 名前 | 詳細 |
|---|---|
|
| コンシューマーグループの現在のトピックパーティションオフセット |
|
| トピックパーティションのコンシューマーグループの現在のラグ (概算値) |
12.4. Kafka Exporter Grafana ダッシュボードの有効化
Kafka Exporter を Kafka クラスターでデプロイした場合、Grafana により公開されるメトリクスデータを表示するように Grafana を有効化できます。
Kafka Exporter ダッシュボードは、JSON ファイルとして提供され、examples/metrics ディレクトリーに含まれています。
-
strimzi-kafka-exporter.json
前提条件
- Kafka クラスターが Kafka Exporter メトリクス設定でデプロイされている必要があります。
- Prometheus および Prometheus Alertmanager が Kafka クラスターにデプロイされている必要があります。
- Grafana が Kafka クラスターにデプロイされている必要があります。
この手順では、Grafana ユーザーインターフェースにアクセスでき、Prometheus がデータソースとして追加されていることを前提とします。ユーザーインターフェースに初めてアクセスする場合は、「Grafana」を参照してください。
手順
- Grafana ユーザーインターフェースにアクセスします。
Dashboards、Import の順にクリックして Import Dashboard ウィンドウを開き、Kafka Exporter ダッシュボードのサンプルをインポートします (または JSON を貼り付けます)。
メトリクスデータが収集されると、Kafka Exporter のチャートにデータが反映されます。
Kafka Exporter Grafana チャート
メトリクスから、チャートを作成して以下を表示できます。
- 毎秒のメッセージ (トピックから)
- 毎分のメッセージ (トピックから)
- コンシューマーグループごとのラグ
- 毎分のメッセージ消費 (コンシューマーグループごと)
Grafana のチャートを使用して、ラグを分析し、ラグ削減の方法が対象のコンシューマーグループに影響しているかどうかを確認します。たとえば、ラグを減らすように Kafka ブローカーを調整する場合、ダッシュボードには コンシューマーグループごとのラグ のチャートが下降し 毎分のメッセージ消費 のチャートが上昇する状況が示されます。
第13章 セキュリティー
AMQ Streams は、Kafka と AMQ Streams コンポーネントとの間で TLS プロトコルを使用して暗号化された通信をサポートします。Kafka ブローカー間の通信 (Interbroker 通信)、ZooKeeper ノード間の通信 (Internodal 通信)、およびこれらと AMQ Streams Operator 間の通信は、常に暗号化されます。Kafka クライアントと Kafka ブローカーとの間の通信は、クラスターが設定された方法に応じて暗号化されます。Kafka および AMQ Streams コンポーネントでは、TLS 証明書も認証に使用されます。
Cluster Operator は、自動で TLS 証明書の設定および更新を行い、クラスター内での暗号化および認証を有効にします。また、Kafka ブローカーとクライアントとの間の暗号化または TLS 認証を有効にする場合、他の TLS 証明書も設定されます。ユーザーが用意した証明書は更新されません。
TLS 暗号化が有効になっている TLS リスナーまたは外部リスナーの、Kafka リスナー証明書 と呼ばれる独自のサーバー証明書を提供できます。詳細は 「Kafka リスナー証明書」 を参照してください。
13.1. 認証局
暗号化のサポートには、AMQ Streams コンポーネントごとに固有の秘密鍵と公開鍵証明書が必要です。すべてのコンポーネント証明書は、クラスター CA と呼ばれる内部認証局 (CA) により署名されます。
同様に、TLS クライアント認証を使用して AMQ Streams に接続する各 Kafka クライアントアプリケーションは、秘密鍵と証明書を提供する必要があります。クライアント CA という第 2 の内部 CA を使用して、Kafka クライアントの証明書に署名します。
13.1.1. CA 証明書
クラスター CA とクライアント CA の両方には、自己署名の公開鍵証明書があります。
Kafka ブローカーは、クラスター CA またはクライアント CA のいずれかが署名した証明書を信頼するように設定されます。クライアントによる接続が不要なコンポーネント (ZooKeeper など) のみが、クラスター CA によって署名された証明書を信頼します。外部リスナーの TLS 暗号化が無効でない限り、クライアントアプリケーションはクラスター CA により署名された証明書を必ず信頼する必要があります。これは、相互 TLS 認証 を実行するクライアントアプリケーションにも当てはまります。
デフォルトで、AMQ Streams はクラスター CA またはクライアント CA によって発行された CA 証明書を自動で生成および更新します。これらの CA 証明書の管理は、Kafka.spec.clusterCa および Kafka.spec.clientsCa オブジェクトで設定できます。ユーザーが用意した証明書は更新されません。
クラスター CA またはクライアント CA に、独自の CA 証明書を提供できます。詳細は「独自の CA 証明書のインストール」を参照してください。独自の証明書を提供する場合は、証明書の更新が必要なときに手作業で更新する必要があります。
13.1.2. CA 証明書の有効期間
CA 証明書の有効期間は、証明書の生成からの日数で提示されます。有効期間は、それぞれ以下で設定できます。
-
クラスター CA 証明書の場合:
Kafka.spec.clusterCa.validityDays -
クライアント CA 証明書の場合:
Kafka.spec.clientsCa.validityDays
13.1.3. 独自の CA 証明書のインストール
この手順では、Cluster Operator で生成される CA 証明書と秘密鍵を使用する代わりに、独自の CA 証明書と秘密鍵をインストールする方法について説明します。
前提条件
- Cluster Operator が稼働している必要があります。
- Kafka クラスターがデプロイされていない必要があります。
クラスター CA またはクライアントの、PEM 形式による独自の X.509 証明書および鍵が必要です。
ルート CA ではないクラスターまたはクライアント CA を使用する場合、証明書ファイルにチェーン全体を含める必要があります。チェーンの順序は以下のとおりです。
- クラスターまたはクライアント CA
- 1 つ以上の中間 CA
- ルート CA
- チェーン内のすべての CA は、X509v3 の基本制約 (Basic Constraint) で CA として設定する必要があります。
手順
使用する CA 証明書を対応する
Secretに挿入します (クラスター CA の場合は<cluster>-cluster-ca-cert、クライアント CA の場合は<cluster>-clients-ca-cert)。以下のコマンドを実行します。
# Delete any existing secret (ignore "Not Exists" errors) oc delete secret <ca-cert-secret> # Create and label the new secret oc create secret generic <ca-cert-secret> --from-file=ca.crt=<ca-cert-file>
# Delete any existing secret (ignore "Not Exists" errors) oc delete secret <ca-cert-secret> # Create and label the new secret oc create secret generic <ca-cert-secret> --from-file=ca.crt=<ca-cert-file>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用する CA キーを対応する
Secretに挿入します (クラスター CA の場合は<cluster>-cluster-ca、クライアント CA の場合は<cluster>-clients-ca)。# Delete the existing secret oc delete secret <ca-key-secret> # Create the new one oc create secret generic <ca-key-secret> --from-file=ca.key=<ca-key-file>
# Delete the existing secret oc delete secret <ca-key-secret> # Create the new one oc create secret generic <ca-key-secret> --from-file=ca.key=<ca-key-file>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 両方の
Secretsにラベルstrimzi.io/kind=Kafkaおよびstrimzi.io/cluster=<my-cluster>を付けます。oc label secret <ca-cert-secret> strimzi.io/kind=Kafka strimzi.io/cluster=<my-cluster> oc label secret <ca-key-secret> strimzi.io/kind=Kafka strimzi.io/cluster=<my-cluster>
oc label secret <ca-cert-secret> strimzi.io/kind=Kafka strimzi.io/cluster=<my-cluster> oc label secret <ca-key-secret> strimzi.io/kind=Kafka strimzi.io/cluster=<my-cluster>Copy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターの
Kafkaリソースを作成し、生成された CA を使用 しない ようにKafka.spec.clusterCaおよびKafka.spec.clientsCaオブジェクトを設定します。独自指定の証明書を使用するようにクラスター CA を設定する
Kafkaリソースの例 (抜粋)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
その他のリソース
- 以前にインストールした CA 証明書を更新する手順は、「独自の CA 証明書の更新」を参照してください。
- 「独自の Kafka リスナー証明書の指定」
13.2. Secret
Strimzi は Secret を使用して、Kafka クラスターコンポーネントおよびクライアントの秘密鍵と証明書を格納します。Secret は、Kafka ブローカー間やブローカーとクライアントの間で TLS で暗号化された接続を確立するために使用されます。Secret は相互 TLS 認証にも使用されます。
- Cluster Secret には、Kafka ブローカー証明書に署名するためのクラスター CA 証明書が含まれます。また、接続クライアントによって、Kafka クラスターとの TLS 暗号化接続を確立してブローカー ID を検証するために使用されます。
- Client Secret にはクライアント CA 証明書が含まれ、これによりユーザーは独自のクライアント証明書に署名し、Kafka クラスターに対する相互認証が可能になります。ブローカーはクライアント CA 証明書を使用してクライアント ID を検証します。
- User Secret には、新規ユーザーの作成時にクライアント CA 証明書によって生成および署名される秘密鍵と証明書が含まれています。この鍵と証明書は、クラスターへのアクセス時の認証および承認に使用されます。
Secret には、PEM 形式および PKCS #12 形式の秘密鍵と証明書が含まれます。PEM 形式の秘密鍵と証明書を使用する場合、ユーザーは Secret からそれらの秘密鍵と証明書を取得し、Java アプリケーションで使用するために対応するトラストストア (またはキーストア) を生成します。PKCS #12 ストレージは、直接使用できるトラストストア (またはキーストア) を提供します。
すべての鍵のサイズは 2048 ビットです。
13.2.1. PKCS #12 ストレージ
PKCS #12 は、暗号化オブジェクトをパスワードで保護された単一のファイルに格納するためのアーカイブファイル形式 (.p12) を定義します。PKCS #12 を使用して、証明書および鍵を一元的に管理できます。
各 Secret には、PKCS #12 特有のフィールドが含まれています。
-
.p12フィールドには、証明書と鍵が含まれます。 -
.passwordフィールドは、アーカイブを保護するパスワードです。
13.2.2. クラスター CA Secret
| Secret 名 | Secret 内のフィールド | 説明 |
|---|---|---|
|
|
| クラスター CA の現在の秘密鍵。 |
|
|
| 証明書および鍵を格納するための PKCS #12 アーカイブファイル。 |
|
| PKCS #12 アーカイブのファイルを保護するパスワード。 | |
|
| クラスター CA の現在の証明書。 | |
|
|
| 証明書および鍵を格納するための PKCS #12 アーカイブファイル。 |
|
| PKCS #12 アーカイブのファイルを保護するパスワード。 | |
|
|
Kafka ブローカー Pod <num> の証明書。 | |
|
| Kafka ブローカー Pod <num> の秘密鍵。 | |
|
|
| 証明書および鍵を格納するための PKCS #12 アーカイブファイル。 |
|
| PKCS #12 アーカイブのファイルを保護するパスワード。 | |
|
|
ZooKeeper ノード <num> の証明書。 | |
|
| ZooKeeper Pod <num> の秘密鍵。 | |
|
|
| 証明書および鍵を格納するための PKCS #12 アーカイブファイル。 |
|
| PKCS #12 アーカイブのファイルを保護するパスワード。 | |
|
|
Entity Operator と Kafka または ZooKeeper との間の TLS 通信の証明書。 | |
|
| Entity Operator と Kafka または ZooKeeper との間の TLS 通信の秘密鍵 |
TLS を介した Kafka ブローカーへの接続時に Kafka ブローカー証明書を検証するため、<cluster>-cluster-ca-cert の CA 証明書は Kafka クライアントアプリケーションによって信頼される必要があります。
クライアントは <cluster>-cluster-ca-cert のみを使用する必要があります。上表の他のすべての Secrets は、AMQ Streams コンポーネントによるアクセスのみが必要です。これは、必要な場合に OpenShift のロールベースのアクセス制御を使用して強制できます。
13.2.3. クライアント CA Secret
| Secret 名 | Secret 内のフィールド | 説明 |
|---|---|---|
|
|
| クライアント CA の現在の秘密鍵。 |
|
|
| 証明書および鍵を格納するための PKCS #12 アーカイブファイル。 |
|
| PKCS #12 アーカイブのファイルを保護するパスワード。 | |
|
| クライアント CA の現在の証明書。 |
<cluster>-clients-ca-cert の証明書は、Kafka ブローカーが信頼する証明書です。
<cluster>-clients-ca は、クライアントアプリケーションの証明書への署名に使用されます。また AMQ Streams コンポーネントにアクセスできる必要があり、User Operator を使わずにアプリケーション証明書を発行する予定であれば管理者のアクセス権限が必要です。これは、必要な場合に OpenShift のロールベースのアクセス制御を使用して強制できます。
13.2.4. User Secret
| Secret 名 | Secret 内のフィールド | 説明 |
|---|---|---|
|
|
| 証明書および鍵を格納するための PKCS #12 アーカイブファイル。 |
|
| PKCS #12 アーカイブのファイルを保護するパスワード。 | |
|
| ユーザーの証明書、クライアント CA により署名されます。 | |
|
| ユーザーの秘密鍵。 |
13.3. 証明書の更新
クラスター CA およびクライアント CA の証明書は、限定された期間、すなわち有効期間に限り有効です。通常、この期間は証明書の生成からの日数として定義されます。自動生成される CA 証明書では、有効期間を Kafka.spec.clusterCa.validityDays および Kafka.spec.clientsCa.validityDays で設定できます。デフォルトの有効期間は、両方の証明書で 365 日です。手動でインストールした CA 証明書には、独自の有効期間を定義する必要があります。
CA 証明書の期限が切れると、その証明書をまだ信頼しているコンポーネントおよびクライアントは、その CA 秘密鍵で署名された証明書を持つ相手からの TLS 接続を受け付けません。代わりに、コンポーネントおよびクライアントは 新しい CA 証明書を信頼する必要があります。
サービスを中断せずに CA 証明書を更新できるようにするため、Cluster Operator は古い CA 証明書が期限切れになる前に証明書の更新を開始します。更新期間は、Kafka.spec.clusterCa.renewalDays および Kafka.spec.clientsCa.renewalDays で設定できます (デフォルトは両方とも 30 日)。更新期間は、現在の証明書の有効期日から逆算されます。
Not Before Not After
| |
|<--------------- validityDays --------------->|
<--- renewalDays --->|
Not Before Not After
| |
|<--------------- validityDays --------------->|
<--- renewalDays --->|
更新期間中の Cluster Operator の動作は、関連する設定が Kafka.spec.clusterCa.generateCertificateAuthority または Kafka.spec.clientsCa.generateCertificateAuthority のいずれかで有効であるかどうかによって異なります。
13.3.1. 生成された CA での更新プロセス
Cluster Operator は以下のプロセスを実行して CA 証明書を更新します。
-
新しい CA 証明書を生成しますが、既存の鍵は保持します。該当する
Secret内のca.crtという名前の古い証明書が新しい証明書に置き換えられます。 - 新しいクライアント証明書を生成します (ZooKeeper ノード、Kafka ブローカー、および Entity Operator 用)。署名鍵は変わっておらず、CA 証明書と同期してクライアント証明書の有効期間を維持するため、これは必須ではありません。
- ZooKeeper ノードを再起動して、ZooKeeper ノードが新しい CA 証明書を信頼し、新しいクライアント証明書を使用するようにします。
- Kafka ブローカーを再起動して、Kafka ブローカーが新しい CA 証明書を信頼し、新しいクライアント証明書を使用するようにします。
- Topic Operator および User Operator を再起動して、それらの Operator が新しい CA 証明書を信頼し、新しいクライアント証明書を使用するようにします。
13.3.2. クライアントアプリケーション
Cluster Operator は、Kafka クラスターを使用するクライアントアプリケーションを認識しません。
クラスターに接続し、クライアントアプリケーションが正しく機能するように確認するには、クライアントアプリケーションは以下を行う必要があります。
- <cluster>-cluster-ca-cert Secret でパブリッシュされるクラスター CA 証明書を信頼する必要があります。
<user-name> Secret でパブリッシュされたクレデンシャルを使用してクラスターに接続します。
User Secret は PEM および PKCS #12 形式のクレデンシャルを提供し、SCRAM-SHA 認証を使用する場合はパスワードを提供できます。ユーザーの作成時に User Operator によってユーザークレデンシャルが生成されます。
同じ OpenShift クラスターおよび namespace 内で実行中のワークロードの場合、Secrets はボリュームとしてマウントできるので、クライアント Pod はそれらのキーストアとトラストストアを現在の状態の Secrets から構築できます。この手順の詳細は、「クラスター CA を信頼する内部クライアントの設定」を参照してください。
13.3.2.1. クライアント証明書の更新
証明書の更新後もクライアントが動作するようにする必要があります。更新プロセスは、クライアントの設定によって異なります。
クライアント証明書と鍵のプロビジョニングを手動で行う場合、新しいクライアント証明書を生成し、更新期間内に新しい証明書がクライアントによって使用されるようにする必要があります。更新期間の終了までにこれが行われないと、クライアントアプリケーションがクラスターに接続できなくなる可能性があります。
13.3.3. CA 証明書の手動更新
Kafka.spec.clusterCa.generateCertificateAuthority および Kafka.spec.clientsCa.generateCertificateAuthority オブジェクトが false に設定されていない限り、クラスターおよびクライアント CA 証明書は、それぞれの証明書の更新期間の開始時に自動で更新されます。セキュリティー上の理由で必要であれば、証明書の更新期間が始まる前に、これらの証明書のいずれかまたは両方を手動で更新できます。更新された証明書は、古い証明書と同じ秘密鍵を使用します。
前提条件
- Cluster Operator が稼働している必要があります。
- CA 証明書と秘密鍵がインストールされている Kafka クラスターが必要です。
手順
strimzi.io/force-renewアノテーションを、更新対象の CA 証明書が含まれるSecretに適用します。Expand 証明書 Secret annotate コマンド クラスター CA
<cluster-name>-cluster-ca-cert
oc annotate secret <cluster-name>-cluster-ca-cert strimzi.io/force-renew=trueクライアント CA
<cluster-name>-clients-ca-cert
oc annotate secret <cluster-name>-clients-ca-cert strimzi.io/force-renew=true
次回の調整で、アノテーションを付けた Secret の新規 CA 証明書が Cluster Operator によって生成されます。メンテナンス時間枠が設定されている場合、Cluster Operator によって、最初の調整時に次のメンテナンス時間枠内で新規 CA 証明書が生成されます。
Cluster Operator によって更新されたクラスターおよびクライアント CA 証明書をクライアントアプリケーションがリロードする必要があります。
13.3.4. 独自の CA 証明書の更新
この手順では、以前にインストールした CA 証明書および秘密鍵を更新する方法を説明します。期限切れ間近の CA 証明書を交換するには、更新期間中にこの手順を実施する必要があります。
前提条件
- Cluster Operator が稼働している必要があります。
- 以前に独自の CA 証明書と秘密鍵をインストールした Kafka クラスターが必要です。
クラスターおよびクライアントの PEM 形式による新しい X.509 証明書と鍵が必要です。これらは、
opensslを使用して以下のようなコマンドで生成できます。openssl req -x509 -new -days <validity> --nodes -out ca.crt -keyout ca.key
openssl req -x509 -new -days <validity> --nodes -out ca.crt -keyout ca.keyCopy to Clipboard Copied! Toggle word wrap Toggle overflow
手順
Secretにすでに存在する CA 証明書を確認します。以下のコマンドを使用します。
oc describe secret <ca-cert-secret>
oc describe secret <ca-cert-secret>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Secret に既存の CA 証明書が含まれるディレクトリーを準備します。
mkdir new-ca-cert-secret cd new-ca-cert-secret
mkdir new-ca-cert-secret cd new-ca-cert-secretCopy to Clipboard Copied! Toggle word wrap Toggle overflow 前のステップで確認した証明書 <ca-certificate> ごとに、以下を実行します。
# Fetch the existing secret oc get secret <ca-cert-secret> -o 'jsonpath={.data.<ca-certificate>}' | base64 -d > <ca-certificate># Fetch the existing secret oc get secret <ca-cert-secret> -o 'jsonpath={.data.<ca-certificate>}' | base64 -d > <ca-certificate>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 古い
ca.crtファイルの名前をca_<date>_.crtに変更します。ここで、<date> は証明書の有効期限日に置き換え、<year>-<month>-<day>_T<hour>_-<minute>-_<second>_Z の形式 (たとえばca-2018-09-27T17-32-00Z.crt) を使用します。mv ca.crt ca-$(date -u -d$(openssl x509 -enddate -noout -in ca.crt | sed 's/.*=//') +'%Y-%m-%dT%H-%M-%SZ').crt
mv ca.crt ca-$(date -u -d$(openssl x509 -enddate -noout -in ca.crt | sed 's/.*=//') +'%Y-%m-%dT%H-%M-%SZ').crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow 新規 CA 証明書をディレクトリーにコピーし、
ca.crtという名前を付けます。cp <path-to-new-cert> ca.crt
cp <path-to-new-cert> ca.crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow CA 証明書
Secretを置き換えます (<cluster>-cluster-caまたは<cluster>-clients-ca)。これは、以下のコマンドで実行できます。# Delete the existing secret oc delete secret <ca-cert-secret> # Re-create the secret with the new private key oc create secret generic <ca-cert-secret> --from-file=.
# Delete the existing secret oc delete secret <ca-cert-secret> # Re-create the secret with the new private key oc create secret generic <ca-cert-secret> --from-file=.Copy to Clipboard Copied! Toggle word wrap Toggle overflow これで、作成したディレクトリーを削除できます。
cd .. rm -r new-ca-cert-secret
cd .. rm -r new-ca-cert-secretCopy to Clipboard Copied! Toggle word wrap Toggle overflow CA キー
Secretを置き換えます (<cluster>-cluster-caまたは<cluster>-clients-ca)。これは、以下のコマンドで実行できます。# Delete the existing secret oc delete secret <ca-key-secret> # Re-create the secret with the new private key oc create secret generic <ca-key-secret> --from-file=ca.key=<ca-key-file>
# Delete the existing secret oc delete secret <ca-key-secret> # Re-create the secret with the new private key oc create secret generic <ca-key-secret> --from-file=ca.key=<ca-key-file>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
13.4. 秘密鍵の交換
クラスター CA およびクライアント CA 証明書によって使用される秘密鍵を交換できます。秘密鍵を交換すると、Cluster Operator は新しい秘密鍵の新規 CA 証明書を生成します。
前提条件
- Cluster Operator が稼働している必要があります。
- CA 証明書と秘密鍵がインストールされている Kafka クラスターが必要です。
手順
strimzi.io/force-replaceアノテーションを、更新対象の秘密鍵が含まれるSecretに適用します。Expand 秘密鍵 Secret annotate コマンド クラスター CA
<cluster-name>-cluster-ca
oc annotate secret <cluster-name>-cluster-ca strimzi.io/force-replace=trueクライアント CA
<cluster-name>-clients-ca
oc annotate secret <cluster-name>-clients-ca strimzi.io/force-replace=true
次回の調整時に、Cluster Operator は以下を生成します。
-
アノテーションを付けた
Secretの新しい秘密鍵 - 新規 CA 証明書
メンテナンス時間枠が設定されている場合、Cluster Operator によって、最初の調整時に次のメンテナンス時間枠内で新しい秘密鍵と CA 証明書が生成されます。
Cluster Operator によって更新されたクラスターおよびクライアント CA 証明書をクライアントアプリケーションがリロードする必要があります。
その他のリソース
13.5. TLS 接続
13.5.1. ZooKeeper の通信
ZooKeeper は TLS 自体をサポートしません。すべての ZooKeeper Pod に TLS サイドカーをデプロイすることで、Cluster Operator はクラスター内の ZooKeeper ノード間でデータ暗号化および認証を提供できるようになります。ZooKeeper は、ループバックインターフェース上で TLS サイドカーのみと通信します。次に TLS サイドカーは、ZooKeeper トラフィック、ZooKeeper Pod 受信時の TLS 復号化データ、および ZooKeeper Pod 送信時の TLS 暗号化データすべてのプロキシーとして動作します。
この TLS 暗号化 stunnel プロキシーは、Kafka リソースに指定された spec.zookeeper.stunnelImage からインスタンス化されます。
13.5.2. Kafka の Interbroker 通信
Kafka ブローカー間の通信は、ポート 9091 の内部リスナーを介して行われます。この通信はデフォルトで暗号化され、Kafka クライアントからはアクセスできません。
Kafka ブローカーと ZooKeeper ノード間の通信では、上記のように TLS サイドカーが使用されます。
13.5.3. Topic Operator および User Operator
Cluster Operator と同様に、Topic Operator および User Operator はそれぞれ ZooKeeper との通信時に TLS サイドカーを使用します。Topic Operator は、ポート 9091 で Kafka ブローカーに接続します。
13.5.4. Kafka クライアント接続
ポート 9093 でリッスンする spec.kafka.listeners.tls リスナーを設定すると、同じ OpenShift クラスター内で稼働している Kafka ブローカーとクライアントとの通信を暗号化できます。
同じ OpenShift クラスターの外部で稼働している Kafka ブローカーとクライアントとの通信を暗号化するには、spec.kafka.listeners.external リスナーを設定します (external リスナーのポートはそのタイプによって異なります)。
暗号化されていないクライアントとブローカーの通信は、ポート 9092 でリッスンする spec.kafka.listeners.plain で設定できます。
13.6. クラスター CA を信頼する内部クライアントの設定
この手順では、OpenShift クラスター内部に存在する Kafka クライアントの設定方法を説明します。ポート 9093 で tls リスナーに接続し、クラスター CA 証明書を信頼するように設定します。
これを内部クライアントで実現するには、ボリュームマウントを使用して、必要な証明書および鍵が含まれる Secrets にアクセスするのが最も簡単な方法です。
以下の手順に従い、クラスター CA によって署名された信頼できる証明書を Java ベースの Kafka Producer、Consumer、および Streams API に設定します。
クラスター CA の証明書の形式が PKCS #12 (.p12) または PEM (.crt) であるかに応じて、手順を選択します。
この手順では、Kafka クラスターの ID を検証する Cluster Secret をクライアント Pod にマウントする方法を説明します。
前提条件
- Cluster Operator が稼働している必要があります。
-
OpenShift クラスター内に
Kafkaリソースが必要です。 - TLS を使用して接続し、クラスター CA 証明書を必ず信頼する Kafka クライアントアプリケーションが、OpenShift クラスター外部に必要です。
-
クライアントアプリケーションが
Kafkaリソースと同じ namespace で実行している必要があります。
PKCS #12 形式 (.p12) の使用
クライアント Pod の定義時に、Cluster Secret をボリュームとしてマウントします。
以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow ここでは、以下をマウントしています。
- PKCS #12 ファイルを設定可能な正確なパスにマウント。
- パスワードを Java 設定に使用できる環境変数にマウント。
Kafka クライアントを以下のプロパティーで設定します。
セキュリティープロトコルのオプション:
-
security.protocol: SSL(TLS 認証ありまたはなしで、暗号化に TLS を使用する場合)。 -
security.protocol: SASL_SSL(TLS 経由で SCRAM-SHA 認証を使用する場合)。
-
-
ssl.truststore.location(証明書がインポートされたトラストストアを指定)。 -
ssl.truststore.password(トラストストアにアクセスするためのパスワードを指定)。 -
ssl.truststore.type=PKCS12(トラストストアのタイプを識別)。
PEM 形式の使用 (.crt)
クライアント Pod の定義時に、Cluster Secret をボリュームとしてマウントします。
以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - X.509 形式の証明書を使用するクライアントでこの証明書を使用します。
13.7. クラスター CA を信頼する外部クライアントの設定
この手順では、OpenShift クラスター外部に存在する Kafka クライアントの設定方法を説明します。ポート 9094 で external リスナーに接続し、クラスター CA 証明書を信頼するように設定します。クライアントのセットアップ時および更新期間中に、古いクライアント CA 証明書を交換する場合に、以下の手順に従います。
以下の手順に従い、クラスター CA によって署名された信頼できる証明書を Java ベースの Kafka Producer、Consumer、および Streams API に設定します。
クラスター CA の証明書の形式が PKCS #12 (.p12) または PEM (.crt) であるかに応じて、手順を選択します。
この手順では、Kafka クラスターの ID を検証する Cluster Secret から証明書を取得する方法を説明します。
CA 証明書の更新期間中に、<cluster-name>-cluster-ca-cert Secret に複数の CA 証明書が含まれます。クライアントは、それらを すべて をクライアントのトラストストアに追加する必要があります。
前提条件
- Cluster Operator が稼働している必要があります。
-
OpenShift クラスター内に
Kafkaリソースが必要です。 - TLS を使用して接続し、クラスター CA 証明書を必ず信頼する Kafka クライアントアプリケーションが、OpenShift クラスター外部に必要です。
PKCS #12 形式 (.p12) の使用
生成された
<cluster-name>-cluster-ca-certSecret から、クラスター CA 証明書およびパスワードを抽出します。oc get secret <cluster-name>-cluster-ca-cert -o jsonpath='{.data.ca\.p12}' | base64 -d > ca.p12oc get secret <cluster-name>-cluster-ca-cert -o jsonpath='{.data.ca\.p12}' | base64 -d > ca.p12Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc get secret <cluster-name>-cluster-ca-cert -o jsonpath='{.data.ca\.password}' | base64 -d > ca.passwordoc get secret <cluster-name>-cluster-ca-cert -o jsonpath='{.data.ca\.password}' | base64 -d > ca.passwordCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka クライアントを以下のプロパティーで設定します。
セキュリティープロトコルのオプション:
-
security.protocol: SSL(TLS 認証ありまたはなしで、暗号化に TLS を使用する場合)。 -
security.protocol: SASL_SSL(TLS 経由で SCRAM-SHA 認証を使用する場合)。
-
-
ssl.truststore.location(証明書がインポートされたトラストストアを指定)。 -
ssl.truststore.password(トラストストアにアクセスするためのパスワードを指定)。このプロパティーは、トラストストアで必要なければ省略できます。 -
ssl.truststore.type=PKCS12(トラストストアのタイプを識別)。
PEM 形式の使用 (.crt)
生成された
<cluster-name>-cluster-ca-certSecret から、クラスター CA 証明書を抽出します。oc get secret <cluster-name>-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crtoc get secret <cluster-name>-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow - X.509 形式の証明書を使用するクライアントでこの証明書を使用します。
13.8. Kafka リスナー証明書
以下のタイプのリスナーに、独自のサーバー証明書と秘密鍵を指定できます。
- クラスター間通信の TLS リスナー
-
Kafka クライアントと Kafka ブローカー間の通信に TLS 暗号化が有効になっている外部リスナー (
route、loadbalancer、ingress、およびnodeportタイプ)
これらのユーザー提供による証明書は、Kafka リスナー証明書 と呼ばれます。
外部リスナーに Kafka リスナー証明書を提供すると、既存のセキュリティーインフラストラクチャー (所属組織のプライベート CA やパブリック CA など) を利用できます。Kafka クライアントは Kafka ブローカーに接続する際に、クラスター CA またはクライアント CA によって署名された証明書ではなく、Kafka リスナー証明書を使用します。
Kafka リスナー証明書の更新が必要な場合は、手作業で更新する必要があります。
13.8.1. 独自の Kafka リスナー証明書の指定
この手順では、独自の秘密鍵と Kafka リスナー証明書と呼ばれるサーバー証明書を使用するようにリスナーを設定する方法について説明します。
Kafka ブローカーの ID を検証するため、クライアントアプリケーションは CA 公開鍵を信頼できる証明書として使用する必要があります。
前提条件
- OpenShift クラスターが必要です。
- Cluster Operator が稼働している必要があります。
リスナーごとに、外部 CA によって署名された互換性のあるサーバー証明書が必要です。
- X.509 証明書を PEM 形式で提供します。
- リスナーごとに正しい SAN (サブジェクト代替名) を指定します。詳細は「Kafka リスナーのサーバー証明書の SAN」を参照してください。
- 証明書ファイルに CA チェーン全体が含まれる証明書を提供できます。
手順
秘密鍵およびサーバー証明書が含まれる
Secretを作成します。oc create secret generic my-secret --from-file=my-listener-key.key --from-file=my-listener-certificate.crt
oc create secret generic my-secret --from-file=my-listener-key.key --from-file=my-listener-certificate.crtCopy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターの
Kafkaリソースを編集します。Secret、証明書ファイル、および秘密鍵ファイルを使用するように、リスナーをconfiguration.brokerCertChainAndKeyプロパティーで設定します。TLS 暗号化が有効な
loadbalancer外部リスナーの設定例Copy to Clipboard Copied! Toggle word wrap Toggle overflow TLS リスナーの設定例
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 新しい設定を適用してリソースを作成または更新します。
oc apply -f kafka.yaml
oc apply -f kafka.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Cluster Operator は、Kafka クラスターのローリングアップデートを開始し、これによりリスナーの設定が更新されます。
注記TLS または外部リスナーによってすでに使用されている
Secretの Kafka リスナー証明書を更新した場合でも、ローリングアップデートが開始されます。
13.8.2. Kafka リスナーのサーバー証明書の SAN
独自の Kafka リスナー証明書で TLS ホスト名検証を使用するには、リスナーごとに SAN (サブジェクト代替名) を使用する必要があります。証明書の SAN は、以下のホスト名を指定する必要があります。
- クラスターのすべての Kafka ブローカー
- Kafka クラスターブートストラップサービス
ワイルドカード証明書は、CA でサポートされれば使用できます。
13.8.2.1. TLS リスナー SAN の例
以下の例を利用して、TLS リスナーの証明書で SAN のホスト名を指定できます。
ワイルドカードの例
ワイルドカードのない例
13.8.2.2. 外部リスナー SAN の例
TLS 暗号化が有効になっている外部リスナーの場合、証明書に指定する必要があるホスト名は、外部リスナーの type によって異なります。
| 外部リスナータイプ | SAN で指定する内容 |
|---|---|
|
|
すべての Kafka ブローカー 一致するワイルドカード名を使用できます。 |
|
|
すべての Kafka ブローカー 一致するワイルドカード名を使用できます。 |
|
| Kafka ブローカー Pod がスケジュールされるすべての OpenShift ワーカーノードのアドレス。 一致するワイルドカード名を使用できます。 |
その他のリソース
第14章 AMQ Streams および Kafka のアップグレード
AMQ Streams は、クラスターのダウンタイムを発生せずにアップグレードできます。AMQ Streams の各バージョンは、Apache Kafka の 1 つ以上のバージョンをサポートします。使用する AMQ Streams バージョンでサポートされれば、より高いバージョンの Kafka にアップグレードできます。サポートされる下位バージョンの Kafka にダウングレードできる場合もあります。
より新しいバージョンの AMQ Streams はより新しいバージョンの Kafka をサポートしますが、AMQ Streams をアップグレードしてから、サポートされる上位バージョンの Kafka にアップグレードする必要があります。
14.1. アップグレードの前提条件
アップグレードプロセスを開始する前に、以下を確認します。
- AMQ Streams がインストールされている必要があります。手順は2章AMQ Streams の使用を参照してください。
- 「AMQ STREAMS 1.4 ON OPENSHIFT リリースノート」に記載されているアップグレードの変更について理解している必要があります。
14.2. アップグレードプロセス
AMQ Streams のアップグレードは 2 段階のプロセスで行います。ダウンタイムなしでブローカーとクライアントをアップグレードするには、以下の順序でアップグレード手順を 必ず 完了してください。
Cluster Operator を最新の AMQ Streams バージョンに更新します。
すべての Kafka ブローカーとクライアントアプリケーションを、最新の Kafka バージョンにアップグレードします。
14.3. Kafka バージョン
Kafka のログメッセージ形式バージョンおよびブローカー間のプロトコルバージョンは、メッセージに追加されるログ形式バージョンとクラスターで使用されるプロトコルのバージョンを指定します。そのためアップグレードプロセスでは、既存の Kafka ブローカーの設定変更およびクライアントアプリケーション (コンシューマーおよびプロデューサー) のコード変更により、必ず正しいバージョンを使用されるようにする必要になります。
以下の表は、Kafka バージョンの違いを示しています。
| Kafka のバージョン | Interbroker プロトコルのバージョン | ログメッセージ形式のバージョン | ZooKeeper バージョン |
|---|---|---|---|
| 2.3.0 | 2.3 | 2.3 | 3.4.14 |
| 2.4.0 | 2.4 | 2.4 | 3.5.7 |
メッセージ形式のバージョン
プロデューサーが Kafka ブローカーにメッセージを送信すると、特定の形式を使用してメッセージがエンコードされます。この形式は Kafka のリリースによって変わるため、メッセージにはエンコードに使用された形式のバージョンが含まれます。ブローカーがメッセージをログに追加する前に、メッセージを新しい形式バージョンから特定の旧形式バージョンに変換するように、Kafka ブローカーを設定できます。
Kafka には、メッセージ形式のバージョンを設定する 2 通りの方法があります。
-
message.format.versionプロパティーはトピックに設定されます。 -
log.message.format.versionプロパティーは Kafka ブローカーに設定されます。
トピックの message.format.version のデフォルト値は、Kafka ブローカーに設定される log.message.format.version によって定義されます。トピックの message.format.version は、トピック設定を編集すると手動で設定できます。
本セクションのアップグレード作業では、メッセージ形式のバージョンが log.message.format.version によって定義されることを前提としています。
14.4. Cluster Operator のアップグレード
このセクションでは、AMQ Streams 1.4 を使用するように Cluster Operator デプロイメントをアップグレードする手順について説明します。
Cluster Operator によって管理される Kafka クラスターの可用性は、アップグレード操作の影響を受けません。
特定バージョンの AMQ Streams へのアップグレード方法については、そのバージョンをサポートするドキュメントを参照してください。
14.4.1. Cluster Operator の後続バージョンへのアップグレード
この手順では、Cluster Operator デプロイメントを後続バージョンにアップグレードする方法を説明します。
前提条件
- 既存の Cluster Operator デプロイメントを利用できる必要があります。
- すでに新規バージョンのインストールファイルをダウンロードしてある必要があります。
手順
既存の Cluster Operator リソースのバックアップを作成します。
oc get all -l app=strimzi -o yaml > strimzi-backup.yaml
oc get all -l app=strimzi -o yaml > strimzi-backup.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Cluster Operator を更新します。
Cluster Operator が稼働している namespace に従い、インストールファイルを編集します。
Linux の場合は、以下を使用します。
sed -i 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yaml
sed -i 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow MacOS の場合は、以下を使用します。
sed -i '' 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yaml
sed -i '' 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 既存の Cluster Operator
Deploymentで 1 つ以上の環境変数を編集した場合、install/cluster-operator/050-Deployment-cluster-operator.yamlファイルを編集し、Cluster Operator の新規バージョンに加えた変更を反映させます。設定を更新したら、残りのインストールリソースとともにデプロイします。
oc apply -f install/cluster-operator
oc apply -f install/cluster-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow ローリングアップデートが完了するのを待ちます。
Kafka Pod のイメージを取得して、アップグレードが正常に完了したことを確認します。
oc get po my-cluster-kafka-0 -o jsonpath='{.spec.containers[0].image}'oc get po my-cluster-kafka-0 -o jsonpath='{.spec.containers[0].image}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow イメージタグには、新しい AMQ Streams バージョンと Kafka バージョンが順に示されます。例:
<New AMQ Streams version>-kafka-<Current Kafka version>既存のリソースを更新して、非推奨になったカスタムリソースプロパティーを処理します。
これで Cluster Operator が更新されましたが、その管理下にあるクラスターで実行している Kafka のバージョンは変わりません。
次のステップ
Cluster Operator のアップグレードの次に、Kafka アップグレードを実行できます。
14.5. Kafka のアップグレード
Cluster Operator をアップグレードしたら、サポートされる上位の Kafka バージョンにブローカーをアップグレードできます。
Kafka のアップグレードは、Cluster Operator を使用して行います。Cluster Operator によるアップグレードの実行方法は、以下のバージョン間の違いによって異なります。
- Interbroker プロトコル
- ログメッセージの形式
- ZooKeeper
現在の Kafka バージョンとアップグレードする Kafka バージョンが同じ場合 (パッチレベルでのアップグレードではよくあります)、Kafka ブローカーのローリングアップデートを 1 回実行して Cluster Operator によるアップグレードを行います。
これらのバージョンが 1 つ以上異なる場合、Kafka ブローカーのローリングアップデートを 2、3 回実行して Cluster Operator でアップグレードを実行する必要があります。
その他のリソース
14.5.1. Kafka バージョンおよびイメージマッピング
Kafka のアップグレード時に、STRIMZI_KAFKA_IMAGES および Kafka.spec.kafka.version プロパティーの設定について考慮してください。
-
それぞれの
KafkaリソースはKafka.spec.kafka.versionで設定できます。 Cluster Operator の
STRIMZI_KAFKA_IMAGES環境変数により、Kafka のバージョンと、指定のKafkaリソースでそのバージョンが要求されるときに使用されるイメージをマッピングできます。-
Kafka.spec.kafka.imageを設定しないと、そのバージョンのデフォルトのイメージが使用されます。 -
Kafka.spec.kafka.imageを設定すると、デフォルトのイメージがオーバーライドされます。
-
Cluster Operator は、Kafka ブローカーの想定されるバージョンが実際にイメージに含まれているかどうかを検証できません。所定のイメージが所定の Kafka バージョンに対応することを必ず確認してください。
14.5.2. クライアントをアップグレードするストラテジー
クライアントアプリケーション (Kafka Connect コネクターを含む) をアップグレードする最善の方法は、特定の状況によって異なります。
消費するアプリケーションは、そのアプリケーションが理解するメッセージ形式のメッセージを受信する必要があります。その状態であることを、以下のいずれかの方法で確認できます。
- プロデューサーをアップグレードする 前に、トピックのすべてのコンシューマーをアップグレードする。
- ブローカーでメッセージをダウンコンバートする。
ブローカーのダウンコンバートを使用すると、ブローカーに余分な負荷が加わるので、すべてのトピックで長期にわたりダウンコンバートに頼るのは最適な方法ではありません。ブローカーの実行を最適化するには、ブローカーがメッセージを一切ダウンコンバートしないようにしてください。
ブローカーのダウンコンバートは 2 通りの方法で設定できます。
-
トピックレベルの
message.format.versionでは単一のとピックが設定されます。 -
ブローカーレベルの
log.message.format.versionは、トピックレベルのmessage.format.versionが設定されてないトピックのデフォルトです。
新バージョンの形式でトピックにパブリッシュされるメッセージは、コンシューマーによって認識されます。これは、メッセージがコンシューマーに送信されるときでなく、ブローカーがプロデューサーからメッセージを受信するときに、ブローカーがダウンコンバートを実行するからです。
クライアントのアップグレードに使用できるストラテジーは複数あります。
- コンシューマーを最初にアップグレード
- コンシューマーとして機能するアプリケーションをすべてアップグレードします。
-
ブローカーレベルの
log.message.format.versionを新バージョンに変更します。 プロデューサーとして機能するアプリケーションをアップグレードします。
このストラテジーは分かりやすく、ブローカーのダウンコンバートの発生をすべて防ぎます。ただし、所属組織内のすべてのコンシューマーを整然とアップグレードできることが前提になります。また、コンシューマーとプロデューサーの両方に該当するアプリケーションには通用しません。さらにリスクとして、アップグレード済みのクライアントに問題がある場合は、新しい形式のメッセージがメッセージログに追加され、以前のコンシューマーバージョンに戻せなくなる場合があります。
- トピック単位でコンシューマーを最初にアップグレード
トピックごとに以下を実行します。
- コンシューマーとして機能するアプリケーションをすべてアップグレードします。
-
トピックレベルの
message.format.versionを新バージョンに変更します。 プロデューサーとして機能するアプリケーションをアップグレードします。
このストラテジーではブローカーのダウンコンバートがすべて回避され、トピックごとにアップグレードできます。この方法は、同じトピックのコンシューマーとプロデューサーの両方に該当するアプリケーションには通用しません。ここでもリスクとして、アップグレード済みのクライアントに問題がある場合は、新しい形式のメッセージがメッセージログに追加される可能性があります。
- トピック単位でコンシューマーを最初にアップグレード、ダウンコンバートあり
トピックごとに以下を実行します。
-
トピックレベルの
message.format.versionを、旧バージョンに変更します (または、デフォルトがブローカーレベルのlog.message.format.versionのトピックを利用します)。 - コンシューマーおよびプロデューサーとして機能するアプリケーションをすべてアップグレードします。
- アップグレードしたアプリケーションが正しく機能することを確認します。
トピックレベルの
message.format.versionを新バージョンに変更します。このストラテジーにはブローカーのダウンコンバートが必要ですが、ダウンコンバートは一度に 1 つのトピック (またはトピックの小さなグループ) のみに必要になるので、ブローカーへの負荷は最小限に抑えられます。この方法は、同じトピックのコンシューマーとプロデューサーの両方に該当するアプリケーションにも通用します。この方法により、新しいメッセージ形式バージョンを使用する前に、アップグレードされたプロデューサーとコンシューマーが正しく機能することが保証されます。
この方法の主な欠点は、多くのトピックやアプリケーションが含まれるクラスターでの管理が複雑になる場合があることです。
-
トピックレベルの
クライアントアプリケーションをアップグレードするストラテジーは他にもあります。
複数のストラテジーを適用することもできます。たとえば、最初のいくつかのアプリケーションとトピックに、「トピック単位でコンシューマーを最初にアップグレード、ダウンコンバートあり」のストラテジーを適用します。これが問題なく適用されたら、より効率的な別のストラテジーの使用を検討できます。
14.5.3. Kafka ブローカーおよびクライアントアプリケーションのアップグレード
この手順では、AMQ Streams Kafka クラスターを Kafka の上位バージョンにアップグレードする方法を説明します。
前提条件
Kafka リソースをアップグレードするには、以下を確認します。
- 両バージョンの Kafka をサポートする Cluster Operator が稼働している。
-
Kafka.spec.kafka.configに、アップグレード先となる Kafka バージョンでサポートされないオプションが含まれていない。 現行の Kafka バージョンの
log.message.format.versionを新しいバージョンに更新する必要があるかどうか。Kafka バージョン表を参照してください。
手順
必要に応じてエディターで Kafka クラスター設定を更新します。
oc edit kafka my-cluster
oc edit kafka my-clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 現行のバージョンの Kafka の
log.message.format.versionが新しい Kafka バージョンでも同じ場合は、次の手順に進みます。それ以外の場合、
Kafka.spec.kafka.configのlog.message.format.versionが 現行 バージョンのデフォルトに設定されていることを確認してください。たとえば、Kafka 2.3.0 からのアップグレードでは以下のようになります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow log.message.format.versionが設定されていない場合は、現行バージョンに設定します。注記log.message.format.versionの値は、浮動小数点数として解釈されないように文字列である必要があります。Kafka.spec.kafka.versionを変更し、新バージョンを指定します (log.message.format.versionは現行バージョンのままにします)。たとえば、Kafka 2.3.0 から 2.4.0 へのアップグレードは以下のようになります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka バージョンのイメージが Cluster Operator の
STRIMZI_KAFKA_IMAGESに定義されているイメージとは異なる場合は、Kafka.spec.kafka.imageを更新します。「Kafka バージョンおよびイメージマッピング」を参照してください。
エディターを保存して終了し、ローリングアップデートの完了を待ちます。
注記新バージョンの Kafka に新しい ZooKeeper バージョンがある場合、追加のローリングアップデートが発生します。
更新をログで確認するか、または Pod 状態の遷移を監視して確認します。
oc logs -f <cluster-operator-pod-name> | grep -E "Kafka version upgrade from [0-9.]+ to [0-9.]+, phase ([0-9]+) of \1 completed"
oc logs -f <cluster-operator-pod-name> | grep -E "Kafka version upgrade from [0-9.]+ to [0-9.]+, phase ([0-9]+) of \1 completed"Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc get po -w
oc get po -wCopy to Clipboard Copied! Toggle word wrap Toggle overflow 現行バージョンと新バージョンの Kafka で、Interbroker プロトコルのバージョンが異なる場合は、Cluster Operator ログで
INFOレベルのメッセージを確認します。Reconciliation #<num>(watch) Kafka(<namespace>/<name>): Kafka version upgrade from <from-version> to <to-version>, phase 2 of 2 completed
Reconciliation #<num>(watch) Kafka(<namespace>/<name>): Kafka version upgrade from <from-version> to <to-version>, phase 2 of 2 completedCopy to Clipboard Copied! Toggle word wrap Toggle overflow または、現行バージョンと新バージョンの Kafka で、Interbroker プロトコルのバージョンが同じ場合は、以下を確認します。
Reconciliation #<num>(watch) Kafka(<namespace>/<name>): Kafka version upgrade from <from-version> to <to-version>, phase 1 of 1 completed
Reconciliation #<num>(watch) Kafka(<namespace>/<name>): Kafka version upgrade from <from-version> to <to-version>, phase 1 of 1 completedCopy to Clipboard Copied! Toggle word wrap Toggle overflow ローリングアップデートでは以下を行います。
- 各 Pod が新バージョンの Kafka のブローカーバイナリーを使用していることを確認します。
新バージョンの Kafka の Interbroker プロトコルを使用してメッセージを送信するように、ブローカーを設定します。
注記クライアントは引き続き旧バージョンを使用するため、ブローカーはメッセージを旧バージョンに変換してからクライアントに送信します。この余分な負荷を最小化するには、できるだけ速やかにクライアントを更新します。
クライアントのアップグレードに選択したストラテジーに応じて、新バージョンのクライアントバイナリーを使用するようにすべてのクライアントアプリケーションをアップグレードします。
「クライアントをアップグレードするストラテジー」を参照してください。
警告この手順を完了すると、ダウングレードできません。この時点で更新を元に戻す必要がある場合は、「Kafka ブローカーおよびクライアントアプリケーションのダウングレード」の手順に従います。
必要に応じて、Kafka Connect および MirrorMaker のバージョンプロパティーを新バージョンの Kafka として設定します。
-
Kafka Connect では、
KafkaConnect.spec.versionを更新します。 -
MirrorMaker では、
KafkaMirrorMaker.spec.versionを更新します。
-
Kafka Connect では、
1. で特定された
log.message.format.versionが、新しいバージョンと同じ場合は、次の手順に進みます。それ以外の場合は、
Kafka.spec.kafka.configのlog.message.format.versionを、現在使用している新バージョンの Kafka のデフォルトバージョンに変更します。たとえば、2.4.0 へのアップグレードでは以下のようになります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Cluster Operator によってクラスターが更新されるまで待ちます。
これで、Kafka クラスターおよびクライアントが新バージョンの Kafka を使用するようになります。
その他のリソース
- AMQ Streams Kafka クラスターをあるバージョンから下位バージョンにダウングレードする手順は、「Kafka ブローカーおよびクライアントアプリケーションのダウングレード」を参照してください。
14.5.4. コンシューマーおよび Kafka Streams アプリケーションの Cooperative Rebalancing へのアップグレード
Kafka コンシューマーおよび Kafka Streams アプリケーションをアップグレードすることで、パーティションの再分散にデフォルトの Eager Rebalance プロトコルではなく Incremental Cooperative Rebalance プロトコルを使用できます。この新しいプロトコルが Kafka 2.4.0 に追加されました。
コンシューマーは、パーティションの割り当てを Cooperative Rebalance で保持し、クラスターの分散が必要な場合にプロセスの最後でのみ割り当てを取り消します。これにより、コンシューマーグループまたは Kafka Streams アプリケーションが使用不可能になる状態が削減されます。
Incremental Cooperative Rebalance プロトコルへのアップグレードは任意です。Eager Rebalance プロトコルは引き続きサポートされます。
前提条件
- Kafka 2.4.0 に Kafka ブローカーおよびクライアントアプリケーションをアップグレード済みであることが必要です。
手順
Incremental Cooperative Rebalance プロトコルを使用するように Kafka コンシューマーをアップグレードするには以下を行います。
-
Kafka クライアント
.jarファイルを新バージョンに置き換えます。 -
コンシューマー設定で、
partition.assignment.strategyにcooperative-stickyを追加します。たとえば、rangeストラテジーが設定されている場合は、設定をrange, cooperative-stickyに変更します。 - グループ内の各コンシューマーを順次再起動し、再起動後に各コンシューマーがグループに再度参加するまで待ちます。
-
コンシューマー設定から前述の
partition.assignment.strategyを削除して、グループの各コンシューマーを再設定し、cooperative-stickyストラテジーのみを残します。 - グループ内の各コンシューマーを順次再起動し、再起動後に各コンシューマーがグループに再度参加するまで待ちます。
Incremental Cooperative Rebalance プロトコルを使用するように Kafka Streams アプリケーションをアップグレードするには以下を行います。
-
Kafka Streams の
.jarファイルを新バージョンに置き換えます。 -
Kafka Streams の設定で、
upgrade.from設定パラメーターをアップグレード前の Kafka バージョンに設定します (例: 2.3)。 - 各ストリームプロセッサー (ノード) を順次再起動します。
-
upgrade.from設定パラメーターを Kafka Streams 設定から削除します。 - グループ内の各コンシューマーを順次再起動します。
その他のリソース
- Apache Kafka ドキュメントの「Notable changes in 2.4.0」。
14.6. Kafka のダウングレード
Kafka バージョンのダウングレードは、Cluster Operator を使用して行います。
Cluster Operator によるダウングレードの実行方法は、以下のバージョン間の違いによって異なります。
- Interbroker プロトコル
- ログメッセージの形式
- ZooKeeper
14.6.1. ダウングレード先のバージョン
Cluster Operator によるダウングレードの操作方法は、log.message.format.version に応じて異なります。
-
ダウングレード先の Kafka バージョンの
log.message.format.versionが現行バージョンと同じ場合、Cluster Operator はブローカーのローリング再起動を 1 回実行してダウングレードを行います。 ダウングレード先の Kafka バージョンの
log.message.format.versionが異なる場合、ダウングレード後の Kafka バージョンが使用するバージョンに設定されたlog.message.format.versionが 常に 実行中のクラスターに存在する場合に限り、ダウングレードが可能です。通常は、アップグレードの手順が
log.message.format.versionの変更前に中止された場合にのみ該当します。その場合、ダウングレードには以下が必要です。- 2 つのバージョンで Interbroker プロトコルが異なる場合、ブローカーのローリング再起動が 2 回必要です。
- 両バージョンで同じ場合は、ローリング再起動が 1 回必要です。
14.6.2. Kafka ブローカーおよびクライアントアプリケーションのダウングレード
この手順では、AMQ Streams Kafka クラスターを Kafka の下位 (以前の) バージョンにダウングレードする方法 (2.4.0 から 2.3.0 へのダウングレードなど) を説明します。
以前のバージョンでサポートされない log.message.format.version が新バージョンで使われていた場合 (log.message.format.versionのデフォルト値が使われていた場合など)、ダウングレードは実行 できません。たとえば以下のリソースの場合、log.message.format.version が変更されていないので、Kafka バージョン 2.3.0 にダウングレードできます。
log.message.format.version が "2.4" に設定されているかまたは値がない (このためパラメーターに 2.4.0 ブローカーのデフォルト値 2.4 が採用される) 場合は、ダウングレードは実施できません。
前提条件
Kafka リソースをダウングレードするには、以下を確認します。
- 両バージョンの Kafka をサポートする Cluster Operator が稼働している。
-
Kafka.spec.kafka.configに、ダウングレード先となる Kafka バージョンでサポートされないオプションが含まれていない。 -
Kafka.spec.kafka.configに、ダウングレード先のバージョンでサポートされるlog.message.format.versionがある。
手順
必要に応じてエディターで Kafka クラスター設定を更新します。
oc editを使用します。oc edit kafka my-cluster
oc edit kafka my-clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka.spec.kafka.versionを変更して、以前のバージョンを指定します。たとえば、Kafka 2.4.0 から 2.3.0 へのダウングレードは以下のようになります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記log.message.format.versionの値は、浮動小数点数として解釈されないように文字列にする必要があります。Kafka バージョンのイメージが Cluster Operator の
STRIMZI_KAFKA_IMAGESに定義されているイメージとは異なる場合は、Kafka.spec.kafka.imageを更新します。「Kafka バージョンおよびイメージマッピング」を参照してください。
エディターを保存して終了し、ローリングアップデートの完了を待ちます。
更新をログで確認するか、または Pod 状態の遷移を監視して確認します。
oc logs -f <cluster-operator-pod-name> | grep -E "Kafka version downgrade from [0-9.]+ to [0-9.]+, phase ([0-9]+) of \1 completed"
oc logs -f <cluster-operator-pod-name> | grep -E "Kafka version downgrade from [0-9.]+ to [0-9.]+, phase ([0-9]+) of \1 completed"Copy to Clipboard Copied! Toggle word wrap Toggle overflow oc get po -w
oc get po -wCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka の前バージョンと現行バージョンで Interbroker プロトコルのバージョンが異なる場合、Cluster Operator ログで
INFOレベルのメッセージを確認します。Reconciliation #<num>(watch) Kafka(<namespace>/<name>): Kafka version downgrade from <from-version> to <to-version>, phase 2 of 2 completed
Reconciliation #<num>(watch) Kafka(<namespace>/<name>): Kafka version downgrade from <from-version> to <to-version>, phase 2 of 2 completedCopy to Clipboard Copied! Toggle word wrap Toggle overflow または、Kafka の前バージョンと現行バージョンで Interbroker プロトコルのバージョンが同じ場合は、以下を確認します。
Reconciliation #<num>(watch) Kafka(<namespace>/<name>): Kafka version downgrade from <from-version> to <to-version>, phase 1 of 1 completed
Reconciliation #<num>(watch) Kafka(<namespace>/<name>): Kafka version downgrade from <from-version> to <to-version>, phase 1 of 1 completedCopy to Clipboard Copied! Toggle word wrap Toggle overflow すべてのクライアントアプリケーション (コンシューマー) をダウングレードして、以前のバージョンのクライアントバイナリーを使用します。
これで、Kafka クラスターおよびクライアントは以前の Kafka バージョンを使用するようになります。
第15章 AMQ Streams リソースのアップグレード
本リリースの AMQ Streams では、API バージョン kafka.strimzi.io/v1alpha1 を使用するリソースを更新して kafka.strimzi.io/v1beta1 を使用するようにする必要があります。
kafka.strimzi.io/v1alpha1 API バージョンは非推奨になりました。
ここでは、リソースのアップグレード手順を説明します。
リソースのアップグレードは、Cluster Operator をアップグレードしてから実施する 必要 があります。これにより、Cluster Operator がリソースを認識できるようになります。
リソースのアップグレードが実施されない場合
アップグレードが実施されない場合、apiVersion を更新するまでリソースを更新できないことを示す警告が、調整に関するログに記録されます。
更新をトリガーするには、カスタムリソースにアノテーション追加などの表面的な変更を加えます。
アノテーションの例:
metadata:
# ...
annotations:
upgrade: "Upgraded to kafka.strimzi.io/v1beta1"
metadata:
# ...
annotations:
upgrade: "Upgraded to kafka.strimzi.io/v1beta1"15.1. Kafka リソースのアップグレード
前提条件
-
v1beta1API バージョンをサポートする Cluster Operator が稼働している必要があります。
手順
デプロイメントの Kafka リソースごとに以下の手順を実行します。
エディターで
Kafkaリソースを更新します。oc edit kafka my-cluster
oc edit kafka my-clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下の行を見つけます。
apiVersion: kafka.strimzi.io/v1alpha1
apiVersion: kafka.strimzi.io/v1alpha1Copy to Clipboard Copied! Toggle word wrap Toggle overflow この行を以下の行に変更します。
apiVersion:kafka.strimzi.io/v1beta1
apiVersion:kafka.strimzi.io/v1beta1Copy to Clipboard Copied! Toggle word wrap Toggle overflow Kafkaリソースに以下があるか確認します。Kafka.spec.topicOperator
Kafka.spec.topicOperatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow ある場合は以下に変更します。
Kafka.spec.entityOperator.topicOperator
Kafka.spec.entityOperator.topicOperatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow たとえば、以下がある場合を考えてみましょう。
spec: # ... topicOperator: {}spec: # ... topicOperator: {}Copy to Clipboard Copied! Toggle word wrap Toggle overflow この行を以下の行に変更します。
spec: # ... entityOperator: topicOperator: {}spec: # ... entityOperator: topicOperator: {}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下があるか確認します。
Kafka.spec.entityOperator.affinity
Kafka.spec.entityOperator.affinityCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka.spec.entityOperator.tolerations
Kafka.spec.entityOperator.tolerationsCopy to Clipboard Copied! Toggle word wrap Toggle overflow あれば以下に変更します。
Kafka.spec.entityOperator.template.pod.affinity
Kafka.spec.entityOperator.template.pod.affinityCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka.spec.entityOperator.template.pod.tolerations
Kafka.spec.entityOperator.template.pod.tolerationsCopy to Clipboard Copied! Toggle word wrap Toggle overflow たとえば、以下の場合を考えてみましょう。
spec: # ... entityOperator: affinity {} tolerations {}spec: # ... entityOperator: affinity {} tolerations {}Copy to Clipboard Copied! Toggle word wrap Toggle overflow これを以下に変更します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下があるか確認します。
Kafka.spec.kafka.affinity
Kafka.spec.kafka.affinityCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka.spec.kafka.tolerations
Kafka.spec.kafka.tolerationsCopy to Clipboard Copied! Toggle word wrap Toggle overflow あれば以下に変更します。
Kafka.spec.kafka.template.pod.affinity
Kafka.spec.kafka.template.pod.affinityCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka.spec.kafka.template.pod.tolerations
Kafka.spec.kafka.template.pod.tolerationsCopy to Clipboard Copied! Toggle word wrap Toggle overflow たとえば、以下の場合を考えてみましょう。
spec: # ... kafka: affinity {} tolerations {}spec: # ... kafka: affinity {} tolerations {}Copy to Clipboard Copied! Toggle word wrap Toggle overflow これを以下に変更します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下があるか確認します。
Kafka.spec.zookeeper.affinity
Kafka.spec.zookeeper.affinityCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka.spec.zookeeper.tolerations
Kafka.spec.zookeeper.tolerationsCopy to Clipboard Copied! Toggle word wrap Toggle overflow あれば以下に変更します。
Kafka.spec.zookeeper.template.pod.affinity
Kafka.spec.zookeeper.template.pod.affinityCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka.spec.zookeeper.template.pod.tolerations
Kafka.spec.zookeeper.template.pod.tolerationsCopy to Clipboard Copied! Toggle word wrap Toggle overflow たとえば、以下の場合を考えてみましょう。
spec: # ... zookeeper: affinity {} tolerations {}spec: # ... zookeeper: affinity {} tolerations {}Copy to Clipboard Copied! Toggle word wrap Toggle overflow これを以下に変更します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - ファイルを保存し、エディターを終了して更新したリソースが調整されるのを待ちます。
15.2. Kafka Connect リソースのアップグレード
前提条件
-
v1beta1API バージョンをサポートする Cluster Operator が稼働している必要があります。
手順
デプロイメントの KafkaConnect リソースごとに以下の手順を実行します。
エディターで
KafkaConnectリソースを更新します。oc edit kafkaconnect my-connect
oc edit kafkaconnect my-connectCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下の行を見つけます。
apiVersion: kafka.strimzi.io/v1alpha1
apiVersion: kafka.strimzi.io/v1alpha1Copy to Clipboard Copied! Toggle word wrap Toggle overflow この行を以下の行に変更します。
apiVersion:kafka.strimzi.io/v1beta1
apiVersion:kafka.strimzi.io/v1beta1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下があるか確認します。
KafkaConnect.spec.affinity
KafkaConnect.spec.affinityCopy to Clipboard Copied! Toggle word wrap Toggle overflow KafkaConnect.spec.tolerations
KafkaConnect.spec.tolerationsCopy to Clipboard Copied! Toggle word wrap Toggle overflow あれば以下に変更します。
KafkaConnect.spec.template.pod.affinity
KafkaConnect.spec.template.pod.affinityCopy to Clipboard Copied! Toggle word wrap Toggle overflow KafkaConnect.spec.template.pod.tolerations
KafkaConnect.spec.template.pod.tolerationsCopy to Clipboard Copied! Toggle word wrap Toggle overflow たとえば、以下の場合を考えてみましょう。
spec: # ... affinity {} tolerations {}spec: # ... affinity {} tolerations {}Copy to Clipboard Copied! Toggle word wrap Toggle overflow これを以下に変更します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - ファイルを保存し、エディターを終了して更新したリソースが調整されるのを待ちます。
15.3. Kafka Connect S2I リソースのアップグレード
前提条件
-
v1beta1API バージョンをサポートする Cluster Operator が稼働している必要があります。
手順
デプロイメントの KafkaConnectS2I リソースごとに以下の手順を実行します。
エディターで
KafkaConnectS2Iリソースを更新します。oc edit kafkaconnects2i my-connect
oc edit kafkaconnects2i my-connectCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下の行を見つけます。
apiVersion: kafka.strimzi.io/v1alpha1
apiVersion: kafka.strimzi.io/v1alpha1Copy to Clipboard Copied! Toggle word wrap Toggle overflow この行を以下の行に変更します。
apiVersion:kafka.strimzi.io/v1beta1
apiVersion:kafka.strimzi.io/v1beta1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下があるか確認します。
KafkaConnectS2I.spec.affinity
KafkaConnectS2I.spec.affinityCopy to Clipboard Copied! Toggle word wrap Toggle overflow KafkaConnectS2I.spec.tolerations
KafkaConnectS2I.spec.tolerationsCopy to Clipboard Copied! Toggle word wrap Toggle overflow あれば以下に変更します。
KafkaConnectS2I.spec.template.pod.affinity
KafkaConnectS2I.spec.template.pod.affinityCopy to Clipboard Copied! Toggle word wrap Toggle overflow KafkaConnectS2I.spec.template.pod.tolerations
KafkaConnectS2I.spec.template.pod.tolerationsCopy to Clipboard Copied! Toggle word wrap Toggle overflow たとえば、以下の場合を考えてみましょう。
spec: # ... affinity {} tolerations {}spec: # ... affinity {} tolerations {}Copy to Clipboard Copied! Toggle word wrap Toggle overflow これを以下に変更します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - ファイルを保存し、エディターを終了して更新したリソースが調整されるのを待ちます。
15.4. Kafka MirrorMaker リソースのアップグレード
前提条件
-
v1beta1API バージョンをサポートする Cluster Operator が稼働している必要があります。
手順
デプロイメントの KafkaMirrorMaker リソースごとに以下の手順を実行します。
エディターで
KafkaMirrorMakerリソースを更新します。oc edit kafkamirrormaker my-connect
oc edit kafkamirrormaker my-connectCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下の行を見つけます。
apiVersion: kafka.strimzi.io/v1alpha1
apiVersion: kafka.strimzi.io/v1alpha1Copy to Clipboard Copied! Toggle word wrap Toggle overflow この行を以下の行に変更します。
apiVersion:kafka.strimzi.io/v1beta1
apiVersion:kafka.strimzi.io/v1beta1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下があるか確認します。
KafkaConnectMirrorMaker.spec.affinity
KafkaConnectMirrorMaker.spec.affinityCopy to Clipboard Copied! Toggle word wrap Toggle overflow KafkaConnectMirrorMaker.spec.tolerations
KafkaConnectMirrorMaker.spec.tolerationsCopy to Clipboard Copied! Toggle word wrap Toggle overflow あれば以下に変更します。
KafkaConnectMirrorMaker.spec.template.pod.affinity
KafkaConnectMirrorMaker.spec.template.pod.affinityCopy to Clipboard Copied! Toggle word wrap Toggle overflow KafkaConnectMirrorMaker.spec.template.pod.tolerations
KafkaConnectMirrorMaker.spec.template.pod.tolerationsCopy to Clipboard Copied! Toggle word wrap Toggle overflow たとえば、以下の場合を考えてみましょう。
spec: # ... affinity {} tolerations {}spec: # ... affinity {} tolerations {}Copy to Clipboard Copied! Toggle word wrap Toggle overflow これを以下に変更します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - ファイルを保存し、エディターを終了して更新したリソースが調整されるのを待ちます。
15.5. Kafka Topic リソースのアップグレード
前提条件
-
v1beta1API バージョンをサポートする Topic Operator が稼働している必要があります。
手順
デプロイメントの KafkaTopic リソースごとに以下の手順を実行します。
エディターで
KafkaTopicリソースを更新します。oc edit kafkatopic my-topic
oc edit kafkatopic my-topicCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下の行を見つけます。
apiVersion: kafka.strimzi.io/v1alpha1
apiVersion: kafka.strimzi.io/v1alpha1Copy to Clipboard Copied! Toggle word wrap Toggle overflow この行を以下の行に変更します。
apiVersion:kafka.strimzi.io/v1beta1
apiVersion:kafka.strimzi.io/v1beta1Copy to Clipboard Copied! Toggle word wrap Toggle overflow - ファイルを保存し、エディターを終了して更新したリソースが調整されるのを待ちます。
15.6. Kafka User リソースのアップグレード
前提条件
-
v1beta1API バージョンをサポートする User Operator が稼働している必要があります。
手順
デプロイメントの KafkaUser リソースごとに以下の手順を実行します。
エディターで
KafkaUserリソースを更新します。oc edit kafkauser my-user
oc edit kafkauser my-userCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下の行を見つけます。
apiVersion: kafka.strimzi.io/v1alpha1
apiVersion: kafka.strimzi.io/v1alpha1Copy to Clipboard Copied! Toggle word wrap Toggle overflow この行を以下の行に変更します。
apiVersion:kafka.strimzi.io/v1beta1
apiVersion:kafka.strimzi.io/v1beta1Copy to Clipboard Copied! Toggle word wrap Toggle overflow - ファイルを保存し、エディターを終了して更新したリソースが調整されるのを待ちます。
第16章 AMQ Streams の管理
本章では、AMQ Streams のデプロイメントを維持するタスクについて説明します。
16.1. カスタムリソースのステータスの確認
この手順では、カスタムリソースのステータスを検出する方法を説明します。
前提条件
- OpenShift クラスターが必要です。
- Cluster Operator が稼働している必要があります。
手順
カスタムリソースを指定し、
-o jsonpathオプションを使用して標準の JSONPath 式を適用してstatusプロパティーを選択します。oc get kafka <kafka_resource_name> -o jsonpath='{.status}'oc get kafka <kafka_resource_name> -o jsonpath='{.status}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow この式は、指定されたカスタムリソースのすべてのステータス情報を返します。
status.listenersまたはstatus.observedGenerationなどのドット表記を使用すると、表示するステータス情報を微調整できます。
その他のリソース
- 「AMQ Streams カスタムリソースのステータス」
- JSONPath の使用に関する詳細は、「JSONPath support」を参照してください。
16.2. 永続ボリュームからのクラスターの復元
Kafka クラスターは、永続ボリューム (PV) が存在していれば、そこから復元できます。
たとえば、以下の場合に行います。
- namespace が意図せずに削除された後。
- OpenShift クラスター全体が失われた後でも PV がインフラストラクチャーに残っている場合。
16.2.1. namespace が削除された場合の復元
永続ボリュームと namespace の関係により、namespace の削除から復元することが可能です。PersistentVolume (PV) は、namespace の外部に存在するストレージリソースです。PV は、namespace 内部に存在する PersistentVolumeClaim (PVC) を使用して Kafka Pod にマウントされます。
PV の回収 (reclaim) ポリシーは、namespace が削除されるときにクラスターに動作方法を指示します。以下に、回収 (reclaim) ポリシーの設定とその結果を示します。
- Delete (デフォルト) に設定すると、PVC が namespace 内で削除されるときに PV が削除されます。
- Retain に設定すると、namespace の削除時に PV は削除されません。
namespace が意図せず削除された場合に PV から復旧できるようにするには、PV 仕様で persistentVolumeReclaimPolicy プロパティーを使用してポリシーを Delete から Retain にリセットする必要があります。
または、PV は、関連付けられたストレージクラスの回収 (reclaim) ポリシーを継承できます。ストレージクラスは、動的ボリュームの割り当てに使用されます。
ストレージクラスの reclaimPolicy プロパティーを設定することで、ストレージクラスを使用する PV が適切な回収 (reclaim) ポリシー で作成されます。ストレージクラスは、storageClassName プロパティーを使用して PV に対して設定されます。
Retain を回収 (reclaim) ポリシーとして使用しながら、クラスター全体を削除する場合は、PV を手動で削除する必要があります。そうしないと、PV は削除されず、リソースに不要な経費がかかる原因になります。
16.2.2. OpenShift クラスター喪失からの復旧
クラスターが失われた場合、ディスク/ボリュームのデータがインフラストラクチャー内に保持されていれば、それらのデータを使用してクラスターを復旧できます。PV が復旧可能でそれらが手動で作成されていれば、復旧の手順は namespace の削除と同じです。
16.2.3. 永続ボリュームからのクラスターの復旧
この手順では、削除されたクラスターを永続ボリューム (PV) から復元する方法を説明します。
この状況では、Topic Operator はトピックが Kafka に存在することを認識しますが、KafkaTopic リソースは存在しません。
クラスター再作成の手順を行うには、2 つの方法があります。
すべての
KafkaTopicリソースを復旧できる場合は、オプション 1 を使用します。これにより、クラスターが起動する前に
KafkaTopicリソースを復旧することで、該当するトピックが Topic Operator によって削除されないようにする必要があります。すべての
KafkaTopicリソースを復旧できない場合は、オプション 2 を使用します。この場合、Topic Operator なしでクラスターをデプロイし、ZooKeeper で Topic Operator データを削除してからそのデータを再デプロイすることで、Topic Operator が該当するトピックから
KafkaTopicリソースを再作成できるようにします。
Topic Operator がデプロイされていない場合は、PersistentVolumeClaim (PVC) リソースのみを復旧する必要があります。
作業を始める前に
この手順では、データの破損を防ぐために PV を正しい PVC にマウントする必要があります。volumeName が PVC に指定されており、それが PV の名前に一致する必要があります。
詳細は以下を参照してください。
この手順には、手動での再作成が必要な KafkaUser リソースの復旧は含まれません。パスワードと証明書を保持する必要がある場合は、KafkaUser リソースの作成前にシークレットを再作成する必要があります。
手順
クラスターの PV についての情報を確認します。
oc get pv
oc get pvCopy to Clipboard Copied! Toggle word wrap Toggle overflow PV の情報がデータとともに表示されます。
この手順で重要な列を示す出力例:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - NAME は各 PV の名前を示します。
- RECLAIM POLICY は PV が 保持される ことを示します。
- CLAIM は元の PVC へのリンクを示します。
元の namespace を再作成します。
oc create namespace myproject
oc create namespace myprojectCopy to Clipboard Copied! Toggle word wrap Toggle overflow 元の PVC リソース仕様を再作成し、PVC を該当する PV にリンクします。
以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow PV 仕様を編集して、元の PVC にバインドされた
claimRefプロパティーを削除します。以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow この例では、以下のプロパティーが削除されます。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Cluster Operator をデプロイします。
oc apply -f install/cluster-operator -n my-project
oc apply -f install/cluster-operator -n my-projectCopy to Clipboard Copied! Toggle word wrap Toggle overflow クラスターを再作成します。
クラスターの再作成に必要なすべての
KafkaTopicリソースがあるかどうかに応じて、以下の手順を実行します。オプション 1: クラスターを失う前に存在した
KafkaTopicリソースが すべて ある場合 (__consumer_offsetsからコミットされたオフセットなどの内部トピックを含む)。すべての
KafkaTopicリソースを再作成します。クラスターをデプロイする前にリソースを再作成する必要があります。そうでないと、Topic Operator によってトピックが削除されます。
Kafka クラスターをデプロイします。
以下に例を示します。
oc apply -f kafka.yaml
oc apply -f kafka.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
オプション 2: クラスターを失う前に存在したすべての
KafkaTopicリソースがない場合。オプション 1 と同様に Kafka クラスターをデプロイしますが、デプロイ前に Kafka リソースから
topicOperatorプロパティーを削除して、Topic Operator がない状態でデプロイします。デプロイメントに Topic Operator が含まれると、Topic Operator によってすべてのトピックが削除されます。
execコマンドを Kafka ブローカー Pod の 1 つに実行し、ZooKeeper シェルスクリプトを開きます。たとえば、my-cluster-kafka-0 はブローカー Pod の名前になります。
oc exec my-cluster-kafka-0 bin/zookeeper-shell.sh localhost:2181
oc exec my-cluster-kafka-0 bin/zookeeper-shell.sh localhost:2181Copy to Clipboard Copied! Toggle word wrap Toggle overflow /strimziパス全体を削除して、Topic Operator ストレージを削除します。deleteall /strimzi
deleteall /strimziCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka クラスターを
topicOperatorプロパティーで再デプロイして TopicOperator を有効にし、KafkaTopicリソースを再作成します。以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- 1
- ここで示すデフォルト設定には、追加のプロパティーはありません。「
EntityTopicOperatorSpecスキーマ参照」に説明されているプロパティーを使用して、必要な設定を指定します。
KafkaTopicリソースのリストを表示して、復旧を確認します。oc get KafkaTopic
oc get KafkaTopicCopy to Clipboard Copied! Toggle word wrap Toggle overflow
16.3. AMQ Streams のアンインストール
この手順では、AMQ Streams をアンインストールし、デプロイメントに関連するリソースを削除する方法を説明します。
前提条件
この手順を実行するには、デプロイメント用に特別に作成され、AMQ Streams リソースから参照されるリソースを特定します。
このようなリソースには以下があります。
- シークレット (カスタム CA および証明書、Kafka Connect Secrets、その他の Kafka シークレット)
-
ロギング
ConfigMaps(タイプはexternal)
これらのリソースは、Kafka、KafkaConnect、KafkaConnectS2I、KafkaMirrorMaker、または KafkaBridge 設定によって参照されます。
手順
Cluster Operator の
Deployment、関連するCustomResourceDefinitionsおよびRBACリソースを削除します。oc delete -f install/cluster-operator
oc delete -f install/cluster-operatorCopy to Clipboard Copied! Toggle word wrap Toggle overflow 警告CustomResourceDefinitionsを削除すると、対応するカスタムリソース (Kafka、KafkaConnect、KafkaConnectS2I、KafkaMirrorMaker、またはKafkaBridge) 、およびそれらに依存するリソース (Deployments、StatefulSets、その他の依存リソース) のガベージコレクションが実行されます。- 前提条件で特定したリソースを削除します。
付録A よくある質問
付録B カスタムリソース API のリファレンス
B.1. Kafka スキーマ参照
| プロパティー | 説明 |
|---|---|
| spec | Kafka および ZooKeeper クラスター、Topic Operator の仕様。 |
| status | Kafka および ZooKeeper クラスター、Topic Operator のステータス。 |
B.2. KafkaSpec スキーマ参照
Kafka で使用
| プロパティー | 説明 |
|---|---|
| kafka | Kafka クラスターの設定。 |
| zookeeper | ZooKeeper クラスターの設定。 |
| topicOperator |
|
| entityOperator | Entity Operator の設定。 |
| clusterCa | クラスター認証局の設定。 |
| clientsCa | クライアント認証局の設定。 |
| kafkaExporter | Kafka Exporter の設定。Kafka Exporter は追加のメトリクスを提供できます (例: トピック/パーティションでのコンシューマーグループのラグなど)。 |
| maintenanceTimeWindows | メンテナンスタスク (証明書の更新) 用の時間枠の一覧。それぞれの時間枠は、cron 式で定義されます。 |
| string array |
B.3. KafkaClusterSpec スキーマ参照
KafkaSpec で使用
| プロパティー | 説明 |
|---|---|
| replicas | クラスター内の Pod 数。 |
| integer | |
| image |
Pod の Docker イメージ。デフォルト値は、設定した |
| string | |
| storage |
ストレージの設定 (ディスク)。更新はできません。タイプは、指定のオブジェクト内の |
| listeners | Kafka ブローカーのリスナーを設定します。 |
| authorization |
Kafka ブローカーの承認設定。タイプは、指定のオブジェクト内の |
| config | Kafka ブローカーの設定。次の接頭辞を持つプロパティーは設定できません: listeners、advertised.、broker.、listener.、host.name、port、inter.broker.listener.name、sasl.、ssl.、security.、password.、principal.builder.class、log.dir、zookeeper.connect、zookeeper.set.acl、authorizer.、super.user |
| map | |
| rack |
|
| brokerRackInitImage |
|
| string | |
| affinity |
|
| tolerations |
|
| Toleration array | |
| livenessProbe | Pod の liveness チェック。 |
| readinessProbe | Pod の readiness チェック。 |
| jvmOptions | Pod の JVM オプション。 |
| jmxOptions | Kafka ブローカーの JMX オプション。 |
| resources | 予約する CPU およびメモリーリソース。 |
| metrics | Prometheus JMX エクスポーターの設定。この設定の構造に関する詳細は、https://github.com/prometheus/jmx_exporter を参照してください。 |
| map | |
| logging |
Kafka のロギング設定。タイプは、指定のオブジェクト内の |
| tlsSidecar | TLS サイドカーの設定。 |
| template |
Kafka クラスターリソースのテンプレート。テンプレートを使用すると、ユーザーは |
| version | Kafka ブローカーのバージョン。デフォルトは 2.4.0 です。バージョンのアップグレードまたはダウングレードに必要なプロセスを理解するには、ユーザードキュメントを参照してください。 |
| string |
B.4. EphemeralStorage スキーマ参照
JbodStorage、KafkaClusterSpec、ZookeeperClusterSpec で使用
type プロパティーは、EphemeralStorage タイプを使用する際に PersistentClaimStorage タイプと区別する識別子です。EphemeralStorage タイプには ephemeral の値が必要です。
| プロパティー | 説明 |
|---|---|
| id | ストレージ ID 番号。これは、'jbod' タイプのストレージで定義されるストレージボリュームのみで必須です。 |
| integer | |
| sizeLimit | type=ephemeral の場合、この EmptyDir ボリュームに必要なローカルストレージの合計容量を定義します (例: 1Gi)。 |
| string | |
| type |
|
| string |
B.5. PersistentClaimStorage スキーマ参照
JbodStorage、KafkaClusterSpec、ZookeeperClusterSpec で使用
type プロパティーは、PersistentClaimStorage タイプを使用する際に EphemeralStorage タイプと区別する識別子です。PersistentClaimStorage タイプには persistent-claim の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string | |
| size | type=persistent-claim の場合、永続ボリューム要求のサイズを定義します (例: 1Gi).。type=persistent-claim の場合には必須です。 |
| string | |
| selector | 使用する特定の永続ボリュームを指定します。このようなボリュームを選択するラベルを表す key:value ペアが含まれます。 |
| map | |
| deleteClaim | クラスターのアンデプロイ時に永続ボリューム要求を削除する必要があるかどうかを指定します。 |
| boolean | |
| class | 動的ボリュームの割り当てに使用するストレージクラス。 |
| string | |
| id | ストレージ ID 番号。これは、'jbod' タイプのストレージで定義されるストレージボリュームのみで必須です。 |
| integer | |
| overrides |
個々のブローカーを上書きします。 |
B.6. PersistentClaimStorageOverride スキーマ参照
| プロパティー | 説明 |
|---|---|
| class | このブローカーの動的ボリュームの割り当てに使用するストレージクラス。 |
| string | |
| broker | Kafka ブローカーの ID (ブローカー ID)。 |
| integer |
B.7. JbodStorage スキーマ参照
KafkaClusterSpec で使用
type プロパティーは、JbodStorage タイプを使用する際に EphemeralStorage および PersistentClaimStorage タイプと区別する識別子です。JbodStorage タイプには jbod の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string | |
| volumes | JBOD ディスクアレイを表すストレージオブジェクトとしてのボリュームの一覧。 |
B.8. KafkaListeners スキーマ参照
KafkaClusterSpec で使用
| プロパティー | 説明 |
|---|---|
| plain | ポート 9092 でプレーンリスナーを設定します。 |
| tls | ポート 9093 で TLS リスナーを設定します。 |
| external |
ポート 9094 で外部リスナーを設定します。タイプは、指定のオブジェクト内の |
|
|
B.9. KafkaListenerPlain スキーマ参照
KafkaListeners で使用
| プロパティー | 説明 |
|---|---|
| authentication |
このリスナーの認証設定。このリスナーは TLS トランスポートを使用しないため、 |
|
| |
| networkPolicyPeers | このリスナーに接続できるピアの一覧。この一覧のピアは、論理演算子 OR を使用して組み合わせます。このフィールドが空であるか、または存在しない場合、このリスナーのすべてのコネクションが許可されます。このフィールドが存在し、1 つ以上の項目が含まれる場合、リスナーはこの一覧の少なくとも 1 つの項目と一致するトラフィックのみを許可します。外部のドキュメント networking.k8s.io/v1 networkpolicypeer を参照してください。 |
| NetworkPolicyPeer array |
B.10. KafkaListenerAuthenticationTls スキーマ参照
KafkaListenerExternalIngress、KafkaListenerExternalLoadBalancer、KafkaListenerExternalNodePort、KafkaListenerExternalRoute、KafkaListenerPlain、KafkaListenerTls で使用
type プロパティーは、KafkaListenerAuthenticationTls タイプを使用する際に KafkaListenerAuthenticationScramSha512 および KafkaListenerAuthenticationOAuth タイプと区別する識別子です。KafkaListenerAuthenticationTls タイプには tls の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string |
B.11. KafkaListenerAuthenticationScramSha512 スキーマ参照
KafkaListenerExternalIngress、KafkaListenerExternalLoadBalancer、KafkaListenerExternalNodePort、KafkaListenerExternalRoute、KafkaListenerPlain、KafkaListenerTls で使用
type プロパティーは、KafkaListenerAuthenticationScramSha512 タイプを使用する際に KafkaListenerAuthenticationTls および KafkaListenerAuthenticationOAuth タイプと区別する識別子です。KafkaListenerAuthenticationScramSha512 タイプには scram-sha-512 の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string |
B.12. KafkaListenerAuthenticationOAuth スキーマ参照
KafkaListenerExternalIngress、KafkaListenerExternalLoadBalancer、KafkaListenerExternalNodePort、KafkaListenerExternalRoute、KafkaListenerPlain、KafkaListenerTls で使用
type プロパティーは、KafkaListenerAuthenticationOAuth タイプを使用する際に KafkaListenerAuthenticationTls および KafkaListenerAuthenticationScramSha512 タイプと区別する識別子です。KafkaListenerAuthenticationOAuth タイプには oauth の値が必要です。
| プロパティー | 説明 |
|---|---|
| accessTokenIsJwt |
アクセストークンを JWT として処理すべきかどうかを設定します。承認サーバーが不透明なトークンを返す場合は |
| boolean | |
| checkAccessTokenType |
アクセストークンタイプのチェックを行うべきかどうかを設定します。承認サーバーの JWT トークンに 'typ' 要求が含まれない場合は、 |
| boolean | |
| clientId | Kafka ブローカーは、OAuth クライアント ID を使用して承認サーバーに対して認証し、イントロスペクションエンドポイント URI を使用することができます。 |
| string | |
| clientSecret | OAuth クライアントシークレットが含まれる OpenShift シークレットへのリンク。Kafka ブローカーは、OAuth クライアントシークレットを使用して承認サーバーに対して認証し、イントロスペクションエンドポイント URI を使用することができます。 |
| disableTlsHostnameVerification |
TLS ホスト名の検証を有効または無効にします。デフォルト値は |
| boolean | |
| enableECDSA |
BouncyCastle 暗号プロバイダーをインストールして、ECDSA サポートを有効または無効にします。デフォルト値は |
| boolean | |
| introspectionEndpointUri | 不透明な JWT 以外のトークンの検証に使用できるトークンイントロスペクションエンドポイントの URI。 |
| string | |
| jwksEndpointUri | ローカルの JWT 検証に使用できる JWKS 証明書エンドポイントの URI。 |
| string | |
| jwksExpirySeconds |
JWKS 証明書が有効とみなされる頻度を設定します。期限切れの間隔は、 |
| integer | |
| jwksRefreshSeconds |
JWKS 証明書が更新される頻度を設定します。更新間隔は、 |
| integer | |
| tlsTrustedCertificates | OAuth サーバーへの TLS 接続の信頼済み証明書。 |
|
| |
| type |
|
| string | |
| userNameClaim |
ユーザープリンシパルとして使用される認証トークンからの要求の名前。デフォルトは |
| string | |
| validIssuerUri | 認証に使用されるトークン発行者の URI。 |
| string |
B.13. GenericSecretSource スキーマ参照
KafkaClientAuthenticationOAuth、KafkaListenerAuthenticationOAuth で使用
| プロパティー | 説明 |
|---|---|
| key | OpenShift シークレットでシークレット値が保存されるキー。 |
| string | |
| secretName | シークレット値が含まれる OpenShift シークレットの名前。 |
| string |
B.14. CertSecretSource スキーマ参照
KafkaAuthorizationKeycloak、KafkaBridgeTls、KafkaClientAuthenticationOAuth、KafkaConnectTls、KafkaListenerAuthenticationOAuth、KafkaMirrorMaker2Tls、KafkaMirrorMakerTls で使用
| プロパティー | 説明 |
|---|---|
| certificate | Secret のファイル証明書の名前。 |
| string | |
| secretName | 証明書が含まれる Secret の名前。 |
| string |
B.15. KafkaListenerTls スキーマ参照
KafkaListeners で使用
| プロパティー | 説明 |
|---|---|
| authentication |
このリスナーの認証設定。タイプは、指定のオブジェクト内の |
|
| |
| configuration | TLS リスナーの設定。 |
| networkPolicyPeers | このリスナーに接続できるピアの一覧。この一覧のピアは、論理演算子 OR を使用して組み合わせます。このフィールドが空であるか、または存在しない場合、このリスナーのすべてのコネクションが許可されます。このフィールドが存在し、1 つ以上の項目が含まれる場合、リスナーはこの一覧の少なくとも 1 つの項目と一致するトラフィックのみを許可します。外部のドキュメント networking.k8s.io/v1 networkpolicypeer を参照してください。 |
| NetworkPolicyPeer array |
B.16. TlsListenerConfiguration スキーマ参照
KafkaListenerTls で使用
| プロパティー | 説明 |
|---|---|
| brokerCertChainAndKey |
証明書と秘密鍵のペアを保持する |
B.17. CertAndKeySecretSource スキーマ参照
IngressListenerConfiguration、KafkaClientAuthenticationTls、KafkaListenerExternalConfiguration、NodePortListenerConfiguration、TlsListenerConfiguration で使用
| プロパティー | 説明 |
|---|---|
| certificate | Secret のファイル証明書の名前。 |
| string | |
| key | Secret の秘密鍵の名前。 |
| string | |
| secretName | 証明書が含まれる Secret の名前。 |
| string |
B.18. KafkaListenerExternalRoute スキーマ参照
KafkaListeners で使用
type プロパティーは、KafkaListenerExternalRoute タイプを使用する際に KafkaListenerExternalLoadBalancer、KafkaListenerExternalNodePort、および KafkaListenerExternalIngress タイプと区別する識別子です。KafkaListenerExternalRoute タイプには route の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string | |
| authentication |
Kafka ブローカーの認証の設定タイプは、指定のオブジェクト内の |
|
| |
| overrides | 外部ブートストラップサービスおよびブローカーサービス、ならびに外部にアドバタイズされたアドレスの上書き。 |
| configuration | 外部リスナーの設定。 |
| networkPolicyPeers | このリスナーに接続できるピアの一覧。この一覧のピアは、論理演算子 OR を使用して組み合わせます。このフィールドが空であるか、または存在しない場合、このリスナーのすべてのコネクションが許可されます。このフィールドが存在し、1 つ以上の項目が含まれる場合、リスナーはこの一覧の少なくとも 1 つの項目と一致するトラフィックのみを許可します。外部のドキュメント networking.k8s.io/v1 networkpolicypeer を参照してください。 |
| NetworkPolicyPeer array |
B.19. RouteListenerOverride スキーマ参照
KafkaListenerExternalRoute で使用
| プロパティー | 説明 |
|---|---|
| bootstrap | 外部ブートストラップサービスの設定。 |
| brokers | 外部ブローカーサービスの設定。 |
B.20. RouteListenerBootstrapOverride スキーマ参照
| プロパティー | 説明 |
|---|---|
| address | ブートストラップサービスの追加のアドレス名。このアドレスは、TLS 証明書のサブジェクトの別名の一覧に追加されます。 |
| string | |
| host |
ブートストラップルートのホスト。このフィールドは OpenShift Route の |
| string |
B.21. RouteListenerBrokerOverride スキーマ参照
| プロパティー | 説明 |
|---|---|
| broker | Kafka ブローカーの ID (ブローカー ID)。 |
| integer | |
| advertisedHost |
ブローカーの |
| string | |
| advertisedPort |
ブローカーの |
| integer | |
| host |
ブローカールートのホスト。このフィールドは OpenShift Route の |
| string |
B.22. KafkaListenerExternalConfiguration スキーマ参照
KafkaListenerExternalLoadBalancer、KafkaListenerExternalRoute で使用
| プロパティー | 説明 |
|---|---|
| brokerCertChainAndKey |
証明書と秘密鍵のペアを保持する |
B.23. KafkaListenerExternalLoadBalancer スキーマ参照
KafkaListeners で使用
type プロパティーは、KafkaListenerExternalLoadBalancer タイプを使用する際に KafkaListenerExternalRoute、KafkaListenerExternalNodePort、および KafkaListenerExternalIngress タイプと区別する識別子です。KafkaListenerExternalLoadBalancer タイプには loadbalancer の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string | |
| authentication |
Kafka ブローカーの認証の設定タイプは、指定のオブジェクト内の |
|
| |
| overrides | 外部ブートストラップサービスおよびブローカーサービス、ならびに外部にアドバタイズされたアドレスの上書き。 |
| configuration | 外部リスナーの設定。 |
| networkPolicyPeers | このリスナーに接続できるピアの一覧。この一覧のピアは、論理演算子 OR を使用して組み合わせます。このフィールドが空であるか、または存在しない場合、このリスナーのすべてのコネクションが許可されます。このフィールドが存在し、1 つ以上の項目が含まれる場合、リスナーはこの一覧の少なくとも 1 つの項目と一致するトラフィックのみを許可します。外部のドキュメント networking.k8s.io/v1 networkpolicypeer を参照してください。 |
| NetworkPolicyPeer array | |
| tls |
リスナーで TLS による暗号化を有効にします。有効な TLS 暗号化の場合、デフォルトで |
| boolean |
B.24. LoadBalancerListenerOverride スキーマ参照
KafkaListenerExternalLoadBalancer で使用
| プロパティー | 説明 |
|---|---|
| bootstrap | 外部ブートストラップサービスの設定。 |
| brokers | 外部ブローカーサービスの設定。 |
B.25. LoadBalancerListenerBootstrapOverride スキーマ参照
LoadBalancerListenerOverride で使用
| プロパティー | 説明 |
|---|---|
| address | ブートストラップサービスの追加のアドレス名。このアドレスは、TLS 証明書のサブジェクトの別名の一覧に追加されます。 |
| string | |
| dnsAnnotations |
|
| map | |
| loadBalancerIP |
ロードバランサーは、このフィールドに指定された IP アドレスで要求されます。この機能は、ロードバランサーの作成時に、基礎となるクラウドプロバイダーが |
| string |
B.26. LoadBalancerListenerBrokerOverride スキーマ参照
LoadBalancerListenerOverride で使用
| プロパティー | 説明 |
|---|---|
| broker | Kafka ブローカーの ID (ブローカー ID)。 |
| integer | |
| advertisedHost |
ブローカーの |
| string | |
| advertisedPort |
ブローカーの |
| integer | |
| dnsAnnotations |
個別のブローカーの |
| map | |
| loadBalancerIP |
ロードバランサーは、このフィールドに指定された IP アドレスで要求されます。この機能は、ロードバランサーの作成時に、基礎となるクラウドプロバイダーが |
| string |
B.27. KafkaListenerExternalNodePort スキーマ参照
KafkaListeners で使用
type プロパティーは、KafkaListenerExternalNodePort タイプを使用する際に KafkaListenerExternalRoute、KafkaListenerExternalLoadBalancer、および KafkaListenerExternalIngress タイプと区別する識別子です。KafkaListenerExternalNodePort タイプには nodeport の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string | |
| authentication |
Kafka ブローカーの認証の設定タイプは、指定のオブジェクト内の |
|
| |
| overrides | 外部ブートストラップサービスおよびブローカーサービス、ならびに外部にアドバタイズされたアドレスの上書き。 |
| configuration | 外部リスナーの設定。 |
| networkPolicyPeers | このリスナーに接続できるピアの一覧。この一覧のピアは、論理演算子 OR を使用して組み合わせます。このフィールドが空であるか、または存在しない場合、このリスナーのすべてのコネクションが許可されます。このフィールドが存在し、1 つ以上の項目が含まれる場合、リスナーはこの一覧の少なくとも 1 つの項目と一致するトラフィックのみを許可します。外部のドキュメント networking.k8s.io/v1 networkpolicypeer を参照してください。 |
| NetworkPolicyPeer array | |
| tls |
リスナーで TLS による暗号化を有効にします。有効な TLS 暗号化の場合、デフォルトで |
| boolean |
B.28. NodePortListenerOverride スキーマ参照
KafkaListenerExternalNodePort で使用
| プロパティー | 説明 |
|---|---|
| bootstrap | 外部ブートストラップサービスの設定。 |
| brokers | 外部ブローカーサービスの設定。 |
B.29. NodePortListenerBootstrapOverride スキーマ参照
| プロパティー | 説明 |
|---|---|
| address | ブートストラップサービスの追加のアドレス名。このアドレスは、TLS 証明書のサブジェクトの別名の一覧に追加されます。 |
| string | |
| dnsAnnotations |
|
| map | |
| nodePort | ブートストラップサービスのノードポート。 |
| integer |
B.30. NodePortListenerBrokerOverride スキーマ参照
| プロパティー | 説明 |
|---|---|
| broker | Kafka ブローカーの ID (ブローカー ID)。 |
| integer | |
| advertisedHost |
ブローカーの |
| string | |
| advertisedPort |
ブローカーの |
| integer | |
| nodePort | ブローカーサービスのノードポート。 |
| integer | |
| dnsAnnotations |
個別のブローカーの |
| map |
B.31. NodePortListenerConfiguration スキーマ参照
KafkaListenerExternalNodePort で使用
| プロパティー | 説明 |
|---|---|
| brokerCertChainAndKey |
証明書と秘密鍵のペアを保持する |
| preferredAddressType |
ノードアドレスとして使用するアドレスタイプを定義します。利用可能なタイプは、 このフィールドは、優先タイプとして使用され、最初にチェックされるアドレスタイプの選択に使用できます。このアドレスタイプのアドレスが見つからない場合は、デフォルトの順序で他のタイプが使用されます。 |
| string ([ExternalDNS、ExternalIP、Hostname、InternalIP、InternalDNS] のいずれか) |
B.32. KafkaListenerExternalIngress スキーマ参照
KafkaListeners で使用
type プロパティーは、KafkaListenerExternalIngress タイプを使用する際に KafkaListenerExternalRoute、KafkaListenerExternalLoadBalancer、および KafkaListenerExternalNodePort タイプと区別する識別子です。KafkaListenerExternalIngress タイプには ingress の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string | |
| authentication |
Kafka ブローカーの認証の設定タイプは、指定のオブジェクト内の |
|
| |
| class |
使用する |
| string | |
| configuration | 外部リスナーの設定。 |
| networkPolicyPeers | このリスナーに接続できるピアの一覧。この一覧のピアは、論理演算子 OR を使用して組み合わせます。このフィールドが空であるか、または存在しない場合、このリスナーのすべてのコネクションが許可されます。このフィールドが存在し、1 つ以上の項目が含まれる場合、リスナーはこの一覧の少なくとも 1 つの項目と一致するトラフィックのみを許可します。外部のドキュメント networking.k8s.io/v1 networkpolicypeer を参照してください。 |
| NetworkPolicyPeer array |
B.33. IngressListenerConfiguration スキーマ参照
KafkaListenerExternalIngress で使用
| プロパティー | 説明 |
|---|---|
| bootstrap | 外部ブートストラップ Ingress の設定。 |
| brokers | 外部ブローカー Ingress の設定。 |
| brokerCertChainAndKey |
証明書と秘密鍵のペアを保持する |
B.34. IngressListenerBootstrapConfiguration スキーマ参照
IngressListenerConfiguration で使用
| プロパティー | 説明 |
|---|---|
| address | ブートストラップサービスの追加のアドレス名。このアドレスは、TLS 証明書のサブジェクトの別名の一覧に追加されます。 |
| string | |
| dnsAnnotations |
|
| map | |
| host | ブートストラップルートのホスト。このフィールドは Ingress リソースで使用されます。 |
| string |
B.35. IngressListenerBrokerConfiguration スキーマ参照
IngressListenerConfiguration で使用
| プロパティー | 説明 |
|---|---|
| broker | Kafka ブローカーの ID (ブローカー ID)。 |
| integer | |
| advertisedHost |
ブローカーの |
| string | |
| advertisedPort |
ブローカーの |
| integer | |
| host | ブローカー Ingress のホスト。このフィールドは Ingress リソースで使用されます。 |
| string | |
| dnsAnnotations |
個別のブローカーの |
| map |
B.36. KafkaAuthorizationSimple スキーマ参照
KafkaClusterSpec で使用
type プロパティーは、KafkaAuthorizationSimple タイプの使用を KafkaAuthorizationKeycloak と区別する識別子です。KafkaAuthorizationSimple タイプには simple の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string | |
| superUsers | スーパーユーザーの一覧。無制限のアクセス権を取得する必要のあるユーザープリンシパルの一覧が含まれなければなりません。 |
| string array |
B.37. KafkaAuthorizationKeycloak スキーマ参照
KafkaClusterSpec で使用
type プロパティーは、KafkaAuthorizationKeycloak タイプの使用を KafkaAuthorizationSimple と区別する識別子です。KafkaAuthorizationKeycloak タイプには keycloak の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string | |
| clientId | Kafka クライアントが OAuth サーバーに対する認証に使用し、トークンエンドポイント URI を使用することができる OAuth クライアント ID。 |
| string | |
| tokenEndpointUri | 承認サーバートークンエンドポイント URI。 |
| string | |
| tlsTrustedCertificates | OAuth サーバーへの TLS 接続の信頼済み証明書。 |
|
| |
| disableTlsHostnameVerification |
TLS ホスト名の検証を有効または無効にします。デフォルト値は |
| boolean | |
| delegateToKafkaAcls |
Keycloak Authorization Services ポリシーにより DENIED となった場合に、承認の決定を 'Simple' オーソライザーに委譲すべきかどうか。デフォルト値は |
| boolean | |
| superUsers | スーパーユーザーの一覧。無制限のアクセス権を取得する必要のあるユーザープリンシパルの一覧が含まれなければなりません。 |
| string array |
B.38. Rack スキーマ参照
KafkaClusterSpec で使用
| プロパティー | 説明 |
|---|---|
| topologyKey |
OpenShift クラスターノードに割り当てられたラベルに一致するキー。ラベルの値を使用して、ブローカーの |
| string |
B.39. Probe スキーマ参照
EntityTopicOperatorSpec、EntityUserOperatorSpec、KafkaBridgeSpec、KafkaClusterSpec、KafkaConnectS2ISpec、KafkaConnectSpec、KafkaExporterSpec、KafkaMirrorMaker2Spec、KafkaMirrorMakerSpec、TlsSidecar、TopicOperatorSpec、ZookeeperClusterSpec で使用
| プロパティー | 説明 |
|---|---|
| failureThreshold | 正常に実行された後に失敗とみなされるプローブの連続失敗回数の最小値。デフォルトは 3 です。最小値は 1 です。 |
| integer | |
| initialDelaySeconds | 最初に健全性をチェックするまでの初期の遅延。 |
| integer | |
| periodSeconds | プローブを実行する頻度 (秒単位)。デフォルトは 10 秒です。最小値は 1 です。 |
| integer | |
| successThreshold | 失敗後に、プローブが正常とみなされるための最小の連続成功回数。デフォルトは 1 です。liveness は 1 でなければなりません。最小値は 1 です。 |
| integer | |
| timeoutSeconds | ヘルスチェック試行のタイムアウト。 |
| integer |
B.40. JvmOptions スキーマ参照
KafkaBridgeSpec、KafkaClusterSpec、KafkaConnectS2ISpec、KafkaConnectSpec、KafkaMirrorMaker2Spec、KafkaMirrorMakerSpec、ZookeeperClusterSpec で使用
| プロパティー | 説明 |
|---|---|
| -XX | JVM への -XX オプションのマップ。 |
| map | |
| -Xms | JVM への -Xms オプション。 |
| string | |
| -Xmx | JVM への -Xmx オプション。 |
| string | |
| gcLoggingEnabled | ガベージコレクションのロギングが有効かどうかを指定します。デフォルトは false です。 |
| boolean | |
| javaSystemProperties |
|
|
|
B.41. SystemProperty スキーマ参照
JvmOptions で使用
| プロパティー | 説明 |
|---|---|
| name | システムプロパティー名。 |
| string | |
| value | システムプロパティーの値。 |
| string |
B.42. KafkaJmxOptions スキーマ参照
KafkaClusterSpec で使用
| プロパティー | 説明 |
|---|---|
| authentication |
Kafka JMX ポートに接続するための認証設定。タイプは、指定のオブジェクト内の |
B.43. KafkaJmxAuthenticationPassword スキーマ参照
KafkaJmxOptions で使用
type プロパティーは、KafkaJmxAuthenticationPassword タイプを使用する際に、今後追加される可能性のある他のサブタイプと区別する識別子です。KafkaJmxAuthenticationPassword タイプには password の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string |
B.44. ResourceRequirements スキーマ参照
EntityTopicOperatorSpec、EntityUserOperatorSpec、KafkaBridgeSpec、KafkaClusterSpec、KafkaConnectS2ISpec、KafkaConnectSpec、KafkaExporterSpec、KafkaMirrorMaker2Spec、KafkaMirrorMakerSpec、TlsSidecar、TopicOperatorSpec、ZookeeperClusterSpec で使用
| プロパティー | 説明 |
|---|---|
| limits | |
| map | |
| requests | |
| map |
B.45. InlineLogging スキーマ参照
EntityTopicOperatorSpec、EntityUserOperatorSpec、KafkaBridgeSpec、KafkaClusterSpec、KafkaConnectS2ISpec、KafkaConnectSpec、KafkaMirrorMaker2Spec、KafkaMirrorMakerSpec、TopicOperatorSpec、ZookeeperClusterSpec で使用
type プロパティーは、InlineLogging タイプの使用を ExternalLogging と区別する識別子です。InlineLogging タイプには inline の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string | |
| loggers | ロガー名からロガーレベルへのマップ。 |
| map |
B.46. ExternalLogging スキーマ参照
EntityTopicOperatorSpec、EntityUserOperatorSpec、KafkaBridgeSpec、KafkaClusterSpec、KafkaConnectS2ISpec、KafkaConnectSpec、KafkaMirrorMaker2Spec、KafkaMirrorMakerSpec、TopicOperatorSpec、ZookeeperClusterSpec で使用
type プロパティーは、ExternalLogging タイプを使用する際に InlineLogging タイプと区別する識別子です。ExternalLogging タイプには external の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string | |
| name |
ロギング設定の取得元となる |
| string |
B.47. TlsSidecar スキーマ参照
EntityOperatorSpec、KafkaClusterSpec、TopicOperatorSpec、ZookeeperClusterSpec で使用
| プロパティー | 説明 |
|---|---|
| image | コンテナーの Docker イメージ。 |
| string | |
| livenessProbe | Pod の liveness チェック。 |
| logLevel |
TLS サイドカーのログレベル。デフォルト値は |
| string ([emerg、debug、crit、err、alert、warning、notice、info] のいずれか) | |
| readinessProbe | Pod の readiness チェック。 |
| resources | 予約する CPU およびメモリーリソース。 |
B.48. KafkaClusterTemplate スキーマ参照
KafkaClusterSpec で使用
| プロパティー | 説明 |
|---|---|
| statefulset |
Kafka |
| pod |
Kafka |
| bootstrapService |
Kafka ブートストラップ |
| brokersService |
Kafka ブローカー |
| externalBootstrapService |
Kafka 外部ブートストラップ |
| perPodService |
OpenShift の外部からアクセスするために使用される Kafka の Pod ごとの |
| externalBootstrapRoute |
Kafka 外部ブートストラップ |
| perPodRoute |
OpenShift の外部からアクセスするために使用される Kafka の Pod ごとの |
| externalBootstrapIngress |
Kafka 外部ブートストラップ |
| perPodIngress |
OpenShift の外部からアクセスするために使用される Kafka の Pod ごとの |
| persistentVolumeClaim |
すべての Kafka |
| podDisruptionBudget |
Kafka |
| kafkaContainer | Kafka ブローカーコンテナーのテンプレート。 |
| tlsSidecarContainer | Kafka ブローカー TLS サイドカーコンテナーのテンプレート。 |
| initContainer | Kafka init コンテナーのテンプレート。 |
B.49. StatefulSetTemplate スキーマ参照
KafkaClusterTemplate、ZookeeperClusterTemplate で使用
| プロパティー | 説明 |
|---|---|
| metadata | リソースに適用する必要のあるメタデータ。 |
| podManagementPolicy |
この StatefulSet に使用される PodManagementPolicy。有効な値は |
| string ([OrderedReady、Parallel] のいずれか) |
B.50. MetadataTemplate スキーマ参照
ExternalServiceTemplate、PodDisruptionBudgetTemplate、PodTemplate、ResourceTemplate、StatefulSetTemplate で使用
| プロパティー | 説明 |
|---|---|
| labels |
リソーステンプレートに追加する必要のあるラベル。 |
| map | |
| annotations |
リソーステンプレートに追加する必要のあるアノテーション。 |
| map |
B.51. PodTemplate スキーマ参照
EntityOperatorTemplate、KafkaBridgeTemplate、KafkaClusterTemplate、KafkaConnectTemplate、KafkaExporterTemplate、KafkaMirrorMakerTemplate、ZookeeperClusterTemplate で使用
| プロパティー | 説明 |
|---|---|
| metadata | リソースに適用済みのメタデータ。 |
| imagePullSecrets | この Pod で使用されるイメージのプルに使用する同じ namespace のシークレットへの参照の一覧です。外部のドキュメント core/v1 localobjectreference を参照してください。 |
| LocalObjectReference array | |
| securityContext | Pod レベルのセキュリティー属性と共通のコンテナー設定を設定します。外部のドキュメント core/v1 podsecuritycontext を参照してください。 |
| terminationGracePeriodSeconds | 猶予期間とは、Pod で実行されているプロセスに終了シグナルが送信されてから、kill シグナルでプロセスを強制的に終了するまでの期間 (秒単位) です。この値は、予想されるプロセスのクリーンアップ時間よりも長く設定します。値は負の数ではない整数にする必要があります。値をゼロに指定すると、ただちに削除されます。デフォルトは 30 秒です。 |
| integer | |
| affinity | Pod のアフィニティールール。外部のドキュメント core/v1 affinity を参照してください。 |
| priorityClassName | これらの Pod を割り当てる優先順位クラスの名前。 |
| string | |
| schedulerName |
この |
| string | |
| tolerations | Pod の許容 (Toleration)。外部のドキュメント core/v1 toleration を参照してください。 |
| Toleration array |
B.52. ResourceTemplate スキーマ参照
EntityOperatorTemplate、KafkaBridgeTemplate、KafkaClusterTemplate、KafkaConnectTemplate、KafkaExporterTemplate、KafkaMirrorMakerTemplate、ZookeeperClusterTemplate で使用
| プロパティー | 説明 |
|---|---|
| metadata | リソースに適用する必要のあるメタデータ。 |
B.53. ExternalServiceTemplate スキーマ参照
| プロパティー | 説明 |
|---|---|
| metadata | リソースに適用する必要のあるメタデータ。 |
| externalTrafficPolicy |
サービスによって外部トラフィックがローカルノードのエンドポイントまたはクラスター全体のエンドポイントにルーティングされるかどうかを指定します。 |
| string ([Local、Cluster] のいずれか) | |
| loadBalancerSourceRanges |
クライアントがロードバランサータイプのリスナーに接続できる CIDR 形式による範囲 (例: |
| string array |
B.54. PodDisruptionBudgetTemplate スキーマ参照
KafkaBridgeTemplate、KafkaClusterTemplate、KafkaConnectTemplate、KafkaMirrorMakerTemplate、ZookeeperClusterTemplate で使用
| プロパティー | 説明 |
|---|---|
| metadata |
|
| maxUnavailable |
自動 Pod エビクションを許可するための利用不可能な Pod の最大数。Pod エビクションは、 |
| integer |
B.55. ContainerTemplate スキーマ参照
EntityOperatorTemplate、KafkaBridgeTemplate、KafkaClusterTemplate、KafkaConnectTemplate、KafkaExporterTemplate、KafkaMirrorMakerTemplate、ZookeeperClusterTemplate で使用
| プロパティー | 説明 |
|---|---|
| env | コンテナーに適用する必要のある環境変数。 |
|
|
B.56. ContainerEnvVar スキーマ参照
| プロパティー | 説明 |
|---|---|
| name | 環境変数のキー。 |
| string | |
| value | 環境変数の値。 |
| string |
B.57. ZookeeperClusterSpec スキーマ参照
KafkaSpec で使用
| プロパティー | 説明 |
|---|---|
| replicas | クラスター内の Pod 数。 |
| integer | |
| image | Pod の Docker イメージ。 |
| string | |
| storage |
ストレージの設定 (ディスク)。更新はできません。タイプは、指定のオブジェクト内の |
| config | ZooKeeper ブローカーの設定。次の接頭辞を持つプロパティーは設定できません: server.、dataDir、dataLogDir、clientPort、authProvider、quorum.auth、requireClientAuthScheme |
| map | |
| affinity |
|
| tolerations |
|
| Toleration array | |
| livenessProbe | Pod の liveness チェック。 |
| readinessProbe | Pod の readiness チェック。 |
| jvmOptions | Pod の JVM オプション。 |
| resources | 予約する CPU およびメモリーリソース。 |
| metrics | Prometheus JMX エクスポーターの設定。この設定の構造に関する詳細は、https://github.com/prometheus/jmx_exporter を参照してください。 |
| map | |
| logging |
ZooKeeper のロギング設定。タイプは、指定のオブジェクト内の |
| tlsSidecar | TLS サイドカーの設定。 |
| template |
ZooKeeper クラスターリソースのテンプレート。テンプレートを使用すると、ユーザーは |
B.58. ZookeeperClusterTemplate スキーマ参照
| プロパティー | 説明 |
|---|---|
| statefulset |
ZooKeeper |
| pod |
ZooKeeper |
| clientService |
ZooKeeper クライアント |
| nodesService |
ZooKeeper ノード |
| persistentVolumeClaim |
すべての ZooKeeper |
| podDisruptionBudget |
ZooKeeper |
| zookeeperContainer | ZooKeeper コンテナーのテンプレート。 |
| tlsSidecarContainer | Kafka ブローカー TLS サイドカーコンテナーのテンプレート。 |
B.59. TopicOperatorSpec スキーマ参照
KafkaSpec で使用
| プロパティー | 説明 |
|---|---|
| watchedNamespace | Topic Operator が監視する必要のある namespace。 |
| string | |
| image | Topic Operator に使用するイメージ。 |
| string | |
| reconciliationIntervalSeconds | 定期的な調整の間隔。 |
| integer | |
| zookeeperSessionTimeoutSeconds | ZooKeeper セッションのタイムアウト。 |
| integer | |
| affinity | Pod のアフィニティールール。外部のドキュメント core/v1 affinity を参照してください。 |
| resources | 予約する CPU およびメモリーリソース。 |
| topicMetadataMaxAttempts | トピックメタデータの取得を試行する回数。 |
| integer | |
| tlsSidecar | TLS サイドカーの設定。 |
| logging |
ロギング設定。タイプは、指定のオブジェクト内の |
| jvmOptions | Pod の JVM オプション。 |
| livenessProbe | Pod の liveness チェック。 |
| readinessProbe | Pod の readiness チェック。 |
B.60. EntityOperatorJvmOptions スキーマ参照
EntityTopicOperatorSpec、EntityUserOperatorSpec、TopicOperatorSpec で使用
| プロパティー | 説明 |
|---|---|
| gcLoggingEnabled | ガベージコレクションのロギングが有効かどうかを指定します。デフォルトは false です。 |
| boolean |
B.61. EntityOperatorSpec スキーマ参照
KafkaSpec で使用
| プロパティー | 説明 |
|---|---|
| topicOperator | Topic Operator の設定。 |
| userOperator | User Operator の設定。 |
| affinity |
|
| tolerations |
|
| Toleration array | |
| tlsSidecar | TLS サイドカーの設定。 |
| template |
Entity Operator リソースのテンプレート。テンプレートを使用すると、ユーザーは |
B.62. EntityTopicOperatorSpec スキーマ参照
| プロパティー | 説明 |
|---|---|
| watchedNamespace | Topic Operator が監視する必要のある namespace。 |
| string | |
| image | Topic Operator に使用するイメージ。 |
| string | |
| reconciliationIntervalSeconds | 定期的な調整の間隔。 |
| integer | |
| zookeeperSessionTimeoutSeconds | ZooKeeper セッションのタイムアウト。 |
| integer | |
| livenessProbe | Pod の liveness チェック。 |
| readinessProbe | Pod の readiness チェック。 |
| resources | 予約する CPU およびメモリーリソース。 |
| topicMetadataMaxAttempts | トピックメタデータの取得を試行する回数。 |
| integer | |
| logging |
ロギング設定。タイプは、指定のオブジェクト内の |
| jvmOptions | Pod の JVM オプション。 |
B.63. EntityUserOperatorSpec スキーマ参照
| プロパティー | 説明 |
|---|---|
| watchedNamespace | User Operator が監視する必要のある namespace。 |
| string | |
| image | User Operator に使用するイメージ。 |
| string | |
| reconciliationIntervalSeconds | 定期的な調整の間隔。 |
| integer | |
| zookeeperSessionTimeoutSeconds | ZooKeeper セッションのタイムアウト。 |
| integer | |
| livenessProbe | Pod の liveness チェック。 |
| readinessProbe | Pod の readiness チェック。 |
| resources | 予約する CPU およびメモリーリソース。 |
| logging |
ロギング設定。タイプは、指定のオブジェクト内の |
| jvmOptions | Pod の JVM オプション。 |
B.64. EntityOperatorTemplate スキーマ参照
| プロパティー | 説明 |
|---|---|
| deployment |
Entity Operator |
| pod |
Entity Operator |
| tlsSidecarContainer | Entity Operator TLS サイドカーコンテナーのテンプレート。 |
| topicOperatorContainer | Entity Topic Operator コンテナーのテンプレート。 |
| userOperatorContainer | Entity User Operator コンテナーのテンプレート。 |
B.65. CertificateAuthority スキーマ参照
KafkaSpec で使用
TLS 証明書のクラスター内での使用方法の設定。これは、クラスター内の内部通信に使用される証明書および Kafka.spec.kafka.listeners.tls を介したクライアントアクセスに使用される証明書の両方に適用されます。
| プロパティー | 説明 |
|---|---|
| generateCertificateAuthority | true の場合、認証局の証明書が自動的に生成されます。それ以外の場合は、ユーザーは CA 証明書で Secret を提供する必要があります。デフォルトは true です。 |
| boolean | |
| validityDays | 生成される証明書の有効日数。デフォルトは 365 です。 |
| integer | |
| renewalDays |
証明書更新期間の日数。これは、証明書の期限が切れるまでの日数です。この間に、更新アクションを実行することができます。 |
| integer | |
| certificateExpirationPolicy |
|
| string ([replace-key、renew-certificate] のいずれか) |
B.66. KafkaExporterSpec スキーマ参照
KafkaSpec で使用
| プロパティー | 説明 |
|---|---|
| image | Pod の Docker イメージ。 |
| string | |
| groupRegex |
収集するコンシューマーグループを指定する正規表現。デフォルト値は |
| string | |
| topicRegex |
収集するトピックを指定する正規表現。デフォルト値は |
| string | |
| resources | 予約する CPU およびメモリーリソース。 |
| logging |
指定の重大度以上のログメッセージのみ。有効な値: [ |
| string | |
| enableSaramaLogging | Kafka Exporter によって使用される Go クライアントライブラリーである Sarama ロギングを有効にします。 |
| boolean | |
| template | デプロイメントテンプレートおよび Pod のカスタマイズ。 |
| livenessProbe | Pod の liveness チェック。 |
| readinessProbe | Pod の readiness チェック。 |
B.67. KafkaExporterTemplate スキーマ参照
| プロパティー | 説明 |
|---|---|
| deployment |
Kafka Exporter |
| pod |
Kafka Exporter |
| service |
Kafka Exporter |
| container | Kafka Exporter コンテナーのテンプレート。 |
B.68. KafkaStatus スキーマ参照
Kafka で使用
| プロパティー | 説明 |
|---|---|
| conditions | ステータス条件の一覧。 |
|
| |
| observedGeneration | 最後に Operator によって調整された CRD の生成。 |
| integer | |
| listeners | 内部リスナーおよび外部リスナーのアドレス。 |
|
|
B.69. Condition スキーマ参照
KafkaBridgeStatus、KafkaConnectorStatus、KafkaConnectS2IStatus、KafkaConnectStatus、KafkaMirrorMaker2Status、KafkaMirrorMakerStatus、KafkaStatus、KafkaTopicStatus、KafkaUserStatus で使用
| プロパティー | 説明 |
|---|---|
| type | リソース内の他の条件と区別するために使用される条件の固有識別子。 |
| string | |
| status | 条件のステータス (True、False、または Unknown のいずれか)。 |
| string | |
| lastTransitionTime | タイプの条件がある状態から別の状態へと最後に変更した時間。必須形式は、UTC タイムゾーンの 'yyyy-MM-ddTHH:mm:ssZ' です。 |
| string | |
| reason | 条件の最後の遷移の理由 (CamelCase の単一の単語)。 |
| string | |
| message | 条件の最後の遷移の詳細を示す、人間が判読できるメッセージ。 |
| string |
B.70. ListenerStatus スキーマ参照
KafkaStatus で使用
| プロパティー | 説明 |
|---|---|
| type |
リスナーのタイプ。次の 3 つのタイプのいずれかになります: |
| string | |
| addresses | このリスナーのアドレス一覧。 |
|
| |
| certificates |
指定のリスナーへの接続時に、サーバーのアイデンティティーを検証するために使用できる TLS 証明書の一覧。 |
| string array |
B.71. ListenerAddress スキーマ参照
ListenerStatus で使用
| プロパティー | 説明 |
|---|---|
| host | Kafka ブートストラップサービスの DNS 名または IP アドレス。 |
| string | |
| port | Kafka ブートストラップサービスのポート。 |
| integer |
B.72. KafkaConnect スキーマ参照
| プロパティー | 説明 |
|---|---|
| spec | Kafka Connect クラスターの仕様。 |
| status | Kafka Connect クラスターのステータス。 |
B.73. KafkaConnectSpec スキーマ参照
KafkaConnect で使用
| プロパティー | 説明 |
|---|---|
| replicas | Kafka Connect グループの Pod 数。 |
| integer | |
| version | Kafka Connect のバージョン。デフォルトは 2.4.0 です。バージョンのアップグレードまたはダウングレードに必要なプロセスを理解するには、ユーザードキュメントを参照してください。 |
| string | |
| image | Pod の Docker イメージ。 |
| string | |
| bootstrapServers | 接続するブートストラップサーバー。これは <hostname>:<port> ペアのコンマ区切りリストとして指定する必要があります。 |
| string | |
| tls | TLS 設定。 |
| authentication |
Kafka Connect の認証設定。タイプは、指定のオブジェクト内の |
|
| |
| config | Kafka Connect の設定。次の接頭辞を持つプロパティーは設定できません: ssl.、sasl.、security.、listeners、plugin.path、rest.、bootstrap.servers、consumer.interceptor.classes、producer.interceptor.classes |
| map | |
| resources | CPU とメモリーリソースおよび要求された初期リソースの上限。 |
| livenessProbe | Pod の liveness チェック。 |
| readinessProbe | Pod の readiness チェック。 |
| jvmOptions | Pod の JVM オプション。 |
| affinity |
|
| tolerations |
|
| Toleration array | |
| logging |
Kafka Connect のロギング設定。タイプは、指定のオブジェクト内の |
| metrics | Prometheus JMX エクスポーターの設定。この設定の構造に関する詳細は、https://github.com/prometheus/jmx_exporter を参照してください。 |
| map | |
| tracing |
Kafka Connect でのトレーシングの設定。タイプは、指定のオブジェクト内の |
| template |
Kafka Connect および Kafka Connect S2I リソースのテンプレート。テンプレートを使用すると、ユーザーは |
| externalConfiguration | Secret または ConfigMap から Kafka Connect Pod にデータを渡し、これを使用してコネクターを設定します。 |
B.74. KafkaConnectTls スキーマ参照
KafkaConnectS2ISpec、KafkaConnectSpec で使用
| プロパティー | 説明 |
|---|---|
| trustedCertificates | TLS 接続の信頼済み証明書。 |
|
|
B.75. KafkaClientAuthenticationTls スキーマ参照
KafkaBridgeSpec、KafkaConnectS2ISpec、KafkaConnectSpec、KafkaMirrorMaker2ClusterSpec、KafkaMirrorMakerConsumerSpec、KafkaMirrorMakerProducerSpec で使用
TLS クライアント認証を使用するには、type プロパティーを tls の値に設定します。TLS クライアント認証は TLS 証明書を使用して認証します。証明書は certificateAndKey プロパティーで指定され、常に OpenShift シークレットからロードされます。シークレットでは、公開鍵と秘密鍵の 2 つの鍵を使用して証明書を X509 形式で保存する必要があります。
TLS クライアント認証は TLS 接続でのみ使用できます。
TLS クライアント認証の設定例
type プロパティーは、KafkaClientAuthenticationTls タイプを使用する際に KafkaClientAuthenticationScramSha512、KafkaClientAuthenticationPlain、および KafkaClientAuthenticationOAuth タイプと区別する識別子です。KafkaClientAuthenticationTls タイプには tls の値が必要です。
| プロパティー | 説明 |
|---|---|
| certificateAndKey |
証明書と秘密鍵のペアを保持する |
| type |
|
| string |
B.76. KafkaClientAuthenticationScramSha512 スキーマ参照
KafkaBridgeSpec、KafkaConnectS2ISpec、KafkaConnectSpec、KafkaMirrorMaker2ClusterSpec、KafkaMirrorMakerConsumerSpec、KafkaMirrorMakerProducerSpec で使用
SASL ベースの SCRAM-SHA-512 認証を設定するには、type プロパティーを scram-sha-512 に設定します。SCRAM-SHA-512 認証メカニズムには、ユーザー名とパスワードが必要です。
-
usernameプロパティーでユーザー名を指定します。 -
passwordSecretプロパティーで、パスワードを含むSecretへのリンクを指定します。secretNameプロパティーにはSecretの名前が含まれ、passwordプロパティーにはSecret内にパスワードが格納されるキーの名前が含まれます。
password フィールドには、実際のパスワードを指定しないでください。
SASL ベースの SCRAM-SHA-512 クライアント認証の設定例
type プロパティーは、KafkaClientAuthenticationScramSha512 タイプを使用する際に KafkaClientAuthenticationTls、KafkaClientAuthenticationPlain、および KafkaClientAuthenticationOAuth タイプと区別する識別子です。KafkaClientAuthenticationScramSha512 タイプには scram-sha-512 の値が必要です。
| プロパティー | 説明 |
|---|---|
| passwordSecret |
パスワードを保持する |
| type |
|
| string | |
| username | 認証に使用されるユーザー名。 |
| string |
B.77. PasswordSecretSource スキーマ参照
KafkaClientAuthenticationPlain、KafkaClientAuthenticationScramSha512 で使用
| プロパティー | 説明 |
|---|---|
| password | パスワードが保存される Secret のキーの名前。 |
| string | |
| secretName | パスワードを含むシークレットの名前。 |
| string |
B.78. KafkaClientAuthenticationPlain スキーマ参照
KafkaBridgeSpec、KafkaConnectS2ISpec、KafkaConnectSpec、KafkaMirrorMaker2ClusterSpec、KafkaMirrorMakerConsumerSpec、KafkaMirrorMakerProducerSpec で使用
SASL ベースの PLAIN 認証を設定するには、type プロパティーを plain に設定します。SASL PLAIN 認証メカニズムには、ユーザー名とパスワードが必要です。
SASL PLAIN メカニズムは、クリアテキストでユーザー名とパスワードをネットワーク全体に転送します。TLS 暗号化が有効になっている場合にのみ SASL PLAIN 認証を使用します。
-
usernameプロパティーでユーザー名を指定します。 -
passwordSecretプロパティーで、パスワードを含むSecretへのリンクを指定します。secretNameプロパティーにはそのようなSecretの名前が含まれ、passwordプロパティーにはSecret内にパスワードが格納されるキーの名前が含まれます。
password フィールドには、実際のパスワードを指定しないでください。
SASL ベースの PLAIN クライアント認証の設定例
type プロパティーは、KafkaClientAuthenticationPlain タイプを使用する際に KafkaClientAuthenticationTls、KafkaClientAuthenticationScramSha512、および KafkaClientAuthenticationOAuth タイプと区別する識別子です。KafkaClientAuthenticationPlain タイプには plain の値が必要です。
| プロパティー | 説明 |
|---|---|
| passwordSecret |
パスワードを保持する |
| type |
|
| string | |
| username | 認証に使用されるユーザー名。 |
| string |
B.79. KafkaClientAuthenticationOAuth スキーマ参照
KafkaBridgeSpec、KafkaConnectS2ISpec、KafkaConnectSpec、KafkaMirrorMaker2ClusterSpec、KafkaMirrorMakerConsumerSpec、KafkaMirrorMakerProducerSpec で使用
OAuth クライアント認証を使用するには、type プロパティーを oauth の値に設定します。OAuth 認証は以下を使用して設定できます。
- クライアント ID およびシークレット
- クライアント ID および更新トークン
- アクセストークン
- TLS
クライアント ID およびシークレット
認証で使用されるクライアント ID およびクライアントシークレットとともに、tokenEndpointUri プロパティーで承認サーバーのアドレスを設定できます。OAuth クライアントは OAuth サーバーに接続し、クライアント ID およびシークレットを使用して認証し、Kafka ブローカーとの認証に使用するアクセストークンを取得します。clientSecret プロパティーで、クライアントシークレットが含まれる Secret へのリンクを指定します。
クライアント ID およびクライアントシークレットを使用した OAuth クライアント認証の例
クライアント ID および更新トークン
OAuth クライアント ID および更新トークンとともに、tokenEndpointUri プロパティーで OAuth サーバーのアドレスを設定できます。OAuth クライアントは OAuth サーバーに接続し、クライアント ID と更新トークンを使用して認証し、Kafka ブローカーとの認証に使用するアクセストークンを取得します。refreshToken プロパティーで、更新トークンが含まれる Secret へのリンクを指定します。
クライアント ID と更新トークンを使用した OAuth クライアント認証の例
アクセストークン
Kafka ブローカーとの認証に使用されるアクセストークンを直接設定できます。この場合、tokenEndpointUri は指定しません。accessToken プロパティーで、アクセストークンが含まれる Secret へのリンクを指定します。
アクセストークンのみを使用した OAuth クライアント認証の例
authentication:
type: oauth
accessToken:
secretName: my-access-token-secret
key: access-token
authentication:
type: oauth
accessToken:
secretName: my-access-token-secret
key: access-tokenTLS
HTTPS プロトコルを使用して OAuth サーバーにアクセスする場合、信頼される認証局によって署名された証明書を使用し、そのホスト名が証明書に記載されている限り、追加の設定は必要ありません。
OAuth サーバーが自己署名証明書を使用している場合、または信頼されていない認証局によって署名されている場合は、カスタムリソースで信頼済み証明書の一覧を設定できます。tlsTrustedCertificates プロパティーには、保存される証明書のキー名があるシークレットのリストが含まれます。証明書は X509 形式で保存する必要があります。
提供される TLS 証明書の例
OAuth クライアントはデフォルトで、OAuth サーバーのホスト名が、証明書サブジェクトまたは別の DNS 名のいずれかと一致することを確認します。必要でない場合は、ホスト名の検証を無効にできます。
無効にされた TLS ホスト名の検証例
type プロパティーは、KafkaClientAuthenticationOAuth タイプを使用する際に KafkaClientAuthenticationTls、KafkaClientAuthenticationScramSha512、および KafkaClientAuthenticationPlain タイプと区別する識別子です。KafkaClientAuthenticationOAuth タイプには oauth の値が必要です。
| プロパティー | 説明 |
|---|---|
| accessToken | 承認サーバーから取得したアクセストークンが含まれる OpenShift シークレットへのリンク。 |
| accessTokenIsJwt |
アクセストークンを JWT として処理すべきかどうかを設定します。承認サーバーが不透明なトークンを返す場合は |
| boolean | |
| clientId | Kafka クライアントが OAuth サーバーに対する認証に使用し、トークンエンドポイント URI を使用することができる OAuth クライアント ID。 |
| string | |
| clientSecret | Kafka クライアントが OAuth サーバーに対する認証に使用し、トークンエンドポイント URI を使用することができる OAuth クライアントシークレットが含まれる OpenShift シークレットへのリンク。 |
| disableTlsHostnameVerification |
TLS ホスト名の検証を有効または無効にします。デフォルト値は |
| boolean | |
| maxTokenExpirySeconds | アクセストークンの有効期間を指定の秒数に設定または制限します。これは、承認サーバーが不透明なトークンを返す場合に設定する必要があります。 |
| integer | |
| refreshToken | 承認サーバーからアクセストークンを取得するために使用できる更新トークンが含まれる OpenShift シークレットへのリンク。 |
| tlsTrustedCertificates | OAuth サーバーへの TLS 接続の信頼済み証明書。 |
|
| |
| tokenEndpointUri | 承認サーバートークンエンドポイント URI。 |
| string | |
| type |
|
| string |
B.80. JaegerTracing スキーマ参照
KafkaBridgeSpec、KafkaConnectS2ISpec、KafkaConnectSpec、KafkaMirrorMaker2Spec、KafkaMirrorMakerSpec で使用
type プロパティーは、JaegerTracing タイプを使用する際に、今後追加される可能性のある他のサブタイプと区別する識別子です。JaegerTracing タイプには jaeger の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string |
B.81. KafkaConnectTemplate スキーマ参照
KafkaConnectS2ISpec、KafkaConnectSpec、KafkaMirrorMaker2Spec で使用
| プロパティー | 説明 |
|---|---|
| deployment |
Kafka Connect |
| pod |
Kafka Connect |
| apiService |
Kafka Connect API |
| connectContainer | Kafka Connect コンテナーのテンプレート。 |
| podDisruptionBudget |
Kafka Connect |
B.82. ExternalConfiguration スキーマ参照
KafkaConnectS2ISpec、KafkaConnectSpec、KafkaMirrorMaker2Spec で使用
| プロパティー | 説明 |
|---|---|
| env | Secret または ConfigMap からのデータを環境変数として Kafka Connect Pod に渡すことを許可します。 |
|
| |
| volumes | Secret または ConfigMap からのデータをボリュームとして Kafka Connect Pod に渡すことを許可します。 |
B.83. ExternalConfigurationEnv スキーマ参照
| プロパティー | 説明 |
|---|---|
| name |
Kafka Connect Pod に渡される環境変数の名前。環境変数に、 |
| string | |
| valueFrom | Kafka Connect Pod に渡される環境変数の値。Secret または ConfigMap フィールドのいずれかへ参照として渡すことができます。このフィールドでは、Secret または ConfigMap を 1 つだけ指定する必要があります。 |
B.84. ExternalConfigurationEnvVarSource スキーマ参照
| プロパティー | 説明 |
|---|---|
| configMapKeyRef | ConfigMap のキーへの参照。外部のドキュメント core/v1 configmapkeyselector を参照してください。 |
| secretKeyRef | Secret のキーへの参照。外部のドキュメント core/v1 secretkeyselector を参照してください。 |
B.85. ExternalConfigurationVolumeSource スキーマ参照
| プロパティー | 説明 |
|---|---|
| configMap | ConfigMap のキーへの参照。Secret または ConfigMap を 1 つだけ指定する必要があります。外部のドキュメント core/v1 configmapvolumesource を参照してください。 |
| name | Kafka Connect Pod に追加されるボリュームの名前。 |
| string | |
| secret | Secret のキーへの参照。Secret または ConfigMap を 1 つだけ指定する必要があります。外部のキュメント core/v1 secretvolumesource を参照してください。 |
B.86. KafkaConnectStatus スキーマ参照
KafkaConnect で使用
| プロパティー | 説明 |
|---|---|
| conditions | ステータス条件の一覧。 |
|
| |
| observedGeneration | 最後に Operator によって調整された CRD の生成。 |
| integer | |
| url | Kafka Connect コネクターの管理および監視用の REST API エンドポイントの URL。 |
| string | |
| connectorPlugins | この Kafka Connect デプロイメントで使用できるコネクタープラグインの一覧。 |
|
|
B.87. ConnectorPlugin スキーマ参照
KafkaConnectS2IStatus、KafkaConnectStatus、KafkaMirrorMaker2Status で使用
| プロパティー | 説明 |
|---|---|
| type |
コネクタープラグインのタイプ。利用可能なタイプは、 |
| string | |
| version | コネクタープラグインのバージョン。 |
| string | |
| class | コネクタープラグインのクラス。 |
| string |
B.88. KafkaConnectS2I スキーマ参照
| プロパティー | 説明 |
|---|---|
| spec | Kafka Connect Source-to-Image (S2I) クラスターの仕様。 |
| status | Kafka Connect Source-to-Image (S2I) クラスターのステータス。 |
B.89. KafkaConnectS2ISpec スキーマ参照
KafkaConnectS2I で使用
| プロパティー | 説明 |
|---|---|
| replicas | Kafka Connect グループの Pod 数。 |
| integer | |
| image | Pod の Docker イメージ。 |
| string | |
| buildResources | 予約する CPU およびメモリーリソース。 |
| livenessProbe | Pod の liveness チェック。 |
| readinessProbe | Pod の readiness チェック。 |
| jvmOptions | Pod の JVM オプション。 |
| affinity |
|
| logging |
Kafka Connect のロギング設定。タイプは、指定のオブジェクト内の |
| metrics | Prometheus JMX エクスポーターの設定。この設定の構造に関する詳細は、https://github.com/prometheus/jmx_exporter を参照してください。 |
| map | |
| template |
Kafka Connect および Kafka Connect S2I リソースのテンプレート。テンプレートを使用すると、ユーザーは |
| authentication |
Kafka Connect の認証設定。タイプは、指定のオブジェクト内の |
|
| |
| bootstrapServers | 接続するブートストラップサーバー。これは <hostname>:<port> ペアのコンマ区切りリストとして指定する必要があります。 |
| string | |
| config | Kafka Connect の設定。次の接頭辞を持つプロパティーは設定できません: ssl.、sasl.、security.、listeners、plugin.path、rest.、bootstrap.servers、consumer.interceptor.classes、producer.interceptor.classes |
| map | |
| externalConfiguration | Secret または ConfigMap から Kafka Connect Pod にデータを渡し、これを使用してコネクターを設定します。 |
| insecureSourceRepository | true の場合、'Local' 参照ポリシーとセキュアでないソースタグを受け入れるインポートポリシーを使用してソースリポジトリーを設定します。 |
| boolean | |
| resources | CPU とメモリーリソースおよび要求された初期リソースの上限。 |
| tls | TLS 設定。 |
| tolerations |
|
| Toleration array | |
| tracing |
Kafka Connect でのトレーシングの設定。タイプは、指定のオブジェクト内の |
| version | Kafka Connect のバージョン。デフォルトは 2.4.0 です。バージョンのアップグレードまたはダウングレードに必要なプロセスを理解するには、ユーザードキュメントを参照してください。 |
| string |
B.90. KafkaConnectS2IStatus スキーマ参照
KafkaConnectS2I で使用
| プロパティー | 説明 |
|---|---|
| conditions | ステータス条件の一覧。 |
|
| |
| observedGeneration | 最後に Operator によって調整された CRD の生成。 |
| integer | |
| url | Kafka Connect コネクターの管理および監視用の REST API エンドポイントの URL。 |
| string | |
| connectorPlugins | この Kafka Connect デプロイメントで使用できるコネクタープラグインの一覧。 |
|
| |
| buildConfigName | ビルド設定の名前。 |
| string |
B.91. KafkaTopic スキーマ参照
| プロパティー | 説明 |
|---|---|
| spec | トピックの仕様。 |
| status | トピックのステータス。 |
B.92. KafkaTopicSpec スキーマ参照
KafkaTopic で使用
| プロパティー | 説明 |
|---|---|
| partitions | トピックに存在するパーティション数。この数はトピック作成後に減らすことはできません。トピック作成後に増やすことはできますが、その影響について理解することが重要となります。特にセマンティックパーティションのあるトピックで重要となります。 |
| integer | |
| replicas | トピックのレプリカ数。 |
| integer | |
| config | トピックの設定。 |
| map | |
| topicName | トピックの名前。これがない場合、デフォルトではトピックの metadata.name に設定されます。トピック名が有効な OpenShift リソース名ではない場合を除き、これを設定しないことが推奨されます。 |
| string |
B.93. KafkaTopicStatus スキーマ参照
KafkaTopic で使用
| プロパティー | 説明 |
|---|---|
| conditions | ステータス条件の一覧。 |
|
| |
| observedGeneration | 最後に Operator によって調整された CRD の生成。 |
| integer |
B.94. KafkaUser スキーマ参照
| プロパティー | 説明 |
|---|---|
| spec | ユーザーの仕様。 |
| status | Kafka User のステータス。 |
B.95. KafkaUserSpec スキーマ参照
KafkaUser で使用
| プロパティー | 説明 |
|---|---|
| authentication |
この Kafka ユーザーに対して有効になっている認証メカニズム。タイプは、指定のオブジェクト内の |
|
| |
| authorization |
この Kafka ユーザーの承認ルール。タイプは、指定のオブジェクト内の |
| quotas | クライアントによって使用されるブローカーリソースを制御する要求のクォータ。ネットワーク帯域幅および要求レートクォータの適用が可能です。Kafka ユーザークォータの Kafka ドキュメントは http://kafka.apache.org/documentation/#design_quotas を参照してください。 |
B.96. KafkaUserTlsClientAuthentication スキーマ参照
KafkaUserSpec で使用
type プロパティーは、KafkaUserTlsClientAuthentication タイプを使用する際に KafkaUserScramSha512ClientAuthentication タイプと区別する識別子です。KafkaUserTlsClientAuthentication タイプには tls の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string |
B.97. KafkaUserScramSha512ClientAuthentication スキーマ参照
KafkaUserSpec で使用
type プロパティーは、KafkaUserScramSha512ClientAuthentication タイプを使用する際に KafkaUserTlsClientAuthentication タイプと区別する識別子です。KafkaUserScramSha512ClientAuthentication タイプには scram-sha-512 の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string |
B.98. KafkaUserAuthorizationSimple スキーマ参照
KafkaUserSpec で使用
type プロパティーは、KafkaUserAuthorizationSimple タイプを使用する際に、今後追加される可能性のある他のサブタイプと区別する識別子です。KafkaUserAuthorizationSimple タイプには simple の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string | |
| ACL | このユーザーに適用される必要のある ACL ルールの一覧。 |
|
|
B.99. AclRule スキーマ参照
KafkaUserAuthorizationSimple で使用
| プロパティー | 説明 |
|---|---|
| host | ACL ルールに記述されているアクションを許可または拒否するホスト。 |
| string | |
| operation | 許可または拒否される操作。サポートされる操作: Read、Write、Create、Delete、Alter、Describe、ClusterAction、AlterConfigs、DescribeConfigs、IdempotentWrite、All |
| string ([Read、Write、Delete、Alter、Describe、All、IdempotentWrite、ClusterAction、Create、AlterConfigs、DescribeConfigs] のいずれか) | |
| resource |
指定の ACL ルールが適用されるリソースを示します。タイプは、指定のオブジェクト内の |
|
| |
| type |
ルールのタイプ。現在サポートされているタイプは |
| string ([allow、deny] のいずれか) |
B.100. AclRuleTopicResource スキーマ参照
AclRule で使用
type プロパティーは、AclRuleTopicResource タイプを使用する際に AclRuleGroupResource、AclRuleClusterResource、および AclRuleTransactionalIdResource タイプと区別する識別子です。AclRuleTopicResource タイプには topic の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string | |
| name |
指定の ACL ルールが適用されるリソースの名前。 |
| string | |
| patternType |
リソースフィールドで使用されるパターンを指定します。サポートされるタイプは |
| string ([prefix、literal] のいずれか) |
B.101. AclRuleGroupResource スキーマ参照
AclRule で使用
type プロパティーは、AclRuleGroupResource タイプを使用する際に AclRuleTopicResource、AclRuleClusterResource、および AclRuleTransactionalIdResource タイプと区別する識別子です。AclRuleGroupResource タイプには group の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string | |
| name |
指定の ACL ルールが適用されるリソースの名前。 |
| string | |
| patternType |
リソースフィールドで使用されるパターンを指定します。サポートされるタイプは |
| string ([prefix、literal] のいずれか) |
B.102. AclRuleClusterResource スキーマ参照
AclRule で使用
type プロパティーは、AclRuleClusterResource タイプを使用する際に AclRuleTopicResource、AclRuleGroupResource、および AclRuleTransactionalIdResource タイプと区別する識別子です。AclRuleClusterResource タイプには cluster の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string |
B.103. AclRuleTransactionalIdResource スキーマ参照
AclRule で使用
type プロパティーは、AclRuleTransactionalIdResource タイプを使用する際に AclRuleTopicResource、AclRuleGroupResource、および AclRuleClusterResource タイプと区別する識別子です。AclRuleTransactionalIdResource タイプには transactionalId の値が必要です。
| プロパティー | 説明 |
|---|---|
| type |
|
| string | |
| name |
指定の ACL ルールが適用されるリソースの名前。 |
| string | |
| patternType |
リソースフィールドで使用されるパターンを指定します。サポートされるタイプは |
| string ([prefix、literal] のいずれか) |
B.104. KafkaUserQuotas スキーマ参照
KafkaUserSpec で使用
Kafka では、ユーザーは特定のクォータを適用して、クライアントによるリソースの使用を制御することができます。クォータは、2 つのカテゴリーに分類されます。
- ネットワーク使用率 クォータ。これは、クォータを共有するクライアントの各グループのバイトレートしきい値として定義されます。
- CPU 使用率 クォータ。これは、クライアントがクォータウィンドウ内の各ブローカーのリクエストハンドラー I/O スレッドおよびネットワークスレッドで使用可能な時間の割合として定義されます。
Kafka クライアントにクォータを使用することは、さまざまな状況で役に立つ場合があります。レートが高すぎる要求を送信する Kafka プロデューサーを誤って設定したとします。このように設定が間違っていると、他のクライアントにサービス拒否を引き起こす可能性があるため、問題のあるクライアントはブロックする必要があります。ネットワーク制限クォータを使用すると、他のクライアントがこの状況の著しい影響を受けないようにすることが可能です。
Strimzi はユーザーレベルのクォータをサポートしますが、クライアントレベルのクォータはサポートしません。
Kafka ユーザークォータの例
spec:
quotas:
producerByteRate: 1048576
consumerByteRate: 2097152
requestPercentage: 55
spec:
quotas:
producerByteRate: 1048576
consumerByteRate: 2097152
requestPercentage: 55Kafka ユーザークォータの詳細は Apache Kafka ドキュメント を参照してください。
| プロパティー | 説明 |
|---|---|
| consumerByteRate | グループのクライアントにスロットリングが適用される前に、各クライアントグループがブローカーから取得できる最大 bps (ビット毎秒) のクオータ。ブローカーごとに定義されます。 |
| integer | |
| producerByteRate | グループのクライアントにスロットリングが適用される前に、各クライアントグループがブローカーにパブリッシュできる最大 bps (ビット毎秒) のクオータ。ブローカーごとに定義されます。 |
| integer | |
| requestPercentage | 各クライアントグループの最大 CPU 使用率のクォータ。ネットワークと I/O スレッドの比率 (パーセント) として指定。 |
| integer |
B.105. KafkaUserStatus スキーマ参照
KafkaUser で使用
| プロパティー | 説明 |
|---|---|
| conditions | ステータス条件の一覧。 |
|
| |
| observedGeneration | 最後に Operator によって調整された CRD の生成。 |
| integer | |
| username | ユーザー名。 |
| string | |
| secret |
認証情報が保存される |
| string |
B.106. KafkaMirrorMaker スキーマ参照
| プロパティー | 説明 |
|---|---|
| spec | Kafka MirrorMaker の仕様。 |
| status | Kafka MirrorMaker のステータス。 |
B.107. KafkaMirrorMakerSpec スキーマ参照
KafkaMirrorMaker で使用
| プロパティー | 説明 |
|---|---|
| replicas |
|
| integer | |
| image | Pod の Docker イメージ。 |
| string | |
| whitelist |
ミラーリングに含まれるトピックの一覧。このオプションは、Java スタイルの正規表現を使用するあらゆる正規表現を許可します。 |
| string | |
| consumer | ソースクラスターの設定。 |
| producer | ターゲットクラスターの設定。 |
| resources | 予約する CPU およびメモリーリソース。 |
| affinity |
|
| tolerations |
|
| Toleration array | |
| jvmOptions | Pod の JVM オプション。 |
| logging |
MirrorMaker のロギング設定。タイプは、指定のオブジェクト内の |
| metrics | Prometheus JMX エクスポーターの設定。この設定の構造に関する詳細は、JMX Exporter のドキュメント を参照してください。 |
| map | |
| tracing |
Kafka MirrorMaker でのトレーシングの設定。タイプは、指定のオブジェクト内の |
| template |
Kafka MirrorMaker のリソースである |
| livenessProbe | Pod の liveness チェック。 |
| readinessProbe | Pod の readiness チェック。 |
| version | Kafka MirrorMaker のバージョン。デフォルトは 2.4.0 です。バージョンのアップグレードまたはダウングレードに必要なプロセスを理解するには、ドキュメントを参照してください。 |
| string |
B.108. KafkaMirrorMakerConsumerSpec スキーマ参照
| プロパティー | 説明 |
|---|---|
| numStreams | 作成するコンシューマーストリームスレッドの数を指定します。 |
| integer | |
| offsetCommitInterval | オフセットの自動コミット間隔をミリ秒単位で指定します。デフォルト値は 60000 です。 |
| integer | |
| groupId | このコンシューマーが属するコンシューマーグループを識別する一意の文字列。 |
| string | |
| bootstrapServers | Kafka クラスターへの最初の接続を確立するための host:port ペアの一覧。 |
| string | |
| authentication |
クラスターに接続するための認証設定。タイプは、指定のオブジェクト内の |
|
| |
| config | MirrorMaker のコンシューマー設定。次の接頭辞を持つプロパティーは設定できません: ssl.、bootstrap.servers、group.id、sasl.、security.、interceptor.classes |
| map | |
| tls | MirrorMaker をクラスターに接続するための TLS 設定。 |
B.109. KafkaMirrorMakerTls スキーマ参照
KafkaMirrorMakerConsumerSpec、KafkaMirrorMakerProducerSpec で使用
tls プロパティーを使用して、TLS 暗号化を設定します。証明書が X.509 形式で保存されるキーの名前でシークレットの一覧を提供します。
TLS 暗号化の設定例
tls:
trustedCertificates:
- secretName: my-cluster-cluster-ca-cert
certificate: ca.crt
tls:
trustedCertificates:
- secretName: my-cluster-cluster-ca-cert
certificate: ca.crt| プロパティー | 説明 |
|---|---|
| trustedCertificates | TLS 接続の信頼済み証明書。 |
|
|
B.110. KafkaMirrorMakerProducerSpec スキーマ参照
| プロパティー | 説明 |
|---|---|
| bootstrapServers | Kafka クラスターへの最初の接続を確立するための host:port ペアの一覧。 |
| string | |
| abortOnSendFailure |
送信失敗時に MirrorMaker が終了するように設定するフラグ。デフォルト値は |
| boolean | |
| authentication |
クラスターに接続するための認証設定。タイプは、指定のオブジェクト内の |
|
| |
| config | MirrorMaker プロデューサーの設定。次の接頭辞を持つプロパティーは設定できません: ssl.、bootstrap.servers、sasl.、security.、interceptor.classes |
| map | |
| tls | MirrorMaker をクラスターに接続するための TLS 設定。 |
B.111. KafkaMirrorMakerTemplate スキーマ参照
| プロパティー | 説明 |
|---|---|
| deployment |
Kafka MirrorMaker |
| pod |
Kafka MirrorMaker |
| mirrorMakerContainer | Kafka MirrorMaker コンテナーのテンプレート。 |
| podDisruptionBudget |
Kafka MirrorMaker |
B.112. KafkaMirrorMakerStatus スキーマ参照
KafkaMirrorMaker で使用
| プロパティー | 説明 |
|---|---|
| conditions | ステータス条件の一覧。 |
|
| |
| observedGeneration | 最後に Operator によって調整された CRD の生成。 |
| integer |
B.113. KafkaBridge スキーマ参照
| プロパティー | 説明 |
|---|---|
| spec | Kafka Bridge の仕様。 |
| status | Kafka Bridge のステータス。 |
B.114. KafkaBridgeSpec スキーマ参照
KafkaBridge で使用
| プロパティー | 説明 |
|---|---|
| replicas |
|
| integer | |
| image | Pod の Docker イメージ。 |
| string | |
| bootstrapServers | Kafka クラスターへの最初の接続を確立するための host:port ペアの一覧。 |
| string | |
| tls | Kafka Bridge をクラスターに接続するための TLS 設定。 |
| authentication |
クラスターに接続するための認証設定。タイプは、指定のオブジェクト内の |
|
| |
| http | HTTP 関連の設定。 |
| consumer | Kafka コンシューマーに関連する設定。 |
| producer | Kafka プロデューサーに関連する設定。 |
| resources | 予約する CPU およびメモリーリソース。 |
| jvmOptions | 現時点でサポートされていない Pod の JVM オプション。 |
| logging |
Kafka Bridge のロギング設定。タイプは、指定のオブジェクト内の |
| metrics | 現時点でサポートされていない Prometheus JMX Exporter 設定。この設定の構造に関する詳細は、JMX Exporter のドキュメント を参照してください。 |
| map | |
| livenessProbe | Pod の liveness チェック。 |
| readinessProbe | Pod の readiness チェック。 |
| template |
Kafka Bridge リソースのテンプレート。テンプレートを使用すると、ユーザーは |
| tracing |
Kafka Bridge でのトレーシングの設定。タイプは、指定のオブジェクト内の |
B.115. KafkaBridgeTls スキーマ参照
KafkaBridgeSpec で使用
| プロパティー | 説明 |
|---|---|
| trustedCertificates | TLS 接続の信頼済み証明書。 |
|
|
B.116. KafkaBridgeHttpConfig スキーマ参照
KafkaBridgeSpec で使用
| プロパティー | 説明 |
|---|---|
| port | サーバーがリッスンするポート。 |
| integer |
B.117. KafkaBridgeConsumerSpec スキーマ参照
KafkaBridgeSpec で使用
| プロパティー | 説明 |
|---|---|
| config | ブリッジによって作成されたコンシューマーインスタンスに使用される Kafka コンシューマーの設定。次の接頭辞を持つプロパティーは設定できません: ssl.、bootstrap.servers、group.id、sasl.、security |
| map |
B.118. KafkaBridgeProducerSpec スキーマ参照
KafkaBridgeSpec で使用
| プロパティー | 説明 |
|---|---|
| config | ブリッジによって作成されたプロデューサーインスタンスに使用される Kafka プロデューサーの設定。次の接頭辞を持つプロパティーは設定できません: ssl.、bootstrap.servers、sasl.、security |
| map |
B.119. KafkaBridgeTemplate スキーマ参照
KafkaBridgeSpec で使用
| プロパティー | 説明 |
|---|---|
| deployment |
Kafka Bridge |
| pod |
Kafka Bridge |
| apiService |
Kafka Bridge API |
| bridgeContainer | Kafka Bridge コンテナーのテンプレート。 |
| podDisruptionBudget |
Kafka Bridge |
B.120. KafkaBridgeStatus スキーマ参照
KafkaBridge で使用
| プロパティー | 説明 |
|---|---|
| conditions | ステータス条件の一覧。 |
|
| |
| observedGeneration | 最後に Operator によって調整された CRD の生成。 |
| integer | |
| url | 外部クライアントアプリケーションが Kafka Bridge にアクセスできる URL。 |
| string |
B.121. KafkaConnector スキーマ参照
| プロパティー | 説明 |
|---|---|
| spec | Kafka Connector の仕様。 |
| status | Kafka Connector のステータス。 |
B.122. KafkaConnectorSpec スキーマ参照
KafkaConnector で使用
| プロパティー | 説明 |
|---|---|
| class | Kafka Connector のクラス。 |
| string | |
| tasksMax | Kafka Connector のタスクの最大数。 |
| integer | |
| config | Kafka Connector の設定。次のプロパティーは設定できません: connector.class、tasks.max |
| map | |
| pause | コネクターを一時停止すべきかどうか。デフォルトは false です。 |
| boolean |
B.123. KafkaConnectorStatus スキーマ参照
KafkaConnector で使用
| プロパティー | 説明 |
|---|---|
| conditions | ステータス条件の一覧。 |
|
| |
| observedGeneration | 最後に Operator によって調整された CRD の生成。 |
| integer | |
| connectorStatus | Kafka Connect REST API によって報告されるコネクターのステータス。 |
| map |
B.124. KafkaMirrorMaker2 スキーマ参照
| プロパティー | 説明 |
|---|---|
| spec | Kafka MirrorMaker 2.0 クラスターの仕様。 |
| status | Kafka MirrorMaker 2.0 クラスターのステータス。 |
B.125. KafkaMirrorMaker2Spec スキーマ参照
| プロパティー | 説明 |
|---|---|
| replicas | Kafka Connect グループの Pod 数。 |
| integer | |
| version | Kafka Connect のバージョン。デフォルトは 2.4.0 です。バージョンのアップグレードまたはダウングレードに必要なプロセスを理解するには、ユーザードキュメントを参照してください。 |
| string | |
| image | Pod の Docker イメージ。 |
| string | |
| connectCluster |
Kafka Connect に使用されるクラスターエイリアス。エイリアスは |
| string | |
| clusters | ミラーリング用の Kafka クラスター。 |
| mirrors | MirrorMaker 2.0 コネクターの設定。 |
| resources | CPU とメモリーリソースおよび要求された初期リソースの上限。 |
| livenessProbe | Pod の liveness チェック。 |
| readinessProbe | Pod の readiness チェック。 |
| jvmOptions | Pod の JVM オプション。 |
| affinity |
|
| tolerations |
|
| Toleration array | |
| logging |
Kafka Connect のロギング設定。タイプは、指定のオブジェクト内の |
| metrics | Prometheus JMX エクスポーターの設定。この設定の構造に関する詳細は、https://github.com/prometheus/jmx_exporter を参照してください。 |
| map | |
| tracing |
Kafka Connect でのトレーシングの設定。タイプは、指定のオブジェクト内の |
| template |
Kafka Connect および Kafka Connect S2I リソースのテンプレート。テンプレートを使用すると、ユーザーは |
| externalConfiguration | Secret または ConfigMap から Kafka Connect Pod にデータを渡し、これを使用してコネクターを設定します。 |
B.126. KafkaMirrorMaker2ClusterSpec スキーマ参照
| プロパティー | 説明 |
|---|---|
| alias | Kafka クラスターの参照に使用されるエイリアス。 |
| string | |
| bootstrapServers |
Kafka クラスターへの接続を確立するための |
| string | |
| config | MirrorMaker 2.0 クラスターの設定。次の接頭辞を持つプロパティーは設定できません: ssl.、sasl.、security.、listeners、plugin.path、rest.、bootstrap.servers、consumer.interceptor.classes、producer.interceptor.classes (ssl.endpoint.identification.algorithm を除く) |
| map | |
| tls | MirrorMaker 2.0 コネクターをクラスターに接続するための TLS 設定。 |
| authentication |
クラスターに接続するための認証設定。タイプは、指定のオブジェクト内の |
|
|
B.127. KafkaMirrorMaker2Tls スキーマ参照
KafkaMirrorMaker2ClusterSpec で使用
| プロパティー | 説明 |
|---|---|
| trustedCertificates | TLS 接続の信頼済み証明書。 |
|
|
B.128. KafkaMirrorMaker2MirrorSpec スキーマ参照
| プロパティー | 説明 |
|---|---|
| sourceCluster |
Kafka MirrorMaker 2.0 コネクターによって使用されるソースクラスターのエイリアス。エイリアスは |
| string | |
| targetCluster |
Kafka MirrorMaker 2.0 コネクターによって使用されるターゲットクラスターのエイリアス。エイリアスは |
| string | |
| sourceConnector | Kafka MirrorMaker 2.0 ソースコネクターの仕様。 |
| checkpointConnector | Kafka MirrorMaker 2.0 チェックポイントコネクターの仕様。 |
| heartbeatConnector | Kafka MirrorMaker 2.0 ハートビートコネクターの仕様。 |
| topicsPattern | ミラーリングするトピックに一致する正規表現 (例: "topic1|topic2|topic3")。コンマ区切りリストもサポートされます。 |
| string | |
| topicsBlacklistPattern | ミラーリングから除外するトピックに一致する正規表現。コンマ区切りリストもサポートされます。 |
| string | |
| groupsPattern | ミラーリングされるコンシューマーグループに一致する正規表現。コンマ区切りリストもサポートされます。 |
| string | |
| groupsBlacklistPattern | ミラーリングから除外するコンシューマーグループに一致する正規表現。コンマ区切りリストもサポートされます。 |
| string |
B.129. KafkaMirrorMaker2ConnectorSpec スキーマ参照
KafkaMirrorMaker2MirrorSpec で使用
| プロパティー | 説明 |
|---|---|
| tasksMax | Kafka Connector のタスクの最大数。 |
| integer | |
| config | Kafka Connector の設定。次のプロパティーは設定できません: connector.class、tasks.max |
| map | |
| pause | コネクターを一時停止すべきかどうか。デフォルトは false です。 |
| boolean |
B.130. KafkaMirrorMaker2Status スキーマ参照
| プロパティー | 説明 |
|---|---|
| conditions | ステータス条件の一覧。 |
|
| |
| observedGeneration | 最後に Operator によって調整された CRD の生成。 |
| integer | |
| url | Kafka Connect コネクターの管理および監視用の REST API エンドポイントの URL。 |
| string | |
| connectorPlugins | この Kafka Connect デプロイメントで使用できるコネクタープラグインの一覧。 |
|
| |
| connectors | Kafka Connect REST API によって報告される MirrorMaker 2.0 コネクターステータスの一覧。 |
| map array |
付録C サブスクリプションの使用
AMQ Streams は、ソフトウェアサブスクリプションから提供されます。サブスクリプションを管理するには、Red Hat カスタマーポータルでアカウントにアクセスします。
アカウントへのアクセス
- access.redhat.com に移動します。
- アカウントがない場合は、作成します。
- アカウントにログインします。
サブスクリプションのアクティベート
- access.redhat.com に移動します。
- サブスクリプション に移動します。
- Activate a subscription に移動し、16 桁のアクティベーション番号を入力します。
Zip および Tar ファイルのダウンロード
zip または tar ファイルにアクセスするには、カスタマーポータルを使用して、ダウンロードする関連ファイルを検索します。RPM パッケージを使用している場合は、この手順は必要ありません。
- ブラウザーを開き、access.redhat.com/downloads で Red Hat カスタマーポータルの Product Downloads ページにログインします。
- JBOSS INTEGRATION AND AUTOMATION カテゴリーの Red Hat AMQ Streams エントリーを見つけます。
- 必要な AMQ Streams 製品を選択します。Software Downloads ページが開きます。
- コンポーネントの Download リンクをクリックします。
改訂日時: 2021-02-10 01:38:47 UTC