Debezium ユーザーガイド
Red Hat build of Debezium 2.7.3 向け
概要
はじめに
Debezium は、データベースの行レベルの変更をキャプチャーする分散サービスのセットで、アプリケーションがそれらの変更を認識し、応答できるようにします。Debezium は、各データベーステーブルにコミットされたすべての行レベルの変更を記録します。各アプリケーションは、対象のトランザクションログを読み取り、発生した順序ですべての操作を確認します。
このガイドでは、以下の Debezium トピックの使用方法を説明します。
Red Hat ドキュメントへのフィードバック
Red Hat ドキュメントに関するご意見やご感想をお寄せください。
改善を提案するには、Jira 課題を作成し、変更案を説明してください。ご要望に迅速に対応できるよう、できるだけ詳細にご記入ください。
前提条件
-
Red Hat カスタマーポータルのアカウントがある。このアカウントを使用すると、Red Hat Jira Software インスタンスにログインできます。
アカウントをお持ちでない場合は、アカウントを作成するように求められます。
手順
- Create issue にアクセスします。
- Summary テキストボックスに、問題の簡単な説明を入力します。
Description テキストボックスに、次の情報を入力します。
- 問題が見つかったページの URL。
-
問題の詳細情報
他のフィールドの情報はデフォルト値のままにすることができます。
- Create をクリックして、Jira 課題をドキュメントチームに送信します。
フィードバックをご提供いただきありがとうございました。
第1章 Debezium の概要
Debezium は、データベースの変更をキャプチャーする分散サービスのセットです。アプリケーションはこれらの変更を利用し、応答できます。Debezium は、各データベーステーブルの行レベルの変更を 1 つずつ変更イベントレコードにキャプチャーし、これらのレコードを Kafka トピックにストリーミングします。これらのストリームはアプリケーションによって読み取られ、変更イベントレコードは生成された順に提供されます。
詳細は、以下を参照してください。
1.1. Debezium の機能
Debezium は、Apache Kafka Connect のソースコネクターのセットです。各コネクターは、CDC (Change Data Capture) のデータベースの機能を使用して、異なるデータベースから変更を取り込みます。ログベースの CDC は、ポーリングや二重書き込みなどのその他の方法とは異なり、Debezium によって実装されます。
- すべてのデータ変更がキャプチャーされたことを確認します。
- 頻度の高いポーリングに必要な CPU 使用率の増加を防ぎながら、非常に低遅延な変更イベントを生成します。たとえば、MySQL または PostgreSQL の場合、遅延はミリ秒の範囲内になります。
- "Last Updated" (最終更新日時) の列など、データモデルへの変更は必要ありません。
- 削除をキャプチャー できます。
- データベースの機能や設定に応じて、トランザクション ID や原因となるクエリーなどの古いレコードの状態や追加のメタデータをキャプチャーできます。
詳細は、ブログの記事 Five Advantages of Log-Based Change Data Capture を参照してください。
Debezium コネクターは、さまざまな関連機能やオプションでデータの変更をキャプチャーします。
- スナップショット: コネクターが起動し、すべてのログが存在していない場合は、任意でデータベースの現在の状態の初期スナップショットを取得できます。通常、これは、データベースが一定期間稼働していて、トランザクションのリカバリーやレプリケーションに不要となったトランザクションログを破棄してしまった場合に該当します。スナップショットの実行モードは複数あります。これには、コネクターのランタイム時にトリガーされる可能性がある 増分 スナップショットのサポートが含まれます。詳細は、使用しているコネクターのドキュメントを参照してください。
- フィルター: キャプチャーされたスキーマ、テーブル、およびコラムは include または exclude リストフィルターで設定できます。
- マスク:たとえば、機密データが含まれている場合など、特定の列からの値はマスクできます。
- 監視: ほとんどのコネクターは JMX を使用して監視できます。
- メッセージルーティング、フィルタリング、イベントフラット化などに、SMT(すぐに使用できる単一のメッセージ変換) などを使用できます。Debezium が提供する SMT の詳細は、Applying transformations to modify messages exchanged with Apache Kafkaを参照してください。
各コネクターのドキュメントには、コネクター機能と設定オプションの詳細が記載されています。
1.2. Debezium アーキテクチャーの説明
Apache Kafka Connect を使用して Debezium をデプロイします。Kafka Connect は、以下を実装および操作するためのフレームワークおよびランタイムです。
- レコードを Kafka に送信する Debezium などのソースコネクター
- Kafka トピックから他のシステムにレコードを伝播する Sink コネクター
以下の図は、Debezium をベースとした Change Data Capture パイプラインのアーキテクチャーを示しています。
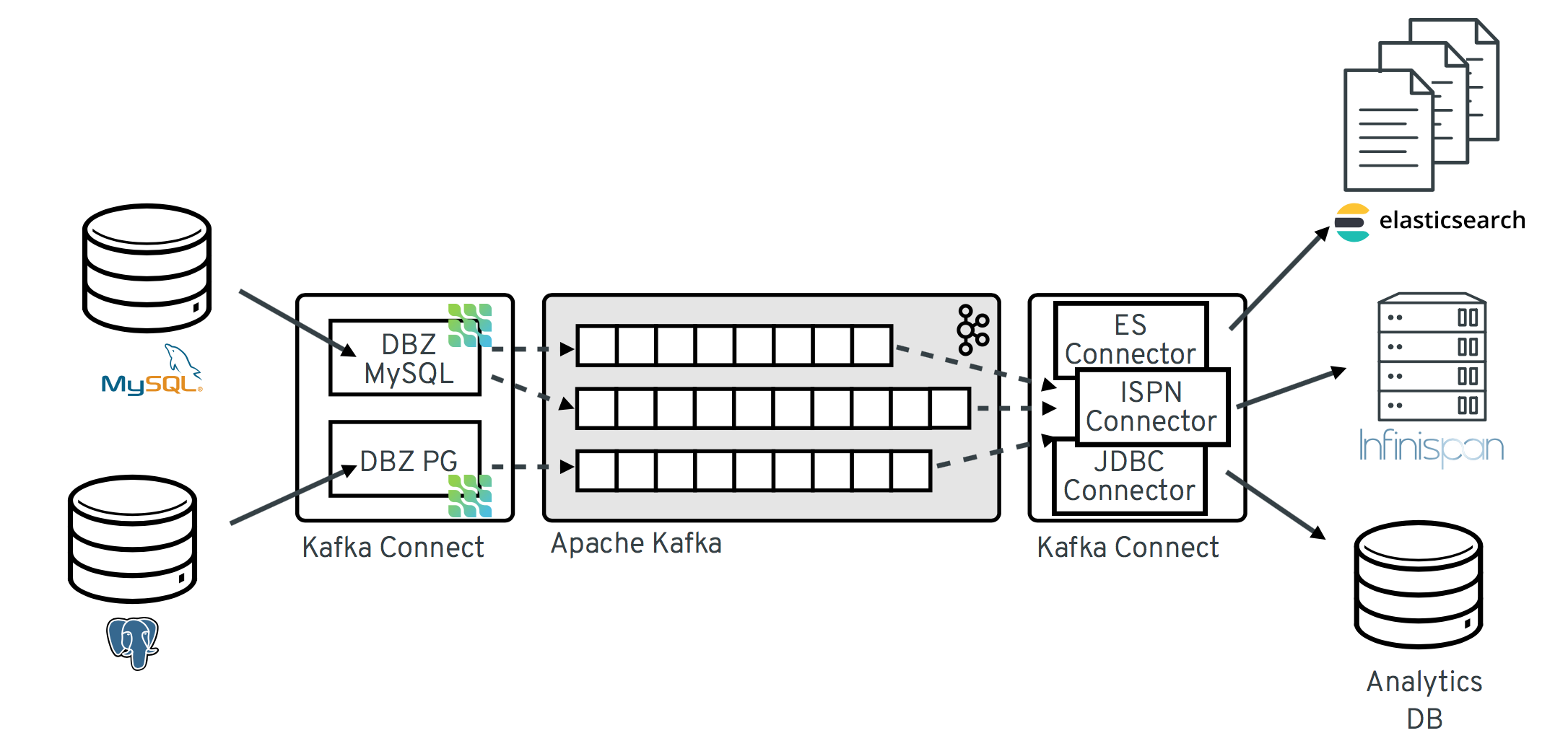
イメージにあるように、MySQL と PostgresSQL の Debezium コネクターは、この 2 種類のデータベースへの変更をキャプチャーするためにデプロイされます。各 Debezium コネクターは、そのソースデータベースへの接続を確立します。
-
MySQL コネクターは、
binlogへのアクセスにクライアントライブラリーを使用します。 - PostgreSQL コネクターは論理レプリケーションストリームから読み取ります。
Kafka Connect は、Kafka ブローカー以外の別のサービスとして動作します。
デフォルトでは、1 つのデータベースからの変更が、名前がテーブル名に対応する Kafka トピックに書き込まれます。必要な場合は、Debezium の トピックルーティング変換 を設定すると、宛先トピック名を調整できます。たとえば、以下を実行できます。
- テーブルの名前と名前が異なるトピックへレコードをルーティングする。
- 複数テーブルの変更イベントレコードを単一のトピックにストリーミングする。
変更イベントレコードが Apache Kafka に保存されると、Kafka Connect エコシステム内のさまざまなコネクターが、Elasticsearch、データウェアハウス、分析システムなどの他のシステムやデータベース、または Infinispan などのキャッシュにレコードをストリーミングできるようになります。選択した sink コネクターによっては、Debezium の 新しいレコード状態の抽出 (Record State Extraction) の変換を設定する必要がある場合があります。この Kafka Connect SMT は、Debezium の変更イベントから sink コネクターに after 構造を伝播します。変更イベントレコードが変更され、デフォルトで伝播されるより詳細で冗長なレコードを置き換えます。
Debezium Server
Debezium Server を使用して Debezium をデプロイすることもできます。Debezium Server は、設定可能ですぐに使用できるアプリケーションで、ソースデータベースからさまざまなメッセージングインフラストラクチャーに変更イベントをストリーミングします。
Debezium Server は、開発者プレビューのソフトウェアのみです。開発者プレビューソフトウェアは、Red Hat では一切サポートされておらず、機能的に完全ではなく、実稼働環境に対応していません。開発者プレビューのソフトウェアを実稼働ワークロードまたはビジネスクリティカルなワークロードには使用しないでください。開発者プレビューソフトウェアは、今後 Red Hat 製品サービスとして追加される可能性のある製品ソフトウェアを前もって早期に利用できます。お客様はこのソフトウェアを使用して機能をテストし、開発プロセス中にフィードバックを提供できます。このソフトウェアにはドキュメントが存在しない可能性があり、変更または削除される可能性があります。また、限定的なテストしか行われていません。Red Hat は、関連する SLA なしに、開発者プレビューソフトウェアに対するフィードバックを送信する手段を提供する場合があります。
Red Hat 開発者プレビューソフトウェアのサポート範囲の詳細は、開発者プレビューのサポート範囲 を参照してください。
次の図は、Debezium Server を使用する変更データキャプチャーパイプラインのアーキテクチャーを示しています。
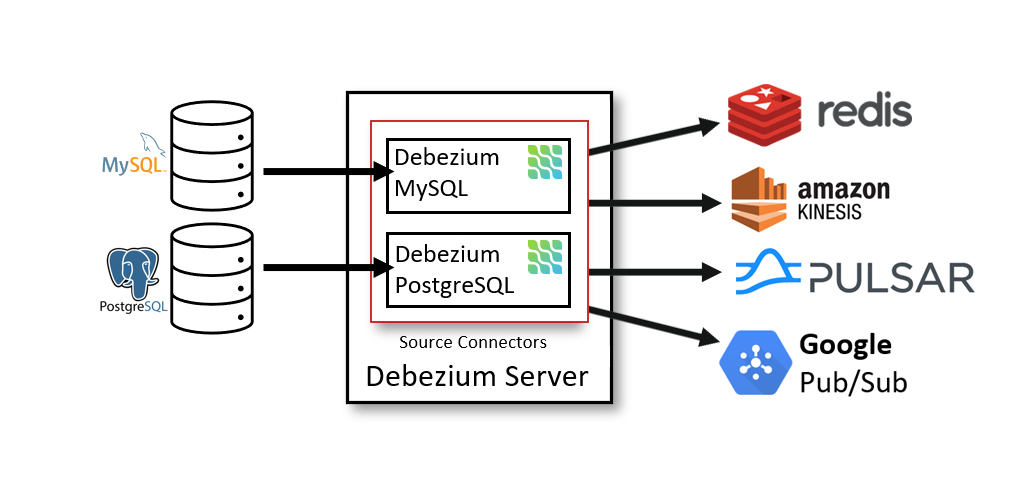
Debezium ソースコネクターの 1 つを使用してソースデータベースからの変更をキャプチャーするように Debezium Server を設定できます。変更イベントは、JSON や Apache Avro などのさまざまな形式にシリアル化でき、その後、Apache Kafka や Redis Streams などのさまざまなメッセージングインフラストラクチャーのいずれかに送信されます。
第2章 ソースコネクター
Debezium は、さまざまなデータベース管理システムからの変更をキャプチャーするソースコネクターのライブラリーを提供します。各コネクターは、構造が非常に類似した変更イベントを生成するため、イベントの発生元に関係なく、アプリケーションがイベントを簡単に使用して応答できるようになります。
現在、Debezium は次のデータベース用のソースコネクターを提供しています。
2.1. Db2 の Debezium コネクター
Debezium の Db2 コネクターは、Db2 データベースのテーブルで行レベルの変更をキャプチャーできます。このコネクターと互換性のある Db2 データベースのバージョンについては、Debezium でサポートされる設定ページを参照してください。
このコネクターは、テーブルを "キャプチャーモード" にする SQL ベースのポーリングモデルを使用する、SQL Server の Debezium 実装から大きく影響を受けます。テーブルがキャプチャーモードの場合、Debezium Db2 コネクターは、そのテーブルへの行レベルの更新ごとに変更イベントを生成し、ストリーミングします。
キャプチャーモードのテーブルには、関連する変更テーブルがあり、このテーブルは Db2 によって作成されます。キャプチャーモードのテーブルに対する変更ごとに、Db2 はその変更に関するデータをテーブルの関連する変更データテーブルに追加します。変更データテーブルには、行の各状態のエントリーが含まれます。また、削除に関する特別なエントリーもあります。Debezium Db2 コネクターは変更イベントを変更データテーブルから読み取り、イベントを Kafka トピックに出力します。
Debezium Db2 コネクターが Db2 データベースに初めて接続すると、コネクターが変更をキャプチャーするように設定されたテーブルの整合性スナップショットを読み取ります。デフォルトでは、システム以外のテーブルがすべて対象になります。キャプチャーモードにするテーブルまたはキャプチャーモードから除外するテーブルを指定できるコネクター設定プロパティーがあります。
スナップショットが完了すると、コネクターはコミットされた更新の変更イベントをキャプチャーモードのテーブルに出力し始めます。デフォルトでは、特定のテーブルの変更イベントは、テーブルと同じ名前を持つ Kafka トピックに移動します。アプリケーションとサービスはこれらのトピックから変更イベントを使用します。
コネクターには、Linux 用の Db2 の標準部分として利用できる抽象構文表記 (ASN) ライブラリーを使用する必要があります。ASN ライブラリーを使用するには、IBM InfoSphere Data Replication (IIDR) のライセンスが必要です。ASN ライブラリーを使用するには、IIDR をインストールする必要はありません。
Debezium Db2 コネクターを使用するための情報および手順は、以下のように設定されています。
2.1.1. Debezium Db2 コネクターの概要
Debezium Db2 コネクターは、Db2 で SQL レプリケーションを有効にする ASN Capture/Apply エージェント をベースにしています。キャプチャーエージェントは以下を行います。
- キャプチャーモードであるテーブルの変更データテーブルを生成します。
- キャプチャーモードのテーブルを監視し、更新の変更イベントを対応する変更データテーブルのテーブルに格納します。
Debezium コネクターは SQL インターフェイスを使用して変更イベントの変更データテーブルに対してクエリーを実行します。
データベース管理者は、変更をキャプチャーするテーブルをキャプチャーモードにする必要があります。便宜上およびテストを自動化するために、以下の管理タスクをコンパイルし、実行できる Debezium 管理ユーザー定義機能 (UDF) が C にあります。
- ASN エージェントの開始、停止、および再初期化。
- テーブルをキャプチャーモードにする。
- レプリケーション (ASN) スキーマと変更データテーブルの作成。
- キャプチャーモードからのテーブルの削除。
また、Db2 制御コマンドを使用してこれらのタスクを実行することもできます。
対象のテーブルがキャプチャーモードになった後、コネクターは対応する変更データテーブルを読み取り、テーブル更新の変更イベントを取得します。コネクターは、変更されたテーブルと同じ名前を持つ Kafka トピックに対して、行レベルの挿入、更新、および削除操作ごとに変更イベントを出力します。これは、変更可能なデフォルトの動作です。クライアントアプリケーションは、対象のデータベーステーブルに対応する Kafka トピックを読み取り、行レベルの各変更イベントに対応できます。
通常、データベース管理者はテーブルのライフサイクルの途中でテーブルをキャプチャーモードにします。つまり、コネクターにはテーブルに加えられたすべての変更の完全な履歴はありません。そのため、Db2 コネクターが最初に特定の Db2 データベースに接続すると、キャプチャーモードである各テーブルで 整合性スナップショット を実行して起動します。コネクターは、スナップショットの完成後に、スナップショットが作成された時点から変更イベントをストリーミングします。これにより、コネクターはキャプチャーモードのテーブルの整合性のあるビューで開始し、スナップショットの実行中に加えられた変更は破棄されません。
Debezium コネクターはフォールトトラレントです。コネクターは変更イベントを読み取りおよび生成すると、変更データテーブルエントリーのログシーケンス番号 (LSN) を記録します。LSN はデータベースログの変更イベントの位置になります。コネクターが何らかの理由で停止した場合 (通信障害、ネットワークの問題、クラッシュなど)、コネクターは再起動後に最後に停止した場所の変更データテーブルの読み取りを続行します。これにはスナップショットが含まれます。つまり、コネクターの停止時にスナップショットが完了しなかった場合、コネクターの再起動時に新しいスナップショットが開始されます。
2.1.2. Debezium Db2 コネクターの仕組み
Debezium Db2 コネクターを最適に設定および実行するには、コネクターによるスナップショットの実行方法、変更イベントのストリーム方法、Kafka トピック名の決定方法、およびスキーマ変更の処理方法を理解すると便利です。
詳細は以下を参照してください。
2.1.2.1. Debezium Db2 コネクターによるデータベーススナップショットの実行方法
Db2 のレプリケーション機能は、データベース変更の完全な履歴を保存するようには設計されていません。そのため、Debezium Db2 コネクターはログからデータベースの履歴全体を取得できません。コネクターがデータベースの現在の状態のベースラインを確立できるようにするには、コネクターの初回起動時に、キャプチャーボード のテーブルの最初の 整合性スナップショット を実行します。スナップショットが変更をキャプチャーするたびに、コネクターはキャプチャーされたテーブルの Kafka トピックに read イベントを発行します。
スナップショットの詳細は、以下のセクションを参照してください。
2.1.2.1.1. Debezium Db2 コネクターが最初のスナップショットの実行に使用するデフォルトのワークフロー
以下のワークフローでは、Debezium がスナップショットを作成する手順を示しています。この手順では、snapshot.mode 設定プロパティーがデフォルト値 (initial) に設定されている場合のスナップショットのプロセスを説明します。snapshot.mode プロパティーの値を変更することで、コネクターがスナップショットを作成する方法をカスタマイズできます。別のスナップショットモードを設定する場合、コネクターはこのワークフローの変更バージョンを使用してスナップショットを完了します。
- データベースへの接続を確立します。
-
キャプチャーモードで、かつスナップショットに含める必要があるテーブルを決定します。デフォルトでは、コネクターはシステム以外のすべてのテーブルのデータをキャプチャーします。スナップショットが完了した後、コネクターは指定されたテーブルのデータをストリーミングし続けます。コネクターで特定のテーブルからのみデータをキャプチャーする場合は、
table.include.listやtable.exclude.listなどのプロパティーを設定して、テーブルまたはテーブル要素のサブセットのみのデータをキャプチャーするようにコネクターに指示できます。 -
キャプチャーモードの各テーブルでロックを取得します。このロックを使用して、スナップショットが完了するまで、それらのテーブルでスキーマの変更が行われないようにします。ロックのレベルは、
snapshot.isolation.modeコネクター設定プロパティーによって決定されます。 - サーバーのトランザクションログで、最上位 (最新) の LSN の位置を読み取ります。
すべてのテーブル、またはキャプチャー対象として指定されたすべてのテーブルのスキーマをキャプチャーします。コネクターは、内部データベースのスキーマ履歴トピックにスキーマ情報を保持します。スキーマ履歴は、変更イベントの発生時に有効な構造に関する情報を提供します。
注記デフォルトでは、コネクターは、キャプチャー用に設定されていないテーブルも含め、キャプチャーモードにあるデータベース内の全テーブルのスキーマをキャプチャーします。テーブルがキャプチャー用に設定されていない場合、最初のスナップショットはテーブルの構造のみをキャプチャーし、テーブルデータはキャプチャーされません。
初期スナップショットに含まれなかったテーブルのスキーマ情報がスナップショットに保持される理由の詳細は、初期スナップショットがすべてのテーブルのスキーマをキャプチャーする理由 を参照してください。
- 手順 3 で取得したロックをすべてリリースします。他のデータベースクライアントは、以前にロックされていたテーブルに書き込みできるようになります。
手順 4 で読み取った LSN 位置で、コネクターはキャプチャーするように指定されたテーブルをスキャンします。スキャン中に、コネクターは次のタスクを実行します。
- スナップショットが開始される前に、テーブルが作成されたことを確認します。スナップショットの開始後にテーブルが作成された場合、コネクターはテーブルをスキップします。スナップショットが完了し、コネクターがストリーミングに移行すると、スナップショットの開始後に作成されたテーブルに対して変更イベントが発行されます。
-
テーブルからキャプチャーされた行ごとに
readイベントを生成します。すべてのreadイベントには、LSN の位置が含まれ、これは手順 4 で取得した LSN の位置と同じです。 -
ソーステーブルの Kafka トピックに各
readイベントを出力します。 - 該当する場合は、データテーブルロックを解放します。
- コネクターオフセットにスナップショットの正常な完了を記録します。
作成された初期スナップショットは、キャプチャーされたテーブルの各行の現在の状態をキャプチャーします。このベースライン状態から、コネクターは発生した後続の変更をキャプチャーします。
スナップショットプロセスが開始されたら、コネクターの障害、リバランス、またはその他の理由でプロセスが中断されると、コネクターの再起動後にプロセスが再起動されます。
コネクターによって最初のスナップショットが完了した後、更新に抜けがないように、手順 4 で読み取った位置からストリーミングを続行します。
何らかの理由でコネクターが再び停止した場合に、コネクターは再起動後に最後に停止した位置から変更のストリーミングを再開します。
| 設定 | 説明 |
|---|---|
|
| コネクターは起動するたびにスナップショットを実行します。スナップショットが完了すると、コネクターは、後続のデータベース変更のに備え、イベントレコードのストリーミングを開始します。 |
|
| コネクターは 初期スナップショットを作成するためのデフォルトのワークフロー で説明されているように、データベーススナップショットを実行します。スナップショットが完了すると、コネクターは、後続のデータベース変更のに備え、イベントレコードのストリーミングを開始します。 |
|
| コネクターはデータベーススナップショットを実行します。スナップショットが完了すると、コネクターは停止し、後続のデータベース変更のイベントレコードをストリーミングしなくなります。 |
|
|
非推奨です。 |
|
|
コネクターは、デフォルトのスナップショットワークフロー で説明されているすべての手順を実行して、関連するすべてのテーブルの構造をキャプチャーします。ただし、コネクターの起動時点のデータセットを表す |
|
| 損失または破損したデータベーススキーマの履歴トピックを復元するにはこのオプションを設定します。再起動後、コネクターはソーステーブルからトピックを再構築するスナップショットを実行します。また、このプロパティーを設定して、予期しない増加が発生するデータベーススキーマ履歴トピックを定期的にプルーニングすることもできます。 警告 最後のコネクターのシャットダウン後にスキーマの変更がデータベースにコミットされた場合、このモードを使用してスナップショットを実行しないでください。 |
|
| コネクターが起動した後、次のいずれかの状況を検出した場合にのみスナップショットが実行されます。
|
詳細は、コネクター設定プロパティーテーブルの snapshot.mode を参照してください。
2.1.2.1.2. 初期スナップショットがすべてのテーブルのスキーマ履歴をキャプチャーする理由
コネクターが実行する最初のスナップショットは、2 種類の情報をキャプチャーします。
- テーブルデータ
-
コネクターの
table.include.listプロパティーにあるテーブルのINSERT、UPDATE、およびDELETE操作に関する情報。 - スキーマデータ
- テーブルに適用される構造の変更を記述する DDL ステートメント。スキーマデータは、内部スキーマ履歴トピックとコネクターのスキーマ変更トピック (設定されている場合) の両方に保持されます。
初期スナップショットを実行すると、キャプチャー対象として指定されていないテーブルのスキーマ情報がスナップショットによってキャプチャーされることが分かります。デフォルトでは、初期スナップショットは、キャプチャー用に指定されたテーブルからだけでなく、データベースに存在するすべてのテーブルのスキーマ情報を取得するように設計されています。コネクターでは、テーブルのスキーマがスキーマ履歴トピックにある状態で、テーブルをキャプチャーする必要があります。初期スナップショットが元のキャプチャーセットの一部ではないテーブルのスキーマデータをキャプチャーできるようにして、後で必要になった場合にこれらのテーブルからイベントデータを簡単にキャプチャーできるように、Debezium はコネクターを準備します。初期スナップショットがテーブルのスキーマをキャプチャーしない場合は、コネクターがテーブルからデータをキャプチャーする前に、履歴トピックにスキーマを追加する必要があります。
場合によっては、最初のスナップショットでのスキーマキャプチャーを制限する場合があります。これは、スナップショットの完了に必要な時間の短縮に便利です。または、Debezium が複数の論理データベースにアクセスできるユーザーアカウントを使用して、データベースインスタンスに接続しているにもかかわらず、コネクターで特定の論理データベース内のテーブルからの変更のみをキャプチャーする場合にも便利です。
関連情報
- 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更なし)
- 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更)
-
schema.history.internal.store.only.captured.tables.ddlプロパティーを設定して、スキーマ情報をキャプチャーするテーブルを指定します。 -
schema.history.internal.store.only.captured.databases.ddlプロパティーを設定して、スキーマ変更をキャプチャーする論理データベースを指定します。
2.1.2.1.3. 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更なし)
コネクターを使用して、最初のスナップショットでスキーマがキャプチャーされなかったテーブルからデータをキャプチャーする場合があります。コネクターの設定によっては、最初のスナップショットはデータベース内の特定のテーブルのテーブルスキーマのみをキャプチャーする場合があります。テーブルスキーマが履歴トピックに存在しない場合、コネクターはテーブルのキャプチャーに失敗し、スキーマ欠落エラーを報告します。
テーブルからデータを取得できる場合もありますが、テーブルスキーマを追加するには別の手順を実行する必要があります。
前提条件
- コネクターにより最初のスナップショット中にキャプチャーされなかったスキーマが含まれるテーブルからデータをキャプチャーしたいと考えている。
- コネクターが読み取った最も初期の変更テーブルエントリーと、最新の変更テーブルエントリーの LSN の間で、スキーマの変更がテーブルに加えられていない。構造が変更された新しいテーブルからデータを取得する方法は、「初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更)」 を参照してください。
手順
- コネクターを停止します。
-
schema.history.internal.kafka.topic プロパティーで指定された内部データベーススキーマ履歴トピックを削除します。 設定された Kafka Connect
offset.storage.topic内のオフセットをクリアします。オフセットを削除する方法の詳細は、Debezium コミュニティーの FAQ を参照してください。警告オフセットの削除は、内部 Kafka Connect データの操作の経験がある上級ユーザーのみが実行してください。この操作によりシステムが破損する場合があるため、最後の手段としてのみ実行してください。
以下の変更をコネクター設定に適用します。
(オプション)
schema.history.internal.captured.tables.ddlの値をfalseに設定します。この設定により、スナップショットですべてのテーブルのスキーマがキャプチャーされ、今後、コネクターがすべてのテーブルのスキーマ履歴を再構築できるようにします。
注記すべてのテーブルのスキーマをキャプチャーするスナップショットは、完了までにさらに時間がかかります。
-
コネクターがキャプチャーするテーブルを
table.include.listに追加します。 snapshot.modeを次のいずれかの値に設定します。Initial-
コネクターを再起動すると、テーブルデータとテーブル構造をキャプチャーするデータベースの完全なスナップショットが作成されます。
このオプションを選択する場合は、コネクターがすべてのテーブルのスキーマをキャプチャーできるように、schema.history.internal.captured.tables.ddlプロパティーの値をfalseに設定することを検討してください。 schema_only- コネクターを再起動すると、テーブルスキーマのみをキャプチャーするスナップショットが作成されます。完全なデータスナップショットとは異なり、このオプションではテーブルデータはキャプチャーされません。完全なスナップショットが作成される前に、早くコネクターを再起動する場合は、このオプションを使用します。
-
コネクターを再起動します。コネクターは、
snapshot.modeで指定されたタイプのスナップショットを完了します。 (オプション) コネクターが
schema_onlyスナップショットを実行した場合、スナップショットの完了後に 増分スナップショット を開始して、追加したテーブルからデータをキャプチャーします。コネクターは、テーブルからリアルタイムの変更をストリーミングし続けながら、スナップショットを実行します。増分スナップショットを実行すると、次のデータ変更がキャプチャーされます。- コネクターが以前にキャプチャーしたテーブルの場合、増分スナップショットは、コネクターが停止している間、つまりコネクターが停止してから現在の再起動までの間に発生した変更をキャプチャーします。
- 新しく追加されたテーブルの場合、増分スナップショットは既存のテーブル行をすべてキャプチャーします。
2.1.2.1.4. 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更)
スキーマ変更がテーブルに適用される場合、スキーマ変更前にコミットされたレコードの構造は、変更後にコミットされたレコードとは異なります。Debezium はテーブルからデータをキャプチャーするときに、スキーマ履歴を読み取り、各イベントに正しいスキーマが適用されていることを確認します。スキーマがスキーマ履歴トピックに存在しない場合、コネクターはテーブルをキャプチャーできず、エラーが発生します。
最初のスナップショットでキャプチャーされず、テーブルのスキーマが変更されたテーブルからデータをキャプチャーする場合、スキーマがまだ使用可能でない場合は、履歴トピックにスキーマを追加する必要があります。新しいスキーマスナップショットを実行するか、テーブルの初期スナップショットを実行して、スキーマを追加できます。
前提条件
- コネクターにより最初のスナップショット中にキャプチャーされなかったスキーマが含まれるテーブルからデータをキャプチャーしたいと考えている。
- スキーマ変更がテーブルに適用されたため、キャプチャーされるレコードの構造が不均一になっている。
手順
- 初期スナップショットにすべてのテーブルのスキーマがキャプチャーされている場合 (
store.only.captured.tables.ddlはfalseに設定されました)。 -
table.include.listプロパティーを編集して、キャプチャーするテーブルを指定します。 - コネクターを再起動します。
- 新しく追加したテーブルから既存のデータをキャプチャーする場合は、増分スナップショット を開始します。
-
- 初期スナップショットにすべてのテーブルのスキーマがキャプチャーされていない場合 (
store.only.captured.tables.ddlがtrueに設定されています)。 最初のスナップショットでキャプチャーするテーブルのスキーマが保存されなかった場合は、次のいずれかの手順を実行します。
- 手順 1: スキーマスナップショット、その後に増分スナップショット
この手順では、コネクターは最初にスキーマのスナップショットを実行します。その後、増分スナップショットを開始して、コネクターがデータを同期できるようにします。
- コネクターを停止します。
-
schema.history.internal.kafka.topic プロパティーで指定された内部データベーススキーマ履歴トピックを削除します。 設定された Kafka Connect
offset.storage.topic内のオフセットをクリアします。オフセットを削除する方法の詳細は、Debezium コミュニティーの FAQ を参照してください。警告オフセットの削除は、内部 Kafka Connect データの操作の経験がある上級ユーザーのみが実行してください。この操作によりシステムが破損する場合があるため、最後の手段としてのみ実行してください。
次の手順の説明に従って、コネクター設定のプロパティーの値を設定します。
-
snapshot.modeプロパティーの値をschema_onlyに設定します。 -
table.include.listを編集して、キャプチャーするテーブルを追加します。
-
- コネクターを再起動します。
- Debezium が新規および既存のテーブルのスキーマをキャプチャーするまで待ちます。コネクターが停止した後にテーブルで発生したデータ変更はキャプチャーされません。
- データが損失されないようにするには、増分スナップショット を開始します。
- 手順 2: 初期スナップショットと、それに続くオプションの増分スナップショット
この手順では、コネクターはデータベースの完全な初期スナップショットを実行します。他の初期スナップショットと同様、多数の大きなテーブルが含まれるデータベースでは、初期スナップショットの実行操作には時間がかかる可能性があります。スナップショットの完了後、任意で増分スナップショットをトリガーして、コネクターがオフラインの間に発生した変更をキャプチャーできます。
- コネクターを停止します。
-
schema.history.internal.kafka.topic プロパティーで指定された内部データベーススキーマ履歴トピックを削除します。 設定された Kafka Connect
offset.storage.topic内のオフセットをクリアします。オフセットを削除する方法の詳細は、Debezium コミュニティーの FAQ を参照してください。警告オフセットの削除は、内部 Kafka Connect データの操作の経験がある上級ユーザーのみが実行してください。この操作によりシステムが破損する場合があるため、最後の手段としてのみ実行してください。
-
table.include.listを編集して、キャプチャーするテーブルを追加します。 次の手順の説明に従って、コネクター設定のプロパティーの値を設定します。
-
snapshot.modeプロパティーの値をinitialに設定します。 -
(オプション)
schema.history.internal.store.only.captured.tables.ddlをfalseに設定します。
-
- コネクターを再起動します。コネクターはデータベース全体のスナップショットを取得します。スナップショットが完了すると、コネクターはストリーミングに移行します。
- (オプション) コネクターがオフラインの間に変更されたデータをキャプチャーするには、増分スナップショット を開始します。
2.1.2.2. アドホックスナップショット
デフォルトでは、コネクターは初回スナップショット操作の開始後にのみ実行されます。通常の状況では、この最初のスナップショットが作成されると、コネクターではスナップショットプロセスは繰り返し処理されません。コネクターがキャプチャーする今後の変更イベントデータはストリーミングプロセス経由でのみ行われます。
ただし、場合によっては、最初のスナップショット中にコネクターを取得したデータが古くなったり、失われたり、または不完全となったり可能性があります。テーブルデータを再キャプチャーするメカニズムを提供するため、Debezium にはアドホックスナップショットを実行するオプションがあります。Debezium 環境で次のいずれかの変更が発生したら、アドホックスナップショットを実行することを推奨します。
- コネクター設定は、異なるテーブルセットをキャプチャーするように変更されます。
- Kafka トピックを削除して、再構築する必要があります。
- 設定エラーや他の問題が原因で、データの破損が発生します。
アドホックと呼ばれるスナップショット を開始することで、以前にスナップショットをキャプチャーしたテーブルのスナップショットを再実行できます。アドホックスナップショットには、シグナルテーブル を使用する必要があります。シグナルリクエストを Debezium シグナルテーブルに送信して、アドホックスナップショットを開始します。
既存のテーブルのアドホックスナップショットを開始すると、コネクターはテーブルにすでに存在するトピックにコンテンツを追加します。既存のトピックが削除された場合には、トピックの自動作成 が有効になっているのであれば、Debezium は自動的にトピックを作成できます。
アドホックのスナップショットシグナルは、スナップショットに追加するテーブルを指定します。スナップショットは、データベースの内容全体をキャプチャーしたり、データベース内のテーブルのサブセットのみをキャプチャーしたりできます。また、スナップショットは、データベース内のテーブルの内容のサブセットをキャプチャできます。
execute-snapshot メッセージをシグナルテーブルに送信してキャプチャーするテーブルを指定します。execute-snapshot シグナルのタイプを incremental または blocking に設定し、スナップショットに含めるテーブルの名前を次の表に示すように指定します。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプを指定します。 |
|
| 該当なし |
スナップショットに含めるテーブルの完全修飾名に一致する正規表現を含む配列。 |
|
| 該当なし |
コネクターがスナップショットに含めるレコードのサブセットを決定するために評価する追加条件のセットを指定する、オプションの配列。
|
|
| 該当なし | スナップショット処理中にコネクターがテーブルのプライマリーキーとして使用する列名を指定するオプションの文字列。 |
アドホック増分スナップショットのトリガー
アドホック増分スナップショットを開始するには、execute-snapshot シグナルタイプのエントリーをシグナリングテーブルに追加するか、シグナルメッセージを Kafka シグナリングトピックに送信します。コネクターがメッセージを処理した後に、スナップショット操作を開始します。スナップショットプロセスは、最初と最後のプライマリーキーの値を読み取り、これらの値を各テーブルの開始ポイントおよびエンドポイントとして使用します。テーブルのエントリー数と設定されたチャンクサイズに基づいて、Debezium はテーブルをチャンクに分割し、チャンクごとに 1 度に 1 つずつスナップショットを順番に作成していきます。
詳細は、スナップショットの増分を参照してください。
アドホックブロッキングスナップショットのトリガー
シグナリングテーブルまたはシグナリングトピックに、execute-snapshot シグナルタイプを持つエントリーを追加することによって、アドホックブロッキングスナップショットを開始します。コネクターがメッセージを処理した後に、スナップショット操作を開始します。コネクターはストリーミングを一時的に停止し、初期スナップショットの時と同じプロセスに従って、指定されたテーブルのスナップショットを開始します。スナップショットが完了すると、コネクターはストリーミングを再開します。
詳細は、ブロッキングスナップショット を参照してください。
2.1.2.3. 増分スナップショット
スナップショットを柔軟に管理するため、Debezium には 増分スナップショット と呼ばれる補助スナップショットメカニズムが含まれています。増分スナップショットは、Debezium コネクターにシグナルを送信するため の Debezium メカニズムに依存します。
増分スナップショットでは、最初のスナップショットのように、データベースの完全な状態を一度にすべてキャプチャーする代わりに、一連の設定可能なチャンクで各テーブルを段階的にキャプチャーします。スナップショットがキャプチャーするテーブルと、各チャンクのサイズ を指定できます。チャンクのサイズにより、データベース上の各フェッチ操作中にスナップショットで収集される行数が決まります。増分スナップショットのデフォルトのチャンクサイズは 1024 行です。
増分スナップショットが進むと、Debezium はウォーターマークを使用して進捗を追跡し、キャプチャーする各テーブル行のレコードを管理します。この段階的なアプローチでは、標準の初期スナップショットプロセスと比較して、以下の利点があります。
- スナップショットが完了するまで、ストリーミングストリーミングを延期する代わりに、ストリームしたデータキャプチャーと並行して増分スナップショットを実行できます。コネクターはスナップショットプロセス全体で変更ログからのほぼリアルタイムイベントをキャプチャーし続け、他の操作はブロックしません。
- 増分スナップショットの進捗が中断された場合は、データを失うことなく再開できます。プロセスが再開すると、スナップショットは最初からテーブルをキャプチャーするのではなく、停止した時点から開始します。
-
いつでも増分スナップショットを実行し、必要に応じてプロセスを繰り返してデータベースの更新に適合できます。たとえば、コネクター設定を変更してテーブルを
table.include.listプロパティーに追加した後にスナップショットを再実行します。
増分スナップショットプロセス
増分スナップショットを実行する場合には、Debezium は各テーブルをプライマリーキー別に分類して、設定されたチャンクサイズ に基づいてテーブルをチャンクに分割します。チャンクごとに作業し、テーブルの行ごとにチャンクでキャプチャーします。キャプチャーする行ごとに、スナップショットは READ イベントを出力します。そのイベントは、対象となるチャンクのスナップショットを開始する時の行の値を表します。
スナップショットの作成が進むにつれ、他のプロセスがデータベースへのアクセスを継続し、テーブルレコードが変更される可能性があります。このような変更を反映させるように、通常通りに INSERT、UPDATE、DELETE 操作がトランザクションログにコミットされます。同様に、継続中の Debezium ストリーミングプロセスは、これらの変更イベントを検出し、対応する変更イベントレコードを Kafka に出力します。
Debezium を使用してプライマリーキーが同じレコード間での競合を解決する方法
場合によっては、ストリーミングプロセスが出力する UPDATE または DELETE イベントを順番に受信できます。つまり、ストリーミングプロセスは、スナップショットがその行の READ イベントが含まれるチャンクをキャプチャーする前に、テーブルの行を変更するイベントを生成する可能性があります。スナップショットが最終的に対象の行にあった READ イベントを出力すると、その値はすでに置き換えられています。Debezium は、シーケンスが到達する増分スナップショットイベントが正しい論理順序で処理されるように、競合を解決するためにバッファースキームを使用します。スナップショットのイベント間で競合が発生し、ストリームされたイベントが解決されてからでないと、Debezium はイベントのレコードを Kafka に送信しません。
スナップショットウィンドウ
遅れて入ってきた READ イベントと、同じテーブルの行を変更するストリーミングイベント間の競合の解決を容易にするために、Debezium は スナップショットウィンドウ と呼ばれるものを使用します。スナップショットウィンドウは、増分スナップショットが指定のテーブルチャンクのデータをキャプチャーしている途中に、間隔を決定します。チャンクのスナップショットウィンドウを開く前に、Debezium は通常の動作に従い、トランザクションログから直接ターゲットの Kafka トピックにイベントをダウンストリームに出力します。ただし、特定のチャンクのスナップショットが開放された瞬間から終了するまで、Debezium は重複除去のステップを実行して、プライマリーキーが同じイベント間での競合を解決します。
データコレクションごとに、Debezium は 2 種類のイベントを出力し、それらの両方のレコードを単一の宛先 Kafka トピックに保存します。テーブルから直接キャプチャーするスナップショットレコードは、READ 操作として出力されます。その間、ユーザーはデータコレクションのレコードの更新を続け、各コミットを反映するようにトランザクションログが更新されるので、Debezium は変更ごとに UPDATE または DELETE 操作を出力します。
スナップショットウィンドウが開放され、Debezium がスナップショットチャンクの処理を開始すると、スナップショットレコードをメモリーバッファーに提供します。スナップショットウィンドウ中に、バッファー内の READ イベントのプライマリーキーは、受信ストリームイベントのプライマリーキーと比較されます。一致するものが見つからない場合、ストリーミングされたイベントレコードが Kafka に直接送信されます。Debezium が一致を検出すると、バッファーされた READ イベントを破棄し、ストリーミングされたレコードを宛先トピックに書き込みます。これは、ストリーミングされたイベントが静的スナップショットイベントよりも論理的に優先されるためです。チャンクのスナップショットウィンドウが終了すると、バッファーに含まれるのは、関連するトランザクションログイベントが存在しない READ イベントのみです。Debezium は、これらの残りの READ イベントをテーブルの Kafka トピックに出力します。
コネクターは各スナップショットチャンクにプロセスを繰り返します。
現在、増分スナップショットを開始するには、次のいずれかの方法を使用できます。
Db2 の Debezium コネクターでは、増分スナップショットの実行中のスキーマの変更はサポートしません。
2.1.2.3.1. 増分スナップショットのトリガー
増分スナップショットを開始するには、ソースデータベースのシグナリングテーブルに アドホックスナップショットシグナル を送信します。スナップショットシグナルは SQL INSERT クエリーとして送信します。
Debezium がシグナルテーブルの変更を検出すると、シグナルを読み取り、要求されたスナップショット操作を実行します。
送信するクエリーはスナップショットに追加するテーブルを指定し、必要に応じてスナップショット操作の種類を指定します。Debezium は現在、incremental と blocking のスナップショットタイプをサポートしています。
スナップショットに追加するテーブルを指定するには、テーブルをリストする data-collections 配列またはテーブルの照合に使用する正規表現の配列を指定します。以下に例を示します。
{"data-collections": ["public.MyFirstTable", "public.MySecondTable"]}
増分スナップショットシグナルの data-collections アレイにはデフォルト値がありません。data-collections 配列が空の場合、Debezium は空の配列をアクションが必要ないと解釈し、スナップショットは作成しません。
スナップショットに含めるテーブルの名前にドット (.)、スペース、またはその他の英数字以外の文字が含まれている場合は、テーブル名を二重引用符でエスケープする必要があります。
たとえば、 public スキーマに存在し、My.Table という名前のテーブルを含めるには、"public.\"My.Table\"" の形式を使用します。
前提条件
- ソースデータベースにシグナリングデータコレクションが存在する。
-
シグナルデータコレクションが
signal.data.collectionプロパティーで指定されている。
ソースシグナリングチャネルを使用して増分スナップショットをトリガーする
SQL クエリーを送信し、アドホック増分スナップショット要求をシグナルテーブルに追加します。
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow コマンドの
id、type、およびdataパラメーターの値は、シグナルテーブルのフィールド に対応します。
以下の表では、この例のパラメーターを説明しています。Expand 表2.3 シグナルテーブルに増分スナップショットシグナルを送信する SQL コマンドのフィールドの説明 項目 値 説明 1
schema.debezium_signalソースデータベースにあるシグナルテーブルの完全修飾名を指定します。
2
ad-hoc-1idパラメーターは、シグナルリクエストのID識別子として割り当てられる任意の文字列を指定します。
この文字列を使用して、シグナルテーブルのエントリーへのログメッセージを特定します。Debezium はこの文字列を使用しません。代わりに、スナップショット作成中に、Debezium は独自のID文字列をウォーターマークシグナルとして生成します。3
execute-snapshottypeパラメーターを指定し、シグナルがトリガーする操作を指定します。
4
data-collectionsシグナルの
dataフィールドの必須コンポーネントで、スナップショットに含めるテーブル名の配列またはテーブル名と一致する正規表現を指定します。
配列には、schema.table形式を使用してテーブルの完全修飾名と一致する正規表現がリストされます。この形式は、コネクターの シグナリングテーブル の名前を指定するために使用する形式と同じです。5
incremental実行するスナップショット操作のタイプを指定する、シグナルの
dataフィールドのオプションのtypeコンポーネント。
有効な値はincrementalとblockingです。
値を指定しない場合、コネクターはデフォルトで増分スナップショットを実行します。6
additional-conditionsコネクターがスナップショットに含めるレコードのサブセットを決定するために評価する追加条件のセットを指定する、オプションの配列。
各追加条件は、data-collectionプロパティーとfilterプロパティーを持つオブジェクトです。データの収集単位で異なるフィルターを指定できます。
*data-collectionプロパティーは、フィルターが適用されるデータコレクションの完全修飾名です。additional-conditionsパラメーターの詳細は、「additional-conditions付きでアドホック増分スナップショットを実行する」 を参照してください。
2.1.2.3.2. additional-conditions 付きでアドホック増分スナップショットを実行する
スナップショットに、テーブル内のコンテンツのサブセットのみを含める場合は、スナップショットシグナルに additional-conditions パラメーターを追加してシグナル要求を変更できます。
一般的なスナップショットの SQL クエリーは、以下の形式を取ります。
SELECT * FROM <tableName> ....
SELECT * FROM <tableName> ....
additional-conditions パラメーターを追加して、以下の例のように WHERE 条件を SQL クエリーに追加します。
SELECT * FROM <data-collection> WHERE <filter> ....
SELECT * FROM <data-collection> WHERE <filter> ....以下の例は、シグナルテーブルに追加の条件を含むアドホック増分スナップショット要求を送信する SQL クエリーを示しています。
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');
たとえば、以下の列が含まれる products テーブルがあるとします。
-
id(プライマリーキー) -
color -
quantity
products テーブルの増分スナップショットに color=blue のデータ項目のみを含める場合は、次の SQL ステートメントを使用してスナップショットをトリガーできます。
INSERT INTO myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["schema1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "schema1.products", "filter": "color=blue"}]}');
INSERT INTO myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["schema1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "schema1.products", "filter": "color=blue"}]}');
additional-conditions パラメーターを使用すると、列が 2 つ以上となる条件を指定することもできます。たとえば、前述の例の products テーブルを使用して、color=blue および quantity>10 だけに一致するアイテムのみのデータが含まれる増分スナップショットをトリガーするクエリーを送信できます。
INSERT INTO myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["schema1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "schema1.products", "filter": "color=blue AND quantity>10"}]}');
INSERT INTO myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["schema1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "schema1.products", "filter": "color=blue AND quantity>10"}]}');以下の例は、コネクターによってキャプチャーされる増分スナップショットイベントの JSON を示しています。
例2.1 増分スナップショットイベントメッセージ
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
実行するスナップショット操作タイプを指定します。 |
| 2 |
|
イベントタイプを指定します。 |
2.1.2.3.3. Kafka シグナルチャネルを使用して増分スナップショットをトリガーする
設定された Kafka トピック にメッセージを送信して、コネクターにアドホック増分スナップショットを実行するよう要求できます。
Kafka メッセージのキーは、topic.prefix コネクター設定オプションの値と一致する必要があります。
メッセージの値は、type と data フィールドが含まれる JSON オブジェクトとなっています。
シグナルタイプは execute-snapshot で、data フィールドには以下のフィールドが必要です。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプ。現在、Debezium は |
|
| 該当なし |
スナップショットに含めるテーブルの完全修飾名と一致する、コンマ区切りの正規表現の配列。 |
|
| 該当なし |
コネクターがスナップショットに含めるレコードのサブセットを指定するために評価する基準を指定する、オプションの追加条件の配列。 |
例2.2 execute-snapshot Kafka メッセージ
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["{collection-container}.table1", "{collection-container}.table2"], "type": "INCREMENTAL"}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["{collection-container}.table1", "{collection-container}.table2"], "type": "INCREMENTAL"}}`additional-conditions 付きのアドホック増分スナップショット
Debezium は additional-conditions フィールドを使用してテーブルのコンテンツのサブセットを選択します。
通常、Debezium はスナップショットを実行するときに、次のような SQL クエリーを実行します。
SELECT * FROM <tableName> ….
スナップショット要求に additional-conditions プロパティーが含まれている場合、プロパティーの data-collection および filter パラメーターが SQL クエリーに追加されます。次に例を示します。
SELECT * FROM <data-collection> WHERE <filter> ….
たとえば、列 id (プライマリーキー)、color、および brand を含む products テーブルがある場合、スナップショットに color='blue' のコンテンツのみを含める場合は、スナップショットをリクエストするときに、コンテンツをフィルタリングする additional-conditions プロパティーを追加することができます。
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["schema1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "schema1.products" ,"filter":"color='blue'"}]}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["schema1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "schema1.products" ,"filter":"color='blue'"}]}}`
また、additional-conditions プロパティーを使用して、複数の列に基づいて条件を渡すこともできます。たとえば、前の例と同じ products テーブルを使用して、color='blue' および brand='MyBrand' である products テーブルのコンテンツのみをスナップショットに含める場合は、次のリクエストを送信できます。
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["schema1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "schema1.products" ,"filter":"color='blue' AND brand='MyBrand'"}]}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["schema1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "schema1.products" ,"filter":"color='blue' AND brand='MyBrand'"}]}}`2.1.2.3.4. 増分スナップショットの停止
状況によっては、増分スナップショットを停止する必要がある場合があります。たとえば、スナップショットが正しく設定されていない場合や、他のデータベース操作にリソースが使用可能であるこのとの確認が必要な場合があります。ソースデータベースのシグナリングテーブルにシグナルを送信することで、すでに実行中のスナップショットを停止できます。
スナップショット停止信号をシグナリングテーブルに送信するには、SQL INSERT クエリーで送信します。stop-snapshot シグナルは、スナップショット操作の type を incremental として指定し、オプションで、現在実行中のスナップショットから省略するテーブルを指定します。Debezium はシグナルテーブルの変更を検出した後、シグナルを読み、増分スナップショット操作が進行中であればそれを停止します。
関連情報
また、JSON メッセージを Kafka シグナリングトピック に送信して、増分スナップショットを停止することもできます。
前提条件
- ソースデータベースにシグナリングデータコレクションが存在する。
-
シグナルデータコレクションが
signal.data.collectionプロパティーで指定されている。
ソースシグナリングチャネルを使用して増分スナップショットを停止する
SQL クエリーを送信して、シグナリングテーブルへのアドホックインクリメンタルスナップショットを停止します。
INSERT INTO <signalTable> (id, type, data) values ('<id>', 'stop-snapshot', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"incremental"}');INSERT INTO <signalTable> (id, type, data) values ('<id>', 'stop-snapshot', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"incremental"}');Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
INSERT INTO myschema.debezium_signal (id, type, data) values ('ad-hoc-1', 'stop-snapshot', '{"data-collections": ["schema1.table1", "schema1.table2"], "type":"incremental"}');INSERT INTO myschema.debezium_signal (id, type, data)1 values ('ad-hoc-1',2 'stop-snapshot',3 '{"data-collections": ["schema1.table1", "schema1.table2"],4 "type":"incremental"}');5 Copy to Clipboard Copied! Toggle word wrap Toggle overflow signal コマンドの
id、type、およびdataパラメーターの値は、シグナルテーブルのフィールド に対応します。
以下の表では、この例のパラメーターを説明しています。Expand 表2.6 シグナリングテーブルに増分スナップショット停止信号を送信するための SQL コマンドのフィールドの説明 項目 値 説明 1
schema.debezium_signalソースデータベースにあるシグナルテーブルの完全修飾名を指定します。
2
ad-hoc-1idパラメーターは、シグナルリクエストのID識別子として割り当てられる任意の文字列を指定します。
この文字列を使用して、シグナルテーブルのエントリーへのログメッセージを特定します。Debezium はこの文字列を使用しません。3
stop-snapshottypeパラメーターを指定し、シグナルがトリガーする操作を指定します。
4
data-collectionsシグナルの
dataフィールドのオプションコンポーネントで、スナップショットから削除するテーブル名の配列またはテーブル名とマッチする正規表現を指定します。
配列には、schema.tableの形式で完全修飾名でテーブルに一致する正規表現がリストされます。dataフィールドからこのコンポーネントを省略すると、シグナルによって進行中の増分スナップショット全体が停止されます。5
incremental停止するスナップショット操作のタイプを指定する信号の
dataフィールドの必須コンポーネント。
現在、有効な唯一のオプションはincrementalです。typeの値を指定しない場合、シグナルは増分スナップショットの停止に失敗します。
2.1.2.3.5. Kafka シグナリングチャネルを使用して増分スナップショットを停止する
設定された Kafka シグナルトピック にシグナルメッセージを送信して、アドホック増分スナップショットを停止できます。
Kafka メッセージのキーは、topic.prefix コネクター設定オプションの値と一致する必要があります。
メッセージの値は、type と data フィールドが含まれる JSON オブジェクトとなっています。
シグナルタイプは stop-snapshot で、data フィールドには以下のフィールドが必要です。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプ。現在、Debezium は |
|
| 該当なし |
テーブルの完全修飾名に一致する、コンマで区切られた正規表現のオプションの配列、スナップショットから削除するテーブル名に一致するテーブル名または正規表現の配列。 |
次の例は、典型的な stop-snapshot の Kafka メッセージを示しています。
Key = `test_connector`
Value = `{"type":"stop-snapshot","data": {"data-collections": ["schema1.table1", "schema1.table2"], "type": "INCREMENTAL"}}`
Key = `test_connector`
Value = `{"type":"stop-snapshot","data": {"data-collections": ["schema1.table1", "schema1.table2"], "type": "INCREMENTAL"}}`2.1.2.4. ブロッキングスナップショット
スナップショットをより柔軟に管理するために、Debezium には ブロッキングスナップショット と呼ばれる補助アドホックスナップショットメカニズムが含まれています。ブロッキングスナップショットは、Debezium コネクターにシグナルを送信 するための Debezium メカニズムに依存します。
ブロッキングスナップショットは、ランタイム時にトリガーできることを除いて、初期スナップショット と同じように動作します。
次のような状況では、標準の初期スナップショットプロセスを使用するのではなく、ブロッキングスナップショットを実行する必要があります。
- 新しいテーブルを追加し、コネクターの実行中にスナップショットを完了したいと考えている。
- 大きなテーブルを追加し、増分スナップショットよりも短い時間でスナップショットを完了したいと考えている。
ブロッキングスナップショットのプロセス
ブロッキングスナップショットを実行すると、Debezium はストリーミングを停止し、初期スナップショットの時と同じプロセスに従って、指定されたテーブルのスナップショットを開始します。スナップショットが完了すると、ストリーミングが再開されます。
スナップショットの設定
シグナルの data コンポーネントでは、次のプロパティーを設定できます。
- data-collections: スナップショットする必要のあるテーブルを指定します。
additional-conditions: テーブルごとに異なるフィルターを指定できます。
-
data-collectionプロパティーは、フィルターが適用されるテーブルの完全修飾名です。 -
filterプロパティーは、snapshot.select.statement.overridesで使用される値と同じになります。
-
以下に例を示します。
{"type": "blocking", "data-collections": ["schema1.table1", "schema1.table2"], "additional-conditions": [{"data-collection": "schema1.table1", "filter": "SELECT * FROM [schema1].[table1] WHERE column1 = 0 ORDER BY column2 DESC"}, {"data-collection": "schema1.table2", "filter": "SELECT * FROM [schema1].[table2] WHERE column2 > 0"}]}
{"type": "blocking", "data-collections": ["schema1.table1", "schema1.table2"], "additional-conditions": [{"data-collection": "schema1.table1", "filter": "SELECT * FROM [schema1].[table1] WHERE column1 = 0 ORDER BY column2 DESC"}, {"data-collection": "schema1.table2", "filter": "SELECT * FROM [schema1].[table2] WHERE column2 > 0"}]}重複の可能性
スナップショットをトリガーするシグナルを送信した時点と、ストリーミングが停止してスナップショットが開始する時点との間に遅延が生じる可能性があります。この遅延の結果、スナップショットが完了した後、コネクターはスナップショットがキャプチャーしたレコードと重複するイベントレコードを発行する可能性があります。
2.1.2.5. Debezium Db2 コネクターによる変更データテーブルの読み取り方法
スナップショットの完了後、Debezium Db2 コネクターが初めて起動すると、キャプチャーモードである各ソーステーブルの変更データテーブルを識別します。コネクターは各変更データテーブルに対して以下を行います。
- 最後に保存された最大 LSN から現在の最大 LSN の間に作成された変更イベントを読み取ります。
- 各イベントのコミット LSN および変更 LSN に従って、変更イベントを順序付けます。これにより、コネクターはテーブルが変更された順序で変更イベントを出力します。
- コミット LSN および変更 LSN をオフセットとして Kafka Connect に渡します。
- コネクターが Kafka Connect に渡した最大 LSN を保存します。
再起動後、コネクターは停止した場所でオフセット (コミット LSN および変更 LSN) から変更イベントの出力を再開します。コネクターが稼働し、変更イベントを出力している間、キャプチャーモードからテーブルを削除したり、テーブルをキャプチャーモードに追加したりすると、コネクターは変更を検出して、それに合わせて動作を変更します。
2.1.2.6. Debezium Db2 変更イベントレコードを受信する Kafka トピックのデフォルト名
デフォルトでは、Db2 コネクターは、テーブルで発生するすべての INSERT、UPDATE、DELETE 操作の変更イベントを、そのテーブルに固有の単一の Apache Kafka トピックに書き込みます。コネクターは以下の規則を使用して変更イベントトピックに名前を付けます。
topicPrefix.schemaName.tableName
以下のリストは、デフォルト名のコンポーネントの定義を示しています。
- topicPrefix
-
topic.prefixコネクター設定プロパティーで指定されたトピック接頭辞。 - schemaName
- 操作が発生したスキーマの名前。
- tableName
- 操作が発生したテーブルの名前。
たとえば、MYSCHEMA スキーマに 4 つのテーブル (PRODUCTS、PRODUCTS_ON_HAND、CUSTOMERS、ORDERS) を含む mydatabase データベースを使用した Db2 インストールについて考えてみます。コネクターはイベントを以下の 4 つの Kafka トピックに出力します。
-
mydatabase.MYSCHEMA.PRODUCTS -
mydatabase.MYSCHEMA.PRODUCTS_ON_HAND -
mydatabase.MYSCHEMA.CUSTOMERS -
mydatabase.MYSCHEMA.ORDERS
コネクターは同様の命名規則を適用して、内部データベーススキーマの履歴トピック (スキーマ変更トピック と トランザクションメタデータトピック) にラベルを付けます。
デフォルトのトピック名が要件を満たさない場合は、カスタムトピック名を設定できます。カスタムトピック名を設定するには、論理トピックルーティング SMT に正規表現を指定します。論理トピックルーティング SMT を使用してトピックの命名をカスタマイズする方法は、トピックルーティング を参照してください。
2.1.2.7. Debezium Db2 コネクターによるデータベーススキーマの変更の処理方法
データベースクライアントがデータベースのクエリーを行うと、クライアントはデータベースの現在のスキーマを使用します。しかし、データベーススキーマはいつでも変更が可能です。そのため、挿入、更新、または削除の操作が記録されるたびに、コネクターはどのスキーマであるかを特定できる必要があります。また、コネクターは必ずしも現在のスキーマをすべてのイベントに適用できるとは限りません。イベントが比較的古い場合は、現在のスキーマが適用される前に記録された可能性があります。
スキーマ変更後に発生するイベントを正しく処理するために、Debezium Db2 コネクターは、関連するデータテーブルの構造をミラーリングする Db2 変更データテーブルの構造に基づいて、新しいスキーマのスナップショットを保存します。コネクターは、データベーススキーマ履歴 Kafka トピックに、スキーマ変更の結果 (複数操作の LSN) と合わせてテーブルのスキーマ情報を保存します。コネクターは、保管されたスキーマ表現を使用して、挿入、更新、または削除の各操作時にテーブルの構造を正しくミラーリングする変更イベントを生成します。
クラッシュまたは正常に停止した後にコネクターが再起動すると、最後に読み取った位置から Db2 変更データテーブル内のエントリーの読み取りを再開します。コネクターがデータベーススキーマ履歴トピックから読み取るスキーマ情報を基に、コネクターが再起動する場所に存在したテーブル構造を適用します。
キャプチャーモードの Db2 テーブルのスキーマを更新する場合は、対応する変更テーブルのスキーマも更新することが重要です。データベーススキーマを更新するには、昇格権限のある Db2 データベース管理者である必要があります。Debezium 環境で Db2 データベーススキーマを更新する方法は、スキーマ履歴の進化 を参照してください。
データベーススキーマ履歴トピックは、内部コネクター専用となっています。オプションで、コネクターは コンシューマーアプリケーション向けの別のトピックにスキーマ変更イベントを送信する こともできます。
関連情報
- Debezium イベントレコードを受信する トピックのデフォルト名。
2.1.2.8. Debezium Db2 コネクターのスキーマ変更トピック
Debezium Db2 コネクターを設定すると、データベーステーブルに適用されるスキーマの変更を記述するスキーマ変更イベントを生成できます。
Debezium は、以下の場合にスキーマ変更トピックにメッセージを出力します。
- 新しいテーブルがキャプチャーモードになる。
- テーブルがキャプチャーモードから削除される。
- データベーススキーマの更新 中に、キャプチャーモードであるテーブルのスキーマが変更される。
コネクターはスキーマ変更イベントを、<topicPrefix> という名前の Kafka スキーマ変更トピックに書き込みます。ここで <topicPrefix> は、topic.prefix コネクター設定プロパティーで指定されたトピック接頭辞です。
スキーマ変更イベントのスキーマには、次の要素があります。
name- スキーマ変更イベントメッセージの名前。
type- 変更イベントメッセージのタイプ。
version- スキーマのバージョン。バージョンは整数で、スキーマが変更されるたびに増加します。
fields- 変更イベントメッセージに含まれるフィールド。
例: Db2 コネクターのスキーマ変更トピックのスキーマ
次の例は、JSON 形式の一般的なスキーマを示しています。
コネクターがスキーマ変更トピックに送信するメッセージには以下の要素などのペイロードが含まれます。
databaseName-
ステートメントが適用されるデータベースの名前。
databaseNameの値は、メッセージキーとして機能します。 pos- ステートメントが表示されるトランザクションログ内の位置。
tableChanges-
スキーマの変更後のテーブルスキーマ全体の構造化表現。
tableChangesフィールドには、テーブルの各列のエントリーなどのアレイが含まれます。構造化された表現は JSON または Avro 形式でデータを表示するため、コンシューマーは DDL パーサーを介して最初にメッセージを処理しなくてもメッセージを簡単に読み取りできます。
キャプチャーモードであるテーブルでは、コネクターはスキーマ変更トピックにスキーマ変更の履歴だけでなく、内部データベーススキーマ履歴トピックにも格納します。内部データベーススキーマ履歴トピックはコネクターのみの使用を対象としており、使用するアプリケーションによる直接使用を目的としていません。スキーマ変更に関する通知が必要なアプリケーションが、スキーマ変更トピックからの情報のみを使用するようにしてください。
データベーススキーマ履歴トピックをパーティションに分割しないでください。データベーススキーマ履歴トピックが正しく機能するには、コネクターが出力するイベントレコードの一貫したグローバル順序を維持する必要があります。
トピックがパーティション間で分割されないようにするには、以下のいずれかの方法を使用してトピックのパーティション数を設定します。
-
データベーススキーマ履歴トピックを手動で作成する場合は、パーティション数を
1に指定します。 -
Apache Kafka ブローカーを使用してデータベーススキーマ履歴トピックを自動的に作成する場合に、トピックが作成されるので、Kafka
num.partitions設定オプションの値を1に設定します。
コネクターがスキーマ変更トピックに出力するメッセージの形式は、初期の状態であり、通知なしに変更される可能性があります。
例: Db2 コネクターのスキーマ変更トピックに出力されるメッセージ
以下の例は、スキーマ変更トピックのメッセージを示しています。メッセージには、テーブルスキーマの論理表現が含まれます。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
| コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 ソースオブジェクトの ts_ms は、データベースで変更が行われた時刻を示す。payload.source.ts_ms の値を payload.ts_ms の値と比較することにより、ソースデータベースの更新と Debezium との間の遅延を判断できます。 |
| 2 |
| 変更が含まれるデータベースとスキーマを識別します。 |
| 3 |
|
Db2 コネクターの場合は常に |
| 4 |
| DDL コマンドによって生成されるスキーマの変更が含まれる 1 つ以上の項目の配列。 |
| 5 |
| 変更の種類を説明します。値は以下のいずれかになります。
|
| 6 |
| 作成、変更、または破棄されたテーブルの完全な識別子。 |
| 7 |
| 適用された変更後のテーブルメタデータを表します。 |
| 8 |
| テーブルのプライマリーキーを設定する列のリスト。 |
| 9 |
| 変更されたテーブルの各列のメタデータ。 |
| 10 |
| 各テーブル変更のカスタム属性メタデータ。 |
コネクターがスキーマ変更トピックに送信するメッセージでは、メッセージキーはスキーマの変更が含まれるデータベースの名前です。以下の例では、payload フィールドにキーが含まれます。
2.1.2.9. トランザクション境界を表す Debezium Db2 コネクターによって生成されたイベント
Debezium は、トランザクション境界を表し、変更データイベントメッセージを強化するイベントを生成できます。
Debezium は、コネクターのデプロイ後に発生するトランザクションに対してのみメタデータを登録し、受信します。コネクターをデプロイする前に発生するトランザクションのメタデータは利用できません。
Debezium は、すべてのトランザクションで BEGIN および END 区切り文字のトランザクション境界イベントを生成します。トランザクション境界イベントには以下のフィールドが含まれます。
status-
BEGINまたはEND id- 一意のトランザクション識別子の文字列表現。
ts_ms-
データソースでのトランザクション境界イベント (
BEGINまたはENDイベント) の時間。データソースから Debezium にイベント時間を渡されない場合、フィールドは代わりに Debezium がイベントを処理する時間を表します。 event_count(ENDイベント用)- トランザクションによって出力されるイベントの合計数。
data_collections(ENDイベント用)-
data_collectionとevent_count要素のペアの配列。これは、コネクターがデータコレクションから発信された変更に対して出力するイベントの数を示します。
例
topic.transaction オプションで上書きされない限り、コネクターはトランザクションイベントを <topic.prefix>.transaction トピックに出力します。
データ変更イベントのエンリッチメント
トランザクションメタデータを有効にすると、コネクターは変更イベント Envelope を新しい transaction フィールドで強化します。このフィールドは、複合フィールドの形式ですべてのイベントに関する情報を提供します。
id- 一意のトランザクション識別子の文字列表現。
total_order- トランザクションによって生成されたすべてのイベントを対象とするイベントの絶対位置。
data_collection_order- トランザクションによって出力されたすべてのイベントを対象とするイベントのデータコレクションごとの位置。
以下は、メッセージの例になります。
2.1.3. Debezium Db2 コネクターのデータ変更イベントの説明
Debezium Db2 コネクターは、行レベルの INSERT、UPDATE、および DELETE 操作ごとにデータ変更イベントを生成します。各イベントにはキーと値が含まれます。キーと値の構造は、変更されたテーブルによって異なります。
Debezium および Kafka Connect は、イベントメッセージの継続的なストリーム を中心として設計されています。ただし、これらのイベントの構造は時間の経過とともに変化する可能性があり、コンシューマーによる処理が困難になることがあります。これに対応するために、各イベントにはコンテンツのスキーマが含まれます。スキーマレジストリーを使用している場合は、コンシューマーがレジストリーからスキーマを取得するために使用できるスキーマ ID が含まれます。これにより、各イベントが自己完結型になります。
以下のスケルトン JSON は、変更イベントの基本となる 4 つの部分を示しています。ただし、アプリケーションで使用するために選択した Kafka Connect コンバーターの設定方法によって、変更イベントのこれら 4 部分の表現が決定されます。schema フィールドは、変更イベントが生成されるようにコンバーターを設定した場合のみ変更イベントに含まれます。同様に、イベントキーおよびイベントペイロードは、変更イベントが生成されるようにコンバーターを設定した場合のみ変更イベントに含まれます。JSON コンバーターを使用し、変更イベントの基本となる 4 つの部分すべてを生成するように設定すると、変更イベントの構造は次のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
最初の |
| 2 |
|
最初の |
| 3 |
|
2 つ目の |
| 4 |
|
2 つ目の |
デフォルトでは、コネクターによって、変更イベントレコードがイベントの元のテーブルと同じ名前を持つトピックにストリーミングされます。詳細は、トピック名 を参照してください。
Debezium Db2 コネクターは、すべての Kafka Connect スキーマ名が Avro スキーマ名の形式 に準拠するようにします。つまり、論理サーバー名はアルファベットまたはアンダースコア (a-z、A-Z、または _) で始まる必要があります。論理サーバー名の残りの各文字と、データベース名とテーブル名の各文字は、アルファベット、数字、またはアンダースコア ( a-z、A-Z、0-9、または \_) でなければなりません。無効な文字がある場合は、アンダースコアに置き換えられます。
論理サーバー名、データベース名、またはテーブル名に無効な文字が含まれ、名前を区別する唯一の文字が無効であると、無効な文字はすべてアンダースコアに置き換えられるため、予期せぬ競合が発生する可能性があります。
また、データベース、スキーマ、およびテーブルの Db2 名では、大文字と小文字を区別することができます。つまり、コネクターは同じ Kafka トピックに複数のテーブルのイベントレコードを出力できます。
詳細は以下を参照してください。
2.1.3.1. Debezium db2 変更イベントのキー
変更イベントのキーには、変更されたテーブルのキーのスキーマと、変更された行の実際のキーのスキーマが含まれます。スキーマとそれに対応するペイロードの両方には、コネクターによってイベントが作成された時点において、変更されたテーブルの PRIMARY KEY (または一意の制約) に存在した各列のフィールドが含まれます。
以下の customers テーブルについて考えてみましょう。この後に、このテーブルの変更イベントキーの例を示します。
テーブルの例
変更イベントキーの例
customers テーブルへの変更をキャプチャーする変更イベントのすべてに、イベントキースキーマがあります。customers テーブルに前述の定義がある限り、customers テーブルへの変更をキャプチャーする変更イベントのキー構造はすべて以下のようになります。JSON では、以下のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
キーのスキーマ部分は、キーの |
| 2 |
|
各フィールドの名前、型、および必要かどうかなど、 |
| 3 |
|
イベントキーの |
| 4 |
|
キーのペイロードの構造を定義するスキーマの名前。このスキーマは、変更されたテーブルのプライマリーキーの構造を記述します。キースキーマ名の形式は connector-name.database-name.table-name.
|
| 5 |
|
この変更イベントが生成された行のキーが含まれます。この例では、キーには値が |
2.1.3.2. Debezium Db2 変更イベントの値
変更イベントの値はキーよりも若干複雑です。キーと同様に、値には schema セクションと payload セクションがあります。schema セクションには、入れ子のフィールドを含む、Envelope セクションの payload 構造を記述するスキーマが含まれています。データを作成、更新、または削除する操作のすべての変更イベントには、Envelope 構造を持つ値 payload があります。
変更イベントキーの例を紹介するために使用した、同じサンプルテーブルについて考えてみましょう。
テーブルの例
customers テーブルのすべての変更イベントのイベント値部分は同じスキーマを指定します。イベント値のペイロードは、イベント型によって異なります。
create イベント
以下の例は、customers テーブルにデータを作成する操作に対して、コネクターによって生成される変更イベントの値の部分を示しています。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
| 値のペイロードの構造を記述する、値のスキーマ。変更イベントの値スキーマは、コネクターが特定のテーブルに生成するすべての変更イベントで同じになります。 |
| 2 |
|
|
| 3 |
|
|
| 4 |
|
|
| 5 |
|
値の実際のデータ。これは、変更イベントが提供する情報です。 |
| 6 |
|
イベント発生前の行の状態を指定する任意のフィールド。この例のように、 |
| 7 |
|
イベント発生後の行の状態を指定する任意のフィールド。この例では、 |
| 8 |
|
イベントのソースメタデータを記述する必須のフィールド。
|
| 9 |
|
コネクターによってイベントが生成される原因となった操作の型を記述する必須文字列。この例では、
|
| 10 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
更新イベント
サンプル customers テーブルにある更新の変更イベントの値には、そのテーブルの 作成 イベントと同じスキーマがあります。同様に、更新イベント値のペイロードは同じ構造を持ちます。ただし、イベント値ペイロードでは 更新 イベントに異なる値が含まれます。以下は、コネクターによって customers テーブルでの更新に生成されるイベントの変更イベント値の例になります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
イベント発生前の行の状態を指定する任意のフィールド。更新 イベント値の |
| 2 |
|
イベント発生後の行の状態を指定する任意のフィールド。 |
| 3 |
|
イベントのソースメタデータを記述する必須のフィールド。
|
| 4 |
|
操作の型を記述する必須の文字列。更新 イベントの値では、 |
| 5 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
行のプライマリーキー/一意キーの列を更新すると、行のキーの値が変更されます。キーが変更されると、3 つのイベントが Debezium によって出力されます。3 つのイベントとは、DELETE イベント、行の古いキーを持つ 廃棄 (tombstone)、およびそれに続く行の新しいキーを持つイベントです。
delete イベント
削除 変更イベントの値は、同じテーブルの 作成 および 更新 イベントと同じ schema の部分になります。サンプル customers テーブルの 削除 イベントのイベント値 payload は以下のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
イベント発生前の行の状態を指定する任意のフィールド。削除 イベント値の |
| 2 |
|
イベント発生後の行の状態を指定する任意のフィールド。削除 イベント値の |
| 3 |
|
イベントのソースメタデータを記述する必須のフィールド。削除 イベント値の
|
| 4 |
|
操作の型を記述する必須の文字列。 |
| 5 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
削除 変更イベントレコードは、この行の削除を処理するために必要な情報を持つコンシューマーを提供します。コンシューマーによっては、削除を適切に処理するために古い値が必要になることがあるため、古い値が含まれます。
Db2 コネクターイベントは、Kafka のログコンパクション と動作するように設計されています。ログコンパクションにより、少なくとも各キーの最新のメッセージが保持される限り、一部の古いメッセージを削除できます。これにより、トピックに完全なデータセットが含まれ、キーベースの状態のリロードに使用できるようにするとともに、Kafka がストレージ領域を確保できるようにします。
行が削除された場合でも、Kafka は同じキーを持つ以前のメッセージをすべて削除できるため、削除 イベントの値はログコンパクションで動作します。ただし、Kafka が同じキーを持つすべてのメッセージを削除するには、メッセージの値が null である必要があります。これを可能にするために、Debezium の Db2 コネクターは 削除 イベントを出力した後に、null 値以外で同じキーを持つ特別な廃棄 (tombstone) イベントを出力します。
2.1.4. Debezium Db2 コネクターによるデータ型のマッピング方法
Db2 がサポートするデータ型の詳細は、Db2 ドキュメントの Data Types を参照してください。
Db2 コネクターは、行が存在するテーブルのように構造化されたイベントで行への変更を表します。イベントには、各列の値のフィールドが含まれます。その値がどのようにイベントで示されるかは、列の Db2 のデータ型によって異なります。ここでは、これらのマッピングを説明します。デフォルトのデータ型変換が要件に合わない場合は、コネクター用の カスタムコンバーターの作成 が可能です。
詳細は以下を参照してください。
基本型
以下の表では、各 Db2 データ型をイベントフィールドの リテラル型 および セマンティック型にマッピングする方法を説明します。
-
literal type は、Kafka Connect スキーマタイプ (
INT8、INT16、INT32、INT64、FLOAT32、FLOAT64、BOOLEAN、STRING、BYTES、ARRAY、MAP、STRUCT) を使用して、値がどのように表現されるかを記述します。 - セマンティック型 は、フィールドの Kafka Connect スキーマの名前を使用して、Kafka Connect スキーマがフィールドの 意味 をキャプチャーする方法を記述します。
| DB2 データ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
| BOOLEAN 型の列のあるテーブルからのみスナップショットを作成できます。現在、Db2 での SQL レプリケーションは BOOLEAN をサポートしないため、Debezium はこれらのテーブルで CDC を実行できません。別の型の使用を検討してください。 |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
|
|
|
|
|
|
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
|
|
列のデフォルト値がある場合は、対応するフィールドの Kafka Connect スキーマに伝達されます。明示的な列値が指定されない限り、変更イベントにはフィールドのデフォルト値が含まれます。そのため、スキーマからデフォルト値を取得する必要はほとんどありません。
時間型
タイムゾーン情報を含む DATETIMEOFFSET データタイプを除き、Db2 は time.precision.mode コネクター設定プロパティーの値に基づいて時間型をマップします。ここでは、以下のマッピングを説明します。
time.precision.mode=adaptive
time.precision.mode 設定プロパティーがデフォルトの adaptive に設定された場合、コネクターは列のデータ型定義に基づいてリテラル型とセマンティック型を決定します。これにより、イベントがデータベースの値を 正確 に表すようになります。
| DB2 データ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
time.precision.mode=connect
time.precision.mode 設定プロパティーが connect に設定された場合、コネクターは Kafka Connect の論理型を使用します。これは、コンシューマーが組み込みの Kafka Connect の論理型のみを処理でき、可変精度の時間値を処理できない場合に便利です。ただし、Db2 はマイクロ秒の 10 分の 1 の精度をサポートするため、connect 時間精度を指定してコネクターによって生成されたイベントは、データベース列の少数秒の精度値が 3 よりも大きい場合に、精度が失われます。
| DB2 データ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
タイムスタンプ型
DATETIME タイプは、タイムゾーン情報のないタイムスタンプを表します。このような列は、UTC を基にして同等の Kafka Connect 値に変換されます。たとえば、"2018-06-20 15:13:16.945104" という DATETIME 値は、"1529507596000" という値の io.debezium.time.Timestamp で表されます。
Kafka Connect および Debezium を実行している JVM のタイムゾーンは、この変換には影響しません。
| DB2 データ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
|
|
|
|
|
|
2.1.5. Debezium コネクターを実行するための Db2 の設定
Db2 テーブルにコミットされた変更イベントを Debezium がキャプチャーするには、必要な権限を持つ Db2 データベース管理者が、変更データキャプチャーのデータベースでテーブルを設定する必要があります。Debezium の実行を開始した後、キャプチャーエージェントの設定を調整してパフォーマンスを最適化できます。
Debezium コネクターと使用するために Db2 を設定する場合の詳細は、以下を参照してください。
2.1.5.1. 変更データキャプチャーの Db2 テーブルの設定
テーブルをキャプチャーモードにするために、Debezium ではユーザー定義関数 (UDF) のセットが提供されます。ここでは、これらの管理 UDF をインストールおよび実行する手順を説明します。また、Db2 制御コマンドを実行してテーブルをキャプチャーモードにすることもできます。その後、管理者は Debezium がキャプチャーする各テーブルに対して、CDC を有効にする必要があります。
前提条件
-
db2instlユーザーとして Db2 にログインしている。 - Db2 ホストの $HOME/asncdctools/src ディレクトリーで Debezium 管理 UDF を使用できる。UDF は Debezium サンプルリポジトリー から入手できます。
-
Db2 コマンド
bldrtnが PATH 上にある。たとえば、export PATH=$PATH:/opt/ibm/db2/V11.5.0.0/samples/c/を Db2 11.5 で実行する。
手順
Db2 で提供される
bldrtnコマンドを使用して、Db2 サーバーホストで Debezium 管理 UDF をコンパイルします。cd $HOME/asncdctools/src
cd $HOME/asncdctools/srcCopy to Clipboard Copied! Toggle word wrap Toggle overflow bldrtn asncdc
bldrtn asncdcCopy to Clipboard Copied! Toggle word wrap Toggle overflow データベースが稼働していない場合は起動します。
DB_NAMEは、Debezium が接続するデータベースの名前に置き換えます。db2 start db DB_NAME
db2 start db DB_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow JDBC が Db2 メタデータカタログを読み取りできるようにします。
cd $HOME/sqllib/bnd
cd $HOME/sqllib/bndCopy to Clipboard Copied! Toggle word wrap Toggle overflow db2 connect to DB_NAME db2 bind db2schema.bnd blocking all grant public sqlerror continue
db2 connect to DB_NAME db2 bind db2schema.bnd blocking all grant public sqlerror continueCopy to Clipboard Copied! Toggle word wrap Toggle overflow データベースが最近バックアップされたことを確認します。ASN エージェントには、読み取りを始める最新の開始点が必要です。バックアップを実行する必要がある場合は、以下のコマンドを実行して、最新のバージョンのみを利用できるようにデータをプルーニングします。古いバージョンのデータを保持する必要がない場合は、バックアップの場所に
dev/nullを指定します。データベースをバックアップします。
DB_NAMEおよびBACK_UP_LOCATIONを適切な値に置き換えます。db2 backup db DB_NAME to BACK_UP_LOCATION
db2 backup db DB_NAME to BACK_UP_LOCATIONCopy to Clipboard Copied! Toggle word wrap Toggle overflow データベースを再起動します。
db2 restart db DB_NAME
db2 restart db DB_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow
データベースに接続して、Debezium 管理 UDF をインストールします。
db2instlユーザーとしてログインしていることを前提とするため、UDF がdb2inst1ユーザーにインストールされている必要があります。db2 connect to DB_NAME
db2 connect to DB_NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow Debezium 管理 UDF をコピーし、その権限を設定します。
cp $HOME/asncdctools/src/asncdc $HOME/sqllib/function
cp $HOME/asncdctools/src/asncdc $HOME/sqllib/functionCopy to Clipboard Copied! Toggle word wrap Toggle overflow chmod 777 $HOME/sqllib/function
chmod 777 $HOME/sqllib/functionCopy to Clipboard Copied! Toggle word wrap Toggle overflow ASN キャプチャーエージェントを開始および停止する Debezium UDF を有効にします。
db2 -tvmf $HOME/asncdctools/src/asncdc_UDF.sql
db2 -tvmf $HOME/asncdctools/src/asncdc_UDF.sqlCopy to Clipboard Copied! Toggle word wrap Toggle overflow ASN 制御テーブルを作成します。
db2 -tvmf $HOME/asncdctools/src/asncdctables.sql
$ db2 -tvmf $HOME/asncdctools/src/asncdctables.sqlCopy to Clipboard Copied! Toggle word wrap Toggle overflow テーブルをキャプチャーモードに追加し、キャプチャーモードからテーブルを削除する Debezium UDF を有効にします。
db2 -tvmf $HOME/asncdctools/src/asncdcaddremove.sql
$ db2 -tvmf $HOME/asncdctools/src/asncdcaddremove.sqlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Db2 サーバーを設定したら、UDF を使用して SQL コマンドで Db2 レプリケーション (ASN) を制御します。UDF によっては戻り値が必要な場合があります。この場合、SQL の
VALUEステートメントを使用して呼び出します。その他の UDF には、SQL のCALLステートメントを使用します。SQL クライアントから ASN エージェントを起動します。
VALUES ASNCDC.ASNCDCSERVICES('start','asncdc');VALUES ASNCDC.ASNCDCSERVICES('start','asncdc');Copy to Clipboard Copied! Toggle word wrap Toggle overflow または、シェルから以下を行います。
db2 "VALUES ASNCDC.ASNCDCSERVICES('start','asncdc');"db2 "VALUES ASNCDC.ASNCDCSERVICES('start','asncdc');"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 前述のステートメントは、以下のいずれかの結果を返します。
-
asncap is already running start --><COMMAND>この場合は、以下の例のように、ターミナルウィンドウに指定の
<COMMAND>を入力します。/database/config/db2inst1/sqllib/bin/asncap capture_schema=asncdc capture_server=SAMPLE &
/database/config/db2inst1/sqllib/bin/asncap capture_schema=asncdc capture_server=SAMPLE &Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
テーブルをキャプチャーモードにします。キャプチャーする各テーブルに対して、以下のステートメントを呼び出します。
MYSCHEMAは、キャプチャーモードにするテーブルが含まれるスキーマの名前に置き換えます。同様に、MYTABLEは、キャプチャーモードにするテーブルの名前に置き換えます。CALL ASNCDC.ADDTABLE('MYSCHEMA', 'MYTABLE');CALL ASNCDC.ADDTABLE('MYSCHEMA', 'MYTABLE');Copy to Clipboard Copied! Toggle word wrap Toggle overflow ASN サービスを再初期化します。
VALUES ASNCDC.ASNCDCSERVICES('reinit','asncdc');VALUES ASNCDC.ASNCDCSERVICES('reinit','asncdc');Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.1.5.2. Db2 キャプチャーエージェント設定のサーバー負荷およびレイテンシーへの影響
データベース管理者がソーステーブルに対して変更データキャプチャーを有効にすると、キャプチャーエージェントの実行が開始されます。エージェントは新しい変更イベントレコードをトランザクションログから読み取り、イベントレコードをキャプチャーテーブルに複製します。変更がソーステーブルにコミットされてから、対応する変更テーブルに変更が反映される間、常に短いレイテンシーが間隔で発生します。この遅延間隔は、ソーステーブルで変更が発生したときから、Debezium がその変更を Apache Kafka にストリーミングできるようになるまでの差を表します。
データの変更に素早く対応する必要があるアプリケーションについては、ソースとキャプチャーテーブル間で密接に同期を維持するのが理想的です。キャプチャーエージェントを実行してできるだけ迅速に変更イベントを継続的に処理すると、スループットが増加し、レイテンシーが減少するため、イベントの発生後にほぼリアルタイムで新しいイベントレコードが変更テーブルに入力されることを想像するかもしれません。しかし、これは必ずしもそうであるとは限りません。同期を即時に行うとパフォーマンスに影響します。変更エージェントが新しいイベントレコードについてデータベースにクエリーを実行するたびに、データベースホストの CPU 負荷が増加します。サーバーへの負荷が増えると、データベース全体のパフォーマンスに悪影響を及ぼす可能性があり、特にデータベースの使用がピークに達するときにトランザクションの効率が低下する可能性があります。
データベースメトリクスを監視して、サーバーがキャプチャーエージェントのアクティビティーをサポートできなくなるレベルにデータベースが達した場合に認識できるようにすることが重要となります。キャプチャーエージェントの実行中にパフォーマンスの問題が発生した場合は、キャプチャーエージェント設定を調整して CPU の負荷を減らします。
2.1.5.3. DB2 キャプチャーエージェントの設定パラメーター
Db2 では、IBMSNAP_CAPPARMS テーブルにはキャプチャーエージェントの動作を制御するパラメーターが含まれています。これらのパラメーターの値を調整して、キャプチャープロセスの設定を調整すると、CPU の負荷を減らしながら許容レベルのレイテンシーを維持することができます。
Db2 のキャプチャーエージェントパラメーターの設定方法に関する具体的なガイダンスは、このドキュメントの範囲外となります。
IBMSNAP_CAPPARMS テーブルでは、CPU 負荷の削減に最も影響を与えるパラメーターは以下のとおりです。
COMMIT_INTERVAL- キャプチャーエージェントがデータを変更データテーブルにコミットするまで待つ期間を秒単位で指定します。
- 値が大きいほど、データベースホストの負荷が減少し、レイテンシーが増加します。
-
デフォルト値は
30です。
SLEEP_INTERVAL- キャプチャーエージェントがアクティブなトランザクションログの最後に到達した後に、新しいコミットサイクルの開始まで待つ期間を秒単位で指定します。
- 値が大きいほど、サーバーの負荷が減少し、レイテンシーが増加します。
-
デフォルト値は
5です。
関連情報
- キャプチャーエージェントパラメーターの詳細は、Db2 のドキュメントを参照してください。
2.1.6. Debezium Db2 コネクターのデプロイ
以下の方法のいずれかを使用して Debezium Db2 コネクターをデプロイできます。
ライセンス要件のため、Debezium Db2 コネクターアーカイブには、Debezium が Db2 データベースに接続するために必要な Db2 JDBC ドライバーは含まれていません。コネクターがデータベースにアクセスできるようにするには、コネクター環境にドライバーを追加する必要があります。ドライバーの入手方法については、Db2JDBC ドライバーの入手を参照してください。
2.1.6.1. Db2 JDBC ドライバーの取得
Debezium が Db2 データベースに接続するために必要な Db2 JDBC ドライバーファイルは、ライセンスの関係で Debezium Db2 コネクターアーカイブに含まれていません。ドライバーは、Maven Central からダウンロード可能です。使用するデプロイメント方法に応じて、Kafka Connect カスタムリソースまたはコネクターイメージの構築に使用する Dockerfile にコマンドを追加して、ドライバーを取得することができます。
-
Streams for Apache Kafka を使用して Kafka Connect イメージにコネクターを追加する場合は、「Streams for Apache Kafka を使用した Debezium Db2 コネクターのデプロイ」 に示されているように、
KafkaConnectカスタムリソースのbuilds.plugins.artifact.urlにドライバーの Maven Central の場所を追加します。 -
Dockerfile を使用してコネクター用のコンテナーイメージを構築する場合、Dockerfile に
curlコマンドを挿入して、Maven Central から必要なドライバーファイルをダウンロードするための URL を指定します。詳細は、「Dockerfile からカスタム Kafka Connect コンテナーイメージをビルドして Debezium Db2 コネクターのデプロイ」 を参照してください。
2.1.6.2. Streams for Apache Kafka を使用した Db2 コネクターのデプロイメント
Debezium 1.7 以降、Debezium コネクターのデプロイに推奨される方法は、Streams for Apache Kafka を使用して、コネクタープラグインを含む Kafka Connect コンテナーイメージをビルドすることです。
デプロイメントプロセス中に、以下のカスタムリソース (CR) を作成し、使用します。
-
Kafka Connect インスタンスを定義し、コネクターアーティファクトに関する情報をイメージに含める必要がある
KafkaConnectCR。 -
コネクターがソースデータベースにアクセスするために使用する情報を提供する
KafkaConnectorCR。Streams for Apache Kafka が Kafka Connect Pod を起動した後、KafkaConnectorCR を適用してコネクターを起動します。
Kafka Connect イメージのビルド仕様では、デプロイ可能なコネクターを指定できます。各コネクタープラグインに対して、デプロイメントに利用可能にする他のコンポーネントを指定することもできます。たとえば、Apicurio Registry アーティファクトや Debezium スクリプトコンポーネントを追加できます。Streams for Apache Kafka は、Kafka Connect イメージをビルドするときに、指定されたアーティファクトをダウンロードし、それをイメージに組み込みます。
Kafka Connect CR の spec.build.output パラメーターは、生成される KafkaConnectコンテナーイメージを格納する場所を指定します。コンテナーイメージは Docker レジストリーまたは OpenShift ImageStream に保存できます。イメージを ImageStream に保存するには、Kafka Connect をデプロイする前に ImageStream を作成する必要があります。ImageStreams は自動的に作成されません。
KafkaConnect リソースを使用してクラスターを作成する場合は、Kafka Connect REST API を使用してコネクターを作成または更新できません。ただし、REST API を使用して情報を取得できます。
関連情報
- 「OpenShift 上の Streams for Apache Kafka のデプロイと管理」の Kafka Connect の設定
- 「OpenShift 上の Streams for Apache Kafka のデプロイと管理」の 新しいコンテナーイメージの自動ビルド
2.1.6.3. Streams for Apache Kafka を使用した Debezium Db2 コネクターのデプロイ
以前のバージョンの Streams for Apache Kafka では、OpenShift に Debezium コネクターをデプロイするには、まずコネクター用の Kafka Connect イメージをビルドする必要がありました。OpenShift にコネクターをデプロイするための現在の推奨方法は、Streams for Apache Kafka のビルド設定を使用して、使用する Debezium コネクタープラグインを含む Kafka Connect コンテナーイメージを自動的にビルドすることです。
ビルドプロセス中に、Streams for Apache Kafka Operator は、Debezium コネクター定義を含む KafkaConnect カスタムリソースの入力パラメーターを Kafka Connect コンテナーイメージに変換します。このビルドは、Red Hat Maven リポジトリーまたは別の設定済みの HTTP サーバーから必要なアーティファクトをダウンロードします。
新規に作成されたコンテナーは .spec.build.output に指定されるコンテナーレジストリーにプッシュされ、Kafka Connect クラスターのデプロイに使用されます。Streams for Apache Kafka が Kafka Connect イメージをビルドした後、ビルドに含まれるコネクターを起動するための KafkaConnector カスタムリソースを作成します。
前提条件
- クラスター Operator がインストールされている OpenShift クラスターにアクセスできる。
- Streams for Apache Kafka Operator が実行されている。
- Apache Kafka クラスターが OpenShift 上の Streams for Apache Kafka のデプロイと管理 に記載されているとおりにデプロイされている。
- Kafka Connect が Streams for Apache Kafka にデプロイされている。
- Red Hat build of Debezium のライセンスを所有している。
-
OpenShift
ocCLI クライアントがインストールされている、または OpenShift Container Platform Web コンソールにアクセスできる。 Kafka Connect ビルドイメージの保存方法に応じて、レジストリーのパーミッションを用意するか、ImageStream リソースを作成している。
- ビルドイメージを Red Hat Quay.io または Docker Hub などのイメージレジストリーに保存する場合は、以下が必要です。
- レジストリーでイメージを作成し、管理するためのアカウントおよびパーミッション
- ビルドイメージをネイティブ OpenShift ImageStream として保存する場合は、以下を行います。
- 新規コンテナーイメージを保存するために、ImageStream リソースをクラスターにデプロイします。クラスターの ImageStream を明示的に作成する必要があります。ImageStreams は、デフォルトでは利用できません。ImageStreams の詳細は、OpenShift Container Platform でのイメージストリームの管理 を参照してください。
手順
- OpenShift クラスターにログインします。
コネクターの Debezium
KafkaConnectカスタムリソース (CR) を作成するか、既存のリソースを変更します。たとえば、metadata.annotationsおよびspec.buildプロパティーを指定するdbz-connect.yamlという名前のKafkaConnectCR を作成します。以下の例は、KafkaConnectカスタムリソースを記述するdbz-connect.yamlファイルからの抜粋を示しています。
例2.3 Debezium コネクターを含む
KafkaConnectカスタムリソースを定義したdbz-connect.yamlファイル次の例では、カスタムリソースは、次のアーティファクトをダウンロードするように設定されています。
- Debezium Db2 コネクターアーカイブ。
- Red Hat build of Apicurio Registry アーカイブApicurio Registry はオプションのコンポーネントです。コネクターで Avro シリアル化を使用する場合にのみ、Apicurio Registry コンポーネントを追加します。
- Debezium スクリプト SMT アーカイブと Debezium コネクターで使用する関連言語の依存関係。SMT アーカイブおよび言語の依存関係は任意のコンポーネントです。Debezium コンテンツベースのルーティング SMT または フィルター SMT を使用する場合にのみ、これらのコンポーネントを追加します。
- Db2 JDBC ドライバー。Db2 データベースに接続するために必要ですが、コネクターアーカイブには含まれていません。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.18 Kafka Connect 設定の説明 項目 説明 1
strimzi.io/use-connector-resourcesアノテーションを"true"に設定して、クラスター Operator がKafkaConnectorリソースを使用してこの Kafka Connect クラスター内のコネクターを設定できるようにします。2
spec.build設定は、ビルドイメージの保存場所を指定し、プラグインアーティファクトの場所とともにイメージに追加するプラグインをリストします。3
build.outputは、新しくビルドされたイメージを保存するレジストリーを指定します。4
イメージ出力の名前およびイメージ名を指定します。
output.typeの有効な値は、Docker Hub や Quay などのコンテナーレジストリーにプッシュする場合はdocker、内部の OpenShift ImageStream にイメージをプッシュする場合はimagestreamです。ImageStream を使用するには、ImageStream リソースをクラスターにデプロイする必要があります。KafkaConnect 設定でbuild.outputを指定する方法の詳細は、{NameConfiguringStreamsOpenShift} の Streams for Apache Kafka ビルドスキーマリファレンス を参照してください。5
plugins設定は、Kafka Connect イメージに追加するすべてのコネクターをリストします。リストの各エントリーについて、プラグインnameと、コネクターのビルドに必要なアーティファクトに関する情報を指定します。必要に応じて、各コネクタープラグインに対して、コネクターと使用できる他のコンポーネントを含めることができます。たとえば、Service Registry アーティファクトまたは Debezium スクリプトコンポーネントを追加できます。6
artifacts.typeの値は、artifacts.urlで指定するアーティファクトのファイルタイプを指定します。有効なタイプはzip、tgz、またはjarです。Debezium コネクターアーカイブは、.zipファイル形式で提供されます。JDBC ドライバーファイルは.jar形式です。typeの値は、urlフィールドで参照されるファイルのタイプと一致させる必要があります。7
artifacts.urlの値は、コネクターアーティファクトのファイルを格納する Maven リポジトリーなどの HTTP サーバーのアドレスを指定します。OpenShift クラスターが指定されたサーバーにアクセスできる必要があります。8
(オプション) Apicurio Registry コンポーネントをダウンロードするためのアーティファクト
typeとurlを指定します。デフォルトの JSON コンバーターを使用する代わりに、コネクターが Apache Avro を使用して Red Hat build of Apicurio Registry でイベントのキーと値をシリアル化する場合にのみ、Apicurio Registry アーティファクトを含めます。9
(オプション) Debezium コネクターで使用する Debezium スクリプト SMT アーカイブのアーティファクト
typeとurlを指定します。Debezium コンテンツベースルーティング SMT または フィルター SMT を使用する場合にのみ、スクリプト SMT を含めます。スクリプト SMT を使用するには、groovy などの JSR 223 準拠のスクリプト実装もデプロイする必要があります。10
(オプション) JSR 223 準拠のスクリプト実装の JAR ファイルのアーティファクト
typeとurlを指定します。これは、Debezium スクリプト SMT で必要です。重要Streams for Apache Kafka を使用してコネクタープラグインを Kafka Connect イメージに組み込む場合、必要なスクリプト言語コンポーネントごとに、
artifacts.urlに JAR ファイルのロケーションを指定し、artifacts.typeの値もjarに設定する必要があります。値が無効な場合は、実行時にコネクターが失敗します。スクリプト SMT で Apache Groovy 言語を使用できるようにするために、この例のカスタムリソースは、次のライブラリーの JAR ファイルを取得します。
-
groovy -
groovy-jsr223(スクリプトエージェント) -
groovy-json(JSON 文字列を解析するためのモジュール)
Debezium スクリプト SMT は、GraalVM JavaScript の JSR 223 実装の使用もサポートします。
11
Maven Central にある Db2 JDBC ドライバーの場所を指定します。必要なドライバーが Debezium Db2 コネクターアーカイブに含まれていない。
以下のコマンドを入力して、
KafkaConnectビルド仕様を OpenShift クラスターに適用します。oc create -f dbz-connect.yaml
oc create -f dbz-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Streams Operator はカスタムリソースで指定された設定に基づいて、デプロイする Kafka Connect イメージを準備します。
ビルドが完了すると、Operator はイメージを指定されたレジストリーまたは ImageStream にプッシュし、Kafka Connect クラスターを起動します。設定にリスト表示されているコネクターアーティファクトはクラスターで利用できます。KafkaConnectorリソースを作成し、デプロイする各コネクターのインスタンスを定義します。
たとえば、以下のKafkaConnectorCR を作成し、db2-inventory-connector.yamlとして保存します。例2.4 Debezium コネクターの
KafkaConnectorカスタムリソースを定義するdb2-inventory-connector.yamlファイルCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.19 コネクター設定の説明 項目 説明 1
Kafka Connect クラスターに登録するコネクターの名前。
2
コネクタークラスの名前。
3
同時に動作できるタスクの数。
4
コネクターの設定。
5
ホストデータベースインスタンスのアドレス。
6
データベースインスタンスのポート番号。
7
Debezium がデータベースへの接続に使用するアカウントの名前。
8
Debezium がデータベースユーザーアカウントに接続するために使用するパスワード。
9
変更をキャプチャーするデータベースの名前。
10
データベースインスタンスまたはクラスターのトピック接頭辞。
指定する名前は、英数字またはアンダースコアのみで設定する必要があります。
トピック接頭辞は、このコネクターから変更イベントを受信する Kafka トピックの接頭辞として使用されるため、名前はクラスターのコネクター間で一意である必要があります。
コネクターを Avro コネクター と統合する場合、この名前空間は、関連する Kafka Connect スキーマの名前や、対応する Avro スキーマの名前空間でも使用されます。11
コネクターが変更イベントをキャプチャーするテーブルのリスト。
以下のコマンドを実行してコネクターリソースを作成します。
oc create -n <namespace> -f <kafkaConnector>.yaml
oc create -n <namespace> -f <kafkaConnector>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc create -n debezium -f db2-inventory-connector.yaml
oc create -n debezium -f db2-inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow コネクターは Kafka Connect クラスターに登録され、
KafkaConnectorCR のspec.config.database.dbnameで指定されたデータベースに対して実行を開始します。コネクター Pod の準備ができると、Debezium が実行されます。
これで、Debezium Db2 のデプロイメントを確認 する準備が整いました。
2.1.6.4. Dockerfile からカスタム Kafka Connect コンテナーイメージをビルドして Debezium Db2 コネクターのデプロイ
Debezium Db2 コネクターをデプロイするには、Debezium コネクターアーカイブが含まれるカスタム Kafka Connect コンテナーイメージをビルドし、このコンテナーイメージをコンテナーレジストリーにプッシュする必要があります。次に、以下のカスタムリソース (CR) を作成する必要があります。
-
Kafka Connect インスタンスを定義する
KafkaConnectCR。imageは Debezium コネクターを実行するために作成したイメージの名前を指定します。この CR は、Red Hat Streams for Apache Kafka がデプロイされている OpenShift インスタンスに適用します。Streams for Apache Kafka は、Apache Kafka を OpenShift に導入する Operator とイメージを提供します。 -
Debezium Db2 コネクターを定義する
KafkaConnectorCR。この CR をKafkaConnectCR を適用したのと同じ OpenShift インスタンスに適用します。
前提条件
- Db2 が実行中で、Db2 をセットアップして Debezium コネクターと連携する 手順を完了している。
- Streams for Apache Kafka が OpenShift にデプロイされ、Apache Kafka および Kafka Connect が実行されている。詳細は、OpenShift 上の Streams for Apache Kafka のデプロイと管理 を参照してください。
- Podman または Docker がインストールされている。
- Kafka Connect サーバーは、Db2 用の必要な JDBC ドライバーをダウンロードするために、Maven Central にアクセスすることができます。また、ドライバーのローカルコピー、またはローカルの Maven リポジトリーや他の HTTP サーバーから利用可能なものを使用することもできます。
-
Debezium コネクターを実行するコンテナーを追加する予定のコンテナーレジストリー (
quay.ioやdocker.ioなど) でコンテナーを作成および管理するアカウントとパーミッションを持っている。
手順
Kafka Connect の Debezium Db2 コンテナーを作成します。
registry.redhat.io/amq-streams-kafka-35-rhel8:2.5.0をベースイメージとして使用して、新規の Dockerfile を作成します。たとえば、ターミナルウィンドウから、以下のコマンドを入力します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 項目 説明 1
任意のファイル名を指定できます。
2
Kafka Connect プラグインディレクトリーへのパスを指定します。Kafka Connect のプラグインディレクトリーが別の場所にある場合は、このパスを実際のディレクトリーのパスに置き換えてください。
このコマンドは、現在のディレクトリーに
debezium-container-for-db2.yamlという名前の Docker ファイルを作成します。前のステップで作成した
debezium-container-for-db2.yamlDocker ファイルからコンテナーイメージをビルドします。ファイルが含まれるディレクトリーから、ターミナルウィンドウを開き、以下のコマンドのいずれかを入力します。podman build -t debezium-container-for-db2:latest .
podman build -t debezium-container-for-db2:latest .Copy to Clipboard Copied! Toggle word wrap Toggle overflow docker build -t debezium-container-for-db2:latest .
docker build -t debezium-container-for-db2:latest .Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドは、
debezium-container-for-db2という名前のコンテナーイメージを構築します。カスタムイメージを quay.io などのコンテナーレジストリーまたは内部のコンテナーレジストリーにプッシュします。コンテナーレジストリーは、イメージをデプロイする OpenShift インスタンスで利用できる必要があります。以下のいずれかのコマンドを実行します。
podman push <myregistry.io>/debezium-container-for-db2:latest
podman push <myregistry.io>/debezium-container-for-db2:latestCopy to Clipboard Copied! Toggle word wrap Toggle overflow docker push <myregistry.io>/debezium-container-for-db2:latest
docker push <myregistry.io>/debezium-container-for-db2:latestCopy to Clipboard Copied! Toggle word wrap Toggle overflow 新しい Debezium Db2
KafkaConnectカスタムリソース (CR) を作成します。たとえば、annotationsおよびimageプロパティーを指定するdbz-connect.yamlという名前のKafkaConnectCR を作成します。以下の例は、KafkaConnectカスタムリソースを記述するdbz-connect.yamlファイルからの抜粋を示しています。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 項目 説明 1
KafkaConnectorリソースはこの Kafka Connect クラスターでコネクターを設定するために使用されることを、metadata.annotationsは Cluster Operator に示します。2
spec.imageは Debezium コネクターを実行するために作成したイメージの名前を指定します。設定された場合、このプロパティーによって Cluster Operator のSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGE変数がオーバーライドされます。以下のコマンドを入力して、
KafkaConnectCR を OpenShift Kafka Connect 環境に適用します。oc create -f dbz-connect.yaml
oc create -f dbz-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、Debezium コネクターを実行するために作成したイメージの名前を指定する Kafka Connect インスタンスを追加します。
Debezium Db2 コネクターインスタンスを設定する
KafkaConnectorカスタムリソースを作成します。通常、コネクターに使用できる設定プロパティーを使用して、
.yamlファイルに Debezium Db2 コネクターを設定します。コネクター設定は、Debezium に対して、スキーマおよびテーブルのサブセットにイベントを生成するよう指示する可能性があり、または機密性の高い、大きすぎる、または不必要な指定のコラムで Debezium が値を無視、マスク、または切り捨てするようにプロパティーを設定する可能性もあります。以下の例では、ポート
50000で Db2 サーバーホスト192.168.99.100に接続する Debezium コネクターを設定します。このホストには、データベース名がmydatabase、テーブル名がinventory、サーバーの論理名がinventory-connector-db2があります。Db2
inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.20 コネクター設定の説明 項目 説明 1
Kafka Connect クラスターに登録する場合のコネクターの名前。
2
この Db2 コネクタークラスの名前。
3
一度に実行できるタスクは 1 つだけです。
4
コネクターの設定。
5
Db2 インスタンスのアドレスであるデータベースホスト。
6
Db2 インスタンスのポート番号。
7
Db2 ユーザーの名前。
8
Db2 ユーザーのパスワード。
9
変更をキャプチャーするデータベースの名前。
10
名前空間を形成する Db2 インスタンス/クラスターの論理名で、コネクターが書き込む Kafka トピックの名前、Kafka Connect スキーマの名前、および Avro コネクター が使用される場合の対応する Avro スキーマの名前空間で使用されます。
11
コネクターは
public.inventoryテーブルからのみ変更をキャプチャーします。Kafka Connect でコネクターインスタンスを作成します。たとえば、
KafkaConnectorリソースをinventory-connector.yamlファイルに保存した場合は、以下のコマンドを実行します。oc apply -f inventory-connector.yaml
oc apply -f inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドは
inventory-connectorを登録し、コネクターはKafkaConnectorCR に定義されているmydatabaseデータベースに対して実行を開始します。
Debezium Db2 コネクターに設定できる設定プロパティーの完全リストは、Db2 コネクタープロパティー を参照してください。
結果
コネクターが起動すると、コネクターが変更をキャプチャーするように設定された Db2 データベーステーブルの 整合性スナップショット が実行されます。その後、コネクターは行レベルの操作のデータ変更イベントの生成を開始し、変更イベントレコードを Kafka トピックにストリーミングします。
2.1.6.5. Debezium Db2 コネクターが実行していることの確認
コネクターがエラーなしで正常に起動すると、コネクターがキャプチャーするように設定された各テーブルのトピックが作成されます。ダウンストリームアプリケーションは、これらのトピックをサブスクライブして、ソースデータベースで発生する情報イベントを取得できます。
コネクターが実行されていることを確認するには、OpenShift Container Platform Web コンソールまたは OpenShift CLI ツール (oc) から以下の操作を実行します。
- コネクターのステータスを確認します。
- コネクターがトピックを生成していることを確認します。
- 各テーブルの最初のスナップショットの実行中にコネクターが生成する読み取り操作 ("op":"r") のイベントがトピックに反映されていることを確認します。
前提条件
- Debezium コネクターが OpenShift 上の Streams for Apache Kafka にデプロイされている。
-
OpenShift
ocCLI クライアントがインストールされている。 - OpenShift Container Platform Web コンソールにアクセスできる。
手順
以下の方法のいずれかを使用して
KafkaConnectorリソースのステータスを確認します。OpenShift Container Platform Web コンソールから以下を実行します。
- Home → Search に移動します。
-
Search ページで Resources をクリックし、Select Resource ボックスを開き、
KafkaConnectorを入力します。 - KafkaConnectors リストから、チェックするコネクターの名前をクリックします (例: inventory-connector-db2)。
- Conditions セクションで、Type および Status 列の値が Ready および True に設定されていることを確認します。
ターミナルウィンドウから以下を実行します。
以下のコマンドを実行します。
oc describe KafkaConnector <connector-name> -n <project>
oc describe KafkaConnector <connector-name> -n <project>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc describe KafkaConnector inventory-connector-db2 -n debezium
oc describe KafkaConnector inventory-connector-db2 -n debeziumCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、以下の出力のようなステータス情報を返します。
例2.5
KafkaConnectorリソースのステータスCopy to Clipboard Copied! Toggle word wrap Toggle overflow
コネクターによって Kafka トピックが作成されたことを確認します。
OpenShift Container Platform Web コンソールから以下を実行します。
- Home → Search に移動します。
-
Search ページで Resources をクリックし、Select Resource ボックスを開き、
KafkaTopicを入力します。 -
KafkaTopics リストから確認するトピックの名前をクリックします (例:
inventory-connector-db2.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d)。 - Conditions セクションで、Type および Status 列の値が Ready および True に設定されていることを確認します。
ターミナルウィンドウから以下を実行します。
以下のコマンドを実行します。
oc get kafkatopics
oc get kafkatopicsCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、以下の出力のようなステータス情報を返します。
例2.6
KafkaTopicリソースのステータスCopy to Clipboard Copied! Toggle word wrap Toggle overflow
トピックの内容を確認します。
- ターミナルウィンドウから、以下のコマンドを入力します。
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory-connector-db2.inventory.products_on_hand
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory-connector-db2.inventory.products_on_handCopy to Clipboard Copied! Toggle word wrap Toggle overflow トピック名を指定する形式は、手順 1 で返された
oc describeコマンドと同じです (例:inventory_connector_db2.inventory.addresses)。トピックの各イベントについて、このコマンドは、以下の出力のような情報を返します。
例2.7 Debezium 変更イベントの内容
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory-connector-db2.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-db2.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-db2.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"int64","optional":false,"field":"ts_us"},{"type":"int64","optional":false,"field":"ts_ns"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.db2.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"int64","optional":true,"field":"ts_us"},{"type":"int64","optional":true,"field":"ts_ns"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory-connector-db2.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"2.7.3.Final-redhat-00001","connector":"db2","name":"inventory-connector-db2","ts_ms":1638985247805,"ts_us":1638985247805000000,"ts_ns":1638985247805000000,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"db2-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"ts_us":1638985247805102,"ts_ns":1638985247805102588,"transaction":null}}{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory-connector-db2.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-db2.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-db2.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"int64","optional":false,"field":"ts_us"},{"type":"int64","optional":false,"field":"ts_ns"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.db2.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"int64","optional":true,"field":"ts_us"},{"type":"int64","optional":true,"field":"ts_ns"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory-connector-db2.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"2.7.3.Final-redhat-00001","connector":"db2","name":"inventory-connector-db2","ts_ms":1638985247805,"ts_us":1638985247805000000,"ts_ns":1638985247805000000,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"db2-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"ts_us":1638985247805102,"ts_ns":1638985247805102588,"transaction":null}}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記の例では、
payload値は、コネクタースナップショットがテーブルinventory.products_on_handから読み込み ("op" ="r") イベントを生成したことを示しています。product_idレコードの"before"状態はnullであり、レコードに以前の値が存在しないことを示しています。"after"状態は、product_id101を持つ項目のquantityが3であることを示しています。
2.1.6.6. Debezium Db2 コネクター設定プロパティーの説明
Debezium Db2 コネクターには、アプリケーションに適したコネクター動作を実現するために使用できる設定プロパティーが多数あります。多くのプロパティーにはデフォルト値があります。プロパティーに関する情報は、以下のように設定されています。
- 必要な設定プロパティー
- 高度な設定プロパティー
- Debezium がデータベース履歴トピックから読み取るイベントを処理する方法を制御する データベース履歴コネクター設定プロパティー
必要な Debezium Db2 コネクター設定プロパティー
以下の設定プロパティーは、デフォルト値がない場合は必須です。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし | コネクターの一意名。同じ名前で再登録を試みると失敗します。このプロパティーはすべての Kafka Connect コネクターに必要です。 | |
| デフォルトなし |
コネクターの Java クラスの名前。Db2 コネクターには、常に | |
|
| このコネクターのために作成する必要のあるタスクの最大数。Db2 コネクターは常に単一のタスクを使用するため、この値を使用しません。そのため、デフォルト値は常に許容されます。 | |
| デフォルトなし | Db2 データベースサーバーの IP アドレスまたはホスト名。 | |
|
| Db2 データベースサーバーの整数のポート番号。 | |
| デフォルトなし | Db2 データベースサーバーに接続するための Db2 データベースユーザーの名前。 | |
| デフォルトなし | Db2 データベースサーバーへの接続時に使用するパスワード。 | |
| デフォルトなし | 変更をストリーミングする Db2 データベースの名前 | |
| デフォルトなし |
Debezium が変更をキャプチャーするデータベースをホストする特定の Db2 データベースサーバーの namespace を提供するトピック接頭辞。トピックの接頭辞名には、英数字、ハイフン、ドット、およびアンダースコアのみを使用する必要があります。このトピック接頭辞は、このコネクターからレコードを受け取るすべての Kafka トピックに使用されるため、トピック接頭辞は他のすべてのコネクターで一意である必要があります。 警告 このプロパティーの値を変更しないでください。名前の値を変更すると、再起動後に、元のトピックにイベントを発行し続けるのではなく、新しい値に基づいた名前のトピックに後続のイベントを発行します。また、コネクターはデータベーススキーマ履歴トピックを復元できません。 | |
| デフォルトなし |
コネクターで変更をキャプチャーするテーブルの完全修飾テーブル識別子と一致する正規表現のコンマ区切りリスト (任意)。このプロパティーが設定されている場合、コネクターは指定されたテーブルからのみ変更をキャプチャします。各識別子の形式は schemaName.tableName です。デフォルトでは、コネクターはシステム以外のテーブルすべての変更をキャプチャーします。
テーブルの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの名前文字列全体と照合されます。 | |
| デフォルトなし |
コネクターで変更をキャプチャーしないテーブルの完全修飾テーブル識別子と一致する正規表現のコンマ区切りリスト (任意)。コネクターは exclude リストに含まれていないシステム以外のテーブルごとに変更をキャプチャーします。各識別子の形式は schemaName.tableName です。
テーブルの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの名前文字列全体と照合されます。 | |
| 空の文字列 |
変更イベントレコード値に含める列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。列の完全修飾名の形式は schemaName.tableName.columnName です。
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列名に存在する可能性のある部分文字列とは一致しない、列の名前文字列全体と照合されます。このプロパティーを設定に含める場合は、 | |
| 空の文字列 |
変更イベント値から除外する列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。列の完全修飾名の形式は schemaName.tableName.columnName です。
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列名に存在する可能性のある部分文字列とは一致しない、列の名前文字列全体と照合されます。プライマリーキー列は、値から除外された場合でも、イベントのキーに常に含まれます。このプロパティーを設定に含める場合は、 | |
| 該当なし |
文字ベースの列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。列の完全修飾名の形式は schemaName.tableName.columnName です。
仮名は、指定された hashAlgorithm と salt を適用すると得られるハッシュ化された値で構成されます。使用されるハッシュ関数に基づいて、参照整合性は保持され、列値は仮名に置き換えられます。サポートされるハッシュ関数は、Java Cryptography Architecture Standard Algorithm Name Documentation の MessageDigest セクションに説明されています。 column.mask.hash.SHA-256.with.salt.CzQMA0cB5K = inventory.orders.customerName, inventory.shipment.customerName
必要な場合は、仮名は自動的に列の長さに短縮されます。コネクター設定には、異なるハッシュアルゴリズムと salt を指定する複数のプロパティーを含めることができます。 | |
|
|
時間、日付、およびタイムスタンプは、異なる精度の種類で表すことができます。 | |
|
|
delete イベントの後に廃棄 (tombstone) イベントが続くかどうかを制御します。 | |
|
| コネクターがデータベーススキーマの変更を、データベースサーバー ID と同じ名前の Kafka トピックに公開するかどうかを指定するブール値。各スキーマの変更は、データベース名が含まれるキーと、スキーマ更新を記述する JSON 構造である値で記録されます。これは、コネクターがデータベーススキーマ履歴を内部で記録する方法には依存しません。 | |
| 該当なし |
文字ベースの列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。プロパティー名の 長さ で指定された文字数を超えた場合に、一連の列のデータを切り捨てる場合は、このプロパティーを設定します。 列の完全修飾名は、次の形式に従います: schemaName.tableName.columnName列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列の名前文字列全体に対して照合されます。式は、列名に存在する可能性のある部分文字列と一致しません。 単一の設定で、異なる長さを持つ複数のプロパティーを指定できます。 | |
| 該当なし |
文字ベースの列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。一連の列の値をコネクターでマスクする場合 (たとえば、列に機密データが含まれている場合) は、このプロパティーを設定します。
列の完全修飾名は、次の形式に従います: schemaName.tableName.columnName. 単一の設定で、異なる長さを持つ複数のプロパティーを指定できます。 | |
| 該当なし | 列のメタデータを表す追加パラメーターをコネクターに発行させたい列の完全修飾名に一致する、オプションのコンマ区切りの正規表現のリスト。このプロパティーが設定されている場合、コネクターは次のフィールドをイベントレコードのスキーマに追加します。
これらのパラメーターは、列の元の型名と長さ (可変幅型の場合) をそれぞれ伝達します。
列の完全修飾名は、次のいずれかの形式に従います: databaseName.tableName.columnName、または databaseName.schemaName.tableName.columnName. | |
| 該当なし | データベース内の列に対して定義されているデータ型の完全修飾名を指定する正規表現のオプションのコンマ区切りリスト。このプロパティーが設定されている場合、データ型が一致する列に対して、コネクターはスキーマに次の追加フィールドを含むイベントレコードを発行します。
これらのパラメーターは、列の元の型名と長さ (可変幅型の場合) をそれぞれ伝達します。
列の完全修飾名の形式は、databaseName.tableName.typeName、または databaseName.schemaName.tableName.typeName のいずれかになります。 Db2 固有のデータ型名の一覧は、Db2 データ型マッピング を参照してください。 | |
| 空の文字列 | 指定のテーブルの Kafka トピックに公開する変更イベントレコードのカスタムメッセージキーを形成するためにコネクターが使用する列を指定する式のリスト。
デフォルトでは、Debezium はテーブルのプライマリーキー列を、出力するレコードのメッセージキーとして使用します。デフォルトの代わりに、またはプライマリーキーのないテーブルのキーを指定するには、1 つ以上の列をもとにカスタムメッセージキーを設定できます。
プロパティーは複数のテーブルのエントリーをリストできます。リスト内の異なるテーブルのエントリーは、セミコロンを使用して、区切ります。 | |
| none |
コネクターで使用されるメッセージコンバータとの互換性のために、スキーマ名をどのように調整するかを指定します。設定可能:
| |
| none |
コネクターで使用されるメッセージコンバータとの互換性のために、フィールド名をどのように調整するかを指定します。設定可能:
詳細は、Avro の命名 を参照してください。 |
高度なコネクター設定プロパティー
以下の 高度な 設定プロパティーには、ほとんどの状況で機能するデフォルト設定があるため、コネクターの設定で指定する必要はほとんどありません。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし |
コネクターが使用できる カスタムコンバーター インスタンスのシンボリック名をコンマ区切りリストで列挙します。以下に例を示します。
コネクターがカスタムコンバーターを使用できるようにするには、
コネクターに設定するコンバーターごとに、コンバーターインターフェイスを実装するクラスの完全修飾名を指定する
以下に例を示します。 isbn.type: io.debezium.test.IsbnConverter
設定されたコンバータの動作をさらに制御したい場合は、1 つ以上の設定パラメーターを追加して、コンバータに値を渡すことができます。追加の設定パラメーターとコンバーターを関連付けるには、パラメーター名の前にコンバーターのシンボリック名を付けます。 isbn.schema.name: io.debezium.db2.type.Isbn | |
| Initial |
コネクターの起動時にスナップショットを実行するための基準を指定します。
| |
| exclusive | コネクターがテーブルロックを保持するかどうか、また保持する時間をコントロールします。テーブルロックは、スナップショット中に他のデータベースクライアントが特定のテーブル操作を実行できないようにします。以下の値を設定できます。
| |
|
|
スナップショットを実行するときにコネクターがデータをクエリーする方法を指定します。
この設定により、 | |
|
|
スナップショットの実行中に、トランザクション分離レベルとキャプチャーモードのテーブルをロックする期間を制御します。使用できる値は次のとおりです。 | |
|
|
イベントの処理中にコネクターが例外を処理する方法を指定します。使用できる値は次のとおりです。 | |
|
| コネクターがイベントのバッチの処理を開始する前に、新しい変更イベントの発生を待つ期間をミリ秒単位で指定する正の整数値。デフォルトは 500 ミリ秒 (0.5 秒) です。 | |
|
| コネクターが処理するイベントの各バッチの最大サイズを指定する正の整数値。 | |
|
|
ブロッキングキューが保持できるレコードの最大数を指定する正の整数値。Debezium はデータベースからストリームされたイベントを読み込む際、Kafka に書き込む前にブロッキングキューにイベントを配置します。ブロッキングキューは、コネクターが Kafka に書き込むよりも速くメッセージを取り込む場合、または Kafka が利用できなくなった場合に、データベースから変更イベントを読み込むためのバックプレッシャーを提供することができます。コネクターがオフセットを定期的に記録すると、キューに保持されるイベントは無視されます。 | |
|
|
ブロッキングキューの最大容量をバイト単位で指定する長整数値。デフォルトでは、ブロックキューにはボリューム制限は指定されません。キューが使用できるバイト数を指定するには、このプロパティーを正の long 値に設定します。 | |
|
|
コネクターがハートビートメッセージを Kafka トピックに送信する頻度を制御します。デフォルトの動作では、コネクターはハートビートメッセージを送信しません。 | |
| デフォルトなし | コネクターの起動時にスナップショットを実行するまでコネクターが待つ必要がある間隔 (ミリ秒単位)。クラスターで複数のコネクターを起動する場合、このプロパティーは、コネクターのリバランスが行われる原因となるスナップショットの中断を防ぐのに役立ちます。 | |
| 0 |
コネクターがスナップショットを完了した後、ストリーミングプロセスの開始を遅延する時間をミリ秒単位で指定します。遅延間隔を設定すると、スナップショットが完了した直後で、ストリーミングプロセスの開始前に障害が発生した場合に、コネクターがスナップショットを再開できないようにします。Kafka Connect ワーカーに設定されている | |
|
|
スナップショットに含めるテーブルの完全修飾名 ( テーブルの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの名前文字列全体と照合されます。 | |
|
| スナップショットの実行中、コネクターは行のバッチでテーブルの内容を読み取ります。このプロパティーは、バッチの行の最大数を指定します。 | |
|
|
スナップショットの実行時に、テーブルロックを取得するまで待つ最大時間 (ミリ秒単位) を指定する正の整数値。コネクターがこの間隔でテーブルロックを取得できないと、スナップショットは失敗します。詳細は、コネクターによるスナップショットの実行方法 を参照してください。その他の可能な設定は次のとおりです。 | |
| デフォルトなし | スナップショットに追加するテーブル行を指定します。スナップショットにテーブルの行のサブセットのみを含める場合は、プロパティーを使用します。このプロパティーはスナップショットにのみ影響します。コネクターがログから読み取るイベントには影響しません。
プロパティーには、
スナップショットにソフト削除以外のレコードのみを含める場合は、soft-delete 列 ( "snapshot.select.statement.overrides": "customer.orders", "snapshot.select.statement.overrides.customer.orders": "SELECT * FROM customers.orders WHERE delete_flag = 0 ORDER BY id DESC"
作成されるスナップショットでは、コネクターには | |
|
|
コネクターがトランザクション境界でイベントを生成し、トランザクションメタデータで変更イベントエンベロープを強化するかどうかを決定します。コネクターにこれを実行させる場合は | |
|
|
ストリーミング中にスキップされる操作タイプのコンマ区切りリスト。挿入/作成は | |
| デフォルトなし |
シグナルをコネクターへの送信に使用されるデータコレクションの完全修飾名 。コレクション名の指定には | |
| source | コネクターに対して有効な信号チャネル名のリスト。デフォルトでは、以下のチャネルが利用可能です。
| |
| デフォルトなし | コネクターに対して有効になっている通知チャネル名のリスト。デフォルトでは、以下のチャネルが利用可能です。
| |
|
| 増分スナップショットのチャンクの実行中にコネクターがメモリーを取得して読み取る行の最大数。スナップショットは、サイズが大きいスナップショットの場合にはクエリーが少なくなるため、チャンクサイズを増やすと効率が上がります。ただし、チャンクサイズが大きい場合には、スナップショットデータのバッファーにより多くのメモリーが必要になります。チャンクサイズは、環境で最適なパフォーマンスを発揮できる値に、調整します。 | |
|
|
増分スナップショットによってキャプチャーされ、ストリーミングの再開後に再キャプチャーされる可能性のあるイベントを重複排除するために、コネクターが増分スナップショット中に使用するウォーターマークメカニズムを指定します。
| |
|
|
データ変更、スキーマ変更、トランザクション、ハートビートイベントなどのトピック名を決定するために使用する TopicNamingStrategy クラスの名前。デフォルトは | |
|
|
トピック名の区切り文字を指定します。デフォルトは | |
|
| トピック名を保持するために使用されるサイズ (bounded concurrent hash map)。このキャッシュは、与えられたデータコレクションに対応するトピック名を決定するのに役立つ。 | |
|
|
コネクターがハートビートメッセージを送信するトピックの名前を制御します。トピック名のパターンは、 | |
|
|
コネクターがトランザクションのメタデータメッセージを送信するトピックの名前を制御します。トピック名のパターンは、 | |
|
| 初期スナップショットを実行するときにコネクターが使用するスレッドの数を指定します。並列初期スナップショットを有効にするには、プロパティーを 1 より大きい値に設定します。並列初期スナップショットでは、コネクターは複数のテーブルを同時に処理します。 重要 並列初期スナップショットはテクノロジープレビュー機能のみとなっています。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。 | |
|
|
コンテキスト情報を提供するメタデータを追加して、MBean オブジェクト名をカスタマイズするタグを定義します。キーと値のペアのコンマ区切りリストを指定します。各キーは MBean オブジェクト名のタグを表し、対応する値はキーの値を表します。たとえば、 コネクターは、指定されたタグを基本 MBean オブジェクト名に追加します。タグは、メトリクスデータを整理および分類するのに役立ちます。特定のアプリケーションインスタンス、環境、リージョン、バージョンなどを識別するためのタグを定義できます。詳細は、カスタマイズされた MBean 名 を参照してください。 | |
|
|
接続エラーなど、再試行可能なエラーが発生する操作の後に、コネクターがどのように応答するかを指定します。
| |
|
|
コネクターがクエリーの完了を待機する時間をミリ秒単位で指定します。タイムアウト制限を削除するには、値を |
Debezium Db2 コネクターデータベーススキーマ履歴設定プロパティー
Debezium には、コネクターがスキーマ履歴トピックと対話する方法を制御する schema.history.internal.* プロパティーのセットが含まれています。
以下の表は、Debezium コネクターを設定するための schema.history.internal プロパティーを説明しています。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし | コネクターがデータベーススキーマの履歴を保存する Kafka トピックの完全名。 | |
| デフォルトなし | Kafka クラスターへの最初の接続を確立するためにコネクターが使用するホストとポートのペアのリスト。このコネクションは、コネクターによって以前に保存されたデータベーススキーマ履歴の取得や、ソースデータベースから読み取られる各 DDL ステートメントの書き込みに使用されます。各ペアは、Kafka Connect プロセスによって使用される同じ Kafka クラスターを示す必要があります。 | |
|
| 永続化されたデータのポーリングが行われている間にコネクターが起動/回復を待つ最大時間 (ミリ秒単位) を指定する整数値。デフォルトは 100 ミリ秒です。 | |
|
| Kafka 管理クライアントを使用してクラスター情報を取得する際に、コネクターが待機すべき最大ミリ秒数を指定する整数値です。 | |
|
| Kafka 管理クライアントを使用して kafka 履歴トピックを作成する間、コネクターが待機する最大ミリ秒数を指定する整数値。 | |
|
|
エラーでコネクターのリカバリーが失敗する前に、コネクターが永続化された履歴データの読み取りを試行する最大回数。データが受信されなかった場合に最大待機する時間は、 | |
|
|
コネクターが不正または不明なデータベースのステートメントを無視するかどうか、または人が問題を修正するために処理を停止するかどうかを指定するブール値。安全なデフォルトは | |
|
|
コネクターがスキーマまたはデータベース内のすべてのテーブルからスキーマ構造を記録するか、キャプチャー対象に指定されたテーブルのみからスキーマ構造を記録するかを指定するブール値。
| |
|
|
コネクターがデータベースインスタンス内のすべての論理データベースのスキーマ構造を記録するかどうかを指定するブール値。
|
パススルー Db2 コネクター設定プロパティー
コネクターは pass-through プロパティーをサポートしており、これにより Debezium は Apache Kafka プロデューサーとコンシューマーの動作を微調整するためのカスタム設定オプションを指定できます。Kafka プロデューサーとコンシューマーの全設定プロパティーの詳細は、Kafka ドキュメント を参照してください。
プロデューサーとコンシューマーのクライアントがスキーマ履歴トピックと対話する方法を設定するための Pass-through プロパティー
Debezium は、データベーススキーマ履歴トピックへのスキーマ変更を記述するために Apache Kafka プロデューサーに依存しています。同様に、コネクターが起動すると、データベーススキーマ履歴トピックから読み取る Kafka コンシューマーに依存します。schema.history.internal.producer.* および schema.history.internal.consumer.* 接頭辞で始まるパススルー設定プロパティーのセットに値を割り当てて、Kafka プロデューサーおよびコンシューマークライアントの設定を定義します。パススループロデューサーおよびコンシューマーデータベーススキーマ履歴プロパティーは、以下の例のように Kafka ブローカーとのこれらのクライアントの接続をセキュアにする方法など、さまざまな動作を制御します。
Debezium は、プロパティーを Kafka クライアントに渡す前に、プロパティー名から接頭辞を削除します。
Kafka プロデューサー設定プロパティー と Kafka コンシューマー設定プロパティー の詳細は、Apache Kafka ドキュメントを参照してください。
Db2 コネクターが Kafka シグナリングトピックと対話する方法を設定するための Pass-through プロパティー
Debezium は、コネクターが Kafka シグナルトピックと対話する方法を制御する signal.* プロパティーのセットを提供します。
以下の表は、Kafka signal プロパティーを説明しています。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| <topic.prefix>-signal | コネクターがアドホックシグナルについて監視する Kafka トピックの名前。 注記 トピックの自動作成 が無効になっている場合は、必要なシグナリングトピックを手動で作成する必要があります。シグナルの順序を維持するには、シグナルトピックが必要です。シグナリングトピックには単一のパーティションが必要です。 | |
| kafka-signal | Kafka コンシューマーによって使用されるグループ ID の名前。 | |
| デフォルトなし | コネクターが Kafka クラスターへの初期接続を確立するために使用するホストとポートのペアのリスト。各ペアは、Debezium Kafka Connect プロセスによって使用される Kafka クラスターを参照します。 | |
|
| コネクターが信号をポーリングするときに待機する最大ミリ秒数を指定する整数値。 | |
|
| Kafka コンシューマーがシグナリングトピックからメッセージを読み取った後にオフセットコミットを書き込むかどうかを指定します。このプロパティーに割り当てる値によって、コネクターがオフラインのときに、シグナリングトピックが受信する要求をコネクターが処理できるかどうかが決まります。次のいずれかの設定を選択します。
|
シグナリングチャネルの Kafka コンシューマークライアントを設定するためのパススループロパティー
Debezium コネクターでは、Kafka コンシューマーのパススルー設定が可能です。パススルーシグナルのプロパティーは、接頭辞 signals.consumer.* で始まります。たとえば、コネクターは signal.consumer.security.protocol=SSL などのプロパティーを Kafka コンシューマーに渡します。
Debezium は、プロパティーを Kafka シグナルコンシューマーに渡す前に、プロパティーから接頭辞を削除します。
Db2 コネクター sink notification チャネルを設定するためのパススループロパティー
次の表では、Debezium sink notification チャネルの設定に使用できるプロパティーについて説明します。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし |
Debezium から通知を受信するトピックの名前。このプロパティーは、有効な通知チャネルの 1 つとして |
Debezium コネクターのパススルーデータベースドライバー設定プロパティー
Debezium コネクターでは、データベースドライバーのパススルー設定が可能です。パススルーデータベースプロパティーは接頭辞 driver.* で始まります。たとえば、コネクターは driver.foobar=false などのプロパティーを JDBC URL に渡します。
Debezium は、プロパティーをデータベースドライバーに渡す前に、プロパティーから接頭辞を削除します。
2.1.7. Debezium Db2 コネクターのパフォーマンスの監視
Debezium Db2 コネクターは、Apache ZooKeeper、Apache Kafka、および Kafka Connect によって提供される JMX メトリクスの組み込みサポートに加えて、3 種類のメトリクスを提供します。
- スナップショットメトリクス は、スナップショットの実行中にコネクター操作に関する情報を提供します。
- メトリクスのストリーミング は、コネクターが変更をキャプチャーし、変更イベントレコードをストリーミングする際のコネクター操作に関する情報を提供します。
- スキーマ履歴メトリクス は、コネクターのスキーマ履歴の状態に関する情報を提供します。
Debezium モニタリングのドキュメント では、JMX を使用してこれらのメトリクスを公開する方法の詳細を説明しています。
2.1.7.1. Db2 コネクタースナップショットおよびストリーミング MBean オブジェクトのカスタマイズされた名前
Debezium コネクターは、コネクターの MBean 名を介してメトリクスを公開します。これらのメトリクスは各コネクターインスタンスに固有であり、コネクターのスナップショット、ストリーミング、およびスキーマ履歴プロセスの動作に関するデータを提供します。
デフォルトでは、正しく設定されたコネクターをデプロイすると、Debezium はさまざまなコネクターメトリクスごとに一意の MBean 名を生成します。コネクタープロセスのメトリクスを表示するには、MBean を監視するように可観測性スタックを設定します。ただし、これらのデフォルトの MBean 名はコネクター設定に依存しており、設定の変更によって MBean 名が変更される場合があります。MBean 名を変更すると、コネクターインスタンスと MBean 間のリンクが切断され、監視アクティビティーが中断されます。このシナリオでは、監視を再開するには、新しい MBean 名を使用するように監視スタックを再設定する必要があります。
MBean 名の変更が原因で監視が中断されないように、カスタムメトリクスタグを設定できます。カスタムメトリクスを設定するには、コネクター設定に custom.metric.tags プロパティーを追加します。このプロパティーは、各キーが MBean オブジェクト名のタグを表し、対応する値がそのタグの値を表すキーと値のペアを受け入れます。たとえば、k1=v1,k2=v2 です。Debezium は、指定されたタグをコネクターの MBean 名に追加します。
コネクターの custom.metric.tags プロパティーを設定した後、指定されたタグに関連付けられたメトリクスを取得するように監視スタックを設定できます。可観測性スタックは、変更可能な MBean 名ではなく、指定されたタグを使用してコネクターを一意に識別します。その後、Debezium が MBean 名の構築方法を再定義したり、コネクター設定の topic.prefix が変更されたりしても、メトリクススクレイプタスクは指定されたタグパターンを使用してコネクターを識別するため、メトリクスの収集は中断されません。
カスタムタグを使用するさらなる利点は、データパイプラインのアーキテクチャーを反映するタグを使用できるため、運用上のニーズに合った方法でメトリクスを整理できることです。たとえば、コネクターアクティビティーのタイプ、アプリケーションコンテキスト、またはデータソースを宣言する値を持つタグを指定できます (例: db1-streaming-for-application-abc)。複数のキーと値のペアを指定すると、指定されたすべてのペアがコネクターの MBean 名に追加されます。
次の例は、タグがデフォルトの MBean 名を変更する方法を示しています。
例2.8 カスタムタグがコネクター MBean 名を変更する方法
デフォルトでは、Db2 コネクターはストリーミングメトリクスに次の MBean 名を使用します。
debezium.db2:type=connector-metrics,context=streaming,server=<topic.prefix>
debezium.db2:type=connector-metrics,context=streaming,server=<topic.prefix>
custom.metric.tags の値を database=salesdb-streaming,table=inventory に設定すると、Debezium は次のカスタム MBean 名を生成します。
debezium.db2:type=connector-metrics,context=streaming,server=<topic.prefix>,database=salesdb-streaming,table=inventory
debezium.db2:type=connector-metrics,context=streaming,server=<topic.prefix>,database=salesdb-streaming,table=inventory2.1.7.2. Db2 データベースのスナップショット作成時の Debezium の監視
MBean は debezium.db2:type=connector-metrics,context=snapshot,server= <topic.prefix> です。
スナップショット操作がアクティブでない場合や、最後のコネクターの起動後にスナップショットの作成が発生した場合に、スナップショットメトリクスは公開されません。
次の表に、使用可能なスナップショットメトリクスを示します。
| 属性 | タイプ | 説明 |
|---|---|---|
|
| コネクターが読み取りした最後のスナップショットイベント。 | |
|
| コネクターが最新のイベントを読み取りおよび処理してからの経過時間 (ミリ秒単位)。 | |
|
| 前回の開始またはリセット以降にコネクターで確認されたイベントの合計数。 | |
|
| コネクターに設定された include/exclude リストのフィルタリングルールによってフィルターされたイベントの数。 | |
|
| コネクターによって取得されるテーブルのリスト。 | |
|
| snapshotter とメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの長さ。 | |
|
| snapshotter とメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの空き容量。 | |
|
| スナップショットに含まれているテーブルの合計数。 | |
|
| スナップショットによってまだコピーされていないテーブルの数。 | |
|
| スナップショットが起動されたかどうか。 | |
|
| スナップショットが一時停止されたかどうか。 | |
|
| スナップショットが中断されたかどうか。 | |
|
| スナップショットが完了したかどうか。 | |
|
| スナップショットが完了したかどうかに関わらず、これまでスナップショットにかかった時間 (秒単位)。スナップショットが一時停止された時間も含まれます。 | |
|
| スナップショットが一時停止された合計秒数。スナップショットが数回一時停止された場合は、一時停止時間が加算されます。 | |
|
| スナップショットの各テーブルに対してスキャンされる行数が含まれるマップ。テーブルは、処理中に増分がマップに追加されます。スキャンされた 10,000 行ごとに、テーブルの完成時に更新されます。 | |
|
|
キューの最大バッファー (バイト単位)。このメトリクスは、 | |
|
| キュー内のレコードの現在の容量 (バイト単位)。 |
コネクターは、増分スナップショットの実行時に、以下の追加のスナップショットメトリクスも提供します。
2.1.7.3. Debezium Db2 コネクターレコードストリーミングの監視
MBean は debezium.db2:type=connector-metrics,context=streaming,server= <topic.prefix> です。
以下の表は、利用可能なストリーミングメトリクスのリストです。
| 属性 | タイプ | 説明 |
|---|---|---|
|
| コネクターが読み取られた最後のストリーミングイベント。 | |
|
| コネクターが最新のイベントを読み取りおよび処理してからの経過時間 (ミリ秒単位)。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、ソースデータベースによって報告されたデータ変更イベントの合計数。Debezium が処理するデータ変更ワークロードを表します。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された作成イベントの合計数。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された更新イベントの合計数。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された削除イベントの合計数。 | |
|
| コネクターに設定された include/exclude リストのフィルタリングルールによってフィルターされたイベントの数。 | |
|
| コネクターによって取得されるテーブルのリスト。 | |
|
| ストリーマーとメイン Kafka Connect ループの間でイベントを渡すために使用されるキューの長さ。 | |
|
| ストリーマーとメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの空き容量。 | |
|
| コネクターが現在データベースサーバーに接続されているかどうかを示すフラグ。 | |
|
| 最後の変更イベントのタイムスタンプとそれを処理するコネクターとの間の期間 (ミリ秒単位)。この値には、データベースサーバーとコネクターが実行されているマシンのクロックの差が組み込まれます。 | |
|
| コミットされた処理済みトランザクションの数。 | |
|
| 最後に受信したイベントの位置。 | |
|
| 最後に処理されたトランザクションのトランザクション識別子。 | |
|
|
キューの最大バッファー (バイト単位)。このメトリクスは、 | |
|
| キュー内のレコードの現在の容量 (バイト単位)。 |
2.1.7.4. Debezium Db2 コネクターのスキーマ履歴の監視
MBean は debezium.db2:type=connector-metrics,context=schema-history,server= <topic.prefix> です。
以下の表は、利用可能なスキーマ履歴メトリクスのリストです。
| 属性 | タイプ | 説明 |
|---|---|---|
|
|
データベーススキーマ履歴の状態を示す | |
|
| リカバリーが開始された時点のエポック秒の時間。 | |
|
| リカバリーフェーズ中に読み取られた変更の数。 | |
|
| リカバリーおよびランタイム中に適用されるスキーマ変更の合計数。 | |
|
| 最後の変更が履歴ストアから復元された時点からの経過時間 (ミリ秒単位)。 | |
|
| 最後の変更が適用された時点からの経過時間 (ミリ秒単位)。 | |
|
| 履歴ストアから復元された最後の変更の文字列表現。 | |
|
| 最後に適用された変更の文字列表現。 |
2.1.8. Debezium Db2 コネクターの管理
Debezium Db2 コネクターをデプロイしたら、Debezium 管理 UDF を使用して、SQL コマンドで Db2 レプリケーション (ASN) を制御します。UDF によっては戻り値が必要な場合があります。この場合、SQL の VALUE ステートメントを使用して呼び出します。その他の UDF には、SQL の CALL ステートメントを使用します。
| タスク | コマンドおよび注記 |
|---|---|
|
| |
|
| |
|
| |
|
| |
|
| |
|
|
2.1.9. Debezium コネクターでのキャプチャーモードの Db2 テーブルのスキーマの更新
Debezium Db2 コネクターはスキーマ変更をキャプチャーできますが、スキーマを更新するには、データベース管理者と協力してコネクターが変更イベントの生成を継続するようにする必要があります。これは、Db2 がレプリケーションを実装する方法に必要です。
Db2 のレプリケーション機能は、キャプチャーモードのテーブルごとに、すべての変更が含まれる変更データテーブルをそのソーステーブルに作成します。ただし、変更データテーブルスキーマは静的です。キャプチャーモードのテーブルのスキーマを更新する場合は、対応する変更データテーブルのスキーマを更新する必要もあります。Debezium Db2 コネクターはこれを実行できません。昇格された権限を持つデータベース管理者は、キャプチャーモードのテーブルのスキーマを更新する必要があります。
同じテーブルの新しいスキーマ更新の前に、スキーマ更新の手順を完全に実行することが重要です。そのため、スキーマ更新の手順を 1 度で完了するために、すべての DDL を 1 つのバッチで実行することが推奨されます。
通常、テーブルスキーマを更新する手順は 2 つあります。
それぞれの方法に長所と短所があります。
2.1.9.1. Debezium Db2 コネクターでのオフラインスキーマ更新の実行
オフラインでスキーマの更新を行う前に、Debezium Db2 コネクターを停止します。これはより安全なスキーマ更新の手順ですが、高可用性の要件のあるアプリケーションには実現できない可能性があります。
前提条件
- スキーマの更新が必要なキャプチャーモードのテーブル 1 つ以上。
手順
- データベースを更新するアプリケーションを一時停止します。
- Debezium コネクターがストリーミングされていない変更イベントレコードをすべてストリーミングするまで待ちます。
- Debezium コネクターを停止します。
- すべての変更をソーステーブルスキーマに適用します。
-
ASN レジスターテーブルで、スキーマが更新されたテーブルを
INACTIVEでマーク付けします。 - ASN キャプチャーサービスを再初期化します。
- キャプチャーモードからテーブルを削除するために Debezium UDF を実行 して、キャプチャーモードから古いスキーマを含まれるソーステーブルを削除します。
- テーブルをキャプチャーモードに追加するために Debezium UDF を実行 して、スキーマが新しいソーステーブルをキャプチャーモードに追加します。
-
ASN レジスターテーブルで、更新されたソーステーブルを
ACTIVEとしてマーク付けします。 - ASN キャプチャーサービスを再初期化します。
- データベースを更新するアプリケーションを再開します。
- Debezium コネクターを再起動します。
2.1.9.2. Debezium Db2 コネクターでのオンラインスキーマ更新の実行
オンラインスキーマの更新ではアプリケーションやデータ処理のダウンタイムは必要ありません。そのため、オンラインスキーマの更新を実行する前に Debezium Db2 コネクターを停止しません。また、オンラインスキーマの更新手順は、オフラインスキーマの更新手順よりも簡単です。
ただし、テーブルがキャプチャーモードの場合は、列名の変更後も Db2 レプリケーション機能は引き続き古い列名を使用します。新しい列名は、Debezium の変更イベントでは表示されません。変更イベントにある新しい列名を確認するには、コネクターを再起動する必要があります。
前提条件
- スキーマの更新が必要なキャプチャーモードのテーブル 1 つ以上。
テーブルの最後に列を追加する場合の手順
- 変更するスキーマのソーステーブルをロックします。
-
ASN レジスターテーブルで、ロックされたテーブルを
INACTIVEとしてマーク付けします。 - ASN キャプチャーサービスを再初期化します。
- ソーステーブルのスキーマにすべての変更を適用します。
- 対応する変更データテーブルのスキーマにすべての変更を適用します。
-
ASN レジスターテーブルで、ソーステーブルを
ACTIVEとしてマーク付けします。 - ASN キャプチャーサービスを再初期化します。
- 任意手順:コネクターを再起動して、変更イベントにある更新された列名を確認します。
テーブルの中に列を追加する場合の手順
- 変更するソーステーブルをロックします。
-
ASN レジスターテーブルで、ロックされたテーブルを
INACTIVEとしてマーク付けします。 - ASN キャプチャーサービスを再初期化します。
変更するソーステーブルごとに以下を行います。
- ソーステーブルのデータをエクスポートします。
- ソーステーブルを切り捨てます。
- ソーステーブルを変更して列を追加します。
- エクスポートしたデータを変更したソーステーブルに読み込みます。
- ソーステーブルの対応する変更データテーブルのデータをエクスポートします。
- 変更データテーブルを切り捨てます。
- 変更データテーブルを変更して、列を追加します。
- エクスポートしたデータを変更した変更データテーブルに読み込みます。
-
ASN レジスターテーブルで、テーブルを
INACTIVEとしてマーク付けします。これにより、古い変更データテーブルが非アクティブとしてマーク付けされるため、それらのテーブルにあるデータは保持されますが、更新されなくなります。 - ASN キャプチャーサービスを再初期化します。
- 任意手順:コネクターを再起動して、変更イベントにある更新された列名を確認します。
2.2. MariaDB 用 Debezium コネクター (テクノロジープレビュー)
MariaDB 用の Debezium コネクターは、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat では、実稼働環境での使用を推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
MariaDB には、データベースにコミットされた順序ですべての操作を記録するバイナリーログ (binlog) があります。これには、テーブルスキーマの変更やテーブルのデータの変更が含まれます。MariaDB はレプリケーションとリカバリーに binlog を使用します。
Debezium MariaDB コネクターは binlog を読み取り、行レベルの INSERT、UPDATE、および DELETE 操作の変更イベントを生成し、変更イベントを Kafka トピックに出力します。クライアントアプリケーションはこれらの Kafka トピックを読み取ります。
MariaDB は通常、指定期間後に binlogs をパージするように設定されているため、MariaDB コネクターは各データベースの最初の整合性スナップショット を実行します。MariaDB コネクターは、スナップショットが作成された時点から binlog を読み取ります。
このコネクターと互換性のある MariaDB データベースのバージョンについては、Debezium でサポートされる設定ページを参照してください。
Debezium MariaDB コネクターの使用に関する情報と手順は、次のように設定されています。
2.2.1. Debezium MariaDB コネクターの仕組み
コネクターがサポートする MariaDB トポロジーの概要は、アプリケーションの計画に役立ちます。Debezium MariaDB コネクターを最適に設定および実行するには、コネクターによるテーブルの構造の追跡方法、スキーマ変更の公開方法、スナップショットの実行方法、および Kafka トピック名の決定方法を理解しておくと便利です。
詳細は以下を参照してください。
2.2.1.1. Debezium コネクターでサポートされる MariaDB トポロジー
Debezium MariaDB コネクターは、次の MariaDB トポロジーをサポートします。
- Standalone
- 単一の MariaDB サーバーを使用する場合、Debezium MariaDB コネクターがサーバーを監視できるように、サーバーで binlog を有効にする必要があります。バイナリーログも増分 [バックアップ] として使用できるため、これは多くの場合で許容されます。この場合、MariaDB コネクターは常にこのスタンドアロン MariaDB サーバーインスタンスに接続し、それに従います。
- Primary and replica
Debezium MariaDB コネクターは、プライマリーサーバーの 1 つ、またはレプリカの 1 つ (そのレプリカの binlog が有効になっている場合) をフォローできますが、コネクターはそのサーバーに表示されるクラスター内の変更のみを検出します。通常、これはマルチプライマリートポロジー以外では問題ではありません。
コネクターは、サーバーの binlog の位置を記録します。この位置は、クラスターの各サーバーごとに異なります。したがって、コネクターは 1 つの MariaDB サーバーインスタンスのみに従う必要があります。このサーバーに障害が発生した場合、サーバーを再起動またはリカバリーしないと、コネクターは継続できません。
- High available clusters
- MariaDB にはさまざまな [高可用性] ソリューションが存在し、問題や障害の耐性をつけ、即座に回復することが大変容易になります。HA MariaDB クラスターは GTID を使用するため、レプリカはプライマリーサーバーで発生するすべての変更を追跡できます。
- Multi-primary
複数のプライマリーサーバーからそれぞれ複製された 1 つ以上の MariaDB レプリカノードを使用します。クラスターレプリケーションは、複数の MariaDB クラスターのレプリケーションを集約する強力な方法を提供します。
Debezium MariaDB コネクターは、これらのマルチプライマリー MariaDB レプリカをソースとして使用し、新しいレプリカが古いレプリカに追いついている限り、異なるマルチプライマリー MariaDB レプリカにフェイルオーバーできます。つまり、新しいレプリカには最初のレプリカで確認されたすべてのトランザクションが含まれます。これは、コネクターがデータベースやテーブルのサブセットのみを使用している場合でも機能します。これは、新しいマルチプライマリー MariaDB レプリカに再接続して binlog 内の正しい位置を見つけようとする場合に、特定の GTID ソースを含めるか除外するようにコネクターを設定できるためです。
- Hosted
Debezium MariaDB コネクターは、Amazon RDS や Amazon Aurora などのホスト型データベースオプションを使用できます。
これらのホストオプションではグローバル読み取りロックの使用が許可されていないため、コネクターは一貫性のあるスナップショットを作成するときにテーブルレベルのロックを使用します。
2.2.1.2. Debezium MariaDB コネクターがデータベーススキーマの変更を処理する方法
データベースクライアントがデータベースのクエリーを行うと、クライアントはデータベースの現在のスキーマを使用します。しかし、データベーススキーマはいつでも変更が可能です。そのため、挿入、更新、または削除の操作が記録されるたびに、コネクターはどのスキーマであるかを特定できる必要があります。また、コネクターは必ずしも現在のスキーマをすべてのイベントに適用できるとは限りません。イベントが比較的古い場合は、現在のスキーマが適用される前に記録された可能性があります。
スキーマ変更後に発生するイベントを正しく処理するために、MariaDB には、データに影響を与える行レベルの変更だけでなく、データベースに適用される DDL ステートメントもトランザクションログに含めます。コネクターは、binlog 内でこれらの DDL ステートメントを検出すると、そのステートメントを解析し、各テーブルのスキーマのインメモリー表現を更新します。コネクターはこのスキーマ表現を使用して、挿入、更新、または削除の操作時にテーブルの構造を特定し、適切な変更イベントを生成します。別のデータベーススキーマ履歴 Kafka トピックでは、コネクターは各 DDL ステートメントがある binlog の場所とともにすべての DDL ステートメントを記録します。
クラッシュするか、正常に停止した後に、コネクターを再起動すると、特定の位置 (特定の時点) から binlog の読み取りを開始します。コネクターは、データベーススキーマ履歴の Kafka トピックを読み取り、コネクターが起動する binlog の時点まですべての DDL ステートメントを解析することで、この時点で存在したテーブル構造を再ビルドします。
このデータベーススキーマ履歴トピックは、内部コネクター専用となっています。オプションで、コネクターは コンシューマーアプリケーション向けの別のトピックにスキーマ変更イベントを送信する こともできます。
MariaDB コネクターが gh-ost や pt-online-schema-change などのスキーマ変更ツールが適用されたテーブルの変更をキャプチャーすると、移行プロセス中にヘルパーテーブルが作成されます。これらのヘルパーテーブルで発生する変更をキャプチャーするようにコネクターを設定する必要があります。コネクターがヘルパーテーブル用に生成するレコードをコンシューマーが必要としない場合は、単一メッセージ変換 (SMT) を設定して、コネクターが発行するメッセージからこれらのレコードを削除します。
関連情報
- Debezium イベントレコードを受信する トピックのデフォルト名。
2.2.1.3. Debezium MariaDB コネクターがデータベーススキーマの変更を公開する方法
Debezium MariaDB コネクターを設定して、データベース内のテーブルに適用されるスキーマの変更を記述するスキーマ変更イベントを生成することができます。コネクターは、スキーマ変更イベントを <topicPrefix> という名前の Kafka トピックに書き込みます。ここで、topicPrefix は topic.prefix コネクター設定プロパティーで指定された名前空間です。コネクターがスキーマ変更トピックに送信するメッセージには、ペイロードと、任意で変更イベントメッセージのスキーマが含まれます。
スキーマ変更イベントのスキーマには、次の要素があります。
name- スキーマ変更イベントメッセージの名前。
type- 変更イベントメッセージのタイプ。
version- スキーマのバージョン。バージョンは整数で、スキーマが変更されるたびに増加します。
fields- 変更イベントメッセージに含まれるフィールド。
例: MariaDB コネクタースキーマ変更トピックのスキーマ
次の例は、JSON 形式の一般的なスキーマを示しています。
スキーマ変更イベントメッセージのペイロードには、以下の要素が含まれます。
ddl-
スキーマの変更につながる SQL
CREATE、ALTER、またはDROPステートメントを提供します。 databaseName-
DDL ステートメントが適用されるデータベースの名前。
databaseNameの値は、メッセージキーとして機能します。 pos- ステートメントが表示される binlog の位置。
tableChanges-
スキーマの変更後のテーブルスキーマ全体の構造化表現。
tableChangesフィールドには、テーブルの各列のエントリーなどのアレイが含まれます。構造化された表現は JSON または Avro 形式でデータを表示するため、コンシューマーは DDL パーサーを介して最初にメッセージを処理しなくてもメッセージを簡単に読み取りできます。
キャプチャーモードであるテーブルでは、コネクターはスキーマ変更トピックにスキーマ変更の履歴だけでなく、内部データベーススキーマ履歴トピックにも格納します。内部データベーススキーマ履歴トピックはコネクターのみの使用を対象としており、使用するアプリケーションによる直接使用を目的としていません。スキーマ変更に関する通知が必要なアプリケーションが、スキーマ変更トピックからの情報のみを使用するようにしてください。
データベーススキーマ履歴トピックをパーティションに分割しないでください。データベーススキーマ履歴トピックが正しく機能するには、コネクターが出力するイベントレコードの一貫したグローバル順序を維持する必要があります。
トピックがパーティション間で分割されないようにするには、以下のいずれかの方法を使用してトピックのパーティション数を設定します。
-
データベーススキーマ履歴トピックを手動で作成する場合は、パーティション数を
1に指定します。 -
Apache Kafka ブローカーを使用してデータベーススキーマ履歴トピックを自動的に作成する場合に、トピックが作成されるので、Kafka
num.partitions設定オプションの値を1に設定します。
コネクターがスキーマ変更トピックに出力するメッセージの形式は、初期の状態であり、通知なしに変更される可能性があります。
例: MariaDB コネクタースキーマ変更トピックに送信されるメッセージ
以下の例は、JSON 形式の一般的なスキーマ変更メッセージを示しています。メッセージには、テーブルスキーマの論理表現が含まれます。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
|
| 2 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 3 |
|
変更が含まれるデータベースとスキーマを識別します。 |
| 4 |
|
このフィールドには、スキーマの変更を行う DDL が含まれます。 |
| 5 |
| DDL コマンドによって生成されるスキーマの変更が含まれる 1 つ以上の項目の配列。 |
| 6 |
| 変更の種類を説明します。値は以下のいずれかになります。
|
| 7 |
|
作成、変更、または破棄されたテーブルの完全な識別子。テーブルの名前が変更されると、この識別子は |
| 8 |
| 適用された変更後のテーブルメタデータを表します。 |
| 9 |
| テーブルのプライマリーキーを設定する列のリスト。 |
| 10 |
| 変更されたテーブルの各列のメタデータ。 |
| 11 |
| 各テーブル変更のカスタム属性メタデータ。 |
詳細は、スキーマ履歴のトピック を参照してください。
2.2.1.4. Debezium MariaDB コネクターがデータベーススナップショットを実行する方法
Debezium MariaDB コネクターが初めて起動されると、データベースの初期 整合性スナップショット が実行されます。このスナップショットにより、コネクターはデータベースの現在の状態のベースラインを確立できます。
Debezium はスナップショットを実行するときにさまざまなモードを使用できます。スナップショットモードは、snapshot.mode 設定プロパティーによって決まります。プロパティーのデフォルト値は initial です。snapshot.mode プロパティーの値を変更することで、コネクターがスナップショットを作成する方法をカスタマイズできます。
スナップショットの詳細は、以下のセクションを参照してください。
コネクターは、スナップショットを実行するときに一連のタスクを完了します。正確な手順は、スナップショットモードと、データベースに対して有効なテーブルロックポリシーによって異なります。Debezium MariaDB コネクターは、グローバル読み取りロック または テーブルレベルロック を使用する初期スナップショットを実行するときに、さまざまな手順を実行します。
2.2.1.4.1. グローバル読み取りロックを使用する初期スナップショット
snapshot.mode プロパティーの値を変更することで、コネクターがスナップショットを作成する方法をカスタマイズできます。別のスナップショットモードを設定する場合、コネクターはこのワークフローの変更バージョンを使用してスナップショットを完了します。グローバル読み取りロックが許可されていない環境でのスナップショットプロセスは、テーブルレベルロックのスナップショットワークフロー を参照してください。
Debezium MariaDB コネクターがグローバル読み取りロックを使用して初期スナップショットを実行するために使用するデフォルトのワークフロー
以下の表は、Debezium がグローバル読み取りロックでスナップショットを作成する際のワークフローの手順を示しています。
| 手順 | アクション |
|---|---|
| 1 | データベースへの接続を確立します。 |
| 2 |
キャプチャーするテーブルを決定します。デフォルトでは、コネクターはシステム以外のすべてのテーブルのデータをキャプチャーします。スナップショットが完了した後、コネクターは指定されたテーブルのデータをストリーミングし続けます。コネクターで特定のテーブルからのみデータをキャプチャーする場合は、 |
| 3 |
キャプチャーするテーブルに対してグローバル読み取りロックを取得し、他のデータベースクライアントによる writes をブロックします。 |
|
4 注記 これらの分離セマンティクスを使用すると、スナップショットの進行が遅くなる可能性があります。スナップショットの完了に時間がかかりすぎる場合は、別の分離設定の使用を検討するか、最初のスナップショットをスキップして、代わりに 増分スナップショット を実行します。 | 5 |
| 現在の binlog の位置を読み取ります。 | 6 |
|
データベース内のすべてのテーブル、またはキャプチャー対象として指定されたすべてのテーブルの構造をキャプチャーします。コネクターは、必要なすべての 注記
デフォルトでは、コネクターは、キャプチャー用に設定されていないテーブルも含め、データベース内のすべてのテーブルのスキーマをキャプチャーします。テーブルがキャプチャー用に設定されていない場合、最初のスナップショットはテーブルの構造のみをキャプチャーし、テーブルデータはキャプチャーされません。 | 7 |
| 手順 3 で取得したグローバル読み取りロックを解放します。他のデータベースクライアントがデータベースに書き込みできるようになりました。 | 8 |
| コネクターが手順 5 で読み取った binlog の位置で、コネクターはキャプチャー用に指定されたテーブルのスキャンを開始します。スキャン中に、コネクターは次のタスクを実行します。
| 9 |
| トランザクションをコミットします。 | 10 |
作成された初期スナップショットは、キャプチャーされたテーブルの各行の現在の状態をキャプチャーします。このベースライン状態から、コネクターは発生した後続の変更をキャプチャーします。
スナップショットプロセスが開始されたら、コネクターの障害、リバランス、またはその他の理由でプロセスが中断されると、コネクターの再起動後にプロセスが再起動されます。
コネクターによって最初のスナップショットが完了した後、更新に抜けがないように、手順 5 で読み取りした位置からストリーミングを続行します。
何らかの理由でコネクターが再び停止した場合に、コネクターは再起動後に最後に停止した位置から変更のストリーミングを再開します。
コネクターの再起動後、ログがプルーニングされている場合、ログ内のコネクターの位置が使用できなくなる可能性があります。その後、コネクターは失敗し、新しいスナップショットが必要であることを示すエラーを返します。この状況でスナップショットを自動的に開始するようにコネクターを設定するには、snapshot.mode プロパティーの値を when_needed に設定します。Debezium MariaDB コネクターのトラブルシューティングに関する詳細は、問題が発生したときの動作 を参照してください。
2.2.1.4.2. テーブルレベルロックを使用する初期スナップショット
一部のデータベース環境では、管理者がグローバル読み取りロックを許可していません。Debezium MariaDB コネクターがグローバル読み取りロックが許可されていないことを検出した場合、コネクターはスナップショットを実行するときにテーブルレベルのロックを使用します。コネクターがテーブルレベルロックを使用するスナップショットを実行するには、Debezium コネクターが MariaDB への接続に使用するデータベースアカウントで LOCK TABLES 権限が必要です。
Debezium MariaDB コネクターがテーブルレベルのロックを使用して初期スナップショットを実行するために使用するデフォルトのワークフロー
次の表は、テーブルレベルの読み取りロックを使用してスナップショットを作成するために Debezium が実行するワークフローの手順を示しています。グローバル読み取りロックが許可されていない環境でのスナップショットプロセスについては、グローバル読み取りロックのスナップショットワークフロー を参照してください。
| 手順 | アクション |
|---|---|
| 1 | データベースへの接続を確立します。 |
| 2 |
キャプチャーするテーブルを決定します。デフォルトでは、コネクターはすべてのシステム以外のテーブルをキャプチャーします。コネクターにテーブルまたはテーブル要素のサブセットをキャプチャーさせるには、 |
| 3 | テーブルレベルロックを取得します。 |
| 4 | 5 |
| 現在の binlog の位置を読み取ります。 | 6 |
|
コネクターが変更をキャプチャーするように設定されたデータベースとテーブルのスキーマを読み取ります。コネクターは、必要なすべての 注記 デフォルトでは、コネクターは、キャプチャー用に設定されていないテーブルも含め、データベース内のすべてのテーブルのスキーマをキャプチャーします。テーブルがキャプチャー用に設定されていない場合、最初のスナップショットはテーブルの構造のみをキャプチャーし、テーブルデータはキャプチャーされません。 初期スナップショットに含まれなかったテーブルのスキーマ情報がスナップショットに保持される理由の詳細は、初期スナップショットがすべてのテーブルのスキーマをキャプチャーする理由 を参照してください。 | 7 |
| コネクターが手順 5 で読み取った binlog の位置で、コネクターはキャプチャー用に指定されたテーブルのスキャンを開始します。スキャン中に、コネクターは次のタスクを実行します。
| 8 |
| トランザクションをコミットします。 | 9 |
| テーブルレベルロックを解除します。他のデータベースクライアントは、以前にロックされていたテーブルに書き込みできるようになります。 | 10 |
| 設定 | 説明 |
|---|---|
|
| コネクターは起動するたびにスナップショットを実行します。スナップショットには、キャプチャーされたテーブルの構造およびデータが含まれます。この値を指定すると、コネクターが起動するたびに、キャプチャーされたテーブルからのデータの完全な表現がトピックに入力されます。スナップショットが完了すると、コネクターは、後続のデータベース変更のに備え、イベントレコードのストリーミングを開始します。 |
|
| コネクターは 初期スナップショットを作成するためのデフォルトのワークフロー で説明されているように、データベーススナップショットを実行します。スナップショットが完了すると、コネクターは、後続のデータベース変更のに備え、イベントレコードのストリーミングを開始します。 |
|
| コネクターはデータベーススナップショットを実行します。スナップショットが完了すると、コネクターは停止し、後続のデータベース変更のイベントレコードをストリーミングしなくなります。 |
|
|
非推奨です。 |
|
|
コネクターは、初期スナップショットを作成するためのデフォルトのワークフロー で説明されているすべての手順を実行して、関連するすべてのテーブルの構造をキャプチャーします。ただし、コネクターの起動時点のデータセットを表す |
|
|
コネクターが起動すると、スナップショットを実行するのではなく、後続のデータベース変更のイベントレコードのストリーミングがすぐに開始されます。 |
|
|
非推奨です。 |
|
|
損失または破損したデータベーススキーマの履歴トピックを復元するにはこのオプションを設定します。再起動後、コネクターはソーステーブルからトピックを再構築するスナップショットを実行します。また、このプロパティーを設定して、予期しない増加が発生するデータベーススキーマ履歴トピックを定期的にプルーニングすることもできます。 |
|
| コネクターが起動した後、次のいずれかの状況を検出した場合にのみスナップショットが実行されます。
|
詳細は、コネクター設定プロパティーテーブルの snapshot.mode を参照してください。
2.2.1.4.3. 初期スナップショットがすべてのテーブルのスキーマ履歴をキャプチャーする理由
コネクターが実行する最初のスナップショットは、2 種類の情報をキャプチャーします。
- テーブルデータ
-
コネクターの
table.include.listプロパティーにあるテーブルのINSERT、UPDATE、およびDELETE操作に関する情報。 - スキーマデータ
- テーブルに適用される構造の変更を記述する DDL ステートメント。スキーマデータは、内部スキーマ履歴トピックとコネクターのスキーマ変更トピック (設定されている場合) の両方に保持されます。
初期スナップショットを実行すると、キャプチャー対象として指定されていないテーブルのスキーマ情報がスナップショットによってキャプチャーされることが分かります。デフォルトでは、初期スナップショットは、キャプチャー用に指定されたテーブルからだけでなく、データベースに存在するすべてのテーブルのスキーマ情報を取得するように設計されています。コネクターでは、テーブルのスキーマがスキーマ履歴トピックにある状態で、テーブルをキャプチャーする必要があります。初期スナップショットが元のキャプチャーセットの一部ではないテーブルのスキーマデータをキャプチャーできるようにして、後で必要になった場合にこれらのテーブルからイベントデータを簡単にキャプチャーできるように、Debezium はコネクターを準備します。初期スナップショットがテーブルのスキーマをキャプチャーしない場合は、コネクターがテーブルからデータをキャプチャーする前に、履歴トピックにスキーマを追加する必要があります。
場合によっては、最初のスナップショットでのスキーマキャプチャーを制限する場合があります。これは、スナップショットの完了に必要な時間の短縮に便利です。または、Debezium が複数の論理データベースにアクセスできるユーザーアカウントを使用して、データベースインスタンスに接続しているにもかかわらず、コネクターで特定の論理データベース内のテーブルからの変更のみをキャプチャーする場合にも便利です。
関連情報
- 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更なし)
- 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更)
-
schema.history.internal.store.only.captured.tables.ddlプロパティーを設定して、スキーマ情報をキャプチャーするテーブルを指定します。 -
schema.history.internal.store.only.captured.databases.ddlプロパティーを設定して、スキーマ変更をキャプチャーする論理データベースを指定します。
2.2.1.4.4. 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更なし)
コネクターを使用して、最初のスナップショットでスキーマがキャプチャーされなかったテーブルからデータをキャプチャーする場合があります。コネクターの設定によっては、最初のスナップショットはデータベース内の特定のテーブルのテーブルスキーマのみをキャプチャーする場合があります。テーブルスキーマが履歴トピックに存在しない場合、コネクターはテーブルのキャプチャーに失敗し、スキーマ欠落エラーを報告します。
テーブルからデータを取得できる場合もありますが、テーブルスキーマを追加するには別の手順を実行する必要があります。
前提条件
- コネクターにより最初のスナップショット中にキャプチャーされなかったスキーマが含まれるテーブルからデータをキャプチャーしたいと考えている。
- トランザクションログでは、テーブルのすべてのエントリーが同じスキーマを使用します。構造変更が行われた新しいテーブルからデータをキャプチャーする方法については、初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更) を参照してください。
手順
- コネクターを停止します。
-
schema.history.internal.kafka.topic プロパティーで指定された内部データベーススキーマ履歴トピックを削除します。 以下の変更をコネクター設定に適用します。
-
snapshot.modeはschema_only_recoveryに設定します。 -
schema.history.internal.store.only.captured.tables.ddlの値をfalseに設定します。 -
コネクターがキャプチャーするテーブルを
table.include.listに追加します。これにより、コネクターは今後すべてのテーブルのスキーマ履歴を再構築できます。
-
- コネクターを再起動します。スナップショットのリカバリープロセスでは、テーブルの現在の構造に基づいてスキーマ履歴が再ビルドされます。
- (オプション) スナップショットが完了したら、増分スナップショット を開始して、コネクターがオフラインだった間に発生した他のテーブルへの変更とともに、新しく追加されたテーブルの既存のデータをキャプチャーします。
-
(オプション)
snapshot.modeをschema_onlyにリセットして、今後の再起動後にコネクターが回復を開始しないようにします。
2.2.1.4.5. 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更)
スキーマ変更がテーブルに適用される場合、スキーマ変更前にコミットされたレコードの構造は、変更後にコミットされたレコードとは異なります。Debezium はテーブルからデータをキャプチャーするときに、スキーマ履歴を読み取り、各イベントに正しいスキーマが適用されていることを確認します。スキーマがスキーマ履歴トピックに存在しない場合、コネクターはテーブルをキャプチャーできず、エラーが発生します。
最初のスナップショットでキャプチャーされず、テーブルのスキーマが変更されたテーブルからデータをキャプチャーする場合、スキーマがまだ使用可能でない場合は、履歴トピックにスキーマを追加する必要があります。新しいスキーマスナップショットを実行するか、テーブルの初期スナップショットを実行して、スキーマを追加できます。
前提条件
- コネクターにより最初のスナップショット中にキャプチャーされなかったスキーマが含まれるテーブルからデータをキャプチャーしたいと考えている。
- スキーマ変更がテーブルに適用されたため、キャプチャーされるレコードの構造が不均一になっている。
手順
- 初期スナップショットにすべてのテーブルのスキーマがキャプチャーされている場合 (
store.only.captured.tables.ddlはfalseに設定されました)。 -
table.include.listプロパティーを編集して、キャプチャーするテーブルを指定します。 - コネクターを再起動します。
- 新しく追加したテーブルから既存のデータをキャプチャーする場合は、増分スナップショット を開始します。
-
- 初期スナップショットにすべてのテーブルのスキーマがキャプチャーされていない場合 (
store.only.captured.tables.ddlがtrueに設定されています)。 最初のスナップショットでキャプチャーするテーブルのスキーマが保存されなかった場合は、次のいずれかの手順を実行します。
- 手順 1: スキーマスナップショット、その後に増分スナップショット
この手順では、コネクターは最初にスキーマのスナップショットを実行します。その後、増分スナップショットを開始して、コネクターがデータを同期できるようにします。
- コネクターを停止します。
-
schema.history.internal.kafka.topic プロパティーで指定された内部データベーススキーマ履歴トピックを削除します。 設定された Kafka Connect
offset.storage.topic内のオフセットをクリアします。オフセットを削除する方法の詳細は、Debezium コミュニティーの FAQ を参照してください。警告オフセットの削除は、内部 Kafka Connect データの操作の経験がある上級ユーザーのみが実行してください。この操作によりシステムが破損する場合があるため、最後の手段としてのみ実行してください。
次の手順の説明に従って、コネクター設定のプロパティーの値を設定します。
-
snapshot.modeプロパティーの値をschema_onlyに設定します。 -
table.include.listを編集して、キャプチャーするテーブルを追加します。
-
- コネクターを再起動します。
- Debezium が新規および既存のテーブルのスキーマをキャプチャーするまで待ちます。コネクターが停止した後にテーブルで発生したデータ変更はキャプチャーされません。
- データが損失されないようにするには、増分スナップショット を開始します。
- 手順 2: 初期スナップショットと、それに続くオプションの増分スナップショット
この手順では、コネクターはデータベースの完全な初期スナップショットを実行します。他の初期スナップショットと同様、多数の大きなテーブルが含まれるデータベースでは、初期スナップショットの実行操作には時間がかかる可能性があります。スナップショットの完了後、任意で増分スナップショットをトリガーして、コネクターがオフラインの間に発生した変更をキャプチャーできます。
- コネクターを停止します。
-
schema.history.internal.kafka.topic プロパティーで指定された内部データベーススキーマ履歴トピックを削除します。 設定された Kafka Connect
offset.storage.topic内のオフセットをクリアします。オフセットを削除する方法の詳細は、Debezium コミュニティーの FAQ を参照してください。警告オフセットの削除は、内部 Kafka Connect データの操作の経験がある上級ユーザーのみが実行してください。この操作によりシステムが破損する場合があるため、最後の手段としてのみ実行してください。
-
table.include.listを編集して、キャプチャーするテーブルを追加します。 次の手順の説明に従って、コネクター設定のプロパティーの値を設定します。
-
snapshot.modeプロパティーの値をinitialに設定します。 -
(オプション)
schema.history.internal.store.only.captured.tables.ddlをfalseに設定します。
-
- コネクターを再起動します。コネクターはデータベース全体のスナップショットを取得します。スナップショットが完了すると、コネクターはストリーミングに移行します。
- (オプション) コネクターがオフラインの間に変更されたデータをキャプチャーするには、増分スナップショット を開始します。
2.2.1.5. アドホックスナップショット
デフォルトでは、コネクターは初回スナップショット操作の開始後にのみ実行されます。通常の状況では、この最初のスナップショットが作成されると、コネクターではスナップショットプロセスは繰り返し処理されません。コネクターがキャプチャーする今後の変更イベントデータはストリーミングプロセス経由でのみ行われます。
ただし、場合によっては、最初のスナップショット中にコネクターを取得したデータが古くなったり、失われたり、または不完全となったり可能性があります。テーブルデータを再キャプチャーするメカニズムを提供するため、Debezium にはアドホックスナップショットを実行するオプションがあります。Debezium 環境で次のいずれかの変更が発生したら、アドホックスナップショットを実行することを推奨します。
- コネクター設定は、異なるテーブルセットをキャプチャーするように変更されます。
- Kafka トピックを削除して、再構築する必要があります。
- 設定エラーや他の問題が原因で、データの破損が発生します。
アドホックと呼ばれるスナップショット を開始することで、以前にスナップショットをキャプチャーしたテーブルのスナップショットを再実行できます。アドホックスナップショットには、シグナルテーブル を使用する必要があります。シグナルリクエストを Debezium シグナルテーブルに送信して、アドホックスナップショットを開始します。
既存のテーブルのアドホックスナップショットを開始すると、コネクターはテーブルにすでに存在するトピックにコンテンツを追加します。既存のトピックが削除された場合には、トピックの自動作成 が有効になっているのであれば、Debezium は自動的にトピックを作成できます。
アドホックのスナップショットシグナルは、スナップショットに追加するテーブルを指定します。スナップショットは、データベースの内容全体をキャプチャーしたり、データベース内のテーブルのサブセットのみをキャプチャーしたりできます。また、スナップショットは、データベース内のテーブルの内容のサブセットをキャプチャできます。
execute-snapshot メッセージをシグナルテーブルに送信してキャプチャーするテーブルを指定します。execute-snapshot シグナルのタイプを incremental または blocking に設定し、スナップショットに含めるテーブルの名前を次の表に示すように指定します。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプを指定します。 |
|
| 該当なし |
スナップショットに含めるテーブルの完全修飾名に一致する正規表現を含む配列。 |
|
| 該当なし |
コネクターがスナップショットに含めるレコードのサブセットを決定するために評価する追加条件のセットを指定する、オプションの配列。
|
|
| 該当なし | スナップショット処理中にコネクターがテーブルのプライマリーキーとして使用する列名を指定するオプションの文字列。 |
アドホック増分スナップショットのトリガー
アドホック増分スナップショットを開始するには、execute-snapshot シグナルタイプのエントリーをシグナリングテーブルに追加するか、シグナルメッセージを Kafka シグナリングトピックに送信します。コネクターがメッセージを処理した後に、スナップショット操作を開始します。スナップショットプロセスは、最初と最後のプライマリーキーの値を読み取り、これらの値を各テーブルの開始ポイントおよびエンドポイントとして使用します。テーブルのエントリー数と設定されたチャンクサイズに基づいて、Debezium はテーブルをチャンクに分割し、チャンクごとに 1 度に 1 つずつスナップショットを順番に作成していきます。
詳細は、スナップショットの増分を参照してください。
アドホックブロッキングスナップショットのトリガー
シグナリングテーブルまたはシグナリングトピックに、execute-snapshot シグナルタイプを持つエントリーを追加することによって、アドホックブロッキングスナップショットを開始します。コネクターがメッセージを処理した後に、スナップショット操作を開始します。コネクターはストリーミングを一時的に停止し、初期スナップショットの時と同じプロセスに従って、指定されたテーブルのスナップショットを開始します。スナップショットが完了すると、コネクターはストリーミングを再開します。
詳細は、ブロッキングスナップショット を参照してください。
2.2.1.6. 増分スナップショット
スナップショットを柔軟に管理するため、Debezium には 増分スナップショット と呼ばれる補助スナップショットメカニズムが含まれています。増分スナップショットは、Debezium コネクターにシグナルを送信するため の Debezium メカニズムに依存します。
増分スナップショットでは、最初のスナップショットのように、データベースの完全な状態を一度にすべてキャプチャーする代わりに、一連の設定可能なチャンクで各テーブルを段階的にキャプチャーします。スナップショットがキャプチャーするテーブルと、各チャンクのサイズ を指定できます。チャンクのサイズにより、データベース上の各フェッチ操作中にスナップショットで収集される行数が決まります。増分スナップショットのデフォルトのチャンクサイズは 1024 行です。
増分スナップショットが進むと、Debezium はウォーターマークを使用して進捗を追跡し、キャプチャーする各テーブル行のレコードを管理します。この段階的なアプローチでは、標準の初期スナップショットプロセスと比較して、以下の利点があります。
- スナップショットが完了するまで、ストリーミングストリーミングを延期する代わりに、ストリームしたデータキャプチャーと並行して増分スナップショットを実行できます。コネクターはスナップショットプロセス全体で変更ログからのほぼリアルタイムイベントをキャプチャーし続け、他の操作はブロックしません。
- 増分スナップショットの進捗が中断された場合は、データを失うことなく再開できます。プロセスが再開すると、スナップショットは最初からテーブルをキャプチャーするのではなく、停止した時点から開始します。
-
いつでも増分スナップショットを実行し、必要に応じてプロセスを繰り返してデータベースの更新に適合できます。たとえば、コネクター設定を変更してテーブルを
table.include.listプロパティーに追加した後にスナップショットを再実行します。
増分スナップショットプロセス
増分スナップショットを実行する場合には、Debezium は各テーブルをプライマリーキー別に分類して、設定されたチャンクサイズ に基づいてテーブルをチャンクに分割します。チャンクごとに作業し、テーブルの行ごとにチャンクでキャプチャーします。キャプチャーする行ごとに、スナップショットは READ イベントを出力します。そのイベントは、対象となるチャンクのスナップショットを開始する時の行の値を表します。
スナップショットの作成が進むにつれ、他のプロセスがデータベースへのアクセスを継続し、テーブルレコードが変更される可能性があります。このような変更を反映させるように、通常通りに INSERT、UPDATE、DELETE 操作がトランザクションログにコミットされます。同様に、継続中の Debezium ストリーミングプロセスは、これらの変更イベントを検出し、対応する変更イベントレコードを Kafka に出力します。
Debezium を使用してプライマリーキーが同じレコード間での競合を解決する方法
場合によっては、ストリーミングプロセスが出力する UPDATE または DELETE イベントを順番に受信できます。つまり、ストリーミングプロセスは、スナップショットがその行の READ イベントが含まれるチャンクをキャプチャーする前に、テーブルの行を変更するイベントを生成する可能性があります。スナップショットが最終的に対象の行にあった READ イベントを出力すると、その値はすでに置き換えられています。Debezium は、シーケンスが到達する増分スナップショットイベントが正しい論理順序で処理されるように、競合を解決するためにバッファースキームを使用します。スナップショットのイベント間で競合が発生し、ストリームされたイベントが解決されてからでないと、Debezium はイベントのレコードを Kafka に送信しません。
スナップショットウィンドウ
遅れて入ってきた READ イベントと、同じテーブルの行を変更するストリーミングイベント間の競合の解決を容易にするために、Debezium は スナップショットウィンドウ と呼ばれるものを使用します。スナップショットウィンドウは、増分スナップショットが指定のテーブルチャンクのデータをキャプチャーしている途中に、間隔を決定します。チャンクのスナップショットウィンドウを開く前に、Debezium は通常の動作に従い、トランザクションログから直接ターゲットの Kafka トピックにイベントをダウンストリームに出力します。ただし、特定のチャンクのスナップショットが開放された瞬間から終了するまで、Debezium は重複除去のステップを実行して、プライマリーキーが同じイベント間での競合を解決します。
データコレクションごとに、Debezium は 2 種類のイベントを出力し、それらの両方のレコードを単一の宛先 Kafka トピックに保存します。テーブルから直接キャプチャーするスナップショットレコードは、READ 操作として出力されます。その間、ユーザーはデータコレクションのレコードの更新を続け、各コミットを反映するようにトランザクションログが更新されるので、Debezium は変更ごとに UPDATE または DELETE 操作を出力します。
スナップショットウィンドウが開放され、Debezium がスナップショットチャンクの処理を開始すると、スナップショットレコードをメモリーバッファーに提供します。スナップショットウィンドウ中に、バッファー内の READ イベントのプライマリーキーは、受信ストリームイベントのプライマリーキーと比較されます。一致するものが見つからない場合、ストリーミングされたイベントレコードが Kafka に直接送信されます。Debezium が一致を検出すると、バッファーされた READ イベントを破棄し、ストリーミングされたレコードを宛先トピックに書き込みます。これは、ストリーミングされたイベントが静的スナップショットイベントよりも論理的に優先されるためです。チャンクのスナップショットウィンドウが終了すると、バッファーに含まれるのは、関連するトランザクションログイベントが存在しない READ イベントのみです。Debezium は、これらの残りの READ イベントをテーブルの Kafka トピックに出力します。
コネクターは各スナップショットチャンクにプロセスを繰り返します。
現在、増分スナップショットを開始するには、次のいずれかの方法を使用できます。
2.2.1.6.1. 増分スナップショットのトリガー
増分スナップショットを開始するには、ソースデータベースのシグナリングテーブルに アドホックスナップショットシグナル を送信します。スナップショットシグナルは SQL INSERT クエリーとして送信します。
Debezium がシグナルテーブルの変更を検出すると、シグナルを読み取り、要求されたスナップショット操作を実行します。
送信するクエリーはスナップショットに追加するテーブルを指定し、必要に応じてスナップショット操作の種類を指定します。Debezium は現在、incremental と blocking のスナップショットタイプをサポートしています。
スナップショットに追加するテーブルを指定するには、テーブルをリストする data-collections 配列またはテーブルの照合に使用する正規表現の配列を指定します。以下に例を示します。
{"data-collections": ["public.MyFirstTable", "public.MySecondTable"]}
増分スナップショットシグナルの data-collections アレイにはデフォルト値がありません。data-collections 配列が空の場合、Debezium は空の配列をアクションが必要ないと解釈し、スナップショットは作成しません。
スナップショットに含めるテーブルの名前にドット (.)、スペース、またはその他の英数字以外の文字が含まれている場合は、テーブル名を二重引用符でエスケープする必要があります。
たとえば、db1 データベースに存在し、My.Table という名前のテーブルを含めるには、"db1.\"My.Table\"" の形式を使用します。
前提条件
- ソースデータベースにシグナリングデータコレクションが存在する。
-
シグナルデータコレクションが
signal.data.collectionプロパティーで指定されます。
ソースシグナリングチャネルを使用して増分スナップショットをトリガーする
SQL クエリーを送信し、アドホック増分スナップショット要求をシグナルテーブルに追加します。
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow コマンドの
id、type、およびdataパラメーターの値は、シグナルテーブルのフィールド に対応します。
以下の表では、この例のパラメーターを説明しています。Expand 表2.28 シグナルテーブルに増分スナップショットシグナルを送信する SQL コマンドのフィールドの説明 項目 値 説明 1
database.debezium_signalソースデータベースにあるシグナルテーブルの完全修飾名を指定します。
2
ad-hoc-1idパラメーターは、シグナルリクエストのID識別子として割り当てられる任意の文字列を指定します。
この文字列を使用して、シグナルテーブルのエントリーへのログメッセージを特定します。Debezium はこの文字列を使用しません。代わりに、スナップショット作成中に、Debezium は独自のID文字列をウォーターマークシグナルとして生成します。3
execute-snapshottypeパラメーターを指定し、シグナルがトリガーする操作を指定します。
4
data-collectionsシグナルの
dataフィールドの必須コンポーネントで、スナップショットに含めるテーブル名の配列またはテーブル名と一致する正規表現を指定します。
配列には、database.table形式を使用してテーブルの完全修飾名と一致する正規表現がリストされます。この形式は、コネクターの シグナリングテーブル の名前を指定するために使用する形式と同じです。5
incremental実行するスナップショット操作のタイプを指定する、シグナルの
dataフィールドのオプションのtypeコンポーネント。
有効な値はincrementalとblockingです。
値を指定しない場合、コネクターはデフォルトで増分スナップショットを実行します。6
additional-conditionsコネクターがスナップショットに含めるレコードのサブセットを決定するために評価する追加条件のセットを指定する、オプションの配列。
各追加条件は、data-collectionプロパティーとfilterプロパティーを持つオブジェクトです。データの収集単位で異なるフィルターを指定できます。
*data-collectionプロパティーは、フィルターが適用されるデータコレクションの完全修飾名です。additional-conditionsパラメーターの詳細は、additional-conditions付きでアドホック増分スナップショットを実行する を参照してください。
additional-conditions 付きでアドホック増分スナップショットを実行する
スナップショットに、テーブル内のコンテンツのサブセットのみを含める場合は、スナップショットシグナルに additional-conditions パラメーターを追加してシグナル要求を変更できます。
一般的なスナップショットの SQL クエリーは、以下の形式を取ります。
SELECT * FROM <tableName> ....
SELECT * FROM <tableName> ....
additional-conditions パラメーターを追加して、以下の例のように WHERE 条件を SQL クエリーに追加します。
SELECT * FROM <data-collection> WHERE <filter> ....
SELECT * FROM <data-collection> WHERE <filter> ....以下の例は、シグナルテーブルに追加の条件を含むアドホック増分スナップショット要求を送信する SQL クエリーを示しています。
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');
たとえば、以下の列が含まれる products テーブルがあるとします。
-
id(プライマリーキー) -
color -
quantity
products テーブルの増分スナップショットに color=blue のデータ項目のみを含める場合は、次の SQL ステートメントを使用してスナップショットをトリガーできます。
INSERT INTO db1.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["db1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "db1.products", "filter": "color=blue"}]}');
INSERT INTO db1.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["db1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "db1.products", "filter": "color=blue"}]}');
additional-conditions パラメーターを使用すると、列が 2 つ以上となる条件を指定することもできます。たとえば、前述の例の products テーブルを使用して、color=blue および quantity>10 だけに一致するアイテムのみのデータが含まれる増分スナップショットをトリガーするクエリーを送信できます。
INSERT INTO db1.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["db1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "db1.products", "filter": "color=blue AND quantity>10"}]}');
INSERT INTO db1.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["db1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "db1.products", "filter": "color=blue AND quantity>10"}]}');以下の例は、コネクターによってキャプチャーされる増分スナップショットイベントの JSON を示しています。
例2.9 増分スナップショットイベントメッセージ
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
実行するスナップショット操作タイプを指定します。 |
| 2 |
|
イベントタイプを指定します。 |
2.2.1.6.2. Kafka シグナルチャネルを使用して増分スナップショットをトリガーする
設定された Kafka トピック にメッセージを送信して、コネクターにアドホック増分スナップショットを実行するよう要求できます。
Kafka メッセージのキーは、topic.prefix コネクター設定オプションの値と一致する必要があります。
メッセージの値は、type と data フィールドが含まれる JSON オブジェクトとなっています。
シグナルタイプは execute-snapshot で、data フィールドには以下のフィールドが必要です。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプ。現在、Debezium は |
|
| 該当なし |
スナップショットに含めるテーブルの完全修飾名と一致する、コンマ区切りの正規表現の配列。 |
|
| 該当なし |
コネクターがスナップショットに含めるレコードのサブセットを指定するために評価する基準を指定する、オプションの追加条件の配列。 |
例2.10 execute-snapshot Kafka メッセージ
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["{collection-container}.table1", "{collection-container}.table2"], "type": "INCREMENTAL"}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["{collection-container}.table1", "{collection-container}.table2"], "type": "INCREMENTAL"}}`additional-conditions 付きのアドホック増分スナップショット
Debezium は additional-conditions フィールドを使用してテーブルのコンテンツのサブセットを選択します。
通常、Debezium はスナップショットを実行するときに、次のような SQL クエリーを実行します。
SELECT * FROM <tableName> ….
スナップショット要求に additional-conditions プロパティーが含まれている場合、プロパティーの data-collection および filter パラメーターが SQL クエリーに追加されます。次に例を示します。
SELECT * FROM <data-collection> WHERE <filter> ….
たとえば、列 id (プライマリーキー)、color、および brand を含む products テーブルがある場合、スナップショットに color='blue' のコンテンツのみを含める場合は、スナップショットをリクエストするときに、コンテンツをフィルタリングする additional-conditions プロパティーを追加することができます。
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.products" ,"filter":"color='blue'"}]}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.products" ,"filter":"color='blue'"}]}}`
また、additional-conditions プロパティーを使用して、複数の列に基づいて条件を渡すこともできます。たとえば、前の例と同じ products テーブルを使用して、color='blue' および brand='MyBrand' である products テーブルのコンテンツのみをスナップショットに含める場合は、次のリクエストを送信できます。
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.products" ,"filter":"color='blue' AND brand='MyBrand'"}]}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.products" ,"filter":"color='blue' AND brand='MyBrand'"}]}}`2.2.1.6.3. 増分スナップショットの停止
状況によっては、増分スナップショットを停止する必要がある場合があります。たとえば、スナップショットが正しく設定されていない場合や、他のデータベース操作にリソースが使用可能であるこのとの確認が必要な場合があります。ソースデータベースのシグナリングテーブルにシグナルを送信することで、すでに実行中のスナップショットを停止できます。
スナップショット停止信号をシグナリングテーブルに送信するには、SQL INSERT クエリーで送信します。stop-snapshot シグナルは、スナップショット操作の type を incremental として指定し、オプションで、現在実行中のスナップショットから省略するテーブルを指定します。Debezium はシグナルテーブルの変更を検出した後、シグナルを読み、増分スナップショット操作が進行中であればそれを停止します。
関連情報
また、JSON メッセージを Kafka シグナリングトピック に送信して、増分スナップショットを停止することもできます。
前提条件
- ソースデータベースにシグナリングデータコレクションが存在する。
-
シグナルデータコレクションが
signal.data.collectionプロパティーで指定されます。
ソースシグナリングチャネルを使用して増分スナップショットを停止する
SQL クエリーを送信して、シグナリングテーブルへのアドホックインクリメンタルスナップショットを停止します。
INSERT INTO <signalTable> (id, type, data) values ('<id>', 'stop-snapshot', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"incremental"}');INSERT INTO <signalTable> (id, type, data) values ('<id>', 'stop-snapshot', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"incremental"}');Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
INSERT INTO db1.debezium_signal (id, type, data) values ('ad-hoc-1', 'stop-snapshot', '{"data-collections": ["db1.table1", "db1.table2"], "type":"incremental"}');INSERT INTO db1.debezium_signal (id, type, data)1 values ('ad-hoc-1',2 'stop-snapshot',3 '{"data-collections": ["db1.table1", "db1.table2"],4 "type":"incremental"}');5 Copy to Clipboard Copied! Toggle word wrap Toggle overflow signal コマンドの
id、type、およびdataパラメーターの値は、シグナルテーブルのフィールド に対応します。
以下の表では、この例のパラメーターを説明しています。Expand 表2.31 シグナリングテーブルに増分スナップショット停止信号を送信するための SQL コマンドのフィールドの説明 項目 値 説明 1
database.debezium_signalソースデータベースにあるシグナルテーブルの完全修飾名を指定します。
2
ad-hoc-1idパラメーターは、シグナルリクエストのID識別子として割り当てられる任意の文字列を指定します。
この文字列を使用して、シグナルテーブルのエントリーへのログメッセージを特定します。Debezium はこの文字列を使用しません。3
stop-snapshottypeパラメーターを指定し、シグナルがトリガーする操作を指定します。
4
data-collectionsシグナルの
dataフィールドのオプションコンポーネントで、スナップショットから削除するテーブル名の配列またはテーブル名とマッチする正規表現を指定します。
配列には、database.tableの形式で完全修飾名でテーブルに一致する正規表現がリストされます。dataフィールドからこのコンポーネントを省略すると、シグナルによって進行中の増分スナップショット全体が停止されます。5
incremental停止するスナップショット操作のタイプを指定する信号の
dataフィールドの必須コンポーネント。
現在、有効な唯一のオプションはincrementalです。typeの値を指定しない場合、シグナルは増分スナップショットの停止に失敗します。
2.2.1.6.4. Kafka シグナリングチャネルを使用して増分スナップショットを停止する
設定された Kafka シグナルトピック にシグナルメッセージを送信して、アドホック増分スナップショットを停止できます。
Kafka メッセージのキーは、topic.prefix コネクター設定オプションの値と一致する必要があります。
メッセージの値は、type と data フィールドが含まれる JSON オブジェクトとなっています。
シグナルタイプは stop-snapshot で、data フィールドには以下のフィールドが必要です。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプ。現在、Debezium は |
|
| 該当なし |
テーブルの完全修飾名に一致する、コンマで区切られた正規表現のオプションの配列、スナップショットから削除するテーブル名に一致するテーブル名または正規表現の配列。 |
次の例は、典型的な stop-snapshot の Kafka メッセージを示しています。
Key = `test_connector`
Value = `{"type":"stop-snapshot","data": {"data-collections": ["db1.table1", "db1.table2"], "type": "INCREMENTAL"}}`
Key = `test_connector`
Value = `{"type":"stop-snapshot","data": {"data-collections": ["db1.table1", "db1.table2"], "type": "INCREMENTAL"}}`2.2.1.7. ブロッキングスナップショット
スナップショットをより柔軟に管理するために、Debezium には ブロッキングスナップショット と呼ばれる補助アドホックスナップショットメカニズムが含まれています。ブロッキングスナップショットは、Debezium コネクターにシグナルを送信 するための Debezium メカニズムに依存します。
ブロッキングスナップショットは、ランタイム時にトリガーできることを除いて、初期スナップショット と同じように動作します。
次のような状況では、標準の初期スナップショットプロセスを使用するのではなく、ブロッキングスナップショットを実行する必要があります。
- 新しいテーブルを追加し、コネクターの実行中にスナップショットを完了したいと考えている。
- 大きなテーブルを追加し、増分スナップショットよりも短い時間でスナップショットを完了したいと考えている。
ブロッキングスナップショットのプロセス
ブロッキングスナップショットを実行すると、Debezium はストリーミングを停止し、初期スナップショットの時と同じプロセスに従って、指定されたテーブルのスナップショットを開始します。スナップショットが完了すると、ストリーミングが再開されます。
スナップショットの設定
シグナルの data コンポーネントでは、次のプロパティーを設定できます。
- data-collections: スナップショットする必要のあるテーブルを指定します。
additional-conditions: テーブルごとに異なるフィルターを指定できます。
-
data-collectionプロパティーは、フィルターが適用されるテーブルの完全修飾名です。 -
filterプロパティーは、snapshot.select.statement.overridesで使用される値と同じになります。
-
以下に例を示します。
{"type": "blocking", "data-collections": ["schema1.table1", "schema1.table2"], "additional-conditions": [{"data-collection": "schema1.table1", "filter": "SELECT * FROM [schema1].[table1] WHERE column1 = 0 ORDER BY column2 DESC"}, {"data-collection": "schema1.table2", "filter": "SELECT * FROM [schema1].[table2] WHERE column2 > 0"}]}
{"type": "blocking", "data-collections": ["schema1.table1", "schema1.table2"], "additional-conditions": [{"data-collection": "schema1.table1", "filter": "SELECT * FROM [schema1].[table1] WHERE column1 = 0 ORDER BY column2 DESC"}, {"data-collection": "schema1.table2", "filter": "SELECT * FROM [schema1].[table2] WHERE column2 > 0"}]}重複の可能性
スナップショットをトリガーするシグナルを送信した時点と、ストリーミングが停止してスナップショットが開始する時点との間に遅延が生じる可能性があります。この遅延の結果、スナップショットが完了した後、コネクターはスナップショットがキャプチャーしたレコードと重複するイベントレコードを発行する可能性があります。
2.2.1.8. Debezium MariaDB 変更イベントレコードを受信する Kafka トピックのデフォルト名
デフォルトでは、MariaDB コネクターは、テーブルで発生するすべての INSERT、UPDATE、および DELETE 操作の変更イベントを、そのテーブルに固有の単一の Apache Kafka トピックに書き込みます。
コネクターは以下の規則を使用して変更イベントトピックに名前を付けます。
topicPrefix.databaseName.tableName
fulfillment はトピック接頭辞、inventory はデータベース名で、データベースに orders、customers、および productsという名前のテーブルが含まれるとします。Debezium MariaDB コネクターは、データベース内の各テーブルに 1 つずつ、3 つの Kafka トピックにイベントを送信します。
fulfillment.inventory.orders fulfillment.inventory.customers fulfillment.inventory.products
fulfillment.inventory.orders
fulfillment.inventory.customers
fulfillment.inventory.products以下のリストは、デフォルト名のコンポーネントの定義を示しています。
- topicPrefix
-
topic.prefixコネクター設定プロパティーで指定されたトピック接頭辞。 - schemaName
- 操作が発生したスキーマの名前。
- tableName
- 操作が発生したテーブルの名前。
コネクターは同様の命名規則を適用して、内部データベーススキーマの履歴トピック (スキーマ変更トピック と トランザクションメタデータトピック) にラベルを付けます。
デフォルトのトピック名が要件を満たさない場合は、カスタムトピック名を設定できます。カスタムトピック名を設定するには、論理トピックルーティング SMT に正規表現を指定します。論理トピックルーティング SMT を使用してトピックの命名をカスタマイズする方法は、トピックルーティング を参照してください。
トランザクションメタデータ
Debezium は、トランザクション境界を表し、データ変更イベントメッセージを強化するイベントを生成できます。
Debezium は、コネクターのデプロイ後に発生するトランザクションに対してのみメタデータを登録し、受信します。コネクターをデプロイする前に発生するトランザクションのメタデータは利用できません。
Debezium は、すべてのトランザクションで BEGIN および END 区切り文字のトランザクション境界イベントを生成します。トランザクション境界イベントには以下のフィールドが含まれます。
status-
BEGINまたはEND id- 一意のトランザクション識別子の文字列表現。
ts_ms-
データソースでのトランザクション境界イベント (
BEGINまたはENDイベント) の時間。データソースから Debezium にイベント時間を渡されない場合、フィールドは代わりに Debezium がイベントを処理する時間を表します。 event_count(ENDイベント用)- トランザクションによって出力されるイベントの合計数。
data_collections(ENDイベント用)-
data_collectionとevent_count要素のペアの配列。これは、コネクターがデータコレクションから発信された変更に対して出力するイベントの数を示します。
例
topic.transaction オプションで上書きされない限り、コネクターはトランザクションイベントを <topic.prefix>.transaction トピックに出力します。
変更データイベントのエンリッチメント
トランザクションメタデータを有効にすると、データメッセージ Envelope は新しい transaction フィールドで強化されます。このフィールドは、複合フィールドの形式ですべてのイベントに関する情報を提供します。
id- 一意のトランザクション識別子の文字列表現。
total_order- トランザクションによって生成されたすべてのイベントを対象とするイベントの絶対位置。
data_collection_order- トランザクションによって出力されたすべてのイベントを対象とするイベントのデータコレクションごとの位置。
以下は、メッセージの例になります。
2.2.2. Debezium MariaDB コネクターデータ変更イベントの説明
Debezium MariaDB コネクターは、行レベルの INSERT、UPDATE、および DELETE 操作ごとにデータ変更イベントを生成します。各イベントにはキーと値が含まれます。キーと値の構造は、変更されたテーブルによって異なります。
Debezium および Kafka Connect は、イベントメッセージの継続的なストリーム を中心として設計されています。ただし、これらのイベントの構造は時間の経過とともに変化する可能性があり、コンシューマーによる処理が困難になることがあります。これに対応するために、各イベントにはコンテンツのスキーマが含まれます。スキーマレジストリーを使用している場合は、コンシューマーがレジストリーからスキーマを取得するために使用できるスキーマ ID が含まれます。これにより、各イベントが自己完結型になります。
以下のスケルトン JSON は、変更イベントの基本となる 4 つの部分を示しています。ただし、アプリケーションで使用するために選択した Kafka Connect コンバーターの設定方法によって、変更イベントのこれら 4 部分の表現が決定されます。schema フィールドは、変更イベントが生成されるようにコンバーターを設定した場合のみ変更イベントに含まれます。同様に、イベントキーおよびイベントペイロードは、変更イベントが生成されるようにコンバーターを設定した場合のみ変更イベントに含まれます。JSON コンバーターを使用し、変更イベントの基本となる 4 つの部分すべてを生成するように設定すると、変更イベントの構造は次のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
最初の |
| 2 |
|
最初の |
| 3 |
|
2 つ目の |
| 4 |
|
2 つ目の |
デフォルトでは、コネクターによって、変更イベントレコードがイベントの元のテーブルと同じ名前を持つトピックにストリーミングされます。トピック名 を参照してください。
MariaDB コネクターは、すべての Kafka Connect スキーマ名が Avro スキーマ名形式 に準拠していることを確認します。つまり、論理サーバー名はアルファベットまたはアンダースコア (a-z、A-Z、または _) で始まる必要があります。論理サーバー名の残りの各文字と、データベース名とテーブル名の各文字は、アルファベット、数字、またはアンダースコア ( a-z、A-Z、0-9、または _) でなければなりません。無効な文字がある場合は、アンダースコアに置き換えられます。
論理サーバー名、データベース名、またはテーブル名に無効な文字が含まれ、名前を区別する唯一の文字が無効であると、無効な文字はすべてアンダースコアに置き換えられるため、予期せぬ競合が発生する可能性があります。
詳細は以下を参照してください。
2.2.2.1. Debezium MariaDB 変更イベントのキーについて
変更イベントのキーには、変更されたテーブルのキーのスキーマと、変更された行の実際のキーのスキーマが含まれます。スキーマとそれに対応するペイロードの両方には、コネクターによってイベントが作成された時点において、変更されたテーブルの PRIMARY KEY (または一意の制約) に存在した各列のフィールドが含まれます。
以下の customers テーブルについて考えてみましょう。この後に、このテーブルの変更イベントキーの例を示します。
customers テーブルへの変更をキャプチャーする変更イベントのすべてに、イベントキースキーマがあります。customers テーブルに前述の定義がある限り、customers テーブルへの変更をキャプチャーする変更イベントのキー構造はすべて以下のようになります。JSON では、以下のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
キーのスキーマ部分は、キーの |
| 2 |
|
キーのペイロードの構造を定義するスキーマの名前。このスキーマは、変更されたテーブルのプライマリーキーの構造を記述します。キースキーマ名の形式は connector-name.database-name.table-name.
|
| 3 |
|
イベントキーの |
| 4 |
|
各フィールドの名前、型、および必要かどうかなど、 |
| 5 |
|
この変更イベントが生成された行のキーが含まれます。この例では、キーには値が |
2.2.2.2. Debezium MariaDB 変更イベントの値について
変更イベントの値はキーよりも若干複雑です。キーと同様に、値には schema セクションと payload セクションがあります。schema セクションには、入れ子のフィールドを含む、Envelope セクションの payload 構造を記述するスキーマが含まれています。データを作成、更新、または削除する操作のすべての変更イベントには、Envelope 構造を持つ値 payload があります。
変更イベントキーの例を紹介するために使用した、同じサンプルテーブルについて考えてみましょう。
このテーブルへの変更に対する変更イベントの値部分には以下について記述されています。
create イベント
以下の例は、customers テーブルにデータを作成する操作に対して、コネクターによって生成される変更イベントの値の部分を示しています。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
| 値のペイロードの構造を記述する、値のスキーマ。変更イベントの値スキーマは、コネクターが特定のテーブルに生成するすべての変更イベントで同じになります。 |
| 2 |
|
|
| 3 |
|
|
| 4 |
|
|
| 5 |
|
値の実際のデータ。これは、変更イベントが提供する情報です。 |
| 6 |
|
コネクターによってイベントが生成される原因となった操作の型を記述する必須文字列。この例では、
|
| 7 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 8 |
|
イベント発生前の行の状態を指定する任意のフィールド。この例のように、 |
| 9 |
|
イベント発生後の行の状態を指定する任意のフィールド。この例では、 |
| 10 |
| イベントのソースメタデータを記述する必須のフィールド。このフィールドには、イベントの発生元、イベントの発生順序、およびイベントが同じトランザクションの一部であるかどうかなど、このイベントと他のイベントを比較するために使用できる情報が含まれています。ソースメタデータには以下が含まれています。
|
更新イベント
サンプル customers テーブルにある更新の変更イベントの値には、そのテーブルの 作成 イベントと同じスキーマがあります。同様に、イベント値のペイロードは同じ構造を持ちます。ただし、イベント値ペイロードでは 更新 イベントに異なる値が含まれます。以下は、コネクターによって customers テーブルでの更新に生成されるイベントの変更イベント値の例になります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
イベント発生前の行の状態を指定する任意のフィールド。更新 イベント値の |
| 2 |
|
イベント発生後の行の状態を指定する任意のフィールド。 |
| 3 |
|
イベントのソースメタデータを記述する必須のフィールド。
|
| 4 |
|
操作の型を記述する必須の文字列。更新 イベントの値では、 |
| 5 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 6 |
| コネクターがイベントを処理した時間をマイクロ秒単位で表示するオプションフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 7 |
| コネクターがイベントを処理した時間をナノ秒単位で表示するオプションフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
行のプライマリーキー/一意キーの列を更新すると、行のキーの値が変更されます。キーが変更されると、3 つのイベントが Debezium によって出力されます。3 つのイベントとは、DELETE イベント、行の古いキーを持つ 廃棄 (tombstone)、およびそれに続く行の新しいキーを持つイベントです。詳細は次のセクションで説明します。
プライマリーキーの更新
行のプライマリーキーフィールドを変更する UPDATE 操作は、プライマリーキーの変更と呼ばれます。プライマリーキーの変更では、UPDATE イベントレコードの代わりにコネクターが古いキーの DELETE イベントレコードと、新しい (更新された) キーの CREATE イベントレコードを出力します。これらのイベントには通常の構造と内容があり、イベントごとにプライマリーキーの変更に関連するメッセージヘッダーがあります。
-
DELETEイベントレコードには、メッセージヘッダーとして__debezium.newkeyが含まれます。このヘッダーの値は、更新された行の新しいプライマリーキーです。 -
CREATEイベントレコードには、メッセージヘッダーとして__debezium.oldkeyが含まれます。このヘッダーの値は、更新された行にあった以前の (古い) プライマリーキーです。
delete イベント
削除 変更イベントの値は、同じテーブルの 作成 および 更新 イベントと同じ schema の部分になります。サンプル customers テーブルの 削除 イベントの payload 部分は以下のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
イベント発生前の行の状態を指定する任意のフィールド。削除 イベント値の |
| 2 |
|
イベント発生後の行の状態を指定する任意のフィールド。削除 イベント値の |
| 3 |
|
イベントのソースメタデータを記述する必須のフィールド。削除 イベント値の
|
| 4 |
|
操作の型を記述する必須の文字列。 |
| 5 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 6 |
| コネクターがイベントを処理した時間をマイクロ秒単位で表示するオプションフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 7 |
| コネクターがイベントを処理した時間をナノ秒単位で表示するオプションフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
削除 変更イベントレコードは、この行の削除を処理するために必要な情報を持つコンシューマーを提供します。コンシューマーによっては、削除を適切に処理するために古い値が必要になることがあるため、古い値が含まれます。
MariaDB コネクターイベントは、Kafka log compaction と連携するように設計されています。ログコンパクションにより、少なくとも各キーの最新のメッセージが保持される限り、一部の古いメッセージを削除できます。これにより、トピックに完全なデータセットが含まれ、キーベースの状態のリロードに使用できるようにするとともに、Kafka がストレージ領域を確保できるようにします。
tombstone イベント
行が削除された場合でも、Kafka は同じキーを持つ以前のメッセージをすべて削除できるため、削除 イベントの値はログコンパクションで動作します。ただし、Kafka が同じキーを持つすべてのメッセージを削除するには、メッセージの値が null である必要があります。これを可能にするために、Debezium MariaDB コネクターは delete イベントを発行した後、null 値以外の同じキーを持つ特別な tombstone イベントを発行します。
truncate イベント
truncate 変更イベントは、テーブルが切り捨てられたことを通知します。truncate イベントのメッセージキーが null です。メッセージの値は次の例のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
イベントのソースメタデータを記述する必須のフィールド。切り捨て (truncate) イベント値の
|
| 2 |
|
操作の型を記述する必須の文字列。 |
| 3 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 4 |
| コネクターがイベントを処理した時間をマイクロ秒単位で表示するオプションフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 5 |
| コネクターがイベントを処理した時間をナノ秒単位で表示するオプションフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
1 つの TRUNCATE ステートメントが複数のテーブルに適用された場合、切り捨てられたテーブルごとに 1 つの切り捨て (truncate) 変更イベントレコードが出力されます。
truncate イベントはテーブル全体に適用される変更を表し、メッセージキーはありません。複数のパーティションにまたがるトピックでは、テーブル全体に適用される変更イベントの順序は保証されません。つまり、(create、update など) やそのテーブルの truncate イベントの順序は保証されません。コンシューマーが異なるパーティションからイベントを読み取る場合、2 番目のパーティションから同じテーブルの truncate イベントを読み取った後にのみ、1 つのパーティションからテーブルの update イベントを読み取ることがあります。
2.2.3. Debezium MariaDB コネクターがデータ型をマッピングする方法
Debezium MariaDB コネクターは、行が存在するテーブルのように構造化されたイベントを使用して行の変更を表します。イベントには、各列の値のフィールドが含まれます。その列の MariaDB データ型によって、Debezium がイベント内の値をどのように表現するかが決まります。
文字列を格納する列は、MariaDB では文字セットと照合順序を使用して定義されます。MariaDB コネクターは、binlog イベント内の列値のバイナリー表現を読み取るときに、列の文字セットを使用します。
コネクターは、MariaDB データ型を literal と semantic 型の両方にマップできます。
- リテラル型: Kafka Connect スキーマタイプを使用して値がどのように表されるか。
- セマンティック型: Kafka Connect スキーマがどのようにフィールド (スキーマ名) の意味をキャプチャーするか。
デフォルトのデータ型変換が要件に合わない場合は、コネクター用の カスタムコンバーターの作成 が可能です。
詳細は以下を参照してください。
基本型
次の表は、コネクターが基本的な MariaDB データ型をどのようにマッピングするかを示しています。
| MariaDB タイプ | リテラル型 | セマンティック型 |
|---|---|---|
|
|
| 該当なし |
|
|
| 該当なし |
|
|
|
|
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
|
精度は、ストレージサイズを決定するためにのみ使用されます。0 から 23 までの精度 |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
|
該当なし |
|
|
|
該当なし |
|
|
|
該当なし |
|
|
| 該当なし |
|
|
|
該当なし |
|
|
|
n/a |
|
|
|
該当なし |
|
|
| 該当なし |
|
|
|
該当なし |
|
|
|
n/a |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
時間型
TIMESTAMP データ型を除き、MariaDB の時間型は、time.precision.mode コネクター設定プロパティーの値に依存します。デフォルト値が CURRENT_TIMESTAMP または NOW として指定される TIMESTAMP 列では、Kafka Connect スキーマのデフォルト値として値 1970-01-01 00:00:00 が使用されます。
MariaDB では、ゼロ値が null 値よりも優先される場合があるため、DATE、DATETIME、および TIMESTAMP 列にゼロ値を許可します。MariaDB コネクターは、列定義で null 値が許可されている場合はゼロ値を null 値として表し、列で null 値が許可されていない場合はエポック日として表します。
タイムゾーンのない時間型
DATETIME 型は、"2018-01-13 09:48:27" のようにローカルの日時を表します。タイムゾーンの情報は含まれません。このような列は、UTC を使用して列の精度に基づいてエポックミリ秒またはマイクロ秒に変換されます。TIMESTAMP 型は、タイムゾーン情報のないタイムスタンプを表します。MariaDB によって、書き込み時にサーバー (またはセッション) の現在のタイムゾーンから UTC に変換され、値を読み戻すときに UTC からサーバー (またはセッション) の現在のタイムゾーンに変換されます。以下に例を示します。
-
値が
2018-06-20 06:37:03のDATETIMEは、1529476623000になります。 -
値が
2018-06-20 06:37:03のTIMESTAMPは2018-06-20T13:37:03Zになります。
このような列は、サーバー (またはセッション) の現在のタイムゾーンに基づいて、UTC の同等の io.debezium.time.ZonedTimestamp に変換されます。タイムゾーンは、デフォルトでサーバーからクエリーされます。
Kafka Connect および Debezium を実行している JVM のタイムゾーンは、これらの変換には影響しません。
時間値に関連するプロパティーの詳細は、MariaDB コネクター設定プロパティー のドキュメントを参照してください。
- time.precision.mode=adaptive_time_microseconds(default)
MariaDB コネクターは、列のデータ型定義に基づいてリテラル型とセマンティック型を決定し、イベントがデータベース内の値を正確に表すようにします。すべての時間フィールドはマイクロ秒単位です。正しくキャプチャーされる
TIMEフィールドの値は、範囲が00:00:00.000000から23:59:59.999999までの正の値です。Expand 表2.40 time.precision.mode=adaptive_time_microseconds の場合のマッピング MariaDB タイプ リテラル型 セマンティック型 DATEINT32io.debezium.time.Date
エポックからの日数を表します。TIME[(M)]INT64io.debezium.time.MicroTime
時間の値をマイクロ秒単位で表し、タイムゾーン情報は含まれません。MariaDB では、Mは0 - 6の範囲で指定できます。DATETIME, DATETIME(0), DATETIME(1), DATETIME(2), DATETIME(3)INT64io.debezium.time.Timestamp
エポックからの経過時間をミリ秒で表し、タイムゾーン情報は含まれません。DATETIME(4), DATETIME(5), DATETIME(6)INT64io.debezium.time.MicroTimestamp
エポックからの経過時間をマイクロ秒で表し、タイムゾーン情報は含まれません。- time.precision.mode=connect
MariaDB コネクターは、定義済みの Kafka Connect 論理型を使用します。この方法はデフォルトの方法よりも精度が低く、データベース列に
3を超える 少数秒の精度値がある場合は、イベントの精度が低くなる可能性があります。00:00:00.000から23:59:59.999までの値のみを処理できます。テーブルのtime.precision.mode=connectの値が、必ずサポートされる範囲内になるようにすることができる場合のみ、TIMEを設定します。connect設定は、今後の Debezium バージョンで削除される予定です。Expand 表2.41 time.precision.mode=connect の場合のマッピング MariaDB タイプ リテラル型 セマンティック型 DATEINT32org.apache.kafka.connect.data.Date
エポックからの日数を表します。TIME[(M)]INT64org.apache.kafka.connect.data.Time
午前 0 時以降の時間値をマイクロ秒で表し、タイムゾーン情報は含まれません。DATETIME[(M)]INT64org.apache.kafka.connect.data.Timestamp
エポックからの経過時間をミリ秒で表し、タイムゾーン情報は含まれません。
10 進数型
Debezium コネクターは、decimal.handling.mode コネクター設定プロパティーの設定に従って小数を処理します。
- decimal.handling.mode=precise
Expand 表2.42 decimal.handling.mode=precise の場合のマッピング MariaDB タイプ リテラル型 セマンティック型 NUMERIC[(M[,D])]BYTESorg.apache.kafka.connect.data.Decimal
scaleスキーマパラメーターには、小数点を移動した桁数を表す整数が含まれます。DECIMAL[(M[,D])]BYTESorg.apache.kafka.connect.data.Decimal
scaleスキーマパラメーターには、小数点を移動した桁数を表す整数が含まれます。- decimal.handling.mode=double
Expand 表2.43 decimal.handling.mode=double の場合のマッピング MariaDB タイプ リテラル型 セマンティック型 NUMERIC[(M[,D])]FLOAT64該当なし
DECIMAL[(M[,D])]FLOAT64該当なし
- decimal.handling.mode=string
Expand 表2.44 decimal.handling.mode=string の場合のマッピング MariaDB タイプ リテラル型 セマンティック型 NUMERIC[(M[,D])]STRING該当なし
DECIMAL[(M[,D])]STRING該当なし
ブール値
MariaDB は、BOOLEAN 値を内部的に特定の方法で処理します。BOOLEAN 列は、内部で TINYINT(1) データ型にマッピングされます。ストリーミング中にテーブルが作成されると、Debezium は元の DDL を受信するため、適切な BOOLEAN マッピングが使用されます。スナップショットの作成中、Debezium は SHOW CREATE TABLE を実行して、BOOLEAN と TINYINT(1) の両方の列に TINYINT(1) を返すテーブル定義を取得します。その後、Debezium は元の型のマッピングを取得する方法はないため、TINYINT(1) にマッピングします。
ソース列をブール型に変換できるように、Debezium は TinyIntOneToBooleanConverter カスタムコンバーター を提供しており、以下のいずれかの方法で使用できます。
-
すべての
TINYINT(1)またはTINYINT(1) UNSIGNED列をBOOLEAN型にマップします。 正規表現のコンマ区切りリストを使用して、列のサブセットを列挙します。
このタイプの変換を使用するには、次の例に示すように、selectorパラメーターを使用してconverters設定プロパティーを設定する必要があります。converters=boolean boolean.type=io.debezium.connector.binlog.converters.TinyIntOneToBooleanConverter boolean.selector=db1.table1.*, db1.table2.column1
converters=boolean boolean.type=io.debezium.connector.binlog.converters.TinyIntOneToBooleanConverter boolean.selector=db1.table1.*, db1.table2.column1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意: 場合によっては、スナップショットが
SHOW CREATE TABLEを実行したときに、データベースがtinyint unsignedの長さを表示されないため、このコンバーターは機能しません。新しいオプションlength.checkerはこの問題を解決することができます。デフォルト値はtrueです。次の例に示すように、length.checkerを無効にして、タイプに基づいてすべての列を変換するのではなく、変換が必要な列をselectedプロパティーに指定します。converters=boolean boolean.type=io.debezium.connector.binlog.converters.TinyIntOneToBooleanConverter boolean.length.checker=false boolean.selector=db1.table1.*, db1.table2.column1
converters=boolean boolean.type=io.debezium.connector.binlog.converters.TinyIntOneToBooleanConverter boolean.length.checker=false boolean.selector=db1.table1.*, db1.table2.column1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
空間型
現在、Debezium MariaDB コネクターは次の空間データ型をサポートしています。
| MariaDB タイプ | リテラル型 | セマンティック型 |
|---|---|---|
|
|
|
|
2.2.4. MariaDB データを代替データ型にマッピングするためのカスタムコンバーター
デフォルトでは、Debezium MariaDB コネクターは、MariaDB データ型用の CustomConverter 実装を複数提供します。これらのカスタムコンバーターは、コネクター設定に基づいて特定のデータ型に対する代替マッピングを提供します。コネクターに CustomConverter を追加するには、カスタムコンバーターのドキュメント の指示に従ってください。
TINYINT(1) からブール値
デフォルトでは、コネクターのスナップショット中に、Debezium MariaDB コネクターは JDBC ドライバーから列タイプを取得し、BOOLEAN 列に TINYINT(1) タイプを割り当てます。Debezium はこれらの JDBC 列タイプを使用して、スナップショットイベントのスキーマを定義します。コネクターがスナップショットからストリーミングフェーズに移行した後、デフォルトのマッピングから生じる変更イベントスキーマによって、BOOLEAN 列のマッピングが不整合になる可能性があります。MariaDB が BOOLEAN 列を均一に出力するようにするには、次の設定例に示すように、カスタム TinyIntOneToBooleanConverter を適用できます。
例: TinyIntOneToBooleanConverter の設定
converters=tinyint-one-to-boolean tinyint-one-to-boolean.type=io.debezium.connector.binlog.converters.TinyIntOneToBooleanConverter tinyint-one-to-boolean.selector=.*.MY_TABLE.DATA tinyint-one-to-boolean.length.checker=false
converters=tinyint-one-to-boolean
tinyint-one-to-boolean.type=io.debezium.connector.binlog.converters.TinyIntOneToBooleanConverter
tinyint-one-to-boolean.selector=.*.MY_TABLE.DATA
tinyint-one-to-boolean.length.checker=false
前の例では、selector と length.checker プロパティーはオプションです。デフォルトでは、コンバーターは TINYINT データ型の長さが 1 であることをチェックします。length.checker が false の場合、コンバーターは TINYINT データ型の長さが 1 であることをを明示的に確認しません。selector は、指定された正規表現に基づいて、変換するテーブルまたは列を指定します。selector プロパティーを省略すると、コンバーターはすべての TINYINT 列を論理 BOOL フィールドタイプにマップします。selector オプションを設定せず、TINYINT 列を TINYINT(1) にマップする場合は、length.checker プロパティーを省略するか、その値を true に設定します。
JDBC sink のデータ型
Debezium JDBC sink コネクターを Debezium MariaDB ソースコネクターと統合すると、MariaDB コネクターはスナップショットフェーズとストリーミングフェーズ中に一部の列属性を異なる方法で出力します。JDBC sink コネクターがスナップショットフェーズとストリーミングフェーズの両方からの変更を一貫して使用するには、次の例に示すように、JdbcSinkDataTypesConverter コンバータを MariaDB ソースコネクター設定の一部として含める必要があります。
例: JdbcSinkDataTypesConverter 設定
前の例では、selector.* および treat.real.as.double 設定プロパティーはオプションです。
selector.* プロパティーは、コンバーターが適用されるテーブルと列を指定する正規表現のコンマ区切りリストを指定します。デフォルトでは、コンバーターはすべてのテーブルに含まれるすべてのブール値、実数、および文字列ベースの列データ型に次のルールを適用します。
-
BOOLEANデータ型は常にINT16論理型として出力され、1はtrue、0はfalseを表します。 -
REALデータ型は常にFLOAT64論理型として出力されます。 -
文字列ベースの列には、列の文字セットを含む
__debezium.source.column.character_setスキーマパラメーターが常に含まれます。
各データ型について、デフォルトのスコープをオーバーライドし、セレクターを特定のテーブルと列にのみ適用するセレクタールールを設定できます。たとえば、ブールコンバーターのスコープを設定するには、前の例のように、 converters.jdbc-sink.selector.boolean=.*.MY_TABLE.BOOL_COL のルールをコネクター設定に追加します。
2.2.5. Debezium コネクターを実行するための MariaDB の設定
Debezium コネクターをインストールして実行する前に、MariaDB セットアップタスクが複数必要です。
詳細は以下を参照してください。
2.2.5.1. Debezium コネクター用の MariaDB ユーザーの作成
Debezium MariaDB コネクターには MariaDB ユーザーアカウントが必要です。この MariaDB ユーザーには、Debezium MariaDB コネクターが変更をキャプチャーするデータベースすべてに対して適切な権限が必要です。
前提条件
- MariaDB サーバー。
- SQL コマンドの基本知識。
手順
MariaDB ユーザーを作成します。
mariadb> CREATE USER 'user'@'localhost' IDENTIFIED BY 'password';
mariadb> CREATE USER 'user'@'localhost' IDENTIFIED BY 'password';Copy to Clipboard Copied! Toggle word wrap Toggle overflow 必要なパーミッションをユーザーに付与します。
mariadb> GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user' IDENTIFIED BY 'password';
mariadb> GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user' IDENTIFIED BY 'password';Copy to Clipboard Copied! Toggle word wrap Toggle overflow 必要な権限の説明は、表2.46「ユーザーパーミッションの説明」 を参照してください。
重要グローバル読み取りロックを許可しない Amazon RDS や Amazon Aurora などのホストオプションを使用している場合、テーブルレベルのロックを使用して 整合性スナップショット を作成します。この場合、作成するユーザーに
LOCK TABLESパーミッションも付与する必要があります。詳細は スナップショット を参照してください。ユーザーのパーミッションの最終処理を行います。
mariadb> FLUSH PRIVILEGES;
mariadb> FLUSH PRIVILEGES;Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.46 ユーザーパーミッションの説明 キーワード 説明 SELECTコネクターがデータベースのテーブルから行を選択できるようにします。これは、スナップショットを実行する場合にのみ使用されます。
RELOAD内部キャッシュのクリアまたはリロード、テーブルのフラッシュ、またはロックの取得を行う
FLUSHステートメントをコネクターが使用できるようにします。これは、スナップショットを実行する場合にのみ使用されます。SHOW DATABASESSHOW DATABASEステートメントを実行して、コネクターがデータベース名を確認できるようにします。これは、スナップショットを実行する場合にのみ使用されます。REPLICATION-SLAVEコネクターが MariaDB サーバーの binlog に接続して読み取ることができるようになります。
REPLICATION CLIENTコネクターが以下のステートメントを使用できるようにします。
-
SHOW MASTER STATUS -
SHOW SLAVE STATUS -
SHOW BINARY LOGS
これは必ずコネクターに必要です。
ONパーミッションが適用されるデータベースを指定します。
TO 'user'パーミッションを付与するユーザーを指定します。
IDENTIFIED BY 'password'ユーザーの MariaDB パスワードを指定します。
-
2.2.5.2. Debezium の MariaDB バイナリーログの有効化
MariaDB レプリケーションのバイナリーログを有効にする必要があります。バイナリーログは、レプリカが変更を伝播できるようにトランザクションの更新を記録します。
前提条件
- MariaDB サーバー。
- 適切な MariaDB ユーザー権限。
手順
-
log-binオプションが有効になっているかどうかを確認します。 binlog が
OFFの場合は、次の表のプロパティーを MariaDB サーバーの設定ファイルに追加します。server-id = 223344 # Querying variable is called server_id, e.g. SELECT variable_value FROM information_schema.global_variables WHERE variable_name='server_id'; log_bin = mariadb-bin binlog_format = ROW binlog_row_image = FULL binlog_expire_logs_seconds = 864000
server-id = 223344 # Querying variable is called server_id, e.g. SELECT variable_value FROM information_schema.global_variables WHERE variable_name='server_id'; log_bin = mariadb-bin binlog_format = ROW binlog_row_image = FULL binlog_expire_logs_seconds = 864000Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 再度 binlog の状態をチェックして、変更を確認します。
Amazon RDS で MariaDB を実行する場合、バイナリーログを実行するには、データベースインスタンスの自動バックアップを有効にする必要があります。データベースインスタンスが自動バックアップを実行するように設定されていないと、前の手順で説明した設定を適用しても binlog は無効になります。
Expand 表2.47 MariaDB binlog 設定プロパティーの説明 プロパティー 説明 server-idserver-idの値は、MariaDB クラスター内の各サーバーおよびレプリケーションクライアントごとに一意である必要があります。log_binlog_binの値は、binlog ファイルのシーケンスのベース名です。binlog_formatbinlog-formatはROWまたはrowに設定する必要があります。binlog_row_imagebinlog_row_imageはFULLまたはfullに設定する必要があります。binlog_expire_logs_secondsbinlog_expire_logs_secondsは、非推奨のシステム変数expire_logs_daysに対応します。これは、binlog ファイルを自動的に削除する秒数です。デフォルト値は2592000で、つまり、30 日です。実際の環境に見合った値を設定します。詳細は、MariaDB による binlog ファイルの消去 を参照してください。
2.2.5.3. Debezium の MariaDB グローバルトランザクション識別子の有効化
グローバルトランザクション識別子 (GTID) は、クラスター内のサーバーで発生するトランザクションを一意に識別します。Debezium MariaDB コネクターでは必須ではありませんが、GTID を使用するとレプリケーションが簡素化され、プライマリーサーバーとレプリカサーバーの整合性が保たれているかどうかを簡単に確認できるようになります。
MariaDB の場合、GTID はデフォルトで有効になっており、追加の設定は必要ありません。
2.2.5.4. Debezium の MariaDB セッションタイムアウトの設定
大規模なデータベースに対して最初の整合性スナップショットが作成されると、テーブルの読み込み時に、確立された接続がタイムアウトする可能性があります。MariaDB 設定ファイルで interactive_timeout と wait_timeout を設定し、この動作を防ぐことができます。
前提条件
- MariaDB サーバー。
- SQL コマンドの基本知識。
- MariaDB 設定ファイルへのアクセス。
手順
interactive_timeoutを設定します。mariadb> interactive_timeout=<duration-in-seconds>
mariadb> interactive_timeout=<duration-in-seconds>Copy to Clipboard Copied! Toggle word wrap Toggle overflow wait_timeoutを設定します。mariadb> wait_timeout=<duration-in-seconds>
mariadb> wait_timeout=<duration-in-seconds>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.48 MariaDB セッションタイムアウトオプションの説明 オプション 説明 interactive_timeoutサーバーが対話的な接続を閉じる前にアクティビティーの発生を待つ時間 (秒単位)。詳細は、以下を参照してください。
wait_timeoutサーバーが非対話型接続を閉じる前にアクティビティーを待機する秒数。
2.2.5.5. Debezium MariaDB コネクターのクエリーログイベントの有効化
各 binlog イベントの元の SQL ステートメントを確認したい場合があります。MariaDB 設定で binlog_annotate_row_events オプションを有効にすると、これを実行できます。
前提条件
- MariaDB サーバー。
- SQL コマンドの基本知識。
- MariaDB 設定ファイルへのアクセス。
手順
MariaDB で
binlog_annotate_row_eventsを有効にします。mariadb> binlog_annotate_row_events=ON
mariadb> binlog_annotate_row_events=ONCopy to Clipboard Copied! Toggle word wrap Toggle overflow binlog_annotate_row_eventsは、binlog エントリーにSQLステートメントが含まれるようにするためのサポートを有効または無効にする値に設定されます。-
ON= 有効化 -
OFF= 無効化
-
2.2.5.6. Debezium MariaDB コネクターの binlog 行値オプションの検証
データベース内の binlog_row_value_options 変数の設定を確認します。コネクターが UPDATE イベントを消費できるようにするには、この変数を PARTIAL_JSON 以外の値に設定する必要があります。
前提条件
- MariaDB サーバー。
- SQL コマンドの基本知識。
- MariaDB 設定ファイルへのアクセス。
手順
現在の変数値を確認する
mariadb> show global variables where variable_name = 'binlog_row_value_options';
mariadb> show global variables where variable_name = 'binlog_row_value_options';Copy to Clipboard Copied! Toggle word wrap Toggle overflow 結果
+--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | binlog_row_value_options | | +--------------------------+-------+
+--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | binlog_row_value_options | | +--------------------------+-------+Copy to Clipboard Copied! Toggle word wrap Toggle overflow 変数の値が
PARTIAL_JSONに設定されている場合、次のコマンドを実行して設定を解除します。mariadb> set @@global.binlog_row_value_options="" ;
mariadb> set @@global.binlog_row_value_options="" ;Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.2.6. Debezium MariaDB コネクターのデプロイメント
Debezium MariaDB コネクターをデプロイするには、次のいずれかの方法を使用できます。
2.2.6.1. Streams for Apache Kafka を使用した MariaDB コネクターのデプロイメント
Debezium 1.7 以降、Debezium コネクターのデプロイに推奨される方法は、Streams for Apache Kafka を使用して、コネクタープラグインを含む Kafka Connect コンテナーイメージをビルドすることです。
デプロイメントプロセス中に、以下のカスタムリソース (CR) を作成し、使用します。
-
Kafka Connect インスタンスを定義し、コネクターアーティファクトに関する情報をイメージに含める必要がある
KafkaConnectCR。 -
コネクターがソースデータベースにアクセスするために使用する情報を提供する
KafkaConnectorCR。Streams for Apache Kafka が Kafka Connect Pod を起動した後、KafkaConnectorCR を適用してコネクターを起動します。
Kafka Connect イメージのビルド仕様では、デプロイ可能なコネクターを指定できます。各コネクタープラグインに対して、デプロイメントに利用可能にする他のコンポーネントを指定することもできます。たとえば、Apicurio Registry アーティファクトや Debezium スクリプトコンポーネントを追加できます。Streams for Apache Kafka は、Kafka Connect イメージをビルドするときに、指定されたアーティファクトをダウンロードし、それをイメージに組み込みます。
Kafka Connect CR の spec.build.output パラメーターは、生成される KafkaConnectコンテナーイメージを格納する場所を指定します。コンテナーイメージは Docker レジストリーまたは OpenShift ImageStream に保存できます。イメージを ImageStream に保存するには、Kafka Connect をデプロイする前に ImageStream を作成する必要があります。ImageStreams は自動的に作成されません。
KafkaConnect リソースを使用してクラスターを作成する場合は、Kafka Connect REST API を使用してコネクターを作成または更新できません。ただし、REST API を使用して情報を取得できます。
関連情報
- 「OpenShift 上の Streams for Apache Kafka のデプロイと管理」の Kafka Connect の設定
- 「OpenShift 上の Streams for Apache Kafka のデプロイと管理」の 新しいコンテナーイメージの自動ビルド
2.2.6.2. Streams for Apache Kafka を使用した Debezium MariaDB コネクターのデプロイ
以前のバージョンの Streams for Apache Kafka では、OpenShift に Debezium コネクターをデプロイするには、まずコネクター用の Kafka Connect イメージをビルドする必要がありました。OpenShift にコネクターをデプロイするための現在の推奨方法は、Streams for Apache Kafka のビルド設定を使用して、使用する Debezium コネクタープラグインを含む Kafka Connect コンテナーイメージを自動的にビルドすることです。
ビルドプロセス中に、Streams for Apache Kafka Operator は、Debezium コネクター定義を含む KafkaConnect カスタムリソースの入力パラメーターを Kafka Connect コンテナーイメージに変換します。このビルドは、Red Hat Maven リポジトリーまたは別の設定済みの HTTP サーバーから必要なアーティファクトをダウンロードします。
新規に作成されたコンテナーは .spec.build.output に指定されるコンテナーレジストリーにプッシュされ、Kafka Connect クラスターのデプロイに使用されます。Streams for Apache Kafka が Kafka Connect イメージをビルドした後、ビルドに含まれるコネクターを起動するための KafkaConnector カスタムリソースを作成します。
前提条件
- クラスター Operator がインストールされている OpenShift クラスターにアクセスできる。
- Streams for Apache Kafka Operator が実行されている。
- Apache Kafka クラスターが OpenShift 上の Streams for Apache Kafka のデプロイと管理 に記載されているとおりにデプロイされている。
- Kafka Connect が Streams for Apache Kafka にデプロイされている。
- Red Hat build of Debezium のライセンスを所有している。
-
OpenShift
ocCLI クライアントがインストールされている、または OpenShift Container Platform Web コンソールにアクセスできる。 Kafka Connect ビルドイメージの保存方法に応じて、レジストリーのパーミッションを用意するか、ImageStream リソースを作成している。
- ビルドイメージを Red Hat Quay.io または Docker Hub などのイメージレジストリーに保存する場合は、以下が必要です。
- レジストリーでイメージを作成し、管理するためのアカウントおよびパーミッション
- ビルドイメージをネイティブ OpenShift ImageStream として保存する場合は、以下を行います。
- ImageStream リソースを新規コンテナーイメージを保存するためにクラスターにデプロイします。クラスターの ImageStream を明示的に作成する必要があります。ImageStreams は、デフォルトでは利用できません。ImageStreams の詳細は、OpenShift Container Platform ドキュメント イメージストリームの管理 を参照してください。
手順
- OpenShift クラスターにログインします。
コネクターの Debezium
KafkaConnectカスタムリソース (CR) を作成するか、既存のリソースを変更します。たとえば、metadata.annotationsおよびspec.buildプロパティーを指定するdbz-connect.yamlという名前のKafkaConnectCR を作成します。以下の例は、KafkaConnectカスタムリソースを記述するdbz-connect.yamlファイルからの抜粋を示しています。
例2.11 Debezium コネクターを含む
KafkaConnectカスタムリソースを定義したdbz-connect.yamlファイル次の例では、カスタムリソースは、次のアーティファクトをダウンロードするように設定されています。
- Debezium MariaDB コネクターアーカイブ。
- Red Hat build of Apicurio Registry アーカイブApicurio Registry はオプションのコンポーネントです。コネクターで Avro シリアル化を使用する場合にのみ、Apicurio Registry コンポーネントを追加します。
- Debezium スクリプティング SMT アーカイブと、Debezium コネクターで使用する関連スクリプティングエンジン。SMT アーカイブとスクリプト言語の依存関係はオプションのコンポーネントです。Debezium コンテンツベースのルーティング SMT または フィルター SMT を使用する場合にのみ、これらのコンポーネントを追加します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.49 Kafka Connect 設定の説明 項目 説明 1
strimzi.io/use-connector-resourcesアノテーションを"true"に設定して、クラスター Operator がKafkaConnectorリソースを使用してこの Kafka Connect クラスター内のコネクターを設定できるようにします。2
spec.build設定は、ビルドイメージの保存場所を指定し、プラグインアーティファクトの場所とともにイメージに追加するプラグインをリストします。3
build.outputは、新しくビルドされたイメージを保存するレジストリーを指定します。4
イメージ出力の名前およびイメージ名を指定します。
output.typeの有効な値は、Docker Hub や Quay などのコンテナーレジストリーにプッシュする場合はdocker、内部の OpenShift ImageStream にイメージをプッシュする場合はimagestreamです。ImageStream を使用するには、ImageStream リソースをクラスターにデプロイする必要があります。KafkaConnect 設定でbuild.outputを指定する方法の詳細は、{NameConfiguringStreamsOpenShift} の Streams for Apache Kafka ビルドスキーマリファレンス を参照してください。5
plugins設定は、Kafka Connect イメージに追加するすべてのコネクターをリストします。リストの各エントリーについて、プラグインnameと、コネクターのビルドに必要なアーティファクトに関する情報を指定します。必要に応じて、各コネクタープラグインに対して、コネクターと使用できる他のコンポーネントを含めることができます。たとえば、Service Registry アーティファクトまたは Debezium スクリプトコンポーネントを追加できます。6
artifacts.typeの値は、artifacts.urlで指定するアーティファクトのファイルタイプを指定します。有効なタイプはzip、tgz、またはjarです。Debezium コネクターアーカイブは、.zipファイル形式で提供されます。typeの値は、urlフィールドで参照されるファイルのタイプと一致させる必要があります。7
artifacts.urlの値は、コネクターアーティファクトのファイルを格納する Maven リポジトリーなどの HTTP サーバーのアドレスを指定します。Debezium コネクターアーティファクトは Red Hat リポジトリーで入手できます。OpenShift クラスターが指定されたサーバーにアクセスできる必要があります。8
(オプション) Apicurio Registry コンポーネントをダウンロードするためのアーティファクト
typeとurlを指定します。デフォルトの JSON コンバーターを使用する代わりに、コネクターが Apache Avro を使用して Red Hat build of Apicurio Registry でイベントのキーと値をシリアル化する場合にのみ、Apicurio Registry アーティファクトを含めます。9
(オプション) Debezium コネクターで使用する Debezium スクリプト SMT アーカイブのアーティファクト
typeとurlを指定します。Debezium コンテンツベースルーティング SMT または フィルター SMT を使用する場合にのみ、スクリプト SMT を含めます。スクリプト SMT を使用するには、groovy などの JSR 223 準拠のスクリプト実装もデプロイする必要があります。10
(オプション) JSR 223 準拠のスクリプト実装の JAR ファイルのアーティファクト
typeとurlを指定します。これは、Debezium スクリプト SMT で必要です。重要Streams for Apache Kafka を使用してコネクタープラグインを Kafka Connect イメージに組み込む場合、必要なスクリプト言語コンポーネントごとに、
artifacts.urlに JAR ファイルのロケーションを指定し、artifacts.typeの値もjarに設定する必要があります。値が無効な場合は、実行時にコネクターが失敗します。スクリプト SMT で Apache Groovy 言語を使用できるようにするために、この例のカスタムリソースは、次のライブラリーの JAR ファイルを取得します。
-
groovy -
groovy-jsr223(スクリプトエージェント) -
groovy-json(JSON 文字列を解析するためのモジュール)
別の方法として、Debezium スクリプト SMT は、GraalVM JavaScript の JSR 223 実装の使用もサポートします。
以下のコマンドを入力して、
KafkaConnectビルド仕様を OpenShift クラスターに適用します。oc create -f dbz-connect.yaml
oc create -f dbz-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Streams Operator はカスタムリソースで指定された設定に基づいて、デプロイする Kafka Connect イメージを準備します。
ビルドが完了すると、Operator はイメージを指定されたレジストリーまたは ImageStream にプッシュし、Kafka Connect クラスターを起動します。設定にリスト表示されているコネクターアーティファクトはクラスターで利用できます。KafkaConnectorリソースを作成し、デプロイする各コネクターのインスタンスを定義します。
たとえば、次のKafkaConnectorCR を作成し、mariadb-inventory-connector.yamlとして保存します。例2.12 Debezium コネクターの
KafkaConnectorカスタムリソースを定義するmariadb-inventory-connector.yamlファイルCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.50 コネクター設定の説明 項目 説明 1
Kafka Connect クラスターに登録するコネクターの名前。
2
コネクタークラスの名前。
3
同時に動作できるタスクの数。
4
コネクターの設定。
5
ホストデータベースインスタンスのアドレス。
6
データベースインスタンスのポート番号。
7
Debezium がデータベースへの接続に使用するアカウントの名前。
8
Debezium がデータベースユーザーアカウントに接続するために使用するパスワード。
9
コネクターの一意の ID (数値)。
10
データベースインスタンスまたはクラスターのトピック接頭辞。
指定する名前は、英数字またはアンダースコアのみで設定する必要があります。
トピック接頭辞は、このコネクターから変更イベントを受信する Kafka トピックの接頭辞として使用されるため、名前はクラスターのコネクター間で一意である必要があります。
コネクターを Avro コネクター と統合する場合、この名前空間は、関連する Kafka Connect スキーマの名前や、対応する Avro スキーマの名前空間でも使用されます。11
コネクターが変更イベントをキャプチャーするテーブルのリスト。
以下のコマンドを実行してコネクターリソースを作成します。
oc create -n <namespace> -f <kafkaConnector>.yaml
oc create -n <namespace> -f <kafkaConnector>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc create -n debezium -f mariadb-inventory-connector.yaml
oc create -n debezium -f mariadb-inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow コネクターは Kafka Connect クラスターに登録され、
KafkaConnectorCR のspec.config.database.dbnameで指定されたデータベースに対して実行を開始します。コネクター Pod の準備ができると、Debezium が実行されます。
これで、Debezium MariaDB デプロイメントを検証する 準備が整いました。
2.2.6.3. Dockerfile からカスタム Kafka Connect コンテナーイメージを構築して Debezium MariaDB コネクターをデプロイする手順
Debezium MariaDB コネクターをデプロイするには、Debezium コネクターアーカイブが含まれるカスタム Kafka Connect コンテナーイメージをビルドし、このコンテナーイメージをコンテナーレジストリーにプッシュする必要があります。次に、以下のカスタムリソース (CR) を作成する必要があります。
-
Kafka Connect インスタンスを定義する
KafkaConnectCR。imageは Debezium コネクターを実行するために作成したイメージの名前を指定します。この CR は、Red Hat Streams for Apache Kafka がデプロイされている OpenShift インスタンスに適用します。Streams for Apache Kafka は、Apache Kafka を OpenShift に導入する Operator とイメージを提供します。 -
Debezium MariaDB コネクターを定義する
KafkaConnectorCR。この CR をKafkaConnectCR を適用するのと同じ OpenShift インスタンスに適用します。
前提条件
- MariaDB が実行中であり、Debezium コネクターで動作するように MariaDB を設定する 手順が完了しました。
- Streams for Apache Kafka が OpenShift にデプロイされ、Apache Kafka および Kafka Connect が実行されている。詳細は、OpenShift 上の Streams for Apache Kafka のデプロイと管理 を参照してください。
- Podman または Docker がインストールされている。
-
Debezium コネクターを実行するコンテナーを追加する予定のコンテナーレジストリー (
quay.ioやdocker.ioなど) でコンテナーを作成および管理するアカウントとパーミッションを持っている。
手順
Kafka Connect 用の Debezium MariaDB コンテナーを作成します。
registry.redhat.io/amq-streams-kafka-35-rhel8:2.5.0をベースイメージとして使用して、新規の Dockerfile を作成します。たとえば、ターミナルウィンドウから、以下のコマンドを入力します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 項目 説明 1
任意のファイル名を指定できます。
2
Kafka Connect プラグインディレクトリーへのパスを指定します。Kafka Connect のプラグインディレクトリーが別の場所にある場合は、このパスを実際のディレクトリーのパスに置き換えてください。
このコマンドは、現在のディレクトリーに
debezium-container-for-mariadb.yamlという名前の Dockerfile を作成します。前の手順で作成した
debezium-container-for-mariadb.yamlDocker ファイルからコンテナーイメージをビルドします。ファイルが含まれるディレクトリーから、ターミナルウィンドウを開き、以下のコマンドのいずれかを入力します。podman build -t debezium-container-for-mariadb:latest .
podman build -t debezium-container-for-mariadb:latest .Copy to Clipboard Copied! Toggle word wrap Toggle overflow docker build -t debezium-container-for-mariadb:latest .
docker build -t debezium-container-for-mariadb:latest .Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドは
debezium-container-for-mariadbという名前のコンテナーイメージを構築します。カスタムイメージを
quay.ioなどのコンテナーレジストリーまたは内部のコンテナーレジストリーにプッシュします。コンテナーレジストリーは、イメージをデプロイする OpenShift インスタンスで利用できる必要があります。以下のいずれかのコマンドを実行します。podman push <myregistry.io>/debezium-container-for-mariadb:latest
podman push <myregistry.io>/debezium-container-for-mariadb:latestCopy to Clipboard Copied! Toggle word wrap Toggle overflow docker push <myregistry.io>/debezium-container-for-mariadb:latest
docker push <myregistry.io>/debezium-container-for-mariadb:latestCopy to Clipboard Copied! Toggle word wrap Toggle overflow 新しい Debezium MariaDB
KafkaConnectカスタムリソース (CR) を作成します。たとえば、annotationsおよびimageプロパティーを指定するdbz-connect.yamlという名前のKafkaConnectCR を作成します。以下の例は、KafkaConnectカスタムリソースを記述するdbz-connect.yamlファイルからの抜粋を示しています。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 項目 説明 1
KafkaConnectorリソースはこの Kafka Connect クラスターでコネクターを設定するために使用されることを、metadata.annotationsは Cluster Operator に示します。2
spec.imageは Debezium コネクターを実行するために作成したイメージの名前を指定します。設定された場合、このプロパティーによって Cluster Operator のSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGE変数がオーバーライドされます。以下のコマンドを入力して、
KafkaConnectCR を OpenShift Kafka Connect 環境に適用します。oc create -f dbz-connect.yaml
oc create -f dbz-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、Debezium コネクターを実行するために作成したイメージの名前を指定する Kafka Connect インスタンスを追加します。
Debezium MariaDB コネクターインスタンスを設定する
KafkaConnectorカスタムリソースを作成します。Debezium MariaDB コネクターは、コネクターの設定プロパティーを指定する
.yamlファイルで設定します。コネクター設定は、Debezium に対して、スキーマおよびテーブルのサブセットにイベントを生成するよう指示する可能性があり、または機密性の高い、大きすぎる、または不必要な指定のコラムで Debezium が値を無視、マスク、または切り捨てするようにプロパティーを設定する可能性もあります。次の例では、ポート
3306で MariaDB ホスト192.168.99.100に接続し、インベントリーデータベースへの変更をキャプチャーする Debezium コネクターを設定します。dbserver1は、サーバーの論理名です。MariaDB
inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.51 コネクター設定の説明 項目 説明 1
コネクターの名前。
2
一度に実行できるタスクは 1 つだけです。MariaDB コネクターは MariaDB サーバーの
binlogを読み取るため、単一のコネクタータスクを使用すると適切な順序とイベント処理が保証されます。Kafka Connect サービスはコネクターを使用して作業を行う 1 つ以上のタスクを開始し、実行中のタスクを自動的に Kafka Connect サービスのクラスター全体に分散します。いずれかのサービスが停止またはクラッシュすると、これらのタスクは稼働中のサービスに再分散されます。3
コネクターの設定。
4
データベースホスト。MariaDB サーバー (
mariadb) を実行しているコンテナーの名前です。5
connector の一意 ID。
6
MariaDB サーバーまたはクラスターのトピック接頭辞。この名前は、変更イベントレコードを受信するすべての Kafka トピックの接頭辞として使用されます。
7
コネクターは
インベントリーテーブルからのみ変更をキャプチャーします。8
DDL ステートメントをデータベーススキーマ履歴トピックに書き込み、復元するためにコネクターによって使用される Kafka ブローカーのリスト。再起動時に、コネクターが読み取りを開始すべき時点で binlog に存在したデータベースのスキーマを復元します。
9
データベーススキーマ履歴トピックの名前。このトピックは内部使用のみを目的としており、コンシューマーが使用しないようにしてください。
Kafka Connect でコネクターインスタンスを作成します。たとえば、
KafkaConnectorリソースをinventory-connector.yamlファイルに保存した場合は、以下のコマンドを実行します。oc apply -f inventory-connector.yaml
oc apply -f inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドは
inventory-connectorを登録し、コネクターはKafkaConnectorCR に定義されているinventoryデータベースに対して実行を開始します。
Debezium MariaDB コネクターに設定できる設定プロパティーの完全なリストについては、MariaDB コネクター設定プロパティー を参照してください。
結果
コネクターが起動すると、コネクターが設定されている MariaDB データベースの 一貫性のあるスナップショットが実行されます。その後、コネクターは行レベルの操作のデータ変更イベントの生成を開始し、変更イベントレコードを Kafka トピックにストリーミングします。
2.2.6.4. Debezium MariaDB コネクターが動作していることの確認
コネクターがエラーなしで正常に起動すると、コネクターでキャプチャーするように設定した各テーブルのトピックが作成されます。ダウンストリームアプリケーションは、これらのトピックをサブスクライブして、ソースデータベースで発生する情報イベントを取得できます。
コネクターが実行されていることを確認するには、OpenShift Container Platform Web コンソールまたは OpenShift CLI ツール (oc) から以下の操作を実行します。
- コネクターのステータスを確認します。
- コネクターがトピックを生成していることを確認します。
- 各テーブルの最初のスナップショットの実行中にコネクターが生成する読み取り操作 ("op":"r") のイベントがトピックに反映されていることを確認します。
前提条件
- Debezium コネクターが OpenShift 上の Streams for Apache Kafka にデプロイされている。
-
OpenShift
ocCLI クライアントがインストールされている。 - OpenShift Container Platform Web コンソールにアクセスできる。
手順
以下の方法のいずれかを使用して
KafkaConnectorリソースのステータスを確認します。OpenShift Container Platform Web コンソールから以下を実行します。
- Home → Search に移動します。
-
Search ページで Resources をクリックし、Select Resource ボックスを開き、
KafkaConnectorを入力します。 - KafkaConnectors リストから、チェックするコネクターの名前をクリックします (例: inventory-connector-mariadb)。
- Conditions セクションで、Type および Status 列の値が Ready および True に設定されていることを確認します。
ターミナルウィンドウから以下を実行します。
以下のコマンドを実行します。
oc describe KafkaConnector <connector-name> -n <project>
oc describe KafkaConnector <connector-name> -n <project>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc describe KafkaConnector inventory-connector-mariadb -n debezium
oc describe KafkaConnector inventory-connector-mariadb -n debeziumCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、以下の出力のようなステータス情報を返します。
例2.13
KafkaConnectorリソースのステータスCopy to Clipboard Copied! Toggle word wrap Toggle overflow
コネクターによって Kafka トピックが作成されたことを確認します。
OpenShift Container Platform Web コンソールから以下を実行します。
- Home → Search に移動します。
-
Search ページで Resources をクリックし、Select Resource ボックスを開き、
KafkaTopicを入力します。 -
KafkaTopics リストから確認するトピックの名前をクリックします (例:
inventory-connector-mariadb.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d)。 - Conditions セクションで、Type および Status 列の値が Ready および True に設定されていることを確認します。
ターミナルウィンドウから以下を実行します。
以下のコマンドを実行します。
oc get kafkatopics
oc get kafkatopicsCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、以下の出力のようなステータス情報を返します。
例2.14
KafkaTopicリソースのステータスCopy to Clipboard Copied! Toggle word wrap Toggle overflow
トピックの内容を確認します。
- ターミナルウィンドウから、以下のコマンドを入力します。
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory-connector-mariadb.inventory.products_on_hand
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory-connector-mariadb.inventory.products_on_handCopy to Clipboard Copied! Toggle word wrap Toggle overflow トピック名を指定する形式は、手順 1 で返された
oc describeコマンドと同じです (例:inventory-connector-mariadb.inventory.addresses)。トピックの各イベントについて、このコマンドは、以下の出力のような情報を返します。
例2.15 Debezium 変更イベントの内容
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory-connector-mariadb.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-mariadb.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-mariadb.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"int64","optional":false,"field":"ts_us"},{"type":"int64","optional":false,"field":"ts_ns"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.mariadb.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"int64","optional":true,"field":"ts_us"},{"type":"int64","optional":true,"field":"ts_ns"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory-connector-mariadb.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"2.7.3.Final-redhat-00001","connector":"mariadb","name":"inventory-connector-mariadb","ts_ms":1638985247805,"ts_us":1638985247805000000,"ts_ns":1638985247805000000,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"mariadb-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"ts_us":1638985247805102,"ts_ns":1638985247805102588,"transaction":null}}{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory-connector-mariadb.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-mariadb.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-mariadb.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"int64","optional":false,"field":"ts_us"},{"type":"int64","optional":false,"field":"ts_ns"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.mariadb.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"int64","optional":true,"field":"ts_us"},{"type":"int64","optional":true,"field":"ts_ns"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory-connector-mariadb.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"2.7.3.Final-redhat-00001","connector":"mariadb","name":"inventory-connector-mariadb","ts_ms":1638985247805,"ts_us":1638985247805000000,"ts_ns":1638985247805000000,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"mariadb-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"ts_us":1638985247805102,"ts_ns":1638985247805102588,"transaction":null}}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記の例では、
payload値は、コネクタースナップショットがテーブルinventory.products_on_handから読み込み ("op" ="r") イベントを生成したことを示しています。product_idレコードの"before"状態はnullであり、レコードに以前の値が存在しないことを示しています。"after"状態は、product_id101を持つ項目のquantityが3であることを示しています。
2.2.6.5. Debezium MariaDB コネクター設定プロパティーの説明
Debezium MariaDB コネクターには、アプリケーションに適切なコネクター動作を実現するために使用できる多数の設定プロパティーがあります。多くのプロパティーにはデフォルト値があります。プロパティーに関する情報は、以下のように設定されています。
- 必要なコネクター設定プロパティー
- 高度なコネクター設定プロパティー
- Debezium がデータベース履歴トピックから読み取るイベントを処理する方法を制御する データベース履歴コネクター設定プロパティー
必要な Debezium MariaDB コネクター設定プロパティー
以下の設定プロパティーは、デフォルト値がない場合は必須です。
bigint.unsigned.handling.mode
デフォルト値:long。
コネクターが変更イベントで BIGINT UNSIGNED 列を表す方法を指定します。以下のオプションのいずれかを設定します。long-
Java の
longデータ型を使用して、BIGINT UNSIGNED 列の値を表します。long型はの精度を最適ではありませんが、大半のコンシューマーで簡単に実装できます。環境の多くでは、これが推奨される設定です。 precise-
値を表すために
java.math.BigDecimalデータ型を使用します。コネクターは、Kafka Connectorg.apache.kafka.connect.data.Decimalデータ型を使用して、エンコードされたバイナリー形式で値を表します。コネクターが通常 2^63 より大きい値で動作する場合は、このオプションを設定します。longデータ型ではそのサイズの値を伝達できません。
binary.handling.modeデフォルト値:
バイト。
変更イベントでコネクターがバイナリー列 (Blob、binary、varbinaryなど) の値を表す方法を指定します。
以下のオプションのいずれかを設定します。bytes- バイナリーデータをバイト配列として表します。
base64- バイナリーデータを base64 でエンコードされた文字列として表します。
base64-url-safe- バイナリーデータを base64-url-safe-encoded 文字列として表します。
hex- バイナリーデータを 16 進数 (base16) でエンコードされた文字列として表します。
column.exclude.listデフォルト値: 空の文字列。
変更イベントレコードの値から除外する列の完全修飾名に一致する、オプションのコンマ区切りの正規表現のリスト。ソースレコード内の他の列は通常どおりキャプチャーされます。列の完全修飾名の形式は databaseName.tableName.columnName です。
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列名に存在する可能性のある部分文字列とは一致しない、列の名前文字列全体と照合されます。このプロパティーを設定に含める場合は、
column.include.listプロパティーも設定しないでください。
column.include.listデフォルト値: 空の文字列。
変更イベントレコードの値に含める列の完全修飾名に一致する、オプションのコンマ区切りの正規表現のリスト。その他の列はイベントレコードから省略されます。列の完全修飾名の形式は databaseName.tableName.columnName です。
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列名に存在する可能性のある部分文字列とは一致しない、列の名前文字列全体と照合されます。
このプロパティーを設定に含める場合は、column.exclude.listプロパティーを設定しないでください。
column.mask.hash.v2.hashAlgorithm.with.salt.saltデフォルト値: デフォルトなし。
文字ベースの列の完全修飾名に一致する、オプションのコンマ区切りの正規表現のリスト。列の完全修飾名の形式は<databaseName>.<tableName>.<columnName>です。
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列の名前文字列全体に対して照合されます。式は、列名に存在する可能性のある部分文字列と一致しません。作成された変更イベントレコードでは、指定された列の値は仮名に置き換えられます。
仮名は、指定された hashAlgorithm と salt を適用した結果のハッシュ値で構成されます。使用されるハッシュ関数に基づいて、参照整合性は保持され、列値は仮名に置き換えられます。サポートされるハッシュ関数は、Java Cryptography Architecture Standard Algorithm Name Documentation の MessageDigest section に説明されています。
次の例では、
CzQMA0cB5Kはランダムに選択された salt です。column.mask.hash.SHA-256.with.salt.CzQMA0cB5K = inventory.orders.customerName, inventory.shipment.customerName
column.mask.hash.SHA-256.with.salt.CzQMA0cB5K = inventory.orders.customerName, inventory.shipment.customerNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 必要な場合は、仮名は自動的に列の長さに短縮されます。コネクター設定には、異なるハッシュアルゴリズムと salt を指定する複数のプロパティーを含めることができます。
使用される hashAlgorithm、選択された salt、および実際のデータセットによっては、結果のデータセットが完全にマスクされない場合があります。
ハッシュストラテジーバージョン 2 は、異なる場所またはシステムでハッシュされる値が整合性を保てるようにします。
column.mask.with.length.charsデフォルト値: デフォルトなし。
文字ベースの列の完全修飾名に一致する、オプションのコンマ区切りの正規表現のリスト。一連の列の値をコネクターでマスクする場合 (たとえば、列に機密データが含まれている場合) は、このプロパティーを設定します。lengthを正の整数に設定して、指定された列のデータをプロパティー名の 長さ で指定されたアスタリスク (*) 文字数で置き換えます。指定した列のデータを空の文字列に置き換えるには、長さ を0(ゼロ) に設定します。列の完全修飾名は、次の形式に従います: databaseName.tableName.columnName列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列の名前文字列全体に対して照合されます。式は、列名に存在する可能性のある部分文字列と一致しません。
単一の設定で、異なる長さを持つ複数のプロパティーを指定できます。
column.propagate.source.typeデフォルト値: デフォルトなし。
コネクターが列のメタデータを表す追加パラメーターを発行する列の完全修飾名に一致する、オプションのコンマ区切りの正規表現のリスト。このプロパティーが設定されている場合、コネクターは次のフィールドをイベントレコードのスキーマに追加します。-
__debezium.source.column.type -
__debezium.source.column.length -
__debezium.source.column.scale
これらのパラメーターは、それぞれ列の元の型名と長さ (可変幅型の場合) を伝播します。
コネクターがこの余分なデータを発行できるようにすると、sink データベース内の特定の数値または文字ベースの列のサイズを適切に設定するのに役立ちます。
列の完全修飾名は、次のいずれかの形式に従います: databaseName.tableName.columnName、または databaseName.schemaName.tableName.columnName.
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列の名前文字列全体に対して照合されます。式は、列名に存在する可能性のある部分文字列と一致しません。
-
column.truncate.to.length.charsデフォルト値: デフォルトなし。
文字ベースの列の完全修飾名に一致する、オプションのコンマ区切りの正規表現のリスト。プロパティー名の 長さ で指定された文字数を超えた場合に、一連の列のデータを切り捨てる場合は、このプロパティーを設定します。lengthを正の整数値に設定します (例:column.truncate.to.20.chars)。列の完全修飾名は、次の形式に従います: databaseName.tableName.columnName列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列の名前文字列全体に対して照合されます。式は、列名に存在する可能性のある部分文字列と一致しません。
単一の設定で、異なる長さを持つ複数のプロパティーを指定できます。
connect.timeout.ms-
デフォルト値:
30000(30 秒)。
接続要求がタイムアウトする前にコネクターが MariaDB データベースサーバーへの接続を確立するまで待機する最大時間 (ミリ秒単位) を指定する正の整数値。
connector.class-
デフォルト値: デフォルトなし。
コネクターの Java クラスの名前。MariaDB コネクターの場合は常に指定します。
database.exclude.listデフォルト値: 空の文字列。
データベースの名前に一致するオプションのコンマ区切りの正規表現のリスト。ただし、コネクターに変更をキャプチャーさせません。コネクターは、database.exclude.listに名前が指定されていないデータベースの変更をキャプチャーします。
データベースの名前を照合するために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、データベースの名前文字列全体に対して照合されます。データベース名に存在する可能性のある部分文字列とは一致しません。
このプロパティーを設定に含める場合は、database.include.listプロパティーも設定しないでください。
database.hostname-
デフォルト値: デフォルトなし。
MariaDB データベースサーバーの IP アドレスまたはホスト名。
database.include.listデフォルト値: 空の文字列。
コネクターが変更をキャプチャーし、さらにデータベースの名前に一致する、オプションのコンマ区切りの正規表現のリスト。コネクターは、名前がdatabase.include.listにないデータベースの変更をキャプチャーしません。デフォルトでは、コネクターはすべてのデータベースの変更をキャプチャーします。
データベースの名前を照合するために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、データベースの名前文字列全体に対して照合されます。データベース名に存在する可能性のある部分文字列とは一致しません。
このプロパティーを設定に含める場合は、database.exclude.listプロパティーも設定しないでください。
database.password-
デフォルト値: デフォルトなし。
コネクターが MariaDB データベースサーバーに接続するために使用する MariaDB ユーザーのパスワード。
database.port-
デフォルト値:
3306。
MariaDB データベースサーバーの整数ポート番号。
database.server.id-
デフォルト値: デフォルトなし。
このデータベースクライアントの数値 ID。指定された ID は、MariaDB クラスター内で現在実行中のすべてのデータベースプロセス全体で一意である必要があります。コネクターは、binlog の読み取りを可能にするために、この一意の ID を使用して、MariaDB データベースクラスターを別のサーバーとして参加させます。
database.user-
デフォルト値: デフォルトなし。
コネクターが MariaDB データベースサーバーに接続するために使用する MariaDB ユーザーの名前。
decimal.handling.modeデフォルト値:
precise。
コネクターが変更イベントでDECIMAL列とNUMERIC列の値を処理する方法を指定します。
以下のオプションのいずれかを設定します。precise(デフォルト)-
値を正確に表すために、バイナリー形式の
java.math.BigDecimal値を使用します。 double-
値を表すために
doubleデータ型を使用します。このオプションを選択すると精度が低下する可能性がありますが、ほとんどのコンシューマーにとって使いやすいものになります。 string- フォーマットされた文字列としてエンコードされます。このオプションは簡単に使用できますが、実際の型に関するセマンティック情報が失われる可能性があります。
event.deserialization.failure.handling.modeデフォルト値:
fail。
binlog イベントのデシリアライズ中に例外が発生した場合にコネクターがどのように反応するかを指定します。このオプションは非推奨です。代わりにevent.processing.failure.handling.modeオプションを使用してください。fail- 問題のあるイベントとその binlog オフセットを示す例外を伝播し、コネクターを停止させます。
warn- 問題のあるイベントとその binlog オフセットをログに記録し、イベントをスキップします。
ignore- 問題のあるイベントを通過し、何もログに記録しません。
field.name.adjustment.modeデフォルト値: デフォルトなし。
コネクターで使用されるメッセージコンバーターとの互換性を確保するために、フィールド名を調整する方法を指定します。以下のオプションのいずれかを設定します。none- 調整はありません。
avro- Avro 名で有効でない文字をアンダースコア文字に置き換えます。
avro_unicodeアンダースコア文字または Avro 名で使用できない文字は、
_uxxxxなどの対応する Unicode に置き換えます。
注記`_` is an escape sequence, similar to a backslash in Java
`_` is an escape sequence, similar to a backslash in JavaCopy to Clipboard Copied! Toggle word wrap Toggle overflow 詳細は、Avro の命名 を参照してください。
gtid.source.excludes-
デフォルト値: デフォルトなし。
コネクターが MariaDB サーバー上の binlog の位置を特定するために使用する GTID セット内のソースドメイン ID に一致する正規表現のコンマ区切りリスト。このプロパティーが設定されている場合、コネクターは、指定されたexcludeパターンのいずれにも一致しないソース UUID が含まれる GTID 範囲のみを使用します。
GTID の値を一致させるために、Debezium は、アンカー 正規表現として指定した正規表現を適用します。つまり、指定された式は GTID のドメイン識別子に対して照合されます。
このプロパティーを設定に含める場合は、gtid.source.includesプロパティーも設定しないでください。
gtid.source.includes-
デフォルト値: デフォルトなし。
コネクターが MariaDB サーバー上の binlog の位置を特定するために使用する GTID セット内のソースドメイン ID に一致する正規表現のコンマ区切りリスト。このプロパティーが設定されている場合、コネクターは、指定されたincludeパターンのいずれかに一致するソース UUID が含まれる GTID 範囲のみを使用します。
GTID の値を一致させるために、Debezium は、アンカー 正規表現として指定した正規表現を適用します。つまり、指定された式は GTID のドメイン識別子に対して照合されます。
このプロパティーを設定に含める場合は、gtid.source.excludesプロパティーも設定しないでください。
include.query-
デフォルト値:
false。
変更イベントを生成した元の SQL クエリーをコネクターに含めるかどうかを指定するブール値。
このオプションをtrueに設定する場合は、MariaDB のbinlog_annotate_row_eventsオプションをONに設定して指定する必要もあります。include.queryがtrueの場合、スナップショットプロセスによって生成されるイベントに対するクエリーは存在しません。include.queryをtrueに設定すると、変更イベントに元の SQL ステートメントを含めることで明示的に除外またはマスクされたテーブルまたはフィールドが公開される可能性があります。そのため、デフォルト設定はfalseです。
各ログイベントに対して元のSQLステートメントを返すようにデータベースを設定する方法の詳細は、クエリーログイベントの有効化 を参照してください。
include.schema.changes-
デフォルト値:
true。
コネクターが、データベーススキーマに加えられた変更をデータベースサーバー ID の名前を持つ Kafka トピックに公開するかどうかを指定するブール値。コネクターがキャプチャーする各スキーマ変更イベントでは、データベース名を含むキーと、変更を記述する DDL ステートメントを含む値が使用されます。この設定により、コネクターが内部データベーススキーマ履歴にスキーマの変更を記録する方法は左右されません。
include.schema.commentsデフォルト値:
false。
コネクターがメタデータオブジェクトのテーブルおよび列のコメントを解析して公開するかどうかを指定するブール値。
注記このオプションを
trueに設定すると、コネクターに含まれるスキーマコメントによって、各スキーマオブジェクトに大量の文字列データが追加される可能性があります。論理スキーマオブジェクトの数とサイズを増やすと、コネクターが使用するメモリーの量が増加します。
inconsistent.schema.handling.modeデフォルト値:
fail。
内部スキーマ表現に存在しないテーブルを参照する binlog イベントにコネクターが応答する方法を指定します。つまり、内部表現はデータベースと一致しません。
以下のオプションのいずれかを設定します。fail- コネクターは、問題のあるイベントとその binlog オフセットを報告する例外を出力します。その後、コネクターが停止します。
warn- コネクターは問題のあるイベントとそのバイナリーログオフセットをログに記録し、イベントをスキップします。
skip- コネクターは問題のあるイベントをスキップして、その旨はログに報告されません。
message.key.columns-
デフォルト値: デフォルトなし。
指定のテーブルの Kafka トピックに公開する変更イベントレコードのカスタムメッセージキーを形成するためにコネクターが使用する列を指定する式のリスト。
デフォルトでは、Debezium はテーブルのプライマリーキー列を、出力するレコードのメッセージキーとして使用します。デフォルトの代わりに、またはプライマリーキーのないテーブルのキーを指定するには、1 つ以上の列をもとにカスタムメッセージキーを設定できます。
テーブルのカスタムメッセージキーを作成するには、テーブルとメッセージキーとして使用する列をリストします。各リストエントリーは、<fully-qualified_tableName>:<keyColumn>,<keyColumn>
の形式を取ります。複数の列名をベースにテーブルキーを作成するには、列名の間にコンマを挿入します。
完全修飾テーブル名はそれぞれ、次の形式の正規表現です。<databaseName>.<tableName>
プロパティーには複数のテーブルのエントリーを含めることができます。セミコロンを使用して、リスト内のテーブルエントリーを区切ります。
以下の例は、テーブルinventory.customersおよびpurchase.orders:inventory.customers:pk1,pk2;(.*).purchaseorders:pk3,pk4
のメッセージキーを設定します。テーブルinventory.customerの場合、列pk1とpk2がメッセージキーとして指定されます。データベースでpurchaseordersテーブルは、pk3およびpk4サーバーのコラムをメッセージキーとして使用します。
カスタムメッセージキーの作成に使用する列の数に制限はありません。ただし、一意の鍵を指定するために必要な最小数を使用することが推奨されます。
name-
デフォルト値: デフォルトなし。
コネクターの一意の名前。同じ名前を使用して別のコネクターを登録しようとすると、登録は失敗します。このプロパティーはすべての Kafka Connect コネクターに必要です。
schema.name.adjustment.modeデフォルト値: デフォルトなし。
コネクターが使用するメッセージコンバーターとの互換性を確保するために、コネクターがスキーマ名を調整する方法を指定します。以下のオプションのいずれかを設定します。none- 調整はありません。
avro- Avro 名で有効でない文字をアンダースコア文字に置き換えます。
avro_unicode-
アンダースコア文字または Avro 名で使用できない文字は、
_uxxxxなどの対応する Unicode に置き換えます。
注記:_はエスケープシーケンスで、Java のバックスラッシュに似ています。
skip.messages.without.change-
デフォルト値:
false。
含まれる列の変更が検出されない場合に、コネクターがレコードのメッセージを発行するかどうかを指定します。列は、column.include.listにリストされている場合、またはcolumn.exclude.listにリストされていない場合は、included とみなされます。含まれる列に変更がない場合にコネクターがレコードをキャプチャーしないようにするには、値をtrueに設定します。
table.exclude.listデフォルト値: 空の文字列。
テーブルの完全修飾テーブル識別子に一致する、オプションのコンマ区切りの正規表現のリスト。ただし、コネクターに変更をキャプチャーさせません。コネクターはtable.exclude.listに含まれていないテーブルの変更をキャプチャーします。各識別子の形式は databaseName.tableName です。
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの名前文字列全体と照合されます。
このプロパティーを設定に含める場合は、table.include.listプロパティーも設定しないでください。
table.include.listデフォルト値: 空の文字列。
変更をキャプチャーするテーブルの完全修飾テーブル識別子に一致する、オプションのコンマ区切りの正規表現のリスト。コネクターは、table.include.listに含まれていないテーブルの変更をキャプチャしません。各識別子の形式は databaseName.tableName です。デフォルトでは、コネクターは変更をキャプチャーするように設定されている全データベース内の非システムテーブルの変更をすべてキャプチャーします。
テーブルの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの名前文字列全体と照合されます。
このプロパティーを設定に含める場合は、table.exclude.listプロパティーも設定しないでください。
tasks.max-
デフォルト値:
1。
このコネクターに対して作成するタスクの最大数。MariaDB コネクターは常に単一のタスクを使用するため、デフォルト値を変更しても効果はありません。
time.precision.modeデフォルト値:
adaptive_time_microseconds。
コネクターが時間、日付、タイムスタンプの値を表すために使用する精度のタイプを指定します。次のいずれかのオプションを設定します。
adaptive_time_microseconds(デフォルト)-
コネクターは、データベース列のタイプに基づいて、ミリ秒、マイクロ秒、またはナノ秒の精度値を使用して、データベースとまったく同じように日付、日付時刻、およびタイムスタンプの値をキャプチャーします。ただし、常にマイクロ秒としてキャプチャーされる TIME タイプフィールドは例外です。
connect- コネクターは常に、データベース列の精度に関係なくミリ秒の精度を使用する、Kafka Connect の組み込みの時間、日付、タイムスタンプの表現を使用して、時間とタイムスタンプの値を表します。
tombstones.on.deleteデフォルト値:
true。
delete イベントの後に tombstone イベントが続くかどうかを指定します。ソースレコードが削除された後、コネクターはトゥームストーンイベント (デフォルトの動作) を発行して、トピックの ログ圧縮 が有効になっている場合に、削除された行のキーに関連するすべてのイベントを Kafka が完全に削除できるようにします。次のいずれかのオプションを設定します。
true(デフォルト)-
コネクターは、delete イベントとそれに続く tombstone イベントを発行することによって削除操作を表します。
false-
コネクターは delete イベントのみを出力します。
topic.prefixデフォルト値: デフォルトなし。
Debezium が変更をキャプチャーしている特定の MariaDB データベースサーバーまたはクラスターの namespace を提供するトピック接頭辞。トピック接頭辞は、このコネクターが発行するイベントを受信するすべての Kafka トピックの名前として使用されるので、トピック接頭辞がすべてのコネクター間で一意であることが重要です。値には、英数字、ハイフン、ドット、アンダースコアのみを使用できます。
警告このプロパティーを設定した後は、値を変更しないでください。値を変更すると、コネクターの再起動後に、コネクターは元のトピックにイベントを引き続き送信するのではなく、新しい値に基づいた名前のトピックに後続のイベントを送信します。また、コネクターはデータベーススキーマ履歴トピックを復元できません。
高度な Debezium MariaDB コネクター設定プロパティー
次のリストは、MariaDB コネクターの高度な設定プロパティーについて説明します。これらのプロパティーのデフォルト値を変更する必要はほぼありません。そのため、コネクター設定にデフォルト値を指定する必要はありません。
connect.keep.alive-
デフォルト値:
true。
MariaDB サーバーまたはクラスターへの接続を維持するために別のスレッドを使用するかどうかを指定するブール値。
convertersデフォルト値: デフォルトなし。
コネクターが使用できる custom converter インスタンスのシンボリック名のコンマ区切りリストを列挙します。
たとえば、booleanです。
このプロパティーは、コネクターがカスタムコンバーターを使用できるようにするために必要です。
コネクターに設定するコンバータごとに、コンバータインターフェイスを実装するクラスの完全修飾名を指定する.typeプロパティーも追加する必要があります。.typeプロパティーでは、以下の形式を使用します。
<converterSymbolicName>.type以下に例を示します。
boolean.type: io.debezium.connector.binlog.converters.TinyIntOneToBooleanConverter
boolean.type: io.debezium.connector.binlog.converters.TinyIntOneToBooleanConverterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 設定されたコンバータの動作をさらに制御したい場合は、1 つ以上の設定パラメーターを追加して、コンバータに値を渡すことができます。これらの追加設定パラメ設定ーターをコンバータに関連付けるには、パラメーター名の前にコンバーターのシンボル名を付けます。
たとえば、
booleanコンバーターが処理する列のサブセットを指定するselectorパラメーターを定義するには、次のプロパティーを追加します。
boolean.selector=db1.table1.*, db1.table2.column1
boolean.selector=db1.table1.*, db1.table2.column1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
custom.metric.tags-
デフォルト値: デフォルトなし。
コンテキスト情報を提供するメタデータを追加して、MBean オブジェクト名をカスタマイズするタグを定義します。キーと値のペアのコンマ区切りリストを指定します。各キーは MBean オブジェクト名のタグを表し、対応する値はキーの値を表します (例:
k1=v1、k2=v2)。
コネクターは、指定されたタグを基本 MBean オブジェクト名に追加します。タグは、メトリクスデータを整理および分類するのに役立ちます。特定のアプリケーションインスタンス、環境、リージョン、バージョンなどを識別するためのタグを定義できます。詳細は、カスタマイズされた MBean 名 を参照してください。
database.initial.statementsデフォルト値: デフォルトなし。
トランザクションログを読み取る接続ではなく、データベースへの JDBC 接続が確立されたときに実行される、セミコロンで区切られた SQL ステートメントのリスト。SQL ステートメントでセミコロンを区切り文字としてではなく、文字として指定する場合は、2 つのセミコロン (;;) を使用します。
コネクターは独自の判断で JDBC 接続を確立する可能性があるため、このプロパティーはセッションパラメーターの設定専用です。DML ステートメントを実行するものではありません。
database.query.timeout.ms-
デフォルト値:
600000(10 分)。
コネクターがクエリーの完了を待機する時間をミリ秒単位で指定します。タイムアウト制限を削除するには、値を0(ゼロ) に設定します。
database.ssl.keystore-
デフォルト値: デフォルトなし。
キーストアファイルの場所を指定するオプションの設定。キーストアファイルは、クライアントと MariaDB サーバー間の双方向認証に使用できます。
database.ssl.keystore.password-
デフォルト値: デフォルトなし。
キーストアファイルのパスワード。database.ssl.keystoreが設定されている場合にのみパスワードを指定します。
database.ssl.modeデフォルト値:
preferred。
コネクターが暗号化された接続を使用するかどうかを指定します。以下の設定が可能です。disabled- 暗号化されていない接続の使用を指定します。
preferred(デフォルト)- サーバーが安全な接続をサポートしている場合、コネクターは暗号化された接続を確立します。サーバーが安全な接続をサポートしていない場合、コネクターは暗号化されていない接続を使用します。
required- コネクターは暗号化された接続を確立します。暗号化された接続を確立できない場合、コネクターは失敗します。
verify_ca-
コネクターは、
requiredのオプションを設定した場合と同じように動作しますが、設定された認証局 (CA) 証明書に対してサーバーの TLS 証明書も検証します。サーバーの TLS 証明書が有効な CA 証明書と一致しない場合、コネクターは失敗します。
verify_identity-
コネクターは
verify_caオプションを設定した場合と同じように動作しますが、サーバー証明書がリモート接続のホストと一致するかどうかも検証します。
database.ssl.truststore-
デフォルト値: デフォルトなし。
サーバー証明書検証用のトラストストアファイルの場所。
database.ssl.truststore.password-
デフォルト値: デフォルトなし。
トラストストアファイルのパスワード。トラストストアの整合性をチェックし、トラストストアのロックを解除するために使用されます。
enable.time.adjusterデフォルト値:
true。
コネクターが 2 桁の年指定を 4 桁に変換するかどうかを示すブール値。変換がデータベースに完全に委任される場合は、値をfalseに設定します。
MariaDB ユーザーは、2 桁または 4 桁の年の値を挿入できます。2 桁の値は、1970 - 2069 の範囲の年にマッピングされます。デフォルトでは、コネクターが変換を実行します。
errors.max.retriesデフォルト値:
-1。
接続エラーなどの再試行可能なエラーが発生する操作が実行された後にコネクターがどのように応答するかを指定します。
以下のオプションのいずれかを設定します。-1- 制限なしコネクターは常に自動的に再起動し、以前の失敗回数に関係なく、操作を再試行します。
0- Disabledコネクターはすぐに失敗し、操作を再試行することはありません。コネクターを再起動するにはユーザーの介入が必要です。
> 0- 指定された最大再試行回数に達するまで、コネクターは自動的に再起動します。次の障害が発生すると、コネクターは停止し、再起動するにはユーザーの介入が必要になります。
event.converting.failure.handling.modeデフォルト値:
warn。
列のデータ型と Debezium 内部スキーマで指定された型が一致しないためにテーブルレコードを変換できない場合にコネクターがどのように応答するかを指定します。
以下のオプションのいずれかを設定します。fail-
例外は、フィールドのデータ型がスキーマタイプと一致しなかったために変換が失敗したことを報告し、変換を正常に行うにはコネクターを
schema _only_recoveryモードで再起動する必要がある可能性があることを示します。 warn-
コネクターは、変換に失敗した列のイベントフィールドに
null値を書き込み、警告ログにメッセージを書き込みます。
skip-
コネクターは、変換に失敗した列のイベントフィールドに
null値を書き込み、デバッグログにメッセージを書き込みます。
event.processing.failure.handling.modeデフォルト値:
fail。
問題のあるイベントに遭遇した場合など、イベントの処理中に発生する障害をコネクターがどのように処理するかを指定します。以下の設定が可能です。fail- コネクターは、問題のあるイベントとその位置を報告する例外を発生させます。その後、コネクターが停止します。
warn- コネクターにより例外が出力されることはありません。代わりに、問題のあるイベントとその位置をログに記録し、イベントをスキップします。
ignore- コネクターは問題のあるイベントを無視し、ログエントリーは生成されません。
heartbeat.action.queryデフォルト値: デフォルトなし。
コネクターがハートビートメッセージを送信するときに、コネクターがソースデータベースで実行するクエリーを指定します。
たとえば、次のクエリーは、ソースデータベースで実行された GTID セットの状態を定期的にキャプチャーします。
INSERT INTO gtid_history_table (select @gtid_executed)
heartbeat.interval.msデフォルト値:
0。
コネクターが Kafka トピックにハートビートメッセージを送信する頻度を指定します。デフォルトでは、コネクターによりハートビートメッセージは送信されません。
ハートビートメッセージは、コネクターがデータベースから変更イベントを受信しているかどうかを監視するのに便利です。ハートビートメッセージは、コネクターの再起動時に再送信する必要がある変更イベントの数を減らすのに役立つ可能性があります。ハートビートメッセージを送信するには、このプロパティーを、ハートビートメッセージの間隔をミリ秒単位で示す正の整数に設定します。
incremental.snapshot.allow.schema.changes-
デフォルト値:
false。
コネクターが増分スナップショット中にスキーマの変更を許可するかどうかを指定します。値がtrueに設定されている場合、コネクターは増分スナップショット中にスキーマの変更を検出し、DDL のロックを回避するために現在のチャンクを再選択します。
プライマリーキーへの変更はサポートされていません。増分スナップショットの作成中にプライマリーを変更すると、誤った結果が生じる可能性があります。さらに他の制限として、スキーマの変更が列のデフォルト値にのみ影響する場合、DDL が binlog ストリームから処理されるまで変更が検出されないことが挙げられます。これはスナップショットイベントの値には影響しませんが、これらのスナップショットイベントのスキーマのデフォルトが古くなっている可能性があります。
incremental.snapshot.chunk.size-
デフォルト値:
1024。
コネクターが増分スナップショットチャンクを取得するときにフェッチしてメモリーに読み込む行の最大数。スナップショットは、サイズが大きいスナップショットの場合にはクエリーが少なくなるため、チャンクサイズを増やすと効率が上がります。ただし、チャンクサイズが大きい場合には、スナップショットデータのバッファーにより多くのメモリーが必要になります。チャンクサイズは、環境で最適なパフォーマンスを発揮できる値に、調整します。
incremental.snapshot.watermarking.strategyデフォルト値:
insert_insert。
増分スナップショットによってキャプチャーされ、ストリーミングの再開後に再キャプチャーされる可能性のあるイベントの重複を排除するために、コネクターが増分スナップショット中に使用するウォーターマークメカニズムを指定します。
以下のオプションのいずれかを指定することができます。insert_insert(デフォルト)- 増分スナップショットを開始するシグナルを送信すると、スナップショット中に Debezium が読み取るチャンクごとに、スナップショットウィンドウを開くシグナルを記録するエントリーがシグナリングデータコレクションに書き込まれます。スナップショットが完了すると、Debezium はウィンドウを閉じるシグナルを記録する 2 番目のエントリーを挿入します。
insert_delete- 増分スナップショットを開始するシグナルを送信すると、Debezium が読み取るチャンクごとに、スナップショットウィンドウを開くシグナルを記録する 1 つのエントリーがシグナリングデータコレクションに書き込まれます。スナップショットが完了すると、このエントリーは削除されます。スナップショットウィンドウを閉じるシグナルのエントリーは作成されません。シグナリングデータコレクションの急増を防ぐには、このオプションを設定します。
max.batch.size-
デフォルト値:
2048。
このコネクターの反復処理中に処理される必要があるイベントの各バッチの最大サイズを指定する正の整数値。
max.queue.size-
デフォルト値:
8192。
ブロッキングキューが保持できるレコードの最大数を指定する正の整数値。Debezium はデータベースからストリームされたイベントを読み込む際、Kafka に書き込む前にブロッキングキューにイベントを配置します。ブロッキングキューは、コネクターが Kafka に書き込むよりも速くメッセージを取り込む場合、または Kafka が利用できなくなった場合に、データベースから変更イベントを読み込むためのバックプレッシャーを提供することができます。コネクターがオフセットを定期的に記録すると、キューに保持されるイベントは無視されます。max.queue.sizeは常にmax.batch.sizeの値よりも大きい値に設定してください。
max.queue.size.in.bytes-
デフォルト値:
0。
ブロッキングキューの最大ボリュームをバイト単位で指定する長整数値。デフォルトでは、ブロックキューにはボリューム制限は指定されません。キューが使用できるバイト数を指定するには、このプロパティーを正の long 値に設定します。max.queue.sizeも設定されている場合、キューのサイズがいずれかのプロパティーで指定された制限に達すると、キューへの書き込みがブロックされます。たとえば、max.queue.size=1000、max.queue.size.in.bytes=5000と設定した場合、キューに 1000 レコードが入った後、あるいはキュー内のレコードの量が 5000 バイトに達した後、キューへの書き込みがブロックされます。
min.row.count.to.stream.resultsデフォルト値:
1000。
スナップショットの作成中に、コネクターは変更をキャプチャーするように設定されている各テーブルをクエリーします。コネクターは各クエリーの結果を使用して、そのテーブルのすべての行のデータが含まれる読み取りイベントを生成します。このプロパティーは、MariaDB コネクターがテーブルの結果をメモリーに格納するか、ストリーミングを行うかを決定します。メモリーへの格納はすばやく処理できますが、大量のメモリーを必要とします。ストリーミングを行うと、処理は遅くなりますが、非常に大きなテーブルにも対応できます。このプロパティーの設定は、コネクターが結果のストリーミングを行う前にテーブルに含まれる必要がある行の最小数を指定します。
すべてのテーブルサイズチェックを省略し、スナップショットの実行中に常にすべての結果をストリーミングする場合は、このプロパティーを
0に設定します。
notification.enabled.channelsデフォルト値: デフォルトなし。
コネクターに対して有効になっている通知チャネル名のリスト。デフォルトでは、以下のチャネルが利用可能です。-
sink -
log -
jmx
-
poll.interval.ms-
デフォルト値:
500(0.5 秒)。
コネクターがイベントのバッチ処理を開始する前に、新しい変更イベントが表示されるのを待機する時間をミリ秒単位で指定する正の整数値。
provide.transaction.metadata-
デフォルト値:
false。
コネクターがトランザクション境界を持つイベントを生成し、トランザクションメタデータを使用して変更イベントエンベロープを強化するかどうかを決定します。コネクターにこれを実行させる場合はtrueを指定します。詳細は、トランザクションメタデータ を参照してください。
signal.data.collection-
デフォルト値: デフォルトなし。
コネクターに シグナル を送信するために使用されるデータコレクションの完全修飾名。<databaseName>.<tableName>の形式を使用してコレクション名を指定します。
signal.enabled.channelsデフォルト値: デフォルトなし。
コネクターに対して有効になっているシグナリングチャネル名のリスト。デフォルトでは、以下のチャネルが利用可能です。-
source -
kafka -
file -
jmx
-
skipped.operations-
デフォルト値:
t。
ストリーミング中にスキップされる操作タイプのコンマ区切りリスト。挿入/作成はc、更新はu、削除はd、切り捨てはt、操作をスキップしない場合はnone となります。デフォルトでは、切り捨て操作が省略されます。
snapshot.delay.ms-
デフォルト値: デフォルトなし。
コネクターの起動時にスナップショットを実行する前にコネクターが待機する間隔 (ミリ秒単位)。クラスターで複数のコネクターを起動する場合、このプロパティーは、コネクターのリバランスが行われる原因となるスナップショットの中断を防ぐのに役立ちます。
snapshot.fetch.size-
デフォルト値: 未設定。
デフォルトでは、スナップショットの作成中に、コネクターはテーブルの内容を行単位で読み取ります。バッチ内の行の最大数を指定するには、このプロパティーを設定します。
snapshot.include.collection.list-
デフォルト値:
table.include.listで指定されたすべてのテーブル。
スナップショットに含めるテーブルの完全修飾名 (<databaseName>.<tableName>) と一致する正規表現のコンマ区切りリスト (任意)。指定する項目は、コネクターのtable.include.listプロパティーで名前を付ける必要があります。このプロパティーは、コネクターのsnapshot.modeプロパティーがnever. 以外の値に設定されている場合にのみ有効です。
このプロパティーは増分スナップショットの動作には影響しません。
テーブルの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの名前文字列全体と照合されます。
snapshot.lock.timeout.ms-
デフォルト値:
10000。
スナップショットを実行するときにテーブルロックを取得するために待機する最大時間 (ミリ秒単位) を指定する正の整数。コネクターがこの期間にテーブルロックを取得できないと、スナップショットは失敗します。詳細は以下を参照してください。
snapshot.locking.modeデフォルト値:
minimal。
コネクターがグローバル MariaDB 読み取りロックを保持するかどうか、および保持する期間を指定します。これにより、コネクターがスナップショットを実行している間、データベースへの更新を加えることができません。以下の設定が可能です。minimal-
コネクターは、データベーススキーマやその他のメタデータを読み取るスナップショットの初期フェーズのみ、グローバル読み取りロックを保持します。スナップショットの次のフェーズでは、コネクターは各テーブルからすべての行を選択するときにロックを解除します。一貫した方法で SELECT 操作を実行するために、コネクターは REPEATABLE READ トランザクションを使用します。グローバル読み取りロックが解除されると、他の MariaDB クライアントがデータベースを更新できるようになりますが、トランザクションの期間中、コネクターは同じデータを読み取り続けるため、REPEATABLE READ 分離を使用すると、スナップショットの一貫性が確保されます。
extended-
スナップショットの作成中にすべての書き込み操作をブロックします。クライアントが MariaDB の REPEATABLE READ 分離レベルと互換性のない同時操作を送信する場合は、この設定を使用します。
none- スナップショット中にコネクターがテーブルロックを取得するのを防ぎます。このオプションはすべてのスナップショットモードで許可されますが、スナップショットの作成中にスキーマの変更が発生しない場合に のみ 安全に使用できます。MyISAM エンジンで定義されたテーブルは常にテーブルロックを取得します。その結果、このオプションを設定しても、このようなテーブルはロックされます。この動作は、行レベルのロックを取得する InnoDB エンジンによって定義されたテーブルとは異なります。
snapshot.max.threadsデフォルト値:
1。
初期スナップショットを実行するときにコネクターが使用するスレッドの数を指定します。並列初期スナップショットを有効にするには、プロパティーを 1 より大きい値に設定します。並列初期スナップショットでは、コネクターは複数のテーブルを同時に処理します。
重要並列初期スナップショットは開発者プレビュー機能のみとなっています。開発者プレビューソフトウェアは、Red Hat では一切サポートされておらず、機能的に完全ではなく、実稼働環境に対応していません。開発者プレビューのソフトウェアを実稼働ワークロードまたはビジネスクリティカルなワークロードには使用しないでください。開発者プレビューソフトウェアは、今後 Red Hat 製品サービスとして追加される可能性のある製品ソフトウェアを前もって早期に利用できます。お客様はこのソフトウェアを使用して機能をテストし、開発プロセス中にフィードバックを提供できます。このソフトウェアはいつでも変更または削除される可能性があり、限定的なテストしか行われていません。Red Hat は、関連する SLA なしに、開発者プレビューソフトウェアに対するフィードバックを送信する手段を提供する場合があります。
Red Hat 開発者プレビューソフトウェアのサポート範囲の詳細は、開発者プレビューのサポート範囲 を参照してください。
snapshot.modeデフォルト値:
initial。
コネクターの起動時にスナップショットを実行するための基準を指定します。以下の設定が可能です。always- コネクターは起動するたびにスナップショットを実行します。スナップショットには、キャプチャーされたテーブルの構造およびデータが含まれます。この値を指定すると、コネクターが起動するたびに、キャプチャーされたテーブルからのデータの完全な表現がトピックに入力されます。
initial(デフォルト)- コネクターは、論理サーバー名のオフセットが記録されていない場合、または以前のスナップショットが完了しなかったことが検出された場合にのみ、スナップショットを実行します。スナップショットが完了すると、コネクターは、後続のデータベース変更のに備え、イベントレコードのストリーミングを開始します。
initial_only- コネクターは、論理サーバー名のオフセットが記録されていない場合にのみスナップショットを実行します。スナップショットが完了すると、コネクターは停止します。binlog からの変更イベントを読み取る際にストリーミングに移行しません。
schema_only-
非推奨です。
no_dataを参照してください。 no_data- コネクターは、テーブルデータではなくスキーマのみをキャプチャーするスナップショットを実行します。トピックにデータの一貫したスナップショットを含める必要はないが、最後のコネクターの再起動後に適用されたスキーマの変更をキャプチャーする場合は、このオプションを設定します。
schema_only_recovery-
非推奨です。
recoveryを参照してください。 recovery損失または破損したデータベーススキーマの履歴トピックを復元するにはこのオプションを設定します。再起動後、コネクターはソーステーブルからトピックを再構築するスナップショットを実行します。また、このプロパティーを設定して、予期しない増加が発生するデータベーススキーマ履歴トピックを定期的にプルーニングすることもできます。
警告最後のコネクターのシャットダウン後にスキーマの変更がデータベースにコミットされた場合、このモードを使用してスナップショットを実行しないでください。
never-
コネクターが起動すると、スナップショットを実行するのではなく、後続のデータベース変更のイベントレコードのストリーミングがすぐに開始されます。
no_dataオプションが優先的に使用されるようになり、このオプションは、今後非推奨にするか検討中です。 when_neededコネクターが起動した後、次のいずれかの状況を検出した場合にのみスナップショットが実行されます。
- トピックのオフセットを検出できません。
- 以前に記録されたオフセットは、サーバー上で使用できない binlog の位置または GTID を指定します。
snapshot.query.modeデフォルト値:
select_all。
スナップショットを実行するときにコネクターがデータをクエリーする方法を指定します。
以下のオプションのいずれかを設定します。select_all(デフォルト)-
コネクターは、
select allクエリーを使用してキャプチャーされたテーブルから行を取得し、必要に応じて、列のincludeおよびexcludeリストの設定に基づいて選択された列を調整します。
この設定により、
snapshot.select.statement.overridesプロパティーを使用する場合と比較して、より柔軟にスナップショットコンテンツを管理できるようになります。
snapshot.select.statement.overridesデフォルト値: デフォルトなし。
スナップショットに含めるテーブル行を指定します。スナップショットにテーブルの行のサブセットのみを含める場合は、プロパティーを使用します。このプロパティーはスナップショットにのみ影響します。コネクターがログから読み取るイベントには影響しません。<databaseName>.<tableName>の形式で完全修飾テーブル名のコンマ区切りリストを指定します。以下に例を示します。
"snapshot.select.statement.overrides": "inventory.products,customers.orders"
リスト内の各テーブルに対して、スナップショットを取得するときにコネクターがテーブルで実行する
SELECTステートメントを指定する別の設定プロパティーを追加します。指定したSELECTステートメントは、スナップショットに追加するテーブル行のサブセットを決定します。このSELECTステートメントプロパティーの名前を指定するには、次の形式を使用します。
snapshot.select.statement.overrides.<databaseName>.<tableName>。たとえば、snapshot.select.statement.overrides.customers.ordersなどです。
ソフト削除列delete_flagを含むcustomers.ordersテーブルから、スナップショットにソフト削除されていないレコードのみを含める場合は、次のプロパティーを追加します。"snapshot.select.statement.overrides": "customer.orders", "snapshot.select.statement.overrides.customer.orders": "SELECT * FROM [customers].[orders] WHERE delete_flag = 0 ORDER BY id DESC"
"snapshot.select.statement.overrides": "customer.orders", "snapshot.select.statement.overrides.customer.orders": "SELECT * FROM [customers].[orders] WHERE delete_flag = 0 ORDER BY id DESC"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 作成されるスナップショットでは、コネクターには
delete_flag = 0のレコードのみが含まれます。
snapshot.tables.order.by.row.countデフォルト値:
disabled。
コネクターが初期スナップショットを実行するときにテーブルを処理する順序を指定します。以下のオプションのいずれかを設定します。descending- コネクターは、行数に基づいて、最上位から最下位の順にテーブルのスナップショットを作成します。
ascending- コネクターは、行数に基づいて、最下位から最上位の順にテーブルのスナップショットを作成します。
disabled- コネクターは、初期スナップショットを実行するときに行数を無視します。
streaming.delay.ms-
デフォルト値:
0。
コネクターがスナップショットを完了した後、ストリーミングプロセスの開始を遅延する時間をミリ秒単位で指定します。遅延間隔を設定すると、スナップショットが完了した直後で、ストリーミングプロセスの開始前に障害が発生した場合に、コネクターがスナップショットを再開できないようにします。Kafka Connect ワーカーに設定されているoffset.flush.interval.msプロパティーの値よりも高い遅延値を設定します。
table.ignore.builtin-
デフォルト値:
true。
組み込みシステムテーブルを無視するかどうかを指定するブール値。これは、テーブルの include および exclude リストに関係なく適用されます。デフォルトでは、システムテーブルの値に加えられた変更はキャプチャーから除外され、Debezium はシステムテーブルの変更に対してイベントを生成しません。
topic.cache.size-
デフォルト値:
10000。
制限された同時ハッシュマップ内のメモリーに格納できるトピック名の数を指定します。コネクターはキャッシュを使用して、データコレクションに対応するトピック名を決定します。
topic.delimiter-
デフォルト値:
.。
コネクターがトピック名のコンポーネント間に挿入する区切り文字を指定します。
topic.heartbeat.prefixデフォルト値:
__debezium-heartbeat。
コネクターがハートビートメッセージを送信するトピックの名前を指定します。トピック名の形式は次のとおりです。
topic.heartbeat.prefix.topic.prefix
たとえば、トピックの接頭辞が
fulfillmentの場合、デフォルトのトピック名は__Debezium-heartbeat.fulfillmentになります。
topic.naming.strategy-
デフォルト値:
io.debezium.schema.DefaultTopicNamingStrategy。
コネクターが使用するTopicNamingStrategyクラスの名前。指定されたストラテジーによって、データ変更、スキーマ変更、トランザクション、ハートビートなどのイベントレコードを格納するトピックにコネクターが名前を付ける方法が決まります。
topic.transactionデフォルト値:
transaction。
コネクターがトランザクションメタデータメッセージを送信するトピックの名前を指定します。トピック名のパターンは次のとおりです。
topic.prefix.topic.transaction
たとえば、トピック接頭辞が
fulfillmentの場合、デフォルトのトピック名はfulfillment.transactionになります。
use.nongraceful.disconnect-
デフォルト値: false。
バイナリーログクライアントのキープアライブスレッドがSO_LINGERソケットオプションを0に設定して、古い TCP 接続をすぐに切断するかどうかを指定するブール値。SSLSocketImpl.closeでコネクターのデッドロックが発生する場合は、値をtrueに設定します。
Debezium コネクターデータベーススキーマ履歴設定プロパティー
Debezium には、コネクターがスキーマ履歴トピックと対話する方法を制御する schema.history.internal.* プロパティーのセットが含まれています。
以下の表は、Debezium コネクターを設定するための schema.history.internal プロパティーを説明しています。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし | コネクターがデータベーススキーマの履歴を保存する Kafka トピックの完全名。 | |
| デフォルトなし | Kafka クラスターへの最初の接続を確立するためにコネクターが使用するホストとポートのペアのリスト。このコネクションは、コネクターによって以前に保存されたデータベーススキーマ履歴の取得や、ソースデータベースから読み取られる各 DDL ステートメントの書き込みに使用されます。各ペアは、Kafka Connect プロセスによって使用される同じ Kafka クラスターを示す必要があります。 | |
|
| 永続化されたデータのポーリングが行われている間にコネクターが起動/回復を待つ最大時間 (ミリ秒単位) を指定する整数値。デフォルトは 100 ミリ秒です。 | |
|
| Kafka 管理クライアントを使用してクラスター情報を取得する際に、コネクターが待機すべき最大ミリ秒数を指定する整数値です。 | |
|
| Kafka 管理クライアントを使用して kafka 履歴トピックを作成する間、コネクターが待機する最大ミリ秒数を指定する整数値。 | |
|
|
エラーでコネクターのリカバリーが失敗する前に、コネクターが永続化された履歴データの読み取りを試行する最大回数。データが受信されなかった場合に最大待機する時間は、 | |
|
|
コネクターが不正または不明なデータベースのステートメントを無視するかどうか、または人が問題を修正するために処理を停止するかどうかを指定するブール値。安全なデフォルトは | |
|
|
コネクターがスキーマまたはデータベース内のすべてのテーブルからスキーマ構造を記録するか、キャプチャー対象に指定されたテーブルのみからスキーマ構造を記録するかを指定するブール値。
| |
|
|
コネクターがデータベースインスタンス内のすべての論理データベースのスキーマ構造を記録するかどうかを指定するブール値。
|
パススルー MariaDB コネクター設定プロパティー
コネクター設定で pass-through プロパティーを設定して、Apache Kafka プロデューサーとコンシューマーの動作をカスタマイズできます。Kafka プロデューサーとコンシューマーの全設定プロパティーの詳細は、Kafka ドキュメント を参照してください。
プロデューサーとコンシューマーのクライアントがスキーマ履歴トピックと対話する方法を設定するための Pass-through プロパティー
Debezium は、データベーススキーマ履歴トピックへのスキーマ変更を記述するために Apache Kafka プロデューサーに依存しています。同様に、コネクターが起動すると、データベーススキーマ履歴トピックから読み取る Kafka コンシューマーに依存します。schema.history.internal.producer.* および schema.history.internal.consumer.* 接頭辞で始まるパススルー設定プロパティーのセットに値を割り当てて、Kafka プロデューサーおよびコンシューマークライアントの設定を定義します。パススループロデューサーおよびコンシューマーデータベーススキーマ履歴プロパティーは、以下の例のように Kafka ブローカーとのこれらのクライアントの接続をセキュアにする方法など、さまざまな動作を制御します。
Debezium は、プロパティーを Kafka クライアントに渡す前に、プロパティー名から接頭辞を削除します。
Kafka プロデューサー設定プロパティー と Kafka コンシューマー設定プロパティー の詳細は、Apache Kafka ドキュメントを参照してください。
MariaDB コネクターが Kafka シグナリングトピックと対話する方法を設定するための Pass-through プロパティー
Debezium は、コネクターが Kafka シグナルトピックと対話する方法を制御する signal.* プロパティーのセットを提供します。
以下の表は、Kafka signal プロパティーを説明しています。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| <topic.prefix>-signal | コネクターがアドホックシグナルについて監視する Kafka トピックの名前。 注記 トピックの自動作成 が無効になっている場合は、必要なシグナリングトピックを手動で作成する必要があります。シグナルの順序を維持するには、シグナルトピックが必要です。シグナリングトピックには単一のパーティションが必要です。 | |
| kafka-signal | Kafka コンシューマーによって使用されるグループ ID の名前。 | |
| デフォルトなし | コネクターが Kafka クラスターへの初期接続を確立するために使用するホストとポートのペアのリスト。各ペアは、Debezium Kafka Connect プロセスによって使用される Kafka クラスターを参照します。 | |
|
| コネクターが信号をポーリングするときに待機する最大ミリ秒数を指定する整数値。 | |
|
| Kafka コンシューマーがシグナリングトピックからメッセージを読み取った後にオフセットコミットを書き込むかどうかを指定します。このプロパティーに割り当てる値によって、コネクターがオフラインのときに、シグナリングトピックが受信する要求をコネクターが処理できるかどうかが決まります。次のいずれかの設定を選択します。
|
シグナリングチャネルの Kafka コンシューマークライアントを設定するためのパススループロパティー
Debezium コネクターでは、Kafka コンシューマーのパススルー設定が可能です。パススルーシグナルのプロパティーは、接頭辞 signals.consumer.* で始まります。たとえば、コネクターは signal.consumer.security.protocol=SSL などのプロパティーを Kafka コンシューマーに渡します。
Debezium は、プロパティーを Kafka シグナルコンシューマーに渡す前に、プロパティーから接頭辞を削除します。
MariaDB コネクター sink notification チャネルを設定するためのパススループロパティー
次の表では、Debezium sink notification チャネルの設定に使用できるプロパティーについて説明します。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし |
Debezium から通知を受信するトピックの名前。このプロパティーは、有効な通知チャネルの 1 つとして |
Debezium コネクターのパススルーデータベースドライバー設定プロパティー
Debezium コネクターでは、データベースドライバーのパススルー設定が可能です。パススルーデータベースプロパティーは接頭辞 driver.* で始まります。たとえば、コネクターは driver.foobar=false などのプロパティーを JDBC URL に渡します。
Debezium は、プロパティーをデータベースドライバーに渡す前に、プロパティーから接頭辞を削除します。
2.2.7. Debezium MariaDB コネクターのパフォーマンスの監視
Debezium MariaDB コネクターは、Zookeeper、Kafka、および Kafka Connect によって提供される JMX メトリクスの組み込みサポートに加えて、3 種類のメトリクスを提供します。
- スナップショットメトリクス は、スナップショットの実行中にコネクター操作に関する情報を提供します。
- ストリーミングメトリック は、コネクターが binlog を読み取る際のコネクター操作に関する情報を提供します。
- スキーマ履歴メトリクス は、コネクターのスキーマ履歴の状態に関する情報を提供します。
Debezium モニタリングのドキュメント では、JMX を使用してこれらのメトリクスを公開する方法の詳細を説明しています。
2.2.7.1. MariaDB コネクタースナップショットとストリーミング MBean オブジェクトのカスタマイズされた名前
Debezium コネクターは、コネクターの MBean 名を介してメトリクスを公開します。これらのメトリクスは各コネクターインスタンスに固有であり、コネクターのスナップショット、ストリーミング、およびスキーマ履歴プロセスの動作に関するデータを提供します。
デフォルトでは、正しく設定されたコネクターをデプロイすると、Debezium はさまざまなコネクターメトリクスごとに一意の MBean 名を生成します。コネクタープロセスのメトリクスを表示するには、MBean を監視するように可観測性スタックを設定します。ただし、これらのデフォルトの MBean 名はコネクター設定に依存しており、設定の変更によって MBean 名が変更される場合があります。MBean 名を変更すると、コネクターインスタンスと MBean 間のリンクが切断され、監視アクティビティーが中断されます。このシナリオでは、監視を再開するには、新しい MBean 名を使用するように監視スタックを再設定する必要があります。
MBean 名の変更が原因で監視が中断されないように、カスタムメトリクスタグを設定できます。カスタムメトリクスを設定するには、コネクター設定に custom.metric.tags プロパティーを追加します。このプロパティーは、各キーが MBean オブジェクト名のタグを表し、対応する値がそのタグの値を表すキーと値のペアを受け入れます。たとえば、k1=v1,k2=v2 です。Debezium は、指定されたタグをコネクターの MBean 名に追加します。
コネクターの custom.metric.tags プロパティーを設定した後、指定されたタグに関連付けられたメトリクスを取得するように監視スタックを設定できます。可観測性スタックは、変更可能な MBean 名ではなく、指定されたタグを使用してコネクターを一意に識別します。その後、Debezium が MBean 名の構築方法を再定義したり、コネクター設定の topic.prefix が変更されたりしても、メトリクススクレイプタスクは指定されたタグパターンを使用してコネクターを識別するため、メトリクスの収集は中断されません。
カスタムタグを使用するさらなる利点は、データパイプラインのアーキテクチャーを反映するタグを使用できるため、運用上のニーズに合った方法でメトリクスを整理できることです。たとえば、コネクターアクティビティーのタイプ、アプリケーションコンテキスト、またはデータソースを宣言する値を持つタグを指定できます (例: db1-streaming-for-application-abc)。複数のキーと値のペアを指定すると、指定されたすべてのペアがコネクターの MBean 名に追加されます。
次の例は、タグがデフォルトの MBean 名を変更する方法を示しています。
例2.16 カスタムタグがコネクター MBean 名を変更する方法
デフォルトでは、MariaDB コネクターはストリーミングメトリクスに次の MBean 名を使用します。
debezium.mariadb:type=connector-metrics,context=streaming,server=<topic.prefix>
debezium.mariadb:type=connector-metrics,context=streaming,server=<topic.prefix>
custom.metric.tags の値を database=salesdb-streaming,table=inventory に設定すると、Debezium は次のカスタム MBean 名を生成します。
debezium.mariadb:type=connector-metrics,context=streaming,server=<topic.prefix>,database=salesdb-streaming,table=inventory
debezium.mariadb:type=connector-metrics,context=streaming,server=<topic.prefix>,database=salesdb-streaming,table=inventory2.2.7.2. MariaDB データベースのスナップショット中の Debezium の監視
MBean は debezium.mariadb:type=connector-metrics,context=snapshot,server=<topic.prefix> です。
スナップショット操作がアクティブでない場合や、最後のコネクターの起動後にスナップショットの作成が発生した場合に、スナップショットメトリクスは公開されません。
次の表に、使用可能なスナップショットメトリクスを示します。
| 属性 | タイプ | 説明 |
|---|---|---|
|
| コネクターが読み取りした最後のスナップショットイベント。 | |
|
| コネクターが最新のイベントを読み取りおよび処理してからの経過時間 (ミリ秒単位)。 | |
|
| 前回の開始またはリセット以降にコネクターで確認されたイベントの合計数。 | |
|
| コネクターに設定された include/exclude リストのフィルタリングルールによってフィルターされたイベントの数。 | |
|
| コネクターによって取得されるテーブルのリスト。 | |
|
| snapshotter とメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの長さ。 | |
|
| snapshotter とメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの空き容量。 | |
|
| スナップショットに含まれているテーブルの合計数。 | |
|
| スナップショットによってまだコピーされていないテーブルの数。 | |
|
| スナップショットが起動されたかどうか。 | |
|
| スナップショットが一時停止されたかどうか。 | |
|
| スナップショットが中断されたかどうか。 | |
|
| スナップショットが完了したかどうか。 | |
|
| スナップショットが完了したかどうかに関わらず、これまでスナップショットにかかった時間 (秒単位)。スナップショットが一時停止された時間も含まれます。 | |
|
| スナップショットが一時停止された合計秒数。スナップショットが数回一時停止された場合は、一時停止時間が加算されます。 | |
|
| スナップショットの各テーブルに対してスキャンされる行数が含まれるマップ。テーブルは、処理中に増分がマップに追加されます。スキャンされた 10,000 行ごとに、テーブルの完成時に更新されます。 | |
|
|
キューの最大バッファー (バイト単位)。このメトリクスは | |
|
| キュー内のレコードの現在の容量 (バイト単位)。 |
コネクターは、増分スナップショットの実行時に、以下の追加のスナップショットメトリクスも提供します。
2.2.7.3. Debezium MariaDB コネクターレコードストリーミングの監視
Debezium MariaDB コネクターは、Zookeeper、Kafka、および Kafka Connect によって提供される JMX メトリクスの組み込みサポートに加えて、3 種類のメトリクスを提供します。
- スナップショットメトリクス は、スナップショットの実行中にコネクター操作に関する情報を提供します。
- ストリーミングメトリック は、コネクターが binlog を読み取る際のコネクター操作に関する情報を提供します。
- スキーマ履歴メトリクス は、コネクターのスキーマ履歴の状態に関する情報を提供します。
Debezium モニタリングのドキュメント では、JMX を使用してこれらのメトリクスを公開する方法の詳細を説明しています。
MBean は debezium.mariadb:type=connector-metrics,context=streaming,server=<topic.prefix> です。
以下の表は、利用可能なストリーミングメトリクスのリストです。
| 属性 | タイプ | 説明 |
|---|---|---|
|
| コネクターが読み取られた最後のストリーミングイベント。 | |
|
| コネクターが最新のイベントを読み取りおよび処理してからの経過時間 (ミリ秒単位)。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、ソースデータベースによって報告されたデータ変更イベントの合計数。Debezium が処理するデータ変更ワークロードを表します。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された作成イベントの合計数。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された更新イベントの合計数。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された削除イベントの合計数。 | |
|
| コネクターに設定された include/exclude リストのフィルタリングルールによってフィルターされたイベントの数。 | |
|
| コネクターによって取得されるテーブルのリスト。 | |
|
| ストリーマーとメイン Kafka Connect ループの間でイベントを渡すために使用されるキューの長さ。 | |
|
| ストリーマーとメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの空き容量。 | |
|
| コネクターが現在データベースサーバーに接続されているかどうかを示すフラグ。 | |
|
| 最後の変更イベントのタイムスタンプとそれを処理するコネクターとの間の期間 (ミリ秒単位)。この値には、データベースサーバーとコネクターが実行されているマシンのクロックの差が組み込まれます。 | |
|
| コミットされた処理済みトランザクションの数。 | |
|
| 最後に受信したイベントの位置。 | |
|
| 最後に処理されたトランザクションのトランザクション識別子。 | |
|
|
キューの最大バッファー (バイト単位)。このメトリクスは | |
|
| キュー内のレコードの現在の容量 (バイト単位)。 |
2.2.7.4. Debezium MariaDB コネクタースキーマ履歴の監視
MBean は debezium.mariadb:type=connector-metrics,context=schema-history,server=<topic.prefix> です。
以下の表は、利用可能なスキーマ履歴メトリクスのリストです。
| 属性 | タイプ | 説明 |
|---|---|---|
|
|
データベーススキーマ履歴の状態を示す | |
|
| リカバリーが開始された時点のエポック秒の時間。 | |
|
| リカバリーフェーズ中に読み取られた変更の数。 | |
|
| リカバリーおよびランタイム中に適用されるスキーマ変更の合計数。 | |
|
| 最後の変更が履歴ストアから復元された時点からの経過時間 (ミリ秒単位)。 | |
|
| 最後の変更が適用された時点からの経過時間 (ミリ秒単位)。 | |
|
| 履歴ストアから復元された最後の変更の文字列表現。 | |
|
| 最後に適用された変更の文字列表現。 |
2.2.8. Debezium MariaDB コネクターが障害や問題を処理する方法
Debezium は、複数のアップストリームデータベースのすべての変更をキャプチャーする分散システムであり、イベントの見逃しや損失は発生しません。システムが正常に操作している場合や、慎重に管理されている場合は、Debezium は変更イベントレコードごとに 1 度だけ 配信します。
障害が発生しても、システムからイベントがなくなることはありません。ただし、Debezium が障害から回復している間に、いくつかの変更イベントが繰り返される可能性があります。このような正常でない状態では、Debezium は Kafka と同様に、変更イベントを 少なくとも 1 回 配信します。
詳細は以下を参照してください。
- 設定および起動エラー
以下の状況では、起動時にコネクターが失敗し、エラーまたは例外がログに記録され、実行が停止されます。
- コネクターの設定が無効である。
- 指定された接続パラメーターを使用してコネクターを MariaDB サーバーに正常に接続できない。
- MariaDB に履歴がない binlog の位置でコネクターが再起動を試行する。
このような場合、エラーメッセージには問題の詳細が含まれ、推奨される回避策も含まれることがあります。設定の修正したり、MariaDB の問題に対処した後、コネクターを再起動します。
ただし、高可用性の MariaDB クラスターに接続している場合は、コネクターをすぐに再起動できます。これはクラスターの別の MariaDB サーバーに接続し、最後のトランザクションを表すサーバーの binlog の場所を特定し、その特定の場所から新しいサーバーの binlog の読み取りを開始します。
- Kafka Connect が正常に停止する
- Kafka Connect が正常に停止すると、Debezium MariaDB コネクタータスクが停止され、新しい Kafka Connect プロセスで再起動される間に短い遅延が発生します。
- Kafka Connect プロセスのクラッシュ
- Kafka Connect がクラッシュすると、プロセスが停止し、最後に処理されたオフセットが記録されずに Debezium MariaDB コネクタータスクが終了します。分散モードでは、Kafka Connect は他のプロセスでコネクタータスクを再起動します。ただし、MariaDB コネクターは以前のプロセスで記録された最後のオフセットから再開します。その結果、代わりのタスクによってクラッシュ前に処理された一部のイベントが再生成され、重複したイベントが作成されることがあります。
各変更イベントメッセージには、重複イベントの特定に使用できるソース固有の情報が含まれます。以下に例を示します。
- イベント元
- MariaDB サーバーのイベント時間
- binlog ファイル名と位置
- GTID
- MariaDB が binlog ファイルをパージする
- Debezium MariaDB コネクターが長時間停止すると、MariaDB サーバーは古い binlog ファイルを消去し、コネクターの最後の位置が失われる可能性があります。コネクターが再起動すると、MariaDB サーバーに開始点がなくなり、コネクターは別の最初のスナップショットを実行します。スナップショットが無効の場合、コネクターはエラーによって失敗します。
MariaDB コネクターが初期スナップショットを実行する方法の詳細は、スナップショット を参照してください。
2.3. MongoDB の Debezium コネクター
Debezium の MongoDB コネクターは、データベースおよびコレクションにおけるドキュメントの変更に対して、MongoDB レプリカセットまたは MongoDB シャードクラスターを追跡し、これらの変更を Kafka トピックのイベントとして記録します。コネクターは、シャードクラスターにおけるシャードの追加または削除、各レプリカセットのメンバーシップの変更、各レプリカセット内の選出、および通信問題の解決待ちを自動的に処理します。
このコネクターと互換性のある MongoDB のバージョンについては、Debezium でサポートされる設定ページを参照してください。
Debezium MongoDB コネクターを使用するための情報および手順は、以下のように設定されています。
2.3.1. Debezium MongoDB コネクターの概要
MongoDB のレプリケーションメカニズムは冗長性と高可用性を提供し、実稼働環境における MongoDB の実行に推奨される方法です。MongoDB コネクターは、レプリカセットまたはシャードクラスターの変更をキャプチャーします。
MongoDB レプリカセット は、すべてが同じデータのコピーを持つサーバーのセットで構成され、レプリケーションによって、クライアントがレプリカセットの プライマリー のドキュメントに追加したすべての変更が、セカンダリーと呼ばれる別のレプリカセットのサーバーに適用されるようにします。MongoDB のレプリケーションでは、プライマリーが oplog (または操作ログ) に変更を記録した後、各セカンダリーがプライマリーの oplog を読み取って、すべての操作を順番に独自のドキュメントに適用します。新規サーバーをレプリカセットに追加すると、そのサーバーは最初にプライマリーのすべてのデータベースおよびコレクションの スナップショット を実行し、次にプライマリーの oplog を読み取り、スナップショットの開始後に加えられたすべての変更を適用します。この新しいサーバーは、プライマリーの oplog の最後に到達するとセカンダリーになり、クエリーを処理できます。
2.3.1.1. MongoDB コネクターが変更ストリームを使用してイベントレコードをキャプチャーする方法の説明
Debezium MongoDB コネクターはレプリカセットの一部ではありませんが、同様のレプリケーションメカニズムを使用して oplog データを取得します。主な違いは、コネクターが直接 oplog を読み取らない点です。代わりに、oplog データの取得およびデコードを MongoDB 変更ストリーム 機能に委譲します。変更ストリームでは、MongoDB サーバーはコレクションで発生する変更をイベントストリームとして公開します。Debezium コネクターはストリームを監視し、変更をダウンストリームに配信します。コネクターが最初にレプリカセットを検出すると、oplog を調べて最後に記録されたトランザクションを取得し、プライマリーのデータベースおよびコレクションのスナップショットを作成します。コネクターがデータのコピーを終了すると、以前に読み取られた oplog の位置から開始する変更ストリームを作成します。
MongoDB コネクターは変更を処理すると、イベントを発信する先の oplog/stream の位置を定期的に記録します。コネクターが停止したら、最後に処理した oplog ストリームの位置を記録するため、再起動後にその位置からストリーミングを再開できます。つまり、コネクターを停止、アップグレード、または維持でき、後で再起動できます。イベントを何も失うことなく、常に停止した場所を正確に特定します。当然ながら、MongoDB oplogs は通常最大サイズに制限されているため、コネクターがそれらを読み取る前に oplog の操作がパージされる可能性があります。この場合、再起動後、足りていない oplog 操作をコネクターが検出し、スナップショットを実行してから、変更をストリームします。
MongoDB コネクターは、レプリカセットのメンバーシップとリーダーシップの変更、シャードクラスター内でのシャードの追加と削除、および通信障害の原因となる可能性のあるネットワーク問題にも非常に寛容です。コネクターは常にレプリカセットのプライマリーノードを使用して変更をストリーミングします。そのため、レプリカセットの選出が行われ、他のノードがプライマリーになると、コネクターはすぐ変更のストリーミングを停止し、新しいプライマリーに接続し、新しいプライマリーを使用して変更のストリーミングを開始します。同様に、プライマリーとして設定されたレプリカとコネクターが通信できない場合は、再接続を試みます (ネットワークまたはレプリカセットを圧迫しないように指数バックオフを使用します)。接続が再確立された後、コネクターはキャプチャーした最後のイベントからの変更を引き続きストリーミングします。これにより、コネクターはレプリカセットメンバーシップの変更を動的に調整し、通信障害を自動的に処理します。
2.3.1.2. MongoDB コネクターが MongoDB 読み取り設定を使用する方法の説明
MongoDB 接続の読み取り設定を指定するには、mongodb.connection.string で readPreference パラメーターを設定します。
2.3.2. Debezium MongoDB コネクターの仕組み
コネクターがサポートする MongoDB トポロジーの概要は、アプリケーションを計画するときに役立ちます。
Debezium MongoDB コネクターの仕組みの詳細は、以下を参照してください。
- 「Debezium コネクターでサポートされる MongoDB トポロジー」
- 「Debezium MongoDB コネクターでレプリカセットおよびシャードクラスターに論理名を使用する方法」
- 「Debezium MongoDB コネクターでのスナップショットの実行方法」
- 「アドホックスナップショット」
- 「増分スナップショット」
- 「Debezium MongoDB コネクターでの変更イベントレコードのストリーミング方法」
- 「Debezium MongoDB 変更イベントレコードを受信する Kafka トピックのデフォルト名」
- 「イベントキーが Debezium MongoDB コネクターのトピックパーティション設定を制御する方法」
- 「トランザクション境界を表す Debezium MongoDB コネクターによって生成されたイベント」
2.3.2.1. Debezium コネクターでサポートされる MongoDB トポロジー
MongoDB コネクターは以下の MongoDB トポロジーをサポートします。
- MongoDB レプリカセット
Debezium MongoDB コネクターは単一の MongoDB レプリカセットから変更をキャプチャーできます。実稼働のレプリカセットには、少なくとも 3 つのメンバー が必要です。
レプリカセットで MongoDB コネクターを使用するには、コネクター設定の
mongodb.connection.stringプロパティーの値を レプリカセットの接続文字列 に設定する必要があります。コネクターが MongoDB 変更ストリームからの変更のキャプチャーを開始する準備ができると、接続タスクが開始されます。次に、接続タスクは、指定された接続文字列を使用して、使用可能なレプリカセットメンバーへの接続を確立します。
- MongoDB のシャードクラスター
MongoDB のシャードクラスター は以下で構成されます。
- レプリカセットとしてデプロイされる 1 つ以上のシャード。
- クラスターの設定サーバーとして動作する個別のレプリカセット。
クライアントが接続し、要求を適切なシャードにルーティングする 1 つ以上の ルーター (
mongosとも呼ばれます)。シャードクラスターで MongoDB コネクターを使用するには、コネクター設定で、
mongodb.connection.stringプロパティーの値を sharded cluster connection string に設定します。
- MongoDB スタンドアロンサーバー
- スタンドアロンサーバーには oplog がないため、MongoDB コネクターはスタンドアロン MongoDB サーバーの変更を監視できません。スタンドアロンサーバーが 1 つのメンバーを持つレプリカセットに変換されると、コネクターが動作します。
MongoDB は、実稼働でのスタンドアロンサーバーの実行を推奨しません。詳細は MongoDB のドキュメント を参照してください。
2.3.2.2. Debezium コネクターに必要なユーザーパーミッション
MongoDB からデータをキャプチャーするために、Debezium は MongoDB ユーザーとしてデータベースに接続します。Debezium 用に作成する MongoDB ユーザーアカウントには、データベースから読み取るための特定のデータベースパーミッションが必要です。コネクターユーザーには次のパーミッションが必要です。
- データベースからの読み取り。
-
helloコマンドを実行します。
コネクターユーザーには次のパーミッションも必要な場合があります。
-
config.shardsシステムコレクションからの読み取り。
データベースの読み取りパーミッション
コネクターユーザーは、コネクターの capture.scope プロパティーの値に応じて、すべてのデータベースから、または特定のデータベースから読み取ることができる必要があります。capture.scope の設定に応じて、ユーザーに次のいずれかのパーミッションを割り当てます。
capture.scopeがdeploymentに設定されている- ユーザーに任意のデータベースを読み取るパーミッションを付与します。
capture.scopeがdatabaseに設定されている-
ユーザーに、コネクターの
capture.targetプロパティーで指定されたデータベースを読み取るパーミッションを付与します。 capture.scopeがcollectionに設定されている-
コネクターの
capture.targetプロパティーで指定されたコレクションを読み取る権限をユーザーに付与します。
capture.scope プロパティーの Debezium collection オプションの使用は、開発者プレビュー機能です。開発者プレビュー機能は、Red Hat ではいかなる形でもサポートされていません。また、機能的には完全ではなく、実稼働環境に対応していません。開発者プレビューのソフトウェアを実稼働ワークロードまたはビジネスクリティカルなワークロードには使用しないでください。開発者プレビューソフトウェアは、今後 Red Hat 製品サービスとして追加される可能性のある製品ソフトウェアを前もって早期に利用できます。お客様はこのソフトウェアを使用して機能をテストし、開発プロセス中にフィードバックを提供できます。Red Hat は、関連する SLA なしに、開発者プレビューソフトウェアに対するフィードバックを送信する手段を提供する場合があります。
Red Hat 開発者プレビューソフトウェアのサポート範囲の詳細は、開発者プレビューのサポート範囲 を参照してください。
MongoDB hello コマンドを使用する権限
capture.scope の設定に関係なく、ユーザーには MongoDB hello コマンドを実行する権限が必要です。
config.shards コレクションを読み取るパーミッション
Debezium 環境に応じて、コネクターがオフセット統合を実行できるようにするには、コネクターユーザーに config.shards コレクションを読み取るための明示的な権限を付与する必要があります。次のコネクター環境では、config.shards コレクションを読み取る権限が必要です。
- コネクターが Debezium 2.5 以前からアップグレードされた場合。
- コネクターがシャードされた MongoDB クラスターからの変更をキャプチャーするように設定されている場合。
2.3.2.3. Debezium MongoDB コネクターでレプリカセットおよびシャードクラスターに論理名を使用する方法
コネクター設定プロパティー topic.prefix は、MongoDB レプリカセットまたはシャードされたクラスターの 論理名 として提供されます。コネクターは論理名をさまざまな方法で使用します。すべてのトピック名の接頭辞として、各レプリカセットの変更ストリームの位置を記録する際に一意の識別子として使用されます。
各 MongoDB コネクターに、ソース MongoDB システムを意味する一意の論理名を命名する必要があります。論理名は、アルファベットまたはアンダースコアで始まり、残りの文字を英数字またはアンダースコアとすることが推奨されます。
2.3.2.4. Debezium MongoDB コネクターがオフセット統合を実行する方法
Debezium MongoDB コネクターは、シャードされた MongoDB デプロイメントへの replica_set 接続をサポートしなくなりました。その結果、replica_set 接続モードを使用したコネクターバージョンによって記録されたオフセットは、現在のバージョンと互換性がありません。
接続モードの変更の影響を最小限に抑え、コネクターが不要なスナップショットを実行しないようにするには、アップグレード後にコネクターが再起動されると、コネクターによりオフセットを統合する手順が実行されます。このオフセット統合の手順を実行中に、コネクターは次の手順を実行して、以前のコネクターバージョンによって記録されたオフセットを調整します。
- コネクターバージョン 2.5 以降で記録されたオフセットはそのまま使用されます。
-
シャードされた MongoDB デプロイメントまたは MongoDB レプリカセットデプロイメントから
sharded接続モードでキャプチャーされたイベントのオフセットは、そのまま使用されます。 次の両方の条件が当てはまる場合、コネクターバージョン 2.5.x 以前で記録されたシャード固有のオフセットはそのまま使用されます。
- オフセットが現在のすべてのデータベースシャードに存在する。
-
オフセットの無効化 が有効になっている。
オフセット無効化が無効になっている場合、コネクターは起動に失敗します。
-
コネクターは、前の手順で既存のオフセットを処理した後、ストリーミングの変更を再開し、キャプチャーした新しいイベントのオフセットをコミットします。
オフセット統合の手順で既存のオフセットが検出されない場合、コネクターは 初期スナップショットを実行します。
2.3.2.5. Debezium MongoDB コネクターでのスナップショットの実行方法
Debezium タスクがレプリカセットを使用して起動すると、コネクターの論理名とレプリカセット名を使用して、コネクターが変更の読み取りを停止した位置を示す オフセット を検出します。オフセットが検出され、oplog に存在する場合、タスクは記録されたオフセットの位置から即座に ストリームの変更 を続行します。
ただし、オフセットが見つからない場合、または oplog にその位置が含まれていない場合、タスクはまず スナップショット を実行してレプリカセットの内容の現在の状態を取得する必要があります。このプロセスは、oplog の現在の位置を記録して開始され、オフセット (スナップショットが開始されたことを示すフラグとともに) として記録します。次に、タスクは各コレクションのコピーに進み、できるだけ多くのスレッド (snapshot.max.threads 設定プロパティーの値まで) を生成して、この作業を並行して実行します。コネクターは、参照したドキュメントごとに個別の 読み取りイベント を記録します。各読み取りイベントには、オブジェクトの識別子、オブジェクトの完全な状態、およびオブジェクトが見つかった MongoDB レプリカセットに関する ソース 情報が含まれます。ソース情報には、イベントがスナップショットの作成中に生成されたことを示すフラグも含まれます。
このスナップショットは、コネクターのフィルターと一致するすべてのコレクションがコピーされるまで継続されます。タスクのスナップショットが完了する前にコネクターが停止した場合は、コネクターを再起動すると、再びスナップショットを開始します。
コネクターがレプリカセットのスナップショットを実行している間、タスクの再割り当てと再設定を回避します。コネクターは、スナップショットの進捗を報告するログメッセージを生成します。最大限の制御を行うために、コネクターごとに個別の Kafka Connect クラスターを実行します。
スナップショットの詳細は、以下のセクションを参照してください。
| 設定 | 説明 |
|---|---|
|
| コネクターは起動するたびにスナップショットを実行します。スナップショットが完了すると、コネクターは、後続のデータベース変更のに備え、イベントレコードのストリーミングを開始します。 |
|
| コネクターが起動すると、初期データベーススナップショットが実行されます。 |
|
| コネクターはデータベーススナップショットを実行します。スナップショットが完了すると、コネクターは停止し、後続のデータベース変更のイベントレコードをストリーミングしなくなります。 |
|
|
非推奨です。 |
|
|
コネクターは関連するすべてのテーブルの構造をキャプチャーしますが、コネクターの起動時点でのデータセットを表す |
|
| コネクターが起動した後、次のいずれかの状況を検出した場合にのみスナップショットが実行されます。
|
詳細は、コネクター設定プロパティーテーブルの snapshot.mode を参照してください。
2.3.2.6. アドホックスナップショット
デフォルトでは、コネクターは初回スナップショット操作の開始後にのみ実行されます。通常の状況では、この最初のスナップショットが作成されると、コネクターではスナップショットプロセスは繰り返し処理されません。コネクターがキャプチャーする今後の変更イベントデータはストリーミングプロセス経由でのみ行われます。
ただし、場合によっては、最初のスナップショット中にコネクターを取得したデータが古くなったり、失われたり、または不完全となったり可能性があります。収集データを再キャプチャーするメカニズムを提供するために、Debezium はアドホックスナップショットを実行するオプションを備えています。Debezium 環境で次のいずれかの変更が発生したら、アドホックスナップショットを実行することを推奨します。
- コネクター設定が変更され、異なるコレクションのセットをキャプチャーします。
- Kafka トピックを削除して、再構築する必要があります。
- 設定エラーや他の問題が原因で、データの破損が発生します。
いわゆる アドホックスナップショット を開始することで、以前にスナップショットをキャプチャしたコレクションに対してスナップショットを再実行することができます。アドホックスナップショットでは、シグナリングコレクション を使用する必要があります。シグナルリクエストを Debezium シグナルコレクションに送信して、アドホックスナップショットを開始します。
既存のコレクションのアドホックスナップショットを開始すると、コネクターはコレクションにすでに存在するトピックにコンテンツを追加します。既存のトピックが削除された場合には、トピックの自動作成 が有効になっているのであれば、Debezium は自動的にトピックを作成できます。
アドホックのスナップショットシグナルは、スナップショットに追加するコレクションを指定します。スナップショットは、データベースの内容全体をキャプチャーしたり、データベース内のコレクションのサブセットのみをキャプチャーしたりできます。また、スナップショットは、データベース内のコレクションの内容のサブセットをキャプチャーできます。
キャプチャーするコレクションは、シグナリングコレクションに execute-snapshot メッセージを送信することで指定します。execute-snapshot シグナルのタイプを incremental または blocking に設定し、スナップショットに含めるコレクションの名前を次の表に示すように指定します。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプを指定します。 |
|
| 該当なし |
スナップショットに含めるコレクションの完全修飾名に一致する正規表現を含む配列。 |
|
| 該当なし |
コネクターがスナップショットに含めるレコードのサブセットを決定するために評価する追加条件のセットを指定する、オプションの配列。
|
|
| 該当なし | スナップショットプロセス中にコネクターがコレクションのプライマリーキーとして使用する列名を指定するオプションの文字列。 |
アドホック増分スナップショットのトリガー
アドホック増分スナップショットを開始するには、execute-snapshot シグナルタイプのエントリーをシグナリングコレクションに追加するか、シグナルメッセージを Kafka シグナリングトピックに送信します。コネクターがメッセージを処理した後に、スナップショット操作を開始します。スナップショットプロセスは、最初と最後のプライマリーキーの値を読み取り、これらの値を各コレクションの開始ポイントおよびエンドポイントとして使用します。コレクションのエントリー数と設定されたチャンクサイズに基づいて、Debezium はコレクションをチャンクに分割し、チャンクごとに 1 度に 1 つずつスナップショットを順番に作成していきます。
詳細は、スナップショットの増分を参照してください。
アドホックブロッキングスナップショットのトリガー
シグナリングコレクションまたはシグナリングトピックに、execute-snapshot シグナルタイプを持つエントリーを追加することによって、アドホックブロッキングスナップショットを開始します。コネクターがメッセージを処理した後に、スナップショット操作を開始します。コネクターはストリーミングを一時的に停止し、初期スナップショットの時と同じプロセスに従って、指定されたコレクションのスナップショットを開始します。スナップショットが完了すると、コネクターはストリーミングを再開します。
詳細は、ブロッキングスナップショット を参照してください。
2.3.2.7. 増分スナップショット
スナップショットを柔軟に管理するため、Debezium には 増分スナップショット と呼ばれる補助スナップショットメカニズムが含まれています。増分スナップショットは、Debezium コネクターにシグナルを送信するため の Debezium メカニズムに依存します。
増分スナップショットでは、最初のスナップショットのように、データベースの完全な状態を一度にすべてキャプチャーする代わりに、一連の設定可能なチャンクで各コレクションを段階的にキャプチャーします。スナップショットがキャプチャーするコレクションと、各チャンクのサイズ を指定できます。チャンクのサイズにより、データベース上の各フェッチ操作中にスナップショットで収集される行数が決まります。増分スナップショットのデフォルトのチャンクサイズは 1024 行です。
Debezium は、増分スナップショットの進行に伴い、その進捗を追跡するために透かしを使用し、キャプチャした各コレクション行の記録を保持します。この段階的なアプローチでは、標準の初期スナップショットプロセスと比較して、以下の利点があります。
- スナップショットが完了するまで、ストリーミングストリーミングを延期する代わりに、ストリームしたデータキャプチャーと並行して増分スナップショットを実行できます。コネクターはスナップショットプロセス全体で変更ログからのほぼリアルタイムイベントをキャプチャーし続け、他の操作はブロックしません。
- 増分スナップショットの進捗が中断された場合は、データを失うことなく再開できます。プロセス再開後、スナップショットは、最初からコレクションを再キャプチャーするのではなく、停止したポイントから開始されます。
-
いつでも増分スナップショットを実行し、必要に応じてプロセスを繰り返してデータベースの更新に適合できます。たとえば、コネクターの設定を変更してコレクションをその
collection.include.listプロパティーにコレクションを追加します。
増分スナップショットプロセス
増分スナップショットを実行する場合には、Debezium は各コレクションをプライマリーキー別に分類して、設定されたチャンクサイズ に基づいてコレクションをチャンクに分割します。チャンクごとに作業し、チャンク内の各コレクション行をキャプチャします。キャプチャーする行ごとに、スナップショットは READ イベントを出力します。そのイベントは、対象となるチャンクのスナップショットを開始する時の行の値を表します。
スナップショットが進むと、他のプロセスがデータベースにアクセスし続け、コレクションのレコードが変更される可能性があります。このような変更を反映させるように、通常通りに INSERT、UPDATE、DELETE 操作がトランザクションログにコミットされます。同様に、継続中の Debezium ストリーミングプロセスは、これらの変更イベントを検出し、対応する変更イベントレコードを Kafka に出力します。
Debezium を使用してプライマリーキーが同じレコード間での競合を解決する方法
場合によっては、ストリーミングプロセスが出力する UPDATE または DELETE イベントを順番に受信できます。つまり、スナップショットがその行の READ イベントを含むチャンクをキャプチャーする前に、ストリーミングプロセスがコレクション行を変更するイベントを発行する可能性があります。スナップショットが最終的に対象の行にあった READ イベントを出力すると、その値はすでに置き換えられています。Debezium は、シーケンスが到達する増分スナップショットイベントが正しい論理順序で処理されるように、競合を解決するためにバッファースキームを使用します。スナップショットのイベント間で競合が発生し、ストリームされたイベントが解決されてからでないと、Debezium はイベントのレコードを Kafka に送信しません。
スナップショットウィンドウ
遅れて到着した READ イベントと、同じコレクション行を変更するストリームイベント間の衝突を解決するために、Debezium はいわゆる スナップショットウィンドウ を採用しています。スナップショットウィンドウは、増分スナップショットが指定されたコレクションチャンクのデータをキャプチャーする間隔を区切ります。チャンクのスナップショットウィンドウを開く前に、Debezium は通常の動作に従い、トランザクションログから直接ターゲットの Kafka トピックにイベントをダウンストリームに出力します。ただし、特定のチャンクのスナップショットが開放された瞬間から終了するまで、Debezium は重複除去のステップを実行して、プライマリーキーが同じイベント間での競合を解決します。
データコレクションごとに、Debezium は 2 種類のイベントを出力し、それらの両方のレコードを単一の宛先 Kafka トピックに保存します。テーブルから直接キャプチャーするスナップショットレコードは、READ 操作として出力されます。その間、ユーザーはデータコレクションのレコードの更新を続け、各コミットを反映するようにトランザクションログが更新されるので、Debezium は変更ごとに UPDATE または DELETE 操作を出力します。
スナップショットウィンドウが開放され、Debezium がスナップショットチャンクの処理を開始すると、スナップショットレコードをメモリーバッファーに提供します。スナップショットウィンドウ中に、バッファー内の READ イベントのプライマリーキーは、受信ストリームイベントのプライマリーキーと比較されます。一致するものが見つからない場合、ストリーミングされたイベントレコードが Kafka に直接送信されます。Debezium が一致を検出すると、バッファーされた READ イベントを破棄し、ストリーミングされたレコードを宛先トピックに書き込みます。これは、ストリーミングされたイベントが静的スナップショットイベントよりも論理的に優先されるためです。チャンクのスナップショットウィンドウが終了すると、バッファーに含まれるのは、関連するトランザクションログイベントが存在しない READ イベントのみです。Debezium は、これらの残りの READ イベントをコレクションの Kafka トピックに発行します。
コネクターは各スナップショットチャンクにプロセスを繰り返します。
現在、増分スナップショットを開始するには、次のいずれかの方法を使用できます。
増分スナップショットでは、各テーブルのプライマリーキーを安定した順序で並べる必要があります。String フィールドには特殊文字を含めることができ、さまざまなエンコーディングの対象となるため、文字列ベースのプライマリーキーは、一貫性のある予測可能な順序で並べ替えるのに適していません。増分スナップショットを実行する場合は、プライマリーキーを String 以外のデータ型に設定することを推奨します。
MongoDB の BSON 文字列型の詳細は、MongoDB のドキュメント を参照してください。
シャードクラスターの増分スナップショット
シャードされた MongoDB クラスターで増分スナップショットを使用するには、incremental.snapshot.chunk.size を変更ストリームパイプラインの 複雑化 に対応する値に設定する必要があります。
2.3.2.7.1. 増分スナップショットのトリガー
増分スナップショットを開始するには、ソースデータベースのシグナリングコレクションに アドホックスナップショットシグナル 送信します。
MongoDB の insert() メソッドを使用して、シグナルコレクションにシグナルを送信します。
Debezium は、信号コレクションの変化を検出した後、信号を読み取り、要求されたスナップショット操作を実行します。
送信するクエリーは、スナップショットに含めるコレクションを指定し、オプションでスナップショット操作の種類を指定します。現在、スナップショット操作に有効なオプションは、incremental と blocking のみです。
スナップショットに含めるテーブルを指定するには、テーブルをリストアップした data-collections 配列、またはテーブルのマッチングに使用する正規表現の配列を指定します。たとえば、{"data-collections": ["public.Collection1", "public.Collection2"]}
増分スナップショットシグナルの data-collections アレイにはデフォルト値がありません。data-collections アレイが空である場合には、アクションが不要であり、スナップショットを実行しないことが、Debezium で検出されます。
スナップショットに含めるコレクションの名前に、データベース、スキーマ、またはテーブルの名前にドット (.) が含まれている場合、そのコレクションを data-collections 配列に追加するには、名前の各パートを二重引用符でエスケープする必要があります。
たとえば、public データベースに存在し、My.Collection という名前のデータコレクションを含めるには、"public"."My.Collection" の形式を使用します。
前提条件
- ソースデータベースにシグナリングデータコレクションが存在する。
-
シグナルデータコレクションが
signal.data.collectionプロパティーで指定されている。
ソースシグナリングチャネルを使用して増分スナップショットをトリガーする
シグナリングコレクションにスナップショットシグナルドキュメントを挿入します。
<signalDataCollection>.insert({"id" : _<idNumber>,"type" : <snapshotType>, "data" : {"data-collections" ["<collectionName>", "<collectionName>"],"type": <snapshotType>, "additional-conditions" : [{"data-collections" : "<collectionName>", "filter" : "<additional-condition>"}] }});<signalDataCollection>.insert({"id" : _<idNumber>,"type" : <snapshotType>, "data" : {"data-collections" ["<collectionName>", "<collectionName>"],"type": <snapshotType>, "additional-conditions" : [{"data-collections" : "<collectionName>", "filter" : "<additional-condition>"}] }});Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow コマンドの
id、type、およびdataパラメーターの値は、シグナリングコレクションのフィールド に対応します。以下の表では、この例のパラメーターを説明しています。
Expand 表2.57 シグナリングコレクションに増分スナップショットシグナルを送信するための MongoDB insert() コマンドのフィールドの説明 項目 値 説明 1
db.debeziumSignalソースデータベース上のシグナリングコレクションの完全修飾名を指定します。
2
null
idパラメーターは、シグナルリクエストのID識別子として割り当てられる任意の文字列を指定します。
前述の例の insert メソッドは、オプションの_idパラメーターの使用が省略されています。ドキュメントはパラメーターの値を明示的に割り当てないため、MongoDB が自動的にドキュメントに割り当てる任意の ID がシグナルリクエストのid識別子になります。
この文字列を使用して、シグナリングコレクションのエントリーにロギングメッセージを識別します。Debezium はこの識別子文字列を使用しません。代わりに、スナップショット作成中に、Debezium は独自のID文字列をウォーターマークシグナルとして生成します。3
execute-snapshottypeパラメーターを指定し、シグナルがトリガーする操作を指定します。
4
data-collectionsシグナルの
dataフィールドの必須コンポーネントで、スナップショットに含めるコレクション名の配列またはコレクション名と一致する正規表現を指定します。
この配列は、完全修飾名でテーブルをマッチさせる正規表現をリストアップします。signal.data.collection設定プロパティーでコネクターのシグナリングテーブル名を指定するのと同じ形式を使用します。5
incremental実行するスナップショット操作のタイプを指定する、シグナルの
dataフィールドのオプションのtypeコンポーネント。
現在、incrementalとblocking型をサポートしています。
値を指定しない場合には、コネクターは増分スナップショットを実行します。6
additional-conditionsコネクターがスナップショットに含めるレコードのサブセットを決定するために評価する追加条件のセットを指定する、オプションの配列。
additional-conditions配列の各要素は、次のキーを含むオブジェクトです。data-collection:: フィルターが適用されるデータコレクションの完全修飾名。filter:: スナップショットに含めるためにデータ収集レコードに存在する必要がある列値を指定します (例:"color='blue'")。
以下の例は、コネクターによってキャプチャーされる増分スナップショットイベントの JSON を示しています。
例: 増分スナップショットイベントメッセージ
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
実行するスナップショット操作タイプを指定します。 |
| 2 |
|
イベントタイプを指定します。 |
2.3.2.7.2. Kafka シグナルチャネルを使用して増分スナップショットをトリガーする
設定された Kafka トピック にメッセージを送信して、コネクターにアドホック増分スナップショットを実行するよう要求できます。
Kafka メッセージのキーは、topic.prefix コネクター設定オプションの値と一致する必要があります。
メッセージの値は、type と data フィールドが含まれる JSON オブジェクトとなっています。
シグナルタイプは execute-snapshot で、data フィールドには以下のフィールドが必要です。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプ。現在、Debezium は |
|
| 該当なし |
スナップショットに含めるテーブルの完全修飾名と一致する、コンマ区切りの正規表現の配列。 |
|
| 該当なし |
コネクターがスナップショットに含めるレコードのサブセットを指定するために評価する基準を指定する、オプションの追加条件の配列。 |
例2.17 execute-snapshot Kafka メッセージ
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["{collection-container}.table1", "{collection-container}.table2"], "type": "INCREMENTAL"}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["{collection-container}.table1", "{collection-container}.table2"], "type": "INCREMENTAL"}}`additional-conditions 付きのアドホック増分スナップショット
Debezium は additional-conditions フィールドを使用してコレクションの内容のサブセットを選択します。
通常、Debezium はスナップショットを実行するときに、次のような SQL クエリーを実行します。
SELECT * FROM <tableName> ….
スナップショット要求に additional-conditions プロパティーが含まれている場合、プロパティーの data-collection および filter パラメーターが SQL クエリーに追加されます。次に例を示します。
SELECT * FROM <data-collection> WHERE <filter> ….
たとえば、列 id (プライマリーキー)、color、および brand を含む products コレクションがある場合、スナップショットに color='blue' のコンテンツのみを含める場合は、スナップショットをリクエストするときに、コンテンツをフィルタリングする additional-conditions プロパティーを追加することができます。
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.products" ,"filter":"color='blue'"}]}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.products" ,"filter":"color='blue'"}]}}`
また、additional-conditions プロパティーを使用して、複数の列に基づいて条件を渡すこともできます。たとえば、前の例と同じ products コレクションを使用して、color='blue' および brand='MyBrand' の products コレクションのコンテンツのみをスナップショットに含める場合は、次のリクエストを送信できます。
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.products" ,"filter":"color='blue' AND brand='MyBrand'"}]}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.products" ,"filter":"color='blue' AND brand='MyBrand'"}]}}`2.3.2.7.3. 増分スナップショットの停止
状況によっては、増分スナップショットを停止する必要がある場合があります。たとえば、スナップショットが正しく設定されていない場合や、他のデータベース操作にリソースが使用可能であるこのとの確認が必要な場合があります。ソースデータベースのコレクションにシグナルを送信することで、すでに実行中のスナップショットを停止できます。
スナップショットの停止シグナルをシグナリングコレクションに送信するには、スナップショットの停止シグナルドキュメントをシグナリングコレクションに挿入します。送信するスナップショット停止シグナルは、スナップショット操作の type を incremental として指定し、オプションで、現在実行中のスナップショットから省略するコレクションを指定します。Debezium はシグナルコレクションの変更を検出した後、シグナルを読み、増分スナップショット操作が進行中であればそれを停止します。
関連情報
また、JSON メッセージを Kafka シグナリングトピック に送信して、増分スナップショットを停止することもできます。
前提条件
- ソースデータベースにシグナリングデータコレクションが存在する。
-
シグナルデータコレクションが
signal.data.collectionプロパティーで指定されている。
ソースシグナリングチャネルを使用して増分スナップショットを停止する
シグナリングコレクションにスナップショット停止のシグナルドキュメントを挿入します。
<signalDataCollection>.insert({"id" : _<idNumber>,"type" : "stop-snapshot", "data" : {"data-collections" ["<collectionName>", "<collectionName>"],"type": "incremental"}});<signalDataCollection>.insert({"id" : _<idNumber>,"type" : "stop-snapshot", "data" : {"data-collections" ["<collectionName>", "<collectionName>"],"type": "incremental"}});Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow signal コマンドの
id、type、およびdataパラメーターの値は、シグナリングコレクションのフィールド に対応します。以下の表では、この例のパラメーターを説明しています。
Expand 表2.59 シグナリングコレクションに増分スナップショットの停止ドキュメントを送信するための insert コマンドのフィールドの説明 項目 値 説明 1
db.debeziumSignalソースデータベース上のシグナリングコレクションの完全修飾名を指定します。
2
null
前述の例の insert メソッドは、オプションの
_idパラメーターの使用が省略されています。ドキュメントはパラメーターの値を明示的に割り当てないため、MongoDB が自動的にドキュメントに割り当てる任意の ID がシグナルリクエストのid識別子になります。
この文字列を使用して、シグナリングコレクションのエントリーにロギングメッセージを識別します。Debezium はこの識別子文字列を使用しません。3
stop-snapshottypeパラメーターを指定し、シグナルがトリガーする操作を指定します。
4
data-collectionsシグナルの
dataフィールドの任意コンポーネントで、スナップショットから削除するコレクション名の配列またはコレクション名と一致する正規表現を指定します。
配列には、database.collection形式の完全修飾名でコレクションに一致する正規表現がリストされます。dataフィールドからdata-collections配列を省略すると、シグナルによって進行中の増分スナップショット全体が停止されます。5
incremental停止するスナップショット操作のタイプを指定する信号の
dataフィールドの必須コンポーネント。
現在、有効な唯一のオプションはincrementalです。typeの値を指定しない場合、シグナルは増分スナップショットの停止に失敗します。
2.3.2.7.4. Kafka シグナリングチャネルを使用して増分スナップショットを停止する
設定された Kafka シグナルトピック にシグナルメッセージを送信して、アドホック増分スナップショットを停止できます。
Kafka メッセージのキーは、topic.prefix コネクター設定オプションの値と一致する必要があります。
メッセージの値は、type と data フィールドが含まれる JSON オブジェクトとなっています。
シグナルタイプは stop-snapshot で、data フィールドには以下のフィールドが必要です。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプ。現在、Debezium は |
|
| 該当なし |
テーブルの完全修飾名に一致する、コンマで区切られた正規表現のオプションの配列、またはスナップショットから削除するコレクション名に一致するコレクション名または正規表現の配列。 |
次の例は、典型的な stop-snapshot の Kafka メッセージを示しています。
Key = `test_connector`
Value = `{"type":"stop-snapshot","data": {"data-collections": ["db1.table1", "db1.table2"], "type": "INCREMENTAL"}}`
Key = `test_connector`
Value = `{"type":"stop-snapshot","data": {"data-collections": ["db1.table1", "db1.table2"], "type": "INCREMENTAL"}}`2.3.2.8. ブロッキングスナップショット
スナップショットをより柔軟に管理するために、Debezium には ブロッキングスナップショット と呼ばれる補助アドホックスナップショットメカニズムが含まれています。ブロッキングスナップショットは、Debezium コネクターにシグナルを送信 するための Debezium メカニズムに依存します。
ブロッキングスナップショットは、ランタイム時にトリガーできることを除いて、初期スナップショット と同じように動作します。
次のような状況では、標準の初期スナップショットプロセスを使用するのではなく、ブロッキングスナップショットを実行する必要があります。
- 新しいコレクションを追加し、コネクターの実行中にスナップショットを完了したいと考えている。
- 大きなコレクションを追加し、増分スナップショットよりも短い時間でスナップショットを完了したいと考えている。
ブロッキングスナップショットのプロセス
ブロッキングスナップショットを実行すると、Debezium はストリーミングを停止し、初期スナップショットの時と同じプロセスに従って、指定されたコレクションのスナップショットを開始します。スナップショットが完了すると、ストリーミングが再開されます。
スナップショットの設定
シグナルの data コンポーネントでは、次のプロパティーを設定できます。
- data-collections: スナップショットする必要のあるコレクションを指定します。
additional-conditions: コレクションごとに異なるフィルターを指定できます。
-
data-collectionプロパティーは、フィルターが適用されるコレクションの完全修飾名です。 -
filterプロパティーは、snapshot.select.statement.overridesで使用される値と同じになります。
-
以下に例を示します。
{"type": "blocking", "data-collections": ["schema1.table1", "schema1.table2"], "additional-conditions": [{"data-collection": "schema1.table1", "filter": "SELECT * FROM [schema1].[table1] WHERE column1 = 0 ORDER BY column2 DESC"}, {"data-collection": "schema1.table2", "filter": "SELECT * FROM [schema1].[table2] WHERE column2 > 0"}]}
{"type": "blocking", "data-collections": ["schema1.table1", "schema1.table2"], "additional-conditions": [{"data-collection": "schema1.table1", "filter": "SELECT * FROM [schema1].[table1] WHERE column1 = 0 ORDER BY column2 DESC"}, {"data-collection": "schema1.table2", "filter": "SELECT * FROM [schema1].[table2] WHERE column2 > 0"}]}重複の可能性
スナップショットをトリガーするシグナルを送信した時点と、ストリーミングが停止してスナップショットが開始する時点との間に遅延が生じる可能性があります。この遅延の結果、スナップショットが完了した後、コネクターはスナップショットがキャプチャーしたレコードと重複するイベントレコードを発行する可能性があります。
2.3.2.9. Debezium MongoDB コネクターでの変更イベントレコードのストリーミング方法
レプリカセットレコードのコネクタータスクがオフセットを取得すると、オフセットを使用して変更のストリーミングを開始する oplog の位置を判断します。その後、タスクは (設定によって) レプリカセットのプライマリーノードに接続するか、レプリカセット全体の変更ストリームに接続し、その位置から変更のストリーミングを開始します。すべての作成、挿入、および削除操作を処理して Debezium の 変更イベント に変換します。各変更イベントには操作が検出された oplog の位置が含まれ、コネクターはこれを最新のオフセットとして定期的に記録します。オフセットが記録される間隔は、Kafka Connect ワーカー設定プロパティーである offset.flush.interval.ms によって制御されます。
コネクターが正常に停止されると、処理された最後のオフセットが記録され、再起動時にコネクターは停止した場所から続行されます。しかし、コネクターのタスクが予期せず終了した場合、最後にオフセットが記録された後、最後のオフセットが記録される前に、タスクによってイベントが処理および生成されることがあります。再起動時に、コネクターは最後に 記録された オフセットから開始し、クラッシュの前に生成された同じイベントを生成する可能性があります。
Kafka パイプライン内のすべてのコンポーネントが正常に動作している場合、Kafka コンシューマーはすべてのメッセージを 1 度だけ 受信します。ただし、問題が発生した場合、Kafka はコンシューマーが 少なくとも 1 回 のみすべてのメッセージを受信することを保証できます。予期しない結果を回避するには、コンシューマーは重複メッセージを処理できる必要があります。
前述のように、コネクタータスクは常にレプリカセットのプライマリーノードを使用して oplog からの変更をストリーミングし、コネクターが可能な限り最新の操作を確認できるようにし、代わりにセカンダリーが使用された場合よりも短いレイテンシーで変更をキャプチャーできるようにします。レプリカセットが新しいプライマリーを選出すると、コネクターは即座に変更のストリーミングを停止し、新しいプライマリーに接続して、同じ場所にある新しいプライマリーノードから変更のストリーミングを開始します。同様に、コネクターとレプリカセットメンバーとの通信で問題が発生した場合は、レプリカセットが過剰にならないように指数バックオフを使用して再接続を試みます。接続の確立後、停止した場所から変更のストリーミングを続行します。これにより、コネクターはレプリカセットメンバーシップの変更を動的に調整でき、通信障害を自動的に処理できます。
要約すると、MongoDB コネクターはほとんどの状況で実行を継続します。通信の問題により、問題が解決されるまでコネクターが待機する可能性があります。
2.3.2.10. Debezium 変更イベントの before フィールドに入力するための MongoDB サポート
MongoDB 6.0 以降では、変更ストリームを設定して、ドキュメントのイメージ前の状態を出力し、MongoDB 変更イベントの before フィールドにデータを投入できます。MongoDB で事前のイメージを使用できるようにするには、db.createCollection()、create、または collMod を使用して、コレクションの changeStreamPreAndPostImages を設定する必要があります。Debezium MongoDB が変更イベントに事前イメージを追加できるようにするには、コネクターの capture.mode を *_with_pre_image オプションのいずれかに設定します。
MongoDB 変更イベントのサイズは 16 メガバイトに制限されます。したがって、事前イメージを使用すると、このしきい値を超過し、障害が発生する可能性があります。変更ストリームの制限を超えないようにする方法は、MongoDB のドキュメント を参照してください。
2.3.2.11. Debezium MongoDB 変更イベントレコードを受信する Kafka トピックのデフォルト名
MongoDB コネクターは、各コレクションのドキュメントに対するすべての挿入、更新、および削除操作のイベントを 1 つの Kafka トピックに書き込みます。Kafka トピックの名前は常に logicalName.databaseName.collectionName の形式を取ります。logicalName は、topic.prefix 設定プロパティーで指定されるコネクターの 論理名、databaseName は操作が発生したデータベースの名前、collectionName は影響を受けるドキュメントが存在する MongoDB コレクションの名前です。
たとえば、products, products_on_hand, customers, and orders の 4 つのコレクションで設定される inventory データベースを含む MongoDB レプリカセットについて考えてみましょう。コネクターが監視するこのデータベースの論理名が fulfillment である場合、コネクターは以下の 4 つの Kafka トピックでイベントを生成します。
-
fulfillment.inventory.products -
fulfillment.inventory.products_on_hand -
fulfillment.inventory.customers -
fulfillment.inventory.orders
トピック名には、レプリカセット名やシャード名が含まれないことに注意してください。その結果、シャード化コレクションへの変更 (各シャードにコレクションのドキュメントのサブセットが含まれる) はすべて同じ Kafka トピックに移動します。
Kafka を設定して、必要に応じてトピックを 自動作成 できます。そうでない場合は、Kafka 管理ツールを使用してコネクターを起動する前にトピックを作成する必要があります。
2.3.2.12. イベントキーが Debezium MongoDB コネクターのトピックパーティション設定を制御する方法
MongoDB コネクターは、イベントのトピックパーティションを明示的に決定しません。代わりに、Kafka はイベントキーに基づいてトピックのパーティションを作成する方法を決定できます。Kafka Connect ワーカー設定に Partitioner 実装の名前を定義することで、Kafka のパーティショニングロジックを変更できます。
Kafka は、1 つのトピックパーティションに書き込まれたイベントのみ、合計順序を維持します。キーでイベントのパーティションを行うと、同じキーを持つすべてのイベントは常に同じパーティションに移動します。これにより、特定のドキュメントのすべてのイベントが常に完全に順序付けされます。
2.3.2.13. トランザクション境界を表す Debezium MongoDB コネクターによって生成されたイベント
Debezium は、トランザクションメタデータ境界を表すイベントを生成でき、データイベントメッセージを補完できます。
Debezium は、コネクターのデプロイ後に発生するトランザクションに対してのみメタデータを登録し、受信します。コネクターをデプロイする前に発生するトランザクションのメタデータは利用できません。
Debezium はすべてのトランザクションの BEGIN および END に対して、以下のフィールドが含まれるイベントを生成します。
status-
BEGINまたはEND id- 一意のトランザクション識別子の文字列表現。
event_count(ENDイベント用)- トランザクションによって出力されるイベントの合計数。
data_collections(ENDイベント用)-
指定のデータコレクションからの変更によって出力されたイベントの数を提供する
data_collectionとevent_countのペアの配列。
以下の例では、一般的なメッセージを示します。
topic.transaction オプションで上書きされない限り、トランザクションイベントは <topic.prefix>.transaction という名前のトピックに書き込まれます。
変更データイベントのエンリッチメント
トランザクションメタデータを有効にすると、データメッセージ Envelope は新しい transaction フィールドで強化されます。このフィールドは、複合フィールドの形式ですべてのイベントに関する情報を提供します。
id- 一意のトランザクション識別子の文字列表現。
total_order- トランザクションによって生成されたすべてのイベントを対象とするイベントの絶対位置。
data_collection_order- トランザクションによって出力されたすべてのイベントを対象とするイベントのデータコレクションごとの位置。
以下は、メッセージの内容の例です。
2.3.3. Debezium MongoDB コネクターのデータ変更イベントの説明
Debezium MongoDB コネクターは、データを挿入、更新、または削除する各ドキュメントレベルの操作に対してデータ変更イベントを生成します。各イベントにはキーと値が含まれます。キーと値の構造は、変更されたコレクションによって異なります。
Debezium および Kafka Connect は、イベントメッセージの継続的なストリーム を中心として設計されています。ただし、これらのイベントの構造は時間の経過とともに変化する可能性があり、コンシューマーによる処理が困難になることがあります。これに対応するために、各イベントにはコンテンツのスキーマが含まれます。スキーマレジストリーを使用している場合は、コンシューマーがレジストリーからスキーマを取得するために使用できるスキーマ ID が含まれます。これにより、各イベントが自己完結型になります。
以下のスケルトン JSON は、変更イベントの基本となる 4 つの部分を示しています。ただし、アプリケーションで使用するために選択した Kafka Connect コンバーターの設定方法によって、変更イベントのこれら 4 部分の表現が決定されます。schema フィールドは、変更イベントが生成されるようにコンバーターを設定した場合のみ変更イベントに含まれます。同様に、イベントキーおよびイベントペイロードは、変更イベントが生成されるようにコンバーターを設定した場合のみ変更イベントに含まれます。JSON コンバーターを使用し、変更イベントの基本となる 4 つの部分すべてを生成するように設定すると、変更イベントの構造は次のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
最初の |
| 2 |
|
最初の |
| 3 |
|
2 つ目の |
| 4 |
|
2 つ目の |
デフォルトでは、コネクターによって、変更イベントレコードがイベントの元のコレクションと同じ名前を持つトピックにストリーミングされます。トピック名 を参照してください。
MongoDB コネクターは、すべての Kafka Connect スキーマ名が Avro スキーマ名の形式 に準拠するようにします。つまり、論理サーバー名はアルファベットまたはアンダースコア (a-z、A-Z、または _) で始まる必要があります。論理サーバー名の残りの各文字と、データベース名とコレクション名の各文字は、アルファベット、数字、またはアンダースコア ( a-z、A-Z、0-9、または _) でなければなりません。無効な文字がある場合は、アンダースコアに置き換えられます。
論理サーバー名、データベース名、またはコレクション名に無効な文字が含まれ、名前を区別する唯一の文字が無効であると、無効な文字はすべてアンダースコアに置き換えられるため、予期せぬ競合が発生する可能性があります。
詳細は、以下のトピックを参照してください。
2.3.3.1. Debezium MongoDB 変更イベントのキー
変更イベントのキーには、変更されたドキュメントのキーのスキーマと、変更されたドキュメントの実際のキーのスキーマが含まれます。特定のコレクションでは、スキーマとそれに対応するペイロードの両方に単一の id フィールドが含まれます。このフィールドの値は、MongoDB Extended JSON のシリアライゼーションの厳格モード から派生する文字列として表されるドキュメントの識別子です。
論理名が fulfillment のコネクター、inventory データベースが含まれるレプリカセット、および以下のようなドキュメントが含まれる customers コレクションについて考えてみましょう。
ドキュメントの例
変更イベントキーの例
customers コレクションへの変更をキャプチャーする変更イベントのすべてに、イベントキースキーマがあります。customers コレクションに前述の定義がある限り、customers コレクションへの変更をキャプチャーする変更イベントのキー構造はすべて以下のようになります。JSON では、以下のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
キーのスキーマ部分は、キーの |
| 2 |
|
キーのペイロードの構造を定義するスキーマの名前。このスキーマは、変更したドキュメントのキーの構造を説明します。キースキーマ名の形式は connector-name.database-name.collection-name.
|
| 3 |
|
イベントキーの |
| 4 |
|
各フィールドの名前、型、および必要かどうかなど、 |
| 5 |
|
この変更イベントが生成されたドキュメントのキーが含まれます。この例では、キーには型 |
この例では、整数の識別子を持つドキュメントを使用しますが、有効な MongoDB ドキュメント識別子は、ドキュメント識別子を含め、同じように動作します。ドキュメント識別子の場合、イベントキーの payload.id 値は、厳格モードを使用する MongoDB Extended JSON シリアライゼーションとして更新されたドキュメントの元の _id フィールドを表す文字列です。以下の表では、さまざまな型の _id フィールドを表す例を示します。
| タイプ | MongoDB _id の値 | キーのペイロード |
|---|---|---|
| Integer | 1234 |
|
| Float | 12.34 |
|
| String | "1234" |
|
| Document |
|
|
| ObjectId |
|
|
| Binary |
|
|
2.3.3.2. Debezium MongoDB 変更イベントの値
変更イベントの値はキーよりも若干複雑です。キーと同様に、値には schema セクションと payload セクションがあります。schema セクションには、入れ子のフィールドを含む、Envelope セクションの payload 構造を記述するスキーマが含まれています。データを作成、更新、または削除する操作のすべての変更イベントには、Envelope 構造を持つ値 payload があります。
変更イベントキーの例を紹介するために使用した、同じサンプルドキュメントについて考えてみましょう。
ドキュメントの例
このドキュメントへの変更に対する変更イベントの値部分には、以下の各イベントタイプについて記述されています。
create イベント
以下の例は、customers コレクションにデータを作成する操作に対して、コネクターによって生成される変更イベントの値の部分を示しています。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
| 値のペイロードの構造を記述する、値のスキーマ。変更イベントの値スキーマは、コネクターが特定のコレクションに生成するすべての変更イベントで同じになります。 |
| 2 |
|
|
| 3 |
|
|
| 4 |
|
|
| 5 |
|
値の実際のデータ。これは、変更イベントが提供する情報です。 |
| 6 |
|
イベント発生後のドキュメントの状態を指定する任意のフィールド。この例では、 |
| 7 |
| イベントのソースメタデータを記述する必須のフィールド。このフィールドには、イベントの発生元、イベントの発生順序、およびイベントが同じトランザクションの一部であるかどうかなど、このイベントと他のイベントを比較するために使用できる情報が含まれています。ソースメタデータには以下が含まれています。
|
| 8 |
|
コネクターによってイベントが生成される原因となった操作の型を記述する必須文字列。この例では、
|
| 9 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 10 |
| コネクターがイベントを処理した時間をマイクロ秒単位で表示するオプションフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 9 |
| コネクターがイベントを処理した時間をナノ秒単位で表示するオプションフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
Chang Streams Capture モード
サンプル customers コレクションにある更新の変更イベントの値には、そのコレクションの 作成 イベントと同じスキーマがあります。同様に、イベント値のペイロードは同じ構造を持ちます。ただし、イベント値ペイロードでは 更新 イベントに異なる値が含まれます。update イベントに after 値が含まれるのは、capture.mode オプションが change_streams_update_full に設定されている場合のみです。capture.mode オプションが *_with_pre_image オプションのいずれかに設定されている場合、before 値が指定されます。この場合、新たな構造化フィールド updateDescription が追加されました。
-
updatedFieldsは、更新されたドキュメントフィールドの JSON 表現とその値を含む文字列フィールドです -
removedFieldsは、ドキュメントから削除されたフィールド名のリストです。 -
truncatedArraysは、省略されたドキュメントのアレイのリストです。
以下は、コネクターによって customers コレクションでの更新に生成されるイベントの変更イベント値の例になります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
コネクターによってイベントが生成される原因となった操作の型を記述する必須文字列。この例では、 |
| 2 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 3 |
| 変更前の実際の MongoDB ドキュメントの JSON 文字列表現が含まれます。
キャプチャーモードが |
| 4 |
|
実際の MongoDB ドキュメントを表す JSON 文字列が含まれます。 |
| 5 |
|
ドキュメントの更新されたフィールド値の JSON 文字列表現が含まれます。この例では、更新により |
| 6 |
| イベントのソースメタデータを記述する必須のフィールド。このフィールドには、同じコレクションの 作成 イベントと同じ情報が含まれますが、oplog の異なる位置からのイベントであるため、値は異なります。ソースメタデータには以下が含まれています。
|
イベント内の after の値は、ドキュメントの at-point-of-time の値として処理される必要があります。この値は動的に計算されるのではなく、コレクションから取得される。このため、複数の更新が次々に行われる場合、すべての 更新 更新イベントには、文書に保存されている最後の値を表す同じ after 値が含まれる可能性がある。
アプリケーションが段階的な変更の進化に依存している場合は、updateDescription のみに依存する必要があります。
delete イベント
delete change イベントの値は、create や update と同じ schema 部分を持ちます。delete イベントの payload 部分には、同じコレクションの 作成 と 更新 イベントとは異なる値が含まれます。特に、delete イベントには after 値も updateDescription 値も含まれません。以下は、customers コレクションのドキュメントの 削除 イベントの例になります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
操作の型を記述する必須の文字列。 |
| 2 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 3 |
| 変更前の実際の MongoDB ドキュメントの JSON 文字列表現が含まれます。
キャプチャーモードが |
| 4 |
| イベントのソースメタデータを記述する必須のフィールド。このフィールドには、同じコレクションの 作成 または 更新 イベントと同じ情報が含まれますが、oplog の異なる位置からのイベントであるため、値は異なります。ソースメタデータには以下が含まれています。
|
MongoDB コネクターイベントは、Kafka ログコンパクション と動作するように設計されています。ログコンパクションにより、少なくとも各キーの最新のメッセージが保持される限り、一部の古いメッセージを削除できます。これにより、トピックに完全なデータセットが含まれ、キーベースの状態のリロードに使用できるようにするとともに、Kafka がストレージ領域を確保できるようにします。
tombstone イベント
一意に識別ドキュメントの MongoDB コネクターイベントはすべて同じキーを持ちます。ドキュメントが削除された場合でも、Kafka は同じキーを持つ以前のメッセージをすべて削除できるため、削除 イベントの値はログコンパクションで動作します。ただし、Kafka がそのキーを持つすべてのメッセージを削除するには、メッセージの値が null である必要があります。これを可能にするために、Debezium の MongoDB コネクターは 削除 イベントを出力した後に、null 値以外で同じキーを持つ特別な廃棄 (tombstone) イベントを出力します。tombstone イベントは、同じキーを持つすべてのメッセージを削除できることを Kafka に通知します。
2.3.4. Debezium コネクターと連携する MongoDB の設定
MongoDB コネクターは MongoDB の変更ストリームを使用して変更をキャプチャーするため、コネクターは MongoDB レプリカセットと、各シャードが個別のレプリカセットであるシャードクラスターとのみ動作します。レプリカセット または シャードクラスター の設定については、MongoDB ドキュメントを参照してください。また、レプリカセットで アクセス制御と認証 を有効にする方法についても理解するようにしてください。
oplog が読み取られる admin データベースを読み取るために適切なロールを持つ MongoDB ユーザーも必要です。さらに、ユーザーはシャードクラスターの設定サーバーで config データベースを読み取りできる必要もあり、listDatabases 権限も必要です。変更ストリームを使用する場合 (デフォルト)、ユーザーはクラスター全体の特権アクションである find および changeStream も持っている必要があります。
pre-image を使用して before フィールドに入力する場合は、最初に db.createCollection()、create、または collMod を使用してコレクションの changeStreamPreAndPostImages を有効にする必要があります。
最適な Oplog 設定
Debezium MongoDB コネクターは 変更ストリーム を読み取り、レプリカセットの oplog データを取得します。oplog は固定サイズの上限付きコレクションです。そのため、設定された最大サイズを超えると、最も古いエントリーを上書きしはじめます。何らかの理由でコネクターが停止した場合、再起動すると、最後の oplog ストリーム位置からストリーミングを再開しようとします。ただし、最後のストリーム位置が oplog から削除されていた場合、コネクターの snapshot.mode プロパティーに指定された値によっては、コネクターが起動に失敗し、無効な再開トークンのエラー が報告される可能性があります。障害が発生した場合は、Debezium がデータベースからレコードを引き続き取得できるように、新しいコネクターを作成する必要があります。詳細は、snapshot.mode が initial に設定されている場合、コネクターが長時間停止した後に失敗する を参照してください。
Debezium がストリーミングを再開するために必要なオフセット値を oplog が保持するようにするには、次のいずれかの方法を使用できます。
- oplog のサイズを大きくします。通常のワークロードに基づいて、oplog サイズを 1 時間あたりの oplog エントリーのピーク数よりも大きい値に設定します。
- oplog エントリーが保持される最小時間数を増やします (MongoDB 4.4 以降)。この設定は時間ベースであるため、oplog が最大設定サイズに達した場合でも、過去 n 時間のエントリーが確実に利用可能になります。これは一般的に推奨されるオプションですが、容量に近づいている高ワークロードのクラスターの場合は、最大 oplog サイズを指定してください。
oplog エントリーの欠落に関連する障害を防ぐには、レプリケーション動作を報告するメトリクスを追跡し、oplog サイズを最適化して Debezium をサポートすることが重要です。特に、Oplog GB/時間およびレプリケーション Oplog ウィンドウの値を監視する必要があります。レプリケーション oplog ウィンドウの値を超える間隔で Debezium がオフラインになり、Debezium がエントリーを消費できる速度よりも速くプライマリー oplog が増加すると、コネクター障害が発生する可能性があります。
これらのメトリクスを監視する方法については、MongoDB のドキュメント を参照してください。
oplog の最大サイズは、予想される 1 時間当たりの oplog の増加 (Oplog GB/時間) に、Debezium の障害に対処するために必要な時間を掛けた値に設定することを推奨します。
すなわち、以下のようになります。
Oplog GB/Hour X average reaction time to Debezium failure
たとえば、oplog のサイズ制限が 1 GB に設定されていて、oplog が 1 時間あたり 3 GB ずつ増加する場合、oplog エントリーは 1 時間に 3 回消去されます。この期間に Debezium で障害が発生した場合、最後の oplog の位置が削除される可能性があります。
oplog が 3 GB/時間の速度で増加し、Debezium が 2 時間オフラインの場合、oplog サイズを 3GB/時間 x 2 時間、つまり 6 GB に設定します。
2.3.5. Debezium MongoDB コネクターのデプロイメント
以下の方法のいずれかを使用して Debezium MongoDB コネクターをデプロイできます。
2.3.5.1. Streams for Apache Kafka を使用した MongoDB コネクターのデプロイメント
Debezium 1.7 以降、Debezium コネクターのデプロイに推奨される方法は、Streams for Apache Kafka を使用して、コネクタープラグインを含む Kafka Connect コンテナーイメージをビルドすることです。
デプロイメントプロセス中に、以下のカスタムリソース (CR) を作成し、使用します。
-
Kafka Connect インスタンスを定義し、コネクターアーティファクトに関する情報をイメージに含める必要がある
KafkaConnectCR。 -
コネクターがソースデータベースにアクセスするために使用する情報を提供する
KafkaConnectorCR。Streams for Apache Kafka が Kafka Connect Pod を起動した後、KafkaConnectorCR を適用してコネクターを起動します。
Kafka Connect イメージのビルド仕様では、デプロイ可能なコネクターを指定できます。各コネクタープラグインに対して、デプロイメントに利用可能にする他のコンポーネントを指定することもできます。たとえば、Apicurio Registry アーティファクトや Debezium スクリプトコンポーネントを追加できます。Streams for Apache Kafka は、Kafka Connect イメージをビルドするときに、指定されたアーティファクトをダウンロードし、それをイメージに組み込みます。
Kafka Connect CR の spec.build.output パラメーターは、生成される KafkaConnectコンテナーイメージを格納する場所を指定します。コンテナーイメージは Docker レジストリーまたは OpenShift ImageStream に保存できます。イメージを ImageStream に保存するには、Kafka Connect をデプロイする前に ImageStream を作成する必要があります。ImageStreams は自動的に作成されません。
KafkaConnect リソースを使用してクラスターを作成する場合は、Kafka Connect REST API を使用してコネクターを作成または更新できません。ただし、REST API を使用して情報を取得できます。
関連情報
- 「OpenShift 上の Streams for Apache Kafka のデプロイと管理」の Kafka Connect の設定
- 「OpenShift 上の Streams for Apache Kafka のデプロイと管理」の 新しいコンテナーイメージの自動ビルド
2.3.5.2. Streams for Apache Kafka を使用した Debezium MongoDB コネクターのデプロイ
以前のバージョンの Streams for Apache Kafka では、OpenShift に Debezium コネクターをデプロイするには、まずコネクター用の Kafka Connect イメージをビルドする必要がありました。OpenShift にコネクターをデプロイするための現在の推奨方法は、Streams for Apache Kafka のビルド設定を使用して、使用する Debezium コネクタープラグインを含む Kafka Connect コンテナーイメージを自動的にビルドすることです。
ビルドプロセス中に、Streams for Apache Kafka Operator は、Debezium コネクター定義を含む KafkaConnect カスタムリソースの入力パラメーターを Kafka Connect コンテナーイメージに変換します。このビルドは、Red Hat Maven リポジトリーまたは別の設定済みの HTTP サーバーから必要なアーティファクトをダウンロードします。
新規に作成されたコンテナーは .spec.build.output に指定されるコンテナーレジストリーにプッシュされ、Kafka Connect クラスターのデプロイに使用されます。Streams for Apache Kafka が Kafka Connect イメージをビルドした後、ビルドに含まれるコネクターを起動するための KafkaConnector カスタムリソースを作成します。
前提条件
- クラスター Operator がインストールされている OpenShift クラスターにアクセスできる。
- Streams for Apache Kafka Operator が実行されている。
- Apache Kafka クラスターが OpenShift 上の Streams for Apache Kafka のデプロイと管理 に記載されているとおりにデプロイされている。
- Kafka Connect が Streams for Apache Kafka にデプロイされている。
- Red Hat build of Debezium のライセンスを所有している。
-
OpenShift
ocCLI クライアントがインストールされている、または OpenShift Container Platform Web コンソールにアクセスできる。 Kafka Connect ビルドイメージの保存方法に応じて、レジストリーのパーミッションを用意するか、ImageStream リソースを作成している。
- ビルドイメージを Red Hat Quay.io または Docker Hub などのイメージレジストリーに保存する場合は、以下が必要です。
- レジストリーでイメージを作成し、管理するためのアカウントおよびパーミッション
- ビルドイメージをネイティブ OpenShift ImageStream として保存する場合は、以下を行います。
- 新規コンテナーイメージを保存するために、ImageStream リソースをクラスターにデプロイします。クラスターの ImageStream を明示的に作成する必要があります。ImageStreams は、デフォルトでは利用できません。ImageStreams の詳細は、OpenShift Container Platform でのイメージストリームの管理 を参照してください。
手順
- OpenShift クラスターにログインします。
コネクターの Debezium
KafkaConnectカスタムリソース (CR) を作成するか、既存のリソースを変更します。たとえば、metadata.annotationsおよびspec.buildプロパティーを指定するdbz-connect.yamlという名前のKafkaConnectCR を作成します。以下の例は、KafkaConnectカスタムリソースを記述するdbz-connect.yamlファイルからの抜粋を示しています。
例2.18 Debezium コネクターを含む
KafkaConnectカスタムリソースを定義したdbz-connect.yamlファイル次の例では、カスタムリソースは、次のアーティファクトをダウンロードするように設定されています。
- Debezium MongoDB コネクターアーカイブ。
- Red Hat build of Apicurio Registry アーカイブApicurio Registry はオプションのコンポーネントです。コネクターで Avro シリアル化を使用する場合にのみ、Apicurio Registry コンポーネントを追加します。
- Debezium スクリプティング SMT アーカイブと、Debezium コネクターで使用する関連スクリプティングエンジン。SMT アーカイブとスクリプト言語の依存関係はオプションのコンポーネントです。Debezium コンテンツベースのルーティング SMT または フィルター SMT を使用する場合にのみ、これらのコンポーネントを追加します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.67 Kafka Connect 設定の説明 項目 説明 1
strimzi.io/use-connector-resourcesアノテーションを"true"に設定して、クラスター Operator がKafkaConnectorリソースを使用してこの Kafka Connect クラスター内のコネクターを設定できるようにします。2
spec.build設定は、ビルドイメージの保存場所を指定し、プラグインアーティファクトの場所とともにイメージに追加するプラグインをリストします。3
build.outputは、新しくビルドされたイメージを保存するレジストリーを指定します。4
イメージ出力の名前およびイメージ名を指定します。
output.typeの有効な値は、Docker Hub や Quay などのコンテナーレジストリーにプッシュする場合はdocker、内部の OpenShift ImageStream にイメージをプッシュする場合はimagestreamです。ImageStream を使用するには、ImageStream リソースをクラスターにデプロイする必要があります。KafkaConnect 設定でbuild.outputを指定する方法の詳細は、{NameConfiguringStreamsOpenShift} の Streams for Apache Kafka ビルドスキーマリファレンス を参照してください。5
plugins設定は、Kafka Connect イメージに追加するすべてのコネクターをリストします。リストの各エントリーについて、プラグインnameと、コネクターのビルドに必要なアーティファクトに関する情報を指定します。必要に応じて、各コネクタープラグインに対して、コネクターと使用できる他のコンポーネントを含めることができます。たとえば、Service Registry アーティファクトまたは Debezium スクリプトコンポーネントを追加できます。6
artifacts.typeの値は、artifacts.urlで指定するアーティファクトのファイルタイプを指定します。有効なタイプはzip、tgz、またはjarです。Debezium コネクターアーカイブは、.zipファイル形式で提供されます。typeの値は、urlフィールドで参照されるファイルのタイプと一致させる必要があります。7
artifacts.urlの値は、コネクターアーティファクトのファイルを格納する Maven リポジトリーなどの HTTP サーバーのアドレスを指定します。Debezium コネクターアーティファクトは Red Hat リポジトリーで入手できます。OpenShift クラスターが指定されたサーバーにアクセスできる必要があります。8
(オプション) Apicurio Registry コンポーネントをダウンロードするためのアーティファクト
typeとurlを指定します。デフォルトの JSON コンバーターを使用する代わりに、コネクターが Apache Avro を使用して Red Hat build of Apicurio Registry でイベントのキーと値をシリアル化する場合にのみ、Apicurio Registry アーティファクトを含めます。9
(オプション) Debezium コネクターで使用する Debezium スクリプト SMT アーカイブのアーティファクト
typeとurlを指定します。Debezium コンテンツベースルーティング SMT または フィルター SMT を使用する場合にのみ、スクリプト SMT を含めます。スクリプト SMT を使用するには、groovy などの JSR 223 準拠のスクリプト実装もデプロイする必要があります。10
(オプション) JSR 223 準拠のスクリプト実装の JAR ファイルのアーティファクト
typeとurlを指定します。これは、Debezium スクリプト SMT で必要です。重要Streams for Apache Kafka を使用してコネクタープラグインを Kafka Connect イメージに組み込む場合、必要なスクリプト言語コンポーネントごとに、
artifacts.urlに JAR ファイルのロケーションを指定し、artifacts.typeの値もjarに設定する必要があります。値が無効な場合は、実行時にコネクターが失敗します。スクリプト SMT で Apache Groovy 言語を使用できるようにするために、この例のカスタムリソースは、次のライブラリーの JAR ファイルを取得します。
-
groovy -
groovy-jsr223(スクリプトエージェント) -
groovy-json(JSON 文字列を解析するためのモジュール)
別の方法として、Debezium スクリプト SMT は、GraalVM JavaScript の JSR 223 実装の使用もサポートします。
以下のコマンドを入力して、
KafkaConnectビルド仕様を OpenShift クラスターに適用します。oc create -f dbz-connect.yaml
oc create -f dbz-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Streams Operator はカスタムリソースで指定された設定に基づいて、デプロイする Kafka Connect イメージを準備します。
ビルドが完了すると、Operator はイメージを指定されたレジストリーまたは ImageStream にプッシュし、Kafka Connect クラスターを起動します。設定にリスト表示されているコネクターアーティファクトはクラスターで利用できます。KafkaConnectorリソースを作成し、デプロイする各コネクターのインスタンスを定義します。
たとえば、以下のKafkaConnectorCR を作成し、mongodb-inventory-connector.yamlとして保存します。例2.19 Debezium コネクターの
KafkaConnectorカスタムリソースを定義するmongodb-inventory-connector.yamlファイルCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.68 コネクター設定の説明 項目 説明 1
Kafka Connect クラスターに登録するコネクターの名前。
2
コネクタークラスの名前。
3
同時に動作できるタスクの数。
4
コネクターの設定。
5
ホストデータベースインスタンスのアドレスおよびポート番号。
7
Debezium がデータベースへの接続に使用するアカウントの名前。
8
Debezium がデータベースユーザーアカウントに接続するために使用するパスワード。
8
データベースインスタンスまたはクラスターのトピック接頭辞。
指定する名前は、英数字またはアンダースコアのみで設定する必要があります。
トピック接頭辞は、このコネクターから変更イベントを受信する Kafka トピックの接頭辞として使用されるため、名前はクラスターのコネクター間で一意である必要があります。
コネクターを Avro コネクター と統合する場合、この名前空間は、関連する Kafka Connect スキーマの名前や、対応する Avro スキーマの名前空間でも使用されます。9
コネクターが変更をキャプチャーするコレクションの名前。
以下のコマンドを実行してコネクターリソースを作成します。
oc create -n <namespace> -f <kafkaConnector>.yaml
oc create -n <namespace> -f <kafkaConnector>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc create -n debezium -f mongodb-inventory-connector.yaml
oc create -n debezium -f mongodb-inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow コネクターは Kafka Connect クラスターに登録され、
KafkaConnectorCR のspec.config.database.dbnameで指定されたデータベースに対して実行を開始します。コネクター Pod の準備ができると、Debezium が実行されます。
これで、Debezium MongoDB のデプロイメントを確認 する準備が整いました。
2.3.5.3. Dockerfile からカスタム Kafka Connect コンテナーイメージをビルドして Debezium MongoDB コネクターのデプロイ
Debezium MongoDB コネクターをデプロイするには、Debezium コネクターアーカイブが含まれるカスタム Kafka Connect コンテナーイメージをビルドし、このコンテナーイメージをコンテナーレジストリーにプッシュする必要があります。次に、2 つのカスタムリソース (CR) を作成します。
-
Kafka Connect インスタンスを定義する
KafkaConnectCR。imageは Debezium コネクターを実行するために作成したイメージの名前を指定します。この CR は、Red Hat Streams for Apache Kafka がデプロイされている OpenShift インスタンスに適用します。Streams for Apache Kafka は、Apache Kafka を OpenShift に導入する Operator とイメージを提供します。 -
Debezium MongoDB コネクターを定義する
KafkaConnectorCR。この CR をKafkaConnectCR を適用するのと同じ OpenShift インスタンスに適用します。
前提条件
- MongoDB が稼働し、MongoDB を設定して Debezium コネクターと連携する 手順が完了済みである必要があります。
- Streams for Apache Kafka が OpenShift にデプロイされ、Apache Kafka および Kafka Connect が実行されている。詳細は、OpenShift 上の Streams for Apache Kafka のデプロイと管理 を参照してください。
- Podman または Docker がインストールされている。
-
Debezium コネクターを実行するコンテナーを追加する予定のコンテナーレジストリー (
quay.ioやdocker.ioなど) でコンテナーを作成および管理するアカウントとパーミッションを持っている。
手順
Kafka Connect の Debezium MongoDB コンテナーを作成します。
registry.redhat.io/amq-streams-kafka-35-rhel8:2.5.0をベースイメージとして使用して、新規の Dockerfile を作成します。たとえば、ターミナルウィンドウから、以下のコマンドを入力します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 項目 説明 1
任意のファイル名を指定できます。
2
Kafka Connect プラグインディレクトリーへのパスを指定します。Kafka Connect のプラグインディレクトリーが別の場所にある場合は、このパスを実際のディレクトリーのパスに置き換えてください。
このコマンドは、現在のディレクトリーに
debezium-container-for-mongodb.yamlという名前の Dockerfile を作成します。前のステップで作成した
debezium-container-for-mongodb.yamlDocker ファイルからコンテナーイメージをビルドします。ファイルが含まれるディレクトリーから、ターミナルウィンドウを開き、以下のコマンドのいずれかを入力します。podman build -t debezium-container-for-mongodb:latest .
podman build -t debezium-container-for-mongodb:latest .Copy to Clipboard Copied! Toggle word wrap Toggle overflow docker build -t debezium-container-for-mongodb:latest .
docker build -t debezium-container-for-mongodb:latest .Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドは、
debezium-container-for-mongodbという名前のコンテナーイメージを構築します。カスタムイメージを
quay.ioなどのコンテナーレジストリーまたは内部のコンテナーレジストリーにプッシュします。コンテナーレジストリーは、イメージをデプロイする OpenShift インスタンスで利用できる必要があります。以下のいずれかのコマンドを実行します。podman push <myregistry.io>/debezium-container-for-mongodb:latest
podman push <myregistry.io>/debezium-container-for-mongodb:latestCopy to Clipboard Copied! Toggle word wrap Toggle overflow docker push <myregistry.io>/debezium-container-for-mongodb:latest
docker push <myregistry.io>/debezium-container-for-mongodb:latestCopy to Clipboard Copied! Toggle word wrap Toggle overflow 新しい Debezium MongoDB
KafkaConnectカスタムリソース (CR) を作成します。たとえば、annotationsおよびimageプロパティーを指定するdbz-connect.yamlという名前のKafkaConnectCR を作成します。以下の例は、KafkaConnectカスタムリソースを記述するdbz-connect.yamlファイルからの抜粋を示しています。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 項目 説明 1
KafkaConnectorリソースはこの Kafka Connect クラスターでコネクターを設定するために使用されることを、metadata.annotationsは Cluster Operator に示します。2
spec.imageは Debezium コネクターを実行するために作成したイメージの名前を指定します。設定された場合、このプロパティーによって Cluster Operator のSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGE変数がオーバーライドされます。以下のコマンドを入力して、
KafkaConnectCR を OpenShift Kafka Connect 環境に適用します。oc create -f dbz-connect.yaml
oc create -f dbz-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、Debezium コネクターを実行するために作成したイメージの名前を指定する Kafka Connect インスタンスを追加します。
Debezium MongoDB コネクターインスタンスを設定する
KafkaConnectorカスタムリソースを作成します。通常、コネクターに使用できる設定プロパティーを使用して、
.yamlファイルに Debezium MongoDB コネクターを設定します。コネクター設定で、Debezium に指示を出して MongoDB レプリカセットまたはシャードクラスターのサブセットの変更イベントを生成する場合があります。任意で、不必要なコレクションを除外するプロパティーを設定できます。以下の例では、
192.168.99.100のポート27017で MongoDB レプリカセットrs0に接続する Debezium コネクターを設定し、inventoryで発生する変更をキャプチャーします。inventory-connector-mongodbはレプリカセットの論理名です。
MongoDB
inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.69 MongoDB inventory-connector.yaml の例の設定の説明 項目 説明 1
コネクターを Kafka Connect に登録するために使用される名前。
2
MongoDB コネクタークラスの名前。
3
MongoDB レプリカセットへの接続に使用するホストアドレス。
4
MongoDB レプリカセットの 論理名。コネクターが書き込む Kafka トピックの名前、Kafka Connect スキーマ名、および Avro コンバーターが使用される場合に対応する Avro スキーマの namespace のすべてに使用されます。
5
監視するすべてのコレクションのコレクション namespace (例: <dbName>.<collectionName>) と一致する正規表現の任意リスト。
Kafka Connect でコネクターインスタンスを作成します。たとえば、
KafkaConnectorリソースをinventory-connector.yamlファイルに保存した場合は、以下のコマンドを実行します。oc apply -f inventory-connector.yaml
oc apply -f inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドは
inventory-connectorを登録し、コネクターはKafkaConnectorCR に定義されているinventoryコレクションに対して実行を開始します。
Debezium MongoDB コネクターに設定できる設定プロパティーの完全リストは、MongoDB コネクター設定プロパティーを参照してください。
結果
コネクターが起動したら、以下のアクションを完了します。
- MongoDB レプリカセットでコレクションの スナップショット 一貫性をもたせて実行する。
- レプリカセットの変更ストリームを読み取る。
- 挿入、更新、削除されたすべてのドキュメントの変更イベントを生成する。
- Kafka トピックに変更イベントレコードをストリーミングする。
2.3.5.4. Debezium MongoDB コネクターが実行していることの確認
コネクターがエラーなしで正常に起動すると、コネクターがキャプチャーするように設定された各テーブルのトピックが作成されます。ダウンストリームアプリケーションは、これらのトピックをサブスクライブして、ソースデータベースで発生する情報イベントを取得できます。
コネクターが実行されていることを確認するには、OpenShift Container Platform Web コンソールまたは OpenShift CLI ツール (oc) から以下の操作を実行します。
- コネクターのステータスを確認します。
- コネクターがトピックを生成していることを確認します。
- 各テーブルの最初のスナップショットの実行中にコネクターが生成する読み取り操作 ("op":"r") のイベントがトピックに反映されていることを確認します。
前提条件
- Debezium コネクターが OpenShift 上の Streams for Apache Kafka にデプロイされている。
-
OpenShift
ocCLI クライアントがインストールされている。 - OpenShift Container Platform Web コンソールにアクセスできる。
手順
以下の方法のいずれかを使用して
KafkaConnectorリソースのステータスを確認します。OpenShift Container Platform Web コンソールから以下を実行します。
- Home → Search に移動します。
-
Search ページで Resources をクリックし、Select Resource ボックスを開き、
KafkaConnectorを入力します。 - KafkaConnectors リストから、チェックするコネクターの名前をクリックします (例: inventory-connector-mongodb)。
- Conditions セクションで、Type および Status 列の値が Ready および True に設定されていることを確認します。
ターミナルウィンドウから以下を実行します。
以下のコマンドを実行します。
oc describe KafkaConnector <connector-name> -n <project>
oc describe KafkaConnector <connector-name> -n <project>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc describe KafkaConnector inventory-connector-mongodb -n debezium
oc describe KafkaConnector inventory-connector-mongodb -n debeziumCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、以下の出力のようなステータス情報を返します。
例2.20
KafkaConnectorリソースのステータスCopy to Clipboard Copied! Toggle word wrap Toggle overflow
コネクターによって Kafka トピックが作成されたことを確認します。
OpenShift Container Platform Web コンソールから以下を実行します。
- Home → Search に移動します。
-
Search ページで Resources をクリックし、Select Resource ボックスを開き、
KafkaTopicを入力します。 -
KafkaTopics リストから確認するトピックの名前をクリックします (例:
inventory-connector-mongodb.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d)。 - Conditions セクションで、Type および Status 列の値が Ready および True に設定されていることを確認します。
ターミナルウィンドウから以下を実行します。
以下のコマンドを実行します。
oc get kafkatopics
oc get kafkatopicsCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、以下の出力のようなステータス情報を返します。
例2.21
KafkaTopicリソースのステータスCopy to Clipboard Copied! Toggle word wrap Toggle overflow
トピックの内容を確認します。
- ターミナルウィンドウから、以下のコマンドを入力します。
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory-connector-mongodb.inventory.products_on_hand
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory-connector-mongodb.inventory.products_on_handCopy to Clipboard Copied! Toggle word wrap Toggle overflow トピック名を指定する形式は、手順 1 で返された
oc describeコマンドと同じです (例:inventory-connector-mongodb.inventory.addresses)。トピックの各イベントについて、このコマンドは、以下の出力のような情報を返します。
例2.22 Debezium 変更イベントの内容
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory-connector-mongodb.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-mongodb.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-mongodb.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"int64","optional":false,"field":"ts_us"},{"type":"int64","optional":false,"field":"ts_ns"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.mongodb.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"int64","optional":true,"field":"ts_us"},{"type":"int64","optional":true,"field":"ts_ns"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory-connector-mongodb.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"2.7.3.Final-redhat-00001","connector":"mongodb","name":"inventory-connector-mongodb","ts_ms":1638985247805,"ts_us":1638985247805000000,"ts_ns":1638985247805000000,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"mongodb-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"ts_us":1638985247805102,"ts_ns":1638985247805102588,"transaction":null}}{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory-connector-mongodb.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-mongodb.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-mongodb.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"int64","optional":false,"field":"ts_us"},{"type":"int64","optional":false,"field":"ts_ns"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.mongodb.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"int64","optional":true,"field":"ts_us"},{"type":"int64","optional":true,"field":"ts_ns"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory-connector-mongodb.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"2.7.3.Final-redhat-00001","connector":"mongodb","name":"inventory-connector-mongodb","ts_ms":1638985247805,"ts_us":1638985247805000000,"ts_ns":1638985247805000000,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"mongodb-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"ts_us":1638985247805102,"ts_ns":1638985247805102588,"transaction":null}}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記の例では、
payload値は、コネクタースナップショットがテーブルinventory.products_on_handから読み込み ("op" ="r") イベントを生成したことを示しています。product_idレコードの"before"状態はnullであり、レコードに以前の値が存在しないことを示しています。"after"状態は、product_id101を持つ項目のquantityが3であることを示しています。
2.3.5.5. Debezium MongoDB コネクターの設定プロパティーを説明します。
Debezium MongoDB コネクターには、アプリケーションに適したコネクター動作を実現するために使用できる設定プロパティーが多数あります。多くのプロパティーにはデフォルト値があります。プロパティーに関する情報は、以下のように設定されています。
以下の設定プロパティーは、デフォルト値がない場合は必須です。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| false |
このプロパティーを 警告 このプロパティーを使用すると、現在のデフォルトの動作を変更できます。デフォルトの動作が変更され、コネクターが以前のコネクターバージョンによって記録されたオフセットを自動的に無効化して統合できるようになると、このプロパティーは今後のリリースで削除される可能性があります。 | |
| デフォルトなし | コネクターの一意名。同じ名前で再登録を試みると失敗します。(このプロパティーはすべての Kafka Connect コネクターに必要です) | |
| デフォルトなし |
コネクターの Java クラスの名前。MongoDB コネクターには、常に | |
| デフォルトなし |
コネクターが MongoDB レプリカセットに接続するために使用する 接続文字列 を指定します。このプロパティーは、MongoDB コネクターの以前のバージョンで使用できた | |
| デフォルトなし |
このコネクターが監視するコネクターや MongoDB レプリカセット、またはシャードクラスターを識別する一意の名前。このサーバー名は、MongoDB レプリカセットまたはクラスターから生成される永続化されたすべての Kafka トピックの接頭辞になるため、各サーバーは最大 1 つの Debezium コネクターによって監視される必要があります。名前を設定する文字は、英数字、ハイフン、ドット、アンダースコアのみです。論理名は、このコネクターからレコードを受信する Kafka トピックに名前を付ける際の接頭辞として使用されるため、他のすべてのコネクターで一意である必要があります。 警告 このプロパティーの値を変更しないでください。名前の値を変更すると、再起動後に、元のトピックにイベントを発行し続けるのではなく、新しい値に基づいた名前のトピックに後続のイベントを発行します。 | |
| DefaultMongoDbAuthProvider |
io.debezium.connector.mongodb.connection.MongoDbAuthProvider インターフェイスの実装である、完全な Java クラス名。このクラスは、MongoDB 接続の認証情報の設定を処理します (アプリケーションの起動ごとに呼び出されます)。デフォルトの動作では、それぞれのドキュメントに従って | |
| デフォルトなし |
デフォルトの | |
| デフォルトなし |
デフォルトの | |
|
|
デフォルトの | |
|
| コネクターは SSL を使用して MongoDB インスタンスに接続します。 | |
|
|
SSL が有効な場合、接続フェーズ中に厳密なホスト名のチェックを無効にするかどうかを制御する設定です。 | |
| regex | 追加/除外するデータベース名とコレクション名に基づいてイベントを照合するために使用されるモード。このプロパティーを以下の値のいずれかに設定します。
| |
| 空の文字列 |
監視対象のデータベース名に一致する正規表現またはリテラルの、オプションのコンマ区切りリスト。デフォルトでは、すべてのデータベースが監視されます。
データベースの名前を照合するために、Debezium は
このプロパティーを設定に含める場合は、 | |
| 空の文字列 |
監視対象から除外するデータベース名に一致する正規表現またはリテラルのオプションのコンマ区切りリスト。
データベースの名前を照合するために、Debezium は
このプロパティーを設定に含める場合は、 | |
| 空の文字列 |
監視対象の MongoDB コレクションの完全修飾名前空間に一致する正規表現またはリテラルの、オプションのコンマ区切りリスト。デフォルトでは、
名前空間の名前を照合するために、Debezium は
このプロパティーを設定に含める場合は、 | |
| 空の文字列 |
監視から除外する MongoDB コレクションの完全修飾名前空間に一致する正規表現またはリテラルの、オプションのコンマ区切りリスト。
名前空間の名前を照合するために、Debezium は
このプロパティーを設定に含める場合は、 | |
|
|
コネクターが MongoDB サーバーから
| |
|
| コネクターが開く 変更ストリームのスコープ を指定します。このプロパティーを以下のいずれかの値に設定します。
| |
|
コネクターが変更を監視するデータベースを指定します。このプロパティーは、 | ||
| 空の文字列 | 変更イベントメッセージ値から除外される必要があるフィールドの完全修飾名のコンマ区切りリスト (任意)。フィールドの完全修飾名の形式はdatabaseName.collectionName.fieldName.nestedFieldName で、databaseName および collectionName にはすべての文字と一致するワイルドカード (*) が含まれることがあります。 | |
| 空の文字列 | イベントメッセージ値のフィールドの名前を変更するために使用されるフィールドの完全修飾置換のコンマ区切りリスト (任意)。フィールドの完全修飾置換の形式は databaseName.collectionName.fieldName.nestedFieldName:newNestedFieldName で、databaseName および collectionName にはすべての文字と一致するワイルドカード (*) が含まれることがあります。コロン (:) は、フィールドの名前変更マッピングを決定するために使用されます。次のフィールドの置換は、リストの前のフィールド置換の結果に適用されるため、同じパスにある複数のフィールドの名前を変更する場合は、この点に注意してください。 | |
|
|
delete イベントの後に廃棄 (tombstone) イベントが続くかどうかを制御します。 | |
| none |
コネクターで使用されるメッセージコンバータとの互換性のために、スキーマ名をどのように調整するかを指定します。設定可能:
| |
| none |
コネクターで使用されるメッセージコンバータとの互換性のために、フィールド名をどのように調整するかを指定します。設定可能:
詳細は、Avro の命名 を参照してください。 |
以下の 高度な 設定プロパティーには、ほとんどの状況で機能する適切なデフォルト設定があるため、コネクターの設定で指定する必要はほとんどありません。
| プロパティー | デフォルト | 説明 |
|---|---|---|
|
|
このオプションを MongoDB 変更ストリームコレクションで使用するには、ドキュメントの事前イメージと事後イメージを返す ようにコレクションを設定する必要があります。操作の事前イメージと事後イメージは、操作が行われる前に必要な設定が利用できる場合にのみ使用できます。 このプロパティーを以下のいずれかの値に設定します。
警告
ルックアッププロセスがドキュメントの取得に失敗した場合、イベントペイロードに ルックアップの失敗は、削除操作によってドキュメントが作成直後に削除されたか、シャーディングキーの変更によってドキュメントが別の場所に移動されたために発生することがあります。キーを設定するプロパティーのいずれかを変更すると、シャーディングキーが変更される可能性があります。
| |
|
| このコネクターの反復処理中に処理される必要があるイベントの各バッチの最大サイズを指定する正の整数値。デフォルトは 2048 です。 | |
|
|
ブロッキングキューが保持できるレコードの最大数を指定する正の整数値。Debezium はデータベースからストリームされたイベントを読み込む際、Kafka に書き込む前にブロッキングキューにイベントを配置します。ブロッキングキューは、コネクターが Kafka に書き込むよりも速くメッセージを取り込む場合、または Kafka が利用できなくなった場合に、データベースから変更イベントを読み込むためのバックプレッシャーを提供することができます。コネクターがオフセットを定期的に記録すると、キューに保持されるイベントは無視されます。 | |
|
|
ブロッキングキューの最大容量をバイト単位で指定する長整数値。デフォルトでは、ブロックキューにはボリューム制限は指定されません。キューが使用できるバイト数を指定するには、このプロパティーを正の long 値に設定します。 | |
|
| 各反復処理の実行中に新しい変更イベントが表示されるまでコネクターが待機する時間 (ミリ秒単位) を指定する正の整数値。デフォルトは 500 ミリ秒 (0.5 秒) です。 | |
|
| 最初に失敗した接続試行の後またはプライマリーが利用できない場合に、プライマリーへの再接続を試行するときの最初の遅延を指定する正の整数値。デフォルトは 1 秒 (1000 ミリ秒) です。 | |
|
| 接続試行に繰り返し失敗した後またはプライマリーが利用できない場合に、プライマリーへの再接続を試行するときの最大遅延を指定する正の整数値。デフォルトは 120 秒 (120,000 ミリ秒) です。 | |
|
|
レプリカセットのプライマリーへの接続を試行する場合の最大失敗回数を指定する正の整数値。この値を越えると、例外が発生し、タスクが中止されます。デフォルトは 16。 | |
|
|
ハートビートメッセージが送信される頻度を制御します。
このプロパティーを | |
|
|
ストリーミング中にスキップされる操作タイプのコンマ区切りリスト。操作には、挿入/作成の | |
| デフォルトなし | スナップショットに含まれるコレクション項目を制御します。このプロパティーはスナップショットにのみ影響します。databaseName.collectionName の形式でコレクション名のコンマ区切りリストを指定します。
指定する各コレクションに対して、別の設定プロパティー ( | |
| デフォルトなし |
コネクターの起動後、スナップショットを取得するまで待機する間隔 (ミリ秒単位)。 | |
| 0 |
コネクターがスナップショットを完了した後、ストリーミングプロセスの開始を遅延する時間をミリ秒単位で指定します。遅延間隔を設定すると、スナップショットが完了した直後で、ストリーミングプロセスの開始前に障害が発生した場合に、コネクターがスナップショットを再開できないようにします。Kafka Connect ワーカーに設定されている | |
|
|
スナップショットの実行中に各コレクションから 1 度に読み取る必要があるドキュメントの最大数を指定します。コネクターは、このサイズの複数のバッチでコレクションの内容を読み取ります。 | |
|
|
スナップショットに含めるスキーマの完全修飾名 ( スキーマの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定した式は、スキーマ名に存在する可能性のある部分文字列とは一致しない、スキーマの名前文字列全体と照合されます。 | |
|
| レプリカセットでコレクションの最初の同期を実行するために使用されるスレッドの最大数を指定する正の整数値。デフォルトは 1 です。 | |
| Initial | コネクターの開始時にスナップショットを実行する基準を指定します。このプロパティーを以下の値のいずれかに設定します。
| |
|
|
詳細は、トランザクションメタデータ を参照してください。 | |
| 10000 (10 秒) | 再試行可能なエラーが発生した後にコネクターを再起動するまで待機する時間 (ミリ秒単位)。 | |
|
| コネクターが新規、削除、または変更したレプリカセットをポーリングする間隔。 | |
| 10000 (10 秒) | 新しい接続試行が中断されるまでドライバーが待機する時間 (ミリ秒単位)。 | |
| 10000 (10 秒) | クラスターモニターが各サーバーへのアクセスを試行する頻度。 | |
| 0 |
ソケットでの送受信がタイムアウトするまでにかかる時間 (ミリ秒単位)。 | |
| 30000 (30 秒) | ドライバーがタイムアウトし、エラーが出力される前に、サーバーが選択されるまでドライバーが待つ時間 (ミリ秒単位)。 | |
| デフォルトなし | ストリーミングが変更されると、この設定は標準の MongoDB 集約ストリームパイプラインの一部としてストリームイベントを変更する処理を適用します。パイプラインは、データをフィルタリングまたは変換するためのデータベースへの命令で構成される MongoDB 集約パイプラインです。これを使用して、コネクターが消費するデータをカスタマイズできます。このプロパティーの値は、JSON 形式で許可された aggregation pipeline stages の配列である必要があります。これは、コネクターのサポートに使用される内部パイプラインの後に追加されることに注意してください (フィルタリング操作の種類、データベース名、コレクション名など)。 | |
| internal_first | 効果的な MongoDB 集約ストリームパイプラインを構築するために使用される順序。このプロパティーを以下の値のいずれかに設定します。
| |
| fail | 指定された BSON サイズを超えるドキュメントの変更イベントを処理するために使用されるストラテジー。このプロパティーを以下の値のいずれかに設定します。
| |
| 0 | 変更イベントが処理される保存済みドキュメントの最大許容サイズ (バイト単位)。これには、データベース操作の前後両方のサイズが含まれます。具体的には、MongoDB 変更イベントの fullDocument フィールドと fullDocumentBeforeChange フィールドのサイズが制限されます。 | |
|
|
実行タイムアウトの例外を発生させる前に、oplog/change stream カーソルが結果を生成するのを待つ最大期間 (ミリ秒単位) を指定します。値 | |
| デフォルトなし |
シグナルをコネクターへの送信に使用されるデータコレクションの完全修飾名 。コレクションを指定するには、 | |
| source | コネクターに対して有効な信号チャネル名のリスト。デフォルトでは、以下のチャネルが利用可能です。
| |
| デフォルトなし | コネクターに対して有効になっている通知チャネル名のリスト。デフォルトでは、以下のチャネルが利用可能です。
| |
|
|
増分スナップショットチャンク中にコネクターがフェッチしてメモリーに読み込むドキュメントの最大数です。スナップショットは、サイズが大きいスナップショットの場合にはクエリーが少なくなるため、チャンクサイズを増やすと効率が上がります。ただし、チャンクサイズが大きい場合には、スナップショットデータのバッファーにより多くのメモリーが必要になります。チャンクサイズは、環境で最適なパフォーマンスを発揮できる値に、調整します。 | |
|
|
増分スナップショットによってキャプチャーされ、ストリーミングの再開後に再キャプチャーされる可能性のあるイベントを重複排除するために、コネクターが増分スナップショット中に使用するウォーターマークメカニズムを指定します。
| |
|
|
データ変更、スキーマ変更、トランザクション、ハートビートイベントなどのトピック名を決定するために使用する TopicNamingStrategy クラスの名前。デフォルトは | |
|
|
トピック名の区切り文字を指定します。デフォルトは | |
|
| トピック名を保持するために使用されるサイズ (bounded concurrent hash map)。このキャッシュは、与えられたデータコレクションに対応するトピック名を決定するのに役立つ。 | |
|
|
コネクターがハートビートメッセージを送信するトピックの名前を制御します。トピック名のパターンは、 | |
|
|
コネクターがトランザクションのメタデータメッセージを送信するトピックの名前を制御します。トピック名のパターンは、 | |
|
|
コンテキスト情報を提供するメタデータを追加して、MBean オブジェクト名をカスタマイズするタグを定義します。キーと値のペアのコンマ区切りリストを指定します。各キーは MBean オブジェクト名のタグを表し、対応する値はキーの値を表します。たとえば、 コネクターは、指定されたタグを基本 MBean オブジェクト名に追加します。タグは、メトリクスデータを整理および分類するのに役立ちます。特定のアプリケーションインスタンス、環境、リージョン、バージョンなどを識別するためのタグを定義できます。詳細は、カスタマイズされた MBean 名 を参照してください。 | |
|
|
接続エラーなど、再試行可能なエラーが発生する操作の後に、コネクターがどのように応答するかを指定します。
|
MongoDB コネクターが Kafka シグナリングトピックと対話する方法を設定するための Pass-through プロパティー
Debezium は、コネクターが Kafka シグナルトピックと対話する方法を制御する signal.* プロパティーのセットを提供します。
以下の表は、Kafka signal プロパティーを説明しています。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| <topic.prefix>-signal | コネクターがアドホックシグナルについて監視する Kafka トピックの名前。 注記 トピックの自動作成 が無効になっている場合は、必要なシグナリングトピックを手動で作成する必要があります。シグナルの順序を維持するには、シグナルトピックが必要です。シグナリングトピックには単一のパーティションが必要です。 | |
| kafka-signal | Kafka コンシューマーによって使用されるグループ ID の名前。 | |
| デフォルトなし | コネクターが Kafka クラスターへの初期接続を確立するために使用するホストとポートのペアのリスト。各ペアは、Debezium Kafka Connect プロセスによって使用される Kafka クラスターを参照します。 | |
|
| コネクターが信号をポーリングするときに待機する最大ミリ秒数を指定する整数値。 | |
|
| Kafka コンシューマーがシグナリングトピックからメッセージを読み取った後にオフセットコミットを書き込むかどうかを指定します。このプロパティーに割り当てる値によって、コネクターがオフラインのときに、シグナリングトピックが受信する要求をコネクターが処理できるかどうかが決まります。次のいずれかの設定を選択します。
|
MongoDB コネクター sink notification チャネルを設定するためのパススループロパティー
次の表では、Debezium sink notification チャネルの設定に使用できるプロパティーについて説明します。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし |
Debezium から通知を受信するトピックの名前。このプロパティーは、有効な通知チャネルの 1 つとして |
2.3.6. Debezium MongoDB コネクターのパフォーマンスの監視
Debezium MongoDB コネクターには、Zookeeper、Kafka、および Kafka Connect にある JMX メトリクスの組み込みサポートに加えて、2 種類のメトリクスがあります。
- スナップショットメトリクス は、スナップショットの実行中にコネクター操作に関する情報を提供します。
- メトリクスのストリーミング は、コネクターが変更をキャプチャーし、変更イベントレコードをストリーミングする際のコネクター操作に関する情報を提供します。
Debezium モニタリングのドキュメント では、JMX を使用してこれらのメトリックを公開する方法の詳細を提供します。
2.3.6.1. MongoDB コネクタースナップショットとストリーミング MBean オブジェクトのカスタマイズされた名前
Debezium コネクターは、コネクターの MBean 名を介してメトリクスを公開します。これらのメトリクスは各コネクターインスタンスに固有であり、コネクターのスナップショット、ストリーミング、およびスキーマ履歴プロセスの動作に関するデータを提供します。
デフォルトでは、正しく設定されたコネクターをデプロイすると、Debezium はさまざまなコネクターメトリクスごとに一意の MBean 名を生成します。コネクタープロセスのメトリクスを表示するには、MBean を監視するように可観測性スタックを設定します。ただし、これらのデフォルトの MBean 名はコネクター設定に依存しており、設定の変更によって MBean 名が変更される場合があります。MBean 名を変更すると、コネクターインスタンスと MBean 間のリンクが切断され、監視アクティビティーが中断されます。このシナリオでは、監視を再開するには、新しい MBean 名を使用するように監視スタックを再設定する必要があります。
MBean 名の変更が原因で監視が中断されないように、カスタムメトリクスタグを設定できます。カスタムメトリクスを設定するには、コネクター設定に custom.metric.tags プロパティーを追加します。このプロパティーは、各キーが MBean オブジェクト名のタグを表し、対応する値がそのタグの値を表すキーと値のペアを受け入れます。たとえば、k1=v1,k2=v2 です。Debezium は、指定されたタグをコネクターの MBean 名に追加します。
コネクターの custom.metric.tags プロパティーを設定した後、指定されたタグに関連付けられたメトリクスを取得するように監視スタックを設定できます。可観測性スタックは、変更可能な MBean 名ではなく、指定されたタグを使用してコネクターを一意に識別します。その後、Debezium が MBean 名の構築方法を再定義したり、コネクター設定の topic.prefix が変更されたりしても、メトリクススクレイプタスクは指定されたタグパターンを使用してコネクターを識別するため、メトリクスの収集は中断されません。
カスタムタグを使用するさらなる利点は、データパイプラインのアーキテクチャーを反映するタグを使用できるため、運用上のニーズに合った方法でメトリクスを整理できることです。たとえば、コネクターアクティビティーのタイプ、アプリケーションコンテキスト、またはデータソースを宣言する値を持つタグを指定できます (例: db1-streaming-for-application-abc)。複数のキーと値のペアを指定すると、指定されたすべてのペアがコネクターの MBean 名に追加されます。
次の例は、タグがデフォルトの MBean 名を変更する方法を示しています。
例2.23 カスタムタグがコネクター MBean 名を変更する方法
デフォルトでは、MongoDB コネクターはストリーミングメトリクスに次の MBean 名を使用します。
debezium.mongodb:type=connector-metrics,context=streaming,server=<topic.prefix>
debezium.mongodb:type=connector-metrics,context=streaming,server=<topic.prefix>
custom.metric.tags の値を database=salesdb-streaming,table=inventory に設定すると、Debezium は次のカスタム MBean 名を生成します。
debezium.mongodb:type=connector-metrics,context=streaming,server=<topic.prefix>,database=salesdb-streaming,table=inventory
debezium.mongodb:type=connector-metrics,context=streaming,server=<topic.prefix>,database=salesdb-streaming,table=inventory2.3.6.2. MongoDB スナップショット作成中の Debezium の監視
MBean は debezium.mongodb:type=connector-metrics,context=snapshot,server=<topic.prefix>,task=<task.id> です。
スナップショット操作がアクティブでない場合や、最後のコネクターの起動後にスナップショットの作成が発生した場合に、スナップショットメトリクスは公開されません。
次の表に、使用可能なスナップショットメトリクスを示します。
| 属性 | タイプ | 説明 |
|---|---|---|
|
| コネクターが読み取りした最後のスナップショットイベント。 | |
|
| コネクターが最新のイベントを読み取りおよび処理してからの経過時間 (ミリ秒単位)。 | |
|
| 前回の開始またはリセット以降にコネクターで確認されたイベントの合計数。 | |
|
| コネクターに設定された include/exclude リストのフィルタリングルールによってフィルターされたイベントの数。 | |
|
| コネクターによって取得されるテーブルのリスト。 | |
|
| snapshotter とメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの長さ。 | |
|
| snapshotter とメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの空き容量。 | |
|
| スナップショットに含まれているテーブルの合計数。 | |
|
| スナップショットによってまだコピーされていないテーブルの数。 | |
|
| スナップショットが起動されたかどうか。 | |
|
| スナップショットが一時停止されたかどうか。 | |
|
| スナップショットが中断されたかどうか。 | |
|
| スナップショットが完了したかどうか。 | |
|
| スナップショットが完了したかどうかに関わらず、これまでスナップショットにかかった時間 (秒単位)。スナップショットが一時停止された時間も含まれます。 | |
|
| スナップショットが一時停止された合計秒数。スナップショットが数回一時停止された場合は、一時停止時間が加算されます。 | |
|
| スナップショットの各テーブルに対してスキャンされる行数が含まれるマップ。テーブルは、処理中に増分がマップに追加されます。スキャンされた 10,000 行ごとに、テーブルの完成時に更新されます。 | |
|
|
キューの最大バッファー (バイト単位)。このメトリクスは | |
|
| キュー内のレコードの現在の容量 (バイト単位)。 |
Debezium MongoDB コネクターは、以下のカスタムスナップショットメトリクスも提供します。
| 属性 | タイプ | 説明 |
|---|---|---|
|
|
| データベースの切断数。 |
2.3.6.3. Debezium MongoDB コネクターレコードストリーミングの監視
MBean は debezium.mongodb:type=connector-metrics,context=streaming,server=<topic.prefix>,task=<task.id> です。
以下の表は、利用可能なストリーミングメトリクスのリストです。
| 属性 | タイプ | 説明 |
|---|---|---|
|
| コネクターが読み取られた最後のストリーミングイベント。 | |
|
| コネクターが最新のイベントを読み取りおよび処理してからの経過時間 (ミリ秒単位)。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、ソースデータベースによって報告されたデータ変更イベントの合計数。Debezium が処理するデータ変更ワークロードを表します。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された作成イベントの合計数。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された更新イベントの合計数。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された削除イベントの合計数。 | |
|
| コネクターに設定された include/exclude リストのフィルタリングルールによってフィルターされたイベントの数。 | |
|
| コネクターによって取得されるテーブルのリスト。 | |
|
| ストリーマーとメイン Kafka Connect ループの間でイベントを渡すために使用されるキューの長さ。 | |
|
| ストリーマーとメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの空き容量。 | |
|
| コネクターが現在データベースサーバーに接続されているかどうかを示すフラグ。 | |
|
| 最後の変更イベントのタイムスタンプとそれを処理するコネクターとの間の期間 (ミリ秒単位)。この値には、データベースサーバーとコネクターが実行されているマシンのクロックの差が組み込まれます。 | |
|
| コミットされた処理済みトランザクションの数。 | |
|
| 最後に受信したイベントの位置。 | |
|
| 最後に処理されたトランザクションのトランザクション識別子。 | |
|
|
キューの最大バッファー (バイト単位)。このメトリクスは | |
|
| キュー内のレコードの現在の容量 (バイト単位)。 |
Debezium MongoDB コネクターは、以下のカスタムストリーミングメトリクスも提供します。
| 属性 | タイプ | 説明 |
|---|---|---|
|
|
| データベースの切断数。 |
|
|
| プライマリーノードの選出数。 |
2.3.7. Debezium MongoDB コネクターによる障害および問題の処理方法
Debezium は、複数のアップストリームデータベースのすべての変更をキャプチャーする分散システムであり、イベントの見逃しや損失は発生しません。システムが正常に操作している場合や、慎重に管理されている場合は、Debezium は変更イベントごとに 1 度だけ 配信します。
障害が発生しても、システムからイベントがなくなることはありません。ただし、障害から復旧している間は、変更イベントが繰り返えされる可能性があります。このような状態では、Debezium は Kafka と同様に、変更イベントを 少なくとも 1 回 配信します。
以下のトピックでは、Debezium MongoDB コネクターがさまざまな種類の障害および問題を処理する方法を詳説します。
設定および起動エラー
以下の状況では、起動時にコネクターが失敗し、エラーまたは例外がログに記録され、実行が停止されます。
- コネクターの設定が無効である。
- 指定の接続パラメーターを使用してコネクターを MongoDB に接続できない。
失敗したら、コネクターは指数バックオフを使用して再接続を試みます。再接続試行の最大数を設定できます。
このような場合、エラーには問題の詳細が含まれ、場合によっては回避策が提示されます。設定が修正されたり、MongoDB の問題が解決された場合はコネクターを再起動できます。
再接の続試行は、3 つのプロパティーで制御されます。
-
connect.backoff.initial.delay.ms- 初回の再接続を試みるまでの遅延。デフォルトは 1 秒 (1000 ミリ秒) です。 -
connect.backoff.max.delay.ms- 再接続を試行するまでの最大遅延。デフォルトは 120 秒 (120,000 ミリ秒) です。 -
connect.max.attempts- エラーが生成されるまでの最大試行回数。デフォルトは 16 です。
各遅延は、最大遅延以下で、前の遅延の 2 倍です。以下の表は、デフォルト値を指定した場合の、失敗した各接続試行の遅延と、失敗前の合計累積時間を表しています。
| 再接続試行回数 | 試行までの遅延 (秒単位) | 試行までの遅延合計 (分および秒単位) |
|---|---|---|
| 1 | 1 | 00:01 |
| 2 | 2 | 00:03 |
| 3 | 4 | 00:07 |
| 4 | 8 | 00:15 |
| 5 | 16 | 00:31 |
| 6 | 32 | 01:03 |
| 7 | 64 | 02:07 |
| 8 | 120 | 04:07 |
| 9 | 120 | 06:07 |
| 10 | 120 | 08:07 |
| 11 | 120 | 10:07 |
| 12 | 120 | 12:07 |
| 13 | 120 | 14:07 |
| 14 | 120 | 16:07 |
| 15 | 120 | 18:07 |
| 16 | 120 | 20:07 |
コネクターを開始できない - InvalidResumeToken または ChangeStreamHistoryLost
長期間停止されたコネクターは起動に失敗し、次の例外を報告します。
Command failed with error 286 (ChangeStreamHistoryLost): 'PlanExecutor error during aggregation :: caused by :: Resume of change stream was not possible, as the resume point may no longer be in the oplog
Command failed with error 286 (ChangeStreamHistoryLost): 'PlanExecutor error during aggregation :: caused by :: Resume of change stream was not possible, as the resume point may no longer be in the oplog上記の例外は、コネクターの再開トークンに対応するエントリーが oplog に存在しないことを示しています。oplog にはコネクターが処理した最後のオフセットが含まれていないため、コネクターはストリーミングを再開できません。
障害から回復するには、次のいずれかのオプションを使用します。
- 障害が発生したコネクターを削除し、同じ設定で異なるコネクター名の新しいコネクターを作成します。
- コネクターを一時停止してからオフセットを削除するか、オフセットトピックを変更します。
再開トークンの欠落に関連する障害を防ぐには、oplog の設定を最適化 します。
Kafka Connect のプロセスは正常に停止する
Kafka Connect が分散モードで実行され、Kafka Connect プロセスが正常に停止された場合は、Kafka Connect はプロセスのシャットダウン前に、すべてのプロセスのコネクタータスクをそのグループの別の Kafka Connect プロセスに移行し、新しいコネクタータスクは、以前のタスクが停止した場所で開始されます。コネクタータスクが正常に停止され、新しいプロセスで再起動されるまでの間、プロセスに短い遅延が発生します。
グループにプロセスが 1 つだけあり、そのプロセスが正常に停止された場合、Kafka Connect はコネクターを停止し、各レプリカセットの最後のオフセットを記録します。再起動時に、レプリカセットタスクは停止した場所で続行されます。
Kafka Connect プロセスのクラッシュ
Kafka Connector プロセスが予期せず停止した場合、最後に処理されたオフセットを記録せずに、実行中のコネクタータスクが終了します。Kafka Connect が分散モードで実行されている場合は、他のプロセスでこれらのコネクタータスクを再起動します。ただし、MongoDB コネクターは以前のプロセスによって 記録 された最後のオフセットから再開します。つまり、新しい代替タスクによって、クラッシュの直前に処理された同じ変更イベントが生成される可能性があります。重複するイベントの数は、オフセットのフラッシュ期間とクラッシュの直前のデータ変更の量によって異なります。
障害からの復旧中に一部のイベントが重複された可能性があるため、コンシューマーは常に一部のイベントが重複している可能性があることを想定する必要があります。Debezium の変更はべき等であるため、一連のイベントは常に同じ状態になります。
Debezium の各変更イベントメッセージには、イベントの生成元に関するソース固有の情報が含まれます。これには、MongoDB イベントの一意なトランザクション識別子 (h) やタイムスタンプ (sec and ord) が含まれます。コンシューマーはこれらの値の他の部分を追跡し、特定のイベントがすでに発生しているかどうかを確認することができます。
snapshot.mode が initialに設定されている場合、コネクターが長時間停止した後に失敗します。
コネクターが正常に停止された場合、ユーザーはレプリカセットメンバーで操作を継続する可能性があります。コネクターがオフライン時に発生する変更は、MongoDB の oplog に記録されます。ほとんどの場合、コネクターは再起動後、oplog のオフセット値を読み取って、各レプリカセットに対して最後にストリーミングした操作を特定し、その時点から変更のストリーミングを再開します。再起動後、コネクターの停止中に発生したデータベース操作は通常どおり Kafka に発行され、しばらくすると、コネクターはデータベースとの遅れを取り戻します。コネクターの操作が遅れを取り戻すのに必要な時間は、Kafka の機能とパフォーマンス、およびデータベースで発生した変更の量によって異なります。
ただし、コネクターが長時間停止したままになっていると、コネクターが非アクティブとなっている間に MongoDB が oplog をパージし、コネクターの最後の位置に関する情報が失われる可能性があります。コネクターの再起動後、コネクターが処理した最後の操作をマークする以前のオフセット値が oplog に含まれていないため、ストリーミングを再開できません。また、snapshot.mode プロパティーが initial に設定されていて、オフセット値が存在しない場合にコネクターは通常どおりにスナップショットを実行できません。この場合、oplog には前のオフセットの値が含まれていないため、不一致が存在しますが、オフセット値はコネクターの内部 Kafka オフセットトピックに存在します。エラーが発生し、コネクターが失敗します。
障害から回復するには、障害が発生したコネクターを削除し、同じ設定で異なるコネクター名で新しいコネクターを作成します。新しいコネクターを開始すると、スナップショットが実行されてデータベースの状態が取り込まれ、ストリーミングが再開されます。
MongoDB による書き込みの損失
失敗した場合の特定の状況では、MongoDB はコミットを失う可能性があり、その場合には MongoDB コネクターでは、失われた変更をキャプチャーできません。たとえば、プライマリーが変更を適用して、その oplog にその変更を記録した後に、突然クラッシュした場合には、セカンダリーノードがコンテンツを読み取るまでに oplog が利用できなくなる可能性があります。その結果、新しいプライマリーノードとして選択されるセカンダリーノードには、oplog からの最新の変更が含まれていない可能性があります。
現時点では、MongoDB のこの副次的な影響を防ぐ方法はありません。
2.4. MySQL の Debezium コネクター
MySQL には、データベースにコミットされた順序ですべての操作を記録するバイナリーログ (binlog) があります。これには、テーブルスキーマの変更やテーブルのデータの変更が含まれます。MySQL はレプリケーションとリカバリーに binlog を使用します。
Debezium MySQL コネクターは binlog を読み取り、行レベルの INSERT、UPDATE、および DELETE 操作の変更イベントを生成し、変更イベントを Kafka トピックに出力します。クライアントアプリケーションはこれらの Kafka トピックを読み取ります。
MySQL は通常、指定期間後に binlogs をパージするように設定されているため、MySQL コネクターは各データベースの最初の整合性スナップショット を実行します。MySQL コネクターは、スナップショットが作成された時点から binlog を読み取ります。
このコネクターと互換性のある MySQL データベースのバージョンについては、Debezium でサポートされる設定ページを参照してください。
Debezium MySQL コネクターの使用に関する情報および手順は、以下のように整理されています。
2.4.1. Debezium MySQL コネクターの仕組み
コネクターがサポートする MySQL トポロジーの概要は、アプリケーションを計画するときに役立ちます。Debezium MySQL コネクターを最適に設定および実行するには、コネクターによるテーブルの構造の追跡方法、スキーマ変更の公開方法、スナップショットの実行方法、および Kafka トピック名の決定方法を理解しておくと便利です。
詳細は以下を参照してください。
2.4.1.1. Debezium コネクターでサポートされる MySQL トポロジー
Debezium MySQL コネクターは以下の MySQL トポロジーをサポートします。
- Standalone
- 単一の MySQL サーバーを使用する場合、Debezium MySQL コネクターがサーバーを監視できるように、サーバーで binlog を有効にする必要があります。バイナリーログも増分 [バックアップ] として使用できるため、これは多くの場合で許容されます。この場合、MySQL コネクターは常にこのスタンドアロン MySQL サーバーインスタンスに接続し、それに従います。
- Primary and replica
Debezium MySQL コネクターは、プライマリーサーバーの 1 つ、またはレプリカの 1 つ (そのレプリカの binlog が有効になっている場合) をフォローできますが、コネクターはそのサーバーに表示されるクラスター内の変更のみを検出します。通常、これはマルチプライマリートポロジー以外では問題ではありません。
コネクターは、サーバーの binlog の位置を記録します。この位置は、クラスターの各サーバーごとに異なります。そのため、コネクターは 1 つの MySQL サーバーインスタンスのみに従う必要があります。このサーバーに障害が発生した場合、サーバーを再起動またはリカバリーしないと、コネクターは継続できません。
- High available clusters
- MySQL にはさまざまな [高可用性] ソリューションが存在し、問題や障害の耐性をつけ、即座に回復することが大変容易になります。HA MySQL クラスターは GTID を使用するため、レプリカはプライマリーサーバーで発生するすべての変更を追跡できます。
- Multi-primary
複数のプライマリーサーバーからそれぞれ複製された 1 つ以上の MySQL レプリカノードを使用します。クラスターレプリケーションは、複数の MySQL クラスターのレプリケーションを集約する強力な方法を提供します。
Debezium MySQL コネクターはこれらのマルチプライマリー MySQL レプリカをソースとして使用することができ、新しいレプリカが古いレプリカに追い付けば、異なるマルチプライマリー MySQL レプリカにフェイルオーバーできます。つまり、新しいレプリカには最初のレプリカで確認されたすべてのトランザクションが含まれます。これは、コネクターがデータベースやテーブルのサブセットのみを使用している場合でも機能します。これは、新しいマルチプライマリー MySQL レプリカに再接続して binlog 内の正しい位置を見つけようとする場合に、特定の GTID ソースを含めるか除外するようにコネクターを設定できるためです。
- Hosted
Debezium MySQL コネクターは、Amazon RDS や Amazon Aurora などのホスト型データベースオプションを使用できます。
これらのホストオプションではグローバル読み取りロックの使用が許可されていないため、コネクターは一貫性のあるスナップショットを作成するときにテーブルレベルのロックを使用します。
2.4.1.2. Debezium MySQL コネクターによるデータベーススキーマの変更の処理方法
データベースクライアントがデータベースのクエリーを行うと、クライアントはデータベースの現在のスキーマを使用します。しかし、データベーススキーマはいつでも変更が可能です。そのため、挿入、更新、または削除の操作が記録されるたびに、コネクターはどのスキーマであるかを特定できる必要があります。また、コネクターは必ずしも現在のスキーマをすべてのイベントに適用できるとは限りません。イベントが比較的古い場合は、現在のスキーマが適用される前に記録された可能性があります。
スキーマ変更後に発生するイベントを正しく処理するために、MySQL には、データに影響を与える行レベルの変更だけでなく、データベースに適用される DDL ステートメントもトランザクションログに含めます。コネクターは、binlog 内でこれらの DDL ステートメントを検出すると、そのステートメントを解析し、各テーブルのスキーマのインメモリー表現を更新します。コネクターはこのスキーマ表現を使用して、挿入、更新、または削除の操作時にテーブルの構造を特定し、適切な変更イベントを生成します。別のデータベーススキーマ履歴 Kafka トピックでは、コネクターは各 DDL ステートメントがある binlog の場所とともにすべての DDL ステートメントを記録します。
クラッシュするか、正常に停止した後に、コネクターを再起動すると、特定の位置 (特定の時点) から binlog の読み取りを開始します。コネクターは、データベーススキーマ履歴の Kafka トピックを読み取り、コネクターが起動する binlog の時点まですべての DDL ステートメントを解析することで、この時点で存在したテーブル構造を再ビルドします。
このデータベーススキーマ履歴トピックは、内部コネクター専用となっています。オプションで、コネクターは コンシューマーアプリケーション向けの別のトピックにスキーマ変更イベントを送信する こともできます。
MySQL コネクターが、gh-ost または pt-online-schema-change などのスキーマ変更ツールが適用されるテーブルで変更をキャプチャーすると、移行プロセス中にヘルパーテーブルが作成されます。これらのヘルパーテーブルで発生する変更をキャプチャーするようにコネクターを設定する必要があります。コネクターがヘルパーテーブル用に生成するレコードをコンシューマーが必要としない場合は、単一メッセージ変換 (SMT) を設定して、コネクターが発行するメッセージからこれらのレコードを削除します。
関連情報
- Debezium イベントレコードを受信する トピックのデフォルト名。
2.4.1.3. Debezium MySQL コネクターによるデータベーススキーマの変更の公開方法
Debezium MySQL コネクターを設定すると、データベーステーブルに適用されるスキーマの変更を記述するスキーマ変更イベントを生成できます。コネクターはスキーマ変更イベントを <topicPrefix> という名前の Kafka トピックに書き込みます。ここで、topicPrefix は topic.prefix コネクター設定プロパティーで指定された名前空間です。コネクターがスキーマ変更トピックに送信するメッセージには、ペイロードと、任意で変更イベントメッセージのスキーマが含まれます。
スキーマ変更イベントのスキーマには、次の要素があります。
name- スキーマ変更イベントメッセージの名前。
type- 変更イベントメッセージのタイプ。
version- スキーマのバージョン。バージョンは整数で、スキーマが変更されるたびに増加します。
fields- 変更イベントメッセージに含まれるフィールド。
例: MySQL コネクターのスキーマ変更トピックのスキーマ
次の例は、JSON 形式の一般的なスキーマを示しています。
スキーマ変更イベントメッセージのペイロードには、以下の要素が含まれます。
ddl-
スキーマの変更につながる SQL
CREATE、ALTER、またはDROPステートメントを提供します。 databaseName-
DDL ステートメントが適用されるデータベースの名前。
databaseNameの値は、メッセージキーとして機能します。 pos- ステートメントが表示される binlog の位置。
tableChanges-
スキーマの変更後のテーブルスキーマ全体の構造化表現。
tableChangesフィールドには、テーブルの各列のエントリーなどのアレイが含まれます。構造化された表現は JSON または Avro 形式でデータを表示するため、コンシューマーは DDL パーサーを介して最初にメッセージを処理しなくてもメッセージを簡単に読み取りできます。
キャプチャーモードであるテーブルでは、コネクターはスキーマ変更トピックにスキーマ変更の履歴だけでなく、内部データベーススキーマ履歴トピックにも格納します。内部データベーススキーマ履歴トピックはコネクターのみの使用を対象としており、使用するアプリケーションによる直接使用を目的としていません。スキーマ変更に関する通知が必要なアプリケーションが、スキーマ変更トピックからの情報のみを使用するようにしてください。
データベーススキーマ履歴トピックをパーティションに分割しないでください。データベーススキーマ履歴トピックが正しく機能するには、コネクターが出力するイベントレコードの一貫したグローバル順序を維持する必要があります。
トピックがパーティション間で分割されないようにするには、以下のいずれかの方法を使用してトピックのパーティション数を設定します。
-
データベーススキーマ履歴トピックを手動で作成する場合は、パーティション数を
1に指定します。 -
Apache Kafka ブローカーを使用してデータベーススキーマ履歴トピックを自動的に作成する場合に、トピックが作成されるので、Kafka
num.partitions設定オプションの値を1に設定します。
コネクターがスキーマ変更トピックに出力するメッセージの形式は、初期の状態であり、通知なしに変更される可能性があります。
例: MySQL コネクタースキーマ変更トピックに出力されるメッセージ
以下の例は、JSON 形式の一般的なスキーマ変更メッセージを示しています。メッセージには、テーブルスキーマの論理表現が含まれます。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
|
| 2 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 3 |
|
変更が含まれるデータベースとスキーマを識別します。 |
| 4 |
|
このフィールドには、スキーマの変更を行う DDL が含まれます。 |
| 5 |
| DDL コマンドによって生成されるスキーマの変更が含まれる 1 つ以上の項目の配列。 |
| 6 |
| 変更の種類を説明します。値は以下のいずれかになります。
|
| 7 |
|
作成、変更、または破棄されたテーブルの完全な識別子。テーブルの名前が変更されると、この識別子は |
| 8 |
| 適用された変更後のテーブルメタデータを表します。 |
| 9 |
| テーブルのプライマリーキーを設定する列のリスト。 |
| 10 |
| 変更されたテーブルの各列のメタデータ。 |
| 11 |
| 各テーブル変更のカスタム属性メタデータ。 |
詳細は、スキーマ履歴トピック を参照してください。
2.4.1.4. Debezium MySQL コネクターによるデータベーススナップショットの実行方法
Debezium MySQL コネクターが最初に起動すると、データベースの最初の 整合性スナップショット が実行されます。このスナップショットにより、コネクターはデータベースの現在の状態のベースラインを確立できます。
Debezium はスナップショットを実行するときにさまざまなモードを使用できます。スナップショットモードは、snapshot.mode 設定プロパティーによって決まります。プロパティーのデフォルト値は initial です。snapshot.mode プロパティーの値を変更することで、コネクターがスナップショットを作成する方法をカスタマイズできます。
スナップショットの詳細は、以下のセクションを参照してください。
コネクターは、スナップショットを実行するときに一連のタスクを完了します。正確な手順は、スナップショットモードと、データベースに対して有効なテーブルロックポリシーによって異なります。Debezium MySQL コネクターは、グローバル読み取りロック または テーブルレベルロック を使用する初期スナップショットを実行するときに、さまざまな手順を実行します。
2.4.1.4.1. グローバル読み取りロックを使用する初期スナップショット
snapshot.mode プロパティーの値を変更することで、コネクターがスナップショットを作成する方法をカスタマイズできます。別のスナップショットモードを設定する場合、コネクターはこのワークフローの変更バージョンを使用してスナップショットを完了します。グローバル読み取りロックが許可されていない環境でのスナップショットプロセスは、テーブルレベルロックのスナップショットワークフロー を参照してください。
Debezium MySQL コネクターがグローバル読み取りロックで初期スナップショットの実行に使用するデフォルトのワークフロー
以下の表は、Debezium がグローバル読み取りロックでスナップショットを作成する際のワークフローの手順を示しています。
| 手順 | アクション |
|---|---|
| 1 | データベースへの接続を確立します。 |
| 2 |
キャプチャーするテーブルを決定します。デフォルトでは、コネクターはシステム以外のすべてのテーブルのデータをキャプチャーします。スナップショットが完了した後、コネクターは指定されたテーブルのデータをストリーミングし続けます。コネクターで特定のテーブルからのみデータをキャプチャーする場合は、 |
| 3 |
キャプチャーするテーブルに対してグローバル読み取りロックを取得し、他のデータベースクライアントによる writes をブロックします。 |
|
4 注記 これらの分離セマンティクスを使用すると、スナップショットの進行が遅くなる可能性があります。スナップショットの完了に時間がかかりすぎる場合は、別の分離設定の使用を検討するか、最初のスナップショットをスキップして、代わりに 増分スナップショット を実行します。 | 5 |
| 現在の binlog の位置を読み取ります。 | 6 |
|
データベース内のすべてのテーブル、またはキャプチャー対象として指定されたすべてのテーブルの構造をキャプチャーします。コネクターは、必要なすべての 注記
デフォルトでは、コネクターは、キャプチャー用に設定されていないテーブルも含め、データベース内のすべてのテーブルのスキーマをキャプチャーします。テーブルがキャプチャー用に設定されていない場合、最初のスナップショットはテーブルの構造のみをキャプチャーし、テーブルデータはキャプチャーされません。 | 7 |
| 手順 3 で取得したグローバル読み取りロックを解放します。他のデータベースクライアントがデータベースに書き込みできるようになりました。 | 8 |
| コネクターが手順 5 で読み取った binlog の位置で、コネクターはキャプチャー用に指定されたテーブルのスキャンを開始します。スキャン中に、コネクターは次のタスクを実行します。
| 9 |
| トランザクションをコミットします。 | 10 |
作成された初期スナップショットは、キャプチャーされたテーブルの各行の現在の状態をキャプチャーします。このベースライン状態から、コネクターは発生した後続の変更をキャプチャーします。
スナップショットプロセスが開始されたら、コネクターの障害、リバランス、またはその他の理由でプロセスが中断されると、コネクターの再起動後にプロセスが再起動されます。
コネクターによって最初のスナップショットが完了した後、更新に抜けがないように、手順 5 で読み取りした位置からストリーミングを続行します。
何らかの理由でコネクターが再び停止した場合に、コネクターは再起動後に最後に停止した位置から変更のストリーミングを再開します。
コネクターの再起動後、ログがプルーニングされている場合、ログ内のコネクターの位置が使用できなくなる可能性があります。その後、コネクターは失敗し、新しいスナップショットが必要であることを示すエラーを返します。この状況でスナップショットを自動的に開始するようにコネクターを設定するには、snapshot.mode プロパティーの値を when_needed に設定します。Debezium MySQL コネクターのトラブルシューティングに関する詳細は、問題が発生したときの動作 を参照してください。
2.4.1.4.2. テーブルレベルロックを使用する初期スナップショット
一部のデータベース環境では、管理者がグローバル読み取りロックを許可していません。Debezium MySQL コネクターがグローバル読み取りロックが許可されていないことを検出した場合、コネクターはスナップショットを実行するときにテーブルレベルのロックを使用します。コネクターがテーブルレベルロックを使用するスナップショットを実行するには、Debezium コネクターが MySQL への接続に使用するデータベースアカウントで LOCK TABLES 権限が必要です。
Debezium MySQL コネクターがテーブルレベルのロックを使用して初期スナップショットを実行するために使用するデフォルトのワークフロー
次の表は、テーブルレベルの読み取りロックを使用してスナップショットを作成するために Debezium が実行するワークフローの手順を示しています。グローバル読み取りロックが許可されていない環境でのスナップショットプロセスについては、グローバル読み取りロックのスナップショットワークフロー を参照してください。
| 手順 | アクション |
|---|---|
| 1 | データベースへの接続を確立します。 |
| 2 |
キャプチャーするテーブルを決定します。デフォルトでは、コネクターはすべてのシステム以外のテーブルをキャプチャーします。コネクターにテーブルまたはテーブル要素のサブセットをキャプチャーさせるには、 |
| 3 | テーブルレベルロックを取得します。 |
| 4 | 5 |
| 現在の binlog の位置を読み取ります。 | 6 |
|
コネクターが変更をキャプチャーするように設定されたデータベースとテーブルのスキーマを読み取ります。コネクターは、必要なすべての 注記 デフォルトでは、コネクターは、キャプチャー用に設定されていないテーブルも含め、データベース内のすべてのテーブルのスキーマをキャプチャーします。テーブルがキャプチャー用に設定されていない場合、最初のスナップショットはテーブルの構造のみをキャプチャーし、テーブルデータはキャプチャーされません。 初期スナップショットに含まれなかったテーブルのスキーマ情報がスナップショットに保持される理由の詳細は、初期スナップショットがすべてのテーブルのスキーマをキャプチャーする理由 を参照してください。 | 7 |
| コネクターが手順 5 で読み取った binlog の位置で、コネクターはキャプチャー用に指定されたテーブルのスキャンを開始します。スキャン中に、コネクターは次のタスクを実行します。
| 8 |
| トランザクションをコミットします。 | 9 |
| テーブルレベルロックを解除します。他のデータベースクライアントは、以前にロックされていたテーブルに書き込みできるようになります。 | 10 |
| 設定 | 説明 |
|---|---|
|
| コネクターは起動するたびにスナップショットを実行します。スナップショットには、キャプチャーされたテーブルの構造およびデータが含まれます。この値を指定すると、コネクターが起動するたびに、キャプチャーされたテーブルからのデータの完全な表現がトピックに入力されます。スナップショットが完了すると、コネクターは、後続のデータベース変更のに備え、イベントレコードのストリーミングを開始します。 |
|
| コネクターは 初期スナップショットを作成するためのデフォルトのワークフロー で説明されているように、データベーススナップショットを実行します。スナップショットが完了すると、コネクターは、後続のデータベース変更のに備え、イベントレコードのストリーミングを開始します。 |
|
| コネクターはデータベーススナップショットを実行します。スナップショットが完了すると、コネクターは停止し、後続のデータベース変更のイベントレコードをストリーミングしなくなります。 |
|
|
非推奨です。 |
|
|
コネクターは、初期スナップショットを作成するためのデフォルトのワークフロー で説明されているすべての手順を実行して、関連するすべてのテーブルの構造をキャプチャーします。ただし、コネクターの起動時点のデータセットを表す |
|
|
コネクターが起動すると、スナップショットを実行するのではなく、後続のデータベース変更のイベントレコードのストリーミングがすぐに開始されます。 |
|
|
非推奨です。 |
|
|
損失または破損したデータベーススキーマの履歴トピックを復元するにはこのオプションを設定します。再起動後、コネクターはソーステーブルからトピックを再構築するスナップショットを実行します。また、このプロパティーを設定して、予期しない増加が発生するデータベーススキーマ履歴トピックを定期的にプルーニングすることもできます。 |
|
| コネクターが起動した後、次のいずれかの状況を検出した場合にのみスナップショットが実行されます。
|
詳細は、コネクター設定プロパティーテーブルの snapshot.mode を参照してください。
2.4.1.4.3. 初期スナップショットがすべてのテーブルのスキーマ履歴をキャプチャーする理由
コネクターが実行する最初のスナップショットは、2 種類の情報をキャプチャーします。
- テーブルデータ
-
コネクターの
table.include.listプロパティーにあるテーブルのINSERT、UPDATE、およびDELETE操作に関する情報。 - スキーマデータ
- テーブルに適用される構造の変更を記述する DDL ステートメント。スキーマデータは、内部スキーマ履歴トピックとコネクターのスキーマ変更トピック (設定されている場合) の両方に保持されます。
初期スナップショットを実行すると、キャプチャー対象として指定されていないテーブルのスキーマ情報がスナップショットによってキャプチャーされることが分かります。デフォルトでは、初期スナップショットは、キャプチャー用に指定されたテーブルからだけでなく、データベースに存在するすべてのテーブルのスキーマ情報を取得するように設計されています。コネクターでは、テーブルのスキーマがスキーマ履歴トピックにある状態で、テーブルをキャプチャーする必要があります。初期スナップショットが元のキャプチャーセットの一部ではないテーブルのスキーマデータをキャプチャーできるようにして、後で必要になった場合にこれらのテーブルからイベントデータを簡単にキャプチャーできるように、Debezium はコネクターを準備します。初期スナップショットがテーブルのスキーマをキャプチャーしない場合は、コネクターがテーブルからデータをキャプチャーする前に、履歴トピックにスキーマを追加する必要があります。
場合によっては、最初のスナップショットでのスキーマキャプチャーを制限する場合があります。これは、スナップショットの完了に必要な時間の短縮に便利です。または、Debezium が複数の論理データベースにアクセスできるユーザーアカウントを使用して、データベースインスタンスに接続しているにもかかわらず、コネクターで特定の論理データベース内のテーブルからの変更のみをキャプチャーする場合にも便利です。
関連情報
- 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更なし)
- 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更)
-
schema.history.internal.store.only.captured.tables.ddlプロパティーを設定して、スキーマ情報をキャプチャーするテーブルを指定します。 -
schema.history.internal.store.only.captured.databases.ddlプロパティーを設定して、スキーマ変更をキャプチャーする論理データベースを指定します。
2.4.1.4.4. 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更なし)
コネクターを使用して、最初のスナップショットでスキーマがキャプチャーされなかったテーブルからデータをキャプチャーする場合があります。コネクターの設定によっては、最初のスナップショットはデータベース内の特定のテーブルのテーブルスキーマのみをキャプチャーする場合があります。テーブルスキーマが履歴トピックに存在しない場合、コネクターはテーブルのキャプチャーに失敗し、スキーマ欠落エラーを報告します。
テーブルからデータを取得できる場合もありますが、テーブルスキーマを追加するには別の手順を実行する必要があります。
前提条件
- コネクターにより最初のスナップショット中にキャプチャーされなかったスキーマが含まれるテーブルからデータをキャプチャーしたいと考えている。
- トランザクションログでは、テーブルのすべてのエントリーが同じスキーマを使用します。構造変更が行われた新しいテーブルからのデータのキャプチャーについては、初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更) を参照してください。
手順
- コネクターを停止します。
-
schema.history.internal.kafka.topic プロパティーで指定された内部データベーススキーマ履歴トピックを削除します。 以下の変更をコネクター設定に適用します。
-
snapshot.modeをschema_only_recoveryに設定します。 -
schema.history.internal.store.only.captured.tables.ddlの値をfalseに設定します。 -
コネクターがキャプチャーするテーブルを
table.include.listに追加します。これにより、コネクターは今後すべてのテーブルのスキーマ履歴を再構築できます。
-
- コネクターを再起動します。スナップショットのリカバリープロセスでは、テーブルの現在の構造に基づいてスキーマ履歴が再ビルドされます。
- (オプション) スナップショットが完了したら、増分スナップショット を開始して、コネクターがオフラインだった間に発生した他のテーブルへの変更とともに、新しく追加されたテーブルの既存のデータをキャプチャーします。
-
(オプション)
snapshot.modeをschema_onlyにリセットして、今後の再起動後にコネクターが回復を開始しないようにします。
2.4.1.4.5. 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更)
スキーマ変更がテーブルに適用される場合、スキーマ変更前にコミットされたレコードの構造は、変更後にコミットされたレコードとは異なります。Debezium はテーブルからデータをキャプチャーするときに、スキーマ履歴を読み取り、各イベントに正しいスキーマが適用されていることを確認します。スキーマがスキーマ履歴トピックに存在しない場合、コネクターはテーブルをキャプチャーできず、エラーが発生します。
最初のスナップショットでキャプチャーされず、テーブルのスキーマが変更されたテーブルからデータをキャプチャーする場合、スキーマがまだ使用可能でない場合は、履歴トピックにスキーマを追加する必要があります。新しいスキーマスナップショットを実行するか、テーブルの初期スナップショットを実行して、スキーマを追加できます。
前提条件
- コネクターにより最初のスナップショット中にキャプチャーされなかったスキーマが含まれるテーブルからデータをキャプチャーしたいと考えている。
- スキーマ変更がテーブルに適用されたため、キャプチャーされるレコードの構造が不均一になっている。
手順
- 初期スナップショットにすべてのテーブルのスキーマがキャプチャーされている場合 (
store.only.captured.tables.ddlはfalseに設定されました)。 -
table.include.listプロパティーを編集して、キャプチャーするテーブルを指定します。 - コネクターを再起動します。
- 新しく追加したテーブルから既存のデータをキャプチャーする場合は、増分スナップショット を開始します。
-
- 初期スナップショットにすべてのテーブルのスキーマがキャプチャーされていない場合 (
store.only.captured.tables.ddlがtrueに設定されています)。 最初のスナップショットでキャプチャーするテーブルのスキーマが保存されなかった場合は、次のいずれかの手順を実行します。
- 手順 1: スキーマスナップショット、その後に増分スナップショット
この手順では、コネクターは最初にスキーマのスナップショットを実行します。その後、増分スナップショットを開始して、コネクターがデータを同期できるようにします。
- コネクターを停止します。
-
schema.history.internal.kafka.topic プロパティーで指定された内部データベーススキーマ履歴トピックを削除します。 設定された Kafka Connect
offset.storage.topic内のオフセットをクリアします。オフセットを削除する方法の詳細は、Debezium コミュニティーの FAQ を参照してください。警告オフセットの削除は、内部 Kafka Connect データの操作の経験がある上級ユーザーのみが実行してください。この操作によりシステムが破損する場合があるため、最後の手段としてのみ実行してください。
次の手順の説明に従って、コネクター設定のプロパティーの値を設定します。
-
snapshot.modeプロパティーの値をschema_onlyに設定します。 -
table.include.listを編集して、キャプチャーするテーブルを追加します。
-
- コネクターを再起動します。
- Debezium が新規および既存のテーブルのスキーマをキャプチャーするまで待ちます。コネクターが停止した後にテーブルで発生したデータ変更はキャプチャーされません。
- データが損失されないようにするには、増分スナップショット を開始します。
- 手順 2: 初期スナップショットと、それに続くオプションの増分スナップショット
この手順では、コネクターはデータベースの完全な初期スナップショットを実行します。他の初期スナップショットと同様、多数の大きなテーブルが含まれるデータベースでは、初期スナップショットの実行操作には時間がかかる可能性があります。スナップショットの完了後、任意で増分スナップショットをトリガーして、コネクターがオフラインの間に発生した変更をキャプチャーできます。
- コネクターを停止します。
-
schema.history.internal.kafka.topic プロパティーで指定された内部データベーススキーマ履歴トピックを削除します。 設定された Kafka Connect
offset.storage.topic内のオフセットをクリアします。オフセットを削除する方法の詳細は、Debezium コミュニティーの FAQ を参照してください。警告オフセットの削除は、内部 Kafka Connect データの操作の経験がある上級ユーザーのみが実行してください。この操作によりシステムが破損する場合があるため、最後の手段としてのみ実行してください。
-
table.include.listを編集して、キャプチャーするテーブルを追加します。 次の手順の説明に従って、コネクター設定のプロパティーの値を設定します。
-
snapshot.modeプロパティーの値をinitialに設定します。 -
(オプション)
schema.history.internal.store.only.captured.tables.ddlをfalseに設定します。
-
- コネクターを再起動します。コネクターはデータベース全体のスナップショットを取得します。スナップショットが完了すると、コネクターはストリーミングに移行します。
- (オプション) コネクターがオフラインの間に変更されたデータをキャプチャーするには、増分スナップショット を開始します。
2.4.1.5. アドホックスナップショット
デフォルトでは、コネクターは初回スナップショット操作の開始後にのみ実行されます。通常の状況では、この最初のスナップショットが作成されると、コネクターではスナップショットプロセスは繰り返し処理されません。コネクターがキャプチャーする今後の変更イベントデータはストリーミングプロセス経由でのみ行われます。
ただし、場合によっては、最初のスナップショット中にコネクターを取得したデータが古くなったり、失われたり、または不完全となったり可能性があります。テーブルデータを再キャプチャーするメカニズムを提供するため、Debezium にはアドホックスナップショットを実行するオプションがあります。Debezium 環境で次のいずれかの変更が発生したら、アドホックスナップショットを実行することを推奨します。
- コネクター設定は、異なるテーブルセットをキャプチャーするように変更されます。
- Kafka トピックを削除して、再構築する必要があります。
- 設定エラーや他の問題が原因で、データの破損が発生します。
アドホックと呼ばれるスナップショット を開始することで、以前にスナップショットをキャプチャーしたテーブルのスナップショットを再実行できます。アドホックスナップショットには、シグナルテーブル を使用する必要があります。シグナルリクエストを Debezium シグナルテーブルに送信して、アドホックスナップショットを開始します。
既存のテーブルのアドホックスナップショットを開始すると、コネクターはテーブルにすでに存在するトピックにコンテンツを追加します。既存のトピックが削除された場合には、トピックの自動作成 が有効になっているのであれば、Debezium は自動的にトピックを作成できます。
アドホックのスナップショットシグナルは、スナップショットに追加するテーブルを指定します。スナップショットは、データベースの内容全体をキャプチャーしたり、データベース内のテーブルのサブセットのみをキャプチャーしたりできます。また、スナップショットは、データベース内のテーブルの内容のサブセットをキャプチャできます。
execute-snapshot メッセージをシグナルテーブルに送信してキャプチャーするテーブルを指定します。execute-snapshot シグナルのタイプを incremental または blocking に設定し、スナップショットに含めるテーブルの名前を次の表に示すように指定します。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプを指定します。 |
|
| 該当なし |
スナップショットに含めるテーブルの完全修飾名に一致する正規表現を含む配列。 |
|
| 該当なし |
コネクターがスナップショットに含めるレコードのサブセットを決定するために評価する追加条件のセットを指定する、オプションの配列。
|
|
| 該当なし | スナップショット処理中にコネクターがテーブルのプライマリーキーとして使用する列名を指定するオプションの文字列。 |
アドホック増分スナップショットのトリガー
アドホック増分スナップショットを開始するには、execute-snapshot シグナルタイプのエントリーをシグナリングテーブルに追加するか、シグナルメッセージを Kafka シグナリングトピックに送信します。コネクターがメッセージを処理した後に、スナップショット操作を開始します。スナップショットプロセスは、最初と最後のプライマリーキーの値を読み取り、これらの値を各テーブルの開始ポイントおよびエンドポイントとして使用します。テーブルのエントリー数と設定されたチャンクサイズに基づいて、Debezium はテーブルをチャンクに分割し、チャンクごとに 1 度に 1 つずつスナップショットを順番に作成していきます。
詳細は、スナップショットの増分を参照してください。
アドホックブロッキングスナップショットのトリガー
シグナリングテーブルまたはシグナリングトピックに、execute-snapshot シグナルタイプを持つエントリーを追加することによって、アドホックブロッキングスナップショットを開始します。コネクターがメッセージを処理した後に、スナップショット操作を開始します。コネクターはストリーミングを一時的に停止し、初期スナップショットの時と同じプロセスに従って、指定されたテーブルのスナップショットを開始します。スナップショットが完了すると、コネクターはストリーミングを再開します。
詳細は、ブロッキングスナップショット を参照してください。
2.4.1.6. 増分スナップショット
スナップショットを柔軟に管理するため、Debezium には 増分スナップショット と呼ばれる補助スナップショットメカニズムが含まれています。増分スナップショットは、Debezium コネクターにシグナルを送信するため の Debezium メカニズムに依存します。
増分スナップショットでは、最初のスナップショットのように、データベースの完全な状態を一度にすべてキャプチャーする代わりに、一連の設定可能なチャンクで各テーブルを段階的にキャプチャーします。スナップショットがキャプチャーするテーブルと、各チャンクのサイズ を指定できます。チャンクのサイズにより、データベース上の各フェッチ操作中にスナップショットで収集される行数が決まります。増分スナップショットのデフォルトのチャンクサイズは 1024 行です。
増分スナップショットが進むと、Debezium はウォーターマークを使用して進捗を追跡し、キャプチャーする各テーブル行のレコードを管理します。この段階的なアプローチでは、標準の初期スナップショットプロセスと比較して、以下の利点があります。
- スナップショットが完了するまで、ストリーミングストリーミングを延期する代わりに、ストリームしたデータキャプチャーと並行して増分スナップショットを実行できます。コネクターはスナップショットプロセス全体で変更ログからのほぼリアルタイムイベントをキャプチャーし続け、他の操作はブロックしません。
- 増分スナップショットの進捗が中断された場合は、データを失うことなく再開できます。プロセスが再開すると、スナップショットは最初からテーブルをキャプチャーするのではなく、停止した時点から開始します。
-
いつでも増分スナップショットを実行し、必要に応じてプロセスを繰り返してデータベースの更新に適合できます。たとえば、コネクター設定を変更してテーブルを
table.include.listプロパティーに追加した後にスナップショットを再実行します。
増分スナップショットプロセス
増分スナップショットを実行する場合には、Debezium は各テーブルをプライマリーキー別に分類して、設定されたチャンクサイズ に基づいてテーブルをチャンクに分割します。チャンクごとに作業し、テーブルの行ごとにチャンクでキャプチャーします。キャプチャーする行ごとに、スナップショットは READ イベントを出力します。そのイベントは、対象となるチャンクのスナップショットを開始する時の行の値を表します。
スナップショットの作成が進むにつれ、他のプロセスがデータベースへのアクセスを継続し、テーブルレコードが変更される可能性があります。このような変更を反映させるように、通常通りに INSERT、UPDATE、DELETE 操作がトランザクションログにコミットされます。同様に、継続中の Debezium ストリーミングプロセスは、これらの変更イベントを検出し、対応する変更イベントレコードを Kafka に出力します。
Debezium を使用してプライマリーキーが同じレコード間での競合を解決する方法
場合によっては、ストリーミングプロセスが出力する UPDATE または DELETE イベントを順番に受信できます。つまり、ストリーミングプロセスは、スナップショットがその行の READ イベントが含まれるチャンクをキャプチャーする前に、テーブルの行を変更するイベントを生成する可能性があります。スナップショットが最終的に対象の行にあった READ イベントを出力すると、その値はすでに置き換えられています。Debezium は、シーケンスが到達する増分スナップショットイベントが正しい論理順序で処理されるように、競合を解決するためにバッファースキームを使用します。スナップショットのイベント間で競合が発生し、ストリームされたイベントが解決されてからでないと、Debezium はイベントのレコードを Kafka に送信しません。
スナップショットウィンドウ
遅れて入ってきた READ イベントと、同じテーブルの行を変更するストリーミングイベント間の競合の解決を容易にするために、Debezium は スナップショットウィンドウ と呼ばれるものを使用します。スナップショットウィンドウは、増分スナップショットが指定のテーブルチャンクのデータをキャプチャーしている途中に、間隔を決定します。チャンクのスナップショットウィンドウを開く前に、Debezium は通常の動作に従い、トランザクションログから直接ターゲットの Kafka トピックにイベントをダウンストリームに出力します。ただし、特定のチャンクのスナップショットが開放された瞬間から終了するまで、Debezium は重複除去のステップを実行して、プライマリーキーが同じイベント間での競合を解決します。
データコレクションごとに、Debezium は 2 種類のイベントを出力し、それらの両方のレコードを単一の宛先 Kafka トピックに保存します。テーブルから直接キャプチャーするスナップショットレコードは、READ 操作として出力されます。その間、ユーザーはデータコレクションのレコードの更新を続け、各コミットを反映するようにトランザクションログが更新されるので、Debezium は変更ごとに UPDATE または DELETE 操作を出力します。
スナップショットウィンドウが開放され、Debezium がスナップショットチャンクの処理を開始すると、スナップショットレコードをメモリーバッファーに提供します。スナップショットウィンドウ中に、バッファー内の READ イベントのプライマリーキーは、受信ストリームイベントのプライマリーキーと比較されます。一致するものが見つからない場合、ストリーミングされたイベントレコードが Kafka に直接送信されます。Debezium が一致を検出すると、バッファーされた READ イベントを破棄し、ストリーミングされたレコードを宛先トピックに書き込みます。これは、ストリーミングされたイベントが静的スナップショットイベントよりも論理的に優先されるためです。チャンクのスナップショットウィンドウが終了すると、バッファーに含まれるのは、関連するトランザクションログイベントが存在しない READ イベントのみです。Debezium は、これらの残りの READ イベントをテーブルの Kafka トピックに出力します。
コネクターは各スナップショットチャンクにプロセスを繰り返します。
現在、増分スナップショットを開始するには、次のいずれかの方法を使用できます。
2.4.1.6.1. 増分スナップショットのトリガー
増分スナップショットを開始するには、ソースデータベースのシグナリングテーブルに アドホックスナップショットシグナル を送信します。スナップショットシグナルは SQL INSERT クエリーとして送信します。
Debezium がシグナルテーブルの変更を検出すると、シグナルを読み取り、要求されたスナップショット操作を実行します。
送信するクエリーはスナップショットに追加するテーブルを指定し、必要に応じてスナップショット操作の種類を指定します。Debezium は現在、incremental と blocking のスナップショットタイプをサポートしています。
スナップショットに追加するテーブルを指定するには、テーブルをリストする data-collections 配列またはテーブルの照合に使用する正規表現の配列を指定します。以下に例を示します。
{"data-collections": ["public.MyFirstTable", "public.MySecondTable"]}
増分スナップショットシグナルの data-collections アレイにはデフォルト値がありません。data-collections 配列が空の場合、Debezium は空の配列をアクションが必要ないと解釈し、スナップショットは作成しません。
スナップショットに含めるテーブルの名前にドット (.)、スペース、またはその他の英数字以外の文字が含まれている場合は、テーブル名を二重引用符でエスケープする必要があります。
たとえば、db1 データベースに存在し、My.Table という名前のテーブルを含めるには、"db1.\"My.Table\"" の形式を使用します。
前提条件
- ソースデータベースにシグナリングデータコレクションが存在する。
-
シグナルデータコレクションが
signal.data.collectionプロパティーで指定されている。
ソースシグナリングチャネルを使用して増分スナップショットをトリガーする
SQL クエリーを送信し、アドホック増分スナップショット要求をシグナルテーブルに追加します。
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow コマンドの
id、type、およびdataパラメーターの値は、シグナルテーブルのフィールド に対応します。
以下の表では、この例のパラメーターを説明しています。Expand 表2.77 シグナルテーブルに増分スナップショットシグナルを送信する SQL コマンドのフィールドの説明 項目 値 説明 1
database.debezium_signalソースデータベースにあるシグナルテーブルの完全修飾名を指定します。
2
ad-hoc-1idパラメーターは、シグナルリクエストのID識別子として割り当てられる任意の文字列を指定します。
この文字列を使用して、シグナルテーブルのエントリーへのログメッセージを特定します。Debezium はこの文字列を使用しません。代わりに、スナップショット作成中に、Debezium は独自のID文字列をウォーターマークシグナルとして生成します。3
execute-snapshottypeパラメーターを指定し、シグナルがトリガーする操作を指定します。
4
data-collectionsシグナルの
dataフィールドの必須コンポーネントで、スナップショットに含めるテーブル名の配列またはテーブル名と一致する正規表現を指定します。
配列には、database.table形式を使用してテーブルの完全修飾名と一致する正規表現がリストされます。この形式は、コネクターの シグナリングテーブル の名前を指定するために使用する形式と同じです。5
incremental実行するスナップショット操作のタイプを指定する、シグナルの
dataフィールドのオプションのtypeコンポーネント。
有効な値はincrementalとblockingです。
値を指定しない場合、コネクターはデフォルトで増分スナップショットを実行します。6
additional-conditionsコネクターがスナップショットに含めるレコードのサブセットを決定するために評価する追加条件のセットを指定する、オプションの配列。
各追加条件は、data-collectionプロパティーとfilterプロパティーを持つオブジェクトです。データの収集単位で異なるフィルターを指定できます。
*data-collectionプロパティーは、フィルターが適用されるデータコレクションの完全修飾名です。additional-conditionsパラメーターの詳細は、「additional-conditions付きでアドホック増分スナップショットを実行する」 を参照してください。
2.4.1.6.2. additional-conditions 付きでアドホック増分スナップショットを実行する
スナップショットに、テーブル内のコンテンツのサブセットのみを含める場合は、スナップショットシグナルに additional-conditions パラメーターを追加してシグナル要求を変更できます。
一般的なスナップショットの SQL クエリーは、以下の形式を取ります。
SELECT * FROM <tableName> ....
SELECT * FROM <tableName> ....
additional-conditions パラメーターを追加して、以下の例のように WHERE 条件を SQL クエリーに追加します。
SELECT * FROM <data-collection> WHERE <filter> ....
SELECT * FROM <data-collection> WHERE <filter> ....以下の例は、シグナルテーブルに追加の条件を含むアドホック増分スナップショット要求を送信する SQL クエリーを示しています。
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');
たとえば、以下の列が含まれる products テーブルがあるとします。
-
id(プライマリーキー) -
color -
quantity
products テーブルの増分スナップショットに color=blue のデータ項目のみを含める場合は、次の SQL ステートメントを使用してスナップショットをトリガーできます。
INSERT INTO db1.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["db1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "db1.products", "filter": "color=blue"}]}');
INSERT INTO db1.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["db1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "db1.products", "filter": "color=blue"}]}');
additional-conditions パラメーターを使用すると、列が 2 つ以上となる条件を指定することもできます。たとえば、前述の例の products テーブルを使用して、color=blue および quantity>10 だけに一致するアイテムのみのデータが含まれる増分スナップショットをトリガーするクエリーを送信できます。
INSERT INTO db1.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["db1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "db1.products", "filter": "color=blue AND quantity>10"}]}');
INSERT INTO db1.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["db1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "db1.products", "filter": "color=blue AND quantity>10"}]}');以下の例は、コネクターによってキャプチャーされる増分スナップショットイベントの JSON を示しています。
例2.24 増分スナップショットイベントメッセージ
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
実行するスナップショット操作タイプを指定します。 |
| 2 |
|
イベントタイプを指定します。 |
2.4.1.6.3. Kafka シグナルチャネルを使用して増分スナップショットをトリガーする
設定された Kafka トピック にメッセージを送信して、コネクターにアドホック増分スナップショットを実行するよう要求できます。
Kafka メッセージのキーは、topic.prefix コネクター設定オプションの値と一致する必要があります。
メッセージの値は、type と data フィールドが含まれる JSON オブジェクトとなっています。
シグナルタイプは execute-snapshot で、data フィールドには以下のフィールドが必要です。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプ。現在、Debezium は |
|
| 該当なし |
スナップショットに含めるテーブルの完全修飾名と一致する、コンマ区切りの正規表現の配列。 |
|
| 該当なし |
コネクターがスナップショットに含めるレコードのサブセットを指定するために評価する基準を指定する、オプションの追加条件の配列。 |
例2.25 execute-snapshot Kafka メッセージ
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["{collection-container}.table1", "{collection-container}.table2"], "type": "INCREMENTAL"}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["{collection-container}.table1", "{collection-container}.table2"], "type": "INCREMENTAL"}}`additional-conditions 付きのアドホック増分スナップショット
Debezium は additional-conditions フィールドを使用してテーブルのコンテンツのサブセットを選択します。
通常、Debezium はスナップショットを実行するときに、次のような SQL クエリーを実行します。
SELECT * FROM <tableName> ….
スナップショット要求に additional-conditions プロパティーが含まれている場合、プロパティーの data-collection および filter パラメーターが SQL クエリーに追加されます。次に例を示します。
SELECT * FROM <data-collection> WHERE <filter> ….
たとえば、列 id (プライマリーキー)、color、および brand を含む products テーブルがある場合、スナップショットに color='blue' のコンテンツのみを含める場合は、スナップショットをリクエストするときに、コンテンツをフィルタリングする additional-conditions プロパティーを追加することができます。
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.products" ,"filter":"color='blue'"}]}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.products" ,"filter":"color='blue'"}]}}`
また、additional-conditions プロパティーを使用して、複数の列に基づいて条件を渡すこともできます。たとえば、前の例と同じ products テーブルを使用して、color='blue' および brand='MyBrand' である products テーブルのコンテンツのみをスナップショットに含める場合は、次のリクエストを送信できます。
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.products" ,"filter":"color='blue' AND brand='MyBrand'"}]}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.products" ,"filter":"color='blue' AND brand='MyBrand'"}]}}`2.4.1.6.4. 増分スナップショットの停止
状況によっては、増分スナップショットを停止する必要がある場合があります。たとえば、スナップショットが正しく設定されていない場合や、他のデータベース操作にリソースが使用可能であるこのとの確認が必要な場合があります。ソースデータベースのシグナリングテーブルにシグナルを送信することで、すでに実行中のスナップショットを停止できます。
スナップショット停止信号をシグナリングテーブルに送信するには、SQL INSERT クエリーで送信します。stop-snapshot シグナルは、スナップショット操作の type を incremental として指定し、オプションで、現在実行中のスナップショットから省略するテーブルを指定します。Debezium はシグナルテーブルの変更を検出した後、シグナルを読み、増分スナップショット操作が進行中であればそれを停止します。
関連情報
また、JSON メッセージを Kafka シグナリングトピック に送信して、増分スナップショットを停止することもできます。
前提条件
- ソースデータベースにシグナリングデータコレクションが存在する。
-
シグナルデータコレクションが
signal.data.collectionプロパティーで指定されている。
ソースシグナリングチャネルを使用して増分スナップショットを停止する
SQL クエリーを送信して、シグナリングテーブルへのアドホックインクリメンタルスナップショットを停止します。
INSERT INTO <signalTable> (id, type, data) values ('<id>', 'stop-snapshot', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"incremental"}');INSERT INTO <signalTable> (id, type, data) values ('<id>', 'stop-snapshot', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"incremental"}');Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
INSERT INTO db1.debezium_signal (id, type, data) values ('ad-hoc-1', 'stop-snapshot', '{"data-collections": ["db1.table1", "db1.table2"], "type":"incremental"}');INSERT INTO db1.debezium_signal (id, type, data)1 values ('ad-hoc-1',2 'stop-snapshot',3 '{"data-collections": ["db1.table1", "db1.table2"],4 "type":"incremental"}');5 Copy to Clipboard Copied! Toggle word wrap Toggle overflow signal コマンドの
id、type、およびdataパラメーターの値は、シグナルテーブルのフィールド に対応します。
以下の表では、この例のパラメーターを説明しています。Expand 表2.80 シグナリングテーブルに増分スナップショット停止信号を送信するための SQL コマンドのフィールドの説明 項目 値 説明 1
database.debezium_signalソースデータベースにあるシグナルテーブルの完全修飾名を指定します。
2
ad-hoc-1idパラメーターは、シグナルリクエストのID識別子として割り当てられる任意の文字列を指定します。
この文字列を使用して、シグナルテーブルのエントリーへのログメッセージを特定します。Debezium はこの文字列を使用しません。3
stop-snapshottypeパラメーターを指定し、シグナルがトリガーする操作を指定します。
4
data-collectionsシグナルの
dataフィールドのオプションコンポーネントで、スナップショットから削除するテーブル名の配列またはテーブル名とマッチする正規表現を指定します。
配列には、database.tableの形式で完全修飾名でテーブルに一致する正規表現がリストされます。dataフィールドからこのコンポーネントを省略すると、シグナルによって進行中の増分スナップショット全体が停止されます。5
incremental停止するスナップショット操作のタイプを指定する信号の
dataフィールドの必須コンポーネント。
現在、有効な唯一のオプションはincrementalです。typeの値を指定しない場合、シグナルは増分スナップショットの停止に失敗します。
2.4.1.6.5. Kafka シグナリングチャネルを使用して増分スナップショットを停止する
設定された Kafka シグナルトピック にシグナルメッセージを送信して、アドホック増分スナップショットを停止できます。
Kafka メッセージのキーは、topic.prefix コネクター設定オプションの値と一致する必要があります。
メッセージの値は、type と data フィールドが含まれる JSON オブジェクトとなっています。
シグナルタイプは stop-snapshot で、data フィールドには以下のフィールドが必要です。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプ。現在、Debezium は |
|
| 該当なし |
テーブルの完全修飾名に一致する、コンマで区切られた正規表現のオプションの配列、スナップショットから削除するテーブル名に一致するテーブル名または正規表現の配列。 |
次の例は、典型的な stop-snapshot の Kafka メッセージを示しています。
Key = `test_connector`
Value = `{"type":"stop-snapshot","data": {"data-collections": ["db1.table1", "db1.table2"], "type": "INCREMENTAL"}}`
Key = `test_connector`
Value = `{"type":"stop-snapshot","data": {"data-collections": ["db1.table1", "db1.table2"], "type": "INCREMENTAL"}}`2.4.1.7. ブロッキングスナップショット
スナップショットをより柔軟に管理するために、Debezium には ブロッキングスナップショット と呼ばれる補助アドホックスナップショットメカニズムが含まれています。ブロッキングスナップショットは、Debezium コネクターにシグナルを送信 するための Debezium メカニズムに依存します。
ブロッキングスナップショットは、ランタイム時にトリガーできることを除いて、初期スナップショット と同じように動作します。
次のような状況では、標準の初期スナップショットプロセスを使用するのではなく、ブロッキングスナップショットを実行する必要があります。
- 新しいテーブルを追加し、コネクターの実行中にスナップショットを完了したいと考えている。
- 大きなテーブルを追加し、増分スナップショットよりも短い時間でスナップショットを完了したいと考えている。
ブロッキングスナップショットのプロセス
ブロッキングスナップショットを実行すると、Debezium はストリーミングを停止し、初期スナップショットの時と同じプロセスに従って、指定されたテーブルのスナップショットを開始します。スナップショットが完了すると、ストリーミングが再開されます。
スナップショットの設定
シグナルの data コンポーネントでは、次のプロパティーを設定できます。
- data-collections: スナップショットする必要のあるテーブルを指定します。
additional-conditions: テーブルごとに異なるフィルターを指定できます。
-
data-collectionプロパティーは、フィルターが適用されるテーブルの完全修飾名です。 -
filterプロパティーは、snapshot.select.statement.overridesで使用される値と同じになります。
-
以下に例を示します。
{"type": "blocking", "data-collections": ["schema1.table1", "schema1.table2"], "additional-conditions": [{"data-collection": "schema1.table1", "filter": "SELECT * FROM [schema1].[table1] WHERE column1 = 0 ORDER BY column2 DESC"}, {"data-collection": "schema1.table2", "filter": "SELECT * FROM [schema1].[table2] WHERE column2 > 0"}]}
{"type": "blocking", "data-collections": ["schema1.table1", "schema1.table2"], "additional-conditions": [{"data-collection": "schema1.table1", "filter": "SELECT * FROM [schema1].[table1] WHERE column1 = 0 ORDER BY column2 DESC"}, {"data-collection": "schema1.table2", "filter": "SELECT * FROM [schema1].[table2] WHERE column2 > 0"}]}重複の可能性
スナップショットをトリガーするシグナルを送信した時点と、ストリーミングが停止してスナップショットが開始する時点との間に遅延が生じる可能性があります。この遅延の結果、スナップショットが完了した後、コネクターはスナップショットがキャプチャーしたレコードと重複するイベントレコードを発行する可能性があります。
2.4.1.8. Debezium MySQL 変更イベントレコードを受信する Kafka トピックのデフォルト名
デフォルトでは、MySQL コネクターは、テーブルで発生するすべての INSERT、UPDATE、DELETE 操作の変更イベントを、そのテーブルに固有の単一の Apache Kafka トピックに書き込みます。
コネクターは以下の規則を使用して変更イベントトピックに名前を付けます。
topicPrefix.databaseName.tableName
fulfillment はトピック接頭辞、inventory はデータベース名で、データベースに orders、customers、および productsという名前のテーブルが含まれるとします。Debezium MySQL コネクターは、データベースのテーブルごとに 1 つずつ、3 つの Kafka トピックにイベントを出力します。
fulfillment.inventory.orders fulfillment.inventory.customers fulfillment.inventory.products
fulfillment.inventory.orders
fulfillment.inventory.customers
fulfillment.inventory.products以下のリストは、デフォルト名のコンポーネントの定義を示しています。
- topicPrefix
-
topic.prefixコネクター設定プロパティーで指定されたトピック接頭辞。 - schemaName
- 操作が発生したスキーマの名前。
- tableName
- 操作が発生したテーブルの名前。
コネクターは同様の命名規則を適用して、内部データベーススキーマの履歴トピック (スキーマ変更トピック と トランザクションメタデータトピック) にラベルを付けます。
デフォルトのトピック名が要件を満たさない場合は、カスタムトピック名を設定できます。カスタムトピック名を設定するには、論理トピックルーティング SMT に正規表現を指定します。論理トピックルーティング SMT を使用してトピックの命名をカスタマイズする方法は、トピックルーティング を参照してください。
トランザクションメタデータ
Debezium は、トランザクション境界を表し、データ変更イベントメッセージを強化するイベントを生成できます。
Debezium は、コネクターのデプロイ後に発生するトランザクションに対してのみメタデータを登録し、受信します。コネクターをデプロイする前に発生するトランザクションのメタデータは利用できません。
Debezium は、すべてのトランザクションで BEGIN および END 区切り文字のトランザクション境界イベントを生成します。トランザクション境界イベントには以下のフィールドが含まれます。
status-
BEGINまたはEND id- 一意のトランザクション識別子の文字列表現。
ts_ms-
データソースでのトランザクション境界イベント (
BEGINまたはENDイベント) の時間。データソースから Debezium にイベント時間を渡されない場合、フィールドは代わりに Debezium がイベントを処理する時間を表します。 event_count(ENDイベント用)- トランザクションによって出力されるイベントの合計数。
data_collections(ENDイベント用)-
data_collectionとevent_count要素のペアの配列。これは、コネクターがデータコレクションから発信された変更に対して出力するイベントの数を示します。
例
topic.transaction オプションで上書きされない限り、コネクターはトランザクションイベントを <topic.prefix>.transaction トピックに出力します。
変更データイベントのエンリッチメント
トランザクションメタデータを有効にすると、データメッセージ Envelope は新しい transaction フィールドで強化されます。このフィールドは、複合フィールドの形式ですべてのイベントに関する情報を提供します。
id- 一意のトランザクション識別子の文字列表現。
total_order- トランザクションによって生成されたすべてのイベントを対象とするイベントの絶対位置。
data_collection_order- トランザクションによって出力されたすべてのイベントを対象とするイベントのデータコレクションごとの位置。
以下は、メッセージの例になります。
2.4.2. Debezium MySQL コネクターのデータ変更イベントの説明
Debezium MySQL コネクターは、行レベルの INSERT、UPDATE、および DELETE 操作ごとにデータ変更イベントを生成します。各イベントにはキーと値が含まれます。キーと値の構造は、変更されたテーブルによって異なります。
Debezium および Kafka Connect は、イベントメッセージの継続的なストリーム を中心として設計されています。ただし、これらのイベントの構造は時間の経過とともに変化する可能性があり、コンシューマーによる処理が困難になることがあります。これに対応するために、各イベントにはコンテンツのスキーマが含まれます。スキーマレジストリーを使用している場合は、コンシューマーがレジストリーからスキーマを取得するために使用できるスキーマ ID が含まれます。これにより、各イベントが自己完結型になります。
以下のスケルトン JSON は、変更イベントの基本となる 4 つの部分を示しています。ただし、アプリケーションで使用するために選択した Kafka Connect コンバーターの設定方法によって、変更イベントのこれら 4 部分の表現が決定されます。schema フィールドは、変更イベントが生成されるようにコンバーターを設定した場合のみ変更イベントに含まれます。同様に、イベントキーおよびイベントペイロードは、変更イベントが生成されるようにコンバーターを設定した場合のみ変更イベントに含まれます。JSON コンバーターを使用し、変更イベントの基本となる 4 つの部分すべてを生成するように設定すると、変更イベントの構造は次のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
最初の |
| 2 |
|
最初の |
| 3 |
|
2 つ目の |
| 4 |
|
2 つ目の |
デフォルトでは、コネクターによって、変更イベントレコードがイベントの元のテーブルと同じ名前を持つトピックにストリーミングされます。トピック名 を参照してください。
MySQL コネクターは、すべての Kafka Connect スキーマ名が Avro スキーマ名の形式 に準拠するようにします。つまり、論理サーバー名はアルファベットまたはアンダースコア (a-z、A-Z、または _) で始まる必要があります。論理サーバー名の残りの各文字と、データベース名とテーブル名の各文字は、アルファベット、数字、またはアンダースコア ( a-z、A-Z、0-9、または _) でなければなりません。無効な文字がある場合は、アンダースコアに置き換えられます。
論理サーバー名、データベース名、またはテーブル名に無効な文字が含まれ、名前を区別する唯一の文字が無効であると、無効な文字はすべてアンダースコアに置き換えられるため、予期せぬ競合が発生する可能性があります。
詳細は以下を参照してください。
2.4.2.1. Debezium MySQL 変更イベントのキー
変更イベントのキーには、変更されたテーブルのキーのスキーマと、変更された行の実際のキーのスキーマが含まれます。スキーマとそれに対応するペイロードの両方には、コネクターによってイベントが作成された時点において、変更されたテーブルの PRIMARY KEY (または一意の制約) に存在した各列のフィールドが含まれます。
以下の customers テーブルについて考えてみましょう。この後に、このテーブルの変更イベントキーの例を示します。
customers テーブルへの変更をキャプチャーする変更イベントのすべてに、イベントキースキーマがあります。customers テーブルに前述の定義がある限り、customers テーブルへの変更をキャプチャーする変更イベントのキー構造はすべて以下のようになります。JSON では、以下のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
キーのスキーマ部分は、キーの |
| 2 |
|
キーのペイロードの構造を定義するスキーマの名前。このスキーマは、変更されたテーブルのプライマリーキーの構造を記述します。キースキーマ名の形式は connector-name.database-name.table-name.
|
| 3 |
|
イベントキーの |
| 4 |
|
各フィールドの名前、型、および必要かどうかなど、 |
| 5 |
|
この変更イベントが生成された行のキーが含まれます。この例では、キーには値が |
2.4.2.2. Debezium MySQL 変更イベントの値
変更イベントの値はキーよりも若干複雑です。キーと同様に、値には schema セクションと payload セクションがあります。schema セクションには、入れ子のフィールドを含む、Envelope セクションの payload 構造を記述するスキーマが含まれています。データを作成、更新、または削除する操作のすべての変更イベントには、Envelope 構造を持つ値 payload があります。
変更イベントキーの例を紹介するために使用した、同じサンプルテーブルについて考えてみましょう。
このテーブルへの変更に対する変更イベントの値部分には以下について記述されています。
create イベント
以下の例は、customers テーブルにデータを作成する操作に対して、コネクターによって生成される変更イベントの値の部分を示しています。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
| 値のペイロードの構造を記述する、値のスキーマ。変更イベントの値スキーマは、コネクターが特定のテーブルに生成するすべての変更イベントで同じになります。 |
| 2 |
|
|
| 3 |
|
|
| 4 |
|
|
| 5 |
|
値の実際のデータ。これは、変更イベントが提供する情報です。 |
| 6 |
|
コネクターによってイベントが生成される原因となった操作の型を記述する必須文字列。この例では、
|
| 7 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 8 |
|
イベント発生前の行の状態を指定する任意のフィールド。この例のように、 |
| 9 |
|
イベント発生後の行の状態を指定する任意のフィールド。この例では、 |
| 10 |
| イベントのソースメタデータを記述する必須のフィールド。このフィールドには、イベントの発生元、イベントの発生順序、およびイベントが同じトランザクションの一部であるかどうかなど、このイベントと他のイベントを比較するために使用できる情報が含まれています。ソースメタデータには以下が含まれています。
|
更新イベント
サンプル customers テーブルにある更新の変更イベントの値には、そのテーブルの 作成 イベントと同じスキーマがあります。同様に、イベント値のペイロードは同じ構造を持ちます。ただし、イベント値ペイロードでは 更新 イベントに異なる値が含まれます。以下は、コネクターによって customers テーブルでの更新に生成されるイベントの変更イベント値の例になります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
イベント発生前の行の状態を指定する任意のフィールド。更新 イベント値の |
| 2 |
|
イベント発生後の行の状態を指定する任意のフィールド。 |
| 3 |
|
イベントのソースメタデータを記述する必須のフィールド。
|
| 4 |
|
操作の型を記述する必須の文字列。更新 イベントの値では、 |
| 5 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 6 |
| コネクターがイベントを処理した時間をマイクロ秒単位で表示するオプションフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 7 |
| コネクターがイベントを処理した時間をナノ秒単位で表示するオプションフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
行のプライマリーキー/一意キーの列を更新すると、行のキーの値が変更されます。キーが変更されると、3 つのイベントが Debezium によって出力されます。3 つのイベントとは、DELETE イベント、行の古いキーを持つ 廃棄 (tombstone)、およびそれに続く行の新しいキーを持つイベントです。詳細は次のセクションで説明します。
プライマリーキーの更新
行のプライマリーキーフィールドを変更する UPDATE 操作は、プライマリーキーの変更と呼ばれます。プライマリーキーの変更では、UPDATE イベントレコードの代わりにコネクターが古いキーの DELETE イベントレコードと、新しい (更新された) キーの CREATE イベントレコードを出力します。これらのイベントには通常の構造と内容があり、イベントごとにプライマリーキーの変更に関連するメッセージヘッダーがあります。
-
DELETEイベントレコードには、メッセージヘッダーとして__debezium.newkeyが含まれます。このヘッダーの値は、更新された行の新しいプライマリーキーです。 -
CREATEイベントレコードには、メッセージヘッダーとして__debezium.oldkeyが含まれます。このヘッダーの値は、更新された行にあった以前の (古い) プライマリーキーです。
delete イベント
削除 変更イベントの値は、同じテーブルの 作成 および 更新 イベントと同じ schema の部分になります。サンプル customers テーブルの 削除 イベントの payload 部分は以下のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
イベント発生前の行の状態を指定する任意のフィールド。削除 イベント値の |
| 2 |
|
イベント発生後の行の状態を指定する任意のフィールド。削除 イベント値の |
| 3 |
|
イベントのソースメタデータを記述する必須のフィールド。削除 イベント値の
|
| 4 |
|
操作の型を記述する必須の文字列。 |
| 5 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 6 |
| コネクターがイベントを処理した時間をマイクロ秒単位で表示するオプションフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 7 |
| コネクターがイベントを処理した時間をナノ秒単位で表示するオプションフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
削除 変更イベントレコードは、この行の削除を処理するために必要な情報を持つコンシューマーを提供します。コンシューマーによっては、削除を適切に処理するために古い値が必要になることがあるため、古い値が含まれます。
MySQL コネクターイベントは、Kafka のログコンパクション と動作するように設計されています。ログコンパクションにより、少なくとも各キーの最新のメッセージが保持される限り、一部の古いメッセージを削除できます。これにより、トピックに完全なデータセットが含まれ、キーベースの状態のリロードに使用できるようにするとともに、Kafka がストレージ領域を確保できるようにします。
tombstone イベント
行が削除された場合でも、Kafka は同じキーを持つ以前のメッセージをすべて削除できるため、削除 イベントの値はログコンパクションで動作します。ただし、Kafka が同じキーを持つすべてのメッセージを削除するには、メッセージの値が null である必要があります。これを可能にするために、Debezium MySQL コネクターは delete イベントを発行した後、null 値以外の同じキーを持つ特別な tombstone イベントを発行します。
truncate イベント
truncate 変更イベントは、テーブルが切り捨てられたことを通知します。truncate イベントのメッセージキーが null です。メッセージの値は次の例のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
イベントのソースメタデータを記述する必須のフィールド。切り捨て (truncate) イベント値の
|
| 2 |
|
操作の型を記述する必須の文字列。 |
| 3 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 4 |
| コネクターがイベントを処理した時間をマイクロ秒単位で表示するオプションフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
| 5 |
| コネクターがイベントを処理した時間をナノ秒単位で表示するオプションフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
1 つの TRUNCATE ステートメントが複数のテーブルに適用された場合、切り捨てられたテーブルごとに 1 つの切り捨て (truncate) 変更イベントレコードが出力されます。
truncate イベントはテーブル全体に適用される変更を表し、メッセージキーはありません。複数のパーティションにまたがるトピックでは、テーブル全体に適用される変更イベントの順序は保証されません。つまり、(create、update など) やそのテーブルの truncate イベントの順序は保証されません。コンシューマーが異なるパーティションからイベントを読み取る場合、2 番目のパーティションから同じテーブルの truncate イベントを読み取った後にのみ、1 つのパーティションからテーブルの update イベントを読み取ることがあります。
2.4.3. Debezium MySQL コネクターによるデータ型のマッピング方法
Debezium MySQL コネクターは、行が存在するテーブルのように構造化されたイベントで行への変更を表します。イベントには、各列の値のフィールドが含まれます。その列の MySQL データ型は、イベントの値を表す方法を指定します。
文字列を格納する列は、文字セットと照合順序を使用して MySQL に定義されます。MySQL コネクターは、binlog イベントの列値のバイナリー表現を読み取るときに、列の文字セットを使用します。
コネクターは MySQL データ型を リテラル 型および セマンティック 型の両方にマップできます。
- リテラル型: Kafka Connect スキーマタイプを使用して値がどのように表されるか。
- セマンティック型: Kafka Connect スキーマがどのようにフィールド (スキーマ名) の意味をキャプチャーするか。
デフォルトのデータ型変換が要件に合わない場合は、コネクター用の カスタムコンバーターの作成 が可能です。
詳細は以下を参照してください。
基本型
以下の表は、コネクターによる基本的な MySQL データ型のマッピング方法を示しています。
| MySQL 型 | リテラル型 | セマンティック型 |
|---|---|---|
|
|
| 該当なし |
|
|
| 該当なし |
|
|
|
|
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
|
精度は、ストレージサイズを決定するためにのみ使用されます。0 から 23 までの精度 |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
|
該当なし |
|
|
|
該当なし |
|
|
|
該当なし |
|
|
| 該当なし |
|
|
|
該当なし |
|
|
|
n/a |
|
|
|
該当なし |
|
|
| 該当なし |
|
|
|
該当なし |
|
|
|
n/a |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
.
時間型
TIMESTAMP データ型を除き、MySQL の時間型は time.precision.mode コネクター設定プロパティーの値によって異なります。デフォルト値が CURRENT_TIMESTAMP または NOW として指定される TIMESTAMP 列では、Kafka Connect スキーマのデフォルト値として値 1970-01-01 00:00:00 が使用されます。
MySQL では、ゼロの値は null よりも優先されることがあるため、DATE、DATETIME、および TIMESTAMP 列にゼロの値を使用できます。MySQL コネクターは、列定義で null 値が許可される場合はゼロの値を null 値として表し、列で null 値が許可されない場合はエポック日として表します。
タイムゾーンのない時間型
DATETIME 型は、"2018-01-13 09:48:27" のようにローカルの日時を表します。タイムゾーンの情報は含まれません。このような列は、UTC を使用して列の精度に基づいてエポックミリ秒またはマイクロ秒に変換されます。TIMESTAMP 型は、タイムゾーン情報のないタイムスタンプを表します。これは、書き込み時に MySQL によってサーバー (またはセッション) の現在のタイムゾーンから UTC に変換され、値を読み戻すときに UTC からサーバー (またはセッション) の現在のタイムゾーンに変換されます。以下に例を示します。
-
値が
2018-06-20 06:37:03のDATETIMEは、1529476623000になります。 -
値が
2018-06-20 06:37:03のTIMESTAMPは2018-06-20T13:37:03Zになります。
このような列は、サーバー (またはセッション) の現在のタイムゾーンに基づいて、UTC の同等の io.debezium.time.ZonedTimestamp に変換されます。タイムゾーンは、デフォルトでサーバーからクエリーされます。
Kafka Connect および Debezium を実行している JVM のタイムゾーンは、これらの変換には影響しません。
時間値に関連するプロパティーの詳細は、MySQL コネクター設定プロパティー のドキュメントを参照してください。
- time.precision.mode=adaptive_time_microseconds(default)
MySQL コネクターは、イベントがデータベースの値を正確に表すようにするため、列のデータ型定義に基づいてリテラル型とセマンテック型を判断します。すべての時間フィールドはマイクロ秒単位です。正しくキャプチャーされる
TIMEフィールドの値は、範囲が00:00:00.000000から23:59:59.999999までの正の値です。Expand 表2.89 time.precision.mode=adaptive_time_microseconds の場合のマッピング MySQL 型 リテラル型 セマンティック型 DATEINT32io.debezium.time.Date
エポックからの日数を表します。TIME[(M)]INT64io.debezium.time.MicroTime
時間の値をマイクロ秒単位で表し、タイムゾーン情報は含まれません。MySQL では、Mを0-6の範囲にすることができます。DATETIME, DATETIME(0), DATETIME(1), DATETIME(2), DATETIME(3)INT64io.debezium.time.Timestamp
エポックからの経過時間をミリ秒で表し、タイムゾーン情報は含まれません。DATETIME(4), DATETIME(5), DATETIME(6)INT64io.debezium.time.MicroTimestamp
エポックからの経過時間をマイクロ秒で表し、タイムゾーン情報は含まれません。- time.precision.mode=connect
MySQL コネクターは定義された Kafka Connect の論理型を使用します。この方法はデフォルトの方法よりも精度が低く、データベース列に
3を超える 少数秒の精度値がある場合は、イベントの精度が低くなる可能性があります。00:00:00.000から23:59:59.999までの値のみを処理できます。テーブルのtime.precision.mode=connectの値が、必ずサポートされる範囲内になるようにすることができる場合のみ、TIMEを設定します。connect設定は、今後の Debezium バージョンで削除される予定です。Expand 表2.90 time.precision.mode=connect の場合のマッピング MySQL 型 リテラル型 セマンティック型 DATEINT32org.apache.kafka.connect.data.Date
エポックからの日数を表します。TIME[(M)]INT64org.apache.kafka.connect.data.Time
午前 0 時以降の時間値をマイクロ秒で表し、タイムゾーン情報は含まれません。DATETIME[(M)]INT64org.apache.kafka.connect.data.Timestamp
エポックからの経過時間をミリ秒で表し、タイムゾーン情報は含まれません。
10 進数型
Debezium コネクターは、decimal.handling.mode コネクター設定プロパティーの設定に従って小数を処理します。
- decimal.handling.mode=precise
Expand 表2.91 decimal.handling.mode=precise の場合のマッピング MySQL 型 リテラル型 セマンティック型 NUMERIC[(M[,D])]BYTESorg.apache.kafka.connect.data.Decimal
scaleスキーマパラメーターには、小数点を移動した桁数を表す整数が含まれます。DECIMAL[(M[,D])]BYTESorg.apache.kafka.connect.data.Decimal
scaleスキーマパラメーターには、小数点を移動した桁数を表す整数が含まれます。- decimal.handling.mode=double
Expand 表2.92 decimal.handling.mode=double の場合のマッピング MySQL 型 リテラル型 セマンティック型 NUMERIC[(M[,D])]FLOAT64該当なし
DECIMAL[(M[,D])]FLOAT64該当なし
- decimal.handling.mode=string
Expand 表2.93 decimal.handling.mode=string の場合のマッピング MySQL 型 リテラル型 セマンティック型 NUMERIC[(M[,D])]STRING該当なし
DECIMAL[(M[,D])]STRING該当なし
ブール値
MySQL は、特定の方法で BOOLEAN の値を内部で処理します。BOOLEAN 列は、内部で TINYINT(1) データ型にマッピングされます。ストリーミング中にテーブルが作成されると、Debezium は元の DDL を受信するため、適切な BOOLEAN マッピングが使用されます。スナップショットの作成中、Debezium は SHOW CREATE TABLE を実行して、BOOLEAN と TINYINT(1) の両方の列に TINYINT(1) を返すテーブル定義を取得します。その後、Debezium は元の型のマッピングを取得する方法はないため、TINYINT(1) にマッピングします。
ソース列をブール型に変換できるように、Debezium は TinyIntOneToBooleanConverter カスタムコンバーター を提供しており、以下のいずれかの方法で使用できます。
-
すべての
TINYINT(1)またはTINYINT(1) UNSIGNED列をBOOLEAN型にマップします。 正規表現のコンマ区切りリストを使用して、列のサブセットを列挙します。
このタイプの変換を使用するには、以下の例のようにselectorパラメーターを使用してconverters設定プロパティーを設定する必要があります。converters=boolean boolean.type=io.debezium.connector.binlog.converters.TinyIntOneToBooleanConverter boolean.selector=db1.table1.*, db1.table2.column1
converters=boolean boolean.type=io.debezium.connector.binlog.converters.TinyIntOneToBooleanConverter boolean.selector=db1.table1.*, db1.table2.column1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意: 場合によっては、スナップショットが
SHOW CREATE TABLEを実行したときに、データベースがtinyint unsignedの長さを表示されないため、このコンバーターは機能しません。新しいオプションlength.checkerはこの問題を解決することができます。デフォルト値はtrueです。次の例に示すように、length.checkerを無効にして、タイプに基づいてすべての列を変換するのではなく、変換が必要な列をselectedプロパティーに指定します。converters=boolean boolean.type=io.debezium.connector.binlog.converters.TinyIntOneToBooleanConverter boolean.length.checker=false boolean.selector=db1.table1.*, db1.table2.column1
converters=boolean boolean.type=io.debezium.connector.binlog.converters.TinyIntOneToBooleanConverter boolean.length.checker=false boolean.selector=db1.table1.*, db1.table2.column1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
空間型
現在、Debezium MySQL コネクターは以下の空間データ型をサポートしています。
| MySQL 型 | リテラル型 | セマンティック型 |
|---|---|---|
|
|
|
|
2.4.4. MySQL データを代替データ型にマッピングするためのカスタムコンバーター
デフォルトでは、Debezium MySQL コネクターは、MySQL データ型用の CustomConverter 実装を複数提供します。これらのカスタムコンバーターは、コネクター設定に基づいて特定のデータ型に対する代替マッピングを提供します。コネクターに CustomConverter を追加するには、カスタムコンバーターのドキュメント の指示に従ってください。
TINYINT(1) からブール値
デフォルトでは、コネクターのスナップショット中に、Debezium MySQL コネクターは JDBC ドライバーから列タイプを取得し、BOOLEAN 列に TINYINT(1) タイプを割り当てます。Debezium はこれらの JDBC 列タイプを使用して、スナップショットイベントのスキーマを定義します。コネクターがスナップショットからストリーミングフェーズに移行した後、デフォルトのマッピングから生じる変更イベントスキーマによって、BOOLEAN 列のマッピングが不整合になる可能性があります。MySQL が BOOLEAN 列を均一に出力するようにするには、次の設定例に示すように、カスタム TinyIntOneToBooleanConverter を適用できます。
例: TinyIntOneToBooleanConverter の設定
converters=tinyint-one-to-boolean tinyint-one-to-boolean.type=io.debezium.connector.binlog.converters.TinyIntOneToBooleanConverter tinyint-one-to-boolean.selector=.*.MY_TABLE.DATA tinyint-one-to-boolean.length.checker=false
converters=tinyint-one-to-boolean
tinyint-one-to-boolean.type=io.debezium.connector.binlog.converters.TinyIntOneToBooleanConverter
tinyint-one-to-boolean.selector=.*.MY_TABLE.DATA
tinyint-one-to-boolean.length.checker=false
前の例では、selector と length.checker プロパティーはオプションです。デフォルトでは、コンバーターは TINYINT データ型の長さが 1 であることをチェックします。length.checker が false の場合、コンバーターは TINYINT データ型の長さが 1 であることをを明示的に確認しません。selector は、指定された正規表現に基づいて、変換するテーブルまたは列を指定します。selector プロパティーを省略すると、コンバーターはすべての TINYINT 列を論理 BOOL フィールドタイプにマップします。selector オプションを設定せず、TINYINT 列を TINYINT(1) にマップする場合は、length.checker プロパティーを省略するか、その値を true に設定します。
JDBC sink のデータ型
Debezium JDBC sink コネクターを Debezium MySQL ソースコネクターと統合すると、MySQL コネクターはスナップショットフェーズとストリーミングフェーズ中に一部の列属性を異なる方法で出力します。JDBC sink コネクターがスナップショットフェーズとストリーミングフェーズの両方からの変更を一貫して使用するには、次の例に示すように、MySQL ソースコネクター設定の一部として JdbcSinkDataTypesConverter コンバーターを含める必要があります。
例: JdbcSinkDataTypesConverter 設定
前の例では、selector.* および treat.real.as.double 設定プロパティーはオプションです。
selector.* プロパティーは、コンバーターが適用されるテーブルと列を指定する正規表現のコンマ区切りリストを指定します。デフォルトでは、コンバーターはすべてのテーブルに含まれるすべてのブール値、実数、および文字列ベースの列データ型に次のルールを適用します。
-
BOOLEANデータ型は常にINT16論理型として出力され、1はtrue、0はfalseを表します。 -
REALデータ型は常にFLOAT64論理型として出力されます。 -
文字列ベースの列には、列の文字セットを含む
__debezium.source.column.character_setスキーマパラメーターが常に含まれます。
各データ型について、デフォルトのスコープをオーバーライドし、セレクターを特定のテーブルと列にのみ適用するセレクタールールを設定できます。たとえば、ブールコンバーターのスコープを設定するには、前の例のように、 converters.jdbc-sink.selector.boolean=.*.MY_TABLE.BOOL_COL のルールをコネクター設定に追加します。
2.4.5. Debezium コネクターを実行するための MySQL の設定
Debezium をインストールおよび実行する前に、一部の MySQL 設定タスクが必要になります。
詳細は以下を参照してください。
2.4.5.1. Debezium コネクターの MySQL ユーザーの作成
Debezium MySQL コネクターには MySQL ユーザーアカウントが必要です。この MySQL ユーザーは、Debezium MySQL コネクターが変更をキャプチャーするすべてのデータベースに対して適切なパーミッションを持っている必要があります。
前提条件
- MySQL サーバー。
- SQL コマンドの基本知識。
手順
MySQL ユーザーを作成します。
mysql> CREATE USER 'user'@'localhost' IDENTIFIED BY 'password';
mysql> CREATE USER 'user'@'localhost' IDENTIFIED BY 'password';Copy to Clipboard Copied! Toggle word wrap Toggle overflow 必要なパーミッションをユーザーに付与します。
mysql> GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user' IDENTIFIED BY 'password';
mysql> GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user' IDENTIFIED BY 'password';Copy to Clipboard Copied! Toggle word wrap Toggle overflow 必要なパーミッションの説明は、表2.95「ユーザーパーミッションの説明」 を参照してください。
重要グローバル読み取りロックを許可しない Amazon RDS や Amazon Aurora などのホストオプションを使用している場合、テーブルレベルのロックを使用して 整合性スナップショット を作成します。この場合、作成するユーザーに
LOCK TABLESパーミッションも付与する必要があります。詳細は、スナップショット を参照してください。ユーザーのパーミッションの最終処理を行います。
mysql> FLUSH PRIVILEGES;
mysql> FLUSH PRIVILEGES;Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.95 ユーザーパーミッションの説明 キーワード 説明 SELECTコネクターがデータベースのテーブルから行を選択できるようにします。これは、スナップショットを実行する場合にのみ使用されます。
RELOAD内部キャッシュのクリアまたはリロード、テーブルのフラッシュ、またはロックの取得を行う
FLUSHステートメントをコネクターが使用できるようにします。これは、スナップショットを実行する場合にのみ使用されます。SHOW DATABASESSHOW DATABASEステートメントを実行して、コネクターがデータベース名を確認できるようにします。これは、スナップショットを実行する場合にのみ使用されます。REPLICATION-SLAVEコネクターが MySQL サーバーの binlog に接続し、読み取りできるようにします。
REPLICATION CLIENTコネクターが以下のステートメントを使用できるようにします。
-
SHOW MASTER STATUS -
SHOW SLAVE STATUS -
SHOW BINARY LOGS
これは必ずコネクターに必要です。
ONパーミッションが適用されるデータベースを指定します。
TO 'user'パーミッションを付与するユーザーを指定します。
IDENTIFIED BY 'password'ユーザーの MySQL パスワードを指定します。
-
2.4.5.2. Debezium の MySQL binlog の有効化
MySQL レプリケーションのバイナリーロギングを有効にする必要があります。バイナリーログは、レプリカが変更を伝播できるようにトランザクションの更新を記録します。
前提条件
- MySQL サーバー。
- 適切な MySQL ユーザーの権限。
手順
-
log-binオプションが有効になっているかどうかを確認します。 binlog が
OFFの場合は、以下の表のプロパティーを MySQL サーバーの設定に追加します。server-id = 223344 # Querying variable is called server_id, e.g. SELECT variable_value FROM information_schema.global_variables WHERE variable_name='server_id'; log_bin = mysql-bin binlog_format = ROW binlog_row_image = FULL binlog_expire_logs_seconds = 864000
server-id = 223344 # Querying variable is called server_id, e.g. SELECT variable_value FROM information_schema.global_variables WHERE variable_name='server_id'; log_bin = mysql-bin binlog_format = ROW binlog_row_image = FULL binlog_expire_logs_seconds = 864000Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 再度 binlog の状態をチェックして、変更を確認します。
Amazon RDS で MySQL を実行する場合、バイナリーロギングを実行するには、データベースインスタンスの自動バックアップを有効にする必要があります。データベースインスタンスが自動バックアップを実行するように設定されていないと、前の手順で説明した設定を適用しても binlog は無効になります。
Expand 表2.96 MySQL binlog 設定プロパティーの説明 プロパティー 説明 server-idserver-idの値は、MySQL クラスターの各サーバーおよびレプリケーションクライアントに対して一意である必要があります。log_binlog_binの値は、binlog ファイルのシーケンスのベース名です。binlog_formatbinlog-formatはROWまたはrowに設定する必要があります。binlog_row_imagebinlog_row_imageはFULLまたはfullに設定する必要があります。binlog_expire_logs_secondsbinlog_expire_logs_secondsは、非推奨のシステム変数expire_logs_daysに対応します。これは、binlog ファイルを自動的に削除する秒数です。デフォルト値は2592000で、つまり、30 日です。実際の環境に見合った値を設定します。詳細は、MySQL による binlog ファイルの消去 を参照してください。
2.4.5.3. Debezium の MySQL グローバルトランザクション識別子の有効化
グローバルトランザクション識別子 (GTID) は、クラスター内のサーバーで発生するトランザクションを一意に識別します。Debezium MySQL コネクターには必要ありませんが、GTID を使用すると、レプリケーションを単純化し、プライマリーサーバーとレプリカサーバーの一貫性が保たれるかどうかを簡単に確認することができます。
GTID は MySQL 5.6.5 以降で利用できます。詳細は MySQL のドキュメント を参照してください。
前提条件
- MySQL サーバー。
- SQL コマンドの基本知識。
- MySQL 設定ファイルへのアクセス。
手順
gtid_modeを有効にします。mysql> gtid_mode=ON
mysql> gtid_mode=ONCopy to Clipboard Copied! Toggle word wrap Toggle overflow enforce_gtid_consistencyを有効にします。mysql> enforce_gtid_consistency=ON
mysql> enforce_gtid_consistency=ONCopy to Clipboard Copied! Toggle word wrap Toggle overflow 変更を確認します。
mysql> show global variables like '%GTID%';
mysql> show global variables like '%GTID%';Copy to Clipboard Copied! Toggle word wrap Toggle overflow 結果
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.97 GTID オプションの説明 オプション 説明 gtid_modeMySQL サーバーの GTID モードが有効かどうかを指定するブール値。
-
ON= 有効化 -
OFF= 無効化
enforce_gtid_consistencyトランザクションに安全な方法でログに記録できるステートメントの実行を許可することにより、サーバーが GTID の整合性を強制するかどうかを指定するブール値。GTID を使用する場合に必須です。
-
ON= 有効化 -
OFF= 無効化
-
2.4.5.4. Debezium の MySQL セッションタイムアウトの設定
大規模なデータベースに対して最初の整合性スナップショットが作成されると、テーブルの読み込み時に、確立された接続がタイムアウトする可能性があります。MySQL 設定ファイルで interactive_timeout と wait_timeout を設定すると、この動作の発生を防ぐことができます。
前提条件
- MySQL サーバー。
- SQL コマンドの基本知識。
- MySQL 設定ファイルへのアクセス。
手順
interactive_timeoutを設定します。mysql> interactive_timeout=<duration-in-seconds>
mysql> interactive_timeout=<duration-in-seconds>Copy to Clipboard Copied! Toggle word wrap Toggle overflow wait_timeoutを設定します。mysql> wait_timeout=<duration-in-seconds>
mysql> wait_timeout=<duration-in-seconds>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.98 MySQL セッションタイムアウトオプションの説明 オプション 説明 interactive_timeoutサーバーが対話的な接続を閉じる前にアクティビティーの発生を待つ時間 (秒単位)。詳細は、以下を参照してください。
wait_timeoutサーバーが非対話型接続を閉じる前にアクティビティーを待機する秒数。
2.4.5.5. Debezium MySQL コネクターのクエリーログイベントの有効化
各 binlog イベントの元の SQL ステートメントを確認したい場合があります。MySQL 設定ファイルで binlog_rows_query_log_events オプションを有効にすると、これを行うことができます。
このオプションは、MySQL 5.6 以降で利用できます。
前提条件
- MySQL サーバー。
- SQL コマンドの基本知識。
- MySQL 設定ファイルへのアクセス。
手順
MySQL で
binlog_rows_query_log_eventsを有効にします。mysql> binlog_rows_query_log_events=ON
mysql> binlog_rows_query_log_events=ONCopy to Clipboard Copied! Toggle word wrap Toggle overflow binlog_rows_query_log_eventsは、binlog エントリーにSQLステートメントが含まれるようにするためのサポートを有効または無効にする値に設定されます。-
ON= 有効化 -
OFF= 無効化
-
2.4.5.6. Debezium MySQL コネクターの binlog 行値オプションを検証する
データベース内の binlog_row_value_options 変数の設定を確認します。コネクターが UPDATE イベントを消費できるようにするには、この変数を PARTIAL_JSON 以外の値に設定する必要があります。
前提条件
- MySQL サーバー。
- SQL コマンドの基本知識。
- MySQL 設定ファイルへのアクセス。
手順
現在の変数値を確認する
mysql> show global variables where variable_name = 'binlog_row_value_options';
mysql> show global variables where variable_name = 'binlog_row_value_options';Copy to Clipboard Copied! Toggle word wrap Toggle overflow 結果
+--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | binlog_row_value_options | | +--------------------------+-------+
+--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | binlog_row_value_options | | +--------------------------+-------+Copy to Clipboard Copied! Toggle word wrap Toggle overflow 変数の値が
PARTIAL_JSONに設定されている場合、次のコマンドを実行して設定を解除します。mysql> set @@global.binlog_row_value_options="" ;
mysql> set @@global.binlog_row_value_options="" ;Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.4.6. Debezium MySQL コネクターのデプロイメント
以下の方法のいずれかを使用して Debezium MySQL コネクターをデプロイできます。
2.4.6.1. Streams for Apache Kafka を使用した MySQL コネクターデプロイメント
Debezium 1.7 以降、Debezium コネクターのデプロイに推奨される方法は、Streams for Apache Kafka を使用して、コネクタープラグインを含む Kafka Connect コンテナーイメージをビルドすることです。
デプロイメントプロセス中に、以下のカスタムリソース (CR) を作成し、使用します。
-
Kafka Connect インスタンスを定義し、コネクターアーティファクトに関する情報をイメージに含める必要がある
KafkaConnectCR。 -
コネクターがソースデータベースにアクセスするために使用する情報を提供する
KafkaConnectorCR。Streams for Apache Kafka が Kafka Connect Pod を起動した後、KafkaConnectorCR を適用してコネクターを起動します。
Kafka Connect イメージのビルド仕様では、デプロイ可能なコネクターを指定できます。各コネクタープラグインに対して、デプロイメントに利用可能にする他のコンポーネントを指定することもできます。たとえば、Apicurio Registry アーティファクトや Debezium スクリプトコンポーネントを追加できます。Streams for Apache Kafka は、Kafka Connect イメージをビルドするときに、指定されたアーティファクトをダウンロードし、それをイメージに組み込みます。
Kafka Connect CR の spec.build.output パラメーターは、生成される KafkaConnectコンテナーイメージを格納する場所を指定します。コンテナーイメージは Docker レジストリーまたは OpenShift ImageStream に保存できます。イメージを ImageStream に保存するには、Kafka Connect をデプロイする前に ImageStream を作成する必要があります。ImageStreams は自動的に作成されません。
KafkaConnect リソースを使用してクラスターを作成する場合は、Kafka Connect REST API を使用してコネクターを作成または更新できません。ただし、REST API を使用して情報を取得できます。
関連情報
- 「OpenShift 上の Streams for Apache Kafka のデプロイと管理」の Kafka Connect の設定
- 「OpenShift 上の Streams for Apache Kafka のデプロイと管理」の 新しいコンテナーイメージの自動ビルド
2.4.6.2. Streams for Apache Kafka を使用した Debezium MySQL コネクターのデプロイ
以前のバージョンの Streams for Apache Kafka では、OpenShift に Debezium コネクターをデプロイするには、まずコネクター用の Kafka Connect イメージをビルドする必要がありました。OpenShift にコネクターをデプロイするための現在の推奨方法は、Streams for Apache Kafka のビルド設定を使用して、使用する Debezium コネクタープラグインを含む Kafka Connect コンテナーイメージを自動的にビルドすることです。
ビルドプロセス中に、Streams for Apache Kafka Operator は、Debezium コネクター定義を含む KafkaConnect カスタムリソースの入力パラメーターを Kafka Connect コンテナーイメージに変換します。このビルドは、Red Hat Maven リポジトリーまたは別の設定済みの HTTP サーバーから必要なアーティファクトをダウンロードします。
新規に作成されたコンテナーは .spec.build.output に指定されるコンテナーレジストリーにプッシュされ、Kafka Connect クラスターのデプロイに使用されます。Streams for Apache Kafka が Kafka Connect イメージをビルドした後、ビルドに含まれるコネクターを起動するための KafkaConnector カスタムリソースを作成します。
前提条件
- クラスター Operator がインストールされている OpenShift クラスターにアクセスできる。
- Streams for Apache Kafka Operator が実行されている。
- Apache Kafka クラスターが OpenShift 上の Streams for Apache Kafka のデプロイと管理 に記載されているとおりにデプロイされている。
- Kafka Connect が Streams for Apache Kafka にデプロイされている。
- Red Hat build of Debezium のライセンスを所有している。
-
OpenShift
ocCLI クライアントがインストールされている、または OpenShift Container Platform Web コンソールにアクセスできる。 Kafka Connect ビルドイメージの保存方法に応じて、レジストリーのパーミッションを用意するか、ImageStream リソースを作成している。
- ビルドイメージを Red Hat Quay.io または Docker Hub などのイメージレジストリーに保存する場合は、以下が必要です。
- レジストリーでイメージを作成し、管理するためのアカウントおよびパーミッション
- ビルドイメージをネイティブ OpenShift ImageStream として保存する場合は、以下を行います。
- ImageStream リソースを新規コンテナーイメージを保存するためにクラスターにデプロイします。クラスターの ImageStream を明示的に作成する必要があります。ImageStreams は、デフォルトでは利用できません。ImageStreams の詳細は、OpenShift Container Platform ドキュメント イメージストリームの管理 を参照してください。
手順
- OpenShift クラスターにログインします。
コネクターの Debezium
KafkaConnectカスタムリソース (CR) を作成するか、既存のリソースを変更します。たとえば、metadata.annotationsおよびspec.buildプロパティーを指定するdbz-connect.yamlという名前のKafkaConnectCR を作成します。以下の例は、KafkaConnectカスタムリソースを記述するdbz-connect.yamlファイルからの抜粋を示しています。
例2.26 Debezium コネクターを含む
KafkaConnectカスタムリソースを定義したdbz-connect.yamlファイル次の例では、カスタムリソースは、次のアーティファクトをダウンロードするように設定されています。
- Debezium MySQL コネクターアーカイブです。
- Red Hat build of Apicurio Registry アーカイブApicurio Registry はオプションのコンポーネントです。コネクターで Avro シリアル化を使用する場合にのみ、Apicurio Registry コンポーネントを追加します。
- Debezium スクリプティング SMT アーカイブと、Debezium コネクターで使用する関連スクリプティングエンジン。SMT アーカイブとスクリプト言語の依存関係はオプションのコンポーネントです。Debezium コンテンツベースのルーティング SMT または フィルター SMT を使用する場合にのみ、これらのコンポーネントを追加します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.99 Kafka Connect 設定の説明 項目 説明 1
strimzi.io/use-connector-resourcesアノテーションを"true"に設定して、クラスター Operator がKafkaConnectorリソースを使用してこの Kafka Connect クラスター内のコネクターを設定できるようにします。2
spec.build設定は、ビルドイメージの保存場所を指定し、プラグインアーティファクトの場所とともにイメージに追加するプラグインをリストします。3
build.outputは、新しくビルドされたイメージを保存するレジストリーを指定します。4
イメージ出力の名前およびイメージ名を指定します。
output.typeの有効な値は、Docker Hub や Quay などのコンテナーレジストリーにプッシュする場合はdocker、内部の OpenShift ImageStream にイメージをプッシュする場合はimagestreamです。ImageStream を使用するには、ImageStream リソースをクラスターにデプロイする必要があります。KafkaConnect 設定でbuild.outputを指定する方法の詳細は、{NameConfiguringStreamsOpenShift} の Streams for Apache Kafka ビルドスキーマリファレンス を参照してください。5
plugins設定は、Kafka Connect イメージに追加するすべてのコネクターをリストします。リストの各エントリーについて、プラグインnameと、コネクターのビルドに必要なアーティファクトに関する情報を指定します。必要に応じて、各コネクタープラグインに対して、コネクターと使用できる他のコンポーネントを含めることができます。たとえば、Service Registry アーティファクトまたは Debezium スクリプトコンポーネントを追加できます。6
artifacts.typeの値は、artifacts.urlで指定するアーティファクトのファイルタイプを指定します。有効なタイプはzip、tgz、またはjarです。Debezium コネクターアーカイブは、.zipファイル形式で提供されます。typeの値は、urlフィールドで参照されるファイルのタイプと一致させる必要があります。7
artifacts.urlの値は、コネクターアーティファクトのファイルを格納する Maven リポジトリーなどの HTTP サーバーのアドレスを指定します。Debezium コネクターアーティファクトは Red Hat リポジトリーで入手できます。OpenShift クラスターが指定されたサーバーにアクセスできる必要があります。8
(オプション) Apicurio Registry コンポーネントをダウンロードするためのアーティファクト
typeとurlを指定します。デフォルトの JSON コンバーターを使用する代わりに、コネクターが Apache Avro を使用して Red Hat build of Apicurio Registry でイベントのキーと値をシリアル化する場合にのみ、Apicurio Registry アーティファクトを含めます。9
(オプション) Debezium コネクターで使用する Debezium スクリプト SMT アーカイブのアーティファクト
typeとurlを指定します。Debezium コンテンツベースルーティング SMT または フィルター SMT を使用する場合にのみ、スクリプト SMT を含めます。スクリプト SMT を使用するには、groovy などの JSR 223 準拠のスクリプト実装もデプロイする必要があります。10
(オプション) JSR 223 準拠のスクリプト実装の JAR ファイルのアーティファクト
typeとurlを指定します。これは、Debezium スクリプト SMT で必要です。重要Streams for Apache Kafka を使用してコネクタープラグインを Kafka Connect イメージに組み込む場合、必要なスクリプト言語コンポーネントごとに、
artifacts.urlに JAR ファイルのロケーションを指定し、artifacts.typeの値もjarに設定する必要があります。値が無効な場合は、実行時にコネクターが失敗します。スクリプト SMT で Apache Groovy 言語を使用できるようにするために、この例のカスタムリソースは、次のライブラリーの JAR ファイルを取得します。
-
groovy -
groovy-jsr223(スクリプトエージェント) -
groovy-json(JSON 文字列を解析するためのモジュール)
別の方法として、Debezium スクリプト SMT は、GraalVM JavaScript の JSR 223 実装の使用もサポートします。
以下のコマンドを入力して、
KafkaConnectビルド仕様を OpenShift クラスターに適用します。oc create -f dbz-connect.yaml
oc create -f dbz-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Streams Operator はカスタムリソースで指定された設定に基づいて、デプロイする Kafka Connect イメージを準備します。
ビルドが完了すると、Operator はイメージを指定されたレジストリーまたは ImageStream にプッシュし、Kafka Connect クラスターを起動します。設定にリスト表示されているコネクターアーティファクトはクラスターで利用できます。KafkaConnectorリソースを作成し、デプロイする各コネクターのインスタンスを定義します。
たとえば、以下のKafkaConnectorCR を作成し、mysql-inventory-connector.yamlとして保存します。例2.27 Debezium コネクターの
KafkaConnectorカスタムリソースを定義するmysql-inventory-connector.yamlファイルCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.100 コネクター設定の説明 項目 説明 1
Kafka Connect クラスターに登録するコネクターの名前。
2
コネクタークラスの名前。
3
同時に動作できるタスクの数。
4
コネクターの設定。
5
ホストデータベースインスタンスのアドレス。
6
データベースインスタンスのポート番号。
7
Debezium がデータベースへの接続に使用するアカウントの名前。
8
Debezium がデータベースユーザーアカウントに接続するために使用するパスワード。
9
コネクターの一意の ID (数値)。
10
データベースインスタンスまたはクラスターのトピック接頭辞。
指定する名前は、英数字またはアンダースコアのみで設定する必要があります。
トピック接頭辞は、このコネクターから変更イベントを受信する Kafka トピックの接頭辞として使用されるため、名前はクラスターのコネクター間で一意である必要があります。
コネクターを Avro コネクター と統合する場合、この名前空間は、関連する Kafka Connect スキーマの名前や、対応する Avro スキーマの名前空間でも使用されます。11
コネクターが変更イベントをキャプチャーするテーブルのリスト。
以下のコマンドを実行してコネクターリソースを作成します。
oc create -n <namespace> -f <kafkaConnector>.yaml
oc create -n <namespace> -f <kafkaConnector>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc create -n debezium -f mysql-inventory-connector.yaml
oc create -n debezium -f mysql-inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow コネクターは Kafka Connect クラスターに登録され、
KafkaConnectorCR のspec.config.database.dbnameで指定されたデータベースに対して実行を開始します。コネクター Pod の準備ができると、Debezium が実行されます。
これで、Debezium MySQL のデプロイメントを確認 する準備が整いました。
2.4.6.3. Dockerfile からカスタム Kafka Connect コンテナーイメージをビルドして Debezium MySQL コネクターのデプロイ
Debezium MySQL コネクターをデプロイするには、Debezium コネクターアーカイブが含まれるカスタム Kafka Connect コンテナーイメージをビルドし、このコンテナーイメージをコンテナーレジストリーにプッシュする必要があります。次に、以下のカスタムリソース (CR) を作成する必要があります。
-
Kafka Connect インスタンスを定義する
KafkaConnectCR。imageは Debezium コネクターを実行するために作成したイメージの名前を指定します。この CR は、Red Hat Streams for Apache Kafka がデプロイされている OpenShift インスタンスに適用します。Streams for Apache Kafka は、Apache Kafka を OpenShift に導入する Operator とイメージを提供します。 -
Debezium MySQL コネクターを定義する
KafkaConnectorCR。この CR をKafkaConnectCR を適用するのと同じ OpenShift インスタンスに適用します。
前提条件
- MySQL が稼働し、Debezium コネクターと連携するように MySQL を設定する手順 が完了済みである必要があります。
- Streams for Apache Kafka が OpenShift にデプロイされ、Apache Kafka および Kafka Connect が実行されている。詳細は、OpenShift 上の Streams for Apache Kafka のデプロイと管理 を参照してください。
- Podman または Docker がインストールされている。
-
Debezium コネクターを実行するコンテナーを追加する予定のコンテナーレジストリー (
quay.ioやdocker.ioなど) でコンテナーを作成および管理するアカウントとパーミッションを持っている。
手順
Kafka Connect の Debezium MySQL コンテナーを作成します。
registry.redhat.io/amq-streams-kafka-35-rhel8:2.5.0をベースイメージとして使用して、新規の Dockerfile を作成します。たとえば、ターミナルウィンドウから、以下のコマンドを入力します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 項目 説明 1
任意のファイル名を指定できます。
2
Kafka Connect プラグインディレクトリーへのパスを指定します。Kafka Connect のプラグインディレクトリーが別の場所にある場合は、このパスを実際のディレクトリーのパスに置き換えてください。
このコマンドは、現在のディレクトリーに
debezium-container-for-mysql.yamlという名前の Dockerfile を作成します。前の手順で作成した
debezium-container-for-mysql.yamlDocker ファイルからコンテナーイメージをビルドします。ファイルが含まれるディレクトリーから、ターミナルウィンドウを開き、以下のコマンドのいずれかを入力します。podman build -t debezium-container-for-mysql:latest .
podman build -t debezium-container-for-mysql:latest .Copy to Clipboard Copied! Toggle word wrap Toggle overflow docker build -t debezium-container-for-mysql:latest .
docker build -t debezium-container-for-mysql:latest .Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドは、
debezium-container-for-mysqlという名前のコンテナーイメージを構築します。カスタムイメージを
quay.ioなどのコンテナーレジストリーまたは内部のコンテナーレジストリーにプッシュします。コンテナーレジストリーは、イメージをデプロイする OpenShift インスタンスで利用できる必要があります。以下のいずれかのコマンドを実行します。podman push <myregistry.io>/debezium-container-for-mysql:latest
podman push <myregistry.io>/debezium-container-for-mysql:latestCopy to Clipboard Copied! Toggle word wrap Toggle overflow docker push <myregistry.io>/debezium-container-for-mysql:latest
docker push <myregistry.io>/debezium-container-for-mysql:latestCopy to Clipboard Copied! Toggle word wrap Toggle overflow 新しい Debezium MySQL
KafkaConnectカスタムリソース (CR) を作成します。たとえば、annotationsおよびimageプロパティーを指定するdbz-connect.yamlという名前のKafkaConnectCR を作成します。以下の例は、KafkaConnectカスタムリソースを記述するdbz-connect.yamlファイルからの抜粋を示しています。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 項目 説明 1
KafkaConnectorリソースはこの Kafka Connect クラスターでコネクターを設定するために使用されることを、metadata.annotationsは Cluster Operator に示します。2
spec.imageは Debezium コネクターを実行するために作成したイメージの名前を指定します。設定された場合、このプロパティーによって Cluster Operator のSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGE変数がオーバーライドされます。以下のコマンドを入力して、
KafkaConnectCR を OpenShift Kafka Connect 環境に適用します。oc create -f dbz-connect.yaml
oc create -f dbz-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、Debezium コネクターを実行するために作成したイメージの名前を指定する Kafka Connect インスタンスを追加します。
Debezium MySQL コネクターインスタンスを設定する
KafkaConnectorカスタムリソースを作成します。通常、コネクター設定プロパティーを設定する
.yamlファイルに Debezium MySQL コネクターを設定します。コネクター設定は、Debezium に対して、スキーマおよびテーブルのサブセットにイベントを生成するよう指示する可能性があり、または機密性の高い、大きすぎる、または不必要な指定のコラムで Debezium が値を無視、マスク、または切り捨てするようにプロパティーを設定する可能性もあります。以下の例では、ポート
3306の MySQL ホスト (192.168.99.100) に接続し、inventoryデータベースへの変更をキャプチャーする Debezium コネクターを設定します。dbserver1は、サーバーの論理名です。MySQL
inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.101 コネクター設定の説明 項目 説明 1
コネクターの名前。
2
一度に実行できるタスクは 1 つだけです。MySQL コネクターは MySQL サーバーの
binlogを読み取るため、単一のコネクタータスクを使用することで、順序とイベントの処理が適切に行われるようになります。Kafka Connect サービスはコネクターを使用して作業を行う 1 つ以上のタスクを開始し、実行中のタスクを自動的に Kafka Connect サービスのクラスター全体に分散します。いずれかのサービスが停止またはクラッシュすると、これらのタスクは稼働中のサービスに再分散されます。3
コネクターの設定。
4
データベースホスト。これは、MySQL サーバーを実行しているコンテナーの名前です (
mysql)。5
connector の一意 ID。
6
MySQL サーバーまたはクラスターのトピック接頭辞。この名前は、変更イベントレコードを受信するすべての Kafka トピックの接頭辞として使用されます。
7
コネクターは
インベントリーテーブルからのみ変更をキャプチャーします。8
DDL ステートメントをデータベーススキーマ履歴トピックに書き込み、復元するためにコネクターによって使用される Kafka ブローカーのリスト。再起動時に、コネクターが読み取りを開始すべき時点で binlog に存在したデータベースのスキーマを復元します。
9
データベーススキーマ履歴トピックの名前。このトピックは内部使用のみを目的としており、コンシューマーが使用しないようにしてください。
Kafka Connect でコネクターインスタンスを作成します。たとえば、
KafkaConnectorリソースをinventory-connector.yamlファイルに保存した場合は、以下のコマンドを実行します。oc apply -f inventory-connector.yaml
oc apply -f inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドは
inventory-connectorを登録し、コネクターはKafkaConnectorCR に定義されているinventoryデータベースに対して実行を開始します。
Debezium MySQL コネクターに設定できる設定プロパティーの完全リストは、MySQL コネクター設定プロパティーを参照してください。
結果
コネクターが起動すると、コネクターが設定された MySQL データベースの 整合性スナップショットが実行 されます。その後、コネクターは行レベルの操作のデータ変更イベントの生成を開始し、変更イベントレコードを Kafka トピックにストリーミングします。
2.4.6.4. Debezium MySQL コネクターが実行していることの確認
コネクターがエラーなしで正常に起動すると、コネクターがキャプチャーするように設定された各テーブルのトピックが作成されます。ダウンストリームアプリケーションは、これらのトピックをサブスクライブして、ソースデータベースで発生する情報イベントを取得できます。
コネクターが実行されていることを確認するには、OpenShift Container Platform Web コンソールまたは OpenShift CLI ツール (oc) から以下の操作を実行します。
- コネクターのステータスを確認します。
- コネクターがトピックを生成していることを確認します。
- 各テーブルの最初のスナップショットの実行中にコネクターが生成する読み取り操作 ("op":"r") のイベントがトピックに反映されていることを確認します。
前提条件
- Debezium コネクターが OpenShift 上の Streams for Apache Kafka にデプロイされている。
-
OpenShift
ocCLI クライアントがインストールされている。 - OpenShift Container Platform Web コンソールにアクセスできる。
手順
以下の方法のいずれかを使用して
KafkaConnectorリソースのステータスを確認します。OpenShift Container Platform Web コンソールから以下を実行します。
- Home → Search に移動します。
-
Search ページで Resources をクリックし、Select Resource ボックスを開き、
KafkaConnectorを入力します。 - KafkaConnectors リストから、チェックするコネクターの名前をクリックします (例: inventory-connector-mysql)。
- Conditions セクションで、Type および Status 列の値が Ready および True に設定されていることを確認します。
ターミナルウィンドウから以下を実行します。
以下のコマンドを実行します。
oc describe KafkaConnector <connector-name> -n <project>
oc describe KafkaConnector <connector-name> -n <project>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc describe KafkaConnector inventory-connector-mysql -n debezium
oc describe KafkaConnector inventory-connector-mysql -n debeziumCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、以下の出力のようなステータス情報を返します。
例2.28
KafkaConnectorリソースのステータスCopy to Clipboard Copied! Toggle word wrap Toggle overflow
コネクターによって Kafka トピックが作成されたことを確認します。
OpenShift Container Platform Web コンソールから以下を実行します。
- Home → Search に移動します。
-
Search ページで Resources をクリックし、Select Resource ボックスを開き、
KafkaTopicを入力します。 -
KafkaTopics リストから確認するトピックの名前をクリックします (例:
inventory-connector-mysql.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d)。 - Conditions セクションで、Type および Status 列の値が Ready および True に設定されていることを確認します。
ターミナルウィンドウから以下を実行します。
以下のコマンドを実行します。
oc get kafkatopics
oc get kafkatopicsCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、以下の出力のようなステータス情報を返します。
例2.29
KafkaTopicリソースのステータスCopy to Clipboard Copied! Toggle word wrap Toggle overflow
トピックの内容を確認します。
- ターミナルウィンドウから、以下のコマンドを入力します。
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory-connector-mysql.inventory.products_on_hand
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory-connector-mysql.inventory.products_on_handCopy to Clipboard Copied! Toggle word wrap Toggle overflow トピック名を指定する形式は、手順 1 で返された
oc describeコマンドと同じです (例:inventory-connector-mysql.inventory.addresses)。トピックの各イベントについて、このコマンドは、以下の出力のような情報を返します。
例2.30 Debezium 変更イベントの内容
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory-connector-mysql.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-mysql.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-mysql.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"int64","optional":false,"field":"ts_us"},{"type":"int64","optional":false,"field":"ts_ns"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.mysql.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"int64","optional":true,"field":"ts_us"},{"type":"int64","optional":true,"field":"ts_ns"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory-connector-mysql.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"2.7.3.Final-redhat-00001","connector":"mysql","name":"inventory-connector-mysql","ts_ms":1638985247805,"ts_us":1638985247805000000,"ts_ns":1638985247805000000,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"mysql-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"ts_us":1638985247805102,"ts_ns":1638985247805102588,"transaction":null}}{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory-connector-mysql.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-mysql.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-mysql.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"int64","optional":false,"field":"ts_us"},{"type":"int64","optional":false,"field":"ts_ns"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.mysql.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"int64","optional":true,"field":"ts_us"},{"type":"int64","optional":true,"field":"ts_ns"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory-connector-mysql.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"2.7.3.Final-redhat-00001","connector":"mysql","name":"inventory-connector-mysql","ts_ms":1638985247805,"ts_us":1638985247805000000,"ts_ns":1638985247805000000,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"mysql-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"ts_us":1638985247805102,"ts_ns":1638985247805102588,"transaction":null}}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記の例では、
payload値は、コネクタースナップショットがテーブルinventory.products_on_handから読み込み ("op" ="r") イベントを生成したことを示しています。product_idレコードの"before"状態はnullであり、レコードに以前の値が存在しないことを示しています。"after"状態は、product_id101を持つ項目のquantityが3であることを示しています。
2.4.6.5. Debezium MySQL コネクター設定プロパティーの説明
Debezium MySQL コネクターには、アプリケーションに適したコネクター動作を実現するために使用できる設定プロパティーが多数あります。多くのプロパティーにはデフォルト値があります。プロパティーに関する情報は、以下のように設定されています。
- 必要なコネクター設定プロパティー
- 高度なコネクター設定プロパティー
- Debezium がデータベース履歴トピックから読み取るイベントを処理する方法を制御する データベース履歴コネクター設定プロパティー。
必要な Debezium MySQL コネクター設定プロパティー
以下の設定プロパティーは、デフォルト値がない場合は必須です。
bigint.unsigned.handling.mode
デフォルト値:long。
コネクターが変更イベントで BIGINT UNSIGNED 列を表す方法を指定します。以下のオプションのいずれかを設定します。long-
Java の
longデータ型を使用して、BIGINT UNSIGNED 列の値を表します。long型はの精度を最適ではありませんが、大半のコンシューマーで簡単に実装できます。環境の多くでは、これが推奨される設定です。 precise-
値を表すために
java.math.BigDecimalデータ型を使用します。コネクターは、Kafka Connectorg.apache.kafka.connect.data.Decimalデータ型を使用して、エンコードされたバイナリー形式で値を表します。コネクターが通常 2^63 より大きい値で動作する場合は、このオプションを設定します。longデータ型ではそのサイズの値を伝達できません。
binary.handling.modeデフォルト値:
バイト。
変更イベントでコネクターがバイナリー列 (Blob、binary、varbinaryなど) の値を表す方法を指定します。
以下のオプションのいずれかを設定します。bytes- バイナリーデータをバイト配列として表します。
base64- バイナリーデータを base64 でエンコードされた文字列として表します。
base64-url-safe- バイナリーデータを base64-url-safe-encoded 文字列として表します。
hex- バイナリーデータを 16 進数 (base16) でエンコードされた文字列として表します。
column.exclude.listデフォルト値: 空の文字列。
変更イベントレコードの値から除外する列の完全修飾名に一致する、オプションのコンマ区切りの正規表現のリスト。ソースレコード内の他の列は通常どおりキャプチャーされます。列の完全修飾名の形式は databaseName.tableName.columnName です。
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列名に存在する可能性のある部分文字列とは一致しない、列の名前文字列全体と照合されます。このプロパティーを設定に含める場合は、
column.include.listプロパティーも設定しないでください。
column.include.listデフォルト値: 空の文字列。
変更イベントレコードの値に含める列の完全修飾名に一致する、オプションのコンマ区切りの正規表現のリスト。その他の列はイベントレコードから省略されます。列の完全修飾名の形式は databaseName.tableName.columnName です。
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列名に存在する可能性のある部分文字列とは一致しない、列の名前文字列全体と照合されます。
このプロパティーを設定に含める場合は、column.exclude.listプロパティーを設定しないでください。
column.mask.hash.v2.hashAlgorithm.with.salt.saltデフォルト値: デフォルトなし。
文字ベースの列の完全修飾名に一致する、オプションのコンマ区切りの正規表現のリスト。列の完全修飾名の形式は<databaseName>.<tableName>.<columnName>です。
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列の名前文字列全体に対して照合されます。式は、列名に存在する可能性のある部分文字列と一致しません。作成された変更イベントレコードでは、指定された列の値は仮名に置き換えられます。
仮名は、指定された hashAlgorithm と salt を適用した結果のハッシュ値で構成されます。使用されるハッシュ関数に基づいて、参照整合性は保持され、列値は仮名に置き換えられます。サポートされるハッシュ関数は、Java Cryptography Architecture Standard Algorithm Name Documentation の MessageDigest section に説明されています。
次の例では、
CzQMA0cB5Kはランダムに選択された salt です。column.mask.hash.SHA-256.with.salt.CzQMA0cB5K = inventory.orders.customerName, inventory.shipment.customerName
column.mask.hash.SHA-256.with.salt.CzQMA0cB5K = inventory.orders.customerName, inventory.shipment.customerNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 必要な場合は、仮名は自動的に列の長さに短縮されます。コネクター設定には、異なるハッシュアルゴリズムと salt を指定する複数のプロパティーを含めることができます。
使用される hashAlgorithm、選択された salt、および実際のデータセットによっては、結果のデータセットが完全にマスクされない場合があります。
ハッシュストラテジーバージョン 2 は、異なる場所またはシステムでハッシュされる値が整合性を保てるようにします。
column.mask.with.length.charsデフォルト値: デフォルトなし。
文字ベースの列の完全修飾名に一致する、オプションのコンマ区切りの正規表現のリスト。一連の列の値をコネクターでマスクする場合 (たとえば、列に機密データが含まれている場合) は、このプロパティーを設定します。lengthを正の整数に設定して、指定された列のデータをプロパティー名の 長さ で指定されたアスタリスク (*) 文字数で置き換えます。指定した列のデータを空の文字列に置き換えるには、長さ を0(ゼロ) に設定します。列の完全修飾名は、次の形式に従います: databaseName.tableName.columnName列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列の名前文字列全体に対して照合されます。式は、列名に存在する可能性のある部分文字列と一致しません。
単一の設定で、異なる長さを持つ複数のプロパティーを指定できます。
column.propagate.source.typeデフォルト値: デフォルトなし。
コネクターが列のメタデータを表す追加パラメーターを発行する列の完全修飾名に一致する、オプションのコンマ区切りの正規表現のリスト。このプロパティーが設定されている場合、コネクターは次のフィールドをイベントレコードのスキーマに追加します。-
__debezium.source.column.type -
__debezium.source.column.length -
__debezium.source.column.scale
これらのパラメーターは、それぞれ列の元の型名と長さ (可変幅型の場合) を伝播します。
コネクターがこの余分なデータを発行できるようにすると、sink データベース内の特定の数値または文字ベースの列のサイズを適切に設定するのに役立ちます。
列の完全修飾名は、次のいずれかの形式に従います: databaseName.tableName.columnName、または databaseName.schemaName.tableName.columnName.
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列の名前文字列全体に対して照合されます。式は、列名に存在する可能性のある部分文字列と一致しません。
-
column.truncate.to.length.charsデフォルト値: デフォルトなし。
文字ベースの列の完全修飾名に一致する、オプションのコンマ区切りの正規表現のリスト。プロパティー名の 長さ で指定された文字数を超えた場合に、一連の列のデータを切り捨てる場合は、このプロパティーを設定します。lengthを正の整数値に設定します (例:column.truncate.to.20.chars)。列の完全修飾名は、次の形式に従います: databaseName.tableName.columnName列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列の名前文字列全体に対して照合されます。式は、列名に存在する可能性のある部分文字列と一致しません。
単一の設定で、異なる長さを持つ複数のプロパティーを指定できます。
connect.timeout.ms-
デフォルト値:
30000(30 秒)。
接続要求がタイムアウトする前にコネクターが MySQL データベースサーバーへの接続を確立するまで待機する最大時間 (ミリ秒単位) を指定する正の整数値。
connector.class-
デフォルト値: デフォルトなし。
コネクターの Java クラスの名前。MySQL コネクターの場合は常に指定します。
database.exclude.listデフォルト値: 空の文字列。
データベースの名前に一致するオプションのコンマ区切りの正規表現のリスト。ただし、コネクターに変更をキャプチャーさせません。コネクターは、database.exclude.listに名前が指定されていないデータベースの変更をキャプチャーします。
データベースの名前を照合するために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、データベースの名前文字列全体に対して照合されます。データベース名に存在する可能性のある部分文字列とは一致しません。
このプロパティーを設定に含める場合は、database.include.listプロパティーも設定しないでください。
database.hostname-
デフォルト値: デフォルトなし。
MySQL データベースサーバーの IP アドレスまたはホスト名。
database.include.listデフォルト値: 空の文字列。
コネクターが変更をキャプチャーし、さらにデータベースの名前に一致する、オプションのコンマ区切りの正規表現のリスト。コネクターは、名前がdatabase.include.listにないデータベースの変更をキャプチャーしません。デフォルトでは、コネクターはすべてのデータベースの変更をキャプチャーします。
データベースの名前を照合するために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、データベースの名前文字列全体に対して照合されます。データベース名に存在する可能性のある部分文字列とは一致しません。
このプロパティーを設定に含める場合は、database.exclude.listプロパティーも設定しないでください。
database.password-
デフォルト値: デフォルトなし。
コネクターが MySQL データベースサーバーに接続するために使用する MySQL ユーザーのパスワード。
database.port-
デフォルト値:
3306。
MySQL データベースサーバーの整数ポート番号。
database.server.id-
デフォルト値: デフォルトなし。
このデータベースクライアントの数値 ID。指定された ID は、MySQL クラスター内で現在実行中のすべてのデータベースプロセス全体で一意である必要があります。コネクターは、binlog の読み取りを可能にするために、この一意の ID を使用して、MySQL データベースクラスターを別のサーバーとして参加させます。
database.user-
デフォルト値: デフォルトなし。
コネクターが MySQL データベースサーバーに接続するために使用する MySQL ユーザー名。
decimal.handling.modeデフォルト値:
precise。
コネクターが変更イベントでDECIMAL列とNUMERIC列の値を処理する方法を指定します。
以下のオプションのいずれかを設定します。precise(デフォルト)-
値を正確に表すために、バイナリー形式の
java.math.BigDecimal値を使用します。 double-
値を表すために
doubleデータ型を使用します。このオプションを選択すると精度が低下する可能性がありますが、ほとんどのコンシューマーにとって使いやすいものになります。 string- フォーマットされた文字列としてエンコードされます。このオプションは簡単に使用できますが、実際の型に関するセマンティック情報が失われる可能性があります。
event.deserialization.failure.handling.modeデフォルト値:
fail。
binlog イベントのデシリアライズ中に例外が発生した場合にコネクターがどのように反応するかを指定します。このオプションは非推奨です。代わりにevent.processing.failure.handling.modeオプションを使用してください。fail- 問題のあるイベントとその binlog オフセットを示す例外を伝播し、コネクターを停止させます。
warn- 問題のあるイベントとその binlog オフセットをログに記録し、イベントをスキップします。
ignore- 問題のあるイベントを通過し、何もログに記録しません。
field.name.adjustment.modeデフォルト値: デフォルトなし。
コネクターで使用されるメッセージコンバーターとの互換性を確保するために、フィールド名を調整する方法を指定します。以下のオプションのいずれかを設定します。none- 調整はありません。
avro- Avro 名で有効でない文字をアンダースコア文字に置き換えます。
avro_unicodeアンダースコア文字または Avro 名で使用できない文字は、
_uxxxxなどの対応する Unicode に置き換えます。
注記`_` is an escape sequence, similar to a backslash in Java
`_` is an escape sequence, similar to a backslash in JavaCopy to Clipboard Copied! Toggle word wrap Toggle overflow 詳細は、Avro の命名 を参照してください。
gtid.source.excludes-
デフォルト値: デフォルトなし。
コネクターが MySQL サーバー上の binlog の位置を特定するために使用する GTID セット内のソースドメイン ID に一致する正規表現のコンマ区切りリスト。このプロパティーが設定されている場合、コネクターは、指定されたexcludeパターンのいずれにも一致しないソース UUID が含まれる GTID 範囲のみを使用します。
GTID の値を一致させるために、Debezium は、アンカー 正規表現として指定した正規表現を適用します。つまり、指定された式は GTID のドメイン識別子に対して照合されます。
このプロパティーを設定に含める場合は、gtid.source.includesプロパティーも設定しないでください。
gtid.source.includes-
デフォルト値: デフォルトなし。
コネクターが MySQL サーバー上のバイナリーログの位置を特定するために使用する GTID セット内のソースドメイン ID に一致する正規表現のコンマ区切りリスト。このプロパティーが設定されている場合、コネクターは、指定されたincludeパターンのいずれかに一致するソース UUID が含まれる GTID 範囲のみを使用します。
GTID の値を一致させるために、Debezium は、アンカー 正規表現として指定した正規表現を適用します。つまり、指定された式は GTID のドメイン識別子に対して照合されます。
このプロパティーを設定に含める場合は、gtid.source.excludesプロパティーも設定しないでください。
include.query-
デフォルト値:
false。
変更イベントを生成した元の SQL クエリーをコネクターに含めるかどうかを指定するブール値。
このオプションをtrueに設定する場合は、MySQL でbinlog_annotate_row_eventsオプションをONに設定する必要があります。include.queryがtrueの場合、スナップショットプロセスによって生成されるイベントに対するクエリーは存在しません。include.queryをtrueに設定すると、変更イベントに元の SQL ステートメントを含めることで明示的に除外またはマスクされたテーブルまたはフィールドが公開される可能性があります。そのため、デフォルト設定はfalseです。
各ログイベントに対して元のSQLステートメントを返すようにデータベースを設定する方法の詳細は、クエリーログイベントの有効化 を参照してください。
include.schema.changes-
デフォルト値:
true。
コネクターが、データベーススキーマに加えられた変更をデータベースサーバー ID の名前を持つ Kafka トピックに公開するかどうかを指定するブール値。コネクターがキャプチャーする各スキーマ変更イベントでは、データベース名を含むキーと、変更を記述する DDL ステートメントを含む値が使用されます。この設定により、コネクターが内部データベーススキーマ履歴にスキーマの変更を記録する方法は左右されません。
include.schema.commentsデフォルト値:
false。
コネクターがメタデータオブジェクトのテーブルおよび列のコメントを解析して公開するかどうかを指定するブール値。
注記このオプションを
trueに設定すると、コネクターに含まれるスキーマコメントによって、各スキーマオブジェクトに大量の文字列データが追加される可能性があります。論理スキーマオブジェクトの数とサイズを増やすと、コネクターが使用するメモリーの量が増加します。
inconsistent.schema.handling.modeデフォルト値:
fail。
内部スキーマ表現に存在しないテーブルを参照する binlog イベントにコネクターが応答する方法を指定します。つまり、内部表現はデータベースと一致しません。
以下のオプションのいずれかを設定します。fail- コネクターは、問題のあるイベントとその binlog オフセットを報告する例外を出力します。その後、コネクターが停止します。
warn- コネクターは問題のあるイベントとそのバイナリーログオフセットをログに記録し、イベントをスキップします。
skip- コネクターは問題のあるイベントをスキップして、その旨はログに報告されません。
message.key.columns-
デフォルト値: デフォルトなし。
指定のテーブルの Kafka トピックに公開する変更イベントレコードのカスタムメッセージキーを形成するためにコネクターが使用する列を指定する式のリスト。
デフォルトでは、Debezium はテーブルのプライマリーキー列を、出力するレコードのメッセージキーとして使用します。デフォルトの代わりに、またはプライマリーキーのないテーブルのキーを指定するには、1 つ以上の列をもとにカスタムメッセージキーを設定できます。
テーブルのカスタムメッセージキーを作成するには、テーブルとメッセージキーとして使用する列をリストします。各リストエントリーは、<fully-qualified_tableName>:<keyColumn>,<keyColumn>
の形式を取ります。複数の列名をベースにテーブルキーを作成するには、列名の間にコンマを挿入します。
完全修飾テーブル名はそれぞれ、次の形式の正規表現です。<databaseName>.<tableName>
プロパティーには複数のテーブルのエントリーを含めることができます。セミコロンを使用して、リスト内のテーブルエントリーを区切ります。
以下の例は、テーブルinventory.customersおよびpurchase.orders:inventory.customers:pk1,pk2;(.*).purchaseorders:pk3,pk4
のメッセージキーを設定します。テーブルinventory.customerの場合、列pk1とpk2がメッセージキーとして指定されます。データベースでpurchaseordersテーブルは、pk3およびpk4サーバーのコラムをメッセージキーとして使用します。
カスタムメッセージキーの作成に使用する列の数に制限はありません。ただし、一意の鍵を指定するために必要な最小数を使用することが推奨されます。
name-
デフォルト値: デフォルトなし。
コネクターの一意の名前。同じ名前を使用して別のコネクターを登録しようとすると、登録は失敗します。このプロパティーはすべての Kafka Connect コネクターに必要です。
schema.name.adjustment.modeデフォルト値: デフォルトなし。
コネクターが使用するメッセージコンバーターとの互換性を確保するために、コネクターがスキーマ名を調整する方法を指定します。以下のオプションのいずれかを設定します。none- 調整はありません。
avro- Avro 名で有効でない文字をアンダースコア文字に置き換えます。
avro_unicode-
アンダースコア文字または Avro 名で使用できない文字は、
_uxxxxなどの対応する Unicode に置き換えます。
注記:_はエスケープシーケンスで、Java のバックスラッシュに似ています。
skip.messages.without.change-
デフォルト値:
false。
含まれる列の変更が検出されない場合に、コネクターがレコードのメッセージを発行するかどうかを指定します。列は、column.include.listにリストされている場合、またはcolumn.exclude.listにリストされていない場合は、included とみなされます。含まれる列に変更がない場合にコネクターがレコードをキャプチャーしないようにするには、値をtrueに設定します。
table.exclude.listデフォルト値: 空の文字列。
テーブルの完全修飾テーブル識別子に一致する、オプションのコンマ区切りの正規表現のリスト。ただし、コネクターに変更をキャプチャーさせません。コネクターはtable.exclude.listに含まれていないテーブルの変更をキャプチャーします。各識別子の形式は databaseName.tableName です。
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの名前文字列全体と照合されます。
このプロパティーを設定に含める場合は、table.include.listプロパティーも設定しないでください。
table.include.listデフォルト値: 空の文字列。
変更をキャプチャーするテーブルの完全修飾テーブル識別子に一致する、オプションのコンマ区切りの正規表現のリスト。コネクターは、table.include.listに含まれていないテーブルの変更をキャプチャしません。各識別子の形式は databaseName.tableName です。デフォルトでは、コネクターは変更をキャプチャーするように設定されている全データベース内の非システムテーブルの変更をすべてキャプチャーします。
テーブルの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの名前文字列全体と照合されます。
このプロパティーを設定に含める場合は、table.exclude.listプロパティーも設定しないでください。
tasks.max-
デフォルト値:
1。
このコネクターに対して作成するタスクの最大数。MySQL コネクターは常に単一のタスクを使用するため、デフォルト値を変更しても効果はありません。
time.precision.modeデフォルト値:
adaptive_time_microseconds。
コネクターが時間、日付、タイムスタンプの値を表すために使用する精度のタイプを指定します。次のいずれかのオプションを設定します。
adaptive_time_microseconds(デフォルト)-
コネクターは、データベース列のタイプに基づいて、ミリ秒、マイクロ秒、またはナノ秒の精度値を使用して、データベースとまったく同じように日付、日付時刻、およびタイムスタンプの値をキャプチャーします。ただし、常にマイクロ秒としてキャプチャーされる TIME タイプフィールドは例外です。
connect- コネクターは常に、データベース列の精度に関係なくミリ秒の精度を使用する、Kafka Connect の組み込みの時間、日付、タイムスタンプの表現を使用して、時間とタイムスタンプの値を表します。
tombstones.on.deleteデフォルト値:
true。
delete イベントの後に tombstone イベントが続くかどうかを指定します。ソースレコードが削除された後、コネクターはトゥームストーンイベント (デフォルトの動作) を発行して、トピックの ログ圧縮 が有効になっている場合に、削除された行のキーに関連するすべてのイベントを Kafka が完全に削除できるようにします。次のいずれかのオプションを設定します。
true(デフォルト)-
コネクターは、delete イベントとそれに続く tombstone イベントを発行することによって削除操作を表します。
false-
コネクターは delete イベントのみを出力します。
topic.prefixデフォルト値: デフォルトなし。
Debezium が変更をキャプチャーしている特定の MySQL データベースサーバーまたはクラスターの namespace を提供するトピック接頭辞。トピック接頭辞は、このコネクターが発行するイベントを受信するすべての Kafka トピックの名前として使用されるので、トピック接頭辞がすべてのコネクター間で一意であることが重要です。値には、英数字、ハイフン、ドット、アンダースコアのみを使用できます。
警告このプロパティーを設定した後は、値を変更しないでください。値を変更すると、コネクターの再起動後に、コネクターは元のトピックにイベントを引き続き送信するのではなく、新しい値に基づいた名前のトピックに後続のイベントを送信します。また、コネクターはデータベーススキーマ履歴トピックを復元できません。
高度な Debezium MySQL コネクター設定プロパティー
次のリストは、高度な MySQL コネクター設定プロパティーについて説明します。これらのプロパティーのデフォルト値を変更する必要はほぼありません。そのため、コネクター設定にデフォルト値を指定する必要はありません。
connect.keep.alive-
デフォルト値:
true。
MySQL サーバーまたはクラスターへの接続を維持するために別のスレッドを使用するかどうかを指定するブール値。
convertersデフォルト値: デフォルトなし。
コネクターが使用できる custom converter インスタンスのシンボリック名のコンマ区切りリストを列挙します。
たとえば、booleanです。
このプロパティーは、コネクターがカスタムコンバーターを使用できるようにするために必要です。
コネクターに設定するコンバータごとに、コンバータインターフェイスを実装するクラスの完全修飾名を指定する.typeプロパティーも追加する必要があります。.typeプロパティーでは、以下の形式を使用します。
<converterSymbolicName>.type以下に例を示します。
boolean.type: io.debezium.connector.binlog.converters.TinyIntOneToBooleanConverter
boolean.type: io.debezium.connector.binlog.converters.TinyIntOneToBooleanConverterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 設定されたコンバータの動作をさらに制御したい場合は、1 つ以上の設定パラメーターを追加して、コンバータに値を渡すことができます。これらの追加設定パラメ設定ーターをコンバータに関連付けるには、パラメーター名の前にコンバーターのシンボル名を付けます。
たとえば、
booleanコンバーターが処理する列のサブセットを指定するselectorパラメーターを定義するには、次のプロパティーを追加します。
boolean.selector=db1.table1.*, db1.table2.column1
boolean.selector=db1.table1.*, db1.table2.column1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
custom.metric.tags-
デフォルト値: デフォルトなし。
コンテキスト情報を提供するメタデータを追加して、MBean オブジェクト名をカスタマイズするタグを定義します。キーと値のペアのコンマ区切りリストを指定します。各キーは MBean オブジェクト名のタグを表し、対応する値はキーの値を表します (例:
k1=v1、k2=v2)。
コネクターは、指定されたタグを基本 MBean オブジェクト名に追加します。タグは、メトリクスデータを整理および分類するのに役立ちます。特定のアプリケーションインスタンス、環境、リージョン、バージョンなどを識別するためのタグを定義できます。詳細は、カスタマイズされた MBean 名 を参照してください。
database.initial.statementsデフォルト値: デフォルトなし。
トランザクションログを読み取る接続ではなく、データベースへの JDBC 接続が確立されたときに実行される、セミコロンで区切られた SQL ステートメントのリスト。SQL ステートメントでセミコロンを区切り文字としてではなく、文字として指定する場合は、2 つのセミコロン (;;) を使用します。
コネクターは独自の判断で JDBC 接続を確立する可能性があるため、このプロパティーはセッションパラメーターの設定専用です。DML ステートメントを実行するものではありません。
database.query.timeout.ms-
デフォルト値:
600000(10 分)。
コネクターがクエリーの完了を待機する時間をミリ秒単位で指定します。タイムアウト制限を削除するには、値を0(ゼロ) に設定します。
database.ssl.keystore-
デフォルト値: デフォルトなし。
キーストアファイルの場所を指定するオプションの設定。キーストアファイルは、クライアントと MySQL サーバー間の双方向認証に使用できます。
database.ssl.keystore.password-
デフォルト値: デフォルトなし。
キーストアファイルのパスワード。database.ssl.keystoreが設定されている場合にのみパスワードを指定します。
database.ssl.modeデフォルト値:
preferred。
コネクターが暗号化された接続を使用するかどうかを指定します。以下の設定が可能です。disabled- 暗号化されていない接続の使用を指定します。
preferred(デフォルト)- サーバーが安全な接続をサポートしている場合、コネクターは暗号化された接続を確立します。サーバーが安全な接続をサポートしていない場合、コネクターは暗号化されていない接続を使用します。
required- コネクターは暗号化された接続を確立します。暗号化された接続を確立できない場合、コネクターは失敗します。
verify_ca-
コネクターは、
requiredのオプションを設定した場合と同じように動作しますが、設定された認証局 (CA) 証明書に対してサーバーの TLS 証明書も検証します。サーバーの TLS 証明書が有効な CA 証明書と一致しない場合、コネクターは失敗します。
verify_identity-
コネクターは
verify_caオプションを設定した場合と同じように動作しますが、サーバー証明書がリモート接続のホストと一致するかどうかも検証します。
database.ssl.truststore-
デフォルト値: デフォルトなし。
サーバー証明書検証用のトラストストアファイルの場所。
database.ssl.truststore.password-
デフォルト値: デフォルトなし。
トラストストアファイルのパスワード。トラストストアの整合性をチェックし、トラストストアのロックを解除するために使用されます。
enable.time.adjusterデフォルト値:
true。
コネクターが 2 桁の年指定を 4 桁に変換するかどうかを示すブール値。変換がデータベースに完全に委任される場合は、値をfalseに設定します。
MySQL ユーザーは、2 桁の値または 4 桁の値を挿入できます。2 桁の値は、1970 - 2069 の範囲の年にマッピングされます。デフォルトでは、コネクターが変換を実行します。
errors.max.retriesデフォルト値:
-1。
接続エラーなどの再試行可能なエラーが発生する操作が実行された後にコネクターがどのように応答するかを指定します。
以下のオプションのいずれかを設定します。-1- 制限なしコネクターは常に自動的に再起動し、以前の失敗回数に関係なく、操作を再試行します。
0- Disabledコネクターはすぐに失敗し、操作を再試行することはありません。コネクターを再起動するにはユーザーの介入が必要です。
> 0- 指定された最大再試行回数に達するまで、コネクターは自動的に再起動します。次の障害が発生すると、コネクターは停止し、再起動するにはユーザーの介入が必要になります。
event.converting.failure.handling.modeデフォルト値:
warn。
列のデータ型と Debezium 内部スキーマで指定された型が一致しないためにテーブルレコードを変換できない場合にコネクターがどのように応答するかを指定します。
以下のオプションのいずれかを設定します。fail-
例外は、フィールドのデータ型がスキーマタイプと一致しなかったために変換が失敗したことを報告し、変換を正常に行うにはコネクターを
schema _only_recoveryモードで再起動する必要がある可能性があることを示します。 warn-
コネクターは、変換に失敗した列のイベントフィールドに
null値を書き込み、警告ログにメッセージを書き込みます。
skip-
コネクターは、変換に失敗した列のイベントフィールドに
null値を書き込み、デバッグログにメッセージを書き込みます。
event.processing.failure.handling.modeデフォルト値:
fail。
問題のあるイベントに遭遇した場合など、イベントの処理中に発生する障害をコネクターがどのように処理するかを指定します。以下の設定が可能です。fail- コネクターは、問題のあるイベントとその位置を報告する例外を発生させます。その後、コネクターが停止します。
warn- コネクターにより例外が出力されることはありません。代わりに、問題のあるイベントとその位置をログに記録し、イベントをスキップします。
ignore- コネクターは問題のあるイベントを無視し、ログエントリーは生成されません。
heartbeat.action.queryデフォルト値: デフォルトなし。
コネクターがハートビートメッセージを送信するときに、コネクターがソースデータベースで実行するクエリーを指定します。
たとえば、次のクエリーは、ソースデータベースで実行された GTID セットの状態を定期的にキャプチャーします。
INSERT INTO gtid_history_table (select @gtid_executed)
heartbeat.interval.msデフォルト値:
0。
コネクターが Kafka トピックにハートビートメッセージを送信する頻度を指定します。デフォルトでは、コネクターによりハートビートメッセージは送信されません。
ハートビートメッセージは、コネクターがデータベースから変更イベントを受信しているかどうかを監視するのに便利です。ハートビートメッセージは、コネクターの再起動時に再送信する必要がある変更イベントの数を減らすのに役立つ可能性があります。ハートビートメッセージを送信するには、このプロパティーを、ハートビートメッセージの間隔をミリ秒単位で示す正の整数に設定します。
incremental.snapshot.allow.schema.changes-
デフォルト値:
false。
コネクターが増分スナップショット中にスキーマの変更を許可するかどうかを指定します。値がtrueに設定されている場合、コネクターは増分スナップショット中にスキーマの変更を検出し、DDL のロックを回避するために現在のチャンクを再選択します。
プライマリーキーへの変更はサポートされていません。増分スナップショットの作成中にプライマリーを変更すると、誤った結果が生じる可能性があります。さらに他の制限として、スキーマの変更が列のデフォルト値にのみ影響する場合、DDL が binlog ストリームから処理されるまで変更が検出されないことが挙げられます。これはスナップショットイベントの値には影響しませんが、これらのスナップショットイベントのスキーマのデフォルトが古くなっている可能性があります。
incremental.snapshot.chunk.size-
デフォルト値:
1024。
コネクターが増分スナップショットチャンクを取得するときにフェッチしてメモリーに読み込む行の最大数。スナップショットは、サイズが大きいスナップショットの場合にはクエリーが少なくなるため、チャンクサイズを増やすと効率が上がります。ただし、チャンクサイズが大きい場合には、スナップショットデータのバッファーにより多くのメモリーが必要になります。チャンクサイズは、環境で最適なパフォーマンスを発揮できる値に、調整します。
incremental.snapshot.watermarking.strategyデフォルト値:
insert_insert。
増分スナップショットによってキャプチャーされ、ストリーミングの再開後に再キャプチャーされる可能性のあるイベントの重複を排除するために、コネクターが増分スナップショット中に使用するウォーターマークメカニズムを指定します。
以下のオプションのいずれかを指定することができます。insert_insert(デフォルト)- 増分スナップショットを開始するシグナルを送信すると、スナップショット中に Debezium が読み取るチャンクごとに、スナップショットウィンドウを開くシグナルを記録するエントリーがシグナリングデータコレクションに書き込まれます。スナップショットが完了すると、Debezium はウィンドウを閉じるシグナルを記録する 2 番目のエントリーを挿入します。
insert_delete- 増分スナップショットを開始するシグナルを送信すると、Debezium が読み取るチャンクごとに、スナップショットウィンドウを開くシグナルを記録する 1 つのエントリーがシグナリングデータコレクションに書き込まれます。スナップショットが完了すると、このエントリーは削除されます。スナップショットウィンドウを閉じるシグナルのエントリーは作成されません。シグナリングデータコレクションの急増を防ぐには、このオプションを設定します。
max.batch.size-
デフォルト値:
2048。
このコネクターの反復処理中に処理される必要があるイベントの各バッチの最大サイズを指定する正の整数値。
max.queue.size-
デフォルト値:
8192。
ブロッキングキューが保持できるレコードの最大数を指定する正の整数値。Debezium はデータベースからストリームされたイベントを読み込む際、Kafka に書き込む前にブロッキングキューにイベントを配置します。ブロッキングキューは、コネクターが Kafka に書き込むよりも速くメッセージを取り込む場合、または Kafka が利用できなくなった場合に、データベースから変更イベントを読み込むためのバックプレッシャーを提供することができます。コネクターがオフセットを定期的に記録すると、キューに保持されるイベントは無視されます。max.queue.sizeは常に、max.batch.sizeの値よりも大きい値に設定します。
max.queue.size.in.bytes-
デフォルト値:
0。
ブロッキングキューの最大ボリュームをバイト単位で指定する長整数値。デフォルトでは、ブロックキューにはボリューム制限は指定されません。キューが使用できるバイト数を指定するには、このプロパティーを正の long 値に設定します。max.queue.sizeも設定されている場合、キューのサイズがどちらかのプロパティーで指定された上限に達すると、キューへの書き込みがブロックされます。たとえば、max.queue.size=1000、max.queue.size.in.bytes=5000と設定した場合、キューに 1000 レコードが入った後、あるいはキュー内のレコードの量が 5000 バイトに達した後、キューへの書き込みがブロックされます。
min.row.count.to.stream.resultsデフォルト値:
1000。
スナップショットの作成中に、コネクターは変更をキャプチャーするように設定されている各テーブルをクエリーします。コネクターは各クエリーの結果を使用して、そのテーブルのすべての行のデータが含まれる読み取りイベントを生成します。このプロパティーは、MySQL コネクターがテーブルの結果をメモリーに格納するか、またはストリーミングを行うかを決定します。メモリーへの格納はすばやく処理できますが、大量のメモリーを必要とします。ストリーミングを行うと、処理は遅くなりますが、非常に大きなテーブルにも対応できます。このプロパティーの設定は、コネクターが結果のストリーミングを行う前にテーブルに含まれる必要がある行の最小数を指定します。
すべてのテーブルサイズチェックを省略し、スナップショットの実行中に常にすべての結果をストリーミングする場合は、このプロパティーを
0に設定します。
notification.enabled.channelsデフォルト値: デフォルトなし。
コネクターに対して有効になっている通知チャネル名のリスト。デフォルトでは、以下のチャネルが利用可能です。-
sink -
log -
jmx
-
poll.interval.ms-
デフォルト値:
500(0.5 秒)。
コネクターがイベントのバッチ処理を開始する前に、新しい変更イベントが表示されるのを待機する時間をミリ秒単位で指定する正の整数値。
provide.transaction.metadata-
デフォルト値:
false。
コネクターがトランザクション境界を持つイベントを生成し、トランザクションメタデータを使用して変更イベントエンベロープを強化するかどうかを決定します。コネクターにこれを実行させる場合はtrueを指定します。詳細は、トランザクションメタデータ を参照してください。
signal.data.collection-
デフォルト値: デフォルトなし。
コネクターに シグナル を送信するために使用されるデータコレクションの完全修飾名。<databaseName>.<tableName>の形式を使用してコレクション名を指定します。
signal.enabled.channelsデフォルト値: デフォルトなし。
コネクターに対して有効になっているシグナリングチャネル名のリスト。デフォルトでは、以下のチャネルが利用可能です。-
source -
kafka -
file -
jmx
-
skipped.operations-
デフォルト値:
t。
ストリーミング中にスキップされる操作タイプのコンマ区切りリスト。挿入/作成はc、更新はu、削除はd、切り捨てはt、操作をスキップしない場合はnone となります。デフォルトでは、切り捨て操作が省略されます。
snapshot.delay.ms-
デフォルト値: デフォルトなし。
コネクターの起動時にスナップショットを実行する前にコネクターが待機する間隔 (ミリ秒単位)。クラスターで複数のコネクターを起動する場合、このプロパティーは、コネクターのリバランスが行われる原因となるスナップショットの中断を防ぐのに役立ちます。
snapshot.fetch.size-
デフォルト値: 未設定。
デフォルトでは、スナップショットの作成中に、コネクターはテーブルの内容を行単位で読み取ります。バッチ内の行の最大数を指定するには、このプロパティーを設定します。
コネクターのパフォーマンスを維持するには、このプロパティーを未設定のデフォルトのままにしておくのが最適です。このデフォルト設定により、MySQL は結果セットを一度に 1 行ずつ Debezium にストリーミングできるようになります。対照的に、このプロパティーを設定すると、Debezium は結果セット全体を一度にメモリーに取得しようとするため、パフォーマンスの問題が発生する可能性があります。
snapshot.include.collection.list-
デフォルト値:
table.include.listで指定されたすべてのテーブル。
スナップショットに含めるテーブルの完全修飾名 (<databaseName>.<tableName>) と一致する正規表現のコンマ区切りリスト (任意)。指定する項目は、コネクターのtable.include.listプロパティーで名前を付ける必要があります。このプロパティーは、コネクターのsnapshot.modeプロパティーがnever以外の値に設定されている場合にのみ有効です。
このプロパティーは増分スナップショットの動作には影響しません。
テーブルの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの名前文字列全体と照合されます。
snapshot.lock.timeout.ms-
デフォルト値:
10000。
スナップショットを実行するときにテーブルロックを取得するために待機する最大時間 (ミリ秒単位) を指定する正の整数。コネクターがこの期間にテーブルロックを取得できないと、スナップショットは失敗します。詳細は以下を参照してください。
snapshot.locking.modeデフォルト値:
minimal。
コネクターがグローバル MySQL 読み取りロックを保持するかどうか、および保持する期間を指定します。これにより、コネクターがスナップショットを実行している間、データベースへの更新を加えることができません。以下の設定が可能です。minimal-
コネクターは、データベーススキーマやその他のメタデータを読み取るスナップショットの初期フェーズのみ、グローバル読み取りロックを保持します。スナップショットの次のフェーズでは、コネクターは各テーブルからすべての行を選択するときにロックを解除します。一貫した方法で SELECT 操作を実行するために、コネクターは REPEATABLE READ トランザクションを使用します。グローバル読み取りロックが解除されると、他の MySQL クライアントがデータベースを更新できるようになりますが、トランザクションの期間中、コネクターは同じデータを読み取り続けるため、REPEATABLE READ 分離を使用すると、スナップショットの一貫性が確保されます。
extended-
スナップショットの作成中にすべての書き込み操作をブロックします。クライアントが MySQL の REPEATABLE READ 分離レベルと互換性のない同時操作を送信する場合は、この設定を使用します。
none- スナップショット中にコネクターがテーブルロックを取得するのを防ぎます。このオプションはすべてのスナップショットモードで許可されますが、スナップショットの作成中にスキーマの変更が発生しない場合に のみ 安全に使用できます。MyISAM エンジンで定義されたテーブルは常にテーブルロックを取得します。その結果、このオプションを設定しても、このようなテーブルはロックされます。この動作は、行レベルのロックを取得する InnoDB エンジンによって定義されたテーブルとは異なります。
snapshot.max.threadsデフォルト値:
1。
初期スナップショットを実行するときにコネクターが使用するスレッドの数を指定します。並列初期スナップショットを有効にするには、プロパティーを 1 より大きい値に設定します。並列初期スナップショットでは、コネクターは複数のテーブルを同時に処理します。
重要並列初期スナップショットは開発者プレビュー機能のみとなっています。開発者プレビューソフトウェアは、Red Hat では一切サポートされておらず、機能的に完全ではなく、実稼働環境に対応していません。開発者プレビューのソフトウェアを実稼働ワークロードまたはビジネスクリティカルなワークロードには使用しないでください。開発者プレビューソフトウェアは、今後 Red Hat 製品サービスとして追加される可能性のある製品ソフトウェアを前もって早期に利用できます。お客様はこのソフトウェアを使用して機能をテストし、開発プロセス中にフィードバックを提供できます。このソフトウェアはいつでも変更または削除される可能性があり、限定的なテストしか行われていません。Red Hat は、関連する SLA なしに、開発者プレビューソフトウェアに対するフィードバックを送信する手段を提供する場合があります。
Red Hat 開発者プレビューソフトウェアのサポート範囲の詳細は、開発者プレビューのサポート範囲 を参照してください。
snapshot.modeデフォルト値:
initial。
コネクターの起動時にスナップショットを実行するための基準を指定します。以下の設定が可能です。always- コネクターは起動するたびにスナップショットを実行します。スナップショットには、キャプチャーされたテーブルの構造およびデータが含まれます。この値を指定すると、コネクターが起動するたびに、キャプチャーされたテーブルからのデータの完全な表現がトピックに入力されます。
initial(デフォルト)- コネクターは、論理サーバー名のオフセットが記録されていない場合、または以前のスナップショットが完了しなかったことが検出された場合にのみ、スナップショットを実行します。スナップショットが完了すると、コネクターは、後続のデータベース変更のに備え、イベントレコードのストリーミングを開始します。
initial_only- コネクターは、論理サーバー名のオフセットが記録されていない場合にのみスナップショットを実行します。スナップショットが完了すると、コネクターは停止します。binlog からの変更イベントを読み取る際にストリーミングに移行しません。
schema_only-
非推奨です。
no_dataを参照してください。 no_data- コネクターは、テーブルデータではなくスキーマのみをキャプチャーするスナップショットを実行します。トピックにデータの一貫したスナップショットを含める必要はないが、最後のコネクターの再起動後に適用されたスキーマの変更をキャプチャーする場合は、このオプションを設定します。
schema_only_recovery-
非推奨です。
recoveryを参照してください。 recovery損失または破損したデータベーススキーマの履歴トピックを復元するにはこのオプションを設定します。再起動後、コネクターはソーステーブルからトピックを再構築するスナップショットを実行します。また、このプロパティーを設定して、予期しない増加が発生するデータベーススキーマ履歴トピックを定期的にプルーニングすることもできます。
警告最後のコネクターのシャットダウン後にスキーマの変更がデータベースにコミットされた場合、このモードを使用してスナップショットを実行しないでください。
never-
コネクターが起動すると、スナップショットを実行するのではなく、後続のデータベース変更のイベントレコードのストリーミングがすぐに開始されます。
no_dataオプションが優先的に使用されるようになり、このオプションは、今後非推奨にするか検討中です。 when_neededコネクターが起動した後、次のいずれかの状況を検出した場合にのみスナップショットが実行されます。
- トピックのオフセットを検出できません。
- 以前に記録されたオフセットは、サーバー上で使用できない binlog の位置または GTID を指定します。
snapshot.query.modeデフォルト値:
select_all。
スナップショットを実行するときにコネクターがデータをクエリーする方法を指定します。
以下のオプションのいずれかを設定します。select_all(デフォルト)-
コネクターは、
select allクエリーを使用してキャプチャーされたテーブルから行を取得し、必要に応じて、列のincludeおよびexcludeリストの設定に基づいて選択された列を調整します。
この設定により、
snapshot.select.statement.overridesプロパティーを使用する場合と比較して、より柔軟にスナップショットコンテンツを管理できるようになります。
snapshot.select.statement.overridesデフォルト値: デフォルトなし。
スナップショットに含めるテーブル行を指定します。スナップショットにテーブルの行のサブセットのみを含める場合は、プロパティーを使用します。このプロパティーはスナップショットにのみ影響します。コネクターがログから読み取るイベントには影響しません。<databaseName>.<tableName>の形式で完全修飾テーブル名のコンマ区切りリストを指定します。以下に例を示します。
"snapshot.select.statement.overrides": "inventory.products,customers.orders"
リスト内の各テーブルに対して、スナップショットを取得するときにコネクターがテーブルで実行する
SELECTステートメントを指定する別の設定プロパティーを追加します。指定したSELECTステートメントは、スナップショットに追加するテーブル行のサブセットを決定します。このSELECTステートメントプロパティーの名前を指定するには、次の形式を使用します。
snapshot.select.statement.overrides.<databaseName>.<tableName>。たとえば、snapshot.select.statement.overrides.customers.ordersなどです。
ソフト削除列delete_flagを含むcustomers.ordersテーブルから、スナップショットにソフト削除されていないレコードのみを含める場合は、次のプロパティーを追加します。"snapshot.select.statement.overrides": "customer.orders", "snapshot.select.statement.overrides.customer.orders": "SELECT * FROM [customers].[orders] WHERE delete_flag = 0 ORDER BY id DESC"
"snapshot.select.statement.overrides": "customer.orders", "snapshot.select.statement.overrides.customer.orders": "SELECT * FROM [customers].[orders] WHERE delete_flag = 0 ORDER BY id DESC"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 作成されるスナップショットでは、コネクターには
delete_flag = 0のレコードのみが含まれます。
snapshot.tables.order.by.row.countデフォルト値:
disabled。
コネクターが初期スナップショットを実行するときにテーブルを処理する順序を指定します。以下のオプションのいずれかを設定します。descending- コネクターは、行数に基づいて、最上位から最下位の順にテーブルのスナップショットを作成します。
ascending- コネクターは、行数に基づいて、最下位から最上位の順にテーブルのスナップショットを作成します。
disabled- コネクターは、初期スナップショットを実行するときに行数を無視します。
streaming.delay.ms-
デフォルト値:
0。
コネクターがスナップショットを完了した後、ストリーミングプロセスの開始を遅延する時間をミリ秒単位で指定します。遅延間隔を設定すると、スナップショットが完了した直後で、ストリーミングプロセスの開始前に障害が発生した場合に、コネクターがスナップショットを再開できないようにします。Kafka Connect ワーカーに設定されているoffset.flush.interval.msプロパティーの値よりも高い遅延値を設定します。
table.ignore.builtin-
デフォルト値:
true。
組み込みシステムテーブルを無視するかどうかを指定するブール値。これは、テーブルの include および exclude リストに関係なく適用されます。デフォルトでは、システムテーブルの値に加えられた変更はキャプチャーから除外され、Debezium はシステムテーブルの変更に対してイベントを生成しません。
topic.cache.size-
デフォルト値:
10000。
制限された同時ハッシュマップ内のメモリーに格納できるトピック名の数を指定します。コネクターはキャッシュを使用して、データコレクションに対応するトピック名を決定します。
topic.delimiter-
デフォルト値:
.。
コネクターがトピック名のコンポーネント間に挿入する区切り文字を指定します。
topic.heartbeat.prefixデフォルト値:
__debezium-heartbeat。
コネクターがハートビートメッセージを送信するトピックの名前を指定します。トピック名の形式は次のとおりです。
topic.heartbeat.prefix.topic.prefix
たとえば、トピックの接頭辞が
fulfillmentの場合、デフォルトのトピック名は__Debezium-heartbeat.fulfillmentになります。
topic.naming.strategy-
デフォルト値:
io.debezium.schema.DefaultTopicNamingStrategy。
コネクターが使用するTopicNamingStrategyクラスの名前。指定されたストラテジーによって、データ変更、スキーマ変更、トランザクション、ハートビートなどのイベントレコードを格納するトピックにコネクターが名前を付ける方法が決まります。
topic.transactionデフォルト値:
transaction。
コネクターがトランザクションメタデータメッセージを送信するトピックの名前を指定します。トピック名のパターンは次のとおりです。
topic.prefix.topic.transaction
たとえば、トピック接頭辞が
fulfillmentの場合、デフォルトのトピック名はfulfillment.transactionになります。
use.nongraceful.disconnect-
デフォルト値: false。
バイナリーログクライアントのキープアライブスレッドがSO_LINGERソケットオプションを0に設定して、古い TCP 接続をすぐに切断するかどうかを指定するブール値。SSLSocketImpl.closeでコネクターのデッドロックが発生する場合は、値をtrueに設定します。
Debezium コネクターデータベーススキーマ履歴設定プロパティー
Debezium には、コネクターがスキーマ履歴トピックと対話する方法を制御する schema.history.internal.* プロパティーのセットが含まれています。
以下の表は、Debezium コネクターを設定するための schema.history.internal プロパティーを説明しています。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし | コネクターがデータベーススキーマの履歴を保存する Kafka トピックの完全名。 | |
| デフォルトなし | Kafka クラスターへの最初の接続を確立するためにコネクターが使用するホストとポートのペアのリスト。このコネクションは、コネクターによって以前に保存されたデータベーススキーマ履歴の取得や、ソースデータベースから読み取られる各 DDL ステートメントの書き込みに使用されます。各ペアは、Kafka Connect プロセスによって使用される同じ Kafka クラスターを示す必要があります。 | |
|
| 永続化されたデータのポーリングが行われている間にコネクターが起動/回復を待つ最大時間 (ミリ秒単位) を指定する整数値。デフォルトは 100 ミリ秒です。 | |
|
| Kafka 管理クライアントを使用してクラスター情報を取得する際に、コネクターが待機すべき最大ミリ秒数を指定する整数値です。 | |
|
| Kafka 管理クライアントを使用して kafka 履歴トピックを作成する間、コネクターが待機する最大ミリ秒数を指定する整数値。 | |
|
|
エラーでコネクターのリカバリーが失敗する前に、コネクターが永続化された履歴データの読み取りを試行する最大回数。データが受信されなかった場合に最大待機する時間は、 | |
|
|
コネクターが不正または不明なデータベースのステートメントを無視するかどうか、または人が問題を修正するために処理を停止するかどうかを指定するブール値。安全なデフォルトは | |
|
|
コネクターがスキーマまたはデータベース内のすべてのテーブルからスキーマ構造を記録するか、キャプチャー対象に指定されたテーブルのみからスキーマ構造を記録するかを指定するブール値。
| |
|
|
コネクターがデータベースインスタンス内のすべての論理データベースのスキーマ構造を記録するかどうかを指定するブール値。
|
パススルー MySQL コネクター設定プロパティー
コネクター設定で pass-through プロパティーを設定して、Apache Kafka プロデューサーとコンシューマーの動作をカスタマイズできます。Kafka プロデューサーとコンシューマーの全設定プロパティーの詳細は、Kafka ドキュメント を参照してください。
プロデューサーとコンシューマーのクライアントがスキーマ履歴トピックと対話する方法を設定するための Pass-through プロパティー
Debezium は、データベーススキーマ履歴トピックへのスキーマ変更を記述するために Apache Kafka プロデューサーに依存しています。同様に、コネクターが起動すると、データベーススキーマ履歴トピックから読み取る Kafka コンシューマーに依存します。schema.history.internal.producer.* および schema.history.internal.consumer.* 接頭辞で始まるパススルー設定プロパティーのセットに値を割り当てて、Kafka プロデューサーおよびコンシューマークライアントの設定を定義します。パススループロデューサーおよびコンシューマーデータベーススキーマ履歴プロパティーは、以下の例のように Kafka ブローカーとのこれらのクライアントの接続をセキュアにする方法など、さまざまな動作を制御します。
Debezium は、プロパティーを Kafka クライアントに渡す前に、プロパティー名から接頭辞を削除します。
Kafka プロデューサー設定プロパティー と Kafka コンシューマー設定プロパティー の詳細は、Apache Kafka ドキュメントを参照してください。
MySQL コネクターが Kafka シグナリングトピックと対話する方法を設定するための Pass-through プロパティー
Debezium は、コネクターが Kafka シグナルトピックと対話する方法を制御する signal.* プロパティーのセットを提供します。
以下の表は、Kafka signal プロパティーを説明しています。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| <topic.prefix>-signal | コネクターがアドホックシグナルについて監視する Kafka トピックの名前。 注記 トピックの自動作成 が無効になっている場合は、必要なシグナリングトピックを手動で作成する必要があります。シグナルの順序を維持するには、シグナルトピックが必要です。シグナリングトピックには単一のパーティションが必要です。 | |
| kafka-signal | Kafka コンシューマーによって使用されるグループ ID の名前。 | |
| デフォルトなし | コネクターが Kafka クラスターへの初期接続を確立するために使用するホストとポートのペアのリスト。各ペアは、Debezium Kafka Connect プロセスによって使用される Kafka クラスターを参照します。 | |
|
| コネクターが信号をポーリングするときに待機する最大ミリ秒数を指定する整数値。 | |
|
| Kafka コンシューマーがシグナリングトピックからメッセージを読み取った後にオフセットコミットを書き込むかどうかを指定します。このプロパティーに割り当てる値によって、コネクターがオフラインのときに、シグナリングトピックが受信する要求をコネクターが処理できるかどうかが決まります。次のいずれかの設定を選択します。
|
シグナリングチャネルの Kafka コンシューマークライアントを設定するためのパススループロパティー
Debezium コネクターでは、Kafka コンシューマーのパススルー設定が可能です。パススルーシグナルのプロパティーは、接頭辞 signals.consumer.* で始まります。たとえば、コネクターは signal.consumer.security.protocol=SSL などのプロパティーを Kafka コンシューマーに渡します。
Debezium は、プロパティーを Kafka シグナルコンシューマーに渡す前に、プロパティーから接頭辞を削除します。
MySQL コネクター sink notification チャネルを設定するためのパススループロパティー
次の表では、Debezium sink notification チャネルの設定に使用できるプロパティーについて説明します。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし |
Debezium から通知を受信するトピックの名前。このプロパティーは、有効な通知チャネルの 1 つとして |
Debezium コネクターのパススルーデータベースドライバー設定プロパティー
Debezium コネクターでは、データベースドライバーのパススルー設定が可能です。パススルーデータベースプロパティーは接頭辞 driver.* で始まります。たとえば、コネクターは driver.foobar=false などのプロパティーを JDBC URL に渡します。
Debezium は、プロパティーをデータベースドライバーに渡す前に、プロパティーから接頭辞を削除します。
2.4.7. Debezium MySQL コネクターのパフォーマンスの監視
Debezium MySQL コネクターは、Zookeeper、Kafka、および Kafka Connect によって提供される JMX メトリクスの組み込みサポートに加えて、3 種類のメトリクスを提供します。
- スナップショットメトリクス は、スナップショットの実行中にコネクター操作に関する情報を提供します。
- ストリーミングメトリック は、コネクターが binlog を読み取る際のコネクター操作に関する情報を提供します。
- スキーマ履歴メトリクス は、コネクターのスキーマ履歴の状態に関する情報を提供します。
Debezium モニタリングのドキュメント では、JMX を使用してこれらのメトリクスを公開する方法の詳細を説明しています。
2.4.7.1. MySQL コネクタースナップショットおよびストリーミング MBean オブジェクトのカスタマイズされた名前
Debezium コネクターは、コネクターの MBean 名を介してメトリクスを公開します。これらのメトリクスは各コネクターインスタンスに固有であり、コネクターのスナップショット、ストリーミング、およびスキーマ履歴プロセスの動作に関するデータを提供します。
デフォルトでは、正しく設定されたコネクターをデプロイすると、Debezium はさまざまなコネクターメトリクスごとに一意の MBean 名を生成します。コネクタープロセスのメトリクスを表示するには、MBean を監視するように可観測性スタックを設定します。ただし、これらのデフォルトの MBean 名はコネクター設定に依存しており、設定の変更によって MBean 名が変更される場合があります。MBean 名を変更すると、コネクターインスタンスと MBean 間のリンクが切断され、監視アクティビティーが中断されます。このシナリオでは、監視を再開するには、新しい MBean 名を使用するように監視スタックを再設定する必要があります。
MBean 名の変更が原因で監視が中断されないように、カスタムメトリクスタグを設定できます。カスタムメトリクスを設定するには、コネクター設定に custom.metric.tags プロパティーを追加します。このプロパティーは、各キーが MBean オブジェクト名のタグを表し、対応する値がそのタグの値を表すキーと値のペアを受け入れます。たとえば、k1=v1,k2=v2 です。Debezium は、指定されたタグをコネクターの MBean 名に追加します。
コネクターの custom.metric.tags プロパティーを設定した後、指定されたタグに関連付けられたメトリクスを取得するように監視スタックを設定できます。可観測性スタックは、変更可能な MBean 名ではなく、指定されたタグを使用してコネクターを一意に識別します。その後、Debezium が MBean 名の構築方法を再定義したり、コネクター設定の topic.prefix が変更されたりしても、メトリクススクレイプタスクは指定されたタグパターンを使用してコネクターを識別するため、メトリクスの収集は中断されません。
カスタムタグを使用するさらなる利点は、データパイプラインのアーキテクチャーを反映するタグを使用できるため、運用上のニーズに合った方法でメトリクスを整理できることです。たとえば、コネクターアクティビティーのタイプ、アプリケーションコンテキスト、またはデータソースを宣言する値を持つタグを指定できます (例: db1-streaming-for-application-abc)。複数のキーと値のペアを指定すると、指定されたすべてのペアがコネクターの MBean 名に追加されます。
次の例は、タグがデフォルトの MBean 名を変更する方法を示しています。
例2.31 カスタムタグがコネクター MBean 名を変更する方法
デフォルトでは、MySQL コネクターはストリーミングメトリクスに次の MBean 名を使用します。
debezium.mysql:type=connector-metrics,context=streaming,server=<topic.prefix>
debezium.mysql:type=connector-metrics,context=streaming,server=<topic.prefix>
custom.metric.tags の値を database=salesdb-streaming,table=inventory に設定すると、Debezium は次のカスタム MBean 名を生成します。
debezium.mysql:type=connector-metrics,context=streaming,server=<topic.prefix>,database=salesdb-streaming,table=inventory
debezium.mysql:type=connector-metrics,context=streaming,server=<topic.prefix>,database=salesdb-streaming,table=inventory2.4.7.2. MySQL データベースのスナップショット作成時の Debezium の監視
MBean は debezium.mysql:type=connector-metrics,context=snapshot,server=<topic.prefix> です。
スナップショット操作がアクティブでない場合や、最後のコネクターの起動後にスナップショットの作成が発生した場合に、スナップショットメトリクスは公開されません。
次の表に、使用可能なスナップショットメトリクスを示します。
| 属性 | タイプ | 説明 |
|---|---|---|
|
| コネクターが読み取りした最後のスナップショットイベント。 | |
|
| コネクターが最新のイベントを読み取りおよび処理してからの経過時間 (ミリ秒単位)。 | |
|
| 前回の開始またはリセット以降にコネクターで確認されたイベントの合計数。 | |
|
| コネクターに設定された include/exclude リストのフィルタリングルールによってフィルターされたイベントの数。 | |
|
| コネクターによって取得されるテーブルのリスト。 | |
|
| snapshotter とメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの長さ。 | |
|
| snapshotter とメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの空き容量。 | |
|
| スナップショットに含まれているテーブルの合計数。 | |
|
| スナップショットによってまだコピーされていないテーブルの数。 | |
|
| スナップショットが起動されたかどうか。 | |
|
| スナップショットが一時停止されたかどうか。 | |
|
| スナップショットが中断されたかどうか。 | |
|
| スナップショットが完了したかどうか。 | |
|
| スナップショットが完了したかどうかに関わらず、これまでスナップショットにかかった時間 (秒単位)。スナップショットが一時停止された時間も含まれます。 | |
|
| スナップショットが一時停止された合計秒数。スナップショットが数回一時停止された場合は、一時停止時間が加算されます。 | |
|
| スナップショットの各テーブルに対してスキャンされる行数が含まれるマップ。テーブルは、処理中に増分がマップに追加されます。スキャンされた 10,000 行ごとに、テーブルの完成時に更新されます。 | |
|
|
キューの最大バッファー (バイト単位)。このメトリクスは | |
|
| キュー内のレコードの現在の容量 (バイト単位)。 |
コネクターは、増分スナップショットの実行時に、以下の追加のスナップショットメトリクスも提供します。
2.4.7.3. Debezium MySQL コネクターレコードストリーミングの監視
Debezium MySQL コネクターは、Zookeeper、Kafka、および Kafka Connect によって提供される JMX メトリクスの組み込みサポートに加えて、3 種類のメトリクスを提供します。
- スナップショットメトリクス は、スナップショットの実行中にコネクター操作に関する情報を提供します。
- ストリーミングメトリック は、コネクターが binlog を読み取る際のコネクター操作に関する情報を提供します。
- スキーマ履歴メトリクス は、コネクターのスキーマ履歴の状態に関する情報を提供します。
Debezium モニタリングのドキュメント では、JMX を使用してこれらのメトリクスを公開する方法の詳細を説明しています。
MBean は debezium.mysql:type=connector-metrics,context=streaming,server=<topic.prefix> です。
以下の表は、利用可能なストリーミングメトリクスのリストです。
| 属性 | タイプ | 説明 |
|---|---|---|
|
| コネクターが読み取られた最後のストリーミングイベント。 | |
|
| コネクターが最新のイベントを読み取りおよび処理してからの経過時間 (ミリ秒単位)。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、ソースデータベースによって報告されたデータ変更イベントの合計数。Debezium が処理するデータ変更ワークロードを表します。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された作成イベントの合計数。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された更新イベントの合計数。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された削除イベントの合計数。 | |
|
| コネクターに設定された include/exclude リストのフィルタリングルールによってフィルターされたイベントの数。 | |
|
| コネクターによって取得されるテーブルのリスト。 | |
|
| ストリーマーとメイン Kafka Connect ループの間でイベントを渡すために使用されるキューの長さ。 | |
|
| ストリーマーとメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの空き容量。 | |
|
| コネクターが現在データベースサーバーに接続されているかどうかを示すフラグ。 | |
|
| 最後の変更イベントのタイムスタンプとそれを処理するコネクターとの間の期間 (ミリ秒単位)。この値には、データベースサーバーとコネクターが実行されているマシンのクロックの差が組み込まれます。 | |
|
| コミットされた処理済みトランザクションの数。 | |
|
| 最後に受信したイベントの位置。 | |
|
| 最後に処理されたトランザクションのトランザクション識別子。 | |
|
|
キューの最大バッファー (バイト単位)。このメトリクスは | |
|
| キュー内のレコードの現在の容量 (バイト単位)。 |
2.4.7.4. Debezium MySQL コネクターのスキーマ履歴の監視
MBean は debezium.mysql:type=connector-metrics,context=schema-history,server=<topic.prefix> です。
以下の表は、利用可能なスキーマ履歴メトリクスのリストです。
| 属性 | タイプ | 説明 |
|---|---|---|
|
|
データベーススキーマ履歴の状態を示す | |
|
| リカバリーが開始された時点のエポック秒の時間。 | |
|
| リカバリーフェーズ中に読み取られた変更の数。 | |
|
| リカバリーおよびランタイム中に適用されるスキーマ変更の合計数。 | |
|
| 最後の変更が履歴ストアから復元された時点からの経過時間 (ミリ秒単位)。 | |
|
| 最後の変更が適用された時点からの経過時間 (ミリ秒単位)。 | |
|
| 履歴ストアから復元された最後の変更の文字列表現。 | |
|
| 最後に適用された変更の文字列表現。 |
2.4.8. Debezium MySQL コネクターによる障害および問題の処理方法
Debezium は、複数のアップストリームデータベースのすべての変更をキャプチャーする分散システムであり、イベントの見逃しや損失は発生しません。システムが正常に操作している場合や、慎重に管理されている場合は、Debezium は変更イベントレコードごとに 1 度だけ 配信します。
障害が発生しても、システムからイベントがなくなることはありません。ただし、Debezium が障害から回復している間に、いくつかの変更イベントが繰り返される可能性があります。このような正常でない状態では、Debezium は Kafka と同様に、変更イベントを 少なくとも 1 回 配信します。
詳細は以下を参照してください。
- 設定および起動エラー
以下の状況では、起動時にコネクターが失敗し、エラーまたは例外がログに記録され、実行が停止されます。
- コネクターの設定が無効である。
- 指定の接続パラメーターを使用してコネクターを MySQL サーバーに接続できない。
- MySQL に履歴がない binlog の位置でコネクターが再起動を試行する。
このような場合、エラーメッセージには問題の詳細が含まれ、推奨される回避策も含まれることがあります。設定の修正したり、MySQL の問題に対処した後、コネクターを再起動します。
ただし、高可用性の MySQL クラスターに接続している場合は、コネクターをすぐに再起動できます。これはクラスターの別の MySQL サーバーに接続し、最後のトランザクションを表すサーバーの binlog の場所を特定し、その特定の場所から新しいサーバーの binlog の読み取りを開始します。
- Kafka Connect が正常に停止する
- Kafka Connect が正常に停止すると、Debezium MySQL コネクタータスクが停止され、新しい Kafka Connect プロセスで再起動される間に短い遅延が発生します。
- Kafka Connect プロセスのクラッシュ
- Kafka Connect がクラッシュすると、プロセスが停止し、最後に処理されたオフセットが記録されずに Debezium MySQL コネクタータスクが終了します。分散モードでは、Kafka Connect は他のプロセスでコネクタータスクを再起動します。ただし、MySQL コネクターは以前のプロセスで記録された最後のオフセットから再開します。その結果、代わりのタスクによってクラッシュ前に処理された一部のイベントが再生成され、重複したイベントが作成されることがあります。
各変更イベントメッセージには、重複イベントの特定に使用できるソース固有の情報が含まれます。以下に例を示します。
- イベント元
- MySQL サーバーのイベント時間
- binlog ファイル名と位置
- GTID (使用されている場合)
- MySQL が binlog ファイルをパージする
- Debezium MySQL コネクターが長時間停止すると、MySQL サーバーは古い binlog ファイルをパージするため、コネクターの最後の位置が失われる可能性があります。コネクターが再起動すると、MySQL サーバーに開始点がなくなり、コネクターは別の最初のスナップショットを実行します。スナップショットが無効の場合、コネクターはエラーによって失敗します。
MySQL コネクターが最初のスナップショットを実行する方法は、スナップショット を参照してください。
2.5. Oracle の Debezium コネクター
Debezium の Oracle コネクターは、Oracle サーバーのデータベースで発生する行レベルの変更をキャプチャーして記録します。これには、コネクターの実行中に追加されたテーブルが含まれます。コネクターを設定して、スキーマおよびテーブルの特定のサブセットの変更イベントを出力したり、特定の列で値を無視、マスク、または切り捨てしたりするように設定できます。
このコネクターと互換性のある Oracle データベースのバージョンについては、Debezium でサポートされる設定ページを参照してください。
ネイティブの LogMiner データベースパッケージを使用して、Debezium が Oracle から最も新しい変更イベントを取り込みます。
Debezium Oracle コネクターの使用に関する情報および手順は、以下のように整理されています。
2.5.1. Debezium Oracle コネクターの仕組み
Debezium Oracle コネクターを最適に設定し実行するには、コネクターがどのようにスナップショットを実行し、変更イベントをストリームして、Kafka トピック名を決定し、メタデータを使用して、イベントバッファリングを実装するのかを理解することが役に立ちます。
詳細は、以下のトピックを参照してください。
2.5.1.1. Debezium Oracle コネクターによるデータベーススナップショットの実行方法
通常、Oracle サーバーの redo ログは、データベースの完全な履歴を保持しないように設定されています。そのため、Debezium Oracle コネクターはログからデータベースの履歴全体を取得できません。コネクターがデータベースの現在の状態のベースラインを確立できるようにするには、コネクターの初回起動時に、データベースの最初の 整合性スナップショット を実行します。
初期スナップショットの完了までにかかる時間が、データベースに設定されている UNDO_RETENTION 時間 (デフォルトでは 15 分) を超えると、ORA-01555 例外が発生する可能性があります。エラーに関する詳細情報と、そこから回復するための手順の詳細は、よくある質問 を参照してください。
テーブルのスナップショット中に、Oracle で ORA-01466 例外が発生する可能性があります。これは、ユーザーがテーブルのスキーマを変更したり、スナップショット対象のテーブルに関連付けられたインデックスまたは関連オブジェクトを追加、変更、または削除したりした場合に発生します。このような事態が発生した場合、コネクターが停止し、初期スナップショットを最初から取得する必要があります。
この問題を解決するには、特定のテーブルのスナップショットが再起動されるように、snapshot.database.errors.max.retries プロパティーを 0 より大きい値に設定してください。再試行時にスナップショット全体が最初から開始されることはありませんが、問題の特定のテーブルは最初から再読み取りされ、テーブルのトピックには重複したスナップショットイベントが含まれます。
スナップショットの詳細は、以下のセクションを参照してください。
2.5.1.1.1. Oracle コネクターが初期スナップショットを実行するために使用するデフォルトのワークフロー
以下のワークフローでは、Debezium がスナップショットを作成する手順を示しています。この手順では、snapshot.mode 設定プロパティーがデフォルト値 (initial) に設定されている場合のスナップショットのプロセスを説明します。snapshot.mode プロパティーの値を変更することで、コネクターがスナップショットを作成する方法をカスタマイズできます。別のスナップショットモードを設定する場合、コネクターはこのワークフローの変更バージョンを使用してスナップショットを完了します。
スナップショットモードがデフォルトに設定されている場合には、コネクターは以下の作業を完了してスナップショットを作成します。
- データベースへの接続を確立します。
-
キャプチャーするテーブルを決定します。デフォルトでは、コネクターは、キャプチャーから除外するスキーマ が含まれるテーブル以外、すべてのテーブルをキャプチャーします。スナップショットが完了した後、コネクターは指定されたテーブルのデータをストリーミングし続けます。コネクターで特定のテーブルからのみデータをキャプチャーする場合は、
table.include.listやtable.exclude.listなどのプロパティーを設定して、テーブルまたはテーブル要素のサブセットのみのデータをキャプチャーするようにコネクターに指示できます。 -
スナップショットの作成中に構造的な変更が発生しないように、キャプチャした各テーブルの
ROW SHARE MODEロックを取得します。Debezium は短期間のみ、ロックを保持します。 - サーバーの REDO ログから現在のシステム変更番号 (SCN) の位置を読み取ります。
すべてのデータベーステーブル、またはキャプチャー対象として指定されたすべてのテーブルの構造をキャプチャーします。コネクターは、内部データベースのスキーマ履歴トピックにスキーマ情報を保持します。スキーマ履歴は、変更イベントの発生時に有効な構造に関する情報を提供します。
注記デフォルトでは、コネクターは、キャプチャー用に設定されていないテーブルも含め、キャプチャーモードにあるデータベース内の全テーブルのスキーマをキャプチャーします。テーブルがキャプチャー用に設定されていない場合、最初のスナップショットはテーブルの構造のみをキャプチャーし、テーブルデータはキャプチャーされません。初期スナップショットに含まれなかったテーブルのスキーマ情報がスナップショットに保持される理由の詳細は、初期スナップショットがすべてのテーブルのスキーマをキャプチャーする理由 を参照してください。
- 手順 3 で取得したロックを解放します。他のデータベースクライアントは、以前にロックされていたテーブルに書き込みできるようになります。
手順 4 で読み取った SCN の位置で、コネクターはキャプチャー用に指定されたテーブル (
SELECT * FROM … AS OF SCN 123) をスキャンします。スキャン中に、コネクターは次のタスクを実行します。- スナップショットが開始される前に、テーブルが作成されたことを確認します。スナップショットの開始後にテーブルが作成された場合、コネクターはテーブルをスキップします。スナップショットが完了し、コネクターがストリーミングに移行すると、スナップショットの開始後に作成されたテーブルに対して変更イベントが発行されます。
-
テーブルからキャプチャーされた行ごとに
readイベントを生成します。すべてのreadイベントには同じ SCN 位置が含まれていますが、これは手順 4 で取得した SCN 位置です。 -
ソーステーブルの Kafka トピックに各
readイベントを出力します。 - 該当する場合は、データテーブルロックを解放します。
- コネクターオフセットにスナップショットの正常な完了を記録します。
作成された初期スナップショットは、キャプチャーされたテーブルの各行の現在の状態をキャプチャーします。このベースライン状態から、コネクターは発生した後続の変更をキャプチャーします。
スナップショットプロセスが開始されたら、コネクターの障害、リバランス、またはその他の理由でプロセスが中断されると、コネクターの再起動後にプロセスが再起動されます。コネクターによって最初のスナップショットが完了した後、更新に抜けがないように、ステップ 3 で読み取りした位置からストリーミングを続行します。何らかの理由でコネクターが再び停止した場合に、コネクターは再起動後に最後に停止した位置から変更のストリーミングを再開します。
| 設定 | 説明 |
|---|---|
|
| 各コネクターの開始時にスナップショットを実行します。スナップショットが完了すると、コネクターは、後続のデータベース変更のに備え、イベントレコードのストリーミングを開始します。 |
|
| コネクターは 初期スナップショットを作成するためのデフォルトのワークフロー で説明されているように、データベーススナップショットを実行します。スナップショットが完了すると、コネクターは、後続のデータベース変更のに備え、イベントレコードのストリーミングを開始します。 |
|
| コネクターはデータベースのスナップショットを実行し、変更イベントレコードをストリーミングする前に停止して、それ以降の変更イベントのキャプチャを許可しません。 |
|
|
非推奨です。 |
|
|
コネクターは関連するすべてのテーブルの構造をキャプチャーし、デフォルトのスナップショットワークフロー に記載されているすべてのステップを実行します。ただし、コネクターの起動時 (Step 6) の時点でデータセットを表す |
|
|
非推奨です。 |
|
|
損失または破損したデータベーススキーマの履歴トピックを復元するにはこのオプションを設定します。再起動後、コネクターはソーステーブルからトピックを再構築するスナップショットを実行します。また、このプロパティーを設定して、予期しない増加が発生するデータベーススキーマ履歴トピックを定期的にプルーニングすることもできます。 |
|
| コネクターが起動した後、次のいずれかの状況を検出した場合にのみスナップショットが実行されます。
|
詳細は、コネクター設定プロパティーテーブルの snapshot.mode を参照してください。
2.5.1.1.2. 初期スナップショットがすべてのテーブルのスキーマ履歴をキャプチャーする理由
コネクターが実行する最初のスナップショットは、2 種類の情報をキャプチャーします。
- テーブルデータ
-
コネクターの
table.include.listプロパティーにあるテーブルのINSERT、UPDATE、およびDELETE操作に関する情報。 - スキーマデータ
- テーブルに適用される構造の変更を記述する DDL ステートメント。スキーマデータは、内部スキーマ履歴トピックとコネクターのスキーマ変更トピック (設定されている場合) の両方に保持されます。
初期スナップショットを実行すると、キャプチャー対象として指定されていないテーブルのスキーマ情報がスナップショットによってキャプチャーされることが分かります。デフォルトでは、初期スナップショットは、キャプチャー用に指定されたテーブルからだけでなく、データベースに存在するすべてのテーブルのスキーマ情報を取得するように設計されています。コネクターでは、テーブルのスキーマがスキーマ履歴トピックにある状態で、テーブルをキャプチャーする必要があります。初期スナップショットが元のキャプチャーセットの一部ではないテーブルのスキーマデータをキャプチャーできるようにして、後で必要になった場合にこれらのテーブルからイベントデータを簡単にキャプチャーできるように、Debezium はコネクターを準備します。初期スナップショットがテーブルのスキーマをキャプチャーしない場合は、コネクターがテーブルからデータをキャプチャーする前に、履歴トピックにスキーマを追加する必要があります。
場合によっては、最初のスナップショットでのスキーマキャプチャーを制限する場合があります。これは、スナップショットの完了に必要な時間の短縮に便利です。または、Debezium が複数の論理データベースにアクセスできるユーザーアカウントを使用して、データベースインスタンスに接続しているにもかかわらず、コネクターで特定の論理データベース内のテーブルからの変更のみをキャプチャーする場合にも便利です。
関連情報
- 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更なし)
- 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更)
-
schema.history.internal.store.only.captured.tables.ddlプロパティーを設定して、スキーマ情報をキャプチャーするテーブルを指定します。 -
schema.history.internal.store.only.captured.databases.ddlプロパティーを設定して、スキーマ変更をキャプチャーする論理データベースを指定します。
2.5.1.1.3. 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更なし)
コネクターを使用して、最初のスナップショットでスキーマがキャプチャーされなかったテーブルからデータをキャプチャーする場合があります。コネクターの設定によっては、最初のスナップショットはデータベース内の特定のテーブルのテーブルスキーマのみをキャプチャーする場合があります。テーブルスキーマが履歴トピックに存在しない場合、コネクターはテーブルのキャプチャーに失敗し、スキーマ欠落エラーを報告します。
テーブルからデータを取得できる場合もありますが、テーブルスキーマを追加するには別の手順を実行する必要があります。
前提条件
- コネクターにより最初のスナップショット中にキャプチャーされなかったスキーマが含まれるテーブルからデータをキャプチャーしたいと考えている。
- トランザクションログでは、テーブルのすべてのエントリーが同じスキーマを使用します。構造が変更された新しいテーブルからデータを取得する方法は、「初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更)」 を参照してください。
手順
- コネクターを停止します。
-
schema.history.internal.kafka.topic プロパティーで指定された内部データベーススキーマ履歴トピックを削除します。 コネクター設定で、以下を行います。
-
snapshot.modeをschema_only_recoveryに設定します。 -
(オプション)
schema.history.internal.store.only.captured.tables.ddlの値をfalseに設定して、コネクターが現在キャプチャー対象として指定されていないテーブルのデータを今後容易にキャプチャーできるようにします。コネクターは、テーブルのスキーマ履歴が履歴トピックに存在する場合にのみ、テーブルからデータをキャプチャーできます。 -
コネクターがキャプチャーするテーブルを
table.include.listに追加します。
-
- コネクターを再起動します。スナップショットのリカバリープロセスでは、テーブルの現在の構造に基づいてスキーマ履歴が再ビルドされます。
- (オプション) スナップショットが完了したら、新しく追加されたテーブルで 増分スナップショット を開始します。増分スナップショットは、最初に新しく追加されたテーブルの履歴データをストリーミングし、次に、そのコネクターがオフラインの間に発生した変更など、以前に設定されたテーブルの REDO ログとアーカイブログからの変更の読み取りを再開します。
-
(オプション)
snapshot.modeをschema_onlyにリセットして、今後の再起動後にコネクターが回復を開始しないようにします。
2.5.1.1.4. 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更)
スキーマ変更がテーブルに適用される場合、スキーマ変更前にコミットされたレコードの構造は、変更後にコミットされたレコードとは異なります。Debezium はテーブルからデータをキャプチャーするときに、スキーマ履歴を読み取り、各イベントに正しいスキーマが適用されていることを確認します。スキーマがスキーマ履歴トピックに存在しない場合、コネクターはテーブルをキャプチャーできず、エラーが発生します。
最初のスナップショットでキャプチャーされず、テーブルのスキーマが変更されたテーブルからデータをキャプチャーする場合、スキーマがまだ使用可能でない場合は、履歴トピックにスキーマを追加する必要があります。新しいスキーマスナップショットを実行するか、テーブルの初期スナップショットを実行して、スキーマを追加できます。
前提条件
- コネクターにより最初のスナップショット中にキャプチャーされなかったスキーマが含まれるテーブルからデータをキャプチャーしたいと考えている。
- スキーマ変更がテーブルに適用されたため、キャプチャーされるレコードの構造が不均一になっている。
手順
- 初期スナップショットにすべてのテーブルのスキーマがキャプチャーされている場合 (
store.only.captured.tables.ddlはfalseに設定されました)。 -
table.include.listプロパティーを編集して、キャプチャーするテーブルを指定します。 - コネクターを再起動します。
- 新しく追加したテーブルから既存のデータをキャプチャーする場合は、増分スナップショット を開始します。
-
- 初期スナップショットにすべてのテーブルのスキーマがキャプチャーされていない場合 (
store.only.captured.tables.ddlがtrueに設定されています)。 最初のスナップショットでキャプチャーするテーブルのスキーマが保存されなかった場合は、次のいずれかの手順を実行します。
- 手順 1: スキーマスナップショット、その後に増分スナップショット
この手順では、コネクターは最初にスキーマのスナップショットを実行します。その後、増分スナップショットを開始して、コネクターがデータを同期できるようにします。
- コネクターを停止します。
-
schema.history.internal.kafka.topic プロパティーで指定された内部データベーススキーマ履歴トピックを削除します。 設定された Kafka Connect
offset.storage.topic内のオフセットをクリアします。オフセットを削除する方法の詳細は、Debezium コミュニティーの FAQ を参照してください。警告オフセットの削除は、内部 Kafka Connect データの操作の経験がある上級ユーザーのみが実行してください。この操作によりシステムが破損する場合があるため、最後の手段としてのみ実行してください。
次の手順の説明に従って、コネクター設定のプロパティーの値を設定します。
-
snapshot.modeプロパティーの値をschema_onlyに設定します。 -
table.include.listを編集して、キャプチャーするテーブルを追加します。
-
- コネクターを再起動します。
- Debezium が新規および既存のテーブルのスキーマをキャプチャーするまで待ちます。コネクターが停止した後にテーブルで発生したデータ変更はキャプチャーされません。
- データが損失されないようにするには、増分スナップショット を開始します。
- 手順 2: 初期スナップショットと、それに続くオプションの増分スナップショット
この手順では、コネクターはデータベースの完全な初期スナップショットを実行します。他の初期スナップショットと同様、多数の大きなテーブルが含まれるデータベースでは、初期スナップショットの実行操作には時間がかかる可能性があります。スナップショットの完了後、任意で増分スナップショットをトリガーして、コネクターがオフラインの間に発生した変更をキャプチャーできます。
- コネクターを停止します。
-
schema.history.internal.kafka.topic プロパティーで指定された内部データベーススキーマ履歴トピックを削除します。 設定された Kafka Connect
offset.storage.topic内のオフセットをクリアします。オフセットを削除する方法の詳細は、Debezium コミュニティーの FAQ を参照してください。警告オフセットの削除は、内部 Kafka Connect データの操作の経験がある上級ユーザーのみが実行してください。この操作によりシステムが破損する場合があるため、最後の手段としてのみ実行してください。
-
table.include.listを編集して、キャプチャーするテーブルを追加します。 次の手順の説明に従って、コネクター設定のプロパティーの値を設定します。
-
snapshot.modeプロパティーの値をinitialに設定します。 -
(オプション)
schema.history.internal.store.only.captured.tables.ddlをfalseに設定します。
-
- コネクターを再起動します。コネクターはデータベース全体のスナップショットを取得します。スナップショットが完了すると、コネクターはストリーミングに移行します。
- (オプション) コネクターがオフラインの間に変更されたデータをキャプチャーするには、増分スナップショット を開始します。
2.5.1.2. アドホックスナップショット
デフォルトでは、コネクターは初回スナップショット操作の開始後にのみ実行されます。通常の状況では、この最初のスナップショットが作成されると、コネクターではスナップショットプロセスは繰り返し処理されません。コネクターがキャプチャーする今後の変更イベントデータはストリーミングプロセス経由でのみ行われます。
ただし、場合によっては、最初のスナップショット中にコネクターを取得したデータが古くなったり、失われたり、または不完全となったり可能性があります。テーブルデータを再キャプチャーするメカニズムを提供するため、Debezium にはアドホックスナップショットを実行するオプションがあります。Debezium 環境で次のいずれかの変更が発生したら、アドホックスナップショットを実行することを推奨します。
- コネクター設定は、異なるテーブルセットをキャプチャーするように変更されます。
- Kafka トピックを削除して、再構築する必要があります。
- 設定エラーや他の問題が原因で、データの破損が発生します。
アドホックと呼ばれるスナップショット を開始することで、以前にスナップショットをキャプチャーしたテーブルのスナップショットを再実行できます。アドホックスナップショットには、シグナルテーブル を使用する必要があります。シグナルリクエストを Debezium シグナルテーブルに送信して、アドホックスナップショットを開始します。
既存のテーブルのアドホックスナップショットを開始すると、コネクターはテーブルにすでに存在するトピックにコンテンツを追加します。既存のトピックが削除された場合には、トピックの自動作成 が有効になっているのであれば、Debezium は自動的にトピックを作成できます。
アドホックのスナップショットシグナルは、スナップショットに追加するテーブルを指定します。スナップショットは、データベースの内容全体をキャプチャーしたり、データベース内のテーブルのサブセットのみをキャプチャーしたりできます。また、スナップショットは、データベース内のテーブルの内容のサブセットをキャプチャできます。
execute-snapshot メッセージをシグナルテーブルに送信してキャプチャーするテーブルを指定します。execute-snapshot シグナルのタイプを incremental または blocking に設定し、スナップショットに含めるテーブルの名前を次の表に示すように指定します。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプを指定します。 |
|
| 該当なし |
スナップショットに含めるテーブルの完全修飾名に一致する正規表現を含む配列。 |
|
| 該当なし |
コネクターがスナップショットに含めるレコードのサブセットを決定するために評価する追加条件のセットを指定する、オプションの配列。
|
|
| 該当なし | スナップショット処理中にコネクターがテーブルのプライマリーキーとして使用する列名を指定するオプションの文字列。 |
アドホック増分スナップショットのトリガー
アドホック増分スナップショットを開始するには、execute-snapshot シグナルタイプのエントリーをシグナリングテーブルに追加するか、シグナルメッセージを Kafka シグナリングトピックに送信します。コネクターがメッセージを処理した後に、スナップショット操作を開始します。スナップショットプロセスは、最初と最後のプライマリーキーの値を読み取り、これらの値を各テーブルの開始ポイントおよびエンドポイントとして使用します。テーブルのエントリー数と設定されたチャンクサイズに基づいて、Debezium はテーブルをチャンクに分割し、チャンクごとに 1 度に 1 つずつスナップショットを順番に作成していきます。
詳細は、スナップショットの増分を参照してください。
アドホックブロッキングスナップショットのトリガー
シグナリングテーブルまたはシグナリングトピックに、execute-snapshot シグナルタイプを持つエントリーを追加することによって、アドホックブロッキングスナップショットを開始します。コネクターがメッセージを処理した後に、スナップショット操作を開始します。コネクターはストリーミングを一時的に停止し、初期スナップショットの時と同じプロセスに従って、指定されたテーブルのスナップショットを開始します。スナップショットが完了すると、コネクターはストリーミングを再開します。
詳細は、ブロッキングスナップショット を参照してください。
2.5.1.3. 増分スナップショット
スナップショットを柔軟に管理するため、Debezium には 増分スナップショット と呼ばれる補助スナップショットメカニズムが含まれています。増分スナップショットは、Debezium コネクターにシグナルを送信するため の Debezium メカニズムに依存します。
増分スナップショットでは、最初のスナップショットのように、データベースの完全な状態を一度にすべてキャプチャーする代わりに、一連の設定可能なチャンクで各テーブルを段階的にキャプチャーします。スナップショットがキャプチャーするテーブルと、各チャンクのサイズ を指定できます。チャンクのサイズにより、データベース上の各フェッチ操作中にスナップショットで収集される行数が決まります。増分スナップショットのデフォルトのチャンクサイズは 1024 行です。
増分スナップショットが進むと、Debezium はウォーターマークを使用して進捗を追跡し、キャプチャーする各テーブル行のレコードを管理します。この段階的なアプローチでは、標準の初期スナップショットプロセスと比較して、以下の利点があります。
- スナップショットが完了するまで、ストリーミングストリーミングを延期する代わりに、ストリームしたデータキャプチャーと並行して増分スナップショットを実行できます。コネクターはスナップショットプロセス全体で変更ログからのほぼリアルタイムイベントをキャプチャーし続け、他の操作はブロックしません。
- 増分スナップショットの進捗が中断された場合は、データを失うことなく再開できます。プロセスが再開すると、スナップショットは最初からテーブルをキャプチャーするのではなく、停止した時点から開始します。
-
いつでも増分スナップショットを実行し、必要に応じてプロセスを繰り返してデータベースの更新に適合できます。たとえば、コネクター設定を変更してテーブルを
table.include.listプロパティーに追加した後にスナップショットを再実行します。
増分スナップショットプロセス
増分スナップショットを実行する場合には、Debezium は各テーブルをプライマリーキー別に分類して、設定されたチャンクサイズ に基づいてテーブルをチャンクに分割します。チャンクごとに作業し、テーブルの行ごとにチャンクでキャプチャーします。キャプチャーする行ごとに、スナップショットは READ イベントを出力します。そのイベントは、対象となるチャンクのスナップショットを開始する時の行の値を表します。
スナップショットの作成が進むにつれ、他のプロセスがデータベースへのアクセスを継続し、テーブルレコードが変更される可能性があります。このような変更を反映させるように、通常通りに INSERT、UPDATE、DELETE 操作がトランザクションログにコミットされます。同様に、継続中の Debezium ストリーミングプロセスは、これらの変更イベントを検出し、対応する変更イベントレコードを Kafka に出力します。
Debezium を使用してプライマリーキーが同じレコード間での競合を解決する方法
場合によっては、ストリーミングプロセスが出力する UPDATE または DELETE イベントを順番に受信できます。つまり、ストリーミングプロセスは、スナップショットがその行の READ イベントが含まれるチャンクをキャプチャーする前に、テーブルの行を変更するイベントを生成する可能性があります。スナップショットが最終的に対象の行にあった READ イベントを出力すると、その値はすでに置き換えられています。Debezium は、シーケンスが到達する増分スナップショットイベントが正しい論理順序で処理されるように、競合を解決するためにバッファースキームを使用します。スナップショットのイベント間で競合が発生し、ストリームされたイベントが解決されてからでないと、Debezium はイベントのレコードを Kafka に送信しません。
スナップショットウィンドウ
遅れて入ってきた READ イベントと、同じテーブルの行を変更するストリーミングイベント間の競合の解決を容易にするために、Debezium は スナップショットウィンドウ と呼ばれるものを使用します。スナップショットウィンドウは、増分スナップショットが指定のテーブルチャンクのデータをキャプチャーしている途中に、間隔を決定します。チャンクのスナップショットウィンドウを開く前に、Debezium は通常の動作に従い、トランザクションログから直接ターゲットの Kafka トピックにイベントをダウンストリームに出力します。ただし、特定のチャンクのスナップショットが開放された瞬間から終了するまで、Debezium は重複除去のステップを実行して、プライマリーキーが同じイベント間での競合を解決します。
データコレクションごとに、Debezium は 2 種類のイベントを出力し、それらの両方のレコードを単一の宛先 Kafka トピックに保存します。テーブルから直接キャプチャーするスナップショットレコードは、READ 操作として出力されます。その間、ユーザーはデータコレクションのレコードの更新を続け、各コミットを反映するようにトランザクションログが更新されるので、Debezium は変更ごとに UPDATE または DELETE 操作を出力します。
スナップショットウィンドウが開放され、Debezium がスナップショットチャンクの処理を開始すると、スナップショットレコードをメモリーバッファーに提供します。スナップショットウィンドウ中に、バッファー内の READ イベントのプライマリーキーは、受信ストリームイベントのプライマリーキーと比較されます。一致するものが見つからない場合、ストリーミングされたイベントレコードが Kafka に直接送信されます。Debezium が一致を検出すると、バッファーされた READ イベントを破棄し、ストリーミングされたレコードを宛先トピックに書き込みます。これは、ストリーミングされたイベントが静的スナップショットイベントよりも論理的に優先されるためです。チャンクのスナップショットウィンドウが終了すると、バッファーに含まれるのは、関連するトランザクションログイベントが存在しない READ イベントのみです。Debezium は、これらの残りの READ イベントをテーブルの Kafka トピックに出力します。
コネクターは各スナップショットチャンクにプロセスを繰り返します。
現在、増分スナップショットを開始するには、次のいずれかの方法を使用できます。
Oracle の Debezium コネクターでは、増分スナップショットの実行中のスキーマの変更はサポートしません。
2.5.1.3.1. 増分スナップショットのトリガー
増分スナップショットを開始するには、ソースデータベースのシグナリングテーブルに アドホックスナップショットシグナル を送信します。スナップショットシグナルは SQL INSERT クエリーとして送信します。
Debezium がシグナルテーブルの変更を検出すると、シグナルを読み取り、要求されたスナップショット操作を実行します。
送信するクエリーはスナップショットに追加するテーブルを指定し、必要に応じてスナップショット操作の種類を指定します。Debezium は現在、incremental と blocking のスナップショットタイプをサポートしています。
スナップショットに追加するテーブルを指定するには、テーブルをリストする data-collections 配列またはテーブルの照合に使用する正規表現の配列を指定します。以下に例を示します。
{"data-collections": ["public.MyFirstTable", "public.MySecondTable"]}
増分スナップショットシグナルの data-collections アレイにはデフォルト値がありません。data-collections 配列が空の場合、Debezium は空の配列をアクションが必要ないと解釈し、スナップショットは作成しません。
スナップショットに含めるテーブルの名前にドット (.)、スペース、またはその他の英数字以外の文字が含まれている場合は、テーブル名を二重引用符でエスケープする必要があります。
たとえば、db1 データベースの public スキーマに存在し、My.Table という名前のテーブルを含めるには、"db1.public.\"My.Table\"" の形式を使用します。
前提条件
- ソースデータベースにシグナリングデータコレクションが存在する。
-
シグナルデータコレクションが
signal.data.collectionプロパティーで指定されている。
ソースシグナリングチャネルを使用して増分スナップショットをトリガーする
SQL クエリーを送信し、アドホック増分スナップショット要求をシグナルテーブルに追加します。
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow コマンドの
id、type、およびdataパラメーターの値は、シグナルテーブルのフィールド に対応します。
以下の表では、この例のパラメーターを説明しています。Expand 表2.107 シグナルテーブルに増分スナップショットシグナルを送信する SQL コマンドのフィールドの説明 項目 値 説明 1
database.schema.debezium_signalソースデータベースにあるシグナルテーブルの完全修飾名を指定します。
2
ad-hoc-1idパラメーターは、シグナルリクエストのID識別子として割り当てられる任意の文字列を指定します。
この文字列を使用して、シグナルテーブルのエントリーへのログメッセージを特定します。Debezium はこの文字列を使用しません。代わりに、スナップショット作成中に、Debezium は独自のID文字列をウォーターマークシグナルとして生成します。3
execute-snapshottypeパラメーターを指定し、シグナルがトリガーする操作を指定します。
4
data-collectionsシグナルの
dataフィールドの必須コンポーネントで、スナップショットに含めるテーブル名の配列またはテーブル名と一致する正規表現を指定します。
配列には、database.schema.table形式を使用してテーブルの完全修飾名と一致する正規表現がリストされます。この形式は、コネクターの シグナリングテーブル の名前を指定するために使用する形式と同じです。5
incremental実行するスナップショット操作のタイプを指定する、シグナルの
dataフィールドのオプションのtypeコンポーネント。
有効な値はincrementalとblockingです。
値を指定しない場合、コネクターはデフォルトで増分スナップショットを実行します。6
additional-conditionsコネクターがスナップショットに含めるレコードのサブセットを決定するために評価する追加条件のセットを指定する、オプションの配列。
各追加条件は、data-collectionプロパティーとfilterプロパティーを持つオブジェクトです。データの収集単位で異なるフィルターを指定できます。
*data-collectionプロパティーは、フィルターが適用されるデータコレクションの完全修飾名です。additional-conditionsパラメーターの詳細は、「additional-conditions付きでアドホック増分スナップショットを実行する」 を参照してください。
2.5.1.3.2. additional-conditions 付きでアドホック増分スナップショットを実行する
スナップショットに、テーブル内のコンテンツのサブセットのみを含める場合は、スナップショットシグナルに additional-conditions パラメーターを追加してシグナル要求を変更できます。
一般的なスナップショットの SQL クエリーは、以下の形式を取ります。
SELECT * FROM <tableName> ....
SELECT * FROM <tableName> ....
additional-conditions パラメーターを追加して、以下の例のように WHERE 条件を SQL クエリーに追加します。
SELECT * FROM <data-collection> WHERE <filter> ....
SELECT * FROM <data-collection> WHERE <filter> ....以下の例は、シグナルテーブルに追加の条件を含むアドホック増分スナップショット要求を送信する SQL クエリーを示しています。
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');
たとえば、以下の列が含まれる products テーブルがあるとします。
-
id(プライマリーキー) -
color -
quantity
products テーブルの増分スナップショットに color=blue のデータ項目のみを含める場合は、次の SQL ステートメントを使用してスナップショットをトリガーできます。
INSERT INTO db1.myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["db1.schema1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "db1.schema1.products", "filter": "color=blue"}]}');
INSERT INTO db1.myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["db1.schema1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "db1.schema1.products", "filter": "color=blue"}]}');
additional-conditions パラメーターを使用すると、列が 2 つ以上となる条件を指定することもできます。たとえば、前述の例の products テーブルを使用して、color=blue および quantity>10 だけに一致するアイテムのみのデータが含まれる増分スナップショットをトリガーするクエリーを送信できます。
INSERT INTO db1.myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["db1.schema1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "db1.schema1.products", "filter": "color=blue AND quantity>10"}]}');
INSERT INTO db1.myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["db1.schema1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "db1.schema1.products", "filter": "color=blue AND quantity>10"}]}');以下の例は、コネクターによってキャプチャーされる増分スナップショットイベントの JSON を示しています。
例2.32 増分スナップショットイベントメッセージ
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
実行するスナップショット操作タイプを指定します。 |
| 2 |
|
イベントタイプを指定します。 |
2.5.1.3.3. Kafka シグナルチャネルを使用して増分スナップショットをトリガーする
設定された Kafka トピック にメッセージを送信して、コネクターにアドホック増分スナップショットを実行するよう要求できます。
Kafka メッセージのキーは、topic.prefix コネクター設定オプションの値と一致する必要があります。
メッセージの値は、type と data フィールドが含まれる JSON オブジェクトとなっています。
シグナルタイプは execute-snapshot で、data フィールドには以下のフィールドが必要です。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプ。現在、Debezium は |
|
| 該当なし |
スナップショットに含めるテーブルの完全修飾名と一致する、コンマ区切りの正規表現の配列。 |
|
| 該当なし |
コネクターがスナップショットに含めるレコードのサブセットを指定するために評価する基準を指定する、オプションの追加条件の配列。 |
例2.33 execute-snapshot Kafka メッセージ
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["{collection-container}.table1", "{collection-container}.table2"], "type": "INCREMENTAL"}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["{collection-container}.table1", "{collection-container}.table2"], "type": "INCREMENTAL"}}`additional-conditions 付きのアドホック増分スナップショット
Debezium は additional-conditions フィールドを使用してテーブルのコンテンツのサブセットを選択します。
通常、Debezium はスナップショットを実行するときに、次のような SQL クエリーを実行します。
SELECT * FROM <tableName> ….
スナップショット要求に additional-conditions プロパティーが含まれている場合、プロパティーの data-collection および filter パラメーターが SQL クエリーに追加されます。次に例を示します。
SELECT * FROM <data-collection> WHERE <filter> ….
たとえば、列 id (プライマリーキー)、color、および brand を含む products テーブルがある場合、スナップショットに color='blue' のコンテンツのみを含める場合は、スナップショットをリクエストするときに、コンテンツをフィルタリングする additional-conditions プロパティーを追加することができます。
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.schema1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.schema1.products" ,"filter":"color='blue'"}]}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.schema1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.schema1.products" ,"filter":"color='blue'"}]}}`
また、additional-conditions プロパティーを使用して、複数の列に基づいて条件を渡すこともできます。たとえば、前の例と同じ products テーブルを使用して、color='blue' および brand='MyBrand' である products テーブルのコンテンツのみをスナップショットに含める場合は、次のリクエストを送信できます。
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.schema1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.schema1.products" ,"filter":"color='blue' AND brand='MyBrand'"}]}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.schema1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.schema1.products" ,"filter":"color='blue' AND brand='MyBrand'"}]}}`2.5.1.3.4. 増分スナップショットの停止
状況によっては、増分スナップショットを停止する必要がある場合があります。たとえば、スナップショットが正しく設定されていない場合や、他のデータベース操作にリソースが使用可能であるこのとの確認が必要な場合があります。ソースデータベースのシグナリングテーブルにシグナルを送信することで、すでに実行中のスナップショットを停止できます。
スナップショット停止信号をシグナリングテーブルに送信するには、SQL INSERT クエリーで送信します。stop-snapshot シグナルは、スナップショット操作の type を incremental として指定し、オプションで、現在実行中のスナップショットから省略するテーブルを指定します。Debezium はシグナルテーブルの変更を検出した後、シグナルを読み、増分スナップショット操作が進行中であればそれを停止します。
関連情報
また、JSON メッセージを Kafka シグナリングトピック に送信して、増分スナップショットを停止することもできます。
前提条件
- ソースデータベースにシグナリングデータコレクションが存在する。
-
シグナルデータコレクションが
signal.data.collectionプロパティーで指定されている。
ソースシグナリングチャネルを使用して増分スナップショットを停止する
SQL クエリーを送信して、シグナリングテーブルへのアドホックインクリメンタルスナップショットを停止します。
INSERT INTO <signalTable> (id, type, data) values ('<id>', 'stop-snapshot', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"incremental"}');INSERT INTO <signalTable> (id, type, data) values ('<id>', 'stop-snapshot', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"incremental"}');Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
INSERT INTO db1.myschema.debezium_signal (id, type, data) values ('ad-hoc-1', 'stop-snapshot', '{"data-collections": ["db1.schema1.table1", "db1.schema1.table2"], "type":"incremental"}');INSERT INTO db1.myschema.debezium_signal (id, type, data)1 values ('ad-hoc-1',2 'stop-snapshot',3 '{"data-collections": ["db1.schema1.table1", "db1.schema1.table2"],4 "type":"incremental"}');5 Copy to Clipboard Copied! Toggle word wrap Toggle overflow signal コマンドの
id、type、およびdataパラメーターの値は、シグナルテーブルのフィールド に対応します。
以下の表では、この例のパラメーターを説明しています。Expand 表2.110 シグナリングテーブルに増分スナップショット停止信号を送信するための SQL コマンドのフィールドの説明 項目 値 説明 1
database.schema.debezium_signalソースデータベースにあるシグナルテーブルの完全修飾名を指定します。
2
ad-hoc-1idパラメーターは、シグナルリクエストのID識別子として割り当てられる任意の文字列を指定します。
この文字列を使用して、シグナルテーブルのエントリーへのログメッセージを特定します。Debezium はこの文字列を使用しません。3
stop-snapshottypeパラメーターを指定し、シグナルがトリガーする操作を指定します。
4
data-collectionsシグナルの
dataフィールドのオプションコンポーネントで、スナップショットから削除するテーブル名の配列またはテーブル名とマッチする正規表現を指定します。
配列には、database.schema.tableの形式で完全修飾名でテーブルに一致する正規表現がリストされます。dataフィールドからこのコンポーネントを省略すると、シグナルによって進行中の増分スナップショット全体が停止されます。5
incremental停止するスナップショット操作のタイプを指定する信号の
dataフィールドの必須コンポーネント。
現在、有効な唯一のオプションはincrementalです。typeの値を指定しない場合、シグナルは増分スナップショットの停止に失敗します。
2.5.1.3.5. Kafka シグナリングチャネルを使用して増分スナップショットを停止する
設定された Kafka シグナルトピック にシグナルメッセージを送信して、アドホック増分スナップショットを停止できます。
Kafka メッセージのキーは、topic.prefix コネクター設定オプションの値と一致する必要があります。
メッセージの値は、type と data フィールドが含まれる JSON オブジェクトとなっています。
シグナルタイプは stop-snapshot で、data フィールドには以下のフィールドが必要です。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプ。現在、Debezium は |
|
| 該当なし |
テーブルの完全修飾名に一致する、コンマで区切られた正規表現のオプションの配列、スナップショットから削除するテーブル名に一致するテーブル名または正規表現の配列。 |
次の例は、典型的な stop-snapshot の Kafka メッセージを示しています。
Key = `test_connector`
Value = `{"type":"stop-snapshot","data": {"data-collections": ["db1.schema1.table1", "db1.schema1.table2"], "type": "INCREMENTAL"}}`
Key = `test_connector`
Value = `{"type":"stop-snapshot","data": {"data-collections": ["db1.schema1.table1", "db1.schema1.table2"], "type": "INCREMENTAL"}}`2.5.1.4. ブロッキングスナップショット
スナップショットをより柔軟に管理するために、Debezium には ブロッキングスナップショット と呼ばれる補助アドホックスナップショットメカニズムが含まれています。ブロッキングスナップショットは、Debezium コネクターにシグナルを送信 するための Debezium メカニズムに依存します。
ブロッキングスナップショットは、ランタイム時にトリガーできることを除いて、初期スナップショット と同じように動作します。
次のような状況では、標準の初期スナップショットプロセスを使用するのではなく、ブロッキングスナップショットを実行する必要があります。
- 新しいテーブルを追加し、コネクターの実行中にスナップショットを完了したいと考えている。
- 大きなテーブルを追加し、増分スナップショットよりも短い時間でスナップショットを完了したいと考えている。
ブロッキングスナップショットのプロセス
ブロッキングスナップショットを実行すると、Debezium はストリーミングを停止し、初期スナップショットの時と同じプロセスに従って、指定されたテーブルのスナップショットを開始します。スナップショットが完了すると、ストリーミングが再開されます。
スナップショットの設定
シグナルの data コンポーネントでは、次のプロパティーを設定できます。
- data-collections: スナップショットする必要のあるテーブルを指定します。
additional-conditions: テーブルごとに異なるフィルターを指定できます。
-
data-collectionプロパティーは、フィルターが適用されるテーブルの完全修飾名です。 -
filterプロパティーは、snapshot.select.statement.overridesで使用される値と同じになります。
-
以下に例を示します。
{"type": "blocking", "data-collections": ["schema1.table1", "schema1.table2"], "additional-conditions": [{"data-collection": "schema1.table1", "filter": "SELECT * FROM [schema1].[table1] WHERE column1 = 0 ORDER BY column2 DESC"}, {"data-collection": "schema1.table2", "filter": "SELECT * FROM [schema1].[table2] WHERE column2 > 0"}]}
{"type": "blocking", "data-collections": ["schema1.table1", "schema1.table2"], "additional-conditions": [{"data-collection": "schema1.table1", "filter": "SELECT * FROM [schema1].[table1] WHERE column1 = 0 ORDER BY column2 DESC"}, {"data-collection": "schema1.table2", "filter": "SELECT * FROM [schema1].[table2] WHERE column2 > 0"}]}重複の可能性
スナップショットをトリガーするシグナルを送信した時点と、ストリーミングが停止してスナップショットが開始する時点との間に遅延が生じる可能性があります。この遅延の結果、スナップショットが完了した後、コネクターはスナップショットがキャプチャーしたレコードと重複するイベントレコードを発行する可能性があります。
2.5.1.5. Debezium Oracle 変更イベントレコードを受信する Kafka トピックのデフォルト名
デフォルトでは、Oracle コネクターは、テーブルで発生するすべての INSERT、UPDATE、DELETE 操作の変更イベントを、そのテーブルに固有の単一の Apache Kafka トピックに書き込みます。コネクターは以下の規則を使用して変更イベントトピックに名前を付けます。
topicPrefix.schemaName.tableName
以下のリストは、デフォルト名のコンポーネントの定義を示しています。
- topicPrefix
-
topic.prefixコネクター設定プロパティーで指定されたトピック接頭辞。 - schemaName
- 操作が発生したスキーマの名前。
- tableName
- 操作が発生したテーブルの名前。
たとえば、fulfillment がサーバー名、inventory がスキーマ名で、データベースに orders、customers、products という名前のテーブルが含まれる場合には、Debezium Oracle コネクターは、データベースのテーブルごとに 1 つ、以下の Kafka トピックにイベントを出力します。
fulfillment.inventory.orders fulfillment.inventory.customers fulfillment.inventory.products
fulfillment.inventory.orders
fulfillment.inventory.customers
fulfillment.inventory.productsコネクターは同様の命名規則を適用して、内部データベーススキーマの履歴トピック (スキーマ変更トピック と トランザクションメタデータトピック) にラベルを付けます。
デフォルトのトピック名が要件を満たさない場合は、カスタムトピック名を設定できます。カスタムトピック名を設定するには、論理トピックルーティング SMT に正規表現を指定します。論理トピックルーティング SMT を使用してトピックの命名をカスタマイズする方法は、トピックルーティング を参照してください。
2.5.1.6. Debezium Oracle コネクターによるデータベーススキーマの変更の処理方法
データベースクライアントがデータベースのクエリーを行うと、クライアントはデータベースの現在のスキーマを使用します。しかし、データベーススキーマはいつでも変更が可能です。そのため、挿入、更新、または削除の操作が記録されるたびに、コネクターはどのスキーマであるかを特定できる必要があります。また、コネクターは必ずしも現在のスキーマをすべてのイベントに適用できるとは限りません。イベントが比較的古い場合は、現在のスキーマが適用される前に記録された可能性があります。
スキーマ変更後に発生するイベントを正しく処理するために、Oracle には、データに影響を与える行レベルの変更だけでなく、データベースに適用される DDL ステートメントも REDO ログに含めます。コネクターは、redo ログ内でこれらの DDL ステートメントを検出すると、そのステートメントを解析し、各テーブルのスキーマのインメモリー表現を更新します。コネクターはこのスキーマ表現を使用して、挿入、更新、または削除の操作時にテーブルの構造を特定し、適切な変更イベントを生成します。別のデータベーススキーマ履歴 Kafka トピックでは、コネクターは各 DDL ステートメントがある redo ログの場所とともにすべての DDL ステートメントを記録します。
クラッシュするか、正常に停止した後に、コネクターを再起動すると、特定の位置 (特定の時点) から redo ログの読み取りを開始します。コネクターは、データベーススキーマ履歴の Kafka トピックを読み取り、コネクターが起動する redo ログの時点まですべての DDL ステートメントを解析することで、この時点で存在したテーブル構造を再ビルドします。
このデータベーススキーマ履歴トピックは、内部コネクター専用となっています。オプションで、コネクターは コンシューマーアプリケーション向けの別のトピックにスキーマ変更イベントを送信する こともできます。
関連情報
- Debezium イベントレコードを受信する トピックのデフォルト名。
2.5.1.7. Debezium Oracle コネクターによるデータベーススキーマの変更の公開方法
Debezium Oracle コネクターは、データベース内のテーブルに適用される構造的な変更を記述するスキーマ変更イベントを生成するように設定できます。コネクターは、スキーマ変更イベントを <serverName> という名前の Kafka トピックに書き込みます。ここで、serverName は topic.prefix 設定プロパティーに指定した名前空間を指します。
Debezium は、新しいテーブルからデータをストリーミングするとき、またはテーブルの構造が変更されるたびに、新しいメッセージをスキーマ変更トピックに送信します。
コネクターがスキーマ変更トピックに送信するメッセージには、ペイロードと、任意で変更イベントメッセージのスキーマが含まれます。
スキーマ変更イベントのスキーマには、次の要素があります。
name- スキーマ変更イベントメッセージの名前。
type- 変更イベントメッセージのタイプ。
version- スキーマのバージョン。バージョンは整数で、スキーマが変更されるたびに増加します。
fields- 変更イベントメッセージに含まれるフィールド。
例: Oracle コネクターのスキーマ変更トピックのスキーマ
次の例は、JSON 形式の一般的なスキーマを示しています。
スキーマ変更イベントメッセージのペイロードには、以下の要素が含まれます。
ddl-
スキーマの変更につながる SQL
CREATE、ALTER、またはDROPステートメントを提供します。 databaseName-
ステートメントが適用されるデータベースの名前。
databaseNameの値は、メッセージキーとして機能します。 tableChanges-
スキーマの変更後のテーブルスキーマ全体の構造化表現。
tableChangesフィールドには、テーブルの各列のエントリーなどのアレイが含まれます。構造化された表現は JSON または Avro 形式でデータを表示するため、コンシューマーは DDL パーサーを介して最初にメッセージを処理しなくてもメッセージを簡単に読み取りできます。
デフォルトでは、コネクターは ALL_TABLES データベースビューを使用して、スキーマ履歴トピックに格納するテーブル名を識別します。そのビュー内で、コネクターは、データベースへの接続に使用するユーザーアカウントが使用できるテーブルからのみデータにアクセスできます。
スキーマ履歴トピックが異なるテーブルのサブセットを格納するように設定を変更できます。以下の方法のいずれかを使用して、トピックが保存するテーブルのセットを変更します。
-
Debezium がデータベースへのアクセスに使用するアカウントのパーミッションを変更し、別のテーブルセットが
ALL_TABLESビューに表示されるようにします。 -
コネクタープロパティー
schema.history.internal.store.only.captured.tables.ddlをtrueに設定します。
コネクターがテーブルをキャプチャーするように設定されている場合、テーブルのスキーマ変更の履歴は、スキーマ変更トピックだけでなく、内部データベーススキーマの履歴トピックにも格納されます。内部データベーススキーマ履歴トピックはコネクターのみの使用を対象としており、使用するアプリケーションによる直接使用を目的としていません。スキーマ変更に関する通知が必要なアプリケーションが、スキーマ変更トピックからの情報のみを使用するようにしてください。
データベーススキーマ履歴トピックをパーティションに分割しないでください。データベーススキーマ履歴トピックが正しく機能するには、コネクターが出力するイベントレコードの一貫したグローバル順序を維持する必要があります。
トピックがパーティション間で分割されないようにするには、以下のいずれかの方法を使用してトピックのパーティション数を設定します。
-
データベーススキーマ履歴トピックを手動で作成する場合は、パーティション数を
1に指定します。 -
Apache Kafka ブローカーを使用してデータベーススキーマ履歴トピックを自動的に作成する場合に、トピックが作成されるので、Kafka
num.partitions設定オプションの値を1に設定します。
例: Oracle コネクタースキーマ変更トピックに発行されたメッセージ
以下の例は、JSON 形式の一般的なスキーマ変更メッセージを示しています。メッセージには、テーブルスキーマの論理表現が含まれます。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
| コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 ソースオブジェクトの ts_ms は、データベースで変更が行われた時刻を示す。payload.source.ts_ms の値を payload.ts_ms の値と比較することにより、ソースデータベースの更新と Debezium との間の遅延を判断できます。 |
| 2 |
| 変更が含まれるデータベースとスキーマを識別します。 |
| 3 |
| このフィールドには、スキーマの変更を行う DDL が含まれます。 |
| 4 |
| DDL コマンドによって生成されるスキーマの変更が含まれる 1 つ以上の項目の配列。 |
| 5 |
|
変更の種類を説明します。
|
| 6 |
|
作成、変更、または破棄されたテーブルの完全な識別子。テーブルの名前が変更されると、この識別子は |
| 7 |
| 適用された変更後のテーブルメタデータを表します。 |
| 8 |
| テーブルのプライマリーキーを設定する列のリスト。 |
| 9 |
| 変更されたテーブルの各列のメタデータ。 |
| 10 |
| 各テーブル変更のカスタム属性メタデータ。 |
コネクターがスキーマ変更トピックに送信するメッセージでは、メッセージキーはスキーマの変更が含まれるデータベースの名前です。以下の例では、payload フィールドに databaseName キーが含まれます。
2.5.1.8. トランザクション境界を表す Debezium Oracle コネクターによって生成されたイベント
Debezium は、トランザクションメタデータ境界を表し、データ変更イベントメッセージを強化するイベントを生成できます。
Debezium は、コネクターのデプロイ後に発生するトランザクションに対してのみメタデータを登録し、受信します。コネクターをデプロイする前に発生するトランザクションのメタデータは利用できません。
データベーストランザクションは、キーワード BEGIN および END で囲まれたステートメントブロックによって表されます。Debezium は、すべてのトランザクションで BEGIN および END 区切り文字のトランザクション境界イベントを生成します。トランザクション境界イベントには以下のフィールドが含まれます。
status-
BEGINまたはEND id- 一意のトランザクション識別子の文字列表現。
ts_ms-
データソースでのトランザクション境界イベント (
BEGINまたはENDイベント) の時間。データソースから Debezium にイベント時間を渡されない場合、フィールドは代わりに Debezium がイベントを処理する時間を表します。 event_count(ENDイベント用)- トランザクションによって出力されるイベントの合計数。
data_collections(ENDイベント用)-
data_collectionとevent_count要素のペアの配列。これは、コネクターがデータコレクションから発信された変更に対して出力するイベントの数を示します。
以下の例は、典型的なトランザクション境界メッセージを示しています。
例: Oracle コネクタートランザクション境界イベント
topic.transaction オプションで上書きされない限り、コネクターはトランザクションイベントを <topic.prefix>.transaction トピックに出力します。
2.5.1.8.1. Debezium Oracle コネクターがトランザクションメタデータで変更イベントメッセージを強化する方法
トランザクションメタデータを有効にすると、データメッセージ Envelope は新しい transaction フィールドで強化されます。このフィールドは、複合フィールドの形式ですべてのイベントに関する情報を提供します。
id- 一意のトランザクション識別子の文字列表現。
total_order- トランザクションによって生成されたすべてのイベントを対象とするイベントの絶対位置。
data_collection_order- トランザクションによって出力されたすべてのイベントを対象とするイベントのデータコレクションごとの位置。
以下の例は、典型的なトランザクションのイベントメッセージを示しています。
LogMiner マイニングストラテジー
Oracle redo ログのエントリーには、DML の変更用に送信する元の SQL ステートメントは保存されません。代わりに、redo エントリーには、一連の変更ベクトルと、これらのベクトルに関連するテーブルスペース、テーブル、および列を表すオブジェクト識別子のセットが保持されます。つまり、redo ログエントリーには、DML 変更の影響を受けるスキーマ、テーブル、または列の名前は含まれません。
Debezium Oracle コネクターは、log.mining.strategy 設定プロパティーを使用して、Oracle LogMiner が変更ベクトル内のオブジェクト識別子の検索を処理する方法を制御します。状況によっては、スキーマの変更に関して、あるログマイニングストラテジーが他のログマイニングストラテジーよりも信頼性が高い場合があります。ただし、ログマイニングストラテジーを選択する前に、それがパフォーマンスとオーバーヘッドに及ぼす影響を考慮することが重要です。
REDO ログへのデータディクショナリーの書き込み
デフォルトのマイニングストラテジーは redo_log_catalog と呼ばれます。このストラテジーでは、データベースは各 REDO ログスイッチの直後にデータディクショナリーのコピーを REDO ログにフラッシュします。これは、データの変更と疎結合されたスキーマの変更を追跡する場合に最も信頼性の高いストラテジーです。これは、Oracle LogMiner には、一連の変更ベクトルでデータディクショナリーの開始状態と終了状態の間を補間する方法があるためです。
ただし、redo_log_catalog モードは、機能するためにいくつかの重要な手順を必要とするため、最もコストがかかります。まず、このモードでは、ログスイッチのたびにデータディクショナリーを REDO ログにフラッシュする必要があります。スイッチするたびにログをフラッシュすると、アーカイブログ内の貴重なスペースがすぐに消費され、アーカイブログの量が多すぎてデータベース管理者が想定した数を超える可能性があります。このモードを使用する場合は、データベース管理者と調整して、データベースが適切に設定されていることを確認してください。
redo_log_catalog モードを使用するようにコネクターを設定する場合は、複数の Debezium Oracle コネクターを使用して、同じ論理データベースからの変更をキャプチャーしないでください。
オンラインカタログの直接使用
次のストラテジーモード online_catalog は、redo_log_catalog モードとは異なる動作をします。ストラテジーが online_catalog に設定されている場合、データベースはデータディクショナリーを REDO ログにフラッシュしません。代わりに、Oracle LogMiner は常に最新のデータディクショナリーの状態を使用して比較を実行します。このストラテジーでは、常に現在のディクショナリーを使用し、REDO ログへのフラッシュを排除することで、オーバーヘッドが少なくなり、より効率的に動作します。ただし、これらの利点は、疎結合されたスキーマの変更とデータの変更を解析できないため、相殺されます。その結果、このストラテジーではイベントが失敗する場合があります。
LogMiner がスキーマ変更後に SQL の信頼性を再構築できなかった場合は、REDO ログで原因を確認してください。OBJ# 123456 (番号はテーブルのオブジェクト識別子) などの名前のテーブルへの参照、または COL1 や COL2 などの名前の列を探します。online_catalog ストラテジーを使用するようにコネクターを設定する場合は、テーブルスキーマとそのインデックスが静的であり、変更されないことを確認するための手順を実行します。Debezium コネクターが online_catalog モードを使用するように設定されており、スキーマ変更を適用する必要がある場合は、次の手順を実行します。
- コネクターが既存のデータ変更 (DML) をすべてキャプチャーするまで待機します。
- スキーマ (DDL) の変更を実行し、コネクターが変更をキャプチャーするまで待機します。
- テーブルのデータ変更 (DML) を再開します。
この手順を実行することで、Oracle LogMiner がすべてのデータ変更に対して SQL を安全に再構築できるようになります。
クエリーモード
Debezium Oracle コネクターは、デフォルトで Oracle LogMiner と統合されます。このインテグレーションには、トランザクションログに記録された変更を変更イベントとして取り込むための複雑な JDBC SQL クエリーの生成など、特殊な一連の手順が必要です。JDBC SQL クエリーで使用される V$LOGMNR_CONTENTS ビューには、クエリーのパフォーマンスを向上させるための索引がありません。そのため、クエリーの実行を改善する方法として、SQL クエリーの生成方法を制御するさまざまなクエリーモードを使用できます。
log.mining.query.filter.mode コネクタープロパティーを次のいずれかで設定して、JDBC SQL クエリーの生成方法を変更できます。
none-
(デフォルト) このモードでは、データベースレベルでの挿入、更新、削除などのさまざまな操作タイプに基づいてフィルタリングのみを行う JDBC クエリーが作成されます。スキーマ、テーブル、またはユーザー名の包含/除外リストに基づいてデータをフィルター処理する場合、これはコネクター内の処理ループ中に行われます。
このモードは、多くの場合、変更があまり多くないデータベースから少数のテーブルをキャプチャーする場合に役立ちます。生成されるクエリーは非常に単純で、データベースのオーバーヘッドを低く抑えてできるだけ早く読み取ることに主に重点を置いています。 in-
このモードでは、データベースレベルの操作タイプだけでなく、スキーマ、テーブル、およびユーザー名の包含/除外リストもフィルタリングする JDBC クエリーが作成されます。クエリーの述語は、包含/除外リスト設定プロパティーで指定された値に基づいて SQL in 句を使用して生成されます。
このモードは通常、変更が過度に存在するデータベースから多数のテーブルをキャプチャーする場合に役立ちます。生成されるクエリーはnoneモードよりもはるかに複雑で、ネットワークオーバーヘッドを削減し、データベースレベルで可能な限り多くのフィルタリングを実行することに重点を置いています。
最後に、スキーマおよびテーブルの包含/除外設定プロパティーの一部として正規表現を 指定しないでください。正規表現を使用すると、コネクターがこれらの設定プロパティーに基づく変更と一致しなくなり、変更が失われる原因になります。 regex-
このモードでは、データベースレベルの操作タイプだけでなく、スキーマ、テーブル、およびユーザー名の包含/除外リストもフィルタリングする JDBC クエリーが作成されます。ただし、
inモードとは異なり、このモードでは、値が含まれるか除外されるかに応じて結合または論理和を使用する OracleREGEXP_LIKE演算子を使用して SQL クエリーを生成します。
このモードは、少数の正規表現を使用して識別できる可変数のテーブルをキャプチャーする場合に便利です。生成されるクエリーは他のモードよりもはるかに複雑で、ネットワークオーバーヘッドを削減し、データベースレベルで可能な限り多くのフィルタリングを実行することに重点を置いています。
2.5.1.9. Debezium Oracle コネクターのイベントバッファリング使用方法
Oracle は、後でロールバックによって破棄された変更を含め、発生した順序で再実行ログにすべての変更を書き込みます。その結果、別のトランザクションからの同時変更はインターットアンドされます。コネクターが最初に変更ストリームを読み取ると、どの変更がコミットまたはロールバックされるかをすぐに判断できないため、変更イベントは内部バッファーに一時的に保存されます。変更がコミットされると、コネクターは変更イベントをバッファーから Kafka に書き込みます。コネクターはロールバックによって破棄される変更イベントを破棄します。
プロパティー log.mining.buffer.type を設定することにより、コネクターが使用するバッファリングメカニズムを設定できます。
ヒープ
デフォルトのバッファータイプは memory を使用して設定されます。デフォルトの memory 設定では、コネクターは JVM プロセスのヒープメモリーを使用してバッファーイベントレコードを割り当て、管理します。memory バッファー設定を使用する場合は、Java プロセスに割り当てるメモリー量が、お使いの環境で長時間実行されるトランザクションや大規模トランザクションに対応することができることを確認してください。
2.5.1.10. Debezium Oracle コネクターが SCN 値のギャップを検出する方法
Debezium Oracle コネクターが LogMiner を使用するよう設定されると、システム変更番号 (SCN) に基づく開始範囲と終了範囲を使用して、Oracle から変更イベントを収集します。コネクターはこの範囲を自動的に管理し、コネクターがほぼリアルタイムで変更を流せるか、データベース内の大規模またはバルクトランザクションの量によって変更のバックログを処理しなければならないかに応じて、範囲を増減させます。
特定の状況下で、Oracle データベースは SCN 値を一定の割合で増加させるのではなく、異常に高い割合で SCN を前進させます。このような SCN 値のジャンプは、特定のインテグレーションがデータベースと対話する方法やホットバックアップなどのイベントの結果により発生する可能性があります。
Debezium Oracle コネクターは、以下の設定プロパティーに依存して SCN ギャップを検出し、マイニング範囲を調整します。
log.mining.scn.gap.detection.gap.size.min- ギャップの最小サイズを指定します。
log.mining.scn.gap.detection.time.interval.max.ms- 最大間隔を指定します。
コネクターは最初に、現在のマイニング範囲で現在の SCN と最大 SCN との間の変更数の違いを比較します。現在の SCN 値と最高 SCN 値の差が最小ギャップサイズより大きい場合、コネクターは SCN ギャップを潜在的に検出していることになる。ギャップが存在するかどうかを確認するために、コネクターは次に前のマイニング範囲の最後に現在の SCN および SCN のタイムスタンプを比較します。タイムスタンプの違いが最大間隔未満の場合、SCN ギャップの存在が確認されます。
SCN ギャップが発生すると、Debezium コネクターは現在のマイマイセッションの範囲のエンドポイントとして現在の SCN を自動的に使用します。これにより、SCN 値が予期せず増加するため、コネクターは変更を返す間で小規模な範囲を減らさずにリアルタイムイベントを迅速にキャッチできます。コネクターが SCN ギャップに応答して前述の手順を実行すると、log.mining.batch.size.max プロパティーで指定された値を無視します。コネクターがマイニングセッションを終了し、リアルタイムのイベントに追いついた後、最大ログマイニングバッチサイズの実施を再開します。
SCN ギャップ検出は、コネクターが動作していて、ほぼリアルタイムでイベントを処理しているときに、大きな SCN 増分が発生した場合にのみ有効です。
2.5.1.11. Debezium は、変更頻度の低いデータベースでオフセットをどのように管理するか ?
Debezium Oracle コネクターは、コネクターオフセットでシステム変更番号を追跡するので、コネクターを再起動したときに、中断したところから開始することができます。これらのオフセットは、発行された各変更イベントの一部です。ただし、データベース変更の頻度が低い場合 (数時間または数日ごと)、オフセットが古くなり、トランザクションログでシステム変更番号が利用できなくなると、コネクターの再起動が正常に行われなくなる可能性があります。
Oracle への接続に非 CDB モードを使用するコネクターの場合、オフセットの同期を維持するために、コネクターが一定間隔でハートビートイベントを発信するように強制するために heartbeat.interval.ms を有効にすると、コネクターが定期的にハートビートイベントを発行するようになり、オフセットの同期が維持されます。
Oracle との接続に CDB モードを使用するコネクターの場合、Synchronization のメンテナンスはより複雑になります。heartbeat.interval.ms を設定する必要があるだけでなく heartbeat.interval.ms を設定する必要があります。CDB モードでは、コネクターは PDB 内の変更のみを追跡するため、両方のプロパティーを指定する必要があります。プラガブルデータベース内から変更イベントをトリガーするための補足的なメカニズムが必要である。一定の間隔で、ハートビートアクションクエリーがコネクターに新しいテーブル行を挿入したり、プラガブルデータベースの既存の行を更新したりします。Debezium は、テーブルの変更を検知し、変更イベントを発行することで、変更処理の頻度が低いプラガブルデータベースでもオフセットの同期を確保します。
コネクターのユーザーアカウント が所有していないテーブルで heartbeat.action.query を使用するには、コネクターのユーザーにそれらのテーブルで必要な INSERT または UPDATE クエリーを実行する権限を付与する必要があります。
2.5.2. Debezium Oracle コネクターのデータ変更イベントの説明
Oracle コネクターが出力する全データ変更イベントにはキーと値があります。キーと値の構造は、変更イベントの発生元となるテーブルによって異なります。Debezium のトピック名を構築する方法は、トピック名を参照してください。
Debezium Db2 コネクターは、すべての Kafka Connect スキーマ名 が Avro スキーマ名の形式 に準拠するようにします。つまり、論理サーバー名はアルファベット文字またはアンダースコア ([a-z,A-Z,_]) で始まり、論理サーバー名の残りの文字と、スキーマおよびテーブル名の残りの文字は英数字またはアンダースコア ([a-z,A-Z,0-9,\_]) で始まる必要があります。コネクターは無効な文字をアンダースコアに自動的に置き換えます。
複数の論理サーバー名、スキーマ名、またはテーブル名の中で区別ができる文字のみが無効な場合に、アンダースコアに置き換えられると、命名で予期しない競合が発生する可能性があります。
Debezium および Kafka Connect は、イベントメッセージの継続的なストリーム を中心として設計されています。ただし、これらのイベントの構造は時間の経過とともに変化する可能性があり、トピックコンシューマーによる処理が困難になることがあります。変更可能なイベント構造の処理を容易にするため、Kafka Connect の各イベントは自己完結型となっています。すべてのメッセージキーと値には、スキーマ と ペイロード の 2 つの部分で設定されます。スキーマはペイロードの構造を記述しますが、ペイロードには実際のデータが含まれます。
SYS、SYSTEM ユーザーアカウントが加える変更は、コネクターではキャプチャーされません。
データ変更イベントの詳細は、以下を参照してください。
2.5.2.1. Debezium Oracle コネクター変更イベントのキー
変更されたテーブルごとに変更イベントキーは、イベントの作成時にテーブルのプライマリーキー (または一意のキー制約) の各コラムにフィールドが存在するように設定されます。
たとえば、inventory データベーススキーマに定義されている customers テーブルには、以下の変更イベントキーが含まれる場合があります。
<topic.prefix>.transaction 設定プロパティーの値が server1 に設定されている場合は、データベースの customers テーブルで発生するすべての変更イベントの JSON 表現には以下のキー構造が使用されます。
キーのスキーマ 部分には、キーの部分の内容を記述する Kafka Connect スキーマが含まれます。上記の例では、payload 値はオプションではなく、構造は server1.DEBEZIUM.CUSTOMERS.Key という名前のスキーマで定義され、タイプ int32 の id という名前の必須フィールドが 1 つあります。キーの payload フィールドの値から、id フィールドが 1 つでその値が 1004 の構造 (JSON では単なるオブジェクト) であることが分かります。
つまり、このキーは、id プライマリーキーの列にある値が 1004 の、inventory.customers テーブルの行 (名前が server1 のコネクターからの出力) を記述していると解釈できます。
2.5.2.2. Debezium Oracle 変更イベントの値
変更イベントメッセージの値の構造は、メッセージの変更イベントの メッセージキーの構造 をミラーリングし、スキーマ セクションと ペイロード セクションの両方が含まれます。
変更イベント値のペイロード
変更イベント値のペイロードセクションの エンベロープ 構造には、以下のフィールドが含まれます。
op-
操作のタイプを記述する文字列値が含まれる必須フィールド。Oracle コネクターの変更イベント値のペイロードの
opフィールドには、c(作成または挿入)、u(更新)、d(delete)、またはr(スナップショットを示す read) のいずれかの値が含まれます。 before-
任意のフィールド。存在する場合は、イベント発生 前 の行の状態を記述します。この構造は、
server1.INVENTORY.CUSTOMERS.ValueKafka Connect スキーマによって記述され、server1コネクターはinventory.customersテーブルのすべての行に使用します。
after-
オプションのフィールドで、存在する場合は、変更が発生した 後 の行の状態が含まれます。構造は、
beforeフィールドに使用されるserver1.INVENTORY.CUSTOMERS.ValueKafka Connect スキーマによって記述されます。 sourceイベントのソースメタデータを記述する構造体を含む必須フィールド。Oracle コネクターの場合、構造には以下のフィールドが含まれます。
- Debezium のバージョン。
- コネクター名。
- イベントが進行中のスナップショットの一部であるかどうか。
- トランザクション ID(スナップショットの含まない)。
- 変更の SCN。
- ソースデータベースのレコードがいつ変更されたかを示すタイムスタンプ (スナップショットの場合、タイムスタンプはスナップショットの発生時刻を示す)。
- 変更を加えたユーザー名
行に関連付けられた ROWID
ヒントcommit_scnフィールドは任意で、変更イベントが参加するトランザクションコミットの SCN を記述します。
ts_ms- 任意のフィールド。存在する場合は、コネクターがイベントを処理した時間 (Kafka Connect タスクを実行する JVM のシステムクロックがベース) が含まれます。
変更イベント値のスキーマ
イベントメッセージの値の スキーマ 部分には、ペイロードのエンベロープ構造と、その中のネストされたフィールドを記述するスキーマが含まれます。
変更イベント値の詳細は、以下を参照してください。
create イベント
次の例は、イベントキーの変更 例で説明した customers テーブルの create イベントの値を示しています。
上記の例では、イベントが以下のスキーマを定義する方法に注目してください。
-
エンベロープ (
server1.DEBEZIUM.CUSTOMERS.Envelope)。 -
ソース構造 (io.debezium.connector.oracle.Source、Oracle コネクターに固有で、すべてのイベントで再利用)。 -
beforeフィールドおよびafterフィールドのテーブル固有のスキーマ。
before フィールドおよび after フィールドのスキーマ名は <logicalName>.<schemaName>.<tableName>.Value の形式であるため、他のすべてのテーブルのスキーマからは完全に独立しています。その結果、Avro コンバーター を使用した場合、各論理ソースのテーブルの Avro スキーマは、それぞれ独自に進化し、独自の履歴を持つことになります。
このイベントの 値 の payload 部分には、イベントに関する情報が含まれます。行が作成された (op=c) ことを術士、および after フィールドの値に、行の ID、FIRST_NAME、LAST_NAME、および EMAIL 列に挿入された値が含まれていることを表しています。
デフォルトでは、イベントの JSON 表現はそれが記述する行よりもはるかに大きいように見えることがあります。サイズが大きいのは、JSON 表現がメッセージのスキーマ部分とペイロード部分の両方を含んでいるためです。Avro コンバーター を使用すると、コネクターが Kafka トピックに記述するメッセージのサイズを小さくすることができます。
更新イベント
次の例は、前の create イベントと同じテーブルからコネクターが捕捉した update change イベントを示しています。
ペイロードは create (挿入) イベントのペイロードと同じですが、以下の値は異なります。
-
opフィールドの値がuであり、この行が更新により変更されたことを示す。 -
beforeフィールドは、updateデータベースのコミット前に存在する値が含まれる行の以前の状態を表示します。 -
afterフィールドは行の更新状態を示しており、EMAILの値は現在anne@example.comに設定されています。 -
sourceフィールドの構造は以前と同じフィールドを含みますが、コネクターが REDO ログ内の異なる位置からイベントをキャプチャしたため、値は異なります。 -
ts_msフィールドは、Debezium がいつイベントを処理したかを示すタイムスタンプを示す。
payload セクションでは、他に有用な情報を複数示しています。たとえば、before と after の構造を比較して、コミットの結果として行がどのように変更されたかを判断できます。ソース 構造で、この変更の記録に関する情報がわかるので、追跡が可能です。また、このトピックや他のトピックの他のイベントと関連して、このイベントが発生した場合に、見識を得ることができます。これは、別のイベントと同じコミットの前、後、または一部として発生していましたか ?
行のプライマリーキー/一意キーの列を更新すると、行のキーの値が変更されます。その結果、Debezium はこのような更新後に 3 つのイベントを出力します。
-
DELETEイベント。 - 行のキーが古い tombstone イベント
-
行に新しいキーを提供する
INSERTイベント。
delete イベント
次の例は、先の create と update のイベント例で示したテーブルの delete イベントを示しています。delete イベントの schema 部分は、これらのイベントの schema 部分と同一です。
イベントの payload 部分は、create または update イベントのペイロードと比較して、いくつかの違いを示しています。
-
opフィールドの値はdであり、行が削除されたことを意味します。 -
beforeフィールドは、データベースのコミットで削除された行の旧状態を示します。 -
afterフィールドの値がnull場合、その行はもはや存在しないことを意味します。 -
sourceフィールドの構造には、create または update イベントに存在する多くのキーが含まれるが、ts_ms、scn、txIdフィールドの値は異なっている。 -
ts_msは、Debezium がこのイベントを処理したタイミングを示すタイムスタンプを示します。
delete イベントは、コンシューマーがこの行の削除を処理するために必要な情報を提供する。
Oracle コネクターのイベントは、Kafka ログコンパクション と連携するように設計されており、すべてのキーで最新のメッセージが保持される限り、古いメッセージを削除できます。これにより、トピックに完全なデータセットが含まれ、キーベースの状態のリロードに使用できるようにするとともに、Kafka がストレージ領域を確保できるようにします。
行が削除されると、Kafka は同じキーを使用する以前のメッセージをすべて削除できるため、前の例で示された delete イベント値は、ログ圧縮でまだ機能します。同じキーを共有する メッセージをすべて 削除するように Kafka に指示するには、メッセージの値を null に設定する必要があります。これを可能にするにはデフォルトで、Debezium Oracle コネクターは、値が null 以外で同じキーを持つ特別な 廃棄 イベントが含まれる 削除 イベントに従います。コネクタープロパティー tombstones.on.delete を設定すると、デフォルトの動作を変更できます。
truncate イベント
truncate 変更イベントは、テーブルが切り捨てられたことを通知します。この場合のメッセージキーは null で、メッセージの値は以下のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
イベントのソースメタデータを記述する必須のフィールド。切り捨て (truncate) イベント値の
|
| 2 |
|
操作の型を記述する必須の文字列。 |
| 3 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。
|
切り捨て (truncate) イベントは、テーブル全体に加えられた変更を表し、メッセージキーを持たないため、コンシューマーが 切り捨て られたイベントや変更イベントを受信する保証はありません (作成、更新 など)。たとえば、コンシューマーが異なるパーティションからイベントを読み込む場合、同じテーブルの truncate イベントを受信した後に、テーブルの update イベントを受信することがあります。順序は、トピックが単一のパーティションを使用する場合にのみ保証されます。
切り捨て (truncate) イベントをキャプチャーしない場合は、skipped.operations オプションを使用して除外します。
2.5.3. Debezium Oracle コネクターによるデータ型のマッピング方法
Debezium Oracle コネクターは、テーブル行の値の変化を検出すると、その変化を表す change イベントを発行します。各変更イベントレコードは、元のテーブルと同じように構造化されており、イベントレコードには列値ごとにフィールドが含まれます。テーブル列のデータ型は、以下のセクションの表に示すように、コネクターが変更イベントフィールドで列の値をどのように表現するかを決定します。
テーブルの各列に対して、Debezium はソースデータ型を対応するイベントフィールドの リテラル型、場合によっては セマンティック型 にマッピングします。
- リテラル型
-
以下のカフカコネクトスキーマタイプのいずれかを使用して、値が文字通りどのように表現されるかを記述します。
INT8、INT16、INT32、INT64、FLOAT32、FLOAT64、BOOLEAN、STRING、BYTES、ARRAY、MAP、およびSTRUCT。 - セマンティック型
- フィールドの Kafka Connect スキーマの名前を使用して、Kafka Connect スキーマがフィールドの 意味 をキャプチャーする方法を記述します。
デフォルトのデータ型変換が要件に合わない場合は、コネクター用の カスタムコンバーターの作成 が可能です。
一部の Oracle ラージオブジェクト (CLOB、NCLOB、BLOB) および数値データ型については、デフォルトの設定プロパティー設定を変更することにより、コネクターがタイプマッピングを実行する方法を操作することができます。Debezium プロパティーがこれらのデータ型のマッピングをどのように制御するかの詳細は、Binary and Character LOB types および Numeric types を参照してください。
Debezium コネクターによる Oracle データ型のマッピング方法に関する詳細は、以下を参照してください。
文字タイプ
以下の表は、コネクターによる基本の文字タイプへのマッピング方法を説明しています。
| Oracle データ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
Debezium Oracle コネクターでの BLOB、CLOB、NCLOB の使用は、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
以下の表は、コネクターによるバイナリーおよび文字 LOB (Large Object) 型へのマッピング方法を説明しています。
| Oracle データ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
| 該当なし | このデータ型はサポートされていません。 |
|
|
|
コネクター設定の
|
|
|
| 該当なし |
|
| 該当なし | このデータタイプはサポートされていません。 |
|
| 該当なし | このデータタイプはサポートされていません。 |
|
|
| 該当なし |
|
| 該当なし |
コネクター設定の
|
Oracle は、CLOB、NCLOB、および BLOB データタイプの列値を、SQL ステートメントで明示的に設定または変更された場合にのみ供給します。その結果、変更イベントには、変更されていない CLOB、NCLOB、または BLOB 列の値が含まれることはありません。代わりに、コネクタープロパティー unavailable.value.placeholder で定義されているプレースホルダーが含まれます。
CLOB、NCLOB、または BLOB 列の値が更新されると、対応する更新変更イベントの after 要素に新しい値が追加されます。before 要素には使用できない値プレースホルダーが含まれます。
数字型
以下の表は、Debezium Oracle コネクターによる数値型のマッピング方法を説明しています。
コネクターの decimal.handling.mode 設定プロパティーの値を変更することで、コネクターが Oracle DECIMAL、NUMBER、NUMERIC、および REAL データ型をマッピングする方法を変更できます。このプロパティーをデフォルト値の precise に設定すると、コネクターは、表に示すように、これらの Oracle データ型を Kafka Connect org.apache.kafka.connect.data.Decimal 論理型にマッピングします。プロパティーの値を double または string に設定すると、コネクターは一部の Oracle データ型に別のマッピングを使用します。詳細は、以下の表の セマンティックタイプおよび注意 事項の欄を参照してください。
| Oracle データ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
| 該当なし |
|
|
| 該当なし |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
スケールが 0 の
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
前述したように、Oracle では NUMBER 型において負のスケールが可能です。これが原因で、数値が Decimal として表示される場合に、Avro 形式への変換中に問題が発生する可能性があります。10 進数 タイプにはスケール情報が含まれますが、Avro 仕様 ではスケールの正の値しか使用できません。使用されるスキーマレジストリーによっては、Avro シリアル化に失敗する場合があります。この問題を回避するには、NumberToZeroScaleConverter を使用できます。これは、スケールが負で、十分に大きな数値 (P - S >= 19) をスケール 0 の Decimal 型に変換します。以下のように設定できます。
converters=zero_scale zero_scale.type=io.debezium.connector.oracle.converters.NumberToZeroScaleConverter zero_scale.decimal.mode=precise
converters=zero_scale
zero_scale.type=io.debezium.connector.oracle.converters.NumberToZeroScaleConverter
zero_scale.decimal.mode=precise
デフォルトでは、数値は Decimal 型 (zero_scale.decimal.mode=precise) に変換されますが、サポート対象の残りの 2 つの型 (double と string) もサポートすることですべてに対応します。
ブール値型
Oracle は、BOOLEAN データ型のネイティブサポートを提供しません。ただし、論理 BOOLEAN データ型の概念をシミュレートするために、特定のセマンティクスと他のデータ型を使用することが一般的です。
ソース列をブールデータ型に変換できるように、Debezium は NumberOneToBooleanConverter カスタムコンバーター を提供しており、以下のいずれかの方法で使用することができます。
-
すべての
NUMBER(1)列をBOOLEANタイプにマッピングします。 正規表現のコンマ区切りリストを使用して、列のサブセットを列挙します。
このタイプの変換を使用するには、以下の例のようにselectorパラメーターを使用してconverters設定プロパティーを設定する必要があります。converters=boolean boolean.type=io.debezium.connector.oracle.converters.NumberOneToBooleanConverter boolean.selector=.*MYTABLE.FLAG,.*.IS_ARCHIVED
converters=boolean boolean.type=io.debezium.connector.oracle.converters.NumberOneToBooleanConverter boolean.selector=.*MYTABLE.FLAG,.*.IS_ARCHIVEDCopy to Clipboard Copied! Toggle word wrap Toggle overflow
時間型
Oracle INTERVAL、TIMESTAMP WITH TIME ZONE、および TIMESTAMP WITH LOCAL TIME ZONE データ型以外では、コネクターが時間型を変換する方法は time.precision.mode 設定プロパティーの値に依存します。
time.precision.mode 設定プロパティーが adaptive (デフォルト) に設定された場合、コネクターは列のデータ型を基に時間型のリテラルおよびセマンティック型を決定し、イベントが正確にデータベースの値を表すようにします。
| Oracle データ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
time.precision.mode 設定プロパティーが connect に設定された場合、コネクターは事前定義された Kafka Connect の論理型を使用します。これは、コンシューマーが組み込みの Kafka Connect の論理型のみを認識し、可変精度の時間値を処理できない場合に便利です。Oracle がサポートする精度レベルは、Kafka Connect サポートの論理型を超過するため、time.precision.mode を connectに設定していて、データベース列の fractional second precision の値が 3 より大きい場合には a loss of precision という結果になります。
| Oracle データ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ROWID タイプ
次の表は、コネクターが ROWID (行アドレス) データ型をどのようにマッピングするかを説明したものです。
| Oracle データ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
| 該当なし |
|
| 該当なし | このデータ型はサポートされていません。 |
Debezium Oracle コネクターでの XMLTYPE の使用は、テクノロジープレビュー機能のみとなっています。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
以下の表は、コネクターによる XMLTYPE データ型へのマッピング方法を説明しています。
| Oracle データ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
|
|
ユーザー定義のタイプ
オラクルでは、組み込みのデータ型では要件を満たせない場合に、カスタムデータ型を定義して柔軟性を持たせることができます。オブジェクト型、REF データ型、Varrays、Nested Tables などのユーザー定義型があります。現時点では、Debezium Oracle コネクターをこれらのユーザー定義タイプで使用することはできません。
Oracle によって提供されたタイプ
Oracle は、組み込み型や ANSI でサポートされている型では不十分な場合に、新しい型を定義するために使用できる SQL ベースのインタフェースを提供しています。Oracle は、Any 型や Spatial 型など、幅広い目的に対応するために一般的に使用されるデータ型をいくつか提供しています。現時点では、Debezium Oracle コネクターはこれらのデータ型では使用できません。
デフォルト値
データベーススキーマの列にデフォルト値が指定されている場合、Oracle コネクターはこの値を対応する Kafka レコードフィールドのスキーマに伝搬させようと試みます。ほとんどの一般的なデータタイプがサポートされています。
-
文字型 (
CHAR、NCHAR、VARCHAR、VARCHAR2、NVARCHAR、NVARCHAR2) -
数値型 (
INTEGER、NUMERIC、など) -
時間型 (
DATE、TIMESTAMP、INTERVALなど)。
一時的なタイプが TO_TIMESTAMP や TO_DATE などの関数呼び出しを使用してデフォルト値を表す場合、コネクターは関数を評価するために追加のデータベース呼び出しを行うことでデフォルト値を解決します。たとえば、DATE 列が TO_DATE('2021-01-02', 'YYYY-MM-DD') というデフォルト値で定義されている場合、その列のデフォルト値はその日付の UNIX エポックからの日数、この場合は 18629 となります。
一時的な型がデフォルト値を表すために SYSDATE 定数を使用する場合、コネクターは、列が NOT NULL または NULL として定義されているかどうかに基づいてこれを解決します。列が NULL を指定可能な場合、デフォルト値は設定されません。ただし、列に NULL を指定できない場合、デフォルト値は 0 (DATE または TIMESTAMP(n) データ型の場合) または 1970-01-01T00:00:00Z (TIMESTAMP WITH TIME ZONE または TIMESTAMP WITH LOCAL TIME ZONE データ型の場合) のいずれかに解決されます。デフォルトの値のタイプは数値です。ただし、列が TIMESTAMP WITH TIME ZONE または TIMESTAMP WITH LOCAL TIME ZONE の場合は文字列として出力されます。
カスタムコンバーター
デフォルトでは、Debezium Oracle コネクターは、Oracle データ型に固有の CustomConverter 実装をいくつか提供します。これらのカスタムコンバーターは、コネクター設定に基づいて特定のデータ型に対する代替マッピングを提供します。コネクターに CustomConverter を追加するには、カスタムコンバーターのドキュメント の指示に従ってください。
Debezium Oracle コネクターは、次のカスタムコンバーターを提供します。
NUMBER(1) をブール値に変換する
Oracle データベースバージョン 23 以降では、BOOLEAN の論理データ型を使用できます。以前のバージョンでは、データベースは、False の場合は値 0、True の場合は値 1 に制約するような、NUMBER(1) データ型を使用して BOOLEAN 型をシミュレートしていました。
デフォルトでは、Debezium は NUMBER(1) データ型を使用するソース列の変更イベントを発行すると、データを INT8 リテラル型に変換します。NUMBER(1) データ型のデフォルトマッピングで要件がを満たされない場合は、次の例に示すように、NumberOneToBooleanConverter を設定することで、これらの列を発行するときに論理 BOOL 型を使用するようにコネクターを設定できます。
例: NumberOneToBooleanConverter の設定
converters=number-to-boolean number-to-boolean.type=io.debezium.connector.oracle.converters.NumberOneToBooleanConverter number-to-boolean.selector=.*.MY_TABLE.DATA
converters=number-to-boolean
number-to-boolean.type=io.debezium.connector.oracle.converters.NumberOneToBooleanConverter
number-to-boolean.selector=.*.MY_TABLE.DATA
前の例では、selector プロパティーはオプションです。selector プロパティーは、コンバーターを適用するテーブルまたは列を指定する正規表現を指定します。セレクター プロパティーを省略すると、Debezium がイベントを発行するときに、NUMBER(1) データ型のすべての列が論理 BOOL 型を使用するフィールドに変換されます。
NUMBER の小数点部分を切り捨て/切り上げする
Oracle は、負 (つまり NUMBER(-2)) の NUMBER ベースの列の作成をサポートしています。すべてのシステムが負の値を処理できるわけではないため、これらの値が原因でパイプラインで処理上の問題が発生する可能性があります。たとえば、Apache Avro はこれらの値をサポートしていないため、Debezium がイベントを Avro 形式に変換すると問題が発生する可能性があります。同様に、これらの値をサポートしていないダウンストリームコンシューマーでもエラーが発生する可能性があります。
設定例
converters=number-zero-scale number-zero-scale.type=io.debezium.connector.oracle.converters.NumberToZeroScaleConverter number-zero-scale.decimal.mode=precise
converters=number-zero-scale
number-zero-scale.type=io.debezium.connector.oracle.converters.NumberToZeroScaleConverter
number-zero-scale.decimal.mode=precise
前の例では、decimal.mode プロパティーはコネクターが小数値を出力する方法を指定します。このプロパティーは任意です。decimal.mode プロパティーを省略すると、コンバーターはデフォルトで PRECISE 小数点処理モードを使用します。
RAW から文字列に変換する
Oracle では RAW などの特定のデータ型の使用は推奨されていませんが、レガシーシステムではそのような型が引き続き使用される可能性があります。デフォルトでは、Debezium は RAW 列タイプを論理 BYTES として出力します。これは、バイナリーまたはテキストベースのデータの保存を可能にするタイプです。
場合によっては、RAW 列に文字データが一連のバイトとして格納されることがあります。コンシューマーによる消費を容易にするために、RawToStringConverter を使用するように Debezium を設定できます。RawToStringConverter は、このような RAW 列を簡単にターゲットにして、値をバイトではなく文字列として出力できるようにします。以下の例は、RawToStringConverter をコネクター設定に追加する方法を示しています。
例: RawToStringConverter の設定
converters=raw-to-string raw-to-string.type=io.debezium.connector.oracle.converters.RawToStringConverter raw-to-string.selector=.*.MY_TABLE.DATA
converters=raw-to-string
raw-to-string.type=io.debezium.connector.oracle.converters.RawToStringConverter
raw-to-string.selector=.*.MY_TABLE.DATA
前の例では、selector プロパティーを使用すると、コンバーターが処理するテーブルまたは列を指定する正規表現を定義できます。selector プロパティーを省略すると、コンバーターはすべての RAW 列タイプを論理 STRING フィールドタイプにマップします。
2.5.4. Debezium と連携させるための Oracle の設定
Debezium Oracle コネクターと連携するように Oracle を設定するには、以下の手順が必要です。以下の手順では、コンテナーデータベースと少なくとも 1 つのプラグ可能なデータベースでマルチテナンシーの設定を使用することを前提としています。マルチテナント設定を使用しない場合は、以下の手順を調整する必要がある場合があります。
Debezium コネクターと使用するために Oracle を設定する場合の詳細は、以下を参照してください。
2.5.4.1. Oracle インストールタイプとの Debezium Oracle コネクターの互換性
Oracle データベースは、スタンドアロンインスタンスまたは Oracle Real Application Cluster (RAC) を使用してインストールできます。Debezium Oracle コネクターはどちらのタイプのインストールとも互換性があります。
2.5.4.2. 変更イベントをキャプチャーする際に Debezium Oracle コネクターが除外するスキーマ
Debezium Oracle コネクターがテーブルをキャプチャーすると、以下のスキーマからテーブルが自動的に除外されます。
-
appqossys -
audsys -
ctxsys -
dvsys -
dbsfwuser -
dbsnmp -
qsmadmin_internal -
lbacsys -
mdsys -
ojvmsys -
olapsys -
orddata -
ordsys -
outln -
sys -
system -
vecsys(Oracle 23+) -
wmsys -
xdb
コネクターがテーブルからの変更をキャプチャできるようにするには、そのテーブルが前述のリストにない名前のスキーマを使用している必要があります。
2.5.4.3. 変更イベントをキャプチャーする際に Debezium Oracle コネクターが除外するテーブル
Debezium Oracle コネクターがテーブルをキャプチャーすると、以下のルールに一致するテーブルが自動的に除外されます。
-
CMP[3|4]$[0-9]+に一致する圧縮アドバイザーテーブル。 -
パターン
SYS_IOT_OVER_%に一致するインデックスで整理された表。 -
MDRT_%、MDRS_%、またはMDXT_%パターンと一致する空間テーブル。 - ネストされたテーブル
コネクターが前述のルールのいずれかに一致する名前のテーブルをキャプチャーできるようにするには、テーブルの名前を変更する必要があります。
2.5.4.4. Debezium で使用する Oracle データベースの準備
Oracle LogMiner に必要な設定
Oracle AWS RDS では、上記のコマンドを実行することも、sysdba としてログインすることもできません。AWS には、LogMiner 設定に使用可能な代わりのコマンドが含まれます。これらのコマンドを実行する前に、Oracle AWS RDS インスタンスでバックアップが有効になっていることを確認してください。
Oracle でバックアップが有効になっていることを確認するには、最初に次のコマンドを実行します。LOG_MODE は ARCHIVELOG となるはずです。そうでない場合は、Oracle AWS RDS インスタンスの再起動が必要になる場合があります。
Oracle AWS RDS LogMiner に必要な設定
SQL> SELECT LOG_MODE FROM V$DATABASE; LOG_MODE ------------ ARCHIVELOG
SQL> SELECT LOG_MODE FROM V$DATABASE;
LOG_MODE
------------
ARCHIVELOGLOG_MODE が ARCHIVELOG に設定されたら、コマンドを実行して LogMiner 設定を完了します。最初のコマンドはデータベースを archivelogs に設定し、2 番目のコマンドは補足ロギングを追加します。
Oracle AWS RDS LogMiner に必要な設定
exec rdsadmin.rdsadmin_util.set_configuration('archivelog retention hours',24);
exec rdsadmin.rdsadmin_util.alter_supplemental_logging('ADD');
exec rdsadmin.rdsadmin_util.set_configuration('archivelog retention hours',24);
exec rdsadmin.rdsadmin_util.alter_supplemental_logging('ADD');
Debezium がデータベース行の変更 前 の状態をキャプチャできるようにするには、キャプチャしたテーブルまたはデータベース全体の補足ロギングも有効にする必要があります。次の例は、1 つの inventory.customers テーブルのすべての列に対して補足的なログを設定する方法を示しています。
ALTER TABLE inventory.customers ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
ALTER TABLE inventory.customers ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;すべてのテーブル列の補助ロギングを有効にすると、Oracle redo ログのボリュームが増えます。ログのサイズに過剰な増加を防ぐには、前述の設定を選択的に適用します。
補完用のロギングは最小限のデータベースレベルで有効にする必要があり、以下のように設定できます。
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;2.5.4.5. データディクショナリーに対応するように Oracle redo ログのサイズを変更
データベースの設定によっては、REDO ログのサイズや数が、許容できるパフォーマンスを得るために十分でない場合があります。Debezium Oracle コネクターを設定する前に、REDO ログの容量がデータベースをサポートするのに十分であることを確認してください。
データベースの REDO ログの容量は、そのデータディクショナリーを保存するのに十分でなければなりません。一般的に、データディクショナリーのサイズは、データベースのテーブルや列の数に応じて大きくなります。REDO ログの容量が十分でない場合、データベースと Debezium コネクターの両方でパフォーマンスの問題が発生する可能性があります。
データベースのログ容量を増やす必要があるかどうかは、データベース管理者に相談してください。
2.5.4.6. Debezium Oracle コネクターが使用するアーカイブログの宛先の指定
Oracle データベース管理者は、アーカイブログの宛先を最大 31 個まで設定できます。管理者は、各宛先のパラメーターを設定して、特定の用途 (物理スタンバイのログ送信や、長期のログの保持を可能にする外部ストレージなど) を指定できます。Oracle は、アーカイブログの宛先に関する詳細を V$ARCHIVE_DEST_STATUS ビューで報告します。
Debezium Oracle コネクターは、ステータスが VALID でタイプが LOCAL の宛先のみを使用します。Oracle 環境にその基準を満たす宛先が複数含まれている場合は、Oracle 管理者に相談して、Debezium が使用するアーカイブログの宛先を決定します。
手順
-
Debezium が使用するアーカイブログの宛先を指定するには、コネクター設定で
log.mining.archive.destination.nameプロパティーを設定します。
たとえば、データベースが 2 つのアーカイブ宛先パス/path/oneと/path/twoで設定されており、V$ARCHIVE_DEST_STATUSテーブルがこれらのパスをDEST_NAMEの列で指定された宛先名に関連付けているとします。両方の宛先が Debezium の基準を満たしている場合 (つまり、statusがVALIDでtypeがLOCALの場合)、データベースが/path/twoに書き込むアーカイブログを使用するようにコネクターを設定するには、log.mining.archive.destination.nameの値を、V$ARCHIVE_DEST_STATUSテーブルで/path/twoに関連付けられているDEST_NAME列の値に設定します。たとえば、DEST_NAMEが/path/twoのLOG_ARCHIVE_DEST_3の場合は、Debezium を以下のように設定します。
{
"log.mining.archive.destination.name": "LOG_ARCHIVE_DEST_3"
}
{
"log.mining.archive.destination.name": "LOG_ARCHIVE_DEST_3"
}
log.mining.archive.destination.name の値は、データベースがアーカイブログに使用するパスに設定しないでください。アーカイブログ保持ポリシーに準じる V$ARCHIVE_DEST_STATUS テーブルの行に対して、DEST_NAME 列にあるアーカイブログ保存先の名前にプロパティーを設定します。
Oracle 環境に基準を満たす宛先が複数含まれており、優先する宛先を指定しなかった場合、Debezium Oracle コネクターは宛先パスをランダムに選択します。各宛先には異なる保持ポリシーが設定されている場合があります。そのため、要求するログデータが削除されたパスをコネクターが選択した場合、エラーが発生する可能性があります。
2.5.4.7. Debezium Oracle コネクターの Oracle ユーザーの作成
Debezium Oracle コネクターが変更イベントをキャプチャーするには、特定のパーミッションを持つ Oracle LogMiner ユーザーとして実行する必要があります。以下の例は、マルチテナントデータベースモデルでコネクターの Oracle ユーザーアカウントを作成する SQL を示しています。
コネクターは、自分の Oracle ユーザーアカウントによって行われたデータベースの変更をキャプチャします。ただし、SYS や SYSTEMのユーザーアカウントで行われた変更は捕捉できません。
コネクターの LogMiner ユーザーの作成
| 項目 | ロール名 | 説明 |
|---|---|---|
| 1 | CREATE SESSION | コネクターが Oracle に接続できるようにします。 |
| 2 | SET CONTAINER | コネクターがプラグ可能なデータベース間の切り替えを可能にします。これは、Oracle インストールでコンテナーデータベースのサポート (CDB) が有効になっている場合にのみ必要です。 |
| 3 | SELECT ON V_$DATABASE |
コネクターによる |
| 4 | FLASHBACK ANY TABLE |
コネクターがデータの初期スナップショットを実行する方法であるフラッシュバッククエリーを実行できるようにします。オプションで、すべてのテーブルに対して |
| 5 | SELECT ANY TABLE |
コネクターで任意のテーブルを読み込めるようにする。オプションで、すべてのテーブルに対して |
| 6 | SELECT_CATALOG_ROLE | Oracle LogMiner セッションで必要とされるデータディクショナリーをコネクターで読み込めるようにします。 |
| 7 | EXECUTE_CATALOG_ROLE | コネクターがデータディクショナリーを Oracle redo ログに書き込むことを可能にします。これは、スキーマの変更を追跡するために必要なものです。 |
| 8 | SELECT ANY TRANSACTION |
スナップショットプロセスで、任意のトランザクションに対してフラッシュバックスナップショットクエリーを実行できるようにします。 |
| 9 | LOGMINING | ロールこのロールは、Oracle LogMiner とそのパッケージへの完全なアクセスを付与する方法として、新しいバージョンの Oracle で追加されました。このロールのない古いバージョンの Oracle では、この付与を無視できます。 |
| 10 | CREATE TABLE | コネクターがそのデフォルトのテーブルスペースにフラッシュテーブルを作成することを有効にします。フラッシュテーブルにより、LGWR 内部バッファーのディスクへのフラッシュをコネクターが明示的に制御することができます。 |
| 11 | LOCK ANY TABLE | スキーマスナップショットの実行中にコネクターがテーブルをロックできるようにします。スナップショットロックが設定により明示的に無効化されている場合、このグラントは安全に無視することができます。 |
| 12 | CREATE SEQUENCE | コネクターがそのデフォルトのテーブルスペースにシーケンスを作成することを有効にします。 |
| 13 | EXECUTE ON DBMS_LOGMNR |
|
| 14 | EXECUTE ON DBMS_LOGMNR_D |
|
| 15 から 25 | SELECT ON V_$…. | コネクターがこれらのテーブルを読み取ることを可能にします。Oracle LogMiner セッションを準備するために、コネクターは Oracle redo およびアーカイブログ、および現在のトランザクションの状態に関する情報を読み取れる必要があります。これらの付与がないと、コネクターは操作できません。 |
2.5.4.8. Oracle スタンバイデータベースでのコネクターの実行
スタンバイデータベースは、プライマリーインスタンスの同期されたコピーを提供します。プライマリーデータベースに障害が発生した場合、スタンバイデータベースが継続的な可用性と障害復旧を提供します。Oracle は、物理スタンバイデータベースと論理スタンバイデータベースの両方を使用します。
フィジカルスタンバイ
フィジカルスタンバイは、プライマリーの実稼働データベースのブロック単位の正確なコピーであり、そのシステム変更番号 (SCN) の値はプライマリーのものと同一です。フィジカルスタンバイは外部接続を受け入れないため、Debezium Oracle コネクターはフィジカルスタンバイデータベースから直接変更イベントをキャプチャーできません。コネクターは、スタンバイがプライマリーデータベースに変換された後にのみ、フィジカルスタンバイからイベントをキャプチャーできます。その後、コネクターは、プライマリーデータベースであるかのように、以前のスタンバイに接続します。
ロジカルスタンバイ
論理スタンバイにはプライマリーと同じ論理データが含まれますが、データは物理的に異なる方法で保存される場合があります。論理スタンバイの SCN オフセットは、プライマリーデータベースのオフセットとは異なります。論理スタンバイデータベースからの変更をキャプチャーするように Debezium Oracle コネクターを設定 できます。
2.5.4.8.1. Oracle フェイルオーバーデータベースからデータをキャプチャーする
フェイルオーバーデータベースを設定する場合、通常は論理スタンバイデータベースではなく物理スタンバイデータベースを使用するのがベストプラクティスです。フィジカルスタンバイは、ロジカルスタンバイよりもプライマリーデータベースとの一貫性の高い状態を維持します。フィジカルスタンバイにはプライマリーデータの正確なレプリカが含まれており、スタンバイのシステム変更番号 (SCN) 値はプライマリーのものと同一です。Debezium 環境では、データベースがフィジカルスタンバイにフェイルオーバーした後、一貫性のある SCN 値が存在するため、コネクターが最後に処理された SCN 値を見つけることができます。
フィジカルスタンバイは読み取り専用モードでロックされ、同期を維持するために管理リカバリーが実行されます。データベースがスタンバイモードの場合、クライアントからの外部 JDBC 接続は受け入れられず、外部アプリケーションからアクセスすることはできません。
障害発生後、Debezium が以前のフィジカルスタンバイに接続できるようにするには、DBA がスタンバイへのフェイルオーバーを有効にして、プライマリーデータベースに昇格するためのいくつかのアクションを実行する必要があります。次のリストは、いくつかの重要なアクションを示しています。
- スタンバイ上の管理リカバリーをキャンセルする。
- アクティブな回復プロセスを完了する。
- スタンバイをプライマリーロールに変換する
- クライアントの読み取りおよび書き込み操作に対する新しいプライマリーを開く。
以前のフィジカルスタンバイが通常どおり使用できるようになったら、それに接続するように Debezium Oracle コネクターを設定できます。コネクターが新しいプライマリーからキャプチャーできるようにするには、コネクター設定内のデータベースホスト名を編集し、元のプライマリーのホスト名を新しいプライマリーのホスト名に置き換えます。
2.5.4.8.2. 論理スタンバイからイベントをキャプチャーするための Debezium Oracle コネクターの設定
Oracle 用の Debezium コネクターは、プライマリーデータベースに接続するときに、内部フラッシュテーブルを使用して Oracle Log Writer Buffer (LGWR) プロセスのフラッシュサイクルを管理します。フラッシュプロセスでは、コネクターがデータベースにアクセスするために使用するユーザーアカウントに、このフラッシュテーブルの作成と書き込みの権限が必要です。ただし、論理スタンバイデータベースでは通常、読み取り専用アクセスが許可されるため、コネクターによるデータベースへの書き込みは防止されます。コネクター設定を変更して、コネクターが論理スタンバイからイベントをキャプチャーできるようにしたり、DBA がコネクターがフラッシュテーブルを格納できる新しい書き込み可能な表領域を作成したりすることができます。
Debezium Oracle コネクターが読み取り専用のロジカルスタンバイデータベースから変更を取り込む機能は、開発者プレビュー機能です。開発者プレビュー機能は、Red Hat ではいかなる形でもサポートされていません。また、機能的には完全ではなく、実稼働環境に対応していません。開発者プレビューのソフトウェアを実稼働ワークロードまたはビジネスクリティカルなワークロードには使用しないでください。開発者プレビューソフトウェアは、今後 Red Hat 製品サービスとして追加される可能性のある製品ソフトウェアを前もって早期に利用できます。お客様はこのソフトウェアを使用して機能をテストし、開発プロセス中にフィードバックを提供できます。このソフトウェアにはドキュメントが存在しない可能性があり、変更または削除される可能性があります。また、限定的なテストしか行われていません。Red Hat は、関連する SLA なしに、開発者プレビューソフトウェアに対するフィードバックを送信する手段を提供する場合があります。
Red Hat 開発者プレビューソフトウェアのサポート範囲の詳細は、開発者プレビューのサポート範囲 を参照してください。
手順
Debezium が Oracle 読み取り専用論理スタンバイデータベースからイベントをキャプチャーできるようにするには、コネクター設定に次のプロパティーを追加して、フラッシュテーブルの作成と管理を無効にします。
internal.log.mining.read.only=true
internal.log.mining.read.only=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow 上記の設定により、データベースは
LOG_MINING_FLUSHテーブルを作成および更新できなくなります。internal.log.mining.read.onlyプロパティーは、Oracle スタンドアロンデータベースまたは Oracle RAC インストールで使用できます。
2.5.5. Debezium Oracle コネクターのデプロイメント
以下の方法のいずれかを使用して Debezium Oracle コネクターをデプロイできます。
Debezium Oracle コネクターのアーカイブには、ライセンスの関係で、Oracle データベースに接続するために必要な Oracle JDBC ドライバーが含まれていません。コネクターがデータベースにアクセスできるようにするには、コネクター環境にドライバーを追加する必要があります。詳細は、Obtaining the Oracle JDBC driverを参照してください。
2.5.5.1. Oracle JDBC ドライバーの取得
Debezium が Oracle データベースに接続するために必要な Oracle JDBC ドライバーファイルは、ライセンスの関係で Debezium Oracle コネクターアーカイブに含まれていません。ドライバーは、Maven Central からダウンロード可能です。使用するデプロイメント方法に応じて、Kafka Connect カスタムリソースまたはコネクターイメージの構築に使用する Dockerfile にコマンドを追加して、ドライバーを取得することができます。
-
Streams for Apache Kafka を使用して Kafka Connect イメージにコネクターを追加する場合は、「Streams for Apache Kafka を使用した Debezium Oracle コネクターのデプロイ」 に示されているように、
KafkaConnectカスタムリソースのbuilds.plugins.artifact.urlにドライバーの Maven Central の場所を追加します。 -
Dockerfile を使用してコネクター用のコンテナーイメージを構築する場合、Dockerfile に
curlコマンドを挿入して、Maven Central から必要なドライバーファイルをダウンロードするための URL を指定します。詳細には、Dockerfile からカスタム Kafka Connect コンテナーイメージを構築して Debezium Oracle コネクターをデプロイ するを参照してください。
2.5.5.2. Streams for Apache Kafka を使用した Debezium Oracle コネクターのデプロイメント
Debezium 1.7 以降、Debezium コネクターのデプロイに推奨される方法は、Streams for Apache Kafka を使用して、コネクタープラグインを含む Kafka Connect コンテナーイメージをビルドすることです。
デプロイメントプロセス中に、以下のカスタムリソース (CR) を作成し、使用します。
-
Kafka Connect インスタンスを定義し、コネクターアーティファクトに関する情報をイメージに含める必要がある
KafkaConnectCR。 -
コネクターがソースデータベースにアクセスするために使用する情報を提供する
KafkaConnectorCR。Streams for Apache Kafka が Kafka Connect Pod を起動した後、KafkaConnectorCR を適用してコネクターを起動します。
Kafka Connect イメージのビルド仕様では、デプロイ可能なコネクターを指定できます。各コネクタープラグインに対して、デプロイメントに利用可能にする他のコンポーネントを指定することもできます。たとえば、Apicurio Registry アーティファクトや Debezium スクリプトコンポーネントを追加できます。Streams for Apache Kafka は、Kafka Connect イメージをビルドするときに、指定されたアーティファクトをダウンロードし、それをイメージに組み込みます。
Kafka Connect CR の spec.build.output パラメーターは、生成される KafkaConnectコンテナーイメージを格納する場所を指定します。コンテナーイメージは Docker レジストリーまたは OpenShift ImageStream に保存できます。イメージを ImageStream に保存するには、Kafka Connect をデプロイする前に ImageStream を作成する必要があります。ImageStreams は自動的に作成されません。
KafkaConnect リソースを使用してクラスターを作成する場合は、Kafka Connect REST API を使用してコネクターを作成または更新できません。ただし、REST API を使用して情報を取得できます。
関連情報
- 「OpenShift 上の Streams for Apache Kafka のデプロイと管理」の Kafka Connect の設定
- 「OpenShift 上の Streams for Apache Kafka のデプロイと管理」の 新しいコンテナーイメージの自動ビルド
2.5.5.3. Streams for Apache Kafka を使用した Debezium Oracle コネクターのデプロイ
以前のバージョンの Streams for Apache Kafka では、OpenShift に Debezium コネクターをデプロイするには、まずコネクター用の Kafka Connect イメージをビルドする必要がありました。OpenShift にコネクターをデプロイするための現在の推奨方法は、Streams for Apache Kafka のビルド設定を使用して、使用する Debezium コネクタープラグインを含む Kafka Connect コンテナーイメージを自動的にビルドすることです。
ビルドプロセス中に、Streams for Apache Kafka Operator は、Debezium コネクター定義を含む KafkaConnect カスタムリソースの入力パラメーターを Kafka Connect コンテナーイメージに変換します。このビルドは、Red Hat Maven リポジトリーまたは別の設定済みの HTTP サーバーから必要なアーティファクトをダウンロードします。
新規に作成されたコンテナーは .spec.build.output に指定されるコンテナーレジストリーにプッシュされ、Kafka Connect クラスターのデプロイに使用されます。Streams for Apache Kafka が Kafka Connect イメージをビルドした後、ビルドに含まれるコネクターを起動するための KafkaConnector カスタムリソースを作成します。
前提条件
- クラスター Operator がインストールされている OpenShift クラスターにアクセスできる。
- Streams for Apache Kafka Operator が実行されている。
- Apache Kafka クラスターが OpenShift 上の Streams for Apache Kafka のデプロイと管理 に記載されているとおりにデプロイされている。
- Kafka Connect が Streams for Apache Kafka にデプロイされている。
- Red Hat build of Debezium のライセンスを所有している。
-
OpenShift
ocCLI クライアントがインストールされている、または OpenShift Container Platform Web コンソールにアクセスできる。 Kafka Connect ビルドイメージの保存方法に応じて、レジストリーのパーミッションを用意するか、ImageStream リソースを作成している。
- ビルドイメージを Red Hat Quay.io または Docker Hub などのイメージレジストリーに保存する場合は、以下が必要です。
- レジストリーでイメージを作成し、管理するためのアカウントおよびパーミッション
- ビルドイメージをネイティブ OpenShift ImageStream として保存する場合は、以下を行います。
- 新規コンテナーイメージを保存するために、ImageStream リソースをクラスターにデプロイします。クラスターの ImageStream を明示的に作成する必要があります。ImageStreams は、デフォルトでは利用できません。ImageStreams の詳細は、OpenShift Container Platform でのイメージストリームの管理 を参照してください。
手順
- OpenShift クラスターにログインします。
コネクターの Debezium
KafkaConnectカスタムリソース (CR) を作成するか、既存のリソースを変更します。たとえば、metadata.annotationsおよびspec.buildプロパティーを指定するdbz-connect.yamlという名前のKafkaConnectCR を作成します。以下の例は、KafkaConnectカスタムリソースを記述するdbz-connect.yamlファイルからの抜粋を示しています。
例2.34 Debezium コネクターを含む
KafkaConnectカスタムリソースを定義したdbz-connect.yamlファイル次の例では、カスタムリソースは、次のアーティファクトをダウンロードするように設定されています。
- Debezium Oracle コネクターアーカイブ。
- Red Hat build of Apicurio Registry アーカイブApicurio Registry はオプションのコンポーネントです。コネクターで Avro シリアル化を使用する場合にのみ、Apicurio Registry コンポーネントを追加します。
- Debezium スクリプト SMT アーカイブと Debezium コネクターで使用する関連言語の依存関係。SMT アーカイブおよび言語の依存関係は任意のコンポーネントです。Debezium コンテンツベースのルーティング SMT または フィルター SMT を使用する場合にのみ、これらのコンポーネントを追加します。
- Oracle JDBC ドライバー。Oracle データベースに接続するために必要ですが、コネクターアーカイブには含まれていません。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.120 Kafka Connect 設定の説明 項目 説明 1
strimzi.io/use-connector-resourcesアノテーションを"true"に設定して、クラスター Operator がKafkaConnectorリソースを使用してこの Kafka Connect クラスター内のコネクターを設定できるようにします。2
spec.build設定は、ビルドイメージの保存場所を指定し、プラグインアーティファクトの場所とともにイメージに追加するプラグインをリストします。3
build.outputは、新しくビルドされたイメージを保存するレジストリーを指定します。4
イメージ出力の名前およびイメージ名を指定します。
output.typeの有効な値は、Docker Hub や Quay などのコンテナーレジストリーにプッシュする場合はdocker、内部の OpenShift ImageStream にイメージをプッシュする場合はimagestreamです。ImageStream を使用するには、ImageStream リソースをクラスターにデプロイする必要があります。KafkaConnect 設定でbuild.outputを指定する方法の詳細は、{NameConfiguringStreamsOpenShift} の Streams for Apache Kafka ビルドスキーマリファレンス を参照してください。5
plugins設定は、Kafka Connect イメージに追加するすべてのコネクターをリストします。リストの各エントリーについて、プラグインnameと、コネクターのビルドに必要なアーティファクトに関する情報を指定します。必要に応じて、各コネクタープラグインに対して、コネクターと使用できる他のコンポーネントを含めることができます。たとえば、Service Registry アーティファクトまたは Debezium スクリプトコンポーネントを追加できます。6
artifacts.typeの値は、artifacts.urlで指定するアーティファクトのファイルタイプを指定します。有効なタイプはzip、tgz、またはjarです。Debezium コネクターアーカイブは、.zipファイル形式で提供されます。JDBC ドライバーファイルは.jar形式です。typeの値は、urlフィールドで参照されるファイルのタイプと一致させる必要があります。7
artifacts.urlの値は、コネクターアーティファクトのファイルを格納する Maven リポジトリーなどの HTTP サーバーのアドレスを指定します。Debezium コネクターアーティファクトは Red Hat リポジトリーで入手できます。OpenShift クラスターが指定されたサーバーにアクセスできる必要があります。8
(オプション) Apicurio Registry コンポーネントをダウンロードするためのアーティファクト
typeとurlを指定します。デフォルトの JSON コンバーターを使用する代わりに、コネクターが Apache Avro を使用して Red Hat build of Apicurio Registry でイベントのキーと値をシリアル化する場合にのみ、Apicurio Registry アーティファクトを含めます。9
(オプション) Debezium コネクターで使用する Debezium スクリプト SMT アーカイブのアーティファクト
typeとurlを指定します。Debezium コンテンツベースルーティング SMT または フィルター SMT を使用する場合にのみ、スクリプト SMT を含めます。スクリプト SMT を使用するには、groovy などの JSR 223 準拠のスクリプト実装もデプロイする必要があります。10
(オプション) JSR 223 準拠のスクリプト実装の JAR ファイルのアーティファクト
typeとurlを指定します。これは、Debezium スクリプト SMT で必要です。重要Streams for Apache Kafka を使用してコネクタープラグインを Kafka Connect イメージに組み込む場合、必要なスクリプト言語コンポーネントごとに、
artifacts.urlに JAR ファイルのロケーションを指定し、artifacts.typeの値もjarに設定する必要があります。値が無効な場合は、実行時にコネクターが失敗します。スクリプト SMT で Apache Groovy 言語を使用できるようにするために、この例のカスタムリソースは、次のライブラリーの JAR ファイルを取得します。
-
groovy -
groovy-jsr223(スクリプトエージェント) -
groovy-json(JSON 文字列を解析するためのモジュール)
Debezium スクリプト SMT は、GraalVM JavaScript の JSR 223 実装の使用もサポートします。
11
Maven Central における Oracle JDBC ドライバーの場所を指定します。必要なドライバーは Debezium Oracle コネクターアーカイブには含まれていません。
以下のコマンドを入力して、
KafkaConnectビルド仕様を OpenShift クラスターに適用します。oc create -f dbz-connect.yaml
oc create -f dbz-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Streams Operator はカスタムリソースで指定された設定に基づいて、デプロイする Kafka Connect イメージを準備します。
ビルドが完了すると、Operator はイメージを指定されたレジストリーまたは ImageStream にプッシュし、Kafka Connect クラスターを起動します。設定にリスト表示されているコネクターアーティファクトはクラスターで利用できます。KafkaConnectorリソースを作成し、デプロイする各コネクターのインスタンスを定義します。
たとえば、以下のKafkaConnectorCR を作成し、oracle-inventory-connector.yamlとして保存します。例2.35 Debezium コネクターの
KafkaConnectorカスタムリソースを定義するoracle-inventory-connector.yamlファイルCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.121 コネクター設定の説明 項目 説明 1
Kafka Connect クラスターに登録するコネクターの名前。
2
コネクタークラスの名前。
3
同時に動作できるタスクの数。
4
コネクターの設定。
5
ホストデータベースインスタンスのアドレス。
6
データベースインスタンスのポート番号。
7
Debezium がデータベースへの接続に使用するアカウントの名前。
8
Debezium がデータベースユーザーアカウントに接続するために使用するパスワード。
9
変更をキャプチャーするデータベースの名前。
10
データベースインスタンスまたはクラスターのトピック接頭辞。
指定する名前は、英数字またはアンダースコアのみで設定する必要があります。
トピック接頭辞は、このコネクターから変更イベントを受信する Kafka トピックの接頭辞として使用されるため、名前はクラスターのコネクター間で一意である必要があります。
コネクターを Avro コネクター と統合する場合、この名前空間は、関連する Kafka Connect スキーマの名前や、対応する Avro スキーマの名前空間でも使用されます。11
コネクターが変更イベントをキャプチャーするテーブルのリスト。
以下のコマンドを実行してコネクターリソースを作成します。
oc create -n <namespace> -f <kafkaConnector>.yaml
oc create -n <namespace> -f <kafkaConnector>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc create -n debezium -f oracle-inventory-connector.yaml
oc create -n debezium -f oracle-inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow コネクターは Kafka Connect クラスターに登録され、
KafkaConnectorCR のspec.config.database.dbnameで指定されたデータベースに対して実行を開始します。コネクター Pod の準備ができると、Debezium が実行されます。
これで、Debezium Oracle デプロイメントを検証する 準備が整いました。
2.5.5.4. Dockerfile からカスタム Kafka Connect コンテナーイメージをビルドして Debezium Oracle コネクターのデプロイ
Debezium Oracle コネクターをデプロイするには、Debezium コネクターアーカイブが含まれるカスタム Kafka Connect コンテナーイメージをビルドし、このコンテナーイメージをコンテナーレジストリーにプッシュする必要があります。次に、以下のカスタムリソース (CR) を作成する必要があります。
-
Kafka Connect インスタンスを定義する
KafkaConnectCR。imageは Debezium コネクターを実行するために作成したイメージの名前を指定します。この CR は、Red Hat Streams for Apache Kafka がデプロイされている OpenShift インスタンスに適用します。Streams for Apache Kafka は、Apache Kafka を OpenShift に導入する Operator とイメージを提供します。 -
Debezium Oracle コネクターを定義する
KafkaConnectorCR。この CR をKafkaConnectCR を適用するのと同じ OpenShift インスタンスに適用します。
前提条件
- Oracle Database が稼働し、Oracle を設定して Debezium コネクターと連携する 手順が完了済みである必要があります。
- Streams for Apache Kafka が OpenShift にデプロイされ、Apache Kafka および Kafka Connect が実行されている。詳細は、OpenShift 上の Streams for Apache Kafka のデプロイと管理を参照してください。
- Podman または Docker がインストールされている。
-
Debezium コネクターを実行するコンテナーを追加する予定のコンテナーレジストリー (
quay.ioやdocker.ioなど) でコンテナーを作成および管理するアカウントとパーミッションを持っている。 Kafka Connect サーバーは、Oracle 用の必要な JDBC ドライバーをダウンロードするために、Maven Central にアクセスすることができます。また、ドライバーのローカルコピー、またはローカルの Maven リポジトリーや他の HTTP サーバーから利用可能なものを使用することもできます。
詳細は、Obtaining the Oracle JDBC driverを参照してください。
手順
Kafka Connect の Debezium Oracle コンテナーを作成します。
registry.redhat.io/amq-streams-kafka-35-rhel8:2.5.0をベースイメージとして使用して、新規の Dockerfile を作成します。たとえば、ターミナルウィンドウから、以下のコマンドを入力します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 項目 説明 1
任意のファイル名を指定できます。
2
Kafka Connect プラグインディレクトリーへのパスを指定します。Kafka Connect のプラグインディレクトリーが別の場所にある場合は、このパスを実際のディレクトリーのパスに置き換えてください。
このコマンドは、現在のディレクトリーに
debezium-container-for-oracle.yamlという名前の Docker ファイルを作成します。前のステップで作成した
debezium-container-for-oracle.yamlDocker ファイルからコンテナーイメージをビルドします。ファイルが含まれるディレクトリーから、ターミナルウィンドウを開き、以下のコマンドのいずれかを入力します。podman build -t debezium-container-for-oracle:latest .
podman build -t debezium-container-for-oracle:latest .Copy to Clipboard Copied! Toggle word wrap Toggle overflow docker build -t debezium-container-for-oracle:latest .
docker build -t debezium-container-for-oracle:latest .Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドは、
debezium-container-for-oracleという名前のコンテナーイメージを構築します。カスタムイメージを quay.io などのコンテナーレジストリーまたは内部のコンテナーレジストリーにプッシュします。コンテナーレジストリーは、イメージをデプロイする OpenShift インスタンスで利用できる必要があります。以下のいずれかのコマンドを実行します。
podman push <myregistry.io>/debezium-container-for-oracle:latest
podman push <myregistry.io>/debezium-container-for-oracle:latestCopy to Clipboard Copied! Toggle word wrap Toggle overflow docker push <myregistry.io>/debezium-container-for-oracle:latest
docker push <myregistry.io>/debezium-container-for-oracle:latestCopy to Clipboard Copied! Toggle word wrap Toggle overflow 新しい Debezium Oracle KafkaConnect カスタムリソース (CR) を作成します。たとえば、
annotationsおよびimageプロパティーを指定するdbz-connect.yamlという名前のKafkaConnectCR を作成します。以下の例は、KafkaConnectカスタムリソースを記述するdbz-connect.yamlファイルからの抜粋を示しています。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 項目 説明 1
KafkaConnectorリソースはこの Kafka Connect クラスターでコネクターを設定するために使用されることを、metadata.annotationsは Cluster Operator に示します。2
spec.imageは Debezium コネクターを実行するために作成したイメージの名前を指定します。設定された場合、このプロパティーによって Cluster Operator のSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGE変数がオーバーライドされます。以下のコマンドを入力して、
KafkaConnectCR を OpenShift Kafka Connect 環境に適用します。oc create -f dbz-connect.yaml
oc create -f dbz-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、Debezium コネクターを実行するために作成したイメージの名前を指定する Kafka Connect インスタンスを追加します。
Debezium Oracle コネクターインスタンスを設定する
KafkaConnectorカスタムリソースを作成します。通常、コネクターに使用できる設定プロパティーを使用して、
.yamlファイルに Debezium Db2 コネクターを設定します。コネクター設定は、Debezium に対して、スキーマおよびテーブルのサブセットにイベントを生成するよう指示する可能性があり、または機密性の高い、大きすぎる、または不必要な指定のコラムで Debezium が値を無視、マスク、または切り捨てするようにプロパティーを設定する可能性もあります。以下の例では、ポート
1521で Oracle ホスト IP アドレスに接続する Debezium コネクターを設定します。このホストにはORCLCDBという名前のデータベースがあり、server1はサーバーの論理名です。Oracle
inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.122 コネクター設定の説明 項目 説明 1
Kafka Connect サービスに登録する場合のコネクターの名前。
2
この Oracle コネクタークラスの名前。
3
Oracle インスタンスのアドレス。
4
Oracle インスタンスのポート番号。
5
コネクターのユーザーの作成 で指定した Oracle ユーザーの名前。
6
コネクターのユーザーの作成 で指定した Oracle ユーザーのパスワード。
7
変更をキャプチャーするデータベースの名前。
8
コネクターが変更をキャプチャーする Oracle のプラグ可能なデータベースの名前。コンテナーデータベース (CDB) のインストールのみで使用されます。
9
topic prefix は、コネクターが変更をキャプチャーする Oracle データベースサーバーの名前空間を識別して提供します。
10
DDL ステートメントをデータベーススキーマの履歴トピックに書き込み、復元するためにコネクターによって使用される Kafka ブローカーのリスト。
11
コネクターが DDL ステートメントを書き、復元するデータベーススキーマの履歴トピックの名前。このトピックは内部使用のみを目的としており、コンシューマーが使用しないようにしてください。
Kafka Connect でコネクターインスタンスを作成します。たとえば、
KafkaConnectorリソースをinventory-connector.yamlファイルに保存した場合は、以下のコマンドを実行します。oc apply -f inventory-connector.yaml
oc apply -f inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドは
inventory-connectorを登録し、コネクターはKafkaConnectorCR に定義されているserver1データベースに対して実行を開始します。
Debezium Oracle コネクターに設定できる設定プロパティーの完全リストは Oracle コネクタープロパティー を参照してください。
結果
コネクターが起動すると、コネクターが設定された Oracle データベースの整合性スナップショットが実行されます。その後、コネクターは行レベルの操作のデータ変更イベントの生成を開始し、変更イベントレコードを Kafka トピックにストリーミングします。
2.5.5.5. コンテナーデータベースとノンコンテナーデータベースの設定
Oracle Database は以下のデプロイメントタイプをサポートしています。
- コンテナーデータベース (CDB)
- 複数の PDB (Multi Pluggable Database) を格納できるデータベース。データベースクライアントは、標準的な非 CDB データベースであるかのように、各 PDB に接続します。
- ノンコンテナーデータベース (非 CDB)
- プラガブルデータベースの作成には対応していない、標準的な Oracle のデータベース。
2.5.5.6. Debezium Oracle コネクターが実行していることの確認
コネクターがエラーなしで正常に起動すると、コネクターがキャプチャーするように設定された各テーブルのトピックが作成されます。ダウンストリームアプリケーションは、これらのトピックをサブスクライブして、ソースデータベースで発生する情報イベントを取得できます。
コネクターが実行されていることを確認するには、OpenShift Container Platform Web コンソールまたは OpenShift CLI ツール (oc) から以下の操作を実行します。
- コネクターのステータスを確認します。
- コネクターがトピックを生成していることを確認します。
- 各テーブルの最初のスナップショットの実行中にコネクターが生成する読み取り操作 ("op":"r") のイベントがトピックに反映されていることを確認します。
前提条件
- Debezium コネクターが OpenShift 上の Streams for Apache Kafka にデプロイされている。
-
OpenShift
ocCLI クライアントがインストールされている。 - OpenShift Container Platform Web コンソールにアクセスできる。
手順
以下の方法のいずれかを使用して
KafkaConnectorリソースのステータスを確認します。OpenShift Container Platform Web コンソールから以下を実行します。
- Home → Search に移動します。
-
Search ページで Resources をクリックし、Select Resource ボックスを開き、
KafkaConnectorを入力します。 - KafkaConnectors リストから、チェックするコネクターの名前をクリックします (例: inventory-connector-oracle)。
- Conditions セクションで、Type および Status 列の値が Ready および True に設定されていることを確認します。
ターミナルウィンドウから以下を実行します。
以下のコマンドを実行します。
oc describe KafkaConnector <connector-name> -n <project>
oc describe KafkaConnector <connector-name> -n <project>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc describe KafkaConnector inventory-connector-oracle -n debezium
oc describe KafkaConnector inventory-connector-oracle -n debeziumCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、以下の出力のようなステータス情報を返します。
例2.36
KafkaConnectorリソースのステータスCopy to Clipboard Copied! Toggle word wrap Toggle overflow
コネクターによって Kafka トピックが作成されたことを確認します。
OpenShift Container Platform Web コンソールから以下を実行します。
- Home → Search に移動します。
-
Search ページで Resources をクリックし、Select Resource ボックスを開き、
KafkaTopicを入力します。 -
KafkaTopics リストから確認するトピックの名前をクリックします (例:
inventory-connector-oracle.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d)。 - Conditions セクションで、Type および Status 列の値が Ready および True に設定されていることを確認します。
ターミナルウィンドウから以下を実行します。
以下のコマンドを実行します。
oc get kafkatopics
oc get kafkatopicsCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、以下の出力のようなステータス情報を返します。
例2.37
KafkaTopicリソースのステータスCopy to Clipboard Copied! Toggle word wrap Toggle overflow
トピックの内容を確認します。
- ターミナルウィンドウから、以下のコマンドを入力します。
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory-connector-oracle.inventory.products_on_hand
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory-connector-oracle.inventory.products_on_handCopy to Clipboard Copied! Toggle word wrap Toggle overflow トピック名を指定する形式は、手順 1 で返された
oc describeコマンドと同じです (例:inventory-connector-oracle.inventory.addresses)。トピックの各イベントについて、このコマンドは、以下の出力のような情報を返します。
例2.38 Debezium 変更イベントの内容
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory-connector-oracle.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-oracle.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-oracle.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"int64","optional":false,"field":"ts_us"},{"type":"int64","optional":false,"field":"ts_ns"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.oracle.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"int64","optional":true,"field":"ts_us"},{"type":"int64","optional":true,"field":"ts_ns"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory-connector-oracle.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"2.7.3.Final-redhat-00001","connector":"oracle","name":"inventory-connector-oracle","ts_ms":1638985247805,"ts_us":1638985247805000000,"ts_ns":1638985247805000000,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"oracle-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"ts_us":1638985247805102,"ts_ns":1638985247805102588,"transaction":null}}{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory-connector-oracle.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-oracle.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-oracle.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"int64","optional":false,"field":"ts_us"},{"type":"int64","optional":false,"field":"ts_ns"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.oracle.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"int64","optional":true,"field":"ts_us"},{"type":"int64","optional":true,"field":"ts_ns"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory-connector-oracle.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"2.7.3.Final-redhat-00001","connector":"oracle","name":"inventory-connector-oracle","ts_ms":1638985247805,"ts_us":1638985247805000000,"ts_ns":1638985247805000000,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"oracle-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"ts_us":1638985247805102,"ts_ns":1638985247805102588,"transaction":null}}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記の例では、
payload値は、コネクタースナップショットがテーブルinventory.products_on_handから読み込み ("op" ="r") イベントを生成したことを示しています。product_idレコードの"before"状態はnullであり、レコードに以前の値が存在しないことを示しています。"after"状態は、product_id101を持つ項目のquantityが3であることを示しています。
2.5.6. Debezium Oracle コネクター設定プロパティーの説明
Debezium Oracle コネクターには、アプリケーションに適したコネクター動作を実現するために使用できる設定プロパティーが多数あります。多くのプロパティーにはデフォルト値があります。プロパティーに関する情報は、以下のように設定されています。
- 必要な Debezium Oracle コネクター設定プロパティー
- Debezium がデータベース履歴トピックから読み取るイベントを処理する方法を制御する データベース履歴コネクター設定プロパティー。
必要な Debezium Oracle コネクター設定プロパティー
以下の設定プロパティーは、デフォルト値がない場合は必須です。
| プロパティー | デフォルト | 説明 |
| デフォルトなし | コネクターの一意名。同じ名前で再登録を試みると失敗します。(このプロパティーはすべての Kafka Connect コネクターに必要です) | |
| デフォルトなし |
コネクターの Java クラスの名前。Oracle コネクターには、常に | |
| デフォルトなし |
コネクターが使用できる カスタムコンバーター インスタンスのシンボリック名をコンマ区切りリストで列挙します。
コネクターに設定するコンバーターごとに、コンバーターインターフェイスを実装するクラスの完全修飾名を指定する
以下に例を示します。 boolean.type: io.debezium.connector.oracle.converters.NumberOneToBooleanConverter
設定されたコンバータの動作をさらに制御したい場合は、1 つ以上の設定パラメーターを追加して、コンバータに値を渡すことができます。追加の設定パラメーターとコンバーターを関連付けるには、パラメーター名の前にコンバーターのシンボリック名を付けます。 boolean.selector: .*MYTABLE.FLAG,.*.IS_ARCHIVED | |
|
| このコネクターに作成するタスクの最大数。Oracle コネクターは常に単一のタスクを使用するため、この値を使用しません。そのため、デフォルト値は常に許容されます。 | |
| デフォルトなし | Oracle データベースサーバーの IP アドレスまたはホスト名。 | |
| デフォルトなし | Oracle データベースサーバーの整数のポート番号。 | |
| デフォルトなし | コネクターが Oracle データベースサーバーへの接続に使用する Oracle ユーザーアカウントの名前。 | |
| デフォルトなし | Oracle データベースサーバーへの接続時に使用するパスワード。 | |
| デフォルトなし | 接続先のデータベースの名前。コンテナーデータベース環境では、含まれるプラグ可能なデータベース (PDB) の名前ではなく、ルートコンテナーデータベース (CDB) の名前を指定します。 | |
| デフォルトなし | raw データベースの JDBC URL を指定します。このプロパティーを使用すると、そのデータベース接続を柔軟に定義できます。有効な値は、raw TNS 名および RAC 接続文字列などです。 | |
| デフォルトなし | 接続先の Oracle のプラグ可能なデータベースの名前。このプロパティーは、コンテナーデータベース (CDB) のインストールでのみ使用してください。 | |
| デフォルトなし |
コネクターが変更をキャプチャーする Oracle データベースサーバーの名前空間を識別して提供するトピック接頭辞。設定した値は、コネクターが出力するすべての Kafka トピック名の接頭辞として使用されます。Debezium 環境のすべてのコネクターで一意のトピック接頭辞を指定します。英数字、ハイフン、ドットおよびアンダースコアの文字が有効です。 警告 このプロパティーの値を変更しないでください。名前の値を変更すると、再起動後に、元のトピックにイベントを発行し続けるのではなく、新しい値に基づいた名前のトピックに後続のイベントを発行します。また、コネクターはデータベーススキーマ履歴トピックを復元できません。 | |
|
| コネクターがデータベースの変更をストリーミングする際に使用するアダプター実装。以下の値を設定できます。
| |
| Initial | このコネクターがキャプチャーされたテーブルのスナップショットを取得するために使用するモードを指定します。以下の値を設定できます。
スナップショットが完了すると、
詳細は、 | |
| shared | コネクターがテーブルロックを保持するかどうか、また保持する時間をコントロールします。テーブルロックは、コネクターがスナップショットを実行している間、特定の種類の変更テーブル操作が発生するのを防ぎます。以下の値を設定できます。
| |
|
|
スナップショットを実行するときにコネクターがデータをクエリーする方法を指定します。
この設定により、 | |
|
コネクターの |
スナップショットに含めるテーブルの完全修飾名 (
マルチテナントコンテナーデータベース (CDB) 環境では、
テーブルの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの名前文字列全体と照合されます。
スナップショットには、コネクターの
このプロパティーは、コネクターの | |
| デフォルトなし | スナップショットに追加するテーブル行を指定します。スナップショットにテーブルの行のサブセットのみを含める場合は、プロパティーを使用します。このプロパティーはスナップショットにのみ影響します。コネクターがログから読み取るイベントには影響しません。
プロパティーには、
スナップショットにソフト削除以外のレコードのみを含める場合は、soft-delete 列 ( "snapshot.select.statement.overrides": "customer.orders", "snapshot.select.statement.overrides.customer.orders": "SELECT * FROM customers.orders WHERE delete_flag = 0 ORDER BY id DESC"
作成されるスナップショットでは、コネクターには | |
| デフォルトなし |
変更をキャプチャーする対象とするスキーマの名前と一致する正規表現のコンマ区切りリスト (任意)。POSIX 正規表現のみが有効です。
スキーマの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定した式は、スキーマ名に存在する可能性のある部分文字列とは一致しない、スキーマの名前文字列全体と照合されます。 | |
|
| コネクターがメタデータオブジェクトでテーブルおよび列のコメントを解析して公開するかどうかを指定するブール値。このオプションを有効にすると、メモリー使用量に影響を及ぼします。論理スキーマオブジェクトの数およびサイズは、Debezium コネクターによって消費されるメモリーの量に大きく影響し、それぞれに大きな文字列データを追加すると、非常に高価になる可能性があります。 | |
| デフォルトなし |
変更をキャプチャーする対象としないスキーマの名前と一致する正規表現のコンマ区切りリスト (任意)。POSIX 正規表現のみが有効です。システムスキーマ以外で、
スキーマの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定した式は、スキーマ名に存在する可能性のある部分文字列とは一致しない、スキーマの名前文字列全体と照合されます。 | |
| デフォルトなし |
キャプチャーするテーブルの完全修飾テーブル識別子と一致する正規表現のコンマ区切りリスト (任意)。POSIX 正規表現のみが有効です。このプロパティーが設定されている場合、コネクターは指定されたテーブルからのみ変更をキャプチャします。各テーブルの識別子は、
テーブルの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの名前文字列全体と照合されます。 | |
| デフォルトなし |
監視から除外するテーブルの完全修飾テーブル識別子と一致する正規表現のコンマ区切りリスト (任意)。POSIX 正規表現のみが有効です。コネクターは除外リストに指定されていないテーブルからの変更をキャプチャーします。
テーブルの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの名前文字列全体と照合されます。 | |
| デフォルトなし |
変更イベントメッセージの値に含まれる必要がある列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。POSIX 正規表現のみが有効です。列の完全修飾名は、
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列名に存在する可能性のある部分文字列とは一致しない、列の名前文字列全体と照合されます。 | |
| デフォルトなし |
変更イベントメッセージの値から除外される必要がある列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。POSIX 正規表現のみが有効です。完全修飾の列名は、
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列名に存在する可能性のある部分文字列とは一致しない、列の名前文字列全体と照合されます。 | |
|
|
含まれる列に変更がない場合にメッセージの公開をスキップするかどうかを指定します。これは基本的に、含まれる列に変更がない場合、 | |
|
| 該当なし |
文字ベースの列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。列の完全修飾名の形式は
仮名は、指定された hashAlgorithm と salt を適用すると得られるハッシュ化された値で構成されます。使用されるハッシュ関数に基づいて、参照整合性は保持され、列値は仮名に置き換えられます。サポートされるハッシュ関数は、Java Cryptography Architecture Standard Algorithm Name Documentation の MessageDigest セクションに説明されています。 column.mask.hash.SHA-256.with.salt.CzQMA0cB5K = inventory.orders.customerName, inventory.shipment.customerName
必要な場合は、仮名は自動的に列の長さに短縮されます。コネクター設定には、異なるハッシュアルゴリズムと salt を指定する複数のプロパティーを含めることができます。 |
| bytes |
バイナリー ( | |
| none |
コネクターで使用されるメッセージコンバータとの互換性のために、スキーマ名をどのように調整するかを指定します。設定可能:
| |
| none |
コネクターで使用されるメッセージコンバータとの互換性のために、フィールド名をどのように調整するかを指定します。設定可能:
詳細は、Avro の命名 を参照してください。 | |
|
|
コネクターが
| |
|
|
| |
|
| イベントの処理中にコネクターが例外に対応する方法を指定します。以下のオプションのいずれかを使用できます。
| |
|
| このコネクターの反復処理中に処理するイベントの各バッチの最大サイズを指定する正の整数値。 | |
|
|
ブロッキングキューが保持できるレコードの最大数を指定する正の整数値。Debezium はデータベースからストリームされたイベントを読み込む際、Kafka に書き込む前にブロッキングキューにイベントを配置します。ブロッキングキューは、コネクターが Kafka に書き込むよりも速くメッセージを取り込む場合、または Kafka が利用できなくなった場合に、データベースから変更イベントを読み込むためのバックプレッシャーを提供することができます。コネクターがオフセットを定期的に記録すると、キューに保持されるイベントは無視されます。 | |
|
|
ブロッキングキューの最大容量をバイト単位で指定する長整数値。デフォルトでは、ブロックキューにはボリューム制限は指定されません。キューが使用できるバイト数を指定するには、このプロパティーを正の long 値に設定します。 | |
|
| 各反復処理の実行中に新しい変更イベントが表示されるまでコネクターが待機する時間 (ミリ秒単位) を指定する正の整数値。 | |
|
| delete イベントの後に廃棄 (tombstone) イベントを行うかどうかを制御します。以下の値が可能です。
ソースレコードを削除すると、廃棄イベント (デフォルトの動作) により、Kafka が log compaction が有効なトピックで削除した列のキーを共有するイベントをすべて完全に削除できるようになります。 | |
| デフォルトなし | 指定のテーブルの Kafka トピックに公開する変更イベントレコードのカスタムメッセージキーを形成するためにコネクターが使用する列を指定する式のリスト。
デフォルトでは、Debezium はテーブルのプライマリーキー列を、出力するレコードのメッセージキーとして使用します。デフォルトの代わりに、またはプライマリーキーのないテーブルのキーを指定するには、1 つ以上の列をもとにカスタムメッセージキーを設定できます。 | |
| デフォルトなし |
文字ベースの列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。一連の列の値をコネクターでマスクする場合 (たとえば、列に機密データが含まれている場合) は、このプロパティーを設定します。
列の完全修飾名は、 単一の設定で、異なる長さを持つ複数のプロパティーを指定できます。 | |
| デフォルトなし |
文字をアスタリスク ( | |
| デフォルトなし | 列のメタデータを表す追加パラメーターをコネクターに発行させたい列の完全修飾名に一致する、オプションのコンマ区切りの正規表現のリスト。このプロパティーが設定されている場合、コネクターは次のフィールドをイベントレコードのスキーマに追加します。
これらのパラメーターは、列の元の型名と長さ (可変幅型の場合) をそれぞれ伝達します。
列の完全修飾名は | |
| デフォルトなし | データベース内の列に対して定義されているデータ型の完全修飾名を指定する正規表現のオプションのコンマ区切りリスト。このプロパティーが設定されている場合、データ型が一致する列に対して、コネクターはスキーマに次の追加フィールドを含むイベントレコードを発行します。
これらのパラメーターは、列の元の型名と長さ (可変幅型の場合) をそれぞれ伝達します。
列の完全修飾名は、 Oracle 固有のデータ型名の一覧は、Oracle データ型マッピング を参照してください。 | |
|
|
コネクターがメッセージをハートビートトピックに送信する頻度を定義する間隔 (ミリ秒単位) を指定します。 | |
| デフォルトなし |
コネクターがハートビートメッセージを送信するときにコネクターがソースデータベースで実行するクエリーを指定します。 このプロパティーを設定し、ハートビートテーブルを作成してハートビートメッセージを受信することで、Debezium が高トラフィックデータベースと同じホスト上にある低トラフィックデータベースのオフセットの同期に失敗 する状況を解決することができます。コネクターは設定されたテーブルにレコードを挿入した後、低トラフィックデータベースから変更を受信し、データベースの SCN 変更を認識することができるので、オフセットをブローカーと同期させることができます。 | |
| デフォルトなし |
スナップショットを作成する前に、コネクターが起動してから待機する間隔をミリ秒単位で指定します。 | |
| 0 |
コネクターがスナップショットを完了した後、ストリーミングプロセスの開始を遅延する時間をミリ秒単位で指定します。遅延間隔を設定すると、スナップショットが完了した直後で、ストリーミングプロセスの開始前に障害が発生した場合に、コネクターがスナップショットを再開できないようにします。Kafka Connect ワーカーに設定されている | |
|
| スナップショットの実行中に各テーブルから 1 度に読み取る必要がある行の最大数を指定します。コネクターは、指定のサイズの複数のバッチでテーブルの内容を読み取ります。 | |
|
|
指定のクエリーのデータベースのラウンドトリップごとにフェッチされる行の数を指定します。 | |
|
|
詳細は、トランザクションメタデータ を参照してください。 | |
|
|
テーブルと列 ID を名前に解決するために Oracle LogMiner が特定のデータディクショナリーをビルドおよび使用する方法を制御するマイニングストラテジーを指定します。 | |
|
|
Oracle LogMiner クエリーの構築方法を制御するマイニングクエリーモードを指定します。 | |
|
|
バッファータイプは、コネクターがトランザクションデータのバッファリングをどのように管理するかを制御します。 | |
|
|
新しいセッションが使用される前に LogMiner セッションをアクティブに保つことができる最大期間 (ミリ秒単位)。 | |
|
|
JDBC 接続を切断して、ログの切り替え時、またはマイニングセッションの最大存続期間のしきい値に到達したときに再開するかを指定します。 | |
|
| このコネクターが redo/archive ログから読み込もうとする最小 SCN 間隔サイズ。また、必要に応じてコネクターのスループットを調整するために、アクティブバッチサイズをこの量だけ増減させます。 | |
|
| このコネクターが REDO/ARCHIVE ログから読み取るときに使用する最大 SCN インターバルサイズです。 | |
|
| コネクターが REDO/ARCHIVE ログからデータを読み取る際に使用する開始 SCN 間隔サイズ。これは、バッチサイズを調整するための手段としても機能します。現在の SCN とバッチの開始/終了 SCN の差がこの値よりも大きい場合、バッチサイズが増減されます。 | |
|
| redo/archive ログからデータを読み込んだ後、再びデータの読み込みを開始するまでのコネクターのスリープ時間の最小値です。値はミリ秒単位です。 | |
|
| redo/archive ログからデータを読み込んだ後、再びデータの読み込みを開始するまでのコネクターイルのスリープ時間の最大値。値はミリ秒単位です。 | |
|
| redo/archive ログからデータを読み込んだ後、再びデータの読み込みを開始するまでのコネクターのスリープ時間の開始値。値はミリ秒単位です。 | |
|
| logminer からデータを読み取る際に、コネクターが最適なスリープ時間を調整するために使用する時間の最大値を上下させる。値はミリ秒単位です。 | |
|
|
SYSDATE からアーカイブログを採掘するまでの過去の時間数です。デフォルトの設定 ( | |
|
|
コネクターが変更をアーカイブログだけから挽くのか、オンライン REDO ログとアーカイブログを組み合わせて挽くのか (デフォルト) を制御します。 | |
|
|
開始システムの変更番号がアーカイブログにあるかどうかを判断するためのポーリングの間に、コネクターがスリープするミリ秒数です。 | |
|
|
正の整数値で、redo ログの切り替えの間に長時間実行されるトランザクションを保持する時間 (ミリ秒) を指定します。 デフォルトでは、LogMiner アダプターは、実行中のすべてのトランザクションのインメモリーバッファーを維持します。トランザクションの一部となるすべての DML 操作は、コミットまたはロールバックが検出されるまでバッファーされるため、そのバッファーがオーバーフローしないように長時間実行されるトランザクションを回避する必要があります。設定されたこの値を超えるトランザクションは完全に破棄され、コネクターはトランザクションに含まれていた操作のメッセージを出力しません。 | |
| デフォルトなし |
LogMiner でアーカイブログをマイニングする際に使用する、設定された Oracle のアーカイブ先を指定します。 | |
| デフォルトなし | LogMiner クエリーから包含するデータベースユーザーのリスト。キャプチャープロセスで、指定したユーザーからの変更を含めるようにするには、このプロパティーを設定すると便利です。 | |
| デフォルトなし | LogMiner クエリーから除外するデータベースユーザーのリスト。特定のユーザーが行った変更を常にキャプチャプロセスから除外したい場合は、このプロパティーを設定すると便利です。 | |
|
|
SCN ギャップがあるかどうかを判断するために、コネクターが現在の SCN 値と前回の SCN 値の差と比較する値を指定します。SCN 値の差が指定された値より大きく、時間差が | |
|
|
SCN ギャップがあるかどうかを判断するために、コネクターが現在の SCN タイムスタンプと前回の SCN タイムスタンプの差と比較する値をミリ秒単位で指定します。タイムスタンプの差が指定された値よりも小さく、SCN デルタが指定された値よりも大きい場合、SCN ギャップが検出され、設定された最大バッチよりも大きいマイニングウィンドウを使用します。 | |
|
|
Oracle LogWriter Buffer (LGWR) の REDO ログへのフラッシュを調整するフラッシュテーブルの名前を指定します。この名前は | |
|
|
REDO ログで構築された SQL ステートメントが | |
|
|
ラージオブジェクト (CLOB または BLOB) の列値を変更イベントで出力するかどうかを制御します。 注記 ラージオブジェクトデータタイプの使用は、テクノロジープレビューの機能です。 | |
|
| コネクターが提供する定数を指定して、元の値がデータベースによって提供されておらず、また変更されていない値であることを示します。 | |
| デフォルトなし | Oracle Real Application Clusters (RAC) ノードのホスト名またはアドレスをコンマで区切って入力してください。このフィールドは、Oracle RAC のデプロイメントとの互換性を有効にするために必要です。 RAC ノードのリストを以下のいずれかの方法で指定します。
| |
|
| ストリーミング中にコネクターがスキップする操作タイプをコンマで区切ったリスト。以下のタイプの操作をスキップするようにコネクターを設定することができます。
デフォルトでは、省略操作のみがスキップされます。 | |
| デフォルト値なし |
シグナルをコネクターへの送信に使用されるデータコレクションの完全修飾名 。このプロパティーを Oracle プラグインデータベース (PDB) で使用する場合、その値にはルートデータベースの名前を設定します。 | |
| source | コネクターに対して有効な信号チャネル名のリスト。デフォルトでは、以下のチャネルが利用可能です。
| |
| デフォルトなし | コネクターに対して有効になっている通知チャネル名のリスト。デフォルトでは、以下のチャネルが利用可能です。
| |
|
| 増分スナップショットのチャンクの実行中にコネクターがメモリーを取得して読み取る行の最大数。スナップショットは、サイズが大きいスナップショットの場合にはクエリーが少なくなるため、チャンクサイズを増やすと効率が上がります。ただし、チャンクサイズが大きい場合には、スナップショットデータのバッファーにより多くのメモリーが必要になります。チャンクサイズは、環境で最適なパフォーマンスを発揮できる値に、調整します。 | |
|
|
増分スナップショットによってキャプチャーされ、ストリーミングの再開後に再キャプチャーされる可能性のあるイベントを重複排除するために、コネクターが増分スナップショット中に使用するウォーターマークメカニズムを指定します。
| |
|
|
データ変更、スキーマ変更、トランザクション、ハートビートイベントなどのトピック名を決定するために使用する TopicNamingStrategy クラスの名前。デフォルトは | |
|
|
トピック名の区切り文字を指定します。デフォルトは | |
|
| トピック名を保持するために使用されるサイズ (bounded concurrent hash map)。このキャッシュは、与えられたデータコレクションに対応するトピック名を決定するのに役立つ。 | |
|
|
コネクターがハートビートメッセージを送信するトピックの名前を制御します。トピック名のパターンは、 | |
|
|
コネクターがトランザクションのメタデータメッセージを送信するトピックの名前を制御します。トピック名のパターンは、 | |
|
| 初期スナップショットを実行するときにコネクターが使用するスレッドの数を指定します。並列初期スナップショットを有効にするには、プロパティーを 1 より大きい値に設定します。並列初期スナップショットでは、コネクターは複数のテーブルを同時に処理します。 重要 並列初期スナップショットはテクノロジープレビュー機能のみとなっています。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。 | |
|
<oracle-property-snapshot-database-errors-max-retries, |
|
データベースエラーが発生したときにテーブルのスナップショットを再試行する回数を指定します。この設定プロパティーは現在、 |
|
|
コンテキスト情報を提供するメタデータを追加して、MBean オブジェクト名をカスタマイズするタグを定義します。キーと値のペアのコンマ区切りリストを指定します。各キーは MBean オブジェクト名のタグを表し、対応する値はキーの値を表します。たとえば、 コネクターは、指定されたタグを基本 MBean オブジェクト名に追加します。タグは、メトリクスデータを整理および分類するのに役立ちます。特定のアプリケーションインスタンス、環境、リージョン、バージョンなどを識別するためのタグを定義できます。詳細は、カスタマイズされた MBean 名 を参照してください。 | |
|
|
接続エラーなど、再試行可能なエラーが発生する操作の後に、コネクターがどのように応答するかを指定します。
| |
|
| クエリーの実行を待機する時間 (ミリ秒単位)。デフォルトは 600 秒 (600,000 ミリ秒) です。ゼロは制限がないことを意味します。 |
Debezium Oracle コネクターデータベーススキーマ履歴の設定プロパティー
Debezium には、コネクターがスキーマ履歴トピックと対話する方法を制御する schema.history.internal.* プロパティーのセットが含まれています。
以下の表は、Debezium コネクターを設定するための schema.history.internal プロパティーを説明しています。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし | コネクターがデータベーススキーマの履歴を保存する Kafka トピックの完全名。 | |
| デフォルトなし | Kafka クラスターへの最初の接続を確立するためにコネクターが使用するホストとポートのペアのリスト。このコネクションは、コネクターによって以前に保存されたデータベーススキーマ履歴の取得や、ソースデータベースから読み取られる各 DDL ステートメントの書き込みに使用されます。各ペアは、Kafka Connect プロセスによって使用される同じ Kafka クラスターを示す必要があります。 | |
|
| 永続化されたデータのポーリングが行われている間にコネクターが起動/回復を待つ最大時間 (ミリ秒単位) を指定する整数値。デフォルトは 100 ミリ秒です。 | |
|
| Kafka 管理クライアントを使用してクラスター情報を取得する際に、コネクターが待機すべき最大ミリ秒数を指定する整数値です。 | |
|
| Kafka 管理クライアントを使用して kafka 履歴トピックを作成する間、コネクターが待機する最大ミリ秒数を指定する整数値。 | |
|
|
エラーでコネクターのリカバリーが失敗する前に、コネクターが永続化された履歴データの読み取りを試行する最大回数。データが受信されなかった場合に最大待機する時間は、 | |
|
|
コネクターが不正または不明なデータベースのステートメントを無視するかどうか、または人が問題を修正するために処理を停止するかどうかを指定するブール値。安全なデフォルトは | |
|
|
コネクターがスキーマまたはデータベース内のすべてのテーブルからスキーマ構造を記録するか、キャプチャー対象に指定されたテーブルのみからスキーマ構造を記録するかを指定するブール値。
| |
|
|
コネクターがデータベースインスタンス内のすべての論理データベースのスキーマ構造を記録するかどうかを指定するブール値。
|
パススルー Oracle コネクター設定プロパティー
コネクターは pass-through プロパティーをサポートしており、これにより Debezium は Apache Kafka プロデューサーとコンシューマーの動作を微調整するためのカスタム設定オプションを指定できます。Kafka プロデューサーとコンシューマーの全設定プロパティーの詳細は、Kafka ドキュメント を参照してください。
プロデューサーとコンシューマーのクライアントがスキーマ履歴トピックと対話する方法を設定するための Pass-through プロパティー
Debezium は、データベーススキーマ履歴トピックへのスキーマ変更を記述するために Apache Kafka プロデューサーに依存しています。同様に、コネクターが起動すると、データベーススキーマ履歴トピックから読み取る Kafka コンシューマーに依存します。schema.history.internal.producer.* および schema.history.internal.consumer.* 接頭辞で始まるパススルー設定プロパティーのセットに値を割り当てて、Kafka プロデューサーおよびコンシューマークライアントの設定を定義します。パススループロデューサーおよびコンシューマーデータベーススキーマ履歴プロパティーは、以下の例のように Kafka ブローカーとのこれらのクライアントの接続をセキュアにする方法など、さまざまな動作を制御します。
Debezium は、プロパティーを Kafka クライアントに渡す前に、プロパティー名から接頭辞を削除します。
Kafka プロデューサー設定プロパティー と Kafka コンシューマー設定プロパティー の詳細は、Apache Kafka ドキュメントを参照してください。
Oracle コネクターが Kafka シグナリングトピックと対話する方法を設定するためのパススループロパティー
Debezium は、コネクターが Kafka シグナルトピックと対話する方法を制御する signal.* プロパティーのセットを提供します。
以下の表は、Kafka signal プロパティーを説明しています。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| <topic.prefix>-signal | コネクターがアドホックシグナルについて監視する Kafka トピックの名前。 注記 トピックの自動作成 が無効になっている場合は、必要なシグナリングトピックを手動で作成する必要があります。シグナルの順序を維持するには、シグナルトピックが必要です。シグナリングトピックには単一のパーティションが必要です。 | |
| kafka-signal | Kafka コンシューマーによって使用されるグループ ID の名前。 | |
| デフォルトなし | コネクターが Kafka クラスターへの初期接続を確立するために使用するホストとポートのペアのリスト。各ペアは、Debezium Kafka Connect プロセスによって使用される Kafka クラスターを参照します。 | |
|
| コネクターが信号をポーリングするときに待機する最大ミリ秒数を指定する整数値。 | |
|
| Kafka コンシューマーがシグナリングトピックからメッセージを読み取った後にオフセットコミットを書き込むかどうかを指定します。このプロパティーに割り当てる値によって、コネクターがオフラインのときに、シグナリングトピックが受信する要求をコネクターが処理できるかどうかが決まります。次のいずれかの設定を選択します。
|
シグナリングチャネルの Kafka コンシューマークライアントを設定するためのパススループロパティー
Debezium コネクターでは、Kafka コンシューマーのパススルー設定が可能です。パススルーシグナルのプロパティーは、接頭辞 signals.consumer.* で始まります。たとえば、コネクターは signal.consumer.security.protocol=SSL などのプロパティーを Kafka コンシューマーに渡します。
Debezium は、プロパティーを Kafka シグナルコンシューマーに渡す前に、プロパティーから接頭辞を削除します。
Oracle コネクター sink 通知チャネルを設定するためのパススループロパティー
次の表では、Debezium sink notification チャネルの設定に使用できるプロパティーについて説明します。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし |
Debezium から通知を受信するトピックの名前。このプロパティーは、有効な通知チャネルの 1 つとして |
Debezium コネクターのパススルーデータベースドライバー設定プロパティー
Debezium コネクターでは、データベースドライバーのパススルー設定が可能です。パススルーデータベースプロパティーは接頭辞 driver.* で始まります。たとえば、コネクターは driver.foobar=false などのプロパティーを JDBC URL に渡します。
Debezium は、プロパティーをデータベースドライバーに渡す前に、プロパティーから接頭辞を削除します。
2.5.7. Debezium Oracle コネクターのパフォーマンスの監視
Debezium Oracle コネクターは、Apache Zookeeper、Apache Kafka、および Kafka Connect に含まれる JMX メトリクスの組み込みサポートに加えて、3 種類のメトリクスを提供します。
- スナップショットの実行時にコネクターを監視するための、スナップショットメトリクス。
- 変更イベントの処理時にコネクターを監視するための、ストリーミングメトリクス。
- コネクターのスキーマ履歴の状態を監視するための、スキーマ履歴メトリクス。
JMX 経由でこれらのメトリクスを公開する方法の詳細は、監視に関するドキュメント を参照してください。
2.5.7.1. Oracle コネクタースナップショットおよびストリーミング MBean オブジェクトのカスタマイズされた名前
Debezium コネクターは、コネクターの MBean 名を介してメトリクスを公開します。これらのメトリクスは各コネクターインスタンスに固有であり、コネクターのスナップショット、ストリーミング、およびスキーマ履歴プロセスの動作に関するデータを提供します。
デフォルトでは、正しく設定されたコネクターをデプロイすると、Debezium はさまざまなコネクターメトリクスごとに一意の MBean 名を生成します。コネクタープロセスのメトリクスを表示するには、MBean を監視するように可観測性スタックを設定します。ただし、これらのデフォルトの MBean 名はコネクター設定に依存しており、設定の変更によって MBean 名が変更される場合があります。MBean 名を変更すると、コネクターインスタンスと MBean 間のリンクが切断され、監視アクティビティーが中断されます。このシナリオでは、監視を再開するには、新しい MBean 名を使用するように監視スタックを再設定する必要があります。
MBean 名の変更が原因で監視が中断されないように、カスタムメトリクスタグを設定できます。カスタムメトリクスを設定するには、コネクター設定に custom.metric.tags プロパティーを追加します。このプロパティーは、各キーが MBean オブジェクト名のタグを表し、対応する値がそのタグの値を表すキーと値のペアを受け入れます。たとえば、k1=v1,k2=v2 です。Debezium は、指定されたタグをコネクターの MBean 名に追加します。
コネクターの custom.metric.tags プロパティーを設定した後、指定されたタグに関連付けられたメトリクスを取得するように監視スタックを設定できます。可観測性スタックは、変更可能な MBean 名ではなく、指定されたタグを使用してコネクターを一意に識別します。その後、Debezium が MBean 名の構築方法を再定義したり、コネクター設定の topic.prefix が変更されたりしても、メトリクススクレイプタスクは指定されたタグパターンを使用してコネクターを識別するため、メトリクスの収集は中断されません。
カスタムタグを使用するさらなる利点は、データパイプラインのアーキテクチャーを反映するタグを使用できるため、運用上のニーズに合った方法でメトリクスを整理できることです。たとえば、コネクターアクティビティーのタイプ、アプリケーションコンテキスト、またはデータソースを宣言する値を持つタグを指定できます (例: db1-streaming-for-application-abc)。複数のキーと値のペアを指定すると、指定されたすべてのペアがコネクターの MBean 名に追加されます。
次の例は、タグがデフォルトの MBean 名を変更する方法を示しています。
例2.39 カスタムタグがコネクター MBean 名を変更する方法
デフォルトでは、Oracle コネクターはストリーミングメトリクスに次の MBean 名を使用します。
debezium.oracle:type=connector-metrics,context=streaming,server=<topic.prefix>
debezium.oracle:type=connector-metrics,context=streaming,server=<topic.prefix>
custom.metric.tags の値を database=salesdb-streaming,table=inventory に設定すると、Debezium は次のカスタム MBean 名を生成します。
debezium.oracle:type=connector-metrics,context=streaming,server=<topic.prefix>,database=salesdb-streaming,table=inventory
debezium.oracle:type=connector-metrics,context=streaming,server=<topic.prefix>,database=salesdb-streaming,table=inventory2.5.7.2. Debezium Oracle コネクターのスナップショットメトリクス
MBean は debezium.oracle:type=connector-metrics,context=snapshot,server=<topic.prefix> です。
スナップショット操作がアクティブでない場合や、最後のコネクターの起動後にスナップショットの作成が発生した場合に、スナップショットメトリクスは公開されません。
次の表に、使用可能なスナップショットメトリクスを示します。
| 属性 | タイプ | 説明 |
|---|---|---|
|
| コネクターが読み取りした最後のスナップショットイベント。 | |
|
| コネクターが最新のイベントを読み取りおよび処理してからの経過時間 (ミリ秒単位)。 | |
|
| 前回の開始またはリセット以降にコネクターで確認されたイベントの合計数。 | |
|
| コネクターに設定された include/exclude リストのフィルタリングルールによってフィルターされたイベントの数。 | |
|
| コネクターによって取得されるテーブルのリスト。 | |
|
| snapshotter とメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの長さ。 | |
|
| snapshotter とメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの空き容量。 | |
|
| スナップショットに含まれているテーブルの合計数。 | |
|
| スナップショットによってまだコピーされていないテーブルの数。 | |
|
| スナップショットが起動されたかどうか。 | |
|
| スナップショットが一時停止されたかどうか。 | |
|
| スナップショットが中断されたかどうか。 | |
|
| スナップショットが完了したかどうか。 | |
|
| スナップショットが完了したかどうかに関わらず、これまでスナップショットにかかった時間 (秒単位)。スナップショットが一時停止された時間も含まれます。 | |
|
| スナップショットが一時停止された合計秒数。スナップショットが数回一時停止された場合は、一時停止時間が加算されます。 | |
|
| スナップショットの各テーブルに対してスキャンされる行数が含まれるマップ。テーブルは、処理中に増分がマップに追加されます。スキャンされた 10,000 行ごとに、テーブルの完成時に更新されます。 | |
|
|
キューの最大バッファー (バイト単位)。このメトリクスは | |
|
| キュー内のレコードの現在の容量 (バイト単位)。 |
コネクターは、増分スナップショットの実行時に、以下の追加のスナップショットメトリクスも提供します。
2.5.7.3. Debezium Oracle コネクターのストリーミングメトリクス
MBean は debezium.oracle:type=connector-metrics,context=streaming,server=<topic.prefix> です。
以下の表は、利用可能なストリーミングメトリクスのリストです。
| 属性 | タイプ | 説明 |
|---|---|---|
|
| コネクターが読み取られた最後のストリーミングイベント。 | |
|
| コネクターが最新のイベントを読み取りおよび処理してからの経過時間 (ミリ秒単位)。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、ソースデータベースによって報告されたデータ変更イベントの合計数。Debezium が処理するデータ変更ワークロードを表します。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された作成イベントの合計数。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された更新イベントの合計数。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された削除イベントの合計数。 | |
|
| コネクターに設定された include/exclude リストのフィルタリングルールによってフィルターされたイベントの数。 | |
|
| コネクターによって取得されるテーブルのリスト。 | |
|
| ストリーマーとメイン Kafka Connect ループの間でイベントを渡すために使用されるキューの長さ。 | |
|
| ストリーマーとメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの空き容量。 | |
|
| コネクターが現在データベースサーバーに接続されているかどうかを示すフラグ。 | |
|
| 最後の変更イベントのタイムスタンプとそれを処理するコネクターとの間の期間 (ミリ秒単位)。この値には、データベースサーバーとコネクターが実行されているマシンのクロックの差が組み込まれます。 | |
|
| コミットされた処理済みトランザクションの数。 | |
|
| 最後に受信したイベントの位置。 | |
|
| 最後に処理されたトランザクションのトランザクション識別子。 | |
|
|
キューの最大バッファー (バイト単位)。このメトリクスは | |
|
| キュー内のレコードの現在の容量 (バイト単位)。 |
Debezium Oracle コネクターは、以下のストリーミングメトリクスも追加で提供します。
| 属性 | タイプ | 説明 |
|---|---|---|
|
| 処理された最新のシステム変更番号です。 | |
|
| トランザクションバッファー内の最も古いシステム変更番号。 | |
|
|
最も古いシステム変更番号の経過時間 (ミリ秒単位)。バッファーが空の場合、値は | |
|
| トランザクションバッファーからの最後のコミットされたシステム変更番号。 | |
|
| 現在、コネクターのオフセットに書き込まれているシステム変更番号。 | |
|
| 現在採掘されているログファイルの配列。 | |
|
| 任意の LogMiner セッションに指定されたログの最小数です。 | |
|
| 任意の LogMiner セッションに指定されたログの最大数。 | |
|
|
| |
|
| 最終日について、データベースがログスイッチを実行した回数。 | |
|
| 最後の LogMiner セッションクエリーで確認される DML 操作の数。 | |
|
| 単一の LogMiner セッションクエリーの処理中に確認される DML 操作の最大数。 | |
|
| 確認された DML 操作の合計数。 | |
|
| 実行された LogMiner セッションクエリー (別名バッチ) の合計数。 | |
|
| 最後の LogMiner セッションクエリーのフェッチ時間 (ミリ秒単位)。 | |
|
| 任意の LogMiner セッションクエリーのフェッチの最大時間 (ミリ秒単位)。 | |
|
| 最後の LogMiner クエリーバッチ処理の時間 (ミリ秒単位)。 | |
|
| DML イベント SQL ステートメントの解析に費やした時間 (ミリ秒単位)。 | |
|
| 最後の LogMiner セッションを開始する期間 (ミリ秒単位)。 | |
|
| LogMiner セッションを開始する最長期間 (ミリ秒単位)。 | |
|
| コネクターが LogMiner セッションを開始するのに費やす合計期間 (ミリ秒単位)。 | |
|
| 単一の LogMiner セッションからの結果を処理するのに費やされた最小時間 (ミリ秒単位)。 | |
|
| 単一の LogMiner セッションからの結果を処理するのに費やされた最大時間 (ミリ秒単位)。 | |
|
| LogMiner セッションからの結果を処理するのに費やされた合計時間 (ミリ秒単位)。 | |
|
| ログマイニングビューからの処理する次の行を取得する JDBC ドライバーによって費やされた合計期間 (ミリ秒単位)。 | |
|
| すべてのセッションでログマイニングビューから処理される行の合計数。 | |
|
| データベースのラウンドトリップごとにログのマイニングクエリーによって取得されるエントリーの数。 | |
|
| ログマイニングビューから結果の別のバッチを取得する前にコネクターがスリープ状態になる期間 (ミリ秒単位)。 | |
|
| ログマイニングビューから処理される行/秒の最大数。 | |
|
| ログマイニングから処理される行/秒の平均数。 | |
|
| 最後のバッチでログマイニングビューから処理された平均行数/秒。 | |
|
| 検出された接続問題の数。 | |
|
|
トランザクションがコミットやロールバックされずにコネクターのインメモリーバッファーに保持されてから破棄されるまでの時間数。詳細は、 | |
|
| トランザクションバッファーの現在のアクティブなトランザクションの数。 | |
|
| トランザクションバッファーのコミットされたトランザクションの数。 | |
|
| トランザクションバッファーのロールバックされたトランザクションの数。 | |
|
| トランザクションバッファーのコミットされた 1 秒あたりのトランザクションの平均数。 | |
|
| トランザクションバッファーに登録された DML 操作の数。 | |
|
| トランザクションログに変更が発生した時刻とそれがトランザクションバッファーに追加された時刻の差 (ミリ秒単位)。 | |
|
| トランザクションログに変更が発生した時刻とそれがトランザクションバッファーに追加された時刻の差の最大値 (ミリ秒単位)。 | |
|
| トランザクションログに変更が発生した時刻とそれがトランザクションバッファーに追加された時刻の差の最小値 (ミリ秒単位)。 | |
|
|
古いためにトランザクションバッファーから削除された、最も新しい放棄されたトランザクション識別子の配列。詳細は、 | |
|
| abandoned transactions リストに含まれる現在のエントリー数。 | |
|
| マイニングされトランザクションバッファーにロールバックされたトランザクション識別子の配列。 | |
|
| 最後のトランザクションバッファーコミット操作の期間 (ミリ秒単位)。 | |
|
| 最長のトランザクションバッファーコミット操作の期間 (ミリ秒単位)。 | |
|
| 検出されたエラーの数。 | |
|
| 検出された警告の数。 | |
|
|
システム変更番号の繰り上げチェックが行われ、変更されなかった回数。高い値は、長時間稼働するトランザクションが進行中で、コネクターのオフセットに最近処理されたシステム変更番号をフラッシュするのを妨げていることを示す場合があります。最適な条件であれば、 | |
|
|
検出されたものの、DDL パーサーで解析できなかった DDL レコードの数です。これは常に、 | |
|
| 現在のマイニングセッションのユーザーグローバルエリア (UGA) のメモリー消費量 (単位: バイト)。 | |
|
| すべてのマイニングセッションでの最大のユーザーグローバルエリア (UGA) のメモリー消費量 (バイト)。 | |
|
| 現在のマイニングセッションのプロセスグローバルエリア (PGA) のメモリー消費量 (単位: バイト)。 | |
|
| 全マイニングセッションのプロセスグローバルエリア (PGA) の最大メモリー消費量 (バイト)。 |
2.5.7.4. Debezium Oracle コネクターのスキーマ履歴メトリクス
MBean は debezium.oracle:type=connector-metrics,context=schema-history,server=<topic.prefix> です。
以下の表は、利用可能なスキーマ履歴メトリクスのリストです。
| 属性 | タイプ | 説明 |
|---|---|---|
|
|
データベーススキーマ履歴の状態を示す | |
|
| リカバリーが開始された時点のエポック秒の時間。 | |
|
| リカバリーフェーズ中に読み取られた変更の数。 | |
|
| リカバリーおよびランタイム中に適用されるスキーマ変更の合計数。 | |
|
| 最後の変更が履歴ストアから復元された時点からの経過時間 (ミリ秒単位)。 | |
|
| 最後の変更が適用された時点からの経過時間 (ミリ秒単位)。 | |
|
| 履歴ストアから復元された最後の変更の文字列表現。 | |
|
| 最後に適用された変更の文字列表現。 |
2.5.8. Oracle コネクターのよくある質問
- Oracle 11g はサポートされますか ?
- Oracle 11g はサポート対象外ですが、ベストエフォートベースで Oracle 11g との後方互換性を確保しています。Red Hat は、コミュニティーを頼りに、Oracle 11g との互換性に関する懸念点を伝え、リグレッションが特定された場合にバグ修正を提供します。
- Oracle LogMiner は非推奨となりましたか ?
- いいえ、Oracle は、Oracle 12c で Oracle LogMiner を使用した継続的なマイニングオプションのみを非推奨にし、Oracle 19c からそのオプションを削除しました。Debezium Oracle コネクターは、このオプションに依存せずに機能するため、新しいバージョンの Oracle で問題なく安全に使用できます。
- オフセットの位置を変更するにはどうすればよいですか ?
Debezium Oracle コネクターは、
scnという名前のフィールドとcommit_scnという別の名前の 2 つの重要な値をオフセットに保持します。scnフィールドは、コネクターが変更をキャプチャーするときに使用する low-watermark の開始位置を表す文字列です。-
コネクターオフセットを含むトピックの名前を見つけます。これは、
offset.storage.topic設定プロパティーとして指定された値に基づいて設定されます。 コネクターの最後のオフセット、格納先のキーを見つけ、そのオフセットの保存に使用するパーティションを特定します。これは、Kafka ブローカーのインストールによって提供される
kafkacatユーティリティースクリプトを使用して実行できます。以下に例を示します。kafkacat -b localhost -C -t my_connect_offsets -f 'Partition(%p) %k %s\n' Partition(11) ["inventory-connector",{"server":"server1"}] {"scn":"324567897", "commit_scn":"324567897: 0x2832343233323:1"}kafkacat -b localhost -C -t my_connect_offsets -f 'Partition(%p) %k %s\n' Partition(11) ["inventory-connector",{"server":"server1"}] {"scn":"324567897", "commit_scn":"324567897: 0x2832343233323:1"}Copy to Clipboard Copied! Toggle word wrap Toggle overflow inventory-connectorのキーは["inventory-connector",{"server":"server1"}]、パーティションは11で、最後のオフセットはキーの後にくるコンテンツです。以前のオフセットに戻すには、コネクターを停止し、次のコマンドを発行する必要があります。
echo '["inventory-connector",{"server":"server1"}]|{"scn":"3245675000","commit_scn":"324567500"}' | \ kafkacat -P -b localhost -t my_connect_offsets -K \| -p 11echo '["inventory-connector",{"server":"server1"}]|{"scn":"3245675000","commit_scn":"324567500"}' | \ kafkacat -P -b localhost -t my_connect_offsets -K \| -p 11Copy to Clipboard Copied! Toggle word wrap Toggle overflow これにより、指定のキーとオフセット値を、
my_connect_offsetsトピックのパーティション11に書き込みます。この例では、コネクターは324567897ではなく SCN3245675000に戻します。
-
コネクターオフセットを含むトピックの名前を見つけます。これは、
- コネクターで、特定のオフセット SCN が含まれるログが見つけられない場合はどうなりますか?
Debezium コネクターは、コネクターオフセットに low-watermark および high-watermark SCN 値を維持します。low-watermark SCN は開始位置を表し、コネクターが正常に起動するために利用可能なオンライン redo または archive ログに存在する必要があります。コネクターがこのオフセット SCN を検出できないと報告した場合は、まだ利用可能なログに SCN が含まれていないため、コネクターが中断した場所から変更をマイニングできないことを示しています。
この場合は、2 つのオプションがあります。1 つ目として、コネクターの履歴トピックとオフセットを削除し、コネクターを再起動して、提案どおりに新しいスナップショットを作成します。こうすることで、すべてのトピックコンシューマーでデータ損失が発生しないようにします。2 つ目として、オフセットを手動で操作し、redo または archive ログで利用可能な位置に SCN を進めます。これにより、古い SCN 値と新しく提供された SCN 値の間で発生した変更がなくなり、トピックに書き込まれなくなります。これは、推奨されません。
- さまざまなマイニングストラテジーの違いは何ですか ?
Debezium Oracle コネクターは、
log.mining.strategyに 3 つのオプションがあります。デフォルトは
redo_in_catalogで、この設定では、ログスイッチが検出されるたびに Oracle データディクショナリーを REDO ログに書き込むようにコネクターに指示されます。このデータディクショナリーは、Oracle LogMiner が redo および archive ログを解析するときにスキーマの変更を効果的に追跡するために必要です。このオプションでは、通常よりも多くのアーカイブログが生成されますが、データ変更のキャプチャーに影響を与えずに、キャプチャーされるテーブルをリアルタイムで操作できます。通常、このオプションはより多くの Oracle データベースメモリーを必要とし、各ログスイッチの後、Oracle LogMiner セッションとプロセスを開始するまでに少し時間がかかります。2 番目のオプション
online_catalogは、データディクショナリーを REDO ログに書き込みません。代わりに、Oracle LogMiner は、テーブルの構造の現在の状態を含むオンラインデータディクショナリーを常に使用します。つまり、テーブルの構造が変更され、オンラインデータディクショナリーと一致しなくなった場合やテーブルの構造が変更された場合は、Oracle LogMiner がテーブルまたは列の名前を解決できなくなります。キャプチャーされるテーブルに対して頻繁にスキーマの変更が適用される場合は、このマイニングストラテジーのオプションを使用しないでください。テーブルのログから変更がすべてキャプチャーされ、コネクターの停止、スキーマの変更適用、コネクターの再起動を行い、テーブルのデータ変更を再開するように、すべてのデータ変更をスキーマの変更でロックステップすることが重要です。このオプションでは、必要な Oracle データベースメモリーが少なくて済み、LogMiner プロセスによってデータディクショナリーをロードまたは準備する必要がないため、通常、Oracle LogMiner セッションの起動ははるかに早くなります。最後のオプションである
hybridは、上記の 2 つのストラテジーの利点を組み合わせ、欠点を取り除きます。このストラテジーはonline_catalogのパフォーマンスとredo_in_catalogのスキーマ追跡の回復力を活用しながら、アーカイブログ生成によるオーバーヘッドとパフォーマンスコストが通常よりも高くならないようにします。このモードではフォールバックモードが利用され、LogMiner がデータベース変更の SQL を再構築できない場合、Debezium コネクターはコネクターによって維持されるメモリー内スキーマモデルに依存して、実行中の SQL を再構築します。このモードは最終的にデフォルトに移行し、今後、唯一の動作モードになる予定です。- LogMiner を使用したハイブリッドマイニングストラテジーには制限がありますか?
-
はい、
log.mining.strategyのハイブリッドモードのストラテジーはまだ開発中であるため、すべてのデータタイプをサポートしていません。現時点でこのモードでは、CLOB、NCLOB、Blob、XML、JSONデータ型に対する操作など、SQL ステートメントを再構築することはできません。つまり、lob.enabledをtrueの値に指定して有効にすると、ハイブリッドストラテジーを使用できなくなり、この組み合わせはサポートされていないためコネクターは起動に失敗します。 - コネクターが AWS での変更のキャプチャーを停止しているように見えるのはなぜですか?
タイムアウト AWS Gateway Load Balancer で 350 秒の修正されたアイドルタイムアウト により、完了までに 350 秒を超える JDBC 呼び出しは無期限にハングする可能性があります。
Oracle LogMiner API の呼び出しが完了するまでに 350 秒以上かかる状況では、タイムアウトが発生し、AWS Gateway Load Balancer がハングアップすることがあります。たとえば、大量のデータを処理する LogMiner セッションと Oracle の定期的なチェックポイントタスクが同時に実行された場合、このようなタイムアウトが発生する可能性があります。
AWS Gateway Load Balancer でタイムアウトが発生しないように、Kafka Connect 環境から root または superuser で次の手順を実行して、キープアライブパケットを有効にします。
ターミナルから、以下のコマンドを実行します。
sysctl -w net.ipv4.tcp_keepalive_time=60
sysctl -w net.ipv4.tcp_keepalive_time=60Copy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/sysctl.confを編集し、以下のように以下の変数の値を設定します。net.ipv4.tcp_keepalive_time=60
net.ipv4.tcp_keepalive_time=60Copy to Clipboard Copied! Toggle word wrap Toggle overflow Oracle コネクターが
database.hostnameではなくdatabase.urlプロパティーを使用するように再設定し、以下の例のように Oracle 接続文字列記述子(ENABLE=broken)を追加します。database.url=jdbc:oracle:thin:username/password!@(DESCRIPTION=(ENABLE=broken)(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(Host=hostname)(Port=port)))(CONNECT_DATA=(SERVICE_NAME=serviceName)))
database.url=jdbc:oracle:thin:username/password!@(DESCRIPTION=(ENABLE=broken)(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(Host=hostname)(Port=port)))(CONNECT_DATA=(SERVICE_NAME=serviceName)))Copy to Clipboard Copied! Toggle word wrap Toggle overflow
前述の手順では、TCP ネットワークスタックが 60 秒ごとにキープアライブパケットを送信するように設定します。その結果、LogMiner API への JDBC 呼び出しが完了するまで 350 秒を超える時間がかかる場合、AWS Gateway ロードバランサーはタイムアウトしません。これにより、コネクターはデータベースのトランザクションログから変更の読み取りを続行します。
- ORA-01555 の原因と対処方法は?
Debezium Oracle コネクターは、最初のスナップショットフェーズの実行時にフラッシュバッククエリーを使用します。フラッシュバッククエリーは、データベースの
UNDO_RETENTIONデータベースパラメーターによって維持されるフラッシュバック領域に依存する特別なタイプのクエリーで、指定の SCN での特定の時点におけるテーブルの内容に基づいてクエリーの結果を返します。デフォルトでは、Oracle は通常、データベース管理者が増減の調節をしない限り、undo または flashback 領域を約 15 分間保持します。大きなテーブルをキャプチャーする設定の場合、最初のスナップショットを実行するのに 15 分以上かかるか、設定したUNDO_RETENTIONの期間分かかる場合があり、最終的に次の例外が発生します。ORA-01555: snapshot too old: rollback segment number 12345 with name "_SYSSMU11_1234567890$" too small
ORA-01555: snapshot too old: rollback segment number 12345 with name "_SYSSMU11_1234567890$" too smallCopy to Clipboard Copied! Toggle word wrap Toggle overflow この例外を扱う方法として、まずデータベース管理者と連携し、
UNDO_RETENTIONデータベースパラメーターを一時的に増やすことができるかどうかを確認します。Oracle データベースの再起動は必要ありません。したがって、データベースの可用性に影響を与えることなく、オンラインで実行できます。ただし、これを変更しても、テーブルスペースに、必要な UNDO データを格納する領域が十分にない場合、上記の例外か、「snapshot too old」の例外が発生する可能性があります。この例外を処理する 2 つ目の方法として、
snapshot.modeをschema_onlyに設定し、最初のスナップショットではなく、増分スナップショットに依存します。増分スナップショットはフラッシュバッククエリーに依存しないため、ORA-01555 例外の対象ではありません。- ORA-04036 の原因と対処方法は?
データベースの変更が頻繁に発生すると、Debezium Oracle コネクターは ORA-04036 例外を報告する可能性があります。Oracle LogMiner セッションが開始され、ログの切り替えが検出されるまで再利用されます。セッションは、Oracle LogMiner で最適なパフォーマンス使用率を達成できるように再利用されますが、マイニングセッションが長時間実行されると、PGA メモリーが過剰に使用され、最終的に次のような例外が発生する可能性があります。
ORA-04036: PGA memory used by the instance exceeds PGA_AGGREGATE_LIMIT
ORA-04036: PGA memory used by the instance exceeds PGA_AGGREGATE_LIMITCopy to Clipboard Copied! Toggle word wrap Toggle overflow この例外は、Oracle が redo ログを切り替える頻度、または Debezium Oracle コネクターがマイニングセッションを再利用できる期間を指定することで回避できます。Debezium Oracle コネクターには、設定オプション
log.mining.session.max.msがあり、現在の Oracle LogMiner セッションを終了して新しいセッションを開始する前に再利用できる期間を制御します。これにより、データベースで許可されている PGA メモリーを超えることなく、データベースリソースを管理できます。- ORA-01882 の原因と対処方法は?
Debezium Oracle コネクターは、Oracle データベースへの接続時に以下の例外を報告する可能性があります。
ORA-01882: timezone region not found
ORA-01882: timezone region not foundCopy to Clipboard Copied! Toggle word wrap Toggle overflow これは、JDBC ドライバーでタイムゾーン情報を正しく解決できない場合に発生します。このドライバー関連の問題を解決するには、地域を使用してタイムゾーンの詳細を解決しないようにドライバーに指示する必要があります。これには、
driver.oracle.jdbc.timezoneAsRegion=falseを使用してドライバーパススループロパティーを指定します。- ORA-25191 の原因と対処方法は?
Debezium Oracle コネクターは、インデックス設定テーブル (IOT) が Oracle LogMiner でサポートされていないため、IOT を自動的に無視します。ただし、ORA-25191 例外が出力された場合は、そのようなマッピングに固有のまれなケースが原因である可能性があり、自動的に除外するには追加のルールが必要になる場合があります。ORA-25191 例外の例を以下に示します。
ORA-25191: cannot reference overflow table of an index-organized table
ORA-25191: cannot reference overflow table of an index-organized tableCopy to Clipboard Copied! Toggle word wrap Toggle overflow ORA-25191 例外が出力された場合は、テーブルとそのマッピング、他の親テーブルに関連する内容など、Jira で問題を起票してください。回避策として、包含/除外設定オプションを調整して、コネクターがそのようなテーブルにアクセスできないようにします。
- SAX feature external-general-entities not supported を解決する方法
-
Debezium 2.4 では Oracle の
XMLTYPE列タイプのサポートが導入されました。この機能をサポートするには、Oraclexdbおよびxmlparserv2の依存関係が必要です。
Oracle のxmlparserv2依存関係は SAX ベースのパーサーを実装しており、ランタイムがクラスパス上の他の実装ではなくこの実装を検出して使用すると、このエラーが発生します。通常使用する SAX 実装を具体的に制御するには、特定の引数を指定して JVM を起動する必要があります。
次の JVM 引数を指定するとこのエラーは発生せず、Oracle コネクターが正常に起動します。
-Djavax.xml.parsers.SAXParserFactory=com.sun.org.apache.xerces.internal.jaxp.SAXParserFactoryImpl
-Djavax.xml.parsers.SAXParserFactory=com.sun.org.apache.xerces.internal.jaxp.SAXParserFactoryImpl2.6. PostgreSQL の Debezium コネクター
Debezium の PostgreSQL コネクターは、PostgreSQL データベースのスキーマで行レベルの変更をキャプチャーします。このコネクターと互換性のある PostgreSQL のバージョンについては、Debezium Supported Configurations page を参照してください。
PostgreSQL サーバーまたはクラスターに初めて接続すると、コネクターはすべてのスキーマの整合性スナップショットを作成します。スナップショットの完了後、コネクターはデータベースのコンテンツを挿入、更新、および削除する行レベルの変更を継続的にキャプチャーします。これらの行レベルの変更は、PostgreSQL データベースにコミットされています。コネクターはデータの変更イベントレコードを生成し、それらを Kafka トピックにストリーミングします。各テーブルのデフォルトの動作では、コネクターは生成されたすべてのイベントをそのテーブルの個別の Kafka トピックにストリーミングします。アプリケーションとサービスは、そのトピックからのデータ変更イベントレコードを使用します。
Debezium PostgreSQL コネクターを使用するための情報および手順は、以下のように設定されています。
- 「Debezium PostgreSQL コネクターの概要」
- 「Debezium PostgreSQL コネクターの仕組み」
- 「Debezium PostgreSQL コネクターのデータ変更イベントの説明」
- 「Debezium PostgreSQL コネクターによるデータ型のマッピング方法」
- 「Debezium コネクターを実行するための PostgreSQL の設定」
- カスタムコンバーター
- 「Debezium PostgreSQL コネクターのデプロイメント」
- 「Debezium PostgreSQL コネクターのパフォーマンスの監視」
- 「Debezium PostgreSQL コネクターによる障害および問題の処理方法」
2.6.1. Debezium PostgreSQL コネクターの概要
PostgreSQL の 論理デコード 機能は、バージョン 9.4 で導入されました。これは、トランザクションログにコミットされた変更の抽出を可能にし、出力プラグイン を用いてユーザーフレンドリーな方法でこれらの変更の処理を可能にするメカニズムです。出力プラグインを使用すると、クライアントは変更を使用できます。
PostgreSQL コネクターには、連携してデータベースの変更を読み取りおよび処理する 2 つの主要部分が含まれています。
-
pgoutputは、PostgreSQL 10+ の標準的な論理デコード出力プラグインです。これは、この Debezium リリースでサポートされている唯一の論理デコード出力プラグインです。このプラグインは PostgreSQL コミュニティーにより維持され、PostgreSQL 自体によって 論理レプリケーション に使用されます。このプラグインは常に存在するため、追加のライブラリーをインストールする必要はありません。Debezium コネクターは、raw レプリケーションイベントストリームを直接変更イベントに変換します。 - PostgreSQL の ストリーミングレプリケーションプロトコル および PostgreSQL JDBC ドライバー を使用して、論理デコード出力プラグインによって生成された変更を読み取る Java コード (実際の Kafka Connect コネクター)。
コネクターは、キャプチャーされた各行レベルの挿入、更新、および削除操作の 変更イベント を生成し、個別の Kafka トピックの各テーブルに対する変更イベントレコードを送信します。クライアントアプリケーションは、対象のデータベーステーブルに対応する Kafka トピックを読み取り、これらのトピックから受け取るすべての行レベルイベントに対応できます。
通常、PostgreSQL は一定期間後にログ先行書き込み (WAL、write-ahead log) をパージします。つまり、コネクターにはデータベースに加えられたすべての変更の完全な履歴はありません。そのため、PostgreSQL コネクターが最初に特定の PostgreSQL データベースに接続すると、データベーススキーマごとに 整合性スナップショット を実行して起動します。コネクターは、スナップショットの完成後に、スナップショットが作成された正確な時点から変更のストリーミングを続行します。これにより、コネクターはすべてのデータの整合性のあるビューで開始し、スナップショットの作成中に加えられた変更は省略されません。
コネクターはフォールトトラレントです。コネクターは変更を読み取り、イベントを生成するため、各イベントの WAL の位置を記録します。コネクターが何らかの理由で停止した場合 (通信障害、ネットワークの問題、クラッシュなど)、コネクターは再起動後に最後に停止した場所から WAL の読み取りを続行します。これにはスナップショットが含まれます。スナップショット中にコネクターが停止した場合、コネクターは再起動時に新しいスナップショットを開始します。
コネクターは PostgreSQL の論理デコード機能に依存および反映します。これには、以下の制限があります。
- 論理デコードは DDL の変更をサポートしません。よって、コネクターは DDL の変更イベントをコンシューマーに報告できません。
-
論理デコードのレプリケーションスロットは、
プライマリーサーバーでのみサポートされます。PostgreSQL サーバーのクラスターがある場合、コネクターはアクティブなprimaryサーバーでのみ実行できます。hotまたはwarmスタンバイのレプリカでは実行できません。primaryサーバーが失敗するか降格されると、コネクターは停止します。primaryサーバーの回復後に、コネクターを再起動できます。別の PostgreSQL サーバーがprimaryに昇格された場合は、コネクターの設定を調整してからコネクターを再起動します。 - 論理デコードレプリケーションスロットはコミット後ではなくコミット中に変更を公開するため、望ましくない副次的な影響が発生する可能性があります。クライアントが矛盾した状態を観察する可能性がある主なシナリオは 2 つあります。まず、レプリケーションが完了する前にマスターが停止した場合に、コミットされていない変更を公開します。2 番目は、複製中のため一時的に読み取れない変更 (つまり、書き込み後の読み取りの一貫性) を公開します。たとえば、EmbeddedEngine コンシューマーは、作成された行の通知を受信しますが、トランザクションでは読み取ることができません。
さらに、pgoutput 論理デコード出力プラグインは生成された列の値をキャプチャーしないため、これらの列のデータはコネクターの出力から欠落することになります。
問題が発生した場合の動作 では、問題の発生時にコネクターがどのように対応するかが説明されています。
Debezium は現在、UTF-8 文字エンコーディングのデータベースのみをサポートしています。1 バイト文字エンコーディングでは、拡張 ASCII コード文字が含まれる文字列を正しく処理できません。
2.6.2. Debezium PostgreSQL コネクターの仕組み
Debezium PostgreSQL コネクターを最適に設定および実行するには、コネクターによるスナップショットの実行方法、変更イベントのストリーム方法、Kafka トピック名の決定方法、およびメタデータの使用方法を理解すると便利です。
詳細は以下を参照してください。
2.6.2.1. PostgreSQL コネクターのセキュリティー
Debezium コネクターを使用して PostgreSQL データベースから変更をストリーミングするには、コネクターは特定の権限がデータベースで必要になります。必要な権限を付与する方法の 1 つとして、ユーザーに superuser 権限を付与する方法がありますが、これにより PostgreSQL データが不正アクセスによって公開される可能性ああります。Debezium ユーザーに過剰な権限を付与するのではなく、特定の特権を付与する専用の Debezium レプリケーションユーザーを作成することが推奨されます。
Debezium PostgreSQL ユーザーの権限設定の詳細は、パーミッションの設定 を参照してください。PostgreSQL の論理レプリケーションセキュリティーの詳細は、PostgreSQL のドキュメント を参照してください。
2.6.2.2. Debezium PostgreSQL コネクターによるデータベーススナップショットの実行方法
ほとんどの PostgreSQL サーバーは、WAL セグメントにデータベースの完全な履歴を保持しないように設定されています。つまり、PostgreSQL コネクターは WAL のみを読み取ってもデータベースの履歴全体を確認できません。そのため、コネクターが最初に起動すると、データベースの最初の 整合性スナップショット が実行されます。
スナップショットの詳細は、以下のセクションを参照してください。
初期スナップショットのデフォルトのワークフロー動作
スナップショットを実行するためのデフォルト動作は、以下の手順で構成されます。この動作を変更するには、snapshot.mode コネクター設定プロパティー を initial 以外の値に設定します。
-
SERIALIZABLE、READ ONLY、DEFERRABLE 分離レベルでトランザクションを開始し、このトランザクションでの後続の読み取りがデータの単一バージョンに対して行われるようにします。他のクライアントによる後続の
INSERT、UPDATE、およびDELETE操作によるデータの変更は、このトランザクションでは確認できません。 - サーバーのトランザクションログの現在の位置を読み取ります。
-
データベーステーブルとスキーマをスキャンし、各行の
READイベントを生成し、そのイベントを適切なテーブル固有の Kafka トピックに書き込みます。 - トランザクションをコミットします。
- コネクターオフセットにスナップショットの正常な完了を記録します。
コネクターに障害が発生した場合、コネクターのリバランスが発生した場合、または 1 の後で 5 の完了前に停止した場合、コネクターは再起動後に新しいスナップショットを開始します。コネクターが最初のスナップショットを完了すると、PostgreSQL コネクターは手順 2 で読み取る位置からストリーミングを続行します。これにより、コネクターが更新を見逃さないようします。何らかの理由でコネクターが再び停止した場合、コネクターは再起動後に最後に停止した位置から変更のストリーミングを続行します。
| オプション | 説明 |
|---|---|
|
|
コネクターは起動時に常にスナップショットを実行します。スナップショットが完了した後、コネクターは上記の手順の 3. から変更のストリーミングを続行します。このモードは、以下のような状況で使用すると便利です。
|
|
| Kafka オフセットトピックが存在しない場合、コネクターはデータベーススナップショットを実行します。データベースのスナップショットが完了すると、Kafka オフセットトピックが書き込まれます。Kafka オフセットトピックに以前保存された LSN がある場合、コネクターはその位置から変更をストリーミングを続行します。 |
|
| コネクターはデータベースのスナップショットを実行し、変更イベントレコードをストリーミングする前に停止します。コネクターが起動していても、停止前にスナップショットを完了しなかった場合、コネクターはスナップショットプロセスを再起動し、スナップショットの完了時に停止します。 |
|
| コネクターはスナップショットを実行しません。コネクターがこのように設定されている場合、起動後は次のように動作します。 Kafka オフセットトピックに以前保存された LSN がある場合、コネクターはその位置から変更をストリーミングを続行します。LSN が保存されていない場合、コネクターは、サーバー上で PostgreSQL 論理レプリケーションスロットが作成された時点から変更のストリーミングを開始します。対象のすべてのデータが WAL に反映されている場合にのみ、このスナップショットモードを使用します。 |
|
|
非推奨。 |
|
| コネクターが起動した後、次のいずれかの状況を検出した場合にのみスナップショットが実行されます。
|
2.6.2.3. アドホックスナップショット
デフォルトでは、コネクターは初回スナップショット操作の開始後にのみ実行されます。通常の状況では、この最初のスナップショットが作成されると、コネクターではスナップショットプロセスは繰り返し処理されません。コネクターがキャプチャーする今後の変更イベントデータはストリーミングプロセス経由でのみ行われます。
ただし、場合によっては、最初のスナップショット中にコネクターを取得したデータが古くなったり、失われたり、または不完全となったり可能性があります。テーブルデータを再キャプチャーするメカニズムを提供するため、Debezium にはアドホックスナップショットを実行するオプションがあります。Debezium 環境で次のいずれかの変更が発生したら、アドホックスナップショットを実行することを推奨します。
- コネクター設定は、異なるテーブルセットをキャプチャーするように変更されます。
- Kafka トピックを削除して、再構築する必要があります。
- 設定エラーや他の問題が原因で、データの破損が発生します。
アドホックと呼ばれるスナップショット を開始することで、以前にスナップショットをキャプチャーしたテーブルのスナップショットを再実行できます。アドホックスナップショットには、シグナルテーブル を使用する必要があります。シグナルリクエストを Debezium シグナルテーブルに送信して、アドホックスナップショットを開始します。
既存のテーブルのアドホックスナップショットを開始すると、コネクターはテーブルにすでに存在するトピックにコンテンツを追加します。既存のトピックが削除された場合には、トピックの自動作成 が有効になっているのであれば、Debezium は自動的にトピックを作成できます。
アドホックのスナップショットシグナルは、スナップショットに追加するテーブルを指定します。スナップショットは、データベースの内容全体をキャプチャーしたり、データベース内のテーブルのサブセットのみをキャプチャーしたりできます。また、スナップショットは、データベース内のテーブルの内容のサブセットをキャプチャできます。
execute-snapshot メッセージをシグナルテーブルに送信してキャプチャーするテーブルを指定します。execute-snapshot シグナルのタイプを incremental または blocking に設定し、スナップショットに含めるテーブルの名前を次の表に示すように指定します。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプを指定します。 |
|
| 該当なし |
スナップショットに含めるテーブルの完全修飾名に一致する正規表現を含む配列。 |
|
| 該当なし |
コネクターがスナップショットに含めるレコードのサブセットを決定するために評価する追加条件のセットを指定する、オプションの配列。
|
|
| 該当なし | スナップショット処理中にコネクターがテーブルのプライマリーキーとして使用する列名を指定するオプションの文字列。 |
アドホック増分スナップショットのトリガー
アドホック増分スナップショットを開始するには、execute-snapshot シグナルタイプのエントリーをシグナリングテーブルに追加するか、シグナルメッセージを Kafka シグナリングトピックに送信します。コネクターがメッセージを処理した後に、スナップショット操作を開始します。スナップショットプロセスは、最初と最後のプライマリーキーの値を読み取り、これらの値を各テーブルの開始ポイントおよびエンドポイントとして使用します。テーブルのエントリー数と設定されたチャンクサイズに基づいて、Debezium はテーブルをチャンクに分割し、チャンクごとに 1 度に 1 つずつスナップショットを順番に作成していきます。
詳細は、スナップショットの増分を参照してください。
アドホックブロッキングスナップショットのトリガー
シグナリングテーブルまたはシグナリングトピックに、execute-snapshot シグナルタイプを持つエントリーを追加することによって、アドホックブロッキングスナップショットを開始します。コネクターがメッセージを処理した後に、スナップショット操作を開始します。コネクターはストリーミングを一時的に停止し、初期スナップショットの時と同じプロセスに従って、指定されたテーブルのスナップショットを開始します。スナップショットが完了すると、コネクターはストリーミングを再開します。
詳細は、ブロッキングスナップショット を参照してください。
2.6.2.4. 増分スナップショット
スナップショットを柔軟に管理するため、Debezium には 増分スナップショット と呼ばれる補助スナップショットメカニズムが含まれています。増分スナップショットは、Debezium コネクターにシグナルを送信するため の Debezium メカニズムに依存します。
増分スナップショットでは、最初のスナップショットのように、データベースの完全な状態を一度にすべてキャプチャーする代わりに、一連の設定可能なチャンクで各テーブルを段階的にキャプチャーします。スナップショットがキャプチャーするテーブルと、各チャンクのサイズ を指定できます。チャンクのサイズにより、データベース上の各フェッチ操作中にスナップショットで収集される行数が決まります。増分スナップショットのデフォルトのチャンクサイズは 1024 行です。
増分スナップショットが進むと、Debezium はウォーターマークを使用して進捗を追跡し、キャプチャーする各テーブル行のレコードを管理します。この段階的なアプローチでは、標準の初期スナップショットプロセスと比較して、以下の利点があります。
- スナップショットが完了するまで、ストリーミングストリーミングを延期する代わりに、ストリームしたデータキャプチャーと並行して増分スナップショットを実行できます。コネクターはスナップショットプロセス全体で変更ログからのほぼリアルタイムイベントをキャプチャーし続け、他の操作はブロックしません。
- 増分スナップショットの進捗が中断された場合は、データを失うことなく再開できます。プロセスが再開すると、スナップショットは最初からテーブルをキャプチャーするのではなく、停止した時点から開始します。
-
いつでも増分スナップショットを実行し、必要に応じてプロセスを繰り返してデータベースの更新に適合できます。たとえば、コネクター設定を変更してテーブルを
table.include.listプロパティーに追加した後にスナップショットを再実行します。
増分スナップショットプロセス
増分スナップショットを実行する場合には、Debezium は各テーブルをプライマリーキー別に分類して、設定されたチャンクサイズ に基づいてテーブルをチャンクに分割します。チャンクごとに作業し、テーブルの行ごとにチャンクでキャプチャーします。キャプチャーする行ごとに、スナップショットは READ イベントを出力します。そのイベントは、対象となるチャンクのスナップショットを開始する時の行の値を表します。
スナップショットの作成が進むにつれ、他のプロセスがデータベースへのアクセスを継続し、テーブルレコードが変更される可能性があります。このような変更を反映させるように、通常通りに INSERT、UPDATE、DELETE 操作がトランザクションログにコミットされます。同様に、継続中の Debezium ストリーミングプロセスは、これらの変更イベントを検出し、対応する変更イベントレコードを Kafka に出力します。
Debezium を使用してプライマリーキーが同じレコード間での競合を解決する方法
場合によっては、ストリーミングプロセスが出力する UPDATE または DELETE イベントを順番に受信できます。つまり、ストリーミングプロセスは、スナップショットがその行の READ イベントが含まれるチャンクをキャプチャーする前に、テーブルの行を変更するイベントを生成する可能性があります。スナップショットが最終的に対象の行にあった READ イベントを出力すると、その値はすでに置き換えられています。Debezium は、シーケンスが到達する増分スナップショットイベントが正しい論理順序で処理されるように、競合を解決するためにバッファースキームを使用します。スナップショットのイベント間で競合が発生し、ストリームされたイベントが解決されてからでないと、Debezium はイベントのレコードを Kafka に送信しません。
スナップショットウィンドウ
遅れて入ってきた READ イベントと、同じテーブルの行を変更するストリーミングイベント間の競合の解決を容易にするために、Debezium は スナップショットウィンドウ と呼ばれるものを使用します。スナップショットウィンドウは、増分スナップショットが指定のテーブルチャンクのデータをキャプチャーしている途中に、間隔を決定します。チャンクのスナップショットウィンドウを開く前に、Debezium は通常の動作に従い、トランザクションログから直接ターゲットの Kafka トピックにイベントをダウンストリームに出力します。ただし、特定のチャンクのスナップショットが開放された瞬間から終了するまで、Debezium は重複除去のステップを実行して、プライマリーキーが同じイベント間での競合を解決します。
データコレクションごとに、Debezium は 2 種類のイベントを出力し、それらの両方のレコードを単一の宛先 Kafka トピックに保存します。テーブルから直接キャプチャーするスナップショットレコードは、READ 操作として出力されます。その間、ユーザーはデータコレクションのレコードの更新を続け、各コミットを反映するようにトランザクションログが更新されるので、Debezium は変更ごとに UPDATE または DELETE 操作を出力します。
スナップショットウィンドウが開放され、Debezium がスナップショットチャンクの処理を開始すると、スナップショットレコードをメモリーバッファーに提供します。スナップショットウィンドウ中に、バッファー内の READ イベントのプライマリーキーは、受信ストリームイベントのプライマリーキーと比較されます。一致するものが見つからない場合、ストリーミングされたイベントレコードが Kafka に直接送信されます。Debezium が一致を検出すると、バッファーされた READ イベントを破棄し、ストリーミングされたレコードを宛先トピックに書き込みます。これは、ストリーミングされたイベントが静的スナップショットイベントよりも論理的に優先されるためです。チャンクのスナップショットウィンドウが終了すると、バッファーに含まれるのは、関連するトランザクションログイベントが存在しない READ イベントのみです。Debezium は、これらの残りの READ イベントをテーブルの Kafka トピックに出力します。
コネクターは各スナップショットチャンクにプロセスを繰り返します。
現在、増分スナップショットを開始するには、次のいずれかの方法を使用できます。
PostgreSQL の Debezium コネクターでは、増分スナップショットの実行中のスキーマの変更はサポートしません。増分スナップショットの開始 前にスキーマの変更が行われ、シグナルが送信された後にスキーマの変更が行われた場合は、スキーマの変更を正しく処理するために、パススルーの設定オプション database.autosave が conservative に設定されます。
2.6.2.4.1. 増分スナップショットのトリガー
増分スナップショットを開始するには、ソースデータベースのシグナリングテーブルに アドホックスナップショットシグナル を送信します。スナップショットシグナルは SQL INSERT クエリーとして送信します。
Debezium がシグナルテーブルの変更を検出すると、シグナルを読み取り、要求されたスナップショット操作を実行します。
送信するクエリーはスナップショットに追加するテーブルを指定し、必要に応じてスナップショット操作の種類を指定します。Debezium は現在、incremental と blocking のスナップショットタイプをサポートしています。
スナップショットに追加するテーブルを指定するには、テーブルをリストする data-collections 配列またはテーブルの照合に使用する正規表現の配列を指定します。以下に例を示します。
{"data-collections": ["public.MyFirstTable", "public.MySecondTable"]}
増分スナップショットシグナルの data-collections アレイにはデフォルト値がありません。data-collections 配列が空の場合、Debezium は空の配列をアクションが必要ないと解釈し、スナップショットは作成しません。
スナップショットに含めるテーブルの名前にドット (.)、スペース、またはその他の英数字以外の文字が含まれている場合は、テーブル名を二重引用符でエスケープする必要があります。
たとえば、 public スキーマに存在し、My.Table という名前のテーブルを含めるには、"public.\"My.Table\"" の形式を使用します。
前提条件
- ソースデータベースにシグナリングデータコレクションが存在する。
-
シグナルデータコレクションが
signal.data.collectionプロパティーで指定されている。
ソースシグナリングチャネルを使用して増分スナップショットをトリガーする
SQL クエリーを送信し、アドホック増分スナップショット要求をシグナルテーブルに追加します。
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow コマンドの
id、type、およびdataパラメーターの値は、シグナルテーブルのフィールド に対応します。
以下の表では、この例のパラメーターを説明しています。Expand 表2.129 シグナルテーブルに増分スナップショットシグナルを送信する SQL コマンドのフィールドの説明 項目 値 説明 1
schema.debezium_signalソースデータベースにあるシグナルテーブルの完全修飾名を指定します。
2
ad-hoc-1idパラメーターは、シグナルリクエストのID識別子として割り当てられる任意の文字列を指定します。
この文字列を使用して、シグナルテーブルのエントリーへのログメッセージを特定します。Debezium はこの文字列を使用しません。代わりに、スナップショット作成中に、Debezium は独自のID文字列をウォーターマークシグナルとして生成します。3
execute-snapshottypeパラメーターを指定し、シグナルがトリガーする操作を指定します。
4
data-collectionsシグナルの
dataフィールドの必須コンポーネントで、スナップショットに含めるテーブル名の配列またはテーブル名と一致する正規表現を指定します。
配列には、schema.table形式を使用してテーブルの完全修飾名と一致する正規表現がリストされます。この形式は、コネクターの シグナリングテーブル の名前を指定するために使用する形式と同じです。5
incremental実行するスナップショット操作のタイプを指定する、シグナルの
dataフィールドのオプションのtypeコンポーネント。
有効な値はincrementalとblockingです。
値を指定しない場合、コネクターはデフォルトで増分スナップショットを実行します。6
additional-conditionsコネクターがスナップショットに含めるレコードのサブセットを決定するために評価する追加条件のセットを指定する、オプションの配列。
各追加条件は、data-collectionプロパティーとfilterプロパティーを持つオブジェクトです。データの収集単位で異なるフィルターを指定できます。
*data-collectionプロパティーは、フィルターが適用されるデータコレクションの完全修飾名です。additional-conditionsパラメーターの詳細は、「additional-conditions付きでアドホック増分スナップショットを実行する」 を参照してください。
2.6.2.4.2. additional-conditions 付きでアドホック増分スナップショットを実行する
スナップショットに、テーブル内のコンテンツのサブセットのみを含める場合は、スナップショットシグナルに additional-conditions パラメーターを追加してシグナル要求を変更できます。
一般的なスナップショットの SQL クエリーは、以下の形式を取ります。
SELECT * FROM <tableName> ....
SELECT * FROM <tableName> ....
additional-conditions パラメーターを追加して、以下の例のように WHERE 条件を SQL クエリーに追加します。
SELECT * FROM <data-collection> WHERE <filter> ....
SELECT * FROM <data-collection> WHERE <filter> ....以下の例は、シグナルテーブルに追加の条件を含むアドホック増分スナップショット要求を送信する SQL クエリーを示しています。
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');
たとえば、以下の列が含まれる products テーブルがあるとします。
-
id(プライマリーキー) -
color -
quantity
products テーブルの増分スナップショットに color=blue のデータ項目のみを含める場合は、次の SQL ステートメントを使用してスナップショットをトリガーできます。
INSERT INTO myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["schema1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "schema1.products", "filter": "color=blue"}]}');
INSERT INTO myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["schema1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "schema1.products", "filter": "color=blue"}]}');
additional-conditions パラメーターを使用すると、列が 2 つ以上となる条件を指定することもできます。たとえば、前述の例の products テーブルを使用して、color=blue および quantity>10 だけに一致するアイテムのみのデータが含まれる増分スナップショットをトリガーするクエリーを送信できます。
INSERT INTO myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["schema1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "schema1.products", "filter": "color=blue AND quantity>10"}]}');
INSERT INTO myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["schema1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "schema1.products", "filter": "color=blue AND quantity>10"}]}');以下の例は、コネクターによってキャプチャーされる増分スナップショットイベントの JSON を示しています。
例2.40 増分スナップショットイベントメッセージ
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
実行するスナップショット操作タイプを指定します。 |
| 2 |
|
イベントタイプを指定します。 |
2.6.2.4.3. Kafka シグナルチャネルを使用して増分スナップショットをトリガーする
設定された Kafka トピック にメッセージを送信して、コネクターにアドホック増分スナップショットを実行するよう要求できます。
Kafka メッセージのキーは、topic.prefix コネクター設定オプションの値と一致する必要があります。
メッセージの値は、type と data フィールドが含まれる JSON オブジェクトとなっています。
シグナルタイプは execute-snapshot で、data フィールドには以下のフィールドが必要です。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプ。現在、Debezium は |
|
| 該当なし |
スナップショットに含めるテーブルの完全修飾名と一致する、コンマ区切りの正規表現の配列。 |
|
| 該当なし |
コネクターがスナップショットに含めるレコードのサブセットを指定するために評価する基準を指定する、オプションの追加条件の配列。 |
例2.41 execute-snapshot Kafka メッセージ
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["{collection-container}.table1", "{collection-container}.table2"], "type": "INCREMENTAL"}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["{collection-container}.table1", "{collection-container}.table2"], "type": "INCREMENTAL"}}`additional-conditions 付きのアドホック増分スナップショット
Debezium は additional-conditions フィールドを使用してテーブルのコンテンツのサブセットを選択します。
通常、Debezium はスナップショットを実行するときに、次のような SQL クエリーを実行します。
SELECT * FROM <tableName> ….
スナップショット要求に additional-conditions プロパティーが含まれている場合、プロパティーの data-collection および filter パラメーターが SQL クエリーに追加されます。次に例を示します。
SELECT * FROM <data-collection> WHERE <filter> ….
たとえば、列 id (プライマリーキー)、color、および brand を含む products テーブルがある場合、スナップショットに color='blue' のコンテンツのみを含める場合は、スナップショットをリクエストするときに、コンテンツをフィルタリングする additional-conditions プロパティーを追加することができます。
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["schema1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "schema1.products" ,"filter":"color='blue'"}]}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["schema1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "schema1.products" ,"filter":"color='blue'"}]}}`
また、additional-conditions プロパティーを使用して、複数の列に基づいて条件を渡すこともできます。たとえば、前の例と同じ products テーブルを使用して、color='blue' および brand='MyBrand' である products テーブルのコンテンツのみをスナップショットに含める場合は、次のリクエストを送信できます。
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["schema1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "schema1.products" ,"filter":"color='blue' AND brand='MyBrand'"}]}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["schema1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "schema1.products" ,"filter":"color='blue' AND brand='MyBrand'"}]}}`2.6.2.4.4. 増分スナップショットの停止
状況によっては、増分スナップショットを停止する必要がある場合があります。たとえば、スナップショットが正しく設定されていない場合や、他のデータベース操作にリソースが使用可能であるこのとの確認が必要な場合があります。ソースデータベースのシグナリングテーブルにシグナルを送信することで、すでに実行中のスナップショットを停止できます。
スナップショット停止信号をシグナリングテーブルに送信するには、SQL INSERT クエリーで送信します。stop-snapshot シグナルは、スナップショット操作の type を incremental として指定し、オプションで、現在実行中のスナップショットから省略するテーブルを指定します。Debezium はシグナルテーブルの変更を検出した後、シグナルを読み、増分スナップショット操作が進行中であればそれを停止します。
関連情報
また、JSON メッセージを Kafka シグナリングトピック に送信して、増分スナップショットを停止することもできます。
前提条件
- ソースデータベースにシグナリングデータコレクションが存在する。
-
シグナルデータコレクションが
signal.data.collectionプロパティーで指定されている。
ソースシグナリングチャネルを使用して増分スナップショットを停止する
SQL クエリーを送信して、シグナリングテーブルへのアドホックインクリメンタルスナップショットを停止します。
INSERT INTO <signalTable> (id, type, data) values ('<id>', 'stop-snapshot', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"incremental"}');INSERT INTO <signalTable> (id, type, data) values ('<id>', 'stop-snapshot', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"incremental"}');Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
INSERT INTO myschema.debezium_signal (id, type, data) values ('ad-hoc-1', 'stop-snapshot', '{"data-collections": ["schema1.table1", "schema1.table2"], "type":"incremental"}');INSERT INTO myschema.debezium_signal (id, type, data)1 values ('ad-hoc-1',2 'stop-snapshot',3 '{"data-collections": ["schema1.table1", "schema1.table2"],4 "type":"incremental"}');5 Copy to Clipboard Copied! Toggle word wrap Toggle overflow signal コマンドの
id、type、およびdataパラメーターの値は、シグナルテーブルのフィールド に対応します。
以下の表では、この例のパラメーターを説明しています。Expand 表2.132 シグナリングテーブルに増分スナップショット停止信号を送信するための SQL コマンドのフィールドの説明 項目 値 説明 1
schema.debezium_signalソースデータベースにあるシグナルテーブルの完全修飾名を指定します。
2
ad-hoc-1idパラメーターは、シグナルリクエストのID識別子として割り当てられる任意の文字列を指定します。
この文字列を使用して、シグナルテーブルのエントリーへのログメッセージを特定します。Debezium はこの文字列を使用しません。3
stop-snapshottypeパラメーターを指定し、シグナルがトリガーする操作を指定します。
4
data-collectionsシグナルの
dataフィールドのオプションコンポーネントで、スナップショットから削除するテーブル名の配列またはテーブル名とマッチする正規表現を指定します。
配列には、schema.tableの形式で完全修飾名でテーブルに一致する正規表現がリストされます。dataフィールドからこのコンポーネントを省略すると、シグナルによって進行中の増分スナップショット全体が停止されます。5
incremental停止するスナップショット操作のタイプを指定する信号の
dataフィールドの必須コンポーネント。
現在、有効な唯一のオプションはincrementalです。typeの値を指定しない場合、シグナルは増分スナップショットの停止に失敗します。
2.6.2.4.5. Kafka シグナリングチャネルを使用して増分スナップショットを停止する
設定された Kafka シグナルトピック にシグナルメッセージを送信して、アドホック増分スナップショットを停止できます。
Kafka メッセージのキーは、topic.prefix コネクター設定オプションの値と一致する必要があります。
メッセージの値は、type と data フィールドが含まれる JSON オブジェクトとなっています。
シグナルタイプは stop-snapshot で、data フィールドには以下のフィールドが必要です。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプ。現在、Debezium は |
|
| 該当なし |
テーブルの完全修飾名に一致する、コンマで区切られた正規表現のオプションの配列、スナップショットから削除するテーブル名に一致するテーブル名または正規表現の配列。 |
次の例は、典型的な stop-snapshot の Kafka メッセージを示しています。
Key = `test_connector`
Value = `{"type":"stop-snapshot","data": {"data-collections": ["schema1.table1", "schema1.table2"], "type": "INCREMENTAL"}}`
Key = `test_connector`
Value = `{"type":"stop-snapshot","data": {"data-collections": ["schema1.table1", "schema1.table2"], "type": "INCREMENTAL"}}`2.6.2.5. ブロッキングスナップショット
スナップショットをより柔軟に管理するために、Debezium には ブロッキングスナップショット と呼ばれる補助アドホックスナップショットメカニズムが含まれています。ブロッキングスナップショットは、Debezium コネクターにシグナルを送信 するための Debezium メカニズムに依存します。
ブロッキングスナップショットは、ランタイム時にトリガーできることを除いて、初期スナップショット と同じように動作します。
次のような状況では、標準の初期スナップショットプロセスを使用するのではなく、ブロッキングスナップショットを実行する必要があります。
- 新しいテーブルを追加し、コネクターの実行中にスナップショットを完了したいと考えている。
- 大きなテーブルを追加し、増分スナップショットよりも短い時間でスナップショットを完了したいと考えている。
ブロッキングスナップショットのプロセス
ブロッキングスナップショットを実行すると、Debezium はストリーミングを停止し、初期スナップショットの時と同じプロセスに従って、指定されたテーブルのスナップショットを開始します。スナップショットが完了すると、ストリーミングが再開されます。
スナップショットの設定
シグナルの data コンポーネントでは、次のプロパティーを設定できます。
- data-collections: スナップショットする必要のあるテーブルを指定します。
additional-conditions: テーブルごとに異なるフィルターを指定できます。
-
data-collectionプロパティーは、フィルターが適用されるテーブルの完全修飾名です。 -
filterプロパティーは、snapshot.select.statement.overridesで使用される値と同じになります。
-
以下に例を示します。
{"type": "blocking", "data-collections": ["schema1.table1", "schema1.table2"], "additional-conditions": [{"data-collection": "schema1.table1", "filter": "SELECT * FROM [schema1].[table1] WHERE column1 = 0 ORDER BY column2 DESC"}, {"data-collection": "schema1.table2", "filter": "SELECT * FROM [schema1].[table2] WHERE column2 > 0"}]}
{"type": "blocking", "data-collections": ["schema1.table1", "schema1.table2"], "additional-conditions": [{"data-collection": "schema1.table1", "filter": "SELECT * FROM [schema1].[table1] WHERE column1 = 0 ORDER BY column2 DESC"}, {"data-collection": "schema1.table2", "filter": "SELECT * FROM [schema1].[table2] WHERE column2 > 0"}]}重複の可能性
スナップショットをトリガーするシグナルを送信した時点と、ストリーミングが停止してスナップショットが開始する時点との間に遅延が生じる可能性があります。この遅延の結果、スナップショットが完了した後、コネクターはスナップショットがキャプチャーしたレコードと重複するイベントレコードを発行する可能性があります。
2.6.2.6. Debezium PostgreSQL コネクターによる変更イベントレコードのストリーミング方法
通常、PostgreSQL コネクターは、接続されている PostgreSQL サーバーから変更をストリーミングするのに大半の時間を費やします。このメカニズムは、PostgreSQL のレプリケーションプロトコル に依存します。このプロトコルにより、クライアントはログシーケンス番号 (LSN) と呼ばれる特定の場所で変更がサーバーのトランザクションログにコミットされる際に、サーバーから変更を受信することができます。
サーバーがトランザクションをコミットするたびに、別のサーバープロセスが 論理デコードプラグイン からコールバック関数を呼び出します。この関数はトランザクションからの変更を処理し、特定の形式 (Debezium プラグインの場合は Protobuf または JSON) に変換して、出力ストリームに書き込みます。その後、クライアントは変更を使用できます。
Debezium PostgreSQL コネクターは PostgreSQL クライアントとして動作します。コネクターが変更を受信すると、イベントを Debezium の create、update、または delete イベントに変換します。これには、イベントの LSN が含まれます。PostgreSQL コネクターは、同じプロセスで実行されている Kafka Connect フレームワークにレコードのこれらの変更イベントを転送します。Kafka Connect プロセスは、変更イベントレコードを適切な Kafka トピックに生成された順序で非同期に書き込みます。
Kafka Connect は定期的に最新の オフセット を別の Kafka トピックに記録します。オフセットは、各イベントに含まれるソース固有の位置情報を示します。PostgreSQL コネクターでは、各変更イベントに記録された LSN がオフセットです。
Kafka Connect が正常にシャットダウンすると、コネクターを停止し、すべてのイベントレコードを Kafka にフラッシュして、各コネクターから受け取った最後のオフセットを記録します。Kafka Connect の再起動時に、各コネクターの最後に記録されたオフセットを読み取り、最後に記録されたオフセットで各コネクターを起動します。コネクターを再起動すると、PostgreSQL サーバーにリクエストを送信し、その位置の直後に開始されるイベントを送信します。
PostgreSQL コネクターは、論理デコードプラグインによって送信されるイベントの一部としてスキーマ情報を取得します。ただし、コネクターはプライマリーキーが設定される列に関する情報を取得しません。コネクターは JDBC メタデータ (サイドチャネル) からこの情報を取得します。テーブルのプライマリーキー定義が変更される場合 (プライマリーキー列の追加、削除、または名前変更によって)、変更される場合、JDBC からのプライマリーキー情報が論理デコードプラグインが生成する変更イベントと同期されないごくわずかな期間が発生します。このごくわずかな期間に、キーの構造が不整合な状態でメッセージが作成される可能性があります。不整合にならないようにするには、以下のようにプライマリーキーの構造を更新します。
- データベースまたはアプリケーションを読み取り専用モードにします。
- Debezium に残りのイベントをすべて処理させます。
- Debezium を停止します。
- 関連するテーブルのプライマリーキー定義を更新します。
- データベースまたはアプリケーションを読み取り/書き込みモードにします。
- Debezium を再起動します。
PostgreSQL 10+ 論理デコードサポート (pgoutput)
PostgreSQL 10+ の時点で、PostgreSQL でネイティブにサポートされる pgoutput と呼ばれる論理レプリケーションストリームモードがあります。つまり、Debezium PostgreSQL コネクターは追加のプラグインを必要とせずにそのレプリケーションストリームを使用できます。これは、プラグインのインストールがサポートされないまたは許可されない環境で特に便利です。
詳細は、PostgreSQL の設定 を参照してください。
2.6.2.7. Debezium PostgreSQL の変更イベントレコードを受信する Kafka トピックのデフォルト名
デフォルトでは、PostgreSQL コネクターは、テーブルで発生するすべての INSERT、UPDATE、DELETE 操作の変更イベントを、そのテーブルに固有の単一の Apache Kafka トピックに書き込みます。コネクターは以下の規則を使用して変更イベントトピックに名前を付けます。
topicPrefix.schemaName.tableName
以下のリストは、デフォルト名のコンポーネントの定義を示しています。
- topicPrefix
-
topic.prefixコネクター設定プロパティーで指定されたトピック接頭辞。 - schemaName
- 変更イベントが発生したデータベーススキーマの名前。
- tableName
- 変更イベントが発生したデータベーステーブルの名前。
たとえば、postgres データベースとproducts、products_on_hand、customers、orders の 4 つのテーブルを含む inventory スキーマを持つ PostgreSQL インストレーションの変更をキャプチャーするコネクターの設定において、fulfillment が論理的なサーバー名であるとします。コネクターは以下の 4 つの Kafka トピックにレコードをストリーミングします。
-
fulfillment.inventory.products -
fulfillment.inventory.products_on_hand -
fulfillment.inventory.customers -
fulfillment.inventory.orders
テーブルは特定のスキーマの一部ではなく、デフォルトの public PostgreSQL スキーマで作成されたとします。Kafka トピックの名前は以下になります。
-
fulfillment.public.products -
fulfillment.public.products_on_hand -
fulfillment.public.customers -
fulfillment.public.orders
コネクターは、同様の命名規則を適用して、トランザクションメタデータのトピック をラベル付けします。
デフォルトのトピック名が要件を満たさない場合は、カスタムトピック名を設定できます。カスタムトピック名を設定するには、論理トピックルーティング SMT に正規表現を指定します。論理トピックルーティング SMT を使用してトピックの命名をカスタマイズする方法は、トピックルーティング を参照してください。
2.6.2.8. トランザクション境界を表す Debezium PostgreSQL コネクターによって生成されたイベント
Debezium は、トランザクション境界を表し、データ変更イベントメッセージを強化するイベントを生成できます。
Debezium は、コネクターのデプロイ後に発生するトランザクションに対してのみメタデータを登録し、受信します。コネクターをデプロイする前に発生するトランザクションのメタデータは利用できません。
Debezium はすべてのトランザクションの BEGIN および END に対して、以下のフィールドが含まれるイベントを生成します。
status-
BEGINまたはEND id-
Postgres トランザクション ID 自体と、コロンで区切られた特定の操作の LSN で構成される一意のトランザクション識別子の文字列表現。形式は
txID:LSNです。 ts_ms-
データソースでのトランザクション境界イベント (
BEGINまたはENDイベント) の時間。データソースから Debezium にイベント時間を渡されない場合、フィールドは代わりに Debezium がイベントを処理する時間を表します。 event_count(ENDイベント用)- トランザクションによって出力されるイベントの合計数。
data_collections(ENDイベント用)-
data_collectionとevent_count要素のペアの配列。これは、コネクターがデータコレクションから発信された変更に対して出力するイベントの数を示します。
例
topic.transaction オプションで上書きされない限り、トランザクションイベントは <topic.prefix>.transaction という名前のトピックに書き込まれます。
変更データイベントのエンリッチメント
トランザクションメタデータを有効にすると、データメッセージ Envelope は新しい transaction フィールドで強化されます。このフィールドは、複合フィールドの形式ですべてのイベントに関する情報を提供します。
id- 一意のトランザクション識別子の文字列表現。
total_order- トランザクションによって生成されたすべてのイベントを対象とするイベントの絶対位置。
data_collection_order- トランザクションによって出力されたすべてのイベントを対象とするイベントのデータコレクションごとの位置。
以下は、メッセージの例になります。
2.6.3. Debezium PostgreSQL コネクターのデータ変更イベントの説明
Debezium PostgreSQL コネクターは、行レベルの INSERT、UPDATE、および DELETE 操作ごとにデータ変更イベントを生成します。各イベントにはキーと値が含まれます。キーと値の構造は、変更されたテーブルによって異なります。
Debezium および Kafka Connect は、イベントメッセージの継続的なストリーム を中心として設計されています。ただし、これらのイベントの構造は時間の経過とともに変化する可能性があり、コンシューマーによる処理が困難になることがあります。これに対応するために、各イベントにはコンテンツのスキーマが含まれます。スキーマレジストリーを使用している場合は、コンシューマーがレジストリーからスキーマを取得するために使用できるスキーマ ID が含まれます。これにより、各イベントが自己完結型になります。
以下のスケルトン JSON は、変更イベントの基本となる 4 つの部分を示しています。ただし、アプリケーションで使用するために選択した Kafka Connect コンバーターの設定方法によって、変更イベントのこれら 4 部分の表現が決定されます。schema フィールドは、変更イベントが生成されるようにコンバーターを設定した場合のみ変更イベントに含まれます。同様に、イベントキーおよびイベントペイロードは、変更イベントが生成されるようにコンバーターを設定した場合のみ変更イベントに含まれます。JSON コンバーターを使用し、変更イベントの基本となる 4 つの部分すべてを生成するように設定すると、変更イベントの構造は次のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
最初の |
| 2 |
|
最初の |
| 3 |
|
2 つ目の |
| 4 |
|
2 つ目の |
デフォルトの動作では、コネクターによって、変更イベントレコードが イベントの元のテーブル名前が同じトピック にストリーミングされます。
Kafka 0.10 以降では、任意でイベントキーおよび値を タイムスタンプ とともに記録できます。このタイムスタンプはメッセージが作成された (プロデューサーによって記録) 時間または Kafka によってログに買い込まれた時間を示します。
PostgreSQL コネクターは、すべての Kafka Connect スキーマ名が Avro スキーマ名の形式 に準拠するようにします。つまり、論理サーバー名はアルファベットまたはアンダースコア (a-z、A-Z、または _) で始まる必要があります。論理サーバー名の残りの各文字と、スキーマ名とテーブル名の各文字は、アルファベット、数字、またはアンダースコア ( a-z、A-Z、0-9、または _) でなければなりません。無効な文字がある場合は、アンダースコアに置き換えられます。
論理サーバー名、スキーマ名、またはテーブル名に無効な文字が含まれ、名前を区別する唯一の文字が無効であると、無効な文字はすべてアンダースコアに置き換えられるため、予期せぬ競合が発生する可能性があります。
詳細は以下を参照してください。
2.6.3.1. Debezium PostgreSQL の変更イベントのキー
指定のテーブルでは、変更イベントのキーは、イベントが作成された時点でテーブルのプライマリーキーの各列のフィールドが含まれる構造を持ちます。また、テーブルの REPLICA IDENTITYが FULL または USING INDEX に設定されている場合は、各ユニークキー制約のフィールドがあります。
public データベーススキーマに定義されている customers テーブルと、そのテーブルの変更イベントキーの例を見てみましょう。
テーブルの例
変更イベントキーの例
topic.prefix コネクター設定プロパティーに PostgreSQL_server の値がある場合、この定義がある限り customers テーブルの変更イベントはすべて同じキー構造を持ち、JSON では以下のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
キーのスキーマ部分は、キーの |
| 2 |
|
キーのペイロードの構造を定義するスキーマの名前。このスキーマは、変更されたテーブルのプライマリーキーの構造を記述します。キースキーマ名の形式は connector-name.database-name.table-name.
|
| 3 |
|
イベントキーの |
| 4 |
|
各フィールドの名前、インデックス、およびスキーマなど、 |
| 5 |
|
この変更イベントが生成された行のキーが含まれます。この例では、キーには値が |
column.exclude.list および column.include.list コネクター設定プロパティーは、テーブル列のサブセットのみをキャプチャーできるようにしますが、プライマリーキーまたは一意キーのすべての列は常にイベントのキーに含まれます。
テーブルにプライマリーキーまたは一意キーがない場合は、変更イベントのキーは null になります。プライマリーキーや一意キーの制約がないテーブルの行は一意に識別できません。
2.6.3.2. Debezium PostgreSQL 変更イベントの値
変更イベントの値はキーよりも若干複雑です。キーと同様に、値には schema セクションと payload セクションがあります。schema セクションには、入れ子のフィールドを含む、Envelope セクションの payload 構造を記述するスキーマが含まれています。データを作成、更新、または削除する操作のすべての変更イベントには、Envelope 構造を持つ値 payload があります。
変更イベントキーの例を紹介するために使用した、同じサンプルテーブルについて考えてみましょう。
この表への変更に対する変更イベントの値は、REPLICA IDENTITY 設定およびイベントの目的である操作により異なります。
詳細は、以下を参照してください。
Replica identity
REPLICA IDENTITY は UPDATE および DELETE イベントの論理デコードプラグインで利用可能な情報量を決定する PostgreSQL 固有のテーブルレベルの設定です。具体的には、REPLICA IDENTITY の設定は、UPDATE または DELETE イベントが発生するたびに、関係するテーブル列の以前の値に利用可能な情報 (ある場合) を制御します。
REPLICA IDENTITY には 4 つの可能性があります。
DEFAULT- テーブルにプライマリーキーがある場合に、UPDATEおよびDELETEイベントにテーブルのプライマリーキー列の以前の値が含まれることがデフォルトの動作になります。UPDATEイベントでは、値が変更されたプライマリーキー列のみが存在します。テーブルにプライマリーキーがない場合、コネクターはそのテーブルの
UPDATEまたはDELETEイベントを出力しません。プライマリーキーのないテーブルの場合、コネクターは 作成 イベントのみを出力します。通常、プライマリーキーのないテーブルは、テーブルの最後にメッセージを追加するために使用されます。そのため、UPDATEおよびDELETEイベントは便利ではありません。-
NOTHING:UPDATEおよびDELETE操作の出力されたイベントにはテーブル列の以前の値に関する情報は含まれません。 -
FULL:UPDATEおよびDELETE操作の出力されたイベントには、テーブルの列すべての以前の値が含まれます。 -
INDEXindex-name:UPDATEおよびDELETE操作の発生したイベントには、指定されたインデックスに含まれる列の以前の値が含まれます。UPDATEイベントには、更新された値を持つインデックス化された列も含まれます。
create イベント
以下の例は、customers テーブルにデータを作成する操作に対して、コネクターによって生成される変更イベントの値の部分を示しています。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
| 値のペイロードの構造を記述する、値のスキーマ。変更イベントの値スキーマは、コネクターが特定のテーブルに生成するすべての変更イベントで同じになります。 |
| 2 |
|
|
| 3 |
|
|
| 4 |
|
|
| 5 |
|
値の実際のデータ。これは、変更イベントが提供する情報です。 |
| 6 |
|
イベント発生前の行の状態を指定する任意のフィールド。この例のように、 注記
このフィールドを利用できるかどうかは、各テーブルの |
| 7 |
|
イベント発生後の行の状態を指定する任意のフィールド。この例では、 |
| 8 |
| イベントのソースメタデータを記述する必須のフィールド。このフィールドには、イベントの発生元、イベントの発生順序、およびイベントが同じトランザクションの一部であるかどうかなど、このイベントと他のイベントを比較するために使用できる情報が含まれています。ソースメタデータには以下が含まれています。
|
| 9 |
|
コネクターによってイベントが生成される原因となった操作の型を記述する必須文字列。この例では、
|
| 10 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
更新イベント
サンプル customers テーブルにある更新の変更イベントの値には、そのテーブルの 作成 イベントと同じスキーマがあります。同様に、イベント値のペイロードは同じ構造を持ちます。ただし、イベント値ペイロードでは 更新 イベントに異なる値が含まれます。以下は、コネクターによって customers テーブルでの更新に生成されるイベントの変更イベント値の例になります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
データベースをコミットする前に行にあった値が含まれる任意のフィールド。この例では、テーブルの
update イベントに、行にあるすべての列に指定されたこれまでの値を含めるには、 |
| 2 |
|
イベント発生後の行の状態を指定する任意のフィールド。この例では、 |
| 3 |
|
イベントのソースメタデータを記述する必須のフィールド。
|
| 4 |
|
操作の型を記述する必須の文字列。更新 イベントの値では、 |
| 5 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
行のプライマリーキー/一意キーの列を更新すると、行のキーの値が変更されます。キーが変更されると、3 つのイベントが Debezium によって出力されます。3 つのイベントとは、DELETE イベント、行の古いキーを持つ 廃棄 (tombstone)、およびそれに続く行の新しいキーを持つイベントです。詳細は次のセクションで説明します。
プライマリーキーの更新
行のプライマリーキーフィールドを変更する UPDATE 操作は、プライマリーキーの変更と呼ばれます。プライマリーキーの変更では、UPDATE イベントレコードの代わりにコネクターが古いキーの DELETE イベントレコードと、新しい (更新された) キーの CREATE イベントレコードを出力します。これらのイベントには通常の構造と内容があり、イベントごとにプライマリーキーの変更に関連するメッセージヘッダーがあります。
-
DELETEイベントレコードには、メッセージヘッダーとして__debezium.newkeyが含まれます。このヘッダーの値は、更新された行の新しいプライマリーキーです。 -
CREATEイベントレコードには、メッセージヘッダーとして__debezium.oldkeyが含まれます。このヘッダーの値は、更新された行にあった以前の (古い) プライマリーキーです。
delete イベント
削除 変更イベントの値は、同じテーブルの 作成 および 更新 イベントと同じ schema の部分になります。サンプル customers テーブルの 削除 イベントの payload 部分は以下のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
イベント発生前の行の状態を指定する任意のフィールド。delete イベント値の |
| 2 |
|
イベント発生後の行の状態を指定する任意のフィールド。削除 イベント値の |
| 3 |
|
イベントのソースメタデータを記述する必須のフィールド。削除 イベント値の
|
| 4 |
|
操作の型を記述する必須の文字列。 |
| 5 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
削除 変更イベントレコードは、この行の削除を処理するために必要な情報を持つコンシューマーを提供します。
プライマリーキーを持たないテーブルに対して生成された 削除 イベントをコンシューマーが処理できるようにするには、テーブルの REPLICA IDENTITY を FULL に設定します。テーブルにプライマリーキーがなく、テーブルの REPLICA IDENTITY が DEFAULT または NOTHING に設定されている場合、削除 イベントの before フィールドはありません。
PostgreSQL コネクターイベントは、Kafka のログコンパクション と動作するように設計されています。ログコンパクションにより、少なくとも各キーの最新のメッセージが保持される限り、一部の古いメッセージを削除できます。これにより、トピックに完全なデータセットが含まれ、キーベースの状態のリロードに使用できるようにするとともに、Kafka がストレージ領域を確保できるようにします。
tombstone イベント
行が削除された場合でも、Kafka は同じキーを持つ以前のメッセージをすべて削除できるため、削除 イベントの値はログコンパクションで動作します。ただし、Kafka が同じキーを持つすべてのメッセージを削除するには、メッセージの値が null である必要があります。これを可能にするには、PostgreSQL コネクターは、値が null 値以外の同じキーを持つ特別な 廃棄 イベントが含まれる 削除 イベントに従います。
truncate イベント
truncate 変更イベントは、テーブルが切り捨てられたことを通知します。この場合のメッセージキーは null で、メッセージの値は以下のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
イベントのソースメタデータを記述する必須のフィールド。切り捨て (truncate) イベント値の
|
| 2 |
|
操作の型を記述する必須の文字列。 |
| 3 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
1 つの TRUNCATE ステートメントが複数のテーブルに適用された場合、切り捨てられたテーブルごとに 1 つの切り捨て (truncate) 変更イベントレコードが出力されます。
切り捨て (truncate) イベントは、テーブル全体に加えた変更を表し、メッセージキーを持たないので、単一のパーティションを持つトピックを使用しない限り、テーブルに関する変更イベント (作成、更新 など) とそのテーブルの 切り捨て (truncate) イベントの順番は保証されません。たとえば、これらのイベントが異なるパーティションから読み取られる場合、コンシューマーは 更新 イベントを 切り捨て (truncate) イベントの後でのみ受け取る可能性があります。
このイベントタイプは、Postgres 14+ の pgoutput プラグインでのみサポートされています (Postgres ドキュメント)。
メッセージイベントは、一般的にpg_logical_emit_message 関数を使用して、汎用の論理デコードメッセージが WAL に直接挿入されたことを通知します。メッセージキーは、ここでは prefix という名前の 1 つのフィールドを持つ Struct で、メッセージを挿入する際に指定された接頭辞を持ちます。トランザクションメッセージの場合、メッセージの値は以下のようになります。
他のイベントタイプとは異なり、非トランザクションメッセージは、関連する BEGIN や END のトランザクションイベントを持ちません。メッセージの値は、非取引メッセージの場合は以下のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
イベントのソースメタデータを記述する必須のフィールド。メッセージ イベント値では、
|
| 2 |
|
操作の型を記述する必須の文字列。 |
| 3 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。
非トランザクション メッセージ イベントの場合、 |
| 4 |
| メッセージのメタデータを格納するフィールド
|
2.6.4. Debezium PostgreSQL コネクターによるデータ型のマッピング方法
PostgreSQL コネクターは、行が存在するテーブルのように構造化されたイベントで行への変更を表します。イベントには、各列の値のフィールドが含まれます。その値がどのようにイベントで示されるかは、列の PostgreSQL のデータ型によって異なります。以下のセクションでは、PostgreSQL データ型をイベントフィールドの リテラル型 および セマンティック型にマッピングする方法を説明します。
-
literal type は、Kafka Connect スキーマタイプ (
INT8、INT16、INT32、INT64、FLOAT32、FLOAT64、BOOLEAN、STRING、BYTES、ARRAY、MAP、STRUCT) を使用して、値がどのように表現されるかを記述します。 - セマンティック型 は、フィールドの Kafka Connect スキーマの名前を使用して、Kafka Connect スキーマがフィールドの 意味 をキャプチャーする方法を記述します。
デフォルトのデータ型変換が要件に合わない場合は、コネクター用の カスタムコンバーターの作成 が可能です。
詳細は以下を参照してください。
基本型
以下の表は、コネクターによる基本型へのマッピング方法を説明しています。
| PostgreSQL のデータ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
| 該当なし |
|
|
| 該当なし |
|
|
|
|
|
|
|
|
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
該当なし |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 該当なし |
|
|
| 該当なし |
|
|
|
該当なし |
|
|
|
n/a |
|
|
|
n/a |
|
|
|
該当なし |
|
|
|
該当なし |
|
|
|
該当なし |
|
|
|
|
時間型
タイムゾーン情報が含まれる PostgreSQL の TIMESTAMPTZ and TIMETZ データ型以外に、時間型がマッピングされる仕組みは time.precision.mode コネクター設定プロパティーの値によって異なります。ここでは、以下のマッピングを説明します。
time.precision.mode=adaptive
time.precision.mode プロパティーがデフォルトの adaptive に設定された場合、コネクターは列のデータ型定義に基づいてリテラル型とセマンティック型を決定します。これにより、イベントがデータベースの値を 正確 に表すようになります。
| PostgreSQL のデータ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
time.precision.mode=adaptive_time_microseconds
time.precision.mode 設定プロパティーが adaptive_time_microseconds に設定されている場合には、コネクターは列のデータ型定義に基づいて一時的な型のリテラル型とセマンティック型を決定します。これにより、マイクロ秒としてキャプチャーされた TIME フィールド以外は、イベントがデータベースの値を 正確 に表すようになります。
| PostgreSQL のデータ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
time.precision.mode=connect
time.precision.mode 設定プロパティーが connect に設定された場合、コネクターは Kafka Connect の論理型を使用します。これは、コンシューマーが組み込みの Kafka Connect の論理型のみを処理でき、可変精度の時間値を処理できない場合に便利です。ただし、PostgreSQL はマイクロ秒の精度をサポートするため、connect 時間精度を指定してコネクターによって生成されたイベントは、データベース列の少数秒の精度値が 3 よりも大きい場合に、精度が失われます。
| PostgreSQL のデータ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
TIMESTAMP 型
TIMESTAMP 型は、タイムゾーン情報のないタイムスタンプを表します。このような列は、UTC を基にして同等の Kafka Connect 値に変換されます。たとえば、time.precision.mode がconnect に設定されていない場合、TIMESTAMP 値 "2018-06-20 15:13:16.945104" は、io.debezium.time.MicroTimestamp の値 "1529507596945104" で表されます。
Kafka Connect および Debezium を実行している JVM のタイムゾーンは、この変換には影響しません。
PostgreSQL は TIMESTAMP 列に +/-infinite の値を使用することをサポートしています。これらの特殊な値は、正の無限大の場合は9223372036825200000、負の無限大の場合は-9223372036832400000 の値を持つタイムスタンプに変換されます。この動作は、PostgreSQL JDBC ドライバーの標準的な動作に似ています。詳細は、org.postgresql.PGStatement インターフェイスを参照してください。
10 進数型
PostgreSQL コネクター設定プロパティーの設定 decimal.handling.mode は、コネクターが 10 進数型をマッピングする方法を決定します。
decimal.handling.mode プロパティーが precise に設定されている場合、コネクターは DECIMAL と NUMERIC、MONEY 列すべてに Kafka Connect org.apache.kafka.connect.data.Decimal 論理型を使用します。これはデフォルトのモードです。
| PostgreSQL のデータ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
このルールには例外があります。スケーリング制約なしで NUMERIC または DECIMAL 型が使用されると、データベースから取得される値のスケールは値ごとに異なります (可変)。この場合、コネクターは io.debezium.data.VariableScaleDecimal を使用し、これには転送された値とスケールの両方が含まれます。
| PostgreSQL のデータ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
|
|
|
|
|
|
decimal.handling.mode プロパティーが double に設定されている場合、コネクターはすべての DECIMAL、NUMERIC、MONEY 値を Java の double 値として表し、次の表のようにエンコードします。
| PostgreSQL のデータ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) |
|---|---|---|
|
|
| |
|
|
| |
|
|
|
decimal.handling.mode 設定プロパティーの最後の設定は string です。この場合、コネクターは DECIMAL、NUMERIC および MONEY 値をフォーマットされた文字列表現として表し、それらを以下の表に示すとおりエンコードします。
| PostgreSQL のデータ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) |
|---|---|---|
|
|
| |
|
|
| |
|
|
|
PostgreSQL は、decimal.handling.mode の設定が string または double の場合、DECIMAL /NUMERIC 値に格納される特別な値として NaN(not a number) をサポートしています。この場合、コネクターは NaN をDouble.NaN または文字列定数 NAN のいずれかとしてエンコードします。
HSTORE 型
PostgreSQL コネクター設定プロパティーの設定 hstore.handling.mode は、コネクターが HSTORE の値をマッピングする方法を決定します。
hstore.handling.mode プロパティーが json (デフォルト) に設定されている場合、コネクターは HSTORE 値を JSON 値の文字列表現として表し、以下の表で示すようにエンコードします。hstore.handling.mode プロパティーが map に設定されている場合、コネクターは HSTORE 値に MAP スキーマタイプを使用します。
| PostgreSQL のデータ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
|
|
|
|
|
該当なし |
ドメイン型
PostgreSQL は、他の基礎となるタイプに基づいたユーザー定義の型をサポートします。このような列型を使用すると、Debezium は完全な型階層に基づいて列の表現を公開します。
PostgreSQL ドメイン型を使用する列で変更をキャプチャーするには、特別に考慮する必要があります。デフォルトデータベース型の 1 つを拡張するドメインタイプと、カスタムの長さまたはスケールを定義するドメインタイプが含まれるように列が定義されると、生成されたスキーマは定義されたその長さとスケールを継承します。
カスタムの長さまたはスケールを定義するドメインタイプを拡張する別のドメインタイプが含まれるように列が定義されていると、その情報は PostgreSQL ドライバーの列メタデータにはないため、生成されたスキーマは定義された長さやスケールを継承 しません。
ネットワークアドレス型
PostgreSQL には、IPv4、IPv6、および MAC アドレスを保存できるデータ型があります。ネットワークアドレスの格納には、プレーンテキスト型ではなくこの型を使用することが推奨されます。ネットワークアドレス型は、入力エラーチェックと特化した演算子および関数を提供します。
| PostgreSQL のデータ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
|
該当なし |
|
|
|
該当なし |
|
|
|
該当なし |
|
|
|
該当なし |
PostGIS タイプ
PostgreSQL コネクターは、すべての PostGIS データ型 をサポートします。
| PostGIS データ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
|
詳細は、Open Geospatial Consortium Simple Features Access を参照してください。 |
|
|
|
詳細は、Open Geospatial Consortium Simple Features Access を参照してください。 |
TOAST 化された値
PostgreSQL ではページサイズにハード制限があります。つまり、約 8KB 以上の値は、TOAST ストレージを使用して保存する必要があるのです。これは、データベースからのレプリケーションメッセージに影響します。TOAST メカニズムを使用して保存され、変更されていない値は、テーブルのレプリカ ID の一部でない限り、メッセージに含まれません。競合が発生する可能性があるため、Debezium が不足している値を直接データベースから読み取る安全な方法はありません。そのため、Debezium は以下のルールに従って、TOAST 化された値を処理します。
-
REPLICA IDENTITY FULL- TOAST 列の値を持つテーブルは、他の列と同様に変更イベントのbeforeおよびafterフィールドの一部となります。 -
REPLICA IDENTITY DEFAULTのあるテーブル - データベースからUPDATEイベントを受信すると、レプリカ ID の一部ではない変更されていない TOAST 列値はイベントに含まれません。同様に、DELETEイベントを受信するときに TOAST 列 (ある場合) はbeforeフィールドにありません。この場合、Debezium は列値を安全に提供できないため、コネクターはコネクター設定プロパティーunavailable.value.placeholderによって定義されたとおりにプレースホルダー値を返します。
デフォルト値
データベーススキーマの列にデフォルト値が指定されている場合、PostgreSQL コネクターは可能な限りこの値を Kafka スキーマに反映させようとします。ほとんどの一般的なデータタイプがサポートされています。
-
BOOLEAN -
数値型 (
(INT、FLOAT、NUMERICなど) -
テキストタイプ (
CHAR、VARCHAR、TEXTなど) -
時間の種類 (
DATE、TIME、INTERVAL、TIMESTAMP、TIMESTAMPTZ) -
JSON,JSONB,XML -
UUID
時間型の場合、デフォルト値の解析は PostgreSQL ライブラリーによって提供されることに注意してください。したがって、PostgreSQL で通常サポートされている文字列表現は、コネクターでもサポートされている必要があります。
デフォルト値がインラインで直接指定されるのではなく関数によって生成される場合、コネクターは代わりに、指定されたデータ型の 0 に相当するものをエクスポートします。これらの値は以下の通りです。
-
BOOLEANではFALSE -
数値タイプの場合、適切な精度で
0 - text/XML タイプの場合は空の文字列
-
JSON タイプの場合は
{} -
1970-01-01DATE、TIMESTAMP、TIMESTAMPTZタイプの場合 -
TIME00:00 -
INTERVALのEPOCH -
00000000-0000-0000-0000-000000000000(UUID)
現在、このサポートは、関数の明示的な使用にのみ適用されます。たとえば、CURRENT_TIMESTAMP(6) は括弧付きでサポートされていますが、CURRENT_TIMESTAMP はサポートされていません。
デフォルト値の伝搬のサポートは、主に、スキーマのバージョン間の互換性を強制するスキーマレジストリーを持つ PostgreSQL コネクターを使用する際に、スキーマを安全に進化させるために存在します。この主な問題と、異なるプラグインのリフレッシュ動作のために、Kafka スキーマに存在するデフォルト値は、データベーススキーマのデフォルト値と常に同期していることは保証されません。
- デフォルト値は、あるプラグインがいつ、どのようにインメモリースキーマの更新をトリガーするかによって、Kafka スキーマに '遅れて' 現れることがあります。リフレッシュの間にデフォルトが何度も変更されると、Kafka スキーマに値が現れないか、スキップされることがある。
- コネクターに処理を待機しているレコードがあるときにスキーマの更新がトリガーされた場合、デフォルト値が Kafka スキーマに '早期' に表示されることがあります。これは、列のメタデータがレプリケーションメッセージに含まれているのではなく、リフレッシュ時にデータベースから読み取られるためです。これは、コネクターが遅れていてリフレッシュが発生した場合や、更新がソースデータベースに書き込まれ続けている間にコネクターが一時的に停止した場合に、コネクターの起動時に発生する可能性があります。
この動作は予想外かもしれませんが、それでも安全です。影響を受けるのはスキーマ定義のみで、メッセージに含まれる実際の値はソースデータベースに書き込まれたものと一貫性を保ちます。
カスタムコンバーター
デフォルトでは、Debezium は、SQL CREATE TYPE ステートメントを使用して作成された複合型など、カスタムのデータ型が指定された列からのデータは複製しません。カスタムデータ型の列を複製するには、カスタムコンバーターを作成する 手順に従いますが、重要な注意事項が複数あります。
-
コネクター設定の
include.unknown.datatypesプロパティーをtrueに設定します。デフォルトのfalse設定では、カスタムコンバーターは常にnull値を返します。 コンバーターに渡される値のタイプは、レプリケーションスロットに設定されている論理デコード出力プラグインにより異なります。
-
decoderbufsは、列データのバイト配列 (byte[]) 表現を渡します。 -
pgoutputは、列データの文字列表現を渡します。
-
2.6.5. Debezium コネクターを実行するための PostgreSQL の設定
このリリースの Debezium では、ネイティブの pgoutput 論理レプリケーションストリームのみがサポートされます。pgoutput プラグインを使用するように PostgreSQL を設定するには、レプリケーションスロットを有効にし、レプリケーションの実行に必要な権限を持つユーザーを設定します。
詳細は以下を参照してください。
2.6.5.1. Debezium pgoutput プラグインのレプリケーションスロットの設定
PostgreSQL の論理デコード機能はレプリケーションスロットを使用します。レプリケーションスロットを設定するには、postgresql.conf ファイルに以下を指定します。
wal_level=logical max_wal_senders=1 max_replication_slots=1
wal_level=logical
max_wal_senders=1
max_replication_slots=1これらの設定は、PostgreSQL サーバーを以下のように指示します。
-
wal_level- 先行書き込みログで論理デコードを使用します。 -
max_wal_senders- WAL 変更の処理に、1 つの個別プロセスの最大を使用します。 -
max_replication_slots- WAL の変更をストリーミングするために作成される 1 つのレプリケーションスロットの最大を許可します。
レプリケーションスロットは、Debezium の停止中でも Debezium に必要なすべての WAL エントリーを保持することが保証されいます。したがって、以下の点を避けるために、レプリケーションスロットを注意して監視することが重要になります。
- 過剰なディスク消費量。
- レプリケーションスロットが長期間使用されないと発生する可能性がある、あらゆる状態 (カタログの肥大化など)。
詳細は、レプリケーションスロットに関する PostgreSQL のドキュメント を参照してください。
PostgreSQL ログ先行書き込みの設定 や仕組みを理解していると、Debezium PostgreSQL コネクターを使用する場合に役立ちます。
2.6.5.2. Debezium コネクターの PostgreSQL パーミッションの設定
PostgreSQL サーバーを設定して Debezium コネクターを実行するには、レプリケーションを実行できるデータベースユーザーが必要です。レプリケーションは、適切なパーミッションを持つデータベースユーザーのみが実行でき、設定された数のホストに対してのみ実行できます。
セキュリティーで説明されているように、スーパーユーザーはデフォルトで必要な REPLICATION および LOGIN ロールを持っていますが、Debezium レプリケーションユーザーの権限を昇格しないことが推奨されます。代わりに、必要最低限の特権を持つ Debezium ユーザーを作成します。
前提条件
- PostgreSQL の管理者権限。
手順
ユーザーにレプリケーションの権限を付与するには、少なくとも
REPLICATIONおよびLOGIN権限を持つ PostgreSQL ロールを定義し、そのロールをユーザーに付与します。以下に例を示します。CREATE ROLE <name> REPLICATION LOGIN;
CREATE ROLE <name> REPLICATION LOGIN;Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.6.5.3. Debezium が PostgreSQL パブリケーションを作成できるように権限を設定
Debezium は、PostgreSQL ソーステーブルの変更イベントを、テーブル用に作成された パブリケーション からストリーミングします。パブリケーションには、1 つ以上のテーブルから生成される変更イベントのフィルターされたセットが含まれます。各パブリケーションのデータは、パブリケーションの仕様に基づいてフィルターされます。この仕様は、PostgreSQL データベース管理者または Debezium コネクターが作成できます。Debezium PostgreSQL コネクターに、パブリケーションの作成やレプリケートするデータの指定を許可するには、コネクターはデータベースで特定の権限で操作する必要があります。
パブリケーションの作成方法を決定するオプションは複数あります。通常、コネクターを設定する前に、キャプチャーするテーブルのパブリケーションを手動で作成することが推奨されます。しかし、Debezium がパブリケーションを自動的に作成し、それに追加するデータを指定できるように、ご使用の環境を設定できます。
Debezium は include list および exclude list プロパティーを使用して、データがパブリケーションに挿入される方法を指定します。Debezium がパブリケーションを作成できるようにするオプションの詳細は、publication.autocreate.modeを参照してください。
Debezium が PostgreSQL パブリケーションを作成するには、以下の権限を持つユーザーとして実行する必要があります。
- パブリケーションにテーブルを追加するためのデータベースのレプリケーション権限。
-
パブリケーションを追加するためのデータベースの
CREATE権限。 -
最初のテーブルデータをコピーするためのテーブルの
SELECT権限。テーブルの所有者には、テーブルに対するSELECT権限が自動的に付与されます。
テーブルをパブリケーションに追加する場合は、ユーザーはテーブルの所有者である必要があります。ただし、ソーステーブルはすでに存在するため、元の所有者と所有権を共有する仕組みが必要です。共有所有権を有効にするには、PostgreSQL レプリケーショングループを作成した後、既存のテーブルの所有者とレプリケーションユーザーをそのグループに追加します。
手順
レプリケーショングループを作成します。
CREATE ROLE <replication_group>;
CREATE ROLE <replication_group>;Copy to Clipboard Copied! Toggle word wrap Toggle overflow テーブルの元の所有者をグループに追加します。
GRANT REPLICATION_GROUP TO <original_owner>;
GRANT REPLICATION_GROUP TO <original_owner>;Copy to Clipboard Copied! Toggle word wrap Toggle overflow Debezium レプリケーションユーザーをグループに追加します。
GRANT REPLICATION_GROUP TO <replication_user>;
GRANT REPLICATION_GROUP TO <replication_user>;Copy to Clipboard Copied! Toggle word wrap Toggle overflow テーブルの所有権を
<replication_group>に移します。ALTER TABLE <table_name> OWNER TO REPLICATION_GROUP;
ALTER TABLE <table_name> OWNER TO REPLICATION_GROUP;Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Debezium がキャプチャ設定を指定するためには、の値が publication.autocreate.mode を filtered に設定する必要があります。
2.6.5.4. Debezium コネクターホストでのレプリケーションを許可するように PostgreSQL を設定
Debezium による PostgreSQL データのレプリケーションを可能にするには、データベースを設定し、PostgreSQL コネクターを実行するホストでのレプリケーションを許可する必要があります。データベースとのレプリケーションが許可されるクライアントを指定するには、エントリーを PostgreSQL ホストベースの認証ファイル pg_hba.conf に追加します。pg_hba.conf ファイルの詳細は、the PostgreSQL のドキュメントを参照してください。
手順
pg_hba.confファイルにエントリーを追加して、データベースホストでレプリケートできる Debezium コネクターホストを指定します。以下に例を示します。pg_hba.confファイルの例です。local replication <youruser> trust host replication <youruser> 127.0.0.1/32 trust host replication <youruser> ::1/128 trust
local replication <youruser> trust1 host replication <youruser> 127.0.0.1/32 trust2 host replication <youruser> ::1/128 trust3 Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.152 pg_hba.conf 設定の説明 項目 説明 1
ローカル (つまりサーバーマシン上) で
<youruser>のレプリケーションを許可するようにサーバーに指示します。2
IPV4を使用してレプリケーションの変更を受信することを、localhostの<youruser>に許可するようサーバーに指示します。3
IPV6を使用したレプリケーション変更の受信をlocalhostの<youruser>に許可するようサーバーに指示します。
ネットワークマスクの詳細は、PostgreSQL のドキュメント を参照してください。
2.6.5.5. Debezium WAL ディスク領域の消費を管理するための PostgreSQL の設定
場合によっては、WAL ファイルによって使用される PostgreSQL ディスク領域が、異常に急上昇したり増加することがあります。このような場合、いくつかの理由が考えられます。
コネクターがデータを受信した最大の LSN は、サーバーの
pg_replication_slotsビューのconfirmed_flush_lsn列で確認できます。この LSN よりも古いデータは利用できず、データベースがディスク領域を解放します。また、
pg_replication_slotsビューのrestart_lsn列には、コネクターが必要とする可能性のある最も古い WAL の LSN が含まれています。confirmed_flush_lsnの値が定期的に増加し、restart_lsnの値に遅延が発生する場合は、データベースは領域を解放する必要があります。データベースは、通常バッチブロックでディスク領域を解放します。これは想定内の動作であり、ユーザーによるアクションは必要ありません。
追跡されるデータベースには多くの更新がありますが、一部の更新のみがコネクターの変更をキャプチャーするテーブルおよびスキーマに関連します。この状況は、定期的なハートビートイベントで簡単に解決できます。コネクターの
heartbeat.interval.msコネクター設定プロパティーを設定します。注記コネクターがハートビートテーブルからイベントを検出して処理するには、publication.name プロパティーで指定された PostgreSQL パブリケーションにテーブルを追加する必要があります。このパブリケーションが Debezium のデプロイメント以前のものである場合、コネクターは定義されたとおりにパブリケーションを使用します。パブリケーションがデータベース内の
FOR ALL TABLESの変更を自動的にレプリケートするように設定されていない場合は、次のように、ハートビートテーブルをパブリケーションに明示的に追加する必要があります。
ALTER PUBLICATION <publicationName> ADD TABLE <heartbeatTableName>;PostgreSQL インスタンスには複数のデータベースが含まれ、その 1 つがトラフィックが多いデータベースです。Debezium は、他のデータベースと比較して、トラフィックが少ない別のデータベースで変更をキャプチャーします。レプリケーションスロットがデータベースごとに機能し、Debezium が呼び出しされないため、Debezium は LSN を確認できません。WAL はすべてのデータベースで共有されているため、Debezium が変更をキャプチャーするデータベースによってイベントが出力されるまで、使用量が増加する傾向にあります。これに対応するには、以下を行う必要があります。
-
heartbeat.interval.msコネクター設定プロパティーを使用して、定期的なハートビートレコードの生成を有効にします。 - Debezium が変更をキャプチャーするデータベースから変更イベントを定期的に送信します。
新しい行を挿入したり、同じ行を定期的に更新することで、別のプロセスがテーブルを定期的に更新します。次に PostgreSQL は Debezium を呼び出して、最新の LSN を確認し、データベースが WAL 領域を解放できるようにします。このタスクは、
heartbeat.action.queryコネクター設定プロパティーを使用して自動化できます。-
同じデータベースサーバーに対する複数のコネクターの設定
Debezium はレプリケーションスロットを使用してデータベースから変更をストリーミングします。これらのレプリケーションスロットは、LSN (ログシーケンス番号) の形式で現在の位置を維持します。LSN は、Debezium コネクターによって使用される WAL 内の場所へのポインターです。これは、PostgreSQL が Debezium によって処理されるまで WAL を利用可能な状態に保つのに役立ちます。1 つのコンシューマーまたはプロセスに対して、1 つのレプリケーションスロットのみ存在できます。異なるコンシューマーごとに状態が異なる、異なる位置からのデータを必要とする可能性があるためです。
レプリケーションスロットは 1 つのコネクターでのみ使用できるため、Debezium コネクターごとに一意のレプリケーションスロットを作成することが重要です。ただし、コネクターがアクティブでない場合、Postgres は他のコネクターがレプリケーションスロットを消費できるようにする場合があります。これは、スロットが各変更を 1 回だけ発行するため、データ損失につながり、危険を伴う可能性があります (詳細参照)。
Debezium は、レプリケーションスロットに加えて、pgoutput プラグインを使用するときにパブリケーションを使用してイベントをストリーミングします。レプリケーションスロットと同様に、パブリケーションはデータベースレベルであり、一連のテーブルに対して定義されます。そのため、コネクターが同じテーブルセットで作業しない限り、各コネクターに固有のパブリケーションが必要になります。Debezium がパブリケーションを作成できるようにするオプションの詳細は、publication.autocreate.mode を参照してください。
各コネクターの一意のレプリケーションスロット名とパブリケーション名を設定する方法は、slot.name および publication.name を参照してください。
2.6.5.6. Debezium がキャプチャーする PostgreSQL データベースのアップグレード
Debezium が使用する PostgreSQL データベースをアップグレードする場合は、データ損失を防止し、Debezium が確実に動作し続けるように、特定の手順を実行する必要があります。一般的に、Debezium はネットワーク障害やその他の機能停止による中断に対して耐性があります。たとえば、コネクターが監視しているデータベースサーバーが停止またはクラッシュした場合、コネクターは PostgreSQL サーバーとの通信を再確立した後、ログシーケンス番号 (LSN) オフセットによって記録された最後の位置から読み取りを続けます。コネクターは、最後に記録されたオフセットに関する情報を Kafka Connect オフセットトピックから取得し、設定された PostgreSQL レプリケーションスロットに対して同じ値のログシーケンス番号 (LSN) をクエリーします。
コネクターを起動して PostgreSQL データベースから変更イベントをキャプチャーするには、レプリケーションスロットが存在する必要があります。ただし、PostgreSQL アップグレードプロセスの一部として、レプリケーションスロットは削除され、アップグレードの完了後に元のスロットは復元されません。その結果、コネクターが再起動してレプリケーションスロットからの最後の既知のオフセットを要求すると、PostgreSQL で、情報を返すことができません。
新しいレプリケーションスロットを作成することもできますが、データが損失されないようにするには、新しいスロットを作成する必要があります。新しいレプリケーションスロットは、スロットの作成後に発生した変更に対してのみ LSN を提供できます。アップグレード前に発生したイベントのオフセットは、提供できません。コネクターが再起動すると、最初に Kafka オフセットトピックから最後の既知のオフセットを要求します。次に、要求をレプリケーションスロットに送信し、オフセットトピックから取得したオフセットの情報を返します。ただし、新しいレプリケーションスロットは、コネクターが想定の位置からストリーミングを再開するために必要な情報を提供できません。その後、コネクターはログ内の既存の変更イベントをスキップし、ログ内の最新の位置からのみストリーミングを再開します。これにより、通知なしにデータ損失が発生する可能性があります。コネクターは、スキップされたイベントのレコードを出力せず、イベントがスキップされたことを示す情報も提供しません。
データ損失のリスクを最小限に抑えながら Debezium がイベントのキャプチャーを継続できるように PostgreSQL データベースのアップグレードを実行する方法は、次の手順を参照してください。
手順
- データベースに書き込むアプリケーションを一時的に停止するか、読み取り専用モードにします。
- データベースをバックアップします。
- データベースへの書き込みアクセスを一時的に無効にします。
- 書き込み操作をブロックする前にデータベースで発生した変更が先行書き込みログ (WAL) に保存されていること、および WAL LSN がレプリケーションスロットに反映されていることを確認します。
-
レプリケーションスロットに書き込まれるすべてのイベントレコードをキャプチャーするのに十分な時間をコネクターに提供します。
この手順により、ダウンタイム前に発生したすべての変更イベントが考慮され、Kafka に保存されるようになります。 - フラッシュされた LSN の値をチェックして、コネクターがレプリケーションスロットからのエントリーの消費を終了したことを確認します。
Kafka Connect を停止して、コネクターを正常にシャットダウンします。
Kafka Connect はコネクターを停止し、すべてのイベントレコードを Kafka にフラッシュし、各コネクターから受信した最後のオフセットを記録します。
注記Kafka Connect クラスター全体を停止する代わりに、コネクターを削除することで停止できます。オフセットトピックは、他の Kafka コネクターと共有される可能性があるため、削除しないでください。後で、データベースへの書き込みアクセスを復元し、コネクターを再起動する準備ができたら、コネクターを再作成する必要があります。
-
PostgreSQL 管理者として、プライマリーデータベースサーバーのレプリケーションスロットを削除します。
slot.drop.on.stopプロパティーを使用して、レプリケーションスロットを削除しないでください。このプロパティーはテスト専用です。 - データベースを停止します。
-
pg_upgrade、pg_dump、pg_restoreなど、承認された PostgreSQL アップグレード手順を使用してアップグレードを実行します。 -
(オプション) 標準の Kafka ツールを使用して、オフセットストレージトピックからコネクターオフセットを削除します。
コネクターオフセットを削除する方法の例は、Debezium コミュニティー FAQ の コネクターオフセットを削除する方法 を参照してください。 - データベースを再起動します。
PostgreSQL 管理者として、データベース上に Debezium 論理レプリケーションスロットを作成します。データベースへの書き込みを有効にする前に、スロットを作成する必要があります。そうしないと、Debezium は変更をキャプチャーできず、データが失われます。
レプリケーションスロットの設定に関する詳細は、「Debezium
pgoutputプラグインのレプリケーションスロットの設定」 を参照してください。- Debezium がキャプチャーするテーブルを定義するパブリケーションがアップグレード後も存在することを確認します。パブリケーションが利用できない場合は、PostgreSQL 管理者としてデータベースに接続し、新しいパブリケーションを作成します。
-
前の手順で新しいパブリケーションを作成する必要があった場合は、Debezium コネクター設定を更新して、新しいパブリケーションの名前を
publication.nameプロパティーに追加します。 - コネクター設定で、コネクターの名前を変更します。
-
コネクター設定で、
slot.nameを Debezium レプリケーションスロットの名前に設定します。 - 新規レプリケーションスロットが利用可能であることを確認します。
- データベースへの書き込みアクセスを復元し、データベースに書き込んだアプリケーションを再起動します。
コネクター設定で、
snapshot.modeプロパティーをneverに設定し、コネクターを再起動します。注記手順 6 で Debezium がデータベース変更の読み取りをすべて完了したことを確認できなかった場合は、
snapshot.mode=initialを設定して新しいスナップショットを実行するようにコネクターを設定できます。必要に応じて、アップグレード直前に取得したデータベースのバックアップの内容をチェックして、コネクターがレプリケーションスロットからすべての変更を読み取るかどうかを確認できます。
2.6.6. Debezium PostgreSQL コネクターのデプロイメント
以下の方法のいずれかを使用して Debezium PostgreSQL コネクターをデプロイできます。
2.6.6.1. Streams for Apache Kafka を使用した PostgreSQL コネクターデプロイメント
Debezium 1.7 以降、Debezium コネクターのデプロイに推奨される方法は、Streams for Apache Kafka を使用して、コネクタープラグインを含む Kafka Connect コンテナーイメージをビルドすることです。
デプロイメントプロセス中に、以下のカスタムリソース (CR) を作成し、使用します。
-
Kafka Connect インスタンスを定義し、コネクターアーティファクトに関する情報をイメージに含める必要がある
KafkaConnectCR。 -
コネクターがソースデータベースにアクセスするために使用する情報を提供する
KafkaConnectorCR。Streams for Apache Kafka が Kafka Connect Pod を起動した後、KafkaConnectorCR を適用してコネクターを起動します。
Kafka Connect イメージのビルド仕様では、デプロイ可能なコネクターを指定できます。各コネクタープラグインに対して、デプロイメントに利用可能にする他のコンポーネントを指定することもできます。たとえば、Apicurio Registry アーティファクトや Debezium スクリプトコンポーネントを追加できます。Streams for Apache Kafka は、Kafka Connect イメージをビルドするときに、指定されたアーティファクトをダウンロードし、それをイメージに組み込みます。
Kafka Connect CR の spec.build.output パラメーターは、生成される KafkaConnectコンテナーイメージを格納する場所を指定します。コンテナーイメージは Docker レジストリーまたは OpenShift ImageStream に保存できます。イメージを ImageStream に保存するには、Kafka Connect をデプロイする前に ImageStream を作成する必要があります。ImageStreams は自動的に作成されません。
KafkaConnect リソースを使用してクラスターを作成する場合は、Kafka Connect REST API を使用してコネクターを作成または更新できません。ただし、REST API を使用して情報を取得できます。
関連情報
- 「OpenShift 上の Streams for Apache Kafka のデプロイと管理」の Kafka Connect の設定
- 「OpenShift 上の Streams for Apache Kafka のデプロイと管理」の 新しいコンテナーイメージの自動ビルド
2.6.6.2. Streams for Apache Kafka を使用した Debezium PostgreSQL コネクターのデプロイ
以前のバージョンの Streams for Apache Kafka では、OpenShift に Debezium コネクターをデプロイするには、まずコネクター用の Kafka Connect イメージをビルドする必要がありました。OpenShift にコネクターをデプロイするための現在の推奨方法は、Streams for Apache Kafka のビルド設定を使用して、使用する Debezium コネクタープラグインを含む Kafka Connect コンテナーイメージを自動的にビルドすることです。
ビルドプロセス中に、Streams for Apache Kafka Operator は、Debezium コネクター定義を含む KafkaConnect カスタムリソースの入力パラメーターを Kafka Connect コンテナーイメージに変換します。このビルドは、Red Hat Maven リポジトリーまたは別の設定済みの HTTP サーバーから必要なアーティファクトをダウンロードします。
新規に作成されたコンテナーは .spec.build.output に指定されるコンテナーレジストリーにプッシュされ、Kafka Connect クラスターのデプロイに使用されます。Streams for Apache Kafka が Kafka Connect イメージをビルドした後、ビルドに含まれるコネクターを起動するための KafkaConnector カスタムリソースを作成します。
前提条件
- クラスター Operator がインストールされている OpenShift クラスターにアクセスできる。
- Streams for Apache Kafka Operator が実行されている。
- Apache Kafka クラスターが OpenShift 上の Streams for Apache Kafka のデプロイと管理 に記載されているとおりにデプロイされている。
- Kafka Connect が Streams for Apache Kafka にデプロイされている。
- Red Hat build of Debezium のライセンスを所有している。
-
OpenShift
ocCLI クライアントがインストールされている、または OpenShift Container Platform Web コンソールにアクセスできる。 Kafka Connect ビルドイメージの保存方法に応じて、レジストリーのパーミッションを用意するか、ImageStream リソースを作成している。
- ビルドイメージを Red Hat Quay.io または Docker Hub などのイメージレジストリーに保存する場合は、以下が必要です。
- レジストリーでイメージを作成し、管理するためのアカウントおよびパーミッション
- ビルドイメージをネイティブ OpenShift ImageStream として保存する場合は、以下を行います。
- 新規コンテナーイメージを保存するために、ImageStream リソースをクラスターにデプロイします。クラスターの ImageStream を明示的に作成する必要があります。ImageStreams は、デフォルトでは利用できません。ImageStreams の詳細は、OpenShift Container Platform でのイメージストリームの管理 を参照してください。
手順
- OpenShift クラスターにログインします。
コネクターの Debezium
KafkaConnectカスタムリソース (CR) を作成するか、既存のリソースを変更します。たとえば、metadata.annotationsおよびspec.buildプロパティーを指定するdbz-connect.yamlという名前のKafkaConnectCR を作成します。以下の例は、KafkaConnectカスタムリソースを記述するdbz-connect.yamlファイルからの抜粋を示しています。
例2.42 Debezium コネクターを含む
KafkaConnectカスタムリソースを定義したdbz-connect.yamlファイル次の例では、カスタムリソースは、次のアーティファクトをダウンロードするように設定されています。
- Debezium PostgreSQL コネクターアーカイブです。
- Red Hat build of Apicurio Registry アーカイブApicurio Registry はオプションのコンポーネントです。コネクターで Avro シリアル化を使用する場合にのみ、Apicurio Registry コンポーネントを追加します。
- Debezium スクリプティング SMT アーカイブと、Debezium コネクターで使用する関連スクリプティングエンジン。SMT アーカイブとスクリプト言語の依存関係はオプションのコンポーネントです。Debezium コンテンツベースのルーティング SMT または フィルター SMT を使用する場合にのみ、これらのコンポーネントを追加します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.153 Kafka Connect 設定の説明 項目 説明 1
strimzi.io/use-connector-resourcesアノテーションを"true"に設定して、クラスター Operator がKafkaConnectorリソースを使用してこの Kafka Connect クラスター内のコネクターを設定できるようにします。2
spec.build設定は、ビルドイメージの保存場所を指定し、プラグインアーティファクトの場所とともにイメージに追加するプラグインをリストします。3
build.outputは、新しくビルドされたイメージを保存するレジストリーを指定します。4
イメージ出力の名前およびイメージ名を指定します。
output.typeの有効な値は、Docker Hub や Quay などのコンテナーレジストリーにプッシュする場合はdocker、内部の OpenShift ImageStream にイメージをプッシュする場合はimagestreamです。ImageStream を使用するには、ImageStream リソースをクラスターにデプロイする必要があります。KafkaConnect 設定でbuild.outputを指定する方法の詳細は、{NameConfiguringStreamsOpenShift} の Streams for Apache Kafka ビルドスキーマリファレンス を参照してください。5
plugins設定は、Kafka Connect イメージに追加するすべてのコネクターをリストします。リストの各エントリーについて、プラグインnameと、コネクターのビルドに必要なアーティファクトに関する情報を指定します。必要に応じて、各コネクタープラグインに対して、コネクターと使用できる他のコンポーネントを含めることができます。たとえば、Service Registry アーティファクトまたは Debezium スクリプトコンポーネントを追加できます。6
artifacts.typeの値は、artifacts.urlで指定するアーティファクトのファイルタイプを指定します。有効なタイプはzip、tgz、またはjarです。Debezium コネクターアーカイブは、.zipファイル形式で提供されます。typeの値は、urlフィールドで参照されるファイルのタイプと一致させる必要があります。7
artifacts.urlの値は、コネクターアーティファクトのファイルを格納する Maven リポジトリーなどの HTTP サーバーのアドレスを指定します。Debezium コネクターアーティファクトは Red Hat リポジトリーで入手できます。OpenShift クラスターが指定されたサーバーにアクセスできる必要があります。8
(オプション) Apicurio Registry コンポーネントをダウンロードするためのアーティファクト
typeとurlを指定します。デフォルトの JSON コンバーターを使用する代わりに、コネクターが Apache Avro を使用して Red Hat build of Apicurio Registry でイベントのキーと値をシリアル化する場合にのみ、Apicurio Registry アーティファクトを含めます。9
(オプション) Debezium コネクターで使用する Debezium スクリプト SMT アーカイブのアーティファクト
typeとurlを指定します。Debezium コンテンツベースルーティング SMT または フィルター SMT を使用する場合にのみ、スクリプト SMT を含めます。スクリプト SMT を使用するには、groovy などの JSR 223 準拠のスクリプト実装もデプロイする必要があります。10
(オプション) JSR 223 準拠のスクリプト実装の JAR ファイルのアーティファクト
typeとurlを指定します。これは、Debezium スクリプト SMT で必要です。重要Streams for Apache Kafka を使用してコネクタープラグインを Kafka Connect イメージに組み込む場合、必要なスクリプト言語コンポーネントごとに、
artifacts.urlに JAR ファイルのロケーションを指定し、artifacts.typeの値もjarに設定する必要があります。値が無効な場合は、実行時にコネクターが失敗します。スクリプト SMT で Apache Groovy 言語を使用できるようにするために、この例のカスタムリソースは、次のライブラリーの JAR ファイルを取得します。
-
groovy -
groovy-jsr223(スクリプトエージェント) -
groovy-json(JSON 文字列を解析するためのモジュール)
別の方法として、Debezium スクリプト SMT は、GraalVM JavaScript の JSR 223 実装の使用もサポートします。
以下のコマンドを入力して、
KafkaConnectビルド仕様を OpenShift クラスターに適用します。oc create -f dbz-connect.yaml
oc create -f dbz-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Streams Operator はカスタムリソースで指定された設定に基づいて、デプロイする Kafka Connect イメージを準備します。
ビルドが完了すると、Operator はイメージを指定されたレジストリーまたは ImageStream にプッシュし、Kafka Connect クラスターを起動します。設定にリスト表示されているコネクターアーティファクトはクラスターで利用できます。KafkaConnectorリソースを作成し、デプロイする各コネクターのインスタンスを定義します。
たとえば、以下のKafkaConnectorCR を作成し、postgresql-inventory-connector.yamlとして保存します。例2.43 Debezium コネクターの
KafkaConnectorカスタムリソースを定義するpostgresql-inventory-connector.yamlファイルCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.154 コネクター設定の説明 項目 説明 1
Kafka Connect クラスターに登録するコネクターの名前。
2
コネクタークラスの名前。
3
同時に動作できるタスクの数。
4
コネクターの設定。
5
ホストデータベースインスタンスのアドレス。
6
データベースインスタンスのポート番号。
7
Debezium がデータベースへの接続に使用するアカウントの名前。
8
Debezium がデータベースユーザーアカウントに接続するために使用するパスワード。
9
変更をキャプチャーするデータベースの名前。
10
データベースインスタンスまたはクラスターのトピック接頭辞。
指定する名前は、英数字またはアンダースコアのみで設定する必要があります。
トピック接頭辞は、このコネクターから変更イベントを受信する Kafka トピックの接頭辞として使用されるため、名前はクラスターのコネクター間で一意である必要があります。
コネクターを Avro コネクター と統合する場合、この名前空間は、関連する Kafka Connect スキーマの名前や、対応する Avro スキーマの名前空間でも使用されます。11
コネクターが変更イベントをキャプチャーするテーブルのリスト。
以下のコマンドを実行してコネクターリソースを作成します。
oc create -n <namespace> -f <kafkaConnector>.yaml
oc create -n <namespace> -f <kafkaConnector>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc create -n debezium -f postgresql-inventory-connector.yaml
oc create -n debezium -f postgresql-inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow コネクターは Kafka Connect クラスターに登録され、
KafkaConnectorCR のspec.config.database.dbnameで指定されたデータベースに対して実行を開始します。コネクター Pod の準備ができると、Debezium が実行されます。
これで、Debezium PostgreSQL デプロイメントを検証する 準備が整いました。
2.6.6.3. Dockerfile からカスタム Kafka Connect コンテナーイメージをビルドして Debezium PostgreSQL コネクターのデプロイ
Debezium PostgreSQL コネクターをデプロイするには、Debezium コネクターアーカイブが含まれるカスタム Kafka Connect コンテナーイメージをビルドし、このコンテナーイメージをコンテナーレジストリーにプッシュする必要があります。次に、2 つのカスタムリソース (CR) を作成する必要があります。
-
Kafka Connect インスタンスを定義する
KafkaConnectCR。imageは Debezium コネクターを実行するために作成したイメージの名前を指定します。この CR は、Red Hat Streams for Apache Kafka がデプロイされている OpenShift インスタンスに適用します。Streams for Apache Kafka は、Apache Kafka を OpenShift に導入する Operator とイメージを提供します。 -
Debezium PostgreSQL コネクターを定義する
KafkaConnectorCR。この CR をKafkaConnectCR を適用したのと同じ OpenShift インスタンスに適用します。
前提条件
- PostgreSQL が実行され、PostgreSQL を設定して Debezium コネクターを実行する 手順が実行済みである。
- Streams for Apache Kafka が OpenShift にデプロイされ、Apache Kafka および Kafka Connect が実行されている。詳細は、OpenShift 上の Streams for Apache Kafka のデプロイと管理 を参照してください。
- Podman または Docker がインストールされている。
-
Debezium コネクターを実行するコンテナーを追加する予定のコンテナーレジストリー (
quay.ioやdocker.ioなど) でコンテナーを作成および管理するアカウントとパーミッションを持っている。
手順
Kafka Connect の Debezium PostgreSQL コンテナーを作成します。
registry.redhat.io/amq-streams-kafka-35-rhel8:2.5.0をベースイメージとして使用して、新規の Dockerfile を作成します。たとえば、ターミナルウィンドウから、以下のコマンドを入力します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 項目 説明 1
任意のファイル名を指定できます。
2
Kafka Connect プラグインディレクトリーへのパスを指定します。Kafka Connect のプラグインディレクトリーが別の場所にある場合は、このパスを実際のディレクトリーのパスに置き換えてください。
このコマンドは、現在のディレクトリーに
debezium-container-for-postgresql.yamlという名前の Dockerfile を作成します。前のステップで作成した
debezium-container-for-postgresql.yamlDocker ファイルからコンテナーイメージをビルドします。ファイルが含まれるディレクトリーから、ターミナルウィンドウを開き、以下のコマンドのいずれかを入力します。podman build -t debezium-container-for-postgresql:latest .
podman build -t debezium-container-for-postgresql:latest .Copy to Clipboard Copied! Toggle word wrap Toggle overflow docker build -t debezium-container-for-postgresql:latest .
docker build -t debezium-container-for-postgresql:latest .Copy to Clipboard Copied! Toggle word wrap Toggle overflow buildコマンドは、debezium-container-for-postgresqlという名前のコンテナーイメージを構築します。カスタムイメージを
quay.ioなどのコンテナーレジストリーまたは内部のコンテナーレジストリーにプッシュします。コンテナーレジストリーは、イメージをデプロイする OpenShift インスタンスで利用できる必要があります。以下のいずれかのコマンドを実行します。podman push <myregistry.io>/debezium-container-for-postgresql:latest
podman push <myregistry.io>/debezium-container-for-postgresql:latestCopy to Clipboard Copied! Toggle word wrap Toggle overflow docker push <myregistry.io>/debezium-container-for-postgresql:latest
docker push <myregistry.io>/debezium-container-for-postgresql:latestCopy to Clipboard Copied! Toggle word wrap Toggle overflow 新しい Debezium PostgreSQL
KafkaConnectカスタムリソース (CR) を作成します。たとえば、annotationsおよびimageプロパティーを指定するdbz-connect.yamlという名前のKafkaConnectCR を作成します。以下の例は、KafkaConnectカスタムリソースを記述するdbz-connect.yamlファイルからの抜粋を示しています。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 項目 説明 1
KafkaConnectorリソースはこの Kafka Connect クラスターでコネクターを設定するために使用されることを、metadata.annotationsは Cluster Operator に示します。2
spec.imageは Debezium コネクターを実行するために作成したイメージの名前を指定します。設定された場合、このプロパティーによって Cluster Operator のSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGE変数がオーバーライドされます。以下のコマンドを実行して、
KafkaConnectCR を OpenShift Kafka インスタンスに適用します。oc create -f dbz-connect.yaml
oc create -f dbz-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow これにより、OpenShift の Kafka Connect 環境が更新され、Debezium コネクターを実行するために作成したイメージの名前を指定する Kafka Connector インスタンスが追加されます。
Debezium PostgreSQL コネクターインスタンスを設定する
KafkaConnectorカスタムリソースを作成します。通常、コネクター設定プロパティーを設定する
.yamlファイルに Debezium PostgreSQL コネクターを設定します。コネクター設定は、Debezium に対して、スキーマおよびテーブルのサブセットにイベントを生成するよう指示する可能性があり、または機密性の高い、大きすぎる、または不必要な指定のコラムで Debezium が値を無視、マスク、または切り捨てするようにプロパティーを設定する可能性もあります。Debezium PostgreSQL コネクターに設定できる設定プロパティーの完全リストは PostgreSQL コネクタープロパティー を参照してください。次の例は、ポート
5432で PostgreSQL サーバーホスト192.168.99.100に接続する Debezium コネクターを設定するカスタムリソースからの抜粋です。このホストには、sampledbという名前のデータベース、publicという名前のスキーマ、inventory-connector-postgresqlという論理名のサーバーがあります。
PostgreSQL
inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.155 PostgreSQL の inventory-connector.yaml サンプルの設定の説明 項目 説明 1
コネクターを Kafka Connect に登録するために使用される名前。
2
このコネクターに作成するタスクの最大数。PostgreSQL コネクターは単一のコネクタータスクを使用して PostgreSQL サーバーの
binlogを読み取るため、適切な順序とイベント処理を確保するため、一度に動作できるタスクは 1 つのみです。Kafka Connect サービスは、コネクターを使用して 1 つ以上のタスクを開始して作業を実行し、実行中のタスクを Kafka Connect サービスのクラスター全体に自動的に分散します。サービスが停止またはクラッシュした場合、タスクは実行中のサービスに再分散されます。3
コネクターの設定。
4
PostgreSQL サーバーを実行するデータベースホストの名前。この例では、データベースのホスト名は
192.168.99.100です。5
一意のトピック接頭辞。トピック接頭辞は、PostgreSQL サーバーまたはサーバーのクラスターの論理識別子です。この文字列は、コネクターから変更イベントレコードを受け取るすべての Kafka トピックの名前の先頭に付加されます。
6
コネクターは
publicスキーマでのみ変更をキャプチャーします。選択したテーブルでのみ変更をキャプチャーするようにコネクターを設定できます。詳細はtable.include.listを参照してください。7
PostgreSQL サーバーにインストールされている PostgreSQL 論理デコードプラグイン の名前。コネクターは
pgoutputプラグインの使用のみをサポートしますが、plugin.nameをpgoutputに明示的に設定する必要があります。Kafka Connect でコネクターインスタンスを作成します。たとえば、
KafkaConnectorリソースをinventory-connector.yamlファイルに保存した場合は、以下のコマンドを実行します。oc apply -f inventory-connector.yaml
oc apply -f inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは
inventory-connectorを登録して、コネクターがKafkaConnectorCR に定義されているsampledbデータベースに対して実行を開始します。
結果
コネクターが起動すると、コネクターが設定された PostgreSQL サーバーデータベースの 整合性スナップショットが実行 されます。その後、コネクターは行レベルの操作のデータ変更イベントの生成を開始し、変更イベントレコードを Kafka トピックにストリーミングします。
2.6.6.4. Debezium PostgreSQL コネクターが実行していることの確認
コネクターがエラーなしで正常に起動すると、コネクターがキャプチャーするように設定された各テーブルのトピックが作成されます。ダウンストリームアプリケーションは、これらのトピックをサブスクライブして、ソースデータベースで発生する情報イベントを取得できます。
コネクターが実行されていることを確認するには、OpenShift Container Platform Web コンソールまたは OpenShift CLI ツール (oc) から以下の操作を実行します。
- コネクターのステータスを確認します。
- コネクターがトピックを生成していることを確認します。
- 各テーブルの最初のスナップショットの実行中にコネクターが生成する読み取り操作 ("op":"r") のイベントがトピックに反映されていることを確認します。
前提条件
- Debezium コネクターが OpenShift 上の Streams for Apache Kafka にデプロイされている。
-
OpenShift
ocCLI クライアントがインストールされている。 - OpenShift Container Platform Web コンソールにアクセスできる。
手順
以下の方法のいずれかを使用して
KafkaConnectorリソースのステータスを確認します。OpenShift Container Platform Web コンソールから以下を実行します。
- Home → Search に移動します。
-
Search ページで Resources をクリックし、Select Resource ボックスを開き、
KafkaConnectorを入力します。 - KafkaConnectors リストから、チェックするコネクターの名前をクリックします (例: inventory-connector-postgresql)。
- Conditions セクションで、Type および Status 列の値が Ready および True に設定されていることを確認します。
ターミナルウィンドウから以下を実行します。
以下のコマンドを実行します。
oc describe KafkaConnector <connector-name> -n <project>
oc describe KafkaConnector <connector-name> -n <project>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc describe KafkaConnector inventory-connector-postgresql -n debezium
oc describe KafkaConnector inventory-connector-postgresql -n debeziumCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、以下の出力のようなステータス情報を返します。
例2.44
KafkaConnectorリソースのステータスCopy to Clipboard Copied! Toggle word wrap Toggle overflow
コネクターによって Kafka トピックが作成されたことを確認します。
OpenShift Container Platform Web コンソールから以下を実行します。
- Home → Search に移動します。
-
Search ページで Resources をクリックし、Select Resource ボックスを開き、
KafkaTopicを入力します。 -
KafkaTopics リストから確認するトピックの名前をクリックします (例:
inventory-connector-postgresql.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d)。 - Conditions セクションで、Type および Status 列の値が Ready および True に設定されていることを確認します。
ターミナルウィンドウから以下を実行します。
以下のコマンドを実行します。
oc get kafkatopics
oc get kafkatopicsCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、以下の出力のようなステータス情報を返します。
例2.45
KafkaTopicリソースのステータスCopy to Clipboard Copied! Toggle word wrap Toggle overflow
トピックの内容を確認します。
- ターミナルウィンドウから、以下のコマンドを入力します。
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory-connector-postgresql.inventory.products_on_hand
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory-connector-postgresql.inventory.products_on_handCopy to Clipboard Copied! Toggle word wrap Toggle overflow トピック名を指定する形式は、手順 1 で返された
oc describeコマンドと同じです (例:inventory-connector-postgresql.inventory.addresses)。トピックの各イベントについて、このコマンドは、以下の出力のような情報を返します。
例2.46 Debezium 変更イベントの内容
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory-connector-postgresql.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-postgresql.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-postgresql.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"int64","optional":false,"field":"ts_us"},{"type":"int64","optional":false,"field":"ts_ns"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.postgresql.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"int64","optional":true,"field":"ts_us"},{"type":"int64","optional":true,"field":"ts_ns"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory-connector-postgresql.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"2.7.3.Final-redhat-00001","connector":"postgresql","name":"inventory-connector-postgresql","ts_ms":1638985247805,"ts_us":1638985247805000000,"ts_ns":1638985247805000000,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"postgresql-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"ts_us":1638985247805102,"ts_ns":1638985247805102588,"transaction":null}}{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory-connector-postgresql.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-postgresql.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-postgresql.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"int64","optional":false,"field":"ts_us"},{"type":"int64","optional":false,"field":"ts_ns"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.postgresql.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"int64","optional":true,"field":"ts_us"},{"type":"int64","optional":true,"field":"ts_ns"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory-connector-postgresql.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"2.7.3.Final-redhat-00001","connector":"postgresql","name":"inventory-connector-postgresql","ts_ms":1638985247805,"ts_us":1638985247805000000,"ts_ns":1638985247805000000,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"postgresql-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"ts_us":1638985247805102,"ts_ns":1638985247805102588,"transaction":null}}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記の例では、
payload値は、コネクタースナップショットがテーブルinventory.products_on_handから読み込み ("op" ="r") イベントを生成したことを示しています。product_idレコードの"before"状態はnullであり、レコードに以前の値が存在しないことを示しています。"after"状態は、product_id101を持つ項目のquantityが3であることを示しています。
2.6.6.5. Debezium PostgreSQL コネクター設定プロパティーの説明
Debezium PostgreSQL コネクターには、アプリケーションに適したコネクター動作を実現するために使用できる設定プロパティーが多数あります。多くのプロパティーにはデフォルト値があります。プロパティーに関する情報は、以下のように設定されています。
必要な Debezium PostgreSQL コネクター設定プロパティー
以下の設定プロパティーは、デフォルト値がない場合は必須です。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし | コネクターの一意名。同じ名前で再登録を試みると失敗します。このプロパティーはすべての Kafka Connect コネクターに必要です。 | |
| デフォルトなし |
コネクターの Java クラスの名前。PostgreSQL コネクターには、常に | |
|
| このコネクターのために作成する必要のあるタスクの最大数。PostgreSQL コネクターは常に単一のタスクを使用するため、この値を使用しません。そのため、デフォルト値は常に許容されます。 | |
|
| PostgreSQL サーバーにインストールされている PostgreSQL 論理デコードプラグイン の名前。
サポートされている値は | |
|
| 特定のデータベース/スキーマの特定のプラグインから変更をストリーミングするために作成された PostgreSQL 論理デコードスロットの名前。サーバーはこのスロットを使用して、設定する Debezium コネクターにイベントをストリーミングします。 スロット名は PostgreSQL レプリケーションスロットの命名ルール に準拠する必要があり、命名ルールには "Each replication slot has a name, which can contain lower-case letters, numbers, and the underscore character." と記載されています。 | |
|
| コネクターが正常に想定されるように停止した場合に論理レプリケーションスロットを削除するかどうか。デフォルトの動作では、コネクターが停止したときにレプリケーションスロットはコネクターに設定された状態を保持します。コネクターが再起動すると、同じレプリケーションスロットがあるため、コネクターは停止した場所から処理を開始できます。
テストまたは開発環境でのみ | |
|
|
このパブリケーションが存在しない場合は起動時に作成され、すべてのテーブルが含まれます。Debezium は、設定されている場合は、独自の include/exclude リストフィルターを適用し、対象となる特定のテーブルのイベントのみをパブリケーションが変更するように制限します。コネクターユーザーがこのパブリケーションを作成するには、スーパーユーザーの権限が必要であるため、通常はコネクターを初めて開始する前にパブリケーションを作成することを推奨します。 パブリケーションがすでに存在し、すべてのテーブルが含まれてているか、テーブルのサブセットで設定されている場合、Debezium は定義されているようにパブリケーションを使用します。 | |
| デフォルトなし | PostgreSQL データベースサーバーの IP アドレスまたはホスト名。 | |
|
| PostgreSQL データベースサーバーのポート番号 (整数)。 | |
| デフォルトなし | PostgreSQL データベースサーバーに接続するための PostgreSQL データベースユーザーの名前。 | |
| デフォルトなし | PostgreSQL データベースサーバーへの接続時に使用するパスワード。 | |
| デフォルトなし | 変更をストリーミングする PostgreSQL データベースの名前。 | |
| デフォルトなし |
Debezium が変更をキャプチャーする特定の PostgreSQL データベースサーバーまたはクラスターの名前空間を提供するトピック接頭辞。接頭辞は、他のコネクター全体で一意となる必要があります。これは、このコネクターからレコードを受信するすべての Kafka トピックのトピック名接頭辞として使用されるためです。データベースサーバーの論理名には英数字とハイフン、ドット、アンダースコアのみを使用する必要があります。 警告 このプロパティーの値を変更しないでください。名前の値を変更すると、再起動後に、元のトピックにイベントを発行し続けるのではなく、新しい値に基づいた名前のトピックに後続のイベントを発行します。 | |
| デフォルトなし |
変更をキャプチャーする対象とするスキーマの名前と一致する正規表現のコンマ区切りリスト (任意)。
スキーマの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定した式は、スキーマ名に存在する可能性のある部分文字列とは一致しない、スキーマの ID 全体と照合されます。 | |
| デフォルトなし |
変更をキャプチャーする対象としないスキーマの名前と一致する正規表現のコンマ区切りリスト (任意)。システムスキーマ以外で、
スキーマの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定した式は、スキーマ名に存在する可能性のある部分文字列とは一致しない、スキーマの ID 全体と照合されます。 | |
| デフォルトなし |
変更をキャプチャーするテーブルの完全修飾テーブル識別子と一致する正規表現のコンマ区切りリスト (任意)。このプロパティーが設定されている場合、コネクターは指定されたテーブルからのみ変更をキャプチャします。各識別子の形式は schemaName.tableName です。デフォルトでは、コネクターは変更がキャプチャーされる各スキーマのシステムでないすべてのテーブルの変更をキャプチャーします。
テーブルの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの ID 全体と照合されます。 | |
| デフォルトなし |
変更をキャプチャーしないテーブルの完全修飾テーブル識別子と一致する正規表現のコンマ区切りリスト (任意)。各識別子の形式は schemaName.tableName です。このプロパティーが設定されている場合、コネクターは、指定のないすべてのテーブルから変更をキャプチャーします。
テーブルの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの ID 全体と照合されます。 | |
| デフォルトなし |
変更イベントレコード値に含まれる必要がある列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。列の完全修飾名の形式は schemaName.tableName.columnName です。
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、列の名前文字列全体を一致させるために式が使用され、列名に存在する可能性のある部分文字列とは一致しません。 | |
| デフォルトなし |
変更イベントレコード値から除外される必要がある列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。列の完全修飾名の形式は schemaName.tableName.columnName です。
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、列の名前文字列全体を一致させるために式が使用され、列名に存在する可能性のある部分文字列とは一致しません。 | |
|
|
含まれる列に変更がない場合にメッセージの公開をスキップするかどうかを指定します。これは基本的に、含まれる列に変更がない場合、 注: テーブルの REPLICA IDENTITY が FULL に設定されている場合にのみ機能します。 | |
|
|
時間、日付、およびタイムスタンプは、異なる精度の種類で表すことができます。 | |
|
|
コネクターによる | |
|
|
コネクターによる | |
|
|
| |
|
|
PostgreSQL サーバーへの暗号化された接続を使用するかどうか。オプションには以下が含まれます。 | |
| デフォルトなし | クライアントの SSL 証明書が含まれるファイルへのパス。詳細は the PostgreSQL のドキュメント を参照してください。 | |
| デフォルトなし | クライアントの SSL 秘密鍵が含まれるファイルへのパス。詳細は the PostgreSQL のドキュメント を参照してください。 | |
| デフォルトなし |
| |
| デフォルトなし | サーバーが検証されるルート証明書が含まれるファイルへのパス。詳細は the PostgreSQL のドキュメント を参照してください。 | |
|
| TCP keep-alive プローブを有効にして、データベース接続がまだ有効であることを確認します。詳細は the PostgreSQL のドキュメント を参照してください。 | |
|
|
delete イベントの後に廃棄 (tombstone) イベントが続くかどうかを制御します。 | |
| 該当なし |
文字ベースの列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。プロパティー名の 長さ で指定された文字数を超えた場合に、一連の列のデータを切り捨てる場合は、このプロパティーを設定します。
列の完全修飾名は、 単一の設定で、異なる長さを持つ複数のプロパティーを指定できます。 | |
| 該当なし |
文字ベースの列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。一連の列の値をコネクターでマスクする場合 (たとえば、列に機密データが含まれている場合) は、このプロパティーを設定します。 列の完全修飾名は、次の形式に従います: schemaName.tableName.columnName列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列の名前文字列全体に対して照合されます。式は、列名に存在する可能性のある部分文字列と一致しません。 単一の設定で、異なる長さを持つ複数のプロパティーを指定できます。 | |
|
| 該当なし |
文字ベースの列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。列の完全修飾名の形式は <schemaName>.<tableName>.<columnName> です。
仮名は、指定された hashAlgorithm と salt を適用すると得られるハッシュ化された値で構成されます。使用されるハッシュ関数に基づいて、参照整合性は保持され、列値は仮名に置き換えられます。サポートされるハッシュ関数は、Java Cryptography Architecture Standard Algorithm Name Documentation の MessageDigest セクションに説明されています。 column.mask.hash.SHA-256.with.salt.CzQMA0cB5K = inventory.orders.customerName, inventory.shipment.customerName
必要な場合は、仮名は自動的に列の長さに短縮されます。コネクター設定には、異なるハッシュアルゴリズムと salt を指定する複数のプロパティーを含めることができます。 |
| 該当なし | 列のメタデータを表す追加パラメーターをコネクターに発行させたい列の完全修飾名に一致する、オプションのコンマ区切りの正規表現のリスト。このプロパティーが設定されている場合、コネクターは次のフィールドをイベントレコードのスキーマに追加します。
これらのパラメーターは、列の元の型名と長さ (可変幅型の場合) をそれぞれ伝達します。
列の完全修飾名は、次のいずれかの形式に従います: databaseName.tableName.columnName、または databaseName.schemaName.tableName.columnName. | |
| 該当なし | データベース内の列に対して定義されているデータ型の完全修飾名を指定する正規表現のオプションのコンマ区切りリスト。このプロパティーが設定されている場合、データ型が一致する列に対して、コネクターはスキーマに次の追加フィールドを含むイベントレコードを発行します。
これらのパラメーターは、列の元の型名と長さ (可変幅型の場合) をそれぞれ伝達します。
列の完全修飾名の形式は、databaseName.tableName.typeName、または databaseName.schemaName.tableName.typeName のいずれかになります。 PostgreSQL 固有のデータ型名の一覧は、PostgreSQL データ型マッピング を参照してください。 | |
| 空の文字列 | 指定のテーブルの Kafka トピックに公開する変更イベントレコードのカスタムメッセージキーを形成するためにコネクターが使用する列を指定する式のリスト。
デフォルトでは、Debezium はテーブルのプライマリーキー列を、出力するレコードのメッセージキーとして使用します。デフォルトの代わりに、またはプライマリーキーのないテーブルのキーを指定するには、1 つ以上の列をもとにカスタムメッセージキーを設定できます。
各完全修飾テーブル名は、 カスタムメッセージキーの作成に使用する列の数に制限はありません。ただし、一意の鍵を指定するために必要な最小数を使用することが推奨されます。
テーブルでこのプロパティーを設定し、 | |
| all_tables |
コネクターが パブリケーション を作成するかどうか、また作成する方法を指定します。この設定は、コネクターが 注記 パブリケーションを作成するには、コネクターは特定の権限があるデータベースアカウントを使用して PostgreSQL にアクセスする必要があります。詳細は、Debezium が PostgreSQL パブリケーションを作成できるように権限を設定 を参照してください。 以下のいずれかの値を指定します。
| |
| 空の文字列 |
この設定は、テーブルレベルで レプリカ ID の値を決定します。 schema1.*:FULL,schema2.table2:NOTHING,schema2.table3:INDEX idx_name | |
| bytes |
変更イベントでのバイナリー ( | |
| none |
コネクターで使用されるメッセージコンバータとの互換性のために、スキーマ名をどのように調整するかを指定します。設定可能:
| |
| none |
コネクターで使用されるメッセージコンバータとの互換性のために、フィールド名をどのように調整するかを指定します。設定可能:
詳しい情報は、Avro naming を参照してください。 | |
|
|
Postgres の | |
| デフォルトなし | コネクターでキャプチャーする論理デコードメッセージの接頭辞と一致するコンマ区切りの正規表現 (任意)。デフォルトでは、コネクターはすべての論理デコードメッセージをキャプチャーします。このプロパティーが設定されている場合、コネクターはプロパティーで指定された接頭辞が含まれる論理デコードメッセージのみをキャプチャーします。その他の論理デコードメッセージはすべて除外されます。 メッセージの接頭辞名を照合するために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、メッセージ接頭辞文字列全体と照合されます。式は、接頭辞に存在する可能性のある部分文字列と一致しません。
このプロパティーを設定に含める場合は、 メッセージ イベントの構造とその順序付けのセマンティクスについては、メッセージイベント を参照してください。 | |
| デフォルトなし |
コネクターでキャプチャーしない論理デコードメッセージの接頭辞名と一致するコンマ区切りの正規表現 (任意)。このプロパティーが設定されている場合、コネクターは、指定された接頭部を使用する論理デコードメッセージをキャプチャーしません。その他のメッセージはすべてキャプチャーされます。 メッセージの接頭辞名を照合するために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、メッセージ接頭辞文字列全体と照合されます。式は、接頭辞に存在する可能性のある部分文字列と一致しません。
このプロパティーを設定に含める場合は、 メッセージ イベントの構造とその順序付けのセマンティクスについては、メッセージイベント を参照してください。 |
高度な Debezium PostgreSQL コネクター設定プロパティー
以下の 高度な 設定プロパティーには、ほとんどの状況で機能するデフォルト設定があるため、コネクターの設定で指定する必要はほとんどありません。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし |
コネクターが使用できる カスタムコンバーター インスタンスのシンボリック名をコンマ区切りリストで列挙します。以下に例を示します。
コネクターがカスタムコンバーターを使用できるようにするには、
コネクターに設定するコンバーターごとに、コンバーターインターフェイスを実装するクラスの完全修飾名を指定する
以下に例を示します。 isbn.type: io.debezium.test.IsbnConverter
設定されたコンバータの動作をさらに制御したい場合は、1 つ以上の設定パラメーターを追加して、コンバータに値を渡すことができます。追加の設定パラメーターとコンバーターを関連付けるには、パラメーター名の前にコンバーターのシンボリック名を付けます。 isbn.schema.name: io.debezium.postgresql.type.Isbn | |
| Initial |
コネクターの起動時にスナップショットを実行するための基準を指定します。
Kafka オフセットトピックに以前保存された LSN がある場合、コネクターはその位置から変更をストリーミングを続行します。LSN が保存されていない場合、コネクターは、サーバー上で PostgreSQL 論理レプリケーションスロットが作成された時点から、変更のストリーミングを開始します。対象のすべてのデータが WAL に反映されている場合にのみ、このスナップショットモードを使用します。
詳細は、 | |
|
|
スキーマスナップショットを実行するときにコネクターがテーブルのロックを保持する方法を指定します。
警告 スナップショット中にスキーマの変更が発生する可能性がある場合は、このモードを使用しないでください。 | |
|
|
スナップショットを実行するときにコネクターがデータをクエリーする方法を指定します。
この設定により、 | |
|
|
スナップショットに含めるテーブルの完全修飾名 ( テーブルの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの名前文字列全体と照合されます。 | |
|
| スナップショットの実行時に、テーブルロックを取得するまで待つ最大時間 (ミリ秒単位) を指定する正の整数値。コネクターがこの期間にテーブルロックを取得できないと、スナップショットは失敗します。詳細は、コネクターによるスナップショットの実行方法 を参照してください。 | |
| デフォルトなし | スナップショットに追加するテーブル行を指定します。スナップショットにテーブルの行のサブセットのみを含める場合は、プロパティーを使用します。このプロパティーはスナップショットにのみ影響します。コネクターがログから読み取るイベントには影響しません。
プロパティーには、
スナップショットにソフト削除以外のレコードのみを含める場合は、soft-delete 列 ( "snapshot.select.statement.overrides": "customer.orders", "snapshot.select.statement.overrides.customer.orders": "SELECT * FROM customers.orders WHERE delete_flag = 0 ORDER BY id DESC"
作成されるスナップショットでは、コネクターには | |
|
|
イベントの処理中にコネクターが例外に反応する方法を指定します。 | |
|
| コネクターが処理するイベントの各バッチの最大サイズを指定する正の整数値。 | |
|
|
ブロッキングキューが保持できるレコードの最大数を指定する正の整数値。Debezium はデータベースからストリームされたイベントを読み込む際、Kafka に書き込む前にブロッキングキューにイベントを配置します。ブロッキングキューは、コネクターが Kafka に書き込むよりも速くメッセージを取り込む場合、または Kafka が利用できなくなった場合に、データベースから変更イベントを読み込むためのバックプレッシャーを提供することができます。コネクターがオフセットを定期的に記録すると、キューに保持されるイベントは無視されます。 | |
|
|
ブロッキングキューの最大容量をバイト単位で指定する長整数値。デフォルトでは、ブロックキューにはボリューム制限は指定されません。キューが使用できるバイト数を指定するには、このプロパティーを正の long 値に設定します。 | |
|
| コネクターがイベントのバッチの処理を開始する前に、新しい変更イベントの発生を待つ期間をミリ秒単位で指定する正の整数値。デフォルトは 500 ミリ秒です。 | |
|
|
コネクターがデータタイプが不明なフィールドを見つけたときのコネクターの動作を指定します。コネクターが変更イベントからフィールドを省略し、警告をログに記録するのがデフォルトの動作です。 注記
| |
| デフォルトなし |
データベースへの JDBC 接続を確立するときにコネクターが実行する SQL ステートメントのセミコロン区切りリスト。セミコロンを区切り文字としてではなく、文字として使用する場合は、2 つの連続したセミコロン | |
|
|
レプリケーションの接続状態をサーバーに送信する頻度をミリ秒単位で指定します。 | |
|
|
コネクターがハートビートメッセージを Kafka トピックに送信する頻度を制御します。デフォルトの動作では、コネクターはハートビートメッセージを送信しません。 | |
| デフォルトなし |
コネクターがハートビートメッセージを送信するときにコネクターがソースデータベースで実行するクエリーを指定します。 | |
|
|
テーブルのインメモリースキーマの更新をトリガーする条件を指定します。 | |
| デフォルトなし | コネクターの起動時にスナップショットを実行するまでコネクターが待つ必要がある間隔 (ミリ秒単位)。クラスターで複数のコネクターを起動する場合、このプロパティーは、コネクターのリバランスが行われる原因となるスナップショットの中断を防ぐのに役立ちます。 | |
| 0 |
コネクターがスナップショットを完了した後、ストリーミングプロセスの開始を遅延する時間をミリ秒単位で指定します。遅延間隔を設定すると、スナップショットが完了した直後で、ストリーミングプロセスの開始前に障害が発生した場合に、コネクターがスナップショットを再開できないようにします。Kafka Connect ワーカーに設定されている | |
|
| スナップショットの実行中、コネクターは行のバッチでテーブルの内容を読み取ります。このプロパティーは、バッチの行の最大数を指定します。 | |
| デフォルトなし |
設定された論理デコードプラグインに渡すパラメーターのセミコロン区切りリスト。たとえば、 | |
|
| レプリケーションスロットへの接続に失敗した場合に、連続して接続を試行する最大回数です。 | |
|
| コネクターがレプリケーションスロットへの接続に失敗した場合に再試行を行う間隔 (ミリ秒単位)。 | |
|
|
コネクターが提供する定数を指定して、元の値がデータベースによって提供されていない Toast 化された値であることを示します。 | |
|
|
コネクターがトランザクション境界でイベントを生成し、トランザクションメタデータで変更イベントエンベロープを強化するかどうかを決定します。コネクターにこれを実行させる場合は | |
|
|
WAL ログを削除できるように、コネクターがソース postgres データベースに、処理されたレコードの LSN をコミットする必要があるかどうかを決定します。コネクターでこれを行わない場合は | |
| 10000 (10 秒) | 再試行可能なエラーが発生した後にコネクターを再起動するまで待機する時間 (ミリ秒単位)。 | |
|
|
ストリーミング中にスキップされる操作タイプのコンマ区切りリスト。挿入/作成は | |
| デフォルト値なし |
シグナルをコネクターへの送信に使用されるデータコレクションの完全修飾名。 | |
| source | コネクターに対して有効な信号チャネル名のリスト。デフォルトでは、以下のチャネルが利用可能です。
| |
| デフォルトなし | コネクターに対して有効になっている通知チャネル名のリスト。デフォルトでは、以下のチャネルが利用可能です。
| |
| 1024 | 増分スナップショットのチャンクの実行中にコネクターがメモリーを取得して読み取る行の最大数。スナップショットは、サイズが大きいスナップショットの場合にはクエリーが少なくなるため、チャンクサイズを増やすと効率が上がります。ただし、チャンクサイズが大きい場合には、スナップショットデータのバッファーにより多くのメモリーが必要になります。チャンクサイズは、環境で最適なパフォーマンスを発揮できる値に、調整します。 | |
|
|
増分スナップショットによってキャプチャーされ、ストリーミングの再開後に再キャプチャーされる可能性のあるイベントを重複排除するために、コネクターが増分スナップショット中に使用するウォーターマークメカニズムを指定します。
| |
|
|
レプリケーションスロットから XMIN が読み込まれる頻度 (ミリ秒単位)。XMIN 値は、新しいレプリケーションスロットの開始位置の下限を示す。デフォルト値の | |
|
|
データ変更、スキーマ変更、トランザクション、ハートビートイベントなどのトピック名を決定するために使用する TopicNamingStrategy クラスの名前。デフォルトは | |
|
|
トピック名の区切り文字を指定します。デフォルトは | |
|
| トピック名を保持するために使用されるサイズ (bounded concurrent hash map)。このキャッシュは、与えられたデータコレクションに対応するトピック名を決定するのに役立つ。 | |
|
|
コネクターがハートビートメッセージを送信するトピックの名前を制御します。トピック名のパターンは、 | |
|
|
コネクターがトランザクションのメタデータメッセージを送信するトピックの名前を制御します。トピック名のパターンは、 | |
|
| 初期スナップショットを実行するときにコネクターが使用するスレッドの数を指定します。並列初期スナップショットを有効にするには、プロパティーを 1 より大きい値に設定します。並列初期スナップショットでは、コネクターは複数のテーブルを同時に処理します。 重要 並列初期スナップショットはテクノロジープレビュー機能のみとなっています。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。 | |
|
|
コンテキスト情報を提供するメタデータを追加して、MBean オブジェクト名をカスタマイズするタグを定義します。キーと値のペアのコンマ区切りリストを指定します。各キーは MBean オブジェクト名のタグを表し、対応する値はキーの値を表します。たとえば、 コネクターは、指定されたタグを基本 MBean オブジェクト名に追加します。タグは、メトリクスデータを整理および分類するのに役立ちます。特定のアプリケーションインスタンス、環境、リージョン、バージョンなどを識別するためのタグを定義できます。詳細は、カスタマイズされた MBean 名 を参照してください。 | |
|
|
接続エラーなど、再試行可能なエラーが発生する操作の後に、コネクターがどのように応答するかを指定します。
| |
|
|
コネクターがクエリーの完了を待機する時間をミリ秒単位で指定します。タイムアウト制限を削除するには、値を |
パススルー PostgreSQL コネクター設定プロパティー
コネクターは pass-through プロパティーをサポートしており、これにより Debezium は Apache Kafka プロデューサーとコンシューマーの動作を微調整するためのカスタム設定オプションを指定できます。Kafka プロデューサーとコンシューマーの全設定プロパティーの詳細は、Kafka ドキュメント を参照してください。
PostgreSQL コネクターが Kafka シグナリングトピックとどのように対話するかを設定するためのパススループロパティー
Debezium は、コネクターが Kafka シグナルトピックと対話する方法を制御する signal.* プロパティーのセットを提供します。
以下の表は、Kafka signal プロパティーを説明しています。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| <topic.prefix>-signal | コネクターがアドホックシグナルについて監視する Kafka トピックの名前。 注記 トピックの自動作成 が無効になっている場合は、必要なシグナリングトピックを手動で作成する必要があります。シグナルの順序を維持するには、シグナルトピックが必要です。シグナリングトピックには単一のパーティションが必要です。 | |
| kafka-signal | Kafka コンシューマーによって使用されるグループ ID の名前。 | |
| デフォルトなし | コネクターが Kafka クラスターへの初期接続を確立するために使用するホストとポートのペアのリスト。各ペアは、Debezium Kafka Connect プロセスによって使用される Kafka クラスターを参照します。 | |
|
| コネクターが信号をポーリングするときに待機する最大ミリ秒数を指定する整数値。 | |
|
| Kafka コンシューマーがシグナリングトピックからメッセージを読み取った後にオフセットコミットを書き込むかどうかを指定します。このプロパティーに割り当てる値によって、コネクターがオフラインのときに、シグナリングトピックが受信する要求をコネクターが処理できるかどうかが決まります。次のいずれかの設定を選択します。
|
シグナリングチャネルの Kafka コンシューマークライアントを設定するためのパススループロパティー
Debezium コネクターでは、Kafka コンシューマーのパススルー設定が可能です。パススルーシグナルのプロパティーは、接頭辞 signals.consumer.* で始まります。たとえば、コネクターは signal.consumer.security.protocol=SSL などのプロパティーを Kafka コンシューマーに渡します。
Debezium は、プロパティーを Kafka シグナルコンシューマーに渡す前に、プロパティーから接頭辞を削除します。
PostgreSQL コネクター sink notification チャネルを設定するためのパススループロパティー
次の表では、Debezium sink notification チャネルの設定に使用できるプロパティーについて説明します。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし |
Debezium から通知を受信するトピックの名前。このプロパティーは、有効な通知チャネルの 1 つとして |
Debezium コネクターのパススルーデータベースドライバー設定プロパティー
Debezium コネクターでは、データベースドライバーのパススルー設定が可能です。パススルーデータベースプロパティーは接頭辞 driver.* で始まります。たとえば、コネクターは driver.foobar=false などのプロパティーを JDBC URL に渡します。
Debezium は、プロパティーをデータベースドライバーに渡す前に、プロパティーから接頭辞を削除します。
2.6.7. Debezium PostgreSQL コネクターのパフォーマンスの監視
Debezium PostgreSQL コネクターは、Zookeeper、Kafka、および Kafka Connect によって提供される JMX メトリクスの組み込みサポートに加えて、2 種類のメトリクスを提供します。
- スナップショットメトリクス は、スナップショットの実行中にコネクター操作に関する情報を提供します。
- メトリクスのストリーミング は、コネクターが変更をキャプチャーし、変更イベントレコードをストリーミングする際のコネクター操作に関する情報を提供します。
Debezium モニタリングのドキュメント では、JMX を使用してこれらのメトリクスを公開する方法の詳細を説明しています。
/ Type: concept .Customized MBean 名
Debezium コネクターは、コネクターの MBean 名を介してメトリクスを公開します。これらのメトリクスは各コネクターインスタンスに固有であり、コネクターのスナップショット、ストリーミング、およびスキーマ履歴プロセスの動作に関するデータを提供します。
デフォルトでは、正しく設定されたコネクターをデプロイすると、Debezium はさまざまなコネクターメトリクスごとに一意の MBean 名を生成します。コネクタープロセスのメトリクスを表示するには、MBean を監視するように可観測性スタックを設定します。ただし、これらのデフォルトの MBean 名はコネクター設定に依存しており、設定の変更によって MBean 名が変更される場合があります。MBean 名を変更すると、コネクターインスタンスと MBean 間のリンクが切断され、監視アクティビティーが中断されます。このシナリオでは、監視を再開するには、新しい MBean 名を使用するように監視スタックを再設定する必要があります。
MBean 名の変更が原因で監視が中断されないように、カスタムメトリクスタグを設定できます。カスタムメトリクスを設定するには、コネクター設定に custom.metric.tags プロパティーを追加します。このプロパティーは、各キーが MBean オブジェクト名のタグを表し、対応する値がそのタグの値を表すキーと値のペアを受け入れます。たとえば、k1=v1,k2=v2 です。Debezium は、指定されたタグをコネクターの MBean 名に追加します。
コネクターの custom.metric.tags プロパティーを設定した後、指定されたタグに関連付けられたメトリクスを取得するように監視スタックを設定できます。可観測性スタックは、変更可能な MBean 名ではなく、指定されたタグを使用してコネクターを一意に識別します。その後、Debezium が MBean 名の構築方法を再定義したり、コネクター設定の topic.prefix が変更されたりしても、メトリクススクレイプタスクは指定されたタグパターンを使用してコネクターを識別するため、メトリクスの収集は中断されません。
カスタムタグを使用するさらなる利点は、データパイプラインのアーキテクチャーを反映するタグを使用できるため、運用上のニーズに合った方法でメトリクスを整理できることです。たとえば、コネクターアクティビティーのタイプ、アプリケーションコンテキスト、またはデータソースを宣言する値を持つタグを指定できます (例: db1-streaming-for-application-abc)。複数のキーと値のペアを指定すると、指定されたすべてのペアがコネクターの MBean 名に追加されます。
次の例は、タグがデフォルトの MBean 名を変更する方法を示しています。
例2.47 カスタムタグがコネクター MBean 名を変更する方法
デフォルトでは、PostgreSQL コネクターはストリーミングメトリクスに次の MBean 名を使用します。
debezium.postgresql:type=connector-metrics,context=streaming,server=<topic.prefix>
debezium.postgresql:type=connector-metrics,context=streaming,server=<topic.prefix>
custom.metric.tags の値を database=salesdb-streaming,table=inventory に設定すると、Debezium は次のカスタム MBean 名を生成します。
debezium.postgresql:type=connector-metrics,context=streaming,server=<topic.prefix>,database=salesdb-streaming,table=inventory
debezium.postgresql:type=connector-metrics,context=streaming,server=<topic.prefix>,database=salesdb-streaming,table=inventory2.6.7.1. PostgreSQL データベースのスナップショット作成時の Debezium の監視
MBean は debezium.postgres:type=connector-metrics,context=snapshot,server=<topic.prefix> です。
スナップショット操作がアクティブでない場合や、最後のコネクターの起動後にスナップショットの作成が発生した場合に、スナップショットメトリクスは公開されません。
次の表に、使用可能なスナップショットメトリクスを示します。
| 属性 | タイプ | 説明 |
|---|---|---|
|
| コネクターが読み取りした最後のスナップショットイベント。 | |
|
| コネクターが最新のイベントを読み取りおよび処理してからの経過時間 (ミリ秒単位)。 | |
|
| 前回の開始またはリセット以降にコネクターで確認されたイベントの合計数。 | |
|
| コネクターに設定された include/exclude リストのフィルタリングルールによってフィルターされたイベントの数。 | |
|
| コネクターによって取得されるテーブルのリスト。 | |
|
| snapshotter とメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの長さ。 | |
|
| snapshotter とメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの空き容量。 | |
|
| スナップショットに含まれているテーブルの合計数。 | |
|
| スナップショットによってまだコピーされていないテーブルの数。 | |
|
| スナップショットが起動されたかどうか。 | |
|
| スナップショットが一時停止されたかどうか。 | |
|
| スナップショットが中断されたかどうか。 | |
|
| スナップショットが完了したかどうか。 | |
|
| スナップショットが完了したかどうかに関わらず、これまでスナップショットにかかった時間 (秒単位)。スナップショットが一時停止された時間も含まれます。 | |
|
| スナップショットが一時停止された合計秒数。スナップショットが数回一時停止された場合は、一時停止時間が加算されます。 | |
|
| スナップショットの各テーブルに対してスキャンされる行数が含まれるマップ。テーブルは、処理中に増分がマップに追加されます。スキャンされた 10,000 行ごとに、テーブルの完成時に更新されます。 | |
|
|
キューの最大バッファー (バイト単位)。このメトリクスは、 | |
|
| キュー内のレコードの現在の容量 (バイト単位)。 |
コネクターは、増分スナップショットの実行時に、以下の追加のスナップショットメトリクスも提供します。
2.6.7.2. Debezium PostgreSQL コネクターレコードストリーミングの監視
MBean は debezium.postgres:type=connector-metrics,context=streaming,server=<topic.prefix> です。
以下の表は、利用可能なストリーミングメトリクスのリストです。
| 属性 | タイプ | 説明 |
|---|---|---|
|
| コネクターが読み取られた最後のストリーミングイベント。 | |
|
| コネクターが最新のイベントを読み取りおよび処理してからの経過時間 (ミリ秒単位)。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、ソースデータベースによって報告されたデータ変更イベントの合計数。Debezium が処理するデータ変更ワークロードを表します。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された作成イベントの合計数。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された更新イベントの合計数。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された削除イベントの合計数。 | |
|
| コネクターに設定された include/exclude リストのフィルタリングルールによってフィルターされたイベントの数。 | |
|
| コネクターによって取得されるテーブルのリスト。 | |
|
| ストリーマーとメイン Kafka Connect ループの間でイベントを渡すために使用されるキューの長さ。 | |
|
| ストリーマーとメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの空き容量。 | |
|
| コネクターが現在データベースサーバーに接続されているかどうかを示すフラグ。 | |
|
| 最後の変更イベントのタイムスタンプとそれを処理するコネクターとの間の期間 (ミリ秒単位)。この値には、データベースサーバーとコネクターが実行されているマシンのクロックの差が組み込まれます。 | |
|
| コミットされた処理済みトランザクションの数。 | |
|
| 最後に受信したイベントの位置。 | |
|
| 最後に処理されたトランザクションのトランザクション識別子。 | |
|
|
キューの最大バッファー (バイト単位)。このメトリクスは、 | |
|
| キュー内のレコードの現在の容量 (バイト単位)。 |
2.6.8. Debezium PostgreSQL コネクターによる障害および問題の処理方法
Debezium は、複数のアップストリームデータベースのすべての変更をキャプチャーする分散システムであり、イベントの見逃しや損失は発生しません。システムが正常に操作している場合や、慎重に管理されている場合は、Debezium は変更イベントレコードごとに 1 度だけ 配信します。
PostgreSQL 変更イベントレコードの 1 回限りの配信は、開発者プレビュー機能のみとなっています。開発者プレビューソフトウェアは、Red Hat では一切サポートされておらず、機能的に完全ではなく、実稼働環境に対応していません。開発者プレビューのソフトウェアを実稼働ワークロードまたはビジネスクリティカルなワークロードには使用しないでください。開発者プレビューソフトウェアは、今後 Red Hat 製品サービスとして追加される可能性のある製品ソフトウェアを前もって早期に利用できます。お客様はこのソフトウェアを使用して機能をテストし、開発プロセス中にフィードバックを提供できます。このソフトウェアにはドキュメントが存在しない可能性があり、変更または削除される可能性があります。また、限定的なテストしか行われていません。Red Hat は、関連する SLA なしに、開発者プレビューソフトウェアに対するフィードバックを送信する手段を提供する場合があります。
Red Hat 開発者プレビューソフトウェアのサポート範囲の詳細は、開発者プレビューのサポート範囲 を参照してください。
障害が発生しても、システムはイベントを失いません。ただし、障害からの回復中に、コネクターが重複した変更イベントを発行する可能性があります。このような正常でない状態では、Debezium は Kafka と同様に、変更イベントを 少なくとも 1 回 配信します。
詳細は以下を参照してください。
設定および起動エラー
以下の状況では、起動時にコネクターが失敗し、エラーまたは例外がログに記録され、実行が停止されます。
- コネクターの設定が無効である。
- 指定の接続パラメーターを使用してコネクターを PostgreSQL に接続できない。
- コネクターは (LSN を使用して) PostgreSQL WAL の以前に記録された位置から再起動され、PostgreSQL ではその履歴が利用できなくなります。
このような場合、エラーメッセージには問題の詳細が含まれ、推奨される回避策も含まれることがあります。設定の修正したり、PostgreSQL の問題に対処した後、コネクターを再起動します。
PostgreSQL コネクターは、最後に処理されたオフセットを PostgreSQL LSN の形式で外部に保存します。コネクターが再起動し、サーバーインスタンスに接続すると、コネクターはサーバーと通信し、その特定のオフセットからストリーミングを続行します。このオフセットは、Debezium レプリケーションスロットがそのままの状態である限り利用できます。プライマリーサーバーでレプリケーションスロットを削除しないでください。削除するとデータが失われます。スロットが削除された場合の障害例は、次のセクションを参照してください。
クラスターの障害
PostgreSQL はリリース 12 より、プライマリーサーバー上でのみ論理レプリケーションスロットを許可するようになりました。つまり、Debezium PostgreSQL コネクターをデータベースクラスターのアクティブなプライマリーサーバーのみにポイントできます。また、レプリケーションスロット自体はレプリカに伝播されません。プライマリーサーバーがダウンした場合は、新しいプライマリーを昇格する必要があります。
一部の管理対象 PostgresSQL サービス (AWS RDS や GCP CloudSQL など) は、ディスクを複製して、スタンバイへのレプリケーションを実装します。つまり、レプリケーションスロットがレプリケートされ、フェイルオーバー後も引き続き使用できます。
新しいプライマリーには、pgoutput プラグインが使用するよう設定されたレプリケーションスロットと、変更をキャプチャーするデータベースが必要です。その後でのみ、コネクターが新しいサーバーを示すようにし、コネクターを再起動することができます。
フェイルオーバーが発生した場合は重要な注意点があります。レプリケーションスロットがそのままの状態で、データを損失していないことを確認するまで Debezium を一時停止する必要があります。フェイルオーバー後に以下を行います。
- アプリケーションが新しいプライマリーに書き込みする前に、Debezium のレプリケーションスロットを再作成するプロセスが必要です。これは重要です。このプロセスがないと、アプリケーションが変更イベントを見逃す可能性があります。
- 古いプライマリーが失敗する前に、Debezium がスロットのすべての変更を読み取りできることを確認する必要があることがあります。
失われた変更があるかどうかを確認し、取り戻すための信頼できる方法の 1 つは、障害が発生したプライマリーのバックアップを、障害が発生する直前まで復旧することです。これは管理が難しい場合がありますが、レプリケーションスロットで未使用の変更があるかどうかを確認することができます。
Kafka Connect のプロセスは正常に停止する
Kafka Connect が分散モードで実行され、Kafka Connect プロセスが正常に停止した場合を想定します。Kafka Connect はそのプロセスをシャットダウンする前に、プロセスのコネクタータスクをそのグループの別の Kafka Connect プロセスに移行します。新しいコネクタータスクは、以前のタスクが停止した場所でプロセスを開始します。コネクタータスクが正常に停止され、新しいプロセスで再起動されるまでの間、プロセスに短い遅延が発生します。
Kafka Connect プロセスのクラッシュ
Kafka Connector プロセスが予期せず停止した場合、最後に処理されたオフセットを記録せずに、実行中のコネクタータスクが終了します。Kafka Connect が分散モードで実行されている場合は、Kafka Connect は他のプロセスでこれらのコネクタータスクを再起動します。ただし、PostgreSQL コネクターは、以前のプロセスで最後に記録されたオフセットから再開します。つまり、新しい代替タスクによって、クラッシュの直前に処理された同じ変更イベントが生成される可能性があります。重複するイベントの数は、オフセットのフラッシュ期間とクラッシュの直前のデータ変更の量によって異なります。
障害からの復旧中に一部のイベントが重複された可能性があるため、コンシューマーは常に重複されたイベントがある可能性を想定する必要があります。Debezium の変更はべき等であるため、一連のイベントは常に同じ状態になります。
各変更イベントレコードでは Debezium コネクターは、イベント発生時の PostgreSQL サーバー時間、サーバートランザクションの ID、トランザクションの変更が書き込まれたログ先行書き込みの位置など、イベント発生元に関するソース固有の情報を挿入します。コンシューマーは、LSN を重点としてこの情報を追跡し、イベントが重複しているかどうかを判断します。
コネクターの一定期間の停止
コネクターが正常に停止された場合、データベースを引き続き使用できます。変更はすべて PostgreSQL WAL に記録されます。コネクターが再起動すると、停止した場所で変更のストリーミングが再開されます。つまり、コネクターが停止した間に発生したデータベースのすべての変更に対して変更イベントレコードが生成されます。
適切に設定された Kafka クラスターは大量のスループットを処理できます。Kafka Connect は Kafka のベストプラクティスに従って作成され、十分なリソースがあれば Kafka Connect コネクターも非常に多くのデータベース変更イベントを処理できます。このため、Debezium コネクターがしばらく停止した後に再起動すると、停止中に発生したデータベースの変更に対して処理の遅れを取り戻す可能性が非常に高くなります。遅れを取り戻すのに掛かる時間は、Kafka の機能やパフォーマンス、および PostgreSQL のデータに加えられた変更の量によって異なります。
2.7. SQL Server の Debezium コネクター
Debezium の SQL Server コネクターは、SQL Server データベースのスキーマで発生する行レベルの変更をキャプチャーします。
このコネクターと互換性のある SQL Server のバージョンについては、Debezium でサポートされる設定ページを参照してください。
Debezium SQL Server コネクターとその使用に関する詳細は、以下を参照してください。
Debezium SQL Server コネクターが SQL Server データベースまたはクラスターに初めて接続すると、データベースのスキーマの整合性スナップショットが作成されます。コネクターは、最初のスナップショットが完了すると、CDC に対して有効になっている SQL Server データベースにコミットされた INSERT、UPDATE または DELETE 操作の行レベルの変更を継続的にキャプチャーします。コネクターは、各データ変更操作のイベントを生成し、それらのイベントを Kafka トピックにストリーミングします。コネクターは、テーブルのすべてのイベントを専用の Kafka トピックにストリーミングします。その後、アプリケーションとサービスは、そのトピックからのデータ変更イベントレコードを使用できます。
2.7.1. Debezium SQL Server コネクターの概要
Debezium SQL Server コネクターは、SQL Server 2016 Service Pack 1 (SP1) およびそれ以降 の Standard エディションまたは Enterprise エディションで利用可能な 変更データキャプチャー 機能に基づいています。SQL Server のキャプチャープロセスでは、指定のデータベースおよびテーブルを監視し、その変更をストアドプロシージャーファサードのある特別に作成された 変更テーブル に格納します。
Debezium SQL Server コネクターがデータベース操作の変更イベントレコードをキャプチャーできるようにするには、最初に SQL Server データベースで変更データキャプチャーを有効にする必要があります。データベースと、キャプチャーする各テーブルの両方で、CDC を有効にする必要があります。ソースデータベースで CDC を設定した後、コネクターはデータベースで発生する行レベルの INSERT、UPDATE および DELETE 操作をキャプチャーできます。コネクターは、各ソーステーブルの各レコードを、そのテーブル専用の Kafka トピックに書き込みます。キャプチャーされたテーブルごとに 1 つのトピックが存在します。クライアントアプリケーションは、対象のデータベーステーブルの Kafka トピックを読み取り、これらのトピックから使用する行レベルのイベントに対応できます。
コネクターが SQL Server データベースまたはクラスターに初めて接続すると、変更をキャプチャーするように設定されたすべてのテーブルのスキーマの整合性スナップショットを作成し、この状態を Kafka にストリーミングします。スナップショットの完了後、コネクターは発生する後続の行レベルの変更を継続的にキャプチャーします。最初にすべてのデータの整合性のあるビューを確立することで、コネクターはスナップショットの実行中に行われた変更を失うことなく読み取りを続行します。
Debezium SQL Server コネクターはフォールトトラレントです。コネクターは変更を読み取り、イベントを生成するため、データベースログにイベントの位置を定期的に記録します (LSN / Log Sequence Number)。コネクターが何らかの理由で停止した場合 (通信障害、ネットワークの問題、クラッシュなど)、コネクターは再起動後に最後に読み取りした場所から SQL Server CDC テーブルの読み取りを再開します。
オフセットは定期的にコミットされます。変更イベントの発生時にはコミットされません。その結果、停止後に重複するイベントが生成される可能性があります。
フォールトトレランスはスナップショットにも適用されます。つまり、スナップショット中にコネクターが停止した場合、コネクターは再起動時に新しいスナップショットを開始します。
2.7.2. Debezium SQL Server コネクターの仕組み
Debezium SQL Server コネクターを最適に設定および実行するには、コネクターによるスナップショットの実行方法、変更イベントのストリーム方法、Kafka トピック名の決定方法、およびメタデータの使用方法を理解すると便利です。
コネクターの仕組みに関する詳細は、以下のセクションを参照してください。
- 「Debezium SQL Server コネクターによるデータベーススナップショットの実行方法」
- 「アドホックスナップショット」
- 「増分スナップショット」
- 「Debezium SQL Server コネクターによる変更データテーブルの読み取り方法」
- 「Debezium SQL Server 変更イベントレコードを受信する Kafka トピックのデフォルト名」
- 「Debezium SQL Server コネクターによるスキーマ変更トピックの使用方法」
- 「Debezium SQL Server コネクターのデータ変更イベントの説明」
- 「トランザクション境界を表す Debezium SQL Server コネクターによって生成されたイベント」
2.7.2.1. Debezium SQL Server コネクターによるデータベーススナップショットの実行方法
SQL Server CDC は、データベースの変更履歴を完全に保存するようには設計されていません。Debezium SQL Server コネクターでデータベースの現在の状態のベースラインを確立するためには、snapshotting と呼ばれるプロセスを使用します。最初のスナップショットは、データベース内のテーブルの構造とデータをキャプチャーします。
スナップショットの詳細は、以下のセクションを参照してください。
2.7.2.1.1. Debezium SQL Server コネクターが最初のスナップショットを実行するために使用するデフォルトのワークフロー
以下のワークフローでは、Debezium がスナップショットを作成する手順を示しています。この手順では、snapshot.mode 設定プロパティーがデフォルト値 (initial) に設定されている場合のスナップショットのプロセスを説明します。snapshot.mode プロパティーの値を変更することで、コネクターがスナップショットを作成する方法をカスタマイズできます。別のスナップショットモードを設定する場合、コネクターはこのワークフローの変更バージョンを使用してスナップショットを完了します。
- データベースへの接続を確立します。
-
キャプチャーするテーブルを決定します。デフォルトでは、コネクターはすべてのシステム以外のテーブルをキャプチャーします。コネクターにテーブルまたはテーブル要素のサブセットをキャプチャーさせるには、
table.include.listやtable.exclude.listなど、データをフィルタリングするための多数のincludeおよびexcludeプロパティーを設定できます。 -
スナップショットの作成時に構造が変更されないように、CDC が有効になっている SQL Server テーブルのロックを取得します。ロックのレベルは、
snapshot.isolation.mode設定プロパティーによって決まります。 - サーバーのトランザクションログでの最大ログシーケンス番号 (LSN) の位置を読み取ります。
すべての非システム、またはキャプチャー対象として指定されたすべてのテーブルの構造をキャプチャーします。コネクターは、内部データベーススキーマ履歴トピックでこの情報を永続化します。スキーマ履歴は、変更イベントの発生時に有効な構造に関する情報を提供します。
注記デフォルトでは、コネクターは、キャプチャー用に設定されていないテーブルも含め、キャプチャーモードにあるデータベース内の全テーブルのスキーマをキャプチャーします。テーブルがキャプチャー用に設定されていない場合、最初のスナップショットはテーブルの構造のみをキャプチャーし、テーブルデータはキャプチャーされません。初期スナップショットに含まれなかったテーブルのスキーマ情報がスナップショットに保持される理由の詳細は、初期スナップショットがすべてのテーブルのスキーマをキャプチャーする理由 を参照してください。
- 必要に応じて、手順 3 で取得したロックを解放します。他のデータベースクライアントは、以前にロックされていたテーブルに書き込みできるようになります。
手順 4 で読み取った LSN の位置で、コネクターはキャプチャーするテーブルをスキャンします。スキャン中に、コネクターは次のタスクを実行します。
- スナップショットが開始される前に、テーブルが作成されたことを確認します。スナップショットの開始後にテーブルが作成された場合、コネクターはテーブルをスキップします。スナップショットが完了し、コネクターがストリーミングに移行すると、スナップショットの開始後に作成されたテーブルに対して変更イベントが発行されます。
-
テーブルからキャプチャーされた行ごとに
readイベントを生成します。すべてのreadイベントには、LSN の位置が含まれ、これは手順 4 で取得した LSN の位置と同じです。 -
テーブルの Kafka トピックに各
readイベントを出力します。
- コネクターオフセットにスナップショットの正常な完了を記録します。
作成された最初のスナップショットは、CDC に対して有効になっているテーブルの各行の現在の状態をキャプチャーします。このベースライン状態から、コネクターは発生した後続の変更をキャプチャーします。
スナップショットプロセスが開始されたら、コネクターの障害、リバランス、またはその他の理由でプロセスが中断されると、コネクターの再起動後にプロセスが再起動されます。
コネクターによって最初のスナップショットが完了した後、更新に抜けがないように、手順 4 で読み取った位置からストリーミングを続行します。
何らかの理由でコネクターが再び停止した場合に、コネクターは再起動後に最後に停止した位置から変更のストリーミングを再開します。
| 設定 | 説明 |
|---|---|
|
| 各コネクターの開始時にスナップショットを実行します。スナップショットが完了すると、コネクターは、後続のデータベース変更のに備え、イベントレコードのストリーミングを開始します。 |
|
| コネクターは 初期スナップショットを作成するためのデフォルトのワークフロー で説明されているように、データベーススナップショットを実行します。スナップショットが完了すると、コネクターは、後続のデータベース変更のに備え、イベントレコードのストリーミングを開始します。 |
|
| コネクターはデータベースのスナップショットを実行し、変更イベントレコードをストリーミングする前に停止して、それ以降の変更イベントのキャプチャを許可しません。 |
|
|
非推奨です。 |
|
|
コネクターは、デフォルトのスナップショットワークフロー で説明されているすべての手順を実行して、関連するすべてのテーブルの構造をキャプチャーします。ただし、コネクターの起動時点のデータセットを表す |
|
|
損失または破損したデータベーススキーマの履歴トピックを復元するにはこのオプションを設定します。再起動後、コネクターはソーステーブルからトピックを再構築するスナップショットを実行します。また、このプロパティーを設定して、予期しない増加が発生するデータベーススキーマ履歴トピックを定期的にプルーニングすることもできます。 + 警告: 最後のコネクターのシャットダウン後にスキーマの変更がデータベースにコミットされた場合、このモードを使用してスナップショットを実行しないでください。 |
|
| コネクターが起動した後、次のいずれかの状況を検出した場合にのみスナップショットが実行されます。
|
詳細は、コネクター設定プロパティーの表の snapshot.mode を参照してください。
2.7.2.1.2. 初期スナップショットがすべてのテーブルのスキーマ履歴をキャプチャーする理由
コネクターが実行する最初のスナップショットは、2 種類の情報をキャプチャーします。
- テーブルデータ
-
コネクターの
table.include.listプロパティーにあるテーブルのINSERT、UPDATE、およびDELETE操作に関する情報。 - スキーマデータ
- テーブルに適用される構造の変更を記述する DDL ステートメント。スキーマデータは、内部スキーマ履歴トピックとコネクターのスキーマ変更トピック (設定されている場合) の両方に保持されます。
初期スナップショットを実行すると、キャプチャー対象として指定されていないテーブルのスキーマ情報がスナップショットによってキャプチャーされることが分かります。デフォルトでは、初期スナップショットは、キャプチャー用に指定されたテーブルからだけでなく、データベースに存在するすべてのテーブルのスキーマ情報を取得するように設計されています。コネクターでは、テーブルのスキーマがスキーマ履歴トピックにある状態で、テーブルをキャプチャーする必要があります。初期スナップショットが元のキャプチャーセットの一部ではないテーブルのスキーマデータをキャプチャーできるようにして、後で必要になった場合にこれらのテーブルからイベントデータを簡単にキャプチャーできるように、Debezium はコネクターを準備します。初期スナップショットがテーブルのスキーマをキャプチャーしない場合は、コネクターがテーブルからデータをキャプチャーする前に、履歴トピックにスキーマを追加する必要があります。
場合によっては、最初のスナップショットでのスキーマキャプチャーを制限する場合があります。これは、スナップショットの完了に必要な時間の短縮に便利です。または、Debezium が複数の論理データベースにアクセスできるユーザーアカウントを使用して、データベースインスタンスに接続しているにもかかわらず、コネクターで特定の論理データベース内のテーブルからの変更のみをキャプチャーする場合にも便利です。
関連情報
- 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更なし)
- 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更)
-
schema.history.internal.store.only.captured.tables.ddlプロパティーを設定して、スキーマ情報をキャプチャーするテーブルを指定します。 -
schema.history.internal.store.only.captured.databases.ddlプロパティーを設定して、スキーマ変更をキャプチャーする論理データベースを指定します。
2.7.2.1.3. 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更なし)
コネクターを使用して、最初のスナップショットでスキーマがキャプチャーされなかったテーブルからデータをキャプチャーする場合があります。コネクターの設定によっては、最初のスナップショットはデータベース内の特定のテーブルのテーブルスキーマのみをキャプチャーする場合があります。テーブルスキーマが履歴トピックに存在しない場合、コネクターはテーブルのキャプチャーに失敗し、スキーマ欠落エラーを報告します。
テーブルからデータを取得できる場合もありますが、テーブルスキーマを追加するには別の手順を実行する必要があります。
前提条件
- コネクターにより最初のスナップショット中にキャプチャーされなかったスキーマが含まれるテーブルからデータをキャプチャーしたいと考えている。
- コネクターが読み取った最も初期の変更テーブルエントリーと、最新の変更テーブルエントリーの LSN の間で、スキーマの変更がテーブルに加えられていない。構造が変更された新しいテーブルからデータを取得する方法は、「初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更)」 を参照してください。
手順
- コネクターを停止します。
-
schema.history.internal.kafka.topic プロパティーで指定された内部データベーススキーマ履歴トピックを削除します。 設定された Kafka Connect
offset.storage.topic内のオフセットをクリアします。オフセットを削除する方法の詳細は、Debezium コミュニティーの FAQ を参照してください。警告オフセットの削除は、内部 Kafka Connect データの操作の経験がある上級ユーザーのみが実行してください。この操作によりシステムが破損する場合があるため、最後の手段としてのみ実行してください。
以下の変更をコネクター設定に適用します。
(オプション)
schema.history.internal.store.only.captured.tables.ddlの値をfalseに設定します。この設定により、スナップショットですべてのテーブルのスキーマがキャプチャーされ、今後、コネクターがすべてのテーブルのスキーマ履歴を再構築できるようにします。
注記すべてのテーブルのスキーマをキャプチャーするスナップショットは、完了までにさらに時間がかかります。
-
コネクターがキャプチャーするテーブルを
table.include.listに追加します。 snapshot.modeを次のいずれかの値に設定します。Initial-
コネクターを再起動すると、テーブルデータとテーブル構造をキャプチャーするデータベースの完全なスナップショットが作成されます。
このオプションを選択する場合は、コネクターがすべてのテーブルのスキーマをキャプチャーできるように、schema.history.internal.store.only.captured.tables.ddlプロパティーの値をfalseに設定することを検討してください。 schema_only- コネクターを再起動すると、テーブルスキーマのみをキャプチャーするスナップショットが作成されます。完全なデータスナップショットとは異なり、このオプションではテーブルデータはキャプチャーされません。完全なスナップショットが作成される前に、早くコネクターを再起動する場合は、このオプションを使用します。
-
コネクターを再起動します。コネクターは、
snapshot.modeで指定されたタイプのスナップショットを完了します。 (オプション) コネクターが
schema_onlyスナップショットを実行した場合、スナップショットの完了後に 増分スナップショット を開始して、追加したテーブルからデータをキャプチャーします。コネクターは、テーブルからリアルタイムの変更をストリーミングし続けながら、スナップショットを実行します。増分スナップショットを実行すると、次のデータ変更がキャプチャーされます。- コネクターが以前にキャプチャーしたテーブルの場合、増分スナップショットは、コネクターが停止している間、つまりコネクターが停止してから現在の再起動までの間に発生した変更をキャプチャーします。
- 新しく追加されたテーブルの場合、増分スナップショットは既存のテーブル行をすべてキャプチャーします。
2.7.2.1.4. 初期スナップショットでキャプチャーされなかったテーブルからのデータのキャプチャー (スキーマ変更)
スキーマ変更がテーブルに適用される場合、スキーマ変更前にコミットされたレコードの構造は、変更後にコミットされたレコードとは異なります。Debezium はテーブルからデータをキャプチャーするときに、スキーマ履歴を読み取り、各イベントに正しいスキーマが適用されていることを確認します。スキーマがスキーマ履歴トピックに存在しない場合、コネクターはテーブルをキャプチャーできず、エラーが発生します。
最初のスナップショットでキャプチャーされず、テーブルのスキーマが変更されたテーブルからデータをキャプチャーする場合、スキーマがまだ使用可能でない場合は、履歴トピックにスキーマを追加する必要があります。新しいスキーマスナップショットを実行するか、テーブルの初期スナップショットを実行して、スキーマを追加できます。
前提条件
- コネクターにより最初のスナップショット中にキャプチャーされなかったスキーマが含まれるテーブルからデータをキャプチャーしたいと考えている。
- スキーマ変更がテーブルに適用されたため、キャプチャーされるレコードの構造が不均一になっている。
手順
- 初期スナップショットにすべてのテーブルのスキーマがキャプチャーされている場合 (
store.only.captured.tables.ddlはfalseに設定されました)。 -
table.include.listプロパティーを編集して、キャプチャーするテーブルを指定します。 - コネクターを再起動します。
- 新しく追加したテーブルから既存のデータをキャプチャーする場合は、増分スナップショット を開始します。
-
- 初期スナップショットにすべてのテーブルのスキーマがキャプチャーされていない場合 (
store.only.captured.tables.ddlがtrueに設定されています)。 最初のスナップショットでキャプチャーするテーブルのスキーマが保存されなかった場合は、次のいずれかの手順を実行します。
- 手順 1: スキーマスナップショット、その後に増分スナップショット
この手順では、コネクターは最初にスキーマのスナップショットを実行します。その後、増分スナップショットを開始して、コネクターがデータを同期できるようにします。
- コネクターを停止します。
-
schema.history.internal.kafka.topic プロパティーで指定された内部データベーススキーマ履歴トピックを削除します。 設定された Kafka Connect
offset.storage.topic内のオフセットをクリアします。オフセットを削除する方法の詳細は、Debezium コミュニティーの FAQ を参照してください。警告オフセットの削除は、内部 Kafka Connect データの操作の経験がある上級ユーザーのみが実行してください。この操作によりシステムが破損する場合があるため、最後の手段としてのみ実行してください。
次の手順の説明に従って、コネクター設定のプロパティーの値を設定します。
-
snapshot.modeプロパティーの値をschema_onlyに設定します。 -
table.include.listを編集して、キャプチャーするテーブルを追加します。
-
- コネクターを再起動します。
- Debezium が新規および既存のテーブルのスキーマをキャプチャーするまで待ちます。コネクターが停止した後にテーブルで発生したデータ変更はキャプチャーされません。
- データが損失されないようにするには、増分スナップショット を開始します。
- 手順 2: 初期スナップショットと、それに続くオプションの増分スナップショット
この手順では、コネクターはデータベースの完全な初期スナップショットを実行します。他の初期スナップショットと同様、多数の大きなテーブルが含まれるデータベースでは、初期スナップショットの実行操作には時間がかかる可能性があります。スナップショットの完了後、任意で増分スナップショットをトリガーして、コネクターがオフラインの間に発生した変更をキャプチャーできます。
- コネクターを停止します。
-
schema.history.internal.kafka.topic プロパティーで指定された内部データベーススキーマ履歴トピックを削除します。 設定された Kafka Connect
offset.storage.topic内のオフセットをクリアします。オフセットを削除する方法の詳細は、Debezium コミュニティーの FAQ を参照してください。警告オフセットの削除は、内部 Kafka Connect データの操作の経験がある上級ユーザーのみが実行してください。この操作によりシステムが破損する場合があるため、最後の手段としてのみ実行してください。
-
table.include.listを編集して、キャプチャーするテーブルを追加します。 次の手順の説明に従って、コネクター設定のプロパティーの値を設定します。
-
snapshot.modeプロパティーの値をinitialに設定します。 -
(オプション)
schema.history.internal.store.only.captured.tables.ddlをfalseに設定します。
-
- コネクターを再起動します。コネクターはデータベース全体のスナップショットを取得します。スナップショットが完了すると、コネクターはストリーミングに移行します。
- (オプション) コネクターがオフラインの間に変更されたデータをキャプチャーするには、増分スナップショット を開始します。
2.7.2.2. アドホックスナップショット
デフォルトでは、コネクターは初回スナップショット操作の開始後にのみ実行されます。通常の状況では、この最初のスナップショットが作成されると、コネクターではスナップショットプロセスは繰り返し処理されません。コネクターがキャプチャーする今後の変更イベントデータはストリーミングプロセス経由でのみ行われます。
ただし、場合によっては、最初のスナップショット中にコネクターを取得したデータが古くなったり、失われたり、または不完全となったり可能性があります。テーブルデータを再キャプチャーするメカニズムを提供するため、Debezium にはアドホックスナップショットを実行するオプションがあります。Debezium 環境で次のいずれかの変更が発生したら、アドホックスナップショットを実行することを推奨します。
- コネクター設定は、異なるテーブルセットをキャプチャーするように変更されます。
- Kafka トピックを削除して、再構築する必要があります。
- 設定エラーや他の問題が原因で、データの破損が発生します。
アドホックと呼ばれるスナップショット を開始することで、以前にスナップショットをキャプチャーしたテーブルのスナップショットを再実行できます。アドホックスナップショットには、シグナルテーブル を使用する必要があります。シグナルリクエストを Debezium シグナルテーブルに送信して、アドホックスナップショットを開始します。
既存のテーブルのアドホックスナップショットを開始すると、コネクターはテーブルにすでに存在するトピックにコンテンツを追加します。既存のトピックが削除された場合には、トピックの自動作成 が有効になっているのであれば、Debezium は自動的にトピックを作成できます。
アドホックのスナップショットシグナルは、スナップショットに追加するテーブルを指定します。スナップショットは、データベースの内容全体をキャプチャーしたり、データベース内のテーブルのサブセットのみをキャプチャーしたりできます。また、スナップショットは、データベース内のテーブルの内容のサブセットをキャプチャできます。
execute-snapshot メッセージをシグナルテーブルに送信してキャプチャーするテーブルを指定します。execute-snapshot シグナルのタイプを incremental または blocking に設定し、スナップショットに含めるテーブルの名前を次の表に示すように指定します。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプを指定します。 |
|
| 該当なし |
スナップショットに含めるテーブルの完全修飾名に一致する正規表現を含む配列。 |
|
| 該当なし |
コネクターがスナップショットに含めるレコードのサブセットを決定するために評価する追加条件のセットを指定する、オプションの配列。
|
|
| 該当なし | スナップショット処理中にコネクターがテーブルのプライマリーキーとして使用する列名を指定するオプションの文字列。 |
アドホック増分スナップショットのトリガー
アドホック増分スナップショットを開始するには、execute-snapshot シグナルタイプのエントリーをシグナリングテーブルに追加するか、シグナルメッセージを Kafka シグナリングトピックに送信します。コネクターがメッセージを処理した後に、スナップショット操作を開始します。スナップショットプロセスは、最初と最後のプライマリーキーの値を読み取り、これらの値を各テーブルの開始ポイントおよびエンドポイントとして使用します。テーブルのエントリー数と設定されたチャンクサイズに基づいて、Debezium はテーブルをチャンクに分割し、チャンクごとに 1 度に 1 つずつスナップショットを順番に作成していきます。
詳細は、スナップショットの増分を参照してください。
アドホックブロッキングスナップショットのトリガー
シグナリングテーブルまたはシグナリングトピックに、execute-snapshot シグナルタイプを持つエントリーを追加することによって、アドホックブロッキングスナップショットを開始します。コネクターがメッセージを処理した後に、スナップショット操作を開始します。コネクターはストリーミングを一時的に停止し、初期スナップショットの時と同じプロセスに従って、指定されたテーブルのスナップショットを開始します。スナップショットが完了すると、コネクターはストリーミングを再開します。
詳細は、ブロッキングスナップショット を参照してください。
2.7.2.3. 増分スナップショット
各 SQL Server サーバーまたはデータベースは、特定の 照合順序 を使用するように設定されています。これにより、文字データの保存、並べ替え、比較、および表示方法が決まります。一部の照合順序セット (SQL Server 照合順序 (SQL_*) など) の並べ替えルールは、Unicode 並べ替えアルゴリズムと互換性がありません。場合によっては、互換性のない並べ替えルールが原因で、コネクターによるアドホックスナップショットの実行時にデータが失われる可能性があります。たとえば、SQL Server が文字列を Unicode として送信するように設定されている場合 (つまり、接続プロパティー sendStringParametersAsUnicode が true に設定されている場合)、コネクターはスナップショット中にレコードをスキップする可能性があります。アドホックスナップショット中にデータが失われないようにするには、driver.sendStringParametersAsUnicode 接続文字列プロパティーの値を false に設定します。
sendStringParametersAsUnicode プロパティーの使用方法の詳細は、SQL Server 接続プロパティーのドキュメント を参照してください。
スナップショットを柔軟に管理するため、Debezium には 増分スナップショット と呼ばれる補助スナップショットメカニズムが含まれています。増分スナップショットは、Debezium コネクターにシグナルを送信するため の Debezium メカニズムに依存します。
増分スナップショットでは、最初のスナップショットのように、データベースの完全な状態を一度にすべてキャプチャーする代わりに、一連の設定可能なチャンクで各テーブルを段階的にキャプチャーします。スナップショットがキャプチャーするテーブルと、各チャンクのサイズ を指定できます。チャンクのサイズにより、データベース上の各フェッチ操作中にスナップショットで収集される行数が決まります。増分スナップショットのデフォルトのチャンクサイズは 1024 行です。
増分スナップショットが進むと、Debezium はウォーターマークを使用して進捗を追跡し、キャプチャーする各テーブル行のレコードを管理します。この段階的なアプローチでは、標準の初期スナップショットプロセスと比較して、以下の利点があります。
- スナップショットが完了するまで、ストリーミングストリーミングを延期する代わりに、ストリームしたデータキャプチャーと並行して増分スナップショットを実行できます。コネクターはスナップショットプロセス全体で変更ログからのほぼリアルタイムイベントをキャプチャーし続け、他の操作はブロックしません。
- 増分スナップショットの進捗が中断された場合は、データを失うことなく再開できます。プロセスが再開すると、スナップショットは最初からテーブルをキャプチャーするのではなく、停止した時点から開始します。
-
いつでも増分スナップショットを実行し、必要に応じてプロセスを繰り返してデータベースの更新に適合できます。たとえば、コネクター設定を変更してテーブルを
table.include.listプロパティーに追加した後にスナップショットを再実行します。
増分スナップショットプロセス
増分スナップショットを実行する場合には、Debezium は各テーブルをプライマリーキー別に分類して、設定されたチャンクサイズ に基づいてテーブルをチャンクに分割します。チャンクごとに作業し、テーブルの行ごとにチャンクでキャプチャーします。キャプチャーする行ごとに、スナップショットは READ イベントを出力します。そのイベントは、対象となるチャンクのスナップショットを開始する時の行の値を表します。
スナップショットの作成が進むにつれ、他のプロセスがデータベースへのアクセスを継続し、テーブルレコードが変更される可能性があります。このような変更を反映させるように、通常通りに INSERT、UPDATE、DELETE 操作がトランザクションログにコミットされます。同様に、継続中の Debezium ストリーミングプロセスは、これらの変更イベントを検出し、対応する変更イベントレコードを Kafka に出力します。
Debezium を使用してプライマリーキーが同じレコード間での競合を解決する方法
場合によっては、ストリーミングプロセスが出力する UPDATE または DELETE イベントを順番に受信できます。つまり、ストリーミングプロセスは、スナップショットがその行の READ イベントが含まれるチャンクをキャプチャーする前に、テーブルの行を変更するイベントを生成する可能性があります。スナップショットが最終的に対象の行にあった READ イベントを出力すると、その値はすでに置き換えられています。Debezium は、シーケンスが到達する増分スナップショットイベントが正しい論理順序で処理されるように、競合を解決するためにバッファースキームを使用します。スナップショットのイベント間で競合が発生し、ストリームされたイベントが解決されてからでないと、Debezium はイベントのレコードを Kafka に送信しません。
スナップショットウィンドウ
遅れて入ってきた READ イベントと、同じテーブルの行を変更するストリーミングイベント間の競合の解決を容易にするために、Debezium は スナップショットウィンドウ と呼ばれるものを使用します。スナップショットウィンドウは、増分スナップショットが指定のテーブルチャンクのデータをキャプチャーしている途中に、間隔を決定します。チャンクのスナップショットウィンドウを開く前に、Debezium は通常の動作に従い、トランザクションログから直接ターゲットの Kafka トピックにイベントをダウンストリームに出力します。ただし、特定のチャンクのスナップショットが開放された瞬間から終了するまで、Debezium は重複除去のステップを実行して、プライマリーキーが同じイベント間での競合を解決します。
データコレクションごとに、Debezium は 2 種類のイベントを出力し、それらの両方のレコードを単一の宛先 Kafka トピックに保存します。テーブルから直接キャプチャーするスナップショットレコードは、READ 操作として出力されます。その間、ユーザーはデータコレクションのレコードの更新を続け、各コミットを反映するようにトランザクションログが更新されるので、Debezium は変更ごとに UPDATE または DELETE 操作を出力します。
スナップショットウィンドウが開放され、Debezium がスナップショットチャンクの処理を開始すると、スナップショットレコードをメモリーバッファーに提供します。スナップショットウィンドウ中に、バッファー内の READ イベントのプライマリーキーは、受信ストリームイベントのプライマリーキーと比較されます。一致するものが見つからない場合、ストリーミングされたイベントレコードが Kafka に直接送信されます。Debezium が一致を検出すると、バッファーされた READ イベントを破棄し、ストリーミングされたレコードを宛先トピックに書き込みます。これは、ストリーミングされたイベントが静的スナップショットイベントよりも論理的に優先されるためです。チャンクのスナップショットウィンドウが終了すると、バッファーに含まれるのは、関連するトランザクションログイベントが存在しない READ イベントのみです。Debezium は、これらの残りの READ イベントをテーブルの Kafka トピックに出力します。
コネクターは各スナップショットチャンクにプロセスを繰り返します。
現在、増分スナップショットを開始するには、次のいずれかの方法を使用できます。
SQL Server の Debezium コネクターでは、増分スナップショットの実行中のスキーマの変更はサポートしません。
2.7.2.3.1. 増分スナップショットのトリガー
増分スナップショットを開始するには、ソースデータベースのシグナリングテーブルに アドホックスナップショットシグナル を送信します。スナップショットシグナルは SQL INSERT クエリーとして送信します。
Debezium がシグナルテーブルの変更を検出すると、シグナルを読み取り、要求されたスナップショット操作を実行します。
送信するクエリーはスナップショットに追加するテーブルを指定し、必要に応じてスナップショット操作の種類を指定します。Debezium は現在、incremental と blocking のスナップショットタイプをサポートしています。
スナップショットに追加するテーブルを指定するには、テーブルをリストする data-collections 配列またはテーブルの照合に使用する正規表現の配列を指定します。以下に例を示します。
{"data-collections": ["public.MyFirstTable", "public.MySecondTable"]}
増分スナップショットシグナルの data-collections アレイにはデフォルト値がありません。data-collections 配列が空の場合、Debezium は空の配列をアクションが必要ないと解釈し、スナップショットは作成しません。
スナップショットに含めるテーブルの名前にドット (.)、スペース、またはその他の英数字以外の文字が含まれている場合は、テーブル名を二重引用符でエスケープする必要があります。
たとえば、db1 データベースの public スキーマに存在し、My.Table という名前のテーブルを含めるには、"db1.public.\"My.Table\"" の形式を使用します。
前提条件
- ソースデータベースにシグナリングデータコレクションが存在する。
-
シグナルデータコレクションが
signal.data.collectionプロパティーで指定されている。
ソースシグナリングチャネルを使用して増分スナップショットをトリガーする
SQL クエリーを送信し、アドホック増分スナップショット要求をシグナルテーブルに追加します。
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow コマンドの
id、type、およびdataパラメーターの値は、シグナルテーブルのフィールド に対応します。
以下の表では、この例のパラメーターを説明しています。Expand 表2.162 シグナルテーブルに増分スナップショットシグナルを送信する SQL コマンドのフィールドの説明 項目 値 説明 1
database.schema.debezium_signalソースデータベースにあるシグナルテーブルの完全修飾名を指定します。
2
ad-hoc-1idパラメーターは、シグナルリクエストのID識別子として割り当てられる任意の文字列を指定します。
この文字列を使用して、シグナルテーブルのエントリーへのログメッセージを特定します。Debezium はこの文字列を使用しません。代わりに、スナップショット作成中に、Debezium は独自のID文字列をウォーターマークシグナルとして生成します。3
execute-snapshottypeパラメーターを指定し、シグナルがトリガーする操作を指定します。
4
data-collectionsシグナルの
dataフィールドの必須コンポーネントで、スナップショットに含めるテーブル名の配列またはテーブル名と一致する正規表現を指定します。
配列には、database.schema.table形式を使用してテーブルの完全修飾名と一致する正規表現がリストされます。この形式は、コネクターの シグナリングテーブル の名前を指定するために使用する形式と同じです。5
incremental実行するスナップショット操作のタイプを指定する、シグナルの
dataフィールドのオプションのtypeコンポーネント。
有効な値はincrementalとblockingです。
値を指定しない場合、コネクターはデフォルトで増分スナップショットを実行します。6
additional-conditionsコネクターがスナップショットに含めるレコードのサブセットを決定するために評価する追加条件のセットを指定する、オプションの配列。
各追加条件は、data-collectionプロパティーとfilterプロパティーを持つオブジェクトです。データの収集単位で異なるフィルターを指定できます。
*data-collectionプロパティーは、フィルターが適用されるデータコレクションの完全修飾名です。additional-conditionsパラメーターの詳細は、「additional-conditions付きでアドホック増分スナップショットを実行する」 を参照してください。
2.7.2.3.2. additional-conditions 付きでアドホック増分スナップショットを実行する
スナップショットに、テーブル内のコンテンツのサブセットのみを含める場合は、スナップショットシグナルに additional-conditions パラメーターを追加してシグナル要求を変更できます。
一般的なスナップショットの SQL クエリーは、以下の形式を取ります。
SELECT * FROM <tableName> ....
SELECT * FROM <tableName> ....
additional-conditions パラメーターを追加して、以下の例のように WHERE 条件を SQL クエリーに追加します。
SELECT * FROM <data-collection> WHERE <filter> ....
SELECT * FROM <data-collection> WHERE <filter> ....以下の例は、シグナルテーブルに追加の条件を含むアドホック増分スナップショット要求を送信する SQL クエリーを示しています。
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');
INSERT INTO <signalTable> (id, type, data) VALUES ('<id>', '<snapshotType>', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"<snapshotType>","additional-conditions":[{"data-collection": "<fullyQualfiedTableName>", "filter": "<additional-condition>"}]}');
たとえば、以下の列が含まれる products テーブルがあるとします。
-
id(プライマリーキー) -
color -
quantity
products テーブルの増分スナップショットに color=blue のデータ項目のみを含める場合は、次の SQL ステートメントを使用してスナップショットをトリガーできます。
INSERT INTO db1.myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["db1.schema1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "db1.schema1.products", "filter": "color=blue"}]}');
INSERT INTO db1.myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["db1.schema1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "db1.schema1.products", "filter": "color=blue"}]}');
additional-conditions パラメーターを使用すると、列が 2 つ以上となる条件を指定することもできます。たとえば、前述の例の products テーブルを使用して、color=blue および quantity>10 だけに一致するアイテムのみのデータが含まれる増分スナップショットをトリガーするクエリーを送信できます。
INSERT INTO db1.myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["db1.schema1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "db1.schema1.products", "filter": "color=blue AND quantity>10"}]}');
INSERT INTO db1.myschema.debezium_signal (id, type, data) VALUES('ad-hoc-1', 'execute-snapshot', '{"data-collections": ["db1.schema1.products"],"type":"incremental", "additional-conditions":[{"data-collection": "db1.schema1.products", "filter": "color=blue AND quantity>10"}]}');以下の例は、コネクターによってキャプチャーされる増分スナップショットイベントの JSON を示しています。
例2.48 増分スナップショットイベントメッセージ
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
実行するスナップショット操作タイプを指定します。 |
| 2 |
|
イベントタイプを指定します。 |
2.7.2.3.3. Kafka シグナルチャネルを使用して増分スナップショットをトリガーする
設定された Kafka トピック にメッセージを送信して、コネクターにアドホック増分スナップショットを実行するよう要求できます。
Kafka メッセージのキーは、topic.prefix コネクター設定オプションの値と一致する必要があります。
メッセージの値は、type と data フィールドが含まれる JSON オブジェクトとなっています。
シグナルタイプは execute-snapshot で、data フィールドには以下のフィールドが必要です。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプ。現在、Debezium は |
|
| 該当なし |
スナップショットに含めるテーブルの完全修飾名と一致する、コンマ区切りの正規表現の配列。 |
|
| 該当なし |
コネクターがスナップショットに含めるレコードのサブセットを指定するために評価する基準を指定する、オプションの追加条件の配列。 |
例2.49 execute-snapshot Kafka メッセージ
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["{collection-container}.table1", "{collection-container}.table2"], "type": "INCREMENTAL"}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["{collection-container}.table1", "{collection-container}.table2"], "type": "INCREMENTAL"}}`additional-conditions 付きのアドホック増分スナップショット
Debezium は additional-conditions フィールドを使用してテーブルのコンテンツのサブセットを選択します。
通常、Debezium はスナップショットを実行するときに、次のような SQL クエリーを実行します。
SELECT * FROM <tableName> ….
スナップショット要求に additional-conditions プロパティーが含まれている場合、プロパティーの data-collection および filter パラメーターが SQL クエリーに追加されます。次に例を示します。
SELECT * FROM <data-collection> WHERE <filter> ….
たとえば、列 id (プライマリーキー)、color、および brand を含む products テーブルがある場合、スナップショットに color='blue' のコンテンツのみを含める場合は、スナップショットをリクエストするときに、コンテンツをフィルタリングする additional-conditions プロパティーを追加することができます。
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.schema1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.schema1.products" ,"filter":"color='blue'"}]}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.schema1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.schema1.products" ,"filter":"color='blue'"}]}}`
また、additional-conditions プロパティーを使用して、複数の列に基づいて条件を渡すこともできます。たとえば、前の例と同じ products テーブルを使用して、color='blue' および brand='MyBrand' である products テーブルのコンテンツのみをスナップショットに含める場合は、次のリクエストを送信できます。
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.schema1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.schema1.products" ,"filter":"color='blue' AND brand='MyBrand'"}]}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["db1.schema1.products"], "type": "INCREMENTAL", "additional-conditions": [{"data-collection": "db1.schema1.products" ,"filter":"color='blue' AND brand='MyBrand'"}]}}`2.7.2.3.4. 増分スナップショットの停止
状況によっては、増分スナップショットを停止する必要がある場合があります。たとえば、スナップショットが正しく設定されていない場合や、他のデータベース操作にリソースが使用可能であるこのとの確認が必要な場合があります。ソースデータベースのシグナリングテーブルにシグナルを送信することで、すでに実行中のスナップショットを停止できます。
スナップショット停止信号をシグナリングテーブルに送信するには、SQL INSERT クエリーで送信します。stop-snapshot シグナルは、スナップショット操作の type を incremental として指定し、オプションで、現在実行中のスナップショットから省略するテーブルを指定します。Debezium はシグナルテーブルの変更を検出した後、シグナルを読み、増分スナップショット操作が進行中であればそれを停止します。
関連情報
また、JSON メッセージを Kafka シグナリングトピック に送信して、増分スナップショットを停止することもできます。
前提条件
- ソースデータベースにシグナリングデータコレクションが存在する。
-
シグナルデータコレクションが
signal.data.collectionプロパティーで指定されている。
ソースシグナリングチャネルを使用して増分スナップショットを停止する
SQL クエリーを送信して、シグナリングテーブルへのアドホックインクリメンタルスナップショットを停止します。
INSERT INTO <signalTable> (id, type, data) values ('<id>', 'stop-snapshot', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"incremental"}');INSERT INTO <signalTable> (id, type, data) values ('<id>', 'stop-snapshot', '{"data-collections": ["<fullyQualfiedTableName>","<fullyQualfiedTableName>"],"type":"incremental"}');Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
INSERT INTO db1.myschema.debezium_signal (id, type, data) values ('ad-hoc-1', 'stop-snapshot', '{"data-collections": ["db1.schema1.table1", "db1.schema1.table2"], "type":"incremental"}');INSERT INTO db1.myschema.debezium_signal (id, type, data)1 values ('ad-hoc-1',2 'stop-snapshot',3 '{"data-collections": ["db1.schema1.table1", "db1.schema1.table2"],4 "type":"incremental"}');5 Copy to Clipboard Copied! Toggle word wrap Toggle overflow signal コマンドの
id、type、およびdataパラメーターの値は、シグナルテーブルのフィールド に対応します。
以下の表では、この例のパラメーターを説明しています。Expand 表2.165 シグナリングテーブルに増分スナップショット停止信号を送信するための SQL コマンドのフィールドの説明 項目 値 説明 1
database.schema.debezium_signalソースデータベースにあるシグナルテーブルの完全修飾名を指定します。
2
ad-hoc-1idパラメーターは、シグナルリクエストのID識別子として割り当てられる任意の文字列を指定します。
この文字列を使用して、シグナルテーブルのエントリーへのログメッセージを特定します。Debezium はこの文字列を使用しません。3
stop-snapshottypeパラメーターを指定し、シグナルがトリガーする操作を指定します。
4
data-collectionsシグナルの
dataフィールドのオプションコンポーネントで、スナップショットから削除するテーブル名の配列またはテーブル名とマッチする正規表現を指定します。
配列には、database.schema.tableの形式で完全修飾名でテーブルに一致する正規表現がリストされます。dataフィールドからこのコンポーネントを省略すると、シグナルによって進行中の増分スナップショット全体が停止されます。5
incremental停止するスナップショット操作のタイプを指定する信号の
dataフィールドの必須コンポーネント。
現在、有効な唯一のオプションはincrementalです。typeの値を指定しない場合、シグナルは増分スナップショットの停止に失敗します。
2.7.2.3.5. Kafka シグナリングチャネルを使用して増分スナップショットを停止する
設定された Kafka シグナルトピック にシグナルメッセージを送信して、アドホック増分スナップショットを停止できます。
Kafka メッセージのキーは、topic.prefix コネクター設定オプションの値と一致する必要があります。
メッセージの値は、type と data フィールドが含まれる JSON オブジェクトとなっています。
シグナルタイプは stop-snapshot で、data フィールドには以下のフィールドが必要です。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプ。現在、Debezium は |
|
| 該当なし |
テーブルの完全修飾名に一致する、コンマで区切られた正規表現のオプションの配列、スナップショットから削除するテーブル名に一致するテーブル名または正規表現の配列。 |
次の例は、典型的な stop-snapshot の Kafka メッセージを示しています。
Key = `test_connector`
Value = `{"type":"stop-snapshot","data": {"data-collections": ["db1.schema1.table1", "db1.schema1.table2"], "type": "INCREMENTAL"}}`
Key = `test_connector`
Value = `{"type":"stop-snapshot","data": {"data-collections": ["db1.schema1.table1", "db1.schema1.table2"], "type": "INCREMENTAL"}}`2.7.2.4. ブロッキングスナップショット
スナップショットをより柔軟に管理するために、Debezium には ブロッキングスナップショット と呼ばれる補助アドホックスナップショットメカニズムが含まれています。ブロッキングスナップショットは、Debezium コネクターにシグナルを送信 するための Debezium メカニズムに依存します。
ブロッキングスナップショットは、ランタイム時にトリガーできることを除いて、初期スナップショット と同じように動作します。
次のような状況では、標準の初期スナップショットプロセスを使用するのではなく、ブロッキングスナップショットを実行する必要があります。
- 新しいテーブルを追加し、コネクターの実行中にスナップショットを完了したいと考えている。
- 大きなテーブルを追加し、増分スナップショットよりも短い時間でスナップショットを完了したいと考えている。
ブロッキングスナップショットのプロセス
ブロッキングスナップショットを実行すると、Debezium はストリーミングを停止し、初期スナップショットの時と同じプロセスに従って、指定されたテーブルのスナップショットを開始します。スナップショットが完了すると、ストリーミングが再開されます。
スナップショットの設定
シグナルの data コンポーネントでは、次のプロパティーを設定できます。
- data-collections: スナップショットする必要のあるテーブルを指定します。
additional-conditions: テーブルごとに異なるフィルターを指定できます。
-
data-collectionプロパティーは、フィルターが適用されるテーブルの完全修飾名です。 -
filterプロパティーは、snapshot.select.statement.overridesで使用される値と同じになります。
-
以下に例を示します。
{"type": "blocking", "data-collections": ["schema1.table1", "schema1.table2"], "additional-conditions": [{"data-collection": "schema1.table1", "filter": "SELECT * FROM [schema1].[table1] WHERE column1 = 0 ORDER BY column2 DESC"}, {"data-collection": "schema1.table2", "filter": "SELECT * FROM [schema1].[table2] WHERE column2 > 0"}]}
{"type": "blocking", "data-collections": ["schema1.table1", "schema1.table2"], "additional-conditions": [{"data-collection": "schema1.table1", "filter": "SELECT * FROM [schema1].[table1] WHERE column1 = 0 ORDER BY column2 DESC"}, {"data-collection": "schema1.table2", "filter": "SELECT * FROM [schema1].[table2] WHERE column2 > 0"}]}重複の可能性
スナップショットをトリガーするシグナルを送信した時点と、ストリーミングが停止してスナップショットが開始する時点との間に遅延が生じる可能性があります。この遅延の結果、スナップショットが完了した後、コネクターはスナップショットがキャプチャーしたレコードと重複するイベントレコードを発行する可能性があります。
2.7.2.5. Debezium SQL Server コネクターによる変更データテーブルの読み取り方法
コネクターが最初に起動すると、キャプチャーされたテーブルの構造のスナップショットを作成し、その情報を内部データベーススキーマ履歴トピックに対して永続化します。その後、コネクターは各ソーステーブルの変更テーブルを特定し、以下の手順を完了します。
- コネクターは、変更テーブルごとに、最後に保存された最大 LSN と現在の最大 LSN の間に作成された変更をすべて読み取ります。
- コネクターは、コミット LSN と変更 LSN の値を基にして、読み取る変更を昇順で並び替えします。この並べ替えの順序により、変更はデータベースで発生した順序で Debezium によって再生されるようになります。
- コネクターは、コミット LSN および変更 LSN をオフセットとして Kafka Connect に渡します。
- コネクターは最大 LSN を保存し、ステップ 1 からプロセスを再開します。
再開後、コネクターは読み取った最後のオフセット (コミットおよび変更 LSN) から処理を再開します。
コネクターは、含まれるソーステーブルに対して CDC が有効または無効化されているかどうかを検出し、その動作を調整することができます。
2.7.2.6. データベースでの最大 LSN の記録なし
次の理由により、最大 LSN がデータベースに記録されない場合があります。
- SQL Server エージェントが実行されていない
- 変更テーブルにまだ変更が記録されていない
- データベースのアクティビティーが少なく、cdc クリーンアップジョブで cdc テーブルから定期的にエントリーが消去される
これらの可能性のうち、実行中の SQL Server エージェントが前提条件であるため、実際には No 1. は問題です (No 2. と 3. は正常です)。
この問題を軽減し、No 1. と他の問題を区別するために、"SELECT CASE WHEN dss.[status]=4 THEN 1 ELSE 0 END AS isRunning FROM [#db].sys.dm_server_services dss WHERE dss.[servicename] LIKE N’SQL Server Agent (%';". のクエリーを使用して SQL Server エージェントのステータスをチェックします。SQL Server Agent が実行されていない場合に、ログに "No maximum LSN recorded in the database; SQL Server Agent is not running" というエラーが書き込まれます。
ステータスクエリーを実行する SQL Server には、VIEW SERVER STATE のサーバーパーミッションが必要です。設定したユーザーにこのパーミッションを付与する必要がない場合は、database.sqlserver.agent.status.query プロパティーで独自のクエリーを設定できます。SQL Server Agent が実行中 (false または 0) で、What minimum permissions do I need to provide to a user so that it can check the status of SQL Server Agent Service? または Safely and Easily Use High-Level Permissions Without Granting Them to Anyone: Server-level で説明されているように、高度なパーミッションを付与せずに安全に使用している場合に、True または 1 を返す関数を定義できます。クエリープロパティーの設定は、database.sqlserver.agent.status.query=SELECT [#db].func_is_sql_server_agent_running() のようになります。[#db] は、データベース名のプレースホルダーとして使用する必要があります。
2.7.2.7. Debezium SQL Server コネクターの制限事項
SQL Server では、変更キャプチャのインスタンスを作成するために、ベースオブジェクトがテーブルであることが特に必要です。そのため、インデックス付きビュー (別名: マテリアライズドビュー) からの変更の取り込みは、SQL Server ではサポートされておらず、したがって Debezium SQL Server コネクターもサポートされていません。
2.7.2.8. Debezium SQL Server 変更イベントレコードを受信する Kafka トピックのデフォルト名
デフォルトでは、SQL Server コネクターは、テーブルで発生するすべての INSERT、UPDATE、DELETE 操作のイベントを、そのテーブルに固有の単一の Apache Kafka トピックに書き込みます。コネクターは、<topicPrefix>.<schemaName>.<tableName> の規則を使用して変更イベントトピックに名前を付けます。
以下のリストは、デフォルト名のコンポーネントの定義を示しています。
- topicPrefix
-
topic.prefix設定プロパティーで指定したサーバーの論理名です。 - schemaName
- 変更イベントが発生したデータベーススキーマの名前。
- tableName
- 変更イベントが発生したデータベーステーブルの名前。
たとえば、fulfillment が論理サーバー名、dbo がスキーマ名で、データベースに products、products_on_hand、customers、orders という名前のテーブルがある場合、コネクターは変更イベントレコードを次の Kafka トピックにストリーミングします。
-
fulfillment.testDB.dbo.products -
fulfillment.testDB.dbo.products_on_hand -
fulfillment.testDB.dbo.customers -
fulfillment.testDB.dbo.orders
コネクターは同様の命名規則を適用して、内部データベーススキーマの履歴トピック (スキーマ変更トピック と トランザクションメタデータトピック) にラベルを付けます。
デフォルトのトピック名が要件を満たさない場合は、カスタムトピック名を設定できます。カスタムトピック名を設定するには、論理トピックルーティング SMT に正規表現を指定します。論理トピックルーティング SMT を使用してトピックの命名をカスタマイズする方法は、トピックルーティング を参照してください。
2.7.2.9. Debezium SQL Server コネクターがデータベーススキーマの変更を処理する方法
データベースクライアントがデータベースのクエリーを行うと、クライアントはデータベースの現在のスキーマを使用します。しかし、データベーススキーマはいつでも変更が可能です。そのため、挿入、更新、または削除の操作が記録されるたびに、コネクターはどのスキーマであるかを特定できる必要があります。また、コネクターは必ずしも現在のスキーマをすべてのイベントに適用できるとは限りません。イベントが比較的古い場合は、現在のスキーマが適用される前に記録された可能性があります。
スキーマ変更後に発生する変更イベントを正しく処理するために、Debezium SQL Server コネクターは、関連するデータテーブルの構造をミラーリングする SQL Server 変更テーブルの構造に基づいて、新しいスキーマのスナップショットを保存します。コネクターは、データベーススキーマ履歴 Kafka トピックに、スキーマ変更の結果 (複数操作の LSN) と合わせてテーブルのスキーマ情報を保存します。コネクターは、保管されたスキーマ表現を使用して、挿入、更新、または削除の各操作時にテーブルの構造を正しくミラーリングする変更イベントを生成します。
クラッシュまたは正常に停止した後にコネクターが再起動すると、最後に読み取った位置から SQL Server CDC テーブル内のエントリーの読み取りを再開します。コネクターがデータベーススキーマ履歴トピックから読み取るスキーマ情報を基に、コネクターが再起動する場所に存在したテーブル構造を適用します。
キャプチャーモードの Db2 テーブルのスキーマを更新する場合は、対応する変更テーブルのスキーマも更新することが重要です。データベーススキーマを更新するには、昇格権限のある SQL Server データベース管理者である必要があります。Debezium 環境での SQL Server データベーススキーマの更新の詳細は、データベーススキーマの進化 を参照してください。
データベーススキーマ履歴トピックは、内部コネクター専用となっています。オプションで、コネクターは コンシューマーアプリケーション向けの別のトピックにスキーマ変更イベントを送信する こともできます。
関連情報
- Debezium イベントレコードを受信する トピックのデフォルト名。
2.7.2.10. Debezium SQL Server コネクターによるスキーマ変更トピックの使用方法
CDC が有効になっているテーブルごとに、Debezium SQL Server コネクターは、データベース内のテーブルに適用されたスキーマ変更イベントの履歴を保存します。コネクターはスキーマ変更イベントを <topicPrefix> という名前の Kafka トピックに書き込みます。ここで、topicPrefix は topic.prefix 設定プロパティーで指定された論理サーバー名です。
コネクターがスキーマ変更トピックに送信するメッセージには、ペイロードと、任意で変更イベントメッセージのスキーマが含まれます。
スキーマ変更イベントのスキーマには、次の要素があります。
name- スキーマ変更イベントメッセージの名前。
type- 変更イベントメッセージのタイプ。
version- スキーマのバージョン。バージョンは整数で、スキーマが変更されるたびに増加します。
fields- 変更イベントメッセージに含まれるフィールド。
例: SQL Server コネクタースキーマ変更トピックのスキーマ
次の例は、JSON 形式の一般的なスキーマを示しています。
スキーマ変更イベントメッセージのペイロードには、以下の要素が含まれます。
databaseName-
ステートメントが適用されるデータベースの名前。
databaseNameの値は、メッセージキーとして機能します。 tableChanges-
スキーマの変更後のテーブルスキーマ全体の構造化表現。
tableChangesフィールドには、テーブルの各列のエントリーなどのアレイが含まれます。構造化された表現は JSON または Avro 形式でデータを表示するため、コンシューマーは DDL パーサーを介して最初にメッセージを処理しなくてもメッセージを簡単に読み取りできます。
コネクターがテーブルをキャプチャーするように設定されている場合、テーブルのスキーマ変更の履歴は、スキーマ変更トピックだけでなく、内部データベーススキーマの履歴トピックにも格納されます。内部データベーススキーマ履歴トピックはコネクターのみの使用を対象としており、使用するアプリケーションによる直接使用を目的としていません。スキーマ変更に関する通知が必要なアプリケーションが、スキーマ変更トピックからの情報のみを使用するようにしてください。
コネクターがスキーマ変更トピックに出力するメッセージの形式は、初期の状態であり、通知なしに変更される可能性があります。
Debezium は、以下のイベントの発生時にスキーマ変更トピックにメッセージを出力します。
- テーブルの CDC を有効にします。
- テーブルの CDC を無効にします。
- スキーマの進化手順 に従って、CDC が有効になっているテーブルの構造を変更します。
例: SQL Server コネクターのスキーマ変更トピックに送信されるメッセージ
以下の例は、スキーマ変更トピックのメッセージを示しています。メッセージには、テーブルスキーマの論理表現が含まれます。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
| コネクターがイベントを処理した時間を表示する任意のフィールド。この時間は、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 ソースオブジェクトの ts_ms は、データベースで変更が行われた時刻を示す。payload.source.ts_ms の値を payload.ts_ms の値と比較することにより、ソースデータベースの更新と Debezium との間の遅延を判断できます。 |
| 2 |
| 変更が含まれるデータベースとスキーマを識別します。 |
| 3 |
|
SQL Server コネクターの場合は常に |
| 4 |
| DDL コマンドによって生成されるスキーマの変更が含まれる 1 つ以上の項目の配列。 |
| 5 |
| 変更の種類を説明します。値は以下のいずれかになります。
|
| 6 |
| 作成、変更、または破棄されたテーブルの完全な識別子。 |
| 7 |
| 適用された変更後のテーブルメタデータを表します。 |
| 8 |
| テーブルのプライマリーキーを設定する列のリスト。 |
| 9 |
| 変更されたテーブルの各列のメタデータ。 |
| 10 |
| 各テーブル変更のカスタム属性メタデータ。 |
コネクターがスキーマ変更トピックに送信するメッセージでは、キーはスキーマの変更が含まれるデータベースの名前です。以下の例では、payload フィールドにキーが含まれます。
2.7.2.11. Debezium SQL Server コネクターのデータ変更イベントの説明
Debezium SQL Server コネクターは、行レベルの INSERT、UPDATE、および DELETE 操作ごとにデータ変更イベントを生成します。各イベントにはキーと値が含まれます。キーと値の構造は、変更されたテーブルによって異なります。
Debezium および Kafka Connect は、イベントメッセージの継続的なストリーム を中心として設計されています。ただし、これらのイベントの構造は時間の経過とともに変化する可能性があり、コンシューマーによる処理が困難になることがあります。これに対応するために、各イベントにはコンテンツのスキーマが含まれます。スキーマレジストリーを使用している場合は、コンシューマーがレジストリーからスキーマを取得するために使用できるスキーマ ID が含まれます。これにより、各イベントが自己完結型になります。
以下のスケルトン JSON は、変更イベントの基本となる 4 つの部分を示しています。ただし、アプリケーションで使用するために選択した Kafka Connect コンバーターの設定方法によって、変更イベントのこれら 4 部分の表現が決定されます。schema フィールドは、変更イベントが生成されるようにコンバーターを設定した場合のみ変更イベントに含まれます。同様に、イベントキーおよびイベントペイロードは、変更イベントが生成されるようにコンバーターを設定した場合のみ変更イベントに含まれます。JSON コンバーターを使用し、変更イベントの基本となる 4 つの部分すべてを生成するように設定すると、変更イベントの構造は次のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
最初の |
| 2 |
|
最初の |
| 3 |
|
2 つ目の |
| 4 |
|
2 つ目の |
デフォルトでは、コネクターによって、変更イベントレコードがイベントの元のテーブルと同じ名前を持つトピックにストリーミングされます。詳細は、トピック名 を参照してください。
SQL Server コネクターは、すべての Kafka Connect スキーマ名が Avro スキーマ名の形式 に準拠するようにします。つまり、論理サーバー名はアルファベットまたはアンダースコア (a-z、A-Z、または _) で始まる必要があります。論理サーバー名の残りの各文字と、データベース名とテーブル名の各文字は、アルファベット、数字、またはアンダースコア ( a-z、A-Z、0-9、または \_) でなければなりません。無効な文字がある場合は、アンダースコアに置き換えられます。
論理サーバー名、データベース名、またはテーブル名に無効な文字が含まれ、名前を区別する唯一の文字が無効であると、無効な文字はすべてアンダースコアに置き換えられるため、予期せぬ競合が発生する可能性があります。
変更イベントの詳細は、以下を参照してください。
2.7.2.11.1. Debezium SQL Server 変更イベントのキー
変更イベントのキーには、変更されたテーブルのキーのスキーマと、変更された行の実際のキーのスキーマが含まれます。スキーマとそれに対応するペイロードの両方には、コネクターによってイベントが作成された時点において、変更されたテーブルのプライマリーキー (または一意なキー制約) に存在した各列のフィールドが含まれます。
以下の customers テーブルについて考えてみましょう。この後に、このテーブルの変更イベントキーの例を示します。
テーブルの例
変更イベントキーの例
customers テーブルへの変更をキャプチャーする変更イベントのすべてに、イベントキースキーマがあります。customers テーブルに前述の定義がある限り、customers テーブルへの変更をキャプチャーする変更イベントのキー構造は、JSON では以下のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
キーのスキーマ部分は、キーの |
| 2 |
|
各フィールドの名前、型、および必要かどうかなど、 |
| 3 |
|
イベントキーの |
| 4 |
|
キーのペイロードの構造を定義するスキーマの名前。このスキーマは、変更されたテーブルのプライマリーキーの構造を記述します。キースキーマ名の形式は connector-name.database-schema-name.table-name.
|
| 5 |
|
この変更イベントが生成された行のキーが含まれます。この例では、キーには値が |
2.7.2.11.2. Debezium SQL Server 変更イベントの値
変更イベントの値はキーよりも若干複雑です。キーと同様に、値には schema セクションと payload セクションがあります。schema セクションには、入れ子のフィールドを含む、Envelope セクションの payload 構造を記述するスキーマが含まれています。データを作成、更新、または削除する操作のすべての変更イベントには、Envelope 構造を持つ値 payload があります。
変更イベントキーの例を紹介するために使用した、同じサンプルテーブルについて考えてみましょう。
このテーブルへの変更に対する変更イベントの値部分には、以下の各イベント型について記述されています。
create イベント
以下の例は、customers テーブルにデータを作成する操作に対して、コネクターによって生成される変更イベントの値の部分を示しています。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
| 値のペイロードの構造を記述する、値のスキーマ。変更イベントの値スキーマは、コネクターが特定のテーブルに生成するすべての変更イベントで同じになります。 |
| 2 |
|
|
| 3 |
|
|
| 4 |
|
|
| 5 |
|
値の実際のデータ。これは、変更イベントが提供する情報です。 |
| 6 |
|
イベント発生前の行の状態を指定する任意のフィールド。この例のように、 |
| 7 |
|
イベント発生後の行の状態を指定する任意のフィールド。この例では、 |
| 8 |
| イベントのソースメタデータを記述する必須のフィールド。このフィールドには、イベントの発生元、イベントの発生順序、およびイベントが同じトランザクションの一部であるかどうかなど、このイベントと他のイベントを比較するために使用できる情報が含まれています。ソースメタデータには以下が含まれています。
|
| 9 |
|
コネクターによってイベントが生成される原因となった操作の型を記述する必須文字列。この例では、
|
| 10 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。イベントメッセージエンベロープでは、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
更新イベント
サンプル customers テーブルにある更新の変更イベントの値には、そのテーブルの 作成 イベントと同じスキーマがあります。同様に、イベント値のペイロードは同じ構造を持ちます。ただし、イベント値ペイロードでは 更新 イベントに異なる値が含まれます。以下は、コネクターによって customers テーブルでの更新に生成されるイベントの変更イベント値の例になります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
イベント発生前の行の状態を指定する任意のフィールド。更新 イベント値の |
| 2 |
|
イベント発生後の行の状態を指定する任意のフィールド。 |
| 3 |
|
イベントのソースメタデータを記述する必須のフィールド。
|
| 4 |
|
操作の型を記述する必須の文字列。更新 イベントの値では、 |
| 5 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。イベントメッセージエンベロープでは、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
行のプライマリーキー/一意キーの列を更新すると、行のキーの値が変更されます。キーが変更されると、3 つ のイベントが Debezium によって出力されます。3 つのイベントとは、delete イベント、行に古いキーが含まれる tombstone イベント、および行に新しいキーが含まれる create イベントを指します。
delete イベント
削除 変更イベントの値は、同じテーブルの 作成 および 更新 イベントと同じ schema の部分になります。サンプル customers テーブルの 削除 イベントの payload 部分は以下のようになります。
| 項目 | フィールド名 | 説明 |
|---|---|---|
| 1 |
|
イベント発生前の行の状態を指定する任意のフィールド。削除 イベント値の |
| 2 |
|
イベント発生後の行の状態を指定する任意のフィールド。削除 イベント値の |
| 3 |
|
イベントのソースメタデータを記述する必須のフィールド。削除 イベント値の
|
| 4 |
|
操作の型を記述する必須の文字列。 |
| 5 |
|
コネクターがイベントを処理した時間を表示する任意のフィールド。イベントメッセージエンベロープでは、Kafka Connect タスクを実行している JVM のシステムクロックを基にします。 |
SQL Server コネクターイベントは、Kafka ログコンパクション と動作するように設計されています。ログコンパクションにより、少なくとも各キーの最新のメッセージが保持される限り、一部の古いメッセージを削除できます。これにより、トピックに完全なデータセットが含まれ、キーベースの状態のリロードに使用できるようにするとともに、Kafka がストレージ領域を確保できるようにします。
tombstone イベント
行が削除された場合でも、Kafka は同じキーを持つ以前のメッセージをすべて削除できるため、削除 イベントの値はログコンパクションで動作します。ただし、Kafka が同じキーを持つすべてのメッセージを削除するには、メッセージの値が null である必要があります。これを可能にするために、Debezium の SQL Server コネクターは delete イベントを出力した後に、null 値以外の同じキーを持つ、特別な廃棄 (tombstone) イベントを出力します。
2.7.2.12. トランザクション境界を表す Debezium SQL Server コネクターによって生成されたイベント
Debezium は、トランザクション境界を表し、データ変更イベントメッセージを強化するイベントを生成できます。
Debezium は、コネクターのデプロイ後に発生するトランザクションに対してのみメタデータを登録し、受信します。コネクターをデプロイする前に発生するトランザクションのメタデータは利用できません。
データベーストランザクションは、キーワード BEGIN および END で囲まれたステートメントブロックによって表されます。Debezium は、すべてのトランザクションで BEGIN および END 区切り文字のトランザクション境界イベントを生成します。トランザクション境界イベントには以下のフィールドが含まれます。
status-
BEGINまたはEND id- 一意のトランザクション識別子の文字列表現。
ts_ms-
データソースでのトランザクション境界イベント (
BEGINまたはENDイベント) の時間。データソースから Debezium にイベント時間を渡されない場合、フィールドは代わりに Debezium がイベントを処理する時間を表します。 event_count(ENDイベント用)- トランザクションによって出力されるイベントの合計数。
data_collections(ENDイベント用)-
data_collectionとevent_count要素のペアの配列。これは、コネクターがデータコレクションから発信された変更に対して出力するイベントの数を示します。
Debezium には、トランザクションがいつ終了したかを確実に識別する方法がありません。このように、トランザクション END マーカーは、別のトランザクションの最初のイベントが到着した後にのみ発行されます。これにより、トラフィックの少ないシステムの場合、END マーカーの配信が遅れる可能性があります。
以下の例は、典型的なトランザクション境界メッセージを示しています。
例: SQL Server コネクタートランザクション境界イベント
topic.transaction オプションで上書きされない限り、トランザクションイベントは <topic.prefix>.transaction という名前のトピックに書き込まれます。
2.7.2.12.1. 変更データイベントのエンリッチメント
トランザクションメタデータを有効にすると、データメッセージ Envelope は新しい transaction フィールドで強化されます。このフィールドは、複合フィールドの形式ですべてのイベントに関する情報を提供します。
id- 一意のトランザクション識別子の文字列表現。
total_order- トランザクションによって生成されたすべてのイベントを対象とするイベントの絶対位置。
data_collection_order- トランザクションによって出力されたすべてのイベントを対象とするイベントのデータコレクションごとの位置。
以下の例は、典型的なメッセージの例を示しています。
2.7.2.13. Debezium SQL Server コネクターによるデータ型のマッピング方法
Debezium SQL Server コネクターは、行が存在するテーブルのように構造化されたイベントを生成して、テーブル行データへの変更を表します。各イベントには、行のコラム値を表すフィールドが含まれます。イベントが操作のコラム値を表す方法は、列の SQL データ型によって異なります。このイベントで、コネクターは各 SQL Server データ型のフィールドを リテラル型 と セマンティック型 の両方にマップします。
コネクターは SQL Server のデータ型を リテラル 型および セマンティック 型の両方にマップできます。
- リテラル型
-
Kafka Connect のスキーマタイプ (
INT8、INT16、INT32、INT64、FLOAT32、FLOAT64、BOOLEAN、STRING、BYTES、ARRAY、MAP、STRUCT) を使用して、値が文字通りどのように表現されるかを記述します。 - セマンティック型
- フィールドの Kafka Connect スキーマの名前を使用して、Kafka Connect スキーマがフィールドの 意味 をキャプチャーする方法を記述します。
デフォルトのデータ型変換が要件に合わない場合は、コネクター用の カスタムコンバーターの作成 が可能です。
データ型マッピングの詳細は、以下を参照してください。
基本型
以下の表は、コネクターによる基本的な SQL Server データ型のマッピング方法を示しています。
| SQL Server のデータ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
| 該当なし |
|
|
|
|
|
|
|
|
その他のデータ型マッピングは、以下のセクションで説明します。
列のデフォルト値がある場合は、対応するフィールドの Kafka Connect スキーマに伝達されます。変更メッセージには、フィールドのデフォルト値が含まれます (明示的な列値が指定されていない場合)。そのため、スキーマからデフォルト値を取得する必要はほとんどありません。
時間値
タイムゾーン情報が含まれる SQL Server の DATETIMEOFFSET 以外の時間型は、time.precision.mode 設定プロパティーの値によって異なります。time.precision.mode 設定プロパティーが adaptive (デフォルト) に設定された場合、コネクターは列のデータ型を基に時間型のリテラルおよびセマンティック型を決定し、イベントが正確 にデータベースの値を表すようにします。
| SQL Server のデータ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
time.precision.mode 設定プロパティーが connect に設定された場合、コネクターは事前定義された Kafka Connect の論理型を使用します。これは、コンシューマーが組み込みの Kafka Connect の論理型のみを認識し、可変精度の時間値を処理できない場合に便利です。一方で、SQL Server はマイクロ秒の 10 分の 1 の精度をサポートするため、connect 時間精度モードでコネクターによって生成されたイベントは、データ列の 少数秒の精度 値が 3 よりも大きい場合に 精度が失われます。
| SQL Server のデータ型 | リテラル型 (スキーマ型) | セマンティック型 (スキーマ名) および注記 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
タイムスタンプ値
DATETIME、SMALLDATETIME および DATETIME2 タイプは、タイムゾーン情報のないタイムスタンプを表します。このような列は、UTC を基にして同等の Kafka Connect 値に変換されます。たとえば、"2018-06-20 15:13:16.945104" という DATETIME2 の値は、"1529507596945104" という値の io.debezium.time.MicroTimestamp で表されます。
Kafka Connect および Debezium を実行している JVM のタイムゾーンは、この変換には影響しないことに注意してください。
10 進数値
Debezium コネクターは、decimal.handling.mode コネクター設定プロパティー の設定にしたがって 10 進数を処理します。
- decimal.handling.mode=precise
Expand 表2.174 decimal.handling.mode=precise の場合のマッピング SQL Server タイプ リテラル型 (スキーマ型) セマンティック型 (スキーマ名) NUMERIC[(P[,S])]BYTESorg.apache.kafka.connect.data.Decimal
scaleスキーマパラメーターには、小数点を移動した桁数を表す整数が含まれます。DECIMAL[(P[,S])]BYTESorg.apache.kafka.connect.data.Decimal
scaleスキーマパラメーターには、小数点を移動した桁数を表す整数が含まれます。SMALLMONEYBYTESorg.apache.kafka.connect.data.Decimal
scaleスキーマパラメーターには、小数点を移動した桁数を表す整数が含まれます。MONEYBYTESorg.apache.kafka.connect.data.Decimal
scaleスキーマパラメーターには、小数点を移動した桁数を表す整数が含まれます。- decimal.handling.mode=double
Expand 表2.175 decimal.handling.mode=double の場合のマッピング SQL Server タイプ リテラル型 セマンティック型 NUMERIC[(M[,D])]FLOAT64該当なし
DECIMAL[(M[,D])]FLOAT64該当なし
SMALLMONEY[(M[,D])]FLOAT64該当なし
MONEY[(M[,D])]FLOAT64該当なし
- decimal.handling.mode=string
Expand 表2.176 decimal.handling.mode=string の場合のマッピング SQL Server タイプ リテラル型 セマンティック型 NUMERIC[(M[,D])]STRING該当なし
DECIMAL[(M[,D])]STRING該当なし
SMALLMONEY[(M[,D])]STRING該当なし
MONEY[(M[,D])]STRING該当なし
2.7.3. Debezium コネクターを実行するための SQL Server のセットアップ
Debezium が SQL Server テーブルから変更イベントをキャプチャーするには、必要な権限を持つ SQL Server の管理者が最初にクエリーを実行してデータベースで CDC を有効にします。その後、管理者は Debezium がキャプチャーする各テーブルに対して、CDC を有効にする必要があります。
デフォルトでは、Microsoft SQL Server への JDBC 接続は SSL 暗号化によって保護されています。SQL Server データベースで SSL が有効になっていない場合、または SSL を使用せずにデータベースに接続する場合は、コネクター設定で database.encrypt プロパティーの値を false に設定して SSL を無効にできます。
Debezium コネクターと使用するための SQL Server の設定に関する詳細は、以下を参照してください。
CDC の適用後、CDC が有効になっているテーブルにコミットされるINSERT、UPDATE、および DELETE 操作がすべてキャプチャーされます。その後、Debezium コネクターはこれらのイベントをキャプチャーして Kafka トピックに出力できます。
2.7.3.1. SQL Server データベースでの CDC の有効化
テーブルの CDC を有効にする前に、SQL Server データベースに対して CDC を有効にする必要があります。SQL Server 管理者は、システムストアドプロシージャーを実行して CDC を有効にします。システムストアドプロシージャーは、SQL Server Management Studio または Transact-SQL を使用すると実行できます。
前提条件
- SQL Server の sysadmin 固定サーバーロールのメンバーである。
- データベースの db_owner である。
- SQL Server Agent が稼働している。
SQL Server の CDC 機能は、ユーザーが作成したテーブルでのみ発生する変更を処理します。SQL Server master データベースで CDC を有効にすることはできません。
手順
- SQL Server Management Studio の View メニューから Template Explorer をクリックします。
- Template Browser で、SQL Server Templates をデプロイメントします。
- Change Data Capture > Configuration をデプロイメントした後、Enable Database for CDC をクリックします。
-
テンプレートで、
USEステートメントのデータベース名を、CDC に対して有効にするデータベースの名前に置き換えます。 ストアドプロシージャー
sys.sp_cdc_enable_dbを実行して、CDC 用のデータベースを有効にします。データベースが CDC に対して有効になったら、
cdcという名前のスキーマ、CDC ユーザー、メタデータテーブル、およびその他のシステムオブジェクトが作成されます。以下の例は、データベース
MyDBに対して CDC を有効にする方法を示しています。例: CDC テンプレートに対する SQL Server データベースの有効化
USE MyDB GO EXEC sys.sp_cdc_enable_db GO
USE MyDB GO EXEC sys.sp_cdc_enable_db GOCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.7.3.2. SQL Server テーブルでの CDC の有効化
SQL Server 管理者は、Debezium がキャプチャーするソーステーブルで変更データキャプチャーを有効にする必要があります。データベースが CDC に対してすでに有効になっている必要があります。テーブルで CDC を有効にするには、SQL Server 管理者はストアドプロシージャー sys.sp_cdc_enable_table をテーブルに対して実行します。ストアドプロシージャーは、SQL Server Management Studio または Transact-SQL を使用すると実行できます。キャプチャーするすべてのテーブルに対して SQL Server の CDC を有効にする必要があります。
前提条件
- CDC が SQL Server データベースで有効になっている。
- SQL Server Agent が稼働している。
-
データベースの
db_owner固定データベースロールのメンバーである。
手順
- SQL Server Management Studio の View メニューから Template Explorer をクリックします。
- Template Browser で、SQL Server Templates をデプロイメントします。
- Change Data Capture > Configuration をデプロイメントした後、Enable Table Specifying Filegroup Option をクリックします。
-
テンプレートで、
USEステートメントのテーブル名を、キャプチャーするテーブルの名前に置き換えます。 ストアドプロシージャー
sys.sp_cdc_enable_tableを実行します。以下の例は、テーブル
MyTableに対して CDC を有効にする方法を示しています。例: SQL Server テーブルに対する CDC の有効化
Copy to Clipboard Copied! Toggle word wrap Toggle overflow <.> キャプチャーするテーブルの名前を指定します。<.> ソーステーブルのキャプチャーされた列で
SELECT権限を付与するユーザーを追加できるMyRoleロールを指定します。sysadminまたはdb_ownerロールのユーザーも、指定された変更テーブルにアクセスできます。@role_nameの値をNULLに設定して、sysadminまたはdb_ownerのメンバーのみがキャプチャーされた情報に完全にアクセスできるようにします。<.> SQL Server がキャプチャーされたテーブルの変更テーブルを配置するfilegroupを指定します。指定されたfilegroupは、すでに存在している必要があります。ソーステーブルに使用するのと同じfilegroupに変更テーブルを置かないことが推奨されます。
2.7.3.3. ユーザーが CDC テーブルにアクセスできることの確認
SQL Server 管理者は、システムストアドプロシージャを実行してデータベースまたはテーブルをクエリーし、その CDC 設定情報を取得できます。ストアドプロシージャーは、SQL Server Management Studio または Transact-SQL を使用すると実行できます。
前提条件
-
キャプチャーインスタンスのキャプチャーされたすべての列に対して
SELECT権限を持っている。db_ownerデータベースロールのメンバーは、定義されたすべてのキャプチャーインスタンスの情報を確認できます。 - クエリーに含まれるテーブル情報に定義したゲーティングロールへのメンバーシップがある。
手順
- SQL Server Management Studio の View メニューから Object Explorer をクリックします。
- Object Explorer から Databases をデプロイメントし、MyDB などのデータベースオブジェクトをデプロイメントします。
- Programmability > Stored Procedures > System Stored Procedures をデプロイメントします。
sys.sp_cdc_help_change_data_captureストアドプロシージャを実行して、テーブルを問い合わせます。クエリーは空の結果を返しません。
次の例では、データベース
MyDB上でストアドプリファレンスsys.sp_cdc_help_change_data_captureを実行します。例: CDC 設定情報のテーブルのクエリー
USE MyDB; GO EXEC sys.sp_cdc_help_change_data_capture GO
USE MyDB; GO EXEC sys.sp_cdc_help_change_data_capture GOCopy to Clipboard Copied! Toggle word wrap Toggle overflow クエリーは、CDC に対して有効になっているデータベースの各テーブルの設定情報を返し、呼び出し元のアクセスが許可される変更データが含まれます。結果が空の場合は、ユーザーにキャプチャーインスタンスと CDC テーブルの両方にアクセスできる権限があることを確認します。
2.7.3.4. Azure 上の SQL Server
Debezium SQL Server コネクターは Azure の SQL Server と併用できます。CDC for SQL Server on Azure の設定と Debezium での使用は、こちらの例 を参考にしてください。
2.7.3.5. SQL Server キャプチャージョブエージェント設定のサーバー負荷およびレイテンシーへの影響
データベース管理者がソーステーブルに対して変更データキャプチャーを有効にすると、キャプチャージョブエージェントの実行が開始されます。エージェントは新しい変更イベントレコードをトランザクションログから読み取り、イベントレコードを変更データテーブルに複製します。変更がソーステーブルにコミットされてから、対応する変更テーブルに変更が反映される間、常に短いレイテンシーが間隔で発生します。この遅延間隔は、ソーステーブルで変更が発生したときから、Debezium がその変更を Apache Kafka にストリーミングできるようになるまでの差を表します。
データの変更に素早く対応する必要があるアプリケーションについては、ソースと変更テーブル間で密接に同期を維持するのが理想的です。キャプチャーエージェントを実行してできるだけ迅速に変更イベントを継続的に処理すると、スループットが増加し、レイテンシーが減少するため、イベントの発生後にほぼリアルタイムで新しいイベントレコードが変更テーブルに入力されることを想像するかもしれません。しかし、これは必ずしもそうであるとは限りません。同期を即時に行うとパフォーマンスに影響します。キャプチャージョブエージェントが新しいイベントレコードについてデータベースにクエリーを実行するたびに、データベースホストの CPU 負荷が増加します。サーバーへの負荷が増えると、データベース全体のパフォーマンスに悪影響を及ぼす可能性があり、特にデータベースの使用がピークに達するときにトランザクションの効率が低下する可能性があります。
データベースメトリクスを監視して、サーバーがキャプチャーエージェントのアクティビティーをサポートできなくなるレベルにデータベースが達した場合に認識できるようにすることが重要となります。パフォーマンスの問題を認識した場合、データベースホストの全体的な CPU 負荷を許容できるレイテンシーで調整するために、SQL Server のキャプチャーエージェント設定を変更できます。
2.7.3.6. SQL Server のキャプチャージョブエージェントの設定パラメーター
SQL Server では、キャプチャージョブエージェントの動作を制御するパラメーターは SQL Server テーブル msdb.dbo.cdc_jobs に定義されます。キャプチャージョブエージェントの実行中にパフォーマンスの問題が発生した場合は、sys.sp_cdc_change_job ストアドプロシージャーを実行し、新しい値を指定することで、キャプチャージョブ設定を調整し、CPU の負荷を軽減します。
SQL Server のキャプチャージョブエージェントパラメーターの設定方法に関する具体的なガイダンスは、このドキュメントの範囲外となります。
以下のパラメーターは、Debezium SQL Server コネクターと使用するキャプチャーエージェントの動作を変更する場合に最も重要になります。
pollinginterval- キャプチャーエージェントがログスキャンのサイクルで待機する秒数を指定します。
- 値が大きいほど、データベースホストの負荷が減少し、レイテンシーが増加します。
-
0を値として指定すると、スキャン間の待ち時間はありません。 -
デフォルト値は
5です。
maxtrans-
各ログスキャンサイクル中に処理するトランザクションの最大数を指定します。キャプチャージョブが指定の数のトランザクションを処理したら、次のスキャンを開始する前に
pollingintervalによって指定された期間、一時停止します。 - 値が小さいほど、データベースホストの負荷が減少し、レイテンシーが増加します。
-
デフォルト値は
500です。
-
各ログスキャンサイクル中に処理するトランザクションの最大数を指定します。キャプチャージョブが指定の数のトランザクションを処理したら、次のスキャンを開始する前に
maxscans-
キャプチャージョブが、データベーストランザクションログの完全な内容のキャプチャーを試みるスキャンサイクルの数の制限を指定します。
continuousパラメーターが1に設定されると、ジョブはスキャンを再開する前にpollingintervalで指定された期間一時停止します。 - 値が小さいほど、データベースホストの負荷が減少し、レイテンシーが増加します。
-
デフォルト値は
10です。
-
キャプチャージョブが、データベーストランザクションログの完全な内容のキャプチャーを試みるスキャンサイクルの数の制限を指定します。
関連情報
- キャプチャーエージェントパラメーターの詳細は、SQL Server のドキュメントを参照してください。
2.7.4. Debezium SQL Server コネクターのデプロイ
以下の方法のいずれかを使用して Debezium SQL Server コネクターをデプロイできます。
2.7.4.1. Streams for Apache Kafka を使用した SQL Server コネクターのデプロイメント
Debezium 1.7 以降、Debezium コネクターのデプロイに推奨される方法は、Streams for Apache Kafka を使用して、コネクタープラグインを含む Kafka Connect コンテナーイメージをビルドすることです。
デプロイメントプロセス中に、以下のカスタムリソース (CR) を作成し、使用します。
-
Kafka Connect インスタンスを定義し、コネクターアーティファクトに関する情報をイメージに含める必要がある
KafkaConnectCR。 -
コネクターがソースデータベースにアクセスするために使用する情報を提供する
KafkaConnectorCR。Streams for Apache Kafka が Kafka Connect Pod を起動した後、KafkaConnectorCR を適用してコネクターを起動します。
Kafka Connect イメージのビルド仕様では、デプロイ可能なコネクターを指定できます。各コネクタープラグインに対して、デプロイメントに利用可能にする他のコンポーネントを指定することもできます。たとえば、Apicurio Registry アーティファクトや Debezium スクリプトコンポーネントを追加できます。Streams for Apache Kafka は、Kafka Connect イメージをビルドするときに、指定されたアーティファクトをダウンロードし、それをイメージに組み込みます。
Kafka Connect CR の spec.build.output パラメーターは、生成される KafkaConnectコンテナーイメージを格納する場所を指定します。コンテナーイメージは Docker レジストリーまたは OpenShift ImageStream に保存できます。イメージを ImageStream に保存するには、Kafka Connect をデプロイする前に ImageStream を作成する必要があります。ImageStreams は自動的に作成されません。
KafkaConnect リソースを使用してクラスターを作成する場合は、Kafka Connect REST API を使用してコネクターを作成または更新できません。ただし、REST API を使用して情報を取得できます。
関連情報
- 「OpenShift 上の Streams for Apache Kafka のデプロイと管理」の Kafka Connect の設定
- 「OpenShift 上の Streams for Apache Kafka のデプロイと管理」の 新しいコンテナーイメージの自動ビルド
2.7.4.2. Streams for Apache Kafka を使用した Debezium SQL Server コネクターのデプロイ
以前のバージョンの Streams for Apache Kafka では、OpenShift に Debezium コネクターをデプロイするには、まずコネクター用の Kafka Connect イメージをビルドする必要がありました。OpenShift にコネクターをデプロイするための現在の推奨方法は、Streams for Apache Kafka のビルド設定を使用して、使用する Debezium コネクタープラグインを含む Kafka Connect コンテナーイメージを自動的にビルドすることです。
ビルドプロセス中に、Streams for Apache Kafka Operator は、Debezium コネクター定義を含む KafkaConnect カスタムリソースの入力パラメーターを Kafka Connect コンテナーイメージに変換します。このビルドは、Red Hat Maven リポジトリーまたは別の設定済みの HTTP サーバーから必要なアーティファクトをダウンロードします。
新規に作成されたコンテナーは .spec.build.output に指定されるコンテナーレジストリーにプッシュされ、Kafka Connect クラスターのデプロイに使用されます。Streams for Apache Kafka が Kafka Connect イメージをビルドした後、ビルドに含まれるコネクターを起動するための KafkaConnector カスタムリソースを作成します。
前提条件
- クラスター Operator がインストールされている OpenShift クラスターにアクセスできる。
- Streams for Apache Kafka Operator が実行されている。
- Apache Kafka クラスターが OpenShift 上の Streams for Apache Kafka のデプロイと管理 に記載されているとおりにデプロイされている。
- Kafka Connect が Streams for Apache Kafka にデプロイされている。
- Red Hat build of Debezium のライセンスを所有している。
-
OpenShift
ocCLI クライアントがインストールされている、または OpenShift Container Platform Web コンソールにアクセスできる。 Kafka Connect ビルドイメージの保存方法に応じて、レジストリーのパーミッションを用意するか、ImageStream リソースを作成している。
- ビルドイメージを Red Hat Quay.io または Docker Hub などのイメージレジストリーに保存する場合は、以下が必要です。
- レジストリーでイメージを作成し、管理するためのアカウントおよびパーミッション
- ビルドイメージをネイティブ OpenShift ImageStream として保存する場合は、以下を行います。
- ImageStream リソースを新規コンテナーイメージを保存するためにクラスターにデプロイします。クラスターの ImageStream を明示的に作成する必要があります。ImageStreams は、デフォルトでは利用できません。ImageStreams の詳細は、OpenShift Container Platform ドキュメント イメージストリームの管理 を参照してください。
手順
- OpenShift クラスターにログインします。
コネクターの Debezium
KafkaConnectカスタムリソース (CR) を作成するか、既存のリソースを変更します。たとえば、metadata.annotationsおよびspec.buildプロパティーを指定するdbz-connect.yamlという名前のKafkaConnectCR を作成します。以下の例は、KafkaConnectカスタムリソースを記述するdbz-connect.yamlファイルからの抜粋を示しています。
例2.50 Debezium コネクターを含む
KafkaConnectカスタムリソースを定義したdbz-connect.yamlファイル次の例では、カスタムリソースは、次のアーティファクトをダウンロードするように設定されています。
- Debezium SQL Server コネクターアーカイブ。
- Red Hat build of Apicurio Registry アーカイブApicurio Registry はオプションのコンポーネントです。コネクターで Avro シリアル化を使用する場合にのみ、Apicurio Registry コンポーネントを追加します。
- Debezium スクリプティング SMT アーカイブと、Debezium コネクターで使用する関連スクリプティングエンジン。SMT アーカイブとスクリプト言語の依存関係はオプションのコンポーネントです。Debezium コンテンツベースのルーティング SMT または フィルター SMT を使用する場合にのみ、これらのコンポーネントを追加します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.177 Kafka Connect 設定の説明 項目 説明 1
strimzi.io/use-connector-resourcesアノテーションを"true"に設定して、クラスター Operator がKafkaConnectorリソースを使用してこの Kafka Connect クラスター内のコネクターを設定できるようにします。2
spec.build設定は、ビルドイメージの保存場所を指定し、プラグインアーティファクトの場所とともにイメージに追加するプラグインをリストします。3
build.outputは、新しくビルドされたイメージを保存するレジストリーを指定します。4
イメージ出力の名前およびイメージ名を指定します。
output.typeの有効な値は、Docker Hub や Quay などのコンテナーレジストリーにプッシュする場合はdocker、内部の OpenShift ImageStream にイメージをプッシュする場合はimagestreamです。ImageStream を使用するには、ImageStream リソースをクラスターにデプロイする必要があります。KafkaConnect 設定でbuild.outputを指定する方法の詳細は、{NameConfiguringStreamsOpenShift} の Streams for Apache Kafka ビルドスキーマリファレンス を参照してください。5
plugins設定は、Kafka Connect イメージに追加するすべてのコネクターをリストします。リストの各エントリーについて、プラグインnameと、コネクターのビルドに必要なアーティファクトに関する情報を指定します。必要に応じて、各コネクタープラグインに対して、コネクターと使用できる他のコンポーネントを含めることができます。たとえば、Service Registry アーティファクトまたは Debezium スクリプトコンポーネントを追加できます。6
artifacts.typeの値は、artifacts.urlで指定するアーティファクトのファイルタイプを指定します。有効なタイプはzip、tgz、またはjarです。Debezium コネクターアーカイブは、.zipファイル形式で提供されます。typeの値は、urlフィールドで参照されるファイルのタイプと一致させる必要があります。7
artifacts.urlの値は、コネクターアーティファクトのファイルを格納する Maven リポジトリーなどの HTTP サーバーのアドレスを指定します。Debezium コネクターアーティファクトは Red Hat リポジトリーで入手できます。OpenShift クラスターが指定されたサーバーにアクセスできる必要があります。8
(オプション) Apicurio Registry コンポーネントをダウンロードするためのアーティファクト
typeとurlを指定します。デフォルトの JSON コンバーターを使用する代わりに、コネクターが Apache Avro を使用して Red Hat build of Apicurio Registry でイベントのキーと値をシリアル化する場合にのみ、Apicurio Registry アーティファクトを含めます。9
(オプション) Debezium コネクターで使用する Debezium スクリプト SMT アーカイブのアーティファクト
typeとurlを指定します。Debezium コンテンツベースルーティング SMT または フィルター SMT を使用する場合にのみ、スクリプト SMT を含めます。スクリプト SMT を使用するには、groovy などの JSR 223 準拠のスクリプト実装もデプロイする必要があります。10
(オプション) JSR 223 準拠のスクリプト実装の JAR ファイルのアーティファクト
typeとurlを指定します。これは、Debezium スクリプト SMT で必要です。重要Streams for Apache Kafka を使用してコネクタープラグインを Kafka Connect イメージに組み込む場合、必要なスクリプト言語コンポーネントごとに、
artifacts.urlに JAR ファイルのロケーションを指定し、artifacts.typeの値もjarに設定する必要があります。値が無効な場合は、実行時にコネクターが失敗します。スクリプト SMT で Apache Groovy 言語を使用できるようにするために、この例のカスタムリソースは、次のライブラリーの JAR ファイルを取得します。
-
groovy -
groovy-jsr223(スクリプトエージェント) -
groovy-json(JSON 文字列を解析するためのモジュール)
別の方法として、Debezium スクリプト SMT は、GraalVM JavaScript の JSR 223 実装の使用もサポートします。
以下のコマンドを入力して、
KafkaConnectビルド仕様を OpenShift クラスターに適用します。oc create -f dbz-connect.yaml
oc create -f dbz-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Streams Operator はカスタムリソースで指定された設定に基づいて、デプロイする Kafka Connect イメージを準備します。
ビルドが完了すると、Operator はイメージを指定されたレジストリーまたは ImageStream にプッシュし、Kafka Connect クラスターを起動します。設定にリスト表示されているコネクターアーティファクトはクラスターで利用できます。KafkaConnectorリソースを作成し、デプロイする各コネクターのインスタンスを定義します。
たとえば、以下のKafkaConnectorCR を作成し、sqlserver-inventory-connector.yamlとして保存します。例2.51 Debezium コネクターの
KafkaConnectorカスタムリソースを定義するsqlserver-inventory-connector.yamlファイルCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.178 コネクター設定の説明 項目 説明 1
Kafka Connect クラスターに登録するコネクターの名前。
2
コネクタークラスの名前。
3
同時に動作できるタスクの数。
4
コネクターの設定。
5
ホストデータベースインスタンスのアドレス。
6
データベースインスタンスのポート番号。
7
Debezium がデータベースへの接続に使用するアカウントの名前。
8
Debezium がデータベースユーザーアカウントに接続するために使用するパスワード。
9
データベースインスタンスまたはクラスターのトピック接頭辞。
指定する名前は、英数字またはアンダースコアのみで設定する必要があります。
トピック接頭辞は、このコネクターから変更イベントを受信する Kafka トピックの接頭辞として使用されるため、名前はクラスターのコネクター間で一意である必要があります。
コネクターを Avro コネクター と統合する場合、この名前空間は、関連する Kafka Connect スキーマの名前や、対応する Avro スキーマの名前空間でも使用されます。10
コネクターが変更イベントをキャプチャーするテーブルのリスト。
以下のコマンドを実行してコネクターリソースを作成します。
oc create -n <namespace> -f <kafkaConnector>.yaml
oc create -n <namespace> -f <kafkaConnector>.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc create -n debezium -f sqlserver-inventory-connector.yaml
oc create -n debezium -f sqlserver-inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow コネクターは Kafka Connect クラスターに登録され、
KafkaConnectorCR のspec.config.database.dbnameで指定されたデータベースに対して実行を開始します。コネクター Pod の準備ができると、Debezium が実行されます。
これで、Debezium SQL ディプロイメントを検証する 準備が整いました。
2.7.4.3. Dockerfile からカスタム Kafka Connect コンテナーイメージをビルドして Debezium SQL Server コネクターのデプロイ
Debezium SQL Server コネクターをデプロイするには、Debezium コネクターアーカイブが含まれるカスタム Kafka Connect コンテナーイメージをビルドし、このコンテナーイメージをコンテナーレジストリーにプッシュする必要があります。次に、以下のカスタムリソース (CR) を作成する必要があります。
-
Kafka Connect インスタンスを定義する
KafkaConnectCR。imageは Debezium コネクターを実行するために作成したイメージの名前を指定します。この CR は、Red Hat Streams for Apache Kafka がデプロイされている OpenShift インスタンスに適用します。Streams for Apache Kafka は、Apache Kafka を OpenShift に導入する Operator とイメージを提供します。 -
Debezium SQL Server コネクターを定義する
KafkaConnectorCR。この CR をKafkaConnectCR を適用するのと同じ OpenShift インスタンスに適用します。
前提条件
- SQL Server が稼働し、Debezium コネクターと連携するように SQL Server を設定する手順 が完了済みである必要があります。
- Streams for Apache Kafka が OpenShift にデプロイされ、Apache Kafka および Kafka Connect が実行されている。詳細は、OpenShift 上の Streams for Apache Kafka のデプロイと管理を参照してください。
- Podman または Docker がインストールされている。
-
Debezium コネクターを実行するコンテナーを追加する予定のコンテナーレジストリー (
quay.ioやdocker.ioなど) でコンテナーを作成および管理するアカウントとパーミッションを持っている。
手順
Kafka Connect の Debezium SQL Server コンテナーを作成します。
registry.redhat.io/amq-streams-kafka-35-rhel8:2.5.0をベースイメージとして使用して、新規の Dockerfile を作成します。たとえば、ターミナルウィンドウから、以下のコマンドを入力します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 項目 説明 1
任意のファイル名を指定できます。
2
Kafka Connect プラグインディレクトリーへのパスを指定します。Kafka Connect のプラグインディレクトリーが別の場所にある場合は、このパスを実際のディレクトリーのパスに置き換えてください。
このコマンドは、現在のディレクトリーに
debezium-container-for-sqlserver.yamlという名前の Dockerfile を作成します。前のステップで作成した
debezium-container-for-sqlserver.yamlDocker ファイルからコンテナーイメージをビルドします。ファイルが含まれるディレクトリーから、ターミナルウィンドウを開き、以下のコマンドのいずれかを入力します。podman build -t debezium-container-for-sqlserver:latest .
podman build -t debezium-container-for-sqlserver:latest .Copy to Clipboard Copied! Toggle word wrap Toggle overflow docker build -t debezium-container-for-sqlserver:latest .
docker build -t debezium-container-for-sqlserver:latest .Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドは、
debezium-container-for-sqlserverという名前のコンテナーイメージを構築します。カスタムイメージを quay.io などのコンテナーレジストリーまたは内部のコンテナーレジストリーにプッシュします。コンテナーレジストリーは、イメージをデプロイする OpenShift インスタンスで利用できる必要があります。以下のいずれかのコマンドを実行します。
podman push <myregistry.io>/debezium-container-for-sqlserver:latest
podman push <myregistry.io>/debezium-container-for-sqlserver:latestCopy to Clipboard Copied! Toggle word wrap Toggle overflow docker push <myregistry.io>/debezium-container-for-sqlserver:latest
docker push <myregistry.io>/debezium-container-for-sqlserver:latestCopy to Clipboard Copied! Toggle word wrap Toggle overflow 新しい Debezium SQL Server KafkaConnect カスタムリソース (CR) を作成します。たとえば、
annotationsおよびimageプロパティーを指定するdbz-connect.yamlという名前のKafkaConnectCR を作成します。以下の例は、KafkaConnectカスタムリソースを記述するdbz-connect.yamlファイルからの抜粋を示しています。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 項目 説明 1
KafkaConnectorリソースはこの Kafka Connect クラスターでコネクターを設定するために使用されることを、metadata.annotationsは Cluster Operator に示します。2
spec.imageは Debezium コネクターを実行するために作成したイメージの名前を指定します。設定された場合、このプロパティーによって Cluster Operator のSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGE変数がオーバーライドされます。以下のコマンドを入力して、
KafkaConnectCR を OpenShift Kafka Connect 環境に適用します。oc create -f dbz-connect.yaml
oc create -f dbz-connect.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、Debezium コネクターを実行するために作成したイメージの名前を指定する Kafka Connect インスタンスを追加します。
Debezium SQL Server コネクターインスタンスを設定する
KafkaConnectorカスタムリソースを作成します。通常、コネクターに使用できる設定プロパティーを使用して、
.yamlファイルに Debezium SQL Server コネクターを設定します。コネクター設定は、Debezium に対して、スキーマおよびテーブルのサブセットにイベントを生成するよう指示する可能性があり、または機密性の高い、大きすぎる、または不必要な指定のコラムで Debezium が値を無視、マスク、または切り捨てするようにプロパティーを設定する可能性もあります。以下の例では、ポート
1433で SQL サーバーホスト192.168.99.100に接続する Debezium コネクターを設定します。このホストには、testDBという名前のデータベース、customersという名前のテーブル、inventory-connector-sqlserverという論理名のサーバーがあります。SQL Server
inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表2.179 コネクター設定の説明 項目 説明 1
Kafka Connect サービスに登録する場合のコネクターの名前。
2
この SQL Server コネクタークラスの名前。
3
SQL Server インスタンスのアドレス。
4
SQL Server インスタンスのポート番号。
5
SQL Server ユーザーの名前。
6
SQL Server ユーザーのパスワード。
7
名前空間を形成する SQL Server インスタンス/クラスターのトピック接頭辞で、コネクターが書き込む Kafka トピックの名前、Kafka Connect スキーマ名、および Avro コンバーター が使用される場合に対応する Avro スキーマの名前空間すべてに使用されます。
8
コネクターは
dbo.customersテーブルからの変更のみをキャプチャーします。9
DDL ステートメントをデータベーススキーマ履歴トピックに書き込み、復元するためにコネクターによって使用される Kafka ブローカーのリスト。
10
コネクターが DDL ステートメントを書き、復元するデータベーススキーマ履歴トピックの名前。このトピックは内部使用のみを目的としており、コンシューマーが使用しないようにしてください。
11
サーバーの署名者証明書を格納する SSL トラストストアへのパス。データベースの暗号化が無効になっている場合 (
database.encrypt=false) を除き、このプロパティーは必須です。12
SSL トラストストアのパスワード。データベースの暗号化が無効になっている場合 (
database.encrypt=false) を除き、このプロパティーは必須です。Kafka Connect でコネクターインスタンスを作成します。たとえば、
KafkaConnectorリソースをinventory-connector.yamlファイルに保存した場合は、以下のコマンドを実行します。oc apply -f inventory-connector.yaml
oc apply -f inventory-connector.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドは
inventory-connectorを登録し、コネクターはKafkaConnectorCR に定義されているtestDBデータベースに対して実行を開始します。
Debezium SQL Server コネクターが実行していることの確認
コネクターがエラーなしで正常に起動すると、コネクターがキャプチャーするように設定された各テーブルのトピックが作成されます。ダウンストリームアプリケーションは、これらのトピックをサブスクライブして、ソースデータベースで発生する情報イベントを取得できます。
コネクターが実行されていることを確認するには、OpenShift Container Platform Web コンソールまたは OpenShift CLI ツール (oc) から以下の操作を実行します。
- コネクターのステータスを確認します。
- コネクターがトピックを生成していることを確認します。
- 各テーブルの最初のスナップショットの実行中にコネクターが生成する読み取り操作 ("op":"r") のイベントがトピックに反映されていることを確認します。
前提条件
- Debezium コネクターが OpenShift 上の Streams for Apache Kafka にデプロイされている。
-
OpenShift
ocCLI クライアントがインストールされている。 - OpenShift Container Platform Web コンソールにアクセスできる。
手順
以下の方法のいずれかを使用して
KafkaConnectorリソースのステータスを確認します。OpenShift Container Platform Web コンソールから以下を実行します。
- Home → Search に移動します。
-
Search ページで Resources をクリックし、Select Resource ボックスを開き、
KafkaConnectorを入力します。 - KafkaConnectors リストから確認するコネクターの名前をクリックします (例: inventory-connector-sqlserver)。
- Conditions セクションで、Type および Status 列の値が Ready および True に設定されていることを確認します。
ターミナルウィンドウから以下を実行します。
以下のコマンドを実行します。
oc describe KafkaConnector <connector-name> -n <project>
oc describe KafkaConnector <connector-name> -n <project>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc describe KafkaConnector inventory-connector-sqlserver -n debezium
oc describe KafkaConnector inventory-connector-sqlserver -n debeziumCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、以下の出力のようなステータス情報を返します。
例2.52
KafkaConnectorリソースのステータスCopy to Clipboard Copied! Toggle word wrap Toggle overflow
コネクターによって Kafka トピックが作成されたことを確認します。
OpenShift Container Platform Web コンソールから以下を実行します。
- Home → Search に移動します。
-
Search ページで Resources をクリックし、Select Resource ボックスを開き、
KafkaTopicを入力します。 -
KafkaTopics リストから確認するトピックの名前をクリックします (例:
inventory-connector-sqlserver.inventory.orders---ac5e98ac6a5d91e04d8ec0dc9078a1ece439081d)。 - Conditions セクションで、Type および Status 列の値が Ready および True に設定されていることを確認します。
ターミナルウィンドウから以下を実行します。
以下のコマンドを実行します。
oc get kafkatopics
oc get kafkatopicsCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、以下の出力のようなステータス情報を返します。
例2.53
KafkaTopicリソースのステータスCopy to Clipboard Copied! Toggle word wrap Toggle overflow
トピックの内容を確認します。
- ターミナルウィンドウから、以下のコマンドを入力します。
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>
oc exec -n <project> -it <kafka-cluster> -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=<topic-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory-connector-sqlserver.inventory.products_on_hand
oc exec -n debezium -it debezium-kafka-cluster-kafka-0 -- /opt/kafka/bin/kafka-console-consumer.sh \ > --bootstrap-server localhost:9092 \ > --from-beginning \ > --property print.key=true \ > --topic=inventory-connector-sqlserver.inventory.products_on_handCopy to Clipboard Copied! Toggle word wrap Toggle overflow トピック名を指定する形式は、手順 1 で返された
oc describeコマンドと同じです (例:inventory-connector-sqlserver.inventory.addresses)。トピックの各イベントについて、このコマンドは、以下の出力のような情報を返します。
例2.54 Debezium 変更イベントの内容
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory-connector-sqlserver.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-sqlserver.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-sqlserver.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"int64","optional":false,"field":"ts_us"},{"type":"int64","optional":false,"field":"ts_ns"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.sqlserver.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"int64","optional":true,"field":"ts_us"},{"type":"int64","optional":true,"field":"ts_ns"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory-connector-sqlserver.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"2.7.3.Final-redhat-00001","connector":"sqlserver","name":"inventory-connector-sqlserver","ts_ms":1638985247805,"ts_us":1638985247805000000,"ts_ns":1638985247805000000,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"sqlserver-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"ts_us":1638985247805102,"ts_ns":1638985247805102588,"transaction":null}}{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"}],"optional":false,"name":"inventory-connector-sqlserver.inventory.products_on_hand.Key"},"payload":{"product_id":101}} {"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-sqlserver.inventory.products_on_hand.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"product_id"},{"type":"int32","optional":false,"field":"quantity"}],"optional":true,"name":"inventory-connector-sqlserver.inventory.products_on_hand.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"int64","optional":false,"field":"ts_us"},{"type":"int64","optional":false,"field":"ts_ns"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":true,"field":"table"},{"type":"int64","optional":false,"field":"server_id"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"query"}],"optional":false,"name":"io.debezium.connector.sqlserver.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"int64","optional":true,"field":"ts_us"},{"type":"int64","optional":true,"field":"ts_ns"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"inventory-connector-sqlserver.inventory.products_on_hand.Envelope"},"payload":{"before":null,"after":{"product_id":101,"quantity":3},"source":{"version":"2.7.3.Final-redhat-00001","connector":"sqlserver","name":"inventory-connector-sqlserver","ts_ms":1638985247805,"ts_us":1638985247805000000,"ts_ns":1638985247805000000,"snapshot":"true","db":"inventory","sequence":null,"table":"products_on_hand","server_id":0,"gtid":null,"file":"sqlserver-bin.000003","pos":156,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1638985247805,"ts_us":1638985247805102,"ts_ns":1638985247805102588,"transaction":null}}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記の例では、
payload値は、コネクタースナップショットがテーブルinventory.products_on_handから読み込み ("op" ="r") イベントを生成したことを示しています。product_idレコードの"before"状態はnullであり、レコードに以前の値が存在しないことを示しています。"after"状態は、product_id101を持つ項目のquantityが3であることを示しています。
Debezium SQL Server コネクターに設定できる設定プロパティーの完全リストは SQL Server コネクタープロパティー を参照してください。
結果
コネクターが起動すると、コネクターが設定された SQL Server データベースの 整合性スナップショットが実行 されます。その後、コネクターは行レベルの操作のデータ変更イベントの生成を開始し、変更イベントレコードを Kafka トピックにストリーミングします。
2.7.4.4. Debezium SQL Server コネクター設定プロパティーの説明
Debezium SQL Server コネクターには、アプリケーションに適したコネクター動作を実現するために使用できる設定プロパティーが多数あります。多くのプロパティーにはデフォルト値があります。
プロパティーに関する情報は、以下のように設定されています。
- 必要なコネクター設定プロパティー
- 高度なコネクター設定プロパティー
- Debezium がデータベース履歴トピックから読み取るイベントを処理する方法を制御する データベース履歴コネクター設定プロパティー。
Debezium SQL Server コネクター設定プロパティー (必須)
以下の設定プロパティーは、デフォルト値がない場合は必須です。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし | コネクターの一意名。同じ名前で再登録を試みると失敗します。(このプロパティーはすべての Kafka Connect コネクターに必要です) | |
| デフォルトなし |
コネクターの Java クラスの名前。SQL Server コネクターには、常に | |
|
| コネクターがデータベースインスタンスからデータをキャプチャーするために使用できるタスクの最大数を指定します。 | |
| デフォルトなし | SQL Server データベースサーバーの IP アドレスまたはホスト名。 | |
|
|
SQL Server データベースサーバーのポート番号 (整数)。 | |
| デフォルトなし | SQL Server データベースサーバーへの接続時に使用するユーザー名。Kerberos 認証を使用する場合は省略可能で、パススループロパティー を使用して設定することができます。 | |
| デフォルトなし | SQL Server データベースサーバーへの接続時に使用するパスワード。 | |
| デフォルトなし |
SQL Server の名前付きインスタンス のインスタンス名を指定します。 | |
| デフォルトなし |
Debezium にキャプチャーさせる SQL Server データベースサーバーの名前空間を提供するトピック接頭辞。接頭辞は、他のコネクター全体で一意となる必要があります。これは、このコネクターからレコードを受信するすべての Kafka トピックの接頭辞として使用されるためです。データベースサーバーの論理名には英数字とハイフン、ドット、アンダースコアのみを使用する必要があります。 警告 このプロパティーの値を変更しないでください。名前の値を変更すると、再起動後に、元のトピックにイベントを発行し続けるのではなく、新しい値に基づいた名前のトピックに後続のイベントを発行します。また、コネクターはデータベーススキーマ履歴トピックを復元できません。 | |
| デフォルトなし |
変更をキャプチャーする対象とするスキーマの名前と一致する正規表現のコンマ区切りリスト (任意)。
スキーマの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定した式は、スキーマ名に存在する可能性のある部分文字列とは一致しない、スキーマの名前文字列全体と照合されます。 | |
| デフォルトなし |
変更をキャプチャーする対象としないスキーマの名前と一致する正規表現のコンマ区切りリスト (任意)。システムスキーマ以外で、
スキーマの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定した式は、スキーマ名に存在する可能性のある部分文字列とは一致しない、スキーマの名前文字列全体と照合されます。 | |
| デフォルトなし |
Debezium にキャプチャーさせるテーブルの完全修飾テーブル識別子に一致する、コンマ区切りの正規表現のリスト (任意)。デフォルトでは、コネクターは指定のスキーマのシステム以外のテーブルをすべてキャプチャーします。このプロパティーが設定されている場合、コネクターは指定されたテーブルからのみ変更をキャプチャします。各識別子の形式は schemaName.tableName です。
テーブルの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの名前文字列全体と照合されます。 | |
| デフォルトなし |
キャプチャーから除外するテーブルの完全修飾テーブル識別子に一致するコンマ区切りの正規表現のリスト (任意)。Debezium は
テーブルの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの名前文字列全体と照合されます。 | |
| 空の文字列 |
変更イベントメッセージの値に含まれる必要がある列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。列の完全修飾名の形式は schemaName.tableName.columnName です。 注記 Debezium がテーブルに対して発行する各変更イベントレコードには、テーブルのプライマリーキーまたは一意のキーの各列のフィールドを含むイベントキーが含まれます。このプロパティーを設定する場合は、キャプチャーされたテーブルのプライマリーキー列を明示的にリストして、イベントキーが正しく生成されるようにします。
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列名に存在する可能性のある部分文字列とは一致しない、列の名前文字列全体と照合されます。 | |
| 空の文字列 |
変更イベントメッセージの値から除外される必要がある列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。列の完全修飾名の形式は schemaName.tableName.columnName です。プライマリーキー列は、値から除外される場合でもイベントのキーに常に含まれることに注意してください。
列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列名に存在する可能性のある部分文字列とは一致しない、列の名前文字列全体と照合されます。 | |
|
|
含まれる列に変更がない場合にメッセージの公開をスキップするかどうかを指定します。これは基本的に、含まれる列に変更がない場合、 | |
|
| 該当なし |
文字ベースの列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。列の完全修飾名の形式は `<schemaName>.<tableName>.<columnName>` です。
仮名は、指定された hashAlgorithm と salt を適用すると得られるハッシュ化された値で構成されます。使用されるハッシュ関数に基づいて、参照整合性は保持され、列値は仮名に置き換えられます。サポートされるハッシュ関数は、Java Cryptography Architecture Standard Algorithm Name Documentation の MessageDigest セクションに説明されています。 column.mask.hash.SHA-256.with.salt.CzQMA0cB5K = inventory.orders.customerName, inventory.shipment.customerName
必要な場合は、仮名は自動的に列の長さに短縮されます。コネクター設定には、異なるハッシュアルゴリズムと salt を指定する複数のプロパティーを含めることができます。 |
|
|
時間、日付、およびタイムスタンプは、異なる精度の種類で表すことができます。 | |
|
|
コネクターによる | |
|
|
コネクターがデータベーススキーマの変更を、データベースサーバー ID と同じ名前の Kafka トピックに公開するかどうかを指定するブール値。各スキーマの変更は、データベース名が含まれるキーと、スキーマ更新を記述する JSON 構造である値で記録されます。これは、コネクターがデータベーススキーマ履歴を内部で記録する方法には依存しません。デフォルトは | |
|
|
delete イベントの後に廃棄 (tombstone) イベントが続くかどうかを制御します。 | |
| 該当なし |
文字ベースの列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。プロパティー名の 長さ で指定された文字数を超えた場合に、一連の列のデータを切り捨てる場合は、このプロパティーを設定します。
列の完全修飾名は、 単一の設定で、異なる長さを持つ複数のプロパティーを指定できます。 | |
| n/a 列の完全修飾名の形式は schemaName.tableName.columnName です。 |
文字ベースの列の完全修飾名と一致する正規表現のコンマ区切りリスト (任意)。一連の列の値をコネクターでマスクする場合 (たとえば、列に機密データが含まれている場合) は、このプロパティーを設定します。 列の完全修飾名は、次の形式に従います: schemaName.tableName.columnName列の名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、列の名前文字列全体に対して照合されます。式は、列名に存在する可能性のある部分文字列と一致しません。 単一の設定で、異なる長さを持つ複数のプロパティーを指定できます。 | |
| 該当なし | 列のメタデータを表す追加パラメーターをコネクターに発行させたい列の完全修飾名に一致する、オプションのコンマ区切りの正規表現のリスト。このプロパティーが設定されている場合、コネクターは次のフィールドをイベントレコードのスキーマに追加します。
これらのパラメーターは、列の元の型名と長さ (可変幅型の場合) をそれぞれ伝達します。
列の完全修飾名は、次の形式に従います: schemaName.tableName.columnName. | |
| 該当なし | データベース内の列に対して定義されているデータ型の完全修飾名を指定する正規表現のオプションのコンマ区切りリスト。このプロパティーが設定されている場合、データ型が一致する列に対して、コネクターはスキーマに次の追加フィールドを含むイベントレコードを発行します。
これらのパラメーターは、列の元の型名と長さ (可変幅型の場合) をそれぞれ伝達します。
列の完全修飾名は、schemaName.tableName.typeName の形式に従います。 SQL Server 固有のデータ型名の一覧は、SQL Server データ型マッピング を参照してください。 | |
| 該当なし | 指定のテーブルの Kafka トピックに公開する変更イベントレコードのカスタムメッセージキーを形成するためにコネクターが使用する列を指定する式のリスト。
デフォルトでは、Debezium はテーブルのプライマリーキー列を、出力するレコードのメッセージキーとして使用します。デフォルトの代わりに、またはプライマリーキーのないテーブルのキーを指定するには、1 つ以上の列をもとにカスタムメッセージキーを設定できます。
各完全修飾テーブル名は、 カスタムメッセージキーの作成に使用する列の数に制限はありません。ただし、一意の鍵を指定するために必要な最小数を使用することが推奨されます。 | |
| bytes |
バイナリー ( | |
| none |
コネクターで使用されるメッセージコンバータとの互換性のために、スキーマ名をどのように調整するかを指定します。設定可能:
| |
| none |
コネクターで使用されるメッセージコンバータとの互換性のために、フィールド名をどのように調整するかを指定します。設定可能:
詳しい情報は、Avro naming を参照してください。 |
高度な SQL Server コネクター設定プロパティー
以下の 高度な 設定プロパティーには、ほとんどの状況で機能する適切なデフォルト設定があるため、コネクターの設定で指定する必要はほとんどありません。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし |
コネクターが使用できる カスタムコンバーター インスタンスのシンボリック名をコンマ区切りリストで列挙します。以下に例を示します。
コネクターがカスタムコンバーターを使用できるようにするには、
コネクターに設定するコンバーターごとに、コンバーターインターフェイスを実装するクラスの完全修飾名を指定する
以下に例を示します。 isbn.type: io.debezium.test.IsbnConverter
設定されたコンバータの動作をさらに制御したい場合は、1 つ以上の設定パラメーターを追加して、コンバータに値を渡すことができます。追加の設定パラメーターとコンバーターを関連付けるには、パラメーター名の前にコンバーターのシンボリック名を付けます。以下に例を示します。 isbn.schema.name: io.debezium.sqlserver.type.Isbn | |
| Initial | キャプチャーされたテーブルの構造 (および必要に応じてデータ) の最初のスナップショットを作成するモード。スナップショットが完了すると、コネクターはデータベースのやり直し (redo) ログから変更イベントの読み取りを続行します。以下の値を使用できます。
| |
| exclusive | コネクターがテーブルロックを保持するかどうか、また保持する時間をコントロールします。テーブルロックは、コネクターがスナップショットを実行している間、特定の種類の変更テーブル操作が発生するのを防ぎます。以下の値を設定できます。
| |
|
|
スナップショットを実行するときにコネクターがデータをクエリーする方法を指定します。
この設定により、 | |
|
|
スナップショットに含めるテーブルの完全修飾名 ( テーブルの名前を一致させるために、Debezium は指定した正規表現を アンカー 正規表現として適用します。つまり、指定された式は、テーブル名に存在する可能性のある部分文字列とは一致しない、テーブルの名前文字列全体と照合されます。 | |
| repeatable_read | 使用されるトランザクション分離レベルと、キャプチャー用に指定されたテーブルをコネクターがロックする期間を制御するモード。以下の値を使用できます。
モードの選択は、データの整合性にも影響します。 | |
|
|
イベントの処理中にコネクターが例外に対応する方法を指定します。 | |
|
| 各反復処理の実行中に新しい変更イベントが表示されるまでコネクターが待機する時間 (ミリ秒単位) を指定する正の整数値。デフォルトは 500 ミリ秒 (0.5 秒) です。 | |
|
|
ブロッキングキューが保持できるレコードの最大数を指定する正の整数値。Debezium はデータベースからストリームされたイベントを読み込む際、Kafka に書き込む前にブロッキングキューにイベントを配置します。ブロッキングキューは、コネクターが Kafka に書き込むよりも速くメッセージを取り込む場合、または Kafka が利用できなくなった場合に、データベースから変更イベントを読み込むためのバックプレッシャーを提供することができます。コネクターがオフセットを定期的に記録すると、キューに保持されるイベントは無視されます。 | |
|
|
ブロッキングキューの最大容量をバイト単位で指定する長整数値。デフォルトでは、ブロックキューにはボリューム制限は指定されません。キューが使用できるバイト数を指定するには、このプロパティーを正の long 値に設定します。 | |
|
| このコネクターの反復処理中に処理される必要があるイベントの各バッチの最大サイズを指定する正の整数値。 | |
|
|
ハートビートメッセージが送信される頻度を制御します。 | |
| デフォルトなし |
コネクターがハートビートメッセージを送信するときにコネクターがソースデータベースで実行するクエリーを指定します。 | |
| デフォルトなし |
コネクターの起動後、スナップショットを取得するまで待機する間隔 (ミリ秒単位)。 | |
| 0 |
コネクターがスナップショットを完了した後、ストリーミングプロセスの開始を遅延する時間をミリ秒単位で指定します。遅延間隔を設定すると、スナップショットが完了した直後で、ストリーミングプロセスの開始前に障害が発生した場合に、コネクターがスナップショットを再開できないようにします。Kafka Connect ワーカーに設定されている | |
|
| スナップショットの実行中に各テーブルから 1 度に読み取る必要がある行の最大数を指定します。コネクターは、このサイズの複数のバッチでテーブルの内容を読み取ります。デフォルトは 2000 です。 | |
| デフォルトなし | 指定のクエリーのデータベースのラウンドトリップごとにフェッチされる行の数を指定します。デフォルトは、JDBC ドライバーのデフォルトのフェッチサイズです。 | |
|
|
スナップショットの実行時に、テーブルロックを取得するまで待つ最大時間 (ミリ秒単位) を指定する整数値。この時間間隔でテーブルロックを取得できない場合、スナップショットは失敗します (スナップショット も参照してください)。 | |
| デフォルトなし | スナップショットに追加するテーブル行を指定します。スナップショットにテーブルの行のサブセットのみを含める場合は、プロパティーを使用します。このプロパティーはスナップショットにのみ影響します。コネクターがログから読み取るイベントには影響しません。
プロパティーには、
スナップショットにソフト削除以外のレコードのみを含める場合は、soft-delete 列 ( "snapshot.select.statement.overrides": "customer.orders", "snapshot.select.statement.overrides.customer.orders": "SELECT * FROM customers.orders WHERE delete_flag = 0 ORDER BY id DESC"
作成されるスナップショットでは、コネクターには | |
|
|
| |
| 10000 (10 秒) | 再試行可能なエラーが発生した後にコネクターを再起動するまで待機する時間 (ミリ秒単位)。 | |
|
|
ストリーミング中にスキップされる操作タイプのコンマ区切りリスト。挿入/作成は | |
| デフォルト値なし |
シグナルをコネクターに送信するために使用されるデータコレクションの完全修飾名 。 | |
| source | コネクターに対して有効な信号チャネル名のリスト。デフォルトでは、以下のチャネルが利用可能です。
| |
| デフォルトなし | コネクターに対して有効になっている通知チャネル名のリスト。デフォルトでは、以下のチャネルが利用可能です。
| |
|
|
増分スナップショット時のスキーマの変更を許可します。有効にすると、コネクターは増分スナップショットの実行中にスキーマの変更を検出し、ロック DDL を回避するために現在のチャンクを再選択します。 | |
|
| 増分スナップショットのチャンクの実行中にコネクターがメモリーを取得して読み取る行の最大数。スナップショットは、サイズが大きいスナップショットの場合にはクエリーが少なくなるため、チャンクサイズを増やすと効率が上がります。ただし、チャンクサイズが大きい場合には、スナップショットデータのバッファーにより多くのメモリーが必要になります。チャンクサイズは、環境で最適なパフォーマンスを発揮できる値に、調整します。 | |
|
|
増分スナップショットによってキャプチャーされ、ストリーミングの再開後に再キャプチャーされる可能性のあるイベントを重複排除するために、コネクターが増分スナップショット中に使用するウォーターマークメカニズムを指定します。
| |
| 500 |
データベースの複数のテーブルからの変更をストリーミングする際に、メモリーの使用量を削減するために使用する、反復ごとの最大トランザクション数を指定します。 | |
|
| 増分スナップショット時に使用するすべての SELECT ステートメントに OPTION(RECOMPILE) クエリーオプションを使用します。これは、発生しうるパラメータースニッフィング問題を解決するのに役立ちますが、クエリーの実行頻度によっては、ソースデータベースの CPU 負荷が増加する可能性があります。 | |
|
|
データ変更、スキーマ変更、トランザクション、ハートビートイベントなどのトピック名を決定するために使用する TopicNamingStrategy クラスの名前。デフォルトは | |
|
|
トピック名の区切り文字を指定します。デフォルトは | |
|
| トピック名を保持するために使用されるサイズ (bounded concurrent hash map)。このキャッシュは、与えられたデータコレクションに対応するトピック名を決定するのに役立つ。 | |
|
|
コネクターがハートビートメッセージを送信するトピックの名前を制御します。トピック名のパターンは、 | |
|
|
コネクターがトランザクションのメタデータメッセージを送信するトピックの名前を制御します。トピック名のパターンは、 詳細は、トランザクションメタデータ を参照してください。 | |
|
| 初期スナップショットを実行するときにコネクターが使用するスレッドの数を指定します。並列初期スナップショットを有効にするには、プロパティーを 1 より大きい値に設定します。並列初期スナップショットでは、コネクターは複数のテーブルを同時に処理します。 重要 並列初期スナップショットはテクノロジープレビュー機能のみとなっています。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。 | |
|
|
コンテキスト情報を提供するメタデータを追加して、MBean オブジェクト名をカスタマイズするタグを定義します。キーと値のペアのコンマ区切りリストを指定します。各キーは MBean オブジェクト名のタグを表し、対応する値はキーの値を表します。たとえば、 コネクターは、指定されたタグを基本 MBean オブジェクト名に追加します。タグは、メトリクスデータを整理および分類するのに役立ちます。特定のアプリケーションインスタンス、環境、リージョン、バージョンなどを識別するためのタグを定義できます。詳細は、カスタマイズされた MBean 名 を参照してください。 | |
|
|
接続エラーなど、再試行可能なエラーが発生する操作の後に、コネクターがどのように応答するかを指定します。
| |
|
| コネクターが CDC データを照会する方法を制御します。以下のモードがサポートされます。
| |
|
|
コネクターがクエリーの完了を待機する時間をミリ秒単位で指定します。タイムアウト制限を削除するには、値を |
Debezium SQL Server コネクターデータベーススキーマ履歴の設定プロパティー
Debezium には、コネクターがスキーマ履歴トピックと対話する方法を制御する schema.history.internal.* プロパティーのセットが含まれています。
以下の表は、Debezium コネクターを設定するための schema.history.internal プロパティーを説明しています。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし | コネクターがデータベーススキーマの履歴を保存する Kafka トピックの完全名。 | |
| デフォルトなし | Kafka クラスターへの最初の接続を確立するためにコネクターが使用するホストとポートのペアのリスト。このコネクションは、コネクターによって以前に保存されたデータベーススキーマ履歴の取得や、ソースデータベースから読み取られる各 DDL ステートメントの書き込みに使用されます。各ペアは、Kafka Connect プロセスによって使用される同じ Kafka クラスターを示す必要があります。 | |
|
| 永続化されたデータのポーリングが行われている間にコネクターが起動/回復を待つ最大時間 (ミリ秒単位) を指定する整数値。デフォルトは 100 ミリ秒です。 | |
|
| Kafka 管理クライアントを使用してクラスター情報を取得する際に、コネクターが待機すべき最大ミリ秒数を指定する整数値です。 | |
|
| Kafka 管理クライアントを使用して kafka 履歴トピックを作成する間、コネクターが待機する最大ミリ秒数を指定する整数値。 | |
|
|
エラーでコネクターのリカバリーが失敗する前に、コネクターが永続化された履歴データの読み取りを試行する最大回数。データが受信されなかった場合に最大待機する時間は、 | |
|
|
コネクターが不正または不明なデータベースのステートメントを無視するかどうか、または人が問題を修正するために処理を停止するかどうかを指定するブール値。安全なデフォルトは | |
|
|
コネクターがスキーマまたはデータベース内のすべてのテーブルからスキーマ構造を記録するか、キャプチャー対象に指定されたテーブルのみからスキーマ構造を記録するかを指定するブール値。
| |
|
|
コネクターがデータベースインスタンス内のすべての論理データベースのスキーマ構造を記録するかどうかを指定するブール値。
|
パススルー SQL Server コネクターの設定プロパティー
コネクターは pass-through プロパティーをサポートしており、これにより Debezium は Apache Kafka プロデューサーとコンシューマーの動作を微調整するためのカスタム設定オプションを指定できます。Kafka プロデューサーとコンシューマーの全設定プロパティーの詳細は、Kafka ドキュメント を参照してください。
プロデューサーとコンシューマーのクライアントがスキーマ履歴トピックと対話する方法を設定するための Pass-through プロパティー
Debezium は、データベーススキーマ履歴トピックへのスキーマ変更を記述するために Apache Kafka プロデューサーに依存しています。同様に、コネクターが起動すると、データベーススキーマ履歴トピックから読み取る Kafka コンシューマーに依存します。schema.history.internal.producer.* および schema.history.internal.consumer.* 接頭辞で始まるパススルー設定プロパティーのセットに値を割り当てて、Kafka プロデューサーおよびコンシューマークライアントの設定を定義します。パススループロデューサーおよびコンシューマーデータベーススキーマ履歴プロパティーは、以下の例のように Kafka ブローカーとのこれらのクライアントの接続をセキュアにする方法など、さまざまな動作を制御します。
Debezium は、プロパティーを Kafka クライアントに渡す前に、プロパティー名から接頭辞を削除します。
Kafka プロデューサー設定プロパティー と Kafka コンシューマー設定プロパティー の詳細は、Apache Kafka ドキュメントを参照してください。
SQL Server コネクターが Kafka シグナリングトピックと対話する方法を設定するためのパススループロパティー
Debezium は、コネクターが Kafka シグナルトピックと対話する方法を制御する signal.* プロパティーのセットを提供します。
以下の表は、Kafka signal プロパティーを説明しています。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| <topic.prefix>-signal | コネクターがアドホックシグナルについて監視する Kafka トピックの名前。 注記 トピックの自動作成 が無効になっている場合は、必要なシグナリングトピックを手動で作成する必要があります。シグナルの順序を維持するには、シグナルトピックが必要です。シグナリングトピックには単一のパーティションが必要です。 | |
| kafka-signal | Kafka コンシューマーによって使用されるグループ ID の名前。 | |
| デフォルトなし | コネクターが Kafka クラスターへの初期接続を確立するために使用するホストとポートのペアのリスト。各ペアは、Debezium Kafka Connect プロセスによって使用される Kafka クラスターを参照します。 | |
|
| コネクターが信号をポーリングするときに待機する最大ミリ秒数を指定する整数値。 | |
|
| Kafka コンシューマーがシグナリングトピックからメッセージを読み取った後にオフセットコミットを書き込むかどうかを指定します。このプロパティーに割り当てる値によって、コネクターがオフラインのときに、シグナリングトピックが受信する要求をコネクターが処理できるかどうかが決まります。次のいずれかの設定を選択します。
|
シグナリングチャネルの Kafka コンシューマークライアントを設定するためのパススループロパティー
Debezium コネクターでは、Kafka コンシューマーのパススルー設定が可能です。パススルーシグナルのプロパティーは、接頭辞 signals.consumer.* で始まります。たとえば、コネクターは signal.consumer.security.protocol=SSL などのプロパティーを Kafka コンシューマーに渡します。
Debezium は、プロパティーを Kafka シグナルコンシューマーに渡す前に、プロパティーから接頭辞を削除します。
SQL Server コネクター sink notification チャネルを設定するためのパススループロパティー
次の表では、Debezium sink notification チャネルの設定に使用できるプロパティーについて説明します。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし |
Debezium から通知を受信するトピックの名前。このプロパティーは、有効な通知チャネルの 1 つとして |
Debezium コネクターのパススルーデータベースドライバー設定プロパティー
Debezium コネクターでは、データベースドライバーのパススルー設定が可能です。パススルーデータベースプロパティーは接頭辞 driver.* で始まります。たとえば、コネクターは driver.foobar=false などのプロパティーを JDBC URL に渡します。
Debezium は、プロパティーをデータベースドライバーに渡す前に、プロパティーから接頭辞を削除します。
2.7.5. スキーマ変更後のキャプチャーテーブルの更新
SQL Server テーブルに対して変更データキャプチャーが有効になっている場合、テーブルで変更が行われると、イベントレコードがサーバーのキャプチャーテーブルに永続化されます。たとえば、新しい列を追加するなどして、ソーステーブル変更の構造に変更を加えても、その変更は変更テーブルに動的に反映されません。キャプチャーテーブルが古いスキーマを使用し続ける限り、Debezium コネクターはテーブルのデータ変更イベントを正しく出力できません。コネクターが変更イベントの処理を再開できるようにするには、介入してキャプチャーテーブルを更新する必要があります。
CDC を SQL Server に実装する方法により、Debezium を使用してキャプチャーテーブルを更新することはできません。キャプチャーテーブルを更新するには、1 つが昇格された権限を持つ SQL Server データベースオペレーターである必要があります。Debezium ユーザーとして、SQL Server データベース operator とタスクを調整して、スキーマの更新を完了し、Kafka トピックへのストリーミングを復元する必要があります。
以下の方法のいずれかを使用すると、スキーマの変更後にキャプチャーテーブルを更新できます。
- オフラインでスキーマ を更新するには、キャプチャーテーブルを更新する前に Debezium コネクターを停止する必要があります。
- オンラインスキーマの更新 は、Debezium コネクターの実行中にキャプチャーテーブルを更新できます。
各手順には長所と短所があります。
オンライン更新またはオフライン更新のどちらを使用する場合でも、同じソーステーブルに後続のスキーマ更新を適用する前に、スキーマ更新プロセス全体を完了する必要があります。手順を一度に実行できるようにするため、すべての DDL を 1 つのバッチで実行することがベストプラクティスとなります。
CDC が有効になっているソーステーブルでは、一部のスキーマの変更がサポートされていません。たとえば、CDC がテーブルで有効になっている場合、SQL Server で列の名前を変更したり、列型を変更すると、テーブルのスキーマを変更できません。
ソーステーブルの列を NULL から NOT NULL またはその逆に変更した後、SQL Server コネクターは新しいキャプチャーインスタンスが作成されるまで変更された情報を正しくキャプチャーできません。列指定の変更後に新しいキャプチャーテーブルを作成しないと、コネクターによって出力される変更イベントレコードは列が任意であるかどうかを正しく示しません。つまり、以前はオプション (または NULL) として定義されていた列が、現在は NOT NULL として定義されているにもかかわらず、引き続きオプションとして定義されているということです。同様に、必要 (NOT NULL) として定義された列は、NULL として定義されても、以前の指定が保持されます。
sp_rename 関数を使用してテーブルの名前を変更すると、コネクターが再起動されるまで、古いソーステーブル名で変更が発行され続けます。コネクターを再起動すると、新しいソーステーブル名で変更が発行されます。
2.7.5.1. スキーマの変更後のオフライン更新の実行
オフラインでスキーマを更新すると、最も安全にキャプチャーテーブルを更新できます。ただし、オフラインでの更新は、高可用性を必要とするアプリケーションでは使用できないことがあります。
前提条件
- CDC が有効になっている SQL Server テーブルのスキーマに更新がコミット済みである。
- 昇格された権限を持つ SQL Server データベース operator である。
手順
- データベースを更新するアプリケーションを一時停止します。
- Debezium コネクターがストリーミングされていない変更イベントレコードをすべてストリーミングするまで待ちます。
- Debezium コネクターを停止します。
- すべての変更をソーステーブルスキーマに適用します。
-
パラメーター
@capture_instanceの一意の値でsys.sp_cdc_enable_tableの手順を使用して、更新ソーステーブルの新しいキャプチャーテーブルを作成します。 - ステップ 1 で一時停止したアプリケーションを再開します。
- Debezium コネクターを起動します。
-
Debezium コネクターが新しいキャプチャーテーブルからストリーミングを開始したら、古いキャプチャーインスタンス名に設定されたパラメーター
@capture_instanceでストアドプロシージャーsys.sp_cdc_disable_tableを実行して、古いキャプチャーテーブルを削除します。
2.7.5.2. スキーマの変更後のオンライン更新の実行
オンラインでスキーマの更新を完了する手順は、オフラインでスキーマの更新を実行する手順よりも簡単です。また、アプリケーションやデータ処理のダウンタイムなしで完了できます。ただし、オンラインでスキーマを更新すると、ソースデータベースでスキーマを更新した後、新しいキャプチャーインスタンスを作成するまでに、処理の差が生じる可能性があります。この間、変更イベントは変更テーブルの古いインスタンスによって引き続きキャプチャーされ、古いテーブルに保存された変更データは、以前のスキーマの構造を保持します。たとえば、新しい列をソーステーブルに追加した場合は、新しいキャプチャーテーブルの準備が整う前に生成された変更イベントには新しい列のフィールドは含まれません。アプリケーションがこのような移行期間を許容しない場合、オフラインでスキーマの更新を行うことが推奨されます。
前提条件
- CDC が有効になっている SQL Server テーブルのスキーマに更新がコミット済みである。
- 昇格された権限を持つ SQL Server データベース operator である。
手順
- すべての変更をソーステーブルスキーマに適用します。
-
パラメーター
@capture_instanceに一意の値を指定してsys.sp_cdc_enable_tableストアドプロシージャーを実行し、更新元テーブルに新しいキャプチャテーブルを作成します。 -
Debezium が新しいキャプチャーテーブルからのストリーミングを開始したら、パラメーター
@capture_instanceに古いキャプチャーインスタンス名を設定して、sys.sp_cdc_disable_tableストアドプロシージャーを実行することで、古いキャプチャーテーブルを削除することができます。
例: データベーススキーマの変更後のオンラインスキーマ更新の実行
次の例は、customers ソーステーブルに phone_number 列が追加された後、change テーブルでオンラインスキーマ更新を完了する方法を示しています。
次のクエリーを実行して
customersソーステーブルのスキーマを変更し、phone_numberフィールドを追加します。ALTER TABLE customers ADD phone_number VARCHAR(32);
ALTER TABLE customers ADD phone_number VARCHAR(32);Copy to Clipboard Copied! Toggle word wrap Toggle overflow sys.sp_cdc_enable_tableストアドプロシージャーを実行して、新しいキャプチャーインスタンスを作成します。EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'customers', @role_name = NULL, @supports_net_changes = 0, @capture_instance = 'dbo_customers_v2'; GO
EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'customers', @role_name = NULL, @supports_net_changes = 0, @capture_instance = 'dbo_customers_v2'; GOCopy to Clipboard Copied! Toggle word wrap Toggle overflow 次のクエリーを実行して、
customersテーブルに新しいデータを挿入します。INSERT INTO customers(first_name,last_name,email,phone_number) VALUES ('John','Doe','john.doe@example.com', '+1-555-123456'); GOINSERT INTO customers(first_name,last_name,email,phone_number) VALUES ('John','Doe','john.doe@example.com', '+1-555-123456'); GOCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka Connect ログは、以下のメッセージのようなエントリーで設定の更新を報告します。
connect_1 | 2019-01-17 10:11:14,924 INFO || Multiple capture instances present for the same table: Capture instance "dbo_customers" [sourceTableId=testDB.dbo.customers, changeTableId=testDB.cdc.dbo_customers_CT, startLsn=00000024:00000d98:0036, changeTableObjectId=1525580473, stopLsn=00000025:00000ef8:0048] and Capture instance "dbo_customers_v2" [sourceTableId=testDB.dbo.customers, changeTableId=testDB.cdc.dbo_customers_v2_CT, startLsn=00000025:00000ef8:0048, changeTableObjectId=1749581271, stopLsn=NULL] [io.debezium.connector.sqlserver.SqlServerStreamingChangeEventSource] connect_1 | 2019-01-17 10:11:14,924 INFO || Schema will be changed for ChangeTable [captureInstance=dbo_customers_v2, sourceTableId=testDB.dbo.customers, changeTableId=testDB.cdc.dbo_customers_v2_CT, startLsn=00000025:00000ef8:0048, changeTableObjectId=1749581271, stopLsn=NULL] [io.debezium.connector.sqlserver.SqlServerStreamingChangeEventSource] ... connect_1 | 2019-01-17 10:11:33,719 INFO || Migrating schema to ChangeTable [captureInstance=dbo_customers_v2, sourceTableId=testDB.dbo.customers, changeTableId=testDB.cdc.dbo_customers_v2_CT, startLsn=00000025:00000ef8:0048, changeTableObjectId=1749581271, stopLsn=NULL] [io.debezium.connector.sqlserver.SqlServerStreamingChangeEventSource]
connect_1 | 2019-01-17 10:11:14,924 INFO || Multiple capture instances present for the same table: Capture instance "dbo_customers" [sourceTableId=testDB.dbo.customers, changeTableId=testDB.cdc.dbo_customers_CT, startLsn=00000024:00000d98:0036, changeTableObjectId=1525580473, stopLsn=00000025:00000ef8:0048] and Capture instance "dbo_customers_v2" [sourceTableId=testDB.dbo.customers, changeTableId=testDB.cdc.dbo_customers_v2_CT, startLsn=00000025:00000ef8:0048, changeTableObjectId=1749581271, stopLsn=NULL] [io.debezium.connector.sqlserver.SqlServerStreamingChangeEventSource] connect_1 | 2019-01-17 10:11:14,924 INFO || Schema will be changed for ChangeTable [captureInstance=dbo_customers_v2, sourceTableId=testDB.dbo.customers, changeTableId=testDB.cdc.dbo_customers_v2_CT, startLsn=00000025:00000ef8:0048, changeTableObjectId=1749581271, stopLsn=NULL] [io.debezium.connector.sqlserver.SqlServerStreamingChangeEventSource] ... connect_1 | 2019-01-17 10:11:33,719 INFO || Migrating schema to ChangeTable [captureInstance=dbo_customers_v2, sourceTableId=testDB.dbo.customers, changeTableId=testDB.cdc.dbo_customers_v2_CT, startLsn=00000025:00000ef8:0048, changeTableObjectId=1749581271, stopLsn=NULL] [io.debezium.connector.sqlserver.SqlServerStreamingChangeEventSource]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 最終的には、
phone_numberフィールドがスキーマに追加され、その値が Kafka トピックに書き込まれたメッセージに表示されます。Copy to Clipboard Copied! Toggle word wrap Toggle overflow sys.sp_cdc_disable_tableストアドプロシージャーを実行して、古いキャプチャーインスタンスを削除します。EXEC sys.sp_cdc_disable_table @source_schema = 'dbo', @source_name = 'dbo_customers', @capture_instance = 'dbo_customers'; GO
EXEC sys.sp_cdc_disable_table @source_schema = 'dbo', @source_name = 'dbo_customers', @capture_instance = 'dbo_customers'; GOCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.7.6. Debezium SQL Server コネクターのパフォーマンスの監視
Debezium SQL Server コネクターは、Zookeeper、Kafka、および Kafka Connect によって提供される JMX メトリクスの組み込みサポートに加えて、3 種類のメトリクスを提供します。コネクターは以下のメトリクスを提供します。
- スナップショットの実行時にコネクターを監視するための、スナップショットメトリクス。
- CDC テーブルデータの読み取り時にコネクターを監視するための、ストリーミングメトリクス。
- コネクターのスキーマ履歴の状態を監視するための、スキーマ履歴メトリクス。
JMX 経由で前述のメトリクスを公開する方法については、Debezium の監視に関するドキュメント を参照してください。
2.7.6.1. SQL Server コネクタースナップショットおよびストリーミング MBean オブジェクトのカスタマイズされた名前
Debezium コネクターは、コネクターの MBean 名を介してメトリクスを公開します。これらのメトリクスは各コネクターインスタンスに固有であり、コネクターのスナップショット、ストリーミング、およびスキーマ履歴プロセスの動作に関するデータを提供します。
デフォルトでは、正しく設定されたコネクターをデプロイすると、Debezium はさまざまなコネクターメトリクスごとに一意の MBean 名を生成します。コネクタープロセスのメトリクスを表示するには、MBean を監視するように可観測性スタックを設定します。ただし、これらのデフォルトの MBean 名はコネクター設定に依存しており、設定の変更によって MBean 名が変更される場合があります。MBean 名を変更すると、コネクターインスタンスと MBean 間のリンクが切断され、監視アクティビティーが中断されます。このシナリオでは、監視を再開するには、新しい MBean 名を使用するように監視スタックを再設定する必要があります。
MBean 名の変更が原因で監視が中断されないように、カスタムメトリクスタグを設定できます。カスタムメトリクスを設定するには、コネクター設定に custom.metric.tags プロパティーを追加します。このプロパティーは、各キーが MBean オブジェクト名のタグを表し、対応する値がそのタグの値を表すキーと値のペアを受け入れます。たとえば、k1=v1,k2=v2 です。Debezium は、指定されたタグをコネクターの MBean 名に追加します。
コネクターの custom.metric.tags プロパティーを設定した後、指定されたタグに関連付けられたメトリクスを取得するように監視スタックを設定できます。可観測性スタックは、変更可能な MBean 名ではなく、指定されたタグを使用してコネクターを一意に識別します。その後、Debezium が MBean 名の構築方法を再定義したり、コネクター設定の topic.prefix が変更されたりしても、メトリクススクレイプタスクは指定されたタグパターンを使用してコネクターを識別するため、メトリクスの収集は中断されません。
カスタムタグを使用するさらなる利点は、データパイプラインのアーキテクチャーを反映するタグを使用できるため、運用上のニーズに合った方法でメトリクスを整理できることです。たとえば、コネクターアクティビティーのタイプ、アプリケーションコンテキスト、またはデータソースを宣言する値を持つタグを指定できます (例: db1-streaming-for-application-abc)。複数のキーと値のペアを指定すると、指定されたすべてのペアがコネクターの MBean 名に追加されます。
次の例は、タグがデフォルトの MBean 名を変更する方法を示しています。
例2.55 カスタムタグがコネクター MBean 名を変更する方法
デフォルトでは、SQL Server コネクターはストリーミングメトリクスに以下の MBean 名を使用します。
debezium.sqlserver:type=connector-metrics,context=streaming,server=<topic.prefix>
debezium.sqlserver:type=connector-metrics,context=streaming,server=<topic.prefix>
custom.metric.tags の値を database=salesdb-streaming,table=inventory に設定すると、Debezium は次のカスタム MBean 名を生成します。
debezium.sqlserver:type=connector-metrics,context=streaming,server=<topic.prefix>,database=salesdb-streaming,table=inventory
debezium.sqlserver:type=connector-metrics,context=streaming,server=<topic.prefix>,database=salesdb-streaming,table=inventory2.7.6.2. Debezium SQL Server コネクターのスナップショットメトリクス
MBean は debezium.sql_server:type=connector-metrics,server=<topic.prefix>,task=<task.id>,context=snapshot です。
スナップショット操作がアクティブでない場合や、最後のコネクターの起動後にスナップショットの作成が発生した場合に、スナップショットメトリクスは公開されません。
次の表に、使用可能なスナップショットメトリクスを示します。
| 属性 | タイプ | 説明 |
|---|---|---|
|
| コネクターが読み取りした最後のスナップショットイベント。 | |
|
| コネクターが最新のイベントを読み取りおよび処理してからの経過時間 (ミリ秒単位)。 | |
|
| 前回の開始またはリセット以降にコネクターで確認されたイベントの合計数。 | |
|
| コネクターに設定された include/exclude リストのフィルタリングルールによってフィルターされたイベントの数。 | |
|
| コネクターによって取得されるテーブルのリスト。 | |
|
| snapshotter とメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの長さ。 | |
|
| snapshotter とメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの空き容量。 | |
|
| スナップショットに含まれているテーブルの合計数。 | |
|
| スナップショットによってまだコピーされていないテーブルの数。 | |
|
| スナップショットが起動されたかどうか。 | |
|
| スナップショットが一時停止されたかどうか。 | |
|
| スナップショットが中断されたかどうか。 | |
|
| スナップショットが完了したかどうか。 | |
|
| スナップショットが完了したかどうかに関わらず、これまでスナップショットにかかった時間 (秒単位)。スナップショットが一時停止された時間も含まれます。 | |
|
| スナップショットが一時停止された合計秒数。スナップショットが数回一時停止された場合は、一時停止時間が加算されます。 | |
|
| スナップショットの各テーブルに対してスキャンされる行数が含まれるマップ。テーブルは、処理中に増分がマップに追加されます。スキャンされた 10,000 行ごとに、テーブルの完成時に更新されます。 | |
|
|
キューの最大バッファー (バイト単位)。このメトリクスは、 | |
|
| キュー内のレコードの現在の容量 (バイト単位)。 |
コネクターは、増分スナップショットの実行時に、以下の追加のスナップショットメトリクスも提供します。
2.7.6.3. Debezium SQL Server コネクターのストリーミングメトリクス
MBean は debezium.sql_server:type=connector-metrics,server=<topic.prefix>,task=<task.id>,context=streaming です。
以下の表は、利用可能なストリーミングメトリクスのリストです。
| 属性 | タイプ | 説明 |
|---|---|---|
|
| コネクターが読み取られた最後のストリーミングイベント。 | |
|
| コネクターが最新のイベントを読み取りおよび処理してからの経過時間 (ミリ秒単位)。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、ソースデータベースによって報告されたデータ変更イベントの合計数。Debezium が処理するデータ変更ワークロードを表します。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された作成イベントの合計数。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された更新イベントの合計数。 | |
|
| コネクターを最後に起動してから、またはメトリクスをリセットしてから、コネクターによって処理された削除イベントの合計数。 | |
|
| コネクターに設定された include/exclude リストのフィルタリングルールによってフィルターされたイベントの数。 | |
|
| コネクターによって取得されるテーブルのリスト。 | |
|
| ストリーマーとメイン Kafka Connect ループの間でイベントを渡すために使用されるキューの長さ。 | |
|
| ストリーマーとメインの Kafka Connect ループの間でイベントを渡すために使用されるキューの空き容量。 | |
|
| コネクターが現在データベースサーバーに接続されているかどうかを示すフラグ。 | |
|
| 最後の変更イベントのタイムスタンプとそれを処理するコネクターとの間の期間 (ミリ秒単位)。この値には、データベースサーバーとコネクターが実行されているマシンのクロックの差が組み込まれます。 | |
|
| コミットされた処理済みトランザクションの数。 | |
|
| 最後に受信したイベントの位置。 | |
|
| 最後に処理されたトランザクションのトランザクション識別子。 | |
|
|
キューの最大バッファー (バイト単位)。このメトリクスは、 | |
|
| キュー内のレコードの現在の容量 (バイト単位)。 |
2.7.6.4. Debezium SQL Server コネクターのスキーマ履歴メトリクス
MBean は debezium.sql_server:type=connector-metrics,context=schema-history,server=<topic.prefix> です。
以下の表は、利用可能なスキーマ履歴メトリクスのリストです。
| 属性 | タイプ | 説明 |
|---|---|---|
|
|
データベーススキーマ履歴の状態を示す | |
|
| リカバリーが開始された時点のエポック秒の時間。 | |
|
| リカバリーフェーズ中に読み取られた変更の数。 | |
|
| リカバリーおよびランタイム中に適用されるスキーマ変更の合計数。 | |
|
| 最後の変更が履歴ストアから復元された時点からの経過時間 (ミリ秒単位)。 | |
|
| 最後の変更が適用された時点からの経過時間 (ミリ秒単位)。 | |
|
| 履歴ストアから復元された最後の変更の文字列表現。 | |
|
| 最後に適用された変更の文字列表現。 |
第3章 シンクコネクター
Debezium は、Apache Kafka トピックなど、ソースからイベントを消費できるシンクコネクターを提供します。シンクコネクターはデータの形式を標準化し、設定されたシンクリポジトリーにイベントデータを保存します。その後、他のシステム、アプリケーション、またはユーザーはデータシンクからイベントにアクセスできるようになります。
シンクコネクターは、消費するイベントデータに一貫した構造を適用するため、データシンクから読み取るダウンストリームのアプリケーションは、そのデータを簡単に解釈して処理できます。
現在、Debezium は以下のシンクコネクターを提供しています。
3.1. JDBC 用の Debezium コネクター
Debezium JDBC コネクターは、複数のソーストピックからイベントを消費し、JDBC ドライバーを使用してそれらのイベントをリレーショナルデータベースに書き込むことができる Kafka Connect sink コネクター実装です。このコネクターは、Db2、MySQL、Oracle、PostgreSQL、SQL Server などのさまざまなデータベース言語をサポートします。
3.1.1. Debezium JDBC コネクターの仕組み
Debezium JDBC コネクターは Kafka Connect sink コネクターであるため、Kafka Connect ランタイムが必要です。コネクターは、サブスクライブしている Kafka トピックを定期的にポーリングし、それらのトピックからのイベントを消費して、設定されたリレーショナルデータベースにイベントを書き込みます。コネクターは、upsert セマンティクスと基本的なスキーマの進化を使用して、べき等書き込み操作をサポートします。
Debezium JDBC コネクターは次の機能を提供します。
- 「Debezium JDBC コネクターが複雑な変更イベントをどのように消費するかの説明」
- 「Debezium JDBC コネクターの at-least-once 配信の説明」
- 「Debezium JDBC の複数タスクの使用の説明」
- 「Debezium JDBC コネクターのデータと列タイプのマッピングの説明」
- 「Debezium JDBC コネクターがソースイベントのプライマリーキーを処理する方法の説明」
-
「
DELETEイベントまたは tombstone イベントの使用時に行を削除するような Debezium JDBC コネクターの設定」 - 「コネクターによるべき等書き込みの実行の有効化」
- 「Debezium JDBC コネクターのスキーマ進化モード」
- 「宛先テーブル名と列名の大文字と小文字を定義するオプションの指定」
- 接続アイドルタイムアウト
3.1.1.1. Debezium JDBC コネクターが複雑な変更イベントをどのように消費するかの説明
デフォルトでは、Debezium ソースコネクターは複雑で、階層分けされた変更イベントを生成します。Debezium コネクターを他の JDBC sink コネクター実装とともに使用する場合、変更イベントのペイロードを sink 実装で使用できるように、ExtractNewRecordState シングルメッセージ変換 (SMT) を適用する必要がある場合があります。Debezium JDBC sink コネクターを実行する場合、Debezium sink コネクターは変換を使用せずにネイティブの Debezium 変更イベントを直接使用できるため、SMT をデプロイする必要はありません。
JDBC sink コネクターが Debezium ソースコネクターから複雑な変更イベントを消費するとき、元の insert または update イベントの after セクションから値を抽出します。削除イベントがシンクコネクターによって消費されるとき、イベントのペイロードの一部は参照されません。
Debezium JDBC sink コネクターは、スキーマ変更トピックから読み取るように設計されていません。ソースコネクターがスキーマ変更をキャプチャーするように設定されている場合は、コネクターがスキーマ変更トピックを消費しないように、JDBC コネクター設定で topics または topic.regex プロパティーを設定します。
3.1.1.2. Debezium JDBC コネクターの at-least-once 配信の説明
Debezium JDBC sink コネクターは、Kafka トピックから消費されるイベントが少なくとも 1 回は処理されるようにします。
3.1.1.3. Debezium JDBC の複数タスクの使用の説明
Debezium JDBC sink コネクターは、複数の Kafka Connect タスクにわたって実行できます。複数のタスクに対してコネクターを実行するには、tasks.max 設定プロパティーでコネクターで使用するタスクの数を設定します。Kafka Connect ランタイムは、指定された数のタスクを開始し、タスクごとにコネクターの 1 つのインスタンスを実行します。複数のタスクの場合は、複数のソーストピックからの変更を並行して読み取り処理することでパフォーマンスを向上させます。
3.1.1.4. Debezium JDBC コネクターのデータと列タイプのマッピングの説明
Debezium JDBC sink コネクターが受信メッセージフィールドのデータ型を送信メッセージフィールドに正しくマップできるようにするには、コネクターはソースイベントに存在する各フィールドのデータ型に関する情報を必要とします。コネクターは、さまざまなデータベース言語にわたる幅広い列タイプのマッピングをサポートします。イベントフィールドの type メタデータから宛先列の型を正しく変換するために、コネクターはソースデータベースに定義されているデータ型マッピングを適用します。ソースコネクター設定で column.propagate.source.type または datatype.propagate.source.type オプションを設定して、コネクターが列のデータ型を解決する方法を強化できます。これらのオプションを有効にすると、Debezium には追加のパラメーターメタデータが含まれ、JDBC sink コネクターが宛先列のデータ型をより正確に解決できるようになります。
Debezium JDBC sink コネクターが Kafka トピックからのイベントを処理するには、Kafka トピックメッセージキー (存在する場合) がプリミティブデータ型または Struct である必要があります。さらに、ソースメッセージのペイロードの Struct は、ネストされた Struct タイプのないフラットな構造、または Debezium の複雑な階層構造に準拠したネストされた Struct レイアウトのいずれかを含む必要があります。
Kafka トピック内のイベントの構造がこれらのルールに準拠していない場合は、カスタムの単一メッセージ変換を実装して、ソースイベントの構造を使用可能な形式に変換する必要があります。
3.1.1.5. Debezium JDBC コネクターがソースイベントのプライマリーキーを処理する方法の説明
デフォルトでは、Debezium JDBC sink コネクターは、ソースイベントのフィールドをイベントのプライマリーキーに変換しません。ビジネス要件によっては、またはシンクコネクターが upsert セマンティクスを使用する場合は、安定したプライマリーキーがないとイベント処理が複雑になる可能性があります。一貫したプライマリーキーを定義するには、次の表に示すプライマリーキーモードのいずれかを使用するようにコネクターを設定できます。
| モード | 説明 |
|---|---|
|
| テーブルの作成時にプライマリーキーフィールドが指定されていません。 |
|
| プライマリーキーは次の 3 つの列で構成されます。
これらの列の値は、Kafka イベントの座標から取得されます。 |
|
|
プライマリーキーは、Kafka イベントのキーで構成されます。 |
|
|
プライマリーキーは、Kafka イベントの値で構成されます。 |
|
|
プライマリーキーは、Kafka イベントのヘッダーで構成されます。 |
一部のデータベース言語では、primary.key.mode を kafka に設定し、schema.evolution を Basic に設定すると例外が発生する場合があります。この例外は、方言が STRING データ型マッピングを TEXT や CLOB などの可変長文字列データ型にマップし、さらにこの方言で、プライマリー列に制限なく長さを指定できない場合に発生します。この問題を回避するには、環境に次の設定を適用します。
-
schema.evolutionをBasicに設定しないでください。 - データベースのテーブルとプライマリーキーのマッピングを事前に作成します。
列がターゲットデータベースのプライマリーキーとして許可されていないデータ型にマップされる場合、primary.key.fields にそのような列を除外する明示的な列リストが必要になります。許可されるデータ型と許可されないデータ型については、特定のデータベースベンダーのドキュメントを参照してください。
3.1.1.6. DELETE イベントまたは tombstone イベントの使用時に行を削除するような Debezium JDBC コネクターの設定
Debezium JDBC sink コネクターは、DELETE または tombstone イベントが消費されると、宛先データベース内の行を削除できます。デフォルトでは、JDBC sink コネクターにより削除モードは有効になりません。
コネクターで行を削除する場合は、コネクター設定で明示的に delete.enabled=true を設定する必要があります。このモードを使用するには、primary.key.fields を none 以外の値に設定する必要もあります。削除はプライマリーキーマッピングに基づいて実行されるため、前述の設定が必要です。そのため、宛先テーブルにプライマリーキーマッピングがない場合、コネクターは行を削除できません。
3.1.1.7. コネクターによるべき等書き込みの実行の有効化
Debezium JDBC sink コネクターはべき等書き込みを実行できるため、同じレコードを繰り返し再生し、データベースの最終状態を変更できません。
コネクターがべき等書き込みを実行できるようにするには、コネクターの insert.mode を明示的に upsert に設定する必要があります。upsert 操作は、指定されたプライマリーキーがすでに存在するかどうかに応じて、update または insert として適用されます。
プライマリーキー値がすでに存在する場合、この操作により行内の値が更新されます。指定されたプライマリーキー値が存在しない場合、insert で新しい行が追加されます。
upsert 操作には SQL 標準がないため、各データベース方言はべき等書き込みを異なる方法で処理します。次の表は、Debezium がサポートするデータベース言語の upsert の DML 構文を示しています。
| 方言 | Upsert 構文 |
|---|---|
| Db2 |
|
| MySQL |
|
| Oracle |
|
| PostgreSQL |
|
| SQL Server |
|
3.1.1.8. Debezium JDBC コネクターのスキーマ進化モード
Debezium JDBC sink コネクターでは、次のスキーマ進化モードを使用できます。
| モード | 説明 |
|---|---|
|
| コネクターは、DDL スキーマの進化を実行しません。 |
|
| コネクターは、イベントペイロード内にあるが宛先テーブルには存在しないフィールドを自動的に検出します。コネクターは宛先テーブルを変更して新しいフィールドを追加します。 |
schema.evolution が Basic に設定されている場合、コネクターは受信イベントの構造に従って宛先データベーステーブルを自動的に作成または変更します。
トピックから初めてイベントを受信し、宛先テーブルがまだ存在しない場合、Debezium JDBC sink コネクターはイベントのキー、またはレコードのスキーマ構造を使用してテーブルの列構造を解決します。スキーマの進化が有効な場合、コネクターは、DML イベントを宛先テーブルに適用する前に、CREATE TABLE SQL ステートメントを準備して実行します。
Debezium JDBC コネクターがトピックからイベントを受信するとき、レコードのスキーマ構造が宛先テーブルのスキーマ構造と異なる場合、コネクターはイベントのキーまたはそのスキーマ構造を使用してどの列が新しいかを識別し、データベーステーブルに追加する必要があります。スキーマの進化が有効な場合、コネクターは、宛先テーブルに DML イベントを適用する前に、ALTER TABLE SQL ステートメントを準備して実行します。列のデータ型の変更、列の削除、およびプライマリーキーの調整は危険な操作であると考えられるため、コネクターではこれらの操作の実行が禁止されています。
各フィールドのスキーマによって、列が NULL か NOT NULL かが決まります。スキーマは各列のデフォルト値も定義します。コネクターが NULL を指定できるかどうかの設定、または必要のないデフォルト値を含めてテーブルを作成しようとしている場合には、事前に手動でテーブルを作成するか、sink コネクターがイベントを処理する前に関連のフィールドのスキーマを調節する必要があります。NULL を指定できるかどうかの設定またはデフォルト値を調整するには、パイプライン内の変更を適用するか、ソースデータベースで定義されている列の状態を変更するカスタムの単一メッセージ変換を導入できます。
フィールドのデータ型は、事前定義されたマッピングのセットに基づいて解決されます。詳細は、「Debezium JDBC コネクターがデータ型をマップする方法」 を参照してください。
宛先データベースにすでに存在するテーブルのイベント構造に新しいフィールドを導入する場合は、新しいフィールドをオプションとして定義するか、フィールドのデフォルト値がデータベーススキーマで指定されている必要があります。フィールドを宛先テーブルから削除する場合は、次のいずれかのオプションを使用します。
- フィールドを手動で削除します。
- 列をドロップします。
- フィールドにデフォルト値を割り当てます。
- フィールドを NULL を指定可能として定義します。
3.1.1.9. 宛先テーブル名と列名の大文字と小文字を定義するオプションの指定
Debezium JDBC sink コネクターは、宛先データベースで実行される DDL (スキーマ変更) または DML (データ変更) SQL ステートメントを構築することによって、Kafka メッセージを消費します。デフォルトでは、コネクターはソーストピックの名前とイベントフィールドの名前を、宛先テーブルのテーブル名と列名の基礎として使用します。構築された SQL では、元の文字列の大文字と小文字を保持するために、識別子が引用符で自動的に区切られることはありません。その結果、デフォルトでは、宛先データベース内のテーブル名または列名のテキストの大文字と小文字の区別については、大文字と小文字が指定されていない場合にデータベースが名前文字列を処理する方法に完全に依存します。
たとえば、宛先データベースの言語が Oracle で、イベントのトピックが order である場合、名前が引用符で囲まれていない場合、Oracle ではデフォルトで大文字の名前が使用されるため、宛先テーブルは ORDERS として作成されます。同様に、宛先データベース言語が PostgreSQL で、イベントのトピックが ORDERS である場合、名前が引用符で囲まれていない場合、PostgreSQL はデフォルトで小文字の名前を使用するため、宛先テーブルは order として作成されます。
Kafka イベントに存在するテーブル名とフィールド名の大文字と小文字を明示的に保持するには、コネクター設定で quote.identifiers プロパティーの値を true に設定します。このオプションが設定されている場合、受信イベントが order というトピックのもので、宛先データベース言語が Oracle である場合、コネクターは、構築された SQL でテーブルの名前が "orders" として定義されているため、orders という名前のテーブルを作成します。引用符を有効にすると、コネクターが列名を作成するときと同じ動作になります。
接続アイドルタイムアウト
Debezium の JDBC sink コネクターは、接続プールを活用してパフォーマンスを向上させます。接続プールは、初期の接続セットを確立し、指定された数の接続を維持し、必要に応じてアプリケーションに効率的に接続を割り当てるように設計されています。ただし、接続がプール内でアイドル状態のままになると問題が発生し、データベースに設定されたアイドルタイムアウトしきい値を超えて、非アクティブの状態が続くと、タイムアウトがトリガーされる可能性があります。
アイドル接続スレッドがタイムアウトをトリガーする可能性を軽減するために、接続プールは各接続のアクティビティーを定期的に検証するメカニズムを提供します。この検証により、接続がアクティブの状態を確保でき、データベースが接続をアイドル状態としてフラグ付けされないようにします。ネットワークが中断された場合に、Debezium が終了した接続を使用しようとすると、コネクターはプールに対して新しい接続を生成するよう要求します。
デフォルトでは、Debezium JDBC sink コネクターはアイドルタイムアウトテストを実行しません。ただし、hibernate.c3p0.idle_test_period プロパティーを設定することで、コネクターがプールに対して、指定の間隔でタイムアウトテストを実行する要求を行うように設定できます。以下に例を示します。
タイムアウト設定の例
{
"hibernate.c3p0.idle_test_period": "300"
}
{
"hibernate.c3p0.idle_test_period": "300"
}Debezium JDBC sink コネクターは、Hibernate C3P0 接続プールを使用します。hibernate.c3p0.*` 設定名前空間でプロパティーを設定することで、CP30 接続プールをカスタマイズできます。上記の例では、hibernate.c3p0.idle_test_period プロパティーの設定により、接続プールが 300 秒ごとにアイドルタイムアウトテストを実行するように設定されます。設定を適用すると、接続プールは 5 分ごとに未使用の接続の評価を開始します。
3.1.2. Debezium JDBC コネクターがデータ型をマップする方法
Debezium JDBC sink コネクターは、論理またはプリミティブ型マッピングシステムを使用して列のデータ型を解決します。プリミティブ型には、整数、浮動小数点、ブール値、文字列、バイトなどの値が含まれます。通常、これらの型は、特定の Kafka Connect Schema 型コードのみで表されます。論理データ型は、フィールド名とスキーマの固定セットが含まれる Struct ベースの型などの値、またはエポックからの日数など、特定のエンコーディングで表される値を含むなど、複雑な型であることがよくあります。
次の例は、プリミティブデータ型と論理データ型の代表的な構造を示しています。
プリミティブフィールドスキーマ
{
"schema": {
"type": "INT64"
}
}
{
"schema": {
"type": "INT64"
}
}論理フィールドスキーマ
Kafka Connect だけが、これらの複雑な論理型のソースというわけではありません。実際、Debezium ソースコネクターは、タイムスタンプ、日付、さらには JSON データなど、さまざまなデータ型を表す同様の論理型を含むフィールドを持つ変更イベントを生成します。
Debezium JDBC sink コネクターは、このようなプリミティブおよび論理型を仕様して JDBC SQL コード (列の方を表す) に列の方を解決します。これらの JDBC SQL コードは、基礎となる Hibernate 永続フレームワークによって使用され、列の型を使用中の方言の論理データ型に解決します。次の表は、Kafka Connect と JDBC SQL 型の間、および Debezium と JDBC SQL 型の間の基本マッピングと論理マッピングを示しています。実際の最終的な列のタイプは、データベースのタイプごとに異なります。
| プリミティブ型 | JDBC SQL 型 |
|---|---|
| INT8 | Types.TINYINT |
| INT16 | Types.SMALLINT |
| INT32 | Types.INTEGER |
| INT64 | Types.BIGINT |
| FLOAT32 | Types.FLOAT |
| FLOAT64 | Types.DOUBLE |
| BOOLEAN | Types.BOOLEAN |
| STRING | Types.CHAR、Types.NCHAR、Types.VARCHAR、Types.NVARCHAR |
| BYTES | Types.VARBINARY |
| 論理型 | JDBC SQL 型 |
|---|---|
| org.apache.kafka.connect.data.Decimal | Types.DECIMAL |
| org.apache.kafka.connect.data.Date | Types.DATE |
| org.apache.kafka.connect.data.Time | Types.TIMESTAMP |
| org.apache.kafka.connect.data.Timestamp | Types.TIMESTAMP |
| 論理型 | JDBC SQL 型 |
|---|---|
| io.debezium.time.Date | Types.DATE |
| io.debezium.time.Time | Types.TIMESTAMP |
| io.debezium.time.MicroTime | Types.TIMESTAMP |
| io.debezium.time.NanoTime | Types.TIMESTAMP |
| io.debezium.time.ZonedTime | Types.TIME_WITH_TIMEZONE |
| io.debezium.time.Timestamp | Types.TIMESTAMP |
| io.debezium.time.MicroTimestamp | Types.TIMESTAMP |
| io.debezium.time.NanoTimestamp | Types.TIMESTAMP |
| io.debezium.time.ZonedTimestamp | Types.TIMESTAMP_WITH_TIMEZONE |
| io.debezium.data.VariableScaleDecimal | Types.DOUBLE |
データベースがタイムゾーンのある時刻またはタイムスタンプをサポートしていない場合、マッピングはタイムゾーンなしの同等のものに解決されます。
| 論理型 | MySQL SQL 型 | PostgreSQL SQL 型 | SQL Server SQL 型 |
|---|---|---|---|
| io.debezium.data.Bits |
|
|
|
| io.debezium.data.Enum |
| Types.VARCHAR | 該当なし |
| io.debezium.data.Json |
|
| 該当なし |
| io.debezium.data.EnumSet |
| 該当なし | 該当なし |
| io.debezium.time.Year |
| 該当なし | 該当なし |
| io.debezium.time.MicroDuration | 該当なし |
| 該当なし |
| io.debezium.data.Ltree | 該当なし |
| 該当なし |
| io.debezium.data.Uuid | 該当なし |
| 該当なし |
| io.debezium.data.Xml | 該当なし |
|
|
上記のプリミティブおよび論理マッピングに加え、変更イベントのソースが Debezium ソースコネクターの場合は、列またはデータ型の伝播を有効にすることで、列のタイプと長さ、制度、スケールの解決も操作できます。強制的に伝播を行うには、ソースコネクター設定で次のプロパティーのいずれかを設定する必要があります。
-
column.propagate.source.type -
datatype.propagate.source.type
Debezium JDBC シンクコネクターは、より高い優先順位で値を適用します。
たとえば、次のフィールドスキーマが変更イベントに含まれているとします。
Debezium は列またはデータ型の伝播を有効にしてイベントフィールドスキーマを変更します
前述の例では、スキーマパラメーターが設定されていない場合、Debezium JDBC シンクコネクターはこのフィールドを Types.SMALLINT の列型にマップします。Types.SMALLINT には、データベース言語に応じて、さまざまな論理データベースタイプを指定できます。MySQL の場合、例の列タイプは、長さが指定されていない TINYINT 列タイプに変換されます。列またはデータ型の伝播がソースコネクターで有効になっている場合、Debezium JDBC シンクコネクターはマッピング情報を使用してデータ型マッピングプロセスを調整し、TINYINT(1) 型の列を作成します。
通常、ソースデータベースとシンクデータベースの両方に同じ種類のデータベースが使用されている場合、列またはデータ型の伝播を使用する効果は非常に大きくなります。
3.1.3. Debezium JDBC コネクターのデプロイメント
Debezium JDBC コネクターをデプロイするには、Debezium JDBC コネクターアーカイブをインストールし、コネクターを設定し、その設定を Kafka Connect に追加してコネクターを起動します。
前提条件
- Apache ZooKeeper、Apache Kafka、および Kafka Connect がインストールされている。
- 宛先データベースがインストールされ、JDBC 接続を受け入れるように設定されている。
手順
- Debezium JDBC connector plug-in archive をダウンロードします。
- ファイルを Kafka Connect 環境にデプロイメントします。
必要に応じて、Maven Central から JDBC ドライバーをダウンロードし、ダウンロードしたドライバーファイルを JDBC シンクコネクター JAR ファイルが含まれるディレクトリーに展開します。
注記Oracle および Db2 用のドライバーは、JDBC シンクコネクターには含まれていません。ドライバーをダウンロードして手動でインストールする必要があります。
- JDBC シンクコネクターがインストールされているパスにドライバー JAR ファイルを追加します。
-
JDBC シンクコネクターをインストールするパスが Kafka Connect
plugin.pathの一部であることを確認してください。 - Kafka Connect プロセスを再起動し、新しい JAR ファイルを取得します。
3.1.3.1. Debezium JDBC コネクターの設定
通常、Debezium JDBC コネクターを登録するには、コネクターの設定プロパティーを指定する JSON リクエストを送信します。次の例は、最も一般的な設定を使用して、orders というトピックからのイベントを消費する Debezium JDBC シンクコネクターのインスタンスを登録する JSON リクエストを示しています。
例: Debezium JDBC コネクターの設定
JDBC コネクター設定の説明
| 項目 | 説明 |
|---|---|
| 1 | Kafka Connect サービスにコネクターを登録するときにコネクターに割り当てられる名前。 |
| 2 | JDBC シンクコネクタークラスの名前。 |
| 3 | このコネクターに作成するタスクの最大数。 |
| 4 | コネクターが書き込み先のシンクデータベースへの接続に使用する JDBC URL。 |
| 5 | 認証に使用されるデータベースユーザーの名前。 |
| 6 | 認証に使用されるデータベースユーザーのパスワード。 |
| 7 | コネクターが使用する insert.mode。 |
| 8 | データベース内のレコードの削除を有効にします。詳細は、delete.enabled 設定プロパティーを参照してください。 |
| 9 | プライマリーキー列の解決に使用する方法を指定します。詳細は、primary.key.mode 設定プロパティーを参照してください。 |
| 10 | コネクターが宛先データベースのスキーマを進化できるようにします。詳細は、schema.evolution 設定プロパティーを参照してください。 |
| 11 | 時間フィールドタイプを書き込むときに使用されるタイムゾーンを指定します。 |
| 12 | 消費するトピックのコンマ区切りのリスト。 |
Debezium JDBC コネクターに設定できる設定プロパティーの完全なリストは、JDBC コネクターのプロパティー を参照してください。
POST コマンドを使用して、この設定を実行中の Kafka Connect サービスに送信できます。サービスは設定を記録し、次の操作を実行するシンクコネクタータスクを開始します。
- データベースに接続します。
- サブスクライブされた Kafka トピックからのイベントを消費します。
- 設定されたデータベースにイベントを書き込みます。
3.1.4. Debezium JDBC コネクター設定プロパティーの説明
Debezium JDBC シンクコネクターには、ニーズを満たすコネクターの動作を実現するために使用できるいくつかの設定プロパティーがあります。多くのプロパティーにはデフォルト値があります。プロパティーに関する情報は、以下のように設定されています。
| プロパティー | デフォルト | 説明 |
|---|---|---|
| デフォルトなし | コネクターの一意名。コネクターの登録時にこの名前を再利用しようとすると失敗します。このプロパティーはすべての Kafka Connect コネクターに必要です。 | |
| デフォルトなし |
コネクターの Java クラスの名前。Debezium JDBC コネクターの場合、 | |
| 1 | このコネクターに使用するタスクの最大数。 | |
| デフォルトなし |
消費するトピックのコンマ区切りのリスト。このプロパティーを | |
| デフォルトなし |
消費するトピックを指定する正規表現。内部的には、正規表現は |
| プロパティー | デフォルト | 説明 |
|---|---|---|
|
| 使用する接続プロバイダーの実装。 | |
| デフォルトなし | データベースへの接続に使用される JDBC 接続 URL。 | |
| デフォルトなし | コネクターがデータベースへの接続に使用するデータベースユーザーアカウントの名前。 | |
| デフォルトなし | コネクターがデータベースへの接続に使用するパスワード。 | |
|
| プール内の最小接続数を指定します。 | |
|
| プールが維持する同時接続の最大数を指定します。 | |
|
| 接続プールが最大サイズを超えた場合にコネクターが取得を試みる接続の数を指定します。 | |
|
| 未使用の接続が破棄されるまで保持する時間 (秒) を指定します。 |
| プロパティー | デフォルト | 説明 |
|---|---|---|
|
| JDBC 時間値を挿入するときに使用するタイムゾーンを指定します。 | |
|
|
コネクターが | |
|
|
コネクターが 注記
JDBC コネクターが Db2 から受信した
上記のクエリーを送信するユーザーアカウントには、切り捨てられるテーブルに対する | |
|
| イベントのデータベースへの挿入に使用するストラテジーを指定します。以下のオプションが利用できます。
| |
|
| コネクターがイベントからプライマリーキー列を解決する方法を指定します。
| |
| デフォルトなし |
プライマリーキー列の名前、またはプライマリーキーの導出元となるフィールドのコンマ区切りリスト。 | |
|
| 生成された SQL ステートメントでテーブル名と列名を区切るために引用符を使用するかどうかを指定します。詳細は 「宛先テーブル名と列名の大文字と小文字を定義するオプションの指定」 のセクションを参照してください。 | |
|
| コネクターが宛先テーブルのスキーマを進化させる方法を指定します。詳細は、「Debezium JDBC コネクターのスキーマ進化モード」 を参照してください。以下のオプションが利用できます。
| |
|
|
コネクターが宛先テーブルの名前を構築するために使用する文字列パターンを指定します。 | |
|
|
PostgreSQL PostGIS エクステンションがインストールされているスキーマ名を指定します。デフォルトは | |
|
|
SQL Server テーブルの identity 列への | |
|
| 宛先テーブルにまとめてバッチ処理するレコードの数を指定します。 注記
Connect ワーカープロパティーの | |
|
| Debezium JDBC コネクターの削減バッファーを有効にするかどうかを指定します。 次のいずれかの設定を選択します。
削減バッファーが有効になっている場合に PostgreSQL シンクデータベースでのクエリー処理を最適化するには、JDBC 接続 URL に | |
| 空の文字列 |
変更イベント値から追加するフィールドの完全修飾名と一致するフィールド名の、オプションのコンマ区切りリスト。フィールドの完全修飾名の形式は、 | |
| 空の文字列 |
変更イベント値から除外するフィールドの完全修飾名と一致するフィールド名の、オプションのコンマ区切りリスト。フィールドの完全修飾名の形式は、 |
| プロパティー | デフォルト | 説明 |
|---|---|---|
|
|
コネクターがイベントフィールド名から列名を解決するために使用する | |
|
|
コネクターが受信イベントトピック名からテーブル名を解決するために使用する
|
JDBC コネクター hibernate.* パススループロパティー
Kafka Connect はパススルー設定をサポートしており、コネクター設定から特定のプロパティーを直接渡すことで、基盤となるシステムの動作を変更できます。デフォルトでは、一部の Hibernate プロパティーは、JDBC コネクター 接続プロパティー (connection.url、connection.username、connection.pool.*_size など) およびコネクターの ランタイムプロパティー (database.time_zone、quote.identifiers など) を通じて公開されます。
他の Hibernate の動作をカスタマイズする場合は、hibernate.* 名前空間を使用するプロパティーをコネクター設定に追加することで、パススルーのメカニズムを利用できます。たとえば、Hibernate がターゲットデータベースのタイプとバージョンを解決できるようにするには、hibernate.dialect プロパティーを追加し、それをデータベースの完全修飾クラス名 (例: org.hibernate.dialect.MariaDBDialect) に設定します。
3.1.5. JDBC コネクターのよくある質問
ExtractNewRecordState単一メッセージ変換は必要ですか?- いいえ、実際には、Debezium JDBC コネクターを他の実装と区別する要素の 1 つです。このコネクターは、競合するコネクターと同様にフラット化されたイベントを取り込むことができますが、特定の種類の変換を必要とせずに、Debezium の複雑な変更イベント構造をネイティブに取り込むこともできます。
- 列の型が変更された場合、または列の名前が変更または削除された場合、これはスキーマの進化によって処理されますか?
- いいえ、Debezium JDBC コネクターは既存の列に変更を加えません。コネクターによってサポートされるスキーマの進化は非常に基本的なものです。これは、イベント構造内のフィールドをテーブルの列リストと単純に比較し、まだ列として定義されていないフィールドをテーブルに追加します。列のタイプまたはデフォルト値が変更された場合、コネクターは宛先データベースでの調整は行いません。列の名前が変更された場合、古い列はそのまま残され、コネクターは新しい名前の列をテーブルに追加します。ただし、古い列のデータを含む既存の行は変更されません。このようなタイプのスキーマ変更は手動で処理する必要があります。
- 列の型が希望する型に解決されない場合、別のデータ型に強制的にマッピングするにはどうすればよいですか?
- Debezium JDBC コネクターは、高度な型システムを使用して列のデータ型を解決します。この型システムが特定のフィールドのスキーマ定義を JDBC 型に解決する方法の詳細は、「Debezium JDBC コネクターのデータと列タイプのマッピングの説明」 セクションを参照してください。別のデータ型マッピングを適用する場合は、テーブルを手動で定義して、優先される列の型を明示的に取得します。
- Kafka トピック名を変更せずに、テーブル名に接頭辞または接尾辞を指定するにはどうすればよいですか?
-
宛先テーブル名に接頭辞または接尾辞を追加するには、table.name.format コネクター設定プロパティーを調整して、必要な接頭辞または接尾辞を適用します。たとえば、すべてのテーブル名に
jdbc_という接頭辞を付けるには、table.name.format設定プロパティーにjdbc_${topic}の値を指定します。コネクターがorderというトピックにサブスクライブされている場合、結果のテーブルはjdbc_ordersとして作成されます。 - 識別子の引用符が有効になっていないにもかかわらず、一部の列が自動的に引用符で囲まれるのはなぜですか?
-
状況によっては、
quote.identifiersが有効になっていない場合でも、特定の列名またはテーブル名が明示的に引用符で囲まれることがあります。これは、列名またはテーブル名が、不正な構文とみなされる特定の規則で始まるか、またはそのような規則が使用されている場合に引用符が必要になることがよくあります。たとえば、primary.key.mode がkafkaに設定されている場合、一部のデータベースでは、列名が引用符で囲まれている場合にのみ、列名をアンダースコアで始めることができます。引用の動作は方言固有であり、データベースの種類によって異なります。
第4章 Debezium の監視
Apache Zookeeper、Apache Kafka、および Kafka Connect が提供する JMX メトリクスを使用して、Debezium を監視することができます。これらのメトリクスを使用するには、Zookeeper、Kafka、および Kafka Connect サービスの起動時にメトリクスを有効にする必要があります。JMX を有効にするには、正しい環境変数を設定する必要があります。
同じマシン上で複数のサービスを実行している場合は、サービスごとに異なる JMX ポートを使用するようにしてください。
4.1. Debezium コネクターを監視するためのメトリクス
Kafka、Zookeeper、および Kafka Connect に組み込まれた JMX メトリクスのサポートに加えて、それぞれのコネクターには動作を監視するための追加のメトリクスが用意されています。
4.2. ローカルインストールでの JMX の有効化
Zookeeper、Kafka、および Kafka Connect では、各サービスの起動時に適切な環境変数を設定して JMX を有効にします。
4.2.1. Zookeeper JMX 環境変数
Zookeeper には JMX のサポートが組み込まれています。ローカルインストールを使用して Zookeeper を実行する場合、zkServer.sh スクリプトは以下の環境変数を認識します。
JMXPORT-
JMX を有効にし、JMX に使用するポート番号を指定します。この値は、JVM パラメーター
-Dcom.sun.management.jmxremote.port=$JMXPORTを指定するために使用されます。 JMXAUTH-
接続時に JMX クライアントがパスワード認証を使用する必要があるかどうかを定義します。
trueまたはfalseのどちらかでなければなりません。デフォルトはfalseです。この値は、JVM パラメーター-Dcom.sun.management.jmxremote.authenticate=$JMXAUTHの指定に使用されます。 JMXSSL-
JMX クライアントが SSL/TLS を使用して接続するかどうかを定義します。
trueまたはfalseのどちらかでなければなりません。デフォルトはfalseです。この値は、JVM パラメーター-Dcom.sun.management.jmxremote.ssl=$JMXSSLを指定するために使用されます。 JMXLOG4J-
Log4J JMX MBean を無効にする必要があるかどうかを定義します。
true(デフォルト) またはfalseのいずれかである必要があります。デフォルトはtrueです。この値は、JVM パラメーター-Dzookeeper.jmx.log4j.disable=$JMXLOG4Jの指定に使用されます。
4.2.2. Kafka JMX 環境変数
ローカルインストールを使用して Kafka を実行する場合、kafka-server-start.sh スクリプトは次の環境変数を認識します。
JMX_PORT-
JMX を有効にし、JMX に使用するポート番号を指定します。この値は、JVM パラメーター
-Dcom.sun.management.jmxremote.port=$JMX_PORTを指定するために使用されます。 KAFKA_JMX_OPTSJMX オプション。起動時に直接 JVM に渡されます。デフォルトのオプションは次のとおりです。
-
-Dcom.sun.management.jmxremote -
-Dcom.sun.management.jmxremote.authenticate=false -
-Dcom.sun.management.jmxremote.ssl=false
-
4.2.3. Kafka Connect JMX 環境変数
ローカルインストールを使用して Kafka を実行する場合、connect-distributed.sh スクリプトは次の環境変数を認識します。
JMX_PORT-
JMX を有効にし、JMX に使用するポート番号を指定します。この値は、JVM パラメーター
-Dcom.sun.management.jmxremote.port=$JMX_PORTを指定するために使用されます。 KAFKA_JMX_OPTSJMX オプション。起動時に直接 JVM に渡されます。デフォルトのオプションは次のとおりです。
-
-Dcom.sun.management.jmxremote -
-Dcom.sun.management.jmxremote.authenticate=false -
-Dcom.sun.management.jmxremote.ssl=false
-
4.3. OpenShift 上での Debezium の監視
OpenShift 上で Debezium を使用している場合、JMX ポートを 9999 番で開放することで JMX メトリクスを取得できます。JMX 接続オプションの設定については、Streams for Apache Kafka API リファレンスの KafkaJmxOptions スキーマリファレンス を参照してください。
また、Prometheus および Grafana を使用して JMX メトリクスを監視できます。詳細は、OpenShift 上の Streams for Apache Kafka の概要 の モニタリング および OpenShift 上の Streams for Apache Kafka のデプロイと管理 の メトリクスとダッシュボードのセットアップ を参照してください。
第5章 Debezium のログ機能
Debezium のコネクターには、さまざまなログ機能が組み込まれています。ログの設定を変更して、ログに表示するメッセージやログの送信先を制御することができます。(Kafka、Kafka Connect、および Zookeeper と同様に) Debezium は Java の Log4j ログフレームワークを使用します。
デフォルトでは、コネクターは起動時に大量の有用な情報を生成しますが、その後コネクターがソースのデータベースとシンクロすると、ほとんどログを生成しません。コネクターが正常に動作している場合はこれで十分ですが、コネクターが予期せぬ動作を示す場合には十分ではない可能性があります。そのような場合は、コネクターがしていること/していないことを記述したより詳細なログメッセージを生成するように、ログのレベルを変更することができます。
5.1. Debezium ログの概念
ログ機能を設定する前に、Log4J の ロガー、ログレベル、および アペンダー について理解しておく必要があります。
ロガー
アプリケーションによって生成されるそれぞれのログメッセージは、特定の ロガー に送信されます (例: io.debezium.connector.mysql)。ロガーは階層構造を取ります。たとえば、io.debezium.connector.mysql ロガーは io.debezium ロガーの子であるio.debezium.connector ロガーの子です。階層最上位の ルートロガー は、それより下位のすべてのロガーのデフォルトロガー設定を定義します。
ログレベル
アプリケーションによって生成されるすべてのログメッセージには、固有の ログレベル も設定される。
-
ERROR: エラー、例外、およびその他の重大な問題に設定される。 -
WARN: 潜在的な問題と課題 -
INFO: ステータスおよび一般的な動作に関する情報 (通常は少量) に設定される。 -
DEBUG: 予期しない挙動の診断に役立つより詳細な動作に関する情報に設定される。 -
TRACE: 非常に冗長で詳細なアクティビティー (通常は非常に大量のデータを扱う)
アペンダー
アペンダー とは、基本的にログメッセージの書き込み先を指します。それぞれのアペンダーは、そのログメッセージのフォーマットを制御します。これにより、ログメッセージの外観をより詳細に制御することができます。
ログ機能を設定するには、希望する各ロガーのレベルおよびそれらのログメッセージが書き込まれるアペンダーを指定します。ロガーは階層構造を取るため、ルートロガーの設定は、それより下位のすべてのロガーのデフォルトとして機能します。ただし、子の (または下位の) ロガーをオーバーライドすることができます。
5.2. デフォルトの Debezium ログ設定
Kafka Connect プロセスで Debezium コネクターを実行している場合、Kafka Connect は Kafka インストールの Log4j 設定ファイル (例: /opt/kafka/config/connect-log4j.properties) を使用します。デフォルトでは、このファイルには以下の設定が含まれています。
例5.1 connect-log4j.properties のデフォルト設定
| プロパティー | 説明 |
|---|---|
| 1 |
デフォルトのロガー設定を定義するルートロガー。デフォルトでは、ロガーには |
| 2 |
ファイルではなくコンソールにログメッセージを書き込むように |
| 3 |
|
| 4 |
|
他のロガーを設定しない限り、Debezium が使用するすべてのロガーは rootLogger 設定を継承します。
5.3. Debezium ログの設定
デフォルトでは、Debezium コネクターはすべての INFO、WARN、および ERROR メッセージをコンソールに書き込みます。次のいずれかの方法を使用して、デフォルトのログ設定を変更できます。
他の方法を使用して、Log4j による Debezium のログを設定することができます。詳細は、アペンダーを設定および使用し、特定の宛先にログメッセージを送信する方法のチュートリアルを検索してください。
5.3.1. ロガーを設定して Debezium のログレベルを変更する
デフォルトの Debezium ログレベルで、コネクターが正常かどうかを判断するのに十分な情報が得られます。ただし、コネクターが正常でない場合は、そのログレベルを変更して問題のトラブルシューティングを行うことができます。
一般に、Debezium コネクターは、ログメッセージを生成している Java クラスの完全修飾名と一致する名前のロガーにログメッセージを送信します。Debezium では、パッケージを使用して、類似または関連する機能のコードを取りまとめます。つまり、特定パッケージ内の特定クラスまたは全クラスのすべてのログメッセージを制御することができます。
手順
-
connect-log4j.propertiesファイルを開きます。 コネクターのロガーを設定します。
以下の例では、MySQL コネクターのロガーおよびコネクターが使用するデータベーススキーマ履歴の実装用ロガーを設定し、それらが
DEBUGレベルのメッセージを記録するように設定します。
例5.2 connect-log4j.properties 設定でのロガーの有効化およびログレベルの
DEBUGへの設定Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表5.2 ロガーの有効化およびログレベルの設定をするための connect-log4j.properties 設定の説明 プロパティー 説明 1
io.debezium.connector.mysqlという名前のロガーを設定して、DEBUG、INFO、WARN、ERRORのメッセージをstdoutのアペンダーに送信します。2
io.debezium.relational.historyという名前のロガーを設定して、DEBUG、INFO、WARN、ERRORのメッセージをstdoutのアペンダーに送信します。3
この
log4j.additivity.ioエントリーのペアは、additivity を無効にします。複数のアペンダーを使用する場合は、additivityの値をfalseに設定して、重複したログメッセージが親ロガーのアペンダに送信されないようにします。必要に応じて、コネクター内のクラスの特定サブセットのログレベルを変更します。
コネクター全体のログレベルを上げるとログがより煩雑になり、状況を把握するのが困難になる場合があります。このような場合は、トラブルシューティングを行う問題に関連するクラスのサブセットのログレベルだけを変更することができます。
-
コネクターのログレベルを
DEBUGまたはTRACEに設定します。 コネクターのログメッセージを確認します。
トラブルシューティングを行う問題に関連するログメッセージを探します。それぞれのログメッセージの末尾には、メッセージを生成した Java クラスの名前が表示されます。
-
コネクターのログレベルを
INFOに戻します。 識別したそれぞれの Java クラスのロガーを設定します。
たとえば、MySQL コネクターが binlog を処理する際にいくつかのイベントをスキップする理由が不明なシナリオを考えてみます。コネクター全体で
DEBUGまたはTRACEログを有効にするのではなく、コネクターのログレベルはINFOのままにして、binlog を読み取るクラスについてのみDEBUGまたはTRACEを設定することができます。例5.3
BinlogReaderクラスのDEBUGログを有効にする connect-log4j.properties 設定Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
コネクターのログレベルを
5.3.2. Kafka Connect API を使用して Debezium のログレベルを動的に変更する
Kafka Connect REST API を使用して、実行時にコネクターのログレベルを動的に設定できます。connect-log4j.properties で設定されるログレベルの変更とは異なり、API 経由で行った変更は即座に反映されるため、ワーカーを再起動する必要はありません。
API に指定するログレベル設定は、要求を受信するエンドポイントのワーカーにのみ適用されます。クラスター内の他のワーカーのログレベルは変更されません。
指定されたレベルは、ワーカーの再起動後に維持されません。ロギングレベルを永続的に変更するには、ロガーを設定する か、マップされた診断コンテキストを追加 して connect-log4j.properties でログレベルを設定します。
手順
以下の情報を指定する
admin/loggersエンドポイントに PUT 要求を送信してログレベルを設定します。- ログレベルを変更するパッケージ。
設定するログレベル。
curl -s -X PUT -H "Content-Type:application/json" http://localhost:8083/admin/loggers/io.debezium.connector.<connector_package> -d '{"level": "<log_level>"}'curl -s -X PUT -H "Content-Type:application/json" http://localhost:8083/admin/loggers/io.debezium.connector.<connector_package> -d '{"level": "<log_level>"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow たとえば、Debezium MySQL コネクターのデバッグ情報をログに記録するには、以下のリクエストを Kafka Connect に送信します。
curl -s -X PUT -H "Content-Type:application/json" http://localhost:8083/admin/loggers/io.debezium.connector.mysql -d '{"level": "DEBUG"}'curl -s -X PUT -H "Content-Type:application/json" http://localhost:8083/admin/loggers/io.debezium.connector.mysql -d '{"level": "DEBUG"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
5.3.3. マッピングされた診断コンテキストを追加して Debezium のロギングレベルの変更
ほとんどの Debezium コネクター (および Kafka Connect ワーカー) は、複数のスレッドを使用してさまざまな動作を実行します。そのために、ログファイルを探し、特定の論理動作のログメッセージだけを識別するのが困難な場合があります。容易にログメッセージを探すことができるように、Debezium にはそれぞれのスレッドの追加情報を提供するさまざまな マッピングされた診断コンテキスト (MDC) が用意されています。
Debezium では、以下の MDC プロパティーを利用することができます。
dbz.connectorType-
コネクタータイプの短縮エイリアスたとえば、
MySQL、Mongo、Postgresなどです。同じ タイプ のコネクターに関連付けられたすべてのスレッドは同じ値を使用するので、これを使用して、特定タイプのコネクターによって生成されたすべてのログメッセージを探すことができます。 dbz.connectorName-
コネクターの設定で定義されているコネクターまたはデータベースサーバーの名前たとえば、
products、serverAなどです。特定の コネクターインスタンス に関連付けられたすべてのスレッドは同じ値を使用するので、あるコネクターインスタンスによって生成されたすべてのログメッセージを探すことができます。 dbz.connectorContext-
コネクターのタスク内で実行されている別のスレッドとして実行されている動作の短縮名たとえば、
main、binlog、snapshotなどです。コネクターが特定のリソース (テーブルやコレクション等) にスレッドを割り当てる場合、そのリソースの名前が使用されることがあります。コネクターに関連付けられたスレッドごとに異なる値を使用するので、この特定の動作に関連付けられたすべてのログメッセージを探すことができます。
コネクターの MDC を有効にするには、connect-log4j.properties ファイルでアペンダーを設定します。
手順
-
connect-log4j.propertiesファイルを開きます。 サポートされている Debezium MDC プロパティーのいずれかを使用するようにアペンダーを設定します。この例では、以下の MDC プロパティーを使用するように
stdoutアペンダーを設定します。例5.4
stdoutアペンダーが MDC プロパティーを使用するように指定する connect-log4j.properties 設定... log4j.appender.stdout.layout.ConversionPattern=%d{ISO8601} %-5p %X{dbz.connectorType}|%X{dbz.connectorName}|%X{dbz.connectorContext} %m [%c]%n ...... log4j.appender.stdout.layout.ConversionPattern=%d{ISO8601} %-5p %X{dbz.connectorType}|%X{dbz.connectorName}|%X{dbz.connectorContext} %m [%c]%n ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 前述の例の設定では、以下の出力のようなログメッセージが生成されます。
... 2017-02-07 20:49:37,692 INFO MySQL|dbserver1|snapshot Starting snapshot for jdbc:mysql://mysql:3306/?useInformationSchema=true&nullCatalogMeansCurrent=false&useSSL=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8&zeroDateTimeBehavior=convertToNull with user 'debezium' [io.debezium.connector.mysql.SnapshotReader] 2017-02-07 20:49:37,696 INFO MySQL|dbserver1|snapshot Snapshot is using user 'debezium' with these MySQL grants: [io.debezium.connector.mysql.SnapshotReader] 2017-02-07 20:49:37,697 INFO MySQL|dbserver1|snapshot GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'debezium'@'%' [io.debezium.connector.mysql.SnapshotReader] ...
... 2017-02-07 20:49:37,692 INFO MySQL|dbserver1|snapshot Starting snapshot for jdbc:mysql://mysql:3306/?useInformationSchema=true&nullCatalogMeansCurrent=false&useSSL=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8&zeroDateTimeBehavior=convertToNull with user 'debezium' [io.debezium.connector.mysql.SnapshotReader] 2017-02-07 20:49:37,696 INFO MySQL|dbserver1|snapshot Snapshot is using user 'debezium' with these MySQL grants: [io.debezium.connector.mysql.SnapshotReader] 2017-02-07 20:49:37,697 INFO MySQL|dbserver1|snapshot GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'debezium'@'%' [io.debezium.connector.mysql.SnapshotReader] ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow
ログのそれぞれの行には、コネクターのタイプ (例: MySQL)、コネクターの名前 (例: dbserver1)、およびスレッドの動作 (例: snapshot) が含まれます。
5.4. OpenShift での Debezium ログ
OpenShift で Debezium を使用している場合、Kafka Connect ロガーを使用して Debezium ロガーおよびログレベルを設定することができます。Kafka Connect スキーマでのロギングプロパティーの設定に関する詳細は、OpenShift 上の Streams for Apache Kafka のデプロイと管理 を参照してください。
第6章 アプリケーション用 Debezium コネクターの設定
Debezium コネクターのデフォルトの動作がアプリケーションに適していない場合、以下の Debezium 機能を使用して必要な動作を設定することができます。
- Kafka Connect 自動トピック作成
- Connect が実行時にトピックを作成し、トピックの名前に基づいて設定をトピックに適用するのを許可します。
- Avro シリアライゼーション
- Debezium PostgreSQL、MongoDB、または SQL Server コネクターが Avro を使用してメッセージのキーと値をシリアライズする設定をサポートします。これにより、変更イベントレコードのコンシューマーがレコードスキーマの変更に容易に適応できるようにします。
- コネクターのステータスを報告する通知設定
- 設定可能なチャネルセットを介してコネクターのステータス情報を公開するメカニズムを提供します。
- CloudEvents コンバーター
- Debezium コネクターが CloudEvents 仕様に準拠する変更イベントレコードを出力できるようにします。
- Debezium コネクターへのシグナル送信
- コネクターの動作を変更したり、アドホックスナップショットの開始などのアクションをトリガーしたりする方法を提供します。
6.1. Kafka Connect 自動トピック作成のカスタマイズ
Kafka には、トピックを自動的に作成するメカニズムが 2 つ用意されています。Kafka ブローカーの自動トピック作成を有効にすることができます。また、Kafka 2.6.0 以降では、Kafka Connect のトピック作成を有効にすることもできます。Kafka ブローカーは、auto.create.topics.enable プロパティーを使用してトピックの自動作成を制御します。Kafka Connect では、topic.creation.enable プロパティーで、Kafka Connect がトピックを作成することを許可するかどうかを指定します。いずれの場合も、プロパティーのデフォルト設定ではトピックの自動作成が有効です。
トピックの自動作成が有効な場合、Debezium ソースコネクターがまだルーティング先トピックが存在しないテーブルの変更イベントレコードを出力すると、イベントレコードが Kafka に取り込まれる際にトピックが実行時に作成されます。
ブローカーと Kafka Connect での自動トピック作成の違い
ブローカーが作成するトピックは、1 つのデフォルト設定の共有に制限されます。ブローカーは、異なるトピックまたはトピックのセットに一意の設定を適用することはできません。対照的に、Kafka Connect では、トピックの作成時に任意のさまざまな設定を適用し、Debezium コネクター設定で指定したレプリケーション係数、パーティション数、およびその他のトピック固有の設定を定義することができます。コネクター設定はトピック作成グループのセットを定義し、トピック設定のプロパティーセットを各グループに関連付けます。
ブローカー設定と Kafka Connect 設定は、互いに独立しています。ブローカーでトピック作成を無効にしたかどうかに関係なく、Kafka Connect はトピックを作成することができます。ブローカーと Kafka Connect の両方でトピックの自動作成を有効にすると Connect の設定が優先され、Kafka Connect のいずれの設定も適用されない場合に限り、ブローカーはトピックを作成します。
詳細は、以下のトピックを参照してください。
6.1.1. Kafka ブローカーの自動トピック作成の無効化
デフォルトでは、トピックがまだ存在しない場合、Kafka ブローカー設定によりブローカーは実行時にトピックを作成することができます。ブローカーによって作成されたトピックにカスタムプロパティーを設定することはできません。2.6.0 より前のバージョンの Kafka を使用し、特定の設定でトピックを作成する場合は、ブローカーの自動トピック作成を無効にし、手動またはカスタムデプロイプロセスのいずれにより明示的にトピックを作成する必要があります。
手順
-
ブローカーの設定で、
auto.create.topics.enableの値をfalseにします。
6.1.2. Kafka Connect の自動トピック作成の設定
Kafka Connect でのトピックの自動作成は、topic.creation.enable プロパティーによって制御されます。次の例に示すように、プロパティーのデフォルト値は true であり、トピックの自動作成を有効にします。
topic.creation.enable = true
topic.creation.enable = true
topic.creation.enable プロパティーの設定は、Connect クラスター内のすべてのワーカーに適用されます。
Kafka Connect の自動トピック作成では、トピックの作成時に Kafka Connect が適用する設定プロパティーを定義する必要があります。トピックグループを定義して Debezium コネクター設定でトピックの設定プロパティーを指定し、続いてそれぞれのグループに適用するプロパティーを指定します。コネクター設定では、デフォルトのトピック作成グループ、およびオプションで 1 つまたは複数のカスタムトピック作成グループを定義します。カスタムトピック作成グループは、トピック名パターンのリストを使用してグループの設定が適用されるトピックを指定します。
Kafka Connect がどのようにトピックをトピック作成グループと照合するかの詳細は、トピック作成グループ を参照してください。設定プロパティーがどのようにグループに割り当てられるかの詳細は、トピック作成グループの設定プロパティー を参照してください。
デフォルトでは、Kafka Connect が作成するトピックは、パターンserver.schema.table に基づいて名前が付けられます (例: dbserver.myschema.inventory)。
手順
-
Kafka Connect がトピックを自動的に作成しないようにするには、次の例のように、
Kafka Connectカスタムリソースで topic.creation.enable の値をfalseに設定します。
Kafka Connect の自動トピック作成では、replication.factor プロパティーと partitions プロパティーを少なくとも default のトピック作成グループに設定する必要があります。グループは、Kafka ブローカーのデフォルト値から必要なプロパティーの値を取得することができます。
6.1.3. 自動的に作成されたトピックの設定
Kafka Connect でトピックを自動的に作成するには、トピックの作成時に適用する設定プロパティーに関するソースコネクターからの情報が必要です。それぞれの Debezium コネクターの設定で、トピックの作成を制御するプロパティーを定義します。Kafka Connect がコネクターから出力されるイベントレコード用のトピックを作成すると、作成されるトピックは該当するグループから設定を取得します。この設定は、そのコネクターによって出力されたイベントレコードにのみ適用されます。
6.1.3.1. トピック作成グループ
トピックプロパティーのセットが、トピック作成グループに関連付けられます。少なくとも default トピック作成グループを定義し、その設定プロパティーを指定する必要があります。それ以外に、オプションとして 1 つまたは複数のカスタムトピック作成グループを定義し、それぞれに一意のプロパティーを指定することができます。
カスタムトピック作成グループを作成する場合、トピック名パターンに基づいて各グループにメンバートピックを定義します。各グループに含めるトピックまたはグループから除外するトピックを記述する命名パターンを指定することができます。include および exclude プロパティーには、トピック名パターンを定義する正規表現のコンマ区切りリストを指定します。たとえば、文字列 dbserver1.inventory で始まるすべてのトピックをグループに含める場合は、その topic.creation.inventory.include プロパティーの値をdbserver1\\.inventory\\.* に設定します。
カスタムトピックグループに include および exclude プロパティーの両方を指定すると、除外ルールが優先され包含ルールがオーバーライドされます。
6.1.3.2. トピック作成グループの設定プロパティー
default トピック作成グループおよびそれぞれのカスタムグループは、一意の設定プロパティーのセットに関連付けられます。任意の Kafka トピックレベルの設定プロパティー をグループの設定に含めることができます。たとえば、トピックグループに 古いトピックセグメントのクリーンアップポリシー、保持時間、または トピックの圧縮タイプ を指定することができます。少なくとも、作成するトピックの設定を記述するプロパティーの最小セットを定義する必要があります。
カスタムグループが登録されていない場合、または登録されているグループの include パターンが作成するトピックの名前とマッチしない場合、Kafka Connect は default グループの設定を使用してトピックを作成します。
トピック設定の概要は、Debezium の OpenShift へのインストールの Kafka トピック作成に関する推奨事項 を参照してください。
6.1.3.3. Debezium デフォルトトピック作成グループ設定の指定
Kafka Connect の自動トピック作成を使用するためには、デフォルトのトピック作成グループを作成し、その設定を定義する必要があります。デフォルトのトピック作成グループの設定は、カスタムトピック作成グループの include リストのパターンにマッチしない名前のすべてのトピックに適用されます。
前提条件
Kafka Connect のカスタムリソースで、
metadata.annotationsのuse-connector-resourcesの値により、クラスターの Operator が KafkaConnector カスタムリソースを使用してクラスター内のコネクターを設定するように指定されている。以下に例を示します。... metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true" ...... metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true" ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow
手順
topic.creation.defaultグループのプロパティーを定義するには、以下の例に示すように、コネクターのカスタムリソースのspec.configにプロパティーを追加します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 任意の Kafka トピックレベルの設定プロパティー を
defaultグループの設定に含めることができます。
| 項目 | 説明 |
|---|---|
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
カスタムグループは、必要なreplication.factor および partitions プロパティーのみに対して、default グループの設定が戻ります。カスタムトピックグループ設定の他のプロパティーが定義されていない場合、default グループで指定された値は適用されません。
6.1.3.4. Debezium カスタムトピック作成グループ設定の指定
複数のカスタムトピックグループを、それぞれ個別の設定で定義することができます。
手順
カスタムトピックグループを定義するには、コネクターのカスタムリソースの
spec.configにtopic.creation.<group_name>.includeプロパティーを追加し、続いてカスタムグループのトピックに適用する設定プロパティーを定義します。次の例では、カスタムトピック作成グループ
inventoryとapplicationlogsを定義するカスタムリソースの抜粋を示しています。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
| 項目 | 説明 |
|---|---|
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
| 5 |
|
6.1.3.5. Debezium カスタムトピック作成グループの登録
カスタムトピック作成グループの設定を指定したら、グループを登録します。
手順
カスタムグループを登録するには、コネクターのカスタムリソースに
topic.creation.groupsプロパティーを追加し、カスタムトピック作成グループをコンマで区切って指定します。カスタムトピック作成グループ
inventoryとapplicationlogsを登録するコネクターカスタムリソースの抜粋を以下に示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
設定の完了
default トピックグループの設定に加えて inventory および applicationlogs カスタムトピック作成グループの設定が含まれる完了した設定の例を以下に示します。
例: デフォルトのトピック作成グループおよび 2 つのカスタムグループの設定
6.2. Avro シリアライゼーションを使用する Debezium コネクターの設定
Debezium コネクターは Kafka Connect のフレームワークで動作し、変更イベントレコードを生成することでデータベース内の各行レベルの変更をキャプチャーします。それぞれの変更イベントレコードについて、Debezium コネクターは以下のアクションを完了します。
- 設定された変換を適用する。
- 設定された Kafka Connect コンバーター を使用して、レコードのキーと値をバイナリー形式にシリアライズする。
- レコードを正しい Kafka トピックに書き込む。
個々の Debezium コネクターインスタンスごとにコンバーターを指定することができます。Kafka Connect は、レコードのキーと値を JSON ドキュメントにシリアライズする JSON コンバーターを提供します。デフォルトの動作では、JSON コンバーターはレコードのメッセージスキーマを含めるので、それぞれのレコードが非常に冗長になります。Debezium スタートガイド に、ペイロードとスキーマの両方が含まれる場合にレコードがどのように見えるかが示されています。レコードを JSON でシリアル化したい場合は、以下のコネクター設定プロパティーを false に設定することを検討してください。
-
key.converter.schemas.enable -
value.converter.schemas.enable
これらのプロパティーを false に設定すると、冗長なスキーマ情報がそれぞれのレコードから除外されます。
あるいは、Apache Avro を使用してレコードのキーと値をシリアライズすることもできます。Avro のバイナリー形式はコンパクトで効率的です。Avro スキーマを使用すると、それぞれのレコードが正しい構造を持つようにすることができます。Avro のスキーマ進化メカニズムにより、スキーマを進化させることが可能です。変更されたデータベーステーブルの構造と一致するように各レコードのスキーマを動的に生成するこのメカニズムは、Debezium コネクターに不可欠です。時間の経過と共に、同じ Kafka トピックに書き込まれる変更イベントレコードが、同じスキーマの別バージョンとなる場合があります。Avro シリアライゼーションを使用すると、変更イベントレコードのコンシューマーはレコードスキーマの変化に容易に対応することができます。
Apache Avro シリアライゼーションを使用するには、Avro メッセージスキーマおよびそのバージョンを管理するスキーマレジストリーをデプロイする必要があります。このレジストリーの設定については OpenShift での Red Hat build of Apicurio Registry のインストールとデプロイ に関するドキュメントを参照してください。
6.2.1. Apicurio Registry について
Red Hat build of Apicurio Registry
Red Hat build of Apicurio Registry は、Avro で動作する次のコンポーネントを提供します。
- Debezium コネクター設定で指定することができる Avro コンバーター。このコンバーターは、Kafka Connect スキーマを Avro スキーマにマッピングします。続いて、コンバーターは Avro スキーマを使用してレコードのキーと値を Avro のコンパクトなバイナリー形式にシリアライズします。
API および以下の項目を追跡するスキーマレジストリー。
- Kafka トピックで使用される Avro スキーマ
- Avro コンバーターが生成した Avro スキーマを送信する先
Avro スキーマはこのレジストリーに保管されるため、各レコードには小さな スキーマ識別子 だけを含める必要があります。これにより、各レコードが非常にコンパクトになります。Kafka など I/O 律速のシステムの場合、これはプロデューサーおよびコンシューマーのトータルスループットが向上することを意味します。
- Kafka プロデューサーおよびコンシューマー用 Avro Serdes (シリアライザー/デシリアライザー)。変更イベントレコードを使用するために作成する Kafka コンシューマーアプリケーションは、Avro Serdes を使用して変更イベントレコードをデシリアライズすることができます。
Debezium で Apicurio Registry を使用するには、Debezium コネクターを実行するのに使用している Kafka Connect コンテナーイメージに Apicurio Registry コンバーターおよびその依存関係を追加します。
Apicurio Registry プロジェクトも JSON コンバーターを提供します。このコンバーターは、メッセージが冗長ではないというメリットを持つのに加えて、人間が判読できる JSON を扱うことができます。メッセージ自体にはスキーマ情報は含まれず、スキーマ ID だけが含まれます。
Apicurio Registry が提供するコンバータを使用するには、apicurio.registry.url を指定する必要があります。
6.2.2. Avro シリアライゼーションを使用する Debezium コネクターのデプロイの概要
Avro シリアライゼーションを使用する Debezium コネクターをデプロイするには、以下の 3 つの主要タスクを完了する必要があります。
- OpenShift での Red Hat build of Apicurio Registry インスタンスのインストールとデプロイ の手順に従って、Red Hat build of Apicurio Registry インスタンスをデプロイします。
- Debezium Service Registry Kafka Connect の zip ファイルをダウンロードして Debezium コネクターのディレクトリーにデプロイメントし、Avro コンバーターをインストールする。
以下のように設定プロパティーを設定して、Avro シリアライゼーションを使用するように Debezium コネクターインスタンスを設定する。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
内部的には、Kafka Connect は常に JSON キー/値コンバーターを使用して設定およびオフセットを保管します。
6.2.3. Debezium コンテナーで Avro を使用するコネクターのデプロイ
ご使用の環境で、提供された Debezium コンテナーを使用して、Avro シリアライゼーションを使用する Debezium コネクターをデプロイしなければならない場合があります。Debezium 用のカスタム Kafka Connect コンテナーイメージをビルドし、Avro コンバーターを使用するように Debezium コネクターを設定するには、以下の手順を完了します。
前提条件
- コンテナーを作成および管理するのに十分な権限と共に Docker をインストールしている。
- Avro シリアライゼーションと共にデプロイする Debezium コネクタープラグインをダウンロードしている。
手順
Apicurio Registry のインスタンスをデプロイします。OpenShift での Red Hat build of Apicurio Registry のインストールとデプロイ を参照してください。
- Apicurio Registry のインストール
- AMQ Streams のインストール
- AMQ Streams ストレージのセットアップ
Debezium コネクターのアーカイブをデプロイメントして、コネクタープラグインのディレクトリー構造を作成します。複数の Debezium コネクターのアーカイブをダウンロードしてデプロイメントした場合、作成されるディレクトリー構造は以下の例のようになります。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Avro シリアライゼーションを使用するように設定する Debezium コネクターが含まれるディレクトリーに Avro コンバーターを追加します。
- Software Downloads に移動し、Apicurio Registry Kafka Connect zip ファイルをダウンロードします。
- 目的の Debezium コネクターディレクトリーにアーカイブをデプロイメントします。
複数のタイプの Debezium コネクターを Avro シリアライゼーションを使用するように設定するには、該当するそれぞれのコネクタータイプのディレクトリーにアーカイブをデプロイメントします。それぞれのディレクトリーにアーカイブを抽出するとファイルが重複しますが、これにより依存関係の競合が生じる可能性がなくなります。
Avro コンバーターを使用するように設定する Debezium コネクターを実行するためのカスタムイメージを作成して公開します。
registry.redhat.io/amq-streams-kafka-35-rhel8:2.5.0をベースイメージとして使用して、新しいDockerfileを作成します。以下の例の my-plugins を、実際のプラグインディレクトリーの名前に置き換えてください。FROM registry.redhat.io/amq-streams-kafka-35-rhel8:2.5.0 USER root:root COPY ./my-plugins/ /opt/kafka/plugins/ USER 1001
FROM registry.redhat.io/amq-streams-kafka-35-rhel8:2.5.0 USER root:root COPY ./my-plugins/ /opt/kafka/plugins/ USER 1001Copy to Clipboard Copied! Toggle word wrap Toggle overflow Kafka Connect は、コネクターの実行を開始する前に、
/opt/kafka/pluginsディレクトリーにあるサードパーティープラグインをロードします。docker コンテナーイメージをビルドします。たとえば、前のステップで作成した docker ファイルを
debezium-container-with-avroとして保存した場合、以下のコマンドを実行します。docker build -t debezium-container-with-avro:latestカスタムイメージをコンテナーレジストリーにプッシュします。例を以下に示します。
docker push <myregistry.io>/debezium-container-with-avro:latest新しいコンテナーイメージを示します。次のいずれかを行います。
KafkaConnectカスタムリソースのKafkaConnect.spec.imageプロパティーを編集します。このプロパティーが設定されていると、クラスターオペレータのSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGE変数がオーバーライドされます。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
install/cluster-operator/050-Deployment-strimzi-cluster-operator.yamlファイルのSTRIMZI_DEFAULT_KAFKA_CONNECT_IMAGE変数を編集し、新しいコンテナーイメージを示すようにした後、Cluster Operator を再インストールします。このファイルを編集する場合は、これを OpenShift クラスターに適用する必要があります。
Avro コンバーターを使用するように設定されたそれぞれの Debezium コネクターをデプロイします。それぞれの Debezium コネクターについて、以下の設定を行います。
Debezium コネクターインスタンスを作成します。次の
inventory-connector.yamlファイルの例では、Avro コンバーターを使用するように設定された MySQL コネクターインスタンスを定義するKafkaConnectorカスタムリソースを作成しています。Copy to Clipboard Copied! Toggle word wrap Toggle overflow コネクターインスタンスを適用します。以下に例を示します。
oc apply -f inventory-connector.yamlこれにより
inventory-connectorが登録され、コネクターがinventoryデータベースに対して実行されるようになります。
コネクターが作成され、指定されたデータベース内の変更の追跡を開始したことを確認します。たとえば
inventory-connectorが起動したときの Kafka Connect のログ出力を見ることで、コネクターのインスタンスを確認することができます。Kafka Connect のログ出力を表示します。
oc logs $(oc get pods -o name -l strimzi.io/name=my-connect-cluster-connect)
oc logs $(oc get pods -o name -l strimzi.io/name=my-connect-cluster-connect)Copy to Clipboard Copied! Toggle word wrap Toggle overflow ログの出力を確認し、初回のスナップショットが実行されたことを確認します。以下のような行が表示されるはずです。
... 2020-02-21 17:57:30,801 INFO Starting snapshot for jdbc:mysql://mysql:3306/?useInformationSchema=true&nullCatalogMeansCurrent=false&useSSL=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8&zeroDateTimeBehavior=CONVERT_TO_NULL&connectTimeout=30000 with user 'debezium' with locking mode 'minimal' (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] 2020-02-21 17:57:30,805 INFO Snapshot is using user 'debezium' with these MySQL grants: (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] ...
... 2020-02-21 17:57:30,801 INFO Starting snapshot for jdbc:mysql://mysql:3306/?useInformationSchema=true&nullCatalogMeansCurrent=false&useSSL=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8&zeroDateTimeBehavior=CONVERT_TO_NULL&connectTimeout=30000 with user 'debezium' with locking mode 'minimal' (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] 2020-02-21 17:57:30,805 INFO Snapshot is using user 'debezium' with these MySQL grants: (io.debezium.connector.mysql.SnapshotReader) [debezium-mysqlconnector-dbserver1-snapshot] ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow スナップショットは、複数のステップを経て作成されます。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow スナップショットの作成が完了した後、Debezium は (例として)
inventoryデータベースのbinlogに生じる変更の追跡を開始し、変更イベントの有無を監視します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
6.2.4. Avro の名前の要件について
Avro の ドキュメント に記載されているように、名前は以下のルールに従う必要があります。
-
[A-Za-z_]で始まる -
その後に
[A-Za-z0-9_]の文字のみが含まれる
Debezium は、対応する Avro フィールドのベースとして列の名前を使用します。これにより、列の名前も Avro の命名規則に従わないと、シリアライズ中に問題が発生する可能性があります。各 Debezium コネクターには、名前に関する Avro ルールに準拠していない列がある場合に、avro に設定できる設定プロパティー field.name.adjustment.mode が用意されています。field.name.adjustment.mode を avro に設定すると、スキーマを実際に変更せずに、適合しないフィールドをシリアライズできます。
6.3. CloudEvents フォーマットでの Debezium 変更イベントレコードの出力
CloudEvents は、共通の方法でイベントデータを記述するための仕様です。その目的は、サービス、プラットフォーム、およびシステム間の相互運用性を提供することです。Debezium では、Db2、MongoDB、MySQL、Oracle、PostgreSQL、または SQL Server コネクターを設定して、CloudEvents 仕様に準拠した変更イベントレコードを出力することができます。
CloudEvents フォーマットでの変更イベントレコードの出力は、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat の実稼働環境のサービスレベルアグリーメント (SLA) ではサポートされません。また、機能的に完全ではない可能性があるため、Red Hat はテクノロジープレビュー機能を実稼働環境に実装することは推奨しません。テクノロジープレビューの機能は、最新の技術をいち早く提供して、開発段階で機能のテストやフィードバックの収集を可能にするために提供されます。サポート範囲の詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
CloudEvents 仕様は、以下の項目を定義します。
- 標準化されたイベント属性のセット
- カスタム属性を定義するためのルール
- イベントフォーマットを JSON や Apache Avro などのシリアライズした表現にマッピングするためのエンコーディングルール
- Apache Kafka、HTTP、または AMQP 等のトランスポート層のプロトコルバインディング
CloudEvents 仕様に準拠する変更イベントレコードを出力するように Debezium コネクターを設定するために、Debezium では Kafka Connect メッセージコンバーターである io.debezium.converters.CloudEventsConverter を利用することができます。
現時点では、構造化マッピングモードだけが使用できます。CloudEvents 変更イベントエンベロープは JSON または Avro にすることができ、各エンベロープタイプの データ 形式として JSON または Avro を使用できます。CloudEvents フォーマットでの変更イベントの出力に関する情報は、以下のように整理されます。
Avro 使用の詳細は、以下を参照してください。
6.3.1. CloudEvents フォーマットでの Debezium 変更イベントレコードの例
以下の例は、PostgreSQL コネクターから出力される CloudEvents 変更イベントレコードを示しています。この例では、PostgreSQL コネクターは CloudEvents フォーマットエンベロープおよび data フォーマットとして JSON を使用するように設定されています。
| 項目 | 説明 |
|---|---|
| 1 | 変更イベントの内容に基づいてコネクターが変更イベントに生成する一意の ID。 |
| 2 |
イベントのソースで、コネクター設定の |
| 3 | CloudEvents 仕様のバージョン。 |
| 4 |
変更イベントを生成したコネクタータイプ。このフィールドの形式は |
| 5 | ソースデータベースの変更時刻。 |
| 6 |
|
| 7 |
操作の ID。許容値は、 |
| 8 |
Debezium 変更イベントから認識されるすべての |
| 9 |
コネクターで有効にすると、Debezium 変更イベントから認識されるそれぞれの |
| 10 |
実際のデータ変更。操作およびコネクターによって、データに |
以下の例も、PostgreSQL コネクターから出力される CloudEvents 変更イベントレコードを示しています。この例でも、PostgreSQL コネクターは CloudEvents フォーマットエンベロープとして JSON を使用するように設定されていますが、ここではコネクターは data フォーマットに Avro を使用するように設定されています。
| 項目 | 説明 |
|---|---|
| 1 |
|
| 2 | Avro データが準拠するスキーマの URI。 |
| 3 |
|
data 属性に加えてエンベロープに Avro を使用することもできます。
6.3.2. Debezium CloudEvents コンバーターの設定例
Debezium コネクター設定で io.debezium.converters.CloudEventsConverter を設定します。次の特性を持つ変更イベントレコードを出力するように CloudEvents コンバーターを設定する方法を以下の例に示します。
- エンベロープとして JSON を使用する。
-
http://my-registry/schemas/ids/1のスキーマレジストリーを使用して、データ属性をバイナリー Avro データとしてシリアライズする。
| 項目 | 説明 |
|---|---|
| 1 |
|
CloudEvents コンバーターは、Kafka レコードの値を変換します。レコードのキーを操作する場合は、同じコネクター設定で key.converter を指定することができます。たとえば、StringConverter、LongConverter、JsonConverter、または AvroConverter を指定できます。
6.3.3. メタデータのソースと一部の CloudEvents フィールドの設定
デフォルトでは、metadata.source プロパティーは次の例に示すように 3 つの部分で構成されます。
"value,id:generate,type:generate,dataSchemaName:generate"
"value,id:generate,type:generate,dataSchemaName:generate"
最初の部分は、レコードのメタデータを取得するためのソースを指定します。許可される値は value と header です。次の部分では、コンバーターが次のメタデータフィールドに値を入力する方法を指定します。
-
id -
type -
dataSchemaName(スキーマがスキーマレジストリーに登録される名前)
コンバーターは、次のいずれかの方法を使用して各フィールドにデータを入力できます。
generate- コンバーターはフィールドの値を生成します。
header- コンバーターはメッセージヘッダーからフィールドの値を取得します。
レコードメタデータの取得
CloudEvent を構築するには、コンバーターにソース、操作、およびトランザクションのメタデータが必要です。通常、コンバーターはレコードの値からメタデータを取得できます。ただし、場合によっては、コンバーターがレコードを受信する前に、レコードの値がメタデータを含まないような形でレコードが処理されることがあります (レコードが送信トレイイベントルーター SMT によって処理された後など)。必要なメタデータを保持するには、次の方法を使用してレコードのヘッダーでメタデータを渡します。
手順
-
たとえば
HeaderFromSMT を使用して、レコードがコンバーターに到達する前にレコードのヘッダーにメタデータを記録するメカニズムを実装します。 -
コンバーターの
metadata.sourceプロパティーの値をheaderに設定します。
次の例は、送信トレイイベントルーター SMT と HeaderFrom SMT を使用するコネクターの設定を示しています。
HeaderFrom 変換を使用するには、廃棄メッセージとハートビートメッセージのフィルタリングが必要な場合があります。
metadata.source プロパティーの header 値はグローバル設定です。そのため、プロパティーの値の一部 (id や type ソースなど) を省略した場合でも、コンバーターは省略された部分の header 値を生成します。
CloudEvent メタデータの取得
デフォルトでは、CloudEvents コンバーターは CloudEvent の id フィールドと type フィールドの値を自動的に生成し、その data フィールドのスキーマ名を生成します。デフォルトを変更し、適切なヘッダーにフィールドの値を指定することにより、コンバーターがこれらのフィールドに値を入力する方法をカスタマイズできます。以下に例を示します。
"value.converter.metadata.source": "value,id:header,type:header,dataSchemaName:header"
"value.converter.metadata.source": "value,id:header,type:header,dataSchemaName:header"
上記の設定を有効にすると、CloudEvents コンバーターに渡す値を含む id および type ヘッダーを追加するようにアップストリーム機能を設定できます。
id ヘッダーにのみ値を指定する場合は、以下を使用します。
"value.converter.metadata.source": "value,id:header,type:generate,dataSchemaName:generate"
"value.converter.metadata.source": "value,id:header,type:generate,dataSchemaName:generate"
ヘッダーから id、type、および dataSchemaName メタデータを取得するようにコンバーターを設定するには、次の短い構文を使用します。
"value.converter.metadata.source": "header"
"value.converter.metadata.source": "header"
コンバーターがヘッダーフィールドからデータスキーマ名を取得できるようにするには、schema.data.name.source.header.enable を true に設定する必要があります。
6.3.4. Debezium CloudEvents コンバーター設定オプション
CloudEvent コンバーターを使用するように Debezium コネクターを設定する場合、以下のオプションを指定できます。
| オプション | デフォルト | 説明 |
|
|
CloudEvents エンベロープ構造に使用するエンコーディングタイプ。値は | |
|
|
| |
| 該当なし |
JSON を使用する際に、ベースとなるコンバーターに渡される任意の設定オプション。 | |
| 該当なし |
Avro を使用する際に、ベースとなるコンバーターに渡される任意の設定オプション。 | |
| none |
コネクターで使用されるメッセージコンバータとの互換性のために、スキーマ名をどのように調整するかを指定します。値は | |
| none |
スキーマレジストリーに登録されるスキーマの CloudEvents スキーマ名を指定します。 | |
| false |
コンバーターがヘッダーから CloudEvents | |
|
|
コンバーターがクラウドイベントを生成するときにエクステンション属性を含めるかどうかを指定します。値は | |
|
|
コンマ区切りのリスト。コンバーターが CloudEvent
設定例については、メタデータのソースと一部の CloudEvents フィールドの設定 を参照してください。 |
6.4. コネクターのステータスを報告する通知設定
Debezium の通知は、コネクターに関するステータス情報を取得するメカニズムを提供します。通知は、以下のチャネルに送信できます。
- SinkNotificationChannel
- Connect API を介して、設定されたトピックに通知を送信します。
- LogNotificationChannel
- 通知がログに追加されます。
- JmxNotificationChannel
- 通知は JMX Bean の属性として公開されます。
- Debezium 通知の詳細は、以下を参照してください。
6.4.1. Debezium 通知形式の説明
通知メッセージには、以下の情報が含まれます。
| プロパティー | 説明 |
|---|---|
| id |
通知に割り当てられる一意の識別子。増分スナップショット通知の場合、 |
| aggregate_type | 通知が関連する集約ルートのデータ型。ドメイン駆動設計では、エクスポートされたイベントは常に集約を参照する必要があります。 |
| type |
|
| additional_data | 通知に関する詳細情報を含む Map<String,String>。例については、増分スナップショットの進行状況に関する Debezium の通知 を参照してください。 |
| timestamp | 通知が作成された時刻。この値は、UNIX エポックからの経過時間をミリ秒数で表します。 |
6.4.2. Debezium 通知の種類
Debezium の通知では、初期スナップショット または 増分スナップショット の進行状況に関する情報が提供されます。
初期スナップショットのステータスに関する Debezium 通知
次の例は、初期スナップショットのステータスを提供する一般的な通知を示しています。
| 項目 | 説明 |
|---|---|
| 1 |
|
次の表では、初期スナップショットのステータスを報告する通知に含まれる可能性のあるさまざまなペイロードの例を紹介しています。
| ステータス | ペイロード |
|---|---|
| 開始 |
|
| IN_PROGRESS |
フィールド |
| TABLE_SCAN_COMPLETED |
上記の例では、
フィールド |
| COMPLETED |
|
| ABORTED |
|
| SKIPPED |
|
6.4.2.1. 例: 増分スナップショットの進行状況をレポートする Debezium 通知
次の表では、増分スナップショットのステータスを報告する通知に含まれる可能性のあるさまざまなペイロードの例を紹介しています。
| ステータス | ペイロード |
|---|---|
| Start |
|
| Paused |
|
| Resumed |
|
| Stopped |
|
| チャンクの処理 |
|
| Snapshot completed for a table |
上記の例では、
|
| Completed |
|
6.4.3. イベントを通知チャネルに送信できるように Debezium の有効化
Debezium が通知を発行できるようにするには、notification.enabled.channels 設定プロパティーを設定して通知チャネルのリストを指定します。デフォルトでは、以下の通知チャネルを利用できます。
-
sink -
log -
jmx
sink 通知チャネルを使用するには、notification.sink.topic.name 設定プロパティーを、Debezium が通知を送信するトピックの名前に設定する必要もあります。
6.4.3.1. JMX Bean を通じて公開されたイベントをレポートするための Debezium 通知の有効化
Debezium が JMX Bean を通じて公開されるイベントをレポートできるようにするには、次の設定手順を実行します。
- JMX MBean サーバーを有効にして、通知 Bean を公開します。
-
コネクター設定の
notification.enabled.channelsプロパティーにjmxを追加します。 - 優先する JMX クライアントを MBean サーバーに接続します。
通知は、debezium.<connector-type>.management.notifications.<server> という名前の Bean の Notifications 属性を通じて公開されます。
次の図は、増分スナップショットの開始を報告する通知を示しています。

通知を破棄するには、Bean で reset 操作を呼び出します。
通知は、debezium.notification タイプの JMX 通知としても公開されます。アプリケーションが MBean が発行する JMX 通知をリッスンできるようにするには、アプリケーションを通知にサブスクライブ します。
6.5. Debezium コネクターへのシグナル送信
Debezium のシグナルメカニズムを使用すると、コネクターの動作を変更したり、テーブルの アドホックスナップショット を起動するなどの 1 回限りのアクションをトリガーする方法が可能になります。シグナルを使用してコネクターをトリガーし、指定されたアクションを実行するには、次のチャネルの 1 つ以上を使用するようにコネクターを設定できます。
- SourceSignalChannel
- SQL コマンドを発行して、特殊なシグナリングデータコレクションにシグナルメッセージを追加できます。ソースデータベース上に作成するシグナリングデータコレクションは、Debezium との通信専用に設計されています。
- KafkaSignalChannel
- シグナルメッセージを設定可能な Kafka トピックに送信します。
- JmxSignalChannel
-
JMX
signal操作でシグナルを送信します。 - FileSignalChannel
- ファイルを使用してシグナルを送信できます。Debezium は、新しい ログレコード または アドホックスナップショットレコード がチャネルに追加されたことを検出すると、シグナルを読み取り、要求された操作を開始します。
シグナリングは、以下の Debezium コネクターで使用可能です。
- Db2
- MariaDB (テクノロジープレビュー)
- MongoDB
- MySQL
- Oracle
- PostgreSQL
- SQL Server
signal.enabled.channels 設定プロパティーを設定して、有効にするチャネルを指定できます。このプロパティーには、有効になっているチャネルの名前がリストされます。デフォルトでは、Debezium は source および kafka のチャネルを提供します。source チャネルは、増分スナップショットシグナルに必要なため、デフォルトで有効になっています。
6.5.1. Debezium ソースシグナリングチャネルの有効化
デフォルトでは、Debezium ソースシグナリングチャネルが有効になっています。
使用するコネクターごとにシグナリングを明示的に設定する必要があります。
手順
- ソースデータベースで、コネクターへのシグナル送信用にデータコレクションテーブルを作成します。シグナリングデータコレクションの必要な構造については、シグナリングデータコレクションの構造を参照してください。
- Db2 や SQL Server など、ネイティブな変更データキャプチャー (CDC) メカニズムを実装しているソースデータベースでは、シグナルテーブルの CDC を有効にします。
-
Debezium コネクターの設定にシグナリングデータコレクションの名前を追加します。
コネクター設定で、プロパティーsignal.data.collectionを追加し、その値を手順 1 で作成したシグナルデータコレクションの完全修飾名に設定します。
例:signal.data.collection = inventory.debezium_signals.
シグナリングコレクションの完全修飾名のフォーマットは、コネクターによって異なります。
次の例では、各コネクターに使用する名前のフォーマットを示しています。
完全修飾テーブル名
- Db2
-
<schemaName>.<tableName> - MariaDB (テクノロジープレビュー)
-
<databaseName>.<tableName> - MongoDB
-
<databaseName>.<collectionName> - MySQL
-
<databaseName>.<tableName> - Oracle
-
<databaseName>.<schemaName>.<tableName> - PostgreSQL
-
<schemaName>.<tableName> - SQL Server
-
<databaseName>.<schemaName>.<tableName>
signal.data.collectionプロパティーの設定の詳細は、お使いのコネクターの設定プロパティーの表を参照してください。
6.5.1.1. Debezium シグナリングデータ収集の必須構造
シグナルデータコレクションまたはシグナルテーブルは、コネクターに送信して指定の操作をトリガーするシグナルを保存します。シグナリングテーブルの構造は、以下の標準フォーマットに準拠する必要があります。
- 3 つのフィールド (列) があります。
- フィールドは、表 1 のように決まった順序で配置されています。
| フィールド | タイプ | 説明 |
|---|---|---|
|
|
|
シグナルのインスタンスを識別する任意のユニークな文字列です。 |
|
|
|
送信する信号の種類を指定します。 |
|
|
|
シグナルアクションに渡す、JSON 形式のパラメーターを指定します。 |
データコレクションのフィールド名は任意です。前述の表には、推奨される名称が記載されています。異なる命名規則を使用している場合は、各フィールドの値が期待される内容と一致していることを確認してください。
6.5.1.2. Debezium シグナルのデータコレクションの作成
標準 SQL の DDL クエリーをソースデータベースに送信して、シグナリングテーブルを作成します。
前提条件
- ソースデータベースでのテーブル作成に十分なアクセス権限がある。
手順
-
SQL クエリーをソースデータベースに送信して、必須の構造 と合致するテーブルを作成します。例:
CREATE TABLE <tableName> (id VARCHAR(<varcharValue>) PRIMARY KEY, type VARCHAR(<varcharValue>) NOT NULL, data VARCHAR(<varcharValue>) NULL);
id 変数の VARCHAR パラメーターに割り当てる容量は、シグナリングテーブルに送信されるシグナルの ID 文字列のサイズを考慮して、十分に確保する必要があります。
ID のサイズが使用可能なスペースを超える場合、コネクターは信号を処理できません。
次の例は、3 列の debezium_signal テーブルを作成する CREATE TABLE コマンドです。
CREATE TABLE debezium_signal (id VARCHAR(42) PRIMARY KEY, type VARCHAR(32) NOT NULL, data VARCHAR(2048) NULL);
CREATE TABLE debezium_signal (id VARCHAR(42) PRIMARY KEY, type VARCHAR(32) NOT NULL, data VARCHAR(2048) NULL);6.5.2. Debezium Kafka シグナリングチャネルの有効化
Kafka シグナリングチャネルを有効にするには、有効にするチャネルを signal.enabled.channels 設定プロパティーに追加し、シグナルを受信するトピックの名前を signal.kafka.topic プロパティーに追加します。シグナリングチャネルを有効にすると、シグナルを使用して、設定したシグナルトピックに送信されるように、kafka コンシューマーが作成されます。
コンシューマーに使用できる追加設定
Kafka シグナリングを使用して大部分のコネクターのアドホック増分スナップショットをトリガーするには、まずコネクター設定で source シグナリングチャネルを有効にする 必要があります。ソースチャネルには、透かしメカニズムが実装されており、増分スナップショットでキャプチャーされ、ストリーミングの再開後に再度キャプチャーされる可能性のあるイベントが重複しないようにします。シグナリングチャネルを使用して、GTID が有効になっている 読み取り専用 MySQL データベースの増分スナップショットをトリガーする場合は、ソースチャネルを有効にする必要はありません。詳細は、MySQL 読み取り専用増分スナップショット を参照してください。
メッセージの形式
Kafka メッセージのキーは、topic.prefix コネクター設定オプションの値と一致する必要があります。
値は、type フィールドと data フィールドが含まれる JSON オブジェクトです。
シグナルタイプが execute-snapshot に設定されている場合、data フィールドには次の表にリストされているフィールドが含まれている必要があります。
| フィールド | デフォルト | 値 |
|---|---|---|
|
|
|
実行するスナップショットのタイプ。現在、Debezium は |
|
| 該当なし |
スナップショットに含めるデータコレクションの完全修飾名と一致する、コンマ区切りの正規表現の配列。 |
|
| 該当なし |
コネクターがスナップショットに含めるレコードのサブセットを決定するために評価する追加条件のセットを指定する、オプションの配列。
|
以下の例は、典型的な execute-snapshot Kafka メッセージを示しています。
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["schema1.table1", "schema1.table2"], "type": "INCREMENTAL"}}`
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["schema1.table1", "schema1.table2"], "type": "INCREMENTAL"}}`6.5.3. Debezium JMX シグナリングチャネルの有効化
JMX シグナリングを有効にするには、コネクター設定の signal.enabled.channels プロパティーに jmx を追加し、JMX MBean サーバーがシグナリング Bean を公開できる ようにします。
手順
- 任意の JMX クライアントを使用して (例:JConsole または JDK Mission Control) MBean サーバーに接続します。
Mbean
debezium.<connector-type>.management.signals.<server>を検索します。Mbean は、以下の入力パラメーターを受け入れるsignal操作を公開します。- p0
- シグナルの ID。
- p1
-
シグナルのタイプ (例:
execute-snapshot)。 - p2
- 指定されたシグナルタイプに関する追加情報を含む JSON データフィールド。
入力パラメーターの値を指定して
execute-snapshotシグナルを送信します。
JSON data フィールドに、以下の表に記載されている情報を含めます。Expand 表6.9 スナップショットデータフィールドの実行 フィールド デフォルト 値 typeincremental実行するスナップショットのタイプ。現在、Debezium は
incremental型とblocking型をサポートしています。data-collections該当なし
スナップショットに含めるテーブルの完全修飾名 と一致する、コンマ区切りの正規表現の配列。
additional-conditions該当なし
コネクターがスナップショットに含めるレコードのサブセットを決定するために評価する追加条件のセットを指定する、オプションの配列。
各追加条件は、アドホックスナップショットがキャプチャーするデータをフィルタリングする基準を指定するオブジェクトです。各追加条件には次のプロパティーを設定できます。data-collection- フィルターを適用する {data-collection} の完全修飾名。各 {data-collection} に異なるフィルターを適用できます。
filterスナップショットに含めるためにデータベースレコードに存在する必要がある列の値を指定します (例:
"color='blue'")。
スナップショットプロセスは、{data-collection} 内のレコードをfilter値に対して評価し、一致する値を含むレコードのみをキャプチャーします。filterプロパティーに割り当てる特定の値は、アドホックスナップショットの種類によって異なります。-
増分スナップショットの場合、スナップショットがクエリーの条件句に追加する検索条件フラグメントを指定します (例:
"color='blue'")。 -
ブロッキングスナップショットの場合、
snapshot.select.statement.overridesプロパティーで設定するものなど、完全なSELECTステートメントを指定します。
-
増分スナップショットの場合、スナップショットがクエリーの条件句に追加する検索条件フラグメントを指定します (例:
以下の図は、JConsole を使用してシグナルを送信する方法の例を示しています。
6.5.4. Debezium シグナルアクションの種類
シグナリングを使用して、以下のアクションを起こすことができます。
一部の信号はすべてのコネクターに対応していません。
6.5.4.1. ロギング信号
log シグナルタイプのシグナリングテーブルエントリーを作成することで、ログにエントリーを追加するようコネクターに要求できます。シグナルの処理後、コネクターは指定されたメッセージをログに出力します。オプションとして、結果として得られるメッセージにストリーミング座標が含まれるようにシグナルを設定することもできます。
| 列 | 値 | 説明 |
|---|---|---|
| id |
| |
| type |
| シグナルのアクションタイプです。 |
| data |
{"message": "Signal message at offset {}"}
|
|
6.5.4.2. アドホックスナップショットシグナル
execute-snapshot シグナルタイプのシグナルを作成すると、アドホックスナップショットの開始をコネクターに要求できます。信号を処理した後、コネクターは要求されたスナップショットオペレーションを実行します。
コネクターが最初に起動したときに実行される最初のスナップショットとは異なり、アドホックスナップショットは、コネクターがすでにデータベースからの変更イベントのストリーミングを開始した後のランタイム中に発生します。いつでもアドホックなスナップショットを開始することができます。
アドホックスナップショットは、以下の Debezium コネクターで利用可能です。
- Db2
- MariaDB (テクノロジープレビュー)
- MongoDB
- MySQL
- Oracle
- PostgreSQL
- SQL Server
| 列 | 値 |
|---|---|
| id |
|
| type |
|
| data |
{"data-collections": ["public.MyFirstTable", "public.MySecondTable"]}
|
| キー | 値 |
|---|---|
| test_connector |
{"type":"execute-snapshot","data": {"data-collections": ["public.MyFirstTable"], "type": "INCREMENTAL", "additional-conditions":[{"data-collection": "public.MyFirstTable", "filter":"color='blue' AND brand='MyBrand'"}]}}
|
アドホックスナップショットの詳細は、お使いのコネクターのドキュメントの スナップショット のトピックを参照してください。
関連情報
アドホックスナップショット停止シグナル
stop-snapshot シグナルタイプでシグナルテーブルエントリーを作成することにより、進行中のアドホックスナップショットを停止するようコネクターに要求できます。シグナルを処理した後、コネクターは現在進行中のスナップショット操作を停止します。
次の Debezium コネクターのアドホックスナップショットを停止できます。
- Db2
- MariaDB (テクノロジープレビュー)
- MongoDB
- MySQL
- Oracle
- PostgreSQL
- SQL Server
| 列 | 値 |
|---|---|
| id |
|
| type |
|
| data |
{"type":"INCREMENTAL", "data-collections": ["public.MyFirstTable"]}
|
シグナルの type を指定する必要があります。data-collections フィールドはオプションです。現在のスナップショットのすべてのアクティビティーを停止するようコネクターに要求するには、data-collections フィールドを空白のままにします。増分スナップショットを続行したいが、スナップショットから特定のコレクションを除外したい場合は、除外するコレクションまたは正規表現の名前のコンマ区切りリストを指定します。コネクターが信号を処理した後、増分スナップショットが続行されますが、指定したコレクションからデータが除外されます。
6.5.4.3. 増分スナップショット
増分スナップショットはアドホックスナップショットの一種です。増分スナップショットでは、初期スナップショットと同様に、指定したテーブルのベースライン状態をキャプチャします。しかし、初期スナップショットとは異なり、増分スナップショットでは、一度にすべてのテーブルをキャプチャーするのではなく、チャンク単位でテーブルをキャプチャします。このコネクターは、スナップショットの進捗状況を追跡するために、電子透かしを使用しています。
増分スナップショットは、指定されたテーブルの初期状態を単一のモノリシックな操作ではなくチャンクでキャプチャーすることにより、初期スナップショットのプロセスに比べて以下のような利点があります。
- コネクターが指定されたテーブルのベースライン状態をキャプチャしている間、トランザクションログからのほぼリアルタイムのイベントのストリーミングは中断することなく継続されます。
- 増分スナップショットの処理が中断されても、中断した時点から再開することができます。
- 増分スナップショットはいつでも開始できます。
増分スナップショットの一時停止シグナル
pause-snapshot シグナルタイプを使用してシグナルテーブルエントリーを作成することにより、進行中の増分スナップショットを一時停止するようコネクターに要求できます。信号を処理した後、コネクターは現在進行中のスナップショット操作の一時停止を停止します。そのため、信号の処理中の位置でスナップショット処理が一時停止されるため、データ収集を指定することはできません。
次の Debezium コネクターの増分スナップショットを一時停止できます。
- Db2
- MariaDB (テクノロジープレビュー)
- MongoDB
- MySQL
- Oracle
- PostgreSQL
- SQL Server
| 列 | 値 |
|---|---|
| id |
|
| type |
|
シグナルの type を指定する必要があります。data フィールドは無視されます。
増分スナップショットの一時停止シグナル
一時停止した増分スナップショットを再開するようコネクターに要求するには、resume-snapshot シグナルタイプでシグナルテーブルエントリーを作成します。信号を処理した後、コネクターは以前に一時停止したスナップショット操作を再開します。
次の Debezium コネクターの増分スナップショットを再開できます。
- Db2
- MariaDB (テクノロジープレビュー)
- MongoDB
- MySQL
- Oracle
- PostgreSQL
- SQL Server
| 列 | 値 |
|---|---|
| id |
|
| type |
|
シグナルの type を指定する必要があります。data フィールドは無視されます。
増分スナップショットの詳細は、お使いのコネクターのドキュメントのスナップショットのトピックを参照してください。
6.5.4.4. ブロッキングスナップショットシグナル
execute-snapshot シグナルタイプと、値 blocking を持つ data.type でシグナルを作成すると、アドホックブロッキングスナップショットの開始をコネクターに要求できます。信号を処理した後、コネクターは要求されたスナップショットオペレーションを実行します。
コネクターが最初に起動したときに実行される初期スナップショットとは異なり、アドホックブロッキングスナップショットは、コネクターがデータベースからの変更イベントのストリーミングを停止した後のランタイム中に発生します。アドホックブロッキングスナップショットはいつでも開始できます。
ブロッキングスナップショットは、以下の Debezium コネクターで利用可能です。
- Db2
- MariaDB (テクノロジープレビュー)
- MySQL
- Oracle
- PostgreSQL
- SQL Server
| 列 | 値 |
|---|---|
| id |
|
| type |
|
| data |
{"type": "blocking", "data-collections": ["schema1.table1", "schema1.table2"], "additional-conditions": [{"data-collection": "schema1.table1", "filter": "SELECT * FROM [schema1].[table1] WHERE column1 = 0 ORDER BY column2 DESC"}, {"data-collection": "schema1.table2", "filter": "SELECT * FROM [schema1].[table2] WHERE column2 > 0"}]}
|
| キー | 値 |
|---|---|
| test_connector |
{"type":"execute-snapshot","data": {"type": "blocking"}
|
ブロッキングスナップショットの詳細は、お使いのコネクターのドキュメントの スナップショット のトピックを参照してください。
6.5.4.5. カスタムシグナルアクションの定義
カスタムアクションを使用すると、Debezium シグナリングフレームワークを拡張して、デフォルトの実装では使用できないアクションをトリガーできます。カスタムアクションは複数のコネクターで使用できます。
カスタムシグナルアクションを定義するには、次のインターフェイスを定義する必要があります。
io.debezium.pipeline.signal.actions.SignalAction は、シグナリングチャネルを介して送信されるメッセージペイロードを表す 1 つのパラメーターを持つ、単一のメソッドを公開します。
カスタムシグナリングアクションを定義した後、SPI インターフェイス io.debezium.pipeline.signal.actions.SignalActionProvider を使用して、カスタムアクションをシグナリングメカニズムで使用できるようにします。
実装では、シグナルアクションのマップを返すはずです。マップキーはアクションの名前に設定します。キーはシグナルの type として使用されます。
6.5.4.6. Debezium コアモジュールの依存関係
カスタムアクション Java プロジェクトには、Debezium コアモジュールに対するコンパイル依存関係があります。プロジェクトの pom.xml ファイルに次のコンパイル依存関係を含めます。
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-core</artifactId>
<version>${version.debezium}</version>
</dependency>
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-core</artifactId>
<version>${version.debezium}</version>
</dependency>
META-INF/services/io.debezium.pipeline.signal.actions.SignalActionProvider ファイルでプロバイダーの実装を宣言します。
6.5.4.7. カスタムシグナルアクションのデプロイ
前提条件
- カスタムアクション Java プログラムがある。
手順
-
Debezium コネクターでカスタムアクションを使用するには、Java プロジェクトを JAR ファイルにエクスポートし、そのファイルを使用する各 Debezium コネクターの JAR ファイルを含むディレクトリーにコピーします。
たとえば、一般的なデプロイメントでは、Debezium コネクターファイルは Kafka Connect ディレクトリーのサブディレクトリー (/kafka/connect) に保存され、各コネクター JAR は独自のサブディレクトリー (/kafka/connect/debezium-connector-db2、/kafka/connect/debezium-connector-mysqlなど) に格納されます。
複数のコネクターでカスタムアクションを使用するには、各コネクターのサブディレクトリーにカスタムシグナリングチャネル JAR ファイルのコピーを配置する必要があります。
第7章 Apache Kafka で交換されたメッセージを修正するためのトランスフォームの適用
Debezium には、変更イベントレコードを修正するために使用できるいくつかのシングルメッセージ変換 (SMT) があります。Apache Kafka にレコードを送信する前に、レコードを修正する変換を適用するようにコネクターを設定することができます。また、Debezium SMT を sink コネクターに適用して、コネクターが Kafka トピックから読み込む前にレコードを修正することもできます。
特定のメッセージのみに選択的に変換を適用する 場合は、Kafka Connect 述語を設定して SMT を適用するための条件を定義できます。
Debezium は以下の SMT を提供しています。
- トピックルーター SMT
- 元のトピック名に適用される正規表現に基づいて、変更イベントレコードを特定のトピックに再ルーティングします。
- コンテンツベースルーター SMT
- イベントの内容に基づいて、指定された変更イベントのレコードを再送します。
- イベントレコード変更 SMT
- イベントメッセージを拡張して、データベース操作後に値が変更されるフィールドまたは変更されないフィールドを識別します。
- メッセージフィルタリング SMT
- イベントレコードのサブセットを宛先の Kafka トピックに伝搬することができます。この変換では、イベントレコードの内容に基づいて、コネクターが発信する変更イベントレコードに正規表現を適用します。式にマッチしたレコードのみが対象のトピックに書き込まれます。その他の記録は無視されます。
- HeaderToValue SMT
- イベントレコードから指定されたヘッダーフィールドを抽出し、そのヘッダーフィールドをイベントレコード内の値にコピーまたは移動します。
- 新記録の状態抽出 SMT
- Debezium の変更イベントレコードの複雑な構造をシンプルなフォーマットにフラット化します。構造を簡略化することで、元の構造を消費できない sink コネクターでの処理が可能になります。
- MongoDB 新記録の状態抽出
- Debezium MongoDB コネクター変更イベントレコードの複雑な構造を簡素化します。構造を簡略化して、元のイベント構造を消費できない sink コネクターでの処理が可能になります。
- 送信トレイ (Outbox) イベントルーター SMT
- 複数のサービス間での安全で信頼性の高いデータ交換を可能にするアウトボックスパターンのサポートを提供します。
- MongoDB outbox event router SMT
- MongoDB コネクターで送信ボックスパターンを使用するためのサポートを提供し、複数のサービス間で安全かつ信頼性の高いデータ交換を可能にします。
- パーティションルーティング SMT
- 指定されたペイロードフィールドの値 1 つ以上に基づいて、イベントを特定の宛先パーティションにルーティングします。
- タイムゾーンコンバーター SMT
- イベントレコード内の Debezium および Kafka Connect のタイムスタンプフィールドを指定されたタイムゾーンに変換します。
7.1. SMT 述語を使用した変換の選択的適用
コネクターに単一メッセージ変換 (SMT) を設定する場合、変換の述語を定義できます。述語は、コネクターが処理するメッセージのサブセットに変換を条件的に適用する方法を指定します。Debezium などのソースコネクターまたは sink コネクターに対して設定する変換に、述語を割り当てることができます。
7.1.1. SMT 述語について
Debezium は、Kafka Connect がレコードを Kafka トピックに保存する前に、イベントレコードを変更するために使用できるさまざまな単一メッセージ変換 (SMT) を提供します。デフォルトでは、Debezium コネクターにこれらの SMT のいずれかを設定する場合、Kafka Connect はコネクターが出力するすべてのレコードに変換を適用します。ただし、共通の特徴を共有する変更イベントメッセージのサブセットのみが変更されるように、一部の変換を適用する場合があります。
たとえば、Debezium コネクターでは、特定のテーブルからのイベントメッセージまたは特定のヘッダーキーが含まれるイベントメッセージでのみ変換を実行する必要がある場合があります。Apache Kafka 2.6 以降を実行する環境では、変換に述語ステートメントを追加して、特定のレコードだけに SMT を適用するように Kafka Connect に指示できます。述語では、Kafka Connect が処理する各メッセージを評価するために使用する条件を指定します。Debezium コネクターが変更イベントメッセージを出力すると、Kafka Connect はメッセージを設定済みの述語条件に対して確認します。イベントメッセージで条件が満たされる場合、Kafka Connect は変換を適用し、メッセージを Kafka トピックに書き込みます。条件に一致しないメッセージは、そのまま Kafka に送信されます。
この状況は、sink コネクター SMT に定義する述語に類似しています。コネクターは Kafka トピックからメッセージを読み取り、Kafka Connect はメッセージを述語条件に対して評価します。メッセージが条件と一致する場合、Kafka Connect は変換を適用し、メッセージを sink コネクターに渡します。
述語を定義したら、それを再利用し、複数の変換に適用できます。述語には negate オプションがあり、これを使うと述語の条件を反転させて、述語文で定義された条件に一致しないレコードにのみ適用することができます。negate オプションを使うと、条件を否定することを前提とした他の変換と述語をペアにすることができます。
述語要素
述語には、以下の要素が含まれます。
-
predicates接頭辞 -
エイリアス (例:
isOutbox Table) -
タイプ (たとえば、
org.apache.kafka.connect.transforms.predicates.TopicNameMatches)。Kafka Connect は、デフォルトの述語型のセットを提供します。これは、独自のカスタム述語を定義することで補足できます。 - 条件ステートメントと追加の設定プロパティー (述語の型 (正規表現の命名パターンなど) による)
デフォルトの述語型
デフォルトでは、以下の述語型を利用できます。
- HasHeaderKey
- Kafka Connect が評価するイベントメッセージのヘッダーのキー名を指定します。述語は、指定された名前を持つヘッダーキーが含まれるレコードを true と評価します。
- RecordIsTombstone
Kafka 廃棄 レコードとマッチします。述語は、
null値を持つすべてのレコードに対してtrueと評価されます。この述語をフィルター SMT と組み合わせて使用して廃棄レコードを削除します。この述語には設定パラメーターはありません。Kafka の tombstone は、0 バイトの
nullペイロードを持つキーを持つレコードです。Debezium コネクターがソースデータベースで削除操作を処理すると、コネクターは削除操作に対して 2 つの変更イベントを出力します。-
データベースレコードの以前の値を提供する削除操作 (
"op" : "d") イベント。 キーは同じだが、値が
nullの墓石イベント。tombstone は、行の削除マーカーを表します。ログコンパクション が Kafka に対して有効になっている場合、コンパクト時に Kafka は tombstone と同じキーを共有するすべてのイベントを削除します。ログコンパクションは、トピックの
delete.retention.ms設定で制御されるコンパクト化の間隔で定期的に行われます。廃棄 (tombstone) イベントを出力しないように Debezium を設定する ことは可能ですが、ログコンパクション中に想定される動作を維持するために Debezium が tombstone を出力するのを許可することを推奨します。tombstone を抑制することにより、ログコンパクション中に削除されたキーのレコードを Kafka が削除しなくなります。環境に tombstone を処理できない sink コネクターが含まれる場合は、
RecordIsTombstone述語で SMT を使用して廃棄レコードをフィルタリングするように sink コネクターを設定できます。
-
データベースレコードの以前の値を提供する削除操作 (
- TopicNameMatches
- Kafka Connect が照合するトピックの名前を指定する正規表現。トピック名が指定の正規表現と一致するコネクターレコードの場合、述語は true になります。この述語を使用して、ソーステーブルの名前に基づいてレコードに SMT を適用します。
7.1.2. SMT 述語の定義
デフォルトでは、Kafka Connect は Debezium コネクター設定の各単一メッセージ変換を、Debezium から受け取るすべての変更イベントレコードに適用します。Apache Kafka 2.6 以降では、Kafka Connect による変換の適用方法を制御するコネクター設定で変換に SMT 述語を定義できます。述語ステートメントは、Kafka Connect が Debezium によって出力されるイベントレコードに変換を適用する条件を定義します。Kafka Connect は述語ステートメントを評価し、SMT を選択的に、述語で定義される条件に一致するレコードのサブセットに適用します。Kafka Connect 述語の設定は、変換の設定と似ています。述語エイリアスを指定し、エイリアスを変換に関連付け、述語の型および設定を定義します。
前提条件
- Debezium 環境が Apache Kafka 2.6 以降を実行している。
- SMT が Debezium コネクター用に設定されている。
手順
-
Debezium コネクターの設定で、
predicatesパラメーターに、IsOutbox Tableなどの predicate エイリアスを指定します。 コネクター設定の変換エイリアスに述語エイリアスを追加して、条件付きに適用する変換に述語エイリアスを関連付けます。
transforms.<TRANSFORM_ALIAS>.predicate=<PREDICATE_ALIAS>
transforms.<TRANSFORM_ALIAS>.predicate=<PREDICATE_ALIAS>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
transforms.outbox.predicate=IsOutboxTable
transforms.outbox.predicate=IsOutboxTableCopy to Clipboard Copied! Toggle word wrap Toggle overflow 型を指定し、設定パラメーターの値を指定して述語を設定します。
型には、Kafka Connect で使用できる以下のデフォルト型のいずれかを指定します。
- HasHeaderKey
- RecordIsTombstone
TopicNameMatches
以下に例を示します。
predicates.IsOutboxTable.type=org.apache.kafka.connect.transforms.predicates.TopicNameMatches
predicates.IsOutboxTable.type=org.apache.kafka.connect.transforms.predicates.TopicNameMatchesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
TopicNameMatch または
HasHeaderKey述語に対して、照合するトピックまたはヘッダー名の正規表現を指定します。以下に例を示します。
predicates.IsOutboxTable.pattern=outbox.event.*
predicates.IsOutboxTable.pattern=outbox.event.*Copy to Clipboard Copied! Toggle word wrap Toggle overflow
条件を反転する場合は、
negateキーワードを変換エイリアスに追加し、trueに設定します。以下に例を示します。
transforms.outbox.negate=true
transforms.outbox.negate=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow 前述のプロパティーは、述語がマッチするレコードセットを反転し、Kafka Connect は述語で指定された条件に一致しないレコードに変換を適用するようにします。
例: 送信トレイイベントルーターの変換用の TopicNameMatch 述語
以下の例に示す Debezium コネクター設定は、送信トレイイベントルーター変換を Debezium が Kafka outbox.event.order トピックに出力するメッセージにだけ適用します。
TopicNameMatch 述語は送信トレイテーブルからのメッセージだけを true と評価するため (outbox.event.*)、データベースの他のテーブルから送信されるメッセージに変換は適用されません。
7.1.3. 廃棄 (tombstone) イベントの無視
Debezium が廃棄 (tombstone) イベントを生成するかどうかや、Kafka がそれらを保持する期間を制御できます。データパイプラインによっては、Debezium が廃棄 (tombstone) イベントを出力しないように、コネクターの tombstones.on.delete プロパティーを設定する必要がある場合があります。
Debezium が tombstone を出力できるようにするかどうかは、トピックがどのように環境で使用されるかと、シンクコンシューマーの特性によって異なります。一部の sink コネクターは、廃棄 (tombstone) イベントに依存してダウンストリームデータストアからレコードを削除します。sink コネクターが廃棄 (tombstone) レコードに依存してダウンストリームデータストアのレコードを削除するタイミングを示す場合は、Debezium がそれらを出力するように設定します。
tombstone を生成するように Debezium を設定する場合、sink コネクターが廃棄 (tombstone) イベントを受信するように追加の設定が必要になります。ログコンパクション中に Kafka がイベントメッセージを削除する前に、コネクターがイベントメッセージを読み取るために、トピックの保持ポリシーを設定する必要があります。コンパクション前にトピックが tombstone を保持する時間の長さは、トピックの delete.retention.ms プロパティーによって制御されます。
デフォルトでは、コネクターの tombstones.on.delete プロパティーが true に設定されているため、delete イベントが発生するたびに、コネクターは tombstone を生成します。このプロパティーを false に設定して、Debezium が Kafka トピックに墓石の記録を保存しないようにすると、墓石の記録がないために意図しない結果になる可能性があります。Kafka はログコンパクション時に tombstone に依存して、削除されたキーに関連するレコードを削除します。
null 値のレコードを処理できない sink コネクターやダウンストリームの Kafka コンシューマーをサポートする必要がある場合、Debezium が廃棄を出力するのを防止するのではなく、コンシューマーが読み取る前に RecordIsTombstone 述語型を使用して廃棄メッセージを削除する述語を使用するコネクターの SMT を設定することを検討してください。
手順
Debezium が削除されたデータベースレコードの tombstone イベントを発行しないようにするには、コネクターオプション
tombstones.on.deleteをfalseに設定します。以下に例を示します。
“tombstones.on.delete”: “false”
“tombstones.on.delete”: “false”Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.2. 指定したトピックへの Debezium イベントレコードのルーティング
データ変更イベントが含まれるそれぞれの Kafka レコードは、デフォルトのルーティング先トピックを持ちます。必要に応じて、レコードが Kafka Connect コンバーターに到達する前に、指定したトピックにレコードを再ルーティングすることができます。そのために、Debezium ではトピックルーティング単一メッセージ変換 (SMT) を利用することができます。Debezium コネクターの Kafka Connect 設定でこの変換を設定します。設定オプションにより、以下の項目を指定することができます。
- 再ルーティングするレコードを識別するための式。
- ルーティング先トピックに解決する式。
- 宛先トピックに再ルーティングされるレコード間でキーの一意性を確保する方法。
変換の設定により必要な動作が得られるようにするのは、ユーザー側の範疇です。Debezium は、変換の設定により得られる動作を検証しません。
トピックルーティング変換は Kafka Connect SMT です。
詳細は以下のセクションを参照してください。
7.2.1. 指定したトピックに Debezium レコードをルーティングするユースケース
Debezium コネクターのデフォルト動作では、それぞれの変更イベントレコードは、名前がデータベースおよび変更が加えられたテーブルの名前から作られるトピックに送信されます。つまり、トピックは 1 つの物理テーブルのレコードを受け取ります。トピックが複数の物理テーブルのレコードを受け取るようにするには、Debezium コネクターを設定してレコードをそのトピックに再ルーティングする必要があります。
論理テーブル
論理テーブルは、複数の物理テーブルのレコードを 1 つのトピックにルーティングする場合の一般的なユースケースです。論理テーブル内には、すべて同じスキーマを持つ複数の物理テーブルがあります。たとえば、シャーディングされたテーブルのスキーマは同一です。論理テーブルは、db_shard1.my_table および db_shard2.my_tableという 2 つ以上のシャード化されたテーブルで構成されている場合があります。テーブルは異なるシャードにあり物理的に別個のものですが、1 つにまとまり論理テーブルを形成します。任意のシャード内のテーブルの変更イベントレコードを、同じトピックに再ルーティングすることができます。
パーティションで分割された PostgreSQL テーブル
Debezium PostgreSQL コネクターがパーティションで分割されたテーブルの変更をキャプチャーする場合、デフォルトの動作では、変更イベントレコードはパーティションごとに異なるトピックにルーティングされます。すべてのパーティションからのレコードを 1 つのトピックに出力するには、トピックルーティング SMT を設定します。パーティションで分割されたテーブルの各キーは必ず一意であるため、キーの一意性を確保するために SMT がキーフィールドを追加しないように key.enforce.uniqueness=false を設定します。デフォルトの動作では、キーフィールドが追加されます。
7.2.2. 複数テーブルの Debezium レコードを 1 つのトピックにルーティングする例
複数の物理テーブルの変更イベントレコードを同じトピックにルーティングするには、Debezium コネクターの Kafka Connect 設定でトピックルーティング変換を設定します。トピックルーティング SMT を設定するには、以下の項目を決定する正規表現を指定する必要があります。
- レコードをルーティングするテーブル。これらのテーブルのスキーマは、すべて同一でなければなりません。
- ルーティング先トピックの名前。
以下の例のコネクター設定では、トピックルーティング SMT の複数のオプションを設定します。
transforms=Reroute transforms.Reroute.type=io.debezium.transforms.ByLogicalTableRouter transforms.Reroute.topic.regex=(.*)customers_shard(.*) transforms.Reroute.topic.replacement=$1customers_all_shards
transforms=Reroute
transforms.Reroute.type=io.debezium.transforms.ByLogicalTableRouter
transforms.Reroute.topic.regex=(.*)customers_shard(.*)
transforms.Reroute.topic.replacement=$1customers_all_shardstopic.regex変更イベントレコードを特定のトピックにルーティングする必要があるかどうかを決定するために、変換がそれぞれのレコードに適用する正規表現を指定します。
この例では、正規表現
(.*)customers_shard(.*)は、名前にcustomers_shard文字列が含まれるテーブルに対する変更のレコードがマッチします。この場合、以下の名前のテーブルのレコードが再ルーティングされます。myserver.mydb.customers_shard1myserver.mydb.customers_shard2myserver.mydb.customers_shard3topic.replacement-
ルーティング先トピックの名前を表す正規表現を指定します。変換により、マッチする各レコードがこの式で識別されるトピックにルーティングされます。この例では、上記 3 つのシャーディングされたテーブルのレコードが
myserver.mydb.customers_all_shardsトピックにルーティングされます。 schema.name.adjustment.mode-
コネクターで使用されるメッセージ変換器との互換性のために、結果のトピック名から派生するメッセージキースキーマ名を調整する方法を指定します。値は
none(デフォルト) またはavroです。
設定のカスタマイズ
変換で処理する、または処理しないテーブルを指定する SMT 述語ステートメント を定義して、設定をカスタマイズできます。述語は、正規表現に一致するテーブルをルーティングするように SMT を設定し、正規表現に一致する特定のテーブルを SMT に再ルーティングさせたくない場合に役立ちます。
7.2.3. 同一トピックにルーティングされる Debezium レコード間でのキーの一意性確保
Debezium の変更イベントキーは、テーブルのプライマリーキーを設定するテーブル列を使用します。複数の物理テーブルのレコードを 1 つのトピックにルーティングするには、それらの全テーブルに渡ってイベントキーが一意でなければなりません。ただし、それぞれの物理テーブルは、そのテーブル内でのみ一意なプライマリーキーを持つことができます。たとえば、myserver.mydb.customers_shard1 テーブルの行は、myserver.mydb.customers_shard2 テーブルの行と同じキー値を持つ場合があります。
変更イベントレコードが同じトピックにルーティングされる全テーブルに渡ってそれぞれのイベントキーが必ず一意になるように、トピックルーティング変換は変更イベントキーにフィールドを挿入します。デフォルトでは、挿入されるフィールドの名前は __dbz__physicalTableIdentifier です。挿入されるフィールドの値は、デフォルトのルーティング先トピックの名前です。
必要に応じて、別のフィールドをキーに挿入するようにトピックルーティング変換を設定することができます。そのためには、key.field.name オプションを指定し、それを既存のプライマリーキーフィールド名と競合しないフィールド名に設定します。以下に例を示します。
transforms=Reroute transforms.Reroute.type=io.debezium.transforms.ByLogicalTableRouter transforms.Reroute.topic.regex=(.*)customers_shard(.*) transforms.Reroute.topic.replacement=$1customers_all_shards transforms.Reroute.key.field.name=shard_id
transforms=Reroute
transforms.Reroute.type=io.debezium.transforms.ByLogicalTableRouter
transforms.Reroute.topic.regex=(.*)customers_shard(.*)
transforms.Reroute.topic.replacement=$1customers_all_shards
transforms.Reroute.key.field.name=shard_id
この例では、ルーティングされるレコードのキー構造に shard_id フィールドが追加されます。
キーの新しいフィールドの値を調整する場合は、以下の両方のオプションを設定します。
key.field.regex- 1 つまたは複数の文字グループをキャプチャーするために、変換がデフォルトのルーティング先トピックの名前に適用する正規表現を指定します。
key.field.replacement- キャプチャーされるこれらのグループに関して、挿入されるキーフィールドの値を決定するための正規表現を指定します。
以下に例を示します。
transforms.Reroute.key.field.regex=(.*)customers_shard(.*) transforms.Reroute.key.field.replacement=$2
transforms.Reroute.key.field.regex=(.*)customers_shard(.*)
transforms.Reroute.key.field.replacement=$2この設定では、デフォルトのルーティング先トピックの名前を以下のように仮定します。
myserver.mydb.customers_shard1myserver.mydb.customers_shard2myserver.mydb.customers_shard3
変換では、2 番目にキャプチャーされたグループの値であるシャード番号が、キーの新しいフィールドの値として使用されます。この例では、挿入されるキーフィールドの値は 1、2、または 3 です。
テーブルにグローバルに一意なキーが含まれ、キー構造を変更する必要がない場合は、key.enforce.uniqueness プロパティーを false に設定することができます。
... transforms.Reroute.key.enforce.uniqueness=false ...
...
transforms.Reroute.key.enforce.uniqueness=false
...7.2.4. トピックルーティング変換を一部適用するオプション
データベースの変更が発生したときに Debezium コネクターが出力する変更イベントメッセージの他に、コネクターはハートビートメッセージなど、他のタイプのメッセージとスキーマ変更およびトランザクションに関するメタデータメッセージも出力します。これらの他のメッセージの構造は、SMT が処理するように設計された変更イベントメッセージの構造とは異なるため、目的のデータ変更メッセージのみを処理するようにコネクターを SMT を選んで適用することが推奨されます。
以下の方法のいずれかを使用して、SMT を選んで適用するようにコネクターを設定できます。
- 変換用の SMT 述語を設定する。
- SMT に topic.regex 設定オプションを使用する。
7.2.5. Debezium トピックルーティング変換設定用のオプション
以下の表で、トピックルーティングの SMT 設定オプションを紹介します。
| オプション | デフォルト | 説明 |
|---|---|---|
| 変更イベントレコードを特定のトピックにルーティングする必要があるかどうかを決定するために、変換がそれぞれのレコードに適用する正規表現を指定します。 | ||
|
ルーティング先トピックの名前を表す正規表現を指定します。変換により、マッチする各レコードがこの式で識別されるトピックにルーティングされます。この式により、 | ||
|
|
レコードの変更イベントキーにフィールドを追加するかどうかを定義します。キーフィールドを追加することで、変更イベントレコードが同じトピックにルーティングされる全テーブルに渡って、それぞれのイベントキーの一意性が確保されます。この設定は、同じキーを持つが異なるソーステーブルに由来するレコードの変更イベントの競合を防ぐのに役立ちます。 | |
|
|
変更イベントキーに追加されるフィールドの名前。このフィールドの値により、元のテーブル名が識別されます。SMT がこのフィールドを追加するには | |
|
1 つまたは複数の文字グループをキャプチャーするために、変換がデフォルトのルーティング先トピックの名前に適用する正規表現を指定します。SMT がこの正規表現を適用するには、 | ||
|
| ||
| none |
結果のトピック名から派生したメッセージキースキーマ名を、コネクターが使用するメッセージコンバーターとの互換性に合わせて調整する方法を指定します。 | |
|
| LRUCache で最大エントリーを保持するために使用されるサイズ。キャッシュは、論理テーブルのキーと値の古い/新しいスキーマを保持し、派生キーとトピックの正規表現の結果もキャッシュして、ソースレコードの変換を改善します。 |
7.3. イベントの内容に応じた変更イベントレコードのトピックへのルーティング
デフォルトでは、Debezium はテーブルから読み取るすべての変更イベントを 1 つの静的なトピックにストリーミングします。ただし、イベントの内容に応じて、選択したイベントを別のトピックに再ルーティングする必要がある状況が考えられます。メッセージをその内容に基づいてルーティングするプロセスは、コンテンツベースのルーティング メッセージングパターンで説明されています。このパターンを Debezium に適用するには、コンテンツベースのルーティング 単一メッセージ変換 (SMT) を使用して、イベントごとに評価される式を記述します。イベントがどのように評価されるかに応じて、SMT はイベントメッセージを元の宛先トピックにルーティングするか、あるいは式で指定したトピックに再ルーティングします。
カスタム SMT を作成してルーティングロジックをエンコードするのに Java を使用することは可能ですが、カスタムコーディングされた SMT の使用にはデメリットがあります。以下に例を示します。
- 変換を事前にコンパイルし、それを Kafka Connect にデプロイする必要がある。
- 変更が生じるたびにコードの再コンパイルおよび再デプロイが必要になり、運用の柔軟性が失われる。
コンテンツベースのルーティング SMT は、JSR 223 (Scripting for the Java™ Platform) と統合するスクリプト言語をサポートしています。
Debezium には、JSR 223 API の実装は同梱されていません。Debezium で式言語を使用するには、その言語の JSR 223 スクリプトエンジン実装をダウンロードする必要があります。Debezium をデプロイする方法によって、必要な成果物を Maven Central から自動的にダウンロードするか、成果物を手動でダウンロードし、言語実装で使用する他の JAR ファイルと共に Debezium コネクターのプラグインディレクトリーに追加することが可能です。
7.3.1. Debezium コンテンツベースのルーティング SMT の設定
セキュリティー上の理由から、コンテンツベースのルーティング SMT は Debezium コネクターアーカイブには含まれていません。代わりに、別のアーティファクト debezium-scripting-2.7.3.Final.tar.gz で提供されます。
Dockerfile からカスタム Kafka Connect コンテナーイメージを構築して Debezium コネクターを導入する場合、フィルター SMT を使用するには、Kafka Connect 環境に SMT アーティファクトを明示的に追加する必要があります。Streams for Apache Kafka を使用してコネクターをデプロイすると、Kafka Connect カスタムリソースで指定した設定パラメーターに基づいて、必要なアーティファクトが自動的にダウンロードされます。重要: ルーティング SMT が Kafka Connect インスタンスに追加されると、インスタンスにコネクターを追加できる任意のユーザーはスクリプト式を実行することができます。許可されたユーザーだけがスクリプト式を実行できるようにするには、ルーティング SMT を追加する前に、Kafka Connect インスタンスおよびその設定インターフェイスをセキュアにする必要があります。
以下の手順は、Dockerfile から Kafka Connect コンテナーイメージを構築する場合に適用されます。Streams for Apache Kafka を使用して Kafka Connect イメージを作成する場合は、コネクターのデプロイメントトピックの手順に従ってください。
手順
-
ブラウザーから ソフトウェアダウンロード を開き、Debezium スクリプト SMT アーカイブ (
debezium-scripting-2.7.3.Final.tar.gz) をダウンロードします。 - アーカイブのコンテンツを Kafka Connect 環境の Debezium プラグインのディレクトリーにデプロイメントします。
- JSR-223 スクリプトエンジンの実装を取得し、そのコンテンツを Kafka Connect 環境の Debezium プラグインのディレクトリーに追加します。
- Kafka Connect プロセスを再起動し、新しい JAR ファイルを取得します。
Groovy 言語には、クラスパスで以下のライブラリーが必要です。
-
groovy -
groovy-json(任意) -
groovy-jsr223
JavaScript 言語には、クラスパスで以下のライブラリーが必要です。
-
graalvm.js -
graalvm.js.scriptengine
7.3.2. 例: Debezium コンテンツベースルーティングの基本設定
イベントの内容に基づいて変更イベントレコードをルーティングするように Debezium コネクターを設定するには、コネクターの Kafka Connect 設定で ContentBasedRouter SMT を設定します。
コンテンツベースのルーティング SMT 設定では、絞り込みの条件を定義する正規表現を指定する必要があります。設定で、ルーティングの条件を定義する正規表現を作成します。式は、イベントレコードを評価するためのパターンを定義します。また、パターンにマッチするイベントをルーティングする宛先トピックの名前も指定します。指定するパターンで、テーブルの挿入、更新、または削除操作などのイベントタイプを指定する場合もあります。特定の列または行の値を照合するパターンを定義することもできます。
たとえば、すべての更新 (u) レコードを updates トピックに再ルーティングするには、コネクター設定に以下の設定を追加します。
上記の例では、Groovy 式言語の使用を指定しています。
パターンにマッチしないレコードは、デフォルトのトピックにルーティングされます。
設定のカスタマイズ
前の例は、op フィールドを含む DML イベントのみを処理するように設計された単純な SMT 設定を示しています。コネクターが発行する他の種類のメッセージ (ハートビートメッセージ、廃棄メッセージ、またはトランザクションまたはスキーマの変更に関するメタデータメッセージ) には、このフィールドは含まれません。処理の失敗を回避するために、特定のイベントのみに 変換を選択して適用する SMT 述語ステートメント を定義できます。
7.3.3. Debezium コンテンツベースルーティングの式で使用される変数
Debezium は、特定の変数を SMT の評価コンテキストにバインドします。ルーティング先を制御するための条件を指定する式を作成する場合、SMT はこれらの変数の値を検索して解釈し、式の条件を評価することができます。
以下の表に、Debezium がコンテンツベースのルーティング SMT の評価コンテキストにバインドする変数のリストを示します。
| 名前 | 説明 | タイプ |
|---|---|---|
|
| メッセージのキー。 |
|
|
| メッセージの値。 |
|
|
| Schema of the message key. |
|
|
| メッセージの値のスキーマ。 |
|
|
| ルーティング先トピックの名前。 | String |
|
|
メッセージヘッダーの Java マッピング。キーフィールドはヘッダー名です。
|
|
式は、その変数に対して任意のメソッドを呼び出すことができます。式は、SMT がメッセージをどのように処理するかを定義するブール値に解決する必要があります。式のルーティング条件が true と評価されると、メッセージは維持されます。ルーティング条件が false と評価されると、メッセージは削除されます。
式がそれ以外の効果を及ぼすことは許されません。つまり、式が渡す変数を変更することは許されません。
7.3.4. コンテンツベースのルーティング変換を一部適用するオプション
データベースの変更が発生したときに Debezium コネクターが出力する変更イベントメッセージの他に、コネクターはハートビートメッセージなど、他のタイプのメッセージとスキーマ変更およびトランザクションに関するメタデータメッセージも出力します。これらの他のメッセージの構造は、SMT が処理するように設計された変更イベントメッセージの構造とは異なるため、目的のデータ変更メッセージのみを処理するようにコネクターを SMT を選んで適用することが推奨されます。以下の方法のいずれかを使用して、SMT を選んで適用するようにコネクターを設定できます。
- 変換用の SMT 述語を設定する。
- SMT に topic.regex 設定オプションを使用する。
7.3.5. 他のスクリプト言語によるコンテンツベースのルーティング条件の設定
コンテンツベースのルーティング条件を記述する方法は、使用するスクリプト言語によって異なります。たとえば、基本設定の例 に示すように、式言語として Groovy を使用する場合、以下の式はすべての更新 (u) レコードを updates トピックにルーティングし、他のレコードをデフォルトのトピックにルーティングします。
value.op == 'u' ? 'updates' : null
value.op == 'u' ? 'updates' : null他の言語では、同じ条件を表すのに異なる方法が使用されます。
Debezium MongoDB コネクターは、after および patch フィールドを構造体ではなくシリアライズされた JSON ドキュメントとして出力します。
MongoDB コネクターで ContentBasedRouting SMT を使うには、まず JSON の配列フィールドを個別のドキュメントにデプロイメントする必要があります。
式の中で JSON パーサーを使用すると、配列の各項目について個別の出力文書を生成することができます。たとえば、表現言語として Groovy を使用している場合、groovy-json アーティファクトをクラスパスに追加し、(new groovy.json.JsonSlurper()).parseText(value.after).last_name == 'Kretchmar' のような表現を追加しています。
JavaScript
式言語に JavaScript を使用する場合、以下の例に示すように、Struct#get() メソッドを呼び出してコンテンツベースのルーティング条件を指定することができます。
value.get('op') == 'u' ? 'updates' : null
value.get('op') == 'u' ? 'updates' : nullJavaScript with Graal.js
JavaScript with Graal.js を使用してコンテンツベースのルーティング条件を作成する場合、Groovy で使用する方法と類似の方法を使用します。以下に例を示します。
value.op == 'u' ? 'updates' : null
value.op == 'u' ? 'updates' : null7.3.6. コンテンツベースのルーティング変換設定用のオプション
| プロパティー | デフォルト | 説明 |
|
イベントのルーティング先トピックの名前を評価するオプションの正規表現で、条件ロジックを適用するかどうかを決定します。ルーティング先トピックの名前が | ||
|
式を記述する言語。 | ||
|
すべてのメッセージに対して評価される式。 | ||
|
|
トランスフォーメーションが
|
7.4. Debezium イベントレコードからのフィールドレベルの変更抽出
Debezium のデータ変更イベントは、さまざまな情報を提供する複雑な構造を持ちます。ただし、場合によっては、元のデータベース変更から生じるフィールドレベルの変更に関する追加情報がないと、ダウンストリームコンシューマーが Debezium 変更イベントメッセージを処理できません。Debezium には、データベース操作がソースデータベースのフィールドを変更する方法を含むイベントメッセージを強化するために、ExtractChangedRecordState 単一メッセージ変換 (SMT) が同梱されています。
イベント変更変換は Kafka Connect SMT です。
7.4.1. Debezium 変更イベントの構造について
Debezium は、複雑な構造を持つデータ変更イベントを生成します。各イベントは以下の部分で構成されています。
メタデータには、次のタイプが含まれますが、限定されません。
- データを変更した操作のタイプ。
- データベースの名前や、変更が発生したテーブルなどのソース情報。
- 変更が加えられたタイミングを識別するタイムスタンプ。
- (任意の項目) トランザクション情報
- 変更前の行データ。
- 変更後の行データ。
次の例は、典型的な Debezium UPDATE 変更イベントの構造の一部を示しています。
前の例の複雑なメッセージ形式により、ソースデータベースで発生した変更に関する詳細情報が提供されます。ただし、この形式は一部のダウンストリームコンシューマーには適していない可能性があります。sink コネクター、または Kafka エコシステムの他の部分では、データベース操作によって変更または変更されないフィールドを明示的に識別するメッセージが必要な場合があります。ExtractChangedRecordState SMT は、変更イベントメッセージにヘッダーを追加して、データベース操作によって変更されるフィールドと変更されないフィールドを識別します。
7.4.2. Debezium イベントの動作による SMT の変更
イベント変更 SMT は、Kafka レコードの Debezium UPDATE 変更イベントから before と after フィールドを抽出します。変換では、before と after イベントの状態構造を調べて、操作によって変更されたフィールドと変更されないフィールドを識別します。コネクターの設定に応じて、変換により、変更されたフィールド、変更されていないフィールド、またはその両方をリストするメッセージヘッダーを追加する変更されたイベントメッセージが生成されます。イベントが INSERT または DELETE を表す場合、この単一のメッセージ変換は効果がありません。
イベント変更 SMT は、Debezium コネクター、または Debezium コネクターによって発行されたメッセージを消費する sink コネクターに対して設定できます。Apache Kafka で元の Debezium 変更イベント全体を保持する場合は、sink コネクターのイベント変更 SMT を設定します。SMT を元のコネクターまたは sink コネクターに適用するかどうかの判断は、特定のユースケースによります。
ユースケースに応じて、以下のタスクのいずれかまたは両方を実行して、元のメッセージを変更するように変換を設定できます。
-
UPDATEイベントによって変更されたフィールドを、ユーザーが設定したheader.changed.nameヘッダーに一覧表示することで識別します。 -
UPDATEイベントによって変更されていないフィールドを、ユーザーが設定したheader.unchanged.nameヘッダーに一覧表示することで識別します。
7.4.3. Debezium イベント変更 SMT の設定
Kafka Connect ソースまたは sink コネクターの Debezium イベント変更 SMT を設定するには、SMT 設定の詳細をコネクターの設定に追加します。ヘッダーを追加しないデフォルトの動作を取得するには、次の例のように、コネクター設定に変換を追加します。
transforms=changes,... transforms.changes.type=io.debezium.transforms.ExtractChangedRecordState
transforms=changes,...
transforms.changes.type=io.debezium.transforms.ExtractChangedRecordState
他の Kafka Connect のコネクター設定と同様に、transforms= にコンマで区切られた複数の SMT エイリアスを設定し、Kafka Connect に SMT を適用させたい順番に設定することができます。
次の例のコネクター設定では、イベント変更 SMT のオプションを複数設定します。
transforms=changes,... transforms.changes.type=io.debezium.transforms.ExtractChangedRecordState transforms.changes.header.changed.name=Changed transforms.changes.header.unchanged.name=Unchanged
transforms=changes,...
transforms.changes.type=io.debezium.transforms.ExtractChangedRecordState
transforms.changes.header.changed.name=Changed
transforms.changes.header.unchanged.name=Unchangedheader.changed.name- データベース操作によって変更されるフィールドのコンマ区切りリストを保存するために使用する Kafka メッセージヘッダー名。
header.unchanged.name- データベース操作後に変更されないフィールドのコンマ区切りリストを保存するために使用する Kafka メッセージヘッダー名。
設定のカスタマイズ
コネクターは、多くの種類のイベントメッセージ (ハートビートメッセージ、廃棄メッセージ、またはトランザクションまたはスキーマの変更に関するメタデータメッセージ) を発行する場合があります。イベントのサブセットに変換を適用するには、特定のイベントだけを対象にして 変換を選択して適用する SMT 述語ステートメント を定義できます。
7.4.4. イベント変更変換を選択的に適用するためのオプション
データベースの変更が発生したときに Debezium コネクターが出力する変更イベントメッセージの他に、コネクターはハートビートメッセージなど、他のタイプのメッセージとスキーマ変更およびトランザクションに関するメタデータメッセージも出力します。これらの他のメッセージの構造は、SMT が処理するように設計された変更イベントメッセージの構造とは異なるため、目的のデータ変更メッセージのみを処理するようにコネクターを SMT を選んで適用することが推奨されます。
SMT を選択的に適用する方法の詳細は、変換用の SMT 述語を設定する を参照してください。
7.4.5. Debezium イベント変更 SMT の設定オプションの説明
次の表で、イベントフラット化 SMT を設定する際に指定できるオプションを説明します。
| オプション | デフォルト | 説明 |
|---|---|---|
| データベース操作によって変更されるフィールドのコンマ区切りリストを保存するために使用する Kafka メッセージヘッダー名。 | ||
| データベース操作後に変更されないフィールドのコンマ区切りリストを保存するために使用する Kafka メッセージヘッダー名。 |
7.5. Debezium 変更イベントレコードの絞り込み
デフォルトでは、Debezium は受信するすべてのデータ変更イベントを Kafka ブローカーに配信します。ただし、プロデューサーから出力されるイベントのサブセットだけが必要となるケースがほとんどです。該当するレコードだけを処理できるように、Debezium では フィルター 単一メッセージ変換 (SMT) を利用することができます。
カスタム SMT を作成してフィルターロジックをエンコードするのに Java を使用することは可能ですが、カスタムコーディングされた SMT の使用にはデメリットがあります。以下に例を示します。
- 変換を事前にコンパイルし、それを Kafka Connect にデプロイする必要がある。
- 変更が生じるたびにコードの再コンパイルおよび再デプロイが必要になり、運用の柔軟性が失われる。
フィルター SMT は、JSR 223 (Scripting for the Java™ Platform) と統合するスクリプト言語をサポートしています。
Debezium には、JSR 223 API の実装は同梱されていません。Debezium で式言語を使用するには、その言語の JSR 223 スクリプトエンジン実装をダウンロードする必要があります。Debezium をデプロイする方法によって、必要な成果物を Maven Central から自動的にダウンロードするか、成果物を手動でダウンロードし、言語実装で使用する他の JAR ファイルと共に Debezium コネクターのプラグインディレクトリーに追加することが可能です。
7.5.1. Debezium フィルター SMT の設定
セキュリティー上の理由から、フィルター SMT は Debezium コネクターアーカイブには含まれていません。代わりに、別のアーティファクト debezium-scripting-2.7.3.Final.tar.gz で提供されます。
Dockerfile からカスタム Kafka Connect コンテナーイメージを構築して Debezium コネクターをデプロイする場合、フィルター SMT を使用するには、明示的に SMT アーカイブをダウンロードし、コネクタープラグインと一緒にファイルをデプロイする必要があります。Streams for Apache Kafka を使用してコネクターをデプロイすると、Kafka Connect カスタムリソースで指定した設定パラメーターに基づいて、必要なアーティファクトが自動的にダウンロードされます。重要: フィルター SMT が Kafka Connect インスタンスに追加されると、インスタンスにコネクターを追加できる任意のユーザーはスクリプト式を実行することができます。許可されたユーザーだけがスクリプト式を実行できるようにするには、フィルター SMT を追加する前に、Kafka Connect インスタンスおよびその設定インターフェイスをセキュアにする必要があります。
以下の手順は、Dockerfile から Kafka Connect コンテナーイメージを構築する場合に適用されます。Streams for Apache Kafka を使用して Kafka Connect イメージを作成する場合は、コネクターのデプロイメントトピックの手順に従ってください。
手順
-
ブラウザーから ソフトウェアダウンロード を開き、Debezium スクリプト SMT アーカイブ (
debezium-scripting-2.7.3.Final.tar.gz) をダウンロードします。 - アーカイブのコンテンツを Kafka Connect 環境の Debezium プラグインのディレクトリーにデプロイメントします。
- JSR-223 スクリプトエンジンの実装を取得し、そのコンテンツを Kafka Connect 環境の Debezium プラグインのディレクトリーに追加します。
- Kafka Connect プロセスを再起動し、新しい JAR ファイルを取得します。
Groovy 言語には、クラスパスで以下のライブラリーが必要です。
-
groovy -
groovy-json(任意) -
groovy-jsr223
JavaScript 言語には、クラスパスで以下のライブラリーが必要です。
-
graalvm.js -
graalvm.js.scriptengine
7.5.2. 例: Debezium フィルター SMT の基本設定
Debezium コネクターの Kafka Connect 設定でフィルター変換を設定します。設定で、ビジネスルールに基づくフィルター条件を定義して、対象のイベントを指定します。フィルター SMT がイベントストリームを処理すると、設定されたフィルター条件に対して各イベントを評価します。フィルター条件の基準を満たすイベントのみがブローカーに渡されます。
変更イベントレコードを絞り込むように Debezium コネクターを設定するには、Debezium コネクターの Kafka Connect 設定で Filter SMT を設定します。フィルター SMT の設定には、フィルター条件を定義する正規表現を指定する必要があります。
たとえば、コネクター設定に以下の設定を追加します。
上記の例では、Groovy 式言語の使用を指定しています。正規表現 value.op == 'u' && value.before.id == 2 は、更新 (u) レコードで id 値が 2 のメッセージを除き、すべてのメッセージを削除します。
設定のカスタマイズ
前の例は、op フィールドを含む DML イベントのみを処理するように設計された単純な SMT 設定を示しています。コネクターが発行する可能性のある他の種類のメッセージ (ハートビートメッセージ、廃棄メッセージ、またはスキーマの変更とトランザクションに関するメタデータメッセージ) には、このフィールドは含まれません。処理の失敗を回避するために、特定のイベントのみに 変換を選択して適用する SMT 述語ステートメント を定義できます。
7.5.3. フィルターの式で使用される変数
Debezium は、特定の変数をフィルター SMT の評価コンテキストにバインドします。フィルター条件を指定する式を作成する場合、Debezium が評価コンテキストにバインドする変数を使用することができます。変数をバインドすることで、Debezium は SMT が式の条件を評価する際に変数の値を検索して解釈できるようにします。
以下の表に、Debezium がフィルター SMT の評価コンテキストにバインドする変数のリストを示します。
| 名前 | 説明 | タイプ |
|---|---|---|
|
| メッセージのキー。 |
|
|
| メッセージの値。 |
|
|
| Schema of the message key. |
|
|
| メッセージの値のスキーマ。 |
|
|
| ルーティング先トピックの名前。 | String |
|
|
メッセージヘッダーの Java マッピング。キーフィールドはヘッダー名です。
|
|
式は、その変数に対して任意のメソッドを呼び出すことができます。式は、SMT がメッセージをどのように処理するかを定義するブール値に解決する必要があります。式のフィルター条件が true と評価されると、メッセージは維持されます。フィルター条件が false と評価されると、メッセージは削除されます。
式がそれ以外の効果を及ぼすことは許されません。つまり、式が渡す変数を変更することは許されません。
7.5.4. フィルター変換を一部適用するオプション
データベースの変更が発生したときに Debezium コネクターが出力する変更イベントメッセージの他に、コネクターはハートビートメッセージなど、他のタイプのメッセージとスキーマ変更およびトランザクションに関するメタデータメッセージも出力します。これらの他のメッセージの構造は、SMT が処理するように設計された変更イベントメッセージの構造とは異なるため、目的のデータ変更メッセージのみを処理するようにコネクターを SMT を選んで適用することが推奨されます。以下の方法のいずれかを使用して、SMT を選んで適用するようにコネクターを設定できます。
- 変換用の SMT 述語を設定する。
- SMT に topic.regex 設定オプションを使用する。
7.5.5. 他のスクリプト言語によるフィルター条件の設定
フィルター条件を記述する方法は、使用するスクリプト言語によって異なります。
たとえば、基本設定の例 に示すように、式言語として Groovy を使用する場合、以下の式は id 値が 2 に設定された更新レコードを除くすべてのメッセージを削除します。
value.op == 'u' && value.before.id == 2
value.op == 'u' && value.before.id == 2他の言語では、同じ条件を表すのに異なる方法が使用されます。
Debezium MongoDB コネクターは、after および patch フィールドを構造体ではなくシリアライズされた JSON ドキュメントとして出力します。
MongoDB コネクターでフィルター SMT を使うには、まず JSON の配列フィールドを個別のドキュメントにデプロイメントする必要があります。
式の中で JSON パーサーを使用すると、配列の各項目について個別の出力文書を生成することができます。たとえば、表現言語として Groovy を使用している場合、groovy-json アーティファクトをクラスパスに追加し、(new groovy.json.JsonSlurper()).parseText(value.after).last_name == 'Kretchmar' のような表現を追加しています。
JavaScript
式言語に JavaScript を使用する場合、以下の例に示すように、Struct#get() メソッドを呼び出してフィルター条件を指定することができます。
value.get('op') == 'u' && value.get('before').get('id') == 2
value.get('op') == 'u' && value.get('before').get('id') == 2JavaScript with Graal.js
JavaScript with Graal.js を使用してフィルター条件を定義する場合、Groovy で使用する方法と類似の方法を使用します。以下に例を示します。
value.op == 'u' && value.before.id == 2
value.op == 'u' && value.before.id == 27.5.6. フィルター変換設定用のオプション
以下の表に、フィルター SMT で使用することができる設定オプションのリストを示します。
| プロパティー | デフォルト | 説明 |
|
イベントのルーティング先トピックの名前を評価するオプションの正規表現で、フィルターロジックを適用するかどうかを決定します。ルーティング先トピックの名前が | ||
|
式を記述する言語。 | ||
|
すべてのメッセージに対して評価される式。Boolean 値に評価されなければならず、結果が | ||
|
|
トランスフォーメーションが
|
7.6. メッセージヘッダーのイベントレコード値への変換
HeaderToValue SMT は、イベントレコードから指定されたヘッダーフィールドを抽出し、そのヘッダーフィールドをイベントレコード内の値にコピーまたは移動します。移動 オプションは、フィールドをペイロードの値として追加する前に、ヘッダーからフィールドを完全に削除します。元のメッセージで複数のヘッダーを操作するように SMT を設定できます。ドット表記を使用して、ヘッダーフィールドをネストするペイロード内のノードを指定できます。SMT の設定に関する詳細は、以下の 例 を参照してください。
7.6.1. 例: Debezium HeaderToValue SMT の基本設定
イベントレコードのメッセージヘッダーをレコード値に抽出するには、コネクターの Kafka Connect 設定で HeaderToValue SMT を設定します。元のヘッダーを削除するかコピーするように変換を設定できます。レコードからヘッダーフィールドを削除するには、move 操作を使用するように SMT を設定します。元のレコードにヘッダーフィールドを保持するには、copy 操作を使用するように SMT を設定します。たとえば、ヘッダー event_timestamp および key をイベントメッセージから削除するには、以下の行をコネクター設定に追加します。
transforms=moveHeadersToValue transforms.moveHeadersToValue.type=io.debezium.transforms.HeaderToValue transforms.moveHeadersToValue.headers=event_timestamp,key transforms.moveHeadersToValue.fields=timestamp,source.id transforms.moveHeadersToValue.operation=move
transforms=moveHeadersToValue
transforms.moveHeadersToValue.type=io.debezium.transforms.HeaderToValue
transforms.moveHeadersToValue.headers=event_timestamp,key
transforms.moveHeadersToValue.fields=timestamp,source.id
transforms.moveHeadersToValue.operation=move次の例は、変換の適用前および適用後のイベントレコードのヘッダーおよび値を示しています。
例7.1 HeaderToValue SMT の適用の影響
HeaderToValue変換によって処理される前のイベントレコード- SMT がイベントレコードを処理する前のヘッダー
{ "header_x": 0, "event_timestamp": 1626102708861, "key": 100, }{ "header_x": 0, "event_timestamp": 1626102708861, "key": 100, }Copy to Clipboard Copied! Toggle word wrap Toggle overflow - SMT がイベントレコードを処理する前の値
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
HeaderToValue変換による処理後のイベントレコード- SMT が指定のフィールドを削除した後のヘッダー
{ "header_x": 0 }{ "header_x": 0 }Copy to Clipboard Copied! Toggle word wrap Toggle overflow - SMT がヘッダーフィールドを値に移動した後の値
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.6.2. HeaderToValue 変換設定のオプション
次の表に、HeaderToValue SMT で使用できる設定オプションを示します。
| プロパティー | 説明 | 型 | デフォルト | 有効な値 | 重要性 |
| 値がレコード値にコピーまたは移動されるレコード内のヘッダー名のコンマ区切りのリスト。 | list | デフォルト値なし | 空でないリスト | 高 | |
|
| list | デフォルト値なし | 空でないリスト | 高 | |
|
次のオプションのいずれかを指定します。 | string | デフォルト値なし | 移動またはコピー | 高 |
7.7. Debezium の変更イベントからステート after ソースレコードを抽出する
Debezium コネクターは、データ変更メッセージを出力し、ソースデータベースからキャプチャーする各操作を表します。コネクターが Apache Kafka に送信するメッセージの構造は複雑で、元のデータベースイベントの詳細を表します。
この複雑なメッセージ形式は、システムで発生する変更に関する情報を正確に詳述しますが、この形式は一部のダウンストリームコンシューマーには適していない場合があります。sink コネクター、または Kafka エコシステムの他の部分では、フィールド名と値が単純化されたフラットな構造で表示されるようにフォーマットされたメッセージが必要になる場合があります。
Debezium コネクターが生成するイベントレコードの形式を簡素化するために、Debezium イベントフラット化単一メッセージ変換 (SMT) を使用できます。コネクターが生成するデフォルトの形式よりも単純な形式の Kafka レコードを必要とするコンシューマーをサポートするように変換を設定します。特定のユースケースに合わせて、SMT を Debezium コネクター、または Debezium コネクターが生成するメッセージを消費する sink コネクターに適用できます。Apache Kafka が Debezium 変更イベントメッセージを元の形式で保持できるようにするには、sink コネクターの SMT を設定します。
イベントフラット化変換は Kafka Connect SMT です。
この章では、Debezium SQL ベースのデータベースコネクターのイベントフラット化シングルメッセージ変換 (SMT) を説明します。Debezium MongoDB コネクターの同等の SMT については、MongoDB 新規ドキュメント状態抽出 を参照してください。
詳細は以下のセクションを参照してください。
7.7.1. Debezium 変更イベントの構造について
Debezium は、複雑な構造を持つデータ変更イベントを生成します。それぞれイベントは、以下の 3 つの部分で構成されます。
以下の項目が含まれるメタデータ (ただし、これらに限定されません)
- データを変更した操作のタイプ。
- データベースの名前や、変更が発生したテーブルなどのソース情報。
- 変更が加えられたタイミングを識別するタイムスタンプ。
- (任意の項目) トランザクション情報
- 変更前の行データ
- 変更後の行データ
以下の例は、UPDATE 変更イベントのメッセージ構造の一部を示しています。
コネクターの変更イベント構造の詳細は、コネクターのドキュメントを参照してください。
イベントフラット化 SMT が前の例のメッセージを処理した後、メッセージ形式が単純化され、次にあるメッセージが生成されます。
{
"field1" : "newvalue1",
"field2" : "newvalue2"
}
{
"field1" : "newvalue1",
"field2" : "newvalue2"
}7.7.2. Debezium イベントフラット化変換の動作
イベントフラットニング SMT は、Kafka レコードの Debezium 変更イベントから after フィールドを抽出します。SMT は元の変更イベントを after フィールドのみで置き換え、シンプルな Kafka レコードを作成します。
Debezium コネクターまたは Debezium コネクターから出力されるメッセージを使用する sink コネクターに、イベントフラット化 SMT を設定することができます。sink コネクターにイベントフラット化を設定するメリットは、Apache Kafka に保存されるレコードに Debezium の変更イベント全体が含まれることです。SMT を元のコネクターまたは sink コネクターに適用するかどうかの判断は、特定のユースケースによります。
以下の操作のいずれかを実行するように変換を設定することができます。
- 変更イベントからのメタデータを簡素化した Kafka レコードに追加する。デフォルト動作では、SMT はメタデータを追加しません。
-
DELETE操作の変更イベントを含む Kafka レコードをストリームに保持します。デフォルトの動作は、SMT がDELETE操作変更イベントの Kafka レコードをドロップするというもので、ほとんどのコンシューマーがまだ処理できないためです。
データベースの DELETE 操作により、Debezium は 2 つの Kafka レコードを生成します。
-
"op": "d"、before行のデータ、その他のフィールドが含まれるレコード。 -
削除された行と同じキーを持ち、値が
nullである墓石のレコード。このレコードは Apache Kafka のマーカーです。これは、ログコンパクション によりこのキーを持つすべてのレコードが削除されることを意味します。
before 行のデータを含むレコードをドロップする代わりに、イベントフラットニング SMT が以下のいずれかを行うように設定することができます。
-
ストリーム内のレコードを保持し、
"value": "null"フィールドのみを持つように編集します。 -
レコードをストリームに維持し、追加した
"__deleted": "true"エントリーと共にbeforeフィールドに含まれていたキー/値のペアが含まれるvalueフィールドを持つようにそのレコードを編集する。
同様に、tombstone レコードを破棄する代わりに、イベントフラット化 SMT を設定して tombstone レコードをストリームに維持することができます。
7.7.3. Debezium イベントフラット化変換の設定
コネクターの設定に SMT 設定の詳細を追加して、Kafka Connect ソースコネクターまたは sink コネクターに Debezium イベントフラット化 SMT を設定します。たとえば、変換のデフォルトの動作を取得するには、次の例のように、オプションを指定せずにコネクター設定に追加します。
transforms=unwrap,... transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
transforms=unwrap,...
transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
他の Kafka Connect のコネクター設定と同様に、transforms= にコンマで区切られた複数の SMT エイリアスを設定し、Kafka Connect に SMT を適用させたい順番に設定することができます。
次の .properties の例では、いくつかのイベントフラットニング SMT オプションを設定しています。
transforms=unwrap,... transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState transforms.unwrap.drop.tombstones=false transforms.unwrap.delete.handling.mode=rewrite transforms.unwrap.add.fields=table,lsn
transforms=unwrap,...
transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
transforms.unwrap.drop.tombstones=false
transforms.unwrap.delete.handling.mode=rewrite
transforms.unwrap.add.fields=table,lsndrop.tombstones=false-
イベントストリームに
DELETE操作の墓石の記録を残します。 delete.handling.mode=rewriteDELETE操作では、変更イベントにあったvalueフィールドをフラット化することで、Kafka レコードを編集します。valueフィールドには、beforeフィールドにあったキーと値のペアが直接入ります。SMT では、たとえば__deletedを追加して、それをtrueに設定します。"value": { "pk": 2, "cola": null, "__deleted": "true" }"value": { "pk": 2, "cola": null, "__deleted": "true" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow add.fields=table,lsn-
tableおよびlsnフィールドの変更イベントメタデータを簡素化した Kafka レコードに追加します。
設定のカスタマイズ
コネクターは、多くの種類のイベントメッセージ (ハートビートメッセージ、廃棄メッセージ、またはトランザクションまたはスキーマの変更に関するメタデータメッセージ) を発行する場合があります。イベントのサブセットに変換を適用するには、特定のイベントだけを対象にして 変換を選択して適用する SMT 述語ステートメント を義できます。
7.7.4. Kafka レコードに Debezium メタデータを追加する例
イベントフラット化 SMT を設定して、元の変更イベントメタデータを簡素化した Kafka レコードに追加できます。たとえば、簡素化したレコードのヘッダーまたは値に、次のいずれかの項目を含めることができます。
- 変更を加えた操作のタイプ
- データベースまたは変更が加えられたテーブルの名前
- Postgres LSN フィールド等のコネクター固有のフィールド
簡略化された Kafka レコードのヘッダーにメタデータを追加するには、add.header オプションを指定します。簡略化された Kafka レコードの値にメタデータを追加するには、add.fields オプションを指定します。これらのオプションには、それぞれ変更イベントフィールド名のコンマ区切りリストを設定します。スペースは指定しないでください。フィールド名が重複している場合、それらのフィールドの 1 つのメタデータを追加するには、フィールドと共に構造体を指定します。以下に例を示します。
transforms=unwrap,... transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState transforms.unwrap.add.fields=op,table,lsn,source.ts_ms transforms.unwrap.add.headers=db transforms.unwrap.delete.handling.mode=rewrite
transforms=unwrap,...
transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
transforms.unwrap.add.fields=op,table,lsn,source.ts_ms
transforms.unwrap.add.headers=db
transforms.unwrap.delete.handling.mode=rewriteこの設定では、簡素化した Kafka レコードには以下のような内容が含まれます。
また、簡略化された Kafka のレコードには、__db ヘッダーが付いています。
簡素化した Kafka レコードでは、SMT はメタデータフィールド名の前にダブルアンダースコアを追加します。また、構造体を指定すると、SMT は構造体名とフィールド名の間にアンダースコアを挿入します。
DELETE 操作用のシンプルな Kafka レコードにメタデータを追加するには、delete.handling.mode=rewrite も設定する必要があります。
7.7.5. イベントフラット化変換を選択的に適用するオプション
データベースの変更が発生したときに Debezium コネクターが出力する変更イベントメッセージの他に、コネクターはハートビートメッセージなど、他のタイプのメッセージとスキーマ変更およびトランザクションに関するメタデータメッセージも出力します。これらの他のメッセージの構造は、SMT が処理するように設計された変更イベントメッセージの構造とは異なるため、目的のデータ変更メッセージのみを処理するようにコネクターを SMT を選んで適用することが推奨されます。
SMT を選択的に適用する方法は、変換用の SMT 述語の設定 を参照してください。
7.7.6. Debezium イベントフラット化変換設定用のオプション
次の表で、イベントフラット化 SMT を設定する際に指定することのできるオプションを説明します。
| オプション | デフォルト | 説明 |
|---|---|---|
|
|
Debezium は、 注記
このオプションは今後のリリースで削除される予定です。代わりに、 | |
|
|
Debezium は、 注記
このオプションは今後のリリースで削除される予定です。代わりに、 | |
| デフォルトなし |
Debezium は、 注記
このオプションの設定は、非推奨の 以下のオプションのいずれかを設定します。
| |
|
行データを使用してレコードをルーティングするトピックを決定するには、このオプションを | ||
| __ (double-underscore) | このオプションの文字列を設定して、フィールドに接頭辞を設定します。 | |
|
このオプションをメタデータフィールドのコンマ区切りリスト (スペースなし) に設定し、簡素化した Kafka レコードの値に追加します。フィールド名が重複している場合、それらのフィールドの 1 つのメタデータを追加するには、フィールドと共に構造体を指定します (例: | ||
| __ (double-underscore) | このオプションの文字列を設定して、ヘッダーに接頭辞を設定します。 | |
|
このオプションをメタデータフィールドのコンマ区切りリスト (スペースなし) に設定し、簡素化した Kafka レコードのヘッダーに追加します。フィールド名が重複している場合、それらのフィールドの 1 つのメタデータを追加するには、フィールドと共に構造体を指定します (例: | ||
| 出力メッセージから削除するソースメッセージ内のフィールド名をリストするために使用する Kafka メッセージヘッダー名。 | ||
|
|
SMT でイベントのキーから | |
|
|
SMT で、 |
7.8. Debezium MongoDB 変更イベントから after 状態のソースドキュメント抽出
Debezium MongoDB コネクターは、MongoDB コレクションで発生する各操作を表すデータ変更メッセージを出力します。これらのイベントメッセージの複雑な構造は、元のデータベースイベントの詳細を忠実に表しています。ただし、ダウンストリームのコンシューマーの中には、メッセージを元の形式で処理できない場合があります。たとえば、データコレクション内のネストされたドキュメントを表すために、コネクターは、ネストされたフィールドを含む形式でイベントメッセージを出力します。sink コネクター、または元のメッセージの階層形式を処理できない他のコンシューマーをサポートするには、Debezium MongoDB イベントフラット化 (ExtractNewDocumentState) の単一メッセージ変換 (SMT) を使用できます。SMT は元のメッセージの構造を簡素化し、他の方法でメッセージを変更してデータを処理しやすくすることができます。
イベントフラット化変換は Kafka Connect SMT です。
この章では、Debezium MongoDB ベースのデータベースコネクターのイベントフラット化シングルメッセージ変換 (SMT) を説明します。リレーショナルデータベースで使用する同等の SMT の詳細は、新記録の状態抽出 SMT のドキュメント を参照してください。
詳細は以下のセクションを参照してください。
- 「Debezium MongoDB 変更イベントの構造の説明」
- 「Debezium MongoDB イベントフラット化変換の動作」
- 「Debezium MongoDB イベントフラット化変換の設定」
- 「MongoDB イベントメッセージで配列をエンコードするためのオプション」
- 「MongoDB イベントメッセージでネストされた構造のフラット化」
-
「Debezium MongoDB コネクターが
$unset操作によって削除されたフィールドの名前を報告する方法」 - 「元のデータベース操作のタイプの判別」
- 「MongoDB イベントフラット化 SMT を使用した Debezium メタデータの Kafka レコード追加」
- 「MongoDB 抽出の新しいドキュメント状態変換を選択して適用するオプション」
- 「MongoDB の Debezium イベントフラット化変換の設定オプション」
- 既知の制限
7.8.1. Debezium MongoDB 変更イベントの構造の説明
Debezium MongoDB コネクターは、構造が複雑な変更イベントを生成します。各イベントメッセージには、以下の部分が含まれます。
- ソースメタデータ
以下のフィールドが含まれますが、これに限定されません。
- コレクション内のデータを変更した操作のタイプ (作成/挿入、更新、または削除)。
- 変更が発生したデータベースおよびコレクションの名前。
- 変更が加えられたタイミングを識別するタイムスタンプ。
- (任意の項目) トランザクション情報
- ドキュメントデータ
beforeデータこのフィールドは、Debezium コネクターの
capture.modeが以下のいずれかの値に設定されている場合に MongoDB 6.0 以降を実行する環境に存在します。-
change_streams_with_pre_image change_streams_update_full_with_pre_image詳細は、MongoDB プレイメージサポート を参照してください。
-
Afterデータ現在の操作後にドキュメントに存在する値を表す JSON 文字列。イベントメッセージに
afterフィールドが存在するかどうかは、イベントの種類とコネクター設定によって異なります。MongoDBinsert操作のcreateイベントには、capture.mode設定に関係なく、常にafterフィールドが含まれます。updateイベントの場合、afterフィールドはcapture.modeが以下のいずれかの値に設定されている場合にのみ存在します。-
change_streams_update_full change_streams_update_full_with_pre_image注記変更イベントメッセージの
after値は、必ずしもイベント直後のドキュメントの状態を表すとは限りません。値は動的に計算されず、コネクターが変更イベントをキャプチャーした後、コレクションをクエリーしてドキュメントの現在の値を取得します。たとえば、複数の操作
a、b、およびcがドキュメントを立て続けに変更する状況を想像してみてください。コネクターが変更aを処理するときに、全ドキュメントのコレクションをクエリーします。その間にbとcの変更が発生します。コネクターが変更aに関する全ドキュメントのクエリーに対する応答を受信すると、後に続くbまたはcの変更をもとにしたドキュメントのバージョンを受信する可能性があります。詳細は、capture.modeプロパティーのドキュメントを参照してください。
-
以下のフラグメントは、MongoDB の insert 操作後にコネクターが発行する create 変更イベントの基本構造を示しています。
{
"op": "c",
"after": "{\"field1\":\"newvalue1\",\"field2\":\"newvalue1\"}",
"source": { ... }
}
{
"op": "c",
"after": "{\"field1\":\"newvalue1\",\"field2\":\"newvalue1\"}",
"source": { ... }
}
前の例の after フィールドの複雑な形式では、ソースデータベースで発生した変更に関する詳細情報を提供します。ただし、一部のコンシューマーは、ネストされた値が含まれるメッセージを処理できません。元のメッセージの複雑なネストされたフィールドを、より単純で普遍的、かつ互換性のある構造に変換するには、MongoDB のイベントフラット化 SMT を使用します。SMT は、以下の例のようにメッセージ内のネストされたフィールドの構造をフラット化します。
{
"field1" : "newvalue1",
"field2" : "newvalue2"
}
{
"field1" : "newvalue1",
"field2" : "newvalue2"
}Debezium MongoDB コネクターによって生成されたメッセージのデフォルト構造の詳細は、コネクターのドキュメント を参照してください。
7.8.2. Debezium MongoDB イベントフラット化変換の動作
MongoDB のイベントフラット化 SMT は、Debezium MongoDB コネクターによって発行された create または update 変更イベントメッセージから after フィールドを抽出します。SMT は、元の変更イベントメッセージを処理した後、after フィールドの内容のみを含む、単純化バージョンを生成します。
ユースケースに応じて、ExtractNewDocumentState SMT を Debezium MongoDB コネクター、または Debezium コネクターが生成するメッセージを消費する sink コネクターに適用できます。SMT を Debezium MongoDB コネクターに適用すると、SMT はコネクターが Apache Kafka に送信する前に出力するメッセージを変更します。Kafka が完全な Debezium 変更イベントメッセージを元の形式で確実に保持するには、SMT を sink コネクターに適用します。
イベントフラット化 SMT を使用して MongoDB コネクターから送信されたメッセージを処理すると、SMT は元のメッセージのレコードの構造を、通常の sink コネクターで使用できるように、適切に型指定された Kafka Connect レコードに変換します。たとえば、SMT は元のメッセージの after 情報を表す JSON 文字列を、任意のコンシューマーが処理できるスキーマ構造に変換します。
オプションとして、MongoDB のイベントフラット化 SMT を設定して、処理中に他の方法でメッセージを変更できます。詳細は 設定トピックを参照してください。
7.8.3. Debezium MongoDB イベントフラット化変換の設定
Debezium MongoDB コネクターによって発行されたメッセージを消費する sink コネクター用に、MongoDB のイベントフラット化 (ExtractNewDocumentState) SMT を設定します。
詳細は以下のセクションを参照してください。
- 「例: Debezium MongoDB イベントフラット化変換の基本設定」
- 「MongoDB イベントメッセージで配列をエンコードするためのオプション」
- 「MongoDB イベントメッセージでネストされた構造のフラット化」
-
「Debezium MongoDB コネクターが
$unset操作によって削除されたフィールドの名前を報告する方法」 - 「元のデータベース操作のタイプの判別」
- 「MongoDB イベントフラット化 SMT を使用した Debezium メタデータの Kafka レコード追加」
- 「MongoDB 抽出の新しいドキュメント状態変換を選択して適用するオプション」
- 「MongoDB の Debezium イベントフラット化変換の設定オプション」
7.8.3.1. 例: Debezium MongoDB イベントフラット化変換の基本設定
SMT のデフォルト動作を取得するには、以下の例のように、オプションを指定せずに sink コネクターの設定に SMT を追加します。
transforms=unwrap,... transforms.unwrap.type=io.debezium.connector.mongodb.transforms.ExtractNewDocumentState
transforms=unwrap,...
transforms.unwrap.type=io.debezium.connector.mongodb.transforms.ExtractNewDocumentState
Kafka Connect コネクター設定と同様に、transforms= を複数のコンマ区切りの SMT エイリアスに設定できます。Kafka Connect は、リスト順で指定した変換を適用します。
MongoDB イベントフラット化 SMT を使用するコネクターに複数のオプションを設定できます。以下の例は、コネクターの drop.tombstones、delete.handling.mode、および add.headers オプションを指定する設定です。
transforms=unwrap,... transforms.unwrap.type=io.debezium.connector.mongodb.transforms.ExtractNewDocumentState transforms.unwrap.drop.tombstones=false transforms.unwrap.delete.handling.mode=drop transforms.unwrap.add.headers=op
transforms=unwrap,...
transforms.unwrap.type=io.debezium.connector.mongodb.transforms.ExtractNewDocumentState
transforms.unwrap.drop.tombstones=false
transforms.unwrap.delete.handling.mode=drop
transforms.unwrap.add.headers=op前の例の設定オプションの詳細は、設定トピック を参照してください。
設定のカスタマイズ
コネクターは、多くの種類のイベントメッセージ (ハートビートメッセージ、廃棄メッセージ、またはトランザクションの変更に関するメタデータメッセージ) を発行する場合があります。イベントのサブセットに変換を適用するには、特定のイベントだけを対象にして 変換を選択して適用する SMT 述語ステートメント を定義できます。
7.8.4. MongoDB イベントメッセージで配列をエンコードするためのオプション
デフォルトでは、イベントフラット化 SMT は MongoDB 配列を Apache Kafka Connect または Apache Avro スキーマと互換性のある配列に変換します。MongoDB 配列には複数のタイプの要素を含めることができますが、Kafka 配列のすべての要素が同じタイプである必要があります。
SMT が環境のニーズを満たす方法で配列をエンコードするようにするには、array.encoding 設定オプションを指定できます。以下の例は、配列エンコーディングを指定するための設定を示しています。
transforms=unwrap,... transforms.unwrap.type=io.debezium.connector.mongodb.transforms.ExtractNewDocumentState transforms.unwrap.array.encoding=<array|document>
transforms=unwrap,...
transforms.unwrap.type=io.debezium.connector.mongodb.transforms.ExtractNewDocumentState
transforms.unwrap.array.encoding=<array|document>設定に応じて、SMT は、次のエンコード方法のいずれかを使用して、ソースメッセージ内の配列の各インスタンスを処理します。
- 配列エンコーディング
-
array.encodingがarray(デフォルト) に設定されている場合、SMT エンコードはarrayデータ型を使用して元のメッセージの配列をエンコードします。正しい処理を確保するには、配列インスタンスのすべての要素が同じタイプである必要があります。このオプションで制限が課されることになりますが、ダウンストリームクライアントが配列を簡単に処理できるようにします。 - ドキュメントのエンコーディング
-
array.encodingがdocumentに設定されている場合に、BSON シリアル化 と同様の方法で、ソースの各配列を structs の中の struct に変換します。メイン struct には、_0、_1、_2などのフィールドが含まれます。各フィールド名は、元の配列内の要素のインデックスを表します。SMT は、これらの各インデックスフィールドに、ソース配列内の同等の要素に対して取得した値を設定します。Avro エンコーディングでは数字で始まるフィールド名が禁止されているため、インデックス名にはアンダースコアが接頭辞として付けられます。
次の例は、Debezium MongoDB コネクターが、異種データ型で構成される配列を含むデータベースドキュメントを表す方法を示しています。
例7.2 例: 複数のデータ型を含む配列のドキュメントエンコーディング
array.encoding が document に設定されている場合、SMT は前述のドキュメントを以下の形式に変換します。
document エンコーディングオプションを使用すると、SMT は異種要素で構成される任意の配列を処理できます。ただし、このオプションを使用する前に、sink コネクターと他のダウンストリームコンシューマーが複数のデータ型を含む配列を処理できることを常に確認してください。
7.8.5. MongoDB イベントメッセージでネストされた構造のフラット化
データベース操作に埋め込みドキュメントが含まれる場合、Debezium MongoDB コネクターは、元のドキュメントの階層構造を反映する Kafka イベントレコードを発行します。つまり、イベントメッセージは、ネストされたフィールド構造のセットとして、ネスト化ドキュメントを表します。ダウンストリームコネクターがネスト化された構造が含まれるメッセージを処理できない環境では、イベントフラット化 SMT を設定して、メッセージ内の階層構造をフラット化できます。フラットなメッセージ構造は、テーブルのようなストレージに適しています。
ネストされた構造をフラット化するように SMT を設定するには、flatten.struct 設定オプションを true に設定します。変換されたメッセージでは、フィールド名がドキュメントソースと一致するよう構築されます。SMT は、親ドキュメントフィールドの名前とネストされたドキュメントフィールドの名前を連結して、フラット化された各フィールドの名前を変更します。名前のコンポーネントを区切るには、flatten.struct.delimiter オプションで定義される区切り文字を使用します。struct.delimiter のデフォルト値はアンダースコア文字 (_) です。
次の例は、SMT がネストされた構造をフラット化するかどうかを指定する設定です。
transforms=unwrap,... transforms.unwrap.type=io.debezium.connector.mongodb.transforms.ExtractNewDocumentState transforms.unwrap.flatten.struct=<true|false> transforms.unwrap.flatten.struct.delimiter=<string>
transforms=unwrap,...
transforms.unwrap.type=io.debezium.connector.mongodb.transforms.ExtractNewDocumentState
transforms.unwrap.flatten.struct=<true|false>
transforms.unwrap.flatten.struct.delimiter=<string>
以下の例は、MongoDB コネクターが出力するイベントメッセージを示しています。メッセージには、ネストされた 2 つのドキュメント b と c のフィールドを含むドキュメント a のフィールドが含まれます。
以下の例のメッセージは、MongoDB の SMT が前のメッセージでネスト化された構造をフラット化した後に表示した出力です。
結果のメッセージでは、元のメッセージでネストされた b フィールドと c フィールドがフラット化され、名前が変更されます。名前が変更されたフィールドは、親ドキュメント a の名前を、ネストされたドキュメントの名前 a_b および a_c と連結することによって形成されます。新しいフィールド名のコンポーネントは、struct.delimiter 設定プロパティーの設定で定義されているようにアンダースコアで区切られます。
7.8.6. Debezium MongoDB コネクターが $unset 操作によって削除されたフィールドの名前を報告する方法
MongoDB では、$unset Operator と $rename Operator の両方がドキュメントからフィールドを削除します。MongoDB コレクションはスキーマレスであるため、更新でドキュメントからフィールドが削除されると、更新済みドキュメントで抜けているフィールドの名前を推測できません。Debezium は、削除されたフィールドの名前をリストする removedFields 要素を含む更新メッセージを発行して、削除済みフィールドに関する情報を必要とする可能性がある sink コネクターまたはその他のコンシューマーをサポートします。
以下の例は、フィールド a を削除する操作の更新メッセージの一部を示しています。
上記の例では、before および after はドキュメントが更新される前と後のソースドキュメントの状態を表します。これらのフィールドは、コネクターの capture.mode が次のリストで説明されているように設定されている場合にのみ、コネクターが発行するイベントメッセージに存在します。
beforeフィールド変更前のドキュメントの状態を提供します。このフィールドは、
capture.modeが以下のいずれかの値に設定されている場合にのみ表示されます。-
change_streams_with_pre_image -
change_streams_update_full_with_pre_image
-
Afterフィールド変更後のドキュメントの完全な状態を提供します。このフィールドは、
capture.modeが以下のいずれかの値に設定されている場合にのみ表示されます。-
change_streams_update_full -
change_streams_update_full_with_pre_image
-
完全なドキュメントをキャプチャーするようにコネクターが設定されていると仮定すると、ExtractNewDocumentState SMT が $unset イベントの update メッセージを受信すると、SMT は、次の例に示すように、削除されたフィールドに null 値があることを表し、メッセージを再エンコードします。
{
"id": 1,
"a": null
}
{
"id": 1,
"a": null
}
完全なドキュメントをキャプチャーするように設定されていないコネクターの場合、SMT が $unset 操作の更新イベントを受信すると、以下の出力メッセージが生成されます。
{
"a": null
}
{
"a": null
}7.8.7. 元のデータベース操作のタイプの判別
SMT がイベントメッセージをフラット化した後、生成されるメッセージでは、イベントを生成した操作が create、update、または初期スナップショットの read であるかを判断できなくなります。通常、delete 操作に関する情報を公開するか、削除に伴うイベントを書き換えるようにコネクターを設定して、削除操作を識別できます。イベントメッセージで廃棄および書き換えに関する情報を公開するようにコネクターを設定する方法は、drop.tombstones および delete.handling.mode プロパティーを参照してください。
イベントメッセージでデータベース操作のタイプを報告させるには、SMT は次の要素のいずれかに op フィールドを追加します。
- イベントメッセージのボディー。
- メッセージヘッダー
たとえば、元の操作のタイプを示すヘッダープロパティーを追加するには、次の例のように、変換を追加してから、add.headers プロパティーをコネクター設定に追加します。
transforms=unwrap,... transforms.unwrap.type=io.debezium.connector.mongodb.transforms.ExtractNewDocumentState transforms.unwrap.add.headers=op
transforms=unwrap,...
transforms.unwrap.type=io.debezium.connector.mongodb.transforms.ExtractNewDocumentState
transforms.unwrap.add.headers=op
上記の設定に基づいて、SMT は op ヘッダーをメッセージに追加し、文字列の値を割り当てて操作のタイプを特定することでイベントタイプを報告します。割り当てられる文字列値は、元の MongoDB 変更イベントメッセージ の op フィールド値に基づいています。
7.8.8. MongoDB イベントフラット化 SMT を使用した Debezium メタデータの Kafka レコード追加
MongoDB のイベントフラット化 SMT は、元の変更イベントメッセージから簡素化されたメッセージにメタデータフィールドを追加できます。追加されたメタデータフィールドには、2 つのアンダースコア ("__") が接頭辞として付けられます。イベントレコードにメタデータを追加すると、変更イベントが発生したコレクションの名前などのコンテンツを含めたり、レプリカセット名などのコネクター固有のフィールドを含めたりすることができます。現在、SMT は、source、transaction、および updateDescription の変更イベントのサブ構造フィールドのみを追加できます。
MongoDB 変更イベント構造の詳細は、MongoDB コネクターのドキュメント を参照してください。
たとえば、次の設定を指定して、変更イベントのレプリカセット名 (rs) とコレクション名を、最終的なフラット化されたイベントレコードに追加できます。
transforms=unwrap,... transforms.unwrap.type=io.debezium.connector.mongodb.transforms.ExtractNewDocumentState transforms.unwrap.add.fields=rs,collection
transforms=unwrap,...
transforms.unwrap.type=io.debezium.connector.mongodb.transforms.ExtractNewDocumentState
transforms.unwrap.add.fields=rs,collection上記の設定により、フラット化されたレコードに次のコンテンツが追加されます。
{ "__rs" : "rs0", "__collection" : "my-collection", ... }
{ "__rs" : "rs0", "__collection" : "my-collection", ... }
SMT でメタデータフィールドを delete イベントに追加する場合には、delete.handling.mode オプションの値を rewrite に設定します。
7.8.9. MongoDB 抽出の新しいドキュメント状態変換を選択して適用するオプション
データベースの変更が発生したときに Debezium コネクターが出力する変更イベントメッセージの他に、コネクターはハートビートメッセージなど、他のタイプのメッセージとスキーマ変更およびトランザクションに関するメタデータメッセージも出力します。これらの他のメッセージの構造は、SMT が処理するように設計された変更イベントメッセージの構造とは異なるため、目的のデータ変更メッセージのみを処理するようにコネクターを SMT を選んで適用することが推奨されます。
SMT を選択的に適用する方法の詳細は、変換用の SMT 述語を設定する を参照してください。
7.8.10. MongoDB の Debezium イベントフラット化変換の設定オプション
以下の表は、MongoDB イベントフラット化 SMT の設定オプションを示しています。
| プロパティー | デフォルト | 説明 |
|---|---|---|
|
| SMT が元のイベントメッセージから読み取る配列をエンコードする際に使用する形式を指定します。以下のオプションのいずれかを設定します。
| |
|
| SMT は、メッセージ内のネストされたプロパティーの名前を設定可能な区切り文字で連結して、単純なフィールド名を形成することで、元のイベントメッセージの構造 (structs) をフラット化します。 | |
|
|
| |
|
|
Debezium は、 注記
このオプションは今後のリリースで削除される予定です。代わりに、 | |
|
|
SMT が
注記
このオプションは今後のリリースで削除される予定です。代わりに、 | |
| デフォルトなし |
Debezium は、 注記
このオプションの設定は、非推奨の 以下のオプションのいずれかを設定します。
| |
|
|
| |
| __ (double-underscore) | このオプションの文字列を設定して、ヘッダーに接頭辞を設定します。 | |
| デフォルトなし |
SMT で簡略化されたメッセージのヘッダーに追加するメタデータフィールドのコンマ区切りのリストを、スペースを入れずに指定します。元のメッセージに重複したフィールド名が含まれている場合、struct の名前とフィールドの名前を一緒に指定することで、変更する特定のフィールドを識別できます (例:
必要に応じて、以下の形式のエントリーをリストに追加し、フィールドの元の名前を上書きして新しい名前を割り当てることができます。
以下に例を示します。 version:VERSION, connector:CONNECTOR, source.ts_ms:EVENT_TIMESTAMP
指定する新しい名前の値では、大文字と小文字が区別されます。 | |
| __ (double-underscore) | フィールド名の前に付けるオプションの文字列を指定します。 | |
| デフォルトなし |
このオプションを、簡略化された Kafka メッセージの
以下に例を示します。 version:VERSION, connector:CONNECTOR, source.ts_ms:EVENT_TIMESTAMP
指定する新しい名前の値では、大文字と小文字が区別されます。
SMT が簡略化したメッセージの |
既知の制限
- MongoDB はスキーマのないデータベースであるため、Debezium を使用してスキーマベースのデータリレーショナルデータベースに変更をストリーミングするときに一貫した列定義を確保するには、名前が同じコレクション内のフィールドに同じ型のデータを格納する必要があります。
- SMT を設定して、sink コネクターと互換性のある形式でメッセージを生成します。sink コネクターが "フラット" なメッセージ構造を必要としているにもかかわらず、ソース MongoDB ドキュメント内の配列を構造体の構造体としてエンコードするメッセージを受信した場合、sink コネクターはメッセージを処理できません。
7.9. 送信トレイパターンを使用する Debezium コネクターの設定
送信トレイパターンを使用することで、複数の (マイクロ) サービス間で安全かつ確実にデータを交換することができます。送信トレイパターンの実装により、サービスの内部状態 (通常はそのデータベースに永続化される) と同じデータを必要とするサービスで使用されるイベントの状態との間に不整合が生じるのを防ぐことができます。
Debezium アプリケーションに送信トレイパターンを実装するには、Debezium コネクターを以下のように設定します。
- 送信トレイテーブルの変更をキャプチャーする
- Debezium 送信トレイイベントルーター単一メッセージ変換 (SMT) を適用する
送信トレイ SMT を適用するように設定された Debezium コネクターは、送信トレイテーブルで生じた変更だけをキャプチャーする必要があります。詳細は、変換を選択的に適用するオプション を参照してください。
コネクターが複数の送信トレイテーブルの変更をキャプチャーすることができるのは、それぞれの送信トレイテーブルが同じ構造を持つ場合に限ります。
送信トレイパターンが有用な理由およびその動作については、Reliable Microservices Data Exchange With the Outbox Pattern を参照してください。
送信トレイイベントルーター SMT は MongoDB コネクターと互換性がありません。
MongoDB ユーザーは、MongoDB 送信ボックスイベントルーター SMT を実行できます。
詳細は以下のセクションを参照してください。
7.9.1. Debezium 送信トレイメッセージの例
Debezium 送信トレイイベントルーター SMT の設定方法を理解するには、以下の Debezium 送信トレイメッセージの例を確認してください。
送信トレイイベントルーター SMT を適用するように設定された Debezium コネクターは、以下のような Debezium のオリジナルメッセージを変換して上記のメッセージを生成します。
この Debezium 送信トレイメッセージの例は、デフォルトの送信トレイイベントルーター設定 に基づいています。ここでは、送信トレイテーブル構造および集約に基づくイベントルーティングを想定しています。動作をカスタマイズするために、送信トレイイベントルーター SMT にはさまざまな 設定オプション が用意されています。
7.9.2. Debezium 送信トレイイベントルーター SMT が要求する送信トレイテーブルの構造
デフォルトの送信トレイイベントルーター SMT 設定を適用するには、送信トレイテーブルに以下の列がなければなりません。
| 列 | 結果 |
|---|---|
|
|
イベントの一意の ID が含まれます。送信トレイメッセージでは、この値はヘッダーです。たとえば、重複するメッセージを削除するために、この ID を使用することができます。 |
|
|
コネクターが送信トレイメッセージを出力するトピックの名前に SMT が追加する値が含まれます。デフォルトの動作では、この値は |
|
|
ペイロードの ID を提供するイベントのキーが含まれます。SMT は、この値を出力される送信トレイメッセージのキーとして使用します。これは、Kafka パーティションで正しい順序を維持するのに重要です。 |
|
|
送信トレイ変更イベントの表現。デフォルトの構造は JSON です。デフォルトでは、Kafka のメッセージ値は |
| 追加のカスタム列 |
送信トレイテーブルの列は、ペイロードセクション内またはメッセージヘッダーのいずれかとして 送信トレイイベントに追加 できます。 |
7.9.3. Debezium 送信トレイイベントルーター SMT の基本設定
送信トレイパターンをサポートするように Debezium コネクターを設定するには、outbox.EventRouter SMT を設定します。SMT のデフォルトの動作を取得するには、次の例のように、オプションを指定せずにコネクター設定に追加します。
transforms=outbox,... transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
transforms=outbox,...
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter設定のカスタマイズ
コネクターは、多くの種類のイベントメッセージ (ハートビートメッセージ、廃棄メッセージ、またはトランザクションまたはスキーマの変更に関するメタデータメッセージ) を発行する場合があります。outbox テーブルで発生したイベントのみに変換を適用するには、これらのイベントのみに 変換を選択的に適用する SMT 述語ステートメント を定義します。
7.9.4. 送信トレイイベントルーター変換を選択的に適用するオプション
データベースの変更が発生したときに Debezium コネクターが出力する変更イベントメッセージの他に、コネクターはハートビートメッセージなど、他のタイプのメッセージとスキーマ変更およびトランザクションに関するメタデータメッセージも出力します。これらの他のメッセージの構造は、SMT が処理するように設計された変更イベントメッセージの構造とは異なるため、目的のデータ変更メッセージのみを処理するようにコネクターを SMT を選んで適用することが推奨されます。以下の方法のいずれかを使用して、SMT を選んで適用するようにコネクターを設定できます。
- 変換用の SMT 述語を設定する。
-
SMT の
route.topic.regex設定オプションを使用する。
7.9.5. ペイロードシリアル化形式
送信トレイイベントルーター SMT は、任意のペイロードフォーマットをサポートします。SMT は、送信トレイテーブルから読み取った payload 列の値を変更せずに渡します。SMT がこれらの列の値を Kafka メッセージフィールドに変換する方法は、SMT の設定方法によって異なります。データをシリアル化するための一般的なペイロード形式は JSON と Avro です。
7.9.5.1. シリアル化形式としての JSON の使用
送信ボックスイベントルーター SMT のデフォルトのシリアル化形式は JSON です。この形式を使用するには、ソース列のデータ型が JSON (たとえば、PostgreSQL では jsonb) である必要があります。
7.9.5.1.1. エスケープされた JSON 文字列の JSON としての拡張生成
Debezium の送信ボックスメッセージが payload を JSON 文字列として表す場合、結果の Kafka メッセージは次の例のように文字列をエスケープします。
送信ボックスイベントルーターを使用すると、JSON ドキュメントからコンパニオンスキーマを推測して、メッセージコンテンツを "実際" の JSON に拡張できます。結果の Kafka メッセージは次の例のようにフォーマットされます。
送信トレイイベントルーター変換の使用を有効にするには、table.expand.json.payload を true に設定し、次の例に示すように JsonConverter を使用します。
transforms=outbox,... transforms.outbox.type=io.debezium.transforms.outbox.EventRouter transforms.outbox.table.expand.json.payload=true value.converter=org.apache.kafka.connect.json.JsonConverter
transforms=outbox,...
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
transforms.outbox.table.expand.json.payload=true
value.converter=org.apache.kafka.connect.json.JsonConverter7.9.5.2. Debezium 送信トレイメッセージでのペイロードフォーマットとしての Apache Avro の使用
Apache Avro は、データをシリアル化するための一般的なフレームワークです。Avro を使用すると、メッセージ形式のガバナンスや、送信トレイイベントスキーマが下位互換性を保ちながら進化し続けることができるようにします。
送信トレイメッセージペイロード用にソースアプリケーションがどのように Avro フォーマットのコンテンツを生成するかは、このドキュメントの範囲外です。1 つの可能性として、KafkaAvroSerializer クラスを利用して GenericRecord インスタンスをシリアライズできます。Kafka メッセージの値が正確な Avro バイナリーデータとなるようにするには、以下の設定をコネクターに適用します。
transforms=outbox,... transforms.outbox.type=io.debezium.transforms.outbox.EventRouter value.converter=io.debezium.converters.BinaryDataConverter
transforms=outbox,...
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
value.converter=io.debezium.converters.BinaryDataConverter
デフォルトでは、payload 列の値 (Avro データ) が唯一のメッセージ値となります。データが Avro 形式で保存される場合、列の形式は PostgreSQL の bytea などのバイナリーデータ型に設定する必要があります。SMT の値コンバーターも BinaryDataConverter に設定して、ペイロード 列のバイナリー値をそのまま Kafka メッセージ値に伝播させる必要があります。
ハートビート、トランザクションメタデータ、またはスキーマ変更イベントを出力するように Debezium コネクターを設定することができます (サポートはコネクターによって異なります)。これらのイベントは BinaryDataConverter でシリアライズできないため、コンバーターがこれらのイベントのシリアライズ方法を認識できるように追加の設定を指定する必要があります。例として、以下の設定では、スキーマがない状態で Apache Kafka JsonConverter を使用することを示しています。
transforms=outbox,... transforms.outbox.type=io.debezium.transforms.outbox.EventRouter value.converter=io.debezium.converters.BinaryDataConverter value.converter.delegate.converter.type=org.apache.kafka.connect.json.JsonConverter value.converter.delegate.converter.type.schemas.enable=false
transforms=outbox,...
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
value.converter=io.debezium.converters.BinaryDataConverter
value.converter.delegate.converter.type=org.apache.kafka.connect.json.JsonConverter
value.converter.delegate.converter.type.schemas.enable=false
委譲 Converter 実装は delegate.converter.type オプションで指定します。コンバーターで追加の設定オプションが必要な場合は (例: 上記の schemas.enable=false を使用したスキーマの無効化)、それらを指定することもできます。
次の例は、Apicurio レジストリーで委譲コンバーターを使用してデータを Avro 形式に変換するように SMT を設定する方法を示しています。
最後に、次の例は、Confluent スキーマレジストリーを備えた委譲コンバーターを使用してデータを Avro 形式に変換するように SMT を設定する方法を示しています。
上記の設定例では、AvroConverter が委譲コンバーターとして設定されているため、サードパーティーのライブラリーが必要です。サードパーティーのライブラリーをクラスパスに追加する方法に関する情報は、このドキュメントの範囲外です。
7.9.6. Debezium 送信トレイメッセージへの追加フィールドの出力
送信トレイテーブルに含まれる列の値を、出力される送信トレイメッセージに追加することができます。たとえば、aggregatetype 列に purchase-order という値を持ち、eventType という列に order-created および order-shipped という値を持つ outbox テーブルを考えてみましょう。column:placement:alias の構文でフィールドを追加することができます。
placement に許可されている値は、header、envelope、partition です。
eventType 列の値を送信トレイメッセージのヘッダーに出力するには、以下のような SMT を設定します。
transforms=outbox,... transforms.outbox.type=io.debezium.transforms.outbox.EventRouter transforms.outbox.table.fields.additional.placement=eventType:header:type
transforms=outbox,...
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
transforms.outbox.table.fields.additional.placement=eventType:header:type
結果は、型 がキーとして Kafka メッセージのヘッダー、および eventType 列の値はその値になります。
eventType 列の値を送信トレイメッセージのエンベロープに出力するには、以下のような SMT を設定します。
transforms=outbox,... transforms.outbox.type=io.debezium.transforms.outbox.EventRouter transforms.outbox.table.fields.additional.placement=eventType:envelope:type
transforms=outbox,...
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
transforms.outbox.table.fields.additional.placement=eventType:envelope:type送信メッセージをどのパーティションで生成するかを制御するには、SMT を次のように設定します。
transforms=outbox,... transforms.outbox.type=io.debezium.transforms.outbox.EventRouter transforms.outbox.table.fields.additional.placement=partitionColumn:partition
transforms=outbox,...
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
transforms.outbox.table.fields.additional.placement=partitionColumn:partition
なお、partition 配置については、エイリアスを追加しても効果はありません。
7.9.7. 送信トレイイベントルーター変換設定用のオプション
次の表で、送信トレイイベントルーター SMT に指定することのできるオプションを説明します。表の グループ 列は、Kafka の設定オプションクラスを示しています。
| オプション | デフォルト | グループ | 説明 |
|---|---|---|---|
|
| テーブル |
送信トレイテーブルに
送信トレイテーブルのすべての変更は、 | |
|
| テーブル |
一意のイベント ID が含まれる送信トレイテーブル列を指定します。この ID は、出力されるイベントのヘッダーの | |
|
| テーブル | イベントキーが含まれる送信トレイテーブル列を指定します。この列に値が含まれる場合、SMT はその値を出力される送信トレイメッセージのキーとして使用します。これは、Kafka パーティションで正しい順序を維持するのに重要です。 | |
| テーブル | デフォルトでは、出力される送信トレイメッセージのタイムスタンプは、Debezium イベントのタイムスタンプです。送信トレイメッセージで別のタイムスタンプを使用するには、このオプションを出力される送信トレイメッセージに使用するタイムスタンプが含まれる送信トレイテーブル列に設定します。 | ||
|
| テーブル | イベントペイロードが含まれる送信トレイテーブル列を指定します。 | |
|
| テーブル |
String ペイロードの JSON 拡張を実行するかどうかを指定します。コンテンツが見つからなかった場合や、解析エラーの場合は、コンテンツは "そのまま" として保持されます。 | |
|
| テーブル |
JSON 拡張プロパティー
| |
| テーブル、エンベロープ | 送信トレイメッセージのヘッダーまたはエンベロープに追加する 1 つまたは複数の送信トレイテーブル列を指定します。ペアのコンマ区切りリストを指定します。それぞれのペアで、列の名前および値をヘッダーとエンベロープのどちらに含めるかを指定します。ペア内の値はコロンで区切ります。以下に例を示します。
列のエイリアスを指定するには、3 番目の値としてエイリアスが含まれるトリオを指定します。以下に例を示します。
2 番目の値は配置で、常に 設定例は、Debezium 送信トレイメッセージへの追加フィールドの出力 に記載されています。 | ||
|
| テーブル、エンベロープ |
| |
| テーブル、スキーマ | このオプションを設定すると、Kafka Connect スキーマ Javadoc で説明されているように、その値がスキーマバージョンとして使用されます。 | ||
|
| ルーター | 送信トレイテーブルの列の名前を指定します。デフォルトの動作では、この列の値が、コネクターが送信トレイメッセージを出力するトピックの名前の一部になります。例を 要求される送信トレイテーブルの説明 に示します。 | |
|
| ルーター |
送信トレイ SMT が RegexRouter で送信トレイテーブルレコードに適用する正規表現を指定します。この正規表現は、 | |
|
| ルーター |
コネクターが送信トレイメッセージを出力するトピックの名前を指定します。デフォルトのトピック名では、
| |
|
| ルーター |
空または |
7.10. 送信トレイパターンを使用する Debezium MongoDB コネクターの設定
この SMT は、Debezium MongoDB コネクターでのみ使用されます。リレーショナルデータベースに送信ボックスイベントルーター SMT を使用する方法は、送信トレイ (Outbox) イベントルーター を参照してください。
送信トレイパターンを使用することで、複数の (マイクロ) サービス間で安全かつ確実にデータを交換することができます。送信トレイパターンの実装により、サービスの内部状態 (通常はそのデータベースに永続化される) と同じデータを必要とするサービスで使用されるイベントの状態との間に不整合が生じるのを防ぐことができます。
Debezium アプリケーションに送信トレイパターンを実装するには、Debezium コネクターを以下のように設定します。
- 送信トレイコレクションの変更をキャプチャーする
- Debezium MongoDB 送信トレイイベントルーター単一メッセージ変換 (SMT) を適用する
MongoDB 送信トレイ SMT を適用するように設定された Debezium コネクターは、送信トレイコレクションで生じた変更だけをキャプチャーする必要があります。詳細は、変換を選択的に適用するオプション を参照してください。
コネクターが複数の送信トレイコレクションの変更をキャプチャーすることができるのは、それぞれの送信トレイコレクションが同じ構造を持つ場合に限ります。
この SMT を使用するには、実際のビジネスコレクションの操作と送信トレイコレクションへの挿入を、ビジネスコレクションおよび送信トレイコレクション間にデータの不整合が発生するのを回避するために、MongoDB 4.0 以降でサポートされているマルチドキュメントトランザクションの一部として実行する必要があります。将来の更新では、既存のデータを更新し、マルチドキュメントトランザクションなしで ACID トランザクションに送信トレイイベントを挿入できるようにするために、送信トレイイベントを、独立した送信トレイコレクションとしてではなく、既存コレクションのサブドキュメントとして保存するための追加の設定をサポートする予定です。
送信トレイパターンの詳細は、Reliable Microservices Data Exchange With the Outbox Pattern を参照してください。
詳細は以下のセクションを参照してください。
7.10.1. Debezium MongoDB 送信トレイメッセージの例
Debezium MongoDB 送信トレイイベントルーター SMT の設定方法を理解するには、以下の Debezium 送信トレイメッセージの例を検討してください。
MongoDB 送信トレイイベントルーター SMT を適用するように設定された Debezium コネクターは、次の例で示すとおり、raw Debezium 変更イベントメッセージを変換して上記のメッセージを生成します。
この Debezium 送信トレイメッセージの例は、デフォルトの送信トレイイベントルーター設定 に基づいています。ここでは、送信トレイコレクション構造および集約に基づくイベントルーティングを想定しています。動作をカスタマイズするために、送信トレイイベントルーター SMT にはさまざまな 設定オプション が用意されています。
7.10.2. Debezium mongodb 送信トレイイベントルーター SMT が要求する送信トレイコレクションの構造
デフォルトの MongoDB 送信トレイイベントルーター SMT 設定を適用するには、送信トレイコレクションに以下のフィールドがなければなりません。
| フィールド | 結果 |
|---|---|
|
|
イベントの一意の ID が含まれます。送信トレイメッセージでは、この値はヘッダーです。たとえば、重複するメッセージを削除するために、この ID を使用することができます。 |
|
|
コネクターが送信トレイメッセージを出力するトピックの名前に SMT が追加する値が含まれます。デフォルトの動作では、この値は |
|
|
ペイロードの ID を提供するイベントのキーが含まれます。SMT は、この値を出力される送信トレイメッセージのキーとして使用します。これは、Kafka パーティションで正しい順序を維持するのに重要です。 |
|
|
送信トレイ変更イベントの表現。デフォルトの構造は JSON です。デフォルトでは、Kafka のメッセージ値は |
| 追加のカスタムフィールド |
送信トレイコレクションの追加フィールドは、ペイロードセクション内に、またはメッセージヘッダーとして、送信トレイイベントに追加 できます。 |
7.10.3. 基本的な Debezium MongoDB 送信トレイイベントルーター SMT 設定
送信トレイパターンをサポートするように Debezium MongoDB コネクターを設定するには、outbox.MongoEventRouter SMT を設定します。SMT のデフォルトの動作を取得するには、次の例のように、オプションを指定せずにコネクター設定に追加します。
transforms=outbox,... transforms.outbox.type=io.debezium.connector.mongodb.transforms.outbox.MongoEventRouter
transforms=outbox,...
transforms.outbox.type=io.debezium.connector.mongodb.transforms.outbox.MongoEventRouter設定のカスタマイズ
コネクターは、多くの種類のイベントメッセージ (ハートビートメッセージ、廃棄メッセージ、またはトランザクションの変更に関するメタデータメッセージ) を発行する場合があります。送信トレイコレクションで発生したイベントだけに変換を適用するには、これらのイベントのみを対象に 変換を選択して適用する SMT 述語ステートメント を定義します。
7.10.4. MongoDB 送信トレイイベントルーター変換を選択的に適用するオプション
データベースの変更が発生したときに Debezium コネクターが出力する変更イベントメッセージの他に、コネクターはハートビートメッセージなど、他のタイプのメッセージとスキーマ変更およびトランザクションに関するメタデータメッセージも出力します。これらの他のメッセージの構造は、SMT が処理するように設計された変更イベントメッセージの構造とは異なるため、目的のデータ変更メッセージのみを処理するようにコネクターを SMT を選んで適用することが推奨されます。以下の方法のいずれかを使用して、SMT を選んで適用するようにコネクターを設定できます。
- 変換用の SMT 述語を設定する。
-
SMT の
route.topic.regex設定オプションを使用する。
7.10.5. Debezium MongoDB 送信トレイメッセージでペイロードフォーマットとして Avro を使用
MongoDB 送信ボックスイベントルーター SMT は、任意のペイロード形式をサポートします。送信トレイコレクションの payload フィールド値は透過的に渡されます。JSON を使用する代わりに、Avro を使用することもできます。これは、メッセージフォーマットの管理や、送信トレイイベントスキーマの後方互換性を維持した進化の確保に役立ちます。
送信トレイメッセージペイロード用にソースアプリケーションがどのように Avro フォーマットのコンテンツを生成するかは、このドキュメントの範囲外です。1 つの可能性として、KafkaAvroSerializer クラスを利用して GenericRecord インスタンスをシリアライズできます。Kafka メッセージの値が正確な Avro バイナリーデータとなるようにするには、以下の設定をコネクターに適用します。
transforms=outbox,... transforms.outbox.type=io.debezium.connector.mongodb.transforms.outbox.MongoEventRouter value.converter=io.debezium.converters.ByteArrayConverter
transforms=outbox,...
transforms.outbox.type=io.debezium.connector.mongodb.transforms.outbox.MongoEventRouter
value.converter=io.debezium.converters.ByteArrayConverter
デフォルトでは、payload フィールドの値 (Avro データ) が唯一のメッセージ値となります。値変換器として ByteArrayConverter を設定すると、payload フィールドの値がそのまま Kafka メッセージの値に伝搬されます。
これは、他の SMT に推奨される BinaryDataConverter とは異なることに注意してください。これは、MongoDB が内部でバイト配列を保存する際に取っているアプローチが異なるためです。
ハートビート、トランザクションメタデータ、またはスキーマ変更イベントを出力するように Debezium コネクターを設定することができます (サポートはコネクターによって異なります)。これらのイベントは ByteArrayConverter でシリアライズできないため、コンバーターがこれらのイベントのシリアライズ方法を認識できるように追加の設定を指定する必要があります。例として、以下の設定では、スキーマがない状態で Apache Kafka JsonConverter を使用することを示しています。
transforms=outbox,... transforms.outbox.type=io.debezium.connector.mongodb.transforms.outbox.MongoEventRouter value.converter=io.debezium.converters.ByteArrayConverter value.converter.delegate.converter.type=org.apache.kafka.connect.json.JsonConverter value.converter.delegate.converter.type.schemas.enable=false
transforms=outbox,...
transforms.outbox.type=io.debezium.connector.mongodb.transforms.outbox.MongoEventRouter
value.converter=io.debezium.converters.ByteArrayConverter
value.converter.delegate.converter.type=org.apache.kafka.connect.json.JsonConverter
value.converter.delegate.converter.type.schemas.enable=false
委譲 Converter 実装は delegate.converter.type オプションで指定します。コンバーターで追加の設定オプションが必要な場合は (例: 上記の schemas.enable=false を使用したスキーマの無効化)、それらを指定することもできます。
7.10.6. Debezium MongoDB 送信トレイメッセージへの追加フィールドの出力
送信トレイコレクションに含まれるフィールドの値を、出力される送信トレイメッセージに追加することができます。たとえば、aggregatetype フィールドに purchase-order という値を持ち、eventType というフィールドに order-created および order-shipped という値を持つ送信トレイコレクションを考えてみましょう。field:placement:alias の構文でフィールドを追加できる。
placement に許可されている値は、header、envelope、partition です。
eventType フィールドの値を送信トレイメッセージのヘッダーに出力するには、以下のような SMT を設定します。
transforms=outbox,... transforms.outbox.type=io.debezium.transforms.outbox.EventRouter transforms.outbox.collection.fields.additional.placement=eventType:header:type
transforms=outbox,...
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
transforms.outbox.collection.fields.additional.placement=eventType:header:type
結果は、type がキーとして Kafka メッセージのヘッダー、および eventType 列の値はその値になります。
eventType フィールドの値を送信トレイメッセージのエンベロープに出力するには、以下のような SMT を設定します。
transforms=outbox,... transforms.outbox.type=io.debezium.transforms.outbox.EventRouter transforms.outbox.collection.fields.additional.placement=eventType:envelope:type
transforms=outbox,...
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
transforms.outbox.collection.fields.additional.placement=eventType:envelope:type送信メッセージをどのパーティションで生成するかを制御するには、SMT を次のように設定します。
transforms=outbox,... transforms.outbox.type=io.debezium.transforms.outbox.EventRouter transforms.outbox.collection.fields.additional.placement=partitionField:partition
transforms=outbox,...
transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
transforms.outbox.collection.fields.additional.placement=partitionField:partition
なお、partition 配置については、エイリアスを追加しても効果はありません。
7.10.7. JSON としてエスケープされた JSON 文字列の拡張
デフォルトでは、Debezium 送信トレイメッセージの payload は文字列として表されます。文字列の元のソースが JSON 形式の場合、次の例に示すように、結果の Kafka メッセージはエスケープシーケンスを使用して文字列を表します。
メッセージの内容をデプロイメントし、エスケープされた JSON を元のエスケープされていない JSON 形式に変換するように、送信トレイイベントルーターを設定できます。変換された文字列では、コンパニオンスキーマは元の JSON ドキュメントから推定されます。次の例は、結果の Kafka メッセージでデプロイメントされた JSON を示しています。
変換時の文字列変換を有効にするには、collection.expand.json.payload の値を true に設定し、次の例に示すように StringConverter を使用します。
transforms=outbox,... transforms.outbox.type=io.debezium.connector.mongodb.transforms.outbox.MongoEventRouter transforms.outbox.collection.expand.json.payload=true value.converter=org.apache.kafka.connect.storage.StringConverter
transforms=outbox,...
transforms.outbox.type=io.debezium.connector.mongodb.transforms.outbox.MongoEventRouter
transforms.outbox.collection.expand.json.payload=true
value.converter=org.apache.kafka.connect.storage.StringConverter7.10.8. 送信トレイイベントルーター変換設定用のオプション
次の表で、送信トレイイベントルーター SMT に指定することのできるオプションを説明します。表の グループ 列は、Kafka の設定オプションクラスを示しています。
| オプション | デフォルト | グループ | 説明 |
|---|---|---|---|
|
| コレクション | 送信トレイコレクションも更新操作がある場合の SMT の動作を決定します。設定可能な値は以下のとおりです。
送信トレイコレクションのすべての変更は、挿入または削除操作であると想定されます。つまり、送信トレイコレクションはキューとして機能します。送信トレイコレクション内のドキュメントの更新は許可されていません。SMT は、送信トレイコレクションの削除操作を自動的に除外します (進行中の送信トレイイベントが削除されるため)。 | |
|
| コレクション |
一意のイベント ID が含まれる送信トレイコレクションフィールドを指定します。この ID は、出力されるイベントのヘッダーの | |
|
| コレクション | イベントキーが含まれる送信トレイコレクションフィールドを指定します。このフィールドに値が含まれる場合、SMT はその値を出力される送信トレイメッセージのキーとして使用します。これは、Kafka パーティションで正しい順序を維持するのに重要です。 | |
| コレクション | デフォルトでは、出力される送信トレイメッセージのタイムスタンプは、Debezium イベントのタイムスタンプです。送信トレイメッセージで別のタイムスタンプを使用するには、このオプションを出力される送信トレイメッセージに使用するタイムスタンプが含まれる送信トレイコレクションフィールドに設定します。 | ||
|
| コレクション | イベントペイロードが含まれる送信トレイコレクションフィールドを指定します。 | |
|
| コレクション |
String ペイロードの JSON 拡張を実行するかどうかを指定します。コンテンツが見つからなかった場合や、解析エラーの場合は、コンテンツは "そのまま" として保持されます。 | |
| コレクション、エンベロープ | 送信トレイメッセージのヘッダーまたはエンベロープに追加する 1 つまたは複数の送信トレイコレクションフィールドを指定します。ペアのコンマ区切りリストを指定します。それぞれのペアで、フィールドの名前および値をヘッダーとエンベロープのどちらに含めるかを指定します。ペア内の値はコロンで区切ります。以下に例を示します。
フィールドのエイリアスを指定するには、3 番目の値としてエイリアスが含まれるトリオを指定します。以下にフィールドを示します。
2 番目の値は配置で、常に 設定例は、Debezium 送信トレイメッセージへの追加フィールドの出力 に記載されています。 | ||
| コレクション、スキーマ | このオプションを設定すると、Kafka Connect スキーマ Javadoc で説明されているように、その値がスキーマバージョンとして使用されます。 | ||
|
| ルーター | 送信トレイコレクションのフィールドの名前を指定します。デフォルトでは、このフィールドで指定された値が、コネクターが送信トレイメッセージを出力するトピックの名前の一部になります。例を 要求される送信トレイコレクションの説明 に示します。 | |
|
| ルーター |
送信トレイ SMT が RegexRouter で送信トレイコレクションドキュメントに適用する正規表現を指定します。この正規表現は、 | |
|
| ルーター |
コネクターが送信トレイメッセージを出力するトピックの名前を指定します。デフォルトのトピック名には、文字列
| |
|
| ルーター |
空または |
7.11. ペイロードフィールドに基づいたパーティションへのレコードのルーティング
デフォルトでは、Debezium がデータコレクション内の変更を検出すると、Debezium が発行する変更イベントは、単一の Apache Kafka パーティションを使用するトピックに送信されます。Kafka Connect 自動トピック作成のカスタマイズ で説明されているように、プライマリーキーのハッシュに基づいてイベントを複数のパーティションにルーティングするようにデフォルト設定をカスタマイズできます。
ただし、場合によっては、Debezium がイベントを特定のトピックパーティションにルーティングすることも必要になる場合があります。パーティションルーティング SMT を使用すると、1 つ以上の指定されたペイロードフィールドの値に基づいて、イベントを特定の宛先パーティションにルーティングできます。Debezium は、宛先パーティションを計算するために、指定したフィールド値のハッシュを使用します。
7.11.1. 例: Debezium パーティションルーティング SMT の基本設定
Debezium コネクターの Kafka Connect 設定でパーティションルーティング変換を設定します。設定では次のパラメーターを指定します。
partition.payload.fields- SMT が宛先パーティションを計算するために使用するイベントペイロード内のフィールドを指定します。ドット表記を使用して、ネストされたペイロードフィールドを指定できます。
partition.topic.num- ルーティング先トピックのパーティション数を指定します。
partition.hash.function- 宛先パーティションの番号を決定するフィールドのハッシュに使用するハッシュ関数を指定します。
デフォルトでは、Debezium は設定されたデータ収集のすべての変更イベントレコードを単一の Apache Kafka トピックにルーティングします。コネクターでは、イベントレコードはトピックの特定のパーティションに転送されません。
イベントを特定のパーティションにルーティングするように Debezium コネクターを設定するには、Debezium コネクターの Kafka Connect 設定で PartitionRouting SMT を設定します。
たとえば、コネクター設定に以下の設定を追加します。
前述の設定に基づいて、SMT は、接頭辞が fulfillment の名前を持つトピックにバインドされたメッセージを受信するたびに、そのメッセージを特定のトピックパーティションにリダイレクトします。
SMT は、メッセージペイロードの name フィールドの値のハッシュからターゲットパーティションを計算します。allTopic 述語を指定して、設定は SMT を選択的に適用します。change という接頭辞は、SMT がデータの before または after の状態を記述するペイロード内の要素を自動的に参照できるようにする特別なキーワードです。指定されたフィールドがイベントメッセージに存在しない場合、SMT はそれを無視します。メッセージにどのフィールドも存在しない場合、変換ではイベントメッセージが完全に無視され、メッセージの元のバージョンがデフォルトの宛先トピックに配信されます。SMT 設定の topic.num 設定で指定されたパーティションの数は、Kafka Connect 設定で指定されたパーティションの数と一致する必要があります。たとえば、前述の設定例では、Kafka Connect プロパティー topic.creation.default.partitions で指定された値は、SMT 設定の topic.num 値と一致します。
Products 表を確認してください。
| id | 名前 | 説明 | 重量 |
| 101 | scooter | 小型二輪スクーター | 3.14 |
| 102 | 車のバッテリー | 12v の車のバッテリー | 8.1 |
| 103 | ドリルビット 12 本パック | #40 から #3 までのサイズのドリルビット 12 本パック | 0.8 |
| 104 | ハンマー | 大工のハンマー 12oz | 0.75 |
| 105 | ハンマー | 大工のハンマー 14oz | 0.875 |
| 106 | ハンマー | 大工のハンマー 16oz | 1.0 |
| 107 | 岩 | さまざまな石が入った箱 | 5.3 |
| 108 | ジャケット | 耐水性の黒のウインドブレーカー | 0.1 |
| 109 | スペアタイヤ | 24 インチのスペアタイヤ | 22.2 |
設定に基づいて、SMT はフィールド名が Hammer であるレコードの変更イベントを同じパーティションにルーティングします。つまり、ID 値が 104、105、および 106 のアイテムは同じパーティションにルーティングされます。
7.11.2. 例: Debezium パーティションルーティング SMT の高度な設定
イベントを 2 つのデータコレクション (t1, t2) から同じトピック (例: my_topic) にルーティングし、フィールド f1 と f2 を使用してデータコレクション t1 からのイベントと、データコレクションから f2 からのイベントに分けます。
次の設定を適用できます。
上記の設定では、特定の宛先トピックに送信されるようにイベントを再ルーティングする方法は指定されていません。デフォルトの宛先トピック以外のトピックにイベントを送信する方法は、トピックルーティング SMT と トピックルーティング SMT を参照してください。
7.11.3. Debezium ComputePartition SMT からの移行
Debezium ComputePartition SMT は廃止されました。次のセクションの情報では、ComputePartition SMT から新しい PartitionRouting SMT に移行する方法を説明します。
設定ですべてのトピックに対して同じ数のパーティションが設定されていると仮定して、次の ComputePartition 設定を PartitionRouting SMT に置き換えます。以下の例は、2 つの設定の比較を示しています。
例: 従来の ComputePartition 設定
上記の ComputePartition を以下の PartitionRouting 設定に置き換えます。例: 以前の ComputePartition 設定を置き換える PartitionRouting 設定
SMT が同じ数のパーティションを共有しないトピックにイベントを発行する場合は、トピックごとに一意の partition.num.mappings 値を指定する必要があります。たとえば、次の例では、レガシーの products コレクションのトピックは 3 つのパーティションで設定され、orders データコレクションのトピックは 2 つのパーティションで設定されています。
例: さまざまなトピックに一意のパーティション値を設定する従来の ComputePartition 設定
前述の ComputePartition 設定は、PartitionRouting 設定 (別のトピックの一意の partition.topic.num 値を設定する.PartitionRouting の設定) に置き換えます。
7.11.4. パーティションルーティング変換設定用のオプション
次の表に、パーティションルーティング SMT に設定できる設定オプションを示します。
| プロパティー | デフォルト | 説明 |
|
SMT がターゲットパーティションを計算するために使用するイベントペイロード内のフィールドを指定します。SMT で元のペイロードのフィールドを出力データ構造の特定のレベルに追加する場合は、ドット表記を使用します。データ収集に関連するフィールドにアクセスするには、 | ||
|
この SMT が動作するトピックのパーティションの数。 | ||
|
|
宛先パーティションの番号を決定するフィールドのハッシュを計算するときに使用されるハッシュ関数。可能な値は次のとおりです。 |
7.12. Debezium イベントレコードのタイムゾーン値の変換
Debezium がイベントレコードを発行する場合、レコード内のタイムスタンプフィールドのタイムゾーン値は、データソースのタイプと設定に応じて異なる場合があります。データ処理パイプラインおよびアプリケーション内でデータの整合性と精度を維持するには、Timezone Converter SMT を使用して、イベントレコードが一貫したタイムゾーンでタイムスタンプデータを表すようにします。
SMT は、converted.timezone 設定オプションを使用して、指定されたフィールドの値をターゲットタイムゾーンに変換します。ターゲットタイムゾーンは、America/New_York などの地理的タイムゾーンとして指定することも、+02:00 などの UTC オフセットとして指定することもできます。レコードのフィールドは UTC であることを前提としています。SMT は、指定されたタイムゾーンに加えて、include.list および exclude.list 設定オプションを使用して、特定のフィールドをタイムゾーン変換に含めたり除外したりする設定オプションも提供します。
SMT は、すべての Debezium および Kafka Connect の一時的および非一時的なタイプをサポートします。
詳細は以下のセクションを参照してください。
夏時間に準拠するには、converted.timezone 設定オプションで地理的タイムゾーンを指定する必要があります。UTC オフセットを指定すると、変換により UTC からの固定オフセットが適用されますが、これは夏時間を採用している地域では不正確になります。固定の UTC オフセットの指定は、夏時間を採用していない特定のタイムゾーンにタイムスタンプフィールドを変換するときに便利です。
include.list と exclude.list の設定オプションは相互に排他的です。これらのオプションのいずれかのみを指定する必要があります。
SMT では、ts_ms などのソース情報ブロック内のイベントメタデータフィールドをターゲットタイムゾーンに変換することもできます。メタデータフィールドを変換するには、include.list または exclude.list 設定オプションの フィールド名 に source の接頭辞を含める必要があります。
ts_ms などのソース情報ブロック内のタイムスタンプフィールドのスキーマが現在、タイムスタンプタイプではない INT64 に設定されている場合、今後のリリースでは、タイムスタンプスキーマの互換性を導入して、このようなフィールドの変換をサポートすることを目指しています。
7.12.1. 例: 基本的な Debezium タイムゾーンコンバーター SMT 設定
コネクターの Kafka Connect 設定で TimezoneConverter SMT を設定して、イベントレコード内の時間ベースのフィールドをターゲットタイムゾーンに変換します。
たとえば、イベントレコード内のすべてのタイムスタンプフィールドを UTC から Pacific/Easter タイムゾーンに変換するには、コネクター設定に次の行を追加します。
transforms=convertTimezone transforms.convertTimezone.type=io.debezium.transforms.TimezoneConverter transforms.convertTimezone.converted.timezone=Pacific/Easter
transforms=convertTimezone
transforms.convertTimezone.type=io.debezium.transforms.TimezoneConverter
transforms.convertTimezone.converted.timezone=Pacific/Easter7.12.1.1. TimezoneConverter SMT を Debezium イベントレコードに適用した場合の効果
次の例は、TimezoneConverter 変換がイベントレコードのタイムスタンプフィールドを変更する方法を示しています。最初の例は、変換によって処理されない Debezium イベントレコードを示しています。レコードは元のタイムスタンプ値を保持します。次の例は、変換の適用後と同じイベントレコードを示しています。基本設定例で指定した設定 に従って、SMT はソースメッセージのタイムスタンプフィールドの元の UTC 値を Pacific/Easter タイムゾーン値に変換します。
例7.3 TimezoneConverter 変換による処理前のイベントレコード値
created_at フィールドの値は UTC 時間を示します。
例7.4 TimezoneConverter 変換による処理後のイベントレコード値
SMT は、created_at フィールドの元の UTC 値を、基本設定 の例で指定されたターゲットタイムゾーンである Pacific/Easter の時間に変換します。SMT は event_timestamp フィールドも追加します。
7.12.2. 例: 高度な Debezium タイムゾーンコンバーター SMT 設定
イベントレコード内のすべてのタイムスタンプフィールドを変換するのではなく、特定のフィールドのみを変換するように SMT を設定できます。次の例は、SMT 設定の include.list オプションを使用して、イベントレコード内の created_at および updated_at タイムスタンプフィールドのみを変換する方法を示しています。次の設定では、地理的タイムゾーン指定子ではなく固定オフセットを使用して、時間を UTC から +05:30 に変換します。
transforms=convertTimezone transforms.convertTimezone.type=io.debezium.transforms.TimezoneConverter transforms.convertTimezone.converted.timezone=+05:30 transforms.convertTimezone.include.list=source:customers:created_at,customers:updated_at
transforms=convertTimezone
transforms.convertTimezone.type=io.debezium.transforms.TimezoneConverter
transforms.convertTimezone.converted.timezone=+05:30
transforms.convertTimezone.include.list=source:customers:created_at,customers:updated_at
場合によっては、特定のタイムスタンプフィールドをタイムゾーン変換から除外することが必要な場合があります。たとえば、イベントレコードの updated_at タイムスタンプフィールドをタイムゾーン変換から除外するには、次の例のように exclude.list 設定オプションを使用します。
transforms=convertTimezone transforms.convertTimezone.type=io.debezium.transforms.TimezoneConverter transforms.convertTimezone.converted.timezone=+05:30 transforms.convertTimezone.exclude.list=source:customers:updated_at
transforms=convertTimezone
transforms.convertTimezone.type=io.debezium.transforms.TimezoneConverter
transforms.convertTimezone.converted.timezone=+05:30
transforms.convertTimezone.exclude.list=source:customers:updated_at7.12.3. Debezium タイムゾーンコンバーター変換を設定するためのオプション
次の表に、TimezoneConverter SMT の設定オプションのリストを示します。
| プロパティー | 説明 | タイプ | 重要性 |
|
タイムスタンプフィールドを変換するターゲットタイムゾーンを指定する文字列。ターゲットタイムゾーンは、 | string | 高 | |
| SMT がタイムゾーン変換に含めるフィールドを指定するルールのコンマ区切りリスト。次のいずれかの形式を使用してルールを指定します。
| list | medium | |
| タイムゾーン変換から除外するフィールドを指定するルールのコンマ区切りリスト。次のいずれかの形式を使用してルールを指定します。
| list | medium |
第8章 Debezium カスタムデータ型コンバーターの開発
カスタム開発コンバーターの使用は、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
Debezium 変更イベントレコードの各フィールドは、ソーステーブルまたはデータコレクションのフィールドまたは列を表します。コネクターが変更イベントレコードを Kafka に送信すると、ソースの各フィールドのデータ型が Kafka Connect スキーマ型に変換されます。列の値も同様に、変換先フィールドのスキーマタイプに一致するように変換されます。コネクターごとに、コネクターが各データ型を変換する方法をデフォルトのマッピングで指定します。これらのデフォルトマッピングは、各コネクターのデータ型のドキュメントで説明されています。
通常、デフォルトのマッピングで十分ですが、一部のアプリケーションでは別のマッピングを適用する場合があります。たとえば、デフォルトのマッピングが UNIX エポック以降のミリ秒の形式を使用して列をエクスポートする場合は、カスタムマッピングが必要になることがありますが、ダウンストリームアプリケーションは、フォーマットされた文字列としてしか、列の値を消費できません。カスタムコンバーターを開発およびデプロイして、データ型マッピングをカスタマイズします。特定のタイプのすべての列に作用するようにカスタムコンバーターを設定するか、特定のテーブル列のみに適用されるように範囲を狭めてください。コンバーター関数は、指定された基準に一致する列のデータ型変換リクエストをインターセプトし、指定の変換を実行します。コンバーターは、指定された基準に一致しない列を無視します。
カスタムコンバーターは、Debezium サービスプロバイダーインターフェイス (SPI) を実装する Java クラスです。コネクター設定で converters プロパティーを設定して、カスタムコンバーターを有効化および設定します。converters プロパティーは、コネクターで使用できるコンバータを指定し、変換動作をさらに変更するサブプロパティーを含めることができます。
コネクターを開始すると、コネクター設定で有効になっているコンバーターがインスタンス化され、レジストリーに追加されます。レジストリーは、各コンバーターと、そのコンバーターの列またはフィールドを関連付けて処理します。Debezium が新しい変更イベントを処理するときはいつでも、設定されたコンバーターを呼び出して、登録されている列またはフィールドを変換します。
以下の手順は、Debezium リレーショナルデータベースソースコネクターにのみ適用されます。この情報を使用して、Debezium MongoDB コネクターまたは Debezium JDBC シンクコネクター用のカスタムコンバータを作成できません。
8.1. Debezium カスタムデータ型コンバーターの作成
以下の例は、インターフェイス io.debezium.spi.converter.CustomConverter を実装する Java クラスのコンバーター実装を示しています。
| 項目 | 説明 |
|---|---|
| 1 | データをある型から別の型に変換します。 |
| 2 | コンバーターを登録するためのコールバック。 |
| 3 | 現在のフィールドの指定のスキーマとコンバーターを登録します。同じフィールドに対して複数回呼び出すことはできません。 |
| 4 | 特定のフィールドで使用するカスタマイズされた値とスキーマコンバーターを登録します。 |
カスタムコンバーターメソッド
CustomConverter インターフェイスの実装には、以下のメソッドが含まれている必要があります。
configure()コネクター設定に指定されたプロパティーをコンバーターインスタンスに渡します。
configureメソッドは、コネクターが初期化されると実行されます。複数のコネクターでコンバーターを使用し、コネクターのプロパティー設定に基づいてその動作を変更できます。configureメソッドは以下の引数を受け入れます。props- コンバーターインスタンスに渡すプロパティーが含まれています。各プロパティーは、特定のタイプの列値を変換する形式を指定します。
converterFor()コンバーターを登録して、データソースの特定の列またはフィールドを処理します。Debezium は、
converterFor()メソッドを呼び出して、コンバーターに変換のregistrationを呼び出すように促します。converterForメソッドは、各列に対して 1 回実行されます。
メソッドは以下の引数を受け入れます。field- 処理されるフィールドまたは列に関するメタデータを渡すオブジェクト。列のメタデータには、列またはフィールドの名前、テーブルまたはコレクションの名前、データ型、サイズなどを含めることができます。
登録-
対象のスキーマ定義と列データを変換するコードを提供する
io.debezium.spi.converter.CustomConverter.ConverterRegistration型のオブジェクト。ソース列が、コンバーターが処理する型と一致する場合に、コンバーターはregistrationパラメーターを呼び出します。registerメソッドを呼び出して、スキーマ内の各列のコンバーターを定義します。スキーマは、Kafka ConnectSchemaBuilderAPI を使用して表されます。
8.1.1. Debezium カスタムコンバーターの例
以下の例は、以下の操作を実行する単純なコンバーターを実装します。
-
コネクター設定で指定された
schema.nameプロパティーの値に基づいてコンバーターを設定するconfigureメソッドを実行します。コンバーターの設定は、各インスタンスに固有です。 データ型が
isbnに設定されているソース列の値を処理するコンバーターを登録するconverterForメソッドを実行します。-
schema.nameプロパティーに指定された値に基づいてターゲットSTRINGスキーマを識別します。 -
ソース列の ISBN データを
String値に変換します。
-
例8.1 簡単なカスタムコンバーター
8.1.2. Debezium および Kafka Connect API モジュールの依存関係
カスタムコンバーター Java プロジェクトには、Debezium API および Kafka Connect API ライブラリーモジュールに対するコンパイル依存関係があります。以下の例のように、これらのコンパイル依存関係は、プロジェクトの pom.xml に含める必要があります。
| 項目 | 説明 |
|---|---|
| 1 |
|
| 2 |
|
8.2. Debezium コネクターでのカスタムコンバーターの使用
カスタムコンバーターは、ソーステーブルの特定の列または列の型に作用して、ソースのデータ型を Kafka Connect スキーマ型に変換する方法を指定します。コネクターでカスタムコンバーターを使用するには、コンバーター JAR ファイルをコネクターファイルとともにデプロイしてから、コンバーターを使用するようにコネクターを設定します。
カスタムコンバーターは、Debezium リレーショナルデータベースソースコネクターによって発行されるメッセージを変更するように設計されています。Debezium MongoDB コネクターまたは Debezium JDBC シンクコネクターをカスタムコンバータを使用するように設定できません。
8.2.1. カスタムコンバーターのデプロイ
前提条件
- カスタムコンバーター Java プログラムがある。
手順
-
Debezium コネクターでカスタムコンバーターを使用するには、Java プロジェクトを JAR ファイルにエクスポートし、そのファイルを使用する各 Debezium コネクターの JAR ファイルを含むディレクトリーにコピーします。
たとえば、一般的なデプロイメントでは、Debezium コネクターファイルは Kafka Connect ディレクトリーのサブディレクトリー (/kafka/connect) に保存され、各コネクター JAR は独自のサブディレクトリー (/kafka/connect/debezium-connector-db2、/kafka/connect/debezium-connector-mysqlなど) に格納されます。コネクターでコンバーターを使用するには、コンバーターの JAR ファイルをコネクターのサブディレクトリーに追加します。
複数のコネクターでコンバーターを使用するには、各コネクターのサブディレクトリーにコンバーター JAR ファイルのコピーを配置する必要があります。
8.2.2. カスタムコンバーターを使用するためのコネクターの設定
コネクターがカスタムコンバーターを使用できるようにするには、Debezium ソースコネクターの設定にコンバーターの名前とクラスを指定するプロパティーを追加します。Debezium JDBC シンクコネクターをカスタムコンバータを使用するように設定できません。コンバーターが特定のデータ型の形式をカスタマイズするためにさらに情報を必要とする場合は、他の設定オプションを定義して、その情報を指定できます。
手順
以下の必須プロパティーをコネクター設定に追加して、コネクターインスタンスのコンバーターを有効にします。
converters: <converterSymbolicName> <converterSymbolicName>.type: <fullyQualifiedConverterClassName>
converters: <converterSymbolicName>1 <converterSymbolicName>.type: <fullyQualifiedConverterClassName>2 Copy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表8.3 コンバーターを有効にするためのコネクター設定プロパティーの説明 項目 説明 1
必須の
convertersプロパティーは、コネクターで使用するコンバーターインスタンスのシンボリック名のコンマ区切りリストを列挙します。このプロパティーに一覧表示される値は、コンバーターに指定する他のプロパティーの値の名前の接頭辞として機能します。2
必須の
<converterSymbolicName>.typeプロパティーは、コンバーターを実装するクラスの名前を指定します。たとえば、前述の カスタムコンバーターのサンプル では、以下のプロパティーをコネクター設定に追加します。
converters: isbn isbn.type: io.debezium.test.IsbnConverter
converters: isbn isbn.type: io.debezium.test.IsbnConverterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 他のプロパティーをカスタムコンバーターに関連付けるには、プロパティー名の前にコンバーターの記号名を付け、その後にドット (
.) を付けます。シンボリック名は、convertersプロパティーの値として指定するラベルです。たとえば、前述のisbnコンバーターのプロパティーを追加して、コンバーターコードのconfigureメソッドに渡すschema.nameを指定するには、以下のプロパティーを追加します。isbn.schema.name: io.debezium.postgresql.type.Isbn
isbn.schema.name: io.debezium.postgresql.type.IsbnCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第9章 ポストプロセッサーを使用したイベントメッセージの変更
ポストプロセッサーは、単一メッセージ変換 (SMT) が実行する変更のような、メッセージごとの軽量の変更を実行します。ただし、Debezium はイベントチェーン内で変換よりも早い段階でポストプロセッサーを呼び出すため、ポストプロセッサーはメッセージがメッセージングランタイムに渡される前にメッセージを処理できます。ポストプロセッサーは Debezium コンテキスト内からメッセージを処理できるため、変換よりも効率的にイベントペイロードを変更できます。
変換によってメッセージを変更するには、メッセージのイミュータブルな ConnectRecord、より正確には SourceRecord を再作成する必要があります。対照的に、ポストプロセッサーは Debezium スコープ内で動作するため、メッセージのイベントペイロード内のミュータブルな Struct タイプを操作して、SourceRecord の構築前にペイロードを変更できます。Debezium との緊密な統合により、ポストプロセッサーは、データベース接続に関する Debezium メタデータ、リレーショナルスキーマモデルなど、Debezium の内部情報にアクセスできるようになります。当該アクセスにより、このような内部情報に依存するタスクを実行する際の効率が向上します。たとえば、Reselect columns ポストプロセッサーは、データベースを自動的に再クエリーしてレコードを再選択し、元の変更イベントから除外された列を取得できます。
Debezium は次のポストプロセッサーを提供します。
- 列の再選択
- 変更イベントによって提供されなかった可能性のある特定の列を再選択します (たとえば、現在の変更により変更されなかった TOASTed 列や Oracle LOB 列など)。
9.1. reselect columns ポストプロセッサーを使用した、変更イベントレコードへのソースフィールドの追加
パフォーマンスを向上させ、ストレージのオーバーヘッドを削減するために、データベースは特定の列に外部ストレージを使用できます。このタイプのストレージは、PostgreSQL TOAST (Oversized-Attribute Storage Technique)、Oracle Large Object (LOB)、または Oracle Exadata Extended String データ型など、大量のデータを格納する列に使用されます。I/O オーバーヘッドを削減してクエリー速度を向上させるために、テーブル行のデータが変更されると、データベースは新しい値を含む列のみを取得し、外部に保存された未変更の列のデータを無視します。その結果、外部に保存された列の値はデータベースログに記録されず、Debezium はその後イベントレコードを発行するときにその列を省略します。必要な値が省略されたイベントレコードを受信するダウンストリームのコンシューマーでは、処理エラーが発生する可能性があります。
外部に保存された列の値がイベントのデータベースログエントリーに存在しない場合、Debezium はイベントのレコードを発行するときに、欠落している値を unavailable.value.placeholder sentinel 値に置き換えます。これらの sentinel 値は、バイトの場合はバイト配列、文字列の場合は文字列、マップの場合はキーと値のマップなど、適切に型指定されたフィールドに挿入されます。
最初のクエリーで利用できなかった列のデータを取得するには、Debezium の reselect columns ポストプロセッサー (ReselectColumnsPostProcessor) を適用します。ポストプロセッサーは、テーブルから 1 つ以上の列を再選択するように設定できます。ポストプロセッサーを設定すると、再選択の対象として指定した列名に対してコネクターが発行するイベントが監視されます。指定された列のイベントを検出すると、ポストプロセッサーはソーステーブルを再クエリーして指定された列のデータを取得し、現在の状態を取得します。
次の列タイプを再選択するようにポストプロセッサーを設定できます。
-
null列。 -
unavailable.value.placeholdersentinel 値を含む列。
ReselectColumnsPostProcessor ポストプロセッサーは、Debezium ソースコネクターでのみ使用できます。
ポストプロセッサーは、Debezium JDBC sink コネクターで動作するように設計されていません。
ReselectColumnsPostProcessor ポストプロセッサーの使用方法の詳細は、次のトピックを参照してください。
9.1.1. キーレステーブルでの Debezium ReselectColumnsPostProcessor の使用
reselect columns ポストプロセッサーは、変更する行を返す再選択クエリーを生成します。クエリーの WHERE 句を構築するために、ポストプロセッサーはデフォルトで、テーブルのプライマリーキー列またはテーブルに定義されている一意のインデックスに基づくリレーショナルテーブルモデルを使用します。
キーレステーブルの場合、ReselectColumnsPostProcessor が送信する SELECT クエリーによって複数の行が返されることがあります。その場合、Debezium は常に最初の行のみを使用します。返される行の順序は指定できません。ポストプロセッサーがキーレステーブルに対して一貫して使用可能な結果を返すようにするには、一意の行を識別できるカスタムキーを指定することが推奨されます。カスタムキーは、列の組み合わせに基づいてソーステーブルのレコードを一意に識別できる必要があります。
このようなカスタムメッセージキーを定義するには、コネクター設定で message.key.columns プロパティーを使用します。カスタムキーを定義した後に、reselect.use.event.key 設定プロパティーを true に設定します。このオプションを設定すると、ポストプロセッサーは、プライマリーキー列の代わりに、指定されたイベントキーフィールドを選択基準として使用できるようになります。必ず設定をテストして、再選択クエリーが期待どおりの結果を返すことを確認してください。
9.1.2. 例: Debezium ReselectColumnsPostProcessor の設定
ポストプロセッサーの設定は、カスタムコンバーター または 単一メッセージ変換 (SMT) の設定と似ています。コネクターが ReselectColumnsPostProcessor を使用できるようにするには、コネクター設定に次のエントリーを追加します。
| 項目 | 説明 |
|---|---|
| 1 | ポストプロセッサー接頭辞のコンマ区切りリスト。 |
| 2 | ポストプロセッサーの完全修飾クラスタイプ名。 |
| 3 |
|
| 4 |
|
| 5 |
|
| 6 | イベントのキーフィールド名に基づく再選択を有効または無効にします。 |
9.1.3. Debezium reselect columns ポストプロセッサーの設定プロパティーの説明
次の表に、Reselect Columns ポストプロセッサーに設定できる設定オプションを示します。
| プロパティー | デフォルト | 説明 |
| デフォルトなし |
ソースデータベースから再選択する列名のコンマ区切りリスト。列名を指定するには、次の形式を使用します。
| |
| デフォルトなし |
再選択から除外するソースデータベース内の列名のコンマ区切りリスト。列名を指定するには、次の形式を使用します。
| |
|
|
列の値がコネクターの | |
|
|
列の値が | |
|
|
ポストプロセッサーがイベントのキーフィールド名に基づいて再選択を行うか、リレーショナルテーブルのプライマリーキーの列名を使用するかを指定します。 |
第10章 Debezium Server (開発者プレビュー)
Debezium Server は、カスタマイズなしにすぐ異様いるアプリケーションで、Apache Kafka Connect インフラストラクチャーに依存せずに、データソースから設定済みのデータシンクに変更イベントを直接ストリーミングします。
Debezium Server は、開発者プレビューのソフトウェアのみです。開発者プレビューソフトウェアは、Red Hat では一切サポートされておらず、機能的に完全ではなく、実稼働環境に対応していません。開発者プレビューのソフトウェアを実稼働ワークロードまたはビジネスクリティカルなワークロードには使用しないでください。開発者プレビューソフトウェアは、今後 Red Hat 製品サービスとして追加される可能性のある製品ソフトウェアを前もって早期に利用できます。お客様はこのソフトウェアを使用して機能をテストし、開発プロセス中にフィードバックを提供できます。このソフトウェアにはドキュメントが存在しない可能性があり、変更または削除される可能性があります。また、限定的なテストしか行われていません。Red Hat は、関連する SLA なしに、開発者プレビューソフトウェアに対するフィードバックを送信する手段を提供する場合があります。
Red Hat 開発者プレビューソフトウェアのサポート範囲の詳細は、開発者プレビューのサポート範囲 を参照してください。
10.1. Debezium Server のシンクの宛先
Debezium Server のこの開発者プレビューリリースでは、次のシンクの宛先を設定できます。
- Apache Kafka
- Redis ストリーム
Debezium コミュニティーのドキュメント では、他のいくつかのデータシンクの使用について言及されています。この開発者プレビューリリースでは、上記のリストにあるデータシンクの 1 つを使用するように Debezium Server を設定します。
Debezium Server には、イベントデータを Kafka sink に直接送信できるコネクターが含まれています。コネクターをデプロイしたり、Kafka Connect クラスターをデプロイしたりする必要はありません。Apache Kafka クラスターをすでに実行している場合は、そのクラスターをシンクの宛先として設定することで、そのクラスターを使用して Debezium Server をテストできます。
Kafka sink を使用して Debezium Server を実行すると、Kafka Connect で Debezium ソースコネクター を実行するときに利用可能な機能の一部を利用できません。たとえば、Debezium Server コネクターはデータシンクに書き込むために 1 つのタスクのみを使用できますが、Kafka Connect で実行されるほとんどのコネクターは複数のタスクを使用できます。また、Debezium Server には、カスタマイズされた自動トピック作成などの高度な機能はありません。
10.3. Debezium Server のデプロイと使用
Debezium Server の開発者プレビューバージョンは、Red Hat カスタマーポータルの Software Downloads から取得できます。
Debezium Server をデプロイして使用する方法は、Debezium コミュニティーのドキュメント を参照してください。
関連情報
- Debezium コネクターを Kafka Connect にデプロイする方法については、ソースコネクターのドキュメント を参照してください。
改訂日時: 2024-10-11