自動化実行の設定
Automation Controller の管理、監視、および使用方法について
概要
はじめに
このガイドでは、カスタムスクリプトや管理ジョブなどを使用した Automation Controller の管理を説明します。自動化実行の設定ガイドは、DevOps エンジニアおよび管理者向けに作成され、Automation Controller の使いやすいグラフィカルインターフェイスによる管理が必要なシステムに関する基本的な理解を前提としています。
Red Hat ドキュメントへのフィードバック (英語のみ)
このドキュメントの改善に関するご意見がある場合や、エラーを発見した場合は、https://access.redhat.com からテクニカルサポートに連絡してリクエストを送信してください。
第1章 Automation Controller の起動、停止、および再起動
Automation Controller には、管理者ユーティリティースクリプト automation-controller-service が含まれています。このスクリプトにより、現在の単一の Automation Controller ノード上で実行中のすべての Automation Controller サービスを起動、停止、再起動できます。統合インストールの場合、スクリプトにはメッセージキューコンポーネントとデータベースが含まれます。
外部データベースは、管理者が明示的に管理する必要があります。サービススクリプトは /usr/bin/automation-controller-service にあり、次のコマンドで呼び出すことができます。
root@localhost:~$ automation-controller-service restart
クラスター化されたインストールの場合、automation-controller-service restart は、再起動するサービスとして PostgreSQL を含みません。これは、PostgreSQL が Automation Controller の外部に存在し、必ずしも再起動する必要がないためです。クラスター環境でサービスを再起動するには、代わりに systemctl restart automation-controller を使用してください。
また、特定の変更を維持するには、ローカルホストインストールの場合とは対照的に、シングルノードではなく各クラスターノードを再起動する必要があります。
クラスター環境の詳細は、クラスタリング セクションを参照してください。
ディストリビューション固有のサービス管理コマンドを使用してサービススクリプトを呼び出すこともできます。ディストリビューションパッケージでは、多くの場合、サービスを管理するための同様のスクリプト (場合によっては init スクリプト) が提供されます。詳細は、お使いのディストリビューション固有のサービス管理システムを参照してください。
コンテナー内で Automation Controller を実行する場合は、automation-controller-service スクリプトを使用しないでください。代わりに、コンテナー環境を使用して Pod を再起動します。
第2章 Automation Controller の設定
ユーザーインターフェイスの Settings メニューを使用して、一部の Automation Controller オプションを設定できます。
Save すると変更が適用されますが、編集ダイアログは終了しません。
Settings ページに戻るには、ナビゲーションパネルから Settings を選択するか、現在のビューの上部にあるブレッドクラムを使用します。
2.1. システム設定の設定
System メニューを使用して、Automation Controller システム設定を定義できます。
手順
- ナビゲーションパネルから、 → → を選択します。System Settings ページが表示されます。
- をクリックします。
以下のオプションを設定できます。
- Base URL of the service: この設定は、有効な URL をサービスにレンダリングする通知などのサービスによって使用されます。
Proxy IP allowed list: サービスがリバースプロキシーまたはロードバランサーの背後にある場合は、この設定を使用して、サービスがカスタム
REMOTE_HOST_HEADERSヘッダーの値を信頼する際に使用するプロキシー IP アドレスを設定します。この設定が空のリスト (デフォルト) の場合、
REMOTE_HOST_HEADERSで指定されたヘッダーは無条件に信頼されます。-
CSRF Trusted Origins List: サービスがリバースプロキシーまたはロードバランサーの背後にある場合、この設定を使用して、サービスがオリジンヘッダーの値を信頼する際に使用する
schema://addressesを設定します。 - Red Hat customer username: このユーザー名は、データを Automation Analytics に送信するために使用されます。
- Red Hat customer password: このパスワードは、データを Automation Analytics に送信するために使用されます。
- Red Hat or Satellite username: このユーザー名は、Automation Analytics にデータを送信するために使用されます。
- Red Hat or Satellite password: このパスワードは、Automation Analytics にデータを送信するために使用されます。
- Global default execution environment: ジョブテンプレートに対して実行環境が設定されていない場合に使用される実行環境。
Custom virtual environment paths: Automation Controller がカスタムの仮想環境を検索するパス。
1 行に 1 つのパスを入力します。
- Last gather date for Automation Analytics: 日付と時刻を設定します。
Automation Analytics Gather Interval データ収集の間隔 (秒単位)。
Gather data for Automation Analytics が false に設定されている場合、この値は無視されます。
- Last cleanup date for HostMetrics: 日付と時刻を設定します。
- Last computing date of HostMetricSummaryMonthly: 日付と時刻を設定します。
-
Remote Host Headers: リモートホスト名または IP を決定するために検索する HTTP ヘッダーとメタキー。リバースプロキシーの背後にある場合は、
HTTP_X_FORWARDED_FORなど、このリストに項目を追加します。詳細は、Red Hat Ansible Automation Platform のプロキシーサポートの設定 を参照してください。 - Automation Analytics upload URL: この値は、設定ファイルに手動で設定されました。この設定は、Automation Analytics のデータ収集用のアップロード URL を設定するために使用されます。
Defines subscription usage model and shows Host Metrics:
以下のオプションを選択できます。
- Enable Activity Stream: アクティビティーストリームのキャプチャーアクティビティーを有効化するように設定します。
- Enable Activity Stream for Inventory Sync: インベントリー同期の実行時に、アクティビティーストリームのアクティビティーのキャプチャーを有効にするように設定します。
- All Users Visible to Organization Admins: 組織管理者が、組織に関連付けられていない場合も含め、すべてのユーザーとチームを表示できるかどうかを制御するように設定します。
Organization Admins Can Manage Users and Teams: 組織管理者がユーザーとチームを作成および管理する権限を持っているかどうかを制御するように設定します。
LDAP または SAML インテグレーションを使用している場合は、この機能を無効化することを推奨します。
- Gather data for Automation Analytics: サービスが自動化のデータを収集し、Automation Analytics に送信できるように設定します。
- をクリックします。
2.2. ジョブの設定
Job オプションを使用して、Automation Controller でジョブの操作を定義できます。
手順
- ナビゲーションパネルから、 → → を選択します。
Job Settings ページで、 をクリックします。

以下のオプションを設定できます。
Ansible Modules Allowed For Ad Hoc Jobs: アドホックジョブで使用できるモジュールのリスト。
サービスが、ジョブの実行および分離用に新規の一時ディレクトリーを作成するディレクトリーです (認証情報ファイルなど)。
When can extra variables contain Jinja templates?: Ansible は、
--extra-varsの Jinja2 テンプレート言語による変数の置換を許可します。これにより、ジョブの起動時に追加の変数を指定できるユーザーが Jinja2 テンプレートを使用して任意の Python を実行できるという潜在的なセキュリティーリスクが生じます。
この値を
templateまたはneverに設定します。Paths to expose to isolated jobs: 分離されたジョブに公開するためのパスのリスト (通常は非表示)。
1 行に 1 つのパスを入力します。特定のファイルへのパスを入力すると、そのファイルを含むディレクトリー全体が実行環境内にマウントされます。
ボリュームは実行ノードからコンテナーにマウントされます。
サポートされるフォーマットは、
HOST-DIR[:CONTAINER-DIR[:OPTIONS]]です。- Extra Environment Variables: Playbook の実行、インベントリーの更新、プロジェクトの更新、通知の送信用に設定された追加の環境変数。
K8S Ansible Runner Keep-Alive Message Interval: コンテナーグループで実行されているジョブにのみ適用されます。
0 以外の場合は、接続を開いたままにするために、指定された秒数ごとにメッセージを送信します。
- Environment Variables for Galaxy Commands: プロジェクトの更新内で ansible-galaxy を呼び出すために設定される追加の環境変数。git ではなく、ansible-galaxy にはプロキシーサーバーを使用する必要がある場合に便利です。
- Standard Output Maximum Display Size: 出力のダウンロードを必要する前に表示する標準出力の最大サイズ (バイト単位)。
-
Job Event Standard Output Maximum Display Size: 単一のジョブまたはアドホックコマンドイベントで表示する標準出力の最大サイズ (バイト単位)。切り捨てられると、stdout は
…で終わります。 Job Event Maximum Websocket Messages Per Second: UI ライブジョブ出力を更新する 1 秒あたりのメッセージの最大数。
値が 0 の場合は制限がないことを意味します。
- Maximum Scheduled Jobs: スケジュールから起動するときに、これ以上作成されなくなるまで実行を待機できる同じジョブテンプレートの最大数。
- Ansible Callback Plugins: ジョブの実行時に使用される追加のコールバックプラグインを検索するためのパスのリスト。
Default Job Timeout: この秒数内に Ansible から出力が検出されない場合、実行は終了します。
アイドルタイムアウトを適用しないことを示すには、値 0 を使用します。
1 行に 1 つのパスを入力します。
Default Job Idle Timeout: この秒数内に Ansible から出力が検出されない場合、実行は終了します。
アイドルタイムアウトを適用しないことを示すには、値 0 を使用します。
Default Inventory Update Timeout: インベントリー更新の実行を許可する最大時間 (秒単位)。
タイムアウトを課さないことを示すには、値 0 を使用します。
個々のインベントリーソースに設定されたタイムアウトは、これをオーバーライドします。
Default Project Update Timeout: プロジェクト更新の実行を許可する最大時間 (秒単位)。
タイムアウトを課さないことを示すには、値 0 を使用します。
個々のプロジェクトに設定されたタイムアウトは、これをオーバーライドします。
Per-Host Ansible Fact Cache Timeout: 保存された Ansible ファクトが最後に変更されてから有効と見なされる最大時間 (秒単位)。
Playbook では、有効で古くないファクトのみにアクセスできます。
これは、データベースからの
ansible_factsの削除には影響しません。タイムアウトを課さないことを示すには、値 0 を使用します。
Maximum number of forks per job: この数を超えるフォークを含むジョブテンプレートを保存すると、エラーが発生します。
0 に設定すると、制限は適用されません。
- Job execution path: Operator ベースのインストールでのみ使用できます。
Container Run Options: Operator ベースのインストールでのみ使用できます。
Podman 実行に渡すオプションのリストの例:
['--network', 'slirp4netns:enable_ipv6=true', '--log-level', 'debug']以下のオプションを設定できます。
-
Run Project Updates With Higher Verbosity: プロジェクト更新に使用される
project_update.ymlの Playbook 実行に CLI-vvvフラグを追加する場合に選択します。 -
Enable Role Download: SCM プロジェクトの
requirements.ymlファイルからロールを動的にダウンロードできるようにする場合に選択します。 -
Enable Collection(s) Download: SCM プロジェクトの
requirements.ymlファイルからコレクションを動的にダウンロードできるようにする場合に選択します。 Follow symlinks: Playbook をスキャンするときにシンボリックリンクに従う場合に選択します。
これを
Trueに設定すると、リンクが自身の親ディレクトリーを指している場合、無限再帰が発生する可能性があることに注意してください。Expose host paths for Container Groups: コンテナーグループによって作成された Pod のパスを hostPath を通じて公開する場合に選択します。
HostPath ボリュームには多くのセキュリティーリスクが伴うため、可能な場合は HostPath の使用を避けることがベストプラクティスとなります。
Ignore Ansible Galaxy SSL Certificate Verification:
trueに設定すると、どの Galaxy サーバーからコンテンツをインストールするときにも、証明書の検証は行われません。追加情報が必要な場合、対象のフィールドの横にあるツールチップアイコン
 をクリックします。
をクリックします。
Galaxy 設定に関する詳細は、自動化実行の使用 の Ansible Galaxy サポート セクションを参照してください。
注記すべてのタイムアウト値は秒単位です。
- をクリックして設定を適用します。
2.3. ロギングとアグリゲーションの設定
これらの設定の詳細は、ロギングのセットアップ を参照してください。
2.4. Automation Analytics の設定
ライセンスの初回インポート時に、Automation Analytics (Ansible Automation Platform サブスクリプションに含まれるクラウドサービス) を強化するデータの収集が自動的にオプトインされます。
前提条件
- console.redhat.com で Automation Analytics Viewer ロールを使用して作成したサービスアカウント。詳細は、サービスアカウントの作成 を参照してください。
手順
- ナビゲーションパネルから、 → → を選択します。
- をクリックします。
- Red Hat Client ID for Analytics という名前のフィールドに、サブスクリプションとコンテンツ情報を取得するためのサービスアカウントを作成したときに受け取ったクライアント ID を入力します。
- Red Hat Client Secret for Analytics という名前のフィールドに、Automation Analytics にデータを送信するためのサービスアカウントを作成したときに受け取ったクライアントシークレットを入力します。
- Options リストで、Gather data for Automation Analytics チェックボックスをオンにします。
- をクリックします。
検証
サービスアカウントを設定した後、テストジョブを実行して、すべてが正しく設定されていることを確認します。
- ナビゲーションパネルから → を選択してジョブを起動します。
- console.redhat.com で分析 を確認して、データが送信されていることを確認します。
2.5. Automation Controller の追加設定
Automation Controller の動作に影響を与える可能性のある追加の詳細設定が存在します。当該設定を Automation Controller UI で行うことはできません。
従来の仮想マシンベースのデプロイメントの場合、/etc/tower/conf.d/custom.py にファイルを作成することで、これらの設定を Automation Controller に提供できます。ファイルベースの設定を通じて Automation Controller に設定を提供する場合、設定ファイルはすべてのコントロールプレーンノードに存在する必要があります。これらのノードは、インストーラーインベントリーの automationcontroller グループに属するハイブリッドまたはコントロールタイプのノードすべてを含みます。
これらの設定を有効にするには、設定ファイルを有する各ノードで、automation-controller-service restart を使用してサービスを再起動します。このファイルで指定した設定が Automation Controller UI にも表示される場合、UI では "Read only" とマークされます。
コンテナーベースのインストールの場合、Automation Controller の変数 の controller_extra_settings を使用してください。コンテナー化されたバージョンは custom.py をサポートしていません。
第3章 Automation Controller のパフォーマンスチューニング
Automation Controller をチューニングしてパフォーマンスとスケーラビリティを最適化します。ワークロードを計画するときは、パフォーマンスとスケーリングのニーズを特定し、制限に合わせて調整し、デプロイメントを監視してください。
Automation Controller は、次のようなチューニング可能なコンポーネントが多数含まれる分散システムです。
- ジョブのスケジューリングを担当するタスクシステム
- ジョブの制御と出力の処理を担当するコントロールプレーン
- ジョブが実行される実行プレーン
- API の提供を担当する Web サーバー
- WebSocket 接続とデータを提供およびブロードキャストする WebSocket システム
- 多くのコンポーネントで使用されるデータベース
3.1. Automation Controller の WebSocket 設定
Automation Controller を設定して、WebSocket 設定を nginx またはロードバランサーの設定と合わせることができます。
Automation Controller ノードは、Websocket を介して相互接続され、Websocket が発行するすべてのメッセージをシステム全体に分散します。この設定セットアップにより、任意のブラウザークライアント Websocket が、任意の Automation Controller ノードで実行されている可能性がある任意のジョブにサブスクライブできるようになります。WebSocket クライアントは特定の Automation Controller ノードにルーティングされません。代わりに、すべての Automation Controller ノードが任意の Websocket 要求を処理できます。各 Automation Controller ノードは、すべてのクライアントに宛てたすべての Websocket メッセージを把握しておく必要があります。
WebSocket は、すべての Automation Controller ノードの /etc/tower/conf.d/websocket_config.py で設定できます。変更はサービスの再起動後に有効になります。
Automation Controller は、データベース内のインスタンスレコードを介して、他の Automation Controller ノードの検出を自動的に処理します。
Automation Controller ノードは、(オープンインターネットではなく) プライベートで信頼できるサブネットを介して Websocket トラフィックをブロードキャストするように設計されています。そのため、Websocket ブロードキャストの HTTPS をオフにすると、Ansible Playbook の標準出力 (stdout) の大部分で構成される Websocket トラフィックは、Automation Controller ノード間で暗号化されずに送信されます。
3.1.1. 他の Automation Controller ノードの自動検出の設定
WebSocket 接続を設定して、Automation Controller がデータベースのインスタンスレコードを使用して他の Automation Controller ノードの検出を自動的に処理できるようにします。
Automation Controller の WebSocket のポートとプロトコルの情報を編集し、WebSocket 接続を確立するときに証明書を検証するかどうかを
TrueまたはFalseで確認します。BROADCAST_WEBSOCKET_PROTOCOL = 'http' BROADCAST_WEBSOCKET_PORT = 80 BROADCAST_WEBSOCKET_VERIFY_CERT = False次のコマンドを使用して Automation Controller を再起動します。
$ automation-controller-service restart
3.2. Automation Controller をデプロイするための容量のプランニング
Automation Controller の容量のプランニングでは、計画されたワークロードを実行する容量を確保できるように、デプロイメントのスケールと特性について計画します。容量のプランニングには次のフェーズが含まれます。
- ワークロードの特徴付け
- さまざまなノードタイプの機能の確認
- ワークロードの要件に基づくデプロイメントのプランニング
3.2.1. ワークロードの特徴
デプロイメントを計画する前に、サポートするワークロードを確立します。Automation Controller ワークロードを特徴付けるために、次の要素を考慮してください。
- 管理対象ホスト
- ホストごとの 1 時間あたりのタスク数
- サポートする同時実行ジョブの最大数
- ジョブに設定するフォークの最大数。フォークによって、ジョブがいくつのホストで同時に動作するかが決まります。
- 1 秒あたりの API 要求の最大数
- デプロイするノードのサイズ (CPU/メモリー/ディスク)
3.2.2. Automation Controller のノードのタイプ
Automation Controller デプロイメントでは、4 種類のノードを設定できます。
- コントロールノード
- ハイブリッドノード
- 実行ノード
- ホップノード
ただし、Operator ベースの環境には、ハイブリッドノードやコントロールノードはありません。Kubernetes クラスター上で実行されるコンテナーを構成するコンテナーグループはあります。それがコントロールプレーンを構成します。このコントロールプレーンは、Red Hat Ansible Automation Platform がデプロイされている Kubernetes クラスターに対してローカルです。
3.2.2.1. コントロールノードをスケーリングする利点
コントロールノードとハイブリッドノードは、制御容量を提供します。これらのノードは、ジョブを開始し、データベースへの出力を処理する機能を提供します。すべてのジョブにはコントロールノードが割り当てられます。デフォルト設定では、各ジョブを制御するには 1 の容量単位が必要です。たとえば、100 の容量単位を持つコントロールノードは、最大 100 個のジョブを制御できます。
より多くのリソースを備えた大規模な仮想マシンをデプロイして、コントロールノードを垂直スケーリングすると、コントロールプレーンの次の機能が向上します。
- コントロールノードが制御タスクを実行できるジョブの数。この数を増やすには、より多くの CPU とメモリーが必要です。
- コントロールノードが同時に処理できるジョブイベントの数。
CPU とメモリーを同じ比率でスケーリングすることを推奨します (例: 1 CPU: 4 GB RAM)。メモリー消費量が多い場合でも、インスタンスの CPU を増やすことで負荷が軽減されることがよくあります。コントロールノードが消費するメモリーの大部分は、メモリーベースのキューに格納されている未処理のイベントによるものです。
コントロールノードを垂直スケーリングしても、Web 要求を処理するワーカーの数は自動的に増加しません。
垂直スケーリングの代わりに、より多くのコントロールノードをデプロイして水平スケーリングを行うこともできます。これにより、ロードバランサーをプロビジョニングしてノード間で要求を分散する場合、制御タスクをより多くのノードに分散できるほか、Web トラフィックもより多くのノードに分散できます。より多くのコントロールノードをデプロイする水平スケーリングのほうが、多くの点で望ましい場合があります。コントロールノードがダウンしたり、通常よりも高い負荷がかかったりした場合に、冗長性が向上し、ワークロードが分離されるためです。
3.2.2.2. 実行ノードをスケーリングする利点
実行ノードとハイブリッドノードは実行容量を提供します。ジョブが消費する容量は、ジョブテンプレートに設定されているフォークの数とインベントリー内のホストの数のいずれか少ない方に、メインの Ansible プロセスを考慮した 1 容量単位を加えたものと等しくなります。たとえば、デフォルトのフォーク値が 5 のジョブテンプレートが 50 台のホストを持つインベントリーで動作している場合、このジョブテンプレートは、割り当てられている実行ノードから 6 容量単位を消費します。
より多くのリソースを備えたより大規模な仮想マシンをデプロイすることで実行ノードを垂直スケーリングすると、ジョブ実行のためのフォークが増加します。これにより、インスタンスで実行できる同時実行ジョブの数が増加します。
一般に、CPU とメモリーを同じ比率でスケーリングすることを推奨します。コントロールノードやハイブリッドノードと同様に、各実行ノードには容量調整があります。容量調整を使用して、Automation Controller が作成する容量消費の推定値に合わせて実際の使用量を調整できます。デフォルトでは、すべてのノードがその範囲の上限に設定されます。実際の監視データによりノードが過剰に使用されていると判明した場合、容量調整を減らすことで、実際の使用量と一致させることができます。
実行ノードを垂直スケーリングする代わりに、より多くの仮想マシンを実行ノードとしてデプロイして、実行プレーンを水平スケーリングすることもできます。水平スケーリングによりワークロードをさらに分離できるため、異なるインスタンスを異なるインスタンスグループに割り当てることができます。これらのインスタンスグループは、組織、インベントリー、またはジョブテンプレートに割り当てることができます。たとえば、特定のインベントリーに対してジョブを実行する場合にのみ使用できるインスタンスグループを設定できます。この場合、実行プレーンを水平スケーリングすることで、優先度の低いジョブが優先度の高いジョブをブロックしないようにすることができます。
3.2.2.3. ホップノードをスケーリングする利点
ホップノードが使用するメモリーと CPU は非常に少ないため、これらのノードを垂直スケーリングしても容量には影響しません。多くの実行ノードとコントロールプレーンの間の唯一の接続として機能するホップノードについては、ネットワーク帯域幅を監視してください。帯域幅の使用量が飽和している場合は、ネットワークの変更を検討してください。
ホップノードを追加して水平スケーリングすると、1 つのホップノードがダウンしても冗長性が提供され、コントロールプレーンと実行ノードの間でトラフィックを流し続けることができます。
3.2.2.4. 制御容量と実行容量の比率
デフォルト設定を前提とすると、従来の仮想マシンのデプロイメントでは、制御容量と実行容量の最大推奨比率は 1:5 です。この比率により、利用可能なすべての実行容量でジョブを実行して出力を処理するための、十分な制御容量が確保されます。実行容量に対して制御容量が少ないと、実行容量を使用する十分な数のジョブを起動できなくなります。
この比率を 1:1 に近づけることが推奨される場合があります。たとえば、ジョブが高レベルのジョブイベントを生成する場合、制御容量に対して実行容量を減らすと、出力を処理するためにコントロールノードに掛かる負荷が軽減されます。
3.3. 容量プランニングの演習例
サポートするワークロード容量を決定したら、ワークロードの要件に基づいてデプロイメントを計画する必要があります。デプロイメントに役立つように、次のプランニング演習を確認してください。
この例では、クラスターは次の容量をサポートする必要があります。
- 300 台の管理対象ホスト
- ホストごとに 1 時間あたり 1,000 タスク、またはホストごとに 1 分あたり 16 タスク
- 10 個の同時ジョブ
- Playbook でフォークが 5 に設定されている。これはデフォルトになります。
- 1 MB の平均イベントサイズ
仮想マシンには、4 つの CPU と 16 GB の RAM、および 3000 IOPS のディスクが搭載されています。
3.3.1. ワークロード要件の例
この容量プランニングの演習例では、次のワークロード要件を使用します。
実行容量
10 個の同時実行ジョブを実行するには、少なくとも 60 単位の実行容量が必要です。
- これは、(10 個のジョブ * 5 つのフォーク) + (10 個のジョブ * ジョブの 1 基本タスクインパクト) = 60 実行容量という式を使用して計算します。
制御容量
- 10 個の同時実行ジョブを制御するには、少なくとも 10 ユニットの制御容量が必要です。
300 台の管理対象ホストで、ホストごとに 1 時間あたり 1,000 個のタスクをサポートするために必要な 1 時間あたりのイベント数を計算するには、次の式を使用します。
- 1 時間あたり 1000 個のタスク * 300 台の管理対象ホスト = 1 時間あたり少なくとも 300,000 個のイベント
- ジョブが生成するイベントの数を正確に確認するには、ジョブを実行する必要があります。これは、イベントの数が特定のタスクと詳細度に依存するためです。たとえば、“Hello World” を出力するデバッグタスクは、1 つのホストで詳細度 1 のジョブイベントを 6 つ生成します。詳細度を 3 にすると、1 つのホストで 34 個のジョブイベントを生成します。したがって、タスクは少なくとも 6 つのイベントを生成すると推定する必要があります。これにより、1 時間あたり 3,000,000 個近くのイベント、つまり 1 秒あたり約 833 個のイベントが生成されることになります。
必要な実行ノードとコントロールノードの数の決定
必要な実行ノードとコントロールノードの数を決定するには、次の表に示す実験結果を参照してください。この表は、1 つのコントロールノードに対して同サイズの実行ノードが 5 つある場合に確認されたイベント処理速度を示しています (API 容量の列)。ジョブテンプレートのデフォルトの “フォーク” 設定は 5 です。そのため、このデフォルト値を使用すると制御容量と実行容量の比率が前述の 1:5 になり、ディスパッチ可能な最大数のジョブをコントロールノードが実行ノードにディスパッチした場合に、CPU/RAM が等しい 5 つの実行ノードが容量を 100% 使用することになります。
| ノード | API 容量 | デフォルトの実行容量 | デフォルトの制御容量 | 容量使用率 100% での平均イベント処理速度 | 容量使用率 50% での平均イベント処理速度 | 容量使用率 40% での平均イベント処理速度 |
|---|---|---|---|---|---|---|
| 4 CPU (2.5 Ghz)、16 GB RAM のコントロールノード、最大 3000 IOPS のディスク | 1 秒あたり約 10 リクエスト | 該当なし | 137 ジョブ | 1 秒あたり 1100 | 1 秒あたり 1400 | 1 秒あたり 1630 |
| 4 CPU (2.5 Ghz)、16 GB RAM の実行ノード、最大 3000 IOPS のディスク | 該当なし | 137 | 該当なし | 該当なし | 該当なし | 該当なし |
| 4 CPU (2.5 Ghz)、16 GB RAM のデータベースノード、最大 3000 IOPS のディスク | 該当なし | 該当なし | 該当なし | 該当なし | 該当なし | 該当なし |
ジョブの制御はコントロールノード上のジョブイベント処理と競合するため、制御容量をオーバープロビジョニングすると処理時間が短縮される可能性があります。処理時間が長い場合、ジョブの実行から API または UI で出力を表示できるようになるまでに遅延が発生する可能性があります。
この例において、300 台の管理対象ホストのワークロードがあり、ホストごとに 1 時間あたり 1000 個のタスクを実行し、Playbook でフォークを 5 に設定した 10 個の同時実行ジョブがあり、平均イベントサイズが 1 MB の場合、次の手順を使用します。
- 4 つの 2.5 Ghz の CPU、16 GB の RAM、および約 3000 IOPS のディスクを備えた 1 つの実行ノード、1 つのコントロールノード、1 つのデータベースノードをデプロイします。
- ジョブテンプレートで、フォーク設定をデフォルトの 5 に維持します。
- コントロールノードの UI のインスタンスビューで容量変更機能を使用して、容量を最低値を 16 まで減らし、イベント処理用に確保するコントロールノードの容量を増やします。
高レベルの API インタラクションを伴うワークロードの詳細は、Scaling Automation Controller for API Driven Workloads を参照してください。インスタンスによる容量の管理に関する詳細は、インスタンスによる容量の管理 を参照してください。Operator ベースのデプロイメントの詳細は、Operator 環境に関する Red Hat Ansible Automation Platform の考慮事項 を参照してください。
3.4. Automation Controller のパフォーマンスのトラブルシューティング
要求のタイムアウト (504 または 503 エラー) が多く発生するか、一般に API レイテンシーが増大します。UI では、クライアントはログインに時間がかかり、ページがロードされるまでの待機時間が長くなります。どのシステムが原因であると考えられますか?
- これらの問題がログイン時にのみ発生し、外部認証を使用する場合は、外部認証プロバイダーのインテグレーションに問題がある可能性があるため、Red Hat サポートにお問い合わせください。
- タイムアウトや API レイテンシーの増大に関するその他の問題は、Web サーバーのチューニング を参照してください。
ジョブ出力がロードされるまでの待機時間が長くなります。
- ジョブ出力は、ansible-playbook を実際に実行する実行ノードから、関連するコントロールノードにストリーミングされます。次に、コールバックレシーバーがこのデータをシリアライズし、データベースに書き込みます。確認およびチューニングする関連設定は、ジョブイベント処理を管理するための設定 および Automation Controller の PostgreSQL データベースの設定およびメンテナンス を参照してください。
- 一般に、この症状を解決するには、コントロールノードの CPU とメモリーの使用状況を確認することが重要です。CPU またはメモリーの使用率が非常に高い場合は、より多くの仮想マシンをコントロールノードとしてデプロイし、コントロールプレーンを水平スケーリングすることで作業をさらに分散させるか、コントロールノードが一度に管理するジョブの数を変更します。詳細は、コントロールノードと実行ノードの容量設定 を参照してください。
- プラットフォームにプルされていない実行環境を使用する初期ジョブ実行では、ジョブ出力遅延が発生する可能性があります。ジョブの実行が完了すると出力が表示されます。
Automation Controller が同時に実行できるジョブの数を増やすにはどうすればよいですか?
ジョブが “保留” 状態のままになる要因は次のとおりです。
- “依存関係” が完了するのを待機している: これには、“起動時の更新” 動作が有効になっている場合のプロジェクトの更新とインベントリーの更新が含まれます。
- ジョブテンプレートの "allow_simultaneous" 設定: 同じジョブテンプレートの複数のジョブが “pending” 状態の場合は、ジョブテンプレートの "allow_simultaneous" 設定 (UI の "Concurrent Jobs" チェックボックス) を確認します。これが有効になっていない場合、ジョブテンプレートのジョブは一度に 1 つしか実行できません。
- ジョブテンプレートの “forks” 値: デフォルト値は 5 です。ジョブの実行に必要な容量は、おおよそフォーク値と等しくなります (多少のオーバーヘッドは考慮されます)。フォーク値を非常に大きな数に設定すると、それを実行できるノードが制限されます。
- 制御容量または実行容量の不足: /api/v2/metrics で利用可能なアプリケーションメトリクスの “awx_instance_remaining_capacity” メトリクスを確認します。メトリクスを確認する方法の詳細は、Automation Controller アプリケーションを監視するためのメトリクス を参照してください。必要な数のジョブを処理するようにデプロイメントを計画する方法は、Automation Controller をデプロイするための容量のプランニング を参照してください。
ローカルマシンよりも Automation Controller の方がジョブの実行に時間がかかります。
- オーバーヘッドは多少増大すると想定されています。これは、Automation Controller が別のノードにジョブをディスパッチしている場合があるためです。この場合、Automation Controller はコンテナーを起動し、そこで ansible-playbook を実行し、すべての出力をシリアライズしてデータベースに書き込みます。
- 起動時のプロジェクト更新と、起動時のインベントリー更新の動作により、ジョブの開始時に遅延が増大する可能性があります。
- プロジェクトはコントロールノードで更新されて実行ノードに転送されるため、プロジェクトのサイズがジョブの開始にかかる時間に影響する可能性があります。内部クラスタールーティングは、ネットワークのパフォーマンスに影響を与える可能性があります。詳細は、内部クラスタールーティング を参照してください。
- コンテナーのプル設定は、ジョブの開始時間に影響を与える可能性があります。実行環境は、ジョブの実行に使用するコンテナーです。コンテナーのプル設定は、“Always”、“Never”、または “If not present” に設定できます。コンテナーが常にプルされている場合、遅延が発生する可能性があります。
- すべてのクラスターノード (実行ノード、コントロールノード、データベースノードを含む) が、最小要件の IOPS を満たすストレージを備えたインスタンスにデプロイされていることを確認してください。これは、Automation Controller が Ansible を実行してイベントデータをキャッシュする方法では、大量のディスク I/O が生じるためです。詳細は、システム要件 を参照してください。
データベースストレージが増加し続けます。
- Automation Controller には、“Cleanup Job Details” というタイトルの管理ジョブがあります。デフォルトでは、120 日分のデータを保持し、週に 1 回実行するように設定されています。データベース内のデータ量を減らすために、保持期間を短縮できます。詳細は、以前のアクティビティーストリームデータの削除 を参照してください。
- クリーンアップジョブを実行すると、データベース内のデータが削除されます。ただし、データベースはいずれかの時点で、ストレージを解放するバキューム操作を実行する必要があります。データベースのバキューム処理の詳細は、Automation Controller の PostgreSQL データベースの設定およびメンテナンス を参照してください。
3.5. Automation Controller を監視するためのメトリクス
Automation Controller ホストをシステムレベルとアプリケーションレベルで監視します。
システムレベルの監視では、次の情報が含まれます。
- ディスク I/O
- RAM 使用率
- CPU 使用率
- ネットワークトラフィック
アプリケーションレベルのメトリクスは、アプリケーションがシステムについて把握しているデータを提供します。このデータには次の情報が含まれます。
- 特定のインスタンスで実行されているジョブの数
- クラスター内のインスタンスに関する容量情報
- 存在するインベントリーの数
- インベントリーに含まれるホストの数
システムおよびアプリケーションのメトリクスを使用すると、サービスが低下したときにアプリケーションで何が起きていたのかを特定するのに役立ちます。Automation Controller の経時的なパフォーマンスに関する情報は、問題の診断や、将来の拡張に備えた容量プランニングを行うときに役立ちます。
3.5.1. Automation Controller アプリケーションを監視するためのメトリクス
アプリケーションレベルの監視のために、Automation Controller は、API エンドポイント /api/v2/metrics で Prometheus スタイルのメトリクスを提供します。これらのメトリクスを使用して、ジョブの出力処理やジョブのスケジューリングなどに関する、ジョブのステータスとサブシステムのパフォーマンスに関する集計データを監視します。
メトリクスエンドポイントには、各メトリクスの説明が含まれます。パフォーマンスに関する特に重要なメトリクスの例は以下のとおりです。
awx_status_total- 各ステータスにあるジョブの現在の合計です。他のイベントをシステム内のアクティビティーに関連付けるのに役立ちます。
- エラーまたは失敗したジョブの増加を監視できます。
awx_instance_remaining_capacity
- 追加のジョブを実行するために残っている容量です。
callback_receiver_event_processing_avg_seconds- 通称 “ジョブイベントラグ” です。
- Ansible でタスクが発生してからユーザーがそれを確認できるようになるまでのラグタイムの移動平均です。これは、コールバックレシーバーがイベントの処理でどれだけ遅延しているかを示します。この数が非常に大きい場合、ユーザーはコントロールプレーンをスケールアップするか、容量調整機能を使用してコントロールノードが制御するジョブの数を減らすことを検討できます。
callback_receiver_events_insert_db- ノードによって挿入されたイベントのカウンターです。特定の期間におけるジョブイベント挿入率を計算するために使用できます。
callback_receiver_events_queue_size_redis- コールバックレシーバーがイベントの処理でどれだけ遅延しているかを示すインジケーターです。値が高すぎると、Redis によってコントロールノードのメモリー不足 (OOM) が発生する可能性があります。
3.5.2. システムレベルの監視
インスタンスの容量管理では、ホストの実際のリソース使用量がイントロスペクトされないため、クラスターホストの CPU とメモリーの使用状況を監視することが重要です。自動化ジョブのリソースへの影響は、Playbook が実行する内容によって異なります。たとえば、多くのクラウドモジュールやネットワークモジュールは、Ansible Playbook を実行する実行ノードでほとんどの処理を行います。Automation Controller への影響は、“yum” のようなネイティブモジュールを実行している場合とは大きく異なります。このようなネイティブモジュールの場合、作業はターゲットホストで実行され、タスクの実行中、実行ノードは多くの時間を結果の待機に費やします。
CPU またはメモリーの使用率が非常に高い場合は、Automation Controller で、関連するインスタンスの容量調整を下げることを検討してください (インスタンスの詳細ページで行うことができます)。これにより、当該インスタンスで実行または制御するジョブの数が制限されます。
ディスク I/O とシステムの使用状況を監視します。Automation Controller ノードが Ansible を実行し、出力をファイルシステムにキャッシュして、最終的にデータベースに保存する方法では、多くのディスク読み取りと書き込みが発生します。ディスクのパフォーマンス低下を早期に特定すると、ユーザーエクスペリエンスの低下やシステムのパフォーマンス低下を防ぐのに役立ちます。
3.6. Automation Controller の PostgreSQL データベースの設定およびメンテナンス
Automation Controller のパフォーマンスを向上させるために、データベースで次の設定パラメーターを設定できます。
メンテナンス
VACUUM タスクと ANALYZE タスクは、パフォーマンスに影響を与える可能性がある重要なメンテナンス作業です。通常の PostgreSQL 操作では、更新によって削除または不要になったタプルはテーブルから物理的に削除されません。これらは、VACUUM が完了するまで残ります。したがって、頻繁に更新されるテーブルでは特に、定期的に VACUUM を実行する必要があります。ANALYZE は、データベース内のテーブルの内容に関する統計情報を収集し、結果を pg_statistic システムカタログに保存します。その後、クエリープランナーはこれらの統計情報を使用して、クエリーの最も効率的な実行計画を決定します。自動バキュームに関する PostgreSQL 設定パラメーターは、VACUUM コマンドおよび ANALYZE コマンドの実行を自動化します。自動バキュームは true に設定することを推奨します。ただし、データベースにアイドル時間がまったくない場合、自動バキュームは実行されません。自動バキュームによってデータベースディスクの領域が十分にクリーンアップされていないことが確認された場合、特定のメンテナンス期間中に特定のバキュームタスクをスケジューリングすることで解決する場合があります。
設定パラメーター
PostgreSQL サーバーのパフォーマンスを向上させるには、データベースメモリーを管理する次の Grand Unified Configuration (GUC) パラメーターを設定します。これらのパラメーターは、データベースサーバーの設定を管理する postgresql.conf ファイルの $PDATA ディレクトリー内にあります。
-
shared_buffers: データをキャッシュするためにサーバーに割り当てるメモリーの量を決定します。このパラメーターのデフォルト値は 128 MB です。この値を変更する場合は、マシンの合計 RAM の 15% - 25% に設定する必要があります。
OpenSSL 3.2 に対して Postgres をコンパイルすると、システムでリグレッションが発生し、起動時にユーザーのパラメーターが削除されます。これを修正するには、open_get_data の代わりに BIO_get_app_data 呼び出しを使用します。このような変更は管理者のみが行うことができますが、PostgreSQL データベースに接続しているすべてのユーザーに影響します。OpenSSL パッチを適用せずにシステムを更新する場合は影響しないため、対処する必要はありません。
shared_buffers の値を変更した後は、データベースサーバーを再起動する必要があります。
OpenSSL 3.2 に対して Postgres をコンパイルすると、システムでリグレッションが発生し、起動時にユーザーのパラメーターが削除されます。これを修正するには、open_get_data の代わりに BIO_get_app_data 呼び出しを使用します。この変更を行えるのは管理者だけです。ただし、この変更は、PostgreSQL データベースに接続しているすべてのユーザーに影響します。
OpenSSL パッチを適用せずにシステムを更新した場合、影響を受けないため、対策を講じる必要はありません。
work_mem: ディスクスワッピングの前に内部ソート操作とハッシュテーブルで使用されるメモリーの量を指定します。ソート操作は、order by、distinct、および merge join 操作に使用されます。ハッシュテーブルは、hash joins と hash-based アグリゲーションで使用されます。このパラメーターのデフォルト値は 4 MB です。work_memパラメーターに正しい値を設定すると、ディスクスワッピングが減少し、検索速度が向上します。-
次の式を使用して、データベースサーバーの
work_memパラメーターの最適な値を計算します。
-
次の式を使用して、データベースサーバーの
Total RAM * 0.25 / max_connections
work_mem に大きな値を設定すると、データベースに対して開いている接続が多すぎる場合に、PostgreSQL サーバーがメモリー不足 (OOM) になる可能性があります。
-
max_connections: データベースサーバーへの同時接続の最大数を指定します。 -
maintenance_work_mem: vacuum、create index、および alter table add foreign key 操作などのメンテナンス操作で使用するメモリーの最大量を指定します。このパラメーターのデフォルト値は 64 MB です。このパラメーターの値を計算するには、次の式を使用します。
Total RAM * 0.05
バキューム処理のパフォーマンスを向上させるには、maintenance_work_mem を work_mem よりも高く設定します。
関連情報
3.6.1. Automation Controller 設定ファイル内のプレーンテキストパスワードの暗号化
Automation Controller 設定ファイルに保存されるパスワードは、プレーンテキストで保存されます。/etc/tower/conf.d/ ディレクトリーへのアクセス権を持つユーザーは、データベースへのアクセスに使用されるパスワードを表示できます。ディレクトリーへのアクセスは権限によって制御されるため、ディレクトリーは保護されていますが、セキュリティーに関する調査結果によっては、この保護は不十分であると考えられています。解決策は、パスワードを個別に暗号化することです。
3.6.1.1. PostgreSQL パスワードハッシュの作成
Automation Controller 設定ファイル内のプレーンテキストパスワードを置き換えるハッシュ値を指定します。
手順
Automation Controller ノードで、次のコマンドを実行します。
# awx-manage shell_plus続いて、python プロンプトから以下を実行します。
>>> from awx.main.utils import encrypt_value, get_encryption_key \ >>> postgres_secret = encrypt_value('$POSTGRES_PASS') \ >>> print(postgres_secret)注記$POSTGRES_PASS変数を、暗号化する実際のプレーンテキストのパスワードに置き換えます。出力は以下のようになります。
$encrypted$UTF8$AESCBC$Z0FBQUFBQmtLdGNRWXFjZGtkV1ZBR3hkNGVVbFFIU3hhY21UT081eXFkR09aUWZLcG9TSmpndmZYQXFyRHVFQ3ZYSE15OUFuM1RHZHBqTFU3S0MyNEo2Y2JWUURSYktsdmc9PQ==これらのハッシュの完全な値をコピーして保存します。
次の例に示すように、ハッシュ値は
$encrypted$で始まり、単なる文字列ではありません。$encrypted$AESCBC$Z0FBQUFBQmNONU9BbGQ1VjJyNDJRVTRKaFRIR09Ib2U5TGdaYVRfcXFXRjlmdmpZNjdoZVpEZ21QRWViMmNDOGJaM0dPeHN2b194NUxvQ1M5X3dSc1gxQ29TdDBKRkljWHc9PQ==$*_PASS値は、インベントリーファイル内ですでにプレーンテキストになっていることに注意してください。
3.6.1.2. Postgres パスワードの暗号化
次の手順では、プレーンテキストのパスワードを暗号化された値に置き換えます。クラスター内の各ノードで次の手順を実行します。
手順
以下を使用して
/etc/tower/conf.d/postgres.pyを編集します。$ vim /etc/tower/conf.d/postgres.pyファイルの先頭に次の行を追加します。
from awx.main.utils import decrypt_value, get_encryption_key'PASSWORD': の後にリストされているパスワード値を削除し、次の行に置き換えて、指定された
$encrytpted..の値を独自のハッシュ値に置き換えます。decrypt_value(get_encryption_key('value'),'$encrypted$AESCBC$Z0FBQUFBQmNONU9BbGQ1VjJyNDJRVTRKaFRIR09Ib2U5TGdaYVRfcXFXRjlmdmpZNjdoZVpEZ21QRWViMmNDOGJaM0dPeHN2b194NUxvQ1M5X3dSc1gxQ29TdDBKRkljWHc9PQ=='),注記このステップのハッシュ値は、
postgres_secretの出力値です。完全な
postgres.pyは次のようになります。# Ansible Automation platform controller database settings. from awx.main.utils import decrypt_value, get_encryption_key DATABASES = { 'default': { 'ATOMIC_REQUESTS': True, 'ENGINE': 'django.db.backends.postgresql', 'NAME': 'awx', 'USER': 'awx', 'PASSWORD': decrypt_value(get_encryption_key('value'),'$encrypted$AESCBC$Z0FBQUFBQmNONU9BbGQ1VjJyNDJRVTRKaFRIR09Ib2U5TGdaYVRfcXFXRjlmdmpZNjdoZVpEZ21QRWViMmNDOGJaM0dPeHN2b194NUxvQ1M5X3dSc1gxQ29TdDBKRkljWHc9PQ=='), 'HOST': '127.0.0.1', 'PORT': 5432, } }
3.7. Automation Controller のチューニング
UI、API、ファイル設定を使用して、次のような多くの Automation Controller 設定を指定できます。
- Automation Controller UI のライブイベント
- ジョブイベントの処理とスケジューリング
- コントロールノードおよび実行ノードの容量
- インスタンスとコンテナーグループの容量
- 内部クラスタールーティング
- Web サーバーのチューニング
3.7.1. Automation Controller UI でのライブイベントの管理
イベントは、ジョブにサブスクライブされた UI クライアントが存在するノードすべてに送信されます。このタスクはコストが高く、クラスターが生成するイベントの数が増加し、コントロールノードの数が増加するにつれて、さらにコストが高くなります。これは、特定のジョブにサブスクライブされたクライアントの数に関係なく、すべてのイベントがすべてのノードにブロードキャストされるためです。
UI にライブイベントを表示するオーバーヘッドを削減するために、管理者は次のいずれかを選択できます。
- ライブストリーミングイベントを無効にします。
- UI でイベントを縮小したり非表示にしたりする前に、1 秒あたりに表示されるイベントの数を減らします。
イベントのライブストリーミングを無効にすると、イベントは、ジョブの出力詳細ページのハードリフレッシュ時にのみロードされます。1 秒あたりに表示されるイベントの数を減らすと、ライブイベントを表示するオーバーヘッドは限定されますが、ハードリフレッシュを行わなくても UI でライブ更新が提供されます。
3.7.1.1. ライブストリーミングイベントの無効化
手順
次のいずれかの方法を使用して、ライブストリーミングイベントを無効にします。
-
API で、
UI_LIVE_UPDATES_ENABLEDを False に設定します。 - Automation Controller に移動します。Miscellaneous System Settings ウィンドウを開きます。Enable Activity Stream のトグルを Off に設定します。
-
API で、
3.7.1.2. イベントのレートとサイズを変更する設定
イベントのサイズが原因でイベントのライブストリーミングを無効にできない場合は、UI に表示されるイベントの数を減らします。次の設定を使用して、表示されるイベントの数を管理できます。
UI または API で編集できる設定:
-
EVENT_STDOUT_MAX_BYTES_DISPLAY: 表示するstdoutの最大量 (バイト単位で測定)。これにより、UI に表示されるサイズが縮小されます。 -
MAX_WEBSOCKET_EVENT_RATE: 1 秒あたりにクライアントに送信するイベントの数。
ファイルベースの設定を使用して利用可能な設定:
-
MAX_UI_JOB_EVENTS: 表示するイベントの数。この設定により、リスト内の残りのイベントが非表示になります。 -
MAX_EVENT_RES_DATA: Ansible コールバックイベントの "res" データ構造の最大サイズ。"res" はモジュールの完全な「結果」です。Ansible コールバックイベントの最大サイズに達すると、残りの出力は切り捨てられます。デフォルト値は 700000 バイトです。 -
LOCAL_STDOUT_EXPIRE_TIME:stdoutファイルの有効期限が切れてローカルで削除されるまでの時間。
3.7.2. ジョブイベント処理を管理するための設定
コールバックレシーバーはジョブのすべての出力を処理し、この出力をジョブイベントとして Automation Controller データベースに書き込みます。コールバックレシーバーには、イベントをバッチで処理するワーカーのプールがあります。ワーカーの数は、インスタンスで使用可能な CPU の数に応じて自動的に増加します。
管理者は、JOB_EVENT_WORKERS 設定を使用してコールバックレシーバーワーカーの数をオーバーライドできます。CPU ごとに複数のワーカーを設定することはできません。また、少なくとも 1 つのワーカーが必要です。値が大きいほど、Automation Controller にイベントがストリーミングされる際に、Redis キューをクリアするのに利用できるワーカーが増えますが、Web サーバーなどの他のプロセスと CPU 秒数で競合する可能性があります。また、より多くのデータベース接続 (ワーカーあたり 1 つ) を使用するほか、各ワーカーがコミットするイベントのバッチサイズが小さくなる可能性があります。
各ワーカーにより、バッチで書き込むイベントのバッファーが増大します。バッチを書き込む前に待機するデフォルトの時間は 1 秒です。これは、JOB_EVENT_BUFFER_SECONDS 設定によって制御されます。ワーカーがバッチ間で待機する時間を増やすと、バッチサイズが大きくなる可能性があります。
3.7.3. コントロールノードと実行ノードの容量設定
次の設定は、クラスターの容量計算に影響します。次のファイルベースの設定を使用して、すべてのコントロールノードでこれらを同じ値に設定します。
-
AWX_CONTROL_NODE_TASK_IMPACT: ジョブの制御の影響を設定します。コントロールプレーンが望ましい使用量を超えて CPU またはメモリーを使用している場合に、この設定を使用して、コントロールプレーンが同時に実行可能なジョブの数を制御できます。 -
SYSTEM_TASK_FORKS_CPUおよびSYSTEM_TASK_FORKS_MEM: Ansible の各フォークが消費すると推定されるリソースの数を制御します。デフォルトでは、Ansible の 1 フォークは、0.25 の CPU と 100 MB のメモリーを使用すると推定されます。
3.7.4. インスタンスグループとコンテナーグループの容量設定
インスタンスグループで使用できる max_concurrent_jobs および max_forks 設定を使用して、インスタンスグループまたはコンテナーグループ全体で消費できるジョブとフォークの数を制限します。
-
コンテナーグループで必要な
max_concurrent_jobsを計算するには、そのコンテナーグループのpod_spec設定を考慮してください。pod_specでは、自動化ジョブ Pod のリソース要求と制限を確認できます。次の式を使用して、必要な同時実行ジョブの最大数を計算します。
((number of worker nodes in kubernetes cluster) * (CPU available on each worker)) / (CPU request on pod_spec) = maximum number of concurrent jobsたとえば、
pod_specで、Pod が 250 mcpu を要求することが示され、Kubernetes クラスターに 2 CPU を備えたワーカーノードが 1 つある場合、開始する必要があるジョブの最大数は 8 です。-
ジョブのフォークのメモリー消費も考慮することができます。次の式を使用して、
max_forksの適切な設定を計算します。
-
ジョブのフォークのメモリー消費も考慮することができます。次の式を使用して、
((number of worker nodes in kubernetes cluster) * (memory available on each worker)) / (memory request on pod_spec) = maximum number of forksたとえば、8 GB のメモリーを持つワーカーノードが 1 つある場合、実行する
max forksは 81 であることがわかります。この場合、1 つのフォークを持つ 39 個のジョブを実行するか (タスクインパクトは常にフォーク + 1 です)、またはフォークが 39 に設定されたジョブを 2 つ実行できます。-
他のビジネス要件では、
max_forksまたはmax_concurrent_jobsを使用して、コンテナーグループ内で起動するジョブの数を制限することが望ましい可能性があります。
-
他のビジネス要件では、
3.7.5. ジョブのスケジューリングの設定
タスクマネージャーは、スケジュールする必要があるタスクを定期的に収集して、どのインスタンスに容量があり、タスクを実行可能かを判断します。タスクマネージャーのワークフローは、以下の通りです。
- 制御インスタンスと実行インスタンスを見つけて割り当てます。
- ジョブのステータスを更新して、待機中にします。
-
pg_notifyを通じてコントロールノードにメッセージを送り、ディスパッチャーがタスクを取得して実行を開始できるようにします。
スケジューリングタスクが TASK_MANAGER_TIMEOUT 秒 (デフォルトは 300 秒) 以内に完了しない場合、タスクは早期に終了します。タイムアウトの問題は通常、保留中のジョブが多数存在する場合に発生します。
タスクマネージャーが 1 回の実行で処理できる作業量を制限する方法の 1 つに、START_TASK_LIMIT 設定があります。これにより、1 回の実行で開始できるジョブの数が制限されます。デフォルトは 100 ジョブです。さらに保留中のジョブがある場合は、新しいスケジューラータスクが直後に実行されるようにスケジュールされます。全体的なスループット向上のために、ジョブの起動から開始までのレイテンシーが潜在的に増大しても構わない場合は、START_TASK_LIMIT を引き上げることを検討できます。タスクマネージャーの個々の実行にかかる時間を確認するには、/api/v2/metrics で入手可能な Prometheus メトリクス task_manager__schedule_seconds を使用します。
タスクマネージャーによって実行の開始が選択されたジョブは、タスクマネージャープロセスが終了して変更がコミットされるまで実行されません。TASK_MANAGER_TIMEOUT 設定は、タスクマネージャーが変更をコミットするまでの 1 回の実行時間を決定します。タスクマネージャーは、タイムアウトに達すると進捗状況をコミットしようとします。タスクは、猶予期間 (TASK_MANAGER_TIMEOUT_GRACE_PERIOD により決定) が経過するまでは強制終了されません。
3.7.6. 内部クラスタールーティング
Automation Controller クラスターホストは、クラスター内のネットワークを介して通信します。従来の仮想マシンインストーラーのインベントリーファイルでは、クラスターノードへのルートを複数指定でき、それらはさまざまな方法で使用されます。
例:
[automationcontroller]
controller1 ansible_user=ec2-user ansible_host=10.10.12.11 node_type=hybrid routable_hostname=somehost.somecompany.org-
controller1は、Automation Controller ホストのインベントリーホスト名です。インベントリーホスト名は、アプリケーションではインスタンスホスト名として表示されるものです。これは、バックアップ/復元方法を使用して異なる IP アドレスを持つ新しいホストのセットにクラスターを復元する、障害復旧シナリオに備える際に役立ちます。この場合、これらのインベントリーホスト名を IP アドレスにマッピングするエントリーを/etc/hostsに含めることができます。そして、内部 IP アドレスを使用して、パブリック DNS 名の解決に関する DNS の問題を軽減できます。 -
ansible_host=10.10.12.11は、インストーラーがホスト (この場合は内部 IP アドレス) に到達する方法を示します。これはインストーラー以外では使用されません。 -
routable_hostname=somehost.somecompany.orgは、receptor メッシュ上でこのノードに接続するピアにとって解決可能なホスト名を示します。複数のネットワークをまたぐ可能性があるため、ホスト名は、receptor ピアで解決可能な IP アドレスにマッピングされるものを使用しています。
3.7.7. Web サーバーのチューニング
コントロールノードとハイブリッドノードはそれぞれ、Automation Controller の UI と API を提供します。WSGI トラフィックは、ローカルソケット上の uwsgi Web サーバーによって処理されます。ASGI トラフィックは、Daphne によって処理されます。NGINX はポート 443 でリッスンし、必要に応じてトラフィックをプロキシー処理します。
Automation Controller の Web サービスをスケーリングするには、次のベストプラクティスに従ってください。
- 複数のコントロールノードをデプロイし、ロードバランサーを使用して Web 要求を複数のサーバーに分散させます。
- Automation Controller ごとの最大接続数を 100 に設定します。
クライアント側で Automation Controller の Web サービスを最適化するには、次のガイドラインに従ってください。
- API を使用してインベントリーホストを個別に作成するのではなく、動的インベントリーソースを使用するようにユーザーに指示します。
- ジョブのステータスをポーリングする代わりに Webhook 通知を使用します。
- ホストの作成とジョブの起動に Bulk API を使用して、要求をバッチ処理します。
- トークン認証を使用します。多くの要求を迅速に行う必要がある自動化クライアントの場合、トークンを使用することがベストプラクティスです。これは、ユーザーのタイプによっては、Basic 認証を使用すると追加のオーバーヘッドが発生する可能性があるためです。
第4章 管理ジョブ
Management Jobs は、システム追跡情報、トークン、ジョブ履歴、アクティビティーストリームなどの古いデータを Automation Controller から消去するのに役立ちます。
これは、特定の保持ポリシーがある場合、または Automation Controller データベースで使用されるストレージを減らす必要がある場合に使用できます。
ナビゲーションパネルから → → を選択します。
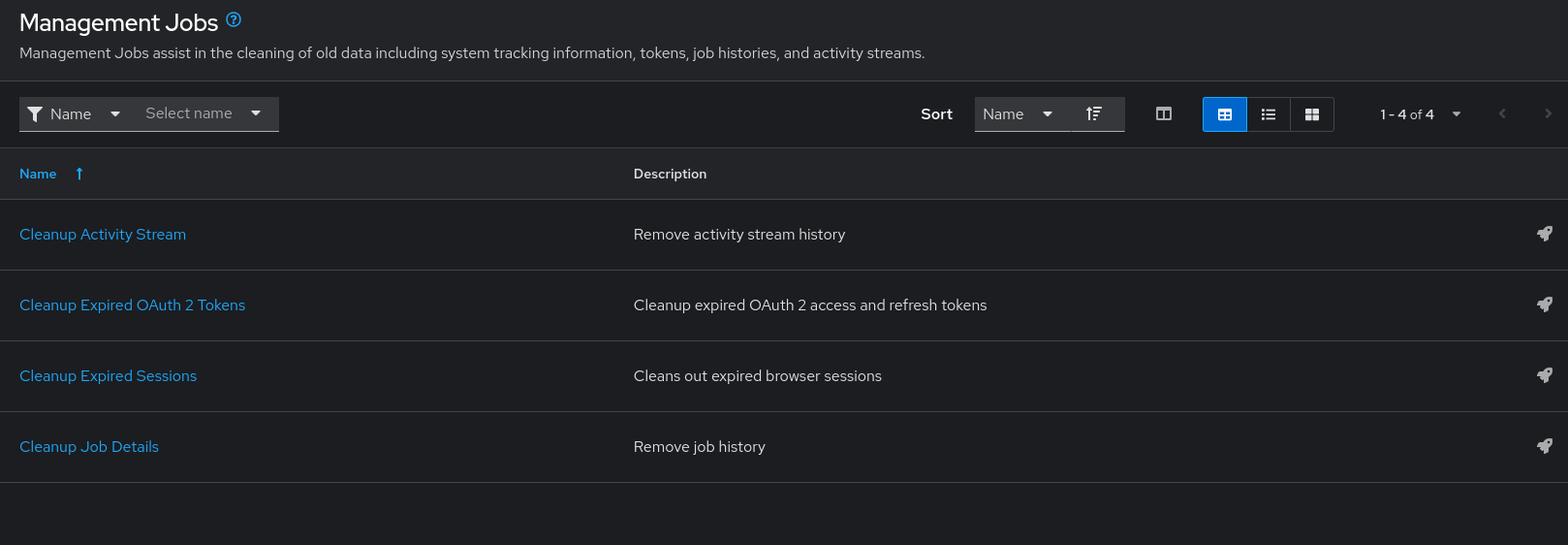
次のジョブタイプをスケジュールして起動できます。
- Cleanup Activity Stream: 指定した日数より前のアクティビティーストリーム履歴を削除します。
- Cleanup Expired Sessions: データベースから期限切れのブラウザーセッションを削除します。
- Cleanup Job Details: 指定した日数より前のジョブ履歴を削除します。
4.1. 以前のアクティビティーストリームデータの削除
以前のアクティビティーストリームデータを削除するには、Cleanup Activity Stream の横にある起動アイコン (
![]() ) をクリックします。
) をクリックします。
データの保存日数を入力し、 をクリックします。
4.1.1. 削除のスケジューリング
削除対象としてマークされたデータを削除するスケジュールを確認または設定するには、次の手順を使用します。
手順
特定のクリーンアップジョブの場合、Schedules タブをクリックします。
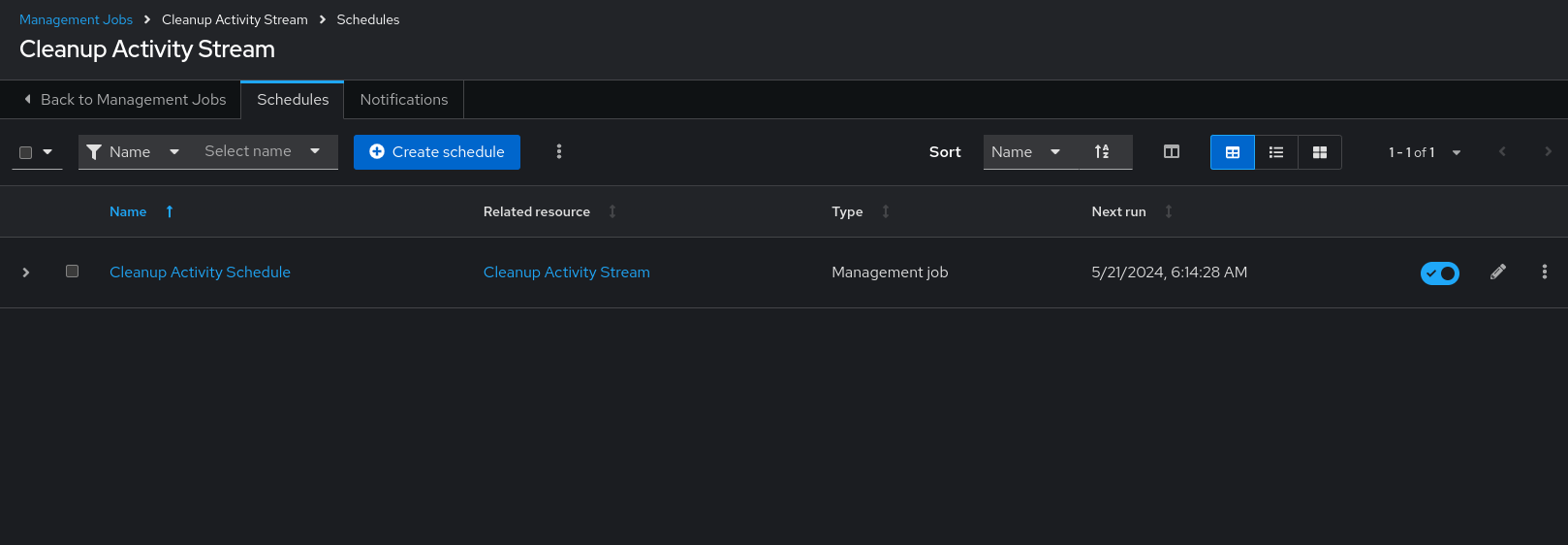
- ジョブ名 (この例では Cleanup Activity Schedule) をクリックして、スケジュール設定を確認します。
をクリックして変更します。 をクリックして、この管理ジョブの新規スケジュールを作成することもできます。
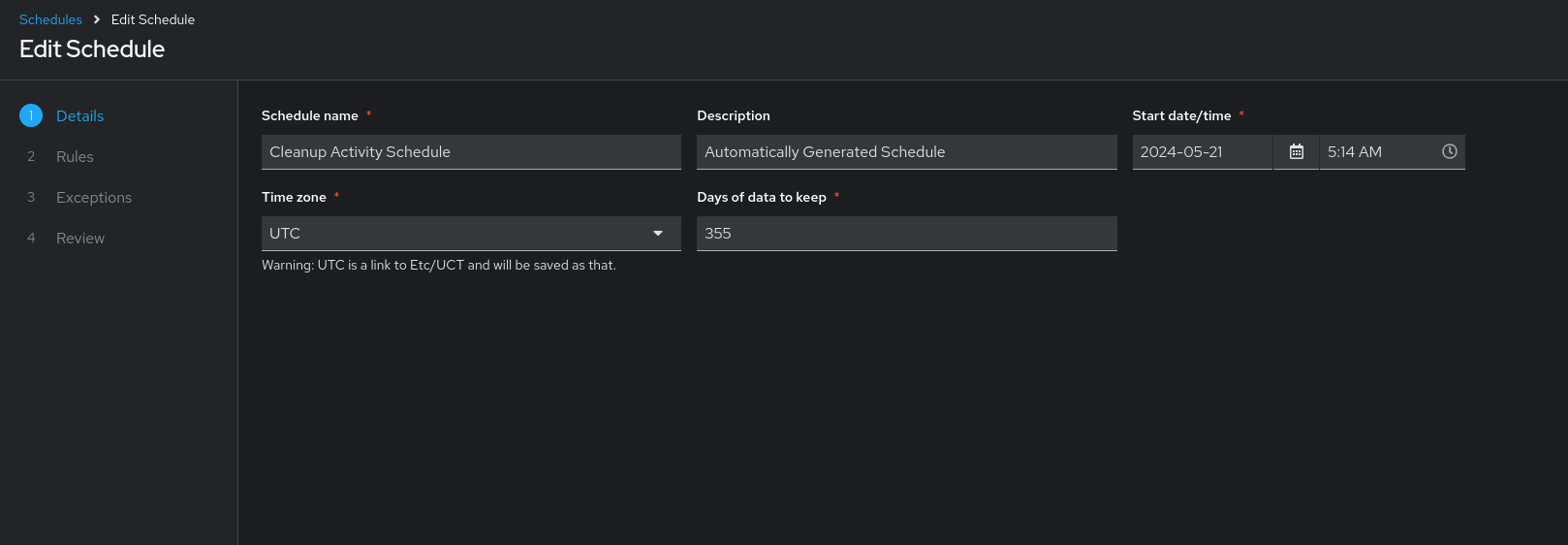
以下のフィールドに適切な情報を入力して、Next をクリックします。
- Schedule name 必須
- Start date/time 必須
- Time zone 入力した Start time はこのタイムゾーンの時間になります。
- Repeat frequency: 更新頻度を変更すると、適切なオプションが表示されます。例外を指定して、対象外とするデータを指定することもできます。
- Days of data to keep 必須 - 保持するデータの量を指定します。
Details タブでは、選択した Local Time Zone でのスケジュールの詳細と、スケジュール実行のリストを表示します。
ジョブは UTC でスケジュールされます。特定の時間に実行される繰り返しのジョブは、夏時間への切り替えまたは夏時間からの切り替えが発生すると、ローカルタイムゾーンに合わせて移動できます。
4.1.2. 通知の設定
管理ジョブに関連する通知を確認または設定するには、次の手順を使用します。
手順
- 特定のクリーンアップジョブは、Notifications タブを選択します。
存在しない場合は、自動化実行の使用 の 通知テンプレートの作成 を参照してください。
4.1.3. 期限切れセッションのクリーンアップ
期限切れのセッションを削除するには、Cleanup Expired Sessions の横にある起動アイコン (
![]() ) をクリックします。
) をクリックします。
期限切れのセッションの消去スケジュールを確認または設定するには、アクティビティーストリーム管理ジョブ向けに記載されているのと同じ手順を実行します。詳細は、削除のスケジューリング を参照してください。
アクティビティーストリーム管理ジョブの 通知 で説明されているのと同じ方法で、この管理ジョブに関連する通知を設定または確認することもできます。
詳細は、自動化実行の使用 の 通知機能 を参照してください。
4.1.4. 以前のジョブ履歴の削除
特定の日数以前のジョブ履歴を削除するには、Cleanup Job Details の横にある起動アイコン (
![]() ) をクリックします。
) をクリックします。
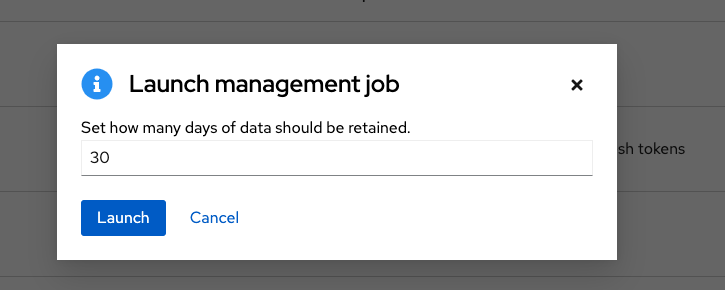
データの保存日数を入力し、 をクリックします。
Automation Controller リソース (プロジェクト、ジョブテンプレートなど) の最初のジョブ実行は、保持値に関係なく、Cleanup Job Details から除外されます。
古いジョブ履歴の消去スケジュールを確認または設定するには、アクティビティーストリーム管理ジョブ向けに記載されているのと同じ手順を実行します。
詳細は、スケジュールの 削除 を参照し てください。
この管理ジョブに関連付けられている通知は、Setting notifications for activity stream management jobs または information に説明したのと同じ方法で設定またはレビューすることもできます。詳細は link:https://docs.redhat.com/en/documentation/red_hat_ansible_automation_platform/2.5/html/using_automation_execution/controller-notificationsNotifiers] を参照してください。
第5章 インベントリーファイルのインポート
Automation Controller を使用すると、インベントリーファイルを最初から作成するのではなく、ソースコントロールから選択できます。ファイルは編集不可であり、ソースでインベントリーが更新されると、関連付けられている group_vars ファイルや host_vars ファイル、またはディレクトリーを含むプロジェクト内のインベントリーも、それに応じて更新されます。SCM タイプは、インベントリーファイルとスクリプトの両方を使用できます。インベントリーファイルとカスタムインベントリータイプはどちらもスクリプトを使用します。
インポートされたホストには、デフォルトで imported という説明があります。これは、特定のホストで _awx_description 変数を設定することでオーバーライドできます。たとえば、ソースの .ini ファイルからインポートする場合は、次のホスト変数を追加できます。
[main]
127.0.0.1 _awx_description="my host 1"
127.0.0.2 _awx_description="my host 2"
同様に、グループの説明もデフォルトでは imported ですが、_awx_description でオーバーライドすることもできます。
ソース管理で古いインベントリースクリプトを使用するには、自動化実行の使用 の 古いインベントリースクリプトのエクスポート を参照してください。
5.1. ソースコントロール管理インベントリーソースフィールド
使用するソースのフィールドは以下のとおりです。
-
source_project: 使用するプロジェクト。 -
source_path: ディレクトリーまたはファイルを示すプロジェクト内の相対パス。空白のままにしても、"" はプロジェクトの root ディレクトリーを示す相対パスを表します。 -
source_vars: "file" タイプのインベントリーソースに設定されている場合には、実行時に環境変数に渡されます。
補足
- プロジェクトを更新すると、そのプロジェクトが使用されているインベントリーの更新が自動的にトリガーされます。
- プロジェクトの更新は、インベントリーソースの作成直後にスケジュールされます。
- インベントリー更新もプロジェクト更新も、関連ジョブの実行中にブロックされることはありません。
-
大規模なプロジェクト (約 10 GB) がある場合、
/tmpのディスク領域が問題になる可能性があります。
インベントリーの Add source ページから、Automation Controller UI で場所を手動で指定できます。インベントリーソースの作成手順は、ソースの追加 を参照してください。
プロジェクトの更新時に、リストを更新して最新のソースコントロール管理 (SCM) 情報を使用します。インベントリーソースが SCM インベントリーソースとしてプロジェクトを使用しない場合、更新時にインベントリーのリストが更新されない可能性があります。
インベントリーが SCM ソースを含む場合、インベントリー更新のジョブの Details ページに、プロジェクト更新のステータスインジケーターとプロジェクト名が表示されます。
ステータスインジケーターはプロジェクト更新ジョブにリンクします。
プロジェクト名はプロジェクトにリンクします。
関連ジョブの実行中にインベントリーの更新を実行できます。
5.1.1. サポートされるファイルの構文
Automation Controller は、Ansible の ansible-inventory モジュールを使用してインベントリーファイルを処理し、Automation Controller で必要となる有効なインベントリー構文をすべてサポートします。
インベントリースクリプトを Python で記述する必要はありません。ソースフィールドには任意の実行可能ファイルを入力できます。そのファイルに対して chmod +x を実行し、Git にチェックインする必要があります。
以下は、Automation Controller がインポート用に読み取ることができる JSON 出力の実際の例です。
{
"_meta": {
"hostvars": {
"host1": {
"fly_rod": true
}
}
},
"all": {
"children": [
"groupA",
"ungrouped"
]
},
"groupA": {
"hosts": [
"host1",
"host10",
"host11",
"host12",
"host13",
"host14",
"host15",
"host16",
"host17",
"host18",
"host19",
"host2",
"host20",
"host21",
"host22",
"host23",
"host24",
"host25",
"host3",
"host4",
"host5",
"host6",
"host7",
"host8",
"host9"
]
}
}第6章 クラスタリング
クラスタリングでは、ホスト間で負荷が共有されます。各インスタンスは、UI および API アクセスのエントリーポイントとして機能できる必要があります。これにより、Automation Controller 管理者は必要な数のインスタンスの手前でロードバランサーを使用し、良好なデータ可視性を維持できるようになります。
負荷分散はオプションで、必要に応じて 1 つまたはすべてのインスタンスで受信することも可能です。
各インスタンスは、Automation Controller のクラスターに参加して、ジョブを実行する機能を拡張できる必要があります。これは、ジョブをどこで実行するかを指定するのではなく、ジョブをどこでも実行できる簡単なシステムです。また、自動化実行の使用 で説明されているように、クラスターインスタンスを インスタンスグループ と呼ばれる異なるプールまたはキューにグループ化することもできます。
Ansible Automation Platform は、Kubernetes を使用したコンテナーベースのクラスターをサポートしています。つまり、このプラットフォームに新しい Automation Controller インスタンスを、機能の変更や転換を行うことなくインストールできます。Kubernetes コンテナーを指定するインスタンスグループを作成できます。詳細は、自動化実行の使用 の インスタンスとコンテナーグループ セクションを参照してください。
サポート対象のオペレーティングシステム
クラスター環境の確立には、以下のオペレーティングシステムがサポートされます。
- Red Hat Enterprise Linux 8.7 以降である。
OpenShift での分離インスタンスと Automation Controller の実行の組み合わせはサポートされません。
6.1. セットアップに関する考慮事項
クラスターの初期セットアップを説明します。既存のクラスターをアップグレードするには、Ansible Automation Platform Upgrade and Migration Guide の Upgrade Planning を参照してください。
新規のクラスタリング環境では、次の重要な留意事項に注意してください。
- PostgreSQL はスタンドアロンインスタンスであり、クラスター化されていません。Automation Controller は、(ユーザーがスタンバイレプリカを設定した場合) レプリカ設定やデータベースフェイルオーバーを管理しません。
- クラスターを起動する場合は、データベースノードをスタンドアロンサーバーにする必要があります。PostgreSQL は Automation Controller ノードの 1 つにインストールしないでください。
-
PgBouncer は、Automation Controller を使用した接続プールには推奨されません。Automation Controller は、さまざまなコンポーネント間でのメッセージの送信に
pg_notifyを使用しているため、PgBouncerをトランザクションプールモードですぐに使用することはできません。 - 全インスタンスは他のすべてのインスタンスからアクセス可能であり、データベースにアクセスできる必要があります。ホストが安定したアドレスまたはホスト名を持つことも重要です (Automation Controller ホストの設定に応じて異なります)。
- 全インスタンスは、地理的に近い場所に配置する必要があります。インスタンス間はレイテンシーが低く信頼性のある接続を使用します。
-
クラスター環境にアップグレードするには、プライマリーインスタンスがインベントリーの
defaultグループに属し、defaultグループの最初のホストとしてリストされている必要があります。 - 手動のプロジェクトでは、顧客が手動で全インスタンスを同期して、一度に全インスタンスを更新する必要があります。
-
プラットフォームデプロイメントの
inventoryファイルは、保存または永続化する必要があります。新規インスタンスをプロビジョニングする場合は、インストールプログラムでパスワード、設定オプション、およびホスト名を使用する必要があります。
6.2. インストールおよび設定
仮想マシンベースのインストール用に新規インスタンスをプロビジョニングするには、inventory ファイルを更新して、セットアップ用 Playbook の再実行が含まれます。インベントリーファイルには、クラスターのインストール時に使用するすべてのパスワードと情報が含まれていることが重要です。含まれていない場合には、他のインスタンスが再設定される場合があります。インベントリーファイルには、単一のインベントリーグループ automationcontroller があります。
インスタンスはすべて、ジョブの起動先や Playbook イベントの処理、定期的なクリーンアップなど、タスクのスケジュールに関連するさまざまなハウスキーピングタスクを担当します。
[automationcontroller]
hostA
hostB
hostC
[instance_group_east]
hostB
hostC
[instance_group_west]
hostC
hostD
リソースに対してグループが選択されていない場合は automationcontroller グループが使用されますが、他のグループが選択されている場合には automationcontroller グループは使用されません。
データベースグループは、外部 PostgreSQL を指定します。データベースホストを個別にプロビジョニングする場合、このグループは空である必要があります。
[automationcontroller]
hostA
hostB
hostC
[database]
hostDBクラスター内の個々のコントローラーインスタンスで Playbook を実行すると、その Playbook の出力は、Automation Controller の WebSocket ベースのストリーミング出力機能の一部として、他のすべてのノードにブロードキャストされます。このデータブロードキャストは、インベントリー内の各ノードにプライベートルーティング可能なアドレスを指定し、内部アドレスを使用して処理する必要があります。
[automationcontroller]
hostA routable_hostname=10.1.0.2
hostB routable_hostname=10.1.0.3
hostC routable_hostname=10.1.0.4
routable_hostname
routable_hostname の詳細は、RPM インストール の 一般的な変数 を参照してください。
Automation Controller の以前のバージョンでは、rabbitmq_host という変数名を使用していました。以前のバージョンのプラットフォームからアップグレードしようとしており、以前にインベントリーに rabbitmq_host を指定している場合は、アップグレードの前に、名前を rabbitmq_host から routable_hostname に変更してください。
6.2.1. Automation Controller と Automation Hub によって使用されるインスタンスとポート
Automation Controller で使用され、オンプレミスの Automation Hub ノードでも必要なポートとインスタンスは次のとおりです。
- ポート 80、443 (通常の Automation Controller ポートおよび Automation Hub ポート)
- ポート 22 (SSH - Ingress のみが必要)
- ポート 5432 (データベースインスタンス - データベースを外部インスタンスにインストールする場合は、Automation Controller インスタンスに対してこのポートを開く必要があります。)
6.3. ブラウザーの API によるステータスの確認およびモニタリング
Automation Controller は、クラスターの健全性を検証するために、/api/v2/ping にあるブラウザー API を使用して可能な限り多くのステータスを報告します。これには、以下のパラメーターが含まれます。
- HTTP 要求にサービスを提供するインスタンス
- クラスター内にある他の全インスタンスが出した最後のハートビートのタイムスタンプ
- これらのグループのインスタンスグループおよびインスタンスのメンバーシップ
実行中のジョブやメンバー情報など、インスタンスおよびインスタンスグループに関する詳細情報は、/api/v2/instances/ および /api/v2/instance_groups/ を参照してください。
6.4. インスタンスサービスおよび障害時の動作
各 Automation Controller インスタンスは、以下のさまざまなサービスで構成されており、これらのサービスは連携しています。
- HTTP サービス
- これには、Automation Controller アプリケーション自体と外部 Web サービスが含まれます。
- Callback receiver
- 実行中の Ansible ジョブからジョブイベントを受信します。
- Dispatcher
- 全ジョブを処理して実行するワーカーキューです。
- Redis
- このキー値ストアは、ansible-playbook からアプリケーションに伝搬されるイベントデータのキューとして使用されます。
- Rsyslog
- ログをさまざまな外部ロギングサービスに配信するために使用されるログ処理サービスです。
Automation Controller は、これらのサービスまたはそのコンポーネントのいずれかが失敗した場合に、すべてのサービスが再起動されるように設定されています。これらが短期間で頻繁に失敗する場合は、予期せぬ動作を引き起こすことなく修復できるように、インスタンス全体が自動的にオフラインになります。
クラスター環境のバックアップと復元は、クラスター環境のバックアップおよび復元 セクションを参照してください。
6.5. ジョブランタイムの動作
ジョブが実行され、Automation Controller の 通常 のユーザーにレポートされる方法は変わりません。システム側では、次の違いに注意してください。
ジョブが API インターフェイスから送信されると、ジョブはディスパッチャーキューにプッシュされます。各 Automation Controller インスタンスは、スケジューリングアルゴリズムを使用してそのキューに接続し、そこからジョブを受け取ります。クラスター内のどのインスタンスも、等しく処理を受け取り、タスクを実行する可能性があります。ジョブの実行中にインスタンスが失敗した場合、その作業は永続的に失敗したものとしてマークされます。
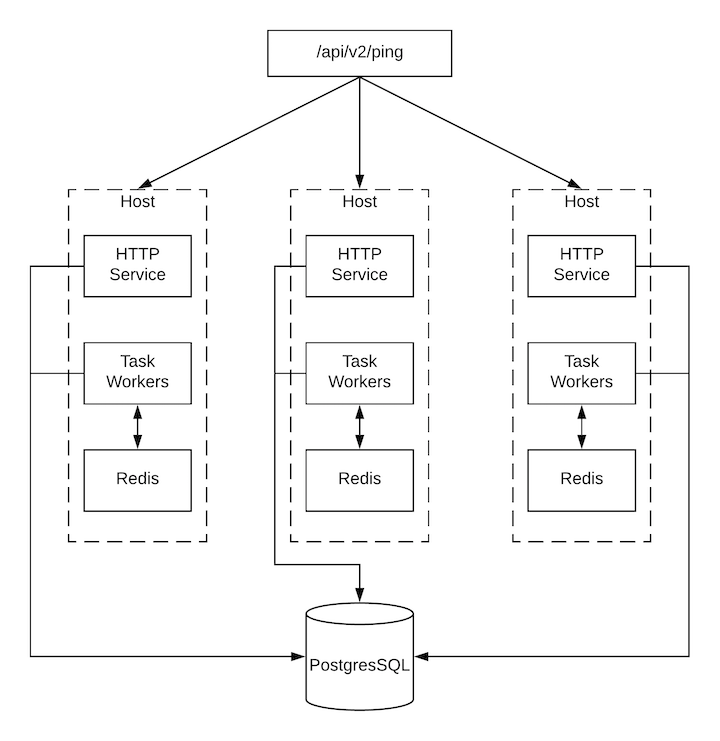
- プロジェクトの更新は、ジョブを実行する可能性のあるすべてのインスタンスで正常に実行されます。プロジェクトは、ジョブを実行する直前に、インスタンス上の正しいバージョンに同期されます。必要なリビジョンがすでにローカルでチェックアウトされており、Galaxy または Collections の更新が必要ない場合は、同期を実行できません。
-
同期が行われると、
launch_type = syncおよびjob_type = runのプロジェクト更新としてデータベースに記録されます。プロジェクトの同期によってプロジェクトのステータスやバージョンは変更されません。代わりに、プロジェクトが実行されているインスタンスでソースツリーのみが更新されます。 -
Galaxy または Collections からの更新が必要な場合は、同期が実行されて必要なロールをダウンロードします。これにより、
/tmp fileの領域がより多く消費されます。大規模なプロジェクト (約 10 GB) がある場合、/tmpのディスク領域が問題になる可能性があります。
6.5.1. ジョブの実行
デフォルトでは、ジョブが Automation Controller キューに送信されると、どのワーカーでもジョブを取得できます。ただし、ジョブを実行するインスタンスを制限するなど、特定のジョブを実行する場所を制御することができます。
インスタンスの一時的なオフライン化をサポートするために、各インスタンスで有効なプロパティーが定義されています。このプロパティーが無効になっている場合、そのインスタンスにはジョブは割り当てられません。既存のジョブは終了しますが、新しいジョブは割り当てられません。
トラブルシューティング
実行中の Automation Controller ジョブに対して cancel 要求を発行すると、Automation Controller は ansible-playbook プロセスに SIGINT を発行します。これにより、Ansible は新しいタスクのディスパッチを停止して終了しますが、多くの場合、すでにリモートホストにディスパッチされたモジュールタスクは完了するまで実行されます。この動作は、コマンドラインでの Ansible の実行中に Ctrl-c を押した場合と似ています。
ソフトウェアの依存関係に関しては、実行中のジョブがキャンセルされた場合、そのジョブは削除されますが、依存関係は残ります。
6.6. インスタンスのプロビジョニング解除
設定用 Playbook を再実行しても、インスタンスのプロビジョニングが自動的に解除されるわけではありません。これは現在、インスタンスが意図的にオフラインにされたのか、障害が原因でオフラインになったのかをクラスターが識別できないためです。代わりに、Automation Controller インスタンスの全サービスをシャットダウンした後に、他のインスタンスからプロビジョニング解除ツールを実行します。
手順
-
コマンド
automation-controller-service stopを使用して、インスタンスをシャットダウンするか、サービスを停止します。 別のインスタンスから次のプロビジョニング解除コマンドを実行して、Automation Controller クラスターからインスタンスを削除します。
$ awx-manage deprovision_instance --hostname=<name used in inventory file>
以下は、プロビジョニング解除コマンドの例です。
$ awx-manage deprovision_instance --hostname=hostBAutomation Controller でインスタンスグループのプロビジョニングを解除しても、インスタンスグループは自動的にプロビジョニング解除されたり削除されたりしません。詳細は、自動化実行の使用 の インスタンスグループのプロビジョニング解除 セクションを参照してください。
第7章 ポリシー適用の実装
自動化実行時におけるポリシー適用とは、ユーザーが Ansible Automation Platform インスタンスを操作する方法を制御するポリシーを、エンコードされたルールを使用して定義、管理、適用する機能です。ポリシーの適用によりポリシー管理が自動化され、セキュリティー、コンプライアンス、効率性が向上します。
OPA (Open Policy Agent) は、Ansible インスタンスからポリシーの決定をオフロードするポリシーエンジンです。ポリシー適用機能は、トリガーされると OPA に接続して設定で指定されているポリシーを取得し、自動化コンテンツにポリシールールを適用します。OPA は、ポリシー違反を検出するとアクションを停止し、ユーザーにポリシー違反に関する情報を提供します。
前提条件
Ansible Automation Platform インスタンスでポリシー適用を実装するには、以下が必要です。
- Ansible Automation Platform デプロイメントからアクセス可能な OPA サーバーへのアクセス。
- OPA サーバーに対する認証に必要な設定が行われた設定済みの Ansible Automation Platform。
- OPA、およびポリシーの記述に使用されている Rego 言語に関するある程度の知識。
ポリシー適用を正しく機能させるには、ポリシー設定で OPA サーバーを設定し、特定のポリシーを特定のリソースに関連付ける必要があります。たとえば、特定の組織、インベントリー、またはジョブテンプレートなどのリソースです。
OPA API V1 は、現在 Ansible Automation Platform でサポートされている唯一のバージョンです。
7.1. ポリシー適用設定
グローバル設定を変更することで、Ansible Automation Platform インスタンスが OPA と対話する方法を指定できます。
前提条件
- ポリシー適用を設定するには、管理者特権が必要です。
ポリシー設定で OPA サーバーを設定しないと、ジョブの実行時にポリシー評価が行われません。
手順
- ナビゲーションパネルから、 → → を選択します。
- Edit policy settings をクリックします。
Policy Settings ページで、次のフィールドに入力します。
- OPA Server hostname
- OPA サービスに接続するホストの名前を入力します。
- OPA server port
- OPA サービスに接続するポートを入力します。
- OPA authentication type
- OPA 認証タイプを選択します。
- OPA custom authentication header
- OPA 認証のリクエストヘッダーに追加するカスタムヘッダーを入力します。
- OPA request timeout
- 接続がタイムアウトするまでの秒数を入力します。
- OPA request retry count
- リクエストが失敗するまでの、OPA サービスへの接続を試行できる回数を入力します。
認証タイプに応じて、次のフィールドに入力する必要がある場合があります。
認証タイプとしてトークンを選択した場合:
- OPA authentication token
- OPA 認証トークンを入力します。
認証タイプとして証明書を選択した場合:
- OPA client certificate content
- mTLS 認証用の CA 証明書の内容を入力します。
- OPA client key content
- mTLS 認証用のクライアントキーを入力します。
- OPA CA certificate content
- mTLS 認証用の CA 証明書の内容を入力します。
Options という見出しの下に以下が表示されます。
- Use SSL for OPA connection
- OPA サービスへの SSL 接続を有効にするには、このボックスをオンにします。
- をクリックします。
7.2. OPA パッケージとルールを理解する
OPA ポリシーは、名前空間を持つルールの集合であるパッケージに編成されます。OPA ポリシーの基本構造は以下のとおりです。
package aap_policy_examples # Package name
import rego.v1 # Import required for Rego v1 syntax
# Rules define the policy logic
allowed := {
"allowed": true,
"violations": []
}ルールの構造の主要なコンポーネントは次のとおりです。
- パッケージの宣言
- ポリシーの名前空間を定義します。
- ルール
- ポリシーのロジックとそれが返す決定を定義します。
これらのコンポーネントを組み合わせて、[package]/[rule] 形式で OPA ポリシー名が構成されます。OPA ポリシー名は、適用ポイントの設定時に入力します。
7.3. 適用ポイントの設定
OPA サーバーと通信するように Ansible Automation Platform インスタンスを設定すると、ポリシーを適用する適用ポイントを設定できるようになります。
ポリシーをジョブテンプレート、インベントリー、または組織に関連付けることができます。適用は次のように実行されます。
- 組織
- 組織が所有するテンプレートから起動されたジョブは、ポリシーに違反すると失敗します。この設定により、組織の境界内での自動化を幅広く制御できます。
- インベントリー
- ポリシーに関連付けられたインベントリーを使用するジョブは、ポリシーに違反すると失敗します。この設定により、特定のインフラストラクチャーリソースへのアクセスを制御できます。
- ジョブテンプレート
- ポリシーに関連付けられたテンプレートから起動されたジョブは、関連付けられたポリシーに違反すると失敗します。この設定により、特定の自動化タスクを細かく制御できます。
ポリシーをリソースに関連付けないと、関連するジョブを実行してもポリシーの評価が行われません。
7.3.1. ポリシーを組織に関連付ける
ポリシーを組織に関連付けるには、次のステップを実行します。
手順
- ナビゲーションパネルから、 → を選択します。
Organizations ページで次の操作を行います。
-
既存の組織を編集するには、編集する組織を見つけ、鉛筆アイコン
 をクリックして編集画面に移動します。
をクリックして編集画面に移動します。
- 新しい組織を作成するには、 をクリックします。
-
既存の組織を編集するには、編集する組織を見つけ、鉛筆アイコン
-
Policy enforcement という名前のフィールドに、実装するポリシーに関連付けられたクエリーパスを入力します。クエリーパスは
package/ruleという形式にする必要があります。 - をクリックし、 をクリックして設定を保存します。
7.3.2. ポリシーをインベントリーに関連付ける
ポリシーをインベントリーに関連付けるには、次のステップを実行します。
手順
- ナビゲーションパネルから → → を選択します。
Inventories ページで次の操作を行います。
-
既存のインベントリーを編集するには、編集するインベントリーを見つけ、鉛筆アイコン
をクリックして編集画面に移動します。
- 新しいインベントリーを作成するには、 をクリックします。
-
既存のインベントリーを編集するには、編集するインベントリーを見つけ、鉛筆アイコン
-
Policy enforcement というタイトルのフィールドに、実装するポリシーに関連付けられたクエリーパスを入力します。クエリーパスは
package/ruleという形式にする必要があります。 - 既存のインベントリーを編集している場合は をクリックし、新しいインベントリーを作成している場合は をクリックします。
7.3.3. ポリシーをジョブテンプレートに関連付ける
ポリシーをジョブテンプレートに関連付けるには、次のステップを実行します。
手順
- ナビゲーションパネルから、 → を選択します。
Automation Templates ページで次の操作を行います。
-
既存のジョブテンプレートを編集するには、編集するジョブテンプレートを見つけ、鉛筆アイコン
をクリックして編集画面に移動します。
- 新しいジョブテンプレートを作成するには、 をクリックします。
-
既存のジョブテンプレートを編集するには、編集するジョブテンプレートを見つけ、鉛筆アイコン
-
Policy enforcement というタイトルのフィールドに、実装するポリシーに関連付けられたクエリーパスを入力します。クエリーパスは
package/ruleという形式にする必要があります。 - 既存のジョブテンプレートを編集している場合は を、新しいジョブテンプレートを作成している場合は をクリックします。
7.4. ポリシー適用の入力と出力
次の入力と出力を使用して、ポリシー適用に使用するポリシーを作成します。
| 入力 | 型 | 説明 |
|---|---|---|
|
| Integer | ジョブの一意の識別子。 |
|
| String | ジョブテンプレート名。 |
|
| Datetime (ISO 8601) | ジョブが作成された日時を示すタイムスタンプ。 |
|
| Object | ジョブを作成したユーザーに関する情報。
|
|
| Object のリスト | ジョブ実行に関連付けられた認証情報。
|
|
| Object | ジョブに使用される実行環境の詳細。
|
|
| JSON | ジョブ実行用に提供される追加の変数。 |
|
| Integer | ジョブ実行に使用される並列プロセスの数。 |
|
| Integer | ジョブの対象となるホストの数。 |
|
| Object | ジョブを処理するインスタンスグループに関する情報。以下が含まれます。
|
|
| Object | ジョブ実行で使用されるインベントリーの詳細。以下が含まれます。
|
|
| Object | ジョブテンプレートに関する情報。以下が含まれます。
|
|
| 選択肢 (String) | ジョブ実行のタイプ。使用できる値は次のとおりです。
|
|
| String | ジョブタイプの判読可能な名前。 |
|
| Object のリスト | ジョブに関連付けられたラベル。以下が含まれます。
|
|
| 選択肢 (String) | ジョブが開始された方法。使用できる値は次のとおりです。
|
|
| String | ジョブ実行に適用される制限。 |
|
| Object | ジョブを開始したユーザーに関する情報。以下が含まれます。
|
|
| Object | ジョブに関連付けられた組織に関する情報。以下が含まれます。
|
|
| String | ジョブ実行で使用される Playbook。 |
|
| Object | ジョブに関連付けられたプロジェクトの詳細。以下が含まれます。
|
|
| String | SCM に使用する特定のブランチ。 |
|
| String | ジョブに使用する SCM リビジョン。 |
|
| Object | ワークフロージョブの詳細 (ジョブがワークフローの一部である場合)。 |
|
| Object | ワークフロージョブテンプレートの詳細。 |
次のコードブロックは、デモジョブテンプレートの起動以降の入力データ例を示しています。
{
"id": 70,
"name": "Demo Job Template",
"created": "2025-03-19T19:07:03.329426Z",
"created_by": {
"id": 1,
"username": "admin",
"is_superuser": true,
"teams": []
},
"credentials": [
{
"id": 3,
"name": "Example Machine Credential",
"description": "",
"organization": null,
"credential_type": 1,
"managed": false,
"kind": "ssh",
"cloud": false,
"kubernetes": false
}
],
"execution_environment": {
"id": 2,
"name": "Default execution environment",
"image": "registry.redhat.io/ansible-automation-platform-25/ee-supported-rhel8@sha256:b9f60d9ebbbb5fdc394186574b95dea5763b045ceff253815afeb435c626914d",
"pull": ""
},
"extra_vars": {
"example": "value"
},
"forks": 0,
"hosts_count": 0,
"instance_group": {
"id": 2,
"name": "default",
"capacity": 0,
"jobs_running": 1,
"jobs_total": 38,
"max_concurrent_jobs": 0,
"max_forks": 0
},
"inventory": {
"id": 1,
"name": "Demo Inventory",
"description": "",
"kind": "",
"total_hosts": 1,
"total_groups": 0,
"has_inventory_sources": false,
"total_inventory_sources": 0,
"has_active_failures": false,
"hosts_with_active_failures": 0,
"inventory_sources": []
},
"job_template": {
"id": 7,
"name": "Demo Job Template",
"job_type": "run"
},
"job_type": "run",
"job_type_name": "job",
"labels": [
{
"id": 1,
"name": "Demo label",
"organization": {
"id": 1,
"name": "Default"
}
}
],
"launch_type": "workflow",
"limit": "",
"launched_by": {
"id": 1,
"name": "admin",
"type": "user",
"url": "/api/v2/users/1/"
},
"organization": {
"id": 1,
"name": "Default"
},
"playbook": "hello_world.yml",
"project": {
"id": 6,
"name": "Demo Project",
"status": "successful",
"scm_type": "git",
"scm_url": "https://github.com/ansible/ansible-tower-samples",
"scm_branch": "",
"scm_refspec": "",
"scm_clean": false,
"scm_track_submodules": false,
"scm_delete_on_update": false
},
"scm_branch": "",
"scm_revision": "",
"workflow_job": {
"id": 69,
"name": "Demo Workflow"
},
"workflow_job_template": {
"id": 10,
"name": "Demo Workflow",
"job_type": null
}
}| 入力 | 型 | 説明 |
|---|---|---|
|
| Boolean | アクションが許可されているかどうかを示します |
|
| String のリスト | アクションが許可されない理由 |
次のコードブロックは、OPA ポリシークエリーからの予想される出力の例を示しています。
{
"allowed": false,
"violations": [
"No job execution is allowed",
...
],
...
}第8章 Automation Controller のログ
Automation Controller ログへのアクセス方法は、Ansible Automation Platform が RPM ベースでインストールされているか、コンテナー化されているかによって異なります。
8.1. コンテナー化された Ansible Automation Platform の Automation Controller ログへのアクセス
コンテナー化された Ansible Automation Platform のログは特定のファイルに保存されません。アプリケーションログはコンテナー stdout に送信され、journald を使用して Podman によって処理されます。
Automation Controller に関連付けられている 3 つのコンテナーは次のとおりです。
-
automation-controller-rsyslog -
automation-controller-task -
automation-controller-web
各コンテナーの目的とログの検証方法は、コンテナー 化インストールでの 問題の特定 を 参照し てください。
8.2. RPM ベースの Ansible Automation Platform の Automation Controller ログへのアクセス
Automation Controller ログファイルには、次の 2 つの一元化された場所からアクセスできます。
-
/var/log/tower/ -
/var/log/supervisor/
/var/log/tower/ ディレクトリーでは、次の方法で取得されたログファイルを確認できます。
- tower.log: ジョブの実行時に発生するランタイムエラーなどのログメッセージを取得します。
- callback_receiver.log: Ansible ジョブの実行時にコールバックイベントを処理するコールバックレシーバーログを取得します。
- dispatcher.log: Automation Controller ディスパッチャワーカーサービスのログメッセージを取得します。
- job_lifecycle.log: ジョブ実行の詳細、ブロックの有無、ブロックの条件などを取得します。
- management_playbooks.log: 管理 Playbook の実行、およびメタデータのコピーといった分離ジョブの実行のログを取得します。
- rsyslog.err: 外部ロギングサービスへのログ送信時に、外部ロギングサービスでの認証で生じた rsyslog エラーを取得します。
- task_system.log: バックグラウンドで Automation Controller が実行しているタスクのログを取得します。たとえば、クラスターインスタンスの追加や、分析のための情報収集/処理に関連するログなどです。
- tower_rbac_migrations.log: rbac データベースの移行またはアップグレードに関するログを取得します。
- tower_system_tracking_migrations.log: コントローラーシステムによる移行またはアップグレードの追跡に関するログを取得します。
- wsbroadcast.log: コントローラーノードの websocket 接続のログを取得します。
/var/log/supervisor/ ディレクトリーでは、次の方法で取得されたログファイルを確認できます。
-
awx-callback-receiver.log:
supervisordで管理されている Ansible ジョブの実行時にコールバックイベントを処理するコールバックレシーバーのログを取得します。 - awx-daphne.log: WebUI の Websocket 通信のログを取得します。
- awx-dispatcher.log: ジョブの実行時など、タスクを Automation Controller インスタンスにディスパッチするときに発生するログを取得します。
-
awx-rsyslog.log:
rsyslogサービスのログを取得します。 - awx-uwsgi.log: アプリケーションサーバーである uWSGI に関連するログを取得します。
- awx-wsbroadcast.log: Automation Controller が使用する websocket サービスのログを取得します。
-
failure-event-handler.stderr.log:
/usr/bin/failure-event-handlerの supervisord サブプロセスの標準エラーを取得します。 -
supervisord.log:
supervisord自体に関連するログを取得します。 - wsrelay.log: websocket リレーサーバー内の通信ログをキャプチャーします。
- ws_heartbeat.log: ホスト上で実行しているサービスの健全性に関する定期的なチェックをキャプチャーします。
- rsyslog_configurer.log: 外部ロギングサービスによる認証に関連する rsyslog 設定アクティビティーをキャプチャーします。
/var/log/supervisor/ ディレクトリーには、全サービスの stdout ファイルも含まれます。
Automation Controller (および Ansible Automation Platform) が使用するサービスにより、次のログパスが生成されると予想されます。
- /var/log/nginx/
- /var/lib/pgsql/data/pg_log/
- /var/log/redis/
トラブルシューティング
エラーログは次の場所にあります。
-
Automation Controller サーバーエラーは
/var/log/towerに記録されます。 -
Supervisor のログは
/var/log/supervisor/にあります。 - Nginx Web サーバーのエラーは httpd エラーログに記録されます。
-
その他の Automation Controller のロギングニーズは
/etc/tower/conf.d/で設定します。
大半のブラウザーに組み込まれている JavaScript コンソールを使用してクライアント側の問題をチェックし、Red Hat カスタマーポータル (https://access.redhat.com/) 経由で Ansible にエラーを報告してください。
第9章 ロギングおよびアグリゲーション
ロギングは、詳細なログをサードパーティーの外部ログアグリゲーションサービスに送信する機能を提供します。このデータフィードに接続されたサービスは、Automation Controller の使用や技術の傾向に関する洞察を得るための手段として機能します。このデータを使用して、インフラストラクチャー内のイベントを分析し、異常を監視し、あるサービスのイベントを別のサービスのイベントと関連付けることができます。
Automation Controller に最も役立つデータのタイプは、ジョブファクトデータ、ジョブイベントまたはジョブ実行、アクティビティーストリームデータ、およびログメッセージです。データは、カスタムハンドラーで、またはインポートされたライブラリーを介して設計された最小限のサービス固有の調整を使用して、HTTP 接続を介して JSON 形式で送信されます。
Automation Controller によってインストールされる rsyslog のバージョンは、次の rsyslog モジュールを含みません。
- rsyslog-udpspoof.x86_64
- rsyslog-libdbi.x86_64
Automation Controller 外部のロギングは、以前は RHEL 提供の rsyslog パッケージを使用して実行していた可能性がありますが、Automation Controller をインストールした後は、Automation Controller 提供の rsyslog パッケージのみを使用する必要があります。
Automation Controller インスタンスでのシステムログの記録にすでに rsyslog を使用している場合は、別の rsyslog プロセス (Automation Controller が使用するのと同じバージョンの rsyslog を使用) を実行し、別の /etc/rsyslog.conf ファイルを指定することで、引き続き rsyslog を使用して Automation Controller の外部からのログを処理できます。
外部ロガーがオフラインになった場合に Automation Controller の rsyslog プロセスで未送信のメッセージを処理する方法を、/api/v2/settings/logging/ エンドポイントを使用して設定します。
LOG_AGGREGATOR_ACTION_MAX_DISK_USAGE_GB: rsyslogd アクションキューの最大ディスク永続性 (GB 単位)。外部ログアグリゲーターの停止時に保存するデータの量 (ギガバイト単位) を指定します (デフォルトは 1)。
rsyslogd queue.maxDiskSpace設定に相当します。LOG_AGGREGATOR_ACTION_QUEUE_SIZE: ログアクションキューに保存できるメッセージの最大数。保存されるメッセージの数に応じて、rsyslog アクションキューをどれだけ大きくするかを定義します。これはメモリー使用量に影響を及ぼす可能性があります。キューがこの数の 75% に達すると、キューはディスクへの書き込みを開始します (
rsyslogのqueue.highWatermark)。90% に達すると、NOTICE、INFO、DEBUGメッセージが破棄され始めます (queue.discardMarkと 'queue.discardSeverity=5`)。アクションの
rsyslogd queue.size設定に相当します。
これは、LOG_AGGREGATOR_MAX_DISK_USAGE_PATH で指定されたディレクトリーにファイルを保存します。
-
LOG_AGGREGATOR_MAX_DISK_USAGE_PATH: 外部ログアグリゲーターの停止後に再試行する必要があるログを保存する場所を指定します (デフォルトは/var/lib/awx)。rsyslogd queue.spoolDirectory設定に相当します。
たとえば、Splunk がオフラインになった場合、rsyslogd は Splunk がオンラインに戻るまでディスクにキューを保存します。デフォルトでは、(Splunk がオフラインの間) 最大 1 GB のイベントが保存されますが、必要に応じて 1 GB 超に増やすことも、キューを保存するパスを変更することもできます。
9.1. ロガー
以下は、予測可能な構造化形式または半構造化形式で大量の情報を提供する特別なロガー (汎用的なサーバーログを構成する awx は除く) です。これらは、API からデータを取得するときと同じ構造を使用します。
-
job_events: Ansible コールバックモジュールから返されるデータを渡します。 -
activity_stream: アプリケーション内のオブジェクトに対する変更の記録を表示します。 -
system_tracking: Ansiblesetupモジュールによって収集されたファクトデータを提供します。つまり、Enable Fact Cache を選択した状態でジョブテンプレートを実行する場合は、gather_facts: trueになります。 -
awx: 通常はファイルに書き込まれるログを含む、汎用的なサーバーログを提供します。これには、すべてのログが有する標準メタデータが含まれます。ただし、含まれるのはログステートメントからのメッセージのみです。
これらのロガーは、INFO のログレベルのみを使用します。例外は awx ロガーで、これはどのレベルでも使用できます。
さらに、標準の Automation Controller ログも、同じメカニズムで配信できます。ローカルの設定ファイルで複雑なディクショナリーを操作せずに、これら 5 つのデータソースをそれぞれ有効または無効にする方法や、標準の Automation Controller ログから使用するログレベルを調整する方法は明らかです。
ナビゲーションパネルから、 → → を選択して、Automation Controller のロギングコンポーネントを設定します。
9.1.1. ログメッセージスキーマ
全ロガーに対する共通のスキーマ
-
cluster_host_id: Automation Controller クラスター内のホストの一意識別子。 -
level: イベントの重要性をほぼ反映する、標準の Python ログレベル。すべてのデータロガーは「レベル」の一部としてINFOレベルを使用しますが、他の Automation Controller ログは必要に応じて異なるレベルを使用します。 -
logger_name: 設定で使用するロガー名 (たとえば "activity_stream")。 -
@timestamp: ログの時刻。 -
path: ログが生成されたコードのファイルパス。
9.1.2. アクティビティーストリームスキーマ
これは、Log message schema にリストされているすべてのロガーに共通のフィールドを使用します。
次の追加フィールドがあります。
-
actor: ログに記述されたアクションを行ったユーザーのユーザー名。 -
changes: 変更されたフィールド、および古い値または新しい値の概要 (JSON)。 -
operation: "associate" など、アクティビティーストリームにログ記録された変更の基本カテゴリー。 -
object1: 操作を行うプライマリーオブジェクトに関する情報。アクティビティーストリームに表示する内容と一貫性があります。 -
object2: 該当する場合には、アクションに関連する 2 つ目のオブジェクト。
このロガーは、ジョブイベントに保存されているデータを反映します。ただし、ロガーの予期される標準フィールドと競合する場合を除きます (この場合、フィールドはネストされます)。特に、job_event モデルのフィールド host は、event_host として指定されます。ペイロード内にはサブディクショナリーフィールド event_data もあり、これには Ansible イベントの詳細に応じて異なるフィールドが含まれます。
このロガーには、ログメッセージスキーマ の共通フィールドも含まれます。
9.1.3. スキャン/ファクト/システム追跡データスキーマ
これらには、サービス、パッケージまたはファイルの詳細なディクショナリータイプのフィールドが含まれます。
services: サービススキャンの場合、このフィールドが含まれ、サービスの名前に基づいたキーを含みます。注記名前の Elastic Search ではピリオドは使用できず、ログフォーマッターによって "_" に置き換えられます。
-
package: パッケージスキャンからのログメッセージに含まれます。 -
files: ファイルスキャンからのログメッセージに含まれます。 -
host: スキャンを適用するホストの名前です。 -
inventory_id: ホストが含まれるインベントリー ID です。
このロガーには、ログメッセージスキーマ の共通フィールドも含まれます。
9.1.4. ジョブステータスの変更
この情報ソースは、ジョブイベントと比較してジョブ状態の変化に関する情報は少量とし、ジョブテンプレートをベースとするジョブ以外で、統合されたジョブタイプに対する変更を取得します。
このロガーには、ログメッセージスキーマ の共通フィールドと、ジョブモデルに存在するフィールドも含まれます。
9.1.5. Automation Controller のログ
このロガーには、ログメッセージスキーマ の共通フィールドも含まれます。
さらに、ログメッセージを含む msg フィールドが含まれます。エラーには別の traceback フィールドが含まれます。ナビゲーションパネルから、 → → を選択します。Logging Settings ページで をクリックし、ENABLE EXTERNAL LOGGING オプションを使用して、ロギングコンポーネントを有効または無効にします。
9.1.6. ログアグリゲーターサービス
ログアグリゲーターサービスは、以下の監視またはデータ分析システムと連携します。
9.1.6.1. Splunk
Automation Controller の Splunk ロギング統合では、Splunk HTTP Collector を使用します。SPLUNK ログアグリゲーターを設定する場合は、次の例のように、完全な URL を HTTP Event Collector ホストに追加します。
https://<yourcontrollerfqdn>/api/v2/settings/logging
{
"LOG_AGGREGATOR_HOST": "https://<yoursplunk>:8088/services/collector/event",
"LOG_AGGREGATOR_PORT": null,
"LOG_AGGREGATOR_TYPE": "splunk",
"LOG_AGGREGATOR_USERNAME": "",
"LOG_AGGREGATOR_PASSWORD": "$encrypted$",
"LOG_AGGREGATOR_LOGGERS": [
"awx",
"activity_stream",
"job_events",
"system_tracking"
],
"LOG_AGGREGATOR_INDIVIDUAL_FACTS": false,
"LOG_AGGREGATOR_ENABLED": true,
"LOG_AGGREGATOR_CONTROLLER_UUID": ""
}
Splunk HTTP Event Collector はデフォルトでポート 8088 をリッスンするため、受信要求が正常に処理されるように、LOG_AGGREGATOR_HOST に完全な HEC イベント URL (ポート番号を含む) を指定する必要があります。
一般的な値を次の例に示します。
HTTP Event Collector の設定の詳細は、Splunk のドキュメント を参照してください。
9.1.6.2. Loggly
Loggly の HTTP エンドポイントを介したログ送信の詳細は、Loggly のドキュメント を参照してください。
Loggly は、次の例の Logging Aggregator フィールドに示す URL 規則を使用します。

9.1.6.3. Sumologic
Sumologic では、JSON ファイルに含まれる検索基準を作成します。JSON ファイルには、必要なデータを収集するのに使用するパラメーターが指定されています。
9.1.6.4. Elastic stack (以前の ELK stack)
独自のバージョンの Elastic Stack をセットアップしている場合、必要な変更は、logstash logstash.conf ファイルに次の行を追加するだけです。
filter {
json {
source => "message"
}
}Elastic 5.0.0 で後方互換性のない変更が導入され、使用するバージョンによっては、異なる設定が必要になる可能性があります。
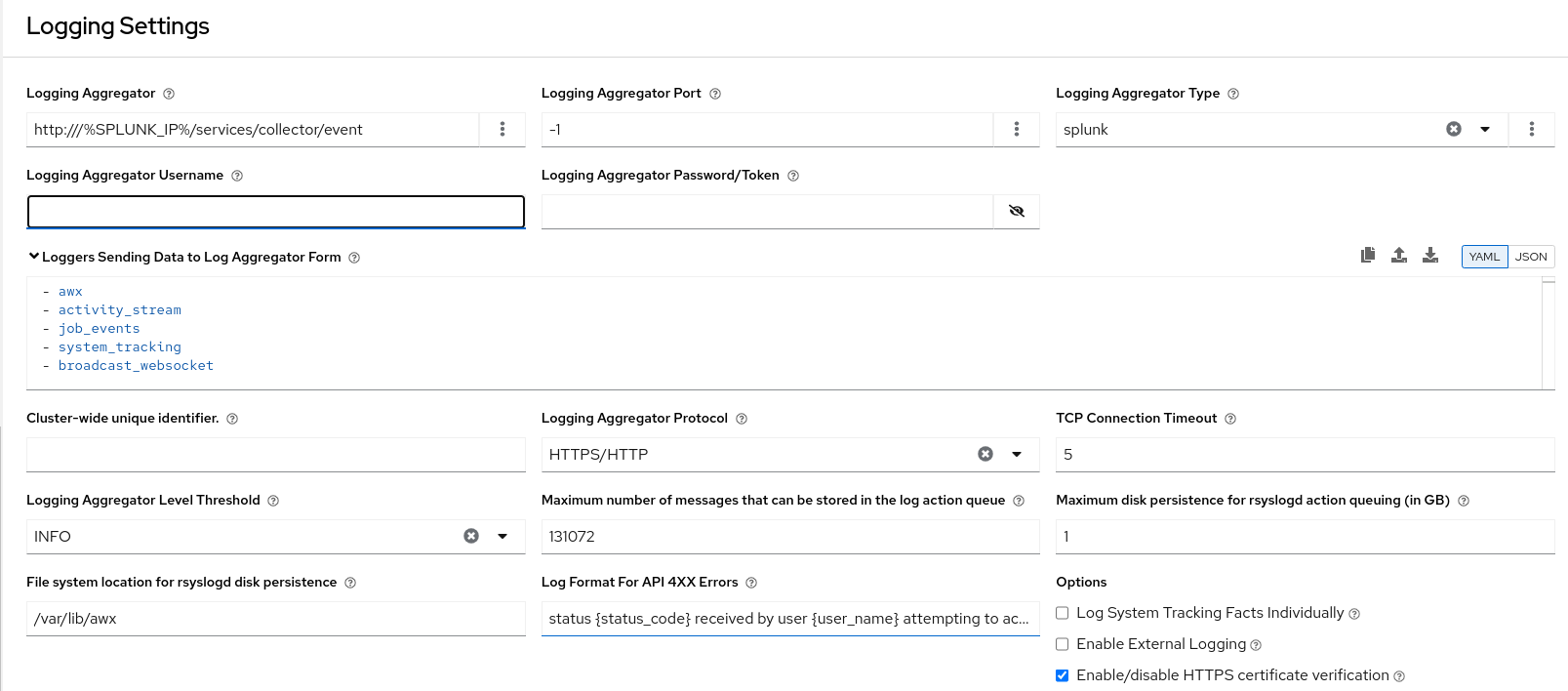
9.2. ロギングのセットアップ
任意のアグリゲータタイプへのロギングをセットアップするには、次の手順を使用します。
手順
- ナビゲーションパネルから、 → → を選択します。
Logging settings ページで、 をクリックします。
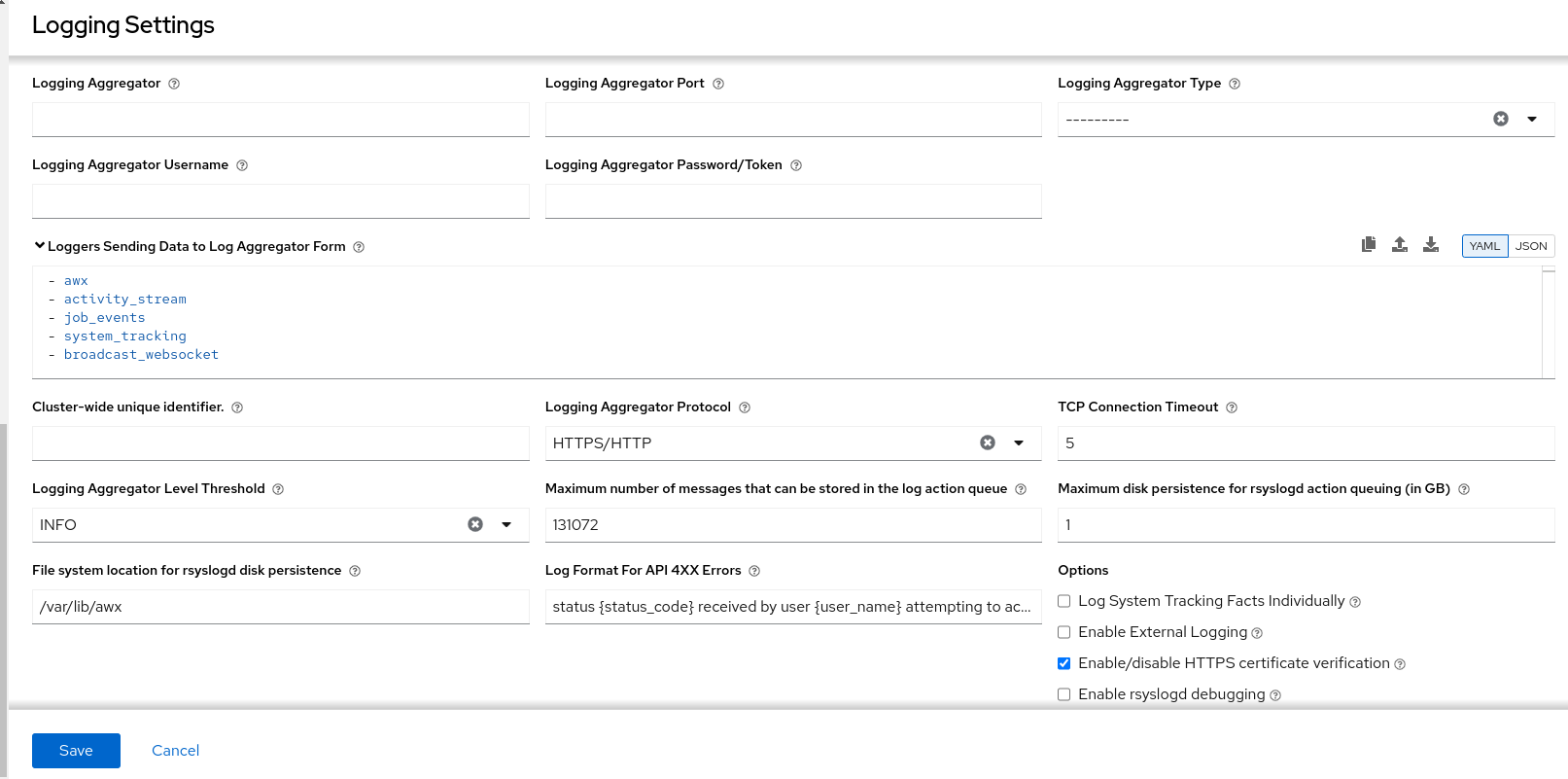
以下のオプションを設定できます。
- Logging Aggregator: ログを送信するホスト名または IP アドレスを入力します。
Logging Aggregator Port: アグリゲーターのポートが必要な場合は、ポートを指定します。
注記接続タイプが HTTPS の場合、ホスト名をポート番号付きの URL として入力できます。その後はポートを再度入力する必要はありません。ただし、TCP 接続と UDP 接続は、URL ではなく、ホスト名とポート番号の組み合わせによって特定されます。したがって、TCP 接続または UDP 接続の場合は、指定されたフィールドでポートを指定します。代わりに URL が Logging Aggregator フィールドに入力された場合、そのホスト名部分がホスト名として抽出されます。
Logging Aggregator Type: クリックして、リストからアグリゲータサービスを選択します。

- Logging Aggregator Username: 必要に応じて、ロギングアグリゲーターのユーザー名を入力します。
- Logging Aggregator Password/Token: 必要に応じて、ロギングアグリゲーターのパスワードを入力します。
-
Loggers to Send Data to the Log Aggregator Form: デフォルトでは、4 種類のデータすべてが事前に入力されています。各データ型の追加情報を表示するには、フィールドの横にあるツールチップアイコン
をクリックします。不要なデータ型を削除します。
- Cluster wide unique identifier: これを使用してインスタンスを一意に識別します。
- Logging Aggregator Protocol: クリックして、ログアグリゲーターと通信するための接続タイプ (プロトコル) を選択します。その後に表示されるオプションは、選択したプロトコルによって異なります。
- TCP Connection Timeout: 接続タイムアウトを秒単位で指定します。このオプションは、HTTPS および TCP ログアグリゲータープロトコルにのみ適用されます。
- Logging Aggregator Level Threshold: ログハンドラーで報告する重大度のレベルを選択します。
-
Maximum number of messages that can be stored in the log action queue: 保存されるメッセージの数に応じて
rsyslogアクションキューがどれだけ大きくなるかを定義します。これはメモリー使用量に影響を及ぼす可能性があります。キューがこの数の 75% に達すると、キューはディスクへの書き込みを開始します (rsyslogのqueue.highWatermark)。90% に達すると、NOTICE、INFO、およびDEBUGメッセージが破棄され始めます (queue.discardMarkとqueue.discardSeverity=5)。 -
Maximum disk persistence for rsyslogd action queuing (in GB):
rsyslogアクションによる受信メッセージの処理に時間がかかる場合 (デフォルトは 1) に、保存するデータ量 (ギガバイト単位) です。アクションのrsyslogd queue.maxdiskspace設定と同等です (例:omhttp)。これは、LOG_AGGREGATOR_MAX_DISK_USAGE_PATHで指定されたディレクトリーにファイルを保存します。 -
File system location for rsyslogd disk persistence: 外部ログアグリゲーターの停止後に再試行する必要のあるログを永続化する場所 (デフォルトは
/var/lib/awx)。rsyslogd queue.spoolDirectory設定に相当します。 - Log Format For API 4XX Errors: 特定のエラーメッセージを設定します。詳細は、API 4XX エラー設定 を参照してください。
以下のオプションを設定します。
Log System Tracking Facts Individually: ツールチップアイコン
をクリックすると、オンに切り替えるか、デフォルトのままオフにしておくかなど、追加情報が表示されます。
選択したロギングアグリゲーションのエントリーを確認します。次の例は Splunk 用にセットアップされています。

- Enable External Logging: ログを外部ログアグリゲーターに送信する場合は、このチェックボックスを選択します。
- Enable/disable HTTPS certificate verification: HTTPS ログプロトコルの証明書検証はデフォルトで有効になっています。接続を確立する前に、外部ログアグリゲーターから送信された HTTPS 証明書をログハンドラーで検証する場合は、このチェックボックスをオンにします。
Enable rsyslogd debugging: このチェックボックスを選択すると、
rsyslogdの詳細度の高いデバッグが有効になります。外部ログアグリゲーションの接続に関する問題のデバッグに役立ちます。- をクリックするか、変更を破棄する場合は をクリックします。
9.3. API 4XX エラー設定
要求で問題が発生すると、API は通常、エラーとともに 400 番台の HTTP エラーコードを返します。この場合、次のパターンに従ったエラーメッセージがログに生成されます。
' status {status_code} received by user {user_name} attempting to access {url_path} from {remote_addr} 'メッセージは必要に応じて設定できます。デフォルトの API 4XX エラーログメッセージの形式を変更するには、次の手順を使用します。
手順
- ナビゲーションパネルから、 → → を選択します。
- Logging settings ページで、 をクリックします。
- Log Format For API 4XX Errors フィールドを変更します。
{} で囲まれた項目はログエラー発生時に置換されます。次の変数を使用できます。
- status_code: API が返す HTTP ステータスコード。
- user_name: API 要求を行うときに認証されたユーザーの名前。
- url_path: 呼び出される URL のパス部分 (別名 API エンドポイント)
- remote_addr :Automation Controller が受信したリモートアドレス。
- error: API によって返されるエラーメッセージ。エラーが指定されていない場合は、HTTP ステータスをテキストで返します。
9.4. ロギングのトラブルシューティング
ロギングアグリゲーション
テストボタンを使用して、設定済みのロギングサービスに http または https 経由でメッセージを送信したものの、メッセージを受信しなかった場合は、/var/log/tower/rsyslog.err ログファイルを確認してください。http または https の外部ロギングサービスで rsyslog を認証するときにエラーが発生した場合、ここにエラーが保存されます。エラーがない場合、このファイルは存在しないことに注意してください。
API 4XX エラー
これらのメッセージのログ形式を変更することにより、4XX エラーの API エラーメッセージを含めることができます。API 4XX エラー設定 を参照してください。
LDAP
LDAP アダプターのロギングメッセージを有効にできます。詳細は、API 4XX エラー設定 を参照してください。
SAML
LDAP のログを有効にするのと同じ方法で、SAML アダプターのメッセージのロギングを有効にできます。
第10章 メトリクス
API ではメトリクスエンドポイント /api/controller/v2/metrics/ が使用できます。このメトリクスエンドポイントは、Automation Controller に関する即時のメトリクスを生成します。メトリクスは、オープンソースプロジェクトの Prometheus といったシステム監視ソフトウェアで使用できます。
metrics/ エンドポイントに表示されるデータのタイプは、Content-type: text/plain および application/json です。
このエンドポイントからは、アクティブなユーザーセッションの数や、各 Automation Controller ノードでアクティブに実行されているジョブの数など、有用な情報が得られます。
Automation Controller メトリクスエンドポイントにアクセスし、このデータを時系列データベースに保存することで、Automation Controller からこれらのメトリクスを収集するように Prometheus を設定できます。
その後、クライアントは Prometheus を他のソフトウェア (Grafana や Metricbeat など) と組み合わせて使用して、データを視覚化したりアラートを設定したりできます。
10.1. Prometheus のセットアップ
Prometheus をセットアップして使用するには、仮想マシンまたはコンテナーに Prometheus をインストールする必要があります。
詳細は、First steps with Prometheus ドキュメントを参照してください。
手順
Prometheus 設定ファイル (通常は
prometheus.yml) で、<token_value>、作成した Automation Controller ユーザーの有効なユーザー名とパスワード、および<controller_host>を指定します。注記あるいは、OAuth2 トークン (
/api/v2/users/N/personal_tokens/で生成可能) を指定することもできます。デフォルトでは、この設定はユーザー名 =admin、パスワード =passwordであるユーザーを想定しています。次の例は、Automation Controller で Prometheus を認証するために
/api/v2/tokensエンドポイントで作成した OAuth2 トークンを使用し、Automation Controller のメトリクスエンドポイントの URL が/https://controller_host:443/metricsである場合の有効な収集設定です。scrape_configs - job_name: 'controller' tls_config: insecure_skip_verify: True metrics_path: /api/v2/metrics scrape_interval: 5s scheme: https bearer_token: <token_value> # basic_auth: # username: admin # password: password static_configs: - targets: - <controller_host>アラートやサービスディスカバリー設定など、Prometheus の他の要素を設定する方法は、Prometheus configuration ドキュメントを参照してください。
Prometheus がすでに実行中の場合には、再読み込みしたエンドポイントに POST 要求を送信するか、Prometheus プロセスまたはサービスを強制終了し、Prometheus を再起動して設定の変更を適用する必要があります。
ブラウザーを使用して
/http://<your_prometheus>:9090/graphにある Prometheus UI のグラフに移動し、いくつかのクエリーをテストします。たとえば、awx_sessions_total{type="user"}を実行すると、現在のアクティブな Automation Controller ユーザーセッションの数をクエリーできます。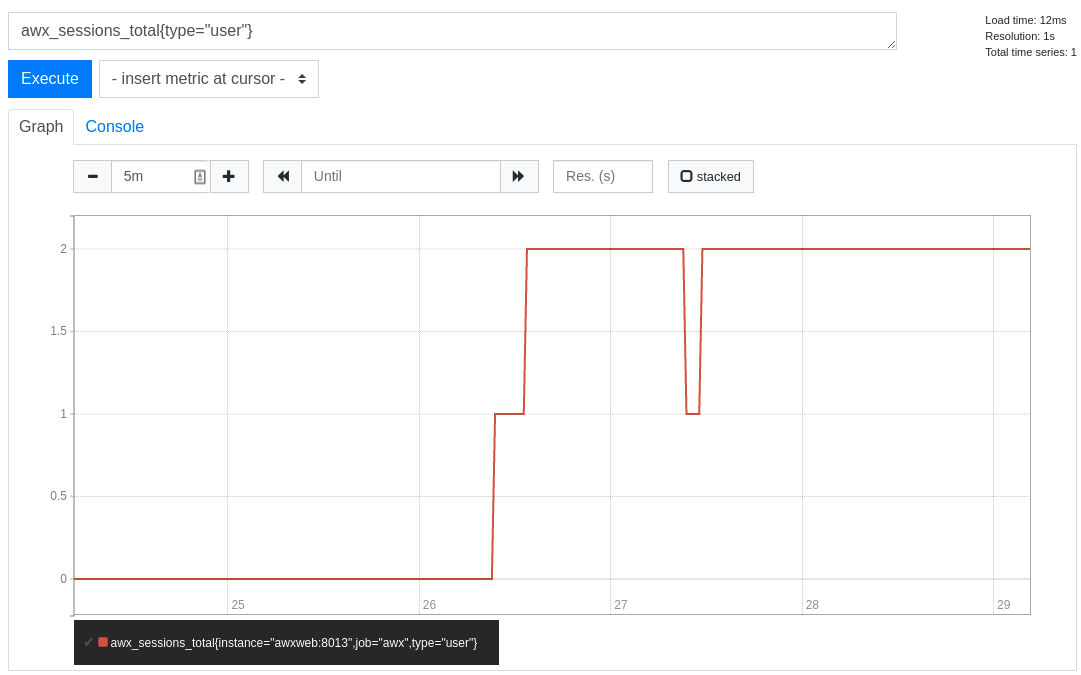
次のステップ
その他のクエリー方法は、インスタンスの Automation Controller API のメトリクスエンドポイント (api/v2/metrics) を参照してください。
第11章 Ansible Automation Platform と Automation Controller のサブスクリプション管理
Ansible Automation Platform は、使用状況の監視、サブスクリプションのアクティブ化、Red Hat サブスクリプション要件に対するコンプライアンス維持を行う機能を提供します。
11.1. ホストメトリクスとサブスクリプション
ホストメトリクスを使用すると、ノードの使用状況を正確にカウントし、サブスクリプションのコンプライアンスを確保できます。たとえば、ホストが使用されなくなった場合や、サブスクリプションの合計数にカウントされるべきでない場合は、そのホストを論理削除できます。
11.1.1. ホストメトリクスダッシュボード
ホストメトリクスを表示するには、ナビゲーションペインで → を選択します。
ホストメトリクスダッシュボードには、管理対象ホストごとに次のような自動化実行の概要が表示されます。
- ホストの最初および最後の自動化。
- ホストに対して自動化が実行された回数、または実行が試行された回数。
- 管理対象ホストが削除された回数。
ホスト上で自動化が実行された回数を表示する機能により、次のことが可能になります。
- 最も頻繁に自動化されるホストを表示します。
- 自動化環境の範囲をより正確に反映します。
11.1.1.1. 論理削除
論理削除により、廃止されたホストをホストメトリクスビューから削除し、潜在的な管理対象ノード数から除外できます。さらに、次のホストタイプも削除できます。
- CI-CD やテスト専用に使用される一時的な、一意にプロビジョニングされたホスト。
- ベンチプロビジョニングまたは一時ホスト。
- 廃止され、自動化されることのない古いホスト。
論理削除は、正当なユースケースシナリオのみを対象としています。たとえば、ノードのリサイクルを目的として、サブスクリプションのカウントに違反する目的で使用することはできません。詳細は、How are "managed nodes" defined as part of the Red Hat Ansible Automation Platform offering? を参照してください。
11.2. Red Hat Ansible Automation Platform のライセンス認証
Red Hat Ansible Automation Platform は、Ansible Automation Platform の使用を許可するために、利用可能なサブスクリプションまたはサブスクリプションマニフェストを使用します。
サブスクリプションを取得するには、次のいずれかを実行できます。
- Ansible Automation Platform を起動するときに、Red Hat のユーザー名とパスワード、サービスアカウントの認証情報、または Satellite の認証情報を使用します。
- Red Hat Ansible Automation Platform インターフェイスを使用するか、Ansible Playbook で手動でサブスクリプションマニフェストファイルをアップロードします。
11.2.1. 認証情報によるライセンス認証
Ansible Automation Platform を初めて起動すると、Ansible Automation Platform サブスクリプションウィザードが自動的に表示されます。組織管理者の場合は、Red Hat サービスアカウントを作成 し、クライアント ID とクライアントシークレットを使用してサブスクリプションを取得して Ansible Automation Platform に直接インポートできます。
管理者アクセス権がない場合は、ユーザー名とパスワード タブに Red Hat のユーザー名とパスワードを入力して、サブスクリプションを検索し、Ansible Automation Platform インスタンスに追加できます。
初めてログインしてプラットフォームをアクティベートすると、デフォルトで Automation Analytics がオプトインされます。これは、Red Hat がユーザーエクスペリエンスを大きく改善し、製品を改良する上で役立ちます。Ansible Automation Platform をアクティベートした後、次の手順でオプトアウトできます。
- ナビゲーションパネルから、 → → を選択します。
- Gather data for Automation Analytics オプションのチェックボックスをオフにします。
- をクリックします。
手順
- Red Hat Ansible Automation Platform にログインします。
- サブスクリプションウィザードで Service Account タブを選択します。
- Client ID と Client secret を入力します。
Subscription リストからサブスクリプションを選択します。
注記クラスターノードが Subscription Manager を通じて Satellite に登録されている場合は、Satellite タブに Satellite のユーザー名とパスワードを入力することもできます。
- 使用許諾契約書を確認し、I agree to the End User License Agreement を選択します。
- をクリックします。
検証
サブスクリプションが承認されると、サブスクリプションの詳細が表示されます。Compliant のステータスは、サブスクリプションが、サブスクリプションカウント内で自動化したホストの数に準拠していることを示します。それ以外の場合、ステータスは Out of Compliance と表示さます。これは、サブスクリプション内のホスト数を超えていることを示しています。表示されるその他の重要な情報は次のとおりです。
- 自動化されたホスト
- ライセンス数を消費するジョブによって自動化されたホスト数
- インポートされたホスト
- すべてのインベントリーソースを考慮したホスト数 (残りのホストには影響しません)
- 残りのホスト
- 合計ホスト数から自動化されたホストを差し引いた数
11.2.2. マニフェストファイルによるライセンス認証
サブスクリプションマニフェストがある場合は、Red Hat Ansible Automation Platform インターフェイスを使用してマニフェストファイルをアップロードできます。
初めてログインしてプラットフォームをアクティベートすると、デフォルトで Automation Analytics がオプトインされます。これは、Red Hat がユーザーエクスペリエンスを大きく改善し、製品を改良する上で役立ちます。Ansible Automation Platform をアクティベートした後、次の手順でオプトアウトできます。
- ナビゲーションパネルから、 → → を選択します。
- Gather data for Automation Analytics オプションのチェックボックスをオフにします。
- をクリックします。
前提条件
Red Hat カスタマーポータルから Red Hat サブスクリプションマニフェストファイルをエクスポートしている。詳細は、マニフェストファイルの取得 を 参照してください。
手順
Red Hat Ansible Automation Platform にログインします。
- すぐにサブスクリプションウィザードが表示されない場合は、 → に移動します。
- Subscription manifest タブを選択します。
- をクリックして、マニフェストファイルを選択します。
- 使用許諾契約書を確認し、I agree to the End User License Agreement を選択します。
をクリックします。
注記サブスクリプションウィザードページで ボタンが無効になっている場合は、USERNAME と PASSWORD フィールドをクリアします。
検証
サブスクリプションが承認されると、サブスクリプションの詳細が表示されます。Compliant のステータスは、サブスクリプションが、サブスクリプションカウント内で自動化したホストの数に準拠していることを示します。それ以外の場合、ステータスは Out of Compliance と表示さます。これは、サブスクリプション内のホスト数を超えていることを示しています。表示されるその他の重要な情報は次のとおりです。
- 自動化されたホスト
- ジョブによって自動化されたホスト数。サブスクリプション数を消費します。
- インポートされたホスト
- すべてのインベントリーソースを考慮したホスト数 (残りのホストには影響しません)
- 残りのホスト
- 合計ホスト数から自動化されたホストを差し引いた数
11.3. サブスクリプションのコンプライアンスを維持する
サブスクリプションには、次の 2 つのステータスがあります。
- Compliant: サブスクリプションが、サブスクリプション数以内の自動化したホストの数に対して適切であることを示します。
- Out of compliance: サブスクリプション内のホスト数を超えていることを示します。
コンプライアンスは次のように計算されます。
managed > manifest_limit => non-compliant
managed =< manifest_limit => compliant
ここで、managed は、削除されていない一意のマネージドホストの数、manifest_limit はサブスクリプションマニフェスト内のマネージドホストの数に置き換えます。
表示されるその他の重要な情報は次のとおりです。
- Hosts automated: ジョブによって自動化されたホストの数。ライセンス数を消費します。
- Hosts imported: すべてのインベントリーソースにおいて一意のホスト名を考慮したホスト数。この数は、残りのホスト数 (Hosts remaining) には影響しません。
- Hosts remaining: 自動化されたホストの数を差し引いたホスト数。
- Hosts deleted: 削除されたホスト数。ライセンス容量が開放されます。
- Active hosts previously deleted: 以前に削除され、現在アクティブになっているホスト数。
たとえば、ホスト 10 台分のサブスクリプションがあるとします。
- 最初は 9 台のホストでしたが、ホストを 2 台追加してから、3 台削除しました。その結果、ホストが 8 台になりました (コンプライアンス準拠)。
- 3 台のホストを再び自動化したところ、ホストが 11 台になり、サブスクリプションの上限である 10 を超えました (コンプライアンス非準拠)。
- ホストを削除する場合は、サブスクリプションの詳細を更新して、数とステータスの変更を確認します。
11.3.1. ユーザーインターフェイスで自動化されたホストを表示する
手順
ナビゲーションパネルで → を選択して、たとえば自動化や削除されたホストなど、ホストに関連付けられたアクティビティーを表示します。
それぞれの一意のホスト名がリストされ、ユーザーの設定に応じて並べ替えられます。
 注記
注記スケジュールされたタスクはこれらの値を毎週自動的に更新し、最後に自動化されたのが 1 年以上前であるホストのジョブを削除します。
必要なホストを選択し、 をクリックして、ホストメトリクスビューから不要なホストを直接削除します。
これらは論理的に削除されるため、レコードは削除されませんが、使用されないため、サブスクリプションにはカウントされません。
11.3.2. CLI で自動化されたホストを表示する
Automation Controller は、コマンドラインインターフェイス (CLI) を通じて、ホストメトリクスデータとホストメトリクス概要の CSV 出力を生成する方法を提供します。API を介してホストを一括して論理削除することもできます。
11.3.2.1. awx-manage ユーティリティー
Ansible Automation Platform でホストメトリクスデータと関連するクラスター情報を収集および管理するには、awx-manage ユーティリティーを使用します。
手順
awx-manageユーティリティーは次のオプションをサポートしています。awx-manage host_metric --csvこのコマンドは、ホストメトリクスデータ、ホストメトリクス概要ファイル、およびクラスター情報ファイルを生成します。配布および共有用にすべてのファイルを 1 つの tar ファイルにパッケージ化するには、次のコマンドを使用します。
awx-manage host_metric --tarball各ファイルに出力する行数 (
<n>) を指定するには、次のようにします。awx-manage host_metric --tarball --rows_per_file <n>- その後、Automation Analytics は JSON ファイルを受信して使用します。
11.3.3. API エンドポイントを使用して自動化されたホストを削除する
API は削除されていないレコードのみをリストし、last_automation 列と used_in_inventories 列で並べ替えることができます。
ホストメトリクス API エンドポイント api/v2/host_metric と以下を使用して、ホストを論理削除することもできます。
api/v2/host_metric <n> DELETE
月次でスケジュールされたタスクでは、ホストを使用するジョブで最後に自動化されたのが 1 年以上前のジョブが、ホストメトリクステーブルから自動的に削除されます。
第12章 metrics-utility による使用状況レポート
Ansible Automation Platform メトリクスユーティリティーツール (metrics-utility) は、Automation Controller のインスタンスを含むシステムにインストールされるコマンドラインユーティリティーです。
metrics-utility は、インストールおよび設定されると、システムから請求関連のメトリクスを収集し、消費量に基づく請求レポートを作成します。metrics-utility ツールは、管理対象ホストが複数あり、消費量ベースの請求を使用するユーザーに特に適しています。レポートが生成されると、設定ファイルで指定した保存先の場所に保存されます。
metrics-utility は、システムから設定データとレポートデータの 2 種類のデータを収集します。
設定データには次の情報が含まれます。
- Automation Controller とオペレーティングシステムのバージョン情報
- サブスクリプション情報
- ベース URL
レポートデータには次の情報が含まれます。
- ジョブ名と ID
- ホスト名
- インベントリー名
- 組織名
- プロジェクト名
- 成功または失敗に関する情報
- レポート日時
metrics-utility が設定どおりに動作し続けるように、レポートディレクトリーから古いレポートを定期的に消去してください。
12.1. metrics-utility の設定
Red Hat Enterprise Linux と OpenShift Container Platform の両方で、Ansible Automation Platform の使用状況データを収集して報告するように metrics-utility を設定します。
12.1.1. Red Hat Enterprise Linux の metrics-utility の設定
前提条件:
- サブスクリプション: アクティブな Ansible Automation Platform サブスクリプション。
-
インストール:
metrics-utilityツールは、デフォルトで Automation Controller ノード上の Ansible Automation Platform インストールに含まれています。別途インストールする必要はありません。 -
ユーザー権限:
metrics-utilityツールを実行するには、rootユーザーまたはawxユーザーとしてログインしている必要があります。
metrics-utility が正常に機能するには、/etc/tower/SECRET_KEY への読み取りアクセスが必要です。このユーティリティーを標準ユーザー(root または非 awx)として実行しようとすると、PermissionError と実行に失敗します。
次の手順では、関連データを収集し、使用状況メトリクスを含む CCSP レポートを生成します。これらのコマンドを cron ジョブとして設定し、毎月の初めに実行されるようにできます。cron 構文の使用方法の詳細は、How to schedule jobs using the Linux cron utility を参照してください。
手順
metrics-utilityにすべての関連データを収集させるための正しい変数を設定するために、ユーザーのホームディレクトリー内に次の 2 つのスクリプトを作成します。/home/my-user/cron-gather内:#!/bin/sh # Specify the following variables to indicate where the report is deposited in your file system export METRICS_UTILITY_SHIP_TARGET=directory export METRICS_UTILITY_SHIP_PATH=/awx_devel/awx-dev/metrics-utility/shipped_data/billing # Run the following command to gather and store the data in the provided SHIP_PATH directory: metrics-utility gather_automation_controller_billing_data --ship --until=10m/home/my-user/cron-report内:#!/bin/sh # Specify the following variables to indicate where the report is deposited in your file system export METRICS_UTILITY_SHIP_TARGET=directory export METRICS_UTILITY_SHIP_PATH=/awx_devel/awx-dev/metrics-utility/shipped_data/billing # Set these variables to generate a report: export METRICS_UTILITY_REPORT_TYPE=CCSPv2 export METRICS_UTILITY_PRICE_PER_NODE=11.55 # in USD export METRICS_UTILITY_REPORT_SKU=MCT3752MO export METRICS_UTILITY_REPORT_SKU_DESCRIPTION="EX: Red Hat Ansible Automation Platform, Full Support (1 Managed Node, Dedicated, Monthly)" export METRICS_UTILITY_REPORT_H1_HEADING="CCSP Reporting <Company>: ANSIBLE Consumption" export METRICS_UTILITY_REPORT_COMPANY_NAME="Company Name" export METRICS_UTILITY_REPORT_EMAIL="email@email.com" export METRICS_UTILITY_REPORT_RHN_LOGIN="test_login" export METRICS_UTILITY_REPORT_COMPANY_BUSINESS_LEADER="BUSINESS LEADER" export METRICS_UTILITY_REPORT_COMPANY_PROCUREMENT_LEADER="PROCUREMENT LEADER" # Build the report metrics-utility build_report
これらのファイルを実行可能にするために、次のコマンドを実行します。
chmod a+x /home/my-user/cron-gather /home/my-user/cron-report編集する
cronファイルを開くには、以下を実行します。crontab -e実行スケジュールを設定するために、ファイルの末尾に次のパラメーターを追加し、
metrics-utilityによって情報を収集してレポートを作成する頻度を cron 構文 を使用して指定します。次の例では、gatherコマンドは毎時 00 分に実行されるように設定されています。build_reportコマンドは、毎月 2 日の午前 4 時に実行されるように設定されています。0 */1 * * * /home/my-user/cron-gather0 4 2 * * /home/my-user/cron-report- ファイルを保存してから閉じます。
検証
正しい設定を確認するには、次の検証手順を使用します。
cronジョブのエントリーが正しく保存されたことを確認するには、次のコマンドを実行します。crontab -lcronログを調べて、cronデーモンがコマンドを実行し、metrics-utilityが出力を生成していることを確認します。cat /var/log/cron参考までに、次の出力例を参照してください。
May 8 09:45:03 ip-10-0-6-23 CROND[51623]: (root) CMDOUT (No billing data for month: 2024-04) May 8 09:45:03 ip-10-0-6-23 CROND[51623]: (root) CMDEND (metrics-utility build_report) May 8 09:45:19 ip-10-0-6-23 crontab[51619]: (root) END EDIT (root) May 8 09:45:34 ip-10-0-6-23 crontab[51659]: (root) BEGIN EDIT (root) May 8 09:46:01 ip-10-0-6-23 CROND[51688]: (root) CMD (metrics-utility gather_automation_controller_billing_data --ship --until=10m) May 8 09:46:03 ip-10-0-6-23 CROND[51669]: (root) CMDOUT (/tmp/9e3f86ee-c92e-4b05-8217-72c496e6ffd9-2024-05-08-093402+0000-2024-05-08-093602+0000-0.tar.gz) May 8 09:46:03 ip-10-0-6-23 CROND[51669]: (root) CMDEND (metrics-utility gather_automation_controller_billing_data --ship --until=10m) May 8 09:46:26 ip-10-0-6-23 crontab[51659]: (root) END EDIT (root)生成されたレポートには、
CCSP-<YEAR>-<MONTH>.xlsxというデフォルトの名前が付けられます。レポートはステップ 1a で指定した送信先パスに保存されます。
時間と日付は、実行スケジュールの設定方法に応じて異なる場合があります。
12.1.2. Ansible Automation Platform Operator から OpenShift Container Platform の metrics-utility を設定する
metrics-utility は、バージョン 4.12、4.512、および 4.6 以降の OpenShift Container Platform イメージに含まれています。システムに metrics-utility がインストールされていない場合は、OpenShift イメージを最新バージョンに更新してください。
Ansible Automation Platform Operator を使用して OpenShift Container Platform で metrics-utility の実行スケジュールを設定するには、次の手順を実行します。
12.1.2.1. OpenShift UI の YAML ビューで ConfigMap を作成する
設定データを含む metrics-utility cronjobs を注入するには、次の手順に従って、OpenShift UI の YAML ビューで ConfigMap を作成します。
前提条件:
- 実行中の OpenShift クラスター
- Operator によって OpenShift Container Platform にインストールされた Ansible Automation Platform
metrics-utility は、設定ファイルで設定したパラメーターに従って実行されます。OpenShift Container Platform では、このユーティリティーを手動で実行することはできません。
手順
- ナビゲーションパネルから、 を選択します。
- をクリックします。
- 次の画面で、YAML view タブを選択します。
YAML フィールドに、次のパラメーターを入力して適切な変数を設定します。
apiVersion: v1 kind: ConfigMap metadata: name: automationcontroller-metrics-utility-configmap data: METRICS_UTILITY_SHIP_TARGET: directory METRICS_UTILITY_SHIP_PATH: /metrics-utility METRICS_UTILITY_REPORT_TYPE: CCSPv2 METRICS_UTILITY_PRICE_PER_NODE: '11' # in USD METRICS_UTILITY_REPORT_SKU: MCT3752MO METRICS_UTILITY_REPORT_SKU_DESCRIPTION: "EX: Red Hat Ansible Automation Platform, Full Support (1 Managed Node, Dedicated, Monthly)" METRICS_UTILITY_REPORT_H1_HEADING: "CCSP Reporting <Company>: ANSIBLE Consumption" METRICS_UTILITY_REPORT_COMPANY_NAME: "Company Name" METRICS_UTILITY_REPORT_EMAIL: "email@email.com" METRICS_UTILITY_REPORT_RHN_LOGIN: "test_login" METRICS_UTILITY_REPORT_COMPANY_BUSINESS_LEADER: "BUSINESS LEADER" METRICS_UTILITY_REPORT_COMPANY_PROCUREMENT_LEADER: "PROCUREMENT LEADER"- をクリックします。
検証
-
ConfigMap が作成され、
metrics-utilityがインストールされていることを確認するために、ナビゲーションパネルから ConfigMap を選択し、リストで ConfigMap を探します。
12.1.2.2. Automation Controller のデプロイ
Automation Controller をデプロイし、metrics-utility によって使用状況情報を収集してレポートを生成する頻度を表す変数を指定するには、次の手順を使用します。
手順
- ナビゲーションパネルから、Installed Operators を選択します。
- Ansible Automation Platform を選択します。
- Operator の詳細で、Automation Controller タブを選択します。
- をクリックします。
YAML view オプションを選択します。YAML に Automation Controller のデフォルトパラメーターが表示されます。
metrics-utilityに関連するパラメーターは次のとおりです。Expand パラメーター 変数 metrics_utility_enabledTrue
metrics_utility_cronjob_gather_schedule@hourlyまたは@daily。metrics_utility_cronjob_report_schedule@dailyまたは@monthly-
metrics_utility_enabledパラメーターを見つけて、変数を true に変更します。 -
metrics_utility_cronjob_gather_scheduleパラメーターを見つけて、ユーティリティーによって使用状況情報を収集する頻度を表す変数を入力します (たとえば、@hourlyまたは@daily)。 -
metrics_utility_cronjob_report_scheduleパラメーターを見つけて、ユーティリティーによってレポートを生成する頻度を表す変数を入力します (たとえば、@dailyまたは@monthly)。 - をクリックします。
12.1.3. Ansible Automation Platform の手動コンテナー化インストールで metrics-utility を設定する
metrics-utility は、バージョン 4.12、4.512、および 4.6 以降の OpenShift Container Platform イメージに含まれています。システムに metrics-utility がインストールされていない場合は、OpenShift イメージを最新バージョンに更新してください。
Ansible Automation Platform Operator を使用して OpenShift Container Platform で metrics-utility の実行スケジュールを設定するには、次の手順を実行します。
Ansible Automation Platform の手動コンテナー化インストールで metrics-utility を設定するには、次の手順に従います。
- ホストディレクトリーとスクリプトを準備します。
- スクリプトを実行可能にします。
- cron ジョブを設定します。
前提条件
- 有効な Ansible Automation Platform サブスクリプション
最小リソース要件
Ansible Automation Platform のコンテナー化されたインストールで metrics-utility ツールを使用するには、次のリソースが必要です。
CPU: 専用 CPU コア 1 個
- 実行中は 1 コアの 100% が使用されます。
メモリー:
- 最小: 256 MB RAM (最大約 10,000 件のジョブホストサマリーをサポート)
- 推奨: 512 MB RAM (標準デプロイメント)
大規模: 1 GB RAM (最大約 100,000 件のジョブホストサマリーをサポート)
注記メモリー要件は、処理されるホストとジョブの数に応じて変化します。
- 実行時間: レポート生成は、データ量に応じて通常 10 - 30 秒以内に完了します。
12.1.3.1. ホストディレクトリーとスクリプトの準備
ホストディレクトリーとスクリプトを準備するには、実行中のコンテナー内で metrics-utility コマンドを実行するための 2 つのシェルスクリプトをホストマシンに作成します。
手順
インベントリーファイルを変更して、[all:vars] セクションの下に次の行を追加し、metrics-utility コンテナーのデプロイメントを有効にします。
metrics_utility_enabled=trueこの設定は、Ansible Automation Platform デプロイメントの一部として専用の
automation-controller-metrics-utilityコンテナーを作成して設定するようにインストーラーに指示します。この行を、他のグローバル変数と一緒に、インベントリーファイルの[all:vars]ヘッダーの下に必ず配置してください。Ansible Automation Platform のデプロイメントがすでに設定されている場合は、インストーラースクリプトを再実行してコンテナーをアクティブ化します。次のコマンドを実行して、ホストレポートの保存先ディレクトリーを作成します。
mkdir -p /home/my-user/aap/controller/data/ホストマシン上のこのディレクトリーには、最終的に生成されたレポートが保存されます。
/home/my-user/cron-gatherという名前のファイルを作成し (/home/my-user/を目的のパスに置き換えます)、次のコンテンツを追加してcron-gatherスクリプトを作成します。#!/bin/sh # Specify the following variables to indicate where the report is deposited in your file system export METRICS_UTILITY_SHIP_TARGET=directory export METRICS_UTILITY_SHIP_PATH=/metrics_utility/data # Run metrics-utility inside the running container podman exec \ -e METRICS_UTILITY_SHIP_TARGET="$METRICS_UTILITY_SHIP_TARGET" \ -e METRICS_UTILITY_SHIP_PATH="$METRICS_UTILITY_SHIP_PATH" \ automation-controller-task \ metrics-utility gather_automation_controller_billing_data --ship --until=10mこのスクリプトは
metrics-utilityを実行して、Ansible Automation Platform インスタンスから課金データを収集し、コンテナー内に一時的に保存します。/home/my-user/cron-reportという名前のファイルを作成し (/home/my-user/を目的のパスに置き換えます)、次のコンテンツを追加してcron-reportスクリプトを作成します。#!/bin/sh # --- Configuration Variables --- # Define variables for the metrics utility parameters export METRICS_UTILITY_SHIP_TARGET="directory" export METRICS_UTILITY_SHIP_PATH="/metrics_utility/data" # This is the *internal* path in the container export METRICS_UTILITY_REPORT_TYPE="CCSPv2" export METRICS_UTILITY_PRICE_PER_NODE="11.55" export METRICS_UTILITY_REPORT_SKU="MCT3752MO" export METRICS_UTILITY_REPORT_SKU_DESCRIPTION="EX: Red Hat {PlatformNameShort}, Full Support (1 Managed Node, Dedicated, Monthly)" export METRICS_UTILITY_REPORT_H1_HEADING="CCSP Reporting <Company>: ANSIBLE Consumption" export METRICS_UTILITY_REPORT_COMPANY_NAME="Company Name" export METRICS_UTILITY_REPORT_EMAIL="email@email.com" export METRICS_UTILITY_REPORT_RHN_LOGIN="test_login" export METRICS_UTILITY_REPORT_COMPANY_BUSINESS_LEADER="BUSINESS LEADER" export METRICS_UTILITY_REPORT_COMPANY_PROCUREMENT_LEADER="PROCUREMENT LEADER" podman exec \ -e METRICS_UTILITY_SHIP_TARGET="$METRICS_UTILITY_SHIP_TARGET" \ -e METRICS_UTILITY_SHIP_PATH="$METRICS_UTILITY_SHIP_PATH" \ -e METRICS_UTILITY_REPORT_TYPE="$METRICS_UTILITY_REPORT_TYPE" \ -e METRICS_UTILITY_PRICE_PER_NODE="$METRICS_UTILITY_PRICE_PER_NODE" \ -e METRICS_UTILITY_REPORT_SKU="$METRICS_UTILITY_REPORT_SKU" \ -e METRICS_UTILITY_REPORT_SKU_DESCRIPTION="$METRICS_UTILITY_REPORT_SKU_DESCRIPTION" \ -e METRICS_UTILITY_REPORT_H1_HEADING="$METRICS_UTILITY_REPORT_H1_HEADING" \ -e METRICS_UTILITY_REPORT_COMPANY_NAME="$METRICS_UTILITY_REPORT_COMPANY_NAME" \ -e METRICS_UTILITY_REPORT_EMAIL="$METRICS_UTILITY_REPORT_EMAIL" \ -e METRICS_UTILITY_REPORT_RHN_LOGIN="$METRICS_UTILITY_REPORT_RHN_LOGIN" \ -e METRICS_UTILITY_REPORT_COMPANY_BUSINESS_LEADER="$METRICS_UTILITY_REPORT_COMPANY_BUSINESS_LEADER" \ -e METRICS_UTILITY_REPORT_COMPANY_PROCUREMENT_LEADER="$METRICS_UTILITY_REPORT_COMPANY_PROCUREMENT_LEADER" \ "automation-controller-metrics-utility" \ metrics-utility build_reportこのスクリプト METRICS_UTILITY_REPORT_SKU_DESCRIPTION
metrics-utilityは、収集されたデータからレポートを作成し、最終レポートをコンテナーから指定されたホストディレクトリーにコピーします。
12.1.3.2. スクリプトを実行可能にする
次の手順を使用して、作成した両方のスクリプトが実行可能であることを確認します。
手順
以下のコマンドを実行します。
chmod a+x /home/my-user/cron-gather /home/my-user/cron-report注記/home/my-user/は実際のパスに置き換えます。
12.1.3.3. cron ジョブの設定
以下の手順を使用して、metrics-utility コマンドが自動的に実行されるように cron を設定します。
手順
cronファイルを開いて編集します。crontab -ecronスケジュールエントリーを追加するには、crontabファイルの末尾に次の行を追加します。0 */1 * * * /home/my-user/cron-gather 0 4 2 * * /home/my-user/cron-reportこれらの例では、
gatherコマンドを毎時 0 分に実行するように設定し、build_reportコマンドを毎月 2 日の午前 4 時に実行するように設定しています。希望するスケジュールに合わせて、必要に応じて cron 構文を調整します。以下に例を示します。
-
0 */1 * * *: 毎時 0 分に実行されます。 -
0 4 2 * *: 2 日の 04:00 に実行されます。
-
- ファイルを保存してから閉じます。
検証
正しい設定を確認するには、次の検証手順を使用します。
cronジョブのエントリーが正しく保存されたことを確認するには、次のコマンドを実行します。crontab -lcronジョブのエントリーが正しく保存されている場合は、cron-gatherとcron-reportに追加した 2 行が表示されます。cronログを調べて、cronデーモンがコマンドを実行しているかどうか、およびmetrics-utilityが出力を生成しているかどうかを確認します。cat /var/log/cron参考までに、次の出力例を参照してください。
# Example Output: Aug 20 09:55:01 aap CROND[72746]: (aap) CMD (/home/aap/Documents/scripts/cron-gather) Aug 20 09:55:03 aap CROND[72744]: (aap) CMDOUT (2025-08-20 08:55:03,581 INFO [-] awx.main.analytics /tmp/3292ca44-3314-4f0b-b3f6-ba4a1e47a2b1-2025-08-20-083506+0000-2025-08-20-084503+0000-0.tar.gz) Aug 20 09:55:03 aap CROND[72744]: (aap) CMDOUT (/tmp/3292ca44-3314-4f0b-b3f6-ba4a1e47a2b1-2025-08-20-083506+0000-2025-08-20-084503+0000-0.tar.gz) Aug 20 09:55:03 aap CROND[72744]: (aap) CMDOUT (2025-08-20 08:55:03,581 INFO [-] awx.main.analytics /tmp/3292ca44-3314-4f0b-b3f6-ba4a1e47a2b1-2025-08-20-083506+0000-2025-08-20-084503+0000-1.tar.gz) Aug 20 09:55:03 aap CROND[72744]: (aap) CMDOUT (/tmp/3292ca44-3314-4f0b-b3f6-ba4a1e47a2b1-2025-08-20-083506+0000-2025-08-20-084503+0000-1.tar.gz) Aug 20 09:55:03 aap CROND[72744]: (aap) CMDEND (/home/aap/Documents/scripts/cron-gather) Aug 20 10:00:02 aap CROND[77629]: (aap) CMD (/home/aap/Documents/scripts/cron-report) Aug 20 10:00:02 aap CROND[77623]: (aap) CMDOUT (Generating metrics report inside the container...) Aug 20 10:00:04 aap CROND[77623]: (aap) CMDOUT (2025-08-20 09:00:04,639 INFO [-] awx.main.analytics No billing data for month 2025-07) Aug 20 10:00:04 aap CROND[77623]: (aap) CMDOUT (No billing data for month 2025-07) Aug 20 10:00:05 aap CROND[77623]: (aap) CMDOUT (Copying generated reports from container to host: /tmp/ansible_metrics_reports) Aug 20 10:00:05 aap CROND[77623]: (aap) CMDOUT (Reports successfully moved to: /tmp/ansible_metrics_reports) Aug 20 10:00:05 aap CROND[77623]: (aap) CMDOUT (Files in destination:) Aug 20 10:00:05 aap CROND[77623]: (aap) CMDOUT (total 0) Aug 20 10:00:05 aap CROND[77623]: (aap) CMDOUT (drwxr-xr-x. 3 aap aap 18 Aug 20 09:43 data) Aug 20 10:00:05 aap CROND[77623]: (aap) CMDEND (/home/aap/Documents/scripts/cron-report)生成されたレポートを見つけます。
-
生成されたレポートのデフォルトの名前の形式は
CCSP-<YEAR>-<MONTH>.xlsx(例:CCSP-2024-07.xlsx) です。レポートは、手順 2 で指定した接頭辞付きパス (例:/home/my-user/aap/controller/data/metrics_utility/data) を持つMETRICS_UTILITY_SHIP_PATHに保存されます。
-
生成されたレポートのデフォルトの名前の形式は
12.2. 月次レポートの取得
Ansible Automation Platform から月次レポートを取得して使用状況メトリクスを収集し、消費量ベースの課金レポートを作成します。Red Hat Enterprise Linux または OpenShift Container Platform で月次レポートを取得するには、次の手順を使用します。
12.2.1. Red Hat Enterprise Linux の月次レポートの取得
Red Hat Enterprise Linux で月次レポートを取得するには、次の手順を使用します。
手順
-
scp -r username@controller_host:$METRICS_UTILITY_SHIP_PATH/data/<YYYY>/<MM>/ /local/directory/を実行します。
生成されたレポートが、指定した送信先パスに CCSP-<YEAR>-<MONTH>.xlsx という名前で保存されます。
12.2.2. Ansible Automation Platform Operator から OpenShift Container Platform の月次レポートを取得する
手順
次の Playbook を使用して、OpenShift Container Platform 上の Ansible Automation Platform の月次消費レポートを取得します。
注記この Playbook を使用するには、マシンに
kubernetes.core.k8sコレクションがインストールされている必要があります。# Requires Ansible and Kubernetes.core collection - name: Copy directory from Kubernetes PVC to local machine hosts: "{{ host | default(omit) }}" vars: report_dir_path: "/mnt/metrics/reports/{{ year }}/{{ month }}/" data_files_dir_path: "/mnt/metrics/data/{{ year }}/{{ month }}/{{ day }}" tasks: - name: Create a temporary pod to access PVC data kubernetes.core.k8s: definition: apiVersion: v1 kind: Pod metadata: name: temp-pod namespace: "{{ namespace_name }}" spec: containers: - name: busybox image: busybox command: ["/bin/sh"] args: ["-c", "sleep 3600"] # Keeps the container alive for 1 hour volumeMounts: - name: "{{ pvc }}" mountPath: "/mnt/metrics" volumes: - name: "{{ pvc }}" persistentVolumeClaim: claimName: automationcontroller-metrics-utility restartPolicy: Never register: pod_creation - name: Wait for both initContainer and main container to be ready kubernetes.core.k8s_info: kind: Pod namespace: "{{ namespace_name }}" name: temp-pod register: pod_status until: > pod_status.resources[0].status.containerStatuses[0].ready retries: 30 delay: 10 - name: Create a tarball of the directory of the report in the container kubernetes.core.k8s_exec: namespace: "{{ namespace_name }}" pod: temp-pod container: busybox command: tar czf /tmp/metrics.tar.gz -C "{{ report_dir_path }}" . register: tarball_creation - name: Create a tarball of the directory of the data files in the container kubernetes.core.k8s_exec: namespace: "{{ namespace_name }}" pod: temp-pod container: busybox command: tar czf /tmp/data_files.tar.gz -C "{{ data_files_dir_path }}" . register: tarball_creation_files - name: Copy the report tarball from the container to the local machine kubernetes.core.k8s_cp: namespace: "{{ namespace_name }}" pod: temp-pod container: busybox state: from_pod remote_path: /tmp/metrics.tar.gz local_path: "{{ local_dir }}/metrics.tar.gz" when: tarball_creation is succeeded - name: Copy the data files tarball from the container to the local machine kubernetes.core.k8s_cp: namespace: "{{ namespace_name }}" pod: temp-pod container: busybox state: from_pod remote_path: /tmp/data_files.tar.gz local_path: "{{ local_dir }}/data_files.tar.gz" when: tarball_creation_files is succeeded - name: Ensure the local directory exists ansible.builtin.file: path: "{{ local_dir }}" state: directory mode: '0755' - name: Extract the report tarball on the local machine ansible.builtin.unarchive: src: "{{ local_dir }}/metrics.tar.gz" dest: "{{ local_dir }}" remote_src: true extra_opts: "--strip-components=1" when: tarball_creation is succeeded - name: Extract the data files tarball on the local machine ansible.builtin.unarchive: src: "{{ local_dir }}/data_files.tar.gz" dest: "{{ local_dir }}" remote_src: true extra_opts: "--strip-components=1" list_files: true register: unarchive_result when: tarball_creation_files is succeeded - name: Extract the extracted data files tarball on the local machine ansible.builtin.unarchive: src: "{{ local_dir }}/{{ item }}" dest: "{{ local_dir }}" remote_src: true extra_opts: "--strip-components=1" loop: "{{ unarchive_result.files }}" when: tarball_creation_files is succeeded ignore_errors: true # noqa ignore-errors - name: Delete the temporary pod kubernetes.core.k8s: api_version: v1 kind: Pod namespace: "{{ namespace_name }}" name: temp-pod state: absent
12.3. 実行スケジュールの変更
指定した時間と間隔で実行するように metrics-utility を設定できます。実行頻度は cronjob で表現されます。cron ユーティリティーの詳細は、How to schedule jobs using the Linux ‘Cron’ utility 参照してください。
Red Hat Enterprise Linux および OpenShift Container Platform で実行スケジュールを変更するには、次のいずれかの手順を使用します。
手順
コマンドラインから次のコマンドを実行します。
crontab -eコードエディターが開いたら、以下に示すように cron 構文を使用して
gatherおよびbuildパラメーターを更新します。*/2 * * * * metrics-utility gather_automation_controller_billing_data --ship --until=10m*/5 * * * * metrics-utility build_report- ファイルを保存してから閉じます。
12.3.1. Ansible Automation Platform Operator から OpenShift Container Platform の実行スケジュールを変更する
OpenShift Container Platform 上で実行されている Ansible Automation Platform デプロイメント内の metrics-utility の実行スケジュールを調整するには、次の手順を使用します。
手順
- ナビゲーションパネルから、 → を選択します。
- 次の画面で、automation-controller-operator-controller-manager を選択します。
- Deployment Details という見出しの下にある下矢印ボタンをクリックして、Pod の数をゼロに変更します。これにより、デプロイメントが一時停止し、実行スケジュールを更新できます。
- ナビゲーションパネルから、Installed Operators を選択します。
- インストールされている Operator のリストから、Ansible Automation Platform を選択します。
- 次の画面で、automation controller タブを選択します。
- 表示されるリストから、Automation Controller インスタンスを選択します。
-
次の画面で、
YAMLタブを選択します。 YAMLファイルで、次のパラメーターを見つけて、metrics-utilityデータを収集する頻度とレポートを生成する頻度を表す変数を入力します。metrics_utility_cronjob_gather_schedule:metrics_utility_cronjob_report_schedule:- をクリックします。
- ナビゲーションメニューから を選択し、automation-controller-operator-controller-manager を選択します。
- Pod の数を 1 に増やします。
metrics-utilityの実行スケジュールが正常に変更されたことを確認するために、次のどちらかの手順または両方を実行します。-
YAMLファイルに戻り、上記のパラメーターが正しい変数を反映していることを確認します。 - ナビゲーションメニューから → を選択し、更新されたスケジュールが cronjob に表示されることを確認します。
-
12.4. 対応ストレージ
サポートされているストレージは、metrics-utility gather_automation_controller_billing_data コマンドを使用して取得された生データの保存と、metrics-utility build_report コマンドを使用して取得された生成レポートの保存に使用できます。Ansible Automation Platform インストールに基づいて、このストレージに環境変数を適用します。
12.4.1. ローカルディスク
Red Hat Enterprise Linux に Ansible Automation Platform をインストールする場合、デフォルトのストレージオプションはローカルディスクです。OpenShift Container Platform の OpenShift デプロイメントを使用する場合、デフォルトのストレージは、アタッチされた永続ボリューム要求内のパスです。
# Set needed ENV VARs for gathering data and generating reports
export METRICS_UTILITY_SHIP_TARGET=directory
# Your path on the local disk
export METRICS_UTILITY_SHIP_PATH=/path_to_data_and_reports/...12.4.2. S3 インターフェイスを備えたオブジェクトストレージ
S3 インターフェイスを備えたオブジェクトストレージ (AWS S3、Ceph Object ストレージ、Minio など) を使用するには、データ収集およびレポート作成コマンドと cron ジョブ用の環境変数を定義する必要があります。
################
export METRICS_UTILITY_SHIP_TARGET=s3
# Your path in the object storage
export METRICS_UTILITY_SHIP_PATH=path_to_data_and_reports/...
################
# Define S3 config
export METRICS_UTILITY_BUCKET_NAME=metricsutilitys3
export METRICS_UTILITY_BUCKET_ENDPOINT="https://s3.us-east-1.amazonaws.com"
# For AWS S3, define also a region
export METRICS_UTILITY_BUCKET_REGION="us-east-1"
################
# Define S3 credentials
export METRICS_UTILITY_BUCKET_ACCESS_KEY=<access_key>
export METRICS_UTILITY_BUCKET_SECRET_KEY=<secret_key>12.5. レポートタイプ
このセクションでは、レポートタイプに基づき、データ収集とレポート作成の追加設定について説明します。Ansible Automation Platform のインストールに基づき、各レポートタイプに環境変数を適用します。
12.5.1. CCSPv2
CCSPv2 は次の内容を示すレポートです。
- 直接および間接的に管理されるノードの使用状況
- すべてのインベントリーの内容
- コンテンツの使用状況
このレポートは主に CCSP プログラムのパートナー様が使用しますが、すべてのお客様がこのレポートを使用して、Automation Controller の組織全体の管理対象ノード、ジョブ、コンテンツの使用状況を示すオンプレミスレポートを取得できます。
METRICS_UTILITY_REPORT_TYPE=CCSPv2 を使用してレポートタイプを設定します。
12.5.2. gather コマンドのオプションのコレクター
gather コマンドでは、次のオプションのコレクターを使用できます。
main_jobhostsummary-
デフォルトで存在する場合、ジョブの実行と自動化された管理対象ノードに関する情報が含まれる Automation Controller データベースの
main_jobhostsummaryテーブルから、データが増分収集されます。
-
デフォルトで存在する場合、ジョブの実行と自動化された管理対象ノードに関する情報が含まれる Automation Controller データベースの
main_host-
Automation Controller データベース内の
main_hostテーブルのスナップショットが毎日収集され、Automation Controller インベントリー全体に管理対象ノードとホストが存在します。
-
Automation Controller データベース内の
main_jobevent-
Automation Controller データベースの
main_jobeventテーブルからデータが増分収集され、使用中のモジュール、ロール、および Ansible コレクションに関する情報が含まれます。
-
Automation Controller データベースの
main_indirectmanagednodeauditAutomation Controller データベースの
main_indirectmanagednodeauditテーブルからデータが増分的に収集され、間接的に管理されるノードに関する情報が含まれます。# Example with all optional collectors export METRICS_UTILITY_OPTIONAL_COLLECTORS="main_host,main_jobevent,main_indirectmanagednodeaudit"
12.5.3. build_report コマンドのオプションシート
build_report コマンドでは、次のオプションシートを使用できます。
ccsp_summaryこれは、CCSP プログラムのパートナー様専用のランディングページです。このレポートでは、概要ページをカスタマイズするために追加のパラメーターを使用します。詳細は、以下の例を参照してください。
export METRICS_UTILITY_PRICE_PER_NODE=11.55 # in USD export METRICS_UTILITY_REPORT_SKU=MCT3752MO export METRICS_UTILITY_REPORT_SKU_DESCRIPTION="EX: Red Hat Ansible Automation Platform, Full Support (1 Managed Node, Dedicated, Monthly)" export METRICS_UTILITY_REPORT_H1_HEADING="CCSP NA Direct Reporting Template" export METRICS_UTILITY_REPORT_COMPANY_NAME="Partner A" export METRICS_UTILITY_REPORT_EMAIL="email@email.com" export METRICS_UTILITY_REPORT_RHN_LOGIN="test_login" export METRICS_UTILITY_REPORT_PO_NUMBER="123" export METRICS_UTILITY_REPORT_END_USER_COMPANY_NAME="Customer A" export METRICS_UTILITY_REPORT_END_USER_CITY="Springfield" export METRICS_UTILITY_REPORT_END_USER_STATE="TX" export METRICS_UTILITY_REPORT_END_USER_COUNTRY="US"
jobs- 起動された Automation Controller ジョブのリストです。ジョブテンプレートごとにグループ化されています。
managed_nodes- Automation Controller によって自動化された管理対象ノードの重複排除リストです。
indirectly_managed_nodes- Automation Controller によって自動化された間接管理対象ノードの重複排除リストです。
infrastructure_summaryこの追加タブには、間接ノードのインフラストラクチャー分類が 3 つのレベルでまとめられています。
- インフラストラクチャー
- デバイスカテゴリー
- デバイスの種別
分類マッピングは、生データ内のファクト列に依存します。
inventory_scope- Automation Controller のすべてのインベントリーに存在する管理対象ノードの重複排除リストです。
usage_by_organizations- 組織の使用状況を示すいくつかのメトリクスが含まれる、すべての Automation Controller 組織のリストです。内部チャージバックを実行するために適したデータが提供されます。
usage_by_collections- これは、Automation Controller ジョブ実行で使用される Ansible コレクションのリストです。
usage_by_roles- Automation Controller のジョブ実行で使用されるロールのリストです。
usage_by_modules- Automation Controller のジョブ実行で使用されるモジュールのリストです。
managed_nodes_by_organization- 組織ごとにシートが生成され、managed_nodes シートと同じ内容で、すべての組織の管理対象ノードがリストされます。
data_collection_status-
レポートが作成された日付範囲について、
gatherコマンドで実行されたすべてのデータ収集のステータスが含まれるシートが生成されます。 収集されたデータの品質の概要を示すために、
data_collection_statusには次の内容もリストされます。- コレクション間の異常なギャップ (collection_start_timestamp に基づく)
収集間隔のギャップ (since と until に基づく)
# Example with all optional sheets export METRICS_UTILITY_OPTIONAL_CCSP_REPORT_SHEETS='ccsp_summary,jobs,managed_nodes,indirectly_managed_nodes,inventory_scope,usage_by_organizations,usage_by_collections,usage_by_roles,usage_by_modules,data_collection_status'
-
レポートが作成された日付範囲について、
12.5.4. 組織別にレポートをフィルタリングする
特定の組織のみが表示されるようにレポートをフィルタリングするには、セミコロンで区切られた組織名のリストと、この環境変数を使用します。
export METRICS_UTILITY_ORGANIZATION_FILTER="ACME;Organization 1"
これにより、作成されたレポートには該当する組織のデータのみが表示されます。このフィルターは現在、次のオプションシートには影響しません。
-
usage_by_collections -
usage_by_roles -
usage_by_modules
12.5.5. CCSPv2 レポートの日付範囲の選択
CCSPv2 レポートのデフォルトの動作では、前月のレポートが作成されます。次の例では、このデフォルトの動作をオーバーライドして、レポートの特定の日付範囲を選択する方法について説明します。
# Build report for a specific month
metrics-utility build_report --month=2025-03
# Build report for a specific date range, including the provided days
metrics-utility build_report --since=2025-03-01 --until=2025-03-31
# Build report for a last 6 months from a current date
metrics-utility build_report --since=6months
# Build report for a last 6 months from a current date overwriting an existing report
metrics-utility build_report --since=6months --force12.5.6. RENEWAL_GUIDANCE
RENEWAL_GUIDANCE レポートは、HostMetric テーブルから使用状況履歴を提供します。その際には、重複排除を適用して、更新を案内するために実際の使用状況履歴を表示します。
このレポートを生成するには、レポートタイプを METRICS_UTILITY_REPORT_TYPE=RENEWAL_GUIDANCE に設定します。
このレポートは現在、テクノロジープレビューソリューションです。awx-manage host_metric コマンドに組み込まれた場合、Automation Controller よりも多くの情報を提供するように設計されています。
12.5.6.1. ストレージと呼び出し
RENEWAL_GUIDANCE レポートでレポート結果を保存するために使用できるのはローカルディスクストレージのみです。このレポートにはデータ収集ステップがありません。コントローラーの HostMetric テーブルから直接読み取るため、METRICS_UTILITY_SHIP_PATH 配下に生データは保存されません。
# All parameters the RENEWAL_GUIDANCE report needs
export METRICS_UTILITY_SHIP_TARGET=controller_db
export METRICS_UTILITY_REPORT_TYPE=RENEWAL_GUIDANCE
export METRICS_UTILITY_SHIP_PATH=/path_to_built_report/...
# Will generate report for 12 months back with ephemeral nodes being nodes
# automated for less than 1 month.
metrics-utility build_report --since=12months --ephemeral=1month12.5.6.2. 一時的な使用状況の表示
RENEWAL_GUIDANCE レポートには、–ephemeral パラメーターが指定されている場合、一時的に使用する追加シートをリストする機能があります。--ephemeral=1month パラメーターを使用すると、最大 1 カ月間自動化され、その後は再度自動化されない管理対象ノードとしてエフェメラルノードを定義できます。このパラメーターを使用すると、12 カ月間の合計エフェメラル使用量は、1 カ月間という期間をローリングした場合のエフェメラルノードの最大使用量として算出されます。このシートもレポートに追加されます。
# Will generate report for 12 months back with ephemeral nodes being nodes
# automated for less than 1 month.
metrics-utility build_report --since=12months --ephemeral=1month12.5.6.3. RENEWAL_GUIDANCE レポートの日付範囲の選択
RENEWAL_GUIDANCE レポートには since パラメーターが必要です。これは、HostMetric データの性質上、パラメーターがサポートされておらず、常に now に設定されているためです。すでに作成されているレポートの日付範囲をオーバーライドするには、コマンドでパラメーター -force を使用します。詳細は、以下の例を参照してください。
# Build report for a specific date range, including the provided days
metrics-utility build_report --since=2025-03-01
# Build report for a last 12 months from a current date
metrics-utility build_report --since=12months
# Build report for a last 12 months from a current date overwriting an existing report
metrics-utility build_report --since=12months --force12.5.7. CCSP
CCSP はオリジナルのレポート形式です。CCSPv2 のカスタマイズの多くは含まれておらず、CCSP パートナープログラムのみでの使用を目的としています。
12.5.8. gather コマンドのオプションのコレクター
gather コマンドでは、次のオプションのコレクターを使用できます。
main_jobhostsummary-
デフォルトで存在する場合、ジョブの実行と自動化された管理対象ノードに関する情報が含まれる
main_jobhostsummaryテーブルが、Automation Controller データベースから増分収集されます。
-
デフォルトで存在する場合、ジョブの実行と自動化された管理対象ノードに関する情報が含まれる
main_host-
Automation Controller データベースから
main_hostテーブルのスナップショットが毎日収集され、Automation Controller インベントリー全体に管理対象ノードまたはホストが存在します。
-
Automation Controller データベースから
main_jobevent-
Automation Controller データベースから
main_jobeventテーブルが増分収集され、使用中のモジュール、ロール、および Ansible コレクションに関する情報が含まれます。
-
Automation Controller データベースから
main_indirectmanagednodeaudit-
Automation Controller データベースから
main_indirectmanagednodeauditテーブルを増分収集し、間接的に管理されているノードに関する情報が含まれます。
-
Automation Controller データベースから
# Example with all optional collectors
export METRICS_UTILITY_OPTIONAL_COLLECTORS="main_host,main_jobevent,main_indirectmanagednodeaudit"12.5.9. build_report コマンドのオプションシート
build_report コマンドでは次のオプションシートを使用できます。
ccsp_summary- CCSP プログラムのパートナー様専用のランディングページです。各 Automation Controller 組織による管理対象ノードの使用状況を表示します。
このレポートでは、概要ページをカスタマイズするために追加のパラメーターを使用します。詳細は、以下の例を参照してください。
export METRICS_UTILITY_PRICE_PER_NODE=11.55 # in USD export METRICS_UTILITY_REPORT_SKU=MCT3752MO export METRICS_UTILITY_REPORT_SKU_DESCRIPTION="EX: Red Hat Ansible Automation Platform, Full Support (1 Managed Node, Dedicated, Monthly)" export METRICS_UTILITY_REPORT_H1_HEADING="CCSP Reporting <Company>: ANSIBLE Consumption" export METRICS_UTILITY_REPORT_COMPANY_NAME="Company Name" export METRICS_UTILITY_REPORT_EMAIL="email@email.com" export METRICS_UTILITY_REPORT_RHN_LOGIN="test_login" export METRICS_UTILITY_REPORT_COMPANY_BUSINESS_LEADER="BUSINESS LEADER" export METRICS_UTILITY_REPORT_COMPANY_PROCUREMENT_LEADER="PROCUREMENT LEADER"
managed_nodes- Automation Controller によって自動化された管理対象ノードの重複排除リストです。
indirectly_managed_nodes- Automation Controller によって自動化された間接管理対象ノードの重複排除リストです。
inventory_scope- Automation Controller のすべてのインベントリーに存在する管理対象ノードの重複排除リストです。
usage_by_collections- Automation Controller のジョブ実行で使用される Ansible コレクションのリストです。
usage_by_roles- Automation Controller のジョブ実行で使用されるロールのリストです。
usage_by_modules- Automation Controller のジョブ実行で使用されるモジュールのリストです。
# Example with all optional sheets
export METRICS_UTILITY_OPTIONAL_CCSP_REPORT_SHEETS='ccsp_summary,managed_nodes,indirectly_managed_nodes,inventory_scope,usage_by_collections,usage_by_roles,usage_by_modules'12.5.10. CCSP レポートの日付範囲の選択
このレポートのデフォルトの動作では、前月のレポートが作成されます。次の例では、このデフォルトの動作をオーバーライドして、レポートの特定の日付範囲を選択する方法について説明します。
# Builds report for a previous month
metrics-utility build_report
# Build report for a specific month
metrics-utility build_report --month=2025-03
# Build report for a specific month overwriting an existing report
metrics-utility build_report --month=2025-03 --force12.6. metrics-utility レポートのホストの重複排除
重複排除により、レポートを作成するときに、metrics-utility が個々のホストレコードをカウント可能な管理対象ノードに結合する方法が変更されます。重複を排除することで、同一のホストが識別され、一意のホストの数が正確に把握されます。
metrics-utility は、ホスト名に基づいて個々のホストを追跡します。同じホスト名を使用するエントリーはすべて同じホストとして追跡されます。環境変数 METRICS_UTILITY_DEDUPLICATOR= を使用して、追加の重複排除ストラテジーも利用できます。
12.6.1. RENEWAL_GUIDANCE レポートの重複排除
METRICS_UTILITY_DEDUPLICATOR=renewal のデフォルト値。これは、host_name、ansible_host、ansible_product_serial、および ansible_machine_id を個別に分析し、これらの項目のいずれかが重複している場合はエントリーをマージする元の方法です。
METRICS_UTILITY_DEDUPLICATOR=renewal は、重複排除を複数の反復で適用します。これは REPORT_RENEWAL_GUIDANCE_DEDUP_ITERATIONS 環境変数によって制限され、デフォルトでは 3 に設定されます。
次の環境変数を使用して METRICS_UTILITY_DEDUPLICATOR を実行することもできます。
-
METRICS_UTILITY_DEDUPLICATOR=renewal-hostname.これはccspに似ていますが、存在する場合はhost_nameよりもansible_hostが優先されます。他のフィールドは考慮されません。 -
METRICS_UTILITY_DEDUPLICATOR=renewal-experimental.これはccsp-experimentalに似ており、最初にホスト名ベースの重複排除を適用し、次に再度重複排除して、両方のシリアルが一致するとマージします。
12.6.2. CCSP または CCSPv2 レポートの重複排除
METRICS_UTILITY_DEDUPLICATOR=ccsp のデフォルト値。これにより、重複排除はホスト名のみに制限されます。
main_host.variables の ansible_host 変数は、存在する場合は、main_jobhostsummary の host_name よりも優先されます。
METRICS_UTILITY_DEDUPLICATOR=ccsp-experimental を設定することもできます。この設定は、ansible_product_serial と ansible_machine_id の両方のファクトが存在し、重複している場合にエントリーをマージします。
第13章 シークレット管理システム
ユーザーとシステム管理者は、マシンとクラウドの認証情報をアップロードして、代わりに自動化でマシンや外部サービスにアクセスできるようにします。デフォルトでは、SSH パスワード、SSH 秘密鍵、クラウドサービスの API トークンなどの機密認証情報の値は、暗号化された後にデータベースに保存されます。
認証情報プラグインによって裏付けられた外部認証情報を使用すると、認証情報フィールド (パスワードや SSH 秘密鍵など) を、Automation Controller に直接提供する代わりに、シークレット管理システム に保存されている値にマップできます。
Automation Controller は、以下の統合を含むシークレット管理システムを提供します。
- AWS Secrets Manager Lookup
- Centrify Vault Credential Provider Lookup
- CyberArk Central Credential Provider Lookup (CCP)
- CyberArk Conjur Secrets Manager Lookup
- HashiCorp Vault Key-Value Store (KV)
- HashiCorp Vault SSH Secrets Engine
- Microsoft Azure Key Management System (KMS)
- Thycotic DevOps Secrets Vault
- Thycotic Secret Server
- GitHub App Token Lookup
これらの外部シークレット値は、それらを必要とする Playbook を実行する前にフェッチされます。
13.2. シークレットルックアップの設定とリンク
サードパーティーシステムからシークレットを取得する場合、認証情報フィールドを外部システムにリンクすることになります。認証情報フィールドを外部システムに保存されている値にリンクするには、そのシステムに対応する外部認証情報を選択し、必要な値を検索するための メタデータ を指定します。メタデータ入力フィールドは、ソース認証情報の外部認証情報タイプ定義の一部です。
Automation Controller は、開発者、インテグレーター、システム管理者、パワーユーザー向けの認証情報プラグインインターフェイスを備えています。このインターフェイスから、新しい外部認証情報タイプを追加して、他のシークレット管理システムをサポートするように拡張できます。
Automation Controller で、サポート対象の各サードパーティーのシークレット管理システムを設定して使用するには、次の手順を実行します。
手順
シークレット管理システムで認証するための外部認証情報を作成します。少なくとも、外部認証情報の名前を指定し、Credential type フィールドで次のいずれかを選択します。
- AWS Secrets Manager Lookup
- Centrify Vault Credential Provider Lookup
- CyberArk Central Credential Provider (CCP) Lookup
- CyberArk Conjur Secrets Manager Lookup
- HashiCorp Vault Secret Lookup
- HashiCorp Vault Signed SSH
- Microsoft Azure Key Vault
- Thycotic DevOps Secrets Vault
- Thycotic Secret Server
GitHub App Installation Access Token Lookup の設定
この例では、デモ認証情報 がターゲット認証情報です。
-
外部認証情報にリンクする Type Details エリアに続くフィールドは、入力フィールドの鍵アイコン
 をクリックし、1 つ以上の入力フィールドを、外部認証情報と、外部システム内のシークレットを検索するためのメタデータにリンクします。
をクリックし、1 つ以上の入力フィールドを、外部認証情報と、外部システム内のシークレットを検索するためのメタデータにリンクします。
- シークレット情報を取得するために使用する入力ソースを選択します。
リンクする認証情報を選択し、 をクリックします。これにより、入力ソースの Metadata タブが表示されます。この例は、HashiVault Secret Lookup のメタデータプロンプトを示しています。メタデータは、選択した入力ソースに固有です。
詳細は、認証情報入力ソースのメタデータ の表を参照してください。
- をクリックして、シークレット管理システムへの接続を確認します。検索が失敗した場合は、エラーメッセージが表示されます。
- をクリックします。対象の認証情報の Details 画面に戻ります。
- ステップ 3 から始めてこれらのステップを繰り返し、ターゲット認証情報の残りの入力フィールドを完了します。この方法で情報をリンクすることで、Automation Controller はユーザー名、パスワード、キー、証明書、トークンなどの機密情報をサードパーティーの管理システムから取得し、ターゲットの認証情報フォームの残りのフィールドにそのデータを入力します。
- 必要に応じて、機密情報の取得方法としてリンクを使用しないフィールドには、情報を手動で入力します。各フィールドの詳細は、該当する 認証情報タイプ を参照してください。
- をクリックします。
関連情報
詳細は、Credential プラグイン の開発ドキュメントを参照してください。
13.2.1. 認証情報入力ソースのメタデータ
入力ソースの Metadata タブに必要な情報です。
AWS Secrets Manager Lookup
| メタデータ | 説明 |
|---|---|
| AWS Secrets Manager Region (必須) | シークレットマネージャーが配置されているリージョン。 |
| AWS Secret Name (必須) | AWS アクセスキーによって生成された AWS シークレット名を指定します。 |
Centrify Vault Credential Provider Lookup
| メタデータ | 説明 |
|---|---|
| アカウント名 (必須) | Centrify Vault に関連付けられたシステムアカウントまたはドメインの名前。 |
| システム名 | Centrify ポータルが使用する名前を指定します。 |
CyberArk Central Credential Provider Lookup
| メタデータ | 説明 |
|---|---|
| オブジェクトクエリー (必須) | オブジェクトの検索クエリー |
| オブジェクトクエリーフォーマット (必須) |
特定のシークレット名には |
| オブジェクトのプロパティー |
返すプロパティーの名前を指定します。たとえば、デフォルトの |
| 理由 | オブジェクトのポリシーごとに必要な場合は、CyberArk は理由のログを記録するので、シークレットをチェックアウトする理由を指定します。 |
CyberArk Conjur Secrets Lookup
| メタデータ | 説明 |
|---|---|
| シークレット識別子 | シークレットの識別子 |
| シークレットのバージョン | 必要に応じてシークレットのバージョンを指定します。しない場合には、空白にしておくと、最新バージョンが使用されます。 |
HashiVault Secret Lookup
| メタデータ | 説明 |
|---|---|
| シークレットバックエンドの名前 | 使用する KV バックエンドの名前を指定します。代わりに Path to Secret フィールドの最初のパスセグメントを使用するには、空白のままにします。 |
| シークレットへのパス (必須) |
|
| キー名 (必須) | シークレット情報を検索するキーの名前を指定します。 |
| シークレットのバージョン (V2 のみ) | 必要に応じてバージョンを指定します。しない場合には、空白にしておくと、最新バージョンが使用されます。 |
HashiCorp Signed SSH
| メタデータ | 説明 |
|---|---|
| 未署名の公開鍵 (必須) | 署名する証明書の公開鍵を指定します。これは、ターゲットホストの認証キーファイルに存在する必要があります。 |
| シークレットへのパス (必須) |
|
| ロール名 (必須) | ロールは、Hashi vault に保存される SSH 設定とパラメーターのコレクションです。通常、たとえば、異なる特権やタイムアウトを持つロールを指定できます。したがって、たとえば、ルートに対して署名された証明書の取得を許可されたロールと、その他の権限の低いロールを指定できます。 |
| 有効なプリンシパル | 格納されているキーの証明書を承認するために Vault に要求する、デフォルト以外のユーザー (複数可) を指定します。Hashi Vault には、署名するデフォルトのユーザー (ec2-user など) があります。 |
Microsoft Azure KMS
| メタデータ | 説明 |
|---|---|
| シークレット名 (必須) | Microsoft Azure の Key Vault アプリで参照されるシークレットの名前。 |
| シークレットのバージョン | 必要に応じてシークレットのバージョンを指定します。しない場合には、空白にしておくと、最新バージョンが使用されます。 |
Thycotic DevOps Secrets Vault
| メタデータ | 説明 |
|---|---|
| シークレットパス (必須) | 機密情報が保存されるパスを指定します (例:/path/username)。 |
Thycotic Secret Server
| メタデータ | 説明 |
|---|---|
| シークレット ID (必須) | シークレットの識別子 |
| シークレットフィールド | シークレットから使用するフィールドを指定します。 |
13.2.2. AWS Secrets Manager lookup
このプラグインにより、Amazon Web Services を認証情報入力ソースとして使用し、Amazon Web Services Secrets Manager からシークレットを取得できるようになります。AWS Secrets Manager は、Microsoft Azure Key Vault と同様のサービスを提供しており、AWS コレクションでそのためのルックアッププラグインが提供されています。
Credential type に AWS Secrets Manager lookup を選択した場合は、ルックアップを設定するために次のメタデータを指定します。
- AWS Access Key (必須): AWS キー管理システムとの通信に使用するアクセスキーを指定します。
- AWS Secret Key (必須): AWS IAM コンソールで取得したシークレットを指定します。
13.2.3. Centrify Vault Credential Provider Lookup
この統合が機能するには、Centrify Vault Web サービスを実行してシークレットを保存する必要があります。Credential Type に Centrify Vault Credential Provider Lookup を選択した場合は、次のメタデータを指定してルックアップを設定します。
- Centrify Tenant URL (必須): Centrify のシークレット管理システムとの通信に使用する URL を指定します。
- Centrify API User (必須): ユーザー名を指定します。
- Centrify API Password (必須): パスワードを指定します。
- OAuth2 Application ID: OAuth2 クライアントに関連付けられている特定の識別子を指定します。
- OAuth2 Scope: OAuth2 クライアントのスコープを指定します。
13.2.4. CyberArk Central Credential Provider (CCP) Lookup
この統合が機能するようするには、CyberArk Central Credential Provider Web サービスが稼働中で、シークレットを保存する必要があります。Credential Type に CyberArk Central Credential Provider Lookup を選択した場合は、次のメタデータを指定して検索を設定します。
- CyberArk CCP URL (必須): CyberArk CCP のシークレット管理システムとの通信に使用する URL を指定します。http や https などの URL スキームを含める必要があります。
- オプション: Web Service ID: Web サービスの識別子を指定します。これを空白のままにすると、デフォルトで AIMWebService になります。
- Application ID (必須): CyberArk CCP サービスによって提供された識別子を指定します。
- Client Key: クライアントキーを貼り付けます (CyberArk から提供されている場合)。
-
Client Certificate: 証明書を貼り付けるときに
BEGIN CERTIFICATE行とEND CERTIFICATE行を含めます (CyberArk から提供されている場合)。 - Verify SSL Certificates: このオプションは、URL が HTTPS を使用している場合にのみ使用できます。サーバーの SSL/TLS 証明書が有効で信頼できるかどうかを検証するには、このオプションをオンにします。内部 CA またはプライベート CA を使用する環境では、このオプションをオフのままにして検証を無効にしてください。
13.2.5. CyberArk Conjur Secrets Manager Lookup
Conjur Cloud テナントをターゲットとして使用できる場合、CyberArk Conjur Secrets Lookup 外部管理システム認証情報プラグインを設定します。
Credential Type に CyberArk Conjur Secrets Manager Lookup を選択した場合は、次のメタデータを指定してルックアップを設定します。
- Conjur URL (必須): CyberArk Conjur のシークレット管理システムとの通信に使用する URL を指定します。これには、http や https などの URL スキームが含まれている必要があります。
- API Key (必須): Conjur の管理者から提供されたキーを指定します。
- Account (必須): 組織のアカウント名
- Username (必須): このサービス用に認証する特定のユーザー
-
Public Key Certificate: 公開鍵を貼り付けるときに
BEGIN CERTIFICATEおよびEND CERTIFICATEの行を含めます (CyberArk から提供されている場合、)。
13.2.6. HashiCorp Vault Secret Lookup
Credential Type に HashiCorp Vault Secret Lookup を選択した場合は、次のメタデータを指定してルックアップを設定します。
- Server URL (必須): HashiCorp Vault のシークレット管理システムとの通信に使用する URL を指定します。
- Token: HashiCorp のサーバーの認証に使用するアクセストークンを指定します。
- CA Certificate: HashiCorp のサーバーの検証に使用される CA 証明書を指定します。
- AppRole role_id: 認証に AppRole を使用している場合は、ID を指定します。
- AppRole secret_id: AppRole 認証に対応するシークレット ID を指定します。
- Client Certificate: Hashicorp Vault が必要とする中間証明書など、TLS 認証方法を使用する場合に、PEM でエンコードされたクライアント証明書を指定します。
- Client Certificate Key: TLS 認証方法を使用する場合に、PEM でエンコードされた証明書の秘密鍵を指定します。
- TLS Authentication Role: TLS 認証方法の使用時にクライアント証明書に対応する Hashicorp Vault でロールまたは証明書名を指定します。指定しないと、Hashicorp Vault は証明書を自動的に一致しようとします。
- Namespace name: namespace 名を指定します (Hashicorp Vault エンタープライズのみ)。
- Kubernetes role: Kubernetes 認証の使用時にロール名を指定します。
- Username: このサービスの認証に使用されるユーザーのユーザー名を入力します。
- Password: このサービスの認証に使用するユーザーに関連付けられたパスワードを入力します。
-
Path to Auth:
/approleのデフォルトパス以外のパスを指定します。 - API Version (必須): 静的ルックアップの場合は v1 を選択し、バージョンを含むルックアップの場合は v2 を選択します。
LDAP 認証では、HashiCorp の Vault UI で LDAP を設定し、ユーザーに追加するポリシーを設定する必要があります。cubbyhole は、デフォルトのシークレットマウントの名前です。適切なパーミッションがある場合は、他のマウントを作成し、キー値をそれらに書き込むことができます。
ルックアップをテストするには、Hashicorp Vault ルックアップを使用する別の認証情報を作成します。
関連情報
LDAP 認証方式およびそのフィールドの詳細は、LDAP 認証メソッドの Vault ドキュメント を参照してください。
AppRole 認証メソッドおよびそのフィールドの詳細は、AppRole auth method の Vault のドキュメント を参照してください。
userpass 認証メソッドおよびそのフィールドの詳細は、userpass auth method の Vault のドキュメント を参照してください。
Kubernetes の auth メソッドおよびそのフィールドの詳細は、Kubernetes auth method の Vault のドキュメント を参照してください。
TLS 証明書認証メソッドおよびそのフィールドの詳細は、TLS certificates auth method の Vault のドキュメント を参照してください。
13.2.7. HashiCorp Vault Signed SSH
Credential Type に HashiCorp Vault Signed SSH を選択した場合は、次のメタデータを指定してルックアップを設定します。
- Server URL (必須): HashiCorp 署名の SSH のシークレット管理システムとの通信に使用する URL を指定します。
- Token: HashiCorp のサーバーの認証に使用するアクセストークンを指定します。
- CA Certificate: HashiCorp のサーバーの検証に使用される CA 証明書を指定します。
- AppRole role_id: AppRole 認証の ID を指定します。
- AppRole secret_id: AppRole 認証に対応するシークレット ID を指定します。
- Client Certificate: Hashicorp Vault が必要とする中間証明書など、TLS 認証方法を使用する場合に、PEM でエンコードされたクライアント証明書を指定します。
- Client Certificate Key: TLS 認証方法を使用する場合に、PEM でエンコードされた証明書の秘密鍵を指定します。
- TLS Authentication Role: TLS 認証方法の使用時にクライアント証明書に対応する Hashicorp Vault でロールまたは証明書名を指定します。指定しないと、Hashicorp Vault は証明書を自動的に一致しようとします。
- Namespace name: namespace 名を指定します (Hashicorp Vault エンタープライズのみ)。
- Kubernetes role: Kubernetes 認証の使用時にロール名を指定します。
- Username: このサービスの認証に使用されるユーザーのユーザー名を入力します。
- Password: このサービスの認証に使用するユーザーに関連付けられたパスワードを入力します。
-
Path to Auth:
/approleのデフォルトパス以外のパスを指定します。
関連情報
AppRole 認証方法とそのフィールドの詳細は、Vault のドキュメントの AppRole 認証方法 を参照してください。
Kubernetes の認証メソッドおよびそのフィールドの詳細は、Kubernetes auth method の Vault ドキュメント を参照してください。
TLS 証明書認証メソッドおよびそのフィールドの詳細は、TLS certificates auth method の Vault のドキュメント を参照してください。
13.2.8. Microsoft Azure Key Vault
Credential Type に Microsoft Azure Key Vault を選択した場合は、次のメタデータを指定してルックアップを設定します。
- Vault URL (DNS Name) (必須): Microsoft Azure の鍵管理システムとの通信に使用する URL を指定します。
- Client ID (必須): Microsoft Entra ID によって取得された識別子を指定します。
- Client Secret (必須): Microsoft Entra ID によって取得されたシークレットを指定します。
- Tenant ID (必須): Azure サブスクリプション内の Microsoft Entra ID インスタンスに関連付けられた一意の識別子を指定します。
- Cloud Environment: 適用するクラウド環境を選択します。
13.2.9. Thycotic DevOps Secrets Vault
Credential Type に Thycotic DevOps Secrets Vault を選択した場合は、次のメタデータを指定してルックアップを設定します。
- Tenant (必須): Thycotic のシークレット管理システムとの通信に使用する URL を指定します
- Top-level Domain (TLD): 統合するシークレット Vault に関連付けられたトップレベルドメインの指定 (com、edu、org など) を提供します。
- Client ID (必須): Thycotic のシークレット管理システムによって取得された識別子を指定します。
- Client Secret (必須): Thycotic のシークレット管理システムによって取得されたシークレットを指定します。
13.2.10. Thycotic Secret Server
Credential Type に Thycotic Secrets Server を選択した場合は、次のメタデータを指定してルックアップを設定します。
- Secret Server URL (必須): Thycotic Secrets Server 管理システムとの通信に使用する URL を指定します。
- Username (必須): このサービスの認証済みユーザーを指定します。
- Domain: (アプリケーション) ユーザードメインを指定します。
- Password (必須): ユーザーに関連付けられたパスワードを指定します。
13.2.11. GitHub App Installation Access Token Lookup の設定
このプラグインを使用すると、GitHub App の RSA 秘密鍵を認証情報入力ソースとして使用し、GitHub App のインストールからアクセストークンを取得できます。プラットフォームゲートウェイは、組織の GitHub リポジトリーからの既存の GitHub 認可を使用します。
詳細は、Generating an installation access token for a GitHub App を参照してください。
手順
- シークレットを保存するルックアップ認証情報を作成します。詳細は、新しい認証情報の作成 を参照してください。
Credential type として GitHub App Installation Access Token Lookup を選択し、次の属性を入力してルックアップを適切に設定します。
- GitHub App ID: GitHub インスタンスによって提供された App ID を入力します。これが認証に使用されます。
- GitHub App Installation ID: アクセストークンのスコープが設定されているターゲット組織に対するアプリケーションの ID を入力します。ターゲットリポジトリーにアクセスできるようにこの属性を設定する必要があります。
- RSA Private Key: GitHub インスタンスによって生成された秘密鍵を入力します。これは GitHub 内の GitHub App メンテナーから入手できます。詳細は、Managing private keys for GitHub Apps を参照してください。
をクリックして、認証情報を確認して保存します。
以下は、設定済みの GitHub App Installation Access Token Lookup 認証情報の例です。

ルックアップ認証情報を検索するターゲット認証情報を作成します。プライベートリポジトリーでルックアップを使用するには、Credential type として Source Control を選択します。次の属性を入力して、ターゲット認証情報を適切に設定します。
-
Username: ユーザー名
x-access-tokenを入力します。 Password: 入力フィールドで外部認証情報を管理するための
アイコンをクリックします。機密情報の取得に使用する入力ソースを設定するように求められます。これはすでに作成したルックアップ認証情報です。

-
Username: ユーザー名
- 要求されるメタデータの説明を必要に応じて入力し、 をクリックします。
- をクリックして、認証情報を確認して保存します。
ルックアップ認証情報とターゲット認証情報の両方が Credentials リストビューで使用可能になっていることを確認します。プロジェクトでターゲット認証情報を使用するには、プロジェクトを作成し、次の情報を入力します。
- Name: プロジェクトの名前を入力します。
- Organization: ドロップダウンメニューから組織の名前を選択します。
- Execution environment: 必要に応じて実行環境を選択します。
Source control type: プライベートリポジトリーと同期する場合は、ソースコントロールとして Git を選択します。
関連情報を入力するための Type Details ビューが開きます。以下の情報を入力します。
- Source control URL: アクセスするプライベートリポジトリーの URL を入力します。branch/tag/commit および refspec に関連するその他のフィールドは、ルックアップ認証情報での使用には関係ありません。
Source control credential: すでに作成したターゲット認証情報を選択します。
以下は、プロジェクトで設定したターゲット認証情報の例です。

をクリックすると、プロジェクトの同期が自動的に開始します。プロジェクトの Details タブにジョブの進行状況が表示されます。

トラブルシューティング
プロジェクトの同期が失敗した場合は、ステップ 2 の GitHub API endpoint URL フィールドに https://api.github.com を手動で再入力し、プロジェクトの同期を再実行する必要がある場合があります。
第14章 シークレットの処理と接続セキュリティー
Automation Controller はシークレットと接続をセキュアに処理します。
14.1. シークレットの処理
Automation Controller は 3 つのシークレットのセットを管理します。
- ローカル Automation Controller ユーザーのユーザーパスワード。
- データベースのパスワードやメッセージバスのパスワードなど、Automation Controller の運用に使用するシークレット。
- SSH キー、クラウド認証情報、外部パスワード vault 認証情報など、自動化で使用するシークレット。
次のユーザーに対しては「ローカル」のユーザーアクセス権が必要です。
- postgres
- awx
- redis
- receptor
- nginx
14.1.1. ローカルユーザー用のユーザーパスワード
Automation Controller は、SHA256 ハッシュを使用して、PBKDF2 アルゴリズムでローカル Automation Controller ユーザーのパスワードをハッシュします。LDAP、SAML、OAuth などの外部アカウントメカニズムで認証を行うユーザーの場合は、パスワードやシークレットが保存されません。
14.1.2. 運用に使用するシークレットの処理
Automation Controller には、運用に使用する以下のシークレットが存在します。
-
/etc/tower/SECRET_KEY: データベース内の自動化シークレットを暗号化するために使用するシークレットキー。SECRET_KEYが変更された場合や不明な場合は、データベース内の暗号化されたフィールドにアクセスできません。 -
/etc/tower/tower.{cert,key}: Automation Controller Web サービスの SSL 証明書とキー。自己署名証明書またはキーはデフォルトでインストールされますが、ローカルで適切な証明書とキーを指定できます。 -
/etc/tower/conf.d/postgres.pyにあるデータベースのパスワード、および/etc/tower/conf.d/channels.pyにあるメッセージバスのパスワード
これらのシークレットは、暗号化されずに Automation Controller サーバーに保存されます。これは、Automation Controller サービスが起動時にこれらのシークレットをすべて自動的に読み取る必要があるためです。すべてのシークレットは UNIX パーミッションによって保護され、root および Automation Controller awx サービスユーザーに制限されます。
これらのシークレットを非表示にする必要がある場合、当該シークレットの読み取り元となるファイルは Python によって解釈されます。これらのファイルは、サービスが再起動するたびに、他のメカニズムでこれらのシークレットを取得するように調整できます。この変更はお客様により指定されるものであり、アップグレードのたびに再適用が必要な場合があります。Red Hat サポートと Red Hat コンサルティングは、そのような変更の例を有しています。
シークレットシステムがダウンしていると、Automation Controller が情報を取得できず、サービスが復元されれば回復できるような障害が発生する可能性があります。システムで冗長性を使用することを強く推奨します。
Automation Controller によって生成された SECRET_KEY が侵害されており、再生成する必要があると思われる場合は、Automation Controller のバックアップおよび復元ツールとよく似た動作をするツールをインストーラーから実行できます。
新しいシークレットキーを生成する前に、Automation Controller データベースを必ずバックアップしてください。
新しいシークレットキーを生成するには、以下を実行します。
- バックアップおよび復元 セクションで説明されている手順に従います。
インストールのインベントリー (バックアップと復元の実行に使用したのと同じインベントリー) を使用して、次のコマンドを実行します。
setup.sh -k.
以前のキーのバックアップコピーは /etc/tower/ に保存されます。
14.1.3. 自動化で使用するシークレットの処理
Automation Controller は、自動化に使用するシークレットや、自動化の結果であるさまざまなシークレットをデータベースに保存します。
これらのシークレットには以下が含まれます。
- すべての認証情報タイプの全シークレットフィールド (パスワード、シークレットキー、認証トークン、シークレットクラウド認証情報)。
- Automation Controller 設定で定義された外部サービスのシークレットトークンとパスワード。
- “password” タイプのサーベイフィールドのエントリー。
シークレットフィールドを暗号化するために、Automation Controller は、暗号化用の 256 ビットキーを使用した CBC モードの AES、PKCS7 パディング、および認証用の SHA256 を使用した HMAC を使用します。
暗号化や復号化のプロセスでは、SECRET_KEY、モデルフィールドのフィールド名、およびデータベースによって割り当てられた自動増分レコード ID から AES-256 ビット暗号化キーが導出されます。したがって、キー生成プロセスで使用される属性が変更された場合、Automation Controller はシークレットを正しく復号化できません。
Automation Controller は次のように設計されています。
-
Automation Controller が起動する Playbook では、
SECRET_KEYを読み取ることはできません。 - Automation Controller ユーザーは、これらのシークレットを読み取ることはできません。
- Automation Controller REST API によって、シークレットフィールド値が利用可能になることはありません。
Playbook でシークレット値が使用されている場合は、誤ってログに記録されないように、タスクで no_log を使用することを推奨します。
14.1.4. 接続セキュリティー
Automation Controller を使用すると、内部サービス、外部アクセス、および管理対象ノードへの接続が可能になります。
次のユーザーに対しては「ローカル」のユーザーアクセス権が必要です。
- postgres
- awx
- redis
- receptor
- nginx
14.1.5. 内部サービス
Automation Controller は、内部操作の一環として次のサービスに接続します。
- PostgreSQL データベース
- PostgreSQL データベースへの接続は、ローカルホスト経由またはリモート (外部データベース経由) で、TCP を介したパスワード認証によって行われます。この接続では、インストーラーサポートによってネイティブに設定されている PostgreSQL の組み込み SSL/TLS サポートを使用できます。SSL/TLS プロトコルは、デフォルトの OpenSSL 設定によって設定されます。
- Redis キーまたは値のストア
- Redis への接続は、ローカルの UNIX ソケットを介して行われ、awx サービスユーザーに制限されます。
14.1.6. 外部アクセス
Automation Controller には、Nginx によって提供される標準ポート上の標準 HTTP/HTTPS を使用してアクセスします。自己署名証明書またはキーはデフォルトでインストールされますが、ローカルで適切な証明書とキーを指定できます。
SSL/TLS アルゴリズムのサポートは、/etc/nginx/nginx.conf 設定ファイルで設定されます。デフォルトでは "intermediate" プロファイルが使用されますが、これは設定可能です。更新するたびに変更を再適用する必要があります。
14.1.7. 管理対象ノード
Automation Controller は、自動化の一環として管理対象マシンおよびサービスに接続します。管理対象マシンへの接続はすべて、SSH、WinRM、SSL/TLS など、標準のセキュアなメカニズムによって行われます。
各メカニズムは、対象となる機能のシステム設定 (システム OpenSSL 設定など) から設定を継承します。
第15章 セキュリティーのベストプラクティス
Automation Controller をデプロイして、一般的な環境をセキュアに自動化できます。ただし、特定のオペレーティングシステム環境、自動化、および Automation Platform を管理するには、セキュリティーを確保するために追加のベストプラクティスが必要になる場合があります。
Red Hat Enterprise Linux をセキュリティー保護するには、以下の各リリースに適したセキュリティーガイドを参照してください。
- Red Hat Enterprise Linux 8 は、セキュリティーの強化 を参照してください。
- Red Hat Enterprise Linux 9 は、セキュリティーの強化 を参照してください。
15.1. Ansible Automation Platform と Automation Controller のアーキテクチャーについて
Ansible Automation Platform と Automation Controller は、汎用的で宣言型の自動化プラットフォームで構成されます。つまり、Ansible Playbook が (Automation Controller によって、またはコマンドラインで直接) 起動されると、Ansible に提供された Playbook、インベントリー、および認証情報は、信頼できるソースとみなされます。特定の Playbook コンテンツ、ジョブ定義、またはインベントリーコンテンツの外部検証に関するポリシーが必要な場合は、自動化を起動する前に、これらのプロセスを完了する必要があります。当該プロセスは、Automation Controller Web UI または Automation Controller API で行います。
ソースコントロールの使用、ブランチング、必須のコードレビューは、Ansible による自動化のベストプラクティスです。このようにソースコントロールを使用する際のプロセスフローを作成するために、役立つツールが存在します。
より高いレベルでは、自動化を含む任意のワークフローに関して、承認およびポリシーベースのアクションを作成できるツールが存在します。これらのツールは、Automation Controller の API 経由で Ansible を使用し、自動化を実行できます。
Automation Controller のインストール時には、セキュアなデフォルトの管理者パスワードを使用する必要があります。詳細は、Automation Controller 管理者パスワードの変更 を参照してください。
Automation Controller は、HTTP トラフィック用のポート 80 や HTTPS トラフィック用のポート 443 など、特定の既知のポートでサービスを公開します。オープンインターネットには Automation Controller を公開しないでください。オープンインターネットに公開しないことで、インストールの脅威が減少します。
15.1.1. アクセス権の付与
システムの特定の部分にアクセス権を付与すると、セキュリティーリスクが生じます。アクセスのセキュリティーを確保するために、次のプラクティスを適用してください。
15.1.2. 管理アカウントを最小限に抑える
システム管理アカウントへのアクセスを最小限に抑えることは、セキュアなシステムを維持するために非常に重要です。システム管理者または root ユーザーは、あらゆるシステムアプリケーションにアクセス、編集、および中断できます。可能な場合は、root アクセスを持つユーザーまたはアカウントの数を制限します。root や awx (Automation Controller ユーザー) への sudo を、信頼できないユーザーに付与しないでください。sudo などのメカニズムを使用して管理アクセスを制限した場合、特定のコマンドセットに制限しても、広範囲のアクセスが許可される可能性があることに注意してください。シェルまたは任意のシェルコマンドの実行を可能にするコマンド、またはシステム上のファイルを変更できるコマンドは、完全な root アクセスと同等です。
Automation Controller を使用すると、Automation Controller の「システム管理者」または「スーパーユーザー」アカウントは、Automation Controller のインベントリーまたは自動化定義を編集、変更、および更新できます。可能な限り、低レベルの Automation Controller 設定および障害復旧専用の最小限のユーザーだけに制限します。
15.1.3. ローカルシステムアクセスを最小限に抑える
ベストプラクティスに従って Automation Controller を使用する場合、管理目的以外のローカルユーザーアクセスは必要ありません。管理者以外のユーザーは、Automation Controller システムにアクセスできません。
15.1.4. 認証情報へのユーザーアクセスを削除する
Automation Controller 認証情報がコントローラーにのみ保存されている場合は、さらにセキュリティーを強化できます。OpenSSH などのサービスは、特定のアドレスからの接続時にのみ認証情報を許可するように設定できます。自動化で使用される認証情報は、システム管理者が障害復旧やその他のアドホック管理に使用する認証情報とは変えることができるため、監査が容易になります。
15.1.5. 職務の分離を強制する
自動化する部分に応じて、さまざまなレベルでシステムにアクセスすることが必要になる場合があります。たとえば、パッチを適用してセキュリティーベースラインチェックを実行する低レベルのシステム自動化を設定する一方で、アプリケーションをデプロイする高レベルの自動化を設定することが考えられます。自動化の各部分に異なるキーまたは認証情報を使用することにより、1 つのキーの脆弱性の影響が最小限に抑えられ、同時にベースライン監査も可能になります。
15.2. 利用可能なリソース
セキュアなプラットフォームを確保するために、Automation Controller などにいくつかのリソースが存在します。次の機能の使用を検討してください。
15.2.1. 既存のセキュリティー機能
以下の点に注意してください。
- SELinux または Automation Controller の既存のマルチテナントコンテインメントを無効にしないでください。
- Automation Controller のロールベースのアクセス制御 (RBAC) を使用して、自動化の実行に必要な最小限の権限を委譲します。詳細は、ロールベースのアクセス制御によるアクセスの管理 を参照してください。
- Automation Controller のチームを使用して、個々のユーザーではなくユーザーのグループにパーミッションを割り当てます。
15.2.2. 外部アカウントストア
Automation Controller ですべてのユーザーを維持することは、大規模な組織では時間のかかるタスクとなる場合があります。Automation Controller は、LDAP、SAML 2.0、および特定の OAuth プロバイダーによる外部アカウントソースへの接続をサポートします。これにより、パーミッションを操作する際のエラーの原因が排除されます。
15.2.3. Django パスワードポリシー
Automation Controller 管理者は、Django を使用して、作成時に AUTH_PASSWORD_VALIDATORS でパスワードポリシーを設定し、Automation Controller のユーザーパスワードを検証できます。Automation Controller インスタンスの /etc/tower/conf.d にある custom.py ファイルに、次のコードブロックの例を追加します。
AUTH_PASSWORD_VALIDATORS = [
{
'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
'OPTIONS': {
'min_length': 9,
}
},
{
'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
},
]変更を有効にするには、必ず Automation Controller インスタンスを再起動してください。詳細は、Automation Controller の起動、停止、および再起動 を 参照してください。
第16章 awx-manage ユーティリティー
awx-manage ユーティリティーは、Automation Controller の詳細な内部情報にアクセスするために使用します。awx-manage のコマンドは、awx ユーザーとしてのみ実行する必要があります。
16.1. インベントリーのインポート
awx-manage は、Automation Controller 管理者がインベントリーを Automation Controller に直接インポートできるメカニズムです。
awx-manage を正しく使用するには、まずインポート先として使用するインベントリーを Automation Controller に作成する必要があります。
awx-manage のヘルプが必要な場合は、次のコマンドを実行します。
awx-manage inventory_import [--help]
inventory_import コマンドは、コアの Ansible でサポートされている、テキストベースのインベントリーファイル、動的なインベントリースクリプト、またはファイルやスクリプトのディレクトリーと、Automation Controller のインベントリーオブジェクトを同期します。
コマンドの実行時に、--inventory-id または --inventory-name、および Ansible インベントリーのソースへのパス (--source) を指定します。
awx-manage inventory_import --source=/ansible/inventory/ --inventory-id=1
デフォルトでは、Automation Controller にすでに保存されているインベントリーデータと外部ソースからのデータは混在します。
外部データのみを使用するには、--overwrite を指定します。
既存のホストが --source からのみ変数データを取得するように指定するには、--overwrite_vars を指定します。
デフォルトの動作では、外部ソースから新しい変数を追加して既存のキーを上書きしますが、外部データソースから取得されていない変数は保持します。
awx-manage inventory_import --source=/ansible/inventory/ --inventory-id=1 --overwrite
インベントリーホスト変数の編集と追加は、--overwrite_vars が設定されていない限り、インベントリーの同期後も維持されます。
16.2. 以前のデータの消去
awx-manage には、Automation Controller から古いデータを消去するためのさまざまなコマンドがあります。Automation Controller 管理者は、Automation Controller の Management Jobs インターフェイスを使用してアクセスするか、コマンドラインを使用できます。
awx-manage cleanup_jobs [--help]このコマンドでは、ジョブの詳細や、指定の日数以前のジョブの出力が完全に削除されます。
awx-manage cleanup_activitystream [--help]これにより、特定の日数より古いアクティビティーストリームデータが完全に削除されます。
16.3. クラスター管理
awx-manage provision_instance および awx-manage deprovision_instance コマンドの詳細は、クラスタリング を参照してください。
Ansible サポートからの指示がない限り、他の awx-manage コマンドは実行しないようにしてください。
16.4. アナリティクスの収集
以下のコマンドを使用して、事前定義の時間枠 (デフォルトは 4 時間) 以外で、オンデマンドでアナリティクスを収集します。
$ awx-manage gather_analytics --ship
切断された環境を使用し、一定期間にわたって、自動化された一意のホストに関する使用情報を収集する場合は、次のコマンドを使用します。
awx-manage host_metric --since YYYY-MM-DD --json
--since パラメーターは任意です。
--json フラグは出力形式を指定するもので、指定は任意です。
第17章 バックアップおよび復元
Ansible Automation Platform セットアップ Playbook を使用して、システムをバックアップおよび復元できます。
詳細は、クラスター環境のバックアップおよび復元 セクションを参照してください。
Ansible Automation Platform をバックアップする場合は、現在インストールされている Ansible Automation Platform のバージョンと同じバージョンのインストールプログラムを使用してください。
Ansible Automation Platform を復元する場合は、復元時に利用可能な最新のインストールプログラムを使用してください。たとえば、バージョン 2.5-1 から作成したバックアップを復元する場合は、復元時に利用可能な最新の 2.5-x インストールプログラムを使用してください。
バックアップおよび復元機能は、現在お使いの Ansible Automation Platform バージョンでサポートされている PostgreSQL バージョンでのみ機能します。詳細は、インストール計画 の システム要件 を参照してください。
Ansible Automation Platform の設定用 Playbook は、プラットフォームインストーラーの tar ファイルを展開したパスから setup.sh として呼び出します。インストール Playbook で使用されるものと同じインベントリーファイルを使用します。セットアップスクリプトでは、バックアップと復元用に以下の引数を指定できます。
-
-b: データベースのインストールではなくバックアップを実行します。 -
-r: データベースのインストールではなく復元を実行します。
root ユーザーとして、適切なパラメーターを指定して setup.sh を呼び出し、設定どおりに Ansible Automation Platform をバックアップまたは復元します。
root@localhost:~# ./setup.sh -b
root@localhost:~# ./setup.sh -r
バックアップファイルは、setup.sh スクリプトと同じパスに作成されます。パスは、次の EXTRA_VARS を指定することで変更できます。
root@localhost:~# ./setup.sh -e 'backup_dest=/path/to/backup_dir/' -b
次の例に示すように、EXTRA_VARS にデフォルト以外のパスを指定しない限り、デフォルトの復元パスが使用されます。
root@localhost:~# ./setup.sh -e 'restore_backup_file=/path/to/nondefault/backup.tar.gz' -rオプションで、セットアップスクリプトに引数として渡すことで、使用したインベントリーファイルをオーバーライドすることができます。
setup.sh -i <inventory file>17.1. Playbook のバックアップおよび復元
setup.sh セットアップ Playbook に含まれる install.yml ファイルに加えて、backup.yml ファイルと restore.yml ファイルもあります。
これらの Playbook はバックアップと復元に役立ちます。
システム全体のバックアップでは、以下をバックアップします。
- データベース
-
SECRET_KEYファイル
システム毎のバックアップには以下が含まれます。
- カスタム設定ファイル
- 手動のプロジェクト
- バックアップの復元では、バックアップされたファイルとデータが、新しくインストールして動作中の Automation Controller の 2 番目のインスタンスに復元されます。
システムを復元する場合、インストールプログラムは復元を開始する前にバックアップファイルが存在するかどうかを確認します。バックアップファイルがない場合には、復元に失敗します。
Automation Controller ホストが SSH キー、ホストファイル内のユーザー変数またはパスワード変数で適切にセットアップされていること、そしてユーザーが sudo アクセス権を持っていることを確認してください。
17.2. バックアップおよび復元に関する留意事項
システムをバックアップおよび復元するときは、次の点を考慮してください。
- ディスク領域
- ディスク領域の要件を確認して、設定ファイル、キー、その他の関連ファイル、および Ansible Automation Platform インストールのデータベースをバックアップするのに十分な領域があることを確認します。
- システム認証情報
ローカルデータベースまたはリモートデータベースを操作する場合は、必要なシステム認証情報があることを確認します。ローカルシステムでは、認証情報のセットアップ方法に応じて、
rootまたはsudoアクセスが必要になる場合があります。リモートシステムでは、バックアップまたは復元しようとしているリモートシステムへのアクセス権を取得するためには別の認証情報が必要になる場合があります。注記Ansible Automation Platform データベースのバックアップは、変数
backup_dirを使用して各ノードの/var/backups/automation-platformに一時的に保存されます。場合によっては、ディスク領域の問題を防ぐために、./setup.sh -bスクリプトを実行する前に、新しいボリュームを/var/backupsにマウントするか、変数backup_dirを使用して一時保存場所を変更する必要があります。- バージョン
- Ansible Automation Platform インストールバージョンをバックアップまたは復元する際は、常にリリースの最新のマイナーバージョンを使用する必要があります。たとえば、現行のプラットフォームバージョンが 2.0.x の場合は、最新の 2.0 インストーラーのみを使用します。
- ファイルパス
-
setup.shを使用してデフォルトの復元ファイルパス/var/lib/awxから復元する場合、復元を実行するには依然として-rが必要ですが、このオプションは引数を受け入れなくなりました。デフォルト以外の復元ファイルパスが必要な場合は、extra_var (root@localhost:~# ./setup.sh -e 'restore_backup_file=/path/to/nondefault/backup.tar.gz' -r) として指定する必要があります。 - ディレクトリー
-
バックアップファイルが
setup.shインストーラーと同じディレクトリーに配置されている場合、復元 Playbook は復元ファイルを自動的に見つけます。この場合、バックアップファイルの場所を指定するために、restore_backup_file追加変数を使用する必要はありません。
17.3. クラスター環境のバックアップおよび復元
クラスター環境のバックアップと復元の手順は、次のいくつかの留意事項を除き、単一インストールと同様です。
クラスター環境のインストールの詳細は、インストールと設定 セクションを参照してください。
- 新規クラスターに復元する場合は、データベースにアクセスする際にはクラスター間で競合状態になる可能性があるので、以前のクラスターをシャットダウンしてから続行するようにしてください。
- ノードごとのバックアップは、バックアップと同じホスト名のノードにのみ復元されます。
既存のクラスターに復元する場合、復元には次の処理が含まれます。
- PostgreSQL データベースのダンプ
- データベースダンプに含まれる UI アーティファクト
-
Automation Controller 設定 (
/etc/towerから取得) - Automation Controller シークレットキー
- 手動のプロジェクト
17.3.1. 異なるクラスターへの復元
バックアップを別のインスタンスまたはクラスターに復元する場合、/etc/tower 配下の手動プロジェクトとカスタム設定は保持されます。ジョブ出力とジョブイベントはデータベースに保存されるため、影響を受けません。
復元プロセスでは、復元前に存在していたインスタンスグループは変更されません。新しいインスタンスグループが導入されることもありません。インスタンスグループに関連付けられた Automation Controller リソースを復元した場合、新しい Automation Controller クラスターのインスタンスグループに当該リソースを再度割り当てることが必要な可能性があります。
バックアップおよび復元操作を使用して Ansible Automation Platform インスタンスを別のクラスターまたは新しいホスト名セットに移行する予定の場合は、イベント駆動型 Ansible Controller に設定した Red Hat Ansible Automation Platform 認証情報はすべて破損し、ルールブックのアクティベーションが失敗します。接続を復元するには、復元操作が完了した後、Automation Controller URL と関連する認証情報を手動で編集して更新する必要があります。
第18章 ユーザビリティーアナリティクスおよびデータ収集
Automation Controller にはユーザビリティーデータ収集が含まれており、ユーザーがどのように Automation Controller と対話するかをよりよく理解するためのデータを収集します。
試用版をインストールしたユーザーまたは新規にインストールしたユーザーのみが、このデータ収集にオプトインされます。
Automation Controller は、製品の改善に役立てるためにユーザーデータを自動的に収集します。
Automation Analytics の設定方法は、Automation Analytics の設定 を参照してください。
18.1. Automation Analytics
ライセンスの初回インポート時に、Automation Analytics (Ansible Automation Platform サブスクリプションに含まれるクラウドサービス) を強化するデータの収集が自動的にオプトインされます。
Automation Analytics のオプトインを有効にするには、Automation Controller のインスタンスが Red Hat Enterprise Linux 上で実行されている必要があります。
Red Hat Insights と同様に、Automation Analytics は必要な最小限のデータだけを収集するように構築されています。認証情報のシークレット、個人データ、自動化変数、またはタスク出力は収集されません。
ライセンスを初めてインポートしたときに、Automation Analytics に自動的にオプトインされます。この機能を設定または無効にするには、Automation Analytics の設定 を参照してください。
デフォルトでは、データは 4 時間ごとに収集されます。この機能を有効にすると、最大 1 カ月 (または前回の収集まで) 遡ってデータが収集されます。このデータ収集は、システム設定ウィンドウの Miscellaneous System settings でいつでもオフにできます。
この設定は、次のエンドポイントのいずれかで INSIGHTS_TRACKING_STATE = true を指定し、API 経由で有効にすることもできます。
-
api/v2/settings/all -
api/v2/settings/system
このデータ収集から生成された Automation Analytics は、Red Hat Cloud Services ポータルで確認できます。
デフォルトのビューは Clusters データです。このグラフは、一定期間における Automation Controller クラスター全体のジョブ実行数を表します。上記の例では、1 週間分の積み上げ棒グラフが表示されています。グラフは、正常に実行されたジョブの数 (緑色) と失敗したジョブの数 (赤色) で構成されています。
クラスターを 1 つ選択して、そのジョブステータス情報を表示することもできます。

この複数の折れ線グラフは、指定した期間における単一の Automation Controller クラスターのジョブ実行数を表します。上記の例では 1 週間分が示されており、正常に実行されたジョブの数 (緑色) と失敗したジョブの数 (赤色) で構成されています。選択したクラスターの成功したジョブ実行数と失敗したジョブ実行数を、1 週間単位、2 週間単位、および月次単位で表示するように指定できます。
クラウドナビゲーションパネルで を選択し、次の情報を表示します。
組織の統計情報ページは、今後のリリースで非推奨になる予定です。
18.1.1. 組織ごとの使用状況
次のグラフは、特定の組織がすべてのジョブ内で実行したタスクの数を表します。

18.1.2. 組織ごとのジョブの実行数
このグラフは、組織ごとのすべての Automation Controller クラスターでの Automation Controller の使用状況を表します。これは、組織が実行したジョブの数に基づいて計算されます。

18.1.3. 組織の状態
この棒グラフは、組織および日付別の Automation Controller の使用状況を表します。これは、組織が特定の日に実行したジョブの数に基づいて計算されます。
あるいは、組織ごとのジョブ実行数を 1 週間単位、2 週間単位、および月次単位で表示するように指定することもできます。

18.2. データ収集の詳細
Automation Analytics は、Automation Controller から次の種類のデータを収集します。
- 有効になっている機能や使用されているオペレーティングシステムなどの基本設定
- 容量と健全性など、Automation Controller 環境とホストのトポロジーおよびステータス
自動化リソースの数:
- 組織、チーム、ユーザー
- インベントリーとホスト
- 認証情報 (タイプで索引付け)
- プロジェクト (タイプで索引付け)
- テンプレート
- スケジュール
- アクティブセッション
- 実行中および保留中のジョブ
- ジョブ実行の詳細 (開始時間、終了時間、起動タイプ、成功)
- 自動化タスクの詳細 (成功、ホスト ID、Playbook/ロール、タスク名、使用モジュール)
awx-manage gather_analytics (--ship なし) を使用して Automation Controller が送信するデータを検査できるため、データ収集に関する懸念に対応できます。これにより、Red Hat に送信される分析データを含む tar ファイルが作成されます。
このファイルには、複数の JSON ファイルと CSV ファイルが含まれています。各ファイルには、異なる分析データのセットが含まれています。
- manifest.json
- config.json
- instance_info.json
- counts.json
- org_counts.json
- cred_type_counts.json
- inventory_counts.json
- projects_by_scm_type.json
- query_info.json
- job_counts.json
- job_instance_counts.json
- unified_job_template_table.csv
- unified_jobs_table.csv
- workflow_job_template_node_table.csv
- workflow_job_node_table.csv
- events_table.csv
18.2.1. manifest.json
manifest.json は、分析データのマニフェストです。これは、コレクションに含まれる各ファイルと、ファイルのスキーマのバージョンを記述しています。
以下は、manifest.json ファイルの例です。
"config.json": "1.1",
"counts.json": "1.0",
"cred_type_counts.json": "1.0",
"events_table.csv": "1.1",
"instance_info.json": "1.0",
"inventory_counts.json": "1.2",
"job_counts.json": "1.0",
"job_instance_counts.json": "1.0",
"org_counts.json": "1.0",
"projects_by_scm_type.json": "1.0",
"query_info.json": "1.0",
"unified_job_template_table.csv": "1.0",
"unified_jobs_table.csv": "1.0",
"workflow_job_node_table.csv": "1.0",
"workflow_job_template_node_table.csv": "1.0"
}18.2.2. config.json
config.json ファイルには、クラスターの設定エンドポイント /api/v2/config のサブセットが含まれています。config.json の例は次のとおりです。
{
"ansible_version": "2.9.1",
"authentication_backends": [
"social_core.backends.azuread.AzureADOAuth2",
"django.contrib.auth.backends.ModelBackend"
],
"external_logger_enabled": true,
"external_logger_type": "splunk",
"free_instances": 1234,
"install_uuid": "d3d497f7-9d07-43ab-b8de-9d5cc9752b7c",
"instance_uuid": "bed08c6b-19cc-4a49-bc9e-82c33936e91b",
"license_expiry": 34937373,
"license_type": "enterprise",
"logging_aggregators": [
"awx",
"activity_stream",
"job_events",
"system_tracking"
],
"pendo_tracking": "detailed",
"platform": {
"dist": [
"redhat",
"7.4",
"Maipo"
],
"release": "3.10.0-693.el7.x86_64",
"system": "Linux",
"type": "traditional"
},
"total_licensed_instances": 2500,
"controller_url_base": "https://ansible.rhdemo.io",
"controller_version": "3.6.3"
}これには次のフィールドが含まれます。
- ansible_version: ホスト上のシステム Ansible バージョン
- authentication_backends: 使用可能なユーザー認証バックエンド。詳細は、認証タイプの設定 を参照してください。
- external_logger_enabled: 外部ロギングが有効かどうか
- external_logger_type: 有効になっている場合に使用されているロギングバックエンド。詳細は、ロギングおよびアグリゲーション を参照してください。
- logging_aggregators: 外部ロギングに送信されるロギングカテゴリー。詳細は、ロギングおよびアグリゲーション を参照してください。
- free_instances: ライセンスで使用できるホストの数。値がゼロの場合は、クラスターがライセンスを完全に消費していることを意味します。
- install_uuid: インストールの UUID (すべてのクラスターノードで同一)
- instance_uuid: インスタンスの UUID (クラスターノードごとに異なる)
- license_expiry: ライセンスの有効期限が切れるまでの時間 (秒単位)
- license_type: ライセンスのタイプ (ほとんどの場合は 'enterprise')
-
pendo_tracking:
usability_data_collectionの状態 - platform: クラスターが実行されているオペレーティングシステム
- total_licensed_instances: ライセンス内のホストの合計数
- controller_url_base: クライアントが使用するクラスターのベース URL (Automation Analytics に表示)
- controller_version: クラスター上のソフトウェアのバージョン
18.2.3. instance_info.json
instance_info.json ファイルには、クラスターを構成するインスタンスに関する詳細情報がインスタンスの UUID ごとにまとめられています。
以下は、instance_info.json ファイルの例です。
{
"bed08c6b-19cc-4a49-bc9e-82c33936e91b": {
"capacity": 57,
"cpu": 2,
"enabled": true,
"last_isolated_check": "2019-08-15T14:48:58.553005+00:00",
"managed_by_policy": true,
"memory": 8201400320,
"uuid": "bed08c6b-19cc-4a49-bc9e-82c33936e91b",
"version": "3.6.3"
}
"c0a2a215-0e33-419a-92f5-e3a0f59bfaee": {
"capacity": 57,
"cpu": 2,
"enabled": true,
"last_isolated_check": "2019-08-15T14:48:58.553005+00:00",
"managed_by_policy": true,
"memory": 8201400320,
"uuid": "c0a2a215-0e33-419a-92f5-e3a0f59bfaee",
"version": "3.6.3"
}
}これには次のフィールドが含まれます。
- capacity: タスクを実行するためのインスタンスの容量
- cpu: インスタンスのプロセッサーコア
- memory: インスタンスのメモリー
- enabled: インスタンスが有効でタスクを受け付けているかどうか
- managed_by_policy: インスタンスグループ内のインスタンスのメンバーシップがポリシーによって管理されているか、手動で管理されているか
- version: インスタンス上のソフトウェアのバージョン
18.2.4. counts.json
counts.json ファイルには、クラスター内の関連するカテゴリーごとの合計オブジェクト数が含まれています。
以下は、counts.json ファイルの例です。
{
"active_anonymous_sessions": 1,
"active_host_count": 682,
"active_sessions": 2,
"active_user_sessions": 1,
"credential": 38,
"custom_inventory_script": 2,
"custom_virtualenvs": 4,
"host": 697,
"inventories": {
"normal": 20,
"smart": 1
},
"inventory": 21,
"job_template": 78,
"notification_template": 5,
"organization": 10,
"pending_jobs": 0,
"project": 20,
"running_jobs": 0,
"schedule": 16,
"team": 5,
"unified_job": 7073,
"user": 28,
"workflow_job_template": 15
}
このファイルの各エントリーは、アクティブセッション数を除いて、/api/v2 の対応する API オブジェクトに関するものです。
18.2.5. org_counts.json
org_counts.json ファイルには、クラスター内の各組織に関する情報と、その組織に関連付けられているユーザーとチームの数が含まれています。
以下は、org_counts.json ファイルの例です。
{
"1": {
"name": "Operations",
"teams": 5,
"users": 17
},
"2": {
"name": "Development",
"teams": 27,
"users": 154
},
"3": {
"name": "Networking",
"teams": 3,
"users": 28
}
}18.2.6. cred_type_counts.json
cred_type_counts.json ファイルには、クラスター内のさまざまな認証情報の種類と、各種類に存在する認証情報の数に関する情報が含まれています。
以下は、cred_type_counts.json ファイルの例です。
{
"1": {
"credential_count": 15,
"managed_by_controller": true,
"name": "Machine"
},
"2": {
"credential_count": 2,
"managed_by_controller": true,
"name": "Source Control"
},
"3": {
"credential_count": 3,
"managed_by_controller": true,
"name": "Vault"
},
"4": {
"credential_count": 0,
"managed_by_controller": true,
"name": "Network"
},
"5": {
"credential_count": 6,
"managed_by_controller": true,
"name": "Amazon Web Services"
},
"6": {
"credential_count": 0,
"managed_by_controller": true,
"name": "OpenStack"
},18.2.7. inventory_counts.json
inventory_counts.json ファイルには、クラスター内のさまざまなインベントリーに関する情報が含まれています。
以下は、inventory_counts.json ファイルの例です。
{
"1": {
"hosts": 211,
"kind": "",
"name": "AWS Inventory",
"source_list": [
{
"name": "AWS",
"num_hosts": 211,
"source": "ec2"
}
],
"sources": 1
},
"2": {
"hosts": 15,
"kind": "",
"name": "Manual inventory",
"source_list": [],
"sources": 0
},
"3": {
"hosts": 25,
"kind": "",
"name": "SCM inventory - test repo",
"source_list": [
{
"name": "Git source",
"num_hosts": 25,
"source": "scm"
}
],
"sources": 1
}
"4": {
"num_hosts": 5,
"kind": "smart",
"name": "Filtered AWS inventory",
"source_list": [],
"sources": 0
}
}18.2.8. projects_by_scm_type.json
projects_by_scm_type.json ファイルには、クラスター内の全プロジェクトの内訳がソースコントロールタイプ別に記載されています。
以下は、projects_by_scm_type.json ファイルの例です。
{
"git": 27,
"hg": 0,
"insights": 1,
"manual": 0,
"svn": 0
}18.2.9. query_info.json
query_info.json ファイルには、データ収集がいつどのように行われたかに関する詳細が記載されています。
以下は、query_info.json ファイルの例です。
{
"collection_type": "manual",
"current_time": "2019-11-22 20:10:27.751267+00:00",
"last_run": "2019-11-22 20:03:40.361225+00:00"
}
collection_type は、manual または automatic のいずれかです。
18.2.10. job_counts.json
job_counts.json ファイルは、クラスターのジョブ履歴の詳細を提供し、ジョブの起動方法とジョブの終了ステータスの両方を記述します。
以下は、job_counts.json ファイルの例です。
"launch_type": {
"dependency": 3628,
"manual": 799,
"relaunch": 6,
"scheduled": 1286,
"scm": 6,
"workflow": 1348
},
"status": {
"canceled": 7,
"failed": 108,
"successful": 6958
},
"total_jobs": 7073
}18.2.11. job_instance_counts.json
job_instance_counts.json ファイルは、job_counts.json と同じ詳細をインスタンスごとに分類して記載します。
以下は、job_instance_counts.json ファイルの例です。
{
"localhost": {
"launch_type": {
"dependency": 3628,
"manual": 770,
"relaunch": 3,
"scheduled": 1009,
"scm": 6,
"workflow": 1336
},
"status": {
"canceled": 2,
"failed": 60,
"successful": 6690
}
}
}
このファイルのインスタンスは、instance_info のように UUID ごとに記載されているのではなく、ホスト名ごとに記載されていることに注意してください。
18.2.12. unified_job_template_table.csv
unified_job_template_table.csv ファイルは、システム内のジョブテンプレートに関する情報を提供します。各行には、ジョブテンプレートに関する次のフィールドが含まれます。
- id: ジョブテンプレート ID。
- name: ジョブテンプレート名。
- polymorphic_ctype_id: テンプレートのタイプの ID。
-
model: テンプレートの
polymorphic_ctype_idの名前。例として、project、systemjobtemplate、jobtemplate、inventorysource、workflowjobtemplateなどがあります。 - created: テンプレートが作成された日時。
- updated: テンプレートが最後に更新された日時。
-
created_by_id: テンプレートを作成した
userid。システムが作成した場合は空白です。 -
modified_by_id: テンプレートを最後に変更した
userid。システムが作成した場合は空白です。 - current_job_id: テンプレートの現在実行中のジョブ ID (該当する場合)。
- last_job_id: ジョブの最後の実行。
- last_job_run: ジョブが最後に実行された時刻。
-
last_job_failed:
last_job_idが失敗したかどうか。 -
status:
last_job_idのステータス。 - next_job_run: テンプレートで次にスケジュールされている実行 (該当する場合)。
-
next_schedule_id:
next_job_runのスケジュール ID (該当する場合)。
18.2.13. unified_jobs_table.csv
unified_jobs_table.csv ファイルは、システムによって実行されるジョブに関する情報を提供します。
各行には、ジョブに関する次のフィールドが含まれます。
- id: ジョブ ID。
- name: ジョブ名 (テンプレートから)。
- polymorphic_ctype_id: ジョブのタイプの ID。
-
model: ジョブの
polymorphic_ctype_idの名前。例として、jobやworkflowなどがあります。 - organization_id: ジョブの組織 ID。
-
organization_name:
organization_idの名前。 - created: ジョブレコードが作成された日時。
- started: ジョブの実行が開始した日時。
- finished: ジョブが終了した日時。
- elapsed: ジョブの経過時間 (秒単位)。
- unified_job_template_id: このジョブのテンプレート。
-
launch_type:
manual、scheduled、relaunched、scm、workflow、dependencyのいずれか。 - schedule_id: ジョブを起動したスケジュールの ID (該当する場合)
- instance_group_id: ジョブを実行したインスタンスグループ。
- execution_node: ジョブを実行したノード (UUID ではなくホスト名)。
- controller_node: ジョブの Automation Controller ノード (分離ジョブとして実行される場合、またはコンテナーグループ内で実行される場合)。
- cancel_flag: ジョブがキャンセルされたかどうか。
- status: ジョブのステータス。
- failed: ジョブが失敗したかどうか。
- job_explanation: 適切に実行できなかったジョブの追加の詳細。
- forks: ジョブに対して実行されたフォークの数。
18.2.14. workflow_job_template_node_table.csv
workflow_job_template_node_table.csv は、システムのワークフロージョブテンプレートで定義されるノードの情報を提供します。
各行には、ワークフローのジョブテンプレートノードに以下のフィールドが含まれます。
- id: ノード ID。
- created: ノードが作成された日時。
- modified: ノードが最後に更新された日時。
- unified_job_template_id: このノードのジョブテンプレート、プロジェクト、インベントリー、またはその他の親リソースの ID。
- workflow_job_template_id: このノードを含むワークフローのジョブテンプレート。
- inventory_id: このノードによって使用されるインベントリー。
- success_nodes: このノードが成功した後にトリガーされるノード。
- failure_nodes: このノードが失敗した後にトリガーされるノード。
- always_nodes: このノードの終了後に常にトリガーされるノード。
- all_parents_must_converge: このノードを起動するためにすべての親条件が満たされる必要があるかどうか。
18.2.15. workflow_job_node_table.csv
workflow_job_node_table.csv は、システム上のワークフローの一部として実行されたジョブに関する情報を提供します。
各行には、ワークフローの一部として実行されるジョブに次のフィールドが含まれています。
- id: ノード ID。
- created: ノードが作成された日時。
- modified: ノードが最後に更新された日時。
- job_id: このノードで実行されるジョブのジョブ ID。
- unified_job_template_id: このノードのジョブテンプレート、プロジェクト、インベントリー、またはその他の親リソースの ID。
- workflow_job_template_id: このノードを含むワークフローのジョブテンプレート。
- inventory_id: このノードによって使用されるインベントリー。
- success_nodes: このノードが成功した後にトリガーされるノード。
- failure_nodes: このノードが失敗した後にトリガーされるノード。
- always_nodes: このノードの終了後に常にトリガーされるノード。
- do_not_run: 開始条件がトリガーされなかったためにワークフローで実行されなかったノード。
- all_parents_must_converge: このノードを起動するためにすべての親条件が満たされる必要があるかどうか。
18.2.16. events_table.csv
events_table.csv ファイルは、システム内のすべてのジョブ実行からのすべてのジョブイベントに関する情報を提供します。
各行には、ジョブイベントに関する次のフィールドが含まれます。
- id: イベント ID。
- uuid: イベント UUID。
- created: イベントが作成された日時。
- parent_uuid: このイベントの親 UUID (存在する場合)。
- event: Ansible イベントタイプ。
-
task_action: このイベントに関連付けられたモジュール (存在する場合) (
commandやyumなど)。 -
failed: イベントが
failedを返したかどうか。 -
changed: イベントが
changedを返したかどうか。 - playbook: イベントに関連付けられた Playbook。
- play: Playbook のプレイ名。
- task: Playbook のタスク名。
- role: Playbook のロール名。
- job_id: このイベントが発生したジョブの ID。
- host_id: このイベントが関連付けられているホストの ID (存在する場合)。
- host_name: このイベントが関連付けられているホストの名前 (存在する場合)。
- start: タスクの開始時刻。
- end: タスクの終了時刻。
- duration: タスクの期間。
- warnings: タスクまたはモジュールからの警告。
- deprecations: タスクまたはモジュールからの非推奨の警告。
18.3. 分析レポート
収集されたデータのレポートを console.redhat.com から利用できます。
現在、プラットフォーム UI から利用およびアクセス可能なその他の Automation Analytics データには、次のものがあります。
Automation Calculator: Automation Calculator ユーティリティーの表示専用バージョンです。サブスクライバーの (可能な) 節約額を示すレポートを表示します。

Host Metrics: ホストが最初に自動化された日時、ホストが最後に自動化された日時、ホストが自動化された回数、各ホストが削除された回数など、ホストのデータを収集した分析レポートです。
Subscription Usage: サブスクリプションの過去の使用状況をレポートします。サブスクリプション容量と月ごとの消費ライセンス数が表示されます。過去 1 年、2 年、または 3 年でフィルタリングできます。
第19章 Automation Controller のトラブルシューティング
以下に、Automation Controller に関する有用なトラブルシューティング情報を示します。
19.1. HTTP 経由で Automation Controller にログインできない
Automation Controller へのアクセスは、セキュアなプロトコル (HTTPS) を使用して意図的に制限されています。Automation Controller ノードをロードバランサーやプロキシーの背後で「HTTP のみ」として実行するようにセットアップしており、SSL を使用せずに当該ノードにアクセスしたい場合 (トラブルシューティングのためなど)、Automation Controller インスタンスの /etc/tower/conf.d にある custom.py ファイルに次の設定を追加する必要があります。
SESSION_COOKIE_SECURE = False
CSRF_COOKIE_SECURE = False
これらの設定を false に変更すると、HTTP プロトコルの使用時に Automation Controller がクッキーとログインセッションを管理できるようになります。この変更は、クラスターインストールのすべてのノードで行う必要があります。
変更を適用するには、以下を実行します。
automation-controller-service restart19.2. ジョブを実行できない
Playbook からジョブを実行できない場合は、Playbook の YAML ファイルを確認します。手動またはソースコントロールメカニズムによって Playbook をインポートする場合、ホスト定義は Automation Controller によって制御され、hosts:all に設定する必要があることに注意してください。
19.3. Playbook がジョブテンプレートリストに表示されない
Playbook が ジョブテンプレート リストに表示されない場合は、次の点を確認してください。
- Playbook が有効な YML で、Ansible で解析できることを確認してください。
-
プロジェクトパス (
/var/lib/awx/projects) のパーミッションと所有権が、"awx" システムユーザーにファイルが表示されるようにセットアップされていることを確認してください。次のコマンドを実行して所有権を変更します。
chown awx -R /var/lib/awx/projects/19.4. Playbook が保留状態で止まる
Playbook のジョブを実行しようとした際に、ジョブが Pending のままになる場合、以下の操作を試行してください。
-
supervisorctl statusを使用して、すべてのスーパーバイザーサービスが実行されていることを確認してください。 -
/var/パーティションに 1 GB を超える空き領域があることを確認してください。/var/パーティションの領域が不十分な場合、ジョブは完了しません。 -
Automation Controller サーバーで
automation-controller-service restartを実行します。
問題が継続する場合には、Automation Controller サーバーで root として sosreport を実行し、その結果を添付した サポートリクエスト を提出してください。
19.5. 外部のデータベースを再利用するとインストールに失敗する
2 回目以降のノードのインストール中に外部データベースを再利用すると、インストールが失敗してしまう件が報告されています。
例
クラスターインストールを実行したとします。もう一度インストールを行う必要があり、2 回目のクラスターインストールは同じ外部データベースを再利用して実行するとします。その場合、この 2 回目のインストールだけが失敗します。
以前のインストールで使用した外部データベースをセットアップする場合、追加のインストールを成功させるには、クラスターノードで使用するデータベースを手動で消去する必要があります。
19.6. Automation Controller インベントリーのプライベート EC2 VPC インスタンスの表示
デフォルトでは、Automation Controller は、Elastic IP (EIP) が関連付けられている VPC のインスタンスのみを表示します。
手順
- ナビゲーションパネルから → → を選択します。
Source が Amazon EC2 に設定されているインベントリーを選択し、Source タブをクリックします。Source Variables フィールドに次のように入力します。
vpc_destination_variable: private_ip_address- をクリックして、グループの更新をトリガーします。
検証
これらの手順を完了すると、VPC インスタンスが表示されます。
インスタンスを設定する場合には、Automation Controller が、インスタンスへのアクセス権がある VPC 内で実行されている必要があります。
第20章 Automation Controller のヒントと裏技
- Automation Controller CLI ツールの使用
- Automation Controller 管理者パスワードの変更
- コマンドラインからの Automation Controller 管理者の作成
- Automation Controller で使用するジャンプホストのセットアップ
- Automation Controller の使用時に JSON コマンド用の Ansible 出力を表示する方法
- Ansible 設定ファイルの場所特定および設定
- 全 ansible_ 変数のリストの表示
- ALLOW_JINJA_IN_EXTRA_VARS 変数
- 通知用の controllerhost ホスト名の設定
- curl でのジョブの起動
- Automation Controller の動的インベントリーソースによるインスタンスの絞り込み
- Ansible ソースから提供されるリリース前のモジュールを Automation Controller で使用する方法
- winrm での Windows への接続
- 既存のインベントリーファイルとホスト/グループ変数の Automation Controller へのインポート
20.1. Automation Controller CLI ツール
Automation Controller は、フル機能のコマンドラインインターフェイスを備えています。
設定と使用方法に関する詳細は、AWX Command Line Interface および AWX manage ユーティリティー セクションを参照してください。
20.2. Automation Controller 管理者パスワードの変更
インストールプロセス中に、Automation Controller によって作成された admin スーパーユーザーまたはシステム管理者用の管理者パスワードを入力するように求められます。SSH を使用してインスタンスにログインすると、プロンプトにデフォルトの管理者パスワードが表示されます。
このパスワードを変更する必要がある場合は、Automation Controller サーバーで root として次のコマンドを実行します。
awx-manage changepassword admin次に、新しいパスワードを入力します。その後は入力したパスワードが Web UI の管理者パスワードとして機能します。
Django を使用して作成時にパスワード検証のポリシーを設定するには、Django パスワードポリシー を参照してください。
20.3. コマンドラインからの Automation Controller 管理者の作成
場合によっては、コマンドラインからシステム管理者 (スーパーユーザー) アカウントを作成すると便利な場合があります。
スーパーユーザーを作成するには、Automation Controller サーバーで root として次のコマンドを実行し、プロンプトに従って管理者の情報を入力します。
awx-manage createsuperuser20.4. 管理対象ノードに接続するジャンプホストを使用するように Automation Controller を設定する
Automation Controller が提供する認証情報は、ProxyCommand によってジャンプホストに送信されることはありません。認証情報は、トンネル接続がセットアップされている場合に、エンドノードにのみ使用されます。
20.4.1. SSH 設定ファイルで固定のユーザー/キーファイルを設定する
ジャンプホスト経由で接続を設定する ProxyCommand 定義の SSH 設定ファイルで、固定のユーザー/キーファイルを設定できます。
前提条件
- 管理対象ノードへの SSH 接続を確立するノード (Hybrid Controller や実行ノードなど) からすべてのジャンプホストに到達できるかどうかを確認する。
手順
各ノードに、次の詳細を含む SSH 設定ファイル
/var/lib/awx .ssh/configを作成します。Host jumphost.example.com Hostname jumphost.example.com User <jumphostuser> Port <jumphostport> IdentityFile ~.ssh/id_rsa StrictHostKeyChecking no ProxyCommand ssh -W %h:%p jumphost.example.com- このコードは、ジャンプホスト 'jumphost.example.com' に接続するために必要な設定を指定します。
- Automation Controller は各ノードから管理対象ノードへの SSH 接続を確立します。
-
例の値
jumphost.example.com、jumphostuser、jumphostport、~/.ssh/id_rsaは、環境に応じて変更する必要があります。 ノード上にすでに作成されている SSH 設定ファイル
/var/lib/awx/.ssh/config`にホストマッチングブロックを追加します。次に例を示します。Host 192.0.* ...-
Host 192.0.*行は、該当するサブネット内のすべてのホストがそのブロックで定義された設定を使用することを指定します。具体的には、該当するサブネット内のすべてのホストは、ProxyCommand設定を使用してアクセスされ、jumphost.example.comを介して接続されます。 すべてのホストが指定のプロキシーを介して接続することを示すために
Host *を使用する場合は、必ずjumphost.example.comをそのマッチングの対象から除外してください。次に例を示します。Host * !jumphost.example.com ...Red Hat Ansible Automation Platform UI の使用
-
- ナビゲーションパネルで、 → → を選択します。
-
をクリックし、Paths to expose isolated jobs に
/var/lib/awx .ssh:/home/runner/.ssh:0を追加します。 - をクリックして変更を保存します。
20.4.2. Ansible インベントリー変数を使用したジャンプホストの設定
インベントリー変数を使用して、Automation Controller インスタンスにジャンプホストを追加できます。
これらの変数は、インベントリー、グループ、またはホストレベルのいずれかで設定できます。インベントリーを使用して Automation Controller 内のジャンプホストの使用を制御する場合は、この方法を使用します。
手順
インベントリーに移動し、選択したレベルの
variablesフィールドに次の変数を追加します。ansible_user: <user_name> ansible_connection: ssh ansible_ssh_common_args: '-o ProxyCommand="ssh -W %h:%p -q <user_name>@<jump_server_name>"'
20.5. Automation Controller の使用時に JSON コマンド用の Ansible 出力を表示する方法
Automation Controller の使用時には、API を使用して JSON 形式のコマンド用の Ansible 出力を取得できます。
Ansible の出力を確認するには、https://<controller server name>/api/v2/jobs/<job_id>/job_events/ を参照します。
20.6. Ansible 設定ファイルの場所特定および設定
Ansible には設定ファイルは必要ありませんが、OS パッケージには多くの場合、カスタマイズできるようにデフォルトで /etc/ansible/ansible.cfg が含まれています。
カスタムの ansible.cfg ファイルを使用するには、それをプロジェクトの root に配置します。Automation Controller は、プロジェクトディレクトリーの root から ansible-playbook を実行し、そこでカスタムの ansible.cfg ファイルを見つけます。
プロジェクトの他の場所にある ansible.cfg ファイルは無視されます。
このファイルで使用できる値は、Ansible ドキュメントの Generating a sample ansible.cfg file を参照してください。
最初はデフォルトを使用することもできますが、デフォルトのモジュールパスや接続タイプなどをここで設定することも可能です。
Automation Controller は、いくつかの ansible.cfg のオプションをオーバーライドします。たとえば、Automation Controller は、SSH ControlMaster ソケット、SSH エージェントソケット、およびその他のジョブ実行ごとのアイテムを、ジョブごとの一時ディレクトリーに保存します。この一時ディレクトリーは、ジョブ実行に使用するコンテナーに渡されます。
20.7. 全 ansible_ 変数のリストの表示
Ansible は、管理下のマシンに関する「ファクト」をデフォルトで収集します。ファクトには、Playbook やテンプレートでアクセス可能です。
マシンに関するすべての使用可能なファクトを表示するには、setup モジュールを ad hoc アクションとして実行します。
ansible -m setup hostnameこれにより、その特定のホストで使用可能なすべてのファクトのディクショナリーが出力されます。詳細は、Ansible ドキュメントの information-discovered-from-systems-facts を参照してください。
20.8. ALLOW_JINJA_IN_EXTRA_VARS 変数
ALLOW_JINJA_IN_EXTRA_VARS = template 設定は、保存されたジョブテンプレートの追加変数に対してのみ機能します。
プロンプト変数と調査変数は 'template' の対象外です。
このパラメーターには 3 つの値があります。
-
Only On Template Definitions: ジョブテンプレート定義に直接保存された Jinja の使用を許可します (デフォルト)。 -
Neverすべての Jinja の使用を無効化します (推奨)。 -
Always常に Jinja を許可します (極力避けてください。以前の互換性のためのオプションになります)。
このパラメーターは、Automation Controller UI の Jobs Settings ページで設定できます。
20.9. 通知用の controllerhost ホスト名の設定
System settings ページから、Base URL of the Service フィールドの https://controller.example.com を希望のホスト名に置き換えて、通知のホスト名を変更できます。
Automation Controller のライセンスを更新すると、通知ホスト名も変更されます。Automation Controller の新規インストールでは、通知用のホスト名を設定する必要はありません。
20.10. curl でのジョブの起動
Automation Controller API を使用してジョブを起動するのは簡単です。
以下に、curl ツールを使用したわかりやすい例をいくつか示します。
ジョブテンプレート ID が '1' で、コントローラーの IP が 192.168.42.100、有効なログイン認証情報が admin および awxsecret である場合、以下のように新規ジョブを作成できます。
curl -f -k -H 'Content-Type: application/json' -XPOST \
--user admin:awxsecret \
https://192.168.42.100/api/v2/job_templates/1/launch/これにより JSON オブジェクトが返されるので、解析し、新規作成したジョブの ID を 'id' フィールドから展開するのに使用してください。次の例のように、追加の変数をジョブテンプレートの呼び出しに渡すこともできます。
curl -f -k -H 'Content-Type: application/json' -XPOST \
-d '{"extra_vars": "{\"foo\": \"bar\"}"}' \
--user admin:awxsecret https://192.168.42.100/api/v2/job_templates/1/launch/
extra_vars パラメーターは、単なる JSON ディクショナリーではなく、JSON を含む文字列である必要があります。引用符などをエスケープする場合は注意してください。
20.11. コントローラーの動的なインベントリーソースによるインスタンスの絞り込み
デフォルトでは、Automation Controller の動的インベントリーソース (AWS や Google など) は、使用するクラウド認証情報で利用可能なすべてのインスタンスを返します。インスタンスは、さまざまな属性に基づいて自動的にグループに参加します。たとえば、AWS インスタンスは、リージョン、タグ名、値、セキュリティーグループごとにグループ化されます。お使いの環境で特定のインスタンスを対象にするには、生成されたグループ名が対象となるように Playbook を記述します。
以下に例を示します。
---
- hosts: tag_Name_webserver
tasks:
...
ジョブテンプレート設定の Limit フィールドを使用して、特定のグループ、ホスト、またはグループとホストの組み合わせのみを対象に Playbook を実行するように制限することもできます。構文は、ansible-playbook コマンドラインの --limit パラメーターと同じです。
自動生成されたグループをカスタムグループにコピーして、独自のグループを作成することもできます。動的インベントリーソースで Overwrite オプションが無効になっていることを確認してください。無効になっていないと、後から同期操作を行った際にカスタムグループが削除され、置き換えられます。
20.12. Ansible ソースから提供されるリリース前のモジュールを Automation Controller で使用する方法
最新の Ansible Core ブランチで利用可能な機能を、Automation Controller システムに活用するのは非常に簡単です。
まず、利用可能な Ansible Core Modules または Ansible Extra Modules GitHub リポジトリーから、使用する更新済みのモジュールを決定します。
次に、Ansible のソース Playbook (/library) と同じディレクトリーレベルに新しいディレクトリーを作成します。
作成したら、使用するモジュールをコピーし、/library ディレクトリーにドロップします。このモジュールは、まずシステムモジュールによって消費され、通常のパッケージマネージャーで安定版を更新した後に削除できます。
20.13. Automation Controller での callback プラグインの使用
Ansible は、callback プラグインと呼ばれる方法で、Playbook の実行中にアクションを柔軟に処理できます。これらのプラグインを Automation Controller で使用すると、Playbook の実行または失敗時にサービスに通知したり、Playbook の実行後に毎回メールを送信したりできます。
callback プラグインアーキテクチャーに関する公式ドキュメントは、Developing plugins を参照してください。
Automation Controller は stdout callback プラグインをサポートしません。Ansible で許可されるのは 1 つだけであり、すでにイベントデータのストリーミングに使用されているためです。
https://github.com/ansible/ansible/tree/devel/lib/ansible/plugins/callback などでサンプルのプラグインも確認してみてください。これらは、各サイトの目的に合わせて変更する必要があります。
これらのプラグインを使用するには、Automation Controller プロジェクトの Playbook と併せて、callback プラグイン .py ファイルを /callback_plugins というディレクトリーに配置します。次に、ジョブ設定の Ansible Callback Plugins フィールドで、パス (1 行に 1 つのパス) を指定します。
Ansible に同梱されているコールバックの大半をシステム全体に適用するには、それらを ansible.cfg の callback_whitelist セクションに追加する必要があります。
カスタムのコールバックがある場合は、Enabling callback plugins を参照してください。
20.14. winrm での Windows への接続
デフォルトでは、Automation Controller はホストへの ssh 接続を試みます。
Windows ホストが属するグループ変数には、winrm 接続情報を追加する必要があります。
まず、ホストが属する Windows グループを編集し、グループのソース画面または編集画面に変数を配置します。
winrm 接続情報を追加するには、以下を実行します。
-
Windows サーバーを含むグループ名の編集アイコン
をクリックして、選択したグループのプロパティーを編集します。"variables" セクションで、
ansible_connection: winrmという接続情報を追加します。
完了したら、編集内容を保存します。Ansible が以前に SSH 接続を試みて失敗している場合は、ジョブテンプレートを再実行する必要があります。
20.15. 既存のインベントリーファイルとホスト/グループ変数の Automation Controller へのインポート
既存の静的インベントリーと付随のホスト変数およびグループ変数を Automation Controller にインポートするには、インベントリーが次のような構造になっている必要があります。
inventory/
|-- group_vars
| `-- mygroup
|-- host_vars
| `-- myhost
`-- hosts
これらのホストおよび変数をインポートするには awx-manage コマンドを実行します。
awx-manage inventory_import --source=inventory/ \
--inventory-name="My Controller Inventory"たとえば、ansible-hosts という名前のインベントリーのファイルがフラットファイルで 1 つしかない場合には、以下のようにインポートします。
awx-manage inventory_import --source=./ansible-hosts \
--inventory-name="My Controller Inventory"競合がある場合や、"My Controller Inventory" という名前のインベントリーを上書きする場合には、以下を実行します。
awx-manage inventory_import --source=inventory/ \
--inventory-name="My Controller Inventory" \
--overwrite --overwrite-vars以下のようなエラーを受信した場合:
ValueError: need more than 1 value to unpackホストファイルおよび group_vars を保持するディレクトリーを作成します。
mkdir -p inventory-directory/group_vars
次に、:vars のリストが含まれるグループごとに、inventory-directory/group_vars/<groupname> という名前のファイルを作成して、変数を YAML 形式にフォーマットします。
これにより、インポーターは変換を正しく処理するようになります。