可観測性ガイド
概要
第1章 ヘルスチェックを使用してインスタンスステータスを追跡する
ヘルス REST エンドポイントを呼び出して、インスタンスの起動が完了し、リクエストを処理する準備ができているかどうかを確認します。
Red Hat build of Keycloak には、ヘルスチェックのサポートが組み込まれています。この章では、Red Hat build of Keycloak のヘルスチェックを有効にして使用する方法を説明します。Red Hat build of Keycloak ヘルスチェックは、デフォルトで管理ポート 9000 で公開されます。詳細は、管理インターフェイスの設定 を参照してください。
1.1. Red Hat build of Keycloak のヘルスチェックエンドポイント
Red Hat build of Keycloak は、次の 4 つのヘルスエンドポイントを公開します。
-
/health/live -
/health/ready -
/health/started -
/health
各エンドポイントの意味は、Quarkus SmallRye Health のドキュメント を参照してください。
これらのエンドポイントは、次のような JSON オブジェクトにより、成功した場合は HTTP ステータス 200 OK、失敗した場合は 503 Service Unavailable で応答します。
追加のチェックごとの情報を含まないエンドポイントの成功応答:
{
"status": "UP",
"checks": []
}データベース接続に関する情報を含むエンドポイントの成功応答:
{
"status": "UP",
"checks": [
{
"name": "Keycloak database connections health check",
"status": "UP"
}
]
}1.2. ヘルスチェックを有効にする
ビルド時に health-enabled オプションを使用して、ヘルスチェックを有効にできます。
bin/kc.[sh|bat] build --health-enabled=trueデフォルトでは、ヘルスエンドポイントからチェックは返されません。
1.3. ヘルスチェックを使用する
ヘルスエンドポイントは、外部 HTTP 要求でモニタリングすることが推奨されます。セキュリティー対策として、Red Hat build of Keycloak のコンテナーイメージから curl とその他のパッケージを削除しているため、ローカルのコマンドベースのモニタリングは容易には機能しません。
コンテナーで Red Hat build of Keycloak を使用していない場合は、任意の手段でヘルスチェックエンドポイントにアクセスできます。
1.3.1. curl
シンプルな HTTP HEAD 要求を使用して、Red Hat build of Keycloak の状態が live か ready かを判断できます。curl は、この目的に適した HTTP クライアントです。
Red Hat build of Keycloak がコンテナーにデプロイされている場合は、前述のセキュリティー対策があるため、このコマンドをコンテナーの外部から実行する必要があります。以下に例を示します。
curl --head -fsS http://localhost:9000/health/ready
コマンドがステータス 0 を返した場合、呼び出したエンドポイントに応じて Red Hat build of Keycloak は live または ready になります。それ以外の場合は問題があります。
1.3.2. Kubernetes
Kubernetes が外部からヘルスエンドポイントをモニタリングできるように、HTTP Probe を定義してください。liveness コマンドは使用しないでください。
1.3.3. HEALTHCHECK
Containerfile イメージの HEALTHCHECK 命令は、コンテナーの実行中にコンテナー内で定期的に実行されるコマンドを定義します。Red Hat build of Keycloak コンテナーには、CLI HTTP クライアントがインストールされていません。コンテナーで Red Hat build of Keycloak を実行する で詳しく説明されているように、追加の RPM として curl をインストールすることを検討してください。これにより、コンテナーの安全性が低下する可能性がある点に注意してください。
1.4. 利用可能なチェック
下表は、使用可能なチェックを示しています。
| チェック | 説明 | メトリクスの要否 |
|---|---|---|
| データベース | データベース接続プールのステータスを返します。 | はい |
一部のチェックでは、Requires Metrics (メトリクスの要否) の列で示されているとおり、メトリクスを有効にする必要があります。メトリクスを有効にするには、次のように metrics-enabled オプションを使用します。
bin/kc.[sh|bat] build --health-enabled=true --metrics-enabled=true1.5. 関連するオプション
| 値 | |
|---|---|
| 🛠
CLI: |
|
第2章 メトリクスから洞察を得る
メトリクスを収集して、実行中の Red Hat build of Keycloak インスタンスの状態とアクティビティーに関する洞察を得ることができます。
Red Hat build of Keycloak には、メトリクスのサポートが組み込まれています。この章では、サーバーメトリクスを有効にし、設定する方法を説明します。
2.1. メトリクスを有効にする
ビルド時に metrics-enabled オプションを使用して、メトリクスを有効にできます。
bin/kc.[sh|bat] start --metrics-enabled=true2.2. メトリクスのクエリー
Red Hat build of Keycloak は、管理インターフェイスの次のエンドポイントでメトリクスを公開します。
-
/metrics
管理インターフェイスの詳細は、管理インターフェイスの設定 を参照してください。エンドポイントからの応答は、application/openmetrics-text コンテンツタイプを使用し、Prometheus (OpenMetrics) テキスト形式に基づいています。以下は、応答例の抜粋です。
# HELP base_gc_total Displays the total number of collections that have occurred. This attribute lists -1 if the collection count is undefined for this collector.
# TYPE base_gc_total counter
base_gc_total{name="G1 Young Generation",} 14.0
# HELP jvm_memory_usage_after_gc_percent The percentage of long-lived heap pool used after the last GC event, in the range [0..1]
# TYPE jvm_memory_usage_after_gc_percent gauge
jvm_memory_usage_after_gc_percent{area="heap",pool="long-lived",} 0.0
# HELP jvm_threads_peak_threads The peak live thread count since the Java virtual machine started or peak was reset
# TYPE jvm_threads_peak_threads gauge
jvm_threads_peak_threads 113.0
# HELP agroal_active_count Number of active connections. These connections are in use and not available to be acquired.
# TYPE agroal_active_count gauge
agroal_active_count{datasource="default",} 0.0
# HELP base_memory_maxHeap_bytes Displays the maximum amount of memory, in bytes, that can be used for memory management.
# TYPE base_memory_maxHeap_bytes gauge
base_memory_maxHeap_bytes 1.6781410304E10
# HELP process_start_time_seconds Start time of the process since unix epoch.
# TYPE process_start_time_seconds gauge
process_start_time_seconds 1.675188449054E9
# HELP system_load_average_1m The sum of the number of runnable entities queued to available processors and the number of runnable entities running on the available processors averaged over a period of time
# TYPE system_load_average_1m gauge
system_load_average_1m 4.005859375
...2.3. 次のステップ
メトリクスの使用方法は、サービスレベルインジケーターを使用してパフォーマンスを監視する および メトリクスを使用したトラブルシューティング の章を参照してください。
2.4. 関連するオプション
| 値 | |
|---|---|
|
CLI: メトリクスが有効になっている場合にのみ使用可能 |
|
|
CLI: メトリクスが有効になっている場合にのみ使用可能 |
|
|
CLI: メトリクスが有効になっている場合にのみ使用可能 | |
| 🛠
CLI: |
|
第3章 イベントメトリクスを使用してユーザーアクティビティーを監視する
イベントメトリクスは、Red Hat build of Keycloak インスタンス内のユーザーアクティビティーの集約ビューを提供します。
現時点では、ユーザーイベントのメトリクスのみがキャプチャーされます。たとえば、ログイン回数、ログイン失敗回数、実行されたトークンの更新回数などを監視できます。
メトリクスは標準メトリクスエンドポイントを使用して公開されます。それを独自のメトリクス収集システムで使用して、ダッシュボードやアラートを作成できます。
メトリクスは、Red Hat build of Keycloak インスタンスごとにカウンターとして報告されます。インスタンスを再起動すると、カウンターはリセットされます。クラスター内で複数のインスタンスが実行されている場合は、すべてのインスタンスからメトリクスを収集し、それらを集約してクラスタービューごとに取得する必要があります。
3.1. イベントメトリクスを有効にする
イベントメトリクスの収集を開始するには、メトリクスを有効にし、ユーザーイベントのメトリクスを有効にします。
必要な起動パラメーターは次のとおりです。
bin/kc.[sh|bat] start --metrics-enabled=true --event-metrics-user-enabled=true ...
デフォルトでは、レルムごとに個別のメトリクスが存在します。メトリクスをクライアントおよびアイデンティティープロバイダー別に分類するには、設定オプションの event-metrics-user-tags を使用してメトリクスディメンションを追加できます。これは、クライアントと IDP の数が少ないインストールで役立ちます。しかし、Red Hat build of Keycloak のメモリー使用量、および監視システムの負荷が増加するため、多数のクライアントまたは IDP があるインストールには推奨されません。
以下は、メトリクスを 3 つのメトリクスディメンションすべてに分類するように Red Hat build of Keycloak を設定する方法を示しています。
bin/kc.[sh|bat] start ... --event-metrics-user-tags=realm,idp,clientId ...Red Hat build of Keycloak がメトリクスを公開するイベントを制限できます。利用可能なイベントの概要は、イベントタイプに関するサーバー管理ガイド を参照してください。
次の例では、収集されるイベントを LOGIN イベントと LOGOUT イベントに制限します。
bin/kc.[sh|bat] start ... --event-metrics-user-events=login,logout ...収集されるメトリクスの説明は、自己提供メトリクス を参照してください。
3.2. 関連するオプション
| 値 | |
|---|---|
| 🛠
CLI: |
|
| 🛠
CLI: メトリクスが有効で、user-event-metrics 機能が有効になっている場合にのみ使用できます。 |
|
|
CLI: ユーザーイベントメトリクスが有効になっている場合にのみ使用できます。
|
|
|
CLI: ユーザーイベントメトリクスが有効になっている場合にのみ使用できます。 |
|
第4章 サービスレベルインジケーターを使用してパフォーマンスを監視する
サービスレベルインジケーター (SLI) とサービスレベル目標 (SLO) を使用して、ユーザーが認識するパフォーマンスと信頼性を追跡します。
サービスレベルインジケーター (SLI) とサービスレベル目標 (SLO) は、実稼働環境での Red Hat build of Keycloak のパフォーマンスと信頼性を監視および維持する上で不可欠なコンポーネントです。
Google の書籍「Site Reliability Engineering」には、次のように定義しています。
- サービスレベルインジケーター (SLI) は、提供されるサービスレベルの特定の側面を慎重に定義した定量的な尺度です。
- サービスレベル目標 (SLO) は、SLI で測定されるサービスレベルの目標とする値または値の範囲です。
定義についてステークホルダーと合意し、追跡することで、サービス所有者は、デプロイメントがユーザーの期待と一致していること、また、過不足なくサービスを提供することを保証できます。
4.1. 前提条件
-
Red Hat build of Keycloak でメトリクスが有効になっており、かつ以下で定義する SLO を測定するために
http-metrics-slosオプションが latency に設定されている。詳細は、メトリクスから洞察を得る の章を参照してください。 - メトリクスを収集する監視システム。以下の段落では、PromQL クエリー言語をサポートする Prometheus または同様のシステムが使用されていることを前提としています。
4.2. 提供されるサービスの定義
次のステップでは、適切な SLI と SLO を識別するために次のサービス定義が使用されます。ユーザーが観察した行動をキャプチャーする必要があります。
Red Hat build of Keycloak ユーザーとして以下を実行できる必要があります。
- ログインする
- トークンを更新する
- ログアウトする
そうすることで、認証に Red Hat build of Keycloak を使用するアプリケーションを使用できるようにします。
4.3. SLI と SLO の定義
以下に、上記のサービスの説明と Red Hat build of Keycloak で利用可能なメトリクスに基づいた SLI と SLO の例を示します。
これらの SLO は実際のシステム負荷とは関係がありませんが、レスポンスが遅い場合にユーザーはシステム負荷を気にしたりしないため、これは意図された設定です。
一方で、ステークホルダーとサービスレベルアグリーメント (SLA) を締結した場合は、これによりシステム負荷が増加し、スケーリングのしきい値に到達するため、Red Hat build of Keycloak の実行者として Red Hat build of Keycloak が受信するトラフィックに対して制限を定義することを検討するでしょう。
| 特徴 | サービスレベルインジケーター | サービスレベル目標* | メトリクスソース |
|---|---|---|---|
| 可用性 | 監視システムによって測定された、Red Hat build of Keycloak がリクエストに応答できる時間の割合 | Red Hat build of Keycloak は、1 カ月の 99.9% が利用可能であること (1 カ月あたり 44 分間は利用不可)。 |
Prometheus |
| レイテンシー | サーバーが測定する、認証関連の HTTP リクエストに対するレスポンス時間 | 30 日間で、認証関連リクエスト全体の 95% が 250 ミリ秒未満であること。 |
|
| エラー | サーバーが測定する、サーバーの問題により失敗した認証リクエスト | サーバー問題を原因とする認証リクエストのエラー率は、30 日間で 0.1% 未満である必要があります。 |
|
* これらの SLO ターゲット値は例であり、ユースケースとデプロイメントに合わせて調整する必要があります。
4.4. PromQL クエリー
これらは、Kubernetes 環境で作成され、監視ツールとして Prometheus で使用されるサンプルクエリーです。ブループリントとして提供されており、ランタイムや監視環境に合わせて調整する必要があります。
アラートやライブダッシュボードに使用する場合、実稼働環境ではこれらのクエリーまたはサブクエリーを recording rule に置き換えて、リソースを使いすぎないようにする必要があります。
4.4.1. 可用性
このメトリクスの値は、Red Hat build of Keycloak インスタンスが利用可能で、Prometheus スクレイプリクエストに応答している場合は少なくとも 1 になり、サービスがダウンしているかアクセスできない場合は 0 になります。
次に、Grafana などのツールを使用して 30 日間の時間範囲を表示し、その期間内のメトリクスの平均を計算します。
count_over_time(
sum (up{
container="keycloak",
namespace="$namespace"
} > 0)[30d:15s]
)
/
count_over_time(vector(1)[30d:15s])
Grafana では、値 30d:15s を $range:$interval に置き換えて、ダッシュボードで選択した時間範囲内の可用性 SLI を計算できます。
4.4.2. 認証リクエストのレイテンシー
この Prometheus クエリーは、過去 30 日間に特定の namespace と Pod を対象とする特定の Red Hat build of Keycloak エンドポイントにおける過去 30 日間のすべての認証リクエストのうち、0.25 秒以内に完了した認証リクエストの割合を計算します。
この例では、Red Hat build of Keycloak 設定の http-metrics-slos に値 250 が含まれている必要があります。これは、250 ミリ秒より速いリクエストと遅いリクエストのバケットが記録されることを示しています。http-metrics-histograms-enabled を true に設定すると、パフォーマンスのトラブルシューティングに役立つ追加のバケットがキャプチャーされます。
sum(
rate(
http_server_requests_seconds_bucket{
uri=~"/realms/{realm}/protocol/{protocol}.*|/realms/{realm}/login-actions.*",
le="0.25",
container="keycloak",
namespace="$namespace"}
[30d]
)
) without (le,uri,status,outcome,method,pod,instance)
/
sum(
rate(
http_server_requests_seconds_count{
uri=~"/realms/{realm}/protocol/{protocol}.*|/realms/{realm}/login-actions.*",
container="keycloak",
namespace="$namespace"}
[30d]
)
) without (le,uri,status,outcome,method,pod,instance)
Grafana では、値 30d を $__range に置き換えて、ダッシュボードで選択した時間範囲内のレイテンシー SLI を計算できます。
4.4.3. 認証リクエストのエラー
この Prometheus クエリーは、過去 30 日間に特定の namespace を対象とするすべての認証リクエストのうち、サーバー側エラーを返した認証リクエストの割合を計算します。
sum(
rate(
http_server_requests_seconds_count{
uri=~"/realms/{realm}/protocol/{protocol}.*|/realms/{realm}/login-actions.*",
outcome="SERVER_ERROR",
container="keycloak",
namespace="$namespace"}
[30d]
)
) without (le,uri,status,outcome,method,pod,instance)
/
sum(
rate(
http_server_requests_seconds_count{
uri=~"/realms/{realm}/protocol/{protocol}.*|/realms/{realm}/login-actions.*",
container="keycloak",
namespace="$namespace"}
[30d]
)
) without (le,uri,status,outcome,method,pod,instance)
Grafana では、値 30d を $__range に置き換えて、ダッシュボードで選択した時間範囲内のエラー SLI を計算できます。
4.5. 参考文献
第5章 メトリクスを使用したトラブルシューティング
エラーやパフォーマンスの問題のトラブルシューティングにメトリクスを使用します。
実行中の Red Hat build of Keycloak デプロイメントでは、システムのパフォーマンスを把握し、パフォーマンスがサービスレベル目標 (SLO) を満たしているかどうかを認識することが重要です。SLO の詳細は、サービスレベルインジケーターを使用してパフォーマンスを監視する の章を参照してください。
このガイドでは、「SLO が満たされない場合はどうすればよいか」という質問への回答を示します。
Red Hat build of Keycloak は複数のコンポーネントで構成されており、そのうちの 1 つに問題や誤設定があると、サービスレベルインジケーターが望ましくない数値に変化する可能性があります。
次の例は、このガイドで提供されている内容を表しています。
観測内容: レイテンシーのサービスレベル目標が達成されていません。
問題を示すメトリクス:
- Red Hat build of Keycloak のデータベース接続プールが頻繁に枯渇し、プールから接続を取得するのを待つスレッドのキューが発生します。
-
Red Hat build of Keycloak の
usersキャッシュヒット率は低く、5% 程度です。これは、20 回のユーザー検索のうちキャッシュからユーザーデータを取得できるのは 1 回のみで、残りはデータベースからデータをロードする必要があることを意味します。
提案される緩和策:
-
usersのキャッシュサイズの数値を増やすと、データベースからの読み取り回数が減少します。 - 接続プール内の接続数を増やします。これは、データベースのメトリクスで確認し、使用可能なプロセッサーの数を増やすなどして、より高い負荷に合わせて調整する必要があります。
- このガイドでは、Red Hat build of Keycloak メトリクスに焦点を当てています。データベース自体のトラブルシューティングは範囲外です。
- このガイドは一般的なガイダンスを提供します。必ず、古い設定と新しい設定の該当するメトリクスを比較するパフォーマンステストを実行して、設定の変更を確認する必要があります。
以下のメトリクスの Grafana ダッシュボードは、ダッシュボードでのアクティビティーの可視化 の章を参照してください。
5.1. Red Hat build of Keycloak 主要メトリクスのリスト
- 自己提供のメトリクス
- JVM メトリック
- データベースメトリクス
- HTTP メトリック
シングルサイトメトリクス (外部 Data Grid なし)
複数サイトのメトリクス (マルチサイトデプロイメント で説明)
5.2. 自己提供のメトリクス
Red Hat build of Keycloak が提供する主要なメトリクスを説明します。
これは、メトリクスを使用したトラブルシューティング 章の一部です。
5.2.1. 前提条件
- Red Hat build of Keycloak でメトリクスを有効にしている。詳細は、メトリクスから洞察を得る の章を参照してください。
- メトリクスを収集する監視システム。
5.2.2. メトリクス
5.2.2.1. ユーザーイベントメトリクス
ユーザーイベントメトリクスはデフォルトで無効になっています。イベントメトリクスを有効にする方法と、記録するタグを設定する方法は、イベントメトリクスを使用してユーザーアクティビティーを監視する を参照してください。
| メトリクス | 説明 |
|---|---|
|
| ユーザーイベントの発生をカウントします。 |
タグ
カーディナリティーが高くなりすぎないようにするため、client_id および idp タグはデフォルトで無効になっています。
realm- レルム
client_id- クライアント ID
idp- アイデンティティープロバイダー
event-
loginやlogoutなどのユーザーイベント。利用可能なイベントの概要は、イベントタイプに関するサーバー管理ガイド を参照してください。 error-
loginイベントのinvalid_user_credentialsなどのイベント固有のエラー。エラーが発生しなかった場合は空の文字列。
以下のスニペットは、メトリクスエンドポイントによって提供されるレスポンスの例です。
# HELP keycloak_user_events_total Keycloak user events
# TYPE keycloak_user_events_total counter
keycloak_user_events_total{client_id="security-admin-console",error="",event="code_to_token",idp="",realm="master",} 1.0
keycloak_user_events_total{client_id="security-admin-console",error="",event="login",idp="",realm="master",} 1.0
keycloak_user_events_total{client_id="security-admin-console",error="",event="logout",idp="",realm="master",} 1.0
keycloak_user_events_total{client_id="security-admin-console",error="invalid_user_credentials",event="login",idp="",realm="master",} 1.05.2.2.2. パスワードのハッシュ
| メトリクス | 説明 |
|---|---|
|
| パスワードハッシュの検証をカウントします。 |
タグ
realm- レルム
algorithm-
パスワードのハッシュ化に使用されるアルゴリズム (例:
argon2) hashing_strength-
ハッシュアルゴリズムの強度 (アルゴリズムに応じた反復回数など) を示す文字列 (例:
Argon2id-1.3[m=7168,t=5,p=1]) outcomeパスワード検証の結果。可能な値:
valid- 正しいパスワード
invalid- 不正なパスワード
error- パスワードのハッシュ化時にエラーが発生しました
使用可能なタグを設定するには、オプション spi-credential-keycloak-password-validations-counter-tags にタグ名のコンマ区切りリストを指定します。デフォルトでは、すべてのタグが有効になっています。
以下のスニペットは、メトリクスエンドポイントによって提供されるレスポンスの例です。
# HELP keycloak_credentials_password_hashing_validations_total Password validations
# TYPE keycloak_credentials_password_hashing_validations_total counter
keycloak_credentials_password_hashing_validations_total{algorithm="argon2",hashing_strength="Argon2id-1.3[m=7168,t=5,p=1]",outcome="valid",realm="realm-0",} 39949.05.2.3. 次のステップ
メトリクスを使用したトラブルシューティング に戻るか、JVM メトリクス に進みます。
5.3. JVM メトリック
JVM メトリクスを使用して Red Hat build of Keycloak のパフォーマンスを観察します。
これは、メトリクスを使用したトラブルシューティング 章の一部です。
5.3.1. 前提条件
- Red Hat build of Keycloak でメトリクスを有効にしている。詳細は、メトリクスから洞察を得る の章を参照してください。
- メトリクスを収集する監視システム。
5.3.2. メトリクス
5.3.2.1. JVM 情報
| メトリクス | 説明 |
|---|---|
|
| バージョン、ランタイム、ベンダーなどの JVM に関する情報。 |
5.3.2.2. ヒープメモリー使用率
| メトリクス | 説明 |
|---|---|
|
| JVM が使用するためにコミットされたメモリーの量。割り当てられたメモリーのうち、必ず JVM が使用できる量を反映します。 |
|
| JVM によって現在使用されているメモリーの量。アプリケーションと JVM 内部による実際のメモリー消費量を示します。 |
5.3.2.3. ガベージコレクション
| メトリクス | 説明 |
|---|---|
|
| 特定の原因により JVM で発生するガベージコレクションの一時停止の最大継続時間 (秒)。これにより、GC の一時停止のタイプ (マイナー、メジャー) を素早く区別できます。 |
|
| ガベージコレクションの一時停止の合計累積時間。JVM でのアプリケーションパフォーマンスに対する GC 一時停止の影響を示します。 |
|
| ガベージコレクションの一時停止イベントの合計数をカウントします。JVM での GC 一時停止の頻度を評価するのに役立ちます。 |
|
| ガベージコレクションに費やされた CPU 時間の割合。JVM でのアプリケーションパフォーマンスに対する GC の影響を示します。これは、アプリケーションコードの実行やその他のタスクの実行ではなく、ガベージコレクション (GC) 操作の実行に費やされる合計 CPU 処理時間の割合を指します。このメトリクスは、GC によってどの程度のオーバーヘッドが発生し、Red Hat build of Keycloak の全体的なパフォーマンスに影響するかどうかを判断するのに役立ちます。 |
5.3.2.4. Kubernetes の CPU 使用率
| メトリクス | 説明 |
|---|---|
|
| コンテナーによって消費された累積 CPU 時間 (コア秒)。 |
5.3.3. 次のステップ
メトリクスを使用したトラブルシューティング に戻るか、データベースメトリクス に進みます
5.4. データベースメトリクス
メトリクスを使用して、Red Hat build of Keycloak のデータベースへの接続を記述します。
これは、メトリクスを使用したトラブルシューティング 章の一部です。
5.4.1. 前提条件
- Red Hat build of Keycloak でメトリクスを有効にしている。詳細は、メトリクスから洞察を得る の章を参照してください。
- メトリクスを収集する監視システム。
5.4.2. データベース接続プールのメトリクス
固定サイズのデータベース接続プールを使用するように、Red Hat build of Keycloak を設定します。詳細は、データベース接続プールの概念 の章を参照してください。
データベース接続を待機しているスレッドの数が多い場合、データベース接続プールのサイズを増やすことが必ずしも最適なオプションとは限りません。データベースに負荷がかかり過ぎ、ボトルネックになる可能性があります。代わりに次のオプションを検討してください。
-
http-pool-max-threadsオプションを使用して HTTP ワーカースレッドの数を減らし、利用可能なデータベース接続と一致させます。そうすることで、Red Hat build of Keycloak での競合とリソース使用量が減少し、スループットが向上します。 -
データベース上で実行されるデータベースステートメントを確認します。たとえば、クライアントとグループに関する大量の情報が取得され、
usersとrealmsのキャッシュがいっぱいになっている場合、これらのキャッシュのサイズを増やすことでデータベースの負荷が軽減されるかどうかを確認する必要がある可能性があります。
| メトリクス | 説明 |
|---|---|
|
| アイドル状態のデータベース接続。 |
|
| 進行中のトランザクションで使用されるデータベース接続。 |
|
| データベース接続が利用可能になるのを待機しているスレッド。 |
5.4.3. 次のステップ
メトリクスを使用したトラブルシューティング に戻るか、HTTP メトリクス に進みます。
5.5. HTTP メトリック
メトリクスを使用して、Red Hat build of Keycloak HTTP リクエストの処理を監視します。
これは、メトリクスを使用したトラブルシューティング 章の一部です。
5.5.1. 前提条件
- Red Hat build of Keycloak でメトリクスを有効にしている。詳細は、メトリクスから洞察を得る の章を参照してください。
- メトリクスを収集する監視システム。
5.5.2. メトリクス
5.5.2.1. Processing time
これらのメトリクスによって処理時間が公開され、Red Hat build of Keycloak のパフォーマンスとリクエストの処理にかかる時間を監視できます。
健全なクラスターでは、平均処理時間は安定しています。処理時間の急増や増加は、一部のノードに負荷がかかっていることを示す初期兆候である可能性があります。
タグ
method- HTTP メソッド。
outcome- より一般的な結果タグ。
status- HTTP ステータスコード。
uri- リクエストされた URI。
| メトリクス | 説明 |
|---|---|
|
| 処理されたリクエストの合計数。 |
|
| 処理されたすべてのリクエストの合計所要時間。 |
http-metrics-histograms-enabled を true に設定することでこのメトリクスのヒストグラムを有効にでき、オプション http-metrics-slos を使用してサービスレベル目標の追加バケットを追加できます。
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成し、レイテンシーを分析するのに役立ちますが、パーセンタイルバケットの収集と公開を行うことで監視システムの負荷が増加します。
5.5.2.2. アクティブなリクエスト
現在アクティブなリクエストの数も確認できます。
| メトリクス | 説明 |
|---|---|
|
| 現在アクティブなリクエストの数 |
5.5.2.3. 帯域幅
以下のメトリクスは、Red Hat build of Keycloak によって使用され、受信または送信されたリクエストとレスポンスによって消費される帯域幅とトラフィックを監視するのに役立ちます。
| メトリクス | 説明 |
|---|---|
|
| 送信されたレスポンスの合計数。 |
|
| 送信されたバイトの合計数。 |
|
| 受信したリクエストの合計数。 |
|
| 受信したバイトの合計数。 |
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成し、レイテンシーを分析するのに役立ちますが、パーセンタイルバケットの収集と公開を行うことで監視システムの負荷が増加します。
5.5.3. 次のステップ
メトリクスを使用したトラブルシューティング に戻るか、以下に進みます
- シングルサイトデプロイメントの場合は、クラスタリングメトリクス に進みます。
- マルチサイトデプロイメントの場合は、マルチサイトデプロイメント用の埋め込み Infinispan メトリクス に進みます。
5.5.4. 関連するオプション
| 値 | |
|---|---|
|
CLI: メトリクスが有効になっている場合にのみ使用可能 |
|
|
CLI: メトリクスが有効になっている場合にのみ使用可能 |
5.6. クラスタリングメトリクス
メトリクスを使用して、Red Hat build of Keycloak のノード間の通信を監視します。
これは、メトリクスを使用したトラブルシューティング 章の一部です。
5.6.1. 前提条件
- Red Hat build of Keycloak でメトリクスを有効にしている。詳細は、メトリクスから洞察を得る の章を参照してください。
- メトリクスを収集する監視システム。
5.6.2. メトリクス
複数の Red Hat build of Keycloak ノードをデプロイすると、それらのノード間で負荷を分散できますが、そのためにはノード間の通信が必要です。このセクションでは、Red Hat build of Keycloak 間の通信を監視して、起こりうる障害を特定するのに役立つメトリクスを説明します。
これはシングルサイトデプロイメントにのみ適用されます。マルチサイトデプロイメント で説明されているように、複数のサイトを使用する場合、Red Hat build of Keycloak ノードはクラスター化されないため、ノード間の直接通信は行われません。
グローバルタグ
cluster=<name>- クラスター名。複数のクラスターからメトリクスを収集している場合、このタグを使用してメトリクスの所属先を識別できます。
node=<node>- メトリクスを報告するノードの名前。
vendor_jgroups_ で始まるすべてのメトリクス名は、トラブルシューティングとデバッグのためだけに提供されています。メトリクス名は、Red Hat build of Keycloak の今後のリリースで予告なく変更される可能性があります。したがって、ダッシュボードや監視およびアラートでは使用しないことが推奨されます。
5.6.2.1. レスポンス時間
次のメトリクスは、リモートリクエストのレスポンス時間を公開します。レスポンス時間は 2 つのノード間で測定され、処理時間も含まれます。すべてのリクエストはこれらのメトリクスによって測定され、レスポンス時間はクラスターのライフサイクルを通じて安定しているはずです。
健全なクラスターでは、レスポンス時間は安定しています。レスポンス時間が増加した場合は、クラスターの性能が低下しているか、ノードの負荷が大きいことを示している可能性があります。
タグ
node=<node>- 送信側ノードを識別します。
target_node=<node>- 受信ノードを識別します。
| メトリクス | 説明 |
|---|---|
|
| 受信ノードへの同期リクエストの数。 |
|
| 受信ノードへの同期リクエストの合計期間 |
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成するのに役立ちますが、パーセンタイルバケットを収集して公開すると、デプロイメントのパフォーマンスに悪影響を与える可能性があります。
5.6.2.2. 帯域幅
Red Hat build of Keycloak によって送受信されるすべてのバイトは、これらのメトリクスによって収集されます。また、ハートビートなどのすべての内部メッセージもカウントされます。そのため、各ノードで現在使用されている帯域幅の計算が可能になります。
メトリクス名は、使用されている JGroups トランスポートプロトコルによって異なります。
| メトリクス | Protocol | 説明 |
|---|---|---|
|
|
| ノードが受信したバイトの合計数。 |
|
|
| |
|
|
| |
|
|
| ノードが送信したバイトの合計数。 |
|
|
| |
|
|
|
5.6.2.3. スレッドプール
スレッドプールのサイズを監視することは、ノードに大きな負荷がかかっているかどうかを示す良い指標となります。受信したすべてのリクエストは処理のためにスレッドプールに追加され、スレッドプールがいっぱいになると、リクエストは破棄されます。再送信メカニズムにより、リソース使用量が増加しても信頼性の高い通信が確保されます。
正常なクラスターでは、スレッドプールが最大サイズ (デフォルトでは 200 スレッド) に近づくことはありません。
スレッドプールメトリクスは仮想スレッドでは使用できません。OpenJDK 21 で実行する場合、仮想スレッドはデフォルトで有効になります。
メトリクス名は、使用されている JGroups トランスポートプロトコルによって異なります。デフォルトのトランスポートプロトコルは TCP です。
| メトリクス | Protocol | 説明 |
|---|---|---|
|
|
| スレッドプール内の現在のスレッド数。 |
|
|
| |
|
|
| |
|
|
| これまでにプール内で同時に存在したスレッドの最大数。 |
|
|
| |
|
|
|
5.6.2.4. フロー制御
フロー制御は、時間の経過とともに、メッセージ送信側の速度を最も遅い受信側の速度に合わせて調整します。これはクレジットベースのシステムを通じて実装され、各送信側のクレジットが送信時に減少します。送信側は、クレジットが 0 を下回るとブロックし、受信側から補充メッセージを受信した場合にのみメッセージの送信を再開します。
以下のメトリクスは、ブロックされたメッセージの数と平均ブロック時間を示しています。値がゼロではない場合、受信側が過負荷になっているためにクラスターのパフォーマンスが低下する可能性があることを示しています。
各ノードには、ユニキャストメッセージ用の UFC とマルチキャストメッセージ用の MFC という、2 つの独立したフロー制御プロトコルがあります。
正常なクラスターでは、すべてのメトリクスの値がゼロになります。
| メトリクス | 説明 |
|---|---|
|
| フロー制御がユニキャストメッセージの送信側をブロックした回数。 |
|
| ユニキャストメッセージを送信しようとしたときにフロー制御でブロックされた平均時間 (ミリ秒)。 |
|
| フロー制御がマルチキャストメッセージの送信側をブロックした回数。 |
|
| マルチキャストメッセージを送信しようとしたときにフロー制御でブロックされた平均時間 (ミリ秒)。 |
5.6.2.5. 再送信
JGroups は信頼性の高いメッセージ配信を提供します。メッセージがネットワーク上でドロップされた場合、または送信側がメッセージを処理できない場合は、再送信する必要があります。再送信によりリソース使用量が増加し、通常これはシステムの過負荷を示しています。
Random Early Drop (RED) は送信側のキューを監視します。キューがほぼいっぱいになると、メッセージはドロップされ、再送信が必要になります。これは、送信側のキューがいっぱいになってスレッドがブロックされることを防ぎます。
正常なクラスターでは、すべてのメトリクスの値がゼロになります。
| メトリクス | 説明 |
|---|---|
|
| 再送信されたメッセージの数。 |
|
| 送信側によってドロップされたメッセージの合計数。 |
|
| 送信がによってドロップされた全メッセージの割合。 |
5.6.2.6. ネットワークパーティション
5.6.2.6.1. クラスターサイズ
クラスターサイズメトリクスは、クラスター内に存在するノードの数を報告します。異なる場合は、ノードが参加途中か、シャットダウンしているか、最悪の場合はネットワークパーティションの発生を示している可能性があります。
正常なクラスターでは、すべてのノードで同じ値が示されます。
| メトリクス | 説明 |
|---|---|
|
| クラスター内のノード数。 |
5.6.2.6.2. ネットワークパーティションイベント
クラスター内のネットワークパーティションはさまざまな理由で発生します。このメトリクスは、ネットワーク分割を予測するためには使用できませんが、ネットワーク分割が発生してクラスターが統合されたことを示します。
正常なクラスターでは、このメトリクスの値はゼロになります。
| メトリクス | 説明 |
|---|---|
|
| ネットワーク分割が検出されてから復旧するまでの時間。 |
5.6.3. 次のステップ
メトリクスを使用したトラブルシューティング に戻るか、シングルサイトデプロイメント用の埋め込み Infinispan メトリクス に進みます
5.7. シングルサイトデプロイメント用の埋め込み Infinispan メトリクス
メトリクスを使用して、キャッシュの健全性とクラスターのレプリケーションを監視します。
これは、メトリクスを使用したトラブルシューティング 章の一部です。
5.7.1. 前提条件
- Red Hat build of Keycloak でメトリクスを有効にしている。詳細は、メトリクスから洞察を得る の章を参照してください。
- メトリクスを収集する監視システム。
5.7.2. メトリクス
グローバルタグ
cache=<name>- キャッシュの名前。
5.7.2.1. サイズ
これら 2 つのメトリクスを使用して、キャッシュ内のエントリーの数を監視します。キャッシュがクラスター化されている場合、各エントリーには所有者ノードと、異なるノードの 0 個以上のバックアップコピーが存在します。
一意のエントリーサイズメトリクスを合計して、クラスターのエントリーの合計数を取得します。
| メトリクス | 説明 |
|---|---|
|
| バックアップコピーを含む、ノードによって保存されるエントリーの概数。 |
|
| バックアップコピーを除く、ノードによって保存されるエントリーの概数。 |
5.7.2.2. データアクセス
次のメトリクスは、読み取り、書き込み、およびその期間などのキャッシュアクセスを監視します。
5.7.2.2.1. 保存
保存操作は、キャッシュに保存されている値を書き込む、または更新する書き込み操作です。
| メトリクス | 説明 |
|---|---|
|
| 保存リクエストの合計数。 |
|
| すべての保存リクエストの合計所要時間。 |
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成するのに役立ちますが、パーセンタイルバケットを収集して公開すると、デプロイメントのパフォーマンスに悪影響を与える可能性があります。
5.7.2.2.2. 読み取り
読み取り操作はキャッシュから値を読み取ります。2 つのグループに分類でき、値が見つかった場合はヒット、見つからなかった場合はミスとなります。
| メトリクス | 説明 |
|---|---|
|
| ヒットに該当する読み取りリクエストの合計数。 |
|
| ヒットに該当するすべての読み取りリクエストの合計所要時間。 |
|
| ミスに該当する読み取りリクエストの合計数。 |
|
| ミスに該当するすべての読み取りリクエストの合計所要時間。 |
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成するのに役立ちますが、パーセンタイルバケットを収集して公開すると、デプロイメントのパフォーマンスに悪影響を与える可能性があります。
5.7.2.2.3. 削除
削除操作はキャッシュから値を削除します。2 つのグループに分類でき、値が存在する場合はヒット、値が存在しない場合はミスとなります。
| メトリクス | 説明 |
|---|---|
|
| ヒットに該当する削除リクエストの合計数。 |
|
| ヒットに該当するすべての削除リクエストの合計所要時間。 |
|
| ミスに該当する削除リクエストの合計数。 |
|
| ミスに該当するすべての削除リクエストの合計所要時間。 |
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成するのに役立ちますが、パーセンタイルバケットを収集して公開すると、デプロイメントのパフォーマンスに悪影響を与える可能性があります。
users および realms キャッシュの場合、データベースの無効化は削除操作に変換されます。これらのメトリクスは、データベースエンティティーがどのくらいの頻度で変更され、そのためにキャッシュから削除されるかを示す優れた指標です。
Hit Ratio for read and remove operations
式を使用して、Prometheus などのシステムのキャッシュのヒット率を計算できます。たとえば、読み取り操作のヒット率は次のように表されます。
vendor_statistics_hit_times_seconds_count
/
(vendor_statistics_hit_times_seconds_count
+ vendor_statistics_miss_times_seconds_count)Read/Write ratio
上記のメトリクスを使用すると、式を使用してキャッシュの読み取り/書き込み比率を計算できます。
(vendor_statistics_hit_times_seconds_count
+ vendor_statistics_miss_times_seconds_count)
/
(vendor_statistics_hit_times_seconds_count
+ vendor_statistics_miss_times_seconds_count
+ vendor_statistics_remove_hit_times_seconds_count
+ vendor_statistics_remove_miss_times_seconds_count
+ vendor_statistics_store_times_seconds_count)5.7.2.2.4. エビクション
エビクションは、キャッシュサイズを制限するプロセスであり、いっぱいになるとエントリーが削除され、新しいエントリーをキャッシュするためのスペースが確保されます。Red Hat build of Keycloak は、users、realms、authorization 内のデータベースエンティティーをキャッシュするため、データベースアクセスは常にエビクションイベントで進行します。
| メトリクス | 説明 |
|---|---|
|
| エビクションイベントの合計数。 |
エビクション率
エビクションの急増と非常に高いデータベース CPU 使用率は、users または realms のキャッシュが小さすぎて、データベースからデータを頻繁に再ロードする必要があるためレスポンスが遅くなり、Red Hat build of Keycloak の操作がスムーズに実行できないことを意味します。十分なメモリーが利用可能な場合は、CLI オプションの cache-embedded-users-max-count または cache-embedded-realms-max-count を使用して、最大キャッシュサイズを増やすことを検討してください。
5.7.2.3. ロック
書き込みおよび削除操作では、値がローカルクラスター内とリモートサイトに複製されるまでロックが保持されます。
正常なクラスターでは、保持されるロックの数は一定に保たれますが、デッドロックによって一時的な急増が生じる可能性があります。
| メトリクス | 説明 |
|---|---|
|
| 現在このノードによって保持されているロックの数。 |
5.7.2.4. トランザクション
トランザクションキャッシュは、トランザクションを完了するために、One-Phase-Commit と Two-Phase-Commit の両方のプロトコルを使用します。これらのメトリクスは操作時間を追跡します。
PESSMISTIC ロックモードでは、One-Phase-Commit が使用され、コミットリクエストは作成されません。
正常なクラスターでは、ロールバックの数はゼロになります。デッドロックはまれですが、ロールバックの回数は増加します。
| メトリクス | 説明 |
|---|---|
|
| 準備リクエストの合計数。 |
|
| すべての準備リクエストの合計所要時間。 |
|
| ロールバックリクエストの合計数。 |
|
| すべてのロールバックリクエストの合計所要時間。 |
|
| コミットリクエストの合計数。 |
|
| すべてのコミットリクエストの合計所要時間。 |
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成するのに役立ちますが、パーセンタイルバケットを収集して公開すると、デプロイメントのパフォーマンスに悪影響を与える可能性があります。
5.7.2.5. 状態遷移
状態遷移は、ノードがクラスターに参加したり、クラスターから離脱したりするときに発生します。保存されたデータのバランスを取り、必要なコピー数を保証する必要があります。
この操作によりリソースの使用量が増加し、全体的なパフォーマンスに悪影響を及ぼします。
| メトリクス | 説明 |
|---|---|
|
| ローカルノードが他のノードに要求した処理中のトランザクションセグメントの数。 |
|
| ローカルノードが他のノードに要求した処理中のセグメントの数。 |
5.7.2.6. クラスターデータレプリケーション
クラスターデータレプリケーションが障害の主な原因となる場合があります。これらのメトリクスは、レスポンス時間を報告します。つまり、更新のレプリケートにかかる時間だけでなく、失敗も報告します。
正常なクラスターでは、平均レプリケーション時間はまったく、またはほとんど変動しません。失敗の数は増加しないはずです。
| メトリクス | 説明 |
|---|---|
|
| 成功したレプリケーションの合計数。 |
|
| 失敗したレプリケーションの合計数。 |
|
| クラスター内でのデータのレプリケートに費やされた平均時間 (ミリ秒)。 |
成功率
次の式を使用して、レプリケーション成功率を計算できます。
(vendor_rpc_manager_replication_count)
/
(vendor_rpc_manager_replication_count
+ vendor_rpc_manager_replication_failures)5.7.3. 次のステップ
メトリクスを使用したトラブルシューティング に戻ります。
5.8. マルチサイトデプロイメント用の埋め込み Infinispan メトリクス
メトリクスを使用してキャッシュの健全性を監視します。
これは、メトリクスを使用したトラブルシューティング 章の一部です。
5.8.1. 前提条件
- Red Hat build of Keycloak でメトリクスを有効にしている。詳細は、メトリクスから洞察を得る の章を参照してください。
- メトリクスを収集する監視システム。
5.8.2. メトリクス
グローバルタグ
cache=<name>- キャッシュの名前。
5.8.2.1. サイズ
これら 2 つのメトリクスを使用して、キャッシュ内のエントリーの数を監視します。キャッシュがクラスター化されている場合、各エントリーには所有者ノードと、異なるノードの 0 個以上のバックアップコピーが存在します。
一意のエントリーサイズメトリクスを合計して、クラスターのエントリーの合計数を取得します。
| メトリクス | 説明 |
|---|---|
|
| バックアップコピーを含む、ノードによって保存されるエントリーの概数。 |
|
| バックアップコピーを除く、ノードによって保存されるエントリーの概数。 |
5.8.2.2. データアクセス
次のメトリクスは、読み取り、書き込み、およびその期間などのキャッシュアクセスを監視します。
5.8.2.2.1. 保存
保存操作は、キャッシュに保存されている値を書き込む、または更新する書き込み操作です。
| メトリクス | 説明 |
|---|---|
|
| 保存リクエストの合計数。 |
|
| すべての保存リクエストの合計所要時間。 |
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成するのに役立ちますが、パーセンタイルバケットを収集して公開すると、デプロイメントのパフォーマンスに悪影響を与える可能性があります。
5.8.2.2.2. 読み取り
読み取り操作はキャッシュから値を読み取ります。2 つのグループに分類でき、値が見つかった場合はヒット、見つからなかった場合はミスとなります。
| メトリクス | 説明 |
|---|---|
|
| ヒットに該当する読み取りリクエストの合計数。 |
|
| ヒットに該当するすべての読み取りリクエストの合計所要時間。 |
|
| ミスに該当する読み取りリクエストの合計数。 |
|
| ミスに該当するすべての読み取りリクエストの合計所要時間。 |
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成するのに役立ちますが、パーセンタイルバケットを収集して公開すると、デプロイメントのパフォーマンスに悪影響を与える可能性があります。
5.8.2.2.3. 削除
削除操作はキャッシュから値を削除します。2 つのグループに分類でき、値が存在する場合はヒット、値が存在しない場合はミスとなります。
| メトリクス | 説明 |
|---|---|
|
| ヒットに該当する削除リクエストの合計数。 |
|
| ヒットに該当するすべての削除リクエストの合計所要時間。 |
|
| ミスに該当する削除リクエストの合計数。 |
|
| ミスに該当するすべての削除リクエストの合計所要時間。 |
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成するのに役立ちますが、パーセンタイルバケットを収集して公開すると、デプロイメントのパフォーマンスに悪影響を与える可能性があります。
users および realms キャッシュの場合、データベースの無効化は削除操作に変換されます。これらのメトリクスは、データベースエンティティーがどのくらいの頻度で変更され、そのためにキャッシュから削除されるかを示す優れた指標です。
Hit Ratio for read and remove operations
式を使用して、Prometheus などのシステムのキャッシュのヒット率を計算できます。たとえば、読み取り操作のヒット率は次のように表されます。
vendor_statistics_hit_times_seconds_count
/
(vendor_statistics_hit_times_seconds_count
+ vendor_statistics_miss_times_seconds_count)Read/Write ratio
上記のメトリクスを使用すると、式を使用してキャッシュの読み取り/書き込み比率を計算できます。
(vendor_statistics_hit_times_seconds_count
+ vendor_statistics_miss_times_seconds_count)
/
(vendor_statistics_hit_times_seconds_count
+ vendor_statistics_miss_times_seconds_count
+ vendor_statistics_remove_hit_times_seconds_count
+ vendor_statistics_remove_miss_times_seconds_count
+ vendor_statistics_store_times_seconds_count)5.8.2.2.4. エビクション
エビクションは、キャッシュサイズを制限するプロセスであり、いっぱいになるとエントリーが削除され、新しいエントリーをキャッシュするためのスペースが確保されます。Red Hat build of Keycloak は、users、realms、authorization 内のデータベースエンティティーをキャッシュするため、データベースアクセスは常にエビクションイベントで進行します。
| メトリクス | 説明 |
|---|---|
|
| エビクションイベントの合計数。 |
エビクション率
エビクションの急増と非常に高いデータベース CPU 使用率は、users または realms のキャッシュが小さすぎて、データベースからデータを頻繁に再ロードする必要があるためレスポンスが遅くなり、Red Hat build of Keycloak の操作がスムーズに実行できないことを意味します。十分なメモリーが利用可能な場合は、CLI オプションの cache-embedded-users-max-count または cache-embedded-realms-max-count を使用して、最大キャッシュサイズを増やすことを検討してください。
5.8.2.3. トランザクション
トランザクションキャッシュは、トランザクションを完了するために、One-Phase-Commit と Two-Phase-Commit の両方のプロトコルを使用します。これらのメトリクスは操作時間を追跡します。
PESSMISTIC ロックモードでは、One-Phase-Commit が使用され、コミットリクエストは作成されません。
正常なクラスターでは、ロールバックの数はゼロになります。デッドロックはまれですが、ロールバックの回数は増加します。
| メトリクス | 説明 |
|---|---|
|
| 準備リクエストの合計数。 |
|
| すべての準備リクエストの合計所要時間。 |
|
| ロールバックリクエストの合計数。 |
|
| すべてのロールバックリクエストの合計所要時間。 |
|
| コミットリクエストの合計数。 |
|
| すべてのコミットリクエストの合計所要時間。 |
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成するのに役立ちますが、パーセンタイルバケットを収集して公開すると、デプロイメントのパフォーマンスに悪影響を与える可能性があります。
5.8.3. 次のステップ
メトリクスを使用したトラブルシューティング に戻るか、外部 Data Grid メトリクス に進みます。
5.9. 外部 Data Grid メトリクス
メトリクスを使用して外部の Data Grid パフォーマンスを監視します。
これは、メトリクスを使用したトラブルシューティング 章の一部です。
5.9.1. 前提条件
5.9.1.1. Data Grid サーバーメトリクスを有効にした。
Data Grid がエンドポイント /metrics でメトリクスを公開している。デフォルトでは有効になっています。メトリクス名がキャッシュ名に依存しなくなるため、name-as-tags 属性を有効にすることが推奨されます。
Data Grid サーバーでメトリクスを設定するには、以下の XML で示すとおり有効にします。
infinispan.xml
<infinispan>
<cache-container statistics="true">
<metrics gauges="true" histograms="false" name-as-tags="true" />
</cache-container>
</infinispan>
Kubernetes の Data Grid Operator を使用すると、カスタム設定の ConfigMap を使用してメトリクスを有効にできます。以下に例を示します。
ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-config
data:
infinispan-config.yaml: >
infinispan:
cacheContainer:
metrics:
gauges: true
namesAsTags: true
histograms: falseinfinispan.yaml CR
apiVersion: infinispan.org/v1
kind: Infinispan
metadata:
name: infinispan
annotations:
infinispan.org/monitoring: 'true'
spec:
configMapName: "cluster-config" 関連情報は、Infinispan のドキュメント および Infinispan Operator のドキュメントを参照してください。
5.9.2. クラスタリングとネットワーク
このセクションでは、Data Grid ノード間の通信を監視して、起こりうるネットワークの問題を特定するために役立つメトリクスを説明します。
グローバルタグ
cluster=<name>- クラスター名。複数のクラスターからメトリクスを収集している場合、このタグを使用してメトリクスの所属先を識別できます。
node=<node>- メトリクスを報告するノードの名前。
vendor_jgroups_ で始まるすべてのメトリクス名は、トラブルシューティングとデバッグのためだけに提供されています。メトリクス名は、Red Hat build of Keycloak の今後のリリースで予告なく変更される可能性があります。したがって、ダッシュボードや監視およびアラートでは使用しないことが推奨されます。
5.9.2.1. レスポンス時間
次のメトリクスは、リモートリクエストのレスポンス時間を公開します。レスポンス時間は 2 つのノード間で測定され、処理時間も含まれます。すべてのリクエストはこれらのメトリクスによって測定され、レスポンス時間はクラスターのライフサイクルを通じて安定しているはずです。
健全なクラスターでは、レスポンス時間は安定しています。レスポンス時間が増加した場合は、クラスターの性能が低下しているか、ノードの負荷が大きいことを示している可能性があります。
タグ
node=<node>- 送信側ノードを識別します。
target_node=<node>- 受信ノードを識別します。
| メトリクス | 説明 |
|---|---|
|
| 受信ノードへの同期リクエストの数。 |
|
| 受信ノードへの同期リクエストの合計期間 |
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成するのに役立ちますが、パーセンタイルバケットを収集して公開すると、デプロイメントのパフォーマンスに悪影響を与える可能性があります。
5.9.2.2. 帯域幅
Data Grid が送受信するすべてのバイトは、これらのメトリクスによって収集されます。また、ハートビートなどのすべての内部メッセージもカウントされます。そのため、各ノードで現在使用されている帯域幅の計算が可能になります。
メトリクス名は、使用されている JGroups トランスポートプロトコルによって異なります。
| メトリクス | Protocol | 説明 |
|---|---|---|
|
|
| ノードが受信したバイトの合計数。 |
|
|
| |
|
|
| |
|
|
| ノードが送信したバイトの合計数。 |
|
|
| |
|
|
|
5.9.2.3. スレッドプール
スレッドプールのサイズを監視することは、ノードに大きな負荷がかかっているかどうかを示す良い指標となります。受信したすべてのリクエストは処理のためにスレッドプールに追加され、スレッドプールがいっぱいになると、リクエストは破棄されます。再送信メカニズムにより、リソース使用量が増加しても信頼性の高い通信が確保されます。
正常なクラスターでは、スレッドプールが最大サイズ (デフォルトでは 200 スレッド) に近づくことはありません。
スレッドプールメトリクスは仮想スレッドでは使用できません。OpenJDK 21 で実行する場合、仮想スレッドはデフォルトで有効になります。
メトリクス名は、使用されている JGroups トランスポートプロトコルによって異なります。デフォルトのトランスポートプロトコルは TCP です。
| メトリクス | Protocol | 説明 |
|---|---|---|
|
|
| スレッドプール内の現在のスレッド数。 |
|
|
| |
|
|
| |
|
|
| これまでにプール内で同時に存在したスレッドの最大数。 |
|
|
| |
|
|
|
5.9.2.4. フロー制御
フロー制御は、時間の経過とともに、メッセージ送信側の速度を最も遅い受信側の速度に合わせて調整します。これはクレジットベースのシステムを通じて実装され、各送信側のクレジットが送信時に減少します。送信側は、クレジットが 0 を下回るとブロックし、受信側から補充メッセージを受信した場合にのみメッセージの送信を再開します。
以下のメトリクスは、ブロックされたメッセージの数と平均ブロック時間を示しています。値がゼロではない場合、受信側が過負荷になっているためにクラスターのパフォーマンスが低下する可能性があることを示しています。
各ノードには、ユニキャストメッセージ用の UFC とマルチキャストメッセージ用の MFC という、2 つの独立したフロー制御プロトコルがあります。
正常なクラスターでは、すべてのメトリクスの値がゼロになります。
| メトリクス | 説明 |
|---|---|
|
| フロー制御がユニキャストメッセージの送信側をブロックした回数。 |
|
| ユニキャストメッセージを送信しようとしたときにフロー制御でブロックされた平均時間 (ミリ秒)。 |
|
| フロー制御がマルチキャストメッセージの送信側をブロックした回数。 |
|
| マルチキャストメッセージを送信しようとしたときにフロー制御でブロックされた平均時間 (ミリ秒)。 |
5.9.2.5. 再送信
JGroups は信頼性の高いメッセージ配信を提供します。メッセージがネットワーク上でドロップされた場合、または送信側がメッセージを処理できない場合は、再送信する必要があります。再送信によりリソース使用量が増加し、通常これはシステムの過負荷を示しています。
Random Early Drop (RED) は送信側のキューを監視します。キューがほぼいっぱいになると、メッセージはドロップされ、再送信が必要になります。これは、送信側のキューがいっぱいになってスレッドがブロックされることを防ぎます。
正常なクラスターでは、すべてのメトリクスの値がゼロになります。
| メトリクス | 説明 |
|---|---|
|
| 再送信されたメッセージの数。 |
|
| 送信側によってドロップされたメッセージの合計数。 |
|
| 送信がによってドロップされた全メッセージの割合。 |
5.9.2.6. ネットワークパーティション
5.9.2.6.1. クラスターサイズ
クラスターサイズメトリクスは、クラスター内に存在するノードの数を報告します。異なる場合は、ノードが参加途中か、シャットダウンしているか、最悪の場合はネットワークパーティションの発生を示している可能性があります。
正常なクラスターでは、すべてのノードで同じ値が示されます。
| メトリクス | 説明 |
|---|---|
|
| クラスター内のノード数。 |
5.9.2.6.2. クロスサイトステータス
クロスサイトステータスは、他のサイトへの接続ステータスを報告します。オンラインの場合は 1 を、オフラインの場合は 0 を返します。2 の値は、ステータスが不明なノードで使用されます。すべてのノードがリモートサイトへの接続を確立するわけではなく、その場合はこの情報は含まれません。
正常なクラスターはゼロより大きい値を示します。
| メトリクス | 説明 |
|---|---|
|
| シングルサイトのステータス (オンラインの場合は 1)。 |
タグ
site=<name>- 宛先サイトの名前。
5.9.2.6.3. ネットワークパーティションイベント
クラスター内のネットワークパーティションはさまざまな理由で発生します。このメトリクスは、ネットワーク分割を予測するためには使用できませんが、ネットワーク分割が発生してクラスターが統合されたことを示します。
正常なクラスターでは、このメトリクスの値はゼロになります。
| メトリクス | 説明 |
|---|---|
|
| ネットワーク分割が検出されてから復旧するまでの時間。 |
5.9.3. Data Grid キャッシュ
このセクションのメトリクスは、Data Grid キャッシュの健全性とクラスターのレプリケーションを監視するために役立ちます。
グローバルタグ
cache=<name>- キャッシュの名前。
5.9.3.1. サイズ
これら 2 つのメトリクスを使用して、キャッシュ内のエントリーの数を監視します。キャッシュがクラスター化されている場合、各エントリーには所有者ノードと、異なるノードの 0 個以上のバックアップコピーが存在します。
一意のエントリーサイズメトリクスを合計して、クラスターのエントリーの合計数を取得します。
| メトリクス | 説明 |
|---|---|
|
| バックアップコピーを含む、ノードによって保存されるエントリーの概数。 |
|
| バックアップコピーを除く、ノードによって保存されるエントリーの概数。 |
5.9.3.2. データアクセス
次のメトリクスは、読み取り、書き込み、およびその期間などのキャッシュアクセスを監視します。
5.9.3.2.1. 保存
保存操作は、キャッシュに保存されている値を書き込む、または更新する書き込み操作です。
| メトリクス | 説明 |
|---|---|
|
| 保存リクエストの合計数。 |
|
| すべての保存リクエストの合計所要時間。 |
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成するのに役立ちますが、パーセンタイルバケットを収集して公開すると、デプロイメントのパフォーマンスに悪影響を与える可能性があります。
5.9.3.2.2. 読み取り
読み取り操作はキャッシュから値を読み取ります。2 つのグループに分類でき、値が見つかった場合はヒット、見つからなかった場合はミスとなります。
| メトリクス | 説明 |
|---|---|
|
| ヒットに該当する読み取りリクエストの合計数。 |
|
| ヒットに該当するすべての読み取りリクエストの合計所要時間。 |
|
| ミスに該当する読み取りリクエストの合計数。 |
|
| ミスに該当するすべての読み取りリクエストの合計所要時間。 |
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成するのに役立ちますが、パーセンタイルバケットを収集して公開すると、デプロイメントのパフォーマンスに悪影響を与える可能性があります。
5.9.3.2.3. 削除
削除操作はキャッシュから値を削除します。2 つのグループに分類でき、値が存在する場合はヒット、値が存在しない場合はミスとなります。
| メトリクス | 説明 |
|---|---|
|
| ヒットに該当する削除リクエストの合計数。 |
|
| ヒットに該当するすべての削除リクエストの合計所要時間。 |
|
| ミスに該当する削除リクエストの合計数。 |
|
| ミスに該当するすべての削除リクエストの合計所要時間。 |
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成するのに役立ちますが、パーセンタイルバケットを収集して公開すると、デプロイメントのパフォーマンスに悪影響を与える可能性があります。
5.9.3.3. ロック
書き込みおよび削除操作では、値がローカルクラスター内とリモートサイトに複製されるまでロックが保持されます。
正常なクラスターでは、保持されるロックの数は一定に保たれますが、デッドロックによって一時的な急増が生じる可能性があります。
| メトリクス | 説明 |
|---|---|
|
| 現在このノードによって保持されているロックの数。 |
5.9.3.4. トランザクション
トランザクションキャッシュは、トランザクションを完了するために、One-Phase-Commit と Two-Phase-Commit の両方のプロトコルを使用します。これらのメトリクスは操作時間を追跡します。
PESSMISTIC ロックモードでは、One-Phase-Commit が使用され、コミットリクエストは作成されません。
正常なクラスターでは、ロールバックの数はゼロになります。デッドロックはまれですが、ロールバックの回数は増加します。
| メトリクス | 説明 |
|---|---|
|
| 準備リクエストの合計数。 |
|
| すべての準備リクエストの合計所要時間。 |
|
| ロールバックリクエストの合計数。 |
|
| すべてのロールバックリクエストの合計所要時間。 |
|
| コミットリクエストの合計数。 |
|
| すべてのコミットリクエストの合計所要時間。 |
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成するのに役立ちますが、パーセンタイルバケットを収集して公開すると、デプロイメントのパフォーマンスに悪影響を与える可能性があります。
5.9.3.5. 状態遷移
状態遷移は、ノードがクラスターに参加したり、クラスターから離脱したりするときに発生します。保存されたデータのバランスを取り、必要なコピー数を保証する必要があります。
この操作によりリソースの使用量が増加し、全体的なパフォーマンスに悪影響を及ぼします。
| メトリクス | 説明 |
|---|---|
|
| ローカルノードが他のノードに要求した処理中のトランザクションセグメントの数。 |
|
| ローカルノードが他のノードに要求した処理中のセグメントの数。 |
5.9.3.6. クラスターデータレプリケーション
クラスターデータレプリケーションが障害の主な原因となる場合があります。これらのメトリクスは、レスポンス時間を報告します。つまり、更新のレプリケートにかかる時間だけでなく、失敗も報告します。
正常なクラスターでは、平均レプリケーション時間はまったく、またはほとんど変動しません。失敗の数は増加しないはずです。
| メトリクス | 説明 |
|---|---|
|
| 成功したレプリケーションの合計数。 |
|
| 失敗したレプリケーションの合計数。 |
|
| クラスター内でのデータのレプリケートに費やされた平均時間 (ミリ秒)。 |
成功率
次の式を使用して、レプリケーション成功率を計算できます。
(vendor_rpc_manager_replication_count)
/
(vendor_rpc_manager_replication_count
+ vendor_rpc_manager_replication_failures)5.9.3.7. クロスサイトデータレプリケーション
このセクションのメトリクスは、クラスターデータレプリケーションと同様に、データを他のサイトにレプリケートするためにかかる時間を測定します。
正常なクラスターでは、クロスサイトレプリケーションの平均時間はまったく、またはほとんど変動しません。
タグ
site=<name>- 受信サイトを示します。
| メトリクス | 説明 |
|---|---|
|
| クロスサイトリクエストの合計数。 |
|
| すべてのクロスサイトリクエストの合計所要時間。 |
|
| クロスサイトリクエストの合計数。このメトリクスは、サイトごとのカウンターを使用することで、さらに詳細になります。 |
|
| すべてのクロスサイトリクエストの合計所要時間。このメトリクスは、サイトごとの所要時間を使用することで、さらに詳細になります。 |
|
| このノードによって処理されるクロスサイトリクエストの合計数。このメトリクスは、サイトごとのカウンターを使用することで、さらに詳細になります。 |
|
|
サイトのステータス。値が 1 の場合、オンラインであることを示します。この値は、Data Grid CLI コマンドの |
ヒストグラムを有効にすると、パーセンタイルバケットが利用可能になります。これらはヒートマップを作成するのに役立ちますが、パーセンタイルバケットを収集して公開すると、デプロイメントのパフォーマンスに悪影響を与える可能性があります。
5.9.4. 次のステップ
メトリクスを使用したトラブルシューティング に戻ります。
第6章 トレーシングによる根本原因分析
OpenTelementry トレーシングを使用してリクエストライフサイクル中に情報を記録し、Red Hat build of Keycloak と接続されたシステムにおけるレイテンシーとエラーの根本原因を特定します。
この章では、OpenTelemetry (OTel) を利用して、Red Hat build of Keycloak で分散トレーシングを有効にして設定する方法を説明します。トレーシングにより、各リクエストのライフサイクルを詳細に監視できるため、問題を迅速に特定して診断し、デバッグとメンテナンスをより効率的に行うことができます。
パフォーマンスのボトルネックに関する貴重な洞察を得ることができ、システム全体の効率とシステム境界を越えた最適化に役立ちます。Red Hat build of Keycloak では、アプリケーショントレースのスムーズなインテグレーションと公開を提供する、サポート対象の Quarkus OTel エクステンション が使用されます。
6.1. トレーシングを有効にする
次のようにビルド時のオプション tracing-enabled を使用して、トレースの公開を有効にできます。
bin/kc.[sh|bat] start --tracing-enabled=true
デフォルトでは、トレースエクスポーターは gRPC プロトコルとエンドポイント http://localhost:4317 を使用して、データをバッチで送信します。
デフォルトのサービス名は keycloak で、tracing-service-name プロパティーで指定され、tracing-resource-attributes プロパティーで定義された service.name よりも優先されます。
tracing-resource-attributes プロパティーを介して提供できるリソース属性の詳細は、Quarkus OpenTelemetry リソース ガイドを参照してください。
トレーシングは、opentelemetry 機能が 有効 になっている場合 (デフォルト) のみ有効にできます。
詳細なトレーシング設定は、以下の可能なすべての設定を参照してください。
6.2. 開発セットアップ
キャプチャーされた Red Hat build of Keycloak トレースを表示するには、Jaeger トレーシングプラットフォームを活用した基本的なセットアップを使用できます。開発目的の場合は、Jaeger-all-in-one を使用してトレースをできるだけ簡単に確認できます。
Jaeger-all-in-one には、Jaeger エージェント、OTel コレクター、クエリーサービス/UI が含まれています。トレースデータを Jaeger に直接送信できるため、別のコレクターをインストールする必要はありません。
podman run --name jaeger \
-p 16686:16686 \
-p 4317:4317 \
-p 4318:4318 \
jaegertracing/all-in-one6.2.1. 公開されたポート
16686- Jaeger UI
4317- OpenTelemetry Protocol gRPC レシーバー (デフォルト)
4318- OpenTelemetry Protocol HTTP レシーバー
トレーシング情報を確認するには、http://localhost:16686/ の Jaeger UI にアクセスしてください。Jaeger UI は、任意の Red Hat build of Keycloak トレースを使用した場合、以下のように表示される可能性があります。

6.3. トレースする情報
6.3.1. スパン
Red Hat build of Keycloak は次のアクティビティーのスパンを作成します。
- 受信 HTTP リクエスト
- 送信データベース (データベース接続の取得を含む)
- 送信 LDAP リクエスト (LDAP サーバーへの接続を含む)
- 送信 HTTP リクエスト (IdP 仲介を含む)
6.3.2. タグ
Red Hat build of Keycloak は、リクエストの種類に応じてトレースにタグを追加します。すべてのタグには kc. という接頭辞が付きます。
以下はタグの例です。
kc.clientId- クライアント ID
kc.realmName- レルム名
kc.sessionId- ユーザーセッション ID
kc.token.id-
トークンに記載されている
ID kc.token.issuer-
トークンに記載されている
issuer kc.token.sid-
トークンに記載されている
sid kc.authenticationSessionId- 認証セッション ID
kc.authenticationTabId- 認証タブ ID
6.3.3. Logs
トレースがサンプリングされている場合、リクエスト中に作成されたすべてのユーザーイベントが含まれます。これには、ユーザーイベントで見つかったすべての詳細と ID を含む LOGIN、LOGOUT、または REFRESH_TOKEN イベントなどが含まれます。
LDAP 通信エラーは、スタックトレースと失敗した操作の詳細とともに、記録されたトレースのログエントリーとして表示されます。
6.4. ログ内のトレース ID
トレースを有効にすると、有効なすべてのログハンドラーのログメッセージにトレース ID が含まれます (詳細は、ロギングの設定 を参照してください)。ログイベントをリクエスト実行に関連付ける場合に役立ち、トレーサビリティーとデバッグが向上する可能性があります。同じリクエストから生成されたすべてのログ行は、ログ内で同じ traceId を持ちます。
ログメッセージには、以下で説明するサンプリングに関連し、スパンがサンプリングされてコレクターに送信されたかを示す sampled フラグも含まれます。
ログレコードの形式は次のように始まります。
2024-08-05 15:27:07,144 traceId=b636ac4c665ceb901f7fdc3fc7e80154, parentId=d59cea113d0c2549, spanId=d59cea113d0c2549, sampled=true WARN [org.keycloak.events] ...6.4.1. ログ内のトレース ID を非表示にする
特定のログハンドラーのトレース ID を非表示にするには、関連する Red Hat build of Keycloak オプション log-<handler-name>-include-trace を指定します。ここで、<handler-name> はログハンドラーの名前になります。たとえば、console ログのトレース情報を無効にするには、次のようにオフにします。
bin/kc.[sh|bat] start --tracing-enabled=true --log=console --log-console-include-trace=false
特定のログハンドラーのログ形式を明示的にオーバーライドすると、*-include-trace オプションは効果がなく、トレーシングは含まれません。
6.5. サンプリング
サンプラーは、トレースを破棄するか転送するかを決定し、コレクターに送信される収集されたトレースの数を制限することでオーバーヘッドを効果的に削減します。これはリソース消費の管理に役立ち、すべてのリクエストをトレーシングするための膨大なストレージコストと潜在的なパフォーマンスの低下を回避します。
実稼働環境の場合は、インフラストラクチャーコストを最小限に抑えるために、サンプリングを適切に設定する必要があります。
Red Hat build of Keycloak は、次のようないくつかの組み込み OpenTelemetry サンプラーをサポートしています。
-
always_on -
always_off -
traceidratio(デフォルト) -
parentbased_always_on -
parentbased_always_off -
parentbased_traceidratio
使用されるサンプラーは、tracing-sampler-type プロパティーを介して変更できます。
6.5.1. デフォルトのサンプラー
Red Hat build of Keycloak のデフォルトのサンプラーは traceidratio です。これは、tracing-sampler-ratio プロパティーで設定可能な指定された比率に基づいてトレースサンプリングのレートを制御します。
6.5.1.1. トレース比率
デフォルトのトレース比率は 1.0 です。これは、すべてのトレースがサンプリングされ、コレクターに送信されることを意味します。比率は [0,1] の範囲の浮動小数点数です。たとえば、比率が 0.1 の場合、トレースの 10% のみがサンプリングされます。
実稼働環境の場合、トレースストアインフラストラクチャーの膨大なコストを防ぎ、パフォーマンスのオーバーヘッドを回避するために、トレース比率を小さくする必要があります。
比率を 0.0 に設定すると、実行時 のサンプリングが完全に無効になります。
6.5.1.2. 理由
サンプラーは、parentbased_traceidratio サンプラーを使用する場合と同様に、親スパンで行われた決定に関係なく、サンプリングされたスパンの現在の比率に基づいて独自のサンプリング決定を行います。
parentbased_traceidratio サンプラーは、親スパンと子スパンの間のサンプリングの一貫性を確保するため、推奨されるデフォルトタイプになる可能性があります。具体的には、親スパンがサンプリングされると、そのすべての子スパンもサンプリングされます。つまり、すべてに対して同じサンプリング決定が行われます。すべてのスパンをまとめて保持し、不完全なトレースの保存を防ぐのに役立ちます。
ただし、DoS 攻撃につながる特定のセキュリティーリスクが発生する可能性があります。外部の呼び出し元がトレースヘッダーを操作したり、親スパンを注入したり、トレースストアが過負荷になったりする可能性があります。適切な HTTP ヘッダー (特に tracestate) フィルタリングと、呼び出し元の信頼性を評価するための十分な対策が必要です。
詳細は、W3C Trace コンテキスト ドキュメントを参照してください。
6.6. Kubernetes 環境でのトレーシング
Red Hat build of Keycloak Operator を使用しているときにトレーシングを有効にすると、デプロイメントに関する特定の情報が基盤となるコンテナーに伝播されます。
6.6.1. Keycloak CR を介した設定
Keycloak CR を介してトレース設定を変更できます。詳細は、詳細設定 を参照してください。
6.6.2. Kubernetes 属性に基づきトレースをフィルタリングする
タグに基づいて、トレーシングバックエンドで必要なトレースをフィルター処理できます。
-
service.name- Red Hat build of Keycloak デプロイメント名 -
k8s.namespace.name- namespace -
host.name- Pod 名
Red Hat build of Keycloak Operator は、管理する Pod に含まれる Red Hat build of Keycloak コンテナーごとに、KC_TRACING_SERVICE_NAME および KC_TRACING_RESOURCE_ATTRIBUTES 環境変数を自動的に設定します。
KC_TRACING_RESOURCE_ATTRIBUTES 変数には、必ず (オーバーライドされない場合) 現在の namespace を表す k8s.namespace.name 属性が含まれます。
6.7. 関連するオプション
| 値 | |
|---|---|
|
CLI: コンソールログハンドラーとトレーシングが有効な場合にのみ使用可能 |
|
|
CLI: File ログハンドラーとトレーシングが有効な場合にのみ使用可能 |
|
|
CLI: Syslog ハンドラーとトレーシングが有効な場合にのみ使用可能 |
|
|
CLI: トレースが有効な場合にのみ使用可能 |
|
| 🛠
CLI: 'opentelemetry' 機能が有効になっている場合にのみ利用可能 |
|
|
CLI: トレースが有効な場合にのみ使用可能 | (デフォルト) |
| 🛠
CLI: トレースが有効な場合にのみ使用可能 |
|
|
CLI: トレースが有効な場合にのみ使用可能 |
|
|
CLI: トレースが有効な場合にのみ使用可能 | |
|
CLI: トレースが有効な場合にのみ使用可能 | (デフォルト) |
| 🛠
CLI: トレースが有効な場合にのみ使用可能 |
|
|
CLI: トレースが有効な場合にのみ使用可能 | (デフォルト) |
第7章 ダッシュボードでアクティビティーを可視化する
Red Hat build of Keycloak Grafana ダッシュボードをインストールして、デプロイメントのステータスとアクティビティーをキャプチャーするメトリクスを可視化します。
Red Hat build of Keycloak は、デプロイメント内で何が起こっているかを観察するためのメトリクスを提供します。メトリクスが時間の経過とともにどのように変化するかを理解するには、それらを収集してグラフで可視化すると役立ちます。
このガイドでは、実行中の Grafana インスタンスで収集された Red Hat build of Keycloak メトリクスを可視化する方法を説明します。
7.1. 前提条件
- Red Hat build of Keycloak が有効になっている。詳細は、メトリクスから洞察を得る の章を参照してください。
- Grafana インスタンスが実行されており、Red Hat build of Keycloak メトリクスは Prometheus インスタンスに集約される。
-
HTTP リクエストのレイテンシーヒートマップを機能させるために、
http-metrics-histograms-enabledをtrueに設定して、HTTP メトリクスのヒストグラムを有効にした。
7.2. Red Hat build of Keycloak Grafana ダッシュボード
Grafana ダッシュボードは、Grafana インスタンスにインポートされる JSON ファイル形式で配布されます。Red Hat build of Keycloak Grafana ダッシュボードの JSON 定義は、keycloak/keycloak-grafana-dashboard GitHub repository で入手できます。
次のステップを実行して、JSON ファイル定義をダウンロードします。
次の表から、使用する
keycloak-grafana-dashboardsのブランチを特定します。Expand Red Hat build of Keycloak バージョン keycloak-grafana-dashboardsブランチ26.1 以降
mainGitHub リポジトリーのクローンを作成します。
git clone -b BRANCH_FROM_STEP_1 https://github.com/keycloak/keycloak-grafana-dashboard.git-
ダッシュボードは
keycloak-grafana-dashboard/dashboardsディレクトリーにあります。
次のセクションでは、各ダッシュボードの目的を説明します。
7.2.1. Red Hat build of Keycloak トラブルシューティングダッシュボード
このダッシュボードは、JSON ファイル keycloak-troubleshooting-dashboard.json として利用できます。
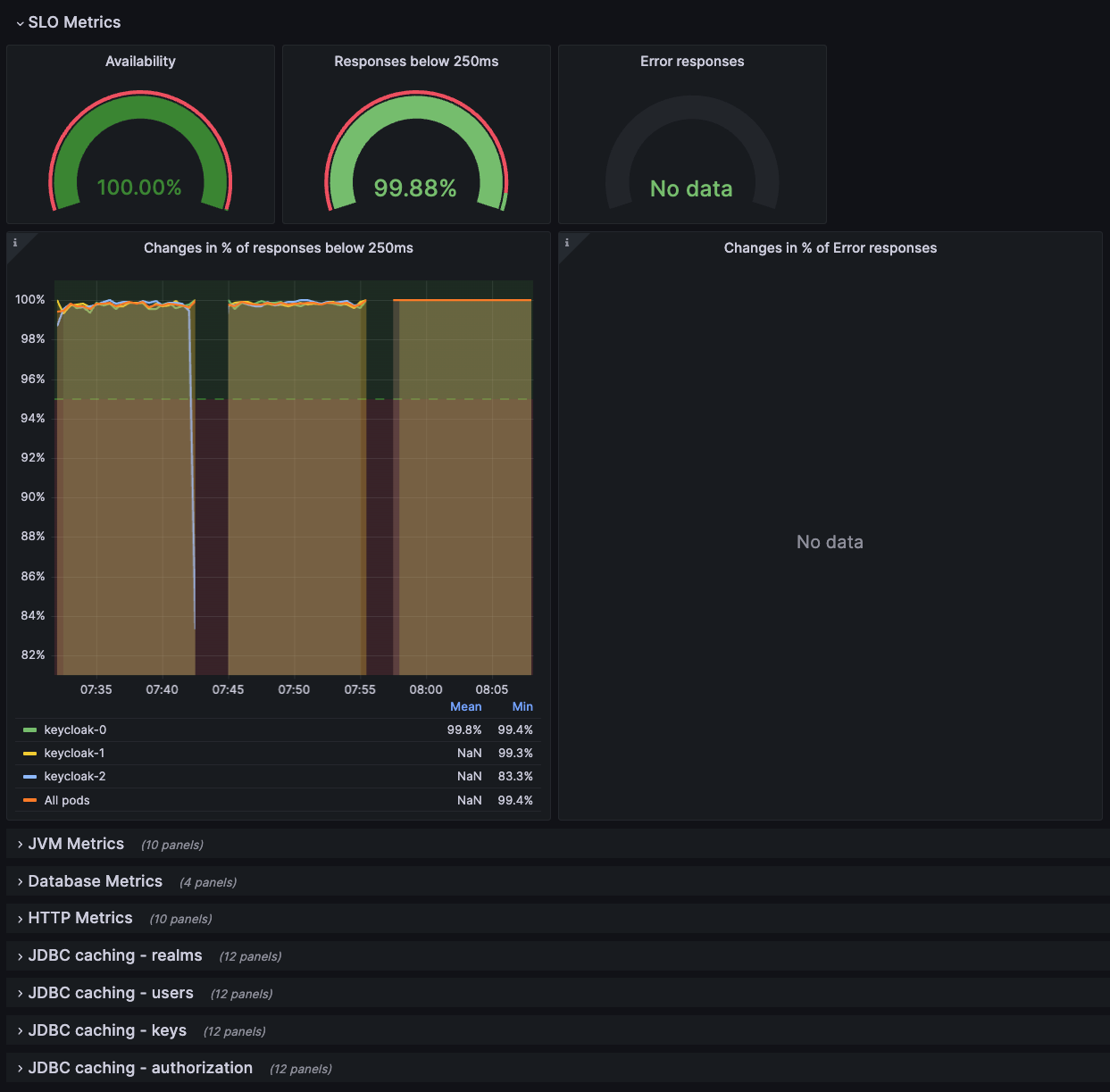
ダッシュボードの上部には、サービスレベルインジケーターを使用してパフォーマンスを監視する で定義されているサービスレベルインジケーターがグラフに表示されます。このダッシュボードは、SLI グラフに想定された結果が表示されない場合などに、メトリクスを使用したトラブルシューティング に従って Red Hat build of Keycloak デプロイメントのトラブルシューティングを行うときにも使用できます。
図7.1 トラブルシューティングダッシュボード
7.2.2. Keycloak キャパシティープランニングダッシュボード
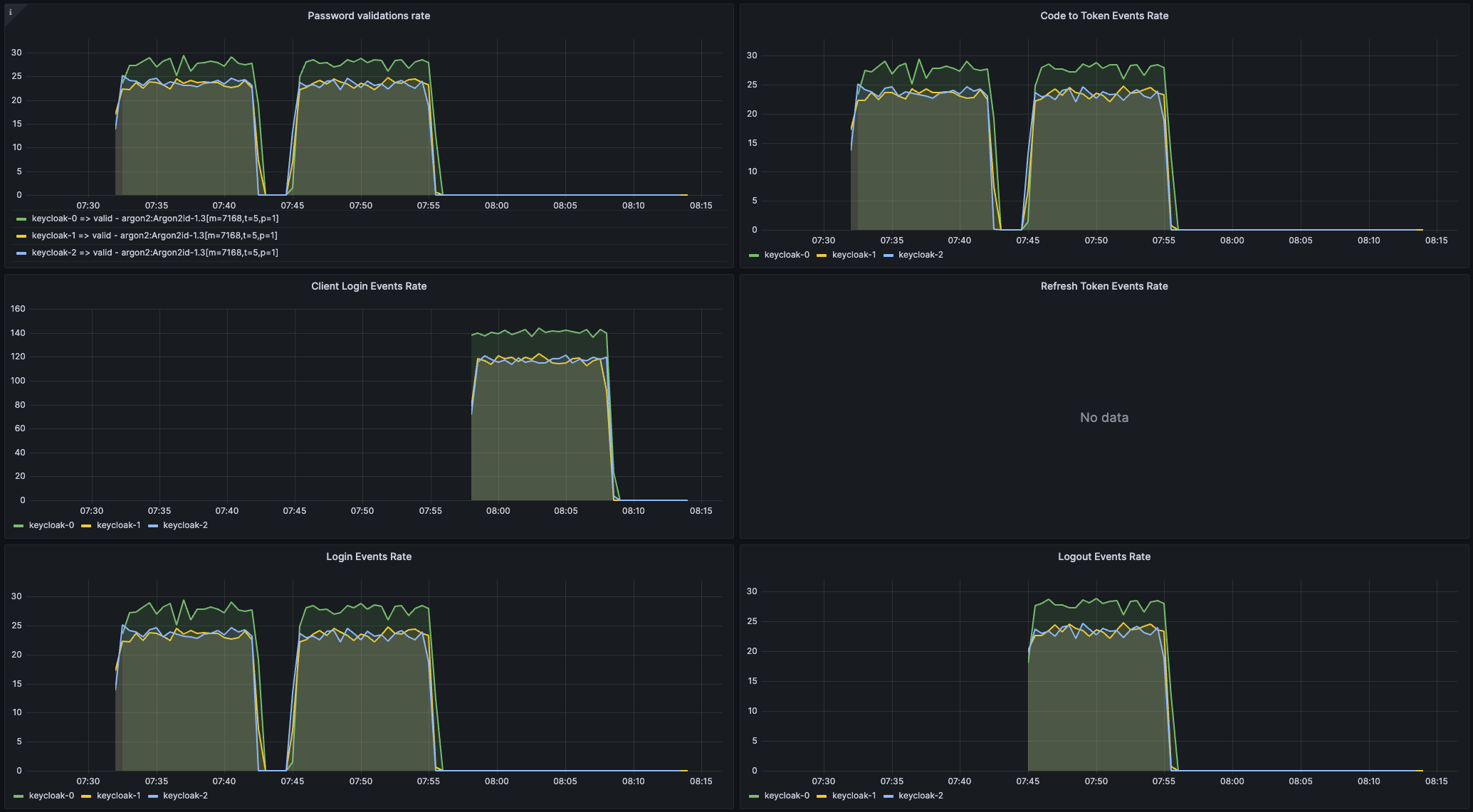
このダッシュボードは、JSON ファイル keycloak-capacity-planning-dashboard.json として利用できます。
このダッシュボードには、Red Hat build of Keycloak デプロイメントによって処理される負荷を見積もる際に重要なメトリクスが表示されます。たとえば、Red Hat build of Keycloak によって実行されたパスワード検証またはログインフローの数が表示されます。これらのメトリクスの詳細は、自己提供メトリクス の章を参照してください。
このダッシュボードが正しく機能するには、Red Hat build of Keycloak イベントメトリクスを有効にする必要があります。これらを有効にするには、イベントメトリクスを使用してユーザーアクティビティーを関しする の章を参照してください。
図7.2 キャパシティープランニングダッシュボード
7.3. ダッシュボードのインポート
- 左側の Grafana メニューからダッシュボードページを開きます。
- New および Import をクリックします。
- Upload dashboard JSON file をクリックし、インポートするダッシュボードの JSON ファイルを選択します。
- Prometheus データソースを選択します。
- Import をクリックします。
7.4. ダッシュボードのエクスポート
ダッシュボードを JSON 形式でエクスポートすると便利な場合があります。たとえば、ダッシュボードリポジトリーの変更を提案したい場合などです。
- エクスポートするダッシュボードを開きます。
- ダッシュボード名の横の左上隅にある share をクリックします。
- Export タブをクリックします。
- Export for sharing externally を有効にします。
- 結果として得た JSON を保存する場所に応じて、Save to file または View JSON、および Copy to Clipboard をクリックします。
7.5. 関連資料
ダッシュボードにトレースを接続する方法は、エグゼンプラーを使用して外れ値とエラーを分析する の章を引き続きお読みください。
第8章 エグゼンプラーを使用して外れ値とエラーを例を分析する
エグゼンプラーを使用して、記録されたトレースにメトリクスを接続し、エラーまたはレイテンシーの根本原因を分析します。
メトリクスは複数のイベントを集計したもので、システムが定義された範囲内で動作しているかどうかを示します。メトリクスは、エラー率やテールレイテンシーの監視、アラートの設定、パフォーマンス最適化の推進に使用できます。しかし、集約されることで、メトリクスで報告されるレイテンシーやエラーの根本原因を見つけることが難しくなります。
トレーシングを有効にすると、エラーやレイテンシーの根本原因を見つけることができます。記録されたトレースにメトリクスを接続する場合、エグゼンプラー という概念を使用します。
エグゼンプラーが設定されると、Red Hat build of Keycloak は最後に記録されたトレースをエグゼンプラーとしてメトリクスを報告します。Grafana のようなダッシュボードツールは、メトリクスダッシュボードからトレースビューにエグゼンプラーをリンクできます。
次のメトリクスは、エグゼンプラーをサポートしています。
-
http_server_requests_seconds_count(ヒストグラムを含む)
このメトリクスの詳細は、HTTP メトリクス の章を参照してください。 -
keycloak_credentials_password_hashing_validations_total
このメトリクスの詳細は、自己提供メトリクス の章を参照してください。 -
keycloak_user_events_total
このメトリクスの詳細は、自己提供メトリクス の章を参照してください。
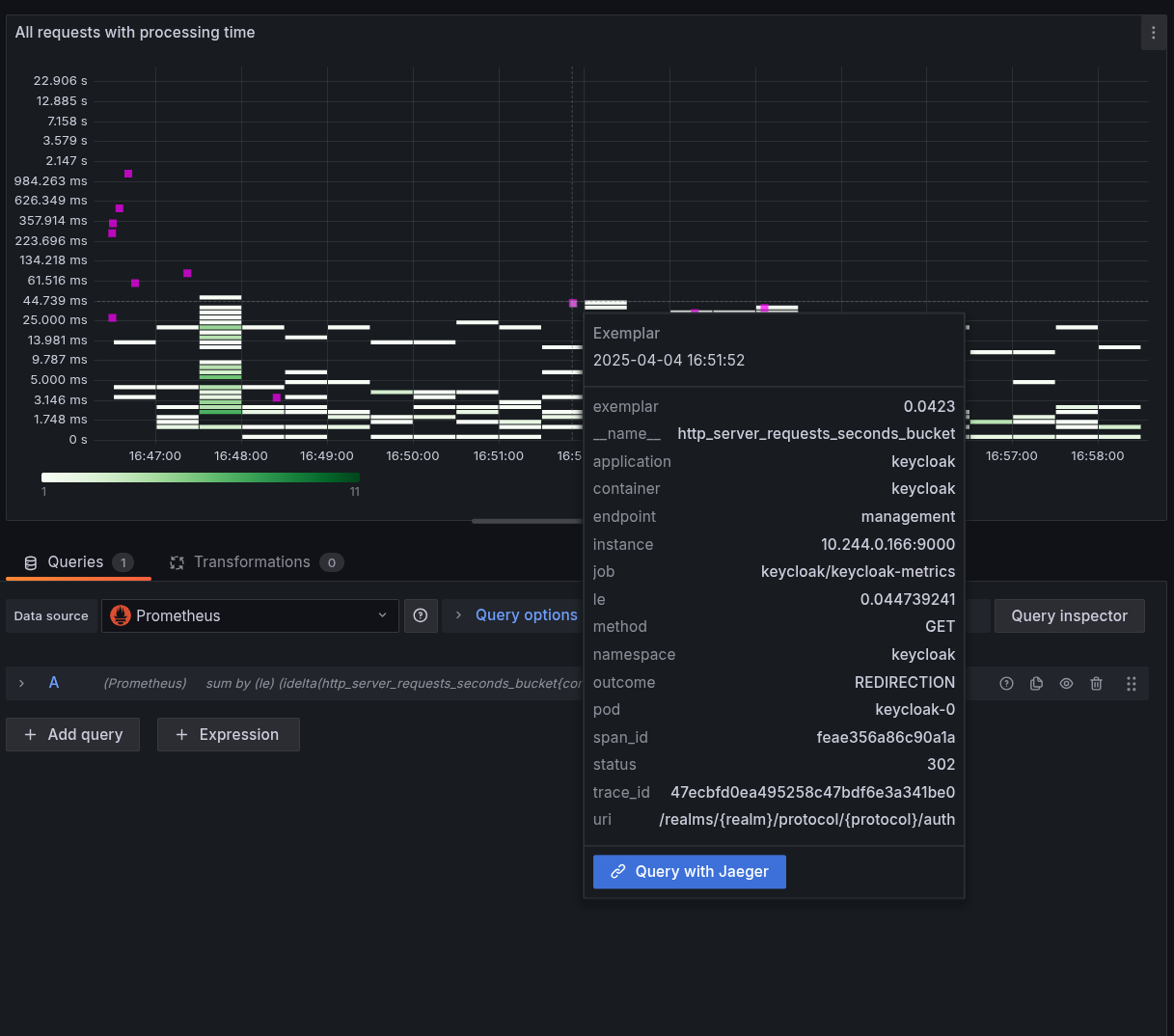
以下に、レイテンシーを可視化したヒートマップのスクリーンショットを示します。ピンク色のインジケーターのいずれかにマウスを移動すると、エグゼンプラーが表示されます。
図8.1 ヒートマップ図とエグゼンプラー
8.1. エグゼンプラーを設定する
エグゼンプラーを活用するには、次のステップを実行します。
- メトリクスから洞察を得る の章の説明に従って、Red Hat build of Keycloak のメトリクスを有効にします。
- トレーシングによる根本原因分析 の章の説明に従って、Red Hat build of Keycloak のトレーシングを有効にします。
監視システムでエグゼンプラーストレージを有効にします。
Prometheus の場合、これは 有効化が必須のプレビュー機能 です。
Prometheus ではデフォルトで有効になっていない
OpenMetricsText1.0.0プロトコルを使用して、メトリクスをスクレイピングします。Kubernetes 環境で
PodMonitorなどを使用している場合は、カスタムリソースの仕様にこれを追加することで実現できます。apiVersion: monitoring.coreos.com/v1 kind: PodMonitor metadata: ... spec: scrapeProtocols: - OpenMetricsText1.0.0トレースのリンク先となるメトリクスデータソースを設定します。
Grafana と Prometheus を使用する場合、これは Prometheus データソースの
exemplarTraceIdDestinationsを設定することを意味し、これは Jaeger や Tempo などのツールが提供するトレーシングデータソースを指します。ダッシュボードでエグゼンプラーを有効にします。
エグゼンプラーを表示する各ダッシュボードの各クエリーで、Exemplars の切り替えを有効にします。正しく設定するとダッシュボードに小さな点や星マークが表示され、これをクリックするとトレースが表示されます。
- スクレイププロトコルを指定しない場合、Prometheus はデフォルトでコンテンツネゴシエーションでそれを送信せず、Keycloak はエグゼンプラーが含まれない PrometheusText プロトコルにフォールバックします。
- トレーシングとメトリクスを有効にしたが、リクエストサンプリングでトレースが記録されなかった場合、公開されたメトリクスにエグゼンプラーは含まれません。
- ブラウザーでメトリクスエンドポイントにアクセスすると、コンテンツネゴシエーションによって PrometheusText 形式が返され、エグゼンプラーは表示されません。
8.2. エグゼンプラーが期待通りに動作するか検証する
以下のステップを実行して、Red Hat build of Keycloak でエグゼンプラーが正しく設定されていることを確認します。
- 指示に従って、Red Hat build of Keycloak のメトリクスとトレーシングを設定します。
-
テストのために、トレーシング比率を
1.0に設定してすべてのトレースを記録します。実稼働システムで推奨されるサンプリング設定は、トレーシングによる根本原因分析 を参照してください。 - Keycloak インスタンスにログインして、トレースを作成します。
次のようなコマンドを使用してメトリクスをスクレイピングし、エグゼンプラーが設定されているメトリクスを検索します。
$ curl -s http://localhost:9000/metrics \ -H 'Accept: application/openmetrics-text; version=1.0.0; charset=utf-8' \ | grep "#.*trace_id"次のような出力になるはずです。追加の
#の後に、スパン ID とトレース ID が追加されることに注意してください。http_server_requests_seconds_count {...} ... # {span_id="...",trace_id="..."} ...